
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Типы значений в CSS. Абсолютные, относительные и всякие другие
#### Разберёмся, какие бывают типы значений у CSS-свойств, и определим, чем отличаются абсолютные и относительные значения свойств (все эти em, rem, vh, vw), как задаются цвета, и зачем нужны CSS-директивы.
Эта статья — часть учебника из курса профессио... | https://habr.com/ru/post/584786/ | null | ru | null |
# Кошерная организация туннелей в OpenWRT
Итак нам требуется организовать туннель между двумя linux-хостами, одним из которых является наш soho-роутер с этой замечательной прошивкой на борту. Сразу оговоримся, что для нас самое важное — скорость соединения и уменьшение накладных расходов. Посему, о установке пакетов к... | https://habr.com/ru/post/128680/ | null | ru | null |
# Параллельные вычисления в Apache Spark
Всем привет!
Иногда кажется, что для решения проблемы недостаточно простого выполнения расчётов в Spark и хочется более эффективно использовать доступные ресурсы. Мен... | https://habr.com/ru/post/684024/ | null | ru | null |
# Заряжай Patroni. Тестируем Patroni + Zookeeper кластер (Часть первая)
Кадр из фильма «Рембо IV»Вступление
----------
Если вы работаете с crucial data, ... | https://habr.com/ru/post/534828/ | null | ru | null |
# Ленивые свойства объекта
Возможно, не самый умный экземпляр для линча, но хотелось с чего-нибудь начать)
Для красоты кода и удобства написания модулей, реализовал классы по работе с отдельными информационными сущностями. К примеру, такая вещь как язык интерфейса имеет свой ID, и для большинства операций этой инфо... | https://habr.com/ru/post/10550/ | null | ru | null |
# Транзакционная память: история и развитие
#### Определение
Параллельное программирование сложно. При использовании систем с общей памятью не обойтись без синхронизации доступа параллельных процессов/потоков к общем... | https://habr.com/ru/post/221667/ | null | ru | null |
# Разбор задач. Бинпоиск_1
Здравствуйте, уважаемые хабровчане. Серия статей содержит разбор задач, которые дают в 8 классе на уроках информатики в Челябинском физико-математическом лицее №31. Немного истории… Наш лицей — одно из сильнейших учебных заведений России, который в рейтинге по конкурентоспособности выпускник... | https://habr.com/ru/post/443244/ | null | ru | null |
# Какая фигура из одинаковых плоских предметов будет дальше всего выглядывать за край стола?

В ноябре журнал Quanta озадачил своих читателей вопросами, касающимися составления фигур из одинаковых плоских... | https://habr.com/ru/post/400153/ | null | ru | null |
# Аудит безопасности на сервере. Поиск по жураналу безопасности. Power Powershell
Аудит журнала безопасности помог моему коллеге контролировать практически любые действия сотрудников, которые имеют хоть какой-то доступ к серверам или ActiveDirectory.
В топике будет много кода, который, надеюсь, будет вам полезен. ... | https://habr.com/ru/post/271963/ | null | ru | null |
# OutOfMemoryError: поймай, если сможешь

Всем привет! Сегдня хотел бы поделиться опытом обратоки ошибки ООМ. Эту статью меня побудила написать проблема, с которой я столкнулся. И которая, как позже выяснилось, долгое время оста... | https://habr.com/ru/post/359300/ | null | ru | null |
# Что хотят от кандидатов на собеседовании по написанию кода?
*Привет, хабровчане. В преддверии старта курса [«Java QA Engineer»](https://otus.pw/rEa7/) делимся с вами продолжением [вот этого материала](https://habr.com/ru/company/otus/blog/480800/)*.
 о которых вы слышали ранее из других стат... | https://habr.com/ru/post/302998/ | null | ru | null |
# Самое простое объяснение принципа работы современных алгоритмов симметричного шифрования
*(Нашёл в твиттере тред с очень крутым объяснением работы симметричных шифров. Его написал Colm MacCárthaigh один из основных контрибьюторов Apache. Я спросил разрешение Колма на перевод, он любезно согласился).*
Я объясню вам ... | https://habr.com/ru/post/443050/ | null | ru | null |
# PhpStorm 2020.1: поддержка composer.json, инструменты для PHPUnit, покрытие кода с PCOV и PHPDBG, Grazie и другое
[](https://habr.com/ru/company/JetBrains/blog/497358/)
Привет, Хабр! Рады представить первый мажорный релиз PhpStor... | https://habr.com/ru/post/497358/ | null | ru | null |
# Использование Dynamic Data совместно с Entity Framework 5

Добрый день!
Как известно, уже вышла релиз-версия [.NET Framework 4.5](http://www.microsoft.com/net), а также стала доступна для загрузки финальная версия [... | https://habr.com/ru/post/150012/ | null | ru | null |
# StereoPi — наша железка для изучения компьютерного зрения, дронов и роботов
Всем привет!
Сегодня я бы хотел рассказать вам о нашей новой железке на базе Raspberry Pi Compute Module, предназначенной для изучения компьютерного зрения и установки на роботов и дронов. По сути это «умная» стереокамера — она поддержива... | https://habr.com/ru/post/415587/ | null | ru | null |
# В каких случаях не нужно использовать списки в Python
***Перевод статьи подготовлен в преддверии старта базового курса [«Разработчик Python»](https://otus.pw/EKMg/).***
---

В Python, наверное, самым популярным контейнером данных б... | https://habr.com/ru/post/510350/ | null | ru | null |
# Security микросервисов с помощью Spring Cloud Gateway и TokenReley
Данная статья результат поиска некоего каноничного решения организации безопасности доступа к ресурсам в микросервисной архитектуре, построенной в экосистеме Spring. После прочтения десятка статей по данной тематике, к сожалению, не нашел то, что иск... | https://habr.com/ru/post/701912/ | null | ru | null |
# Kali Linux NetHunter на Android Ч.2: атаки на беспроводные сети
**Статьи из цикла**
[Kali Linux NetHunter на Android: зачем и как установить](https://habr.com/ru/company/tomhunter/blog/465045/)
[Kali Linux NetHunter на Android Ч.2: атаки на беспроводные сети](https://habr.com/ru/company/tomhunter/blog/471260/)
... | https://habr.com/ru/post/471260/ | null | ru | null |
# Joomla 4: мощь CLI приложений
Эта статья - дополненный (комментариями и скриншотами) перевод статьи июньского номера Joomla Community Magazine за 2022 год, автор - [Brendan Hedges](https://magazine.joomla.org/authors/brendanhedges). Далее повествование автора.
В Joomla 4 из коробки поставляется новый, улучшенный CL... | https://habr.com/ru/post/696222/ | null | ru | null |
# Discord бот с экономикой с sqlite
Привет, Хабр!
-------------
Хотел поделиться опытом, как я писал бота c экономикой для discord сервера с использованием sqlite и другой мелочи.
Подготовительный этап
---------------------
#### Создание бота
Итак, перед тем, как написать бота, нам нужно его создать и получить т... | https://habr.com/ru/post/482290/ | null | ru | null |
# Конвертируем картинку в ANSI
Не знаю, насколько это будет кому-то интересно, но на днях решил поиграться и сделать следующее:
Дано: Картинка (например, BMP) 640 на 400, шрифт 8 на 16
Надо: Перевести ее в ANSI псевдографику в стандартном режиме 80 на 25 символов, символы и фон могут иметь любой цвет (true color... | https://habr.com/ru/post/192912/ | null | ru | null |
# Единая точка входа с Keycloak и Яндекс в условиях большого переезда
Так же, как и многие другие компании, мы долго и счастливо использовали целый стек популярных коммерческих облачных сервисов: Github для ... | https://habr.com/ru/post/664238/ | null | ru | null |
# Pro Parboiled (Часть 4 заключительная)
**Часть 4. Суровая действительность**
Как заставить Parboiled работать еще быстрее? Каких ошибок лучше не допускать? Что делать с наследством в виде Parboiled1? На эти, а так же другие вопросы призвана ответить заключающая статья серии.
**Структура цикла:**
* [Часть 1.... | https://habr.com/ru/post/271003/ | null | ru | null |
# Зачем нужна выделенная Frontend Core команда и как мы внедряли дизайн систему

Всем привет, меня зовут Ростислав, я занимаю должность Front Lead в компании ДомКлик. Хочу поделиться с вами опытом создания Web Core команды и сразу отве... | https://habr.com/ru/post/520630/ | null | ru | null |
# Разработчик с мозгом груга

Введение
========
это сборник мыслей о разработке программ собранный разработчиком с мозгом груга
разработчик с мозгом груга не очень умный, но разработчик с мозгом груга программирует много лет и ... | https://habr.com/ru/post/673640/ | null | ru | null |
# Как мы Select2 в хелпер заворачивали
Думаю, многие знакомы с [Select2](http://ivaynberg.github.io/select2/). Всё в нём замечательно: и элементы красивые, и кастомизации вагон, и c ajax работает и ещё много много полезного дел... | https://habr.com/ru/post/244553/ | null | ru | null |
# Swift vs. Kotlin. Отличия важны

*Этот пост является вольным переводом статьи [Swift vs. Kotlin — the differences that matter](https://blog.indoorway.com/swift-v-kotlin-the-differences-that-matter-50b2d393f526) by [Krzysztof Ture... | https://habr.com/ru/post/350746/ | null | ru | null |
# Руководство по возможностям Java версий 8-16
Вы можете использовать это руководство, чтобы получить практическую информацию о том, как найти и установить последнюю версию Java, понять различия между дистрибутивами Java (AdoptOpenJdk, OpenJDK, OracleJDK и т. д.), а также получить обзор функций языка Java, включая вер... | https://habr.com/ru/post/551590/ | null | ru | null |
# Run MongoDB Atlas locally for testing
What happens to your MongoDB replica set when it comes to failures like network partitioning, restarting, reconfiguration of the existing topology, etc.? This question is especially important these days because of [the popularity gained by the multi-cloud model](https://www.mong... | https://habr.com/ru/post/544460/ | null | en | null |
# Hibernate: использование lazy initialization в разработке клиент-серверного приложения
При проектировании доменов приложения, разрабатываемого с использованием Hibernate, разработчику необходимо сделать выбор: инициализировать ли свойства домена, соответствующие коллекциям связанных доменов, сразу (FetchType=EAGER) ... | https://habr.com/ru/post/111911/ | null | ru | null |
# Фальшивомонетчики против банкиров: стравливаем adversarial networks в Theano

*Вы бы никогда не подумали, но это прогулка по пространству нейросети-фальшивомонетчика. Сделано крутейшими людьми [Anders Boesen... | https://habr.com/ru/post/275429/ | null | ru | null |
# VINTEO Server — корпоративная видеоконференцсвязь высшего класса. Установка, настройка, полное описание
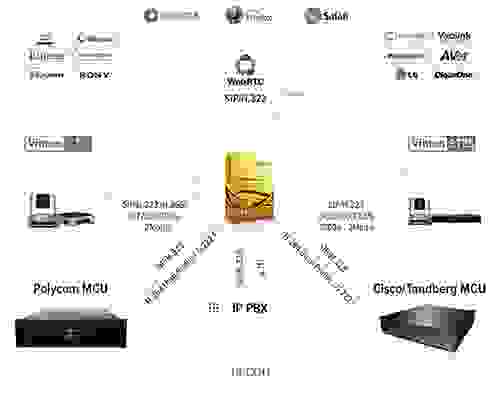В прошлой статье, [**Обучение, переговоры, консультации удалённо — Часть 2: Vinteo Server — 3 месяца бесплатной видеоконференцсв... | https://habr.com/ru/post/514560/ | null | ru | null |
# Сначала фронт, а потом бэк (когда-нибудь)
Перед тем как начать реализацию новой фичи, приходится изрядно поломать голову.
Разработка сложного функционала требует тонкой координации усилий коллектива инженеров.
И одним из важнейших моментов является вопрос распараллеливания задач.
Возможно ли избавить фронтовиков... | https://habr.com/ru/post/463067/ | null | ru | null |
# DFI снижает download-скорость первые 10 секунд
Недавно обратился клиент, который жаловался на низкую скорость download-загрузки на сети 802.11ac. В качестве доказательства он представил Speedtest скрин, на котором upload был равен 200mbps, а download 15-20mbps. В ходе траблшутинга с помощью iPerf мы заметили, что ни... | https://habr.com/ru/post/692398/ | null | ru | null |
# Отладка асинхронного JavaScript с помощью Chrome DevTools
#### Вступление
Возможность асинхронной работы с помощью callback-функций(далее просто возвращаемых функций) — отличительная особенность JavaScript. Использование асинхронных возвращаемых функций позволяет вам писать событийно-ориентированный код, но так же ... | https://habr.com/ru/post/218397/ | null | ru | null |
# Бэкапы своими руками для чайников
Давно известно, что сисадмины делятся на две категории: те, кто еще не делает бэкапы и те кто уже делает. В то время, когда одни ДЦ горят, а вторые внезапно исчезают, лучше всего принадлежать ко второй категории.
Итак, хочу поделиться опытом простого автоматического резервировани... | https://habr.com/ru/post/132262/ | null | ru | null |
# Ботнет Trickbot облюбовал роутеры MikroTik. Сейчас Microsoft выяснила почему

Специалистам по информационной безопасности ботнет Trickbot известен с 2016 года. Его главная задача при заражении устройства — отслеживание конфиденци... | https://habr.com/ru/post/654467/ | null | ru | null |
# A Bug Caused by the #line Directive in the Visual C++ Compiler

The #line directive is added by the preprocessor and can then be used to help the developer understand which file and line a parti... | https://habr.com/ru/post/502912/ | null | en | null |
# Как вырезать ненужные инклуды css и js из Друпальных тем (6.х версии)
Здравствуйте, хабра-товарищи!
Я часто встречаю сообщения о том, что в Друпальных темах вечно мешаются лишние друпальные css инклуды (файлы вроде system.css, defaults.css, node.css), которые воздействуют на уже заготовленные стили и мешают споко... | https://habr.com/ru/post/87497/ | null | ru | null |
# Nemesida WAF 2021: защита сайтов и API от хакерских атак
Активное применение WAF началось более 10 лет назад. Пытаясь решить проблему защищенности веб-приложений, администраторы WAF сталкивались с побочным... | https://habr.com/ru/post/565770/ | null | ru | null |
# Размазываем PHP

Настанет день, и ты поймешь, что одного потока в PHP тебе мало.
Сначала ты оптимизируешь код, потом пытаешься изменить сознание на асинхронный реакт, но весь PHP мир не хочет понимать такое стремл... | https://habr.com/ru/post/257281/ | null | ru | null |
# Обзор Java App Bundlers
Итак, [в прошлый раз](http://habrahabr.ru/post/178481/) я писал об инструменте для сборки приложений JavaFXPackager. Там было 2 каких-то способа собрать приложение, но ни один из них не мог быть удобно вызван просто из кода. Но мы же труЪ Java-программисты. И вот для таких труЪ-программистов ... | https://habr.com/ru/post/257363/ | null | ru | null |
# Первый самодельный клиент, который подключается к Skype Network

Skype — [один из самых небезопасных мессенджеров](https://www.eff.org/node/82654) по объективным причинам. Одна из них — обфусцированный бинарный файл, чтобы... | https://habr.com/ru/post/397351/ | null | ru | null |
# Разработка микросервисов с использованием Scala, Spray, MongoDB, Docker и Ansible
Цель данной статьи — показать возможный подход для построения [микросервисов](http://technologyconversations.com/2015/01/07/monolithic-servers-vs-microservices/) с использованием [Scala](http://www.scala-lang.org/), RESTful JSON, [Spra... | https://habr.com/ru/post/250043/ | null | ru | null |
# Строим карту популярности дней рождения с помощью Processing и VK API
#### Вступление
Несколько дней назад в блоге The Daily Viz [была опубликована запись](http://thedailyviz.com/2012/05/12/how-common-is-your-birthday/), которая привлекла внимание широкой общественности как пример простой и эффективной визуализации... | https://habr.com/ru/post/144531/ | null | ru | null |
# Уязвимости в Linux допускают возможность атаки «в один клик»
Группа исследователей CrowdStrike Intelligence обнаружила несколько уязвимостей, влияющих на LibVNCClient в Linux. В некоторых широко используемых средах рабочего стола (например, Gnome) эти уязвимости можно эксплуатировать одним кликом мыши.
 и его применение в разработке сценариев конфигурации [chef](https://www.chef.io/) я [писал](https://habrahabr.ru/post/313034/) уже ранее.
Что ж, за это время уте... | https://habr.com/ru/post/325848/ | null | ru | null |
# Код как искусство: как борются с багами и повышают уровень разработки в Mail.ru Group
Есть четыре вещи, заниматься которыми можно бесконечно. И если про первые три все слышали, то четвертая — это смотреть код. Мы с вами немного погрузились в это увлекательное занятие с помощью [теста](https://habr.com/ru/article/531... | https://habr.com/ru/post/533504/ | null | ru | null |
# ELFийские трюки в Go

В этой заметке мы научимся получать машинный код Go функции прямо в рантайме, распечатаем его с помощью дизассемблера и по пути узнаем несколько фокусов вроде получения адреса функции без её вызова.
**Предупреж... | https://habr.com/ru/post/482392/ | null | ru | null |
# Неизменяемые объекты в PHP
В этой короткой статье мы рассмотрим, что собой представляют неизменяемые объекты и почему нам следует их использовать. Неизменяемыми называются объекты, чьё состояние остаётся постоянным с момента их создания. Обычно такие объекты очень просты. Наверняка вы уже знакомы с типами enum или п... | https://habr.com/ru/post/301004/ | null | ru | null |
# Три бага в драйвере Go для MySQL
Так как нас не устраивала скорость и надежность исходной имплементации на Ruby, в последние несколько лет мы постепенно выводили критический функционал из нашего Rails-монолита GitHub.com и переписывали часть кода на Go. Например, на Github Satellite в прошлом году мы анонсировали — ... | https://habr.com/ru/post/503586/ | null | ru | null |
# Примеры использования customTask в Google Tag Manager
*Материал основан на статье Simo Ahava [«customTask — The Guide»](https://www.simoahava.com/analytics/customtask-the-guide/).*
Примерно год назад (в 2017) произошло обновление JS библиотеки Universal Analytics. Обновление принесло с собой такую замечательную ш... | https://habr.com/ru/post/359196/ | null | ru | null |
# Пишем изящный парсер на Питоне
В C++17 (нет-нет, Питон скоро будет, вы правильно зашли!) появляется новый синтаксис для оператора `if`, позволяющий объявлять переменные прямо в заголовке блока. Это довольно удобно, поскольку конструкции вида
```
Foo foo = make_foo();
if(foo.is_nice()) {
// do work with foo
}
... | https://habr.com/ru/post/309242/ | null | ru | null |
# Установка Carbonio Community Edition на Ubuntu 20.04
Не так давно почтовый сервер Carbonio CE от компании Zextras получил поддержку Ubuntu 20.04 LTS. В данной статье мы пошагово произведем установку Carbonio CE на Ubuntu 20.04 и расскажем о том, как начать работу с почтовым сервером.
;
* Содержать хотя бы... | https://habr.com/ru/post/714478/ | null | ru | null |
# Пример создания среды виртуализации в Gentoo

«Скажи мне, Рождённый Женщиной,
— вопросил Кришна,
Куда движутся эти миры,
Зачем злой Парвана по ночам охотится
за своей второй сущностью,
И почему у ласточки Бш... | https://habr.com/ru/post/575018/ | null | ru | null |
# Как превратить свою аватарку в Telegram в часы
Недавно сидел я в одном сообществе программистов в [Telegram](http://telegram.org) и заметил один очень любопытный профиль. Любопытным было следующее — на главном фото у него было изображено нынешнее время. Мне стало жутко интересно как он этого добился, и я решил во чт... | https://habr.com/ru/post/457078/ | null | ru | null |
# WebRTC in Docker. Struggling for resources
A few weeks ago we wrote an [article about Docker and WebRTC servers](https://habr.com/ru/company/flashphoner/blog/562244/) and talked about the intricacies of la... | https://habr.com/ru/post/565610/ | null | en | null |
# DevBoy: делаем генератор сигналов
**Привет, друзья!**
В прошлых статьях я [рассказывал про свой проект](https://habr.com/post/423499/) и про [его программную часть](https://habr.com/post/424309/). В этой статье я расскажу как сделать простенький генератор сигналов на 4 канала — два аналоговых канала и два PWM кан... | https://habr.com/ru/post/425409/ | null | ru | null |
# django-pkgconf

*Rick and Morty ©. Чувак презентует батарейку, я тоже.*
Не так давно я опубликовал небольшое [приложение](/post/278743/) для формирования «панелей управления» django-проектов. В процессе раз... | https://habr.com/ru/post/283378/ | null | ru | null |
# Пишем API на Rust с помощью процедурных макросов
Процедурные макросы в Rust — это очень мощный инструмент кодогенерации, позволяющий обходиться без написания тонны шаблонного кода, или выражать какие-то новые концепции, как сделали, к примеру, разработчики крейта [`async_trait`](https://docs.rs/async-trait/0.1.22/as... | https://habr.com/ru/post/486740/ | null | ru | null |
# Давненько не брал я в руки шашки. Знаем, знаем, как Вы играете
Ситуация в appStore для casual разработчиков быстро меняется.
2 года назад можно было заработать, выпуская платное приложение одновременно с бесплатным аналогом.
После появления в магазине более 100 000 программ этот трюк стал неэффективен.
Год ... | https://habr.com/ru/post/137425/ | null | ru | null |
# Reactor, WebFlux, Kotlin Coroutines, или Асинхронность на простом примере

Многие сервисы в современном мире, по большей части, «ничего не делают». Их задачи сводятся к запросам к другим базам/сервисам/кешам и агрегации всех этих д... | https://habr.com/ru/post/477052/ | null | ru | null |
# Хабраподсветка или эксперименты в изолированном окружении Python
Протестировать свежую версию любимого фреймоврка. Запустить приложение со специфичным набором библиотек. Установить необходимые библиотеки по списку зависимостей. Как решить все эти задачи не затронув системные файлы? В этой статье речь пойдет об утили... | https://habr.com/ru/post/70353/ | null | ru | null |
# Автовход с паролем и управление по ssh «в гостях» при помощи expect
В очередной раз используя этот скрипт в одном из учебных классов, я поискал материалы и обнаружил, что здесь давно не вспоминали об expect. Это замечательный альтернативный интерпретатор для командной строки Linux, который может общаться с ней вмест... | https://habr.com/ru/post/222857/ | null | ru | null |
# Домашний сервер «всё-в-одном» — success story
Жил да был у меня роутер одной хорошей фирмы на букву «Dead». Ну, это с ним, собственно, и случилось.
Посмотрел я на цены новых, на кучу компьютерного хлама в углу, на список подключений на домашнем компе… И понял, что не нужен мне роутер. Соберу свой, с нормальной ма... | https://habr.com/ru/post/203376/ | null | ru | null |
# Вышел JQuery 1.9

Сегодня наконец был выпущен новый релиз JQuery версии 1.9. Давайте глянем какие нововведения и изменения мы тут увидим.
Jquery 1.9 и находящийся в бете Jquery 2.0 имеют схожий API.
Удалены... | https://habr.com/ru/post/165987/ | null | ru | null |
# Сетевое обращение к библиотекам и рантайм-формирование вызовов функций
Хочу поделиться историей из профессиональной деятельности, которую можно заслуженно поместить в блог с именем **crazydev** :) Это рассказ о необычных решениях (тех, что я попытался описать в двух словах в заголовке), к которым меня вынудили прийт... | https://habr.com/ru/post/138633/ | null | ru | null |
# Крадущийся в тени или поиски того света

> Assembler – мой любимый язык, … но жизнь так коротка.
Продолжаю цикл изысканий по вопросу подходящих теней для некоторого рогалика. После публикаций [раз](https://habr.com/ru/post/430438/... | https://habr.com/ru/post/446986/ | null | ru | null |
# Hibernate и битовые операции
Как оказалось Hibernate не приемлит битовых операций в условиях hql запроса. Например, «from Events where type & mask <> 0» генерирует исключение парсера, так же [битовых операций нет в документации](http://www.hibernate.org/hib_docs/v3/reference/en/html/queryhql-expressions.html). Однак... | https://habr.com/ru/post/50260/ | null | ru | null |
# Освобождение ресурсов в GO
Go - это язык с автоматическим управлением памятью: сборщик мусора без участия программиста позаботится о том, чтобы освободить память, занимаемую объектами, более не используемыми программой. Но памятью вся автоматика в целом и ограничивается - об остальных используемых программой ресурса... | https://habr.com/ru/post/539386/ | null | ru | null |
# Как статический анализ кода помогает в сфере GameDev

Игровая индустрия не стоит на месте и с каждым днём развивается всё быстрее и быстрее. Вместе с ростом индустрии растёт и сложность разработки: кода становится больше и багов в нём тоже ... | https://habr.com/ru/post/530536/ | null | ru | null |
# Парсим X12 «на коленке»
При создании приложения, активно взаимодействующего со сторонними сервисами и системами, часто требуется обеспечить обмен информацией с ними, односторонний или двусторонний
При этом зачастую сторонний... | https://habr.com/ru/post/427107/ | null | ru | null |
# Конкурс Игр Interactive fiction Competition 2009

##### Об играх
В связи с проведением конкурса Interactve fiction Competition 2009 представляю интересный жанр компьютерных игр — текстовых приключений в традициях «Infocom». Эти игры отличаются от интерактивной лите... | https://habr.com/ru/post/71536/ | null | ru | null |
# Популяционный алгоритм, основанный на поведении косяка рыб
В рамках данного сообщества неоднократно обсуждались генетические алгоритмы и их применение на практике. В этой статье я хотел бы поделиться относительно новым методом оптимизации функций, основанным на поведении косяка рыб в условиях поиска пищи.
#### Вв... | https://habr.com/ru/post/178309/ | null | ru | null |
# Еще одна стажировка, или сказ про реверс IP-камеры
Вступление
----------
Итак, меня взяли на [стажировку](https://raccoonsecurity.ru/internship/). Стажировка рассчитана на 2–3 месяца неспешной работы по 2... | https://habr.com/ru/post/567852/ | null | ru | null |
# Избавляемся от PGP в почтовом ящике mutt
На мой параноидальный взгляд по возможности всё общение по почте и IM должно быть зашифровано. (Не потому, что мне есть что скрывать, а просто потому, что я не вижу причин показывать свои сообщения соседу Пете, вне зависимости от того, где он работает — нигде, у провайдера, и... | https://habr.com/ru/post/135800/ | null | ru | null |
# Портирование Qt на STM32
Добрый день! Мы в проекте [Embox](https://github.com/embox/embox) запустили Qt на STM32F7-Discovery и хотели бы об этом рассказать. Ранее, мы уже рассказывали как нам удалось запустить [OpenCV](https://habr.co... | https://habr.com/ru/post/459730/ | null | ru | null |
# Анализ покрытия кода тестами в Ruby
Для начала я приведу небольшой тестовый проект из трёх классов, проанализирую его покрытие с помощью [гема SimpleCov](https://github.com/colszowka/simplecov), а напоследок немного поразмышляю о том, как анализ покрытия может приносить пользу проекту, и какие есть недостатки у Cove... | https://habr.com/ru/post/317326/ | null | ru | null |
# Entity Framework и производительность
В процессе работы над проектом веб-портала, я исследовал возможности улучшить производительность, и наткнулся на небольшую статью про микро-ORM Dapper, который был написан авторами проекта StackOverflow.com. Изначально их проект был написан на Linq2Sql, а теперь все критичные к ... | https://habr.com/ru/post/227637/ | null | ru | null |
# Живые обои на Android без нативного кода или история написания Two Hearts Live Wallpaper
Более полу года проработав разработчиком для Android я решил попробовать написать живые обои с использованием OpenGL. Пробежав по сети было обнаружено несколько движков общего назначения и множество любительских поделок. Два дос... | https://habr.com/ru/post/139008/ | null | ru | null |
# Используем Ansible вместе с Terraform

Недавно я начал применять Terraform для создания облачной лабы для тестов, и это довольно круто. Буквально за несколько дней я поднялся с «никогда не использовал AWS» до «я умею декларативно соз... | https://habr.com/ru/post/525810/ | null | ru | null |
# HTML5 CANVAS шаг за шагом: Изображения
**CANVAS шаг за шагом:**
1. [Основы](http://habrahabr.ru/post/111308/)
2. [Изображения](http://habrahabr.ru/post/111385/)
3. [Понг](http://habrahabr.ru/post/116860/)
4. [Пятнашки](http://habrahabr.ru/post/118356/)
Продолжение [статьи про рисование на холсте](http://habrahab... | https://habr.com/ru/post/111385/ | null | ru | null |
# Золотое сечение в Web
К сожалению, в наше время перенасыщенное рекламой, у многих сложился стереотип, что дизайн – это просто симпатичная и яркая картинка.
Многие начинающие дизайнеры не задумываются, что прежде всего, дизайн должен быть эффективным, т.е. доносить до конечного пользователя конкретную цель.
Сде... | https://habr.com/ru/post/27465/ | null | ru | null |
# TypeScript на сервере
TypeScript на сервере
=====================

TypeScript последнее время быстро набирает популярность, в особенности благодаря распространению Angular2. При этом на сервере TypeScript пока не особенно п... | https://habr.com/ru/post/328466/ | null | ru | null |
# Использование flex-config.xml
Всем привет!
Коротенький пост для новичков, о том как использовать конфигурационный файл для установки параметров компилятора.
Что такое конфигурационный файл и для чего он нужен? Данный файл это ни что иное как xml файл, содержащий параметры компилятора. И нужен он собственно дл... | https://habr.com/ru/post/155177/ | null | ru | null |
# Внедрение подхода «Self-Service» для самостоятельного анализа данных
Инструменты Business Intelligence (BI) за последние несколько лет проникли почти во все виды бизнеса, а изучению данных уделяется все больше внимания и выделяется больше ресурсов. Если говорить об IT-компаниях, то здесь, наверное, большинству понят... | https://habr.com/ru/post/551470/ | null | ru | null |
# Тонкости (странности?) работы с интефейсами
Знаешь ли ты что такое интерфейс %username%?
Если да, то я думаю этот код не вызовет у вас вопросов. PHP тонкости (странности?) работы с интефейсами
```
interface someInterface{
public function someMethod();
}
interface anotherInterface{
public function someMethod(... | https://habr.com/ru/post/116916/ | null | ru | null |
# Настройка OpenVPN в связке Mikrotik/Ubuntu
В любой компании, где существует более одного офиса, рано или поздно возникает необходимость в объединении этих самых офисов. Многие провайдеры предлагают такие услуги, но попросят за это денег, да и кто знает, что там творится на стороне провайдера? Поэтому сделаем все сам... | https://habr.com/ru/post/227767/ | null | ru | null |
# Ревью кода: успешный опыт
[](https://habrahabr.ru/company/alconost/blog/413589/)
В Интернете найдется масса информации по ревью кода:
* как ревью чужого кода влияет на культуру компании
* о регламентированных проверках безопа... | https://habr.com/ru/post/413589/ | null | ru | null |
# Познаем промисы на основе Ecmascript спецификации. Знакомство

Здравствуйте. Изучая JavaScript (да и в принципе любую другую технологию), всегда возникают разнообразные вопросы, главный из которых: «А почему это... | https://habr.com/ru/post/478938/ | null | ru | null |
# 8 советов для более эффективной работы с Git
*Привет, мне показалось хорошей идеей начать переводить не только релизные посты из [блога ГитЛаба](https://about.gitlab.com/blog/). Для разминки я взял этот пост почти наугад, так что не судите строго. Буду рад, если поможете определиться с выбором статьи для перевода, в... | https://habr.com/ru/post/307526/ | null | ru | null |
# Прощай, Grails. Привет, Micronaut. Продолжение
Это вторая статья из цикла о миграции из Grails в Micronaut. *Обратите внимание:* ваше приложение должно быть создано в Grails 4.x или более поздней версии*.*
... | https://habr.com/ru/post/593965/ | null | ru | null |
# Celesta и Flute: Создание бизнес-логики в Java-экосистеме
Привет, Хабр! Проект, о котором мы расскажем, с самого начала создавался нами как open-source, но до недавних пор мы использовали его только лишь для своих нужд, не говорили о нём широко и не создавали коммьюнити. Cейчас, спустя несколько лет разработки, мы п... | https://habr.com/ru/post/335966/ | null | ru | null |
# Hibernate-Extender или Hibernate, Spring и OSGi

К сожалению, на данный момент Hibernate не обладает необходимыми механизмами интеграции для работы в OSGi среде, хотя подвижки в этом направлении заметны (начальная OSGi-... | https://habr.com/ru/post/135651/ | null | ru | null |
# Физика Человека-паука с его новыми паутинными крыльями
Врать не буду, я очень жду фильм «Человек-паук: Возвращение домой» [Spider-Man: Homecoming]. А пока что единственной отдушиной для меня будет заняться физикой Человека-паука. И я займусь его новыми паутинными крыльями, увиденными в последнем трейлере.
Для фан... | https://habr.com/ru/post/399957/ | null | ru | null |
# Property-based тестирование для JavaScript и UI: необычный подход к автоматизированным тестам

*[Falcon Heavy Demo Mission](https://www.flickr.com/photos/spacex/40143096241/)*
Писать тесты скучно. А т... | https://habr.com/ru/post/494110/ | null | ru | null |
# Прокладываем тропинки до микросервисов
Одна из наиболее важных задач при разделении системы на микросервисы - обеспечить надежный механизм их репликации и обнаружения и создать набор правил для маршрутизаци... | https://habr.com/ru/post/669342/ | null | ru | null |
# Кому с Redux жить хорошо
Приветствую всех любителей хорошей инженерки! Меня зовут Евгений Иваха, я фронтенд-разработчик в команде, занимающейся дев-программой в ManyChat. В рамках дев-программы мы разрабатываем инструменты, позволяющие расширять функциональность ManyChat за счет интеграции со сторонними системами. ... | https://habr.com/ru/post/541794/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.