
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
deepinsight/insightface | pytorch | 2,550 | New Button to be translated | ## New Tag is a Span added by the theme when the item is checked as NEW in the product page
``` html
<span class="new product-label">New</span>
``` | open | 2024-03-27T19:29:55Z | 2024-03-27T19:29:55Z | https://github.com/deepinsight/insightface/issues/2550 | [] | Delev94 | 0 |
huggingface/datasets | numpy | 7,107 | load_dataset broken in 2.21.0 | ### Describe the bug
`eval_set = datasets.load_dataset("tatsu-lab/alpaca_eval", "alpaca_eval_gpt4_baseline", trust_remote_code=True)`
used to work till 2.20.0 but doesn't work in 2.21.0
In 2.20.0:
 -> dict:
print('inside hello_world')
return {'message': 'hello world'}
routes = [
Route('/', method='GET', handler=hello_world)
]
app = ASyncApp(routes=ro... | closed | 2018-04-25T15:11:28Z | 2018-09-25T14:26:37Z | https://github.com/encode/apistar/issues/489 | [] | marekkosta | 8 |
dynaconf/dynaconf | django | 604 | Allow dotted first level variables on .ini and .properties [was:how to load simple config without sections?] | I have following config sample:
```
#
# Use this file to override default entries in /usr/share/web/WEB-INF/classes/app.properties
#
app.web.serverURL=https://app.host.org
securitySalt=l56MPNX9I1XnTghgkRaCjlxfzyPZJR6zOjCQ3vBF8
```
I can not load it with any parser | closed | 2021-06-26T14:05:03Z | 2022-06-02T19:21:50Z | https://github.com/dynaconf/dynaconf/issues/604 | [
"RFC"
] | amg-web | 2 |
3b1b/manim | python | 2,003 | An example of manim pi creature scene with different emotions of them | Here we found some pi creatures: https://www.3blue1brown.com/images/pi-creatures/happy.svg and so on, the "happy.svg" can be replaced by other "modes" that appear in 3b1b's video source code (like "hooray" and "sad"). These pi creatures are shown [here](https://github.com/CaftBotti/manim_pi_creatures). Do not use for ... | closed | 2023-03-12T09:59:59Z | 2023-03-13T02:18:24Z | https://github.com/3b1b/manim/issues/2003 | [] | CaftBotti | 0 |
feature-engine/feature_engine | scikit-learn | 232 | Is it possible to generalize PRatioEncoder as VarEncoder? | To encode categories PRE uses formula
p(1)/p(0)
and only suitable for y~Ber (classification).
But here is an idea: variance of Bernoulli distributed X is equal p(1)*p(0), which is close and should be correlated to the first formula. Computing variance should also allow PRE to be used in regression tasks (when y i... | closed | 2021-01-27T14:58:19Z | 2021-02-08T12:03:57Z | https://github.com/feature-engine/feature_engine/issues/232 | [] | glevv | 1 |
flairNLP/flair | nlp | 3,270 | [Feature]: Add Documentation link to Github repo | ### Problem statement
It's always nice to quickly reference documentation when coding. Currently users have to scroll down "below the fold" to click one of several links to access the documentation.
### Solution
Add the [documentation link](https://flairnlp.github.io/) to the sidebar of the github page. This i... | closed | 2023-06-15T21:31:18Z | 2023-06-20T02:58:18Z | https://github.com/flairNLP/flair/issues/3270 | [
"feature"
] | DecafSunrise | 2 |
coqui-ai/TTS | deep-learning | 4,135 | [Bug] When I generate a TTS model and play it, I only hear noise. | ### Describe the bug
Hello,
I wanted to create a TTS model using my voice with Coqui TTS, so I followed the tutorial to implement it.
I wrote a train.py file to train the voice model, but when I try to play TTS using the model I created, I only hear noise.
I thought the issue might be with my audio files, so I tried m... | closed | 2025-01-22T06:44:25Z | 2025-02-16T23:11:42Z | https://github.com/coqui-ai/TTS/issues/4135 | [
"bug"
] | chuyeonhak | 5 |
benbusby/whoogle-search | flask | 921 | [BUG] locally hosted services with IP addresses are still prepended with m. and mobile. | When setting the social media redirect to a locally hosted service, ex. http://192.168.0.209:3401, if mobile links appear, the link will point to http://mobile.192.168.0.209:3401 or http://m.192.168.0.209:3401. I think this requires the same solution as #913.
**To Reproduce**
Steps to reproduce the behavior:
1. Se... | closed | 2023-01-02T02:53:31Z | 2023-01-03T17:19:41Z | https://github.com/benbusby/whoogle-search/issues/921 | [
"bug"
] | cazwacki | 1 |
mwaskom/seaborn | data-science | 3,023 | Error during legend creation with mixture of marks | Here's a minimal example, it seems that you need all three layers to trigger the error:
```python
(
so.Plot(penguins, "bill_length_mm", "bill_depth_mm", color="species")
.add(so.Dots())
.add(so.Line(), so.PolyFit(1))
.add(so.Line(), so.PolyFit(2))
)
```
<details><summary>Traceback</summary>... | closed | 2022-09-13T21:24:39Z | 2022-10-04T23:44:57Z | https://github.com/mwaskom/seaborn/issues/3023 | [
"bug",
"objects-plot"
] | mwaskom | 1 |
ultralytics/ultralytics | python | 19,553 | Build a dataloader without training | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi. I would like to examine data in a train dataloader. How can I build one ... | closed | 2025-03-06T12:17:34Z | 2025-03-06T14:01:49Z | https://github.com/ultralytics/ultralytics/issues/19553 | [
"question",
"dependencies",
"detect"
] | daniellehot | 3 |
mckinsey/vizro | plotly | 541 | Mobile version layout bugs | ### Description
Here's some configurations where layout is not working as expected:
1. Table in one container, graph in second
<img width="294" alt="image" src="https://github.com/mckinsey/vizro/assets/35569332/f4a6c52f-72d0-4392-b678-340486a39cf5">
2. Table in one container, graph in second in horizontal orien... | open | 2024-06-21T13:06:28Z | 2024-06-27T08:28:34Z | https://github.com/mckinsey/vizro/issues/541 | [
"Bug Report :bug:"
] | l0uden | 0 |
Neoteroi/BlackSheep | asyncio | 63 | Correct error happening with latest pip-20.3.1 | ```bash
ERROR: Cannot install blacksheep and blacksheep==0.2.8 because these package versions have conflicting dependencies.
The conflict is caused by:
blacksheep 0.2.8 depends on essentials==1.1.4
essentials-openapi 0.0.9 depends on essentials==1.1.3
blacksheep 0.2.8 depends on essentials==1.1.4
... | closed | 2020-12-11T20:16:48Z | 2020-12-11T23:39:12Z | https://github.com/Neoteroi/BlackSheep/issues/63 | [] | RobertoPrevato | 0 |
TencentARC/GFPGAN | deep-learning | 275 | GFPGAN to TorchScript/TensorRT | Hello, I am trying to convert the GFPGAN model to TorchScript/TensorRT to increase model performance. Has there be made any efforts yet on this?
So far I made a successful conversion to onnx (including the StyleGAN Decoder)
However the conversion to torchscript (or even just tracing) results in some errors of the S... | open | 2022-09-27T10:24:54Z | 2023-11-29T13:57:11Z | https://github.com/TencentARC/GFPGAN/issues/275 | [] | lschaupp | 10 |
gee-community/geemap | jupyter | 1,352 | the properties of draw_features is {} | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
python ==3.8.8 Windows
```python
Map = geemap.Map(center=[34, 99], zoom=4, add_google_map=True)
Map
Map.draw_features[0].getInfo()
```
### Description
upgrade geemap from 0.17.3-->0.18.1. I have drew a ... | closed | 2022-12-01T03:57:14Z | 2022-12-02T00:04:12Z | https://github.com/gee-community/geemap/issues/1352 | [
"bug"
] | wurenzhe163 | 3 |
pinry/pinry | django | 310 | Upload and api auth | Hi I'm trying to upload a set of images on my pinry running on docker using the script you advice in #305:
https://github.com/winkidney/PickTrue/blob/feature/import-to-pinry/src/picktrue/pinry/uploader.py
The problem is that I'm not able to autenticate.
Calling /api/v2/profile/login/ return 403.
Looking at ... | closed | 2021-12-13T10:00:19Z | 2021-12-16T08:32:12Z | https://github.com/pinry/pinry/issues/310 | [] | mbelletti | 2 |
littlecodersh/ItChat | api | 641 | 搜索聊天记录功能 | open | 2018-04-19T14:22:36Z | 2018-06-06T05:15:56Z | https://github.com/littlecodersh/ItChat/issues/641 | [
"help wanted"
] | imporseble | 0 | |
pydata/xarray | pandas | 9,647 | Could we defer to flox for `GroupBy.first`? | ### Is your feature request related to a problem?
I was wondering why a `groupby("foo").first()` call was going so slowly — I think we run a python loop for this, rather than calling into flox:
https://github.com/pydata/xarray/blob/b9780e7a32b701736ebcf33d9cb0b380e92c91d5/xarray/core/groupby.py#L1218-L1231
### Des... | closed | 2024-10-18T20:55:43Z | 2025-03-19T14:48:04Z | https://github.com/pydata/xarray/issues/9647 | [
"enhancement",
"topic-groupby"
] | max-sixty | 4 |
OpenBB-finance/OpenBB | python | 6,848 | [🕹️] Starry-eyed Supporter | ### What side quest or challenge are you solving?
Starry-eyed Supporter
### Points
150
### Description
github accounts:
https://github.com/umairullah0905
https://github.com/akaswang
https://github.com/umeshs25
https://github.com/giteshsarvaiya
https://github.com/Hamsegg
### Provide proof that you've complete... | closed | 2024-10-23T07:30:21Z | 2024-10-23T12:37:26Z | https://github.com/OpenBB-finance/OpenBB/issues/6848 | [] | rajeevDewangan | 2 |
zappa/Zappa | flask | 696 | [Migrated] Attribute not found decorator | Originally from: https://github.com/Miserlou/Zappa/issues/1777 by [dadrake3](https://github.com/dadrake3)
<!--- Provide a general summary of the issue in the Title above -->
## Context
def zappa_async(func):
print('here')
@wraps(func)
@task(capture_response=True)
def... | closed | 2021-02-20T12:33:04Z | 2022-07-16T06:36:58Z | https://github.com/zappa/Zappa/issues/696 | [] | jneves | 1 |
psf/requests | python | 6,015 | Possible issue with proxies and TLS versions when using a session. | Using a session or a request object with the same parameters should yield the same results.
When a proxy is used, and when the target website supports TLS 1.0 and TLS 1.1 (or does not support TLS 1.3, I could not figure it out), a request object works fine, whereas a session throws a SSL Error.
## Expected Result... | open | 2021-12-27T11:27:52Z | 2024-05-24T21:23:59Z | https://github.com/psf/requests/issues/6015 | [] | defunes43 | 3 |
openapi-generators/openapi-python-client | fastapi | 408 | async syntax error | I'm using openapi-generator-cli v3.0.x, code generation process is ok, but in the moment of use the api, i've the following issue:
`blorente@drama-laptop:~/Documentos/repos/openapi/test$ python3 test.py
Traceback (most recent call last):
File "test.py", line 1, in <module>
import openapi_client
File "/hom... | closed | 2021-05-04T18:51:11Z | 2021-05-04T18:53:25Z | https://github.com/openapi-generators/openapi-python-client/issues/408 | [
"🐞bug"
] | brunolorente | 1 |
mlflow/mlflow | machine-learning | 14,915 | [FR] automatically update artifact view in UI | ### Willingness to contribute
No. I cannot contribute this feature at this time.
### Proposal Summary
We often use a `.txt` artifact as a log and append to it over the course of a run. If would be nice if the artifact display was able to refresh the view when the the artifact changes, like the plot windows to.
Idea... | open | 2025-03-08T18:51:09Z | 2025-03-09T07:47:36Z | https://github.com/mlflow/mlflow/issues/14915 | [
"enhancement",
"area/uiux"
] | mazer-ai | 1 |
ivy-llc/ivy | numpy | 28,136 | Getting the stateful tests up and running | Trying to run the stateful tests throws an error, e.g. running the tests for `ivy_tests/test_ivy/test_stateful/test_activations.py::test_elu` throws an error
```
E ModuleNotFoundError: No module named ‘ELU'
```
This is the same across all other stateful tests. The goal of this task is to fix this error so th... | closed | 2024-01-31T11:11:05Z | 2024-05-06T10:47:36Z | https://github.com/ivy-llc/ivy/issues/28136 | [
"Bounty"
] | vedpatwardhan | 7 |
flairNLP/flair | pytorch | 3,401 | A missing implementation of a method causing training to be stopped | ### Describe the bug
A missing implementation of a method called "to_params" in "flair/embeddings/base.py" causing training to be stopped in the middle
### To Reproduce
```python
from flair.data import Corpus, Sentence, Label
from flair.embeddings import WordEmbeddings, FlairEmbeddings, DocumentLSTMEmbeddings
from... | closed | 2024-02-02T09:14:46Z | 2024-02-03T02:01:39Z | https://github.com/flairNLP/flair/issues/3401 | [
"bug"
] | SanjanaVHerur | 3 |
cs230-stanford/cs230-code-examples | computer-vision | 7 | Organization of the blog posts | ### General (common between TensorFlow and PyTorch)
1. Introduction to project starter code
2. Logging + hyperparams
3. AWS setup
4. Train/Dev/Test set
### TensorFlow
1. Getting started
2. Dataset pipeline: `tf.data`
3. Creating the model (`tf.layers`) + training + evaluation
- model
- training ops
-... | closed | 2018-01-31T03:39:22Z | 2018-02-01T09:51:48Z | https://github.com/cs230-stanford/cs230-code-examples/issues/7 | [] | omoindrot | 0 |
jina-ai/serve | machine-learning | 6,119 | Release Note | # Release Note
This release contains 1 bug fix.
## 🐞 Bug Fixes
### Fix dependency on OpenTelemetry Exporter Prometheus (#6118)
We fixed the dependency version with `opentelemetry-exporter-prometheus` to avoid using deprecated versions.
## 🤟 Contributors
We would like to thank all contributors to th... | closed | 2023-12-01T08:33:41Z | 2023-12-01T10:47:10Z | https://github.com/jina-ai/serve/issues/6119 | [] | JoanFM | 0 |
JoeanAmier/XHS-Downloader | api | 32 | 可以采集到用户名和发布时间吗 | 作为文件名/文件夹名称可选配置项,可以自行在配置文件中设置。
另外要说下真的好用,谢谢分享 | open | 2023-12-25T09:18:20Z | 2023-12-25T14:03:35Z | https://github.com/JoeanAmier/XHS-Downloader/issues/32 | [] | lqg5522 | 2 |
RobertCraigie/prisma-client-py | pydantic | 620 | Investigate memory usage | ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
We haven't put any effort towards investigating whether or not there are any memory leaks / improvements that could be made.
## Suggested solution
<!-- A clear and concise description of what you... | open | 2022-11-29T11:21:30Z | 2024-08-20T15:57:43Z | https://github.com/RobertCraigie/prisma-client-py/issues/620 | [
"kind/improvement",
"topic: internal",
"topic: perf",
"priority/medium",
"level/unknown"
] | RobertCraigie | 1 |
Sanster/IOPaint | pytorch | 109 | SD1.5 : RuntimeError: Input type (float) and bias type (c10::Half) should be the same | I'm getting "RuntimeError: Input type (float) and bias type (c10::Half) should be the same" using SD1.5 with those parameters :
lama-cleaner --model=sd1.5 --device=cpu --port=8181 --sd-run-local --sd-cpu-textencoder
any idea how to fix this ? | closed | 2022-11-03T11:01:16Z | 2023-06-06T21:17:22Z | https://github.com/Sanster/IOPaint/issues/109 | [] | AntoineTurmel | 5 |
pytorch/pytorch | python | 149,556 | dynamo: dont graph break on `torch.jit.isinstance` | It looks like this is a flavor of `isinstance()` that is meant to make torchscript happy. From user empathy day, it looks like `torchaudio` uses this API pretty heavily. We should probably just handle it in dynamo (by mapping it to builtin `isinstance`). Example: https://github.com/pytorch/audio/blob/main/src/torchaudi... | open | 2025-03-19T21:41:37Z | 2025-03-24T10:41:06Z | https://github.com/pytorch/pytorch/issues/149556 | [
"triaged",
"oncall: pt2",
"module: dynamo"
] | bdhirsh | 0 |
thp/urlwatch | automation | 2 | os.getlogin() - Inappropriate ioctl for device | Hello. In the file `handler.py`, line 173, you use `os.getlogin()`.
According to the `os.getlogin()` doc, it « Returns the user logged in to the controlling terminal of the process. ».
It means that if there is no controlling terminal, because urlwatch is launched by cron, or by a systemd.service for example, it will ... | closed | 2014-07-14T09:09:47Z | 2020-06-09T22:15:41Z | https://github.com/thp/urlwatch/issues/2 | [] | ghost | 1 |
Lightning-AI/LitServe | rest-api | 352 | How to route /docs path in litserve behind a proxy? | I have hosted litserve as kubernetes(EKS) deployment with a service, now it is further connected to a proxy with Virtual service CRD and gateway.
In eks deployment,
- Model: the url works 0.0.0.0:4000/predict after port forwarding.
- Docs: The url works 0.0.0.0:4000/docs after port forwarding.
In EKS Servic... | closed | 2024-11-04T05:04:09Z | 2024-11-10T20:07:29Z | https://github.com/Lightning-AI/LitServe/issues/352 | [
"bug",
"help wanted"
] | Mayurji | 6 |
tqdm/tqdm | jupyter | 1,503 | Progress bar is not showing while training. | - [ ] I have marked all applicable categories:
+ [ ] exception-raising bug
+ [ ] visual output bug
- [ ] I have visited the [source website], and in particular
read the [known issues]
- [ ] I have searched through the [issue tracker] for duplicates
- [ ] I have mentioned version numbers, operating syste... | open | 2023-08-26T08:41:32Z | 2023-08-26T08:44:13Z | https://github.com/tqdm/tqdm/issues/1503 | [] | faizan1234567 | 0 |
httpie/http-prompt | rest-api | 56 | Auto suggestion (like the fish shell) | Adding auto-suggestion should be easy with the help of prompt_toolkit.
Reference: http://python-prompt-toolkit.readthedocs.io/en/stable/pages/building_prompts.html#auto-suggestion
| closed | 2016-06-16T06:42:17Z | 2016-06-20T06:14:28Z | https://github.com/httpie/http-prompt/issues/56 | [
"enhancement",
"todo"
] | eliangcs | 1 |
scikit-image/scikit-image | computer-vision | 6,979 | Move testing with nightly wheels to shedule | ### Description:
Could we move our testing with nightly wheels to a regular schedule instead of running on every action? I feel like that would create less noise in PRs for contributors and maintainers alike; contributors might be confused / maintainers have to go digging to make sure it can be ignored (e.g. see https... | open | 2023-06-01T16:43:22Z | 2023-11-30T02:26:13Z | https://github.com/scikit-image/scikit-image/issues/6979 | [
":robot: type: Infrastructure",
":pray: Feature request",
":sleeping: Dormant"
] | lagru | 4 |
aminalaee/sqladmin | fastapi | 680 | on_form_prefill functionality | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
I want to be able to have a field depend on another field and have it populate with a certain value when selected.
flask-admin has this for [editing](https://flask-admin.r... | closed | 2023-12-07T19:15:27Z | 2023-12-12T19:52:49Z | https://github.com/aminalaee/sqladmin/issues/680 | [] | JettScythe | 3 |
wkentaro/labelme | deep-learning | 1,529 | When an image is rotated (EXIF orientation is not equal to 1), the labels generated by labelme_json_to_dataset do not match. | ### Provide environment information
with latest labelme_json_to_dataset.py script and the .exe as well
### What OS are you using?
windows 11
### Describe the Bug
When an image is rotated (EXIF orientation is not equal to 1), the labels generated by labelme_json_to_dataset do not match.
])
```
In dash >= 2.17, this will throw an error:
```python
app.layout = ["Select City", dcc.Dropdown()]
```
Here is a full example. When I run the app, I see the following error. After refreshing the s... | open | 2024-06-17T16:03:07Z | 2024-08-13T19:52:07Z | https://github.com/plotly/dash/issues/2890 | [
"bug",
"P3"
] | AnnMarieW | 0 |
benbusby/whoogle-search | flask | 843 | night mode enter text can't see——Heroku | **Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Deployment Method**
- [ ] Heroku (one-click deploy)
- [ ] Docker
- [ ] `run` executable
- [ ] pip/pipx
- [... | open | 2022-09-10T00:20:13Z | 2022-09-10T00:24:17Z | https://github.com/benbusby/whoogle-search/issues/843 | [
"bug"
] | rrn21833 | 0 |
zappa/Zappa | flask | 630 | [Migrated] Feature: pass response_id to async function enabling update task status | Originally from: https://github.com/Miserlou/Zappa/issues/1600 by [kiarashm](https://github.com/kiarashm)
## Description
<!-- Please describe the changes included in this PR -->
I was using the asynchronous functionality of zappa and wanted to be able to update the status of my executing 'task' in the dynamodb tabl... | closed | 2021-02-20T12:26:53Z | 2024-04-13T17:36:00Z | https://github.com/zappa/Zappa/issues/630 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
ivy-llc/ivy | pytorch | 28,311 | ivy.conj | **Why should this be implemented?**
- 3+ of the native frameworks have this function
- it's needed for a complex/long frontend function implementation
**Links to native framework implementations**
- [Jax](https://jax.readthedocs.io/en/latest/_autosummary/jax.lax.conj.html)
- [PyTorch](https://pytorch.org/docs/st... | closed | 2024-02-17T17:12:36Z | 2024-03-20T03:56:41Z | https://github.com/ivy-llc/ivy/issues/28311 | [
"Next Release",
"Suggestion",
"Ivy API Experimental",
"Useful Issue"
] | ZenithFlux | 3 |
pallets-eco/flask-sqlalchemy | flask | 741 | comparing adjacent rows in R | Hi there,
In my dataframe, I have a column "dates" and I would like for R to walk through each row of dates in a loop to see if the date before or after it is within a 3-14 day range, and if not, it's indexed to a list to be removed at the end of the loop.
for example:
my_dates <- c( 1/4/2019, 1/18/2019, 4/3/... | closed | 2019-05-22T21:44:47Z | 2020-12-05T20:21:50Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/741 | [] | StephZank | 0 |
explosion/spaCy | deep-learning | 11,992 | spacy-clausie problem | ### Discussed in https://github.com/explosion/spaCy/discussions/11991
<div type='discussions-op-text'>
<sup>Originally posted by **Abelcanc3rhack3r** December 19, 2022</sup>
Hi,
I have a problem running spacy-clausie:
https://spacy.io/universe/project/spacy-clausie
I installed spacy-clausie by running: `pyt... | closed | 2022-12-19T04:12:47Z | 2022-12-19T04:13:51Z | https://github.com/explosion/spaCy/issues/11992 | [] | Abelcanc3rhack3r | 1 |
matplotlib/mplfinance | matplotlib | 486 | How to avoid 2 y axis? | I used the following code to generate the plot. But I'm having a very weird issue that in some serial data, the y axis will be 2.
This is the error one, the "BOLLINGER_HBAND" and "BOLLINGER_LBAND" are not using the same y Axis.
<img src="https://github.com/banhao/CoinBasePro-Trading-Simulator/blob/main/screenshot/XR... | closed | 2021-12-27T07:00:49Z | 2021-12-28T15:10:33Z | https://github.com/matplotlib/mplfinance/issues/486 | [
"question"
] | banhao | 6 |
aiortc/aiortc | asyncio | 758 | Can't hear client-side Audio after first burst of audio | I'm sending audio back to the client using this setup.
```python
class AudioStreamSendTrack(MediaStreamTrack):
kind = "audio"
def __init__(self, audio_send_queue: asyncio.Queue):
super().__init__()
self.audio_send_queue = audio_send_queue
self.resampler = AudioResampler(format... | closed | 2022-08-16T12:58:43Z | 2023-05-25T11:49:43Z | https://github.com/aiortc/aiortc/issues/758 | [] | tand22 | 2 |
drivendataorg/cookiecutter-data-science | data-science | 137 | The need for a data/queries? | Throughout my DS career I've always worked with DB connections and structured parameterized SQL queries. I also like to place them in a dedicated folder, and have been placing them in the `data/raw` directory (which I think is wrong given the cookiecutter philosophy).
Also, in my work environment I keep a dedicated... | closed | 2018-08-16T14:45:41Z | 2019-01-29T17:53:10Z | https://github.com/drivendataorg/cookiecutter-data-science/issues/137 | [] | GuiMarthe | 3 |
guohongze/adminset | django | 93 | webssh中使用private key连接报错 | webssh程序报错:
File "/usr/lib/python2.7/site-packages/webssh-0.8.0-py2.7.egg/webssh/handler.py", line 323, in ssh_connect_wrapped
worker = self.ssh_connect()
File "/usr/lib/python2.7/site-packages/webssh-0.8.0-py2.7.egg/webssh/handler.py", line 297, in ssh_connect
args = self.get_args()
... | open | 2019-02-13T02:14:34Z | 2020-06-11T10:33:38Z | https://github.com/guohongze/adminset/issues/93 | [] | wenbc | 2 |
ray-project/ray | tensorflow | 51,632 | [Serve] Ray Serve Autoscaling supports the configuration of custom-metrics and policy | ### Description
Currently, Ray Serve Autoscaling only supports scaling based on the ongoing HTTP Request metrics by built-in policy, and doesn't support custom-defined metrics. This often proves to be inflexible in some practical scenarios. For example, if an application hopes to do autoscaling based on the average CP... | open | 2025-03-24T03:37:52Z | 2025-03-24T03:37:52Z | https://github.com/ray-project/ray/issues/51632 | [
"enhancement",
"triage"
] | plotor | 0 |
scikit-learn/scikit-learn | machine-learning | 30,257 | Estimator creating `_more_tags` and inheriting from `BaseEstimator` will not warn about old tag infrastructure | While making the code of `skrub` compatible with scikit-learn 1.6, I found that the following is really surprising:
```python
# %%
import numpy as np
from sklearn.base import BaseEstimator, RegressorMixin
class MyRegressor(RegressorMixin, BaseEstimator):
def __init__(self, seed=None):
self.seed =... | closed | 2024-11-09T19:27:10Z | 2024-11-23T03:54:44Z | https://github.com/scikit-learn/scikit-learn/issues/30257 | [
"Blocker"
] | glemaitre | 4 |
stitchfix/hamilton | numpy | 297 | Restructure docs like https://diataxis.fr/ suggests. | # What
The structure of our docs could be better thought out. https://diataxis.fr/ is a good model - we should emulate what it prescribes.
# Why
Good docs are the foundation of any open source project. Having a clear structure and thus content that maps appropriately will help with that.
# Task
What needs to b... | closed | 2023-01-31T00:51:31Z | 2023-02-26T17:22:51Z | https://github.com/stitchfix/hamilton/issues/297 | [
"documentation"
] | skrawcz | 1 |
sunscrapers/djoser | rest-api | 97 | Registration: Won't allow plus signs in email or username | Trying the following:
`curl -X POST http://127.0.0.1:8000/auth/register/ --data 'username=max+djoser@domain.com&password=djoser'`
I get:
`{"username":["Enter a valid username. This value may contain only letters, numbers and @/./+/-/_ characters."]}`
As you can see, the message even states explicitly that all my sp... | closed | 2015-11-16T19:56:33Z | 2015-11-16T21:11:22Z | https://github.com/sunscrapers/djoser/issues/97 | [] | cpury | 5 |
shibing624/text2vec | nlp | 56 | 是否支持模型加速 | 请教目前是否可以支持模型加速部署的链路?或者可以用hugging face的API来做ONNX部署?
| closed | 2023-03-05T16:48:30Z | 2023-04-14T00:35:34Z | https://github.com/shibing624/text2vec/issues/56 | [
"question"
] | flydsc | 4 |
microsoft/hummingbird | scikit-learn | 463 | Add support for 'tpot.builtins.stacking_estimator.StackingEstimator'. | I am using tpot for auto ml and unable to convert the model into pytorch getting following error.
Unable to find converter for model type <class '**tpot.builtins.stacking_estimator.StackingEstimator**'>.
It usually means the pipeline being converted contains a
transformer or a predictor with no corresponding convert... | open | 2021-03-11T06:40:41Z | 2021-03-11T16:52:49Z | https://github.com/microsoft/hummingbird/issues/463 | [
"enhancement"
] | muhammad49 | 1 |
aleju/imgaug | machine-learning | 165 | WithColorspace doesn't support HLS | Hi,
I was trying to change the brightness of an image and when i used WithColorspace with the target space HLS it give me the error : KeyError: 'HLS2RGB'.
This code work fine :
`image = cv2.imread(imagePath)`
`lighter = iaa.WithColorspace(to_colorspace="HSV",
from_colorspace="RGB",
children=iaa.WithChan... | open | 2018-08-16T21:26:13Z | 2018-08-19T03:16:13Z | https://github.com/aleju/imgaug/issues/165 | [] | robert405 | 2 |
MilesCranmer/PySR | scikit-learn | 323 | PySR paper is out! | This is long-overdue but I finally finished a methods paper describing the algorithm in PySR and SymbolicRegression.jl. You can find it here: https://github.com/MilesCranmer/pysr_paper and the arXiv here: https://arxiv.org/abs/2305.01582.
I consider this paper to be a "v1," based on an older version of the codebase... | open | 2023-05-05T15:51:02Z | 2024-07-04T18:31:51Z | https://github.com/MilesCranmer/PySR/issues/323 | [
"documentation"
] | MilesCranmer | 2 |
cle-b/httpdbg | pytest | 141 | Feature Request: Collapsible Initiator Groups | It would be great if the UI supported expanding/collapsing requests per initiator group like so:
## All initiator groups expanded

## `test_product_connection` collapsed
".

# client start shell
sudo python3 ./bench_servi... | open | 2025-03-08T10:08:49Z | 2025-03-10T02:33:32Z | https://github.com/vllm-project/vllm/issues/14487 | [
"bug"
] | Oneal65 | 4 |
Nemo2011/bilibili-api | api | 213 | [需求] 创建投票类... | 新增了对投票的创建和更新...没投票类难办 | closed | 2023-02-23T14:23:34Z | 2023-02-23T16:07:14Z | https://github.com/Nemo2011/bilibili-api/issues/213 | [
"need"
] | z0z0r4 | 3 |
httpie/cli | python | 652 | Array in GET request | How do I add an array of tags to a GET request? I have tried below to no avail
`› http :3000/api/caters tags:='[\"vegan\"]' `
I get back an error
```
usage: http [--json] [--form] [--pretty {all,colors,format,none}]
[--style STYLE] [--print WHAT] [--headers] [--body] [--verbose]
[--... | closed | 2018-02-16T11:24:35Z | 2018-02-16T11:29:33Z | https://github.com/httpie/cli/issues/652 | [] | hahmed | 1 |
marcomusy/vedo | numpy | 1,092 | typing.Self is not compatible with python3.10 | Currently getting an ImportError when using vedo with python 3.10.
As per [this comment](https://stackoverflow.com/a/77247460), using typing.Self with versions of python prior to 3.11 requires the use of typing_extensions.
| closed | 2024-04-12T01:40:58Z | 2024-06-13T18:40:41Z | https://github.com/marcomusy/vedo/issues/1092 | [] | Linus-Foley | 1 |
Kanaries/pygwalker | pandas | 282 | Readme Privacy Policy code does not work | The readme [Privacy Policy section](https://github.com/Kanaries/pygwalker#privacy-policy) says the following:
```python
import pygwalker as pyg, pygwalker.utils_config as pyg_conf
pyg_conf.set_config( { 'privacy': 'meta' }, save=True)
```
However, it seems `utils_config` has been separated out from the rest of... | closed | 2023-10-24T19:29:07Z | 2023-11-03T10:55:46Z | https://github.com/Kanaries/pygwalker/issues/282 | [
"bug",
"P1"
] | EricPostMaster | 1 |
ivy-llc/ivy | numpy | 28,437 | Fix Frontend Failing Test: paddle - tensor.torch.Tensor.masked_fill | To-do list: https://github.com/unifyai/ivy/issues/27500 | closed | 2024-02-27T11:25:45Z | 2024-04-30T15:38:55Z | https://github.com/ivy-llc/ivy/issues/28437 | [
"Sub Task"
] | StefanSan26 | 0 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 182 | Attention value is strange | **When i train the transfomer, i found the attention values are almost same**
**Encoder**:
[0.10000075, 0.10000038, 0.09999962, 0.10000114, 0.09999923, 0.09999923, 0.1 0.09999847, 0.10000038, 0.10000075, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
**Decoder**:
[0.19999756 0.2000006 0.20000137 0.2000006 0.19999985 0.... | open | 2021-07-31T13:40:46Z | 2023-03-20T14:17:24Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/182 | [] | YPatrickW | 1 |
d2l-ai/d2l-en | tensorflow | 2,523 | pip install d2l==1.0.0b0 Fails to Install on Linux Mint/Ubuntu 22.04 | Error Message:
Collecting d2l==1.0.0b0
Using cached d2l-1.0.0b0-py3-none-any.whl (141 kB)
Collecting jupyter (from d2l==1.0.0b0)
Using cached jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
Requirement already satisfied: numpy in /home/remote/miniconda3/envs/pt/lib/python3.10/site-packages (from d2l==1.0.0b0) (1... | closed | 2023-07-01T17:56:41Z | 2023-07-01T18:12:09Z | https://github.com/d2l-ai/d2l-en/issues/2523 | [] | k7e7n7t | 1 |
google-research/bert | nlp | 897 | export_saved_model output file does not exist | I couldn't find the output file in the expected directory. Probably, I'm making a simple mistake. Can you help me solve this problem?
<img width="1094" alt="Screen Shot 2019-11-01 at 3 24 16 PM" src="https://user-images.githubusercontent.com/5379104/68031386-d8eceb00-fcbb-11e9-97b4-3f2b98d0a86a.png">
<img width=... | open | 2019-11-01T14:27:08Z | 2019-11-01T16:49:19Z | https://github.com/google-research/bert/issues/897 | [] | emrecalisir | 0 |
sinaptik-ai/pandas-ai | data-visualization | 1,120 | PANDAS API KEY needed (and used!!!) if agent.train is utilized | ### System Info
pandasai: v2.0.33
azure openai with gpt-4, api version 2024-02-01
### 🐛 Describe the bug
I defined the pandas ai api key like this, because it seems there is a bug that requires it in combination with azure open ai api (I get "pandasai.exceptions.MissingVectorStoreError: No vector store provide... | closed | 2024-04-17T18:35:54Z | 2024-04-19T09:34:59Z | https://github.com/sinaptik-ai/pandas-ai/issues/1120 | [] | flashtheman | 3 |
davidsandberg/facenet | computer-vision | 958 | AttributeError: module 'facenet' has no attribute 'write_arguments_to_file' | closed | 2019-01-23T10:03:08Z | 2019-01-23T10:03:22Z | https://github.com/davidsandberg/facenet/issues/958 | [] | wanggoudanscd | 0 | |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 695 | No module named pathlib | > matteo@MBP-di-matteo Real-Time-Voice-Cloning-master % python demo_cli.py
> Traceback (most recent call last):
> File "demo_cli.py", line 2, in <module>
> from utils.argutils import print_args
> File "/Users/matteo/Real-Time-Voice-Cloning-master/utils/argutils.py", line 22
> def print_args(args: argpa... | closed | 2021-03-07T10:40:27Z | 2021-03-08T21:24:20Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/695 | [] | matteopuppis | 3 |
donnemartin/data-science-ipython-notebooks | pandas | 49 | Some of the links are giving 404 error | I tried rnn-lstm in Keras, the link seems to be expired.

There are other many links too showing 404 error. Please fix them. | closed | 2017-06-23T03:26:56Z | 2021-04-24T16:07:39Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/49 | [
"bug"
] | Lplenka | 2 |
Gozargah/Marzban | api | 1,027 | ماکس رو در سینگ باکس غیرفعال کنید لطفا | در اپدیت اخیر در مرزبان dev با تمپلت یا بدون تمپلت سینگ باکس در هر حالت اگه ماکس در پنل فعال باشه دیگه اون کانفیگ در سینگ باکس کار نمینه (چون ماکس در سینگ باکس فعال میشه که نباید بشه) تا قبل از این، اینطور نبود و ماکس در سینگ باکس فعال نمیشد | closed | 2024-06-02T05:42:30Z | 2024-06-02T05:59:14Z | https://github.com/Gozargah/Marzban/issues/1027 | [
"Duplicate"
] | plasticgholam | 1 |
pydantic/pydantic | pydantic | 10,851 | AliasPath support for Models | ### Initial Checks
- [X] I have searched Google & GitHub for similar requests and couldn't find anything
- [X] I have read and followed [the docs](https://docs.pydantic.dev) and still think this feature is missing
### Description
Given what I could test/research about the `AliasPath` feature, it seems to only suppor... | open | 2024-11-15T02:51:34Z | 2025-03-20T18:24:54Z | https://github.com/pydantic/pydantic/issues/10851 | [
"feature request",
"help wanted"
] | TheCaffinatedDeveloper | 6 |
QuivrHQ/quivr | api | 3,260 | #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3260 #3... | Create knowledge should add url files | closed | 2024-09-25T16:02:00Z | 2024-09-25T16:08:31Z | https://github.com/QuivrHQ/quivr/issues/3260 | [] | linear[bot] | 1 |
recommenders-team/recommenders | data-science | 1,718 | [ASK] How can I save SASRec model for re-training and prediction? | I have tried to save trained SASRec model.
pickle, tf.saved_model.save, model.save(), and surprise.dump are not working.
While saving, I got warning saying 'Found untraced functions',
and while loading, 'AttributeError: 'SASREC' object has no attribute 'seq_max_len''.
Plz someone let me know how to save and... | open | 2022-05-13T18:23:23Z | 2023-08-30T14:03:13Z | https://github.com/recommenders-team/recommenders/issues/1718 | [
"help wanted"
] | beomso0 | 2 |
jschneier/django-storages | django | 959 | AWS_S3_FILE_OVERWRITE should be False by default | All Django's builtin storages do not overwrite files by default -- they append a number when there's collision.
I've been using `S3Boto3Storage` for quite some time, and suddenly found that many of my files were mixed up -- models seems to have a reference to the wrong on-disk file. After some research, it turns out... | open | 2020-11-22T20:36:55Z | 2023-06-22T16:46:41Z | https://github.com/jschneier/django-storages/issues/959 | [] | WhyNotHugo | 1 |
mkhorasani/Streamlit-Authenticator | streamlit | 176 | no cookie is written - help would be great ;) | I've tried a lot but I can't get it to work - any help would be much appreciated
Problem is that no cookie is written. So the reauthentication is not working.
here are the versions used:
```
Package Version
-------------------------- ---------
extra-streamlit-components 0.1.71
streamlit ... | closed | 2024-07-10T07:56:20Z | 2024-07-10T08:40:13Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/176 | [
"help wanted"
] | Volker-H | 1 |
joeyespo/grip | flask | 213 | Fresh install of Grip (4.3.2) installing components in /usr/local/lib/python2.7 instead of python3 | Everything works, but I want to use Python 3 instead of 2.7 (philosophical reasons + OCD).
Here's what I see when I upgrade:
```
$ pip install --upgrade grip
Requirement already up-to-date: grip in /usr/local/lib/python2.7/site-packages
Requirement already up-to-date: docopt>=0.6.2 in /usr/local/lib/python2.7/site-pa... | closed | 2016-09-30T18:26:49Z | 2016-09-30T21:50:58Z | https://github.com/joeyespo/grip/issues/213 | [
"not-a-bug"
] | erikr | 2 |
vanna-ai/vanna | data-visualization | 335 | Multiple rounds of conversations | Does Vanna support multiple rounds of dialogue?
Ask again based on the answer to the previous question | closed | 2024-04-03T04:19:39Z | 2024-04-04T02:03:20Z | https://github.com/vanna-ai/vanna/issues/335 | [] | tzh5477 | 0 |
allenai/allennlp | nlp | 5,734 | New version with upper bounds on dependencies removed | The upper bound on the version of spaCy allowed was removed in #5733. When can we expect a new release of AllenNLP with this change?
Thanks!
| closed | 2022-11-22T19:54:41Z | 2022-12-07T16:20:21Z | https://github.com/allenai/allennlp/issues/5734 | [
"Feature request",
"stale"
] | Frost45 | 2 |
scikit-hep/awkward | numpy | 3,403 | Question on performance | ### Version of Awkward Array
2.7.4
### Description and code to reproduce
numpy 1.26.4
pyarrow 19.0.0
The origin of the data I will use here is not really important, but for reference, it is:
[1.9GB of points](
https://github.com/geoarrow/geoarrow-data/releases/download/v0.1.0/microsoft-buildings-point.arrow) in fea... | open | 2025-02-21T23:26:44Z | 2025-02-27T15:53:16Z | https://github.com/scikit-hep/awkward/issues/3403 | [
"performance"
] | martindurant | 17 |
marimo-team/marimo | data-visualization | 3,348 | Group By Transform in `mo.ui.dataframe(df)` does not return valid Polars code | ### Describe the bug
Group By Transform in `mo.ui.dataframe(df)` does not return valid Polars code.
Details in example below. It is pretty easy to see what is going wrong.
### Environment
<details>
In WASM, so unsure how to run `marimo env`
Instead, here are the package versions I am using
```
marimo.__version__: ... | closed | 2025-01-06T12:58:02Z | 2025-01-08T15:48:39Z | https://github.com/marimo-team/marimo/issues/3348 | [
"bug"
] | henryharbeck | 1 |
dinoperovic/django-salesman | rest-api | 48 | Modify order | Often an order that is placed needs to be changed before shipping - i.e. customer calls in and meant to add 7 more widgets to the order.
It would be awesome if there was a method or workflow to facilitate the modification of an order. I have also considered "replacing" an order so that order history is preserved - b... | open | 2024-08-06T15:02:08Z | 2024-08-06T15:02:08Z | https://github.com/dinoperovic/django-salesman/issues/48 | [] | thenewguy | 0 |
amdegroot/ssd.pytorch | computer-vision | 391 | one problem | forward
loss_c[pos] = 0 # filter out pos boxes for now
IndexError: The shape of the mask [1, 8732] at index 0 does not match the shape of the indexed tensor [8732, 1] at index 0
How can i deal with it?Please help me | open | 2019-07-29T08:48:19Z | 2019-09-12T09:52:54Z | https://github.com/amdegroot/ssd.pytorch/issues/391 | [] | OscarYoungDepend | 3 |
google-research/bert | nlp | 690 | Why not use a more powerful tokenizer here | https://github.com/google-research/bert/blob/0fce551b55caabcfba52c61e18f34b541aef186a/run_squad.py#L239-L245
The word with punctuation cannot be separated. The function `improve answer span` is used to recover from this error? | open | 2019-06-11T01:57:36Z | 2019-06-11T01:57:57Z | https://github.com/google-research/bert/issues/690 | [] | lixinsu | 0 |
miguelgrinberg/Flask-SocketIO | flask | 889 | client not receiving emit from socketio.emit at a certain part of code | socketio.emit('my_response',
{'message':'First emit'},
namespace='/test') # saw 'SENDING' on the log and received by client
'''
CODE FOR SOME LONG RUNNNIG PROCESS (> 1 min)
'''
socketio.emit('my_respons... | closed | 2019-01-29T20:31:52Z | 2019-05-19T07:36:57Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/889 | [
"question"
] | witchapong | 1 |
strawberry-graphql/strawberry | django | 3,759 | `all_fields=True` causes incompatibility with redis-om package in pydantic v2 | <!-- Provide a general summary of the bug in the title above. -->
I was able to narrow down a compatibility bug to adding `all_fields=True` in redis-om's custom pydantic models
namely: `HashModel`, `JsonModel`, `EmbeddedJsonModel`
<!--- This template is entirely optional and can be removed, but is here to help both ... | open | 2025-01-30T21:10:48Z | 2025-02-15T05:45:02Z | https://github.com/strawberry-graphql/strawberry/issues/3759 | [
"bug"
] | XChikuX | 2 |
davidsandberg/facenet | tensorflow | 1,191 | Batch Size for Online Triplet Mining | Hi,
I read through the official paper of FaceNet and there it is stated, that a batch size of 1800 is used for online triplet mining. This number seems to be quite high. I have acces to an IBM Power Instance with a 32GB Nvidia Tesla V100 GPU but having a batch size that large with images from the LFW is infeasible. ... | open | 2021-01-18T16:18:16Z | 2021-03-05T12:08:27Z | https://github.com/davidsandberg/facenet/issues/1191 | [] | Neihtq | 1 |
collerek/ormar | pydantic | 746 | Unable to use `.json` on pydantic Model containing ormar Model with ForeignKey | **Describe the bug**
Using `.json()` on a pydantic `Model` that has ormar `Model` with a `ForeignKey` in its fields results in
`AttributeError: 'Model' object has no attribute '_orm'`.
**To Reproduce**
```py
import asyncio
import databases
import ormar
import pydantic
import sqlalchemy
DATABASE_URL = "s... | closed | 2022-07-17T04:51:39Z | 2022-07-19T15:11:18Z | https://github.com/collerek/ormar/issues/746 | [
"bug"
] | Shmookoff | 1 |
autogluon/autogluon | data-science | 4,971 | GPU Acceleration Feature Request | ## Description
This feature request proposes adding GPU acceleration capabilities through RAPIDS integration across all modules (`multimodal`, `tabular`, `timeseries`). The goal is to provide significant performance improvements for data processing and model training by leveraging GPU acceleration instead of CPU-only o... | open | 2025-03-10T18:47:13Z | 2025-03-18T13:44:18Z | https://github.com/autogluon/autogluon/issues/4971 | [
"enhancement",
"module: tabular",
"module: timeseries",
"module: core"
] | raphasamymarcura | 0 |
ultralytics/ultralytics | pytorch | 19,471 | The matrix multiplication in the post-processing stage of YOLOSEG is quite time-consuming when performed on the CPU of edge devices. Why not include this operation in the model during export and utilize the GPU for inference? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
The matrix multiplication in the post-processing stage of YOLOSEG is quite t... | open | 2025-02-28T03:38:07Z | 2025-03-04T08:44:15Z | https://github.com/ultralytics/ultralytics/issues/19471 | [
"question",
"segment",
"embedded",
"exports"
] | luoshiyong | 8 |
pytest-dev/pytest-xdist | pytest | 861 | "Pin" certain parameters to a process? | I have a bunch of tests (all in one project) following pretty much the same pattern:
```python
import pytest
@pytest.mark.parametrize("foo", ["a", "b"]) # pin those permutations to one process?
@pytest.mark.parametrize("bar", ["c", "d"])
def test_something(foo: str, bar: str):
pass
```
I'd like to pa... | closed | 2022-12-31T15:27:27Z | 2023-01-09T12:22:23Z | https://github.com/pytest-dev/pytest-xdist/issues/861 | [] | s-m-e | 1 |
pnkraemer/tueplots | matplotlib | 53 | Updates to the beamer styles | ### Updates to the beamer styles:
* The 0.8 in beamer should be replaced by rel_width, which should default to 0.8. (do we want to default rel_height=0.9 and rel_width=0.6?)
* The font-weights of the beamer_moml() setting should be set to "light", akin to
```python
plt.rcParams["font.weight"] = "light"
plt.rcPa... | closed | 2022-01-12T18:01:10Z | 2022-01-13T06:41:29Z | https://github.com/pnkraemer/tueplots/issues/53 | [] | pnkraemer | 0 |
dask/dask | scikit-learn | 11,230 | Roundtripping timezone-aware DataFrame through parquet doesn't preserve timestamp resolution | While diagnosing some of the failures we're seeing over in https://github.com/coiled/dask-bigquery/pull/81, I stumbled across an issue with roundtripping timezone-aware timeseries data through parquet with Dask. Here's a minimal reproducer:
```python
import random
import pandas as pd
import dask.dataframe as dd... | closed | 2024-07-16T21:30:09Z | 2024-07-17T16:25:48Z | https://github.com/dask/dask/issues/11230 | [
"dataframe"
] | jrbourbeau | 0 |
plotly/dash | dash | 3,044 | html.Script not rendering the javascript code | Hi,
I'm trying to run a javascript code wrapped in `html.Script`. But it's not rendering the JS code.
```
recharts_js = """
const { BarChart, Bar, XAxis, YAxis, Tooltip, Legend, CartesianGrid, ResponsiveContainer } = Recharts;
const data = [
{ dmu: "dmu1", "Efficiency score": 100, Status: "Efficient" },
... | closed | 2024-10-16T18:13:35Z | 2024-10-16T19:39:13Z | https://github.com/plotly/dash/issues/3044 | [] | namakshenas | 1 |
waditu/tushare | pandas | 796 | 新股数据接口,上市日期还没有,建议返回null | 如下图,新股还没有上市建议返回null哈,而不是"nan"
欢迎奖励积分
邮箱:max_lzd@163.com
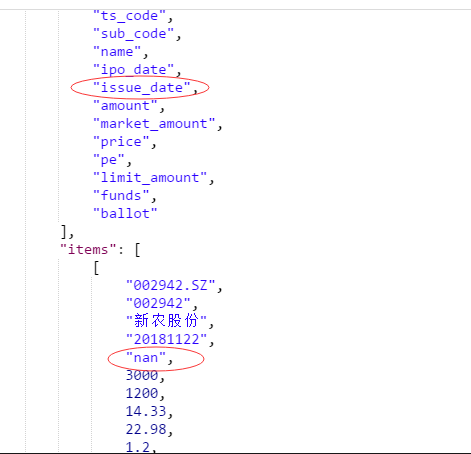
| open | 2018-11-02T16:18:48Z | 2018-11-02T16:18:48Z | https://github.com/waditu/tushare/issues/796 | [] | LeoZeda | 0 |
ultralytics/ultralytics | python | 19,648 | can not run tensorrt,bug error: module 'tensorrt' has no attribute '__version__' | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Install
### Bug
i download the right cuda、cudnn、torch、vision,and the i download the tensorrt 8.5 GA in my windows.
when i ... | closed | 2025-03-11T18:20:51Z | 2025-03-12T07:18:29Z | https://github.com/ultralytics/ultralytics/issues/19648 | [
"dependencies",
"exports"
] | Hitchliff | 4 |
simple-login/app | flask | 1,973 | Your domains got blocked in disposable list | Hi!
On https://github.com/mstfknn/email-providers/ list you got blocked!
Can you please take a look?
For now pm.me, proton.me, protonmail.com, protonmail.ch, slmail.me got blocked!
@nguyenkims @acasajus @cquintana92 | open | 2023-12-16T09:52:59Z | 2024-02-17T14:43:56Z | https://github.com/simple-login/app/issues/1973 | [] | Jasi1997 | 1 |
Farama-Foundation/Gymnasium | api | 796 | [Bug Report] Environment not resetting at termination. | ### Describe the bug
The environment not resetting when the termination condition is True.
### Code example
```shell
import numpy as np
import gymnasium as gym
from gymnasium import spaces
from stable_baselines3.common.env_checker import check_env
ARRAY = np.linspace(0, 10)
TOTAL_DAYS = len(ARRAY)
N_D... | closed | 2023-11-27T05:58:36Z | 2023-11-27T09:33:39Z | https://github.com/Farama-Foundation/Gymnasium/issues/796 | [
"bug"
] | psymbio | 2 |
huggingface/transformers | python | 36,579 | AutoModel failed with empty tensor error | ### System Info
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.50.0.dev0
- Platform: Linux-4.18.0-553.16.1.el8_10.x86_64-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.28.1
- Safetensors version: 0.5.2
- Accelerate version... | closed | 2025-03-06T07:57:25Z | 2025-03-13T17:18:16Z | https://github.com/huggingface/transformers/issues/36579 | [
"bug"
] | jiqing-feng | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.