
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Зловред в официальной версии Transmission. Первый известный троян-вымогатель для Mac
В официальной версии open source торрент-клиента Transmission 2.90 под Mac обнаружена вредоносная программа [OSX.KeRanger.A](https://www.virustotal.com/en/file/d1ac55a4e610380f0ab239fcc1c5f5a42722e8ee1554cba8074bbae4a5f6dbe1/analysi... | https://habr.com/ru/post/357534/ | null | ru | null |
# Telegram-like анимированный placeholder для HTML-инпутов
В качестве улучшения UX/UI я часто сижу и думаю, что можно было бы улучшить в приложении, чтобы пользователю было чуточку веселее пользоваться им.
Как-то раз я заметил интересную анимацию placeholder'a в нативном Desktop приложении Telegram. Подумал, что бу... | https://habr.com/ru/post/265497/ | null | ru | null |
# FlexRAID View — объединение нескольких дисков в единый массив
Мне очень нравилась функциональность Windows Home Server по объединению нескольких дисков в единый массив без создания RAID'ов, с возможностью удалять и добавлять диски в любой момент, при смерти одного из винтов информация на остальных оставалась жива и ... | https://habr.com/ru/post/113708/ | null | ru | null |
# Многопоточный прокси на Perl, или как покупать на books.ru удобно

Пообщались мы как-то с пользователем [icoz](https://habrahabr.ru/users/icoz/) по поводу покупок в books.ru и решения, ... | https://habr.com/ru/post/237259/ | null | ru | null |
# Подробное руководство по HTML-инъекциям

**HTML** считается каркасом для каждого веб-приложения, определяющим его структуру. Но порой даже самую продуманную экосистему можно испортить парочкой простых скриптов.
Сегодня мы узнаем,... | https://habr.com/ru/post/530862/ | null | ru | null |
# Выпуск#33: ITренировка — актуальные вопросы и задачи от ведущих компаний
Привет! У кого какой день карантина? Побочная сила коронвариуса — он убил все остальные новости. А все остальные новости, как известно, плохие, так что это хорошая новость.
 про его подход к редактированию в реальном времени через [CRDT](https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type) и ощутил жгучее отчаяние. Его подход хорош на... | https://habr.com/ru/post/521288/ | null | ru | null |
# Генераторы на корутинах C++
Предисловие или крик души
-------------------------
Данное предисловие имеет опосредованное отношение к теме статьи. Поэтому, если вы пришли чисто за примером - можете его пропу... | https://habr.com/ru/post/578366/ | null | ru | null |
# Алгоритм Дугласа-Пекера
#### Предисловие
Не так давно пришлось поработать с упрощением полигональной цепи (*процесс, позволяющий уменьшить число точек полилинии*). В целом, данный тип задач очень распространен при обработке векторной графики и при построении карт. В качестве примера можно взять цепь, несколько точе... | https://habr.com/ru/post/448618/ | null | ru | null |
# Импорт в Я.Коннект из файла списка пользователей через API
**Столкнулся с проблемой «ненахода» актуального скрипта для массового создания сотрудников.**
Проблема связана с переходом Яндекса с PDD (Почта для домена), на Я.Коннект с новой версией API.
Скрипты которые мне попадались, были написаны только для «ста... | https://habr.com/ru/post/448036/ | null | ru | null |
# Led Romb
Дело было вечером, делать было нечего. (с)

Дело было года 3 назад. Случайно наткнулся на одно видео [LED cube 8x8x8 demo](http://www.youtube.com/watch?v=6mXM-oGggrM) и скажу честно, оно меня впечатлило. У мен... | https://habr.com/ru/post/234019/ | null | ru | null |
# Как я встраивал JS в свой игровой движок
Писать на С++ игры долго и дорого, но при этом по перфомансу получается хорошо. Но далеко не всё в играх, требовательно к производительности, особенно 2D. Например всякие окошечки не производят тяжелых расчетов внутри. А на больших проектах они могут занимать до 80% всего объ... | https://habr.com/ru/post/673904/ | null | ru | null |
# WebSockets в Angular. Часть 2. Продуктовые решения
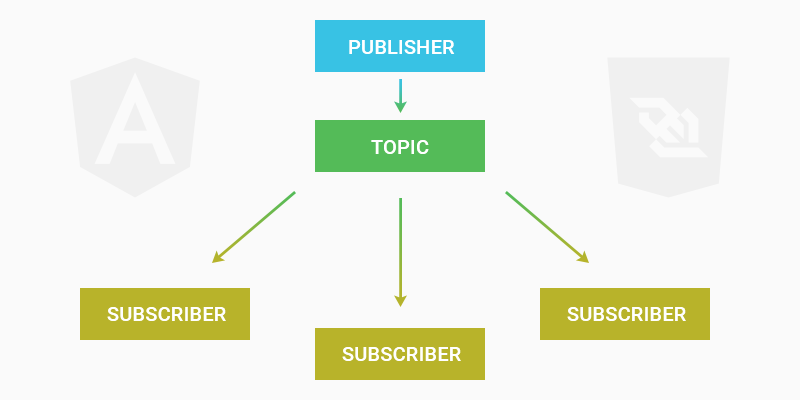
В [предыдущей статье](https://habr.com/post/416155/) речь шла об общем решении для вебсокетов в Angular, где мы на основе WebSocketSubject построили шину с реконнектом и серв... | https://habr.com/ru/post/419099/ | null | ru | null |
# Spring MVC — JavaConfig либо конфигурация проекта без XML файлов
Доброго времени суток уважаемые хабравчане. Как-то мне пришлось писать небольшой проект, так как у меня была возможность свободного выбора технологий я решил использовать **Spring Framework**. Сразу же хочу сказать я не являюсь гуру в данном фреймворке... | https://habr.com/ru/post/226663/ | null | ru | null |
# Варианты operator<< для логгера
Уважаемые хабровчане, у меня родилась публикация — вопрос. С удовольствием выслушаю вашу критику в комментариях.
В проекте пришлось набросать небольшую обертку над существующей системой логирования и помимо ее основного предназначения захотелось ее использовать в стиле работы с поток... | https://habr.com/ru/post/342160/ | null | ru | null |
# Drush — командная строка для CMS Drupal
**[Drush](http://drupal.org/project/drush)** — мощная утилита значительно уменьшающая кол-во рутинных действий при работе с CMS Drupal. Установка друпала требует скачивать значительное количество модулей из разных разделов drupal.org, drush позволяет одной командой скачать все... | https://habr.com/ru/post/94846/ | null | ru | null |
# Быстрое сравнение double
Вчера здесь вышла [статья](https://habr.com/ru/company/ruvds/blog/542640/) о быстром парсинге double, я зашёл во блог к её автору, и нашёл там [ещё один интересный трюк](https://lemire.me/blog/2020/12/14/converting-floating-point-numbers-to-integers-while-preserving-order/). При сравнении чи... | https://habr.com/ru/post/542836/ | null | ru | null |
# Обзор алгоритмов SLAM для камер глубины в ROS
Добрый день уважаемые читатели! В [последней статье](https://geektimes.ru/post/290295/) я уже писал об алгоритме rtabmap SLAM в контексте методов визуальной одометрии. В этой статье я расскажу об этом алгоритме SLAM более подробно, а также представлю обзор другого извест... | https://habr.com/ru/post/373707/ | null | ru | null |
# Сравниваем Nim и Rust
*Предлагаю читателям «Хабрахабра» перевод статьи [«A Quick Comparison of Nim vs. Rust»](http://arthurtw.github.io/2015/01/12/quick-comparison-nim-vs-rust.html). Мои замечания будут выделены курсивом.*
[Rust](http://www.rust-lang.org/) и [Nim](http://nim-lang.org/) — два новых языка программи... | https://habr.com/ru/post/259993/ | null | ru | null |
# JCoro — асинхронность на сопрограммах в Java
К исследованиям в этой сфере меня вдохновила статья [Асинхронность: назад в будущее](http://habrahabr.ru/post/201826/). В ней автор описывает идею о том, как, используя [сопрограммы](https://ru.wikipedia.org/wiki/Сопрограмма), можно упростить асинхронный код так, чтобы вы... | https://habr.com/ru/post/269021/ | null | ru | null |
# Подсчитываем энергобюджет радиолинии для спутника формата CubeSat
Предисловие
===========
Думаю, нужно коротко пояснить, почему вдруг такая, казалось бы, тривиальная тема с подсчетом энергобюджета и почему именно спутники CubeSat? Ну, здесь всё достаточно просто: моя короткая педагогическая практика показала (мне),... | https://habr.com/ru/post/447728/ | null | ru | null |
# Как мы (почти) победили DirCrypt

*Перевод [статьи](http://www.checkpoint.com/download/public-files/TCC_WP_Hacking_The_Hacker.pdf) от компании Check Point’s Malware Research Team.*
DirCrypt — один из самых злостных вид... | https://habr.com/ru/post/235487/ | null | ru | null |
# Создаём модульное приложение
 Вы захотели сделать браузер с плагинами, программу с темами, игру с аддонами или какое-то другое модульное приложение для Android? Но как это сделать? Я расскажу, как сделать пр... | https://habr.com/ru/post/123306/ | null | ru | null |
# Как управлять состоянием React приложения без сторонних библиотек

*Реакт это все что вам нужно для управления состоянием вашего приложения.*
Управление состоянием это одна из сложнейших задач при разработки... | https://habr.com/ru/post/507572/ | null | ru | null |
# Агрегация ответов в краудсорсинге. Пример с открытой библиотекой Яндекса
Краудсорсинг позволяет размечать данные для разных задач, но популярнее всего, конечно, задачи классификации объектов — текстов и картинок. Обычно в краудсорсинге несколько человек размечают каждый объект, что требует агрегации — выбора верного... | https://habr.com/ru/post/594057/ | null | ru | null |
# Погружение в автотестирование на iOS. Часть 4. Ожидания в XCUITest
Привет, Хабр!
В UI тестах не все события происходят синхронно друг за другом. Сетевые запросы, анимации, чтение файлов – все это требует ... | https://habr.com/ru/post/547422/ | null | ru | null |
# Функциональные языки в разработке аппаратуры
Функциональные языки, как правило, не слишком подходят для низкоуровнеого программирования, хотя и применяются для кодогенерации.
**Примеры проектов**генераци... | https://habr.com/ru/post/316748/ | null | ru | null |
# Симуляция гидравлической эрозии

*Гидравлическая эрозия* — это процесс постепенного преображения водой рельеф. В основном она вызывается осадками, но на неё также влияют разбивающиеся о побережье волны океана, а также течения рек. ... | https://habr.com/ru/post/506764/ | null | ru | null |
# Создание и настройка портативной сборки Jupyter Notebook и Lab на Windows. Часть 1
Всем привет. Когда я начинал изучение Python, устанавливал впервые Jupyter Notebook, потом пытался передать с созданное в нём приложение на предприятие, я часто сталкивался с различными проблемами. То кириллица в имени пользователя ме... | https://habr.com/ru/post/438934/ | null | ru | null |
# Асинхронные операции и пересоздание Activity в Android
В одной статье на хабре ([274635](https://habrahabr.ru/post/274635/)) было продемонстрировано любопытное решение для передачи объекта из `onSaveInstanceState` в `onRestoreInstanceState` без сериализации. Там используется метод `writeStrongBinder(IBInder)` класса... | https://habr.com/ru/post/281290/ | null | ru | null |
# Знакомимся с COBOL — ч.1
Этой статьей я планирую начать целый цикл, который может быть со временем соберется в книгу. Информация про COBOL на русском представлена фактически статьей в Википедии и двумя советскими ГОСТами. Вы можете спросить меня зачем я начинаю “раскапывать труп” и прочие аналогичные вопросы. Ответ ... | https://habr.com/ru/post/115813/ | null | ru | null |
# Третья проверка Qt 5 с помощью PVS-Studio

Время от времени наша команда повторно проверяет проекты, про которые мы уже писали статьи. Очередным таким перепроверенным проектом стал Qt. Посл... | https://habr.com/ru/post/426485/ | null | ru | null |
# Простой компонент на TypeScript для отображения дерева
В процессе работы над небольшим web-проектом мне потребовался компонент для отображения дерева элементов на странице. Компонент должен позволять развернуть/свернуть уз... | https://habr.com/ru/post/183434/ | null | ru | null |
# jQuery плагин для добавления ссылок в буфер обмена
У многих из нас есть блоги, интернет-магазины, новостные сайты etc… Понятное дело стараемся опубликовывать оригинальный контент, но что же происходит после появления контента в интернетах, его конечно же просматривают и если он интересный, пользователи иногда обмени... | https://habr.com/ru/post/101763/ | null | ru | null |
# Мечтают ли андроиды об электропанке? Как я учил нейросеть писать музыку
На курсах по машинному обучению в [Artezio](http://artezio.com/) я познакомился с учебной моделью, способной создавать музыку. Музыка – существенная часть моей жизни, я много лет играл в группах (панк-рок, регги, хип-хоп, рок и т. д.) и являюсь ... | https://habr.com/ru/post/439546/ | null | ru | null |
# Интуиция Искусственного Интеллекта — миф или реальность?
Одно из самых известных, наиболее интересное и совсем не изученное свойство человеческого разума с давних пор привлекавшее исследователей это интуиция.
Со времен древности философы и математики пытались хоть как как то понять и определить смысл этого могуче... | https://habr.com/ru/post/550032/ | null | ru | null |
# jQuery.keyboard v0.1.0

У меня есть на примете как минимум два проекта, в которых понадобится активное управление с помощью клавиатуры. Поэтому, я сел и написал удобный и красивый плагин для jQuery, котор... | https://habr.com/ru/post/76424/ | null | ru | null |
# Классификация больших объемов данных на Apache Spark с использованием произвольных моделей машинного обучения
Часть 2: Решение
----------------
И снова здравствуйте! Сегодня я продолжу свой рассказ о том, как мы классифицируем большие объёмы данных на Apache Spark, используя произвольные модели машинного обучения. ... | https://habr.com/ru/post/413141/ | null | ru | null |
# Лаконичная реализация конечных автоматов в Matlab, Octave, C
Актуальность
------------
Конечные автоматы (finite state machines, fsm) — штука полезная. Особенно они могут быть востребованы в средах, где в принципе нет развитой многозадачности (например, в Octave, который является в значительной степени бесплатным а... | https://habr.com/ru/post/563120/ | null | ru | null |
# Tarantool Kubernetes Operator

Kubernetes has already become a de-facto standard for running stateless applications, mainly because it can reduce time-to-market for new features. Launching stateful appli... | https://habr.com/ru/post/472428/ | null | en | null |
# Ускорение Maven сборки
#### Узнайте, как сделать сборки Maven более быстрыми и эффективными
Для сборки требуется несколько свойств, главное из которых - воспроизводимость.
Я считаю, что скорость должна быть ниже в порядке приоритета. Тем не менее, это также один из самых лимитирующих факторов на ваш цикл выпуск... | https://habr.com/ru/post/582688/ | null | ru | null |
# Подробности о JavaScript-объектах
Автор материала, перевод которого мы сегодня публикуем, говорит, что в JavaScript-объектах содержится много такого, о существовании чего можно и не подозревать, пользуясь ими в повседневной работе. Объекты в JavaScript очень легко создавать, с ними удобно работать, они кажутся понят... | https://habr.com/ru/post/438794/ | null | ru | null |
# Эксперимент: ищем int i = 0xDEADBEEF в дампе физической памяти
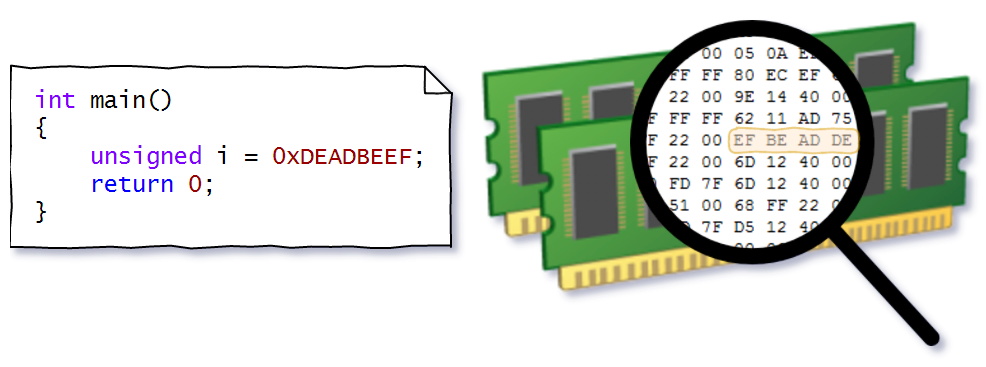
Изучение виртуального адресного пространства и алгоритма преобразования адресов заметно упростится, если начать с несложного практического примера. Для этог... | https://habr.com/ru/post/322636/ | null | ru | null |
# 30 секунд CSS

Предлагаем вашему вниманию коллекцию полезных CSS-сниппетов, в которых вы можете разобраться за 30 секунд, а то и быстрее.
Clearfix
--------
Позволяет элементу автоматически применять clear к своим дочерним элементам... | https://habr.com/ru/post/350160/ | null | ru | null |
# В поисках жирного (The Quest For FAT)
При разработке некоего программно-аппаратного комплекса потребовалось создать клиентское устройство, которое для прочих устройств должно выглядеть как обычная USB-флешка, или если более формально, то USB Mass Storage Device. Необычность устройства в том, что оно должно имитирова... | https://habr.com/ru/post/134432/ | null | ru | null |
# Особенности построения хранилища данных на базе ClickHouse в Yandex Cloud
В данной статье делимся опытом внедрения решения на базе СУБД ClickHouse и сервисов Yandex Cloud. Мы не коснёмся тонких настроек Cli... | https://habr.com/ru/post/688126/ | null | ru | null |
# SwipeRefreshLayout: не сферический и не в вакууме
Про новый [SwipeRefreshLayout](http://developer.android.com/reference/android/support/v4/widget/SwipeRefreshLayout.html) из библиотеки Android support на Хабре [уже писали](http://habrahabr.ru/post/218365/), да и Google любезно выдаёт множество ссылок на подобные при... | https://habr.com/ru/post/256947/ | null | ru | null |
# Monitor linux — cross platform firmware with zabbix server
About
-----
This is small cross-platform linux-distro with zabbix server. It's a simple way to deploy powerful monitoring system on ARM platfornms and x86\_64.
Worked as firmware (non-changeable systemd image with config files), have web-interface for syst... | https://habr.com/ru/post/487986/ | null | en | null |
# Курс по Ruby+Rails. Часть 2. Объектно-ориентированное программирование
В этой лекции мы рассмотрим объектно-ориентированный стиль в Ruby: поговорим об объектах, классах и модулях, а также вспомним три принц... | https://habr.com/ru/post/691858/ | null | ru | null |
# Викинги атакуют (Worm.Win32.Viking.hb)
Надоело. Вылетает второй раз за день вылетает окошко отладчика с ошибкой в [rundl132.dll](http://www.viruslist.com/ru/viruses/encyclopedia?virusid=151648). Хочется вылечить заразу — устала руками файлы каждый раз удалять и реестр чистить. Помучилась, помучилась, и нашла чудесно... | https://habr.com/ru/post/46544/ | null | ru | null |
# IPSec — история, архитектура, подключение
IPSec
-----
IP Security — это комплект протоколов, в состав которого входят почти 20 предложений по стандартам и 18 RFC. Он позволяет осуществлять подтверждение подлинности (аутентификацию), проверку целостности и/или шифрование IP-пакетов. IPsec также включает в себя прото... | https://habr.com/ru/post/680178/ | null | ru | null |
# Всем выйти из сумрака: как добавить тень на Android
Когда заходит речь про тени на Android, возникает сразу несколько вопросов. Первый: зачем они нужны? Второй: почему нельзя использовать системные тени и жить счастливо? Третий: если нельзя использовать системные тени, как реализовать кастомные?
Это Сергей Петров,... | https://habr.com/ru/post/696006/ | null | ru | null |
# Что дает установка SSD в Mac mini?
Привет, Geektimes! Если у вас вдруг завалялся Mac mini 2011 или 2012 года выпуска (а, может быть, вы до сих пор пользуетесь им как основным), не спешите отправлять этого «малыша» на покой раньше времени. Самый доступный компьютер в линейке Apple довольно хорошо поддается апгрейду, ... | https://habr.com/ru/post/371947/ | null | ru | null |
# Го — неведомые земли
***Стратегия ведения войны такова: существуют рассеивающие местности,
ненадежные местности, спорные местности,
пересекающиеся местности, узловые местности,
трудные местности, местности-ловушки,
ок... | https://habr.com/ru/post/365671/ | null | ru | null |
# Проблема установки Ruby on Rails в конце 2019 года
Всем привет любители программировать и улучшать мир к лучшему.
В данном посте я расскажу как мучился с установкой Ruby on Rails, сразу скажу, до этого я никогда не сталкивался с данным решением и задание мне дал потенциальный работодатель, написать определенное р... | https://habr.com/ru/post/471160/ | null | ru | null |
# Строим систему реактивных компонентов с помощью Kotlin

Всем привет! Меня зовут Анатолий Варивончик, я Android-разработчик Badoo. Сегодня я поделюсь с вами переводом второй части статьи моего коллеги Zsolt Kocsi о реализации MVI, к... | https://habr.com/ru/post/430550/ | null | ru | null |
# ASP.NET MVC 3 сервер на NAS Synology — solution

Имея в хозяйстве замечательный накопитель от компании Synology, я довольно долгое время грустил по поводу того, что в нём отсутствует хостинг .NET приложений. И вот, воор... | https://habr.com/ru/post/142672/ | null | ru | null |
# Анализ keygenme от Ra$cal на базе виртуальной машины
#### 0. Инфо
[Страница KeygenMe на crackmes.de](http://crackmes.de/users/racal/racal_crackme_n3_with_vm/)
Crackme with simple vm. Key check algorithm is simple, so main target — vm.
difficult of pcode is growing from start to end. first part seems like emul... | https://habr.com/ru/post/164437/ | null | ru | null |
# Защита от легкого DDoS'a
Совсем недавно на хабре уже появилась рекламная [статья](https://habr.com/company/cleantalk/blog/354374/) о борьбе с DDoS атаками на уровне приложения. У меня был аналогичный опыт поиска оптимального алгоритма противодействия нападениям, может кому пригодится — когда человек в первый раз ста... | https://habr.com/ru/post/354744/ | null | ru | null |
# Примитивно-рекурсивные функции и функция Аккермана
[Функция Аккермана](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F_%D0%90%D0%BA%D0%BA%D0%B5%D1%80%D0%BC%D0%B0%D0%BD%D0%B0) — одна из самых знаменитых функций в Computer Science. С ней связан как минимум один фундаментальный результат и как ... | https://habr.com/ru/post/486548/ | null | ru | null |
# Мега-Учебник Flask, Часть XXII: Фоновые задачи
(издание 2018)
--------------
### *Miguel Grinberg*
---
 [Туда](https://habrahabr.ru/post/354322/) [Сюда](https://habr.com/post/358152/) Сегодня, 3 ноября, 42 версия браузера Firefox сменила статус бета-версии на релизную. На компьютеры сотен миллионов пользователей свежая «лиса» уже начала попадать через внутреннюю ... | https://habr.com/ru/post/386289/ | null | ru | null |
# Алгоритм для WRO: непрерывное считывание цветов кубиков
Здесь я бы хотел рассказать про интересный алгоритм, который я использовал в решении WRO Senior (старшая категория, которая), для непрерывного считывания цветов в сезоне 2019 года. Весь код будет написан на C++ в реализации (правильнее будет сказать, что почти ... | https://habr.com/ru/post/569456/ | null | ru | null |
# Повесть о том, как я «воевал» с xhtml+jspx+tomcat6
Доброго времени суток.
В данной статье я бы хотел рассказать о разработке своего первого стартапа, а так же о том, как я потратил 3 часа в пустую из-за ~~своей самоуверенности~~ недостатка знаний.
#### Предисловие
Честно признаться у меня давно «чесались» рук... | https://habr.com/ru/post/128723/ | null | ru | null |
# Web Vulnerabilities Playground
> *Уже 3 ноября в OTUS пройдет день открытых дверей по курсу* [*"Безопасность веб-приложений"*](https://otus.pw/CnMr/)*, в рамках которого вы сможете подробно узнать о курсе и пообщаться с нашими экспертами. А прямо сейчас хотим поделиться с вами авторской статьёй эксперта OTUS, вирусн... | https://habr.com/ru/post/525486/ | null | ru | null |
# SAP — ABAP. Изменение строки подсуммирования в ALV grid
Работаю ABAP разработчиком в одной из отечественных компаний, внедряющих SAP.
На днях от консультанта пришла спецификация с задачей сделать специальную строку подсуммирования (ALV GRID), в который будут всевозможные суммы, значения, наименования и т.д., кото... | https://habr.com/ru/post/270197/ | null | ru | null |
# Моделирование отказоустойчивых кластеров на базе PostgreSQL и Pacemaker
Введение
========
Некоторое время назад передо мной поставили задачу разработать отказоустойчивый кластер для [PostgreSQL](https://www.postgresql.org), работающий в нескольких дата-центрах, объединенных оптоволокном в рамках одного города, и сп... | https://habr.com/ru/post/516538/ | null | ru | null |
# Транспорт-бот Jabber конференций для Telegram

Доброго времени суток.
В один прекрасный день, после значительного перерыва, судьба вновь столкнула меня с jabber-конференциями. Правда, среди знакомых jabber уже никто не ... | https://habr.com/ru/post/305858/ | null | ru | null |
# Добавляем GPRS в домашнюю GSM сеть
Третья статья из цикла покажет как исследовать работу пакетных данных в сетях GSM при помощи Osmocom. Другими словами мы будем раздавать интернет с ноутбука абонентам нашей домашней сети на основе двух osmocombb-совместимых телефонов и анализировать TCP/IP трафик.
, [Vim](https://github.com/mechatroner/rainbow_csv), [Sublime Text 3](https://packagecontr... | https://habr.com/ru/post/429548/ | null | ru | null |
# Асимптотический анализ алгоритмов
Прежде чем приступать к обзору асимптотического анализа алгоритмов, хочу сказать пару слов о том, в каких случаях написанное здесь будет актуальным. Наверное многие программисты читая эти строки, думают про себя о том, что они всю жизнь прекрасно обходились без всего этого и конечно... | https://habr.com/ru/post/78728/ | null | ru | null |
# iBeacon: Руководство к действию

> iBeacon является новой технологией, которая построена на основе Bluetooth Low Energy или BLE. Пока iBeacon более всего ассоциируется с Apple. Начиная с 2013 года iBeaco... | https://habr.com/ru/post/226037/ | null | ru | null |
# Проверка исходного кода библиотек .NET Core статическим анализатором PVS-Studio

Библиотеки .NET Core — один из самых популярных C# проектов на GitHub. Неудивительно, с учётом его широкой известности и используемости. Тем... | https://habr.com/ru/post/463537/ | null | ru | null |
# Неконстантные константные выражения
// <какой-то код>
int main ()
{
constexpr int a = f ();
constexpr int b = f ();
static\_assert (a != b, "fail");
}
Можно ли... | https://habr.com/ru/post/268141/ | null | ru | null |
# Изучаем VoIP-движок Mediastreamer2. Часть 9
Материал статьи взят с моего [дзен-канала](https://zen.yandex.ru/id/5e3f8e0751f5346faab4fc7a).

Дуплексное переговорное устройство
----------------------------------
 хотим предложить несколько рекомендаций как содержать свои контроллеры максимально... | https://habr.com/ru/post/123200/ | null | ru | null |
# Хвостовая рекурсия в C++ с использованием 64-битных переменных — Часть 1
В этот раз я хочу поделиться с вами одной проблемой, с которой столкнулся, когда решил сравнить итерационные и рекурсивные функции в C++. Между рекурсией и итерацией есть несколько отличий: о них подробно рассказано в этой [стать](http://www.vi... | https://habr.com/ru/post/261027/ | null | ru | null |
# Скрипт настройки Windows 10

Давно хотел поделиться своим скриптом по автоматизации настройки Windows 10 (на данный момент актуальная версия **19041**), да все руки не доходили. Возможно, он будет ко... | https://habr.com/ru/post/465365/ | null | ru | null |
# Валидация Javascript в VisualStudio с помощью google closure
Увиденный недавно топик, про [валидацию css в Visual Studio](http://habrahabr.ru/blogs/vs/134326/) подстегнул к написанию похожей вещи про валидацию Яваскрипта.
Когда яваскрипт в веб-проекте занимает достаточно большую долю кода, и клиентские скрипты вы... | https://habr.com/ru/post/134344/ | null | ru | null |
# Первый древнейший: в чём уникальность языка программирования LISP
В этой статье мы поговорим об одном из самых старых языков программирования ― Lisp. Несмотря на свой внушающий уважение возраст, он всё ещё находится в строю и заставляет переосмысливать всю теорию программирования. Так что же это за язык и чем он при... | https://habr.com/ru/post/655509/ | null | ru | null |
# Первые шаги с Fiddler Classic
Привет! После знакомства с [Charles Proxy](https://habr.com/ru/company/youla/blog/527648/) большинство из читателей захотело узнать больше про инструменты мониторинга и анализа HTTP/HTTPS трафика. Расскажем про популярный у многих тестировщиков Fiddler. Описать все возможности Fiddler в... | https://habr.com/ru/post/533138/ | null | ru | null |
# Генерация документов с помощью ONLYOFFICE DocumentBuilder

Привет, Хабр.
Я хочу рассказать об утилите под названием DocumentBuilder, которая позволяет генерировать документы, таблицы и презентации, а также показать, как можно его и... | https://habr.com/ru/post/466217/ | null | ru | null |
# Революция в JavaScript. Буквально
Сегодня 22 апреля юбилейного 2017 года, день рождения человека, без которого не состоялись бы события столетней давности. А значит, есть повод поговорить о революционной истории. Но причём тут Хабр? — Оказалось, всё в этом мире может иметь самую неожиданную связь.

Привет, хабражители!
Сейчас какой-то спец с многолетним опытом работы с Qt подумал: «Что за фигня? Хабр — для вещей покруче!». Но ведь даже спецам с многолетним опытом ин... | https://habr.com/ru/post/150329/ | null | ru | null |
# Реализация горячей перезагрузки С++ кода в Linux и macOS: копаем глубже

\*Ссылка на библиотеку и демо видео в конце статьи. Для понимания того, что происходит, и кто все эти люди, рекомендую прочитать [предыдущую статью](https://hab... | https://habr.com/ru/post/437312/ | null | ru | null |
# How old is this house. Как я делал карту возраста домов Петербурга

### Идея
Примерно из ниоткуда возникает идея сделать прекрасную складную карту Петербурга, показывающую возраст домов, их архитектурный стиль и на которой будут выд... | https://habr.com/ru/post/504216/ | null | ru | null |
# Network Infrastructure — how is it seen by hyperscalers
### Introduction
Знакомство
----------
Привет! Меня зовут Наталья. В Каруне я пишу в команде высоконагруженные сервисы на Elixir.
Это третья компания, в которой я работ... | https://habr.com/ru/post/650835/ | null | ru | null |
# 6 полезных привычек, которые, что удивительно, есть лишь у немногих программистов
Если поразмышлять о том, какие качества характерны для того, кого можно назвать «хорошим программистом», то на ум тут же придут некоторые привычки. Такие привычки, которые, с чем согласится большинство разработчиков, иметь весьма полез... | https://habr.com/ru/post/503638/ | null | ru | null |
# Почем нынче на рынке яблочки?
Яблочный рынок приложений, или *Apple App Store*, потребляет и порождает деньги. Чем больше Вы вкладываете денег, тем выше отдача. Однако, заработанное не всегда больше потраченного. С недавних пор в моей голове вдруг сформировался типичный график потраченных/полученных средств.

SQL Server 2000 поддерживал четыре уровня изоляции транзакций: «read uncommitted» (nolock), «read committed», «repeatable read» ... | https://habr.com/ru/post/662235/ | null | ru | null |
# Программируем умный дом

Многие годы мы [мечтали](https://yewtu.be/watch?v=AqWHldmJjOI) о светлом будущем, когда роботы наконец-то придут в нашу жизнь и начнут кормить нас с ложечки. Мечты сбываются. У нас появилась армия роботов, ... | https://habr.com/ru/post/593659/ | null | ru | null |
# Получение Method из Method Reference в Java
Я столкнулся с проблемой — как получить из method reference вида
```
Function fun = String::length;
```
вызываемый метод класса (или хотя бы его имя), т.е. в примере это `java.lang.String.length()`. Как выяснилось, не одного меня волновал этот вопрос, нашлись такие обсуж... | https://habr.com/ru/post/522774/ | null | ru | null |
# Пишем GraphQL API сервер на Yii2 с клиентом на Polymer + Apollo. Часть 2. Клиент
[Часть 1. Сервер](https://habrahabr.ru/post/336758/)
**Часть 2. Клиент**
[Часть 3. Мутации](https://habrahabr.ru/post/337046/)
[Часть 4. Валидация. Выводы](https://habrahabr.ru/post/337236/)
Для реализации UI рассмотрим пример... | https://habr.com/ru/post/337044/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.