
text stringlengths 0 59.1k |
|---|
fp16=True, # or bf16=True for newer GPUs |
# Reduces memory usage by ~50% |
) |
``` |
**Gradient Checkpointing**: |
```python |
model.gradient_checkpointing_enable() |
# Trades computation for memory |
``` |
**Early Stopping**: |
```python |
from transformers import EarlyStoppingCallback |
trainer = Trainer( |
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)] |
) |
``` |
## Tools and Platforms |
### Development Tools |
If you're new to fine-tuning, **Hugging Face AutoTrain** lets you do it without code and picks the best settings automatically. It handles the technical stuff so you can focus on preparing data and checking results. |
**Axolotl** uses simple YAML config files instead. It's ready for production, supports different training methods, and gives you flexibility for complex cases. Here's what a typical config looks like: |
```yaml |
base_model: meta-llama/Llama-2-7b-hf |
load_in_4bit: true |
adapter: lora |
lora_r: 16 |
datasets: |
- path: data.jsonl |
type: alpaca |
``` |
**LLaMA-Factory** has a web interface that's both easy and flexible. It supports multiple models and has team-friendly features, great for projects where not everyone is comfortable with the command line. |
### Cloud Platforms |
For cloud infrastructure, **AWS SageMaker** gives you fully managed servers with automatic scaling and enterprise features. It's good for production when you need reliability and scale. |
**Google Vertex AI** works smoothly with Google Cloud Platform, has AutoML features and good monitoring tools. If you're already using GCP, this is usually the easiest choice. |
If you're watching costs, **Modal** and **RunPod** offer cheap GPU access where you pay only for what you use. They're great for experiments and development when you don't need servers running all the time. |
### Hardware Requirements |
Approximate VRAM needs: |
- **7B full fine-tuning**: 48GB+ |
- **7B with LoRA**: 16GB |
- **7B with QLoRA**: 8GB |
- **13B with QLoRA**: 12GB |
## Common Pitfalls and Solutions |
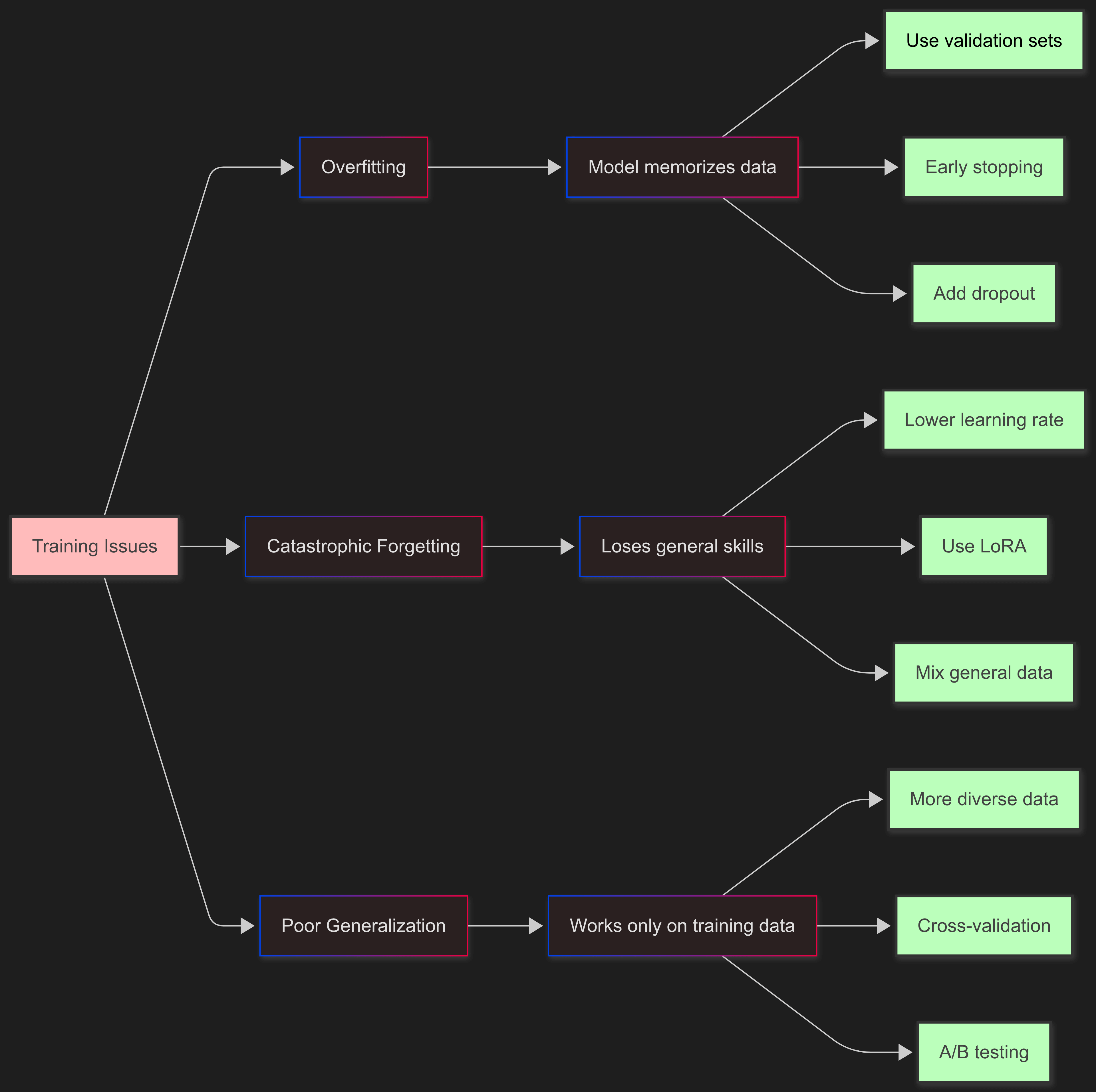 |
### Overfitting |
The model memorizes training data instead of learning patterns. |
**Solutions**: The best way to fight overfitting is using validation sets to check how the model does on new data. Early stopping stops training when validation scores stop improving. Adding dropout and regularization helps the model generalize, and mixing in different types of data makes sure it sees lots of examples. |
### Catastrophic Forgetting |
The model loses general capabilities while learning specific tasks. |
**Solutions**: To stop catastrophic forgetting, you need to train gently. Use lower learning rates so the model changes slowly. Use LoRA instead of full fine-tuning to keep most of the original model intact. Mix in some general instruction data to keep broad skills, and techniques like elastic weight consolidation can ... |
### Poor Generalization |
Good training metrics but poor real-world performance. |
**Solutions**: To improve generalization, add more diverse data to cover different scenarios. Test regularly on completely new data to see if the model really learned or just memorized. Use cross-validation for better performance estimates, and A/B test in production to see if it really works. |
## Real-World Examples |
### Customer Support Automation |
**Challenge**: Generic models lack product knowledge and company policies. |
**Approach**: |
- Fine-tuned Llama-2-13B using LoRA |
- 5,000 annotated support conversations |
- Included product documentation |
**Results**: |
- 70% faster response times |
- 45% improvement in resolution rates |
- 90%+ customer satisfaction |
### Code Generation for Proprietary Systems |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.