
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# «Hack Me на TryHackMe», или Небезопасное изучение инфобеза на известной платформе
Привет, Хабрчане. Сегодня мы поговорим об одной проблеме, которую обнаружил мой хороший знакомый [Иван Глинкин](https://www.... | https://habr.com/ru/post/562826/ | null | ru | null |
# Учебник Thymeleaf: Глава 19. Приложение B: Полезные выражения
[Оглавление](https://habrahabr.ru/post/350862/)
19 Приложение B: Полезные выражения
-----------------------------------
**Информация о выполнении**
**#execInfo**: выражения, предоставляющие полезную информацию о шаблоне, обрабатываемом внутри Thyme... | https://habr.com/ru/post/352556/ | null | ru | null |
# Графический стек Linux
*(оригинал — Jasper St. Pierre, разработчик GNOME Shell, [взято отсюда](http://blog.mecheye.net/2012/06/the-linux-graphics-stack/))*
Это обзорная статья о составных частях графического стека Linux и том, как они уживаются вместе. Изначально я написал её для себя после разговоров об этом сте... | https://habr.com/ru/post/148954/ | null | ru | null |
# Управление свайпами в игровом проекте на Godot Engine
Всем Приветствие! Сегодня я бы хотел рассказать о том, как реализовать управление свайпами в игровом проекте для Android на движке Godot Engine.

Меня... | https://habr.com/ru/post/492144/ | null | ru | null |
# jQuery изнутри — манипуляции с DOM
Каникулы продолжаются и мы воспользуемся этим для получения новых знаний, укрепления и расширения старых.
Долго думал, что же разобрать дальше — атрибуты, свойства и данные или манипуляцию с DOM, даже начал писать обе статьи. И вроде бы сначала хорошо было бы дать первую тему, н... | https://habr.com/ru/post/164677/ | null | ru | null |
# Классификация покрова земли при помощи eo-learn. Часть 3
Когда нужны результаты лучше, чем "удовлетворительно"
[Часть 1](https://habr.com/ru/post/452284/)
[Часть 2](https://habr.com/ru/post/452378/)

*Переход зоны из зимнего сез... | https://habr.com/ru/post/453354/ | null | ru | null |
# Ruby on Rails соглашение. Часть 3

### Ни одна парадигма
Существует эмоциональная привязанность при выборе определенной центральной идеи как фундамента вашей архитектуры и следованию ей до логического завершения при разраб... | https://habr.com/ru/post/329844/ | null | ru | null |
# Философия информации, глава 2. Существование информации

*Перед прочтением этого текста рекомендуется прочитать [начало](https://habr.com/post/403225/) этой истории. Иначе будет не понятно, зачем понадобилось выстраивать с... | https://habr.com/ru/post/403327/ | null | ru | null |
# Решение проблемы border-radius + overflow:hidden с помощью canvas
Передо мной стояла следующая задача:

Есть блок с фоном (необязательно однородным), в нем какое-то количество круглых элементов с... | https://habr.com/ru/post/179525/ | null | ru | null |
# Отправляем SMS из Erlang/Elixir. Короткая инструкция

Photo by [Science in HD](https://unsplash.com/@scienceinhd)
Если вам когда-либо приходилось решать задачу отправки SMS из кода вашего приложения, скорее всего, вы использовал... | https://habr.com/ru/post/535594/ | null | ru | null |
# Побеждаем NPE hell в Java 6 и 7, используя Intellij Idea
#### Disclaimer
* Статья не претендует на открытие Америки и носит популяризаторско-реферативный характер. Способы борьбы с NPE в коде далеко не новые, но намного менее известные, чем этого хотелось бы.
* Разовый NPE — это, наверное, самая простая из все возм... | https://habr.com/ru/post/237843/ | null | ru | null |
# Пример реализации Stencil буфера с помощью CUDA

Stencil buffer используется для маскировки отражений в тех местах где их на самом деле нет. Техника Stencil используется в OpenGL и DirectX. Перед применением алгоритма ... | https://habr.com/ru/post/151640/ | null | ru | null |
# MySQL и MongoDB — когда и что лучше использовать

*Петр Зайцев показывает разницу между MySQL и MongoDB. Это — расшифровка доклада с [Highload++](http://www.highload.ru/) 2016.*
Если посмотреть такой известный [DB-Engi... | https://habr.com/ru/post/322532/ | null | ru | null |
# Стиль сына маминой подруги
Привет, Хабр! Мы продолжаем нашу экспериментальную серию статей, наблюдая за которой вы можете в реальном времени влиять на ход создания игры на UWP. В этой части расскажем о стиле приложения и покажем, что делать красиво не так уж и сложно. Не забывайте оставлять комментарии!

Недавно я начал изучать machine learning. Начал с прекрасного, на мой взгляд, [курса](https://www.coursera.org/learn/mac... | https://habr.com/ru/post/428417/ | null | ru | null |
# Неопределенное поведение в C++
Достаточно сложной темой для программистов на С++ является undefined behavior. Даже опытные разработчики зачастую не могут четко сформулировать причины его возникновения. Статья призвана внести чуть больше ясности в этот вопрос.
Статья является ПЕРЕВОДОМ нескольких статей и выдержек... | https://habr.com/ru/post/216189/ | null | ru | null |
# Когда использовать статические методы
*tl;dr Использовать ли статические методы? Да, когда они не зависят от внутреннего состояния объекта.*
В обсуждениях к [посту](http://verraes.net/2014/06/named-constructors-in-php/) ([перевод](https://habrahabr.ru/post/279919/)) о именованных конструкторах прозвучало мнение, ... | https://habr.com/ru/post/279921/ | null | ru | null |
# Принципы работы IQueryable и LINQ-провайдеров данных
Средства LINQ позволяют .Net-разработчикам единообразно работать как с коллекциями объектов в памяти, так и с объектами, хранящимися в базе данных или ином удаленном источнике. Например, для запроса десяти красных яблок из списка в памяти и из БД средствами Entity... | https://habr.com/ru/post/256821/ | null | ru | null |
# Контроллер дистанционного управления для ПК-сервера с текстовой консолью, без паяльника и Arduino
#### Аннотация
Хотя один из героев второго плана — ИК-порт на материнской плате, не стану я рассказывать про пульты от телевизоров и переключение ими треков в любимом медиаплеере. В продолжение истории про [сервер Free... | https://habr.com/ru/post/217299/ | null | ru | null |
# Представляем последнюю Preview-версию Windows Terminal — 0.11
Рады вернуться с последним крупным обновлением перед релизом версии 1.0! Выпуски с настоящего времени и до выхода v1.0 будут ревизиями этой версии. Как и всегда вы можете загрузить Терминал из [Microsoft Store](https://www.microsoft.com/en-us/p/windows-te... | https://habr.com/ru/post/499128/ | null | ru | null |
# PHP-Дайджест № 186 (3 – 17 августа 2020)
[](https://habr.com/ru/post/515416/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 8 Beta 1, снова о синтаксисе атрибутов в PHP 8: `#[Attr]` ... | https://habr.com/ru/post/515416/ | null | ru | null |
# Layers + Unity Container
Всем привет! Хочу привести пример layers-архитектуры и роль контейнера Unity в ней. А то народ про сам контейнер пишет, а как его c с пользой использовать толком написать не могут. Давайте я попробую.
Начну очень издалека, извините сразу. Просто, для того, чтобы объяснить что-то полезное,... | https://habr.com/ru/post/63698/ | null | ru | null |
# Оптимизация псевдостриминга FLV-видео
Один из проектов нашей компании — это сервис online-видео, аналогичный youtube. Для вещания и реализации возможностей стриминга используется замечательный веб-сервер nginx с модулем ngx\_http\_flv\_module.
Все было хорошо, пока количество просмотров не достигло уровня, когда ... | https://habr.com/ru/post/142031/ | null | ru | null |
# Как выглядит ваш текст?
Друзья, отличной всем пятницы. Хотим поделиться с вами переводом статьи, подготовленным специально для студентов курса [«Android-разработчик. Продвинутый курс»](https://otus.pw/7EWN/). Приятного прочтения.
 ... | https://habr.com/ru/post/456110/ | null | ru | null |
# Основные проблемы использования видеосвязи в переговорных комнатах и их решение
[В прошлый раз](https://geektimes.ru/company/unitsolutions/blog/280990/) мы подробно рассказали про различное оборудование видеоконференцсвязи для переговорных комнат.
В этой статье мы хотим рассказать про наиболее частые проблемы, во... | https://habr.com/ru/post/370465/ | null | ru | null |
# Алгоритм обратного распространения ошибки на примере Word2Vec
Поскольку я столкнулся с существенными затруднениями в поисках объяснения механизма обратного распространения ошибки, которое мне понравилось бы, я решил написать собственный пост об обратном распространении ошибки реализовав алгоритм Word2Vec. Моя цель, ... | https://habr.com/ru/post/496186/ | null | ru | null |
# Повторяющийся зубчатый фон на CSS
[](http://jsfiddle.net/CyberAP/eSx3d/)
Давно на хабре не было постов про CSS и я решил восполнить этот пробел. Сегодня мы учимся готовить зубчатый фон используя только средства CSS и ни... | https://habr.com/ru/post/176591/ | null | ru | null |
# Примеры GraphQL на Java для начинающих [со Spring Boot]
В этой статье мы рассмотрим пример GraphQL на Java и создадим простой сервер GraphQL со Spring Boot.

*Таким цыпочкам тоже нравятся примеры GraphQL на Java со Spring Boot!*
... | https://habr.com/ru/post/513170/ | null | ru | null |
# Фреймворк Автоматизации Морских Перевозок (SAF)
Александр Гусятинер, Олег Жихарев
ВВЕДЕНИЕ
--------
Фреймворк Автоматизации Морских Перевозок (SAF)
===============================================

Sea-F... | https://habr.com/ru/post/426265/ | null | ru | null |
# Project Loom: Современная маcштабируемая многопоточность для платформы Java

Эффективное использование многочисленных ядер современных процессоров — сложная, но всё более важная задача. Java была одним из первых языков программирован... | https://habr.com/ru/post/543272/ | null | ru | null |
# Один из лучших классов для загрузки файлов на сервер. (PHP)
Хочу познакомить вас с одним из лучших классов, на мой взгляд, для загрузки файлов на сервер.
позволяет делать с изображением все что угодно
Ничего лучше чем пример быть не может, так что сразу к делу…
Читаем дальше если интересно...
Самый прос... | https://habr.com/ru/post/39969/ | null | ru | null |
# Ограничение скорости на DIR-320N/RU
Понадобилось устроить шейпер на какой-нибудь дешевой железке. Железкой планировался быть **DIR-320** от известного китайского производителя. Но вместо хорошего и простого **DIR-320** приехал ужасный и непонятный **DIR-320NRU** и начались проблемы.
Изначально идея была проста: с... | https://habr.com/ru/post/133476/ | null | ru | null |
# Обновляем платформу 1С на сервере под управлением Linux
Вступление
----------
Здравствуйте, меня зовут Шилин Никита и в прошлом я довольно много работал разработчиком 1С, а так же выполнял сопутствующие задачи. В настоящий момент я всё больше занимаюсь управлением командой и исполняю функции CTO на производственном... | https://habr.com/ru/post/709308/ | null | ru | null |
# PHP-Дайджест № 177 (23 марта – 6 апреля 2020)
[](https://habr.com/ru/post/495838/)
Свежая подборка со ссылками на новости и материалы. В выпуске: расписание релиза PHP 8, анализ эргономики объектов в PHP и 5 свежих RFC из PHP Int... | https://habr.com/ru/post/495838/ | null | ru | null |
# Бюджетный 3D принтер как конструктор. Заменяем материнскую плату и прошивку
К нам приехал принтер Creality Ender 3 v2 с процессором GD (GigaDevice) вместо ожидаемого STM (STMicroelectronics). Принтер в базовой комплектации еще как-то работает (хотя прошивка очень урезана), но часть периферии принтера не работает вов... | https://habr.com/ru/post/715538/ | null | ru | null |
# Flutter BloC паттерн + Provider + тесты + запоминаем состояние
Эта статья выросла из публикации “[BLoC паттерн на простом примере](https://habr.com/ru/post/475404/)” где мы разобрались, что это за паттерн и как его применить в классическом простом примере счетчика.
По комментам и для своего лучшего понимания я реши... | https://habr.com/ru/post/485002/ | null | ru | null |
# Redux Action Creators. Без констант и головной боли

Всем привет! Эта статья будет полезна тем, кто устал использовать constants в Redux (частично показано на превью выше). Под катом я покажу очередной возможный велосипед и... | https://habr.com/ru/post/310854/ | null | ru | null |
# Как мы автоматизировали запуск Selenium-тестов через Moon и OpenShift
14 декабря на митапе в Санкт-Петербурге я (Артем Соковец) совместно с коллегой, Дмитрием Маркеловым, рассказывал о текущей инфраструктуре для автотестов в СберТехе. Пересказ нашего выступления — в этом посте.
 — способ оперирования элементами интерфейса в интерфейсах пользователя
(как графическим, так и текстовым, где элементы GUI реализованы при по... | https://habr.com/ru/post/679444/ | null | ru | null |
# История о том, как я парсер для дневника мастерил
Год назад я начал писать ботов для всеми любимого Телеграма. На Питоне, конечно. И вот недавно мой сын пошёл в школу, где, как оказалось, был электронный дневник под названием [МРКО](https://mrko.mos.ru/dnevnik/). Как вы могли догадаться, самая первая мысль — сделать... | https://habr.com/ru/post/323856/ | null | ru | null |
# Параллелизм в PostgreSQL: не сферический, не конь, не в вакууме
Масштабирование СУБД – это непрерывно наступающее будущее. СУБД совершенствуются и лучше масштабируются на аппаратных платформах, а сами аппаратные платформы наращи... | https://habr.com/ru/post/423685/ | null | ru | null |
# http://http://http://@http://http://?http://#http://
Пару дней назад я опубликовал этот твит:
Учитывая то, насколько много я получил комментов и ответов, я решил разобрать это подробнее. Правда ли это вали... | https://habr.com/ru/post/687402/ | null | ru | null |
# Вложенные привязки в WPF
В WPF существует три вида привязок: **Binding**, **PriorityBinding** и **MultiBinding**. Все три привязки наследуются от одного базового класса **BindingBase**. PriorityBinding и MultiBinding позволяют к одному свойству привязать несколько других привязок, например:
```
```
**Исходный к... | https://habr.com/ru/post/277157/ | null | ru | null |
# Разработка ERP на tryton: Часть 1
К нам пришел крупный проект по созданию ERP-системы для компании производителя. В качестве сервера выбор пал на tryton. Однако у них с документацией достаточно плохо. На просторах интернета удалось найти [официальную документацию](http://doc.tryton.org/3.2/), [куски кода с описанием... | https://habr.com/ru/post/222121/ | null | ru | null |
# Теплый ламповый текстовый интерфейс. Просто о простом
Периодически просматривая топики на хабре, постоянно ловлю себя на мысли, что ещё чуть-чуть и какой-нибудь нейроинтерфейс в ноутбуке станет реальностью. В работе постоянно натыкаюсь на то, что современные люди не очень понимают и любят простую командную строку. А... | https://habr.com/ru/post/205222/ | null | ru | null |
# React, всплывающие подсказки (tooltips), для самых маленьких
Что такое всплывающие подсказки?
--------------------------------
Если дословно, то сам термин «tooltips» — английского происхождения и переводится как «советы по инструментам». Под этим термином согласно Википедии понимают информационную подсказку или по... | https://habr.com/ru/post/714270/ | null | ru | null |
# Amazon S3 скрестили с BitTorrent
Компания Amazon разрешает скачивать файлы с хостинга S3 [по протоколу BitTorrent](https://docs.aws.amazon.com/AmazonS3/latest/dev/S3Torrent.html). Через торренты можно распространять любые общедоступные файлы Amazon S3 размером не более 5 ГБ (возможно, в будущем это ограничение сниму... | https://habr.com/ru/post/357774/ | null | ru | null |
# Навеянное Prolog-ом коммерческое решение пробыло больше 10 лет в эксплуатации
Для большинства программистов которые хотя бы слышали про Prolog это только странный артефакт из времён когда компьютеры были размером с динозавров. Некоторые сдали и забыли в институте. И лишь узкие как листочек A4 специалисты сталкивалис... | https://habr.com/ru/post/526262/ | null | ru | null |
# PostgreSQL на многоядерных серверах Power 8

### Аннотация
При помощи московского представительства компании IBM мы провели тестирование производительности последних версий СУБД PostgreSQL на серверах Power8, изучили мас... | https://habr.com/ru/post/270827/ | null | ru | null |
# Наш опыт работы с данными в etcd Kubernetes-кластера напрямую (без K8s API)
Все чаще к нам обращаются клиенты с просьбой обеспечить доступ в Kubernetes-кластер для возможности обращения к сервисам внутри кластера: чтобы можно было напрямую подключиться к какой-то базе данных или сервису, для связи локального приложе... | https://habr.com/ru/post/501956/ | null | ru | null |
# Обходим Windows Defender дешево и сердито: обфускация Mimikatz

Всем привет. Сегодня рассмотрим вариант запуска mimikatz на Windows 10. Mimikatz — инструмент, реализующий функционал Windows Credenti... | https://habr.com/ru/post/454758/ | null | ru | null |
# PostgreSQL: как и почему пухнет WAL
 Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидент... | https://habr.com/ru/post/421061/ | null | ru | null |
# Лямбда-функция в Python простыми словами
В этой статье вы подробнее изучите анонимные функции, так же называемые "лямбда-функции". Давайте разберемся, что это такое, каков их синтаксис и как их использовать... | https://habr.com/ru/post/674234/ | null | ru | null |
# Уязвимости Киевстара: 1) разбор предыдущего поста про пароли + 2) инфо о покупках, проходящих через сервисы Киевстара
Привет. Я тот, кто полгода назад получил логины и пароли Киевстара от таких важных сервисов, как: JIRA, Amazon Web Services, Apple Developer, Google Developer, Bitbucket и многих других, зарепортил и... | https://habr.com/ru/post/435074/ | null | ru | null |
# Пишем плагин к Intellij IDEA: Регистрация типа файла
Недавняя [статья](http://habrahabr.ru/post/148996) на Хабре напомнила мне о том, сколько времени я провел пытаясь написать свой плагин к Intellij IDEA. Официальная документация по созданию плагинов хоть и есть, но её неожиданно мало.
В этой статье я расскажу о... | https://habr.com/ru/post/149100/ | null | ru | null |
# Использование TTreeView в Firemonkey приложениях
На днях мне пришлось столкнуться с компонентом TTreeView. Заказчик настаивал на привычном ему компоненте — «Дереве», и хотел, чтобы приложение выглядело так, как он привык в VCL.
В этой статье я хотел бы рассказать о компоненте TTreeView (ветка дерева) и его исполь... | https://habr.com/ru/post/243933/ | null | ru | null |
# CSS-переменные
CSS-переменные (их ещё называют «пользовательскими свойствами») поддерживаются веб-браузерами уже почти четыре года. Я пользуюсь ими там, где они могут пригодиться. Это зависит от проекта, над которым я работаю, и от конкретных задач, которые мне приходится решать. Работать с CSS-переменными просто, о... | https://habr.com/ru/post/523370/ | null | ru | null |
# Трассировка Python GIL

Есть много статей, объясняющих, для чего нужен Python GIL (The Global Interpreter Lock) (я подразумеваю CPython). Если вкратце, то GIL не даёт многопоточному чистому коду на Python использовать несколько я... | https://habr.com/ru/post/538706/ | null | ru | null |
# Безопасная авторизация с передачей хешированного пароля
При разработке одного проекта, появилась задача осуществить защиту в случае просмотра трафика, и просмотра исходника (могут узнать хеш пароля) злоумышленниками. Имея доступ ко всем данным, никто не должен авторизоваться на сервере, не зная исходный пароль. Вари... | https://habr.com/ru/post/85698/ | null | ru | null |
# Эффективное использование WebAPI: self hosting REST-сервисов
С выходом [ASP.NET WebAPI](http://www.asp.net/web-api) у разработчиков появилась возможность быстро создавать REST-сервисы в удобном виде, с одной стороны полностью реализуя принципы REST, а с другой используя всю мощь платформы ASP.NET.
Про возможности... | https://habr.com/ru/post/145178/ | null | ru | null |
# Минуя бесконечность: t-тест своими руками
В этом посте речь пойдёт о реализации процедуры вычисления значения функции распределения Стьюдента без использования каких-либо специальных математических библиотек. Только Java (либо C/C++, код вполне универсален).
T-тест это...
=============
Для старта, вспомним немного... | https://habr.com/ru/post/307712/ | null | ru | null |
# Взломан linux.com
Только что пришло письмо с известием того, что сайт linux.com взломан.
Адреса электронной почты, пароли и ssh ключи могут быть скомпрометированы.
Текст письма:
`Attention Linux.com and LinuxFoundation.org users,
We are writing you because you have an account on Linux.com,
LinuxFounda... | https://habr.com/ru/post/128211/ | null | ru | null |
# AnnotatedSQL: schema + content provider
Наконец дошли руки описать изменения, которые произошли в библиотеке [AnnotatedSQL](https://github.com/hamsterksu/Android-AnnotatedSQL)
Анонс:
1. Изменения в плагине
2. Изменения в аннотациях схемы
3. Что такое content provider в моем понимании
4. Генерируем co... | https://habr.com/ru/post/166051/ | null | ru | null |
# Helidon, Testcontainers, Cucumber, Kafka и многое другое
**Helidon** отлично подходит для создания **микросервисов**, для простого и быстрого развертывания в проде, и демострирует действительно впечатляющу... | https://habr.com/ru/post/591655/ | null | ru | null |
# Рецепт вращения планет в космосе на HTML5 + JavaScript
В рамках создания нашей браузерной космической игры, перед нами стояла задача разработать простую и наименее ресурсозатратную анимацию вращения планет в звездной си... | https://habr.com/ru/post/268975/ | null | ru | null |
# Авторизация для API с помощью токенов
Как и обещал ранее, продолжаю свою серию статей про создание API на Symfony2. Сегодня я бы хотел рассказать о авторизации. Из популярных бандлов есть JWTAuthenticationBundle и FOSOAuthServerBundle, у каждого есть свои плюсы и минусы, но мне хотелось бы рассказать как сделать авт... | https://habr.com/ru/post/258903/ | null | ru | null |
# Очень шустрый блог на WordPress при помощи связки nginx + PHP-FPM + MariaDB + Varnish
В данной статье я расскажу о том, как я заставил свой блог на WordPress летать за счёт грамотного кэширования, сжатия и другой оптимизации серверной и клиентской сторон. На момент написания статьи характеристики VDS следующие:
>... | https://habr.com/ru/post/278189/ | null | ru | null |
# Векторные иконки на HTML5 + JS
[](http://raphaeljs.com/icons/)
На первый взгляд это обычные одноцветные иконки, но если призумить — их качество не ухудшится. Очевидный профит таких иконок: с ними можно с... | https://habr.com/ru/post/110526/ | null | ru | null |
# Браузер Brave первым добавил поддержку IPFS

*С выпуском версии 1.19 пользователи Brave могут напрямую получать доступ к содержимому распределённой файловой системы IPFS, вводя URI, начинающиеся с ipfs://*
Brave стал первым браузером, который [внед... | https://habr.com/ru/post/538196/ | null | ru | null |
# Ненадёжный Ethernet
В продолжение предыдущей статьи "[Ethernet & FC](http://habrahabr.ru/post/224869/)", хотел бы дать конкретные рекомендации по оптимизации Ethernet сети для работы с СХД NetApp FAS. Хотя, полагаю, многие вещи описанные здесь могут быть полезны и для других решений.

РАМ-машина — абстрактная вычислительная машина, обладающая полнотой по Тьюрингу, и принадлежащая классу регистровых машин. Она эквивалентна универсальной машине Тьюринга, при этом бол... | https://habr.com/ru/post/115229/ | null | ru | null |
# Все, что нужно знать об ALBERT, RoBERTa и DistilBERT
### Обзор различий и сходств различных трансформеров BERT из библиотеки Hugging Face и как их использовать
Привет Хабр! Представляю вам перевод статьи [Everything you need to know about ALBERT, RoBERTa, and DistilBERT](https://towardsdatascience.com/everything-yo... | https://habr.com/ru/post/680986/ | null | ru | null |
# Azure Active Directory Gateway теперь на .NET Core 3.1
*\*Gateway — шлюз*
Azure Active Directory Gateway — это обратный прокси-сервер, который работает с сотнями служб, входящих в Azure Active Directory (A... | https://habr.com/ru/post/561706/ | null | ru | null |
# Хранимые процедуры, функции и триггеры на Java
Всем привет! Сегодня мы расскажем о полезной возможности СУБД Ред База Данных - создании внешних подпрограмм, то есть процедур, функций и триггеров на языке Java. Например, язык PSQL не позволяет работать с объектами файловой системы или сети, а Java запросто решает так... | https://habr.com/ru/post/699732/ | null | ru | null |
# Как сделать объекты из массивов в PHP с подсказками?
Когда надоело запоминать ключи массивов и хочется пользоваться подсказками любимого редактора кода на помощь приходит PHPDoc и немного смекалки.
Недавно я очень близко познакомился с TypeScript и познал всю прелесть строгой типизации. Как же это приятно, когда ре... | https://habr.com/ru/post/653091/ | null | ru | null |
# Задавать Height и Width для изображений снова важно
*Приветствую. Представляю вашему вниманию перевод статьи* [*«Setting Height And Width On Images Is Important Again»*](https://www.smashingmagazine.com/2020/03/setting-height-width-images-important-again/)*, опубликованной 9 марта 2020 года автором Barry Pollard*
С... | https://habr.com/ru/post/524918/ | null | ru | null |
# Разрешение конфликтов в транзитивных зависимостях — Хороший, Плохой, Злой
#### Вместо предисловия
В ближайшую субботу мы с [EvgenyBorisov](https://habrahabr.ru/users/evgenyborisov/) будем [выступать в Питере на JUG.ru](http://jugru.timepad.ru/event/72119/). Будет много веселого трэша и интересной инфы (иногда не ра... | https://habr.com/ru/post/191246/ | null | ru | null |
# Видео на электронной книжке. Попытка использовать е-ink reader в качестве второго монитора в linux
Данное сочинение навеяно вот [этой публикацией](https://habrahabr.ru/post/274831/) за 2012 год, в которой изложен отличный способ избежать покупки пока единственного существующего в мире usb-монитора на жидких чернилах... | https://habr.com/ru/post/341748/ | null | ru | null |
# BotAuth — вход и регистрация при помощи ботов

BotAuth — пакет, который позволяет реализовать вход при помощи бота Вконтакте, FaceBook, Telegram.
Основная задача BotAuth, упростить посетителям Веб сайтов/PWA вход через социаль... | https://habr.com/ru/post/455104/ | null | ru | null |
# Как использовать polyfill-библиотеку Webshims
Данная статья является переводом с дополнениями поста [css-tricks.com/how-to-use-the-webshims-polyfill](http://css-tricks.com/how-to-use-the-webshims-polyfill/)
В этой статье речь пойдет о HTML5 polyfill библиотеке под названием [Webshims](http://afarkas.github.com/we... | https://habr.com/ru/post/159325/ | null | ru | null |
# Android Environments
### Предисловие
Из далекого 2012, на просторах Хабра мне запомнился коммент:
> [… если нет корпуса с самого начала, то устройство так и останется
>
> недоделанным, ляжет пылиться на полке...](https://habr.com/ru/post/140426/#comment_16585645)
Топик далеко не про хардварную составляющую. Р... | https://habr.com/ru/post/462751/ | null | ru | null |
# Приватное облако для Интернета Вещей

Приветствую, Хабр!
Мы, команда ИТ архитекторов из IBM, которая занимается созданием и продвижением на рынок индустриальных решений для разных отраслей. В свободное от основной работы время и... | https://habr.com/ru/post/426135/ | null | ru | null |
# Собираем простейшую ZigBee-сеть, программируем под Mbed, общаемся через MQTT
Эта статья — большой учебный практикум начального уровня по использованию XBee-модуля в связке с микроконтроллером, имеющим на борту Mbed OS. ZigBee — давно и прочно укоренившийся стандарт в системах «Умного дома» (например, он используется... | https://habr.com/ru/post/497200/ | null | ru | null |
# Zend_Form_Element: создание своего элемента
#### 0. Intro.
В процессе разработки достаточно часто нужно использовать различные кастомные селекты, инпуты, загрузщики файлов и прочее. В этом случае приходится писать дополнительные обработчики на стороне клиента, так как ZF из коробки не знает ничего, кроме стандартны... | https://habr.com/ru/post/126133/ | null | ru | null |
# Java с Opera 10 на Gentoo amd64
Взято с [блога Gentoo](http://ken.ath.cx/kens_code_pit/2009/09/21/java-with-opera-10-on-gentoo-amd64/) и переведено.
Запуск браузера Opera 64-битной сборки с поддержкой Java оказалось довольно просто.
Для начала убедитесь, что у вас есть последний sun-jdk: например dev-java/sun-... | https://habr.com/ru/post/70210/ | null | ru | null |
# Создание аудиоплагинов, часть 2
Все посты серии:
[Часть 1. Введение и настройка](http://habrahabr.ru/post/224911/)
[Часть 2. Изучение кода](http://habrahabr.ru/post/225019/)
[Часть 3. VST и AU](http://habrahabr.ru/post/225457/)
[Часть 4. Цифровой дисторшн](http://habrahabr.ru/post/225751/)
[Часть 5. П... | https://habr.com/ru/post/225019/ | null | ru | null |
# Seagate Business Storage NAS 1-bay — хранение файлов и multimedia
В сети можно найти множество обзоров NAS серверов, но большинство их них будет посвящено «настоящим» NAS’ам типа Synology, QNAP.
Только вот стоимость только устройства без жестких дисков — несколько сот баксов. Я прекрасно понимаю, что оно того сто... | https://habr.com/ru/post/231593/ | null | ru | null |
# Использование Linux в SAN сети. Маленькая хитрость
Всем доброго времени суток.
Я не думаю, что ситуация, описанная мной, типична для большинства, но тем не менее думаю это будет полезно знать. Мой рассказ о способе защиты «от дурака» в случае, когда у вас есть [SAN](http://ru.wikipedia.org/wiki/SAN) сеть, есть не... | https://habr.com/ru/post/112453/ | null | ru | null |
# JavaScript нанобенчмарки и преждевременные тормоза
Здравствуйте, меня зовут Дмитрий Карловский и раньше я… ежедневно измерял [свою пипирку](https://habr.com/ru/users/nin-jin/), но у распространённых линеек никак не хватало точности для измерения столь малых размеров.


Про преимущества и недостатки REST написано уже довольно много статей (и еще больше в комментариях к ним) ). И если уж так вышло, что вам предстоит разрабо... | https://habr.com/ru/post/449906/ | null | ru | null |
# SparkleShare + SCM-Manager: Очень простая альтернатива DropBox для локальной сети под Windows
Это руководство подскажет вам, как буквально за 10 минут создать простой, удобный и надежный аналог Dropbox, который будет под вашим полным контролем и позволит обмениваться файлами с коллегами по локальной сети.
##### ... | https://habr.com/ru/post/186270/ | null | ru | null |
# Я являюсь причиной появления венгерской нотации в Android
Все из нас видели это:
```
private String mName;
```
Это из-за меня.
Я так и сказал — это моя вина.
Эта тема всплывает снова и снова, [обсуждение на reddit](https://www.reddit.com/r/androiddev/comments/6nq9xl/do_people_actually_use_this_naming_conve... | https://habr.com/ru/post/333596/ | null | ru | null |
# Операция TA505, часть четвертая. Близнецы
[](https://habr.com/ru/company/pt/blog/475328/)
Продолжаем рассказывать о деятельности хакерской группировки TA505. Всем известная фраза «новое — это хорошо забытое старое» как нельзя луч... | https://habr.com/ru/post/475328/ | null | ru | null |
# Холодные запуски AWS Lambda — решение проблемы
Что такое холодные запуски AWS Lambda?
--------------------------------------
Холодные запуски могут оказаться губительными для [производительности AWS Lambda... | https://habr.com/ru/post/586516/ | null | ru | null |
# Как в Яндекс.Практикуме побеждали рассинхрон на фронтенде: акробатический номер с Redux-Saga, postMessage и Jupyter
Меня зовут Артём Несмиянов, я фулстек-разработчик в Яндекс.Практикуме, занимаюсь в основном фронтендом. Мы верим в то, что учиться программированию, дата-аналитике и другим цифровым ремёслам можно и ну... | https://habr.com/ru/post/453876/ | null | ru | null |
# Тестовое задание. Проверка вхождения точки в произвольный полигон
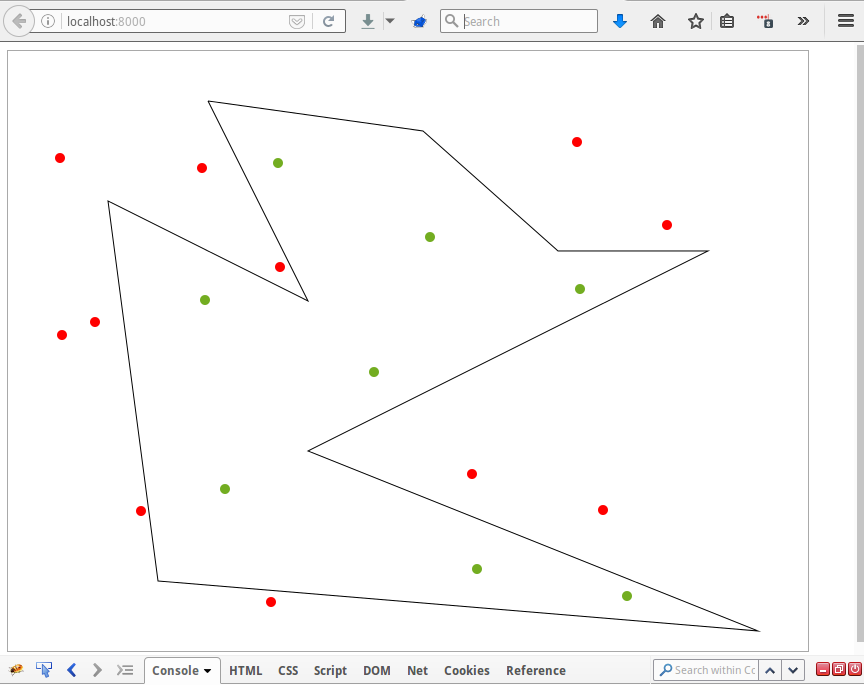
#### Вводная
Сразу оговорюсь кому может быть интересна данная публикация. Это начинающие Django + JQuery программисты, интересующиеся векторной графикой в... | https://habr.com/ru/post/283294/ | null | ru | null |
# Привязка ресурсов в Microsoft DirectX 12. Вопросы производительности

Давайте подробнее рассмотрим привязку ресурсов на платформах Intel. Сейчас это особенно актуально в связи с выпуском 6-го поколения процессоров семейств... | https://habr.com/ru/post/277121/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.