
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Mac Mini на M1: взгляд изнутри

Ранее мы говорили про [Mac Mini в дата-центрах](https://habr.com/ru/company/selectel/blog/540494/). В этой статье мы заглянем «под капот» новейшего mac на базе SoC M1 в прямом и переносном смыслах. ... | https://habr.com/ru/post/544378/ | null | ru | null |
# Это мог быть очередной JavaScript-фреймворк
Прошлым летом, в процессе подготовки [статьи](https://habr.com/ru/company/lanit/blog/462855/) для Хабра, я не поленился упаковать свой шаблон для бэкэнд-приложений на Node.js в npm-пакет, сделав из него cli-утилиту для быстрого старта.
Никаких надежд на то, что этим пакет... | https://habr.com/ru/post/487648/ | null | ru | null |
# #2 Блок управления видеослайдером
Привет, хабравчане! Помните мой [моторизованный видеослайдер](https://geektimes.ru/post/259040/) из мебельной фурнитуры, строительного правило и оргстекла?)
Сегодня я вам покажу новую штуку, чуть попроще, чем предыдущий проект. На этот раз без рельсы, только электрическая часть.... | https://habr.com/ru/post/395557/ | null | ru | null |
# Каламбуры на css
Хабровчане, всех с пятницей! Сейчас у подавляющего большинства читателей хабра рабочий день уже закончился, поэтому можно расслабиться и немного отвлечься от серьезных тем. Вы знали, что на css можно каламбур... | https://habr.com/ru/post/261769/ | null | ru | null |
# test.it — не опять, а снова
Добрый день хабр.
После моей [статьи](http://habrahabr.ru/post/188268/) о **test.it** прошла ~~вечность~~ неделя. И как я не планировал растянуть этот срок хотя бы на месяц, но пришло время для новой публикации.
Картинка для привлечения внимания:
 с длинным названием (и, конечно же, имени очередного великого лидера партии) я увидел в куче хлама, п... | https://habr.com/ru/post/242263/ | null | ru | null |
# Small Basic — для тех, кто только начинает
Всем привет, а особенный привет тем, кто хочет начать программировать, и не знает на чем начать и какую среду разработки предпочесть.
Сегодня я расскаж... | https://habr.com/ru/post/87447/ | null | ru | null |
# Моделирование доходов от подписки
Если вы являетесь аналитиком данных в SaaS-компании или предприятии электронной коммерции с компонентом подписки, вас обязательно попросят проанализировать такие метрики, как отток, апгрейды и даунгрейды. Данные показатели помогают бизнесу понять состояние вашей базы подписчиков:
*... | https://habr.com/ru/post/704240/ | null | ru | null |
# Автоматизация загрузки только новых серий torrent-раздач (.bat + curl + aria2c) [HowTo]
За ужином интересно посмотреть что-то взрывное престольное или из позднего.
И совсем неприятно, когда стол накрыт, а ты начинаешь лихорадочно проверять по всем раздачам «а не появилось ли чего нового».
И в лучшем случае да... | https://habr.com/ru/post/180173/ | null | ru | null |
# Как я делал хардварный чат — а получился всё равно софтварный ¯\\_(ツ)_/¯
[](https://habr.com/ru/company/ruvds/blog/707568/)*Картинка [rawpixel.com, Freepik](https://www.freepik.com/free-photo/cloud-computing-banner-background-smart... | https://habr.com/ru/post/707568/ | null | ru | null |
# Kali Linux: упражнения по модификации пакетов, сборке ядра и созданию ISO-образов
Сегодня публикуем перевод завершения девятой главы книги «[Kali Linux Revealed](https://kali.training/introduction/kali-linux-revealed-book/)». Здесь будут подведены итоги таких тем, как модификация пакетов, сборка ядра и создание собс... | https://habr.com/ru/post/342406/ | null | ru | null |
# Простой zero-copy рендеринг аппаратно ускоренного видео в QML
Введение
--------
Целью данной статьи является продемонстрировать способ как можно подружить сторонние видео буфера и QML. Основная идея — использовать стандартный QML компонент VideoOutput. Он позволяет подсовывать сторонние источники, неплохо документи... | https://habr.com/ru/post/486062/ | null | ru | null |
# PostgreSQL 8.3
 Джош Беркус (Josh Berkus) [объявил](http://www.postgresql.org/about/news.872) о выходе PostgreSQL 8.3beta1 (см. [официальный Changelog](http://www.postgresql.org/docs/8.3/static/release-8-3.html)). Более полугода потребовалось р... | https://habr.com/ru/post/14933/ | null | ru | null |
# Telegram MTPROTO Proxy — всё что мы знаем о нём

Сразу после событий с блокировками Telegram в Иране и России, в бета-версиях мессенджера начал появлятся новый тип Proxy, а если быть точным, новый п... | https://habr.com/ru/post/359348/ | null | ru | null |
# Сэмплирование Томпсона
Сэмплирование Томпсона — это один из самых сложных способов решения задачи «многорукого бандита».
Задача
------
Маленький Робот потерялся в торговом центре. С помощью обучения с подкреплением мы хотим помочь ему найти свою маму. Но прежде чем он начнёт её искать, ему нужно подзарядиться от н... | https://habr.com/ru/post/547258/ | null | ru | null |
# Краткий курс компьютерной графики, аддендум: ambient occlusion
---
### Official translation (with a bit of polishing) is available [here.](https://github.com/ssloy/tinyrenderer/wiki)
---
В кратком курсе компьютерной графики, что я предоставил вашему рассмотрению пару недель назад, мы пользовались методами локальн... | https://habr.com/ru/post/250769/ | null | ru | null |
# Как собрать статистику с веб-сайта и не набить себе шишек

Привет, Хабр! Меня зовут Слава Волков, и я фронтенд-разработчик в Badoo. Сегодня я хотел бы немного рассказать про сбор статистики с фрон... | https://habr.com/ru/post/325062/ | null | ru | null |
# Применение R при вычислениях с повышенной точностью
Периодически встречаются задачи, даже в обыденной жизни, когда разрядной точности `float64`/`int64` оказывается недостаточной для того, чтобы получить ответ с требуемой точностью. Метаться в поисках другого инструмента? Тоже вариант.
А можно этого и не делать, а п... | https://habr.com/ru/post/501472/ | null | ru | null |
# How to Get Nice Error Reports Using SARIF in GitHub
Let's say you use GitHub, write code, and do other fun stuff. You also use a static analyzer to enhance your work quality and optimize the timing. Once you come up with an idea - why not view the errors that the analyzer gave right in GitHub? Yeah, and also it woul... | https://habr.com/ru/post/541540/ | null | en | null |
# Использование эмоциональных иконок Emoji в коммитах на GitHub

Некоторое время назад, сервис GitHub [анонсировал](https://github.com/blog/1289-emoji-autocomplete) возможность использовать эмоциональные ик... | https://habr.com/ru/post/205010/ | null | ru | null |
# Различия между MVVM и остальными MV*-паттернами

> *От переводчика*:
>
> *Уже опубликовано много материалов по MVC и его производным паттернам, но каждый понимает их по-своему. На этой почве возникают разногласия и холив... | https://habr.com/ru/post/313538/ | null | ru | null |
# Парсинг сайтов судов общей юрисдикции в России
### История о том, как выявлять новые иски к клиенту
Содержание
----------
1. [Введение](https://1)
2. [Парсить сайты судов общей юрисдикции - законно?](https://2)
3. [Разведка боем](https://3)
4. [Что нужно от сайта](https://4)
5. [Выбор стратегии поиска](https://5)
... | https://habr.com/ru/post/679514/ | null | ru | null |
# Статическое тестирование безопасности опенсорсными инструментами

Уязвимости в своём коде хочется находить как можно быстрее, а значит нужно автоматизировать этот процесс. Как именно автоматизировать поиск уязвимостей? Существует д... | https://habr.com/ru/post/486722/ | null | ru | null |
# Продакшн-реди eBPF, или как мы исправили BSD socket API
Разрабатывая новые продукты, мы зачастую выводим нашу операционную систему — Linux — за рамки общепринятых возможностей. Распространенной темой было и... | https://habr.com/ru/post/660561/ | null | ru | null |
# TAG_ADD Plugin
**Привет, %username%**
Как-то раз мне пришлось писать форму для добавления постов в блог. Помимо стандартных полей (название, дата, текст и.т.д.) необходимо было привинтить юзабельную форму добавления тегов.
Т.к. я кодю в jQu... | https://habr.com/ru/post/66125/ | null | ru | null |
# Cron в Linux: история, использование и устройство

Классик писал, что счастливые часов не наблюдают. В те дикие времена ещё не было ни программистов, ни Unix, но в наши дни программисты знают твёрдо: вместо них за временем просле... | https://habr.com/ru/post/468061/ | null | ru | null |
# Как я изобретал велосипед, изучая технологии
Неоднократно слышал утверждение, что язык программирования изучать лучше всего в процессе создания чего-либо. Не мог с этим не согласиться, и решил, что это распространяется не... | https://habr.com/ru/post/151641/ | null | ru | null |
# Alias DNS-записи: что это и когда использовать

Привет, Хабр! Меня зовут Виктор, я разработчик в Selectel. Часто ко мне обращаются клиенты и спрашивают, в каких ситуациях использовать DNS-записи типа alias. Вопросы появляются на по... | https://habr.com/ru/post/712722/ | null | ru | null |
# Устройство и работа портов ввода-вывода микроконтроллеров AVR. Часть 2
**Подключение светодиода к линии порта ввода/вывода**
Изучив данный материал, в котором все очень детально и подробно описано с большим количеством примеров, вы сможете легко овладеть и программировать порты ввода/вывода микроконтроллеров AVR.... | https://habr.com/ru/post/253961/ | null | ru | null |
# Робот-тележка на ROS. Часть 8. Управляем с телефона-ROS Control, GPS-нода
Продолжение цикла статей.
Посты серии:
[8. Управляем с телефона-ROS Control, GPS-нода](https://habr.com/ru/post/474650/)
[7. Локализация робота: gmapping, AMCL, реперные точки на карте помещения](https://habr.com/ru/post/472984/)
[... | https://habr.com/ru/post/474650/ | null | ru | null |
# Оптимизация сборки мусора в высоконагруженном .NET сервисе
Ежедневно в сервисе Pyrus работают десятки тысяч сотрудников из нескольких тысяч организаций по всему миру. Отзывчивость сервиса (скорость обработки запросов) мы считаем важным конкурентным преимуществом, так как она напрямую влияет на впечатление пользовате... | https://habr.com/ru/post/452298/ | null | ru | null |
# ‘Hello World’ tutorial — Ваше первое приложение на Play framework (Часть 2)
Это очень поверхностное руководство, которое только познакомит с базовым функционалом Play framework на примере создания приложения ‘Hello World’.
[(Часть 1)](http://habrahabr.ru/blogs/java/111420/)
Создание формы
==============
Начнё... | https://habr.com/ru/post/111464/ | null | ru | null |
# Интересные способы использования Go каналов (перевод)
*Предлагаю вам перевод статьи [Gary Willoughby](http://nomad.so/author/admin/) [«Interesting ways of using Go channels»](http://nomad.so/2016/01/interesting-ways-of-using-go-channels/).*
*Статья предназначена для тех, кто уже немного разбирается в Go.*
[ В этом посте я расскажу об инструменте для быстрого поиска строк в базе данных и навигации по ним. Если вы работаете в поддержке и вам приходится выполнять много запросов к б... | https://habr.com/ru/post/478638/ | null | ru | null |
# Дудл от Гугл на день всех влюбленных
[Гугл](http://google.ru) вывесил на главную дудл ко дню всех влюбленных.
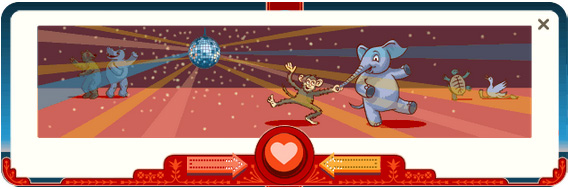
Дудл представляет собой небольшую игру, в которой две карусели играют ... | https://habr.com/ru/post/169355/ | null | ru | null |
# Создание игры Tower Defense в Unity — Часть 2
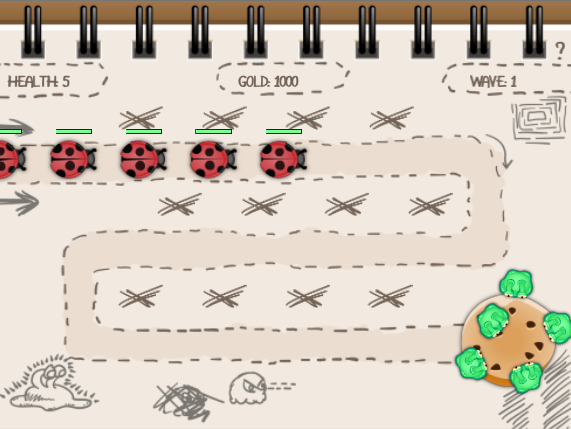
Это вторая часть туториала *«Создание игры Tower Defense в Unity»*. Мы создаём в Unity игру жанра tower defense, и к концу [первой части](https://habr.c... | https://habr.com/ru/post/413915/ | null | ru | null |
# Автоматизируем ведение большого количества пользователей в AD
Автоматизируем ведение большого количества пользователей в AD:
Добрый день! В этой статье я бы хотел описать применённое мной практическое решение по автоматизации одной рутинной задачи второй линии технической поддержки одного крупного предприятия. ... | https://habr.com/ru/post/553666/ | null | ru | null |
# Cli-IDE для Oracle СУБД. Ну. Почти IDE
Добрый день.
Первый вопрос: зачем, есть же Toad/SQL-developer/PLSQL-developer и т.п. графические ide-среды.
Ну. Да. Есть. Однако не всем именно они нужны, как средство работы с объектами oracle-субд.
Т.е. я тут, в этой статье - не именно для oracle-разработчиков буду расск... | https://habr.com/ru/post/539118/ | null | ru | null |
# Next js. Куда, откуда и причем здесь google?
Прошло уже почти 2 недели с момента презентации next 11. К сожалению, эта новость обошла хабр стороной и пора бы это исправить. Сперва немного о презентации. Эт... | https://habr.com/ru/post/565122/ | null | ru | null |
# Интеграция phpBB в сайт (Codeigniter). Сквозная авторизация
Несколько недель назад по некой нужде было необходимо добавить форум в только что написанный сайт. Сайт на этапе завершения, пользователей раз-два и обчелся. С... | https://habr.com/ru/post/253773/ | null | ru | null |
# Дерево разделов неограниченной вложенности и URL
В данной статье мы рассмотрим один из возможных подходов к генерации полного пути на раздел, у которого может быть неограниченная вложенность в другие разделы, а также быстрое получение нужного раздела по заданному пути.
Представим, что мы программируем интернет-ма... | https://habr.com/ru/post/279233/ | null | ru | null |
# Планшет — не роскошь
*«У современных мобильных телефонов такая же вычислительная мощь, что и у компьютеров NASA в 60-е годы. И в то время этого хватало, чтобы запустить человека в космос, а сегодня — только чтобы запускать птиц в свиней.»
Фольклор*
*«Вы назовете это извращением. Но кто сказал, что извращение —... | https://habr.com/ru/post/168411/ | null | ru | null |
# Числовые подписи
Меня всегда завораживала магия программирования — маленькие фокусы, в которых бессмысленный на первый взгляд код делает что-то интересное. Самые известные из них — «подписи», которые выводят на печать короткий текст (обычно имя автора). В прошлый раз я [показала](http://habrahabr.ru/blogs/crazydev/1... | https://habr.com/ru/post/112831/ | null | ru | null |
# Совместное моделирование быстродействующих систем средствами TIA Portal и Simulink
В этой работе показана детальная авторская реализация объединения сред TIA Portal и Simulink для совместного моделирования с обменом данными, работающая при любом, даже самом малом, шаге квантования (моделирования). Этот вариант позво... | https://habr.com/ru/post/689654/ | null | ru | null |
# Для чего компании нужен UI KIT? (Frontend + Design)
*В этой статье мы расскажем, что такое UI KIT, для чего он нужен, и как он сэкономит время и деньги.*
В статье мы подойдем к китам, которые сделаны не только дизайнерами, но также переведены в компоненты фронтенд-разработчиками.
### Что такое UI KIT?
Это единый ... | https://habr.com/ru/post/583876/ | null | ru | null |
# Алгоритм Order-Independent Transparency c использованием связных списков на Direct3D 11 и OpenGL 4
Реализацию порядко-независимой прозрачности ([order-independent transparency](http://en.wikipedia.org/w... | https://habr.com/ru/post/224003/ | null | ru | null |
# Оптимизируем память Rails сервиса (реальный кейс)
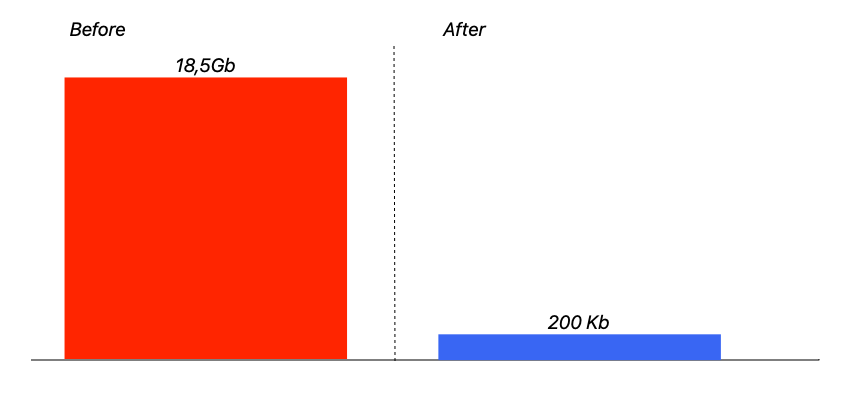
> Для Ruby и Ruby on Rails разработчиков уровня Junior+, Middle
Мы часто пишем код, не вникая, сколько ресурсов уйдет на его выполнение. И это может быть ок. Но, во-первых, каждый н... | https://habr.com/ru/post/494862/ | null | ru | null |
# Самые распространенные ошибки в вашем React коде, которые вы (возможно) делаете

Вдохновленный прочитанными статьями на медиуме, я решил написать свою статью и рассказать вам как можно избегать самых распространенных ошибок в вашем... | https://habr.com/ru/post/416511/ | null | ru | null |
# Скорость времени
Сколько нужно времени, чтобы снять показания времени? Каков хронометраж времени? Эти странные вопросы выплыли в публичную плоскость еще в 2014 году, когда Netflix переносил свои сервисы с CentOS Linux на Ubuntu, а автору этой статьи довелось помогать в отладке некоторых причудливых проблем с произво... | https://habr.com/ru/post/682930/ | null | ru | null |
# Рисуем коммитами на Гитхабе
[Пятничное]
Всегда хотел сделать свой график активности пользовательского профиля на Гитхабе. Например, выкладывать коммиты каждый день так, чтобы через год этот график превратился в какую-нибудь картинку, пусть и с ограничением по размерам в 52×7 квадратиков-пикселей (52 недели в году ×... | https://habr.com/ru/post/319298/ | null | ru | null |
# Перемещаем ViewState в конец страницы
### Проблема
Продолжаем борьбу с ViewState при использовании WebForms (использование данной технологии обусловлено ~~политикой партии~~ применением [паттерна WCSF](http://msdn.microsoft.com/ru-ru/library/bb264518(en-us).aspx) в проектах фирмы).
В [предыдущей статье](http://h... | https://habr.com/ru/post/77187/ | null | ru | null |
# Основные приемы работы с Canvas [Part 1]
Привет! Сегодня я хотел бы начать цикл статей на тему того, как работать с canvas в HTML5 и как применять знания в области матанализа для реализации необычных и инт... | https://habr.com/ru/post/650175/ | null | ru | null |
# MagOS Linux (сентябрьский выпуск)
Из многих Linux дистрибутивов хотелось найти что-то необычное и обязательно разработанное своими софтвэр энжиниирами, оригинальное.
Magos оказался не совсем дистрибутивом в привычном понимании, а новым шагом живых операционных систем.
 я рассказал о возможности доступа к методам раздела messages через документацию, для чего достаточно было лишь авторизоваться на сайте ВК. Многие тогда заявили, что это не является угрозой л... | https://habr.com/ru/post/491554/ | null | ru | null |
# Катаморфизм в F#
### Введение
Упомяну сразу, данная статья написана по мотивам целой серии постов в отличном блоге [Inside F#](http://lorgonblog.spaces.live.com). Тем не менее она не является переводом в чистом виде, а скорее вольным изложением, чтобы доступным языком объяснить — что же за зверь такой, катаморфизм,... | https://habr.com/ru/post/57503/ | null | ru | null |
# Про утечку памяти в одном серверном приложении
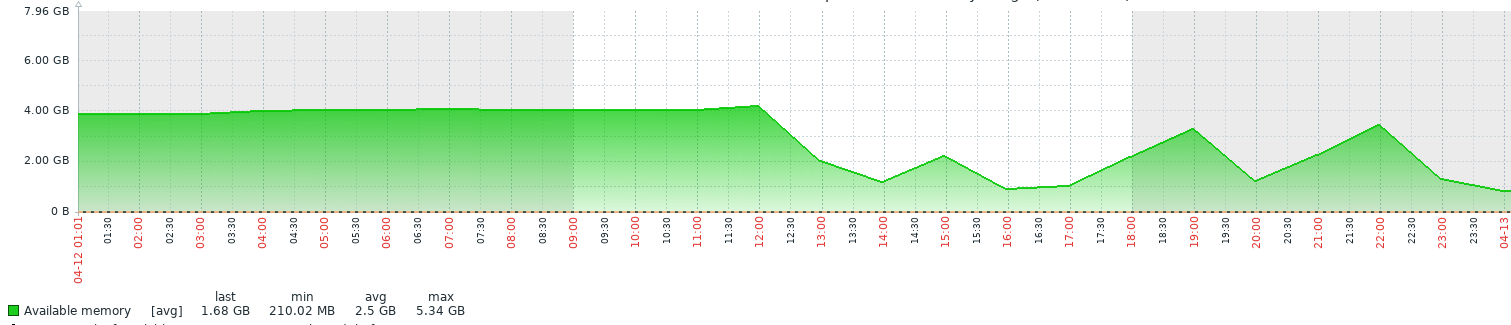
Прочитав данную заметку вы узнаете, через что пришлось пройти после неожиданно возникшей утечки памяти серверного приложения в ОС FreeBSD. Какие современные средства обнаружения подоб... | https://habr.com/ru/post/354370/ | null | ru | null |
# Настройка DKIM/SPF/DMARC записей или защищаемся от спуфинга
Приветствую, Хабр! В этой статье будет инструкция по настройке DKIM/SPF/DMARC записей. А побудило меня написать эту статью полное отсутствие документации на русском языке. Все статьи на эту тему, которые были мной найдены, были крайне не информативны.
##... | https://habr.com/ru/post/322616/ | null | ru | null |
# Учим NAS Synology маршрутизировать трафик в OpenVPN туннель с аутентификацией по сертификату
Понадобилось мне чтобы некоторые сайты думали что я нахожусь не в Европе, а в России. Да и свой интерес ... | https://habr.com/ru/post/216197/ | null | ru | null |
# Замолвим слово об отладке и профилировании [PHP]
Все идет от лени. Вы получили чужой очень большой проект в котором нужно сделать небольшие правки, или же написали скрипт и сразу не очевидно, что в нем еще требует оптимизации. Как быть? Читать и анализировать код, выводить каждый шаг на экран или в файл (var\_dump()... | https://habr.com/ru/post/210202/ | null | ru | null |
# MS SQL 2011 — Обработка ошибок
Новое полезное дополнение для SQL Server 2011 (Denali) – выражение **Throw**. Разработчики на .Net уже догадались наверно, где и как оно будет использоваться.
Это слово может использоваться в сочетании с управляющей конструкцией Try…Catch и позволяет послать уведомление о возникнов... | https://habr.com/ru/post/123507/ | null | ru | null |
# SIM800L + STM32 Bluepill + Rust. Как оно?
Несколько лет назад сделал себе на Arduino блок мониторинга питания дачного котла от UPS. Как показала практика, связка Arduino MEGA + шилд на SIM900 со стандартными библио... | https://habr.com/ru/post/594885/ | null | ru | null |
# Knight rider. Программируем плавную анимацию на микроконтроллере
Доброго времени суток.
Сегодня хочу вам рассказать как сделать плавную анимацию на микроконтроллере с помощью светодиодов. За основу взято микросхему attiny2313 фирмы Atmel, именно такая у меня ~~валялась~~ нашлась. Не буду углубляться в подробности... | https://habr.com/ru/post/79481/ | null | ru | null |
# Функциональное тестирование веб-приложений без боли
Иногда в жизни бывает так — вот ждёшь, ждёшь чего-то, изучаешь теорию по данному вопросу, рассматриваешь разные подходы к решению, дискутируешь с такими же ищущими как ты, внимаешь гласу признанных гуру, но не продвигаешься дальше ни на дюйм. Потом бросаешь, забыва... | https://habr.com/ru/post/109077/ | null | ru | null |
# Готовим плацдарм для react-приложения

Я хочу рассказать о процессе создание платформы для react приложения, которая использует [mobx](https://github.com/mobxjs/mobx) в качестве **M**odel-и. Пройти путь от пустой директор... | https://habr.com/ru/post/324232/ | null | ru | null |
# Понятие песочницы при разработке расширений для браузера Google Chrome
За 5 лет разработки расширений для браузера Google Chrome накопился некоторый опыт, которым хотелось бы поделиться в цикле статей и, по возможности, пояснить некоторые тонкости, подводные камни, а также описать как были удачно применены современн... | https://habr.com/ru/post/312290/ | null | ru | null |
# Как установить Kubernetes на сервер Ubuntu без Docker

Kubernetes прекращает поддержку Docker. Теперь, вся тяжелая работа, которую вы вложили в изучение, сильно изменится. Даже с самого начала пути ... | https://habr.com/ru/post/542042/ | null | ru | null |
# Вторая жизнь старых стрелочных индикаторов
Как-то попались мне в руки старые стрелочные индикаторы уровня от старого магнитофона, и я решил вдохнуть в них новую жизнь, сделав из них «хардварные виджеты» для отображения загрузки процессора и оперативной памяти компьютера.
[Всем привет! Меня зовут Саша и я backend разработчик. Нет, не на rust. Но раст мой любимый язык и недавно я задался целью портировать движок онлайн игры, написанный на C++. П... | https://habr.com/ru/post/690514/ | null | ru | null |
# Гравитационное поле на поверхности тел неправильной формы на примере кометы Чурюмова-Герасименко
Из закона всемирного тяготения известно, что на поверхности тел шарообразной формы ускорение свободного падения постоянно по модулю и направлено к центру шара. Для тел неправильной формы это правило, очевидно, не выполня... | https://habr.com/ru/post/271451/ | null | ru | null |
# Как за месяц сильно прокачаться в Data Science
Привет, хабр!

Меня зовут [Глеб](https://ru.linkedin.com/in/morozovgleb), я долгое время работаю в ритейловой аналитике и сейчас занимаюсь применением машинного обучения в ... | https://habr.com/ru/post/266421/ | null | ru | null |
# АНБ, Ghidra и единороги

На этот раз взгляд команды PVS-Studio привлекла Ghidra — большой и злой фреймворк для реверс-инжиниринга, с помощью которого можно анализировать различные бинарные файлы и делать с ни... | https://habr.com/ru/post/504780/ | null | ru | null |
# 1000-мерный куб: можно ли сегодня создать вычислительную модель человеческой памяти?
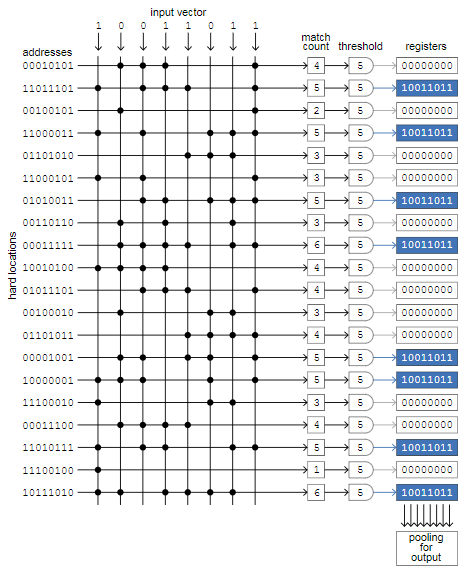
Сегодня утром на пути к кампусу Беркли я провёл пальцами по листьям ароматного куста, а затем вдохнул знакомый запах. Я делаю так каждый ден... | https://habr.com/ru/post/419147/ | null | ru | null |
# yUML — средство для генерации UML диаграмм для веба
Обнаружил забавное средство для быстрой генерации UML-диаграм для вставки в блоги, статьи и прочее. Интересность в том, что для того, чтобы вставить диаграмму в статью, нужно просто указать ссылку на изображение, в которой и описываются сами классы, с помощью специ... | https://habr.com/ru/post/59190/ | null | ru | null |
# Как применять Branch by Abstraction в проекте на примере Android-разработки
Представим простую историю. Вы заканчиваете делать рефакторинг, которым занимались последние 2 недели. Вы хорошо над ним поработал... | https://habr.com/ru/post/652029/ | null | ru | null |
# Два парадокса в программах на языке C
Хочу рассказать о двух странностях, с которыми мне пришлось столкнуться, программируя вычислительные алгоритмы на языке C.
Итак, первое неожиданное поведение для некоторых программистов. Вот маленькая прога.
```
#include
int main()
{
unsigned char a = 1, b;
b = ~a >> 1;... | https://habr.com/ru/post/201868/ | null | ru | null |
# Solaris Container (zone). Создание и администрирование. Часть 1
[Solaris Container (zone). Создание и администрирование. Часть 2](http://habrahabr.ru/blogs/sysadm/123621/)
#### Введение
Технология Solaris Zone (Solaris Container) – это технология, позволяющая разделить на программном уровне Solaris 10 ОС на конт... | https://habr.com/ru/post/123221/ | null | ru | null |
# Цифровой словарь от А до Я
Одной из самых полезных программ на ПК и смартфоне в моем понимании является электронный словарь. В те стародавние времена, когда я учил иностранный язык, каждое слово приходилось искать в бумажном словаре. Эту тривиальную операцию я проделывал сотни раз, а некоторые зловредные слова прихо... | https://habr.com/ru/post/421075/ | null | ru | null |
# Обзор uniset2-testsuite — небольшого велосипеда для функционального тестирования. Часть 2

В [первой части](https://habrahabr.ru/post/323290/) был обзор возможностей. А в этой части рассмотрим, какие уже реализованы интерф... | https://habr.com/ru/post/323444/ | null | ru | null |
# Машинное обучение для поиска ошибок в коде: как я стажировался в JetBrains Research
Недавно мы [рассказывали](https://habr.com/company/hsespb/blog/432912/) о том, как попасть на стажировку в Google. Помимо Google наши студенты пробуют свои силы в JetBrains, Яндекс, Acronis и других компаниях.
В этой статье я поде... | https://habr.com/ru/post/434368/ | null | ru | null |
# Внутренние механизмы ТСР, влияющие на скорость загрузки: часть 1
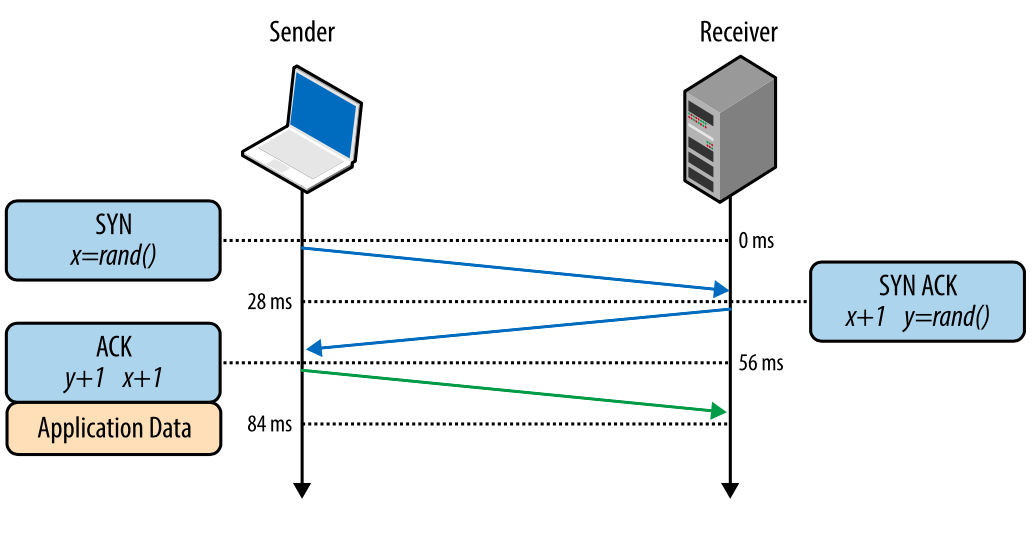
Ускорение каких-либо процессов невозможно без детального представления их внутреннего устройства. Ускорение интернета невозможно без понимания (и соответств... | https://habr.com/ru/post/326258/ | null | ru | null |
# Устаревшие Python-библиотеки, с которыми пора попрощаться
В Python, с каждым релизом, добавляют новые модули, появляются новые и улучшенные способы решения различных задач. Все мы привыкли пользоваться старыми добрыми Python-библиотеками, привыкли к определённым способам работы. Но пришло время обновиться, время вос... | https://habr.com/ru/post/681284/ | null | ru | null |
# Записки ярого спаммера (чукча не читатель!)
#### Комментирование блогов

**Комментирование блогов** — это размещение комментариев со ссылкой на продвигаемый сайт в блогах.
В данном случае, п... | https://habr.com/ru/post/143274/ | null | ru | null |
# Почему стоит полностью переходить на Ceylon или Kotlin (часть 1)
В последнее время активную популярность набирает Kotlin. А что если попробовать выбрать более экзотические языки, и применить к ним те же аргументы? Статья написана по мотивам [этой](https://habrahabr.ru/company/mailru/blog/329294/), практически повтор... | https://habr.com/ru/post/330412/ | null | ru | null |
# Введение в JavaScript итераторы на ES6
В EcmaScript 2015 (также известном как ES6) представлена совершенно новая концепция итераторов, которая позволяет задать последовательности (ограниченные и другие) на уровне языка.
Давайте поговорим об этом детальнее. Все мы хорошо знакомы с оператором цикла for, а многие да... | https://habr.com/ru/post/264345/ | null | ru | null |
# Доступ к VM в разных облаках по RDP и SSH (Windows и Linux)
[](https://habr.com/ru/company/ruvds/blog/696124/)
[IAP Desktop](https://github.com/GoogleCloudPlatform/iap-desktop) — полезная программа под Windows, которая управляет не... | https://habr.com/ru/post/696124/ | null | ru | null |
# Используем SWC с Firebase функциями
В этой статье рассмотрим использование компилятора для js-кода облачных функций.
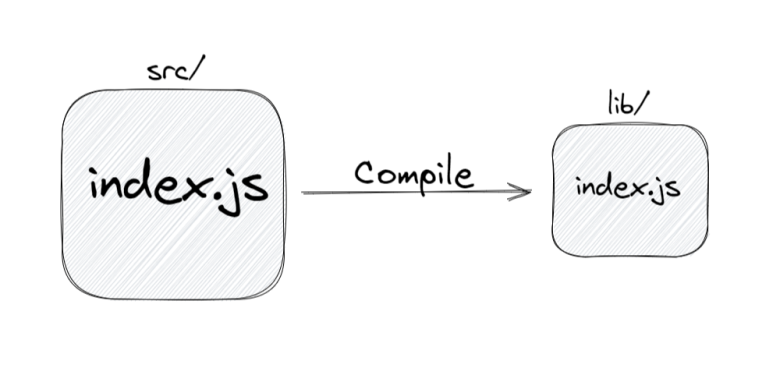Проблема
--------
Создаем проект. Добавляем Firebase функцию.
```
// index.js
export c... | https://habr.com/ru/post/670954/ | null | ru | null |
# bobaoskit — аксессуары, dnssd и WebSocket

Таким образом я описал строение системы управляемых программных аксессуаров.
Упрощенная модель включает в себя главный процесс(`bobaoskit.worker`) и скрипты аксессуаров(использующие объекты... | https://habr.com/ru/post/437846/ | null | ru | null |
# Definer.js — простая модульная система
Пока JavaScript не обзавёлся настоящими модулями мы продолжаем импровизировать.
Так появилась на свет ещё одна реализация модулей — [definer](https://github.com/tenorok/definer).
Главная идея этой модульной системы в отсутствии модульной системы. Исходные коды приложения ... | https://habr.com/ru/post/212817/ | null | ru | null |
# Service mesh для микросервисов. Часть II, основы работы с Istio
*Перевод статьи подготовлен специально для студентов курса [«Инфраструктурная платформа на основе Kubernetes»](https://otus.pw/w5x9/).*

Настройка базового микросервиса... | https://habr.com/ru/post/477434/ | null | ru | null |
# Запускаем консольные Java приложения на Android
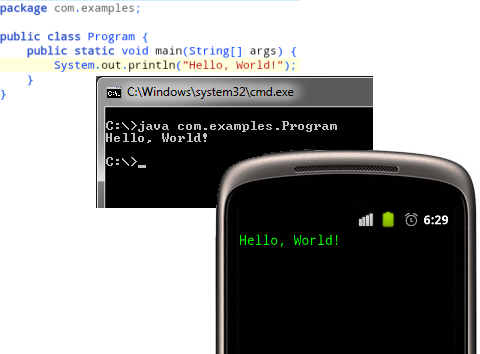
Речь пойдёт о проекте-утилитке, который может пригодиться всякому кто изучает Java и не всегда имеет под рукой ПК для просмотра работы примера кода в полев... | https://habr.com/ru/post/162741/ | null | ru | null |
# Оказывается, собственные NVMe-накопители Apple невероятно быстры, только если вы не заботитесь о целостности данных
Факт того, что в MacOS функция `fsync()` работает по-другому, не как в привычном всем Linux, далеко не новость. Но многие о нем забывают. Особенной хронической формой маразма страдают авторы бенчмарков... | https://habr.com/ru/post/653527/ | null | ru | null |
# EventBus — Система событий для Unity
В этой статье я расскажу вам о том, что такое система событий применительно к Unity. Изучим популярные методы и подробно разберем реализацию на интерфейсах, с которой я познакомился, работая в Owlcat Games.

*От переводчика: данная статья является девятой в цикле переводов официального руководства по библиотеке SFML. Прошлую статью можно найти [тут.](https://habrahabr.ru/post/279689/ "Предыдущ... | https://habr.com/ru/post/279957/ | null | ru | null |
# Может ли email быть «резиновым»?
[](http://habrahabr.ru/company/pechkin/blog/262585/)
Нравится это вам или нет, отрицать распространенность HTML-писем невозможно, также как и переход электронной почты в мобильную среду ([... | https://habr.com/ru/post/262585/ | null | ru | null |
# Пишем презентации в LaTeX
В процессе подготовки доклада на GolangConf'2019 я использовал LaTeX. Несмотря на некоторые устаревшие вещи, немного необычное поведение, скудную или сложную документацию, я внезапно получил удовольствие. Я не стал "гуру" LaTeX, но я смог делать весьма неплохие слайды. И я хочу описать осно... | https://habr.com/ru/post/471352/ | null | ru | null |
# Level Up для новичков: gulp и requirejs
* [Вода](#water)
* [Gulp](#gulp)
* [Require.js](#requirejs)
Предисловие
-----------
Качество приложения зависит не только от того, какие задачи и с какой скоростью оно решает, но и от таких, казалось бы, второстепенных факторов как «красота кода».
Под красотой кода я (пол... | https://habr.com/ru/post/264869/ | null | ru | null |
# Mantis + Subversion у себя на компьютере с Windows XP. Пошаговая инструкция для удобной организации работы с кодом
[](http://my.jetscreenshot.com/2/20100302-v8tx-15kb)
Исторически сложилось, что багтрек... | https://habr.com/ru/post/86083/ | null | ru | null |
# HTTP-заголовок Feature-Policy и контроль поведения веб-страниц в браузерах
Существует одна совершенно бесподобная методика, позволяющая держать производительность веб-проекта под контролем. Она заключается во внедрении в процесс разработки механизмов, результаты работы которых хорошо заметны. Эти механизмы нацелены ... | https://habr.com/ru/post/490624/ | null | ru | null |
# Микросервисный фронтенд — современный подход к разделению фронта
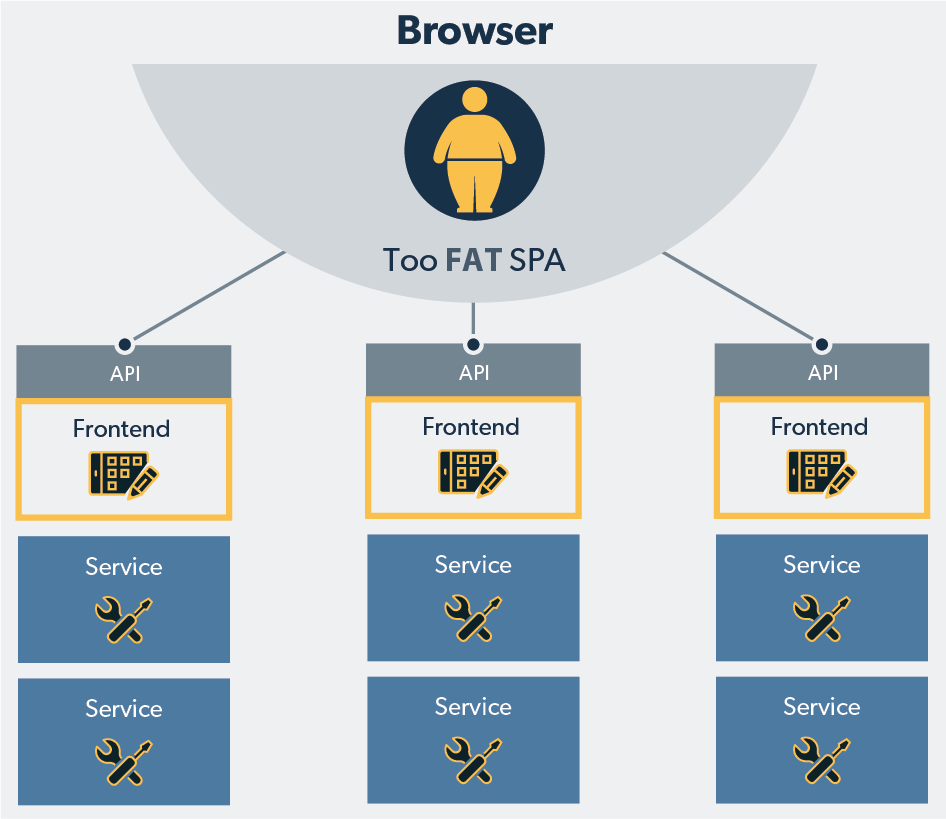
**[Микросервисная архитектура](https://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BA%D1%80%D0%BE%D1%81%D0%B5%D1%80%D0%B2%D0%B8%D1%81%D0%BD%D0%B0%D1%8F_%D0%B0%D... | https://habr.com/ru/post/420753/ | null | ru | null |
# К чему приводят тестовые задания или как я реализовал Match-3 для терминала
Вы когда-нибудь играли в Match-3 в текстовом терминале? Вот и я бы не подумал, что поводом для этого, может стать очередное тестов... | https://habr.com/ru/post/663156/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.