
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Обработка sms на куче одинаковых gsm модемов без насилия над udev
**Дано:**
Есть бухгалтерия, которая работает с множеством коммерческих организаций. Банковские web-клиенты шлют коды подтверждения для той или иной банковской операции в виде sms. Одинаковые GSM модемы воткнуты в USB хаб Linux сервера. На сервере у... | https://habr.com/ru/post/280574/ | null | ru | null |
# АнтиAJAX
Некоторые сайты злоупотребляют аяксом и подгружают в фоновом режиме рекламу, разные свои фишки, типа статистики, аяксовых чатов и т.п. А я просто хочу почитать, например, статью на сайте.
В Firefox аякс убивается вводом в адресной строке простой команды:
`javascript:void(XMLHttpRequest=null)`
Можно... | https://habr.com/ru/post/16156/ | null | ru | null |
# Java и время: часть первая
Восемь лет назад я принимал участие в проектировании и разработке сервиса, который был должен обслуживать запросы пользователей со всех уголков земного шара и координировать их действия. Работая над проектом я понял, что очень часто многие важные аспекты работы со временем просто игнорирую... | https://habr.com/ru/post/274811/ | null | ru | null |
# Что такое dinghy или как ускорить docker

Однажды я заглянул на Хабр, чтобы посмотреть как разработчики используют динги (dinghy) и вообще ускоряют работу докера на маке. На моё удивление по запросу динги я нашёл ровно ноль ... | https://habr.com/ru/post/338198/ | null | ru | null |
# x-acl легковесная утилита для организации Access Control List (ACL)
Приветствую, хабра-сообщество!
У каждого проекта (веб-проекта) возникают вопросы по организации прав доступа. В данной области есть определенные готовые инструменты для различных фреймворков Zend, Symfony, Yii и т. д. Вероятно кто-то с чем-то ста... | https://habr.com/ru/post/155099/ | null | ru | null |
# Допиливание exdupe.exe — шустрого дедуплицирующего архиватора
Какое-то время назад я столкнулся с неприятной проблемой — понадобилось бэкапить несколько виртуальных машин. Надо сказать, что бэкапить для меня — значит иметь в результате не только архив с последней копией, а небольшую кучку этих архивов, сделанных по ... | https://habr.com/ru/post/206534/ | null | ru | null |
# Навигация внутри Android приложения
### Введение
При Андроид разработке мы используем разные архитектурные решения(паттерны). Например *Mvp*, *Mvvm*, *Mvi* и т.д… Каждый из этих паттернов решает несколько важных задач и поскольку они не идеальны они нам оставляют кое-какие нерешенные задачи. К примеру этих задач от... | https://habr.com/ru/post/435248/ | null | ru | null |
# Область видимости переменной в Javascript (ликбез)
Для меня одним из самых проблемных мест Javascript было управление переменными. Излагаю простым русским языком.
Области видимости переменных
----------------------------
Переменные в Javascript бывают глобальными и локальными. Глобальная переменная доступна везд... | https://habr.com/ru/post/78991/ | null | ru | null |
# Кому на бюджете жить хорошо?

ВСТУПЛЕНИЕ
----------
```
В каком году — рассчитывай,
В какой земле — угадывай,
На столбовой дороженьке
Сошлись семь мужиков:
Семь временнообязанных,
Подтянутой губернии,
Уезда Терпигорева,
Пустопорожне... | https://habr.com/ru/post/501760/ | null | ru | null |
# Рекомендации по запуску приложений в OpenShift Service Mesh
В этом посте мы собрали советы и рекомендации, которые стоит изучить, прежде чем переносить свои приложения в сервисную сетку OpenShift Service Mesh (OSSM). Если вы никогда не сталкивались с сервисными сетками Service Mesh, то для начала можно глянуть [стра... | https://habr.com/ru/post/552450/ | null | ru | null |
# Структура PKCS7-файла
Привет!
Довелось мне на днях столкнуться с такой напастью как p7s файл и, как вследствие этого, с Cryptographic Message Syntax (CMS). На хабре нашлась интересная [статья](http://habrahabr.ru/company/aktiv-company/blog/191866/) описывающая структуру CMS данных, но в ней к сожалению нет пример... | https://habr.com/ru/post/256367/ | null | ru | null |
# AMD APP SDK: Intermediate Language (IL)

ATI Stream SDK было переименовано в AMD Accelerated Parallel Processing (APP) SDK, на смену основного языка программирования GPGPU вы... | https://habr.com/ru/post/138954/ | null | ru | null |
# Защита от сохрания изображений

Здравствуйте, уважаемые харбрачитатели.
Некоторое время назад я столкнулся с очень, на мой взгляд, интересной задачей. Суть задачи заключалась в том, что необходимо максимально усложнить процесс сохранения картинок со стран... | https://habr.com/ru/post/132228/ | null | ru | null |
# .NET Core 2.1 Global Tools
Пару недель назад [вышел .NET Core 2.1 RC1](https://blogs.msdn.microsoft.com/dotnet/2018/05/07/announcing-net-core-2-1-rc-1/). Это первая версия SDK, где есть фича под названием "Глобальные утилиты .NET Core" (".NET Core Global Tools"). Она дает простой способ создания кросс-платформенных ... | https://habr.com/ru/post/359006/ | null | ru | null |
# Парсинг YouTube, включая подгружаемые данные, без YouTube API
Вступление
----------
Чтобы подгрузить данные контента на ютубе, обычно используют либо Selenium, либо YouTube API. Однако везде есть свои минусы.
1. Selenium слишком медленный для парсинга. Представьте себе парсинг плейлиста из ~1000 роликов селениум... | https://habr.com/ru/post/505888/ | null | ru | null |
# Учим машину разбираться в генах человека
Всегда приятно осознавать, что применение технологий сводится не только к финансовой выгоде, бывают ещё и идеи, делающие мир лучше. Об одном из проектов с такой идеей мы и расскажем в этот морозный пятничный день. Вы узнаете о решении, которое позволило увеличить точность экс... | https://habr.com/ru/post/343604/ | null | ru | null |
# Как в Redash заметили и исправили проблему, вызвавшую деградацию производительности Python-кода
Недавно в Redash приступили к смене одной системы выполнения задач на другую. А именно — они начали переход с Celery на RQ. На первом этапе на новую платформу перевели лишь те задания, которые не выполняют запросы напряму... | https://habr.com/ru/post/475250/ | null | ru | null |
# Об одной ошибке оптимизации времени выполнения
Изначально пост планировалось посвятить ошибке 64х-битового компилятора xlc которую я безуспешно отлавливал многие часы и которая имеет место быть на серверах фирмы IBM архитектуры AIX... | https://habr.com/ru/post/131615/ | null | ru | null |
# Добавляем реактивность в строковые шаблонизаторы
Одним из преимуществ строковых шаблонизаторов таких как JUST.js, jqueryTmpl или handlebarsjs перед шаблонизаторами на основе виртуального DOM дерева (VUE.js, angular) это низкий порог вхождения и простота в использовании. Ещё как мне кажется со строковыми шаблонизатор... | https://habr.com/ru/post/331400/ | null | ru | null |
# MISRA C: struggle for code quality and security
A couple of years ago the PVS-Studio analyzer got its first diagnostic rules to check program code compliance with the MISRA C and MISRA C++ standards. We collected feedback and saw that our clients were interested in using the analyzer to check their projects for MISR... | https://habr.com/ru/post/579428/ | null | en | null |
# Автоматизированное тестирование облачного провайдера Open Telekom Cloud на основе Robot Framework
В этой статье я расскажу об инфраструктуре нашего проекта для запуска REST API автотестов для сервисов Open ... | https://habr.com/ru/post/650631/ | null | ru | null |
# Как использовать PivotViewer для Silverlight в реальном проекте (часть I)
На Хабре уже несколько раз писали об элементе управления [PivotViewer](http://www.silverlight.net/learn/pivotviewer/), предназначенном для визуализации и фильтрации больших объемов данных. Я хочу поделиться опытом использования этого крайне ин... | https://habr.com/ru/post/102912/ | null | ru | null |
# 3 истории сбоев Kubernetes в production: anti-affinity, graceful shutdown, webhook

***Прим. перев.**: Представляем вниманию мини-подборку из постмортемов о фатальных проблемах, с которыми столкнулись инженеры разных компаний при... | https://habr.com/ru/post/475026/ | null | ru | null |
# Добавляем Sign in with Apple на back-end
На WWDC 2019 Apple представила новую систему авторизации пользователей — Sign in with Apple. Возникла задача интегрировать её в наш back-end и синхронизировать её с уже существующими методами авторизации при помощи email, Google и Facebook. За задачу взялся наш коллега [kuren... | https://habr.com/ru/post/470175/ | null | ru | null |
# Как мы мультиплеер для NFS MW писали
Привет, Хабр! В своём первом посте я расскажу, как мы уже полгода как пишем неофициальный мультиплеер для NFS Most Wanted 2005 года выпуска. Сразу скажу — ссылок не будет, лишь скриншоты, дабы не сочли за банальную рекламу. Если будет интересно — спросите в комментариях. Поехали!... | https://habr.com/ru/post/334744/ | null | ru | null |
# Go в API для мобильного приложения. Создаем совместный список покупок с мгновенными уведомлениями
В [предыдущей статье](https://habr.com/ru/company/otus/blog/666004/) мы рассмотрели использование Go для соз... | https://habr.com/ru/post/667308/ | null | ru | null |
# Поиск неинициализированных членов класса

К нам достаточно давно обращались клиенты и потенциальные клиенты с просьбой реализовать диагностику для поиска неинициализированных член... | https://habr.com/ru/post/269599/ | null | ru | null |
# Найден программист, взломавший kernel.org в 2011 году

28 августа 2011 года сообщество Linux было слегка потрясено, узнав о взломе kernel.org — основного сервера для распространения исходного кода ядра Linux, главного мес... | https://habr.com/ru/post/357552/ | null | ru | null |
# Оптимизация OneToMany коллекций Doctrine
В этой статье будет показан пример того, как уменьшить количество запросов к базе данных до одного при работе с коллекциями сущностей иерархической структуры в контексте PHP и Doctrine ORM. Полный пример решения вы можете посмотреть в специальном [репозитории](https://github.... | https://habr.com/ru/post/715942/ | null | ru | null |
# System.IO.Pipelines: высокоэффективный IO в .NET
[System.IO.Pipelines](https://www.nuget.org/packages/System.IO.Pipelines/) — это новая библиотека, упрощающая организацию кода в .NET. Трудно обеспечить высокую производительность и точность, если приходится иметь дело со сложным кодом. Задача System.IO.Pipelines — уп... | https://habr.com/ru/post/423105/ | null | ru | null |
# ejabberd: мигрируем с mnesia на mysql
По мере использования xmpp сервера ejabberd наблюдаю крайний дефицит документации. Каждый чих чуть отклоняющийся от стандартных потребностей приходится придумывать самому, либо собирать по кусочкам из конференций, списков рассылки, комментариев в svn и непосредственно исходников... | https://habr.com/ru/post/154535/ | null | ru | null |
# «Жизнь» Конвея из каждой буквы, только в Emacs!
#### Одним рабочим декабрьским вечером
Все мы так или иначе сталкивались с [игрой **«Жизнь»** Конвея](http://ru.wikipedia.org/wiki/%D0%96%D0%B8%D0%B7%D0%BD%D1%8C_(%D0%B8%D0%B3%D1%80%D0%B0)). Кто-то писал сам, кто-то смотрел и дивился, кто-то играл…
Под новый год, с... | https://habr.com/ru/post/136597/ | null | ru | null |
# Контроллер-луковка. Разбиваем экраны на части
В дизайне популярен atomic design и дизайн системы: это когда всё состоит из компонентов, от контролов до экранов. Программисту писать отдельные контролы несложно, но что делать с целыми экранами?
Разберём на новогоднем примере:
* налепим всё в кучу;
* разделим на конт... | https://habr.com/ru/post/434470/ | null | ru | null |
# Сюрпризы chef-a или история одного расследования
Не так давно мы в компании Acronis перешли на провиженинг части наших виртуальных машин на Chef. Ничего особенно нового: все виртуальные машины создаются посредством ESXI,... | https://habr.com/ru/post/239335/ | null | ru | null |
# Как не утонуть в рутине, или Наш опыт сравнения AWR-дампов при проведении нагрузочного тестирования
Всем привет! Меня зовут Людмила, я занимаюсь нагрузочным тестированием, хочу поделиться тем, как мы выполнили автоматизацию сравнительного анализа регрессионного профиля нагрузочного тестирования системы с БД под СУБД... | https://habr.com/ru/post/470726/ | null | ru | null |
# AOP in action. AspectJ (CTW) + Spring + LTW
Решил внедрить АОП логирование на проект и не внедрил. Как и почему, собственно и хочу поделиться.
Я не буду описывать суть и принципы АОП, а опишу только те проблемы, с которыми я столкнулся, и решения которых заняло много времени.
У меня было в распоряжении Spring,... | https://habr.com/ru/post/186940/ | null | ru | null |
# Laravel: объясняем основные понятия. Часть первая: «Теория»
*Друзья, у нас отличные новости. В августе мы в OTUS запустили новый курс — [«Framework Laravel»](https://otus.pw/HKEW/), но желающих обучаться было столько, что не все успели попасть в группу. Новый поток по курсу стартует уже в конце октября! Ждем всех и ... | https://habr.com/ru/post/470794/ | null | ru | null |
# Диагностика утечек памяти в Java
В данной заметке я хочу показать каким образом можно определять и устранять утечки памяти в Java на примере из моей повседневной работы. Мы не будем здесь рассматривать возможные причины появления утечек, об этом будет отдельная статья, так как тема достаточно обширная. Стоит заметит... | https://habr.com/ru/post/324144/ | null | ru | null |
# Хостим Bitwarden — open-source менеджер паролей

Менеджеры паролей действительно полезны и важны как для отдельных пользователей, так и для организаций, и они пригодятся, когда у вас много разных учетных записей и паролей. Обычно л... | https://habr.com/ru/post/540574/ | null | ru | null |
# Flutter. RenderObject — замеряй и властвуй
Всем привет, меня зовут Дмитрий Андриянов. Я [Flutter-разработчик](https://surf.ru/flutter/) в [Surf](https://surf.ru/). Чтобы построить эффективный и производительный UI достаточно основной библиотеки Flutter. Но бывают случаи, когда нужно реализовывать специфичные кейсы и... | https://habr.com/ru/post/513070/ | null | ru | null |
# Как я боролся с воровством… с помощью php

Когда мы платим ежедневно за услуги — это покупка услуг.
Когда мы платим ежедневно за ничего (порой даже не подозревая об этом) — это воровство.
Добрый день, читатели Хабра! ... | https://habr.com/ru/post/422379/ | null | ru | null |
# TREX: 27-ричная симметричная система счисления
Каждый специалист по компьютерам знает, насколько сложно работать с длинными последовательностями нулей и единиц. На помощь ему приходят восьмеричная и шестна... | https://habr.com/ru/post/560928/ | null | ru | null |
# Как писать подзапросы EXISTS с помощью JPA и Hibernate
### Введение
В этой статье я покажу вам, как писать подзапросы EXISTS с помощью JPA и Hibernate.
Подзапросы EXISTS очень полезны, так как позволяют реализовать [SemiJoins](https://en.wikipedia.org/wiki/Relational_algebra#Semijoin). К сожалению, многие разработ... | https://habr.com/ru/post/652591/ | null | ru | null |
# Поиск всех групп пользователя AD по протоколу LDAP
Мне по роду занятий часто приходится иметь дело с сервисами интегрирующимися с AD. К сожалению в большинстве таких сервисов напрочь отсутствует поддержка такой удобной «фичи» AD как [Nested Groups](http://technet.microsoft.com/en-us/library/cc776499%28v=ws.10%29.asp... | https://habr.com/ru/post/187044/ | null | ru | null |
# Erlang для самых маленьких. Глава 3: Базовый синтаксис функций
Доброй ночи, Хабр! Мы продолжаем изучение Erlang для самых маленьких.
В [прошлой главе](http://haru-atari.com/blog/19/erlang-for-the-li... | https://habr.com/ru/post/211815/ | null | ru | null |
# Разбор алгоритмических задач с собеседований в Google, Facebook, Amazon
### ▍ Введение
Всем привет!
В данный момент времени я активно готовлюсь к алгоритмическим собеседованиям на позицию стажера в одну из около-FAANG компаний. В данной статье пройдемся по двум задачам из списка часто встречаемых задач с [leetco... | https://habr.com/ru/post/586598/ | null | ru | null |
# Вышла Java 19
Вышла общедоступная версия [Java 19](https://openjdk.org/projects/jdk/19/). В этот релиз попало более [двух тысяч закрытых задач и 7 JEP'ов](https://builds.shipilev.net/backports-monitor/release-notes-19.html). Release Notes можно посмотреть [здесь](http://jdk.java.net/19/release-notes). Изменения API ... | https://habr.com/ru/post/689344/ | null | ru | null |
# Tele2 в Омске

В пятницу зашел на [сайт](http://omsk.tele2.ru) омского ТЕЛЕ2 посмотрел на главную и обрадовался пестрел заголовок о том, что мой сотовый оператор, которым я пользуюсь достаточно давно рад предоставить своим абонентам услугу безлимитного интер... | https://habr.com/ru/post/105486/ | null | ru | null |
# Написание расширений PostgreSQL на языке С — это интересно
PostgreSQL — это мощная система управления реляционными базами данных с открытым исходным кодом. Она дополняет язык SQL новыми фичами. СУБД определ... | https://habr.com/ru/post/685880/ | null | ru | null |
# Как по заказу: история о том, как строка кода превратилась в килотонны угля

Телефон Брэда разразился знакомой трелью внутриофисного звонка.
— Да? – рявкнул он, поднимая трубку. – Чего вам?
По меркам Брэда, такая манера обща... | https://habr.com/ru/post/501536/ | null | ru | null |
# Законотворчество и программирование: заметка об интерпретации текстов
Все юристы работают с текстами. Читают, пишут, изучают, трактуют, убеждают в своих трактовках. Программисты — работают с текстами. Читают, пишут. Убеждают компилятор в своей правоте. Я — разработчик. Я пишу много текста, вроде такого:
```
class H... | https://habr.com/ru/post/556108/ | null | ru | null |
# Как Олимпиада в Лондоне транслировалась через облако
[](http://pikucha.ru/i96aT "olympics-london.jpeg")
Ранее в этом году мы анонсировали [Windows Azure Media Services](http://weblogs.asp.net/scottgu/archive/2012/04/16/announcing-windo... | https://habr.com/ru/post/150115/ | null | ru | null |
# IT квест-марафон для хабра-хабра
Затекли? Хотите размять мозги? Вперед!
Hand-tailored специально для вас. Одним из вас.
Мы любим головоломки. Мы любим интересные конкурсы и терпеть не можем яблоки (поэтому будем их солить и выбрасывать в окно).
Это уже не первый наш опыт.
Предыдущий эксперимент увенчался... | https://habr.com/ru/post/205396/ | null | ru | null |
# Axgio Windows Mini PC. Из Китая с приветом — обзор атомного малыша

Появлению этой статьи способствовало совпадение двух факторов: 1) у меня внезапно кончились игрушки; 2) Intel анонсировал выход своего собственного микро... | https://habr.com/ru/post/377183/ | null | ru | null |
# Введение в google api
В этой статье я хотел бы дать обзор api, которые предоставляет google. Я не буду рассматривать все api и давать детальную инструкцию по их использованию, а расскажу только про те, которые считаю наиболее полезными, и дам примеры кодов с комментариями (примеры взяты из документации к api).
Ра... | https://habr.com/ru/post/64515/ | null | ru | null |
# Микросервисы: от CRUD до Native Image. Часть вторая
Сегодня я продолжу рассуждать о том, как мы пишем микросервисы. В [прошлый раз](https://habr.com/ru/post/542448/) упор был на теорию: нужно было вспомнить, как код писался раньше, понять сущность архитектуры и связи между компонентами.
Эта половина статьи сосредо... | https://habr.com/ru/post/547508/ | null | ru | null |
# Кооператив на Unity за «Бесплатно», или p2p соединение через ISteamNetworkingMessages
Разрабатывая вторую игру на Unity я решил замахнуться на кооперативный режим. Так как новая игра тоже выйдет на площадке Steam, сервисы стима уже интегрированны, а взнос за приложение уже уплачен, было решено попробовать сетевые се... | https://habr.com/ru/post/597783/ | null | ru | null |
# Разработка расширения для firefox, или мой первый опыт, на примере скриншотера
После написания статьи [Системные скрипты на php для linux, пишем скриншотер](https://habrahabr.ru/post/310694/), у меня появилась идея «А почему бы, не написать расширение которое завязать на мой скрипт, с возможностью автоматической выг... | https://habr.com/ru/post/310844/ | null | ru | null |
# STM32 и LCD через I2C

Для использования в дальнейшем понадобилось связать, используя I2C микроконтроллер STM32 с экраном 2004. Не найдя аналогичного решения в сети, публикую здесь. Данный рецепт подойдё... | https://habr.com/ru/post/223947/ | null | ru | null |
# Создание IPSec GRE туннеля между Mikrotik hEX S и Juniper SRX через USB Модем
#### Цель
Необходимо организовать VPN Tunnel между двумя устройствами, таких как Mikrotik и Juniper линейки SRX.
#### Что имеем
Из микротиков выбрали на сайте микротика вики, модель которая сможет поддерживать аппаратное шифрование IP... | https://habr.com/ru/post/455425/ | null | ru | null |
# Настраиваем принтер Canon LBP3010 в Ubuntu 10.10
[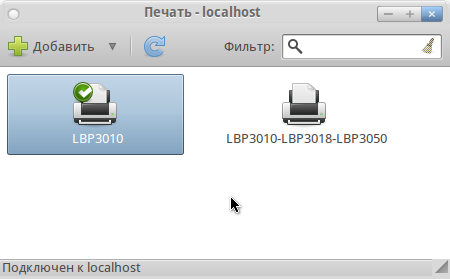](https://habrastorage.org/storage/habraeffect/df/ab/dfab9f9cb6717d8ccb675514fadbda9f.png "Хабрэффект.ру")
Я почти полтора месяца пытался заставить работать этот пр... | https://habr.com/ru/post/107893/ | null | ru | null |
# Машинное обучение для поиска аномалий
Поиск аномалий и выявление подозрительных операций широко применяется в клиентской аналитике, банковском аудите и других видах бизнес аналитики. Суть данной методики заключается в анализе больших объемов данных и выявлении поставщиков, клиентов, транзакций или иных активностей с... | https://habr.com/ru/post/671670/ | null | ru | null |
# Play «osu!», but Watch Out for Bugs

Hi, all of you collectors of exotic and plain bugs alike! We've got a rare specimen on our PVS-Studio test bench today – a game called «osu!», written in C#. As... | https://habr.com/ru/post/483436/ | null | en | null |
# Настройка DKIM, SPF, DMARC и rDNS в Carbonio
Более 90% от общего объема мирового трафика электронной почты сейчас составляет спам. Это побуждает системных администраторов и держателей публичных почтовых серверов максимально крепко закручивать гайки и отклонять электронные письма даже при малейших подозрениях на их ... | https://habr.com/ru/post/662962/ | null | ru | null |
# Управление Mikrotik с помощью Telegram бота
Хочу написать об интересных возможностях связки Mikrotik и Telegram бота. Возможно похожие решения, где то публиковались ранее, предложу свои варианты использования
Бот для блокировки интернета
----------------------------
Вариант подойдет для блокировки и разблокировки... | https://habr.com/ru/post/698178/ | null | ru | null |
# Docs as Code. Часть 1: автоматизируем обновление
В больших проектах, состоящих из десятков и сотен взаимодействующих сервисов, всё чаще становится обязательным подход к документации как к коду — [docs as code](https://www.writethedocs.org/g... | https://habr.com/ru/post/459640/ | null | ru | null |
# Работаем с Compound File
С составными файлами я работаю давно, больше 15 лет. За все время работы у меня накопилось достаточно информации о плюсах и минусах составных файлов.
С одной стороны они являются действительно очень удобным хранилищем информации, позволяющим менять данные на лету, с другой стороны это удо... | https://habr.com/ru/post/254541/ | null | ru | null |
# Google AI Challenge. Как написать своего бота. Часть 1, 2
###### Этот топик — перевод первых двух частей руководства по написанию своего бота для Google AI Challenge.
Весь код написан на языке Python.
#### Шаг 1: Как избежать столкновений
##### План
Чтобы муравьи не сталкивались надо:
1) Предотвратить перемещ... | https://habr.com/ru/post/130931/ | null | ru | null |
# Начинаем работу Python + Qt5 + QML урок №1
Всем привет. Сегодня познакомимся с QML. Узнаем что это такое и с чем его едят. Создадим небольшое приложение с использованием данной технологии.
### Небольшое отступление:
QML (Qt Meta Language) — декларативный язык программирования, основанный на JavaScript, предназнач... | https://habr.com/ru/post/326268/ | null | ru | null |
# Javascript: чтение двоичных данных из реестра
Сегодня возникла необходимость узнать смещение по вертикали панели задач Windows из HTA приложения используя JavaScript.
Необходимое значение находится в HKEY\_CURRENT\_USER\Software\Microsoft\Internet Explorer\Desktop\Components\0, двоичный параметр Position.
В ит... | https://habr.com/ru/post/65679/ | null | ru | null |
# 9 команд для проверки информации о CPU в Linux
**Информация об аппаратном обеспечении CPU**
Информация о CPU (Central Processing Unit. Центральный процессор) включает в себя подробные сведения о процессоре... | https://habr.com/ru/post/581796/ | null | ru | null |
# Построение систем доставки видео на основе HTTP Dynamic Streaming от Adobe и OpenSource
В рамках проекта для одного из наших заказчиков в очередной раз встала задача построить систему конвертации/ хранения/ доставки видео в интернет. Типичная такая задача создания своего маленького (или не очень маленького) “Тьюба” ... | https://habr.com/ru/post/110135/ | null | ru | null |
# Android Camera2 API от чайника, часть 3. Media Codec и стрим видео по UDP
Итак, со съемками фоточек и записью видео при помощи Camera2 API мы вроде бы, разобрались. Осталось только научиться передавать видеопоток c Android устройства страждущим получателям извне. Конечной целью, как уже неоднократно ранее говорилось... | https://habr.com/ru/post/473036/ | null | ru | null |
# Умное цветоводство, или Пусти ИТшника в огород… Часть 2
Друзья, наши технологические раскопки на ниве домашне-офисного озеленения вызвали явный интерес с вашей стороны (предыдущая статья [Умное цветоводство, или Пусти ИТ-шника в огород… Часть 1](https://habrahabr.ru/company/jetinfosystems/blog/312024/)). Посему, как... | https://habr.com/ru/post/313308/ | null | ru | null |
# Браузерные расширения, необходимые каждому веб-разработчику
Современные браузеры — это не только отличные приложения для просмотра веб-страниц.
Браузеры — это ещё и платформы, предлагающие веб-разработчикам массу удобных инструментов, помогающих создавать замечательные сайты. В распоряжении разработчика, помимо в... | https://habr.com/ru/post/488662/ | null | ru | null |
# Самые известные и странные олдовые компьютерные вирусы (часть 2)
[](https://habr.com/ru/company/ruvds/blog/689872/)
[В первой части](https://habr.com/ru/company/ruvds/blog/688706/) мы рассказали о нескольких самых ранних из извест... | https://habr.com/ru/post/689872/ | null | ru | null |
# (Архив) Matreshka.js v0.1
**Статья устарела. См. [актуальную историю версий](http://ru.matreshka.io/#whats-new).**
* [Введение](http://habrahabr.ru/post/196146/)
* [Наследование](http://habrahabr.ru/post/200078/)
* [MK.Object](http://habrahabr.ru/post/196886/)
* [MK.Array](http://habrahabr.ru/post/198212/)
* **Ma... | https://habr.com/ru/post/217241/ | null | ru | null |
# Машинное обучение для менеджеров: таинство сепуления
### Введение
Очередной раз работая с компанией, делающей проект, связанный с машинным обучением (ML), я обратил внимание, что менеджеры используют термины из области ML, не понимая их сути. Хотя слова произносятся грамматически правильно и в нужных местах предлож... | https://habr.com/ru/post/447094/ | null | ru | null |
# Raspberry Pi + FreeBPX(asterisk) + Mikrotik = АТС мини
**Настройка "с нуля"**
* Введение, начало
* Установка и настройка FreePBX
* Подключение GSM модема
* Настройка fail2ban
* Настройка Mikrotik
Введение, начало
----------------
В небольшой офис потребовалась АТС, для звонков по России и между сотрудниками. Был ... | https://habr.com/ru/post/550734/ | null | ru | null |
# Установка Sharepoint фермы
Начали собирать ферму из 2ух фронтендов + сервер MS SQL.
На обе машины — MOSS 2007 + WSS SP1 + MOSS SP1
Настроили все как обычно, сделали базу на одной машине — потом накатили **Infrastructure Update**
НИ В КОЕМ СЛУЧАЕ НЕ СТАВЬТЕ ЭТОТ АПДЕЙТ СРАЗУ ЕСЛИ СОБИРАЕТЕСЬ ОБЬЕДИНЯТЬ СЕ... | https://habr.com/ru/post/57195/ | null | ru | null |
# Обеспечение обратной совместимости .NET-приложений при использовании WinRT
Создание Windows Runtime (WinRT) в качестве API, с одной стороны, можно только приветствовать, так как предыдущий — WinAPI — особой простотой и человеколюбием не отличался. С другой стороны, в полный рост при этом всплывает проблема обратной ... | https://habr.com/ru/post/258015/ | null | ru | null |
# Однократные подписки
При создании разных сервисов очередей часто возникает вопрос: «А как лучше реализовать систему уведомлений о событиях в очереди?» Она часто бывает сложнее в реализации, нежели сам серви... | https://habr.com/ru/post/590375/ | null | ru | null |
# Трассировка лучей на GPU в Unity — Часть 3
[[Первая](https://habr.com/ru/post/355018/) и [вторая](https://habr.com/ru/post/412685/) части.]

Сегодня мы совершим большой скачок. Мы отойдём от исключител... | https://habr.com/ru/post/450308/ | null | ru | null |
# Работа с изображениями средствами phpThumbOf
phpThumbOf — это аддон для MODx, основанный на популярном скрипте phpThumb. Он позволяет модифицировать изображения средствами различных графических библиотек «на лету».
Я не буду описывать процесс установки аддона из репозитория. Будем считать, что вы уже скачали его ... | https://habr.com/ru/post/131424/ | null | ru | null |
# Retrofit2 на Android используя Kotlin
Сегодня мы рассмотрим работу с **Retrofit** 2. Правды ради стоит отметить, что мы будем работать еще с 2 отдельными библиотеками, а именно **Picasso** и **Spots-dialog**.
Это статью я рекомендую к прочтению только для тех, кто еще не работал с Retrofit 2. Ведь в этой статье я... | https://habr.com/ru/post/520544/ | null | ru | null |
# Новые сборки оперы. Юнайт по выбору
Пока Opera Unite еще дорабатывается до полностью рабочего состояния, сборки разделились на две категории: Opera 10.0 и Opera 10.10, соответственно, без Unite и с оной. Релиз бета-версии Оперы 10.10 намечается сразу после релиза основной версии 10.0.
Если у вас уже включена опци... | https://habr.com/ru/post/67593/ | null | ru | null |
# Exim: как скрыть связь одного сервера и несколкьких доменов
Заказчики попросили меня добавить на их почтовый сервер Exim еще доменов, но при условии, чтобы не была обнаружена связь их основного домена и каждого следующего доменов.
Естественно обратную запись в ДНС не изменить для каждого домена персонально. Я наш... | https://habr.com/ru/post/125407/ | null | ru | null |
# Обертка над WWW в Unity3D

Всем привет! Решил поделиться своим велосипедиком для работы с WWW в Unity3D.
Что такое WWW?
**WWW** — это класс, который позволяет отправлять веб запросы на указанный UR... | https://habr.com/ru/post/211482/ | null | ru | null |
# Полезный NaN
О NaN больше всего известно то, что он не равен самому себе.
```
NaN === NaN // false
```
И что операции, невозможные арифметически, вернут NaN.
```
'BlaBlaBla'/0 // NaN
```
Но у NaN есть одно мало известное(?), и, как мне кажется, весьма полезное применение.
### TL;DR Все дело в Date
В дву... | https://habr.com/ru/post/336124/ | null | ru | null |
# Портируем html5 игру на Android
Это продолжение моей прошлой статьи "[Создаем html5 мини-бродилку на CraftyJS](http://habrahabr.ru/blogs/gdev/125857/)". Я подумал, сейчас так много возможностей относительно просто портировать любое html5 приложение на мобильную платформы, почему бы не попробовать?
 инвесторы часто задаются вопросом о том, как отобрать для себя идеальное соотношение активов входящих в портфель. Часто (или не очень, но знаю про двух точно) у некоторых брокеров эту функцию выполняет торговый робот. Но заложенные в ... | https://habr.com/ru/post/500262/ | null | ru | null |
# NGINX: Перехват ошибок 5хх с помощью отладочного сервера
#### Является ли ошибкой ответ 5хх, если его никто не видит? [[1]](https://ru.wikipedia.org/wiki/%D0%97%D0%B2%D1%83%D0%BA_%D0%BF%D0%B0%D0%B4%D0%B0%D1%8E%D1%89%D0%B5%D0%B3%D0%BE_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%B0_%D0%B2_%D0%BB%D0%B5%D1%81%D1%83)
 – это независимая последовательность инструкций в ... | https://habr.com/ru/post/67693/ | null | ru | null |
# Как изобрести велосипед и познакомиться с FRP
Недавно мне выпал шанс заняться веб-приложением для взаимодействия с интерактивной доской (!) для мобильных устройств (!!) на любом стеке технологий, как серверных, так и клиентских (!!!). На этапе прототипа задача представляла собой простейший графический редактор. Зака... | https://habr.com/ru/post/245269/ | null | ru | null |
# Экспорт пользовательского интерфейса из Фотошопа
#### Экспорт пользовательского интерфейса из Фотошопа
Каждый разработчик игр в сталкивается с проблемой переноса/натягивания пользовательского интерфейса.
Большинство моих знакомых просят художников делать текстурные атласы, и потом в ручную или при помощи встроен... | https://habr.com/ru/post/135429/ | null | ru | null |
# Как разыграть соседа по комнате
#### От переводчика
Студент [Университета Тафтса](https://ru.wikipedia.org/wiki/%D0%A3%D0%BD%D0%B8%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%82%D0%B5%D1%82_%D0%A2%D0%B0%D1%84%D1%82%D1%81%D0%B0) рассказывает, как подкалывал своего соседа по комнате. Он даже меня подколол, когда начал свою исто... | https://habr.com/ru/post/417915/ | null | ru | null |
# Добавляем в Android-приложение систему локального поиска
Многие программы нуждаются в функции поиска. Сегодня мы рассмотрим пример реализации подобного функционала в приложении для ресторана. Наша основная цель – дать пользователю возможность быстро и легко найти в меню из множества блюд то, чего ему хочется.
Мы ... | https://habr.com/ru/post/276099/ | null | ru | null |
# Разбираемся с промисами в JavaScript
Доброго времени суток, Хабр! Представляю вашему вниманию перевод статьи [«Understanding Promises in JavaScript»](https://blog.bitsrc.io/understanding-promises-in-javascript-c5248de9ff8f) автора Sukhjinder Arora.
 простейший синтезатор мелодий. В Интернете немало статей для начинающих, посвящённых этой теме. Как правило, для генерации частоты (нот) ... | https://habr.com/ru/post/454514/ | null | ru | null |
# Конвертация длинных ссылок в короткие
Небольшой скрипт для приведение URL в емаксе в приличный вид. Работает через сервис bit.ly.
Интерфейс представлен функцией short-url-dwim. Если она вызвана, когда курсор находится над URL (указания протокола требуется), то URL заменяется на короткую ссылку. В другом случае бу... | https://habr.com/ru/post/63995/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.