
text stringlengths 0 59.1k |
|---|
--- |
title: Fine Tuning LLMs - A Practical Guide |
slug: fine-tuning-llm |
authors: necatiozmen |
tags: [llm] |
description: Learn how to fine-tune large language models for specific needs. A practical guide covering techniques, tools, and best practices. |
image: https://cdn.voltagent.dev/2025-08-11-llm-finetuning/social.png |
--- |
Large language models like ChatGPT and Claude are great, but they often don't work well for specific tasks. They might not know your industry's jargon, have trouble keeping formats consistent, or not understand your company's systems. |
Fine-tuning solves this, it teaches these general models to do specific tasks really well. This guide shows you how to get started. |
## Understanding Fine-Tuning |
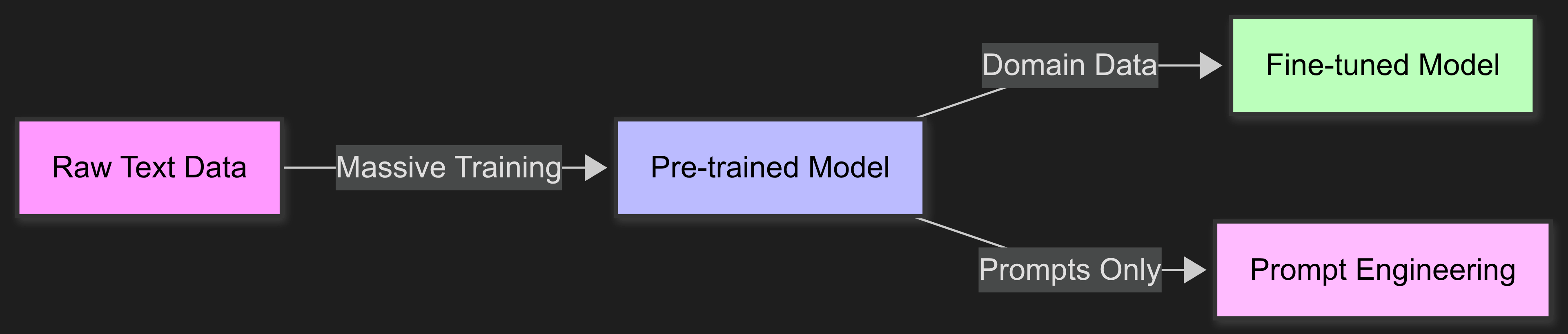
Think of LLMs as smart generalists. They know a lot about everything but need special training for specific areas. There are three main ways to do this: |
**Pre-training** builds the base model from scratch using huge amounts of data. This needs tons of resources and is usually done by big AI companies. |
**Fine-tuning** takes a pre-trained model and keeps training it on your specific data. It's like giving extra training to someone who already knows the basics. |
**Prompt engineering** means writing better instructions without any training. It's quick to try but doesn't always give consistent results. |
 |
### Fine-Tuning Methods |
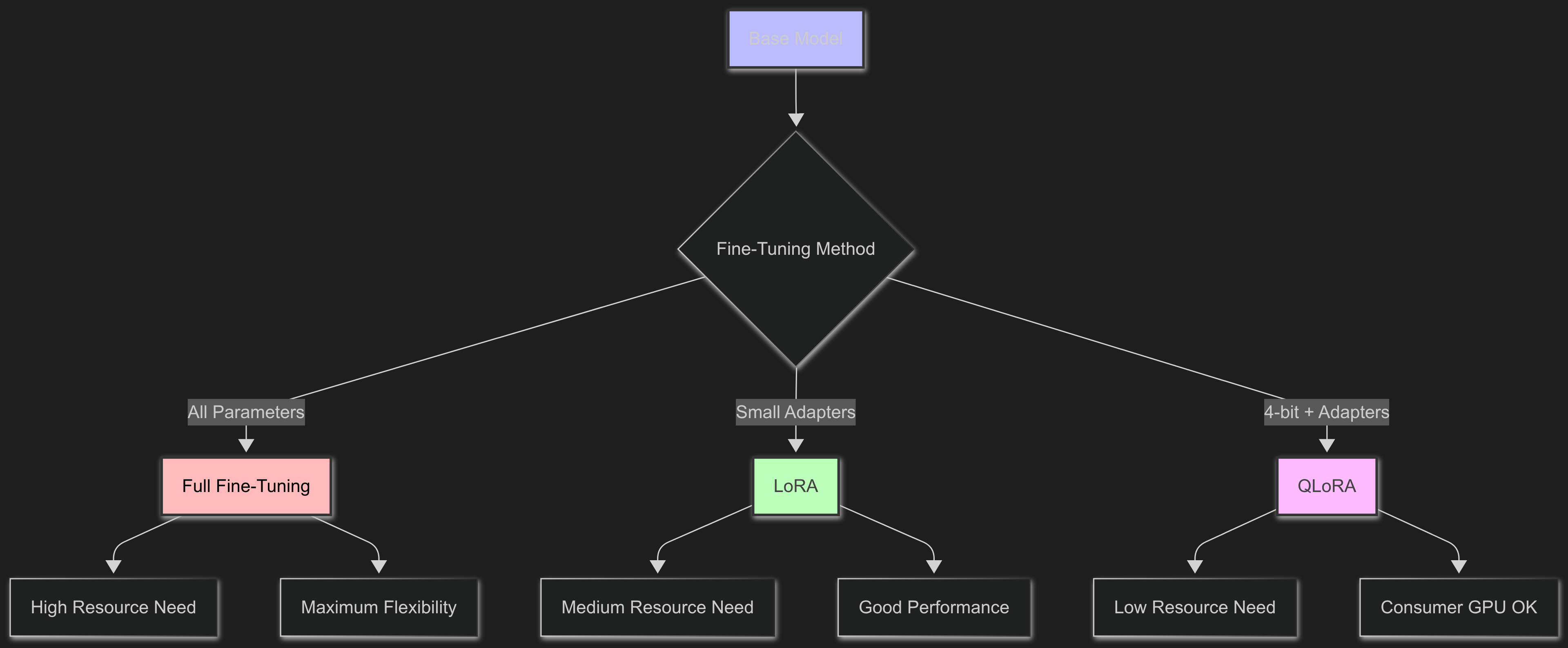 |
#### Full Fine-Tuning |
This method updates all the model's parameters. It gives you the most control, but needs a lot of computing power and might make the model forget its general skills. |
```python |
# Full fine-tuning example |
from transformers import AutoModelForCausalLM |
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf") |
# All parameters are trainable - billions of them |
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad) |
print(f"Trainable parameters: {trainable_params:,}") |
``` |
#### LoRA (Low-Rank Adaptation) |
LoRA adds small adapter layers instead of changing the whole model. This makes training much easier while keeping good performance. |
```python |
from peft import LoraConfig, get_peft_model |
lora_config = LoraConfig( |
r=16, # rank determines capacity |
lora_alpha=32, |
target_modules=["q_proj", "v_proj"], # which layers to adapt |
lora_dropout=0.1, |
) |
model = get_peft_model(model, lora_config) |
# Only ~0.1% of parameters need training |
``` |
#### QLoRA (Quantized LoRA) |
QLoRA combines LoRA with quantization, loading the base model in 4-bit precision while training adapters in higher precision. This lets you fine-tune big models on regular consumer GPUs. |
## When to Consider Fine-Tuning |
### Good Use Cases |
Fine-tuning works great when you have **special terms** from fields like medicine, law, or tech where general models don't know the vocabulary. It's also useful when you need **consistent formatting** for outputs that have to follow specific patterns every time. |
For **repetitive tasks** done thousands of times, fine-tuning can really boost speed and accuracy. Companies with **sensitive data** that can't leave their servers love fine-tuning because they can run models locally. But you need **enough training data** - usually at least 1,000 good examples. |
### When to Avoid Fine-Tuning |
Fine-tuning isn't always the answer. With **too little data** (less than 500 examples), the model won't learn well and might do worse than just using better prompts. When needs **change often**, keeping multiple fine-tuned models gets messy and expensive. If current models already work fine, or if you don't know how to... |
Rule of thumb: If creating 100 perfect examples manually is difficult, fine-tuning probably won't help. |
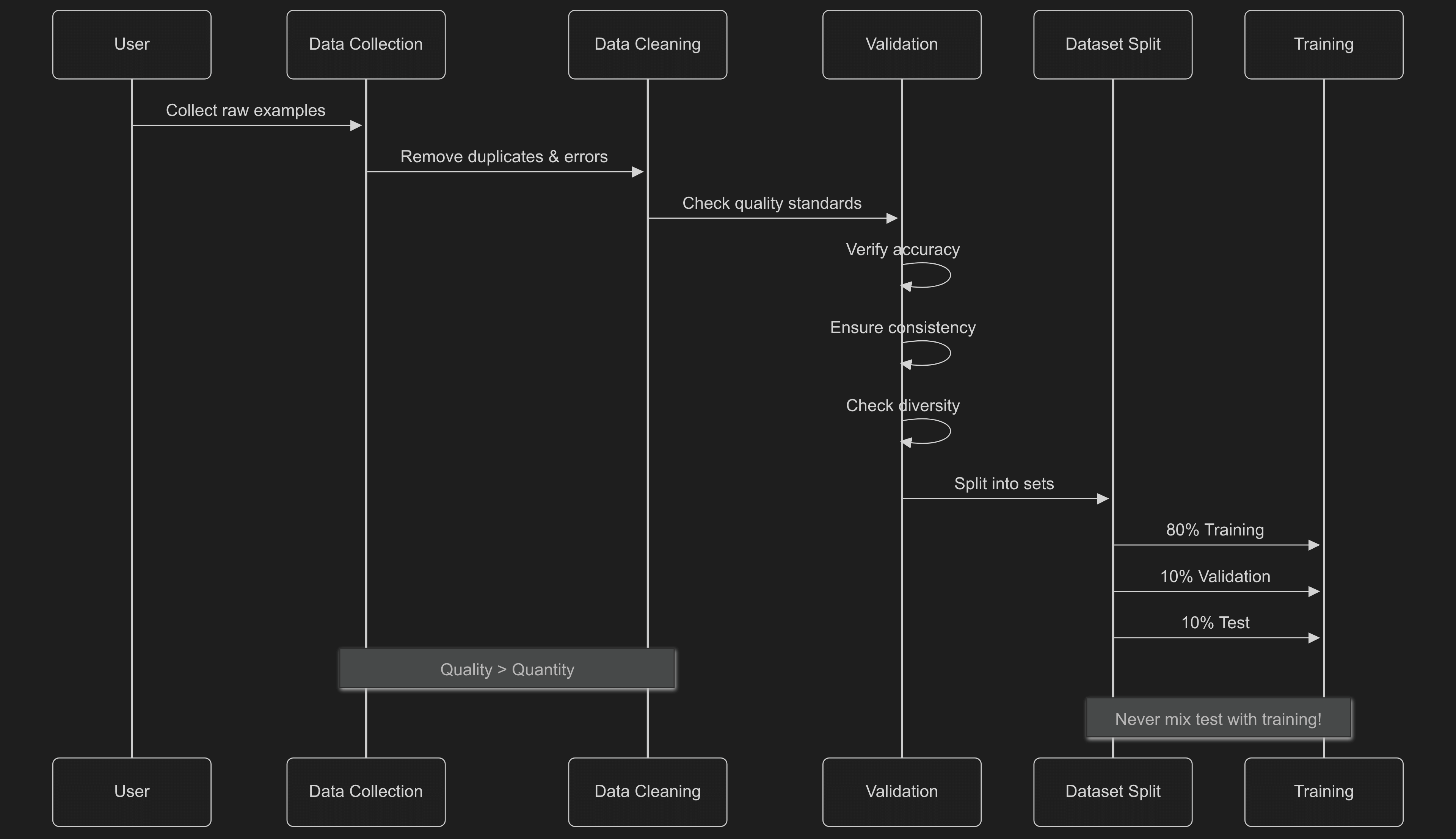
## Data Preparation |
Good data makes good models. Bad data makes bad models, no matter what technique you use. |
 |
### Quality Standards |
Data **accuracy** is the most important thing. Every example needs to be correct and labeled right, because even a little bad data can mess up your model. Quality beats quantity every time - a small set of perfect examples works better than lots of okay ones. |
**Consistency** helps the model learn patterns. When your formatting and style jump around randomly, the model gets confused about what you want. Keep everything consistent - how you label things, how outputs look, even your writing style. |
Dataset **diversity** makes your model stronger. Include weird cases, variations, and different scenarios so your model doesn't break when it sees something new. A model trained only on simple, similar examples will fail when it hits real-world messiness. |
### Dataset Size Guidelines |
How much data you need depends on what you're doing: |
- **Classification tasks**: 500-1,000 examples |
- **Structured generation**: 1,000-5,000 examples |
- **Complex reasoning**: 10,000+ examples |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.