
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Grid Layout как основа современной раскладки
В темные века верстальщики строили сайты на таблицах. Потом они освоили float и flexbox, и тьма отступила. В 2017-м наступила эпоха Просвещения с приходом CSS Grid Layout.
Grid учитывает горизонтальное и вертикальное пространство, с ним можно менять раскладку, не трога... | https://habr.com/ru/post/433320/ | null | ru | null |
# MongoDB — варим хороший кофе
##### Введение
Друзья, в первую очередь хочу поблагодарить вас за высокую оценку моего труда, это приятно, и мотивирует меня продолжать. Итак, почему надо покупать наших слонов я думаю вы уже поняли из [первой статьи](http://habrahabr.ru/blogs/webdev/74144/), кто-то уже скачал и попробо... | https://habr.com/ru/post/74273/ | null | ru | null |
# Запросы в PostgreSQL: 1. Этапы выполнения
Привет, Хабр! Начинаю еще один цикл статей об устройстве PostgreSQL, на этот раз о том, как планируются и выполняются запросы.
> Предыдущие циклы были посвящены [индексам](https://habr.com/ru/company/postgrespro/blog/326096/), [изоляции и многоверсионности](https://habr.co... | https://habr.com/ru/post/574702/ | null | ru | null |
# Советы для профессионального использования RecyclerView. Часть 1

Я решил написать эту статью, т.к. заметил, что многие разработчики допускаю... | https://habr.com/ru/post/425945/ | null | ru | null |
# Пошаговая инструкция по настройке Wireguard VPN + DNSCrypt + DNS server (Unbound) + Pihole
Давно была идея сделать свой VPN сервер, для того чтобы "ходить" на ресурсы типа [Linkedin](https://www.linkedin.com/). Со временем подумал, что неплохо было бы сделать еще и блокировку рекламы, а потом и DNS сервер. Простых и... | https://habr.com/ru/post/594877/ | null | ru | null |
# Решения разработки баз данных
Добрый день! В процессе развития проекта приходится сталкиваться с проблемой производительности баз данных, т.к. объём данных растёт, и волей неволей выплывают проблемные участки.
В данном посте описаны не очень удачные решения, которые незаметны на ранних стадиях проекта. И решения... | https://habr.com/ru/post/234721/ | null | ru | null |
# Использование игрового ПК с Windows в качестве (Linux) Docker-хоста
[](https://habr.com/ru/company/ruvds/blog/694968/)
Docker Desktop – это прекрасный обслуживаемый способ использования Docker в MacOS или Windows, но для нестандарт... | https://habr.com/ru/post/694968/ | null | ru | null |
# Автоматизация снятия показаний со счетчиков воды
Все знают, что лень двигатель прогресса. Так случилось и в моем случае.

В квартире присутствует 6 точек раздачи воды (3 холодные и 3 горячие). На каждой из точек стоит счетчик. ... | https://habr.com/ru/post/232903/ | null | ru | null |
# mac: Как и почему стоит хранить свой домашний каталог на другой партиции
Почему стоит хранить свой домашний каталог на другой партиции? Среди макпользователей ведется спор о том, разбивать ли предустановленный Macintoch HD на 2 и более разделов (в терминах винды — дисков) или нет. Для себя я однозначно решил, что ст... | https://habr.com/ru/post/23547/ | null | ru | null |
# Как я сделал кастомный прерыватель Okhttp через котлиновские корутины
Начнём с постановки задачи.
1. Надо в каждом запросе в header’s отправлять токен и id юзера
2. Надо из каждого ответа вытаскивать из headers новый токен и id юзера
3. Полученные данные надо сохранять
Библиотека для серверного взаимодействия – ... | https://habr.com/ru/post/465781/ | null | ru | null |
# Коротко об архитектуре компонента Symfony Config

Компонент Symfony 2 Config предназначен для работы с конфигурационными файлами и предоставляет следующие возможности:
* Поддержка древовидной структуры конфигурации
* ... | https://habr.com/ru/post/271417/ | null | ru | null |
# Что нового в .NET 6?
На момент написания этих строк вышло уже семь превью-версий .NET 6. Дальше — только релиз-кандидаты. Все основные фичи уже добавлены во фреймворк, идёт отладка, тестирование и оптимизация. Ожидать чего-то кардинально нового в RC-версиях, пожалуй, уже не стоит. Пришла пора рассмотреть .NET 6 побл... | https://habr.com/ru/post/573434/ | null | ru | null |
# XSLT преобразование внутренней таблицы в ABAP, имеющей поле типа «generic reference»
#### Пролог
**О чем заметка?** Как из внутренней таблицы, строка которой содержит ссылку на неизвестный (обобщенный) тип (REF TO DATA), которая, по факту, хранит ссылку на такую же таблицу, получить XML заданного формата. При этом,... | https://habr.com/ru/post/220079/ | null | ru | null |
# Крик души 1С-ника (в разрезе, масштаб 1:1)
Хмурое октябрьское утро началось, как обычно с просмотра телеграмчика. И почти сразу же я увидел, что мне там накидали ссылок на статью "[Почему уходят из 1С](https://habr.com/ru/post/695734/)", где упоминался ваш покорный слуга и которая являлась обличительным ответом на м... | https://habr.com/ru/post/696082/ | null | ru | null |
# Global site tag (gtag.js) в Google Analytics. Что это такое и нужен ли он вам?
Если недавно вы добавляли код отслеживания Google Analytics на сайт, то заметили совершенно другой код счётчика, который выглядит так:
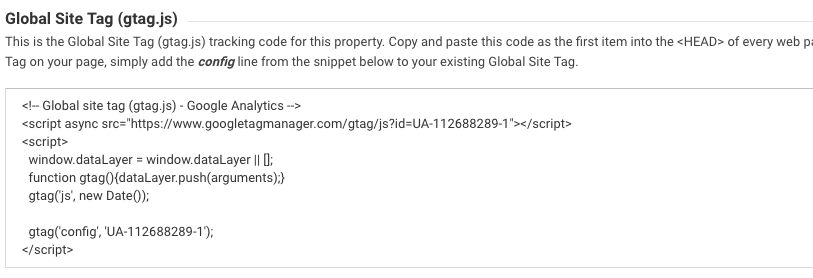
Сложилась кака... | https://habr.com/ru/post/353572/ | null | ru | null |
# Установка SVN+Trac+TracWebAdmin
Привет всем!
Сегодня я расскажу как правильно и без гемора установить связку SVN + Trac + TracWebAdmin.
Для чего все это...?
====================
Представьте себе ситуацию: у вас есть проект, который находится на стадии разработки. Скрипты содержат тысячи строк кода. Постоянное... | https://habr.com/ru/post/26117/ | null | ru | null |
# Практический JS: проблемы innerHTML
*Примечание: ниже перевод статьи Julien Lecomte [«The Problem With innerHTML»](http://www.julienlecomte.net/blog/2007/12/38/), в которой автор рассматривает проблемы при использовании метода innerHTML в современных браузерах и предлагает ряд советов, как ее можно избежать. Мои ком... | https://habr.com/ru/post/31413/ | null | ru | null |
# PHP: Расширенный текучий интерфейс
Уверен, что многим из вас, кто читает этот текст, знакомо понятие Текучий интерфейс. И даже если вы про него не слышали, уверен, что вы им пользовались и не раз. Это действительно удобно. Так о чем же идет речь?
```
php
class Images {
public $width;
public $height;
publ... | https://habr.com/ru/post/132115/ | null | ru | null |
# Как изменить формат данных JSON на Snake Case в ASP.NET Core Web API
Стандартный способ отображения данных в ASP.NET Web API - это Camel Case. Но иногда возникают задачи, когда нужно изменить формат данных на нечто другое. Например, на фронтенде у вас может быть SPA, которое как раз работает с данными в формате snak... | https://habr.com/ru/post/543370/ | null | ru | null |
# Autoscaling — инструмент автоматического вертикального масштабирования ресурсов (CPU|RAM|HDD)
#### В начале этого года у наших [облачных VDS](http://bit.ly/habr-vds) появился [публичный API](http://bit.ly/netangels-API). Он позволяет клиенту делать практически все те же действия с облачными виртуальными машинами и д... | https://habr.com/ru/post/312174/ | null | ru | null |
# Вычисление числа Пи с помощью Intel Threading Building Blocks
Многие Android-устройства используют процессоры с несколькими вычислительными ядрами, поэтому в отрасли разработки мобильных приложений всё более важным становится умение создавать многопоточные программы. Компания Intel предлагает ценный инструментарий д... | https://habr.com/ru/post/260083/ | null | ru | null |
# Разбираем протокол пейджерных сообщений POCSAG, ч1
Привет, Habr!
Давным-давно, когда мобильный телефон стоил 2000$ и минута звонка стоила 50 центов, была такая популярная штука как пейджинговая связь. Затем связь стала дешевле, и пейджер сначала превратился из престижного атрибута делового человека в непрестижный... | https://habr.com/ru/post/438602/ | null | ru | null |
# Плотностный алгоритм кластеризации пространственных данных с присутствием шума — DBSCAN
Доброго времени суток!
Хотел бы с вами поделиться реализацией в MATLAB плотностного алгоритма для кластеризации пространственных данных с присутствием шума — DBSCAN (Density Based Spatial Clustering of Applications with Noise)... | https://habr.com/ru/post/143151/ | null | ru | null |
# Печатаем по сети на любом Windows-принтере
Если у вас есть принтер, подключенный к Windows машине, то настроить его для сетевой печати на Mac достаточно просто, даже если драйверов для OSX для этого принтера не существует.
**Для этого нужны три вещи:**
* Принтер, исправно работающий на Windows машине
* [Ghosts... | https://habr.com/ru/post/63440/ | null | ru | null |
# Распространённые ошибки веб-дизайнеров или как угодить верстальщику
В этом посте речь пойдет о тех ошибках, которые допускают дизайнеры в макетах, предназначенных для вёрстки. Рассмотрим наиболее часто встречающиеся проблемы, с которыми сталкивается верстальщик при работе с psd-макетами. Если Вы дизайнер, и Вам част... | https://habr.com/ru/post/220681/ | null | ru | null |
# Как вызывать методы audio vk
Как все начиналось:
-------------------
### Дело было вечером, делать было нечего… И я решил полазить по методам vk\_api.
Наткнулся на интересный метод [«execute»](http://vk.com/dev/execute).
Получилось отправить себе подарок:
**Код**
```
var gift = 813;
return API.gifts.send... | https://habr.com/ru/post/429504/ | null | ru | null |
# Berkeley Unified Parallel C (UPC). Отладка с помощью GNU gdb C debbuger. Стек вызова
Доброго здравия!
 Unified Parallel C (UPC) — это расширение языка C, разработанное для высокопроизводительных вычислений н... | https://habr.com/ru/post/317196/ | null | ru | null |
# Краткое руководство по работе с интерфейсом Map в Kotlin
Если в сферу ваших интересов входит [разработка приложений под Android](https://blog.logrocket.com/kotlin-vs-flutter-android-development/) или мульти... | https://habr.com/ru/post/671678/ | null | ru | null |
# Реализуем свой dropDown ViewController (aka iOS 8 Mail app) в 200 строк
Еще с beta версии iOS 8 мне очень понравилась эта новая фича приложения почты: при создании нового письма можно просто смахнуть это окно вниз и продолжить работу на предыдущем экране. Не уверен, насколько эта фича оказалась полезной конкретно в ... | https://habr.com/ru/post/276799/ | null | ru | null |
# Earth Engine от Google — уникальная платформа для анализа больших геоданных
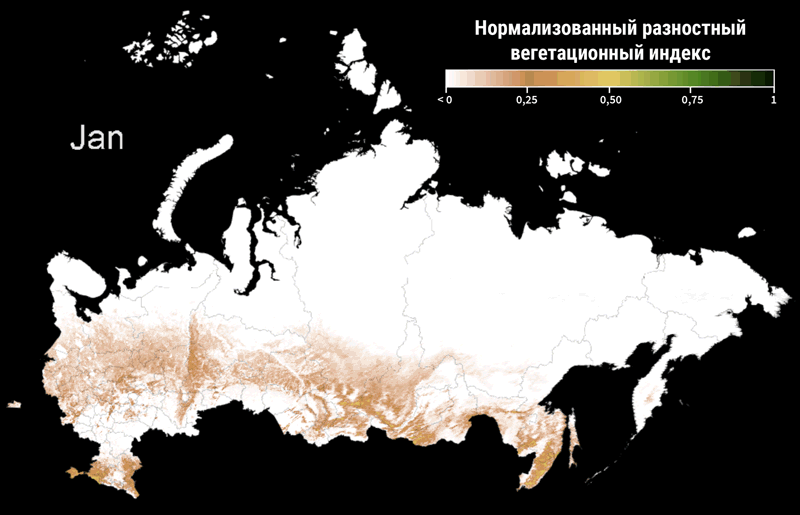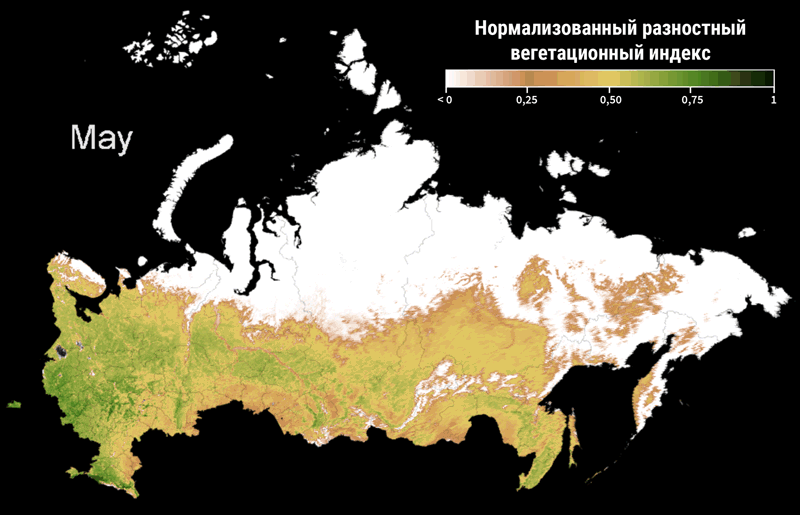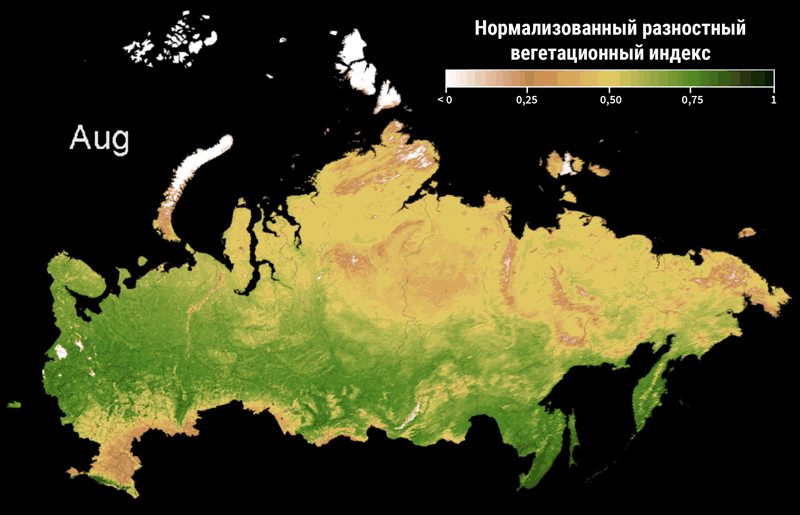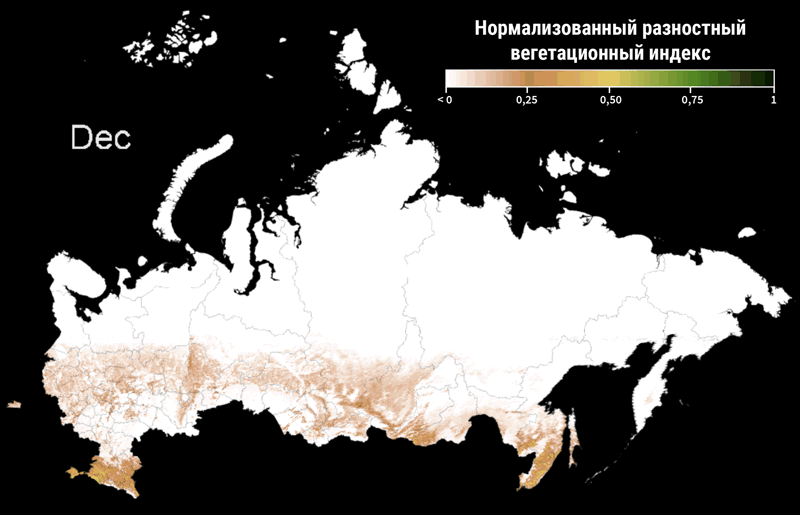
Earth Engine — это облачная платформа для геопространственного анализа данных в планетарных масштабах. Она позволяет использовать огромные вычислительные мощности к... | https://habr.com/ru/post/500020/ | null | ru | null |
# Создание Cocos2D-x проекта в Marmalade SDK

Некоторое время назад RIM совместно с Marmalade проводили [акцию](http://habrahabr.ru/post/151882/) по которой и мне удалось получить планшет Blackberry Playbook. По условиям ... | https://habr.com/ru/post/157599/ | null | ru | null |
# Перестаньте использовать SQLite в Unit-тестах
Предисловие от переводчикаНесмотря на то, что статья была написана почти 3 года назад, она абсолютно не потеряла актуальности. SQLite по прежнему не поддерживает часть базовых функций старших СУБД (MySQL, PostgeSQL).
Автор оригинальной статьи использует термин "Unit-тес... | https://habr.com/ru/post/691838/ | null | ru | null |
# Изучаем ELK. Часть II — Установка Kibana и Logstash
Вступительное слово
-------------------
В [предыдущей статье](https://habr.com/ru/post/538840/) была описана процедура установки Elasticsearch и настройк... | https://habr.com/ru/post/538974/ | null | ru | null |
# Подготовка графиков в MatLab
В написании научных статей немалую часть времени занимает подготовка иллюстраций, графиков и диаграмм. Хочу поделиться некоторыми мыслями и примерами того, как можно ускорить этот процесс. Материал пригодиться тем, кто пользуется системой MatLab.
MatLab предоставляет широкие возможнос... | https://habr.com/ru/post/195842/ | null | ru | null |
# Трюки, облегчающие жизнь в zsh
Zsh — одна из лучших командных оболочек, обладающая впечатляющим набором возможностей. Однако, из‐за большого количества возможностей нет ничего удивительного в том, что некоторые из них проходят мимо внимания или возможность их применения для решения повседневных задач неочевидна. В э... | https://habr.com/ru/post/272581/ | null | ru | null |
# Пишем асинхронного Телеграм-бота
Привет! Меня зовут Александр, я руководитель бэкенд-разработки в [KTS](https://kts.studio/).
Сегодня я покажу, как написать своего Телеграм-бота на основе asyncio и aiohtt... | https://habr.com/ru/post/598575/ | null | ru | null |
# Spring Boot + ControllerAdvice + ResponseBodyAdvice или как обернуть ответ контроллеров
Введение
--------
Всем привет, друзья! Сегодня хочу рассказать про способ использования *ControllerAdvice* для оборачивания объекта, возвращаемого контроллерами, в новый класс на уровне *DispatcherServlet*.
**Пример:**
Допуст... | https://habr.com/ru/post/567056/ | null | ru | null |
# Просто о сложном. Начало создания беспроводного «умного дома». На основе технологии Linux, Z-Wave и ПО MajorDoMo
### Часть первая: Небольшая пошаговая инструкция по установке и первоначальной настройке «Умного дома»

Так сл... | https://habr.com/ru/post/416007/ | null | ru | null |
# High-Quality Text-to-Speech Made Accessible, Simple and Fast

There is a lot of commotion in text-to-speech now. There is a great variety of toolkits, a plethora of commercial APIs from GAFA companies... | https://habr.com/ru/post/549482/ | null | en | null |
# Почему буфер должен расти экспоненциально
Сотрудник Mozilla Николас Нетеркот опубликовал заметку с очень [чётким объяснением](https://blog.mozilla.org/nnethercote/2014/11/04/please-grow-your-buffers-exponentially/), почему размер буфера памяти для программы нужно увеличивать экспоненциально, а не линейно.
Предпол... | https://habr.com/ru/post/242279/ | null | ru | null |
# Серверная кластеризация маркеров на карте. От теории к практике
Привет Хабр. История начинается с того что мы решили сделать гео сервис с возможностью размещения меток на карте самими пользователями.
И когда решили залить в базу 1 миллион маркеров то поняли, что даже если запрашивать маркеры только в определенном... | https://habr.com/ru/post/268621/ | null | ru | null |
# Что делать, когда малое предприятие всерьез задумалось о переходе с Windows на Linux
Предисловие. Надеюсь мой рассказ поможет начинающим или нерешительным юзерам быстро и без проволочек перейти на Линукс с Винды, не удаляя Windows.
Начало. Волей судьбы я являюсь ~~системным администратором~~ эникейщиком малого п... | https://habr.com/ru/post/346310/ | null | ru | null |
# Вычисления без инструкций на x86
В этой статье обсуждается необычное применение особенностей [защищённого режима](https://en.wikipedia.org/wiki/Protected_mode) архитектуры x86 — для произведения вычислений... | https://habr.com/ru/post/533388/ | null | ru | null |
# Трассировка печатной платы в KiCAD

Введение
========
Одним из критических замечаний к [предыдущей статье](https://geektimes.ru/post/278282/) было следующее: дескать фу таким быть, стрелять из пушки по воробьям да ещё про... | https://habr.com/ru/post/395933/ | null | ru | null |
# Надежное user-friendly управление силовыми нагрузками умного дома: Domoticz + ручной переключатель
Привет, Geektimes!
Я реализую свой умный дом и хочу поделиться несколькими выстраданными решениями.
В качестве центрального контроллера в моей версии умного дома я использую Raspberry Pi с установленными Domoticz... | https://habr.com/ru/post/397621/ | null | ru | null |
# DataVault на Greenplum с помощью DBT
Введение
--------
Привет, Хабр!
Меня зовут Марк Порошин, я занимаюсь DataScience в DV Group. Недавно я уже [рассказывал](https://www.notion.so/DBT-Data-Built-Tool-aa97... | https://habr.com/ru/post/671836/ | null | ru | null |
# Как насчёт класть каждую функцию в свой файл?
Минусующим: я в курсе что такое ООП и постоянно использую его в разработке. Или из-за чего вы там минусуете с пренебрежением к подобному подходу? Как это может быть ни удивительно для вас, но проекты можно писать в том числе и используя простые функции, вместо запихивани... | https://habr.com/ru/post/311748/ | null | ru | null |
# Управляем роботом-пылесосом iRobot Roomba через ИК

Перед новым годом у меня появился полезный питомец — iRobot Roomba 630. Это самая простоя модель Roomba без функций планировщика. В общем-то мне эти функции не нужны,... | https://habr.com/ru/post/168033/ | null | ru | null |
# Проверки работоспособности в Kubernetes
### В Kubernetes есть механизм проверки работоспособности, с помощью которого можно узнать, работает контейнер в pod’е или нет.
](https://habr.com/ru/company/piter/blog/540346/) Привет, Хаброжители! Код высокого качества — это не просто код без ошибок. Он должен быть чистым, удобочитаемым и простым в сопровождении. Путь от ря... | https://habr.com/ru/post/540346/ | null | ru | null |
# Учебное пособие по кэшированию, часть 1
Довольно подробное и интересное изложение материала, касающегося кэша и его использования. [Часть 2](http://habrahabr.ru/post/204464/).
Автор, [Mark Nottingham](http://www.mnot.net/personal/), — признанный эксперт в области HTTP-протокола и веб-кэширования. Является председ... | https://habr.com/ru/post/203548/ | null | ru | null |
# Настраиваем GitHub Actions для Android с последующим деплоем в PlayMarket
Привет, Хаброжители! На днях начал изучать GitHub Actions для Android. Ранее у меня была удачная попытка настройки данного функционала для проекта на Flutter, но без деплоя, для которого полно информации и гайдов как на англоязычных ресурсах, ... | https://habr.com/ru/post/506700/ | null | ru | null |
# Упорядоченные списки, счётчики и экспрешн для IE
Представьте ситуацию: в макете страницы, которую вам надо сверстать, есть упорядоченный список. Всё бы ничего, да в дизайне стиль текста в списке отличается от стиля цифр, выступающих в роли маркера каждого пункта.
И ладно, если отличие небольшое — в размере шрифта... | https://habr.com/ru/post/69055/ | null | ru | null |
# NILFS2 — пуленепробиваемая файловая система для /home

Как известно, если неприятность может произойти, то она обязательно произойдёт. Наверное, у каждого были случаи, когда случайно был стёрт свежий важный файл, или случайно был в... | https://habr.com/ru/post/477388/ | null | ru | null |
# Как заставить Ansible работать быстрее – 8 советов по плейбукам
[Ansible](https://www.ansible.com/?intcmp=701f20000012ngPAAQ) – это мощный и простой инструмент автоматизации с открытым кодом. Он помогает о... | https://habr.com/ru/post/650679/ | null | ru | null |
# Резервное копирование — виртуальные клоны против неконсистентных кентавров
*или простой способ создания консистентныx резервныx копий без остановки сервера с помощью клонировани... | https://habr.com/ru/post/142198/ | null | ru | null |
# Вариационные автокодировщики: теория и рабочий код

*Вариационный автокодировщик (автоэнкодер) — это генеративная модель, которая учится отображать объекты в заданное скрытое пространство.*
Когда-нибудь задавались вопросом, к... | https://habr.com/ru/post/429276/ | null | ru | null |
# Еще одна новая фича pg_filedump: восстанавливаем каталог PostgreSQL

В [прошлой статье](https://habrahabr.ru/company/postgrespro/blog/319770/) мы узнали, как при помощи утилиты pg\_filedump можно восстановить данные, или,... | https://habr.com/ru/post/323644/ | null | ru | null |
# Еще один подход к построению архитектуры на фронте
Добрый день, дорогие читатели. В этой статье я постараюсь рассказать о принципе построения архитектуры для фронтенда, в частности для React, так как хороша... | https://habr.com/ru/post/548666/ | null | ru | null |
# Введение в Javascript Source Maps
Вы когда-нибудь думали, как было бы здорово, если бы слитый в один файл и минифицированный яваскрипт код в production-окружении можно было удобно читать и даже отлаживать без ущерба производительности? Теперь это возможно, если использовать штуку под названием [source maps](https://... | https://habr.com/ru/post/148098/ | null | ru | null |
# Простая Scada на Python (продолжение)
### Формирование динамических объектов мнемосхемы
Развивая тему [предыдущей статьи](https://habrahabr.ru/post/339008/), опишу некоторые функции для формирования объектов мнемосхемы простой SCADA программы выполненной на Python.
Объекты визуально отображают состояние аналогов... | https://habr.com/ru/post/339678/ | null | ru | null |
# Big O нотация в Swift
Что такое Big O нотация?
------------------------
Обозначение Big O нотация (или просто Big O) — это способ оценки относительной производительности структуры данных или алгоритма, обычно по двум осям: времени и пространству.
Доминирующие операции
---------------------
Способ, которым мы опре... | https://habr.com/ru/post/645723/ | null | ru | null |
# Разработка интерактивной карты распространения коронавируса типа 2019-nCoV на Python
Коронавирус типа 2019-nCoV, после вспышки заболевания в китайском городе Ухань, стремительно распространяется по миру. На момент написания оригинальной статьи (30 января 2020 года) сообщалось о более чем 9000 заражённых и о 213 умер... | https://habr.com/ru/post/487688/ | null | ru | null |
# uptodate.js — библиотека для автообновления элементов времени
Как часто Вы используете конструкции вида «5 минут назад», «Полчаса назад» на вашем сайте? А что если пользователь открыл вкладку и забыл про нее на пару часов? «5 минут назад» явно теряет свою актуальность.
Именно для того чтобы исправить это досадное... | https://habr.com/ru/post/178427/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #40
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [NativeScript](https://github.com/NativeScript/NativeScript)
[ — для получения нескольких значений из кэша, что позволяет сокра... | https://habr.com/ru/post/66663/ | null | ru | null |
# Бесплатный грид контрол для Xamarin от DevExpress
В предыдущей статье ([Особенности разработки под Xamarin.Forms](http://habrahabr.ru/company/devexpress/blog/263645/)) я рассказал о нашем опыте разработки под фреймворк Xamarin.Forms, который позволяет создавать нативные пользовательские интерфейсы под три мобильные ... | https://habr.com/ru/post/264039/ | null | ru | null |
# Кодогенерация в Go на примере создания клиента к БД
В данной статье хотелось бы рассмотреть вопросы кодогенерации в Golang. Заметил, что часто в комментариях к статьям по Go упоминают кодогенерацию и рефлексию, что вызывает бурные споры. При этом на хабре статей по кодогенерации мало, хотя она применяется довольно м... | https://habr.com/ru/post/501000/ | null | ru | null |
# Как завладеть сетью /16 с помощью libpcap и libdnet
[](https://habr.com/ru/company/ruvds/blog/688314/)
Всем привет. Сегодня я попытаюсь рассказать про сетевое программирование на довольно низком уровне, с библиотеками libpacp и lib... | https://habr.com/ru/post/688314/ | null | ru | null |
# Вконтакте wall.post посредством C#
В рамках одного нашего проекта в [Brights](https://brights.io) появилась необходимость реализовать автоматическую публикацию обновлений на стену сообщества Вконтакте. Подобная задача, думаю, встречается довольно часто. Подкатом предлагаю готовый пример реализации на языке C#.
Дл... | https://habr.com/ru/post/125409/ | null | ru | null |
# Разработка приложения с использованием Python и OpenCV на Android устройстве
В это статье я хочу показать пример того, как андроид устройство можно использовать для разработки на таких языках программирования как python с библиоте... | https://habr.com/ru/post/528604/ | null | ru | null |
# Как узнать какие порты на коммутаторах уже не используются
Чуть больше года назад столкнулся с проблемой, знакомой, наверное, каждому админу: в одном из коммуникационных шкафов закончились почти все свободные порты. Визуально было видно, что почти к каждому порту подключён кабель, свободных осталось только один-два ... | https://habr.com/ru/post/121890/ | null | ru | null |
# Карты лояльности. Google Pay API for Passes в ASP.NET
Приложения-хранилища банковских карт стремительно вошли в нашу жизнь благодаря Apple Wallet и Google Pay. Обе платформы, помимо банковских, позволяют также работать и с другими типами карт — картами лояльности, подарочными картами, билетами на мероприятия, посадо... | https://habr.com/ru/post/434486/ | null | ru | null |
# Может ли сойти с ума искусственный интеллект?
Меньше месяца назад я нашел себе новое развлечение — инфов. Если вдруг кто еще не знает о них, почитайте [здесь](http://habrahabr.ru/blogs/i_am_advertising/54232/). Для простых людей, вроде меня, инфы — это как семечки. Толку ноль, но оторваться почти невозможно. Здесь я... | https://habr.com/ru/post/57182/ | null | ru | null |
# Flutter ListView и ScrollPhysics: Детальный взгляд
Подробное изучение виджета ListView и его особенностей.
Некоторое время назад я написал статью [об основах использования ListView и GridView во Flutter](https://mediu... | https://habr.com/ru/post/540794/ | null | ru | null |
# Выбираем логин на Яндекс.Почте
Много лет назад я зарегистрировал себе несколько трех- и четырехсимвольных адресов на Яндекс.Почте. Они оказались очень удобными, потому что их легко писать и диктовать, особенно вместе с доменом [ya.ru](https://ya.ru).
Спустя время решил проверить, остались ли еще свободные короткие ... | https://habr.com/ru/post/582816/ | null | ru | null |
# Правила перезаписи PostgreSQL

Представления (Views) — это не совсем то, о чём вы можете подумать. В этой статье мы разберём правила перезаписи PostgreSQL, как они работают, что они могут и чего не могут делать.
Начиная с версии... | https://habr.com/ru/post/656673/ | null | ru | null |
# Сброс пробега для RICOH SP 150SUw
Я не верю в теорию заговора производителей (электроники) о сокращении ресурса изделия, просто выполняется поиск оптимального соотношения цены / качества для определенного сегмента рынка. Но есть один момент, от которого у меня дико подгорает чуть ниже живота. Это производители принт... | https://habr.com/ru/post/541674/ | null | ru | null |
# Стань повелителем загрузки Linux
Сначала мы познакомимся с udev и научимся с его помощью исследовать установленные в компьютере устройства прямо во время загрузки: в качестве примера будем автоматически выбирать настройки видеокарт для Xorg. Затем решим задачу работы с одним образом на десятках компьютеров одновреме... | https://habr.com/ru/post/254415/ | null | ru | null |
# Как я делал игру под KolibriOS
Всем привет. В этой публикации хочу рассказать о том, как делал игру под операционную систему KolibriOS, о существовании которой раньше даже и не подозревал.

### Как всё началось?
А нача... | https://habr.com/ru/post/248001/ | null | ru | null |
# Cisco: первые шаги
Итак, в [сообществе Cisco](http://habrahabr.ru/blogs/cisconetworks/) научили самым базовым основам интерфейса. Т.е. вход в привилегированный режим, в режим конфигурирования и т. д… А я тогда задался целью попробовать сделать что-нибудь сам.
И я попробовал сделать из циски маленький SOHO-роутер.... | https://habr.com/ru/post/44235/ | null | ru | null |
# Первые две недели курса CS188.1x Artificial Intelligence или самообучение алгоритмам ИИ
Как вы думаете, что машины с искусственным интеллектом сегодня уже умеют делать, а что нет?

*На фото робот, умеющий складывать по... | https://habr.com/ru/post/255285/ | null | ru | null |
# Arduino <> Firmata <> Visual Basic .NET
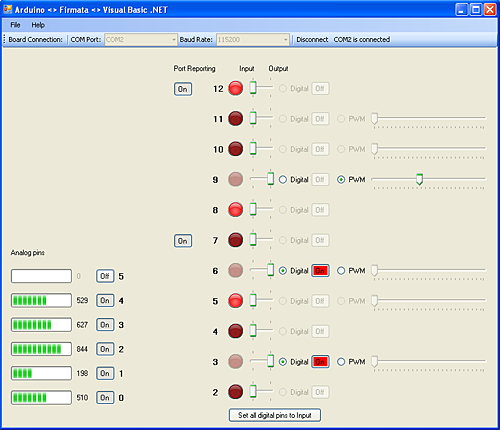
В данной статье, я хочу сделать обзор библиотеки на языке .NET для взаимодействия с аппаратной платформой Arduino.
Так как на просторах Хабра, я не видел упоминания о данной б... | https://habr.com/ru/post/169707/ | null | ru | null |
# Модифицируем паттерн Filter с помощью обобщенных лямбда-выражений
Мы можем оптимизировать паттерн Pipeline & Filter (конвейер и фильтры), сократив количество кода, необходимое на его реализацию, используя лямбда-выраже... | https://habr.com/ru/post/537982/ | null | ru | null |
# Почему typeof null === 'object'?
Все JavaScript-программисты давно привыкли к тому, что `typeof null === 'object'; // true`, хотя фактически null — примитивное значение. Многие знают, что это баг, и лично Брэндан Айк это [признает](http://wiki.ecmascript.org/doku.php?id=harmony:typeof_null). Этот баг, вероятно, нико... | https://habr.com/ru/post/200664/ | null | ru | null |
# Пишем примитивный и никому не нужный компилятор
Я считаю, что каждый программист должен написать свой компилятор.
Я сам долгое время считал, что создание компиляторов — это удел элиты, а простому смертному программисту не постичь этой науки. Попробую доказать, что это не так.
В посте мы рассмотрим, как можно н... | https://habr.com/ru/post/133780/ | null | ru | null |
# Эффекты фильтрации SVG. Часть 4. Двухцветные изображения при помощи feComponentTransfer
Эта четвертая статья серии об SVG-фильтрах, в которой Sara Soueidan покажет вам, как использовать **feComponentTransfer** для создания эффекта двухтонового фильтра.

Если вы читаете эту статью, вероятно, вы уже знакомы с возможностями, которые открываются при использовании API (Application Programming Interface).
Добавив в... | https://habr.com/ru/post/464705/ | null | ru | null |
# Автоматическая подсветка лестницы с помощью Arduino
Добрый день! В этом посте хочу поделится с хабро сообществом о том, как мне довелось сделать автоматическое освещение лестницы в своем двухэтажном коттедже. Начну с небо... | https://habr.com/ru/post/142685/ | null | ru | null |
# Конструктор форм в Yii
Привет хабраюзеры!
В большинстве проектов на Yii которые я видел, работа с формами была организована самым простым способом, где рендеринг формы определялся в файле вида через виджет ActiveForm. Да, это безусловно оправдано для сложных форм, которые проблематично уместить в шаблон. Но сегод... | https://habr.com/ru/post/155127/ | null | ru | null |
# Microsoft Graph API Requests или иной способ управления Microsoft 365
Довольно часто приходят задачи написать скрипты для Microsoft 365, будь то репортинг или какие-то автоматизации. Как правило, сервисы вх... | https://habr.com/ru/post/571132/ | null | ru | null |
# Портрет Хабра-tutorial
> В наш век только бесполезные вещи и необходимы человеку. Оскар Уайльд, Портрет Дориана Грея ([источник](http://ru.wikiquote.org/wiki/%D0%9E%D1%81%D0%BA%D0%B0%D1%80_%D0%A3%D0%B0%D0%B9%D0%BB%D1%8C%D0%B4))
А вы никогда не задумывались, чем обычный пост на хабре (порошок обычный*TM*) отличаетс... | https://habr.com/ru/post/218607/ | null | ru | null |
# Чекалка: ваш личный Hosttracker (и не только)
Компания в которой я работаю, производит разнообразные веб сервисы. Мы используем как свои собственные разработки, так и всяческие открытые инструменты и фреймв... | https://habr.com/ru/post/524690/ | null | ru | null |
# Microsoft призвала удалить обновление Windows 11 KB5013943, которое вызывает сбои приложений
Пользователи Windows 11 [столкнулись](https://www.bleepingcomputer.com/news/microsoft/windows-11-kb5013943-update-causes-0xc0000135-application-errors/) с ошибкой 0xc0000135 при попытке запуска приложений. Её вызвала установ... | https://habr.com/ru/post/665508/ | null | ru | null |
# Лучшие практики модальных окон. Компоненты дизайн системы
Всем привет
-----------
Меня зовут Андрей Насонов, я работаю UI/UX-дизайнером и руковожу дизайн-отделом. В 2008 году я начал заниматься графическим... | https://habr.com/ru/post/693272/ | null | ru | null |
# В ожидании ExtJS 4: Динамическая загрузка и новая система классов
*От переводчика*: Sencha Inc, производитель известного RIA-фреймворка Ext JS, заговорила о грядущей четвертой версии 22 ноября прошлого года. Релиз обещанного планировался на 28 февраля.
Что бы подогреть интерес комьюнити (ведь API, по словам разра... | https://habr.com/ru/post/112802/ | null | ru | null |
# Вибрация геймпада XboxOne для Unity3d
 В Unity3d есть универсальная поддержка контроллеров через класс Input. После предварительной настройки осей и кнопок, можно добиться сносной работы любого контроллера. К сожалению, при этом будет отсутс... | https://habr.com/ru/post/243021/ | null | ru | null |
# Бескомпромиссный CI-конвейер для питонистов
Любому Python-проекту может пойти на пользу надёжный и стабильный конвейер непрерывной интеграции (Continuous Integration, CI). В рамках таких конвейеров выполняется сборка приложений, запуск тестов, проверка кода линтерами, контроль качества программ, анализ уязвимости пр... | https://habr.com/ru/post/675304/ | null | ru | null |
# Saving Routing State to the Disk in a Cross-Platform .NET Core GUI App with ReactiveUI and Avalonia

User interfaces of modern enterprise applications are quite complex. You, as a developer, often need to implement in-app naviga... | https://habr.com/ru/post/462307/ | null | en | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.