
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Compile-time рефлексия D
Доброго времени суток, хабр!
Сегодня поговорим о том, что делает метапрограммирование в D таким гибким и мощным — compile-time рефлексии. D позволяет программисту напрямую пользоваться информацией, которой оперирует компилятор, а не выводить её хитрыми способами. Так какую информацию позв... | https://habr.com/ru/post/261349/ | null | ru | null |
# Выключка по ширине, или Убей «text-align: justify;»
Надеюсь этой записью открыть серию статей, посвящённых типографике в целом и веб-типографике в частности.
Логически следующая статья будет посвящена использованию разнообразных пробелов и разделительных интервалов (такой заказ был в комментариях к [статье о тире... | https://habr.com/ru/post/20653/ | null | ru | null |
# Нюансы коммерческой разработки на WordPress

Доброго времени суток, уважаемый читатель. Судьба сложилась так, что я один из тех, кто отвечает за разработку проектов интернет-агентства в любимом, для меня, городе Хабаровск... | https://habr.com/ru/post/252393/ | null | ru | null |
# COVID-19: как перестать читать новости и начать анализировать данные

Привет, Хабр! Где-то месяц назад у меня появилось чувство постоянного беспокойства. Я стал плохо есть, еще хуже спать и постоянно ч... | https://habr.com/ru/post/497340/ | null | ru | null |
# Unity Editor Adventures: Сериализованная Матрёшка
### Краткое вступление
Как правило, для того чтобы добраться до интересующего нас поля сериализованного свойства, мануальная терапия советует нам использовать метод FindPropertyRelative(), в который прокидывается название переменной.
По определённым причинам тако... | https://habr.com/ru/post/502836/ | null | ru | null |
# Новые баги utorrent или что для нас готовят программисты Bittorrent
Многие пользователи utorrent переходят на новые версии программы по привычке или до того момента пока у них не перестаёт что-то работать. Кто-то остановился на 2.2.1 или 2.0.4 как последних более-менее стабильных, а кто-то по сей день верен 1.8.2 и ... | https://habr.com/ru/post/251625/ | null | ru | null |
# Боль и слёзы в Svelte 3
#### Вместо предисловия
Статья будет полезна тем, кто так-же как и Мы решил попробовать [Svelte](http://svelte.dev) в живом проекте. В нашу небольшую компанию пришёл заказ на разработку веб-админки для сервиса с бекэндом на Mongodb Stitch. В последние пару лет frontend Мы пишем на React или ... | https://habr.com/ru/post/469361/ | null | ru | null |
# Основные принципы настройки Garbage Collection с нуля
В данной статье я бы не хотел заострять внимание на принципе работы сборщика мусора — об этом прекрасно и наглядно описано здесь: [habrahabr.ru/post/112676](http://habrahabr.ru/post/112676/). Хочется больше перейти к практическим основам и количественным характер... | https://habr.com/ru/post/223401/ | null | ru | null |
# Как я начал сходить с ума от программирования

Всем привет, меня зовут Артур, и мне 15 лет. С программированием я познакомился ещё в возрасте 12 лет, но начал изучать только с 14, потому что у меня в данный промежуток времени ... | https://habr.com/ru/post/518504/ | null | ru | null |
# Интерактивная 3D-инсталляция по мотивам «Звёздных войн»
Где-то в далёкой-далёкой галактике (хотя и в нашей тоже) неофициально день «Звёздных войн» 4 мая отмечается. Не случайно он выбран, из фильма цитата тому подтверждение «May the Force be with you» («Да пребудет с тобой Сила»), как намёк звучит она для поклоннико... | https://habr.com/ru/post/328022/ | null | ru | null |
# Магия Chocolatey: apt-get и yum для Windows
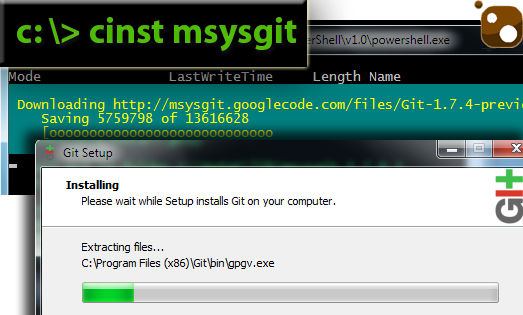
Сегодня я расскажу Вам о волшебстве. И это волшебство способно изменить жизнь системного администратора Windows раз и навсегда.
В наше время становится все ... | https://habr.com/ru/post/210626/ | null | ru | null |
# Фильтры данных на ASP.NET MVC и Entity Framework
Очень часто в различных веб-приложениях мы работаем с данными, выбранными из таблиц БД. И нередко необходимо предоставлять пользователю возможность фильтровать эти данные. Можно, конечно, для каждого случая собирать данные с формы в ручную и в ручную создавать соответ... | https://habr.com/ru/post/141440/ | null | ru | null |
# Быль о типографе
Было время, когда каждый веб-разработчик писал свой типограф или думал о нём. Я не стал исключением и написал типограф на PHP. Но как сделать типограф без нормальной поддержки UTF-8, в то время я не представлял, в итоге забросил идею.
Прошло время, но идея создания типографа не оставляла, и я реш... | https://habr.com/ru/post/266563/ | null | ru | null |
# Маленькая задача — вывести дату
Я хочу рассказать о простой задаче — вывод даты на главной странице [Mail.Ru](http://mail.ru). Маленькая задача, нетривиальное решение.

Решение в лоб:
```
func... | https://habr.com/ru/post/143627/ | null | ru | null |
# Руководство по фоновой работе в Android. Часть 1
О фоновой работе приложений в Android есть много статей, но мне не удалось найти подробного руководства по реализации работы в фоне – думаю, из-за того, что появляется все больше новых инструментов для такой работы. Поэтому я решил написать серию статей о принципах, и... | https://habr.com/ru/post/348894/ | null | ru | null |
# Нейросети для чайников. Часть 2 — Перцептрон
В предыдущей [статье](http://habrahabr.ru/post/143129/) были рассмотрены самые азы для понимания темы нейронных сетей. Полученная система не являлась полноценной нейрон... | https://habr.com/ru/post/144881/ | null | ru | null |
# Enyo 2. ООП

[Первый](http://habrahabr.ru/post/202288/) топик постигла участь многих пятничных постов, но не беда!
Я не сдаюсь, а значит мы продолжаем…
В этом топике мы осветим следующие темы:... | https://habr.com/ru/post/204598/ | null | ru | null |
# Делаем калейдоскоп на CSS+JS
Я как-то раньше никогда не задумывался над такой штукой, как калейдоскоп на странице. Видел их как-то раньше, но не обращал особо внимания. А тут увидел у Лебедева в портфолио [калейд... | https://habr.com/ru/post/99019/ | null | ru | null |
# OpenSCG’s HA failover solution “PGHA”. Решение Master-Slave для PostgreSQL 9.3
Ниже будет описан опыт настройки отказоустойчивой системы Master-Slave с использованием собственных ресурсов PostgresSQL — Asynchronous Replication + pgBouncer + PGHA — в формате вольного перевода с комментариями [одного поста](http://www... | https://habr.com/ru/post/223825/ | null | ru | null |
# Next.js: подробное руководство. Итерация вторая

Привет, друзья!
Хочу поделиться с вами заметками о `Next.js` (надеюсь, кому-нибудь пригодится).
`Next.js` — это основанный на `React` фреймворк, предназначенный для разработки веб-... | https://habr.com/ru/post/590157/ | null | ru | null |
# Безопасная работа с секретами при сборке в Docker Compose
***Перевод статьи подготовлен в преддверии старта курса [«Web-разработчик на Python»](https://otus.pw/CXIC/).***

---
Когда вы собираете Docker-образ вам могут понадобит... | https://habr.com/ru/post/501580/ | null | ru | null |
# Отправка уведомлений о пропущенных звонках из Asterisk
В данном посте я расскажу вам о возможностях отправки уведомлений о пропущенных звонках с помощью Asterisk. Я постараюсь привести простые примеры конфигурации и подробнее раскрыть данную тему, далее вы можете экспериментировать по своему усмотрению или потребнос... | https://habr.com/ru/post/162825/ | null | ru | null |
# Mac Maniac
Привет! Это мой первый **хабратопик** (не считая песочницы)
и я даже не знаю увидит его кто-нибудь или нет :-)
Ну вот мне нравится некоторые фишки на Mac которых нету в Винде. По мере возможности я пишу их на скриптовом языке AutoHotKey дабы не чувствовать себя обделённым) Что? Вы ещё не знаете про... | https://habr.com/ru/post/50707/ | null | ru | null |
# Книга «Путь Python. Черный пояс по разработке, масштабированию, тестированию и развертыванию»
[](https://habr.com/ru/company/piter/blog/466027/) Привет, Хаброжители! «Путь Python» позволяет отточить ваши профессиональные навыки... | https://habr.com/ru/post/466027/ | null | ru | null |
# Можно ли доверять библиотекам, которые использует ваше приложение?
Если вы знакомы с современными техниками написания высококачественного кода, тогда, пожалуй, вам не стоит волноваться об уязвимостях кода, который вы написали. Однако, обычно приложения используют сторонние библиотеки (зависимости) - можно ли доверят... | https://habr.com/ru/post/693890/ | null | ru | null |
# Сниппеты против Клевера – обыгрываем популярнейшую викторину в реальном времени
Апрель 2018-го года. Мне было 14. Мы с друзьями играли в тогда очень популярную онлайн-викторину «Клевер» от ВКонтакте. Один из нас (обычно я) всегда был за ноутбуком, чтобы пытаться быстро гуглить вопросы и глазами искать в поисковой вы... | https://habr.com/ru/post/435360/ | null | ru | null |
# PowerShell и GUI. Это — не сложно
Некоторое время назад в компании была развернута терминальная ферма.
Первым делом в неё были выселены пользователи некой желтой программы.
После чего отдел поддержки желтой программы спросил меня, можно ли отсылать сообщения пользователям фермы всем сразу. [XaocCPS](https://ha... | https://habr.com/ru/post/138008/ | null | ru | null |
# Преобразование черно-белых изображений в ASCII-графику при помощи неотрицательного матричного разложения

В общем случае преобразование изображения в ASCII-графику представляет собой довольно трудоемкую задачу, однако существуют ал... | https://habr.com/ru/post/463193/ | null | ru | null |
# Настройка окружения для сборки и тестирования приложения в закрытом периметре
Добрый день, хаброчитатели.
Снова хочу поделиться с вами небольшими практическими наработками.
Совсем недавно в рамках одного проекта мне была поставлена задача подготовить для команды тестеров стандартное окружение для сборки и тест... | https://habr.com/ru/post/176719/ | null | ru | null |
# Как я участвовал в IOCCC-'19 (и проиграл). Часть 2: «Симулятор NOR»
Это вторая часть цикла статей о том, как я участвовал в IOCCC'19

1. [Как я участвовал в IOCCC-'19 (и проиграл). Часть 1: «Крестики-нолики»](https://habr.com/ru... | https://habr.com/ru/post/516296/ | null | ru | null |
# Git: много хуков полезных и разных
Статья является вольным переводом вот [этого материала](http://krisjordan.com/essays/setting-up-push-to-deploy-with-git). Любителям длинных и заумных первоисточников можно сразу читать оригинал.
Когда перед нами ставится задача при изменении кодбейса, например, в Github-репозито... | https://habr.com/ru/post/329804/ | null | ru | null |
# Полный обзор webpack
[](https://habr.com/ru/company/piter/blog/710844/)
Поскольку грань между веб-сайтами и веб-приложениями продолжает размываться, возможности и проблемы для разработчиков становятся все более сложными. В свя... | https://habr.com/ru/post/710844/ | null | ru | null |
# Запуск ОС Андроид с SD-карты для устройств на процессоре Amlogic S912
В статье детально, с приведением исходного кода, описывается работа, проведенная по переносу и запуску с SD-карты программной прошивки с ОС Андроид для устройств на процессоре Amlogic S912.
Мне нравятся миниатюрные компьютеры, выполненные по техн... | https://habr.com/ru/post/525116/ | null | ru | null |
# Особенности загрузки объектов из карты формата KML на карту Яндекса
В API Яндекс.Карт есть [средства для загрузки географических данных](http://tech.yandex.ru/maps/doc/jsapi/2.1/dg/concepts/geoxml-docpage/) в формате XML. API поддерживает карты в двух форматах: YMapsML и KML. В документации по технологиям Яндекса ес... | https://habr.com/ru/post/242697/ | null | ru | null |
# Как компьютерное зрение помогает определить координаты спутниковых снимков
*Привет, Хабр!
Меня зовут Андрей, и я data scientist. В этой статье расскажу о том, как я занял второе место в конкурсе «Цифрово... | https://habr.com/ru/post/696422/ | null | ru | null |
# leOS — многозадачное ядро для Arduino
Итальянский разработчик [Леонардо Милиани](http://www.leonardomiliani.com/?author=1) выложил в открытый доступ исходники leOS (little embedded operating system) – маленького многозадачного ядра для Arduino. В своем блоге он пишет:
> To be honest, it should more correct to say... | https://habr.com/ru/post/150443/ | null | ru | null |
# Статья-рецепт про удобную разработку на GWT в IDEA с помощью DCEVM
В IDEA 13-ой версии, в отличие от Eclipse, при запуске проекта GWT с помощью стандартного плагина (и, как в последствие выяснилось, и без него, а просто запуск GWT DevMode — приложение для запуска в режиме разработки и debug'а, а конкретно com.google... | https://habr.com/ru/post/236075/ | null | ru | null |
# ChaiScript — скриптовый язык для C++
Когда возникает потребность внедрить скриптовый язык в проект на C++, первым делом большинство людей вспоминает Lua. В этой статье его не будет, я расскажу о другом, не менее удобном и легком в освоении языке под названием ChaiScript.

Привет, Хабр! Представляю вашему вниманию перевод статьи [«How to use the JavaScript console: going beyond console.log()»](https://www.freecodecamp.org/news/how-to-use-the-javascript-console-going-beyond-console-log-5128af9d573b/?utm_source=mybridg... | https://habr.com/ru/post/492366/ | null | ru | null |
# phpThread: нити в PHP? Запросто
Если вы хотите научиться писать многопоточные приложения на PHP или здорово упростить себе жизнь — статья для вас.
Раньше для этих целей я пользовался либо запуском несколько копий скрипта, либо же использовал pcntl на более низком уровне, чем хотелось бы. Это, а от части и Java-ид... | https://habr.com/ru/post/59982/ | null | ru | null |
# Возрождение ActionScript2.0 c помощью JavaScript
И вот уже март 2017 года, Adobe Flash Player уже не запускается по умолчанию без явных действий пользователя, по крайней мере в Google Chrome для автоматического запуска контента Adobe Flash Player необходимо выполнить [следующии инструкции](http://).Таким образом, ак... | https://habr.com/ru/post/323388/ | null | ru | null |
# Представляем Sencha Ext JS 5

От имени компании Sencha и всей команды Ext JS я горд объявить, что сегодня мы выпускаем Ext JS 5. Ext JS 5 — это гигантский шаг вперёд и мы хотим воспользоваться случаем и п... | https://habr.com/ru/post/225169/ | null | ru | null |
# Тестирование инсталляторов в Windows, когда надо быстро и дешево
Счастливы веб-тестеры, бери селениум и не ошибешься. Счастливы java-tester'ы — для них есть тест-фреймворки, в особо тяжелых случаях- siculi. Принесли на тесты консольные приложения — тут приятны python, perl. А как же desktop? Тестирование приложений ... | https://habr.com/ru/post/197586/ | null | ru | null |
# Замедление хеширования паролей. Зачем?
 Доброго времени суток, хабрапараноик! Сегодня мы поговорим о немного необычном способе повышения безопасности, а именно **замедлении хеширования паролей**. Казалось бы, когда вс... | https://habr.com/ru/post/100138/ | null | ru | null |
# Особенности программного ProxyChanging'а в Android. Часть 1: от Jelly Bean до Lollipop
Как-то раз, для собственного удобства, мне захотелось написать приложение, которое меняет настройки прокси в конфигурации сетей Wifi для Android. Задача, как мне тогда показалось, была на раз плюнуть, однако, на деле, как всегда, ... | https://habr.com/ru/post/311388/ | null | ru | null |
# Многопоточность в C++ и SObjectizer с CSP-шными каналами, но совсем без акторов…
Раньше мы рассказывали про [SObjectizer](https://habrahabr.ru/post/304386/) как про акторный фреймворк для C++, хотя в действительности это не совсем так. Например, уже давно в SObjectizer есть такая классная штука, как [mchain-ы](https... | https://habr.com/ru/post/336854/ | null | ru | null |
# Основы и заблуждения насчет JavaScript
#### Объекты, классы, конструкторы
> ECMAScript, будучи высоко-абстрактным объектно-ориентированным языком программирования, оперирует объектами. Существуют также и примитивы, но и они, когда требуется, также преобразуются в объекты. Объект — это коллекция свойств, имеющая так... | https://habr.com/ru/post/120193/ | null | ru | null |
# Обнаружение объектов с помощью YOLOv3 на Tensorflow 2.0
Кадр из аниме "Жрица и медведь"До появления YOLO большинство способов обнаружения объектов пытались адаптировать класс... | https://habr.com/ru/post/556404/ | null | ru | null |
# Автоматическое принятие приглашений к обмену документами в ЭДО Диадок по API
Предпосылки
-----------
ФНС в 2020 году утвердила концепцию перехода документооборота с контрагентами в электронный вид. В июле 2021 года обмен первичными документами и счетами-фактурами по закупке и продаже некоторых товаров уже стал беза... | https://habr.com/ru/post/588957/ | null | ru | null |
# Сортировка товаров и показ выбранного пользователем количества товаров в 1С-Битрикс
Исторически так сложилось, что комплексный компонент 1С-Битрикс не позволяет пользователю в публичной части отсортировать товары, хотя бы по цене, дате, наименованию, а также выбрать сколько товаров на странице ему выбрать. Но ни оди... | https://habr.com/ru/post/271307/ | null | ru | null |
# PHP модуль — это всё ещё просто. Часть вторая
Пока [nerezus](https://habrahabr.ru/users/nerezus/) сочиняет статью о встраивании PHP, я постараюсь продолжить его рассказ о написании расширений. Рассказано будет далеко не всё, поскольку я считаю, что сложность наращивать надо постепенно, иначе материал будет трудноусв... | https://habr.com/ru/post/75445/ | null | ru | null |
# Переходим с Disqus на комментарии Github
Какое-то время я хотел убрать комментарии из своего блога; в основном, потому что здесь вообще мало комментариев, да и не хочется возиться с лишними «тормозами» от [Disqus](https://disqus.com/). Посмотрев на время загрузки Disqus, я был потрясён тем, что приходится терпеть по... | https://habr.com/ru/post/327424/ | null | ru | null |
# «Краткость сестра...» или интеграция SMS API в бизнес процессы
Иногда так хочется ненадолго вернуться в ранние нулевые. Ах, ностальгия! Сборная еще не взяла бронзу на Евро, сентябрь не сгорел, Бандурин и Ва... | https://habr.com/ru/post/704162/ | null | ru | null |
# Особенности строк в .NET
Строковый тип данных является одним из самых важных в любом языке программировании. Вряд ли можно написать полезную программу не задействовав этот тип данных. При этом многие разработчики не знают некоторых нюансов связанных с этим типом. Поэтому давайте рассмотрим кое-какие особенности этог... | https://habr.com/ru/post/172627/ | null | ru | null |
# Максимально точное измерение кода

В моей статье полугодичной давности [о длинной арифметике](http://habrahabr.ru/post/135590/) есть замеры скорости (throughput в тактах) очень коротких фрагментов кода — всего по неско... | https://habr.com/ru/post/147852/ | null | ru | null |
# PHP модуль — это просто
Недавно мы опубликовали визард для VisualStudio, с помощью которого можно создать экстеншн в пару кликов мыши. Теперь с помощью него мы напишем наши два первых расширения: «Привет, мир» и «вытащим иконку из exe».
Сразу прошу прощение, что очень сильно задержал статью, но жизненные обстояте... | https://habr.com/ru/post/75388/ | null | ru | null |
# Функциональные интерфейсы в Java 8 → Consumer, Supplier, Predicate и Function. Что к чему и зачем нужны
 Java представила поддержку функционального программирования в выпуске Java версии 8. Этот конкретны... | https://habr.com/ru/post/677610/ | null | ru | null |
# Просто Angular

**Введение**
------------
8-9-го декабря 2016 года была [проведена первая конференция](https://www.youtube.com/watch?v=aJIMoLgqU_o) по Angular в Бельгии. [Игор Минар](https://github.com/igorminar) (ведущий разработчик Angular) выступи... | https://habr.com/ru/post/318682/ | null | ru | null |
# Клиентский мониторинг производительности

Привет, Хабр! Меня зовут Влад, я лид направления Web Performance в Тинькофф.
В этом цикле статей я расскаж... | https://habr.com/ru/post/508256/ | null | ru | null |
# Мониторинг проектов: сравнительный анализ существующих решений

*Предлагаем вашему вниманию публикацию, написанную по мотивам выступления [Антона Баранова](http://conf.1c-bitrix.ru/summer2015/agenda/Monitoring_proektov_sr... | https://habr.com/ru/post/270341/ | null | ru | null |
# Создание и использование собственных атрибутов AD в PowerShell

В этой статье я покажу вам, как можно расширять схему AD, создавать нестандартные атрибуты и управлять ими в AD — и всё это с помощью Windows PowerShell. Следуя этому ... | https://habr.com/ru/post/654627/ | null | ru | null |
# PVS-Studio in the Clouds: CircleCI

This is a new piece of our series of articles about using the PVS-Studio static analyzer with cloud CI systems. Today we are going to look at another service, ... | https://habr.com/ru/post/470465/ | null | en | null |
# Добавляем watermark к изображению
Привет, Хабрахабр!
Вчера, прочитав [статью](http://sergeyvoyteshonok.habrahabr.ru/blog/41499/ "статья") [SergeyVoyteshonok](https://habrahabr.ru/users/sergeyvoyteshonok/), посвященную отрисовке логотипа сайта или компании (проще говоря, «водяного знака») на загружаемых пользовате... | https://habr.com/ru/post/41546/ | null | ru | null |
# Недружественные почтовые сервера
«Не препятствуйте доставке почты»Всем привет. Долго думал, о чём здесь написать — к сожалению, редко нах... | https://habr.com/ru/post/662555/ | null | ru | null |
# Быстрый консольный ввод на .NET
Во времена, когда .NET был закрытой технологией только для Windows, за ним и языком C# закрепилась репутация платформы, которая отлично подходит для решения бизнес-задач, но непригодна для соревновательного программирования и написания высокопроизводительного кода.
Часто приходится с... | https://habr.com/ru/post/705834/ | null | ru | null |
# Пользовательские литералы в C++11
Более полугода прошло с момента принятия стандарта C++11. В сети можно найти много материалов посвященных новому стандарту, однако большинство из них касаются самых простых возможностей, самых сладких. Я говорю о лямбда-функциях, системе автоматического выведения типов, новых специф... | https://habr.com/ru/post/140357/ | null | ru | null |
# Извлечение аппаратного ключа полнодисковой защиты в телефонах Android на процессорах Qualcomm
### Эксплоит [опубликован на Github](https://github.com/laginimaineb/ExtractKeyMaster)
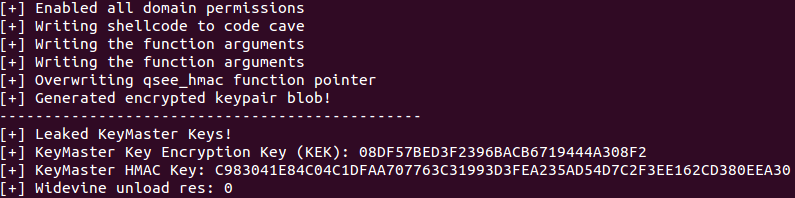
Компания Google начала внедрять полное ... | https://habr.com/ru/post/395643/ | null | ru | null |
# Простой Web-доступ к VI приложениям LabVIEW в PHP через ActiveX Server
В LabVIEW уже много лет существует возможность «прикрутить» Web к VI приборам без каких-либо сложных настроек публикации и серверов со стороны LabVIEW, используя только втроенный сервер ActiveX. Не является исключением и LabVIEW 2020 Community ed... | https://habr.com/ru/post/502496/ | null | ru | null |
# Причины массового обжорства SSD на Macbook с процессорами M1
Мир сошел с ума. Где только не писали о проблеме повышенного аппетита на ресурс SSD-накопителей у новых моделей Macbook Air и Macbook Pro с процессорами M1. Тема обсуждалась на всех популярных технических форумах. И несмотря на массовость проблемы, все обс... | https://habr.com/ru/post/558680/ | null | ru | null |
# Qmmp: продолжение. Альтернативные интерфейсы
Этот топик — продолжение [предыдущего](http://habrahabr.ru/blogs/linux/95931/) про замечательный музыкальный плеер Qmmp. Исходя из комментариев, многим не нравится его winamp-подобный GUI, но немногие знают, что он поддерживает альтернативные интерфейсы ( спасибо [dexon](... | https://habr.com/ru/post/96108/ | null | ru | null |
# Ещё раз о том, как не надо делать розыгрыши призов
Ещё недавно отгремели скандалы про [МТС и Nestea](http://www.siliconrus.com/2013/12/mts-vs-nestea/) и [Ebay и Biglion](http://habrahabr.ru/company/boxowerview/blog/201308/), а разработчики всё не учатся на чужих ошибках. На этот раз у нас отличилась компания FRIMA с... | https://habr.com/ru/post/212373/ | null | ru | null |
# Компиляция iOS приложений для Windows Store

В апреле этого года на конференции //Build был сделан очень интересный анонс, который показал возможность [компиляции и сборки ObjectiveC](https://channel9.msd... | https://habr.com/ru/post/264321/ | null | ru | null |
# Вконтакте представили SDK для Android
 #### На днях ВКонтакте в разделе для разработчиков выложили SDK для Android.
Популярная социальная сеть ВКонтакте пополнила свой н... | https://habr.com/ru/post/209974/ | null | ru | null |
# Vespa лучше Elasticsearch для поиска пар среди миллионов мужчин и женщин

Неотъемлемой частью сайта для знакомств OkCupid являются рекомендации потенциальных партнёров. Они основаны на совпадении множест... | https://habr.com/ru/post/521364/ | null | ru | null |
# Изучаем календарь
 Эта статья получилась из вопроса, который я сам себе задал вчера.
> «Существует ли год, в котором ни один месяц не начинается в понедельник?»
На первый взгляд — да. Год может начинаться с любого дня недели, месяц... | https://habr.com/ru/post/458356/ | null | ru | null |
# Интеграция с ЕСИА на базе oauth2-client (PHP)

Представляем yet another PHP-пакет интеграции с ЕСИА — [`ekapusta/oauth2-esia`](https://packagist.org/packages/ekapusta/oauth2-esia). Реализован как адаптер к популярному [`league/oauth2... | https://habr.com/ru/post/358834/ | null | ru | null |
# Пишем программы для микроконтроллеров AVR в среде Code::Blocks 10.5
Привет, Хабр!
В этом небольшом топике будет показано как использовать популярную IDE Code::Blocks 10.5 для написания программ для микроконтроллеров семейства AVR фирмы ATMEL.

В нашей прошлой [статье](https://habr.com/ru/post/584750/) про синтез речи мы дали много обещаний: уб... | https://habr.com/ru/post/660565/ | null | ru | null |
# Простой интерпретатор с нуля на Python (часть 3)

**Содержание**[Простой интерпретатор с нуля на Python #1](http://habrahabr.ru/post/206320/)
[Простой интерпретатор с нуля на Python #2](http://hab... | https://habr.com/ru/post/208872/ | null | ru | null |
# TWAPT — пентестим по-белому в домашних условиях

> Чтобы поймать преступника, ты должен думать, как преступник, ты должен чувствовать, как преступник!
>
> Статья носит информационный характер. Не нарушайте... | https://habr.com/ru/post/551978/ | null | ru | null |
# Новый вид mozilla vlc plugin
При реализации одного из проектов столкнулся с небольшой задачей, а именно встраивание на страницу сайта vlc плеера при этом плеер должен поддерживать возможность стилизации и воспроизведение рекламного ролика перед проигрыванием основного медиафайла или потока.
Так как ранее уже дов... | https://habr.com/ru/post/188232/ | null | ru | null |
# UI-пасьянс: делаем свой StackView в Android
В этой статье мы хотим поделиться опытом создания кастомного ViewGroup в Android, который мы разработали в рамках одного из проектов Программы «Единая фронтальная система». Перед нами стояла задача создать красивую галерею банковских карт. При этом обычный список, который ... | https://habr.com/ru/post/340998/ | null | ru | null |
# Dependency Injection, JavaScript и ES6-модули
Ещё одна имплементация [Dependency Injection в JavaScript](https://www.npmjs.com/search?q=Dependency%20Injection) — с ES6-модулями, с возможностью использовать один и тот же код в браузере, и в nodejs и не использовать транспиляторы.

После выхода 10.1 pre-release версии решил потестить её на drawTriangles()
Написано приложение, которое в 800x600 рисует 2700 крутящихся текстурированн... | https://habr.com/ru/post/75584/ | null | ru | null |
# Низкоуровневая оптимизация кода на платформе Эльбрус: векторное сложение uint16_t с помощью интринсиков

В этой статье мы расскажем про более низкоуровневые оптимизации, которые можно делать на процессорах Эльбрус.
*В принципе... | https://habr.com/ru/post/351134/ | null | ru | null |
# Bhunter — взламываем узлы бот-сетей
Вирусные аналитики и исследователи компьютерной безопасности стремятся собрать как можно больше образцов новых ботнетов. В своих целях они используют honeypot'ы.… Но что если хочется понаблюдать за зловредом в реальных условиях? Подставить под удар свой сервер, маршрутизатор? А чт... | https://habr.com/ru/post/491098/ | null | ru | null |
# 2D магия в деталях. Часть четвёртая. Вода
> — Я тут воду для проекта запилил.
>
> — О, круто! А почему она плоская? Даёшь волны!
>
> …
>
> — Слушай, ты тогда про волны говорил, помнишь? Зацени!
>
> — Да, хорошие волны, а преломление и каустику ещё не делал?
>
> …
>
> — Привет, я тут игрался с... | https://habr.com/ru/post/308220/ | null | ru | null |
# Организация кнопок на сайте с помощью Sass
Довольно часто наши любимые дизайнеры делают в макетах кнопки разных размеров и величин, некоторые из которых повторяются, некоторые нет. Неплохо было бы организовать систему для быстрого добавления и редактирования этих самых кнопок, в чем на могут помочь sass @extend's. П... | https://habr.com/ru/post/271311/ | null | ru | null |
# Jivosite больше не снизит Google Speed
Передо мной возникла одна задачка - повысить Google Speed на одном из интернет-ресурсов.
Задачка ещё та, учитывая то, что большинство пунктов выполнено, но при этом просадка капитальная. А всё из-за чего? Куча метрик, яндекс информеры *(оцени Я.Маркет, рейтинг Я.Маркет)* и... ... | https://habr.com/ru/post/590905/ | null | ru | null |
# Графы для самых маленьких: BFS
В [предыдущем посте](http://habrahabr.ru/post/200074/) рассказывалось об обходе графа в глубину. Сегодня я бы хотел рассказать о не менее важном алгоритме теории графов — об обходе в ширину.
В прошлый раз мы уже научились искать какой-нибудь путь сквозь лабиринт. Всех желающих найти... | https://habr.com/ru/post/200252/ | null | ru | null |
# Настройка пользовательского интерфейса при установке приложений на nanoCAD Plus 8.5

Для значительного числа пользователей установка приложения равнозначна появлению ярлыка на рабочем столе или кнопки на панели инструментов. В данн... | https://habr.com/ru/post/343496/ | null | ru | null |
# Почему мы пишем бизнес-логику на Lua
Привет, Хабр. В этом посте мы хотим рассказать о том, как и почему мы в IPONWEB используем язык программирования с красивым названием Lua.
Lua — скриптовый встраиваемый язык программирования со свободно распространяемым интерпретатором и открытыми исходными текстами на C. Он б... | https://habr.com/ru/post/469049/ | null | ru | null |
# Логирование Git revision в Java с помощью Maven
Наша компания перешла с [mercurial](https://ru.wikipedia.org/wiki/Mercurial) на [Git](https://ru.wikipedia.org/wiki/Git), после чего мне пришлось разобраться как у нас до этого выводилась в лог информация о развертывающейся ветки и переписать это под git. Возможно, кто... | https://habr.com/ru/post/310738/ | null | ru | null |
# Java 14: записи (records preview)
В скором времени в [грядущей Java 14](https://openjdk.java.net/projects/jdk/14/) появится новая синтаксическая фича — *записи* (records). После изучения [превью](https://openjdk.java.net/jeps/359), в котором вкратце описано, как выглядят записи и с “чем их едят”, я осмелился адаптир... | https://habr.com/ru/post/484700/ | null | ru | null |
# Navigation Component-дзюцу, vol. 3 — Corner-кейсы

В этой части трилогии про Navigation Component разберем как организовать навигацию в многомодульных приложениях, как работается с диплинками, а также рассмотрим кейсы со встраиваем... | https://habr.com/ru/post/520198/ | null | ru | null |
# Сделаем код чище: Что можно исправить в ядре Linux
Наверняка многие хотели бы попробовать что-то изменить в ядре Linux к лучшему, но не знают с чего начать. Я хочу описать несколько проблем, исправить которые под силу каждому, и на примере показать путь от нахождения проблемы до опубликования её исправления в списке... | https://habr.com/ru/post/253123/ | null | ru | null |
# Зачем студентам теория графов

**Информация об изображении**
(Здание кёнигсбергской биржи (построено в 1875 году, сохранилось до сих пор) и [Зелёный мост](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%B9%D0%BB:%D0%91%D0%B8%D1%80%... | https://habr.com/ru/post/570970/ | null | ru | null |
# Настройка Guard для автоматизации Ruby on Rails разработки
Всем привет! По моему мнению, каждый программист должен стремиться к автоматизации и оптимизации всего, что движется и еще нет. В этой статье будет рассказано о том, как автоматизировать рабочий процесс Ruby on Rails разработчика с помощью Ruby гема под назв... | https://habr.com/ru/post/238667/ | null | ru | null |
# Своя браузерка — путь мыши: Теория
Итак, вы решили поднять свою браузерку.
Вы понимаете все сопутствующие нюансы и принципы поведения Администратора браузерки: [habrahabr.ru/post/249625](https://habrahabr.ru/post/249625/)
Вы чётко осознаёте, что единственный разумный вариант, зачем в это стоит впрягаться — это... | https://habr.com/ru/post/275767/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.