
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Печать из Vista на сетевом Linux-принтере
Переведя компьютеры в нашей организации на лицензионное программное обеспечение, мы обнаружили проблему с ораганизацией печати документов. Компьютер под управлением Windows Vista Business не стал печататать на сетевом принтере, подключенном к Linux-компьютеру. Причем не рабо... | https://habr.com/ru/post/83430/ | null | ru | null |
# Tcl/Tk: Загрузчик на Яндекс.Фотки из контекстного меню (preβ)
На относительно скорую руку сделал аплоадер картинок. Выкладываю его в таком состоянии, чтобы узнать, куда и как следует дорабатывать скрипт.
](https://habr.com/ru/company/skillfactory/blog/520992/)
Рассказываем о нейросети, которая применяет глубокое обучение и обучение с подкреплением, чтобы играть в Змейку. Код на Githu... | https://habr.com/ru/post/520992/ | null | ru | null |
# Использование новых NVMe SSD в качестве загрузочного диска на старых системах с Legacy BIOS (для любой ОС)
Короткий мануал — как реализовать поддержку загрузочного NVMe SSD на старых материнских платах с Legacy BIOS и с использованием Clover (для любых ОС). По следам вот этого [поста](https://habr.com/ru/post/472068... | https://habr.com/ru/post/472224/ | null | ru | null |
# AI, практический курс. Сбор и исследование изображений

В данной статье обсуждаются методы, используемые при сборе данных с изображениями в музыкальном проекте со слайд-шоу. Возникли ограничения, вынудившие нас воспользоваться су... | https://habr.com/ru/post/413839/ | null | ru | null |
# Макросы с переменным числом параметров
Недавно пришлось мне разбираться с одним Open Source проектом. Нужно было разобраться с одной ошибкой. Ошибка была плавающей и проявлялась исключительно на стенде, после получаса раб. Да и то не всегда. Поэтому было принято решение логировать определенные участки кода.
Поэто... | https://habr.com/ru/post/138150/ | null | ru | null |
# Отладка и устранение проблем в PostgreSQL Streaming Replication
Потоковая репликация, которая появилась в 2010 году, стала одной из прорывных фич PostgreSQL и в настоящее время практически ни одна инсталляция не обходится без использования потоковой репликации. Она надежна, легка в настройке, нетребовательна к ресур... | https://habr.com/ru/post/414111/ | null | ru | null |
# Пишем Policy server на C++ для Unity3d

Зачем нужен policy server?
--------------------------
В [Unity](http://unity3d.com/ru/), начиная с версии 3.0, для сборок под Web player используются механизмы обеспечения безопасно... | https://habr.com/ru/post/268091/ | null | ru | null |
# Разбираемся с доступом к атрибутам в Python
> Перевод статьи опубликован специально для будущих студентов курса ["**Python Developer. Professional"**](https://otus.pw/7cLp/).
>
>

---
Интересно, сколько людей пони... | https://habr.com/ru/post/528304/ | null | ru | null |
# Как настроить мониторинг событий в Kubernetes: 4 бесплатных инструмента

[Flying Ships Harbour by annewipf](https://www.deviantart.com/annewipf/art/Flying-Ships-Harbour-497290494)
Отсутствие встроенного инструмента наблюдаемос... | https://habr.com/ru/post/570500/ | null | ru | null |
# Решение задачи о двух мудрецах и числах от 1 до 100
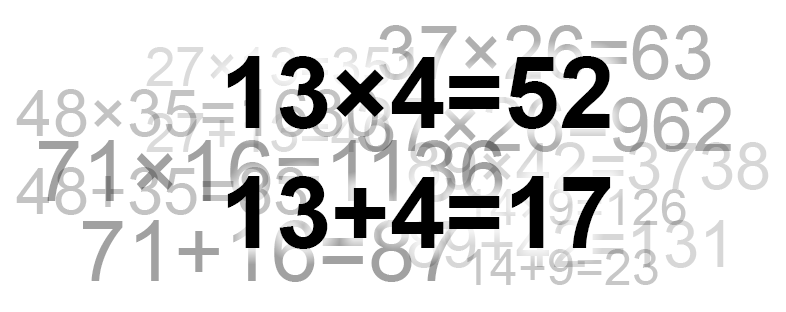
Недавно на Хабре промелькнула интересная задачка про двух мудрецов. Здесь я хочу предложить свой вариант решения и рассказать, как к этому решению можно прийти. Напомню ... | https://habr.com/ru/post/256293/ | null | ru | null |
# po.js — супер простая утилита для i18n
Когда я разрабатываю системы на Zend Framework, то всегда использую gettext и Zend\_Translate. Всё лаконично просто и обычно не возникает никаких проблем с переводом даже больших проектов. Для каждого языка генерируются свои файлы .po и .mo, переводы пляшут от дефолтного языка,... | https://habr.com/ru/post/229495/ | null | ru | null |
# Из чего сделан JavaScript?
В течение первых нескольких лет использования JavaScript я чувствовал себя чуть ли не самозванцем. Даже хотя я и мог создавать веб-сайты с помощью фреймворков, я ощущал, что мне чего-то не хватает. Собеседования по JavaScript внушали мне страх из-за того, что у меня не было чёткого пониман... | https://habr.com/ru/post/482472/ | null | ru | null |
# О конфликтах Sass и сравнительно новых возможностей CSS
Сравнительно недавно в CSS появилось много интересных возможностей, таких, как [CSS-переменные](https://css-tricks.com/guides/css-custom-properties/) и новые [функции](https://css-tricks.com/complete-guide-to-css-functions/). Хотя всё это и может сильно упрости... | https://habr.com/ru/post/511596/ | null | ru | null |
# Работа с иностранными текстами. Как увеличить процент понимания и выучить язык?
По жизни или по работе иногда приходится сталкиваться с текстами на иностранном языке, знания которого еще далеки от совершенства. Чтобы прочесть и понять, о чем идет речь (и, в лучшем случае, выучить несколько новых слов), я обычно испо... | https://habr.com/ru/post/224301/ | null | ru | null |
# Тестирование базы данных
Вступление
----------
Современные приложения в основном состоят из фронтенда и бэкенда. Что касается тестирования бэкенда, то оно в основном ассоциируется с тестированием базы данн... | https://habr.com/ru/post/715272/ | null | ru | null |
# MSSQL Server. Пример применения связанного сервера
Сегодня решил поделиться статьей как однажды мне пришел на выручку связанный сервер при работе с MSSQL. Сначала опишу ситуацию, в которой мне пришлось с ним познакомиться.
Я работал web программистом в информационном центре одного из министерств с около сотней ... | https://habr.com/ru/post/346232/ | null | ru | null |
# Часто задаваемые вопросы по фреймворку WatchKit
[](https://habrahabr.ru/company/alconost/blog/257023/) Для разработчиков Apple Watch — не просто нашумевший гаджет. Теперь им приходится осваивать Watch Kit, чтобы создавать и ... | https://habr.com/ru/post/257023/ | null | ru | null |
# Об ограничениях в применимости метрики Минковского в цифровой обработке данных
Как-то давным-давно я наткнулся на вот [статью](http://habrahabr.ru/post/208368/) на хабре, в которой народ пишет как все круто и как хорошо работает метрика Минковского. Время шло и шло, а я все хотел и хотел. Наконец подвернулась задача... | https://habr.com/ru/post/264451/ | null | ru | null |
# Учим webworkers хорошим манерам
Рано или поздно у каждого кто работал с webworkers возникает ситуация когда код превращается в кашу вроде этого:
**main.js**
```
const worker = new Worker('test.worker.js');
worker.onmessage = (data) => {
if(data.eventName === 'someFuncResult')
someFunc();
else if(data.even... | https://habr.com/ru/post/337492/ | null | ru | null |
# Не бойтесь велосипедов. Или еще один Grand Central Dispatch (GCD) на C++11
#### ИМХО (Имею Мнение Хрен Оспоришь)
С моей точки зрения самое полезное, что может сделать программист для повышения своего профессионального уровня — это написание велосипедов. Велосипедостроение — очень увлекательный процесс. Иногда он ув... | https://habr.com/ru/post/186200/ | null | ru | null |
# А оно не пиарится
Как попасть со своим пресс релизом на страницы новостных сайтов и информ. агентств?
Инфо повод есть (нормальный такой, не спамный, правда без скандалов и интриг). Пресс релизы рассылались, в никуда похоже. Имена в событии известные были, не спасло.
*Интересует был ли у кого опыт проскальзыв... | https://habr.com/ru/post/58520/ | null | ru | null |
# Как я написал свой язык и онлайн IDE
[Здесь онлайн интерпретатор](https://llesha.github.io/regina/ide), [здесь документация](https://llesha.github.io/regina/regina/).
### Зачем
В сентябре 2020 года я учился на 2 курсе. В том же месяце я **впервые написал программу, которая мне понравилась**. Она создаёт svg изобра... | https://habr.com/ru/post/709300/ | null | ru | null |
# Маленькие хитрости Java
Я уже достаточно много лет занимаюсь разработкой на java и повидал довольно много чужого кода. Как это не странно, но постоянно от одного проекта к другому я вижу одни и те же проблемы. Этот топик — попытка ликбеза в наиболее часто используемых конструкциях языка. Часть описанного — это довол... | https://habr.com/ru/post/132241/ | null | ru | null |
# Моя вторая неделя с Haiku: множество скрытых алмазов и приятных сюрпризов, а также некоторые проблемы
*Редактирование снимка экрана для этой статьи — в Haiku*
**TL;DR:** Производительность намного лучше, чем изначально. Виноват б... | https://habr.com/ru/post/468059/ | null | ru | null |
# Технический обзор систем NEC HYDRAstor HS8 и не только
Когда в нашей стране люди слышат название компании NEC первым делом люди старшего поколения вспоминают вот это:

Те кто чуть моложе вот это:
 исполнилось 30 лет

*Фото из Вики*
19 сентября 1982 года — Скотт Фалман, профессор питтсбургской компьютерной школы, придумал данный символ. Наличие смайликов помогало отличать серьезные соо... | https://habr.com/ru/post/151756/ | null | ru | null |
# Система мониторинга как точка проникновения на компьютеры предприятия
Это продолжение памятки про систему мониторинга Zabbix, опубликованной недавно в нашем блоге. Выражаем огромную благодарность пользователю [Shodin](https://habrahabr.ru/users/shodin/), который внес значительный вклад в исследование и написал данну... | https://habr.com/ru/post/350108/ | null | ru | null |
# HackTheBox. Прохождение Laser. Jetdirect, RPC и кража SSH
Продолжаю публикацию решений, отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu).
В данной статье мы работаем с принтером и получаем д... | https://habr.com/ru/post/533562/ | null | ru | null |
# Опыт разработки и внедрения систем объектовой видеоаналитики на СХД
СХД – это системы хранения данных, сервера или иные устройства с большим количеством установленных дисков и системами быстрого доступа к ним с гарантией сохранности информации (например, аппаратные или программные RAID-контроллеры). Если речь идёт п... | https://habr.com/ru/post/478450/ | null | ru | null |
# Оптимизируем React приложение для отображения списка элементов
Отображение списка (множества) элементов на странице — это стандартная задача для практически любого web-приложения. В этом посте я хотел бы поделиться некоторыми советами по повышению производительности.
Для тестового примера я создам небольшое прило... | https://habr.com/ru/post/304340/ | null | ru | null |
# Использование протокола MQTT в PHP
[](https://habr.com/ru/company/ruvds/blog/676284/)
Статья посвящена использованию библиотеки php-mqtt/client в PHP-проектах для реализации функций подключения, подписки, отписки, а также обмена со... | https://habr.com/ru/post/676284/ | null | ru | null |
# Комбинирование адаптивной верстки и шаблонов для мобильных
Статья является переводом отличного, вдохновляющего, хоть и небольшого поста [Mixing Responsive Design and Mobile Templates](http://css-tricks.com/mixing-responsive-design-and-mobile-templates/) от одного из создателей [CodePen](http://codepen.io/), [Криса К... | https://habr.com/ru/post/171709/ | null | ru | null |
# Создание анаморфных искажений в Unity
Всем привет! Сейчас я работаю в VRTech, и в рамках работы я натолкнулся на интересную задачу о которой хочется рассказать. Задача заключалась в том, чтобы получить анаморфное отображение картинки. Я попытаюсь рассказать, что такое анаморфные искажения, как рассчитать простейший ... | https://habr.com/ru/post/320926/ | null | ru | null |
# Linux в домашних условиях или…
Как заставить Linux запускать через Wine профессиональный софт на примере Adobe Photoshop СС 2018 без использования инструментария Play on Linux.
============================================================================================================================================... | https://habr.com/ru/post/421703/ | null | ru | null |
# Создаем калькулятор с единицами измерений
Как-то раз мне нужно было реализовать калькулятор для складывания и конвертации физических величин. У меня тогда не было ограничений по времени, поэтому я решил проблему на высоком уровне абстракции и, соответственно, под широкий спектр задач. Предлагаю на ваш суд мое решени... | https://habr.com/ru/post/359198/ | null | ru | null |
# Что же там такого тяжелого в обработке исключений C++?

Исключения и связанная с ними раскрутка стека – одна из самых приятных методик в C++. Обработка исключений интуитивно понятно согласуется с бл... | https://habr.com/ru/post/208006/ | null | ru | null |
# Новинки альфы Opera 12.00 для разработчиков
Свежая сборка альфы Opera 12.00 принесла с собой столько интересного, что мы решили рассказать об этом подробнее. Ссылки на сборку можно найти [в блоге Desktop Team](http://... | https://habr.com/ru/post/138130/ | null | ru | null |
# Общий финансовый анализ на Python (Часть 2)
Ну что [продолжим](https://habr.com/ru/post/492364/)?
#### Скользящее окно (Moving Windows)
В заголовке я привел дословный перевод. Если кто меня поправит, и другой термин более применим — то спасибо.
Смысл скользящего окна– с каждым новым значением функция пересчит... | https://habr.com/ru/post/494636/ | null | ru | null |
# Самая короткая программа вывода десятичного числа
В 1984-ом году вышла культовая книга Стивена Леви “[Хакеры: герои компьютерной революции](https://en.wikipedia.org/wiki/Hackers:_Heroes_of_the_Computer_Revolution)”. Существует любительский русский перевод, но он далёк от идеала. Я было взялся исправлять неточности в... | https://habr.com/ru/post/496914/ | null | ru | null |
# Система сбора измерений на примере метеостанции
Казалось бы, каждый, кто осваивает ардуино, первым делом конструирует или повторяет прибор для измерения температуры и(или) прочих параметров окружающей среды. Только больш... | https://habr.com/ru/post/302164/ | null | ru | null |
# OPA и SPIFFE — два новых проекта в CNCF для безопасности облачных приложений

В конце марта у фонда CNCF, помогающего развивать Open Source-проекты для облачных (cloud native) приложений, случилось двойное пополнение: в «песочницу»... | https://habr.com/ru/post/353808/ | null | ru | null |
# Закачка ролика на ruTube с использованием cURL
На хабре уже были топики, посвященные открытому **API** для работы с сервисом **ruTube**. В примере, который можно скачать с сайта **ruTube** (<http://rutube.ru/partners/phpapi.html>), отправка ролика осуществляется следующим образом (код взят из примера без правок):
... | https://habr.com/ru/post/42158/ | null | ru | null |
# Redfish в GAGAR>IN BMC
На сегодняшний день большинство крупных производителей серверного оборудования, таких как (DELL, IBM, HP) включают поддержку RedFish в прошивки для своих BMC контроллеров (Baseboard management controller) Разумеется, разрабатывая серверы GAGAR>IN, мы также добавили поддержку Redfish в наш BMC,... | https://habr.com/ru/post/549192/ | null | ru | null |
# Виды тестирования и подходы к их применению
Из институтского курса по технологиям программирования я вынес следующую классификацию видов тестирования (критерий — степень изолированности кода). Тестирование бывает:* Блочное ([Unit testing](http://en.wikipedia.org/wiki/Unit_testing)) — тестирование одного модуля в изо... | https://habr.com/ru/post/81226/ | null | ru | null |
# Очередной умный дом (или как потерять 2 месяца из-за одной глупой ошибки)
Предыстория
-----------
я, не знающий своей глу... | https://habr.com/ru/post/555830/ | null | ru | null |
# JBrowser: реинкарнация MozSwing
Вспомним, что же такое [MozSwing](http://sourceforge.net/projects/mozswing/). MozSwing — единственное адекватное (по моему мнению) бесплатное и кросс-платформенное решение для вс... | https://habr.com/ru/post/91884/ | null | ru | null |
# Getting Started with the PVS-Studio Static Analyzer for Visual C++

In this article, I'm going to tell you about PVS-Studio, an analyzer for C and C++ code, and show you how to use it in the Vis... | https://habr.com/ru/post/461007/ | null | en | null |
# Broadcast Event Messaging в Unity3D
При разработке игр, довольно часто возникает необходимость в построении системы широковещательной рассылки сообщений. Предположим, Вы хотите сделать так, чтобы в тот момент когда персонаж, управляемый игроком, вошел в определенную зону, или выполнил определенное действие, все заин... | https://habr.com/ru/post/254239/ | null | ru | null |
# Proxygen — HTTP-фреймворк для С++ от Facebook
[Proxygen](https://github.com/facebook/proxygen) — это коллекция библиотек для использования протокола HTTP на С++, включающая в числе прочего очень простой в использовании HTTP-с... | https://habr.com/ru/post/243181/ | null | ru | null |
# Apache Spark 3.1: Spark on Kubernetes теперь общедоступен

С выходом [Apache Spark](https://www.datamechanics.co/apache-spark) 3.1 в марте 2021-го проект [Spark on Kubernetes](https://www.datamechanics.co/spark-on-kubernetes) офици... | https://habr.com/ru/post/552370/ | null | ru | null |
# Ошибки LINQ to SQL на сайтах при нагрузке (> 30 пользователей)
Совсем недавно начал использовать LINQ to SQL и при нагрузках на сайт стал замечать такого рода ошибки,
при чем появляются в стиле корейского Random-а:
вариант 1) InvalidCastException
вариант 2) DataReader is closed
вариант 3) SQL Server та... | https://habr.com/ru/post/67207/ | null | ru | null |
# Анонсируем поддержку ECMAScript модулей в Node.js
Node.js 13.2.0 идет с поддержкой [ECMAScript модулей](https://hacks.mozilla.org/2018/03/es-modules-a-cartoon-deep-dive/), известных по своему синтаксису import и export. Ранее эта функциональность была за флагом `--experimental-modules`, который больше не требуется. ... | https://habr.com/ru/post/477168/ | null | ru | null |
# Тест-тренировка зрительного внимания
> *Если я напишу 2, потом 4, потом 6, тогда мы почувствуем себя хорошо, потому что мы знаем, что дальше идет 8. Мы можем это предвидеть, мы не в руках судьбы. Однако, к сожалению, это не имеет ничего общего с истиной...*
>
> х/ф «Оксфордские убийства»
, [Enter the Gungeon](http://store.steampowered.com/app/311690/Enter_the_Gungeon/) и [Descenders](http:... | https://habr.com/ru/post/471084/ | null | ru | null |
# My Pascal compiler and Polish contemporary art
Origins
-------
Several years ago I wrote a Pascal compiler. The motivation was simple: as a teenager, I had learnt from my first programming textbooks that a compiler is a very sophisticated thing. This claim eventually became a challenge and required to be tested by ... | https://habr.com/ru/post/440372/ | null | en | null |
# Дюк, вынеси мусор! — 6. Shenandoah GC
Несмотря на то, что мы уже успели достаточно подробно рассмотреть целых шесть сборщиков мусора ([Serial](https://habr.com/ru/post/269707/#serial_gc), [Parallel](https:/... | https://habr.com/ru/post/681256/ | null | ru | null |
# ~/mysql_history и безопасность
Как правило, безопасность обратно пропорциональна удобству. Сохранять историю команд, по которой можно перемещаться в CLI, — очень удобно. Так делает, например, bash. Так делает и MySQL, бережно и построчно записывая команды в ~/.mysql\_history в виде простого текста (включая пароли). ... | https://habr.com/ru/post/76936/ | null | ru | null |
# Эволюция PHP — от 5.6 до 8.0 (Часть 2)
***Перевод статьи подготовлен в преддверии старта курса***[***«Backend-разработчик на PHP»***](https://otus.pw/mGPb/)
[*(Читать первую часть)*](https://habr.com/ru/company/otus/blog/524270/)
 в [Twitch](https://www.twitch.tv/) используется во многих нагруженных системах. Простота, безопасность, производительность и читабельность делают его хорошим инструментом для решения проблем, с которыми сталкиваются сервисы, например при стриминге ... | https://habr.com/ru/post/305614/ | null | ru | null |
# Как Youtube и Instagram: интернационализация и локализация приложения на Python
Язык Python лежит в основе всемирно известных приложений, таких как Youtube, Instagram и Pinterest. Для продвижения на мировом рынке приложению необходима локализация, то есть адаптация к особенностям той или иной страны, и интернационал... | https://habr.com/ru/post/479738/ | null | ru | null |
# Верстка e-mail рассылок — «подводные камни». Часть первая. Картинки
Добрый день, уважаемые хабравчане!
Не так давно мы вплотную столкнулись с задачей верстки e-mail р... | https://habr.com/ru/post/114472/ | null | ru | null |
# Announcing .NET Core 3.0 Preview 6
Today, we are announcing [.NET Core 3.0 Preview 6](https://dotnet.microsoft.com/download/dotnet-core/3.0). It includes updates for compiling assemblies for improved startup, optimizing applications for size with linker and EventPipe improvements. We’ve also released new Docker imag... | https://habr.com/ru/post/456224/ | null | en | null |
# Под капотом: сборка и открытие исходников flint
Программы статического анализа кода — это необычный класс программ-верификаторов, и в течение некоторого времени я не был убежден в необходимости их использования при разработке для фейсбука. Я не терплю стилистические правила на своей шее, и ложные предупреждения об о... | https://habr.com/ru/post/224419/ | null | ru | null |
# Наследование ActiveRecord's, описывающих одну таблицу (паттерн single table inheritance) в Yii2
В большинстве реляционных баз данных, к сожалению, нет поддержки наследования, так что приходится реализовывать это вручную. В этой статье я хочу кратко показать, как реализовать такой подход к наследованию, как «single t... | https://habr.com/ru/post/274925/ | null | ru | null |
# Как мы не смогли создать медицинского чат-бота. История проекта, который так и не увидел свет
*Привет,*
*Это статья нашего бывшего коллеги, Андрея Лукьяненко, который работал над проектом по созданию мед... | https://habr.com/ru/post/670144/ | null | ru | null |
# Гайд по автоматическому аудиту смарт-контрактов. Часть 3: Mythril
**Warning**
-----------
Данная статья — это не рейтинг эффективности автоанализаторов. Я применяю их к собственным контрактам, намеренно синтезируя ошибки, и изучаю реакции. Такое исследование не может являться основанием для определения "лучше-хуже"... | https://habr.com/ru/post/442114/ | null | ru | null |
# Интеграция JIRA 4.1 с Active Directory
Встала задача интеграции JIRA 4.1 с Active Directory со следующими условиями:
1. Синхронизация пользователей и групп (версия 4.1 не поддерживает синхронизацию)
2. Прозрачная аутентификация (в качестве логинов в JIRA используются почтовые адреса)
3. Заполнение свойства пользо... | https://habr.com/ru/post/141144/ | null | ru | null |
# Как устроен The Update Framework (TUF). Обзор технологии безопасного обновления ПО
[The Update Framework](https://theupdateframework.io/) (TUF) — программный фреймворк с открытым кодом для защиты репозиториев, из которых скачиваются обновления. Главная задача TUF — предоставить возможность обновлять софт безопасно, ... | https://habr.com/ru/post/578958/ | null | ru | null |
# Ускоряем CI/CD-пайплайн с помощью Kubernetes в Docker (KinD)
> В нашей новой переводной статье разбираемся с KinD на практическом примере.
Создание кластера [Kubernetes](https://kubernetes.io/) со временем становится все проще. На рынке доступно несколько решений под ключ, и сейчас никто не выбирает сложный путь! ... | https://habr.com/ru/post/535728/ | null | ru | null |
# Сборка Qt5 в Visual Studio 2012 или я могу пришить глаз кенгуру пока течет мой любимый кетчуп
Не так давно вышел новый Qt, обещающий большое и светлое будущее, и я решил опробовать сие чудо. Но для начала работы с этим чудом мне понадобилось собрать его для моей установленной студии 2012 года из исходных файлов. А с... | https://habr.com/ru/post/168671/ | null | ru | null |
# Ajax image прелоадер
На днях на работе поставили задачу, нужно было сделать смену картинок. Задача решается в 5 минут при помощи jQuery. И как всегда есть одно «НО», картинки размером 1000x500 =)
И тут то оказалось что событие onLoad отрабатывает когда становятся извесны размеры изображения, а в случае больших ка... | https://habr.com/ru/post/23360/ | null | ru | null |
# Наука логики в программировании

Данная статья посвящена сравнительному анализу логических сущностей из произведения немецкого философа Георга Вильгельма Фридриха Гегеля "Науки... | https://habr.com/ru/post/448948/ | null | ru | null |
# Проверка Bitcoin

Ничего эпического в этой статье не будет. Мы проверили с помощью PVS-Studio исходный код Bitcoin. Нашли всего пару подозрительных мест. Это не удивительно. Думаю, эти ... | https://habr.com/ru/post/231489/ | null | ru | null |
# Нечто «крадет» место на диске?
Если Вы не следите за оставшимся свободным местом в корневом разделе — то Вас могут ожидать неприятные новости. В случае переполнения данного раздела, важные для Вашего проекта сервисы перестанут работать. Согласитесь, неработающий **MySQL** или **web server** скажется на проекте не лу... | https://habr.com/ru/post/271101/ | null | ru | null |
# Cache-Conscious Binary Search
Рассмотрим простую задачу: есть некоторый достаточно большой неизменный набор чисел, к нему осуществляется множество запросов на наличие некоторого числа в этом наборе, необходимо максимально быстро эти запросы обрабатывать. Одно из классических решений заключается в формировании отсорт... | https://habr.com/ru/post/202820/ | null | ru | null |
# JFStorage: Альтернатива cookies
Навеяно топиком [~~Альтернатива cookies посредством Java Script~~](http://habrahabr.ru/blog/javascript/46817.html)
Ипользование cookie ограничено 4 кб. размера, так же они видны пользователю.
При использование Flash Storage прочитать cookie немного сложнее и позволяет сохранять ... | https://habr.com/ru/post/29376/ | null | ru | null |
# История одного garbage collection'а
Эта поучительная история повествует о том, как важно развивать навыки гугления, и о том, как я боролся с ежечасным полным Garbage collection.
### Краткое описание проблемы
После того, как мы мигрировали в продакшене один из компонентов системы (единственный, работающий на Tomc... | https://habr.com/ru/post/179309/ | null | ru | null |
# Как безболезненно перевести образовательное учреждение на Linux и СПО?
Доброго времени суток.
С самого начала оговорюсь: переход на Linux и пакет СПО — не совсем безболезненная штука, да и не все ПО в конце перехода остается свободным. Но об этом позже.
Итак, начнем.
Возможно, многие уже знают, что в школах... | https://habr.com/ru/post/108588/ | null | ru | null |
# Свой Web проект на D под ОС Ubuntu
Этот материал родился благодаря статье [Простой сайт на D](http://habrahabr.ru/post/181548/) автора [danial72](http://habrahabr.ru/users/danial72/). Только там был разобран момент под **ОС Windows**. В моей же статье, будет пошагово рассмотрен процесс подготовки рабочего окружения ... | https://habr.com/ru/post/185878/ | null | ru | null |
# Пришло ли время забыть о React и перейти на Svelte?
Каждый год выходит исследование [State of JavaScript](https://2019.stateofjs.com/), которое обобщает результаты опроса, изучающего текущее состояние экосистемы JavaScript. Это исследование затрагивает фронтенд-фреймворки, серверную и мобильную разработку, тестирова... | https://habr.com/ru/post/488660/ | null | ru | null |
# DBA: когда почти закончился serial
*"Шеф, всё пропало, у нас* `serial` *на мегатаблице почти закончился!" -* а это значит, что либо вы его [неаккуратно накрутили](https://habr.com/ru/company/tensor/blog/507688/) сами, либо у вас действительно данных столько, что **разрядности** `integer`**-столбца уже не хватает** д... | https://habr.com/ru/post/547740/ | null | ru | null |
# MapReduce: более продвинутые примеры, попробуем без зауми
Чтобы не откладывать в долгий ящик сразу порассказываю несколько других примеров для MapReduce, обещанные в топике "[MapReduce без зауми](http://habrahabr.ru/blogs/algorithm/103467/)". (Если не понимаете полностью что такое MapReduce — прочитайте тот топик сн... | https://habr.com/ru/post/103490/ | null | ru | null |
# Анимированные иконки сайта, только Firefox?
Что-то неверно с кодом? или только движок Mozilla отображает анимированые gif как favicons сайта?
Проверьте сайт [www.pokelondon.com](http://www.pokelondon.com)
. Это заинтересовало меня. Почему я должен использовать MediatR? Какие преимущества он мне предоставляет? Здесь я собираюсь рассмотреть эти вопросы.
### Как пользоваться MediatR
На базо... | https://habr.com/ru/post/588887/ | null | ru | null |
# ZoomX. Меняем правила шаблонизации в MODX Revolution
Привет, друзья! Хорошая новость для модыксеров — компонент, о котором мы много говорили в сообществе, вышел. Возможно не все в курсе о чём речь. Давайте я расскажу поподробнее.
Что такое ZoomX
---------------
Задача, которую позволяет решать данный компонент ... | https://habr.com/ru/post/525158/ | null | ru | null |
# Начинаем работу с Zynq 7000. Пособие для начинающих
Совсем недавно мне в руки попался один из вариантов отладочной платы с SoC Zynq XC7Z020. Поискав в Интернете материалы, а-ля how-to, и попробовав накидать свой минимальный проект обнаружил, что есть целый ряд подводных камней. Именно об этом я и хотел бы рассказать... | https://habr.com/ru/post/559946/ | null | ru | null |
# Тестирование инфраструктуры как кода Terraform: анализ модульных тестов и сквозной разработки путем тестирования поведен

> Для будущих студентов курса [«Infrastructure as a code in Ansible»](https://otus.pw/FLGWq/) и всех интересу... | https://habr.com/ru/post/533416/ | null | ru | null |
# Почти ОС реального времени — 2
Теперь, когда [инструмент](http://habrahabr.ru/blogs/controllers/58366/ "Ссылка на предыдущий пост") готов, его уже можно и нужно использовать.
Предварительно пара слов про Главный Таймер.
На плате предусмотрен внешний генератор импульсов (часы DS1307). Генератор настроен на част... | https://habr.com/ru/post/58472/ | null | ru | null |
# Автоматическое заполнение файлами документов Word и подписей к ним с помощью Python и библиотеки docx
Рассмотрим пример простой программы на **Python** с помощью библотекы **docx** для автоматизации рабочего процесса, а именно автоматической вставки файлов (в данном случае изображений) и их подпись в документах Word... | https://habr.com/ru/post/579094/ | null | ru | null |
# Разработка интеллектуальных ботов с помощью Microsoft Bot Framework, Azure Cognitive Services и NER систем. Часть 1
На сегодняшний момент лишь мессенджеры (и, частично, игры) показывают стабильный рост аудитории на фоне падения всех статистических показателей классических мобильных приложений. WhatsApp заявляет об 1... | https://habr.com/ru/post/312286/ | null | ru | null |
# Asterisk. Dialplan Askozia 6. Исходящие звонки
В статье пойдет речь о бесплатной АТС **Askozia версии 6**. При разработке телефонной станции одной из первых задач была организация исходящих звонков.
### Как это было
В старой версии Askozia использовались стандартные “**шаблоны**” dialplan.
* **X!** — все ном... | https://habr.com/ru/post/445536/ | null | ru | null |
# AWS Insight: Как работают Placement Groups
Привет! 
У многих есть проекты с «хайлоадом». Немногие используют кластеры на AWS. И те, кто всё-таки их используют, должны использовать Placement группы.
#### Что это ... | https://habr.com/ru/post/161315/ | null | ru | null |
# Безопасное использование C++
От переводчика. Данный текст является переводом документа [Safer Usage Of C++](https://docs.google.com/document/d/e/2PACX-1vRZr-HJcYmf2Y76DhewaiJOhRNpjGHCxliAQTBhFxzv1QTae9o8mhBmDl32CRIuaWZLt5kVeH9e9jXv/pub), выложенного в общий доступ командой Chromium/Chrome из компании Google. Текст а... | https://habr.com/ru/post/580762/ | null | ru | null |
# Как проиндексировать логи бизнес-приложений в Hadoop (SolrCloud)
Введение
--------
У одного из наших клиентов возникла задача вынести логи из большинства корпоративных приложений и их баз данных «куда-нибудь» — уж больно с ними много возни: растут как на дрожжах, чисти их периодически, а к некоторым еще и доступ до... | https://habr.com/ru/post/234049/ | null | ru | null |
# Zabbix 3.4: Макросы в интервалах времени
Привет. Продолжаем освещать нововведения Zabbix 3.4. Сегодня поговорим об использовании макросов в интервалах обновления и других временных периодах.

Пару слов о макросах
===================... | https://habr.com/ru/post/344492/ | null | ru | null |
# Краткий обзор и настройка Kata Containers
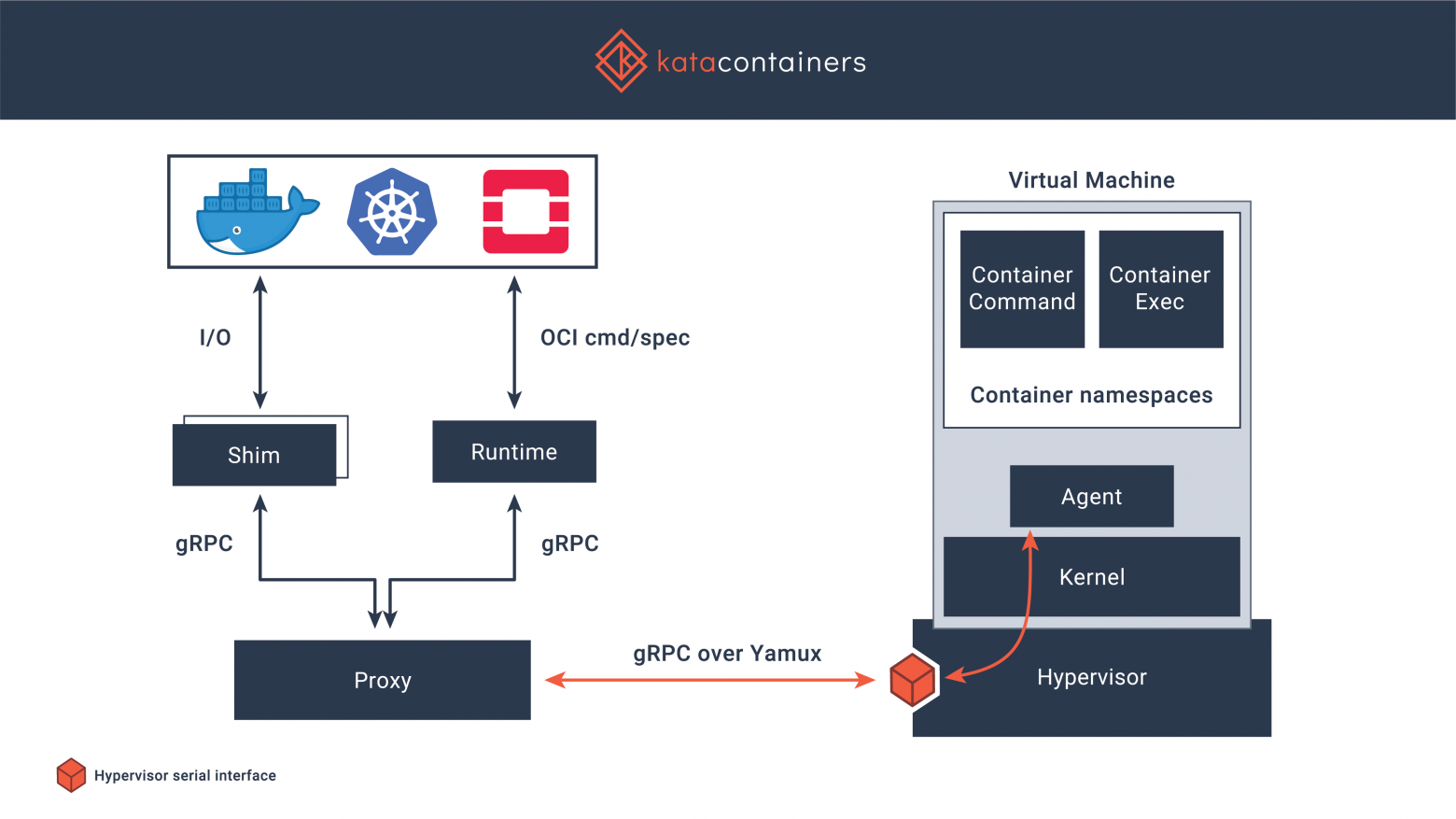
В этой статье будет рассмотрен принцип работы [Kata Containers](https://katacontainers.io/), а также будет практическая часть с их подключением к Docker.
Про общие проблемы с Docker и вар... | https://habr.com/ru/post/489940/ | null | ru | null |
# XenForo: добавляем новую страницу в раздел помощи
Недавно мне понадобилось создать отдельную страницу в разделе помощь на форуме, работающем на движке XenForo. Как оказалось, сделать это проще простого. Более того, не пришлось править код самого движка, что естественно, в будущем при обновлении ядра нам облегчит жиз... | https://habr.com/ru/post/137153/ | null | ru | null |
# Вышел GitLab 9.3: Code Quality и межпроектные графики конвейеров
Вышел GitLab 9.3: Code Quality и межпроектные графики конвейеров
================================================================

В GitLab 9.3 мы представляем Code Quality, межпроектны... | https://habr.com/ru/post/332204/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.