
text stringlengths 0 59.1k |
|---|
Start with smaller datasets to validate the approach before scaling up. |
### Data Formats |
Instruction-following format: |
```json |
{ |
"instruction": "Summarize the customer complaint", |
"input": "Ordered item X but received item Y. Very disappointed with service...", |
"output": "Wrong item delivered - customer ordered X, received Y" |
} |
``` |
Conversational format: |
```json |
{ |
"messages": [ |
{ "role": "system", "content": "You are a technical assistant" }, |
{ "role": "user", "content": "How do I implement caching?" }, |
{ "role": "assistant", "content": "Here are several caching strategies..." } |
] |
} |
``` |
### Data Cleaning Checklist |
Good data cleaning stops lots of problems before they start. First, **remove duplicates** - repeated examples cause overfitting and mess up your metrics. Then **check formatting** on everything - if your JSON structure or field names keep changing, you'll confuse the training. |
When **splitting datasets**, keep training and test data totally separate to get real performance numbers. For classification, **balance your classes** so each type is equally represented - otherwise the model just learns to predict whatever's most common. Last, **remove sensitive stuff** like personal information and ... |
## Choosing Base Models |
### Open-Source Options |
The **Llama 3 Series** (comes in 8B, 70B, and 405B sizes) is really popular because it works well and has great community support. These models handle multiple languages well and are the first choice for lots of fine-tuning projects because they're both powerful and easy to use. |
**Mistral and Mixtral** models (7B and 8x7B versions) are built to be fast. They're especially good at coding tasks, perfect for technical stuff where you need quick responses. |
If you don't have much computing power, **Phi-3** models (3.8B and 14B) are surprisingly good for their size. They're made for edge deployment and work well without needing tons of resources like bigger models do. |
### Proprietary Options |
**GPT-3.5 and GPT-4** from OpenAI are still the best in raw performance. They cost more, but their simple fine-tuning API means you don't have to manage infrastructure, which is great if you want easy over cheap. |
**Claude** from Anthropic is good at reasoning and has built-in safety features, making it great for sensitive uses. But you can't fine-tune it as easily as other options. |
### Selection Criteria |
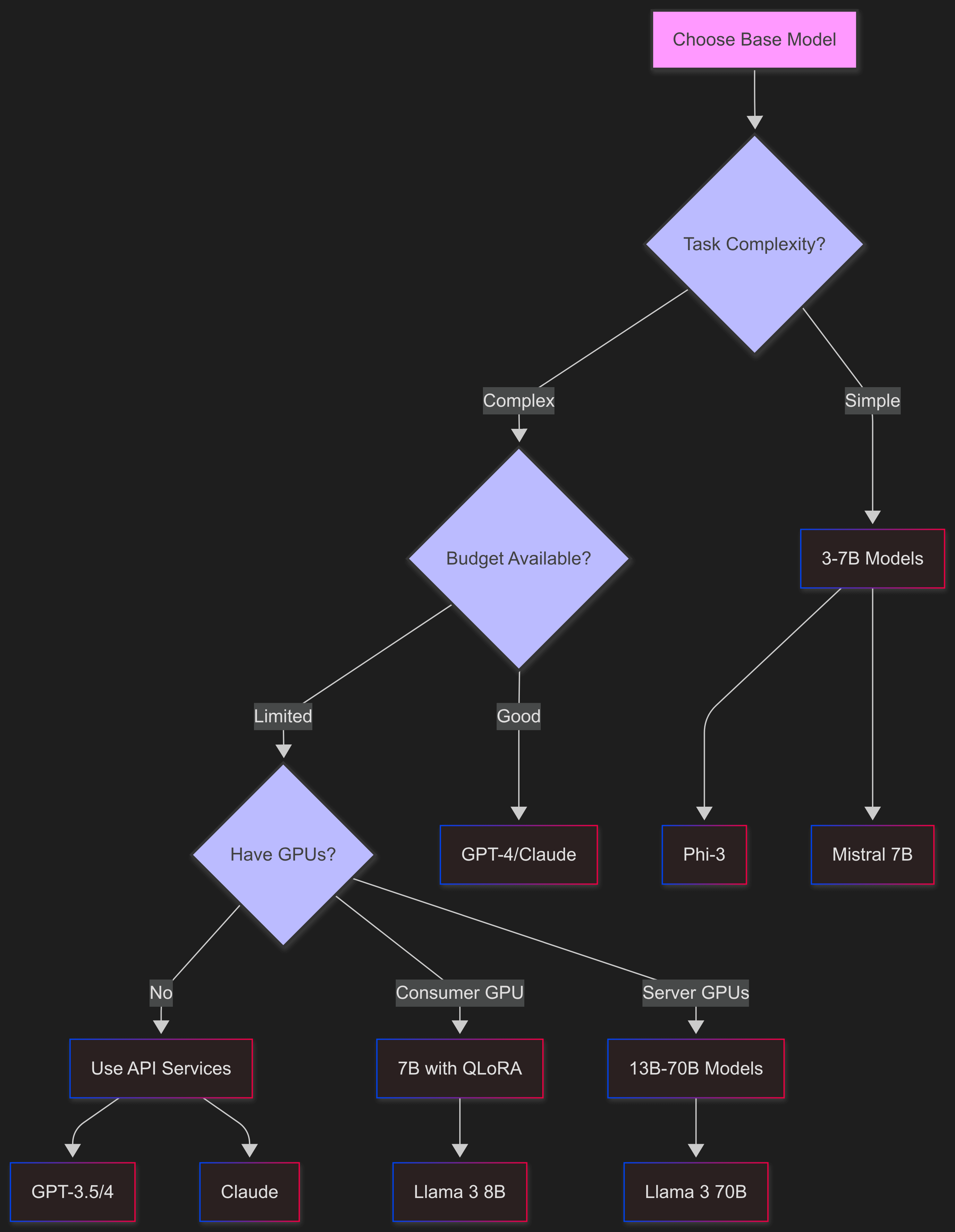 |
Picking the right base model means juggling different needs. **Task complexity** decides how big your model needs to be - simple classification might work with 3B parameters, but complex reasoning usually needs 7B or more. **Speed requirements** usually mean smaller models, since they respond faster and handle more use... |
**Budget** matters a lot. Open-source models don't have API costs but you need to pay for servers and maintenance. Proprietary models charge per token but they handle all the infrastructure stuff. And **what hardware you have** sets hard limits - if you've only got consumer GPUs with 12GB VRAM, big models won't work un... |
## The Fine-Tuning Process |
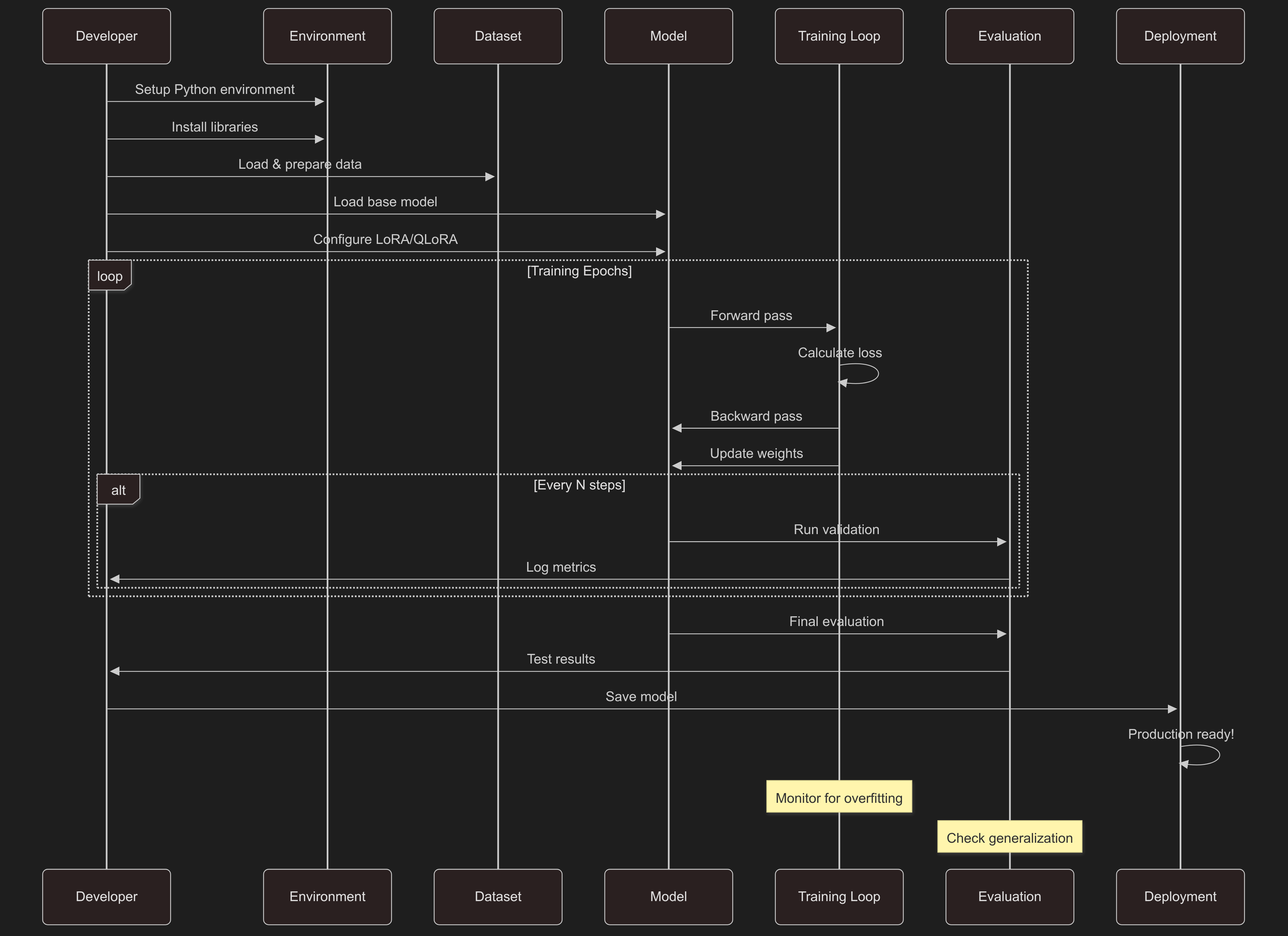 |
### Environment Setup |
```bash |
# Create virtual environment |
python -m venv venv |
source venv/bin/activate # Windows: venv\Scripts\activate |
# Install required packages |
pip install torch transformers datasets accelerate peft bitsandbytes |
# For QLoRA support |
pip install auto-gptq |
``` |
### Key Hyperparameters |
```python |
from transformers import TrainingArguments |
training_args = TrainingArguments( |
output_dir="./results", |
num_train_epochs=3, # Typical starting point |
per_device_train_batch_size=4, # Adjust based on GPU memory |
gradient_accumulation_steps=4, # Simulate larger batches |
warmup_steps=100, # Gradual learning rate increase |
learning_rate=2e-5, # Standard for fine-tuning |
logging_steps=10, |
save_steps=500, |
evaluation_strategy="steps", |
eval_steps=100, |
) |
``` |
### Optimization Techniques |
**Mixed Precision Training**: |
```python |
training_args = TrainingArguments( |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.