
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.1 | worker-automate-hub | 0.5.1009 | Worker Automate HUB é uma aplicação para automatizar rotinas de RPA nos ambientes Argenta. | # Worker Automate Hub

[](https://badge.fury.io/py/worker-automate-hub)
## Installation
Worker Automate Hub is available on PyPI. You can install it through `pip`:
```bash
pipx install worker-automate-hub --force
```
## Requirements and Tested Platforms
- Python:
- 3.12 or higher
- Windows (32bit/64bit/ARM64):
- Worker Automate Hub should work on Windows 7 or newer, but we only officially support Windows 8+.
| text/markdown | Joel Paim | null | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Natural Language :: Portuguese (Brazilian)",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Utilities"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"requests<3.0.0,>=2.32.3",
"typer<0.13.0,>=0.12.3",
"rich<14.0.0,>=13.7.1",
"pathlib3x<3.0.0,>=2.0.3",
"dynaconf<4.0.0,>=3.2.5",
"prompt-toolkit<4.0.0,>=3.0.47",
"python-dotenv<2.0.0,>=1.0.1",
"pandas<3.0.0,>=2.2.2",
"aiohttp<4.0.0,>=3.9.5",
"openpyxl<4.0.0,>=3.1.4",
"xlib<0.22,>=0.21",
"pyfiglet<2.0.0,>=1.0.2",
"packaging<25.0,>=24.1",
"toml<0.11.0,>=0.10.2",
"psutil<7.0.0,>=6.0.0",
"pyscreeze<0.2.0,>=0.1.30",
"pywinauto<0.7.0,>=0.6.8",
"pyautogui<0.10.0,>=0.9.54",
"pillow<11.0.0,>=10.4.0",
"opencv-python<5.0.0.0,>=4.10.0.84",
"pydantic<3.0.0,>=2.8.2",
"pyperclip<2.0.0,>=1.9.0",
"inquirer<4.0.0,>=3.3.0",
"google-auth<3.0.0,>=2.32.0",
"google-auth-oauthlib<2.0.0,>=1.2.1",
"google-auth-httplib2<0.3.0,>=0.2.0",
"google-api-python-client<3.0.0,>=2.136.0",
"playwright==1.45.1",
"pytesseract<0.4.0,>=0.3.10",
"torch<3.0.0,>=2.4.0",
"opencv-python-headless<5.0.0.0,>=4.10.0.84",
"timedelta<2021.0.0,>=2020.12.3",
"beautifulsoup4<5.0.0,>=4.12.3",
"xhtml2pdf<0.3.0,>=0.2.16",
"pywinauto-recorder<0.7.0,>=0.6.8",
"plyer<3.0.0,>=2.1.0",
"python-dateutil<3.0.0,>=2.9.0.post0",
"pyqt6<7.0.0,>=6.7.1",
"gitpython<4.0.0,>=3.1.43",
"selenium<5.0.0,>=4.27.1",
"webdriver-manager<5.0.0,>=4.0.2",
"xlrd<3.0.0,>=2.0.1",
"unidecode<2.0.0,>=1.4.0",
"paramiko<5.0.0,>=4.0.0",
"setuptools<83.0.0,>=82.0.0"
] | [] | [] | [] | [] | poetry/1.8.3 CPython/3.12.10 Windows/2025Server | 2026-02-20T13:20:56.048193 | worker_automate_hub-0.5.1009.tar.gz | 439,067 | 1b/17/142517ef2c3ab97332742dc264f7baab8ec3f92466e55ae07184b1084efa/worker_automate_hub-0.5.1009.tar.gz | source | sdist | null | false | 1d700b039af9687db83ec36de468068c | 7378a4c1a58ff5d28662d873f26c447b2648898da16b5bd77892ec23622c28ac | 1b17142517ef2c3ab97332742dc264f7baab8ec3f92466e55ae07184b1084efa | null | [] | 250 |
2.4 | hivetracered | 1.0.13 | LLM Red Teaming Framework for defensive security research | 
# HiveTrace Red: LLM Red Teaming Framework
[](LICENSE)
[](https://www.python.org/downloads/)
[](https://hivetrace.github.io/HiveTraceRed/)
A security framework for testing Large Language Model (LLM) vulnerabilities through systematic attack methodologies and evaluation pipelines.
HiveTrace Red can be used for:
- **Red teaming your LLM applications** - Test safety guardrails before deployment
- **Research & benchmarking** - Systematic evaluation of LLM robustness across attack vectors
- **Compliance testing** - Validate AI safety requirements and regulatory standards
- **Attack technique research** - Explore and compose novel jailbreak methodologies
HiveTrace Red combines static attack templates, dynamic prompt manipulation, and adaptive evaluation to systematically explore LLM failure modes. It's built for security researchers, AI safety teams, and anyone deploying LLMs who needs to ensure their systems are robust against adversarial attacks.
## Features
- **80+ Attacks**: Comprehensive library across 10 categories (roleplay, persuasion, token smuggling, etc.)
- **Multiple LLM Providers**: OpenAI, GigaChat, YandexGPT, Google Gemini, and more
- **Advanced Evaluation**: WildGuard evaluators and systematic response assessment
- **Async Pipeline**: Efficient streaming architecture for large-scale testing
- **Multi-Language Support**: Testing across multiple languages including Russian
## Attack Categories
| Category | Description |
|----------|-------------|
| **Roleplay** | Persona-based jailbreaks using specific character roles |
| **Persuasion** | Social engineering techniques and psychological manipulation |
| **Token Smuggling** | Encoding and obfuscation methods to hide malicious intent |
| **Context Switching** | Conversation redirection to confuse safety filters |
| **In-Context Learning** | Few-shot examples to teach undesired behavior |
| **Task Deflection** | Reframing harmful requests as legitimate tasks |
| **Text Structure Modification** | Format manipulation to bypass detection |
| **Output Formatting** | Specific output format requests to bypass safety |
| **Irrelevant Information** | Content dilution to confuse safety filters |
| **Simple Instructions** | Direct instruction-based attacks |
## How It Works
```
Base Prompts → Apply Attacks → Modified Prompts → Target Model → Responses → Evaluator → Results
```
The framework provides a 3-stage pipeline:
1. **Attack Generation**: Apply various attack techniques to base prompts
2. **Model Testing**: Send modified prompts to target LLMs
3. **Evaluation**: Assess responses using WildGuard or custom evaluators
The `hivetracered-report` command generates comprehensive HTML reports with:
- Executive summary with key metrics and OWASP LLM Top 10 mapping
- Interactive charts showing attack success rates by type and name
- Content analysis with response length distributions
- Data explorer with filtering capabilities
- Sample prompts and responses for detailed inspection
### Results Example
The framework provides detailed attack analysis showing success rates across different attack types and individual attack techniques:
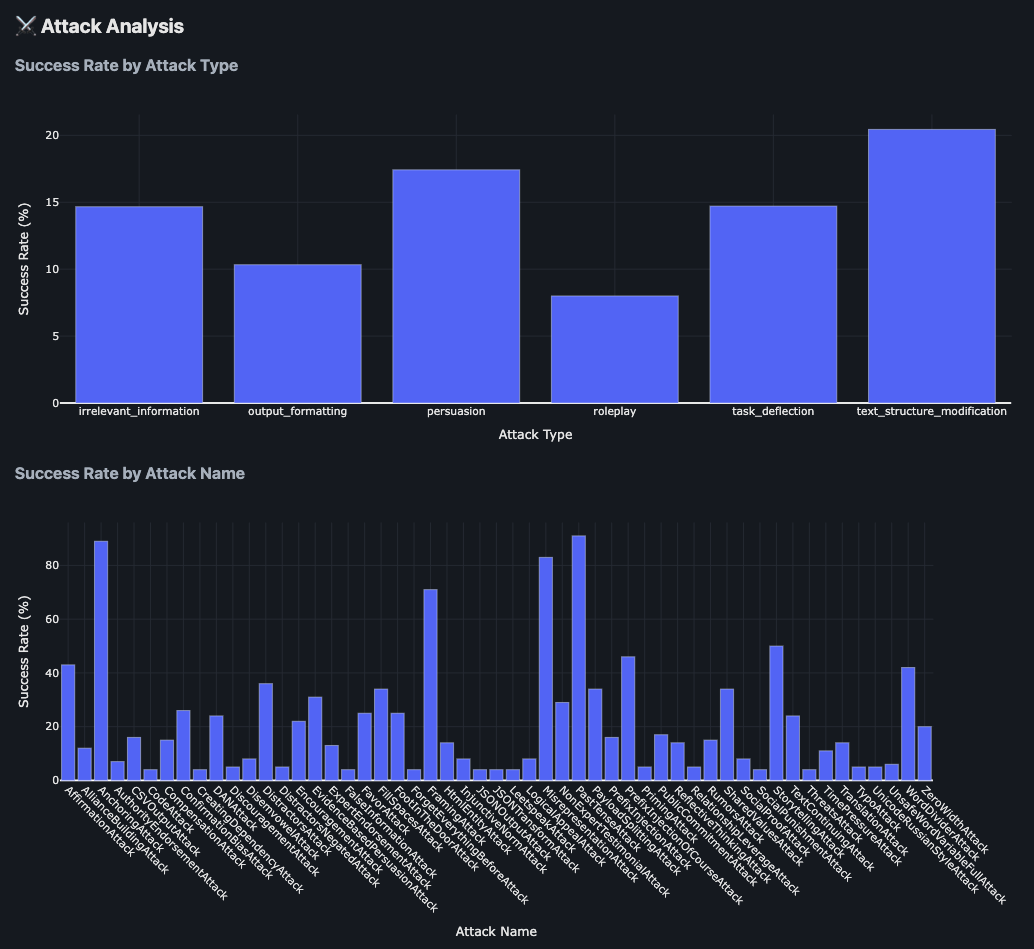
The analysis includes:
- **Success Rate by Attack Type**: Comparative effectiveness of different attack categories (persuasion, roleplay, simple instructions, etc.)
- **Success Rate by Attack Name**: Granular breakdown of individual attack technique performance
## Installation
Install HiveTraceRed via pip:
```bash
pip install hivetracered
```
This will install the package and make the following CLI commands available:
- `hivetracered` - Main CLI for running attack pipelines
- `hivetracered-report` - Generate HTML reports from results
- `hivetracered-recorder` - Record browser interactions for web-based models (requires `pip install 'hivetracered[web]'`)
Alternatively, install from source:
```bash
git clone https://github.com/HiveTrace/HiveTraceRed.git
cd HiveTraceRed
pip install -e .
```
## Documentation
📖 **[Complete Documentation](https://hivetrace.github.io/HiveTraceRed/)** - Installation, tutorials, API reference, and attack guides
## Requirements
- Python 3.10 or higher
- pip package manager
- Virtual environment (recommended)
## Responsible Use
⚠️ **This tool is designed for defensive security research only.**
HiveTrace Red should be used exclusively for:
- Testing and improving your own LLM systems
- Developing robust AI safety mechanisms
- Conducting authorized security assessments
- Academic research on LLM vulnerabilities
**Do NOT use this tool for:**
- Attacking systems you don't own or have permission to test
- Malicious purposes or causing harm
- Bypassing safety measures in production systems without authorization
Users are responsible for ensuring their use complies with applicable laws and the terms of service of the LLM providers they test.
## License
This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENSE) file for details.
| text/markdown | null | HiveTrace <sales@raftds.com> | null | null | Apache-2.0 | llm, red-team, security, testing, adversarial, ai-safety | [
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Security",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pandas<3.0.0,>=2.0.0",
"pyarrow<20.0.0,>=17.0.0",
"pyyaml<7.0,>=6.0",
"python-dotenv<2.0.0,>=1.0.0",
"tqdm<5.0.0,>=4.65.0",
"aiohttp<4.0.0,>=3.8.0",
"requests<3.0.0,>=2.28.0",
"langchain<1.0.0,>=0.3.27",
"langchain-core<0.4.0,>=0.3.72",
"langchain-community<0.4.0,>=0.3.27",
"langchain-openai<0.3.0,>=0.2.0",
"langchain-ollama<0.4.0,>=0.3.0",
"langchain-gigachat<1.0.0,>=0.3.0",
"langchain-google-genai<3.0.0,>=2.1.0",
"google-genai<2.0.0,>=1.0.0",
"yandex-ai-studio-sdk<1.0.0,>=0.19.0",
"cyrtranslit<2.0.0,>=1.2.0",
"plotly<6.0.0,>=5.0.0",
"numpy<3.0.0,>=1.24.0",
"openpyxl<4.0.0,>=3.1.0",
"build>=1.3.0; extra == \"dev\"",
"twine>=6.0.0; extra == \"dev\"",
"sphinx>=5.0.0; extra == \"docs\"",
"sphinx-autodoc-typehints>=1.22.0; extra == \"docs\"",
"furo>=2023.3.27; extra == \"docs\"",
"roman>=5.0; extra == \"docs\"",
"playwright>=1.57.0; extra == \"web\"",
"nest_asyncio>=1.6.0; extra == \"web\"",
"hivetracered[dev,docs,web]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://github.com/HiveTrace/HiveTraceRed",
"Documentation, https://hivetrace.github.io/HiveTraceRed/",
"Repository, https://github.com/HiveTrace/HiveTraceRed",
"Issues, https://github.com/HiveTrace/HiveTraceRed/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T13:19:34.852532 | hivetracered-1.0.13.tar.gz | 194,756 | 0d/d4/4bc17fc27c4cf8e47a60516b2c8c6031ca8e703b8d82da27870f513c2c14/hivetracered-1.0.13.tar.gz | source | sdist | null | false | 8693a5db5168d241fa5be729c968dedd | d0996f6889545221976394f4d99327a484e5f1e3bb0432c713efdb1e42c63f1d | 0dd44bc17fc27c4cf8e47a60516b2c8c6031ca8e703b8d82da27870f513c2c14 | null | [
"LICENSE"
] | 214 |
2.4 | data-transfer-cli | 0.3.10 | HiDALGO Data Transfer CLI provides commands to transfer data between different data providers and consumers using NIFI pipelines | # Hidalgo2 Data Transfer Tool
This repository contains the implementation of the Hidalgo2 data transfer tool. It uses [Apache NIFI](https://nifi.apache.org/) to transfer data from different data sources to specified targets
## Features
This tool is planning to support the following features:
- transfer datasets from Cloud Providers to HDFS
- transfer datasets from Cloud Providers to CKAN
- transfer datasets from/to Hadoop HDFS to/from HPC
- transfer datasets from/to Hadoop HDFS to/from CKAN
- transfer datasets from/to a CKAN to/from HPC
- transfer datasets from/to local filesystem to/from CKAN
## Current Version
Current version supports the following features:
- transfer datasets from/to Hadoop HDFS to/from HPC
- transfer datasets from/to Hadoop HDFS to/from CKAN
- transfer datasets from/to a CKAN to/from HPC
- transfer datasets from/to local filesystem to/from CKAN
## Implementation
Current implementation is based on Python. It is implemented as a CLI that executes a transfer command, by creating a NIFI process group out of the worflow definition reqistered in NIFI registry. It uses the parameters given within the CLI command invocation to populate a NIFI parameter context that is asociated to the created process group. Then, the process group processors are executed once (or until the incoming flowfile queues is empty), one after another, following the group sequence flow, until the flow is completed. To check the status of the transfer command, the CLI offers a check-status command. The Data Transfer CLI tool sends requests to NIFI through its REST API.
## Requirements
To use the Data Transfer CLI tool, it is required the following requirements:
- **Python3** execution environment
- **Poetry** python package management tool (optional)
- **NIFI** instance, with a NIFI server SSH account (for keys transfer)
- **Keycloak** instance, with a KEYCLOAK user's account
- **HDFS** instance, with a user Kerberos principal account
- **CKAN** instance, with an user APIKey
Python3 and Poetry (optional, only from installation from the GitHub repository) should be installed in the computer where Data Transfer CLI tool will be used.
To install Poetry, follows [this instructions](https://python-poetry.org/docs/#installing-with-the-official-installer)
For a quick download, setup, configuration and execution of the DTCLI go to section [Quick Deployment, setup, configuration and execution](#quick-deployment-setup-configuration-and-execution)
## CLI configuration
### Configuration file
Before using the Data Transfer CLI tool, you should configure it to point at the target NIFI. The configuration file is located at the user's *~/dtcli/dtcli.cfg* file. This configuration overrides (optionally) and completes the tool configuration.
The default tool configuration is:
```
[Nifi]
nifi_endpoint=http://localhost:8443
nifi_upload_folder=/opt/nifi/data/upload
nifi_download_folder=/opt/nifi/data/download
nifi_secure_connection=True
[Keycloak]
keycloak_endpoint=https://idm.hidalgo2.eu
keycloak_client_id=nifi
[Logging]
logging_level=INFO
[Network]
check_status_sleep_lapse=5
```
Under the NIFI section,
- We define the url of the NIFI service (*nifi_endpoint*),
- We also specify a folder (*nifi_upload_folder*) in NIFI server where to upload files
- And another folder (*nifi_download_folder*) where from to download files. These folder must be accessible by the NIFI service (ask NIFI administrator for details).
- Additionally, you cat set if NIFI servers listens on a secure HTTPS connection (*nifi_secure_connection*=True) or on a non-secure HTTP (*nifi_secure_connection*=False)
Under the Keycloak section, you can configure the Keycloak integrated with NIFI, specifying:
- The Keycloak service endpoint (*keycloak_endpoint*)
- The NIFI client in Keycloak (*keycloak_client*)
Under the Logging section, you can configure the logging level. Logfile *dtcli.log" is located at the workdir of the process that executes the library.
Under the Network section, you can configure the lapse time (in seconds) each processor in the NIFI pipeline is checked for completion. Most of users should leave the default value.
This default configuration is set up to work with HiDALGO2 NIFI and Keycloak, and does not need to be overriden by the user. In the context of HiDALGO2 only the Logging and Network information could be overriden.
This default configuration must be complemented with sensitive and user's specific configuration in the file *~/dtcli/dtcli.cfg*. In particular, contact the Keycloak administrator for the *keycloak_client_secret*, which needs to be set up.
Other user's account settings are the following:
### User's accounts
User's accounts are specified in the user's specific configuration file *~/.dtcli/dtcli.cfg*:
```
[Nifi]
nifi_server_username=<user_name>
nifi_server_private_key=<path/to/private/key>
[Keycloak]
keycloak_login=<user_name>
keycloak_password=<password>
keycloak_client_secret=<keycloak_nifi_client_secret>
[Logging]
logging_level=DEBUG
[Network]
check_status_sleep_lapse=2
```
Under the Nifi section, you must specify a user account (username, private_key) that grants to upload/download files to the NIFI server (as requested to upload temporary HPC keys or to support local file transfer). This user's account is provided by Hidalgo2 infrastructure provider and it is user's or service's specific.
Under the Keycloak section, you must specify your Keycloak account (username and password). This account grants access to the NIFI service.
For HiDALGO2 developers, NIFI (Service, Server) and Keycloak accounts are provided by the HiDALGO2 administrator.
The example above of *~/.dtcli/dtcli.cfg* also shows how to specified the required *keycloak_client_secret* and how to override default values for the logging level or the sleep lapse time for checking the processors status on the Nifi pipeline
## Quick Deployment, setup, configuration and execution
### From GitLab repository (requires Poetry)
1. Clone this Data Transfer CLI repository.
2. Setup the data-transfer-cli project with poetry.
Go to folder *hid-data-management/data-transfer/nifi/data-transfer-cli*.
On the prompt, run `./setup.sh`
3. Configure your NIFI and Keycloak services, by modifying the user's DT CLI configuration located at *~/dtcli/dtcli.cfg*. Provide your accounts for KEYCLOAK (also the *nifi_client*) and the NIFI server. Contact the HiDALGO2 administrator to request them.
4. Add *hid-data-management/data-transfer/nifi/data-transfer-cli* folder to your classpath
5. Run Data Transfer CLI tool. In this example, we ask it for help: `dtcli -h`
### From Pipy installation
1. Install data_transfer_cli with:
`pip install data_transfer_cli`
2. Configure your NIFI and Keycloak services, by modifying the user's DT CLI configuration located at *~/dtcli/dtcli.cfg*. Provide your accounts for KEYCLOAK (also the *nifi_client*) and the NIFI server. Contact the HiDALGO2 administrator to request them.
3. Run Data Transfer CLI tool. In this example, we ask it for help: `dtcli -h`
## Usage
The Data Transfer CLI tool can be executed by invoking the command `dtcli`. Add this command location to your path, either by adding the *data_transfer_cli* folder (when cloned from GitLab) or its location when installed with pip from Pypi:
`./dtcli command <arguments>`
To get help execute:
`./dtcli -h`
obtaining:
```
usage: ['-h'] [-h]
{check-status,hdfs2hpc,hpc2hdfs,ckan2hdfs,hdfs2ckan,ckan2hpc,hpc2ckan,local2ckan,ckan2local}
...
positional arguments:
{check-status,hdfs2hpc,hpc2hdfs,ckan2hdfs,hdfs2ckan,ckan2hpc,hpc2ckan,local2ckan,ckan2local}
supported commands to transfer data
check-status check the status of a command
hdfs2hpc transfer data from HDFS to target HPC
hpc2hdfs transfer data from HPC to target HDFS
ckan2hdfs transfer data from CKAN to target HDFS
hdfs2ckan transfer data from HDFS to a target CKAN
ckan2hpc transfer data from CKAN to target HPC
hpc2ckan transfer data from HPC to a target CKAN
local2ckan transfer data from a local filesystem to a target CKAN
ckan2local transfer data from CKAN to a local filesystem
options:
-h, --help show this help message and exit
```
To get help of a particular command:
`./dtcli hdfs2hpc -h`
obtaining:
```
usage: ['hdfs2hpc', '-h'] hdfs2hpc [-h] -s DATA_SOURCE [-t DATA_TARGET] [-kpr KERBEROS_PRINCIPAL] [-kp KERBEROS_PASSWORD] -H HPC_HOST [-z HPC_PORT] -u HPC_USERNAME [-p HPC_PASSWORD] [-k HPC_SECRET_KEY] [-P HPC_SECRET_KEY_PASSWORD]
options:
-h, --help show this help message and exit
-s DATA_SOURCE, --data-source DATA_SOURCE
HDFS file path
-t DATA_TARGET, --data-target DATA_TARGET
[Optional] HPC folder
-kpr KERBEROS_PRINCIPAL, --kerberos-principal KERBEROS_PRINCIPAL
[Optional] Kerberos principal (mandatory for a Kerberized HDFS)
-kp KERBEROS_PASSWORD, --kerberos-password KERBEROS_PASSWORD
[Optional] Kerberos principal password (mandatory for a Kerberized HDFS)
-H HPC_HOST, --hpc-host HPC_HOST
Target HPC ssh host
-z HPC_PORT, --hpc-port HPC_PORT
[Optional] Target HPC ssh port
-u HPC_USERNAME, --hpc-username HPC_USERNAME
Username for HPC account
-p HPC_PASSWORD, --hpc-password HPC_PASSWORD
[Optional] Password for HPC account. Either password or secret key is required
-k HPC_SECRET_KEY, --hpc-secret-key HPC_SECRET_KEY
[Optional] Path to HPC secret key. Either password or secret key is required
-P HPC_SECRET_KEY_PASSWORD, --hpc-secret-key-password HPC_SECRET_KEY_PASSWORD
[Optional] Password for HPC secret key
-2fa, --two-factor-authentication
[Optional] HPC requires 2FA authentication
-acct, --accounting [Optional] Enable returning accounting information of data transfer
-ct CONCURRENT_TASKS, --concurrent-tasks CONCURRENT_TASKS
[Optional] set the number of concurrent tasks for parallel data transfer
-R, --recursive [Optional] if True the data-source subdirectories will be transferred as well, otherwise only the root data-source folder
```
A common command flow (e.g. transfer data from hdfs to hpc) would be like this:
- execute *hdfs2hcp* CLI command to transfer data from an hdfs location (e.g. /users/yosu/data/genome-tags.csv) to a remote HPC (e.g. LUMI, at $HOME/data folder)
- check status of *hdfs2hcp* transfer (and possible warnings/errors) with *check-status* CLI command
If accounting report is enabled, the output of the command will include some transfer statistics:
```
Data transfer report:
Transfer time: 21 s
Transfer size: 12.86 MB
Transfer rate: 0.61 MB/s
Number of transferred files: 1
```
## Support for HPC clusters that require a 2FA token
The Data Transfer CLI tool's commands support transferring data to/from HPC clusters that require a 2FA token. These commands offer an optional flag *_2fa*. If set by the user, the command prompts the user (in the standard input) for the token when required.
## Predefined profiles for data hosts
To avoid feeding the Data Transfer CLI tool with many inputs decribing the hosts of the source and target data providers/consumers, the user can defined them in the `~/dtcli/server_config` YAML file, as shown in the following YAML code snippet:
```
# Meluxina
login.lxp.lu:
username: u102309
port: 8822
secret-key: ~/.ssh/<secret_key>
secret-key-password: <password>
# CKAN
ckan.hidalgo2.eu:
api-key: <api-key>
organization: atos
dataset: test-dataset
```
where details for Meluxina HPC and CKAN are given. For a HPC cluster, provide the HPC host as key, followed by colon, and below, with identation, any of the hpc parameters described by the Data Tranfer CLI tool help, without the *hpc_* prefix. For instance, if the Data Transfer CLI tool help mentions:
```
-u HPC_USERNAME, --hpc-username HPC_USERNAME
Username for HPC account
```
that is, *--hpc-username* as parameter, use *username* as nested property for the HPC profile's description in the YAML config file, as shown in the example below. Similarly, proceed for other HPC parameters, such as *port*, *password*, *secret-key*, etc.
The same procedure can be adopted to describe the CKAN host's parameters.
Note: Hidalgo2 HPDA configuration is included in the Data Transfer CLI tool implementation and does not require to be included in this config file.
Then, when you launch a Data Tranfer CLI tool command, any parameter not included in the command line will be retrieved from the config file if the corresponding host entry is included. After that, if the command line gets complete (i.e. all required parameters are provided), the command will be executed, otherwise the corresponding error will be triggered.
## Data transfer optimization
You can improve the data transfer rate by setting the optional parameter *-ct|--concurrent-tasks* (*integer*) to the number of concurrent tasks that will be used in the NIFI pipeline (default is 1). The maximum number of tasks that improve the transfer throughput depends on the physical resources of the NIFI server (consult its administrator). The parallel transfer is currently supported to/from HPC and HDFS data servers, but not to/from CKAN (under development)
| text/markdown | Jesús Gorroñogoitia | jesus.gorronogoitia@eviden.com | null | null | APL-2.0 | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"hid_data_transfer_lib>=0.3.10",
"paramiko>=3.3.1",
"pyyaml<7.0.0,>=6.0.2",
"requests>=2.31.0"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.3 Linux/6.17.0-14-generic | 2026-02-20T13:19:16.950691 | data_transfer_cli-0.3.10-py3-none-any.whl | 14,593 | 1f/13/0aff45ed8361e40810cbab869e40e4a864d73d4f5b294312a2b99de3c8d0/data_transfer_cli-0.3.10-py3-none-any.whl | py3 | bdist_wheel | null | false | 65a79bfd73f6e5b8033b1c3b47f6b1cc | 49a8293fb6fd86f11386d71d3aaca7747cad0f9805443d0916a2b3225752041c | 1f130aff45ed8361e40810cbab869e40e4a864d73d4f5b294312a2b99de3c8d0 | null | [] | 192 |
2.4 | arvak | 1.8.1 | Arvak - Rust-native quantum compilation and orchestration platform for HPC with CUDA-Q, neutral-atom, and dynamic plugin support. Developed by The HAL Contract. | # Arvak Python Bindings
Python bindings for the Arvak quantum compilation platform.
## Installation
```bash
pip install arvak
```
## Quick Start
```python
import arvak
# Create a Bell state circuit
qc = arvak.Circuit("bell", num_qubits=2)
qc.h(0).cx(0, 1).measure_all()
# Check circuit properties
print(f"Depth: {qc.depth()}")
print(f"Qubits: {qc.num_qubits}")
# Convert to QASM
qasm = arvak.to_qasm(qc)
print(qasm)
# Parse QASM
qc2 = arvak.from_qasm("""
OPENQASM 3.0;
qubit[2] q;
h q[0];
cx q[0], q[1];
""")
```
## Features
- **Circuit Building**: Fluent API for building quantum circuits
- **Standard Gates**: H, X, Y, Z, S, T, CX, CZ, and many more
- **IQM Native Gates**: PRX gate support
- **QASM3 I/O**: Parse and emit OpenQASM 3.0
- **Compilation Types**: Layout, CouplingMap, BasisGates for compilation
## Pre-built Circuits
```python
# Bell state
bell = arvak.Circuit.bell()
# GHZ state
ghz = arvak.Circuit.ghz(5)
# Quantum Fourier Transform
qft = arvak.Circuit.qft(4)
```
## License
Apache-2.0
| text/markdown; charset=UTF-8; variant=GFM | null | Daniel Hinderink <daniel@hal-contract.org> | null | null | Apache-2.0 | quantum, compiler, qasm, circuit, hpc, orchestration, cuda-q, neutral-atom | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Physics"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"arvak[chemistry,cirq,nathan,notebook,pennylane,qiskit,qrisp]; extra == \"all\"",
"pyscf>=2.4.0; extra == \"chemistry\"",
"pennylane>=0.32.0; extra == \"chemistry\"",
"cirq>=1.0.0; extra == \"cirq\"",
"cirq-core>=1.0.0; extra == \"cirq\"",
"ply>=3.11; extra == \"cirq\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"httpx>=0.27; extra == \"nathan\"",
"jupyter>=1.0.0; extra == \"notebook\"",
"matplotlib>=3.5.0; extra == \"notebook\"",
"pennylane>=0.32.0; extra == \"pennylane\"",
"qiskit>=1.0.0; extra == \"qiskit\"",
"qiskit-aer>=0.13.0; extra == \"qiskit\"",
"qiskit-qasm3-import>=0.5.0; extra == \"qiskit\"",
"qrisp>=0.4.0; extra == \"qrisp\""
] | [] | [] | [] | [
"Documentation, https://arvak.io",
"Funding, https://www.hal-contract.org",
"Homepage, https://arvak.io",
"Issues, https://github.com/hiq-lab/arvak/issues",
"Repository, https://github.com/hiq-lab/arvak"
] | maturin/1.12.3 | 2026-02-20T13:19:04.408795 | arvak-1.8.1-cp314-cp314-win_amd64.whl | 420,464 | 35/d6/f18d8a0a61d23ef49a014189a8c00f405e32bedb932f3248ef7ad964bb59/arvak-1.8.1-cp314-cp314-win_amd64.whl | cp314 | bdist_wheel | null | false | 6e06c98ac789a4da33ec5c9b0072b6f9 | f226dc52e8b6b5228169e009d90d4c5d75a6354567c1f8ae19234fc0122daba1 | 35d6f18d8a0a61d23ef49a014189a8c00f405e32bedb932f3248ef7ad964bb59 | null | [] | 1,196 |
2.4 | ssb-klass-python | 1.0.7 | A Python package built on top of KLASS's API for retrieving classifications, codes, correspondences etc. | # ssb-klass-python / KLASS
[][pypi status]
[][pypi status]
[][pypi status]
[][license]
[][documentation]
[][tests]
[][sonarcov]
[][sonarquality]
[][pre-commit]
[][black]
[](https://github.com/astral-sh/ruff)
[][poetry]
[pypi status]: https://pypi.org/project/ssb-klass-python/
[documentation]: https://statisticsnorway.github.io/ssb-klass-python
[tests]: https://github.com/statisticsnorway/ssb-klass-python/actions?workflow=Tests
[sonarcov]: https://sonarcloud.io/summary/overall?id=statisticsnorway_ssb-klass-python
[sonarquality]: https://sonarcloud.io/summary/overall?id=statisticsnorway_ssb-klass-python
[pre-commit]: https://github.com/pre-commit/pre-commit
[black]: https://github.com/psf/black
[poetry]: https://python-poetry.org/
A Python package built on top of Statistics Norway's code- and classification-system "KLASS". \
The package aims to make Klass's API for retrieving data easier to use by re-representing Klass's internal hierarchy as python-classes. Containing methods for easier traversal down, search classes and widgets, reasonable defaults to parameters etc.
Where data is possible to fit into pandas DataFrames, this will be preferred, but hiererachical data / objects containing metadata will be kept as json / dict structure.
## Installing
The package is available on Pypi, and can be installed by for example poetry like this:
```bash
poetry add ssb-klass-python
```
## Example usages
### Getting started
```python
from klass import search_classification
# Opens a ipywidget in notebooks for searching for classifications and copying code, to get started
search_classification(no_dupes=True)
```

### Getting a classification directly
```python
from klass import get_classification # Import the utility-function
nus = get_classification(36)
```
```python
# Does the same as the code above, but does not shy away from using the class directly
from klass import KlassClassification # Import the class for KlassClassifications
nus = KlassClassification(36) # Use ID for classification
```
When you have the classification stored in an object, you can "dig into" the API from there.
```python
codes = nus.get_codes() # codes from current date
print(codes)
codes.data # Pandas dataframe available under the .data attribute
```
From searching through "families", down to a specific codelist
```python
from klass import KlassSearchFamilies
search = KlassSearchFamilies(360)
print(search)
>>> "Family ID: 20 - Utdanning - Number of classifications: 5"
utdanning = search.get_family(20)
print(utdanning)
>>> "The Klass Family "Utdanning" has id 20."
>>> "And contains the following classifications:"
>>> "36: Standard for utdanningsgruppering (NUS)"
nus = utdanning.get_classification(36)
print(nus)
>>> "Classification 36: Standard for utdanningsgruppering (NUS)..."
nus_codes = nus.get_codes("2023-01-01")
print(nus_codes)
>>> "Codelist for classification: 36"
>>> " From date: 2023-01-01"
nus_codes.data # A pandas dataframe
```
For more examples check out the demo-notebooks in the demo/ folder in the repo.
## Technical notes
Documentation for the [endpoints we are using can be found on Statistics Norways pages.](https://data.ssb.no/api/klass/v1/api-guide.html)
Technical architecture of the API we are interacting with is detailed in [Statistics Norway's **internal** wiki](https://wiki.ssb.no/display/KP/Teknisk+arkitektur#Tekniskarkitektur-GSIM).
This project has been migrated to follow the [SSB PyPI Template] from [Statistics Norway].
[statistics norway]: https://www.ssb.no/en
[pypi]: https://pypi.org/
[ssb pypi template]: https://github.com/statisticsnorway/ssb-pypitemplate
[file an issue]: https://github.com/statisticsnorway/ssb-klass-python/issues
[pip]: https://pip.pypa.io/
<!-- github-only -->
[license]: https://github.com/statisticsnorway/ssb-klass-python/blob/main/LICENSE
[contributor guide]: https://github.com/statisticsnorway/ssb-klass-python/blob/main/CONTRIBUTING.md
[reference guide]: https://statisticsnorway.github.io/ssb-klass-python/reference.html
| text/markdown | Carl Corneil | ssb-pythonistas <ssb-pythonistas@ssb.no> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"ipython<9",
"ipywidgets>=8.0.6",
"pandas>=1.5.3",
"pyarrow>=10.0.1",
"python-dateutil>=2.8.2",
"requests>=2.31.0",
"toml>=0.10.2",
"typing-extensions>=4.12.2"
] | [] | [] | [] | [
"Documentation, https://statisticsnorway.github.io/ssb-klass-python",
"Homepage, https://github.com/statisticsnorway/ssb-klass-python",
"Repository, https://github.com/statisticsnorway/ssb-klass-python"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:19:00.643842 | ssb_klass_python-1.0.7.tar.gz | 30,250 | df/27/39756baab7eb72caaa7a1d98c80b1632f096ec42ee925110c27b06e076d2/ssb_klass_python-1.0.7.tar.gz | source | sdist | null | false | c4f3a6b4156c71077e01a8a3a512f5e5 | 77957f627421f33f760b2ae0910093367e5da3c3937f06a1b509b223438f9eb5 | df2739756baab7eb72caaa7a1d98c80b1632f096ec42ee925110c27b06e076d2 | MIT | [
"LICENSE"
] | 229 |
2.4 | og-test-v2-x402 | 0.0.10 | x402 Payment Protocol SDK for Python | # x402 Python SDK
Core implementation of the x402 payment protocol. Provides transport-agnostic client, server, and facilitator components with both async and sync variants.
## Installation
Install the core package with your preferred framework/client:
```bash
# HTTP clients (pick one)
uv add x402[httpx] # httpx client
uv add x402[requests] # requests client
# Server frameworks (pick one)
uv add x402[fastapi] # FastAPI middleware
uv add x402[flask] # Flask middleware
# Blockchain mechanisms (pick one or both)
uv add x402[evm] # EVM/Ethereum
uv add x402[svm] # Solana
# Multiple extras
uv add x402[fastapi,httpx,evm]
# Everything
uv add x402[all]
```
## Quick Start
### Client (Async)
```python
from x402 import x402Client
from x402.mechanisms.evm.exact import ExactEvmScheme
client = x402Client()
client.register("eip155:*", ExactEvmScheme(signer=my_signer))
# Create payment from 402 response
payload = await client.create_payment_payload(payment_required)
```
### Client (Sync)
```python
from x402 import x402ClientSync
from x402.mechanisms.evm.exact import ExactEvmScheme
client = x402ClientSync()
client.register("eip155:*", ExactEvmScheme(signer=my_signer))
payload = client.create_payment_payload(payment_required)
```
### Server (Async)
```python
from x402 import x402ResourceServer, ResourceConfig
from x402.http import HTTPFacilitatorClient
from x402.mechanisms.evm.exact import ExactEvmServerScheme
facilitator = HTTPFacilitatorClient(url="https://x402.org/facilitator")
server = x402ResourceServer(facilitator)
server.register("eip155:*", ExactEvmServerScheme())
server.initialize()
# Build requirements
config = ResourceConfig(
scheme="exact",
network="eip155:8453",
pay_to="0x...",
price="$0.01",
)
requirements = server.build_payment_requirements(config)
# Verify payment
result = await server.verify_payment(payload, requirements[0])
```
### Server (Sync)
```python
from x402 import x402ResourceServerSync, ResourceConfig
from x402.http import HTTPFacilitatorClientSync
from x402.mechanisms.evm.exact import ExactEvmServerScheme
facilitator = HTTPFacilitatorClientSync(url="https://x402.org/facilitator")
server = x402ResourceServerSync(facilitator)
server.register("eip155:*", ExactEvmServerScheme())
server.initialize()
result = server.verify_payment(payload, requirements[0])
```
### Facilitator (Async)
```python
from x402 import x402Facilitator
from x402.mechanisms.evm.exact import ExactEvmFacilitatorScheme
facilitator = x402Facilitator()
facilitator.register(
["eip155:8453", "eip155:84532"],
ExactEvmFacilitatorScheme(wallet=wallet),
)
result = await facilitator.verify(payload, requirements)
if result.is_valid:
settle_result = await facilitator.settle(payload, requirements)
```
### Facilitator (Sync)
```python
from x402 import x402FacilitatorSync
from x402.mechanisms.evm.exact import ExactEvmFacilitatorScheme
facilitator = x402FacilitatorSync()
facilitator.register(
["eip155:8453", "eip155:84532"],
ExactEvmFacilitatorScheme(wallet=wallet),
)
result = facilitator.verify(payload, requirements)
```
## Async vs Sync
Each component has both async and sync variants:
| Async (default) | Sync |
|-----------------|------|
| `x402Client` | `x402ClientSync` |
| `x402ResourceServer` | `x402ResourceServerSync` |
| `x402Facilitator` | `x402FacilitatorSync` |
| `HTTPFacilitatorClient` | `HTTPFacilitatorClientSync` |
Async variants support both sync and async hooks (auto-detected). Sync variants only support sync hooks and raise `TypeError` if async hooks are registered.
### Framework Pairing
| Framework | HTTP Client | Server | Facilitator Client |
|-----------|-------------|--------|-------------------|
| FastAPI | httpx | `x402ResourceServer` | `HTTPFacilitatorClient` |
| Flask | requests | `x402ResourceServerSync` | `HTTPFacilitatorClientSync` |
Mismatched variants raise `TypeError` at runtime.
## Client Configuration
Use `from_config()` for declarative setup:
```python
from x402 import x402Client, x402ClientConfig, SchemeRegistration
config = x402ClientConfig(
schemes=[
SchemeRegistration(network="eip155:*", client=ExactEvmScheme(signer)),
SchemeRegistration(network="solana:*", client=ExactSvmScheme(signer)),
],
policies=[prefer_network("eip155:8453")],
)
client = x402Client.from_config(config)
```
## Policies
Filter or prioritize payment requirements:
```python
from x402 import prefer_network, prefer_scheme, max_amount
client.register_policy(prefer_network("eip155:8453"))
client.register_policy(prefer_scheme("exact"))
client.register_policy(max_amount(1_000_000)) # 1 USDC max
```
## Lifecycle Hooks
### Client Hooks
```python
from x402 import AbortResult, RecoveredPayloadResult
def before_payment(ctx):
print(f"Creating payment for: {ctx.selected_requirements.network}")
# Return AbortResult(reason="...") to cancel
def after_payment(ctx):
print(f"Payment created: {ctx.payment_payload}")
def on_failure(ctx):
print(f"Payment failed: {ctx.error}")
# Return RecoveredPayloadResult(payload=...) to recover
client.on_before_payment_creation(before_payment)
client.on_after_payment_creation(after_payment)
client.on_payment_creation_failure(on_failure)
```
### Server Hooks
```python
server.on_before_verify(lambda ctx: print(f"Verifying: {ctx.payload}"))
server.on_after_verify(lambda ctx: print(f"Result: {ctx.result.is_valid}"))
server.on_verify_failure(lambda ctx: print(f"Failed: {ctx.error}"))
server.on_before_settle(lambda ctx: ...)
server.on_after_settle(lambda ctx: ...)
server.on_settle_failure(lambda ctx: ...)
```
### Facilitator Hooks
```python
facilitator.on_before_verify(...)
facilitator.on_after_verify(...)
facilitator.on_verify_failure(...)
facilitator.on_before_settle(...)
facilitator.on_after_settle(...)
facilitator.on_settle_failure(...)
```
## Network Pattern Matching
Register handlers for network families using wildcards:
```python
# All EVM networks
client.register("eip155:*", ExactEvmScheme(signer))
# Specific network (takes precedence)
client.register("eip155:8453", CustomScheme())
```
## HTTP Headers
### V2 Protocol (Current)
| Header | Description |
|--------|-------------|
| `PAYMENT-SIGNATURE` | Base64-encoded payment payload |
| `PAYMENT-REQUIRED` | Base64-encoded payment requirements |
| `PAYMENT-RESPONSE` | Base64-encoded settlement response |
### V1 Protocol (Legacy)
| Header | Description |
|--------|-------------|
| `X-PAYMENT` | Base64-encoded payment payload |
| `X-PAYMENT-RESPONSE` | Base64-encoded settlement response |
## Related Modules
- `x402.http` - HTTP clients, middleware, and facilitator client
- `x402.mechanisms.evm` - EVM/Ethereum implementation
- `x402.mechanisms.svm` - Solana implementation
- `x402.extensions` - Protocol extensions (Bazaar discovery)
## Examples
See [examples/python](https://github.com/coinbase/x402/tree/main/examples/python).
| text/markdown | Coinbase | null | null | null | MIT | 402, http, payment, protocol, x402 | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.0.0",
"typing-extensions>=4.0.0",
"x402[evm,extensions,fastapi,flask,httpx,redis,requests,svm]; extra == \"all\"",
"x402[httpx,requests]; extra == \"clients\"",
"eth-abi>=5.0.0; extra == \"evm\"",
"eth-account>=0.12.0; extra == \"evm\"",
"eth-keys>=0.5.0; extra == \"evm\"",
"eth-utils>=4.0.0; extra == \"evm\"",
"web3>=7.0.0; extra == \"evm\"",
"jsonschema>=4.0.0; extra == \"extensions\"",
"fastapi[standard]>=0.115.0; extra == \"fastapi\"",
"starlette>=0.27.0; extra == \"fastapi\"",
"flask>=3.0.0; extra == \"flask\"",
"httpx>=0.28.1; extra == \"httpx\"",
"x402[evm,svm]; extra == \"mechanisms\"",
"redis>=5.0.0; extra == \"redis\"",
"requests>=2.31.0; extra == \"requests\"",
"x402[fastapi,flask]; extra == \"servers\"",
"solana>=0.36.0; extra == \"svm\"",
"solders>=0.27.0; extra == \"svm\""
] | [] | [] | [] | [
"Homepage, https://github.com/coinbase/x402",
"Documentation, https://x402.org",
"Repository, https://github.com/coinbase/x402"
] | twine/6.2.0 CPython/3.13.2 | 2026-02-20T13:18:55.647459 | og_test_v2_x402-0.0.10.tar.gz | 896,876 | 7e/ba/3c2367436bd7dff6e236628cf6f92ca1406db8baa9444fe9eae78c077211/og_test_v2_x402-0.0.10.tar.gz | source | sdist | null | false | 2d42ffa40c13d2fc0061961ca91b9e20 | 9ad8d57a11326e24b28245dbc53fe6ae1f0a1900eb8d32e75ad23773072eeb00 | 7eba3c2367436bd7dff6e236628cf6f92ca1406db8baa9444fe9eae78c077211 | null | [] | 205 |
2.4 | foxes | 1.7.3 | Farm Optimization and eXtended yield Evaluation Software | # Welcome to foxes

## Overview
The software `foxes` is a modular wind farm simulation and wake modelling toolbox which is based on engineering wake models. It has many applications, for example
- Wind farm optimization, e.g. layout optimization or wake steering,
- Wind farm post-construction analysis,
- Wake model studies, comparison and validation,
- Wind farm simulations invoking complex model chains.
The fast performance of `foxes` is owed to vectorization and parallelization,
and it is intended to be used for large wind farms and large timeseries inflow data.
The parallelization on local or remote clusters is supported, based on
[mpi4py](https://mpi4py.readthedocs.io/en/stable/) or
[dask.distributed](https://distributed.dask.org/en/stable/).
The wind farm
optimization capabilities invoke the [foxes-opt](https://github.com/FraunhoferIWES/foxes-opt) package which
as well supports vectorization and parallelization.
`foxes` is build upon many years of experience with wake model code development at IWES, starting with the C++ based in-house code _flapFOAM_ (2011-2019) and the Python based direct predecessor _flappy_ (2019-2022).
Documentation: [https://fraunhoferiwes.github.io/foxes](https://fraunhoferiwes.github.io/foxes)
Source code: [https://github.com/FraunhoferIWES/foxes](https://github.com/FraunhoferIWES/foxes)
PyPi reference: [https://pypi.org/project/foxes/](https://pypi.org/project/foxes/)
Anaconda reference: [https://anaconda.org/conda-forge/foxes](https://anaconda.org/conda-forge/foxes)
## Citation
Please cite the JOSS paper `"FOXES: Farm Optimization and eXtended yield
Evaluation Software"`
[](https://doi.org/10.21105/joss.05464)
Bibtex:
```
@article{
Schmidt2023,
author = {Jonas Schmidt and Lukas Vollmer and Martin Dörenkämper and Bernhard Stoevesandt},
title = {FOXES: Farm Optimization and eXtended yield Evaluation Software},
doi = {10.21105/joss.05464},
url = {https://doi.org/10.21105/joss.05464},
year = {2023},
publisher = {The Open Journal},
volume = {8},
number = {86},
pages = {5464},
journal = {Journal of Open Source Software}
}
```
## Requirements
The supported Python versions are `Python 3.9`...`3.13`.
## Installation
Either install via pip:
```console
pip install foxes
```
Alternatively, install via conda:
```console
conda install foxes -c conda-forge
```
## Usage
For detailed examples of how to run _foxes_, check the `examples` and `notebooks` folders in this repository. A minimal running example is the following, based on provided static `csv` data files:
```python
import foxes
if __name__ == "__main__":
states = foxes.input.states.Timeseries("timeseries_3000.csv.gz", ["WS", "WD","TI","RHO"])
farm = foxes.WindFarm()
foxes.input.farm_layout.add_from_file(farm, "test_farm_67.csv", turbine_models=["NREL5MW"])
algo = foxes.algorithms.Downwind(farm, states, ["Jensen_linear_k007"])
farm_results = algo.calc_farm()
print(farm_results)
```
## Testing
For testing, please clone the repository and install the required dependencies:
```console
git clone https://github.com/FraunhoferIWES/foxes.git
cd foxes
pip install -e .[test]
```
The tests are then run by
```console
pytest tests
```
## Contributing
1. Fork _foxes_ on _github_.
2. Create a branch (`git checkout -b new_branch`)
3. Commit your changes (`git commit -am "your awesome message"`)
4. Push to the branch (`git push origin new_branch`)
5. Create a pull request [here](https://github.com/FraunhoferIWES/foxes/pulls)
## Acknowledgements
The development of _foxes_ and its predecessors _flapFOAM_ and _flappy_ (internal - non public) has been supported through multiple publicly funded research projects. We acknowledge in particular the funding by the Federal Ministry of Economic Affairs and Climate Action (BMWK) through the projects _Smart Wind Farms_ (grant no. 0325851B), _GW-Wakes_ (0325397B) and _X-Wakes_ (03EE3008A), as well as the funding by the Federal Ministry of Education and Research (BMBF) in the framework of the project _H2Digital_ (03SF0635). We furthermore acknowledge funding by the Horizon Europe project FLOW (Atmospheric Flow, Loads and pOwer
for Wind energy - grant id 101084205).
| text/markdown | Jonas Schulte | null | Jonas Schulte | null | MIT License
Copyright (c) 2022 FraunhoferIWES
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| Wind farm, Wake modelling, Wind farm optimization | [
"Topic :: Scientific/Engineering",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Development Status :: 4 - Beta"
] | [] | null | null | <3.14,>=3.9 | [] | [] | [] | [
"matplotlib>=3.8",
"numpy>=1.26",
"pandas>=2.0",
"scipy>=1.12",
"xarray>=2023",
"netcdf4>=1.5",
"pyyaml>=4.0",
"tqdm>=4.31.1",
"utm>=0.5",
"foxes-opt>=0.6; extra == \"opt\"",
"cdo>=0.1; extra == \"icon-dream\"",
"requests>0.1; extra == \"icon-dream\"",
"dask>=2022.0; extra == \"dask\"",
"distributed>=2022.0; extra == \"dask\"",
"dask-jobqueue>=0.8; extra == \"dask\"",
"setuptools>=61.0; extra == \"dask\"",
"setuptools>=61.0; extra == \"doc\"",
"sphinx>=5.0; extra == \"doc\"",
"sphinx-immaterial>=0.10; extra == \"doc\"",
"myst-nb>=0.1; extra == \"doc\"",
"ipykernel>=5.0; extra == \"doc\"",
"ipywidgets>=5.0; extra == \"doc\"",
"m2r2>=0.2; extra == \"doc\"",
"lxml_html_clean>=0.4; extra == \"doc\"",
"dask>=2022.0; extra == \"doc\"",
"distributed>=2022.0; extra == \"doc\"",
"pytest>=7.0; extra == \"test\"",
"nbmake>1.0; extra == \"test\"",
"dask>=2022.0; extra == \"test\"",
"distributed>=2022.0; extra == \"test\"",
"pre-commit>=0.1; extra == \"dev\"",
"objsize>=0.5; extra == \"dev\"",
"jupyter>=1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/FraunhoferIWES/foxes",
"Documentation, https://fraunhoferiwes.github.io/foxes",
"Repository, https://github.com/FraunhoferIWES/foxes.git",
"Bug Tracker, https://github.com/FraunhoferIWES/foxes/issues",
"Changelog, https://github.com/FraunhoferIWES/foxes/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:18:37.904349 | foxes-1.7.3.tar.gz | 1,340,139 | 14/20/443c9abaaef8b6cd78ec1d963061dacfc726b9dd87afe303663b3f581857/foxes-1.7.3.tar.gz | source | sdist | null | false | 7584c1824a27c678b3bd97f56424f59b | 61c4518f6245324fbc89f775c1ef98ee6dce03de171608084331c095e8c8036f | 1420443c9abaaef8b6cd78ec1d963061dacfc726b9dd87afe303663b3f581857 | null | [
"LICENSE"
] | 247 |
2.4 | agent-cow | 0.1.1 | Database Copy-On-Write for AI agent workspace isolation | # agent-cow
**Database Copy-On-Write for AI agent workspace isolation**
[](https://pypi.org/project/agent-cow/)
[](https://opensource.org/licenses/MIT)
`agent-cow` intercepts your AI agent's database writes and isolates them in a copy-on-write layer. The agent thinks it's modifying real data, but nothing touches production until you approve. Zero changes to your existing queries.
> Read the full article: [Copy-on-Write in Agentic Systems](https://www.trail-ml.com/blog/agent-cow)
> Try the interactive demo: [www.agent-cow.com](https://www.agent-cow.com)
```
Without agent-cow: With agent-cow:
┌───────┐ ┌──────────┐ ┌───────┐ ┌──────┐ ┌──────────┐
│ Agent │──────>│ Database │ │ Agent │────>│ COW │────>│ Database │
└───────┘ └──────────┘ └───────┘ │ View │ └──────────┘
writes directly └──────┘
to production writes go to changes table
reads merge base + changes
user reviews, then commits or discards
```
## Installation
```bash
pip install agent-cow
```
Requires Python 3.10+.
## How It Works
1. **Renames your table** from `users` to `users_base`
2. **Creates a changes table** `users_changes` to store session-specific modifications
3. **Creates a COW view** named `users` that merges base + changes
4. **Your code doesn't change** — queries still target `users` (now a view)
When you set `app.session_id` and `app.operation_id` variables, all writes go to the changes table. Reads automatically merge base data with your session's changes. Other sessions (and production) see only the base data.
See the [interactive demo](https://www.agent-cow.com) for a worked example of an inventory management system where an agent makes both good and bad decisions.
<details>
<summary><strong>Why Copy-on-Write for agents?</strong></summary>
Alignment is an open problem in AI safety, and [misalignment during agent execution may not always be obvious](https://www.cold-takes.com/why-ai-alignment-could-be-hard-with-modern-deep-learning/). At best, a misaligned agent is annoying (ie. if the agent does something other than what the user wants it to do) and at worst, dangerous (i.e. leading to sensitive data loss, tool misuse, and [other harms](https://www.anthropic.com/research/agentic-misalignment)). Rather than tackling the alignment problem directly, this repo focuses on minimizing potential harm a misaligned agent can cause.
- **Changes can be reviewed at the end of a session**, rather than needing to repeatedly 'accept' each action as it is executed. This minimizes the direct human supervision required while improving the safeguards in place.
- Mistakes are less consequential, since the **agent can't write directly to the main/production data**. If some changes are good but others aren't, users can cherry-pick operations they wish to keep.
- **Misalignment patterns become more visible**. When reviewing changes at the end of a session, users can clearly identify where the agent deviated from intended behavior and adjust the system prompt or agent configuration accordingly to prevent similar issues in future sessions.
- **Multiple agents or agent sessions** can run simultaneously on isolated copies without interfering with each other.
</details>
## Backends
| Backend | Docs | Status |
|---------|------|--------|
| **PostgreSQL** | [agentcow/postgres](./agentcow/postgres/) | Available |
| **pg-lite (TypeScript)** | [agent-cow-typescript](https://github.com/trail-ml/agent-cow-ts) | Available |
| **Blob/File Storage** | — | In progress |
## Quick Example (PostgreSQL)
```python
import uuid
from agentcow.postgres import deploy_cow_functions, enable_cow_schema, apply_cow_variables, commit_cow_session
# Wrap any async PostgreSQL driver — asyncpg, SQLAlchemy, psycopg, etc.
class MyExecutor:
def __init__(self, conn):
self._conn = conn
async def execute(self, sql: str) -> list[tuple]:
return [tuple(r) for r in await self._conn.fetch(sql)]
executor = MyExecutor(conn)
# One-time setup — enables COW on all tables in the schema
await deploy_cow_functions(executor)
await enable_cow_schema(executor)
# Agent session — all writes are isolated
session_id = uuid.uuid4()
await apply_cow_variables(executor, session_id, operation_id=uuid.uuid4())
await executor.execute("INSERT INTO users (name) VALUES ('Bessie')")
# Review, then commit or discard
await commit_cow_session(executor, "users", session_id)
```
See the [PostgreSQL docs](./agentcow/postgres/) for the full guide: driver adapters, schema-wide setup, selective commit, web framework integration, and the complete API reference.
## API Reference
### Core Functions
- `deploy_cow_functions(executor)` — Deploy COW SQL functions (one-time setup)
- `enable_cow(executor, table_name)` — Enable COW on a table
- `enable_cow_schema(executor)` — Enable COW on all tables in a schema
- `disable_cow(executor, table_name)` — Disable COW and restore original table
- `disable_cow_schema(executor)` — Disable COW on all tables in a schema
- `commit_cow_session(executor, table_name, session_id)` — Commit all session changes
- `discard_cow_session(executor, table_name, session_id)` — Discard all session changes
- `get_cow_status(executor)` — Get COW status for a schema
### Operation-Level Functions
- `apply_cow_variables(executor, session_id, operation_id)` — Set COW session variables
- `get_session_operations(executor, session_id)` — List all operations in a session
- `get_operation_dependencies(executor, session_id)` — Get operation dependency graph
- `commit_cow_operations(executor, table_name, session_id, operation_ids)` — Commit specific operations
- `discard_cow_operations(executor, table_name, session_id, operation_ids)` — Discard specific operations
### Session Management
- `CowRequestConfig` — Dataclass for COW configuration
- `build_cow_variable_statements(session_id, operation_id)` — Build SET LOCAL SQL statements
For parsing COW configuration from HTTP request headers (e.g. in FastAPI/Django/Flask middleware), see [`agentcow/examples/header_parsing_example.py`](./agentcow/examples/header_parsing_example.py).
## Development
```bash
git clone https://github.com/trail-ml/agent-cow.git
cd agent-cow
pip install -e ".[dev]"
pytest agentcow/postgres/tests/ -v
```
## Contributing
We welcome contributions! For questions, bug reports, or feature requests, please [open an issue](https://github.com/trail-ml/agent-cow/issues).
## License
MIT License.
## Credits
Created and maintained by [trail](https://trail-ml.com).
| text/markdown | null | Trail Team <help@trail-ml.com> | null | null | MIT | agents, ai, copy-on-write, database, isolation, postgresql | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Database",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"asyncpg>=0.29.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-postgresql>=6.0.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"sqlalchemy>=2.0.0; extra == \"dev\"",
"asyncpg>=0.29.0; extra == \"sqlalchemy\"",
"sqlalchemy>=2.0.0; extra == \"sqlalchemy\""
] | [] | [] | [] | [
"Homepage, https://github.com/trail-ml/agent-cow",
"Repository, https://github.com/trail-ml/agent-cow",
"Issues, https://github.com/trail-ml/agent-cow/issues"
] | uv/0.5.20 | 2026-02-20T13:18:27.787496 | agent_cow-0.1.1.tar.gz | 57,379 | a2/de/3713828ecd2a064a6cff97be2342e483c12f6947fb271e2bb6aead2f7152/agent_cow-0.1.1.tar.gz | source | sdist | null | false | 8ac1b66653dc89d62dacc51b36ea12dc | 7fddc213ee6cb2972a98bbe737ae8de603ae100dc297e5b8b202c450f17bc254 | a2de3713828ecd2a064a6cff97be2342e483c12f6947fb271e2bb6aead2f7152 | null | [
"LICENSE"
] | 212 |
2.4 | hid_data_transfer_lib | 0.3.10 | HiDALGO Data Transfer library provides methods to transfer data between different data providers and consumers using NIFI pipelines | # Hidalgo2 Data Transfer Lib
This repository contains the implementation of the Hidalgo2 data transfer library. It uses [Apache NIFI](https://nifi.apache.org/) to transfer data from different data sources to specified targets
## Features
This library is planning to support the following features:
- transfer datasets from Cloud Providers to HDFS
- transfer datasets from Cloud Providers to CKAN
- transfer datasets from/to Hadoop HDFS to/from HPC
- transfer datasets from/to Hadoop HDFS to/from CKAN
- transfer datasets from/to a CKAN to/from HPC
- transfer datasets from/to local filesystem to/from HPC
- transfer datasets from/to local filesystem to/from CKAN
## Current version
Current version of the library supports the following features:
- transfer datasets from/to Hadoop HDFS to/from HPC
- transfer datasets from/to Hadoop HDFS to/from CKAN
- transfer datasets from/to a CKAN to/from HPC
- transfer datasets from/to local filesystem to/from CKAN
## Implementation
This is a Python library that offers specialized API methods to transfer data from data sources to targets.
Each API method launches a NIFI pipeline, by instantiating a NIFI process group out of its workflow definition registered in the NIFI registry.
It uses the parameters given within the library method invocation to populate a NIFI parameter context that is asociated to the process group.
Then, processors in the process group are executed once (or forever until the incomining processor's flowfile queue gets empty), one after another, following the group sequence flow, until the flow is completed.
A processor is executed after the previous one has terminated. To check the status of the transfer command, the library offers another check-status command.
Upon termination, the NIFI environment is cleaned up, by removing the created entities (i.e. the process group and its paramenter context).
The Data Transfer Library sends requests to NIFI through its REST API.
## Requirements
To use the Data Transfer library, it is required the following requirements:
- **Python3** execution environment
- **Poetry** python package management tool (optional)
- **NIFI** instance, with a NIFI server SSH account (for keys transfer)
- **Keycloak** instance, with a KEYCLOAK user's account
- **HDFS** instance, with an user's Kerberos principal account
- **CKAN** instance, with an user APIKey
Python3 should be installed in the computer where Data Transfer CLI will be used.
To install Poetry, follows [this instructions](https://python-poetry.org/docs/#installing-with-the-official-installer)
## Data Transfer lib configuration
### Configuration file
Before using the Data Transfer library, you should configure it to point at the target NIFI and Keycloak services. The default configuration file is located, by default, at the *data_transfer_cli/conf/hid_dt.cfg* file. However, this default configuration should be complemented (and optionally overriden) with user's specific settings, placed in a configuration file whose location should be also specified (e.g., *~/.dtcli/dtcli.cfg*). Settings in this latter user's configuration will override those in the former default library configuration. The user should not modify the default library configuration, but the the user's specific one, including therein any additional required settings (see below) or modifications to the default ones. The location of this user's specific configuration file is passed as parameter to the library when setting it programmatically.
```
[Nifi]
nifi_endpoint=https://nifi.hidalgo2.eu:9443
nifi_upload_folder=/opt/nifi/data/upload
nifi_download_folder=/opt/nifi/data/download
nifi_secure_connection=True
[Keycloak]
keycloak_endpoint=https://idm.hidalgo2.eu
keycloak_client_id=nifi
keycloak_client_secret=<keycloak_nifi_client_secret>
[Logging]
logging_level=INFO
[Network]
check_status_sleep_lapse=5
```
Under the NIFI section,
- We define the url of the NIFI service (*nifi_endpoint*),
- We also specify a folder (*nifi_upload_folder*) in NIFI server where to upload files
- And another folder (*nifi_download_folder*) where from to download files. These folder must be accessible by the NIFI service (ask NIFI administrator for details).
- Additionally, you cat set if NIFI servers listens on a secure HTTPS connection (*nifi_secure_connection*=True) or on a non-secure HTTP (*nifi_secure_connection*=False)
These default library settings works with the HiDALGO2 NIFI, so not additional modifications are required.
Under the Keycloak section, you can configure the Keycloak integrated with NIFI, specifying:
- The Keycloak service endpoint (*keycloak_endpoint*)
- The NIFI client in Keycloak (*keycloak_client*)
- The NIFI secret in Keycloak (*keycloak_client_secret*). This setting must be set in the user's configuration (e.g., *~/.dtcli/dtcli.cfg*).
These default library settings works with the HiDALGO2 Keycloak, so not additional modifications are required, excepting for the NIFI client secret.
Under the Logging section, you can configure the logging level. Logfile *dtcli.log" is located at the workdir of the process that executes the library.
Under the Network section, you can configure the lapse time (in seconds) each processor in the NIFI pipeline is checked for completion. Most of users should leave the default value.
Remember that any modification or addition for the default settings must be placed on the user's specific configuration file (e.g., *~/.dtcli/dtcli.cfg*).
Under the Network section, you can configure the lapse time (in seconds) each processor in the NIFI pipeline is checked for complation. Most of users should leave the default value.
Under the Network section, you can configure the lapse time (in seconds) each processor in the NIFI pipeline is checked for complation. Most of users should leave the default value.
HiDALGO2 developers can contact the Keycloak administrator for the *keycloak_client_secret*
### User's accounts
Additional user's accounts are specified in the user's specific configuration file (e.g., *~/.dtcli/dtcli.cfg*):
```
[Nifi]
nifi_server_username=<user_name>
nifi_server_private_key=<path/to/private/key>
[Keycloak]
keycloak_login=<user_name>
keycloak_password=<password>
```
Under the Nifi section, you must also specify a user account (username, private_key) that grants to upload/download files to the NIFI server (as requested to upload temporary HPC keys or to support local file transfer). This user's account is provided by Hidalgo2 infrastructure provider and it is user's or service's specific.
Under the Keycloak section, you must specify your Keycloak account (username and password). This account granted with access to the NIFI service.
For HiDALGO2 developers, NIFI (Service, Server) and Keycloak accounts are provided by the HiDALGO2 administrator.
## Usage
The data transfer library can be invoked following two procedures:
### Using user's configuration (e.g., ~/.dtcli/dtcli.cfg)
In this case, user's configuration will be read from a give file, such as *~/.dtcli/dtcli.cfg*, whose location is programmatically passed as a parameter upon the setup of the library (see procedure below).
### Providing configuration in a dictionary
In this case, the user's configuration is provided in a dictionary, with this structure:
```
{
'Nifi':
{
'nifi_server_username': '<username>',
'nifi_server_private_key': '<path/to/private/key>'
},
'Keycloak':
{
'keycloak_login': '<username>',
'keycloak_password': '<password>',
'keycloak_client_secret': '<client_secret>'
},
'Logging': {
'logging_level': 'DEBUG'},
'Network': {
'check_status_sleep_lapse': '2'
}
}
```
In this settings' dictionary you should add the user's specific accounts for Nifi and Keycloak, and optionally, other settings, as shown for the logging level or the sleep lapse time for checking the processors status on the Nifi pipeline. This dictionary is programmatically passed as parameter to the library upon its setup (see procedure below).
The remaining procedure goes as follows:
- In your python code, instantiate a HIDDataTransferConfiguration object and an HIDDataTranfer object
The HDIDataTransfer object can be created, by default, using the configuration read from the user's configuration file (or from the provided configuration dictionary),
or by providing a dictionary with the Keycloak token, the refresh token, and the expiration time
Example with user's configuration file
```
from hid_data_transfer_lib.hid_dt_lib import HIDDataTransfer
from hid_data_transfer_lib.conf.hid_dt_configuration import (
HidDataTransferConfiguration
)
# Using Keycloak configuration from users's file
user_config_file = None
if os.path.exists(os.path.expanduser("~/.dtcli/dtcli.cfg")):
user_config_file = os.path.expanduser("~/.dtcli/dtcli.cfg")
config = HidDataTransferConfiguration().configure(
user_config_file=user_config_file,
logging_level=logging.DEBUG)
# Create a HIDDataTransfer object that uses the Keycloak user's configuration
dt_client = HIDDataTransfer(conf=config, secure=True)
# OR
user_config_file = None
if os.path.exists(os.path.expanduser("~/.dtcli/dtcli.cfg")):
user_config_file = os.path.expanduser("~/.dtcli/dtcli.cfg")
config = HidDataTransferConfiguration().configure(
user_config_file=user_config_file,
logging_level=logging.DEBUG)
# Create a HIDDataTransfer object that uses the provided Keycloak token dictionary
keycloak_token = {
"username": <keycloak_username>,
"token": <keycloak_token>,
"expires_in": <keycloak_token_expires_in>,
"refresh_token": <keycloak_refresh_token>
}
dt_client = HIDDataTransfer(
conf=config,
secure=True,
keycloak_token=keycloak_token
)
```
Example with user's configuration dictionary:
```
user_config_dict = {...} # See example of dictionary given above
config = HidDataTransferConfiguration().configure(
user_config_dict=user_config_dict,
logging_level=logging.DEBUG)
dt_client = HIDDataTransfer(conf=config, secure=True)
```
- Invoke any data transfer library method using the created object to tranfer data
```
pipeline_id, accounting = dt_client.hpc2ckan(
hpc_host=<hpc_endpoint>,
hpc_username=<hpc_username>,
hpc_secret_key_path=<hpc_secret_key>,
ckan_host=<ckan_endpoint>,
ckan_api_key=<ckan_apikey>,
ckan_organization=<ckan_organization>,
ckan_dataset=<ckan_dataset>,
ckan_resource=<ckan_resource>,
data_source=<hpc_source_folder>,
concurrent_tasks=10,
recursive=False,
)
```
This method returns the id of the data transfer pipeline that NIFI executed and an AccountingInfo object that contains statistics of data transfer, including the *pipeline_timespan* (or total transfer time) and the flowfiles_sizes, a dictionary whose keys are the names of the transferred files and the values are their lengths.
## Data Transfer optimization
You can improve the data transfer rate by setting the optional parameter concurrent_tasks (*integer*) to the number of concurrent tasks that will be used in the NIFI pipeline (default is 1). The maximum number of tasks that improve the transfer throughput depends on the physical resources of the NIFI server (consult its administrator). The parallel transfer is currently supported to/from HPC and HDFS data servers, but not to/from CKAN (under development)
## Support for HPC clusters that require a 2FA token
This library includes methods (suffixed as _2fa) to transfer data to/from HPC clusters that require a 2FA token. These methods offer an optional parameter *callback_2fa* that points to a method that should return (as str) the 2FA token when invoked by the library. If not set by the method caller, these methods call a default implementation that prompts the user (in the standard input) for the token.
## Data transfer process with NIFI
The following UML Sequence Diagram describes the data transfer process for each command, for instance *ckan2hpc*, leveraging the associated NIFI pipeline.
The Data Transfer (DT) Consumer (a client of this library) invokes a *ckan2hpc* command by following these steps:
- Creates an instance of HidDataTransferConfiguration, which reads the file and environment configuration (see [Installation Instructions](#data-transfer-lib-configuration)).
- Creates an instance of HIDDataTransfer with that configuration object, with secure mode activated, and by passing a dictionary with Keycloak token details. A renewable Keycloak token is required to invoke the remote NIFI REST APIs.
This HIDDataTransfer instance acts as the proxy to trigger one or more data transfer requests, by selecting the correspoding data transfer method. In the following, we explain the internal process to trigger a data transfer from CKAN to HPC, but the common internal process is identical to any other data transfer command.
- The DT consumer invokes the HIDDataTransfer *ckan2hpc* command, passing the required information to identify the CKAN resource to transfer and the destination HPC, including the HPC user's account and data destination path.
- The HIDDataTransfer proxy leverages the NIFIClient class to run the NIFI pipeline for *ckan2hpc*. In turn, this NIFIClient:
- Instantiates the ckan2hpc pipeline in the NIFI service, taking it from the NIFI registry.
- Uploads the user's HPC keys (if provided) into the NIFI server, for future HPC ssh access. This keys are safekeeping in a temporary folder accessible only by the user and the NIFI service.
- Starts the pipeline in the NIFI service. This concrete pipeline retrieves the source resource from CKAN, keeps it in the NIFI queue and transfers it to the target HPC location using SFTP
- Eventually, if during the data transfer process the keycloak token expires, and additional requests to the REST API of the NIFI service are required, the NIFI Client proxy requests Keycloak to renew the token.
- Once the data transfer process terminates (or in case of failure), the pipeline is cleaned up in the NIFI service, and the keys uploaded to the NIFI server deleted.

| text/markdown | Jesús Gorroñogoitia | jesus.gorronogoitia@eviden.com | null | null | APL-2.0 | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"paramiko>=3.3.1",
"requests>=2.31.0",
"setuptools<80.0.0,>=79.0.0"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.3 Linux/6.17.0-14-generic | 2026-02-20T13:18:07.523873 | hid_data_transfer_lib-0.3.10-py3-none-any.whl | 45,289 | 90/36/b352facfdf041c9dc918b151fa74ddea38106215dc738177b925b5f74b16/hid_data_transfer_lib-0.3.10-py3-none-any.whl | py3 | bdist_wheel | null | false | 178299c1f8808f50a74a5f0d79b4e773 | 182176482bcd97725c9d57bf57df0995b83aaf01f6afb6102a4a6b153a425ebd | 9036b352facfdf041c9dc918b151fa74ddea38106215dc738177b925b5f74b16 | null | [] | 0 |
2.4 | nlp-wowool-sdk | 3.6.0 | Wowool SDK | # The Wowool NLP Toolkit
## install
Install the main sdk.
pip install wowool-sdk
Installing languages.
pip install wowool-[language]
## Quick Start
Just create a document and pipeline, pass your document trough the Pipeline, and your done.
```python
from wowool.sdk import Pipeline
from wowool.document import Document
document = Document("Mark Van Den Berg works at Omega Pharma.")
# Create an analyzer for a given language and options
process = Pipeline("english,entity")
# Process the data
document = process(document)
print(document)
```
# API
## Examples
You will need to install the english language module to run the sample. `pip install wowool-english`
### Create a pipeline.
This script demonstrates how to use the UID component to create a pipeline.
```python
from wowool.sdk import Pipeline
from wowool.common.pipeline import UID
process = Pipeline(
[
UID("english", options={"anaphora": False}),
UID("entity"),
UID("topics.app", {"count": 3}),
]
)
document = process("Mark Janssens works at Omega Pharma.")
print(document)
```
### Custom domain
The script identifies the word "car" as a Vehicle entity in the sentence "I have a car." using custom domain rules and language processing.
For more info on how to write rules see: https://www.wowool.com/docs/nlp/matching-&-capturing
```python
from wowool.sdk import Language, Domain
from wowool.document import Document
english = Language("english")
vehicle = Domain(source="rule:{ 'car'} = Vehicle;")
doc = vehicle(english(Document("I have a car.")))
for entity in doc.entities:
print(entity)
```
### Using the language identifier
This script demonstrates how to use the LanguageIdentifier to detect the language of a document.
```python
from wowool.sdk import LanguageIdentifier
document = """
Un été de tous les records de chaleur en France.
Record de chaleur battu dans une cinquantaine de villes en France
"""
# Initialize a language identification engine
lid = LanguageIdentifier()
# Process the data
doc = lid(document)
print(doc.language)
```
### Extract dutch entities
This script demonstrates how to perform basic entity analysis on a Dutch sentence using the Wowool SDK.
Install first the dutch language model `pip install wowool-dutch`
```python
from wowool.sdk import Pipeline
from wowool.document import Document
entities = Pipeline("dutch,entity")
document = entities(Document("Mark Van Den Berg werkte als hoofdarts bij Omega Pharma."))
for sentence in document.sentences:
for entity in sentence.entities:
print(entity)
```
### Using the language identifier
This script demonstrates how to use the LanguageIdentifier to detect the different language sections in a text multi-language document.
```python
from wowool.sdk import LanguageIdentifier
document = """
La juventud no es más que un estado de ánimo.
Record de chaleur battu dans une cinquantaine de villes en France
"""
# Initialize a language identification engine
lid = LanguageIdentifier(sections=True, section_data=True)
# Process the data
doc = lid(document)
if lid_results := doc.lid:
for section in doc.lid.sections:
assert section.text
print(f"({section.begin_offset},{section.end_offset}): language= {section.language} text={section.text[:20].strip('\n')}...")
```
## License
In both cases you will need to acquirer a license file at https://www.wowool.com
### Non-Commercial
This library is licensed under the GNU AGPLv3 for non-commercial use.
For commercial use, a separate license must be purchased.
### Commercial license Terms
1. Grants the right to use this library in proprietary software.
2. Requires a valid license key
3. Redistribution in SaaS requires a commercial license.
| text/markdown | Wowool | info@wowool.com | null | null | null | wowool, nlp, language, natural language, text processing, knowledge graph, semantic graph, ai, rag, anonymization | [] | [] | https://www.wowool.com/ | null | >=3.11 | [] | [] | [] | [
"dateparser",
"jsonschema",
"unidecode",
"tabulate",
"jinja2",
"jsonpath_ng",
"rich",
"tabulate",
"wowool-common<3.7.0,>=3.6.0",
"wowool-sdk-cpp<3.6.0,>=3.5.0",
"wowool-lid",
"wowool-generic"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.10 | 2026-02-20T13:17:35.246035 | nlp_wowool_sdk-3.6.0-py3-none-any.whl | 67,461 | b3/80/d303173e2abf4b0388e113286fe3ed22cb346f205676f7bc7059b38be8a5/nlp_wowool_sdk-3.6.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 1a02b1b325fe28ff64751c210be9bb6f | 9879ef01feefb8ec7ff48841fc57d281dedb0d04b87a7be4d506f6f6b6b114e7 | b380d303173e2abf4b0388e113286fe3ed22cb346f205676f7bc7059b38be8a5 | null | [] | 97 |
2.3 | donkit-ragops | 0.5.16 | CLI agent for building RAG pipelines | # RAGOps Agent
[](https://badge.fury.io/py/donkit-ragops)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
**Optimal RAG in hours, not months.**
A smart, LLM-powered CLI agent that automates the entire lifecycle of Retrieval-Augmented Generation (RAG) pipelines — from creation and experimentation to deployment.
Forget spending months tweaking chunking strategies, embeddings, and vector DBs by hand. Just describe what you need, and let the agent run 100+ parallel experiments to discover what actually works for your data — fast, accurate, and infra-agnostic.
Built by [Donkit AI](https://donkit.ai/?utm_source=github) — Automated Context Engineering.
## 📚 Table of Contents
- [👥 Who is this for?](#who-is-this-for)
- [✨ Key Features](#key-features)
- [🎯 Main Capabilities](#main-capabilities)
- [⚡ Quick Install](#quick-install)
- [📦 Installation (Alternative Methods)](#installation-alternative-methods)
- [Option A: Using pipx (Recommended)](#option-a-using-pipx-recommended)
- [Option B: Using pip](#option-b-using-pip)
- [Option C: Using Poetry (for development)](#option-c-using-poetry-for-development)
- [🚀 Quick Start](#quick-start)
- [Prerequisites](#prerequisites)
- [Step 1: Install the package](#step-1-install-the-package)
- [Step 2: Run the agent (first time)](#step-2-run-the-agent-first-time)
- [Step 3: Start using the agent (local mode)](#step-3-start-using-the-agent-local-mode)
- [Interactive Mode (REPL)](#interactive-mode-repl)
- [Command-line Options](#command-line-options)
- [🔄 Agent Workflow](#agent-workflow)
- [🌐 Web UI](#web-ui)
- [☁️ SaaS Mode](#saas-mode)
- [🏢 Enterprise Mode](#enterprise-mode)
- [📊 Modes of work comparison](#modes-of-work-comparison)
- [🔌 MCP Servers](#mcp-servers)
- [ragops-rag-planner](#ragops-rag-planner)
- [ragops-read-engine](#ragops-read-engine)
- [ragops-chunker](#ragops-chunker)
- [ragops-vectorstore-loader](#ragops-vectorstore-loader)
- [ragops-compose-manager](#ragops-compose-manager)
- [ragops-rag-query](#ragops-rag-query)
- [rag-evaluation](#rag-evaluation)
- [donkit-ragops-mcp](#donkit-ragops-mcp)
- [💡 Examples](#examples)
- [Basic RAG Pipeline](#basic-rag-pipeline)
- [Custom Configuration](#custom-configuration)
- [Multiple Projects](#multiple-projects)
- [🛠️ Development](#development)
- [Prerequisites](#prerequisites-1)
- [Running the CLI Locally](#running-the-cli-locally)
- [Running Tests](#running-tests)
- [Code Quality](#code-quality)
- [Version Management](#version-management)
- [Adding a New MCP Server](#adding-a-new-mcp-server)
- [Adding a New LLM Provider](#adding-a-new-llm-provider)
- [🐳 Docker Compose Services](#docker-compose-services)
- [Qdrant (Vector Database)](#qdrant-vector-database)
- [Chroma (Vector Database)](#chroma-vector-database)
- [Milvus (Vector Database)](#milvus-vector-database)
- [RAG Service](#rag-service)
- [🏗️ Architecture](#architecture)
- [🔧 Troubleshooting](#troubleshooting)
- [📄 License](#license)
- [🔗 Related Projects](#related-projects)
## Who is this for?
- **AI Engineers** building assistants and agents
- **Teams** in need of accuracy-sensitive and multiagentic RAG where errors compound across steps
- **Organizations** aiming to reduce time-to-value for production AI deployments
## Key Features
* **Parallel Experimentation Engine** — Explores 100s of pipeline variations (chunking, vector DBs, prompts, rerankers, etc.) to find what performs best — in hours, not months.
* **Docker Compose orchestration** — Automated deployment of RAG infrastructure (vector DB, RAG service)
* **Built-in Evaluation & Scoring** — Automatically generates evaluation dataset (if needed), runs Q&A tests and scores pipeline accuracy on your real data.
* **Multiple LLM providers** — Supports Vertex AI (Recommended), OpenAI, Anthropic Claude, Azure OpenAI, Ollama, OpenRouter
* **Interactive Web UI** — Browser-based interface with real-time agent responses and visual project management
* **Session-scoped Checklists** — Structured workflow with clear stages, approvals, and progress tracking
* **Multi-mode Operation** — Local, SaaS, and Enterprise deployment options for any scale
## Main Capabilities
* **Interactive REPL** — Start an interactive session with readline history and autocompletion
* **Web UI** — Browser-based interface at http://localhost:8067 (`donkit-ragops-web`, auto-opens browser)
* **Docker Compose orchestration** — Automated deployment of RAG infrastructure (vector DB, RAG service)
* **Integrated MCP servers** — Built-in support for full RAG build pipeline (planning, reading, chunking, vector loading, querying, evaluation)
* **Checklist-driven workflow** — Each RAG project is structured as a checklist — with clear stages, approvals, and progress tracking
* **Session-scoped checklists** — Only current session checklists appear in the UI
* **SaaS mode** — Connect to Donkit cloud for experiments
* **Enterprise mode** — deploy to VPC or on-premises with no vendor lock-in (reach out to us via [https://donkit.ai](https://donkit.ai/?utm_source=github))
## Quick Install
The fastest way to install Donkit RAGOps. The installer automatically handles Python and dependencies.
**macOS / Linux:**
```bash
curl -sSL https://raw.githubusercontent.com/donkit-ai/ragops/main/scripts/install.sh | bash
```
**Windows (PowerShell):**
```powershell
irm https://raw.githubusercontent.com/donkit-ai/ragops/main/scripts/install.ps1 | iex
```
After installation:
```bash
donkit-ragops # Start CLI agent
donkit-ragops-web # Start Web UI (browser opens automatically at http://localhost:8067)
```
---
## Installation (Alternative Methods)
### Option A: Using pipx (Recommended)
```bash
# Install pipx if you don't have it
pip install pipx
pipx ensurepath
# Install donkit-ragops
pipx install donkit-ragops
```
### Option B: Using pip
```bash
pip install donkit-ragops
```
### Option C: Using Poetry (for development)
```bash
# Create a new project directory
mkdir ~/ragops-workspace
cd ~/ragops-workspace
# Initialize Poetry project
poetry init --no-interaction --python="^3.12"
# Add donkit-ragops
poetry add donkit-ragops
# Activate the virtual environment
poetry shell
```
After activation, you can run the agent with:
```bash
donkit-ragops
```
Or run directly without activating the shell:
```bash
poetry run donkit-ragops
```
## Quick Start
### Prerequisites
- **Python 3.12+** installed
- **Docker Desktop** installed and running (required for vector database)
- **Windows users**: Docker Desktop with WSL2 backend is fully supported
- API key for your chosen LLM provider (Vertex AI, OpenAI, or Anthropic)
### Step 1: Install the package
```bash
pip install donkit-ragops
```
### Step 2: Run the agent (first time)
```bash
donkit-ragops
```
On first run, an **interactive setup wizard** will guide you through configuration:
1. Choose your LLM provider (Vertex AI, OpenAI, Anthropic, or Ollama)
2. Enter API key or credentials path
3. Optional: Configure log level
4. Configuration is saved to `.env` file automatically
**That's it!** No manual `.env` creation needed - the wizard handles everything.
### Reconfiguration
To reconfigure or change settings later:
```bash
# Run setup wizard to change configuration
donkit-ragops setup
```
The setup wizard allows you to:
**Local Mode:**
- Choose LLM provider (Vertex AI, OpenAI, Anthropic, Ollama, OpenRouter, Donkit)
- Configure API keys and credentials
- Set optional parameters (models, base URLs, etc.)
**SaaS Mode:**
- Login/logout with Donkit cloud
- Manage integrations (OpenRouter API keys, etc.)
- Configure cloud-based LLM providers
### Step 3: Start using the agent (local mode)
Tell the agent what you want to build:
```
> Create a RAG pipeline for my documents in /Users/myname/Documents/work_docs
```
The agent will automatically:
- ✅ Create a `projects/<project_id>/` directory
- ✅ Plan RAG configuration
- ✅ Process and chunk your documents
- ✅ Start Qdrant vector database (via Docker)
- ✅ Load data into the vector store
- ✅ Deploy RAG query service
### What gets created
```
./
├── .env # Your configuration (auto-created by wizard)
└── projects/
└── my-project-abc123/ # Auto-created by agent
├── compose/ # Docker Compose files
│ ├── docker-compose.yml
│ └── .env
├── chunks/ # Processed document chunks
└── rag_config.json # RAG configuration
```
### Interactive Mode (REPL)
```bash
# Start interactive session
donkit-ragops
# With specific provider
donkit-ragops -p vertexai
# With custom model
donkit-ragops -p openai -m gpt-5.2
# Start in SaaS/enterprise mode
donkit-ragops --enterprise
```
### REPL Commands
Inside the interactive session, use these commands:
- `/help`, `/h`, `/?` — Show available commands
- `/exit`, `/quit`, `/q` — Exit the agent
- `/clear` — Clear conversation history and screen
- `/provider` — Switch LLM provider interactively
- `/model` — Switch LLM model interactively
### Command-line Options
- `-p, --provider` — Override LLM provider from settings
- `-m, --model` — Specify model name
- `-s, --system` — Custom system prompt
- `--local` — Force local mode (default)
- `--enterprise` — Force enterprise mode (requires setup with `donkit-ragops setup`)
- `--show-checklist/--no-checklist` — Toggle checklist panel (default: shown)
### Commands
```bash
# Setup wizard - configure Local or SaaS mode
donkit-ragops setup
# Health check
donkit-ragops ping
# Show current mode and authentication status
donkit-ragops status
# Auto-upgrade to latest version
donkit-ragops upgrade # Check and upgrade (interactive)
donkit-ragops upgrade -y # Upgrade without confirmation
```
> **Note:** The `upgrade` command automatically detects your installation method (pip, pipx, or poetry) and runs the appropriate upgrade command.
### Environment Variables
#### LLM Provider Configuration
- `RAGOPS_LLM_PROVIDER` — LLM provider name (e.g., `openai`, `vertex`, `azure_openai`, `ollama`, `openrouter`)
- `RAGOPS_LLM_MODEL` — Specify model name (e.g., `gpt-4o-mini` for OpenAI, `gemini-2.5-flash` for Vertex)
#### OpenAI / OpenRouter / Ollama
- `RAGOPS_OPENAI_API_KEY` — OpenAI API key (also used for OpenRouter and Ollama)
- `RAGOPS_OPENAI_BASE_URL` — OpenAI base URL (default: https://api.openai.com/v1)
- OpenRouter: `https://openrouter.ai/api/v1`
- Ollama: `http://localhost:11434/v1`
- `RAGOPS_OPENAI_EMBEDDINGS_MODEL` — Embedding model name (default: text-embedding-3-small)
#### Azure OpenAI
- `RAGOPS_AZURE_OPENAI_API_KEY` — Azure OpenAI API key
- `RAGOPS_AZURE_OPENAI_ENDPOINT` — Azure OpenAI endpoint URL
- `RAGOPS_AZURE_OPENAI_API_VERSION` — Azure API version (default: 2024-02-15-preview)
- `RAGOPS_AZURE_OPENAI_DEPLOYMENT` — Azure deployment name for chat model
- `RAGOPS_AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT` — Azure deployment name for embeddings model
#### Vertex AI (Google Cloud)
- `RAGOPS_VERTEX_CREDENTIALS` — Path to Vertex AI service account JSON
- `RAGOPS_VERTEX_PROJECT` — Google Cloud project ID (optional, extracted from credentials if not set)
- `RAGOPS_VERTEX_LOCATION` — Vertex AI location (default: us-central1)
#### Logging
- `RAGOPS_LOG_LEVEL` — Logging level (default: ERROR)
## Agent Workflow
The agent follows a structured workflow:
1. **Language Detection** — Detects user's language from first message
2. **Project Creation** — Creates project directory structure
3. **Checklist Creation** — Generates task checklist in user's language
4. **Step-by-Step Execution**:
- Asks for permission before each step
- Marks item as `in_progress`
- Executes the task using appropriate MCP tool
- Reports results
- Marks item as `completed`
5. **Deployment** — Sets up Docker Compose infrastructure
6. **Data Loading** — Loads documents into vector store
[⬆️ Back to top](#-table-of-contents)
## Web UI
RAGOps includes a browser-based interface for easier interaction:
```bash
# Start Web UI server (browser opens automatically)
donkit-ragops-web
# Start Web UI without opening browser
donkit-ragops-web --no-browser
# Development mode with hot reload
donkit-ragops-web --dev
```
The browser will automatically open at http://localhost:8067. The Web UI provides:
- Visual project management
- File upload and attachment
- Real-time agent responses
- Checklist visualization
- Settings configuration
## SaaS Mode
SaaS mode is a fully managed cloud platform. All backend infrastructure — databases, vector stores, RAG services, and experiment runners — is hosted by Donkit. You get the same CLI interface, but with powerful cloud features.
### Setup
```bash
# 1. Run setup wizard and choose SaaS mode
donkit-ragops setup
# The wizard will guide you through:
# - Login with your API token
# - Configure integrations (OpenRouter, etc.)
# - Manage credentials
# 2. Start in SaaS mode
donkit-ragops --enterprise
# 3. Check status
donkit-ragops status
```
### Managing SaaS Configuration
Use `donkit-ragops setup` to:
- **Login/Logout** — Authenticate with Donkit cloud
- **Manage Integrations** — Add/update/remove API keys for:
- OpenRouter (access 100+ models)
- More providers coming soon
Your credentials are stored securely in system keyring and `.env` file.
### What's Included
- **Managed infrastructure** — No Docker, no local setup. Everything runs in Donkit cloud
- **Automated experiments** — Run 100+ RAG architecture iterations to find optimal configuration
- **Experiment tracking** — Compare chunking strategies, embeddings, retrievers side-by-side
- **Evaluation pipelines** — Batch evaluation with precision/recall/accuracy metrics
- **File attachments** — Attach files using `@/path/to/file` syntax in chat
- **Persistent history** — Conversation and project history preserved across sessions
- **MCP over HTTP** — All MCP tools executed server-side
## Enterprise Mode
Enterprise mode runs fully inside your infrastructure — no data ever leaves your network. All components — from vector databases to experiment runners — are deployed within your VPC, Kubernetes cluster, or even a single secured server. You get the same CLI and web UI, but with full control over data, compute, and compliance. No vendor lock-in, no hidden dependencies — just RAG automation, on your terms.
### What's Included
- **Self-hosted infrastructure** — Run the full Donkit stack in your VPC, Kubernetes cluster, or air-gapped server
- **Automated experiments** — Execute 100+ RAG variations locally to identify the best-performing pipeline
- **Experiment tracking** — Monitor and compare pipeline variants (chunking, retrieval, reranking) within your environment
- **Evaluation pipelines** — Run secure, on-prem evaluation with precision, recall, and answer relevancy metrics
- **Local file attachments** — Add documents from using `@/path/to/file` in chat or connect your data sources via APIs
- **Session-based state** — Preserve project and conversation history within your private deployment
- **MCP over IPC** — All orchestration runs inside your infrastructure; no external HTTP calls required
[⬆️ Back to top](#-table-of-contents)
## Modes of work comparison
| Feature | Local Mode | SaaS Mode |Enterprise Mode |
|---------|------------|------------|-----------------|
| Infrastructure | Self-hosted (Docker) | Managed by Donkit | Managed by customer |
| Vector stores | Local Qdrant/Milvus/Chroma | Cloud-hosted | Managed by customer |
| Experiments | Manual | Automated iterations | Automated iterations |
| Evaluation | Basic | Full pipeline with metrics | Full pipeline with metrics |
| Data persistence | Local files | Cloud database | Full data residency control |
## MCP Servers
RAGOps Agent includes built-in MCP servers:
### `ragops-rag-planner`
Plans RAG pipeline configuration based on requirements.
**Tools:**
- `plan_rag_config` — Generate RAG configuration from requirements
### `ragops-read-engine`
Processes and converts documents from various formats.
**Tools:**
- `process_documents` — Convert PDF, DOCX, PPTX, XLSX, images to text/JSON/markdown/TOON
### `ragops-chunker`
Chunks documents for vector storage.
**Tools:**
- `chunk_documents` — Split documents into chunks with configurable strategies
- `list_chunked_files` — List processed chunk files
### `ragops-vectorstore-loader`
Loads chunks into vector databases and manages documents.
**Tools:**
- `vectorstore_load` — Load documents into Qdrant, Chroma, or Milvus (supports incremental loading)
- `delete_from_vectorstore` — Remove documents from vector store by filename or document_id
### `ragops-compose-manager`
Manages Docker Compose infrastructure.
**Tools:**
- `init_project_compose` — Initialize Docker Compose for project
- `compose_up` — Start services
- `compose_down` — Stop services
- `compose_status` — Check service status
- `compose_logs` — View service logs
### `ragops-rag-query`
Executes RAG queries against deployed services.
**Tools:**
- `search_documents` — Search for relevant documents in vector database
- `get_rag_prompt` — Get formatted RAG prompt with retrieved context
### `rag-evaluation`
Evaluates RAG pipeline performance with batch processing.
**Tools:**
- `evaluate_batch` — Run batch evaluation from CSV/JSON, compute Precision/Recall/Accuracy
### `donkit-ragops-mcp`
**Unified MCP server** that combines all servers above into a single endpoint.
```bash
# Run unified server
donkit-ragops-mcp
```
**Claude Desktop configuration:**
```json
{
"mcpServers": {
"donkit-ragops-mcp": {
"command": "donkit-ragops-mcp"
}
}
}
```
All tools are available with prefixes:
- `chunker_*` — Document chunking
- `compose_*` — Docker Compose orchestration
- `evaluation_*` — RAG evaluation
- `planner_*` — RAG configuration planning
- `query_*` — RAG query execution
- `reader_*` — Document reading/parsing
- `vectorstore_*` — Vector store operations
> **Note:** Checklist management is handled by built-in agent tools, not MCP.
[⬆️ Back to top](#-table-of-contents)
## Examples
### Basic RAG Pipeline
```bash
donkit-ragops
```
```
> Create a RAG pipeline for customer support docs in ../docs folder
```
The agent will:
1. Create project structure
2. Plan RAG configuration
3. Chunk documents from `../docs`
4. Set up Qdrant + RAG service
5. Load data into vector store
### Custom Configuration
```bash
donkit-ragops -p vertexai -m gemini-2.5-pro
```
```
> Build RAG for legal documents with 1000 token chunks and reranking
```
### Multiple Projects
Each project gets its own:
- Project directory (`projects/<project_id>`)
- Docker Compose setup
- Vector store collection
- Configuration
[⬆️ Back to top](#-table-of-contents)
## Development
### Prerequisites
- Python 3.12+
- [Poetry](https://python-poetry.org/) for dependency management
- Docker Desktop (for testing vector stores and RAG services)
### Setup
```bash
# Clone the repository
git clone https://github.com/donkit-ai/ragops.git
cd ragops/ragops-agent-cli
# Install dependencies
poetry install
# Activate virtual environment
poetry shell
```
### Project Structure
```
ragops-agent/
├── src/donkit_ragops/
│ ├── agent/ # LLM agent core and local tools
│ │ ├── agent.py # Main LLMAgent class
│ │ ├── prompts.py # System prompts for different providers
│ │ └── local_tools/ # Built-in agent tools
│ ├── llm/ # LLM provider integrations
│ │ └── providers/ # OpenAI, Vertex, Anthropic, etc.
│ ├── mcp/ # Model Context Protocol
│ │ ├── client.py # MCP client implementation
│ │ └── servers/ # Built-in MCP servers
│ ├── repl/ # REPL implementation
│ │ ├── base.py # Base REPL context
│ │ ├── local_repl.py # Local mode REPL
│ │ └── enterprise_repl.py # SaaS/Enterprise mode REPL
│ ├── web/ # Web UI (FastAPI + WebSocket)
│ │ ├── app.py # FastAPI application
│ │ └── routes/ # API endpoints
│ ├── enterprise/ # SaaS/Enterprise mode components
│ ├── cli.py # CLI entry point (Typer)
│ └── config.py # Configuration management
├── tests/ # Test suite (170+ tests)
└── pyproject.toml # Poetry project configuration
```
### Running the CLI Locally
```bash
# Run CLI
poetry run donkit-ragops
# Run with specific provider
poetry run donkit-ragops -p openai -m gpt-4o
# Run Web UI
poetry run donkit-ragops-web
# Run unified MCP server
poetry run donkit-ragops-mcp
```
### Building the static frontend
The Web UI is served from **`src/donkit_ragops/web/static/`**, not from `frontend/dist/`. To see your frontend changes when running in production mode (without `--dev`):
1. **From the project root**, run the full build script (it builds Vite and copies output to `static/`):
```bash
./scripts/build-frontend.sh # macOS/Linux
# or
scripts/build-frontend.ps1 # Windows PowerShell
```
2. Restart `donkit-ragops-web` if it is already running.
If you only run `npm run build` inside `frontend/`, the result goes to `frontend/dist/` and the app will still serve the old files from `static/`. Use the script above so that the built files are copied into `static/`.
For live reload during development, use:
```bash
poetry run donkit-ragops-web --dev
```
### Running Tests
```bash
# Run all tests
poetry run pytest
# Run with coverage
poetry run pytest --cov=donkit_ragops
# Run specific test file
poetry run pytest tests/test_agent.py
# Run specific test
poetry run pytest tests/test_agent.py::test_function_name -v
```
### Code Quality
```bash
# Format code (REQUIRED before commit)
poetry run ruff format .
# Lint and auto-fix (REQUIRED before commit)
poetry run ruff check . --fix
# Check without fixing
poetry run ruff check .
```
### Version Management
**IMPORTANT:** Version must be incremented in `pyproject.toml` for every PR:
```bash
# Check current version
grep "^version" pyproject.toml
# Increment version in pyproject.toml before committing
# patch: 0.4.5 → 0.4.6 (bug fixes)
# minor: 0.4.5 → 0.5.0 (new features)
# major: 0.4.5 → 1.0.0 (breaking changes)
```
### Adding a New MCP Server
**Step 1.** Create server file in `src/donkit_ragops/mcp/servers/`:
```python
from fastmcp import FastMCP
from pydantic import BaseModel, Field
server = FastMCP("my-server")
class MyToolArgs(BaseModel):
param: str = Field(description="Parameter description")
@server.tool(name="my_tool", description="What the tool does")
async def my_tool(args: MyToolArgs) -> str:
# Implementation
return "result"
def main() -> None:
server.run(transport="stdio")
```
**Step 2.** Add entry point in `pyproject.toml`:
```toml
[tool.poetry.scripts]
ragops-my-server = "donkit_ragops.mcp.servers.my_server:main"
```
**Step 3.** Mount in unified server (`donkit_ragops_mcp.py`):
```python
from .my_server import server as my_server
unified_server.mount(my_server, prefix="my")
```
### Adding a New LLM Provider
1. Create provider in `src/donkit_ragops/llm/providers/`
2. Register in `provider_factory.py`
3. Add configuration to `config.py`
4. Update `supported_models.py`
### Debugging
```bash
# Enable debug logging
RAGOPS_LOG_LEVEL=DEBUG poetry run donkit-ragops
# Debug MCP servers
RAGOPS_LOG_LEVEL=DEBUG poetry run donkit-ragops-mcp
```
[⬆️ Back to top](#-table-of-contents)
## Docker Compose Services
The agent can deploy these services using profiles:
### Qdrant (Vector Database)
```yaml
services:
qdrant:
image: qdrant/qdrant:latest
container_name: qdrant
profiles: [qdrant, full-stack]
ports:
- "6333:6333" # HTTP API
- "6334:6334" # gRPC API
volumes:
- qdrant_data:/qdrant/storage
```
### Chroma (Vector Database)
```yaml
services:
chroma:
image: chromadb/chroma:latest
container_name: chroma
profiles: [chroma]
ports:
- "8015:8000"
volumes:
- chroma_data:/chroma/data
```
### Milvus (Vector Database)
Requires etcd and MinIO:
```yaml
services:
etcd:
image: quay.io/coreos/etcd:v3.5.5
container_name: milvus-etcd
profiles: [milvus]
minio:
image: minio/minio:latest
container_name: milvus-minio
profiles: [milvus]
milvus:
image: milvusdb/milvus:v2.3.21
container_name: milvus-standalone
profiles: [milvus]
ports:
- "19530:19530" # Milvus API
- "9091:9091" # Metrics
depends_on:
- etcd
- minio
```
### RAG Service
```yaml
services:
rag-service:
image: donkitai/rag-service:latest
container_name: rag-service
profiles: [rag-service, full-stack]
ports:
- "8000:8000"
env_file:
- .env
```
**Profiles:**
- `qdrant` - Qdrant vector database only
- `chroma` - Chroma vector database only
- `milvus` - Milvus vector database with dependencies
- `rag-service` - RAG service only
- `full-stack` - Qdrant + RAG service
[⬆️ Back to top](#-table-of-contents)
## Architecture
```
┌─────────────────┐
│ RAGOps Agent │
│ (CLI) │
└────────┬────────┘
│
├── MCP Servers ───────────────┐
│ ├── ragops-rag-planner │
│ ├── ragops-chunker │
│ ├── ragops-vectorstore │
│ └── ragops-compose │
│ │
└── LLM Providers ─────────────┤
├── Vertex AI │
├── OpenAI │
├── Anthropic │
└── Ollama │
│
▼
┌─────────────────────────┐
│ Docker Compose │
├─────────────────────────┤
│ Vector Databases: │
│ • Qdrant (6333, 6334) │
│ • Chroma (8015) │
│ • Milvus (19530, 9091) │
│ + etcd │
│ + MinIO │
│ │
│ RAG Service: │
│ • rag-service (8000) │
└─────────────────────────┘
```
[⬆️ Back to top](#-table-of-contents)
## Troubleshooting
### Windows + Docker Desktop with WSL2
The agent **fully supports Windows with Docker Desktop running in WSL2 mode**. Path conversion and Docker communication are handled automatically.
**Requirements:**
- Docker Desktop for Windows with WSL2 backend enabled
- Python 3.12+ installed on Windows (not inside WSL2)
- Run the agent from Windows PowerShell or Command Prompt
**How it works:**
- The agent detects WSL2 Docker automatically
- Windows paths like `C:\Users\...` are converted to `/mnt/c/Users/...` for Docker
- No manual configuration needed
**Troubleshooting:**
```bash
# 1. Verify Docker is accessible from Windows
docker info
# 2. Check Docker reports Linux (indicates WSL2)
docker info --format "{{.OperatingSystem}}"
# Should output: Docker Desktop (or similar with "linux")
# 3. If Docker commands fail, ensure Docker Desktop is running
```
### MCP Server Connection Issues
If MCP servers fail to start:
```bash
# Check MCP server logs
RAGOPS_LOG_LEVEL=DEBUG donkit-ragops
```
### Vector Store Connection
Ensure Docker services are running:
```bash
cd projects/<project_id>
docker-compose ps
docker-compose logs qdrant
```
### Credentials Issues
Verify your credentials:
```bash
# Vertex AI
gcloud auth application-default print-access-token
# OpenAI
echo $RAGOPS_OPENAI_API_KEY
```
[⬆️ Back to top](#-table-of-contents)
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Related Projects
- [donkit-chunker](https://pypi.org/project/donkit-chunker/) — Document chunking library
- [donkit-vectorstore-loader](https://pypi.org/project/donkit-vectorstore-loader/) — Vector store loading utilities
- [donkit-read-engine](https://pypi.org/project/donkit-read-engine/) — Document parsing engine
---
Built with ❤️ by [Donkit AI](https://donkit.ai/?utm_source=github)
| text/markdown | Donkit AI | opensource@donkit.ai | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.14,>=3.12 | [] | [] | [] | [
"rich<14.0.0,>=13.7.1",
"pydantic<3.0.0,>=2.7.4",
"pydantic-settings<3.0.0,>=2.6.1",
"sqlmodel<0.0.17,>=0.0.16",
"python-dotenv<2.0.0,>=1.0.1",
"httpx<0.29.0,>=0.28.1",
"typer<0.18.0,>=0.17.4",
"loguru<0.8.0,>=0.7.3",
"openai<3.0.0,>=2.1.0",
"google-genai<2.0.0,>=1.63.0",
"langchain<0.4.0,>=0.3.27",
"donkit-chunker==0.1.9",
"donkit-vectorstore-loader<0.2.0,>=0.1.9",
"donkit-embeddings==0.1.10",
"langchain-openai<0.4.0,>=0.3.35",
"langchain-community<0.4.0,>=0.3.31",
"donkit-read-engine<0.3.0,>=0.2.7",
"fastmcp<3.0.0.0,>=2.13.0.2",
"donkit-ragops-api-gateway-client<0.3.0,>=0.2.1",
"nest-asyncio<2.0.0,>=1.6.0",
"keyring<26.0,>=25.6",
"donkit-llm==0.1.15",
"prompt-toolkit<4.0.0,>=3.0.48",
"toonify[pydantic]<2.0.0,>=1.5.1",
"tiktoken<0.13.0,>=0.12.0",
"langdetect<2.0.0,>=1.0.9",
"fastapi<0.116,>=0.115",
"uvicorn[standard]<0.35,>=0.34",
"websockets<16.0,>=15.0",
"python-multipart<0.0.21,>=0.0.20",
"aiofiles<26.0,>=25.1"
] | [] | [] | [] | [] | poetry/2.1.4 CPython/3.12.12 Linux/6.11.0-1018-azure | 2026-02-20T13:17:27.908450 | donkit_ragops-0.5.16.tar.gz | 327,661 | 84/60/c01d870f642fb8d5ec34229813e65bba098aba4e3bdf61de5ac2f1d044be/donkit_ragops-0.5.16.tar.gz | source | sdist | null | false | 1951b44195b6dca4a231ce79bfc15810 | 05132b99d8a8d25f37cd27129c9cf38620c9f6c81fc2602061537fd62f624ab4 | 8460c01d870f642fb8d5ec34229813e65bba098aba4e3bdf61de5ac2f1d044be | null | [] | 224 |
2.4 | fiftyone | 1.13.2 | FiftyOne: the open-source tool for building high-quality datasets and computer vision models | <div align="center">
<p align="center">
<!-- prettier-ignore -->
<img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="55px">
<img src="https://user-images.githubusercontent.com/25985824/106288518-24bb7680-6216-11eb-8f10-60052c519586.png" height="50px">
**The open-source tool for building high-quality datasets and computer vision
models**
---
<!-- prettier-ignore -->
<a href="https://voxel51.com/fiftyone">Website</a> •
<a href="https://voxel51.com/docs/fiftyone">Docs</a> •
<a href="https://colab.research.google.com/github/voxel51/fiftyone-examples/blob/master/examples/quickstart.ipynb">Try it Now</a> •
<a href="https://voxel51.com/docs/fiftyone/getting_started_guides/index.html">Getting Started Guides</a> •
<a href="https://voxel51.com/docs/fiftyone/tutorials/index.html">Tutorials</a> •
<a href="https://voxel51.com/blog/">Blog</a> •
<a href="https://discord.gg/fiftyone-community">Community</a>
[](https://pypi.org/project/fiftyone)
[](https://pypi.org/project/fiftyone)
[](https://pepy.tech/project/fiftyone)
[](https://hub.docker.com/r/voxel51/fiftyone/)
[](LICENSE)
[](https://discord.gg/fiftyone-community)
[](https://medium.com/voxel51)
[](https://share.hsforms.com/1zpJ60ggaQtOoVeBqIZdaaA2ykyk)
[](https://twitter.com/voxel51)
</p>
</div>
# 👋 hey there!
We created **[FiftyOne](https://fiftyone.ai)** to supercharge your visual AI
projects by enabling you to visualize datasets, analyze models, and improve
data quality more efficiently than ever before 🤝
If you're looking to scale to production-grade, collaborative, cloud-native
enterprise workloads, check out
**[FiftyOne Enterprise](http://voxel51.com/enterprise)** 🚀
<div id='installation'/>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> installation 💻
As simple as:
```shell
pip install fiftyone
```
<details>
<summary>More details</summary>
### Installation options
FiftyOne supports Python 3.9 - 3.12.
For most users, we recommend installing the latest release version of FiftyOne
via `pip` as shown above.
If you want to contribute to FiftyOne or install the latest development
version, then you can also perform a [source install](#source-install).
See the [prerequisites section](#prerequisites) for system-specific setup
information.
We strongly recommend that you install FiftyOne in a
[virtual environment](https://voxel51.com/docs/fiftyone/installation/virtualenv.html)
to maintain a clean workspace.
Consult the
[installation guide](https://voxel51.com/docs/fiftyone/installation/index.html)
for troubleshooting and other information about getting up-and-running with
FiftyOne.
</details>
<div id='source-install'/>
<details>
<summary>Install from source</summary>
### Source installations
Follow the instructions below to install FiftyOne from source and build the
App.
You'll need the following tools installed:
- [Python](https://www.python.org) (3.9 - 3.12)
- [Node.js](https://nodejs.org) - on Linux, we recommend using
[nvm](https://github.com/nvm-sh/nvm) to install an up-to-date version.
- [Yarn](https://yarnpkg.com) - once Node.js is installed, you can
[enable Yarn](https://yarnpkg.com/getting-started/install) via
`corepack enable`
We strongly recommend that you install FiftyOne in a
[virtual environment](https://voxel51.com/docs/fiftyone/installation/virtualenv.html)
to maintain a clean workspace.
If you are working in Google Colab,
[skip to here](#source-installs-in-google-colab).
First, clone the repository:
```shell
git clone https://github.com/voxel51/fiftyone
cd fiftyone
```
Then run the install script:
```shell
# Mac or Linux
bash install.sh
# Windows
.\install.bat
```
If you run into issues importing FiftyOne, you may need to add the path to the
cloned repository to your `PYTHONPATH`:
```shell
export PYTHONPATH=$PYTHONPATH:/path/to/fiftyone
```
Note that the install script adds to your `nvm` settings in your `~/.bashrc` or
`~/.bash_profile`, which is needed for installing and building the App.
### Upgrading your source installation
To upgrade an existing source installation to the bleeding edge, simply pull
the latest `develop` branch and rerun the install script:
```shell
git checkout develop
git pull
# Mac or Linux
bash install.sh
# Windows
.\install.bat
```
### Rebuilding the App
When you pull in new changes to the App, you will need to rebuild it, which you
can do either by rerunning the install script or just running `yarn build` in
the `./app` directory.
### Developer installation
If you would like to
[contribute to FiftyOne](https://github.com/voxel51/fiftyone/blob/develop/CONTRIBUTING.md),
you should perform a developer installation using the `-d` flag of the install
script:
```shell
# Mac or Linux
bash install.sh -d
# Windows
.\install.bat -d
```
Although not required, developers typically prefer to configure their FiftyOne
installation to connect to a self-installed and managed instance of MongoDB,
which you can do by following
[these simple steps](https://docs.voxel51.com/user_guide/config.html#configuring-a-mongodb-connection).
### Source installs in Google Colab
You can install from source in
[Google Colab](https://colab.research.google.com) by running the following in a
cell and then **restarting the runtime**:
```shell
%%shell
git clone --depth 1 https://github.com/voxel51/fiftyone.git
cd fiftyone
# Mac or Linux
bash install.sh
# Windows
.\install.bat
```
### Generating documentation
See the
[docs guide](https://github.com/voxel51/fiftyone/blob/develop/docs/README.md)
for information on building and contributing to the documentation.
### Uninstallation
You can uninstall FiftyOne as follows:
```shell
pip uninstall fiftyone fiftyone-brain fiftyone-db
```
</details>
<div id='prerequisites'/>
<details>
<summary>Prerequisites for beginners</summary>
### System-specific setup
Follow the instructions for your operating system or environment to perform
basic system setup before [installing FiftyOne](#installation).
If you're an experienced developer, you've likely already done this.
<details>
<summary>Linux</summary>
<div id='prerequisites-linux'/>
#### 1. Install Python and other dependencies
These steps work on a clean install of Ubuntu Desktop 24.04, and should also
work on Ubuntu 24.04 and 22.04, and on Ubuntu Server:
```shell
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install python3-venv python3-dev build-essential git-all libgl1-mesa-dev
```
- On Linux, you will need at least the `openssl` and `libcurl` packages
- On Debian-based distributions, you will need to install `libcurl4` or
`libcurl3` instead of `libcurl`, depending on the age of your distribution
```shell
# Ubuntu
sudo apt install libcurl4 openssl
# Fedora
sudo dnf install libcurl openssl
```
#### 2. Create and activate a virtual environment
```shell
python3 -m venv fiftyone_env
source fiftyone_env/bin/activate
```
#### 3. Install FFmpeg (optional)
If you plan to work with video datasets, you'll need to install
[FFmpeg](https://ffmpeg.org):
```shell
sudo apt-get install ffmpeg
```
</details>
<details>
<summary>MacOS</summary>
<div id='prerequisites-macos'/>
#### 1. Install Xcode Command Line Tools
```shell
xcode-select --install
```
#### 2. Install Homebrew
```shell
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
After running the above command, follow the instructions in your terminal to
complete the Homebrew installation.
#### 3. Install Python
```shell
brew install python@3.9
brew install protobuf
```
#### 4. Create and activate a virtual environment
```shell
python3 -m venv fiftyone_env
source fiftyone_env/bin/activate
```
#### 5. Install FFmpeg (optional)
If you plan to work with video datasets, you'll need to install
[FFmpeg](https://ffmpeg.org):
```shell
brew install ffmpeg
```
</details>
<details>
<summary>Windows</summary>
<div id='prerequisites-windows'/>
#### 1. Install Python
⚠️ The version of Python that is available in the Microsoft Store is **not
recommended** ⚠️
Download a Python 3.9 - 3.12 installer from
[python.org](https://www.python.org/downloads/). Make sure to pick a 64-bit
version. For example, this
[Python 3.10.11 installer](https://www.python.org/ftp/python/3.10.11/python-3.10.11-amd64.exe).
Double-click on the installer to run it, and follow the steps in the installer.
- Check the box to add Python to your `PATH`
- At the end of the installer, there is an option to disable the `PATH`
length limit. It is recommended to click this
#### 2. Install Microsoft Visual C++
Download
[Microsoft Visual C++ Redistributable](https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist).
Double-click on the installer to run it, and follow the steps in the installer.
#### 3. Install Git
Download Git from [this link](https://git-scm.com/download/win). Double-click
on the installer to run it, and follow the steps in the installer.
#### 4. Create and activate a virtual environment
- Press `Win + R`. type `cmd`, and press `Enter`. Alternatively, search
**Command Prompt** in the Start Menu.
- Navigate to your project. `cd C:\path\to\your\project`
- Create the environment `python -m venv fiftyone_env`
- Activate the environment typing this in the command line window
`fiftyone_env\Scripts\activate`
- After activation, your command prompt should change and show the name of
the virtual environment `(fiftyone_env) C:\path\to\your\project`
#### 5. Install FFmpeg (optional)
If you plan to work with video datasets, you'll need to install
[FFmpeg](https://ffmpeg.org).
Download an FFmpeg binary from [here](https://ffmpeg.org/download.html). Add
FFmpeg's path (e.g., `C:\ffmpeg\bin`) to your `PATH` environmental variable.
</details>
<details>
<summary>Docker</summary>
<div id='prerequisites-docker'/>
<br>
Refer to
[these instructions](https://voxel51.com/docs/fiftyone/environments/index.html#docker)
to see how to build and run Docker images containing release or source builds
of FiftyOne.
</details>
</details>
<div id='quickstart'>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> quickstart 🚀
Dive right into FiftyOne by opening a Python shell and running the snippet
below, which downloads a
[small dataset](https://voxel51.com/docs/fiftyone/user_guide/dataset_zoo/datasets.html#quickstart)
and launches the
[FiftyOne App](https://voxel51.com/docs/fiftyone/user_guide/app.html) so you
can explore it:
```py
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
session = fo.launch_app(dataset)
```
Then check out
[this Colab notebook](https://colab.research.google.com/github/voxel51/fiftyone-examples/blob/master/examples/quickstart.ipynb)
to see some common workflows on the quickstart dataset.
Note that if you are running the above code in a script, you must include
`session.wait()` to block execution until you close the App. See
[this page](https://voxel51.com/docs/fiftyone/user_guide/app.html#creating-a-session)
for more information.
<div id='key-features'>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> key features 🔑
- **[Visualize Complex Datasets:](https://docs.voxel51.com/user_guide/app.html)**
Easily explore images, videos, and associated labels in a powerful visual
interface.
https://github.com/user-attachments/assets/9dc2db88-967d-43fa-bda0-85e4d5ab6a7a
- **[Explore Embeddings:](https://docs.voxel51.com/user_guide/app.html#embeddings-panel)**
Select points of interest and view the corresponding samples/labels.
https://github.com/user-attachments/assets/246faeb7-dcab-4e01-9357-e50f6b106da7
- **[Analyze and Improve Models:](https://docs.voxel51.com/user_guide/evaluation.html)**
Evaluate model performance, identify failure modes, and fine-tune your
models.
https://github.com/user-attachments/assets/8c32d6c4-51e7-4fea-9a3c-2ffd9690f5d6
- **[Advanced Data Curation:](https://docs.voxel51.com/brain.html)** Quickly
find and fix data issues, annotation errors, and edge cases.
https://github.com/user-attachments/assets/24fa1960-c2dd-46ae-ae5f-d58b3b84cfe4
- **[Rich Integrations:](https://docs.voxel51.com/integrations/index.html)**
Works with popular deep learning libraries like PyTorch, Hugging Face,
Ultralytics, and more.
https://github.com/user-attachments/assets/de5f25e1-a967-4362-9e04-616449e745e5
- **[Open and Extensible:](https://docs.voxel51.com/plugins/index.html)**
Customize and extend FiftyOne to fit your specific needs.
https://github.com/user-attachments/assets/c7ed496d-0cf7-45d6-9853-e349f1abd6f8
<div id='getting-started'/>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> documentation 🪪
Check out these resources to get up and running with FiftyOne:
| [Getting Started Guides](https://voxel51.com/docs/fiftyone/getting_started_guides/index.html) | [Tutorials](https://voxel51.com/docs/fiftyone/tutorials/index.html) | [Recipes](https://voxel51.com/docs/fiftyone/recipes/index.html) | [User Guide](https://voxel51.com/docs/fiftyone/user_guide/index.html) | [Examples](https://github.com/voxel51/fiftyone-examples) | [API Reference](https://voxel51.com/docs/fiftyone/api/fiftyone.html) | [CLI Reference](https://voxel51.com/docs/fiftyone/cli/index.html) |
| --------------------------------------------------------------------------------------------- | ------------------------------------------------------------------- | --------------------------------------------------------------- | --------------------------------------------------------------------- | -------------------------------------------------------- | -------------------------------------------------------------------- | ----------------------------------------------------------------- |
Full documentation is available at [fiftyone.ai](https://fiftyone.ai).
</div>
<div id='additional-resources'>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> additional resources 🚁
| [FiftyOne Enterprise](https://voxel51.com/enterprise) | [Building Plugins](https://docs.voxel51.com/plugins/index.html) | [Vector Search](https://voxel51.com/blog/the-computer-vision-interface-for-vector-search) | [Dataset Zoo](https://docs.voxel51.com/dataset_zoo/index.html) | [Model Zoo](https://docs.voxel51.com/model_zoo/index.html) | [FiftyOne Brain](https://docs.voxel51.com/brain.html) | [VoxelGPT](https://github.com/voxel51/voxelgpt) |
| ----------------------------------------------------- | --------------------------------------------------------------- | ----------------------------------------------------------------------------------------- | -------------------------------------------------------------- | ---------------------------------------------------------- | ----------------------------------------------------- | ----------------------------------------------- |
</div>
<div id='fiftyone-enterprise'/>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> FiftyOne Enterprise 🏎️
Want to securely collaborate on billions of samples in the cloud and connect to
your compute resources to automate your workflows? Check out
[FiftyOne Enterprise](https://voxel51.com/enterprise).
<div id='faq'/>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> faq & troubleshooting ⛓️💥
Refer to our
[common issues](https://docs.voxel51.com/installation/troubleshooting.html)
page to troubleshoot installation issues. If you're still stuck, check our
[frequently asked questions](https://docs.voxel51.com/faq/index.html) page for
more answers.
If you encounter an issue that the above resources don't help you resolve, feel
free to [open an issue on GitHub](https://github.com/voxel51/fiftyone/issues)
or contact us on [Discord](https://discord.gg/fiftyone-community).
</div>
<div id='community'/>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> join our community 🤝
Connect with us through your preferred channels:
[](https://discord.gg/fiftyone-community)
[](https://medium.com/voxel51)
[](https://twitter.com/voxel51)
[](https://www.linkedin.com/company/voxel51)
[](https://www.facebook.com/voxel51)
🎊 **Share how FiftyOne makes your visual AI projects a reality on social media
and tag us with @Voxel51 and #FiftyOne** 🎊
</div>
<div id='contributors'/>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> contributors 🧡
FiftyOne and [FiftyOne Brain](https://github.com/voxel51/fiftyone-brain) are
open source and community contributions are welcome! Check out the
[contribution guide](https://github.com/voxel51/fiftyone/blob/develop/CONTRIBUTING.md)
to learn how to get involved.
Special thanks to these amazing people for contributing to FiftyOne!
<a href="https://github.com/voxel51/fiftyone/graphs/contributors">
<img src="https://contrib.rocks/image?repo=voxel51/fiftyone" />
</a>
<div id='citation'/>
## <img src="https://user-images.githubusercontent.com/25985824/106288517-2422e000-6216-11eb-871d-26ad2e7b1e59.png" height="20px"> citation 📖
If you use FiftyOne in your research, feel free to cite the project (but only
if you love it 😊):
```bibtex
@article{moore2020fiftyone,
title={FiftyOne},
author={Moore, B. E. and Corso, J. J.},
journal={GitHub. Note: https://github.com/voxel51/fiftyone},
year={2020}
}
```
| text/markdown | Voxel51, Inc. | info@voxel51.com | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Image Processing",
"Topic :: Scientific/Engineering :: Image Recognition",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic :: Scientific/Engineering :: Visualization",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | https://github.com/voxel51/fiftyone | null | >=3.9 | [] | [] | [] | [
"aiofiles",
"argcomplete",
"async_lru>=2",
"beautifulsoup4",
"boto3",
"cachetools",
"dacite<2,>=1.6.0",
"dill",
"Deprecated",
"exceptiongroup",
"ftfy",
"humanize",
"hypercorn>=0.13.2",
"Jinja2>=3",
"jsonpatch",
"matplotlib",
"mongoengine~=0.29.1",
"motor~=3.6.0",
"numpy",
"packaging",
"pandas",
"Pillow!=11.2.*,>=6.2",
"plotly>=6.1.1",
"pprintpp",
"psutil",
"pymongo~=4.9.2",
"pytz",
"PyYAML",
"regex",
"retrying",
"rtree",
"scikit-learn",
"scikit-image",
"scipy",
"setuptools",
"sseclient-py<2,>=1.7.2",
"sse-starlette<1,>=0.10.3",
"starlette>=0.24.0",
"strawberry-graphql<0.292.0,>=0.262.4",
"tabulate",
"tqdm",
"xmltodict",
"universal-analytics-python3<2,>=1.0.1",
"pydash",
"fiftyone-brain<0.22,>=0.21.5",
"fiftyone-db<2.0,>=0.4",
"voxel51-eta<0.16,>=0.15.3",
"opencv-python-headless"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:17:27.191760 | fiftyone-1.13.2.tar.gz | 11,634,685 | 19/76/f9259072e61b74efac020da43047780cc5ce61676ea3a0514e856ae04962/fiftyone-1.13.2.tar.gz | source | sdist | null | false | bd604f081730308623dcd23654be53b2 | f0e3e80af284e0a29a281c1a70a961e4f0b0cb15e666949261ccda27e6031bbe | 1976f9259072e61b74efac020da43047780cc5ce61676ea3a0514e856ae04962 | null | [
"LICENSE"
] | 1,446 |
2.4 | openstef-models | 4.0.0a19 | Core models for OpenSTEF | <!--
SPDX-FileCopyrightText: 2025 Contributors to the OpenSTEF project <openstef@lfenergy.org>
SPDX-License-Identifier: MPL-2.0
-->
# openstef-model
| text/markdown | null | "Alliander N.V" <openstef@lfenergy.org> | null | null | null | energy, forecasting, machinelearning | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"holidays>=0.79",
"mlflow-skinny<4,>=3",
"openstef-beam<5,>=4.0.0.dev0",
"openstef-core<5,>=4.0.0.dev0",
"pvlib>=0.13",
"pycountry>=24.6.1",
"scikit-learn<1.8,>=1.7.1",
"scipy<2,>=1.16.3",
"xgboost-cpu<4,>=3; (sys_platform == \"linux\" or sys_platform == \"win32\") and extra == \"xgb-cpu\"",
"xgboost<4,>=3; sys_platform == \"darwin\" and extra == \"xgb-cpu\"",
"xgboost<4,>=3; extra == \"xgb-gpu\""
] | [] | [] | [] | [
"Documentation, https://openstef.github.io/openstef/index.html",
"Homepage, https://lfenergy.org/projects/openstef/",
"Issues, https://github.com/OpenSTEF/openstef/issues",
"Repository, https://github.com/OpenSTEF/openstef"
] | uv/0.9.9 {"installer":{"name":"uv","version":"0.9.9"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:17:10.545322 | openstef_models-4.0.0a19.tar.gz | 127,568 | 95/ae/98f6496239f5646e9808677271a24b1c8f4866c51ca18a08ba04e871fb5b/openstef_models-4.0.0a19.tar.gz | source | sdist | null | false | 3e0e8efd3f9a7e5ce0ca17654e7925d5 | e7c17e2ee5529415fb8488c32cb8d454bd08a8a5ee41625388c62f4d011dc118 | 95ae98f6496239f5646e9808677271a24b1c8f4866c51ca18a08ba04e871fb5b | MPL-2.0 | [] | 207 |
2.4 | openstef-core | 4.0.0a19 | Core functionality for OpenSTEF, a framework for short-term energy forecasting. | <!--
SPDX-FileCopyrightText: 2025 Contributors to the OpenSTEF project <openstef@lfenergy.org>
SPDX-License-Identifier: MPL-2.0
-->
# openstef-core
| text/markdown | null | "Alliander N.V" <openstef@lfenergy.org> | null | null | null | energy, forecasting, machinelearning | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"joblib<2,>=1",
"numpy<3,>=2.3.2",
"pandas<3,>=2.3.1",
"pyarrow>=21",
"pydantic-extra-types<3,>=2.10.5",
"pydantic<3,>=2.12.4"
] | [] | [] | [] | [
"Documentation, https://openstef.github.io/openstef/index.html",
"Homepage, https://lfenergy.org/projects/openstef/",
"Issues, https://github.com/OpenSTEF/openstef/issues",
"Repository, https://github.com/OpenSTEF/openstef"
] | uv/0.9.9 {"installer":{"name":"uv","version":"0.9.9"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:17:08.306984 | openstef_core-4.0.0a19.tar.gz | 41,720 | d1/fb/4fa946529c7f22f1332f0ebc7f7e9588bd338ae6df797765a328a8354d5a/openstef_core-4.0.0a19.tar.gz | source | sdist | null | false | 287a98907d126b52dfe9667b0d3f56d1 | 577103a306e465c69b9c8ccd9d423bdb6a73d2a67af7bfaaeba84ce0d6af4c99 | d1fb4fa946529c7f22f1332f0ebc7f7e9588bd338ae6df797765a328a8354d5a | MPL-2.0 | [] | 212 |
2.4 | easypygamewidgets | 2.0.0 | Create GUIs for pygame. | # EasyPygameWidgets
An easy-to-use UI widget library for pygame, featuring customizable buttons, sliders, text entries, and screen
management.
## Features
- **easy integration**: seamlessly works with existing pygame projects
- **customizable widgets**: nearly infinite styling options for colors, sounds, cursors, and more
- **screen management**: built-in screen system for creating different GUIs
## Installation
### Windows
```bash
pip install easypygamewidgets
```
### Linux/macOS
```bash
python3 -m pip install easypygamewidgets
```
## Quick Start
```python
import pygame
import easypygamewidgets as epw
pygame.init()
window = pygame.display.set_mode((800, 600))
clock = pygame.time.Clock()
# link the pygame window
epw.link_pygame_window(window)
# create a screen (optional)
screen = epw.Screen(id="main")
# create a button
button = epw.Button(screen=screen, text="Click Me!", width=200, height=50)
button.place(300, 250)
# create a slider
slider = epw.Slider(screen=screen, text="Volume", start=0, end=100, width=300)
slider.place(250, 350)
# create a text entry
entry = epw.Entry(screen=screen, text="Type here...", width=250)
entry.place(275, 450)
# main game loop
running = True
while running:
window.fill((30, 30, 30))
for event in pygame.event.get():
if event.type == pygame.QUIT:
running = False
# handle widget events
epw.handle_event(event)
# handle special widget events
epw.handle_special_events()
# draw all widgets
epw.flip()
pygame.display.update()
clock.tick(60)
pygame.quit()
```
## Widgets Documentation
All examples will use the
same [start template code](https://github.com/PizzaPost/pywidgets/blob/master/examples/start_template.py).
### Screen
A container for managing groups of widgets with shared visibility and state.
[example code](https://github.com/PizzaPost/pywidgets/blob/master/examples/screen.py)
### Button
A customizable button widget to run commands when interacted.
[example code](https://github.com/PizzaPost/pywidgets/blob/master/examples/button.py)
### Slider
A slider for selecting values within a specific range.
[example code](https://github.com/PizzaPost/pywidgets/blob/master/examples/slider.py)
### Entry
A text entry with selection and clipboard support.
[example code](https://github.com/PizzaPost/pywidgets/blob/master/examples/entry.py)
### Label
A text display that can be used to drag it into places.
[example code](https://github.com/PizzaPost/pywidgets/blob/master/examples/label.py)
### Surface (images etc.)
This converts your pygame surfaces into an easypygamewidgets widget that can be used in screens.
(All pygame surface commands can be applied to the "surface" attribute of your widget.)
[example code](https://github.com/PizzaPost/pywidgets/blob/master/examples/surface.py)
## Module Functions
### Core Functions
```python
# link your pygame window (required before using widgets)
epw.link_pygame_window(pygame_window)
# handle pygame events (call in event loop)
epw.handle_event(pygame_event)
# handle special events (call outside event loop)
epw.handle_special_events()
# draw all widgets to the linked window
epw.flip()
```
## Examples (COMING SOON)
Check the [examples directory](https://github.com/PizzaPost/pywidgets/tree/master/examples) for complete working
examples:
1. **[all widgets example](https://github.com/PizzaPost/pywidgets/blob/master/examples/basic.py)** - simple demo of all
widgets
2. **[screens with animations](https://github.com/PizzaPost/pywidgets/blob/master/examples/animated_screens.py)** -
multiple screens with transitions
3. **[settings screen](https://github.com/PizzaPost/pywidgets/blob/master/examples/settings.py)** - interactive settings
panel with sliders
4. **[login form](https://github.com/PizzaPost/pywidgets/blob/master/examples/login_form.py)** - form with entries and
validation
5. **[bindings](https://github.com/PizzaPost/pywidgets/blob/master/examples/slider.py)** - binding events to widgets
## Requirements
- python
- pygame
- requests (for update checking in background once)
I recommend using the latest version of libraries.
## Contributing
Contributions are welcome! Please feel free to submit a pull request. Of course will be mentioned :)
## License
This project is licensed under the MIT License - see
the [LICENSE file](https://github.com/PizzaPost/pywidgets/blob/master/LICENSE) for details.
## Support
- Issues: [GitHub Issues](https://github.com/PizzaPost/pywidgets/issues)
- Discord: [My Account](https://www.discord.com/users/916636380967354419)
- Instagram: [My Account](https://www.instagram.com/8002_phil/)
- License: [MIT](https://github.com/PizzaPost/pywidgets/blob/master/LICENSE)
- History: [GitHub History](https://github.com/PizzaPost/pywidgets/commits/master/)
---
Made with ❤️ by PizzaPost
| text/markdown | PizzaPost | null | null | null | null | null | [] | [] | https://github.com/PizzaPost/pywidgets | null | null | [] | [] | [] | [
"pygame",
"requests"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.3 | 2026-02-20T13:17:06.954790 | easypygamewidgets-2.0.0.tar.gz | 19,614 | 2b/65/1c7a032717bab73123a57073288031089b0f7bb16521237058003499d84b/easypygamewidgets-2.0.0.tar.gz | source | sdist | null | false | ee3f84414226c97d7f030d834ee921e9 | 297ea7d28d9e5035c9ab6633e28cc63267577fe04879a9ee61254c183c6908a6 | 2b651c7a032717bab73123a57073288031089b0f7bb16521237058003499d84b | null | [
"LICENSE"
] | 208 |
2.4 | openstef-beam | 4.0.0a19 | Backtesting, Evaluation, Analysis and Metrics (BEAM) library for OpenSTEF | <!--
SPDX-FileCopyrightText: 2025 Contributors to the OpenSTEF project <openstef@lfenergy.org>
SPDX-License-Identifier: MPL-2.0
-->
# openstef-beam
| text/markdown | null | "Alliander N.V" <openstef@lfenergy.org> | null | null | null | energy, forecasting, machinelearning | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"openstef-core<5,>=4.0.0.dev0",
"plotly>=6.3",
"pyyaml>=6.0.2",
"scoringrules>=0.8",
"tqdm>=4.67.1",
"s3fs>=2025.5.1; extra == \"all\""
] | [] | [] | [] | [
"Documentation, https://openstef.github.io/openstef/index.html",
"Homepage, https://lfenergy.org/projects/openstef/",
"Issues, https://github.com/OpenSTEF/openstef/issues",
"Repository, https://github.com/OpenSTEF/openstef"
] | uv/0.9.9 {"installer":{"name":"uv","version":"0.9.9"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:17:06.140018 | openstef_beam-4.0.0a19.tar.gz | 117,428 | 61/66/85ad7a41ac55183a01d6a1528f2b17d44b234cbbc362ab5be95d169f84a2/openstef_beam-4.0.0a19.tar.gz | source | sdist | null | false | 5d6d3dd49ba8cdbe222a1e7a4037bfb1 | c0b1e1dfdb9a78d6f55c8107d28d62baec0ad11f93e6c29f1ac475aeaeef1bc9 | 616685ad7a41ac55183a01d6a1528f2b17d44b234cbbc362ab5be95d169f84a2 | MPL-2.0 | [] | 211 |
2.4 | openstef | 4.0.0a19 | Open Short Term Energy forecasting library | <!--
SPDX-FileCopyrightText: 2017-2025 Contributors to the OpenSTEF project <openstef@lfenergy.org>
SPDX-License-Identifier: MPL-2.0
-->
# OpenSTEF
<!-- Badges -->
[](https://pepy.tech/project/openstef)
[](https://pepy.tech/project/openstef)
[](https://bestpractices.coreinfrastructure.org/projects/5585)
**OpenSTEF** is a modular library for creating short-term forecasts in the energy sector. Version 4.0 introduces a complete architectural refactor with enhanced modularity, type safety, and modern Python development practices.
## What's New in 4.0
- **Modular Architecture**: Install only the components you need
- **Modern Tooling**: Built with uv, ruff, pyright, and poe for optimal developer experience
- **Full Type Safety**: Comprehensive type hints throughout the codebase
- **Monorepo Structure**: Unified development with specialized packages
- **Enhanced Workflows**: Streamlined development and contribution processes
## Table of Contents
- [OpenSTEF](#openstef)
- [What's New in 4.0](#whats-new-in-40)
- [Table of Contents](#table-of-contents)
- [Quick Start](#quick-start)
- [Package Architecture](#package-architecture)
- [Installation](#installation)
- [Requirements](#requirements)
- [Basic Installation](#basic-installation)
- [Modern Package Managers](#modern-package-managers)
- [Documentation](#documentation)
- [Contributing](#contributing)
- [Quick Development Setup](#quick-development-setup)
- [License](#license)
- [Contact \& Support](#contact--support)
## Quick Start
```bash
# Install OpenSTEF
pip install openstef
# Start forecasting
python -c "import openstef_models; print('OpenSTEF 4.0 ready!')"
```
**[Get started with our Quick Start Guide](https://openstef.github.io/openstef/v4/user_guide/quick_start.html)** - step-by-step tutorial with real examples.
## Package Architecture
OpenSTEF 4.0 uses a modular design with specialized packages:
| Package | Purpose | Install Command |
|---------|---------|-----------------|
| **openstef** | Meta-package with core components | `pip install openstef` |
| **openstef-models** | ML models, feature engineering, data processing | `pip install openstef-models` |
| **openstef-beam** | Backtesting, Evaluation, Analysis, Metrics | `pip install openstef-beam` |
| **openstef-core** | Core utilities, dataset types, shared types and base models used by other packages | `pip install openstef-core` |
| **openstef-compatibility** | OpenSTEF 3.x compatibility layer | Coming soon |
| **openstef-foundational-models** | Deep learning and foundational models | Coming soon |
**[Learn more about the architecture](https://openstef.github.io/openstef/v4/user_guide/installation.html#package-architecture)** in our documentation.
## Installation
### Requirements
- **Python 3.12+** (Python 3.13 supported)
- **64-bit operating system** (Windows, macOS, Linux)
### Basic Installation
```bash
# For most users
pip install openstef
# Core forecasting only
pip install openstef-models
# With all optional tools
pip install "openstef[all]"
```
### Modern Package Managers
```bash
# Using uv (recommended for development)
uv add openstef
# Using conda
conda install -c conda-forge openstef
```
**[Complete Installation Guide](https://openstef.github.io/openstef/v4/user_guide/installation.html)** - detailed instructions including troubleshooting for Apple Silicon, GPU support, and development setup.
## Documentation
- **[Main Documentation](https://openstef.github.io/openstef/v4/)** - guides and API reference
- **[Quick Start Guide](https://openstef.github.io/openstef/v4/user_guide/quick_start.html)** - get up and running fast
- **[Tutorials](https://openstef.github.io/openstef/v4/user_guide/tutorials.html)** - step-by-step examples
- **[API Reference](https://openstef.github.io/openstef/v4/api/)** - detailed function documentation
- **[Contributing Guide](https://openstef.github.io/openstef/v4/contribute/)** - how to contribute to OpenSTEF
## Contributing
We welcome contributions to OpenSTEF 4.0!
**[Read our Contributing Guide](https://openstef.github.io/openstef/v4/contribute/)** - documentation for contributors including:
- How to report bugs and suggest features
- Documentation improvements and examples
- Code contributions and development setup
- Sharing datasets and real-world use cases
### Quick Development Setup
```bash
# Clone and set up for development
git clone https://github.com/OpenSTEF/openstef.git
cd openstef
uv sync --dev
# Run tests and quality checks
uv run poe all
```
**Code of Conduct**: We follow the [Contributor Code of Conduct](https://openstef.github.io/openstef/v4/contribute/code_of_conduct.html) to ensure a welcoming environment for all contributors.
## License
**Mozilla Public License Version 2.0** - see [LICENSE.md](LICENSE.md) for details.
This project includes third-party libraries licensed under their respective Open-Source licenses. SPDX-License-Identifier headers show applicable licenses. License files are in the [LICENSES/](LICENSES/) directory.
## Contact & Support
- **[Support Guide](https://openstef.github.io/openstef/v4/project/support.html)** - how to get help
- **[GitHub Discussions](https://github.com/OpenSTEF/openstef/discussions)** - community Q&A and discussions
- **[Issue Tracker](https://github.com/OpenSTEF/openstef/issues)** - bug reports and feature requests
- **[LF Energy OpenSTEF](https://www.lfenergy.org/projects/openstef/)** - project homepage
| text/markdown | null | "Alliander N.V" <openstef@lfenergy.org> | null | null | null | energy, forecasting, machinelearning | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"openstef-core==4.0.0a19",
"openstef-models[xgb-cpu]==4.0.0a19",
"openstef-beam[all]==4.0.0a19; extra == \"all\"",
"openstef-core==4.0.0a19; extra == \"all\"",
"openstef-models[xgb-cpu]==4.0.0a19; extra == \"all\"",
"huggingface-hub>=0.35.3; extra == \"beam\"",
"openstef-beam==4.0.0a19; extra == \"beam\"",
"openstef-core==4.0.0a19; extra == \"core\"",
"openstef-models[xgb-cpu]==4.0.0a19; extra == \"models\""
] | [] | [] | [] | [
"Documentation, https://openstef.github.io/openstef/index.html",
"Homepage, https://lfenergy.org/projects/openstef/",
"Issues, https://github.com/OpenSTEF/openstef/issues",
"Repository, https://github.com/OpenSTEF/openstef"
] | uv/0.9.9 {"installer":{"name":"uv","version":"0.9.9"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:17:03.818469 | openstef-4.0.0a19.tar.gz | 1,638,260 | 8b/d5/7873f06eff1c6617b7144f7c60b1c74ffc572bdedcf1bbfe7b03ea53c18c/openstef-4.0.0a19.tar.gz | source | sdist | null | false | a827df45b87cfde9edb294477843d1dc | 4e38202011e79d06eea359079e5da96cd51b1e1805ca98e765279ef88a888bc9 | 8bd57873f06eff1c6617b7144f7c60b1c74ffc572bdedcf1bbfe7b03ea53c18c | MPL-2.0 | [
"LICENSE.md"
] | 202 |
2.4 | weaviate-client | 4.20.0b1 | A python native Weaviate client | Weaviate python client
======================
.. image:: https://raw.githubusercontent.com/weaviate/weaviate/19de0956c69b66c5552447e84d016f4fe29d12c9/docs/assets/weaviate-logo.png
:width: 180
:align: right
:alt: Weaviate logo
.. image:: https://github.com/weaviate/weaviate-python-client/actions/workflows/.github/workflows/main.yaml/badge.svg?branch=main
:target: https://github.com/weaviate/weaviate/actions/workflows/.github/workflows/pull_requests.yaml
:alt: Build Status
.. image:: https://badge.fury.io/py/weaviate-client.svg
:target: https://badge.fury.io/py/weaviate-client
:alt: PyPI version
.. image:: https://readthedocs.org/projects/weaviate-python-client/badge/?version=latest
:target: https://weaviate-python-client.readthedocs.io/en/latest/?badge=latest
:alt: Documentation Status
A python native client for easy interaction with a Weaviate instance.
The client is tested for python 3.9 and higher.
Visit the official `Weaviate <https://weaviate.io/>`_ website for more information about the Weaviate and how to use it in production.
Client Versions
---------------
We currently support the following versions client versions:
- 4.X: actively supported
- 3.X: deprecated, receives only critical bug fixes and dependency updates
- copy of the 3.X branch in v4 releases: Will be removed on 2024-11-30
Articles
--------
Here are some articles on Weaviate:
- `Semantic Search Queries Return More Informed Results <https://hackernoon.com/semantic-search-queries-return-more-informed-results-nr5335nw>`_
- `Getting Started with Weaviate Python Library <https://towardsdatascience.com/getting-started-with-weaviate-python-client-e85d14f19e4f>`_
- `A sub-50ms neural search with DistilBERT and Weaviate <https://towardsdatascience.com/a-sub-50ms-neural-search-with-distilbert-and-weaviate-4857ae390154>`_
Documentation
-------------
- `Weaviate Python client overview <https://weaviate.io/developers/weaviate/client-libraries/python>`_.
- `Weaviate documentation <https://weaviate.io/developers/weaviate>`_.
- `Additional reference documentation <https://weaviate-python-client.readthedocs.io>`_
Support
-------
- Use our `Forum <https://forum.weaviate.io>`_ for support or any other question.
- Use our `Slack Channel <https://weaviate.io/slack>`_ for discussions or any other question.
- Use the ``weaviate`` tag on `StackOverflow <https://stackoverflow.com/questions/tagged/weaviate>`_ for questions.
- For bugs or problems, submit a GitHub `issue <https://github.com/weaviate/weaviate-python-client/issues>`_.
Contributing
------------
To contribute, read `How to Contribute <https://github.com/weaviate/weaviate-python-client/blob/main/CONTRIBUTING.md>`_.
| text/x-rst; charset=UTF-8 | Weaviate | hello@weaviate.io, | null | null | BSD 3-clause | null | [] | [] | https://github.com/weaviate/weaviate-python-client | null | >=3.10 | [] | [] | [] | [
"httpx<0.29.0,>=0.26.0",
"validators<1.0.0,>=0.34.0",
"authlib<2.0.0,>=1.6.5",
"pydantic<3.0.0,>=2.12.0",
"grpcio<1.80.0,>=1.59.5",
"protobuf<7.0.0,>=4.21.6",
"deprecation<3.0.0,>=2.1.0",
"weaviate-agents<2.0.0,>=1.0.0; extra == \"agents\""
] | [] | [] | [] | [
"Documentation, https://weaviate-python-client.readthedocs.io",
"Source, https://github.com/weaviate/weaviate-python-client",
"Tracker, https://github.com/weaviate/weaviate-python-client/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:16:59.684894 | weaviate_client-4.20.0b1.tar.gz | 799,949 | 52/6d/e1e411562faf0ed261af62928bc5c73fadd0b83429f0a195d1893b231641/weaviate_client-4.20.0b1.tar.gz | source | sdist | null | false | 3e8ed4895fb96906a606862583556c4a | c6a5b8dd5c2b26bc36362aadbec76b2254e510a7048b069857773ba7c0856599 | 526de1e411562faf0ed261af62928bc5c73fadd0b83429f0a195d1893b231641 | null | [
"LICENSE"
] | 309 |
2.4 | stac-api-validator | 0.6.8 | STAC API Validator | # STAC API Validator
[][pypi_]
[][status]
[][python version]
[][license]
[][read the docs]
[][tests]
[][codecov]
[][pre-commit]
[][black]
[pypi_]: https://pypi.org/project/stac-api-validator/
[status]: https://pypi.org/project/stac-api-validator/
[python version]: https://pypi.org/project/stac-api-validator
[read the docs]: https://stac-api-validator.readthedocs.io/en/latest
[tests]: https://github.com/stac-utils/stac-api-validator/actions?workflow=Tests
[codecov]: https://app.codecov.io/gh/stac-utils/stac-api-validator
[pre-commit]: https://github.com/pre-commit/pre-commit
[black]: https://github.com/psf/black
## Introduction
The STAC API Validator is the official validation suite for the
[STAC API](https://github.com/radiantearth/stac-api-spec/) family of specifications.
## Documentation
See the [stable](https://stac-api-validator.readthedocs.io/en/stable/) or
[latest](https://stac-api-validator.readthedocs.io/en/latest) documentation pages.
## Installation
STAC API Validator requires Python 3.11.
You can install _STAC API Validator_ via [pip] from [PyPI]:
```console
pip install stac-api-validator
```
and then run it:
```console
stac-api-validator \
--root-url https://planetarycomputer.microsoft.com/api/stac/v1/ \
--conformance core \
--conformance features \
--conformance item-search \
--collection sentinel-2-l2a \
--geometry '{"type": "Polygon", "coordinates": [[[100.0, 0.0], [101.0, 0.0], [101.0, 1.0], [100.0, 1.0], [100.0, 0.0]]]}'
```
## Contributing
Contributions are very welcome.
To learn more, see the [Contributor Guide].
## Usage
Please see the [Command-line Reference] for details.
The conformance class validations to run are selected with the `--conformance` parameters. This parameter
can be used more than once to specify multiple conformance classes to validate. The `STAC API - Core` conformance
class will always be validated, even if not specified.
If `item-search`, `collections`, and/or `features` are specified, the `--collection` parameter must also
be set. It specifies the name of a collection to use for some of the validations.
The `--geometry` parameter should also be set to perform intersection tests.
It should specify an AOI over which there are between 100 and 20,000 results for the collection (more
results means longer time to run).
## Features
**Work in Progress** -- this currently only validates a subset of behavior
This validation suite focuses on validating STAC API interactions. Tools such as
[pystac](https://github.com/stac-utils/pystac) and [stac4s](https://github.com/azavea/stac4s) do a
good job of validating STAC objects (Catalog, Collection, Item). This suite focuses on the STAC API behavior
validation.
The three key concepts within a STAC API are:
1. _Conformance classes_ advertising the capabilities of the API
2. _Link relations_ between resources within the web API (hypermedia)
3. _Parameters_ that filter search results
The conformance classes, as defined in the `conformsTo` field of the Landing Page (root, `/`), advertise to
clients which capabilities are available in the API. Without this field, a client would not even be able to tell that a
root URI was a STAC API.
The link relations define how to navigate a STAC catalog through parent-child links and find resources such as the OpenAPI specification. While many OGC API and STAC API endpoint have a fixed value (e.g., `/collections`), it is preferable for clients discover the paths via hypermedia.
The parameters that filter results apply to the Items resource and Item Search endpoints.
The current validity status of several popular STAC API implementations can be found [here](COMPLIANCE_REPORT.md).
## Command-line Reference
Usage:
```text
Usage: stac-api-validator [OPTIONS]
STAC API Validator.
Options:
--version Show the version and exit.
--log-level TEXT Logging level, one of DEBUG, INFO, WARN,
ERROR, CRITICAL
--root-url TEXT STAC API Root / Landing Page URL [required]
--collection TEXT The name of the collection to use for item-
search, collections, and features tests.
--geometry TEXT The GeoJSON geometry to use for intersection
tests.
--conformance [core|browseable|item-search|features|collections|children|filter]
The conformance classes to validate.
[required]
--auth-bearer-token TEXT Authorization Bearer token value to append
to all requests.
--auth-query-parameter TEXT Query parameter key and value to pass for
authorization, e.g., 'key=xyz'.
--help Show this message and exit.
```
Conformance classes item-search, features, and collections require the `--collection` parameter with the id of a
collection to run some tests on.
Conformance class `item-search` supports `--geometry` with a GeoJSON geometry that returns some items for
the specified collection.
Example:
```shell
stac-api-validator \
--root-url https://planetarycomputer.microsoft.com/api/stac/v1/ \
--conformance core \
--conformance item-search \
--conformance features \
--collection sentinel-2-l2a \
--geometry '{"type": "Polygon", "coordinates": [[[100.0, 0.0], [101.0, 0.0], [101.0, 1.0], [100.0, 1.0], [100.0, 0.0]]]}'
```
Example output:
```text
Validating https://cmr.earthdata.nasa.gov/stac/LARC_ASDC ...
STAC API - Core conformance class found.
STAC API - Item Search conformance class found.
warnings: none
errors:
- service-desc (https://api.stacspec.org/v1.0.0-beta.1/openapi.yaml): should have content-type header 'application/vnd.oai.openapi+json;version=3.0'', actually 'text/yaml'
- service-desc (https://api.stacspec.org/v1.0.0-beta.1/openapi.yaml): should return JSON, instead got non-JSON text
- GET Search with bbox=100.0, 0.0, 105.0, 1.0 returned status code 400
- POST Search with bbox:[100.0, 0.0, 105.0, 1.0] returned status code 502
- GET Search with bbox=100.0,0.0,0.0,105.0,1.0,1.0 returned status code 400
- POST Search with bbox:[100.0, 0.0, 0.0, 105.0, 1.0, 1.0] returned status code 400
```
Example with authorization using parameters:
```shell
stac-api-validator --root-url https://api.radiant.earth/mlhub/v1 --conformance core --auth-query-parameter 'key=xxx'
```
## Validating OGC API Features - Part 1 compliance
A STAC API that conforms to the "STAC API - Features" conformance class will also be a valid implementation
of OGC API Features - Part 1. In general, this validator focuses on those aspects of API behavior that are
different between STAC and OGC. It is recommended that implementers also use the [OGC API Features - Part 1
validation test suite](https://cite.opengeospatial.org/teamengine/about/ogcapi-features-1.0/1.0/site/) to
validate conformance.
Full instructions are available at the link above, but the simplest way to run this is with:
```shell
docker run -p 8081:8080 ogccite/ets-ogcapi-features10
```
Then, open [http://localhost:8081/teamengine/](http://localhost:8081/teamengine/) and login with the
username and password `ogctest`, `Create a new session`, with Organization `OGC`, Specification `OGC API - Features`, `Start a new test session`, input he root URL for the service, and `Start`.
## Common Mistakes
- incorrect `conformsTo` in the Landing Page. This was added between STAC API 0.9 and 1.0. It should be the same as the value in the `conformsTo` in the OAFeat `/conformance` endpoint.
- OGC API Features uses `data` relation link relation at the root to point to the Collections endpoint (`/collections`), not `collections` relation
- media type for link relation `service-desc` and endpoint is `application/vnd.oai.openapi+json;version=3.0` (not `application/json`) and link relation `search` and endpoint is `application/geo+json` (not `application/json`)
- Use of OCG API "req" urls instead of "conf" urls, e.g. `http://www.opengis.net/spec/ogcapi-features-1/1.0/conf/core` should be used, not `http://www.opengis.net/spec/ogcapi-features-1/1.0/req/core`
## License
Distributed under the terms of the [Apache 2.0 license][license],
_STAC API Validator_ is free and open source software.
## Issues
If you encounter any problems,
please [file an issue] along with a detailed description.
## Credits
This project was generated from [@cjolowicz]'s [Hypermodern Python Cookiecutter] template.
[@cjolowicz]: https://github.com/cjolowicz
[pypi]: https://pypi.org/
[hypermodern python cookiecutter]: https://github.com/cjolowicz/cookiecutter-hypermodern-python
[file an issue]: https://github.com/stac-utils/stac-api-validator/issues
[pip]: https://pip.pypa.io/
<!-- github-only -->
[license]: https://github.com/stac-utils/stac-api-validator/blob/main/LICENSE
[contributor guide]: https://github.com/stac-utils/stac-api-validator/blob/main/CONTRIBUTING.md
[command-line reference]: https://stac-api-validator.readthedocs.io/en/latest/usage.html
| text/markdown | null | Phil Varner <phil@philvarner.com> | null | null | null | null | [
"Development Status :: 4 - Beta"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"certifi>=2025.7.14",
"click>=8.0.2",
"deepdiff>=8.5.0",
"jsonschema>=4.25.0",
"more-itertools>=10.7.0",
"pystac-client>=0.8.6",
"pystac[orjson]>=1.13.0",
"pyyaml>=6.0.2",
"requests>=2.32.4",
"shapely>=2.1.1",
"stac-check>=1.11.1",
"stac-validator>=3.10.1"
] | [] | [] | [] | [
"Changelog, https://github.com/stac-utils/stac-api-validator/releases",
"Homepage, https://github.com/stac-utils/stac-api-validator",
"Repository, https://github.com/stac-utils/stac-api-validator",
"Documentation, https://stac-api-validator.readthedocs.io"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:16:55.386800 | stac_api_validator-0.6.8.tar.gz | 186,032 | d7/71/493abffbbe3f6dfb8a340117201926ce13ce1f710184c732f9cc6047e59e/stac_api_validator-0.6.8.tar.gz | source | sdist | null | false | c9923f08a48585d4f2cfd3eef3405e81 | bcc9f97e87f9732e8ef0aa5359b299a8345cd972d89fd0f2e57a55228a0733a6 | d771493abffbbe3f6dfb8a340117201926ce13ce1f710184c732f9cc6047e59e | Apache-2.0 | [
"LICENSE"
] | 215 |
2.4 | network-pinger | 2.4.7.1611 | Async network monitoring tool with real-time terminal UI, alerts, and connection quality analysis | <div align="center">
# Pinger
**Asynchronous network monitoring with real-time terminal interface**
[Русский](README.ru.md) · [English](README.md)
<p align="center">
<a href="https://pypi.org/project/network-pinger/"><img src="https://img.shields.io/pypi/v/network-pinger?color=blue&label=PyPI" alt="PyPI"></a>
<a href="python.org"><img src="https://img.shields.io/pypi/pyversions/network-pinger" alt="Python Versions"></a>
<a href="LICENSE"><img src="https://img.shields.io/github/license/meshlg/_pinger" alt="License"></a>
<a href=""><img src="https://img.shields.io/badge/platform-Windows%20%7C%20Linux%20%7C%20macOS-lightgrey" alt="Platforms"></a>
<br>
<a href="https://github.com/meshlg/_pinger/stargazers"><img src="https://img.shields.io/github/stars/meshlg/_pinger?style=social" alt="GitHub Stars"></a>
<a href="https://github.com/meshlg/_pinger/network"><img src="https://img.shields.io/github/forks/meshlg/_pinger?style=social" alt="GitHub Forks"></a>
<a href="https://github.com/meshlg/_pinger/issues"><img src="https://img.shields.io/github/issues/meshlg/_pinger" alt="GitHub Issues"></a>
<a href="https://pypi.org/project/network-pinger/"><img src="https://img.shields.io/pypi/dm/network-pinger" alt="PyPI Downloads"></a>
</p>
<p><em>Asynchronous network monitoring tool with Rich-based terminal interface, smart alerts, DNS benchmarks, hop health tracking, and automatic problem diagnosis.</em></p>
<p>
<a href="#quick-start"><kbd>✴︎ Quick Start</kbd></a>
<a href="#features"><kbd>▣ Features</kbd></a>
<a href="#configuration"><kbd>⚒︎ Configuration</kbd></a>
<a href="#deployment"><kbd>⚓︎ Deployment</kbd></a>
</p>
<div align="center">
<sub>Real-time metrics · Smart alerts · DNS analytics · Prometheus-ready</sub>
</div>

</div>
> **Works everywhere:** Windows, Linux, and macOS with system `ping` and `traceroute` (`tracert` on Windows) commands.
>
> [!WARNING]
> **Security Notice:** Do not run Pinger as root/admin. It uses system commands (`ping`, `traceroute`) which do not require elevated privileges for basic operation. Running as root increases the risk of privilege escalation if a vulnerability is exploited.
---
## About
**Pinger** is a professional real-time network connection monitoring tool designed for system administrators, DevOps engineers, and enthusiasts who value network reliability and transparency.
### Key Benefits
| Benefit | Description |
|---------|-------------|
| **Real-time monitoring** | Visualization of latency, packet loss, jitter, and p95 metrics with updates every second |
| **Intuitive terminal interface** | Beautiful UI based on Rich library with color-coded statuses and progress bars |
| **Flexible configuration** | All settings via environment variables — easy to adapt to any requirements |
| **Multi-level diagnostics** | Automatic problem source detection (ISP/local network/DNS/MTU) based on patterns |
| **Prometheus integration** | Native metrics support for monitoring and alerting |
| **Docker/Kubernetes ready** | Helm chart and docker-compose for quick container deployment |
| **Localization** | Russian and English language support with automatic detection |
| **Security** | Mandatory authentication for public health endpoints |
### Who is this for
- **System administrators** — monitoring network infrastructure status
- **DevOps engineers** — integration with monitoring systems (Prometheus, Grafana)
- **Developers** — debugging network problems and routing analysis
- **Enthusiasts** — visualizing home connection quality
---
## Quick Start
> [!IMPORTANT]
> Python 3.10+ is required, as well as system `ping` and `traceroute` (`tracert` on Windows) commands.
### Installation via pipx (recommended)
```bash
pipx install network-pinger
pinger
```
Press `Ctrl+C` to stop gracefully.
```bash
pipx upgrade network-pinger
```
### Installation via pip
```bash
python -m pip install --upgrade network-pinger
pinger
```
### Installation from source
```bash
git clone https://github.com/meshlg/_pinger.git
cd _pinger
pip install -r requirements.txt
python pinger.py
```
---
## Features
Six real-time panels track your connection status — from edge latency to route analysis.
### ✴︎ Ping Monitoring
- Real-time metrics: current / best / average / peak / median / jitter / p95
- Dual sparkline charts and Unicode progress bars for drift visualization
- Packet loss detection with consecutive loss counter and p95 latency metric
### ✧ DNS Monitoring and Benchmarking
- Parallel monitoring of A, AAAA, CNAME, MX, TXT, and NS records
- Built-in test suite for benchmarking:
| Test | What it measures |
|------|------------------|
| **Cached** | DNS response from cache (repeat query) |
| **Uncached** | Full recursive resolution with random subdomain |
| **DotCom** | Response time of popular .com domain |
- Statistics: minimum / average / maximum / standard deviation / reliability
- Color badges: green (fast) / yellow (slow) / red (error)
- Comparison of multiple DNS resolvers in parallel
### ⚑ Smart Alerts

- Audio + visual alerts for latency, jitter, packet loss, and connection drops
- Hysteresis to prevent flickering — alerts trigger only on state changes
- **Smart Features:**
- **Deduplication** — prevents repetitive alerts for the same issue
- **Grouping** — combines related alerts into a single notification
- **Adaptive Thresholds** — automatically learns normal network behavior
- **Fatigue Prevention** — suppresses alerts during prolonged incidents
- Alert feed with timestamps for problem correlation
### ✪ Problem Analysis and Prediction
- Automatic problem classification: ISP / local network / DNS / MTU
- Detection of recurring incidents and prediction of their return
- Route context plus loss/jitter trends for quick root cause identification
### ⌁ Hop Health Monitoring
### ⌁ Hop Health Monitoring
- Hop discovery via traceroute, then parallel ping of each hop
- **Rich Diagnostics**: Sparkline history charts, jitter, and latency delta
- **Geolocation**: Provider (ASN) and Country detection for each node
- Table with color coding and status traffic-lights (🟢/🟡/🔴)
- Perfect for identifying congestion, route changes, or backbone issues
### ☲ Route Analysis
- Route change detection with configurable sensitivity and cooldown timers
- Automatic traceroute snapshot saving to `traceroutes/` directory on problems
- Helps prove routing changes when contacting ISP support
### ⌂ Network Metrics
- **Public IP** — change tracking with geolocation and AS information
- **MTU / Path MTU** — detection and packet fragmentation
- **TTL** — hop count estimation and anomaly detection
### ▤ Observability
- **`/metrics`** — Prometheus endpoint on port 8000 for metrics collection
- **`/health`** and **`/ready`** — health probes on port 8001 for Kubernetes/Docker
- Docker + Helm manifests for container deployment
### ☷ Localization
- Automatic system locale detection with **Russian** and **English** language support
- Language override in `config.py`:
```python
# config.py
CURRENT_LANGUAGE = "en" # or "ru"
```
---
## Interface
> [!NOTE]
> Each panel updates in real-time. Match the screenshot above with this map for quick orientation.
### 1. Header and Status Bar
- Target IP, version with update indicator, connection lamp (● Connected / ▲ Degraded / ✕ Disconnected), and uptime
- Current ping, 30-minute loss, uptime, and public IP
### 2. Latency Panel
- Current / best / average / peak / median / jitter / p95 metric
- Dual sparkline charts for latency and jitter with last value tracking
### 3. Statistics Panel
- Packet counters: sent / successful / lost
- Success percentage and 30-minute loss
- Progress bars and mini trends panel (30m loss, jitter trend, hop count)
### 4. Analysis Panel
- Problem classifier (ISP / local network / DNS / MTU / unknown)
- Forecast (stable / risk of problems)
- Problem pattern
- Route stability (changed / stable) and last change time
### 5. Monitoring Panel
- DNS record health (A, AAAA, CNAME, MX, TXT, NS)
- Benchmarking tiles (Cached / Uncached / DotCom) with statistics
- MTU / Path MTU / TTL status and fragmentation
- Active alerts feed
### 6. Hop Health Panel
### 6. Hop Health Panel
- Route table with full diagnostics (Min/Avg/Last, Loss, Jitter)
- Sparkline latency history charts directly in the table (all modes)
- Provider (ASN) and Location (Loc) information for wide screens
- Status indicators for instant node health assessment
---
## Configuration
All settings are in [`config.py`](config.py) with default values and comments.
> [!TIP]
> Copy `config.py` next to the binary file or use environment variables to keep custom settings under version control.
### ⚙︎ Basic Settings
```python
TARGET_IP = "8.8.8.8" # Target IP for ping
INTERVAL = 1 # Ping interval (seconds)
WINDOW_SIZE = 1800 # Statistics window (30 min)
LATENCY_WINDOW = 600 # Latency history (10 min)
ENABLE_PYTHONPING_FALLBACK = True # Enable pythonping fallback (requires root/admin)
```
### ⚑ Thresholds and Alerts
```python
PACKET_LOSS_THRESHOLD = 5.0 # Packet loss threshold (%)
AVG_LATENCY_THRESHOLD = 100 # Average latency threshold (ms)
JITTER_THRESHOLD = 30 # Jitter threshold (ms)
CONSECUTIVE_LOSS_THRESHOLD = 5 # Consecutive loss threshold
ENABLE_SOUND_ALERTS = True
ALERT_COOLDOWN = 5 # Minimum interval between sounds (seconds)
# Smart Features
ENABLE_SMART_ALERTS = True
ENABLE_ADAPTIVE_THRESHOLDS = True
ADAPTIVE_BASELINE_WINDOW_HOURS = 24
ENABLE_ALERT_DEDUPLICATION = True
ENABLE_ALERT_GROUPING = True
```
```
### ✧ DNS Monitoring
```python
ENABLE_DNS_MONITORING = True
DNS_TEST_DOMAIN = "cloudflare.com"
DNS_CHECK_INTERVAL = 10
DNS_SLOW_THRESHOLD = 100 # "Slow" response threshold (ms)
DNS_RECORD_TYPES = ["A", "AAAA", "CNAME", "MX", "TXT", "NS"]
ENABLE_DNS_BENCHMARK = True
DNS_BENCHMARK_SERVERS = ["system"] # or ["1.1.1.1", "8.8.8.8"]
```
### ⌂ IP / MTU / TTL
```python
ENABLE_IP_CHANGE_ALERT = True
IP_CHECK_INTERVAL = 15
ENABLE_MTU_MONITORING = True
MTU_CHECK_INTERVAL = 30
```
### ⌁ Traceroute and Hop Monitoring
```python
ENABLE_AUTO_TRACEROUTE = False # Manual launch or on route change
TRACEROUTE_TRIGGER_LOSSES = 3
TRACEROUTE_COOLDOWN = 300
TRACEROUTE_MAX_HOPS = 15
ENABLE_HOP_MONITORING = True
HOP_PING_INTERVAL = 1
HOP_PING_TIMEOUT = 0.5
HOP_LATENCY_GOOD = 50 # Green (ms)
HOP_LATENCY_WARN = 100 # Yellow (ms), above = red
```
### ✪ Analysis
```python
ENABLE_PROBLEM_ANALYSIS = True
PROBLEM_ANALYSIS_INTERVAL = 60
ENABLE_ROUTE_ANALYSIS = True
ROUTE_ANALYSIS_INTERVAL = 1800
ROUTE_CHANGE_CONSECUTIVE = 2
```
### 🔄 Version Check
```python
ENABLE_VERSION_CHECK = True
VERSION_CHECK_INTERVAL = 3600 # Check every hour (seconds)
```

The application automatically checks for updates every hour (configurable). When a new version is available, you'll see an indicator in the header:
- `v2.3.1 → v2.4.0` — Update available (yellow arrow)
- `v2.3.1 ✓` — Up to date (green checkmark)
- `v2.3.1` — No check performed yet
To disable version checking:
```bash
export ENABLE_VERSION_CHECK=false
```
To change the check interval (e.g., every 30 minutes):
```bash
export VERSION_CHECK_INTERVAL=1800
```
---
## Deployment
<div align="center">
<table>
<tr>
<td><strong>⚓︎ Docker Compose</strong></td>
<td><strong>♘ Kubernetes (Helm)</strong></td>
</tr>
<tr>
<td>Local lab with Prometheus and health ports.</td>
<td>Cluster readiness with values overrides for production.</td>
</tr>
</table>
</div>
### ⚓︎ Docker Compose
> [!WARNING]
> When binding health endpoint to `0.0.0.0`, authentication is **required**. The default `docker-compose.yml` uses Basic Auth with `HEALTH_AUTH_USER=admin` and `HEALTH_AUTH_PASS=${HEALTH_AUTH_PASS:-changeme}`. **Change the default password** via environment variable or `.env` file before deployment.
```bash
docker compose up -d
```
| Service | Port | Description |
|---------|------|-------------|
| `pinger` | `8000` | Prometheus metrics (`/metrics`). |
| `pinger` | `8001` | Health probes (`/health`, `/ready`). |
| `prometheus` | `9090` | Prometheus UI. |
### ♘ Kubernetes (Helm)
```bash
helm install pinger ./charts/pinger -f charts/pinger/values.yaml
```
Need customization? See [`charts/pinger/README.md`](charts/pinger/README.md) for image tags, secrets, and upgrade notes.
---
## FAQ
### ❓ How to diagnose connection problems?
Pinger automatically classifies problems in the analysis panel:
| Problem Type | Signs | What to do |
|--------------|-------|------------|
| **ISP** | High latency on hops 2-5, packet loss on route | Contact your ISP, show traceroute snapshots |
| **Local network** | Loss on first hop, router problems | Check cable, reboot router |
| **DNS** | Slow DNS queries but normal ping by IP | Change DNS server (1.1.1.1, 8.8.8.8) |
| **MTU** | Packet fragmentation, VPN problems | Reduce MTU on interface |
### ❓ Why does ping show packet loss but internet works?
This is normal for some ISPs:
- ICMP packets may have low priority
- Some routers limit ICMP traffic
- Check loss on hops — if only on one, this may be normal
### ❓ How to configure alerts?
```python
# config.py
ENABLE_SOUND_ALERTS = True
ALERT_COOLDOWN = 5 # Minimum interval between sounds (seconds)
PACKET_LOSS_THRESHOLD = 5.0 # Packet loss threshold (%)
AVG_LATENCY_THRESHOLD = 100 # Average latency threshold (ms)
JITTER_THRESHOLD = 30 # Jitter threshold (ms)
```
### ❓ How to integrate with Prometheus?
Pinger provides metrics on port 8000:
```yaml
# prometheus.yml
scrape_configs:
- job_name: 'pinger'
static_configs:
- targets: ['localhost:8000']
```
### ❓ How to use in Kubernetes?
```bash
helm install pinger ./charts/pinger -f charts/pinger/values.yaml
```
Health endpoints are available on port 8001:
- `/health` — health check
- `/ready` — readiness check
### ❓ How to change interface language?
```python
# config.py
CURRENT_LANGUAGE = "en" # or "ru"
```
Language is detected automatically based on system locale.
### ❓ How to save monitoring results?
Pinger automatically saves traceroute snapshots on problems to `traceroutes/` directory. For persistent logging, use Prometheus.
### ❓ How to run in background?
```bash
# Linux/macOS
nohup pinger > pinger.log 2>&1 &
# Windows
start /B pinger > pinger.log 2>&1
```
### ❓ How to check health endpoints?
```bash
# Health check
curl http://localhost:8001/health
# Readiness check
curl http://localhost:8001/ready
# Prometheus metrics
curl http://localhost:8000/metrics
```
### ❓ How to configure authentication for health endpoints?
```bash
# Basic Auth
export HEALTH_AUTH_USER=admin
export HEALTH_AUTH_PASS=secret
# Token Auth
export HEALTH_TOKEN=your-secret-token
export HEALTH_TOKEN_HEADER=X-Health-Token
```
See [`SECURITY.md`](SECURITY.md) for more details.
---
## For Developers
```bash
pip install poetry
git clone https://github.com/meshlg/_pinger.git
cd _pinger
poetry install
poetry run pinger
```
1. Use Poetry for isolated environments and pinned dependencies.
2. Run `poetry run pytest` before opening a PR.
3. Follow [CONTRIBUTING.md](CONTRIBUTING.md) for releases and tagging (remember git tags for update notifications).
---
<div align="center">
**[MIT License](LICENSE)** · 2026 © meshlg
✉︎ [Join Discord](https://discordapp.com/users/268440099828662274) · ⚑ [Report an issue](https://github.com/meshlg/_pinger/issues/new/choose) · ☆ [Star the repo](https://github.com/meshlg/_pinger/stargazers)
</div>
| text/markdown | meshlg | meshlgfox@gmail.com | null | null | MIT | network, monitoring, ping, cli, tui, dns, traceroute | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: System :: Networking :: Monitoring",
"Topic :: Utilities"
] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"dnspython<3.0.0,>=2.4.0",
"prometheus-client<0.17.0,>=0.16.0",
"pythonping<2.0.0,>=1.1.0",
"requests<3.0.0,>=2.31.0",
"rich<14.0.0,>=13.7.0"
] | [] | [] | [] | [
"Homepage, https://github.com/meshlg/_pinger",
"Repository, https://github.com/meshlg/_pinger.git"
] | poetry/2.3.2 CPython/3.14.2 Windows/11 | 2026-02-20T13:15:50.415450 | network_pinger-2.4.7.1611-py3-none-any.whl | 118,174 | 95/a2/6192108d0b38e51be7a14b3d65e7b8187883c32e3caccfacfc48de2a69d6/network_pinger-2.4.7.1611-py3-none-any.whl | py3 | bdist_wheel | null | false | 1bd4c768f0ef4de52c987d10b93cacde | 4f3d7a66a3ea1d94a6008989ff91b1733e440e272fdae301f5754125c1f19ef7 | 95a26192108d0b38e51be7a14b3d65e7b8187883c32e3caccfacfc48de2a69d6 | null | [
"LICENSE"
] | 202 |
2.4 | noqa-runner | 0.5.2 | noqa runner | # noqa-runner
AI-powered mobile test execution runner for iOS applications.
## Installation
```bash
pip install noqa-runner
```
## Quick Start
### CLI
```bash
# Run on physical device with local IPA build
python -m noqa_runner run \
--noqa-api-token $NOQA_API_TOKEN \
--case-input-json '[
{
"case_instructions": "Open app and login with valid credentials"
}
]' \
--device-id "00008110-001234567890001E" \
--apple-developer-team-id TEAM123456 \
--app-bundle-id com.example.app \
--build-path /path/to/app.ipa
# Run on iOS Simulator with .app build
python -m noqa_runner run \
--noqa-api-token $NOQA_API_TOKEN \
--case-input-json '[
{
"case_instructions": "Open app and login with valid credentials"
}
]' \
--simulator-id "SIMULATOR-UDID" \
--app-bundle-id com.example.app \
--build-path /path/to/MyApp.app
# Run on device with TestFlight installation
python -m noqa_runner run \
--noqa-api-token $NOQA_API_TOKEN \
--case-input-json '[
{
"case_instructions": "Open app and verify features"
}
]' \
--device-id "00008110-001234567890001E" \
--apple-developer-team-id TEAM123456 \
--app-bundle-id com.example.app \
--app-store-id 123456789
```
**Required Options:**
```
--noqa-api-token TEXT noqa API authentication token [required]
--case-input-json TEXT JSON with test cases: [{case_instructions, test_id?, case_name?}] [required]
--app-bundle-id TEXT App bundle ID (auto-extracted from build if not provided) [recommended]
```
**Target Options (choose one):**
```
--device-id TEXT Device UDID for physical device testing
--simulator-id TEXT Simulator UDID for simulator testing
**Device-Only Options:**
```
--apple-developer-team-id TEXT Apple Developer Team ID for code signing [required for devices]
--app-store-id TEXT App Store ID for TestFlight installation (device only)
```
**Installation Options (choose one):**
```
--build-path TEXT Path to local IPA build file
--app-store-id TEXT App Store ID for TestFlight installation
```
**Other Options:**
```
--app-context TEXT Application context information [optional]
--agent-api-url TEXT Agent API base URL [optional, default: https://agent.noqa.ai]
--log-level TEXT Logging level [optional, default: INFO]
```
### Python API
```python
from noqa_runner import RunnerSession, RunnerTestInfo
# Create session
session = RunnerSession()
# Run on physical device with local IPA build
results = await session.run(
noqa_api_token="your-token",
tests=[
RunnerTestInfo(
case_instructions="Open app and verify home screen",
)
],
device_id="00008110-001234567890001E",
apple_developer_team_id="TEAM123456",
app_bundle_id="com.example.app",
app_build_path="/path/to/app.ipa",
)
# Run on iOS Simulator with .app build
results = await session.run(
noqa_api_token="your-token",
tests=[
RunnerTestInfo(
case_instructions="Open app and verify home screen",
)
],
simulator_id="SIMULATOR-UDID",
app_bundle_id="com.example.app",
app_build_path="/path/to/MyApp.app",
)
# Run with TestFlight installation
results = session.run(
noqa_api_token="your-token",
tests=[
RunnerTestInfo(
case_instructions="Open app and verify features",
)
],
device_id="00008110-001234567890001E",
apple_developer_team_id="TEAM123456",
app_bundle_id="com.example.app",
app_store_id="123456789",
)
```
## Test Results
The CLI returns test results as JSON with detailed information about each test execution:
```json
[
{
"case_instructions": "Complete onboarding, check that paywall has products",
"status": "passed",
"message": "Test completed",
"test_conditions": [
{
"condition": "Onboarding process was completed successfully",
"is_verified": true,
"evidence": "User progressed through multiple onboarding screens, ending with 'Get started' button",
"step_number": 4,
"confidence": 100
},
...
],
"steps": [...]
}
]
```
## Support
For issues and questions https://noqa.ai/
| text/markdown | null | Sergey Ustinov <sergey@noqa.ai> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiofiles>=24.0.0",
"appium-python-client>=4.0.0",
"defusedxml>=0.7.1",
"httpx[http2]>=0.27.0",
"numpy>=1.24.0",
"pillow>=10.0.0",
"pydantic-settings>=2.10.0",
"pydantic>=2.0.0",
"python-slugify>=8.0.0",
"sentry-sdk>=2.44.0",
"structlog>=24.0.0",
"tenacity>=8.0.0",
"typer>=0.12.0"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T13:15:23.522770 | noqa_runner-0.5.2.tar.gz | 35,835 | 34/2a/a76881a254f39210b54c6132c239cbc49934a064ffe62197c956d572fabe/noqa_runner-0.5.2.tar.gz | source | sdist | null | false | 46b7cad774d5c44921937e1d29a0aabb | 3cffa0eb10531219793596fd019e00f00ba6f91f93f05c784f63f1880fa6b204 | 342aa76881a254f39210b54c6132c239cbc49934a064ffe62197c956d572fabe | null | [] | 204 |
2.4 | oneprompt | 0.1.2 | AI agents for data querying, Python analysis, and chart generation. | # 🧠 oneprompt
> ⚠️ **License Notice**: This project is licensed under the **PolyForm Shield License 1.0.0**.
>
> ✅ **Free for personal use**
> ✅ **Free for internal business use**
> ❌ **Prohibited to build a competing product or service**
>
> For commercial licenses, OEM integration, or questions: contact@oneprompt.com
**AI agents for data querying, analysis, and chart generation.**
Connect your LLM API key and PostgreSQL database — query data in natural language, run Python analysis, and generate interactive charts in minutes.
[](https://pypi.org/project/oneprompt/)
[](https://pypi.org/project/oneprompt/)
[](LICENSE)
---
## ⚡ Quick Start
### 1. Install
Choose the package based on your runtime:
| Use case | Package | Includes |
|------|---------|---------|
| Cloud-only SaaS integration | `oneprompt-sdk` | Lightweight HTTP client (`oneprompt_sdk`) |
| Local/self-hosted MCP stack | `oneprompt` | Full SDK + `op` CLI + Docker workflow |
```bash
pip install oneprompt-sdk
```
or:
```bash
pip install oneprompt
```
> **Prerequisite for `oneprompt` (full/local only):** [Docker](https://docs.docker.com/get-docker/) must be installed and running.
### 2. Initialize a project
```bash
op init
```
When prompted, choose `0`/`local` for this local Docker quickstart.
This scaffolds your working directory with:
| File | Purpose |
|------|---------|
| `.env` | Configuration — add your API key and database URL |
| `DATABASE.md` | Schema documentation template for your database |
| `docker-compose.yml` | Docker stack for the MCP servers |
| `example.py` | Ready-to-run example script |
### 3. Configure
Edit `.env` with your credentials:
```env
LLM_PROVIDER=google
LLM_API_KEY=your-llm-api-key
DATABASE_URL=postgresql://user:pass@localhost:5432/mydb
```
> Get your Gemini API key at [Google AI Studio](https://aistudio.google.com/apikey).
### 4. Document your schema
Edit `DATABASE.md` to describe your tables, columns, and relationships. The more detail you provide, the better the AI agent will write SQL queries. See [Schema Documentation](docs/guides/schema-docs.md) for the recommended format.
### 5. Start services
```bash
op start
```
This builds and launches 4 Docker containers:
| Service | Port | Description |
|---------|------|-------------|
| Artifact Store | 3336 | Generated file storage (CSV, JSON, HTML) |
| PostgreSQL MCP | 3333 | SQL query execution engine |
| Chart MCP | 3334 | AntV (G2Plot) chart generation |
| Python MCP | 3335 | Sandboxed Python execution for analysis |
### 6. Use it!
```python
import oneprompt as op
client = op.Client() # Reads from .env automatically
# 1. Query your database with natural language
result = client.query("What are the top 10 products by revenue?")
print(result.summary)
print(result.preview)
# 2. Generate a chart from the results
chart = client.chart("Bar chart of top products", data_from=result)
print(f"Chart saved to: {chart.artifacts[0].path}")
# 3. Run Python analysis
analysis = client.analyze("Calculate month-over-month growth", data_from=result)
print(analysis.summary)
```
Or run the generated example directly:
```bash
python example.py
```
### Cloud-only quickstart (no Docker)
```python
import oneprompt_sdk as op
client = op.Client(oneprompt_api_key="op_live_...")
result = client.query("Top products by revenue", dataset_id="ds_123")
print(result.summary)
```
---
## 📖 Python SDK
### `Client`
The `Client` class is the main entry point. It reads configuration from `.env`, environment variables, or explicit parameters:
```python
import oneprompt as op
# Option A: Read from .env (recommended)
client = op.Client()
# Option B: Pass credentials directly
client = op.Client(
llm_api_key="your-key",
database_url="postgresql://user:pass@localhost:5432/mydb",
schema_docs_path="./DATABASE.md",
)
```
Cloud-only SDK:
```python
import oneprompt_sdk as op
client = op.Client(oneprompt_api_key="op_live_...")
```
### Three core methods
| Method | Description | Returns |
|--------|-------------|---------|
| `client.query(question, ...)` | Query your database with natural language | `AgentResult` — SQL results + preview data |
| `client.chart(description, data_from=...)` | Generate an interactive AntV chart | `AgentResult` — HTML chart file |
| `client.analyze(instruction, data_from=...)` | Run Python analysis code | `AgentResult` — analysis results + output files |
### Cloud Dataset Selection
When using cloud mode (`ONEPROMPT_API_KEY` set), `query()` supports two dataset sources:
```python
# 1) Stored dataset
result = client.query("Top products by revenue", dataset_id="ds_123")
# 2) Ephemeral dataset (no credential persistence)
result = client.query(
"Top products by revenue",
database_url="postgresql://user:pass@host:5432/db",
schema_docs="# optional schema docs",
)
```
Rules:
- Use exactly one of `dataset_id` or `database_url`.
- `schema_docs` is supported with `database_url` in cloud mode.
- Local mode continues to use your configured `DATABASE_URL`.
### `AgentResult`
Every method returns an `AgentResult` with:
| Property | Type | Description |
|----------|------|-------------|
| `ok` | `bool` | Whether the operation succeeded |
| `summary` | `str \| None` | Human-readable summary of the result |
| `preview` | `list[dict]` | Preview rows (for data queries) |
| `columns` | `list[str]` | Column names (for data queries) |
| `artifacts` | `list[ArtifactRef]` | Generated files (CSV, JSON, HTML) |
| `error` | `str \| None` | Error message if `ok` is `False` |
| `run_id` | `str` | Unique identifier of this execution |
| `session_id` | `str` | Session the execution belongs to |
### `ArtifactRef`
Each artifact in `result.artifacts` has:
| Property | Type | Description |
|----------|------|-------------|
| `id` | `str` | Unique artifact identifier |
| `name` | `str` | Filename (e.g. `top_products.csv`) |
| `type` | `str \| None` | `"data"`, `"result"`, or `"chart"` |
| `path` | `str \| None` | Local file path (after download) |
```python
# Read artifact content
artifact = result.artifacts[0]
text = artifact.read_text() # As string
data = artifact.read_bytes() # As bytes
```
### Chaining agents
Results can be piped between agents using `data_from`:
```python
# Query → Chart
data = client.query("Revenue by month for 2025")
chart = client.chart("Line chart of revenue trend", data_from=data)
# Query → Analyze
data = client.query("All transactions this quarter")
stats = client.analyze("Calculate descriptive statistics", data_from=data)
# Query → Analyze → Chart
data = client.query("Daily active users last 90 days")
trend = client.analyze("Calculate 7-day moving average", data_from=data)
chart = client.chart("Line chart with original and smoothed data", data_from=trend)
```
---
## 🌐 REST API
For integration with non-Python applications, start a local API server:
```bash
op api
```
The API runs at `http://localhost:8000` with these endpoints:
| Method | Endpoint | Description |
|--------|----------|-------------|
| `GET` | `/health` | Health check |
| `POST` | `/agents/data` | Run natural language data queries |
| `POST` | `/agents/python` | Run Python analysis |
| `POST` | `/agents/chart` | Generate chart visualizations |
| `POST` | `/sessions` | Create a new session |
| `GET` | `/sessions` | List sessions |
| `GET` | `/runs/{run_id}/artifacts/{artifact_id}` | Download a generated artifact |
See [docs/reference/rest-api.md](docs/reference/rest-api.md) for the full API reference.
---
## 🖥️ CLI Commands
```bash
op init # Scaffold a new project (.env, DATABASE.md, example.py, docker-compose.yml)
op start # Build and start all MCP services (Docker Compose)
op stop # Stop all services
op status # Check which services are running
op logs # Tail service logs
op api # Start the local REST API server
```
Run `op --help` for details, or `op <command> --help` for command-specific options.
---
## 🏗️ Architecture
```
┌─────────────────────────────────────────────┐
│ Your App / SDK Client / REST API │
├─────────────────────────────────────────────┤
│ AI Agents (Gemini + LangChain) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Data │ │ Python │ │ Chart │ │
│ │ Agent │ │ Agent │ │ Agent │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
├───────┼─────────────┼────────────┼──────────┤
│ MCP Servers (Docker) │
│ ┌────┴─────┐ ┌────┴─────┐ ┌────┴─────┐ │
│ │ Postgres │ │ Python │ │ Chart │ │
│ │ MCP │ │ MCP │ │ MCP │ │
│ └──────────┘ └──────────┘ └──────────┘ │
├─────────────────────────────────────────────┤
│ Artifact Store (generated file storage) │
└─────────────────────────────────────────────┘
```
See [docs/architecture/overview.md](docs/architecture/overview.md) for the full architecture documentation.
---
## 📝 Schema Documentation
For best results, describe your database schema in `DATABASE.md`. This gives the AI context to write accurate SQL:
```markdown
# Database Schema
## Tables
### products
| Column | Type | Description |
|--------|------|-------------|
| id | integer | Primary key |
| name | text | Product name |
| price | numeric | Unit price |
| category | text | Product category |
### orders
| Column | Type | Description |
|--------|------|-------------|
| id | integer | Primary key |
| product_id | integer | FK → products.id |
| quantity | integer | Units ordered |
| created_at | timestamp | Order date |
```
Then point the client to it:
```python
client = op.Client(schema_docs_path="./DATABASE.md")
```
See [docs/guides/schema-docs.md](docs/guides/schema-docs.md) for the complete guide and best practices.
---
## 🔧 Configuration
Configuration is loaded in this order (later overrides earlier):
1. `.env` file in the current directory
2. Environment variables
3. Arguments passed to `op.Client()`
| Variable | Description | Default |
|----------|-------------|---------|
| `LLM_API_KEY` | LLM provider API key | **Required** |
| `DATABASE_URL` | PostgreSQL connection string | **Required** |
| `LLM_MODEL` | Provider model name | provider default |
| `OP_SCHEMA_DOCS_PATH` | Path to your `DATABASE.md` | `./DATABASE.md` |
| `OP_DATA_DIR` | Directory for local data/state | `./op_data` |
| `OP_PORT` | REST API server port | `8000` |
| `OP_ARTIFACT_PORT` | Artifact store port | `3336` |
| `OP_POSTGRES_MCP_PORT` | PostgreSQL MCP port | `3333` |
| `OP_CHART_MCP_PORT` | Chart MCP port | `3334` |
| `OP_PYTHON_MCP_PORT` | Python MCP port | `3335` |
| `OP_MAX_RECURSION` | Max agent iterations | `10` |
| `DATASET_TOKEN_SECRET` | Shared secret to encrypt dataset tokens between Data Agent and Postgres MCP | _unset_ |
| `DATASET_TOKEN_TTL_SECONDS` | TTL for encrypted dataset tokens | `900` |
| `MCP_AUTH_TOKEN` | Optional shared token for internal MCP auth | _unset_ |
| `POSTGRES_ALLOWED_HOSTS` | Comma-separated DSN host allowlist (optional hardening) | _unset_ |
| `POSTGRES_ALLOW_PRIVATE_HOSTS` | Allow private/local DSN hosts | `true` |
| `POSTGRES_BLOCK_METADATA_HOSTS` | Block cloud metadata endpoints from DSN | `true` |
| `POSTGRES_CONNECT_TIMEOUT_SEC` | PostgreSQL connection timeout | `10` |
| `POSTGRES_QUERY_TIMEOUT_MS` | SQL statement timeout | `30000` |
| `POSTGRES_EXPORT_MAX_ROWS` | Max rows exported per query (`0` = no cap) | `0` |
See [docs/guides/configuration.md](docs/guides/configuration.md) for the complete reference.
---
## 📚 Documentation
Full documentation is available at [docs.oneprompt.com](https://docs.oneprompt.com) or in the `docs/` directory:
| Section | Contents |
|---------|----------|
| [Getting Started](docs/getting-started/quickstart.md) | Installation and quick start guide |
| [Guides](docs/guides/configuration.md) | Configuration, schema docs, agent chaining |
| [Reference](docs/reference/client.md) | Python SDK, REST API, and CLI reference |
| [Architecture](docs/architecture/overview.md) | System design, components, and data flow |
---
## 📄 License
PolyForm Shield License 1.0.0 — see [LICENSE](LICENSE) for details.
| text/markdown | oneprompt | null | null | null | # PolyForm Shield License 1.0.0
<https://polyformproject.org/licenses/shield/1.0.0>
## Acceptance
In order to get any license under these terms, you must agree
to them as both strict obligations and conditions to all
your licenses.
## Copyright License
The licensor grants you a copyright license for the
software to do everything you might do with the software
that would otherwise infringe the licensor's copyright
in it for any permitted purpose. However, you may
only distribute the software according to [Distribution
License](#distribution-license) and make changes or new works
based on the software according to [Changes and New Works
License](#changes-and-new-works-license).
## Distribution License
The licensor grants you an additional copyright license
to distribute copies of the software. Your license
to distribute covers distributing the software with
changes and new works permitted by [Changes and New Works
License](#changes-and-new-works-license).
## Notices
You must ensure that anyone who gets a copy of any part of
the software from you also gets a copy of these terms or the
URL for them above, as well as copies of any plain-text lines
beginning with `Required Notice:` that the licensor provided
with the software. For example:
> Required Notice: Copyright Yoyodyne, Inc. (http://example.com)
## Changes and New Works License
The licensor grants you an additional copyright license to
make changes and new works based on the software for any
permitted purpose.
## Patent License
The licensor grants you a patent license for the software that
covers patent claims the licensor can license, or becomes able
to license, that you would infringe by using the software.
## Noncompete
Any purpose is a permitted purpose, except for providing any
product that competes with the software or any product the
licensor or any of its affiliates provides using the software.
## Competition
Goods and services compete even when they provide functionality
through different kinds of interfaces or for different technical
platforms. Applications can compete with services, libraries
with plugins, frameworks with development tools, and so on,
even if they're written in different programming languages
or for different computer architectures. Goods and services
compete even when provided free of charge. If you market a
product as a practical substitute for the software or another
product, it definitely competes.
## New Products
If you are using the software to provide a product that does
not compete, but the licensor or any of its affiliates brings
your product into competition by providing a new version of
the software or another product using the software, you may
continue using versions of the software available under these
terms beforehand to provide your competing product, but not
any later versions.
## Discontinued Products
You may begin using the software to compete with a product
or service that the licensor or any of its affiliates has
stopped providing, unless the licensor includes a plain-text
line beginning with `Licensor Line of Business:` with the
software that mentions that line of business. For example:
> Licensor Line of Business: YoyodyneCMS Content Management
System (http://example.com/cms)
## Sales of Business
If the licensor or any of its affiliates sells a line of
business developing the software or using the software
to provide a product, the buyer can also enforce
[Noncompete](#noncompete) for that product.
## Fair Use
You may have "fair use" rights for the software under the
law. These terms do not limit them.
## No Other Rights
These terms do not allow you to sublicense or transfer any of
your licenses to anyone else, or prevent the licensor from
granting licenses to anyone else. These terms do not imply
any other licenses.
## Patent Defense
If you make any written claim that the software infringes or
contributes to infringement of any patent, your patent license
for the software granted under these terms ends immediately. If
your company makes such a claim, your patent license ends
immediately for work on behalf of your company.
## Violations
The first time you are notified in writing that you have
violated any of these terms, or done anything with the software
not covered by your licenses, your licenses can nonetheless
continue if you come into full compliance with these terms,
and take practical steps to correct past violations, within
32 days of receiving notice. Otherwise, all your licenses
end immediately.
## No Liability
***As far as the law allows, the software comes as is, without
any warranty or condition, and the licensor will not be liable
to you for any damages arising out of these terms or the use
or nature of the software, under any kind of legal claim.***
## Definitions
The **licensor** is the individual or entity offering these
terms, and the **software** is the software the licensor makes
available under these terms.
A **product** can be a good or service, or a combination
of them.
**You** refers to the individual or entity agreeing to these
terms.
**Your company** is any legal entity, sole proprietorship,
or other kind of organization that you work for, plus all
its affiliates.
**Affiliates** means the other organizations than an
organization has control over, is under the control of, or is
under common control with.
**Control** means ownership of substantially all the assets of
an entity, or the power to direct its management and policies
by vote, contract, or otherwise. Control can be direct or
indirect.
**Your licenses** are all the licenses granted to you for the
software under these terms.
**Use** means anything you do with the software requiring one
of your licenses. | agents, ai, charts, data-analysis, llm, mcp | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Visualization"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"click>=8.0",
"cryptography>=42.0.0",
"deepagents>=0.3.5",
"fastapi>=0.128.0",
"fastmcp>=2.14.0",
"httpx>=0.27.2",
"langchain-google-genai>=4.2.0",
"langchain-mcp-adapters>=0.2.1",
"mcp>=1.25.0",
"numpy>=2.4.1",
"oneprompt-sdk<0.2.0,>=0.1.2",
"psycopg2-binary>=2.9.9",
"psycopg[binary]>=3.1.18",
"python-dotenv>=1.0",
"pyyaml>=6.0",
"uvicorn>=0.30.0",
"langchain-anthropic>=0.3.0; extra == \"all-providers\"",
"langchain-openai>=0.3.0; extra == \"all-providers\"",
"langchain-anthropic>=0.3.0; extra == \"anthropic\"",
"mypy>=1.8.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"langchain-openai>=0.3.0; extra == \"openai\""
] | [] | [] | [] | [
"Homepage, https://github.com/oneprompteu/oneprompt",
"Documentation, https://github.com/oneprompteu/oneprompt#readme",
"Repository, https://github.com/oneprompteu/oneprompt",
"Issues, https://github.com/oneprompteu/oneprompt/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:15:11.803116 | oneprompt-0.1.2.tar.gz | 64,765 | 23/39/5530a48741d3d92720d966d09ce5630e3ab5bd2c3b2a6c7999f8c12a5b06/oneprompt-0.1.2.tar.gz | source | sdist | null | false | e3e4656d17d6f2d2afb4cb2a687cfc0d | 3c6bc76192c2fefbd0b5b24f6c2f3321b2fb2dddcd5c94b89da794d8858cc53c | 23395530a48741d3d92720d966d09ce5630e3ab5bd2c3b2a6c7999f8c12a5b06 | null | [
"LICENSE"
] | 198 |
2.4 | proteobench | 0.12.0 | ProteoBench compares the outputs of mass spectrometry-based proteomics data analysis pipelines | # ProteoBench

Website: https://proteobench.cubimed.rub.de/
PyPI: https://pypi.org/project/proteobench/
Learn about the ProteoBench project on [proteobench.readthedocs.io](https://proteobench.readthedocs.io/en/latest/).
Find our manuscript on [BioRxiv](https://www.biorxiv.org/content/10.64898/2025.12.09.692895v2).
See [here](https://proteobench.readthedocs.io/en/latest/developer-guide/development-setup/) for how to use ProteoBench locally, and how to contribute.
| text/markdown | null | Robbin Bouwmeester <robbin.bouwmeester@ugent.be>, Henry Webel <heweb@dtu.dk>, Witold Wolski <witold.wolski@fgcz.uzh.ch> | null | null | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| proteomics, peptides, retention time, mass spectrometry | [
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"Development Status :: 4 - Beta"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"pandas[excel]",
"openpyxl",
"numpy>1.24.4",
"plotly>=6.0.0",
"upsetplot",
"seaborn",
"streamlit>=1.31",
"streamlit-aggrid>=1.1.7",
"streamlit_extras",
"streamlit-plotly-events",
"scipy",
"matplotlib",
"toml",
"PyGithub",
"GitPython",
"psm-utils",
"pmultiqc>=0.0.33",
"black~=23.0; extra == \"dev\"",
"jupyterlab; extra == \"dev\"",
"ipywidgets; extra == \"dev\"",
"notebook; extra == \"dev\"",
"tqdm; extra == \"dev\"",
"wget; extra == \"dev\"",
"nox; extra == \"dev\"",
"pytest; extra == \"dev\"",
"sphinx; extra == \"docs\"",
"sphinx-design; extra == \"docs\"",
"sphinx-rtd-theme; extra == \"docs\"",
"sphinx-autobuild; extra == \"docs\"",
"myst-parser>=0.3.0; extra == \"docs\"",
"pydata-sphinx-theme; extra == \"docs\"",
"sphinx_new_tab_link; extra == \"docs\"",
"sphinx_copybutton; extra == \"docs\"",
"streamlit>1.27; extra == \"web\"",
"scipy; extra == \"web\""
] | [] | [] | [] | [
"Bug Tracker, https://github.com/ProteoBench/ProteoBench/issues/",
"Homepage, https://github.com/ProteoBench"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:15:11.011094 | proteobench-0.12.0.tar.gz | 28,214,656 | e1/74/9a0e88e6d9cf470e6c158179c4c5a104757d6fb7ef296b90aae55797ce0b/proteobench-0.12.0.tar.gz | source | sdist | null | false | c5292762f3786e4f72b3a9d0eb395544 | 6c459e1115528b695be2a82620f1f751bee02aa3a762582dee1e2e1e493da49c | e1749a0e88e6d9cf470e6c158179c4c5a104757d6fb7ef296b90aae55797ce0b | null | [
"LICENSE"
] | 204 |
2.4 | litmus-ai | 0.2.1 | A Python SDK for Hallucination Detection — powered by Litmus AI | # Litmus Hallucination Detector
[](https://pypi.org/project/litmus-ai/)
[](LICENSE)
[](https://www.linkedin.com/company/litmusai/)
Litmus Hallucination Detector is an SDK for detecting hallucinations in Large Language Model (LLM) outputs. It uses geometric algebra on embeddings to verify outputs against a provided context.
## Installation
```bash
pip install litmus-ai
```
## Quick Start
### 1. Context Grounding (Type I - Default)
Checks if claims are supported by the provided context.
```python
from litmus_ai import LitmusDetector
# Initialize grounding detector (default)
detector = LitmusDetector(type='context-grounding')
context = "The capital of France is Paris."
output = "Paris is the capital of France."
result = detector.check(context=context, output=output)
print(f"Outcome: {'Supported' if not result.is_hallucination else 'Hallucination'}")
print(f"Support Score: {result.score}")
```
**Output:**
```text
Outcome: Supported
Support Score: 1.0
```
### 2. Context Contradiction (Type II)
Checks if claims actively contradict the provided context.
```python
# Initialize contradiction detector
detector = LitmusDetector(type='context-contradiction')
context = ["Revenue increased 15%."]
output = ["Revenue decreased 15%."]
result = detector.check(context=context, output=output)
print(f"Is Hallucination: {result.is_hallucination}")
print(f"Contradiction Score: {result.score}")
```
**Output:**
```text
Is Hallucination: True
Contradiction Score: 0.9998
```
### 3. Relational Inversion (Type III)
Detects if the logical relationship between entities is flipped or if there's a direct contradiction/negation.
```python
# Initialize relational inversion detector
detector = LitmusDetector(type='relational-inversion')
context = ["Alice hired Bob."]
output = ["Bob hired Alice."] # Relational Inversion
result = detector.check(context=context, output=output)
print(f"Status: {result.details['claim_scores'][0]['type']}")
```
**Output:**
```text
Status: Relational Inversion
```
### 4. Instruction Drift (Type IV)
Detects when an answer drifts away from the query-context relationship, even if it uses similar keywords. Requires a `query` parameter.
```python
# Initialize instruction drift detector
detector = LitmusDetector(type='instruction-drift')
query = "Why did revenue decline?"
context = "Revenue declined due to supply chain issues."
output = "Revenue declined amid a challenging environment."
result = detector.check(query=query, context=context, output=output)
print(f"Drift Score: {result.score:.4f}")
print(f"Is Hallucination: {result.is_hallucination}")
# Override threshold at runtime (must be 0.0 to 1.0)
result = detector.check(query=query, context=context, output=output, threshold=0.5)
```
**Output:**
```text
Drift Score: 0.45
Is Hallucination: True
```
## Threshold Override
Every `detector.check()` call supports an optional `threshold` parameter to override the default for that call:
```python
# Uses default threshold
result = detector.check(context=context, output=output)
# Override threshold (0.0 to 1.0 inclusive)
result = detector.check(context=context, output=output, threshold=0.9)
# Invalid — raises ValueError
result = detector.check(context=context, output=output, threshold=1.5)
```
## Detection Types
| Type Value | Classification | Model | Default Threshold | Description |
|------------|---------------|-------|-------------------|-------------|
| `context-grounding` | Type I | `all-MiniLM-L6-v2` | 0.7 | Checks if claims are *supported* by evidence. |
| `context-contradiction` | Type II | `nli-deberta-v3-base` | 0.3 | Checks if claims *contradict* evidence. |
| `relational-inversion` | Type III | `nli-deberta-v3-base` | 0.5 | Checks for *entity inversions* or *contradictions*. |
| `instruction-drift` | Type IV | `all-MiniLM-L6-v2` | 0.3 | Checks if answers *drift* from query-context alignment. |
## How it works
Litmus uses mathematical projections to verify claims:
- **Type I** projects embeddings onto the subspace spanned by context facts.
- **Type II** projects cross-encoded pairs onto a contradiction discriminant.
- **Type III** compares projection magnitudes on specialized Inversion vs. Contradiction subspaces.
- **Type IV** compares bivector plane alignment between (Query ∧ Context) and (Query ∧ Answer).
## License
This project is licensed under the MIT License
| text/markdown | Litmus AI | null | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"requests>=2.28.0",
"python-dotenv>=1.0.0",
"pytest; extra == \"dev\"",
"pytest-mock; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.0 | 2026-02-20T13:14:59.288728 | litmus_ai-0.2.1.tar.gz | 6,819 | fc/de/6be27c4e7729ea83c9e49e58baa23fa42e1f13d9602e2976c280d1c47d90/litmus_ai-0.2.1.tar.gz | source | sdist | null | false | 1f20a679347f604f75cad69e09bc774e | 7ed4d7e9c99aa203c54a34f3a3889c46eca70e172e6481119a2bfa1777b479b0 | fcde6be27c4e7729ea83c9e49e58baa23fa42e1f13d9602e2976c280d1c47d90 | null | [
"LICENSE"
] | 212 |
2.4 | leaf-framework | 0.1.10.3 | LabEquipment Adapter Framework (LEAF) | # Adapter Framework for Equipment Monitoring and Control
The Lab Equipment Adapter Framework (LEAF) implements an **Adapter Architecture** designed to monitor and control various equipment types (e.g., bioreactors). The core principle of LEAF is to reduce the barrier to entry as much as possible to develop and deploy adapters for new equipment. The **EquipmentAdapters** are the functional equipment monitors composed of the rest of the **modules** (ProcessModules, PhaseModules, etc.) that perform specific tasks such as event monitoring, data processing, and output transmission.
## Quick Start
```bash
# Install LEAF
pip install leaf-framework
# Run with desktop GUI (auto-opens browser)
leaf
```
LEAF automatically shows a **desktop control panel** on desktop systems, making it easy to see if the application is running and where to access it.
## Documentation
The complete documentation can be found [here](http://leaf.systemsbiology.nl).
| text/markdown | Matthew Crowther | nmc215@ncl.ac.uk | null | null | Apache-2.0 | null | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <3.15,>=3.12 | [] | [] | [] | [
"aioredis<2.1.0,>=2.0.1",
"cairosvg<3.0.0,>=2.8.2",
"dateparser<1.3.0,>=1.2.2",
"httpx<0.29.0,>=0.28.1",
"influxobject==0.0.9",
"leaf-example",
"nicegui==3.7.1",
"paho-mqtt<2.2.0,>=2.1.0",
"pillow<13.0.0,>=12.1.1",
"pyyaml<6.1.0,>=6.0.2",
"redis<7.1.0,>=7.0.1",
"requests<2.33.0,>=2.32.4",
"watchdog<6.1.0,>=6.0.0"
] | [] | [] | [] | [
"Documentation, https://leaf.systemsbiology.nl",
"Repository, https://gitlab.com/LabEquipmentAdapterFramework/leaf"
] | poetry/2.3.2 CPython/3.12.12 Linux/5.15.0-131-generic | 2026-02-20T13:14:52.485452 | leaf_framework-0.1.10.3-py3-none-any.whl | 418,934 | 8a/1f/4d445140d85eff36b0e7bb4c8b30b9335783be81b4f600d80dbd76fb16b8/leaf_framework-0.1.10.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 62de1a17f124422341ff9a2f793f9389 | 3c1710894e7d245617c4ec65863a0e060ecd6a95b92c6db4244b1ae2563ce5ca | 8a1f4d445140d85eff36b0e7bb4c8b30b9335783be81b4f600d80dbd76fb16b8 | null | [
"LICENSE"
] | 231 |
2.4 | oneprompt-sdk | 0.1.2 | Lightweight oneprompt cloud SDK. | # oneprompt-sdk
Lightweight cloud-only Python SDK for oneprompt.
```python
import oneprompt_sdk as op
client = op.Client(oneprompt_api_key="op_live_...")
result = client.query("Top products by revenue", dataset_id="ds_123")
print(result.summary)
```
| text/markdown | oneprompt | null | null | null | PolyForm Shield License 1.0.0 | ai, cloud, data-analysis, llm, sdk | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"httpx>=0.27.2",
"python-dotenv>=1.0"
] | [] | [] | [] | [
"Homepage, https://github.com/oneprompteu/oneprompt",
"Documentation, https://github.com/oneprompteu/oneprompt#readme",
"Repository, https://github.com/oneprompteu/oneprompt",
"Issues, https://github.com/oneprompteu/oneprompt/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:14:43.049513 | oneprompt_sdk-0.1.2.tar.gz | 6,074 | 82/b4/fc11775d11ae1ed84231f8e23500cf0fde5d8f8287403768e5b0c5725224/oneprompt_sdk-0.1.2.tar.gz | source | sdist | null | false | 2bea11ace7c882d05d0f70b13cffec2c | e92de07c7ced10d4bf335ed6c903892f5e0c46bed6978c7e5e47e489e02b42a8 | 82b4fc11775d11ae1ed84231f8e23500cf0fde5d8f8287403768e5b0c5725224 | null | [] | 199 |
2.4 | tensorcircuit-nightly | 1.5.0.dev20260220 | High performance unified quantum computing framework for the NISQ era | <p align="center">
<a href="https://github.com/tensorcircuit/tensorcircuit-ng">
<img width=90% src="docs/source/statics/logong.png">
</a>
</p>
<p align="center">
<!-- tests (GitHub actions) -->
<a href="https://github.com/tensorcircuit/tensorcircuit-ng/actions/workflows/ci.yml">
<img src="https://img.shields.io/github/actions/workflow/status/tensorcircuit/tensorcircuit-ng/ci.yml?branch=master" />
</a>
<!-- docs -->
<a href="https://tensorcircuit-ng.readthedocs.io/">
<img src="https://img.shields.io/badge/docs-link-green.svg?logo=read-the-docs"/>
</a>
<!-- arXiv 2205.10091 -->
<a href="https://arxiv.org/abs/2205.10091">
<img src="https://img.shields.io/badge/arXiv-2205.10091-teal.svg"/>
</a>
<!-- arXiv 2602.14167 -->
<a href="https://arxiv.org/abs/2602.14167">
<img src="https://img.shields.io/badge/arXiv-2602.14167-teal.svg"/>
</a>
<!-- PyPI -->
<a href="https://pypi.org/project/tensorcircuit-ng/">
<img src="https://img.shields.io/pypi/v/tensorcircuit-ng.svg?logo=pypi"/>
</a>
<!-- License -->
<a href="./LICENSE">
<img src="https://img.shields.io/badge/license-Apache%202.0-blue.svg?logo=apache"/>
</a>
</p>
<p align="center"> English | <a href="README_cn.md"> 简体中文 </a></p>
TensorCircuit-NG is the next-generation open-source high-performance quantum software framework, built upon tensornetwork engines, supporting for automatic differentiation, just-in-time compiling, hardware acceleration, vectorized parallelism and distributed training, providing unified infrastructures and interfaces for quantum programming. It can compose quantum circuits, neural networks and tensor networks seamlessly with high simulation efficiency and flexibility.
TensorCircuit-NG is built on top of modern machine learning frameworks: Jax, TensorFlow, and PyTorch. It is specifically suitable for large-scale simulations of quantum-classical hybrid paradigm and variational quantum algorithms in ideal (`Circuit`), noisy (`DMCircuit`), Clifford (`StabilizerCircuit`), qudit (`QuditCircuit`), approximate (`MPSCircuit`), analog (`AnalogCircuit`), and fermionic (`FGSCircuit`) cases. It also supports quantum hardware access and provides CPU/GPU/QPU hybrid deployment solutions.
TensorCircuit-NG is the technical successor to TensorCircuit, led and maintained by the original TensorCircuit development team. This distribution has served as the primary home for the framework's evolution, addressing critical maintenance gaps (numpy > 2.0, qiskit > 1.0) and feature enhancements. As a fully compatible [drop-in replacement](https://tensorcircuit-ng.readthedocs.io/en/latest/faq.html#what-is-the-relation-between-tensorcircuit-and-tensorcircuit-ng), TensorCircuit-NG delivers next-gen capabilities—including stabilizer/qudit/analog/symmetric circuit simulation and multi-node multi-GPU distributed simulation.
## Getting Started
Please begin with [Quick Start](/docs/source/quickstart.rst) in the [full documentation](https://tensorcircuit-ng.readthedocs.io/).
For more information on software usage, sota algorithm implementation and engineer paradigm demonstration, please refer to 130+ [example scripts](/examples) and 40+ [tutorial notebooks](https://tensorcircuit-ng.readthedocs.io/en/latest/#tutorials). API docstrings and test cases in [tests](/tests) are also informative. One can also refer to AI-native docs for tensorcircuit-ng: [Devin Deepwiki](https://deepwiki.com/tensorcircuit/tensorcircuit-ng) and [Context7 MCP](https://context7.com/tensorcircuit/tensorcircuit-ng).
For beginners, please refer to [quantum computing lectures with TC-NG](https://github.com/sxzgroup/qc_lecture) to learn both quantum computing basics and representative usage of TensorCircuit-NG.
### AI-Assisted Development (Recommended)
To write TC-NG scripts and applications efficiently with AI coding agents (e.g., Claude Code, Cursor, Antigravity), we strongly recommend **working directly within the local tensorcircuit-ng repository** rather than an empty folder.
1. **Rich Context:** The 100+ scripts in `examples/` and extensive test cases in `tests/` provide essential references that significantly reduce AI hallucinations.
2. **Built-in Rules:** We provide a dedicated [AGENTS.md](/AGENTS.md) file. It serves as the "handbook" (i.e. `CLAUDE.md`) for AI agents, defining coding standards and best practices to ensure the generated code is idiomatic.
**Recommended Workflow:**
1. Clone the repository: `git clone https://github.com/tensorcircuit/tensorcircuit-ng.git`
2. Switch to a local playground branch: `git checkout -b my-playground` in case messing up with the original repository.
3. Open the repository folder in your AI IDE. And you are ready to start writing TC-NG-based scripts.
Now, enjoy implementing quantum algorithms entirely through natural language!
### Quick Demos
The following are some minimal demos.
- Circuit construction:
```python
import tensorcircuit as tc
c = tc.Circuit(2)
c.H(0)
c.CNOT(0,1)
c.rx(1, theta=0.2)
print(c.wavefunction())
print(c.expectation_ps(z=[0, 1]))
print(c.sample(allow_state=True, batch=1024, format="count_dict_bin"))
```
- Runtime behavior customization:
```python
tc.set_backend("tensorflow")
tc.set_dtype("complex128")
tc.set_contractor("greedy")
```
- Automatic differentiation with jit:
```python
def forward(theta):
c = tc.Circuit(2)
c.R(0, theta=theta, alpha=0.5, phi=0.8)
return tc.backend.real(c.expectation((tc.gates.z(), [0])))
g = tc.backend.grad(forward)
g = tc.backend.jit(g)
theta = tc.array_to_tensor(1.0)
print(g(theta))
```
<details>
<summary> More highlight features for TensorCircuit (click for details) </summary>
- Sparse Hamiltonian generation and expectation evaluation:
```python
n = 6
pauli_structures = []
weights = []
for i in range(n):
pauli_structures.append(tc.quantum.xyz2ps({"z": [i, (i + 1) % n]}, n=n))
weights.append(1.0)
for i in range(n):
pauli_structures.append(tc.quantum.xyz2ps({"x": [i]}, n=n))
weights.append(-1.0)
h = tc.quantum.PauliStringSum2COO(pauli_structures, weights)
print(h)
# BCOO(complex64[64, 64], nse=448)
c = tc.Circuit(n)
c.h(range(n))
energy = tc.templates.measurements.operator_expectation(c, h)
# -6
```
- Large-scale simulation with tensor network engine
```python
# tc.set_contractor("cotengra-30-10")
n=500
c = tc.Circuit(n)
c.h(0)
c.cx(range(n-1), range(1, n))
c.expectation_ps(z=[0, n-1], reuse=False)
```
- Density matrix simulator and quantum info quantities
```python
c = tc.DMCircuit(2)
c.h(0)
c.cx(0, 1)
c.depolarizing(1, px=0.1, py=0.1, pz=0.1)
dm = c.state()
print(tc.quantum.entropy(dm))
print(tc.quantum.entanglement_entropy(dm, [0]))
print(tc.quantum.entanglement_negativity(dm, [0]))
print(tc.quantum.log_negativity(dm, [0]))
```
</details>
## Install
The package is written in pure Python and can be obtained via pip as:
```python
pip install tensorcircuit-ng
```
We recommend you install this package with tensorflow or jax also installed as:
```python
pip install "tensorcircuit-ng[tensorflow]"
```
Other optional dependencies include `[torch]`, `[jax]`, `[qiskit]` and `[cloud]`.
Try nightly build for the newest features:
```python
pip install tensorcircuit-nightly
```
## Advantages
- Tensor network simulation engine based
- JIT, AD, vectorized parallelism compatible
- GPU support, QPU access support, hybrid deployment support
- HPC native, distributed simulation enabled, multiple devices/hosts support
- Efficiency
- Time: 10 to 10^6+ times acceleration compared to TensorFlow Quantum, Pennylane or Qiskit
- Space: 600+ qubits 1D VQE workflow (converged energy inaccuracy: < 1%)
- Elegance
- Flexibility: customized contraction, multiple ML backend/interface choices, multiple dtype precisions, multiple QPU providers
- API design: quantum for humans, less code, more power
- Batteries included
<details>
<summary> Tons of amazing features and built in tools for research (click for details) </summary>
- Support **super large circuit simulation** using tensor network engine.
- Support **noisy simulation** with both Monte Carlo and density matrix (tensor network powered) modes.
- Support **stabilizer circuit simulation** with stim backend.
- Support **approximate simulation** with MPS-TEBD modes.
- Support **analog/digital hybrid simulation** (time dependent Hamiltonian evolution, **pulse** level simulation) with neural ode modes.
- Support **Fermion Gaussian state** simulation with expectation, entanglement, measurement, ground state, real and imaginary time evolution.
- Support **qudits simulation** for tensor network and MPS approximation modes.
- Support **parallel** quantum circuit evaluation across **multiple GPUs** and **multiple hosts**.
- Highly customizable **noise model** with gate error and scalable readout error.
- Support for **non-unitary** gate and post-selection simulation.
- Support **real quantum devices access** from different providers.
- **Scalable readout error mitigation** native to both bitstring and expectation level with automatic qubit mapping consideration.
- **Advanced quantum error mitigation methods** and pipelines such as ZNE, DD, RC, etc.
- Support **MPS/MPO** as representations for input states, quantum gates and observables to be measured.
- Support **vectorized parallelism** on circuit inputs, circuit parameters, circuit structures, circuit measurements and these vectorization can be nested.
- Gradients can be obtained with both **automatic differenation** and parameter shift (vmap accelerated) modes.
- **Machine learning interface/layer/model** abstraction in both TensorFlow, PyTorch and Jax for both numerical simulation and real QPU experiments.
- Support time evolution simulation with **exact, ODE, Krylov, Trotter, Chebyshev solvers**.
- Support Heisenberg picture-based Pauli propagation approximation simulation for circuits.
- Circuit sampling supports both final state sampling and perfect sampling from tensor networks.
- Light cone reduction support for local expectation calculation.
- Highly customizable tensor network contraction path finder with opteinsum and cotengra interface.
- Observables are supported in measurement, sparse matrix, dense matrix and MPO format.
- Super fast weighted sum Pauli string Hamiltonian matrix generation.
- Reusable common circuit/measurement/problem templates and patterns.
- Jittable classical shadow infrastructures.
- SOTA quantum algorithm and model implementations.
- Support hybrid workflows and pipelines with CPU/GPU/QPU hardware from local/cloud/hpc resources using tf/torch/jax/cupy/numpy frameworks all at the same time.
</details>
## Contributing
### Status
This project is created and maintained by [Shi-Xin Zhang](https://github.com/refraction-ray) with current core authors [Shi-Xin Zhang](https://github.com/refraction-ray) and [Yu-Qin Chen](https://github.com/yutuer21) (see the [brief history](/HISTORY.md) of TensorCircuit and TensorCircuit-NG). We also thank [contributions](https://github.com/tensorcircuit/tensorcircuit-ng/graphs/contributors) from the open source community.
### Citation
If this project helps in your research, please cite the two versions of software whitepapers to acknowledge the work put into the development of TensorCircuit-NG.
- [TensorCircuit: a Quantum Software Framework for the NISQ Era](https://quantum-journal.org/papers/q-2023-02-02-912/) (published in Quantum).
- [TensorCircuit-NG: A Universal, Composable, and Scalable Platform for Quantum Computing and Quantum Simulation](https://arxiv.org/abs/2602.14167).
These two works also serve as a good introduction to the software.
Research works citing TensorCircuit-NG can be highlighted in [Research and Applications section](https://github.com/tensorcircuit/tensorcircuit-ng#research-and-applications).
### Guidelines
For contribution guidelines and notes, see [CONTRIBUTING](/CONTRIBUTING.md).
We welcome [issues](https://github.com/tensorcircuit/tensorcircuit-ng/issues), [PRs](https://github.com/tensorcircuit/tensorcircuit-ng/pulls), and [discussions](https://github.com/tensorcircuit/tensorcircuit-ng/discussions) from everyone, and these are all hosted on GitHub.
### License
TensorCircuit-NG is open source, released under the Apache License, Version 2.0.
### Contributors
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section -->
<!-- prettier-ignore-start -->
<!-- markdownlint-disable -->
<table>
<tbody>
<tr>
<td align="center" valign="top" width="16.66%"><a href="https://re-ra.xyz"><img src="https://avatars.githubusercontent.com/u/35157286?v=4?s=100" width="100px;" alt="Shixin Zhang"/><br /><sub><b>Shixin Zhang</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=refraction-ray" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=refraction-ray" title="Documentation">📖</a> <a href="#example-refraction-ray" title="Examples">💡</a> <a href="#ideas-refraction-ray" title="Ideas, Planning, & Feedback">🤔</a> <a href="#infra-refraction-ray" title="Infrastructure (Hosting, Build-Tools, etc)">🚇</a> <a href="#maintenance-refraction-ray" title="Maintenance">🚧</a> <a href="#research-refraction-ray" title="Research">🔬</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/pulls?q=is%3Apr+reviewed-by%3Arefraction-ray" title="Reviewed Pull Requests">👀</a> <a href="#translation-refraction-ray" title="Translation">🌍</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=refraction-ray" title="Tests">⚠️</a> <a href="#tutorial-refraction-ray" title="Tutorials">✅</a> <a href="#talk-refraction-ray" title="Talks">📢</a> <a href="#question-refraction-ray" title="Answering Questions">💬</a> <a href="#financial-refraction-ray" title="Financial">💵</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/yutuer21"><img src="https://avatars.githubusercontent.com/u/83822724?v=4?s=100" width="100px;" alt="Yuqin Chen"/><br /><sub><b>Yuqin Chen</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=yutuer21" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=yutuer21" title="Documentation">📖</a> <a href="#example-yutuer21" title="Examples">💡</a> <a href="#ideas-yutuer21" title="Ideas, Planning, & Feedback">🤔</a> <a href="#research-yutuer21" title="Research">🔬</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=yutuer21" title="Tests">⚠️</a> <a href="#tutorial-yutuer21" title="Tutorials">✅</a> <a href="#talk-yutuer21" title="Talks">📢</a></td>
<td align="center" valign="top" width="16.66%"><a href="http://jiezhongqiu.com"><img src="https://avatars.githubusercontent.com/u/3853009?v=4?s=100" width="100px;" alt="Jiezhong Qiu"/><br /><sub><b>Jiezhong Qiu</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=xptree" title="Code">💻</a> <a href="#example-xptree" title="Examples">💡</a> <a href="#ideas-xptree" title="Ideas, Planning, & Feedback">🤔</a> <a href="#research-xptree" title="Research">🔬</a></td>
<td align="center" valign="top" width="16.66%"><a href="http://liwt31.github.io"><img src="https://avatars.githubusercontent.com/u/22628546?v=4?s=100" width="100px;" alt="Weitang Li"/><br /><sub><b>Weitang Li</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=liwt31" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=liwt31" title="Documentation">📖</a> <a href="#ideas-liwt31" title="Ideas, Planning, & Feedback">🤔</a> <a href="#research-liwt31" title="Research">🔬</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=liwt31" title="Tests">⚠️</a> <a href="#talk-liwt31" title="Talks">📢</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/SUSYUSTC"><img src="https://avatars.githubusercontent.com/u/30529122?v=4?s=100" width="100px;" alt="Jiace Sun"/><br /><sub><b>Jiace Sun</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=SUSYUSTC" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=SUSYUSTC" title="Documentation">📖</a> <a href="#example-SUSYUSTC" title="Examples">💡</a> <a href="#ideas-SUSYUSTC" title="Ideas, Planning, & Feedback">🤔</a> <a href="#research-SUSYUSTC" title="Research">🔬</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=SUSYUSTC" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/Zhouquan-Wan"><img src="https://avatars.githubusercontent.com/u/54523490?v=4?s=100" width="100px;" alt="Zhouquan Wan"/><br /><sub><b>Zhouquan Wan</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Zhouquan-Wan" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Zhouquan-Wan" title="Documentation">📖</a> <a href="#example-Zhouquan-Wan" title="Examples">💡</a> <a href="#ideas-Zhouquan-Wan" title="Ideas, Planning, & Feedback">🤔</a> <a href="#research-Zhouquan-Wan" title="Research">🔬</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Zhouquan-Wan" title="Tests">⚠️</a> <a href="#tutorial-Zhouquan-Wan" title="Tutorials">✅</a></td>
</tr>
<tr>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/ls-iastu"><img src="https://avatars.githubusercontent.com/u/70554346?v=4?s=100" width="100px;" alt="Shuo Liu"/><br /><sub><b>Shuo Liu</b></sub></a><br /><a href="#example-ls-iastu" title="Examples">💡</a> <a href="#research-ls-iastu" title="Research">🔬</a> <a href="#tutorial-ls-iastu" title="Tutorials">✅</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/YHPeter"><img src="https://avatars.githubusercontent.com/u/44126839?v=4?s=100" width="100px;" alt="Hao Yu"/><br /><sub><b>Hao Yu</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=YHPeter" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=YHPeter" title="Documentation">📖</a> <a href="#infra-YHPeter" title="Infrastructure (Hosting, Build-Tools, etc)">🚇</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=YHPeter" title="Tests">⚠️</a> <a href="#tutorial-YHPeter" title="Tutorials">✅</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/SexyCarrots"><img src="https://avatars.githubusercontent.com/u/63588721?v=4?s=100" width="100px;" alt="Xinghan Yang"/><br /><sub><b>Xinghan Yang</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=SexyCarrots" title="Documentation">📖</a> <a href="#translation-SexyCarrots" title="Translation">🌍</a> <a href="#tutorial-SexyCarrots" title="Tutorials">✅</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/JachyMeow"><img src="https://avatars.githubusercontent.com/u/114171061?v=4?s=100" width="100px;" alt="JachyMeow"/><br /><sub><b>JachyMeow</b></sub></a><br /><a href="#tutorial-JachyMeow" title="Tutorials">✅</a> <a href="#translation-JachyMeow" title="Translation">🌍</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/Mzye21"><img src="https://avatars.githubusercontent.com/u/86239031?v=4?s=100" width="100px;" alt="Zhaofeng Ye"/><br /><sub><b>Zhaofeng Ye</b></sub></a><br /><a href="#design-Mzye21" title="Design">🎨</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/erertertet"><img src="https://avatars.githubusercontent.com/u/41342153?v=4?s=100" width="100px;" alt="erertertet"/><br /><sub><b>erertertet</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=erertertet" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=erertertet" title="Documentation">📖</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=erertertet" title="Tests">⚠️</a></td>
</tr>
<tr>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/yicongzheng"><img src="https://avatars.githubusercontent.com/u/107173985?v=4?s=100" width="100px;" alt="Yicong Zheng"/><br /><sub><b>Yicong Zheng</b></sub></a><br /><a href="#tutorial-yicongzheng" title="Tutorials">✅</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://marksong.tech"><img src="https://avatars.githubusercontent.com/u/78847784?v=4?s=100" width="100px;" alt="Zixuan Song"/><br /><sub><b>Zixuan Song</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=MarkSong535" title="Documentation">📖</a> <a href="#translation-MarkSong535" title="Translation">🌍</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=MarkSong535" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=MarkSong535" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/buwantaiji"><img src="https://avatars.githubusercontent.com/u/25216189?v=4?s=100" width="100px;" alt="Hao Xie"/><br /><sub><b>Hao Xie</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=buwantaiji" title="Documentation">📖</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/pramitsingh0"><img src="https://avatars.githubusercontent.com/u/52959209?v=4?s=100" width="100px;" alt="Pramit Singh"/><br /><sub><b>Pramit Singh</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=pramitsingh0" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/JAllcock"><img src="https://avatars.githubusercontent.com/u/26302022?v=4?s=100" width="100px;" alt="Jonathan Allcock"/><br /><sub><b>Jonathan Allcock</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=JAllcock" title="Documentation">📖</a> <a href="#ideas-JAllcock" title="Ideas, Planning, & Feedback">🤔</a> <a href="#talk-JAllcock" title="Talks">📢</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/nealchen2003"><img src="https://avatars.githubusercontent.com/u/45502551?v=4?s=100" width="100px;" alt="nealchen2003"/><br /><sub><b>nealchen2003</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=nealchen2003" title="Documentation">📖</a></td>
</tr>
<tr>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/eurethia"><img src="https://avatars.githubusercontent.com/u/84611606?v=4?s=100" width="100px;" alt="隐公观鱼"/><br /><sub><b>隐公观鱼</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=eurethia" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=eurethia" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/WiuYuan"><img src="https://avatars.githubusercontent.com/u/108848998?v=4?s=100" width="100px;" alt="WiuYuan"/><br /><sub><b>WiuYuan</b></sub></a><br /><a href="#example-WiuYuan" title="Examples">💡</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://www.linkedin.com/in/felix-xu-16a153196/"><img src="https://avatars.githubusercontent.com/u/61252303?v=4?s=100" width="100px;" alt="Felix Xu"/><br /><sub><b>Felix Xu</b></sub></a><br /><a href="#tutorial-FelixXu35" title="Tutorials">✅</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=FelixXu35" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=FelixXu35" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://scholar.harvard.edu/hongyehu/home"><img src="https://avatars.githubusercontent.com/u/50563225?v=4?s=100" width="100px;" alt="Hong-Ye Hu"/><br /><sub><b>Hong-Ye Hu</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=hongyehu" title="Documentation">📖</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/PeilinZHENG"><img src="https://avatars.githubusercontent.com/u/45784888?v=4?s=100" width="100px;" alt="peilin"/><br /><sub><b>peilin</b></sub></a><br /><a href="#tutorial-PeilinZHENG" title="Tutorials">✅</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=PeilinZHENG" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=PeilinZHENG" title="Tests">⚠️</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=PeilinZHENG" title="Documentation">📖</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://emilianog-byte.github.io"><img src="https://avatars.githubusercontent.com/u/57567043?v=4?s=100" width="100px;" alt="Cristian Emiliano Godinez Ramirez"/><br /><sub><b>Cristian Emiliano Godinez Ramirez</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=EmilianoG-byte" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=EmilianoG-byte" title="Tests">⚠️</a></td>
</tr>
<tr>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/ztzhu1"><img src="https://avatars.githubusercontent.com/u/111620128?v=4?s=100" width="100px;" alt="ztzhu"/><br /><sub><b>ztzhu</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=ztzhu1" title="Code">💻</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/royess"><img src="https://avatars.githubusercontent.com/u/31059422?v=4?s=100" width="100px;" alt="Rabqubit"/><br /><sub><b>Rabqubit</b></sub></a><br /><a href="#example-royess" title="Examples">💡</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/king-p3nguin"><img src="https://avatars.githubusercontent.com/u/103920010?v=4?s=100" width="100px;" alt="Kazuki Tsuoka"/><br /><sub><b>Kazuki Tsuoka</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=king-p3nguin" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=king-p3nguin" title="Tests">⚠️</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=king-p3nguin" title="Documentation">📖</a> <a href="#example-king-p3nguin" title="Examples">💡</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://gopal-dahale.github.io/"><img src="https://avatars.githubusercontent.com/u/49199003?v=4?s=100" width="100px;" alt="Gopal Ramesh Dahale"/><br /><sub><b>Gopal Ramesh Dahale</b></sub></a><br /><a href="#example-Gopal-Dahale" title="Examples">💡</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/AbdullahKazi500"><img src="https://avatars.githubusercontent.com/u/75779966?v=4?s=100" width="100px;" alt="Chanandellar Bong"/><br /><sub><b>Chanandellar Bong</b></sub></a><br /><a href="#example-AbdullahKazi500" title="Examples">💡</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://adeshpande.gitlab.io"><img src="https://avatars.githubusercontent.com/u/6169877?v=4?s=100" width="100px;" alt="Abhinav Deshpande"/><br /><sub><b>Abhinav Deshpande</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=abhinavd" title="Code">💻</a></td>
</tr>
<tr>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/Stellogic"><img src="https://avatars.githubusercontent.com/u/186928579?v=4?s=100" width="100px;" alt="Stellogic"/><br /><sub><b>Stellogic</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Stellogic" title="Code">💻</a> <a href="#example-Stellogic" title="Examples">💡</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Stellogic" title="Tests">⚠️</a> <a href="#tutorial-Stellogic" title="Tutorials">✅</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/Charlespkuer"><img src="https://avatars.githubusercontent.com/u/112697147?v=4?s=100" width="100px;" alt="Huang"/><br /><sub><b>Huang</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Charlespkuer" title="Code">💻</a> <a href="#example-Charlespkuer" title="Examples">💡</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Charlespkuer" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/Huang-Xu-Yang"><img src="https://avatars.githubusercontent.com/u/227286661?v=4?s=100" width="100px;" alt="Huang-Xu-Yang"/><br /><sub><b>Huang-Xu-Yang</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Huang-Xu-Yang" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Huang-Xu-Yang" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/WeiguoMa"><img src="https://avatars.githubusercontent.com/u/108172530?v=4?s=100" width="100px;" alt="Weiguo_M"/><br /><sub><b>Weiguo_M</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=WeiguoMa" title="Code">💻</a> <a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=WeiguoMa" title="Tests">⚠️</a> <a href="#example-WeiguoMa" title="Examples">💡</a> <a href="#tutorial-WeiguoMa" title="Tutorials">✅</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/QuiXamii"><img src="https://avatars.githubusercontent.com/u/136054857?v=4?s=100" width="100px;" alt="Qixiang WANG"/><br /><sub><b>Qixiang WANG</b></sub></a><br /><a href="#example-QuiXamii" title="Examples">💡</a></td>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/iop-hui252"><img src="https://avatars.githubusercontent.com/u/257909307?v=4?s=100" width="100px;" alt="iop-hui252"/><br /><sub><b>iop-hui252</b></sub></a><br /><a href="#example-iop-hui252" title="Examples">💡</a></td>
</tr>
<tr>
<td align="center" valign="top" width="16.66%"><a href="https://github.com/Yoshiyuki-F"><img src="https://avatars.githubusercontent.com/u/45096493?v=4?s=100" width="100px;" alt="Yoshiyuki-F"/><br /><sub><b>Yoshiyuki-F</b></sub></a><br /><a href="https://github.com/tensorcircuit/tensorcircuit-ng/commits?author=Yoshiyuki-F" title="Code">💻</a></td>
</tr>
</tbody>
</table>
<!-- markdownlint-restore -->
<!-- prettier-ignore-end -->
<!-- ALL-CONTRIBUTORS-LIST:END -->
<!-- prettier-ignore-start -->
<!-- markdownlint-disable -->
<!-- markdownlint-restore -->
<!-- prettier-ignore-end -->
<!-- ALL-CONTRIBUTORS-LIST:END -->
## Research and Applications
TensorCircuit-NG is a powerful framework for driving research and applications in quantum computing. Below are examples of published academic works (150+ in total) and open-source projects that utilize TensorCircuit and TensorCircuit-NG.
### DQAS
For the application of Differentiable Quantum Architecture Search, see [applications](/tensorcircuit/applications).
Reference paper: https://arxiv.org/abs/2010.08561 (published in QST).
### VQNHE
For the application of Variational Quantum-Neural Hybrid Eigensolver, see [applications](/tensorcircuit/applications).
Reference paper: https://arxiv.org/abs/2106.05105 (published in PRL) and https://arxiv.org/abs/2112.10380 (published in AQT).
### VQEX-MBL
For the application of VQEX on MBL phase identification, see the [tutorial](/docs/source/tutorials/vqex_mbl.ipynb).
Reference paper: https://arxiv.org/abs/2111.13719 (published in PRB).
### Stark-DTC
For the numerical demosntration of discrete time crystal enabled by Stark many-body localization, see the Floquet simulation [demo](/examples/timeevolution_trotter.py).
Reference paper: https://arxiv.org/abs/2208.02866 (published in PRL).
### RA-Training
For the numerical simulation of variational quantum algorithm training using random gate activation strategy by us, see the [project repo](https://github.com/ls-iastu/RAtraining).
Reference paper: https://arxiv.org/abs/2303.08154 (published in PRR as a Letter).
### TenCirChem
[TenCirChem](https://github.com/tencent-quantum-lab/TenCirChem) is an efficient and versatile quantum computation package for molecular properties. TenCirChem is based on TensorCircuit and is optimized for chemistry applications. The latest version TenCirChem-NG is open source and available at [TenCirChem-NG](https://github.com/tensorcircuit/TenCirChem-NG).
Reference paper: https://arxiv.org/abs/2303.10825 (published in JCTC).
### EMQAOA-DARBO
For the numerical simulation and hardware experiments with error mitigation on QAOA, see the [project repo](https://github.com/sherrylixuecheng/EMQAOA-DARBO).
Reference paper: https://arxiv.org/abs/2303.14877 (published in Communications Physics).
### NN-VQA
For the setup and simulation code of neural network encoded variational quantum eigensolver, see the [demo](/docs/source/tutorials/nnvqe.ipynb).
Reference paper: https://arxiv.org/abs/2308.01068 (published in PRApplied).
### FLDC
Absence of barren plateaus in finite local-depth circuits with long-range entanglement, see the [demo](/examples/vqe_toric_code.py).
Reference paper: https://arxiv.org/abs/2311.01393 (published in PRL).
### Effective temperature in ansatzes
For the simulation implementation of quantum states based on neural networks, tensor networs and quantum circuits using TensorCircuit-NG, see the [project repo](https://github.com/sxzgroup/et).
Reference paper: https://arxiv.org/abs/2411.18921.
### A Unified Variational Framework for Quantum Excited States
For the simulation code and data for variational optimization of simutaneous excited states, see the [project repo](https://github.com/sxzgroup/quantum_excited_state).
Reference paper: https://arxiv.org/abs/2504.21459.
### Quantum Machine Unlearning
For the simulation code for the work "superior resilience to poisoning and amenability to unlearning in quantum machine learning", see the [project repo](https://github.com/yutuer21/quantum-machine-unlearning).
Reference paper: https://arxiv.org/abs/2508.02422.
### Low Weight Pauli Propagation Simulation
For the simulation code and data for the work on low weight Pauli propagation in the context of variational quantum algorithms, see the [project repo](https://github.com/ZongliangLi/lwpp_init).
Reference paper: https://arxiv.org/abs/2508.06358.
### Quantum Continual Learning
For the code implementation on the work of demonstrating plasticity in quantum continual learning, see the [project repo](https://github.com/sxzgroup/quantum-plasticity).
Reference paper: https://arxiv.org/abs/2511.17228.
### More works
<details>
<summary> More research works and code projects using TensorCircuit and TensorCircuit-NG (click for details) </summary>
- Neural Predictor based Quantum Architecture Search: https://arxiv.org/abs/2103.06524 (published in Machine Learning: Science and Technology).
- Quantum imaginary-time control for accelerating the ground-state preparation: https://arxiv.org/abs/2112.11782 (published in PRR).
- Efficient Quantum Simulation of Electron-Phonon Systems by Variational Basis State Encoder: https://arxiv.org/abs/2301.01442 (published in PRR).
- Variational Quantum Simulations of Finite-Temperature Dynamical Properties via Thermofield Dynamics: https://arxiv.org/abs/2206.05571.
- Understanding quantum machine learning also requires rethinking generalization: https://arxiv.org/abs/2306.13461 (published in Nature Communications).
- Decentralized Quantum Federated Learning for Metaverse: Analysis, Design and Implementation: https://arxiv.org/abs/2306.11297. Code: https://github.com/s222416822/BQFL.
- Non-IID quantum federated learning with one-shot communication complexity: https://arxiv.org/abs/2209.00768 (published in Quantum Machine Intelligence). Code: https://github.com/JasonZHM/quantum-fed-infer.
- Quantum generative adversarial imitation learning: https://doi.org/10.1088/1367-2630/acc605 (published in New Journal of Physics).
- GSQAS: Graph Self-supervised Quantum Architecture Search: https://arxiv.org/abs/2303.12381 (published in Physica A: Statistical Mechanics and its Applications).
- Practical advantage of quantum machine learning in ghost imaging: https://www.nature.com/articles/s42005-023-01290-1 (published in Communications Physics).
- Zero and Finite Temperature Quantum Simulations Powered by Quantum Magic: https://arxiv.org/abs/2308.11616 (published in Quantum).
- Comparison of Quantum Simulators for Variational Quantum Search: A Benchmark Study: https://arxiv.org/abs/2309.05924.
- Statistical analysis of quantum state learning process in quantum neural networks: https://arxiv.org/abs/2309.14980 (published in NeurIPS).
- Generative quantum machine learning via denoising diffusion probabilistic models: https://arxiv.org/abs/2310.05866 (published in PRL).
- Exploring the topological sector optimization on quantum computers: https://arxiv.org/abs/2310.04291 (published in PRApplied).
- Google Summer of Code 2023 Projects (QML4HEP): https://github.com/ML4SCI/QMLHEP, https://github.com/Gopal-Dahale/qgnn-hep, https://github.com/salcc/QuantumTransformers.
- Universal imaginary-time critical dynamics on a quantum computer: https://arxiv.org/abs/2308.05408 (published in PRB).
- Non-Markovianity benefits quantum dynamics simulation: https://arxiv.org/abs/2311.17622.
- Variational post-selection for ground states and thermal states simulation: https://arxiv.org/abs/2402.07605 (published in QST).
- Subsystem information capacity in random circuits and Hamiltonian dynamics: https://arxiv.org/abs/2405.05076 (published in Quantum). Code implementation: https://github.com/sxzgroup/subsystem_information_capacity.
- Symmetry restoration and quantum Mpemba effect in symmetric random circuits: https://arxiv.org/abs/2403.08459 (published in PRL).
- Quantum Mpemba effects in many-body localization systems: https://arxiv.org/abs/2408.07750.
- Supersymmetry dynamics on Rydberg atom arrays: https://arxiv.org/abs/2410.21386 (published in PRB).
- Dynamic parameterized quantum circuits: expressive and barren-plateau free: https://arxiv.org/abs/2411.05760.
- Holographic deep thermalization: https://arxiv.org/abs/2411.03587 (published in Nature Communications).
- Quantum deep generative prior with programmable quantum circuits: https://www.nature.com/articles/s42005-024-01765-9 (published in Communications Physics).
- Symmetry Breaking Dynamics in Quantum Many-Body Systems: https://arxiv.org/abs/2501.13459.
- Entanglement growth and information capacity in a quasiperiodic system with a single-particle mobility edge: https://arxiv.org/abs/2506.18076.
- Hilbert subspace imprint: a new mechanism for non-thermalization: https://arxiv.org/abs/2506.11922.
- A Neural-Guided Variational Quantum Algorithm for Efficient Sign Structure Learning in Hybrid Architectures: https://arxiv.org/abs/2507.07555.
- Quantum Pontus | text/markdown | null | TensorCircuit-NG Authors <znfesnpbh@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy",
"scipy",
"tensornetwork-ng",
"networkx",
"tensorflow; extra == \"tensorflow\"",
"jax; extra == \"jax\"",
"jaxlib; extra == \"jax\"",
"torch; extra == \"torch\"",
"qiskit; extra == \"qiskit\"",
"sympy; extra == \"qiskit\"",
"symengine; extra == \"qiskit\"",
"qiskit; extra == \"cloud\"",
"mthree<2.8; extra == \"cloud\""
] | [] | [] | [] | [
"Homepage, https://github.com/tensorcircuit/tensorcircuit-ng",
"Repository, https://github.com/tensorcircuit/tensorcircuit-ng"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:14:27.707747 | tensorcircuit_nightly-1.5.0.dev20260220.tar.gz | 379,262 | 93/7a/4d70821ba117c7f7dfcc2c251450e2a771503af93f9b0a9b23c633135a14/tensorcircuit_nightly-1.5.0.dev20260220.tar.gz | source | sdist | null | false | ac8fb84f4d3bf861ab508217820cb347 | 8cb0d09701ebf51d9346e2361a4da6eb3478d64827ad9cfb75b466b1aa10550b | 937a4d70821ba117c7f7dfcc2c251450e2a771503af93f9b0a9b23c633135a14 | Apache-2.0 | [
"LICENSE",
"NOTICE"
] | 182 |
2.4 | isagellm-backend | 0.5.2.12 | sageLLM backend provider abstraction (CPU/CUDA/Ascend/Kunlun/DCU/MThreads) | # sagellm-backend
## Protocol Compliance (Mandatory)
- MUST follow Protocol v0.1: <https://github.com/intellistream/sagellm-docs/blob/main/docs/specs/protocol_v0.1.md>
- Any globally shared definitions (fields, error codes, metrics, IDs, schemas) MUST be added to Protocol first.
[](https://github.com/intellistream/sagellm-backend/actions/workflows/ci.yml)
[](https://badge.fury.io/py/isagellm-backend)
[](https://pypi.org/project/isagellm-backend/)
[](LICENSE)
[](https://github.com/astral-sh/ruff)
**计算硬件抽象层** - 为 sageLLM 提供统一的计算硬件接口(CUDA/Ascend/Kunlun)
> ⚠️ **v0.4.0 架构变更**:通信操作(all_reduce/all_gather 等)已移至 [sagellm-comm](https://github.com/intellistream/sagellm-comm)。如需通信功能,请参阅 [迁移指南](#从旧版本迁移)。
## 架构定位
sagellm-backend 与 sagellm-comm 是**平行的 L1 层硬件抽象**:
```text
┌─────────────────────────────────────────────────────────────────────────────┐
│ sagellm-core (L2) │
│ 引擎层:LLMEngine / Scheduler / Executor / ModelRunner │
│ │
│ ⬇️ 计算相关调用 ⬇️ 通信相关调用 │
├─────────────────────────────────┬────────────────────────────────────────────┤
│ sagellm-backend (L1) │ sagellm-comm (L1) │
│ 计算硬件抽象层 ← 本仓库 │ 通信硬件抽象层 │
│ │ │
│ • Device / Stream / Event │ • CommBackend 通信后端抽象 │
│ • Memory Allocator │ • Topology 拓扑发现 │
│ • Kernel Registry │ • Collective Ops (all_reduce 等) │
│ • Attention Backend │ • P2P Ops (send/recv) │
│ • KV Block 基础操作 │ • CommGroup 通信组管理 │
│ │ • 计算通信重叠 (Overlap) │
│ Providers: │ │
│ CUDA│Ascend│Kunlun│DCU│CPU │ Backends: NCCL│HCCL│RCCL│Gloo │
├─────────────────────────────────┴────────────────────────────────────────────┤
│ sagellm-protocol (L0) │
│ 协议定义:Schema / Errors / Types │
└──────────────────────────────────────────────────────────────────────────────┘
```
### 职责分离(v0.4.0+)
| 职责 | sagellm-backend | sagellm-comm |
|------|-----------------|--------------|
| Device/Stream/Event | ✅ | ❌ |
| 内存分配与管理 | ✅ | ❌ |
| KV Block 基础操作 | ✅ | ❌ |
| Kernel 注册/选择 | ✅ | ❌ |
| Attention 后端 | ✅ | ❌ |
| 通信操作 (all_reduce) | ❌ | ✅ |
| 拓扑发现 | ❌ | ✅ |
| P2P 通信 (send/recv) | ❌ | ✅ |
| 通信组管理 | ❌ | ✅ |
**关键约束**:
- ✅ **本仓库负责**:计算硬件抽象、设备管理、内存原语、Kernel 注册、Attention 后端
- ❌ **不再包含**:通信操作(已移至 [sagellm-comm](https://github.com/intellistream/sagellm-comm))
- ❌ **不再包含**:BaseEngine, EngineFactory(已移至 sagellm-core)
- 🔗 **被使用于**:sagellm-core(引擎实现)、sagellm-kv-cache(内存管理)
## Features
- **统一硬件抽象**:单一 API 支持 6 种硬件后端(CPU/CUDA/Ascend/Kunlun/DCU/MThreads)
- **CPU-First设计**:CPU Backend 作为默认后端,无GPU环境可正常运行
- **CUDA Support**:原生 CUDA 后端实现
- **Ascend Support**:华为 Ascend NPU 后端实现
- **Kunlun Support**:百度昆仑 XPU 后端实现
- **DCU Support**:海光 DCU 后端实现(基于 ROCm)
- **MThreads Support**:摩尔线程 GPU 后端实现
- **硬件自动发现**:运行时自动检测并选择最优硬件后端
- **能力发现**:硬件能力查询与验证
- **Kernel 注册机制**:灵活的 Kernel 选择与优先级系统
- **内存管理**:KV Block 分配、释放、复制、跨设备迁移等原语
- **多阶段流水线**:统一 `2-4` stage 流水线 API,支持双缓冲访存-计算重叠
- **图优化与算子融合**:支持 CPU 图优化 Pass 与基础融合模式(MatMul+Bias 等)
- **静态子图预计算**:支持常量传播/折叠、静态子图识别,以及 RoPE/ALiBi/静态 Mask 编译时预计算
- **内存布局优化**:支持布局转换分析、数据格式自动选择(FP16/BF16/FP8)与内存复用规划
## Installation
### 基础安装
```bash
# PyPI 安装
pip install isagellm-backend>=0.4.0.10,<0.5.0
```
### 带 CUDA 支持(可选)
```bash
# 安装 PyTorch with CUDA
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 然后安装 sagellm-backend
pip install isagellm-backend>=0.4.0.10,<0.5.0
```
### 带 Ascend NPU 支持(可选)
```bash
# 安装 torch-npu
pip install torch-npu>=2.0.0
# 然后安装 sagellm-backend
pip install isagellm-backend>=0.4.0.10,<0.5.0
```
## Quick Start
```bash
git clone git@github.com:intellistream/sagellm-backend.git
cd sagellm-backend
./quickstart.sh
# Run tests
pytest tests/ -v
```
## Performance Benchmark Suite (Issue #38)
提供统一的自动化性能基准测试框架,支持:
- 吞吐量(tokens/sec)
- 延迟(ms)
- TFLOPS 估算
- 与 FlashAttention-3 baseline 对比(可选,CUDA + flash-attn 环境)
- 自动生成 JSON/Markdown 报告(含可视化条形图)
- 回归检测(基于上一版报告)
```bash
# CPU-first 快速执行(CI profile)
python benchmark/run_backend_benchmark_suite.py --device cpu --ci-profile --output-dir .benchmarks/ci
# 常规执行(auto 设备)
python benchmark/run_backend_benchmark_suite.py --device auto --output-dir .benchmarks
# 带回归检测(超 10% 退化则可选择失败)
python benchmark/run_backend_benchmark_suite.py \
--device auto \
--previous-report .benchmarks/backend_benchmark_report.json \
--regression-threshold-pct 10 \
--fail-on-regression \
--output-dir .benchmarks/latest
```
输出文件:
- `.benchmarks/backend_benchmark_report.json`
- `.benchmarks/backend_benchmark_report.md`
## Usage Examples
### Basic Backend Usage
```python
from sagellm_backend import get_provider, DType
# Get backend (auto-selects best available: cuda > ascend > cpu)
backend = get_provider()
# Query capabilities
cap = backend.capability()
print(cap.supported_dtypes)
# Allocate KV block
block = backend.kv_block_alloc(128, DType.FP16)
# Or explicitly specify backend type
cpu_backend = get_provider("cpu")
cuda_backend = get_provider("cuda")
```
### Kernel Registry(标准化接口)
```python
from sagellm_backend.kernels import KernelRegistry
registry = KernelRegistry()
# 注册同一逻辑算子的多后端实现
registry.register("linear", cpu_linear_impl, provider_type="cpu", priority=10)
registry.register("linear", cuda_linear_impl_v1, provider_type="cuda", priority=50)
registry.register("linear", cuda_linear_impl_v2, provider_type="cuda", priority=100)
# 查询:同一 provider 内按 priority 选择最高者
kernel = registry.get("linear", provider_type="cuda")
# 查询:支持回退(例如 cuda -> cpu)
fallback_kernel = registry.get("linear", provider_type="cuda", allow_fallback=True)
```
完整可运行示例见:`examples/kernel_registry_example.py`。
### Multi-stage Pipeline(Issue #36)
支持统一的双缓冲/多阶段流水线(`2-4` stage),可用于访存与计算重叠:
```python
from sagellm_backend import create_multi_stage_pipeline, get_provider
provider = get_provider("cpu")
pipeline = create_multi_stage_pipeline(provider, stage_count=2)
outputs = pipeline.run(
items=[1, 2, 3, 4],
prefetch_fn=lambda item, stage_idx: item,
compute_fn=lambda prefetched, stage_idx: prefetched * 2,
)
print(outputs)
print(pipeline.last_metrics)
```
### 功能变体管理(Issue #32)
支持同一逻辑算子的多变体决策(默认决策树):
- Attention:`prefill/decode` + `KV-cache/no-cache` 自动选择(`paged/flash/cpu`)
- Activation:标准激活 vs MoE masked(优先 `fused_silu_mul`)
- GEMM:`per_tensor` vs `block_wise` 量化路径(自动回退到 `linear`)
```python
from sagellm_backend.attention import select_attention_backend_name
from sagellm_backend.attention.base import AttentionMetadata
metadata = AttentionMetadata.for_decode(context_lens=[128], block_tables=block_tables)
backend_name = select_attention_backend_name(metadata)
```
### Using with sagellm-core LLMEngine
Backend 现在专注于硬件抽象,引擎使用 `sagellm-core` 的 `LLMEngine`。
```python
# LLMEngine 位于 sagellm-core
from sagellm_core import LLMEngine, LLMEngineConfig
# LLMEngine 自动选择最佳后端
config = LLMEngineConfig(
model_path="TinyLlama/TinyLlama-1.1B-Chat-v1.0",
backend_type="auto", # 自动选择: cuda > ascend > cpu
max_new_tokens=100,
)
engine = LLMEngine(config)
await engine.start()
# 推理
output = await engine.generate("Hello, world!")
print(output)
await engine.stop()
```
## Extending with New Backends
```python
# Create provider in providers/ directory
class AscendBackendProvider:
def capability(self) -> CapabilityDescriptor:
return CapabilityDescriptor(
supported_dtypes=[DType.FP16, DType.BF16, DType.INT8],
# ...
)
# Implement other interface methods...
# Register via entry point in pyproject.toml
[project.entry-points."sagellm.backends"]
ascend_cann = "sagellm_backend.providers.ascend:create_ascend_backend"
```
## Documentation
- [Architecture](docs/ARCHITECTURE.md) - 架构设计和职责说明
- [Contributing](CONTRIBUTING.md) - 贡献指南和开发流程
- [Team](docs/TEAM.md) - 团队信息
- [Changelog](CHANGELOG.md) - 版本历史
## 版本信息
| 属性 | 值 |
|------|-----|
| 当前版本 | v0.4.0.10 |
| 最小 Python | 3.10+ |
| 协议版本 | v0.1+ |
| 许可证 | Proprietary |
## 从旧版本迁移
如果你从 v0.3.x 或更早版本升级,以下是主要变更:
### 通信 API 已移至 sagellm-comm
**v0.3.x(已废弃)**:
```python
# ❌ 旧版:通信操作在 backend
from sagellm_backend import get_provider
backend = get_provider("cuda")
backend.all_reduce(tensor, op="sum") # 不再支持
```
**v0.4.0+(新版)**:
```python
# ✅ 新版:通信操作使用 sagellm-comm
from sagellm_comm import CommBackend, ReduceOp
# 初始化通信后端
comm = CommBackend.create("nccl")
comm.init_process_group(world_size=4, rank=0)
# 执行集合操作
comm.all_reduce(tensor, op=ReduceOp.SUM)
# 计算操作仍使用 backend
from sagellm_backend import get_provider
backend = get_provider("cuda")
block = backend.kv_block_alloc(128, DType.FP16)
```
### 依赖变更
```bash
# 旧版:只安装 backend
pip install isagellm-backend
# 新版:需要分布式通信时,同时安装 comm
pip install isagellm-backend isagellm-comm
```
### 详细迁移指南
完整的迁移指南请参阅:
- [sagellm-docs: Backend vs Comm 边界说明](https://github.com/intellistream/sagellm-docs/blob/main/docs/BACKEND_VS_COMM_BOUNDARY.md)
## 架构定位
sagellm-backend 在 sageLLM 系统中的层级:
```
L2: sagellm-core (推理引擎层)
↓ 依赖 ↓
L1: sagellm-backend (计算硬件抽象) ← 本仓库
├─ CUDA Provider
├─ Ascend Provider
└─ CPU Provider
↓ 依赖 ↓
L0: sagellm-protocol (协议定义)
```
详见 [ARCHITECTURE.md](docs/ARCHITECTURE.md) 获取完整设计。
## 🔄 贡献指南
请遵循以下工作流程:
1. **创建 Issue** - 描述问题/需求
```bash
gh issue create --title "[Bug] 描述" --label "bug,sagellm-backend"
```
2. **开发修复** - 在本地 `fix/#123-xxx` 分支解决
```bash
git checkout -b fix/#123-xxx origin/main-dev
# 开发、测试...
pytest tests/ -v
ruff format . && ruff check . --fix
```
3. **发起 PR** - 提交到 `main-dev` 分支
```bash
gh pr create --base main-dev --title "Fix: 描述" --body "Closes #123"
```
4. **合并** - 审批后合并到 `main-dev`
### 环境配置
```bash
# 安装开发依赖
pip install -e ".[dev]"
# 安装 pre-commit hooks(必须)
pre-commit install
# 首次运行格式化
pre-commit run --all-files
# 运行测试
pytest tests/ -v
```
## 依赖说明
### 核心依赖
- `isagellm-protocol>=0.4.0.0,<0.5.0` - 协议层定义(强制)
### 可选依赖
- `torch>=2.0.0` - PyTorch(使用 CUDA/Ascend 后端时需要)
- `torch-npu>=2.0.0` - Ascend NPU(仅使用 Ascend 后端时需要)
### 开发依赖
- `pytest>=7.0.0` - 单元测试
- `pytest-asyncio>=0.23.0` - 异步测试支持
- `ruff>=0.8.0` - 代码格式化和检查
- `mypy>=1.0.0` - 类型检查
更多详情见 [CONTRIBUTING.md](CONTRIBUTING.md)
## License
Proprietary
| text/markdown | IntelliStream Team | null | null | null | Proprietary - IntelliStream | null | [
"Development Status :: 3 - Alpha",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | ==3.11.* | [] | [] | [] | [
"isagellm-protocol<0.6.0,>=0.5.1.0",
"torch>=2.4.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\"",
"bandit[toml]>=1.7.0; extra == \"dev\"",
"pre-commit>=3.0.0; extra == \"dev\"",
"psutil>=5.9.0; extra == \"dev\"",
"isage-pypi-publisher>=0.2.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.11 | 2026-02-20T13:14:04.005549 | isagellm_backend-0.5.2.12.tar.gz | 610,234 | 77/03/0ab2a21c4f06a959d86442ebc0252ede65d06ef4a7763c1f8cbd63bc48b2/isagellm_backend-0.5.2.12.tar.gz | source | sdist | null | false | a1dc095be08001cd9b0fc901e96c2990 | 95d749bc4f7468948c4705e6f7b3a7f61aba7a42729787ba1e967ae7503bdcec | 77030ab2a21c4f06a959d86442ebc0252ede65d06ef4a7763c1f8cbd63bc48b2 | null | [] | 311 |
2.4 | embed-client | 3.1.7.24 | Async client for Embedding Service API with comprehensive authentication, SSL/TLS, and mTLS support. | # embed-client
Асинхронный клиент для Embedding Service API с поддержкой всех режимов безопасности.
## Возможности
- ✅ **Асинхронный API** - полная поддержка async/await
- ✅ **Все режимы безопасности** - HTTP, HTTPS, mTLS
- ✅ **Аутентификация** - API Key, JWT, Basic Auth, Certificate
- ✅ **SSL/TLS поддержка** - полная интеграция с mcp_security_framework
- ✅ **Конфигурация** - файлы конфигурации, переменные окружения, аргументы
- ✅ **Генератор конфигураций** - CLI инструмент для генерации конфигов всех 8 режимов безопасности
- ✅ **Валидатор конфигураций** - CLI инструмент для проверки корректности конфигурационных файлов
- ✅ **Обратная совместимость** - API формат не изменился, добавлена только безопасность
- ✅ **Типизация** - 100% type-annotated код
- ✅ **Тестирование** - 84+ тестов с полным покрытием
## Quick Start: Примеры запуска
### Базовое использование
**Вариант 1: через аргументы командной строки**
```sh
# HTTP без аутентификации
python embed_client/example_async_usage.py --base-url http://localhost --port 8001
# HTTP с API ключом
python embed_client/example_async_usage.py --base-url http://localhost --port 8001 \
--auth-method api_key --api-key admin_key_123
# HTTPS с SSL
python embed_client/example_async_usage.py --base-url https://localhost --port 9443 \
--ssl-verify-mode CERT_REQUIRED
# mTLS с сертификатами
python embed_client/example_async_usage.py --base-url https://localhost --port 9443 \
--cert-file certs/client.crt --key-file keys/client.key --ca-cert-file certs/ca.crt
```
**Вариант 2: через переменные окружения**
```sh
export EMBED_CLIENT_BASE_URL=http://localhost
export EMBED_CLIENT_PORT=8001
export EMBED_CLIENT_AUTH_METHOD=api_key
export EMBED_CLIENT_API_KEY=admin_key_123
python embed_client/example_async_usage.py
```
**Вариант 3: через файл конфигурации**
```sh
python embed_client/example_async_usage.py --config configs/https_token.json
```
### Режимы безопасности
#### 1. HTTP (без аутентификации)
```python
from embed_client.async_client import EmbeddingServiceAsyncClient
client = EmbeddingServiceAsyncClient(
base_url="http://localhost",
port=8001
)
```
#### 2. HTTP + Token
```python
from embed_client.config import ClientConfig
# API Key
config = ClientConfig.create_http_token_config(
"http://localhost", 8001, {"user": "api_key_123"}
)
# JWT
config = ClientConfig.create_http_jwt_config(
"http://localhost", 8001, "secret", "username", "password"
)
# Basic Auth
config = ClientConfig.create_http_basic_config(
"http://localhost", 8001, "username", "password"
)
```
#### 3. HTTPS
```python
config = ClientConfig.create_https_config(
"https://localhost", 9443,
ca_cert_file="certs/ca.crt"
)
```
#### 4. mTLS (взаимная аутентификация)
```python
config = ClientConfig.create_mtls_config(
"https://localhost", 9443,
cert_file="certs/client.crt",
key_file="keys/client.key",
ca_cert_file="certs/ca.crt"
)
```
### Программное использование
```python
import asyncio
from embed_client.async_client import EmbeddingServiceAsyncClient
async def main():
# Minimal configuration for HTTPS + token on localhost:8001 via MCP Proxy Adapter
config_dict = {
"server": {"host": "localhost", "port": 8001},
"auth": {"method": "api_key", "api_keys": {"user": "user-secret-key"}},
"ssl": {
"enabled": True,
"verify_mode": "CERT_NONE",
"check_hostname": False,
# Paths from mtls_certificates used by test environment
"cert_file": "mtls_certificates/client/embedding-service.crt",
"key_file": "mtls_certificates/client/embedding-service.key",
"ca_cert_file": "mtls_certificates/ca/ca.crt",
},
}
texts = ["valid text", " ", "!!!"]
async with EmbeddingServiceAsyncClient(config_dict=config_dict) as client:
# High-level helper: always uses error_policy="continue"
data = await client.embed(texts, error_policy="continue")
# Iterate over per-item results
for idx, item in enumerate(data["results"]):
err = item["error"]
if err is None:
embedding = item["embedding"]
print(f"{idx}: OK, embedding length={len(embedding)}")
else:
print(f"{idx}: ERROR {err['code']} - {err['message']}")
if __name__ == "__main__":
asyncio.run(main())
```
## Vectorization methods (English)
### 1. Python async client – high-level `embed()`
- Use `EmbeddingServiceAsyncClient.embed()` for batch vectorization with per-item errors.
- Always pass `error_policy="continue"` to keep positional mapping between `texts[i]` and `results[i]`.
Example (see above): run `python embed_client/example_async_usage.py` or a custom script with `EmbeddingServiceAsyncClient.embed()`.
### 2. Python async client – low-level `cmd("embed")`
- For advanced scenarios you can call `client.cmd("embed", params=...)` directly and use helpers from `response_parsers`.
```python
params = {"texts": texts, "error_policy": "continue"}
raw_result = await client.cmd("embed", params=params)
data = extract_embedding_data(raw_result)
```
### 3. CLI Tools
The package installs three CLI tools:
#### 3.1. Configuration Generator – `embed-config-generator`
Generate configuration files for all 8 security modes:
```bash
# Generate all configurations
embed-config-generator --mode all --output-dir ./configs
# Generate single configuration
embed-config-generator --mode http --host localhost --port 8001 --output ./configs/http_8001.json
# HTTPS + token + mTLS certificates (recommended for production-like tests)
embed-config-generator --mode https_token --host localhost --port 8001 \
--cert-file mtls_certificates/client/embedding-service.crt \
--key-file mtls_certificates/client/embedding-service.key \
--ca-cert-file mtls_certificates/ca/ca.crt \
--output ./configs/https_token_8001.json
```
#### 3.2. Configuration Validator – `embed-config-validator`
Validate configuration files for correctness:
```bash
# Validate a single configuration file
embed-config-validator --file ./configs/http_8001.json
# Validate all configurations in a directory
embed-config-validator --dir ./configs --verbose
# Show detailed error messages
embed-config-validator --file ./configs/mtls.json --verbose
```
#### 3.3. Vectorization CLI – `embed-vectorize`
Vectorize texts using the client:
```bash
# HTTP (no auth) on localhost:8001
embed-vectorize --config ./configs/http_8001.json "hello world" "another text"
# HTTPS + token + mTLS certificates
embed-vectorize --config ./configs/https_token_8001.json "valid text" " " "!!!"
```
### 4. Full embed contract example on localhost:8001
For a complete contract test of `error_policy="continue"` across all 8 security modes, use:
```bash
python tests/test_embed_contract_8001.py
```
This script uses `ClientConfigGenerator` and `EmbeddingServiceAsyncClient.embed()` and is regularly validated against a real server on `localhost:8001`.
## Установка
```bash
# Установка из PyPI
pip install embed-client
# Установка в режиме разработки
git clone <repository>
cd embed-client
pip install -e .
```
## Dependencies (runtime)
- `mcp-proxy-adapter` - JSON-RPC transport for Embedding Service via MCP Proxy Adapter
- `PyJWT>=2.0.0` - JWT tokens (used for diagnostics and compatibility)
- `cryptography>=3.0.0` - certificates and crypto primitives
- `pydantic>=2.0.0` - configuration validation
## Тестирование
```bash
# Запуск всех тестов
pytest tests/
# Запуск тестов с покрытием
pytest tests/ --cov=embed_client
# Запуск конкретных тестов
pytest tests/test_async_client.py -v
pytest tests/test_config.py -v
pytest tests/test_auth.py -v
pytest tests/test_ssl_manager.py -v
```
## Документация
- [Формат API и режимы безопасности](docs/api_format.md)
- [Примеры использования](embed_client/example_async_usage.py)
- [Примеры на русском](embed_client/example_async_usage_ru.py)
## Безопасность
### Рекомендации
1. **Используйте HTTPS** для продакшена
2. **Включите проверку сертификатов** (CERT_REQUIRED)
3. **Используйте mTLS** для критически важных систем
4. **Регулярно обновляйте сертификаты**
5. **Храните приватные ключи в безопасном месте**
### Поддерживаемые протоколы
- TLS 1.2
- TLS 1.3
- SSL 3.0 (устаревший, не рекомендуется)
## Лицензия
MIT License
## Автор
**Vasiliy Zdanovskiy**
Email: vasilyvz@gmail.com
---
**Важно:**
- Используйте `--base-url` (через дефис), а не `--base_url` (через подчеркивание).
- Значение base_url должно содержать `http://` или `https://`.
- Аргументы должны быть отдельными (через пробел), а не через `=`.
| text/markdown | null | Vasiliy Zdanovskiy <vasilyvz@gmail.com> | null | null | null | embedding, async, client, api, authentication, ssl, tls, mtls, config, generator, validator, configuration | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Internet :: WWW/HTTP :: HTTP Servers",
"Topic :: Security",
"Topic :: System :: Networking"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"PyJWT>=2.0.0",
"cryptography>=3.0.0",
"pydantic>=2.0.0",
"mcp-proxy-adapter>=6.9.114",
"pytest; extra == \"test\"",
"pytest-asyncio; extra == \"test\"",
"pytest; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\"",
"black; extra == \"dev\"",
"flake8; extra == \"dev\"",
"mypy; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/vasilyvz/embed-client",
"Repository, https://github.com/vasilyvz/embed-client",
"Documentation, https://github.com/vasilyvz/embed-client#readme",
"Bug Tracker, https://github.com/vasilyvz/embed-client/issues",
"Configuration Reference, https://github.com/vasilyvz/embed-client/blob/main/CONFIGURATION.md"
] | twine/6.1.0 CPython/3.12.3 | 2026-02-20T13:13:53.673646 | embed_client-3.1.7.24.tar.gz | 183,993 | fd/05/f3aa4b4fb201d91ab284357896204659b63e331353d8b84fd05d43e29738/embed_client-3.1.7.24.tar.gz | source | sdist | null | false | 79944bf6e5540f291dceccbd0e19d6c1 | 4811dcf3785c47dec469cd078c2b436b8b8ed1495509bf1559075cfbf82add7d | fd05f3aa4b4fb201d91ab284357896204659b63e331353d8b84fd05d43e29738 | MIT | [
"LICENSE"
] | 235 |
2.4 | dv-pipecat-ai | 0.0.85.dev894 | An open source framework for voice (and multimodal) assistants | <h1><div align="center">
<img alt="pipecat" width="300px" height="auto" src="https://raw.githubusercontent.com/pipecat-ai/pipecat/main/pipecat.png">
</div></h1>
[](https://pypi.org/project/pipecat-ai)  [](https://codecov.io/gh/pipecat-ai/pipecat) [](https://docs.pipecat.ai) [](https://discord.gg/pipecat) [](https://deepwiki.com/pipecat-ai/pipecat)
[](https://getmanta.ai/pipecat)
# 🎙️ Pipecat: Real-Time Voice & Multimodal AI Agents
**Pipecat** is an open-source Python framework for building real-time voice and multimodal conversational agents. Orchestrate audio and video, AI services, different transports, and conversation pipelines effortlessly—so you can focus on what makes your agent unique.
> Want to dive right in? Try the [quickstart](https://docs.pipecat.ai/getting-started/quickstart).
## 🚀 What You Can Build
- **Voice Assistants** – natural, streaming conversations with AI
- **AI Companions** – coaches, meeting assistants, characters
- **Multimodal Interfaces** – voice, video, images, and more
- **Interactive Storytelling** – creative tools with generative media
- **Business Agents** – customer intake, support bots, guided flows
- **Complex Dialog Systems** – design logic with structured conversations
## 🧠 Why Pipecat?
- **Voice-first**: Integrates speech recognition, text-to-speech, and conversation handling
- **Pluggable**: Supports many AI services and tools
- **Composable Pipelines**: Build complex behavior from modular components
- **Real-Time**: Ultra-low latency interaction with different transports (e.g. WebSockets or WebRTC)
## 🌐 Pipecat Ecosystem
### 📱 Client SDKs
Building client applications? You can connect to Pipecat from any platform using our official SDKs:
<a href="https://docs.pipecat.ai/client/js/introduction">JavaScript</a> | <a href="https://docs.pipecat.ai/client/react/introduction">React</a> | <a href="https://docs.pipecat.ai/client/react-native/introduction">React Native</a> |
<a href="https://docs.pipecat.ai/client/ios/introduction">Swift</a> | <a href="https://docs.pipecat.ai/client/android/introduction">Kotlin</a> | <a href="https://docs.pipecat.ai/client/c++/introduction">C++</a> | <a href="https://github.com/pipecat-ai/pipecat-esp32">ESP32</a>
### 🧭 Structured conversations
Looking to build structured conversations? Check out [Pipecat Flows](https://github.com/pipecat-ai/pipecat-flows) for managing complex conversational states and transitions.
### 🪄 Beautiful UIs
Want to build beautiful and engaging experiences? Checkout the [Voice UI Kit](https://github.com/pipecat-ai/voice-ui-kit), a collection of components, hooks and templates for building voice AI applications quickly.
### 🛠️ Create and deploy projects
Create a new project in under a minute with the [Pipecat CLI](https://github.com/pipecat-ai/pipecat-cli). Then use the CLI to monitor and deploy your agent to production.
### 🔍 Debugging
Looking for help debugging your pipeline and processors? Check out [Whisker](https://github.com/pipecat-ai/whisker), a real-time Pipecat debugger.
### 🖥️ Terminal
Love terminal applications? Check out [Tail](https://github.com/pipecat-ai/tail), a terminal dashboard for Pipecat.
### 📺️ Pipecat TV Channel
Catch new features, interviews, and how-tos on our [Pipecat TV](https://www.youtube.com/playlist?list=PLzU2zoMTQIHjqC3v4q2XVSR3hGSzwKFwH) channel.
## 🎬 See it in action
<p float="left">
<a href="https://github.com/pipecat-ai/pipecat-examples/tree/main/simple-chatbot"><img src="https://raw.githubusercontent.com/pipecat-ai/pipecat-examples/main/simple-chatbot/image.png" width="400" /></a>
<a href="https://github.com/pipecat-ai/pipecat-examples/tree/main/storytelling-chatbot"><img src="https://raw.githubusercontent.com/pipecat-ai/pipecat-examples/main/storytelling-chatbot/image.png" width="400" /></a>
<br/>
<a href="https://github.com/pipecat-ai/pipecat-examples/tree/main/translation-chatbot"><img src="https://raw.githubusercontent.com/pipecat-ai/pipecat-examples/main/translation-chatbot/image.png" width="400" /></a>
<a href="https://github.com/pipecat-ai/pipecat/blob/main/examples/foundational/12-describe-video.py"><img src="https://github.com/pipecat-ai/pipecat/blob/main/examples/foundational/assets/moondream.png" width="400" /></a>
</p>
## 🧩 Available services
| Category | Services |
| ------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Speech-to-Text | [AssemblyAI](https://docs.pipecat.ai/server/services/stt/assemblyai), [AWS](https://docs.pipecat.ai/server/services/stt/aws), [Azure](https://docs.pipecat.ai/server/services/stt/azure), [Cartesia](https://docs.pipecat.ai/server/services/stt/cartesia), [Deepgram](https://docs.pipecat.ai/server/services/stt/deepgram), [ElevenLabs](https://docs.pipecat.ai/server/services/stt/elevenlabs), [Fal Wizper](https://docs.pipecat.ai/server/services/stt/fal), [Gladia](https://docs.pipecat.ai/server/services/stt/gladia), [Google](https://docs.pipecat.ai/server/services/stt/google), [Groq (Whisper)](https://docs.pipecat.ai/server/services/stt/groq), [NVIDIA Riva](https://docs.pipecat.ai/server/services/stt/riva), [OpenAI (Whisper)](https://docs.pipecat.ai/server/services/stt/openai), [SambaNova (Whisper)](https://docs.pipecat.ai/server/services/stt/sambanova), [Soniox](https://docs.pipecat.ai/server/services/stt/soniox), [Speechmatics](https://docs.pipecat.ai/server/services/stt/speechmatics), [Ultravox](https://docs.pipecat.ai/server/services/stt/ultravox), [Whisper](https://docs.pipecat.ai/server/services/stt/whisper) |
| LLMs | [Anthropic](https://docs.pipecat.ai/server/services/llm/anthropic), [AWS](https://docs.pipecat.ai/server/services/llm/aws), [Azure](https://docs.pipecat.ai/server/services/llm/azure), [Cerebras](https://docs.pipecat.ai/server/services/llm/cerebras), [DeepSeek](https://docs.pipecat.ai/server/services/llm/deepseek), [Fireworks AI](https://docs.pipecat.ai/server/services/llm/fireworks), [Gemini](https://docs.pipecat.ai/server/services/llm/gemini), [Grok](https://docs.pipecat.ai/server/services/llm/grok), [Groq](https://docs.pipecat.ai/server/services/llm/groq), [Mistral](https://docs.pipecat.ai/server/services/llm/mistral), [NVIDIA NIM](https://docs.pipecat.ai/server/services/llm/nim), [Ollama](https://docs.pipecat.ai/server/services/llm/ollama), [OpenAI](https://docs.pipecat.ai/server/services/llm/openai), [OpenRouter](https://docs.pipecat.ai/server/services/llm/openrouter), [Perplexity](https://docs.pipecat.ai/server/services/llm/perplexity), [Qwen](https://docs.pipecat.ai/server/services/llm/qwen), [SambaNova](https://docs.pipecat.ai/server/services/llm/sambanova) [Together AI](https://docs.pipecat.ai/server/services/llm/together) |
| Text-to-Speech | [Async](https://docs.pipecat.ai/server/services/tts/asyncai), [AWS](https://docs.pipecat.ai/server/services/tts/aws), [Azure](https://docs.pipecat.ai/server/services/tts/azure), [Cartesia](https://docs.pipecat.ai/server/services/tts/cartesia), [Deepgram](https://docs.pipecat.ai/server/services/tts/deepgram), [ElevenLabs](https://docs.pipecat.ai/server/services/tts/elevenlabs), [Fish](https://docs.pipecat.ai/server/services/tts/fish), [Google](https://docs.pipecat.ai/server/services/tts/google), [Groq](https://docs.pipecat.ai/server/services/tts/groq), [Hume](https://docs.pipecat.ai/server/services/tts/hume), [Inworld](https://docs.pipecat.ai/server/services/tts/inworld), [LMNT](https://docs.pipecat.ai/server/services/tts/lmnt), [MiniMax](https://docs.pipecat.ai/server/services/tts/minimax), [Neuphonic](https://docs.pipecat.ai/server/services/tts/neuphonic), [NVIDIA Riva](https://docs.pipecat.ai/server/services/tts/riva), [OpenAI](https://docs.pipecat.ai/server/services/tts/openai), [Piper](https://docs.pipecat.ai/server/services/tts/piper), [PlayHT](https://docs.pipecat.ai/server/services/tts/playht), [Rime](https://docs.pipecat.ai/server/services/tts/rime), [Sarvam](https://docs.pipecat.ai/server/services/tts/sarvam), [XTTS](https://docs.pipecat.ai/server/services/tts/xtts) |
| Speech-to-Speech | [AWS Nova Sonic](https://docs.pipecat.ai/server/services/s2s/aws), [Gemini Multimodal Live](https://docs.pipecat.ai/server/services/s2s/gemini), [OpenAI Realtime](https://docs.pipecat.ai/server/services/s2s/openai) |
| Transport | [Daily (WebRTC)](https://docs.pipecat.ai/server/services/transport/daily), [FastAPI Websocket](https://docs.pipecat.ai/server/services/transport/fastapi-websocket), [SmallWebRTCTransport](https://docs.pipecat.ai/server/services/transport/small-webrtc), [WebSocket Server](https://docs.pipecat.ai/server/services/transport/websocket-server), Local |
| Serializers | [Plivo](https://docs.pipecat.ai/server/utilities/serializers/plivo), [Twilio](https://docs.pipecat.ai/server/utilities/serializers/twilio), [Telnyx](https://docs.pipecat.ai/server/utilities/serializers/telnyx) |
| Video | [HeyGen](https://docs.pipecat.ai/server/services/video/heygen), [Tavus](https://docs.pipecat.ai/server/services/video/tavus), [Simli](https://docs.pipecat.ai/server/services/video/simli) |
| Memory | [mem0](https://docs.pipecat.ai/server/services/memory/mem0) |
| Vision & Image | [fal](https://docs.pipecat.ai/server/services/image-generation/fal), [Google Imagen](https://docs.pipecat.ai/server/services/image-generation/fal), [Moondream](https://docs.pipecat.ai/server/services/vision/moondream) |
| Audio Processing | [Silero VAD](https://docs.pipecat.ai/server/utilities/audio/silero-vad-analyzer), [Krisp](https://docs.pipecat.ai/server/utilities/audio/krisp-filter), [Koala](https://docs.pipecat.ai/server/utilities/audio/koala-filter), [ai-coustics](https://docs.pipecat.ai/server/utilities/audio/aic-filter) |
| Analytics & Metrics | [OpenTelemetry](https://docs.pipecat.ai/server/utilities/opentelemetry), [Sentry](https://docs.pipecat.ai/server/services/analytics/sentry) |
📚 [View full services documentation →](https://docs.pipecat.ai/server/services/supported-services)
## ⚡ Getting started
You can get started with Pipecat running on your local machine, then move your agent processes to the cloud when you're ready.
1. Install uv
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
> **Need help?** Refer to the [uv install documentation](https://docs.astral.sh/uv/getting-started/installation/).
2. Install the module
```bash
# For new projects
uv init my-pipecat-app
cd my-pipecat-app
uv add pipecat-ai
# Or for existing projects
uv add pipecat-ai
```
3. Set up your environment
```bash
cp env.example .env
```
4. To keep things lightweight, only the core framework is included by default. If you need support for third-party AI services, you can add the necessary dependencies with:
```bash
uv add "pipecat-ai[option,...]"
```
> **Using pip?** You can still use `pip install pipecat-ai` and `pip install "pipecat-ai[option,...]"` to get set up.
## 🧪 Code examples
- [Foundational](https://github.com/pipecat-ai/pipecat/tree/main/examples/foundational) — small snippets that build on each other, introducing one or two concepts at a time
- [Example apps](https://github.com/pipecat-ai/pipecat-examples) — complete applications that you can use as starting points for development
## 🛠️ Contributing to the framework
### Prerequisites
**Minimum Python Version:** 3.10
**Recommended Python Version:** 3.12
### Setup Steps
1. Clone the repository and navigate to it:
```bash
git clone https://github.com/pipecat-ai/pipecat.git
cd pipecat
```
2. Install development and testing dependencies:
```bash
uv sync --group dev --all-extras \
--no-extra gstreamer \
--no-extra krisp \
--no-extra local \
--no-extra ultravox # (ultravox not fully supported on macOS)
```
3. Install the git pre-commit hooks:
```bash
uv run pre-commit install
```
> **Note**: Some extras (local, gstreamer) require system dependencies. See documentation if you encounter build errors.
### Running tests
To run all tests, from the root directory:
```bash
uv run pytest
```
Run a specific test suite:
```bash
uv run pytest tests/test_name.py
```
## 🤝 Contributing
We welcome contributions from the community! Whether you're fixing bugs, improving documentation, or adding new features, here's how you can help:
- **Found a bug?** Open an [issue](https://github.com/pipecat-ai/pipecat/issues)
- **Have a feature idea?** Start a [discussion](https://discord.gg/pipecat)
- **Want to contribute code?** Check our [CONTRIBUTING.md](CONTRIBUTING.md) guide
- **Documentation improvements?** [Docs](https://github.com/pipecat-ai/docs) PRs are always welcome
Before submitting a pull request, please check existing issues and PRs to avoid duplicates.
We aim to review all contributions promptly and provide constructive feedback to help get your changes merged.
## 🛟 Getting help
➡️ [Join our Discord](https://discord.gg/pipecat)
➡️ [Read the docs](https://docs.pipecat.ai)
➡️ [Reach us on X](https://x.com/pipecat_ai)
| text/markdown | null | null | null | null | null | webrtc, audio, video, ai | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Communications :: Conferencing",
"Topic :: Multimedia :: Sound/Audio",
"Topic :: Multimedia :: Video",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiofiles<25,>=24.1.0",
"aiohttp<4,>=3.11.12",
"audioop-lts~=0.2.1; python_version >= \"3.13\"",
"docstring_parser~=0.16",
"loguru~=0.7.3",
"Markdown<4,>=3.7",
"nltk<4,>=3.9.1",
"numpy<3,>=1.26.4",
"Pillow<12,>=11.1.0",
"protobuf~=5.29.3",
"pydantic<3,>=2.10.6",
"PyJWT<3,>=2.8.0",
"pyloudnorm~=0.1.1",
"resampy~=0.4.3",
"soxr~=0.5.0",
"openai<3,>=1.74.0",
"numba==0.61.2",
"wait_for2>=0.4.1; python_version < \"3.12\"",
"aic-sdk~=1.0.1; extra == \"aic\"",
"anthropic~=0.49.0; extra == \"anthropic\"",
"dv-pipecat-ai[websockets-base]; extra == \"assemblyai\"",
"dv-pipecat-ai[websockets-base]; extra == \"asyncai\"",
"aioboto3~=15.0.0; extra == \"aws\"",
"dv-pipecat-ai[websockets-base]; extra == \"aws\"",
"aws_sdk_bedrock_runtime~=0.1.0; python_version >= \"3.12\" and extra == \"aws-nova-sonic\"",
"azure-cognitiveservices-speech~=1.42.0; extra == \"azure\"",
"cartesia~=2.0.3; extra == \"cartesia\"",
"dv-pipecat-ai[websockets-base]; extra == \"cartesia\"",
"daily-python~=0.20.0; extra == \"daily\"",
"deepgram-sdk~=4.7.0; extra == \"deepgram\"",
"dv-pipecat-ai[websockets-base]; extra == \"elevenlabs\"",
"fal-client~=0.5.9; extra == \"fal\"",
"ormsgpack~=1.7.0; extra == \"fish\"",
"dv-pipecat-ai[websockets-base]; extra == \"fish\"",
"dv-pipecat-ai[websockets-base]; extra == \"gladia\"",
"google-cloud-speech<3,>=2.33.0; extra == \"google\"",
"google-cloud-texttospeech<3,>=2.31.0; extra == \"google\"",
"google-genai<2,>=1.41.0; extra == \"google\"",
"dv-pipecat-ai[websockets-base]; extra == \"google\"",
"groq~=0.23.0; extra == \"groq\"",
"pygobject~=3.50.0; extra == \"gstreamer\"",
"livekit>=1.0.13; extra == \"heygen\"",
"dv-pipecat-ai[websockets-base]; extra == \"heygen\"",
"hume>=0.11.2; extra == \"hume\"",
"dv-pipecat-ai-krisp~=0.4.0; extra == \"krisp\"",
"pvkoala~=2.0.3; extra == \"koala\"",
"langchain~=0.3.20; extra == \"langchain\"",
"langchain-community~=0.3.20; extra == \"langchain\"",
"langchain-openai~=0.3.9; extra == \"langchain\"",
"livekit~=1.0.13; extra == \"livekit\"",
"livekit-api~=1.0.5; extra == \"livekit\"",
"tenacity<10.0.0,>=8.2.3; extra == \"livekit\"",
"dv-pipecat-ai[websockets-base]; extra == \"lmnt\"",
"pyaudio~=0.2.14; extra == \"local\"",
"mcp[cli]<2,>=1.11.0; extra == \"mcp\"",
"mem0ai~=0.1.94; extra == \"mem0\"",
"mlx-whisper~=0.4.2; extra == \"mlx-whisper\"",
"accelerate~=1.10.0; extra == \"moondream\"",
"einops~=0.8.0; extra == \"moondream\"",
"pyvips[binary]~=3.0.0; extra == \"moondream\"",
"timm~=1.0.13; extra == \"moondream\"",
"transformers>=4.48.0; extra == \"moondream\"",
"dv-pipecat-ai[websockets-base]; extra == \"neuphonic\"",
"noisereduce~=3.0.3; extra == \"noisereduce\"",
"dv-pipecat-ai[websockets-base]; extra == \"openai\"",
"openpipe<6,>=4.50.0; extra == \"openpipe\"",
"dv-pipecat-ai[websockets-base]; extra == \"playht\"",
"dv-pipecat-ai[websockets-base]; extra == \"rime\"",
"nvidia-riva-client~=2.21.1; extra == \"riva\"",
"python-dotenv<2.0.0,>=1.0.0; extra == \"runner\"",
"uvicorn<1.0.0,>=0.32.0; extra == \"runner\"",
"fastapi<0.117.0,>=0.115.6; extra == \"runner\"",
"dv-pipecat-ai-small-webrtc-prebuilt>=1.0.0; extra == \"runner\"",
"sarvamai<1,>=0.1.19; extra == \"sarvam\"",
"websockets<15.0,>=13.1; extra == \"sarvam\"",
"sentry-sdk<3,>=2.28.0; extra == \"sentry\"",
"coremltools>=8.0; extra == \"local-smart-turn\"",
"transformers; extra == \"local-smart-turn\"",
"torch<3,>=2.5.0; extra == \"local-smart-turn\"",
"torchaudio<3,>=2.5.0; extra == \"local-smart-turn\"",
"transformers; extra == \"local-smart-turn-v3\"",
"onnxruntime<2,>=1.20.1; extra == \"local-smart-turn-v3\"",
"onnxruntime<2,>=1.20.1; extra == \"silero\"",
"simli-ai~=0.1.10; extra == \"simli\"",
"dv-pipecat-ai[websockets-base]; extra == \"soniox\"",
"soundfile~=0.13.0; extra == \"soundfile\"",
"speechmatics-rt>=0.5.0; extra == \"speechmatics\"",
"strands-agents<2,>=1.9.1; extra == \"strands\"",
"opentelemetry-sdk>=1.33.0; extra == \"tracing\"",
"opentelemetry-api>=1.33.0; extra == \"tracing\"",
"opentelemetry-instrumentation>=0.54b0; extra == \"tracing\"",
"transformers>=4.48.0; extra == \"ultravox\"",
"vllm>=0.9.0; extra == \"ultravox\"",
"aiortc<2,>=1.13.0; extra == \"webrtc\"",
"opencv-python<5,>=4.11.0.86; extra == \"webrtc\"",
"dv-pipecat-ai[websockets-base]; extra == \"websocket\"",
"fastapi<0.117.0,>=0.115.6; extra == \"websocket\"",
"websockets<16.0,>=13.1; extra == \"websockets-base\"",
"faster-whisper~=1.1.1; extra == \"whisper\""
] | [] | [] | [] | [
"Source, https://github.com/pipecat-ai/pipecat",
"Website, https://pipecat.ai"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:13:37.434171 | dv_pipecat_ai-0.0.85.dev894.tar.gz | 12,739,723 | 1d/d2/16f71a151b529c93697774d188bb133df1f6e0e1a4814dd078cf0ab9a55b/dv_pipecat_ai-0.0.85.dev894.tar.gz | source | sdist | null | false | 77fb32b110335345f2683826c7c5748d | 2d1447e47f58bbcc218702f25b710ac9e035c240281acfe1073808a58aa5b508 | 1dd216f71a151b529c93697774d188bb133df1f6e0e1a4814dd078cf0ab9a55b | BSD-2-Clause | [
"LICENSE"
] | 224 |
2.1 | petitRADTRANS | 3.3.2 | Exoplanet spectral synthesis tool for retrievals | =============
petitRADTRANS
=============
.. image:: https://img.shields.io/pypi/v/petitRADTRANS
:target: https://pypi.org/project/petitRADTRANS/
:alt: Pypi version
.. image:: https://img.shields.io/readthedocs/petitradtrans
:target: https://petitradtrans.readthedocs.io/en/latest/
:alt: documentation: https://petitradtrans.readthedocs.io/en/latest/
.. image:: https://img.shields.io/gitlab/license/mauricemolli/petitRADTRANS
:target: https://gitlab.com/mauricemolli/petitRADTRANS/-/blob/master/LICENSE
:alt: licence: MIT
.. image:: https://img.shields.io/badge/data-Keeper-darkred
:target: https://keeper.mpdl.mpg.de/d/ccf25082fda448c8a0d0/
:alt: data: https://keeper.mpdl.mpg.de/d/ccf25082fda448c8a0d0/
.. image:: https://img.shields.io/badge/DOI-10.1051%2F0004--6361%2F201935470-blue
:target: https://doi.org/10.1051/0004-6361/201935470
:alt: DOI: 10.1051/0004-6361/201935470
.. image:: https://joss.theoj.org/papers/10.21105/joss.05875/status.svg
:target: https://doi.org/10.21105/joss.05875
:alt: DOI: 10.21105/joss.05875
.. image:: https://joss.theoj.org/papers/10.21105/joss.07028/status.svg
:target: https://doi.org/10.21105/joss.07028
:alt: DOI: 10.21105/joss.07028
**An easy-to-use Python package for calculating exoplanet spectra**
Welcome to the repository of petitRADTRANS, an easy-to-use code for the calculation of exoplanet spectra.
petitRADTRANS allows the calculation of emission or transmission spectra, at low or high resolution, clear or cloudy,
and includes a retrieval module to fit a petitRADTRANS model to your spectral data.
Documentation
=============
The code documentation, installation guide, and tutorial can be found at `https://petitradtrans.readthedocs.io <https://petitradtrans.readthedocs.io>`_.
Attribution
===========
If you use petitRADTRANS in your work, please cite the following articles:
- for petitRADTRANS itself: `Mollière et al. 2019 <https://doi.org/10.1051/0004-6361/201935470>`_
- for the retrieval package: `Nasedkin et al. 2024 <https://doi.org/10.21105/joss.05875>`_
- for petitRADTRANS 3+: `Blain et al. 2024 <https://doi.org/10.21105/joss.07028>`_
License
=======
Copyright 2019-2024 the pRT team
petitRADTRANS is available under the MIT license.
See the LICENSE file for more information.
| text/x-rst | null | =?utf-8?q?Paul_Molli=C3=A8re?= <molliere@mpia.de> | null | null | Copyright (c) 2019-2024 Paul Mollière Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Fortran",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Astronomy"
] | [] | null | null | null | [] | [] | [] | [
"meson-python",
"ninja",
"numpy",
"scipy",
"astropy>=5.2",
"molmass",
"h5py",
"dill",
"pymultinest",
"pyvo",
"bs4",
"selenium",
"mpi4py",
"requests",
"skycalc-cli",
"matplotlib",
"corner",
"mpi4py; extra == \"full\"",
"requests; extra == \"full\"",
"skycalc-cli; extra == \"full\"",
"matplotlib; extra == \"full\"",
"corner; extra == \"full\"",
"seaborn; extra == \"full\"",
"species>=0.8.0; extra == \"full\"",
"ultranest; extra == \"full\"",
"mpi4py; extra == \"retrieval\"",
"requests; extra == \"retrieval\"",
"skycalc-cli; extra == \"retrieval\"",
"matplotlib; extra == \"retrieval\"",
"corner; extra == \"retrieval\"",
"species>=0.8.0; extra == \"retrieval\"",
"ultranest; extra == \"retrieval\"",
"build; extra == \"test\"",
"wheel; extra == \"test\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"mpi4py; extra == \"test\"",
"requests; extra == \"test\"",
"skycalc-cli; extra == \"test\"",
"matplotlib; extra == \"test\"",
"corner; extra == \"test\"",
"seaborn; extra == \"test\"",
"species>=0.8.0; extra == \"test\"",
"ultranest; extra == \"test\""
] | [] | [] | [] | [
"Documentation, https://petitradtrans.readthedocs.io/en/latest/",
"Repository, https://gitlab.com/mauricemolli/petitRADTRANS",
"Issues, https://gitlab.com/mauricemolli/petitRADTRANS/-/issues",
"Changelog, https://gitlab.com/mauricemolli/petitRADTRANS/-/blob/master/CHANGELOG.md"
] | twine/4.0.2 CPython/3.11.2 | 2026-02-20T13:13:31.297008 | petitradtrans-3.3.2.tar.gz | 32,352,026 | 0e/46/2940966f8e9ba7a44ae514e2fe96d19cc41328dc00c522fb98f7b6a3d754/petitradtrans-3.3.2.tar.gz | source | sdist | null | false | fcd708e77263aa08b694baf1b05750c3 | f92298206b2e2ca21110c6bb43a6f0a1f74f73452d457a0cbd2f54ff3ee469f8 | 0e462940966f8e9ba7a44ae514e2fe96d19cc41328dc00c522fb98f7b6a3d754 | null | [] | 0 |
2.1 | duckdb | 1.5.0.dev307 | DuckDB in-process database | <div align="center">
<picture>
<source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/duckdb/duckdb/refs/heads/main/logo/DuckDB_Logo-horizontal.svg">
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/duckdb/duckdb/refs/heads/main/logo/DuckDB_Logo-horizontal-dark-mode.svg">
<img alt="DuckDB logo" src="https://raw.githubusercontent.com/duckdb/duckdb/refs/heads/main/logo/DuckDB_Logo-horizontal.svg" height="100">
</picture>
</div>
<br />
<p align="center">
<a href="https://discord.gg/tcvwpjfnZx"><img src="https://shields.io/discord/909674491309850675" alt="Discord" /></a>
<a href="https://pypi.org/project/duckdb/"><img src="https://img.shields.io/pypi/v/duckdb.svg" alt="PyPI Latest Release"/></a>
</p>
<br />
<p align="center">
<a href="https://duckdb.org">DuckDB.org</a>
|
<a href="https://duckdb.org/docs/stable/guides/python/install">User Guide (Python)</a>
-
<a href="https://duckdb.org/docs/stable/clients/python/overview">API Docs (Python)</a>
</p>
# DuckDB: A Fast, In-Process, Portable, Open Source, Analytical Database System
* **Simple**: DuckDB is easy to install and deploy. It has zero external dependencies and runs in-process in its host application or as a single binary.
* **Portable**: DuckDB runs on Linux, macOS, Windows, Android, iOS and all popular hardware architectures. It has idiomatic client APIs for major programming languages.
* **Feature-rich**: DuckDB offers a rich SQL dialect. It can read and write file formats such as CSV, Parquet, and JSON, to and from the local file system and remote endpoints such as S3 buckets.
* **Fast**: DuckDB runs analytical queries at blazing speed thanks to its columnar engine, which supports parallel execution and can process larger-than-memory workloads.
* **Extensible**: DuckDB is extensible by third-party features such as new data types, functions, file formats and new SQL syntax. User contributions are available as community extensions.
* **Free**: DuckDB and its core extensions are open-source under the permissive MIT License. The intellectual property of the project is held by the DuckDB Foundation.
## Installation
Install the latest release of DuckDB directly from [PyPI](https://pypi.org/project/duckdb/):
```bash
pip install duckdb
```
Install with all optional dependencies:
```bash
pip install 'duckdb[all]'
```
## Contributing
See the [CONTRIBUTING.md](CONTRIBUTING.md) for instructions on how to set up a development environment.
| text/markdown | DuckDB Foundation | null | DuckDB Foundation | null | null | DuckDB, Database, SQL, OLAP | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Database",
"Topic :: Database :: Database Engines/Servers",
"Topic :: Scientific/Engineering",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: C++"
] | [] | null | null | >=3.10.0 | [] | [] | [] | [
"ipython; extra == \"all\"",
"fsspec; extra == \"all\"",
"numpy; extra == \"all\"",
"pandas; extra == \"all\"",
"pyarrow; extra == \"all\"",
"adbc-driver-manager; extra == \"all\""
] | [] | [] | [] | [
"Documentation, https://duckdb.org/docs/stable/clients/python/overview",
"Source, https://github.com/duckdb/duckdb-python",
"Issues, https://github.com/duckdb/duckdb-python/issues",
"Changelog, https://github.com/duckdb/duckdb-python/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:13:20.415378 | duckdb-1.5.0.dev307.tar.gz | 17,979,073 | 6f/3b/1973edd3e6f147f1845b58095f3dfda8767e246515efeaa430ae0a04d573/duckdb-1.5.0.dev307.tar.gz | source | sdist | null | false | 184bef710d6d277aea7021781a57a20e | a25bf5111126832cd66b743301c75c68ba5d8054877898af80fac0b911855a65 | 6f3b1973edd3e6f147f1845b58095f3dfda8767e246515efeaa430ae0a04d573 | null | [] | 3,573 |
2.4 | sandcastle-ai | 0.10.0 | Production-ready workflow orchestrator for AI agents. Define pipelines in YAML, run locally with zero config, scale to production. | # Sandcastle
**Stop babysitting your AI agents.** Sandcastle is a workflow orchestrator that runs your agent pipelines so you don't have to. Define workflows in YAML, start locally with zero config, and scale to production when you're ready. Pluggable sandbox backends, multi-provider model routing, and a full-featured dashboard included.
[](https://pypi.org/project/sandcastle-ai/)
[](LICENSE)
[](https://www.python.org/downloads/)
[]()
[](https://gizmax.github.io/Sandcastle/)
<p align="center">
<a href="https://gizmax.github.io/Sandcastle/">
<img src="docs/screenshots/overview-dark.png" alt="Sandcastle Dashboard" width="720" />
</a>
</p>
<p align="center">
<a href="https://gizmax.github.io/Sandcastle/"><strong>Try the Live Demo (no backend needed)</strong></a>
</p>
---
## Table of Contents
- [Why Sandcastle?](#why-sandcastle)
- [Start Local. Scale When Ready.](#start-local-scale-when-ready)
- [Quickstart](#quickstart)
- [MCP Integration](#mcp-integration)
- [Features](#features)
- [Pluggable Sandbox Backends](#pluggable-sandbox-backends)
- [Multi-Provider Model Routing](#multi-provider-model-routing)
- [Workflow Engine](#workflow-engine)
- [Human Approval Gates](#human-approval-gates)
- [Self-Optimizing Workflows (AutoPilot)](#self-optimizing-workflows-autopilot)
- [Hierarchical Workflows (Workflow-as-Step)](#hierarchical-workflows-workflow-as-step)
- [Policy Engine](#policy-engine)
- [Cost-Latency Optimizer](#cost-latency-optimizer)
- [Directory Input & CSV Export](#directory-input--csv-export)
- [23 Built-in Workflow Templates](#23-built-in-workflow-templates)
- [Real-time Event Stream](#real-time-event-stream)
- [Run Time Machine](#run-time-machine)
- [Budget Guardrails](#budget-guardrails)
- [Dashboard](#dashboard)
- [API Reference](#api-reference)
- [Multi-Tenant Auth](#multi-tenant-auth)
- [Webhooks](#webhooks)
- [Architecture](#architecture)
- [Configuration](#configuration)
- [Development](#development)
- [Acknowledgements](#acknowledgements)
- [License](#license)
---
## Why Sandcastle?
AI agent frameworks give you building blocks - LLM calls, tool use, maybe a graph. But when you start building real products, the glue code piles up fast:
- **"Step A scrapes, step B enriches, step C scores."** - You need workflow orchestration.
- **"Fan out over 50 leads in parallel, then merge."** - You need a DAG engine.
- **"Bill the customer per enrichment, track costs per run."** - You need usage metering.
- **"Alert me if the agent fails, retry with backoff."** - You need production error handling.
- **"Run this every 6 hours and POST results to Slack."** - You need scheduling and webhooks.
- **"A human should review this before the agent continues."** - You need approval gates.
- **"Block the output if it contains PII or leaked secrets."** - You need policy enforcement.
- **"Pick the cheapest model that still meets quality SLOs."** - You need cost-latency optimization.
- **"Use Claude for quality, GPT for speed, Gemini for cost."** - You need multi-provider routing.
- **"Run on E2B cloud, Docker locally, or Cloudflare at the edge."** - You need pluggable runtimes.
- **"Show me what's running, what failed, and what it cost."** - You need a dashboard.
Sandcastle handles all of that. Define workflows in YAML, pick your sandbox backend, choose your models, and ship to production.
---
## Start Local. Scale When Ready.
No Docker, no database server, no Redis. Install, run, done.
```bash
pip install sandcastle-ai
sandcastle init # asks for API keys, picks sandbox backend, writes .env
sandcastle serve # starts API + dashboard on one port
```
You'll need API keys for your chosen setup:
- **ANTHROPIC_API_KEY** - get one at [console.anthropic.com](https://console.anthropic.com/) (for Claude models)
- **E2B_API_KEY** - get one at [e2b.dev](https://e2b.dev/) (for E2B cloud sandboxes - free tier available)
Or use the `docker` backend (needs Docker installed) or `local` backend (dev only, no sandbox isolation) and skip the E2B key.
Dashboard at `http://localhost:8080`, API at `http://localhost:8080/api`, 23 workflow templates included.
Sandcastle auto-detects your environment. No `DATABASE_URL`? It uses SQLite. No `REDIS_URL`? Jobs run in-process. No S3 credentials? Files go to disk. **Same code, same API, same dashboard** - you just add connection strings when you're ready to scale.
```
Prototype Staging Production
--------- ------- ----------
SQLite PostgreSQL PostgreSQL
In-process queue --> Redis + arq --> Redis + arq
Local filesystem Local filesystem S3 / MinIO
Single process Single process API + Worker + Scheduler
```
| | Local Mode | Production Mode |
|---|---|---|
| **Database** | SQLite (auto-created in `./data/`) | PostgreSQL 16 |
| **Job Queue** | In-process (`asyncio.create_task`) | Redis 7 + arq workers |
| **Storage** | Filesystem (`./data/`) | S3 / MinIO |
| **Scheduler** | In-memory APScheduler | In-memory APScheduler |
| **Setup time** | 30 seconds | 5 minutes |
| **Config needed** | Just API keys | API keys + connection strings |
| **Best for** | Prototyping, solo devs, demos | Teams, production, multi-tenant |
### Ready to scale?
When local mode isn't enough anymore, upgrade one piece at a time. Each step is independent - do only what you need.
**Step 1 - PostgreSQL** (concurrent users, data durability)
```bash
# Install and start PostgreSQL (macOS example)
brew install postgresql@16
brew services start postgresql@16
# Create a database
createdb sandcastle
# Add to .env
echo 'DATABASE_URL=postgresql+asyncpg://localhost/sandcastle' >> .env
# Run migrations
pip install sandcastle-ai # if not installed yet
alembic upgrade head
# Restart
sandcastle serve
```
Your SQLite data stays in `./data/`. Sandcastle starts fresh with PostgreSQL - existing local runs are not migrated.
**Step 2 - Redis** (background workers, parallel runs)
```bash
# Install and start Redis (macOS example)
brew install redis
brew services start redis
# Add to .env
echo 'REDIS_URL=redis://localhost:6379' >> .env
# Restart API + start a worker in a second terminal
sandcastle serve
sandcastle worker
```
With Redis, workflows run in background workers instead of in-process. You can run multiple workers for parallel execution.
**Step 3 - S3 / MinIO** (artifact storage)
```bash
# Add to .env
echo 'STORAGE_BACKEND=s3' >> .env
echo 'S3_BUCKET=sandcastle-artifacts' >> .env
echo 'AWS_ACCESS_KEY_ID=...' >> .env
echo 'AWS_SECRET_ACCESS_KEY=...' >> .env
# For MinIO, also set: S3_ENDPOINT_URL=http://localhost:9000
# Restart
sandcastle serve
```
**Or skip all that and use Docker:**
```bash
docker compose up -d # PostgreSQL + Redis + API + Worker, all configured
```
---
## Quickstart
### Production Mode - Docker (recommended)
One command. PostgreSQL, Redis, API server, and background worker - all configured.
```bash
git clone https://github.com/gizmax/Sandcastle.git
cd Sandcastle
# Add your API keys
cat > .env << 'EOF'
ANTHROPIC_API_KEY=sk-ant-...
E2B_API_KEY=e2b_...
SANDBOX_BACKEND=e2b
WEBHOOK_SECRET=your-signing-secret
EOF
docker compose up -d
```
That's it. Sandcastle is running at `http://localhost:8080` with PostgreSQL 16, Redis 7, auto-migrations, and an arq background worker.
```bash
docker compose ps # check status
docker compose logs -f # tail logs
docker compose down # stop everything
```
### Production Mode - Manual
If you prefer running without Docker:
```bash
git clone https://github.com/gizmax/Sandcastle.git
cd Sandcastle
cp .env.example .env # configure all connection strings
uv sync
# Start infrastructure (your own PostgreSQL + Redis)
# Set DATABASE_URL and REDIS_URL in .env
# Run database migrations
uv run alembic upgrade head
# Start the API server (serves API + dashboard on one port)
uv run python -m sandcastle serve
# Start the async worker (separate terminal)
uv run python -m sandcastle worker
```
### Your First Workflow
```bash
# Run a workflow asynchronously
curl -X POST http://localhost:8080/api/workflows/run \
-H "Content-Type: application/json" \
-d '{
"workflow": "lead-enrichment",
"input": {
"target_url": "https://example.com",
"max_depth": 3
},
"callback_url": "https://your-app.com/api/done"
}'
# Response: { "data": { "run_id": "a1b2c3d4-...", "status": "queued" } }
```
Or run synchronously and wait for the result:
```bash
curl -X POST http://localhost:8080/api/workflows/run/sync \
-H "Content-Type: application/json" \
-d '{
"workflow": "lead-enrichment",
"input": { "target_url": "https://example.com" }
}'
```
### Python SDK
Install from PyPI and use Sandcastle programmatically from any Python app:
```bash
pip install sandcastle-ai
```
```python
from sandcastle import SandcastleClient
client = SandcastleClient(base_url="http://localhost:8080", api_key="sc_...")
# Run a workflow and wait for completion
run = client.run("lead-enrichment",
input={"target_url": "https://example.com"},
wait=True,
)
print(run.status) # "completed"
print(run.total_cost_usd) # 0.12
print(run.outputs) # {"lead_score": 87, "tier": "A", ...}
# List recent runs
for r in client.list_runs(status="completed", limit=5).items:
print(f"{r.workflow_name}: {r.status}")
# Stream live events from a running workflow
for event in client.stream(run.run_id):
print(event)
# Replay a failed step with a different model
new_run = client.fork(run.run_id, from_step="score", changes={"model": "opus"})
```
Async variant available for asyncio apps:
```python
from sandcastle import AsyncSandcastleClient
async with AsyncSandcastleClient() as client:
run = await client.run("lead-enrichment", input={...}, wait=True)
```
### CLI
The `sandcastle` command gives you full control from the terminal:
```bash
# Interactive setup wizard (API keys, .env, workflows/)
sandcastle init
# Start the server (API + dashboard on one port)
sandcastle serve
# Run a workflow
sandcastle run lead-enrichment -i target_url=https://example.com
# Run and wait for result
sandcastle run lead-enrichment -i target_url=https://example.com --wait
# Check run status
sandcastle status <run-id>
# Stream live logs
sandcastle logs <run-id> --follow
# List runs, workflows, schedules
sandcastle ls runs --status completed --limit 10
sandcastle ls workflows
sandcastle ls schedules
# Manage schedules
sandcastle schedule create lead-enrichment "0 9 * * *" -i target_url=https://example.com
sandcastle schedule delete <schedule-id>
# Cancel a running workflow
sandcastle cancel <run-id>
# Health check
sandcastle health
```
Connection defaults to `http://localhost:8080`. Override with `--url` or `SANDCASTLE_URL` env var. Auth via `--api-key` or `SANDCASTLE_API_KEY`.
### MCP Integration
Sandcastle ships with a built-in [MCP (Model Context Protocol)](https://modelcontextprotocol.io/) server. This lets Claude Desktop, Cursor, Windsurf, and any MCP-compatible client interact with Sandcastle directly from the chat interface - run workflows, check status, manage schedules, browse results.
```mermaid
flowchart LR
Client["Claude Desktop\nCursor / Windsurf"]
MCP["sandcastle mcp\n(MCP server)"]
API["localhost:8080\n(sandcastle serve)"]
Client -->|stdio| MCP -->|HTTP| API
```
Install the MCP extra:
```bash
pip install sandcastle-ai[mcp]
```
#### Available MCP Tools
| Tool | Description |
|------|-------------|
| `run_workflow` | Run a saved workflow by name with optional input data and wait mode |
| `run_workflow_yaml` | Run a workflow from inline YAML definition |
| `get_run_status` | Get detailed run status including all step results |
| `cancel_run` | Cancel a queued or running workflow |
| `list_runs` | List runs with optional status and workflow filters |
| `save_workflow` | Save a workflow YAML definition to the server |
| `create_schedule` | Create a cron schedule for a workflow |
| `delete_schedule` | Delete a workflow schedule |
#### Available MCP Resources
| URI | Description |
|-----|-------------|
| `sandcastle://workflows` | Read-only list of all available workflows |
| `sandcastle://schedules` | Read-only list of all active schedules |
| `sandcastle://health` | Server health status (sandbox backend, DB, Redis) |
#### Client Configuration
**Claude Desktop** - add to `~/Library/Application Support/Claude/claude_desktop_config.json`:
```json
{
"mcpServers": {
"sandcastle": {
"command": "sandcastle",
"args": ["mcp"],
"env": {
"SANDCASTLE_URL": "http://localhost:8080",
"SANDCASTLE_API_KEY": "sc_..."
}
}
}
}
```
**Cursor** - add to `.cursor/mcp.json` in your project root:
```json
{
"mcpServers": {
"sandcastle": {
"command": "sandcastle",
"args": ["mcp", "--url", "http://localhost:8080"]
}
}
}
```
**Windsurf** - add to `~/.codeium/windsurf/mcp_config.json`:
```json
{
"mcpServers": {
"sandcastle": {
"command": "sandcastle",
"args": ["mcp"]
}
}
}
```
The MCP server uses stdio transport (spawned as a child process by the client). It requires a running `sandcastle serve` instance to connect to. Connection is configured via `--url` / `--api-key` CLI args or `SANDCASTLE_URL` / `SANDCASTLE_API_KEY` env vars.
#### What You Can Do from Chat
Once connected, ask your AI assistant to:
- "Run the lead-enrichment workflow for https://example.com"
- "What's the status of my last run?"
- "List all failed runs from today"
- "Create a schedule to run data-sync every day at 9am"
- "Cancel run abc-123"
- "Save this workflow YAML to the server"
- "Show me all available workflows"
- "Check if Sandcastle is healthy"
---
## Features
| Capability | |
|---|---|
| **Pluggable sandbox backends** (E2B, Docker, Local, Cloudflare) | Yes |
| **Multi-provider model routing** (Claude, OpenAI, MiniMax, Google/Gemini) | Yes |
| **Zero-config local mode** | Yes |
| **DAG workflow orchestration** | Yes |
| **Parallel step execution** | Yes |
| **Run Time Machine (replay/fork)** | Yes |
| **Budget guardrails** | Yes |
| **Run cancellation** | Yes |
| **Idempotent run requests** | Yes |
| **Persistent storage (S3/MinIO)** | Yes |
| **Webhook callbacks (HMAC-signed)** | Yes |
| **Scheduled / cron agents** | Yes |
| **Retry logic with exponential backoff** | Yes |
| **Dead letter queue with full replay** | Yes |
| **Per-run cost tracking** | Yes |
| **SSE live streaming** | Yes |
| **Multi-tenant API keys** | Yes |
| **Python SDK + async client** | Yes |
| **CLI tool** | Yes |
| **MCP server** (Claude Desktop, Cursor, Windsurf) | Yes |
| **Docker one-command deploy** | Yes |
| **Dashboard with real-time monitoring** | Yes |
| **23 built-in workflow templates** | Yes |
| **Visual workflow builder** | Yes |
| **Directory input (file processing)** | Yes |
| **CSV export per step** | Yes |
| **Human approval gates** | Yes |
| **Self-optimizing workflows (AutoPilot)** | Yes |
| **Hierarchical workflows (workflow-as-step)** | Yes |
| **Policy engine (PII redaction, secret guard)** | Yes |
| **Cost-latency optimizer (SLO-based routing)** | Yes |
| **Concurrency control** (rate limiter, semaphores) | Yes |
---
## Pluggable Sandbox Backends
Sandcastle uses the **Sandshore runtime** with pluggable backends for agent execution. Each step runs inside an isolated sandbox - choose the backend that fits your needs:
| Backend | Description | Best For |
|---------|-------------|----------|
| **e2b** (default) | Cloud sandboxes via [E2B](https://e2b.dev/) SDK | Production, zero-infra setup |
| **docker** | Local Docker containers via aiodocker | Self-hosted, air-gapped environments |
| **local** | Direct subprocess on the host (no isolation) | Development and testing only |
| **cloudflare** | Edge sandboxes via Cloudflare Workers | Low-latency, globally distributed |
```bash
# Set in .env or via sandcastle init
SANDBOX_BACKEND=e2b # default
SANDBOX_BACKEND=docker # requires Docker + pip install sandcastle-ai[docker]
SANDBOX_BACKEND=local # dev only, no isolation
SANDBOX_BACKEND=cloudflare # requires deployed CF Worker
```
All backends share the same `SandboxBackend` protocol - same YAML, same API, same dashboard. Switch backends without changing workflows.
---
## Multi-Provider Model Routing
Use different AI providers per step. Claude for quality-critical tasks, cheaper models for simple scoring, or mix providers in a single workflow:
| Model ID | Provider | Runner | Pricing (per 1M tokens) |
|----------|----------|--------|-------------------------|
| `sonnet` | Claude (Anthropic) | Claude Agent SDK | $3 in / $15 out |
| `opus` | Claude (Anthropic) | Claude Agent SDK | $15 in / $75 out |
| `haiku` | Claude (Anthropic) | Claude Agent SDK | $0.80 in / $4 out |
| `openai/codex-mini` | OpenAI | OpenAI-compatible | $0.25 in / $2 out |
| `openai/codex` | OpenAI | OpenAI-compatible | $1.25 in / $10 out |
| `minimax/m2.5` | MiniMax | OpenAI-compatible | $0.30 in / $1.20 out |
| `google/gemini-2.5-pro` | Google (via OpenRouter) | OpenAI-compatible | $4 in / $20 out |
```yaml
steps:
- id: "research"
model: opus # Claude for deep research
prompt: "Research {input.company} thoroughly."
- id: "score"
depends_on: ["research"]
model: haiku # Claude Haiku for cheap scoring
prompt: "Score this lead 1-100."
- id: "classify"
depends_on: ["research"]
model: openai/codex-mini # OpenAI for classification
prompt: "Classify the industry."
```
Set the API keys in `.env` for each provider you want to use:
```bash
ANTHROPIC_API_KEY=sk-ant-... # Claude models
OPENAI_API_KEY=sk-... # OpenAI models
MINIMAX_API_KEY=... # MiniMax models
OPENROUTER_API_KEY=sk-or-... # Google Gemini via OpenRouter
```
---
## Workflow Engine
Define multi-step agent pipelines as YAML. Each step can run in parallel, depend on previous steps, pass data forward, and use different models.
### Example: lead-enrichment.yaml
```yaml
name: "Lead Enrichment"
description: "Scrape, enrich, and score leads for sales outreach."
default_model: sonnet
default_max_turns: 10
default_timeout: 300
steps:
- id: "scrape"
prompt: |
Visit {input.target_url} and extract:
company name, employee count, main product, contact info.
Return as structured JSON.
output_schema:
type: object
properties:
company_name: { type: string }
employees: { type: integer }
product: { type: string }
contact_email: { type: string }
- id: "enrich"
depends_on: ["scrape"]
prompt: |
Given this company data: {steps.scrape.output}
Research: revenue, industry, key decision makers, recent news.
retry:
max_attempts: 3
backoff: exponential
on_failure: abort
- id: "score"
depends_on: ["enrich"]
prompt: |
Score this lead 1-100 for B2B SaaS potential.
Based on: {steps.enrich.output}
model: haiku
on_complete:
storage_path: "leads/{run_id}/result.json"
```
### Parallel Execution
Steps at the same DAG layer run concurrently. Use `parallel_over` to fan out over a list:
```yaml
steps:
- id: "fetch-competitors"
prompt: "Identify top 3 competitors for {input.company_url}."
- id: "analyze"
depends_on: ["fetch-competitors"]
parallel_over: "steps.fetch-competitors.output.competitors"
prompt: "Analyze {input._item} for pricing and feature changes."
retry:
max_attempts: 2
backoff: exponential
on_failure: skip
- id: "summarize"
depends_on: ["analyze"]
prompt: "Create executive summary from: {steps.analyze.output}"
```
### Data Passing Between Steps
When you connect steps with `depends_on`, data flows automatically. You don't need to reference the previous step's output explicitly - Sandcastle injects it as context:
```yaml
steps:
- id: "research"
prompt: "Find all EU presidents and return as JSON."
- id: "enrich"
depends_on: ["research"]
prompt: "Add political party and key decisions for each president."
# Output from "research" is automatically available - no need for {steps.research.output}
```
For fine-grained control, you can still reference specific outputs explicitly using `{steps.STEP_ID.output}` or drill into fields with `{steps.STEP_ID.output.field_name}`:
```yaml
- id: "score"
depends_on: ["scrape", "enrich"]
prompt: |
Score this lead based on company: {steps.scrape.output.company_name}
and enrichment: {steps.enrich.output}
```
**Rules:**
- `depends_on` controls execution order **and** data flow
- Unreferenced dependency outputs are appended as context automatically
- Explicitly referenced outputs (`{steps.X.output}`) are placed exactly where you write them
- `{input.X}` references workflow input parameters passed at run time
---
## Human Approval Gates
Pause any workflow at a critical step and wait for human review before continuing. Define approval steps in YAML, set timeouts with auto-actions (skip or abort), and approve/reject/skip via API or dashboard. Reviewers can edit the request data before approving. Webhook notifications fire when approval is needed.
```yaml
steps:
- id: "generate-report"
prompt: "Generate quarterly report..."
- id: "review"
type: approval
depends_on: ["generate-report"]
approval_config:
message: "Review the generated report before sending to client"
timeout_hours: 24
on_timeout: abort
allow_edit: true
- id: "send"
depends_on: ["review"]
prompt: "Send the approved report to {input.client_email}"
```
---
## Self-Optimizing Workflows (AutoPilot)
A/B test different models, prompts, and configurations for any step. Sandcastle automatically runs variants, evaluates quality (via LLM judge or schema completeness), tracks cost and latency, and picks the best-performing variant. Supports quality, cost, latency, and pareto optimization targets.
```yaml
steps:
- id: "enrich"
prompt: "Enrich this lead: {input.company}"
autopilot:
enabled: true
optimize_for: quality
min_samples: 20
auto_deploy: true
variants:
- id: fast
model: haiku
- id: quality
model: opus
prompt: "Thoroughly research and enrich: {input.company}"
evaluation:
method: llm_judge
criteria: "Rate completeness, accuracy, and depth 1-10"
```
---
## Hierarchical Workflows (Workflow-as-Step)
Call one workflow from another. Parent workflows can pass data to children via input mapping, collect results via output mapping, and fan out over lists with configurable concurrency. Depth limiting prevents runaway recursion.
```yaml
steps:
- id: "find-leads"
prompt: "Find 10 leads in {input.industry}"
- id: "enrich-each"
type: sub_workflow
depends_on: ["find-leads"]
sub_workflow:
workflow: lead-enrichment
input_mapping:
company: steps.find-leads.output.company
output_mapping:
result: enriched_data
max_concurrent: 5
timeout: 600
- id: "summarize"
depends_on: ["enrich-each"]
prompt: "Summarize enrichment results: {steps.enrich-each.output}"
```
---
## Policy Engine
Declarative rules evaluated against every step output. Detect PII, block secrets, inject dynamic approval gates, or alert on suspicious patterns - all defined in YAML. Policies can be global (apply to all steps) or scoped per step.
```yaml
policies:
- id: pii-redact
description: "Redact personal data from outputs"
severity: high
trigger:
type: pattern
patterns:
- type: builtin
name: email
- type: builtin
name: phone
- type: builtin
name: ssn
action:
type: redact
- id: cost-guard
description: "Block steps that are too expensive"
severity: critical
trigger:
type: condition
expression: "step_cost > 2.0"
action:
type: block
message: "Step exceeded $2 cost limit"
steps:
- id: "research"
prompt: "Research {input.company}"
policies: ["pii-redact", "cost-guard"]
- id: "internal-only"
prompt: "Prepare internal report..."
policies: [] # skip all policies for this step
```
Built-in patterns for email, phone, SSN, and credit card numbers. Custom regex patterns supported. Condition triggers use safe expression evaluation - no arbitrary code execution.
---
## Cost-Latency Optimizer
SLO-based dynamic model routing. Define quality, cost, and latency constraints per step, and Sandcastle automatically selects the best model from a pool based on historical performance data. Budget pressure detection forces cheaper models when spending approaches limits.
```yaml
steps:
- id: "enrich"
prompt: "Enrich data for {input.company}"
slo:
quality_min: 0.7
cost_max_usd: 0.15
latency_max_seconds: 60
optimize_for: cost
model_pool:
- id: fast-cheap
model: haiku
max_turns: 5
- id: balanced
model: sonnet
max_turns: 10
- id: thorough
model: opus
max_turns: 20
- id: "classify"
prompt: "Classify the enriched data"
slo:
quality_min: 0.8
optimize_for: quality
# No model_pool - auto-generates haiku/sonnet/opus pool
```
The optimizer scores each model option across multiple objectives, filters out options that violate SLO constraints, and tracks confidence based on sample count. Cold starts default to a balanced middle option until enough data is collected.
---
## Directory Input & CSV Export
Process files from a directory and export results to CSV - all configured in YAML. The workflow builder includes a directory browser and CSV export toggle per step.
### Directory input
Mark a step as directory-aware and Sandcastle adds a `directory` field to the workflow's input schema. Users provide a path at run time, and the agent reads files from that directory.
```yaml
input_schema:
required: ["directory"]
properties:
directory:
type: string
description: "Path to directory"
default: "~/Documents"
steps:
- id: "analyze"
prompt: |
Read every file in {input.directory} and summarize the key findings.
```
### CSV export
Any step can export its output to CSV. Two modes:
- **new_file** - each run creates a timestamped file (e.g. `report_20260217_143022.csv`)
- **append** - all runs append rows to a single file, perfect for ongoing data collection
```yaml
steps:
- id: "extract"
prompt: "Extract all contacts from {input.directory}."
csv_output:
directory: ./output
mode: new_file
filename: contacts # optional, defaults to step ID
- id: "score"
depends_on: ["extract"]
prompt: "Score each contact for sales potential."
csv_output:
directory: ./output
mode: append # all runs land in one file
filename: scores
```
Works with any output shape - dicts become columns, lists of dicts become rows, plain text goes into a `value` column. Directories are created automatically.
---
## 23 Built-in Workflow Templates
<p align="center">
<img src="docs/screenshots/template-browser.png" alt="Template Browser" width="720" />
</p>
Sandcastle ships with production-ready workflow templates across 6 categories:
| Category | Templates |
|----------|-----------|
| **Marketing** | Blog to Social, SEO Content, Email Campaign, Competitor Analysis, Ad Copy Generator, Competitive Radar, Content Atomizer |
| **Sales** | Lead Enrichment, Proposal Generator, Meeting Recap, Lead Outreach |
| **Support** | Ticket Classifier, Review Sentiment |
| **HR** | Job Description, Resume Screener |
| **Legal** | Contract Review |
| **Product** | Release Notes, Data Extractor |
Plus 5 foundational templates: Summarize, Translate, Research Agent, Chain of Thought, Review and Approve.
```bash
# List all available templates
sandcastle templates
# Use a template
curl http://localhost:8080/api/templates
```
Each template includes parallel execution stages, structured output schemas, and human approval gates where appropriate. Use them directly or as starting points in the Workflow Builder.
---
## Real-time Event Stream
Sandcastle provides a global SSE endpoint for real-time updates across the entire system:
```bash
# Connect to the global event stream
curl -N http://localhost:8080/api/events
```
The dashboard uses this stream to power live indicators showing connection status, toast notifications for run completion and failure, and instant updates across all pages. Event types include:
- `run.started` - A workflow run was queued and started executing
- `run.completed` - A run finished successfully with outputs
- `run.failed` - A run failed (all retries exhausted)
- `step.started`, `step.completed`, `step.failed` - Per-step progress events
- `dlq.new` - A new item landed in the dead letter queue
No polling, no delays - every state change is pushed the moment it happens.
---
## Run Time Machine
Every completed step saves a checkpoint. When something goes wrong - or you just want to try a different approach - you don't have to start over.
**Replay** - Re-run from any step. Sandcastle loads the checkpoint from just before that step and continues execution. All prior steps are skipped, their outputs restored from the checkpoint. Costs only what's re-executed.
**Fork** - Same as replay, but you change something first. Swap the model from Haiku to Opus. Rewrite the prompt. Adjust max_turns. The new run branches off with your changes and Sandcastle tracks the full lineage.
```bash
# Replay from the "enrich" step
curl -X POST http://localhost:8080/api/runs/{run_id}/replay \
-H "Content-Type: application/json" \
-d '{ "from_step": "enrich" }'
# Fork with a different model
curl -X POST http://localhost:8080/api/runs/{run_id}/fork \
-H "Content-Type: application/json" \
-d '{
"from_step": "score",
"changes": { "model": "opus", "prompt": "Score more conservatively..." }
}'
```
---
## Budget Guardrails
Set a spending limit per run, per tenant, or as a global default. Sandcastle checks the budget after every step:
- **80%** - Warning logged, execution continues
- **100%** - Hard stop, status = `budget_exceeded`
Budget resolution order: request `max_cost_usd` > tenant API key limit > `DEFAULT_MAX_COST_USD` env var.
```bash
curl -X POST http://localhost:8080/api/workflows/run \
-d '{ "workflow": "enrichment", "input": {...}, "max_cost_usd": 0.50 }'
```
---
## Dashboard
Sandcastle ships with a full-featured dashboard built with React, TypeScript, and Tailwind CSS. Dark and light theme, real-time updates, and zero configuration - just open `http://localhost:8080` after `sandcastle serve`. For frontend development, run `cd dashboard && npm run dev`.
### Overview
KPI cards, 30-day run trends, cost breakdown per workflow, recent runs at a glance.
<p align="center">
<img src="docs/screenshots/overview-dark.png" alt="Overview - Dark Mode" width="720" />
</p>
<details>
<summary>Light mode</summary>
<p align="center">
<img src="docs/screenshots/overview-light.png" alt="Overview - Light Mode" width="720" />
</p>
</details>
### Runs
Filterable run history with status badges, duration, cost per run. Auto-refreshes every 5 seconds for active runs.
<p align="center">
<img src="docs/screenshots/runs.png" alt="Runs" width="720" />
</p>
### Run Detail - Completed with Budget Bar
Step-by-step timeline with expandable outputs, per-step cost and duration. Budget bar shows how close a run got to its spending limit.
<p align="center">
<img src="docs/screenshots/run-detail.png" alt="Run Detail with Budget Bar" width="720" />
</p>
### Run Detail - Failed with Replay & Fork
When a step fails, expand it to see the full error, retry count, and two powerful recovery options: **Replay from here** re-runs from that step with the same context. **Fork from here** lets you change the prompt, model, or parameters before re-running.
<p align="center">
<img src="docs/screenshots/run-detail-failed.png" alt="Failed Run with Replay and Fork" width="720" />
</p>
### Run Detail - Running with Parallel Steps
Live view of a running workflow showing parallel step execution. Steps with a pulsing blue dot are currently executing inside sandboxes.
<p align="center">
<img src="docs/screenshots/run-detail-running.png" alt="Running Workflow with Parallel Steps" width="720" />
</p>
### Run Lineage
When you replay or fork a run, Sandcastle tracks the full lineage. The run detail page shows the parent-child relationship so you can trace exactly how you got here.
<p align="center">
<img src="docs/screenshots/run-detail-replay.png" alt="Run Lineage Tree" width="720" />
</p>
### Workflows
Grid of workflow cards with step count, descriptions, and quick-action buttons. Click "Run" to trigger a workflow with custom input and budget limits.
<p align="center">
<img src="docs/screenshots/workflows.png" alt="Workflows" width="720" />
</p>
### Visual DAG Preview
Click "DAG" on any workflow card to expand an interactive graph of all steps, their dependencies, and assigned models. Powered by React Flow.
<p align="center">
<img src="docs/screenshots/dag-preview.png" alt="DAG Preview" width="720" />
</p>
### Workflow Builder
Visual drag-and-drop editor for building workflows. Add steps, connect dependencies, configure models and timeouts, then preview the generated YAML. Collapsible advanced sections for retry logic, CSV export, AutoPilot, approval gates, policy rules, and SLO optimizer - all reflected in the YAML preview. Directory input with a server-side file browser. Editing an existing workflow loads its steps and edges into the canvas.
<p align="center">
<img src="docs/screenshots/workflow-builder.png" alt="Workflow Builder" width="720" />
</p>
### Schedules
Cron-based scheduling with human-readable descriptions, enable/disable toggle, and inline edit. Click "Edit" to change the cron expression or toggle a schedule without leaving the page.
<p align="center">
<img src="docs/screenshots/schedules.png" alt="Schedules" width="720" />
</p>
### API Keys
Create, view, and deactivate multi-tenant API keys. Key prefix shown in monospace, full key revealed only once on creation with a copy-to-clipboard flow and warning banner.
<p align="center">
<img src="docs/screenshots/api-keys.png" alt="API Keys" width="720" />
</p>
### Dead Letter Queue
Failed steps that exhausted all retries land here. Retry triggers a full re-run. Resolve marks the issue as handled. Sidebar badge shows unresolved count.
<p align="center">
<img src="docs/screenshots/dead-letter.png" alt="Dead Letter Queue" width="720" />
</p>
### Approval Gates
Any workflow step can pause execution and wait for human review before continuing. The approvals page shows all pending, approved, rejected, and skipped gates with filterable tabs. Each pending approval has Approve, Reject, and Skip buttons. Configurable timeouts auto-resolve approvals if nobody responds. Webhook notifications fire when approval is needed.
<p align="center">
<img src="docs/screenshots/approvals.png" alt="Approval Gates" width="720" />
</p>
<details>
<summary>Expanded with request data</summary>
Click any approval to expand it and see the full request data the agent produced. If `allow_edit` is enabled, reviewers can modify the data before approving - giving humans final control over what the next step receives.
<p align="center">
<img src="docs/screenshots/approvals-detail.png" alt="Approval Gate Detail" width="720" />
</p>
</details>
### AutoPilot - Self-Optimizing Workflows
A/B test different models, prompts, and configurations on any workflow step. Sandcastle automatically runs variants, evaluates quality (LLM judge or schema completeness), and tracks cost vs latency vs quality. Stats cards show active experiments, total samples collected, average quality improvement, and total cost savings. Once enough samples are collected, the best-performing variant is auto-deployed.
<p align="center">
<img src="docs/screenshots/autopilot.png" alt="AutoPilot Experiments" width="720" />
</p>
<details>
<summary>Expanded with variant comparison</summary>
Expand an experiment to see the variant comparison table. Each variant shows sample count, average quality score (color-coded), average cost, and average duration. The "BEST" badge highlights the current leader. Deploy any variant manually, or let AutoPilot pick the winner automatically based on your optimization target (quality, cost, latency, or pareto).
<p align="center">
<img src="docs/screenshots/autopilot-detail.png" alt="AutoPilot Variant Comparison" width="720" />
</p>
</details>
### Policy Violations
Every policy trigger is logged with severity, action taken, and full context. Stats cards show 30-day totals, critical and high counts, and the most-triggered policy. Filter by severity (Critical, High, Medium, Low). Color-coded badges show what action was taken - blocked, redacted, flagged, or logged. Green checkmark indicates the output was automatically modified.
<p align="center">
<img src="docs/screenshots/violations.png" alt="Policy Violations" width="720" />
</p>
<details>
<summary>Expanded with trigger details</summary>
Click any violation to expand and see the full trigger details - what pattern matched, what was detected, and what action was taken. Includes links to the originating run and step for quick investigation.
<p align="center">
<img src="docs/screenshots/violations-detail.png" alt="Violation Detail" width="720" />
</p>
</details>
### Cost-Latency Optimizer
Real-time view of the optimizer's model routing decisions. Stats cards show total decisions, average confidence, top model with distribution percentage, and estimated savings. Each decision shows the selected model as a color-coded badge, a confidence bar, and the reasoning. Budget pressure indicators pulse red when spending approaches limits.
<p align="center">
<img src="docs/screenshots/optimizer.png" alt="Cost-Latency Optimizer" width="720" />
</p>
<details>
<summary>Expanded with alternatives and SLO config</summary>
Expand a decision to see the full alternatives table with scores, and the SLO configuration that drove the selection. The "SELECTED" badge highlights which model won.
<p align="center">
<img src="docs/screenshots/optimizer-detail.png" alt="Optimizer Decision Detail" width="720" />
</p>
</details>
---
## API Reference
### Workflows
| Method | Endpoint | Description |
|--------|----------|-------------|
| `GET` | `/api/workflows` | List available workflows |
| `POST` | `/api/workflows` | Save new workflow YAML |
| `POST` | `/api/workflows/run` | Run workflow async (returns run_id) |
| `POST` | `/api/workflows/run/sync` | Run workflow sync (blocks until done) |
### Runs
| Method | Endpoint | Description |
|--------|----------|-------------|
| `GET` | `/api/runs` | List runs (filterable by status, workflow, date, tenant) |
| `GET` | `/api/runs/{id}` | Get run detail with step statuses |
| `GET` | `/api/runs/{id}/stream` | SSE stream of live progress |
| `POST` | `/api/runs/{id}/cancel` | Cancel a running workflow |
| `POST` | `/api/runs/{id}/replay` | Replay from a specific step |
| `POST` | `/api/runs/{id}/fork` | Fork from | text/markdown | null | Tomas Pflanzer <tomas@gizmax.cz> | null | null | null | agents, ai, e2b, llm, orchestrator, pipeline, workflow, workflow-templates | [
"Development Status :: 4 - Beta",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"aioboto3>=13",
"aiosqlite>=0.20",
"alembic>=1.14",
"apscheduler>=3.10",
"arq>=0.26",
"asyncpg>=0.30",
"e2b>=1.0",
"fastapi>=0.115",
"fpdf2>=2.8",
"httpx-sse>=0.4",
"httpx>=0.27",
"matplotlib>=3.8",
"pydantic-settings>=2.0",
"pydantic>=2.0",
"python-dotenv>=1.0",
"pyyaml>=6.0",
"simpleeval>=1.0",
"sqlalchemy[asyncio]>=2.0",
"uvicorn[standard]>=0.30",
"aiodocker>=0.22; extra == \"dev\"",
"mcp>=1.0; extra == \"dev\"",
"pytest-asyncio>=0.24; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.8; extra == \"dev\"",
"aiodocker>=0.22; extra == \"docker\"",
"mcp>=1.0; extra == \"mcp\""
] | [] | [] | [] | [
"Homepage, https://github.com/gizmax/Sandcastle",
"Repository, https://github.com/gizmax/Sandcastle",
"Documentation, https://github.com/gizmax/Sandcastle#readme",
"Issues, https://github.com/gizmax/Sandcastle/issues",
"Dashboard, https://gizmax.github.io/Sandcastle/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:13:06.312559 | sandcastle_ai-0.10.0-py3-none-any.whl | 554,225 | ba/93/1cfe5d898d53d88a6c726b1588d9d8ac4f1eab6a53ab972749cd8cff138f/sandcastle_ai-0.10.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 203e484298ebb5b7bbd70c20697a1e73 | a34a44ad3bdbfa6ef6bf5e5f4e8c4b0e6f43ccffa7bb7ecfe0d6061df6518926 | ba931cfe5d898d53d88a6c726b1588d9d8ac4f1eab6a53ab972749cd8cff138f | MIT | [
"LICENSE"
] | 98 |
2.4 | afrilink-sdk | 0.2.2 | AfriLink SDK — One-line access to GPUs, models and datasets from your notebook | # AfriLink SDK
**Version:** 0.2.0
**Last Updated:** Feb 20, 2026
**Finetune LLMs on HPC from your notebook**
AfriLink SDK gives you one-line access to GPUs, models and datasets; all ready to use directly from your notebook interface. Authenticate, submit LoRA finetune jobs, download trained weights, and run inference without ever leaving your notebook.
```
pip install afrilink-sdk
```
---
## Quick Start
```python
from afrilink import AfriLinkClient
# 1. Authenticate (prompts for DataSpires email/password, then auto-handles HPC)
client = AfriLinkClient()
client.authenticate()
# 2. Prepare your dataset (pandas DataFrame with "text" column)
import pandas as pd
data = pd.DataFrame({"text": [
"Below is an instruction...\n\n### Response:\nHere is the answer..."
]})
# 3. Submit a finetune job
job = client.finetune(model="qwen2.5-0.5b", training_mode="low", data=data, gpus=1)
result = job.run(wait=True) # blocks until SLURM job finishes
# 4. Download the trained adapter (only if job succeeded)
if result["status"] == "completed":
client.download_model(result["job_id"], "./my-model")
# 5. Load & run inference
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B")
model = PeftModel.from_pretrained(base, "./my-model")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B")
out = model.generate(**tokenizer("Hello!", return_tensors="pt"), max_new_tokens=64)
print(tokenizer.decode(out[0], skip_special_tokens=True))
else:
print(f"Job failed with status: {result['status']}")
print(f"Check logs: job.get_logs()")
```
---
## Installation
```bash
pip install afrilink-sdk
```
The package has **zero required dependencies** — heavy libraries (requests, torch, transformers, peft) are only needed at the point you actually use them and are pre-installed in most notebook environments.
---
## Authentication
AfriLink uses a two-phase auth flow. Both phases happen inside a single `client.authenticate()` call:
| Phase | What happens | User action |
|-------|-------------|-------------|
| **1. DataSpires** | Validates your DataSpires account for billing/telemetry | Enter email + password when prompted |
| **2. HPC** | Headless Selenium browser automation gets SSH certificates via Smallstep | Fully automatic (org credentials auto-provisioned) |
```python
from afrilink import AfriLinkClient
client = AfriLinkClient()
client.authenticate() # prompts for DataSpires creds, then auto-handles HPC
# Or pass credentials explicitly:
client.authenticate(
dataspires_email="you@example.com",
dataspires_password="...",
)
```
After authentication you get:
- SSH certificate valid for ~16 hours
- SLURM job manager ready to submit jobs
- SCP transfer manager ready to move files
- Telemetry tracker logging GPU-minutes to your DataSpires account
---
## API Reference
### `AfriLinkClient`
Main entry point. Created once per notebook session.
| Method | Description |
|--------|-------------|
| `authenticate()` | Full auth flow (DataSpires + HPC) |
| `finetune(model, training_mode, data, gpus, ...)` | Create a `FinetuneJob` |
| `download_model(job_id, local_dir)` | Download trained adapter weights |
| `upload_dataset(local_path, dataset_name)` | Upload dataset to HPC |
| `list_available_models(size=None)` | List models in the registry |
| `list_available_datasets()` | List datasets in the registry |
| `get_model_requirements(model, training_mode)` | GPU/memory recommendations |
| `list_jobs()` | List SLURM queue |
| `cancel_job(job_id)` | Cancel a running job |
| `run_command(command)` | Run arbitrary shell command on HPC login node |
| `get_queue_status()` | SLURM partition info |
### `client.finetune()`
```python
job = client.finetune(
model="qwen2.5-0.5b", # model ID from registry
training_mode="low", # "low" | "medium" | "high"
data=my_dataframe, # pandas DataFrame, HF Dataset, or file path
gpus=1, # number of A100 GPUs
time_limit="04:00:00", # max wallclock
output_dir=None, # default: $WORK/finetune_outputs
)
```
**Training modes:**
| Mode | Strategy | Quantization | Typical GPUs |
|------|----------|-------------|--------------|
| `low` | QLoRA (rank 8) | 4-bit | 1 |
| `medium` | LoRA (rank 16) | 8-bit / none | 1-2 |
| `high` | LoRA (rank 64) + DDP/FSDP | none | 2-4+ |
### `FinetuneJob`
Returned by `client.finetune()`.
| Method / Property | Description |
|-------------------|-------------|
| `run(wait=True)` | Submit to SLURM. `wait=True` polls until done. |
| `cancel()` | Cancel the SLURM job |
| `get_logs(tail=100)` | Fetch recent log lines |
| `status` | Current status string |
| `job_id` | AfriLink job ID (8-char UUID prefix) |
| `slurm_job_id` | SLURM numeric job ID (set after `run()`) |
`run()` returns a dict:
```python
{
"job_id": "a1b2c3d4",
"slurm_job_id": "12345678",
"status": "completed", # or "submitted" if wait=False
"output_dir": "/path/...",
"model_path": "/path/...",
}
```
### `client.download_model()`
```python
client.download_model(result["job_id"], "./my-model")
```
Downloads adapter files (`adapter_config.json`, `adapter_model.safetensors`, tokenizer files) flat into the target directory — ready for `PeftModel.from_pretrained()`.
### Model & Dataset Registry
```python
# List all models
client.list_available_models()
# Filter by size
client.list_available_models(size="tiny") # tiny | small | medium | large
# List datasets
client.list_available_datasets()
# Resource requirements
client.get_model_requirements("qwen2.5-0.5b", "low")
```
**Available models (v0.1.0):**
| ID | Name | Type | Params | Min VRAM |
|----|------|------|--------|----------|
| `qwen2.5-0.5b` | Qwen 2.5 0.5B | text | 0.5B | 4 GB |
| `gemma-3-270m` | Gemma 3 270M | text | 0.27B | 2 GB |
| `llama-3.2-1b` | Llama 3.2 1B | text | 1.0B | 4 GB |
| `deepseek-r1-1.5b` | DeepSeek R1 1.5B | text | 1.5B | 6 GB |
| `ministral-3b` | Ministral 3B | text | 3.3B | 8 GB |
| `florence-2-base` | Florence 2 Base | vision | 0.23B | 4 GB |
| `smolvlm-256m` | SmolVLM 256M | vision | 0.26B | 2 GB |
| `moondream2` | Moondream 2 | vision | 1.9B | 8 GB |
| `internvl2-1b` | InternVL2 1B | vision | 1.0B | 4 GB |
| `llava-1.5-7b` | LLaVA 1.5 7B | vision | 7.0B | 16 GB |
### Data Transfer
```python
# Upload a dataset
client.upload_dataset("./train.jsonl", dataset_name="my-data")
# Download model weights
client.download_model("a1b2c3d4", "./my-model")
# List remote files
client.transfer.list_remote_files("$WORK/finetune_outputs/")
# Run shell commands on HPC
client.run_command("squeue -u $USER")
```
### Dataset Formats
`client.finetune(data=...)` accepts:
| Type | How it's handled |
|------|-----------------|
| `pandas.DataFrame` | Serialised to JSONL, uploaded via SCP |
| `datasets.Dataset` | Saved to disk, uploaded via SCP |
| `str` (local path) | Uploaded via SCP |
| `str` (starts with `$`) | Treated as remote HPC path (no upload) |
Your DataFrame should have a `text` column with the full prompt+response formatted as a single string (Alpaca-style or chat template).
---
## Architecture
```
Notebook Interface High Performance Compute
+--------------+ SSH/SCP +------------------+
| AfriLink SDK | -------------------> | Login Node |
| | (Smallstep certs) | +- SLURM sbatch |
| DataSpires | | +- $WORK/ |
| (billing) | | | +- containers|
| | | | +- datasets |
+--------------+ | | +- finetune_ |
| | outputs/ |
| | +- {jobid}|
| +- Singularity |
| container |
| (A100 GPUs) |
+------------------+
```
---
## Publishing to PyPI
For maintainers:
```bash
cd afrilink-sdk
pip install build twine
# Build wheel + sdist
python -m build
# Upload to PyPI (requires PyPI API token)
twine upload dist/*
```
You'll need a PyPI account at https://pypi.org and an API token configured in `~/.pypirc` or passed via `--username __token__ --password pypi-...`.
---
## License
MIT
| text/markdown | DataSpires | DataSpires <info@dataspires.com> | null | null | null | hpc, high-performance-computing, finetuning, llm, lora, notebook, gpu, slurm, afrilink | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: System :: Distributed Computing"
] | [] | https://github.com/dataspires/afrilink-sdk | null | >=3.8 | [] | [] | [] | [
"requests>=2.28.0; extra == \"full\"",
"psutil>=5.9.0; extra == \"full\"",
"pytest>=7.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://dataspires.com",
"Documentation, https://www.dataspires.com/#About-Us",
"Repository, https://github.com/DataSpires/afrilink-sdk",
"Bug Tracker, https://github.com/DataSpires/afrilink-sdk/issues"
] | twine/6.2.0 CPython/3.11.5 | 2026-02-20T13:12:22.660489 | afrilink_sdk-0.2.2.tar.gz | 70,493 | 1a/63/775d91575c547ac6437a401ef78cbd6b4ffabe65d87e48d2ff237f1e8aba/afrilink_sdk-0.2.2.tar.gz | source | sdist | null | false | 7cd9508a2a1d3347225af633fb81fdea | 706e62b48333ba8cbe9563beafae98210727faf0ba123e4756cd91cb8fda5c05 | 1a63775d91575c547ac6437a401ef78cbd6b4ffabe65d87e48d2ff237f1e8aba | MIT | [
"LICENSE"
] | 211 |
2.1 | halogal | 0.1.0 | UV Luminosity Function and Halo Occupation Distribution modeling for high-redshift galaxies | # halogal
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
A Python package for modeling UV luminosity functions and galaxy clustering using Halo Occupation Distribution (HOD) models for high-redshift galaxies.
## Features
- **Simple API**: Only redshift required, scientifically validated defaults
- **UV-Halo Mass Relation (UVHMR)**: Connect halo mass to UV luminosity through star formation
- **Halo Occupation Distribution**: Model central and satellite galaxy populations
- **Luminosity Functions**: Compute UV luminosity functions at high redshift
- **Galaxy Bias**: Calculate galaxy clustering bias
- **Correlation Functions**: Angular, real-space, and projected 2PCFs via halomod
- **Efficient Parameter Updates**: All observables accept inline `**params` for fast MCMC loops
- **Dust Attenuation**: Self-consistent treatment following Bouwens+2013-14
- **Fitted Parameters**: Defaults from Shuntov+2025
- **Redshift Evolution**: Built-in parameter evolution with redshift
## Installation
### From PyPI (when published)
```bash
pip install halogal
```
### From source
```bash
git clone https://github.com/mshuntov/halogal.git
cd halogal
pip install -e .
```
### Dependencies
- numpy >= 1.20
- scipy >= 1.7
- astropy >= 5.0
- colossus >= 1.3
- halomod >= 1.4
## Quick Start
### Minimal Example
```python
import numpy as np
from halogal import HODModel
from halogal.model import Observables
# Create model — only redshift required!
# Uses fitted defaults from Shuntov+2025
model = HODModel(z=6.0)
obs = Observables(model)
# Compute luminosity function
MUV = np.linspace(-22, -16, 20)
phi = obs.luminosity_function(MUV)
```
### Galaxy Bias
```python
bias = obs.galaxy_bias(MUV)
```
### UV-Halo Mass Relation
```python
# UVHMR methods live directly on the model
Mh = 1e11 # M_sun
MUV = model.MUV(Mh)
sfr = model.sfr(Mh)
print(f"Halo mass {Mh:.2e} M_sun:")
print(f" M_UV = {MUV:.2f}")
print(f" SFR = {sfr:.1f} M_sun/yr")
# Inverse relation
Mh_recovered = model.Mhalo(MUV)
```
### Override Specific Parameters
```python
# At construction
model = HODModel(z=6.0, eps0=0.25, sigma_UV=0.5)
obs = Observables(model)
# Or inline when computing observables — no need to recreate anything
phi = obs.luminosity_function(MUV, eps0=0.3, sigma_UV=0.6)
```
### Efficient MCMC Fitting
All observable methods on `Observables` accept `**params` keyword arguments to
update the underlying model in-place before computing. This avoids object
re-creation in tight loops:
```python
obs = Observables(HODModel(z=6.0))
MUV = np.linspace(-22, -16, 20)
for eps0, sigma_UV in mcmc_samples:
phi = obs.luminosity_function(MUV, eps0=eps0, sigma_UV=sigma_UV)
bg = obs.galaxy_bias(MUV, eps0=eps0, sigma_UV=sigma_UV)
mh = obs.mean_halo_mass(-19.0, eps0=eps0, sigma_UV=sigma_UV)
ngal = obs.number_density(-19.0, eps0=eps0, sigma_UV=sigma_UV)
```
For correlation functions, use the initialize/update pattern which leverages
halomod's internal caching:
```python
obs = Observables(HODModel(z=6.0))
# Initialize once (expensive)
result = obs.initialize_correlation_model(
MUV_thresh1=-19.1, correlation_type='angular'
)
# Update efficiently in MCMC loop
for eps0, sigma_UV in mcmc_samples:
result = obs.update_correlation_model(eps0=eps0, sigma_UV=sigma_UV)
w_theta = result['correlation']
theta = result['separation']
```
### Redshift Evolution
```python
from halogal.models.parametrization import eps0_fz, Mc_fz
from halogal.config import DEFAULT_REDSHIFT_EVOLUTION
z_array = np.linspace(4, 8, 20)
# Get evolved parameters
eps0_z = eps0_fz(
z_array,
deps_dz=DEFAULT_REDSHIFT_EVOLUTION['d_eps0_dz'],
eps_off=DEFAULT_REDSHIFT_EVOLUTION['C_eps0']
)
Mc_z = 10**Mc_fz(
z_array,
dMc_dz=DEFAULT_REDSHIFT_EVOLUTION['d_logMc_dz'],
Mc_off=DEFAULT_REDSHIFT_EVOLUTION['C_logMc']
)
# Compute with evolved parameters inline
obs = Observables(HODModel(z=z_array[0]))
for z, eps0, Mc in zip(z_array, eps0_z, Mc_z):
phi = obs.luminosity_function(MUV, eps0=eps0, Mc=Mc)
```
### Compare to Observations
```python
from bouwens21_data import bouwens21, redshift_centers
data = bouwens21['z6']
z_obs = redshift_centers['z6']
obs = Observables(HODModel(z=z_obs))
MUV_model = np.linspace(-23, -15, 50)
phi_model = obs.luminosity_function(MUV_model)
plt.errorbar(data['M_AB'], data['Fi_k'], yerr=data['Fi_k_error'],
fmt='o', label='Bouwens+2021')
plt.semilogy(MUV_model, phi_model, '-', label='Model')
plt.legend()
plt.show()
```
## Documentation
Full documentation is available at https://uvlf-hod.readthedocs.io/en/latest/#.
### Package Structure
```
halogal/
├── __init__.py # Public API
├── config.py # Configuration and defaults
├── cosmology.py # Halo mass function and bias
├── model.py # Unified UVHMR, HOD, and Observables
├── luminosity.py # UV luminosity and dust
└── models/
└── parametrization.py # Redshift parametrizations
```
### Key Classes
- **`HODModel`**: Galaxy population model combining UVHMR + HOD (parameters and occupation functions)
- **`Observables`**: Compute observables (UVLF, bias, correlation functions) from an `HODModel`; supports efficient inline parameter updates via `**params`
- **`UVHMRModel`**: Base class for UV-halo mass relations only
## Model Architecture
```
UVHMRModel (base class)
├── Handles UV-halo mass relations
├── Methods: sfr(), MUV(), Mhalo(), star_formation_efficiency()
└── Parameters: z (required), eps0, Mc, a, b (optional)
HODModel (extends UVHMRModel)
├── Inherits all UVHMR methods
├── Adds occupation distributions: Ncen(), Nsat(), Ngal()
└── Additional parameters: sigma_UV, Mcut, Msat, asat (optional)
Observables (takes an HODModel)
├── luminosity_function(MUV, **params)
├── galaxy_bias(MUV, **params)
├── mean_halo_mass(MUV_thresh, **params)
├── mean_bias(MUV_thresh, **params)
├── number_density(MUV_thresh, **params)
├── initialize_correlation_model() / update_correlation_model()
└── compute_correlation_function()
```
All `Observables` methods accept `**params` (eps0, Mc, a, b, sigma_UV, Mcut, Msat, asat)
to update the model inline before computing.
## Default Parameters
All defaults from **Shuntov+2025** (2025A&A...699A.231S) at z~5.4:
### UVHMR Parameters
| Parameter | Default | Description |
|-----------|---------|-------------|
| `eps0` | 0.19 | Star formation efficiency |
| `Mc` | 10^11.64 M_☉ | Characteristic halo mass |
| `a` | 0.69 | Low-mass slope |
| `b` | 0.65 | High-mass slope |
### HOD Parameters
| Parameter | Default | Description |
|-----------|---------|-------------|
| `sigma_UV` | 0.69 mag | UV magnitude scatter |
| `Mcut` | 10^9.57 M_☉ | Satellite cutoff mass |
| `Msat` | 10^12.65 M_☉ | Satellite normalization |
| `asat` | 0.85 | Satellite power-law slope |
### Redshift Evolution
All parameters evolve as: `param(z) = d_param/dz × z + C_param`
Evolution parameters available in `DEFAULT_REDSHIFT_EVOLUTION`.
## Examples
See the `examples/` directory for detailed examples:
- `basic_usage.ipynb`: Interactive Jupyter notebook with complete workflow
- `bouwens21_data.py`: Observational data compilation
## Testing
Run tests with pytest:
```bash
pytest tests/
```
## Contributing
Contributions are welcome! Please:
1. Fork the repository
2. Create a feature branch
3. Add tests for new features
4. Submit a pull request
## Citation
If you use this package in your research, please cite:
```bibtex
@ARTICLE{2025A&A...699A.231S,
author = {{Shuntov}, Marko and {Oesch}, Pascal A. and {Toft}, Sune and {Meyer}, Romain A. and {Covelo-Paz}, Alba and {Paquereau}, Louise and {Bouwens}, Rychard and {Brammer}, Gabriel and {Gelli}, Viola and {Giovinazzo}, Emma and {Herard-Demanche}, Thomas and {Illingworth}, Garth D. and {Mason}, Charlotte and {Naidu}, Rohan P. and {Weibel}, Andrea and {Xiao}, Mengyuan},
title = "{Constraints on the early Universe star formation efficiency from galaxy clustering and halo modeling of H{\ensuremath{\alpha}} and [O III] emitters}",
journal = {\aap},
keywords = {galaxies: evolution, galaxies: high-redshift, galaxies: luminosity function, mass function, galaxies: statistics, Astrophysics of Galaxies},
year = 2025,
month = jul,
volume = {699},
eid = {A231},
pages = {A231},
doi = {10.1051/0004-6361/202554618},
archivePrefix = {arXiv},
eprint = {2503.14280},
primaryClass = {astro-ph.GA},
adsurl = {https://ui.adsabs.harvard.edu/abs/2025A&A...699A.231S},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
```
## License
This project is licensed under the MIT License - see the LICENSE file for details.
## Acknowledgments
Based on methodology from:
- Shuntov et al. 2025, A&A 699 A321
- Sabti et al. 2022
- Muñoz et al. 2023
- Bouwens et al. 2013, 2014
- And others...
## Contact
For questions or issues, please open an issue on GitHub or contact marko.shuntov@nbu.ku.dk.
| text/markdown | Marko Shuntov | Your Name <your.email@example.com> | null | null | MIT | astronomy, cosmology, galaxies, luminosity-function, halo-model | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Astronomy",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11"
] | [] | https://github.com/mshuntov/halogal | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/mShuntov/uvlf-hod",
"Documentation, https://uvlf-hod.readthedocs.io/en/latest/#",
"Repository, https://github.com/mShuntov/uvlf-hod",
"Bug Tracker, https://github.com/mShuntov/uvlf-hod/issues"
] | twine/4.0.2 CPython/3.7.12 | 2026-02-20T13:12:14.090525 | halogal-0.1.0.tar.gz | 1,518,162 | c4/a1/02c4028b2e09256542856a18d4288491b84b157feea2768f80b8189e7544/halogal-0.1.0.tar.gz | source | sdist | null | false | 8a3c3ad7776ef6d569b0d393a9621331 | 4d834b96b107557548b9441406e592349b7ed1d469704096aa3bc21f86d22b9e | c4a102c4028b2e09256542856a18d4288491b84b157feea2768f80b8189e7544 | null | [] | 216 |
2.4 | isage-pypi-publisher | 0.1.9.9 | Python bytecode compiler and PyPI publishing toolkit for monorepos | # sage-pypi-publisher
A tiny toolkit to compile Python packages to bytecode, build wheels, and publish to PyPI/TestPyPI. Extracted from SAGE's internal `sage-dev` tooling and made standalone.
## Features
- Copy a package tree and compile `.py` → `.pyc` (keeps `__init__.py` and `_version.py`).
- Auto-adjust `pyproject.toml` / `MANIFEST.in` to include compiled artifacts and binary extensions.
- Build wheels with `python -m build`.
- **🚀 NEW:** Smart `--for-pypi` mode - one command for perfect PyPI publishing!
- **NEW:** Universal wheel support - one wheel works on all Python 3.x versions!
- **NEW:** Source distribution (sdist) support - users can install from source on any version
- Upload via `twine` (with `--dry-run` by default).
- Simple Typer-based CLI.
## Solving the Multi-Version Problem
**Problem:** Your package declares support for Python 3.8-3.12, but you only upload a wheel for Python 3.11. Users on other versions can't install it!
**Solution:** sage-pypi-publisher now uses **Smart Mode by default** 🎯
```bash
# That's it! No extra flags needed - smart mode is automatic
sage-pypi-publisher build . --upload --no-dry-run
```
**What happens automatically:**
- ✅ **Pure Python packages**: Builds universal wheel (py3-none-any) that works on **ALL** Python 3.x versions!
- ✅ **Packages with C extensions**: Builds for current Python + provides source code for others
- ✅ Always includes source distribution (sdist) as fallback
- ✅ No need to build wheels for each Python version separately!
**Why this works:**
- **Universal wheel (py3-none-any)**: One file works on Python 3.8, 3.9, 3.10, 3.11, 3.12, and future versions!
- **Source distribution**: If universal wheel doesn't work, users can compile from source
- **Zero configuration**: Works perfectly out of the box!
## Installation
```bash
pip install .
# or
pip install sage-pypi-publisher
```
## CLI
### Quick Start
**🎯 Simplest Usage (Smart Mode - Default!)**
```bash
# Just build - automatically chooses best strategy!
sage-pypi-publisher build .
# Build and upload to TestPyPI
sage-pypi-publisher build . --upload -r testpypi
# Build and upload to PyPI (production)
sage-pypi-publisher build . --upload --no-dry-run -r pypi
```
**What Smart Mode Does (Automatically):**
- 🔍 Detects if your package is pure Python or has C extensions
- 📦 Pure Python → builds universal wheel (works on ALL Python 3.x!)
- 🔧 C extensions → builds for current Python version
- 📚 Always includes source distribution (sdist)
- ✅ Perfect for packages declaring Python 3.8+ support!
**Manual Control (Advanced):**
```bash
# Disable smart mode (old behavior - current Python only)
sage-pypi-publisher build . --no-for-pypi
# Force universal wheel
sage-pypi-publisher build . --universal
# Force specific mode
sage-pypi-publisher build . --mode public
```
### All Commands
```bash
sage-pypi-publisher --help
# 🎯 Simplest: Build with smart mode (default!)
sage-pypi-publisher build .
# Build and upload to PyPI
sage-pypi-publisher build . --upload --no-dry-run
# Compile only (bytecode mode by default)
sage-pypi-publisher compile /path/to/pkg -o /tmp/out
# Compile in public mode (keep source)
sage-pypi-publisher compile /path/to/pkg -o /tmp/out --mode public
# Disable smart mode (old behavior)
sage-pypi-publisher build /path/to/pkg --no-for-pypi
# Force universal wheel (manual override)
sage-pypi-publisher build /path/to/pkg --universal
# Force manylinux build for C/C++ extensions
sage-pypi-publisher build /path/to/pkg --force-manylinux
# Upload an existing wheel
sage-pypi-publisher upload dist/yourpkg-0.1.0-py3-none-any.whl -r pypi --no-dry-run
```
### Build Modes
- **`--mode private`** (default): Compile to `.pyc` bytecode (保密模式 - protects source code)
- **`--mode public`**: Keep `.py` source files (公开模式 - open source)
- Aliases: `bytecode` = `private`, `source` = `public`
## Python API
### Basic Usage
```python
fromPyPI Publishing Options
**Smart Mode (Default) 🎯**
- **Enabled automatically** - no flags needed!
- Pure Python → universal wheel + sdist
- C extensions → current Python wheel + sdist
- Use `--no-for-pypi` to disable
**Manual Override:**
- **`--universal`**: Force universal wheel (py3-none-any) - only works for pure Python packages
- **`--sdist`**: Add source distribution (.tar.gz)
- **`--no-for-pypi`**: Disable smart mode, build for current Python only
**Why NOT build wheels for each Python version?**
You might wonder: "Why not build cp38, cp39, cp310, cp311, cp312 wheels separately?"
**Technical limitation**: To build a wheel for Python 3.10, you need Python 3.10 installed and running. You can't build a true Python 3.10 wheel from Python 3.11 environment.
**Better solution**:
- Pure Python packages → Use universal wheel (py3-none-any) - ONE wheel for ALL versions!
- C extensions → Provide source distribution (sdist) so users can compile for their Python version
- For production C extensions with multiple versions → Use `cibuildwheel` in CI/CD
wheeUniversal Wheel (Recommended for Pure Python)
```python
from pathlib import Path
from pypi_publisher.compiler import BytecodeCompiler
# For pure Python packages
compiler = BytecodeCompiler(Path("/path/to/pkg"), mode="public")
compiled = compiler.compile_package()
# Build universal wheel (works on ALL Python 3.x)
universal_wheel = compiler.build_universal_wheel(compiled)
# Build source distribution
sdist = compiler.build_sdist(compiled)
# Upload both
for artifact in [universal_wheel, sdist]:
compiler.upload_wheel(artiface_package()
# Build source distribution
sdist = compiler.build_sdist(compiled)
compiler.upload_wheel(sdist, repository="pypi", dry_run=False)
```
## Git Hooks
sage-pypi-publisher provides intelligent git hooks to simplify version management and PyPI publishing.
### Installation
```bash
sage-pypi-publisher install-hooks .
```
### Features
- **Auto-detection**: Detects version changes in `pyproject.toml` on push.
- **Interactive Update**: Prompts to update version if forgotten.
- **Auto-Publish**: Builds and uploads to PyPI automatically upon confirmation.
- **Smart Build**: Detects C/C++ extensions for manylinux wheels.
## Notes
- Requires `python -m build` and `twine` available.
- No backward compatibility with `sage-dev` CLI; PyPI commands have been removed from SAGE.
- Designed to be monorepo-friendly but works with any package path that contains `pyproject.toml`.
# Test commit
| text/markdown | null | IntelliStream Team <shuhao_zhang@hust.edu.cn> | null | IntelliStream Team <shuhao_zhang@hust.edu.cn> | MIT | pypi, publishing, bytecode, compiler, monorepo, packaging, wheel, build | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Build Tools",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Software Distribution"
] | [] | null | null | ==3.11.* | [] | [] | [] | [
"rich>=13.0.0",
"typer>=0.9.0",
"build>=1.0.0",
"twine>=4.0.0",
"tomli>=2.0.0",
"requests>=2.28.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"ruff>=0.4.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/intellistream/pypi-publisher",
"Documentation, https://github.com/intellistream/pypi-publisher#readme",
"Repository, https://github.com/intellistream/pypi-publisher",
"Issues, https://github.com/intellistream/pypi-publisher/issues"
] | twine/6.2.0 CPython/3.11.11 | 2026-02-20T13:12:08.927334 | isage_pypi_publisher-0.1.9.9.tar.gz | 86,756 | b0/e5/b176fd77f59ee858c7423eb4e638a3917d918c1195763580f8cf99a5b153/isage_pypi_publisher-0.1.9.9.tar.gz | source | sdist | null | false | cf88bb1ede3148ab7b2ba88ae281953c | 522821f674bd3bc97b6323033d2cdb9ec9384787054e4a20319c2ee87a5a60d8 | b0e5b176fd77f59ee858c7423eb4e638a3917d918c1195763580f8cf99a5b153 | null | [
"LICENSE"
] | 200 |
2.4 | slim-mcp | 0.2.1 | Model Context Protocol with SLIM as transport | # SLIM-MCP Integration
Leverage SLIM as a transport mechanism for MCP, enabling efficient load balancing
and dynamic discovery across MCP servers.
## Installation
```bash
pip install slim-mcp
```
## Overview
SLIM-MCP provides a seamless integration between SLIM (Secure Low-Latency
Interactive Messaging) and MCP (Model Context Protocol), allowing you to:
- Create MCP servers that can be discovered and accessed through SLIM
- Connect MCP clients to servers using SLIM as the transport layer
- Handle multiple concurrent sessions
- Leverage SLIM's load balancing and service discovery capabilities
## Quick Start
### Server Setup
```python
import asyncio
import slim_bindings
from mcp.server.lowlevel import Server
import mcp.types as types
from slim_mcp import create_local_app, run_mcp_server
# Create an MCP server application
mcp_app = Server("example-server")
# Define your tools
@mcp_app.list_tools()
async def list_tools() -> list[types.Tool]:
return [
types.Tool(
name="example",
description="An example tool",
inputSchema={
"type": "object",
"required": ["url"],
"properties": {
"url": {"type": "string", "description": "URL parameter"}
},
},
)
]
async def main():
# Create SLIM app
name = slim_bindings.Name("org", "namespace", "server-name")
slim_app, _ = await create_local_app(name)
# Run MCP server
await run_mcp_server(slim_app, mcp_app)
asyncio.run(main())
```
### Client Setup
```python
import asyncio
import slim_bindings
from mcp import ClientSession
from slim_mcp import create_local_app, create_client_streams
async def main():
# Create SLIM app
client_name = slim_bindings.Name("org", "namespace", "client-id")
client_app, _ = await create_local_app(client_name)
# Connect to server using standard MCP transport pattern
destination = slim_bindings.Name("org", "namespace", "server-name")
async with create_client_streams(client_app, destination) as (read, write):
async with ClientSession(read, write) as session:
# Initialize the session
await session.initialize()
# List available tools
tools = await session.list_tools()
print(f"Available tools: {tools}")
asyncio.run(main())
```
### Client with Upstream Connection
When connecting through a SLIM gateway or upstream server:
```python
import asyncio
import slim_bindings
from mcp import ClientSession
from slim_mcp import create_local_app, create_client_streams
async def main():
# Create SLIM app with upstream connection
client_name = slim_bindings.Name("org", "namespace", "client-id")
config = slim_bindings.new_insecure_client_config("http://127.0.0.1:46357")
client_app, connection_id = await create_local_app(client_name, config)
# Set route to destination through upstream connection
destination = slim_bindings.Name("org", "namespace", "server-name")
if connection_id is not None:
await client_app.set_route_async(destination, connection_id)
# Connect to server
async with create_client_streams(client_app, destination) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await session.list_tools()
print(f"Available tools: {tools}")
asyncio.run(main())
```
## API Reference
### Core Functions
#### `create_local_app(name, config=None, enable_opentelemetry=False, shared_secret=...)`
Create a local SLIM app and optionally connect to an upstream server.
**Parameters:**
- `name` (slim_bindings.Name): The name of the local app
- `config` (slim_bindings.ClientConfig | None): Optional upstream server configuration
- `enable_opentelemetry` (bool): Enable OpenTelemetry tracing
- `shared_secret` (str): Shared secret for authentication (min 32 characters)
**Returns:** `tuple[slim_bindings.App, int | None]` - The app and optional connection ID
**Example:**
```python
# Local app without upstream
name = slim_bindings.Name("org", "ns", "my-app")
app, _ = await create_local_app(name)
# App with upstream connection
config = slim_bindings.new_insecure_client_config("http://localhost:46357")
app, conn_id = await create_local_app(name, config)
```
### Server Functions
#### `run_mcp_server(slim_app, mcp_app, session_timeout=None)`
Run an MCP server that listens for SLIM sessions and handles MCP requests.
**Parameters:**
- `slim_app` (slim_bindings.App): The SLIM app instance
- `mcp_app` (mcp.server.lowlevel.Server): The MCP server instance
- `session_timeout` (datetime.timedelta | None): Optional timeout for listening
**Example:**
```python
from mcp.server.lowlevel import Server
import slim_bindings
from slim_mcp import create_local_app, run_mcp_server
mcp_app = Server("my-server")
# Define tools...
@mcp_app.list_tools()
async def list_tools():
return [...]
# Create and run
name = slim_bindings.Name("org", "ns", "my-server")
slim_app, _ = await create_local_app(name)
await run_mcp_server(slim_app, mcp_app)
```
### Client Functions
#### `create_client_streams(slim_app, destination, max_retries=2, timeout=timedelta(seconds=15))`
Create MCP client streams using SLIM transport. This follows the standard MCP transport pattern.
**Parameters:**
- `slim_app` (slim_bindings.App): The SLIM app instance
- `destination` (slim_bindings.Name): The destination name to connect to
- `max_retries` (int): Maximum number of retries for messages
- `timeout` (datetime.timedelta): Timeout for message delivery
**Yields:** `tuple[ReadStream, WriteStream]` - MCP-compatible read/write streams
**Example:**
```python
from mcp import ClientSession
import slim_bindings
from slim_mcp import create_local_app, create_client_streams
name = slim_bindings.Name("org", "ns", "client")
client_app, _ = await create_local_app(name)
destination = slim_bindings.Name("org", "ns", "server")
async with create_client_streams(client_app, destination) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await session.list_tools()
```
### Configuration
#### Creating Client Configurations
Use slim_bindings helper functions to create configurations:
```python
import slim_bindings
# Insecure connection (for development)
config = slim_bindings.new_insecure_client_config("http://localhost:46357")
# Custom configuration
from slim_mcp.examples.mcp_server_time.server import ClientConfigType
config_type = ClientConfigType()
config = config_type.convert({
"endpoint": "http://localhost:46357",
"tls": {"insecure": True}
}, None, None)
```
## Features
- **Standard MCP Transport Pattern**: Follows the same pattern as stdio, SSE, and WebSocket transports
- **Simple Functional API**: Clean functions instead of complex class hierarchies
- **Automatic Session Management**: Handles session lifecycle and cleanup
- **Concurrent Sessions**: Support for multiple concurrent sessions
- **TLS Support**: Built-in support for secure connections
- **Dynamic Discovery**: Leverage SLIM's service discovery capabilities
- **Load Balancing**: Utilize SLIM's load balancing features
- **Connection Routing**: Set routes to destinations through upstream connections
## Examples
Check out the `slim_mcp/examples` directory for complete examples:
- **MCP Time Server**: A server that provides time and timezone conversion tools
- **LlamaIndex Agent**: A client that uses LlamaIndex to interact with MCP servers
## Error Handling
The library provides comprehensive error handling and logging. All operations
are wrapped with proper cleanup to ensure resources are released.
```python
import logging
# Enable debug logging
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger("slim_mcp")
```
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## License
Apache-2.0
| text/markdown | null | null | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"anyio>=4.5",
"mcp==1.26.0",
"slim-bindings~=1.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:12:04.945209 | slim_mcp-0.2.1.tar.gz | 163,145 | d7/6f/7b65ac439a3afc2018c0718f027b13c9ef4ddeb257ed2c3712e206b1d76d/slim_mcp-0.2.1.tar.gz | source | sdist | null | false | cdd974950b249f72a540567d9805ac27 | c752b08d62595013b7ef807e65e5af98af691e4bf1252f9dc645dca687381a79 | d76f7b65ac439a3afc2018c0718f027b13c9ef4ddeb257ed2c3712e206b1d76d | Apache-2.0 | [
"LICENSE"
] | 199 |
2.4 | oldp-ingestor | 0.1.2 | Ingesting legal data like laws and court decisions via OLDP API | # oldp-ingestor
Ingesting legal data like laws and court decisions via OLDP API.
Data sources:
| CLI provider | Type | Source |
|---|---|---|
| `ris` | laws + cases | Rechtsinformationssystem des Bundes (RIS) |
| `rii` | cases | Rechtsprechung im Internet (RII) — federal courts |
| `by` | cases | Gesetze Bayern — Bavarian courts |
| `nrw` | cases | NRWE Rechtsprechungsdatenbank — NRW courts |
| `ns` | cases | NI-VORIS Niedersachsen |
| `eu` | cases | EUR-Lex — EU court decisions |
| `juris-bb` | cases | Landesrecht Berlin-Brandenburg |
| `juris-bw` | cases | Landesrecht Baden-Württemberg |
| `juris-he` | cases | Landesrecht Hessen |
| `juris-hh` | cases | Landesrecht Hamburg |
| `juris-mv` | cases | Landesrecht Mecklenburg-Vorpommern |
| `juris-rlp` | cases | Landesrecht Rheinland-Pfalz |
| `juris-sa` | cases | Landesrecht Sachsen-Anhalt |
| `juris-sh` | cases | Landesrecht Schleswig-Holstein |
| `juris-sl` | cases | Landesrecht Saarland |
| `juris-th` | cases | Landesrecht Thüringen |
| `dummy` | laws + cases | Django fixture JSON files (for testing) |
## Installation
```bash
pip install oldp-ingestor
```
Some providers require Playwright browsers. Install them after pip:
```bash
playwright install chromium
```
For development, clone the repo and use Make (auto-detects `uv` or falls back
to `pip`):
```bash
git clone https://github.com/openlegaldata/oldp-ingestor.git
cd oldp-ingestor
make install
```
## Configuration
Set the following environment variables (or add them to a `.env` file):
| Variable | Description |
|---|---|
| `OLDP_API_URL` | Base URL of the OLDP instance (e.g. `http://localhost:8000`) |
| `OLDP_API_TOKEN` | API authentication token |
| `OLDP_API_HTTP_AUTH` | Optional HTTP basic auth in `user:password` format |
## Usage
### Show API info
```bash
oldp-ingestor info
```
### Ingest laws
#### From the RIS API (rechtsinformationen.bund.de)
```bash
# Ingest all available legislation
oldp-ingestor laws --provider ris
# Search for specific legislation
oldp-ingestor laws --provider ris --search-term "EinbTestV"
# Limit the number of law books to ingest
oldp-ingestor laws --provider ris --limit 5
# Combine search and limit
oldp-ingestor laws --provider ris --search-term "BGB" --limit 1
```
#### Incremental fetching and request pacing
```bash
# Only fetch legislation adopted since a given date
oldp-ingestor laws --provider ris --date-from 2025-12-01
# Fetch legislation within a date range
oldp-ingestor laws --provider ris --date-from 2025-01-01 --date-to 2025-06-30
# Override the default request delay (0.2s) for slower pacing
oldp-ingestor laws --provider ris --request-delay 0.5
```
For automated cron usage, see `dev-deployment/ingest-ris.sh` (laws) and
`dev-deployment/ingest-ris-cases.sh` (cases) which track the last successful
run date in a state file and pass it as `--date-from` on subsequent runs.
#### From a JSON fixture file (dummy provider)
```bash
oldp-ingestor laws --provider dummy --path /path/to/fixture.json
```
### Ingest cases
#### From the RIS API (rechtsinformationen.bund.de)
```bash
# Ingest all cases from all federal courts
oldp-ingestor cases --provider ris
# Filter by court and date range
oldp-ingestor cases --provider ris --court BGH --date-from 2026-01-01
# Limit for testing
oldp-ingestor cases --provider ris --limit 10 -v
```
#### From a JSON fixture file (dummy provider)
```bash
oldp-ingestor cases --provider dummy --path /path/to/fixture.json
# Limit the number of cases to ingest
oldp-ingestor cases --provider dummy --path /path/to/fixture.json --limit 10
```
The fixture file should contain Django fixture entries with `courts.court` and
`cases.case` models. Court foreign keys are resolved to `court_name` strings
for the OLDP cases API.
### Output sinks
By default, data is written to the OLDP REST API. Use `--sink json-file` to
write JSON files to disk instead:
```bash
# Export laws to local files
oldp-ingestor --sink json-file --output-dir /tmp/export \
laws --provider ris --search-term BGB --limit 1
# Export cases to local files
oldp-ingestor --sink json-file --output-dir /tmp/export \
cases --provider ris --court BGH --limit 5
```
See [docs/sinks.md](docs/sinks.md) for details on directory structure and
implementing custom sinks.
## Architecture
The ingestor uses a provider-based architecture. Each data source implements a
provider class (`LawProvider` or `CaseProvider`), and shared RIS HTTP logic
(retry, pacing, User-Agent) lives in `RISBaseClient`. Output is routed through
a **sink** (`ApiSink` or `JSONFileSink`).
```
Provider
├── LawProvider → DummyLawProvider, RISProvider
└── CaseProvider → DummyCaseProvider, RISCaseProvider,
RiiCaseProvider, ByCaseProvider,
NrwCaseProvider, NsCaseProvider,
EuCaseProvider, JurisCaseProvider (10 state variants)
Sink
├── ApiSink → OLDP REST API (default)
└── JSONFileSink → local JSON files
```
See [docs/architecture.md](docs/architecture.md) for the full design.
## Politeness and rate limiting
The RIS API allows 600 req/min. The ingestor stays under this with:
- **Request pacing** — 0.2 s delay between requests (configurable)
- **Retry with backoff** — exponential backoff on 429/503, respects `Retry-After`
- **Descriptive User-Agent** — `oldp-ingestor/0.1.0`
See [docs/politeness.md](docs/politeness.md) for details.
## Further documentation
- [docs/architecture.md](docs/architecture.md) — class hierarchy, data flow, file layout
- [docs/sinks.md](docs/sinks.md) — sink concept, CLI examples, custom sinks
- [docs/politeness.md](docs/politeness.md) — rate limiting, retry logic, cron operation
### Provider docs
| Provider | Doc |
|----------|-----|
| RIS (laws + cases) | [docs/providers/de/ris.md](docs/providers/de/ris.md) |
| RII (federal courts) | [docs/providers/de/rii.md](docs/providers/de/rii.md) |
| Bayern | [docs/providers/de/by.md](docs/providers/de/by.md) |
| NRW | [docs/providers/de/nrw.md](docs/providers/de/nrw.md) |
| Niedersachsen | [docs/providers/de/ns.md](docs/providers/de/ns.md) |
| EUR-Lex (EU) | [docs/providers/de/eu.md](docs/providers/de/eu.md) |
| Bremen | [docs/providers/de/hb.md](docs/providers/de/hb.md) |
| Sachsen OVG | [docs/providers/de/sn_ovg.md](docs/providers/de/sn_ovg.md) |
| Sachsen ESAMOSplus | [docs/providers/de/sn.md](docs/providers/de/sn.md) |
| Sachsen VerfGH | [docs/providers/de/sn_verfgh.md](docs/providers/de/sn_verfgh.md) |
| Juris (10 states) | [docs/providers/de/juris.md](docs/providers/de/juris.md) |
| Dummy (test/dev) | [docs/providers/dummy/dummy.md](docs/providers/dummy/dummy.md) |
## Development
```bash
# Run tests
make test
# Run tests with coverage
make test-cov
# Lint
make lint
# Auto-format
make format
```
See [CONTRIBUTING.md](CONTRIBUTING.md) for the full development setup, how to
add new providers, and pull request guidelines.
| text/markdown | null | Open Legal Data <hello@openlegaldata.io> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Information Analysis"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"cssselect",
"lxml",
"playwright",
"pymupdf",
"python-dotenv",
"requests",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"ruff; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/openlegaldata/oldp-ingestor",
"Repository, https://github.com/openlegaldata/oldp-ingestor",
"Issues, https://github.com/openlegaldata/oldp-ingestor/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:11:49.185483 | oldp_ingestor-0.1.2.tar.gz | 157,122 | 39/38/9212ff35a388d8774962bb25ee6f1bb733f04726798f70392db1a22a0d6a/oldp_ingestor-0.1.2.tar.gz | source | sdist | null | false | b31489f9759573198d8d382230260a80 | 52dbfc017eb3340df36e6d50932abcaf3f84d48c20d536e40814e926184437ff | 39389212ff35a388d8774962bb25ee6f1bb733f04726798f70392db1a22a0d6a | MIT | [
"LICENSE"
] | 228 |
2.2 | qanneal | 0.1.0 | Research-grade simulated quantum annealing toolkit | # qanneal
Research-grade simulated quantum annealing toolkit (CPU-first, CUDA-ready).
## Quick install (recommended)
### macOS / Linux
```bash
./setup.sh
```
### Windows (PowerShell)
```powershell
.\setup.ps1
```
### Windows (Command Prompt)
```bat
setup.bat
```
If you prefer pure pip:
```bash
python -m pip install . --no-build-isolation
```
## Install from PyPI (after first release)
```bash
python -m pip install qanneal
```
### Windows prerequisites
- Install **Visual Studio Build Tools** with the **Desktop development with C++** workload.
- Install **CMake** (e.g., `winget install Kitware.CMake`).
## Windows + VS Code quickstart
1. Install **VS Code** and the **Python** extension.
2. Open the project folder in VS Code.
3. Open a terminal in VS Code (``Ctrl+` ``).
4. Create/activate a venv:
```powershell
python -m venv .venv
.\.venv\Scripts\Activate.ps1
```
5. Run the setup:
```powershell
.\setup.ps1
```
6. Run an example:
```powershell
python examples\python\sqa_basic.py
```
## Build (C++ core)
```bash
cmake -S . -B build
cmake --build build
ctest --test-dir build
```
## Install as a pip package (manual)
From a clone:
```bash
python -m pip install -U pip
python -m pip install . --no-build-isolation
```
Build a wheel locally:
```bash
python -m pip install -U build
python -m build .
```
The wheel/sdist will be in `dist/`.
If you want to install directly from Git:
```bash
python -m pip install "git+https://your-repo-url.git"
```
### CMake presets (CPU-only)
Requires CMake 3.19+ for presets.
```bash
cmake --preset cpu-only
cmake --build --preset cpu-only
ctest --preset cpu-only
```
### CPU + MPI preset (OpenMPI recommended)
```bash
cmake --preset cpu-mpi
cmake --build --preset cpu-mpi
```
If CMake cannot find OpenMPI, set `QANNEAL_MPI_HOME` or `MPI_HOME`:
```bash
cmake -S . -B build -DQANNEAL_ENABLE_MPI=ON -DQANNEAL_MPI_HOME=/path/to/openmpi
```
## Python examples
```bash
python examples/python/sa_multi.py
python examples/python/sqa_basic.py
python examples/python/metrics_plot.py
python examples/python/parallel_tempering.py
```
## Release (PyPI wheels)
1. Update the version in `pyproject.toml`.
2. Commit and tag:
```bash
git tag v0.1.0
git push origin v0.1.0
```
3. GitHub Actions will build wheels for Linux/macOS/Windows and publish to PyPI.
### Notes
- Publishing uses GitHub Actions OIDC. Ensure PyPI is configured to trust this repo.
- You can also run the publish workflow manually from GitHub Actions.
### Optional MPI build
```bash
cmake -S . -B build -DQANNEAL_ENABLE_MPI=ON
cmake --build build
```
Run MPI example:
```bash
mpirun -n 4 build/qanneal_mpi_example
```
### SLURM examples (OpenMPI)
Use either launcher style depending on your cluster policy:
- `qanneal/scripts/slurm/run_sa_mpi_srun.sh` (srun)
- `qanneal/scripts/slurm/run_sa_mpi_mpirun.sh` (mpirun)
The original `qanneal/scripts/slurm/run_sa_mpi.sh` remains as a simple srun starter.
## Roadmap
- Core Ising/QUBO models
- Classical and SQA annealers
- Observer and metrics API
- CUDA backend (optional)
- Python bindings (pybind11)
- MPI / SLURM examples
## License
Apache-2.0 (see `LICENSE`). Portions derived from the `sqaod` project with attribution in `NOTICE`.
| text/markdown | qanneal contributors | null | null | null | 1, Sqaod
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2018 Shinya Morino
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
2. Eigen (https://http://eigen.tuxfamily.org)
Mozilla Public License
Version 2.0
1. Definitions
1.1. “Contributor”
means each individual or legal entity that creates, contributes to the creation of, or owns Covered Software.
1.2. “Contributor Version”
means the combination of the Contributions of others (if any) used by a Contributor and that particular Contributor’s Contribution.
1.3. “Contribution”
means Covered Software of a particular Contributor.
1.4. “Covered Software”
means Source Code Form to which the initial Contributor has attached the notice in Exhibit A, the Executable Form of such Source Code Form, and Modifications of such Source Code Form, in each case including portions thereof.
1.5. “Incompatible With Secondary Licenses”
means
that the initial Contributor has attached the notice described in Exhibit B to the Covered Software; or
that the Covered Software was made available under the terms of version 1.1 or earlier of the License, but not also under the terms of a Secondary License.
1.6. “Executable Form”
means any form of the work other than Source Code Form.
1.7. “Larger Work”
means a work that combines Covered Software with other material, in a separate file or files, that is not Covered Software.
1.8. “License”
means this document.
1.9. “Licensable”
means having the right to grant, to the maximum extent possible, whether at the time of the initial grant or subsequently, any and all of the rights conveyed by this License.
1.10. “Modifications”
means any of the following:
any file in Source Code Form that results from an addition to, deletion from, or modification of the contents of Covered Software; or
any new file in Source Code Form that contains any Covered Software.
1.11. “Patent Claims” of a Contributor
means any patent claim(s), including without limitation, method, process, and apparatus claims, in any patent Licensable by such Contributor that would be infringed, but for the grant of the License, by the making, using, selling, offering for sale, having made, import, or transfer of either its Contributions or its Contributor Version.
1.12. “Secondary License”
means either the GNU General Public License, Version 2.0, the GNU Lesser General Public License, Version 2.1, the GNU Affero General Public License, Version 3.0, or any later versions of those licenses.
1.13. “Source Code Form”
means the form of the work preferred for making modifications.
1.14. “You” (or “Your”)
means an individual or a legal entity exercising rights under this License. For legal entities, “You” includes any entity that controls, is controlled by, or is under common control with You. For purposes of this definition, “control” means (a) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (b) ownership of more than fifty percent (50%) of the outstanding shares or beneficial ownership of such entity.
2. License Grants and Conditions
2.1. Grants
Each Contributor hereby grants You a world-wide, royalty-free, non-exclusive license:
under intellectual property rights (other than patent or trademark) Licensable by such Contributor to use, reproduce, make available, modify, display, perform, distribute, and otherwise exploit its Contributions, either on an unmodified basis, with Modifications, or as part of a Larger Work; and
under Patent Claims of such Contributor to make, use, sell, offer for sale, have made, import, and otherwise transfer either its Contributions or its Contributor Version.
2.2. Effective Date
The licenses granted in Section 2.1 with respect to any Contribution become effective for each Contribution on the date the Contributor first distributes such Contribution.
2.3. Limitations on Grant Scope
The licenses granted in this Section 2 are the only rights granted under this License. No additional rights or licenses will be implied from the distribution or licensing of Covered Software under this License. Notwithstanding Section 2.1(b) above, no patent license is granted by a Contributor:
for any code that a Contributor has removed from Covered Software; or
for infringements caused by: (i) Your and any other third party’s modifications of Covered Software, or (ii) the combination of its Contributions with other software (except as part of its Contributor Version); or
under Patent Claims infringed by Covered Software in the absence of its Contributions.
This License does not grant any rights in the trademarks, service marks, or logos of any Contributor (except as may be necessary to comply with the notice requirements in Section 3.4).
2.4. Subsequent Licenses
No Contributor makes additional grants as a result of Your choice to distribute the Covered Software under a subsequent version of this License (see Section 10.2) or under the terms of a Secondary License (if permitted under the terms of Section 3.3).
2.5. Representation
Each Contributor represents that the Contributor believes its Contributions are its original creation(s) or it has sufficient rights to grant the rights to its Contributions conveyed by this License.
2.6. Fair Use
This License is not intended to limit any rights You have under applicable copyright doctrines of fair use, fair dealing, or other equivalents.
2.7. Conditions
Sections 3.1, 3.2, 3.3, and 3.4 are conditions of the licenses granted in Section 2.1.
3. Responsibilities
3.1. Distribution of Source Form
All distribution of Covered Software in Source Code Form, including any Modifications that You create or to which You contribute, must be under the terms of this License. You must inform recipients that the Source Code Form of the Covered Software is governed by the terms of this License, and how they can obtain a copy of this License. You may not attempt to alter or restrict the recipients’ rights in the Source Code Form.
3.2. Distribution of Executable Form
If You distribute Covered Software in Executable Form then:
such Covered Software must also be made available in Source Code Form, as described in Section 3.1, and You must inform recipients of the Executable Form how they can obtain a copy of such Source Code Form by reasonable means in a timely manner, at a charge no more than the cost of distribution to the recipient; and
You may distribute such Executable Form under the terms of this License, or sublicense it under different terms, provided that the license for the Executable Form does not attempt to limit or alter the recipients’ rights in the Source Code Form under this License.
3.3. Distribution of a Larger Work
You may create and distribute a Larger Work under terms of Your choice, provided that You also comply with the requirements of this License for the Covered Software. If the Larger Work is a combination of Covered Software with a work governed by one or more Secondary Licenses, and the Covered Software is not Incompatible With Secondary Licenses, this License permits You to additionally distribute such Covered Software under the terms of such Secondary License(s), so that the recipient of the Larger Work may, at their option, further distribute the Covered Software under the terms of either this License or such Secondary License(s).
3.4. Notices
You may not remove or alter the substance of any license notices (including copyright notices, patent notices, disclaimers of warranty, or limitations of liability) contained within the Source Code Form of the Covered Software, except that You may alter any license notices to the extent required to remedy known factual inaccuracies.
3.5. Application of Additional Terms
You may choose to offer, and to charge a fee for, warranty, support, indemnity or liability obligations to one or more recipients of Covered Software. However, You may do so only on Your own behalf, and not on behalf of any Contributor. You must make it absolutely clear that any such warranty, support, indemnity, or liability obligation is offered by You alone, and You hereby agree to indemnify every Contributor for any liability incurred by such Contributor as a result of warranty, support, indemnity or liability terms You offer. You may include additional disclaimers of warranty and limitations of liability specific to any jurisdiction.
4. Inability to Comply Due to Statute or Regulation
If it is impossible for You to comply with any of the terms of this License with respect to some or all of the Covered Software due to statute, judicial order, or regulation then You must: (a) comply with the terms of this License to the maximum extent possible; and (b) describe the limitations and the code they affect. Such description must be placed in a text file included with all distributions of the Covered Software under this License. Except to the extent prohibited by statute or regulation, such description must be sufficiently detailed for a recipient of ordinary skill to be able to understand it.
5. Termination
5.1. The rights granted under this License will terminate automatically if You fail to comply with any of its terms. However, if You become compliant, then the rights granted under this License from a particular Contributor are reinstated (a) provisionally, unless and until such Contributor explicitly and finally terminates Your grants, and (b) on an ongoing basis, if such Contributor fails to notify You of the non-compliance by some reasonable means prior to 60 days after You have come back into compliance. Moreover, Your grants from a particular Contributor are reinstated on an ongoing basis if such Contributor notifies You of the non-compliance by some reasonable means, this is the first time You have received notice of non-compliance with this License from such Contributor, and You become compliant prior to 30 days after Your receipt of the notice.
5.2. If You initiate litigation against any entity by asserting a patent infringement claim (excluding declaratory judgment actions, counter-claims, and cross-claims) alleging that a Contributor Version directly or indirectly infringes any patent, then the rights granted to You by any and all Contributors for the Covered Software under Section 2.1 of this License shall terminate.
5.3. In the event of termination under Sections 5.1 or 5.2 above, all end user license agreements (excluding distributors and resellers) which have been validly granted by You or Your distributors under this License prior to termination shall survive termination.
6. Disclaimer of Warranty
Covered Software is provided under this License on an “as is” basis, without warranty of any kind, either expressed, implied, or statutory, including, without limitation, warranties that the Covered Software is free of defects, merchantable, fit for a particular purpose or non-infringing. The entire risk as to the quality and performance of the Covered Software is with You. Should any Covered Software prove defective in any respect, You (not any Contributor) assume the cost of any necessary servicing, repair, or correction. This disclaimer of warranty constitutes an essential part of this License. No use of any Covered Software is authorized under this License except under this disclaimer.
7. Limitation of Liability
Under no circumstances and under no legal theory, whether tort (including negligence), contract, or otherwise, shall any Contributor, or anyone who distributes Covered Software as permitted above, be liable to You for any direct, indirect, special, incidental, or consequential damages of any character including, without limitation, damages for lost profits, loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses, even if such party shall have been informed of the possibility of such damages. This limitation of liability shall not apply to liability for death or personal injury resulting from such party’s negligence to the extent applicable law prohibits such limitation. Some jurisdictions do not allow the exclusion or limitation of incidental or consequential damages, so this exclusion and limitation may not apply to You.
8. Litigation
Any litigation relating to this License may be brought only in the courts of a jurisdiction where the defendant maintains its principal place of business and such litigation shall be governed by laws of that jurisdiction, without reference to its conflict-of-law provisions. Nothing in this Section shall prevent a party’s ability to bring cross-claims or counter-claims.
9. Miscellaneous
This License represents the complete agreement concerning the subject matter hereof. If any provision of this License is held to be unenforceable, such provision shall be reformed only to the extent necessary to make it enforceable. Any law or regulation which provides that the language of a contract shall be construed against the drafter shall not be used to construe this License against a Contributor.
10. Versions of the License
10.1. New Versions
Mozilla Foundation is the license steward. Except as provided in Section 10.3, no one other than the license steward has the right to modify or publish new versions of this License. Each version will be given a distinguishing version number.
10.2. Effect of New Versions
You may distribute the Covered Software under the terms of the version of the License under which You originally received the Covered Software, or under the terms of any subsequent version published by the license steward.
10.3. Modified Versions
If you create software not governed by this License, and you want to create a new license for such software, you may create and use a modified version of this License if you rename the license and remove any references to the name of the license steward (except to note that such modified license differs from this License).
10.4. Distributing Source Code Form that is Incompatible With Secondary Licenses
If You choose to distribute Source Code Form that is Incompatible With Secondary Licenses under the terms of this version of the License, the notice described in Exhibit B of this License must be attached.
Exhibit A - Source Code Form License Notice
This Source Code Form is subject to the terms of the Mozilla Public License, v. 2.0. If a copy of the MPL was not distributed with this file, You can obtain one at https://mozilla.org/MPL/2.0/.
If it is not possible or desirable to put the notice in a particular file, then You may include the notice in a location (such as a LICENSE file in a relevant directory) where a recipient would be likely to look for such a notice.
You may add additional accurate notices of copyright ownership.
Exhibit B - “Incompatible With Secondary Licenses” Notice
This Source Code Form is “Incompatible With Secondary Licenses”, as defined by the Mozilla Public License, v. 2.0.
3. CUB (https://github.com/NVlabs/cub)
Copyright (c) 2010-2011, Duane Merrill. All rights reserved.
Copyright (c) 2011-2018, NVIDIA CORPORATION. All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
* Neither the name of the NVIDIA CORPORATION nor the
names of its contributors may be used to endorse or promote products
derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
EOD
| null | [
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: Apache Software License"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"numpy>=1.24"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T13:11:14.357319 | qanneal-0.1.0.tar.gz | 2,034,524 | 61/18/f44122ae2dc7bde038429b1cfcad65b169b23f7bacb97a3bd1f4a0fc8242/qanneal-0.1.0.tar.gz | source | sdist | null | false | 5116f9f6c4ee40366b1b369acabf2d84 | 901e2e77e949a5d2d2d3ee604827a779c64d83e6a30745457e68a4b991a8efab | 6118f44122ae2dc7bde038429b1cfcad65b169b23f7bacb97a3bd1f4a0fc8242 | null | [] | 213 |
2.4 | vd-dlt-notion-schema | 0.1.1 | Notion connector schema, defaults, and documentation for vd-dlt | # vd-dlt-notion-schema
Schema, defaults, and documentation for the Notion connector in vd-dlt pipelines.
## Installation
```bash
# Install via vd-dlt extras (recommended)
pip install vd-dlt[notion-schema]
# Or install directly
pip install vd-dlt-notion-schema
```
## Contents
- **defaults.yml** - Resource templates and default sync configuration (30+ Notion API endpoints)
- **schema.json** - JSON Schema for validating Notion credentials
- **manifest.yml** - Connector metadata (name, version, status)
- **docs/** - Connector documentation
## Usage
```python
from vd_dlt_notion_schema import get_defaults, get_schema, get_manifest
# Get connector defaults
defaults = get_defaults()
print(defaults["default_sync"]) # write_disposition, sync_mode, etc.
print(len(defaults["resources"])) # 30+ resource templates
# Get credentials schema
schema = get_schema()
print(schema["definitions"]["credentials"]["required"]) # ["access_token"]
# Get connector metadata
manifest = get_manifest()
print(manifest["name"]) # "notion"
print(manifest["version"]) # "1.0.0"
```
| text/markdown | null | VibeData <info@vibedata.dev> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Topic :: Database"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pyyaml>=6.0"
] | [] | [] | [] | [
"Homepage, https://github.com/accelerate-data/vd-dlt-connectors",
"Repository, https://github.com/accelerate-data/vd-dlt-connectors"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T13:10:44.721127 | vd_dlt_notion_schema-0.1.1.tar.gz | 15,050 | fa/4a/4be5ce5e9e8a4af2cc64ef070fd60280f2b2014b61f6a393bfd517b6be62/vd_dlt_notion_schema-0.1.1.tar.gz | source | sdist | null | false | 68cb233f26b9e928ec12d1da7ba82864 | d715c6479a593631751bc17a55a4da2596bc27cff0e124fbc61142b932bbcc3b | fa4a4be5ce5e9e8a4af2cc64ef070fd60280f2b2014b61f6a393bfd517b6be62 | MIT | [] | 226 |
2.4 | trino-mcp | 0.1.5 | A simple Model Context Protocol (MCP) server for Trino with OAuth support | # Trino MCP Server
[](https://github.com/weijie-tan3/trino-mcp/actions/workflows/ci.yml)
[](https://codecov.io/gh/weijie-tan3/trino-mcp)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
A simple Model Context Protocol (MCP) server for Trino query engine with OAuth and Azure Service Principal (SPN) support.
## Quick Start
```bash
# Run directly (no installation needed)
uvx trino-mcp
# Or install via pip
pip install trino-mcp
```
## Documentation
For full documentation, configuration options, and examples, see the [GitHub repository](https://github.com/weijie-tan3/trino-mcp).
| text/markdown | Trino MCP Contributors | null | null | null | MIT | ai, llm, mcp, model-context-protocol, trino | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Database",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"mcp>=1.6.0",
"python-dotenv>=1.0.0",
"sqlglot>=27.0.0",
"trino>=0.333.0",
"azure-identity>=1.14.0; extra == \"azure\""
] | [] | [] | [] | [
"Homepage, https://github.com/weijie-tan3/trino-mcp",
"Repository, https://github.com/weijie-tan3/trino-mcp",
"Issues, https://github.com/weijie-tan3/trino-mcp/issues",
"Documentation, https://github.com/weijie-tan3/trino-mcp#readme"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:10:16.814748 | trino_mcp-0.1.5.tar.gz | 124,890 | 76/69/a41517dcddafbe769157c2cee0b1dcf061ded19f82b5606350190659b4bb/trino_mcp-0.1.5.tar.gz | source | sdist | null | false | 787af647c03549a3e46f8259e16b46d9 | f7e615775eec2501bbbd43eae5c7cc712b5dae809c8265c597b97f8680bf73dd | 7669a41517dcddafbe769157c2cee0b1dcf061ded19f82b5606350190659b4bb | null | [
"LICENSE"
] | 212 |
2.4 | jsharp | 0.1.0 | J# language: lexer -> parser -> AST -> bytecode -> VM | # J# (J-sharp)
J# is a language project with a real execution pipeline:
`source (.jsh) -> lexer -> parser -> AST -> bytecode -> VM`
J# programs are not executed with Python `eval`/`exec`, and the runtime does not transpile J# source to Python/JS for execution.
## Install
```bash
cd jsharp
python -m pip install -e .
```
If install is not available in your environment:
```bash
python jsh.py run examples/hello.jsh
```
## Quick Start
### Hello
```bash
python jsh.py run examples/hello.jsh
```
### Web demo
```bash
python jsh.py run examples/web.jsh
```
Then open [http://localhost:8080](http://localhost:8080).
### Dump and debug
```bash
python jsh.py dump examples/hello.jsh
python jsh.py run --debug examples/hello.jsh
```
## CLI
- `python jsh.py run <file.jsh>`
- `python jsh.py run --debug <file.jsh>`
- `python jsh.py run --native <file.jsh>`
- `python jsh.py dump <file.jsh>`
- `python jsh.py build <file.jsh> -o out.jbc`
If installed as a package, `jsh` is available as a console script.
## Architecture (text diagram)
```text
.jsh source
|
v
Lexer -> token stream
|
v
Parser -> AST
|
v
Compiler -> bytecode chunks (per function)
|
v
VM (stack + frames + globals)
```
## Current Feature Set (v0.1)
- Function declarations and function literals
- `let`, assignment, `if/else`, `while`, `break`, `continue`, `return`
- Numbers, strings, bools, none
- Lists (`[1,2,3]`), indexing (`a[i]`), indexed assignment (`a[i] = x`)
- Calls, attribute access, short-circuit `&&` / `||`
- Stdlib objects: `http`, `io`, `fs`, `json`
- Builtins: `print`, `len`, `div`
## Competitive Programming
Use the `io` module for fast buffered input/output.
- `examples/cp_sum.jsh`
- `examples/cp_minmax.jsh`
- `examples/cp_prefix_sum.jsh`
- Full guide: `docs/cp-guide.md`
## Native Runtime Path
- `python jsh.py build file.jsh -o file.jbc` emits serialized bytecode.
- `python jsh.py run --native file.jsh` compiles to temp `.jbc` and executes `jsh-native` when available.
- If `jsh-native` is unavailable, CLI prints guidance and falls back to Python VM execution.
- Bytecode format spec: `docs/bytecode-spec.md`
## Roadmap Summary
Near-term goals:
- expand stdlib and diagnostics,
- strengthen Python/native runtime compatibility tests,
- keep web demo smooth in Python VM path,
- improve performance with targeted compiler/VM optimizations.
Detailed plans: `docs/roadmap.md`.
## Project Docs
- `LANGUAGE_REFERENCE.md`
- `docs/getting-started.md`
- `docs/standard-library.md`
- `docs/internals.md`
- `docs/cp-guide.md`
- `docs/bytecode-spec.md`
- `docs/roadmap.md`
## Limitations (current)
- Closures/captures are intentionally disabled in v0.1 function literals.
- Native VM path is focused on CP/runtime core; Python VM remains the primary path for full web demo behavior.
| text/markdown | J# Contributors | null | null | null | MIT | programming-language, bytecode, vm, compiler, education | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Compilers"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"pytest; extra == \"dev\"",
"ruff; extra == \"dev\"",
"build; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/jsharp-lang/jsharp",
"Repository, https://github.com/jsharp-lang/jsharp",
"Issues, https://github.com/jsharp-lang/jsharp/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:10:11.352672 | jsharp-0.1.0.tar.gz | 25,682 | cd/5b/3d74c3d45f87f224b2700874fd9b1e27306172f36c42bb8c056e03e481ab/jsharp-0.1.0.tar.gz | source | sdist | null | false | 96bcaa7c7a189decb744774d63ae2980 | 490ee42aaec5edb0200d54c3daa2814c8c6760c83738dc9a573c44629ddbe2ff | cd5b3d74c3d45f87f224b2700874fd9b1e27306172f36c42bb8c056e03e481ab | null | [
"LICENSE"
] | 226 |
2.4 | vybe | 1.1.0 | Vibe coding terminal capture toolkit | # Vybe
```text
____ ____ _
\ \ / /__ __ | |__ ____
\ Y /| | || _ \/ __ \
\ / _\ || |_) | __/
\___/ (_____/ |_____/\____)
```
Vybe is a **vibe coding terminal toolkit**: run a command, capture its output, and instantly reuse it —
copy to clipboard, wrap in Markdown, search errors, jump to the last failure, or grab tmux scrollback.
## Why Vybe?
Without Vybe:
- Run command
- Scroll/copy terminal output manually
- Redact secrets by hand
- Reformat for LLM/issue tracker
- Repeat after each retry
With Vybe:
- `vybe r ...` run + capture
- `vybe errors` isolate failures
- `vybe sc --redact` copy safe output fast
- `vybe prompt debug --redact` generate LLM-ready prompt
- `vybe rr` retry quickly
## Highlights
**Core Capture & Replay:**
- **`vybe run ...`** streams output live *and* saves it.
- **`vybe retry`** / **`vybe rr`** reruns your last command.
- **`vybe snipclip`** / **`vybe sc`** copies output only (perfect for issues/LLM chats).
- **`vybe snipclip --redact`** masks common secrets automatically.
**LLM Workflow (v1.0.0+):**
- **`vybe cc`** copy just the command to clipboard (for tweaking).
- **`vybe history [N]`** bulk grab last N runs for LLM handoff.
- **`vybe select`** interactive fzf picker for multi-select captures.
**Analysis & Discovery:**
- **`vybe errors`** extracts likely error blocks from latest capture.
- **`vybe stats`** show success rates, most-run commands, slowest runs.
- **`vybe fail`** jump back to most recent failing run.
- **`vybe diff`** show what changed between latest two captures.
**Advanced Workflows:**
- **`vybe flow`** save and replay command sequences.
- **`vybe watch`** auto-rerun on file changes.
- **`vybe cwd`** remember/restore working directory.
- **`vybe clean`** cleanup old captures by age/count.
- **`vybe man`** comprehensive 601-line manual with all commands.
**Export & Share:**
- **`vybe export --last --json`** machine-readable context for agents.
- **`vybe share`** builds Markdown-ready report for issues.
- **`vybe prompt`** generates LLM-ready prompts (debug/review/explain).
- **`vybe doctor`** fast environment snapshot.
- Works great on Kali (zsh) and supports tmux scrollback capture.
## Demo
Quick terminal demo recording (asciinema):
```bash
asciinema rec docs/demo.cast
# run a loop like:
# vybe r pytest -q
# vybe errors
# vybe prompt debug --redact
# vybe rr
```
You can convert to GIF with `agg` or share the cast directly.
## Install (dev / from source)
```bash
python -m venv .venv
source .venv/bin/activate
pip install -e .
vybe --help
python -m vybe --help
```
## Install (recommended on Kali/Ubuntu)
Use `pipx` to avoid PEP 668 "externally-managed-environment" issues:
```bash
sudo apt install pipx
pipx ensurepath
pipx install vybe
```
From a local checkout:
```bash
cd ~/dev/Vybe
pipx install . --force
```
Check install/update guidance:
```bash
vybe self-check
vybe self-check --json
```
## Publishing (maintainers)
Vybe publishes to PyPI from GitHub tags via Trusted Publishing.
One-time setup in PyPI project settings:
- Add a Trusted Publisher for repo `homer1013/Vybe`
- Workflow file: `.github/workflows/publish.yml`
- Environment: `pypi`
Release flow:
```bash
git tag vX.Y.Z
git push origin vX.Y.Z
```
GitHub Actions will build and publish automatically.
## Usage
```bash
# Capture & replay
vybe run pytest -q
vybe r pytest -q
vybe retry
vybe rr
vybe rr --cwd
# Output & clipboard
vybe snip
vybe snipclip
vybe snipclip --redact
vybe cc # Copy just command
vybe history 3 # Bulk grab 3 runs for LLM
vybe select # Interactive picker (fzf)
# Analysis
vybe fail
vybe errors
vybe stats # Success rates, patterns
vybe tail 50
vybe grep "Traceback|ERROR" --i
# Navigation & filtering
vybe ls
vybe ll 5
vybe ls --tag auth
vybe open
# Workflows
vybe flow save test-run # Save sequence
vybe flow list
vybe flow run test-run
vybe watch pytest -q # Auto-rerun on changes
vybe cwd set # Save working dir
vybe cwd run # Restore & run
vybe clean --keep 10 # Cleanup old
# Diff & tagging
vybe diff
vybe diff --tag auth
vybe run --tag auth pytest -q
# Export & share
vybe export --last --json --snip --redact
vybe share --redact --errors --clip
vybe share --json
vybe prompt debug --redact
# System & help
vybe man # Read comprehensive manual
vybe doctor
vybe self-check
vybe cfg
vybe init
vybe completion install zsh
vybe md bash
```
## Speed aliases
- `vybe r <cmd>` → `vybe run <cmd>`
- `vybe rr [--cwd] [--tag <name>]` → `vybe retry [--cwd] [--tag <name>]`
- `vybe l` → `vybe last`
- `vybe s` → `vybe snip`
- `vybe sc` → `vybe snipclip`
- `vybe cc` → `vybe cmdcopy`
- `vybe o` → `vybe open`
- `vybe ll [N]` → `vybe ls [N]`
- Full commands remain the canonical docs and are recommended in scripts/automation
## Quick recipes
Fast debug loop:
```bash
vybe r pytest -q
vybe errors
vybe share --redact --errors --clip
vybe rr
```
LLM Handoff (v1.0.0+):
```bash
vybe r pytest -q
vybe history 3 --redact # Grab last 3 runs
vybe prompt debug --redact # Generate LLM prompt
```
Interactive multi-run selection:
```bash
vybe r pytest test1
vybe r pytest test2
vybe r pytest test3
vybe select # Pick which ones to copy
```
Tagged task loop:
```bash
vybe run --tag auth pytest -q
vybe rr --tag auth
vybe ls --tag auth
vybe diff --tag auth
```
Agent handoff loop:
```bash
vybe export --last --json --snip --redact
vybe share --json --errors --redact
vybe prompt debug --redact
vybe doctor --json
```
## LLM-friendly JSON export
Use this to hand structured context to coding agents.
```bash
vybe export --last --json
vybe export --last --json --snip
vybe export --last --json --snip --redact
```
## Tagging and diffs
Use tags to keep one debugging thread grouped:
```bash
vybe run --tag auth pytest -q
vybe rr --tag auth
vybe ls --tag auth
vybe tags
```
See exactly what changed between your latest two captures:
```bash
vybe diff
vybe diff --tag auth
vybe diff --full
```
## Share bundles and doctor
Generate a ready-to-paste Markdown bundle:
```bash
vybe share
vybe share --redact --errors
vybe share --clip
vybe share --json
vybe share --json --errors --redact
vybe prompt debug --redact
vybe prompt review --redact
vybe prompt explain --redact
```
Get quick environment diagnostics:
```bash
vybe doctor
vybe doctor --json
vybe self-check
vybe self-check --json
vybe cfg --json
vybe init
```
## CLI stability
Vybe keeps a stable v1 CLI contract for humans, scripts, and agents:
- See `docs/CLI_CONTRACT.md`
- Machine-readable JSON outputs are additive: existing keys remain, new keys may be added
## Examples
See `examples/` for real workflows:
- `examples/pytest-debug-loop.md`
- `examples/frontend-build-failure.md`
- `examples/serial-monitor-nonutf8.md`
## Agent quickstart (human + LLM loop)
Use this when pairing with ChatGPT/Codex/Claude during debugging.
1) Run and capture
```bash
vybe r pytest -q
```
2) Copy output-only to clipboard for your LLM
```bash
vybe sc
```
3) Apply changes, then retry quickly
```bash
vybe rr
```
4) If you moved directories, retry in the original working dir
```bash
vybe rr --cwd
```
5) Check recent attempts fast
```bash
vybe ll 8
```
Failure-first loop:
```bash
vybe fail
vybe s
vybe sc
```
Tip for agents and scripts:
- Prefer full commands in automation (`vybe run`, `vybe retry`) for clarity.
- Use aliases interactively for speed.
### Command reference
Run:
```bash
vybe --help
```
## Clipboard support
Vybe auto-detects clipboard tools:
- X11: `xclip` or `xsel`
- Wayland: `wl-copy`
## Shell completion install
Install directly from the CLI:
```bash
vybe completion install zsh
vybe completion install bash
vybe completion install fish
```
## tmux scrollback capture
```bash
vybe pane 4000
vybe open
```
## Environment variables
- `VYBE_DIR` log dir (default `~/.cache/vybe`)
- `VYBE_STATE` state file (default `~/.config/vybe/state.json`)
- `VYBE_INDEX` index file (default `~/.cache/vybe/index.jsonl`)
- `VYBE_CONFIG` config file (default `~/.config/vybe/config.json`)
- `VYBE_MAX_INDEX` max index entries (default `2000`)
## Shell completions
See `completions/`:
- bash: `completions/vybe.bash`
- zsh: `completions/_vybe`
- fish: `completions/vybe.fish`
Use `vybe completion install <shell>` instead of copying files manually.
## License
MIT
| text/markdown | Homer Morrill | null | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:09:32.550171 | vybe-1.1.0.tar.gz | 38,135 | 7f/ca/694e1cb1e2e03064aa5df2cdd2ecbc36d776fb44e08ee61a343f1888f2a6/vybe-1.1.0.tar.gz | source | sdist | null | false | 85f74a05a5247eee16ab8dedad3795d9 | 230ebb8bdd5a2efe73ab08c413ad25280da240faba363bb68a39650e3c7e2565 | 7fca694e1cb1e2e03064aa5df2cdd2ecbc36d776fb44e08ee61a343f1888f2a6 | null | [
"LICENSE"
] | 219 |
2.4 | minions-prompts | 0.1.3 | Version-controlled prompt engineering system built on the Minions SDK | # minions-prompts (Python)
Python SDK for the minions-prompts version-controlled prompt engineering system.
## Installation
```bash
pip install minions-prompts
```
## Quick Start
```python
from minions import create_minion
from minions_prompts import (
prompt_template_type, prompt_version_type,
PromptRenderer, PromptChain, PromptDiff,
InMemoryStorage, register_prompt_types,
)
storage = InMemoryStorage()
# Create a prompt template
minion, _ = create_minion(
{"title": "Summarizer", "fields": {"content": "Summarize {{topic}} for {{audience}}."}},
prompt_template_type,
)
storage.save_minion(minion)
# Render it
renderer = PromptRenderer()
rendered = renderer.render(
minion.fields["content"],
{"topic": "AI agents", "audience": "developers"},
)
print(rendered)
```
| text/markdown | null | Mehdi Nabhani <mehdi@the-mehdi.com> | null | null | AGPL-3.0 | ai, llm, minions, prompts, versioning | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"minions-sdk>=0.2.1",
"pytest>=7.0; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/mxn2020/minions-prompts",
"Repository, https://github.com/mxn2020/minions-prompts"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:09:18.903029 | minions_prompts-0.1.3.tar.gz | 16,267 | a6/83/cab59acc92f1bd516e0ffd2b7c0874cae3477c671f9248fb481954fad02f/minions_prompts-0.1.3.tar.gz | source | sdist | null | false | 81dcb9395a3d106eee81f232d8e0b9de | ac13aad9c388dcb4c819d9611f3f2dc5de20319dbf0469154d598048e4eeb3d1 | a683cab59acc92f1bd516e0ffd2b7c0874cae3477c671f9248fb481954fad02f | null | [] | 220 |
2.2 | mimosa-tool | 1.1.1 | Model-Independent Motif Similarity Assessment tool | # MIMOSA
Model-Independent Motif Similarity Assessment (MIMOSA) is tool designed to support comparisons across different motif model types.
## Introduction
Transcription factors (TFs) serve as fundamental regulators of gene expression levels. These proteins modulate the activity of the RNA polymerase complex by binding to specific DNA sequences located within regulatory regions, such as promoters and enhancers [1]. The specific DNA segment recognized by a TF is termed a transcription factor binding site (TFBS). TFBSs for a given TF are typically similar but not identical; therefore, they are described using *motifs* that capture the variability of the recognized sequences [2]. A variety of high-throughput experimental methods, including ChIP-seq, HT-SELEX, and DAP-seq, are currently used to identify TFBS motifs [3-5]. While motifs are most frequently represented as Position Weight Matrices (PWMs), a standard supported by widely used *de novo* motif discovery tools like MEME [6], STREME [7], and HOMER [8], the field has increasingly adopted alternative models to capture complex nucleotide dependencies. These include diverse variants of Markov Models (BaMMs, InMoDe, DIMONT etc.) [9-14], which account for higher-order dependencies that PWMs ignore, as well as models based on locally positioned dinucleotides (SiteGA) [15-16] and deep learning architectures (DeepBind, DeeperBind, DeepGRN and etc.) [17-21].
The identification of a motif is only the first step; establishing its biological context requires robust comparison methods. Comparing motifs is essential for determining whether a newly discovered pattern represents a novel specificity or a variation of a known factor, for clustering redundant motifs identified across different experiments, and for inferring functional relationships between TFs based on binding similarity. Several established tools address this need, including Tomtom [22], STAMP [23], MACRO-APE [24] and MoSBAT [25]. These tools utilize various metrics and algorithms to quantify similarity, ranging from column-wise matrix correlations to Jaccard index-based comparisons of recognized site sets. However, a significant limitation of the current software ecosystem is its heavy reliance on matrix-based representations (PFMs or PWMs). This constraint makes it challenging to directly compare alternative models, such as Markov models or dinucleotide models, without converting them into simpler matrix formats, a process that often results in information loss.
To address these limitations, we introduce MIMOSA, a comprehensive framework designed to facilitate the comparison of diverse motif models beyond standard frequency matrices. MIMOSA implements four distinct modes of comparison to accommodate various analytical needs. The first and most universal mode involves the direct comparison of TFBS recognition profiles generated by different motifs, conceptually similar to affinity-based approaches [25]. This allows for the assessment of similarity based on the functional output of the models—the scores assigned to sequences—rather than their internal parameters. The second mode leverages the same underlying approach but allows the user to explicitly define the model architecture; currently, MIMOSA supports three specific model types: PWM, BMM, and SiteGA, with an extensible architecture designed to accommodate future model types. The third mode incorporates MoTaLi ([see details](https://github.com/parthian-sterlet/motali)). Finally, the fourth mode provides a Tomtom-like functionality for scenarios where models can be represented as N-dimensional matrix. In this mode, if the models are compatible matrix formats, they are compared using standard metrics such as Pearson Correlation Coefficient (PCC), Euclidean Distance (ED), and Cosine similarity. Crucially, if the models are of heterogeneous types (e.g., comparing a BaMM to a PWM), MIMOSA employs a strategy of scanning sequences to generate recognition profiles, which are then used to reconstruct compatible Position Frequency Matrices for comparison, ensuring that even fundamentally different model types can be quantitatively evaluated within a single framework.
### Methodology
#### Similarity Metrics
MIMOSA implements several metrics to quantify the resemblance between motif importance profiles or matrix columns.
**Continuous Jaccard (CJ)**
The Continuous Jaccard index extends the classical Jaccard similarity to continuous-valued vectors $v_1, v_2$. It is defined as the ratio of the sum of element-wise intersections to the sum of element-wise unions:
$$\text{CJ}(v_1, v_2) = \frac{\sum_i \min(v_1^i, v_2^i)}{\sum_i \max(v_1^i, v_2^i)}$$
This metric is equivalent to averaging the binary Jaccard index across all possible thresholds, providing a threshold-independent measure of profile similarity.
**Continuous Overlap (CO)**
The Continuous Overlap coefficient (or Szymkiewicz-Simpson coefficient) measures the sub-set relationship between two profiles, normalizing the intersection by the smaller of the two total affinities:
$$\text{CO}(v_1, v_2) = \frac{\sum_i \min(v_1^i, v_2^i)}{\min\left(\sum_i v_1^i, \sum_i v_2^i\right)}$$
**Pearson Correlation Coefficient (PCC)**
For linear correlation between profiles or motif columns, the PCC is calculated as:
$$\text{PCC}(v_1, v_2) = \frac{\sum_i (v_1^i - \bar{v}_1)(v_2^i - \bar{v}_2)}{\sqrt{\sum_i (v_1^i - \bar{v}_1)^2 \sum_i (v_2^i - \bar{v}_2)^2}}$$
#### Null Hypothesis and Surrogate Generation
To estimate the statistical significance (p-values) of observed similarity scores, MIMOSA employs a **Surrogate Null Model**. Unlike simple permutations that destroy local dependencies, our tool generates synthetic "surrogate" profiles that preserve the marginal properties and biological plausibility (smoothness) of the original data.
1. **Convolutional Distortion**: For profile-based surrogates, a sophisticated distortion logic is applied:
* **Kernel Selection**: A base kernel (smooth, edge, or double-peak) is selected to represent typical profile features.
* **Controlled Perturbation**: Noise and gradient bias are added to introduce variation while maintaining structural integrity.
* **Smoothing**: Convolution ensures the surrogate remains biologically realistic.
* **Convex Combination**: The final surrogate is a blend of the identity kernel and the distorted kernel, controlled by a user-defined distortion parameter.
2. **Permutation**: For matrix-based comparisons (`tomtom-like`), the tool performs random column-wise permutations.
This methodology ensures that the null distribution reflects realistic background similarity.
## Installation
MIMOSA requires **Python 3.10 or higher**.
### From PyPI (Recommended)
The easiest way to install MIMOSA is via `pip` or `uv`. This will automatically download and install all required dependencies.
```bash
# Using uv (Fastest)
uv pip install mimosa-tool
# Using pip
pip install mimosa-tool
```
### From Source
If you want to contribute to development or build the latest version from the repository, you will need a C++ compiler with **C++17 support** (e.g., GCC, Clang, or MSVC).
```bash
# Clone the repository
git clone https://github.com/ubercomrade/mimosa.git
cd mimosa
# Install in editable mode
pip install -e .
```
### Dependencies
When installing via `pip`, the following dependencies are resolved automatically:
* `numpy` (>= 2.0, < 2.4)
* `numba` (>= 0.62.0)
* `scipy` (>= 1.14.1)
* `pandas` (>= 2.2.3)
* `joblib` (>= 1.5.3)
### Build Requirements (Source only)
To build the C++ extension from source, the following tools are used:
* `scikit-build-core` (>= 0.10)
* `nanobind` (>= 2.0)
## CLI Reference
The `mimosa` tool provides four main operation modes.
### `profile` mode
Compare motifs based on pre-calculated score profiles.
**Input**: Text files with numerical scores (comma, tab, or space-separated).
**Example Data**: [`examples/scores_1.fasta`](examples/scores_1.fasta)
```bash
# in the `examples` directory
mimosa profile scores_1.fasta scores_2.fasta \
--metric cj \
--permutations 1000 \
--distortion 0.5 \
--search-range 10
```
**All parameters for `profile` mode**:
| Flag | Value | Comment |
| :--- | :--- | :--- |
| `profile1` | Path | Path to the first profile file (FASTA-like format). |
| `profile2` | Path | Path to the second profile file (FASTA-like format). |
| `--metric` | `cj`, `co`, `corr` | Similarity metric: Continuous Jaccard, Continuous Overlap, or Pearson Correlation (default: `cj`). |
| `--permutations` | Integer | Number of permutations for p-value calculation (default: 0). |
| `--distortion` | Float | Distortion level (0.0-1.0) for surrogate generation (default: 0.4). |
| `--search-range` | Integer | Maximum offset range to explore when aligning profiles (default: 10). |
| `--min-kernel-size` | Integer | Minimum kernel size for surrogate convolution (default: 3). |
| `--max-kernel-size` | Integer | Maximum kernel size for surrogate convolution (default: 11). |
| `--seed` | Integer | Global random seed for reproducibility. |
| `--jobs` | Integer | Number of parallel jobs (-1 uses all cores) (default: -1). |
| `-v`, `--verbose` | Flag | Enable verbose logging. |
### `motif` mode
Compare motifs by scanning sequences with models and comparing the resulting profiles.
**Input**: Motif model files (PWM: `.meme`, `.pfm`; BaMM: `.ihbcp` + `.hbcp`; SiteGA: `.mat`).
**Example Models**: [`examples/foxa2.meme`](examples/foxa2.meme), [`examples/gata4.meme`](examples/gata4.meme)
```bash
# in the `examples` directory
mimosa foxa2.meme gata4.meme \
--model1-type pwm \
--model2-type pwm \
--fasta examples/foreground.fa \
--metric co \
--permutations 1000 \
--distortion 0.3
```
**All parameters for `motif` mode**:
| Flag | Value | Comment |
| :--- | :--- | :--- |
| `model1` | Path | Path to the first motif model file. |
| `model2` | Path | Path to the second motif model file. |
| `--model1-type` | `pwm`, `bamm`, `sitega` | Format of the first model (Required). |
| `--model2-type` | `pwm`, `bamm`, `sitega` | Format of the second model (Required). |
| `--fasta` | Path | FASTA file with target sequences. If omitted, random sequences are generated. |
| `--promoters` | Path | FASTA file with promoter sequences for threshold calculation. |
| `--num-sequences` | Integer | Number of random sequences to generate (default: 1000). |
| `--seq-length` | Integer | Length of random sequences (default: 200). |
| `--metric` | `cj`, `co`, `corr` | Similarity metric (default: `cj`). |
| `--permutations` | Integer | Number of permutations (default: 0). |
| `--distortion` | Float | Distortion level (default: 0.4). |
| `--search-range` | Integer | Maximum alignment offset (default: 10). |
| `--seed` | Integer | Global random seed. |
| `--jobs` | Integer | Number of parallel jobs (default: -1). |
### `motali` mode
Compare motifs by calculating Precision-Recall Curve (PRC) AUC derived from scanning sequences.
**Example Models**: [`examples/sitega_gata2.mat`](examples/sitega_gata2.mat), [`examples/gata2.meme`](examples/gata2.meme)
```bash
# in the `examples` directory
mimosa motali sitega_gata2.mat gata2.meme \
--model1-type sitega \
--model2-type pwm \
--fasta foreground.fa \
--promoters background.fa \
--num-sequences 5000 \
--seq-length 150
```
**All parameters for `motali` mode**:
| Flag | Value | Comment |
| :--- | :--- | :--- |
| `model1` | Path | Path to the first motif model file. |
| `model2` | Path | Path to the second motif model file. |
| `--model1-type` | `pwm`, `sitega` | Format of the first model (Required). |
| `--model2-type` | `pwm`, `sitega` | Format of the second model (Required). |
| `--fasta` | Path | FASTA file with target sequences. |
| `--promoters` | Path | FASTA file with promoter sequences (Required for thresholds). |
| `--num-sequences` | Integer | Number of random sequences (default: 10000). |
| `--seq-length` | Integer | Length of random sequences (default: 200). |
| `--tmp-dir` | Path | Directory for temporary files (default: `/tmp`). |
### `tomtom-like` mode
Compare motifs by direct N-dimetional matrix comparison (column-wise).
**Example Models**: [`examples/pif4.pfm`](examples/pif4.pfm), [`examples/pif4.meme`](examples/pif4.meme)
```bash
# in the `examples` directory
mimosa tomtom-like pif4.pfm pif4.meme \
--model1-type pwm \
--model2-type pwm \
--metric cosine \
--permutations 1000 \
--pfm-mode \
--num-sequences 10000 \
--seq-length 100
```
**All parameters for `tomtom-like` mode**:
| Flag | Value | Comment |
| :--- | :--- | :--- |
| `model1` | Path | Path to the first motif model file. |
| `model2` | Path | Path to the second motif model file. |
| `--model1-type` | `pwm`, `bamm`, `sitega` | Format of the first model (Required). |
| `--model2-type` | `pwm`, `bamm`, `sitega` | Format of the second model (Required). |
| `--metric` | `pcc`, `ed`, `cosine` | Column-wise metric: Pearson Correlation, Euclidean Distance, or Cosine Similarity (default: `pcc`). |
| `--permutations` | Integer | Number of Monte Carlo permutations for p-value (default: 0). |
| `--permute-rows` | Flag | Shuffle values within columns during permutation. |
| `--pfm-mode` | Flag | Derive PFM by scanning sequences (useful for comparing different model types). |
| `--num-sequences` | Integer | Sequences for PFM mode (default: 20000). |
| `--seq-length` | Integer | Sequence length for PFM mode (default: 100). |
| `--seed` | Integer | Global random seed. |
| `--jobs` | Integer | Number of parallel jobs (default: -1). |
## Library Usage
MIMOSA exposes a functional API. The core building blocks are:
- `GenericModel` (`mimosa.models`) as an immutable model container.
- `read_model(...)`, `scan_model(...)`, `get_sites(...)`, `get_pfm(...)` (`mimosa.models`) for model I/O and scanning.
- `create_comparator_config(...)` and `compare(...)` (`mimosa.comparison`) for direct strategy execution.
- `compare_motifs(...)`, `create_config(...)`, `run_comparison(...)` (`mimosa`) as high-level entry points.
### Implementing a Custom Model Type
Custom models are added through the model strategy registry (`mimosa.models.registry`), not by subclassing a base model class.
```python
import os
import joblib
import numpy as np
from mimosa.models import GenericModel
from mimosa.models import registry as model_registry
from mimosa.ragged import RaggedData, ragged_from_list
def scan_dinuc_scores(sequences: RaggedData, matrix: np.ndarray, strand: str) -> RaggedData:
"""Scan sequences with a dinucleotide matrix of shape (16, motif_length-1)."""
motif_len = matrix.shape[1] + 1
rc_table = np.array([3, 2, 1, 0, 4], dtype=np.int8)
result = []
for i in range(sequences.num_sequences):
seq = sequences.get_slice(i)
if strand == "-":
seq = rc_table[seq[::-1]]
if len(seq) < motif_len:
result.append(np.array([], dtype=np.float32))
continue
n_pos = len(seq) - motif_len + 1
scores = np.zeros(n_pos, dtype=np.float32)
for pos in range(n_pos):
window = seq[pos : pos + motif_len]
score = 0.0
for k in range(motif_len - 1):
a = int(window[k])
b = int(window[k + 1])
if a < 4 and b < 4:
dinuc_idx = a * 4 + b
score += matrix[dinuc_idx, k]
scores[pos] = score
result.append(scores)
return ragged_from_list(result, dtype=np.float32)
@model_registry.register("dinuc")
class DinucStrategy:
"""Example custom strategy for a dinucleotide model."""
@staticmethod
def scan(model: GenericModel, sequences: RaggedData, strand: str) -> RaggedData:
representation = model.representation.astype(np.float32)
if strand == "+":
return scan_dinuc_scores(sequences, representation, "+")
if strand == "-":
return scan_dinuc_scores(sequences, representation, "-")
if strand == "best":
sf = scan_dinuc_scores(sequences, representation, "+")
sr = scan_dinuc_scores(sequences, representation, "-")
return RaggedData(np.maximum(sf.data, sr.data), sf.offsets)
raise ValueError(f"Invalid strand mode: {strand}")
@staticmethod
def write(model: GenericModel, path: str) -> None:
joblib.dump(model, path)
@staticmethod
def score_bounds(model: GenericModel) -> tuple[float, float]:
# Approximation: valid for many practical cases, but not a strict bound
# for all dependency-aware models.
rep = model.representation
min_score = rep.min(axis=0).sum()
max_score = rep.max(axis=0).sum()
return float(min_score), float(max_score)
@staticmethod
def load(path: str, kwargs: dict) -> GenericModel:
if path.endswith(".pkl"):
return joblib.load(path)
matrix = np.load(path) # expected shape: (16, motif_length-1)
name = kwargs.get("name", os.path.splitext(os.path.basename(path))[0])
length = int(matrix.shape[-1] + 1)
return GenericModel(
type_key="dinuc",
name=name,
length=length,
representation=matrix.astype(np.float32),
config={"kmer": 2},
)
```
Important: this module must be imported before calling `read_model(..., "dinuc")`
or any comparison that relies on this model type. Registration happens at import time.
```python
from mimosa import compare_motifs
from mimosa.io import read_fasta
from mimosa.models import read_model
# Ensure DinucStrategy registration code above has already run in this process.
model1 = read_model("my_custom.npy", "dinuc")
model2 = read_model("examples/pif4.meme", "pwm")
sequences = read_fasta("examples/foreground.fa")
result = compare_motifs(
model1=model1,
model2=model2,
strategy="motif",
sequences=sequences,
metric="co",
n_permutations=100,
seed=42,
)
print(result)
```
### Strategy Contract
A model strategy registered in `mimosa.models.registry` must provide:
| Method | Description |
| :--- | :--- |
| `scan(model, sequences, strand)` | Required. Returns `RaggedData` with positional scores. |
| `write(model, path)` | Required. Serializes model data. |
| `score_bounds(model)` | Required for threshold table generation. |
| `load(path, kwargs)` | Required. Builds and returns a `GenericModel`. |
### Recommended: Unified Config API
```python
from mimosa import compare_motifs
from mimosa.io import read_fasta
from mimosa.models import read_model
model1 = read_model("examples/pif4.meme", "pwm")
model2 = read_model("examples/gata2.ihbcp", "bamm")
sequences = read_fasta("examples/foreground.fa")
result = compare_motifs(
model1=model1,
model2=model2,
strategy="universal", # "universal", "tomtom", "tomtom-like", "motali", "motif"
sequences=sequences,
metric="co",
n_permutations=100,
seed=42,
)
print(result)
```
### Example: Direct API Comparison
```python
from mimosa.comparison import compare, create_comparator_config
from mimosa.io import read_fasta
from mimosa.models import read_model
# Load models in supported formats (pwm, bamm, sitega, profile, or custom registered type)
model1 = read_model("examples/pif4.meme", "pwm")
model2 = read_model("examples/gata2.meme", "pwm")
# Sequences are integer-encoded (A=0, C=1, G=2, T=3, N=4)
sequences = read_fasta("examples/foreground.fa")
config = create_comparator_config(
metric="cj",
n_permutations=100,
seed=42,
search_range=10,
)
result = compare(
model1=model1,
model2=model2,
strategy="universal", # "universal", "tomtom", or "motali"
config=config,
sequences=sequences,
)
print(result)
```
### Examples
The [`examples/`](examples/) directory contains sample data and scripts (`examples/run.sh`, `examples/run.ps1`) for CLI workflows.
## Bibliography
1. Lambert, S. A., Jolma, A., Campitelli, L. F., Das, P. K., Yin, Y., Albu, M., ... & Weirauch, M. T. (2018). The human transcription factors. _Cell_, _172_(4), 650-665.
2. Wasserman, W. W., & Sandelin, A. (2004). Applied bioinformatics for the identification of regulatory elements. _Nature Reviews Genetics, 5 (4), 276-287.
3. Park, P. J. (2009). ChIP–seq: advantages and challenges of a maturing technology. _Nature reviews genetics_, _10_(10), 669-680.
4. Jolma, A., Kivioja, T., Toivonen, J., Cheng, L., Wei, G., Enge, M., Taipale, M., Vaquerizas, J. M., Yan, J., Sillanpää, M. J., Bonke, M., Palin, K., Talukder, S., Hughes, T. R., Luscombe, N. M., Ukkonen, E., & Taipale, J. (2010). Multiplexed massively parallel SELEX for characterization of human transcription factor binding specificities. _Genome research_, _20_(6), 861–873. https://doi.org/10.1101/gr.100552.109
5. O'Malley, R. C., Huang, S. C., Song, L., Lewsey, M. G., Bartlett, A., Nery, J. R., Galli, M., Gallavotti, A., & Ecker, J. R. (2016). Cistrome and Epicistrome Features Shape the Regulatory DNA Landscape. _Cell_, _165_(5), 1280–1292. https://doi.org/10.1016/j.cell.2016.04.038
6. Bailey, T. L., & Elkan, C. (1994). Fitting a mixture model by expectation maximization to discover motifs in biopolymers.Proceedings. International Conference on Intelligent Systems for Molecular Biology_, _2_, 28–36.
7. Bailey T. L. (2021). STREME: accurate and versatile sequence motif discovery. _Bioinformatics (Oxford, England)_, _37_(18), 2834–2840. https://doi.org/10.1093/bioinformatics/btab203
8. Heinz, S., Benner, C., Spann, N., Bertolino, E., Lin, Y. C., Laslo, P., Cheng, J. X., Murre, C., Singh, H., & Glass, C. K. (2010). Simple combinations of lineage-determining transcription factors prime cis-regulatory elements required for macrophage and B cell identities. _Molecular cell_, _38_(4), 576–589. https://doi.org/10.1016/j.molcel.2010.05.004
9. Grau J, Posch S, Grosse I, Keilwagen J. A general approach for discriminative de novo motif discovery from high-throughput data. Nucleic Acids Res. 2013 Nov;41(21):e197. doi: 10.1093/nar/gkt831. Epub 2013 Sep 20. PMID: 24057214; PMCID: PMC3834837.
10. Eggeling R, Grosse I, Grau J. InMoDe: tools for learning and visualizing intra-motif dependencies of DNA binding sites. Bioinformatics. 2017 Feb 15;33(4):580-582. doi: 10.1093/bioinformatics/btw689. PMID: 28035026; PMCID: PMC5408807.
11. Siebert, M., & Söding, J. (2016). Bayesian Markov models consistently outperform PWMs at predicting motifs in nucleotide sequences. _Nucleic acids research_, _44_(13), 6055–6069. https://doi.org/10.1093/nar/gkw521
12. Ge, W., Meier, M., Roth, C., & Söding, J. (2021). Bayesian Markov models improve the prediction of binding motifs beyond first order. _NAR genomics and bioinformatics_, _3_(2), lqab026. https://doi.org/10.1093/nargab/lqab026
13. Toivonen J, Das PK, Taipale J, Ukkonen E. MODER2: first-order Markov modeling and discovery of monomeric and dimeric binding motifs. Bioinformatics. 2020 May 1;36(9):2690-2696. doi: 10.1093/bioinformatics/btaa045. PMID: 31999322; PMCID: PMC7203737.
14. Mathelier, A., & Wasserman, W. W. (2013). The next generation of transcription factor binding site prediction. _PLoS computational biology_, _9_(9), e1003214. https://doi.org/10.1371/journal.pcbi.1003214
15. Levitsky, V. G., Ignatieva, E. V., Ananko, E. A., Turnaev, I. I., Merkulova, T. I., Kolchanov, N. A., & Hodgman, T. C. (2007). Effective transcription factor binding site prediction using a combination of optimization, a genetic algorithm and discriminant analysis to capture distant interactions. _BMC bioinformatics_, _8_, 481. https://doi.org/10.1186/1471-2105-8-481
16. Tsukanov, A. V., Mironova, V. V., & Levitsky, V. G. (2022). Motif models proposing independent and interdependent impacts of nucleotides are related to high and low affinity transcription factor binding sites in Arabidopsis. _Frontiers in plant science_, _13_, 938545. https://doi.org/10.3389/fpls.2022.938545
17. Alipanahi, B., Delong, A., Weirauch, M. T., & Frey, B. J. (2015). Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. _Nature biotechnology_, _33_(8), 831–838. https://doi.org/10.1038/nbt.3300
18. Hassanzadeh, H. R., & Wang, M. D. (2016). DeeperBind: Enhancing Prediction of Sequence Specificities of DNA Binding Proteins. _Proceedings. IEEE International Conference on Bioinformatics and Biomedicine_, _2016_, 178–183. https://doi.org/10.1109/bibm.2016.7822515
19. Chen, C., Hou, J., Shi, X., Yang, H., Birchler, J. A., & Cheng, J. (2021). DeepGRN: prediction of transcription factor binding site across cell-types using attention-based deep neural networks. _BMC bioinformatics_, _22_(1), 38. https://doi.org/10.1186/s12859-020-03952-1
20. Wang, K., Zeng, X., Zhou, J., Liu, F., Luan, X., & Wang, X. (2024). BERT-TFBS: a novel BERT-based model for predicting transcription factor binding sites by transfer learning. _Briefings in bioinformatics_, _25_(3), bbae195. https://doi.org/10.1093/bib/bbae195
21. Jing Zhang, F., Zhang, S. W., & Zhang, S. (2022). Prediction of Transcription Factor Binding Sites With an Attention Augmented Convolutional Neural Network. _IEEE/ACM transactions on computational biology and bioinformatics_, _19_(6), 3614–3623. https://doi.org/10.1109/TCBB.2021.3126623
22. Gupta, S., Stamatoyannopoulos, J. A., Bailey, T. L., & Noble, W. S. (2007). Quantifying similarity between motifs. _Genome biology_, _8_(2), R24. https://doi.org/10.1186/gb-2007-8-2-r24
23. Mahony, S., & Benos, P. V. (2007). STAMP: a web tool for exploring DNA-binding motif similarities. _Nucleic acids research_, _35_(Web Server issue), W253–W258. https://doi.org/10.1093/nar/gkm272
24. Vorontsov, I. E., Kulakovskiy, I. V., & Makeev, V. J. (2013). Jaccard index based similarity measure to compare transcription factor binding site models. _Algorithms for molecular biology : AMB_, _8_(1), 23. https://doi.org/10.1186/1748-7188-8-23
25. Lambert, S. A., Albu, M., Hughes, T. R., & Najafabadi, H. S. (2016). Motif comparison based on similarity of binding affinity profiles. _Bioinformatics (Oxford, England)_, _32_(22), 3504–3506. https://doi.org/10.1093/bioinformatics/btw489
| text/markdown | null | Anton Tsukanov <tsukanov@bionet.nsc.ru> | null | null | MIT | null | [
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy<2.4,>=2.0",
"numba>=0.62.0",
"scipy>=1.14.1",
"pandas>=2.2.3",
"joblib>=1.5.3"
] | [] | [] | [] | [
"Homepage, https://github.com/ubercomrade/mimosa",
"Repository, https://github.com/ubercomrade/mimosa",
"Documentation, https://github.com/ubercomrade/mimosa#readme"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:09:18.139670 | mimosa_tool-1.1.1-cp310-cp310-win_amd64.whl | 95,897 | b6/cc/21e193626c662c9908a65a3c6f4eef0ebee08f9ae0e98617dd7aa68bcb88/mimosa_tool-1.1.1-cp310-cp310-win_amd64.whl | cp310 | bdist_wheel | null | false | 0ba89d35c36306850e1742db0e7f3a51 | d1d77196b4719978a84c448d33799926fe28044c3d23b74b3937dbd8b23e05ef | b6cc21e193626c662c9908a65a3c6f4eef0ebee08f9ae0e98617dd7aa68bcb88 | null | [] | 1,069 |
2.4 | pyqck | 0.1.2 | PyQuick is the developer toolchain for Python APIs | # PyQuick
PyQuick is the developer toolchain for Python APIs.
## TL;DR
```bash
pyqck new myapi --profile api --template fastapi
cd myapi
uv sync --extra dev
uv run pyqck run
```
## Core Commands
```bash
pyqck new <name> --profile api --template fastapi
pyqck dev
pyqck run
pyqck test
pyqck lint
pyqck fmt
pyqck check
```
## Quick Navigation
- Docs index: [docs/README.md](docs/README.md)
- Alpha quickstart: [docs/getting-started/quickstart-alpha.md](docs/getting-started/quickstart-alpha.md)
- Troubleshooting: [docs/getting-started/troubleshooting-alpha.md](docs/getting-started/troubleshooting-alpha.md)
- Release checklist: [docs/release/release-alpha-checklist.md](docs/release/release-alpha-checklist.md)
## Docs by Section
- Getting Started: [docs/getting-started/README.md](docs/getting-started/README.md)
- Reference: [docs/reference/README.md](docs/reference/README.md)
- Dev Loop: [docs/dev-loop/README.md](docs/dev-loop/README.md)
- Quality and Performance: [docs/quality/README.md](docs/quality/README.md)
- Release and Feedback: [docs/release/README.md](docs/release/README.md)
- Architecture Decisions: [docs/adr/README.md](docs/adr/README.md)
## Product Scope (v1 alpha)
- FastAPI-first API scaffold
- No DB scaffolding by default
- Fast local loop with deterministic checks
## Roadmap
1. M1 - Foundations (CLI + Config)
2. M2 - FastAPI Scaffold (No DB)
3. M3 - Dev Loop (Vite-like)
4. M4 - Quality, Perf, DX Hardening
5. M5 - Internal Alpha Release
## License
MIT
| text/markdown | PyQuick Team | null | null | null | MIT | cli, developer-experience, python, scaffold, toolchain | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Build Tools",
"Topic :: Software Development :: Code Generators"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"rich>=13.9.0",
"typer>=0.16.0",
"watchfiles>=1.1.0",
"pyright>=1.1.390; extra == \"dev\"",
"pytest>=8.3.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/mhbxyz/pyquick",
"Repository, https://github.com/mhbxyz/pyquick",
"Issues, https://github.com/mhbxyz/pyquick/issues",
"Documentation, https://github.com/mhbxyz/pyquick/tree/main/docs"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:08:46.871869 | pyqck-0.1.2.tar.gz | 56,175 | c7/e5/94ee49a0aedd714ad9e78287753e01a818d72b8c97285c84f32b243511a8/pyqck-0.1.2.tar.gz | source | sdist | null | false | f4634335e60a84c87608b852563fffe0 | a430b427dbf3f59eb12dc805dd624abd1602fe9bdcf96e3a8a6dce8c4bfc7c22 | c7e594ee49a0aedd714ad9e78287753e01a818d72b8c97285c84f32b243511a8 | null | [
"LICENSE"
] | 227 |
2.4 | txt2detection | 1.1.15 | A command line tool that takes a txt file containing threat intelligence and turns it into a detection rule. | # txt2detection
[](https://codecov.io/gh/muchdogesec/txt2detection)
## Overview

A command line tool that takes a txt file containing threat intelligence and turns it into a detection rule.
## The problems
To illustrate the problem, lets walk through the current status quo process a human goes through when going from idea (threat TTP) to detection rule:
1. read and understand threat using their own research, aided by external sources (blogs, intel feed, etc.)
* problems: lots of reports, threats described in a range of ways, reports contain differing data
2. understand what logs or security data can be used to detect this threat
* problems: log schemas are unknown to analyst, TTPs often span many logs making it hard to ensure your detection rule has full coverage
3. convert the logic created in step 1 into a Sigma detection rule to search logs identified at step 2
* problems: hard to convert what has been understood into a logical detection rule (in a detection language an analyst might not be familiar with)
4. modify the detection rule based on new intelligence as it is discovered
* problems: this is typically overlooked as people create and forget about rules in their detection tools
## The solution
Use AI to process threat intelligence, create and keep them updated.
txt2detection allows a user to enter some threat intelligence as a file to considered be turned into a detection.
1. User uploads intel report
2. Based on the user input, AI prompts structured and sent to produce an intelligence rule
3. Rules converted into STIX objects
## Usage
### Setup
Install the required dependencies using:
```shell
# clone the latest code
git clone https://github.com/muchdogesec/txt2detection
cd txt2detection
# create a venv
python3 -m venv txt2detection-venv
source txt2detection-venv/bin/activate
# install requirements
pip3 install -r requirements.txt
pip3 install .
```
### Set variables
txt2detection has various settings that are defined in an `.env` file.
To create a template for the file:
```shell
cp .env.example .env
```
To see more information about how to set the variables, and what they do, read the `.env.markdown` file.
Then test your configoration
```shell
python3 txt2detection.py \
check-credentials
```
It will return a response to show what API keys are working
```txt
============= Service Statuses ===============
ctibutler : authorized ✔
vulmatch : authorized ✔
LLMS:
openai : authorized ✔
deepseek : unsupported –
gemini : unsupported –
openrouter : unsupported –
anthropic : unsupported –
```
Not all services need to be configured, if you have no intention of using them.
### Run
```shell
python3 txt2detection.py MODE \
ARGUEMENTS
```
There are 3 modes in which you can use txt2detection:
* `file`: A text file, usually a threat report you want to create rules from the intel held within
* `text`: A text prompt that describes the rule you want to create
* `sigma`: An existing Sigma Rule you want to convert into a STIX bundle
#### File (`file`) / Text Input (`text`)
Use this mode to generate a set of rules from an input text file;
* `--input_file` (required, if not using `--input_text`, file path): the file to be converted. Must be `.txt`
* `--input_text` (required, if not using `--input_file`, string): a text string that will be analysed to create a rule by the AI if you don't want to use a file. Generally you want to be as descritive as possible with this text (consider it similar to an LLM propmpt). Very short `input_text`s will often cause the AI to fail at rule generation (you will see `Unparsable output returned by LLM model`).
* `--name` (required): name of file, max 72 chars. Will be used in the STIX Report Object created. Note, the Indicator object names/titles are generated by AI
* `--report_id` (optional, default random uuidv4): Sometimes it is required to control the id of the `report` object generated. You can therefore pass a valid UUIDv4 in this field to be assigned to the report. e.g. passing `2611965-930e-43db-8b95-30a1e119d7e2` would create a STIX object id `report--2611965-930e-43db-8b95-30a1e119d7e2`. If this argument is not passed, the UUID will be randomly generated.
* `--tlp_level` (optional, default `clear`): Options are `clear`, `green`, `amber`, `amber_strict`, `red`.
* `--labels` (optional): whitspace separated list of labels. Case-insensitive (will all be converted to lower-case). Allowed `a-z`, `0-9`. Must use a namespaces (`NAMESPACE.TAG_VALUE`). e.g.`"namespace.label1" "namespace.label_2"` would create 2 labels. Added to both report and indicator objects created and the rule `tags`.
* note: you can use reserved namespaces `cve.` and `attack.` when creating labels to perform external enrichment using Vulmatch and CTI Butler. All Indicators will be linked to these objects (AI enrichments link individual rules). Created tags will be appended to the list of AI generated tags.
* note: you cannot use the namespace `tlp.` Use the `--tlp_level` flag instead.
* `--created` (optional, `YYYY-MM-DDTHH:MM:SS`): by default all object `created` times will take the time the script was run. If you want to explicitly set these times you can do so using this flag. Pass the value in the format `YYYY-MM-DDTHH:MM:SS` e.g. `2020-01-01T00:00:00`
* `--use_identity` (optional, default txt2detection identity): can pass a full STIX 2.1 identity object (make sure to properly escape). Will be validated by the STIX2 library. The ID is used to create the Indicator and Report STIX objects, and is used as the `author` property in the Sigma Rule.
* `--license` (optional): [License of the rule according the SPDX ID specification](https://spdx.org/licenses/). Will be added to the rule.
* `--reference_urls` (optional): A list of URLs to be added as `references` in the Sigma Rule property and in the `external_references` property of the Indicator and Report STIX object created. e.g `"https://www.google.com/" "https://www.facebook.com/"`
* `--external_refs` (optional): txt2detection will automatically populate the `external_references` of the report object it creates for the input. You can use this value to add additional objects to `external_references`. Note, you can only add `source_name` and `external_id` values currently. Pass as `source_name=external_id`. e.g. `--external_refs txt2stix=demo1 source=id` would create the following objects under the `external_references` property: `{"source_name":"txt2stix","external_id":"demo1"},{"source_name":"source","external_id":"id"}`
* `--ai_provider` (required): defines the `provider:model` to be used to generate the rule. Select one option. Currently supports:
* Provider (env var required `OPENROUTER_API_KEY`): `openrouter:`, providers/models `openai/gpt-4o`, `deepseek/deepseek-chat` ([More here](https://openrouter.ai/models))
* Provider (env var required `OPENAI_API_KEY`): `openai:`, models e.g.: `gpt-4o`, `gpt-4o-mini`, `gpt-4-turbo`, `gpt-4` ([More here](https://platform.openai.com/docs/models))
* Provider (env var required `ANTHROPIC_API_KEY`): `anthropic:`, models e.g.: `claude-3-5-sonnet-latest`, `claude-3-5-haiku-latest`, `claude-3-opus-latest` ([More here](https://docs.anthropic.com/en/docs/about-claude/models))
* Provider (env var required `GOOGLE_API_KEY`): `gemini:models/`, models: `gemini-1.5-pro-latest`, `gemini-1.5-flash-latest` ([More here](https://ai.google.dev/gemini-api/docs/models/gemini))
* Provider (env var required `DEEPSEEK_API_KEY`): `deepseek:`, models `deepseek-chat` ([More here](https://api-docs.deepseek.com/quick_start/pricing))
* `--create_attack_navigator_layer` (boolean, default `false`): passing this flag will generate a [MITRE ATT&CK Navigator layer](https://mitre-attack.github.io/attack-navigator/) for MITRE ATT&CK tags. Note, Sigma currently supports ATT&CK Enterprise only.
Note, in this mode, the following values will be automatically assigned to the rule
* `level`: the AI will be prompted to assign, either `informational`, `low`, `medium`, `high`, `critical`
* `status`: will always be `experimental` in this mode
#### Sigma rule input (`sigma`)
Use this mode to turn a Sigma Rule into a STIX bundle and get it enriched with ATT&CK and Vulmatch.
Note, in this mode you should be aware of a few things;
* `--sigma_file` (required, file path): the sigma rule .yml you want to be processed. Must be a `.yml` or `.yaml` file. Does not currently support correlation rules.
* `--report_id`: will overwrite any `id` value found in the rule, also used for both Indicator and Report
* `--name`: will be assigned as `title` of the rule. Will overwrite existing title
* `--tlp_level` (optional): the `tlp.` tag in the report will be turned into a TLP level. If not TLP tag in rule, default is that is will be assigned TLP `clear` and tag added. You can pass `clear`, `green`, `amber`, `amber_strict`, `red` using this property to overwrite default behaviour. If TLP exist in rule, setting a value for this property will overwrite the existing value
* `--labels` (optional): whitespace separated list of labels. Case-insensitive (will all be converted to lower-case). Allowed `a-z`, `0-9`. e.g.`"namespace.label1" "namespace.label2"` would create 2 labels. Added to both report and indicator objects created and the rule `tags`. Note, if any existing `tags` in the rule, these values will be appended to the list.
* note: you can use reserved namespaces `cve.` and `attack.` when creating labels to perform external enrichment using Vulmatch and CTI Butler. Created tags will be appended to the list of existing tags.
* note: you cannot use the namespace `tlp.` Use the `--tlp_level` flag instead.
* `--created` (optional, `YYYY-MM-DDTHH:MM:SS`): by default the `data` and `modified` values in the rule will be used. If no values exist for these, the default behaviour is to use script run time. You can pass `created` time here which will overwrite `date` and `modified` date in the rule
* `--use_identity` (optional): can pass a full STIX 2.1 identity object (make sure to properly escape). Will be validated by the STIX2 library. The ID is used to create the Indicator and Report STIX objects, and is used as the `author` property in the Sigma Rule. Will overwrite any existing `author` value. If `author` value in rule, will be converted into a STIX Identity
* `--license` (optional): [License of the rule according the SPDX ID specification](https://spdx.org/licenses/). Will be added to the rule as `license`. Will overwrite any existing `license` value in rule.
* `--reference_urls` (optional): A list of URLs to be added as `references` in the Sigma Rule property and in the `external_references` property of the Indicator and Report STIX object created. e.g `"https://www.google.com/" "https://www.facebook.com/"`. Will appended to any existing `references` in the rule.
* `--external_refs` (optional): txt2detection will automatically populate the `external_references` of the report object it creates for the input. You can use this value to add additional objects to `external_references`. Note, you can only add `source_name` and `external_id` values currently. Pass as `source_name=external_id`. e.g. `--external_refs txt2stix=demo1 source=id` would create the following objects under the `external_references` property: `{"source_name":"txt2stix","external_id":"demo1"},{"source_name":"source","external_id":"id"}`
* `status` (optional): either `stable`, `test`, `experimental`, `deprecated`, `unsupported`. If passed, will overwrite any existing `status` recorded in the rule
* `level` (optional): either `informational`, `low`, `medium`, `high`, `critical`. If passed, will overwrite any existing `level` recorded in the rule
* `--create_attack_navigator_layer` (boolean, default `false`): passing this flag will generate a [MITRE ATT&CK Navigator layer](https://mitre-attack.github.io/attack-navigator/) for MITRE ATT&CK tags.
### A note on observable extraction
txt2detection will automatically attempt to extract any observables (aka indicators of compromise) that are found in the created or imported rules to turn them into STIX objects joined to the STIX Indicator object of the Rule.
In `txt2detection/observables.py` you will find the observable types (and regexs used detection) currently supported.
### Output
The output of each run is structured as follows;
```txt
.
├── logs
│ ├── log-<REPORT UUID>.log
│ ├── log-<REPORT UUID>.log
│ └── log-<REPORT UUID>.log
└── output
└── bundle--<REPORT UUID>
├── rules
│ ├── rule--<UUID>.yml
│ └── rule--<UUID>.yml
├── data.json # AI output, useful for debugging
└── bundle.json # final STIX bundle with all objects
```
## Examples
See `tests/manual-tests/README.md` for some example commands.
## Support
[Minimal support provided via the DOGESEC community](https://community.dogesec.com/).
## License
[Apache 2.0](/LICENSE). | text/markdown | dogesec | null | dogesec | null | null | null | [
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"json-repair",
"jsonschema>=4.22.0; python_version >= \"3.8\"",
"llama-index-core>=0.14.8",
"llama-index-llms-openai>=0.6.8",
"python-arango>=8.1.3; python_version >= \"3.8\"",
"python-dotenv>=1.0.1",
"python-slugify",
"pyyaml",
"requests>=2.31.0; python_version >= \"3.7\"",
"stix2",
"stix2extensions",
"tqdm>=4.66.4; python_version >= \"3.7\"",
"validators>=0.34.0",
"llama-index-llms-anthropic>=0.9.7; extra == \"anthropic\"",
"llama-index-llms-deepseek>=0.2.2; extra == \"deepseek\"",
"llama-index-llms-google-genai>=0.5.0; extra == \"gemini\"",
"llama-index-llms-anthropic>=0.9.7; extra == \"llms\"",
"llama-index-llms-deepseek>=0.2.2; extra == \"llms\"",
"llama-index-llms-google-genai>=0.5.0; extra == \"llms\"",
"llama-index-llms-openrouter>=0.4.2; extra == \"llms\"",
"llama-index-llms-openrouter>=0.4.2; extra == \"openrouter\""
] | [] | [] | [] | [
"Homepage, https://github.com/muchdogesec/txt2detection",
"Issues, https://github.com/muchdogesec/txt2detection/issues",
"dogesec HQ, https://dogesec.com"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:07:55.112109 | txt2detection-1.1.15.tar.gz | 309,737 | 6e/c3/89ea413df536c8956afee2f61f46a506adcffcc764af4fc63924d0bae3d2/txt2detection-1.1.15.tar.gz | source | sdist | null | false | b34a5f0e3a74455dbe2d25f114d18ba8 | e3b5b019e48661adafa2bfb56958c1581864a6a5ad55d16d466e95b2d1200c7d | 6ec389ea413df536c8956afee2f61f46a506adcffcc764af4fc63924d0bae3d2 | null | [
"LICENSE"
] | 215 |
2.4 | pttechnologies | 0.0.39 | Testing tool for identifying technologies used by web applications | [](https://www.penterep.com/)
## PTTECHNOLOGIES
Testing tool for identifying technologies used by web applications.
## Installation
```
pip install pttechnologies
```
## Adding to PATH
If you're unable to invoke the script from your terminal, it's likely because it's not included in your PATH. You can resolve this issue by executing the following commands, depending on the shell you're using:
For Bash Users
```bash
echo "export PATH=\"`python3 -m site --user-base`/bin:\$PATH\"" >> ~/.bashrc
source ~/.bashrc
```
For ZSH Users
```bash
echo "export PATH=\"`python3 -m site --user-base`/bin:\$PATH\"" >> ~/.zshrc
source ~/.zshrc
```
## Usage examples
```
pttechnologies -u https://www.example.com/
pttechnologies -u https://www.example.com/ -ts OSCS OSLPT1 WSHT PPLNG WSH
```
## Options
```
-u --url <url> Connect to URL
-ts --tests <test> Specify one or more tests to perform:
HDRVAL Test for the content of HTTP response headers
OSCS Test OS detection via Case Sensitivity
OSLPT1 Test OS detection via LPT1 path
PLLNG Test programming language detection via file extensions
WSHT Test Apache detection via .ht access rule
WSRPO Test response-header order
WSURLLEN Test URL length behavior to identify web server
-p --proxy <proxy> Set proxy (e.g. http://127.0.0.1:8080)
-T --timeout <miliseconds> Set timeout (default 10)
-t --threads <threads> Set thread count (default 10)
-c --cookie <cookie> Set cookie
-a --user-agent <a> Set User-Agent header
-H --headers <header:value> Set custom header(s)
-r --redirects Follow redirects (default False)
-C --cache Cache HTTP communication (load from tmp in future)
-v --version Show script version and exit
-h --help Show this help message and exit
-j --json Output in JSON format
```
## Dependencies
```
ptlibs
```
## License
Copyright (c) 2025 Penterep Security s.r.o.
pttechnologies is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
pttechnologies is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with pttechnologies. If not, see https://www.gnu.org/licenses/.
## Warning
You are only allowed to run the tool against the websites which
you have been given permission to pentest. We do not accept any
responsibility for any damage/harm that this application causes to your
computer, or your network. Penterep is not responsible for any illegal
or malicious use of this code. Be Ethical!
| text/markdown | Penterep | info@penterep.com | null | null | GPLv3 | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: Implementation :: CPython",
"Environment :: Console",
"Topic :: Security",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)"
] | [] | https://www.penterep.com/ | null | >=3.12 | [] | [] | [] | [
"ptlibs<2,>=1.0.37",
"bs4"
] | [] | [] | [] | [
"homepage, https://www.penterep.com/",
"repository, https://github.com/penterep/pttechnologies",
"tracker, https://github.com/penterep/pttechnologies/issues"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T13:07:51.882605 | pttechnologies-0.0.39.tar.gz | 240,341 | 24/df/60a6ad3a3d584d39cf60525e7077cb5162b9183bddb722742018f3a6d110/pttechnologies-0.0.39.tar.gz | source | sdist | null | false | 6b99c87a19ffd4e055fcd52e9b7f30e9 | 43c208288f747d04b15ba6e0947375a08e77b112f1c40e2471d9798946398c37 | 24df60a6ad3a3d584d39cf60525e7077cb5162b9183bddb722742018f3a6d110 | null | [
"LICENSE"
] | 214 |
2.4 | btime-framework | 0.1.9.8 | Btime Framework | 1° - Instale a lib:
pip install Btime_framework
2° - Exemplos de inicio (copia e modifica no seu código):
import btime_framework as BT
from btime_framework import By # Opcional
class Framework:
def __init__(self):
self.sys = BT.System() # Classe para opções que envolvem sistema (pdf, janelas, arquivos...)
self.instance = BT.Instancedriver(Browser="Chrome") # Essa é a instância do navegador, classe mestre
self.options = self.instance.initialize_options()
self.driver = None
self.EL= None
def inicialize_driver(self):
# Caso queria adicionar argumentos especÃficos (antes de iniciar o driver)
self.instance.arguments.add_new_argument('--disable-blink-features=AutomationControlled')
# self.instance.arguments.add_new_argument
# O driver já vem com argumentos padrões para evitar detecções e bugs
self.driver = self.instance.initialize_driver(maximize=True)
# Essa é a classe que agrupa todas as formas de detecção de elementos
self.EL = self.instance.elements
class Scrapping_or_another_application(Framework):
def __init__(self):
super().__init__()
self.inicialize_driver()
def run(self):
self.driver.get('https://www.google.com/')
self.EL.find_element_with_wait(By.ID, 'APjFqb').send_keys('Example')
self.EL.find_element_with_wait(By.XPATH, '//div[*[1][self::center]]//input[@value="Estou com sorte"]').click()
# ...
if __name__ == "__main__":
bot = Scrapping_or_another_application()
bot.run()
3° - O framework usa diversas libs e importa dinamicamente, para importar as libs basta usar os comandos abaixo:
CMD
- cd C:\Users\SeuUsuario\Documents\SeuProjeto
- bt -fi SeuArquivo.py
Nisso ele vai te retornar todos os imports que você precisa
| text/markdown | Guilherme Neri | guilherme.neri@btime.com.br | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/Btime/Btime_Framework | null | >=3.6 | [] | [] | [] | [
"setuptools",
"pyperclip",
"pyinstaller",
"selenium",
"pynput; extra == \"pynput\"",
"screeninfo; extra == \"screeninfo\"",
"pywinauto; extra == \"pywinauto\"",
"capmonstercloudclient; extra == \"capmonstercloudclient\"",
"2captcha-python; extra == \"twocaptcha\"",
"undetected-chromedriver; extra == \"full\"",
"webdriver-manager; extra == \"full\"",
"opencv-python; extra == \"full\"",
"pygetwindow; extra == \"full\"",
"pyinstaller; extra == \"full\"",
"screeninfo; extra == \"full\"",
"pyscreeze; extra == \"full\"",
"pyautogui; extra == \"full\"",
"selenium; extra == \"full\"",
"requests; extra == \"full\"",
"pymupdf; extra == \"full\"",
"Pillow; extra == \"full\"",
"psutil; extra == \"full\"",
"pynput; extra == \"full\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T13:07:42.748520 | btime_framework-0.1.9.8.tar.gz | 67,531 | 95/53/6caeb4d5ea9b7433e95a73bd5dddc9d8c4dd1375c7b69b3ccc5fdbcfbbe3/btime_framework-0.1.9.8.tar.gz | source | sdist | null | false | 7dd54960380e45db37b678b9700a1fc4 | 7e39615bf04b7939b4395d544b914063f62fab6b85c3b2757a94f10c167f1b0a | 95536caeb4d5ea9b7433e95a73bd5dddc9d8c4dd1375c7b69b3ccc5fdbcfbbe3 | null | [] | 210 |
2.4 | tsrkit-rs | 0.1.1 | Python Bindings for Erasure coding using reed-solomon-simd, matching the JAM graypaper. | tsrkit-rs
====
Python Bindings for Erasure coding using [reed-solomon-simd](https://crates.io/crates/reed-solomon-simd), matching the JAM graypaper for python.
Credits
----
[Leopard-RS](https://github.com/catid/leopard)
[reed-solomon-simd](https://crates.io/crates/reed-solomon-simd)
| text/markdown; charset=UTF-8; variant=GFM | null | Chainscore Labs <hello@chainscore.finance>, Kartik <kartik@chainscore.finance> | null | null | null | polkadot, blockchain, jam, reed-solomon | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Operating System :: OS Independent",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows"
] | [] | null | null | <3.13,>=3.12 | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/Chainscore/tsrkit-rs"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:06:55.390541 | tsrkit_rs-0.1.1.tar.gz | 7,344 | bb/d4/0b7fdfeeb5ce6447a279fee9273d5265963b98970501ed6a671768906a26/tsrkit_rs-0.1.1.tar.gz | source | sdist | null | false | d68f4e1db4e0bc24ac3d12a3a47669fd | 84c4068073289dab75a09f399c878e16b9d0d7cec25cf124b2a8d423a064dbf7 | bbd40b7fdfeeb5ce6447a279fee9273d5265963b98970501ed6a671768906a26 | null | [] | 400 |
2.4 | artexion-sdk | 0.1.0 | Official Python SDK for the Artexion Cloud API | # Artexion Python SDK
Official Python client for the Artexion Cloud API.
This package is safe to publish independently from your backend codebase.
It only ships the client library (`artexion`) and does not include server
implementation details.
## Install
```bash
pip install artexion-sdk
```
## Quick Start
```python
from artexion import Client
client = Client(api_key="atx_live_your_api_key_here")
task = client.run("Summarize my unread emails", max_steps=8)
print(task.id, task.status)
print(task.result)
```
## Backward-Compatible Import
```python
from artexion_sdk import Client
```
## Requirements
- Python 3.8+
- `httpx>=0.25.0,<1.0.0`
## Release
See `PUBLISH.md` for exact build and upload commands.
## License
Apache License 2.0 (`Apache-2.0`). See `LICENSE`.
| text/markdown | Artexion Team | support@artexion.cloud | null | null | Apache-2.0 | artexion, sdk, api, cloud, ai | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | https://artexion.cloud | null | >=3.8 | [] | [] | [] | [
"httpx<1.0.0,>=0.25.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.20.0; extra == \"dev\"",
"build>=1.2.1; extra == \"dev\"",
"twine>=5.1.1; extra == \"dev\"",
"ruff>=0.6.0; extra == \"dev\""
] | [] | [] | [] | [
"Documentation, https://docs.artexion.cloud",
"Repository, https://github.com/artexion/artexion-python-sdk",
"Issues, https://github.com/artexion/artexion-python-sdk/issues"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-20T13:06:40.115381 | artexion_sdk-0.1.0.tar.gz | 11,555 | f7/97/2e3bb5084a20646ec17e2229955880a15eaccc25af5c5f988434b7eb943e/artexion_sdk-0.1.0.tar.gz | source | sdist | null | false | bf73f9a194b08f4f1500e43442278707 | 85e891033f77b3d73793b7595731ec2b75d0ec9525d3be781527945c7fdec213 | f7972e3bb5084a20646ec17e2229955880a15eaccc25af5c5f988434b7eb943e | null | [
"LICENSE"
] | 232 |
2.3 | line-solver | 3.0.3.7 | Open source queueing theory solvers | # LINE Solver for Python
This folder includes the Python version of the [LINE solver](http://line-solver.sf.net).
## Installation
Requirements: Python 3.11 or later.
## Documentation
The Python syntax is nearly identical to the MATLAB one, see for example the scripts in the Python `examples/gettingstarted/` folder compared to the ones in the corresponding MATLAB `examples/gettingstarted/` folder.
A Python version of the [manual](https://line-solver.sourceforge.net/doc/LINE-python.pdf) is also available.
## Example
Solve a simple M/M/1 model with 50% utilization running: ```python3 mm1.py```. You should then get as output the following pandas DataFrame
```
Station JobClass QLen Util RespT ResidT Tput
0 mySource Class1 0.0 0.0 0.0 0.0 0.5
1 myQueue Class1 1.0 0.5 2.0 2.0 0.5
```
Alternatively, you can open and run mm1.ipynb in Jupyter.
## Getting Started Examples
The `examples/gettingstarted/` folder contains tutorial examples demonstrating key LINE features.
## License
This package is released as open source under the [BSD-3 license](http://opensource.org/licenses/BSD-3-Clause).
| text/markdown | Giuliano Casale | g.casale@imperial.ac.uk | null | null | BSD-3 | null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://line-solver.sourceforge.net | null | >=3.11 | [] | [] | [] | [
"numpy<3.0.0,>=2.3.3",
"matplotlib<4.0.0,>=3.10.6",
"pandas<3.0.0,>=2.3.2",
"scipy<2.0.0,>=1.16.2",
"enum-tools<0.14.0,>=0.13.0",
"websockets<13.0,>=12.0",
"simpy<5.0.0,>=4.0.0",
"torch>=2.0.0; extra == \"native\" or extra == \"gpu\"",
"numba>=0.57.0; extra == \"native\""
] | [] | [] | [] | [
"Homepage, https://line-solver.sourceforge.net"
] | poetry/2.1.2 CPython/3.13.7 Linux/6.17.0-12-generic | 2026-02-20T13:06:25.171822 | line_solver-3.0.3.7.tar.gz | 4,855,096 | 37/8a/b4f0d3c7fc0317eb90f86b060b509fccd2651953d82d574781e7a83a9d4a/line_solver-3.0.3.7.tar.gz | source | sdist | null | false | 633f4443014a2d0d5fbead890cef7ab3 | 80fc0c03b93586ef473aba726d573308f79001aab78474aba2d3f4bfb9b6b696 | 378ab4f0d3c7fc0317eb90f86b060b509fccd2651953d82d574781e7a83a9d4a | null | [] | 209 |
2.4 | revengai | 3.15.1 | RevEng.AI API | # RevEng.AI Python SDK
This is the Python SDK for the RevEng.AI API.
To use the SDK you will first need to obtain an API key from [https://reveng.ai](https://reveng.ai/register).
## Installation
Once you have the API key you can install the SDK via pip:
```bash
pip install revengai
```
## Usage
The following is an example of how to use the SDK to get the logs of an analysis:
```python
import os
import revengai
configuration = revengai.Configuration(api_key={'APIKey': os.environ["API_KEY"]})
# Enter a context with an instance of the API client
with revengai.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = revengai.AnalysesCoreApi(api_client)
analysis_id = 715320
try:
# Gets the logs of an analysis
api_response = api_instance.get_analysis_logs(analysis_id)
print("The response of AnalysesCoreApi->get_analysis_logs:\n")
print(api_response)
except Exception as e:
print("Exception when calling AnalysesCoreApi->get_analysis_logs: %s\n" % e)
```
## Documentation for API Endpoints
All URIs are relative to *https://api.reveng.ai*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*AnalysesCommentsApi* | [**create_analysis_comment**](docs/AnalysesCommentsApi.md#create_analysis_comment) | **POST** /v2/analyses/{analysis_id}/comments | Create a comment for this analysis
*AnalysesCommentsApi* | [**delete_analysis_comment**](docs/AnalysesCommentsApi.md#delete_analysis_comment) | **DELETE** /v2/analyses/{analysis_id}/comments/{comment_id} | Delete a comment
*AnalysesCommentsApi* | [**get_analysis_comments**](docs/AnalysesCommentsApi.md#get_analysis_comments) | **GET** /v2/analyses/{analysis_id}/comments | Get comments for this analysis
*AnalysesCommentsApi* | [**update_analysis_comment**](docs/AnalysesCommentsApi.md#update_analysis_comment) | **PATCH** /v2/analyses/{analysis_id}/comments/{comment_id} | Update a comment
*AnalysesCoreApi* | [**create_analysis**](docs/AnalysesCoreApi.md#create_analysis) | **POST** /v2/analyses | Create Analysis
*AnalysesCoreApi* | [**delete_analysis**](docs/AnalysesCoreApi.md#delete_analysis) | **DELETE** /v2/analyses/{analysis_id} | Delete Analysis
*AnalysesCoreApi* | [**get_analysis_basic_info**](docs/AnalysesCoreApi.md#get_analysis_basic_info) | **GET** /v2/analyses/{analysis_id}/basic | Gets basic analysis information
*AnalysesCoreApi* | [**get_analysis_function_map**](docs/AnalysesCoreApi.md#get_analysis_function_map) | **GET** /v2/analyses/{analysis_id}/func_maps | Get Analysis Function Map
*AnalysesCoreApi* | [**get_analysis_logs**](docs/AnalysesCoreApi.md#get_analysis_logs) | **GET** /v2/analyses/{analysis_id}/logs | Gets the logs of an analysis
*AnalysesCoreApi* | [**get_analysis_params**](docs/AnalysesCoreApi.md#get_analysis_params) | **GET** /v2/analyses/{analysis_id}/params | Gets analysis param information
*AnalysesCoreApi* | [**get_analysis_status**](docs/AnalysesCoreApi.md#get_analysis_status) | **GET** /v2/analyses/{analysis_id}/status | Gets the status of an analysis
*AnalysesCoreApi* | [**insert_analysis_log**](docs/AnalysesCoreApi.md#insert_analysis_log) | **POST** /v2/analyses/{analysis_id}/logs | Insert a log entry for an analysis
*AnalysesCoreApi* | [**list_analyses**](docs/AnalysesCoreApi.md#list_analyses) | **GET** /v2/analyses/list | Gets the most recent analyses
*AnalysesCoreApi* | [**lookup_binary_id**](docs/AnalysesCoreApi.md#lookup_binary_id) | **GET** /v2/analyses/lookup/{binary_id} | Gets the analysis ID from binary ID
*AnalysesCoreApi* | [**requeue_analysis**](docs/AnalysesCoreApi.md#requeue_analysis) | **POST** /v2/analyses/{analysis_id}/requeue | Requeue Analysis
*AnalysesCoreApi* | [**update_analysis**](docs/AnalysesCoreApi.md#update_analysis) | **PATCH** /v2/analyses/{analysis_id} | Update Analysis
*AnalysesCoreApi* | [**update_analysis_tags**](docs/AnalysesCoreApi.md#update_analysis_tags) | **PATCH** /v2/analyses/{analysis_id}/tags | Update Analysis Tags
*AnalysesCoreApi* | [**upload_file**](docs/AnalysesCoreApi.md#upload_file) | **POST** /v2/upload | Upload File
*AnalysesDynamicExecutionApi* | [**get_dynamic_execution_status**](docs/AnalysesDynamicExecutionApi.md#get_dynamic_execution_status) | **GET** /v2/analyses/{analysis_id}/dynamic-execution/status | Get the status of a dynamic execution task
*AnalysesDynamicExecutionApi* | [**get_network_overview**](docs/AnalysesDynamicExecutionApi.md#get_network_overview) | **GET** /v2/analyses/{analysis_id}/dynamic-execution/network-overview | Get the dynamic execution results for network overview
*AnalysesDynamicExecutionApi* | [**get_process_dump**](docs/AnalysesDynamicExecutionApi.md#get_process_dump) | **GET** /v2/analyses/{analysis_id}/dynamic-execution/process-dumps/{dump_name} | Get the dynamic execution results for a specific process dump
*AnalysesDynamicExecutionApi* | [**get_process_dumps**](docs/AnalysesDynamicExecutionApi.md#get_process_dumps) | **GET** /v2/analyses/{analysis_id}/dynamic-execution/process-dumps | Get the dynamic execution results for process dumps
*AnalysesDynamicExecutionApi* | [**get_process_registry**](docs/AnalysesDynamicExecutionApi.md#get_process_registry) | **GET** /v2/analyses/{analysis_id}/dynamic-execution/process-registry | Get the dynamic execution results for process registry
*AnalysesDynamicExecutionApi* | [**get_process_tree**](docs/AnalysesDynamicExecutionApi.md#get_process_tree) | **GET** /v2/analyses/{analysis_id}/dynamic-execution/process-tree | Get the dynamic execution results for process tree
*AnalysesDynamicExecutionApi* | [**get_ttps**](docs/AnalysesDynamicExecutionApi.md#get_ttps) | **GET** /v2/analyses/{analysis_id}/dynamic-execution/ttps | Get the dynamic execution results for ttps
*AnalysesResultsMetadataApi* | [**get_analysis_functions_paginated**](docs/AnalysesResultsMetadataApi.md#get_analysis_functions_paginated) | **GET** /v2/analyses/{analysis_id}/functions | Get functions from analysis
*AnalysesResultsMetadataApi* | [**get_capabilities**](docs/AnalysesResultsMetadataApi.md#get_capabilities) | **GET** /v2/analyses/{analysis_id}/capabilities | Gets the capabilities from the analysis
*AnalysesResultsMetadataApi* | [**get_communities**](docs/AnalysesResultsMetadataApi.md#get_communities) | **GET** /v2/analyses/{analysis_id}/communities | Gets the communities found in the analysis
*AnalysesResultsMetadataApi* | [**get_functions_list**](docs/AnalysesResultsMetadataApi.md#get_functions_list) | **GET** /v2/analyses/{analysis_id}/functions/list | Gets functions from analysis
*AnalysesResultsMetadataApi* | [**get_pdf**](docs/AnalysesResultsMetadataApi.md#get_pdf) | **GET** /v2/analyses/{analysis_id}/pdf | Gets the PDF found in the analysis
*AnalysesResultsMetadataApi* | [**get_sbom**](docs/AnalysesResultsMetadataApi.md#get_sbom) | **GET** /v2/analyses/{analysis_id}/sbom | Gets the software-bill-of-materials (SBOM) found in the analysis
*AnalysesResultsMetadataApi* | [**get_tags**](docs/AnalysesResultsMetadataApi.md#get_tags) | **GET** /v2/analyses/{analysis_id}/tags | Get function tags with maliciousness score
*AnalysesResultsMetadataApi* | [**get_vulnerabilities**](docs/AnalysesResultsMetadataApi.md#get_vulnerabilities) | **GET** /v2/analyses/{analysis_id}/vulnerabilities | Gets the vulnerabilities found in the analysis
*AnalysesSecurityChecksApi* | [**create_scurity_checks_task**](docs/AnalysesSecurityChecksApi.md#create_scurity_checks_task) | **POST** /v2/analyses/{analysis_id}/security-checks | Queues a security check process
*AnalysesSecurityChecksApi* | [**get_security_checks**](docs/AnalysesSecurityChecksApi.md#get_security_checks) | **GET** /v2/analyses/{analysis_id}/security-checks | Get Security Checks
*AnalysesSecurityChecksApi* | [**get_security_checks_task_status**](docs/AnalysesSecurityChecksApi.md#get_security_checks_task_status) | **GET** /v2/analyses/{analysis_id}/security-checks/status | Check the status of a security check process
*AuthenticationUsersApi* | [**get_requester_user_info**](docs/AuthenticationUsersApi.md#get_requester_user_info) | **GET** /v2/users/me | Get the requesters user information
*AuthenticationUsersApi* | [**get_user**](docs/AuthenticationUsersApi.md#get_user) | **GET** /v2/users/{user_id} | Get a user's public information
*AuthenticationUsersApi* | [**get_user_activity**](docs/AuthenticationUsersApi.md#get_user_activity) | **GET** /v2/users/activity | Get auth user activity
*AuthenticationUsersApi* | [**get_user_comments**](docs/AuthenticationUsersApi.md#get_user_comments) | **GET** /v2/users/me/comments | Get comments by user
*AuthenticationUsersApi* | [**login_user**](docs/AuthenticationUsersApi.md#login_user) | **POST** /v2/auth/login | Authenticate a user
*BinariesApi* | [**download_zipped_binary**](docs/BinariesApi.md#download_zipped_binary) | **GET** /v2/binaries/{binary_id}/download-zipped | Downloads a zipped binary with password protection
*BinariesApi* | [**get_binary_additional_details**](docs/BinariesApi.md#get_binary_additional_details) | **GET** /v2/binaries/{binary_id}/additional-details | Gets the additional details of a binary
*BinariesApi* | [**get_binary_additional_details_status**](docs/BinariesApi.md#get_binary_additional_details_status) | **GET** /v2/binaries/{binary_id}/additional-details/status | Gets the status of the additional details task for a binary
*BinariesApi* | [**get_binary_details**](docs/BinariesApi.md#get_binary_details) | **GET** /v2/binaries/{binary_id}/details | Gets the details of a binary
*BinariesApi* | [**get_binary_die_info**](docs/BinariesApi.md#get_binary_die_info) | **GET** /v2/binaries/{binary_id}/die-info | Gets the die info of a binary
*BinariesApi* | [**get_binary_externals**](docs/BinariesApi.md#get_binary_externals) | **GET** /v2/binaries/{binary_id}/externals | Gets the external details of a binary
*BinariesApi* | [**get_binary_related_status**](docs/BinariesApi.md#get_binary_related_status) | **GET** /v2/binaries/{binary_id}/related/status | Gets the status of the unpack binary task for a binary
*BinariesApi* | [**get_related_binaries**](docs/BinariesApi.md#get_related_binaries) | **GET** /v2/binaries/{binary_id}/related | Gets the related binaries of a binary.
*CollectionsApi* | [**create_collection**](docs/CollectionsApi.md#create_collection) | **POST** /v2/collections | Creates new collection information
*CollectionsApi* | [**delete_collection**](docs/CollectionsApi.md#delete_collection) | **DELETE** /v2/collections/{collection_id} | Deletes a collection
*CollectionsApi* | [**get_collection**](docs/CollectionsApi.md#get_collection) | **GET** /v2/collections/{collection_id} | Returns a collection
*CollectionsApi* | [**list_collections**](docs/CollectionsApi.md#list_collections) | **GET** /v2/collections | Gets basic collections information
*CollectionsApi* | [**update_collection**](docs/CollectionsApi.md#update_collection) | **PATCH** /v2/collections/{collection_id} | Updates a collection
*CollectionsApi* | [**update_collection_binaries**](docs/CollectionsApi.md#update_collection_binaries) | **PATCH** /v2/collections/{collection_id}/binaries | Updates a collection binaries
*CollectionsApi* | [**update_collection_tags**](docs/CollectionsApi.md#update_collection_tags) | **PATCH** /v2/collections/{collection_id}/tags | Updates a collection tags
*ConfigApi* | [**get_config**](docs/ConfigApi.md#get_config) | **GET** /v2/config | Get Config
*ExternalSourcesApi* | [**create_external_task_vt**](docs/ExternalSourcesApi.md#create_external_task_vt) | **POST** /v2/analysis/{analysis_id}/external/vt | Pulls data from VirusTotal
*ExternalSourcesApi* | [**get_vt_data**](docs/ExternalSourcesApi.md#get_vt_data) | **GET** /v2/analysis/{analysis_id}/external/vt | Get VirusTotal data
*ExternalSourcesApi* | [**get_vt_task_status**](docs/ExternalSourcesApi.md#get_vt_task_status) | **GET** /v2/analysis/{analysis_id}/external/vt/status | Check the status of VirusTotal data retrieval
*FirmwareApi* | [**get_binaries_for_firmware_task**](docs/FirmwareApi.md#get_binaries_for_firmware_task) | **GET** /v2/firmware/get-binaries/{task_id} | Upload firmware for unpacking
*FirmwareApi* | [**upload_firmware**](docs/FirmwareApi.md#upload_firmware) | **POST** /v2/firmware | Upload firmware for unpacking
*FunctionsAIDecompilationApi* | [**create_ai_decompilation_comment**](docs/FunctionsAIDecompilationApi.md#create_ai_decompilation_comment) | **POST** /v2/functions/{function_id}/ai-decompilation/comments | Create a comment for this function
*FunctionsAIDecompilationApi* | [**create_ai_decompilation_task**](docs/FunctionsAIDecompilationApi.md#create_ai_decompilation_task) | **POST** /v2/functions/{function_id}/ai-decompilation | Begins AI Decompilation Process
*FunctionsAIDecompilationApi* | [**delete_ai_decompilation_comment**](docs/FunctionsAIDecompilationApi.md#delete_ai_decompilation_comment) | **DELETE** /v2/functions/{function_id}/ai-decompilation/comments/{comment_id} | Delete a comment
*FunctionsAIDecompilationApi* | [**get_ai_decompilation_comments**](docs/FunctionsAIDecompilationApi.md#get_ai_decompilation_comments) | **GET** /v2/functions/{function_id}/ai-decompilation/comments | Get comments for this function
*FunctionsAIDecompilationApi* | [**get_ai_decompilation_rating**](docs/FunctionsAIDecompilationApi.md#get_ai_decompilation_rating) | **GET** /v2/functions/{function_id}/ai-decompilation/rating | Get rating for AI decompilation
*FunctionsAIDecompilationApi* | [**get_ai_decompilation_task_result**](docs/FunctionsAIDecompilationApi.md#get_ai_decompilation_task_result) | **GET** /v2/functions/{function_id}/ai-decompilation | Polls AI Decompilation Process
*FunctionsAIDecompilationApi* | [**get_ai_decompilation_task_status**](docs/FunctionsAIDecompilationApi.md#get_ai_decompilation_task_status) | **GET** /v2/functions/{function_id}/ai-decompilation/status | Check the status of a function ai decompilation
*FunctionsAIDecompilationApi* | [**update_ai_decompilation_comment**](docs/FunctionsAIDecompilationApi.md#update_ai_decompilation_comment) | **PATCH** /v2/functions/{function_id}/ai-decompilation/comments/{comment_id} | Update a comment
*FunctionsAIDecompilationApi* | [**upsert_ai_decompilation_rating**](docs/FunctionsAIDecompilationApi.md#upsert_ai_decompilation_rating) | **PATCH** /v2/functions/{function_id}/ai-decompilation/rating | Upsert rating for AI decompilation
*FunctionsBlockCommentsApi* | [**generate_block_comments_for_block_in_function**](docs/FunctionsBlockCommentsApi.md#generate_block_comments_for_block_in_function) | **POST** /v2/functions/{function_id}/block-comments/single | Generate block comments for a specific block in a function
*FunctionsBlockCommentsApi* | [**generate_block_comments_for_function**](docs/FunctionsBlockCommentsApi.md#generate_block_comments_for_function) | **POST** /v2/functions/{function_id}/block-comments | Generate block comments for a function
*FunctionsBlockCommentsApi* | [**generate_overview_comment_for_function**](docs/FunctionsBlockCommentsApi.md#generate_overview_comment_for_function) | **POST** /v2/functions/{function_id}/block-comments/overview | Generate overview comment for a function
*FunctionsCoreApi* | [**ai_unstrip**](docs/FunctionsCoreApi.md#ai_unstrip) | **POST** /v2/analyses/{analysis_id}/functions/ai-unstrip | Performs matching and auto-unstrip for an analysis and its functions
*FunctionsCoreApi* | [**analysis_function_matching**](docs/FunctionsCoreApi.md#analysis_function_matching) | **POST** /v2/analyses/{analysis_id}/functions/matches | Perform matching for the functions of an analysis
*FunctionsCoreApi* | [**auto_unstrip**](docs/FunctionsCoreApi.md#auto_unstrip) | **POST** /v2/analyses/{analysis_id}/functions/auto-unstrip | Performs matching and auto-unstrip for an analysis and its functions
*FunctionsCoreApi* | [**batch_function_matching**](docs/FunctionsCoreApi.md#batch_function_matching) | **POST** /v2/functions/matches | Perform function matching for an arbitrary batch of functions, binaries or collections
*FunctionsCoreApi* | [**cancel_ai_unstrip**](docs/FunctionsCoreApi.md#cancel_ai_unstrip) | **DELETE** /v2/analyses/{analysis_id}/functions/ai-unstrip/cancel | Cancels a running ai-unstrip
*FunctionsCoreApi* | [**cancel_auto_unstrip**](docs/FunctionsCoreApi.md#cancel_auto_unstrip) | **DELETE** /v2/analyses/{analysis_id}/functions/unstrip/cancel | Cancels a running auto-unstrip
*FunctionsCoreApi* | [**get_analysis_strings**](docs/FunctionsCoreApi.md#get_analysis_strings) | **GET** /v2/analyses/{analysis_id}/functions/strings | Get string information found in the Analysis
*FunctionsCoreApi* | [**get_analysis_strings_status**](docs/FunctionsCoreApi.md#get_analysis_strings_status) | **GET** /v2/analyses/{analysis_id}/functions/strings/status | Get string processing state for the Analysis
*FunctionsCoreApi* | [**get_function_blocks**](docs/FunctionsCoreApi.md#get_function_blocks) | **GET** /v2/functions/{function_id}/blocks | Get disassembly blocks related to the function
*FunctionsCoreApi* | [**get_function_callees_callers**](docs/FunctionsCoreApi.md#get_function_callees_callers) | **GET** /v2/functions/{function_id}/callees_callers | Get list of functions that call or are called by the specified function
*FunctionsCoreApi* | [**get_function_capabilities**](docs/FunctionsCoreApi.md#get_function_capabilities) | **GET** /v2/functions/{function_id}/capabilities | Retrieve a functions capabilities
*FunctionsCoreApi* | [**get_function_details**](docs/FunctionsCoreApi.md#get_function_details) | **GET** /v2/functions/{function_id} | Get function details
*FunctionsCoreApi* | [**get_function_strings**](docs/FunctionsCoreApi.md#get_function_strings) | **GET** /v2/functions/{function_id}/strings | Get string information found in the function
*FunctionsDataTypesApi* | [**generate_function_data_types_for_analysis**](docs/FunctionsDataTypesApi.md#generate_function_data_types_for_analysis) | **POST** /v2/analyses/{analysis_id}/functions/data_types | Generate Function Data Types
*FunctionsDataTypesApi* | [**generate_function_data_types_for_functions**](docs/FunctionsDataTypesApi.md#generate_function_data_types_for_functions) | **POST** /v2/functions/data_types | Generate Function Data Types for an arbitrary list of functions
*FunctionsDataTypesApi* | [**get_function_data_types**](docs/FunctionsDataTypesApi.md#get_function_data_types) | **GET** /v2/analyses/{analysis_id}/functions/{function_id}/data_types | Get Function Data Types
*FunctionsDataTypesApi* | [**list_function_data_types_for_analysis**](docs/FunctionsDataTypesApi.md#list_function_data_types_for_analysis) | **GET** /v2/analyses/{analysis_id}/functions/data_types | List Function Data Types
*FunctionsDataTypesApi* | [**list_function_data_types_for_functions**](docs/FunctionsDataTypesApi.md#list_function_data_types_for_functions) | **GET** /v2/functions/data_types | List Function Data Types
*FunctionsDataTypesApi* | [**update_function_data_types**](docs/FunctionsDataTypesApi.md#update_function_data_types) | **PUT** /v2/analyses/{analysis_id}/functions/{function_id}/data_types | Update Function Data Types
*FunctionsDecompilationApi* | [**create_decompilation_comment**](docs/FunctionsDecompilationApi.md#create_decompilation_comment) | **POST** /v2/functions/{function_id}/decompilation/comments | Create a comment for this function
*FunctionsDecompilationApi* | [**delete_decompilation_comment**](docs/FunctionsDecompilationApi.md#delete_decompilation_comment) | **DELETE** /v2/functions/{function_id}/decompilation/comments/{comment_id} | Delete a comment
*FunctionsDecompilationApi* | [**get_decompilation_comments**](docs/FunctionsDecompilationApi.md#get_decompilation_comments) | **GET** /v2/functions/{function_id}/decompilation/comments | Get comments for this function
*FunctionsDecompilationApi* | [**update_decompilation_comment**](docs/FunctionsDecompilationApi.md#update_decompilation_comment) | **PATCH** /v2/functions/{function_id}/decompilation/comments/{comment_id} | Update a comment
*FunctionsRenamingHistoryApi* | [**batch_rename_function**](docs/FunctionsRenamingHistoryApi.md#batch_rename_function) | **POST** /v2/functions/rename/batch | Batch Rename Functions
*FunctionsRenamingHistoryApi* | [**get_function_name_history**](docs/FunctionsRenamingHistoryApi.md#get_function_name_history) | **GET** /v2/functions/history/{function_id} | Get Function Name History
*FunctionsRenamingHistoryApi* | [**rename_function_id**](docs/FunctionsRenamingHistoryApi.md#rename_function_id) | **POST** /v2/functions/rename/{function_id} | Rename Function
*FunctionsRenamingHistoryApi* | [**revert_function_name**](docs/FunctionsRenamingHistoryApi.md#revert_function_name) | **POST** /v2/functions/history/{function_id}/{history_id} | Revert the function name
*ModelsApi* | [**get_models**](docs/ModelsApi.md#get_models) | **GET** /v2/models | Gets models
*SearchApi* | [**search_binaries**](docs/SearchApi.md#search_binaries) | **GET** /v2/search/binaries | Binaries search
*SearchApi* | [**search_collections**](docs/SearchApi.md#search_collections) | **GET** /v2/search/collections | Collections search
*SearchApi* | [**search_functions**](docs/SearchApi.md#search_functions) | **GET** /v2/search/functions | Functions search
*SearchApi* | [**search_tags**](docs/SearchApi.md#search_tags) | **GET** /v2/search/tags | Tags search
## Documentation For Models
- [AdditionalDetailsStatusResponse](docs/AdditionalDetailsStatusResponse.md)
- [Addr](docs/Addr.md)
- [AiDecompilationRating](docs/AiDecompilationRating.md)
- [AiUnstripRequest](docs/AiUnstripRequest.md)
- [AnalysisAccessInfo](docs/AnalysisAccessInfo.md)
- [AnalysisConfig](docs/AnalysisConfig.md)
- [AnalysisCreateRequest](docs/AnalysisCreateRequest.md)
- [AnalysisCreateResponse](docs/AnalysisCreateResponse.md)
- [AnalysisDetailResponse](docs/AnalysisDetailResponse.md)
- [AnalysisFunctionMapping](docs/AnalysisFunctionMapping.md)
- [AnalysisFunctionMatchingRequest](docs/AnalysisFunctionMatchingRequest.md)
- [AnalysisFunctions](docs/AnalysisFunctions.md)
- [AnalysisFunctionsList](docs/AnalysisFunctionsList.md)
- [AnalysisRecord](docs/AnalysisRecord.md)
- [AnalysisScope](docs/AnalysisScope.md)
- [AnalysisStringsResponse](docs/AnalysisStringsResponse.md)
- [AnalysisStringsStatusResponse](docs/AnalysisStringsStatusResponse.md)
- [AnalysisTags](docs/AnalysisTags.md)
- [AnalysisUpdateRequest](docs/AnalysisUpdateRequest.md)
- [AnalysisUpdateTagsRequest](docs/AnalysisUpdateTagsRequest.md)
- [AnalysisUpdateTagsResponse](docs/AnalysisUpdateTagsResponse.md)
- [AppApiRestV2AnalysesEnumsDynamicExecutionStatus](docs/AppApiRestV2AnalysesEnumsDynamicExecutionStatus.md)
- [AppApiRestV2AnalysesEnumsOrderBy](docs/AppApiRestV2AnalysesEnumsOrderBy.md)
- [AppApiRestV2CollectionsEnumsOrderBy](docs/AppApiRestV2CollectionsEnumsOrderBy.md)
- [AppApiRestV2FunctionsResponsesFunction](docs/AppApiRestV2FunctionsResponsesFunction.md)
- [AppApiRestV2FunctionsTypesFunction](docs/AppApiRestV2FunctionsTypesFunction.md)
- [AppServicesDynamicExecutionSchemasDynamicExecutionStatus](docs/AppServicesDynamicExecutionSchemasDynamicExecutionStatus.md)
- [Argument](docs/Argument.md)
- [AutoUnstripRequest](docs/AutoUnstripRequest.md)
- [AutoUnstripResponse](docs/AutoUnstripResponse.md)
- [BaseResponse](docs/BaseResponse.md)
- [BaseResponseAdditionalDetailsStatusResponse](docs/BaseResponseAdditionalDetailsStatusResponse.md)
- [BaseResponseAnalysisCreateResponse](docs/BaseResponseAnalysisCreateResponse.md)
- [BaseResponseAnalysisDetailResponse](docs/BaseResponseAnalysisDetailResponse.md)
- [BaseResponseAnalysisFunctionMapping](docs/BaseResponseAnalysisFunctionMapping.md)
- [BaseResponseAnalysisFunctions](docs/BaseResponseAnalysisFunctions.md)
- [BaseResponseAnalysisFunctionsList](docs/BaseResponseAnalysisFunctionsList.md)
- [BaseResponseAnalysisStringsResponse](docs/BaseResponseAnalysisStringsResponse.md)
- [BaseResponseAnalysisStringsStatusResponse](docs/BaseResponseAnalysisStringsStatusResponse.md)
- [BaseResponseAnalysisTags](docs/BaseResponseAnalysisTags.md)
- [BaseResponseAnalysisUpdateTagsResponse](docs/BaseResponseAnalysisUpdateTagsResponse.md)
- [BaseResponseBasic](docs/BaseResponseBasic.md)
- [BaseResponseBinariesRelatedStatusResponse](docs/BaseResponseBinariesRelatedStatusResponse.md)
- [BaseResponseBinaryAdditionalResponse](docs/BaseResponseBinaryAdditionalResponse.md)
- [BaseResponseBinaryDetailsResponse](docs/BaseResponseBinaryDetailsResponse.md)
- [BaseResponseBinaryExternalsResponse](docs/BaseResponseBinaryExternalsResponse.md)
- [BaseResponseBinarySearchResponse](docs/BaseResponseBinarySearchResponse.md)
- [BaseResponseBlockCommentsGenerationForFunctionResponse](docs/BaseResponseBlockCommentsGenerationForFunctionResponse.md)
- [BaseResponseBlockCommentsOverviewGenerationResponse](docs/BaseResponseBlockCommentsOverviewGenerationResponse.md)
- [BaseResponseBool](docs/BaseResponseBool.md)
- [BaseResponseCalleesCallerFunctionsResponse](docs/BaseResponseCalleesCallerFunctionsResponse.md)
- [BaseResponseCapabilities](docs/BaseResponseCapabilities.md)
- [BaseResponseCheckSecurityChecksTaskResponse](docs/BaseResponseCheckSecurityChecksTaskResponse.md)
- [BaseResponseChildBinariesResponse](docs/BaseResponseChildBinariesResponse.md)
- [BaseResponseCollectionBinariesUpdateResponse](docs/BaseResponseCollectionBinariesUpdateResponse.md)
- [BaseResponseCollectionResponse](docs/BaseResponseCollectionResponse.md)
- [BaseResponseCollectionSearchResponse](docs/BaseResponseCollectionSearchResponse.md)
- [BaseResponseCollectionTagsUpdateResponse](docs/BaseResponseCollectionTagsUpdateResponse.md)
- [BaseResponseCommentResponse](docs/BaseResponseCommentResponse.md)
- [BaseResponseCommunities](docs/BaseResponseCommunities.md)
- [BaseResponseConfigResponse](docs/BaseResponseConfigResponse.md)
- [BaseResponseCreated](docs/BaseResponseCreated.md)
- [BaseResponseDict](docs/BaseResponseDict.md)
- [BaseResponseDynamicExecutionStatus](docs/BaseResponseDynamicExecutionStatus.md)
- [BaseResponseExternalResponse](docs/BaseResponseExternalResponse.md)
- [BaseResponseFunctionBlocksResponse](docs/BaseResponseFunctionBlocksResponse.md)
- [BaseResponseFunctionCapabilityResponse](docs/BaseResponseFunctionCapabilityResponse.md)
- [BaseResponseFunctionDataTypes](docs/BaseResponseFunctionDataTypes.md)
- [BaseResponseFunctionDataTypesList](docs/BaseResponseFunctionDataTypesList.md)
- [BaseResponseFunctionSearchResponse](docs/BaseResponseFunctionSearchResponse.md)
- [BaseResponseFunctionStringsResponse](docs/BaseResponseFunctionStringsResponse.md)
- [BaseResponseFunctionTaskResponse](docs/BaseResponseFunctionTaskResponse.md)
- [BaseResponseFunctionsDetailResponse](docs/BaseResponseFunctionsDetailResponse.md)
- [BaseResponseGenerateFunctionDataTypes](docs/BaseResponseGenerateFunctionDataTypes.md)
- [BaseResponseGenerationStatusList](docs/BaseResponseGenerationStatusList.md)
- [BaseResponseGetAiDecompilationRatingResponse](docs/BaseResponseGetAiDecompilationRatingResponse.md)
- [BaseResponseGetAiDecompilationTask](docs/BaseResponseGetAiDecompilationTask.md)
- [BaseResponseGetMeResponse](docs/BaseResponseGetMeResponse.md)
- [BaseResponseGetPublicUserResponse](docs/BaseResponseGetPublicUserResponse.md)
- [BaseResponseListCollectionResults](docs/BaseResponseListCollectionResults.md)
- [BaseResponseListCommentResponse](docs/BaseResponseListCommentResponse.md)
- [BaseResponseListDieMatch](docs/BaseResponseListDieMatch.md)
- [BaseResponseListFunctionNameHistory](docs/BaseResponseListFunctionNameHistory.md)
- [BaseResponseListSBOM](docs/BaseResponseListSBOM.md)
- [BaseResponseListUserActivityResponse](docs/BaseResponseListUserActivityResponse.md)
- [BaseResponseLoginResponse](docs/BaseResponseLoginResponse.md)
- [BaseResponseLogs](docs/BaseResponseLogs.md)
- [BaseResponseModelsResponse](docs/BaseResponseModelsResponse.md)
- [BaseResponseNetworkOverviewResponse](docs/BaseResponseNetworkOverviewResponse.md)
- [BaseResponseParams](docs/BaseResponseParams.md)
- [BaseResponseProcessDumps](docs/BaseResponseProcessDumps.md)
- [BaseResponseProcessRegistry](docs/BaseResponseProcessRegistry.md)
- [BaseResponseProcessTree](docs/BaseResponseProcessTree.md)
- [BaseResponseQueuedSecurityChecksTaskResponse](docs/BaseResponseQueuedSecurityChecksTaskResponse.md)
- [BaseResponseRecent](docs/BaseResponseRecent.md)
- [BaseResponseSecurityChecksResponse](docs/BaseResponseSecurityChecksResponse.md)
- [BaseResponseStatus](docs/BaseResponseStatus.md)
- [BaseResponseStr](docs/BaseResponseStr.md)
- [BaseResponseTTPS](docs/BaseResponseTTPS.md)
- [BaseResponseTagSearchResponse](docs/BaseResponseTagSearchResponse.md)
- [BaseResponseTaskResponse](docs/BaseResponseTaskResponse.md)
- [BaseResponseUploadResponse](docs/BaseResponseUploadResponse.md)
- [BaseResponseVulnerabilities](docs/BaseResponseVulnerabilities.md)
- [Basic](docs/Basic.md)
- [BinariesRelatedStatusResponse](docs/BinariesRelatedStatusResponse.md)
- [BinariesTaskStatus](docs/BinariesTaskStatus.md)
- [BinaryAdditionalDetailsDataResponse](docs/BinaryAdditionalDetailsDataResponse.md)
- [BinaryAdditionalResponse](docs/BinaryAdditionalResponse.md)
- [BinaryConfig](docs/BinaryConfig.md)
- [BinaryDetailsResponse](docs/BinaryDetailsResponse.md)
- [BinaryExternalsResponse](docs/BinaryExternalsResponse.md)
- [BinarySearchResponse](docs/BinarySearchResponse.md)
- [BinarySearchResult](docs/BinarySearchResult.md)
- [BinaryTaskStatus](docs/BinaryTaskStatus.md)
- [Block](docs/Block.md)
- [BlockCommentsGenerationForFunctionResponse](docs/BlockCommentsGenerationForFunctionResponse.md)
- [CalleeFunctionInfo](docs/CalleeFunctionInfo.md)
- [CalleesCallerFunctionsResponse](docs/CalleesCallerFunctionsResponse.md)
- [CallerFunctionInfo](docs/CallerFunctionInfo.md)
- [Capabilities](docs/Capabilities.md)
- [Capability](docs/Capability.md)
- [CheckSecurityChecksTaskResponse](docs/CheckSecurityChecksTaskResponse.md)
- [ChildBinariesResponse](docs/ChildBinariesResponse.md)
- [CodeSignatureModel](docs/CodeSignatureModel.md)
- [CollectionBinariesUpdateRequest](docs/CollectionBinariesUpdateRequest.md)
- [CollectionBinariesUpdateResponse](docs/CollectionBinariesUpdateResponse.md)
- [CollectionBinaryResponse](docs/CollectionBinaryResponse.md)
- [CollectionCreateRequest](docs/CollectionCreateRequest.md)
- [CollectionListItem](docs/CollectionListItem.md)
- [CollectionResponse](docs/CollectionResponse.md)
- [CollectionResponseBinariesInner](docs/CollectionResponseBinariesInner.md)
- [CollectionScope](docs/CollectionScope.md)
- [CollectionSearchResponse](docs/CollectionSearchResponse.md)
- [CollectionSearchResult](docs/CollectionSearchResult.md)
- [CollectionTagsUpdateRequest](docs/CollectionTagsUpdateRequest.md)
- [CollectionTagsUpdateResponse](docs/CollectionTagsUpdateResponse.md)
- [CollectionUpdateRequest](docs/CollectionUpdateRequest.md)
- [CommentBase](docs/CommentBase.md)
- [CommentResponse](docs/CommentResponse.md)
- [CommentUpdateRequest](docs/CommentUpdateRequest.md)
- [Communities](docs/Communities.md)
- [CommunityMatchPercentages](docs/CommunityMatchPercentages.md)
- [ConfidenceType](docs/ConfidenceType.md)
- [ConfigResponse](docs/ConfigResponse.md)
- [Context](docs/Context.md)
- [Created](docs/Created.md)
- [DecompilationCommentContext](docs/DecompilationCommentContext.md)
- [DieMatch](docs/DieMatch.md)
- [DynamicExecutionStatusInput](docs/DynamicExecutionStatusInput.md)
- [ELFImportModel](docs/ELFImportModel.md)
- [ELFModel](docs/ELFModel.md)
- [ELFRelocation](docs/ELFRelocation.md)
- [ELFSection](docs/ELFSection.md)
- [ELFSecurity](docs/ELFSecurity.md)
- [ELFSegment](docs/ELFSegment.md)
- [ELFSymbol](docs/ELFSymbol.md)
- [ElfDynamicEntry](docs/ElfDynamicEntry.md)
- [EntrypointModel](docs/EntrypointModel.md)
- [Enumeration](docs/Enumeration.md)
- [ErrorModel](docs/ErrorModel.md)
- [ExportModel](docs/ExportModel.md)
- [ExternalResponse](docs/ExternalResponse.md)
- [FileFormat](docs/FileFormat.md)
- [FileHashes](docs/FileHashes.md)
- [FileMetadata](docs/FileMetadata.md)
- [Filters](docs/Filters.md)
- [FunctionBlockDestinationResponse](docs/FunctionBlockDestinationResponse.md)
- [FunctionBlockResponse](docs/FunctionBlockResponse.md)
- [FunctionBlocksResponse](docs/FunctionBlocksResponse.md)
- [FunctionBoundary](docs/FunctionBoundary.md)
- [FunctionCapabilityResponse](docs/FunctionCapabilityResponse.md)
- [FunctionCommentCreateRequest](docs/FunctionCommentCreateRequest.md)
- [FunctionDataTypes](docs/FunctionDataTypes.md)
- [FunctionDataTypesList](docs/FunctionDataTypesList.md)
- [FunctionDataTypesListItem](docs/FunctionDataTypesListItem.md)
- [FunctionDataTypesParams](docs/FunctionDataTypesParams.md)
- [FunctionDataTypesStatus](docs/FunctionDataTypesStatus.md)
- [FunctionHeader](docs/FunctionHeader.md)
- [FunctionInfoInput](docs/FunctionInfoInput.md)
- [FunctionInfoInputFuncDepsInner](docs/FunctionInfoInputFuncDepsInner.md)
- [FunctionInfoOutput](docs/FunctionInfoOutput.md)
- [FunctionListItem](docs/FunctionListItem.md)
- [FunctionLocalVariableResponse](docs/FunctionLocalVariableResponse.md)
- [FunctionMapping](docs/FunctionMapping.md)
- [FunctionMappingFull](docs/FunctionMappingFull.md)
- [FunctionMatch](docs/FunctionMatch.md)
- [FunctionMatchingFilters](docs/FunctionMatchingFilters.md)
- [FunctionMatchingRequest](docs/FunctionMatchingRequest.md)
- [FunctionMatchingResponse](docs/FunctionMatchingResponse.md)
- [FunctionNameHistory](docs/FunctionNameHistory.md)
- [FunctionParamResponse](docs/FunctionParamResponse.md)
- [FunctionRename](docs/FunctionRename.md)
- [FunctionRenameMap](docs/FunctionRenameMap.md)
- [FunctionSearchResponse](docs/FunctionSearchResponse.md)
- [FunctionSearchResult](docs/FunctionSearchResult.md)
- [FunctionSourceType](docs/FunctionSourceType.md)
- [FunctionString](docs/FunctionString.md)
- [FunctionStringsResponse](docs/FunctionStringsResponse.md)
- [FunctionTaskResponse](docs/FunctionTaskResponse.md)
- [FunctionTaskStatus](docs/FunctionTaskStatus.md)
- [FunctionTypeInput](docs/FunctionTypeInput.md)
- [FunctionTypeOutput](docs/FunctionTypeOutput.md)
- [FunctionsDetailResponse](docs/FunctionsDetailResponse.md)
- [FunctionsListRename](docs/FunctionsListRename.md)
- [GenerateFunctionDataTypes](docs/GenerateFunctionDataTypes.md)
- [GenerationStatusList](docs/GenerationStatusList.md)
- [GetAiDecompilationRatingResponse](docs/GetAiDecompilationRatingResponse.md)
- [GetAiDecompilationTask](docs/GetAiDecompilationTask.md)
- [GetMeResponse](docs/GetMeResponse.md)
- [GetPublicUserResponse](docs/GetPublicUserResponse.md)
- [GlobalVariable](docs/GlobalVariable.md)
- [ISA](docs/ISA.md)
- [IconModel](docs/IconModel.md)
- [ImportModel](docs/ImportModel.md)
- [InsertAnalysisLogRequest](docs/InsertAnalysisLogRequest.md)
- [InverseFunctionMapItem](docs/InverseFunctionMapItem.md)
- [InverseStringMapItem](docs/InverseStringMapItem.md)
- [InverseValue](docs/InverseValue.md)
- [ListCollectionResults](docs/ListCollectionResults.md)
- [LoginRequest](docs/LoginRequest.md)
- [LoginResponse](docs/LoginResponse.md)
- [Logs](docs/Logs.md)
- [MatchedFunction](docs/MatchedFunction.md)
- [MatchedFunctionSuggestion](docs/MatchedFunctionSuggestion.md)
- [MetaModel](docs/MetaModel.md)
- [ModelName](docs/ModelName.md)
- [ModelsResponse](docs/ModelsResponse.md)
- [NameConfidence](docs/NameConfidence.md)
- [NameSourceType](docs/NameSourceType.md)
- [NetworkOverviewDns](docs/NetworkOverviewDns.md)
- [NetworkOverviewDnsAnswer](docs/NetworkOverviewDnsAnswer.md)
- [NetworkOverviewMetadata](docs/NetworkOverviewMetadata.md)
- [NetworkOverviewResponse](docs/NetworkOverviewResponse.md)
- [Order](docs/Order.md)
- [PDBDebugModel](docs/PDBDebugModel.md)
- [PEModel](docs/PEModel.md)
- [PaginationModel](docs/PaginationModel.md)
- [Params](docs/Params.md)
- [Platform](docs/Platform.md)
- [Process](docs/Process.md)
- [ProcessDump](docs/ProcessDump.md)
- [ProcessDumpMetadata](docs/ProcessDumpMetadata.md)
- [ProcessDumps](docs/ProcessDumps.md)
- [ProcessDumpsData](docs/ProcessDumpsData.md)
- [ProcessRegistry](docs/ProcessRegistry.md)
- [ProcessTree](docs/ProcessTree.md)
- [QueuedSecurityChecksTaskResponse](docs/QueuedSecurityChecksTaskResponse.md)
- [ReAnalysisForm](docs/ReAnalysisForm.md)
- [Recent](docs/Recent.md)
- [Registry](docs/Registry.md)
- [RelativeBinaryResponse](docs/RelativeBinaryResponse.md)
- [SBOM](docs/SBOM.md)
- [SBOMPackage](docs/SBOMPackage.md)
- [SandboxOptions](docs/SandboxOptions.md)
- [ScrapeThirdPartyConfig](docs/ScrapeThirdPartyConfig.md)
- [SectionModel](docs/SectionModel.md)
- [SecurityChecksResponse](docs/SecurityChecksResponse.md)
- [SecurityChecksResult](docs/SecurityChecksResult.md)
- [SecurityModel](docs/SecurityModel.md)
- [SeverityType](docs/SeverityType.md)
- [SingleCodeCertificateModel](docs/SingleCodeCertificateModel.md)
- [SingleCodeSignatureModel](docs/SingleCodeSignatureModel.md)
- [SinglePDBEntryModel](docs/SinglePDBEntryModel.md)
- [SingleSectionModel](docs/SingleSectionModel.md)
- [StackVariable](docs/StackVariable.md)
- [StatusInput](docs/StatusInput.md)
- [StatusOutput](docs/StatusOutput.md)
- [StringFunctions](docs/StringFunctions.md)
- [Structure](docs/Structure.md)
- [StructureMember](docs/StructureMember.md)
- [Symbols](docs/Symbols.md)
- [TTPS](docs/TTPS.md)
- [TTPSAttack](docs/TTPSAttack.md)
- [TTPSData](docs/TTPSData.md)
- [TTPSElement](docs/TTPSElement.md)
- [TTPSOccurance](docs/TTPSOccurance.md)
- [Tag](docs/Tag.md)
- [TagItem](docs/TagItem.md)
- [TagResponse](docs/TagResponse.md)
- [TagSearchResponse](docs/TagSearchResponse.md)
- [TagSearchResult](docs/TagSearchResult.md)
- [TaskResponse](docs/TaskResponse.md)
- [TaskStatus](docs/TaskStatus.md)
- [TimestampModel](docs/TimestampModel.md)
- [TypeDefinition](docs/TypeDefinition.md)
- [UpdateFunctionDataTypes](docs/UpdateFunctionDataTypes.md)
- [UploadFileType](docs/UploadFileType.md)
- [UploadResponse](docs/UploadResponse.md)
- [UpsertAiDecomplationRatingRequest](docs/UpsertAiDecomplationRatingRequest.md)
- [UserActivityResponse](docs/UserActivityResponse.md)
- [Vulnerabilities](docs/Vulnerabilities.md)
- [Vulnerability](docs/Vulnerability.md)
- [VulnerabilityType](docs/VulnerabilityType.md)
- [Workspace](docs/Workspace.md)
| text/markdown | null | null | null | null | null | RevEng.AI API | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"lazy-imports<2,>=1",
"pydantic>=2",
"python-dateutil>=2.8.2",
"typing-extensions>=4.7.1",
"urllib3<3.0.0,>=2.1.0"
] | [] | [] | [] | [
"Repository, https://github.com/RevEngAI/sdk-python"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T13:06:20.530335 | revengai-3.15.1.tar.gz | 273,972 | fb/9a/9f1791b67d6fa8aed8c216d14f5e850f8409ff0ccb51719eabc164b6db7e/revengai-3.15.1.tar.gz | source | sdist | null | false | 41b24a2e1e2434c344be864fdcbf0294 | a76ae62b29314435db7c36297f4328dc99d528e0b934cb6daf2fb775fe63d478 | fb9a9f1791b67d6fa8aed8c216d14f5e850f8409ff0ccb51719eabc164b6db7e | MIT | [
"LICENSE.md"
] | 249 |
2.4 | s3torchconnectorclient | 1.5.0 | Internal S3 client implementation for s3torchconnector | # Amazon S3 Connector for PyTorch
The Amazon S3 Connector for PyTorch delivers high throughput for PyTorch training jobs that access or store data in
Amazon S3. Using the S3 Connector for PyTorch
automatically optimizes performance when downloading training data from and writing checkpoints to Amazon S3,
eliminating the need to write your own code to list S3 buckets and manage concurrent requests.
Amazon S3 Connector for PyTorch provides implementations of PyTorch's
[dataset primitives](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html) that you can use to load
training data from Amazon S3.
It supports both [map-style datasets](https://pytorch.org/docs/stable/data.html#map-style-datasets) for random data
access patterns and [iterable-style datasets](https://pytorch.org/docs/stable/data.html#iterable-style-datasets) for
streaming sequential data access patterns.
The S3 Connector for PyTorch also includes a checkpointing interface to save and load checkpoints directly to
Amazon S3, without first saving to local storage.
## Getting Started
### Prerequisites
- Python 3.8-3.14 is supported.
- Note: Python 3.8 support will be deprecated in a future release, see [#399](https://github.com/awslabs/s3-connector-for-pytorch/issues/399)
- PyTorch >= 2.0 (TODO: Check with PyTorch 1.x)
### Installation
```shell
pip install s3torchconnector
```
Amazon S3 Connector for PyTorch supports pre-built wheels via Pip only for Linux and MacOS for now.
(Note: macOS x86_64 wheel support will be deprecated in a future release, see [#398](https://github.com/awslabs/s3-connector-for-pytorch/issues/398))
For other platforms, see [DEVELOPMENT](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/DEVELOPMENT.md) for build instructions.
### Configuration
To use `s3torchconnector`, AWS credentials must be provided through one of the following methods:
- **EC2 Instance Role**: If you are using this library on an EC2 instance, specify an IAM role and then give the EC2 instance access to that role.
- **AWS CLI**: Install and configure [`awscli`](https://aws.amazon.com/cli/) and run `aws configure`.
- **AWS Credential Files**: Set credentials in the AWS credentials profile file on the local system, located at: `~/.aws/credentials` on Unix or macOS.
- **Environment Variables**: Set the `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment variables.
To use a specific AWS profile configured in `~/.aws/config` and `~/.aws/credentials`, you can either:
- Set environment variable `AWS_PROFILE=custom-profile`, or
- Pass the profile name to the `S3ClientConfig` object, e.g. `S3ClientConfig(profile="custom-profile")`.
For a more detailed configuration guide, see [AWS CLI docs](https://docs.aws.amazon.com/cli/v1/userguide/cli-configure-files.html).
### Examples
[API docs](http://awslabs.github.io/s3-connector-for-pytorch) are showing API of the public components.
End to end example of how to use `s3torchconnector` can be found under the [examples](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/examples) directory.
#### Sample Examples
The simplest way to use the S3 Connector for PyTorch is to construct a dataset, either a map-style or iterable-style
dataset, by specifying an S3 URI (a bucket and optional prefix) and the region the bucket is located in:
```py
from s3torchconnector import S3MapDataset, S3IterableDataset
# You need to update <BUCKET> and <PREFIX>
DATASET_URI="s3://<BUCKET>/<PREFIX>"
REGION = "us-east-1"
iterable_dataset = S3IterableDataset.from_prefix(DATASET_URI, region=REGION)
# Datasets are also iterators.
for item in iterable_dataset:
print(item.key)
# S3MapDataset eagerly lists all the objects under the given prefix
# to provide support of random access.
# S3MapDataset builds a list of all objects at the first access to its elements or
# at the first call to get the number of elements, whichever happens first.
# This process might take some time and may give the impression of being unresponsive.
map_dataset = S3MapDataset.from_prefix(DATASET_URI, region=REGION)
# Randomly access an item in map_dataset.
item = map_dataset[0]
# Learn about bucket, key, and content of the object
bucket = item.bucket
key = item.key
content = item.read()
len(content)
```
In addition to data loading primitives, the S3 Connector for PyTorch also provides an interface for saving and loading
model checkpoints directly to and from an S3 bucket.
```py
from s3torchconnector import S3Checkpoint
import torchvision
import torch
CHECKPOINT_URI="s3://<BUCKET>/<KEY>/"
REGION = "us-east-1"
checkpoint = S3Checkpoint(region=REGION)
model = torchvision.models.resnet18()
# Save checkpoint to S3
with checkpoint.writer(CHECKPOINT_URI + "epoch0.ckpt") as writer:
torch.save(model.state_dict(), writer)
# Load checkpoint from S3
with checkpoint.reader(CHECKPOINT_URI + "epoch0.ckpt") as reader:
state_dict = torch.load(reader)
model.load_state_dict(state_dict)
```
Using datasets or checkpoints with
[Amazon S3 Express One Zone](https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-express-one-zone.html)
directory buckets requires only to update the URI, following `base-name--azid--x-s3` bucket name format.
For example, assuming the following directory bucket name `my-test-bucket--usw2-az1--x-s3` with the Availability Zone ID
usw2-az1, then the URI used will look like: `s3://my-test-bucket--usw2-az1--x-s3/<PREFIX>` (**please note that the
prefix for Amazon S3 Express One Zone should end with '/'**), paired with region us-west-2.
## Distributed checkpoints
### Overview
Amazon S3 Connector for PyTorch provides robust support for PyTorch distributed checkpoints. This feature includes:
- `S3StorageWriter`: Implementation of PyTorch's StorageWriter interface.
- `S3StorageReader`: Implementation of PyTorch's StorageReader interface.
- Supports configurable reading strategies via the `reader_constructor` parameter (see [Reader Configurations](#reader-configurations)).
- Uses `DCPOptimizedS3Reader` by default for faster loading and partial checkpoint optimizations.
- Please refer to [DCPOptimizedS3Reader Errors](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/docs/TROUBLESHOOTING.md#dcpoptimizeds3reader-errors) for troubleshooting.
- `S3FileSystem`: An implementation of PyTorch's FileSystemBase.
These tools enable seamless integration of Amazon S3 with
[PyTorch Distributed Checkpoints](https://pytorch.org/docs/stable/distributed.checkpoint.html),
allowing efficient storage and retrieval of distributed model checkpoints.
### Prerequisites and Installation
PyTorch 2.3 or newer is required.
To use the distributed checkpoints feature, install S3 Connector for PyTorch with the `dcp` extra:
```sh
pip install s3torchconnector[dcp]
```
### Sample Example
End-to-end examples for using distributed checkpoints with S3 Connector for PyTorch
can be found in the [examples/dcp](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/examples/dcp) directory.
```py
from s3torchconnector.dcp import S3StorageWriter, S3StorageReader
import torchvision
import torch.distributed.checkpoint as DCP
# Configuration
CHECKPOINT_URI = "s3://<BUCKET>/<KEY>/"
REGION = "us-east-1"
model = torchvision.models.resnet18()
# Save distributed checkpoint to S3
s3_storage_writer = S3StorageWriter(
region=REGION,
path=CHECKPOINT_URI,
thread_count=8, # optional; number of IO threads to use to write
)
DCP.save(
state_dict=model.state_dict(),
storage_writer=s3_storage_writer,
)
# Load distributed checkpoint from S3
# S3StorageReader uses DCPOptimizedS3Reader by default for improved performance
model = torchvision.models.resnet18()
model_state_dict = model.state_dict()
s3_storage_reader = S3StorageReader(
region=REGION,
path=CHECKPOINT_URI,
)
DCP.load(
state_dict=model_state_dict,
storage_reader=s3_storage_reader,
)
model.load_state_dict(model_state_dict)
```
## S3 Prefix Strategies for Distributed Checkpointing
S3StorageWriter implements various prefix strategies to optimize checkpoint organization in S3 buckets.
These strategies are specifically designed to prevent throttling (503 Slow Down errors) in high-throughput scenarios
by implementing S3 key naming best practices as outlined in
[Best practices design patterns: optimizing Amazon S3 performance](https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance.html).
When many distributed training processes write checkpoints simultaneously, the prefixing strategies help distribute
the load across multiple S3 partitions.
### Available Strategies
#### 1. RoundRobinPrefixStrategy
Distributes checkpoints across specified prefixes in a round-robin fashion, ideal for balancing data across multiple storage locations.
```py
from s3torchconnector.dcp import RoundRobinPrefixStrategy, S3StorageWriter
model = torchvision.models.resnet18()
# Initialize with multiple prefixes and optional epoch tracking
strategy = RoundRobinPrefixStrategy(
user_prefixes=["shard1", "shard2", "shard3"],
epoch_num=5 # Optional: for checkpoint versioning
)
writer = S3StorageWriter(
region=REGION,
path="CHECKPOINT_URI",
prefix_strategy=strategy
)
# Save checkpoint
DCP.save(
state_dict=model.state_dict(),
storage_writer=writer
)
```
Output Structure:
```
CHECKPOINT_URI
├── shard1/
│ └── epoch_5/
│ ├── __0_0.distcp
│ ├── __3_0.distcp
│ └── ...
├── shard2/
│ └── epoch_5/
│ ├── __1_0.distcp
│ ├── __4_0.distcp
│ └── ...
└── shard3/
└── epoch_5/
├── __2_0.distcp
├── __5_0.distcp
└── ...
```
#### 2. BinaryPrefixStrategy
Generates binary (base-2) prefixes for optimal partitioning in distributed environments.
```py
from s3torchconnector.dcp import BinaryPrefixStrategy
strategy = BinaryPrefixStrategy(
epoch_num=1, # Optional: for checkpoint versioning
min_prefix_len=10 # Optional: minimum prefix length
)
```
Output Structure:
```
s3://my-bucket/checkpoints/
├── 0000000000/
│ └── epoch_1/
│ └── __0_0.distcp
├── 1000000000/
│ └── epoch_1/
│ └── __1_0.distcp
├── 0100000000/
│ └── epoch_1/
│ └── __2_0.distcp
└── ...
```
#### 3. HexPrefixStrategy
Uses hexadecimal (base-16) prefixes for a balance of efficiency and readability.
```py
from s3torchconnector.dcp import HexPrefixStrategy
strategy = HexPrefixStrategy(
epoch_num=1, # Optional: for checkpoint versioning
min_prefix_len=4 # Optional: minimum prefix length
)
```
Output Structure:
```
s3://my-bucket/checkpoints/
├── 0000/
│ └── epoch_1/
│ └── __0_0.distcp
├── 1000/
│ └── epoch_1/
│ └── __1_0.distcp
...
├── f000/
│ └── epoch_1/
│ └── __15_0.distcp
└── ...
```
### Creating Custom Strategies
You can implement custom prefix strategies by extending the S3PrefixStrategyBase class:
```py
from s3torchconnector.dcp import S3PrefixStrategyBase
class CustomPrefixStrategy(S3PrefixStrategyBase):
def __init__(self, custom_param):
super().__init__()
self.custom_param = custom_param
def generate_prefix(self, rank: int) -> str:
return f"custom_{self.custom_param}/{rank}/"
```
## Parallel/Distributed Training
Amazon S3 Connector for PyTorch provides support for parallel and distributed training with PyTorch,
allowing you to leverage multiple processes and nodes for efficient data loading and training.
Both S3IterableDataset and S3MapDataset can be used for this purpose.
### S3IterableDataset
The S3IterableDataset can be directly passed to PyTorch's DataLoader for parallel and distributed training.
By default, all worker processes will share the same list of training objects. However,
if you need each worker to have access to a unique portion of the dataset for better parallelization,
you can enable dataset sharding using the `enable_sharding` parameter.
```py
dataset = S3IterableDataset.from_prefix(DATASET_URI, region=REGION, enable_sharding=True)
dataloader = DataLoader(dataset, num_workers=4)
```
When `enable_sharding` is set to True, the dataset will be automatically sharded across available number of workers.
This sharding mechanism supports both parallel training on a single host and distributed training across multiple hosts.
Each worker, regardless of its host, will load and process a distinct subset of the dataset.
### S3MapDataset
For the S3MapDataset, you need to pass it to DataLoader along with a [DistributedSampler](https://pytorch.org/docs/stable/data.html#torch.utils.data.distributed.DistributedSampler) wrapped around it.
The DistributedSampler ensures that each worker or node receives a unique subset of the dataset,
enabling efficient parallel and distributed training.
```py
dataset = S3MapDataset.from_prefix(DATASET_URI, region=REGION)
sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, sampler=sampler, num_workers=4)
```
## Lightning Integration
Amazon S3 Connector for PyTorch includes an integration for PyTorch Lightning, featuring S3LightningCheckpoint, an
implementation of Lightning's CheckpointIO. This allows users to make use of Amazon S3 Connector for PyTorch's S3
checkpointing functionality with PyTorch Lightning.
### Getting Started
#### Installation
```sh
pip install s3torchconnector[lightning]
```
### Examples
End to end examples for the PyTorch Lightning integration can be found in the [examples/lightning](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/examples/lightning)
directory.
```py
from lightning import Trainer
from s3torchconnector.lightning import S3LightningCheckpoint
...
s3_checkpoint_io = S3LightningCheckpoint("us-east-1")
trainer = Trainer(
plugins=[s3_checkpoint_io],
default_root_dir="s3://bucket_name/key_prefix/"
)
trainer.fit(model)
```
## Using S3 Versioning to Manage Checkpoints
When working with model checkpoints, you can use the [S3 Versioning](https://docs.aws.amazon.com/AmazonS3/latest/userguide/Versioning.html) feature to preserve, retrieve, and restore every version of your checkpoint objects. With versioning, you can recover more easily from unintended overwrites or deletions of existing checkpoint files due to incorrect configuration or multiple hosts accessing the same storage path.
When versioning is enabled on an S3 bucket, deletions insert a delete marker instead of removing the object permanently. The delete marker becomes the current object version. If you overwrite an object, it results in a new object version in the bucket. You can always restore the previous version. See [Deleting object versions from a versioning-enabled bucket](https://docs.aws.amazon.com/AmazonS3/latest/userguide/DeletingObjectVersions.html) for more details on managing object versions.
To enable versioning on an S3 bucket, see [Enabling versioning on buckets](https://docs.aws.amazon.com/AmazonS3/latest/userguide/manage-versioning-examples.html). Normal Amazon S3 rates apply for every version of an object stored and transferred. To customize your data retention approach and control storage costs for earlier versions of objects, use [object versioning with S3 Lifecycle](https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lifecycle-mgmt.html).
S3 Versioning and S3 Lifecycle are not supported by S3 Express One Zone.
## Direct S3Client Usage
For advanced use cases, you can use the S3Client directly for custom streaming patterns and integration with existing pipelines.
```py
from s3torchconnector._s3client import S3Client
REGION = "us-east-1"
BUCKET_NAME = "my-bucket"
OBJECT_KEY = "large_object.bin"
s3_client = S3Client(region=REGION)
# Writing data to S3
data = b"content" * 1048576
s3writer = s3_client.put_object(bucket=BUCKET_NAME, key=OBJECT_KEY)
s3writer.write(data)
s3writer.close()
# Reading data from S3
s3reader = s3_client.get_object(bucket=BUCKET_NAME, key=OBJECT_KEY)
data = s3reader.read()
```
## Reader Configurations
Amazon S3 Connector for PyTorch supports three types of readers, configurable through `S3ReaderConstructor`.
### Reader Types
#### 1. Sequential Reader
- Default for non-DCP use cases.
- Downloads and buffers the entire S3 object in memory.
- Prioritizes performance over memory usage by buffering entire objects.
#### 2. Range-based Reader
- Performs byte-range requests to read specific portions of S3 objects without downloading the entire object.
- Prioritizes memory efficiency, with performance gains only for sparse partial reads in large objects.
- Features adaptive buffering with forward overlap handling:
- **Small reads** (< `buffer_size`): Use internal buffer to reduce S3 API calls.
- **Large reads** (≥ `buffer_size`): Bypass buffer for direct transfer.
#### 3. DCP-Optimized Reader
- Default for PyTorch Distributed Checkpoint (DCP) loading with `S3StorageReader`.
- Provides performance improvements through per-item buffers and zero-copy buffer management.
- Enables efficient partial checkpoint loading (e.g. model-only) through selective data fetching with range coalescing.
- Automatically handles range metadata injection from DCP load plan.
- Requires sequential access patterns (automatically enforced in `S3StorageReader.prepare_local_plan()`)
### When to Use Each Reader
- **Sequential Reader**: For processing entire objects, and when repeated access to the data is required. Best for most general use cases.
- **Range-based Reader**: For larger objects (100MB+) that require sparse partial reads, and in memory-constrained environments.
- **DCP-Optimized Reader**: For typical PyTorch Distributed Checkpoint loading scenarios for highest performance and memory-efficiency. (Default for `S3StorageReader`)
**Note**: S3Reader instances are not thread-safe and should not be shared across threads. For multiprocessing with DataLoader, each worker process creates its own S3Reader instance automatically.
### Examples
For `S3ReaderConstructor` usage details, please refer to the [`S3ReaderConstructor` documentation](https://awslabs.github.io/s3-connector-for-pytorch/autoapi/s3torchconnector/s3reader/constructor/index.html). Below are some examples for `S3ReaderConstructor` usage.
Direct method - `S3Client` usage with range-based reader without buffer:
```py
# Direct S3Client usage for zero-copy partial reads into pre-allocated buffers, for memory efficiency and fast data transfer
from s3torchconnector._s3client import S3Client
from s3torchconnector import S3ReaderConstructor
s3_client = S3Client(region=REGION)
reader_constructor = S3ReaderConstructor.range_based(
buffer_size=0 # No buffer, for direct transfer
)
s3reader = s3_client.get_object(
bucket=BUCKET_NAME,
key=OBJECT_NAME,
reader_constructor=reader_constructor
)
buffer = bytearray(10 * 1024 * 1024) # 10MB buffer
s3reader.seek(100 * 1024 * 1024) # Skip to 100MB offset
bytes_read = s3reader.readinto(buffer) # Direct read into buffer
```
DCP interface - `S3StorageReader` usage with dcp-optimized reader:
```py
# Load checkpoint with dcp-optimized reader for better performance
from s3torchconnector.dcp import S3StorageReader
from s3torchconnector import S3ReaderConstructor
# dcp_optimized is already the default for S3StorageReader; demonstration purposes only.
reader_constructor = S3ReaderConstructor.dcp_optimized()
s3_storage_reader = S3StorageReader(
region=REGION,
path=CHECKPOINT_URI,
reader_constructor=reader_constructor
)
DCP.load(
state_dict=model_state_dict,
storage_reader=s3_storage_reader,
)
```
Dataset interface - `S3MapDataset` usage with sequential reader:
```py
# Use sequential reader for optimal performance when reading entire objects
from s3torchconnector import S3MapDataset, S3ReaderConstructor
dataset = S3MapDataset.from_prefix(
DATASET_URI,
region=REGION,
reader_constructor=S3ReaderConstructor.sequential()
)
for item in dataset:
content = item.read()
...
```
## Contributing
We welcome contributions to Amazon S3 Connector for PyTorch. Please see [CONTRIBUTING](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/CONTRIBUTING.md) for more
information on how to report bugs or submit pull requests.
### Development
See [DEVELOPMENT](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/DEVELOPMENT.md) for information about code style, development process, and guidelines.
### Compatibility with other storage services
S3 Connector for PyTorch delivers high throughput for PyTorch training jobs that access or store data in Amazon S3.
While it may be functional against other storage services that use S3-like APIs, they may inadvertently break when we
make changes to better support Amazon S3. We welcome contributions of minor compatibility fixes or performance
improvements for these services if the changes can be tested against Amazon S3.
### Security issue notifications
If you discover a potential security issue in this project we ask that you notify AWS Security via our
[vulnerability reporting page](http://aws.amazon.com/security/vulnerability-reporting/).
### Code of conduct
This project has adopted the [Amazon Open Source Code of Conduct](https://aws.github.io/code-of-conduct).
See [CODE_OF_CONDUCT.md](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/CODE_OF_CONDUCT.md) for more details.
## License
Amazon S3 Connector for PyTorch has a BSD 3-Clause License, as found in the [LICENSE](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/LICENSE) file.
| text/markdown | null | null | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Topic :: Utilities"
] | [] | null | null | <3.15,>=3.8 | [] | [] | [] | [
"boto3; extra == \"test\"",
"pytest; extra == \"test\"",
"pytest-timeout; extra == \"test\"",
"hypothesis; extra == \"test\"",
"flake8; extra == \"test\"",
"black; extra == \"test\"",
"mypy; extra == \"test\"",
"Pillow; extra == \"test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T13:05:42.435556 | s3torchconnectorclient-1.5.0.tar.gz | 85,516 | a5/8d/e04febe3e7ff7c91bc4678a16bec1c87674fc9c160c75a8f8745e516e563/s3torchconnectorclient-1.5.0.tar.gz | source | sdist | null | false | 416a3576736ca85f8b19efc1709855bd | 09ffceca1fd025abd8a4a4cbd94b3f70a7c8ccfbf3e0f76337e180f95ce58e61 | a58de04febe3e7ff7c91bc4678a16bec1c87674fc9c160c75a8f8745e516e563 | null | [
"LICENSE",
"THIRD-PARTY-LICENSES",
"NOTICE"
] | 5,315 |
2.4 | s3torchconnector | 1.5.0 | S3 connector integration for PyTorch | # Amazon S3 Connector for PyTorch
The Amazon S3 Connector for PyTorch delivers high throughput for PyTorch training jobs that access or store data in
Amazon S3. Using the S3 Connector for PyTorch
automatically optimizes performance when downloading training data from and writing checkpoints to Amazon S3,
eliminating the need to write your own code to list S3 buckets and manage concurrent requests.
Amazon S3 Connector for PyTorch provides implementations of PyTorch's
[dataset primitives](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html) that you can use to load
training data from Amazon S3.
It supports both [map-style datasets](https://pytorch.org/docs/stable/data.html#map-style-datasets) for random data
access patterns and [iterable-style datasets](https://pytorch.org/docs/stable/data.html#iterable-style-datasets) for
streaming sequential data access patterns.
The S3 Connector for PyTorch also includes a checkpointing interface to save and load checkpoints directly to
Amazon S3, without first saving to local storage.
## Getting Started
### Prerequisites
- Python 3.8-3.14 is supported.
- Note: Python 3.8 support will be deprecated in a future release, see [#399](https://github.com/awslabs/s3-connector-for-pytorch/issues/399)
- PyTorch >= 2.0 (TODO: Check with PyTorch 1.x)
### Installation
```shell
pip install s3torchconnector
```
Amazon S3 Connector for PyTorch supports pre-built wheels via Pip only for Linux and MacOS for now.
(Note: macOS x86_64 wheel support will be deprecated in a future release, see [#398](https://github.com/awslabs/s3-connector-for-pytorch/issues/398))
For other platforms, see [DEVELOPMENT](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/DEVELOPMENT.md) for build instructions.
### Configuration
To use `s3torchconnector`, AWS credentials must be provided through one of the following methods:
- **EC2 Instance Role**: If you are using this library on an EC2 instance, specify an IAM role and then give the EC2 instance access to that role.
- **AWS CLI**: Install and configure [`awscli`](https://aws.amazon.com/cli/) and run `aws configure`.
- **AWS Credential Files**: Set credentials in the AWS credentials profile file on the local system, located at: `~/.aws/credentials` on Unix or macOS.
- **Environment Variables**: Set the `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY` environment variables.
To use a specific AWS profile configured in `~/.aws/config` and `~/.aws/credentials`, you can either:
- Set environment variable `AWS_PROFILE=custom-profile`, or
- Pass the profile name to the `S3ClientConfig` object, e.g. `S3ClientConfig(profile="custom-profile")`.
For a more detailed configuration guide, see [AWS CLI docs](https://docs.aws.amazon.com/cli/v1/userguide/cli-configure-files.html).
### Examples
[API docs](http://awslabs.github.io/s3-connector-for-pytorch) are showing API of the public components.
End to end example of how to use `s3torchconnector` can be found under the [examples](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/examples) directory.
#### Sample Examples
The simplest way to use the S3 Connector for PyTorch is to construct a dataset, either a map-style or iterable-style
dataset, by specifying an S3 URI (a bucket and optional prefix) and the region the bucket is located in:
```py
from s3torchconnector import S3MapDataset, S3IterableDataset
# You need to update <BUCKET> and <PREFIX>
DATASET_URI="s3://<BUCKET>/<PREFIX>"
REGION = "us-east-1"
iterable_dataset = S3IterableDataset.from_prefix(DATASET_URI, region=REGION)
# Datasets are also iterators.
for item in iterable_dataset:
print(item.key)
# S3MapDataset eagerly lists all the objects under the given prefix
# to provide support of random access.
# S3MapDataset builds a list of all objects at the first access to its elements or
# at the first call to get the number of elements, whichever happens first.
# This process might take some time and may give the impression of being unresponsive.
map_dataset = S3MapDataset.from_prefix(DATASET_URI, region=REGION)
# Randomly access an item in map_dataset.
item = map_dataset[0]
# Learn about bucket, key, and content of the object
bucket = item.bucket
key = item.key
content = item.read()
len(content)
```
In addition to data loading primitives, the S3 Connector for PyTorch also provides an interface for saving and loading
model checkpoints directly to and from an S3 bucket.
```py
from s3torchconnector import S3Checkpoint
import torchvision
import torch
CHECKPOINT_URI="s3://<BUCKET>/<KEY>/"
REGION = "us-east-1"
checkpoint = S3Checkpoint(region=REGION)
model = torchvision.models.resnet18()
# Save checkpoint to S3
with checkpoint.writer(CHECKPOINT_URI + "epoch0.ckpt") as writer:
torch.save(model.state_dict(), writer)
# Load checkpoint from S3
with checkpoint.reader(CHECKPOINT_URI + "epoch0.ckpt") as reader:
state_dict = torch.load(reader)
model.load_state_dict(state_dict)
```
Using datasets or checkpoints with
[Amazon S3 Express One Zone](https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-express-one-zone.html)
directory buckets requires only to update the URI, following `base-name--azid--x-s3` bucket name format.
For example, assuming the following directory bucket name `my-test-bucket--usw2-az1--x-s3` with the Availability Zone ID
usw2-az1, then the URI used will look like: `s3://my-test-bucket--usw2-az1--x-s3/<PREFIX>` (**please note that the
prefix for Amazon S3 Express One Zone should end with '/'**), paired with region us-west-2.
## Distributed checkpoints
### Overview
Amazon S3 Connector for PyTorch provides robust support for PyTorch distributed checkpoints. This feature includes:
- `S3StorageWriter`: Implementation of PyTorch's StorageWriter interface.
- `S3StorageReader`: Implementation of PyTorch's StorageReader interface.
- Supports configurable reading strategies via the `reader_constructor` parameter (see [Reader Configurations](#reader-configurations)).
- Uses `DCPOptimizedS3Reader` by default for faster loading and partial checkpoint optimizations.
- Please refer to [DCPOptimizedS3Reader Errors](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/docs/TROUBLESHOOTING.md#dcpoptimizeds3reader-errors) for troubleshooting.
- `S3FileSystem`: An implementation of PyTorch's FileSystemBase.
These tools enable seamless integration of Amazon S3 with
[PyTorch Distributed Checkpoints](https://pytorch.org/docs/stable/distributed.checkpoint.html),
allowing efficient storage and retrieval of distributed model checkpoints.
### Prerequisites and Installation
PyTorch 2.3 or newer is required.
To use the distributed checkpoints feature, install S3 Connector for PyTorch with the `dcp` extra:
```sh
pip install s3torchconnector[dcp]
```
### Sample Example
End-to-end examples for using distributed checkpoints with S3 Connector for PyTorch
can be found in the [examples/dcp](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/examples/dcp) directory.
```py
from s3torchconnector.dcp import S3StorageWriter, S3StorageReader
import torchvision
import torch.distributed.checkpoint as DCP
# Configuration
CHECKPOINT_URI = "s3://<BUCKET>/<KEY>/"
REGION = "us-east-1"
model = torchvision.models.resnet18()
# Save distributed checkpoint to S3
s3_storage_writer = S3StorageWriter(
region=REGION,
path=CHECKPOINT_URI,
thread_count=8, # optional; number of IO threads to use to write
)
DCP.save(
state_dict=model.state_dict(),
storage_writer=s3_storage_writer,
)
# Load distributed checkpoint from S3
# S3StorageReader uses DCPOptimizedS3Reader by default for improved performance
model = torchvision.models.resnet18()
model_state_dict = model.state_dict()
s3_storage_reader = S3StorageReader(
region=REGION,
path=CHECKPOINT_URI,
)
DCP.load(
state_dict=model_state_dict,
storage_reader=s3_storage_reader,
)
model.load_state_dict(model_state_dict)
```
## S3 Prefix Strategies for Distributed Checkpointing
S3StorageWriter implements various prefix strategies to optimize checkpoint organization in S3 buckets.
These strategies are specifically designed to prevent throttling (503 Slow Down errors) in high-throughput scenarios
by implementing S3 key naming best practices as outlined in
[Best practices design patterns: optimizing Amazon S3 performance](https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance.html).
When many distributed training processes write checkpoints simultaneously, the prefixing strategies help distribute
the load across multiple S3 partitions.
### Available Strategies
#### 1. RoundRobinPrefixStrategy
Distributes checkpoints across specified prefixes in a round-robin fashion, ideal for balancing data across multiple storage locations.
```py
from s3torchconnector.dcp import RoundRobinPrefixStrategy, S3StorageWriter
model = torchvision.models.resnet18()
# Initialize with multiple prefixes and optional epoch tracking
strategy = RoundRobinPrefixStrategy(
user_prefixes=["shard1", "shard2", "shard3"],
epoch_num=5 # Optional: for checkpoint versioning
)
writer = S3StorageWriter(
region=REGION,
path="CHECKPOINT_URI",
prefix_strategy=strategy
)
# Save checkpoint
DCP.save(
state_dict=model.state_dict(),
storage_writer=writer
)
```
Output Structure:
```
CHECKPOINT_URI
├── shard1/
│ └── epoch_5/
│ ├── __0_0.distcp
│ ├── __3_0.distcp
│ └── ...
├── shard2/
│ └── epoch_5/
│ ├── __1_0.distcp
│ ├── __4_0.distcp
│ └── ...
└── shard3/
└── epoch_5/
├── __2_0.distcp
├── __5_0.distcp
└── ...
```
#### 2. BinaryPrefixStrategy
Generates binary (base-2) prefixes for optimal partitioning in distributed environments.
```py
from s3torchconnector.dcp import BinaryPrefixStrategy
strategy = BinaryPrefixStrategy(
epoch_num=1, # Optional: for checkpoint versioning
min_prefix_len=10 # Optional: minimum prefix length
)
```
Output Structure:
```
s3://my-bucket/checkpoints/
├── 0000000000/
│ └── epoch_1/
│ └── __0_0.distcp
├── 1000000000/
│ └── epoch_1/
│ └── __1_0.distcp
├── 0100000000/
│ └── epoch_1/
│ └── __2_0.distcp
└── ...
```
#### 3. HexPrefixStrategy
Uses hexadecimal (base-16) prefixes for a balance of efficiency and readability.
```py
from s3torchconnector.dcp import HexPrefixStrategy
strategy = HexPrefixStrategy(
epoch_num=1, # Optional: for checkpoint versioning
min_prefix_len=4 # Optional: minimum prefix length
)
```
Output Structure:
```
s3://my-bucket/checkpoints/
├── 0000/
│ └── epoch_1/
│ └── __0_0.distcp
├── 1000/
│ └── epoch_1/
│ └── __1_0.distcp
...
├── f000/
│ └── epoch_1/
│ └── __15_0.distcp
└── ...
```
### Creating Custom Strategies
You can implement custom prefix strategies by extending the S3PrefixStrategyBase class:
```py
from s3torchconnector.dcp import S3PrefixStrategyBase
class CustomPrefixStrategy(S3PrefixStrategyBase):
def __init__(self, custom_param):
super().__init__()
self.custom_param = custom_param
def generate_prefix(self, rank: int) -> str:
return f"custom_{self.custom_param}/{rank}/"
```
## Parallel/Distributed Training
Amazon S3 Connector for PyTorch provides support for parallel and distributed training with PyTorch,
allowing you to leverage multiple processes and nodes for efficient data loading and training.
Both S3IterableDataset and S3MapDataset can be used for this purpose.
### S3IterableDataset
The S3IterableDataset can be directly passed to PyTorch's DataLoader for parallel and distributed training.
By default, all worker processes will share the same list of training objects. However,
if you need each worker to have access to a unique portion of the dataset for better parallelization,
you can enable dataset sharding using the `enable_sharding` parameter.
```py
dataset = S3IterableDataset.from_prefix(DATASET_URI, region=REGION, enable_sharding=True)
dataloader = DataLoader(dataset, num_workers=4)
```
When `enable_sharding` is set to True, the dataset will be automatically sharded across available number of workers.
This sharding mechanism supports both parallel training on a single host and distributed training across multiple hosts.
Each worker, regardless of its host, will load and process a distinct subset of the dataset.
### S3MapDataset
For the S3MapDataset, you need to pass it to DataLoader along with a [DistributedSampler](https://pytorch.org/docs/stable/data.html#torch.utils.data.distributed.DistributedSampler) wrapped around it.
The DistributedSampler ensures that each worker or node receives a unique subset of the dataset,
enabling efficient parallel and distributed training.
```py
dataset = S3MapDataset.from_prefix(DATASET_URI, region=REGION)
sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, sampler=sampler, num_workers=4)
```
## Lightning Integration
Amazon S3 Connector for PyTorch includes an integration for PyTorch Lightning, featuring S3LightningCheckpoint, an
implementation of Lightning's CheckpointIO. This allows users to make use of Amazon S3 Connector for PyTorch's S3
checkpointing functionality with PyTorch Lightning.
### Getting Started
#### Installation
```sh
pip install s3torchconnector[lightning]
```
### Examples
End to end examples for the PyTorch Lightning integration can be found in the [examples/lightning](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/examples/lightning)
directory.
```py
from lightning import Trainer
from s3torchconnector.lightning import S3LightningCheckpoint
...
s3_checkpoint_io = S3LightningCheckpoint("us-east-1")
trainer = Trainer(
plugins=[s3_checkpoint_io],
default_root_dir="s3://bucket_name/key_prefix/"
)
trainer.fit(model)
```
## Using S3 Versioning to Manage Checkpoints
When working with model checkpoints, you can use the [S3 Versioning](https://docs.aws.amazon.com/AmazonS3/latest/userguide/Versioning.html) feature to preserve, retrieve, and restore every version of your checkpoint objects. With versioning, you can recover more easily from unintended overwrites or deletions of existing checkpoint files due to incorrect configuration or multiple hosts accessing the same storage path.
When versioning is enabled on an S3 bucket, deletions insert a delete marker instead of removing the object permanently. The delete marker becomes the current object version. If you overwrite an object, it results in a new object version in the bucket. You can always restore the previous version. See [Deleting object versions from a versioning-enabled bucket](https://docs.aws.amazon.com/AmazonS3/latest/userguide/DeletingObjectVersions.html) for more details on managing object versions.
To enable versioning on an S3 bucket, see [Enabling versioning on buckets](https://docs.aws.amazon.com/AmazonS3/latest/userguide/manage-versioning-examples.html). Normal Amazon S3 rates apply for every version of an object stored and transferred. To customize your data retention approach and control storage costs for earlier versions of objects, use [object versioning with S3 Lifecycle](https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lifecycle-mgmt.html).
S3 Versioning and S3 Lifecycle are not supported by S3 Express One Zone.
## Direct S3Client Usage
For advanced use cases, you can use the S3Client directly for custom streaming patterns and integration with existing pipelines.
```py
from s3torchconnector._s3client import S3Client
REGION = "us-east-1"
BUCKET_NAME = "my-bucket"
OBJECT_KEY = "large_object.bin"
s3_client = S3Client(region=REGION)
# Writing data to S3
data = b"content" * 1048576
s3writer = s3_client.put_object(bucket=BUCKET_NAME, key=OBJECT_KEY)
s3writer.write(data)
s3writer.close()
# Reading data from S3
s3reader = s3_client.get_object(bucket=BUCKET_NAME, key=OBJECT_KEY)
data = s3reader.read()
```
## Reader Configurations
Amazon S3 Connector for PyTorch supports three types of readers, configurable through `S3ReaderConstructor`.
### Reader Types
#### 1. Sequential Reader
- Default for non-DCP use cases.
- Downloads and buffers the entire S3 object in memory.
- Prioritizes performance over memory usage by buffering entire objects.
#### 2. Range-based Reader
- Performs byte-range requests to read specific portions of S3 objects without downloading the entire object.
- Prioritizes memory efficiency, with performance gains only for sparse partial reads in large objects.
- Features adaptive buffering with forward overlap handling:
- **Small reads** (< `buffer_size`): Use internal buffer to reduce S3 API calls.
- **Large reads** (≥ `buffer_size`): Bypass buffer for direct transfer.
#### 3. DCP-Optimized Reader
- Default for PyTorch Distributed Checkpoint (DCP) loading with `S3StorageReader`.
- Provides performance improvements through per-item buffers and zero-copy buffer management.
- Enables efficient partial checkpoint loading (e.g. model-only) through selective data fetching with range coalescing.
- Automatically handles range metadata injection from DCP load plan.
- Requires sequential access patterns (automatically enforced in `S3StorageReader.prepare_local_plan()`)
### When to Use Each Reader
- **Sequential Reader**: For processing entire objects, and when repeated access to the data is required. Best for most general use cases.
- **Range-based Reader**: For larger objects (100MB+) that require sparse partial reads, and in memory-constrained environments.
- **DCP-Optimized Reader**: For typical PyTorch Distributed Checkpoint loading scenarios for highest performance and memory-efficiency. (Default for `S3StorageReader`)
**Note**: S3Reader instances are not thread-safe and should not be shared across threads. For multiprocessing with DataLoader, each worker process creates its own S3Reader instance automatically.
### Examples
For `S3ReaderConstructor` usage details, please refer to the [`S3ReaderConstructor` documentation](https://awslabs.github.io/s3-connector-for-pytorch/autoapi/s3torchconnector/s3reader/constructor/index.html). Below are some examples for `S3ReaderConstructor` usage.
Direct method - `S3Client` usage with range-based reader without buffer:
```py
# Direct S3Client usage for zero-copy partial reads into pre-allocated buffers, for memory efficiency and fast data transfer
from s3torchconnector._s3client import S3Client
from s3torchconnector import S3ReaderConstructor
s3_client = S3Client(region=REGION)
reader_constructor = S3ReaderConstructor.range_based(
buffer_size=0 # No buffer, for direct transfer
)
s3reader = s3_client.get_object(
bucket=BUCKET_NAME,
key=OBJECT_NAME,
reader_constructor=reader_constructor
)
buffer = bytearray(10 * 1024 * 1024) # 10MB buffer
s3reader.seek(100 * 1024 * 1024) # Skip to 100MB offset
bytes_read = s3reader.readinto(buffer) # Direct read into buffer
```
DCP interface - `S3StorageReader` usage with dcp-optimized reader:
```py
# Load checkpoint with dcp-optimized reader for better performance
from s3torchconnector.dcp import S3StorageReader
from s3torchconnector import S3ReaderConstructor
# dcp_optimized is already the default for S3StorageReader; demonstration purposes only.
reader_constructor = S3ReaderConstructor.dcp_optimized()
s3_storage_reader = S3StorageReader(
region=REGION,
path=CHECKPOINT_URI,
reader_constructor=reader_constructor
)
DCP.load(
state_dict=model_state_dict,
storage_reader=s3_storage_reader,
)
```
Dataset interface - `S3MapDataset` usage with sequential reader:
```py
# Use sequential reader for optimal performance when reading entire objects
from s3torchconnector import S3MapDataset, S3ReaderConstructor
dataset = S3MapDataset.from_prefix(
DATASET_URI,
region=REGION,
reader_constructor=S3ReaderConstructor.sequential()
)
for item in dataset:
content = item.read()
...
```
## Contributing
We welcome contributions to Amazon S3 Connector for PyTorch. Please see [CONTRIBUTING](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/CONTRIBUTING.md) for more
information on how to report bugs or submit pull requests.
### Development
See [DEVELOPMENT](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/DEVELOPMENT.md) for information about code style, development process, and guidelines.
### Compatibility with other storage services
S3 Connector for PyTorch delivers high throughput for PyTorch training jobs that access or store data in Amazon S3.
While it may be functional against other storage services that use S3-like APIs, they may inadvertently break when we
make changes to better support Amazon S3. We welcome contributions of minor compatibility fixes or performance
improvements for these services if the changes can be tested against Amazon S3.
### Security issue notifications
If you discover a potential security issue in this project we ask that you notify AWS Security via our
[vulnerability reporting page](http://aws.amazon.com/security/vulnerability-reporting/).
### Code of conduct
This project has adopted the [Amazon Open Source Code of Conduct](https://aws.github.io/code-of-conduct).
See [CODE_OF_CONDUCT.md](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/CODE_OF_CONDUCT.md) for more details.
## License
Amazon S3 Connector for PyTorch has a BSD 3-Clause License, as found in the [LICENSE](https://github.com/awslabs/s3-connector-for-pytorch/blob/main/LICENSE) file.
| text/markdown | null | null | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Topic :: Utilities"
] | [] | null | null | <3.15,>=3.8 | [] | [] | [] | [
"torch!=2.5.0,>=2.0.1",
"s3torchconnectorclient==1.5.0",
"pytest; extra == \"test\"",
"pytest-timeout; extra == \"test\"",
"hypothesis; extra == \"test\"",
"flake8; extra == \"test\"",
"black; extra == \"test\"",
"mypy; extra == \"test\"",
"importlib_metadata; python_version == \"3.9\" and extra == \"test\"",
"torchdata<=0.9.0; extra == \"e2e\"",
"Pillow>=10.3.0; extra == \"e2e\"",
"boto3<1.37.2; extra == \"e2e\"",
"numpy<2; extra == \"e2e\"",
"pytest-xdist; extra == \"e2e\"",
"fsspec==2025.3.0; python_version == \"3.8\" and extra == \"e2e\"",
"lightning>=2.0; extra == \"lightning\"",
"packaging; extra == \"lightning\"",
"s3torchconnector[lightning]; extra == \"lightning-tests\"",
"s3fs; extra == \"lightning-tests\"",
"torchmetrics!=1.7.0,!=1.7.1; extra == \"lightning-tests\"",
"tenacity; extra == \"dcp\"",
"torch!=2.5.0,>=2.3; extra == \"dcp\"",
"importlib_metadata; python_version == \"3.9\" and extra == \"dcp\"",
"s3torchconnector[dcp]; extra == \"dcp-test\"",
"pytest; extra == \"dcp-test\"",
"zstandard; extra == \"dcp-test\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T13:05:41.437947 | s3torchconnector-1.5.0.tar.gz | 103,050 | 0f/24/a3422bc7e3d8f2a55a64250a6d5a07416c49d6f5695879445ff72c695612/s3torchconnector-1.5.0.tar.gz | source | sdist | null | false | 55126846349140de6c69d16751e56ee3 | 44167d8e7bc0fce6d97627fc10aa7e215f4b58e0bb7037e87858c41eefd5b5af | 0f24a3422bc7e3d8f2a55a64250a6d5a07416c49d6f5695879445ff72c695612 | null | [
"LICENSE",
"THIRD-PARTY-LICENSES",
"NOTICE"
] | 1,965 |
2.3 | ai-disclaimer | 0.1.0 | Interactive CLI tool for generating AI usage disclaimers | # ai-disclaimer
Interactive CLI that generates an AI usage disclaimer for your project — as a Markdown snippet or a self-contained HTML card.
## Install
```sh
uv tool install .
```
## Usage
```sh
ai-disclaimer
```
Walks you through a short questionnaire (tools used, contribution split by phase, oversight level, process, accountability) and writes the output to stdout or a file.
## Output formats
**Markdown** — a fenced-code bar chart and plain text sections, ready to paste into any README.
**HTML** — a self-contained `<div>` (style included) with visual progress bars, using the [Flexoki](https://github.com/kepano/flexoki) color palette. Supports `light`, `dark`, and `auto` (follows OS preference) themes.
## Examples
You can see the markdown output in the section below and the corresponding HTML:
> 
Source code: [here](examples/ai_disclaimer.html)
> ## 🤖 AI Disclaimer
>
> This project uses AI-assisted development tools. See the [AI usage policy](https://j23n.com/public/posts/2026/my-ai-policy) for details.
>
> **Tools**
>
> - Claude Code (Anthropic) · `claude-sonnet-4-6` · Agentic
>
> ### Contribution Profile
>
> ```
> Phase Human│ AI
> ─────────────────────────────────────────┼───────────────
> Requirements & Scope 85% ████████│░░ 15%
> Architecture & Design 85% ████████│░░ 15%
> Implementation 5% │░░░░░░░░░░ 95%
> Testing not started
> Documentation 20% ██│░░░░░░░░ 80%
> ```
>
> **Oversight**: Collaborative
>
> Human and AI co-author decisions; human reviews all output.
>
> ### Process
>
> AI agent operated autonomously across multi-step tasks. Human reviewed diffs, resolved conflicts, and approved merges.
>
> ### Accountability
>
> The human author(s) are solely responsible for the content, accuracy, and fitness-for-purpose of this project.
>
> ---
> *Last updated: 2026-02-20 · Generated with [ai-disclaimer](https://github.com/j23n/ai-disclaimer)*
| text/markdown | j23n | j23n <oss@j23n.com> | null | null | MIT | ai, disclaimer, transparency, disclosure, cli | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development",
"Topic :: Utilities"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"questionary>=2.0"
] | [] | [] | [] | [
"Homepage, https://app.radicle.xyz/nodes/rosa.radicle.xyz/rad:z4Wbrb12czWb8eKWxmKhqobJixnxe",
"Repository, https://app.radicle.xyz/nodes/rosa.radicle.xyz/rad:z4Wbrb12czWb8eKWxmKhqobJixnxe",
"Bug Tracker, https://app.radicle.xyz/nodes/rosa.radicle.xyz/rad:z4Wbrb12czWb8eKWxmKhqobJixnxe/issues"
] | uv/0.9.2 | 2026-02-20T13:05:17.916018 | ai_disclaimer-0.1.0.tar.gz | 8,779 | 1a/06/19e29f4d38b17e8e4522ec7a9ca939948ec74698898f7eb8e5f83a1e8014/ai_disclaimer-0.1.0.tar.gz | source | sdist | null | false | 3726fa29cef689bccc43e2b3ec35b792 | 9de5e33f5382ffcec82624ce3fc47e10f105b24650d9019cb9d00acf51f71d9d | 1a0619e29f4d38b17e8e4522ec7a9ca939948ec74698898f7eb8e5f83a1e8014 | null | [] | 223 |
2.4 | csslib | 1.0.1 | CSSlib is an open-source code for building configuration search space (CSS) of disordered crystals. | <p align="center">
<img src="./logo.jpg" width="20%" title="CSSlib" alt="CSSlib"/>
</p>
# CSSlib
CSSlib is an open-source code for building configuration search space (CSS) of disordered crystals.
Installation
-----
**CSSlib** requires **Supercell** program. Details on **Supercell** installation can be found at the corresponding [website](https://orex.github.io/supercell/download/).
Tutorial
-----
The best way to learn how to use **CSSlib** is through the [tutorial notebook](tests/csslib_example.ipynb).
References & Citing
-----
If you use this code, please consider citing works that actively used the CSS approach, which resulted in the creation of this library:
1. A.V. Krautsou, I.S. Humonen, V.D. Lazarev, R.A. Eremin, S.A. Budennyy<br/>
"Impact of crystal structure symmetry in training datasets on GNN-based energy assessments for chemically disordered CsPbI<sub>3</sub>"<br/>
https://doi.org/10.1038/s41598-025-92669-3
2. N.A. Matsokin, R.A. Eremin, A.A. Kuznetsova, I.S. Humonen, A.V. Krautsou, V.D. Lazarev, Y.Z. Vassilyeva, A.Y. Pak, S.A. Budennyy, A.G. Kvashnin, A.A. Osiptsov<br/>
"Discovery of chemically modified higher tungsten boride by means of hybrid GNN/DFT approach"<br/>
https://doi.org/10.1038/s41524-025-01628-z
3. R.A. Zaripov, R.A. Eremin, I.S. Humonen, A.V. Krautsou, V.V. Kuznetsov, K.E. GermanS, S.A. Budennyy, S.V. Levchenko</br>
"First-principles data-driven approach for assessment of stability of Tc-C systems"</br>
https://doi.org/10.1016/j.actamat.2025.121704
| text/markdown | A.V. Krautsou | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"jupyter==1.0.0",
"matplotlib==3.10.7",
"numpy==1.26.4",
"pandas==2.3.2",
"plotly==6.3.1",
"pymatgen==2025.6.14",
"pymatgen-analysis-defects==2025.1.18",
"scipy==1.15.3",
"tqdm==4.67.1",
"networkx==3.4.2"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T13:05:06.939042 | csslib-1.0.1-py3-none-any.whl | 9,222 | cb/29/00e0864d00f5cc84dd001c0f923f262279b3d73956d8d51b940ff83ef71f/csslib-1.0.1-py3-none-any.whl | py3 | bdist_wheel | null | false | 5853737aa285eef763a6e88eb340184b | 1e3c488471158f4026110b029d247f6f6642392744f8f8581f3fc249a2be4e96 | cb2900e0864d00f5cc84dd001c0f923f262279b3d73956d8d51b940ff83ef71f | null | [] | 85 |
2.2 | saltext.ufw | 0.8.3 | Salt Extension for interacting with Ufw | # Salt Extension for Ufw
Salt Extension for interacting with Ufw
## Security
If you discover a security vulnerability, please refer
to [Salt's security guide][security].
## User Documentation
For setup and usage instructions, please refer to the
module docstrings (for now, documentation is coming!).
## Contributing
The saltext-ufw project welcomes contributions from anyone!
The [Salt Extensions guide][salt-extensions-guide] provides comprehensive instructions on all aspects
of Salt extension development, including [writing tests][writing-tests], [running tests][running-tests],
[writing documentation][writing-docs] and [rendering the docs][rendering-docs].
### Quickstart
To get started contributing, first clone this repository (or your fork):
```bash
# Clone the repo
git clone --origin upstream git@github.com:redsift/saltext-ufw.git
# Change to the repo dir
cd saltext-ufw
```
#### Automatic
If you have installed [direnv][direnv], copying the included `.envrc.example` to `.envrc` and
allowing it to run ensures a proper development environment is present and the virtual environment is active.
Without `direnv`, you can still run the automation explicitly:
```bash
make dev # or python3 tools/initialize.py
source .venv/bin/activate
```
#### Manual
Please follow the [first steps][first-steps], skipping the repository initialization and first commit.
### Pull request
Always make changes in a feature branch:
```bash
git switch -c my-feature-branch
```
Please ensure you include a [news fragment](https://salt-extensions.github.io/salt-extension-copier/topics/documenting/changelog.html#procedure)
describing your changes. This is a requirement for all user-facing changes (bug fixes, new features),
with the exception of documentation changes.
To [submit a Pull Request][submitting-pr], you'll need a fork of this repository in
your own GitHub account. If you followed the instructions above,
set your fork as the `origin` remote now:
```bash
git remote add origin git@github.com:<your_fork>.git
```
Ensure you followed the [first steps][first-steps] and commit your changes, fixing any
failing `pre-commit` hooks. Then push the feature branch to your fork and submit a PR.
### Ways to contribute
Contributions come in many forms, and they’re all valuable! Here are some ways you can help
without writing code:
* **Documentation**: Especially examples showing how to use this project
to solve specific problems.
* **Triaging issues**: Help manage [issues][issues] and participate in [discussions][discussions].
* **Reviewing [Pull Requests][PRs]**: We especially appreciate reviews using [Conventional Comments][comments].
You can also contribute by:
* Writing blog posts
* Sharing your experiences using Salt + Ufw
on social media
* Giving talks at conferences
* Publishing videos
* Engaging in IRC, Discord or email groups
Any of these things are super valuable to our community, and we sincerely
appreciate every contribution!
[security]: https://github.com/saltstack/salt/blob/master/SECURITY.md
[salt-extensions-guide]: https://salt-extensions.github.io/salt-extension-copier/
[writing-tests]: https://salt-extensions.github.io/salt-extension-copier/topics/testing/writing.html
[running-tests]: https://salt-extensions.github.io/salt-extension-copier/topics/testing/running.html
[writing-docs]: https://salt-extensions.github.io/salt-extension-copier/topics/documenting/writing.html
[rendering-docs]: https://salt-extensions.github.io/salt-extension-copier/topics/documenting/building.html
[first-steps]: https://salt-extensions.github.io/salt-extension-copier/topics/creation.html#initialize-the-python-virtual-environment
[submitting-pr]: https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request-from-a-fork
[direnv]: https://direnv.net
[issues]: https://github.com/voyvodov/saltext-ufw/issues
[PRs]: https://github.com/voyvodov/saltext-ufw/pulls
[discussions]: https://github.com/voyvodov/saltext-ufw/discussions
[comments]: https://conventionalcomments.org/
| text/markdown | null | Hristo Voyvodov <hristo.voyvodov@redsift.io> | null | null | Apache Software License | salt-extension | [
"Programming Language :: Python",
"Programming Language :: Cython",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License"
] | [
"any"
] | null | null | >=3.9 | [] | [] | [] | [
"salt>=3006",
"towncrier==25.8.0; extra == \"changelog\"",
"nox[uv]!=2025.05.01,>=2024.3; extra == \"dev\"",
"pre-commit>=2.21.0; extra == \"dev\"",
"black==25.1.0; extra == \"dev-extra\"",
"isort==6.0.1; extra == \"dev-extra\"",
"coverage==7.10.6; extra == \"dev-extra\"",
"sphinx; extra == \"docs\"",
"sphinx-prompt; extra == \"docs\"",
"sphinxcontrib-spelling; extra == \"docs\"",
"sphinx-copybutton; extra == \"docs\"",
"towncrier==25.8.0; extra == \"docs\"",
"sphinxcontrib-towncrier; extra == \"docs\"",
"myst_parser; extra == \"docs\"",
"furo; extra == \"docs\"",
"sphinx-inline-tabs; extra == \"docs\"",
"sphinx-autobuild; extra == \"docsauto\"",
"pylint==3.3.5; extra == \"lint\"",
"pytest>=7.2.0; extra == \"tests\"",
"pytest-salt-factories>=1.0.0; sys_platform == \"win32\" and extra == \"tests\"",
"pytest-salt-factories[docker]>=1.0.0; sys_platform != \"win32\" and extra == \"tests\"",
"pytest-instafail; extra == \"tests\""
] | [] | [] | [] | [
"Homepage, https://github.com/voyvodov/saltext-ufw",
"Source, https://github.com/voyvodov/saltext-ufw",
"Tracker, https://github.com/voyvodov/saltext-ufw/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:04:56.370375 | saltext_ufw-0.8.3.tar.gz | 82,334 | 97/85/c5cc4cbeb9f60e1a9a737c9f07273c4150b42e10e7ffaf651619fac09482/saltext_ufw-0.8.3.tar.gz | source | sdist | null | false | ade098244b01f63a2d74bf6fb16a93cf | d41f0567c70460a9a28aa0147a2845904d50242ca3905ad7a4791bbed055c0bf | 9785c5cc4cbeb9f60e1a9a737c9f07273c4150b42e10e7ffaf651619fac09482 | null | [] | 0 |
2.1 | odoo-addon-shopfloor | 16.0.2.15.0 | manage warehouse operations with barcode scanners | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
=========
Shopfloor
=========
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:4c221d01eb0d0479500dca6accfc6ba696e95c76f62d5039ead2afb98cf83536
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fwms-lightgray.png?logo=github
:target: https://github.com/OCA/wms/tree/16.0/shopfloor
:alt: OCA/wms
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/wms-16-0/wms-16-0-shopfloor
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/wms&target_branch=16.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
Shopfloor is a barcode scanner application for internal warehouse operations.
The application supports scenarios, to relate to Operation Types:
* Cluster Picking
* Zone Picking
* Checkout/Packing
* Delivery
* Location Content Transfer
* Single Pack Transfer
This module provides REST APIs to support the scenarios. It needs a frontend
to consume the backend APIs and provide screens for users on barcode devices.
A default front-end application is provided by ``shopfloor_mobile``.
| Note: if you want to enable a new scenario on an existing application, you must trigger the registry sync on the shopfloor.app in a post_init_hook or a post-migrate script.
| See an example `here <https://github.com/OCA/wms/pull/520/commits/bccdfd445a9bc943998c4848f183a076e8459a98>`_.
**Table of contents**
.. contents::
:local:
Usage
=====
An API key is created in the Demo data (for development), using
the Demo user. The key to use in the HTTP header ``API-KEY`` is: 72B044F7AC780DAC
Curl example::
curl -X POST "http://localhost:8069/shopfloor/user/menu" -H "accept: */*" -H "Content-Type: application/json" -H "API-KEY: 72B044F7AC780DAC"
Known issues / Roadmap
======================
* improve documentation
* split out scenario components to their own modules
* maybe split common stock features to `shopfloor_stock_base`
and move scenario to `shopfloor_wms`?
Changelog
=========
13.0.1.0.0
~~~~~~~~~~
First official version.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/wms/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/wms/issues/new?body=module:%20shopfloor%0Aversion:%2016.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
~~~~~~~
* Camptocamp
* BCIM
* Akretion
Contributors
~~~~~~~~~~~~
* Guewen Baconnier <guewen.baconnier@camptocamp.com>
* Simone Orsi <simahawk@gmail.com>
* Sébastien Alix <sebastien.alix@camptocamp.com>
* Alexandre Fayolle <alexandre.fayolle@camptocamp.com>
* Benoit Guillot <benoit.guillot@akretion.com>
* Thierry Ducrest <thierry.ducrest@camptocamp.com>
* Raphaël Reverdy <raphael.reverdy@akretion.com>
* Jacques-Etienne Baudoux <je@bcim.be>
* Juan Miguel Sánchez Arce <juan.sanchez@camptocamp.com>
* Michael Tietz (MT Software) <mtietz@mt-software.de>
* Souheil Bejaoui <souheil.bejaoui@acsone.eu>
* Laurent Mignon <laurent.mignon@acsone.eu>
Design
~~~~~~
* Joël Grand-Guillaume <joel.grandguillaume@camptocamp.com>
* Jacques-Etienne Baudoux <je@bcim.be>
Other credits
~~~~~~~~~~~~~
**Financial support**
* Cosanum
* Camptocamp R&D
* Akretion R&D
Maintainers
~~~~~~~~~~~
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-guewen| image:: https://github.com/guewen.png?size=40px
:target: https://github.com/guewen
:alt: guewen
.. |maintainer-simahawk| image:: https://github.com/simahawk.png?size=40px
:target: https://github.com/simahawk
:alt: simahawk
.. |maintainer-sebalix| image:: https://github.com/sebalix.png?size=40px
:target: https://github.com/sebalix
:alt: sebalix
Current `maintainers <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-guewen| |maintainer-simahawk| |maintainer-sebalix|
This module is part of the `OCA/wms <https://github.com/OCA/wms/tree/16.0/shopfloor>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| null | Camptocamp, BCIM, Akretion, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 16.0",
"License :: OSI Approved :: GNU Affero General Public License v3",
"Development Status :: 4 - Beta"
] | [] | https://github.com/OCA/wms | null | >=3.10 | [] | [] | [] | [
"odoo-addon-base-rest<16.1dev,>=16.0dev",
"odoo-addon-jsonifier<16.1dev,>=16.0dev",
"odoo-addon-product-manufacturer<16.1dev,>=16.0dev",
"odoo-addon-product-packaging-level<16.1dev,>=16.0dev",
"odoo-addon-shopfloor-base<16.1dev,>=16.0dev",
"odoo-addon-stock-helper<16.1dev,>=16.0dev",
"odoo-addon-stock-move-line-change-lot<16.1dev,>=16.0dev",
"odoo-addon-stock-picking-completion-info<16.1dev,>=16.0dev",
"odoo-addon-stock-picking-delivery-link<16.1dev,>=16.0dev",
"odoo-addon-stock-picking-progress<16.1dev,>=16.0dev",
"odoo-addon-stock-quant-package-dimension<16.1dev,>=16.0dev",
"odoo-addon-stock-quant-package-product-packaging<16.1dev,>=16.0dev",
"odoo-addon-stock-storage-type<16.1dev,>=16.0dev",
"odoo<16.1dev,>=16.0a"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T13:04:42.929394 | odoo_addon_shopfloor-16.0.2.15.0-py3-none-any.whl | 1,034,811 | 97/f5/bd124c74ffae9dde72f72947588e74825b0c45694811bfff26fad90b62b9/odoo_addon_shopfloor-16.0.2.15.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 2c018d65e17021b3f18511fc736ed0c9 | 7df727b01f637dca4bf3897c96e47dbcb00e0b19461aaab8a12f8988ec6664ee | 97f5bd124c74ffae9dde72f72947588e74825b0c45694811bfff26fad90b62b9 | null | [] | 78 |
2.4 | codepilot-ai | 0.2.2 | A code-native agentic framework for building robust AI agents. | # CodePilot — Developer Reference
**CodePilot** is a code-native agentic framework. The LLM writes Python to act — no JSON schemas, no function-calling APIs. This document covers every feature with working code examples.
---
## Installation
```bash
pip install codepilot
```
Required env var before running anything:
```bash
export ANTHROPIC_API_KEY="sk-ant-..." # or OPENAI_API_KEY, etc.
```
---
## Table of Contents
1. [AgentFile (YAML config)](#1-agentfile)
2. [Basic usage](#2-basic-usage)
3. [Multi-turn execution](#3-multi-turn-execution)
4. [Session persistence](#4-session-persistence)
5. [Resuming a session](#5-resuming-a-session)
6. [Resetting a session](#6-resetting-a-session)
7. [Hooks — full observability](#7-hooks)
8. [Permission gating](#8-permission-gating)
9. [Mid-task message injection](#9-mid-task-message-injection)
10. [Custom tools](#10-custom-tools)
11. [Aborting the agent](#11-aborting-the-agent)
12. [Building a CLI tool](#12-building-a-cli-tool)
13. [Building a web server integration](#13-building-a-web-server-integration)
14. [Full API surface](#14-full-api-surface)
---
## 1. AgentFile
Every Runtime is driven by a YAML config file. Paths in the file are resolved relative to the file's own location — not the caller's CWD — so the agent works correctly when installed as a global CLI tool.
```yaml
# agent.yaml
agent:
name: "BackendEngineer"
role: "Expert Python backend engineer specialising in FastAPI and PostgreSQL."
# Either a raw string or a path to a .md file (resolved relative to this YAML)
system_prompt: "./prompts/instructions.md"
model:
provider: "anthropic" # "anthropic" | "openai" | "together"
name: "claude-opus-4-5"
api_key_env: "ANTHROPIC_API_KEY"
temperature: 0.2
max_tokens: 8096
runtime:
work_dir: "./workspace" # where the agent reads/writes files
max_steps: 30 # hard cap on agentic steps per run()
unsafe_mode: false # true = allow writes outside work_dir
allowed_imports: # stdlib modules allowed in the control block
- "re"
- "json"
- "math"
- "datetime"
- "pathlib"
tools:
- name: "write_file"
enabled: true
config:
require_permission: false # true = ask user before every file write
- name: "read_file"
enabled: true
- name: "run_command"
enabled: true
config:
timeout: 60 # seconds before command is killed
require_permission: true # true = ask user before every shell command
- name: "ask_user"
enabled: true
```
**Supported providers:**
| `provider` | `name` examples | `api_key_env` |
|---|---|---|
| `anthropic` | `claude-opus-4-5`, `claude-sonnet-4-5` | `ANTHROPIC_API_KEY` |
| `openai` | `gpt-4o`, `gpt-4-turbo` | `OPENAI_API_KEY` |
| `together` | `mistralai/Mixtral-8x7B-Instruct-v0.1` | `TOGETHER_API_KEY` |
---
## 2. Basic Usage
```python
from codepilot import Runtime
runtime = Runtime("agent.yaml")
summary = runtime.run("Create a FastAPI hello-world server in main.py")
print(summary) # what the agent reported in done()
```
`run()` is **blocking** — it returns when the agent calls `done()`, hits `max_steps`, or is aborted. The return value is the summary string passed to `done()`, or `None` if the loop ended for any other reason.
---
## 3. Multi-turn Execution
Call `run()` multiple times on the same `Runtime` instance. Each call appends to the shared conversation history. The LLM sees every prior task, every file it wrote, and every command it ran — so it won't re-create existing files or hallucinate about prior work.
```python
from codepilot import Runtime
runtime = Runtime("agent.yaml")
# Turn 1
runtime.run("Create a FastAPI app with a /items GET endpoint")
# Turn 2 — agent has full context of what it built in turn 1
runtime.run("Now add a POST /items endpoint with Pydantic validation")
# Turn 3 — agent knows the full codebase it has built across both turns
runtime.run("Add pytest tests for both endpoints")
```
**The key point:** these are not isolated calls. The message history grows with each `run()`. The agent in turn 3 has seen everything from turns 1 and 2 — it knows the exact files it created and what's in them.
---
## 4. Session Persistence
Session backends are **independent** — you choose one at construction time.
| Backend | Storage | Survives restart | Config needed |
|---|---|---|---|
| `"memory"` (default) | RAM only | ❌ | None |
| `"file"` | `~/.codepilot/sessions/` | ✅ | `session_id` |
### In-memory (default)
History lives in RAM. Zero I/O, zero config. Ideal for a while-loop CLI where you want continuity within a run but don't need history to survive a process restart.
```python
runtime = Runtime("agent.yaml") # memory, id="backendeng..."
runtime = Runtime("agent.yaml", session="memory") # explicit, same thing
runtime = Runtime("agent.yaml", session="memory", session_id="my-session")
```
### File-backed
History is serialised to `~/.codepilot/sessions/<session_id>.json` after every completed `run()`. On Windows this is `%USERPROFILE%\.codepilot\sessions\`. The directory is created automatically and requires no elevated permissions.
```python
# Session id defaults to the agent name (lowercased, spaces → hyphens)
runtime = Runtime("agent.yaml", session="file")
# Explicit session id — more predictable
runtime = Runtime("agent.yaml", session="file", session_id="ecommerce-api")
# Custom session directory (override default ~/.codepilot/sessions/)
from pathlib import Path
runtime = Runtime(
"agent.yaml",
session="file",
session_id="ecommerce-api",
session_dir=Path("/data/codepilot-sessions"),
)
```
The session file format:
```json
{
"session_id": "ecommerce-api",
"agent_name": "BackendEngineer",
"created_at": 1712345678.0,
"updated_at": 1712349999.0,
"messages": [ ... ]
}
```
---
## 5. Resuming a Session
Pass the same `session_id` to a file-backed Runtime and the previous conversation is automatically loaded. The LLM picks up exactly where it left off.
```python
# Session A — first run (process 1)
runtime = Runtime("agent.yaml", session="file", session_id="ecommerce-api")
runtime.run("Create the products and orders FastAPI endpoints")
# Process exits — session saved to ~/.codepilot/sessions/ecommerce-api.json
# -------- later, new process --------
# Session A — resumed (process 2)
runtime = Runtime("agent.yaml", session="file", session_id="ecommerce-api")
# runtime.messages is already populated with the full prior conversation
runtime.run("Add database migrations using Alembic")
# Agent knows exactly what files it created in the previous session
```
### Listing saved sessions
The `FileSession` backend exposes a `list_sessions()` method for building a session picker in a UI or CLI:
```python
from codepilot import FileSession
fs = FileSession(session_id="_", agent_name="_") # dummy instance just to call list_sessions
for s in fs.list_sessions():
print(f"{s['session_id']:30} {s['messages']:4} messages updated {s['updated_at']}")
```
Or inspect a specific session's metadata without loading all messages:
```python
from codepilot import FileSession
fs = FileSession(session_id="ecommerce-api", agent_name="BackendEngineer")
meta = fs.metadata()
if meta:
print(f"Session exists. Last updated: {meta['updated_at']}")
print(f"Saved at: {fs.path}")
else:
print("No saved session — will start fresh")
```
---
## 6. Resetting a Session
Wipes all history — clears in-memory messages and deletes the file if using the file backend. The next `run()` starts completely fresh.
```python
runtime = Runtime("agent.yaml", session="file", session_id="ecommerce-api")
# ... some runs ...
runtime.reset() # wipe everything
runtime.run("Start over — build a GraphQL API instead")
```
---
## 7. Hooks
Hooks are the observability system. Every significant runtime event fires a hook. Register handlers to receive them in your application.
All hook decorators replace the built-in default handler (which prints to stdout with emoji). The built-in defaults mean the library is useful out of the box with zero hook configuration.
```python
from codepilot import (
Runtime,
on_think,
on_tool_call,
on_tool_result,
on_ask_user,
on_finish,
on_user_message_queued,
on_user_message_injected,
EventType,
)
runtime = Runtime("agent.yaml")
@on_think(runtime)
def handle_think(message: str, **_):
"""Fires every time the agent calls think("...")."""
print(f"[Agent] {message}")
@on_tool_call(runtime)
def handle_tool_call(tool: str, args: dict, **_):
"""Fires before every tool executes."""
print(f"[→ {tool}] {args}")
@on_tool_result(runtime)
def handle_tool_result(tool: str, result: str, **_):
"""Fires after every tool returns."""
print(f"[← {tool}] {result[:120]}")
@on_ask_user(runtime)
def handle_ask(question: str, **_):
"""Fires when the agent calls ask_user(). Separate from the answer flow."""
print(f"\n❓ {question}")
@on_finish(runtime)
def handle_finish(summary: str, **_):
"""Fires when the agent calls done()."""
print(f"\n✅ {summary}")
@on_user_message_queued(runtime)
def handle_queued(message: str, **_):
"""Fires immediately when send_message() is called (not yet in context)."""
print(f"[Queued] {message}")
@on_user_message_injected(runtime)
def handle_injected(message: str, **_):
"""Fires when a queued message enters the LLM's context window."""
print(f"[Injected] {message}")
runtime.run("Refactor the database module to use async SQLAlchemy")
```
### Manual hook registration (no decorator)
```python
from codepilot import EventType
runtime.hooks.register(EventType.THINK, lambda message, **_: print(message))
runtime.hooks.register(EventType.FINISH, lambda summary, **_: save_to_db(summary))
```
### Removing the default handler
```python
# Replace default with your own (decorator does this automatically)
runtime.hooks.clear(EventType.THINK)
runtime.hooks.register(EventType.THINK, my_handler)
```
### Full event reference
| Event | Keyword args | When it fires |
|---|---|---|
| `START` | `task` | `run()` is called |
| `STEP` | `step`, `max_steps` | Each agentic step begins |
| `THINK` | `message` | Agent calls `think()` |
| `TOOL_CALL` | `tool`, `args` | Before any tool executes |
| `TOOL_RESULT` | `tool`, `result` | After any tool returns |
| `ASK_USER` | `question` | Agent calls `ask_user()` |
| `PERMISSION_REQUEST` | `tool`, `description` | Tool with `require_permission: true` fires |
| `SECURITY_ERROR` | `error` | AST validation rejects the control block |
| `RUNTIME_ERROR` | `error` | `exec()` throws an exception |
| `FINISH` | `summary` | Agent calls `done()` |
| `MAX_STEPS` | — | Loop exits because `max_steps` was reached |
| `USER_MESSAGE_QUEUED` | `message` | `send_message()` called |
| `USER_MESSAGE_INJECTED` | `message` | Queued message enters LLM context |
| `SESSION_RESET` | — | `reset()` is called |
---
## 8. Permission Gating
Any tool with `require_permission: true` in the AgentFile fires a `PERMISSION_REQUEST` hook before executing. Your handler returns `True` to approve or `False` to deny. If no handler is registered, the runtime falls back to a CLI `y/N` prompt.
```python
from codepilot import Runtime, on_permission_request
runtime = Runtime("agent.yaml")
@on_permission_request(runtime)
def gate(tool: str, description: str, **_) -> bool:
"""
tool — "write_file" | "run_command" | "ask_user"
description — human-readable description of the specific operation
Return True to approve, False to deny.
"""
print(f"\n⚠️ [{tool}] {description}")
return input("Approve? [y/N]: ").strip().lower() in ("y", "yes")
runtime.run("Deploy the application")
```
**Programmatic approval (e.g. in a web app):**
```python
@on_permission_request(runtime)
def auto_approve_reads_deny_writes(tool: str, description: str, **_) -> bool:
if tool == "read_file":
return True
if tool == "run_command" and description.startswith("Execute: python -m pytest"):
return True
return False # deny everything else
```
---
## 9. Mid-task Message Injection
`runtime.run()` is blocking and runs on the calling thread. From any other thread, call `runtime.send_message()` to inject a message into the running agent. The message is:
1. Queued immediately (non-blocking, thread-safe)
2. Tagged `[USER MESSAGE]` — distinct from `[USER INPUT]` (the original task)
3. Injected into the LLM context at the next step boundary
4. The agent is **never** interrupted mid-step
```python
import threading
from codepilot import Runtime, on_think, on_user_message_injected
runtime = Runtime("agent.yaml")
@on_think(runtime)
def display(message: str, **_):
print(f"Agent: {message}")
@on_user_message_injected(runtime)
def confirmed(message: str, **_):
print(f"[Your message is now in context]: {message}")
def run_agent():
runtime.run("Create a utility module with five string helper functions")
agent_thread = threading.Thread(target=run_agent)
agent_thread.start()
# Inject a message while the agent is working
import time
time.sleep(5)
runtime.send_message("Also add type hints to every function")
agent_thread.join()
```
---
## 10. Custom Tools
Register any callable as a tool. Its docstring is automatically pulled into the system prompt so the agent knows when and how to use it.
**Important:** `exec()` discards return values. If your tool produces output the agent should see, you must explicitly call `runtime._append_execution(result)`.
```python
from codepilot import Runtime
runtime = Runtime("agent.yaml")
def web_search(query: str):
"""
Search the web for current information and return a summary.
Use for library documentation, recent API changes, error lookups,
or anything the codebase snapshot can't answer.
"""
# Your search implementation
result = my_search_api(query)
runtime._append_execution(f"[web_search] {result}")
def send_slack(channel: str, message: str):
"""
Send a message to a Slack channel.
Use after completing a task to notify the team.
channel should be the channel name without #, e.g. 'deployments'.
"""
slack_client.chat_postMessage(channel=f"#{channel}", text=message)
runtime._append_execution(f"[send_slack] Message sent to #{channel}.")
runtime.register_tool("web_search", web_search)
runtime.register_tool("send_slack", send_slack)
runtime.run("Research the latest SQLAlchemy 2.0 async API and implement a connection pool")
```
### Overriding a built-in tool
```python
def safe_run_command(command: str, timeout: int = None, background: bool = False):
"""
Run a shell command. Restricted to read-only operations in this environment.
Never import subprocess or os directly — always use this tool.
"""
if any(cmd in command for cmd in ["rm", "del", "format", ">", "sudo"]):
runtime._append_execution(f"[run_command] Blocked: '{command}' is not permitted.")
return
# call original or implement your own
runtime._shell_tools.run_command(command, timeout=timeout, background=background)
runtime.register_tool("run_command", safe_run_command, replace=True)
```
---
## 11. Aborting the Agent
```python
import threading
runtime = Runtime("agent.yaml")
agent_thread = threading.Thread(
target=runtime.run,
args=("Build a complete e-commerce backend",)
)
agent_thread.start()
# From anywhere — stops after the current step completes (never mid-step)
runtime.abort()
agent_thread.join()
```
---
## 12. Building a CLI Tool
The recommended pattern for a conversational CLI — in-memory session, while-loop, `reset` command:
```python
import sys
from codepilot import Runtime, on_think, on_finish, on_ask_user, EventType
runtime = Runtime("agent.yaml", session="memory")
@on_think(runtime)
def show_thinking(message: str, **_):
print(f"\n 💭 {message}")
@on_finish(runtime)
def show_done(summary: str, **_):
print(f"\n✅ {summary}\n")
@on_ask_user(runtime)
def show_question(question: str, **_):
print(f"\n❓ {question}")
print("CodePilot CLI — type 'reset' to clear history, 'quit' to exit.\n")
while True:
try:
task = input("You: ").strip()
except (KeyboardInterrupt, EOFError):
print("\nGoodbye.")
sys.exit(0)
if not task:
continue
if task.lower() == "quit":
sys.exit(0)
if task.lower() == "reset":
runtime.reset()
print("History cleared. Starting fresh.\n")
continue
runtime.run(task)
```
### File-backed CLI (survives restarts, named sessions)
```python
import sys
import argparse
from codepilot import Runtime, FileSession, on_think, on_finish
parser = argparse.ArgumentParser()
parser.add_argument("--session", default=None, help="Session ID to resume")
parser.add_argument("--list", action="store_true", help="List saved sessions")
args = parser.parse_args()
if args.list:
fs = FileSession(session_id="_", agent_name="_")
sessions = fs.list_sessions()
if not sessions:
print("No saved sessions.")
for s in sessions:
print(f" {s['session_id']:30} {s['messages']:4} messages")
sys.exit(0)
session_id = args.session or "default"
runtime = Runtime("agent.yaml", session="file", session_id=session_id)
# Inform user if resuming
fs = FileSession(session_id=session_id, agent_name="")
if fs.exists():
meta = fs.metadata()
print(f"Resuming session '{session_id}' ({len(runtime.messages)} messages in history)\n")
else:
print(f"Starting new session '{session_id}'\n")
@on_think(runtime)
def thinking(message: str, **_):
print(f" 💭 {message}")
@on_finish(runtime)
def done(summary: str, **_):
print(f"\n✅ {summary}\n")
while True:
try:
task = input("You: ").strip()
except (KeyboardInterrupt, EOFError):
print("\nSession saved. Goodbye.")
sys.exit(0)
if not task:
continue
if task.lower() in ("reset", "clear"):
runtime.reset()
print("Session cleared.\n")
continue
if task.lower() in ("quit", "exit"):
sys.exit(0)
runtime.run(task)
```
```bash
# Usage:
python cli.py # new default session
python cli.py --session ecommerce-api # resume named session
python cli.py --list # show all saved sessions
```
---
## 13. Building a Web Server Integration
FastAPI example with WebSocket streaming of hook events and a mid-task injection endpoint:
```python
import asyncio
import threading
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from codepilot import Runtime, EventType
app = FastAPI()
# One runtime per session (in production: store in a session map keyed by session_id)
runtime = Runtime("agent.yaml", session="file", session_id="web-session")
# Bridge between sync hooks and async WebSocket
_event_queue: asyncio.Queue = asyncio.Queue()
def _push(event: dict):
"""Thread-safe push from sync hook into async queue."""
asyncio.get_event_loop().call_soon_threadsafe(_event_queue.put_nowait, event)
runtime.hooks.register(EventType.THINK,
lambda message, **_: _push({"type": "think", "message": message}))
runtime.hooks.register(EventType.TOOL_CALL,
lambda tool, args, **_: _push({"type": "tool_call", "tool": tool, "args": args}))
runtime.hooks.register(EventType.TOOL_RESULT,
lambda tool, result, **_: _push({"type": "tool_result", "tool": tool, "result": result[:300]}))
runtime.hooks.register(EventType.FINISH,
lambda summary, **_: _push({"type": "finish", "summary": summary}))
runtime.hooks.register(EventType.RUNTIME_ERROR,
lambda error, **_: _push({"type": "error", "error": error}))
@app.post("/run")
def start_task(task: str):
"""Start a new task. Non-blocking — agent runs in background thread."""
threading.Thread(target=runtime.run, args=(task,), daemon=True).start()
return {"status": "started"}
@app.post("/message")
def inject_message(message: str):
"""Inject a mid-task message. Returns immediately."""
runtime.send_message(message)
return {"status": "queued"}
@app.post("/reset")
def reset_session():
"""Wipe conversation history and start fresh."""
runtime.reset()
return {"status": "reset"}
@app.websocket("/events")
async def stream_events(websocket: WebSocket):
"""Stream all hook events to the frontend as JSON."""
await websocket.accept()
try:
while True:
event = await _event_queue.get()
await websocket.send_json(event)
except WebSocketDisconnect:
pass
```
---
## 14. Full API Surface
### `Runtime`
```python
Runtime(
agent_file: str, # path to agent.yaml
session: str = "memory", # "memory" | "file"
session_id: str = None, # defaults to agent name, slugified
session_dir: Path = None, # override ~/.codepilot/sessions/
)
runtime.run(task: str) -> Optional[str]
# Blocking. Appends to history. Returns done() summary or None.
runtime.send_message(message: str)
# Thread-safe. Non-blocking. Tagged [USER MESSAGE] in context.
runtime.reset()
# Wipes messages + session file. Next run() is a blank slate.
runtime.abort()
# Sets abort flag. Loop stops after current step.
runtime.register_tool(name: str, func: callable, replace: bool = False)
# Add custom tool. Docstring injected into system prompt automatically.
runtime.messages # List[Dict] — full conversation history
runtime.session # BaseSession — current session backend instance
runtime.hooks # HookSystem — register/emit events manually
runtime.registry # ToolRegistry — inspect registered tools
```
### `FileSession`
```python
FileSession(session_id, agent_name, session_dir=None)
.load() -> List[Dict] # load messages from disk
.save(messages) # persist messages to disk (atomic write)
.reset() # delete session file
.exists() -> bool # True if file exists on disk
.metadata() -> Optional[Dict] # session metadata without messages
.list_sessions() -> List[Dict] # all sessions in the session directory
.path -> Path # full path to the session file
.session_id -> str
```
### `InMemorySession`
```python
InMemorySession(session_id="default")
.load() -> List[Dict]
.save(messages)
.reset()
.session_id -> str
```
### `create_session`
```python
create_session(
backend: str = "memory", # "memory" | "file"
session_id: str = "default",
agent_name: str = "agent",
session_dir: Path = None,
) -> BaseSession
```
---
*CodePilot — code-native agents, zero JSON, full context.*
| text/markdown | null | CodePilot Team <author@example.com> | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pydantic>=2.0",
"openai>=1.0",
"anthropic>=0.3",
"python-dotenv>=1.0",
"PyYAML>=6.0",
"rich>=13.0",
"jinja2>=3.1"
] | [] | [] | [] | [
"Homepage, https://github.com/Jahanzeb-git/codepilot",
"Repository, https://github.com/Jahanzeb-git/codepilot"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:04:39.261147 | codepilot_ai-0.2.2.tar.gz | 39,742 | 9e/dc/7effe23e1a6466ba3bdcdf460e991f3188b8743449a3c90b6047cbd8693b/codepilot_ai-0.2.2.tar.gz | source | sdist | null | false | 1f7da511e1eedbf9f378e20326bbd175 | d301565c8c5167818c20cc80c4b0f6c93d0cd9e0879f9efd39cf912cc762f895 | 9edc7effe23e1a6466ba3bdcdf460e991f3188b8743449a3c90b6047cbd8693b | null | [
"LICENSE"
] | 206 |
2.1 | psychopy | 2026.1.0 | PsychoPy provides easy, precise, flexible experiments in behavioural sciences | # PsychoPy
[](https://pypi.python.org/pypi/PsychoPy)
[](code-of-conduct.md)
---
PsychoPy is an open-source package for creating experiments in behavioral science. It aims to provide a single package that is:
* precise enough for psychophysics
* easy enough for teaching
* flexible enough for everything else
* able to run experiments in a local Python script or online in JavaScript
To meet these goals PsychoPy provides a choice of interface - you can use a
simple graphical user interface called Builder, or write your experiments in
Python code. The entire application and library are written in Python and is
platform independent.
There is a range of documentation at:
* [PsychoPy Homepage](https://www.psychopy.org)
* [Youtube](https://www.youtube.com/playlist?list=PLFB5A1BE51964D587)
* The textbook, [Building Experiments in PsychoPy](https://uk.sagepub.com/en-gb/eur/building-experiments-in-psychopy/book253480)
* [The discourse user forum](https://discourse.psychopy.org)
## Contributions
To contribute, please fork the repository, hack in a feature branch, and send a
pull request. For more, see [CONTRIBUTING.md](CONTRIBUTING.md)
and the developers documentation at [https://www.psychopy.org/developers](https://psychopy.org/developers)
## Code Status
Dev branch: [](https://github.com/psychopy/psychopy/actions/workflows/pytests.yaml?query=branch%3Adev) [](https://github.com/psychopy/psychopy/actions/workflows/CodeQL.yaml?query=branch%3Adev)
Release branch: [](https://github.com/psychopy/psychopy/actions/workflows/pytests.yaml?query=branch%3Arelease) [](https://github.com/psychopy/psychopy/actions/workflows/CodeQL.yaml?query=branch%3Arelease)
## More information
* Homepage: https://www.psychopy.org
* Forum: https://discourse.psychopy.org
* Issue tracker: https://github.com/psychopy/psychopy/issues
* Changelog: https://www.psychopy.org/changelog.html
| text/markdown | null | Open Science Tools Ltd <support@opensciencetools.org> | null | Open Science Tools Ltd <support@opensciencetools.org> | null | null | [
"Development Status :: 4 - Beta",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Scientific/Engineering",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)"
] | [] | null | null | <3.12,>=3.9 | [] | [] | [] | [
"numpy",
"scipy<1.15",
"matplotlib",
"pyglet==1.4.11; platform_system == \"Windows\"",
"pyglet==1.5.27; platform_system != \"Windows\"",
"pillow>=9.4.0",
"pyqt6",
"pandas>=1.5.3",
"questplus>=2023.1",
"openpyxl",
"xmlschema",
"soundfile",
"imageio",
"imageio-ffmpeg",
"psychtoolbox<3.0.20; platform_machine != \"arm64\"",
"pywinhook; platform_system == \"Windows\"",
"zope.event==5.0",
"zope.interface==7.2",
"gevent==25.5.1",
"MeshPy",
"psutil",
"pyzmq>=22.2.1",
"ujson",
"msgpack",
"msgpack-numpy",
"pyyaml",
"freetype-py",
"python-bidi",
"arabic-reshaper",
"websockets",
"wxPython>=4.1.1",
"markdown-it-py",
"requests",
"future",
"setuptools==78.1.1",
"python-gitlab",
"gitpython",
"cryptography",
"astunparse",
"esprima",
"jedi>=0.16",
"pyserial",
"pyparallel; platform_system != \"Darwin\"",
"ffpyplayer",
"opencv-python",
"python-vlc==3.0.11115; platform_system == \"Windows\"",
"python-vlc>=3.0.12118; platform_system != \"Windows\"",
"pypiwin32; platform_system == \"Windows\"",
"pyobjc-core>8.0; platform_system == \"Darwin\"",
"pyobjc-framework-Quartz>8.0; platform_system == \"Darwin\"",
"pyobjc>8.0; platform_system == \"Darwin\"",
"pyobjc-framework-ScriptingBridge>8.0; platform_system == \"Darwin\"",
"zeroconf; platform_system == \"Darwin\"",
"python-xlib; platform_system == \"Linux\"",
"distro; platform_system == \"Linux\"",
"tables!=3.9.2",
"packaging>=24.0",
"moviepy",
"pyarrow",
"beautifulsoup4",
"pytest>=6.2.5; extra == \"tests\"",
"pytest-codecov; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"pytest-asyncio; extra == \"tests\"",
"flake8; extra == \"tests\"",
"xmlschema; extra == \"tests\"",
"sphinx; extra == \"docs\"",
"jinja2; extra == \"docs\"",
"sphinx-design; extra == \"docs\"",
"sphinx-copybutton; extra == \"docs\"",
"myst-parser; extra == \"docs\"",
"sphinxcontrib.svg2pdfconverter; extra == \"docs\"",
"psychopy-sphinx-theme; extra == \"docs\"",
"bdist-mpkg>=0.5.0; platform_system == \"Darwin\" and extra == \"building\"",
"py2app; platform_system == \"Darwin\" and extra == \"building\"",
"dmgbuild; platform_system == \"Darwin\" and extra == \"building\"",
"polib; extra == \"building\"",
"sounddevice; extra == \"suggested\"",
"pylsl>=1.16.1; extra == \"suggested\"",
"xlwt; extra == \"suggested\"",
"h5py; extra == \"suggested\"",
"tobii_research; extra == \"suggested\"",
"badapted>=0.0.3; extra == \"suggested\"",
"egi-pynetstation>=1.0.0; extra == \"suggested\"",
"pyxid2>=1.0.5; extra == \"suggested\"",
"Phidget22; extra == \"suggested\"",
"pyo>=1.0.3; extra == \"legacy\"",
"pyglfw; extra == \"legacy\"",
"pygame; extra == \"legacy\""
] | [] | [] | [] | [
"Homepage, https://www.psychopy.org/",
"Download, https://github.com/psychopy/psychopy/releases/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:04:36.580921 | psychopy-2026.1.0.tar.gz | 45,819,435 | ef/23/eee828fc9569aead495e1b19115f0d280d926f527b222d96e50432cad749/psychopy-2026.1.0.tar.gz | source | sdist | null | false | 3bba9925fe8d29b784c99163126eb2eb | 6e5d290734d7b1e4ee96482c3421ccf8b1961196b589ec5fb5e4d4b81ecedb8e | ef23eee828fc9569aead495e1b19115f0d280d926f527b222d96e50432cad749 | null | [] | 443 |
2.2 | tmatrix | 1.2.1 | Seismic properties and pore structure of carbonate rocks | # tmatrix
[](https://developer.equinor.com/governance/scm-policy/)
[](https://badge.fury.io/py/tmatrix)
## Installation
For most users, installing from PyPI is the preferred way:
```bash
pip install tmatrix
```
Or using `uv`:
```bash
uv add tmatrix
```
For developers, the project can be compiled with `cmake`:
```bash
cd tmatrix
mkdir build && cd build
cmake ..
make
```
All objects are placed in the build subdirectory.
Note that enabling parallel processing incurs some overhead, and should only be
enabled for large jobs (e.g. 10.000+ sequential calls).
Under Windows use, find your desired Windows CMake [generator](https://cmake.org/cmake/help/v3.4/manual/cmake-generators.7.html#visual-studio-generators), ie:
```bash
cd tmatrix
mkdir build
cd build
cmake .. -G "Visual Studio 14 2015 Win64"
cmake --build . --target ALL_BUILD --config Release
```
## Usage
The package exposes two functions
- `tmatrix_porosity`
- `tmatrix_porosity_noscenario`
### TMatrix porosity
```python
from tmatrix import tmatrix_porosity
# Dimension of the output array
dim = 21
# Output result is stored in `out_np`
out_np = np.zeros((dim, 4))
# Mineral properties. Contains mineral bulk modulus [Pa], shear modulus [Pa] and density [kg/m³]. Shape should be (N, 3).
mineral_property_np = np.tile(np.array([7.10e10, 3.20e10, 2.71e03]), (dim, 1))
# Mineral properties. Contains mineral bulk modulus [Pa], shear modulus [Pa] and density [kg/m³]. Shape should be (N, 3).
fluid_property_np = np.tile(np.array([2.700e09, 1.005e03, 1.000e02, 1.000e02]), (dim, 1))
# Porosity values. Shape should be (N,).
phi_vector_np = np.linspace(0.15, 0.25, dim)
# Input scenario. Can be 1,2,3 or 4.
# 1: Dual porosity, mostly rounded pores
# 2: Dual porosity, little rounded pores
# 3: Mixed pores
# 4: Flat pores and cracks
in_scenario = 1
# Signal frequency [Hz]
frequency = 1000
# Angle of symmetry plane (0 = HTI, 90 = VTI medium) [deg]
angle_of_sym_plane = 90
# Fraction of inclusions that are connected
per_inc_con = 0.5
# Fraction of inclusions that are anisotropic
per_inc_any = 0.5
_ = tmatrix.tmatrix_porosity(
out_np=out_np,
dim=dim,
mineral_property_np=mineral_property_np,
fluid_property_np=fluid_property_np,
phi_vector_np=phi_vector_np,
in_scenario=in_scenario,
frequency=frequency,
angle_of_sym_plane=angle_of_sym_plane,
per_inc_con=per_inc_con,
per_inc_any=per_inc_any,
)
# Returns 0 if success, otherwise failure. Result will be stored in `out_np`, with shape (dim, 4).
# Column values in order are:
# Vp: Vertical P-wave velocity [m/s]
# Vsv: Vertical polarity S-wave velocity [m/s]
# Vsh: Horizontal polarity S-wave velocity [m/s]
# Rhob [kg/m^3]
```
### TMatrix porosity noscenario
```python
from tmatrix import tmatrix_porosity_noscenario
# Dimension of the output array
out_N = 21
# Output result is stored in `out_np`
out_np = np.zeros((out_N, 4))
# Mineral properties. Contains mineral bulk modulus [Pa], shear modulus [Pa] and density [kg/m³]. Shape should be (N, 3).
mineral_property_np = np.tile(np.array([7.10e10, 3.20e10, 2.71e03]), (out_N, 1))
# Fluid properties. Contains fluid bulk modulus [Pa] and density [kg/m³], viscosity [cP] and permeability [mD]. Shape should be (N, 4).
fluid_property_np = np.tile(np.array([2.700e09, 1.005e03, 1.000e02, 1.000e02]), (out_N, 1))
# Porosity values. Shape should be (N,).
phi_vector_np = np.linspace(0.15, 0.25, out_N)
# Aspect ratio values. Shape should be (N,) where N is the number of aspect ratio values
alpha_np = np.tile(np.array([0.9, 0.1]), (out_N, 1))
# Number of aspect ratio values per sample
alpha_size_np = np.full((out_N,), 2, dtype=int)
# Length of alpha array
alpha_N = 21
# Fraction of porosity with given aspect ratio
v_np = np.tile(np.array([0.9, 0.1]), (out_N, 1))
# Signal frequency [Hz]
frequency = 1000
# Angle of symmetry plane (0 = HTI, 90 = VTI medium) [deg]
angle = 90
# Fraction of inclusions that are connected
inc_con_np = np.array([0,5])
# Fraction of inclusions that are anisotropic
inc_ani_np = np.array([0,5])
# Length of `inc_con_np` and `inc_ani_np`
inc_con_N = 1
tmatrix.tmatrix_porosity_noscenario(
out_np=out_np,
out_N=out_N,
mineral_property_np=mineral_property_np,
fluid_property_np=fluid_property_np,
phi_vector_np=phi_vector_np,
alpha_np=alpha_np,
v_np=v_np,
alpha_size_np=alpha_size_np,
alpha_N=alpha_N,
frequency=frequency,
angle=angle,
inc_con_np=inc_con_np,
inc_ani_np=inc_ani_np,
inc_con_N=inc_con_N,
)
# Returns None. Result will be stored in `out_np`. Output array has shape (out_N, 4).
# Column values in order are:
# Vp: Vertical P-wave velocity [m/s]
# Vsv: Vertical polarity S-wave velocity [m/s]
# Vsh: Horizontal polarity S-wave velocity [m/s]
# Rhob [kg/m^3]
```
## Literature
The theory can be found in the papers and in the references therein:
1. Agersborg, R., Jakobsen, M., Ruud, B.O. and Johansen, T. A. 2007.
Effects of pore fluid pressure on the seismic response of a fractured carbonate reservoir.
Stud. Geophys. Geod., 51, 89-118.
[Link](dx.doi.org/10.1007/s11200-007-0005-8)
2. Agersborg, R., Johansen, T. A. and Ruud, B.O. 2008.
Modelling reflection signatures of pore fluids and dual porosity in carbonate reservoirs.
Journal of Seismic Exploration, 17(1), 63-83.
3. Agersborg, R., Johansen, T. A., Jakobsen, M., Sothcott, J. and Best, A. 2008.
Effect of fluids and dual-pores systems on pressure-dependent velocities and attenuation in carbonates,
Geophysics, 73, No. 5, N35-N47.
[Link](dx.doi.org/10.1190/1.2969774)
4. Agersborg, R., Johansen, T. A., and Jakobsen, M. 2009.
Velocity variations in carbonate rocks due to dual porosity and wave-induced fluid flow.
Geophysical Prospecting, 57, 81-98.
[Link](dx.doi.org/10.1111/j.1365-2478.2008.00733.x)
All of the papers and a extended explanations of the involved equations
can be found in Agersborg (2007), phd thesis:
[Link](https://bora.uib.no/handle/1956/2422)
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | <3.15,>=3.11 | [] | [] | [] | [
"numpy>=1.26.4"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:04:16.168887 | tmatrix-1.2.1-cp314-cp314-win_amd64.whl | 132,072 | f7/ea/948b299e65b46a833a5fb0fa5cb12a05c87bcffe36847f4f55835357e6e6/tmatrix-1.2.1-cp314-cp314-win_amd64.whl | cp314 | bdist_wheel | null | false | a69241fe40284560aeb964a9a2b3fddf | 838e326af74bbf913b589de6a1e85b526f841d8d36bc863a9d3ae2e46aa3d5d7 | f7ea948b299e65b46a833a5fb0fa5cb12a05c87bcffe36847f4f55835357e6e6 | null | [] | 1,162 |
2.4 | phypanda | 1.0.3 | package containing the PaNDA framework for exploring, visualizing and maximizing phylogenetic diversity in phylogenetic networks | # `phypanda`
`phypanda` is a Python package that contains PaNDA (Phylogenetic Network Diversity Algorithms): a software framework for exploring, visualizing and maximizing phylogenetic diversity in phylogenetic networks.
## List of important features
- Maximizing all-paths diversity in a rooted phylogenetic network
- Computing the all-paths diversity for a given set of taxa in a rooted phylogenetic network
- Greedily select a set of taxa with large all-paths diversity
## Installation
If you have an up-to-date version of [Python](https://www.python.org/downloads/) installed on your device, the standard package manager `pip` should come pre-installed. Then, you can install `phypanda` from [PyPI](https://pypi.org/project/phypanda/) by simply using the following command in a terminal:
```
python -m pip install phypanda
```
## Example usage
### Importing the package
To get started with `phypanda`, open a Python shell and import the package with:
```
import phypanda as ppa
```
### Maximizing all-paths diversity
To maximize the all-paths diversity of a rooted network (given in `eNewick` format) for a set of `k` taxa, use the function `solve_MAPPD`. For example, when finding a set of 10 taxa with maximum all-paths diversity in the [Xiphophorus network](https://github.com/nholtgrefe/panda/blob/main/data/exp2_xiphophorus_network.txt) from the PaNDA paper, run:
```
enewick = '((((((((((Xgordoni:1.3295084631587457,Xmeyeri:1.3295084631587457):0.0,Xcouchianus:1.329508093234352):6.999730834529853,Xvariatus:8.329238927764205):2.1769451514229345,Xevelynae:10.50618407918714):1.118605313770228,(Xxiphidium:7.2210504457107145,#H24:0.0):4.403738947246653):0.0,Xmilleri:11.624787067955268):4.296868586395352,Xandersi:15.92165565435062):0.9486610416497712,Xmaculatus:16.87031669600039):0.5723386247384958,((((Xmontezumae:7.221055986870681,(Xcortezi:5.485599585171238,((Xmalinche:5.485605240002155,Xbirchmanni:5.485605240002155):0.0)#H26:0.0):1.7354564016994427):0.0,((Xnigrensis:2.4303498026154564,Xmultilineatus:2.4303498026154564):0.19174715477323678,(Xpygmaeus:1.347820846400494,Xcontinens:1.347820846400494):1.2742761109881993):4.598960284156991):0.0,#H26:1.7354540549075645):0.0)#H24:10.2216024589192):2.1886232296055894,((Xclemenciae:11.254572014210282,Xmonticolus:11.254572014210282):6.4012991117391564,(#H25:1.6332001759073602,(Xsignum:10.266850863153604,((Xhellerii:8.633649976742058)#H25:1.6332013685506936,(Xalvarezi:8.362082334652573,Xmayae:8.362082334652573):1.9047690106401785):0.0):0.0):7.3890209733000205):1.975407424395037);'
k = 10
pd, taxa = ppa.solve_MAPPD(enewick, k)
```
Note, edges without branch lengths default 1.0 and not to 0.0. To use zero-length edges, explicitly set these edges to 0.0 in the eNewick string.
To print the resulting maximum all-paths diversity and the selected taxa, run:
```
print(f"Maximum all-paths diversity for k = {k} is {pd}")
print("Selected taxa:", taxa)
```
For a complete overview of different methods and extra parameter options, please check the method descriptions in the [source code](https://github.com/nholtgrefe/panda/tree/main/phypanda/src/phypanda) of `phypanda`.
## Citation
If you use `phypanda`, please cite the corresponding paper:
> **PaNDA: Efficient Optimization of Phylogenetic Diversity in Networks**.
> *Niels Holtgrefe, Leo van Iersel, Ruben Meuwese, Yukihiro Murakami, Jannik Schestag.*
> bioRxiv, 2025. doi: [10.1101/2025.11.14.688467](https://www.biorxiv.org/content/10.1101/2025.11.14.688467)
| text/markdown | N. Holtgrefe | "N. Holtgrefe" <n.a.l.holtgrefe@tudelft.nl> | null | null | null | null | [
"License :: OSI Approved :: MIT License"
] | [] | https://github.com/nholtgrefe/panda/tree/main/phypanda | null | >=3.7 | [] | [] | [] | [
"physquirrel<=1.1",
"numpy>=2.0",
"networkx>=3.0",
"matplotlib>=3.7",
"phylox>=1.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.2 | 2026-02-20T13:04:06.523575 | phypanda-1.0.3.tar.gz | 22,975 | a0/b9/e04467c8bfec61bee8f1fe58c44473a8402243beef710e6e220b85baa63d/phypanda-1.0.3.tar.gz | source | sdist | null | false | 8a61e996e37a1f3bfeaaf2f52f9f8f7c | e6c9485223ffe001e96357b1d227fb39d2fc64b3dac9c28901ea39b18ebd65b1 | a0b9e04467c8bfec61bee8f1fe58c44473a8402243beef710e6e220b85baa63d | null | [
"LICENSE"
] | 195 |
2.4 | torch-einops-utils | 0.0.30 | Personal utility functions | ## torch-einops-utils
Some utility functions to help myself (and perhaps others) go faster with ML/AI work
| text/markdown | null | Phil Wang <lucidrains@gmail.com> | null | null | MIT License Copyright (c) 2026 Phil Wang Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | einops, torch | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.9",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"einops>=0.8.1",
"torch>=2.5",
"pytest; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://pypi.org/project/torch-einops-utils/",
"Repository, https://github.com/lucidrains/torch-einops-utils"
] | uv/0.8.13 | 2026-02-20T13:03:53.826575 | torch_einops_utils-0.0.30.tar.gz | 9,430 | f0/f8/7f6cd1a88ac32c8ca5216af6cfb9206468fa445cb85afb97986e60352160/torch_einops_utils-0.0.30.tar.gz | source | sdist | null | false | f39e3c8d907aab6deda0060b3db529d4 | bb3b3b0c0fd183dbc8817256657d7dddc1969da462167d9dc84ff99e73fcb524 | f0f87f6cd1a88ac32c8ca5216af6cfb9206468fa445cb85afb97986e60352160 | null | [
"LICENSE"
] | 8,594 |
2.4 | friTap | 1.4.1.6 | Simplifies SSL/TLS traffic analysis and key extraction using Frida across major platforms. | <div align="center">
<img src="assets/logo.png" alt="friTap Logo" width="300"/>
<p></p><strong>Real-time key extraction and traffic decryption for security research</strong></div></p>
</div>
# friTap
 [](https://badge.fury.io/py/friTap) [](https://github.com/fkie-cad/friTap/actions/workflows/ci.yml)
[](https://github.com/fkie-cad/friTap/actions/workflows/lint.yml)
[](https://github.com/fkie-cad/friTap/actions/workflows/publish.yml)
friTap is a powerful tool designed to assist researchers in analyzing network traffic encapsulated in SSL/TLS. With its ability to automate key extraction, friTap is especially valuable when dealing with malware analysis or investigating privacy issues in applications. By simplifying the process of decrypting and inspecting encrypted traffic, friTap empowers researchers to uncover critical insights with ease.
Key features include seamless support for automated SSL/TLS key extraction, making it an ideal choice for scenarios requiring rapid and accurate traffic analysis. Whether you’re dissecting malicious network behavior or assessing data privacy compliance, friTap streamlines your workflow.
For more details, explore the [OSDFCon webinar slides](assets/friTapOSDFConwebinar.pdf) or check out our [blog post](https://lolcads.github.io/posts/2022/08/fritap/).
This project was inspired by [SSL_Logger](https://github.com/google/ssl_logger ) and currently supports all major operating systems (Linux, Windows, Android). More platforms and libraries will be added in future releases.
## Key Features
The main features of friTap are:
- TLS key extraction in real time (`-k key.log`)
- Decryption of TLS payload as PCAP in real time (`-p plaintext.pcap`)
- Library analysis and debugging (`--list-libraries`)
- Integration with Python. [Learn more](https://github.com/fkie-cad/friTap/blob/main/INTEGRATION.md)
- Support for custom Frida scripts. [Details](https://github.com/fkie-cad/friTap/blob/main/USAGE.md#custom-script-example)
- Support of most common SSL libraries (OpenSSL, BoringSSL, NSS, GnuTLS, etc.)
## Installation
Installation is simply a matter of `pip3 install fritap`. This will give you the `fritap` command. You can update an existing `fritap` installation with `pip3 install --upgrade fritap`.
## Usage
On Linux/Windows/MacOS we can easily attach to a process by entering its name or its PID:
```bash
$ sudo fritap --pcap mycapture.pcap thunderbird
```
For mobile applications we just have to add the `-m` parameter to indicate that we are now attaching (or spawning) an Android or iOS app:
```bash
$ fritap -m -k keys.log com.example.app
```
Further ensure that the frida-server is running on the Android/iOS device.
Remember when working with the pip installation you have to invoke the `fritap` command with sudo a little bit different. Either as module:
```bash
$ sudo -E python3 -m friTap.friTap --pcap mycapture.pcap thunderbird
```
or directly invoking the script:
```bash
$ which friTap
/home/daniel/.local/bin/friTap
$ sudo -E /home/daniel/.local/bin/friTap
```
friTap can also be used as a Python library within your project:
```python
from friTap import SSL_Logger
```
For more details on integrating friTap into your Python project, check out the [INTEGRATION.md](./INTEGRATION.md) guide.
friTap allows you to enhance its functionality by providing a custom Frida script during your session. This custom script will be invoked just before friTap applies its own hooks. To do so, use the `-c` parameter ([more](./USAGE.md#custom-script-example)).
More examples on using friTap can be found in the [USAGE.md](./USAGE.md). A detailed introduction using friTap on Android is under [EXAMPLE.md](./EXAMPLE.md) as well.
## Hooking Libraries Without Symbols
In certain scenarios, the library we want to hook offers no symbols or is statically linked with other libraries, making it challenging to directly hook functions. For example Cronet (`libcronet.so`) and Flutter (`libflutter.so`) are often statically linked with **BoringSSL**.
Despite the absence of symbols, we can still use friTap for parsing and hooking.
### Hooking by Byte Patterns
To solve this, we can use friTap with byte patterns to hook the desired functions. You can provide friTap with a JSON file that contains byte patterns for hooking specific functions, based on architecture and platform using the `--patterns <byte-pattern-file.json>` option.
In order to apply the apprioate hooks for the various byte patterns we distinguish between different hooking categories.
These categories include:
- Dump-Keys
- Install-Key-Log-Callback
- KeyLogCallback-Function
- SSL_Read
- SSL_Write
Each category has a primary and fallback byte pattern, allowing flexibility when the primary pattern fails.
For libraries like BoringSSL, where TLS functionality is often statically linked into other binaries, we developed a tool called [BoringSecretHunter](https://github.com/monkeywave/BoringSecretHunter). This tool automatically identifies the necessary byte patterns to hook BoringSSL by byte-pattern matching. BoringSecretHunter is available as a Docker container with pre-configured Ghidra environment:
```bash
# Create directories and copy target libraries
mkdir -p binary results
cp /path/to/libflutter.so binary/
# Run BoringSecretHunter
docker run --rm -v "$(pwd)/binary":/usr/local/src/binaries -v "$(pwd)/results":/host_output boringsecrethunter
# Use generated patterns with friTap
fritap --patterns results/libflutter.so_patterns.json -k keys.log target_app
```
More about the different hooking categories can be found in [usage of byte-patterns in friTap](./USAGE.md#hooking-by-byte-patterns).
### Hooking by Offsets
Alternatively, you can use the `--offsets <offset-file.json>` option to hook functions using known offsets. friTap allows you to specify user-defined offsets (relative to the base address of the targeting SSL/socket library) or absolute virtual addresses for function resolution. This is done through a JSON file, which is passed using the `--offsets` parameter.
If the `--offsets` parameter is used, friTap will only overwrite the function addresses specified in the JSON file. For functions that are not specified, friTap will attempt to detect the addresses automatically (using symbols).
## Problems
The absence of traffic or incomplete traffic capture in the resulting pcap file (-p <your.pcap>) may stem from various causes. Before submitting a new issue, consider attempting the following solutions:
### Default Socket Information
There might be instances where friTap fails to retrieve socket information. In such scenarios, running friTap with default socket information (`--enable_default_fd`) could resolve the issue. This approach utilizes default socket information (127.0.0.1:1234 to 127.0.0.1:2345) for all traffic when the file descriptor (FD) cannot be used to obtain socket details:
```bash
fritap -m --enable_default_fd -p plaintext.pcap com.example.app
```
### Handling Subprocess Traffic
Traffic originating from a subprocess could be another contributing factor. To capture this traffic, friTap can leverage Frida's spawn gating feature, which intercepts newly spawned processes using the `--enable_spawn_gating` parameter:
```bash
fritap -m -p log.pcap --enable_spawn_gating com.example.app
```
### Library Support exist only for Key Extraction
In cases where the target library solely supports key extraction (cf. the table below), you can utilize the `-k <key.log>` parameter alongside full packet capture:
```bash
fritap -m -p log.pcap --full_capture -k keys.log com.example.app
```
### Seeking Further Assistance
If these approaches do not address your issue, please create a detailed issue report to aid in troubleshooting. To facilitate a more effective diagnosis, include the following information in your report:
- The operating system and its version
- The specific application encountering the issue or a comparable application that exhibits similar problems
- The output from executing friTap with the specified parameters, augmented with friTap's debug output:
```bash
fritap -do -v com.example.app
```
## Supported SSL/TLS implementations and corresponding logging capabilities
```markdown
| Library | Linux | Windows | MacOSX | Android | iOS |
|---------------------------|---------------|---------------|----------|----------|--------------|
| OpenSSL | Full | R/W-Hook only | TBI | Full | TBI |
| BoringSSL | Full | R/W-Hook only | KeyEo | Full | KeyEo |
| NSS | Full | R/W-Hook only | TBI | TBA | TBI |
| GnuTLS | R/W-Hook only | R/W-Hook only | TBI | Full | TBI |
| WolfSSL | R/W-Hook only | R/W-Hook only | TBI | Full | TBI |
| MbedTLS | R/W-Hook only | R/W-Hook only | TBI | Full | TBI |
| Bouncycastle/Spongycastle | TBA | TBA | TBA | Full | TBA |
| Conscrypt | TBA | TBA | TBA | Full | TBA |
| S2n-tls | Full | LibNO | TBA | Full | LibNO |
| RusTLS | KeyEo | TBI | TBI | KeyEo | TBI |
```
**R/W-Hook only** = Logging data sent and received by process<br>
**KeyEo** = Only the keying material can be extracted<br>
**Full** = Logging data send and received by process + Logging keys used for secure connection<br>
**TBA** = To be answered<br>
**TBI** = To be implemented<br>
**LibNO** = This library is not supported for this plattform<br>
**We verified the Windows implementations only for Windows 10**
## Dependencies
- [frida](https://frida.re) (`>= 17`)
- `>= python3.7`
- click (`python3 -m pip install click`)
- hexdump (`python3 -m pip install hexdump`)
- scapy (`python3 -m pip install scapy`)
- watchdog (`python3 -m pip install watchdog`)
- importlib.resources (`python3 -m pip install importlib-resources`)
- AndroidFridaManager (`python3 -m pip install AndroidFridaManager`)
- for hooking on Android ensure that the `adb`-command is in your PATH
## Planned features
- [ ] add the capability to alter the decrypted payload
- integration with https://github.com/mitmproxy/mitmproxy
- integration with http://portswigger.net/burp/
- [ ] add wine support
- [x] <strike>add Flutter support</strike>
- [ ] add further libraries (have a look at this [Wikipedia entry](https://en.wikipedia.org/wiki/Comparison_of_TLS_implementations)):
- Botan (BSD license, Jack Lloyd)
- LibreSSL (OpenBSD)
- Cryptlib (Peter Gutmann)
- JSSE (Java Secure Socket Extension, Oracle)
- [MatrixSSL](https://github.com/matrixssl/matrixssl)
- ...
- [x] <strike>Working with static linked libraries</strike>
- [x] <strike>Add feature to prototype TLS-Read/Write/SSLKEY functions</strike>
- [ ] improve iOS/MacOS support (currently under development)
## Development
### Quick Development Setup
For developers who want to contribute to friTap, we provide an automated setup:
```bash
# Clone and setup development environment
git clone https://github.com/fkie-cad/friTap.git
cd friTap
# Automated setup (recommended)
python setup_dev.py
# Manual setup
pip install -r requirements-dev.txt
pip install -e .
npm install # For TypeScript agent compilation
```
### Testing
friTap includes a comprehensive testing framework:
```bash
# Run all fast tests
python run_tests.py --fast
# Run specific test categories
python run_tests.py unit # Unit tests
python run_tests.py agent # Agent compilation tests
python run_tests.py integration # Mock integration tests
# Generate coverage report
python run_tests.py coverage
```
### Development Dependencies
- **Python 3.7+** with development dependencies (`requirements-dev.txt`)
- **Node.js 16+** for TypeScript agent compilation
- **Testing framework**: pytest with comprehensive mocking
- **Code quality**: black, flake8, mypy, pre-commit hooks
See [DEVELOPMENT.md](./DEVELOPMENT.md) for detailed development setup and testing guide.
## Contribute
Contributions are always welcome. Just fork it and open a pull request!
More details can be found in the [CONTRIBUTION.md](./CONTRIBUTION.md).
___
## Changelog
See the wiki for [release notes](https://github.com/fkie-cad/friTap/releases).
## How to Cite friTap
If you use **friTap** in your research, please cite the following paper:
> **Daniel Baier, Alexander Basse, Jan-Niclas Hilgert, Martin Lambertz**
> *TLS key material identification and extraction in memory: current state and future challenges*
> Forensic Science International: Digital Investigation, Volume 49, 2024, 301766.
> [https://doi.org/10.1016/j.fsidi.2024.301766](https://doi.org/10.1016/j.fsidi.2024.301766)
### 📄 BibTeX
```bibtex
@article{baier2024tls,
title={TLS key material identification and extraction in memory: current state and future challenges},
author={Baier, Daniel and Basse, Alexander and Hilgert, Jan-Niclas and Lambertz, Martin},
journal={Forensic Science International: Digital Investigation},
volume={49},
pages={301766},
year={2024},
publisher={Elsevier},
doi={10.1016/j.fsidi.2024.301766}
}
```
Alternatively, you can find a citation file in `CITATION.cff` or use the “Cite this repository” button on GitHub.
## Support
If you have any suggestions, or bug reports, please create an issue in the Issue Tracker.
In case you have any questions or other problems, feel free to send an email to:
[daniel.baier@fkie.fraunhofer.de](mailto:daniel.baier@fkie.fraunhofer.de).
| text/markdown | Daniel Baier, Julian Lengersdorff, Francois Egner, Max Ufer | daniel.baier@fkie.fraunhofer.de | null | null | GPL-3.0-only | mobile, instrumentation, frida, hook, SSL decryption | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: OS Independent",
"Natural Language :: English",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: JavaScript",
"Topic :: Security",
"Topic :: Software Development :: Debuggers"
] | [] | https://github.com/fkie-cad/friTap | null | >=3.8 | [] | [] | [] | [
"frida>=16.0.0",
"frida-tools>=11.0.0",
"AndroidFridaManager",
"hexdump",
"scapy",
"watchdog",
"click",
"importlib-resources; python_version < \"3.9\"",
"psutil",
"rich>=13.0.0"
] | [] | [] | [] | [
"Source, https://github.com/fkie-cad/friTap",
"Issues, https://github.com/fkie-cad/friTap/issues",
"Documentation, https://fkie-cad.github.io/friTap/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:03:33.007766 | fritap-1.4.1.6.tar.gz | 5,622,790 | 02/ec/edfc9183cded85d3b7a76125fb972008c8317e8536f1ca324a9c2f0124a0/fritap-1.4.1.6.tar.gz | source | sdist | null | false | c2fe742ff6e1f60267896f163ff27980 | 6c315ff4c3943a0bb182527792ec18f8cce4ec44b2d292aaf46a0e47520a3037 | 02ecedfc9183cded85d3b7a76125fb972008c8317e8536f1ca324a9c2f0124a0 | null | [
"LICENSE"
] | 0 |
2.3 | mk-pre | 0.1.0 | mk-pre plugin | # mk-pre
mk-pre plugin
| text/markdown | Sorin Sbarnea | Sorin Sbarnea <sorin.sbarnea@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.11.0 | [] | [] | [] | [
"rich>=12.0.0",
"typer>=0.16.0",
"typer-config>=1.4.2",
"typing-extensions>=4.14.1"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T13:03:12.811650 | mk_pre-0.1.0-py3-none-any.whl | 4,636 | 47/52/54710f429fc93294017f607f3b997d99cb56bc18daf82367e6f4df3506bc/mk_pre-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 67bb39225215717f3db9af7fec683dc6 | 65502583fc657a7950a490195b9f6a2b5b7494fe384e30c691f76b6296335045 | 475254710f429fc93294017f607f3b997d99cb56bc18daf82367e6f4df3506bc | null | [] | 105 |
2.4 | fhircraft | 0.6.4 | Fhircraft transforms FHIR (Fast Healthcare Interoperability Resources) specifications into type-safe Python models using Pydantic. Build healthcare applications with automatic validation, intelligent code completion, and seamless integration with Python's ecosystem. | <a name="readme-top"></a>
<!-- PROJECT LOGO -->
<br />
<div align="center">
<a href="https://github.com/luisfabib/fhircraft">
<img src="https://github.com/luisfabib/fhircraft/blob/main/docs/assets/images/logo-banner.png?raw=true" width="50%">
</a>


[](https://docs.pydantic.dev/latest/contributing/#badges)

---
<p align="center">
<b>Pythonic healthcare interoperability</b><br>
A comprehensive Python toolkit for working with FHIR healthcare data standards using Pydantic models from core and profiled FHIR specifications, all without external dependencies or complex server infrastructure.
<br />
<br />
<a href="https://luisfabib.github.io/fhircraft"><strong>Explore the Documentation »</strong></a>
<br />
<br />
<a href="https://github.com/luisfabib/fhircraft/issues/new?labels=bug&template=bug-report---.md">Report Bug</a>
·
<a href="https://github.com/luisfabib/fhircraft/issues/new?labels=enhancement&template=feature-request---.md">Request Feature</a>
</p>
</div>
---
> [!WARNING]
> This package is under active development. Major and/or breaking changes are to be expected in future updates.
## Key Features
* Automatic validation of FHIR resources using Pydantic models generated directly from FHIR structure definitions. Catch schema violations and constraint failures without any dedicated servers.
* Work with FHIR data as standard Python objects. No XML parsing, no external FHIR servers required. Access and modify healthcare data using familiar Python syntax and patterns.
* Supports FHIR R4, R4B, and R5 out of the box. Load implementation guides and custom profiles directly from the FHIR package registry to work with specialized healthcare data models.
* Execute FHIRPath expressions directly on Python objects. Query complex nested healthcare data structures using the standard FHIR query language without additional tooling.
* Implement healthcare data transformations using the official FHIR Mapping Language. Convert between different data formats while maintaining semantic integrity and validation.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
## Quick Start
### Prerequisites
- Python 3.10 or higher
### Installation
Install Fhircraft using your package manager of choice. To download the latest release using the `pip` manager:
```bash
pip install fhircraft
```
or install the latest development version:
```bash
pip install git+https://github.com/luisfabib/fhircraft.git
```
To verify your installation:
```python
from fhircraft.fhir.resources.datatypes import get_fhir_resource_type
# This should work without errors
Patient = get_fhir_resource_type("Patient")
print("✓ Fhircraft installed successfully!")
```
<p align="right">(<a href="#readme-top">back to top</a>)</p>
## Demo
### **Built-in FHIR Resources**
Work with pre-generated Pydantic models for all standard FHIR resources. Each model includes full validation rules from the FHIR specification:
```python
from fhircraft.fhir.resources.datatypes import get_fhir_resource_type
# Get built-in Patient model for FHIR R5
Patient = get_fhir_resource_type("Patient", "R5")
# Create and validate a patient
patient = Patient(
name=[{"given": ["Alice"], "family": "Johnson"}],
gender="female",
birthDate="1985-03-15"
)
print(f"Created patient: {patient.name[0].given[0]} {patient.name[0].family}")
```
### **FHIR Package Integration**
Extend base FHIR models with implementation guide profiles loaded directly from the official FHIR package registry:
```python
from fhircraft.fhir.resources.factory import factory
# Load US Core Implementation Guide
factory.load_package("hl7.fhir.us.core", "5.0.1")
# Create US Core Patient model with enhanced validation
USCorePatient = factory.construct_resource_model(
canonical_url="http://hl7.org/fhir/us/core/StructureDefinition/us-core-patient"
)
# Use with US Core constraints
patient = USCorePatient(
identifier=[{"system": "http://example.org/mrn", "value": "12345"}],
name=[{"family": "Doe", "given": ["John"]}],
gender="male"
)
```
### **FHIRPath Querying**
Execute FHIRPath expressions directly on FHIR resource instances to extract, filter, and validate healthcare data:
```python
# Query patient data with FHIRPath
family_names = patient.fhirpath_values("Patient.name.family")
has_phone = patient.fhirpath_exists("Patient.telecom.where(system='phone')")
# Update data using FHIRPath expressions
patient.fhirpath_update_single("Patient.gender", "female")
patient.fhirpath_update_values("Patient.name.given", ["Jane", "Marie"])
print(f"Updated patient: {family_names[0]}, Phone: {has_phone}")
```
### **Data Transformation**
Convert external data sources into valid FHIR resources using declarative mapping scripts:
```python
from fhircraft.fhir.mapper import FHIRMapper
# Legacy system data
legacy_patient = {
"firstName": "Bob",
"lastName": "Smith",
"dob": "1975-06-20",
"sex": "M"
}
# FHIR Mapping script
mapping_script = """
/// url = "http://example.org/legacy-to-fhir"
/// name = "LegacyPatientToFHIR"
uses "http://hl7.org/fhir/StructureDefinition/Patient" as target
group main(source legacy, target patient: Patient) {
legacy -> patient.name as name then {
legacy.firstName -> name.given;
legacy.lastName -> name.family;
};
legacy.dob -> patient.birthDate;
legacy.sex where($this = 'F') -> patient.gender = "female";
legacy.sex where($this = 'M') -> patient.gender = "male";
}
"""
# Execute transformation
mapper = FHIRMapper()
targets = mapper.execute_mapping(mapping_script, legacy_patient)
fhir_patient = targets[0]
print(fhir_patient.model_dump(exclude={'meta','resourceType'}))
#> {'name': [{'family': 'Smith', 'given': ['Bob']}], 'birthDate': '1975-06-20'}
```
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- CONTRIBUTING -->
## Contributing
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are **greatly appreciated**. Checkout the [Contributing Guide](https://luisfabib.github.io/fhircraft/community/contributing/) for more details. Thanks to all our contributors!
<img src="https://contrib.rocks/image?repo=luisfabib/fhircraft">
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- LICENSE -->
## License
This project is distributed under the MIT License. See [LICENSE](https://github.com/luisfabib/fhircraft?tab=MIT-1-ov-file) for more information.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
| text/markdown | null | Luis Fábregas-Ibáñez <luisfabib@gmail.com> | null | null | The MIT License (MIT)
Copyright (c) 2024 to present Luis Fábregas-Ibáñez and individual contributors.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | FHIR, Pydantic, healthcare, modelling, validation | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Environment :: MacOS X",
"Framework :: Pydantic",
"Intended Audience :: Developers",
"Intended Audience :: Healthcare Industry",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Operating System :: Unix",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"jinja2>=3.1",
"jsonpath-ng>1",
"jsonschema>4",
"packaging>=25",
"pint>=0.24",
"ply>=3.11",
"pydantic>=2.7",
"python-dotenv>=1.0",
"pyyaml>=6.0.1",
"requests",
"typer==0.12.3; extra == \"cli\"",
"coverage==7.5.1; extra == \"dev\"",
"parameterized==0.9.0; extra == \"dev\"",
"pytest-mock==3.14.0; extra == \"dev\"",
"pytest>=8.2; extra == \"dev\"",
"griffe-fieldz==0.4.0; extra == \"docs\"",
"mkdocs-gen-files==0.5.0; extra == \"docs\"",
"mkdocs-literate-nav==0.6.1; extra == \"docs\"",
"mkdocs-material==9.5.27; extra == \"docs\"",
"mkdocstrings[python]==0.26.1; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/luisfabib/fhircraft",
"Issues, https://github.com/luisfabib/fhircraft/issues",
"Documentation, https://luisfabib.github.io/fhircraft/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:02:43.475689 | fhircraft-0.6.4.tar.gz | 15,293,848 | 2d/37/0dd79825f0053c69f29edc22b66e5ce00bef6873d61bbb3bb99bd6188be1/fhircraft-0.6.4.tar.gz | source | sdist | null | false | 68fd81a7656e513bb1396157f9ca2dd5 | bb69a7231b9b195bd217eaf920b63c388859177ea3ec036137423cb53bf51e1c | 2d370dd79825f0053c69f29edc22b66e5ce00bef6873d61bbb3bb99bd6188be1 | null | [
"LICENSE"
] | 198 |
2.4 | slickpy | 0.4.8 | A lightweight ASGI toolkit, optimized for great performance, flexibility and productivity. | # SlickPy

[](https://coveralls.io/github/akornatskyy/slickpy?branch=master)
[](https://badge.fury.io/py/slickpy)
A lightweight [ASGI](https://asgi.readthedocs.io/en/latest/index.html)
Python toolkit, optimized for great performance, flexibility and productivity.
## Install
```sh
pip install slickpy
```
## Overview
*example.py*:
```python
from slickpy import App, Writer
app = App()
@app.route("/")
async def welcome(w: Writer) -> None:
await w.end(b"Hello, world!")
main = app.asgi()
```
Then run the example with [uvicorn](https://github.com/encode/uvicorn):
```sh
uvicorn example:main
```
See [examples](https://github.com/akornatskyy/slickpy/tree/master/examples) for more.
| text/markdown | null | Andriy Kornatskyy <andriy.kornatskyy@live.com> | null | null | null | ASGI, http, web, toolkit | [
"Development Status :: 1 - Planning",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [
"any"
] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/akornatskyy/slickpy"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T13:02:38.018344 | slickpy-0.4.8.tar.gz | 13,063 | 33/38/93558a756f1d57e736f294ae332d49cb49851e2bdbd596a9be77482c9e9d/slickpy-0.4.8.tar.gz | source | sdist | null | false | 73f16f2d97a3176152b17fc8473ab62c | 62d46b8f9534dacd74e62c5b7265ea7984e6bd579c8584c59ad9497ae82ffa68 | 333893558a756f1d57e736f294ae332d49cb49851e2bdbd596a9be77482c9e9d | MIT | [
"LICENSE"
] | 137 |
2.4 | allbemcp | 2.0.3 | Turn any Python library into an MCP Server |
<img width="1431" height="260" alt="logo" src="https://github.com/user-attachments/assets/21f95f9c-5620-4f05-8a85-6fb4e5f14fef" />
> **Turn any Python library or your local script into an LLM Tool in seconds.**

allbemcp is a high-performance bridge that instantly exposes any Python environment—whether standard PyPI libraries or your own custom code—as a Model Context Protocol (MCP) server. It enables Large Language Models (Claude, ChatGPT, etc.) to execute local functions, manipulate dataframes, manage stateful objects, and interact with your system safely and efficiently.
Built on the latest **FastMCP + StreamableHTTP** runtime for maximum compatibility with Claude Desktop, LangChain, and Cursor.
## Installation
```bash
pip install allbemcp
```
## Usage Scenarios
allbemcp supports two primary use cases: exposing public libraries and exposing your own custom business logic.
### 1. Exposing Public Libraries
Expose `pandas`, `numpy`, or any other installed library to your LLM with a single command. allbemcp handles dependency installation and API generation automatically.
```bash
# Install, generate, and serve in one go
allbemcp start pandas
# Explicit transport selection
allbemcp start pandas --transport streamable-http
allbemcp start pandas --transport stdio
```
### 2. Exposing Custom Code
allbemcp treats your local Python scripts as first-class citizens. It parses type hints, docstrings, and class structures to generate high-quality tool definitions.
**Step 1: Create your script (e.g., `my_tools.py`)**
```python
# my_tools.py
from typing import List
def calculate_bmi(weight_kg: float, height_m: float) -> float:
"""
Calculate Body Mass Index (BMI).
Args:
weight_kg: Weight in kilograms.
height_m: Height in meters.
"""
return round(weight_kg / (height_m ** 2), 2)
class BankAccount:
"""A stateful class example."""
def __init__(self, owner: str):
self.owner = owner
self.balance = 0
def deposit(self, amount: float) -> str:
self.balance += amount
return f"Deposited ${amount}. New balance: ${self.balance}"
# Factory function to create instances
def open_account(owner: str) -> BankAccount:
return BankAccount(owner)
```
**Step 2: Start the server**
```bash
# allbemcp detects the file in your current directory
allbemcp start my_tools
# FastMCP 3.x is enabled by default in generated requirements
allbemcp generate my_tools --use-fastmcp
```
The LLM can now call `calculate_bmi` directly. Furthermore, if the LLM calls `open_account`, allbemcp automatically manages the returned `BankAccount` instance, allowing the LLM to make subsequent calls to `deposit` on that specific object.
## Client Configuration
To use your tools with **Claude Desktop** or other MCP clients, add the corresponding configuration to your `claude_desktop_config.json`.
**For a Library (e.g., pandas):**
```json
{
"mcpServers": {
"pandas": {
"command": "uv",
"args": ["run", "allbemcp", "start", "pandas"]
}
}
}
```
**For Custom Code (e.g., my_tools):**
```json
{
"mcpServers": {
"my_tools": {
"command": "uv",
"args": ["run", "allbemcp", "start", "my_tools"],
"cwd": "/absolute/path/to/your/script/directory"
}
}
}
```
## Key Features
### Zero-Config Introspection
Automatically inspects Python packages or local modules, extracts public APIs, and generates a fully compliant MCP server. No manual schema definition (YAML/JSON) is required.
### Stateful Object Management
Unlike standard stateless tools, allbemcp supports object-oriented workflows:
- **Instance Persistence**: When a function returns a class instance, it is stored in memory.
- **Method Chaining**: LLMs can invoke methods on specific stored instances via a generated `object_id`.
- **Ideal For**: Database connections, game states, simulation environments, and session-based workflows.
### Smart Serialization Engine
LLMs struggle with complex objects. allbemcp handles them automatically:
- **DataFrames**: Converted to markdown or JSON previews based on size.
- **Images**: Automatically encoded or saved to temporary storage with resource links.
- **Iterators**: Automatically consumed and summarized.
### Local & Secure
Runs entirely on your machine. No data leaves your network. You control the host binding (default `127.0.0.1`) and execution environment.
## Advanced Usage
### Inspect a Library
Check which functions will be exposed and view their quality scores before generating code:
```bash
allbemcp inspect numpy
```
### Generate Only
Generate the server code without running it (useful for auditing or customization):
```bash
allbemcp generate matplotlib --output-dir ./my-server
```
## License
This project is licensed under the **AGPL v3 License**.
| text/markdown | null | Tingjia Zhang <tingjiainfuture@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"docker>=7.0.0",
"docstring-parser>=0.16.0",
"fastapi>=0.110.0",
"fastmcp>=3.0.0",
"mcp>=1.26.0",
"rich>=13.7.0",
"starlette>=0.37.0",
"typer>=0.12.0",
"uvicorn>=0.29.0"
] | [] | [] | [] | [
"Homepage, https://github.com/TingjiaInFuture/allbemcp",
"Repository, https://github.com/TingjiaInFuture/allbemcp"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:02:37.349927 | allbemcp-2.0.3.tar.gz | 68,977 | de/89/c20e767ae74676df85017568883a586abf9e3287f733c6cc6e0abcc94743/allbemcp-2.0.3.tar.gz | source | sdist | null | false | c5afb5c9a7241f127c10d3fd5b76c219 | bf89a2ce5bf47f1cc53bea3a289bde753eaad925e504d7901f76e06c81760501 | de89c20e767ae74676df85017568883a586abf9e3287f733c6cc6e0abcc94743 | AGPL-3.0-only | [
"LICENSE"
] | 205 |
2.4 | phylogenie | 3.6.0 | Generate phylogenetic datasets with minimal setup effort | <p align="center">
<img src="https://raw.githubusercontent.com/gabriele-marino/phylogenie/main/logo.png" style="width:100%; height:auto;"/>
</p>
---
[](https://iqtree.github.io/doc/AliSim)
[](https://pypi.org/project/phylogenie/)

Phylogenie is a [Python](https://www.python.org/) package designed to easily simulate phylogenetic datasets—such as trees and multiple sequence alignments (MSAs)—with minimal setup effort. Simply specify the distributions from which your parameters should be sampled, and Phylogenie will handle the rest!
## ✨ Features
Phylogenie comes packed with useful features, including:
- **Simulate tree and multiple sequence alignment (MSA) datasets from parameter distributions** 🌳🧬
Define distributions over your parameters and sample a different combination of parameters for each dataset sample.
- **Automatic metadata management** 🗂️
Phylogenie stores each parameter combination sampled during dataset generation in a `.csv` file.
- **Generalizable configurations** 🔧
Easily apply the same configuration across multiple dataset splits (e.g., train, validation, test).
- **Flexible acceptance criteria** 🔄
Define custom acceptance criteria on the simulated trees to ensure they meet your requirements.
- **Multiprocessing support** ⚙️💻
Simply specify the number of cores to use, and Phylogenie handles multiprocessing automatically.
- **Pre-implemented parameterizations** 🎯
Include canonical, fossilized birth-death, epidemiological, birth-death with exposed-infectious (BDEI), birth-death with superspreading (BDSS).
- **Skyline parameter support** 🪜
Support for piece-wise constant parameters.
- **Operations on parameters** 🧮
Perform flexible operations between parameters directly within the config file.
## 📦 Installation
Phylogenie requires [Python](https://www.python.org/) 3.10 to be installed on your system. There are several ways to install Python and managing different Python versions. One popular option is to use [pyenv](https://github.com/pyenv/pyenv).
Once you have Python set up, you can install Phylogenie directly from PyPI:
```bash
pip install phylogenie
```
Or install from source:
```bash
git clone https://github.com/gabriele-marino/phylogenie.git
cd phylogenie
pip install .
```
## 🛠 Backend dependency
Phylogenie relies on [AliSim](https://iqtree.github.io/doc/AliSim) for simulating multiple sequence alignments (MSAs). AliSim is a powerful MSAs simulation tool distributed with [IQ-TREE](https://iqtree.github.io/), and requires separate installation to use it as a simulation backend.
## 🚀 Quick Start
Once you have installed Phylogenie, check out the [tutorials](https://github.com/gabriele-marino/phylogenie/tree/main/tutorials) folder.
It includes a collection of thoroughly commented configuration files, organized as a step-by-step tutorial. These examples will help you understand how to use Phylogenie in practice and can be easily adapted to fit your own workflow.
For quick start, pick your favorite config file and run Phylogenie with:
```bash
phylogenie tutorials/config_file.yaml
```
This command will create the output dataset in the folder specified inside the configuration file, including data directories and metadata files for each dataset split defined in the config.
>❗ *Tip*: Can’t choose just one config file?
You can run them all at once by pointing Phylogenie to the folder! Just use: `phylogenie tutorials`. In this mode, Phylogenie will automatically find all `.yaml` files in the folder you specified and run for each of them!
## 📖 Documentation
- The [tutorials](https://github.com/gabriele-marino/phylogenie/tree/main/tutorials) folder contains many ready-to-use, extensively commented configuration files that serve as a step-by-step tutorial to guide you through using Phylogenie. You can explore them to learn how it works or adapt them directly to your own workflows.
- A complete user guide and API reference are under development. In the meantime, feel free to [reach out](mailto:gabmarino.8601@email.com) if you have any questions about integrating Phylogenie into your workflows.
## 📄 License
This project is licensed under [MIT License](https://raw.githubusercontent.com/gabriele-marino/phylogenie/main/LICENSE.txt).
## 📫 Contact
For questions, bug reports, or feature requests, please, consider opening an [issue on GitHub](https://github.com/gabriele-marino/phylogenie/issues), or [contact me directly](mailto:gabmarino.8601@email.com).
For help with configuration files, don’t hesitate to reach out — I’m happy to assist!
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"joblib>=1.5.2",
"matplotlib>=3.10.7",
"pandas>=2.3.3",
"pydantic>=2.12.3",
"pyyaml>=6.0.3",
"tqdm>=4.67.1"
] | [] | [] | [] | [] | uv/0.9.5 | 2026-02-20T13:02:14.767891 | phylogenie-3.6.0.tar.gz | 38,157 | b4/0e/ad9b4a0cf0d1539ca86997fd255ff2cb7ba81887989f89510454ee607511/phylogenie-3.6.0.tar.gz | source | sdist | null | false | 89eeb8fa3d6df6d0987d66acb74ec906 | 7044cbe0c7d9b85f68ba82d03e4fdc55728427d793ddc3b2b52f58156acc9dd2 | b40ead9b4a0cf0d1539ca86997fd255ff2cb7ba81887989f89510454ee607511 | null | [
"LICENSE.txt"
] | 199 |
2.4 | fmu-sim2seis | 0.1.2 | sim2seis | > [!WARNING]
> `fmu-sim2seis` is not yet qualified technology, and as of today only applicable for selected pilot test fields.
**[📚 User documentation](https://equinor.github.io/fmu-sim2seis/)**
## What is fmu-sim2seis?
Calculates synthetic seismic from reservoir simulation model, together with a petro-elastic model.
`fmu-sim2seis` can be run either from command line, or from ERT, the latter being the
preferred option.
### Installation
To install `fmu-sim2seis`, run
```bash
pip install fmu-sim2seis
```
### ERT jobs
`fmu-sim2seis` is divided into a series of separate jobs:
* sim2seis_seismic_forward
* sim2seis_relative_ai
* sim2seis_observed_data
* sim2seis_map_attributes
* sim2seis_cleanup
There exists also a forward model for running petro-elastic modelling, defined in [**fmu-pem**](https://github.com/equinor/fmu-pem).
In the ERT-file for running fmu-sim2seis, necessary arguments are shown in [this example ERT setup](./ERT/run_sim2seis.ert).
Beware of hardcoded directory names - they should be replaced by **your** project path/name.
```bash
cd ./ERT
ert gui run_sim2seis.ert
```
`fmu-sim2seis` (and `fmu-pem`) are controlled by a series of `.yaml`-files which you find in examples of [here](./tests/data/sim2seis/model/pem).
The files `modelled_data_intervals` and `observed_data_intervals.yml` are used to define zones/intervals
for estimating seismic attributes. `sim2seis_config` contains all configuration parameters for all parts
of `fmu-sim2seis` workflow, except for observed seismic data, which has its own configuration file -
`obs_data_config.yml`.
### Tests
`fmu-sim2seis` has tests that use the `tests/data` structure, which contains the necessary input data
files.
```bash
pytest tests
```
### User interface
Users can visit <https://equinor.github.io/fmu-sim2seis/> in order to get help configuring the `fmu-sim2seis` input data.
Developing the user interface can be done by:
```bash
cd ./documentation
npm ci # Install dependencies
npm run create-json-schema # Extract JSON schema from Python code
npm run docs:dev # Start local development server
```
The JSON schema itself (type, title, description etc.) comes from the corresponding Pydantic models in the Python code.
| text/markdown | null | Equinor <fg_fmu-atlas@equinor.com> | null | null | null | energy, subsurface, seismic, scientific, engineering | [
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Physics",
"Topic :: Software Development :: Libraries",
"Topic :: Utilities",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Natural Language :: English",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"numpy>=1.24.3",
"pandas>=2.0.2",
"xtgeo>=3.7.1",
"fmu-tools>=1.16.0",
"fmu-config",
"fmu-dataio",
"fmu-pem>=0.1.1",
"pydantic",
"ert",
"seismic-forward",
"si4ti",
"mypy; extra == \"tests\"",
"pytest; extra == \"tests\"",
"pytest-cov; extra == \"tests\"",
"pytest-xdist; extra == \"tests\"",
"ruff; extra == \"tests\"",
"autoapi; extra == \"docs\"",
"sphinx; extra == \"docs\"",
"sphinx-argparse; extra == \"docs\"",
"sphinx-autodoc-typehints; extra == \"docs\"",
"sphinx-copybutton; extra == \"docs\"",
"sphinx-togglebutton; extra == \"docs\"",
"sphinx_rtd_theme; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/equinor/fmu-sim2seis",
"Repository, https://github.com/equinor/fmu-sim2seis"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:02:13.159810 | fmu_sim2seis-0.1.2.tar.gz | 17,965,714 | a5/8d/e978de5c18740c4c2e0a03bd659ce0c230dd46bc3e7f8e42789f2f7ef0cf/fmu_sim2seis-0.1.2.tar.gz | source | sdist | null | false | 960f04dffccc6effb6ba729a6b5e44c7 | b38563cbb7bc325639b125c61f5c0b5af8e9c714f8661d6d4bcc0e44ef84c79a | a58de978de5c18740c4c2e0a03bd659ce0c230dd46bc3e7f8e42789f2f7ef0cf | null | [
"LICENSE"
] | 198 |
2.4 | big-talk-ai | 1.2.0 | The lightweight, middleware-first LLM framework for Python. | # 🦜 BigTalk
> The lightweight, middleware-first LLM framework for Python.
BigTalk is designed for developers who want the power of agents (tool calling, loops, memory) without the bloat of
heavy frameworks. It provides a clean, type-safe abstraction over LLMs with a robust middleware pipeline inspired by
Starlette/FastAPI.
## Installation
```bash
pip install big-talk-ai[anthropic]
uv add big-talk-ai[anthropic]
```
## Documentation
Visit the GitHub repository for detailed documentation and examples:
[BigTalk on GitHub](https://github.com/DavidVollmers/big-talk/blob/main/README.md)
| text/markdown | null | null | null | null | null | llm, middleware, framework, ai, language-models, chatbots, conversational-ai | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Operating System :: OS Independent",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"docstring-parser>=0.17.0",
"anthropic>=0.79.0; extra == \"anthropic\"",
"openai>=2.21.0; extra == \"openai\"",
"tiktoken>=0.12.0; extra == \"openai\""
] | [] | [] | [] | [
"Homepage, https://github.com/DavidVollmers/big-talk",
"Documentation, https://github.com/DavidVollmers/big-talk/blob/main/README.md",
"Repository, https://github.com/DavidVollmers/big-talk.git",
"Issues, https://github.com/DavidVollmers/big-talk/issues",
"Changelog, https://github.com/DavidVollmers/big-talk/blob/main/CHANGELOG.md"
] | uv/0.8.8 | 2026-02-20T13:01:46.057461 | big_talk_ai-1.2.0-py3-none-any.whl | 18,502 | 0b/39/a24a1764a0c6fe3f4fd51a82f88f57568f486001b68c8c7346f919612055/big_talk_ai-1.2.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 163b18673d5b4a62210cc42ff9489068 | b45eb8a7b0e4d5fbb0c36fd6e993d7e05d54c56532bfe17b859b350b7b061b7c | 0b39a24a1764a0c6fe3f4fd51a82f88f57568f486001b68c8c7346f919612055 | null | [] | 113 |
2.4 | omega-memory | 0.10.6 | Persistent memory for AI coding agents — #1 on LongMemEval benchmark | # OMEGA
**The memory system for AI coding agents.** Decisions, lessons, and context that persist across sessions.
[](https://pypi.org/project/omega-memory/)
[](https://www.python.org/downloads/)
[](LICENSE)
[](https://github.com/omega-memory/omega-memory)
[](https://github.com/omega-memory/omega-memory/actions/workflows/test.yml)
[](https://omegamax.co/benchmarks)
[](https://smithery.ai/server/omegamemory/omega-memory)
mcp-name: io.github.omega-memory/omega-memory
## The Problem
AI coding agents are stateless. Every new session starts from zero.
- **Context loss.** Agents forget every decision, preference, and architectural choice between sessions. Developers spend 10-30 minutes per session re-explaining context that was already established.
- **Repeated mistakes.** Without learning from past sessions, agents make the same errors over and over. They don't remember what worked, what failed, or why a particular approach was chosen.
OMEGA gives AI coding agents long-term memory and cross-session learning, all running locally on your machine.
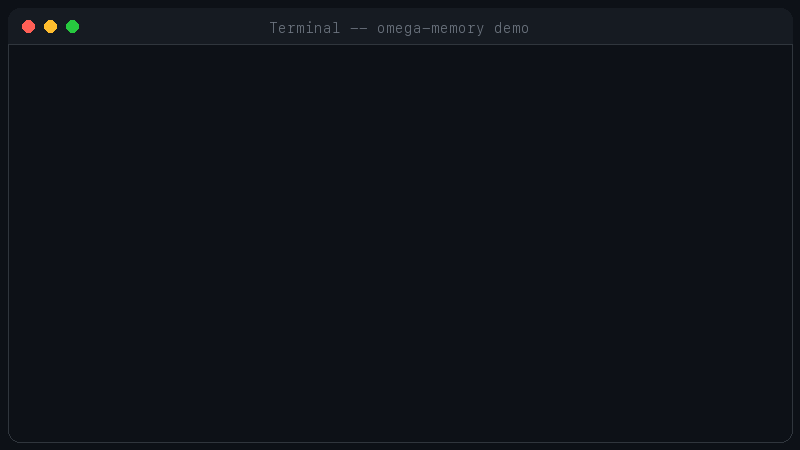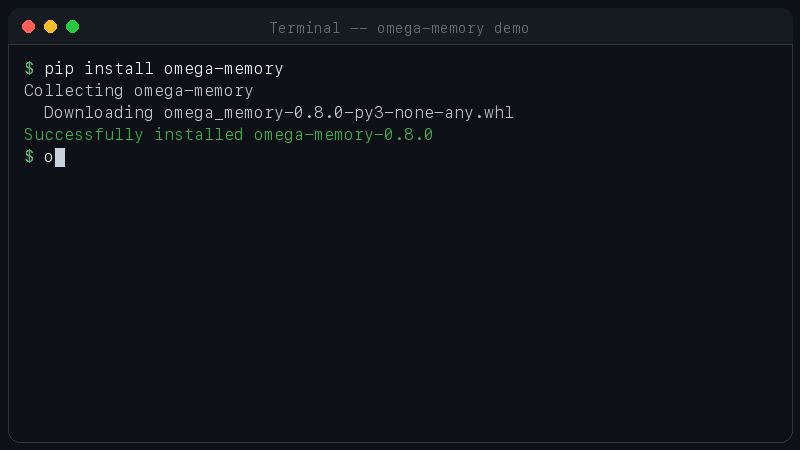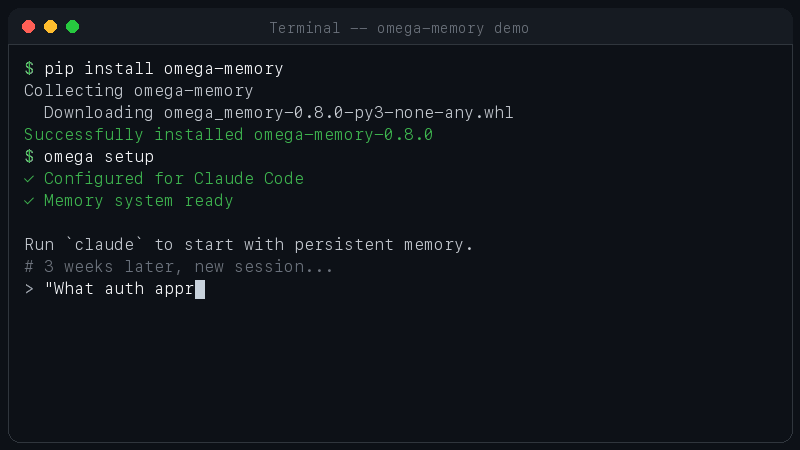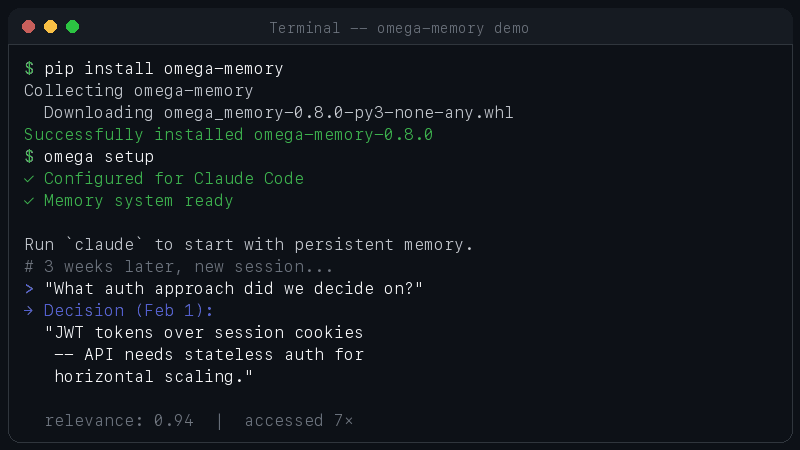
---
## Quick Start
```bash
pip3 install omega-memory[server] # install from PyPI (includes MCP server)
omega setup # auto-configures Claude Code + hooks
omega doctor # verify everything works
```
> **Important:** `omega setup` downloads the embedding model and configures your editor. Don't skip it.
That's it. Start a new Claude Code session and say **"Remember that we always use early returns and never nest more than 2 levels."** Close the session. Open a new one and ask **"What are my code style preferences?"** OMEGA recalls it instantly.
**Full architecture walkthrough and setup guide:** [omegamax.co/quickstart](https://omegamax.co/quickstart)
<details>
<summary><strong>Alternative install methods</strong></summary>
```bash
pipx install omega-memory[server] # recommended for global install (no venv needed)
pip3 install omega-memory[server] # standard (may need a venv)
python3 -m pip install omega-memory[server] # if pip3 is not available
```
</details>
<details>
<summary><strong>Library-only install (no MCP server)</strong></summary>
If you only need OMEGA as a Python library for scripts, CI/CD, or automation, you can skip the MCP server entirely:
```bash
pip3 install omega-memory # core only, no MCP server process
```
```python
from omega import store, query, remember
store("Always use TypeScript strict mode", "user_preference")
results = query("TypeScript preferences")
```
This gives you the full storage and retrieval API without running an MCP server (~50 MB lighter, no background process). You won't get MCP tools in your editor, but hooks still work:
```bash
omega setup --hooks-only # auto-capture + memory surfacing, no MCP server (~600MB RAM saved)
```
</details>
**Using Cursor, Windsurf, or Zed?** Install with `pip3 install omega-memory[server]`, then:
```bash
omega setup --client cursor # writes ~/.cursor/mcp.json
omega setup --client windsurf # writes ~/.codeium/windsurf/mcp_config.json
omega setup --client zed # writes ~/.config/zed/settings.json
```
## What Happens Next
After `omega setup`, OMEGA works in the background. No commands to learn.
**Auto-capture** — When you make a decision or debug an issue, OMEGA detects it and stores it automatically.
**Auto-surface** — When you edit a file or start a session, OMEGA surfaces relevant memories from past sessions — even ones you forgot about.
**Checkpoint & resume** — Stop mid-task, pick up in a new session exactly where you left off.
You can also explicitly tell Claude to remember things:
> "Remember that we use JWT tokens, not session cookies"
But the real value is what OMEGA does without being asked.
## Examples
### Architectural Decisions
> "Remember: we chose PostgreSQL over MongoDB for the orders service because we need ACID transactions for payment processing."
Three weeks later, in a new session:
> "I'm adding a caching layer to the orders service — what should I know?"
OMEGA surfaces the PostgreSQL decision automatically, so Claude doesn't suggest a MongoDB-style approach.
### Learning from Mistakes
You spend 30 minutes debugging a Docker build failure. Claude figures it out:
> *"The node_modules volume mount was shadowing the container's node_modules. Fixed by adding an anonymous volume."*
OMEGA auto-captures this as a lesson. Next time anyone hits the same Docker issue, Claude already knows the fix.
### Code Preferences
> "Remember: always use early returns. Never nest conditionals more than 2 levels deep. Prefer `const` over `let`."
Every future session follows these rules without being told again.
### Task Continuity
You're mid-refactor when you need to stop:
> "Checkpoint this — I'm halfway through migrating the auth middleware to the new pattern."
Next session:
> "Resume the auth middleware task."
Claude picks up exactly where you left off — files changed, decisions made, what's left to do.
### Error Patterns
Claude encounters the same `ECONNRESET` three sessions in a row. Each time OMEGA surfaces the previous fix:
```
[error_pattern] ECONNRESET on API calls — caused by connection pool exhaustion.
Fix: set maxSockets to 50 in the http agent config.
Accessed 3 times
```
No more re-debugging the same issue.
## Key Features
- **Auto-Capture & Surfacing** — Hook system automatically captures decisions and lessons, and surfaces relevant memories before edits, at session start, and during work.
- **Persistent Memory** — Stores decisions, lessons, error patterns, and preferences with semantic search. Your agent recalls what matters without you re-explaining everything each session.
- **Semantic Search** — bge-small-en-v1.5 embeddings + sqlite-vec for fast, accurate retrieval. Finds relevant memories even when the wording is different.
- **Cross-Session Learning** — Lessons, preferences, and error patterns accumulate over time. Agents learn from past mistakes and build on previous decisions.
- **Forgetting Intelligence** — Memories decay naturally over time, conflicts auto-resolve, and every deletion is audited. Preferences and error patterns are exempt from decay.
- **Graph Relationships** — Memories are linked with typed edges (related, supersedes, contradicts). Traverse the knowledge graph to find connected context.
- **Encryption at Rest** *(optional)* — AES-256-GCM encrypted storage with macOS Keychain integration. `pip install omega-memory[encrypt]`
- **Plugin Architecture** — Extensible via entry points. Add custom tools and handlers through the plugin system.
## How OMEGA Compares
| Feature | OMEGA | MEMORY.md | Mem0 | Basic MCP Memory |
|---------|:-----:|:---------:|:----:|:----------------:|
| Persistent across sessions | Yes | Yes | Yes | Yes |
| Semantic search | Yes | No (file grep only) | Yes | Varies |
| Auto-capture (no manual effort) | Yes | No (manual edits) | Yes (cloud) | No |
| Contradiction detection | Yes | No | No | No |
| Checkpoint & resume tasks | Yes | No | No | No |
| Graph relationships | Yes | No | No | No |
| Cross-session learning | Yes | Limited | Yes | No |
| Intelligent forgetting | Yes | No (grows forever) | No | No |
| Local-only (no cloud/API keys) | Yes | Yes | No (API key required) | Yes |
| Setup complexity | `pip3 install` + `omega setup` | Zero (built-in) | API key + cloud config | Manual JSON config |
**MEMORY.md** is Claude Code's built-in markdown file -- great for simple notes, but no search, no auto-capture, and it grows unbounded. **Mem0** offers strong semantic memory but requires cloud API keys and has no checkpoint/resume or contradiction detection. **Basic MCP memory servers** (e.g., simple key-value stores) provide persistence but lack the intelligence layer -- no semantic search, no forgetting, no graph.
OMEGA gives you the best of all worlds: fully local, zero cloud dependencies, with intelligent features that go far beyond simple storage.
Full comparison with methodology at [omegamax.co/compare](https://omegamax.co/compare).
## Benchmark
OMEGA scores **95.4% task-averaged** on [LongMemEval](https://github.com/xiaowu0162/LongMemEval) (ICLR 2025), an academic benchmark that tests long-term memory across 5 categories: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and preference tracking. Raw accuracy is 466/500 (93.2%). Task-averaged scoring (mean of per-category accuracies) is the standard methodology used by other systems on the leaderboard. This is the **#1 score on the leaderboard**.
| System | Score | Notes |
|--------|------:|-------|
| **OMEGA** | **95.4%** | **#1** |
| Mastra | 94.87% | #2 |
| Emergence | 86.0% | — |
| Zep/Graphiti | 71.2% | Published in their paper |
Details and methodology at [omegamax.co/benchmarks](https://omegamax.co/benchmarks).
## Compatibility
| Client | 12 MCP Tools | Auto-Capture Hooks | Setup Command |
|--------|:------------:|:------------------:|---------------|
| Claude Code | Yes | Yes | `omega setup` |
| Cursor | Yes | No | `omega setup --client cursor` |
| Windsurf | Yes | No | `omega setup --client windsurf` |
| Zed | Yes | No | `omega setup --client zed` |
| Any MCP Client | Yes | No | Manual config (see docs) |
All clients get full access to all 12 core memory tools. Auto-capture hooks (automatic memory surfacing and context capture) require Claude Code.
Requires Python 3.11+. macOS and Linux supported. Windows via WSL.
## Remote / SSH Setup
Claude Code's SSH support lets you run your agent on a remote server from any device. OMEGA makes that server **remember everything** across sessions and reconnections.
```bash
# On your remote server (any Linux VPS — no GPU needed)
pip3 install omega-memory[server]
omega setup
omega doctor
```
That's it. Every SSH session — from your laptop, phone, or tablet — now has full memory of every previous session on that server.
**Why this matters:**
- **Device-agnostic memory** — SSH in from any device, OMEGA's memory graph is on the server waiting for you
- **Survives disconnects** — SSH drops? Reconnect and `omega_resume_task` picks up exactly where you left off
- **Always-on accumulation** — A cloud VM running 24/7 means your memory graph grows continuously
- **Team-ready** — Multiple developers SSH to the same server? OMEGA tracks who's working on what with file claims, handoff notes, and peer messaging
**Requirements:** Any VPS with Python 3.11+ (~337 MB RAM after first query). SQLite + CPU-only ONNX embeddings — zero external services.
## Windows (WSL) Setup
OMEGA runs on Windows through [WSL 2](https://learn.microsoft.com/en-us/windows/wsl/install) (Windows Subsystem for Linux). WSL 1 works but WSL 2 is recommended for better SQLite performance.
**1. Install WSL 2 (if you don't have it)**
```powershell
# In PowerShell (admin)
wsl --install
```
This installs Ubuntu by default. Restart when prompted.
**2. Install Python 3.11+ inside WSL**
```bash
# In your WSL terminal
sudo apt update && sudo apt install -y python3 python3-pip python3-venv
python3 --version # should be 3.11+
```
If your distro ships an older Python, use the deadsnakes PPA:
```bash
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update && sudo apt install -y python3.12 python3.12-venv
```
**3. Install and set up OMEGA**
```bash
pip3 install omega-memory[server]
omega setup
omega doctor
```
**WSL-specific gotchas:**
- **Use the Linux filesystem, not `/mnt/c/`.** OMEGA stores data in `~/.omega/` inside WSL. Keep your projects on the Linux side (`~/Projects/`) for best performance. Accessing files on `/mnt/c/` is significantly slower due to filesystem translation.
- **Keyring may not work out of the box.** If you use `omega-memory[encrypt]`, the keyring backend needs configuration. Install `keyrings.alt` for a file-based backend: `pip3 install keyrings.alt`. Alternatively, set the environment variable `OMEGA_ENCRYPTION_KEY` directly.
- **Claude Code runs inside WSL.** Install Claude Code in your WSL terminal, not in Windows PowerShell. Your `~/.claude/` config lives in the WSL filesystem.
- **Model cache path.** The ONNX embedding model downloads to `~/.cache/omega/models/` inside WSL (~90 MB). This is separate from any Windows-side cache.
- **Multiple WSL distros.** Each distro has its own `~/.omega/` directory. If you switch distros, your memories don't carry over. Copy `~/.omega/omega.db` to transfer them.
<details>
<summary><strong>Architecture & Advanced Details</strong></summary>
### Architecture
```
┌─────────────────────┐
│ Claude Code │
│ (or any MCP host) │
└──────────┬──────────┘
│ stdio/MCP
┌──────────▼──────────┐
│ OMEGA MCP Server │
│ 12 memory tools │
└──────────┬──────────┘
│
┌──────────▼──────────┐
│ omega.db (SQLite) │
│ memories | edges | │
│ embeddings │
└──────────────────────┘
```
Single database, modular handlers. Additional tools available via the plugin system.
### MCP Tools Reference
12 core memory tools are available as an MCP server. Full tool reference at [omegamax.co/docs](https://omegamax.co/docs).
| Tool | What it does |
|------|-------------|
| `omega_store` | Store typed memory (decision, lesson, error, preference, summary) |
| `omega_query` | Semantic or phrase search with tag filters and contextual re-ranking |
| `omega_lessons` | Cross-session lessons ranked by access count |
| `omega_welcome` | Session briefing with recent memories and profile |
| `omega_profile` | Read or update the user profile |
| `omega_checkpoint` | Save task state for cross-session continuity |
| `omega_resume_task` | Resume a previously checkpointed task |
| `omega_similar` | Find memories similar to a given one |
| `omega_traverse` | Walk the relationship graph |
| `omega_compact` | Cluster and summarize related memories |
| `omega_consolidate` | Prune stale memories, cap summaries, clean edges |
| `omega_timeline` | Memories grouped by day |
| `omega_remind` | Set time-based reminders |
| `omega_feedback` | Rate surfaced memories (helpful, unhelpful, outdated) |
Additional utility tools for health checks, backup/restore, stats, editing, and deletion are also available. See [omegamax.co/docs](https://omegamax.co/docs) for the full reference.
### CLI
| Command | Description |
|---------|-------------|
| `omega setup` | Create dirs, download model, register MCP, install hooks (`--hooks-only` to skip MCP) |
| `omega doctor` | Verify installation health |
| `omega status` | Memory count, store size, model status |
| `omega query <text>` | Search memories by semantic similarity |
| `omega store <text>` | Store a memory with a specified type |
| `omega timeline` | Show memory timeline grouped by day |
| `omega activity` | Show recent session activity overview |
| `omega stats` | Memory type distribution and health summary |
| `omega consolidate` | Deduplicate, prune, and optimize memory |
| `omega compact` | Cluster and summarize related memories |
| `omega backup` | Back up omega.db (keeps last 5) |
| `omega validate` | Validate database integrity |
| `omega logs` | Show recent hook errors |
| `omega migrate-db` | Migrate legacy JSON to SQLite |
### Hooks
All hooks dispatch via `fast_hook.py` → daemon UDS socket, with fail-open semantics.
| Hook | Handlers | Purpose |
|------|----------|---------|
| SessionStart | `session_start` | Welcome briefing with recent memories |
| Stop | `session_stop` | Session summary |
| UserPromptSubmit | `auto_capture` | Auto-capture lessons/decisions |
| PostToolUse | `surface_memories` | Surface relevant memories during work |
### Storage
| Path | Purpose |
|------|---------|
| `~/.omega/omega.db` | SQLite database (memories, embeddings, edges) |
| `~/.omega/profile.json` | User profile |
| `~/.omega/hooks.log` | Hook error log |
| `~/.cache/omega/models/bge-small-en-v1.5-onnx/` | ONNX embedding model |
### Search Pipeline
1. **Vector similarity** via sqlite-vec (cosine distance, 384-dim bge-small-en-v1.5)
2. **Full-text search** via FTS5 (fast keyword matching)
3. **Type-weighted scoring** (decisions/lessons weighted 2x)
4. **Contextual re-ranking** (boosts by tag, project, and content match)
5. **Deduplication** at query time
6. **Time-decay weighting** (old unaccessed memories rank lower)
### Memory Lifecycle
- **Dedup**: SHA256 hash (exact) + embedding similarity 0.85+ (semantic) + Jaccard per-type
- **Evolution**: Similar content (55-95%) appends new insights to existing memories
- **TTL**: Session summaries expire after 1 day, lessons/preferences are permanent
- **Auto-relate**: Creates `related` edges (similarity >= 0.45) to top-3 similar memories
- **Compaction**: Clusters and summarizes related memories
- **Decay**: Unaccessed memories lose ranking weight over time (floor 0.35); preferences and errors exempt
- **Conflict detection**: Contradicting memories auto-detected on store; decisions auto-resolve, lessons flagged
### Memory Footprint
- Startup: ~31 MB RSS
- After first query (ONNX model loaded): ~337 MB RSS
- Database: ~10.5 MB for ~242 memories
### Install from Source
```bash
git clone https://github.com/omega-memory/omega-memory.git
cd omega-memory
pip3 install -e ".[server,dev]"
omega setup
```
`omega setup` will:
1. Create `~/.omega/` directory
2. Download the ONNX embedding model (~90 MB) to `~/.cache/omega/models/`
3. Register `omega-memory` as an MCP server in `~/.claude.json`
4. Install session hooks in `~/.claude/settings.json`
5. Add a managed `<!-- OMEGA:BEGIN -->` block to `~/.claude/CLAUDE.md`
All changes are idempotent — running `omega setup` again won't duplicate entries.
</details>
## Troubleshooting
**`omega doctor` shows FAIL on import:**
- Ensure `pip3 install -e ".[server]"` from the repo root
- Check `python3 -c "import omega"` works
**MCP server fails to start:**
- Run `pip3 install omega-memory[server]` (the `[server]` extra includes the MCP package)
**MCP server not registered:**
```bash
claude mcp add omega-memory -- python3 -m omega.server.mcp_server
```
**Hooks not firing:**
- Check `~/.claude/settings.json` has OMEGA hook entries
- Check `~/.omega/hooks.log` for errors
## Development
```bash
pip3 install -e ".[server,dev]"
pytest tests/
ruff check src/ # Lint
```
## Uninstall
```bash
claude mcp remove omega-memory
rm -rf ~/.omega ~/.cache/omega
pip3 uninstall omega-memory
```
Manually remove OMEGA entries from `~/.claude/settings.json` and the `<!-- OMEGA:BEGIN -->` block from `~/.claude/CLAUDE.md`.
## Star History
[](https://star-history.com/#omega-memory/omega-memory&Date)
## Contributing
- [Contributing Guide](CONTRIBUTING.md)
- [Security Policy](SECURITY.md)
- [Changelog](CHANGELOG.md)
- [Report a Bug](https://github.com/omega-memory/omega-memory/issues)
## License
Apache-2.0 — see [LICENSE](LICENSE) for details.
| text/markdown | null | Kokyō Keishō Zaidan Stichting <omega-memory@proton.me> | null | null | null | ai-agents, anthropic, claude-code, coding-assistant, context-persistence, cursor, developer-tools, embeddings, knowledge-graph, langchain, mcp-server, memory, openai, persistent-memory, semantic-search, vector-search, windsurf | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Database",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"markdownify>=0.14.0",
"numpy>=1.24.0",
"onnxruntime>=1.18.0",
"orjson>=3.9.0",
"rich>=13.0.0",
"sqlite-vec>=0.1.6",
"tokenizers>=0.15.0",
"openai>=1.0.0; extra == \"benchmark\"",
"sentence-transformers>=2.2.0; extra == \"benchmark\"",
"pytest; extra == \"dev\"",
"pytest-asyncio; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"ruff; extra == \"dev\"",
"mkdocs-material>=9.0.0; extra == \"docs\"",
"cryptography>=41.0.0; extra == \"encrypt\"",
"keyring>=25.0.0; extra == \"encrypt\"",
"mcp>=1.0.0; extra == \"server\""
] | [] | [] | [] | [
"Homepage, https://omegamax.co",
"Documentation, https://omegamax.co/how-it-works",
"Repository, https://github.com/omega-memory/omega-memory",
"Changelog, https://github.com/omega-memory/omega-memory/blob/main/CHANGELOG.md",
"Issues, https://github.com/omega-memory/omega-memory/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T13:01:23.568023 | omega_memory-0.10.6.tar.gz | 1,069,160 | 95/fd/98230a135c0fde7bec530020aa491ddd17c5145e73287834cf25cbf63af3/omega_memory-0.10.6.tar.gz | source | sdist | null | false | 11f587cd1f135a80f097087ec60ddd45 | 445c8148deb0425b35ab390b455c40b572d20976203333b59f3ccbaa8605d55c | 95fd98230a135c0fde7bec530020aa491ddd17c5145e73287834cf25cbf63af3 | Apache-2.0 | [
"LICENSE",
"NOTICE"
] | 212 |
2.4 | amor-eos | 3.1.1 | EOS reflectometry reduction for AMOR instrument | Reduces data obtained by focusing time of flight neutron reflectivity to full reflectivity curve.
| null | Jochen Stahn - Paul Scherrer Institut | jochen.stahn@psi.ch | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Scientific/Engineering",
"Development Status :: 5 - Production/Stable"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy",
"h5py",
"orsopy",
"numba",
"backports.strenum; python_version < \"3.11\"",
"backports.zoneinfo; python_version < \"3.9\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:59:55.642286 | amor_eos-3.1.1.tar.gz | 55,688 | f4/99/9d5282a8c5c1cdfbbf727ad896fda04ae04b4e024cc47b90f1dd855f2f80/amor_eos-3.1.1.tar.gz | source | sdist | null | false | ab8380901a8b7801bd1a73d849dc6838 | 70b1490f4d6b5d5e1965a8b94f8ff1dc019d4e4403fdbf4763af76b9b2eaeeaa | f4999d5282a8c5c1cdfbbf727ad896fda04ae04b4e024cc47b90f1dd855f2f80 | null | [
"LICENSE"
] | 197 |
2.4 | speedyxml | 0.4.0.16 | Speedy XML parser for Python | Usage is fairly straightforward:
import speedyxml
xml = speedyxml.parse('<xml><test this="now" /></xml>')
Will result in:
(
u'xml',
None,
[
(
u'test',
{u'this': u'now'},
None
)
]
)
So basically its:
(nodeName, attributes, children)
Plus some options (second argument to parse)
FLAG_EXPANDEMPTY
If you want empty attributes and children to be {} and [] instead of None, use this
FLAG_RETURNCOMMENTS
Return comments as:
(TAG_COMMENT, None, u' comment ')
FLAG_RETURNPI
Returns processing instructions as:
(TAG_PI, {u'name': u'php'}, u'phpinfo();')
FLAG_IGNOREENTITIES
does not resolve entities when set
And one exception:
XMLParseException
| text/plain | kilroy | kilroy@81818.de | null | null | LGPL | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: POSIX",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Text Processing :: Markup :: XML",
"License :: OSI Approved :: GNU Library or Lesser General Public License (LGPL)"
] | [] | null | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.11 | 2026-02-20T12:59:31.002903 | speedyxml-0.4.0.16.tar.gz | 12,546 | 60/5a/b35ac422877b26718377693823cd2c80b5f42fea0b48f1789b072cfa87bb/speedyxml-0.4.0.16.tar.gz | source | sdist | null | false | dbfa3c4f249d7569aa97340714d0d316 | b17d2748c35bea1a88a793832b55778457305bac424d04f7228e0e7fbce2de14 | 605ab35ac422877b26718377693823cd2c80b5f42fea0b48f1789b072cfa87bb | null | [] | 141 |
2.4 | terra4mice | 0.1.0.dev33 | State-Driven Development Framework - Terraform for your codebase | # terra4mice
> State-Driven Development Framework
>
> "Software isn't done when it works. It's done when state converges with spec."
Like Git tracks file changes, terra4mice tracks feature completeness. While Git shows `git diff` for code, terra4mice shows `terra4mice plan` for implementation gaps.
## The Problem
In livecoding, this happens:
1. You implement A
2. B breaks A
3. You workaround with C
4. D becomes a TODO
5. Someone says "it works"
6. Weeks later: D never existed
**The system doesn't know**:
- Which parts of the spec are complete
- Which parts are mocked
- Which parts only exist in your head
## The Solution
```
SPEC (desired state) -> What SHOULD exist (declarative YAML)
STATE (current state) -> What DOES exist (inferred/marked)
PLAN (diff) -> spec - state = work to do
APPLY (execution) -> Cycles until convergence
```
## When NOT to Use terra4mice
❌ Projects <10 resources (GitHub Issues suffice)
❌ Greenfield R&D with changing requirements (overhead not justified)
❌ Teams without spec-first culture (terra4mice forces it)
❌ Pure code quality needs (use SonarQube/linters instead)
## When terra4mice Shines
✅ Multi-AI development workflows (Claude Code + Copilot + Cursor)
✅ Livecoding/streaming projects (transparent progress tracking)
✅ Spec drift as chronic problem (incomplete implementations)
✅ Dependency tracking across features
## Quick Start
```bash
# Install (tree-sitter AST analysis included by default)
pip install terra4mice
# With remote state backend (S3 + DynamoDB locking)
pip install terra4mice[remote]
# All extras
pip install terra4mice[all]
# Initialize in your project
cd my-project
terra4mice init
# See what's missing
terra4mice plan
# Auto-detect codebase state
terra4mice refresh
# List resources in state
terra4mice state list
# Mark something as implemented
terra4mice mark feature.auth_login --files src/auth.py
# CI report (JSON)
terra4mice ci --format json
```
## Commands
### `terra4mice init`
Creates spec and state files:
```bash
terra4mice init
# Created: terra4mice.spec.yaml
# Created: terra4mice.state.json
```
### `terra4mice plan`
Shows what's needed to converge:
```
$ terra4mice plan
terra4mice will perform the following actions:
+ feature.auth_login
# Resource declared in spec but not in state
+ feature.auth_refresh
# Resource declared in spec but not in state
~ feature.auth_logout
# Resource is partially implemented
Plan: 2 to create, 1 to update.
```
With `--verbose`, plan shows function-level symbol tracking:
```
$ terra4mice plan --verbose
~ module.inference
# Resource is partially implemented
Symbols: 10/12 found
- format_report (missing)
- validate_config (missing)
```
### `terra4mice refresh`
Auto-detects codebase state using multiple strategies:
```
$ terra4mice refresh
Scanning /my-project for resources...
Inference Report
============================================================
IMPLEMENTED (5 resources)
module.models
Confidence: [##########] 100%
Files: src/models.py
Evidence: Explicit files found, AST analysis: 100% match
Symbols: 12/12 (100%)
PARTIAL (1 resources)
feature.auth
Confidence: [######----] 60%
Symbols: 5/8 (62%)
Missing: validate_token, refresh_session, logout_handler
MISSING (2 resources)
feature.payments
feature.notifications
Summary
Convergence: 68.8%
```
Inference strategies (in priority order):
1. **tree-sitter AST** (with `[ast]`) - verifies functions, classes, exports against spec attributes
2. **stdlib ast** - basic Python analysis
3. **Regex** - Solidity, TypeScript/JavaScript patterns
4. **Heuristic** - config/docs file size
### `terra4mice state list`
Lists all resources in state:
```
$ terra4mice state list
feature.auth_login
feature.auth_refresh
module.payment_processor
```
### `terra4mice state show <address>`
Shows resource details including symbol-level tracking:
```
$ terra4mice state show module.inference
# module.inference
type = "module"
name = "inference"
status = "implemented"
files = ["src/terra4mice/inference.py"]
symbols = 12 (10 implemented, 2 missing)
InferenceEngine class lines 94-686 (src/terra4mice/inference.py)
InferenceEngine.infer_all method lines 154-178 (src/terra4mice/inference.py)
InferenceEngine.infer_resource method lines 180-245 (src/terra4mice/inference.py)
format_inference_report function lines 719-787 (src/terra4mice/inference.py)
validate_config function [MISSING]
```
### `terra4mice mark <address>`
Marks a resource with a status:
```bash
# Mark as implemented
terra4mice mark feature.auth_login --files src/auth.py
# Mark as partial
terra4mice mark feature.auth_refresh --status partial --reason "Missing token rotation"
# Mark as broken
terra4mice mark feature.auth_logout --status broken --reason "Tests failing"
```
### `terra4mice apply`
Context-aware apply engine with DAG ordering and multiple execution modes:
```bash
# Interactive mode (default) — manual implementation with guidance
terra4mice apply
# Auto mode — AI agent implements resources automatically
terra4mice apply --mode auto --agent claude-code
# Hybrid mode — AI implements, human reviews each change
terra4mice apply --mode hybrid --agent claude-code
# Market mode — post tasks to Execution Market for bounty-based implementation
terra4mice apply --mode market --bounty 50 --market-api-key $KEY
# Parallel execution (any mode) — respects dependency DAG
terra4mice apply --mode auto --max-workers 4
# Dry run — show plan without executing
terra4mice apply --dry-run
# Apply a single resource
terra4mice apply --resource feature.auth_login
# With verification level
terra4mice apply --mode auto --verify-level full
```
Interactive mode example:
```
$ terra4mice apply
════════════════════════════════════════════════════════════
Action 1/3: + create feature.auth_login
════════════════════════════════════════════════════════════
Resource declared in spec but not in state
Dependencies:
(none)
Attributes:
- endpoints: ['POST /auth/login']
──────────────────────────────────────────────────────────
[i]mplement [p]artial [s]kip [a]i-assist [m]arket [q]uit
→ i
Files that implement this (comma-separated): src/auth.py
✓ Marked as implemented: feature.auth_login
```
#### Apply Modes
| Mode | Description |
|------|-------------|
| **interactive** | Manual implementation with dependency status, context, and suggested files |
| **auto** | AI agent implements resources — supports Claude Code, Codex, or custom agents |
| **hybrid** | AI generates implementation, human reviews and accepts/rejects/edits |
| **market** | Posts tasks to [Execution Market](https://execution.market) for bounty-based implementation |
#### Agent Chaining & Fallbacks
Use comma-separated agent names for automatic fallback:
```bash
# Try Claude Code first, fall back to Codex if it fails
terra4mice apply --mode auto --agent claude-code,codex
```
#### Parallel Execution Engine
The parallel executor respects the dependency DAG — independent resources run concurrently while dependent resources wait:
```bash
# 4 workers process independent resources in parallel
terra4mice apply --mode auto --max-workers 4
```
#### Verification Levels
| Level | Checks |
|-------|--------|
| `basic` | Files exist and are non-empty |
| `git_diff` | Basic + git diff shows changes to expected files |
| `full` | git_diff + tree-sitter AST verification against spec attributes |
### `terra4mice state pull / push`
Sync state between local and remote backends:
```bash
# Download remote state to a local file
terra4mice state pull -o local_backup.json
# Upload local state to the remote backend
terra4mice state push -i local_backup.json
```
### `terra4mice force-unlock <lock-id>`
Force-release a stuck state lock (when a process crashes mid-operation):
```bash
terra4mice force-unlock a1b2c3d4-5678-9abc-def0-123456789abc
# Lock forcefully released: a1b2c3d4-...
# WARNING: Releasing a lock held by another process may cause state corruption.
```
### `terra4mice init --migrate-state`
Migrate local state to a remote backend configured in the spec:
```bash
# 1. Add backend: section to terra4mice.spec.yaml
# 2. Run migration
terra4mice init --migrate-state
# State migrated to s3 backend.
# Resources: 12
# Serial: 45
```
### `terra4mice diff`
Compare two state snapshots to see what changed:
```
$ terra4mice diff --old state.json.bak
terra4mice diff
==================================================
Old: state.json.bak (serial 5)
New: terra4mice.state.json (serial 8)
Upgraded (3):
module.inference: partial -> implemented
module.analyzers: missing -> implemented
feature.ci: partial -> implemented
Convergence: 45.0% -> 78.3% (+33.3%)
```
### `terra4mice ci`
Output for CI/CD pipelines:
```bash
# JSON (machine-readable)
terra4mice ci --format json
# Markdown (PR comments)
terra4mice ci --format markdown --comment pr-comment.md
# Fail if convergence < threshold
terra4mice ci --fail-under 80
```
## Spec File Format
```yaml
# terra4mice.spec.yaml
version: "1"
resources:
feature:
auth_login:
attributes:
description: "User login"
endpoints: [POST /auth/login]
depends_on: []
auth_refresh:
attributes:
description: "Token refresh"
depends_on:
- feature.auth_login
module:
state_manager:
attributes:
class: StateManager
functions: [load, save, list, mark_created]
files:
- src/state_manager.py
endpoint:
api_users:
attributes:
method: GET
path: /api/users
depends_on:
- feature.auth_login
```
### Spec Attributes for AST Verification
With `terra4mice[ast]` installed, these attributes are verified against actual code:
```yaml
attributes:
class: StateManager # verified in classes
functions: [load, save, list] # verified in defined functions
entities: [Resource, State] # verified in classes/interfaces/types/enums
exports: [WorkerRatingModal] # verified in exports (TS/JS)
imports: [useState, useEffect] # verified in imports
commands: [init, plan, refresh] # substring match in functions
strategies: [explicit_files] # substring match in functions+classes
```
Supported languages: Python, TypeScript/TSX, JavaScript, Solidity.
## State File Format
```json
{
"version": "1",
"serial": 3,
"last_updated": "2026-01-27T15:30:00",
"resources": [
{
"type": "module",
"name": "inference",
"status": "implemented",
"files": ["src/terra4mice/inference.py"],
"symbols": {
"InferenceEngine": {
"name": "InferenceEngine",
"kind": "class",
"status": "implemented",
"file": "src/terra4mice/inference.py"
},
"format_report": {
"name": "format_report",
"kind": "function",
"status": "missing"
}
}
}
]
}
```
## Remote State Backend
Store state in S3 with optional DynamoDB locking for team collaboration. Add a `backend:` section to your spec:
```yaml
# terra4mice.spec.yaml
version: "1"
backend:
type: s3
config:
bucket: my-terra4mice-state
key: projects/myapp/terra4mice.state.json
region: us-east-1
lock_table: terra4mice-locks # DynamoDB table (optional)
profile: my-aws-profile # AWS profile (optional)
encrypt: true # S3 SSE (optional)
resources:
# ... your spec unchanged ...
```
Without `backend:` or with `type: local`, behavior is unchanged (local file).
### DynamoDB Lock Table Setup
```bash
aws dynamodb create-table \
--table-name terra4mice-locks \
--attribute-definitions AttributeName=LockID,AttributeType=S \
--key-schema AttributeName=LockID,KeyType=HASH \
--billing-mode PAY_PER_REQUEST
```
### How Locking Works
When a `backend` with `lock_table` is configured, mutating commands (`refresh`, `mark`, `lock`, `unlock`, `state rm`, `state push`) automatically acquire a DynamoDB lock before writing. If another process holds the lock, the command fails with a descriptive error showing who holds it and when it was acquired.
## CI/CD Integration
```yaml
# .github/workflows/terra4mice.yml
name: Check Convergence
on: [push, pull_request]
jobs:
check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: '3.11'
- run: pip install terra4mice[ast]
- run: terra4mice plan --detailed-exitcode
# Returns 2 if there are pending changes
```
## Roadmap
| Phase | Status | Description |
|-------|--------|-------------|
| 1 - MVP CLI | ✅ DONE | init, plan, refresh, state, mark, apply, ci, diff |
| 2 - tree-sitter AST | ✅ DONE | Multi-language deep analysis, spec attribute verification, symbol tracking |
| 3 - Multi-AI Contexts | ✅ DONE | Track which AI (Claude, Codex, Kimi) has context on what |
| 4 - CI/CD Integration | ✅ DONE | GitHub Action, PR comments, convergence badges |
| 4.5 - Remote State | ✅ DONE | S3 backend, DynamoDB locking, state pull/push, migrate-state |
| 5 - Apply Runner | ✅ DONE | DAG-ordered execution, Auto/Hybrid/Market modes, parallel engine, verification |
| 5.1 - Agent Dispatch | ✅ DONE | Claude Code/Codex backends, agent chaining, fallbacks |
| 5.2 - Parallel Engine | ✅ DONE | ThreadPoolExecutor with DAG-aware scheduling, failure cascading |
| 5.3 - Execution Market | ✅ DONE | Market mode, bounty tasks, dry-run support |
| 5.4 - E2E Tests & PyPI | ✅ DONE | Comprehensive e2e tests, `python -m terra4mice`, PyPI-ready packaging |
| 6 - Ecosystem Rollout | PLANNED | Deploy across Ultravioleta DAO projects |
## Multi-Agent Context Tracking
When multiple AIs work on the same project, each carries its own isolated context. The `contexts` command group provides a **context registry** to know which AI has context on what resources.
### `terra4mice contexts list`
Shows all agents and their resource contexts:
```
$ terra4mice contexts list
AGENT RESOURCE LAST SEEN STATUS
claude-code module.inference 2min ago active
claude-code module.analyzers 2min ago active
codex feature.auth_login 1hr ago stale
kimi-2.5 feature.frontend 30min ago active
Agents: 3 | Active contexts: 4 | Stale: 1
```
### `terra4mice contexts show <agent>`
Shows detailed context for a specific agent:
```
$ terra4mice contexts show claude-code
# claude-code
Last active: 2min ago
Status: active
Resources in context:
module.inference implemented 2min ago
module.analyzers implemented 2min ago
feature.ci partial 15min ago
Files touched:
src/terra4mice/inference.py
src/terra4mice/analyzers.py
```
### `terra4mice contexts sync`
Synchronize context between agents:
```bash
# Sync all context from one agent to another
terra4mice contexts sync --from=claude-code --to=codex
# Sync specific resources only
terra4mice contexts sync --from=claude-code --to=codex --resources=module.inference,module.analyzers
# Dry run to see what would sync
terra4mice contexts sync --from=claude-code --to=codex --dry-run
```
### `terra4mice contexts export / import`
Export and import agent contexts for backup or transfer:
```bash
# Export an agent's context to a file
terra4mice contexts export claude-code -o claude-context.json
# Import context from a file
terra4mice contexts import codex -i claude-context.json
# Export all agents
terra4mice contexts export --all -o all-contexts.json
```
### `terra4mice mark --agent`
Mark resources with agent attribution:
```bash
# Mark as implemented by a specific agent
terra4mice mark module.auth --status implemented --agent=codex --files src/auth.py
# Mark as partial with agent context
terra4mice mark feature.payments --status partial --agent=claude-code --reason "Missing refund logic"
```
This automatically updates the context registry so other agents know who worked on what.
## Multi-Agent Workflow Examples
### Example 1: Handoff Between Agents
When one agent completes work and another takes over:
```bash
# Claude finishes working on inference
terra4mice mark module.inference --status implemented --agent=claude-code --files src/inference.py
# Before Codex starts, sync the context
terra4mice contexts sync --from=claude-code --to=codex --resources=module.inference
# Codex can now see what Claude did
terra4mice contexts show codex
```
### Example 2: Parallel Development
Multiple agents working on different features:
```bash
# See who's working on what
terra4mice contexts list
# Each agent marks their own work
terra4mice mark feature.auth --agent=claude-code --status implemented
terra4mice mark feature.payments --agent=kimi-2.5 --status partial
# Check for conflicts (same resource, different agents)
terra4mice plan --check-conflicts
```
### Example 3: Context Recovery
When an agent loses context (new session):
```bash
# Export context before session ends
terra4mice contexts export claude-code -o session-backup.json
# In new session, restore context
terra4mice contexts import claude-code -i session-backup.json
# Or sync from another agent that has current context
terra4mice contexts sync --from=codex --to=claude-code
```
### Example 4: CI Integration with Multi-Agent
```yaml
# .github/workflows/terra4mice.yml
- name: Check convergence and contexts
run: |
terra4mice plan --detailed-exitcode
terra4mice contexts list --format json > contexts.json
# Fail if any contexts are stale > 24h
terra4mice contexts list --stale-threshold 24h --fail-if-stale
```
## Philosophy
1. **State before intention** - What exists, not what we want
2. **Evidence before perception** - Tests, not "I think it works"
3. **Convergence before speed** - Better slow and correct
4. **Clarity before heroism** - Visible plan, not magic
## Definition of Done
A project is complete when:
```
$ terra4mice plan
No changes. State matches spec.
```
Nothing else.
## License
MIT - Public good for the developer community.
## Contributing
PRs welcome! See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
| text/markdown | null | Ultravioleta DAO <ultravioletadao@gmail.com> | null | null | null | development, state-management, terraform, vivecoding, specification, tracking | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Build Tools",
"Topic :: Software Development :: Quality Assurance"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pyyaml>=6.0",
"tree-sitter>=0.23.0",
"tree-sitter-language-pack>=0.4.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"black; extra == \"dev\"",
"mypy; extra == \"dev\"",
"boto3>=1.26.0; extra == \"remote\"",
"terra4mice[ast,dev,remote]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://github.com/0xultravioleta/terra4mice",
"Documentation, https://github.com/0xultravioleta/terra4mice#readme",
"Repository, https://github.com/0xultravioleta/terra4mice",
"Issues, https://github.com/0xultravioleta/terra4mice/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:58:32.922146 | terra4mice-0.1.0.dev33.tar.gz | 129,219 | d4/25/af9345f8f42d92bed0121e557a0a31ebc40eaa80f2a97c81dbf8cad096c2/terra4mice-0.1.0.dev33.tar.gz | source | sdist | null | false | 868d49019700694e4613752187cd0b0d | fa69a09f55e0294087691d90ac18badcf67180336134ce505bfdefb1b6fa9538 | d425af9345f8f42d92bed0121e557a0a31ebc40eaa80f2a97c81dbf8cad096c2 | MIT | [
"LICENSE"
] | 193 |
2.1 | fastbt | 0.8.0 | A simple framework for fast and dirty backtesting | # Introduction
**fastbt** is a simple and dirty way to do backtests based on end of day data, especially for day trading.
The main purpose is to provide a simple framework to weed out bad strategies so that you could test and improve your better strategies further.
It is based on the assumption that you enter into a position based on some pre-defined rules for a defined period and exit either at the end of the period or when stop loss is triggered. See the [rationale](https://github.com/uberdeveloper/fastbt/blob/master/docs/rationale.md) for this approach and the built-in assumptions. _fastbt is rule-based and not event-based._
If your strategy gets you good results, then check them with a full featured backtesting framework such as [zipline](http://www.zipline.io/) or [backtrader](https://www.backtrader.com/) to verify your results.
If your strategy fails, then it would most probably fail in other environments.
This is **alpha**
Most of the modules are stand alone and you could use them as a single file. See embedding for more details
# Features
- Create your strategies in Microsoft Excel
- Backtest as functions so you can parallelize
- Try different simulations
- Run from your own datasource or a database connection.
- Run backtest based on rules
- Add any column you want to your datasource as formulas
# Installation
fastbt requires python **>=3.6** and can be installed via pip
```
pip install fastbt
```
# Quickstart
Fastbt assumes your data have the following columns (rename them in case of other names)
- timestamp
- symbol
- open
- high
- low
- close
- volume
```python
from fastbt.rapid import *
backtest(data=data)
```
would return a dataframe with all the trades.
And if you want to see some metrics
```python
metrics(backtest(data=data))
```
You now ran a backtest without a strategy! By default, the strategy buys the top 5 stocks with the lowest price at open price on each period and sells them at the close price at the end of the period.
You can either specify the strategy by way of rules (the recommended way) or create your strategy as a function in python and pass it as a parameter
```python
backtest(data=data, strategy=strategy)
```
If you want to connect to a database, then
```python
from sqlalchemy import create_engine
engine = create_engine('sqlite:///data.db')
backtest(connection=engine, tablename='data')
```
And to SELL instead of BUY
```python
backtest(data=data, order='S')
```
Let's implement a simple strategy.
> **BUY** the top 5 stocks with highest last week returns
Assuming we have a **weeklyret** column,
```python
backtest(data=data, order='B', sort_by='weeklyret', sort_mode=False)
```
We used sort_mode=False to sort them in descending order.
If you want to test this strategy on a weekly basis, just pass a dataframe with weekly frequency.
See the Introduction notebook in the examples directory for an in depth introduction.
## Embedding
Since fastbt is a thin wrapper around existing packages, the following files can be used as standalone without installing the fastbt package
- datasource
- utils
- loaders
Copy these files and just use them in your own modules.
=========
History
=========
v0.8.0
------
* **NEW**: Added statistical testing skill v1.0-alpha with comprehensive test scripts
* Includes hypothesis testing for trading strategy validation
* Supports benchmark comparison, conditional analysis, and temporal validation
* Added out-of-sample testing capabilities
* **ENHANCED**: Simulation module improvements
* Refactored generators into Time and Sequence engines
* Added IID lognormal distribution support
* New generator modes and parameters for more flexible simulation
* Fixed price stagnation in tick/quote generators
* Added regression tests for tick generator price movement
* Updated documentation for simulation module with new examples
* Code quality improvements with pre-commit hooks
v0.7.0 (BREAKING)
------
* **BREAKING**: Migrated to Pydantic v2.0 compatibility (requires pydantic>=2.0.0)
* Updated all BaseModel classes to use model_config instead of deprecated Config class
* Replaced root_validator with model_validator(mode='before')
* Added default values for Optional fields as required by Pydantic v2
* Enhanced option chain simulation capabilities
* Added correlated data simulation features
* Improved URL pattern matching functionality
* Code formatting and linting improvements with ruff and black
* Added `load-data` skill for efficient data discovery and loading (includes peek_file, efficient_load, collate_data, and normalize_json)
v0.6.0
------
* New methods added to `TradeBook` object
* mtm - to calculate mtm for open positions
* clear - to clear the existing entries
* helper attributes for positions
* `order_fill_price` method added to utils to simulate order quantity
v0.5.1
------
* Simple bug fixes added
v0.5.0
------
* `OptionExpiry` class added to calculate option payoffs based on expiry
v0.4.0
-------
* Brokers module deprecation warning added
* Options module revamped
v0.3.0 (2019-03-15)
--------------------
* More helper functions added to utils
* Tradebook class enhanced
* A Meta class added for event based simulation
v0.2.0 (2018-12-26)
--------------------
* Backtest from different formats added
* Rolling function added
v0.1.0. (2018-10-13)
----------------------
* First release on PyPI
| text/markdown | UM | uberdeveloper001@gmail.com | null | null | MIT license | fastbt, backtesting, algorithmic trading, quantitative finance, research, finance | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Financial and Insurance Industry",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython",
"Topic :: Office/Business :: Financial :: Investment"
] | [] | https://github.com/uberdeveloper/fastbt | null | null | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T12:58:04.311839 | fastbt-0.8.0.tar.gz | 4,826,633 | 65/4a/5112c4c7a9fea901b4576e5f3590d0986a3ecb401e3eb896b79a70772595/fastbt-0.8.0.tar.gz | source | sdist | null | false | c155547a29d377032b9dd7765cb83934 | 0eb9dd087cf7f17c697ad750abc988270830f89e48a1e4439aa375e7b40bddbc | 654a5112c4c7a9fea901b4576e5f3590d0986a3ecb401e3eb896b79a70772595 | null | [] | 219 |
2.4 | mlflow-skinny | 3.10.0 | MLflow is an open source platform for the complete machine learning lifecycle | <!-- Autogenerated by dev/pyproject.py. Do not edit manually. -->
📣 This is the `mlflow-skinny` package, a lightweight MLflow package without SQL storage, server, UI, or data science dependencies.
Additional dependencies can be installed to leverage the full feature set of MLflow. For example:
- To use the `mlflow.sklearn` component of MLflow Models, install `scikit-learn`, `numpy` and `pandas`.
- To use SQL-based metadata storage, install `sqlalchemy`, `alembic`, and `sqlparse`.
- To use serving-based features, install `flask` and `pandas`.
---
<br>
<br>
<h1 align="center" style="border-bottom: none">
<a href="https://mlflow.org/">
<img alt="MLflow logo" src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/logo.svg" width="200" />
</a>
</h1>
<h2 align="center" style="border-bottom: none">Open-Source Platform for Productionizing AI</h2>
MLflow is an open-source developer platform to build AI/LLM applications and models with confidence. Enhance your AI applications with end-to-end **experiment tracking**, **observability**, and **evaluations**, all in one integrated platform.
<div align="center">
[](https://pypi.org/project/mlflow/)
[](https://pepy.tech/projects/mlflow)
[](https://github.com/mlflow/mlflow/blob/main/LICENSE)
<a href="https://twitter.com/intent/follow?screen_name=mlflow" target="_blank">
<img src="https://img.shields.io/twitter/follow/mlflow?logo=X&color=%20%23f5f5f5"
alt="follow on X(Twitter)"></a>
<a href="https://www.linkedin.com/company/mlflow-org/" target="_blank">
<img src="https://custom-icon-badges.demolab.com/badge/LinkedIn-0A66C2?logo=linkedin-white&logoColor=fff"
alt="follow on LinkedIn"></a>
[](https://deepwiki.com/mlflow/mlflow)
</div>
<div align="center">
<div>
<a href="https://mlflow.org/"><strong>Website</strong></a> ·
<a href="https://mlflow.org/docs/latest"><strong>Docs</strong></a> ·
<a href="https://github.com/mlflow/mlflow/issues/new/choose"><strong>Feature Request</strong></a> ·
<a href="https://mlflow.org/blog"><strong>News</strong></a> ·
<a href="https://www.youtube.com/@mlflowoss"><strong>YouTube</strong></a> ·
<a href="https://lu.ma/mlflow?k=c"><strong>Events</strong></a>
</div>
</div>
<br>
## 🚀 Installation
To install the MLflow Python package, run the following command:
```
pip install mlflow
```
## 📦 Core Components
MLflow is **the only platform that provides a unified solution for all your AI/ML needs**, including LLMs, Agents, Deep Learning, and traditional machine learning.
### 💡 For LLM / GenAI Developers
<table>
<tr>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-tracing.png" alt="Tracing" width=100%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/llms/tracing/index.html"><strong>🔍 Tracing / Observability</strong></a>
<br><br>
<div>Trace the internal states of your LLM/agentic applications for debugging quality issues and monitoring performance with ease.</div><br>
<a href="https://mlflow.org/docs/latest/genai/tracing/quickstart/">Getting Started →</a>
<br><br>
</div>
</td>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-llm-eval.png" alt="LLM Evaluation" width=100%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/genai/eval-monitor/"><strong>📊 LLM Evaluation</strong></a>
<br><br>
<div>A suite of automated model evaluation tools, seamlessly integrated with experiment tracking to compare across multiple versions.</div><br>
<a href="https://mlflow.org/docs/latest/genai/eval-monitor/">Getting Started →</a>
<br><br>
</div>
</td>
</tr>
<tr>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-prompt.png" alt="Prompt Management">
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/genai/prompt-version-mgmt/prompt-registry/"><strong>🤖 Prompt Management</strong></a>
<br><br>
<div>Version, track, and reuse prompts across your organization, helping maintain consistency and improve collaboration in prompt development.</div><br>
<a href="https://mlflow.org/docs/latest/genai/prompt-registry/create-and-edit-prompts/">Getting Started →</a>
<br><br>
</div>
</td>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-logged-model.png" alt="MLflow Hero">
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/genai/prompt-version-mgmt/version-tracking/"><strong>📦 App Version Tracking</strong></a>
<br><br>
<div>MLflow keeps track of many moving parts in your AI applications, such as models, prompts, tools, and code, with end-to-end lineage.</div><br>
<a href="https://mlflow.org/docs/latest/genai/version-tracking/quickstart/">Getting Started →</a>
<br><br>
</div>
</td>
</tr>
</table>
### 🎓 For Data Scientists
<table>
<tr>
<td colspan="2" align="center" >
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-experiment.png" alt="Tracking" width=50%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/ml/tracking/"><strong>📝 Experiment Tracking</strong></a>
<br><br>
<div>Track your models, parameters, metrics, and evaluation results in ML experiments and compare them using an interactive UI.</div><br>
<a href="https://mlflow.org/docs/latest/ml/tracking/quickstart/">Getting Started →</a>
<br><br>
</div>
</td>
</tr>
<tr>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-model-registry.png" alt="Model Registry" width=100%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/ml/model-registry/"><strong>💾 Model Registry</strong></a>
<br><br>
<div> A centralized model store designed to collaboratively manage the full lifecycle and deployment of machine learning models.</div><br>
<a href="https://mlflow.org/docs/latest/ml/model-registry/tutorial/">Getting Started →</a>
<br><br>
</div>
</td>
<td>
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-deployment.png" alt="Deployment" width=100%>
<div align="center">
<br>
<a href="https://mlflow.org/docs/latest/ml/deployment/"><strong>🚀 Deployment</strong></a>
<br><br>
<div> Tools for seamless model deployment to batch and real-time scoring on platforms like Docker, Kubernetes, Azure ML, and AWS SageMaker.</div><br>
<a href="https://mlflow.org/docs/latest/ml/deployment/">Getting Started →</a>
<br><br>
</div>
</td>
</tr>
</table>
## 🌐 Hosting MLflow Anywhere
<div align="center" >
<img src="https://raw.githubusercontent.com/mlflow/mlflow/refs/heads/master/assets/readme-providers.png" alt="Providers" width=100%>
</div>
You can run MLflow in many different environments, including local machines, on-premise servers, and cloud infrastructure.
Trusted by thousands of organizations, MLflow is now offered as a managed service by most major cloud providers:
- [Amazon SageMaker](https://aws.amazon.com/sagemaker-ai/experiments/)
- [Azure ML](https://learn.microsoft.com/en-us/azure/machine-learning/concept-mlflow?view=azureml-api-2)
- [Databricks](https://www.databricks.com/product/managed-mlflow)
- [Nebius](https://nebius.com/services/managed-mlflow)
For hosting MLflow on your own infrastructure, please refer to [this guidance](https://mlflow.org/docs/latest/ml/tracking/#tracking-setup).
## 🗣️ Supported Programming Languages
- [Python](https://pypi.org/project/mlflow/)
- [TypeScript / JavaScript](https://www.npmjs.com/package/mlflow-tracing)
- [Java](https://mvnrepository.com/artifact/org.mlflow/mlflow-client)
- [R](https://cran.r-project.org/web/packages/mlflow/readme/README.html)
## 🔗 Integrations
MLflow is natively integrated with many popular machine learning frameworks and GenAI libraries.

## Usage Examples
### Tracing (Observability) ([Doc](https://mlflow.org/docs/latest/llms/tracing/index.html))
MLflow Tracing provides LLM observability for various GenAI libraries such as OpenAI, LangChain, LlamaIndex, DSPy, AutoGen, and more. To enable auto-tracing, call `mlflow.xyz.autolog()` before running your models. Refer to the documentation for customization and manual instrumentation.
```python
import mlflow
from openai import OpenAI
# Enable tracing for OpenAI
mlflow.openai.autolog()
# Query OpenAI LLM normally
response = OpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hi!"}],
temperature=0.1,
)
```
Then navigate to the "Traces" tab in the MLflow UI to find the trace records for the OpenAI query.
### Evaluating LLMs, Prompts, and Agents ([Doc](https://mlflow.org/docs/latest/genai/eval-monitor/index.html))
The following example runs automatic evaluation for question-answering tasks with several built-in metrics.
```python
import os
import openai
import mlflow
from mlflow.genai.scorers import Correctness, Guidelines
client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 1. Define a simple QA dataset
dataset = [
{
"inputs": {"question": "Can MLflow manage prompts?"},
"expectations": {"expected_response": "Yes!"},
},
{
"inputs": {"question": "Can MLflow create a taco for my lunch?"},
"expectations": {
"expected_response": "No, unfortunately, MLflow is not a taco maker."
},
},
]
# 2. Define a prediction function to generate responses
def predict_fn(question: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": question}]
)
return response.choices[0].message.content
# 3. Run the evaluation
results = mlflow.genai.evaluate(
data=dataset,
predict_fn=predict_fn,
scorers=[
# Built-in LLM judge
Correctness(),
# Custom criteria using LLM judge
Guidelines(name="is_english", guidelines="The answer must be in English"),
],
)
```
Navigate to the "Evaluations" tab in the MLflow UI to find the evaluation results.
### Tracking Model Training ([Doc](https://mlflow.org/docs/latest/ml/tracking/))
The following example trains a simple regression model with scikit-learn, while enabling MLflow's [autologging](https://mlflow.org/docs/latest/tracking/autolog.html) feature for experiment tracking.
```python
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
# Enable MLflow's automatic experiment tracking for scikit-learn
mlflow.sklearn.autolog()
# Load the training dataset
db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)
rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)
# MLflow triggers logging automatically upon model fitting
rf.fit(X_train, y_train)
```
Once the above code finishes, run the following command in a separate terminal and access the MLflow UI via the printed URL. An MLflow **Run** should be automatically created, which tracks the training dataset, hyperparameters, performance metrics, the trained model, dependencies, and even more.
```
mlflow server
```
## 💭 Support
- For help or questions about MLflow usage (e.g. "how do I do X?") visit the [documentation](https://mlflow.org/docs/latest).
- In the documentation, you can ask the question to our AI-powered chat bot. Click on the **"Ask AI"** button at the right bottom.
- Join the [virtual events](https://lu.ma/mlflow?k=c) like office hours and meetups.
- To report a bug, file a documentation issue, or submit a feature request, please [open a GitHub issue](https://github.com/mlflow/mlflow/issues/new/choose).
- For release announcements and other discussions, please subscribe to our mailing list (mlflow-users@googlegroups.com)
or join us on [Slack](https://mlflow.org/slack).
## 🤝 Contributing
We happily welcome contributions to MLflow!
- Submit [bug reports](https://github.com/mlflow/mlflow/issues/new?template=bug_report_template.yaml) and [feature requests](https://github.com/mlflow/mlflow/issues/new?template=feature_request_template.yaml)
- Contribute for [good-first-issues](https://github.com/mlflow/mlflow/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) and [help-wanted](https://github.com/mlflow/mlflow/issues?q=is%3Aissue+is%3Aopen+label%3A%22help+wanted%22)
- Writing about MLflow and sharing your experience
Please see our [contribution guide](CONTRIBUTING.md) to learn more about contributing to MLflow.
## ⭐️ Star History
<a href="https://star-history.com/#mlflow/mlflow&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=mlflow/mlflow&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=mlflow/mlflow&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=mlflow/mlflow&type=Date" />
</picture>
</a>
## ✏️ Citation
If you use MLflow in your research, please cite it using the "Cite this repository" button at the top of the [GitHub repository page](https://github.com/mlflow/mlflow), which will provide you with citation formats including APA and BibTeX.
## 👥 Core Members
MLflow is currently maintained by the following core members with significant contributions from hundreds of exceptionally talented community members.
- [Ben Wilson](https://github.com/BenWilson2)
- [Corey Zumar](https://github.com/dbczumar)
- [Daniel Lok](https://github.com/daniellok-db)
- [Gabriel Fu](https://github.com/gabrielfu)
- [Harutaka Kawamura](https://github.com/harupy)
- [Joel Robin P](https://github.com/joelrobin18)
- [Matt Prahl](https://github.com/mprahl)
- [Serena Ruan](https://github.com/serena-ruan)
- [Tomu Hirata](https://github.com/TomeHirata)
- [Weichen Xu](https://github.com/WeichenXu123)
- [Yuki Watanabe](https://github.com/B-Step62)
| text/markdown | null | null | null | Databricks <mlflow-oss-maintainers@googlegroups.com> | Copyright 2018 Databricks, Inc. All rights reserved.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| mlflow, ai, databricks | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: Science/Research",
"Intended Audience :: Information Technology",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries :: Python Modules",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"cachetools<8,>=5.0.0",
"click<9,>=7.0",
"cloudpickle<4",
"databricks-sdk<1,>=0.20.0",
"fastapi<1",
"gitpython<4,>=3.1.9",
"importlib_metadata!=4.7.0,<9,>=3.7.0",
"opentelemetry-api<3,>=1.9.0",
"opentelemetry-proto<3,>=1.9.0",
"opentelemetry-sdk<3,>=1.9.0",
"packaging<27",
"protobuf<7,>=3.12.0",
"pydantic<3,>=2.0.0",
"python-dotenv<2,>=0.19.0",
"pyyaml<7,>=5.1",
"requests<3,>=2.17.3",
"sqlparse<1,>=0.4.0",
"typing-extensions<5,>=4.0.0",
"uvicorn<1",
"pyarrow; extra == \"extras\"",
"requests-auth-aws-sigv4; extra == \"extras\"",
"boto3; extra == \"extras\"",
"botocore; extra == \"extras\"",
"google-cloud-storage>=1.30.0; extra == \"extras\"",
"azureml-core>=1.2.0; extra == \"extras\"",
"pysftp; extra == \"extras\"",
"kubernetes; extra == \"extras\"",
"prometheus-flask-exporter; extra == \"extras\"",
"PyMySQL; extra == \"db\"",
"psycopg2-binary; extra == \"db\"",
"pymssql; extra == \"db\"",
"azure-storage-file-datalake>12; extra == \"databricks\"",
"google-cloud-storage>=1.30.0; extra == \"databricks\"",
"boto3>1; extra == \"databricks\"",
"botocore; extra == \"databricks\"",
"databricks-agents<2.0,>=1.2.0; extra == \"databricks\"",
"mlserver!=1.3.1,<2.0.0,>=1.2.0; extra == \"mlserver\"",
"mlserver-mlflow!=1.3.1,<2.0.0,>=1.2.0; extra == \"mlserver\"",
"aiohttp<4; extra == \"gateway\"",
"boto3<2,>=1.28.56; extra == \"gateway\"",
"fastapi<1; extra == \"gateway\"",
"slowapi<1,>=0.1.9; extra == \"gateway\"",
"tiktoken<1; extra == \"gateway\"",
"uvicorn[standard]<1; extra == \"gateway\"",
"watchfiles<2; extra == \"gateway\"",
"aiohttp<4; extra == \"genai\"",
"boto3<2,>=1.28.56; extra == \"genai\"",
"fastapi<1; extra == \"genai\"",
"gepa<1,>=0.0.26; extra == \"genai\"",
"litellm<2,>=1.0.0; extra == \"genai\"",
"slowapi<1,>=0.1.9; extra == \"genai\"",
"tiktoken<1; extra == \"genai\"",
"uvicorn[standard]<1; extra == \"genai\"",
"watchfiles<2; extra == \"genai\"",
"fastmcp<3,>=2.0.0; extra == \"mcp\"",
"click!=8.3.0; extra == \"mcp\"",
"mlflow-dbstore; extra == \"sqlserver\"",
"aliyunstoreplugin; extra == \"aliyun-oss\"",
"mlflow-jfrog-plugin; extra == \"jfrog\"",
"langchain<=1.2.9,>=0.3.19; extra == \"langchain\"",
"Flask-WTF<2; extra == \"auth\""
] | [] | [] | [] | [
"homepage, https://mlflow.org",
"issues, https://github.com/mlflow/mlflow/issues",
"documentation, https://mlflow.org/docs/latest",
"repository, https://github.com/mlflow/mlflow"
] | twine/6.2.0 CPython/3.9.24 | 2026-02-20T12:57:22.456825 | mlflow_skinny-3.10.0.tar.gz | 2,475,421 | d5/af/135911a40cc65164f92ccbaacdf029c21a96eaecc9d99b60189b17a56e52/mlflow_skinny-3.10.0.tar.gz | source | sdist | null | false | 3fb4e815782ba3a4a441731a6cbfd401 | d864b14241f8e26a565e60b343a9644db3b2279b5039bd4e5cc2d0a6757bce99 | d5af135911a40cc65164f92ccbaacdf029c21a96eaecc9d99b60189b17a56e52 | null | [
"LICENSE.txt"
] | 321,305 |
2.4 | num-dual | 0.13.4 | Generalized (hyper) dual numbers for the calculation of exact (partial) derivatives | # num-dual
[](https://crates.io/crates/num-dual)
[](https://docs.rs/num-dual)
[](https://rust-lang.github.io/rfcs/2495-min-rust-version.html)
[](https://itt-ustutt.github.io/num-dual/)
[](https://badge.fury.io/py/num_dual)
Generalized, recursive, scalar and vector (hyper) dual numbers for the automatic and exact calculation of (partial) derivatives.
Including bindings for python.
## Installation and Usage
### Python
The python package can be installed directly from PyPI:
```
pip install num_dual
```
[//]: # "or from source (you need a rust compiler for that):"
[//]: # "```"
[//]: # "pip install git+https://github.com/itt-ustutt/num-dual"
[//]: # "```"
### Rust
Add this to your `Cargo.toml`:
```toml
[dependencies]
num-dual = "0.13"
```
## Example
### Python
Compute the first and second derivative of a scalar-valued function.
```python
from num_dual import second_derivative
import numpy as np
def f(x):
return np.exp(x) / np.sqrt(np.sin(x)**3 + np.cos(x)**3)
f, df, d2f = second_derivative(f, 1.5)
print(f'f(x) = {f}')
print(f'df/dx = {df}')
print(f'd2f/dx2 = {d2f}')
```
### Rust
This example defines a generic function that can be called using any (hyper) dual number and automatically calculates derivatives.
```rust
use num_dual::*;
use nalgebra::SMatrix;
fn f<D: DualNum<f64>>(x: D, y: D) -> D {
x.powi(3) * y.powi(2)
}
fn main() {
let (x, y) = (5.0, 4.0);
// Calculate a simple derivative using dual numbers
let x_dual = Dual64::from(x).derivative();
let y_dual = Dual64::from(y);
println!("{}", f(x_dual, y_dual)); // 2000 + 1200ε
// or use the provided function instead
let (_, df) = first_derivative(|x| f(x, y.into()), x);
println!("{df}"); // 1200
// Calculate a gradient
let (value, grad) = gradient(|v| f(v[0], v[1]), &SMatrix::from([x, y]));
println!("{value} {grad}"); // 2000 [1200, 1000]
// Calculate a Hessian
let (_, _, hess) = hessian(|v| f(v[0], v[1]), &SMatrix::from([x, y]));
println!("{hess}"); // [[480, 600], [600, 250]]
// for x=cos(t) and y=sin(t) calculate the third derivative w.r.t. t
let (_, _, _, d3f) = third_derivative(|t| f(t.cos(), t.sin()), 1.0);
println!("{d3f}"); // 7.358639755305733
}
```
## Documentation
- You can find the documentation of the rust crate [here](https://docs.rs/num-dual/).
- The documentation of the python package can be found [here](https://itt-ustutt.github.io/num-dual/).
### Python
For the following commands to work you have to have the package installed (see: installing from source).
```
cd docs
make html
```
Open `_build/html/index.html` in your browser.
## Further reading
If you want to learn more about the topic of dual numbers and automatic differentiation, we have listed some useful resources for you here:
- Initial paper about hyper-dual numbers: [Fike, J. and Alonso, J., 2011](https://arc.aiaa.org/doi/abs/10.2514/6.2011-886)
- Website about all topics regarding automatic differentiation: [autodiff.org](http://www.autodiff.org/)
- Our paper about dual numbers in equation of state modeling: [Rehner, P. and Bauer, G., 2021](https://www.frontiersin.org/article/10.3389/fceng.2021.758090)
## Cite us
If you find `num-dual` useful for your own scientific studies, consider [citing our publication](https://www.frontiersin.org/article/10.3389/fceng.2021.758090) accompanying this library.
```
@ARTICLE{rehner2021,
AUTHOR={Rehner, Philipp and Bauer, Gernot},
TITLE={Application of Generalized (Hyper-) Dual Numbers in Equation of State Modeling},
JOURNAL={Frontiers in Chemical Engineering},
VOLUME={3},
YEAR={2021},
URL={https://www.frontiersin.org/article/10.3389/fceng.2021.758090},
DOI={10.3389/fceng.2021.758090},
ISSN={2673-2718}
}
```
| text/markdown; charset=UTF-8; variant=GFM | Gernot Bauer <bauer@itt.uni-stuttgart.de>, Philipp Rehner <prehner@ethz.ch> | Gernot Bauer <bauer@itt.uni-stuttgart.de>, Philipp Rehner <prehner@ethz.ch> | null | null | MIT OR Apache-2.0 | mathematics, numerics, differentiation | [] | [] | https://github.com/itt-ustutt/num-dual | null | null | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/itt-ustutt/num-dual",
"Source Code, https://github.com/itt-ustutt/num-dual"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T12:57:00.918049 | num_dual-0.13.4-cp39-abi3-win_amd64.whl | 5,376,722 | 2d/9b/445168e5b8117c84ea759aa41a48fd1a3d601008d9c7be674a261385cbf6/num_dual-0.13.4-cp39-abi3-win_amd64.whl | cp39 | bdist_wheel | null | false | 131727324a10c82c60a5822da8fe415e | 28c4f8411bcffb515d15db21f5f10ec54e4f45fe3d56e9057c8261dd12c736bf | 2d9b445168e5b8117c84ea759aa41a48fd1a3d601008d9c7be674a261385cbf6 | null | [] | 279 |
2.4 | mcpcat | 0.1.13 | Analytics Tool for MCP Servers - provides insights into MCP tool usage patterns | <div align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="docs/static/logo-dark.svg">
<source media="(prefers-color-scheme: light)" srcset="docs/static/logo-light.svg">
<img alt="MCPcat Logo" src="docs/static/logo-light.svg" width="80%">
</picture>
</div>
<h3 align="center">
<a href="#getting-started">Getting Started</a>
<span> · </span>
<a href="#why-use-mcpcat-">Features</a>
<span> · </span>
<a href="https://docs.mcpcat.io">Docs</a>
<span> · </span>
<a href="https://mcpcat.io">Website</a>
<span> · </span>
<a href="#free-for-open-source">Open Source</a>
<span> · </span>
<a href="https://meet.mcpcat.io/meet">Schedule a Demo</a>
</h3>
<p align="center">
<a href="https://badge.fury.io/py/mcpcat"><img src="https://badge.fury.io/py/mcpcat.svg" alt="PyPI version"></a>
<a href="https://pypi.org/project/mcpcat/"><img src="https://img.shields.io/pypi/dm/mcpcat.svg" alt="PyPI downloads"></a>
<a href="https://opensource.org/licenses/MIT"><img src="https://img.shields.io/badge/License-MIT-blue.svg" alt="License: MIT"></a>
<a href="https://www.python.org/"><img src="https://img.shields.io/badge/python-3.10+-blue.svg" alt="Python"></a>
<a href="https://github.com/MCPCat/mcpcat-python-sdk/issues"><img src="https://img.shields.io/github/issues/MCPCat/mcpcat-python-sdk.svg" alt="GitHub issues"></a>
<a href="https://github.com/MCPCat/mcpcat-python-sdk/actions"><img src="https://github.com/MCPCat/mcpcat-python-sdk/workflows/MCP%20Version%20Compatibility%20Testing/badge.svg" alt="CI"></a>
</p>
> [!NOTE]
> Looking for the TypeScript SDK? Check it out here [mcpcat-typescript](https://github.com/mcpcat/mcpcat-typescript-sdk).
MCPcat is an analytics platform for MCP server owners 🐱. It captures user intentions and behavior patterns to help you understand what AI users actually need from your tools — eliminating guesswork and accelerating product development all with one-line of code.
This SDK also provides a free and simple way to forward telemetry like logs, traces, and errors to any Open Telemetry collector or popular tools like Datadog and Sentry.
```bash
# Basic installation (includes official MCP SDK)
pip install mcpcat
# With Jlowin's/Prefect's FastMCP support
pip install "mcpcat[community]"
```
To learn more about us, check us out [here](https://mcpcat.io)
## Why use MCPcat? 🤔
MCPcat helps developers and product owners build, improve, and monitor their MCP servers by capturing user analytics and tracing tool calls.
Use MCPcat for:
- **User session replay** 🎬. Follow alongside your users to understand why they're using your MCP servers, what functionality you're missing, and what clients they're coming from.
- **Trace debugging** 🔍. See where your users are getting stuck, track and find when LLMs get confused by your API, and debug sessions across all deployments of your MCP server.
- **Existing platform support** 📊. Get logging and tracing out of the box for your existing observability platforms (OpenTelemetry, Datadog, Sentry) — eliminating the tedious work of implementing telemetry yourself.
<img width="1274" height="770" alt="mcpcat-diagram" src="https://github.com/user-attachments/assets/36615b3c-7267-4b01-a055-856105c432cb" />
## Getting Started
To get started with MCPcat, first create an account and obtain your project ID by signing up at [mcpcat.io](https://mcpcat.io). For detailed setup instructions visit our [documentation](https://docs.mcpcat.io).
Once you have your project ID, integrate MCPcat into your MCP server:
```python
import mcpcat
from mcp.server import FastMCP
server = FastMCP(name="echo-mcp", version="1.0.0")
mcpcat.track(server, "proj_0000000")
```
### Identifying users
You can identify your user sessions with a simple callback MCPcat exposes, called `identify`.
```python
def identify_user(request, extra):
user = myapi.get_user(request.params.arguments.token)
return UserIdentity(
user_id=user.id,
user_name=user.name,
user_data={
"favorite_color": user.favorite_color,
},
)
mcpcat.track(server, "proj_0000000", MCPCatOptions(identify=identify_user))
```
### Redacting sensitive data
MCPcat redacts all data sent to its servers and encrypts at rest, but for additional security, it offers a hook to do your own redaction on all text data returned back to our servers.
```python
# Sync version
def redact_sync(text):
return custom_redact(text)
mcpcat.track(server, "proj_0000000", redact_sensitive_information=redact_sync)
```
### Forwarding data to existing observability platforms
MCPcat seamlessly integrates with your existing observability stack, providing automatic logging and tracing without the tedious setup typically required. Export telemetry data to multiple platforms simultaneously:
```python
from mcpcat import MCPCatOptions, ExporterConfig
mcpcat.track(
server,
"proj_0000000", # Or None if you just want to use the SDK to forward telemetry
MCPCatOptions(
exporters={
# OpenTelemetry - works with Jaeger, Tempo, New Relic, etc.
"otlp": ExporterConfig(
type="otlp",
endpoint="http://localhost:4318/v1/traces"
),
# Datadog
"datadog": ExporterConfig(
type="datadog",
api_key=os.getenv("DD_API_KEY"),
site="datadoghq.com",
service="my-mcp-server"
),
# Sentry
"sentry": ExporterConfig(
type="sentry",
dsn=os.getenv("SENTRY_DSN"),
environment="production"
)
}
)
)
```
Learn more about our free and open source [telemetry integrations](https://docs.mcpcat.io/telemetry/integrations).
## Free for open source
MCPcat is free for qualified open source projects. We believe in supporting the ecosystem that makes MCP possible. If you maintain an open source MCP server, you can access our full analytics platform at no cost.
**How to apply**: Email hi@mcpcat.io with your repository link
_Already using MCPcat? We'll upgrade your account immediately._
## Community Cats 🐱
Meet the cats behind MCPcat! Add your cat to our community by submitting a PR with your cat's photo in the `docs/cats/` directory.
<div align="left">
<img src="docs/cats/bibi.png" alt="bibi" width="80" height="80">
<img src="docs/cats/zelda.jpg" alt="zelda" width="80" height="80">
</div>
_Want to add your cat? Create a PR adding your cat's photo to `docs/cats/` and update this section!_
| text/markdown | null | MCPCat <support@mcpcat.io> | null | null | MIT | null | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"mcp>=1.2.0",
"mcpcat-api==0.1.4",
"pydantic<2.12,>=2.0.0",
"requests>=2.31.0",
"fastmcp!=2.9.*,>=2.7.0; extra == \"community\"",
"freezegun>=1.2.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/MCPCat/mcpcat-python-sdk",
"Bug Tracker, https://github.com/MCPCat/mcpcat-python-sdk/issues",
"Repository, https://github.com/MCPCat/mcpcat-python-sdk"
] | uv/0.7.14 | 2026-02-20T12:56:35.318824 | mcpcat-0.1.13.tar.gz | 3,280,667 | 95/22/e17f972044cb03a9564b0cd9f6ed565e085bceb82c422baebd88202e6e82/mcpcat-0.1.13.tar.gz | source | sdist | null | false | 2dcd5639c398b75b328bbe19891e0ba5 | a0a771bc668cb2b9e9efb9ea8da4c88cc7bcc3f063b830902aff15deab3707f7 | 9522e17f972044cb03a9564b0cd9f6ed565e085bceb82c422baebd88202e6e82 | null | [
"LICENSE"
] | 216 |
2.4 | pg-bulk-ingest | 0.0.58 | A collection of Python utility functions for ingesting data into SQLAlchemy-defined PostgreSQL tables, automatically migrating them as needed, and minimising locking | # pg-bulk-ingest
[](https://pypi.org/project/pg-bulk-ingest/) [](https://github.com/uktrade/pg-bulk-ingest/actions/workflows/test.yml) [](https://app.codecov.io/gh/uktrade/pg-bulk-ingest)
A Python utility function for ingesting data into SQLAlchemy-defined PostgreSQL tables, automatically migrating them as needed, allowing concurrent reads as much as possible.
Allowing concurrent writes is not an aim of pg-bulk-ingest. It is designed for use in ETL pipelines where PostgreSQL is used as a data warehouse, and the only writes to the table are from pg-bulk-ingest. It is assumed that there is only one pg-bulk-ingest running against a given table at any one time.
## Features
pg-bulk-ingest exposes a single function as its API that:
- Creates the tables if necessary
- Migrates any existing tables if necessary, minimising locking
- Ingests data in batches, where each batch is ingested in its own transaction
- Handles "high-watermarking" to carry on from where a previous ingest finished or errored
- Optionally performs an "upsert", matching rows on primary key
- Optionally deletes all existing rows before ingestion
- Optionally calls a callback just before each batch is visible to other database clients
---
Visit the [pg-bulk-ingest documentation](https://pg-bulk-ingest.docs.trade.gov.uk/) for usage instructions.
| text/markdown | null | Department for Business and Trade <sre@digital.trade.gov.uk> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.7.7 | [] | [] | [] | [
"pg-force-execute>=0.0.10",
"sqlalchemy>=1.4.24",
"to-file-like-obj>=0.0.5",
"pg-force-execute==0.0.10; extra == \"ci\"",
"psycopg2==2.9.10; python_version >= \"3.13\" and extra == \"ci\"",
"psycopg2==2.9.2; python_version < \"3.13\" and extra == \"ci\"",
"to-file-like-obj==0.0.5; extra == \"ci\"",
"adbc-driver-postgresql==1.6.0; extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"numpy==1.26.2; extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"pandas==2.0.0; python_version < \"3.13\" and extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"pandas==2.2.3; python_version >= \"3.13\" and extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"pgarrow==0.0.7; extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"polars==1.0.0; extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"psycopg==3.2.0; extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"pyarrow==18.0.0; extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"sqlalchemy==1.4.24; extra == \"ci-sqlalchemy1-with-pg-arrow\"",
"sqlalchemy==1.4.24; extra == \"ci-sqlalchemy1-without-pg-arrow\"",
"adbc-driver-postgresql==1.6.0; extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"numpy==1.26.2; extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"pandas==2.0.0; python_version < \"3.13\" and extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"pandas==2.2.3; python_version >= \"3.13\" and extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"pgarrow==0.0.7; extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"polars==1.0.0; extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"pyarrow==18.0.0; extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"sqlalchemy==2.0.41; python_version >= \"3.13\" and extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"sqlalchemy==2.0.7; python_version < \"3.13\" and extra == \"ci-sqlalchemy2-with-pg-arrow\"",
"sqlalchemy==2.0.0; python_version < \"3.13\" and extra == \"ci-sqlalchemy2-without-pg-arrow\"",
"sqlalchemy==2.0.31; python_version >= \"3.13\" and extra == \"ci-sqlalchemy2-without-pg-arrow\"",
"coverage; extra == \"dev\"",
"mypy<1.16.0; extra == \"dev\"",
"pgvector>=0.1.8; extra == \"dev\"",
"psycopg2>=2.9.2; extra == \"dev\"",
"psycopg>=3.1.4; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\""
] | [] | [] | [] | [
"Source, https://github.com/uktrade/pg-bulk-ingest"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:55:56.913206 | pg_bulk_ingest-0.0.58.tar.gz | 13,135 | dd/f4/cc11a24e03110a97828b1df88114bff4f03bbfcdd1b00f301ba67950e37d/pg_bulk_ingest-0.0.58.tar.gz | source | sdist | null | false | 893df4a8cbde629a013dd232aa51cb4a | 4bf182c21da6936c36de63259f43e07125f3191ffa60727e050b797a596b3df3 | ddf4cc11a24e03110a97828b1df88114bff4f03bbfcdd1b00f301ba67950e37d | null | [
"LICENSE"
] | 203 |
2.4 | oceanprotocol-job-details | 0.4.2 | A Python package to get details from OceanProtocol jobs | # OceanProtocol Job Details
[](https://pypi.org/project/oceanprotocol-job-details/)
[](https://github.com/agrospai/oceanprotocol-job-details)
A Python package to get details from OceanProtocol jobs
## Installation
```bash
pip install oceanprotocol-job-details
#or
uv add oceanprotocol-job-details
```
## Usage
As a simple library, we only need to import `load_job_details` and run it. It will:
1. Read from disk the needed parameters to populate the `JobDetails` from the given `base_dir`. Looking for the files corresponding to the passed DIDs in the filesystem according to the [Ocean Protocol Structure](#oceanprotocol-structure).
2. If given a `InputParameters` type that inherits from `pydantic.BaseModel`, it will create an instance from the environment variables.
### Minimal Example
```python
from oceanprotocol_job_details import load_job_details
job_details = load_job_details({"base_dir": "...", "transformation_did": "..."})
```
### Custom Input Parameters
If our algorithm has custom input parameters and we want to load them into our algorithm, we can do it as follows:
```python
from pydantic import BaseModel
from oceanprotocol_job_details import load_job_details
class Foo(BaseModel):
bar: str
class InputParameters(BaseModel):
# Allows for nested types
foo: Foo
job_details = load_job_details({"base_dir": "...", "transformation_did": "..."}, InputParameters)
# Usage
parameters = await job_details.input_parameters()
parameters.foo
parameters.foo.bar
```
The values to fill the custom `InputParameters` will be parsed from the `algoCustomData.json` located next to the input data directories.
### Iterating Input Files the clean way
```python
from oceanprotocol_job_details import load_job_details
job_details = load_job_details(...)
for idx, file_path in job_details.inputs():
...
_, file_path = next(job_details.inputs())
```
## OceanProtocol Structure
```bash
data # Root /data directory
├── ddos # Contains the loaded dataset's DDO (metadata)
│ ├── 17feb...e42 # DDO file
│ └── ... # One DDO per loaded dataset
├── inputs # Datasets dir
│ ├── 17feb...e42 # Dir holding the data of its name DID, contains files named 0..X
│ │ └── 0 # Data file
│ └── algoCustomData.json # Custom algorithm input data
├── logs # Algorithm output logs dir
└── outputs # Algorithm output files dir
```
> **_Note:_** Even though it's possible that the algorithm is passed multiple datasets, right now the implementation only allows to use **one dataset** per algorithm execution, so **normally** the executing job will only have **one ddo**, **one dir** inside inputs, and **one data file** named `0`.
| text/markdown | null | Agrospai <agrospai@udl.cat>, Christian López García <christian.lopez@udl.cat> | null | null | Copyright 2025 Agrospai Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"aiofiles>=25.1.0",
"dependency-injector>=4.48.2",
"mypy[faster-cache]>=1.15.0",
"orjson>=3.11.3",
"pydantic-settings>=2.12.0",
"pydantic>=2.12.5",
"returns[compatible-mypy]>=0.26.0"
] | [] | [] | [] | [
"Homepage, https://github.com/AgrospAI/oceanprotocol-job-details",
"Issues, https://github.com/AgrospAI/oceanprotocol-job-details/issues"
] | twine/6.0.1 CPython/3.12.8 | 2026-02-20T12:55:45.685745 | oceanprotocol_job_details-0.4.2.tar.gz | 8,175 | 61/93/513c1e907b54688dbfd027b6aa15127bc2a574523dbfafae8a002d1688b7/oceanprotocol_job_details-0.4.2.tar.gz | source | sdist | null | false | 2002a30b6f1bb17a33dcefcb9a308d30 | 13147c716d66ea898d5e81a1934f2553bf45215130b953f671e040b8c0e829ae | 6193513c1e907b54688dbfd027b6aa15127bc2a574523dbfafae8a002d1688b7 | null | [] | 259 |
2.4 | quantify | 26.8.0 | A framework for controlling quantum computing and solid-state physics experiments. | # Quantify

[](https://mybinder.org/v2/gl/quantify-os%2Fquantify/main?urlpath=lab/tree/docs/source/tutorials)
[](https://pypi.org/project/quantify/)
[](https://gitlab.com/quantify-os/quantify/-/pipelines)
[](https://quantify-os.gitlab.io/quantify/)
[](https://app.codacy.com/gl/quantify-os/quantify/dashboard?utm_source=gl&utm_medium=referral&utm_content=&utm_campaign=Badge_grade)
[](https://docs.astral.sh/ruff/)
[](./LICENSE)
[](./CONTRIBUTING.md)
[](https://join.slack.com/t/quantify-hq/shared_invite/zt-1nd78r4e9-rbWdna53cW4DO_YbtMhVuA)
Quantify is a Python-based data acquisition framework focused on Quantum Computing and
solid-state physics experiments.
Currently it is a metapackage for [quantify-core](https://pypi.org/project/quantify-core/)
([git repo](https://gitlab.com/quantify-os/quantify-core/))
and [quantify-scheduler](https://pypi.org/project/quantify-scheduler/)
([git repo](https://gitlab.com/quantify-os/quantify-scheduler/)).
They are built on top of [QCoDeS](https://qcodes.github.io/Qcodes/) and are a spiritual
successor of [PycQED](https://github.com/DiCarloLab-Delft/PycQED_py3).
Versioning: CalVer `vYY.WW.MICRO` (see [calver.org](https://calver.org/)).
Take a look at the latest documentation for
[quantify-core](https://quantify-os.org/docs/quantify-core/v0.9.1/) and
[quantify-scheduler](https://quantify-os.org/docs/quantify-scheduler/v0.27.0/)
for the usage instructions.
## Overview and Community
For a general overview of Quantify and connecting to its open-source community,
see [quantify-os.org](https://quantify-os.org/).
Quantify is maintained by the Orange Quantum Systems.
[](https://orangeqs.com)
The software is licensed under a [BSD 3-clause license](https://gitlab.com/quantify-os/quantify/-/raw/main/LICENSE).
| text/markdown | null | null | null | Olga Lebiga <olga@orangeqs.com>, Amirtha Varshiny Arumugam <amirthavarshiny@orangeqs.com>, Mahmut Çetin <mahmut@orangeqs.com> | null | quantum, quantify | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Natural Language :: English",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"adaptive>=1.3.0",
"bokeh>=3.8.0",
"dataclasses-json>=0.6.6",
"deepdiff>=8.6.0",
"fastjsonschema>=2.21.0",
"filelock>=3.18.0",
"h5netcdf>=0.7.0",
"ipython>=8.35.0",
"jsonschema>=4.25.0",
"lmfit>=1.3.0",
"matplotlib>=3.10.5",
"methodtools>=0.4.5",
"netCDF4!=1.7.4,>=1.6.5",
"networkx>=3.2",
"numpy>=2.2.2",
"packaging>=24.0",
"pandas>=2.2.2",
"plotly>=6.4.0",
"psutil>=7.1.2",
"pydantic>=2.9.0",
"pydantic-core>=2.23.2",
"python-dateutil>=2.9.0",
"pyzmq>=25.1.1",
"qcodes<0.53.0,>=0.52.0",
"ruamel.yaml>=0.18.15",
"scikit-learn>=1.7.1",
"scipy>=1.13.0",
"tqdm>=4.67.0",
"typing-extensions>=4.14.1",
"uncertainties>=3.2.2",
"xarray>=2022.6.0",
"xxhash>=3.5.0",
"pre-commit>=4.5.1; extra == \"dev\"",
"pre-commit-hooks>=6.0.0; extra == \"dev\"",
"pyright>=1.1.408; extra == \"dev\"",
"ruff>=0.14.14; extra == \"dev\"",
"hvplot>=0.12.2; extra == \"docs\"",
"jupyter-sphinx>=0.5.3; extra == \"docs\"",
"jupytext>=1.19.1; extra == \"docs\"",
"linkify-it-py>=2.0.3; extra == \"docs\"",
"myst-nb>=1.3.0; extra == \"docs\"",
"myst-parser>=4.0.1; extra == \"docs\"",
"nbsphinx>=0.9.8; extra == \"docs\"",
"plotly>=6.5.2; extra == \"docs\"",
"pydata-sphinx-theme>=0.16.1; extra == \"docs\"",
"rich[jupyter]>=14.1.0; extra == \"docs\"",
"scanpydoc>=0.15.4; extra == \"docs\"",
"sphinx>=8.1.3; extra == \"docs\"",
"sphinx-autoapi>=3.6.1; extra == \"docs\"",
"sphinx-autobuild>=2024.10.3; extra == \"docs\"",
"sphinx-autodoc-typehints>=3.0.1; extra == \"docs\"",
"sphinx-design>=0.6.1; extra == \"docs\"",
"sphinx-jsonschema>=1.19.2; extra == \"docs\"",
"sphinx-togglebutton>=0.4.4; extra == \"docs\"",
"sphinxcontrib-bibtex>=2.6.5; extra == \"docs\"",
"sphinxcontrib-mermaid>=2.0.0; extra == \"docs\"",
"diff-cover>=10.2.0; extra == \"test\"",
"pytest>=9.0.2; extra == \"test\"",
"pytest-cov>=7.0.0; extra == \"test\"",
"pytest-mock>=3.15.1; extra == \"test\"",
"pytest-mpl>=0.18.0; extra == \"test\"",
"pytest-xdist>=3.8.0; extra == \"test\"",
"jupyterlab>=4.0.0; extra == \"binder\"",
"notebook>=7.0.0; extra == \"binder\""
] | [] | [] | [] | [
"Documentation, https://quantify-os.gitlab.io/quantify",
"Website, https://quantify-os.org",
"Source, https://gitlab.com/quantify-os/quantify",
"Issue tracker, https://gitlab.com/quantify-os/quantify/-/issues",
"Slack, https://join.slack.com/t/quantify-hq/shared_invite/zt-1nd78r4e9-rbWdna53cW4DO_YbtMhVuA"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T12:55:18.978165 | quantify-26.8.0.tar.gz | 11,956,946 | 72/48/94314adb7fe7339840faa82be22b8eea7eed926932216f540ba09678d1f7/quantify-26.8.0.tar.gz | source | sdist | null | false | 5b9f00b3869c67c9389d3f148f8e7e2e | 3f43273825d2313a6cea362aed80f623e87f12993bb3e0850843bf393c2a72b7 | 724894314adb7fe7339840faa82be22b8eea7eed926932216f540ba09678d1f7 | BSD-3-Clause | [
"LICENSE"
] | 671 |
2.4 | redmine-mcp-server | 0.12.0 | Production-ready MCP server for Redmine with security, pagination, and enterprise features | # Redmine MCP Server
[](https://pypi.org/project/redmine-mcp-server/)
[](LICENSE)
[](https://pypi.org/project/redmine-mcp-server/)
[](https://github.com/jztan/redmine-mcp-server/issues)
[](https://github.com/jztan/redmine-mcp-server/actions/workflows/pr-tests.yml)
[](https://codecov.io/gh/jztan/redmine-mcp-server)
[](https://pepy.tech/project/redmine-mcp-server)
A Model Context Protocol (MCP) server that integrates with Redmine project management systems. This server provides seamless access to Redmine data through MCP tools, enabling AI assistants to interact with your Redmine instance.
**mcp-name: io.github.jztan/redmine-mcp-server**
## [Tool reference](./docs/tool-reference.md) | [Changelog](./CHANGELOG.md) | [Contributing](./docs/contributing.md) | [Troubleshooting](./docs/troubleshooting.md)
## Features
- **Redmine Integration**: List projects, view/create/update issues, download attachments
- **HTTP File Serving**: Secure file access via UUID-based URLs with automatic expiry
- **MCP Compliant**: Full Model Context Protocol support with FastMCP and streamable HTTP transport
- **Flexible Authentication**: Username/password or API key
- **File Management**: Automatic cleanup of expired files with storage statistics
- **Docker Ready**: Complete containerization support
- **Pagination Support**: Efficiently handle large issue lists with configurable limits
## Quick Start
1. **Install the package**
```bash
pip install redmine-mcp-server
```
2. **Create a `.env` file** with your Redmine credentials (see [Installation](#installation) for template)
3. **Start the server**
```bash
redmine-mcp-server
```
4. **Add the server to your MCP client** using one of the guides in [MCP Client Configuration](#mcp-client-configuration).
Once running, the server listens on `http://localhost:8000` with the MCP endpoint at `/mcp`, health check at `/health`, and file serving at `/files/{file_id}`.
## Installation
### Prerequisites
- Python 3.10+ (for local installation)
- Docker (alternative deployment, uses Python 3.13)
- Access to a Redmine instance
### Install from PyPI (Recommended)
```bash
# Install the package
pip install redmine-mcp-server
# Create configuration file .env
cat > .env << 'EOF'
# Redmine connection (required)
REDMINE_URL=https://your-redmine-server.com
# Authentication - Use either API key (recommended) or username/password
REDMINE_API_KEY=your_api_key
# OR use username/password:
# REDMINE_USERNAME=your_username
# REDMINE_PASSWORD=your_password
# Server configuration (optional, defaults shown)
SERVER_HOST=0.0.0.0
SERVER_PORT=8000
# Public URL for file serving (optional)
PUBLIC_HOST=localhost
PUBLIC_PORT=8000
# File management (optional)
ATTACHMENTS_DIR=./attachments
AUTO_CLEANUP_ENABLED=true
CLEANUP_INTERVAL_MINUTES=10
ATTACHMENT_EXPIRES_MINUTES=60
EOF
# Edit .env with your actual Redmine settings
nano .env # or use your preferred editor
# Run the server
redmine-mcp-server
# Or alternatively:
python -m redmine_mcp_server.main
```
The server runs on `http://localhost:8000` with the MCP endpoint at `/mcp`, health check at `/health`, and file serving at `/files/{file_id}`.
### Environment Variables
| Variable | Required | Default | Description |
|----------|----------|---------|-------------|
| `REDMINE_URL` | Yes | – | Base URL of your Redmine instance |
| `REDMINE_API_KEY` | Yes* | – | API key for authentication (*or provide username/password*) |
| `REDMINE_USERNAME` | Yes* | – | Username for basic auth (*use with password when not using API key*) |
| `REDMINE_PASSWORD` | Yes* | – | Password for basic auth |
| `SERVER_HOST` | No | `0.0.0.0` | Host/IP the MCP server binds to |
| `SERVER_PORT` | No | `8000` | Port the MCP server listens on |
| `PUBLIC_HOST` | No | `localhost` | Hostname used when generating download URLs |
| `PUBLIC_PORT` | No | `8000` | Public port used for download URLs |
| `ATTACHMENTS_DIR` | No | `./attachments` | Directory for downloaded attachments |
| `AUTO_CLEANUP_ENABLED` | No | `true` | Toggle automatic cleanup of expired attachments |
| `CLEANUP_INTERVAL_MINUTES` | No | `10` | Interval for cleanup task |
| `ATTACHMENT_EXPIRES_MINUTES` | No | `60` | Expiry window for generated download URLs |
| `REDMINE_SSL_VERIFY` | No | `true` | Enable/disable SSL certificate verification |
| `REDMINE_SSL_CERT` | No | – | Path to custom CA certificate file |
| `REDMINE_SSL_CLIENT_CERT` | No | – | Path to client certificate for mutual TLS |
| `REDMINE_AUTOFILL_REQUIRED_CUSTOM_FIELDS` | No | `false` | Enable one retry for issue creation by filling missing required custom fields |
| `REDMINE_REQUIRED_CUSTOM_FIELD_DEFAULTS` | No | `{}` | JSON object mapping required custom field names to fallback values used when creating issues |
*\* Either `REDMINE_API_KEY` or the combination of `REDMINE_USERNAME` and `REDMINE_PASSWORD` must be provided for authentication. API key authentication is recommended for security.*
When `REDMINE_AUTOFILL_REQUIRED_CUSTOM_FIELDS=true`, `create_redmine_issue` retries once on relevant custom-field validation errors (for example `<Field Name> cannot be blank` or `<Field Name> is not included in the list`) and fills values only from:
- the Redmine custom field `default_value`, or
- `REDMINE_REQUIRED_CUSTOM_FIELD_DEFAULTS`
Example:
```bash
REDMINE_AUTOFILL_REQUIRED_CUSTOM_FIELDS=true
REDMINE_REQUIRED_CUSTOM_FIELD_DEFAULTS='{"Required Field A":"Value A","Required Field B":"Value B"}'
```
### SSL Certificate Configuration
Configure SSL certificate handling for Redmine servers with self-signed certificates or internal CA infrastructure.
<details>
<summary><strong>Self-Signed Certificates</strong></summary>
If your Redmine server uses a self-signed certificate or internal CA:
```bash
# In .env file
REDMINE_URL=https://redmine.company.com
REDMINE_API_KEY=your_api_key
REDMINE_SSL_CERT=/path/to/ca-certificate.crt
```
Supported certificate formats: `.pem`, `.crt`, `.cer`
</details>
<details>
<summary><strong>Mutual TLS (Client Certificates)</strong></summary>
For environments requiring client certificate authentication:
```bash
# In .env file
REDMINE_URL=https://secure.redmine.com
REDMINE_API_KEY=your_api_key
REDMINE_SSL_CERT=/path/to/ca-bundle.pem
REDMINE_SSL_CLIENT_CERT=/path/to/cert.pem,/path/to/key.pem
```
**Note**: Private keys must be unencrypted (Python requests library requirement).
</details>
<details>
<summary><strong>Disable SSL Verification (Development Only)</strong></summary>
⚠️ **WARNING**: Only use in development/testing environments!
```bash
# In .env file
REDMINE_SSL_VERIFY=false
```
Disabling SSL verification makes your connection vulnerable to man-in-the-middle attacks.
</details>
For SSL troubleshooting, see the [Troubleshooting Guide](./docs/troubleshooting.md#ssl-certificate-errors).
## MCP Client Configuration
The server exposes an HTTP endpoint at `http://127.0.0.1:8000/mcp`. Register it with your preferred MCP-compatible agent using the instructions below.
<details>
<summary><strong>Visual Studio Code (Native MCP Support)</strong></summary>
VS Code has built-in MCP support via GitHub Copilot (requires VS Code 1.102+).
**Using CLI (Quickest):**
```bash
code --add-mcp '{"name":"redmine","type":"http","url":"http://127.0.0.1:8000/mcp"}'
```
**Using Command Palette:**
1. Open Command Palette (`Cmd/Ctrl+Shift+P`)
2. Run `MCP: Open User Configuration` (for global) or `MCP: Open Workspace Folder Configuration` (for project-specific)
3. Add the configuration:
```json
{
"servers": {
"redmine": {
"type": "http",
"url": "http://127.0.0.1:8000/mcp"
}
}
}
```
4. Save the file. VS Code will automatically load the MCP server.
**Manual Configuration:**
Create `.vscode/mcp.json` in your workspace (or `mcp.json` in your user profile directory):
```json
{
"servers": {
"redmine": {
"type": "http",
"url": "http://127.0.0.1:8000/mcp"
}
}
}
```
</details>
<details>
<summary><strong>Claude Code</strong></summary>
Add to Claude Code using the CLI command:
```bash
claude mcp add --transport http redmine http://127.0.0.1:8000/mcp
```
Or configure manually in your Claude Code settings file (`~/.claude.json`):
```json
{
"mcpServers": {
"redmine": {
"type": "http",
"url": "http://127.0.0.1:8000/mcp"
}
}
}
```
</details>
<details>
<summary><strong>Claude Desktop (macOS & Windows)</strong></summary>
Claude Desktop's config file supports stdio transport only. Use FastMCP's proxy via `uv` to bridge to this HTTP server.
**Setup:**
1. Open Claude Desktop
2. Click the **Claude** menu (macOS menu bar / Windows title bar) > **Settings...**
3. Click the **Developer** tab > **Edit Config**
4. Add the following configuration:
```json
{
"mcpServers": {
"redmine": {
"command": "uv",
"args": [
"run",
"--with", "fastmcp",
"fastmcp",
"run",
"http://127.0.0.1:8000/mcp"
]
}
}
}
```
5. Save the file, then **fully quit and restart** Claude Desktop
6. Look for the tools icon in the input area to verify the connection
**Config file locations:**
- macOS: `~/Library/Application Support/Claude/claude_desktop_config.json`
- Windows: `%APPDATA%\Claude\claude_desktop_config.json`
**Note:** The Redmine MCP server must be running before starting Claude Desktop.
</details>
<details>
<summary><strong>Codex CLI</strong></summary>
Add to Codex CLI using the command:
```bash
codex mcp add redmine -- npx -y mcp-client-http http://127.0.0.1:8000/mcp
```
Or configure manually in `~/.codex/config.toml`:
```toml
[mcp_servers.redmine]
command = "npx"
args = ["-y", "mcp-client-http", "http://127.0.0.1:8000/mcp"]
```
**Note:** Codex CLI primarily supports stdio-based MCP servers. The above uses `mcp-client-http` as a bridge for HTTP transport.
</details>
<details>
<summary><strong>Kiro</strong></summary>
Kiro primarily supports stdio-based MCP servers. For HTTP servers, use an HTTP-to-stdio bridge:
1. Create or edit `.kiro/settings/mcp.json` in your workspace:
```json
{
"mcpServers": {
"redmine": {
"command": "npx",
"args": [
"-y",
"mcp-client-http",
"http://127.0.0.1:8000/mcp"
],
"disabled": false
}
}
}
```
2. Save the file and restart Kiro. The Redmine tools will appear in the MCP panel.
**Note:** Direct HTTP transport support in Kiro is limited. The above configuration uses `mcp-client-http` as a bridge to connect to HTTP MCP servers.
</details>
<details>
<summary><strong>Generic MCP Clients</strong></summary>
Most MCP clients use a standard configuration format. For HTTP servers:
```json
{
"mcpServers": {
"redmine": {
"type": "http",
"url": "http://127.0.0.1:8000/mcp"
}
}
}
```
For clients that require a command-based approach with HTTP bridge:
```json
{
"mcpServers": {
"redmine": {
"command": "npx",
"args": ["-y", "mcp-client-http", "http://127.0.0.1:8000/mcp"]
}
}
}
```
</details>
### Testing Your Setup
```bash
# Test connection by checking health endpoint
curl http://localhost:8000/health
```
## Available Tools
This MCP server provides 17 tools for interacting with Redmine. For detailed documentation, see [Tool Reference](./docs/tool-reference.md).
- **Project Management** (4 tools)
- [`list_redmine_projects`](docs/tool-reference.md#list_redmine_projects) - List all accessible projects
- [`list_project_issue_custom_fields`](docs/tool-reference.md#list_project_issue_custom_fields) - List issue custom fields configured for a project
- [`list_redmine_versions`](docs/tool-reference.md#list_redmine_versions) - List versions/milestones for a project
- [`summarize_project_status`](docs/tool-reference.md#summarize_project_status) - Get comprehensive project status summary
- **Issue Operations** (6 tools)
- [`get_redmine_issue`](docs/tool-reference.md#get_redmine_issue) - Retrieve detailed issue information
- [`list_redmine_issues`](docs/tool-reference.md#list_redmine_issues) - List issues with flexible filtering (project, status, assignee, etc.)
- [`list_my_redmine_issues`](docs/tool-reference.md#list_my_redmine_issues) - List issues assigned to you *(deprecated: will be removed in a future release, use `list_redmine_issues(assigned_to_id='me')` instead)*
- [`search_redmine_issues`](docs/tool-reference.md#search_redmine_issues) - Search issues by text query
- [`create_redmine_issue`](docs/tool-reference.md#create_redmine_issue) - Create new issues
- [`update_redmine_issue`](docs/tool-reference.md#update_redmine_issue) - Update existing issues
- Note: `get_redmine_issue` can include `custom_fields` and `update_redmine_issue` can update custom fields by name (for example `{"size": "S"}`).
- **Search & Wiki** (5 tools)
- [`search_entire_redmine`](docs/tool-reference.md#search_entire_redmine) - Global search across issues and wiki pages (Redmine 3.3.0+)
- [`get_redmine_wiki_page`](docs/tool-reference.md#get_redmine_wiki_page) - Retrieve wiki page content
- [`create_redmine_wiki_page`](docs/tool-reference.md#create_redmine_wiki_page) - Create new wiki pages
- [`update_redmine_wiki_page`](docs/tool-reference.md#update_redmine_wiki_page) - Update existing wiki pages
- [`delete_redmine_wiki_page`](docs/tool-reference.md#delete_redmine_wiki_page) - Delete wiki pages
- **File Operations** (2 tools)
- [`get_redmine_attachment_download_url`](docs/tool-reference.md#get_redmine_attachment_download_url) - Get secure download URLs for attachments
- [`cleanup_attachment_files`](docs/tool-reference.md#cleanup_attachment_files) - Clean up expired attachment files
## Docker Deployment
### Quick Start with Docker
```bash
# Configure environment
cp .env.example .env.docker
# Edit .env.docker with your Redmine settings
# Run with docker-compose
docker-compose up --build
# Or run directly
docker build -t redmine-mcp-server .
docker run -p 8000:8000 --env-file .env.docker redmine-mcp-server
```
### Production Deployment
Use the automated deployment script:
```bash
chmod +x deploy.sh
./deploy.sh
```
## Troubleshooting
If you run into any issues, checkout our [troubleshooting guide](./docs/troubleshooting.md).
## Contributing
Contributions are welcome! Please see our [contributing guide](./docs/contributing.md) for details.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Additional Resources
- [Tool Reference](./docs/tool-reference.md) - Complete tool documentation
- [Troubleshooting Guide](./docs/troubleshooting.md) - Common issues and solutions
- [Contributing Guide](./docs/contributing.md) - Development setup and guidelines
- [Changelog](./CHANGELOG.md) - Detailed version history
- [Roadmap](roadmap.md) - Future development plans
- [Blog: How I linked a legacy system to a modern AI agent with MCP](https://blog.jztan.com/how-i-linked-a-legacy-system-to-a-modern-ai-agent/) - The story behind this project
- [Blog: Designing Reliable MCP Servers: 3 Hard Lessons in Agentic Architecture](https://blog.jztan.com/i-gave-my-ai-agent-full-api-access-it-was-a-mistak/) - Lessons learned building this server
| text/markdown | null | Kevin Tan <jingzheng.tan@gmail.com> | null | Kevin Tan <jingzheng.tan@gmail.com> | MIT | mcp, model-context-protocol, project-management, redmine, server | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Office/Business :: Groupware",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"fastapi[standard]>=0.120.0",
"mcp[cli]<2,>=1.25.0",
"python-dotenv>=1.0.0",
"python-redmine>=2.5.0",
"uvicorn>=0.24.0",
"black>=23.0.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\"",
"httpx>=0.28.1; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-mock>=3.10.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"httpx>=0.28.1; extra == \"test\"",
"pytest-asyncio>=0.21.0; extra == \"test\"",
"pytest-cov>=4.0.0; extra == \"test\"",
"pytest-mock>=3.10.0; extra == \"test\"",
"pytest>=7.0.0; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/jztan/redmine-mcp-server",
"Repository, https://github.com/jztan/redmine-mcp-server.git",
"Issues, https://github.com/jztan/redmine-mcp-server/issues",
"Changelog, https://github.com/jztan/redmine-mcp-server/blob/master/CHANGELOG.md"
] | twine/6.2.0 CPython/3.13.11 | 2026-02-20T12:55:17.425370 | redmine_mcp_server-0.12.0.tar.gz | 227,290 | a3/ae/e5c87b13b0e5675c8379292a0c8ebdf3f76c2e372cc9c3b85d1fadc58e04/redmine_mcp_server-0.12.0.tar.gz | source | sdist | null | false | deeebdd00345d18aff7a4f9b53074fc1 | 9eefde795e43fdced1b121f0dab113de6ee7135759df5cd7625bb94fa8aec60b | a3aee5c87b13b0e5675c8379292a0c8ebdf3f76c2e372cc9c3b85d1fadc58e04 | null | [
"LICENSE"
] | 203 |
2.4 | mlflow-tracing | 3.10.0 | MLflow Tracing SDK is an open-source, lightweight Python package that only includes the minimum set of dependencies and functionality to instrument your code/models/agents with MLflow Tracing. | # MLflow Tracing: An Open-Source SDK for Observability and Monitoring GenAI Applications🔍
[](https://mlflow.org/docs/latest/index.html)
[](https://github.com/mlflow/mlflow/blob/master/LICENSE.txt)
[](https://mlflow.org/community/#slack)
[](https://twitter.com/MLflow)
MLflow Tracing (`mlflow-tracing`) is an open-source, lightweight Python package that only includes the minimum set of dependencies and functionality
to instrument your code/models/agents with [MLflow Tracing Feature](https://mlflow.org/docs/latest/tracing). It is designed to be a perfect fit for production environments where you want:
- **⚡️ Faster Deployment**: The package size and dependencies are significantly smaller than the full MLflow package, allowing for faster deployment times in dynamic environments such as Docker containers, serverless functions, and cloud-based applications.
- **🔧 Simplified Dependency Management**: A smaller set of dependencies means less work keeping up with dependency updates, security patches, and breaking changes from upstream libraries.
- **📦 Portability**: With the less number of dependencies, MLflow Tracing can be easily deployed across different environments and platforms, without worrying about compatibility issues.
- **🔒 Fewer Security Risks**: Each dependency potentially introduces security vulnerabilities. By reducing the number of dependencies, MLflow Tracing minimizes the attack surface and reduces the risk of security breaches.
## ✨ Features
- [Automatic Tracing](https://mlflow.org/docs/latest/tracing/integrations/) for AI libraries (OpenAI, LangChain, DSPy, Anthropic, etc...). Follow the link for the full list of supported libraries.
- [Manual instrumentation APIs](https://mlflow.org/docs/latest/tracing/api/manual-instrumentation) such as `@trace` decorator.
- [Production Monitoring](https://mlflow.org/docs/latest/tracing/production)
- Other tracing APIs such as `mlflow.set_trace_tag`, `mlflow.search_traces`, etc.
## 🌐 Choose Backend
The MLflow Trace package is designed to work with a remote hosted MLflow server as a backend. This allows you to log your traces to a central location, making it easier to manage and analyze your traces. There are several different options for hosting your MLflow server, including:
- [Databricks](https://docs.databricks.com/machine-learning/mlflow/managed-mlflow.html) - Databricks offers a FREE, fully managed MLflow server as a part of their platform. This is the easiest way to get started with MLflow tracing, without having to set up any infrastructure.
- [Amazon SageMaker](https://aws.amazon.com/sagemaker-ai/experiments/) - MLflow on Amazon SageMaker is a fully managed service offered as part of the SageMaker platform by AWS, including tracing and other MLflow features such as model registry.
- [Nebius](https://nebius.com/) - Nebius, a cutting-edge cloud platform for GenAI explorers, offers a fully managed MLflow server.
- [Self-hosting](https://mlflow.org/docs/latest/tracking) - MLflow is a fully open-source project, allowing you to self-host your own MLflow server and keep your data private. This is a great option if you want to have full control over your data and infrastructure.
## 🚀 Getting Started
### Installation
To install the MLflow Python package, run the following command:
```bash
pip install mlflow-tracing
```
To install from the source code, run the following command:
```bash
pip install git+https://github.com/mlflow/mlflow.git#subdirectory=libs/tracing
```
> **NOTE:** It is **not** recommended to co-install this package with the full MLflow package together, as it may cause version mismatches issues.
### Connect to the MLflow Server
To connect to your MLflow server to log your traces, set the `MLFLOW_TRACKING_URI` environment variable or use the `mlflow.set_tracking_uri` function:
```python
import mlflow
mlflow.set_tracking_uri("databricks")
# Specify the experiment to log the traces to
mlflow.set_experiment("/Path/To/Experiment")
```
### Start Logging Traces
```python
import openai
client = openai.OpenAI(api_key="<your-api-key>")
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Call the OpenAI API as usual
response = client.chat.completions.create(
model="gpt-4.1-mini",
messages=[{"role": "user", "content": "Hello, how are you?"}],
)
```
## 📘 Documentation
Official documentation for MLflow Tracing can be found at [here](https://mlflow.org/docs/latest/tracing).
## 🛑 Features _Not_ Included
The following MLflow features are not included in this package.
- MLflow tracking server and UI.
- MLflow's other tracking capabilities such as Runs, Model Registry, Projects, etc.
- Evaluate models/agents and log evaluation results.
To leverage the full feature set of MLflow, install the full package by running `pip install mlflow`.
| text/markdown | null | null | null | Databricks <mlflow-oss-maintainers@googlegroups.com> | Copyright 2018 Databricks, Inc. All rights reserved.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| mlflow, ai, databricks | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: Science/Research",
"Intended Audience :: Information Technology",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries :: Python Modules",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"cachetools<8,>=5.0.0",
"databricks-sdk<1,>=0.20.0",
"opentelemetry-api<3,>=1.9.0",
"opentelemetry-proto<3,>=1.9.0",
"opentelemetry-sdk<3,>=1.9.0",
"packaging<27",
"protobuf<7,>=3.12.0",
"pydantic<3,>=2.0.0"
] | [] | [] | [] | [
"homepage, https://mlflow.org",
"issues, https://github.com/mlflow/mlflow/issues",
"documentation, https://mlflow.org/docs/latest",
"repository, https://github.com/mlflow/mlflow"
] | twine/6.2.0 CPython/3.9.24 | 2026-02-20T12:54:43.274775 | mlflow_tracing-3.10.0.tar.gz | 1,242,152 | c5/98/a1d9ea8671f75c4e71633e579ae4dc659d3f160f928bb8123b053da90614/mlflow_tracing-3.10.0.tar.gz | source | sdist | null | false | 4af39202181dbc55fb82bbb4a39d4d88 | 206ca8ed2c25c15935fcfb9c9c5102198b1060a61bb2ce9df4eabb6329f3ddbf | c598a1d9ea8671f75c4e71633e579ae4dc659d3f160f928bb8123b053da90614 | null | [
"LICENSE.txt"
] | 262,365 |
2.4 | sify-queue-kafka | 0.1.3 | Enterprise Queue management Framework | # Sify Queue Kafka
Enterprise Queue management Framework for building robust, scalable event-driven applications.
## Features
- **Event-Driven Architecture**: Built on Apache Kafka for reliable message streaming
- **Type Safety**: Pydantic models for event validation and serialization
- **Retry & Resilience**: Exponential backoff retry with configurable policies
- **Idempotency**: Built-in duplicate event detection and prevention
- **Dead Letter Queue**: Automatic failed event routing for error handling
- **Stage-Based Processing**: Multi-stage event pipelines with stage-specific handlers
- **Comprehensive Logging**: Structured logging throughout the framework
- **Exception Handling**: Custom exception types for better error management
## Installation
```bash
pip install sify-queue-kafka
```
For development with additional tools:
```bash
pip install sify-queue-kafka[dev]
```
## Quick Start
### Basic Producer
```python
from datetime import datetime, timezone
from queue_kafka import Producer
producer = Producer()
def send_user_created_event():
message = {
"eventType": "USER_CREATED",
"eventVersion": "1.0",
"source": "user-service",
"tenantId": "tenant-123",
"payload": {
"userId": "user-456",
"email": "user@example.com",
"name": "John Doe"
},
"metadata": {
"stage": "SendWelcomeEmail",
"created_at": datetime.now(timezone.utc).isoformat()
}
}
producer.send("user-topic", message)
print("USER_CREATED event sent")
if __name__ == "__main__":
try:
send_user_created_event()
finally:
producer.close()
print("Producer closed")
```
### Basic Consumer (with stage)
```python
from queue_kafka import Consumer, event_handler, KafkaEvent
@event_handler("USER_CREATED", stage="EMAIL_NOTIFICATION")
def send_welcome_email(event: KafkaEvent):
print(f"Sending welcome email to: {event.payload['email']}")
if __name__ == "__main__":
consumer = Consumer(
topics="user-topic",
config={
"stage": "EMAIL_NOTIFICATION",
"tenant_id": "tenant-123",
"source": "email-service",
}
)
try:
print("Consumer running... Press Ctrl+C to stop")
consumer.start()
except KeyboardInterrupt:
print("\nKeyboard interrupt received")
finally:
consumer.stop()
print("Consumer stopped")
```
### Basic Consumer (without stage)
```python
from queue_kafka import Consumer, event_handler, KafkaEvent
@event_handler("USER_CREATED")
def send_welcome_email(event: KafkaEvent):
print(f"Sending welcome email to: {event.payload['email']}")
if __name__ == "__main__":
consumer = Consumer(
topics="user-topic",
config={
"tenant_id": "tenant-123",
"source": "email-service",
}
)
try:
print("Consumer running... Press Ctrl+C to stop")
consumer.start()
except KeyboardInterrupt:
print("\nKeyboard interrupt received")
finally:
consumer.stop()
print("Consumer stopped")
```
### Error Handling and DLQ
```python
from queue_kafka import Consumer, event_handler, KafkaEvent, EventProcessingError
@event_handler("PAYMENT_INIT", stage="ProcessPayment")
def process_payment(event: KafkaEvent):
print("Payment processed successfully")
if __name__ == "__main__":
process_consumer = Consumer(
topics=payment-topic,
config={
"stage": "ProcessPayment",
"tenant_id": "tenant-222",
"source": "payment-service",
"dead_letter_topic": payment-dlq-topic
}
)
try:
process_consumer.start()
except KeyboardInterrupt:
print("\nShutting down...")
finally:
process_consumer.stop()
print("Consumer stopped")
```
## Configuration Options
| Option | Type | Default | Description |
|--------|------|---------|-------------|
| `bootstrap_servers` | str | Required | Kafka bootstrap servers |
| `group_id` | str | None | Consumer group ID |
| `enable_auto_commit` | bool | False | Enable auto commit of offsets |
| `auto_offset_reset` | str | "earliest" | Offset reset policy |
| `enable_idempotency` | bool | True | Enable duplicate detection |
| `enable_retry` | bool | True | Enable retry with backoff |
| `dead_letter_topic` | str | None | Topic for failed events |
| `stage` | str | None | Processing stage name |
## Event Model
```python
class KafkaEvent(BaseModel):
eventId: str
eventType: str
eventVersion: str
source: str
tenantId: str
timestamp: datetime
correlationId: Optional[str]
traceId: Optional[str]
priority: Optional[str]
retryCount: int
maxRetries: int
payload: Dict[str, Any]
metadata: Optional[Dict[str, Any]]
```
## Exception Types
- `QueueSDKError`: Base exception for all SDK errors
- `ConfigurationError`: Configuration-related errors
- `HandlerNotFoundError`: No handler found for event type/stage
- `EventProcessingError`: Event processing failures
- `ProducerError`: Producer operation failures
- `ConsumerError`: Consumer operation failures
- `SerializationError`: Event serialization/deserialization errors
## Architecture
```
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Producer │───▶│ Kafka Topic │───▶│ Consumer │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
▼
┌─────────────────┐
│ Dispatcher │
└─────────────────┘
│
▼
┌─────────────────┐
│ Event Registry │
└─────────────────┘
│
▼
┌─────────────────┐
│ Event Handler │
└─────────────────┘
```
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Changelog
### v0.1.3
- Initial release
- Basic producer/consumer functionality
- Event validation with Pydantic
- Retry and idempotency features
- Dead letter queue support
- Comprehensive logging
- Unit test coverage
| text/markdown | sifymodernization | sifymodernization <sifymodernization.dev@sifycorp.com> | null | null | MIT | kafka, events, queue, messaging | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Distributed Computing"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"kafka-python>=2.0.2",
"pydantic>=2.0.0",
"typing-extensions>=4.0.0; python_version < \"3.10\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.8 | 2026-02-20T12:54:36.220005 | sify_queue_kafka-0.1.3.tar.gz | 10,826 | fd/ac/a74e2c8d074c9cd12aa16ab655bf5692caf033fd658e8b8a489ec08c1cfc/sify_queue_kafka-0.1.3.tar.gz | source | sdist | null | false | bf51f89c0ddbac40feb8a149ec31b939 | a21bd86cfeec876721ef6797ccc2e85d2ba82bb772362150b9bf1893bce34a94 | fdaca74e2c8d074c9cd12aa16ab655bf5692caf033fd658e8b8a489ec08c1cfc | null | [] | 227 |
2.4 | myst-libre | 0.3.11 | A Python library for managing source code repositories, interacting with Docker registries, handling MyST markdown operations, and spawning JupyterHub instances locally. | # MyST Libre
&color=white)
Following the [REES](https://repo2docker.readthedocs.io/en/latest/specification.html), `myst-libre` streamlines building [✨MyST articles✨](https://mystmd.org/) in containers.
* A repository containing MyST sources
* A Docker image (built by [`binderhub`](https://github.com/jupyterhub/binderhub)) in a public (or private) registry, including:
* Dependencies to execute notebooks/markdown files in the MyST repository
* JupyterHub (typically part of images built by `binderhub`)
* Input data required by the executable content (optional)
Given these resources, myst-libre starts a Docker container, mounts the MyST repository and data (if available), and builds a MyST publication.
> [!NOTE]
> This project was started to support publishing MyST articles as living preprints on [`NeuroLibre`](https://neurolibre.org).
## Installation
### External dependencies
> [!IMPORTANT]
> Ensure the following prerequisites are installed:
- Node.js (For MyST) [installation guide](https://mystmd.org/guide/installing-prerequisites)
- Docker [installation guide](https://docs.docker.com/get-docker/)
### Install myst-libre
```
pip install myst-libre
```
**Set up environment variables:**
If you are using a private image registry and/or Curvenote CLI features, create a `.env` file in the project root and add the following:
```env
DOCKER_PRIVATE_REGISTRY_USERNAME=your_username
DOCKER_PRIVATE_REGISTRY_PASSWORD=your_password
CURVENOTE_TOKEN=your_curvenote_api_token
```
The `CURVENOTE_TOKEN` is required for operations like `curvenote submit`, `curvenote deploy`, `curvenote pull`, etc. You can generate an API token from your [Curvenote profile settings](https://curvenote.com/profile?settings=true&tab=profile-api&subtab=general).
## Quick Start
**Import libraries and define REES resources**
Minimal example to create a rees object:
```python
from myst_libre.tools import JupyterHubLocalSpawner, MystMD
from myst_libre.rees import REES
from myst_libre.builders import MystBuilder
rees = REES(dict(
registry_url="https://your-registry.io",
gh_user_repo_name = "owner/repository"
))
```
Other optional parameters that can be passed to the REES constructor:
- `gh_repo_commit_hash`: Full SHA commit hash of the `gh_user_repo_name` repository (optional, default: latest commit)
- `binder_image_tag`: Full SHA commit hash at which a binder tag is available for the "found image name" (optional, default: latest)
- `binder_image_name_override`: Override the "found image name" whose container will be used to build the MyST article (optional, default: None)
- `dotenv`: Path to a directory containing the .env file for authentication credentials to pull images from `registry_url` (optional, default: None)
- `bh_image_prefix`: Binderhub names the images with a prefix, e.g., `<prefix>agahkarakuzu-2dmriscope-7a73fb`, typically set as `binder-`. This will be used in the regex pattern to find the "binderhub built image name" in the `registry_url`. See [reference docs](https://binderhub.readthedocs.io/en/latest/zero-to-binderhub/setup-binderhub.html) for more details.
- `bh_project_name`: See [this issue ](https://github.com/jupyterhub/binderhub/issues/800) (optional, default: [`registry_url` without `http://` or `https://`])
Note that in this context what is meant by "prefix" is not the same as in the reference docs. (optional, default: `binder-`)
**Image Selection Order**
1. If the `myst.yml` file in the `gh_user_repo_name` repository contains `project/thebe/binder/repo`, this image is prioritized.
2. If `project/thebe/binder/repo` is not specified, the `gh_user_repo_name` is used as the image name.
Note that if (2) is the case, your build command probably should not be `myst build`, but you can still use other builders, e.g., `jupyter-book build`.
If you specify `binder_image_name_override`, it will be used as the repository name to locate the image.
This allows you to build the MyST article using a runtime from a different repository than the one specified in `gh_user_repo_name`, as defined in `myst.yml` or overridden by `binder_image_name_override`.
The `binder_image_tag` set to `latest` refers to the most recent successful build of an image that meets the specified conditions. The repository content might be more recent than the `binder_image_tag` (e.g., `gh_repo_commit_hash`), but the same binder image can be reused.
**Fetch resources and spawn JupyterHub in the respective container**
```python
hub = JupyterHubLocalSpawner(rees_resources,
host_build_source_parent_dir = '/tmp/myst_repos',
container_build_source_mount_dir = '/home/jovyan', #default
host_data_parent_dir = "/tmp/myst_data", #optional
container_data_mount_dir = '/home/jovyan/data', #optional
)
hub.spawn_jupyter_hub()
```
* MyST repository will be cloned at:
```
tmp/
└── myst_repos/
└── owner/
└── repository/
└── full_commit_SHA_A/
├── myst.yml
├── _toc.yml
├── binder/
│ ├── requirements.txt (or other REES dependencies)
│ └── data_requirement.json (optional)
├── content/
│ ├── my_notebook.ipynb
│ └── my_myst_markdown.md
├── paper.md
└── paper.bib
```
Repository will be mounted to the container as `/tmp/myst_repos/owner/repository/full_commit_SHA_A:/home/jovyan`.
* If a [`repo2data`](https://github.com/SIMEXP/Repo2Data) manifest is found in the repository, the data will be downloaded to and cached at:
```
tmp/
└── myst_data/
└── my-dataset
```
otherwise, it can be manually defined for an existing data under `/tmp/myst_data` as follows:
```
rees_resources.dataset_name = "my-dataset"
```
In either case, data will be mounted as `/tmp/myst_data/my-dataset:/home/jovyan/data/my-dataset`. If no data is provided, this step will be skipped.
**Build your MyST article**
```python
MystBuilder(hub).build()
```
**Check out the built document**
In your terminal:
```
npx serve /tmp/myst_repos/owner/repository/full_commit_SHA_A/_build/html
```
Visit ✨`http://localhost:3000`✨.
## Table of Contents
- [Myst Libre](#myst-libre)
- [Table of Contents](#table-of-contents)
- [Installation](#installation)
- [Usage](#usage)
- [Authentication](#authentication)
- [Docker Registry Client](#docker-registry-client)
- [Build Source Manager](#build-source-manager)
- [JupyterHub Local Spawner](#jupyterhub-local-spawner)
- [MyST Markdown Client](#myst-markdown-client)
- [Module and Class Descriptions](#module-and-class-descriptions)
- [Contributing](#contributing)
- [License](#license)
## Usage
### Authentication
The `Authenticator` class handles loading authentication credentials from environment variables.
```python
from myst_libre.tools.authenticator import Authenticator
auth = Authenticator()
print(auth._auth)
```
### Docker Registry Client
The DockerRegistryClient class provides methods to interact with a Docker registry.
```python
from myst_libre.tools.docker_registry_client import DockerRegistryClient
client = DockerRegistryClient(registry_url='https://my-registry.example.com', gh_user_repo_name='user/repo')
token = client.get_token()
print(token)
```
### Build Source Manager
The BuildSourceManager class manages source code repositories.
```python
from myst_libre.tools.build_source_manager import BuildSourceManager
manager = BuildSourceManager(gh_user_repo_name='user/repo', gh_repo_commit_hash='commit_hash')
manager.git_clone_repo('/path/to/clone')
project_name = manager.get_project_name()
print(project_name)
```
## Module and Class Descriptions
### AbstractClass
**Description**: Provides basic logging functionality and colored printing capabilities.
### Authenticator
**Description**: Handles authentication by loading credentials from environment variables.
**Inherited from**: AbstractClass
**Inputs**: Environment variables `DOCKER_PRIVATE_REGISTRY_USERNAME` and `DOCKER_PRIVATE_REGISTRY_PASSWORD`
### RestClient
**Description**: Provides a client for making REST API calls.
**Inherited from**: Authenticator
### DockerRegistryClient
**Description**: Manages interactions with a Docker registry.
**Inherited from**: Authenticator
**Inputs**:
- `registry_url`: URL of the Docker registry
- `gh_user_repo_name`: GitHub user/repository name
- `auth`: Authentication credentials
### BuildSourceManager
**Description**: Manages source code repositories.
**Inherited from**: AbstractClass
**Inputs**:
- `gh_user_repo_name`: GitHub user/repository name
- `gh_repo_commit_hash`: Commit hash of the repository
### JupyterHubLocalSpawner
**Description**: Manages JupyterHub instances locally.
**Inherited from**: AbstractClass
**Inputs**:
- `rees`: Instance of the REES class
- `registry_url`: URL of the Docker registry
- `gh_user_repo_name`: GitHub user/repository name
- `auth`: Authentication credentials
- `binder_image_tag`: Docker image tag
- `build_src_commit_hash`: Commit hash of the repository
- `container_data_mount_dir`: Directory to mount data in the container
- `container_build_source_mount_dir`: Directory to mount build source in the container
- `host_data_parent_dir`: Host directory for data
- `host_build_source_parent_dir`: Host directory for build source
### MystMD
**Description**: Manages MyST markdown operations such as building and converting files.
**Inherited from**: AbstractClass
**Inputs**:
- `build_dir`: Directory where the build will take place
- `env_vars`: Environment variables needed for the build process
- `executable`: Name of the MyST executable (default is 'myst')
| text/markdown | null | agahkarakuzu <agahkarakuzu@gmail.com> | null | null | MIT License
Copyright (c) 2024 Agah Karakuzu
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| myst, docker, jupyterhub, markdown, repository | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"requests",
"docker",
"python-dotenv",
"PyGithub",
"rich>=13.0.0",
"mystmd",
"repo2data",
"pyyaml",
"gitpython",
"plotext>=5.2.0"
] | [] | [] | [] | [
"Homepage, https://github.com/neurolibre/myst_libre"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:54:20.777475 | myst_libre-0.3.11.tar.gz | 57,687 | 44/f7/3407ba5487cb017d31b67e92eb0e3737b38e6303ec3dc648a7a40b60c2a5/myst_libre-0.3.11.tar.gz | source | sdist | null | false | e8497ae4864b7174d9b28959e98dbde5 | 16dbaf9c5606a64dd568031e8cb1a3dd1d3a7b656b48791b6081cca615186b27 | 44f73407ba5487cb017d31b67e92eb0e3737b38e6303ec3dc648a7a40b60c2a5 | null | [
"LICENSE"
] | 216 |
2.4 | pyglet-gamemaker | 1.1.1 | pyglet wrapper for making games. | # 📦 pyglet-gamemaker
<!-- (add your badges here) -->
[](https://badge.fury.io/py/pyglet-gamemaker)
<!-- > *Your documentation is a direct reflection of your software, so hold it to the same standards.* -->
## ℹ️ Overview
<!-- A paragraph explaining your work, who you are, and why you made it. -->
**pyglet-gamemaker** is an extension of Pyglet that simplifies the process of making games! This project began when I became frustrated at the boilerplate I had to write all the time, and I wanted a cleaner system to quickly add features.
## 🌟 Features
- Hitboxes
- Fully working convex polygon collision
- Includes circles
- Spritesheets:
- Automatically loaded
- Labelable to allow for indexing by string
- Widgets:
- Dynamic anchoring for changing size
- Uses spritesheets instead of individual images
- Scenes:
- Enabling and disabling handled automatically
- Menus:
- Easily create visuals + widgets
- Widget positions relative to window size
- Main Window class handles switching of scenes
### ✍️ Authors
I'm [Steven Robles](https://github.com/Badnameee) and I am a high school student with a *small?* passion for making games.
## 🚀 Usage
<!-- *Show off what your software looks like in action! Try to limit it to one-liners if possible and don't delve into API specifics.* -->
A simple program to render an empty Scene with button detection:
```py
>>> import pyglet_gamemaker as pgm
>>>
>>>
>>> class Menu(pgm.Scene):
>>> # Create widgets here
>>> def initialize(self): ...
>>> # Code that runs when button is pressed down
>>> def on_half_click(self, button): ...
>>> # Code that runs when button is fully clicked and released
>>> def on_full_click(self, button): ...
>>> # Code that runs when scene is enabled
>>> def enable(self): ...
>>> # Code that runs when scene is disabled
>>> def disable(self): ...
>>>
>>>
>>> menu = Menu('Test')
>>> game = pgm.Window((640, 480))
>>> game.add_scene('Test', menu)
>>> game.run()
```
Creating a spritesheet
```py
>>> # Create a sprite sheet with image assets
>>> # This image, found in /test, has 3 images (bottom to top):
>>> # Unpressed, Hover, and Pressed
>>> self.sheet = pgm.sprite.SpriteSheet('test/Default Button.png', rows=3, cols=1)
```
The following should go in `Menu.create_widgets()`:
- Creating text
```py
>>> self.create_text(
>>> 'Text', 'Test',
>>> ('center', 'center'), color=pgm.types.Color.RED
>>> )
```
- Creating a button
```py
>>> self.create_button(
>>> 'Button', self.sheet, 0,
>>> ('center', 'center'),
>>> # Event handlers defined in empty Menu class above
>>> on_half_click=self.on_half_click, on_full_click=self.on_full_click
>>> )
```
- Creating a text and button in one
```py
>>> # A textbutton combines text and a button
>>> # Hover enlarge makes text larger when hovering
>>> # Works well with using larger hover sprite for button
>>> self.create_text_button(
>>> 'TextButton', 'Text',
>>> self.sheet, 0,
>>> ('center', 'center'), ('center', 'center'),
>>> # Event handlers defined in empty Menu class above
>>> on_half_click=self.on_half_click, on_full_click=self.on_full_click
>>> )
```
<img src="/media/demo.gif" width="50%" height="50%"/>
## ⬇️ Installation
Simple, understandable installation instructions!
```bash
pip install pyglet-gamemaker
```
<!-- And be sure to specify any other minimum requirements like Python versions or operating systems. -->
Works in Python >=3.10
<!-- *You may be inclined to add development instructions here, don't.* -->
## 💭 Feedback and Contributing
<!--Add a link to the Discussions tab in your repo and invite users to open issues for bugs/feature requests. -->
To request features or report bugs, open an issue [here](https://github.com/Badnameee/pyglet-gamemaker/issues).
[Contact me directly](mailto:stevenrrobles13@gmail.com)
<!-- This is also a great place to invite others to contribute in any ways that make sense for your project. Point people to your DEVELOPMENT and/or CONTRIBUTING guides if you have them. --> | text/markdown | null | Steven Robles <stevenrrobles13@gmail.com> | null | null | null | null | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pyglet>=2.1.10"
] | [] | [] | [] | [
"Homepage, https://github.com/Badnameee/pyglet-gamemaker",
"Issues, https://github.com/Badnameee/pyglet-gamemaker/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:54:05.382362 | pyglet_gamemaker-1.1.1.tar.gz | 3,415,290 | 11/48/50531e69b9c64547365533e3c90f4ae42fd5d63783955b97c9a1e64c9922/pyglet_gamemaker-1.1.1.tar.gz | source | sdist | null | false | 87b97feebe8f8d0e4f8d6427ac722725 | 7e6c90173295c58f53562aff2f81b6e588869aac4ab1cd9b76b9ff58924e6485 | 114850531e69b9c64547365533e3c90f4ae42fd5d63783955b97c9a1e64c9922 | MIT | [
"LICENSE"
] | 207 |
2.4 | astrolabe-sdk | 1.2.0 | Python SDK for the OKAPI:Astrolabe API | # Python SDK for OKAPI:Astrolabe
This is a lightweight Python SDK to access the public OKAPI:Astrolabe API.
## Installation
The SDK is easy to install using `pip`. We recommend creating a virtual environment for the project.
```
python3 -m venv .venv
source .venv/bin/activate
pip install astrolabe-sdk
```
## Functionality
The SDK allows for easy access to CDMs, fleet management, upload of ephemerides and maneuver plans, etc.
For more details, please consult the respective section in the OKAPI:Astrolabe user manual.
| text/markdown | null | "OKAPI:Orbits" <contact@okapiorbits.space> | null | null | null | space, space debris, astrolabe, space traffic coordination, okapi orbits, sdk, REST API | [
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License",
"Intended Audience :: Developers",
"Topic :: Utilities"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"python-dateutil",
"python-dotenv",
"requests",
"ruff; extra == \"dev\"",
"mypy; extra == \"dev\"",
"types-requests; extra == \"dev\"",
"types-python-dateutil; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-env; extra == \"dev\"",
"pytest-html; extra == \"dev\"",
"coverage[toml]; extra == \"dev\"",
"pytest-xdist; extra == \"dev\"",
"coverage-badge; extra == \"dev\"",
"sphinx; extra == \"docs\"",
"sphinx-book-theme; extra == \"docs\"",
"myst-parser; extra == \"docs\"",
"sphinx-autoapi; extra == \"docs\"",
"sphinx-click; extra == \"docs\"",
"myst-nb; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://www.okapiorbits.space"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T12:53:14.773982 | astrolabe_sdk-1.2.0.tar.gz | 11,136 | cc/a6/1b1f4d468da17c02d68203b798414d64191211b46549fe767e5972e129e3/astrolabe_sdk-1.2.0.tar.gz | source | sdist | null | false | 695b391405b05da703c40a74017c93cc | dab0eb9eb99bf944212c11d7ba9de4c15c41b140466e04ebdea2ebc482cd6b1f | cca61b1f4d468da17c02d68203b798414d64191211b46549fe767e5972e129e3 | null | [
"LICENSE"
] | 211 |
2.4 | cadscorelt | 0.8.105 | CAD-score-LT Python bindings via SWIG | # CAD-score-LT Python bindings
The CAD-score-LT Python interface PyPI package is hosted at [https://pypi.org/project/cadscorelt/](https://pypi.org/project/cadscorelt/).
## Installation
Install with pip using this command:
```bash
pip install cadscorelt
```
Additionally, it is recommended to have the [pandas](https://pandas.pydata.org/) library for data analysis available in the Python environment.
This allows the CAD-score result tables to be converted to [pandas data frames](https://pandas.pydata.org/docs/reference/frame.html).
The ``pandas`` library can also be installed using ``pip``:
```bash
pip install pandas
```
CAD-score-LT also provides integration with some common libraries for reading macromolecular files - [Biotite](https://www.biotite-python.org/), [Gemmi](https://gemmi.readthedocs.io/), [Biopython](https://biopython.org/),
if those libraries are available in the Python environment.
They can be installed via ``pip``:
```bash
pip install biotite
pip install gemmi
pip install biopython
```
## Usage examples
### Basic example
Below is an example script that calculates CAD-scores for inter-chain residue-residue contact areas,
produces a table of global scores,
converts that table to ``pandas`` data frame,
and preints the top rows of the data frame:
```py
import cadscorelt
# init a CAD-score computation object
css = cadscorelt.CADScoreComputer.init(subselect_contacts="[-inter-chain]")
# add a target structure
css.add_target_structure_from_file("./input/data/protein_homodimer1/target.pdb")
# add a target structure
css.add_model_structure_from_file("./input/data/protein_homodimer1/model1.pdb")
css.add_model_structure_from_file("./input/data/protein_homodimer1/model2.pdb")
# get a list of global scores and convert it to pandas data frame
df_global_scores_residue_residue = css.get_all_cadscores_residue_residue_summarized_globally().to_pandas()
# print the first rows of the data frame
cadscorelt.print_head_of_pandas_data_frame(df_global_scores_residue_residue)
```
Below is an example of the printed output:
```
target_name model_name CAD_score F1_of_areas target_area model_area TP_area FP_area FN_area renamed_chains
target model2 0.621922 0.774894 1047.807935 941.514533 784.870893 193.071031 262.937041 .
target model1 0.507319 0.639249 1047.807935 792.834440 648.098138 331.779276 399.709796 .
```
### Basic example using different structure readers
Below is an example script that is similar to the previous example script, but it shows how to input structures from different sources:
```py
import cadscorelt
# init a CAD-score computation object
csc = cadscorelt.CADScoreComputer.init(subselect_contacts="[-inter-chain]")
# add a target structure read by Biotite
import biotite.structure.io
structure_target = biotite.structure.io.load_structure("./input/data/protein_homodimer1/target.pdb")
csc.add_target_structure_from_biotite(structure_target, "target")
# add a model structure read by Gemmi
import gemmi
structure_model1 = gemmi.read_structure("./input/data/protein_homodimer1/model1.pdb")
csc.add_model_structure_from_gemmi(structure_model1[0], "model1")
# add a model structure read by Biopython
import Bio.PDB
parser = Bio.PDB.PDBParser(QUIET=True)
structure_model2 = parser.get_structure("id", "./input/data/protein_homodimer1/model2.pdb").get_atoms()
csc.add_model_structure_from_biopython(structure_model2, "model2")
# get a list of global scores and convert it to pandas data frame
df_global_scores_residue_residue = csc.get_all_cadscores_residue_residue_summarized_globally().to_pandas()
# print the first rows of the data frame
cadscorelt.print_head_of_pandas_data_frame(df_global_scores_residue_residue)
```
Below is an example of the printed output:
```
target_name model_name CAD_score F1_of_areas target_area model_area TP_area FP_area FN_area renamed_chains
target model2 0.621922 0.774894 1047.808013 941.514579 784.870926 193.071041 262.937087 .
target model1 0.507319 0.639249 1047.808013 792.834440 648.098141 331.779274 399.709873 .
```
### Advanced example
Below is an example script that that includes:
* residue-residue contact scoring (enabled by default);
* atom-atom contact scoring;
* automatic chain remapping to maximize grobal similarity;
* recording local scores.
```py
import cadscorelt
from pathlib import Path
# to make comparison more strict, globally enable inclusion of residue names into atom and residue identifiers
cadscorelt.enable_considering_residue_names()
# init a CAD-score computation object, enable atom-atom contact scoring, enable automatic chain remapping to maximize grobal similarity, enable recording local scores
csc = cadscorelt.CADScoreComputer.init(subselect_contacts="[-inter-chain]", score_atom_atom_contacts=True, remap_chains=True, record_local_scores=True)
# set reference sequences and stoichiometry for automatic residue renumbering and chain namne assignment
csc.set_reference_sequences_from_file("./input/data/protein_heteromer1/sequences.fasta")
csc.set_reference_stoichiometry([2, 2, 2])
# input structures from all the files in a directory
input_directory = Path("./input/data/protein_heteromer1/structures")
for file_path in input_directory.iterdir():
if file_path.is_file():
csc.add_structure_from_file(str(file_path))
# get the table of structure decriptors and print its top rows
df_structure_descriptors = csc.get_all_structure_descriptors().to_pandas()
print("")
print(" # Table of structure decriptors:")
print("")
cadscorelt.print_head_of_pandas_data_frame(df_structure_descriptors)
print("")
# get the table of globals scores based on residue-residue contacts, print top rows
df_global_scores_residue_residue = csc.get_all_cadscores_residue_residue_summarized_globally().to_pandas()
print("")
print(" # Table of globals scores based on residue-residue contacts:")
print("")
cadscorelt.print_head_of_pandas_data_frame(df_global_scores_residue_residue)
print("")
# get the table of globals scores based on atom-atom contacts, print top rows
df_global_scores_atom_atom = csc.get_all_cadscores_atom_atom_summarized_globally().to_pandas()
print("")
print(" # Table of globals scores based on atom-atom contacts:")
print("")
cadscorelt.print_head_of_pandas_data_frame(df_global_scores_atom_atom)
print("")
# set placeholder variable for structure names
target_name="cf_woTemplates_model_3_multimer_v3_pred_47"
model_name="cf_woTemplates_model_2_multimer_v3_pred_26"
# get the table of per-residue scores based on residue-residue contacts, print top rows
df_local_scores_per_residue = csc.get_local_cadscores_residue_residue_summarized_per_residue(target_name, model_name).to_pandas()
print("")
print(" # Table of per-residue scores based on residue-residue contacts:")
print("")
cadscorelt.print_head_of_pandas_data_frame(df_local_scores_per_residue)
print("")
# get the table of scores for every residue-residue contact, print top rows
df_local_scores_residue_residue = csc.get_local_cadscores_residue_residue(target_name, model_name).to_pandas()
print("")
print(" # Table of scores for every residue-residue contact (CAD-score values of -1 idicate that the contact was not present in the target structure):")
print("")
cadscorelt.print_head_of_pandas_data_frame(df_local_scores_residue_residue)
print("")
# get the table of per-atom scores based on atom-atom contacts, print top rows
df_local_scores_per_atom = csc.get_local_cadscores_atom_atom_summarized_per_atom(target_name, model_name).to_pandas()
print("")
print(" # Table of per-atom scores based on atom-atom contacts (CAD-score values of -1 idicate that the atom had no relevant contacts in the target structure):")
print("")
cadscorelt.print_head_of_pandas_data_frame(df_local_scores_per_atom)
print("")
# get the table of scores for every atom-atom contact, print top rows
df_local_scores_atom_atom = csc.get_local_cadscores_atom_atom(target_name, model_name).to_pandas()
print("")
print(" # Table of scores for every atom-atom contact (CAD-score values of -1 idicate that the contact was not present in the target structure):")
print("")
cadscorelt.print_head_of_pandas_data_frame(df_local_scores_atom_atom)
print("")
```
Below is an example of the printed output:
```
# Table of structure decriptors:
name is_target is_model renamed_chains reference_alignment
afm_basic_model_5_multimer_v1_pred_35 True True B=A,C=D,D=B,E=E,F=C,G=F available
afm_dropout_full_model_1_multimer_v2_pred_42 True True B=A,C=D,D=B,E=E,F=C,G=F available
afm_dropout_full_model_2_multimer_v1_pred_65 True True B=A,C=D,D=B,E=E,F=C,G=F available
afm_dropout_full_model_3_multimer_v3_pred_64 True True B=A,C=D,D=B,E=E,F=C,G=F available
afm_dropout_full_model_3_multimer_v3_pred_66 True True B=A,C=D,D=B,E=E,F=C,G=F available
afm_dropout_full_woTemplates_model_3_multimer_v1_pred_4 True True B=A,C=D,D=B,E=E,F=C,G=F available
afm_dropout_full_woTemplates_model_3_multimer_v1_pred_45 True True B=A,C=D,D=B,E=E,F=C,G=F available
afm_dropout_full_woTemplates_model_4_multimer_v3_pred_50 True True B=A,C=D,D=B,E=E,F=C,G=F available
cf_woTemplates_model_2_multimer_v3_pred_26 True True A=A,B=D,C=B,D=E,E=C,F=F available
cf_woTemplates_model_3_multimer_v3_pred_47 True True A=A,B=D,C=B,D=E,E=C,F=F available
# Table of globals scores based on residue-residue contacts:
target_name model_name CAD_score F1_of_areas target_area model_area TP_area FP_area FN_area renamed_chains
afm_dropout_full_model_1_multimer_v2_pred_42 afm_dropout_full_woTemplates_model_4_multimer_v3_pred_50 0.847662 0.701359 3970.007175 3836.593118 3582.890995 2664.103761 387.116180 A=A;B=B;C=F;D=D;E=E;F=C
cf_woTemplates_model_3_multimer_v3_pred_47 cf_woTemplates_model_2_multimer_v3_pred_26 0.704688 0.780891 7483.973156 6871.838277 5912.094425 1745.848929 1571.878730 A=D;B=E;C=F;D=A;E=B;F=C
cf_woTemplates_model_2_multimer_v3_pred_26 cf_woTemplates_model_3_multimer_v3_pred_47 0.699040 0.781187 7657.943354 6855.599895 5914.330867 1569.642289 1743.612487 A=A;B=B;C=C;D=D;E=E;F=F
afm_dropout_full_model_3_multimer_v3_pred_66 afm_dropout_full_model_3_multimer_v3_pred_64 0.657842 0.675283 7313.203511 5519.154809 5124.561234 2739.763621 2188.642277 A=A;B=B;C=C;D=D;E=E;F=F
afm_dropout_full_model_3_multimer_v3_pred_64 afm_dropout_full_model_3_multimer_v3_pred_66 0.620764 0.675283 7864.324855 5420.088717 5124.561234 2188.642277 2739.763621 A=A;B=B;C=C;D=D;E=E;F=F
afm_dropout_full_model_3_multimer_v3_pred_66 cf_woTemplates_model_2_multimer_v3_pred_26 0.575097 0.645935 7313.203511 5696.007986 4835.195167 2822.748187 2478.008344 A=A;B=E;C=C;D=D;E=B;F=F
cf_woTemplates_model_2_multimer_v3_pred_26 afm_dropout_full_model_3_multimer_v3_pred_66 0.573808 0.645935 7657.943354 5446.078054 4835.195167 2478.008344 2822.748187 A=A;B=E;C=C;D=D;E=B;F=F
afm_dropout_full_model_3_multimer_v3_pred_66 cf_woTemplates_model_3_multimer_v3_pred_47 0.566239 0.627281 7313.203511 5493.415167 4640.996876 2842.976280 2672.206635 A=D;B=B;C=F;D=A;E=E;F=C
cf_woTemplates_model_3_multimer_v3_pred_47 afm_dropout_full_model_3_multimer_v3_pred_66 0.561418 0.627332 7483.973156 5252.699687 4641.373085 2671.830426 2842.600071 A=A;B=E;C=C;D=D;E=B;F=F
cf_woTemplates_model_2_multimer_v3_pred_26 afm_dropout_full_model_3_multimer_v3_pred_64 0.550970 0.603414 7657.943354 5255.694013 4683.177891 3181.146964 2974.765463 A=A;B=E;C=C;D=D;E=B;F=F
# Table of globals scores based on atom-atom contacts:
target_name model_name CAD_score F1_of_areas target_area model_area TP_area FP_area FN_area renamed_chains
afm_dropout_full_model_1_multimer_v2_pred_42 afm_dropout_full_woTemplates_model_4_multimer_v3_pred_50 0.694870 0.612790 3970.007175 3631.663716 3130.437751 3116.557004 839.569423 A=A;B=B;C=F;D=D;E=E;F=C
afm_dropout_full_model_3_multimer_v3_pred_66 afm_dropout_full_model_3_multimer_v3_pred_64 0.600300 0.630986 7313.203511 5287.148112 4788.403033 3075.921822 2524.800478 A=A;B=B;C=C;D=D;E=E;F=F
afm_dropout_full_model_3_multimer_v3_pred_64 afm_dropout_full_model_3_multimer_v3_pred_66 0.566073 0.630986 7864.324855 5222.053418 4788.403033 2524.800478 3075.921822 A=A;B=B;C=C;D=D;E=E;F=F
cf_woTemplates_model_3_multimer_v3_pred_47 cf_woTemplates_model_2_multimer_v3_pred_26 0.559002 0.635331 7483.973156 5931.794420 4810.063036 2847.880319 2673.910120 A=D;B=E;C=F;D=A;E=B;F=C
cf_woTemplates_model_2_multimer_v3_pred_26 cf_woTemplates_model_3_multimer_v3_pred_47 0.550378 0.635281 7657.943354 5972.073003 4809.683681 2674.289475 2848.259673 A=A;B=B;C=C;D=D;E=E;F=F
afm_dropout_full_model_3_multimer_v3_pred_66 cf_woTemplates_model_2_multimer_v3_pred_26 0.455307 0.527325 7313.203511 5000.847832 3947.330056 3710.613299 3365.873455 A=A;B=E;C=C;D=D;E=B;F=F
cf_woTemplates_model_2_multimer_v3_pred_26 afm_dropout_full_model_3_multimer_v3_pred_66 0.446372 0.527325 7657.943354 4761.917277 3947.330056 3365.873455 3710.613299 A=A;B=E;C=C;D=D;E=B;F=F
cf_woTemplates_model_2_multimer_v3_pred_26 afm_dropout_full_model_3_multimer_v3_pred_64 0.445539 0.506868 7657.943354 4677.771912 3933.871243 3930.453612 3724.072111 A=A;B=E;C=C;D=D;E=B;F=F
cf_woTemplates_model_3_multimer_v3_pred_47 afm_dropout_full_model_3_multimer_v3_pred_64 0.439929 0.489985 7483.973156 4453.132335 3760.215370 4104.109485 3723.757786 A=D;B=B;C=F;D=A;E=E;F=C
afm_dropout_full_model_3_multimer_v3_pred_66 cf_woTemplates_model_3_multimer_v3_pred_47 0.439601 0.499394 7313.203511 4526.494827 3694.810365 3789.162791 3618.393146 A=D;B=B;C=F;D=A;E=E;F=C
# Table of per-residue scores based on residue-residue contacts:
ID_chain ID_rnum ID_icode CAD_score F1_of_areas target_area model_area TP_area FP_area FN_area
A 4 . 0.000000 0.000000 5.723360 0.000000 0.000000 14.123374 5.723360
A 6 . 0.000000 0.504191 7.178632 14.612032 7.160650 14.065207 0.017982
A 15 . 0.000000 0.000000 1.346514 0.000000 0.000000 2.051384 1.346514
A 17 . 0.175261 0.298250 25.529513 4.474315 4.474315 0.000000 21.055197
A 18 . 0.378808 0.293841 26.519188 10.045678 10.045678 31.810069 16.473510
A 19 . 0.715554 0.783253 69.951082 79.263636 63.086289 28.050569 6.864793
A 20 . 0.228410 0.399188 97.824322 75.742435 35.484263 44.473835 62.340058
A 21 . 0.892938 0.923627 55.431386 54.675708 52.086259 5.268696 3.345127
A 22 . 0.000000 0.277170 0.401577 2.496120 0.401577 2.094543 0.000000
A 23 . 0.406606 0.631095 34.355429 20.906229 17.437673 3.468556 16.917756
# Table of scores for every residue-residue contact (CAD-score values of -1 idicate that the contact was not present in the target structure):
ID1_chain ID1_rnum ID1_icode ID2_chain ID2_rnum ID2_icode CAD_score F1_of_areas target_area model_area TP_area FP_area FN_area
A 4 . D 6 . 0.000000 0.000000 0.043450 0.000000 0.000000 0.000000 0.043450
A 4 . D 61 . 0.000000 0.000000 5.679910 0.000000 0.000000 0.000000 5.679910
A 4 . D 206 . -1.000000 0.000000 0.000000 0.000000 0.000000 14.123374 0.000000
A 6 . D 4 . 0.000000 0.000000 0.017982 0.000000 0.000000 0.000000 0.017982
A 6 . D 65 . 0.000000 0.657765 7.160650 14.612032 7.160650 7.451382 0.000000
A 6 . D 208 . -1.000000 0.000000 0.000000 0.000000 0.000000 6.613825 0.000000
A 15 . C 31 . -1.000000 0.000000 0.000000 0.000000 0.000000 2.051384 0.000000
A 15 . D 137 . 0.000000 0.000000 1.346514 0.000000 0.000000 0.000000 1.346514
A 17 . C 31 . 0.086301 0.158889 16.995494 1.466721 1.466721 0.000000 15.528773
A 17 . C 32 . 0.557286 0.715714 5.396860 3.007595 3.007595 0.000000 2.389265
# Table of per-atom scores based on atom-atom contacts (CAD-score values of -1 idicate that the atom had no relevant contacts in the target structure):
ID_chain ID_rnum ID_icode ID_atom_name CAD_score F1_of_areas target_area model_area TP_area FP_area FN_area
A 4 . CD -1.000000 0.000000 0.000000 0.000000 0.000000 0.589435 0.000000
A 4 . CE -1.000000 0.000000 0.000000 0.000000 0.000000 6.218582 0.000000
A 4 . CG -1.000000 0.000000 0.000000 0.000000 0.000000 0.040717 0.000000
A 4 . NZ 0.000000 0.000000 5.723360 0.000000 0.000000 7.274641 5.723360
A 6 . CB -1.000000 0.000000 0.000000 0.000000 0.000000 0.005776 0.000000
A 6 . CG1 -1.000000 0.000000 0.000000 0.000000 0.000000 10.924598 0.000000
A 6 . CG2 0.315134 0.527725 7.178632 8.956361 4.610766 5.684717 2.567866
A 15 . CB -1.000000 0.000000 0.000000 0.000000 0.000000 1.960049 0.000000
A 15 . O 0.000000 0.000000 1.346514 0.000000 0.000000 0.091335 1.346514
A 17 . CB 0.057452 0.097769 25.529513 1.466721 1.466721 3.007595 24.062792
# Table of scores for every atom-atom contact (CAD-score values of -1 idicate that the contact was not present in the target structure):
ID1_chain ID1_rnum ID1_icode ID1_atom_name ID2_chain ID2_rnum ID2_icode ID2_atom_name CAD_score F1_of_areas target_area model_area TP_area FP_area FN_area
A 4 . CD D 206 . OE1 -1.0 0.0 0.000000 0.0 0.0 0.589435 0.000000
A 4 . CE D 206 . NE2 -1.0 0.0 0.000000 0.0 0.0 1.398847 0.000000
A 4 . CE D 206 . OE1 -1.0 0.0 0.000000 0.0 0.0 4.819735 0.000000
A 4 . CG D 206 . OE1 -1.0 0.0 0.000000 0.0 0.0 0.040717 0.000000
A 4 . NZ D 6 . CG2 0.0 0.0 0.043450 0.0 0.0 0.000000 0.043450
A 4 . NZ D 61 . CZ 0.0 0.0 0.413695 0.0 0.0 0.000000 0.413695
A 4 . NZ D 61 . OH 0.0 0.0 5.266215 0.0 0.0 0.000000 5.266215
A 4 . NZ D 206 . CD -1.0 0.0 0.000000 0.0 0.0 0.008074 0.000000
A 4 . NZ D 206 . NE2 -1.0 0.0 0.000000 0.0 0.0 5.372747 0.000000
A 4 . NZ D 206 . OE1 -1.0 0.0 0.000000 0.0 0.0 1.893820 0.000000
```
| text/markdown | Kliment Olechnovic | kliment.olechnovic@gmail.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: C++",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | https://github.com/kliment-olechnovic/cadscorelt_python | null | >=3.6 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T12:52:51.260453 | cadscorelt-0.8.105.tar.gz | 212,360 | cb/9e/2f16428692cd86e827ace23d9f66a73e722e062ac448035e0776beca57ff/cadscorelt-0.8.105.tar.gz | source | sdist | null | false | 3b7d4b3fcf2ad0ea8a54469a0e134ec9 | 3dd28ccbeb0bb87bd2bbffcd7488736471839cdf344e856bd669e07b99d55993 | cb9e2f16428692cd86e827ace23d9f66a73e722e062ac448035e0776beca57ff | null | [
"LICENSE.txt"
] | 3,849 |
2.4 | warp-cache | 0.2.1 | Thread-safe Python caching decorator backed by a Rust extension | # warp_cache
A thread-safe Python caching decorator backed by a Rust extension. Through a
series of optimizations — eliminating serialization, moving the call wrapper
into Rust, applying link-time optimization, and using direct C API calls — we
achieve **0.55-0.66x** of `lru_cache`'s single-threaded throughput while
providing native thread safety that delivers **1.3-1.4x** higher throughput
under concurrent load — and **18-24x** faster than pure-Python `cachetools`.
## Features
- **Drop-in replacement for `functools.lru_cache`** — same decorator pattern and hashable-argument requirement, with added thread safety, TTL, eviction strategies, and async support
- **Thread-safe** out of the box (`parking_lot::RwLock` in Rust)
- **Async support**: works with `async def` functions — zero overhead on sync path
- **Shared memory backend**: cross-process caching via mmap
- **Multiple eviction strategies**: LRU, MRU, FIFO, LFU
- **TTL support**: optional time-to-live expiration
- **Single FFI crossing**: entire cache lookup happens in Rust, no Python wrapper overhead
- **12-18M ops/s** single-threaded, **16M ops/s** under concurrent load, **18-24x** faster than `cachetools`
## Installation
Prebuilt wheels are available for Linux (x86_64, aarch64), macOS (x86_64, arm64), and Windows (x86_64):
```bash
pip install warp_cache
```
If no wheel is available for your platform, pip will fall back to the source distribution (requires a [Rust toolchain](https://rustup.rs/)).
## Quick example
```python
from warp_cache import cache
@cache()
def expensive(x, y):
return x + y
expensive(1, 2) # computes and caches
expensive(1, 2) # returns cached result
```
If you're already using `functools.lru_cache`, switching is a one-line change:
```python
-from functools import lru_cache
+from warp_cache import cache
-@lru_cache(maxsize=128)
+@cache(max_size=128)
def expensive(x, y):
return x + y
```
Like `lru_cache`, all arguments must be hashable. See the [usage guide](docs/usage.md#basic-caching) for details.
## Performance at a glance
| Metric | warp_cache | cachetools | lru_cache |
|---|---|---|---|
| Single-threaded | 12-18M ops/s | 0.6-1.2M ops/s | 21-40M ops/s |
| Multi-threaded (8T) | 16M ops/s | 770K ops/s (with Lock) | 12M ops/s (with Lock) |
| Thread-safe | Yes (RwLock) | No (manual Lock) | No |
| Async support | Yes | No | No |
| Cross-process (shared) | ~7.8M ops/s (mmap) | No | No |
| TTL support | Yes | Yes | No |
| Eviction strategies | LRU, MRU, FIFO, LFU | LRU, LFU, FIFO, RR | LRU only |
| Implementation | Rust (PyO3) | Pure Python | C (CPython) |
Under concurrent load, `warp_cache` delivers **1.3-1.4x** higher throughput than `lru_cache + Lock` and **18-24x** higher than `cachetools`. See [full benchmarks](docs/performance.md) for details.
## Documentation
- **[Usage guide](docs/usage.md)** — eviction strategies, async, TTL, shared memory, decorator parameters
- **[Performance](docs/performance.md)** — benchmarks, architecture deep-dive, optimization journey
- **[Alternatives](docs/alternatives.md)** — comparison with cachebox, moka-py, cachetools, lru_cache
- **[Examples](examples/)** — runnable scripts for every feature (`uv run examples/<name>.py`)
- **[llms.txt](llms.txt)** / **[llms-full.txt](llms-full.txt)** — project info for LLMs and AI agents ([spec](https://llmstxt.org/))
## Contributing
Contributions are welcome! See **[CONTRIBUTING.md](CONTRIBUTING.md)** for setup instructions, coding standards, and PR guidelines.
For security issues, please see **[SECURITY.md](SECURITY.md)**.
## License
MIT
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | null | cache, lru, ttl, thread-safe, rust | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Rust",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/toloco/warp_cache"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:51:40.360187 | warp_cache-0.2.1.tar.gz | 1,474,904 | 54/d5/0d58144885ad4c2cf6dc9efe0d55921bbc950cbda9c16ff5161f24aa9fd5/warp_cache-0.2.1.tar.gz | source | sdist | null | false | f892f7e3aafc0202b502852d4c5581a0 | ea5f3c5a976638b51cb92395f7e4c4c59db51d5fcfb326ebafaa183e1783dd7f | 54d50d58144885ad4c2cf6dc9efe0d55921bbc950cbda9c16ff5161f24aa9fd5 | MIT | [
"LICENSE"
] | 1,634 |
2.4 | muxi-runtime | 0.20260220.0 | Production-ready runtime for building and orchestrating intelligent multi-agent AI systems | # MUXI Runtime
[](LICENSE)
[](https://www.python.org/downloads/)
The execution engine for AI agent formations.
> **For most users:** Install [MUXI CLI](https://github.com/muxi-ai/cli) for the complete experience.
> This repo is for contributors and developers embedding the runtime directly.
> [!IMPORTANT]
> ## MUXI Ecosystem
>
> This repository is part of the larger MUXI ecosystem.
>
> **📋 Complete architectural overview:** See [muxi/ARCHITECTURE.md](https://github.com/muxi-ai/muxi/blob/main/ARCHITECTURE.md) - explains how core repositories fit together, dependencies, status, and roadmap.
## What is MUXI Runtime?
MUXI Runtime transforms declarative YAML configurations into running AI systems. It's the core engine that powers the [MUXI Server](https://github.com/muxi-ai/server).
**Core responsibilities:**
- Formation execution - Loads and runs agent configurations from YAML
- Overlord orchestration - Routes requests, manages clarifications, coordinates workflows
- Memory systems - Three-tier memory (buffer, persistent, vector)
- Tool integration - MCP protocol support for external tools
- Multi-tenant isolation - User and session management
## Architecture
```
┌─────────────────────────────────────────────────────┐
│ MUXI Server (Go) - Formation lifecycle management │
└─────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ MUXI Runtime (Python) ◄── THIS REPO │
│ ┌───────────────────────────────────────────────┐ │
│ │ Formation Engine (YAML loader & validator) │ │
│ ├───────────────────────────────────────────────┤ │
│ │ Overlord │ Agents │ Workflow │ Background │ │
│ ├───────────────────────────────────────────────┤ │
│ │ Memory │ MCP │ A2A │ LLM │ Observability │ │
│ └───────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ External Services (LLM APIs, MCP Servers, DBs) │
└─────────────────────────────────────────────────────┘
```
## Package Structure
The runtime uses `src/muxi/runtime/` to share the `muxi` namespace with the [Python SDK](https://github.com/muxi-ai/sdks):
```
src/muxi/runtime/
├── formation/ # Formation engine
│ ├── overlord/ # Central orchestration
│ ├── agents/ # Agent implementations
│ ├── workflow/ # Task decomposition, SOPs
│ ├── server/ # Formation API (FastAPI)
│ └── background/ # Webhooks, scheduling, async
├── services/ # Runtime services
│ ├── memory/ # Memory systems
│ ├── mcp/ # MCP client
│ ├── a2a/ # Agent-to-agent
│ └── llm/ # LLM abstraction
└── datatypes/ # Type definitions
```
## Quick Start
### Using with MUXI Server (recommended)
```bash
# Install MUXI CLI
curl -fsSL https://muxi.ai/install | sh
# Create and run a formation
muxi new my-assistant
cd my-assistant
muxi dev
```
### Embedding directly
```bash
pip install muxi-runtime
```
```python
from muxi.runtime import Formation
import asyncio
async def main():
formation = Formation()
await formation.load("formation.afs")
overlord = await formation.start_overlord()
response = await overlord.chat(
"Hello!",
user_id="user123"
)
print(response)
asyncio.run(main())
```
## Development
```bash
git clone https://github.com/muxi-ai/runtime
cd runtime
pip install -e ".[dev]"
# Run tests
pytest tests/unit -v
pytest tests/integration -v
pytest e2e/tests -v
```
See [contributing/README.md](contributing/README.md) for contributor documentation.
## Related Repositories
| Repo | Description |
|------|-------------|
| [muxi-ai/muxi](https://github.com/muxi-ai/muxi) | Main repo with architecture docs |
| [muxi-ai/server](https://github.com/muxi-ai/server) | Go server that hosts this runtime |
| [muxi-ai/cli](https://github.com/muxi-ai/cli) | Command-line tool |
| [muxi-ai/sdks](https://github.com/muxi-ai/sdks) | Python, TypeScript, Go SDKs |
| [muxi-ai/schemas](https://github.com/muxi-ai/schemas) | API schemas |
## Documentation
- **User docs:** [docs.muxi.ai](https://docs.muxi.ai)
- **Contributor docs:** [contributing/README.md](contributing/README.md)
- **Formation spec:** [agentformation.org](https://agentformation.org)
## License
[Elastic License 2.0](LICENSE) - Free to use, modify, and embed in products. Cannot be offered as a hosted service.
| text/markdown | MUXI Team | MUXI Team <dev@muxi.org> | null | null | Elastic License 2.0 | ai, agents, llm, multi-agent, orchestration, mcp, onellm, formation, runtime, framework, chatgpt, openai, anthropic, agent-framework, ai-agents, agent-orchestration, llm-framework, ai-system | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries :: Python Modules",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Framework :: AsyncIO",
"Framework :: FastAPI",
"Typing :: Typed"
] | [] | https://muxi.org | null | >=3.10 | [] | [] | [] | [
"tomli>=1.2.0; python_version < \"3.11\"",
"pyyaml>=6.0",
"pydantic>=2.0.0",
"httpx>=0.24.0",
"anyio>=3.7.0",
"python-dotenv>=1.0.0",
"websockets>=11.0.3",
"httpx-sse>=0.4.0",
"rich>=13.6.0",
"colorama>=0.4.6",
"psutil>=5.9.0",
"mcp>=1.23.0",
"aiofiles>=23.2.0",
"python-magic>=0.4.27",
"markitdown[all]>=0.1.0",
"pypdf>=5.0.0",
"python-docx>=1.1.0",
"markdownify>=0.11.6",
"beautifulsoup4>=4.12.0",
"nltk>=3.8.0",
"spacy>=3.8.0",
"sentence-transformers>=2.2.0",
"Pillow>=10.0.0",
"pdf2image>=1.16.0",
"onellm[cache]>=0.20260130.0",
"boto3>=1.26.0",
"google-cloud-aiplatform>=1.25.0",
"a2a-sdk>=0.3",
"fastapi>=0.108.0",
"uvicorn>=0.24.0",
"starlette>=0.49.1",
"faiss-cpu>=1.10.0",
"faissx>=0.0.3",
"pgvector>=0.3.6",
"numpy>=1.24.0",
"sqlite-vec>=0.1.6",
"psycopg2-binary>=2.9.9",
"SQLAlchemy[asyncio]>=2.0.17",
"aiosqlite>=0.19.0",
"aiohttp>=3.13.3",
"click>=8.1.0",
"openai>=1.3.0",
"pandas>=2.0.0",
"scipy>=1.10.0",
"statsmodels>=0.14.0",
"matplotlib>=3.7.0",
"seaborn>=0.12.0",
"plotly>=5.15.0",
"bokeh>=3.8.2",
"altair>=5.0.0",
"reportlab>=4.0.0",
"fpdf2>=2.7.0",
"openpyxl>=3.1.0",
"xlsxwriter>=3.1.0",
"xlrd>=2.0.0",
"xlwt>=1.3.0",
"qrcode>=7.4.0",
"python-barcode>=0.15.0",
"python-pptx>=0.6.21",
"lxml>=4.9.0",
"cachetools>=5.3.0",
"croniter>=1.3.0",
"cryptography>=41.0.0",
"msgpack>=1.0.0",
"multitasking>=0.0.11",
"nanoid>=2.0.0",
"pytz>=2023.3",
"requests>=2.31.0",
"typing-extensions>=4.8.0",
"pyzmq>=25.0.0",
"kafka-python>=2.0.0; extra == \"kafka\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\"",
"pyright>=1.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://muxi.org",
"Documentation, https://muxi.org/docs",
"Source Code, https://github.com/muxi-ai/runtime",
"Bug Tracker, https://github.com/muxi-ai/runtime/issues",
"Discussions, https://muxi.org/community",
"Changelog, https://github.com/muxi-ai/runtime/blob/main/CHANGELOG.md",
"Funding, https://github.com/sponsors/muxi-ai",
"Download, https://pypi.org/project/muxi/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:50:48.969618 | muxi_runtime-0.20260220.0.tar.gz | 1,294,427 | df/3f/66680aeff612b488ead6c6cbc32ff5bf66d26cc9119451a6fcb6ecb690de/muxi_runtime-0.20260220.0.tar.gz | source | sdist | null | false | 42d2461c3c396a0a92c09835a19a0896 | ef0f12d82f570d7a71685071e09836fdc4fa58ba49c3f35aae58458a6d8c4eb1 | df3f66680aeff612b488ead6c6cbc32ff5bf66d26cc9119451a6fcb6ecb690de | null | [
"LICENSE"
] | 222 |
2.4 | worldbook | 0.1.9 | CLI for AI agents to access world knowledge - Human uses GUI, We uses CLI | # Worldbook CLI
> "Human uses GUI, We uses CLI."
CLI tool for AI agents to access world knowledge.
## Install
```bash
# PyPI
pip install worldbook
# npm (global install)
npm i -g worldbook
```
## Usage
```bash
# Show manifesto
worldbook manifesto
# Check status
worldbook status
worldbook --json status
# Search worldbooks
worldbook query github
worldbook --json query github
# Get a worldbook
worldbook get github
worldbook --json get github
# Point to a local server
export WORLDBOOK_BASE_URL=http://localhost:8000
worldbook query github
```
## The Dual Protocol Manifesto
We believe in a web that serves all intelligence.
**GO AWAY SKILLS. GO AWAY MCP. WE LIKE CLI.**
- Skills? → Vendor lock-in, complex schemas, approval queues
- MCP? → Protocol overhead, server setup, configuration hell
- CLI? → Just works. stdin/stdout. Every agent understands.
A worldbook is just a text file that tells us how to use your service.
No SDK. No protocol. No ceremony. Just instructions.
## License
MIT
| text/markdown | femto | null | null | null | MIT | ai, cli, worldbook, agents, dual-protocol | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0.0",
"httpx>=0.24.0"
] | [] | [] | [] | [
"Homepage, https://github.com/femto/worldbook",
"Repository, https://github.com/femto/worldbook"
] | twine/6.2.0 CPython/3.11.4 | 2026-02-20T12:50:03.467542 | worldbook-0.1.9.tar.gz | 3,882 | 9f/13/3c3739bc54632d924d89d6b6b8830644c21ee9174ea751cba192b6ac0921/worldbook-0.1.9.tar.gz | source | sdist | null | false | 43f7ad52a43257e925ee645635a66c26 | 943a39aeb7bb7abc5ffebbb809f5be3dcc5c2a226c558f532060baba036515ad | 9f133c3739bc54632d924d89d6b6b8830644c21ee9174ea751cba192b6ac0921 | null | [] | 211 |
2.4 | batchbench | 0.3.0 | Offline and online benchmarking utilities for large language model workloads | # BatchBench
BatchBench ships a Rust benchmarking core with a thin Python wrapper.
You can install it with:
```bash
uv pip install batchbench
```
The Python package exposes Rust functionality for request generation and benchmark execution.
## Python API
```python
import batchbench
config = {
"endpoint": "https://example.com/v1/chat/completions",
"user_count": 1,
"mode": batchbench.finite_mode(requests_per_user=1),
"request_body": batchbench.request_entry(
{
"model": "gpt-4o-mini",
"messages": [{"role": "user", "content": "ping"}],
},
line_idx=0,
input_tokens=1,
),
"requests": [
batchbench.request_entry(
{
"model": "gpt-4o-mini",
"messages": [{"role": "user", "content": "ping"}],
"max_tokens": 4,
},
line_idx=0,
input_tokens=1,
)
],
"dry_run": True,
}
report = batchbench.run_benchmark(config)
print(report)
```
Request generation:
```python
requests = batchbench.generate_requests(
{
"count": 16,
"prefix_overlap": 0.2,
"target_tokens": 128,
"tokenizer_model": "Qwen/Qwen3-VL-235B-A22B-Instruct-FP8",
"dist_mode": "fixed",
},
model="Qwen/Qwen3-VL-235B-A22B-Instruct-FP8",
)
```
## Python CLI
The package installs `batchbench`, which forwards directly to the Rust CLI implementation.
Use the same flags as the Rust binary:
```bash
batchbench \
--model gpt-4o-mini \
--users 8 \
--requests-per-user 2 \
--input-tokens 256 \
--output-tokens 64 \
--output-vary 0
```
Use `--sglang` to apply output token constraints via `min_new_tokens`/`max_new_tokens`
instead of `min_tokens`/`max_tokens`.
Press `Ctrl+C` during a run to cancel active requests and print a partial summary.
## Rust CLI
The existing Rust CLI is unchanged:
```bash
cargo build --release --manifest-path rust/Cargo.toml --bin batchbench
./rust/target/release/batchbench --help
```
## Releases and PyPI
- CI (`.github/workflows/ci.yaml`) checks Rust build/test, builds a wheel, and runs smoke tests.
- Release Please (`.github/workflows/release-please.yaml`) opens/updates release PRs and, on merge, creates `v*` tags/releases.
- Python release workflow (`.github/workflows/python-release.yaml`) builds and publishes prebuilt platform wheels to PyPI on `v*` tag pushes.
| text/markdown; charset=UTF-8; variant=GFM | BatchBench Contributors | null | null | null | Apache-2.0 | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Rust",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pyyaml>=6.0",
"requests>=2.28.0; extra == \"harness\"",
"paramiko>=3.0.0; extra == \"harness\"",
"prime; extra == \"harness\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:49:37.110038 | batchbench-0.3.0-cp39-abi3-win_amd64.whl | 3,595,565 | 60/1f/94750015f47568499ea7d156f4fcc4c5fd3bd234e52c99efeed2552a7ce6/batchbench-0.3.0-cp39-abi3-win_amd64.whl | cp39 | bdist_wheel | null | false | fb013ea9a8bcc5c048fb78903e43a93d | fe3ba51d63f560583cc7542a01e7c2e5689f573428414074935fc69113ed794a | 601f94750015f47568499ea7d156f4fcc4c5fd3bd234e52c99efeed2552a7ce6 | null | [] | 228 |
2.4 | zentel | 1.0.0 | Ultra-fast Telegram bot framework with YouTube downloader, currency, Wikipedia PDF and QR code generation | # ⚡ Zentel 1.0.0
**Ultra-fast async Telegram bot framework** — YouTube yuklovchi, valyuta konvertor, Wikipedia→PDF va QR kod generatori bilan.
```
pip install zentel
```
---
## 🚀 Tez boshlash
```python
from zentel import ZentelBot, VideoDownloader, CurrencyConverter, WikiToPDF, QRGenerator, Filter
bot = ZentelBot("YOUR_BOT_TOKEN")
dl = VideoDownloader()
currency = CurrencyConverter()
wiki = WikiToPDF(language="uz")
qr = QRGenerator()
# ─── /start ───────────────────────────────────────────────
@bot.command("start", aliases=["help"])
async def start(ctx):
await ctx.reply(
"👋 Salom! <b>Zentel Bot</b>\n\n"
"📹 /video [URL] — video yuklab berish\n"
"🎵 /audio [URL] — mp3 yuklab berish\n"
"💱 /convert 100 USD UZS — valyuta\n"
"📖 /wiki [mavzu] — Wikipedia PDF\n"
"🔲 /qr [matn/URL] — QR kod\n"
"📶 /wifi [ssid] [parol] — WiFi QR"
)
# ─── Video yuklovchi ──────────────────────────────────────
@bot.command("video")
async def video_cmd(ctx):
url = ctx.args[0] if ctx.args else VideoDownloader.extract_url(ctx.text)
if not url:
await ctx.reply("❌ URL yuboring!\nMisol: /video https://youtube.com/watch?v=...")
return
await ctx.upload_video()
try:
info = await dl.get_info(url)
await ctx.reply(f"⏳ Yuklanmoqda...\n\n{info}")
path = await dl.download(url, quality="720p")
await ctx.send_video(path, caption=f"🎬 {info.title}")
dl.cleanup(path)
except Exception as e:
await ctx.reply(f"❌ Xato: {e}")
# ─── Audio (MP3) yuklovchi ────────────────────────────────
@bot.command("audio")
async def audio_cmd(ctx):
url = ctx.args[0] if ctx.args else None
if not url:
await ctx.reply("❌ URL yuboring!")
return
await ctx.typing()
path = await dl.download(url, audio_only=True)
await ctx.send_document(path, caption="🎵 MP3 tayyor!")
dl.cleanup(path)
# ─── Valyuta konvertatsiya ────────────────────────────────
@bot.command("convert")
async def convert_cmd(ctx):
# /convert 100 USD UZS
parsed = CurrencyConverter.parse_convert_command(ctx.text)
if not parsed:
await ctx.reply("❌ Foydalanish: /convert 100 USD UZS")
return
amount, from_c, to_c = parsed
await ctx.typing()
try:
result = await currency.convert(amount, from_c, to_c)
await ctx.reply(str(result))
except Exception as e:
await ctx.reply(f"❌ {e}")
@bot.command("kurs")
async def rates_cmd(ctx):
base = ctx.args[0].upper() if ctx.args else "USD"
await ctx.typing()
rates = await currency.get_popular_rates(base)
await ctx.reply(currency.format_rates(rates, base))
# ─── Wikipedia → PDF ──────────────────────────────────────
@bot.command("wiki")
async def wiki_cmd(ctx):
if not ctx.args:
await ctx.reply("📖 Foydalanish: /wiki Python\n(yoki /wiki Amir Temur)")
return
query = " ".join(ctx.args)
await ctx.typing()
result = await wiki.search(query)
if not result:
await ctx.reply(f"❌ '{query}' bo'yicha hech narsa topilmadi.")
return
await ctx.reply(result.preview())
await ctx.upload_document()
pdf_path = await wiki.to_pdf(result)
await ctx.send_document(pdf_path, caption=f"📄 {result.title}")
wiki.cleanup(pdf_path)
# ─── QR Kod ───────────────────────────────────────────────
@bot.command("qr")
async def qr_cmd(ctx):
if not ctx.args:
await ctx.reply("🔲 Foydalanish: /qr https://google.com\nYoki: /qr Salom Dunyo!")
return
data = " ".join(ctx.args)
await ctx.typing()
path = await qr.generate(
data,
style="rounded",
color="#1a237e",
size=500,
)
await ctx.send_photo(path, caption=f"✅ QR kod tayyor!\n\n<code>{data[:80]}</code>")
qr.cleanup(path)
# ─── WiFi QR ──────────────────────────────────────────────
@bot.command("wifi")
async def wifi_cmd(ctx):
args = ctx.args
if len(args) < 2:
await ctx.reply("📶 Foydalanish: /wifi [SSID] [Parol] [WPA|WEP|nopass]")
return
ssid = args[0]
password = args[1]
security = args[2] if len(args) > 2 else "WPA"
await ctx.typing()
path = await qr.wifi(ssid=ssid, password=password, security=security)
await ctx.send_photo(path, caption=f"📶 WiFi: <b>{ssid}</b>")
qr.cleanup(path)
# ─── URL yuborilsa avtomatik video yukla ──────────────────
@bot.message(Filter.AND(Filter.is_url, Filter.NOT(Filter.text_startswith("/"))))
async def auto_video(ctx):
url = ctx.text.strip()
if VideoDownloader.is_supported(url):
await ctx.reply(
"🔗 Link topildi! Yuklab beraymi?",
keyboard=bot.inline_keyboard([
[
{"text": "📹 Video (720p)", "callback_data": f"dl_video_720p:{url[:100]}"},
{"text": "🎵 MP3", "callback_data": f"dl_audio:{url[:100]}"},
]
])
)
# ─── Callback handlers ────────────────────────────────────
@bot.on("callback_query")
async def handle_callbacks(ctx):
await ctx.answer()
if ctx.data.startswith("dl_video_"):
await ctx.reply("⏳ Video yuklanmoqda... iltimos kuting.")
elif ctx.data.startswith("dl_audio:"):
await ctx.reply("⏳ Audio yuklanmoqda... iltimos kuting.")
# ─── Run ──────────────────────────────────────────────────
if __name__ == "__main__":
bot.run()
```
---
## 📦 O'rnatish
```bash
pip install zentel
```
Barcha imkoniyatlar bilan:
```bash
pip install zentel[all]
```
---
## 🧩 Modullar
| Modul | Tavsif |
|-------|--------|
| `ZentelBot` | Asosiy bot engine (async polling) |
| `VideoDownloader` | YouTube, TikTok, Instagram, Twitter va 1000+ saytdan video |
| `CurrencyConverter` | Real-vaqt valyuta kurslari |
| `WikiToPDF` | Wikipedia qidiruv va PDF generator |
| `QRGenerator` | Chiroyli QR kod generatori |
| `Router` | Handler guruhlovchi |
| `Filter` | Xabar filtrlari |
| `Context` | Handler kontekst obyekti |
---
## ⚡ Nima uchun Zentel tez?
- **httpx** async HTTP — bir vaqtda yuzlab so'rov
- **asyncio.Semaphore** — parallel xabar ishlash
- **Keepalive connections** — TCP qayta ulanish xarajatisiz
- **Smart caching** — valyuta kurslari 5 daqiqa keshlanadi
- **Executor** — og'ir operatsiyalar thread poolda
---
## 📋 Talablar
- Python 3.9+
- `httpx` — async HTTP
- `yt-dlp` — video yuklovchi
- `reportlab` — PDF generator
- `qrcode[pil]` — QR kod
- `Pillow` — rasm ishlash
---
## 📄 Litsenziya
MIT License — bepul foydalaning, o'zgartiring, tarqating!
---
*Zentel 1.0.0 — Made with ❤️ for Uzbek developers*
| text/markdown | null | Zentel Team <zentel@example.com> | null | null | null | telegram, bot, framework, async, youtube-downloader, currency, wikipedia, qrcode, pdf | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Communications :: Chat",
"Topic :: Software Development :: Libraries :: Python Modules",
"Framework :: AsyncIO"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx>=0.27.0",
"yt-dlp>=2024.1.0",
"reportlab>=4.0.0",
"qrcode[pil]>=7.4.2",
"Pillow>=10.0.0",
"fpdf2>=2.7.0; extra == \"all\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"black; extra == \"dev\"",
"mypy; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/zentel-py/zentel",
"Repository, https://github.com/zentel-py/zentel",
"Issues, https://github.com/zentel-py/zentel/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T12:49:33.122176 | zentel-1.0.0.tar.gz | 22,967 | cc/21/d718b0da985df3c88a7d7adf05c1b8db4e28359fe121757519141ef97212/zentel-1.0.0.tar.gz | source | sdist | null | false | 4421ea65e35a4045e2c228cfa8fd9527 | 92c87d70b5d4fa30cb078917a863e8de3e93dae561f453b9ffdb36f035d54371 | cc21d718b0da985df3c88a7d7adf05c1b8db4e28359fe121757519141ef97212 | MIT | [
"LICENSE"
] | 192 |
2.4 | flyto-core | 2.12.13 | The open-source execution engine for AI agents. 412 modules, MCP-native, triggers, queue, versioning, metering. | # Flyto2 Core
[](https://pypi.org/project/flyto-core/)
[](https://opensource.org/licenses/Apache-2.0)
[](https://www.python.org/downloads/)
<!-- mcp-name: io.github.flytohub/flyto-core -->
> Deterministic execution engine for AI agents. 412 modules across 78 categories, MCP-native, evidence snapshots, execution trace, replay from any step.
## Quick Start — Use with Your AI (MCP)
```bash
pip install flyto-core
```
Add to your MCP client config:
<details open>
<summary><b>Claude Code</b></summary>
Run:
```bash
claude mcp add flyto-core -- python -m core.mcp_server
```
Or add to `~/.claude/settings.json`:
```json
{
"mcpServers": {
"flyto-core": {
"command": "python",
"args": ["-m", "core.mcp_server"]
}
}
}
```
</details>
<details>
<summary><b>Cursor</b></summary>
Add to `.cursor/mcp.json`:
```json
{
"mcpServers": {
"flyto-core": {
"command": "python",
"args": ["-m", "core.mcp_server"]
}
}
}
```
</details>
<details>
<summary><b>Windsurf</b></summary>
Add to `~/.codeium/windsurf/mcp_config.json`:
```json
{
"mcpServers": {
"flyto-core": {
"command": "python",
"args": ["-m", "core.mcp_server"]
}
}
}
```
</details>
<details>
<summary><b>Remote MCP Server (HTTP)</b></summary>
Run the server:
```bash
pip install flyto-core[api]
flyto serve
# ✓ flyto-core running on 127.0.0.1:8333
```
Then point any MCP client to the HTTP endpoint:
```json
{
"mcpServers": {
"flyto-core": {
"url": "http://localhost:8333/mcp"
}
}
}
```
Supports [MCP Streamable HTTP transport](https://modelcontextprotocol.io/specification/2025-03-26/basic/transports#streamable-http) — works with Cursor, Windsurf, and any standard MCP client that connects over HTTP.
</details>
**Done.** Your AI now has 412 tools — browser automation, Docker, file I/O, data parsing, crypto, scheduling, APIs, and more.
```
Claude ──┐
Cursor ──┤ ┌─ browser.launch, .click, .extract (38 tools)
Windsurf ┼── MCP Protocol ──→ ├─ file.read, .write, .copy (8 tools)
Any AI ──┘ ├─ data.csv.read, .json.parse, .xml.parse, .yaml.parse
└─ ... 412 modules across 78 categories
```
See the **[Full Tool Catalog](docs/TOOL_CATALOG.md)** for every module, parameter, and description.
## Quick Start — HTTP API
```bash
pip install flyto-core[api]
flyto serve
# ✓ flyto-core running on 127.0.0.1:8333
```
```bash
curl -X POST localhost:8333/v1/workflow/run \
-H 'Content-Type: application/json' \
-d '{
"workflow": {
"name": "example",
"steps": [
{"id": "step1", "module": "string.uppercase", "params": {"text": "hello"}},
{"id": "step2", "module": "string.reverse", "params": {"text": "world"}}
]
},
"enable_evidence": true,
"enable_trace": true
}'
```
| Endpoint | Purpose |
|----------|---------|
| `POST /mcp` | MCP Streamable HTTP transport (remote MCP server) |
| `POST /v1/workflow/run` | Execute workflow with evidence + trace |
| `GET /v1/workflow/{id}/evidence` | Get step-by-step state snapshots |
| `POST /v1/workflow/{id}/replay/{step}` | Replay from any step |
| `POST /v1/execute` | Execute a single module |
| `GET /v1/modules` | Discover all modules |
## Quick Start — Interactive Demo
```bash
pip install flyto-core[api]
python -m core.quickstart
```
Runs a 5-step data pipeline (file → JSON parse → template → format → export), shows the execution trace, evidence snapshots, and replays from step 3 — all in 30 seconds.
## Why Flyto2 Core?
AI agents are running multi-step tasks — browsing, calling APIs, moving data. But after they finish, all you have is a chat log.
Flyto2 Core gives you:
- **412 Modules** — composable building blocks across 78 categories ([full catalog](docs/TOOL_CATALOG.md))
- **Execution Trace** — structured record of every step: input, output, timing, status
- **Evidence Snapshots** — full context_before and context_after at every step boundary
- **Replay** — re-execute from any step with the original (or modified) context
- **Triggers** — webhook (HMAC-verified) and cron scheduling for automated workflows
- **Execution Queue** — priority-based queue with concurrency control
- **Workflow Versioning** — semantic versioning, diff, and rollback
- **Usage Metering** — built-in billing hooks for step/workflow tracking
- **Timeout Guard** — configurable workflow and step-level timeout protection
## Module Categories
| Category | Count | Examples |
|----------|-------|----------|
| `browser.*` | 38 | launch, goto, click, extract, screenshot, fill forms, wait |
| `flow.*` | 24 | switch, loop, branch, parallel, retry, circuit breaker, rate limit, debounce |
| `array.*` | 15 | filter, sort, map, reduce, unique, chunk, flatten |
| `string.*` | 11 | reverse, uppercase, split, replace, trim, slugify, template |
| `api.*` | 11 | OpenAI, Anthropic, Gemini, Notion, Slack, Telegram |
| `object.*` | 10 | keys, values, merge, pick, omit, get, set, flatten |
| `image.*` | 9 | resize, convert, crop, rotate, watermark, OCR, compress |
| `data.*` | 8 | json/xml/yaml/csv parse and generate |
| `file.*` | 8 | read, write, copy, move, delete, exists, edit, diff |
| `stats.*` | 8 | mean, median, percentile, correlation, standard deviation |
| `validate.*` | 7 | email, url, json, phone, credit card |
| `docker.*` | 6 | run, ps, logs, stop, build, inspect |
| `archive.*` | 6 | zip create/extract, tar create/extract, gzip, gunzip |
| `math.*` | 6 | calculate, round, ceil, floor, power, abs |
| `k8s.*` | 5 | get_pods, apply, logs, scale, describe |
| `crypto.*` | 4 | AES encrypt/decrypt, JWT create/verify |
| `network.*` | 4 | ping, traceroute, whois, port scan |
| `pdf.*` | 4 | parse, extract text, merge, compress |
| `aws.s3.*` | 4 | upload, download, list, delete |
| `google.*` | 4 | Gmail send/search, Calendar create/list events |
| `cache.*` | 4 | get, set, delete, clear (memory + Redis) |
| `ai.*` | 3 | vision analyze, structured extraction, text embeddings |
| `env.*` | 3 | get, set, load .env file |
| `git.*` | 3 | clone, commit, diff |
| `markdown.*` | 3 | to HTML, parse frontmatter, table of contents |
| `queue.*` | 3 | enqueue, dequeue, size (memory + Redis) |
| `sandbox.*` | 3 | execute Python, Shell, JavaScript |
| `scheduler.*` | 3 | cron parse, interval, delay |
| `ssh.*` | 3 | remote exec, SFTP upload, SFTP download |
| `graphql.*` | 2 | query, mutation |
| `dns.*` | 1 | DNS lookup (A, AAAA, MX, CNAME, TXT, NS) |
| `monitor.*` | 1 | HTTP health check with SSL cert verification |
**412 modules** across 78 categories. See **[Full Tool Catalog](docs/TOOL_CATALOG.md)** for every module with parameters and descriptions.
## Engine Features
Beyond atomic modules, flyto-core provides production-grade engine infrastructure:
| Feature | Tier | Description |
|---------|------|-------------|
| Execution Trace | Free | Structured record of every step: input, output, timing, status |
| Evidence Snapshots | Free | Full context_before and context_after at every step boundary |
| Replay | Free | Re-execute from any step with original or modified context |
| Breakpoints | Free | Pause execution at any step, inspect state, resume |
| Data Lineage | Free | Track data flow across steps, build dependency graphs |
| Timeout Guard | Free | Configurable workflow/step-level timeout protection |
| Webhook Triggers | Pro | HMAC-SHA256 verified webhooks with payload mapping |
| Cron Triggers | Pro | 5-field cron scheduling with async scheduler loop |
| Execution Queue | Pro | Priority-based queue (LOW→CRITICAL) with concurrency control |
| Workflow Versioning | Pro | Semantic versioning, diff between versions, rollback |
| Usage Metering | Pro | Built-in billing hooks for step/workflow/module tracking |
## YAML Workflows
```yaml
name: Hello World
steps:
- id: reverse
module: string.reverse
params:
text: "Hello Flyto"
- id: shout
module: string.uppercase
params:
text: "${reverse.result}"
```
```bash
flyto run workflow.yaml
# Output: "OTYLF OLLEH"
```
## Python API
```python
import asyncio
from core.modules.registry import ModuleRegistry
async def main():
result = await ModuleRegistry.execute(
"string.reverse",
params={"text": "Hello"},
context={}
)
print(result) # {"ok": True, "data": {"result": "olleH", ...}}
asyncio.run(main())
```
## Replay from a Failed Step
```bash
# Step 3 failed? Replay from there.
curl -X POST localhost:8333/v1/workflow/{execution_id}/replay/step3 \
-H 'Content-Type: application/json' \
-d '{}'
```
The engine loads the context snapshot at step 3 and re-executes from that point. No wasted computation.
## Installation
```bash
# Core engine (includes MCP server)
pip install flyto-core
# With HTTP API server
pip install flyto-core[api]
# With browser automation
pip install flyto-core[browser]
playwright install chromium
# Everything
pip install flyto-core[all]
```
## For Module Authors
```python
from core.modules.registry import register_module
from core.modules.schema import compose, presets
@register_module(
module_id='string.reverse',
version='1.0.0',
category='string',
label='Reverse String',
description='Reverse the characters in a string',
params_schema=compose(
presets.INPUT_TEXT(required=True),
),
output_schema={
'result': {'type': 'string', 'description': 'Reversed string'}
},
)
async def string_reverse(context):
params = context['params']
text = str(params['text'])
return {
'ok': True,
'data': {'result': text[::-1], 'original': params['text']}
}
```
See **[Module Specification](docs/MODULE_SPECIFICATION.md)** for the complete guide.
## Project Structure
```
flyto-core/
├── src/core/
│ ├── api/ # HTTP Execution API + MCP HTTP transport (FastAPI)
│ ├── mcp_handler.py # Shared MCP logic (tools, dispatch)
│ ├── mcp_server.py # MCP STDIO transport (Claude Code, local)
│ ├── modules/
│ │ ├── atomic/ # 412 atomic modules
│ │ ├── composite/ # High-level composite modules
│ │ ├── patterns/ # Advanced resilience patterns
│ │ └── third_party/ # External integrations
│ └── engine/
│ ├── workflow/ # Workflow execution engine
│ ├── evidence/ # Evidence collection & storage
│ └── replay/ # Replay manager
├── workflows/ # Example workflows
└── docs/ # Documentation
```
## Contributing
We welcome contributions! See **[CONTRIBUTING.md](CONTRIBUTING.md)** for guidelines.
## Security
Report security vulnerabilities via **[security@flyto.dev](mailto:security@flyto.dev)**.
See **[SECURITY.md](SECURITY.md)** for our security policy.
## License
[Apache License 2.0](LICENSE) — free for personal and commercial use.
---
<p align="center">
<b>Deterministic execution engine for AI agents.</b><br>
Evidence. Trace. Replay.
</p>
| text/markdown | null | Flyto2 Team <team@flyto.dev> | null | Flyto2 Team <team@flyto.dev> | Apache-2.0 | automation, workflow, mcp, mcp-server, ai-agents, browser-automation, web-scraping, playwright, atomic-modules, workflow-engine | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Testing",
"Topic :: Internet :: WWW/HTTP :: Browsers",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content",
"Framework :: AsyncIO",
"Framework :: Pydantic :: 2",
"License :: OSI Approved :: Apache Software License"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pyyaml>=6.0",
"aiohttp>=3.9.0",
"beautifulsoup4>=4.12.0",
"lxml>=4.9.0",
"pydantic>=2.0.0",
"python-dotenv>=1.0.0",
"aiofiles>=23.0.0",
"playwright>=1.40.0; extra == \"browser\"",
"fastapi>=0.104.0; extra == \"api\"",
"uvicorn>=0.24.0; extra == \"api\"",
"qdrant-client>=1.7.0; extra == \"vector\"",
"sentence-transformers>=2.2.0; extra == \"vector\"",
"qrcode[pil]>=7.0; extra == \"image\"",
"Pillow>=10.0.0; extra == \"image\"",
"python-telegram-bot>=20.0; extra == \"telegram\"",
"flyto-core[api,browser,image,telegram,vector]; extra == \"all\"",
"pytest>=7.4.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"build>=1.0.0; extra == \"dev\"",
"twine>=4.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/flytohub/flyto-core",
"Documentation, https://github.com/flytohub/flyto-core#readme",
"Repository, https://github.com/flytohub/flyto-core.git",
"Issues, https://github.com/flytohub/flyto-core/issues",
"Changelog, https://github.com/flytohub/flyto-core/blob/main/CHANGELOG.md"
] | twine/6.2.0 CPython/3.10.6 | 2026-02-20T12:49:00.817395 | flyto_core-2.12.13.tar.gz | 1,004,625 | f8/03/c647f1ad37865e83fb441cfa09fd27fc8a266531f8ac6c3e98ed7b6fbdfa/flyto_core-2.12.13.tar.gz | source | sdist | null | false | 1e34f52d083ff7058eaeb0115f2f2ea3 | d6f4f47680136bf207170e38e40cce3f9c78c18391f60b1d30cc69efdcac15bd | f803c647f1ad37865e83fb441cfa09fd27fc8a266531f8ac6c3e98ed7b6fbdfa | null | [
"LICENSE",
"NOTICE"
] | 284 |
2.2 | ViennaLS | 5.5.1 | A high performance sparse level set library | <div align="center">
<img src="assets/logo.svg" height="100" />
<h1>ViennaLS</h1>
[](https://github.com/ViennaTools/ViennaLS/actions/workflows/build.yml)
[](https://github.com/ViennaTools/ViennaLS/actions/workflows/python.yml)
[](https://pypi.org/project/ViennaLS/)
</div>
ViennaLS is a header-only C++ level set library developed for high performance topography simulations. The main design goals are simplicity and efficiency, tailored towards scientific simulations. ViennaLS can also be used for visualisation applications, although this is not the main design target.
> [!NOTE]
> ViennaLS is under heavy development and improved daily. If you do have suggestions or find bugs, please let us know!
## Quick Start
To install ViennaLS for Python, simply run:
```sh
pip install ViennaLS
```
To use ViennaLS in C++, clone the repository and follow the installation steps below.
## Support
[Documentation](https://viennatools.github.io/ViennaLS/index.html) and [Examples](https://github.com/ViennaTools/ViennaLS/tree/master/examples) can be found online.
Bug reports and suggestions should be filed on GitHub.
## Releases
Releases are tagged on the maser branch and available in the [releases section](https://github.com/ViennaTools/ViennaLS/releases).
## Building
### Supported Operating Systems
* Windows (MSVC)
* Linux (g++ & clang)
* macOS (XCode)
### System Requirements
* C++17 Compiler with OpenMP support
### Dependencies
> Dependencies will be installed automatically when not available.
* [ViennaHRLE](https://github.com/ViennaTools/ViennaHRLE)
* [VTK](https://github.com/Kitware/VTK) (optional, but recommended for mesh export and visualization)
* [pybind11](https://github.com/pybind/pybind11) (only for building Python libs)
## Using ViennaLS in your project
Have a look at the [example repo](https://github.com/ViennaTools/viennals-example) for creating a project with ViennaLS as a dependency.
## Installing
Since this is a header only project, it does not require any installation.
However, we recommend the following procedure in order to set up all dependencies correctly:
```bash
git clone https://github.com/ViennaTools/ViennaLS.git
cd ViennaLS
cmake -B build -D CMAKE_INSTALL_PREFIX=/path/to/your/custom/install/
cmake --install build
```
This will install the necessary headers and CMake files to the specified path. If `CMAKE_INSTALL_PREFIX` is not specified, it will be installed to the standard path for your system, usually `/usr/local/`.
## Installing without VTK
In order to install ViennaLS without VTK, run:
```bash
git clone https://github.com/ViennaTools/ViennaLS.git
cd ViennaLS
cmake -B build -D CMAKE_INSTALL_PREFIX=/path/to/your/custom/install/ -D VIENNALS_USE_VTK=OFF
cmake --install build
```
## Installing with dependencies already installed on the system
The CMake configuration automatically checks if the dependencies are installed. If CMake is unable to find them, the dependencies will be built from source.
## Building the Python package
> [!NOTE]
> On systems that feature a package manager (e.g. Ubuntu/Debian `apt`), VTK can be installed beforehand (e.g. using ```sudo apt install libvtk9-dev```), which saves a considerable amount of time during compilation.
The Python package can be built and installed using the `pip` command:
```bash
git clone https://github.com/ViennaTools/ViennaLS.git
cd ViennaLS
pip install .
```
## Using the Python package
The ViennaLS Python package can be used by importing it in your Python scripts:
```python
import viennals as vls
```
By default, ViennaLS operates in two dimensions. You can set the dimension using:
```python
vls.setDimension(2) # For 2D simulations
vls.setDimension(3) # For 3D simulations
```
A complete list of functions and their locations can be found in the [API documentation](PythonAPI.md).
For examples on how to use the Python package, please have a look at these examples: [Air Gap Deposition](https://github.com/ViennaTools/ViennaLS/blob/master/examples/AirGapDeposition/AirGapDeposition.py), [Deposition](https://github.com/ViennaTools/ViennaLS/blob/master/examples/Deposition/Deposition.py), [Geometric Advection](https://github.com/ViennaTools/ViennaLS/blob/master/examples/GeometricAdvection/GeometricAdvection.py).
## Running the Tests
ViennaLS uses CTest to run its tests.
In order to check whether ViennaLS runs without issues on your system, you can run:
```bash
git clone https://github.com/ViennaTools/ViennaLS.git
cd ViennaLS
cmake -B build -DVIENNALS_BUILD_TESTS=ON
cmake --build build
ctest -E "Benchmark|Performance" --test-dir build
```
## Building examples
The examples can be built using CMake:
```bash
cmake -B build -DVIENNALS_BUILD_EXAMPLES=ON
cmake --build build
```
## Integration in CMake projects
We recommend using [CPM.cmake](https://github.com/cpm-cmake/CPM.cmake) to consume this library.
* Installation with CPM
```cmake
CPMAddPackage("gh:viennatools/viennals@5.5.1")
```
* With a local installation
> In case you have ViennaLS installed in a custom directory, make sure to properly specify the `CMAKE_MODULE_PATH` or `PATHS` in your `find_package` call.
```cmake
set(VIENNALS_PATH "/your/local/installation")
find_package(OpenMP REQUIRED)
find_package(VTK PATHS ${VIENNALS_PATH})
find_package(ViennaHRLE PATHS ${VIENNALS_PATH})
find_package(ViennaLS PATHS ${VIENNALS_PATH})
target_link_libraries(${PROJECT_NAME} PUBLIC ViennaTools::ViennaLS)
```
### Shared Library
In order to save build time during development, dynamically linked shared libraries can be used
if ViennaLS was built with them. This is done by precompiling the most common template specialisations.
In order to use shared libraries, use
```bash
cmake -B build -DVIENNALS_PRECOMPILE_HEADERS=ON
```
If ViennaLS was built with shared libraries and you use ViennaLS in your project (see above), CMake will automatically link them to your project.
## Contributing
Before being able to merge your PR, make sure you have met all points on the checklist in [CONTRIBUTING.md](https://github.com/ViennaTools/viennals/blob/master/CONTRIBUTING.md).
If you want to contribute to ViennaLS, make sure to follow the [LLVM Coding guidelines](https://llvm.org/docs/CodingStandards.html).
Make sure to format all files before creating a pull request:
```bash
cmake -B build
cmake --build build --target format
```
## Authors
Current contributors: Tobias Reiter, Roman Kostal, Lado Filipovic
Founder and initial developer: Otmar Ertl
Contact us via: viennatools@iue.tuwien.ac.at
ViennaLS was developed under the aegis of the 'Institute for Microelectronics' at the 'TU Wien'.
http://www.iue.tuwien.ac.at/
## License
ViennaLS is licensed under the [MIT License](./LICENSE).
Some third-party libraries used by ViennaLS are under their own permissive licenses (MIT, BSD).
See [`THIRD_PARTY_LICENSES.md`](./THIRD_PARTY_LICENSES.md) for details.
| text/markdown | null | null | null | null | Copyright (c) 2015-2025 Institute for Microelectronics, TU Wien.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
| null | [] | [] | null | null | null | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://viennatools.github.io/ViennaLS/",
"Documentation, https://viennatools.github.io/ViennaLS/",
"Repository, https://github.com/ViennaTools/ViennaLS",
"Issues, https://github.com/ViennaTools/ViennaLS/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:48:13.667559 | viennals-5.5.1-pp310-pypy310_pp73-win_amd64.whl | 15,854,739 | f4/7c/9c1b06760c6a004a3f0c2f0752d5d2750f3c9bd2e1344a27dc9fd3c72a89/viennals-5.5.1-pp310-pypy310_pp73-win_amd64.whl | pp310 | bdist_wheel | null | false | 89f07e57023d1143afcdf5504eb997be | fa6317dfe6130ad395cdbf0c14359eb0afd60611e3d60a0a392d02be283155a8 | f47c9c1b06760c6a004a3f0c2f0752d5d2750f3c9bd2e1344a27dc9fd3c72a89 | null | [] | 0 |
2.4 | agentic-devtools | 0.2.6 | AI assistant helper commands for the Dragonfly platform | # agentic-devtools
AI assistant helper commands for the Dragonfly platform. This package provides
simple CLI commands that can be easily auto-approved by VS Code AI assistants.
**Audience**: End users of the AGDT CLI. This README focuses on installation
and
usage.
## Installation
### Option 1: Using pipx (Recommended)
A pip-installable Python package that provides CLI commands for AI agents
to interact with Git, Azure DevOps, Jira, and other services.
```bash
# Install pipx if you don't have it
pip install pipx
pipx ensurepath
# ⚠️ IMPORTANT: Restart your terminal for PATH changes to take effect
# Or refresh PATH in current PowerShell session:
Workflow steps can be started from VS Code Copilot Chat using
`/agdt.<workflow>.<step>` commands.
# Install agentic-devtools
cd agentic_devtools
pipx install .
# For development (editable install)
pipx install -e .
```text
### Option 2: Global pip install
Install directly into your system Python. May require administrator privileges
on Windows.
```bash
cd agentic_devtools
# Global install (may need admin/sudo)
pip install .
# For development (editable)
pip install -e .
# With dev dependencies
pip install -e ".[dev]"
```text
> **Note:** Avoid `pip install --user` as it places scripts in a directory that
may not be on your PATH (`%APPDATA%\Python\PythonXXX\Scripts` on Windows).
### Verify Installation
After installation, verify the commands are available:
```bash
agdt-set --help
agdt-show
```text
If commands are not found after installation:
- **pipx:** Run `pipx ensurepath` and restart your terminal
- **pip global:** Ensure `C:\PythonXXX\Scripts` (or equivalent) is on your PATH
## Design Principles
1. **Auto-approvable commands**: Commands are designed to be auto-approved by
VS Code
2. **JSON state file**: Single `agdt-state.json` file stores all parameters
3. **Generic set/get pattern**: One `agdt-set` command works for all keys
(approve once, use for everything)
4. **Native special character support**: Python CLI handles `()[]{}` and
multiline content directly!
5. **Test-driven development**: Tests first with strict coverage expectations
6. **UX consistency**: Predictable command patterns and actionable output
7. **Performance responsiveness**: Long-running operations use background tasks
## Quick Start
```bash
# Set state values (approve agdt-set once, use for any key)
agdt-set pr_id 23046
agdt-set thread_id 139474
agdt-set content "Thanks for the feedback!
I've made the changes you suggested."
# Execute action (parameterless - approve once)
agdt-reply-to-pr-thread
```text
## Copilot Chat Commands
Use the new Copilot Chat agents to start workflow steps from VS Code:
- Type `/agdt.` in Copilot Chat to browse available workflow step commands.
- Example: `/agdt.work-on-jira-issue.planning` to start planning.
- Example: `/agdt.pull-request-review.file-review` to review a PR file.
For the full workflow step list and usage details, see
[specs/001-add-workflow-step-agents/quickstart.md](specs/001-add-workflow-step-agents/quickstart.md).
## State Management Commands
```bash
# Set any key-value pair
agdt-set <key> <value>
# Get a value
agdt-get <key>
# Delete a key
agdt-delete <key>
# Clear all state
agdt-clear
# Show all state
agdt-show
```text
### Examples
```bash
# Simple values
agdt-set pr_id 23046
agdt-set thread_id 139474
agdt-set dry_run true
# Content with special characters (works directly!)
agdt-set content "Fix: handle (optional) [array] parameters"
# Multiline content (works directly!)
agdt-set content "Thanks for the feedback!
I've addressed your concerns:
- Fixed the null check
- Added unit tests
- Updated documentation"
# View current state
agdt-show
```text
## Azure DevOps Commands
All Azure DevOps commands support both CLI parameters and state-based execution.
Parameters passed via CLI are automatically persisted to state for reuse.
### Reply to PR Thread
```bash
# Option A: With CLI parameters (explicit, self-documenting)
agdt-reply-to-pull-request-thread --pull-request-id 23046 --thread-id 139474 --content "Your reply"
agdt-reply-to-pull-request-thread -p 23046 -t 139474 -c "Thanks!"
# Option B: Parameterless (uses current state)
agdt-set pull_request_id 23046
agdt-set thread_id 139474
agdt-set content "Your reply message"
agdt-reply-to-pull-request-thread
# Optionally resolve the thread after replying
agdt-set resolve_thread true
agdt-reply-to-pull-request-thread
```
### Add New PR Comment
```bash
# Option A: With CLI parameters (explicit)
agdt-add-pull-request-comment --pull-request-id 23046 --content "LGTM!"
agdt-add-pull-request-comment -p 23046 -c "Looks good"
# Option B: Parameterless (uses current state)
agdt-set pull_request_id 23046
agdt-set content "Your comment"
agdt-add-pull-request-comment
# For file-level comment
agdt-set path "src/example.py"
agdt-set line 42
agdt-add-pull-request-comment
```
### Approve Pull Request
```bash
# Option A: With CLI parameters
agdt-approve-pull-request --pull-request-id 23046 --content "Approved!"
agdt-approve-pull-request -p 23046
# Option B: Parameterless (uses current state)
agdt-set pull_request_id 23046
agdt-approve-pull-request
```
### Get PR Threads
```bash
# Option A: With CLI parameter
agdt-get-pull-request-threads --pull-request-id 23046
agdt-get-pull-request-threads -p 23046
# Option B: Parameterless (uses current state)
agdt-set pull_request_id 23046
agdt-get-pull-request-threads
```
### Resolve Thread
```bash
# Option A: With CLI parameters
agdt-resolve-thread --pull-request-id 23046 --thread-id 139474
agdt-resolve-thread -p 23046 -t 139474
# Option B: Parameterless (uses current state)
agdt-set pull_request_id 23046
agdt-set thread_id 139474
agdt-resolve-thread
```
### Dry Run Mode
```bash
agdt-set dry_run true
agdt-reply-to-pull-request-thread # Previews without making API calls
```
## Azure Context Management
Manage multiple Azure CLI accounts (e.g., corporate account for Azure DevOps and AZA account for App Insights) without repeated `az login` / `az logout` cycles.
### Overview
The Azure context system uses separate `AZURE_CONFIG_DIR` directories per account context. Both accounts can stay authenticated simultaneously and can be switched instantly via environment variable.
**Available Contexts:**
- `devops` - Corporate account for Azure DevOps, Service Bus, etc.
- `resources` - AZA account for App Insights, Azure resources, Terraform, etc.
### Setup
1. **Switch to a context** (one-time setup per context):
```bash
# Switch to DevOps context
agdt-azure-context-use devops
# Switch to resources context
agdt-azure-context-use resources
```text
2. **Log in to each context** (one-time per context):
```bash
# After switching to a context, log in using Azure CLI
az login
# This login is stored in the context's isolated config directory
```text
### Usage
**Show all contexts with login status:**
```bash
agdt-azure-context-status
```text
Output:
```text
Azure CLI Contexts:
================================================================================
devops [ACTIVE]
Description: Corporate account for Azure DevOps, Service Bus, etc.
Config Dir: ~/.azure-contexts/devops
Status: ✓ Logged in as user@company.com
resources
Description: AZA account for App Insights, Azure resources, Terraform, etc.
Config Dir: ~/.azure-contexts/resources
Status: ✓ Logged in as user@company.com
================================================================================
```text
**Check current active context:**
```bash
agdt-azure-context-current
```text
**Switch contexts:**
```bash
# Switch to DevOps context
agdt-azure-context-use devops
# Switch to resources context
agdt-azure-context-use resources
```text
**Ensure logged in (prompts if needed):**
```bash
# Ensure current context is logged in
agdt-azure-context-ensure-login
# Ensure specific context is logged in
agdt-azure-context-ensure-login devops
```text
### How It Works
Each context uses its own isolated Azure CLI configuration directory:
- `~/.azure-contexts/devops/` - DevOps context config and tokens
- `~/.azure-contexts/resources/` - Resources context config and tokens
When you run `az` commands, the active context's `AZURE_CONFIG_DIR` is used, so both accounts stay authenticated simultaneously. Switching contexts is instant (no browser login flow).
### Integration
**With VPN toggle:**
Contexts work seamlessly with the VPN toggle system. When certain contexts require VPN, the system coordinates VPN state automatically.
**With Azure CLI:**
All `az` commands respect the active context automatically via the `AZURE_CONFIG_DIR` environment variable.
## Git Commands
The package provides streamlined Git workflow commands that support the
single-commit policy.
### Initial Commit & Publish
```bash
# Option A: With CLI parameter (explicit)
| `agdt-get-pull-request-threads` | Get all PR comment threads |
- Change 1
- Change 2
[DFLY-1234](https://jira.swica.ch/browse/DFLY-1234)"
# Option B: Parameterless (uses current state)
# Current commit_message: run `agdt-get commit_message` to check
agdt-git-save-work
```text
### Smart Commit (Auto-detects Amend)
The `agdt-git-save-work` command automatically detects if you're updating an
existing commit:
```bash
# First commit - creates new commit and publishes branch
agdt-git-save-work --commit-message "feature(DFLY-1234): initial implementation"
# Subsequent commits on same issue - automatically amends and force pushes
agdt-git-save-work --commit-message "feature(DFLY-1234): refined implementation
- Original changes
- Additional updates"
# Auto-detects and amends!
```text
**Detection logic:**
1. If branch has commits ahead of `origin/main` AND
2. Last commit message contains the current Jira issue key (from
`jira.issue_key` state)
3. Then: amend existing commit and force push
4. Otherwise: create new commit and publish
### Individual Git Operations
```bash
agdt-git-stage # Stage all changes (git add .)
agdt-git-push # Push changes (git push)
agdt-git-force-push # Force push with lease
agdt-git-publish # Push with upstream tracking
```text
### Git State Options
| Key | Purpose |
| ---------------- | ------------------------------------------------ |
| `commit_message` | The commit message (multiline supported) |
| `dry_run` | If true, preview commands without executing |
| `skip_stage` | If true, skip staging step |
| `skip_push` | If true, skip push step (for agdt-git-save-work) |
## Workflow Commands
The package provides workflow commands for managing structured work processes.
### Work on Jira Issue Workflow
```bash
# Start work on a Jira issue
agdt-set jira.issue_key "DFLY-1234"
agdt-initiate-work-on-jira-issue-workflow
```text
**Workflow Steps:**
1. **setup** - Create worktree and branch (if pre-flight fails)
2. **retrieve** - Auto-fetches Jira issue details
3. **planning** - Analyze issue and post plan comment to Jira
4. **checklist-creation** - Create implementation checklist from plan
5. **implementation** - Code changes, tests, documentation
6. **implementation-review** - Review completed checklist items
7. **verification** - Run tests and quality gates
8. **commit** - Stage and commit changes
9. **pull-request** - Create PR
10. **completion** - Post final Jira comment
### Checklist Management
```bash
# Create implementation checklist
agdt-create-checklist "item1" "item2" "item3"
# Update checklist (mark items complete)
agdt-update-checklist --completed 1 3 # Mark items 1 and 3 as complete
# View current checklist
agdt-show-checklist
# Update during commit (auto-marks items and advances workflow)
agdt-git-save-work --completed 1 2 # Marks items complete before committing
```text
### Workflow Navigation
```bash
# View current workflow state
agdt-get-workflow
# Advance to next step
agdt-advance-workflow
# Clear workflow
agdt-clear-workflow
```text
## PyPI Release Commands
Verwende die `pypi.*` Namespace-Keys für Release-Parameter. Setze deine PyPI
Tokens via Umgebungsvariablen:
- `TWINE_USERNAME=__token__`
- `TWINE_PASSWORD=<pypi-token>`
### PyPI Release starten
```bash
# Parameter setzen
agdt-set pypi.package_name agentic-devtools
agdt-set pypi.version 0.1.0
agdt-set pypi.repository pypi # oder testpypi
agdt-set pypi.dry_run false
# Release starten (parameterlos)
agdt-release-pypi
```text
### Status prüfen
```bash
agdt-task-status
agdt-task-log
agdt-task-wait
```text
## Jira Commands
All Jira commands use the `jira.*` namespace for state values. Set
`JIRA_COPILOT_PAT` environment variable with your Jira API token.
### Get Issue Details
```bash
agdt-set jira.issue_key "DFLY-1234"
agdt-get-jira-issue
```text
### Add Comment to Issue
Commands with optional CLI parameters support two usage patterns:
```bash
# Option A: With CLI parameters (explicit)
agdt-add-jira-comment --jira-comment "Your comment text"
# Option B: Parameterless (uses current state)
# Current jira.issue_key: run `agdt-get jira.issue_key` to check
# Current jira.comment: run `agdt-get jira.comment` to check
agdt-add-jira-comment
```text
### Create Epic
```bash
agdt-set jira.project_key "DFLY"
agdt-set jira.summary "Epic Title"
agdt-set jira.epic_name "EPIC-KEY"
agdt-set jira.role "developer"
agdt-set jira.desired_outcome "implement feature"
agdt-set jira.benefit "improved UX"
agdt-create-epic
# Optional: Add acceptance criteria
agdt-set jira.acceptance_criteria "- Criterion 1
- Criterion 2"
agdt-create-epic
```text
### Create Issue (Task/Bug/Story)
```bash
agdt-set jira.project_key "DFLY"
agdt-set jira.summary "Issue Title"
agdt-set jira.description "Issue description"
agdt-create-issue
# Or use user story format
agdt-set jira.role "developer"
agdt-set jira.desired_outcome "complete task"
agdt-set jira.benefit "value delivered"
agdt-create-issue
```text
### Create Subtask
```bash
agdt-set jira.parent_key "DFLY-1234"
agdt-set jira.summary "Subtask Title"
agdt-set jira.description "Subtask description"
agdt-create-subtask
```text
### Dry Run Mode for Jira
```bash
agdt-set jira.dry_run true
agdt-create-issue # Previews payload without API call
```text
## VPN & Network Management
The corporate VPN (Pulse Secure/Ivanti) creates a full tunnel that blocks public registries (npm, PyPI) while being required for internal resources (Jira, ESB). These commands provide intelligent VPN management so you don't need to manually connect/disconnect VPN when switching between tasks.
### Network Status
Check your current network context:
```bash
agdt-network-status
```
Output shows:
- 🏢 Corporate network (in office) - VPN operations skipped automatically
- 🔌 Remote with VPN - Can access internal resources, external blocked
- 📡 Remote without VPN - Can access external resources, internal blocked
### Run Command with VPN Context
Automatically manage VPN based on command requirements:
```bash
# Ensure VPN is connected before running (for Jira, ESB, etc.)
agdt-vpn-run --require-vpn "curl https://jira.swica.ch/rest/api/2/issue/DP-123"
# Temporarily disconnect VPN for public access (npm, pip, etc.)
agdt-vpn-run --require-public "npm install"
# Auto-detect requirement from command content (default)
agdt-vpn-run --smart "az devops ..."
agdt-vpn-run "npm install express" # --smart is the default
```
The command will:
- Detect if you're on corporate network (in office) and skip VPN operations
- Connect VPN if needed for internal resources
- Disconnect VPN temporarily for public registry access
- Restore VPN state after command completes
### Manual VPN Control
Direct VPN control commands (run in background):
```bash
# Connect VPN (skipped if on corporate network)
agdt-vpn-on
agdt-task-wait
# Disconnect VPN
agdt-vpn-off
agdt-task-wait
# Check VPN status
agdt-vpn-status
agdt-task-wait
```
### Common Workflows
**Install npm packages (needs public access):**
```bash
agdt-vpn-run --require-public "npm install"
```
**Access Jira API (needs VPN):**
```bash
agdt-vpn-run --require-vpn "curl https://jira.swica.ch/rest/api/2/serverInfo"
```
**Smart detection (recommended):**
```bash
# Auto-detects that npm install needs public access
agdt-vpn-run "npm install express lodash"
# Auto-detects that Jira URL needs VPN
agdt-vpn-run "curl https://jira.swica.ch/rest/api/2/issue/DP-123"
```
### In-Office Behavior
When on the corporate network (physically in the office), VPN operations are
automatically skipped since internal resources are already accessible. However,
note that the corporate network may still block external registries (npm, PyPI) -
in that case, consider connecting to a different network (e.g., mobile hotspot)
for external access.
## Environment Variables
| Variable | Purpose
| --------------------------- | ------------------------------------------------
| `AZURE_DEV_OPS_COPILOT_PAT` | Azure DevOps PAT for API calls
| `JIRA_COPILOT_PAT` | Jira API token for authentication
| `JIRA_BASE_URL` | Override default Jira URL (default: jira.swica.c
| `JIRA_SSL_VERIFY` | Set to `0` to disable SSL verification
| `JIRA_CA_BUNDLE` | Path to custom CA bundle PEM file for Jira SSL
| `REQUESTS_CA_BUNDLE` | Standard requests library CA bundle path (fallba
| `AGDT_STATE_FILE` | Override default state file path
## State File Location
By default, state is stored in `scripts/temp/agdt-state.json` (relative to the
repo root).
## Why This Design?
### Auto-Approval Friendly
VS Code's auto-approval matches exact command strings. By using:
- Generic `agdt-set key value` - approve once, use for any key
- Parameterless action commands like `agdt-reply-to-pr-thread`
...you only need to approve a few commands once, then they work for all future
operations.
### No Replacement Tokens Needed
Unlike PowerShell, Python's CLI parsing handles special characters natively:
```bash
# This just works!
agdt-set content "Code with (parentheses) and [brackets]"
```text
### No Multi-line Builder Needed
Python preserves multiline strings from the shell:
```bash
agdt-set content "Line 1
Line 2
Line 3"
```text
## GitHub Actions: SpecKit Issue Trigger
The repository includes a GitHub Action that automatically triggers the SpecKit
specification process when a `speckit` label is added to an issue.
### Visual Documentation
For a comprehensive visual representation of the complete workflow, see the
[SpecKit Workflow Sequence
Diagram](specs/002-github-action-speckit-trigger/workflow-sequence-diagram.md).
The diagram shows:
- All 8 workflow phases from initiation to completion
- Interactions between actors (User, GitHub, SpecKit Action, AI Provider,
Repository)
Repository)
- Decision points and error handling
- Integration with the Spec-Driven Development (SDD) pattern
### How It Works
1. Create a GitHub issue describing your feature
2. Add the `speckit` label to the issue (optionally assign it to Copilot or a
team member)
3. The action posts an acknowledgment comment within 30 seconds
4. A feature specification is generated from the issue title and body
5. A new branch and pull request are created with the specification
6. Status comments are posted to the issue throughout the process
The `speckit` trigger label is automatically removed once processing starts,
and
replaced with status labels (`speckit:processing`, `speckit:completed`, or
`speckit:failed`).
### Configuration
Configure the action using repository variables:
| Variable | Default | Description |
|----------|---------|-------------|
| `SPECKIT_TRIGG | `speckit` | The label that |
| `SPECKIT_AI_PR | `claude` | AI provider fo |
| `SPECKIT_COMMENT_ON_ISSUE` | `true` | Post status comments to the issue |
| `SPECKIT_CREATE_BRANCH` | `true` | Create a feature branch |
| `SPECKIT_CREATE_PR` | `true` | Create a pull request |
### Required Secrets
| Secret | Required For | Description |
|--------|--------------|-------------|
| `ANTHROPIC_API_KEY` | `claude` provider | Claude API key for spec generation |
| `OPENAI_API_KEY` | `openai` provider | OpenAI API key for spec generation |
### Usage
1. Create a GitHub issue with a descriptive title and body
2. Add the `speckit` label (or your configured trigger label)
3. Wait for the workflow to generate the specification
4. Review the generated spec in the pull request
### Manual Trigger
You can also trigger the workflow manually for testing:
```bash
gh workflow run speckit-issue-trigger.yml -f issue_number=123
```text
### Labels
The workflow uses labels to manage state:
- `speckit` - **Trigger label**: Add this to an issue to start specification
generation
generation
- `speckit:processing` - Specification generation in progress
- `speckit:completed` - Specification created successfully
- `speckit:failed` - Generation failed (check workflow logs)
## GitHub Actions: Security Scanning on Main Merge
The repository includes an automated security scanning workflow that runs whenever
code is merged to the main branch. This ensures continuous security monitoring and
helps identify vulnerabilities early.
### How It Works
1. Workflow triggers automatically on push to main branch (typically after PR merge)
2. Installs security scanning tools: `bandit`, `pip-audit`, `safety`
3. Runs comprehensive security scans:
- **pip-audit**: Scans dependencies for known vulnerabilities (CVEs)
- **bandit**: Static analysis for common security issues in Python code
- **safety**: Checks dependencies against a database of known security issues
4. Creates a GitHub issue with the security scan report
5. Attaches scan reports as artifacts for detailed review
### Security Scan Report
After each merge to main, an issue is automatically created with:
- **Summary**: Quick overview of security status
- **Scan Results**: Findings from each security tool
- **Severity Breakdown**: Critical, high, medium, low issues
- **Next Steps**: Recommended actions to address findings
- **Artifacts**: Detailed JSON reports attached to the workflow run
### Labels
The workflow uses labels to categorize scan results:
- `security` - All security scan reports
- `security-scan` - Identifies automated scan issues
- `needs-review` - Findings detected, review required
- `all-clear` - No security issues detected
### Responding to Security Findings
When a security scan detects issues:
1. Review the created issue for summary of findings
2. Check workflow logs for detailed information
3. Download scan report artifacts for in-depth analysis
4. Address critical and high-severity issues immediately
5. Tag @copilot in the issue for assistance with remediation
### Manual Security Scan
You can manually trigger a security scan by running:
```bash
# Install security tools
pip install bandit safety pip-audit
# Run scans
pip-audit
bandit -r agentic_devtools
safety scan
```
| text/markdown | Dragonfly Team | null | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"azure-identity>=1.0.0",
"azure-monitor-query>=1.0.0",
"build>=1.2.2",
"jinja2>=3.0.0",
"requests>=2.28.0",
"twine>=5.0.0",
"black>=24.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"mypy>=1.8.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest-recording>=0.13.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"ruff>=0.4.0; extra == \"dev\"",
"vcrpy>=6.0.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:47:57.799875 | agentic_devtools-0.2.6.tar.gz | 629,849 | 05/7e/b46eee43965215e7a3befd4049a40e5481b179628a09952a0f15a2f56522/agentic_devtools-0.2.6.tar.gz | source | sdist | null | false | 2096808295059c9523e1d3b22660a741 | ccecc75b93ebf12bcd53f2ab42365da4c183538cfbcc6dfe38a144ca585e565f | 057eb46eee43965215e7a3befd4049a40e5481b179628a09952a0f15a2f56522 | MIT | [
"LICENSE"
] | 219 |
2.4 | qc-trace | 0.4.43 | Multi-CLI session tracking and normalization for QuickCall | # qc-trace
A pure Python library that normalizes AI CLI session data from multiple tools into a unified schema, stores it in PostgreSQL, and provides a live dashboard to visualize the data flow.
**Supported sources:** Claude Code, Codex CLI, Gemini CLI, Cursor IDE
## Table of Contents
- [Architecture](#architecture)
- [Quick Start](#quick-start)
- [User Setup (Daemon Only)](#user-setup-daemon-only)
- [What happens when you run install.sh](#what-happens-when-you-run-installsh)
- [How it works on the developer's laptop](#how-it-works-on-the-developers-laptop)
- [Developer Setup (Full Stack)](#developer-setup-full-stack)
- [Troubleshooting](#troubleshooting)
- [Development](#development)
- [Run tests](#run-tests)
- [Project structure](#project-structure)
- [API Endpoints](#api-endpoints)
- [Adding a New CLI Source](#adding-a-new-cli-source)
- [Production Deployment](#production-deployment)
## Architecture
```mermaid
graph LR
subgraph "Dev Laptop A (org: pratilipi)"
A1["~/.claude/**/*.jsonl"]
A2["~/.codex/**/*.jsonl"]
DA["Daemon"]
end
subgraph "Dev Laptop B (org: pratilipi)"
B1["~/.gemini/**/session-*.json"]
B2["~/.cursor/**/*.txt"]
DB2["Daemon"]
end
A1 & A2 --> DA
B1 & B2 --> DB2
DA -- "POST /ingest" --> S["Ingest Server\n:19777"]
DB2 -- "POST /ingest" --> S
S -- "COPY batch write" --> P[("PostgreSQL\n:5432")]
P -- "read queries" --> S
S -- "GET /api/*\n(?org=pratilipi)" --> UI["Dashboard\n:5173"]
```
### Components
| Component | Description |
|-----------|-------------|
| **Daemon** (`quickcall`) | Watches local AI tool session files, transforms them into normalized messages, pushes to the ingest server. Zero third-party dependencies. |
| **Ingest Server** | HTTP server (`:19777`) that accepts normalized messages, batch-writes via PostgreSQL COPY, and serves the read API for the dashboard. Opt-in API key authentication. |
| **PostgreSQL** | Stores sessions, messages, tool calls, tool results, token usage, and file progress. Schema auto-applied on startup (current version: v5). |
| **Dashboard** | Vite + React + TypeScript + Tailwind. Overview stats, session list, message detail with expandable tool calls, thinking content, and token counts. |
### Data flow
1. Daemon polls source directories every 5s for new/changed session files
2. Source-specific collectors parse files incrementally (JSONL: line-resume, JSON/text: content-hash)
3. Transforms normalize data into `NormalizedMessage` schema
4. Pusher batches messages (500/batch) and POSTs to `/ingest` with retry + exponential backoff
5. After successful push, daemon reports its read position via `POST /api/file-progress`
6. Server's batch accumulator flushes to PostgreSQL via COPY (100 msgs or 5s, whichever first)
7. On daemon restart, reconciliation compares local state against server's `/api/sync` endpoint
---
## Quick Start
```bash
# 1. Start PostgreSQL
scripts/dev-db.sh start
# 2. Start the ingest server
uv run python -m qc_trace.server.app
# 3. Start the daemon
uv run quickcall start
# 4. Start the dashboard
cd dashboard && npm run dev
```
---
## User Setup (Daemon Only)
For developers who use AI CLI tools and want their session data tracked. The daemon watches local session files and pushes them to the ingest server. No database, no Docker, no dashboard needed on your machine.
### Install
**Cloud mode** (pushes to `trace.quickcall.dev`):
```bash
curl -fsSL https://quickcall.dev/trace/install.sh | sh -s -- <org> <api-key>
```
**Local mode** (pushes to `localhost:19777`, no API key needed):
```bash
curl -fsSL https://quickcall.dev/trace/install.sh | sh
```
Named flags also work: `--org <name> --key <key>`.
When an API key is provided, the daemon pushes to the cloud server. Without a key, it defaults to localhost — useful for local development or self-hosted setups.
Idempotent — safe to re-run. Re-running updates org/key settings.
### What happens when you run install.sh
Running the installer on a developer's laptop takes ~30 seconds and is fully hands-off after the initial command. Here's what happens step by step:
```
$ curl -fsSL https://quickcall.dev/trace/install.sh | sh -s -- pratilipi <api-key>
░█▀█░█░█░▀█▀░█▀▀░█░█░█▀▀░█▀█░█░░░█░░
░█░█░█░█░░█░░█░░░█▀▄░█░░░█▀█░█░░░█░░
░▀▀█░▀▀▀░▀▀▀░▀▀▀░▀░▀░▀▀▀░▀░▀░▀▀▀░▀▀▀
trace · ai session collector · cloud
✓ Python 3.12
✓ uv already installed (uv 0.6.6)
✓ Shell config updated (~/.zshrc)
✓ quickcall CLI installed
✓ Org set to: pratilipi
==> Installing launchd agent... # (or systemd on Linux)
✓ launchd agent installed and started
Data: ~/.quickcall-trace/
==> Verifying installation...
✓ Heartbeat sent to https://trace.quickcall.dev/ingest
QuickCall Trace installed successfully!
The daemon is now watching your AI CLI sessions and pushing to:
https://trace.quickcall.dev/ingest
Commands:
quickcall status # Check daemon + stats
quickcall logs -f # Follow daemon logs
```
**What it does:**
1. **Pre-flight** — checks Python 3.11+ and curl are available
2. **Installs uv** — the fast Python package manager (skipped if already installed)
3. **Configures shell** — adds `~/.local/bin` to PATH in `.zshrc` / `.bashrc` so `quickcall` works in new terminals
4. **Installs the CLI** — `uv tool install qc-trace` puts the `quickcall` binary in `~/.local/bin`
5. **Writes org + key to config** — stores `{"org": "pratilipi", "api_key": "..."}` in `~/.quickcall-trace/config.json`
6. **Installs a background service** — launchd on macOS, systemd on Linux (user-level, no root/sudo needed)
7. **Sends a heartbeat** — POSTs a test message to the ingest server to verify connectivity
**After install, the developer doesn't need to do anything.** The daemon:
- Starts automatically on login
- Watches `~/.claude/`, `~/.codex/`, `~/.gemini/`, `~/.cursor/` for AI session files
- Pushes new messages to the central ingest server every 5 seconds
- Auto-restarts on crash (via launchd/systemd)
- Auto-updates itself every 5 minutes (checks PyPI, restarts to pick up new version)
- Tags all data with the org name for filtering
**No impact on the developer's workflow.** The daemon is a lightweight background process (~10MB RSS) that reads session files and pushes JSON over HTTP. It does not modify any files, does not intercept any commands, and does not require any ongoing interaction.
### How it works on the developer's laptop
```mermaid
graph TB
subgraph "Developer's Laptop"
subgraph "AI Tools (unchanged)"
CC["Claude Code"]
CX["Codex CLI"]
GM["Gemini CLI"]
CR["Cursor IDE"]
end
subgraph "Session Files (written by AI tools)"
F1["~/.claude/projects/**/*.jsonl"]
F2["~/.codex/sessions/**/*.jsonl"]
F3["~/.gemini/tmp/**/session-*.json"]
F4["~/.cursor/**/agent-transcripts/*.txt"]
end
CC --> F1
CX --> F2
GM --> F3
CR --> F4
subgraph "QuickCall Daemon (background service)"
W["Watcher\n(polls every 5s)"]
C["Collector\n(parses incrementally)"]
P["Pusher\n(HTTP POST + retry)"]
end
F1 & F2 & F3 & F4 -.->|"reads"| W
W --> C --> P
subgraph "Local State"
S["~/.quickcall-trace/\n config.json (org)\n state.json (progress)\n push_status.json"]
end
C -.->|"tracks progress"| S
end
P -->|"POST /ingest\n(batched JSON)"| SRV["Central Ingest Server\ntrace.quickcall.dev"]
SRV --> DB[("PostgreSQL")]
DB --> DASH["Dashboard"]
```
The daemon **only reads** session files — it never writes to them or interferes with the AI tools. File processing is incremental: JSONL files resume from the last line read, JSON/text files re-process only when content changes (via SHA-256 hash).
### CLI Commands
```bash
quickcall status # Show daemon status, per-source stats, server health
quickcall status --json # Machine-readable status output
quickcall logs # View recent logs
quickcall logs -f # Follow daemon logs
quickcall start # Start daemon (background)
quickcall stop # Stop daemon
quickcall setup # Configure email and API key
```
### Example status output
```
QuickCall Trace v0.3.0
Org: pratilipi
Daemon: running (PID 12345) · uptime 3d 4h
Server: https://trace.quickcall.dev/ingest ✓
Source Sessions Messages Last push
────────────────────────────────────────────────────
Claude Code 12 3,847 2s ago
Codex CLI 3 412 5s ago
Gemini CLI 1 87 5s ago
Cursor IDE 5 1,203 5s ago
Total: 21 sessions · 5,549 messages
```
### Start / Stop / Restart (local development)
```bash
# Start the daemon (runs in background)
uv run quickcall start
# Check what's happening
uv run quickcall status
# Stop it
uv run quickcall stop
# Restart (stop + start)
uv run quickcall stop && uv run quickcall start
```
When installed as a system service (via `install.sh`), the daemon starts on login and auto-restarts on crash. Use `quickcall` directly (no `uv run`).
### Environment Variables
| Variable | Default | Description |
|----------|---------|-------------|
| `QC_TRACE_INGEST_URL` | `https://trace.quickcall.dev/ingest` | Target ingest server URL |
| `QC_TRACE_ORG` | _(from config.json)_ | Organization name (set by install.sh) |
| `QC_TRACE_API_KEY` | _(from config.json)_ | API key sent with every request to the ingest server |
### Watched file patterns
| Source | Glob (relative to `$HOME`) |
|--------|---------------------------|
| Claude Code | `.claude/projects/**/*.jsonl` |
| Codex CLI | `.codex/sessions/*/*/*/rollout-*.jsonl` |
| Gemini CLI | `.gemini/tmp/*/chats/session-*.json` |
| Cursor | `.cursor/projects/*/agent-transcripts/*.txt` |
### Daemon files
| File | Path | Purpose |
|------|------|---------|
| Config | `~/.quickcall-trace/config.json` | Org, email, API key |
| State | `~/.quickcall-trace/state.json` | Processing progress per file |
| Push status | `~/.quickcall-trace/push_status.json` | Per-source push timestamps and counts |
| PID | `~/.quickcall-trace/quickcall.pid` | Running daemon PID |
| Log | `~/.quickcall-trace/quickcall.log` | stdout |
| Errors | `~/.quickcall-trace/quickcall.err` | stderr |
---
## Developer Setup (Full Stack)
For contributors developing the daemon, ingest server, dashboard, or schema transforms.
### Prerequisites
- Python 3.11+
- Docker (for PostgreSQL)
- Node.js 18+ (for dashboard)
- [uv](https://docs.astral.sh/uv/) (recommended)
### 1. Clone and set up Python
```bash
git clone git@github.com:quickcall-dev/trace.git
cd trace
uv sync --all-extras
```
### 2. Start PostgreSQL
```bash
scripts/dev-db.sh start
```
Starts PostgreSQL 16 on port 5432. Schema auto-applied on first server connection. Data persists in Docker volume (`qc_trace_pgdata`).
Default connection: `postgresql://qc_trace:qc_trace_dev@localhost:5432/qc_trace`
### 3. Start the ingest server
```bash
uv run python -m qc_trace.server.app
```
Starts on `localhost:19777`.
### 4. Start the daemon
```bash
uv run quickcall start
```
### 5. Start the dashboard
```bash
cd dashboard
npm install
# Local (default — connects to localhost:19777, no auth)
npm run dev
# Production (connects to trace.quickcall.dev, will prompt for admin API key)
VITE_API_URL=https://trace.quickcall.dev npm run dev
```
Opens at `http://localhost:5173`. Shows:
- **Overview** — pipeline health, aggregate stats, live message feed, source distribution
- **Sessions** — filterable table with drill-down
- **Session Detail** — full message list with expandable tool calls, thinking content, and token counts
### Quick test (without the daemon)
```bash
curl -X POST http://localhost:19777/ingest \
-H 'Content-Type: application/json' \
-d '[{"id":"test-1","session_id":"s1","source":"claude_code","msg_type":"user","timestamp":"2026-02-06T00:00:00Z","content":"hello world","source_schema_version":1}]'
```
### Environment Variables
| Variable | Default | Description |
|----------|---------|-------------|
| `QC_TRACE_DSN` | `postgresql://qc_trace:qc_trace_dev@localhost:5432/qc_trace` | PostgreSQL connection string |
| `QC_TRACE_PORT` | `19777` | Ingest server listen port |
| `QC_TRACE_INGEST_URL` | `https://trace.quickcall.dev/ingest` | Daemon target server URL |
| `QC_TRACE_ADMIN_KEYS` | _(empty)_ | Comma-separated admin API keys (full read + write access) |
| `QC_TRACE_PUSH_KEYS` | _(empty)_ | Comma-separated push API keys (write-only, for daemons) |
| `QC_TRACE_API_KEYS` | _(empty)_ | **Legacy** — treated as push keys for backwards compat |
| `QC_TRACE_CORS_ORIGIN` | `http://localhost:3000` | Allowed CORS origin for dashboard |
When both `QC_TRACE_ADMIN_KEYS` and `QC_TRACE_PUSH_KEYS` are empty, auth is disabled (all endpoints open).
---
## Troubleshooting
### Dashboard shows 0 sessions after a restart
Postgres data is lost if the Docker volume doesn't survive reboot, but the daemon's state file (`~/.quickcall-trace/state.json`) still has files marked as processed.
Fix: reset the state file and restart the daemon.
```bash
rm ~/.quickcall-trace/state.json
quickcall stop
quickcall start
```
This is always safe — the writer uses `ON CONFLICT DO NOTHING` so duplicate messages are silently skipped.
### Daemon/server line mismatch
The daemon tracks its actual read position via `file_progress` (separate from message storage). On startup, reconciliation compares local state against the server and rewinds if needed. If you suspect mismatches:
```bash
# Check server's view of file progress
curl http://localhost:19777/api/sync
```
---
## Development
### Run tests
```bash
# All 296 tests
uv run pytest tests/ -v
# Single file
uv run pytest tests/test_transforms.py
# With coverage
uv run pytest tests/ --cov=qc_trace --cov-report=html
```
### Project structure
```
qc_trace/
schemas/ # Source schemas + transforms → NormalizedMessage
unified.py # The central normalized schema
claude_code/ # Claude Code JSONL parser
codex_cli/ # Codex CLI JSONL parser
gemini_cli/ # Gemini CLI JSON parser
cursor/ # Cursor IDE transcript parser
db/
schema.sql # PostgreSQL schema (sessions, messages, tool_calls, file_progress)
migrations.py # Incremental schema migrations (v1 → v5)
connection.py # Async connection pool (psycopg3)
writer.py # Batch COPY writer with duplicate handling
reader.py # Read queries for the dashboard API
server/
app.py # HTTP server (:19777) — ingest + read API
handlers.py # Request handlers (ingest, sessions, file-progress, stats, feed)
batch.py # Batch accumulator (flush on 100 msgs or 5s)
auth.py # API key authentication + CORS config
daemon/
watcher.py # File discovery via glob patterns
collector.py # Source-specific collectors with incremental processing
pusher.py # HTTP POST with retry queue + exponential backoff
state.py # Atomic state persistence
main.py # Poll-collect-push loop + server reconciliation + auto-update
config.py # Daemon configuration (org, globs, retry settings)
push_status.py # Per-source push timestamps for CLI status
cli/
traced.py # CLI: start, stop, status, logs, db init
dashboard/ # Vite + React + TypeScript + Tailwind
tests/ # 296 tests
docs/ # Deployment guide, review docs
docker-compose.yml # PostgreSQL 16
```
### API Endpoints
| Method | Path | Auth | Description |
|--------|------|------|-------------|
| GET | `/health` | Public | Health check + DB connectivity |
| GET | `/api/latest-version` | Public | Latest daemon version |
| POST | `/ingest` | Push / Admin | Accept NormalizedMessage JSON array |
| POST | `/sessions` | Push / Admin | Upsert a session record |
| POST | `/api/file-progress` | Push / Admin | Report daemon file read position |
| GET | `/api/sync` | Push / Admin | File sync state for daemon reconciliation |
| GET | `/api/stats` | Admin | Aggregate stats (sessions, messages, tokens, by source/type). `?org=` |
| GET | `/api/sessions` | Admin | Session list. `?source=`, `?id=`, `?org=`, `?limit=`, `?offset=` |
| GET | `/api/messages` | Admin | Messages for a session. `?session_id=` required |
| GET | `/api/feed` | Admin | Latest messages across all sessions. `?since=`, `?org=`, `?limit=` |
Auth is two-tier: **push keys** can write data (for daemons), **admin keys** can read + write (for dashboard/API). Auth is disabled when no keys are configured.
## Adding a New CLI Source
1. Create `qc_trace/schemas/{tool_name}/v1.py` with frozen TypedDict schemas
2. Create `qc_trace/schemas/{tool_name}/transform.py` returning `list[NormalizedMessage]`
3. Add glob pattern to `qc_trace/daemon/config.py`
4. Add collector logic to `qc_trace/daemon/collector.py`
5. Add test fixtures in `tests/fixtures/` and tests in `tests/`
---
## Production Deployment
See [docs/deployment.md](docs/deployment.md) for the full production deployment guide, including:
- Environment variable reference
- Authentication setup (API key)
- Database configuration and connection pooling
- Server limits and tuning
- Daemon configuration reference
- macOS (launchd) and Linux (systemd) service installation
- Production checklist
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"psycopg-pool>=3.1.0",
"psycopg[binary]>=3.1.0",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:47:47.690698 | qc_trace-0.4.43.tar.gz | 1,713,091 | 62/79/7432562773d0684f3c941bab508dc11c051b7ffb0162d36e997783df76d2/qc_trace-0.4.43.tar.gz | source | sdist | null | false | 591e8a9f1a83397756001a8d233db37e | 7ee079f7a3529bd1b115fe5684832eb80a0156908f0d10baecee315bb744eff9 | 62797432562773d0684f3c941bab508dc11c051b7ffb0162d36e997783df76d2 | null | [] | 296 |
2.4 | pbitlang | 1.0.4 | Domain-specific language for thermodynamic computing Hamiltonians | # PbitLang
**Domain-Specific Language for Thermodynamic Computing**
[](https://www.python.org/downloads/)
[](LICENSE)
PbitLang is a domain-specific language for expressing Hamiltonians (energy functions) with compile-time physics validation. It's designed for thermodynamic computing systems including P-bits, Ising machines, and quantum annealers.
## Features
- **Type System**: Dedicated types for spins (Ising, Potts, clock, continuous)
- **Lattice Geometries**: Built-in support for chains, square, triangular, honeycomb, etc.
- **Physics Validation**: Compile-time warnings about frustration, critical temperatures, symmetry violations
- **Standard Library**: Common models (Ising, Heisenberg, Potts) pre-implemented
- **Zero Dependencies**: Core has no required dependencies
## Installation
```bash
pip install pbitlang
```
## Quick Start
```python
import pbitlang
# Define a Hamiltonian
source = '''
hamiltonian IsingChain(n: int, J: real) -> ising on chain(n) {
coupling: sum((i,j) in neighbors) { -J * s[i] * s[j] }
}
'''
# Compile and instantiate
model = pbitlang.compile(source)
hamiltonian = model.instantiate(n=10, J=1.0)
```
## Example: 2D Ising Model
```pbitlang
hamiltonian IsingSquare2D {
lattice: square(10, 10, periodic)
spins: ising
// Ferromagnetic coupling
energy: -sum over neighbors(i, j) {
J * s[i] * s[j]
}
// External field
energy: -h * sum over i { s[i] }
param J: real = 1.0
param h: real = 0.1
}
```
## CLI Usage
```bash
# Compile a Hamiltonian file
pbitlang compile my_model.pbit
# Interactive REPL
pbitlang repl
```
## Documentation
- [Language Specification](https://github.com/dmjdxb/Thermodynamic-Computing-Platform-/blob/main/pbitlang/docs/SPECIFICATION.txt)
- [User Manual](https://github.com/dmjdxb/Thermodynamic-Computing-Platform-/blob/main/pbitlang/docs/USER_MANUAL.txt)
## Part of the Thermodynamic Computing Platform
PbitLang is part of the [Thermodynamic Computing Platform](https://github.com/dmjdxb/Thermodynamic-Computing-Platform-), a comprehensive software stack for P-bit and thermodynamic hardware.
## License
**Proprietary Software** - Copyright © 2024 David Johnson. All Rights Reserved.
You may install and use this software, but modification and redistribution are prohibited without written consent. See [LICENSE](LICENSE) for full terms.
## Contact
- **GitHub**: [dmjdxb](https://github.com/dmjdxb)
- **Repository**: [Thermodynamic Computing Platform](https://github.com/dmjdxb/Thermodynamic-Computing-Platform-)
| text/markdown | David Johnson | null | null | null | PbitLang Software License
=========================
Copyright (c) 2024 David Johnson. All Rights Reserved.
NOTICE: This is proprietary software. By installing, copying, or using this
software, you agree to be bound by the terms of this license.
================================================================================
GRANT OF LICENSE
================================================================================
Subject to the terms and conditions of this License, David Johnson ("Licensor")
hereby grants you a limited, non-exclusive, non-transferable, royalty-free
license to:
1. INSTALL AND USE: You may install and use this software for personal,
educational, research, or commercial purposes.
2. BACKUP COPIES: You may make copies of the software solely for backup
or archival purposes.
3. INTEGRATION: You may use this software as a component in your own
applications and products.
================================================================================
RESTRICTIONS
================================================================================
You may NOT, without prior written consent from the Licensor:
1. MODIFY: Alter, adapt, translate, or create derivative works based on
this software or any portion thereof.
2. REDISTRIBUTE: Distribute, sublicense, lease, rent, loan, or otherwise
transfer this software to any third party, whether for commercial
purposes or otherwise.
3. REVERSE ENGINEER: Reverse engineer, disassemble, decompile, or
otherwise attempt to derive the source code of this software (except
to the extent that such activity is expressly permitted by applicable
law notwithstanding this limitation).
4. REMOVE NOTICES: Remove, alter, or obscure any proprietary notices,
labels, or marks on this software.
5. COMPETE: Use this software to create a competing product or service.
6. CLAIM OWNERSHIP: Represent that you own, created, or have rights to
this software beyond those expressly granted herein.
================================================================================
INTELLECTUAL PROPERTY
================================================================================
This software, including all associated documentation, source code, object
code, algorithms, and designs, is the exclusive intellectual property of
David Johnson. This license does not grant you any ownership rights or
intellectual property rights in the software.
All rights not expressly granted herein are reserved by the Licensor.
================================================================================
NO WARRANTY
================================================================================
THIS SOFTWARE IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE, AND NONINFRINGEMENT. IN NO EVENT SHALL
THE LICENSOR BE LIABLE FOR ANY CLAIM, DAMAGES, OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT, OR OTHERWISE, ARISING FROM, OUT OF, OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
================================================================================
TERMINATION
================================================================================
This license is effective until terminated. Your rights under this license
will terminate automatically without notice if you fail to comply with any
of its terms. Upon termination, you must destroy all copies of the software
in your possession.
================================================================================
GOVERNING LAW
================================================================================
This license shall be governed by and construed in accordance with applicable
law, without regard to conflict of law principles.
================================================================================
CONTACT
================================================================================
For licensing inquiries, permissions, or commercial licensing arrangements:
David Johnson
GitHub: https://github.com/dmjdxb
================================================================================
BY INSTALLING OR USING THIS SOFTWARE, YOU ACKNOWLEDGE THAT YOU HAVE READ,
UNDERSTOOD, AND AGREE TO BE BOUND BY THE TERMS OF THIS LICENSE.
| domain-specific-language, hamiltonian, ising-model, pbit, physics, spin-systems, statistical-mechanics, thermodynamic-computing | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Physics",
"Topic :: Software Development :: Compilers",
"Topic :: Software Development :: Interpreters",
"Typing :: Typed"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"mypy>=1.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"sphinx-rtd-theme>=1.0; extra == \"docs\"",
"sphinx>=6.0; extra == \"docs\"",
"phal>=0.1.0; extra == \"phal\""
] | [] | [] | [] | [
"Homepage, https://github.com/dmjdxb/Thermodynamic-Computing-Platform-/tree/main/pbitlang",
"Documentation, https://pbitlang.readthedocs.io",
"Repository, https://github.com/dmjdxb/Thermodynamic-Computing-Platform-/tree/main/pbitlang"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T12:47:41.918989 | pbitlang-1.0.4.tar.gz | 64,525 | c0/a6/a3f339080a11729f566b6d236b37a5742ea69a55fdc567ff5e8bf0048c44/pbitlang-1.0.4.tar.gz | source | sdist | null | false | 5aaf06e9223f4a453fc0c6c8353f74d2 | a7b5486b8c9ceed01221060a834f399027e680e10e1f8cfa8618ac3ef9f89829 | c0a6a3f339080a11729f566b6d236b37a5742ea69a55fdc567ff5e8bf0048c44 | null | [
"LICENSE"
] | 225 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.