
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Kotlin DSL, Fixtures и элегантные UI тесты в Android
Когда познакомился с Kotlin DSL, подумал: отличная штука, жалко в продуктовой разработке она не пригодится. Однако, я был неправ: он нам помог сделать очень лаконичный и элегантный способ написания End-to-end UI тестов в Android.
Основная концепция работыВчера я зарелизил свой первый Python фреймворк. Нет, не еще один. Это в мире - еще один. А для меня пока что... | https://habr.com/ru/post/543570/ | null | ru | null |
# GUID-подобные первичные ключи в SQLite на Android
Интро
-----
Каждая таблица в SQLite по умолчанию содержит приватный ключ на основе автоматически генерируемого 64-битного целого. Это эффективно и удобно в большинстве ситуаций. Неудобства начинаются, пожалуй, только в двух случаях:
* когда диапазона 64 бит не хват... | https://habr.com/ru/post/323794/ | null | ru | null |
# Как компьютер сам свой код улучшал, или программируем процесс программирования
На носу было придумывание темы для диплома, на кафедре популярностью пользовались различные варианты идей связанных с генетическими алгоритмами, а мне самому хотелось сделать что-нибудь этакое. Так и родилась идея, давшая начало данному п... | https://habr.com/ru/post/265195/ | null | ru | null |
# Rust. Borrow checker через итераторы
Привет, Хабр!
Я уже около года изучаю и, в свободное время, пишу на расте. Мне нравится как его авторы решили проблему управления памятью и обошлись без сборщика мусора — через концепцию заимствования. В этой статье подойду к этой идее через итераторы.
Последнее время scala... | https://habr.com/ru/post/499108/ | null | ru | null |
# 6 вещей на JavaScript, которые можно делать и нельзя
Язык JavaScript претерпел много изменений с момента своего создания. Поэтому сейчас не так просто отслеживать хорошие практики с таким количеством новых функций, изменений и фреймворков.
В этой статье мы рассмотрим некоторые общие правила, которые лучше всего исп... | https://habr.com/ru/post/656583/ | null | ru | null |
# Непрерывная интеграция проектов .NET: NAnt и/или MSBuild?
Привет всем читателям Хабра!
Не так давно я начал использовать для сборки сервером непрерывной интеграции некоторых проектов NAnt наряду с уже освоенным MSBuild. Как всегда, в процессе работы обнаруживаются бонусы с разными знаками (как плюс, так и минус).... | https://habr.com/ru/post/192828/ | null | ru | null |
# Уже можно использовать две новые библиотеки из будущей PHPixie 3

Пока еще только ведутся работы над третьей версией фреймворка [PHPixie](http://phpixie.com), но уже можно точно сказать ч... | https://habr.com/ru/post/216107/ | null | ru | null |
# Hi Programming Language
*Начиная с этой статьи мы приступаем к публикации концепта реализации нового языка программирования Hi.
Необходимость разработки нового языка, а не копирование синтаксиса любого из существующих распространенных языков программирования обусловлено своеобразным исходным концептом, о котором ... | https://habr.com/ru/post/519978/ | null | ru | null |
# Как Яндекс научил меня собеседовать программистов
После того, как я изложил свою историю «трудоустройства» в Яндекс [в комменте](/ru/post/470337/#comment_20719957) к нашумевшей заметке «Как я проработала 3 месяца в Я.Маркете и уволилась», было бы несправедливо утаить и ту пользу, которую я вынес из своего опыта Янде... | https://habr.com/ru/post/470407/ | null | ru | null |
# Настройка Single Sign-On в Zimbra Collaboration Suite 9 Open-Source Edition
Одной из важных технологий для обеспечения удобства и безопасности работы пользователей во внутренней сети предприятия является технология Single Sign-On. Данная технология позволяет сотрудникам проходить процедуру аутентификации всего один ... | https://habr.com/ru/post/533328/ | null | ru | null |
# Symfony 4: Тестируем плагин Symfony Flex
Несколько месяцев назад вышла альфа версия Composer плагина [Symfony Flex](https://github.com/symfony/flex). С выпуском Symfony 3.3 стало возможным протестировать работу данного плагина и «попробовать на вкус» подход к построению приложений на Symfony 4. Что мы сейчас и попро... | https://habr.com/ru/post/331526/ | null | ru | null |
# Динамическое программирование в олимпиадных задачах
Привет!
Недавно решал задачи с архива [Timus Online Judge](http://acm.timus.ru/) и наткнулся на раздел под названием *задачи динамического программирования*. Задачи такого типа вызывают у меня особый интерес, потому что зачастую такой подход обеспечивает быстро... | https://habr.com/ru/post/418867/ | null | ru | null |
# Хостинг FastVPS.ru или почему OpenVZ Это зло
Пару лет назад мы с товарищем купили виртуальный сервер на двоих у компании FastVPS.ru. Сервер был отличный, и нас очень радовал низкой стоимостью и большим функционалом. Вдумайтесь, на сервере был поднят bind для всех наших доменов, 8 сайтов, пара баз данных для них, ftp... | https://habr.com/ru/post/89851/ | null | ru | null |
# 3\. Частотные характеристики. 3.10 Минимально-фазовые и не минимально-фазовые звенья
Рассмотренные ранее типовые звенья имели передаточные функции, которые можно представить в виде:

Скорее всего, из названия статьи вы уже догадались, что в центре внимания ошибки в исходном коде. Но это вовсе не единственное, о чем п... | https://habr.com/ru/post/449472/ | null | ru | null |
# NetApp ONTAP & ESXi 6.х tuning
В продолжение темы об оптимизации ESXi хоста для взаимодействия с СХД NetApp ONTAP, эта статья будет просвещена оптимизации производительности VMWare ESXi 6.X, предыдущие статьи были посвящены тюнингу ОС [Linux](http://habrahabr.ru/post/245357/), [Windows](http://habrahabr.ru/post/2431... | https://habr.com/ru/post/314778/ | null | ru | null |
# Кража закрытых видео YouTube по одному кадру

В декабре 2019 года, спустя несколько месяцев после того, как я занялся хакингом по программе Google VRP, я обратил внимание на YouTube. Мне хотелось найти способ получать доступ к за... | https://habr.com/ru/post/562748/ | null | ru | null |
# Обзор языка Idris
> [Agda is too mainstream!](https://twitter.com/puffnfresh/status/409021679398952960)
**«Предвидение»** 
([источник](http://chrisdone.com/posts/prescience))
Материалов о языке ... | https://habr.com/ru/post/228957/ | null | ru | null |
# Symfony 2.0 краткий обзор, часть 2
Итак, продолжаю осмотр фреймворка Symfony 2.0. В [первой части](http://habrahabr.ru/blogs/symfony/89134/) я описал содержимое приложения symfony-sandbox созданного на базе Symfony 2.0. В этой части я загляну в содержимое самого фреймворка.
Перейдя в директорию `src/vendor/symfon... | https://habr.com/ru/post/89157/ | null | ru | null |
# Как провести Testing Dojo

Есть такая штука — Testing Dojo. Это соревнования, где участники ищут баги в приложениях. Кто больше найдёт — тот и победил. Обычно соревнуются командами. Если баги приходится искать вручную, уч... | https://habr.com/ru/post/263157/ | null | ru | null |
# Веб-технологии, которые могут работать не так, как ожидается
Веб-технологии постоянно развиваются, а у разработчиков появляется возможность создавать всё более качественные и совершенные онлайн-проекты. Правда, бывает так, что какие-то новые веб-возможности работают не так, как того можно было бы ожидать. Это может ... | https://habr.com/ru/post/575350/ | null | ru | null |
# Упаковка N кругов различных диаметров на X листов (прямоугольников), заданных габаритов
Другими словами мы имеем частный случай задачи по раскрою материала.
Немного предыстории: в одном из своих проектов у меня появилась задача по расчету необходимого количества листов металла для производства деталей круглой форм... | https://habr.com/ru/post/708810/ | null | ru | null |
# Как программируют слабовидящие программисты?
**От переводчика**
#### Что это за пост? Он не похож на статью
Это действительно не статья. Это компиляция самых интересных, на мой взгляд, ответов на заглавный вопрос: «[Как программируют слабовидящие программисты?](http://www.quora.com/How-does-a-visually-impaired... | https://habr.com/ru/post/262363/ | null | ru | null |
# Быстрое вычисление точной 3D карты расстояний с использованием технологии CUDA
Карта расстояний (Distance Map) — это объект, позволяющий быстро получить расстояние от заданной точки до определенной поверхнос... | https://habr.com/ru/post/119603/ | null | ru | null |
# «Раз, два, три – ёлочка гори!» или мой первый взгляд на контроллер CANNY 3 tiny
«Новый год» это мандарины, оливье, выходные и конечно же подарки.
Как вы, уже наверняка догадались я неожиданно стал обладателем микроконтроллера CANNY 3 Tiny. Правда я особо DIY электроникой не увлекаюсь и последний раз сам пытался ... | https://habr.com/ru/post/482948/ | null | ru | null |
# Пишем панельный менеджер для сертификатов на linux shell
Привет Хабр!
Многие разработчики недооценивают shell скрипты, пытаясь сравнивать их с другими скриптовыми языками. Но ведь linux shell - в первую очередь оболочка операционной системы, сделанная системными инженерами для системных инженеров. И если для других... | https://habr.com/ru/post/539612/ | null | ru | null |
# Объединяем две локальные сети через интернет. Vpn lan to lan. Asus wl520gu+dd-wrt и FreeBSD+mpd5
**Введение.**
Мне повезло работать в организации которая развивается, и время от времени возникают новые задачи, позволяющие и мне расти. На этот раз мне было необходимо объединить головной офис и второй филиал. Задач... | https://habr.com/ru/post/99925/ | null | ru | null |
# Измерение веса руды по току статора. Практика. Часть 2. Программная реализация на МК
Последняя часть из цикла **«Измерение веса полезных ископаемых»**. В данной статье будет показана программная реализация на МК.
Вспомним основы данного метода измерение веса полезных ископаемых по току статора шахтной подъемной ... | https://habr.com/ru/post/276051/ | null | ru | null |
# Доступ к SOAP веб-сервисам 1С из JavaScript и Html
Описанный метод позволяет обратиться к веб-сервисам 1С из html-страницы через JavaScript. В качестве примера выводится список справочников. При нажатии на любой справочник выводятся первые буквы наименований. При нажатии на букву выводятся данные с наименованиями, н... | https://habr.com/ru/post/184540/ | null | ru | null |
# Вытаскиваем кучу паролей из пиринговых сетей
[](http://habrastorage.org/storage/habraeffect/8d/f1/8df190601ff2e5b90fc80a9741070f04.png "95 wand.dat всего с восьми хабов; скриншот сделан в 8:30 MSK 29 апреля 2010")Появ... | https://habr.com/ru/post/92343/ | null | ru | null |
# Swift. Struct vs Class memory and performance comparison или следует ли всегда использовать Struct
Проблема
--------
Как и многие iOS разработчики, я столкнулся с дилеммой: какой объект использовать для построения архитектуры проекта. Взять для примера реализацию паттерна фасад. Этот объект должен принять некоторое... | https://habr.com/ru/post/670790/ | null | ru | null |
# OnPropertyChanged со строгими именами
Меня дико бесит OnPropertyChanged. Он требует передачи ему строки с именем идентификатора… Мало того, что такой код не верифицируется компилятором, так еще и никакого Intellisence — тайпи весь идентификатор от начала до конца… А если опечатаешся — так проглотит и во время выполн... | https://habr.com/ru/post/103991/ | null | ru | null |
# Restate — или как превратить бревно Redux в дерево
История развития IT намного интереснее любой мыльной оперы, но пересказывать ее мы не будем. Скажем только, что были свидетили принципа «data-driven», адреналинщики с two-way-binding и беспредельщики без принципов и понятий.
> Бог создал людей сильными и слабыми... | https://habr.com/ru/post/346116/ | null | ru | null |
# LUA в nginx: горячий кеш в памяти

Решил пополнить копилку статей на Хабре про такой замечательный ЯП, как lua, парой примеров его использования под капотом nginx. Разбил на два независимых поста, второй ... | https://habr.com/ru/post/215237/ | null | ru | null |
# «Мечта лентяя» или скриптовый движок на самом себе
У разработчиков прикладного ПО очень часто возникает потребность встроить в свой продукт некий скриптовый язык, который бы решал часть задач, не описанных детально на момент проектирования системы. Действительно удобно: и возможность расширения функциональности есть... | https://habr.com/ru/post/327096/ | null | ru | null |
# Дайджест интересных новостей и материалов из мира PHP за последние две недели №20 (18.06.2013 — 30.06.2013)

Предлагаем вашему вниманию очередную подборку с ссылками на новости и материалы.
Приятного чтения!
### ... | https://habr.com/ru/post/185142/ | null | ru | null |
# Полезные идиомы многопоточности С++

### Введение
Данная статья является продолжением цикла статей: [Использование паттерна синглтон [1]](http://habrahabr.ru/post/116577/), [Синглтон и время жизни объекта [2]](http://... | https://habr.com/ru/post/184436/ | null | ru | null |
# Будущее внедрения зависимостей в Android
*Предлагаю вашему вниманию перевод [оригинальной статьи](https://medium.com/default-to-open/android-pie-and-the-future-of-dependency-injection-2fdbc65cb79b) от [Jamie Sanson](https://medium.com/@jamiesanson)*
. Вместе с этим нововведением места для ключевого слова `class` стало ещё меньше. Kotli... | https://habr.com/ru/post/581476/ | null | ru | null |
# Империя наносит ответный удар

Недавно появилась статья «Hackathon 2: Time lapse analysis of Unreal Engine 4», в которой рассказывается, как взяв инструмент Klocwork, можно найти мно... | https://habr.com/ru/post/270783/ | null | ru | null |
# Как устроены технические индикаторы на фондовых рынках
Любой кто когда-нибудь интересовался фондовыми или криптовалютными рынками видел эти дополнительные линии. И вы наверно слышали мнения от матерых трейдеров о том, что они не работают и как они не используют ничего. Но многим они очень помогают и мой торговый тер... | https://habr.com/ru/post/419239/ | null | ru | null |
# Перепиливаем JDBC DB2 под .NET
В очень странное время мы живем .NET становится кроссплатформенным, JAVA становится слаще. Но пока мы вместе движемся в общее светлое будущее есть много унаследованных решений которые необходимо поддерживать. И пока это удается с помощью лобзика и напильника…
### Прежде чем
В текущ... | https://habr.com/ru/post/303878/ | null | ru | null |
# VPN везде и всюду: IPsec без L2TP со strongSwan

*достаточно сильный лебедь*
Если вы когда-либо искали VPN, который будет работать на десктопах, мобильных устройствах и роутерах без установки доп... | https://habr.com/ru/post/250859/ | null | ru | null |
# Вам посылка, или Как мы доставляем сообщения с сервера на клиент в реальном времени
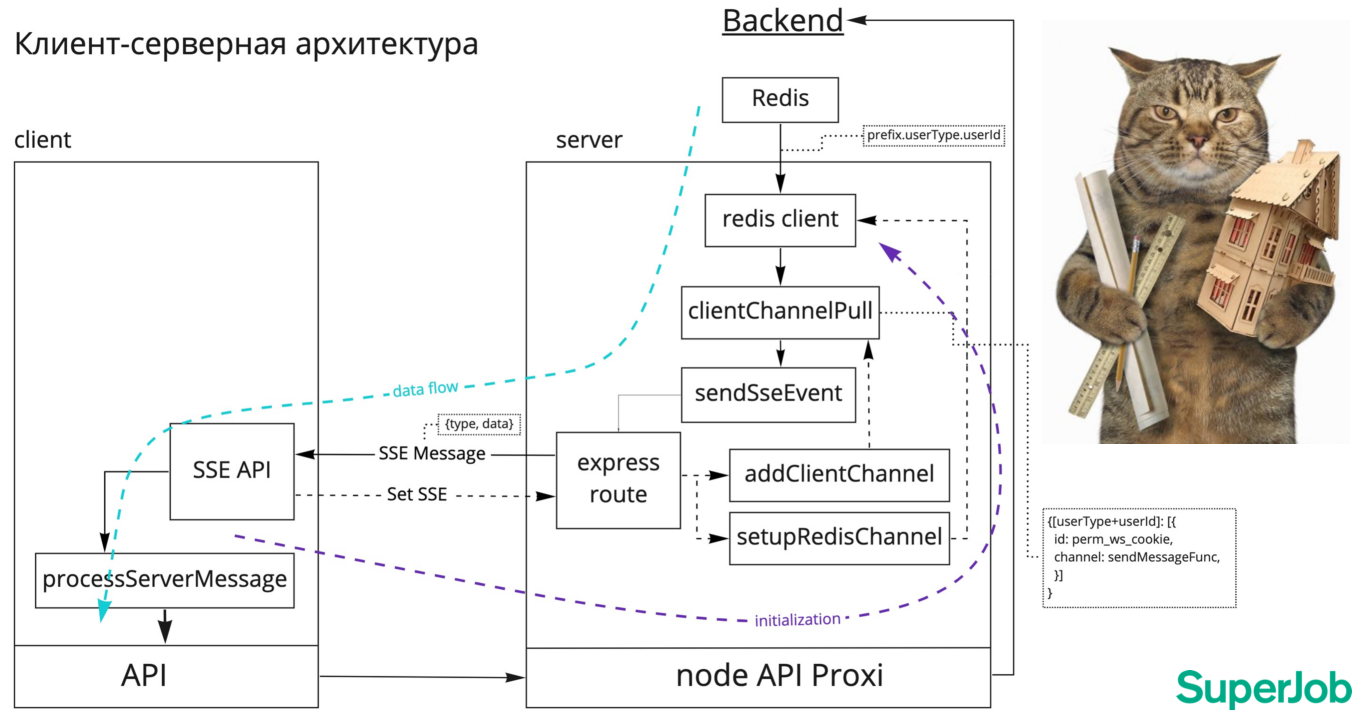*Меня зовут Алексей Комаров, я* — *старший frontend-разработчик в SuperJob. Хочу поделиться опытом реализации механизма об... | https://habr.com/ru/post/649053/ | null | ru | null |
# Классы и метаклассы в Javascript
Хочу рассказать о решении, которое я использую для одиночного наследования в JavaScript. Оно настолько маленькое, что наверняка в том или ином варианте встречается где-нибудь еще. Надеюсь, кому-то из читателей оно окажется полезным.
Это часть фреймворка, который я сделал для своей... | https://habr.com/ru/post/94070/ | null | ru | null |
# Как я ушёл с InDesign'а в LaTeX
InDesign, безусловно, является флагманом в индустрии вёрстки. Но, проработав в нём немалое количество времени, я вернулся к старому ~~доброму~~ TeX'у, с которым познакомился ещё во время своей учёбы в университете. Почему так вышло? Почему от понятного WYSIWYG-редактора я ушёл к языку... | https://habr.com/ru/post/310344/ | null | ru | null |
# PyRegs: анализатор регулярных выражений Python 3
#### Когда не стало Kodos
Беда пришла неожиданно. Из Debian Wheezy изъяли старый, добрый PyQt3. А с ним на покой отправился и [Kodos](http://kodos.sourceforge.net) — мой любимый дебаггер регулярных выражений Питона. Много лет он помогал тестировать красивые и жуткие ... | https://habr.com/ru/post/183486/ | null | ru | null |
# Продолжаем изобретать function
Под влиянием [предыдущей статьи](http://habrahabr.ru/post/159389/) предлагаю продолжить тему создания собственной реализации такой полезной идиомы, как *function* в C++, и рассмотреть некоторые аспекты ее использования.
Что такое function и зачем писать еще одну
--------------------... | https://habr.com/ru/post/166589/ | null | ru | null |
# Kubernetes 1.16 — как обновиться и ничего не сломать

Сегодня, 18 сентября, выходит очередная версия Kubernetes — 1.16. Как всегда нас ждет много улучшений и новинок. Но я хотел бы обратить ваше внимание на разделы Action Required ... | https://habr.com/ru/post/467883/ | null | ru | null |
# Zustand — руководство по простому управлению состоянием
Эта статья — перевод оригинальной статьи Madushika Perera "[Zustand’s Guide to Simple State Management](https://blog.bitsrc.io/zustands-guide-to-simple-state-management-12c654c69990)"
Также я веду телеграм канал “[Frontend по-флотски](https://t.me/frontend_pas... | https://habr.com/ru/post/661411/ | null | ru | null |
# Интеграция ASP.NET MVC 3 приложений с Facebook OAuth API. Часть 1: Авторизация
Зачем нужна авторизация на вашем сайте через [Facebook](http://facebook.com)?
На данный момент в социальной сети Facebook более 500 млн. пользователей. Многие сайты предоставляют возможность авторизироваться без дополнительной регистра... | https://habr.com/ru/post/120837/ | null | ru | null |
# Проблема с периодически долго выполняемыми запросами в MS SQL Server
### Предисловие
Есть информационная система, которую я администрирую. Система состоит из следующих компонент:
**1.** База данных MS SQL Server
**2.** Серверное приложение
**3.** Клиентские приложения
Данные информационные системы устан... | https://habr.com/ru/post/313998/ | null | ru | null |
# Как связать Rstudio с Github: актуально для пользователей Mac OS
 rawpixel.com - ru.freepik.com")Design фото создан(а) rawpixel.com... | https://habr.com/ru/post/683768/ | null | ru | null |
# FTP-протокол + WinSocks на примере простого FTP-клиента (зеркала) на ASM!
Это еще одна статья «давно гуляющая» по интернету, и опять, как автор, сделаю перепост. Думаю пригодиться и тут.
##### Введение
В этой статье я не ставлю себе целью пересказать все RFC касающиеся протокола FTP, коих не мало, в них вы сможе... | https://habr.com/ru/post/111241/ | null | ru | null |
# План-факт, динамика и прибыль на одной диаграмме c помощью R
Каждый раз, когда подводятся финансовые итоги прошедшего года и готовится соответствующая презентация, люди ломают голову, как бы уместить основные цифры на одной диаграмме. Какова бы ни была сфера деятельности организации, подведение итогов, как правило, ... | https://habr.com/ru/post/220135/ | null | ru | null |
# Подключение сторонних инструментов в IntelliJ IDEA на примере pylint
В этом посте я хочу рассказать про довольно интересную фичу `IntelliJ IDEA` — подключение сторонних утилит, а также продемонстрировать её на довольно типичном примере: я подключу `pylint` — анализатор кода для python проектов.
### External Tools... | https://habr.com/ru/post/163227/ | null | ru | null |
# AlertDialog setMultiChoiceItems, баг или неочевидная особенность
Привет, Хабр!
#### Вступление
Последние пару месяцев работаю над одним проектом под Android. Но речь сейчас пойдет не о нем, о нем я постараюсь обязательно написать, но всему свое время
За все время работы над проектом, случалось (и случается) м... | https://habr.com/ru/post/139322/ | null | ru | null |
# $mol — лучшее средство от геморроя
Всем привет, меня зовут Дмитрий Карловский и я… хочу причинить вам боль. Много боли. Я напомню вам обо всех страданиях, что вы исптываете находясь в плену своего любимого js-фреймворка. Я опущу вас на самое дно самой глубокой безысходности. А потом, когда вы совсем отчаетесь и поте... | https://habr.com/ru/post/341146/ | null | ru | null |
# Как подписать свой первый скрипт за 48 часов
#### Проблема
Когда задача, требующая решения, небольшая, совсем не хочется писать для её решения отдельную утилиту, особенно, если ты — .NET-программист.
Скрипт? Однозначно, да, но ставить на боевую машину под управлением Windows сторонний интерпретатор совсем уж не... | https://habr.com/ru/post/137884/ | null | ru | null |
# 4,5 года из жизни iOS-команды в пяти историях и одном техрадаре
Привет, я Стас, лид мобильной разработки Туту.ру. Хочу поделиться, к чему мы пришли, к чему только идём, а от чего избавились за пять лет, чт... | https://habr.com/ru/post/648073/ | null | ru | null |
# Отладка native-кода под Android: ручное и автоматизированное тестирование
С развитием и ростом популярности ОС Android количество и разнообразие устройств под её управлением неуклонно растёт. Из-за различий в архитектуре, предназначении и оптимизации скорость и стабильность работы исполняемого кода может значительно... | https://habr.com/ru/post/204642/ | null | ru | null |
# IVR on Webhook
An online chatbot is a recent trend on the market. But how to interact with the clients that are offline? A significant percentage of people prefer to interact over the phone. And the business needs either a large s... | https://habr.com/ru/post/474178/ | null | en | null |
# Определяем, что у пользователя заблокирована Википедия
Недавно Роскомнадзор [предпринял попытку блокировки доступа с территории РФ](http://habrahabr.ru/post/265367/) к Википедии. Попытка [провалилась](http://rublacklist.net/12468/), и самое время перейти в контрнаступление. В статье под катом я покажу, что, если пол... | https://habr.com/ru/post/266553/ | null | ru | null |
# DataGrip 2019.1: поддержка новых баз, инициализационные скрипты, новые инспекции и другое
Привет! Посмотрим на новые штуки в [DataGrip 2019.1](https://www.jetbrains.com/datagrip/download). Напомним, что функциональность DataGrip включена и в другие наши платные IDE, кроме WebStorm.

Моя предыдущая статья [«Чего я ждал от HTML5 и CSS3»](http://habrahabr.ru/blogs/webstandards/101746/) затронула достаточно щекотливую тему, но не ответила на в... | https://habr.com/ru/post/102720/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #16
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [PourOver](http://nytimes.github.io/pourover/)
[В этой статье я продолжу перевод и исследование *WGPU*, библиотеки языка Rust для работы с графикой.
Для тех, кто не читал [первую](https://habr.com/ru/post/690514/... | https://habr.com/ru/post/698426/ | null | ru | null |
# Лучшее время для изучения микроконтроллеров

Признайтесь, как часто вы думали о том, чтоб освоить азы программирования микроконтроллеров? Наверняка у вас есть в голове несколько идей потенциальных п... | https://habr.com/ru/post/209218/ | null | ru | null |
# Настройка FreePBX + GoIP
В Интернете довольно много примеров настройки. Но ни один из них у меня не заработал как надо. Одной из проблем с которой я столкнулся было неправильное определение линии при входящем звонке. В свое время нигде не нашел мануал для решения этой проблемы. Поэтому решил выложить свою версию инс... | https://habr.com/ru/post/464765/ | null | ru | null |
# Arduino и резистивный тачскрин, библиотека KrokoTS
Сейчас почти все устройства управляются сенсорными экранами, и у многих возникает желание оборудовать свой arduino-проект дисплеем и GUI, чтобы даже убеждённые "мышатники" смогли разобраться.
Необходимые компоненты и цена вопроса
-----------------------------------... | https://habr.com/ru/post/589143/ | null | ru | null |
# Делаем код в адаптере чище с помощью MergeAdapter
Надоели перегруженные и сложные адаптеры в вашем проекте, напоминающие картинку ниже? Каждый раз, при добавлении нового типа ячейки хочется переписать адаптер для RecyclerView, чтобы код читался проще? Есть множество подходов, чаще всего рекомендуется использовать по... | https://habr.com/ru/post/523840/ | null | ru | null |
# Электронная библиотека для PocketBook: автоматическая обработка
Наверное каждому электрочитателю хотелось бы всю свою коллекцию книг содержать прямо на электронной книге-читалке, и при этом, не смотря на общую тормознутость устройства, иметь удобную навигацию.
Зачастую в электронной книге проблематично содержать ... | https://habr.com/ru/post/143492/ | null | ru | null |
# Тонкости AngularJS: select внутри шаблона директивы
Эта статья будет описывать решение одной конкретной задачи, а также на примере показывать как работает $transclude.
Задача такая: сделать директиву, обертку для select-а. Предположим, что мы хотим одним тегом добавлять сразу и селект и label к нему (потом можно... | https://habr.com/ru/post/228863/ | null | ru | null |
# Пробуем Gnome 3 на Ubuntu 11.04 Natty Narwhal
Сегодня я установил Ubuntu 11.04 Natty Narwhal Beta 1, дабы поглядеть, что натворили Canonical и нарепортить багов, специфических для моей конфигурации. В результате потратил полдня на попытки хоть как-то разобраться в Unity, но мне не хватило интеллекта: кое-как нашёл с... | https://habr.com/ru/post/117283/ | null | ru | null |
# Как избежать фейлов при разработке продукта: 10 советов от Rookee
Разработка продуктов — процесс трудоемкий. Рынок постоянно нуждается в новых решениях, но на пути создания инноваций любую компанию подстерегают провалы. В данной статье мы собрали воедино свой собственный опыт работы [в высокотехнологичном сервисе](h... | https://habr.com/ru/post/426721/ | null | ru | null |
# Начинаем использовать Tarantool в Java проекте
В статье ниже я попытаюсь кратко рассказать о том, что такое Tarantool и как начать его использовать в уже существующем проекте если вы программируете на Java. Если же вы программируете на другом языке, то вам могут быть интересны некоторые инструменты доступные в конне... | https://habr.com/ru/post/155575/ | null | ru | null |
# Знакомство с межпроцессным взаимодействием на Linux
Межпроцессное взаимодействие (*Inter-process communication (IPC)*) — это набор методов для обмена данными между потоками процессов. Процессы могут быть запущены как на одном и том же компьютере, так и на разных, соединенных сетью. IPC бывают нескольких типов: «сигн... | https://habr.com/ru/post/122108/ | null | ru | null |
# Левитрон на Arduino
Добрый вечер! В этой публикации я расскажу о своей маленькой самоделке, задумал которую я достаточно давно.
Некоторое время назад я прочитал статью об интересных устройствах – [левитронах](https://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D0%B2%D0%B8%D1%82%D1%80%D0%BE%D0%BD), которые бывают как чисто... | https://habr.com/ru/post/255647/ | null | ru | null |
# .NET nanoFramework — платформа для разработки приложений на C# для микроконтроллеров
[](https://habrastorage.org/webt/pv/9y/ln/pv9yln6jimphiuxpkn0c3ez2_98.png)
[.NET nanoFramework](https://nanoframework.net/) — это бес... | https://habr.com/ru/post/549012/ | null | ru | null |
# Swift 5.0. Что нового?
Swift 5 — долгожданный релиз, включающий в себя несколько десятков улучшений и исправлений. Но самой главной целью релиза Swift 5.0 было достижение ABI стабильности. В этой статье вы узнаете, что такое ABI и что стабильный ABI даст iOS/macOS разработчикам. А также проведём разбор нескольких но... | https://habr.com/ru/post/444862/ | null | ru | null |
# Группировка вебсокет соединений для асинхронного фреймворка Starlette
Cегодня мы с вами напишем решение для фреймворка Starlette, которое позволит группировать открытые вебсокет соединения.
### Вступление
[Starlette](https://www.starlette.io/) довольно молодой фреймворк, и какие-то «плюшки» для него приходится п... | https://habr.com/ru/post/506056/ | null | ru | null |
# 5 вещей, о которых должен знать любой разработчик Apache Kafka

Apache Kafka — это платформа потоковой обработки событий, которую используют 30% компаний из Fortune 500. У Kafka много функций, благодаря которым платформа задает ста... | https://habr.com/ru/post/547264/ | null | ru | null |
# Управление устройствами интернета вещей через Kubernetes
Kubernetes последовательно захватывает все новые ниши для декларативного описания ожидаемого состояния и теперь ресурсами Kubernetes можно управлять ... | https://habr.com/ru/post/686332/ | null | ru | null |
# Маршрутизация IPv6 через WireGuard с поддержкой SLAAC
Вдохновившись аргументами из статьи «[IPv6 — прекрасный мир, стоящий скорого перехода на него](https://habr.com/ru/post/490378/)», мне стало катастрофически не хватать IPv6. Конечная цель: обеспечить каждое из своих устройств уникальным публичным псевдостатически... | https://habr.com/ru/post/565692/ | null | ru | null |
# Hibernate — о чем молчат туториалы
Эта статья не будет затрагивать основы hibernate (как определить entity или написать criteria query). Тут я постараюсь рассказать о более интересных моментах, действительно полезных в работе. Информацию о которых я не встречал в одной месте.

Недавно на работе получил задачу от руководителя: сделай так чтобы телефон android не сливал данные гуглу. Можете представить мой восторг (и предвкушение) ибо спустя 2 недели тестов я вп... | https://habr.com/ru/post/520642/ | null | ru | null |
# Туториал по JUnit 5 - Аннотация @RepeatedTest
> Это продолжение туториала по JUnit 5. Введение опубликовано [здесь](https://habr.com/ru/post/590607/).
>
>
Аннотация `@RepeatedTest` используется для написания повторяющихся тестовых шаблонов, которые могут выполняться несколько раз в JUnit. Частоту повторения можно... | https://habr.com/ru/post/590927/ | null | ru | null |
# Unity3D 3.x Получение текущего активного окна
Недавно перед нашей командой встала довольно простая задача. Нам нужно было сделать перетаскивание вещи из инвентаря в другие окна (эквип, сундук). Если два окна находятся друг над другом, то вещь должна упасть в то окно, которое выше.

Позавчера компания Microsoft [опубликовала исходный код](https://habrahabr.ru/post/308076/) PowerShell. Таким образом, это средство автоматизации и конф... | https://habr.com/ru/post/308140/ | null | ru | null |
# Применяем визуальные эффекты к изображениям в Django
При написании собственного «инстаграма» появилась необходимость в наложении фильтров на изображение при аплоаде. Изначально, чтобы особо не нагружать сервер, было решено вынести процесс преобразования картинки на клиентскую сторону. Основная идея – загрузка изобра... | https://habr.com/ru/post/215811/ | null | ru | null |
# Создание 1k/4k intro для Linux, часть 2
Не прошло и полгода! Как вы можете, поднапрягшись, вспомнить, [в прошлый раз](http://habrahabr.ru/post/134551/) мы остановились на унынии и обещании нырнуть в ассемблер.
Ну что же, пацан сказал — пацан сделал. Из этого аляповатого нагромождения букв вы узнаете, как можно ин... | https://habr.com/ru/post/143766/ | null | ru | null |
# Reticulum — радиопротокол для mesh-сети. Зашифрованная пиринговая связь без интернета

Как мы [обсуждали](https://habr.com/ru/company/globalsign/blog/652647/) ранее, отключение интернета в конкретной стране или городе — не вымышл... | https://habr.com/ru/post/662489/ | null | ru | null |
# Продление жизни временных значений в С++: рецепты и подводные камни
Прочитав эту статью вы узнаете:
1. Способы, которыми можно продлить время жизни временного объекта в С++.
2. Рекомендации и подводные камни этого механизма, с которыми может столкнуться С++ программист, и с которыми сталкивался на работе я.
Информ... | https://habr.com/ru/post/669474/ | null | ru | null |
# Пытливый взгляд АНБ: что такое война за Интернет-безопасность (Часть 2)
[](http://habrahabr.ru/company/1cloud/blog/248675/)
Предположения о том, что разведывательные агентства опередили нас настольк... | https://habr.com/ru/post/248675/ | null | ru | null |
# Расширение Visual Studio для визуализации пользовательских классов в режиме отладки
Доброго времени суток,
В этой статье я хочу рассказать о создании расширения для Visual Studio, которое помогает визуализировать сложные пользовательские классы в процессе отладки приложения.
#### Предыстория
В своем проекте м... | https://habr.com/ru/post/242231/ | null | ru | null |
# Интеграция XML данных — другой путь
В данной статье описывается «нетрадиционная», но достаточно мощная технология обработки XML, позволяющая импортировать любые XML-данные и преобразовывать их структуру эффективно и просто, при этом один и тот же процесс обработки позволяет трансформировать исходные данные любой стр... | https://habr.com/ru/post/325186/ | null | ru | null |
# Ключевое слово «mutable» в C++
Ключевое слово **mutable** относится к малоизвестным уголкам языка С++. В то же время оно может быть очень полезным, или даже необходимым в случае, если вы хотите строго придерживаться const-корректности вашего кода или писать лямбда-функции, способные изменять своё состояние.
Пару ... | https://habr.com/ru/post/341264/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.