
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | qodev-gitlab-cli | 0.2.2 | Agent-friendly CLI for the GitLab API | [](https://github.com/qodevai/gitlab-cli/actions/workflows/ci.yml)
[](https://pypi.org/project/qodev-gitlab-cli/)
# qodev-gitlab-cli
Agent-friendly CLI for the GitLab API. Designed for both human and AI-agent workflows, with structured JSON output, consistent flags, and predictable error codes.
## Why this CLI?
- **Agent-friendly** — `--json` on every command, consistent flags, predictable exit codes
- **Built for AI agent workflows** — works seamlessly with Claude Code, scripts, and automation pipelines
- **How it compares**: [`glab`](https://gitlab.com/gitlab-org/cli) is GitLab's official interactive CLI for humans; `qodev-gitlab` is optimized for programmatic and agent use
## Installation
```bash
pip install qodev-gitlab-cli
```
Or run directly without installing:
```bash
uvx qodev-gitlab-cli
```
## Quick Start
```bash
# Set your GitLab token
export GITLAB_TOKEN="glpat-xxxxxxxxxxxxxxxxxxxx"
```
```bash
# List open merge requests
$ qodev-gitlab mrs list
!42 Add authentication opened feature/auth → main
# Get MR details as JSON (for scripts/agents)
$ qodev-gitlab mrs get 42 --json
{"iid": 42, "title": "Add authentication", "state": "opened", ...}
# List pipelines
$ qodev-gitlab pipelines list
12345 running main 2m ago
# Get details of a specific issue
$ qodev-gitlab issues get 42
# Create a merge request from the current branch
$ qodev-gitlab mrs create --title "Add new feature"
```
## Commands
| Group | Subcommand | Description |
|---|---|---|
| **projects** | `list` | List projects (`--owned` for owned only) |
| | `get` | Get project details |
| **mrs** | `list` | List merge requests (`--state`) |
| | `get` | Get merge request details |
| | `create` | Create a merge request (`--title`, `--source`, `--target`, `--description`, `--labels`, `--squash`) |
| | `update` | Update a merge request (`--title`, `--description`, `--labels`, `--target`) |
| | `merge` | Merge a merge request (`--squash`, `--when-pipeline-succeeds`) |
| | `close` | Close a merge request |
| | `discussions` | List discussions on a merge request |
| | `changes` | Show diff for a merge request |
| | `commits` | List commits in a merge request |
| | `approvals` | Show approval status |
| | `comment` | Comment on a merge request (`--body`) |
| | `pipelines` | List pipelines for a merge request |
| **pipelines** | `list` | List pipelines (`--ref`, `--limit`) |
| | `get` | Get pipeline details |
| | `jobs` | List jobs for a pipeline |
| | `wait` | Wait for a pipeline to complete (`--timeout`, `--interval`) |
| **jobs** | `get` | Get job details |
| | `log` | Get job log output |
| | `retry` | Retry a failed job |
| **issues** | `list` | List issues (`--state`, `--labels`, `--milestone`) |
| | `get` | Get issue details |
| | `create` | Create an issue (`--title`, `--description`, `--labels`) |
| | `update` | Update an issue (`--title`, `--description`, `--labels`) |
| | `close` | Close an issue |
| | `comment` | Comment on an issue (`--body`) |
| | `notes` | List comments/notes on an issue |
| **releases** | `list` | List releases |
| | `get` | Get release details by tag |
| | `create` | Create a release (`--tag`, `--name`, `--description`, `--ref`) |
| **variables** | `list` | List CI/CD variables (values hidden) |
| | `get` | Get a CI/CD variable |
| | `set` | Set (create or update) a CI/CD variable (`--protected`, `--masked`) |
## Configuration
### Authentication
Set the `GITLAB_TOKEN` environment variable, or pass `--token` on each invocation:
```bash
export GITLAB_TOKEN="glpat-xxxxxxxxxxxxxxxxxxxx"
```
### GitLab Instance
By default the CLI targets `https://gitlab.com`. Override with the `GITLAB_URL` environment variable or the `--url` flag:
```bash
export GITLAB_URL="https://gitlab.example.com"
```
### Global Options
| Flag | Description | Default |
|---|---|---|
| `--json` | Output as JSON (for scripting / agents) | `false` |
| `--project`, `-p` | Project ID or path | auto-detected from git remote |
| `--limit` | Results per page | `25` |
| `--page` | Page number | `1` |
| `--token` | GitLab token (overrides `GITLAB_TOKEN`) | |
| `--url` | GitLab URL (overrides `GITLAB_URL`) | |
### Exit Codes
| Code | Meaning |
|---|---|
| `0` | Success |
| `80` | Authentication error |
| `81` | Not found |
| `82` | API error |
| `83` | Validation error |
| `84` | Configuration error |
## License
MIT -- see [LICENSE](LICENSE) for details.
| text/markdown | null | Jan Scheffler <jan.scheffler@qodev.ai> | null | null | MIT | api, cli, devops, gitlab | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"cyclopts>=3.0",
"qodev-gitlab-api>=0.1.0",
"rich>=13.0",
"mypy>=1.13.0; extra == \"dev\"",
"pytest-mock>=3.15; extra == \"dev\"",
"pytest>=9.0; extra == \"dev\"",
"ruff>=0.15; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/qodevai/gitlab-cli",
"Repository, https://github.com/qodevai/gitlab-cli",
"Issues, https://github.com/qodevai/gitlab-cli/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:47:22.670791 | qodev_gitlab_cli-0.2.2.tar.gz | 16,293 | e1/9a/87cda78a96bf15bda9eda24c8243bc59617b94695e47dc2eb9d68c6bb575/qodev_gitlab_cli-0.2.2.tar.gz | source | sdist | null | false | 78bd6eb4c037eeda139623574464c542 | 000ab790f27c80b762f9016064a509db7faf13d1257814aa985d4d8e6af8e3ec | e19a87cda78a96bf15bda9eda24c8243bc59617b94695e47dc2eb9d68c6bb575 | null | [
"LICENSE"
] | 200 |
2.4 | openkrx-mcp | 0.1.1 | KRX(한국거래소) Open API MCP Server - 주식, 채권, 파생상품, ETF/ETN/ELW, 지수, 일반상품, ESG 시세정보 | # OpenKRX MCP Server
한국거래소(KRX) Open API를 MCP(Model Context Protocol) 도구로 제공하는 서버입니다.
## 지원 API (31개)
| 카테고리 | 도구 수 | 내용 |
|---------|--------|------|
| 지수 (idx) | 5 | KRX/KOSPI/KOSDAQ/채권/파생상품 지수 일별시세 |
| 주식 (sto) | 8 | KOSPI/KOSDAQ/KONEX 일별매매정보 + 종목기본정보 |
| ETP (etp) | 3 | ETF/ETN/ELW 일별매매정보 |
| 채권 (bon) | 3 | 국채/일반채권/소액채권 일별매매정보 |
| 파생상품 (drv) | 6 | 선물/옵션 일별매매정보 (KOSPI/KOSDAQ 주식선물·옵션 포함) |
| 일반상품 (gen) | 3 | 석유/금/배출권 시장 일별매매정보 |
| ESG (esg) | 3 | SRI채권/ESG ETP/ESG 지수 정보 |
## 설치 및 사용
### 사전 준비
[KRX Open API](http://openapi.krx.co.kr)에서 회원가입 후 API 인증키를 발급받으세요.
### Claude Desktop
`claude_desktop_config.json`에 추가:
```json
{
"mcpServers": {
"openkrx": {
"command": "uvx",
"args": ["openkrx-mcp"],
"env": {
"KRX_API_KEY": "<YOUR_API_KEY>"
}
}
}
}
```
### Claude Code
```bash
claude mcp add openkrx -e KRX_API_KEY=<YOUR_API_KEY> -- uvx openkrx-mcp
```
### 직접 실행
```bash
# stdio (로컬)
KRX_API_KEY=<YOUR_API_KEY> uvx openkrx-mcp
# SSE (원격)
KRX_API_KEY=<YOUR_API_KEY> uvx openkrx-mcp --transport sse --port 8000
```
### Docker
```bash
docker build -t openkrx-mcp .
docker run -e KRX_API_KEY=<YOUR_API_KEY> -p 8000:8000 openkrx-mcp
```
## 참고
- 데이터는 2010년 이후 일별 데이터이며, 매일 오전 8시(KST)에 갱신됩니다.
- 날짜 파라미터(`basDd`)는 `YYYYMMDD` 형식입니다.
- API 호출 한도: 10,000건
## 라이선스
MIT
| text/markdown | null | RealYoungk <youngjin5394@gmail.com> | null | null | null | exchange, financial, korea, kosdaq, kospi, krx, mcp, openkrx, stock | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Office/Business :: Financial"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27.0",
"mcp[cli]>=1.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/RealYoungk/openkrx-mcp",
"Repository, https://github.com/RealYoungk/openkrx-mcp",
"Issues, https://github.com/RealYoungk/openkrx-mcp/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T12:46:19.642222 | openkrx_mcp-0.1.1.tar.gz | 49,723 | b2/5c/884bdac1f75412d58a6ced2f6be5118e33dee3bb6bf88cc3afa1042937bb/openkrx_mcp-0.1.1.tar.gz | source | sdist | null | false | a1a73cb0403d46c9c122e2e5518fd2e7 | 6588ae17c5f568b6a75dfe1e2edca2c19064467a04616487f83367fa3d7fd534 | b25c884bdac1f75412d58a6ced2f6be5118e33dee3bb6bf88cc3afa1042937bb | MIT | [] | 217 |
2.4 | skip-django-is-core | 2.28.1 | Information systems core. | Prolog
======
Django IS Core is a lightweight framework built on Django. It augments Django great design patterns and minimizes
annoying programming work. It takes best from Django-admin. ISCore provides a simple way how to build a rich
administration. It is very simlar to Django admin but there are several differences that justifies why IS Core is
created.
Features
--------
* same detail/add/table views as Django admin, but it uses REST and AJAX call to achieve it (it adds easier usage and
broaden usability)
* it can be used for creation only REST resources without UI
* models UI (add/detail) is more linked together, links between foreign keys are automatically added
* it provides more posibilities for read-only fields (e.g. the fields defined only inside form can be readonly too)
* add new custom view is for Django admin is nightmare, with IS Core is very easy
* it uses class based views, it is cleaner and changes are simplier
* add new model administration without its registration
* generated forms from models with validations
* generated REST resources from models again with validations (no code duplication)
* automatic exports to XLSX, PDF, CSV can be very simply add to a table view
* automatic filtering and sorting for list views
* pre-built reusable views and forms
* automatic CRUD views for models (with REST resources)
* authorization (token based) and permissions
* advanced permissions (e.g. a link between objects is not added to UI if a user does not have permissions to see it)
* and much more ...
Docs
----
For more details see [docs](http://django-is-core.readthedocs.org/)
Development Setup
-----------------
All development (running tests, building docs, etc.) is done through the **example application**. The example app's virtual environment includes django-is-core installed in editable mode along with all required dependencies.
### Prerequisites
- Python 3
- `virtualenv` command available
- Docker (for running required services)
### Setting Up the Development Environment
1. Navigate to the example directory:
```bash
cd example
```
2. Start the required Docker services (Elasticsearch and DynamoDB):
```bash
make runservices
```
3. Install and set up the application:
```bash
make install
```
This will:
- Create a virtual environment at `example/var/ve`
- Install django-is-core in editable mode (from the parent directory)
- Install all dependencies (Django, test tools, etc.)
- Initialize the database
- Set up logging directories
4. Activate the virtual environment:
```bash
source var/ve/bin/activate
```
### Running Tests
With the virtual environment activated:
```bash
cd example
make test
```
### Running the Example Application
```bash
cd example
make runserver
```
The application will be available at http://localhost:8080
### Stopping Services
When done, stop the Docker services:
```bash
make stopservices
```
### Other Useful Commands
From the `example` directory:
```bash
make clean # Remove Python bytecode files
make resetdb # Reset the database
make showurls # Display all registered URLs
```
Building Documentation
----------------------
Documentation requires the example app's virtual environment since it uses autodoc to generate API documentation from the django-is-core source code.
1. First, set up the development environment (see above)
2. Install documentation dependencies:
```bash
source example/var/ve/bin/activate
pip install sphinx sphinx_rtd_theme
```
3. Build the HTML documentation:
```bash
cd docs
make html
```
4. View the documentation by opening `docs/.build/html/index.html` in your browser, or serve it locally:
```bash
python -m http.server 8000 --directory .build/html
```
Then visit http://localhost:8000
Contribution
------------
| text/markdown | Lubos Matl | matllubos@gmail.com | null | null | BSD | django, admin, information systems, REST | [
"Development Status :: 3 - Alpha",
"Framework :: Django",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Topic :: Internet :: WWW/HTTP"
] | [] | https://github.com/skip-pay/django-is-core | null | null | [] | [] | [] | [
"django>=4.2",
"import_string>=0.1.0",
"skip-django-block-snippets>=2.1.0",
"skip-django-chamber>=0.7.2",
"skip-django-pyston>=2.17.0",
"python-dateutil>=2.8.1",
"pytz",
"Unidecode"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:46:17.451269 | skip_django_is_core-2.28.1.tar.gz | 1,968,840 | c7/d7/682eb32ff8847ad65770e643e52ec7e893cb2ba152e86558c0fc0a4ec00f/skip_django_is_core-2.28.1.tar.gz | source | sdist | null | false | fb4e0624e718db08ca6cb7d7c593e722 | e78f3ba6e4e947e0731b9297f4e200004ae5be2c746028abec3fdfd63877a4a5 | c7d7682eb32ff8847ad65770e643e52ec7e893cb2ba152e86558c0fc0a4ec00f | null | [
"LICENSE"
] | 232 |
2.4 | ha-mcp | 6.7.1 | Home Assistant MCP Server - Complete control of Home Assistant through MCP | <div align="center">
<img src="docs/img/ha-mcp-logo.png" alt="Home Assistant MCP Server Logo" width="300"/>
# The Unofficial and Awesome Home Assistant MCP Server
<!-- mcp-name: io.github.homeassistant-ai/ha-mcp -->
<p align="center">
<img src="https://img.shields.io/badge/tools-95+-blue" alt="95+ Tools">
<a href="https://github.com/homeassistant-ai/ha-mcp/releases"><img src="https://img.shields.io/github/v/release/homeassistant-ai/ha-mcp" alt="Release"></a>
<a href="https://github.com/homeassistant-ai/ha-mcp/actions/workflows/e2e-tests.yml"><img src="https://img.shields.io/github/actions/workflow/status/homeassistant-ai/ha-mcp/e2e-tests.yml?branch=master&label=E2E%20Tests" alt="E2E Tests"></a>
<a href="LICENSE.md"><img src="https://img.shields.io/github/license/homeassistant-ai/ha-mcp.svg" alt="License"></a>
<br>
<a href="https://github.com/homeassistant-ai/ha-mcp/commits/master"><img src="https://img.shields.io/github/commit-activity/m/homeassistant-ai/ha-mcp.svg" alt="Activity"></a>
<a href="https://github.com/jlowin/fastmcp"><img src="https://img.shields.io/badge/Built%20with-FastMCP-purple" alt="Built with FastMCP"></a>
<img src="https://img.shields.io/python/required-version-toml?tomlFilePath=https%3A%2F%2Fraw.githubusercontent.com%2Fhomeassistant-ai%2Fha-mcp%2Fmaster%2Fpyproject.toml" alt="Python Version">
<a href="https://github.com/sponsors/julienld"><img src="https://img.shields.io/badge/GitHub_Sponsors-☕-blueviolet" alt="GitHub Sponsors"></a>
</p>
<p align="center">
<em>A comprehensive Model Context Protocol (MCP) server that enables AI assistants to interact with Home Assistant.<br>
Using natural language, control smart home devices, query states, execute services and manage your automations.</em>
</p>
</div>
---

---
## 🚀 Get Started
### Full guide to get you started with Claude Desktop (~10 min)
*No paid subscription required.* Click on your operating system:
<p>
<a href="https://homeassistant-ai.github.io/ha-mcp/guide-macos/"><img src="https://img.shields.io/badge/Setup_Guide_for_macOS-000000?style=for-the-badge&logo=apple&logoColor=white" alt="Setup Guide for macOS" height="120"></a> <a href="https://homeassistant-ai.github.io/ha-mcp/guide-windows/"><img src="https://img.shields.io/badge/Setup_Guide_for_Windows-0078D6?style=for-the-badge&logo=windows&logoColor=white" alt="Setup Guide for Windows" height="120"></a>
</p>
### Quick install (~5 min)
<details>
<summary><b>🍎 macOS</b></summary>
1. Go to [claude.ai](https://claude.ai) and sign in (or create a free account)
2. Open **Terminal** and run:
```sh
curl -LsSf https://raw.githubusercontent.com/homeassistant-ai/ha-mcp/master/scripts/install-macos.sh | sh
```
3. [Download Claude Desktop](https://claude.ai/download) (or restart: Claude menu → Quit)
4. Ask Claude: **"Can you see my Home Assistant?"**
You're now connected to the demo environment! [Connect your own Home Assistant →](https://homeassistant-ai.github.io/ha-mcp/guide-macos/#step-6-connect-your-home-assistant)
</details>
<details>
<summary><b>🪟 Windows</b></summary>
1. Go to [claude.ai](https://claude.ai) and sign in (or create a free account)
2. Open **Windows PowerShell** (from Start menu) and run:
```powershell
irm https://raw.githubusercontent.com/homeassistant-ai/ha-mcp/master/scripts/install-windows.ps1 | iex
```
3. [Download Claude Desktop](https://claude.ai/download) (or restart: File → Exit)
4. Ask Claude: **"Can you see my Home Assistant?"**
You're now connected to the demo environment! [Connect your own Home Assistant →](https://homeassistant-ai.github.io/ha-mcp/guide-windows/#step-6-connect-your-home-assistant)
</details>
### 🧙 Setup Wizard for 15+ clients
**Claude Code, Gemini CLI, ChatGPT, Open WebUI, VSCode, Cursor, and more.**
<p>
<a href="https://homeassistant-ai.github.io/ha-mcp/setup/"><img src="https://img.shields.io/badge/Open_Setup_Wizard-4A90D9?style=for-the-badge" alt="Open Setup Wizard" height="40"></a>
</p>
Having issues? Check the **[FAQ & Troubleshooting](https://homeassistant-ai.github.io/ha-mcp/faq/)**
---
## 💬 What Can You Do With It?
Just talk to Claude naturally. Here are some real examples:
| You Say | What Happens |
|---------|--------------|
| *"Create an automation that turns on the porch light at sunset"* | Creates the automation with proper triggers and actions |
| *"Add a weather card to my dashboard"* | Updates your Lovelace dashboard with the new card |
| *"The motion sensor automation isn't working, debug it"* | Analyzes execution traces, identifies the issue, suggests fixes |
| *"Make my morning routine automation also turn on the coffee maker"* | Reads the existing automation, adds the new action, updates it |
| *"Create a script that sets movie mode: dim lights, close blinds, turn on TV"* | Creates a reusable script with the sequence of actions |
Spend less time configuring, more time enjoying your smart home.
---
## ✨ Features
| Category | Capabilities |
|----------|--------------|
| **🔍 Search** | Fuzzy entity search, deep config search, system overview |
| **🏠 Control** | Any service, bulk device control, real-time states |
| **🔧 Manage** | Automations, scripts, helpers, dashboards, areas, zones, groups, calendars, blueprints |
| **📊 Monitor** | History, statistics, camera snapshots, automation traces, ZHA devices |
| **💾 System** | Backup/restore, updates, add-ons, device registry |
<details>
<summary><b>🛠️ Complete Tool List (97 tools)</b></summary>
| Category | Tools |
|----------|-------|
| **Search & Discovery** | `ha_search_entities`, `ha_deep_search`, `ha_get_overview`, `ha_get_state` |
| **Service & Device Control** | `ha_call_service`, `ha_bulk_control`, `ha_get_operation_status`, `ha_get_bulk_status`, `ha_list_services` |
| **Automations** | `ha_config_get_automation`, `ha_config_set_automation`, `ha_config_remove_automation` |
| **Scripts** | `ha_config_get_script`, `ha_config_set_script`, `ha_config_remove_script` |
| **Helper Entities** | `ha_config_list_helpers`, `ha_config_set_helper`, `ha_config_remove_helper` |
| **Dashboards** | `ha_config_get_dashboard`, `ha_config_set_dashboard`, `ha_config_update_dashboard_metadata`, `ha_config_delete_dashboard`, `ha_get_dashboard_guide`, `ha_get_card_types`, `ha_get_card_documentation` |
| **Areas & Floors** | `ha_config_list_areas`, `ha_config_set_area`, `ha_config_remove_area`, `ha_config_list_floors`, `ha_config_set_floor`, `ha_config_remove_floor` |
| **Labels** | `ha_config_get_label`, `ha_config_set_label`, `ha_config_remove_label`, `ha_manage_entity_labels` |
| **Zones** | `ha_get_zone`, `ha_create_zone`, `ha_update_zone`, `ha_delete_zone` |
| **Groups** | `ha_config_list_groups`, `ha_config_set_group`, `ha_config_remove_group` |
| **Todo Lists** | `ha_get_todo`, `ha_add_todo_item`, `ha_update_todo_item`, `ha_remove_todo_item` |
| **Calendar** | `ha_config_get_calendar_events`, `ha_config_set_calendar_event`, `ha_config_remove_calendar_event` |
| **Blueprints** | `ha_list_blueprints`, `ha_get_blueprint`, `ha_import_blueprint` |
| **Device Registry** | `ha_get_device`, `ha_update_device`, `ha_remove_device`, `ha_rename_entity` |
| **ZHA & Integrations** | `ha_get_zha_devices`, `ha_get_entity_integration_source` |
| **Add-ons** | `ha_get_addon` |
| **Camera** | `ha_get_camera_image` |
| **History & Statistics** | `ha_get_history`, `ha_get_statistics` |
| **Automation Traces** | `ha_get_automation_traces` |
| **System & Updates** | `ha_check_config`, `ha_restart`, `ha_reload_core`, `ha_get_system_info`, `ha_get_system_health`, `ha_get_updates` |
| **Backup & Restore** | `ha_backup_create`, `ha_backup_restore` |
| **Utility** | `ha_get_logbook`, `ha_eval_template`, `ha_get_domain_docs`, `ha_get_integration` |
</details>
---
## 🧠 Better Results with Agent Skills
This server gives your AI agent tools to control Home Assistant. For better configurations, pair it with [Home Assistant Agent Skills](https://github.com/homeassistant-ai/skills) — domain knowledge that teaches the agent Home Assistant best practices.
An MCP server can create automations, helpers, and dashboards, but it has no opinion on *how* to structure them. Without domain knowledge, agents tend to over-rely on templates, pick the wrong helper type, or produce automations that are hard to maintain. The skills fill that gap: native constructs over Jinja2 workarounds, correct helper selection, safe refactoring workflows, and proper use of automation modes.
---
## 🧪 Dev Channel
Want early access to new features and fixes? Dev releases (`.devN`) are published on every push to master.
**[Dev Channel Documentation](docs/dev-channel.md)** — Instructions for pip/uvx, Docker, and Home Assistant add-on.
---
## 🤝 Contributing
For development setup, testing instructions, and contribution guidelines, see **[CONTRIBUTING.md](CONTRIBUTING.md)**.
For comprehensive testing documentation, see **[tests/README.md](tests/README.md)**.
---
## 🔒 Privacy
Ha-mcp runs **locally** on your machine. Your smart home data stays on your network.
- **Configurable telemetry** — optional anonymous usage stats
- **No personal data collection** — we never collect entity names, configs, or device data
- **User-controlled bug reports** — only sent with your explicit approval
For full details, see our [Privacy Policy](PRIVACY.md).
---
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
---
## 🙏 Acknowledgments
- **[Home Assistant](https://home-assistant.io/)**: Amazing smart home platform (!)
- **[FastMCP](https://github.com/jlowin/fastmcp)**: Excellent MCP server framework
- **[Model Context Protocol](https://modelcontextprotocol.io/)**: Standardized AI-application communication
- **[Claude Code](https://github.com/anthropics/claude-code)**: AI-powered coding assistant
## 👥 Contributors
### Maintainers
- **[@julienld](https://github.com/julienld)** — Project creator & core maintainer.
- **[@sergeykad](https://github.com/sergeykad)** — Dashboard CRUD, search pagination, `__main__` security refactor, pre-commit hooks & CI lint, addon Docker fixes, `.gitattributes` enforcement, human-readable log timestamps, and removed the textdistance/numpy dependency.
- **[@kingpanther13](https://github.com/kingpanther13)** — Dev channel documentation, bulk control validation, OAuth 2.1 docs, tool consolidation, error handling improvements, native solutions guidance, default dashboard editing fix, and search response optimization.
### Contributors
- **[@airlabno](https://github.com/airlabno)** — Support for `data` field in schedule time blocks.
- **[@ryphez](https://github.com/ryphez)** — Codex Desktop UI MCP quick setup guide.
- **[@Danm72](https://github.com/Danm72)** — Entity registry tools (`ha_set_entity`, `ha_get_entity`) for managing entity properties.
- **[@Raygooo](https://github.com/Raygooo)** — SOCKS proxy support.
- **[@cj-elevate](https://github.com/cj-elevate)** — Integration & entity management tools (enable/disable/delete).
- **[@maxperron](https://github.com/maxperron)** — Beta testing.
- **[@kingbear2](https://github.com/kingbear2)** — Windows UV setup guide.
- **[@konradwalsh](https://github.com/konradwalsh)** — Financial support via [GitHub Sponsors](https://github.com/sponsors/julienld). Thank you! ☕
---
## 💬 Community
- **[GitHub Discussions](https://github.com/homeassistant-ai/ha-mcp/discussions)** — Ask questions, share ideas
- **[Issue Tracker](https://github.com/homeassistant-ai/ha-mcp/issues)** — Report bugs, request features, or suggest tool behavior improvements
---
## ⭐ Star History
[](https://star-history.com/#homeassistant-ai/ha-mcp&Date)
| text/markdown | null | Julien <github@qc-h.net> | null | null | MIT | mcp, home-assistant, ai, automation, smart-home | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Topic :: Home Automation",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | <3.14,>=3.13 | [] | [] | [] | [
"fastmcp<3.0.0,>=2.11.0",
"mcp>=1.24.0",
"httpx[socks]<1.0,>=0.27.0",
"jq>=1.8.0; sys_platform != \"win32\"",
"pydantic>=2.5.0",
"python-dotenv>=1.0.0",
"truststore>=0.10.0",
"websockets>=12.0",
"cryptography>=45.0.7"
] | [] | [] | [] | [
"Homepage, https://github.com/homeassistant-ai/ha-mcp",
"Bug Tracker, https://github.com/homeassistant-ai/ha-mcp/issues",
"Repository, https://github.com/homeassistant-ai/ha-mcp"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:45:56.243174 | ha_mcp-6.7.1.tar.gz | 230,265 | 10/b6/6760f130d57e33ef1d9a4d5a6bc5a42d84c902b97ec51cdc65c8eba3ec10/ha_mcp-6.7.1.tar.gz | source | sdist | null | false | d1e7c1344243e79cd2f10c7378d4e868 | 683a45bef9c75df130cf91485c3bf3b81c62b891e64c2082b246fb7169ff0d3e | 10b66760f130d57e33ef1d9a4d5a6bc5a42d84c902b97ec51cdc65c8eba3ec10 | null | [
"LICENSE"
] | 3,279 |
2.4 | alphapepttools | 0.1.0 | Search- and quantification-engine agnostic biological interpretation of proteomics data | # alphapepttools

[![Tests][badge-tests]][tests]
[![Documentation][badge-docs]][documentation]
[badge-tests]: https://img.shields.io/github/actions/workflow/status/MannLabs/alphapepttools/test.yaml?branch=main
[badge-docs]: https://github.com/MannLabs/alphapepttools/actions/workflows/docs.yaml/badge.svg
Search- and quantification-engine agnostic downstream processing of proteomics data
## `alphapepttools` was made to make your life in proteomics easier!
Functionalities are intended to be as close to pure python as possible, avoiding closed end-to-end implementations, which is reflected in several design choices:
1. AnnData is used in favor of a custom data class to enable interoperability with any other tool from the Scverse.
2. matplotlib _Axes_ and _Figure_ instances are used for visualization, giving the user full autonomy to layer on custom visualizations with searborn, matplotlib, or any other compatible visualization package.
3. Statistical and preprocessing functions are standalone and set with strong defaults, meaning that any function can be used outside of the `alphapepttools` context.
### Design choices of `alphapepttools`:
- **Data handling**: `AnnData` was chosen as a data container for two main reasons:
1. For presenting a lightweight, powerful solution to a fundamental challenge with dataframes, which is keeping numerical data and metadata aligned together at all times. Using dataframes, the options are to either include non-numeric metadata columns in the dataframe (complicating data operations) or to add cumbersome multi-level indices and
2. For their compatibility with the Scverse, Scanpy and all associated tools, essentially removing the barrier between proteomics and transcriptomics data analysis and enabling multi-omics analyses.
- **Plotting**: Inspired by the [`stylia`] package, `alphapepttools` aims to provide a consistent and aesthetically pleasing visual experience for all plots. A core component of this implementation is the fact that `create_figure` returns subplots as an iterable data structure, meaning that once the basic layout of a plot is decided, users simply jump from one plot window to the next and populate each one with figure elements.
- **Standardization**: A key consideration of this package is the loading of proteomics data, the biggest painpoint of which is the nonstandard output of various proteomic search engines. By building on `alphabase`, we handle this complexity early and provide the user with AnnData objects containing either proteins or precursors, where the familiar Pandas DataFrame is always just a '`df = adata.to_df().join(adata.obs)`' away.
[`stylia`]: https://github.com/ersilia-os/stylia.git
## Getting started
Please refer to the [documentation][],
in particular, the [API documentation][].
## Installation
You need to have Python 3.10 or newer installed on your system.
If you don't have Python installed, we recommend installing [Mambaforge][].
There are several alternative options to install alphapepttools:
1. Install the latest release of `alphapepttools` from [PyPI](https://pypi.org/project/alphapepttools/):
```bash
pip install alphapepttools
```
As the package is still under development, consider installing the latest development version with the latest changes, features, and bug fixes:
2. Development version
```bash
pip install git+https://github.com/MannLabs/alphapepttools.git@main
```
### Installation extras
Depending on your use case, you might want to install specific versions of packages or additional dependencies.
If you want to use `alphapepttools` in an isolated environment and enforce stringent dependencies, you can install the stable version:
```bash
pip install "alphapepttools[stable]"
```
Note that this installs only a subset of alphapepttools functionality, as it misses
the `alphaquant` and `inmoose` packages (required for advanced differential expression analysis).
If you encounter a respective warning, you need to install the `full` extra option
```bash
pip install "alphapepttools[full]" # or [full-stable]
```
or install the respective packages manually.
For development purposes like running tests, pre-commit hooks, and building the documentation locally, install the optional development dependencies:
```bash
git clone https://github.com/MannLabs/alphapepttools.git && cd alphapepttools
pip install -e ".[test, dev]"
```
## Release notes
See the [GitHub Release page](https://github.com/MannLabs/alphapepttools/releases).
## Developer Guide
This document gathers information on how to develop and contribute to the alphapepttools project.
### Release process
#### Tagging of changes
In order to have release notes automatically generated, changes need to be tagged with labels.
The following labels are used (should be safe-explanatory):
`breaking-change`, `bug`, `enhancement`.
#### Release a new version
This package uses a shared release process defined in the
[alphashared](https://github.com/MannLabs/alphashared) repository. Please see the instructions
[there](https://github.com/MannLabs/alphashared/blob/reusable-release-workflow/.github/workflows/README.md#release-a-new-version)
## Contact
For questions and help requests, you can reach out in the [scverse discourse][].
If you found a bug, please use the [issue tracker][].
## Citation
> t.b.a
[mambaforge]: https://github.com/conda-forge/miniforge#mambaforge
[scverse discourse]: https://discourse.scverse.org/
[issue tracker]: https://github.com/MannLabs/alphapepttools/issues
[tests]: https://github.com/MannLabs/alphapepttools/actions/workflows/test.yml
<!-- TODO: Change documentation pages back to readthedocs upon public release -->
<!-- [documentation]: https://alphapepttools.readthedocs.io -->
<!-- [changelog]: https://alphapepttools.readthedocs.io/en/latest/changelog.html -->
<!-- [api documentation]: https://alphapepttools.readthedocs.io/en/latest/api.html -->
[documentation]: https://mannlabs.github.io/alphapepttools/index.html
[changelog]: https://github.com/MannLabs/alphapepttools/releases
[api documentation]: https://mannlabs.github.io/alphapepttools/api.html
[pypi]: https://pypi.org/project/alphapepttools
| text/markdown | MannLabs | null | null | MannLabs <brennsteiner@biochem.mpg.de> | Apache License Version 2.0
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright (c) 2024, MannLabs
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | null | [
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"alphabase",
"anndata",
"bpca>=0.1",
"cmcrameri",
"matplotlib",
"numpy",
"openpyxl",
"pandas<3",
"pyarrow",
"scanpy",
"scikit-learn",
"session-info2",
"pre-commit; extra == \"dev\"",
"twine>=4.0.2; extra == \"dev\"",
"docutils!=0.18.*,!=0.19.*,>=0.8; extra == \"doc\"",
"ipykernel; extra == \"doc\"",
"ipython; extra == \"doc\"",
"myst-nb>=1.1; extra == \"doc\"",
"setuptools; extra == \"doc\"",
"sphinx-autodoc-typehints; extra == \"doc\"",
"sphinx-book-theme>=1; extra == \"doc\"",
"sphinx-copybutton; extra == \"doc\"",
"sphinx-tabs; extra == \"doc\"",
"sphinx>=4; extra == \"doc\"",
"sphinxcontrib-bibtex>=1; extra == \"doc\"",
"sphinxext-opengraph; extra == \"doc\"",
"alphaquant; extra == \"full\"",
"inmoose; extra == \"full\"",
"alphaquant==0.3; extra == \"full-stable\"",
"inmoose==0.8.1; extra == \"full-stable\"",
"alphabase==1.8.1; extra == \"stable\"",
"anndata==0.11.4; extra == \"stable\"",
"cmcrameri==1.9; extra == \"stable\"",
"matplotlib==3.10; extra == \"stable\"",
"numpy==2.2.6; extra == \"stable\"",
"openpyxl==3.1.5; extra == \"stable\"",
"pandas==2.3.3; extra == \"stable\"",
"pyarrow==23; extra == \"stable\"",
"scanpy==1.11.5; extra == \"stable\"",
"scikit-learn==1.7.2; extra == \"stable\"",
"session-info2==0.3; extra == \"stable\"",
"coverage; extra == \"test\"",
"nbmake; extra == \"test\"",
"pytest; extra == \"test\""
] | [] | [] | [] | [
"Documentation, https://alphapepttools.readthedocs.io/",
"Homepage, https://github.com/MannLabs/alphapepttools",
"Source, https://github.com/MannLabs/alphapepttools"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:45:49.325167 | alphapepttools-0.1.0-py3-none-any.whl | 93,204 | c6/13/ace77a566fdcece68752b5b1dc14f5b6c116e303c667a264c8fd9369959e/alphapepttools-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 498a04c38a873f13067d2772342353e6 | ccdc07e522b6817f59f5589292f2ae7ab352b3ef1efd7e11ef1ee55773d499c4 | c613ace77a566fdcece68752b5b1dc14f5b6c116e303c667a264c8fd9369959e | null | [
"LICENSE"
] | 102 |
2.4 | searchfox | 0.10.6 | Python bindings for searchfox.org API | # searchfox-cli
[](https://crates.io/crates/searchfox-cli)
[](https://opensource.org/licenses/MIT)
[](https://www.apache.org/licenses/LICENSE-2.0)
[](https://github.com/padenot/searchfox-cli/actions)
[](https://www.rust-lang.org)
[](https://rust-reportcard.xuri.me/report/github.com/padenot/searchfox-cli)
[](https://deps.rs/repo/github/padenot/searchfox-cli)
[](https://crates.io/crates/searchfox-cli)
A command-line interface for searching Mozilla codebases using searchfox.org, written by and for Claude Code.
Also available as a Rust library (`searchfox-lib`) and Python package (`searchfox-py`).
## Features
- Search across multiple Mozilla repositories (mozilla-central, autoland, beta, release, ESR branches, comm-central)
- Symbol search using searchfox's native indexing for precise lookups
- Advanced definition finding with complete function/class extraction using intelligent brace matching
- **Call graph analysis**: Understand code flow with `calls-from`, `calls-to`, and `calls-between` queries (LLM-friendly markdown output)
- **Field layout inspection**: Display C++ class/struct memory layout with size, alignment, and field offsets
- Language filtering (C++, C, WebIDL, JavaScript)
- Path patterns and regular expressions
- Request logging for performance analysis
## Installation
```bash
cargo install searchfox-cli
```
## CLI Usage
### Basic Search
```bash
# Search for "AudioStream" in mozilla-central
searchfox-cli -q AudioStream
# Search with case sensitivity
searchfox-cli -q AudioStream -C
# Search with regular expressions
searchfox-cli -q '^Audio.*' -r
# Limit results to 10 matches
searchfox-cli -q AudioStream -l 10
```
### Symbol and Definition Search
```bash
# Find symbol definitions
searchfox-cli --symbol AudioContext
# Find exact identifier matches (not prefix-based)
searchfox-cli --id main
# Search for symbols using searchfox's symbol index
searchfox-cli --symbol 'AudioContext'
searchfox-cli --symbol 'CreateGain'
# Search for symbols in specific paths
searchfox-cli -q 'path:dom/media symbol:AudioStream'
```
### Repository Selection
```bash
# Search in autoland repository
searchfox-cli -q AudioStream -R autoland
# Search in beta branch
searchfox-cli -q AudioStream -R mozilla-beta
```
### Path Filtering
```bash
# Search only in dom/media directory
searchfox-cli -q AudioStream -p ^dom/media
# Search in specific file patterns
searchfox-cli -q AudioStream -p '\.cpp$'
# Use -p alone to search for files by path pattern
searchfox-cli -p PContent.ipdl
searchfox-cli -p AudioContext.cpp
# Using advanced path syntax in query
searchfox-cli -q 'path:dom/media AudioStream'
searchfox-cli -q 'pathre:^dom/(media|audio) AudioStream'
```
### Language Filtering
Filter search results by programming language using language-specific flags:
```bash
# Search only in C++ files (.cc, .cpp, .h, .hh, .hpp)
searchfox-cli -q AudioContext --cpp
searchfox-cli --define AudioContext -p dom/media --cpp
# Search only in C files (.c, .h)
searchfox-cli -q malloc --c
# Search only in WebIDL files (.webidl)
searchfox-cli -q AudioContext --webidl
# Search only in JavaScript files (.js, .mjs, .ts, .cjs, .jsx, .tsx)
searchfox-cli -q AudioContext --js
# Without language filters, all file types are included
searchfox-cli --define AudioContext -p dom/media
```
### Advanced Query Features
```bash
# Search with context lines
searchfox-cli -q AudioStream --context 3
# Text search with regex
searchfox-cli -q 're:AudioContext::.*Create'
# Exact text search (escapes regex chars)
searchfox-cli -q 'text:function main()'
# Combined advanced queries
searchfox-cli -q 'context:3 pathre:dom/media symbol:AudioStream'
```
### Symbol Search
The `--symbol` flag uses searchfox's native symbol indexing for precise symbol lookups:
```bash
# Search for symbols by name
searchfox-cli --symbol 'AudioContext'
searchfox-cli --symbol 'CreateGain'
# Combine with path filtering
searchfox-cli -q 'path:dom/media symbol:AudioStream'
```
Symbol search relies on searchfox's own symbol database, which includes properly mangled C++ symbols and other language constructs as indexed by the searchfox infrastructure.
### Advanced Definition Finding
The `--define` flag provides an advanced way to find symbol definitions by:
1. **Symbol Search**: Uses `id:` prefix internally for precise symbol lookups
2. **Class/Struct Priority**: Prioritizes class and struct definitions over constructors
3. **Definition Resolution**: Searches both "Definitions" and "Declarations" categories (for C++ classes)
4. **Context Extraction**: Fetches the source file and displays the complete method/function/class
```bash
# Find class definition with full body
searchfox-cli --define AudioContext -p dom/media
# Find method definition with full context
searchfox-cli --define 'AudioContext::CreateGain'
# Filter by language
searchfox-cli --define AudioContext -p dom/media --cpp
# The tool will:
# 1. Search using id:AudioContext for precise matches
# 2. Prioritize class definitions over constructor declarations
# 3. Extract the complete class body (with brace matching)
# 4. Display the full definition with proper highlighting
```
This approach leverages searchfox's comprehensive symbol database for reliable definition finding.
#### Example Output:
**For class definitions:**
```bash
$ searchfox-cli --define AudioContext -p dom/media --cpp
>>> 135: class AudioContext final : public DOMEventTargetHelper,
136: public nsIMemoryReporter,
137: public RelativeTimeline {
138: AudioContext(nsPIDOMWindowInner* aParentWindow, bool aIsOffline,
139: uint32_t aNumberOfChannels = 0, uint32_t aLength = 0,
140: float aSampleRate = 0.0f);
141: ~AudioContext();
142:
143: public:
144: typedef uint64_t AudioContextId;
145:
146: NS_DECL_ISUPPORTS_INHERITED
147: NS_DECL_CYCLE_COLLECTION_CLASS_INHERITED(AudioContext, DOMEventTargetHelper)
148: MOZ_DEFINE_MALLOC_SIZE_OF(MallocSizeOf)
...
335: void RegisterNode(AudioNode* aNode);
... : (method too long, truncated)
```
**For method definitions:**
```bash
$ searchfox-cli --define 'AudioContext::CreateGain'
>>> 469: already_AddRefed<GainNode> AudioContext::CreateGain(ErrorResult& aRv) {
470: return GainNode::Create(*this, GainOptions(), aRv);
471: }
```
The tool automatically:
- Searches searchfox's structured data for definition entries
- Uses searchfox's native symbol indexing for accurate results
- Finds the actual source file location (not generated binding files)
- Fetches the source code and displays complete methods/functions
- Highlights the exact definition line with `>>>`
#### Complete Function and Class Extraction
When using `--define`, the tool automatically detects and extracts complete function/method bodies and class definitions using intelligent brace matching:
**For simple functions:**
```bash
$ searchfox-cli --define 'AudioContext::CreateGain'
>>> 469: already_AddRefed<GainNode> AudioContext::CreateGain(ErrorResult& aRv) {
470: return GainNode::Create(*this, GainOptions(), aRv);
471: }
```
**For complex constructors with initializer lists:**
```bash
$ searchfox-cli --define 'AudioContext::AudioContext'
>>> 154: AudioContext::AudioContext(nsPIDOMWindowInner* aWindow, bool aIsOffline,
155: uint32_t aNumberOfChannels, uint32_t aLength,
156: float aSampleRate)
157: : DOMEventTargetHelper(aWindow),
158: mId(gAudioContextId++),
159: mSampleRate(GetSampleRateForAudioContext(
160: aIsOffline, aSampleRate,
161: aWindow->AsGlobal()->ShouldResistFingerprinting(
162: RFPTarget::AudioSampleRate))),
163: mAudioContextState(AudioContextState::Suspended),
164: ...
179: mSuspendedByChrome(nsGlobalWindowInner::Cast(aWindow)->IsSuspended()) {
180: bool mute = aWindow->AddAudioContext(this);
181: // ... full method body continues ...
205: }
```
**Features of complete extraction:**
- **Multi-language support**: Handles C++, Rust, and JavaScript function syntax
- **Class and struct definitions**: Extracts complete class/struct bodies with proper brace matching
- **Smart brace matching**: Ignores braces in strings, comments, and character literals
- **Complex signatures**: Handles multi-line function signatures and initializer lists
- **Constructor support**: Properly extracts C++ constructors with member initialization lists
- **Class termination**: Handles classes/structs ending with semicolons correctly
- **Safety limits**: Truncates extremely long definitions (>200 lines) to prevent output overflow
- **Accurate parsing**: Correctly handles nested braces, escape sequences, and comment blocks
### File Retrieval
```bash
# Fetch and display a specific file
searchfox-cli --get-file dom/media/AudioStream.h
```
## Available Repositories
- `mozilla-central` (default) - Main Firefox development
- `autoland` - Integration repository
- `mozilla-beta` - Beta release branch
- `mozilla-release` - Release branch
- `mozilla-esr115` - ESR 115 branch
- `mozilla-esr128` - ESR 128 branch
- `mozilla-esr140` - ESR 140 branch
- `comm-central` - Thunderbird development
## Command Line Options
- `-q, --query <QUERY>` - Search query string (supports advanced syntax)
- `-R, --repo <REPO>` - Repository to search in (default: mozilla-central)
- `-p, --path <PATH>` - Filter results by path prefix using regex, or search for files by path pattern
- `-C, --case` - Enable case-sensitive search
- `-r, --regexp` - Enable regular expression search
- `-l, --limit <LIMIT>` - Maximum number of results to display (default: 50)
- `--get-file <FILE>` - Fetch and display contents of a specific file
- `--symbol <SYMBOL>` - Search for symbol definitions using searchfox's symbol index
- `--id <IDENTIFIER>` - Search for exact identifier matches
- `--context <N>` - Show N lines of context around matches
- `--define <SYMBOL>` - Find and display the definition of a symbol with full context
- `--log-requests` - Enable detailed HTTP request logging with timing and size information
- `--cpp` - Filter results to C++ files only (.cc, .cpp, .h, .hh, .hpp)
- `--c` - Filter results to C files only (.c, .h)
- `--webidl` - Filter results to WebIDL files only (.webidl)
- `--js` - Filter results to JavaScript files only (.js, .mjs, .ts, .cjs, .jsx, .tsx)
- `--calls-from <SYMBOL>` - Show what functions are called by the specified symbol
- `--calls-to <SYMBOL>` - Show what functions call the specified symbol
- `--calls-between <SOURCE,TARGET>` - Show direct calls from source class/namespace to target class/namespace
- `--depth <N>` - Set traversal depth for call graph searches (default: 1)
- `--field-layout <CLASS>` - Display C++ class/struct memory layout (aliases: `--class-layout`, `--struct-layout`)
### Call Graph Analysis
Understand code flow and dependencies with LLM-friendly markdown output:
```bash
# What does a function call?
searchfox-cli --calls-from 'mozilla::AudioCallbackDriver::DataCallback'
# What calls this function?
searchfox-cli --calls-to 'mozilla::AudioCallbackDriver::Start'
# How do two classes interact?
searchfox-cli --calls-between 'mozilla::dom::AudioContext,mozilla::MediaTrackGraph' --depth 2
```
**Output features:**
- Results grouped by parent class/namespace
- Both definition and declaration locations shown
- Overloaded functions collapsed with all variants listed
- Mangled symbols included for subsequent queries
- Direct call edges (for `calls-between`)
## Examples
```bash
# Find all AudioStream references
searchfox-cli -q AudioStream
# Find function definitions starting with "Audio"
searchfox-cli -q '^Audio.*' -r
# Search only in media-related files
searchfox-cli -q AudioStream -p ^dom/media
# Get a specific file
searchfox-cli --get-file dom/media/AudioStream.h
# Search in Thunderbird codebase
searchfox-cli -q "MailServices" -R comm-central
# Find where AudioContext is defined
searchfox-cli --symbol AudioContext
# Find exact matches for "main" function
searchfox-cli --id main
# Search with context lines
searchfox-cli -q AudioStream --context 5
# Symbol search using searchfox's symbol index
searchfox-cli --symbol 'AudioContext'
searchfox-cli --symbol 'CreateGain'
# Find complete definition with context
searchfox-cli --define 'AudioContext::CreateGain'
searchfox-cli --define 'AudioContext'
# Language filtering
searchfox-cli --define AudioContext -p dom/media --cpp
searchfox-cli -q malloc --c
searchfox-cli -q AudioContext --js
# File path search
searchfox-cli -p PContent.ipdl
searchfox-cli -p AudioContext.cpp
# Advanced query syntax
searchfox-cli -q 'path:dom/media symbol:AudioStream'
searchfox-cli -q 're:AudioContext::.*Create'
# Class memory layout inspection
searchfox-cli --field-layout 'mozilla::dom::AudioContext'
searchfox-cli --class-layout 'soundtouch::SoundTouch'
# Performance analysis with request logging
searchfox-cli --log-requests --define 'AudioContext::CreateGain'
searchfox-cli --log-requests -q AudioStream -l 10
```
### Request Logging
```bash
searchfox-cli --log-requests --define 'AudioContext::CreateGain'
```
Shows HTTP request timing, response sizes, and baseline latency for performance analysis.
## Python API
```python
import searchfox
client = searchfox.SearchfoxClient("mozilla-central")
results = client.search(query="AudioStream", limit=10)
definition = client.get_definition("AudioContext::CreateGain")
content = client.get_file("dom/media/AudioStream.h")
```
**Installation:**
```bash
cd searchfox-py && maturin develop # Development
cd searchfox-py && maturin build --release # Distribution wheel
```
See `python/examples/` for complete examples.
## License
Licensed under either of
* Apache License, Version 2.0, ([LICENSE-APACHE](LICENSE-APACHE) or http://www.apache.org/licenses/LICENSE-2.0)
* MIT license ([LICENSE-MIT](LICENSE-MIT) or http://opensource.org/licenses/MIT)
at your option.
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT OR Apache-2.0 | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | maturin/1.12.3 | 2026-02-20T12:45:43.223142 | searchfox-0.10.6-cp312-cp312-manylinux_2_34_x86_64.whl | 2,971,938 | 8f/2c/65b180fc55ae6a32245c1927da5c312e09e34d23763c0440298b11a7a532/searchfox-0.10.6-cp312-cp312-manylinux_2_34_x86_64.whl | cp312 | bdist_wheel | null | false | 673b6ad2c2282b3ade5a8d90e2f2a8af | 7998c96485e52f93fb54685530ad986f556fd3f19631d58417a8b093492eac31 | 8f2c65b180fc55ae6a32245c1927da5c312e09e34d23763c0440298b11a7a532 | null | [] | 95 |
2.4 | codex-lb | 1.0.4 | Codex load balancer and proxy for ChatGPT accounts with usage dashboard | <!--
About
Codex/ChatGPT account load balancer & proxy with usage tracking, dashboard, and OpenCode-compatible endpoints
Topics
python oauth sqlalchemy dashboard load-balancer openai rate-limit api-proxy codex fastapi usage-tracking chatgpt opencode
Resources
-->
# codex-lb
Load balancer for ChatGPT accounts. Pool multiple accounts, track usage, manage API keys, view everything in a dashboard.
|  |  |
|:---:|:---:|
<details>
<summary>More screenshots</summary>
| Settings | Login |
|:---:|:---:|
|  |  |
| Dashboard (dark) | Accounts (dark) | Settings (dark) |
|:---:|:---:|:---:|
|  |  |  |
</details>
## Features
<table>
<tr>
<td><b>Account Pooling</b><br>Load balance across multiple ChatGPT accounts</td>
<td><b>Usage Tracking</b><br>Per-account tokens, cost, 28-day trends</td>
<td><b>API Keys</b><br>Per-key rate limits by token, cost, window, model</td>
</tr>
<tr>
<td><b>Dashboard Auth</b><br>Password + optional TOTP</td>
<td><b>OpenAI-compatible</b><br>Codex CLI, OpenCode, any OpenAI client</td>
<td><b>Auto Model Sync</b><br>Available models fetched from upstream</td>
</tr>
</table>
## Quick Start
```bash
# Docker (recommended)
docker volume create codex-lb-data
docker run -d --name codex-lb \
-p 2455:2455 -p 1455:1455 \
-v codex-lb-data:/var/lib/codex-lb \
ghcr.io/soju06/codex-lb:latest
# or uvx
uvx codex-lb
```
Open [localhost:2455](http://localhost:2455) → Add account → Done.
## Client Setup
Point any OpenAI-compatible client at codex-lb. If [API key auth](#api-key-authentication) is enabled, pass a key from the dashboard as a Bearer token.
| Logo | Client | Endpoint | Config |
|---|--------|----------|--------|
| <img src="https://avatars.githubusercontent.com/u/14957082?s=200" width="32" alt="OpenAI"> | **Codex CLI** | `http://127.0.0.1:2455/backend-api/codex` | `~/.codex/config.toml` |
| <img src="https://avatars.githubusercontent.com/u/208539476?s=200" width="32" alt="OpenCode"> | **OpenCode** | `http://127.0.0.1:2455/v1` | `~/.config/opencode/opencode.json` |
| <img src="https://avatars.githubusercontent.com/u/252820863?s=200" width="32" alt="OpenClaw"> | **OpenClaw** | `http://127.0.0.1:2455/v1` | `~/.openclaw/openclaw.json` |
| <img src="https://cdn.jsdelivr.net/gh/devicons/devicon/icons/python/python-original.svg" width="32" alt="Python"> | **OpenAI Python SDK** | `http://127.0.0.1:2455/v1` | Code |
<details>
<summary><img src="https://avatars.githubusercontent.com/u/14957082?s=200" width="20" align="center" alt="OpenAI"> <b>Codex CLI / IDE Extension</b></summary>
<br>
`~/.codex/config.toml`:
```toml
model = "gpt-5.3-codex"
model_reasoning_effort = "xhigh"
model_provider = "codex-lb"
[model_providers.codex-lb]
name = "OpenAI" # MUST be "OpenAI" - enables /compact endpoint
base_url = "http://127.0.0.1:2455/backend-api/codex"
wire_api = "responses"
requires_openai_auth = true
```
**With API key auth:**
```toml
model = "gpt-5.3-codex"
model_reasoning_effort = "xhigh"
model_provider = "codex-lb"
[model_providers.codex-lb]
name = "OpenAI" # MUST be "OpenAI" - enables /compact endpoint
base_url = "http://127.0.0.1:2455/backend-api/codex"
wire_api = "responses"
env_key = "CODEX_LB_API_KEY"
```
```bash
export CODEX_LB_API_KEY="sk-clb-..." # key from dashboard
codex
```
</details>
<details>
<summary><img src="https://avatars.githubusercontent.com/u/208539476?s=200" width="20" align="center" alt="OpenCode"> <b>OpenCode</b></summary>
<br>
`~/.config/opencode/opencode.json`:
```jsonc
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"codex-lb": {
"npm": "@ai-sdk/openai-compatible",
"name": "codex-lb",
"options": {
"baseURL": "http://127.0.0.1:2455/v1"
},
"models": {
"gpt-5.3-codex": { "name": "GPT-5.3 Codex", "reasoning": true, "interleaved": { "field": "reasoning_details" } }
}
}
},
"model": "codex-lb/gpt-5.3-codex"
}
```
This keeps OpenCode's default providers/connections available and adds `codex-lb` as an extra selectable provider.
If you use `enabled_providers`, include every provider you want to keep plus `codex-lb`; otherwise non-listed providers are hidden.
**With API key auth:**
```jsonc
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"codex-lb": {
"npm": "@ai-sdk/openai-compatible",
"name": "codex-lb",
"options": {
"baseURL": "http://127.0.0.1:2455/v1",
"apiKey": "{env:CODEX_LB_API_KEY}" // reads from env var
},
"models": {
"gpt-5.3-codex": { "name": "GPT-5.3 Codex", "reasoning": true, "interleaved": { "field": "reasoning_details" } }
}
}
},
"model": "codex-lb/gpt-5.3-codex"
}
```
```bash
export CODEX_LB_API_KEY="sk-clb-..." # key from dashboard
opencode
```
</details>
<details>
<summary><img src="https://avatars.githubusercontent.com/u/252820863?s=200" width="20" align="center" alt="OpenClaw"> <b>OpenClaw</b></summary>
<br>
`~/.openclaw/openclaw.json`:
```jsonc
{
"agents": {
"defaults": {
"model": { "primary": "codex-lb/gpt-5.3-codex" }
}
},
"models": {
"mode": "merge",
"providers": {
"codex-lb": {
"baseUrl": "http://127.0.0.1:2455/v1",
"apiKey": "${CODEX_LB_API_KEY}", // or "dummy" if API key auth is disabled
"api": "openai-completions",
"models": [
{ "id": "gpt-5.3-codex", "name": "GPT-5.3 Codex" },
{ "id": "gpt-5.3-codex-spark", "name": "GPT-5.3 Codex Spark" }
]
}
}
}
}
```
Set the env var or replace `${CODEX_LB_API_KEY}` with a key from the dashboard. If API key auth is disabled, any value works.
</details>
<details>
<summary><img src="https://cdn.jsdelivr.net/gh/devicons/devicon/icons/python/python-original.svg" width="20" align="center" alt="Python"> <b>OpenAI Python SDK</b></summary>
<br>
```python
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:2455/v1",
api_key="sk-clb-...", # from dashboard, or any string if auth is disabled
)
response = client.chat.completions.create(
model="gpt-5.3-codex",
messages=[{"role": "user", "content": "Hello!"}],
)
print(response.choices[0].message.content)
```
</details>
## API Key Authentication
API key auth is **disabled by default** — the proxy is open to any client. Enable it in **Settings → API Key Auth** on the dashboard.
When enabled, clients must pass a valid API key as a Bearer token:
```
Authorization: Bearer sk-clb-...
```
**Creating keys**: Dashboard → API Keys → Create. The full key is shown **only once** at creation. Keys support optional expiration, model restrictions, and rate limits (tokens / cost per day / week / month).
## Configuration
Environment variables with `CODEX_LB_` prefix or `.env.local`. See [`.env.example`](.env.example).
Dashboard auth is configured in Settings.
## Data
| Environment | Path |
|-------------|------|
| Local / uvx | `~/.codex-lb/` |
| Docker | `/var/lib/codex-lb/` |
Backup this directory to preserve your data.
## Development
```bash
# Docker
docker compose watch
# Local
uv sync && cd frontend && bun install && cd ..
uv run fastapi run app/main.py --reload # backend :2455
cd frontend && bun run dev # frontend :5173
```
## Contributors ✨
Thanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section -->
<!-- prettier-ignore-start -->
<!-- markdownlint-disable -->
<table>
<tbody>
<tr>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/Soju06"><img src="https://avatars.githubusercontent.com/u/34199905?v=4?s=100" width="100px;" alt="Soju06"/><br /><sub><b>Soju06</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=Soju06" title="Code">💻</a> <a href="https://github.com/Soju06/codex-lb/commits?author=Soju06" title="Tests">⚠️</a> <a href="#maintenance-Soju06" title="Maintenance">🚧</a> <a href="#infra-Soju06" title="Infrastructure (Hosting, Build-Tools, etc)">🚇</a></td>
<td align="center" valign="top" width="14.28%"><a href="http://jonas.kamsker.at/"><img src="https://avatars.githubusercontent.com/u/11245306?v=4?s=100" width="100px;" alt="Jonas Kamsker"/><br /><sub><b>Jonas Kamsker</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=JKamsker" title="Code">💻</a> <a href="https://github.com/Soju06/codex-lb/issues?q=author%3AJKamsker" title="Bug reports">🐛</a> <a href="#maintenance-JKamsker" title="Maintenance">🚧</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/Quack6765"><img src="https://avatars.githubusercontent.com/u/5446230?v=4?s=100" width="100px;" alt="Quack"/><br /><sub><b>Quack</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=Quack6765" title="Code">💻</a> <a href="https://github.com/Soju06/codex-lb/issues?q=author%3AQuack6765" title="Bug reports">🐛</a> <a href="#maintenance-Quack6765" title="Maintenance">🚧</a> <a href="#design-Quack6765" title="Design">🎨</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/hhsw2015"><img src="https://avatars.githubusercontent.com/u/103614420?v=4?s=100" width="100px;" alt="Jill Kok, San Mou"/><br /><sub><b>Jill Kok, San Mou</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=hhsw2015" title="Code">💻</a> <a href="https://github.com/Soju06/codex-lb/commits?author=hhsw2015" title="Tests">⚠️</a> <a href="#maintenance-hhsw2015" title="Maintenance">🚧</a> <a href="https://github.com/Soju06/codex-lb/issues?q=author%3Ahhsw2015" title="Bug reports">🐛</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/pcy06"><img src="https://avatars.githubusercontent.com/u/44970486?v=4?s=100" width="100px;" alt="PARK CHANYOUNG"/><br /><sub><b>PARK CHANYOUNG</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=pcy06" title="Documentation">📖</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/choi138"><img src="https://avatars.githubusercontent.com/u/84369321?v=4?s=100" width="100px;" alt="Choi138"/><br /><sub><b>Choi138</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=choi138" title="Code">💻</a> <a href="https://github.com/Soju06/codex-lb/issues?q=author%3Achoi138" title="Bug reports">🐛</a> <a href="https://github.com/Soju06/codex-lb/commits?author=choi138" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/dwnmf"><img src="https://avatars.githubusercontent.com/u/56194792?v=4?s=100" width="100px;" alt="LYA⚚CAP⚚OCEAN"/><br /><sub><b>LYA⚚CAP⚚OCEAN</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=dwnmf" title="Code">💻</a> <a href="https://github.com/Soju06/codex-lb/commits?author=dwnmf" title="Tests">⚠️</a></td>
</tr>
<tr>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/azkore"><img src="https://avatars.githubusercontent.com/u/7746783?v=4?s=100" width="100px;" alt="Eugene Korekin"/><br /><sub><b>Eugene Korekin</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=azkore" title="Code">💻</a> <a href="https://github.com/Soju06/codex-lb/issues?q=author%3Aazkore" title="Bug reports">🐛</a> <a href="https://github.com/Soju06/codex-lb/commits?author=azkore" title="Tests">⚠️</a></td>
<td align="center" valign="top" width="14.28%"><a href="https://github.com/JordxnBN"><img src="https://avatars.githubusercontent.com/u/259802500?v=4?s=100" width="100px;" alt="jordan"/><br /><sub><b>jordan</b></sub></a><br /><a href="https://github.com/Soju06/codex-lb/commits?author=JordxnBN" title="Code">💻</a> <a href="https://github.com/Soju06/codex-lb/issues?q=author%3AJordxnBN" title="Bug reports">🐛</a> <a href="https://github.com/Soju06/codex-lb/commits?author=JordxnBN" title="Tests">⚠️</a></td>
</tr>
</tbody>
</table>
<!-- markdownlint-restore -->
<!-- prettier-ignore-end -->
<!-- ALL-CONTRIBUTORS-LIST:END -->
This project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome!
| text/markdown | null | Soju06 <qlskssk@gmail.com> | null | Soju06 <qlskssk@gmail.com> | MIT License
Copyright (c) 2025 Soju06
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | chatgpt, codex, dashboard, fastapi, load-balancer, proxy, rate-limit, usage | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Framework :: FastAPI",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.13",
"Topic :: Internet :: Proxy Servers",
"Topic :: Software Development :: Libraries",
"Topic :: System :: Networking"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"aiohttp-retry>=2.9.1",
"aiohttp>=3.13.3",
"aiosqlite>=0.22.1",
"alembic>=1.16.5",
"asyncpg>=0.30.0",
"bcrypt>=4.3.0",
"brotli>=1.2.0",
"cryptography>=46.0.3",
"fastapi[standard]>=0.128.0",
"greenlet>=3.3.0",
"psycopg[binary]>=3.2.12",
"pydantic-settings>=2.12.0",
"pydantic>=2.12.5",
"pyotp>=2.9.0",
"python-dotenv>=1.2.1",
"python-multipart>=0.0.21",
"segno>=1.6.6",
"sqlalchemy>=2.0.45",
"zstandard>=0.25.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:45:07.591968 | codex_lb-1.0.4.tar.gz | 2,500,007 | b1/4c/de39af9c89298d9f557e6215d3a77e34765bbb9415216103dda867d5ccc1/codex_lb-1.0.4.tar.gz | source | sdist | null | false | 13c44ffd461312001a7be0c84d8602d1 | acaef83835b86031d09a565efdf6313e1636e56795ba525e48e559bcf5a1d3c2 | b14cde39af9c89298d9f557e6215d3a77e34765bbb9415216103dda867d5ccc1 | null | [
"LICENSE"
] | 233 |
2.4 | minions-sdk | 0.2.2 | Python SDK for the Minions structured object system | # minions-sdk (Python)
> Python SDK for the [Minions](https://github.com/mxn2020/minions) structured object system — queryable, nestable, evolvable, and AI-readable.
## Install
```bash
pip install minions-sdk
```
## Quick Start
```python
from minions import TypeRegistry, create_minion, RelationGraph
# 1. Get the built-in agent type
registry = TypeRegistry()
agent_type = registry.get_by_slug("agent")
# 2. Create an agent
minion, validation = create_minion(
{"title": "Research Assistant", "fields": {"role": "researcher", "model": "gpt-4"}},
agent_type,
)
# 3. Link minions together
graph = RelationGraph()
graph.add({"source_id": minion.id, "target_id": "skill-001", "type": "parent_of"})
```
## Cross-SDK Interop
Minions created in Python can be serialized to JSON and read by the TypeScript SDK:
```python
import json
data = minion.to_dict() # camelCase keys
json_str = json.dumps(data) # → valid JSON, TS-compatible
```
## Documentation
- 📘 [Docs](https://minions.wtf)
- 📄 [Specification v0.1](https://github.com/mxn2020/minions/blob/main/spec/v0.1.md)
## License
[MIT](../../LICENSE)
| text/markdown | Minions Contributors | null | null | null | MIT | agents, ai, minions, schema, structured-objects | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"pytest>=7.0; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/mxn2020/minions",
"Documentation, https://minions.wtf",
"Repository, https://github.com/mxn2020/minions"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:43:53.795156 | minions_sdk-0.2.2.tar.gz | 21,397 | 82/3f/1ca55a2ce7b3f8ee9f17d3177c2323d3a1f94ae6b1ea80619e4ddbd659f1/minions_sdk-0.2.2.tar.gz | source | sdist | null | false | 20279ced15121485a59ec555a8bd0520 | 3c947a9e836604a2edf1d9d96df02731e925fd2f249b4889ee504bbbb97c167f | 823f1ca55a2ce7b3f8ee9f17d3177c2323d3a1f94ae6b1ea80619e4ddbd659f1 | null | [] | 317 |
2.3 | bakesite | 0.7.2 | The Simplest Static Site Generator | # Bakesite :pie:
A refreshingly simple static site generator.
Write in Markdown, get HTML out.
# Installation
Install Bakesite using pip:
```
pip install bakesite
```
# Getting Started
To create a new site, run the following command:
```
bakesite init
```
This will create a couple of files, including the content directory and the `bakesite.yaml` file necessary for building the site.
To bake the site and view it locally, run
```
bakesite serve --bake
```
This will generate the static files and start a local server.
Then visit `http://localhost:8200`
## `bakesite.yaml` Configuration
Configure your site by editing the `bakesite.yaml` file in your project root:
```yaml
# Base path for the site (leave empty for root directory)
base_path: ""
# Site metadata
subtitle: "My Awesome Website"
author: "John Doe"
site_url: "https://example.com"
# Social links
github_url: "https://github.com/yourusername"
linkedin_url: "https://www.linkedin.com/in/yourprofile"
# Analytics
gtag_id: "G-XXXXXXXXXX"
# Custom domain (optional)
cname: "yourcustomdomain.com"
```
## Front Matter
Add metadata to your markdown files using YAML front matter at the top of each file:
```markdown
---
title: My First Blog Post
author: Jane Doe
render: true
---
Your content goes here...
```
### Available Front Matter Fields
- `title`: The title of your post or page
- `author`: Override the default author for this specific post
- `render`: Set to `true` to enable Jinja2 template rendering within your markdown content, allowing you to use template variables and parameters
- Any custom fields you define will be available in your templates
### Example with Template Rendering
When `render: true` is set, you can use template variables in your markdown:
```markdown
---
title: About {{ author }}
render: true
---
Welcome to {{ site_url }}! This site was built in {{ current_year }}.
```
### Motivation
While I have used Jekyll, Pelican and Hugo for different iterations of my personal blog, I always felt the solution to the simple problem of static site building was over-engineered.
If you look into the code bases of these projects, understanding, altering or contributing back is a daunting task.
Why did it have to be so complicated? And how hard could it be to build?
In addition, I wanted a workflow for publishing posts from my Obsidian notes to be simple and fast.
## Acknowledgements
Thanks to a previous project by Sunaina Pai, Makesite, for providing the foundations of this project.
## Philosophy
> Make the easy things simple, and the hard things possible.
> This site was built to last.
## A Heads Up
If you are looking for a site generator with reactive html elements, this project is most likely not for you.
| text/markdown | Andrew Graham-Yooll | Andrew Graham-Yooll <andrewgy8@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"click>=8.1.8",
"jinja2>=3.1.5",
"markdown-it-py[plugins]",
"pyyaml>=6.0.2"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T12:43:14.568613 | bakesite-0.7.2.tar.gz | 9,403 | 32/46/50cf10026b04c586eb6dad83f4798b3f565e3d8f2c26a1f709912352172b/bakesite-0.7.2.tar.gz | source | sdist | null | false | 50a1e3eee3c25a3b0b365422ab411a03 | 59ec8d5e63a5d9d5ae16e0024782d287817619b2c6b0d5cc8d019a276c93b2f5 | 324650cf10026b04c586eb6dad83f4798b3f565e3d8f2c26a1f709912352172b | null | [] | 221 |
2.4 | ftllexengine | 0.116.0 | Fluent (FTL) implementation with locale-aware parsing for numbers, dates, and currency | <!--
RETRIEVAL_HINTS:
keywords: [ftllexengine, fluent, localization, i18n, l10n, ftl, translation, plurals, babel, cldr, python, parsing, currency, dates, thread-safe, fiscal, iso, territory, decimal-digits]
answers: [what is ftllexengine, how to install, quick start, fluent python, localization library, currency parsing, date parsing, thread safety, fiscal calendar, iso introspection, territory currency]
related: [docs/QUICK_REFERENCE.md, docs/DOC_00_Index.md, docs/PARSING_GUIDE.md, docs/TERMINOLOGY.md]
-->
[](https://github.com/resoltico/FTLLexEngine)
-----
[](https://pypi.org/project/ftllexengine/)
[](https://pypi.org/project/ftllexengine/)
[](https://codecov.io/github/resoltico/FTLLexEngine)
[](https://opensource.org/licenses/MIT)
-----
# FTLLexEngine
**Declarative localization for Python. Bidirectional parsing, thread-safe formatting, and Decimal precision -- in `.ftl` files, not your code.**
## Why FTLLexEngine?
- **Bidirectional** -- Format data for display *and* parse user input back to Python types
- **Thread-safe** -- No global state. 100 concurrent requests, zero locale conflicts
- **Strict mode** -- Opt-in fail-fast. Errors raise exceptions, not silent `{$amount}` fallbacks
- **Introspectable** -- Query what variables a message needs before you call it
- **Declarative grammar** -- Plurals, gender, cases in `.ftl` files. Code stays clean
- **Decimal precision** -- `Decimal` throughout. No float math, no rounding surprises
---
Meet **Alice** and **Bob**.
**Alice** exports specialty coffee. Her invoices ship to buyers in Tokyo, Hamburg, and New York. Three languages, three currency formats, zero tolerance for rounding errors. "1 bag" in English, "1 Sack" in German, "1袋" in Japanese -- and Polish has four plural forms, Arabic has six. She moved grammar rules to `.ftl` files and never looked back.
**Bob** runs supply operations at Mars Colony 1. Personnel from Germany, Japan, and Colombia order provisions in their own locale. A German engineer types `"12.450,00 EUR"`. A Japanese technician enters `"¥1,245,000"`. Bob's system needs exact `Decimal` values from both. One parsing error on a cargo manifest means delayed shipments for 200 colonists.
FTLLexEngine keeps their systems coherent. Built on the [Fluent specification](https://projectfluent.org/) that powers Firefox. 200+ locales via Unicode CLDR. Thread-safe by default.
---
## Quick Start
```python
from ftllexengine import FluentBundle
bundle = FluentBundle("en_US")
bundle.add_resource("""
shipment = { $bags ->
[one] 1 bag of coffee
*[other] { $bags } bags of coffee
}
""")
result, _ = bundle.format_pattern("shipment", {"bags": 500})
# "500 bags of coffee"
```
**Parse user input back to Python types:**
```python
from ftllexengine.parsing import parse_currency
# German buyer enters a bid price
result, errors = parse_currency("12.450,00 EUR", "de_DE", default_currency="EUR")
if not errors:
amount, currency = result # (Decimal('12450.00'), 'EUR')
```
---
## Table of Contents
- [Installation](#installation)
- [Multi-Locale Formatting — Alice Ships to Every Port](#multi-locale-formatting--alice-ships-to-every-port)
- [Bidirectional Parsing — Bob Parses Every Input](#bidirectional-parsing--bob-parses-every-input)
- [Thread-Safe Concurrency — 100 Threads, Zero Race Conditions](#thread-safe-concurrency--100-threads-zero-race-conditions)
- [Message Introspection — Pre-Flight Checks](#message-introspection--pre-flight-checks)
- [Currency and Fiscal Data — Operations Across Borders](#currency-and-fiscal-data--operations-across-borders)
- [Architecture at a Glance](#architecture-at-a-glance)
- [When to Use FTLLexEngine](#when-to-use-ftllexengine)
- [Documentation](#documentation)
- [Contributing](#contributing)
- [License](#license)
---
## Installation
```bash
uv add ftllexengine[babel]
```
Or with pip:
```bash
pip install ftllexengine[babel]
```
**Requirements**: Python >= 3.13 | Babel >= 2.18
<details>
<summary>Parser-only installation (no Babel dependency)</summary>
```bash
uv add ftllexengine
```
Or: `pip install ftllexengine`
**Works without Babel:**
- FTL syntax parsing (`parse_ftl()`, `serialize_ftl()`)
- AST manipulation and transformation
- Validation and introspection
**Requires Babel:**
- `FluentBundle` (locale-aware formatting)
- `FluentLocalization` (multi-locale fallback)
- Bidirectional parsing (numbers, dates, currency)
</details>
---
## Multi-Locale Formatting — Alice Ships to Every Port
Alice's invoices go to Tokyo, Hamburg, and New York. Same data, different languages, different number formats. She maintains one `.ftl` file per locale. Translators edit the files. Her trading platform ships features.
**English (New York buyer):**
```python
from decimal import Decimal
from ftllexengine import FluentBundle
bundle = FluentBundle("en_US")
bundle.add_resource("""
shipment-line = { $bags ->
[0] No bags shipped
[one] 1 bag of { $origin } beans
*[other] { $bags } bags of { $origin } beans
}
invoice-total = Total: { CURRENCY($amount, currency: "USD") }
""")
result, _ = bundle.format_pattern("shipment-line", {"bags": 500, "origin": "Colombian"})
# "500 bags of Colombian beans"
result, _ = bundle.format_pattern("invoice-total", {"amount": Decimal("187500.00")})
# "Total: $187,500.00"
```
**German (Hamburg buyer):**
```python
bundle_de = FluentBundle("de_DE")
bundle_de.add_resource("""
shipment-line = { $bags ->
[0] Keine Saecke versandt
[one] 1 Sack { $origin } Bohnen
*[other] { $bags } Saecke { $origin } Bohnen
}
invoice-total = Gesamt: { CURRENCY($amount, currency: "EUR") }
""")
result, _ = bundle_de.format_pattern("shipment-line", {"bags": 500, "origin": "kolumbianische"})
# "500 Saecke kolumbianische Bohnen"
result, _ = bundle_de.format_pattern("invoice-total", {"amount": Decimal("187500.00")})
# "Gesamt: 187.500,00 €" (CLDR: locale-specific symbol with non-breaking space)
```
**Japanese (Tokyo buyer):**
```python
bundle_ja = FluentBundle("ja_JP")
bundle_ja.add_resource("""
shipment-line = { $bags ->
[0] 出荷なし
*[other] { $origin }豆 { $bags }袋
}
invoice-total = 合計:{ CURRENCY($amount, currency: "JPY") }
""")
result, _ = bundle_ja.format_pattern("shipment-line", {"bags": 500, "origin": "コロンビア"})
# "コロンビア豆 500袋"
result, _ = bundle_ja.format_pattern("invoice-total", {"amount": Decimal("28125000")})
# "合計:¥28,125,000"
```
Bob uses the same pattern at Mars Colony 1. Spanish for the Colombian agronomists? Add one `.ftl` file. Zero code changes.
> In production, translators maintain separate `.ftl` files per locale. Your code loads them with `Path("invoice_de.ftl").read_text()`.
---
## Bidirectional Parsing — Bob Parses Every Input
Most libraries only format outbound data. That's a one-way trip.
Bob's colonists type orders and quantities in their local format. A German engineer enters `"12.450,00 EUR"`. A Colombian agronomist enters `"45.000.000 COP"`. A Japanese technician files a delivery date as `"2026年3月15日"`. FTLLexEngine parses them all to exact Python types.
```python
from decimal import Decimal
from ftllexengine.parsing import parse_currency, parse_decimal, parse_date
# German engineer enters a bid in EUR
bid_result, errors = parse_currency("12.450,00 EUR", "de_DE", default_currency="EUR")
if not errors:
bid_amount, bid_currency = bid_result # (Decimal('12450.00'), 'EUR')
# Colombian agronomist enters an ask in COP
ask_result, errors = parse_currency("45.000.000 COP", "es_CO", default_currency="COP")
if not errors:
ask_amount, ask_currency = ask_result # (Decimal('45000000'), 'COP')
# Japanese technician enters a delivery date
contract_date, errors = parse_date("2026年3月15日", "ja_JP")
# datetime.date(2026, 3, 15)
```
```mermaid
flowchart TB
A["German Engineer<br>12.450,00 EUR"] --> PA["parse_currency()<br>de_DE"]
B["Colombian Agronomist<br>45.000.000 COP"] --> PB["parse_currency()<br>es_CO"]
C["Japanese Technician<br>2026年3月15日"] --> PC["parse_date()<br>ja_JP"]
PA --> RA["Decimal('12450.00')<br>EUR"]
PB --> RB["Decimal('45000000')<br>COP"]
PC --> RC["date(2026, 3, 15)"]
RA & RB & RC --> SYS[("Inventory System<br>Exact Python types")]
style PA fill:#f9f,stroke:#333,stroke-width:2px
style PB fill:#f9f,stroke:#333,stroke-width:2px
style PC fill:#f9f,stroke:#333,stroke-width:2px
```
**When parsing fails, you get structured errors -- not exceptions:**
```python
price, errors = parse_decimal("twelve thousand", "en_US")
# price = None
# errors = (FrozenFluentError(...),)
if errors:
err = errors[0]
print(err) # "Failed to parse decimal 'twelve thousand' for locale 'en_US': ..."
```
### Decimal Precision
Alice calculates contract values. Float math fails: `0.1 + 0.2 = 0.30000000000000004`.
FTLLexEngine uses `Decimal` throughout:
```python
from decimal import Decimal
from ftllexengine.parsing import parse_currency
# Parse the contract price
price_result, errors = parse_currency("$4.25", "en_US", default_currency="USD")
if not errors:
price_per_lb, currency = price_result # (Decimal('4.25'), 'USD')
bags = 500
lbs_per_bag = Decimal("132") # Standard 60kg bag
total_lbs = bags * lbs_per_bag
contract_value = total_lbs * price_per_lb
# Decimal('280500.00') - exact, every time
```
### No Silent Failures in Space
> [!NOTE]
> A missing variable normally returns a fallback string like `"Contract: 500 bags at {!CURRENCY}/lb"`. In financial systems or mission-critical operations, displaying this to a user is unacceptable.
Enable `strict=True`. FTLLexEngine raises immediately -- no bad data reaches the user.
```python
from decimal import Decimal
from ftllexengine import FluentBundle
from ftllexengine.integrity import FormattingIntegrityError
from ftllexengine.runtime.cache_config import CacheConfig
# strict=True raises on ANY formatting error instead of returning fallback
# integrity_strict=True (default) raises on cache corruption/write conflicts
bundle = FluentBundle("en_US", strict=True, cache=CacheConfig())
bundle.add_resource('confirm = Contract: { $bags } bags at { CURRENCY($price, currency: "USD") }/lb')
# Works normally
result, _ = bundle.format_pattern("confirm", {"bags": 500, "price": Decimal("4.25")})
# "Contract: 500 bags at $4.25/lb"
# Missing variable? Raises immediately
try:
bundle.format_pattern("confirm", {"bags": 500}) # forgot $price
except FormattingIntegrityError as e:
print(f"HALT: {e.message_id} failed")
# e.fallback_value = "Contract: 500 bags at {!CURRENCY}/lb"
# e.fluent_errors = (FrozenFluentError(...),)
```
---
## Thread-Safe Concurrency — 100 Threads, Zero Race Conditions
Alice's trading desk gets busy. Bids from Frankfurt, asks from Bogota, confirmations to Tokyo -- concurrent requests, each in a different locale. Bob's colony runs the same pattern: 200 settlers, simultaneous orders, mixed locales.
**The problem:** Python's `locale` module uses global state. Thread A sets German, Thread B reads it, chaos ensues.
**The solution:** FTLLexEngine bundles are isolated. No global state. No locks you manage. No race conditions.
```python
from concurrent.futures import ThreadPoolExecutor
from decimal import Decimal
from ftllexengine import FluentBundle
# Create locale-specific bundles (typically done once at startup)
de_bundle = FluentBundle("de_DE")
es_bundle = FluentBundle("es_CO")
ja_bundle = FluentBundle("ja_JP")
ftl_source = 'confirm = { CURRENCY($amount, currency: "USD") } per { $unit }'
de_bundle.add_resource(ftl_source)
es_bundle.add_resource(ftl_source)
ja_bundle.add_resource(ftl_source)
def format_confirmation(bundle, amount, unit):
result, _ = bundle.format_pattern("confirm", {"amount": amount, "unit": unit})
return result
with ThreadPoolExecutor(max_workers=100) as executor:
futures = [
executor.submit(format_confirmation, de_bundle, Decimal("4.25"), "lb"),
executor.submit(format_confirmation, es_bundle, Decimal("4.25"), "lb"),
executor.submit(format_confirmation, ja_bundle, Decimal("4.25"), "lb"),
]
confirmations = [f.result() for f in futures]
# ["4,25 $ per lb", "US$4,25 per lb", "$4.25 per lb"] (CLDR locale symbols)
```
`FluentBundle` and `FluentLocalization` are thread-safe by design:
- Multiple threads can format messages simultaneously (read lock)
- Adding resources or functions acquires exclusive access (write lock)
- You don't manage any of this -- it just works
---
## Message Introspection — Pre-Flight Checks
Bob's systems generate cargo manifests. Before calling `format_pattern()`, they verify: *what variables does this message require? Are all of them available?*
Alice's compliance team uses the same introspection to catch missing variables at build time, not during live operations.
```python
from ftllexengine import FluentBundle
bundle = FluentBundle("en_US")
bundle.add_resource("""
contract = { $buyer } purchases { $bags ->
[one] 1 bag
*[other] { $bags } bags
} of { $grade } from { $seller } at { CURRENCY($price, currency: "USD") }/lb.
Shipment: { $port } by { DATETIME($ship_date) }.
""")
info = bundle.introspect_message("contract")
info.get_variable_names()
# frozenset({'buyer', 'bags', 'grade', 'seller', 'price', 'port', 'ship_date'})
info.get_function_names()
# frozenset({'CURRENCY', 'DATETIME'})
info.has_selectors
# True (uses plural selection for bags)
info.requires_variable("price")
# True
```
**Use cases:**
- Verify all required data before generating manifests or confirmations
- Auto-generate input fields from message templates
- Catch missing variables at build time, not during live operations
---
## Currency and Fiscal Data — Operations Across Borders
Alice sources beans from Colombia, Ethiopia, and Brazil. She sells to importers in Japan, Germany, and the US. Each country uses different currencies with different decimal places. Each has different fiscal years for compliance reporting.
Bob faces the same complexity on Mars: colony expenditures reported to three national space agencies, each with its own fiscal calendar.
### Currency Data
```python
from ftllexengine.introspection.iso import get_territory_currencies, get_currency
# New buyer in Japan - what currency?
currencies = get_territory_currencies("JP")
# ("JPY",)
# How many decimal places for yen?
jpy = get_currency("JPY")
jpy.decimal_digits
# 0 - no decimal places for yen
# Compare to Colombian peso
cop = get_currency("COP")
cop.decimal_digits
# 2 - but typically displayed without decimals for large amounts
# Multi-currency territories
panama_currencies = get_territory_currencies("PA")
# ("PAB", "USD") - Panama uses both Balboa and US Dollar
```
Alice's invoices format correctly: JPY 28,125,000 in Tokyo, $187,500.00 in New York.
### Fiscal Calendars
```python
from datetime import date
from ftllexengine.parsing.fiscal import FiscalCalendar, fiscal_year, fiscal_quarter
# UK importer: fiscal year starts April
uk_calendar = FiscalCalendar(start_month=4)
# US operations: calendar year
us_calendar = FiscalCalendar(start_month=1)
# Japan operations: fiscal year starts April
jp_calendar = FiscalCalendar(start_month=4)
today = date(2026, 3, 15)
# Same calendar date, different fiscal years
uk_calendar.fiscal_year(today) # 2026 (UK FY2026 runs Apr 2025 - Mar 2026)
us_calendar.fiscal_year(today) # 2026
jp_calendar.fiscal_year(today) # 2026
# Quick lookups without creating calendar objects
fiscal_quarter(today, start_month=4) # 4 (Q4 of fiscal year)
fiscal_quarter(today, start_month=1) # 1 (Q1 of calendar year)
# When does UK Q4 end for filing?
uk_calendar.quarter_end_date(2026, 4)
# date(2026, 3, 31)
```
Alice's compliance team in London, New York, and Tokyo each see the correct fiscal periods for their jurisdiction. Bob reports colony expenditures on all three calendars simultaneously.
---
## Architecture at a Glance
| Component | What It Does | Requires Babel? |
|:----------|:-------------|:----------------|
| **Syntax** — `ftllexengine.syntax` | FTL parser, AST, serializer, visitor pattern | No |
| **Runtime** — `ftllexengine.runtime` | `FluentBundle`, message resolution, thread-safe formatting, built-in functions (CURRENCY, DATETIME) | Yes |
| **Localization** — `ftllexengine.localization` | `FluentLocalization` multi-locale fallback chains | Yes |
| **Parsing** — `ftllexengine.parsing` | Bidirectional parsing: numbers, dates, currency back to Python types | Yes |
| **Fiscal** — `ftllexengine.parsing.fiscal` | Fiscal calendar arithmetic, quarter calculations | No |
| **Introspection** — `ftllexengine.introspection` | Message variable/function extraction, ISO 3166/4217 territory and currency data | Partial |
| **Validation** — `ftllexengine.validation` | Cycle detection, reference validation, semantic checks | No |
| **Diagnostics** — `ftllexengine.diagnostics` | Structured error types, error codes, formatting | No |
| **Integrity** — `ftllexengine.integrity` | BLAKE2b checksums, strict mode, immutable exceptions | No |
---
## When to Use FTLLexEngine
### Use It When:
| Scenario | Why FTLLexEngine |
| :--- | :--- |
| **Parsing user input** | Errors as data, not exceptions. Show helpful feedback. |
| **Financial calculations** | `Decimal` precision. Strict mode available. |
| **Concurrent systems** | Thread-safe. No global locale state. |
| **Complex plurals** | Polish has 4 forms. Arabic has 6. Handle them declaratively. |
| **Multi-locale apps** | 200+ locales. CLDR-compliant. |
| **Multi-currency operations** | ISO 4217 data. Territory-to-currency mapping. Decimal places. |
| **Cross-border compliance** | UK/Japan/US fiscal years. Quarter calculations. |
| **AI integrations** | Introspect messages before formatting. |
| **Content/code separation** | Translators edit `.ftl` files. Developers ship code. |
### Use Something Simpler When:
| Scenario | Why Skip It |
| :--- | :--- |
| **Single locale, no user input** | `f"{value:,.2f}"` is enough |
| **No grammar logic** | No plurals, no conditionals |
| **Zero dependencies required** | You need pure stdlib |
---
## Documentation
| Resource | Description |
|:---------|:------------|
| [Quick Reference](docs/QUICK_REFERENCE.md) | Copy-paste patterns for common tasks |
| [API Reference](docs/DOC_00_Index.md) | Complete class and function documentation |
| [Parsing Guide](docs/PARSING_GUIDE.md) | Bidirectional parsing deep-dive |
| [Data Integrity](docs/DATA_INTEGRITY_ARCHITECTURE.md) | Strict mode, checksums, immutable errors |
| [Terminology](docs/TERMINOLOGY.md) | Fluent and FTLLexEngine concepts |
| [Examples](examples/) | Working code you can run |
---
## Contributing
Contributions welcome. See [CONTRIBUTING.md](CONTRIBUTING.md) for setup and guidelines.
---
## License
MIT License - See [LICENSE](LICENSE).
Implements the [Fluent Specification](https://github.com/projectfluent/fluent/blob/master/spec/fluent.ebnf) (Apache 2.0).
**Legal**: [PATENTS.md](PATENTS.md) | [NOTICE](NOTICE)
| text/markdown | Ervins Strauhmanis | null | null | null | MIT | babel, cldr, currency, date, decimal, fluent, formatting, ftl, i18n, internationalization, l10n, locale, localization, number, parsing, plurals, thread-safe, translation | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Internationalization",
"Topic :: Software Development :: Localization",
"Topic :: Text Processing :: Linguistic",
"Typing :: Typed"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"babel<3.0.0,>=2.18.0; extra == \"babel\"",
"babel<3.0.0,>=2.18.0; extra == \"full\""
] | [] | [] | [] | [
"Homepage, https://github.com/resoltico/ftllexengine",
"Documentation, https://github.com/resoltico/ftllexengine#readme",
"Repository, https://github.com/resoltico/ftllexengine.git",
"Issues, https://github.com/resoltico/ftllexengine/issues",
"Changelog, https://github.com/resoltico/ftllexengine/blob/main/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:43:13.226842 | ftllexengine-0.116.0.tar.gz | 1,315,629 | cd/21/9a78da9d36329f794025bbdc39005fe8181b388d43087e3df0e7b6878cf1/ftllexengine-0.116.0.tar.gz | source | sdist | null | false | 4541b73c8c3117181b4d6f5eeee47948 | 3fe4cef70405aa9f51f739698a571655cd1e9b03cefb5c55074362fea43cf6a9 | cd219a78da9d36329f794025bbdc39005fe8181b388d43087e3df0e7b6878cf1 | null | [
"LICENSE",
"NOTICE"
] | 233 |
2.4 | orionis | 0.755.0 | Orionis Framework — Async-first full-stack framework for modern Python applications. | ## Welcome to Orionis Framework – An Opinionated Python Framework
⚡ Orionis Framework – Elegant, Fast, and Powerful 🚀
<div align="center" style="margin-bottom: 20px;">
<img src="https://orionis-framework.com/svg/logo.svg" alt="Orionis Framework" width="300"/>
</div>
<div align="center" style="margin-bottom: 20px;">
<img src="https://orionis-framework.com/svg/text.svg" alt="Orionis Framework" width="400"/>
</div>
**Orionis** is a modern and expressive Python framework that transforms the way you build applications. Designed for developers who value clarity, productivity, and scalability, Orionis combines an elegant structure with powerful tools so you can focus on what truly matters: **creating amazing software**.
---
## 🚀 Why Orionis?
- ✨ **Clear and expressive syntax**
Code that reads like natural language.
- ⚙️ **Clean and modular architecture**
Professional organization and best practices.
- ⏱️ **Agile and efficient development**
Reduce repetition and accelerate your workflow with built-in utilities.
- 🧪 **Ready for testing and production**
Quality and stability at the core.
---
## 🧱 Main Features
* 🧩 Intuitive routing system
* 🔧 Simple and powerful dependency injection
* 🧬 Flexible and easy-to-use ORM
* 🎯 Customizable service containers
* 🧰 Ready-to-use console commands
* 🛡️ Declarative validations
* 📦 Professional package structure
* ⚡ Support for asynchronous programming
---
## 🧠 Philosophy
Orionis aims to make Python development elegant, modern, and productive. It promotes clear separation of concerns, consistent conventions, and an **intuitive, seamless** developer experience.
---
## 📢 Community and Contribution
Want to be part of Orionis' evolution? Your contribution is welcome!
- Report bugs and request improvements
- Propose new features
- Create and share your own packages
---
## 🌠 Join the Python Revolution
Orionis is more than a framework—it's a new way to build. If you're ready to go beyond the traditional and embrace a modern ecosystem, **look to the sky... and start with Orionis.**
---
## 📬 Contact & Connect
Have questions, ideas, or want to get involved? Reach out and join the Orionis community!
- 📧 **Email:** [raulmauriciounate@gmail.com](mailto:raulmauriciounate@gmail.com)
- 💬 **GitHub Discussions:** [Orionis Framework Discussions](https://github.com/orgs/orionis-framework/discussions)
- 💼 **LinkedIn:** [Raul Mauricio Unate Castro](https://www.linkedin.com/in/raul-mauricio-unate-castro/)
I'm passionate about open-source and empowering developers worldwide. Explore the repositories, open issues, suggest features, or contribute code—your collaboration makes Orionis better!
[](https://github.com/sponsors/rmunate)
Let's build the future of Python development together! 🚀
| text/markdown | null | Raul Mauricio Uñate Castro <raulmauriciounate@gmail.com> | null | null | MIT | orionis, async framework, asgi framework, rsgi framework, asyncio, dependency injection, service container, service providers, facades, mvc, full stack framework, web framework, api framework, websockets | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Environment :: Web Environment",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.14",
"Typing :: Typed",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Framework :: AsyncIO"
] | [] | null | null | >=3.14 | [] | [] | [] | [
"apscheduler~=3.11.0",
"cryptography~=46.0.0",
"dotty-dict~=1.3.0",
"granian[dotenv,pname,reload,uvloop,winloop]>=2.7.0",
"pendulum~=3.2.0",
"psutil~=7.2.0",
"python-dotenv~=1.2.0",
"rich~=14.3.0",
"uvloop>=0.22.1; sys_platform != \"win32\"",
"winloop>=0.5.0; sys_platform == \"win32\"",
"ruff>=0.14.14; extra == \"dev\"",
"twine>=6.2.0; extra == \"dev\"",
"pyclean>=3.5.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/orionis-framework/framework",
"Documentation, https://orionis-framework.com/",
"Repository, https://github.com/orionis-framework/framework"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T12:41:34.682856 | orionis-0.755.0-py3-none-any.whl | 846,324 | 81/9c/2f67304d7c68e4769fcebdfca46b2b2402d3de92ccce4f3538687c471b1b/orionis-0.755.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 99d3f2b09edbb5a759d94d2f9998c39c | c3451a4e95c37320083cccd425e9a11f0e94239f5a3720dff93d3d4d66400981 | 819c2f67304d7c68e4769fcebdfca46b2b2402d3de92ccce4f3538687c471b1b | null | [
"LICENCE"
] | 206 |
2.4 | rerun-notebook | 0.30.0a6 | Implementation helper for running rerun-sdk in notebooks | # `rerun-notebook`
Part of the [Rerun](https://github.com/rerun-io/rerun) project.
## What?
`rerun-notebook` is a support package for [`rerun-sdk`](https://pypi.org/project/rerun-sdk/)'s notebook integration. This is an implementation package that shouldn't be directly interacted with. It is typically installed using the `notebook` [extra](https://packaging.python.org/en/latest/specifications/dependency-specifiers/#extras) of `rerun-sdk`:
```sh
pip install "rerun-sdk[notebook]"
```
## Why a separate package?
There are several reasons for this package to be separate from the main `rerun-sdk` package:
- `rerun-notebook` includes the JS+Wasm distribution of the Rerun viewer (~31MiB). Adding it to the main `rerun-sdk` package would double its file size.
- `rerun-notebook` uses [hatch](https://hatch.pypa.io/) as package backend, and benefits from the [hatch-jupyter-builder](https://github.com/jupyterlab/hatch-jupyter-builder) plug-in. Since `rerun-sdk` must use [Maturin](https://www.maturin.rs), it would make the package management more complex.
- Developer experience: building `rerun-notebook` implies building `rerun_js`, which is best avoided when iterating on `rerun-sdk` outside of notebook environments.
## Ways to access the widget assets
Even though `rerun_notebook` ships with the assets bundled in, by default it will try to load them from
`https://app.rerun.io`. This is because the way anywiget transmits the asset at the moment results in
[a memory leak](https://github.com/manzt/anywidget/issues/613) of the entire module for each cell execution.
If your network does not allow you to access `app.rerun.io`, the behavior can be changed by setting the
the `RERUN_NOTEBOOK_ASSET` environment variable before you import `rerun_notebook`. This variable must
be set prior to your import because `AnyWidget` stores the resource on the widget class instance
once at import time.
The assets are:
- `re_viewer_bg.wasm`, which is our Viewer compiled to Wasm, and
- `widget.js`, which is the glue code used to bind it to a Jupyter widget.
Both can be built in the [`rerun`](https://github.com/rerun-io/rerun) repository by running `pixi run py-build-notebook`.
### Inlined assets
Setting:
```
RERUN_NOTEBOOK_ASSET=inline
```
Will cause `rerun_notebook` to directly transmit the inlined assets to the widget over Jupyter comms.
This will be the most portable way to use the widget, but is currently known to leak memory and
has some performance issues in environments such as Google colab. The browser cannot cache the resulting
JS/Wasm, so it ends up spending a lot more time loading it in every output cell.
### Locally served assets
Setting:
```
RERUN_NOTEBOOK_ASSET=serve-local
```
Will cause `rerun_notebook` to launch a thread serving the assets from the local machine during
the lifetime of the kernel. This will be the best way to use the widget in a notebook environment
when your notebook server is running locally.
The JS and Wasm are served separately, so the Wasm can be stream-compiled, resulting in much faster
startup times. Both can also be cached by the browser.
### Manually hosted assets
Setting:
```
RERUN_NOTEBOOK_ASSET=https://your-hosted-asset-url.com/widget.js
```
Will cause `rerun_notebook` to load the assets from the provided URL. This is the most flexible way to
use the widget, but requires you to host the asset yourself.
Note that we require the URL to point to a `widget.js` file, but the Wasm file must be accessible from
a URL directly adjacent to it. Your server should provide both files:
- `https://your-hosted-asset-url.com/widget.js`
- `https://your-hosted-asset-url.com/re_viewer_bg.wasm`
The `rerun_notebook` package has a minimal server that can be used to serve the assets manually by running:
```
python -m rerun_notebook serve
```
However, any hosting platform can be used to serve the assets, as long as it is accessible to the notebook
and has appropriate CORS headers set. See: `asset_server.py` for a simple example.
## Run from source
Use Pixi:
```sh
# build rerun-sdk and rerun-notebook from source
pixi run py-build && pixi run py-build-notebook
# run jupyter
pixi run uv run jupyter notebook
```
## Development
Run the `pixi run py-build-notebook` build command any time you make changes to the Viewer or TypeScript code.
Changing python code only requires restarting the Jupyter kernel.
| text/markdown | null | "Rerun.io" <opensource@rerun.io> | null | null | MIT OR Apache-2.0 | notebook, rerun | [] | [] | null | null | null | [] | [] | [] | [
"anywidget",
"ipykernel<7.0.0",
"jupyter-ui-poll",
"hatch; extra == \"dev\"",
"jupyterlab; extra == \"dev\"",
"watchfiles; extra == \"dev\""
] | [] | [] | [] | [] | maturin/1.10.2 | 2026-02-20T12:41:24.017420 | rerun_notebook-0.30.0a6-py2.py3-none-any.whl | 13,265,776 | 1e/4f/f0b1bcb7b59be477cbfeddc2ea04c10b6beedf7d8b328381ac0f5c8acbdb/rerun_notebook-0.30.0a6-py2.py3-none-any.whl | py2.py3 | bdist_wheel | null | false | 287943e70e023cbb20e47a0862deaebc | 3fa659d1d770b683987e99ec45ace6062658010c367ef6223d8b48151d76cdd5 | 1e4ff0b1bcb7b59be477cbfeddc2ea04c10b6beedf7d8b328381ac0f5c8acbdb | null | [] | 81 |
2.4 | datamarket | 0.10.11 | Utilities that integrate advanced scraping knowledge into just one library. | # datamarket
`datamarket` is a Python library of reusable scraping, data ingestion, and integration utilities used across DataMarket projects.
This README explains what the library is, how to run it locally, how to use it, and where deeper documentation lives.
It solves a practical problem: different scrapers and ETL jobs often re-implement the same low-level pieces (HTTP retries, proxy rotation, SQLAlchemy batch writes, cloud storage clients, LLM wrappers). This repository centralizes those capabilities in a single package so projects can stay focused on business logic.
## Project Overview
- **Primary value**: standardized interfaces for data collection, transformation, and delivery.
- **Language/runtime**: Python `^3.12` (from `pyproject.toml`).
- **Package manager/build**: Poetry (`pyproject.toml`, `poetry.lock`).
- **Testing**: pytest-based tests in `tests/`.
- **Lint/format**: pre-commit hooks (Ruff + Ruff format) via `pre-commit-config` submodule.
## High-Level Architecture
Core package code lives in `src/datamarket/` and is organized by responsibility:
- `src/datamarket/interfaces/`: service-facing interfaces (LLM, SQLAlchemy, proxy, AWS, Azure Blob, Drive, FTP, Tinybird, Nominatim, PeerDB).
- `src/datamarket/utils/`: shared helpers (HTTP client wrapper, config loading, logging, Playwright/Selenium helpers, string normalization, data quality sampler).
- `src/datamarket/exceptions/`: custom exception types used across request and proxy workflows.
- `src/datamarket/params/`: static parameter dictionaries/constants (for example, Nominatim enrichment data).
For architecture diagrams and deeper design notes, see `docs/2. Architecture Overview.md`.
## Prerequisites
- Python `3.12`.
- `pip` (for install) and optionally `poetry` (for dependency/workflow management).
- Optional: Conda if you want to use the bootstrap helper in `init.sh`.
## Installation
To install this library in your Python environment:
`pip install datamarket`
## Environment Setup
### Option A: Poetry workflow
```bash
poetry install
poetry shell
```
### Option B: Conda bootstrap script
`init.sh` creates a Conda environment named `<package>_env`, installs the package in editable mode, initializes submodules, and installs pre-commit hooks.
```bash
bash init.sh
```
## Basic Usage
This section shows how to use the package from consumer projects.
- Import interfaces directly from module paths, for example:
- `from datamarket.interfaces.llm import LLMInterface`
- `from datamarket.interfaces.proxy import ProxyInterface`
- `from datamarket.interfaces.alchemy import AlchemyInterface`
- Load INI-style config using `datamarket.utils.main.get_config` when needed.
- Run end-to-end examples from `examples/` for LLM and vision use cases.
## Development Workflow
### Run examples
```bash
python examples/llm_usage_examples.py
python examples/llm_vision_examples.py
```
### Run tests
```bash
pytest -v
```
### Lint and format
This repo uses pre-commit hooks defined in `pre-commit-config/.pre-commit-config.yaml`:
```bash
pre-commit run --all-files
```
### Build artifacts
```bash
poetry build
```
Built distributions are output to `dist/`.
## Configuration
This library is configuration-driven. Most interfaces expect either:
- a dict-like object (`config["section"]["key"]`), or
- a `ConfigParser`/`RawConfigParser` object for INI files.
Common sections used by interfaces include:
- `[llm]` for `LLMInterface` (`provider`, `api_key`, `model`).
- `[db]` for `AlchemyInterface` and Postgres peer operations.
- `[proxy]` for `ProxyInterface` (`hosts`, optional `tor_password`).
- `[tinybird]`, `[osm]`, `[drive]`.
- Profile-based sections such as `[aws:<profile>]`, `[azure:<profile>]`, `[ftp:<profile>]`.
- PeerDB-specific sections: `[peerdb]`, `[clickhouse]`, `[peerdb-s3]`.
See the generated wiki pages in `docs/` for concrete config and workflow details, especially `docs/3. Workflows.md` and `docs/Deep Dive/Interfaces.md`.
## Deployment and Release Notes
- This repository is a library package, not a deployable service.
- Release packaging is supported through Poetry (`poetry build`) and Twine can be used for publishing.
- CI/CD release automation is **not configured in this repository** (no `.github/workflows/` present).
- See `docs/4. ADRs.md` for architecture-level release and maintenance trade-offs.
## Troubleshooting
- `ModuleNotFoundError` for optional features: install required extras (for example `.[llm]`, `.[pytest]`, `.[boto3]`).
- `Configuration must contain 'llm' section`: include `[llm]` with `api_key` before creating `LLMInterface`.
- `No working proxies available`: verify `[proxy] hosts` format (`host:port` or `user:pass@host:port`) and network access.
- SQLAlchemy connection errors: verify `[db]` credentials and engine string.
- Pre-commit command not found: install `pre-commit` in your active environment.
## Contributing (Summary)
- Keep changes scoped and aligned with existing module boundaries in `src/datamarket/`.
- Add or update tests under `tests/` for behavioral changes.
- Run `pytest -v` and `pre-commit run --all-files` before opening a PR.
- Keep docs current when interfaces, config keys, or workflows change.
## Documentation Map
- Wiki home: `docs/Home.md`
- Project overview: `docs/1. Project Overview.md`
- Architecture overview (C4): `docs/2. Architecture Overview.md`
- Workflows: `docs/3. Workflows.md`
- Architecture decisions: `docs/4. ADRs.md`
- Deep dives: `docs/Deep Dive/Interfaces.md`, `docs/Deep Dive/LLM.md`, `docs/Deep Dive/SQLAlchemy.md`, `docs/Deep Dive/Utilities.md`, `docs/Deep Dive/Geo Enrichment.md`
- Digital twin artifacts: `docs/_twin/inventory.json`, `docs/_twin/graph.json`, `docs/_twin/domain-map.md`, `docs/_twin/patterns.md`
## Documentation Status
Diataxis type: Reference.
- This README is the entry point and is maintained incrementally from validated repository summaries.
- Current generated references in this run:
- `docs/1. Project Overview.md`
- `docs/2. Architecture Overview.md`
- `docs/3. Workflows.md`
- `docs/4. ADRs.md`
- Known unknowns:
- `UNKNOWN`: linked pages under the external `docs` submodule may differ from this local snapshot.
## License
GPL-3.0-or-later. See `LICENSE`.
Sources: README.md (summary_hash: 905c027d111146820a6ea5c807c7b4a0f7094f9b36ab6528f36500a3f5e07520)
| text/markdown | DataMarket | techsupport@datamarket.es | null | null | GPL-3.0-or-later | null | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"SQLAlchemy<3.0.0,>=2.0.0",
"azure-storage-blob<13.0.0,>=12.0.0; extra == \"azure-storage-blob\"",
"babel<3.0.0,>=2.0.0",
"beautifulsoup4<5.0.0,>=4.0.0",
"boto3<1.36.0,>=1.35.0; extra == \"boto3\" or extra == \"aws\" or extra == \"peerdb\"",
"botocore<1.36.0,>=1.35.0; extra == \"boto3\" or extra == \"aws\"",
"browserforge<2.0.0,>=1.2.0; extra == \"camoufox\"",
"camoufox[geoip]<0.5.0,>=0.4.11; extra == \"camoufox\"",
"chompjs<2.0.0,>=1.0.0; extra == \"chompjs\"",
"click<9.0.0,>=8.0.0; extra == \"click\"",
"clickhouse-connect<0.12.0,>=0.11.0; extra == \"clickhouse-connect\"",
"clickhouse-driver<0.3.0,>=0.2.0; extra == \"clickhouse-driver\" or extra == \"peerdb\"",
"croniter<4.0.0,>=3.0.0",
"cryptography<44.0.0,>=43.0.0; extra == \"boto3\" or extra == \"aws\"",
"datetime<6.0,>=5.0; extra == \"datetime\"",
"ddgs<10.0.0,>=9.0.0; extra == \"ddgs\"",
"demjson3<4.0.0,>=3.0.0; extra == \"demjson3\"",
"dnspython<3.0.0,>=2.0.0; extra == \"dnspython\"",
"dynaconf<4.0.0,>=3.0.0",
"fake-useragent<3.0.0,>=2.0.0; extra == \"fake-useragent\"",
"geoalchemy2<0.18.0,>=0.17.0; extra == \"geoalchemy2\"",
"geopandas<2.0.0,>=1.0.0; extra == \"geopandas\"",
"geopy<3.0.0,>=2.0.0",
"google-api-python-client<3.0.0,>=2.0.0; extra == \"google-api-python-client\"",
"google-auth-httplib2<0.3.0,>=0.2.0; extra == \"google-auth-httplib2\"",
"google-auth-oauthlib<2.0.0,>=1.0.0; extra == \"google-auth-oauthlib\"",
"html2text<2025.0.0,>=2024.0.0; extra == \"html2text\"",
"httpx[http2]<0.29.0,>=0.28.0; extra == \"httpx\"",
"inflection<0.6.0,>=0.5.0",
"jellyfish<2.0.0,>=1.0.0",
"jinja2<4.0.0,>=3.0.0",
"json5<0.11.0,>=0.10.0; extra == \"json5\"",
"lxml[html-clean]<6.0.0,>=5.0.0; extra == \"lxml\"",
"matplotlib<4.0.0,>=3.0.0; extra == \"matplotlib\"",
"nodriver<0.45,>=0.44; extra == \"nodriver\"",
"numpy<3.0.0,>=2.0.0",
"openai<3.0.0,>=2.0.0; extra == \"openai\" or extra == \"llm\"",
"openpyxl<4.0.0,>=3.0.0; extra == \"openpyxl\"",
"pandarallel<2.0.0,>=1.0.0; extra == \"pandarallel\"",
"pandas<3.0.0,>=2.0.0; extra == \"pandas\"",
"pandera<0.23.0,>=0.22.0; extra == \"pandera\"",
"pendulum<4.0.0,>=3.0.0",
"pillow<12.0.0,>=11.0.0; extra == \"pillow\"",
"playwright==1.47.0; extra == \"playwright\" or extra == \"camoufox\"",
"plotly<7.0.0,>=6.0.0; extra == \"plotly\"",
"pre-commit<5.0.0,>=4.0.0",
"presidio-analyzer[phonenumbers]<3.0.0,>=2.0.0; extra == \"pii\"",
"presidio-anonymizer<3.0.0,>=2.0.0; extra == \"pii\"",
"psycopg2-binary<3.0.0,>=2.0.0",
"pyarrow<20.0.0,>=19.0.0; extra == \"pyarrow\"",
"pycountry<25.0.0,>=24.0.0",
"pydantic<3.0.0,>=2.0.0; extra == \"pydantic\" or extra == \"llm\"",
"pydrive2<2.0.0,>=1.0.0; extra == \"pydrive2\" or extra == \"drive\"",
"pymupdf<2.0.0,>=1.0.0; extra == \"pymupdf\"",
"pyproj<4.0.0,>=3.0.0; extra == \"pyproj\"",
"pyrate-limiter<4.0.0,>=3.0.0; extra == \"pyrate-limiter\"",
"pysocks<2.0.0,>=1.0.0; extra == \"pysocks\"",
"pyspark<4.0.0,>=3.0.0; extra == \"pyspark\"",
"pytest<9.0.0,>=8.0.0; extra == \"pytest\"",
"python-string-utils<2.0.0,>=1.0.0",
"rapidfuzz<4.0.0,>=3.0.0",
"requests<3.0.0,>=2.0.0",
"retry<0.10.0,>=0.9.0; extra == \"retry\"",
"rnet<4.0.0,>=3.0.0rc10",
"shapely<3.0.0,>=2.0.0; extra == \"shapely\"",
"soda-core-mysql-utf8-hotfix<4.0.0,>=3.0.0; extra == \"soda-core-mysql\"",
"soda-core-postgres<4.0.0,>=3.0.0; extra == \"soda-core-postgres\"",
"spacy<4.0.0,>=3.0.0; extra == \"pii\"",
"spacy-langdetect<0.2.0,>=0.1.0; extra == \"pii\"",
"sqlparse<0.6.0,>=0.5.0; extra == \"sqlparse\"",
"stem<2.0.0,>=1.0.0",
"tenacity<10.0.0,>=9.0.0",
"tqdm<5.0.0,>=4.0.0; extra == \"tqdm\"",
"typer<0.16.0,>=0.15.0",
"unidecode<2.0.0,>=1.0.0",
"xmltodict<0.15.0,>=0.14.0; extra == \"xmltodict\""
] | [] | [] | [] | [
"Documentation, https://github.com/Data-Market/datamarket",
"Homepage, https://datamarket.es",
"Repository, https://github.com/Data-Market/datamarket"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T12:41:18.375813 | datamarket-0.10.11.tar.gz | 89,214 | cc/98/294defa080d213dc7b9391ef6351819345fbbf5f4749d69cc0502be0f9af/datamarket-0.10.11.tar.gz | source | sdist | null | false | ff2e44d6ea90faf69b02b928b1ec26b7 | 66dc51c154dad47e647b30a7fc136a7b6aa35cd4493938b96f192df160d208c8 | cc98294defa080d213dc7b9391ef6351819345fbbf5f4749d69cc0502be0f9af | null | [
"LICENSE"
] | 238 |
2.4 | angel-cpu | 0.8 | A CPU framework | Hello!\
Have you ever tried to make a cpu simulation but don't want to write 300+ lines of code?\
Well then you don't have to anymore!\
AngelCPU does most of the heavy lifting for you, so let's get started before I fall asleep while typing this.
# Getting Started
First lets install Angel
```bash
pip install angel-cpu
```
Now, let's start with some simple stuff,
*give me a second i'm setting up*
```python
from angel_cpu import *
ARCH=cpu("ARCH")
```
*Alright now i'm done setting up.*
As you can see we have a class here
```python
from angel_cpu import *
ARCH=cpu("ARCH")#THIS RIGHT HERE
```
Let's first set up the basic CPU ARCH
```python
from angel_cpu import *
ARCH=cpu("ARCH")
# no reset does NOT reset the ARCH's registers and ram it just resets the ARCH's PC and Program
ARCH.reset()
# The name of the Register doesn't matter go crazy if you want
# The amount of Registers also don't matter, you can add like 50 of them and it wouldn't care
ARCH.add_register("Rxa")
ARCH.add_register("Rxb")
ARCH.add_register("Rxc")
ARCH.add_register("Rxe")
# the size is calculated by the x (400) times the y (200)
ARCH.add_ram(400,200)
# 32 bit integer limit
ARCH.set_max(0xffffffff)
# we're setting the command symbol to be ; so it's like real ASM
ARCH.set_comment_symbol(";")
```
*huff* that took me 30 minutes to write... (all of the time was because of the comments XD)\
Anyway... let's go over what the eclipse is all of these before my head explodes
`ARCH.reset()`
Resets the ARCH's PC and Program
`ARCH.add_register("Register name")`
adds a register
`ARCH.add_ram(400,200)`
set's the ram size which with this one will be... *give me a sec i'm calculating...* 80000 cells... *WOW*
`ARCH.set_max(0xffffffff)`
sets the integer limit, I just put the 32 bit limit because it's the bare minimum *trust me with this, you are going to need **much** more than 4294967295 bits **trust me***
`ARCH.set_comment_symbol(";")`
This Sets the comment symbol, any line that starts with it will be ignored in the assembler.\
Now that we got that covered it's time to add some opcodes so we can actually do stuff
```python
from angel_cpu import *
ARCH=cpu("ARCH")
# no reset does NOT reset the ARCH's registers and ram it just resets the ARCH's PC and Program
ARCH.reset()
# The name of the Register doesn't matter go crazy if you want
# The amount of Registers also don't matter, you can add like 50 of them and it wouldn't care
ARCH.add_register("Rxa")
ARCH.add_register("Rxb")
ARCH.add_register("Rxc")
ARCH.add_register("Rxe")
# the size is calculated by the x (400) times the y (200)
ARCH.add_ram(400,200)
# 32 bit integer limit
ARCH.set_max(0xffffffff)
# we're setting the command symbol to be ; so it's like real ASM
ARCH.set_comment_symbol(";")
def MOV(reg,value):
ARCH.set_register(reg,value)
def LOG(txt):
if txt in ARCH.registers:
print(ARCH.registers[txt])
else:
print(txt)
# It's important to note that when adding opcodes don't put parentheses on the function
# ARCH.add_opcode(0x0,MOV()) <-- incorrect, paratheses arnt opposed to be in the opcodes
# ARCH.add_opcode(0x0,MOV) <-- correct
ARCH.add_opcode(0x0,MOV)
ARCH.add_opcode(0x1,LOG)
c="""
MOV Rxa 10
LOG Rxa
"""
ARCH.assemble(c)
ARCH.run()
```
Okay there's a lot of stuff here so let's talk about the things that changed
`ARCH.add_opcode(hex_ID function)`
This adds an opcode, and when adding the function, please, **do not add parentheses**
`ARCH.assemble(code)`
This assembles the code from ASM format into something that the CPU can actually understand, then it loads it into the CPU's program ready to run.
`ARCH.run()`
This takes the code from the Program and runs it, simple and very useful.
Now let's talk about the ASM format
```AngelASM
MOV Rxa 10
LOG Rxa
```
The command comes first, each argument comes after the command separated by spaces, but then you might be wondering, "what about strings with spaces in them?" well, strings are strings so there has to be these (") surrounding them, without that it wouldn't be a string!
Alright this is taking a long time so i'll just boot something give me a sec...
**\[BIOS\]: BOOTING CMD DUMP...**
**\[BIOS\]: INIT REG**
**\[REG\]: \[OK\]**
**\[BIOS\]: INIT SD**
**\[SD\]: \[OK\]**
**\[BOOTING ASM_HELPER\]: \[OK\]**
**\[ASM_HELPER\]: \[OK\]**
Alright, I booted ASM_helper to speed things along, here's the rest of the commands along with some stuff I already covered
`add_register`:
adds a register, there's not much to say about this, but registers can be named anything, however their *value* cannot go over the integer limit, we'll go over how to set that in a bit
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.add_register("register")
```
`add_ram`:
sets the ram, the size is calulated by the X times the Y however the RAM is a 1D plane, so you can just use `get_ram(addr)` with the addr being an int
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.add_ram("size_x","size_y")
```
`add_opcode`:
adds an opcode for a function, please note that commands must be inputted without parentheses or you RISC *(haha get it?)* making the commands have set arguments
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.add_opcode("opcode","commmand")
```
`add_instruction`:
This is for those of you who want to make your own assembler, or those of you who just want to add instructions without the assembler
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.add_instruction("opcode")
```
`set_window_name`:
This sets the Window's name, and as a side note the window's name starts as the arch's name, but you can set this to what ever you want
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.set_window_name("name")
```
`set_max`:
sets the integer limit, it can be any type of int, like hex, and i recomend using hex because it's much easier to write large numbers in hex, for example 0xffffffff in decimal is 4294967295, now you see what i mean?
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.set_max("number")
```
`set_pc`:
sets the PC, for those of you who aren't fluent in tech, PC means program counter, it tells the CPU what instruction it's meant to be looking at, and it's very useful with making commands like JMP
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.set_pc("number")
```
`set_register`: sets a register's value, however if the register's value overflows to more than the integer limit the register's value resets back to it's base, depending on the type of data the register was holding the fallback will be different, for example
if it was holding a string, and the string's length was longer than the max interger limit it falls back to an empty string ("") the same is for lists, dicts, tuples, and ints, with ints having a fallback of 0x0
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.set_register("register","value")
```
`set_ram`:
sets a ram cell's value, if the value is larger than the integer limit it will fall back to empty, with lists,dicts, and tuples they will fallback to and empty version of themselves with ints falling back to 0x0
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.set_ram("address","value")
```
`reset`:
resets the PC and the program of the CPU, with the PC resetting to 0x0 and the program resetting back to none
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.reset()
```
`set_comment_symbol`:
sets the command symbol, if you where to set it to ; any line starting with ; would be commented out and ignored by the assembler
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.set_comment_symbol("symbol")
```
`get_register`:
returns the value of the selected register, that's it.
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.get_register("register")
```
`get_ram`:
gets the value of the selected ram cell, that's it
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.get_ram("address")
```
`get_pc`:
returns the value of the PC of the CPU, that's it.
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.get_pc()
```
`text`:
prints text onto the screen window, the `text` will not render until `frame` is called, the AddToTxtLog input must either be `True` or `False`, `False` means when you write `text_input` the text will not show up on the screen, while `True` means it will, the `end` input is what will be put on the end of the text, if end is not `"\n"` then it will not create a new line when drawing, the first input in the `customy` input must either be `True` or `False`, `True` means `customy` is enabled, if it is False then `customy` will not be enabled, the second input for `customy` is the y value, note that the y value will only be that if `customy` is enabled
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.text("text","x_pos",("color_R","color_G","color_B"),"Add_to_text_log","end",("Is customy enabled?","y_pos"))
```
`wait`:
waits for the set amount of time, note that the time is in milliseconds.
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.wait(1000)
```
`scroll`:
scrolls the screen by the set amount
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.scroll("X","Y")
```
`is_Mouse_Touching_Surface`:
it returns True is the mouse if touching a surface, else, it returns False
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.is_Mouse_Touching_Surface("name")
```
`show_mouse`:
it sets the mouse's visiblity, if true it shows the mouse, if false it doesn't else? it breaks, it must either be true or false
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.show_mouse("True, or False")
```
`quit`:
when this command is called it quits the screen and the app, i recommend only using it when you need to close EVERYTHING
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.quit()
```
`frame`:
displays the next frame on the screen window, that's it, it just displays the next frame
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.frame()
```
`load_pixels`:
loads the pixels from the pixel buffer to the screen, it needs frame to display the changes to the screen
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.load_pixels()
```
`events`:
events returns the events that happened with key presses it returns kDWN and then the key that's pressed so for e it would return kDWNe, for key release it will return kUP so releasing the key e would make it return kUPe, for mouse down it would return a tuple, with the first being mDWN and the second being another tuple containing the mouse X and Y, when the mouse is UP it returns mUP with the pos following
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.events()
```
`clear`:
clears the screen buffer, the changes don't update until frame is called
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.clear()
```
`clear_logs`:
clears the screen logs, this makes it useful with `text_input` because it stops trailing text
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.clear_logs()
```
`is_held`:
it returns true if the inputted key is held down, else it returns false
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.is_held("key")
```
`render_surfaces`:
This renders the surfaces, you have to call frame to see the effects though
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.render_surfaces()
```
`add_surface`:
This adds a surface, you have to call render_furfaces and frame to see them
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.add_surface("name","width","height",("color_R","color_G","colo_rB"),"pos_X","pos_Y")
```
`add_pixel`:
adds a pixel, you have to call load_pixels and frame to see the effects
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.add_pixel("pos_x","pos_y",("color_R","color_G","colo_rB"),"size","group","addtopixellog")
```
`text_input`:
Text_input displays text on the screen as a prompt, then after the key enter is pressed, it returns what the user typed
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.text_input("prompt",("color_R","color_G","colo_rB"),"prompt_end","prompt_x")
```
`mouse_down_on_group`:
This returns True if the mouse has clicked a pixel group
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.mouse_down_on_group("event output","group")
```
`mouse_pos`:
returns the mouse pos in a tuple
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.mouse_pos()
```
`assemble`:
one of the most useful commands in angel, it compiles your ASM code into opcodes so your CPU can run it, now it compiles ASM not the opcodes themselves so don't go inputting 0x0 for MOV or 0x1 for JMP that just won't work
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.assemble("code")
```
`run`:
runs the code in the program, the program is set by using assemble
```python
from angel_cpu import *
ARCH=cpu("ARCH")
ARCH.run()
```
`0.7 commands`:
the following commands are the new commands added in angel-cpu 0.7
**\[SD\]: LOADING 0.7 COMMANDS**
**\[SD\]: \[OK\]**
`add_disk`:
Adds a disk, add_disk returns a disk class, using this you can create disks and persisting storage, if you are trying to use the ARCH object with the disk use `attach_device`
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.add_disk("sector_size","sectors")
```
**\[SD\]: found multiple entries in the `Disk` class, go over them as well?**
uh... sure...
**\[SD\]: Loading `Disk` sub commands...**
`write`:
writes to the inputted address, note that the address is a tuple, with the first input being the sector and the second being the cell
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.add_disk("sector_size","sectors")
x.write(("addr-sector","addr_cell"),"data")
```
`read`:
reads from the inputted address, note that the address is a tuple, with the first input being the sector and the second being the cell
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.add_disk("sector_size","sectors")
x.read(("addr_sector","addr_cell"))
```
`format`:
formats the Disk, returns the Disk back to when it was first defined
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.add_disk("sector_size","sectors")
x.format()
```
`dump`:
dumps the disk, this dumps the disk to a file, the `name` input is the name of the file, so i recomend you select one name and stick with it
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.add_disk("sector_size","sectors")
x.dump("name")
```
`load`:
loads the disk from the inputted file, note that the name must be exactly what the Disk's file name is
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.add_disk("sector_size","sectors")
x.load("name")
```
**\[SD\]: `Disk` sub commands completed, returning back to CPU commands...**
`attach_device`:
attaches a device to the CPU, the devices can be anything, extra storage, disks, and if you wanted to, you could add an entire second CPU as an device, but i recommend you don't do that, it's hard to manage two CPUs a once,
```python
from angel_cpu import *
ARCH=cpu("ARCH")
device=ARCH.add_disk("sector_size","sectors")
ARCH.attach_device("name",device)
```
`get_device`:
returns the inputted device, this one returns the inputted device's class object, but like how not everything is a potato, not all devices are class based, so it returns whatever the device is
```python
from angel_cpu import *
ARCH=cpu("ARCH")
x=ARCH.add_disk("sector_size","sectors")
ARCH.attach_device("disk",x)
div=ARCH.get_device("disk")
```
And that's all for this update!
| text/markdown | ERROR-Xmakernotfound | null | null | null | null | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"pygame"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.9 | 2026-02-20T12:40:52.928198 | angel_cpu-0.8.tar.gz | 15,569 | 32/b6/7d59d84befa43e4874cd704d54b90a839541b69ad3efa0d11630bfe5a0e2/angel_cpu-0.8.tar.gz | source | sdist | null | false | d078c1a7fca7e1245aa209f48f4c1c20 | 8e0a76d9ef446fcef90aa7dd3034f48455ed225fce4288b9fe7ee5b67ae5d1ab | 32b67d59d84befa43e4874cd704d54b90a839541b69ad3efa0d11630bfe5a0e2 | null | [
"LICENSE"
] | 236 |
2.1 | odoo-addon-l10n-es-aeat-mod347 | 18.0.1.2.2 | AEAT modelo 347 | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
===============
AEAT modelo 347
===============
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:b36e47ab18c55fd15a683b6b1dbc4c072cdbc7a89c42507a905f69f0b02da564
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fl10n--spain-lightgray.png?logo=github
:target: https://github.com/OCA/l10n-spain/tree/18.0/l10n_es_aeat_mod347
:alt: OCA/l10n-spain
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/l10n-spain-18-0/l10n-spain-18-0-l10n_es_aeat_mod347
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/l10n-spain&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
(Declaración Anual de Operaciones con Terceros) Basado en la Orden
EHA/3012/2008, de 20 de Octubre, por el que se aprueban los diseños
físicos y lógicos del 347.
De acuerdo con la normativa de la Hacienda Española, están obligados a
presentar el modelo 347:
- Todas aquellas personas físicas o jurídicas que no esten acogidas al
régimen de módulos en el IRPF, de naturaleza pública o privada que
desarrollen actividades empresariales o profesionales, siempre y
cuando hayan realizado operaciones que, en su conjunto, respecto de
otra persona o Entidad, cualquiera que sea su naturaleza o carácter,
hayan superado la cifra de 3.005,06 € durante el año natural al que se
refiere la declaración. Para el cálculo de la cifra de 3.005,06 € se
computan de forma separada las entregas de biene y servicios y las
adquisiciones de los mismos.
- En el caso de Sociedades Irregulares, Sociedades Civiles y Comunidad
de Bienes no acogidas el regimen de módulos en el IRPF, deben incluir
las facturas sin incluir la cuantía del IRPF.
- En el caso de facturas de proveedor con IRPF, no deben ser presentadas
en este modelo. Se presentan en el modelo 190. Desactivar en la ficha
del proveedor la opción de "Incluir en el informe 347".
De acuerdo con la normativa, no están obligados a presentar el modelo
347:
- Quienes realicen en España actividades empresariales o profesionales
sin tener en territorio español la sede de su actividad, un
establecimiento permanente o su domicilio fiscal.
- Las personas físicas y entidades en régimen de atribución de rentas en
el IRPF, por las actividades que tributen en dicho impuesto por el
régimen de estimación objetiva y, simultáneamente, en el IVA por los
régimenes especiales simplificados o de la agricultura, ganadería y
pesca o recargo de equivalencia, salvo las operaciones que estén
excluidas de la aplicación de los expresados regímenes.
- Los obligados tributarios que no hayan realizado operaciones que en su
conjunto superen la cifra de 3.005,06 €.
- Los obligados tributarios que hayan realizado exclusivamente
operaciones no declarables.
- Los obligados tributarios que deban informar sobre las operaciones
incluidas en los libros registro de IVA (modelo 340) salvo que
realicen operaciones que expresamente deban incluirse en el modelo
347.
(http://www.boe.es/boe/dias/2008/10/23/pdfs/A42154-42190.pdf)
**Table of contents**
.. contents::
:local:
Installation
============
Para instalar este módulo, es necesario el módulo *account_tax_balance*,
disponible en:
https://github.com/OCA/account-financial-reporting
Usage
=====
Para realizar una declaración del modelo 347:
1. Vaya a *Facturación > Declaraciones AEAT > Modelo 347*.
2. Pulse en el botón "Crear".
3. Seleccione el año para la declaración.
4. Pulse en "Calcular".
5. Al cabo de un rato (dependerá de la cantidad de registros que
tenga), aparecerá una nueva pestaña "Registros de empresas", en la
que se podrán revisar cada uno de los registros detectados.
6. Si la línea del registro aparece en rojo, significa que falta algún
dato que debe ser rellenado para poder realizar la declaración en la
AEAT.
7. Puede enviar masivamente los datos de todos los registros al primer
contacto de facturación que esté establecido en la empresa pulsando
el botón "Enviar correos electrónicos". Esto realizará el envío
masivo, dejando el mensaje enviado en el hilo de comunicación
(chatter) de cada registro. En ese momento, todos los registros
pasarán a estado "Enviado"
8. Puede acceder a los detalles del registro y ver el hilo de
comunicación pulsando sobre el smart-button "Registros" que aparece
en la parte superior derecha de la pestaña "Registros de empresa".
9. También se pueden realizar envíos aislados de cada registro si
todavía no está en estado "Enviado" (o pulsando previamente en el
botón "Establecer a pendiente" de la vista de detalle), pulsando
sobre el botón "Enviar" de la vista de detalle, o en el icono del
sobre en la vista de listado.
10. Puede registrar a mano la conformidad o disconformidad del registro
pulsando sobre los botones del check de verificación o de la X en la
vista de listado, o bien sobre los botones "Confirmar como válido" o
"Establecer a no válido" de la vista de detalle del registro.
11. Cuando establezca como válido el registro, la línea aparecerá en un
gris atenuado, y si por el contrario lo establece como no válido,
aparecerá en un marrón claro.
12. En la plantilla del correo enviado a las empresas, se incluyen 2
botones que permiten la aceptación/rechazo automático del registro.
**NOTA:** Para poder realizarlo, su Odoo debe ser accesible al
exterior y tener bien configurados URL, redirecciones, proxy, etc.
Cuando la empresa externa pulse en uno de esos botones, se realizará
la validación/rechazo en el registro.
13. La empresa externa también puede responder al correo recibido, y
entonces la respuesta se colocará en el hilo de ese registro y
notificará a los seguidores que estén del mismo. Por defecto, el
único seguidor que se añade es el usuario que ha realizado la
declaración. **NOTA:** Para que esto funcione, debe tener bien
configurado todos los parámetros relativos a catchall, correo
entrante, etc.
14. También puede introducir manualmente los registros de inmuebles para
aquellos que no estén reflejados en el modelo 115.
15. Una vez cotejados todos los registros, se puede pulsar en el botón
"Confirmar" para confirmar la declaración y dejar los datos ya
fijos.
16. Pulsando en el botón "Exportar a BOE", podrá obtener un archivo para
su subida en la web de la AEAT.
Known issues / Roadmap
======================
- Permitir que un asiento (y por tanto, una factura) puede tener una
fecha específica a efectos del modelo 347, para así cuadrar la fecha
del proveedor con nuestro modelo aunque a efectos de IVA se declare en
el siguiente periodo.
- Permitir indicar que una factura es de transmisión de inmuebles para
tenerlo en cuenta en la suma de totales.
- No se incluye el cálculo automático de las claves de declaración C, D,
E, F y G.
- Realizar declaración solo de proveedores.
- No se permite marcar las operaciones como de seguro (para entidades
aseguradoras).
- No se permite marcar las operaciones como de arrendamiento.
- No se incluye la gestión del criterio de caja.
- No se incluye la gestión de inversión de sujeto pasivo.
- No se incluye la gestión de depósito aduanero.
- No se rellena el año origen en caso de no coincidir con el actual para
las operaciones de efectivo.
- Las operaciones con retención o arrendamientos aparecen en el 347 por
defecto al tener también IVA asociado. Si no se quiere que aparezcan,
hay que marcar la empresa o la factura con la casilla de no incluir en
el 347.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/l10n-spain/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/l10n-spain/issues/new?body=module:%20l10n_es_aeat_mod347%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Tecnativa
* PESOL
Contributors
------------
- Pexego (http://www.pexego.es)
- ASR-OSS (http://www.asr-oss.com)
- NaN·tic (http://www.nan-tic.com)
- Acysos (http://www.acysos.com)
- Joaquín Gutierrez (http://gutierrezweb.es)
- Angel Moya <angel.moya@pesol.es>
- Albert Cabedo <albert@gafic.com>
- `Tecnativa <https://www.tecnativa.com>`__:
- Antonio Espinosa
- Pedro M. Baeza
- Cristina Martín
- Carlos Dauden
- `Sygel <https://www.sygel.es>`__:
- Manuel Regidor
- `Moduon <https://www.moduon.team>`__
- Emilio Pascual
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/l10n-spain <https://github.com/OCA/l10n-spain/tree/18.0/l10n_es_aeat_mod347>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Tecnativa,PESOL,Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/l10n-spain | null | >=3.10 | [] | [] | [] | [
"odoo-addon-account_tax_balance==18.0.*",
"odoo-addon-l10n_es_aeat==18.0.*",
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T12:40:20.383843 | odoo_addon_l10n_es_aeat_mod347-18.0.1.2.2-py3-none-any.whl | 431,569 | 69/45/0f91649fadf3c08c2c2c80fb64f632af2352b95cf0c19c9379fc5327bfe3/odoo_addon_l10n_es_aeat_mod347-18.0.1.2.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 579d7c8614e1abdb5c389191bff37a44 | 0178235db8d4133e3793a24c73ec00460c1c44f9f431521a2e5628170d2b773e | 69450f91649fadf3c08c2c2c80fb64f632af2352b95cf0c19c9379fc5327bfe3 | null | [] | 110 |
2.4 | django-sphinx-docs | 0.4.1 | Serve Sphinx docs from Django. | # django-sphinx-docs
[](https://pypi.python.org/pypi/django-sphinx-docs/)
[](https://raw.githubusercontent.com/littlepea/django-docs/master/LICENSE)
`django-sphinx-docs` allows to serve Sphinx generated docs directly from Django.
This is a fork of https://github.com/littlepea/django-docs to support Django 4.0+.
## Dependencies
* Python 3.10+
* Django 3.2+
## Installation
1. Install `django-sphinx-docs` package:
```bash
pip install django-sphinx-docs
```
2. Add `django_sphinx_docs` to `INSTALLED_APPS` in `settings.py`:
```python
INSTALLED_APPS = (
...
'django_sphinx_docs',
...
)
```
3. Add `django_sphinx_docs.urls` to `urls.py`:
```python
urlpatterns = [
...
path('docs/', include('django_sphinx_docs.urls')),
...
]
```
4. Customize configuration:
```python
DOCS_ROOT = os.path.join(PROJECT_PATH, '../docs/_build/html')
DOCS_ACCESS = 'staff'
```
## Configuration
### `DOCS_ROOT` (required)
Absolute path to the root directory of html docs generated by Sphinx (just like `STATIC_ROOT` / `MEDIA_ROOT` settings).
### `DOCS_ACCESS` (optional)
Docs access level (`public` by default). Possible values:
* `public` - (default) docs are visible to everyone
* `login_required` - docs are visible only to authenticated users
* `staff` - docs are visible only to staff users (`user.is_staff == True`)
* `superuser` - docs are visible only to superusers (`user.is_superuser == True`)
## Running the tests
```bash
uv run pytest
```
## Running the example project
```bash
cd example
uv run python manage.py migrate
uv run python manage.py runserver
```
| text/markdown | null | Evgeny Demchenko <little_pea@list.ru>, Adam Hill <github@adamghill.com> | null | null | BSD | null | [
"Development Status :: 4 - Beta",
"Framework :: Django",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"django>=3.2"
] | [] | [] | [] | [
"Homepage, https://github.com/adamghill/django-sphinx-docs"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:40:08.045171 | django_sphinx_docs-0.4.1.tar.gz | 29,257 | 44/d6/1ac32ff61affc826e59f5309056cef808ee5668ddd4eb2bf334befb3ff5b/django_sphinx_docs-0.4.1.tar.gz | source | sdist | null | false | c149eff6f7fe9d011e384fdd4fbbd4cc | eb220566ae371f958bae4cf7913371084ce03e97e3f4be31250cd53bfe55e073 | 44d61ac32ff61affc826e59f5309056cef808ee5668ddd4eb2bf334befb3ff5b | null | [
"AUTHORS",
"LICENSE"
] | 235 |
2.4 | cloudbeds-pms-v1-3 | 1.10.0 | OpenAPI client for Cloudbeds PMS v1.3 API. | # Cloudbeds PMS V1.3
<p> Welcome to the documentation for <strong>Cloudbeds API Version v1.3</strong>! If you are looking to learn how to use the Cloudbeds API to access guest information, reservations, or similar data for your Cloudbeds customers, then you've come to the right place. </p> <p> In this document you will find all the API methods we provide along with explanations for parameters and response examples. </p> <p> If you have questions about different implementation steps (e.g. how to implement OAuth 2.0), please refer to our <a href=\"https://integrations.cloudbeds.com/hc/en-us\">Integrations Portal</a>. </p> <p> Be sure to <a href=\"https://go.pardot.com/l/308041/2018-07-24/qb2lg\">subscribe</a> to the monthly Cloudbeds API announcement mailing list to receive information on new additions and improvements to the Cloudbeds API and related developer tools. </p> <p> <strong>Endpoint:</strong> https://api.cloudbeds.com/api/v1.3/{method} </p> <p> <strong>HTTPS:</strong> Our API requires HTTPS. We'll respond with an appropriate error if you're not using it. </p> <p> <strong>Request Format:</strong> HTTP GET, POST and PUT (Content-Type: application/x-www-form-urlencoded) </p> <p> <strong>Response Format:</strong> JSON </p> <p> <strong>Response Header:</strong> X-Request-ID is added to response headers in all calls to help accelerate support and troubleshooting. </p> <p> <strong> <a href=\"https://integrations.cloudbeds.com/hc/en-us/articles/14104678058267-API-Documentation#postman-collection\"> <img src=\"https://run.pstmn.io/button.svg\" alt=\"Run in Postman\"> </a> </strong> use this link to access our Public collection in Postman. </p>
The `cloudbeds_pms_v1_3` package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: v1.3
- Package version: 1.10.0
- Generator version: 7.11.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
## Requirements.
Python 3.8+
## Installation & Usage
This python library package is generated without supporting files like setup.py or requirements files
To be able to use it, you will need these dependencies in your own package that uses this library:
* urllib3 >= 1.25.3, < 3.0.0
* python-dateutil >= 2.8.2
* pydantic >= 2
* typing-extensions >= 4.7.1
## Getting Started
In your own code, to use this library to connect and interact with Cloudbeds PMS V1.3,
you can run the following:
```python
import cloudbeds_pms_v1_3
from cloudbeds_pms_v1_3.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://api.cloudbeds.com/api/v1.3
# See configuration.py for a list of all supported configuration parameters.
configuration = cloudbeds_pms_v1_3.Configuration(
host = "https://api.cloudbeds.com/api/v1.3"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
configuration.access_token = os.environ["ACCESS_TOKEN"]
# Configure API key authorization: api_key
configuration.api_key['api_key'] = os.environ["API_KEY"]
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['api_key'] = 'Bearer'
# Enter a context with an instance of the API client
with cloudbeds_pms_v1_3.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = cloudbeds_pms_v1_3.AdjustmentApi(api_client)
reservation_id = 'reservation_id_example' # str | Reservation identifier
adjustment_id = 'adjustment_id_example' # str | Adjustment identifier
property_id = 'property_id_example' # str | Property ID (optional)
try:
# deleteAdjustment
api_response = api_instance.delete_adjustment_delete(reservation_id, adjustment_id, property_id=property_id)
print("The response of AdjustmentApi->delete_adjustment_delete:\n")
pprint(api_response)
except ApiException as e:
print("Exception when calling AdjustmentApi->delete_adjustment_delete: %s\n" % e)
```
## Documentation for API Endpoints
All URIs are relative to *https://api.cloudbeds.com/api/v1.3*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*AdjustmentApi* | [**delete_adjustment_delete**](cloudbeds_pms_v1_3/docs/AdjustmentApi.md#delete_adjustment_delete) | **DELETE** /deleteAdjustment | deleteAdjustment
*AdjustmentApi* | [**post_adjustment_post**](cloudbeds_pms_v1_3/docs/AdjustmentApi.md#post_adjustment_post) | **POST** /postAdjustment | postAdjustment
*AllotmentBlocksApi* | [**create_allotment_block_notes_post**](cloudbeds_pms_v1_3/docs/AllotmentBlocksApi.md#create_allotment_block_notes_post) | **POST** /createAllotmentBlockNotes | createAllotmentBlockNotes
*AllotmentBlocksApi* | [**create_allotment_block_post**](cloudbeds_pms_v1_3/docs/AllotmentBlocksApi.md#create_allotment_block_post) | **POST** /createAllotmentBlock | createAllotmentBlock
*AllotmentBlocksApi* | [**delete_allotment_block_post**](cloudbeds_pms_v1_3/docs/AllotmentBlocksApi.md#delete_allotment_block_post) | **POST** /deleteAllotmentBlock | deleteAllotmentBlock
*AllotmentBlocksApi* | [**get_allotment_blocks_get**](cloudbeds_pms_v1_3/docs/AllotmentBlocksApi.md#get_allotment_blocks_get) | **GET** /getAllotmentBlocks | getAllotmentBlocks
*AllotmentBlocksApi* | [**list_allotment_block_notes_get**](cloudbeds_pms_v1_3/docs/AllotmentBlocksApi.md#list_allotment_block_notes_get) | **GET** /listAllotmentBlockNotes | listAllotmentBlockNotes
*AllotmentBlocksApi* | [**update_allotment_block_notes_post**](cloudbeds_pms_v1_3/docs/AllotmentBlocksApi.md#update_allotment_block_notes_post) | **POST** /updateAllotmentBlockNotes | updateAllotmentBlockNotes
*AllotmentBlocksApi* | [**update_allotment_block_post**](cloudbeds_pms_v1_3/docs/AllotmentBlocksApi.md#update_allotment_block_post) | **POST** /updateAllotmentBlock | updateAllotmentBlock
*AppSettingsApi* | [**delete_app_property_settings_post**](cloudbeds_pms_v1_3/docs/AppSettingsApi.md#delete_app_property_settings_post) | **POST** /deleteAppPropertySettings | deleteAppPropertySettings
*AppSettingsApi* | [**get_app_property_settings_get**](cloudbeds_pms_v1_3/docs/AppSettingsApi.md#get_app_property_settings_get) | **GET** /getAppPropertySettings | getAppPropertySettings
*AppSettingsApi* | [**post_app_property_settings_post**](cloudbeds_pms_v1_3/docs/AppSettingsApi.md#post_app_property_settings_post) | **POST** /postAppPropertySettings | postAppPropertySettings
*AppSettingsApi* | [**put_app_property_settings_post**](cloudbeds_pms_v1_3/docs/AppSettingsApi.md#put_app_property_settings_post) | **POST** /putAppPropertySettings | putAppPropertySettings
*AuthenticationApi* | [**access_token_post**](cloudbeds_pms_v1_3/docs/AuthenticationApi.md#access_token_post) | **POST** /access_token | access_token
*AuthenticationApi* | [**oauth_metadata_get**](cloudbeds_pms_v1_3/docs/AuthenticationApi.md#oauth_metadata_get) | **GET** /oauth/metadata | metadata
*AuthenticationApi* | [**userinfo_get**](cloudbeds_pms_v1_3/docs/AuthenticationApi.md#userinfo_get) | **GET** /userinfo | userinfo
*CurrencyApi* | [**get_currency_settings_get**](cloudbeds_pms_v1_3/docs/CurrencyApi.md#get_currency_settings_get) | **GET** /getCurrencySettings | getCurrencySettings
*CustomFieldsApi* | [**get_custom_fields_get**](cloudbeds_pms_v1_3/docs/CustomFieldsApi.md#get_custom_fields_get) | **GET** /getCustomFields | getCustomFields
*CustomFieldsApi* | [**post_custom_field_post**](cloudbeds_pms_v1_3/docs/CustomFieldsApi.md#post_custom_field_post) | **POST** /postCustomField | postCustomField
*DashboardApi* | [**get_dashboard_get**](cloudbeds_pms_v1_3/docs/DashboardApi.md#get_dashboard_get) | **GET** /getDashboard | getDashboard
*EmailsApi* | [**get_email_schedule_get**](cloudbeds_pms_v1_3/docs/EmailsApi.md#get_email_schedule_get) | **GET** /getEmailSchedule | getEmailSchedule
*EmailsApi* | [**get_email_templates_get**](cloudbeds_pms_v1_3/docs/EmailsApi.md#get_email_templates_get) | **GET** /getEmailTemplates | getEmailTemplates
*EmailsApi* | [**post_email_schedule_post**](cloudbeds_pms_v1_3/docs/EmailsApi.md#post_email_schedule_post) | **POST** /postEmailSchedule | postEmailSchedule
*EmailsApi* | [**post_email_template_post**](cloudbeds_pms_v1_3/docs/EmailsApi.md#post_email_template_post) | **POST** /postEmailTemplate | postEmailTemplate
*GroupsApi* | [**get_group_notes_get**](cloudbeds_pms_v1_3/docs/GroupsApi.md#get_group_notes_get) | **GET** /getGroupNotes | getGroupNotes
*GroupsApi* | [**get_groups_get**](cloudbeds_pms_v1_3/docs/GroupsApi.md#get_groups_get) | **GET** /getGroups | getGroups
*GroupsApi* | [**patch_group_post**](cloudbeds_pms_v1_3/docs/GroupsApi.md#patch_group_post) | **POST** /patchGroup | patchGroup
*GroupsApi* | [**post_group_note_post**](cloudbeds_pms_v1_3/docs/GroupsApi.md#post_group_note_post) | **POST** /postGroupNote | postGroupNote
*GroupsApi* | [**put_group_post**](cloudbeds_pms_v1_3/docs/GroupsApi.md#put_group_post) | **POST** /putGroup | putGroup
*GuestApi* | [**delete_guest_note_delete**](cloudbeds_pms_v1_3/docs/GuestApi.md#delete_guest_note_delete) | **DELETE** /deleteGuestNote | deleteGuestNote
*GuestApi* | [**get_guest_get**](cloudbeds_pms_v1_3/docs/GuestApi.md#get_guest_get) | **GET** /getGuest | getGuest
*GuestApi* | [**get_guest_list_get**](cloudbeds_pms_v1_3/docs/GuestApi.md#get_guest_list_get) | **GET** /getGuestList | getGuestList
*GuestApi* | [**get_guest_notes_get**](cloudbeds_pms_v1_3/docs/GuestApi.md#get_guest_notes_get) | **GET** /getGuestNotes | getGuestNotes
*GuestApi* | [**get_guests_by_filter_get**](cloudbeds_pms_v1_3/docs/GuestApi.md#get_guests_by_filter_get) | **GET** /getGuestsByFilter | getGuestsByFilter
*GuestApi* | [**get_guests_by_status_get**](cloudbeds_pms_v1_3/docs/GuestApi.md#get_guests_by_status_get) | **GET** /getGuestsByStatus | getGuestsByStatus
*GuestApi* | [**get_guests_modified_get**](cloudbeds_pms_v1_3/docs/GuestApi.md#get_guests_modified_get) | **GET** /getGuestsModified | getGuestsModified
*GuestApi* | [**post_guest_document_post**](cloudbeds_pms_v1_3/docs/GuestApi.md#post_guest_document_post) | **POST** /postGuestDocument | postGuestDocument
*GuestApi* | [**post_guest_note_post**](cloudbeds_pms_v1_3/docs/GuestApi.md#post_guest_note_post) | **POST** /postGuestNote | postGuestNote
*GuestApi* | [**post_guest_photo_post**](cloudbeds_pms_v1_3/docs/GuestApi.md#post_guest_photo_post) | **POST** /postGuestPhoto | postGuestPhoto
*GuestApi* | [**post_guest_post**](cloudbeds_pms_v1_3/docs/GuestApi.md#post_guest_post) | **POST** /postGuest | postGuest
*GuestApi* | [**post_guests_to_room_post**](cloudbeds_pms_v1_3/docs/GuestApi.md#post_guests_to_room_post) | **POST** /postGuestsToRoom | postGuestsToRoom
*GuestApi* | [**put_guest_note_put**](cloudbeds_pms_v1_3/docs/GuestApi.md#put_guest_note_put) | **PUT** /putGuestNote | putGuestNote
*GuestApi* | [**put_guest_put**](cloudbeds_pms_v1_3/docs/GuestApi.md#put_guest_put) | **PUT** /putGuest | putGuest
*HotelApi* | [**get_files_get**](cloudbeds_pms_v1_3/docs/HotelApi.md#get_files_get) | **GET** /getFiles | getFiles
*HotelApi* | [**get_hotel_details_get**](cloudbeds_pms_v1_3/docs/HotelApi.md#get_hotel_details_get) | **GET** /getHotelDetails | getHotelDetails
*HotelApi* | [**get_hotels_get**](cloudbeds_pms_v1_3/docs/HotelApi.md#get_hotels_get) | **GET** /getHotels | getHotels
*HotelApi* | [**post_file_post**](cloudbeds_pms_v1_3/docs/HotelApi.md#post_file_post) | **POST** /postFile | postFile
*HouseAccountApi* | [**get_house_account_list_get**](cloudbeds_pms_v1_3/docs/HouseAccountApi.md#get_house_account_list_get) | **GET** /getHouseAccountList | getHouseAccountList
*HouseAccountApi* | [**post_new_house_account_post**](cloudbeds_pms_v1_3/docs/HouseAccountApi.md#post_new_house_account_post) | **POST** /postNewHouseAccount | postNewHouseAccount
*HouseAccountApi* | [**put_house_account_status_put**](cloudbeds_pms_v1_3/docs/HouseAccountApi.md#put_house_account_status_put) | **PUT** /putHouseAccountStatus | putHouseAccountStatus
*HousekeepingApi* | [**get_housekeepers_get**](cloudbeds_pms_v1_3/docs/HousekeepingApi.md#get_housekeepers_get) | **GET** /getHousekeepers | getHousekeepers
*HousekeepingApi* | [**get_housekeeping_status_get**](cloudbeds_pms_v1_3/docs/HousekeepingApi.md#get_housekeeping_status_get) | **GET** /getHousekeepingStatus | getHousekeepingStatus
*HousekeepingApi* | [**post_housekeeper_post**](cloudbeds_pms_v1_3/docs/HousekeepingApi.md#post_housekeeper_post) | **POST** /postHousekeeper | postHousekeeper
*HousekeepingApi* | [**post_housekeeping_assignment_post**](cloudbeds_pms_v1_3/docs/HousekeepingApi.md#post_housekeeping_assignment_post) | **POST** /postHousekeepingAssignment | postHousekeepingAssignment
*HousekeepingApi* | [**post_housekeeping_status_post**](cloudbeds_pms_v1_3/docs/HousekeepingApi.md#post_housekeeping_status_post) | **POST** /postHousekeepingStatus | postHousekeepingStatus
*HousekeepingApi* | [**put_housekeeper_put**](cloudbeds_pms_v1_3/docs/HousekeepingApi.md#put_housekeeper_put) | **PUT** /putHousekeeper | putHousekeeper
*IntegrationApi* | [**delete_webhook_delete**](cloudbeds_pms_v1_3/docs/IntegrationApi.md#delete_webhook_delete) | **DELETE** /deleteWebhook | deleteWebhook
*IntegrationApi* | [**get_app_settings_get**](cloudbeds_pms_v1_3/docs/IntegrationApi.md#get_app_settings_get) | **GET** /getAppSettings | getAppSettings
*IntegrationApi* | [**get_app_state_get**](cloudbeds_pms_v1_3/docs/IntegrationApi.md#get_app_state_get) | **GET** /getAppState | getAppState
*IntegrationApi* | [**get_webhooks_get**](cloudbeds_pms_v1_3/docs/IntegrationApi.md#get_webhooks_get) | **GET** /getWebhooks | getWebhooks
*IntegrationApi* | [**post_app_error_post**](cloudbeds_pms_v1_3/docs/IntegrationApi.md#post_app_error_post) | **POST** /postAppError | postAppError
*IntegrationApi* | [**post_app_state_post**](cloudbeds_pms_v1_3/docs/IntegrationApi.md#post_app_state_post) | **POST** /postAppState | postAppState
*IntegrationApi* | [**post_government_receipt_post**](cloudbeds_pms_v1_3/docs/IntegrationApi.md#post_government_receipt_post) | **POST** /postGovernmentReceipt | postGovernmentReceipt
*IntegrationApi* | [**post_webhook_post**](cloudbeds_pms_v1_3/docs/IntegrationApi.md#post_webhook_post) | **POST** /postWebhook | postWebhook
*ItemApi* | [**append_custom_item_post**](cloudbeds_pms_v1_3/docs/ItemApi.md#append_custom_item_post) | **POST** /appendCustomItem | appendCustomItem
*ItemApi* | [**get_item_categories_get**](cloudbeds_pms_v1_3/docs/ItemApi.md#get_item_categories_get) | **GET** /getItemCategories | getItemCategories
*ItemApi* | [**get_item_get**](cloudbeds_pms_v1_3/docs/ItemApi.md#get_item_get) | **GET** /getItem | getItem
*ItemApi* | [**get_items_get**](cloudbeds_pms_v1_3/docs/ItemApi.md#get_items_get) | **GET** /getItems | getItems
*ItemApi* | [**post_custom_item_post**](cloudbeds_pms_v1_3/docs/ItemApi.md#post_custom_item_post) | **POST** /postCustomItem | postCustomItem
*ItemApi* | [**post_item_category_post**](cloudbeds_pms_v1_3/docs/ItemApi.md#post_item_category_post) | **POST** /postItemCategory | postItemCategory
*ItemApi* | [**post_item_post**](cloudbeds_pms_v1_3/docs/ItemApi.md#post_item_post) | **POST** /postItem | postItem
*ItemApi* | [**post_items_to_inventory_post**](cloudbeds_pms_v1_3/docs/ItemApi.md#post_items_to_inventory_post) | **POST** /postItemsToInventory | postItemsToInventory
*ItemApi* | [**post_void_item_post**](cloudbeds_pms_v1_3/docs/ItemApi.md#post_void_item_post) | **POST** /postVoidItem | postVoidItem
*ItemApi* | [**put_item_to_inventory_put**](cloudbeds_pms_v1_3/docs/ItemApi.md#put_item_to_inventory_put) | **PUT** /putItemToInventory | putItemToInventory
*PackageApi* | [**get_package_names_get**](cloudbeds_pms_v1_3/docs/PackageApi.md#get_package_names_get) | **GET** /getPackageNames | getPackageNames
*PackageApi* | [**get_packages_get**](cloudbeds_pms_v1_3/docs/PackageApi.md#get_packages_get) | **GET** /getPackages | getPackages
*PaymentApi* | [**get_payment_methods_get**](cloudbeds_pms_v1_3/docs/PaymentApi.md#get_payment_methods_get) | **GET** /getPaymentMethods | getPaymentMethods
*PaymentApi* | [**get_payments_capabilities_get**](cloudbeds_pms_v1_3/docs/PaymentApi.md#get_payments_capabilities_get) | **GET** /getPaymentsCapabilities | getPaymentsCapabilities
*PaymentApi* | [**post_charge_post**](cloudbeds_pms_v1_3/docs/PaymentApi.md#post_charge_post) | **POST** /postCharge | postCharge
*PaymentApi* | [**post_credit_card_post**](cloudbeds_pms_v1_3/docs/PaymentApi.md#post_credit_card_post) | **POST** /postCreditCard | postCreditCard
*PaymentApi* | [**post_custom_payment_method_post**](cloudbeds_pms_v1_3/docs/PaymentApi.md#post_custom_payment_method_post) | **POST** /postCustomPaymentMethod | postCustomPaymentMethod
*PaymentApi* | [**post_payment_post**](cloudbeds_pms_v1_3/docs/PaymentApi.md#post_payment_post) | **POST** /postPayment | postPayment
*PaymentApi* | [**post_void_payment_post**](cloudbeds_pms_v1_3/docs/PaymentApi.md#post_void_payment_post) | **POST** /postVoidPayment | postVoidPayment
*RateApi* | [**get_rate_get**](cloudbeds_pms_v1_3/docs/RateApi.md#get_rate_get) | **GET** /getRate | getRate
*RateApi* | [**get_rate_jobs_get**](cloudbeds_pms_v1_3/docs/RateApi.md#get_rate_jobs_get) | **GET** /getRateJobs | getRateJobs
*RateApi* | [**get_rate_plans_get**](cloudbeds_pms_v1_3/docs/RateApi.md#get_rate_plans_get) | **GET** /getRatePlans | getRatePlans
*RateApi* | [**patch_rate_post**](cloudbeds_pms_v1_3/docs/RateApi.md#patch_rate_post) | **POST** /patchRate | patchRate
*RateApi* | [**put_rate_post**](cloudbeds_pms_v1_3/docs/RateApi.md#put_rate_post) | **POST** /putRate | putRate
*ReservationApi* | [**delete_reservation_note_delete**](cloudbeds_pms_v1_3/docs/ReservationApi.md#delete_reservation_note_delete) | **DELETE** /deleteReservationNote | deleteReservationNote
*ReservationApi* | [**get_reservation_assignments_get**](cloudbeds_pms_v1_3/docs/ReservationApi.md#get_reservation_assignments_get) | **GET** /getReservationAssignments | getReservationAssignments
*ReservationApi* | [**get_reservation_get**](cloudbeds_pms_v1_3/docs/ReservationApi.md#get_reservation_get) | **GET** /getReservation | getReservation
*ReservationApi* | [**get_reservation_notes_get**](cloudbeds_pms_v1_3/docs/ReservationApi.md#get_reservation_notes_get) | **GET** /getReservationNotes | getReservationNotes
*ReservationApi* | [**get_reservations_get**](cloudbeds_pms_v1_3/docs/ReservationApi.md#get_reservations_get) | **GET** /getReservations | getReservations
*ReservationApi* | [**get_reservations_with_rate_details_get**](cloudbeds_pms_v1_3/docs/ReservationApi.md#get_reservations_with_rate_details_get) | **GET** /getReservationsWithRateDetails | getReservationsWithRateDetails
*ReservationApi* | [**get_sources_get**](cloudbeds_pms_v1_3/docs/ReservationApi.md#get_sources_get) | **GET** /getSources | getSources
*ReservationApi* | [**post_reservation_document_post**](cloudbeds_pms_v1_3/docs/ReservationApi.md#post_reservation_document_post) | **POST** /postReservationDocument | postReservationDocument
*ReservationApi* | [**post_reservation_note_post**](cloudbeds_pms_v1_3/docs/ReservationApi.md#post_reservation_note_post) | **POST** /postReservationNote | postReservationNote
*ReservationApi* | [**post_reservation_post**](cloudbeds_pms_v1_3/docs/ReservationApi.md#post_reservation_post) | **POST** /postReservation | postReservation
*ReservationApi* | [**put_reservation_note_put**](cloudbeds_pms_v1_3/docs/ReservationApi.md#put_reservation_note_put) | **PUT** /putReservationNote | putReservationNote
*ReservationApi* | [**put_reservation_put**](cloudbeds_pms_v1_3/docs/ReservationApi.md#put_reservation_put) | **PUT** /putReservation | putReservation
*RoomApi* | [**delete_room_block_delete**](cloudbeds_pms_v1_3/docs/RoomApi.md#delete_room_block_delete) | **DELETE** /deleteRoomBlock | deleteRoomBlock
*RoomApi* | [**get_available_room_types_get**](cloudbeds_pms_v1_3/docs/RoomApi.md#get_available_room_types_get) | **GET** /getAvailableRoomTypes | getAvailableRoomTypes
*RoomApi* | [**get_reservation_room_details_get**](cloudbeds_pms_v1_3/docs/RoomApi.md#get_reservation_room_details_get) | **GET** /getReservationRoomDetails | getReservationRoomDetails
*RoomApi* | [**get_room_blocks_get**](cloudbeds_pms_v1_3/docs/RoomApi.md#get_room_blocks_get) | **GET** /getRoomBlocks | getRoomBlocks
*RoomApi* | [**get_room_types_get**](cloudbeds_pms_v1_3/docs/RoomApi.md#get_room_types_get) | **GET** /getRoomTypes | getRoomTypes
*RoomApi* | [**get_rooms_fees_and_taxes_get**](cloudbeds_pms_v1_3/docs/RoomApi.md#get_rooms_fees_and_taxes_get) | **GET** /getRoomsFeesAndTaxes | getRoomsFeesAndTaxes
*RoomApi* | [**get_rooms_get**](cloudbeds_pms_v1_3/docs/RoomApi.md#get_rooms_get) | **GET** /getRooms | getRooms
*RoomApi* | [**get_rooms_unassigned_get**](cloudbeds_pms_v1_3/docs/RoomApi.md#get_rooms_unassigned_get) | **GET** /getRoomsUnassigned | getRoomsUnassigned
*RoomApi* | [**post_room_assign_post**](cloudbeds_pms_v1_3/docs/RoomApi.md#post_room_assign_post) | **POST** /postRoomAssign | postRoomAssign
*RoomApi* | [**post_room_block_post**](cloudbeds_pms_v1_3/docs/RoomApi.md#post_room_block_post) | **POST** /postRoomBlock | postRoomBlock
*RoomApi* | [**post_room_check_in_post**](cloudbeds_pms_v1_3/docs/RoomApi.md#post_room_check_in_post) | **POST** /postRoomCheckIn | postRoomCheckIn
*RoomApi* | [**post_room_check_out_post**](cloudbeds_pms_v1_3/docs/RoomApi.md#post_room_check_out_post) | **POST** /postRoomCheckOut | postRoomCheckOut
*RoomApi* | [**put_room_block_put**](cloudbeds_pms_v1_3/docs/RoomApi.md#put_room_block_put) | **PUT** /putRoomBlock | putRoomBlock
*TaxesAndFeesApi* | [**get_taxes_and_fees_get**](cloudbeds_pms_v1_3/docs/TaxesAndFeesApi.md#get_taxes_and_fees_get) | **GET** /getTaxesAndFees | getTaxesAndFees
*UserApi* | [**get_users_get**](cloudbeds_pms_v1_3/docs/UserApi.md#get_users_get) | **GET** /getUsers | getUsers
## Documentation For Models
- [DeleteAdjustmentResponse](cloudbeds_pms_v1_3/docs/DeleteAdjustmentResponse.md)
- [DeleteGuestNoteResponse](cloudbeds_pms_v1_3/docs/DeleteGuestNoteResponse.md)
- [DeleteReservationNoteResponse](cloudbeds_pms_v1_3/docs/DeleteReservationNoteResponse.md)
- [DeleteRoomBlockResponse](cloudbeds_pms_v1_3/docs/DeleteRoomBlockResponse.md)
- [DeleteWebhookResponse](cloudbeds_pms_v1_3/docs/DeleteWebhookResponse.md)
- [GetAllotmentBlocksResponse](cloudbeds_pms_v1_3/docs/GetAllotmentBlocksResponse.md)
- [GetAllotmentBlocksResponseDataInner](cloudbeds_pms_v1_3/docs/GetAllotmentBlocksResponseDataInner.md)
- [GetAllotmentBlocksResponseDataInnerAllotmentIntervalsInner](cloudbeds_pms_v1_3/docs/GetAllotmentBlocksResponseDataInnerAllotmentIntervalsInner.md)
- [GetAllotmentBlocksResponseDataInnerAllotmentIntervalsInnerAvailabilityInner](cloudbeds_pms_v1_3/docs/GetAllotmentBlocksResponseDataInnerAllotmentIntervalsInnerAvailabilityInner.md)
- [GetAllotmentBlocksResponseDataInnerAllotmentIntervalsInnerRestrictions](cloudbeds_pms_v1_3/docs/GetAllotmentBlocksResponseDataInnerAllotmentIntervalsInnerRestrictions.md)
- [GetAllotmentBlocksResponseDataInnerAutoReleaseInner](cloudbeds_pms_v1_3/docs/GetAllotmentBlocksResponseDataInnerAutoReleaseInner.md)
- [GetAppPropertySettingsResponse](cloudbeds_pms_v1_3/docs/GetAppPropertySettingsResponse.md)
- [GetAppPropertySettingsResponseData](cloudbeds_pms_v1_3/docs/GetAppPropertySettingsResponseData.md)
- [GetAppPropertySettingsResponseDataOneOf](cloudbeds_pms_v1_3/docs/GetAppPropertySettingsResponseDataOneOf.md)
- [GetAppSettingsResponse](cloudbeds_pms_v1_3/docs/GetAppSettingsResponse.md)
- [GetAppSettingsResponseData](cloudbeds_pms_v1_3/docs/GetAppSettingsResponseData.md)
- [GetAppStateResponse](cloudbeds_pms_v1_3/docs/GetAppStateResponse.md)
- [GetAppStateResponseData](cloudbeds_pms_v1_3/docs/GetAppStateResponseData.md)
- [GetAvailableRoomTypesResponse](cloudbeds_pms_v1_3/docs/GetAvailableRoomTypesResponse.md)
- [GetAvailableRoomTypesResponseDataInner](cloudbeds_pms_v1_3/docs/GetAvailableRoomTypesResponseDataInner.md)
- [GetAvailableRoomTypesResponseDataInnerPropertyCurrencyInner](cloudbeds_pms_v1_3/docs/GetAvailableRoomTypesResponseDataInnerPropertyCurrencyInner.md)
- [GetAvailableRoomTypesResponseDataInnerPropertyRoomsInner](cloudbeds_pms_v1_3/docs/GetAvailableRoomTypesResponseDataInnerPropertyRoomsInner.md)
- [GetAvailableRoomTypesResponseDataInnerPropertyRoomsInnerIndividualRoomsInner](cloudbeds_pms_v1_3/docs/GetAvailableRoomTypesResponseDataInnerPropertyRoomsInnerIndividualRoomsInner.md)
- [GetAvailableRoomTypesResponseDataInnerPropertyRoomsInnerRoomRateDetailedInner](cloudbeds_pms_v1_3/docs/GetAvailableRoomTypesResponseDataInnerPropertyRoomsInnerRoomRateDetailedInner.md)
- [GetCurrencySettingsResponse](cloudbeds_pms_v1_3/docs/GetCurrencySettingsResponse.md)
- [GetCurrencySettingsResponseData](cloudbeds_pms_v1_3/docs/GetCurrencySettingsResponseData.md)
- [GetCurrencySettingsResponseDataFormat](cloudbeds_pms_v1_3/docs/GetCurrencySettingsResponseDataFormat.md)
- [GetCurrencySettingsResponseDataRates](cloudbeds_pms_v1_3/docs/GetCurrencySettingsResponseDataRates.md)
- [GetCurrencySettingsResponseDataRatesFixedInner](cloudbeds_pms_v1_3/docs/GetCurrencySettingsResponseDataRatesFixedInner.md)
- [GetCustomFieldsResponse](cloudbeds_pms_v1_3/docs/GetCustomFieldsResponse.md)
- [GetCustomFieldsResponseDataInner](cloudbeds_pms_v1_3/docs/GetCustomFieldsResponseDataInner.md)
- [GetDashboardResponse](cloudbeds_pms_v1_3/docs/GetDashboardResponse.md)
- [GetDashboardResponseData](cloudbeds_pms_v1_3/docs/GetDashboardResponseData.md)
- [GetEmailScheduleResponse](cloudbeds_pms_v1_3/docs/GetEmailScheduleResponse.md)
- [GetEmailScheduleResponseDataInner](cloudbeds_pms_v1_3/docs/GetEmailScheduleResponseDataInner.md)
- [GetEmailTemplatesResponse](cloudbeds_pms_v1_3/docs/GetEmailTemplatesResponse.md)
- [GetEmailTemplatesResponseDataInner](cloudbeds_pms_v1_3/docs/GetEmailTemplatesResponseDataInner.md)
- [GetFilesResponse](cloudbeds_pms_v1_3/docs/GetFilesResponse.md)
- [GetFilesResponseDataInner](cloudbeds_pms_v1_3/docs/GetFilesResponseDataInner.md)
- [GetGroupNotesResponse](cloudbeds_pms_v1_3/docs/GetGroupNotesResponse.md)
- [GetGroupNotesResponseData](cloudbeds_pms_v1_3/docs/GetGroupNotesResponseData.md)
- [GetGroupsResponse](cloudbeds_pms_v1_3/docs/GetGroupsResponse.md)
- [GetGroupsResponseDataInner](cloudbeds_pms_v1_3/docs/GetGroupsResponseDataInner.md)
- [GetGroupsResponseDataInnerContactsInner](cloudbeds_pms_v1_3/docs/GetGroupsResponseDataInnerContactsInner.md)
- [GetGroupsResponseDataInnerContactsInnerEmailsInner](cloudbeds_pms_v1_3/docs/GetGroupsResponseDataInnerContactsInnerEmailsInner.md)
- [GetGroupsResponseDataInnerContactsInnerPhonesInner](cloudbeds_pms_v1_3/docs/GetGroupsResponseDataInnerContactsInnerPhonesInner.md)
- [GetGuestListResponse](cloudbeds_pms_v1_3/docs/GetGuestListResponse.md)
- [GetGuestListResponseDataValue](cloudbeds_pms_v1_3/docs/GetGuestListResponseDataValue.md)
- [GetGuestListResponseDataValueGuestNotesInner](cloudbeds_pms_v1_3/docs/GetGuestListResponseDataValueGuestNotesInner.md)
- [GetGuestNotesResponse](cloudbeds_pms_v1_3/docs/GetGuestNotesResponse.md)
- [GetGuestNotesResponseDataInner](cloudbeds_pms_v1_3/docs/GetGuestNotesResponseDataInner.md)
- [GetGuestResponse](cloudbeds_pms_v1_3/docs/GetGuestResponse.md)
- [GetGuestResponseData](cloudbeds_pms_v1_3/docs/GetGuestResponseData.md)
- [GetGuestResponseDataBirthDate](cloudbeds_pms_v1_3/docs/GetGuestResponseDataBirthDate.md)
- [GetGuestResponseDataCustomFieldsInner](cloudbeds_pms_v1_3/docs/GetGuestResponseDataCustomFieldsInner.md)
- [GetGuestResponseDataDocumentExpirationDate](cloudbeds_pms_v1_3/docs/GetGuestResponseDataDocumentExpirationDate.md)
- [GetGuestResponseDataDocumentIssueDate](cloudbeds_pms_v1_3/docs/GetGuestResponseDataDocumentIssueDate.md)
- [GetGuestsByFilterResponse](cloudbeds_pms_v1_3/docs/GetGuestsByFilterResponse.md)
- [GetGuestsByFilterResponseDataInner](cloudbeds_pms_v1_3/docs/GetGuestsByFilterResponseDataInner.md)
- [GetGuestsByStatusResponse](cloudbeds_pms_v1_3/docs/GetGuestsByStatusResponse.md)
- [GetGuestsByStatusResponseDataInner](cloudbeds_pms_v1_3/docs/GetGuestsByStatusResponseDataInner.md)
- [GetGuestsModifiedResponse](cloudbeds_pms_v1_3/docs/GetGuestsModifiedResponse.md)
- [GetGuestsModifiedResponseDataInner](cloudbeds_pms_v1_3/docs/GetGuestsModifiedResponseDataInner.md)
- [GetGuestsModifiedResponseDataInnerCustomFieldsInner](cloudbeds_pms_v1_3/docs/GetGuestsModifiedResponseDataInnerCustomFieldsInner.md)
- [GetHotelDetailsResponse](cloudbeds_pms_v1_3/docs/GetHotelDetailsResponse.md)
- [GetHotelDetailsResponseData](cloudbeds_pms_v1_3/docs/GetHotelDetailsResponseData.md)
- [GetHotelDetailsResponseDataPropertyAddress](cloudbeds_pms_v1_3/docs/GetHotelDetailsResponseDataPropertyAddress.md)
- [GetHotelDetailsResponseDataPropertyCurrency](cloudbeds_pms_v1_3/docs/GetHotelDetailsResponseDataPropertyCurrency.md)
- [GetHotelDetailsResponseDataPropertyImageInner](cloudbeds_pms_v1_3/docs/GetHotelDetailsResponseDataPropertyImageInner.md)
- [GetHotelDetailsResponseDataPropertyPolicy](cloudbeds_pms_v1_3/docs/GetHotelDetailsResponseDataPropertyPolicy.md)
- [GetHotelsResponse](cloudbeds_pms_v1_3/docs/GetHotelsResponse.md)
- [GetHotelsResponseDataInner](cloudbeds_pms_v1_3/docs/GetHotelsResponseDataInner.md)
- [GetHotelsResponseDataInnerPropertyCurrencyInner](cloudbeds_pms_v1_3/docs/GetHotelsResponseDataInnerPropertyCurrencyInner.md)
- [GetHouseAccountListResponse](cloudbeds_pms_v1_3/docs/GetHouseAccountListResponse.md)
- [GetHouseAccountListResponseDataInner](cloudbeds_pms_v1_3/docs/GetHouseAccountListResponseDataInner.md)
- [GetHousekeepersResponse](cloudbeds_pms_v1_3/docs/GetHousekeepersResponse.md)
- [GetHousekeepersResponseDataInner](cloudbeds_pms_v1_3/docs/GetHousekeepersResponseDataInner.md)
- [GetHousekeepingStatusResponse](cloudbeds_pms_v1_3/docs/GetHousekeepingStatusResponse.md)
- [GetHousekeepingStatusResponseDataInner](cloudbeds_pms_v1_3/docs/GetHousekeepingStatusResponseDataInner.md)
- [GetItemCategoriesResponse](cloudbeds_pms_v1_3/docs/GetItemCategoriesResponse.md)
- [GetItemCategoriesResponseDataInner](cloudbeds_pms_v1_3/docs/GetItemCategoriesResponseDataInner.md)
- [GetItemResponse](cloudbeds_pms_v1_3/docs/GetItemResponse.md)
- [GetItemResponseData](cloudbeds_pms_v1_3/docs/GetItemResponseData.md)
- [GetItemResponseDataFeesInner](cloudbeds_pms_v1_3/docs/GetItemResponseDataFeesInner.md)
- [GetItemResponseDataTaxesInner](cloudbeds_pms_v1_3/docs/GetItemResponseDataTaxesInner.md)
- [GetItemsResponse](cloudbeds_pms_v1_3/docs/GetItemsResponse.md)
- [GetItemsResponseDataInner](cloudbeds_pms_v1_3/docs/GetItemsResponseDataInner.md)
- [GetListAllotmentBlockNotesResponse](cloudbeds_pms_v1_3/docs/GetListAllotmentBlockNotesResponse.md)
- [GetListAllotmentBlockNotesResponseDataInner](cloudbeds_pms_v1_3/docs/GetListAllotmentBlockNotesResponseDataInner.md)
- [GetMetadataResponse](cloudbeds_pms_v1_3/docs/GetMetadataResponse.md)
- [GetMetadataResponseData](cloudbeds_pms_v1_3/docs/GetMetadataResponseData.md)
- [GetMetadataResponseDataApi](cloudbeds_pms_v1_3/docs/GetMetadataResponseDataApi.md)
- [GetPackagesResponse](cloudbeds_pms_v1_3/docs/GetPackagesResponse.md)
- [GetPackagesResponseData](cloudbeds_pms_v1_3/docs/GetPackagesResponseData.md)
- [GetPaymentMethodsResponse](cloudbeds_pms_v1_3/docs/GetPaymentMethodsResponse.md)
- [GetPaymentMethodsResponseData](cloudbeds_pms_v1_3/docs/GetPaymentMethodsResponseData.md)
- [GetPaymentMethodsResponseDataGateway](cloudbeds_pms_v1_3/docs/GetPaymentMethodsResponseDataGateway.md)
- [GetPaymentMethodsResponseDataMethodsInner](cloudbeds_pms_v1_3/docs/GetPaymentMethodsResponseDataMethodsInner.md)
- [GetPaymentMethodsResponseDataMethodsInnerCardTypesInner](cloudbeds_pms_v1_3/docs/GetPaymentMethodsResponseDataMethodsInnerCardTypesInner.md)
- [GetPaymentsCapabilitiesResponse](cloudbeds_pms_v1_3/docs/GetPaymentsCapabilitiesResponse.md)
- [GetPaymentsCapabilitiesResponseDataInner](cloudbeds_pms_v1_3/docs/GetPaymentsCapabilitiesResponseDataInner.md)
- [GetRateJobsResponse](cloudbeds_pms_v1_3/docs/GetRateJobsResponse.md)
- [GetRateJobsResponseDataInner](cloudbeds_pms_v1_3/docs/GetRateJobsResponseDataInner.md)
- [GetRateJobsResponseDataInnerUpdatesInner](cloudbeds_pms_v1_3/docs/GetRateJobsResponseDataInnerUpdatesInner.md)
- [GetRatePlansResponse](cloudbeds_pms_v1_3/docs/GetRatePlansResponse.md)
- [GetRatePlansResponseDataInner](cloudbeds_pms_v1_3/docs/GetRatePlansResponseDataInner.md)
- [GetRatePlansResponseDataInnerAddOnsInner](cloudbeds_pms_v1_3/docs/GetRatePlansResponseDataInnerAddOnsInner.md)
- [GetRatePlansResponseDataInnerRoomRateDetailedInner](cloudbeds_pms_v1_3/docs/GetRatePlansResponseDataInnerRoomRateDetailedInner.md)
- [GetRateResponse](cloudbeds_pms_v1_3/docs/GetRateResponse.md)
- [GetRateResponseData](cloudbeds_pms_v1_3/docs/GetRateResponseData.md)
- [GetRateResponseDataRoomRateDetailedInner](cloudbeds_pms_v1_3/docs/GetRateResponseDataRoomRateDetailedInner.md)
- [GetReservationAssignmentsResponse](cloudbeds_pms_v1_3/docs/GetReservationAssignmentsResponse.md)
- [GetReservationAssignmentsResponseDataInner](cloudbeds_pms_v1_3/docs/GetReservationAssignmentsResponseDataInner.md)
- [GetReservationAssignmentsResponseDataInnerAssignedInner](cloudbeds_pms_v1_3/docs/GetReservationAssignmentsResponseDataInnerAssignedInner.md)
- [GetReservationNotesResponse](cloudbeds_pms_v1_3/docs/GetReservationNotesResponse.md)
- [GetReservationNotesResponseDataInner](cloudbeds_pms_v1_3/docs/GetReservationNotesResponseDataInner.md)
- [GetReservationResponse](cloudbeds_pms_v1_3/docs/GetReservationResponse.md)
- [GetReservationResponseData](cloudbeds_pms_v1_3/docs/GetReservationResponseData.md)
- [GetReservationResponseDataAssignedInner](cloudbeds_pms_v1_3/docs/GetReservationResponseDataAssignedInner.md)
- [GetReservationResponseDataAssignedInnerDailyRatesInner](cloudbeds_pms_v1_3/docs/GetReservationResponseDataAssignedInnerDailyRatesInner.md)
- [GetReservationResponseDataBalanceDetailed](cloudbeds_pms_v1_3/docs/GetReservationResponseDataBalanceDetailed.md)
- [GetReservationResponseDataBalanceDetailedOneOf](cloudbeds_pms_v1_3/docs/GetReservationResponseDataBalanceDetailedOneOf.md)
- [GetReservationResponseDataCardsOnFileInner](cloudbeds_pms_v1_3/docs/GetReservationResponseDataCardsOnFileInner.md)
- [GetReservationResponseDataGroupInventoryInner](cloudbeds_pms_v1_3/docs/GetReservationResponseDataGroupInventoryInner.md)
- [GetReservationResponseDataGuestListValue](cloudbeds_pms_v1_3/docs/GetReservationResponseDataGuestListValue.md)
- [GetReservationResponseDataGuestListValueCustomFieldsInner](cloudbeds_pms_v1_3/docs/GetReservationResponseDataGuestListValueCustomFieldsInner.md)
- [GetReservationResponseDataGuestListValueGuestBirthdate](cloudbeds_pms_v1_3/docs/GetReservationResponseDataGuestListValueGuestBirthdate.md)
- [GetReservationResponseDataGuestListValueRoomsInner](cloudbeds_pms_v1_3/docs/GetReservationResponseDataGuestListValueRoomsInner.md)
- [GetReservationResponseDataGuestListValueUnassignedRoomsInner](cloudbeds_pms_v1_3/docs/GetReservationResponseDataGuestListValueUnassignedRoomsInner.md)
- [GetReservationResponseDataUnassignedInner](cloudbeds_pms_v1_3/docs/GetReservationResponseDataUnassignedInner.md)
- [GetReservationRoomDetailsResponse](cloudbeds_pms_v1_3/docs/GetReservationRoomDetailsResponse.md)
- [GetReservationRoomDetailsResponseData](cloudbeds_pms_v1_3/docs/GetReservationRoomDetailsResponseData.md)
- [GetReservationRoomDetailsResponseDataGuestsInner](cloudbeds_pms_v1_3/docs/GetReservationRoomDetailsResponseDataGuestsInner.md)
- [GetReservationsResponse](cloudbeds_pms_v1_3/docs/GetReservationsResponse.md)
- [GetReservationsResponseDataInner](cloudbeds_pms_v1_3/docs/GetReservationsResponseDataInner.md)
- [GetReservationsResponseDataInnerGuestListValue](cloudbeds_pms_v1_3/docs/GetReservationsResponseDataInnerGuestListValue.md)
- [GetReservationsResponseDataInnerGuestListValueRoomsInner](cloudbeds_pms_v1_3/docs/GetReservationsResponseDataInnerGuestListValueRoomsInner.md)
- [GetReservationsResponseDataInnerGuestListValueUnassignedRoomsInner](cloudbeds_pms_v1_3/docs/GetReservationsResponseDataInnerGuestListValueUnassignedRoomsInner.md)
- [GetReservationsResponseDataInnerRoomsInner](cloudbeds_pms_v1_3/docs/GetReservationsResponseDataInnerRoomsInner.md)
- [GetReservationsWithRateDetailsResponse](cloudbeds_pms_v1_3/docs/GetReservationsWithRateDetailsResponse.md)
- [GetReservationsWithRateDetailsResponseDataInner](cloudbeds_pms_v1_3/docs/GetReservationsWithRateDetailsResponseDataInner.md)
- [GetReservationsWithRateDetailsResponseDataInnerBalanceDetailed](cloudbeds_pms_v1_3/docs/GetReservationsWithRateDetailsResponseDataInnerBalanceDetailed.md)
- [GetReservationsWithRateDetailsResponseDataInnerGuestListValue](cloudbeds_pms_v1_3/docs/GetReservationsWithRateDetailsResponseDataInnerGuestListValue.md)
- [GetReservationsWithRateDetailsResponseDataInnerRoomsInner](cloudbeds_pms_v1_3/docs/GetReservationsWithRateDetailsResponseDataInnerRoomsInner.md)
- [GetReservationsWithRateDetailsResponseDataInnerSource](cloudbeds_pms_v1_3/docs/GetReservationsWithRateDetailsResponseDataInnerSource.md)
- [GetRoomBlocksResponse](cloudbeds_pms_v1_3/docs/GetRoomBlocksResponse.md)
- [GetRoomBlocksResponseDataInner](cloudbeds_pms_v1_3/docs/GetRoomBlocksResponseDataInner.md)
- [GetRoomBlocksResponseDataInnerRoomsInner](cloudbeds_pms_v1_3/docs/GetRoomBlocksResponseDataInnerRoomsInner.md)
- [GetRoomTypesResponse](cloudbeds_pms_v1_3/docs/GetRoomTypesResponse.md)
- [GetRoomTypesResponseDataInner](cloudbeds_pms_v1_3/docs/GetRoomTypesResponseDataInner.md)
- [GetRoomsFeesAndTaxesResponse](cloudbeds_pms_v1_3/docs/GetRoomsFeesAndTaxesResponse.md)
- [GetRoomsFeesAndTaxesResponseData](cloudbeds_pms_v1_3/docs/GetRoomsFeesAndTaxesResponseData.md)
- [GetRoomsFeesAndTaxesResponseDataFeesInner](cloudbeds_pms_v1_3/docs/GetRoomsFeesAndTaxesResponseDataFeesInner.md)
- [GetRoomsFeesAndTaxesResponseDataTaxesInner](cloudbeds_pms_v1_3/docs/GetRoomsFeesAndTaxesResponseDataTaxesInner.md)
- [GetRoomsResponse](cloudbeds_pms_v1_3/docs/GetRoomsResponse.md)
- [GetRoomsResponseDataInner](cloudbeds_pms_v1_3/docs/GetRoomsResponseDataInner.md)
- [GetRoomsResponseDataInnerRoomsInner](cloudbeds_pms_v1_3/docs/GetRoomsResponseDataInnerRoomsInner.md)
- [GetRoomsResponseDataInnerRoomsInnerLinkedRoomTypeQtyInner](cloudbeds_pms_v1_3/docs/GetRoomsResponseDataInnerRoomsInnerLinkedRoomTypeQtyInner.md)
- [GetRoomsUnassignedResponse](cloudbeds_pms_v1_3/docs/GetRoomsUnassignedResponse.md)
- [GetRoomsUnassignedResponseDataInner](cloudbeds_pms_v1_3/docs/GetRoomsUnassignedResponseDataInner.md)
- [GetRoomsUnassignedResponseDataInnerRoomsInner](cloudbeds_pms_v1_3/docs/GetRoomsUnassignedResponseDataInnerRoomsInner.md)
- [GetSourcesResponse](cloudbeds_pms_v1_3/docs/GetSourcesResponse.md)
- [GetSourcesResponseDataInner](cloudbeds_pms_v1_3/docs/GetSourcesResponseDataInner.md)
- [GetSourcesResponseDataInnerFeesInner](cloudbeds_pms_v1_3/docs/GetSourcesResponseDataInnerFeesInner.md)
- [GetSourcesResponseDataInnerTaxesInner](cloudbeds_pms_v1_3/docs/GetSourcesResponseDataInnerTaxesInner.md)
- [GetTaxesAndFeesResponse](cloudbeds_pms_v1_3/docs/GetTaxesAndFeesResponse.md)
- [GetTaxesAndFeesResponseDataInner](cloudbeds_pms_v1_3/docs/GetTaxesAndFeesResponseDataInner.md)
- [GetTaxesAndFeesResponseDataInnerAmountAdult](cloudbeds_pms_v1_3/docs/GetTaxesAndFeesResponseDataInnerAmountAdult.md)
- [GetTaxesAndFeesResponseDataInnerAmountChild](cloudbeds_pms_v1_3/docs/GetTaxesAndFeesResponseDataInnerAmountChild.md)
- [GetTaxesAndFeesResponseDataInnerAmountRateBasedInner](cloudbeds_pms_v1_3/docs/GetTaxesAndFeesResponseDataIn | text/markdown | Cloudbeds | null | null | null | The MIT License
Copyright (c) 2025 Cloudbeds (http://cloudbeds.com)
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
| null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"urllib3<3.0.0,>=2.6.3",
"python-dateutil<3.0.0,>=2.8.2",
"pydantic>=2",
"typing-extensions>=4.7.1",
"pytest; extra == \"testing\"",
"coverage; extra == \"testing\""
] | [] | [] | [] | [
"Documentation, https://github.com/cloudbeds/cloudbeds-api-python/tree/release/v1#README",
"Repository, https://github.com/cloudbeds/cloudbeds-api-python/tree/release/v1"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:39:33.898838 | cloudbeds_pms_v1_3-1.10.0.tar.gz | 323,614 | 27/05/7251f71269f25a8572590c6903951f940079b53c0647c9b43c0c7abbdea8/cloudbeds_pms_v1_3-1.10.0.tar.gz | source | sdist | null | false | e671796f34280739bea3b53b9bafa87c | ac742e07dd0bc7d45b7d00c98be7c26e03efa45f37c51b6e9c72eff02108dbac | 27057251f71269f25a8572590c6903951f940079b53c0647c9b43c0c7abbdea8 | null | [
"LICENSE"
] | 248 |
2.4 | tror-yong-ocr | 0.1.1 | Optical Character Recognition Model | # TrorYong OCR Model
`TrorYongOCR`, is an Optical Character Recognition Model implemented by KrorngAI.
`TrorYong` (ត្រយ៉ង) is Khmer word for giant ibis, the bird that symbolises __Cambodia__.
## Support My Work
While this work comes truly from the heart, each project represents a significant investment of time -- from deep-dive research and code preparation to the final narrative and editing process.
I am incredibly passionate about sharing this knowledge, but maintaining this level of quality is a major undertaking.
If you find my work helpful and are in a position to do so, please consider supporting my work with a donation.
You can click <a href="https://pay.ababank.com/oRF8/8yp6hy53">here</a> to donate or scan the QR code below.
Your generosity acts as a huge encouragement and helps ensure that I can continue creating in-depth, valuable content for you.
<figure>
<div style="text-align: center;"><a name='slotMachine' ><img src="https://kimang18.github.io/assets/fig/aba_qr_kimang.JPG" width="500" /></a></div>
<figcaption> Using Cambodian bank account, you can donate by scanning my ABA QR code here. (or click <a href="https://pay.ababank.com/oRF8/8yp6hy53">here</a>. Make sure that receiver's name is 'Khun Kim Ang'.) </figcaption>
</figure>
# Installation
You can easily install `tror-yong-ocr` using `pip` command as the following:
```bash
pip install tror-yong-ocr
```
# Usage
## Loading tokenizer
`TrorYongOCR` is a small optical character recognition model that you can train from scratch.
With this goal, you can use your own tokenizer to pair with `TrorYongOCR`.
Just make sure that the __tokenizer used for training__ and the __tokenizer used for inference__ is __the same__.
Your tokenizer must contain begin of sequence (`bos`), end of sequence (`eos`) and padding (`pad`) tokens.
`bos` token id and `eos` token id are used in decoding function.
`pad` token id is used during training.
I also provide a tokenizer that supports Khmer and English.
```python
from tror_yong_ocr import get_tokenizer
tokenizer = get_tokenizer(charset=None)
print(len(tokenizer)) # you should receive 185
text = 'Amazon បង្កើនការវិនិយោគជិត១'
print(tokenizer.decode(tokenizer.encode(data[0]['text'], add_special_tokens=True), ignore_special_tokens=False))
# this should print <s>Amazon បង្កើនការវិនិយោគជិត១</s>
```
When preparing a dataset to train `TrorYongOCR`, you just need to transform the text into token ids using the tokenizer
```python
sentence = 'Cambodia needs peace.'
token_ids = tokenizer.encode(sentence, add_special_tokens=True)
```
__NOTE:__ I want to highlight that my tokenizer works at character level.
## Loading TrorYongOCR model
Inspired by [`PARSeq`](https://github.com/baudm/parseq/tree/main) and [`DTrOCR`](https://github.com/arvindrajan92/DTrOCR), I design `TrorYongOCR` as the following: given `n_layer` transformer layers
- `n_layer-1` are encoding layers for encoding a given image
- the final layer is a decoding layer without cross-attention mechanism
- for the decoding layer,
- the __latent state__ of an image (the output of encoding layers) is concatenated with the __input character embedding__ (token embedding including `bos` token plus position embedding) to create __context vector__, _i.e._ __key and value vectors__ (think of it like a prompt prefill)
- and the __input character embedding__ (token embedding plus position embedding) is used as __query vector__.
The architecture of TrorYongOCR can be found in Figure 1 below.
<figure>
<div style="text-align: center;"><a name='slotMachine' ><img src="https://raw.githubusercontent.com/Kimang18/KrorngAI/refs/heads/main/tror-yong-ocr/TrorYongOCR.drawio.png" width="500" /></a></div>
<figcaption> Figure 1: TrorYongOCR architecture overview. The input image is transformed into patch embedding. Image embedding is obtained by additioning patch embedding and position embedding. The image embedding is passed through L-1 encoder blocks to generate image encoding (latent state). The image encoding is concatenated with character embedding (i.e. token embedding plus position embedding) before undergoing causal self-attention mechanism in the single decoder block to generate next token.</figcaption>
</figure>
New technologies in Attention mechanism such as Rotary Positional Embedding (RoPE), and Sigmoid Linear Unit (SiLU) and Gated Linear Unit (GLU) in MLP of Transformer block are implemented in TrorYongOCR.
### Compared to PARSeq
For `PARSeq` model which is an encoder-decoder architecture, text decoder uses position embedding as __query vector__, character embedding (token embedding plus position embedding) as __context vector__, and the __latent state__ from image encoder as __memory__ for the cross-attention mechanism (see Figure 3 of their paper).
### Compared to DTrOCR
For DTrOCR which is a decoder-only architecture, the image embedding (patch embedding plus position embedding) is concatenated with input character embedding (a `[SEP]` token is added at the beginning of input character embedding to indicate sequence separation. `[SEP]` token is equivalent to `bos` token in `TrorYongOCR`), and causal self-attention mechanism is applied to the concatenation from layer to layer to generate text autoregressively (see Figure 2 of their paper).
```python
from tror_yong_ocr import TrorYongOCR, TrorYongConfig
from tror_yong_ocr import get_tokenizer
tokenizer = get_tokenizer()
config = TrorYongConfig(
img_size=(32, 128),
patch_size=(4, 8),
n_channel=3,
vocab_size=len(tokenizer),
block_size=192,
n_layer=4,
n_head=6,
n_embed=384,
dropout=0.1,
bias=True,
)
model = TrorYongOCR(config, tokenizer)
```
## Train TrorYongOCR
You can check out the notebook below to train your own Small OCR Model.
[](https://colab.research.google.com/github/Kimang18/SourceCode-KrorngAI-YT/blob/main/FinetuneTrorYongOCR.ipynb)
I also have a video about training TrorYongOCR below
[](https://youtu.be/3W8P0mByFBY)
## Inference
I also provide `decode` function to decode image in `TrorYongOCR` class.
Note that it can process only one image at a time.
```python
from tror_yong_ocr import TrorYongOCR, TrorYongConfig
from tror_yong_ocr import get_tokenizer
tokenizer = get_tokenizer()
config = TrorYongConfig(
img_size=(32, 128),
patch_size=(4, 8),
n_channel=3,
vocab_size=len(tokenizer), # exclude pad and unk tokens
block_size=192,
n_layer=4,
n_head=6,
n_embed=384,
dropout=0.1,
bias=True,
)
model = TrorYongOCR(config, tokenizer)
model.load_state_dict(torch.load('path/to/your/weights.pt', map_location='cpu'))
pred = model.decode(batch['img_tensor'][0], max_tokens=192, temperature=0.001, top_k=None)
print(tokenizer.decode(pred[0].tolist(), ignore_special_tokens=True))
```
## TODO:
- [X] implement model with KV cache `TrorYongOCR`
- [X] notebook colab for training `TrorYongOCR`
- [ ] benchmarking
| text/markdown | KHUN Kimang | kimang.khun@polytechnique.org | null | null | null | null | [] | [] | https://github.com/kimang18/KrorngAI | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.10 | 2026-02-20T12:39:27.689509 | tror_yong_ocr-0.1.1.tar.gz | 12,862 | 01/95/196627ecb4f7413f2f4e4cd1ce5828b64afaeb10c6c7a637324f6b0c4e23/tror_yong_ocr-0.1.1.tar.gz | source | sdist | null | false | 0b130563e6ee6fdf4fdb410336b4ee66 | 9253c0561c1f07149c80fb2a6ed3dc1e9aa441dca9b925e34c2c281e5259c835 | 0195196627ecb4f7413f2f4e4cd1ce5828b64afaeb10c6c7a637324f6b0c4e23 | null | [
"LICENSE"
] | 169 |
2.1 | odoo-addon-automation-oca | 18.0.1.0.4 | Automate actions in threaded models | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
==============
Automation Oca
==============
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:8c5ee1bbe20408570f22eec88bdd435335dcf91225a59571b55b5f3eb4e1496e
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fautomation-lightgray.png?logo=github
:target: https://github.com/OCA/automation/tree/18.0/automation_oca
:alt: OCA/automation
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/automation-18-0/automation-18-0-automation_oca
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/automation&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module allows to automate several process according to some rules.
This is useful for creating automated actions on your database like:
- Send a welcome email to all new partners (or filtered according to
some rules)
- Remember to online customers that they forgot their basket with some
items
- Send documents to sign to all new employees
**Table of contents**
.. contents::
:local:
Use Cases / Context
===================
Odoo core provides ``base_automation``, which is well suited for
**simple, isolated rules** triggered by **internal record changes**
(e.g. *on create*, *on update*, *on delete*, or *timed conditions*).
When processes become more complex (multiple steps, different timings,
conditional paths), it can be harder to understand and maintain the
whole flow in ``base_automation``.
``automation_oca`` focuses on **workflow-based automations**, where the
full process is defined as a sequence of steps with **timings** and
**dependencies**, and can also react to **external events** such as
email interactions (opened, replied, clicked, bounced, etc).
In short:
- use **``base_automation``** for simple automations driven by internal
record updates
- use **``automation_oca``** for multi-step workflows with timings,
dependencies, and external events
Usage
=====
Configure your processes
------------------------
1. Access the ``Automation`` menu.
2. Create a new Automation Configuration.
3. Set the model and domains.
4. Go to Configuration -> Filters to create filters as a preconfigured
domains. Filters can be established in the proper field in the
Automation Configuration record.
5. Create the different steps by clicking the "ADD" button inside the
automation configuration form.
6. Create child steps by clicking the "Add child activity" at the
bottom of a created step.
7.
8. Select the kind of configuration you create. You can choose between:
- *Periodic configurations*: every 6 hours, a process will check if
new records need to be created.
- *On demand configurations*: user need to execute manually the job.
9. Press ``Start``.
10. Inside the process, you can check all the created items.
|Configuration Screenshot|
Configuration of steps
----------------------
Steps can trigger one of the following options:
- ``Mail``: Sends an email using a template.
- ``Server Action``: Executes a server action.
- ``Activity``: Creates an activity to the related record.
All the steps need to specify the moment of execution. We will set the
number of hours/days and a trigger type:
- ``Start of workflow``: It will be executed at the
previously-configured time after we create the record.
- ``Execution of another step``: It will be executed at the
previously-configured time after the previous step is finished
properly.
- ``Mail opened``: It will be executed at the previously-configured time
after the mail from the previous step is opened.
- ``Mail not opened``: It will be executed at the previously-configured
time after the mail from the previous step is sent if it is not opened
before this time.
- ``Mail replied``: It will be executed at the previously-configured
time after the mail from the previous step is replied.
- ``Mail not replied``: It will be executed at the previously-configured
time after the mail from the previous step is opened if it has not
been replied.
- ``Mail clicked``: It will be executed at the previously-configured
time after the links of the mail from the previous step are clicked.
- ``Mail not clicked``: It will be executed at the previously-configured
time after the mail from the previous step is opened and no links are
clicked.
- ``Mail bounced``: It will be executed at the previously-configured
time after the mail from the previous step is bounced back for any
reason.
- ``Activity has been finished``: It will be executed at the
previously-configured time after the activity from the previous action
is done.
- ``Activity has not been finished``: It will be executed at the
previously-configured time after the previous action is executed if
the related activity is not done.
Important to remember to define a proper template when sending the
email. It will the template without using a notification template. Also,
it is important to define correctly the text partner or email to field
on the template
Records creation
----------------
Records are created using a cron action. This action is executed every 6
hours by default.
Step execution
--------------
Steps are executed using a cron action. This action is executed every
hour by default. On the record view, you can execute manually an action.
There is a way to enforce step execution when finalize the previous one.
If we set a negative value on the period, the execution will be
immediate without a cron.
.. |Configuration Screenshot| image:: https://raw.githubusercontent.com/OCA/automation/18.0/automation_oca/static/description/configuration.png
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/automation/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/automation/issues/new?body=module:%20automation_oca%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Dixmit
Contributors
------------
- Enric Tobella (`Dixmit <https://www.dixmit.com/>`__)
Other credits
-------------
The development of this module has been financially supported by:
- Associacion Española de Odoo (`AEODOO <https://www.aeodoo.org/>`__)
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/automation <https://github.com/OCA/automation/tree/18.0/automation_oca>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Dixmit,Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/automation | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T12:38:55.283421 | odoo_addon_automation_oca-18.0.1.0.4-py3-none-any.whl | 200,217 | dd/19/e78f91ef1bc2ce36877f0bef88de7c79907c23529bb95c37ca4ca8396c1c/odoo_addon_automation_oca-18.0.1.0.4-py3-none-any.whl | py3 | bdist_wheel | null | false | 645482797d448e328f8114c443fb80d5 | f10c9ae0ff09dbe816bae93780bd6838135113f9320736014db064947a83cbaa | dd19e78f91ef1bc2ce36877f0bef88de7c79907c23529bb95c37ca4ca8396c1c | null | [] | 91 |
2.4 | tensorbored-nightly | 2.21.0a20260220 | TensorBored: a PyTorch-first TensorBoard fork | TensorBored is a suite of web applications for inspecting and understanding
your training runs and graphs, with a focus on PyTorch compatibility.
This is a fork of TensorBoard. Install with ``pip install tensorbored``.
For PyTorch projects, use ``from tensorbored.torch import SummaryWriter`` —
a drop-in replacement that removes the need to install the original
``tensorboard`` package.
| null | TensorBored authors | null | null | null | Apache 2.0 | pytorch tensorboard tensor machine learning visualizer | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3 :: Only",
"Topic :: Scientific/Engineering :: Mathematics",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Libraries"
] | [] | https://github.com/Demonstrandum/tensorbored | null | >=3.9 | [] | [] | [] | [
"absl-py>=0.4",
"grpcio>=1.48.2",
"markdown>=2.6.8",
"numpy>=1.12.0",
"packaging",
"pillow",
"protobuf!=4.24.0,>=3.19.6",
"tensorboard-data-server<0.8.0,>=0.7.0",
"werkzeug>=1.0.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:38:19.645748 | tensorbored_nightly-2.21.0a20260220-py3-none-any.whl | 6,150,579 | 33/f6/87bcd6b812f6efc8012ade5b93fc6f8c38569433e772b4982118eb719936/tensorbored_nightly-2.21.0a20260220-py3-none-any.whl | py3 | bdist_wheel | null | false | 78763aa42369ea10fedbd6e918919aa6 | 1ec36a6a8abce79c57fb68c68f2de335caa837aee95faad27a3a5e0dfd2e9f42 | 33f687bcd6b812f6efc8012ade5b93fc6f8c38569433e772b4982118eb719936 | null | [
"LICENSE"
] | 74 |
2.3 | bplusplus | 2.1.1 | A simple method to create AI models for biodiversity, with collect and prepare pipeline | # B++ repository
[](https://zenodo.org/badge/latestdoi/765250194)
[](https://pypi.org/project/bplusplus/)
[](https://pypi.org/project/bplusplus/)
[](https://pypi.org/project/bplusplus/)
[](https://pepy.tech/project/bplusplus)
[](https://pepy.tech/project/bplusplus)
[](https://pepy.tech/project/bplusplus)
This project provides a complete, end-to-end pipeline for building a custom insect classification system. The framework is designed to be **domain-agnostic**, allowing you to train a powerful detection and classification model for **any insect species** by simply providing a list of names.
Using the `Bplusplus` library, this pipeline automates the entire machine learning workflow, from data collection to video inference.
## Key Features
- **Automated Data Collection**: Downloads hundreds of images for any species from the GBIF database.
- **Intelligent Data Preparation**: Uses a pre-trained model to automatically find, crop, and resize insects from raw images, ensuring high-quality training data.
- **Hierarchical Classification**: Trains a model to identify insects at three taxonomic levels: **family, genus, and species**.
- **Video Inference & Tracking**: Processes video files to detect, classify, and track individual insects over time, providing aggregated predictions.
## Pipeline Overview
The process is broken down into five main steps, all detailed in the `full_pipeline.ipynb` notebook:
1. **Collect Data**: Select your target species and fetch raw insect images from the web.
2. **Prepare Data**: Filter, clean, and prepare images for training.
3. **Train Model**: Train the hierarchical classification model.
4. **Validate Model**: Evaluate the performance of the trained model.
5. **Run Inference**: Run the full pipeline on a video file for real-world application.
## How to Use
### Prerequisites
- Python 3.10+
### Setup
1. **Create and activate a virtual environment:**
```bash
python3 -m venv venv
source venv/bin/activate
```
2. **Install the required packages:**
```bash
pip install bplusplus
```
### Running the Pipeline
The pipeline can be run step-by-step using the functions from the `bplusplus` library. While the `full_pipeline.ipynb` notebook provides a complete, executable workflow, the core functions are described below.
#### Step 1: Collect Data
Download images for your target species from the GBIF database. You'll need to provide a list of scientific names.
```python
import bplusplus
from pathlib import Path
# Define species and directories
names = ["Vespa crabro", "Vespula vulgaris", "Dolichovespula media"]
GBIF_DATA_DIR = Path("./GBIF_data")
# Define search parameters
search = {"scientificName": names}
# Run collection
bplusplus.collect(
group_by_key=bplusplus.Group.scientificName,
search_parameters=search,
images_per_group=200, # Recommended to download more than needed
output_directory=GBIF_DATA_DIR,
num_threads=5
)
```
#### Step 2: Prepare Data
Process the raw images to extract, crop, and resize insects. This step uses a pre-trained model to ensure only high-quality images are used for training.
```python
PREPARED_DATA_DIR = Path("./prepared_data")
bplusplus.prepare(
input_directory=GBIF_DATA_DIR,
output_directory=PREPARED_DATA_DIR,
img_size=640, # Target image size for training
conf=0.6, # Detection confidence threshold (0-1)
valid=0.1, # Validation split ratio (0-1), set to 0 for no validation
blur=None, # Gaussian blur as fraction of image size (0-1), None = disabled
)
```
**Note:** The `blur` parameter applies Gaussian blur before resizing, which can help reduce noise. Values are relative to image size (e.g., `blur=0.01` means 1% of the smallest dimension). Supported image formats: JPG, JPEG, and PNG.
#### Step 3: Train Model
Train the hierarchical classification model on your prepared data. The model learns to identify family, genus, and species.
```python
TRAINED_MODEL_DIR = Path("./trained_model")
bplusplus.train(
batch_size=4,
epochs=30,
patience=3,
img_size=640,
data_dir=PREPARED_DATA_DIR,
output_dir=TRAINED_MODEL_DIR,
species_list=names,
backbone="resnet50", # Choose: "resnet18", "resnet50", or "resnet101"
# num_workers=0, # Optional: force single-process loading (most stable)
# train_transforms=custom_transforms, # Optional: custom torchvision transforms
)
```
**Note:** The `num_workers` parameter controls DataLoader multiprocessing (defaults to 0 for stability). The `backbone` parameter allows you to choose between different ResNet architectures—use `resnet18` for faster training or `resnet101` for potentially better accuracy.
#### Step 4: Validate Model
Evaluate the trained model on a held-out validation set. This calculates precision, recall, and F1-score at all taxonomic levels.
```python
HIERARCHICAL_MODEL_PATH = TRAINED_MODEL_DIR / "best_multitask.pt"
results = bplusplus.validate(
species_list=names,
validation_dir=PREPARED_DATA_DIR / "valid",
hierarchical_weights=HIERARCHICAL_MODEL_PATH,
img_size=640, # Must match training
batch_size=32,
backbone="resnet50", # Must match training
)
```
#### Step 5: Run Inference on Video
Processes a video through a multi-phase pipeline: motion-based detection (GMM), Hungarian tracking, path topology confirmation, and hierarchical classification. Detection and tracking are powered by [BugSpot](bugspot/), a lightweight core that runs on any platform including edge devices.
The species list is automatically loaded from the model checkpoint.
```python
HIERARCHICAL_MODEL_PATH = TRAINED_MODEL_DIR / "best_multitask.pt"
results = bplusplus.inference(
video_path="my_video.mp4",
output_dir="./output",
hierarchical_model_path=HIERARCHICAL_MODEL_PATH,
backbone="resnet50", # Must match training
img_size=60, # Must match training
# --- Optional ---
# species_list=names, # Override species from checkpoint
# fps=None, # None = all frames, or set target FPS
# config="config.yaml", # Custom detection parameters (YAML/JSON)
# classify=False, # Detection only, NaN for classification
# save_video=True, # Annotated + debug videos
# crops=False, # Save crop per detection per track
# track_composites=False, # Composite image per track (temporal trail)
)
print(f"Confirmed: {results['confirmed_tracks']} / {results['tracks']} tracks")
```
**Output files:**
| File | Description | Flag |
|------|-------------|------|
| `{video}_results.csv` | Aggregated results per confirmed track | Always |
| `{video}_detections.csv` | Frame-by-frame detections | Always |
| `{video}_annotated.mp4` | Video with detection boxes and paths | `save_video=True` |
| `{video}_debug.mp4` | Side-by-side with GMM motion mask | `save_video=True` |
| `{video}_crops/` | Crop images per track | `crops=True` |
| `{video}_composites/` | Composite images per track | `track_composites=True` |
**Detection configuration** can be customized via a YAML/JSON file passed as `config=`. Download a template from the [releases page](https://github.com/Tvenver/Bplusplus/releases).
<details>
<summary><b>Full Configuration Parameters</b> (click to expand)</summary>
| Parameter | Default | Description |
|-----------|---------|-------------|
| **GMM Background Subtractor** | | *Motion detection model* |
| `gmm_history` | 500 | Frames to build background model |
| `gmm_var_threshold` | 16 | Variance threshold for foreground detection |
| **Morphological Filtering** | | *Noise removal* |
| `morph_kernel_size` | 3 | Morphological kernel size (NxN) |
| **Cohesiveness** | | *Filters scattered motion (plants) vs compact motion (insects)* |
| `min_largest_blob_ratio` | 0.80 | Min ratio of largest blob to total motion |
| `max_num_blobs` | 5 | Max separate blobs allowed in detection |
| `min_motion_ratio` | 0.15 | Min ratio of motion pixels to bbox area |
| **Shape** | | *Filters by contour properties* |
| `min_area` | 200 | Min detection area (px²) |
| `max_area` | 40000 | Max detection area (px²) |
| `min_density` | 3.0 | Min area/perimeter ratio |
| `min_solidity` | 0.55 | Min convex hull fill ratio |
| **Tracking** | | *Controls track behavior* |
| `min_displacement` | 50 | Min net movement for confirmation (px) |
| `min_path_points` | 10 | Min points before path analysis |
| `max_frame_jump` | 100 | Max jump between frames (px) |
| `max_lost_frames` | 45 | Frames before lost track deleted (e.g., 45 @ 30fps = 1.5s) |
| `max_area_change_ratio` | 3.0 | Max area change ratio between frames |
| **Tracker Matching** | | *Hungarian algorithm cost function* |
| `tracker_w_dist` | 0.6 | Weight for distance cost (0-1) |
| `tracker_w_area` | 0.4 | Weight for area cost (0-1) |
| `tracker_cost_threshold` | 0.3 | Max cost for valid match (0-1) |
| **Path Topology** | | *Confirms insect-like movement patterns* |
| `max_revisit_ratio` | 0.30 | Max ratio of revisited positions |
| `min_progression_ratio` | 0.70 | Min forward progression |
| `max_directional_variance` | 0.90 | Max heading variance |
| `revisit_radius` | 50 | Radius (px) for revisit detection |
</details>
### Customization
To train the model on your own set of insect species, you only need to change the `names` list in **Step 1**. The pipeline will automatically handle the rest.
```python
# To use your own species, change the names in this list
names = [
"Vespa crabro",
"Vespula vulgaris",
"Dolichovespula media",
# Add your species here
]
```
#### Handling an "Unknown" Class
To train a model that can recognize an "unknown" class for insects that don't belong to your target species, add `"unknown"` to your `species_list`. You must also provide a corresponding `unknown` folder containing images of various other insects in your data directories (e.g., `prepared_data/train/unknown`).
```python
# Example with an unknown class
names_with_unknown = [
"Vespa crabro",
"Vespula vulgaris",
"unknown"
]
```
## Directory Structure
The pipeline will create the following directories to store artifacts:
- `GBIF_data/`: Stores the raw images downloaded from GBIF.
- `prepared_data/`: Contains the cleaned, cropped, and resized images ready for training (`train/` and optionally `valid/` subdirectories).
- `trained_model/`: Saves the trained model weights (`best_multitask.pt`).
- `output/`: Inference results including annotated videos and CSV files.
# Citation
All information in this GitHub is available under MIT license, as long as credit is given to the authors.
**Venverloo, T., Duarte, F., B++: Towards Real-Time Monitoring of Insect Species. MIT Senseable City Laboratory, AMS Institute.**
| text/markdown | Titus Venverloo | tvenver@mit.edu | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"bugspot>=0.1.0",
"requests==2.25.1",
"pandas==2.1.4",
"ultralytics==8.3.173",
"pyyaml==6.0.1",
"tqdm==4.66.4",
"prettytable==3.7.0",
"pillow<12.0.0,>=10.0.0; sys_platform == \"win32\"",
"pillow<12.0.0,>=10.0.0; sys_platform == \"darwin\"",
"pillow<12.0.0,>=10.0.0; sys_platform == \"linux\"",
"torch<2.8.0,>=2.0.0; sys_platform == \"win32\"",
"torch<2.3.0,>=2.2.0; sys_platform == \"darwin\" and platform_machine == \"x86_64\"",
"torch<2.8.0,>=2.0.0; sys_platform == \"darwin\" and platform_machine == \"arm64\"",
"torch<2.8.0,>=2.0.0; sys_platform == \"linux\"",
"numpy<1.26.5,>=1.26.0; sys_platform == \"win32\"",
"numpy<1.27.0,>=1.26.0; sys_platform == \"darwin\" and platform_machine == \"arm64\"",
"numpy<1.27.0,>=1.26.0; sys_platform == \"darwin\" and platform_machine == \"x86_64\"",
"numpy<1.27.0,>=1.26.0; sys_platform == \"linux\" and platform_machine == \"aarch64\"",
"numpy<1.27.0,>=1.26.0; sys_platform == \"linux\" and platform_machine == \"x86_64\"",
"scikit-learn<1.7.0,>=1.3.0; sys_platform == \"win32\"",
"scikit-learn<1.8.0,>=1.4.0; sys_platform == \"darwin\" and platform_machine == \"arm64\"",
"scikit-learn<1.8.0,>=1.4.0; sys_platform == \"darwin\" and platform_machine == \"x86_64\"",
"scikit-learn<1.7.0,>=1.3.0; sys_platform == \"linux\" and platform_machine == \"aarch64\"",
"scikit-learn<1.8.0,>=1.4.0; sys_platform == \"linux\" and platform_machine == \"x86_64\"",
"pygbif==0.6.5",
"validators==0.33.0",
"tabulate==0.9.0"
] | [] | [] | [] | [] | poetry/2.1.3 CPython/3.10.12 Linux/6.8.0-94-generic | 2026-02-20T12:37:52.876988 | bplusplus-2.1.1.tar.gz | 49,963 | 66/1d/b704d84eba32ea6d648ca14f31939bab9d7cae38a9cdefacfb2f1fa9b7e8/bplusplus-2.1.1.tar.gz | source | sdist | null | false | fc833398b43a5b04cea693fc5f5a84d1 | fbf0a40d6bd4eae10d701beb0996b1083b9261a713a9a61a0e2dfa74a1c8f29d | 661db704d84eba32ea6d648ca14f31939bab9d7cae38a9cdefacfb2f1fa9b7e8 | null | [] | 246 |
2.4 | thai-backchannel | 0.3.1 | thai backchannel classifier - detect backchannels vs real responses in thai asr output | # thai backchannel classifier
detects thai backchannel responses (fillers like ครับ, ค่ะ, อืม) vs real user input for voice ai systems.
## why
thai voice bots using asr → llm → tts pipelines need to distinguish between backchannels (acknowledgment sounds that should be ignored) and real responses that need processing. simple exact matching fails on asr variants and misses edge cases.
## approach
gradient boosting classifier with 23 handcrafted thai-specific features:
| feature | importance |
|---|---|
| remaining_ratio | 0.9098 |
| has_request | 0.0406 |
| has_negation | 0.0274 |
| particle_ratio | 0.0108 |
key idea: strip known backchannel components from the text, measure what's left (`remaining_ratio`). if nothing remains, it's a backchannel.
### features
- **remaining_ratio**: strips known backchannel components, measures residual text
- polite particle detection (ครับ/ค่ะ/จ้ะ variants)
- backchannel sound patterns (อืม/อ๋อ/เออ with tone variants)
- question/negation/request/continuation markers
- handles asr misspellings (ค่า→ค่ะ, คับ→ครับ, อื้ม→อืม)
## results
### cross-validation
- **99.49% f1** (5-fold cv, gradient boosting)
- logistic regression baseline: 98.97% f1
### full training set
```
precision recall f1-score support
real_response 1.00 1.00 1.00 96
backchannel 1.00 1.00 1.00 194
accuracy 1.00 290
```
### test suite: 94/94 (100%)
the test suite (`tests/test_classifier.py`) covers:
**backchannels (49 cases):**
- basic polite particles: ครับ, ค่ะ, คับ, คะ, จ้ะ, จ้า
- dai + particle: ได้ครับ, ได้ค่ะ, ได้จ้ะ
- filler sounds: อืม, อือ, อื้อ, เออ, เอ่อ, อ่า
- oh: อ๋อ, อ๋อครับ, อ๋อค่ะ
- agreement: ใช่, จริง, ถูก, แน่นอน
- ok variants: โอเคครับ, โอเคค่ะ
- question-like: เหรอ, หรอ, งั้นเหรอ
- compound: ครับ ฮัลโหล, อ่ะ ใช่ๆๆ, อ่าฮะ ครับ
- asr tone variants: อื้ม, อ๊าา, อ้า, อึม
**real responses (45 cases):**
- greetings: สวัสดีครับ, ขอบคุณครับ
- negations: ไม่ครับ, ไม่ใช่ค่ะ, ยังครับ
- questions: ราคาเท่าไหร่ครับ, ทำไมครับ, กี่โมงครับ
- requests: ผมต้องการจองตั๋วครับ, ช่วยเช็คให้หน่อยได้ไหมครับ
- **tricky edge cases** (backchannel + continuation):
- "ใช่ แต่ว่า" → real (has continuation marker)
- "ครับ แล้วก็" → real
- "ได้ครับ แต่ขอเปลี่ยนวัน" → real
- "อ๋อ แล้วเรื่องที่สอง" → real
- "อืม แต่ว่าผมไม่แน่ใจ" → real
- short real: ไม่, ยัง, เอา, ได้เลย
## usage
```python
from detect import is_backchannel
is_bc, confidence = is_backchannel("ครับ") # (True, 1.0)
is_bc, confidence = is_backchannel("ไม่ครับ") # (False, 0.0)
is_bc, confidence = is_backchannel("ใช่ แต่ว่า") # (False, 0.0)
```
cli:
```bash
python detect.py ครับ
# 'ครับ' -> BACKCHANNEL (confidence: 1.0000)
```
## testing
```bash
python -m pytest tests/ -v
```
or without pytest:
```bash
python tests/test_classifier.py
```
## files
- `train.py` - training script with all data + features
- `detect.py` - inference module (import or cli)
- `backchannel_model.pkl` - trained model (~50kb)
- `tests/test_classifier.py` - comprehensive test suite (94 cases)
## requirements
- python 3.8+
- scikit-learn
- numpy
| text/markdown | null | "100x.fi" <kiri@100x.fi> | null | null | MIT | thai, nlp, backchannel, voice, asr, classifier | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Text Processing :: Linguistic"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"scikit-learn>=1.0",
"numpy>=1.20"
] | [] | [] | [] | [
"Homepage, https://github.com/100x-fi/backchannel-classifier",
"Repository, https://github.com/100x-fi/backchannel-classifier"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T12:37:19.778336 | thai_backchannel-0.3.1.tar.gz | 12,959 | db/d5/29669599554fc05ae05cf8150b8a47a99f6958bf431208952af90984a4a5/thai_backchannel-0.3.1.tar.gz | source | sdist | null | false | ce989a0f4b619104b921f22727a5d252 | 88647e97e4c302d66a8301fc10385a8ddd1a4391cc9b3c17127dba7987f4cf32 | dbd529669599554fc05ae05cf8150b8a47a99f6958bf431208952af90984a4a5 | null | [
"LICENSE"
] | 222 |
2.4 | openai-whisper-api-cli | 0.1.1 | Simple CLI wrapper for OpenAI Speech-to-Text API | # openai-whisper-api-cli
Simple Python CLI wrapper for OpenAI Speech-to-Text.
## Features
- Transcribe local audio/video files with OpenAI Speech-to-Text
- API key from `--api-key` or `OPENAI_API_KEY`
- Print result to stdout (default)
- Optionally write result to a file
- Supports multiple response formats
## Install (Recommended)
```bash
python3 -m pip install --user pipx
python3 -m pipx ensurepath
pipx install openai-whisper-api-cli
```
Verify:
```bash
owhisper --version
```
Upgrade:
```bash
pipx upgrade openai-whisper-api-cli
```
## Install From Source
```bash
python3 -m venv .venv
source .venv/bin/activate
pip install -e ".[dev]"
```
## Authentication
Set env var:
```bash
export OPENAI_API_KEY="sk-..."
```
Or pass key directly:
```bash
owhisper transcribe ./audio.mp3 --api-key "sk-..."
```
`--api-key` takes precedence over `OPENAI_API_KEY`.
## Usage
Print transcription to stdout:
```bash
owhisper transcribe ./audio.mp3
```
Write transcription to file:
```bash
owhisper transcribe ./audio.mp3 --output-file ./transcript.txt
```
Use custom model and response format:
```bash
owhisper transcribe ./audio.mp3 \
--model gpt-4o-transcribe \
--response-format json \
--language en
```
### Supported models
- `gpt-4o-transcribe`
- `gpt-4o-mini-transcribe`
- `gpt-4o-transcribe-diarize`
- `whisper-1`
Model list source:
- https://developers.openai.com/api/docs/guides/speech-to-text/
## CI and Publishing
GitHub Actions workflows:
- `.github/workflows/ci.yml`: runs tests on push/PR
- `.github/workflows/publish.yml`: builds and publishes to PyPI on tag push (`v*`)
### PyPI trusted publishing setup
1. Create your project on PyPI: `openai-whisper-api-cli`.
2. In PyPI project settings, add a Trusted Publisher:
- Owner: your GitHub org/user
- Repository: `openai-whisper-api-cli`
- Workflow: `publish.yml`
- Environment: `pypi`
3. In GitHub repo settings, ensure environment `pypi` exists (optional protection rules).
### Release
```bash
python -m pytest
python -m build
python -m twine check dist/*
git tag v0.1.0
git push origin v0.1.0
```
Pushing the tag triggers automated publish.
## Local manual publish (optional)
```bash
python -m build
python -m twine upload dist/*
```
## License
MIT (see `LICENSE`).
| text/markdown | null | null | null | null | null | openai, whisper, speech-to-text, transcription, cli | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Multimedia :: Sound/Audio :: Speech",
"Topic :: Software Development :: User Interfaces"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.1.7",
"openai>=1.0.0",
"build>=1.2.2; extra == \"dev\"",
"pytest>=8.2.0; extra == \"dev\"",
"twine>=5.1.1; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/NmadeleiDev/openai-whisper-api-cli",
"Issues, https://github.com/NmadeleiDev/openai-whisper-api-cli/issues",
"Repository, https://github.com/NmadeleiDev/openai-whisper-api-cli"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:36:46.295621 | openai_whisper_api_cli-0.1.1.tar.gz | 5,501 | 0e/fc/687bc0d04a54ce72dea64ecbcc038e33917174416c3d0b0beef7f79fcdb7/openai_whisper_api_cli-0.1.1.tar.gz | source | sdist | null | false | 05682f0886b5779cb1537cbad03f497f | 2def269dfcdf87dd7fcd26090d938c97071abfc3f194e2b4ee4d4d22f686a575 | 0efc687bc0d04a54ce72dea64ecbcc038e33917174416c3d0b0beef7f79fcdb7 | MIT | [
"LICENSE"
] | 233 |
2.4 | Sardou | 0.4.3 | Sardou TOSCA Library | # TOSCA in Swarmchestrate
This repository is home to TOSCA in the [Swarmchestrate](https://www.swarmchestrate.eu/) project, which will use TOSCA v2.0 to describe applications and capacities managed in a Swarmchestrate Universe.
## Sardou TOSCA Library
Sardou validates and extracts info from a Swarmchestrate TOSCA template.
### Prerequisites
- Python 3.11+
- Puccini: Should work with any 0.22.x version, but prefer the latest (currently unreleased) version. Build from source from [Go-Puccini](https://github.com/tliron/go-puccini) or use the prebuilts attached to [this release](https://github.com/Swarmchestrate/tosca/releases/tag/v0.2.4) in this repository
- Minimum GLIBC 2.34 (Ubuntu 22.04 or higher)
Install Puccini on Linux by:
```sh
wget https://github.com/Swarmchestrate/tosca/releases/download/v0.2.4/go-puccini_0.22.7-SNAPSHOT-3e85b40_linux_amd64.deb
sudo dpkg -i go-puccini_0.22.7-SNAPSHOT-3e85b40_linux_amd64.deb || sudo apt --fix-broken install -y
```
### Installation
Install using the PyPi package
```bash
pip install Sardou
```
### Usage
Import the Sardou TOSCA Library
```python
from sardou import Sardou # note the uppercase S
```
Create a new `Sardou` object, passing it the path to your Swarmchestrate TOSCA template.
This will validate the template and complete the representation, inheriting from parent
types.
```python
>>> tosca = Sardou("my_app.yaml")
Processed successfully: my_app.yaml
>>> tosca
{'description': 'stressng on Swarmchestrate', 'nodeTemplates': {'resource-1': {'metadata': {}, 'description': '', 'types': {'eu.swarmchestrate:0.1::EC2.micro.t3': {'description': 'An EC2 compute node from the University of Westminster provision\n', 'parent': 'eu.swarmchestrate:0.1::Resource'} ...
```
The template is not resolved at this point (i.e. statisfied requirements and created
relationships) - that functionality to come. If there are errors or warnings, they will be
presented at this time.
Get the raw, uncompleted (original YAML) with the `raw` attribute.
```python
>>> tosca.raw
{'tosca_definitions_version': 'tosca_2_0', 'description': 'stressng on Swarmchestrate', 'imports': [{'namespace': 'swch' ...
```
Grab the QoS requirements as a Python object with `get_qos()`
You could dump this to JSON or YAML.
```python
>>> tosca.get_qos()
[{'energy': {'type': 'swch:QoS.Energy.Budget', 'properties': {'priority': 0.3, 'target': 10}}}...
```
Grab the Resource requirements as a Python object with `get_requirements()`
You could dump this to JSON or YAML.
```python
>>> tosca.get_requirements()
{'worker-node': {'metadata': {'created_by': 'floria-tosca-lib', 'created_at': '2025-09-16T14:51:24Z', 'description': 'Generated from node worker-node', 'version': '1.0'}, 'capabilities': {'host': {'properties': {'num-cpus': {'$greater_than': 4}, 'mem-size': {'$greater_than': '8 GB'}}}, ...
```
Get the specification of the resources as a Python object with `get_cluster()`
You could dump this to JSON or YAML.
```python
>>> tosca.get_cluster()
{'resource-1': {'image_id': 'ami-0c02fb291006c7d929', 'instance_type': 't3.micro', 'key_name': 'mykey', 'region_name': 'us-east-1' ...
```
You can traverse YAML maps using dot notation if needed (which leads to some unexpected behaviour,
so this may not be a long-term feature)
```python
>>> tosca.nodeTemplates
{'resource-1': {'metadata': {}, 'description': '', 'types': {'eu.swarmchestrate:0.1::EC2.micro.t3' ...
```
## Devs
It is recommended that developers open a GitHub Codespace on this repository, which includes dependencies and a Makefile for running Puccini manually.
## TOSCA Template Validation with Puccini
This is an added feature that provides a Python validation library and script to check whether TOSCA service templates are valid using the [Go-Puccini](https://github.com/tliron/go-puccini) parser.
##### Validation Library (`lib/validation.py `)
- A library that defines the `validate_template()` function to validate a single TOSCA YAML file.
- Returns `True` if the template is valid, `False` if not.
##### Validation Script (`run_validation.py`)
- A script that searches the `templates/` folder and validates all `.yaml` files in one run.
- Prints total successes/failures and exits with code `1` if any file fails.
Run:
- `python3 run_validation.py`
##### Kubernetes Manifest Generator (manifestGenerator.py)
- Provides the function get_kubernetes_manifest(tosca_yaml: str, image_pull_secret: str = "test") -> list.
- **Purpose**: Converts a TOSCA YAML template into Kubernetes manifests (Deployments + Services).
- **Supported fields**: image, args, env, ports, volumes, nodeSelector, replicas, imagePullSecrets.
- Automatically injects an external imagePullSecret if provided.
###### **Input**:
- A valid TOSCA YAML template as a string.
- Optional: name of an imagePullSecret to include in all generated Deployments.
###### **Output:**
- A list of dictionaries representing Kubernetes manifests ready to be serialized to YAML.
##### Manifest Generation Script (run_manifest_generator.py)
- Takes a single TOSCA YAML file and generates Kubernetes manifests as a multi-document YAML file (output.yaml).
- Usage: update the TOSCA_FILE and OUTPUT_FILE variables in the script and run:
```python
python3 run_manifest_generator.py
```
## Contact
Contact Jay at Westminster for support with TOSCA and/or this repository.
| text/markdown | null | Jay DesLauriers <j.deslauriers@westminster.ac.uk> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"ruamel-yaml"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T12:36:39.663927 | sardou-0.4.3.tar.gz | 11,041 | d9/71/129dfc7f2ea5828f4f5a9a2c4f29e1d3771534d6921639579c327e4d1905/sardou-0.4.3.tar.gz | source | sdist | null | false | 346e946c9cb34900b2365b7c4d137cec | 834e6d8045b82fedf81f3505ed04a40de1de4abcfc9ff9f1049406b409d31bf2 | d971129dfc7f2ea5828f4f5a9a2c4f29e1d3771534d6921639579c327e4d1905 | null | [] | 0 |
2.4 | cognite-toolkit | 0.7.120 | Official Cognite Data Fusion tool for project templates and configuration deployment | # Cognite Data Fusion Toolkit
[](https://github.com/cognitedata/toolkit/actions/workflows/release.yaml)
[](https://github.com/cognitedata/toolkit)
[](https://pypi.org/project/cognite-toolkit/)
[](https://pypistats.org/packages/cognite-toolkit)
[](https://github.com/cognitedata/toolkit/blob/master/LICENSE)
[](https://hub.docker.com/r/cognite/toolkit)
[](https://github.com/astral-sh/ruff)
[](http://mypy-lang.org)
The CDF Toolkit is a command-line interface (`cdf`) used for configuring and administrating
Cognite Data Fusion (CDF) projects. It ships with modularised `templates` that helps you
configure Cognite Data Fusion according to best practices.
It supports three different modes of operation:
1. As an **interactive command-line tool** used alongside the Cognite Data Fusion web application to retrieve and
push configuration of the different Cognite Data Fusion services like data sets, data models, transformations,
and more. This mode also supports configuration of new Cognite Data Fusion projects to quickly get started.
2. As tool to support the **project life-cycle by scripting and automating** configuration and management of Cognite Data
Fusion projects where CDF configurations are kept as yaml-files that can be checked into version
control. This mode also supports DevOps workflows with development, staging, and production projects.
3. As a **tool to deploy official Cognite project templates** to your Cognite Data Fusion project. The tool comes
bundled with templates useful for getting started with Cognite Data Fusion, as well as for specific use cases
delivered by Cognite or its partners. You can also create your own templates and share them.
## Usage
Install the Toolkit by running:
```bash
pip install cognite-toolkit
```
Then run `cdf --help` to get started with the interactive command-line tool.
## For more information
More details about the tool can be found at
[docs.cognite.com](https://docs.cognite.com/cdf/deploy/cdf_toolkit/).
You can find an overview of the modules and packages in the
[module and package documentation](https://docs.cognite.com/cdf/deploy/cdf_toolkit/references/resource_library).
See [./CONTRIBUTING.md](./CONTRIBUTING.md) for information about how to contribute to the `cdf-tk` tool or
templates.
| text/markdown | Cognite AS | Cognite AS <support@cognite.com> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Build Tools",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"python-dotenv>=1.0.0",
"cognite-sdk<8.0.0,>=7.87.0",
"httpx>=0.28.1",
"pandas<3.0.0,>=1.5.3",
"pyyaml>=6.0.1",
"typer<1.0.0,>=0.12.0",
"rich>=13.9.4",
"questionary>=2.0.1",
"tomli<3.0.0,>=2.0.1; python_full_version < \"3.11\"",
"packaging>=25",
"typing-extensions>=4.0.0",
"toml>=0.10.2",
"sentry-sdk>=2.1.0",
"mixpanel>=4.10.1",
"pydantic>=2.11.0",
"python-dateutil>=2.9.0",
"pip>=25.0.1",
"filelock>=3.18.0",
"sqlparse>=0.5.3; extra == \"sql\"",
"pyarrow>=20.0.0; extra == \"table\"",
"openpyxl>=3.1.5; extra == \"table\"",
"cognite-neat>=1.0.39; extra == \"v08\""
] | [] | [] | [] | [
"Homepage, https://docs.cognite.com/cdf/deploy/cdf_toolkit/",
"Changelog, https://github.com/cognitedata/toolkit/releases",
"GitHub, https://github.com/cognitedata/toolkit",
"Documentation, https://docs.cognite.com/cdf/deploy/cdf_toolkit/references/resource_library"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T12:36:26.764714 | cognite_toolkit-0.7.120.tar.gz | 562,821 | 0b/b0/4101990b5d8d7d35e4f1c093d39fc06dea0063dd4e1468a042d19a51b8c7/cognite_toolkit-0.7.120.tar.gz | source | sdist | null | false | eac79917dce31a19fcf847058fe51a6b | 5b0580e4e2138fd45ffff3d50d2fb37a68d8556fe85a493384c50365e4867b7b | 0bb04101990b5d8d7d35e4f1c093d39fc06dea0063dd4e1468a042d19a51b8c7 | Apache-2.0 | [] | 272 |
2.4 | pupil-labs-neon-usb | 0.0.2 | Library for connecting to Neon via USB | # Pupil Labs Neon USB
[](https://github.com/pupil-labs/pl-neon-usb/actions/workflows/main.yml)
[](https://pupil-labs.github.io/pl-neon-usb/)
[](https://github.com/astral-sh/uv)
[](https://github.com/astral-sh/ruff)
[](https://github.com/pre-commit/pre-commit)
[](https://pypi.org/project/pupil-labs-neon-usb/)
[](https://pypi.org/project/pupil-labs-neon-usb/)
[](https://pupil-labs.com/)
Library for connecting to Neon via USB
## Installation
```
pip install pupil-labs-neon-usb
```
or
```bash
pip install -e git+https://github.com/pupil-labs/pl-neon-usb.git
```
| text/markdown | null | Pupil Labs GmbH <info@pupil-labs.com> | null | null | MIT | null | [
"Intended Audience :: Developers",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | <=3.11,>=3.10 | [] | [] | [] | [
"numpy<2",
"opencv-python>=4.11.0.86",
"pupil-labs-neon-recording",
"pupil-labs-neon-usb-imu>=1.0.0",
"pupil-labs-uvc>=1.0.0",
"pyusb>=1.3.1",
"matplotlib; extra == \"examples\"",
"tqdm>=4.67.1; extra == \"examples\""
] | [] | [] | [] | [
"Homepage, https://pupil-labs.github.io/pl-neon-usb",
"Documentation, https://pupil-labs.github.io/pl-neon-usb",
"Repository, https://github.com/pupil-labs/pl-neon-usb",
"Issues, https://github.com/pupil-labs/pl-neon-usb/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:35:59.965320 | pupil_labs_neon_usb-0.0.2.tar.gz | 176,362 | 62/9d/86ec4fa240adf7be8a51710ad5c42b6fafc9807d69f47b9903ea8681349f/pupil_labs_neon_usb-0.0.2.tar.gz | source | sdist | null | false | be30c7293bf3ce3bfcab1aecfb4f209d | c03801db24e4121d7a5d1df76994e838b9108d633538ff17adbb66e543db1743 | 629d86ec4fa240adf7be8a51710ad5c42b6fafc9807d69f47b9903ea8681349f | null | [
"LICENSE"
] | 216 |
2.4 | gw-skymap-finder | 0.1.1 | Gravitational wave skymap downloader and overlap analysis tools | # gw-skymap-finder
Tools for downloading and analyzing gravitational-wave skymaps from LIGO/Virgo GraceDB, with a focus on Binary Black Hole (BBH) events and sky-localization overlap analysis.
This package began as a notebook-based workflow for identifying event pairs with high sky overlap and is now packaged for reuse as a Python library.
---
## Features
- **GraceDB querying**
- Query recent superevents from GraceDB with configurable:
- Time window (e.g. last 32 months)
- False Alarm Rate (FAR) threshold
- Minimum BBH classification probability
- **Skymap download and organization**
- Download BAYESTAR and BILBY skymaps for each event
- Intelligent filename pattern matching for common GraceDB skymap names
- Skip known-bad / excluded files (e.g. by keyword)
- Extract basic FITS metadata (distance info, NSIDE, ordering, coordinate system)
- Save a JSON manifest of all downloaded skymaps
- **Notebook workflow (example)**
- Example Jupyter notebook showing:
- Querying events from GraceDB
- Computing overlap integrals between sky localizations
- Visualizing skymaps and high-overlap pairs
- Basic statistical analysis and plotting
---
## Installation
From PyPI:
pip install gw-skymap-finderThis installs the library package `skymap_finder` (import name) and its core dependencies.
---
## Quick Start
### 1. Import and initialize GraceDB client
import skymap_finder as sf
# Create a GraceDB client (requires network access and, for some endpoints, credentials)
client = sf.initialize_gracedb_client()### 2. Query BBH events
event_ids = sf.query_bbh_events(
client,
far_threshold=2.3e-5, # False Alarm Rate threshold
lookback_months=32, # Time window for events
bbh_probability_threshold=0.5,
)
print(f"Found {len(event_ids)} candidate BBH events")### 3. Download skymaps for those events
from pathlib import Path
output_dir = Path("./BBH_skymaps")
downloads = sf.download_skymaps_batch(
event_ids,
output_dir=output_dir,
save_manifest=True,
)
print(f"Downloaded {len(downloads)} skymaps to {output_dir}")Each `download` entry is a `SkymapMeta` dataclass with useful metadata (event ID, pipeline, local path, distance info, etc.).
---
## Package API
The main public objects are exported at the top level:
import skymap_finder as sf
sf.SkymapMeta
sf.initialize_gracedb_client
sf.download_skymap_for_event
sf.download_skymaps_batch
sf.query_bbh_events- **`SkymapMeta`**: dataclass describing a single skymap file and its metadata.
- **`initialize_gracedb_client()`**: returns a `GraceDb` REST client.
- **`download_skymap_for_event(client, event_id, output_dir)`**: attempt to download one or more skymaps for a single event.
- **`download_skymaps_batch(event_ids, output_dir, save_manifest=True)`**: batch-download skymaps for a list of event IDs, with an optional manifest.
- **`query_bbh_events(client, far_threshold, lookback_months, bbh_probability_threshold)`**: query for BBH-like events using p_astro classification files.
---
## Example Notebook
This repository includes a Jupyter notebook `skymap_finder.ipynb` that demonstrates:
- Connecting to GraceDB and querying events
- Downloading and caching skymaps
- Computing overlap integrals between skymaps
- Visualizing high-overlap sky localizations and distributions of overlaps
You can run it with:
jupyter notebook skymap_finder.ipynb(Ensure you have installed the extra scientific/plotting dependencies listed in `requirements.txt`.)
---
## Dependencies
Core dependencies include:
- `numpy`, `tqdm`
- `ligo.skymap`, `ligo.gracedb`
- `astropy`, `astropy-healpix`
- `healpy`
- `matplotlib`, `seaborn`
- `pathos`, `tqdm-pathos`
- `requests`
For a complete list, see `requirements.txt`.
---
## Development
Clone the repository and install in editable mode:
git clone https://github.com/your-username/gw-skymap-finder.git
cd gw-skymap-finder
pip install -e .You can then edit the code under `src/skymap_finder/` and rerun the notebook or scripts.
---
## License
This project is licensed under the MIT License.
---
## Citation
If you use this package or the associated methodology, please cite:
- Singer et al. (2014), *The First Two Years of Electromagnetic Follow-Up with Advanced LIGO and Virgo* (`https://doi.org/10.3847/1538-4357/aabfd2`)
- The LIGO/Virgo Collaboration skymap and GraceDB documentation
| text/markdown | Kaitlyn Pak | null | null | null | MIT | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"tqdm",
"healpy",
"ligo.skymap",
"ligo.gracedb",
"astropy",
"astropy-healpix",
"pathos",
"tqdm-pathos",
"matplotlib",
"seaborn",
"requests"
] | [] | [] | [] | [
"Homepage, https://github.com/yourname/skymap_finder"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-20T12:35:47.522406 | gw_skymap_finder-0.1.1.tar.gz | 3,696 | f9/80/a3c254fc0909b796fc163d9dafa5f281a4fc420fc8338fd0f65c9f4b8d94/gw_skymap_finder-0.1.1.tar.gz | source | sdist | null | false | e6a3744cb00c8ebe89db2136c0a8f25e | 8d8859cd0d9b950952b50b5ef7ecd6711803e5db51abf2d006c1e529b6513c5e | f980a3c254fc0909b796fc163d9dafa5f281a4fc420fc8338fd0f65c9f4b8d94 | null | [
"LICENSE"
] | 236 |
2.4 | filesystempack | 1.1.3 | File system to handle connection with microsevice | # filesystem-integration
Biblioteka służy do obsługi plików z mikroserwisu do twojego projektu.
## Instalacja
Postaw kontenery z mikroserwisem
https://github.com/gufi2115/Microservice-to-save-files
``pip install filesystempack``
## Jak używać jeśli używasz DRF
W setttings.py dodaj:
```python
INSTALLED_APPS = ["filesystempack.drf_filesystem"]
```
```python
FILES_MICROSERVICE_URL = "http://host:6767/api/file/"
```
```python
FILES_MICROSERVICE_API_KEY = API_KEY
```
W models.py:
```python
from filesystempack.drf_filesystem.models import FileInfoM
class TwójModel(FileInfoM):
pass
```
W serializers.py:
```python
from filesystempack.drf_filesystem.serializers import FileSerializer
class TwójSerializer(FileSerializer):
class Meta:
model = TwójModel
fields = FileSerializer.Meta.fields + ('twoje_pola')
read_only_fields = FileSerializer.Meta.read_only_fields + ('twoje_pola')
```
W views.py:
```python
from filesystempack.drf_filesystem.views import FileViewSet
class TwójViewSet(FileViewSet):
queryset = TwójModel
serializer_class = TwójSerializer
```
## Jak używać bez DRF
```from filesystempack.filesystem import Filesystem```
Storzenie instancji na przykład w helpers.py
```file_system = Filesystem(url="http://host:6767/api/file/", api_key=twój_api_key_z_mikroserwisu)```
POST
``uuid = file_system.save_file(file=plik, content_type=mime_type_opcjonalnie)``
GET
``file, content_type = file_system.get_file(uuid)``
DELETE
``delete = file_system.delete_file(uuid)``
status
``status = file_system.status`` | text/markdown | null | buber2006xdd@gmail.com | null | null | MIT | Connection, File handling, Microservice | [
"Programming Language :: Python"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"django>=5.2.9",
"djangorestframework>=3.16.1",
"niquests",
"python-magic"
] | [] | [] | [] | [
"Repository, https://github.com/gufi2115/filesystem-integration",
"Microservice_repository, https://github.com/gufi2115/Microservice-to-save-files"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-20T12:35:46.209972 | filesystempack-1.1.3.tar.gz | 560,281 | d1/e0/00ab02b50c409c7da6daacd521a34721700ef72e0568b0fb9cad188f7d47/filesystempack-1.1.3.tar.gz | source | sdist | null | false | 7199386e7c846a093ccbe30244b80aa4 | 9de70265f4033a1ea71b9eecc8bb995376e74b5e411f75fe7009d2d8f656dc8f | d1e000ab02b50c409c7da6daacd521a34721700ef72e0568b0fb9cad188f7d47 | null | [] | 240 |
2.4 | seeme | 0.42.0 | No-Code/Low Code AI Platform: Innovate. Integrate. Iterate. | # Welcome to SeeMe.ai
SeeMe.ai is a no/low code AI platform aiming to be the simplest way you create, use, and share AI.
You can use SeeMe.ai without any code to automate the full AI lifecycle of your datasets and models.
The Python SDK gives easy access to all of your datasets, models, jobs, ... on the platform.
# Installation
```bash
$ pip install seeme
```
# Getting started
```Python
from seeme import Client
cl = Client()
# -- Registration --
my_username = # example: "my_username"
my_email = # example: "jan.vandepoel@seeme.ai"
my_password = # example: "supersecurepassword"
my_firstname = # example: "Jan"
my_name = # example: "Van de Poel"
cl.register(
username=my_username,
email=my_email,
password=my_password,
firstname=my_firstname,
name=my_name
)
# -- Log in --
cl.login(username, password)
# -- Log out --
cl.logout()
```
# Datasets
Manage the entire lifecyle of your datasets:
* create
* manage
* version
* label
* annotate
* import/export
```Python
from seeme import Dataset, DatasetContentType
# -- Get datasets --
datasets = cl.get_datasets()
my_dataset = Dataset(
name= "Cloud classifier",
description= "Classify clouds from pictures",
default_splits= True, # If `True`, adds 'train', 'valid', and 'test' default_splits
content_type= DatasetContentType.IMAGES,
multi_label= False
}
my_dataset = cl.create_dataset(my_dataset)
```
Checkout the [dataset documentation](https://docs.seeme.ai/python-sdk/#datasets) to see all possibilities and detailed guides.
# Models
Manage the entire lifecycle of your AI models:
* create
* manage
* version
* converst
* predicti
* import/export
```Python
from seeme import Model, Framework, ApplicationType
# -- Get models --
models = cl.get_models()
# -- Application ID --
application_id = cl.get_application_id(
base_framework=Framework.PYTORCH,
framework=Framework.FASTAI,
base_framework_version=str(torch.__version__),
framework_version=str(fastai.__version__),
application=ApplicationType.IMAGE_CLASSIFICATION
)
# -- Create model --
model_name = "Cloud classifier"
description = "Classify clouds from images"
my_model = Model(
name= model_name,
description= description,
application_id= application_id,
auto_convert= True # Automatically converts your model to ONNX, CoreML, and TensorFlow Lite.
)
my_model = cl.create_model(my_model)
model_file_location = "my_exported_model.pkl"
cl.upload_model(my_model.id, model_file_location)
image_location = "my_image.png"
cl.inference(my_model.id, image_location)
```
Checkout the [model] documentation](https://docs.seeme.ai/python-sdk/#models) to see all possibilities and detailed guides.
# Jobs
Schedule training, validation, and model conversion jobs with a simple command:
```Python
from seeme import Job, JobItem, JobType, ValueType
jobs = cl.get_jobs()
job = Job(
name= "v3 image classifier",
description= "A new dataset for an improved model",
application_id= application_id,
job_type= JobType.TRAINING,
dataset_id= dataset_id,
dataset_version_id= datset_version_id,
model_id= model_id,
model_version_id= model_version_id,
items= [
JobItem(
name= "image_size",
value= "224",
value_type= ValueType.INT
),
JobItem(
name= "arch",
value= "resnet50",
value_type= ValueType.TEXT
)
]
)
```
# Applications
[SeeMe.ai](https://seeme.ai) automates the full lifecycle of data and models for a wide range of AI applications, such as:
- image classification
- object detection
- structured data
- language models
- multi lingual text classification
- object character recognition (OCR)
- named entity recognition (NER)
for a number of AI frameworks and their versions:
- [fastai](https://fast.ai)
- [ONNX](https://onnxruntime.ai)
- [Core ML](https://developer.apple.com/documentation/coreml)
- [TensorFlow Lite](https://www.tensorflow.org/lite)
- [PyTorch](https://pytorch.org)
- [Yolo v4](https://github.com/AlexeyAB/darknet)
- [Spacy](https://spacy.io/)
- [Tesseract](https://github.com/tesseract-ocr/tesseract)
- [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)
- [Llama-cpp-python](https://github.com/abetlen/llama-cpp-python)
For a full list of frameworks and their versions:
```python
# -- Get applications --
all_applications = cl.get_applications()
print(all_applications)
```
# SDK Documentation
For more detailed SDK documentation see https://docs.seeme.ai.
| text/markdown | Jan Van de Poel | jan.vandepoel@seeme.ai | null | null | Apache | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | https://seeme.ai | null | >=3.7.0 | [] | [] | [] | [
"requests>=2.18.4",
"requests-toolbelt==0.10.1",
"python-dotenv",
"pydantic<3.0.0,>=2.0.0",
"urllib3==1.26.15",
"pandas",
"dill; extra == \"storage\"",
"bm25s; extra == \"search\"",
"numba; extra == \"search\"",
"pypdf; extra == \"documents\"",
"python-docx; extra == \"documents\"",
"pycryptodome; extra == \"documents\"",
"nltk; extra == \"documents\"",
"sentence-transformers; extra == \"documents\"",
"ollama; extra == \"ollama\"",
"instructor; extra == \"ollama\"",
"vllm; extra == \"vllm\"",
"beautifulsoup4; extra == \"web\"",
"dill; extra == \"all\"",
"bm25s; extra == \"all\"",
"pypdf; extra == \"all\"",
"python-docx; extra == \"all\"",
"pycryptodome; extra == \"all\"",
"ollama; extra == \"all\"",
"instructor; extra == \"all\"",
"vllm; extra == \"all\"",
"nltk; extra == \"all\"",
"beautifulsoup4; extra == \"all\"",
"sentence-transformers; extra == \"all\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.9 | 2026-02-20T12:35:21.969633 | seeme-0.42.0-py3-none-any.whl | 31,749 | fb/1b/16217ef73084cb3c39589f8c2d01e2030c3b5062afbc906fedf41c60dcc3/seeme-0.42.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 5d4a182975b571473b4d738529967311 | 59a2f813196ae23ddcd5c9e1fb2b0d770f80b36428572f6df6a9caacb76d16e5 | fb1b16217ef73084cb3c39589f8c2d01e2030c3b5062afbc906fedf41c60dcc3 | null | [] | 95 |
2.4 | sahaidachny | 0.7.4 | Hierarchical task planning and autonomous agentic execution for Claude Code | <p align="center">
<img src="assets/logo.png" alt="Sahaidachny" width="180">
</p>
<h1 align="center">Sahaidachny</h1>
<p align="center">
<strong>Autonomous AI agent orchestrator for hierarchical task execution in Claude Code and Codex</strong>
</p>
<p align="center">
<a href="https://github.com/roman-romanov-o/sahaidachny/actions/workflows/ci.yml"><img src="https://github.com/roman-romanov-o/sahaidachny/actions/workflows/ci.yml/badge.svg" alt="CI"></a>
<a href="https://pypi.org/project/sahaidachny/"><img src="https://img.shields.io/pypi/v/sahaidachny.svg" alt="PyPI"></a>
<a href="https://pypi.org/project/sahaidachny/"><img src="https://img.shields.io/pypi/pyversions/sahaidachny.svg" alt="Python Versions"></a>
</p>
<p align="center">
<a href="#installation">Installation</a> •
<a href="#quick-start">Quick Start</a> •
<a href="#how-it-works">How It Works</a> •
<a href="#documentation">Documentation</a>
</p>
---
> Named after [Petro Sahaidachny](https://en.wikipedia.org/wiki/Petro_Konashevych-Sahaidachny), the legendary Ukrainian Cossack hetman known for strategic planning and decisive execution.
## What is Sahaidachny?
Sahaidachny solves a fundamental problem in AI-assisted coding: **how to reliably implement complex features that span multiple files, require architectural decisions, and need verification**.
It's a Claude Code plugin for planning plus a runner-agnostic execution loop that enables:
- **Structured Planning** — Build hierarchical task specifications with user stories, design decisions, API contracts, and test specs
- **Autonomous Execution** — Run agentic loops across multiple context windows that implement, verify, and iterate
- **State Persistence** — Maintain learnings and progress between iterations, enabling resume after interruption
### Why Not Just Prompt Claude?
| Aspect | Simple Prompting | Sahaidachny |
|--------|------------------|-------------|
| Task structure | Single prompt | Hierarchical artifacts |
| Planning | Ad-hoc | Guided workflow |
| Implementation | One-shot | Iterative with feedback |
| Verification | Manual | Automated DoD checks |
| Code quality | Hope for the best | Ruff, ty, complexity checks |
| State | Lost on context switch | Persisted to disk |
## Installation
### Complete Installation Guide (From Scratch)
Don't have Python or any tools installed? No problem! Follow these steps:
#### Step 1: Install Python 3.11+
**macOS:**
```bash
# Using Homebrew (recommended)
brew install python@3.11
```
**Linux (Ubuntu/Debian):**
```bash
sudo apt update
sudo apt install python3.11 python3.11-venv python3-pip
```
**Windows:**
Download from [python.org](https://www.python.org/downloads/) (version 3.11 or higher)
#### Step 2: Install uv (Fast Python Package Manager)
```bash
# macOS/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows (PowerShell)
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
Restart your terminal after installation.
#### Step 3: Install Sahaidachny
```bash
uv tool install sahaidachny
```
**Alternative options:**
Using pipx (recommended for CLI tools):
```bash
pipx install sahaidachny
```
Using pip:
```bash
pip install sahaidachny
```
#### Step 4: Install a CLI for Planning
Claude Code is recommended for `/saha:*` slash-command planning:
```bash
# macOS/Linux
curl -fsSL https://install.claude.ai | sh
# Verify installation
claude --version
```
For Windows or detailed instructions, see: https://docs.anthropic.com/en/docs/claude-code
Optional CLIs:
```bash
# Codex CLI
codex --version
# Gemini CLI
gemini --version
```
#### Step 5: Verify Everything Works
```bash
# Check Sahaidachny
saha version
saha tools
# Check Claude Code
claude --version
```
You should see version information for both tools. You're ready to go! 🚀
### Optional: Install Quality Tools
For the execution loop to run code quality checks, install these tools:
```bash
uv tool install ruff # Linting and formatting
uv tool install ty # Type checking
uv tool install complexipy # Complexity analysis
uv pip install pytest # Testing
```
### Install from Source (For Development)
```bash
git clone https://github.com/roman-romanov-o/sahaidachny.git
cd sahaidachny
uv tool install .
```
## Quick Start
### 1. Sync Artifacts to Local CLI Directories
```bash
# Sync .claude, .codex, and .gemini in current project
saha sync --target all
```
### 2. Launch Your Preferred Planning CLI
```bash
saha claude
# or
saha codex
# or
saha gemini
```
`/saha:*` slash commands are Claude Code features. For Codex/Gemini, use synced artifacts in `.codex/` or `.gemini/` as local planning resources.
### 3. Initialize a Task
```bash
# In Claude Code:
/saha:init user-authentication --mode=full
```
### 4. Plan the Task
```bash
/saha:research # Explore codebase (for existing projects)
/saha:task # Define what to build
/saha:stories # Generate user stories
/saha:verify # Approve artifacts
/saha:plan # Create implementation phases
```
### 5. Execute Autonomously
```bash
# Back in terminal:
saha run task-01
```
To run execution agents with Codex instead of Claude Code, set:
```bash
export SAHA_AGENTS__DEFAULT_RUNNER=codex
```
Or run a single task with Codex:
```bash
saha run task-01 --runner codex
```
### 6. Monitor Progress
```bash
saha status task-01 --verbose
```
## How It Works
Sahaidachny operates in two phases:
### Phase 1: Planning (Interactive)
You work with Claude Code using slash commands to create structured task artifacts:
```
/saha:init → /saha:research → /saha:task → /saha:stories → /saha:plan
```
This produces a task folder with:
```
task-01/
├── task-description.md # What to build
├── user-stories/ # Requirements with acceptance criteria
├── design-decisions/ # Architecture decisions
├── implementation-plan/ # Phased execution steps
└── test-specs/ # Test specifications
```
### Phase 2: Execution (Autonomous)
The agentic loop runs without intervention:
```
┌─────────────────┐
│ Implementation │ ← Write code according to plan
└────────┬────────┘
▼
┌─────────────────┐
│ QA │ ← Verify acceptance criteria
└────────┬────────┘
│
DoD achieved? ──No──┐
│ │
Yes │
▼ │
┌─────────────────┐ │
│ Code Quality │ │
└────────┬────────┘ │
│ │
Quality passed? ─No──┤
│ │
Yes │
▼ ▼
┌─────────────────┐ ┌──────────┐
│ Manager │ │ fix_info │
└────────┬────────┘ └────┬─────┘
▼ │
┌─────────────────┐ │
│ DoD Check │ │
└────────┬────────┘ │
│ │
Task complete? ──No────┘
│
Yes
▼
DONE
```
Each iteration learns from previous failures via `fix_info`, enabling targeted fixes.
## Planning Commands
| Command | Purpose |
|---------|---------|
| `/saha:init` | Create task folder structure |
| `/saha:research` | Explore codebase patterns |
| `/saha:task` | Define task description |
| `/saha:stories` | Generate user stories |
| `/saha:decide` | Record design decisions |
| `/saha:contracts` | Define API contracts |
| `/saha:test-specs` | Write test specifications |
| `/saha:plan` | Create implementation phases |
| `/saha:verify` | Approve artifacts |
| `/saha:status` | Show planning progress |
## Execution Commands
| Command | Purpose |
|---------|---------|
| `saha run <task-id>` | Execute task autonomously |
| `saha resume <task-id>` | Resume interrupted execution |
| `saha status [task-id]` | Check execution status |
| `saha tools` | List available quality tools |
| `saha clean [task-id]` | Remove execution state |
| `saha sync [--target ...]` | Sync local CLI artifacts |
| `saha claude` | Launch Claude Code with plugin |
| `saha codex` | Launch Codex CLI with synced artifacts |
| `saha gemini` | Launch Gemini CLI with synced artifacts |
To stop a running loop, press `Ctrl+C`. Sahaidachny will stop the current agent, run the Manager to update task artifacts, and mark the task as stopped so you can resume later.
## Code Quality Tools
The execution loop integrates with:
- **[Ruff](https://github.com/astral-sh/ruff)** — Fast Python linter
- **[ty](https://github.com/astral-sh/ty)** — Fast Python type checker
- **[complexipy](https://github.com/rohaquinern/complexipy)** — Cognitive complexity analyzer
- **[pytest](https://pytest.org)** — Test runner
## Configuration
Configure via environment variables (prefix: `SAHA_`) or `.env` file:
```bash
SAHA_MAX_ITERATIONS=15
SAHA_RUNNER=claude
SAHA_TOOL_COMPLEXITY_THRESHOLD=20
SAHA_HOOK_NTFY_ENABLED=true
# Use Codex for execution agents
# SAHA_AGENTS__DEFAULT_RUNNER=codex
# SAHA_CODEX_MODEL=o3
# SAHA_CODEX_DANGEROUSLY_BYPASS_SANDBOX=false
# SAHA_CLAUDE_DANGEROUSLY_SKIP_PERMISSIONS=false
```
## Documentation
- **[User Guide](docs/user-guide.md)** — Complete usage guide
- **[Architecture](docs/architecture.md)** — Developer reference
## Status
**Alpha** — Actively developed. API may change.
## License
[MIT](LICENSE)
---
<p align="center">
<sub>Built for <a href="https://claude.ai/code">Claude Code</a> planning and multi-runner execution (Claude Code, Codex, Gemini)</sub>
</p>
| text/markdown | null | Roman Romanov <roman.romanov.4work@gmail.com> | null | null | null | agents, ai, automation, claude, llm, task-planning, workflow | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"pydantic-settings>=2.0",
"pydantic>=2.0",
"pyyaml>=6.0",
"rich>=13.0",
"typer>=0.12.0",
"anthropic>=0.40.0; extra == \"anthropic\"",
"mypy>=1.10; extra == \"dev\"",
"pytest-cov>=5.0; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.5; extra == \"dev\"",
"testcontainers>=4.0; extra == \"dev\"",
"types-pyyaml>=6.0; extra == \"dev\"",
"complexipy>=0.4; extra == \"tools\"",
"ruff>=0.5; extra == \"tools\"",
"ty>=0.0.1; extra == \"tools\""
] | [] | [] | [] | [
"Homepage, https://github.com/roman-romanov-o/sahaidachny",
"Repository, https://github.com/roman-romanov-o/sahaidachny",
"Issues, https://github.com/roman-romanov-o/sahaidachny/issues",
"Changelog, https://github.com/roman-romanov-o/sahaidachny/blob/main/CHANGELOG.md",
"Documentation, https://github.com/roman-romanov-o/sahaidachny#readme"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:35:01.748762 | sahaidachny-0.7.4.tar.gz | 124,109 | 29/12/4d9a2fcbdb5dc75a3ba6e0ce84c3964a30ff4816cbf18d838ea9e82c0c13/sahaidachny-0.7.4.tar.gz | source | sdist | null | false | 2400b02a5926002248b3e6cdbf084929 | a3268711103480a2172ea5e82f95d803859caa08e29da9107f1213e3b4450534 | 29124d9a2fcbdb5dc75a3ba6e0ce84c3964a30ff4816cbf18d838ea9e82c0c13 | MIT | [
"LICENSE"
] | 215 |
2.1 | odoo-addon-auth-jwt | 18.0.1.0.2 | JWT bearer token authentication. | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
========
Auth JWT
========
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:0f9850eea2daf7003512ee2b445ac6de73eb66b8264c0c463354414a8bc61236
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-LGPL--3-blue.png
:target: http://www.gnu.org/licenses/lgpl-3.0-standalone.html
:alt: License: LGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fserver--auth-lightgray.png?logo=github
:target: https://github.com/OCA/server-auth/tree/18.0/auth_jwt
:alt: OCA/server-auth
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/server-auth-18-0/server-auth-18-0-auth_jwt
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/server-auth&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
JWT bearer token authentication.
**Table of contents**
.. contents::
:local:
Installation
============
This module requires the ``pyjwt`` library to be installed.
Usage
=====
This module lets developpers add a new ``jwt`` authentication method on
Odoo controller routes.
To use it, you must:
- Create an ``auth.jwt.validator`` record to configure how the JWT token
will be validated.
- Add an ``auth="jwt_{validator-name}"`` or
``auth="public_or_jwt_{validator-name}"`` attribute to the routes you
want to protect where ``{validator-name}`` corresponds to the name
attribute of the JWT validator record.
The ``auth_jwt_demo`` module provides examples.
The JWT validator can be configured with the following properties:
- ``name``: the validator name, to match the
``auth="jwt_{validator-name}"`` route property.
- ``audience``: a comma-separated list of allowed audiences, used to
validate the ``aud`` claim.
- ``issuer``: used to validate the ``iss`` claim.
- Signature type (secret or public key), algorithm, secret and JWK URI
are used to validate the token signature.
In addition, the ``exp`` claim is validated to reject expired tokens.
If the ``Authorization`` HTTP header is missing, malformed, or contains
an invalid token, the request is rejected with a 401 (Unauthorized)
code, unless the cookie mode is enabled (see below).
If the token is valid, the request executes with the configured user id.
By default the user id selection strategy is ``static`` (i.e. the same
for all requests) and the selected user is configured on the JWT
validator. Additional strategies can be provided by overriding the
``_get_uid()`` method and extending the ``user_id_strategy`` selection
field.
The selected user is *not* stored in the session. It is only available
in ``request.uid`` (and thus it is the one used in ``request.env``). To
avoid any confusion and mismatches between the bearer token and the
session, this module rejects requests made with an authenticated user
session.
Additionally, if a ``partner_id_strategy`` is configured, a partner is
searched and if found, its id is stored in the
``request.jwt_partner_id`` attribute. If ``partner_id_required`` is set,
a 401 (Unauthorized) is returned if no partner was found. Otherwise
``request.jwt_partner_id`` is left falsy. Additional strategies can be
provided by overriding the ``_get_partner_id()`` method and extending
the ``partner_id_strategy`` selection field.
The decoded JWT payload is stored in ``request.jwt_payload``.
The ``public_auth_jwt`` method delegates authentication to the standard
Odoo ``public`` method when the Authorization header is not set. If it
is set, the regular JWT authentication is performed as described above.
This method is useful for public endpoints that need to work for
anonymous users, but can be enhanced when an authenticated user is know.
A typical use case is a "add to cart" endpoint that can work for
anonymous users, but can be enhanced by binding the cart to a known
customer when the authenticated user is known.
You can enable a cookie mode on JWT validators. In this case, the JWT
payload obtained from the ``Authorization`` header is returned as a
Http-Only cookie. This mode is sometimes simpler for front-end
applications which do not then need to store and protect the JWT token
across requests and can simply rely on the cookie management mechanisms
of browsers. When both the ``Authorization`` header and a cookie are
provided, the cookie is ignored in order to let clients authenticate
with a different user by providing a new JWT token.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/server-auth/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/server-auth/issues/new?body=module:%20auth_jwt%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* ACSONE SA/NV
Contributors
------------
- Stéphane Bidoul <stephane.bidoul@acsone.eu>
- Mohamed Alkobrosli <malkobrosly@kencove.com>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
.. |maintainer-sbidoul| image:: https://github.com/sbidoul.png?size=40px
:target: https://github.com/sbidoul
:alt: sbidoul
Current `maintainer <https://odoo-community.org/page/maintainer-role>`__:
|maintainer-sbidoul|
This module is part of the `OCA/server-auth <https://github.com/OCA/server-auth/tree/18.0/auth_jwt>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | ACSONE SA/NV,Odoo Community Association (OCA) | support@odoo-community.org | null | null | LGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)"
] | [] | https://github.com/OCA/server-auth | null | >=3.10 | [] | [] | [] | [
"cryptography",
"odoo==18.0.*",
"pyjwt"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T12:35:00.152904 | odoo_addon_auth_jwt-18.0.1.0.2-py3-none-any.whl | 43,146 | 22/31/4aeb979df8a85b2d175212bfff7e29281231c7d2435925cf9b5545f336d5/odoo_addon_auth_jwt-18.0.1.0.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 33c2309fc695688dd8385bb7d6e9e1e3 | 55478cc6415613b46134bdfdc261d643ca6fbb940e34f3e7b21110e21080deae | 22314aeb979df8a85b2d175212bfff7e29281231c7d2435925cf9b5545f336d5 | null | [] | 97 |
2.4 | coldpy | 0.1.0 | Analyze Python startup import performance and memory usage | # ColdPy
ColdPy profiles Python startup import cost by measuring import time and memory per module.
It is built for serverless, microservices, and large Python apps where cold start matters.
## What it measures
- Import duration (milliseconds)
- Import memory peak (MB) using `tracemalloc`
- Per-module status (success/error)
- Heavy module hints for lazy loading opportunities
## Safety caveat
ColdPy measures *real imports*, so target module import code is executed in isolated subprocesses.
This prevents state leakage between modules, but import side effects in target code may still occur.
## Install
```bash
uv sync
```
## Usage
```bash
coldpy scan
coldpy scan ./myproject
coldpy scan ./myproject --json report.json
coldpy scan ./myproject --exclude "migrations/**" --exclude "scripts/**"
coldpy top 10
coldpy top 20 --sort memory --threshold-mb 20
```
## Commands
- `coldpy scan [PATH=. ] [--json OUTPUT_JSON] [--threshold-ms N] [--threshold-mb N] [--no-cache]`
- `coldpy scan PATH [--python PYTHON] [--env-file ENV_FILE] [--no-project-env] [--exclude PATTERN]`
- `coldpy top [N=10] [--sort time|memory] [--threshold-ms N] [--threshold-mb N]`
`coldpy top` reads `./.coldpy/cache.json` and fails if no cache exists.
For `scan`, ColdPy auto-detects project virtualenv Python in `.venv`, `venv`, or `env`
and auto-loads environment variables from `.env`/`.env.local` when present.
Use `--python` and `--env-file` only when you need to override auto-detection.
ColdPy also excludes common migration paths by default (`alembic/**`, `migrations/**`).
## JSON schema (v1)
```json
{
"schema_version": "1.0",
"generated_at": "2026-02-20T10:00:00+00:00",
"project_root": "/path/to/project",
"settings": {
"threshold_ms": 100,
"threshold_mb": 50,
"exclusions": ["tests", "venv"]
},
"summary": {
"total_modules": 3,
"scanned_modules": 2,
"failed_modules": 1
},
"modules": [
{
"name": "pkg.fast",
"file": "/path/to/project/pkg/fast.py",
"import_time_ms": 1.234,
"memory_mb": 0.123,
"status": "ok",
"error": null,
"notes": []
}
]
}
```
## Cache behavior
- Cache path: `./.coldpy/cache.json`
- Written by `scan` by default
- Disable with `--no-cache`
- Read by `top`
## Troubleshooting
- `Cache not found`: run `coldpy scan <path>` first.
- `No Python modules found`: verify path and exclusions.
- Import failures: check module side effects and importability from project root.
## PyPI release setup
GitHub workflows are included in `/Users/denis/Documents/ColdPy/.github/workflows`:
- `ci.yml`: test matrix on Python 3.10/3.11/3.12.
- `package.yml`: build and validate `sdist` + `wheel`.
- `publish.yml`: publish on GitHub Release (PyPI) or manual dispatch (TestPyPI/PyPI).
Recommended publishing model is Trusted Publisher (OIDC):
1. Create a PyPI project for `coldpy` (and optionally a TestPyPI project).
2. In PyPI project settings, add your GitHub repo as a trusted publisher.
3. Create a GitHub Release to publish to PyPI.
4. Use workflow dispatch with `target=testpypi` for preflight package checks.
If you prefer API tokens instead of OIDC, set `password` input in the publish action
and store the token in GitHub Secrets.
| text/markdown | null | null | null | null | null | cli, cold-start, imports, performance, profiling, python | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Testing",
"Topic :: System :: Benchmark"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"rich>=13.7.0",
"typer>=0.12.0"
] | [] | [] | [] | [
"Homepage, https://github.com/Eaglemann/ColdPy.git",
"Repository, https://github.com/Eaglemann/ColdPy.git",
"Issues, https://github.com/denis/ColdPy/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:34:50.863895 | coldpy-0.1.0.tar.gz | 49,397 | 88/86/fc5b39341311d0cdbc30b3433d63b64e8e774915252c233a47fb8a5a6e1b/coldpy-0.1.0.tar.gz | source | sdist | null | false | c9c34a2a4b804404cedd48df2b64086e | 2366254871bdd0b86cdd56ce70a65c91a5d63884cdc22da4108bceb2ef1b9b54 | 8886fc5b39341311d0cdbc30b3433d63b64e8e774915252c233a47fb8a5a6e1b | MIT | [
"LICENSE"
] | 227 |
2.3 | voltarium | 0.5.0 | Asynchronous Python client for CCEE (Brazilian Electric Energy Commercialization Chamber) API | # Voltarium
[](https://github.com/joaodaher/voltarium-python/actions/workflows/ci.yml)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/Apache-2.0)
**Modern, asynchronous Python client for the CCEE (Brazilian Electric Energy Commercialization Chamber) API.** Built with Python 3.13+ and designed for high-performance energy sector applications.
## 🚀 Key Features
- **🔥 Asynchronous**: Built with `httpx` and `asyncio` for maximum performance
- **🔒 Type Safe**: Complete type hints with Pydantic models for bulletproof code
- **🛡️ Robust**: Automatic OAuth2 token management with intelligent retry logic
- **🏗️ Real Staging Data**: 60+ authentic CCEE credentials for comprehensive testing
- **⚡ Modern**: Python 3.13+ with UV for lightning-fast dependency management
- **✅ Production Ready**: Comprehensive test suite and error handling
## 📦 Installation
```bash
# Using UV (recommended)
uv add voltarium
# Using pip
pip install voltarium
```
## 🔥 Quick Start
```python
import asyncio
from voltarium import VoltariumClient
async def main():
async with VoltariumClient(
client_id="your_client_id",
client_secret="your_client_secret"
) as client:
# List retailer migrations with automatic pagination
migrations = client.list_migrations(
initial_reference_month="2024-01",
final_reference_month="2024-12",
agent_code="12345",
profile_code="67890"
)
# Stream results efficiently
async for migration in migrations:
print(f"Migration {migration.migration_id}: {migration.migration_status}")
asyncio.run(main())
```
## 🏗️ Real Staging Environment
Test with **real CCEE data** using our comprehensive staging environment:
```python
from voltarium.sandbox import RETAILERS, UTILITIES
from voltarium import SANDBOX_BASE_URL
# Use real staging credentials
retailer = RETAILERS[0] # 30+ available retailers
utility = UTILITIES[0] # 30+ available utilities
# Test with actual CCEE staging API
async with VoltariumClient(
base_url=SANDBOX_BASE_URL,
client_id=retailer.client_id,
client_secret=retailer.client_secret
) as client:
# All operations work with real data
migrations = await client.list_migrations(...)
```
## 📚 Comprehensive Documentation
Visit our **[complete documentation](https://voltarium.github.io/voltarium-python/)** for:
- **[About](https://voltarium.github.io/voltarium-python/about/)** - Architecture and detailed features
- **[Supported Endpoints](https://voltarium.github.io/voltarium-python/endpoints/)** - Complete API reference
- **[Examples](https://voltarium.github.io/voltarium-python/examples/)** - Practical usage patterns
- **[Staging Environment](https://voltarium.github.io/voltarium-python/staging/)** - Real data testing & roadmap
## 🛠️ Development
```bash
# Clone and setup
git clone https://github.com/joaodaher/voltarium-python.git
cd voltarium-python
# Install dependencies (requires UV)
task install-dev
# Run tests
task test
# Quality checks
task lint && task format && task typecheck
```
## 🎯 Current Status
**Alpha Release** - Core migration endpoints fully supported:
✅ **Retailer Migrations** - Complete CRUD operations
🚧 **Utility Migrations** - Under development
📋 **Additional Endpoints** - [See roadmap](https://voltarium.github.io/voltarium-python/staging/#roadmap)
## 🤝 Contributing
We welcome contributions! Please see our [documentation](https://voltarium.github.io/voltarium-python/) for details on:
- Feature roadmap and priorities
- Development setup and guidelines
- Testing with real staging data
## 📄 License
Apache License 2.0 - see [LICENSE.md](LICENSE.md) for details.
---
**Built for the Brazilian energy sector** 🇧🇷 | **Powered by modern Python** 🐍
| text/markdown | joaodaher | joaodaher <joao@daher.dev> | null | null | Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS APPENDIX: How to apply the Apache License to your work. To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "{}" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives. Copyright {yyyy} {name of copyright owner} Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. | ccee, energy, brazil, api, async | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"httpx>=0.28.1",
"pydantic>=2.12.5",
"tenacity>=9.1.4"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/joaodaher/voltarium-python/issues",
"Documentation, https://github.com/joaodaher/voltarium-python",
"Homepage, https://github.com/joaodaher/voltarium-python",
"Repository, https://github.com/joaodaher/voltarium-python"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T12:34:19.483622 | voltarium-0.5.0.tar.gz | 22,604 | 3f/68/e803f4f57436f3d381c4a57fd33a7b98d8ca345dca827ecc0220a8481140/voltarium-0.5.0.tar.gz | source | sdist | null | false | f176cfa249bcf57f231404af9cf77cfb | 351af101a05f5d77bf68cd5961e422f8ab6a18a1effb68d83f646163de4905d7 | 3f68e803f4f57436f3d381c4a57fd33a7b98d8ca345dca827ecc0220a8481140 | null | [] | 212 |
2.4 | django-brevo-analytics | 0.4.0 | Django admin integration for Brevo transactional email analytics | # Django Brevo Analytics
A reusable Django package that integrates transactional email analytics from Brevo directly into Django admin with an interactive Vue.js interface.
## Features
### Analytics Dashboard
- **KPI Metrics**: Total emails sent, delivery rate, open rate, click rate
- **Real-time Stats**: Bounced and blocked emails count
- **Recent Messages**: Last 20 sent messages with quick access
- **Interactive Vue.js SPA**: Fast, responsive interface with modal-based navigation
### Email Tracking
- **Message-level View**: All emails grouped by message with aggregate statistics
- **Email Detail Modal**: Complete event timeline for each recipient
- **Status Filtering**: Filter by delivered, opened, clicked, bounced, blocked
- **Event Timeline**: Chronological view of all email events with metadata
### Blacklist Management
- **Check Individual Emails**: Verify if an email is in Brevo's blacklist
- **Manage Blacklist**: View and manage all blacklisted emails
- **Brevo API Integration**: Real-time synchronization with Brevo
- **Remove from Blacklist**: Unblock emails directly from the UI
### Internationalization
- **Multi-language Support**: English and Italian translations
- **Localized UI**: All interface elements respect Django's `LANGUAGE_CODE`
- **Date Formatting**: Locale-aware date and time display
### Real-time Webhook Integration
- **Instant Updates**: Process Brevo events as they occur
- **Bearer Token Authentication**: Secure webhook authentication via Authorization header
- **Auto-enrichment**: Bounce reasons automatically fetched from Brevo API
### Historical Data Import
- **CSV Import**: Import historical email data from raw Brevo logs
- **DuckDB Processing**: Efficient bulk data processing
- **Bounce Enrichment**: Automatic bounce reason lookup during import
- **Statistics Verification**: Validate data against Brevo API
## Requirements
- Python 3.8+
- Django 4.2+ (including Django 5.x)
- Django REST Framework 3.14+
- PostgreSQL (for JSONField support)
## Installation
```bash
pip install django-brevo-analytics
```
## Quick Start
### 1. Add to INSTALLED_APPS
```python
INSTALLED_APPS = [
# ...
'rest_framework',
'corsheaders',
'brevo_analytics',
]
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware', # Add at top
# ... other middleware
]
```
### 2. Configure Settings
```python
# Django REST Framework
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.IsAdminUser',
],
}
# CORS (adjust for production)
CORS_ALLOWED_ORIGINS = [
"http://localhost:8000",
]
# Brevo Analytics Configuration
BREVO_ANALYTICS = {
'WEBHOOK_SECRET': 'your-webhook-secret', # From Brevo dashboard
'API_KEY': 'your-brevo-api-key', # Optional, for bounce enrichment
'ALLOWED_SENDERS': [ # Filter emails by sender
'info@yourproject.com',
],
}
```
### 3. Run Migrations
```bash
python manage.py migrate brevo_analytics
```
### 4. Include URLs
```python
# your_project/urls.py
urlpatterns = [
path('admin/', admin.site.urls),
path('brevo-analytics/', include('brevo_analytics.urls')), # API endpoints for Vue.js frontend
]
```
**Note:** The API endpoints are mounted at `/brevo-analytics/` to serve the Vue.js SPA. The dashboard itself is accessed through Django admin (see step 6).
### 5. Set Up Brevo Webhook
Configure webhook in Brevo dashboard:
- URL: `https://yourdomain.com/brevo-analytics/webhook/`
- Events: All transactional email events
- Add webhook secret to settings
### 6. Access Dashboard
Navigate to `/admin/brevo_analytics/brevomessage/` (requires staff permissions)
## Management Commands
### Import Historical Data
```bash
python manage.py import_brevo_logs /path/to/brevo_logs.csv
```
Options:
- `--dry-run`: Preview import without saving
- `--clear`: Clear existing data before import
### Verify Statistics
```bash
python manage.py verify_brevo_stats
```
Compares local statistics with Brevo API to ensure data accuracy.
## Architecture
### Django-Native Design
- **Models**: Data stored directly in PostgreSQL via Django ORM
- **JSONField Events**: Email events stored as JSON array for optimal performance
- **Denormalized Stats**: Pre-calculated statistics for fast queries
- **Cached Status**: Current status field for efficient filtering
### REST API
- **Django REST Framework**: 6 API endpoints for dashboard and analytics
- **Admin-Only Access**: All endpoints require Django admin permissions
- **Serialized Data**: Optimized JSON responses for Vue.js frontend
### Vue.js SPA
- **Composition API**: Modern Vue 3 with reactivity
- **Hash-based Routing**: Client-side routing without server config
- **Modal Overlays**: Email details shown in modals, no page reloads
- **Responsive Design**: Mobile-friendly interface
### Security
- **Bearer Token Webhook Authentication**: Verify webhook authenticity via Authorization header
- **Admin Permissions**: All views require Django staff access
- **CORS Protection**: Configurable CORS for API endpoints
- **SQL Injection Safe**: Django ORM prevents SQL injection
## Configuration Options
### Required
- `WEBHOOK_SECRET`: Secret key from Brevo webhook configuration
### Optional
- `API_KEY`: Brevo API key for bounce enrichment and blacklist management
- `ALLOWED_SENDERS`: List of sender emails to filter (for multi-client accounts)
- `CLIENT_UID`: UUID for tracking client (defaults to generated UUID)
## Data Flow
```
Brevo → Webhook → Django Model → PostgreSQL
↓
DRF API
↓
Vue.js SPA
```
## Multi-Client Support
For shared Brevo accounts, use `ALLOWED_SENDERS` to filter:
- Emails with matching sender: always included
- Emails without sender info: included only if in local database
- This prevents showing other clients' data
## Development
### Clone Repository
```bash
git clone https://github.com/guglielmo/django-brevo-analytics.git
cd django-brevo-analytics
```
### Install Dependencies
```bash
pip install -r requirements.txt
```
### Run Tests
```bash
python manage.py test brevo_analytics
```
### Build Package
```bash
python -m build
```
## Troubleshooting
### Webhook Not Working
- Verify `WEBHOOK_SECRET` matches Brevo configuration
- Check webhook URL is publicly accessible
- Review Django logs for authentication errors
- Test webhook with `curl` to check connectivity
### Empty Dashboard
- Run `import_brevo_logs` to import historical data
- Verify webhook is configured and receiving events
- Check `ALLOWED_SENDERS` filter isn't too restrictive
- Ensure migrations have been applied
### Blacklist Management Not Working
- Add `API_KEY` to `BREVO_ANALYTICS` settings
- Verify API key has correct permissions on Brevo
- Check network connectivity to Brevo API
## Contributing
Contributions welcome! Please:
1. Fork the repository
2. Create a feature branch
3. Add tests for new functionality
4. Submit a pull request
See [AUTHORS.md](AUTHORS.md) for contributors.
## License
MIT License - see [LICENSE](LICENSE) file for details.
## Credits
- Built with [Django](https://www.djangoproject.com/) and [Django REST Framework](https://www.django-rest-framework.org/)
- Frontend powered by [Vue.js 3](https://vuejs.org/)
- CSV processing with [DuckDB](https://duckdb.org/)
## Links
- [PyPI Package](https://pypi.org/project/django-brevo-analytics/)
- [GitHub Repository](https://github.com/guglielmo/django-brevo-analytics)
- [Issue Tracker](https://github.com/guglielmo/django-brevo-analytics/issues)
- [Changelog](CHANGELOG.md)
| text/markdown | null | Guglielmo Celata <guglielmo.celata@gmail.com> | null | null | MIT | null | [
"Environment :: Web Environment",
"Framework :: Django",
"Framework :: Django :: 4.2",
"Framework :: Django :: 5.0",
"Framework :: Django :: 5.1",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Internet :: WWW/HTTP :: Dynamic Content"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"Django<6.0,>=4.2",
"djangorestframework>=3.14.0",
"django-cors-headers>=4.3.0",
"requests>=2.31.0",
"duckdb>=0.10.0"
] | [] | [] | [] | [
"Homepage, https://github.com/guglielmo/django-brevo-analytics",
"Documentation, https://github.com/guglielmo/django-brevo-analytics/blob/main/README.md",
"Repository, https://github.com/guglielmo/django-brevo-analytics",
"Changelog, https://github.com/guglielmo/django-brevo-analytics/blob/main/CHANGELOG.md"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T12:32:45.279894 | django_brevo_analytics-0.4.0.tar.gz | 75,793 | d7/4c/a5ec9e29f9a03ee0da50d92afe55d8d7c07d8b944cd4ba44bc1b863cda71/django_brevo_analytics-0.4.0.tar.gz | source | sdist | null | false | 4f09fb0cc21cce5311e4bd046aba2b74 | 4227a720ba7551b9bd01ae0faa822e04cf5f6213ea3ace3c1263816b5e20b273 | d74ca5ec9e29f9a03ee0da50d92afe55d8d7c07d8b944cd4ba44bc1b863cda71 | null | [
"LICENSE",
"AUTHORS.md"
] | 225 |
2.4 | thoa | 0.1.3 | Thoa Command Line Interface for Remote Job Submission | # thoa
Thoa CLI for submitting jobs to Thoa platform
| text/markdown | GWC GmbH | hello@gwc-solutions.ch | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.9 | [] | [] | [] | [
"azure-storage-blob<13.0.0,>=12.26.0",
"httpx<0.29.0,>=0.28.1",
"pydantic-settings<3.0.0,>=2.10.1",
"typer<0.17.0,>=0.16.0",
"typing-extensions<5.0.0,>=4.14.1",
"websockets<16.0.0,>=15.0.1"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.10.19 Linux/6.11.0-1018-azure | 2026-02-20T12:32:38.836294 | thoa-0.1.3-py3-none-any.whl | 24,595 | 96/e6/7a0cf0aba22be43372b14c52044a70a324afcc19e9049a808b075850fe4b/thoa-0.1.3-py3-none-any.whl | py3 | bdist_wheel | null | false | 43ed83b75562cd8c29617052c84d0772 | 50b7add604fb674a9a49f4eeedbca59d620c815eedf2a754e6bbac18ee6d4cab | 96e67a0cf0aba22be43372b14c52044a70a324afcc19e9049a808b075850fe4b | null | [
"LICENSE"
] | 221 |
2.4 | grafana-foundation-sdk | 0.0.9 | A set of tools, types and libraries for building and manipulating Grafana objects. | # Grafana Foundation SDK – Python
A set of tools, types and *builder libraries* for building and manipulating Grafana objects in Python.
## Installing
```shell
python3 -m pip install 'grafana_foundation_sdk==v0.0.9'
```
## Example usage
### Building a dashboard
```python
from grafana_foundation_sdk.builders.dashboard import Dashboard, Row
from grafana_foundation_sdk.builders.prometheus import Dataquery as PrometheusQuery
from grafana_foundation_sdk.builders.timeseries import Panel as Timeseries
from grafana_foundation_sdk.cog.encoder import JSONEncoder
from grafana_foundation_sdk.models.common import TimeZoneBrowser
def build_dashboard() -> Dashboard:
builder = (
Dashboard("[TEST] Node Exporter / Raspberry")
.uid("test-dashboard-raspberry")
.tags(["generated", "raspberrypi-node-integration"])
.refresh("1m")
.time("now-30m", "now")
.timezone(TimeZoneBrowser)
.with_row(Row("Overview"))
.with_panel(
Timeseries()
.title("Network Received")
.unit("bps")
.min_val(0)
.with_target(
PrometheusQuery()
.expr('rate(node_network_receive_bytes_total{job="integrations/raspberrypi-node", device!="lo"}[$__rate_interval]) * 8')
.legend_format("{{ device }}")
)
)
)
return builder
if __name__ == '__main__':
dashboard = build_dashboard().build()
encoder = JSONEncoder(sort_keys=True, indent=2)
print(encoder.encode(dashboard))
```
### Unmarshaling a dashboard
```python
import json
from grafana_foundation_sdk.cog.plugins import register_default_plugins
from grafana_foundation_sdk.models.dashboard import Dashboard as DashboardModel
if __name__ == '__main__':
# Required to correctly unmarshal panels and dataqueries
register_default_plugins()
with open("dashboard.json", "r") as f:
decoded_dashboard = DashboardModel.from_json(json.load(f))
print(decoded_dashboard)
```
### Defining a custom query type
While the SDK ships with support for all core datasources and their query types,
it can be extended for private/third-party plugins.
To do so, define a type and a builder for the custom query:
```python
# src/customquery.py
from typing import Any, Optional, Self
from grafana_foundation_sdk.cog import variants as cogvariants
from grafana_foundation_sdk.cog import runtime as cogruntime
from grafana_foundation_sdk.cog import builder
class CustomQuery(cogvariants.Dataquery):
# ref_id and hide are expected on all queries
ref_id: Optional[str]
hide: Optional[bool]
# query is specific to the CustomQuery type
query: str
def __init__(self, query: str, ref_id: Optional[str] = None, hide: Optional[bool] = None):
self.query = query
self.ref_id = ref_id
self.hide = hide
def to_json(self) -> dict[str, object]:
payload: dict[str, object] = {
"query": self.query,
}
if self.ref_id is not None:
payload["refId"] = self.ref_id
if self.hide is not None:
payload["hide"] = self.hide
return payload
@classmethod
def from_json(cls, data: dict[str, Any]) -> Self:
args: dict[str, Any] = {}
if "query" in data:
args["query"] = data["query"]
if "refId" in data:
args["ref_id"] = data["refId"]
if "hide" in data:
args["hide"] = data["hide"]
return cls(**args)
def custom_query_variant_config() -> cogruntime.DataqueryConfig:
return cogruntime.DataqueryConfig(
# datasource plugin ID
identifier="custom-query",
from_json_hook=CustomQuery.from_json,
)
class CustomQueryBuilder(builder.Builder[CustomQuery]):
_internal: CustomQuery
def __init__(self, query: str):
self._internal = CustomQuery(query=query)
def build(self) -> CustomQuery:
return self._internal
def ref_id(self, ref_id: str) -> Self:
self._internal.ref_id = ref_id
return self
def hide(self, hide: bool) -> Self:
self._internal.hide = hide
return self
```
Register the type with cog, and use it as usual to build a dashboard:
```python
from grafana_foundation_sdk.builders.dashboard import Dashboard, Row
from grafana_foundation_sdk.builders.timeseries import Panel as Timeseries
from grafana_foundation_sdk.cog.encoder import JSONEncoder
from grafana_foundation_sdk.cog.plugins import register_default_plugins
from grafana_foundation_sdk.cog.runtime import register_dataquery_variant
from src.customquery import custom_query_variant_config, CustomQueryBuilder
if __name__ == '__main__':
# Required to correctly unmarshal panels and dataqueries
register_default_plugins()
# This lets cog know about the newly created query type and how to unmarshal it.
register_dataquery_variant(custom_query_variant_config())
dashboard = (
Dashboard("Custom query type")
.uid("test-custom-query")
.refresh("1m")
.time("now-30m", "now")
.with_row(Row("Overview"))
.with_panel(
Timeseries()
.title("Sample panel")
.with_target(
CustomQueryBuilder("query here")
)
)
).build()
print(JSONEncoder(sort_keys=True, indent=2).encode(dashboard))
```
### Defining a custom panel type
While the SDK ships with support for all core panels, it can be extended for
private/third-party plugins.
To do so, define a type and a builder for the custom panel's options:
```python
# src/custompanel.py
from typing import Any, Self
from grafana_foundation_sdk.cog import builder
from grafana_foundation_sdk.cog import runtime as cogruntime
from grafana_foundation_sdk.builders.dashboard import Panel as PanelBuilder
from grafana_foundation_sdk.models import dashboard
class CustomPanelOptions:
make_beautiful: bool
def __init__(self, make_beautiful: bool = False):
self.make_beautiful = make_beautiful
def to_json(self) -> dict[str, object]:
return {
"makeBeautiful": self.make_beautiful,
}
@classmethod
def from_json(cls, data: dict[str, Any]) -> Self:
args: dict[str, Any] = {}
if "makeBeautiful" in data:
args["make_beautiful"] = data["makeBeautiful"]
return cls(**args)
def custom_panel_variant_config() -> cogruntime.PanelCfgConfig:
return cogruntime.PanelCfgConfig(
# plugin ID
identifier="custom-panel",
options_from_json_hook=CustomPanelOptions.from_json,
)
class CustomPanelBuilder(PanelBuilder, builder.Builder[dashboard.Panel]):
def __init__(self):
super().__init__()
# plugin ID
self._internal.type_val = "custom-panel"
def make_beautiful(self) -> Self:
if self._internal.options is None:
self._internal.options = CustomPanelOptions()
assert isinstance(self._internal.options, CustomPanelOptions)
self._internal.options.make_beautiful = True
return self
```
Register the type with cog, and use it as usual to build a dashboard:
```python
from grafana_foundation_sdk.builders.dashboard import Dashboard, Row
from grafana_foundation_sdk.cog.encoder import JSONEncoder
from grafana_foundation_sdk.cog.plugins import register_default_plugins
from grafana_foundation_sdk.cog.runtime import register_panelcfg_variant
from src.custompanel import custom_panel_variant_config, CustomPanelBuilder
if __name__ == '__main__':
# Required to correctly unmarshal panels and dataqueries
register_default_plugins()
# This lets cog know about the newly created panel type and how to unmarshal it.
register_panelcfg_variant(custom_panel_variant_config())
dashboard = (
Dashboard("Custom panel type")
.uid("test-custom-panel")
.refresh("1m")
.time("now-30m", "now")
.with_row(Row("Overview"))
.with_panel(
CustomPanelBuilder()
.title("Sample panel")
.make_beautiful()
)
).build()
print(JSONEncoder(sort_keys=True, indent=2).encode(dashboard))
```
## Maturity
The code in this repository should be considered as "public preview". While it is used by Grafana Labs in production, it still is under active development.
> [!NOTE]
> Bugs and issues are handled solely by Engineering teams. On-call support or SLAs are not available.
## License
[Apache 2.0 License](./LICENSE)
| text/markdown | Grafana Labs | null | null | null | null | grafana, logs, metrics, observability, sdk, traces | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries",
"Topic :: System :: Monitoring"
] | [] | null | null | >=3.11 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/grafana/grafana-foundation-sdk",
"Repository, https://github.com/grafana/grafana-foundation-sdk.git",
"Issues, https://github.com/grafana/grafana-foundation-sdk/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:32:38.230488 | grafana_foundation_sdk-0.0.9.tar.gz | 610,379 | c7/e3/101b6667f18d6261dc56c80cafc53fd28b792b4442828d5b1d7d035f860c/grafana_foundation_sdk-0.0.9.tar.gz | source | sdist | null | false | 3d145d1552c190cea49e8805ac7396af | d0c51ef10b8e8ea373d3e58a37ffcb00a655168263cb481dc0320b3bb1fa58e8 | c7e3101b6667f18d6261dc56c80cafc53fd28b792b4442828d5b1d7d035f860c | null | [
"LICENSE"
] | 223 |
2.4 | mlnew | 1.2.7 | One command ML project scaffolding CLI — works on Windows, Mac, and Linux. | <div align="center">
<img src="https://raw.githubusercontent.com/alexcj10/mlsetup/main/assets/logo.svg" width="400" alt="mlnew">
**Professional ML project scaffolding CLI — one command, zero config.**
[](https://pypi.org/project/mlnew/)
</div>
## Quick Start
```bash
pip install mlnew
```
```bash
mlnew init my_project
```
That's it. Your entire ML workspace is ready.
> Run `pip install -U mlnew` to always get the latest version.
## What It Does
A single `mlnew init` command will:
| Step | Action |
|:--:|:--|
| 1 | Create a professional folder structure (`data`, `src`, `notebooks`, `configs`, `logs`, `tests`) |
| 2 | Generate essential files (`.gitignore`, `.env`, `config.yaml`, `train.py`, `eda.ipynb`) |
| 3 | Include a full `SETUP_GUIDE.md` manual inside every project |
| 4 | Set up a virtual environment (`.venv`) with `pip`, `setuptools`, `wheel` |
| 5 | Install 10 core ML/DS packages (NumPy, Pandas, Scikit-learn, etc.) |
| 6 | Pin exact versions in `requirements.txt` |
| 7 | Generate a project-specific `README.md` |
| 8 | Initialize Git with an initial commit |
## Default Packages
All packages install the **latest compatible version** automatically.
| Package | Description |
|:--|:--|
| `numpy` | Numerical computing |
| `pandas` | Data manipulation |
| `scikit-learn` | Machine learning algorithms |
| `matplotlib` | Visualization |
| `seaborn` | Statistical visualization |
| `jupyter` | Interactive notebooks |
| `mlflow` | Experiment tracking |
| `fastapi` | REST API framework |
| `uvicorn` | ASGI server |
| `python-dotenv` | Environment variable management |
```bash
mlnew packages # View all defaults anytime
```
> Note: These 10 core packages include their own transitive dependencies (~150+ total), all of which are auto-detected and pinned in `requirements.txt`.
## Customize Packages
Override any default or add new packages with `--pkg`:
```bash
# Pin specific versions
mlnew init my_project --pkg numpy==1.24.0 --pkg pandas==2.0.0
# Install latest (no pin)
mlnew init my_project --pkg numpy==latest
# Add packages not in defaults
mlnew init my_project --pkg torch --pkg transformers
# Mix and match
mlnew init my_project --pkg numpy==1.24.0 --pkg torch --pkg transformers==4.40.0
```
## Project Structure
```
my_project/
├── .venv/ Virtual environment (auto-created)
├── data/
│ ├── raw/ Original, untouched data
│ └── processed/ Cleaned and transformed data
├── notebooks/
│ └── eda.ipynb Exploration and visualization
├── src/
│ ├── features/ Feature engineering
│ ├── models/ Model definitions
│ ├── training/
│ │ └── train.py Training entry point
│ └── inference/ Prediction and serving
├── configs/
│ └── config.yaml Settings and hyperparameters
├── logs/ Training logs
├── tests/ Unit and integration tests
├── .env Secrets (never committed)
├── .gitignore
├── requirements.txt Pinned dependencies
├── SETUP_GUIDE.md Full manual reference
└── README.md
```
## After Setup
```bash
cd my_project
# Activate virtual environment
source .venv/bin/activate # Mac / Linux
.venv\Scripts\Activate.ps1 # Windows (PowerShell)
# Start training
python src/training/train.py
```
## All Commands
| Command | Description |
|:--|:--|
| `mlnew init <name>` | Create project with default packages |
| `mlnew init <name> --pkg <spec>` | Override specific packages |
| `mlnew packages` | List default packages and versions |
| `mlnew --version` | Show version |
| `mlnew --help` | Show help |
## Requirements
- **Python** 3.8+
- **Git** (optional, for auto `git init`)
## Troubleshooting
<details>
<summary><b>Command not found: <code>mlnew</code> (Windows)</b></summary>
If you see `mlnew: The term 'mlnew' is not recognized...`, your Python Scripts folder is not in PATH.
**Fix PATH (Recommended):**
1. Search Windows for *"Edit the system environment variables"*
2. Click *"Environment Variables"*
3. Under *"User variables"*, find `Path` and click *"Edit"*
4. Add your Python Scripts folder (e.g., `C:\Users\YourName\AppData\Roaming\Python\Python313\Scripts`)
5. Restart your terminal
**Or use Python module directly:**
```bash
python -m mlnew init my_project
```
</details>
## License
[MIT](LICENSE)
| text/markdown | null | null | null | null | MIT | machine-learning, cli, scaffold, data-science, project-template | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Environment :: Console",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"pytest; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.1 | 2026-02-20T12:32:25.080818 | mlnew-1.2.7.tar.gz | 14,332 | 5b/30/6d4c8e4d2986a4d1602ac3f9ddc32d5dc65a6184fb87a1a40b5e228cd054/mlnew-1.2.7.tar.gz | source | sdist | null | false | 28298ace85768ba7db74d755fc884b4d | 273c2931c0f7d2cf9a7fb9898ba6680394156249ad6553f1c484cd40b4ef0db1 | 5b306d4c8e4d2986a4d1602ac3f9ddc32d5dc65a6184fb87a1a40b5e228cd054 | null | [
"LICENSE"
] | 174 |
2.4 | kmathbraille | 1.0.1 | Korean Mathematical Braille converter | [🇰🇷 한국어](https://github.com/qualia-bridge/kmathbraille/blob/main/README.ko.md) | 🇺🇸 English
# kmathbraille ⠿
> Standard Python library for translating LaTeX math expressions
> into Korean Braille
> (as specified in the Ministry of Culture, Sports and Tourism Notice No. 2024-5.)
by [Qualia Bridge](https://www.linkedin.com/in/iamboram)
---
## ✨ Why kmathbraille?
In Korea, visually impaired students often cannot access
math education in Braille.
Existing tools lack accuracy, transparency, and extensibility.
kmathbraille is built by someone who sits at a rare intersection:
- 📖 Braille specialist
- 📊 Statistics & Data Science M.S.
- 📈 Data visualization developer
---
## 🚧 Status
Currently in active development (stealth mode).
Star this repo to follow along!
### Roadmap
- [x] v0.1 — Basic arithmetic (+, -, *, /) & parentheses
- [x] v0.2 — Fractions (`\frac`) & mixed numbers
- [x] v0.3 — Exponents & subscripts (`^`, `_`)
- [x] v0.4 — Square roots (`\sqrt`)
- [x] v0.5 — Trigonometric functions
- [x] v1.0 — PyPI release 🚀
- [ ] v1.1 — Full validation of Alphabetic Braille using in Korea
- [ ] v2.0 — To be continued
- [ ] v3.0 — To be continued
---
## 📦 Installation
You can install it via your terminal using the following command:
```bash
pip install kmathbraille
```
After installation, you can use it in your Python code as follows:
```python
from kmathbraille import to_braille as tb
print(tb(r"\frac{1}{2}")) # Output: ⠼⠃⠌⠼⠁ (Fractions)
print(tb(r"x^{2}")) # Output: ⠭⠘⠼⠃ (Exponents & subscripts)
print(tb(r"\sqrt{2}")) # Output: ⠜⠼⠃ (Square roots)
print(tb(r"\sin{x}")) # Output: ⠖⠎⠭ (Trigonometric functions)
```
---
## 🤝 Contributing
Contributions welcome!
Especially from Braille specialists and math educators.
---
## 📄 License
MIT License © 2026 Qualia Bridge
| text/markdown | null | null | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/qualia-bridge/kmathbraille-dev"
] | twine/6.2.0 CPython/3.13.2 | 2026-02-20T12:31:50.898366 | kmathbraille-1.0.1.tar.gz | 10,422 | 9f/37/3bf6c6e2f3c67f93d2a0059814541c6f4eaae9231d6e694b992c2f49d5ad/kmathbraille-1.0.1.tar.gz | source | sdist | null | false | c04bed3655ff62b88e68cd84eb2b436d | fc3be76e5fca1bd07f4fb5a283962f7dca894196c47e67e3a6a5968df6d376d2 | 9f373bf6c6e2f3c67f93d2a0059814541c6f4eaae9231d6e694b992c2f49d5ad | null | [
"LICENSE"
] | 216 |
2.4 | mlx.robot2rst | 3.6.0 | Python script for converting a Robot Framework file to a reStructuredText (.rst) file | .. image:: https://github.com/melexis/robot2rst/actions/workflows/python-package.yml/badge.svg?branch=master
:target: https://github.com/melexis/robot2rst/actions/workflows/python-package.yml
:alt: Build status
.. image:: https://img.shields.io/badge/Documentation-published-brightgreen.svg
:target: https://melexis.github.io/robot2rst/
:alt: Documentation
.. image:: https://img.shields.io/badge/contributions-welcome-brightgreen.svg?style=flat
:target: https://github.com/melexis/robot2rst/issues
:alt: Contributions welcome
=======================
Documentation robot2rst
=======================
This script can convert your .robot files from Robot Framework to reStructuredText (.rst) files with traceable items.
.. contents:: `Contents`
:depth: 2
:local:
----
Goal
----
This script allows you to connect your requirements to test cases via the `mlx.traceability`_ Sphinx extension.
Test cases get converted to traceable items. The documentation of each test gets used to generate the body of the item.
Test case names get converted to item IDs with a configurable prefix. Tags can be used to link to other traceable items.
-----
Usage
-----
.. code-block:: console
robot2rst -i example.robot -o test_plan.rst --prefix ITEST_MY_LIB- \
--tags SWRQT- SYSRQT- --relationships validates ext_toolname --coverage 100 66.66
$ robot2rst --help
usage: robot2rst [-h] -i ROBOT_FILE -o RST_FILE [--only EXPRESSION] [-p PREFIX]
[-r [RELATIONSHIPS ...]] [-t [TAGS ...]] [--include [INCLUDE ...]]
[-c [COVERAGE ...]] [--type TYPE] [--trim-suffix]
Convert robot test cases to reStructuredText with traceable items.
options:
-h, --help show this help message and exit
-i ROBOT_FILE, --robot ROBOT_FILE
Input robot file
-o RST_FILE, --rst RST_FILE
Output RST file, e.g. my_component_qtp.rst
--only EXPRESSION Expression of tags for Sphinx' `only` directive that surrounds all
RST content. By default, no `only` directive is generated.
-p PREFIX, --prefix PREFIX
Overrides the default 'QTEST-' prefix.
-r [RELATIONSHIPS ...], --relationships [RELATIONSHIPS ...]
Name(s) of the relationship(s) used to link to items in Tags section.
The default value is 'validates'.
-t [TAGS ...], --tags [TAGS ...]
Zero or more Python regexes for matching tags to treat them as
traceable targets via a relationship. All tags get matched by
default.
--include [INCLUDE ...]
Zero or more Python regexes for matching tags to filter test cases.
If every regex matches at least one of a test case's tags, the test
case is included.
-c [COVERAGE ...], --coverage [COVERAGE ...]
Minimum coverage percentages for the item-matrix(es); 1 value per tag
in -t, --tags.
--type TYPE Give value that starts with 'q' or 'i' (case-insensitive) to
explicitly define the type of test: qualification/integration test.
The default is 'qualification'.
--trim-suffix If the suffix of any prefix or --tags argument ends with '_-' it gets
trimmed to '-'.
-------------
Configuration
-------------
To include the script's output in your documentation you want to add the aforementioned extension to your
``extensions`` list in your *conf.py* like so:
.. code-block:: python
extensions = [
'mlx.traceability',
]
Please read the `documentation of mlx.traceability`_ for additional configuration steps.
If you use the ``--only`` input argument, you should also add |sphinx_selective_exclude.eager_only|_ to the
``extensions`` list to prevent mlx.traceability from parsing the content and ignoring the effect of the
``only`` directive.
.. _`mlx.traceability`: https://pypi.org/project/mlx.traceability/
.. _`documentation of mlx.traceability`: https://melexis.github.io/sphinx-traceability-extension/readme.html
.. |sphinx_selective_exclude.eager_only| replace:: ``'sphinx_selective_exclude.eager_only'``
.. _sphinx_selective_exclude.eager_only: https://pypi.org/project/sphinx-selective-exclude/
| text/x-rst | Jasper Craeghs | jce@melexis.com | null | null | Apache License Version 2.0 | robot, robotframework, sphinx, traceability | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Documentation",
"Topic :: Documentation :: Sphinx",
"Topic :: Utilities"
] | [
"any"
] | https://github.com/melexis/robot2rst | null | >=3.8 | [] | [] | [] | [
"robotframework>=3.2",
"mako"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T12:31:38.054372 | mlx_robot2rst-3.6.0.tar.gz | 20,567 | f1/53/f24ee6466052638d5e8375b0832ce24ecfb7647f163cfb67e71b46c579f9/mlx_robot2rst-3.6.0.tar.gz | source | sdist | null | false | 11fb90bfb57c4f20a8bb979a6dac3900 | e4daa0178afa05daae5fba7036e64118edac3543694875da7f5ba89a0bfb3718 | f153f24ee6466052638d5e8375b0832ce24ecfb7647f163cfb67e71b46c579f9 | null | [
"LICENSE"
] | 0 |
2.4 | domain-scout-ct | 0.5.0 | Discover internet domains associated with a business entity via CT logs, RDAP, and DNS | # domain-scout
[](https://github.com/minghsuy/domain-scout/actions/workflows/ci.yml)
[](https://pypi.org/project/domain-scout-ct/)
Discover internet domains associated with a business entity using Certificate Transparency logs, RDAP, and DNS.
Useful for security teams, asset inventories, and M&A due diligence — where seed domains can be wrong, misspelled, or belong to a parent company.
## Install
```bash
pip install domain-scout-ct # core library + CLI
pip install domain-scout-ct[api] # + REST API server
pip install domain-scout-ct[cache] # + DuckDB query cache
pip install domain-scout-ct[all] # everything
```
For development:
```bash
uv sync --all-groups --all-extras
```
## Usage
### CLI
```bash
# Basic usage
domain-scout --name "Guidewire Software" --location "San Mateo, CA"
# With seed domain
domain-scout --name "Palo Alto Networks" --location "Santa Clara, CA" --seed "paloaltonetworks.com"
# Multiple seeds — cross-verification boosts confidence for domains found by both
domain-scout --name "Walmart" --seed walmart.com --seed samsclub.com
# Deep mode — GeoDNS global resolution for non-resolving domains
domain-scout --name "Walmart" --seed "walmart.com" --deep
# JSON output
domain-scout --name "Acme Corp" --output json > results.json
# Verbose logging
domain-scout --name "Cloudflare" --seed "cloudflare.com" -v
```
### REST API
```bash
# Start the API server (cache enabled by default)
domain-scout serve --port 8080
# Health check
curl http://localhost:8080/health
# Run a scan
curl -X POST http://localhost:8080/scan \
-H "Content-Type: application/json" \
-d '{"entity": {"company_name": "Walmart", "seed_domain": ["walmart.com"]}}'
# Readiness check (probes crt.sh connectivity)
curl http://localhost:8080/ready
```
### Docker
```bash
# Build
docker build -t domain-scout-ct .
# Run API server
docker run -p 8080:8080 domain-scout-ct
# Run CLI scan
docker run domain-scout-ct scout --name "Walmart" --seed walmart.com
# Persist cache across runs
docker run -p 8080:8080 -v scout-cache:/data/cache domain-scout-ct
```
### Cache
```bash
# Enable cache for CLI scans
domain-scout scout --name "Walmart" --seed walmart.com --cache
# View cache statistics
domain-scout cache stats
# Clear cache
domain-scout cache clear
```
### Library
```python
from domain_scout import Scout
result = Scout().discover(
company_name="Palo Alto Networks",
location="Santa Clara, CA",
seed_domain=["paloaltonetworks.com"],
)
for domain in result.domains:
print(f"{domain.domain:40s} {domain.confidence:.2f} {domain.sources}")
```
### Async
```python
import asyncio
from domain_scout import Scout, EntityInput
async def main():
scout = Scout()
result = await scout.discover_async(EntityInput(
company_name="Palo Alto Networks",
seed_domain=["paloaltonetworks.com"],
))
return result
result = asyncio.run(main())
```
## How it works
1. **Seed validation** — DNS-resolves the seed domain, checks RDAP registrant org and CT cert org names against the company name
2. **CT org search** — Queries crt.sh Postgres for certificates where the Subject Organization matches the company name
3. **Seed expansion** — Finds all SANs on certs covering the seed domain, revealing related domains (e.g., acquired companies)
4. **Domain guessing** — Generates candidates from the company name + common TLDs, resolves them, verifies via CT
5. **Cross-seed verification** — With multiple seeds, domains found independently by 2+ seeds get a confidence boost
6. **RDAP corroboration** — Queries RDAP registrant org on top discovered domains, confirming ownership matches the target company
7. **Confidence scoring** — Corroboration-level model scores each domain 0–1 based on the combination of evidence: CT org match, SAN co-occurrence, DNS resolution, RDAP registrant match, cross-seed verification, and shared infrastructure
### Data sources
| Source | Method | Rate limited |
|--------|--------|-------------|
| crt.sh | Postgres (primary), JSON API (fallback) | 5 concurrent queries, 1s burst delay |
| RDAP | rdap.org universal bootstrap | Per-request |
| DNS | dnspython (8.8.8.8, 1.1.1.1) | 5 concurrent |
| Shodan GeoDNS | geonet.shodan.io (deep mode) | 3 concurrent, 0.5s delay |
## Development
```bash
make install # uv sync --all-groups
make test # unit tests (mocked external calls)
make lint # ruff + mypy
make format # ruff --fix + ruff format
make check # format + lint + test
```
Integration tests hit real crt.sh:
```bash
make test-integration
```
## License
MIT
| text/markdown | Ming Yang | null | null | null | null | certificate-transparency, dns, domain-discovery, rdap, security | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Topic :: Internet :: Name Service (DNS)",
"Topic :: Security",
"Typing :: Typed"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"dnspython>=2.7.0",
"httpx>=0.28.0",
"psycopg2-binary>=2.9.11",
"pydantic>=2.10.0",
"rapidfuzz>=3.11.0",
"structlog>=24.4.0",
"typer>=0.15.0",
"duckdb>=1.0.0; extra == \"all\"",
"fastapi>=0.115.0; extra == \"all\"",
"prometheus-client>=0.21.0; extra == \"all\"",
"pyyaml>=6.0; extra == \"all\"",
"uvicorn[standard]>=0.32.0; extra == \"all\"",
"fastapi>=0.115.0; extra == \"api\"",
"uvicorn[standard]>=0.32.0; extra == \"api\"",
"duckdb>=1.0.0; extra == \"cache\"",
"pyyaml>=6.0; extra == \"eval\"",
"prometheus-client>=0.21.0; extra == \"metrics\""
] | [] | [] | [] | [
"Repository, https://github.com/minghsuy/domain-scout",
"Changelog, https://github.com/minghsuy/domain-scout/blob/main/CHANGELOG.md",
"Issues, https://github.com/minghsuy/domain-scout/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:31:31.453068 | domain_scout_ct-0.5.0.tar.gz | 178,785 | 78/ad/a093510729c540b3aa84b6e04676ef35688ccf0e2cd7f2ae7f3309e5bf6f/domain_scout_ct-0.5.0.tar.gz | source | sdist | null | false | bc3866cfae19e29f90c07ccfd5a872f2 | b831d58ff1b174b3ec6f9c15a9b4d1c07883c1cf6309e06a8079e1e692f440fa | 78ada093510729c540b3aa84b6e04676ef35688ccf0e2cd7f2ae7f3309e5bf6f | MIT | [
"LICENSE"
] | 218 |
2.4 | youtube-summarize | 0.2.2 | MCP server that fetches YouTube video transcripts and optionally summarizes them | # youtube-summarize
MCP server that fetches YouTube video transcripts and optionally summarizes them.

## Features
- **Fetch transcripts** in multiple formats (text, JSON, SRT, WebVTT, pretty-print)
- **Summarize videos** — returns transcript with instructions for the LLM to produce a summary
- **List available languages** for any video's transcripts
- **Flexible URL parsing** — accepts full YouTube URLs (`youtube.com/watch?v=`, `youtu.be/`, `youtube.com/embed/`, `youtube.com/shorts/`) or bare video IDs
- **Multi-language support** — request transcripts in specific languages with fallback priority
## Tools
### `get_transcript`
Fetch a YouTube video's transcript.
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `url` | string | *required* | YouTube video URL or video ID |
| `languages` | string[] | `["en"]` | Preferred languages in priority order |
| `format` | string | `"text"` | Output format: `text`, `json`, `pretty`, `webvtt`, `srt` |
| `preserve_formatting` | boolean | `false` | Keep HTML formatting tags in the transcript |
### `summarize_transcript`
Fetch a transcript and return it with summarization instructions for the LLM client.
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `url` | string | *required* | YouTube video URL or video ID |
| `prompt` | string | *(default prompt)* | Custom summarization instructions |
| `languages` | string[] | `["en"]` | Preferred languages in priority order |
### `list_transcripts`
List available transcript languages for a video.
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| `url` | string | *required* | YouTube video URL or video ID |
## Installation
### Quick start (recommended)
```bash
uvx youtube-summarize
```
### Claude Desktop
Add to your `claude_desktop_config.json`:
- macOS: `~/Library/Application Support/Claude/claude_desktop_config.json`
- Windows: `%APPDATA%\Claude\claude_desktop_config.json`
```json
{
"mcpServers": {
"youtube-summarize": {
"command": "uvx",
"args": ["youtube-summarize"]
}
}
}
```
### Claude Code
```bash
claude mcp add youtube-summarize -- uvx youtube-summarize
```
### Other MCP clients
Run the server over stdio:
```bash
uvx youtube-summarize
```
## Prerequisites
- Python 3.13+
- [uv](https://docs.astral.sh/uv/) package manager
## Development
```bash
# Install dependencies
uv sync
# Launch the MCP inspector (web UI for testing tools)
uv run mcp dev main.py
```
## License
MIT
---
mcp-name: io.github.zlatkoc/youtube-summarize
| text/markdown | Zlatko Cajic | null | null | null | null | mcp, model-context-protocol, summarize, transcript, youtube | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"mcp[cli]>=1.26.0",
"youtube-transcript-api>=1.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/zlatkoc/youtube-summarize",
"Repository, https://github.com/zlatkoc/youtube-summarize",
"Issues, https://github.com/zlatkoc/youtube-summarize/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:31:27.455334 | youtube_summarize-0.2.2.tar.gz | 4,732 | 39/31/c2e92e9a2cda3bd2d7dab136411965794b4799327f02583186811d6628d9/youtube_summarize-0.2.2.tar.gz | source | sdist | null | false | 52bd7dfd66a49c6511953e5a75ade729 | e7ff6e469bff25ee9fa5840256f670ed8bd7380579bea1b0a57dd0075e055a10 | 3931c2e92e9a2cda3bd2d7dab136411965794b4799327f02583186811d6628d9 | MIT | [
"LICENSE"
] | 203 |
2.4 | wazzup | 0.1.1 | A python package for sending messages using the official Whatsapp API | # WaZZup
| text/markdown | null | Rafael model <rafael.model@d7.dev> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"requests>=2.25.0",
"pytest>=8.0; extra == \"dev\"",
"pytest-mock>=3.14; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/7ws/wazzup",
"Issues, https://github.com/7ws/wazzup/issues"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T12:31:18.661267 | wazzup-0.1.1.tar.gz | 8,666 | 28/be/396561ed0d42921bc5a7fff8d2c3a2f2fe5ca1daf89378f85bee49ec82c0/wazzup-0.1.1.tar.gz | source | sdist | null | false | bc95b518091970d3843c72001ce428cc | 7abdbea99394ac2e4c32223cff6001296bc36e04b3729e27ef4c3294d30983b6 | 28be396561ed0d42921bc5a7fff8d2c3a2f2fe5ca1daf89378f85bee49ec82c0 | MIT | [
"LICENCE"
] | 216 |
2.4 | tcmb | 0.5.0 | A Python client for the Central Bank of the Republic of Türkiye (TCMB) EVDS-API. | # tcmb
[](https://pypi.org/project/tcmb/)
[](https://github.com/kaymal/tcmb-py/blob/main/LICENSE)
[](https://pepy.tech/project/tcmb)
[]()
[](https://github.com/psf/black)

`tcmb` is a Python API wrapper around the Central Bank of the Republic of Türkiye (TCMB) Web Service. It is an _unofficial_ open-source Python package intended for personal use ([Disclaimer](#disclaimer)).
---
_`tcmb`, Türkiye Cumhuriyeti Merkez Bankası (TCMB) Web Servisi'ne Python aracılığıyla erişimi sağlayan resmi olmayan API uygulamasıdır. Kişisel kullanım ve araştırma maksadıyla hazırlanmıştır ([Elektronik Veri Dağıtım Sistemi (EVDS) Kullanım Koşulları](https://evds3.tcmb.gov.tr/igmevdsms-dis/documents/showDocument?docId=18))._
## Quickstart
```shell
pip install tcmb
# or with uv
uv add tcmb
```
```python
import tcmb
client = tcmb.Client(api_key="...")
data = client.read(series="TP.DK.USD.S.YTL")
```
## Overview
### Data Hierarchy
1. Categories:
Categories are at the top level of the TCMB data hierarchy.
```python
client = tcmb.Client(api_key="...")
# show categories
client.categories
{'CATEGORY_ID': 1.0,
'TOPIC_TITLE_ENG': 'MARKET STATISTICS',
'TOPIC_TITLE_TR': 'PİYASA VERİLERİ'}
```
It is also possible to get the same information using the `client.get_categories_metadata()` method.
2. Data Groups:
Each category consists of a number of data groups.
```python
client = tcmb.Client(api_key="...")
# show data groups
client.datagroups
[{'DATAGROUP_CODE': 'bie_pyrepo',
'CATEGORY_ID': 1,
'DATAGROUP_NAME': 'Açık Piyasa Repo ve Ters Repo İşlemleri',
'DATAGROUP_NAME_ENG': 'Open Market Repo and Reverse Repo Transactions',
...}
{'DATAGROUP_CODE': 'bie_mkbral',
'CATEGORY_ID': 0,
'DATAGROUP_NAME': 'Altın Borsası İşlemleri-İstanbul (TL-ABD Doları)(Arşiv)',
'DATAGROUP_NAME_ENG': 'Istanbul Gold Exchange (TRY-USD)(Archive)',
...}]
```
It is also possible to filter the datagroups metadata using the `client.get_datagroups_metadata()` method.
3. Series
Datagroups consist of time series, each with a series key such as `TP.YSSK.A1` or `TP.DK.USD.S.YTL`. Series can be read using the `.read()` method.
```python
import tcmb
client = tcmb.Client(api_key="...")
# read one time series
data = client.read("TP.YSSK.A1")
# read multiple time series
data = client.read(["TP.YSSK.A1", "TP.YSSK.A2", "TP.YSSK.A3"])
```
A convenient way to read time series without initializing a `Client` instance is to use the package-level `read()` function.
```python
import tcmb
# read one time series
data = tcmb.read("TP.YSSK.A1", api_key="...")
# read multiple time series
data = tcmb.read(["TP.YSSK.A1", "TP.YSSK.A2", "TP.YSSK.A3"], api_key="...")
```
Series metadata can be fetched with the `.get_series_metadata()` method.
```python
# show metadata of each series within a data group
client.get_series_metadata(datagroup="bie_yssk")
[{'SERIE_CODE': 'TP.YSSK.A1',
'DATAGROUP_CODE': 'bie_yssk',
'SERIE_NAME': '1-2 Yıl(ABD doları)',
'SERIE_NAME_ENG': '1-2 Years(USD)',
...},
{'SERIE_CODE': 'TP.YSSK.A2',
'DATAGROUP_CODE': 'bie_yssk',
'SERIE_NAME': '3 Yıl(ABD doları)',
'SERIE_NAME_ENG': '3 Years(USD)',
...}]
# show metadata of a specific time series
client.get_series_metadata(series="TP.YSSK.A1")
[{'SERIE_CODE': 'TP.YSSK.A1',
'DATAGROUP_CODE': 'bie_yssk',
'SERIE_NAME': '1-2 Yıl(ABD doları)',
'SERIE_NAME_ENG': '1-2 Years(USD)',
...}]
```
## Wildcard Characters
Wildcard characters are `*` and `?`. The asterisk `*` matches zero or more characters, and the question mark `?` matches exactly one character. Additionally, omitting a value has the same effect as using an asterisk. Note that wildcard support is not a feature of the TCMB web service itself; pattern matching is implemented inside `tcmb` package and depends on package data.
```python
>>> data = tcmb.read("TP.DK.USD.*.YTL")
>>> print(data.columns)
Index(['TP_DK_USD_A_YTL', 'TP_DK_USD_S_YTL', 'TP_DK_USD_C_YTL',
'TP_DK_USD_A_EF_YTL', 'TP_DK_USD_S_EF_YTL'],
dtype='object')
```
## Installation
```sh
pip install tcmb
# or with uv
uv add tcmb
```
## Authentication
An API key is required to access the web service. Users can sign up on the [login](https://evds3.tcmb.gov.tr/login) page. After signing in, generate an API key from the Profile page.
There are two ways to provide an API key to `tcmb`.
- Using environment variables:
```shell
$ export TCMB_API_KEY="..."
```
```python
import os
os.environ["TCMB_API_KEY"] = "..."
```
- Passing `api_key` when initializing the `Client` class.
```python
import tcmb
client = tcmb.Client(api_key="...")
# optional: override EVDS base URL
client = tcmb.Client(api_key="...", base_url="https://evds3.tcmb.gov.tr/igmevdsms-dis/)
```
## Disclaimer
`tcmb` is an **unofficial** open-source package intended for personal use and research purposes. Please see TCMB's [EVDS Disclaimer](https://evds3.tcmb.gov.tr/igmevdsms-dis/documents/showDocument?docId=18) for the official terms of use of the EVDS Web Service.
| text/markdown | null | Kaymal <gutkyle@gmail.com> | null | null | MIT License
Copyright (c) 2022 T.Kaymal
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| tcmb, evds, api, client, python, financial data, currency, exchange rates, central bank, turkey | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"pandas",
"numpy",
"requests",
"pytest; extra == \"dev\"",
"black; extra == \"dev\"",
"ruff; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"pandas-stubs; extra == \"dev\"",
"types-requests; extra == \"dev\"",
"ipykernel; extra == \"ide\"",
"jupyterlab; extra == \"ide\""
] | [] | [] | [] | [
"repository, https://github.com/kaymal/tcmb-py",
"pypi, https://pypi.org/project/tcmb"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-20T12:31:10.943501 | tcmb-0.5.0.tar.gz | 173,444 | 4a/03/10b0bab2f1998359c4b19b012c4bf262e14b68dc94041f5c35cd8bd2b13c/tcmb-0.5.0.tar.gz | source | sdist | null | false | b4d474b39622e3511b8c6b504df25b2c | 5e758c133b64a7b903fb83821275b42b1b59682091c0e9031989e245e8e29c32 | 4a0310b0bab2f1998359c4b19b012c4bf262e14b68dc94041f5c35cd8bd2b13c | null | [
"LICENSE"
] | 210 |
2.3 | factorialhr | 6.0.0 | Python package for the api of FactorialHR | FactorialHR api python wrapper
==============================
This package provides a python wrapper to the `api of FactorialHR <https://apidoc.factorialhr.com/docs>`_.
The package currently supports the api version `v2026-01-01 <https://apidoc.factorialhr.com/v2026-01-01/docs/getting-started>`_.
The openapi schema can be found at https://api.factorialhr.com/oas
**I derived some types from the examples given. They might be incorrect. If you encounter any problems, please create an issue and/or contribute a fix.**
Disclaimer
----------
I am not affiliated, associated, authorized, endorsed by, or in any way officially connected with EVERYDAY SOFTWARE, S.L. or FactorialHR, or any of its subsidiaries or its affiliates. The official factorialhr.com website can be found at https://factorialhr.com/
Usage
-----
Get all employees:
.. code-block:: python
import factorialhr
authorizer = factorialhr.ApiKeyAuth('<api_key>') # checkout other authorization methods
async with factorialhr.ApiClient(auth=authorizer) as api:
all_employees = await factorialhr.EmployeesEndpoint(api).all() # fetches all employees. on big companies you might want to increase the timeout by using timeout=...
Get a dictionary with team id as key and a list of member as value:
.. code-block:: python
import asyncio
import factorialhr
authorizer = factorialhr.AccessTokenAuth('<access_token>') # checkout other authorization methods
async with factorialhr.ApiClient(auth=authorizer) as api:
employees_endpoint = factorialhr.EmployeesEndpoint(api)
teams_endpoint = factorialhr.TeamsEndpoint(api)
all_employees, all_teams = await asyncio.gather(employees_endpoint.all(), teams_endpoint.all()) # remember to increase the timeout if you have a lot of employees or teams
employees_by_team_id = {team.id: [employee for employee in all_employees.data() if employee.id in team.employee_ids] for team in all_teams.data()}
Contribute
----------
Feel free to contribute! Please fork this repository, install the development dependencies with ``uv sync --dev``
and create pull request.
| text/x-rst | Leon Budnick | Leon Budnick <y6q6ea9w@mail-proxy.org> | null | null | null | FactorialHR, HR | [
"License :: OSI Approved :: GNU Affero General Public License v3",
"Operating System :: OS Independent",
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"Topic :: Office/Business",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <3.15,>=3.11 | [] | [] | [] | [
"anyio>=4.7.0",
"httpx>=0.28.1",
"pydantic>=2.10.6"
] | [] | [] | [] | [
"Repository, https://github.com/leon1995/factorialhr",
"Bug Tracker, https://github.com/leon1995/factorialhr/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:31:04.777651 | factorialhr-6.0.0.tar.gz | 86,003 | 9a/47/bd57eaada127af85d0be20eb27f250185ff8ed6c966c3732873d190dfd1b/factorialhr-6.0.0.tar.gz | source | sdist | null | false | d2c1c72c4f7d124571fab124aaf12907 | 74d2189f5a77155f42c441e1389bc94f5e29c11c6cf264ed78b9fc59fb9fd21e | 9a47bd57eaada127af85d0be20eb27f250185ff8ed6c966c3732873d190dfd1b | null | [] | 210 |
2.4 | ansys-simai-core | 0.3.10 | A python wrapper for Ansys SimAI | PySimAI
=======
|pyansys| |python| |pypi| |GH-CI| |codecov| |MIT| |ruff|
.. |pyansys| image:: https://img.shields.io/badge/Py-Ansys-ffc107.svg?logo=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAIAAACQkWg2AAABDklEQVQ4jWNgoDfg5mD8vE7q/3bpVyskbW0sMRUwofHD7Dh5OBkZGBgW7/3W2tZpa2tLQEOyOzeEsfumlK2tbVpaGj4N6jIs1lpsDAwMJ278sveMY2BgCA0NFRISwqkhyQ1q/Nyd3zg4OBgYGNjZ2ePi4rB5loGBhZnhxTLJ/9ulv26Q4uVk1NXV/f///////69du4Zdg78lx//t0v+3S88rFISInD59GqIH2esIJ8G9O2/XVwhjzpw5EAam1xkkBJn/bJX+v1365hxxuCAfH9+3b9/+////48cPuNehNsS7cDEzMTAwMMzb+Q2u4dOnT2vWrMHu9ZtzxP9vl/69RVpCkBlZ3N7enoDXBwEAAA+YYitOilMVAAAAAElFTkSuQmCC
:target: https://docs.pyansys.com/
:alt: PyAnsys
.. |python| image:: https://img.shields.io/pypi/pyversions/ansys-simai-core?logo=pypi
:target: https://pypi.org/project/ansys-simai-core/
:alt: Python
.. |pypi| image:: https://img.shields.io/pypi/v/ansys-simai-core.svg?logo=python&logoColor=white
:target: https://pypi.org/project/ansys-simai-core
:alt: PyPI
.. |codecov| image:: https://codecov.io/gh/ansys/pysimai/branch/main/graph/badge.svg
:target: https://codecov.io/gh/ansys/pysimai
:alt: Codecov
.. |GH-CI| image:: https://github.com/ansys/pysimai/actions/workflows/ci_cd.yml/badge.svg
:target: https://github.com/ansys/pysimai/actions/workflows/ci_cd.yml
:alt: GH-CI
.. |MIT| image:: https://img.shields.io/badge/License-MIT-yellow.svg
:target: https://opensource.org/licenses/MIT
:alt: MIT
.. |ruff| image:: https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json
:target: https://github.com/astral-sh/ruff
:alt: Ruff
A Python wrapper for Ansys SimAI
How to install
--------------
At least two installation modes are provided: user and developer.
For users
^^^^^^^^^
In order to install PySimAI, make sure you
have the latest version of `pip`_. To do so, run:
.. code:: bash
python -m pip install -U pip
Then, you can simply execute:
.. code:: bash
python -m pip install ansys-simai-core
For developers
^^^^^^^^^^^^^^
Installing PySimAI in developer mode allows
you to modify the source and enhance it.
Before contributing to the project, please refer to the `PyAnsys Developer's guide`_. You will
need to follow these steps:
#. Start by cloning this repository:
.. code:: bash
git clone https://github.com/ansys/pysimai
#. `Install uv <https://docs.astral.sh/uv/>`_. NB: If you are a Windows user, make sure that Python is installed on your system and it is added to the Path.
#. Use uv to run commands
.. code:: shell
uv run pytest -xlv
#. Finally, verify your development installation by running:
.. code:: bash
uv tool install tox --with tox-uv
tox
#. Alternatively, you can also run tasks defined in `pyproject.toml` using `poethepoet`:
.. code:: shell
uv tool install poethepoet
uv run poe lint
uv run poe test
uv run poe doc
How to test
-----------
This project takes advantage of `tox`_. This tool allows to automate common
development tasks (similar to Makefile) but it is oriented towards Python
development.
Using tox
^^^^^^^^^
As Makefile has rules, `tox`_ has environments. In fact, the tool creates its
own virtual environment so anything being tested is isolated from the project in
order to guarantee project's integrity. The following environments commands are provided:
- **tox -e style**: will check for coding style quality.
- **tox -e py**: checks for unit tests.
- **tox -e py-coverage**: checks for unit testing and code coverage.
- **tox -e doc**: checks for documentation building process.
Raw testing
^^^^^^^^^^^
If required, you can always call the style commands (`ruff`_) or unit testing ones (`pytest`_) from the command line. However,
this does not guarantee that your project is being tested in an isolated
environment, which is the reason why tools like `tox`_ exist.
A note on pre-commit
^^^^^^^^^^^^^^^^^^^^
The style checks take advantage of `pre-commit`_. Developers are not forced but
encouraged to install this tool via:
.. code:: bash
uv tool install pre-commit && pre-commit install
Documentation
-------------
For building documentation, you can either run the usual rules provided in the
`Sphinx`_ Makefile, such as:
.. code:: bash
uv run make -C doc/ html && open doc/html/index.html
However, the recommended way of checking documentation integrity is using:
.. code:: bash
tox -e doc && open .tox/doc_out/index.html
Distributing
------------
uv commands can help you build or publish the package
.. code:: bash
uv build
uv publish
.. LINKS AND REFERENCES
.. _ruff: https://github.com/astral-sh/ruff
.. _pip: https://pypi.org/project/pip/
.. _pre-commit: https://pre-commit.com/
.. _PyAnsys Developer's guide: https://dev.docs.pyansys.com/
.. _pytest: https://docs.pytest.org/en/stable/
.. _Sphinx: https://www.sphinx-doc.org/en/master/
.. _tox: https://tox.wiki/
| text/x-rst | null | "ANSYS, Inc." <pyansys.core@ansys.com> | null | PyAnsys developers <pyansys.maintainers@ansys.com> | MIT License
Copyright (c) 2023 - 2026 ANSYS, Inc. and/or its affiliates.
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic :: Scientific/Engineering :: Physics"
] | [] | null | null | <4,>=3.9 | [] | [] | [] | [
"filelock>=3.10.7",
"httpx-retries>=0.4.2",
"httpx-sse>=0.4.1",
"httpx>=0.28.1",
"pydantic<3,>=2.5.1",
"semver>=3.0.2",
"tomli<3,>=2.0.1",
"tqdm>=4.66.1",
"truststore>=0.10.0; python_version >= \"3.10\"",
"typing-extensions>=4.12.0",
"wakepy>=0.8.0"
] | [] | [] | [] | [
"Bugs, https://github.com/ansys/pysimai/issues",
"Documentation, https://simai.docs.pyansys.com",
"Source, https://github.com/ansys/pysimai",
"Discussions, https://github.com/ansys/pysimai/discussions",
"Releases, https://github.com/ansys/pysimai/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:30:46.677488 | ansys_simai_core-0.3.10.tar.gz | 965,584 | d6/01/94c5c0b48e73a471129cbc919c599fe226b7a638e09e5fe7bb4dfdb7e2a9/ansys_simai_core-0.3.10.tar.gz | source | sdist | null | false | 15bab9c40cc0bbfe808fa5cd82101161 | 8c7f5d8bf02c6d0c388be088cbd80f09362b493a519ad5a358b23247c8ac6dc5 | d60194c5c0b48e73a471129cbc919c599fe226b7a638e09e5fe7bb4dfdb7e2a9 | null | [
"AUTHORS",
"LICENSE"
] | 224 |
2.4 | async-customerio | 2.8.0 | Async CustomerIO Client - a Python client to interact with CustomerIO in an async fashion. | # async-customerio is a lightweight asynchronous client to interact with CustomerIO
[](https://pypi.python.org/pypi/async-customerio/)
[](https://pypi.python.org/pypi/async-customerio/)
[](https://pypi.python.org/pypi/async-customerio/)
[](https://pypi.python.org/pypi/async-customerio/)
[](https://github.com/healthjoy/async-customerio/actions/workflows/ci.yml)
[](https://www.codacy.com/gh/healthjoy/async-customerio/dashboard?utm_source=github.com&utm_medium=referral&utm_content=healthjoy/async-customerio&utm_campaign=Badge_Coverage)
- Free software: MIT license
- Requires: Python 3.10+
## Features
- Fully async
- Interface preserved as Official Python Client `customerio` has
- Send push notification
- Send messages (email, SMS, push, inbox)
## Installation
```shell script
pip install async-customerio
```
## Getting started
```python
import asyncio
from async_customerio import AsyncCustomerIO, Regions
async def main():
site_id = "Some-id-gotten-from-CustomerIO"
api_key = "Some-key-gotten-from-CustomerIO"
cio = AsyncCustomerIO(site_id, api_key, region=Regions.US)
await cio.identify(
id=5,
email="customer@example.com",
first_name="John",
last_name="Doh",
subscription_plan="premium",
)
await cio.track(
customer_id=5, name="product.purchased", product_sku="XYZ-12345", price=23.45
)
if __name__ == "__main__":
asyncio.run(main())
```
### Instantiating `AsyncCustomerIO` object
Create an instance of the client with your [Customer.io credentials](https://fly.customer.io/settings/api_credentials).
```python
from async_customerio import AsyncCustomerIO, Regions
cio = AsyncCustomerIO(site_id, api_key, region=Regions.US)
```
`region` is optional and takes one of two values — `Regions.US` or `Regions.EU`. If you do not specify your region, we assume
that your account is based in the US (`Regions.US`). If your account is based in the EU and you do not provide the correct region
(`Regions.EU`), we'll route requests to our EU data centers accordingly, however, this may cause data to be logged in the US.
### Custom User-Agent
By default every request is sent with the `User-Agent` header set to `async-customerio/<version>`.
You can override it via the `user_agent` parameter:
```python
cio = AsyncCustomerIO(site_id, api_key, user_agent="my-app/1.0")
```
The same parameter is available on `AsyncAPIClient`.
## Track API v2
The v2 Track API is accessed via the `.v2` property on the `AsyncCustomerIO` instance. It provides
typed convenience methods for all person and object operations, sharing the same connection and
credentials as the v1 client.
### Person operations
```python
import asyncio
from async_customerio import AsyncCustomerIO, Regions
async def main():
async with AsyncCustomerIO(site_id="site", api_key="key", region=Regions.US) as cio:
# Identify (create or update) a person
await cio.v2.identify_person(identifiers={"id": 123}, name="Jane", plan="premium")
# Track an event
await cio.v2.track_person_event(identifiers={"id": 123}, name="purchase", amount=49.99)
# Page view / screen view (mobile)
await cio.v2.person_pageview(identifiers={"id": 123}, name="/pricing")
await cio.v2.person_screen(identifiers={"id": 123}, name="home_screen")
# Device management
await cio.v2.add_person_device(identifiers={"id": 123}, device_id="tok_abc", platform="ios")
await cio.v2.delete_person_device(identifiers={"id": 123}, device_id="tok_abc")
# Suppress / unsuppress
await cio.v2.suppress_person(identifiers={"id": 123})
await cio.v2.unsuppress_person(identifiers={"id": 123})
# Merge two person profiles (secondary is deleted)
await cio.v2.merge_persons(primary={"id": 123}, secondary={"email": "old@example.com"})
# Delete a person
await cio.v2.delete_person(identifiers={"id": 123})
if __name__ == "__main__":
asyncio.run(main())
```
### Object operations
```python
async with AsyncCustomerIO(site_id="site", api_key="key") as cio:
# Identify (create or update) an object
await cio.v2.identify_object(
identifiers={"object_type_id": "1", "object_id": "acme"},
name="Acme Corp",
industry="Software",
)
# Track an event on an object
await cio.v2.track_object_event(
identifiers={"object_type_id": "1", "object_id": "acme"},
name="plan_changed",
)
# Delete an object
await cio.v2.delete_object(identifiers={"object_type_id": "1", "object_id": "acme"})
```
### Relationships
```python
async with AsyncCustomerIO(site_id="site", api_key="key") as cio:
# Relate a person to an object
await cio.v2.add_person_relationships(
identifiers={"id": 123},
relationships=[{"identifiers": {"object_type_id": "1", "object_id": "acme"}}],
)
# Relate an object to people
await cio.v2.add_object_relationships(
identifiers={"object_type_id": "1", "object_id": "acme"},
relationships=[{"identifiers": {"id": 123}}, {"identifiers": {"id": 456}}],
)
# Remove relationships
await cio.v2.delete_person_relationships(
identifiers={"id": 123},
relationships=[{"identifiers": {"object_type_id": "1", "object_id": "acme"}}],
)
```
### Batch operations
```python
from async_customerio.track_v2 import Actions
async with AsyncCustomerIO(site_id="site", api_key="key") as cio:
batch = [
{
"type": "person",
"action": Actions.identify.value,
"identifiers": {"id": 123},
"attributes": {"name": "Jane"},
},
{
"type": "object",
"action": Actions.identify.value,
"identifiers": {"object_type_id": "1", "object_id": "acme"},
"attributes": {"name": "Acme Corp"},
},
]
await cio.v2.send_batch(batch)
```
### Notes
- All v2 methods validate required parameters and raise `AsyncCustomerIOError` for missing identifiers, names, etc.
- The API enforces size limits: each item <= 32 KB, whole batch < 500 KB.
- HTTP 200 and 207 are treated as success (methods return `None`). HTTP 400+ raises `AsyncCustomerIOError`.
- The legacy `cio.send_entity()` and `cio.send_batch()` methods still work for backwards compatibility but delegate to the `.v2` class internally.
## Sending transactional inbox messages
```python
import asyncio
from async_customerio import AsyncAPIClient, SendInboxMessageRequest, Regions
async def main():
api = AsyncAPIClient(key="your-app-api-key", region=Regions.US)
request = SendInboxMessageRequest(
transactional_message_id="3",
identifiers={"id": "user_123"},
message_data={"name": "Jane", "order_id": "1234"},
)
response = await api.send_inbox_message(request)
print(response)
if __name__ == "__main__":
asyncio.run(main())
```
## Securely verify requests [doc](https://customer.io/docs/journeys/webhooks/#securely-verify-requests)
```python
from async_customerio import validate_signature
def main():
webhook_signing_key = (
"755781b5e03a973f3405a85474d5a032a60fd56fabaad66039b12eadd83955fa"
)
x_cio_timestamp = 1692633432 # header value
x_cio_signature = "d7c655389bb364d3e8bdbb6ec18a7f1b6cf91f39bba647554ada78aa61de37b9" # header value
body = b'{"key": "value"}'
if validate_signature(
signing_key=webhook_signing_key,
timestamp=x_cio_timestamp,
request_body=body,
signature=x_cio_signature,
):
print("Request is sent from CustomerIO")
else:
print("Malicious request received")
if __name__ == "__main__":
main()
```
## License
`async-customerio` is offered under the MIT license.
## Source code
The latest developer version is available in a GitHub repository:
[https://github.com/healthjoy/async-customerio](https://github.com/healthjoy/async-customerio)
| text/markdown | Aleksandr Omyshev | oomyshev@healthjoy.com | Healthjoy Developers | developers@healthjoy.com | MIT | async, asyncio, customerio, messaing, python3, data-driven-emails, push notifications, in-app messages, SMS | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: 3 :: Only"
] | [] | https://github.com/healthjoy/async-customerio | null | <3.15,>=3.10 | [] | [] | [] | [
"httpx[http2]<1.0.0,>=0.28.1",
"h11>=0.16.0"
] | [] | [] | [] | [
"Repository, https://github.com/healthjoy/async-customerio"
] | poetry/2.2.1 CPython/3.12.3 Linux/6.11.0-1018-azure | 2026-02-20T12:29:53.451317 | async_customerio-2.8.0.tar.gz | 19,711 | 23/51/e76ff49a9cccde3fb1902092316f9982b98a61df6d76261377de5912c05f/async_customerio-2.8.0.tar.gz | source | sdist | null | false | a5c0a625de5c2b64a4f2887926a67238 | e0c545da2781f52dc1e63764654511f125466da3f139446a87864ec5c8319027 | 2351e76ff49a9cccde3fb1902092316f9982b98a61df6d76261377de5912c05f | null | [] | 239 |
2.3 | exasol-saas-api | 2.8.0 | API enabling Python applications connecting to Exasol database SaaS instances and using their SaaS services | # SaaS API for Python
API enabling Python applications connecting to Exasol database SaaS instances and using their SaaS services.
The model layer of this API is generated from the OpenAPI specification in JSON format of the SaaS API https://cloud.exasol.com/openapi.json using [openapi-python-client](https://github.com/openapi-generators/openapi-python-client).
A GitHub action will check each morning if the generated model layer is outdated.
See
* [User Guide](doc/user_guide/user-guide.md)
* [Developer Guide](doc/developer_guide/developer_guide.md)
| text/markdown | Christoph Kuhnke | christoph.kuhnke@exasol.com | Christoph Kuhnke | christoph.kuhnke@exasol.com | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | https://github.com/exasol/saas-api-python | null | <4.0,>=3.10.0 | [] | [] | [] | [
"requests<3.0.0,>=2.32.4",
"types-requests<3.0.0.0,>=2.31.0.6",
"ifaddr<0.3.0,>=0.2.0",
"tenacity<9.0.0,>=8.2.3",
"httpx>=0.23.0",
"python-dateutil<3.0.0,>=2.8.0",
"attrs>=22.2.0"
] | [] | [] | [] | [
"Homepage, https://github.com/exasol/saas-api-python",
"Documentation, https://github.com/exasol/saas-api-python",
"Source, https://github.com/exasol/saas-api-python",
"Issues, https://github.com/exasol/saas-api-python/issues"
] | poetry/2.1.2 CPython/3.12.3 Linux/6.11.0-1018-azure | 2026-02-20T12:29:27.953480 | exasol_saas_api-2.8.0.tar.gz | 29,728 | e8/87/fae0fe20ebebb3ae3f0f9906af5b6cbe56aeaa587cef45813b139681d533/exasol_saas_api-2.8.0.tar.gz | source | sdist | null | false | 45c726d1433c070ac500670ef33e020a | 7cc31f01737749f464b9032d14631a5e4189f006021197a201b1786740ead238 | e887fae0fe20ebebb3ae3f0f9906af5b6cbe56aeaa587cef45813b139681d533 | null | [] | 358 |
2.4 | snakemake-interface-storage-plugins | 4.3.3 | This package provides a stable interface for interactions between Snakemake and its storage plugins. | # snakemake-interface-storage-plugins
This package provides a stable interface for interactions between Snakemake and its storage plugins.
Plugins should implement the following skeleton to comply with this interface.
It is recommended to use [Snakedeploy to set up the skeleton](https://snakedeploy.readthedocs.io/en/stable/snakemake_developers/scaffold_snakemake_plugins.html) (and automated testing) within a python package.
```python
from dataclasses import dataclass, field
from typing import Any, Iterable, Optional, List
from snakemake_interface_storage_plugins.settings import StorageProviderSettingsBase
from snakemake_interface_storage_plugins.storage_provider import (
StorageProviderBase,
StorageQueryValidationResult,
ExampleQuery,
Operation,
)
from snakemake_interface_storage_plugins.storage_object import (
StorageObjectRead,
StorageObjectWrite,
StorageObjectGlob,
StorageObjectTouch,
retry_decorator,
)
from snakemake_interface_storage_plugins.io import IOCacheStorageInterface
# Optional:
# Define settings for your storage plugin (e.g. host url, credentials).
# They will occur in the Snakemake CLI as --storage-<storage-plugin-name>-<param-name>
# Make sure that all defined fields are 'Optional' and specify a default value
# of None or anything else that makes sense in your case.
# Note that we allow storage plugin settings to be tagged by the user. That means,
# that each of them can be specified multiple times (an implicit nargs=+), and
# the user can add a tag in front of each value (e.g. tagname1:value1 tagname2:value2).
# This way, a storage plugin can be used multiple times within a workflow with different
# settings.
@dataclass
class StorageProviderSettings(StorageProviderSettingsBase):
myparam: Optional[int] = field(
default=None,
metadata={
"help": "Some help text",
# Optionally request that setting is also available for specification
# via an environment variable. The variable will be named automatically as
# SNAKEMAKE_<storage-plugin-name>_<param-name>, all upper case.
# This mechanism should only be used for passwords, usernames, and other
# credentials.
# For other items, we rather recommend to let people use a profile
# for setting defaults
# (https://snakemake.readthedocs.io/en/stable/executing/cli.html#profiles).
"env_var": False,
# Optionally specify a function that parses the value given by the user.
# This is useful to create complex types from the user input.
"parse_func": ...,
# If a parse_func is specified, you also have to specify an unparse_func
# that converts the parsed value back to a string.
"unparse_func": ...,
# Optionally specify that setting is required when the executor is in use.
"required": True,
# Optionally specify multiple args with "nargs": True
},
)
# Required:
# Implementation of your storage provider
# This class can be empty as the one below.
# You can however use it to store global information or maintain e.g. a connection
# pool.
# Inside of the provider, you can use self.logger (a normal Python logger of type
# logging.Logger) to log any additional informations or
# warnings.
class StorageProvider(StorageProviderBase):
# For compatibility with future changes, you should not overwrite the __init__
# method. Instead, use __post_init__ to set additional attributes and initialize
# futher stuff.
def __post_init__(self):
# This is optional and can be removed if not needed.
# Alternatively, you can e.g. prepare a connection to your storage backend here.
# and set additional attributes.
pass
@classmethod
def example_queries(cls) -> List[ExampleQuery]:
"""Return valid example queries (at least one) with description."""
...
def rate_limiter_key(self, query: str, operation: Operation) -> Any:
"""Return a key for identifying a rate limiter given a query and an operation.
This is used to identify a rate limiter for the query.
E.g. for a storage provider like http that would be the host name.
For s3 it might be just the endpoint URL.
"""
...
def default_max_requests_per_second(self) -> float:
"""Return the default maximum number of requests per second for this storage
provider."""
...
def use_rate_limiter(self) -> bool:
"""Return False if no rate limiting is needed for this provider."""
...
@classmethod
def is_valid_query(cls, query: str) -> StorageQueryValidationResult:
"""Return whether the given query is valid for this storage provider."""
# Ensure that also queries containing wildcards (e.g. {sample}) are accepted
# and considered valid. The wildcards will be resolved before the storage
# object is actually used.
...
# If required, overwrite the method postprocess_query from StorageProviderBase
# in order to e.g. normalize the query or add information from the settings to it.
# Otherwise, remove this method as it will be inherited from the base class.
def postprocess_query(self, query: str) -> str:
return query
# This can be used to change how the rendered query is displayed in the logs to
# prevent accidentally printing sensitive information e.g. tokens in a URL.
def safe_print(self, query: str) -> str:
"""Process the query to remove potentially sensitive information when printing.
"""
return query
# Required:
# Implementation of storage object. If certain methods cannot be supported by your
# storage (e.g. because it is read-only see
# snakemake-storage-http for comparison), remove the corresponding base classes
# from the list of inherited items.
# Inside of the object, you can use self.provider to access the provider (e.g. for )
# self.provider.logger, see above, or self.provider.settings).
class StorageObject(
StorageObjectRead,
StorageObjectWrite,
StorageObjectGlob,
StorageObjectTouch
):
# For compatibility with future changes, you should not overwrite the __init__
# method. Instead, use __post_init__ to set additional attributes and initialize
# futher stuff.
def __post_init__(self):
# This is optional and can be removed if not needed.
# Alternatively, you can e.g. prepare a connection to your storage backend here.
# and set additional attributes.
pass
async def inventory(self, cache: IOCacheStorageInterface):
"""From this file, try to find as much existence and modification date
information as possible. Only retrieve that information that comes for free
given the current object.
"""
# This is optional and can be left as is
# If this is implemented in a storage object, results have to be stored in
# the given IOCache object, using self.cache_key() as key.
# Optionally, this can take a custom local suffix, needed e.g. when you want
# to cache more items than the current query: self.cache_key(local_suffix=...)
pass
def get_inventory_parent(self) -> Optional[str]:
"""Return the parent directory of this object."""
# this is optional and can be left as is
return None
def local_suffix(self) -> str:
"""Return a unique suffix for the local path, determined from self.query."""
...
def cleanup(self):
"""Perform local cleanup of any remainders of the storage object."""
# self.local_path() should not be removed, as this is taken care of by
# Snakemake.
...
# Fallible methods should implement some retry logic.
# The easiest way to do this (but not the only one) is to use the retry_decorator
# provided by snakemake-interface-storage-plugins.
@retry_decorator
def exists(self) -> bool:
# return True if the object exists
...
@retry_decorator
def mtime(self) -> float:
# return the modification time
...
@retry_decorator
def size(self) -> int:
# return the size in bytes
...
@retry_decorator
def local_footprint(self) -> int:
# Local footprint is the size of the object on the local disk.
# For directories, this should return the recursive sum of the
# directory file sizes.
# If the storage provider supports ondemand eligibility (see retrieve_object()
# below), this should return 0 if the object is not downloaded but e.g.
# mounted upon retrieval.
# If this method is not overwritten here, it defaults to self.size().
...
@retry_decorator
def retrieve_object(self):
# Ensure that the object is accessible locally under self.local_path()
# Optionally, this can make use of the attribute self.is_ondemand_eligible,
# which indicates that the object could be retrieved on demand,
# e.g. by only symlinking or mounting it from whatever network storage this
# plugin provides. For example, objects with self.is_ondemand_eligible == True
# could mount the object via fuse instead of downloading it.
# The job can then transparently access only the parts that matter to it
# without having to wait for the full download.
# On demand eligibility is calculated via Snakemake's access pattern annotation.
# If no access pattern is annotated by the workflow developers,
# self.is_ondemand_eligible is by default set to False.
...
# The following two methods are only required if the class inherits from
# StorageObjectReadWrite.
@retry_decorator
def store_object(self):
# Ensure that the object is stored at the location specified by
# self.local_path().
...
@retry_decorator
def remove(self):
# Remove the object from the storage.
...
# The following method is only required if the class inherits from
# StorageObjectGlob.
@retry_decorator
def list_candidate_matches(self) -> Iterable[str]:
"""Return a list of candidate matches in the storage for the query."""
# This is used by glob_wildcards() to find matches for wildcards in the query.
# The method has to return concretized queries without any remaining wildcards.
# Use snakemake_executor_plugins.io.get_constant_prefix(self.query) to get the
# prefix of the query before the first wildcard.
...
# The following method is only required if the class inherits from
# StorageObjectTouch
@retry_decorator
def touch(self):
"""Touch the object, updating its modification date."""
...
```
| text/markdown | Johannes Koester | johannes.koester@uni-due.de | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"humanfriendly<11,>=10.0",
"reretry>=0.11.8",
"snakemake-interface-common>=1.12.0",
"throttler>=1.2.2",
"wrapt>=1.15.0"
] | [] | [] | [] | [
"Homepage, https://github.com/snakemake/snakemake-interface-storage-plugins"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:29:26.916366 | snakemake_interface_storage_plugins-4.3.3.tar.gz | 14,554 | 89/95/35d6421faa328b4bc4df1179b1b4219720b967f34dd2e88671f9d35759f7/snakemake_interface_storage_plugins-4.3.3.tar.gz | source | sdist | null | false | 1571c60a663ca0a90dd901d410f1c93a | fd6afe2f0bed6cb02fd4b34a54c3bd9bbc9a606ff27476b8a55edbc3b54a0905 | 899535d6421faa328b4bc4df1179b1b4219720b967f34dd2e88671f9d35759f7 | null | [
"LICENSE"
] | 5,301 |
2.1 | ory-client | 1.22.25 | Ory APIs | # ory-client
# Introduction
Documentation for all public and administrative Ory APIs. Administrative APIs can only be accessed
with a valid Personal Access Token. Public APIs are mostly used in browsers.
## SDKs
This document describes the APIs available in the Ory Network. The APIs are available as SDKs for the following languages:
| Language | Download SDK | Documentation |
| -------------- | ---------------------------------------------------------------- | ------------------------------------------------------------------------------------ |
| Dart | [pub.dev](https://pub.dev/packages/ory_client) | [README](https://github.com/ory/sdk/blob/master/clients/client/dart/README.md) |
| .NET | [nuget.org](https://www.nuget.org/packages/Ory.Client/) | [README](https://github.com/ory/sdk/blob/master/clients/client/dotnet/README.md) |
| Elixir | [hex.pm](https://hex.pm/packages/ory_client) | [README](https://github.com/ory/sdk/blob/master/clients/client/elixir/README.md) |
| Go | [github.com](https://github.com/ory/client-go) | [README](https://github.com/ory/sdk/blob/master/clients/client/go/README.md) |
| Java | [maven.org](https://search.maven.org/artifact/sh.ory/ory-client) | [README](https://github.com/ory/sdk/blob/master/clients/client/java/README.md) |
| JavaScript | [npmjs.com](https://www.npmjs.com/package/@ory/client) | [README](https://github.com/ory/sdk/blob/master/clients/client/typescript/README.md) |
| JavaScript (With fetch) | [npmjs.com](https://www.npmjs.com/package/@ory/client-fetch) | [README](https://github.com/ory/sdk/blob/master/clients/client/typescript-fetch/README.md) |
| PHP | [packagist.org](https://packagist.org/packages/ory/client) | [README](https://github.com/ory/sdk/blob/master/clients/client/php/README.md) |
| Python | [pypi.org](https://pypi.org/project/ory-client/) | [README](https://github.com/ory/sdk/blob/master/clients/client/python/README.md) |
| Ruby | [rubygems.org](https://rubygems.org/gems/ory-client) | [README](https://github.com/ory/sdk/blob/master/clients/client/ruby/README.md) |
| Rust | [crates.io](https://crates.io/crates/ory-client) | [README](https://github.com/ory/sdk/blob/master/clients/client/rust/README.md) |
This Python package is automatically generated by the [OpenAPI Generator](https://openapi-generator.tech) project:
- API version: v1.22.25
- Package version: v1.22.25
- Generator version: 7.17.0
- Build package: org.openapitools.codegen.languages.PythonClientCodegen
## Requirements.
Python 3.9+
## Installation & Usage
### pip install
If the python package is hosted on a repository, you can install directly using:
```sh
pip install git+https://github.com/ory/sdk.git
```
(you may need to run `pip` with root permission: `sudo pip install git+https://github.com/ory/sdk.git`)
Then import the package:
```python
import ory_client
```
### Setuptools
Install via [Setuptools](http://pypi.python.org/pypi/setuptools).
```sh
python setup.py install --user
```
(or `sudo python setup.py install` to install the package for all users)
Then import the package:
```python
import ory_client
```
### Tests
Execute `pytest` to run the tests.
## Getting Started
Please follow the [installation procedure](#installation--usage) and then run the following:
```python
import ory_client
from ory_client.rest import ApiException
from pprint import pprint
# Defining the host is optional and defaults to https://playground.projects.oryapis.com
# See configuration.py for a list of all supported configuration parameters.
configuration = ory_client.Configuration(
host = "https://playground.projects.oryapis.com"
)
# The client must configure the authentication and authorization parameters
# in accordance with the API server security policy.
# Examples for each auth method are provided below, use the example that
# satisfies your auth use case.
# Configure Bearer authorization: oryAccessToken
configuration = ory_client.Configuration(
access_token = os.environ["BEARER_TOKEN"]
)
# Enter a context with an instance of the API client
with ory_client.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = ory_client.CourierApi(api_client)
id = 'id_example' # str | MessageID is the ID of the message.
try:
# Get a Message
api_response = api_instance.get_courier_message(id)
print("The response of CourierApi->get_courier_message:\n")
pprint(api_response)
except ApiException as e:
print("Exception when calling CourierApi->get_courier_message: %s\n" % e)
```
## Documentation for API Endpoints
All URIs are relative to *https://playground.projects.oryapis.com*
Class | Method | HTTP request | Description
------------ | ------------- | ------------- | -------------
*CourierApi* | [**get_courier_message**](docs/CourierApi.md#get_courier_message) | **GET** /admin/courier/messages/{id} | Get a Message
*CourierApi* | [**list_courier_messages**](docs/CourierApi.md#list_courier_messages) | **GET** /admin/courier/messages | List Messages
*EventsApi* | [**create_event_stream**](docs/EventsApi.md#create_event_stream) | **POST** /projects/{project_id}/eventstreams | Create an event stream for your project.
*EventsApi* | [**delete_event_stream**](docs/EventsApi.md#delete_event_stream) | **DELETE** /projects/{project_id}/eventstreams/{event_stream_id} | Remove an event stream from a project
*EventsApi* | [**list_event_streams**](docs/EventsApi.md#list_event_streams) | **GET** /projects/{project_id}/eventstreams | List all event streams for the project. This endpoint is not paginated.
*EventsApi* | [**set_event_stream**](docs/EventsApi.md#set_event_stream) | **PUT** /projects/{project_id}/eventstreams/{event_stream_id} | Update an event stream for a project.
*FrontendApi* | [**create_browser_login_flow**](docs/FrontendApi.md#create_browser_login_flow) | **GET** /self-service/login/browser | Create Login Flow for Browsers
*FrontendApi* | [**create_browser_logout_flow**](docs/FrontendApi.md#create_browser_logout_flow) | **GET** /self-service/logout/browser | Create a Logout URL for Browsers
*FrontendApi* | [**create_browser_recovery_flow**](docs/FrontendApi.md#create_browser_recovery_flow) | **GET** /self-service/recovery/browser | Create Recovery Flow for Browsers
*FrontendApi* | [**create_browser_registration_flow**](docs/FrontendApi.md#create_browser_registration_flow) | **GET** /self-service/registration/browser | Create Registration Flow for Browsers
*FrontendApi* | [**create_browser_settings_flow**](docs/FrontendApi.md#create_browser_settings_flow) | **GET** /self-service/settings/browser | Create Settings Flow for Browsers
*FrontendApi* | [**create_browser_verification_flow**](docs/FrontendApi.md#create_browser_verification_flow) | **GET** /self-service/verification/browser | Create Verification Flow for Browser Clients
*FrontendApi* | [**create_fedcm_flow**](docs/FrontendApi.md#create_fedcm_flow) | **GET** /self-service/fed-cm/parameters | Get FedCM Parameters
*FrontendApi* | [**create_native_login_flow**](docs/FrontendApi.md#create_native_login_flow) | **GET** /self-service/login/api | Create Login Flow for Native Apps
*FrontendApi* | [**create_native_recovery_flow**](docs/FrontendApi.md#create_native_recovery_flow) | **GET** /self-service/recovery/api | Create Recovery Flow for Native Apps
*FrontendApi* | [**create_native_registration_flow**](docs/FrontendApi.md#create_native_registration_flow) | **GET** /self-service/registration/api | Create Registration Flow for Native Apps
*FrontendApi* | [**create_native_settings_flow**](docs/FrontendApi.md#create_native_settings_flow) | **GET** /self-service/settings/api | Create Settings Flow for Native Apps
*FrontendApi* | [**create_native_verification_flow**](docs/FrontendApi.md#create_native_verification_flow) | **GET** /self-service/verification/api | Create Verification Flow for Native Apps
*FrontendApi* | [**disable_my_other_sessions**](docs/FrontendApi.md#disable_my_other_sessions) | **DELETE** /sessions | Disable my other sessions
*FrontendApi* | [**disable_my_session**](docs/FrontendApi.md#disable_my_session) | **DELETE** /sessions/{id} | Disable one of my sessions
*FrontendApi* | [**exchange_session_token**](docs/FrontendApi.md#exchange_session_token) | **GET** /sessions/token-exchange | Exchange Session Token
*FrontendApi* | [**get_flow_error**](docs/FrontendApi.md#get_flow_error) | **GET** /self-service/errors | Get User-Flow Errors
*FrontendApi* | [**get_login_flow**](docs/FrontendApi.md#get_login_flow) | **GET** /self-service/login/flows | Get Login Flow
*FrontendApi* | [**get_recovery_flow**](docs/FrontendApi.md#get_recovery_flow) | **GET** /self-service/recovery/flows | Get Recovery Flow
*FrontendApi* | [**get_registration_flow**](docs/FrontendApi.md#get_registration_flow) | **GET** /self-service/registration/flows | Get Registration Flow
*FrontendApi* | [**get_settings_flow**](docs/FrontendApi.md#get_settings_flow) | **GET** /self-service/settings/flows | Get Settings Flow
*FrontendApi* | [**get_verification_flow**](docs/FrontendApi.md#get_verification_flow) | **GET** /self-service/verification/flows | Get Verification Flow
*FrontendApi* | [**get_web_authn_java_script**](docs/FrontendApi.md#get_web_authn_java_script) | **GET** /.well-known/ory/webauthn.js | Get WebAuthn JavaScript
*FrontendApi* | [**list_my_sessions**](docs/FrontendApi.md#list_my_sessions) | **GET** /sessions | Get My Active Sessions
*FrontendApi* | [**perform_native_logout**](docs/FrontendApi.md#perform_native_logout) | **DELETE** /self-service/logout/api | Perform Logout for Native Apps
*FrontendApi* | [**to_session**](docs/FrontendApi.md#to_session) | **GET** /sessions/whoami | Check Who the Current HTTP Session Belongs To
*FrontendApi* | [**update_fedcm_flow**](docs/FrontendApi.md#update_fedcm_flow) | **POST** /self-service/fed-cm/token | Submit a FedCM token
*FrontendApi* | [**update_login_flow**](docs/FrontendApi.md#update_login_flow) | **POST** /self-service/login | Submit a Login Flow
*FrontendApi* | [**update_logout_flow**](docs/FrontendApi.md#update_logout_flow) | **GET** /self-service/logout | Update Logout Flow
*FrontendApi* | [**update_recovery_flow**](docs/FrontendApi.md#update_recovery_flow) | **POST** /self-service/recovery | Update Recovery Flow
*FrontendApi* | [**update_registration_flow**](docs/FrontendApi.md#update_registration_flow) | **POST** /self-service/registration | Update Registration Flow
*FrontendApi* | [**update_settings_flow**](docs/FrontendApi.md#update_settings_flow) | **POST** /self-service/settings | Complete Settings Flow
*FrontendApi* | [**update_verification_flow**](docs/FrontendApi.md#update_verification_flow) | **POST** /self-service/verification | Complete Verification Flow
*IdentityApi* | [**batch_patch_identities**](docs/IdentityApi.md#batch_patch_identities) | **PATCH** /admin/identities | Create multiple identities
*IdentityApi* | [**create_identity**](docs/IdentityApi.md#create_identity) | **POST** /admin/identities | Create an Identity
*IdentityApi* | [**create_recovery_code_for_identity**](docs/IdentityApi.md#create_recovery_code_for_identity) | **POST** /admin/recovery/code | Create a Recovery Code
*IdentityApi* | [**create_recovery_link_for_identity**](docs/IdentityApi.md#create_recovery_link_for_identity) | **POST** /admin/recovery/link | Create a Recovery Link
*IdentityApi* | [**delete_identity**](docs/IdentityApi.md#delete_identity) | **DELETE** /admin/identities/{id} | Delete an Identity
*IdentityApi* | [**delete_identity_credentials**](docs/IdentityApi.md#delete_identity_credentials) | **DELETE** /admin/identities/{id}/credentials/{type} | Delete a credential for a specific identity
*IdentityApi* | [**delete_identity_sessions**](docs/IdentityApi.md#delete_identity_sessions) | **DELETE** /admin/identities/{id}/sessions | Delete & Invalidate an Identity's Sessions
*IdentityApi* | [**disable_session**](docs/IdentityApi.md#disable_session) | **DELETE** /admin/sessions/{id} | Deactivate a Session
*IdentityApi* | [**extend_session**](docs/IdentityApi.md#extend_session) | **PATCH** /admin/sessions/{id}/extend | Extend a Session
*IdentityApi* | [**get_identity**](docs/IdentityApi.md#get_identity) | **GET** /admin/identities/{id} | Get an Identity
*IdentityApi* | [**get_identity_by_external_id**](docs/IdentityApi.md#get_identity_by_external_id) | **GET** /admin/identities/by/external/{externalID} | Get an Identity by its External ID
*IdentityApi* | [**get_identity_schema**](docs/IdentityApi.md#get_identity_schema) | **GET** /schemas/{id} | Get Identity JSON Schema
*IdentityApi* | [**get_session**](docs/IdentityApi.md#get_session) | **GET** /admin/sessions/{id} | Get Session
*IdentityApi* | [**list_identities**](docs/IdentityApi.md#list_identities) | **GET** /admin/identities | List Identities
*IdentityApi* | [**list_identity_schemas**](docs/IdentityApi.md#list_identity_schemas) | **GET** /schemas | Get all Identity Schemas
*IdentityApi* | [**list_identity_sessions**](docs/IdentityApi.md#list_identity_sessions) | **GET** /admin/identities/{id}/sessions | List an Identity's Sessions
*IdentityApi* | [**list_sessions**](docs/IdentityApi.md#list_sessions) | **GET** /admin/sessions | List All Sessions
*IdentityApi* | [**patch_identity**](docs/IdentityApi.md#patch_identity) | **PATCH** /admin/identities/{id} | Patch an Identity
*IdentityApi* | [**update_identity**](docs/IdentityApi.md#update_identity) | **PUT** /admin/identities/{id} | Update an Identity
*JwkApi* | [**create_json_web_key_set**](docs/JwkApi.md#create_json_web_key_set) | **POST** /admin/keys/{set} | Create JSON Web Key
*JwkApi* | [**delete_json_web_key**](docs/JwkApi.md#delete_json_web_key) | **DELETE** /admin/keys/{set}/{kid} | Delete JSON Web Key
*JwkApi* | [**delete_json_web_key_set**](docs/JwkApi.md#delete_json_web_key_set) | **DELETE** /admin/keys/{set} | Delete JSON Web Key Set
*JwkApi* | [**get_json_web_key**](docs/JwkApi.md#get_json_web_key) | **GET** /admin/keys/{set}/{kid} | Get JSON Web Key
*JwkApi* | [**get_json_web_key_set**](docs/JwkApi.md#get_json_web_key_set) | **GET** /admin/keys/{set} | Retrieve a JSON Web Key Set
*JwkApi* | [**set_json_web_key**](docs/JwkApi.md#set_json_web_key) | **PUT** /admin/keys/{set}/{kid} | Set JSON Web Key
*JwkApi* | [**set_json_web_key_set**](docs/JwkApi.md#set_json_web_key_set) | **PUT** /admin/keys/{set} | Update a JSON Web Key Set
*MetadataApi* | [**get_version**](docs/MetadataApi.md#get_version) | **GET** /version | Return Running Software Version.
*OAuth2Api* | [**accept_o_auth2_consent_request**](docs/OAuth2Api.md#accept_o_auth2_consent_request) | **PUT** /admin/oauth2/auth/requests/consent/accept | Accept OAuth 2.0 Consent Request
*OAuth2Api* | [**accept_o_auth2_login_request**](docs/OAuth2Api.md#accept_o_auth2_login_request) | **PUT** /admin/oauth2/auth/requests/login/accept | Accept OAuth 2.0 Login Request
*OAuth2Api* | [**accept_o_auth2_logout_request**](docs/OAuth2Api.md#accept_o_auth2_logout_request) | **PUT** /admin/oauth2/auth/requests/logout/accept | Accept OAuth 2.0 Session Logout Request
*OAuth2Api* | [**accept_user_code_request**](docs/OAuth2Api.md#accept_user_code_request) | **PUT** /admin/oauth2/auth/requests/device/accept | Accepts a device grant user_code request
*OAuth2Api* | [**create_o_auth2_client**](docs/OAuth2Api.md#create_o_auth2_client) | **POST** /admin/clients | Create OAuth 2.0 Client
*OAuth2Api* | [**delete_o_auth2_client**](docs/OAuth2Api.md#delete_o_auth2_client) | **DELETE** /admin/clients/{id} | Delete OAuth 2.0 Client
*OAuth2Api* | [**delete_o_auth2_token**](docs/OAuth2Api.md#delete_o_auth2_token) | **DELETE** /admin/oauth2/tokens | Delete OAuth 2.0 Access Tokens from specific OAuth 2.0 Client
*OAuth2Api* | [**delete_trusted_o_auth2_jwt_grant_issuer**](docs/OAuth2Api.md#delete_trusted_o_auth2_jwt_grant_issuer) | **DELETE** /admin/trust/grants/jwt-bearer/issuers/{id} | Delete Trusted OAuth2 JWT Bearer Grant Type Issuer
*OAuth2Api* | [**get_o_auth2_client**](docs/OAuth2Api.md#get_o_auth2_client) | **GET** /admin/clients/{id} | Get an OAuth 2.0 Client
*OAuth2Api* | [**get_o_auth2_consent_request**](docs/OAuth2Api.md#get_o_auth2_consent_request) | **GET** /admin/oauth2/auth/requests/consent | Get OAuth 2.0 Consent Request
*OAuth2Api* | [**get_o_auth2_login_request**](docs/OAuth2Api.md#get_o_auth2_login_request) | **GET** /admin/oauth2/auth/requests/login | Get OAuth 2.0 Login Request
*OAuth2Api* | [**get_o_auth2_logout_request**](docs/OAuth2Api.md#get_o_auth2_logout_request) | **GET** /admin/oauth2/auth/requests/logout | Get OAuth 2.0 Session Logout Request
*OAuth2Api* | [**get_trusted_o_auth2_jwt_grant_issuer**](docs/OAuth2Api.md#get_trusted_o_auth2_jwt_grant_issuer) | **GET** /admin/trust/grants/jwt-bearer/issuers/{id} | Get Trusted OAuth2 JWT Bearer Grant Type Issuer
*OAuth2Api* | [**introspect_o_auth2_token**](docs/OAuth2Api.md#introspect_o_auth2_token) | **POST** /admin/oauth2/introspect | Introspect OAuth2 Access and Refresh Tokens
*OAuth2Api* | [**list_o_auth2_clients**](docs/OAuth2Api.md#list_o_auth2_clients) | **GET** /admin/clients | List OAuth 2.0 Clients
*OAuth2Api* | [**list_o_auth2_consent_sessions**](docs/OAuth2Api.md#list_o_auth2_consent_sessions) | **GET** /admin/oauth2/auth/sessions/consent | List OAuth 2.0 Consent Sessions of a Subject
*OAuth2Api* | [**list_trusted_o_auth2_jwt_grant_issuers**](docs/OAuth2Api.md#list_trusted_o_auth2_jwt_grant_issuers) | **GET** /admin/trust/grants/jwt-bearer/issuers | List Trusted OAuth2 JWT Bearer Grant Type Issuers
*OAuth2Api* | [**o_auth2_authorize**](docs/OAuth2Api.md#o_auth2_authorize) | **GET** /oauth2/auth | OAuth 2.0 Authorize Endpoint
*OAuth2Api* | [**o_auth2_device_flow**](docs/OAuth2Api.md#o_auth2_device_flow) | **POST** /oauth2/device/auth | The OAuth 2.0 Device Authorize Endpoint
*OAuth2Api* | [**oauth2_token_exchange**](docs/OAuth2Api.md#oauth2_token_exchange) | **POST** /oauth2/token | The OAuth 2.0 Token Endpoint
*OAuth2Api* | [**patch_o_auth2_client**](docs/OAuth2Api.md#patch_o_auth2_client) | **PATCH** /admin/clients/{id} | Patch OAuth 2.0 Client
*OAuth2Api* | [**perform_o_auth2_device_verification_flow**](docs/OAuth2Api.md#perform_o_auth2_device_verification_flow) | **GET** /oauth2/device/verify | OAuth 2.0 Device Verification Endpoint
*OAuth2Api* | [**reject_o_auth2_consent_request**](docs/OAuth2Api.md#reject_o_auth2_consent_request) | **PUT** /admin/oauth2/auth/requests/consent/reject | Reject OAuth 2.0 Consent Request
*OAuth2Api* | [**reject_o_auth2_login_request**](docs/OAuth2Api.md#reject_o_auth2_login_request) | **PUT** /admin/oauth2/auth/requests/login/reject | Reject OAuth 2.0 Login Request
*OAuth2Api* | [**reject_o_auth2_logout_request**](docs/OAuth2Api.md#reject_o_auth2_logout_request) | **PUT** /admin/oauth2/auth/requests/logout/reject | Reject OAuth 2.0 Session Logout Request
*OAuth2Api* | [**revoke_o_auth2_consent_sessions**](docs/OAuth2Api.md#revoke_o_auth2_consent_sessions) | **DELETE** /admin/oauth2/auth/sessions/consent | Revoke OAuth 2.0 Consent Sessions of a Subject
*OAuth2Api* | [**revoke_o_auth2_login_sessions**](docs/OAuth2Api.md#revoke_o_auth2_login_sessions) | **DELETE** /admin/oauth2/auth/sessions/login | Revokes OAuth 2.0 Login Sessions by either a Subject or a SessionID
*OAuth2Api* | [**revoke_o_auth2_token**](docs/OAuth2Api.md#revoke_o_auth2_token) | **POST** /oauth2/revoke | Revoke OAuth 2.0 Access or Refresh Token
*OAuth2Api* | [**set_o_auth2_client**](docs/OAuth2Api.md#set_o_auth2_client) | **PUT** /admin/clients/{id} | Set OAuth 2.0 Client
*OAuth2Api* | [**set_o_auth2_client_lifespans**](docs/OAuth2Api.md#set_o_auth2_client_lifespans) | **PUT** /admin/clients/{id}/lifespans | Set OAuth2 Client Token Lifespans
*OAuth2Api* | [**trust_o_auth2_jwt_grant_issuer**](docs/OAuth2Api.md#trust_o_auth2_jwt_grant_issuer) | **POST** /admin/trust/grants/jwt-bearer/issuers | Trust OAuth2 JWT Bearer Grant Type Issuer
*OidcApi* | [**create_oidc_dynamic_client**](docs/OidcApi.md#create_oidc_dynamic_client) | **POST** /oauth2/register | Register OAuth2 Client using OpenID Dynamic Client Registration
*OidcApi* | [**create_verifiable_credential**](docs/OidcApi.md#create_verifiable_credential) | **POST** /credentials | Issues a Verifiable Credential
*OidcApi* | [**delete_oidc_dynamic_client**](docs/OidcApi.md#delete_oidc_dynamic_client) | **DELETE** /oauth2/register/{id} | Delete OAuth 2.0 Client using the OpenID Dynamic Client Registration Management Protocol
*OidcApi* | [**discover_oidc_configuration**](docs/OidcApi.md#discover_oidc_configuration) | **GET** /.well-known/openid-configuration | OpenID Connect Discovery
*OidcApi* | [**get_oidc_dynamic_client**](docs/OidcApi.md#get_oidc_dynamic_client) | **GET** /oauth2/register/{id} | Get OAuth2 Client using OpenID Dynamic Client Registration
*OidcApi* | [**get_oidc_user_info**](docs/OidcApi.md#get_oidc_user_info) | **GET** /userinfo | OpenID Connect Userinfo
*OidcApi* | [**revoke_oidc_session**](docs/OidcApi.md#revoke_oidc_session) | **GET** /oauth2/sessions/logout | OpenID Connect Front- and Back-channel Enabled Logout
*OidcApi* | [**set_oidc_dynamic_client**](docs/OidcApi.md#set_oidc_dynamic_client) | **PUT** /oauth2/register/{id} | Set OAuth2 Client using OpenID Dynamic Client Registration
*PermissionApi* | [**batch_check_permission**](docs/PermissionApi.md#batch_check_permission) | **POST** /relation-tuples/batch/check | Batch check permissions
*PermissionApi* | [**check_permission**](docs/PermissionApi.md#check_permission) | **GET** /relation-tuples/check/openapi | Check a permission
*PermissionApi* | [**check_permission_or_error**](docs/PermissionApi.md#check_permission_or_error) | **GET** /relation-tuples/check | Check a permission
*PermissionApi* | [**expand_permissions**](docs/PermissionApi.md#expand_permissions) | **GET** /relation-tuples/expand | Expand a Relationship into permissions.
*PermissionApi* | [**post_check_permission**](docs/PermissionApi.md#post_check_permission) | **POST** /relation-tuples/check/openapi | Check a permission
*PermissionApi* | [**post_check_permission_or_error**](docs/PermissionApi.md#post_check_permission_or_error) | **POST** /relation-tuples/check | Check a permission
*ProjectApi* | [**create_organization**](docs/ProjectApi.md#create_organization) | **POST** /projects/{project_id}/organizations | Create an Enterprise SSO Organization
*ProjectApi* | [**create_organization_onboarding_portal_link**](docs/ProjectApi.md#create_organization_onboarding_portal_link) | **POST** /projects/{project_id}/organizations/{organization_id}/onboarding-portal-links | Create organization onboarding portal link
*ProjectApi* | [**create_project**](docs/ProjectApi.md#create_project) | **POST** /projects | Create a Project
*ProjectApi* | [**create_project_api_key**](docs/ProjectApi.md#create_project_api_key) | **POST** /projects/{project}/tokens | Create project API key
*ProjectApi* | [**delete_organization**](docs/ProjectApi.md#delete_organization) | **DELETE** /projects/{project_id}/organizations/{organization_id} | Delete Enterprise SSO Organization
*ProjectApi* | [**delete_organization_onboarding_portal_link**](docs/ProjectApi.md#delete_organization_onboarding_portal_link) | **DELETE** /projects/{project_id}/organizations/{organization_id}/onboarding-portal-links/{onboarding_portal_link_id} | Delete an organization onboarding portal link
*ProjectApi* | [**delete_project_api_key**](docs/ProjectApi.md#delete_project_api_key) | **DELETE** /projects/{project}/tokens/{token_id} | Delete project API key
*ProjectApi* | [**get_organization**](docs/ProjectApi.md#get_organization) | **GET** /projects/{project_id}/organizations/{organization_id} | Get Enterprise SSO Organization by ID
*ProjectApi* | [**get_organization_onboarding_portal_links**](docs/ProjectApi.md#get_organization_onboarding_portal_links) | **GET** /projects/{project_id}/organizations/{organization_id}/onboarding-portal-links | Get the organization onboarding portal links
*ProjectApi* | [**get_project**](docs/ProjectApi.md#get_project) | **GET** /projects/{project_id} | Get a Project
*ProjectApi* | [**get_project_members**](docs/ProjectApi.md#get_project_members) | **GET** /projects/{project}/members | Get all members associated with this project
*ProjectApi* | [**list_organizations**](docs/ProjectApi.md#list_organizations) | **GET** /projects/{project_id}/organizations | List all Enterprise SSO organizations
*ProjectApi* | [**list_project_api_keys**](docs/ProjectApi.md#list_project_api_keys) | **GET** /projects/{project}/tokens | List a project's API keys
*ProjectApi* | [**list_projects**](docs/ProjectApi.md#list_projects) | **GET** /projects | List All Projects
*ProjectApi* | [**patch_project**](docs/ProjectApi.md#patch_project) | **PATCH** /projects/{project_id} | Patch an Ory Network Project Configuration
*ProjectApi* | [**patch_project_with_revision**](docs/ProjectApi.md#patch_project_with_revision) | **PATCH** /projects/{project_id}/revision/{revision_id} | Patch an Ory Network Project Configuration based on a revision ID
*ProjectApi* | [**purge_project**](docs/ProjectApi.md#purge_project) | **DELETE** /projects/{project_id} | Irrecoverably purge a project
*ProjectApi* | [**remove_project_member**](docs/ProjectApi.md#remove_project_member) | **DELETE** /projects/{project}/members/{member} | Remove a member associated with this project
*ProjectApi* | [**set_project**](docs/ProjectApi.md#set_project) | **PUT** /projects/{project_id} | Update an Ory Network Project Configuration
*ProjectApi* | [**update_organization**](docs/ProjectApi.md#update_organization) | **PUT** /projects/{project_id}/organizations/{organization_id} | Update an Enterprise SSO Organization
*ProjectApi* | [**update_organization_onboarding_portal_link**](docs/ProjectApi.md#update_organization_onboarding_portal_link) | **POST** /projects/{project_id}/organizations/{organization_id}/onboarding-portal-links/{onboarding_portal_link_id} | Update organization onboarding portal link
*RelationshipApi* | [**check_opl_syntax**](docs/RelationshipApi.md#check_opl_syntax) | **POST** /opl/syntax/check | Check the syntax of an OPL file
*RelationshipApi* | [**create_relationship**](docs/RelationshipApi.md#create_relationship) | **PUT** /admin/relation-tuples | Create a Relationship
*RelationshipApi* | [**delete_relationships**](docs/RelationshipApi.md#delete_relationships) | **DELETE** /admin/relation-tuples | Delete Relationships
*RelationshipApi* | [**get_relationships**](docs/RelationshipApi.md#get_relationships) | **GET** /relation-tuples | Query relationships
*RelationshipApi* | [**list_relationship_namespaces**](docs/RelationshipApi.md#list_relationship_namespaces) | **GET** /namespaces | Query namespaces
*RelationshipApi* | [**patch_relationships**](docs/RelationshipApi.md#patch_relationships) | **PATCH** /admin/relation-tuples | Patch Multiple Relationships
*WellknownApi* | [**discover_json_web_keys**](docs/WellknownApi.md#discover_json_web_keys) | **GET** /.well-known/jwks.json | Discover Well-Known JSON Web Keys
*WorkspaceApi* | [**create_workspace**](docs/WorkspaceApi.md#create_workspace) | **POST** /workspaces | Create a new workspace
*WorkspaceApi* | [**create_workspace_api_key**](docs/WorkspaceApi.md#create_workspace_api_key) | **POST** /workspaces/{workspace}/tokens | Create workspace API key
*WorkspaceApi* | [**delete_workspace_api_key**](docs/WorkspaceApi.md#delete_workspace_api_key) | **DELETE** /workspaces/{workspace}/tokens/{token_id} | Delete workspace API key
*WorkspaceApi* | [**get_workspace**](docs/WorkspaceApi.md#get_workspace) | **GET** /workspaces/{workspace} | Get a workspace
*WorkspaceApi* | [**list_workspace_api_keys**](docs/WorkspaceApi.md#list_workspace_api_keys) | **GET** /workspaces/{workspace}/tokens | List a workspace's API keys
*WorkspaceApi* | [**list_workspace_projects**](docs/WorkspaceApi.md#list_workspace_projects) | **GET** /workspaces/{workspace}/projects | List all projects of a workspace
*WorkspaceApi* | [**list_workspaces**](docs/WorkspaceApi.md#list_workspaces) | **GET** /workspaces | List workspaces the user is a member of
*WorkspaceApi* | [**update_workspace**](docs/WorkspaceApi.md#update_workspace) | **PUT** /workspaces/{workspace} | Update an workspace
## Documentation For Models
- [AcceptDeviceUserCodeRequest](docs/AcceptDeviceUserCodeRequest.md)
- [AcceptOAuth2ConsentRequest](docs/AcceptOAuth2ConsentRequest.md)
- [AcceptOAuth2ConsentRequestSession](docs/AcceptOAuth2ConsentRequestSession.md)
- [AcceptOAuth2LoginRequest](docs/AcceptOAuth2LoginRequest.md)
- [AccountExperienceColors](docs/AccountExperienceColors.md)
- [AccountExperienceConfiguration](docs/AccountExperienceConfiguration.md)
- [AddProjectToWorkspaceBody](docs/AddProjectToWorkspaceBody.md)
- [Attribute](docs/Attribute.md)
- [AttributeFilter](docs/AttributeFilter.md)
- [AttributesCountDatapoint](docs/AttributesCountDatapoint.md)
- [AuthenticatorAssuranceLevel](docs/AuthenticatorAssuranceLevel.md)
- [BasicOrganization](docs/BasicOrganization.md)
- [BatchCheckPermissionBody](docs/BatchCheckPermissionBody.md)
- [BatchCheckPermissionResult](docs/BatchCheckPermissionResult.md)
- [BatchPatchIdentitiesResponse](docs/BatchPatchIdentitiesResponse.md)
- [BillingPeriodBucket](docs/BillingPeriodBucket.md)
- [CheckOplSyntaxResult](docs/CheckOplSyntaxResult.md)
- [CheckPermissionResult](docs/CheckPermissionResult.md)
- [CheckPermissionResultWithError](docs/CheckPermissionResultWithError.md)
- [CloudAccount](docs/CloudAccount.md)
- [ConsistencyRequestParameters](docs/ConsistencyRequestParameters.md)
- [ContinueWith](docs/ContinueWith.md)
- [ContinueWithRecoveryUi](docs/ContinueWithRecoveryUi.md)
- [ContinueWithRecoveryUiFlow](docs/ContinueWithRecoveryUiFlow.md)
- [ContinueWithRedirectBrowserTo](docs/ContinueWithRedirectBrowserTo.md)
- [ContinueWithSetOrySessionToken](docs/ContinueWithSetOrySessionToken.md)
- [ContinueWithSettingsUi](docs/ContinueWithSettingsUi.md)
- [ContinueWithSettingsUiFlow](docs/ContinueWithSettingsUiFlow.md)
- [ContinueWithVerificationUi](docs/ContinueWithVerificationUi.md)
- [ContinueWithVerificationUiFlow](docs/ContinueWithVerificationUiFlow.md)
- [CourierMessageStatus](docs/CourierMessageStatus.md)
- [CourierMessageType](docs/CourierMessageType.md)
- [CreateCustomDomainBody](docs/CreateCustomDomainBody.md)
- [CreateEventStreamBody](docs/CreateEventStreamBody.md)
- [CreateFedcmFlowResponse](docs/CreateFedcmFlowResponse.md)
- [CreateIdentityBody](docs/CreateIdentityBody.md)
- [CreateInviteResponse](docs/CreateInviteResponse.md)
- [CreateJsonWebKeySet](docs/CreateJsonWebKeySet.md)
- [CreateOnboardingLinkResponse](docs/CreateOnboardingLinkResponse.md)
- [CreateOrganizationOnboardingPortalLinkBody](docs/CreateOrganizationOnboardingPortalLinkBody.md)
- [CreateProjectApiKeyRequest](docs/CreateProjectApiKeyRequest.md)
- [CreateProjectBody](docs/CreateProjectBody.md)
- [CreateProjectBranding](docs/CreateProjectBranding.md)
- [CreateProjectMemberInviteBody](docs/CreateProjectMemberInviteBody.md)
- [CreateProjectNormalizedPayload](docs/CreateProjectNormalizedPayload.md)
- [CreateRecoveryCodeForIdentityBody](docs/CreateRecoveryCodeForIdentityBody.md)
- [CreateRecoveryLinkForIdentityBody](docs/CreateRecoveryLinkForIdentityBody.md)
- [CreateRelationshipBody](docs/CreateRelationshipBody.md)
- [CreateSubscriptionBody](docs/CreateSubscriptionBody.md)
- [CreateSubscriptionCommon](docs/CreateSubscriptionCommon.md)
- [CreateVerifiableCredentialRequestBody](docs/CreateVerifiableCredentialRequestBody.md)
- [CreateWorkspaceApiKeyBody](docs/CreateWorkspaceApiKeyBody.md)
- [CreateWorkspaceBody](docs/CreateWorkspaceBody.md)
- [CreateWorkspaceMemberInviteBody](docs/CreateWorkspaceMemberInviteBody.md)
- [CreateWorkspaceOrganizationBody](docs/CreateWorkspaceOrganizationBody.md)
- [CreateWorkspaceSubscriptionBody](docs/CreateWorkspaceSubscriptionBody.md)
- [CredentialSupportedDraft00](docs/CredentialSupportedDraft00.md)
- [CustomDomain](docs/CustomDomain.md)
- [DeleteMySessionsCount](docs/DeleteMySessionsCount.md)
- [DeviceAuthorization](docs/DeviceAuthorization.md)
- [DeviceUserAuthRequest](docs/DeviceUserAuthRequest.md)
- [EmailTemplateData](docs/EmailTemplateData.md)
- [EmailTemplateDataBody](docs/EmailTemplateDataBody.md)
- [ErrorAuthenticatorAssuranceLevelNotSatisfied](docs/ErrorAuthenticatorAssuranceLevelNotSatisfied.md)
- [ErrorBrowserLocationChangeRequired](docs/ErrorBrowserLocationChangeRequired.md)
- [ErrorFlowReplaced](docs/ErrorFlowReplaced.md)
- [ErrorGeneric](docs/ErrorGeneric.md)
- [ErrorOAuth2](docs/ErrorOAuth2.md)
- [EventStream](docs/EventStream.md)
- [ExpandedPermissionTree](docs/ExpandedPermissionTree.md)
- [FlowError](docs/FlowError.md)
- [GenericError](docs/GenericError.md)
- [GenericErrorContent](docs/GenericErrorContent.md)
- [GenericOIDCProvider](docs/GenericOIDCProvider.md)
- [GenericUsage](docs/GenericUsage.md)
- [GetAttributesCount](docs/GetAttributesCount.md)
- [GetManagedIdentitySchemaLocation](docs/GetManagedIdentitySchemaLocation.md)
- [GetMetricsCount](docs/GetMetricsCount.md)
- [GetMetricsEventAttributes](docs/GetMetricsEventAttributes.md)
- [GetMetricsEventTypes](docs/GetMetricsEventTypes.md)
- [GetOrganizationResponse](docs/GetOrganizationResponse.md)
- [GetProjectEvents](docs/GetProjectEvents.md)
- [GetProjectEventsBody](docs/GetProjectEventsBody.md)
- [GetProjectMetrics](docs/GetProjectMetrics.md)
- [GetSessionActivity](docs/GetSessionActivity.md)
- [GetVersion200Response](docs/GetVersion200Response.md)
- [HealthNotReadyStatus](docs/HealthNotReadyStatus.md)
- [HealthStatus](docs/HealthStatus.md)
- [Identity](docs/Identity.md)
- [IdentityCredentials](docs/IdentityCredentials.md)
- [IdentityCredentialsCode](docs/IdentityCredentialsCode.md)
- [IdentityCredentialsCodeAddress](docs/IdentityCredentialsCodeAddress.md)
- [IdentityCredentialsOidc](docs/IdentityCredentialsOidc.md)
- [IdentityCredentialsOidcProvider](docs/IdentityCredentialsOidcProvider.md)
- [IdentityCredentialsPassword](docs/IdentityCredentialsPassword.md)
- [IdentityPatch](docs/IdentityPatch.md)
- [IdentityPatchResponse](docs/IdentityPatchResponse.md)
- [IdentitySchemaContainer](docs/IdentitySchemaContainer.md)
- [IdentitySchemaPreset](docs/IdentitySchemaPreset.md)
- [IdentityWithCredentials](docs/IdentityWithCredentials.md)
- [IdentityWithCredentialsOidc](docs/IdentityWithCredentialsOidc.md)
- [IdentityWithCredentialsOidcConfig](docs/IdentityWithCredentialsOidcConfig.md)
- [IdentityWithCredentialsOidcConfigProvider](docs/IdentityWithCredentialsOidcConfigProvider.md)
- [IdentityWithCredentialsPassword](docs/IdentityWithCredentialsPassword.md)
- [IdentityWithCredentialsPasswordConfig](docs/IdentityWithCredentialsPasswordConfig.md)
- [IdentityWithCredentialsSaml](docs/IdentityWithCredentialsSaml.md)
- [IdentityWithCredentialsSamlConfig](docs/IdentityWithCredentialsSamlConfig.md)
- [IdentityWithCredentialsSamlConfigProvider](docs/IdentityWithCredentialsSamlConfigProvider.md)
- [InternalGetProjectBrandingBody](docs/InternalGetProjectBrandingBody.md)
- [InternalIsAXWelcomeScreenEnabledForProjectBody](docs/InternalIsAXWelcomeScreenEnabledForProjectBody.md)
- [InternalIsOwnerForProjectBySlug](docs/InternalIsOwnerForProjectBySlug.md)
- [InternalIsOwnerForProjectBySlugBody](docs/InternalIsOwnerForProjectBySlugBody.md)
- [IntrospectedOAuth2Token](docs/IntrospectedOAuth2Token.md)
- [InviteTokenBody](docs/InviteTokenBody.md)
- [Invoice](docs/Invoice.md)
- [InvoiceDataV1](docs/InvoiceDataV1.md)
- [IsOwnerForProjectBySlug](docs/IsOwnerForProjectBySlug.md)
- [JsonPatch](docs/JsonPatch.md)
- [JsonWebKey](docs/JsonWebKey.md)
- [JsonWebKeySet](docs/JsonWebKeySet.md)
- [KetoNamespace](docs/KetoNamespace.md)
- [KeysetPaginationRequestParameters](docs/KeysetPaginationRequestParameters.md)
- [KeysetPaginationResponseHeaders](docs/KeysetPaginationResponseHeaders.md)
- [LineItemV1](docs/LineItemV1.md)
- [ListEventStreams](docs/ListEventStreams.md)
- [ListInvoicesResponse](docs/ListInvoicesResponse.md)
- [ListOrganizationsResponse](docs/ListOrganizationsResponse.md)
- [ListWorkspaceProjects](docs/ListWorkspaceProjects.md)
- [ListWorkspaces](docs/ListWorkspaces.md)
- [LoginFlow](docs/LoginFlow.md)
- [LoginFlowState](docs/LoginFlowState.md)
- [LogoutFlow](docs/LogoutFlow.md)
- [ManagedIdentitySchema](docs/ManagedIdentitySchema.md)
- [ManagedIdentitySchemaValidationResult](docs/ManagedIdentitySchemaValidationResult.md)
- [MemberInvite](docs/MemberInvite.md)
- [Message](docs/Message.md)
- [MessageDispatch](docs/MessageDispatch.md)
- [MetricsDatapoint](docs/MetricsDatapoint.md)
- [Money](docs/Money.md)
- [Namespace](docs/Namespace.md)
- [NeedsPrivilegedSessionError](docs/NeedsPrivilegedSessionError.md)
- [NormalizedProject](docs/NormalizedProject.md)
- [NormalizedProjectRevision](docs/NormalizedProjectRevision.md)
- [NormalizedProjectRevisionCourierChannel](docs/NormalizedProjectRevisionCourierChannel.md)
- [NormalizedProjectRevisionHook](docs/NormalizedProjectRevisionHook.md)
- [NormalizedProjectRevisionIdentitySchema](docs/NormalizedProjectRevisionIdentitySchema.md)
- [NormalizedProjectRevisionSAMLProvider](docs/NormalizedProjectRevisionSAMLProvider.md)
- [NormalizedProjectRevisionScimClient](docs/NormalizedProjectRevisionScimClient.md)
- [NormalizedProjectRevisionThirdPartyProvider](docs/NormalizedProjectRevisionThirdPartyProvider.md)
- [NormalizedProjectRevisionTokenizerTemplate](docs/NormalizedProjectRevisionTokenizerTemplate.md)
- [OAuth2Client](docs/OAuth2Client.md)
- [OAuth2ClientTokenLifespans](docs/OAuth2ClientTokenLifespans.md)
- [OAuth2ConsentRequest](docs/OAuth2ConsentRequest.md)
- [OAuth2ConsentRequestOpenIDConnectContext](docs/OAuth2ConsentRequestOpenIDConnectContext.md)
- [OAuth2ConsentSession](docs/OAuth2ConsentSession.md)
- [OAuth2LoginRequest](docs/OAuth2LoginRequest.md)
- [OAuth2LogoutRequest](docs/OAuth2LogoutRequest.md)
- [OAuth2RedirectTo](docs/OAuth2RedirectTo.md)
- [OAuth2TokenExchange](docs/OAuth2TokenExchange.md)
- [OidcConfiguration](docs/OidcConfiguration.md)
- [OidcUserInfo](docs/OidcUserInfo.md)
- [OnboardingPortalLink](docs/OnboardingPortalLink.md)
- [OnboardingPortalOrganization](docs/OnboardingPortalOrganization.md)
- [Organization](docs/Organization.md)
- [OrganizationBody](docs/OrganizationBody.md)
- [OrganizationOnboardingPortalLinksResponse](docs/OrganizationOnboardingPortalLinksResponse.md)
- [ParseError](docs/ParseError.md)
- [PatchIdentitiesBody](docs/PatchIdentitiesBody.md)
- [PerformNativeLogoutBody](docs/PerformNativeLogoutBody.md)
- [PermissionsOnWorkspace](docs/PermissionsOnWorkspace.md)
- [Plan](docs/Plan.md)
- [PlanDetails](docs/PlanDetails.md)
- [PostCheckPermissionBody](docs/PostCheckPermissionBody.md)
- [PostCheckPermissionOrErrorBody](docs/PostCheckPermissionOrErrorBody.md)
- [Project](docs/Project.md)
- [ProjectApiKey](docs/ProjectApiKey.md)
- [ProjectBranding](docs/ProjectBranding.md)
- [ProjectBrandingColors](docs/ProjectBrandingColors.md)
- [ProjectBrandingTheme](docs/ProjectBrandingTheme.md)
- [ProjectCors](docs/ProjectCors.md)
- [ProjectEventsDatapoint](docs/ProjectEventsDatapoint.md)
- [ProjectHost](docs/ProjectHost.md)
- [ProjectMember](docs/ProjectMember.md)
- [ProjectMetadata](docs/ProjectMetadata.md)
- [ProjectServiceAccountExperience](docs/ProjectServiceAccountExperience.md)
- [ProjectServiceIdentity](docs/ProjectServiceIdentity.md)
- [ProjectServiceOAuth2](docs/ProjectServiceOAuth2.md)
- [ProjectSe | text/markdown | API Support | API Support <support@ory.sh> | null | null | Apache 2.0 | OpenAPI, OpenAPI-Generator, Ory APIs | [] | [] | https://github.com/ory/sdk | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/ory/sdk"
] | twine/4.0.2 CPython/3.11.2 | 2026-02-20T12:28:20.160544 | ory_client-1.22.25.tar.gz | 411,525 | b3/5f/dbcabb0364c20dc155a03395f52b70fff987758c7becc7e8684de796ad82/ory_client-1.22.25.tar.gz | source | sdist | null | false | 1776208632233804d29b4f203298b4b6 | 8de6b86752b5547afc52a82809d3997cb623c30de91db6cb5b695ed56075baf5 | b35fdbcabb0364c20dc155a03395f52b70fff987758c7becc7e8684de796ad82 | null | [] | 277 |
2.4 | bpx | 1.1.0 | An implementation of the Battery Parameter eXchange (BPX) format in Pydantic. | # 🔋 BPX

[](https://codecov.io/gh/FaradayInstitution/BPX)
An implementation of the Battery Parameter eXchange (BPX) format in Pydantic. BPX, an outcome of the Faraday Institution [Multi-scale Modelling project](https://www.faraday.ac.uk/research/lithium-ion/battery-system-modelling/), is an open standard for physics-based Li-ion battery models that has been developed to reduce costs and time-to-market through a common definition of physics-based battery models that can be used widely across industry. To find out more, visit the [BPX website](https://bpxstandard.com/).
This repository features a Pydantic-based parser for JSON files in the BPX format, which validates your file against the schema.
To support the new open standard, [About:Energy](https://www.aboutenergy.io/) have supplied two parameter sets for an NMC and LFP cell. The BPX files and associated examples and information can be found on the [A:E BPX Parameterisation repository](https://github.com/About-Energy-OpenSource/About-Energy-BPX-Parameterisation/).
To see how to use BPX with [PyBaMM](https://www.pybamm.org/), check out the [BPX example notebook](https://github.com/pybamm-team/PyBaMM/blob/develop/docs/source/examples/notebooks/parameterization/bpx.ipynb).
## 🚀 Installation
The BPX package can be installed using pip
```bash
pip install bpx
```
or conda
```bash
conda install -c conda-forge bpx
```
BPX is available on GNU/Linux, MacOS and Windows. We strongly recommend to install PyBaMM within a python [virtual environment](https://docs.python.org/3/tutorial/venv.html), in order not to alter any distribution python files.
## 💻 Usage
To create a BPX object from a JSON file, you can use the `parse_bpx_file` function
```python
import bpx
filename = 'path/to/my/file.json'
my_params = bpx.parse_bpx_file(filename)
```
`my_params` will now be of type `BPX`, which acts like a python dataclass with the same attributes as the BPX format. To obtain example files, see the `examples` folder, or the [A:E BPX Parameterisation repository](https://github.com/About-Energy-OpenSource/About-Energy-BPX-Parameterisation/).
Attributes of the class can be printed out using the standard Python dot notation, for example, you can print out the reference temperature of the cell using
```python
print('Reference temperature of cell:', my_params.parameterisation.cell.reference_temperature)
```
Alternatively, you can export the `BPX` object as a dictionary and use the string names (aliases) of the parameters from the standard
```python
my_params_dict = my_params.model_dump(by_alias=True)
print('Reference temperature of cell:', my_params_dict["Parameterisation"]["Cell"]["Reference temperature [K]"])
```
The entire BPX object can be pretty-printed using the `devtools` package
```python
from devtools import pprint
pprint(my_params)
```
You can convert any `Function` objects in `BPX` to regular callable Python functions, for example:
```python
positive_electrode_diffusivity = my_params.parameterisation.positive_electrode.diffusivity.to_python_function()
diff_at_one = positive_electrode_diffusivity(1.0)
print('positive electrode diffusivity at x = 1.0:', diff_at_one)
```
If you want to output the complete JSON schema in order to build a custom tool yourself, you can do so:
```python
print(bpx.BPX.schema_json(indent=2))
```
According to the `pydantic` docs, the generated schemas are compliant with the specifications: JSON Schema Core, JSON Schema Validation and OpenAPI.
## 📖 Documentation
API documentation for the `bpx` package can be built locally using [Sphinx](https://www.sphinx-doc.org/en/master/). To build the documentation first [clone the repository](https://github.com/git-guides/git-clone), install the `bpx` package, and then run the following command:
```bash
sphinx-build docs docs/_build/html
```
This will generate a number of html files in the `docs/_build/html` directory. To view the documentation, open the file `docs/_build/html/index.html` in a web browser, e.g. by running
```bash
open docs/_build/html/index.html
```
## 📫 Get in touch
If you have any questions please get in touch via email <bpx@faraday.ac.uk>.
| text/markdown | null | Martin Robinson <martin.robinson@dtc.ox.ac.uk> | null | null | Copyright (c) 2022 University of Oxford
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | battery, bpx | [
"Development Status :: 4 - Beta",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.6",
"pyparsing",
"pyyaml",
"coverage[toml]>=6.5; extra == \"dev\"",
"devtools; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"pyclean; extra == \"dev\"",
"pytest; extra == \"dev\"",
"ruff; extra == \"dev\"",
"myst-parser; extra == \"docs\"",
"pydata-sphinx-theme; extra == \"docs\"",
"sphinx-copybutton; extra == \"docs\"",
"sphinx-design; extra == \"docs\"",
"sphinx-inline-tabs; extra == \"docs\"",
"sphinx-rtd-theme>=0.5; extra == \"docs\"",
"sphinx>=6; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://github.com/FaradayInstitution/BPX",
"Repository, https://github.com/FaradayInstitution/BPX"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:28:00.438539 | bpx-1.1.0.tar.gz | 74,228 | cc/b4/cdbe99b2fc9b1411f65017f4a3bfa19d0ad75099554060aa404260d4141f/bpx-1.1.0.tar.gz | source | sdist | null | false | c6e28564947c2509fd180d26b24625b2 | 5ac3ca84bee5541d22c449d5fd3c30f2a45016ae5e6f678955deff40ed2410a9 | ccb4cdbe99b2fc9b1411f65017f4a3bfa19d0ad75099554060aa404260d4141f | null | [
"LICENSE.txt"
] | 341 |
2.4 | angel-claw | 0.5.0 | Angel Claw personal AI agent framework | # 🪽 Angel Claw
A personal AI agent framework inspired by OpenClaw, using `angel-recall` for memory and `litellm` for LLM interactions.
## Features
- **FastAPI Gateway**: HTTP interface for interacting with the agent.
- **Multi-Channel Bridge**: Connect and pair your agent with **Telegram** for mobile access.
- **Agent-Native Memory**: Powered by `angel-recall`, providing long-term, evolvable memory for each session.
- **Proactive Tasks**: Built-in background worker for `at`, `every`, and `cron` schedules.
- **Multi-Model Support**: Uses `litellm` to connect to various providers (OpenAI, Anthropic, Ollama, etc.).
## Setup
1. **Install dependencies**:
```bash
pip install angel-claw
```
2. **Run the CLI chat**:
```bash
angel-claw chat
```
*Note: On your first run, Angel Claw will automatically create a `.env` file from `.env.example`. Make sure to edit it and add your API keys.*
3. **Configure environment**:
Edit the `.env` file and fill in your API keys.
- `MODEL_KEY`: Your LLM API key.
- `TELEGRAM_TOKEN`: (Optional) Your bot token from @BotFather.
4. **Run the gateway (optional)**:
```bash
angel-claw
```
## Usage
For detailed instructions on how to use Angel Claw and its skills system, see the [Documentation](docs/index.md).
## Out-of-the-Box Capabilities
Angel Claw comes pre-loaded with several powerful features. Here are some examples of what you can do:
### 1. Long-Term Memory
The agent automatically stores and retrieves facts about you.
- **Prompt:** "Remember that I'm allergic to peanuts."
- **Prompt (Later):** "What should I avoid at the Thai restaurant?"
- **Result:** Angel Claw will retrieve your allergy fact and advise you accordingly.
### 2. Proactive Messaging & Scheduling
Schedule tasks or reminders that the agent will trigger on its own.
- **Prompt:** "Remind me to check the oven in 20 minutes."
- **Prompt:** "Every day at 9 AM, check the weather in London and message me if it's raining."
- **Prompt:** "Schedule a task named 'daily-report' to run `0 18 * * *` that summarizes my day."
### 3. Web Search & Browser Automation
The agent can browse the web to find information or interact with sites.
- **Prompt:** "Search for the latest news about SpaceX and summarize it."
- **Prompt:** "Go to https://news.ycombinator.com and tell me the top story."
### 4. Custom Skill Generation
If Angel Claw doesn't have a tool, it can write one for itself.
- **Prompt:** "Create a skill called 'currency_converter' that uses an API to convert USD to EUR."
### 5. ClawHub Skills
Angel Claw can search for and install community-contributed skills from [ClawHub.ai](https://clawhub.ai).
- **Search:** "Search ClawHub for frontend skills."
- **Install:** "Install the 'slopwork-marketplace' skill from ClawHub."
- **Note:** Installed skills provide instructions (SKILL.md) that the agent will follow immediately.
> ⚠️ **Security Warning:** ClawHub skills are community-contributed and unvetted. Always review skills before use, as malicious skills may attempt to steal API keys or sensitive data.
### Telegram Bridge
You can interact with Angel Claw from your phone using Telegram:
1. **Get a Bot Token**: Create a bot using [@BotFather](https://t.me/botfather) and add `TELEGRAM_TOKEN` to your `.env`.
2. **Start your bot** on Telegram and press "Start".
3. **Pair your chat**: Use the `/pair` command with your session ID (e.g., `/pair cli-default`).
4. Angel Claw will now respond to your Telegram messages using that session's memory and skills.
### WhatsApp Bridge
Angel Claw supports WhatsApp via a "Link Device" (QR code) method:
1. **Enable WhatsApp**: Add `WHATSAPP_ENABLED=True` to your `.env`.
2. **Link Your Device**: Run the dedicated login command:
```bash
angel-claw login-whatsapp
```
3. **Scan QR Code**: Scan the QR code that appears in your terminal using your phone (WhatsApp > Linked Devices).
4. **Start Angel Claw**: Once linked, you can run `angel-claw chat` as normal.
5. **Pair your chat**: On WhatsApp, send `/pair <session-id>` (e.g., `/pair cli-default`) to yourself or the bot's number.
6. Angel Claw is now connected to your WhatsApp!
### Basic Chat
Send a POST request to `/chat`:
```bash
curl -X POST http://localhost:8000/chat \
-H "Content-Type: application/json" \
-d '{"session_id": "user-123", "message": "Hi, I am Alex. Remember that I like Python.", "user_id": "alex"}'
```
## Testing
```bash
pytest
```
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"fastapi",
"uvicorn",
"pydantic",
"pydantic-settings",
"python-dotenv",
"angel-recall",
"litellm",
"croniter",
"httpx",
"python-telegram-bot",
"telegram>=0.0.1",
"aiohttp",
"qrcode",
"neonize",
"pytest; extra == \"test\"",
"pytest-asyncio; extra == \"test\""
] | [] | [] | [] | [] | uv/0.10.0 {"installer":{"name":"uv","version":"0.10.0","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Linux Mint","version":"22.1","id":"xia","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T12:27:51.478797 | angel_claw-0.5.0.tar.gz | 29,822 | fb/41/f32d8a73c90ec784c6e8e2a33fcf3cc802edbc20d55c2a9299fc8a657213/angel_claw-0.5.0.tar.gz | source | sdist | null | false | 567a04ea3f577d2fbc0a6647b53c9029 | b170c53c2d686602daa9cc1c9369eb9c0a9c29834a661b691d633df2b25e4d6d | fb41f32d8a73c90ec784c6e8e2a33fcf3cc802edbc20d55c2a9299fc8a657213 | null | [
"LICENSE"
] | 228 |
2.4 | klayout-pex | 0.3.9 | Parasitic Extraction Tool for KLayout | <!--
--------------------------------------------------------------------------------
SPDX-FileCopyrightText: 2024-2025 Martin Jan Köhler and Harald Pretl
Johannes Kepler University, Institute for Integrated Circuits.
This file is part of KPEX
(see https://github.com/iic-jku/klayout-pex).
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
SPDX-License-Identifier: GPL-3.0-or-later
--------------------------------------------------------------------------------
-->
[](https://pypi.org/project/klayout-pex/)
[](https://github.com/iic-jku/klayout-pex/issues)
[](https://doi.org/10.5281/zenodo.17822625)
# KLayout-PEX
KLayout-PEX is a parasitic extraction tool for [KLayout](https://klayout.org).
There a multiple engines supported:
- FasterCap (requires [FasterCap](https://github.com/iic-jku/FasterCap) installation)
- MAGIC wrapper (requires [MAGIC](https://github.com/RTimothyEdwards/magic) installation)
- 2.5D engine (**under development**)
Check out the [documentation website](https://iic-jku.github.io/klayout-pex-website) for more information.
## Install
`pip install klayout-pex`
After that, you should be able to run `kpex --help`.
## Acknowledgements
This project is funded by the JKU/SAL [IWS Lab](https://research.jku.at/de/projects/jku-lit-sal-intelligent-wireless-systems-lab-iws-lab/), a collaboration of [Johannes Kepler University](https://jku.at) and [Silicon Austria Labs](https://silicon-austria-labs.com).
This project is further funded by the German project [FMD-QNC (16ME0831)](https://www.elektronikforschung.de/projekte/fmd-qnc).
<p align="center">
<a href="https://iic.jku.at" target="_blank">
<img src="https://github.com/iic-jku/klayout-pex-website/raw/main/figures/funding/iic-jku.svg" alt="Johannes Kepler University: Institute for Integrated Circuits and Quantum Computing" width="300"/>
</a>
<a href="https://silicon-austria-labs.com" target="_blank">
<img src="https://github.com/iic-jku/klayout-pex-website/raw/main/figures/funding/silicon-austria-labs-logo.svg" alt="Silicon Austria Labs" width="300"/>
</a>
</p>
<p align="center">
<a href="https://www.elektronikforschung.de/projekte/fmd-qnc" target="_blank">
<img src="https://github.com/iic-jku/klayout-pex-website/raw/main/figures/funding/bfmtr-bund-de-logo.svg" alt="Bundesministerium für Forschung, Technologie und Raumfahrt" width="300">
</a>
</p>
| text/markdown | Martin Köhler | info@martinjankoehler.com | null | null | GPL-3.0-or-later | electronic, pex, parasitic, extraction, vlsi, eda, ic, spice, klayout, analog, fsic, gds, FasterCap, magic | [
"Development Status :: 2 - Pre-Alpha",
"Environment :: Console",
"Intended Audience :: Manufacturing",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: C++",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: 3 :: Only",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Electronic Design Automation (EDA)"
] | [] | null | null | <4.0,>=3.12 | [] | [] | [] | [
"cairosvg>=2.7.1",
"klayout>=0.30.3",
"matplotlib>=3.10.1",
"protobuf>=6.33.5",
"rich>=13.9.4",
"rich-argparse>=1.6.0"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/iic-jku/klayout-pex/issues",
"Homepage, https://iic-jku.github.io/klayout-pex-website/",
"Repository, https://github.com/iic-jku/klayout-pex.git"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:26:30.977706 | klayout_pex-0.3.9.tar.gz | 193,072 | ef/6e/4a359fab666e4019bf79d029db4d1953ce9901e5440e5fd963eece79d3a7/klayout_pex-0.3.9.tar.gz | source | sdist | null | false | ed773baac9249b9263b3d407ad467374 | 933aa6c45252e397d2d50a17063e20f6269528eec1c20f81227aa2fcd1a6ec64 | ef6e4a359fab666e4019bf79d029db4d1953ce9901e5440e5fd963eece79d3a7 | null | [
"LICENSE"
] | 218 |
2.1 | cdk8s-cdktf-resolver | 0.0.239 | @cdk8s/cdktf-resolver | # CDK For Terraform Resolver
The `CdkTfResolver` is able to resolve any [`TerraformOutput`](https://developer.hashicorp.com/terraform/cdktf/concepts/variables-and-outputs#output-values)
defined by your CDKTF application. In this example, we create an S3 `Bucket` with the CDKTF, and pass its (deploy time generated)
name as an environment variable to a Kubernetes `CronJob` resource.
```python
import * as tf from "cdktf";
import * as aws from "@cdktf/provider-aws";
import * as k8s from 'cdk8s';
import * as kplus from 'cdk8s-plus-26';
import { CdkTfResolver } from '@cdk8s/cdktf-resolver';
const awsApp = new tf.App();
const stack = new tf.TerraformStack(awsApp, 'aws');
const k8sApp = new k8s.App({ resolvers: [new resolver.CdktfResolver({ app: awsApp })] });
const manifest = new k8s.Chart(k8sApp, 'Manifest', { resolver });
const bucket = new aws.s3Bucket.S3Bucket(stack, 'Bucket');
const bucketName = new tf.TerraformOutput(constrcut, 'BucketName', {
value: bucket.bucket,
});
new kplus.CronJob(manifest, 'CronJob', {
schedule: k8s.Cron.daily(),
containers: [{
image: 'job',
envVariables: {
// directly passing the value of the `TerraformOutput` containing
// the deploy time bucket name
BUCKET_NAME: kplus.EnvValue.fromValue(bucketName.value),
}
}]
});
awsApp.synth();
k8sApp.synth();
```
During cdk8s synthesis, the custom resolver will detect that `bucketName.value` is not a concrete value,
but rather a value of a `TerraformOutput`. It will then perform `cdktf` CLI commands in order to fetch the
actual value from the deployed infrastructure in your account. This means that in order
for `cdk8s synth` to succeed, it must be executed *after* the CDKTF resources have been deployed.
So your deployment workflow should (conceptually) be:
1. `cdktf deploy`
2. `cdk8s synth`
> Note that the `CdkTfResolver` is **only** able to fetch tokens that have a `TerraformOutput` defined for them.
##### Permissions
Since running `cdk8s synth` will now require reading terraform outputs, it must have permissions to do so.
In case a remote state file is used, this means providing a set of credentials for the account that have access
to where the state is stored. This will vary depending on your cloud provider, but in most cases will involve giving
read permissions on a blob storage device (e.g S3 bucket).
Note that the permissions cdk8s require are far more scoped down than those normally required for the
deployment of CDKTF applications. It is therefore recommended to not reuse the same set of credentials,
and instead create a scoped down `ReadOnly` role dedicated for cdk8s resolvers.
Following are the set of commands the resolver will execute:
* [`cdktf output`](https://developer.hashicorp.com/terraform/cdktf/cli-reference/commands#output)
## Cross Repository Workflow
As we've seen, your `cdk8s` application needs access to the objects defined in your cloud application. If both applications
are defined within the same file, this is trivial to achieve. If they are in different files, a simple `import` statement will suffice.
However, what if the applications are managed in two separate repositories? This makes it a little trickier, but still possible.
In this scenario, `cdktf.ts` in the CDKTF application, stored in a dedicated repository.
```python
import * as tf from "cdktf";
import * as aws from "@cdktf/provider-aws";
import { CdkTfResolver } from '@cdk8s/cdktf-resolver';
const awsApp = new tf.App();
const stack = new tf.TerraformStack(awsApp, 'aws');
const bucket = new aws.s3Bucket.S3Bucket(stack, 'Bucket');
const bucketName = new tf.TerraformOutput(constrcut, 'BucketName', {
value: bucket.bucket,
});
awsApp.synth();
```
In order for the `cdk8s` application to have cross repository access, the CDKTF object instances
that we want to expose need to be available via a package repository. To do this, break up the
CDKTF application into the following files:
`app.ts`
```python
import * as tf from "cdktf";
import * as aws from "@cdktf/provider-aws";
import { CdkTfResolver } from '@cdk8s/cdktf-resolver';
// export the app so we can pass it to the cdk8s resolver
export const awsApp = new tf.App();
const stack = new tf.TerraformStack(awsApp, 'aws');
const bucket = new aws.s3Bucket.S3Bucket(stack, 'Bucket');
// export the thing we want to have available for cdk8s applications
export const bucketName = new tf.TerraformOutput(constrcut, 'BucketName', {
value: bucket.bucket,
});
// note that we don't call awsApp.synth here
```
`main.ts`
```python
import { awsApp } from './app.ts'
awsApp.synth();
```
Now, publish the `app.ts` file to a package manager, so that your `cdk8s` application can install and import it.
This approach might be somewhat counter intuitive, because normally we only publish classes to the package manager,
not instances. Indeed, these types of applications introduce a new use-case that requires the sharing of instances.
Conceptually, this is no different than writing state<sup>*</sup> to an SSM parameter or an S3 bucket, and it allows us to remain
in the boundaries of our programming language, and the typing guarantees it provides.
> <sup>*</sup> Actually, we are only publishing instructions for fetching state, not the state itself.
Assuming `app.ts` was published as the `my-cdktf-app` package, our `cdk8s` application will now look like so:
```python
import * as k8s from 'cdk8s';
import * as kplus from 'cdk8s-plus-27';
// import the desired instance from the CDKTF app.
import { bucketName, awsApp } from 'my-cdktf-app';
import { CdkTfResolver } from '@cdk8s/cdktf-resolver';
const k8sApp = new k8s.App({ resolvers: [new resolver.CdktfResolver({ app: awsApp })] });
const manifest = new k8s.Chart(k8sApp, 'Manifest');
new kplus.CronJob(manifest, 'CronJob', {
schedule: k8s.Cron.daily(),
containers: [{
image: 'job',
envVariables: {
// directly passing the value of the `TerraformOutput` containing
// the deploy time bucket name
BUCKET_NAME: kplus.EnvValue.fromValue(bucketName.value),
}
}]
});
k8sApp.synth();
```
| text/markdown | Amazon Web Services | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved"
] | [] | https://github.com/cdk8s-team/cdk8s-cdktf-resolver.git | null | ~=3.9 | [] | [] | [] | [
"cdk8s<3.0.0,>=2.68.91",
"cdktf<0.21.0,>=0.20.8",
"constructs<11.0.0,>=10.3.0",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/cdk8s-team/cdk8s-cdktf-resolver.git"
] | twine/6.1.0 CPython/3.14.2 | 2026-02-20T12:25:57.490082 | cdk8s_cdktf_resolver-0.0.239.tar.gz | 35,151 | bb/89/e5cbed5828603f36eebc87c91fb00d3384312631aec297bc75719a4bfde6/cdk8s_cdktf_resolver-0.0.239.tar.gz | source | sdist | null | false | 4155474c4463e3000dbebbf56ffa9475 | d1c1dbe8dbc25fbe6631e1f6ca5495b87447e52b165d39ee7157874a82854b36 | bb89e5cbed5828603f36eebc87c91fb00d3384312631aec297bc75719a4bfde6 | null | [] | 229 |
2.4 | dcoraid | 1.1.0 | GUI/CLI for managing data on DCOR | |DCOR-Aid|
==========
|PyPI Version| |Build Status| |Coverage Status|
DCOR-Aid is a GUI for managing data on DCOR (https://dc.readthedocs.io).
Installation
------------
Installers for Windows and macOS are available at the
`release page <https://github.com/DCOR-dev/DCOR-Aid/releases>`__.
If you have Python 3 installed, you can install DCOR-Aid with::
pip install dcoraid[GUI]
After installation with pip, you can start DCOR-Aid with::
python -m dcoraid
Testing
-------
By default, testing is done with https://dcor-dev.mpl.mpg.de and the user
"dcoraid". The API key must either be present in the environment variable
``DCOR_API_KEY`` or in the file ``tests/api_key``.
::
pip install -e .[GUI]
pip install pytest pytest-qt
pytest tests
.. |DCOR-Aid| image:: https://raw.github.com/DCOR-dev/DCOR-Aid/main/dcoraid/img/splash.png
.. |PyPI Version| image:: https://img.shields.io/pypi/v/dcoraid.svg
:target: https://pypi.python.org/pypi/DCOR-Aid
.. |Build Status| image:: https://img.shields.io/github/actions/workflow/status/DCOR-dev/DCOR-Aid/check.yml
:target: https://github.com/DCOR-dev/DCOR-Aid/actions?query=workflow%3AChecks
.. |Coverage Status| image:: https://img.shields.io/codecov/c/github/DCOR-dev/DCOR-Aid/main.svg
:target: https://codecov.io/gh/DCOR-dev/DCOR-Aid
| text/x-rst | Paul Müller, Raghava Alajangi | null | null | Paul Müller <dev@craban.de> | null | RT-DC, DC, deformability, cytometry | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Intended Audience :: Science/Research"
] | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"dclab[dcor]>=0.64.2",
"numpy>=1.21",
"requests>=2.31",
"urllib3>=2.0",
"requests_cache",
"requests_toolbelt>=1.0.0",
"PyQt6; extra == \"gui\""
] | [] | [] | [] | [
"source, https://github.com/DCOR-dev/DCOR-Aid",
"tracker, https://github.com/DCOR-dev/DCOR-Aid/issues",
"documentation, https://dc.readthedocs.io",
"changelog, https://github.com/DCOR-dev/DCOR-Aid/blob/master/CHANGELOG"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T12:25:48.716135 | dcoraid-1.1.0.tar.gz | 1,015,748 | b6/42/9d45f12598589c6bfa8c445c739c411c24f3a2cd63c4cb0485366cbcd2b5/dcoraid-1.1.0.tar.gz | source | sdist | null | false | 15ae1012efab7746cc620c4190ef7cab | 4e894d1566bb17cd3e3b919552a61ea1d85d229b00d2e8cfc8c6aa9ab0e19adb | b6429d45f12598589c6bfa8c445c739c411c24f3a2cd63c4cb0485366cbcd2b5 | GPL-3.0-or-later | [
"LICENSE"
] | 220 |
2.4 | spseeker | 0.0.1 | InsideOpt Seeker Distribution for SoPlenty on Linux | ================
insideopt-seeker
================
InsideOpt Seeker for SoPlenty on Linux Distribution
Credits
-------
This package was created with Cookiecutter_.
.. _Cookiecutter: https://github.com/audreyr/cookiecutter
.. _`audreyr/cookiecutter-pypackage`: https://github.com/audreyr/cookiecutter-pypackage
| null | Meinolf Sellmann | info@insideopt.com | null | null | null | insideopt, seeker, optimization | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Natural Language :: English",
"Programming Language :: Python :: 3.12",
"Operating System :: POSIX :: Linux"
] | [] | null | null | >=3.12.0 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T12:25:22.546180 | spseeker-0.0.1.tar.gz | 5,515,186 | 11/2e/0a4d6add5e51ad6833f7d49e3f713704730e06f31645c9d32fd6fa84d810/spseeker-0.0.1.tar.gz | source | sdist | null | false | 22ca72ba8583334888252aca949ee18a | bcde8b3b1f10f6e7c2ada7ab4459f772f7f22b1dbfcd6d96e03b5f8ced65cb87 | 112e0a4d6add5e51ad6833f7d49e3f713704730e06f31645c9d32fd6fa84d810 | null | [
"LICENSE.rst",
"AUTHORS.rst"
] | 223 |
2.4 | droidrun | 0.5.0.dev6 | A framework for controlling Android devices through LLM agents | <picture align="center">
<source media="(prefers-color-scheme: dark)" srcset="./static/droidrun-dark.png">
<source media="(prefers-color-scheme: light)" srcset="./static/droidrun.png">
<img src="./static/droidrun.png" width="full">
</picture>
<div align="center">
[](https://docs.droidrun.ai)
[](https://cloud.droidrun.ai/sign-in?waitlist=true)
[](https://github.com/droidrun/droidrun/stargazers)
[](https://droidrun.ai)
[](https://x.com/droid_run)
[](https://discord.gg/ZZbKEZZkwK)
[](https://droidrun.ai/benchmark)
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.producthunt.com/widgets/embed-image/v1/top-post-badge.svg?post_id=983810&theme=dark&period=daily&t=1753948032207">
<source media="(prefers-color-scheme: light)" srcset="https://api.producthunt.com/widgets/embed-image/v1/top-post-badge.svg?post_id=983810&theme=neutral&period=daily&t=1753948125523">
<a href="https://www.producthunt.com/products/droidrun-framework-for-mobile-agent?embed=true&utm_source=badge-top-post-badge&utm_medium=badge&utm_source=badge-droidrun" target="_blank"><img src="https://api.producthunt.com/widgets/embed-image/v1/top-post-badge.svg?post_id=983810&theme=neutral&period=daily&t=1753948125523" alt="Droidrun - Give AI native control of physical & virtual phones. | Product Hunt" style="width: 200px; height: 54px;" width="200" height="54" /></a>
</picture>
[Deutsch](https://zdoc.app/de/droidrun/droidrun) |
[Español](https://zdoc.app/es/droidrun/droidrun) |
[français](https://zdoc.app/fr/droidrun/droidrun) |
[日本語](https://zdoc.app/ja/droidrun/droidrun) |
[한국어](https://zdoc.app/ko/droidrun/droidrun) |
[Português](https://zdoc.app/pt/droidrun/droidrun) |
[Русский](https://zdoc.app/ru/droidrun/droidrun) |
[中文](https://zdoc.app/zh/droidrun/droidrun)
</div>
DroidRun is a powerful framework for controlling Android and iOS devices through LLM agents. It allows you to automate device interactions using natural language commands. [Checkout our benchmark results](https://droidrun.ai/benchmark)
## Why Droidrun?
- 🤖 Control Android and iOS devices with natural language commands
- 🔀 Supports multiple LLM providers (OpenAI, Anthropic, Gemini, Ollama, DeepSeek)
- 🧠 Planning capabilities for complex multi-step tasks
- 💻 Easy to use CLI with enhanced debugging features
- 🐍 Extendable Python API for custom automations
- 📸 Screenshot analysis for visual understanding of the device
- Execution tracing with Arize Phoenix
## 📦 Installation
> **Note:** Python 3.14 is not currently supported. Please use Python 3.11 – 3.13.
```bash
pip install droidrun
```
## 🚀 Quickstart
Read on how to get droidrun up and running within seconds in [our docs](https://docs.droidrun.ai/v3/quickstart)!
[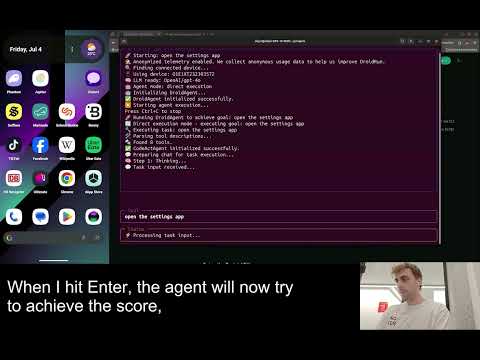](https://www.youtube.com/watch?v=4WT7FXJah2I)
## 🎬 Demo Videos
1. **Accommodation booking**: Let Droidrun search for an apartment for you
[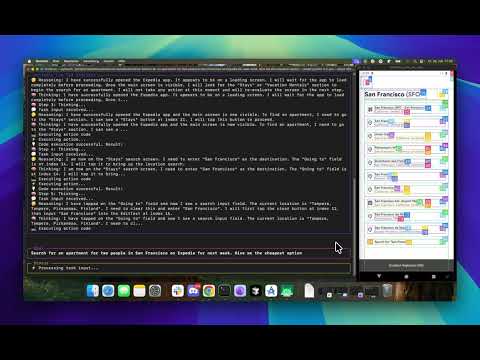](https://youtu.be/VUpCyq1PSXw)
<br>
2. **Trend Hunter**: Let Droidrun hunt down trending posts
[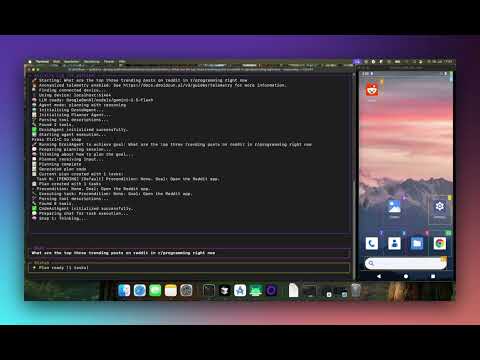](https://youtu.be/7V8S2f8PnkQ)
<br>
3. **Streak Saver**: Let Droidrun save your streak on your favorite language learning app
[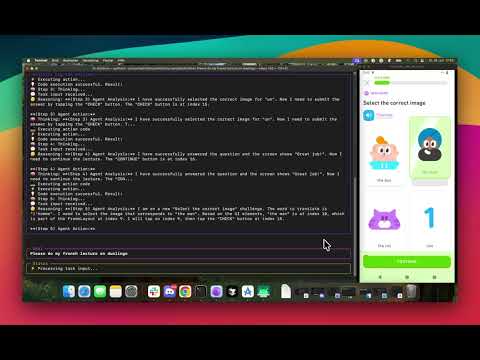](https://youtu.be/B5q2B467HKw)
## 💡 Example Use Cases
- Automated UI testing of mobile applications
- Creating guided workflows for non-technical users
- Automating repetitive tasks on mobile devices
- Remote assistance for less technical users
- Exploring mobile UI with natural language commands
## 👥 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## 📄 License
This project is licensed under the MIT License - see the LICENSE file for details.
## Security Checks
To ensure the security of the codebase, we have integrated security checks using `bandit` and `safety`. These tools help identify potential security issues in the code and dependencies.
### Running Security Checks
Before submitting any code, please run the following security checks:
1. **Bandit**: A tool to find common security issues in Python code.
```bash
bandit -r droidrun
```
2. **Safety**: A tool to check your installed dependencies for known security vulnerabilities.
```bash
safety scan
```
| text/markdown | null | Niels Schmidt <niels.schmidt@droidrun.ai> | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Communications :: Chat",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries :: Application Frameworks",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Quality Assurance",
"Topic :: Software Development :: Testing",
"Topic :: Software Development :: Testing :: Acceptance",
"Topic :: System :: Emulators",
"Topic :: Utilities"
] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"aiofiles>=25.1.0",
"arize-phoenix>=12.3.0",
"async-adbutils",
"httpx>=0.27.0",
"llama-index-callbacks-arize-phoenix>=0.6.1",
"llama-index-llms-google-genai>=0.8.5",
"llama-index-llms-ollama>=0.7.2",
"llama-index-llms-openai-like>=0.5.1",
"llama-index-llms-openai>=0.5.6",
"llama-index-llms-openrouter>=0.4.2",
"llama-index-workflows==2.8.3",
"llama-index==0.14.4",
"mcp>=1.26.0",
"mobilerun-sdk",
"posthog>=6.7.6",
"pydantic>=2.11.10",
"python-dotenv>=1.2.1",
"rich>=14.1.0",
"textual>=6.11.0",
"anthropic>=0.67.0; extra == \"anthropic\"",
"llama-index-llms-anthropic<0.9.0,>=0.8.6; extra == \"anthropic\"",
"llama-index-llms-deepseek>=0.2.1; extra == \"deepseek\"",
"bandit>=1.8.6; extra == \"dev\"",
"black==25.9.0; extra == \"dev\"",
"langfuse==3.12.1; extra == \"dev\"",
"llama-index-instrumentation; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"openinference-instrumentation-llama-index>=3.0.0; extra == \"dev\"",
"ruff>=0.13.0; extra == \"dev\"",
"safety>=3.2.11; extra == \"dev\"",
"langfuse==3.12.1; extra == \"langfuse\"",
"llama-index-instrumentation; extra == \"langfuse\"",
"openinference-instrumentation-llama-index>=3.0.0; extra == \"langfuse\""
] | [] | [] | [] | [
"Homepage, https://github.com/droidrun/droidrun",
"Bug Tracker, https://github.com/droidrun/droidrun/issues",
"Documentation, https://docs.droidrun.ai/"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:23:45.914487 | droidrun-0.5.0.dev6.tar.gz | 703,096 | f5/a0/ea0646844559e8a58365eaad9e265156a49f72e9b103a35ea14e18271e91/droidrun-0.5.0.dev6.tar.gz | source | sdist | null | false | d2ff05d8a0b30b5272718d31bc24fd86 | 7b69ac33e4948090d35d5733d747b49dd875f6c95038663e12f0568e0802bfbf | f5a0ea0646844559e8a58365eaad9e265156a49f72e9b103a35ea14e18271e91 | null | [
"LICENSE"
] | 204 |
2.4 | pagi | 0.3.0 | ORM-agnostic pagination toolkit for Python | # pagi
A minimal, ORM-agnostic pagination toolkit for Python.
`pagi` lets you define pagination logic once and reuse it across different ORMs (SQLAlchemy, Django, etc.), returning consistent, typed responses powered by Pydantic.
---
## Features
* Offset/limit pagination with validation via Pydantic
* Unified response model (`PaginatedResponse`)
* SQLAlchemy support (sync and async)
* Django ORM support
* Tortoise ORM support
* Strategy-based internal design for easy extensibility
* ORM-agnostic public API
---
## Installation
```bash
pip install pagi
```
Or with development dependencies:
```bash
pip install -e .[dev]
```
or if you are using uv
```bash
uv pip install -e .[dev]
```
## Basic Usage
### Importing
The installable package name is `pagi`, but the Python module is `paginator`.
Recommended import:
```python
from paginator.paginator import paginate, paginate_sync
```
---
## SQLAlchemy (Synchronous)
```python
from sqlalchemy import select
from sqlalchemy.orm import Session
from paginator import paginate_sync
def get_users(session: Session):
return paginate_sync(
session,
lambda: select(User),
offset=10,
limit=5,
backend="sqlalchemy",
)
```
## SQLAlchemy (Asynchronous)
```python
from sqlalchemy import select
from sqlalchemy.ext.asyncio import AsyncSession
from paginator import paginate
async def get_users(session: AsyncSession):
return await paginate(
session,
lambda: select(User),
offset=10,
limit=5,
backend="sqlalchemy",
)
```
The correct strategy (sync vs async) is selected automatically based on the session type.
---
## Django ORM
```python
from paginator import paginate_sync
from myapp.models import User
result = paginate_sync(
connection=None,
query_func=lambda: User.objects.all(),
offset=20,
limit=10,
backend="django",
)
```
Notes:
* `query_func` must return an unevaluated Django `QuerySet`
* Django pagination is synchronous (async execution is not supported)
## Tortoise ORM
```python
from paginator import paginate
from myapp.models import User
result = await paginate(
connection=None,
query_func=lambda: User.all().order_by("id"),
offset=20,
limit=10,
backend="tortoise",
)
```
Notes:
* Tortoise ORM is async-first, so only `paginate()` (async) is supported
* `paginate_sync()` will raise a `RuntimeError`
* Make sure Tortoise is initialized before calling pagination functions
## Design and Architecture
`pagi` is built around the **Strategy pattern**, allowing multiple ORMs to be supported while keeping a single, simple public API.
* `paginator.paginator` exposes the public functions (`paginate`, `paginate_sync`)
* Each ORM implements its own pagination strategy
* A small factory selects the appropriate strategy at runtime based on the backend and connection type
* Pagination logic is decoupled from data access, making new backends easy to add
### SQLAlchemy Strategy Selection
For SQLAlchemy, `pagi` uses a factory-based approach:
* Passing a `Session` enables synchronous pagination
* Passing an `AsyncSession` enables asynchronous pagination
* The correct strategy is chosen automatically without extra configuration
---
## Roadmap
* Cursor-based pagination (cursor tokens instead of offset/limit)
* Optional total count for performance-sensitive queries
---
## Testing and Edge Cases
The following edge cases should be considered when testing pagination across all backends:
### Common Edge Cases
* **Empty result set** - Query returns 0 records
* **First page** - `offset=0, limit=N`
* **Last page (partial)** - Requested limit exceeds remaining records
* **Exact page boundary** - `offset + limit == total`
* **Offset beyond total** - `offset > total` should return empty items
* **Maximum limit** - Test with `limit=100` (the configured maximum)
* **Limit validation** - `limit=0` or `limit > 100` should raise validation errors
* **Negative offset** - Should raise validation errors
### Backend-Specific Considerations
| Backend | Sync | Async | Notes |
|---------|------|-------|-------|
| SQLAlchemy | yes | yes | Strategy auto-selected by Session type |
| Django | yes | no | Wrap with `sync_to_async` if needed |
| Tortoise | no | yes | Async-first ORM |
---
## Development
Run tests with:
```bash
pytest
```
The test suite covers:
* SQLAlchemy (sync)
* Django ORM
* Tortoise ORM
---
## License
MIT
| text/markdown | null | Daryll Lorenzo Alfonso <daryllla77@gmail.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Topic :: Software Development :: Libraries",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"build>=1.3.0",
"pydantic>=2.0.0",
"twine>=6.2.0",
"pytest>=8.0.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"django; extra == \"dev\"",
"sqlalchemy; extra == \"dev\"",
"aiosqlite; extra == \"dev\"",
"tortoise-orm; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/DaryllLorenzo/pagi",
"Repository, https://github.com/DaryllLorenzo/pagi"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-20T12:23:38.660408 | pagi-0.3.0.tar.gz | 7,909 | 03/aa/6f0f6f8b066b7ced5cd9d49934f181cc7e9e4b4aa6d1ff2a473679becf8e/pagi-0.3.0.tar.gz | source | sdist | null | false | 985e89ff61da84bd7f83cdb3420b48e0 | 7eb06b52c9d437c47346f67ee6c39cb10103baf2eb5579b0d12230da1ffa38c5 | 03aa6f0f6f8b066b7ced5cd9d49934f181cc7e9e4b4aa6d1ff2a473679becf8e | MIT | [
"LICENSE"
] | 209 |
2.4 | hexicodes | 0.3.0 | Minimal contract-driven coding-agent runtime + CLI | # Hexi v0.3.0

Hexi is a minimal, contract-driven (hexagonal) coding-agent runtime and CLI.
It runs exactly one agent step per invocation against a local git repository.
## Test Drive (5 Minutes)
Run this in any local git repo you can safely modify.
1. Install Hexi:
```bash
pip install -e .
```
Optional OpenRouter support:
```bash
pip install -e ".[openrouter]"
```
2. Initialize Hexi files:
```bash
hexi init
```
3. Onboard provider/model and key:
```bash
hexi onboard
```
When prompted, pick any provider. For OpenRouter providers, install the optional extra and provide `OPENROUTER_API_KEY`.
4. Verify setup:
```bash
hexi doctor
```
Expected: provider/model printed and `Doctor check passed`.
5. Run one agent step:
```bash
hexi run "Add one tiny test for an existing function and run pytest"
```
6. Inspect what changed:
```bash
hexi diff
tail -n 20 .hexi/runlog.jsonl
```
7. If you want to switch providers later:
```bash
hexi onboard
```
Re-run onboarding to update `.hexi/local.toml`.
## What it is
- Python package (PyPI distribution): `hexicodes`
- Core contracts in `hexi.core`
- Side-effect adapters in `hexi.adapters`
- One-step execution with structured event logging to `.hexi/runlog.jsonl`
## What it is not
- No daemon, no background workers, no web UI
- No MCP server and no SQLite in v0.3.0
- No multi-agent orchestration
## Install
```bash
pip install -e .
```
### OpenRouter support (optional)
- HTTP adapter only (`openrouter_http` provider):
```bash
pip install -e ".[openrouter-http]"
```
- SDK adapter only (`openrouter_sdk` provider):
```bash
pip install -e ".[openrouter-sdk]"
```
- Both OpenRouter adapters:
```bash
pip install -e ".[openrouter]"
```
Dev/test dependencies:
```bash
pip install -e ".[dev]"
```
## Pythonic Task Automation (`poe`)
Hexi includes a project-local task runner using [Poe the Poet](https://poethepoet.natn.io/), so you do not need to memorize long command chains.
Install dev tooling:
```bash
pip install -e ".[dev]"
```
Common tasks:
```bash
poe test # run pytest
poe docs # mkdocs serve (local docs server)
poe docs-build # mkdocs static build
poe check # tests + docs build
poe build # package build + twine check
poe release # build + twine check + tests + docs build
poe publish-testpypi # upload dist/* to TestPyPI via repository URL
poe publish-pypi # upload dist/* to PyPI
```
## CLI
- `hexi --help` or `hexi help` : show command help
- `hexi -v ...` / `hexi -vv ...` : increase runtime verbosity (trace lines + richer event payloads)
- `hexi --version` or `hexi version` : print installed version
- `hexi init` : create `.hexi/config.toml`, `.hexi/local.toml`, `.hexi/runlog.jsonl`
- `hexi onboard` : interactive setup for provider/model and optional local key paste
- `hexi new` : scaffold a project from built-in Hexi templates (non-interactive by default)
- `hexi demo` : fancy interactive flow with random/model-generated ideas and template scaffolding
- `hexi run "<task>"` : execute one agent step and emit structured events
- `hexi apply --plan plan.json` : execute a validated ActionPlan file directly (debug/replay mode)
- `hexi diff` : show current git diff
- `hexi doctor` : verbose diagnostics; use `--probe-model` for live “What model are you?” check
- `hexi plan-check --file plan.json` : validate/troubleshoot ActionPlan JSON directly
## Documentation (MkDocs + Read the Docs)
Build docs locally:
```bash
pip install -e ".[docs]"
mkdocs serve
```
Read the Docs config is in `.readthedocs.yml`.
CI runs on GitHub Actions and validates:
- `poe check` (tests + docs build)
- package smoke flow (build wheel, install wheel, verify templates, run `hexi new`)
## Configuration design choices
Hexi uses layered TOML configuration:
1. `.hexi/config.toml` (repo defaults)
2. `.hexi/local.toml` (local machine overrides)
3. Environment variables (recommended for secrets)
For secrets, env vars are preferred. `hexi onboard` can write keys to `.hexi/local.toml` for local/testing convenience.
## Config shape (`.hexi/config.toml`)
```toml
[model]
provider = "openai_compat" # openrouter_http | openrouter_sdk | openai_compat | anthropic_compat
model = "gpt-4o-mini"
[providers.openrouter_http]
base_url = "https://openrouter.ai/api/v1"
api_style = "openai" # openai | anthropic
[providers.openrouter_sdk]
base_url = "https://openrouter.ai/api/v1"
[providers.openai_compat]
base_url = "https://api.openai.com/v1"
[providers.anthropic_compat]
base_url = "https://api.anthropic.com"
[policy]
allow_commands = ["git status", "git diff", "pytest", "python -m pytest"]
max_diff_chars = 4000
max_file_read_chars = 4000
```
## Local override example (`.hexi/local.toml`)
```toml
[model]
provider = "openrouter_http"
model = "anthropic/claude-sonnet-4-6"
[providers.openrouter_http]
api_style = "anthropic"
[secrets]
openrouter_api_key = "..."
```
## Env vars
- `OPENROUTER_API_KEY` for `openrouter_http` and `openrouter_sdk`
- `OPENAI_API_KEY` for `openai_compat`
- `ANTHROPIC_API_KEY` for `anthropic_compat`
## Packaging
- Distribution name: `hexicodes`
- Console script: `hexi`
- Optional extras:
- `openrouter-http`
- `openrouter-sdk`
- `openrouter`
- `docs`
- `dev`
## Included example projects
- `examples/todo_refiner` : minimal CLI-wrapper agent integration
- `examples/embedded_step` : direct embedded `RunStepService` usage
- `examples/policy_loop` : multi-step user-gated loop using repeated `hexi run`
## Example ActionPlans (`hexi apply`)
- `examples/action_plans/read_only.json` : inspect file + emit progress
- `examples/action_plans/write_file.json` : create a file in-repo
- `examples/action_plans/run_tests.json` : run `pytest -q`
- `examples/action_plans/mixed_step.json` : read + write + run + emit
- `examples/action_plans/list_files.json` : list files by path/glob
- `examples/action_plans/search_text.json` : search text matches by path/glob
Try one now:
```bash
hexi plan-check --file examples/action_plans/mixed_step.json
hexi apply --plan examples/action_plans/mixed_step.json --task "ActionPlan debug run"
```
## Included Hexi-native templates
- `templates/hexi-python-lib` : tested library starter with Hexi wiring
- `templates/hexi-fastapi-service` : FastAPI service starter with Hexi wiring
- `templates/hexi-typer-cli` : Typer CLI starter with Hexi wiring
- `templates/hexi-data-job` : data job starter with dry-run and Hexi wiring
- `templates/hexi-agent-worker` : embedded Hexi runtime starter
## Provenance
Made with ❤️ from 🇵🇪. El Perú es clave 🔑.
| text/markdown | Antonio Ognio | null | Antonio Ognio | null | MIT | ai, agent, coding-agent, cli, developer-tools, hexagonal-architecture, openrouter, typer | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Build Tools",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Testing"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"typer<1,>=0.12",
"httpx<1,>=0.27",
"rich<15,>=13.7",
"tomli>=2.0.1; python_version < \"3.11\"",
"requests<3,>=2.31; extra == \"openrouter-http\"",
"openrouter<1,>=0.6.0; extra == \"openrouter-sdk\"",
"requests<3,>=2.31; extra == \"openrouter\"",
"openrouter<1,>=0.6.0; extra == \"openrouter\"",
"mkdocs<2,>=1.6; extra == \"docs\"",
"mkdocs-material<10,>=9.5; extra == \"docs\"",
"build<2,>=1.2; extra == \"dev\"",
"poethepoet<1,>=0.29; extra == \"dev\"",
"pytest<9,>=8.2; extra == \"dev\"",
"pytest-asyncio<1,>=0.23; extra == \"dev\"",
"requests<3,>=2.31; extra == \"dev\"",
"twine<6,>=5.1; extra == \"dev\"",
"responses<1,>=0.25; extra == \"dev\"",
"respx<1,>=0.21; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://hexi.readthedocs.io",
"Documentation, https://hexi.readthedocs.io",
"Source, https://github.com/hexi-codes/hexi",
"Issues, https://github.com/hexi-codes/hexi/issues"
] | twine/6.2.0 CPython/3.13.1 | 2026-02-20T12:23:12.157847 | hexicodes-0.3.0.tar.gz | 40,670 | 85/ba/a8b487f3d2de6260e1a9aa3909fe71f454ee7656483a7c64ddf246cf0af8/hexicodes-0.3.0.tar.gz | source | sdist | null | false | 83c6267bc36940b465e58e7a0823cc3d | 0d584cb51cb812baea010682b374733592a717195d06f93b160c55aa61868a88 | 85baa8b487f3d2de6260e1a9aa3909fe71f454ee7656483a7c64ddf246cf0af8 | null | [
"LICENSE"
] | 229 |
2.4 | mediaref | 0.5.2 | Pydantic media reference for images and video frames with lazy loading and optimized batch decoding | # MediaRef
[](https://github.com/open-world-agents/MediaRef/actions?query=event%3Apush+branch%3Amain+workflow%3ACI)
[](https://pypi.python.org/pypi/mediaref)
[](https://github.com/open-world-agents/MediaRef)
[](https://github.com/open-world-agents/MediaRef/blob/main/LICENSE)
<!-- [](https://pepy.tech/project/mediaref) -->
Pydantic media reference for images and video frames (with timestamp support) from data URIs, HTTP URLs, file URIs, and local paths. Features lazy loading and optimized batch video decoding.
Works with any container format (Parquet, HDF5, mcap, rosbag, etc.) and any media format (JPEG, PNG, H.264, H.265, AV1, etc.).
## Why MediaRef?
**1. Separate heavy media from lightweight metadata**
Store 1TB of videos separately while keeping only 1MB of references in your dataset tables. Break free from rigid structures where media must be embedded inside tables—MediaRef enables flexible, decoupled storage architectures for any format that stores strings.
```python
# Store lightweight references in your dataset, not heavy media
import pandas as pd
# Image references: 37 bytes vs entire embedded image(>100KB)
df_images = pd.DataFrame([
{"action": [0.1, 0.2], "observation": MediaRef(uri="frame_001.png").model_dump()},
{"action": [0.3, 0.4], "observation": MediaRef(uri="frame_002.png").model_dump()},
])
# Video frame references: 35-42 bytes vs entire video file embedded(several GBs)
df_video = pd.DataFrame([
{"action": [0.1, 0.2], "observation": MediaRef(uri="episode_01.mp4", pts_ns=0).model_dump()},
{"action": [0.3, 0.4], "observation": MediaRef(uri="episode_01.mp4", pts_ns=50_000_000).model_dump()},
])
# Works with any container format (Parquet, HDF5, mcap, rosbag, etc.)
# and any media format (JPEG, PNG, H.264, H.265, AV1, etc.)
```
MediaRef is already used in production ML data formats at scale. For example, the [D2E research project](https://worv-ai.github.io/d2e/) uses MediaRef via [OWAMcap](https://open-world-agents.github.io/open-world-agents/data/technical-reference/format-guide/) to store **10TB+** of gameplay data with [screen observations](https://github.com/open-world-agents/open-world-agents/blob/main/projects/owa-msgs/owa/msgs/desktop/screen.py#L49).
**2. Future-proof specification built on standards**
The MediaRef schema(`uri`, `pts_ns`) is designed to be **permanent**, built entirely on established standards ([RFC 2397](https://datatracker.ietf.org/doc/html/rfc2397) for data URIs, [RFC 3986](https://datatracker.ietf.org/doc/html/rfc3986) for URI syntax). Use it anywhere with confidence—no proprietary formats, no breaking changes.
**3. Optimized performance where it matters**
Due to lazy loading, MediaRef has **zero CPU and I/O overhead** when the media is not accessed. When you do need to load the media, convenient APIs handle the complexity of multi-source media (local files, URLs, embedded data) with a single unified interface.
When loading multiple frames from the same video, `batch_decode()` opens the video file once and reuses the handle, achieving **4.9× faster throughput** and **2.2× better I/O efficiency** compared to sequential decoding.
<p align="center">
<img src=".github/assets/decoding_benchmark.png" alt="Decoding Benchmark" width="800">
</p>
> **Benchmark details**: Decoding throughput = decoded frames per second during dataloading; I/O efficiency = inverse of disk I/O operations per frame loaded. Measured on real ML dataloader workloads (Minecraft dataset: 64×5 min episodes, 640×360 @ 20Hz, FSLDataset with 4096 token sequences). See [D2E paper](https://worv-ai.github.io/d2e/) Section 3 and Appendix A for full methodology.
## Installation
**Quick install:**
```bash
# Core package with image loading support
pip install mediaref
# With video decoding support (adds PyAV for video frame extraction)
pip install mediaref[video]
```
**Add to your project:**
```bash
# Core package
uv add mediaref~=0.5.0
# With video decoding support
uv add 'mediaref[video]~=0.5.0'
```
**Versioning Policy**: MediaRef follows [semantic versioning](https://semver.org/). Patch releases (e.g., 0.5.0 → 0.5.1) contain only bug fixes and performance improvements with **no API changes**. Minor releases (e.g., 0.5.x → 0.6.0) may introduce new features while maintaining backward compatibility. Use `~=0.5.0` to automatically receive patch updates.
## Quick Start
### Basic Usage
```python
from mediaref import MediaRef, DataURI, batch_decode
import numpy as np
# 1. Create references (lightweight, no loading yet)
ref = MediaRef(uri="image.png") # Local file
ref = MediaRef(uri="https://example.com/image.jpg") # Remote URL
ref = MediaRef(uri="video.mp4", pts_ns=1_000_000_000) # Video frame at 1.0s
# 2. Load media
rgb = ref.to_ndarray() # Returns (H, W, 3) RGB array
pil = ref.to_pil_image() # Returns PIL.Image
# 3. Embed as data URI
data_uri = DataURI.from_image(rgb, format="png") # e.g., "data:image/png;base64,iVBORw0KG..."
ref = MediaRef(uri=data_uri) # Self-contained reference
# 4. Batch decode video frames (opens video once, reuses handle)
refs = [MediaRef(uri="video.mp4", pts_ns=int(i*1e9)) for i in range(10)]
frames = batch_decode(refs) # Much faster than loading individually
# 5. Serialize for storage in any container format (Parquet, HDF5, mcap, rosbag, etc.)
json_str = ref.model_dump_json() # Lightweight JSON string
# Store in your dataset format of choice - works with any format that stores strings
```
### Batch Decoding - Optimized Video Frame Loading
When loading multiple frames from the same video, use `batch_decode()` to open the video file once and reuse the handle—achieving significantly better performance than loading frames individually.
```python
from mediaref import MediaRef, batch_decode
# Use optimized batch decoding (default: PyAV backend)
refs = [MediaRef(uri="video.mp4", pts_ns=int(i*1e9)) for i in range(10)]
frames = batch_decode(refs)
# Or use TorchCodec for GPU-accelerated decoding
frames = batch_decode(refs, decoder="torchcodec") # Requires: pip install torchcodec
```
Both decoders follow unified [playback semantics](docs/playback_semantics.md)—querying a timestamp returns the frame being displayed at that moment, ensuring consistent behavior across backends.
### Embedding Media Directly in MediaRef
You can embed image data directly into `MediaRef` objects, making them self-contained and portable (useful for serialization, caching, or sharing).
```python
from mediaref import MediaRef, DataURI
import numpy as np
# Create embedded MediaRef from numpy array
rgb = np.random.randint(0, 255, (100, 100, 3), dtype=np.uint8)
embedded_ref = MediaRef(uri=DataURI.from_image(rgb, format="png"))
# Or from file
embedded_ref = MediaRef(uri=DataURI.from_file("image.png"))
# Or from PIL Image
from PIL import Image
pil_img = Image.open("image.png")
embedded_ref = MediaRef(uri=DataURI.from_image(pil_img, format="jpeg", quality=90))
# Or from BGR array (OpenCV uses BGR by default - input_format="bgr" is REQUIRED)
import cv2
bgr_array = cv2.imread("image.jpg") # OpenCV loads as BGR, not RGB!
embedded_ref = MediaRef(uri=DataURI.from_image(bgr_array, format="png", input_format="bgr"))
# Use just like any other MediaRef
rgb = embedded_ref.to_ndarray() # (H, W, 3) RGB array
pil = embedded_ref.to_pil_image() # PIL Image
# Serialize with embedded data
serialized = embedded_ref.model_dump_json() # Contains image data
restored = MediaRef.model_validate_json(serialized) # No external file needed!
# Properties
print(data_uri.mimetype) # "image/png"
print(len(data_uri)) # URI length in bytes
print(data_uri.is_image) # True for image/* types
```
### Path Resolution & Serialization
Resolve relative paths and serialize MediaRef objects for storage in any container format (Parquet, HDF5, mcap, rosbag, etc.).
```python
# Resolve relative paths
ref = MediaRef(uri="relative/video.mkv", pts_ns=123456)
resolved = ref.resolve_relative_path("/data/recordings")
# Handle unresolvable URIs (embedded/remote)
remote = MediaRef(uri="https://example.com/image.jpg")
resolved = remote.resolve_relative_path("/data", on_unresolvable="ignore") # No warning
# Serialization (Pydantic-based) - works with any container format
ref = MediaRef(uri="video.mp4", pts_ns=1_500_000_000)
# As dict (for Python-based formats)
data = ref.model_dump()
# Output: {'uri': 'video.mp4', 'pts_ns': 1500000000}
# As JSON string (for Parquet, HDF5, mcap, rosbag, etc.)
json_str = ref.model_dump_json()
# Output: '{"uri":"video.mp4","pts_ns":1500000000}'
# Deserialization
ref = MediaRef.model_validate(data) # From dict
ref = MediaRef.model_validate_json(json_str) # From JSON
```
## Documentation
- **[API Reference](docs/API.md)** - Detailed API documentation
- **[Playback Semantics](docs/playback_semantics.md)** - How frame selection works at specific timestamps
## Potential Future Enhancements
- [ ] **HuggingFace datasets integration**: Add native `MediaRef` feature type to [HuggingFace datasets](https://github.com/huggingface/datasets) for seamless integration with the ML ecosystem
- [ ] **msgspec support**: Replace pydantic BaseModel into [msgspec](https://jcristharif.com/msgspec/)
- [ ] **Thread-safe resource caching**: Implement thread-safe `ResourceCache` for concurrent video decoding workloads
- [ ] **Audio support**: Extend MediaRef to support audio references with timestamp-based extraction
- [ ] **Cloud storage support**: Integrate `fsspec` for cloud URIs (e.g., `s3://`, `gs://`, `az://`)
- [ ] **Additional video decoders**: Support for more decoder backends (e.g., OpenCV, decord)
## Dependencies
**Core dependencies** (automatically installed):
- `pydantic>=2.0` - Data validation and serialization (requires Pydantic v2 API)
- `numpy` - Array operations
- `opencv-python` - Image loading and color conversion
- `pillow>=9.4.0` - Image loading from various sources
- `requests>=2.32.2` - HTTP/HTTPS URL loading
- `loguru` - Logging (disabled by default for library code)
**Optional dependencies**:
- `[video]` extra: `av>=15.0` (PyAV for video frame extraction)
- TorchCodec: `torchcodec` (install separately for GPU-accelerated decoding)
## Acknowledgments
The video decoder interface design references [TorchCodec](https://github.com/pytorch/torchcodec)'s API design.
## License
MediaRef is released under the [MIT License](LICENSE).
| text/markdown | null | Suhwan Choi <milkclouds00@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Multimedia :: Graphics",
"Topic :: Multimedia :: Video",
"Topic :: Scientific/Engineering",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"loguru",
"numpy",
"opencv-python",
"pillow>=9.4.0",
"pydantic>=2.0",
"requests>=2.32.2",
"av>=15.0; extra == \"video\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T12:23:01.391424 | mediaref-0.5.2-py3-none-any.whl | 34,807 | 46/13/889ec3cd1ed8973f52cccb1e5db3064beb8d9f2a4b31010a1b9d503cc640/mediaref-0.5.2-py3-none-any.whl | py3 | bdist_wheel | null | false | c8d4deeae03477caf902f34280456406 | 08b99410adc6544fb18998e1224027abf0551b408ee34f7be49abc6a68ab4c39 | 4613889ec3cd1ed8973f52cccb1e5db3064beb8d9f2a4b31010a1b9d503cc640 | null | [
"LICENSE"
] | 227 |
2.4 | amulet-map-editor | 0.10.50b3 | A new Minecraft world editor and converter that supports all versions since Java 1.12 and Bedrock 1.7. | # Amulet Map Editor



[](https://amulet-map-editor.readthedocs.io)
A new Minecraft world editor and converter that supports all versions since Java 1.12 and Bedrock 1.7.

## Installing (Currently Windows only)
Purchase and download the installer for your operating system from [amuletmc.com](https://www.amuletmc.com).
Run the installer and follow the instructions.
## Running from Source
**If you are running a compiled build you do NOT need to do this.**
See instructions on [amuletmc.com](https://www.amuletmc.com/installing-from-source)
## Running with Docker (Linux)
The Docker image runs on any Linux distro with Docker support.
To run the Docker image, clone this repository and run `rundocker.sh`.
Compatibility with wayland is done through xwayland for x11 support.
## Legacy builds
Old versions (prior to 0.10.45) can be found on our [releases page](https://github.com/Amulet-Team/Amulet-Map-Editor/releases).
Extract the contained folder to a location on your computer and run `amulet_app.exe`.
## Contributing
For information about contributing to this project, please read the [contribution](contributing.md) file.
| text/markdown | James Clare, Ben Gothard et al. | amuleteditor@gmail.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [
"any"
] | https://www.amuletmc.com | null | >=3.11 | [] | [] | [] | [
"Pillow>=10.0.1",
"wxPython",
"numpy~=1.17",
"pyopengl~=3.0",
"packaging",
"platformdirs~=3.1",
"amulet-core>=1.9.36,~=1.9",
"amulet-nbt~=2.0",
"pymctranslate~=1.2",
"minecraft-resource-pack~=1.3",
"amulet-faulthandler~=1.0",
"Sphinx>=1.7.4; extra == \"docs\"",
"sphinx-autodoc-typehints>=1.3.0; extra == \"docs\"",
"sphinx_rtd_theme>=0.3.1; extra == \"docs\"",
"black>=22.3; extra == \"dev\"",
"pre_commit>=1.11.1; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.9 | 2026-02-20T12:22:39.193415 | amulet_map_editor-0.10.50b3.tar.gz | 1,835,378 | f6/21/f935d2da67b10a25f74ae005a38d3237956fa810c4dcf9c758a0dbe264bb/amulet_map_editor-0.10.50b3.tar.gz | source | sdist | null | false | 03620711279bf0cb9c21169283d669ec | 810a262c08552499c00380553e70e86a4ed0e11f499db0980b0105af13d298c2 | f621f935d2da67b10a25f74ae005a38d3237956fa810c4dcf9c758a0dbe264bb | null | [
"LICENSE"
] | 183 |
2.4 | form2sdc | 4.4.0 | Convert forms to SDC4-compliant templates using Gemini AI | # Form2SDCTemplate
[](https://github.com/SemanticDataCharter/Form2SDCTemplate)
[](LICENSE)
[](https://github.com/SemanticDataCharter/SDCRM)
[](https://colab.research.google.com/github/SemanticDataCharter/Form2SDCTemplate/blob/main/notebooks/form_to_template.ipynb)
Convert PDF, DOCX, and image forms into SDC4-compliant templates — powered by Gemini AI.
---
## Overview
Form2SDCTemplate provides two ways to generate SDC4 templates:
1. **Google Colab Notebook** (new) — Upload a form, get a validated template automatically
2. **Manual LLM Usage** — Upload `Form2SDCTemplate.md` to any LLM as instructions
Both approaches produce standards-compliant SDC4 templates ready for SDCStudio upload.
## Quick Start with Google Colab
The fastest way to convert a form to an SDC4 template:
1. Open the [Form2SDCTemplate Colab notebook](https://colab.research.google.com/github/SemanticDataCharter/Form2SDCTemplate/blob/main/notebooks/form_to_template.ipynb)
2. Enter your [Google AI API key](https://aistudio.google.com/apikey)
3. Upload your form (PDF, DOCX, PNG, JPG)
4. Download the generated SDC4 markdown template
5. Upload to SDCStudio for processing
### Quick Start with Python
```bash
pip install "form2sdc[gemini]"
```
```python
from form2sdc.analyzer import GeminiAnalyzer
from form2sdc.core import FormToTemplatePipeline
from pathlib import Path
analyzer = GeminiAnalyzer(api_key="YOUR_KEY")
pipeline = FormToTemplatePipeline(analyzer)
result = pipeline.process(Path("your_form.pdf"))
print(result.template) # SDC4 markdown
print(result.validation.valid) # True if valid
```
### Validate an existing template
```python
from form2sdc.validator import Form2SDCValidator
validator = Form2SDCValidator()
result = validator.validate(open("template.md").read())
if result.valid:
print("Template is valid!")
else:
for error in result.errors:
print(f"[{error.code}] {error.message}")
```
## Manual LLM Usage
### Option 1: Direct Download (Recommended)
1. Click on [Form2SDCTemplate.md](Form2SDCTemplate.md) in this repository
2. Look for the **Download** button (down arrow ⬇) in the upper right of the file view
3. Save the file to your computer
4. Upload `Form2SDCTemplate.md` to your preferred LLM (Claude, ChatGPT, etc.)
5. Provide your form description, PDF, or requirements to the LLM
6. Review the generated template and upload it to SDCStudio for processing
### Option 2: Clone Repository (For Contributors)
1. Clone this repository:
```bash
git clone https://github.com/SemanticDataCharter/Form2SDCTemplate.git
cd Form2SDCTemplate
```
2. Upload `Form2SDCTemplate.md` to your preferred LLM (e.g., Claude, ChatGPT, etc.)
3. Provide your form description, PDF, or requirements to the LLM
4. The LLM will generate a properly formatted SDCStudio template
5. Review the generated template and upload it to SDCStudio for processing
## Features
### LLM-Optimized Instructions
- Comprehensive step-by-step guide for AI assistants
- Complete keyword glossary with usage examples
- Clear structure and formatting requirements
- Multi-language support (keywords in English, content in source language)
### SDC4 Compliance
- Generates templates conforming to SDC 4.0 specifications
- Supports all SDC4 data types (XdString, XdCount, XdQuantity, etc.)
- User-friendly type system (text, integer, decimal, date, etc.)
- Intelligent type mapping based on context clues
### Complete Template Generation
- YAML front matter with metadata
- Dataset overview and business context
- SDC4 named tree organization (Data, Subject, Provider, Participation, Workflow, Attestation, Audit, Links)
- Column definitions with constraints and enumerations
- Component reuse support (NIEM, FHIR, HL7v3)
- Example templates in English, French, and Brazilian Portuguese
### Rapid Development
- Eliminates manual template creation
- Reduces development time from hours to minutes
- Enables iterative refinement through conversational AI
- Supports forms in any language
## Use Cases
This tool is designed for:
- **Healthcare Organizations** developing clinical data collection forms
- **Research Institutions** creating standardized research data templates
- **Data Architects** prototyping SDC4 template structures
- **Developers** integrating SDC4 into existing systems
- **Data Governance Teams** standardizing data collection processes
## Documentation
- [Form2SDCTemplate.md](Form2SDCTemplate.md) - Complete LLM instructions and reference guide
- [CLAUDE.md](CLAUDE.md) - Detailed guidance for AI-assisted development
- [CONTRIBUTING.md](CONTRIBUTING.md) - How to contribute to this project
- [SECURITY.md](SECURITY.md) - Security policy and vulnerability reporting
- [CHANGELOG.md](CHANGELOG.md) - Version history and release notes
## How It Works
1. **Upload Instructions**: Upload `Form2SDCTemplate.md` to an LLM (Claude, ChatGPT, etc.)
2. **Provide Form**: Share your form description, PDF, or requirements
3. **LLM Generates**: The LLM creates a properly formatted template following SDC4 specifications
4. **Review & Upload**: Review the generated template and upload to SDCStudio
5. **Automatic Processing**: SDCStudio's MD2PD system parses and validates the template
## Usage Examples
Below are example prompts showing how to request template generation from an LLM. Upload `Form2SDCTemplate.md` first, then use one of these prompts along with your form/PDF.
### English (en)
```
Please use the instructions in Form2SDCTemplate.md along with the attached PDF form
to create an SDCStudio template in markdown format.
Key requirements:
- Use English keywords (Type, Description, Enumeration, etc.)
- Keep all field names, descriptions, and values in the same language as the form
- Include all fields from the PDF with appropriate data types
- Add constraints for required fields and validation rules
- Use enumerations for dropdown lists and radio buttons
- Provide realistic examples for each field
```
### French (fr)
```
Veuillez utiliser les instructions dans Form2SDCTemplate.md avec le formulaire PDF
ci-joint pour créer un template SDCStudio au format markdown.
Exigences clés :
- Utiliser les mots-clés en anglais (Type, Description, Enumeration, etc.)
- Conserver tous les noms de champs, descriptions et valeurs dans la langue du formulaire
- Inclure tous les champs du PDF avec les types de données appropriés
- Ajouter des contraintes pour les champs obligatoires et les règles de validation
- Utiliser des énumérations pour les listes déroulantes et boutons radio
- Fournir des exemples réalistes pour chaque champ
```
### Brazilian Portuguese (pt-BR)
```
Por favor, use as instruções no Form2SDCTemplate.md junto com o formulário PDF
anexado para criar um template SDCStudio em formato markdown.
Requisitos principais:
- Usar palavras-chave em inglês (Type, Description, Enumeration, etc.)
- Manter todos os nomes de campos, descrições e valores no idioma do formulário
- Incluir todos os campos do PDF com os tipos de dados apropriados
- Adicionar restrições para campos obrigatórios e regras de validação
- Usar enumerações para listas suspensas e botões de opção
- Fornecer exemplos realistas para cada campo
```
### Spanish (es)
```
Por favor, utiliza las instrucciones en Form2SDCTemplate.md junto con el formulario PDF
adjunto para crear una plantilla SDCStudio en formato markdown.
Requisitos clave:
- Usar palabras clave en inglés (Type, Description, Enumeration, etc.)
- Mantener todos los nombres de campos, descripciones y valores en el idioma del formulario
- Incluir todos los campos del PDF con los tipos de datos apropiados
- Agregar restricciones para campos obligatorios y reglas de validación
- Usar enumeraciones para listas desplegables y botones de opción
- Proporcionar ejemplos realistas para cada campo
```
### Advanced Usage Examples
**With specific domain context:**
```
I'm uploading a healthcare patient intake form (PDF attached). Please use
Form2SDCTemplate.md to create a template.
Additional context:
- Domain: Healthcare
- This form will be used in a clinical setting
- Fields like patient_id, date_of_birth, and medical_record_number should use
identifier type
- Include HIPAA-relevant field classifications where applicable
- Enable LLM enrichment (set enable_llm: true)
```
**Multiple forms/sections:**
```
I have three related forms (PDFs attached):
1. Patient Demographics
2. Medical History
3. Insurance Information
Please use Form2SDCTemplate.md to create a single template with three sub-clusters,
one for each form. Use appropriate data types and maintain the relationships between
sections.
```
**Form in specific language:**
```
Attached is a Brazilian government form (Cadastro de Contribuinte) in Portuguese.
Please use Form2SDCTemplate.md to generate the template.
Important:
- Keep all keywords in English (Type, Description, etc.)
- Keep all content in Portuguese (field names, descriptions, examples)
- Include Brazilian-specific fields (CPF, CNPJ, CEP, UF)
- Use proper Brazilian address format
- Include all 27 Brazilian states in UF enumeration
```
## Related Projects
Part of the Semantic Data Charter ecosystem:
- [SDCRM](https://github.com/SemanticDataCharter/SDCRM) - Reference model and schemas
- [SDCObsidianTemplate](https://github.com/SemanticDataCharter/SDCObsidianTemplate) - Obsidian vault template
- [sdcvalidator](https://github.com/SemanticDataCharter/sdcvalidator) - Python validation library
- [sdcvalidatorJS](https://github.com/SemanticDataCharter/sdcvalidatorJS) - JavaScript/npm validator
## System Requirements
**For Colab/Python usage:**
- Python 3.10+
- Google AI API key (free tier available at [aistudio.google.com](https://aistudio.google.com/apikey))
**For manual LLM usage:**
- LLM with markdown file upload capability (Claude, ChatGPT, etc.)
- Basic understanding of form structure and data collection
**Optional:** SDCStudio for template testing and refinement
## Standards Compliance
Form2SDCTemplate supports generation of templates compliant with:
- W3C XML Schema (XSD)
- W3C RDF/OWL for semantic modeling
- ISO 11179 metadata standards
- ISO 20022 data component specifications
- HL7 standards for healthcare data
## Version Information
**Current Version:** 4.3.0
The major version (4.x.x) aligns with SDC Generation 4, ensuring compatibility across the SDC4 ecosystem. See [CHANGELOG.md](CHANGELOG.md) for detailed version history.
## Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for:
- How to submit issues and feature requests
- Guidelines for pull requests
- Development workflow and testing procedures
- Community standards and code of conduct
## Security
For security concerns or vulnerability reports, please refer to our [SECURITY.md](SECURITY.md) policy or contact security@axius-sdc.com.
## License
Copyright 2025 Axius-SDC, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
## Acknowledgments
This project builds upon:
- The Semantic Data Charter (SDC) framework
- International standards from W3C, ISO, and HL7
- Open source contributions from the data modeling community
- Academic research in semantic data representation (12+ peer-reviewed papers, 165+ citations)
## Support
- **Issues:** [GitHub Issues](https://github.com/SemanticDataCharter/Form2SDCTemplate/issues)
- **Discussions:** [GitHub Discussions](https://github.com/SemanticDataCharter/Form2SDCTemplate/discussions)
- **Email:** security@axius-sdc.com
- **Website:** Coming soon
---
**Semantic Data Charter™** and **SDC™** are trademarks of Axius-SDC, Inc.
| text/markdown | Axius-SDC, Inc. | null | null | Tim Cook <contact@axius-sdc.com> | null | sdc4, data-modeling, template-generation, gemini, form-conversion | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering",
"Topic :: Software Development :: Code Generators"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.0",
"pyyaml>=6.0",
"google-genai>=1.0; extra == \"gemini\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"form2sdc[dev,gemini]; extra == \"all\""
] | [] | [] | [] | [
"Homepage, https://github.com/SemanticDataCharter/Form2SDCTemplate",
"Documentation, https://github.com/SemanticDataCharter/Form2SDCTemplate#readme",
"Repository, https://github.com/SemanticDataCharter/Form2SDCTemplate",
"Issues, https://github.com/SemanticDataCharter/Form2SDCTemplate/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:22:34.401826 | form2sdc-4.4.0.tar.gz | 57,752 | b4/af/bf27eae04a890ff03627e068413d0fee1f5511c5a6ab4d16f0d02d2dc84a/form2sdc-4.4.0.tar.gz | source | sdist | null | false | a62ab2afc32697707f370d3baa56bc63 | a080668744553b69dba0befe5735e61682eb9fe62ac855d49bdffac807219362 | b4afbf27eae04a890ff03627e068413d0fee1f5511c5a6ab4d16f0d02d2dc84a | Apache-2.0 | [
"LICENSE"
] | 224 |
2.4 | badweathermounttester | 0.8.0 | Test telescope mount periodic error indoors using a simulated star on a monitor | # Bad Weather Mount Tester
[](https://github.com/jscheidtmann/BadWeatherMountTester/actions/workflows/python-app.yml)
[](https://pypi.org/project/BadWeatherMountTester/)
[](https://github.com/jscheidtmann/BadWeatherMountTester/releases/latest)
[](https://github.com/jscheidtmann/BadWeatherMountTester/releases/latest)
[](https://libraries.io/pypi/BadWeatherMountTester)
<picture>
<source media="(prefers-color-scheme: dark)" srcset="docs/BWMT_logo_w.svg">
<source media="(prefers-color-scheme: light)" srcset="docs/BWMT_logo_b.svg">
<img alt="Bad Weather Mount Tester Logo" src="BWMT_logo_b.svg">
</picture>
When you buy a new telescope mount, the first things to do is to measure the periodic error, because if the periodic error is really high, you would like to
complain and send it back as fast as possible. Unfortunately, most of the time there will be bad weather after buying astro gear for an indefinite amount of time.
**Bad Weather Mount Tester to the rescue!**
Using this program you can test the periodic error of your mount any time, any place, provided you have a spare computer and monitor and a little bit of space.
## Documentation
The full user manual is available in [docs/manual.md](docs/manual.md).
A hosted version of the documentation site is available at <https://jscheidtmann.github.io/BadWeatherMountTester/>.
## How to Install
### From PyPI (all platforms)
Using pip:
```bash
pip install BadWeatherMountTester
```
Or using [pipx](https://pipx.pypa.io/) for an isolated install:
```bash
pipx install BadWeatherMountTester
```
Then run the application:
```bash
bwmt
```
### From GitHub Releases (pre-built binaries)
Download the latest release from the [GitHub Releases](https://github.com/jscheidtmann/BadWeatherMountTester/releases) page.
- **Linux:** Download the `.tar.gz` archive, extract it, and run `./bwmt`
- **Windows:** Download the `.zip` archive, extract it, and run `bwmt.exe`
- **macOS:** Download the `.tar.gz` archive, extract it, and run `./bwmt`
### From Source
```bash
git clone https://github.com/jscheidtmann/BadWeatherMountTester.git
cd BadWeatherMountTester
```
Install [uv](https://docs.astral.sh/uv/) if you don't have it, then:
```bash
uv sync
uv run bwmt
```
## How to Contribute
1. Fork the repository and clone your fork
2. Install development dependencies:
```bash
uv sync --dev
```
3. Run the tests:
```bash
uv run pytest
```
4. Lint:
```bash
uv run flake8
```
5. **Internationalization:** The project supports German, English, and French via Flask-Babel. Translation files live in the locale directories.
6. Submit a pull request against `main`
# Credit
This software is based on the idea by [Klaus Weyer from Solingen, Germany](https://web.archive.org/web/20241013053734/https://watchgear.de/SWMT/SWMT.html). Rest in Peace, Klaus!
# Author, Copyright & License
Copyright (c) 2026 Jens Scheidtmann and contributors (see CONTRIBUTORS.md)
This file is part of BWMT, the Bad Weather Mount Tester.
BWMT is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
BWMT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with BWMT. If not, see <http://www.gnu.org/licenses/>.
| text/markdown | Jens Scheidtmann | null | null | null | null | PHD2, astronomy, guiding, mount, periodic error, telescope | [
"Development Status :: 4 - Beta",
"Environment :: MacOS X",
"Environment :: Win32 (MS Windows)",
"Environment :: X11 Applications",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Astronomy"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"flask-babel>=4.0.0",
"flask>=3.0.0",
"matplotlib>=3.10.8",
"numpy>=1.24.0",
"pillow>=10.0.0",
"pygame>=2.5.0",
"pyyaml>=6.0.0",
"waitress>=3.0.0",
"babel>=2.14.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=7.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\"",
"zensical>=0.0.21; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/jscheidtmann/BadWeatherMountTester",
"Repository, https://github.com/jscheidtmann/BadWeatherMountTester",
"Issues, https://github.com/jscheidtmann/BadWeatherMountTester/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:22:20.222923 | badweathermounttester-0.8.0.tar.gz | 16,520,847 | ce/9d/2250ef71ffddd7e6ce4d003f5b190e3ee1c6a20bbed86662791cc5e5efe5/badweathermounttester-0.8.0.tar.gz | source | sdist | null | false | ed67994571373a5addc9d7144e73a058 | e37b8d5e3045b590fef639e0f69699c95ae043ed50b9be8f8e47e0629badb9be | ce9d2250ef71ffddd7e6ce4d003f5b190e3ee1c6a20bbed86662791cc5e5efe5 | GPL-3.0-or-later | [
"LICENSE"
] | 220 |
2.3 | codex-sdk-python | 0.104.0 | Python SDK for the Codex CLI agent with async threads, streaming events, and structured outputs | # 
Embed the Codex agent in Python workflows. This SDK wraps the bundled `codex` CLI, streams JSONL events over stdin/stdout, and exposes structured, typed results.
<div align="left">
<table>
<tr>
<td><strong>Lifecycle</strong></td>
<td>
<a href="#ci-cd"><img src="https://img.shields.io/badge/CI%2FCD-Active-16a34a?style=flat&logo=githubactions&logoColor=white" alt="CI/CD badge" /></a>
<img src="https://img.shields.io/badge/Release-0.104.0-6b7280?style=flat&logo=pypi&logoColor=white" alt="Release 0.104.0 badge" />
<a href="#license"><img src="https://img.shields.io/badge/License-Apache--2.0-0f766e?style=flat&logo=apache&logoColor=white" alt="License badge" /></a>
</td>
</tr>
<tr>
<td><strong>Core Stack</strong></td>
<td>
<img src="https://img.shields.io/badge/Python-3.8%2B-3776AB?style=flat&logo=python&logoColor=white" alt="Python badge" />
<img src="https://img.shields.io/badge/Codex-CLI-111827?style=flat&logo=gnubash&logoColor=white" alt="Codex CLI badge" />
<img src="https://img.shields.io/badge/JSONL-Events-0ea5e9?style=flat&logo=json&logoColor=white" alt="JSONL badge" />
<img src="https://img.shields.io/badge/Pydantic-v2-0b3b2e?style=flat&logo=pydantic&logoColor=white" alt="Pydantic badge" />
<img src="https://img.shields.io/badge/PydanticAI-Integrations-0b3b2e?style=flat&logo=pydantic&logoColor=white" alt="PydanticAI badge" />
</td>
</tr>
<tr>
<td><strong>Navigation</strong></td>
<td>
<a href="#quick-start"><img src="https://img.shields.io/badge/Local%20Setup-Quick%20Start-059669?style=flat&logo=serverless&logoColor=white" alt="Quick start" /></a>
<a href="#features"><img src="https://img.shields.io/badge/Overview-Features-7c3aed?style=flat&logo=simpleicons&logoColor=white" alt="Features" /></a>
<a href="#configuration"><img src="https://img.shields.io/badge/Config-Options%20%26%20Env-0ea5e9?style=flat&logo=json&logoColor=white" alt="Config" /></a>
<a href="#pydantic-ai"><img src="https://img.shields.io/badge/Integrations-PydanticAI-0b3b2e?style=flat&logo=pydantic&logoColor=white" alt="PydanticAI" /></a>
<a href="#architecture"><img src="https://img.shields.io/badge/Design-Architecture-1f2937?style=flat&logo=serverless&logoColor=white" alt="Architecture" /></a>
<a href="#testing"><img src="https://img.shields.io/badge/Quality-Testing-2563eb?style=flat&logo=pytest&logoColor=white" alt="Testing" /></a>
</td>
</tr>
</table>
</div>
- Runtime dependency-free: uses only the Python standard library.
- Codex CLI binaries are downloaded separately; use `scripts/setup_binary.py` from the repo or install the Codex CLI and set `codex_path_override`.
- Async-first API with sync helpers, streaming events, and structured output.
- Python 3.8/3.9 support is deprecated and will be removed in a future release; use Python 3.10+.
<a id="quick-start"></a>
## 
1. Install the SDK:
```bash
uv add codex-sdk-python
```
2. Ensure a `codex` binary is available (required for local runs):
```bash
# From the repo source (downloads vendor binaries from the matching npm release)
python scripts/setup_binary.py
```
If you installed from PyPI, install the Codex CLI separately and either add it to your PATH
or pass `CodexOptions.codex_path_override`.
3. Authenticate with Codex:
```bash
codex login
```
Or export an API key:
```bash
export CODEX_API_KEY="<your-api-key>"
```
4. Run a first turn:
```python
import asyncio
from codex_sdk import Codex
async def main() -> None:
codex = Codex()
thread = codex.start_thread()
turn = await thread.run("Diagnose the test failure and propose a fix")
print(turn.final_response)
print(turn.items)
if __name__ == "__main__":
asyncio.run(main())
```
For single-turn sessions with approval handling, use the turn session wrapper:
```python
import asyncio
from codex_sdk import AppServerClient, AppServerOptions, ApprovalDecisions
async def main() -> None:
async with AppServerClient(AppServerOptions()) as app:
thread = await app.thread_start(model="gpt-5-codex-high", cwd=".")
thread_id = thread["thread"]["id"]
session = await app.turn_session(
thread_id,
"Run tests and summarize failures.",
approvals=ApprovalDecisions(command_execution="accept"),
)
async for notification in session.notifications():
print(notification.method)
final_turn = await session.wait()
print(final_turn)
if __name__ == "__main__":
asyncio.run(main())
```
### Examples
Try the examples under `examples/`:
```bash
python examples/basic_usage.py
python examples/streaming_example.py
python examples/thread_resume.py
python examples/app_server_basic.py
python examples/app_server_fork.py
python examples/app_server_requirements.py
python examples/app_server_skill_input.py
python examples/app_server_approvals.py
python examples/app_server_turn_session.py
python examples/config_overrides.py
python examples/hooks_streaming.py
python examples/notify_hook.py
```
<a id="features"></a>
## 
| Feature Badge | Details |
| ------------------------------------------------------------------------------------------------------------------ | ----------------------------------------------------------------------- |
|  | Each `Thread` keeps context; resume by thread id or last session. |
|  | `run_streamed()` yields structured events as they happen. |
|  | `ThreadHooks` lets you react to streamed events inline. |
|  | `run_json()` validates JSON output against a schema. |
|  | `run_pydantic()` derives schema and validates with Pydantic v2. |
|  | Thread options map to Codex CLI sandbox and approval policies. |
|  | Codex can act as a PydanticAI model or as a delegated tool. |
|  | Cancel running turns via `AbortController` and `AbortSignal`. |
|  | Optional spans if Logfire is installed and initialized. |
<a id="configuration"></a>
## 
### Installation extras
```bash
uv add "codex-sdk-python[pydantic]" # Pydantic v2 schema helpers
uv add "codex-sdk-python[pydantic-ai]" # PydanticAI integrations
uv add "codex-sdk-python[logfire]" # Optional tracing
```
### Environment variables
```bash
CODEX_API_KEY=<api-key>
OPENAI_BASE_URL=https://api.openai.com/v1
CODEX_HOME=~/.codex
```
Notes:
- `CODEX_API_KEY` is forwarded to the `codex` process; `CodexOptions.api_key` overrides the environment.
- `OPENAI_BASE_URL` is set when `CodexOptions.base_url` is provided.
- `CODEX_HOME` controls where sessions are stored and where `resume_last_thread()` looks.
### CodexOptions (client)
```python
from codex_sdk import Codex, CodexOptions
codex = Codex(
CodexOptions(
codex_path_override="/path/to/codex",
base_url="https://api.openai.com/v1",
api_key="<key>",
env={"CUSTOM_ENV": "custom"},
config_overrides={
"analytics.enabled": True,
"notify": ["python3", "/path/to/notify.py"],
},
)
)
```
- `codex_path_override`: use a custom CLI binary path.
- `base_url`: sets `OPENAI_BASE_URL` for the child process.
- `api_key`: sets `CODEX_API_KEY` for the child process.
- `env`: when set, replaces inherited environment variables; the SDK still injects required values.
### ThreadOptions (per thread)
```python
from codex_sdk import ThreadOptions
ThreadOptions(
model="gpt-5-codex-high",
sandbox_mode="workspace-write",
working_directory="/path/to/project",
skip_git_repo_check=True,
model_reasoning_effort="high",
model_instructions_file="/path/to/instructions.md",
model_personality="friendly",
max_threads=4,
network_access_enabled=True,
web_search_mode="cached",
shell_snapshot_enabled=True,
background_terminals_enabled=True,
apply_patch_freeform_enabled=False,
exec_policy_enabled=True,
remote_models_enabled=False,
collaboration_modes_enabled=True,
connectors_enabled=True,
responses_websockets_enabled=True,
request_compression_enabled=True,
approval_policy="on-request",
additional_directories=["../shared"],
config_overrides={"analytics.enabled": True},
)
```
Important mappings to the Codex CLI:
- `sandbox_mode` maps to `--sandbox` (`read-only`, `workspace-write`, `danger-full-access`).
- `working_directory` maps to `--cd`.
- `additional_directories` maps to repeated `--add-dir`.
- `skip_git_repo_check` maps to `--skip-git-repo-check`.
- `model_reasoning_effort` maps to `--config model_reasoning_effort=...`.
- `model_instructions_file` maps to `--config model_instructions_file=...`.
- `model_personality` maps to `--config model_personality=...`.
- `max_threads` maps to `--config agents.max_threads=...`.
- `network_access_enabled` maps to `--config sandbox_workspace_write.network_access=...`.
- `web_search_mode` maps to `--config web_search="disabled|cached|live"`.
- `web_search_enabled`/`web_search_cached_enabled` map to `--config web_search=...` for legacy
compatibility.
- `shell_snapshot_enabled` maps to `--config features.shell_snapshot=...`.
- `background_terminals_enabled` maps to `--config features.unified_exec=...`.
- `apply_patch_freeform_enabled` maps to `--config features.apply_patch_freeform=...`.
- `exec_policy_enabled` maps to `--config features.exec_policy=...`.
- `remote_models_enabled` maps to `--config features.remote_models=...`.
- `collaboration_modes_enabled` maps to `--config features.collaboration_modes=...`.
- `connectors_enabled` maps to `--config features.connectors=...`.
- `responses_websockets_enabled` maps to `--config features.responses_websockets=...`.
- `request_compression_enabled` maps to `--config features.enable_request_compression=...`.
- `feature_overrides` maps to `--config features.<key>=...` (explicit options take precedence).
- `approval_policy` maps to `--config approval_policy=...`.
- `config_overrides` maps to repeated `--config key=value` entries.
Note: `skills_enabled` is deprecated in Codex 0.80+ (skills are always enabled).
Note: Codex defaults `agents.max_threads` to 6; `max_threads` must be `>= 1` if set.
Note: Codex 0.88.0+ ignores `experimental_instructions_file`; use
`model_instructions_file` instead.
Feature overrides example:
```python
ThreadOptions(
feature_overrides={
"web_search_cached": True,
"powershell_utf8": True,
}
)
```
### App server (JSON-RPC)
For richer integrations (thread fork, requirements, explicit skill input), use the app-server
protocol. The client handles the initialize/initialized handshake and gives you access to
JSON-RPC notifications.
```python
import asyncio
from codex_sdk import AppServerClient, AppServerOptions
async def main() -> None:
async with AppServerClient(AppServerOptions()) as app:
thread = await app.thread_start(model="gpt-5-codex-high", cwd=".")
thread_id = thread["thread"]["id"]
await app.turn_start(
thread_id,
[
{"type": "text", "text": "Use $my-skill and summarize."},
{"type": "skill", "name": "my-skill", "path": "/path/to/SKILL.md"},
],
)
async for notification in app.notifications():
print(notification.method, notification.params)
if __name__ == "__main__":
asyncio.run(main())
```
Text inputs may include `textElements` with `byteRange` to preserve UI annotations in history.
The SDK also accepts `text_elements`/`byte_range` and normalizes them to camelCase.
Codex 0.86.0+ supports optional `SKILL.toml` metadata alongside `SKILL.md`. When present,
`skills_list` responses include an `interface` object (display name, icons, brand color,
default prompt) for richer UI integrations.
#### App-server convenience methods
The SDK also exposes helpers for most app-server endpoints:
- Threads: `thread_start`, `thread_resume`, `thread_fork`, `thread_list`, `thread_loaded_list`,
`thread_read`, `thread_archive`, `thread_unarchive`, `thread_name_set`,
`thread_compact_start`, `thread_rollback`
- Config: `config_read`, `config_value_write`, `config_batch_write`, `config_requirements_read`
- Skills: `skills_list`, `skills_remote_read`, `skills_remote_write`, `skills_config_write`
- Turns/review: `turn_start`, `turn_interrupt`, `review_start`, `turn_session`
- Models: `model_list`
- Collaboration modes: `collaboration_mode_list` (experimental)
- One-off commands: `command_exec`
- MCP auth/status: `mcp_server_oauth_login`, `mcp_server_refresh`, `mcp_server_status_list`
- Account: `account_login_start`, `account_login_cancel`, `account_logout`,
`account_rate_limits_read`, `account_read`
- Feedback: `feedback_upload`
These map 1:1 to the Codex app-server protocol; see `codex/codex-rs/app-server/README.md`
for payload shapes and event semantics.
Note: some endpoints and fields are gated behind an experimental capability; set
`AppServerOptions(experimental_api_enabled=True)` to opt in.
`thread_list` supports `archived`, `sort_key`, and `source_kinds` filters (unchanged), and now also accepts `cwd`
for scoped thread queries. `config_read` accepts an optional `cwd` to compute effective layered config for a specific
working directory.
`skills_remote_read` supports `cwds`, `enabled`, `hazelnut_scope`, and `product_surface` filters. `model_list` accepts
an optional `include_hidden` flag.
```python
threads = await app.thread_list(archived=False, sort_key="updatedAt", source_kinds=["local"], cwd=".")
config = await app.config_read(include_layers=True, cwd=".")
skills = await app.skills_remote_read(
cwds=["."], enabled=True, hazelnut_scope="user", product_surface="codex_desktop"
)
models = await app.model_list(limit=20, include_hidden=False)
```
### Observability (OTEL) and notify
Codex emits OTEL traces/logs/metrics when configured in `~/.codex/config.toml`.
For headless runs (`codex exec`), set `analytics.enabled=true` and provide OTEL exporters
in the config file. You can also pass overrides with `config_overrides`.
```python
CodexOptions(
config_overrides={
"analytics.enabled": True,
"notify": ["python3", "/path/to/notify.py"],
}
)
```
See `examples/notify_hook.py` for a ready-to-use notify script.
### TurnOptions (per turn)
```python
from codex_sdk import TurnOptions
TurnOptions(
output_schema={"type": "object", "properties": {"ok": {"type": "boolean"}}},
signal=controller.signal,
)
```
- `output_schema` must be a JSON object (mapping). The SDK writes it to a temp file and passes `--output-schema`.
- `signal` is an `AbortSignal` for canceling an in-flight turn.
### Bundled CLI binary and platform support
The SDK resolves a platform-specific Codex CLI binary under `src/codex_sdk/vendor/<target>/codex/`.
It selects the target triple based on OS and CPU and ensures the binary is executable on POSIX.
Supported target triples:
- Linux: `x86_64-unknown-linux-musl`, `aarch64-unknown-linux-musl`
- macOS: `x86_64-apple-darwin`, `aarch64-apple-darwin`
- Windows: `x86_64-pc-windows-msvc`, `aarch64-pc-windows-msvc`
If you are working from source and the vendor directory is missing, run
`python scripts/setup_binary.py` to fetch and assemble the platform `@openai/codex`
artifacts into `src/codex_sdk/vendor/`.
<a id="auth"></a>
## 
The SDK delegates authentication to the Codex CLI:
- Run `codex login` to create local credentials (stored under `~/.codex/` by the CLI).
- Or set `CODEX_API_KEY` (or pass `CodexOptions.api_key`) for headless use.
- `CodexOptions.base_url` sets `OPENAI_BASE_URL` to target an OpenAI-compatible endpoint.
<a id="usage"></a>
## 
### Basic run
```python
from codex_sdk import Codex
codex = Codex()
thread = codex.start_thread()
turn = await thread.run("Summarize the repository")
print(turn.final_response)
```
### Sync helpers (non-async)
```python
from pydantic import BaseModel
class RepoStatus(BaseModel):
summary: str
turn = thread.run_sync("Summarize the repository")
parsed = thread.run_json_sync("Summarize", output_schema={"type": "object"})
validated = thread.run_pydantic_sync("Summarize", output_model=RepoStatus)
```
Note: sync helpers raise `CodexError` if called from an active event loop.
### Streaming events
```python
result = await thread.run_streamed("Diagnose the test failure")
async for event in result.events:
if event.type == "item.completed":
print(event.item.type)
elif event.type == "turn.completed":
print(event.usage)
```
To iterate directly without the wrapper:
```python
async for event in thread.run_streamed_events("Diagnose the test failure"):
print(event.type)
```
### Hooks for streamed events
Use `ThreadHooks` to react to events without manually wiring an event loop.
```python
from codex_sdk import ThreadHooks
hooks = ThreadHooks(
on_event=lambda event: print("event", event.type),
on_item_type={
"command_execution": lambda item: print("command", item.command),
},
)
turn = await thread.run_with_hooks("Run the tests and summarize failures.", hooks=hooks)
print(turn.final_response)
```
### Event types (ThreadEvent)
- `thread.started`
- `turn.started`
- `turn.completed` (includes token usage)
- `turn.failed`
- `item.started`
- `item.updated`
- `item.completed`
- `error`
### Item types (ThreadItem)
- `agent_message`
- `reasoning`
- `command_execution`
- `file_change`
- `mcp_tool_call`
- `web_search`
- `todo_list`
- `error`
### Structured output (JSON schema)
```python
schema = {
"type": "object",
"properties": {
"summary": {"type": "string"},
"status": {"type": "string", "enum": ["ok", "action_required"]},
},
"required": ["summary", "status"],
"additionalProperties": False,
}
result = await thread.run_json("Summarize repository status", output_schema=schema)
print(result.output)
```
### Pydantic output validation
```python
from pydantic import BaseModel
class RepoStatus(BaseModel):
summary: str
status: str
result = await thread.run_pydantic("Summarize repository status", output_model=RepoStatus)
print(result.output)
```
### Images + text
```python
turn = await thread.run(
[
{"type": "text", "text": "Describe these screenshots"},
{"type": "local_image", "path": "./ui.png"},
{"type": "text", "text": "Focus on failures"},
{"type": "local_image", "path": "./diagram.jpg"},
]
)
```
### Abort a running turn
```python
import asyncio
from codex_sdk import AbortController, TurnOptions
controller = AbortController()
options = TurnOptions(signal=controller.signal)
task = asyncio.create_task(thread.run("Long task", options))
controller.abort("user requested cancel")
await task
```
### Thread resume helpers
```python
from codex_sdk import Codex
codex = Codex()
thread = codex.resume_thread("<thread-id>")
# Or resume the most recent session (uses CODEX_HOME or ~/.codex)
last_thread = codex.resume_last_thread()
```
### Turn helpers
Each `Turn` provides convenience filters: `agent_messages()`, `reasoning()`, `commands()`,
`file_changes()`, `mcp_tool_calls()`, `web_searches()`, `todo_lists()`, and `errors()`.
<a id="api"></a>
## 
Core classes:
- `Codex`: `start_thread()`, `resume_thread()`, `resume_last_thread()`.
- `Thread`: `run()`, `run_streamed()`, `run_streamed_events()`, `run_json()`, `run_pydantic()`,
plus `run_sync()`, `run_json_sync()`, `run_pydantic_sync()`.
- `Turn`: `items`, `final_response`, `usage`, and helper filters.
- `AppServerClient`, `AppServerTurnSession`, `ApprovalDecisions` for app-server integrations.
- `ThreadHooks` for event callbacks.
- `CodexOptions`, `ThreadOptions`, `TurnOptions`.
- `AbortController`, `AbortSignal`.
Exceptions:
- `CodexError`, `CodexCLIError`, `CodexParseError`, `CodexAbortError`, `TurnFailedError`.
Typed events and items:
- `ThreadEvent` union of `thread.*`, `turn.*`, `item.*`, and `error` events.
- `ThreadItem` union of `agent_message`, `reasoning`, `command_execution`, `file_change`,
`mcp_tool_call`, `web_search`, `todo_list`, `error`.
<a id="examples"></a>
## 
Example scripts under `examples/`:
- `basic_usage.py`: minimal `Codex` + `Thread` usage.
- `streaming_example.py`: live event streaming.
- `structured_output.py`: JSON schema output parsing.
- `thread_resume.py`: resume with `CODEX_THREAD_ID`.
- `permission_levels_example.py`: sandbox modes and working directory.
- `model_configuration_example.py`: model selection and endpoint config.
- `app_server_turn_session.py`: approval-handled turns over app-server.
- `hooks_streaming.py`: event hooks for streaming runs.
- `notify_hook.py`: notify script for CLI callbacks.
- `pydantic_ai_model_provider.py`: Codex as a PydanticAI model provider.
- `pydantic_ai_handoff.py`: Codex as a PydanticAI tool.
<a id="sandbox"></a>
## 
The SDK forwards sandbox and approval controls directly to `codex exec`.
- `read-only`: can read files and run safe commands, no writes.
- `workspace-write`: can write inside the working directory and added directories.
- `danger-full-access`: unrestricted (use with caution).
Additional controls:
- `working_directory`: restricts where the CLI starts and what it can access.
- `additional_directories`: allowlist extra folders when using `workspace-write`.
- `approval_policy`: `never`, `on-request`, `on-failure`, `untrusted`.
- `network_access_enabled`: toggles network access in workspace-write sandbox.
- `web_search_mode`: toggles web search (`disabled`, `cached`, `live`).
<a id="pydantic-ai"></a>
## 
This SDK offers two ways to integrate with PydanticAI:
### 1) Codex as a PydanticAI model provider
Use `CodexModel` to delegate tool-call planning and text generation to Codex, while PydanticAI executes tools and validates outputs.
```python
from pydantic_ai import Agent, Tool
from codex_sdk.integrations.pydantic_ai_model import CodexModel
from codex_sdk.options import ThreadOptions
def add(a: int, b: int) -> int:
return a + b
model = CodexModel(
thread_options=ThreadOptions(
model="gpt-5",
sandbox_mode="read-only",
skip_git_repo_check=True,
)
)
agent = Agent(model, tools=[Tool(add)])
result = agent.run_sync("What's 19 + 23? Use the add tool.")
print(result.output)
```
How it works:
- `CodexModel` builds a JSON schema envelope with `tool_calls` and `final`.
- Codex emits tool calls as JSON strings; PydanticAI runs them.
- If `allow_text_output` is true, Codex can place final text in `final`.
- Streaming APIs (`Agent.run_stream_events()`, `Agent.run_stream_sync()`) are supported; Codex
emits streamed responses as a single chunk once the turn completes.
Safety defaults (you can override with your own `ThreadOptions`):
- `sandbox_mode="read-only"`
- `skip_git_repo_check=True`
- `approval_policy="never"`
- `web_search_mode="disabled"`
- `network_access_enabled=False`
### 2) Codex as a PydanticAI tool (handoff)
Register Codex as a tool and let a PydanticAI agent decide when to delegate tasks.
```python
from pydantic_ai import Agent
from codex_sdk import ThreadOptions
from codex_sdk.integrations.pydantic_ai import codex_handoff_tool
tool = codex_handoff_tool(
thread_options=ThreadOptions(
sandbox_mode="workspace-write",
skip_git_repo_check=True,
working_directory=".",
),
include_items=True,
items_limit=20,
)
agent = Agent(
"openai:gpt-5",
tools=[tool],
system_prompt=(
"You can delegate implementation details to the codex_handoff tool. "
"Use it for repository-aware edits, command execution, or patches."
),
)
result = await agent.run(
"Use the codex_handoff tool to scan this repository and suggest one small DX improvement."
)
print(result.output)
```
Handoff options:
- `persist_thread`: keep a single Codex thread across tool calls (default true).
- `include_items`: include a summarized item list in tool output.
- `items_limit`: cap the number of items returned.
- `include_usage`: include token usage.
- `timeout_seconds`: wrap the run in `asyncio.wait_for`.
<a id="telemetry"></a>
## 
If `logfire` is installed and initialized, the SDK emits spans:
- `codex_sdk.exec`
- `codex_sdk.thread.turn`
- `codex_sdk.pydantic_ai.model_request`
- `codex_sdk.pydantic_ai.handoff`
If Logfire is missing or not initialized, the span context manager is a no-op.
<a id="architecture"></a>
<a id="acheature"></a>
## 
### System components
```mermaid
flowchart LR
subgraph App[Your Python App]
U[User Code]
T[Thread API]
end
subgraph SDK[Codex SDK]
C[Codex]
E[CodexExec]
P[Event Parser]
end
subgraph CLI[Bundled Codex CLI]
X["codex exec --experimental-json"]
end
FS[(Filesystem)]
NET[(Network)]
U --> T --> C --> E --> X
X -->|JSONL events| P --> T
X --> FS
X --> NET
```
### Streaming event lifecycle
```mermaid
sequenceDiagram
participant Dev as Developer
participant Thread as Thread.run_streamed()
participant Exec as CodexExec
participant CLI as codex exec
Dev->>Thread: run_streamed(prompt)
Thread->>Exec: spawn CLI with flags
Exec->>CLI: stdin prompt
CLI-->>Exec: JSONL line
Exec-->>Thread: raw line
Thread-->>Dev: ThreadEvent
CLI-->>Exec: JSONL line
Exec-->>Thread: raw line
Thread-->>Dev: ThreadEvent
CLI-->>Exec: exit code
Exec-->>Thread: completion
Thread-->>Dev: turn.completed / turn.failed
```
### PydanticAI model-provider loop
```mermaid
sequenceDiagram
participant Agent as PydanticAI Agent
participant Model as CodexModel
participant SDK as Codex SDK
participant CLI as codex exec
participant Tools as User Tools
Agent->>Model: request(messages, tools)
Model->>SDK: start_thread + run_json(prompt, output_schema)
SDK->>CLI: codex exec --output-schema
CLI-->>SDK: JSON envelope {tool_calls, final}
SDK-->>Model: ParsedTurn
alt tool_calls present
Model-->>Agent: ToolCallPart(s)
Agent->>Tools: execute tool(s)
Tools-->>Agent: results
else final text allowed
Model-->>Agent: TextPart(final)
end
```
### PydanticAI handoff tool
```mermaid
flowchart LR
Agent[PydanticAI Agent] --> Tool[codex_handoff_tool]
Tool --> SDK[Codex SDK Thread]
SDK --> CLI[Codex CLI]
CLI --> SDK
SDK --> Tool
Tool --> Agent
```
<a id="testing"></a>
## 
This repo uses unit tests with mocked CLI processes to keep the test suite fast and deterministic.
Test focus areas:
- `tests/test_exec.py`: CLI invocation, environment handling, config flags, abort behavior.
- `tests/test_thread.py`: parsing, streaming, JSON schema, Pydantic validation, input normalization.
- `tests/test_codex.py`: resume helpers and option wiring.
- `tests/test_abort.py`: abort signal semantics.
- `tests/test_telemetry.py`: Logfire span behavior.
- `tests/test_pydantic_ai_*`: PydanticAI model provider and handoff integration.
### Run tests
```bash
uv sync
uv run pytest
```
Note: PydanticAI tests are skipped unless `pydantic-ai` is installed.
### Coverage
```bash
uv run pytest --cov=codex_sdk
```
Coverage is configured in `pyproject.toml` with `fail_under = 95`.
### Upgrade checklist
For SDK release updates, follow `UPGRADE_CHECKLIST.md`.
### Format and lint
```bash
uv run black src tests
uv run isort src tests
uv run flake8 src tests
```
### Type checking
```bash
uv run mypy src
```
<a id="ci-cd"></a>
## 
This repository includes GitHub Actions workflows under `.github/workflows/`.
The CI pipeline runs linting, type checks, and `pytest --cov=codex_sdk`.
Release automation creates GitHub releases from `CHANGELOG_SDK.md` when you push a
`vX.Y.Z` tag or manually dispatch the workflow, then the publish workflow uploads
the package to PyPI on release publish.
<a id="operations"></a>
## 
- Sessions are stored under `~/.codex/sessions` (or `CODEX_HOME`).
- Use `resume_thread(thread_id)` to continue a known session.
- Use `resume_last_thread()` to pick the most recent session automatically.
- Clean up stale sessions by removing old `rollout-*.jsonl` files if needed.
<a id="troubleshooting"></a>
## 
- **Codex CLI exited non-zero**: Catch `CodexCLIError` and inspect `.stderr`.
- **Unknown event type**: `CodexParseError` means the CLI emitted an unexpected JSONL entry.
- **Turn failed**: `TurnFailedError` indicates a `turn.failed` event.
- **Run canceled**: `CodexAbortError` indicates a triggered `AbortSignal`.
- **No thread id**: Ensure a `thread.started` event is emitted before resuming.
<a id="production"></a>
## 
- Prefer `read-only` or `workspace-write` sandboxes in production.
- Set `working_directory` to a repo root and keep `skip_git_repo_check=False` where possible.
- Configure `approval_policy` for any tool execution requiring user consent.
- Disable `web_search_mode` and `network_access_enabled` unless explicitly needed.
<a id="license"></a>
## 
Apache-2.0
| text/markdown | Vectorfy Co | Vectorfy Co <git@vectorfy.co> | Vectorfy Co | Vectorfy Co <git@vectorfy.co> | Apache-2.0 | codex, sdk, python, api, cli, agent, async, streaming | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Software Development :: Build Tools"
] | [] | null | null | >=3.8 | [] | [] | [] | [
"logfire; extra == \"logfire\"",
"pydantic>=2; extra == \"pydantic\"",
"pydantic-ai; python_full_version >= \"3.10\" and extra == \"pydantic-ai\""
] | [] | [] | [] | [
"Homepage, https://vectorfy.co",
"Repository, https://github.com/vectorfy-co/codex-sdk-python",
"Documentation, https://github.com/vectorfy-co/codex-sdk-python#readme",
"Issues, https://github.com/vectorfy-co/codex-sdk-python/issues",
"Changelog, https://github.com/vectorfy-co/codex-sdk-python/blob/main/CHANGELOG_SDK.md"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T12:22:17.830988 | codex_sdk_python-0.104.0.tar.gz | 59,266 | b9/ae/22e1925d95a54913282a4911f3e7d47029f92fa695cf57b2795afd56f0a9/codex_sdk_python-0.104.0.tar.gz | source | sdist | null | false | 9365c2437c3f1a4336a695349dcbc27a | 5738b30dfd765ca83cadece8c53c9779be34f6afdaa434ceecf5602496c37068 | b9ae22e1925d95a54913282a4911f3e7d47029f92fa695cf57b2795afd56f0a9 | null | [] | 208 |
2.4 | feather-ai-sdk | 0.1.20 | The lightest Agentic AI Framework you'll ever see | <div align="center">
<img src="design/feather-ai-logo.svg" alt="FeatherAI Logo" width="200"/>
# FeatherAI
**The lightest Agentic AI framework you'll ever see**
[](https://www.python.org/downloads/)
[](LICENSE)
[](https://github.com/lucabzt/feather-ai)
</div>
---
## What is FeatherAI?
FeatherAI is a lightweight Python library designed to make building AI agents incredibly simple. Whether you're creating chatbots, automation tools, or complex multi-agent systems, FeatherAI provides an elegant API that gets out of your way.
### Key Features
- **Simple & Intuitive API** - Create powerful AI agents in just a few lines of code
- **Multi-Provider Support** - Works with OpenAI, Anthropic Claude, Google Gemini, and Mistral
- **Tool Calling** - Easily integrate custom functions and external APIs
- **Structured Output** - Get responses in validated Pydantic schemas
- **Multimodal Support** - Process text, images, and PDFs seamlessly
- **Async/Await Ready** - Built-in support for asynchronous execution
- **Built-in Tools** - Web search, code execution, and more out of the box
- **Lightweight** - Minimal dependencies, maximum performance
---
## Installation
```bash
pip install feather-ai-sdk
```
### Environment Setup
Create a `.env` file in your project root with your API keys:
```bash
# OpenAI (for GPT models)
OPENAI_API_KEY=your_openai_key_here
# Anthropic (for Claude models)
ANTHROPIC_API_KEY=your_anthropic_key_here
# Google (for Gemini models)
GOOGLE_API_KEY=your_google_key_here
# Mistral
MISTRAL_API_KEY=your_mistral_key_here
# For web search tools (optional)
TAVILY_API_KEY=your_tavily_key_here
```
> **Note:** You only need to set the API keys for the providers you'll use.
---
## Quick Start
### Basic Agent
```python
from feather_ai import AIAgent
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Create an agent
agent = AIAgent(model="gpt-4")
# Run the agent
response = agent.run("What is the capital of France?")
print(response.content) # Output: Paris
```
### Agent with Instructions
```python
from feather_ai import AIAgent
# Create an agent with custom instructions
agent = AIAgent(
model="claude-haiku-4-5",
instructions="You are a helpful assistant that provides concise answers. Always explain concepts in simple terms."
)
response = agent.run("Explain quantum computing")
print(response.content)
```
### Agent with Tools
```python
from feather_ai import AIAgent
# Define a custom tool
def get_weather(location: str) -> str:
"""Get the current weather for a location."""
return f"The weather in {location} is sunny and 72°F"
# Create an agent with tools
agent = AIAgent(
model="gpt-4",
instructions="You are a helpful weather assistant. Use the available tools to answer questions.",
tools=[get_weather]
)
response = agent.run("What's the weather like in San Francisco?")
print(response.content)
print(f"Tools called: {response.tool_calls}")
```
### Structured Output
```python
from feather_ai import AIAgent
from pydantic import BaseModel, Field
# Define your output schema
class WeatherResponse(BaseModel):
location: str = Field(..., description="The location requested")
temperature: int = Field(..., description="Temperature in Fahrenheit")
conditions: str = Field(..., description="Weather conditions")
confidence: float = Field(..., description="Confidence in answer (0-1)")
# Create agent with structured output
agent = AIAgent(
model="gpt-4",
output_schema=WeatherResponse
)
response = agent.run("What's the weather in Paris?")
print(response.content.location) # Validated Pydantic object
print(response.content.temperature) # Type-safe access
print(response.content.confidence)
```
### Multimodal Input
```python
from feather_ai import AIAgent, Prompt
# Create a prompt with documents
prompt = Prompt(
text="Summarize these documents",
documents=["report.pdf", "chart.png", "data.txt"]
)
agent = AIAgent(model="claude-sonnet-4-5")
response = agent.run(prompt)
print(response.content)
```
### Async Execution
```python
import asyncio
from feather_ai import AIAgent
async def main():
agent = AIAgent(model="claude-haiku-4-5")
response = await agent.arun("What is machine learning?")
print(response.content)
asyncio.run(main())
```
---
## Supported Models
FeatherAI supports a wide range of LLM providers:
- **OpenAI:** `gpt-4`, `gpt-5-nano`, `gpt-4-turbo`, etc.
- **Anthropic:** `claude-sonnet-4-5`, `claude-haiku-4-5`, `claude-opus-4`, etc.
- **Google:** `gemini-2.5-flash-lite`, `gemini-pro`, etc.
- **Mistral:** `mistral-small-2506`, `mistral-large`, etc.
---
## Documentation
For detailed documentation, examples, and guides, visit our [documentation site](https://lucabzt.github.io/feather-ai/).
### Topics Covered:
- Getting Started
- System Instructions
- Tool Calling
- Structured Output
- Multimodal Input
- Native Tools
- Asynchronous Execution
- Real-World Examples
---
## Featured Projects
### 🍝 [Piatto Cooks](https://piatto-cooks.com/)
An AI-powered cooking assistant that helps you discover recipes, plan meals, and get personalized cooking guidance.
- Recipe Generation
- Meal Planning
- Dietary Preferences
### 🎓 [NexoraAI](https://www.nexora-ai.de/)
An intelligent mentoring platform that connects mentors and mentees, providing personalized guidance and learning paths.
- Personalized Learning
- Skill Assessment
- Progress Tracking
---
## Contributing
We welcome contributions! If you'd like to improve FeatherAI, please:
1. Fork the repository
2. Create a feature branch
3. Make your changes
4. Submit a pull request
---
## License
FeatherAI is released under the MIT License. See [LICENSE](LICENSE) for details.
---
## Links
- **GitHub:** [github.com/lucabzt/feather-ai](https://github.com/lucabzt/feather-ai)
- **Documentation:** [lucabzt.github.io/feather-ai](https://lucabzt.github.io/feather-ai/)
---
<div align="center">
Made with ❤️ by the FeatherAI team
</div>
| text/markdown | Luca Bozzetti | null | null | null | null | null | [] | [] | null | null | <3.14,>=3.9 | [] | [] | [] | [
"langchain-google-genai>=3.1.0",
"langchain-openai>=1.0.3",
"langchain-anthropic>=1.1.0",
"langchain-mistralai>=1.0.1",
"langchain-deepseek>=1.0.1",
"tavily-python>=00.7.13",
"langchain-experimental>=0.4.0",
"requests",
"aiohttp",
"certifi"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T12:21:47.488950 | feather_ai_sdk-0.1.20.tar.gz | 32,024 | b5/36/ec6de5a972b5186f507095eff506c769dcc7129ba969a6543fc60e92927e/feather_ai_sdk-0.1.20.tar.gz | source | sdist | null | false | 4c761d3908696b84cf2dc20331519e9e | 74de89f399bf94abea1e5bb791b3c949645d8c6e4ef74618bfaf2c05bd4cd704 | b536ec6de5a972b5186f507095eff506c769dcc7129ba969a6543fc60e92927e | null | [] | 219 |
2.4 | stochastic-rs | 1.2.4 | A high-performance Rust library for simulating stochastic processes with first-class bindings. | 
[](https://crates.io/crates/stochastic-rs)

[](https://codecov.io/gh/dancixx/stochastic-rs)
[](https://app.fossa.com/projects/git%2Bgithub.com%2Fdancixx%2Fstochastic-rs?ref=badge_shield)
# stochastic-rs
A high-performance Rust library for simulating stochastic processes, with first-class bindings. Built for quantitative finance, statistical modeling and synthetic data generation.
## Features
- **85+ stochastic models** - diffusions, jump processes, stochastic volatility, interest rate models, autoregressive models, noise generators, and probability distributions
- **Copulas** - bivariate, multivariate, and empirical copulas with correlation utilities
- **Quant toolbox** - option pricing, bond analytics, calibration, loss models, order book, and trading strategies
- **Statistics** - MLE, kernel density estimation, fractional OU estimation, and CIR parameter fitting
- **SIMD-optimized** - fractional Gaussian noise, fractional Brownian motion, and all probability distributions use wide SIMD for fast sample generation
- **Parallel sampling** - `sample_par(m)` generates `m` independent paths in parallel via rayon
- **Generic precision** - most models support both `f32` and `f64`
- **Bindings** - full stochastic model coverage with numpy integration; all models return numpy arrays
## Installation
### Rust
```toml
[dependencies]
stochastic-rs = "1.0.0"
```
### Bindings
```bash
pip install stochastic-rs
```
For development builds from source (requires [maturin](https://www.maturin.rs/)):
```bash
pip install maturin
maturin develop --release
```
## Usage
### Rust
```rust
use stochastic_rs::stochastic::process::fbm::FBM;
use stochastic_rs::stochastic::volatility::heston::Heston;
use stochastic_rs::stochastic::volatility::HestonPow;
use stochastic_rs::traits::ProcessExt;
fn main() {
// Fractional Brownian Motion
let fbm = FBM::new(0.7, 1000, None);
let path = fbm.sample();
// Parallel batch sampling
let paths = fbm.sample_par(1000);
// Heston stochastic volatility
let heston = Heston::new(
Some(100.0), // s0
Some(0.04), // v0
2.0, // kappa
0.04, // theta
0.3, // sigma
-0.7, // rho
0.05, // mu
1000, // n
None, // t
HestonPow::Sqrt,
Some(false),
);
let [price, variance] = heston.sample();
}
```
### Bindings
All models return numpy arrays. Use `dtype="f32"` or `dtype="f64"` (default) to control precision.
```python
import stochastic_rs as sr
# Basic processes
fbm = sr.PyFBM(0.7, 1000)
path = fbm.sample() # shape (1000,)
paths = fbm.sample_par(500) # shape (500, 1000)
# Stochastic volatility
heston = sr.PyHeston(mu=0.05, kappa=2.0, theta=0.04, sigma=0.3, rho=-0.7, n=1000)
price, variance = heston.sample()
# Models with callable parameters
hw = sr.PyHullWhite(theta=lambda t: 0.04 + 0.01*t, alpha=0.1, sigma=0.02, n=1000)
rates = hw.sample()
# Jump processes with custom jump distributions
import numpy as np
merton = sr.PyMerton(
alpha=0.05, sigma=0.2, lambda_=3.0, theta=0.01,
distribution=lambda: np.random.normal(0, 0.1),
n=1000,
)
log_prices = merton.sample()
```
## Benchmarks
CUDA build details (Windows/Linux commands) are documented in `src/stochastic/cuda/CUDA_BUILD.md`.
### CUDA fallback (if auto-build fails)
If `cargo build --features cuda` fails (for example: `nvcc fatal : Cannot find compiler 'cl.exe'`), use prebuilt CUDA FGN binaries.
1. Download the platform file from GitHub Releases:
`https://github.com/dancixx/stochastic-rs/releases`
2. Place it at:
- Windows: `src/stochastic/cuda/fgn_windows/fgn.dll`
- Linux: `src/stochastic/cuda/fgn_linux/libfgn.so`
3. Set runtime path explicitly:
```powershell
$env:STOCHASTIC_RS_CUDA_FGN_LIB_PATH='src/stochastic/cuda/fgn_windows/fgn.dll'
```
```bash
export STOCHASTIC_RS_CUDA_FGN_LIB_PATH=src/stochastic/cuda/fgn_linux/libfgn.so
```
### FGN CPU vs CUDA (`sample`, `sample_par`, `sample_cuda`)
Measured with Criterion in `--release` using:
```bash
$env:STOCHASTIC_RS_CUDA_FGN_LIB_PATH='src/stochastic/cuda/fgn_windows/fgn.dll'
cargo bench --bench fgn_cuda --features cuda -- --noplot
```
Environment:
- GPU: NVIDIA GeForce RTX 4070 SUPER
- Rust: `rustc 1.93.1`
- CUDA library: `src/stochastic/cuda/fgn_windows/fgn.dll` (fatbin `sm_75+`)
Note: one-time CUDA init is excluded via warmup (`sample_cuda(...)` called once before each benchmark case).
Single path (`sample` vs `sample_cuda(1)`, `f32`, H=0.7):
| n | CPU `sample` | CUDA `sample_cuda(1)` | CUDA speedup (CPU/CUDA) |
|---:|---:|---:|---:|
| 1,024 | 10.112 us | 62.070 us | 0.16x |
| 4,096 | 40.901 us | 49.040 us | 0.83x |
| 16,384 | 184.060 us | 59.592 us | 3.09x |
| 65,536 | 1.0282 ms | 121.160 us | 8.49x |
Batch (`sample_par(m)` vs `sample_cuda(m)`, `f32`, H=0.7):
| n, m | CPU `sample_par(m)` | CUDA `sample_cuda(m)` | CUDA speedup (CPU/CUDA) |
|---|---:|---:|---:|
| 4,096, 32 | 148.840 us | 154.080 us | 0.97x |
| 4,096, 128 | 364.690 us | 1.1255 ms | 0.32x |
| 4,096, 512 | 1.7975 ms | 4.3293 ms | 0.42x |
| 16,384, 128 | 1.7029 ms | 4.5458 ms | 0.37x |
| 16,384, 512 | 5.5850 ms | 17.2110 ms | 0.32x |
Interpretation:
- CUDA wins for large single-path generation (from roughly `n >= 16k` in this setup).
- For the tested batch sizes, CPU `sample_par` is faster than current CUDA path.
### Distribution Sampling (Compact Summary)
SIMD distribution sampling (`stochastic-rs`) vs `rand_distr` measured with Criterion (`benches/distributions.rs`).
| Distribution family | Observed speedup range |
|---|---:|
| Normal | 2.88x - 3.37x |
| Exponential | 4.81x - 5.19x |
| LogNormal | 2.62x - 2.83x |
| Cauchy | 1.67x - 4.37x |
| Gamma | 2.34x - 2.71x |
| Weibull | 1.46x - 1.47x |
| Beta | 3.42x - 4.12x |
| ChiSquared | 2.39x - 2.71x |
| StudentT | 2.63x - 2.97x |
| Poisson | 5.11x |
| Pareto | 2.10x - 2.27x |
| Uniform | ~1.00x |
## Contributing
Contributions are welcome - bug reports, feature suggestions, or PRs. Open an issue or start a discussion on GitHub.
## License
MIT - see [LICENSE](https://github.com/dancixx/stochastic-rs/blob/main/LICENSE).
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT | stochastic, quant, finance, simulation, statistics | [
"Programming Language :: Rust",
"Topic :: Scientific/Engineering :: Mathematics",
"Topic :: Office/Business :: Financial"
] | [] | https://github.com/dancixx/stochastic-rs | null | >=3.9 | [] | [] | [] | [
"numpy"
] | [] | [] | [] | [
"Documentation, https://docs.rs/stochastic-rs",
"Homepage, https://github.com/rust-dd/stochastic-rs",
"Repository, https://github.com/rust-dd/stochastic-rs"
] | maturin/1.12.3 | 2026-02-20T12:20:33.079074 | stochastic_rs-1.2.4.tar.gz | 232,187 | bc/df/e4b1df10c266ac142b1ca80197a0b1961a78e10e627ff1e040a615dc91a4/stochastic_rs-1.2.4.tar.gz | source | sdist | null | false | eb1c6935de2f4b32b277f73abdcbc4c8 | c52fc0acbb775531beb0b739311192e5c133b60c5242ab65760f2ed6301eafaa | bcdfe4b1df10c266ac142b1ca80197a0b1961a78e10e627ff1e040a615dc91a4 | null | [] | 1,771 |
2.4 | bagpipes | 1.3.5 | Galaxy spectral fitting | **Bayesian Analysis of Galaxies for Physical Inference and Parameter EStimation**
Bagpipes is a state of the art code for generating realistic model galaxy spectra and fitting these to spectroscopic and photometric observations. For further information please see the Bagpipes documentation at `bagpipes.readthedocs.io <http://bagpipes.readthedocs.io>`_.
**Installation**
Bagpipes can be installed with pip:
.. code::
pip install bagpipes
Please note you cannot run the code just by cloning the repository as the large grids of models aren't included.
**Sampling algorithms within Bagpipes**
The default sampler (and historically the only option) for fitting models to data is the `MultiNest <https://github.com/JohannesBuchner/MultiNest>`_ code, however this requires separate installation, which can be challenging on some systems. Bagpipes is now also compatible with the pure Python `nautilus <https://github.com/johannesulf/nautilus>`_ nested sampling algorithm, which is now installed by default along with Bagpipes, and will be automatically used for fitting if MultiNest is not installed. Even if you are used to using Bagpipes with Multinest, you may wish to try out Nautlus, as this may yield faster and/or more accurate results in some circumstances. For more information please see the `bagpipes documentation <http://bagpipes.readthedocs.io>`_.
**Published papers and citing the code**
Bagpipes is described primarily in Section 3 of `Carnall et al. (2018) <https://arxiv.org/abs/1712.04452>`_, with further development specific to spectroscopic fitting described in Section 4 of `Carnall et al. (2019b) <https://arxiv.org/abs/1903.11082>`_. These papers are the best place to start if you want to understand how the code works.
If you make use of Bagpipes, please include a citation to `Carnall et al. (2018) <https://arxiv.org/abs/1712.04452>`_ in any publications. You may also consider citing `Carnall et al. (2019b) <https://arxiv.org/abs/1903.11082>`_, particularly if you are fitting spectroscopy.
Please note development of the code has been ongoing since these works were published, so certain parts of the code are no longer as described. Please inquire if in doubt.
.. image:: docs/images/sfh_from_spec.png
| null | Adam Carnall | adamc@roe.ac.uk | null | null | null | null | [] | [] | https://bagpipes.readthedocs.io | null | null | [] | [] | [] | [
"numpy<=2.2",
"corner",
"pymultinest>=2.11",
"h5py",
"pandas",
"astropy",
"matplotlib>=2.2.2",
"scipy",
"msgpack",
"spectres",
"nautilus-sampler>=1.0.2"
] | [] | [] | [] | [
"readthedocs, https://bagpipes.readthedocs.io",
"GitHub, https://github.com/ACCarnall/bagpipes",
"ArXiv, https://arxiv.org/abs/1712.04452"
] | twine/6.2.0 CPython/3.13.0 | 2026-02-20T12:20:19.449757 | bagpipes-1.3.5.tar.gz | 251,643,463 | 6e/0f/3718d7d3001d4a38d965136cd980c8d5847f990899e73c048489586ed1d5/bagpipes-1.3.5.tar.gz | source | sdist | null | false | bb9ac5181c5fea8dd3c5b1872c523636 | af7df351841d2be0598900888bca5e68f761b754c191adc31c7ca049efbb40b4 | 6e0f3718d7d3001d4a38d965136cd980c8d5847f990899e73c048489586ed1d5 | null | [
"LICENSE.txt"
] | 243 |
2.4 | wordlift-sdk | 5.1.1 | Python toolkit for orchestrating WordLift imports and structured data workflows. | # WordLift Python SDK
A Python toolkit for orchestrating WordLift imports: fetch URLs from sitemaps, Google Sheets, or explicit lists, filter out already imported pages, enqueue search console jobs, push RDF graphs, and call the WordLift APIs to import web pages.
## Features
- URL sources: XML sitemaps (with optional regex filtering), Google Sheets (`url` column), or Python lists.
- Change detection: skips URLs that are already imported unless `OVERWRITE` is enabled; re-imports when `lastmod` is newer.
- Web page imports: sends URLs to WordLift with embedding requests, output types, retry logic, and pluggable callbacks.
- Python 3.14 compatibility: retry filters use `pydantic_core.ValidationError` via the public API.
- Search Console refresh: triggers analytics imports when top queries are stale.
- Graph templates: renders `.ttl.liquid` templates under `data/templates` with account data and uploads the resulting RDF graphs.
- Extensible: override protocols via `WORDLIFT_OVERRIDE_DIR` without changing the library code.
## Installation
```bash
pip install wordlift-sdk
# or
poetry add wordlift-sdk
```
Requires Python 3.10–3.14.
## Configuration
Settings are read in order: `config/default.py` (or a custom path you pass to `ConfigurationProvider.create`), environment variables, then (when available) Google Colab `userdata`.
Common options:
- `WORDLIFT_KEY` (required): WordLift API key.
- `API_URL`: WordLift API base URL, defaults to `https://api.wordlift.io`.
- `SITEMAP_URL`: XML sitemap to crawl; `SITEMAP_URL_PATTERN` optional regex to filter URLs.
- `SHEETS_URL`, `SHEETS_NAME`, `SHEETS_SERVICE_ACCOUNT`: use a Google Sheet as source; service account points to credentials file.
- `URLS`: list of URLs (e.g., `["https://example.com/a", "https://example.com/b"]`).
- `OVERWRITE`: re-import URLs even if already present (default `False`).
- `WEB_PAGE_IMPORT_WRITE_STRATEGY`: WordLift write strategy (default `createOrUpdateModel`).
- `EMBEDDING_PROPERTIES`: list of schema properties to embed.
- `WEB_PAGE_TYPES`: output schema types, defaults to `["http://schema.org/Article"]`.
- `GOOGLE_SEARCH_CONSOLE`: enable/disable Search Console handler (default `True`).
- `CONCURRENCY`: max concurrent handlers, defaults to `min(cpu_count(), 4)`.
- `WORDLIFT_OVERRIDE_DIR`: folder containing protocol overrides (default `app/overrides`).
## TLS/SSL
The SDK enforces SSL verification. On macOS it uses the system CA bundle when available and falls back to `certifi` if needed. You can override the CA bundle path explicitly in code:
```python
from wordlift_sdk.client import ClientConfigurationFactory
from wordlift_sdk.structured_data import CreateRequest
factory = ClientConfigurationFactory(
key="your-api-key",
api_url="https://api.wordlift.io",
ssl_ca_cert="/path/to/ca.pem",
)
configuration = factory.create()
request = CreateRequest(
url="https://example.com",
target_type="Thing",
output_dir=Path("."),
base_name="structured-data",
jsonld_path=None,
yarrml_path=None,
api_key="your-api-key",
base_url=None,
ssl_ca_cert="/path/to/ca.pem",
debug=False,
headed=False,
timeout_ms=30000,
max_retries=2,
quality_check=True,
max_xhtml_chars=40000,
max_text_node_chars=400,
max_nesting_depth=2,
verbose=True,
validate=True,
wait_until="networkidle",
)
```
Note: `target_type` is used for agent guidance and validation shape selection. The YARRRML materialization pipeline now preserves authored mapping semantics and does not coerce nodes to `Review`/`Thing`.
Example `config/default.py`:
```python
WORDLIFT_KEY = "your-api-key"
SITEMAP_URL = "https://example.com/sitemap.xml"
SITEMAP_URL_PATTERN = r"^https://example.com/article/.*$"
GOOGLE_SEARCH_CONSOLE = True
WEB_PAGE_TYPES = ["http://schema.org/Article"]
EMBEDDING_PROPERTIES = [
"http://schema.org/headline",
"http://schema.org/abstract",
"http://schema.org/text",
]
```
## Running the import workflow
```python
import asyncio
from wordlift_sdk import run_kg_import_workflow
if __name__ == "__main__":
asyncio.run(run_kg_import_workflow())
```
The workflow:
1. Renders and uploads RDF graphs from `data/templates/*.ttl.liquid` using account info.
2. Builds the configured URL source and filters out unchanged URLs (unless `OVERWRITE`).
3. Sends each URL to WordLift for import with retries and optional Search Console refresh.
You can build components yourself when you need more control:
```python
import asyncio
from wordlift_sdk.container.application_container import ApplicationContainer
async def main():
container = ApplicationContainer()
workflow = await container.create_kg_import_workflow()
await workflow.run()
asyncio.run(main())
```
## Custom callbacks and overrides
Override the web page import callback by placing `web_page_import_protocol.py` with a `WebPageImportProtocol` class under `WORDLIFT_OVERRIDE_DIR` (default `app/overrides`). The callback receives a `WebPageImportResponse` and can push to `graph_queue` or `entity_patch_queue`.
## Templates
Add `.ttl.liquid` files under `data/templates`. Templates render with `account` fields available (e.g., `{{ account.dataset_uri }}`) and are uploaded before URL handling begins.
## Validation
SHACL validation utilities and generated Google Search Gallery shapes are included. When a feature includes both container types (for example `ItemList`, `BreadcrumbList`, `QAPage`, `FAQPage`, `Quiz`, `ProfilePage`, `Product`, `Recipe`, `Course`, `Review`) and their contained types (`ListItem`, `Question`, `Answer`, `Comment`, `Offer`, `AggregateOffer`, `HowToStep`, `Person`, `Organization`, `Rating`, `AggregateRating`, `Review`, `ItemList`), the generator scopes the contained constraints under the container properties to avoid enforcing them on unrelated nodes. For Product snippets, `offers` is scoped as `Offer` or `AggregateOffer`, matching Google requirements. The generator also captures "one of" requirements expressed in prose lists and emits `sh:or` constraints so any listed property satisfies the requirement. Schema.org grammar checks are intentionally permissive and accept URL/text literals for all properties.
Use `wordlift_sdk.validation.validate_jsonld_from_url` to render a URL with Playwright, extract JSON-LD fragments, and validate them against SHACL shapes.
Playwright is required for URL rendering. After installing dependencies, install the browser binaries:
```bash
poetry run playwright install
```
## Structured Data Tokens
YARRRML mappings are now executed directly by `morph-kgc` native YARRRML support.
There is no JS transpile step via `yarrrml-parser`, and no temporary `mapping.ttl`
conversion artifact in the materialization pipeline.
Customer-authored mappings can use runtime tokens:
- `__XHTML__` for the local XHTML source path used by materialization.
- `__URL__` for canonical page URL injection.
- `__ID__` for callback/import entity IRI injection.
`__URL__` resolution order is:
1. `response.web_page.url`
2. explicit `url` argument passed to materialization
`__ID__` resolution source is:
1. `response.id` (legacy import callbacks)
2. `existing_web_page_id` injected by `kg_build` scrape callbacks
When unresolved:
- strict mode (`strict_url_token=True`): fail fast
- default non-strict mode: warn and keep `__URL__` unchanged
- `__ID__`: fail closed with an explicit error
Recommendation: use `__ID__` in subject/object IRI positions instead of
temporary hardcoded page subjects such as `{{ dataset_uri }}/web-pages/page`.
Compatibility note: `morph-kgc` native YARRRML behavior may differ from legacy
JS parser behavior for some advanced XPath/function constructs.
When preparing XHTML sources from raw HTML, `HtmlConverter` strips undeclared
namespace prefixes from tag names and removes undeclared prefixed attributes to
avoid `xml.etree.ElementTree.ParseError: unbound prefix` failures in XPath
materialization flows.
It also removes XML-invalid comments/processing instructions, validates output
with `xml.etree.ElementTree.fromstring()`, and runs a strict fallback sanitation
pass before surfacing a context-rich conversion error.
## KG Build Module
The SDK now includes a profile-driven cloud mapping module under `wordlift_sdk.kg_build`.
- Public module import: `wordlift_sdk.kg_build`
- Postprocessor runner entrypoint: `python -m wordlift_sdk.kg_build.postprocessor_runner`
- Persistent postprocessor worker entrypoint: `python -m wordlift_sdk.kg_build.postprocessor_worker`
- URL handling parity with legacy workflow:
- `WebPageScrapeUrlHandler` is always enabled for `kg_build`
- `SearchConsoleUrlHandler` is enabled when `GOOGLE_SEARCH_CONSOLE=True` (default)
- Legacy `ApplicationContainer` workflow continues to use `WebPageImportUrlHandler`.
- Postprocessor manifests are loaded from:
1. `profiles/_base/postprocessors.toml`
2. `profiles/<profile>/postprocessors.toml`
- Execution is manifest-based only (hard cutover): no legacy `.py` or `*.command.toml` discovery.
- Postprocessor runtime mode:
- `POSTPROCESSOR_RUNTIME=oneshot` (default): start one subprocess per callback call.
- `POSTPROCESSOR_RUNTIME=persistent`: keep one long-lived subprocess per configured class and reuse it across callbacks.
- Postprocessor authoring contract:
- supported method: `process_graph(self, graph, context)`
- supported return values: `Graph`, `None`, or an awaitable resolving to `Graph | None`
- in persistent mode, each worker instance processes one job at a time (callbacks can still run concurrently across different workers/classes)
- `context.profile` contains the resolved/interpolated profile object (including inherited fields)
- `context.account_key` contains the runtime API key and is required for postprocessor execution
- keep `context.account` as the clean `/me` account object (no injected key)
- API base URL should be read from `context.profile["settings"]["api_url"]` (defaults to `https://api.wordlift.io`)
## Ingestion Module
The SDK now includes a reusable 2-axis ingestion module under `wordlift_sdk.ingestion`:
- Axis A (`INGEST_SOURCE`): `auto|urls|sitemap|sheets|local`
- Axis B (`INGEST_LOADER`): `auto|simple|proxy|playwright|premium_scraper|web_scrape_api|passthrough`
Default loader is `web_scrape_api`. If an item already includes embedded HTML and
`INGEST_PASSTHROUGH_WHEN_HTML=True` (default), ingestion uses `passthrough`
before network loaders.
Legacy compatibility is preserved:
- Source keys: `URLS`, `SITEMAP_URL`, `SHEETS_*`
- Loader key: `WEB_PAGE_IMPORT_MODE`
- Mapping: `default -> web_scrape_api`, `proxy -> proxy`, `premium_scraper -> premium_scraper`
Quick start:
```python
from wordlift_sdk.ingestion import run_ingestion
result = run_ingestion(
{
"INGEST_SOURCE": "urls",
"URLS": ["https://example.com"],
"INGEST_LOADER": "web_scrape_api",
"WORDLIFT_KEY": "your-api-key",
}
)
```
## Testing
```bash
poetry install --with dev
poetry run pytest
```
## Documentation
- [Documentation Index](docs/INDEX.md): Quick index for all user and agent-facing docs.
- [Ingestion Pipeline](docs/ingestion_pipeline.md): 2-axis source/loader architecture and compatibility rules.
- [Public Entry Points](docs/public_entry_points.md): Task-oriented inventory of client APIs by module file.
- [Google Sheets Lookup](docs/google_sheets_lookup.md): Utility for O(1) lookups from Google Sheets.
- [Web Page Import](docs/web_page_import.md): Configure fetch options, proxies, and JS rendering.
- [Structured Data](docs/structured_data.md): Structured data architecture and pipeline behavior.
- [Canonical ID Policy](docs/canonical_id_policy.md): Scope strategy, deterministic type precedence, and URL-preserving rewrite guarantees.
- [Customer Project Contract](docs/CUSTOMER_PROJECT_CONTRACT.md): Profile repo contract and manifest-based postprocessor runtime.
- [Structured Data Spec](specs/structured_data.md): Internal technical details for runtime placeholder resolution.
- [Ingestion Pipeline Spec](specs/INGESTION_PIPELINE.md): Internal source/loader contract and precedence rules.
- [Profile Config Spec](specs/PROFILE_CONFIG.md): Profile inheritance, environment interpolation, and manifest postprocessor contract.
- [Pipeline Architecture Spec](specs/PIPELINE_ARCHITECTURE.md): `kg_build` runtime flow and callback architecture.
- [Migration Guide](MIGRATION.md): Breaking changes for structured data refactor.
- [Changelog](CHANGELOG.md): Versioned release notes.
| text/markdown | David Riccitelli | david@wordlift.io | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"advertools<1.0.0,>0.16.6",
"aiohttp<4.0.0,>=3.10.5",
"certifi",
"google-auth<3.0.0,>=2.35.0",
"gql[aiohttp]<4.0.0,>=3.5.2",
"gspread<7.0.0,>=6.1.2",
"jinja2<4.0.0,>=3.1.6",
"morph-kgc<3.0.0,>=2.10.0",
"pandas<2.3.0,>=2.1.4",
"playwright<2.0.0,>=1.52.0",
"pycountry<25.0.0,>=24.6.1",
"pyshacl<0.32.0,>=0.31.0",
"python-liquid<3.0.0,>=2.0.1",
"rdflib<8.0.0,>=7.0.0",
"tenacity<10.0.0,>=9.0.0",
"tqdm<5.0.0,>=4.67.1",
"wordlift-client<2.0.0,>=1.140.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:19:46.734614 | wordlift_sdk-5.1.1.tar.gz | 286,463 | c8/67/83a578ed0ac8559bb96aa4e209b9fd296a16e70ac71713e622d537307b2b/wordlift_sdk-5.1.1.tar.gz | source | sdist | null | false | 0448c64e4c6d4e86d4018406852f8f2a | b6abea23e766cce2e88a419c5694711737e1961c9efeaf3923e06bafbd48c965 | c86783a578ed0ac8559bb96aa4e209b9fd296a16e70ac71713e622d537307b2b | null | [] | 233 |
2.4 | llm-scope-observer | 0.1.0a4 | Lightweight observability and diagnostics for local and self-hosted LLMs (Ollama, FastAPI, OpenWebUI).I know I messed it up for both of us and I am sorry, she will understand.. you can go ahead and use the library. | # llm-scope-observer
> Lightweight observability and diagnostics for local and self-hosted LLMs.
I know I messed it up for both of us and I am sorry, she will understand.. you can go ahead and use the library.
`llm-scope-observer` is a small Python package that wraps your local LLM calls (Ollama, FastAPI backends, OpenWebUI integrations, custom Python code) and records:
- Latency per call
- Token usage (input, output, total, tokens/sec)
- CPU / RAM / (optional) GPU utilization
- Simple hallucination-risk heuristics
- Error information
All metrics are stored locally (SQLite by default) and visualized in a small FastAPI-based dashboard.
---
## Features
- **Request interceptor**: Decorator to wrap any Python function that calls an LLM.
```python
from llm_scope import monitor
import ollama
@monitor(model="llama3")
def generate(prompt: str) -> str:
result = ollama.generate(model="llama3", prompt=prompt)
return result["response"]
```
- **Token estimation**:
- Approximate input and output tokens
- Track total tokens and tokens/sec per call
- **System metrics snapshot** (per request):
- CPU %
- RAM %
- GPU % (optional, via `pynvml` if installed)
- **Hallucination risk heuristic** (simple, signal-based):
- Very long answer vs. short prompt
- Strong claims without references
- Repetition patterns
- Basic self-contradiction patterns
- **Local dashboard**:
- FastAPI backend + simple HTML UI
- SQLite storage by default
- Shows latency, token trends, errors, and resource correlation per model
---
## Installation
```bash
pip install llm-scope-observer
```
Optional GPU metrics:
```bash
pip install "llm-scope-observer[gpu]"
```
Requires Python 3.9+.
---
## Quickstart
### 1. Instrument your LLM call
```python
from llm_scope import monitor
import time
@monitor(model="test-model")
def generate(prompt: str) -> str:
time.sleep(0.1)
return "hello from llm-scope-observer"
```
Every time `generate(...)` runs, a record is written to a local SQLite database (`llm_scope.db` by default).
### 2. Run the dashboard
After some traffic:
```bash
llm-scope ui --host 127.0.0.1 --port 8000
# or
python -m llm_scope.cli ui --host 127.0.0.1 --port 8000
```
Open:
- http://127.0.0.1:8000/
and you’ll see:
- Average latency per model
- Slowest calls (tail latency)
- Token usage and tokens/sec
- Error counts
- CPU / RAM / GPU vs. latency
- Hallucination score per call
---
## How it works (high level)
- **Middleware / decorator**:
- `@monitor(model="llama3")` wraps any function.
- Captures `start`/`end` times, prompt, response, and errors.
- Sends a metrics record to the storage backend.
- **Metrics**:
- Token estimation from prompt and response text.
- System stats from `psutil` (and optionally `pynvml`).
- Simple heuristics for hallucination risk.
- **Storage**:
- SQLite via `sqlite3` by default.
- One table: `llm_calls` with timestamps, model, metrics, error, tags.
- **Dashboard**:
- FastAPI app.
- Reads from the same SQLite file.
- Renders an HTML summary page (no external JS required).
---
## Roadmap
This is an early MVP. Planned next steps include:
- Prompt clustering and slow-prompt detection
- Model A vs. Model B comparison
- Basic alerting hooks and export to tools like Grafana
- Optional HTTP ingestion mode (sidecar / agent model)
---
## License
MIT
| text/markdown | llm-scope maintainers | null | null | null | MIT | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"fastapi>=0.110",
"uvicorn[standard]>=0.27",
"psutil>=5.9",
"pydantic>=2.0",
"jinja2>=3.1",
"pynvml>=11.0; extra == \"gpu\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T12:19:36.292157 | llm_scope_observer-0.1.0a4.tar.gz | 10,283 | 35/8b/b75330fd11848d0f1cb4a7704789f8e16b39627b190a17af6a94bd94fc93/llm_scope_observer-0.1.0a4.tar.gz | source | sdist | null | false | daf2ba09df1cf6e5a7deb257d3bbe800 | a02dbb5a9652b82a14d06478f2aef8c94889ac6296c66a8782ba50c01a024aaf | 358bb75330fd11848d0f1cb4a7704789f8e16b39627b190a17af6a94bd94fc93 | null | [] | 180 |
2.4 | fluxopt | 0.0.1rc0 | Energy system optimization with linopy — progressive modeling, from simple to complex. | # fluxopt
Energy system optimization with [linopy](https://github.com/PyPSA/linopy) — detailed dispatch, scaled to multi period planning.
[](https://pypi.org/project/fluxopt/)
[](https://pypi.org/project/fluxopt/)
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
[](https://github.com/astral-sh/ruff)
> **Early development** — the API may change between releases.
> Planned features and progress are tracked in [Issues](https://github.com/FBumann/fluxopt/issues).
## Installation
```bash
pip install fluxopt
```
Includes the [HiGHS](https://highs.dev/) solver out of the box.
## Quick Start
```python
from datetime import datetime, timedelta
import fluxopt as fx
timesteps = [datetime(2024, 1, 1) + timedelta(hours=i) for i in range(4)]
result = fx.optimize(
timesteps=timesteps,
buses=[fx.Bus('electricity')],
effects=[fx.Effect('cost', is_objective=True)],
ports=[
fx.Port('grid', imports=[
fx.Flow(bus='electricity', size=200, effects_per_flow_hour={'cost': 0.04}),
]),
fx.Port('demand', exports=[
fx.Flow(bus='electricity', size=100, fixed_relative_profile=[0.5, 0.8, 1.0, 0.6]),
]),
],
)
```
## Development
Requires [uv](https://docs.astral.sh/uv/) and Python >= 3.12.
```bash
uv sync --group dev # Install deps
uv run pytest -v # Run tests
uv run ruff check . # Lint
uv run ruff format . # Format
```
## License
MIT
| text/markdown | null | Felix Bumann <felixbumann387@gmail.com> | null | Felix Bumann <felixbumann387@gmail.com> | null | energy systems, linear programming, linopy, optimization | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"highspy>=1.13.1",
"linopy>=0.6",
"netcdf4>=1.6.0",
"numpy>=1.26",
"pandas>=2.1",
"xarray>=2024.1.0",
"plotly>=6; extra == \"viz\""
] | [] | [] | [] | [
"repository, https://github.com/FBumann/fluxopt"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:19:27.014534 | fluxopt-0.0.1rc0.tar.gz | 33,014 | 5d/f6/06b2879f596c1e06e6f35a176b4d78a2cee8d1023924b8fba46327afcc8c/fluxopt-0.0.1rc0.tar.gz | source | sdist | null | false | 32f4acec8584ece634d020da5f4f5960 | 69ac7bc26c8b28da62726baff3722c5c834f60573a5899c61a7eab3614d79d59 | 5df606b2879f596c1e06e6f35a176b4d78a2cee8d1023924b8fba46327afcc8c | MIT | [
"LICENSE"
] | 197 |
2.4 | qodev-gitlab-mcp | 0.2.2 | Production-ready GitLab MCP server exposing projects, merge requests, pipelines, and discussions | [](https://github.com/qodevai/gitlab-mcp/actions/workflows/ci.yml)
[](https://pypi.org/project/qodev-gitlab-mcp/)
# qodev-gitlab-mcp
A Model Context Protocol (MCP) server for GitLab integration. Exposes projects, merge requests, pipelines, discussions, issues, releases, and more through a standardized interface for AI assistants like Claude.
## Installation
```bash
pip install qodev-gitlab-mcp
```
Or run directly with uvx:
```bash
uvx qodev-gitlab-mcp
```
## Configuration
Set the following environment variables:
```env
# Required
GITLAB_TOKEN=glpat-YOUR-TOKEN-HERE
# Optional (defaults to https://gitlab.com)
GITLAB_URL=https://gitlab.com
```
### Claude Code
Add to your MCP configuration:
```json
{
"mcpServers": {
"gitlab": {
"command": "uvx",
"args": ["qodev-gitlab-mcp"],
"env": {
"GITLAB_TOKEN": "your-token-here",
"GITLAB_URL": "https://gitlab.com"
}
}
}
}
```
## Quick Start
Once configured, the MCP server gives your AI assistant access to GitLab. Example interactions:
- "Is my MR ready to merge?" -- checks pipeline, approvals, and unresolved discussions
- "Create a merge request for this branch" -- creates MR with auto-detected source branch
- "Wait for the pipeline to finish" -- monitors pipeline and reports results with failed job logs
- "Comment on MR !42 saying LGTM" -- posts a comment on the merge request
## Features
- Merge request management (create, comment, merge, close, inline comments)
- Pipeline monitoring with `wait_for_pipeline` tool
- Issue tracking (create, update, close, comment)
- Release management
- CI/CD variable management
- File uploads with image support
- Automatic "current" project/branch detection via MCP workspace roots
## Tools
The server exposes the following MCP tools:
### Merge Requests
| Tool | Description |
|------|-------------|
| `create_merge_request` | Create a new merge request |
| `update_merge_request` | Update MR title, description, labels, assignees, reviewers |
| `merge_merge_request` | Merge a merge request |
| `close_merge_request` | Close a merge request (with optional comment) |
| `comment_on_merge_request` | Leave a comment on a merge request |
| `create_inline_comment` | Add an inline comment on a specific line in a MR diff |
| `reply_to_discussion` | Reply to an existing discussion thread |
| `resolve_discussion_thread` | Resolve or unresolve a discussion thread |
### Pipelines
| Tool | Description |
|------|-------------|
| `wait_for_pipeline` | Wait for a pipeline to complete and return results |
| `download_artifact` | Download a job artifact to local filesystem |
| `retry_job` | Retry a failed CI/CD job |
### Issues
| Tool | Description |
|------|-------------|
| `create_issue` | Create a new issue |
| `update_issue` | Update an existing issue |
| `close_issue` | Close an issue |
| `comment_on_issue` | Leave a comment on an issue |
### Releases
| Tool | Description |
|------|-------------|
| `create_release` | Create a new release with tag, description, and assets |
### CI/CD Variables
| Tool | Description |
|------|-------------|
| `set_project_ci_variable` | Create or update a CI/CD variable (upsert) |
### Files
| Tool | Description |
|------|-------------|
| `upload_file` | Upload a file to GitLab for embedding in issues or MRs |
All tools support `project_id="current"` to auto-detect the project from the current working directory. Merge request tools also support `mr_iid="current"` to detect the MR for the current branch.
## Resources
The server exposes the following read-only MCP resources:
### Projects
| Resource URI | Description |
|--------------|-------------|
| `gitlab://projects/` | List all accessible projects |
| `gitlab://projects/{project_id}` | Get project details |
### Merge Requests
| Resource URI | Description |
|--------------|-------------|
| `gitlab://projects/{project_id}/merge-requests/` | List open merge requests |
| `gitlab://projects/{project_id}/merge-requests/{mr_iid}` | Full MR overview (metadata, discussions, changes, commits, pipeline, approvals) |
| `gitlab://projects/{project_id}/merge-requests/{mr_iid}/status` | Lightweight merge-readiness check |
| `gitlab://projects/{project_id}/merge-requests/{mr_iid}/discussions` | MR discussion threads |
| `gitlab://projects/{project_id}/merge-requests/{mr_iid}/changes` | MR diff/changes |
| `gitlab://projects/{project_id}/merge-requests/{mr_iid}/commits` | MR commit history |
| `gitlab://projects/{project_id}/merge-requests/{mr_iid}/approvals` | MR approval status |
| `gitlab://projects/{project_id}/merge-requests/{mr_iid}/pipeline-jobs` | Jobs from the MR's latest pipeline |
### Pipelines & Jobs
| Resource URI | Description |
|--------------|-------------|
| `gitlab://projects/{project_id}/pipelines/` | List recent pipelines |
| `gitlab://projects/{project_id}/pipelines/{pipeline_id}` | Get pipeline details |
| `gitlab://projects/{project_id}/pipelines/{pipeline_id}/jobs` | List jobs in a pipeline |
| `gitlab://projects/{project_id}/jobs/{job_id}/log` | Full job log output |
| `gitlab://projects/{project_id}/jobs/{job_id}/artifacts` | List job artifacts |
| `gitlab://projects/{project_id}/jobs/{job_id}/artifacts/{path}` | Read a specific artifact file |
### Issues
| Resource URI | Description |
|--------------|-------------|
| `gitlab://projects/{project_id}/issues/` | List open issues |
| `gitlab://projects/{project_id}/issues/{issue_iid}` | Get issue details |
| `gitlab://projects/{project_id}/issues/{issue_iid}/notes` | Get issue comments |
### Releases
| Resource URI | Description |
|--------------|-------------|
| `gitlab://projects/{project_id}/releases/` | List all releases |
| `gitlab://projects/{project_id}/releases/{tag_name}` | Get release by tag |
### CI/CD Variables
| Resource URI | Description |
|--------------|-------------|
| `gitlab://projects/{project_id}/variables/` | List CI/CD variables (metadata only, values hidden) |
| `gitlab://projects/{project_id}/variables/{key}` | Get variable metadata by key |
### Help
| Resource URI | Description |
|--------------|-------------|
| `gitlab://help` | Server capabilities and usage guide |
## License
MIT
| text/markdown | Jan Scheffler | null | null | null | MIT | ai, claude, gitlab, mcp, model-context-protocol | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"fastmcp>=2.2.5",
"qodev-gitlab-api>=0.1.2",
"mypy>=1.13.0; extra == \"dev\"",
"pytest-asyncio>=0.24.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest-mock>=3.12.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/qodevai/gitlab-mcp",
"Repository, https://github.com/qodevai/gitlab-mcp",
"Issues, https://github.com/qodevai/gitlab-mcp/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:19:25.234949 | qodev_gitlab_mcp-0.2.2.tar.gz | 132,400 | 3c/11/dd315b5874f0c67c1a9f180c3bfa1134d2fb6f252e06178fb369f2cc3557/qodev_gitlab_mcp-0.2.2.tar.gz | source | sdist | null | false | d06f0a22ef8a0841a618fcb7a8eda621 | 95e40a2ee061f141d2b02346483cdde57f0d6f7e19518fdb081ec91ef8bcd52e | 3c11dd315b5874f0c67c1a9f180c3bfa1134d2fb6f252e06178fb369f2cc3557 | null | [
"LICENSE"
] | 189 |
2.4 | angles-python-client-sarm333 | 1.0.0 | Python client for the Angles Dashboard API | # angles-python-client
A small Python client for the **Angles Dashboard** REST API, designed to be a **like-for-like** port of
`angles-javascript-client`.
## Install (local / editable)
```bash
pip install -e .
```
## Quick usage (singleton reporter)
```python
from angles_python_client import angles_reporter
from angles_python_client.models import Artifact, ScreenshotPlatform, Platform
angles_reporter.set_base_url("http://127.0.0.1:3000/rest/api/v1.0/")
build = angles_reporter.start_build(
name="TestRunName",
team="Team",
environment="Environment",
component="Component",
phase="optional-phase",
)
angles_reporter.add_artifacts([
Artifact(groupId="angles-ui", artifactId="anglesHQ", version="1.0.0")
])
angles_reporter.start_test(title="test1", suite="suite1")
angles_reporter.add_action("My first action")
platform = ScreenshotPlatform(
platformName="Android",
platformVersion="10",
browserName="Chrome",
browserVersion="89.0",
deviceName="Samsung Galaxy S9",
)
screenshot = angles_reporter.save_screenshot_with_platform(
file_path="/path/to/screenshot.png",
view="view_1",
tags=["smoke", "home"],
platform=platform,
)
angles_reporter.info_with_screenshot("Checking my view on android", screenshot.get("_id"))
angles_reporter.pass_step("Assertion", expected="true", actual="true", info="Just doing an assertion")
angles_reporter.fail_step("Assertion", expected="true", actual="false", info="Just doing an assertion")
execution = angles_reporter.save_test()
```
## Direct requests usage
```python
from angles_python_client import AnglesHttpClient
from angles_python_client.requests import BuildRequests
http = AnglesHttpClient(base_url="http://127.0.0.1:3000/rest/api/v1.0/")
builds = BuildRequests(http)
build = builds.get_build("your-build-id")
```
### Publish a release to PyPI
1. Bump `project.version` in `pyproject.toml`
2. Push a tag like `v1.0.1`:
```bash
git tag v1.0.1
git push origin v1.0.1
```
The workflow `.github/workflows/publish.yml` will build and publish to PyPI.
### Publish to TestPyPI first (optional)
- Push a tag like `test-v1.0.1`, or run the `Publish to TestPyPI` workflow manually.
- Install from TestPyPI to validate:
```bash
python -m pip install -i https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple angles-python-client
```
### Build locally (manual)
```bash
python -m pip install -U pip build twine
python -m build
python -m twine check dist/*
python -m twine upload dist/*
```
## Versioning
This project uses a standard `pyproject.toml` `version = "X.Y.Z"` field.
### Bump version locally (and create a tag)
```bash
pip install -U bump2version
bump2version patch # or minor / major
git push --follow-tags
```
### Bump via GitHub Actions (and publish)
Run the **Bump version and tag** workflow (Actions tab) and choose:
- `target=pypi` → creates a tag like `v1.0.1` (triggers the PyPI publish workflow)
- `target=testpypi` → creates a tag like `test-v1.0.1` (triggers the TestPyPI publish workflow)
## Auto-release on main/master
This repo includes an **optional** workflow: `.github/workflows/release-on-main.yml`.
When enabled (it is committed by default), **every push to `main` or `master`** will:
1. Read the current `project.version` from `pyproject.toml`
2. Create and push a git tag `vX.Y.Z` (if it doesn't already exist)
3. Build and publish to PyPI (Trusted Publishing)
4. Bump the version **patch** for the next release and push that commit back to the default branch
To avoid loops, the post-bump commit includes `[skip release]` and the workflow ignores commits containing that marker.
| text/markdown | AnglesHQ community | null | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"requests>=2.31.0",
"build>=1.2.1; extra == \"dev\"",
"twine>=5.1.1; extra == \"dev\"",
"bump2version>=1.0.1; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://angleshq.github.io/",
"Repository, https://github.com/sarm333/angles-python-client",
"Issues, https://github.com/sarm333/angles-python-client/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:19:12.345440 | angles_python_client_sarm333-1.0.0.tar.gz | 16,769 | c5/29/ff26cf8536554f1f54af7076717fb9b0670f3392df240d38f340ba8c8c93/angles_python_client_sarm333-1.0.0.tar.gz | source | sdist | null | false | 0d00cf362e738d5659ae8b46d54a227d | 706de4cd34b2d67e1b344bfbc6a08064019999c4dc18a934ceeaacb21a2a386b | c529ff26cf8536554f1f54af7076717fb9b0670f3392df240d38f340ba8c8c93 | null | [
"LICENSE"
] | 172 |
2.4 | gftools | 0.9.991 | Google Fonts Tools is a set of command-line tools for testing font projects | [](https://github.com/googlefonts/gftools/actions/workflows/ci.yml?query=workflow%3ATest+branch%3Amain)
[](https://pypi.org/project/gftools/)
# Google Fonts Tools
This project contains tools used for working with the Google Fonts collection, plus **Google Fonts Glyph Set Documentation** in the [/encodings](https://github.com/googlefonts/gftools/tree/main/Lib/gftools/encodings) subdirectory. While these tools are primarily intended for contributors to the Google Fonts project, anyone who works with fonts could find them useful.
Additional documentation in [`/docs`](https://github.com/googlefonts/gftools/blob/main/docs)
The tools and files under this directory are available under the Apache License v2.0, for details see [LICENSE](LICENSE)
## Google Fonts Official Glyph Sets
The glyph sets useful for type designers that were previously hosted in this repository have been moved to:
<https://github.com/googlefonts/glyphsets/tree/main/GF_glyphsets>
## Tool Usage Examples
Compare fonts:
gftools compare-font font1.ttf font2.ttf
Add a METADATA.pb to a family directory
gftools add-font ../ofl/newfamily
Sanity check a family directory:
gftools sanity-check --repair_script=/tmp/fix.py ../ofl/josefinsans
gftools sanity-check --repair_script=/tmp/fix.py --fix_type=fsSelection ../ufl
Check a font family against the same family hosted on Google Fonts:
gftools qa [fonts.ttf] -gfb -a -o qa
Check a variable font family against the same family as static fonts:
gftools qa -f [vf_fonts] -fb [static_fonts] --diffenator --diffbrowsers -o ~/path/out
Fix a non hinted font
gftools fix-nonhinting font_in.ttf font_out.ttf
Package and PR a family update to google/fonts. Find much more detailed [documentation in `/docs/gftools-packager`](./docs/gftools-packager).
gftools packager "Family Sans" path/to/local/google/fonts -py
## Tool Installation
**Please note that gftools requires [Python 3.7](http://www.python.org/download/) or later.**
Please install these tools using pip:
pip install gftools
If you would like to use `gftools qa`:
brew install pkg-config # needed for interpolation checks
pip install 'gftools[qa]'
### Tool Requirements and Dependencies
`gftools packager` needs the command line `git` program in a version >= Git 2.5 (Q2 2015) in order to perform a shallow clone (`--depth 1`) of the font upstream repository and branch. This is not supported by pygit2/libgit2 yet.
`gftools manage-traffic-jam` requires two private files which contain sensitive data. Ask m4rc1e for them.
### Google Fonts API Key
In order to use the scripts **gftools qa** and **gftools family-html-snippet**, you will need to generate a Google Fonts api key, https://developers.google.com/fonts/. You will then need to create a new text file located on your system at `~/.gf-api-key` (where ~ is your home directory), which contains the following:
```
[Credentials]
key = your-newly-generated-googlefonts-api-key
```
**Upstream project repos**
* https://github.com/google/protobuf
* https://github.com/behdad/fonttools
## Developers
### Releasing a New Version
0. Commit and push your final changes for the new version.
1. Create an annotated Git tag of the version number, with a prepended "v", like so: `git tag -a v3.1.1`
2. Write the release notes into the tag message. They will show up as release notes on the release page in GitHub.
| text/markdown | Felipe Sanches, Lasse Fister, Eli Heuer, Roderick Sheeter | Marc Foley <m.foley.88@gmail.com>, Dave Crossland <dave@lab6.com>, Simon Cozens <simon@simon-cozens.org> | null | null | null | null | [
"Environment :: Console",
"Intended Audience :: Developers",
"Topic :: Text Processing :: Fonts",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"FontTools[ufo]>=4.60.0",
"axisregistry>=0.4.9",
"absl-py",
"glyphsLib",
"gflanguages>=0.6.0",
"gfsubsets>=2024.02.05",
"glyphsets>=0.6.13",
"PyGithub",
"pillow",
"protobuf<4,>=3.19.4",
"requests",
"tabulate",
"unidecode",
"opentype-sanitizer",
"vttlib",
"pygit2>=1.16.0",
"strictyaml",
"fontmake[json]>=3.3.0",
"skia-pathops",
"statmake",
"PyYAML",
"babelfont",
"ttfautohint-py",
"brotli",
"jinja2",
"fontFeatures",
"vharfbuzz",
"bumpfontversion",
"nanoemoji>=0.15.0",
"font-v",
"afdko",
"beautifulsoup4",
"rich",
"packaging",
"ninja",
"networkx",
"ruamel.yaml",
"ffmpeg-python",
"ufomerge>=1.8.1",
"tomli; python_version < \"3.11\"",
"fontbakery[googlefonts]; extra == \"qa\"",
"diffenator2>=0.2.0; extra == \"qa\"",
"pycairo; extra == \"qa\"",
"black==24.10.0; extra == \"test\"",
"pytest; extra == \"test\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:19:09.398262 | gftools-0.9.991.tar.gz | 8,447,615 | f3/8a/3931ff15b3ec8b16696aec9206b643d2e7dadada4c308083b0c477dd706a/gftools-0.9.991.tar.gz | source | sdist | null | false | 49b57821bc9d9a9db8bc3648e07d1332 | 68642b26a145e328b818cef42172757291d4e474e1ecaecadf111f17a19a8d8d | f38a3931ff15b3ec8b16696aec9206b643d2e7dadada4c308083b0c477dd706a | null | [
"LICENSE"
] | 436 |
2.2 | meodin | 0.1.3 | Optical Design Integrated Network | ODIN is a demo Python package for optical engineers.
We believe in a straightforward path to great design and tolerancing.
Let the best wavefront win😄
## Requirements
- Python 3.x, ZOSAPI, NumPy, clr, os, winreg, random
# Math Module
## Interferometry Math Utilities
Lightweight Python helpers for common interferometry conversions.
Convert surface irregularity and optical power between fringes,
millimeters, and radius of curvature.
## Features
- Irregularity conversion: fringes ↔ millimeters
- Optical power conversion: fringes ↔ millimeters
- Supports concave (CC) and convex (CX) surfaces
- NumPy-only dependency
- Simple random value generator for simulation/testing
## Main Class
```Python
Math()
```
- Main interface for using Math functions.
## Functions
```Python
irrFrToMm(fringes, wavelength_nm)
```
- Convert surface irregularity from fringes to millimeters.
```Python
irrMmToFr(irregularity_mm, wavelength_nm)
```
- Convert surface irregularity from millimeters to fringes.
```Python
powFrToMm(diameter_mm, nominal_radius_mm, surface_type, fringes, wavelength_nm)
```
- Convert power in fringes to corrected radius in millimeters.
```Python
powMmToFr(diameter_mm, nominal_radius_mm, surface_type, power_mm, wavelength_nm)
```
- Convert power in millimeters to fringes.
```Python
randomValue(distribution="uniform")
```
- Generate a random value between -1 and 1.
- Distributions: uniform, gauss, parabolic
# ZOSpy Module
A demo Python wrapper for Zemax OpticStudio (ZOS-API)
## ZOSpy – OpticStudio Automation Utilities
Lightweight Python interface for connecting to Zemax OpticStudio,
manipulating lens data, merit functions, and running tolerancing
analyses via ZOS-API.
## Features
- Offline ZMX file read/write/edit without OpticStudio
- Connect to OpticStudio (Interactive or Standalone)
- Open, save, and modify ZMX/ZOS files
- Lens Data Editor (LDE) surface and parameter control
- Merit Function Editor (MFE) access
- Local optimization control
- Monte Carlo tolerancing utilities
## Main Class
```Python
ZOSpy()
```
- Main interface for connecting to and controlling OpticStudio.
## File Handling
```Python
readOfflineZmx(pathToZmx)
```
- Read a .zmx file as text into memory.
```Python
writeOfflineZmx(pathToZmxWithNewName)
```
- Write modified offline .zmx content to file.
```Python
openFile(path)
```
- Open a ZMX or ZOS file in OpticStudio.
```Python
saveFile()
```
- Save the current system.
```Python
saveAsFile(pathWithName)
```
- Save the system under a new name.
## Connections
```Python
connectOS()
```
- Connect via Interactive Extension.
```Python
connectOSSA()
```
- Connect via Standalone Application.
```Python
disconnectOS()
```
- Close OpticStudio and release the connection.
## OfflineLDE
```Python
OfflineLDE.getParameter(surface, parameter)
```
- Read a surface parameter from offline ZMX text.
```Python
OfflineLDE.setParameter(surface, parameter, value)
```
- Modify a surface parameter in offline ZMX text.
## LDE (Lens Data Editor)
```Python
LDE.getSurfaceByComment(comment)
```
- Find a surface index by comment.
```Python
LDE.addSurfaceAfter(surface)
LDE.addSurfaceBefore(surface)
```
- Add new surfaces relative to an existing one.
```Python
LDE.removeSurfaces(first_surface, last_surface)
```
- Remove a range of surfaces.
```Python
LDE.setSurfaceType(surface, type)
```
- Change the surface type.
```Python
LDE.setParameter(surface, parameter, value)
```
- Set a surface parameter.
```Python
LDE.getParameter(surface, parameter)
```
- Get a surface parameter value.
```Python
LDE.ignoreSurface(surface, bool)
```
- Enable or ignore a surface.
```Python
LDE.setUiUpdate(bool)
```
- Enable or disable live UI updates.
```Python
LDE.removeAllVariable()
```
- Remove all variables from the system.
```Python
LDE.setCoordinateBreakToElement(surface_1, surface_2, color)
```
- Group surfaces into an element using coordinate breaks.
## MFE (Merit Function Editor)
```Python
MFE.loadMeritFunction(path)
```
- Load a merit function file.
```Python
MFE.calculateMeritFunction()
```
- alculate the current merit function.
```Python
MFE.getTarget(line)
MFE.setTarget(line, target)
```
- Get or set merit function targets.
```Python
MFE.getWeight(line)
MFE.setWeight(line, weight)
```
- Get or set merit function weights.
```Python
MFE.getValue(line)
```
- Read a merit function value.
## TDE (Tolerance Data Editor)
```Python
TDE.loadTDE(path)
```
## Tolerancing
```Python
Tolerancing.getMonteCarlo()
```
- Run a single Monte Carlo tolerancing analysis.
```Python
Tolerancing.runMonteCarlos(cores, ScriptIndex, NumberOfRuns, NumberToSave)
```
- Run multiple Monte Carlo simulations.
```Python
Tolerancing.getData(column)
```
- Extract a column of Monte Carlo result data.
## Database Module
### SQL Server Database Utilities
Lightweight Python helper class for connecting to and interacting
with a Microsoft SQL Server database.
Provides simple methods for connection handling, table inspection,
and filtered data retrieval.
Uses a config.ini file for credential management.
### Features
- Connect / disconnect using config file
- List all database tables
- Show table structure (columns, types, length)
- Display full table content
- Filtered data retrieval (pn, sn)
- Table whitelist for basic SQL injection protection
- Uses pymssql
### Main Class
```Python
Database()
```
- Main interface for managing database operations.
### Functions
```Python
connect(config_path)
```
- Connect to the database using a config.ini file.
```Python
disconnect()
```
- Close the active database connection.
```Python
listTables()
```
- List all base tables in the database.
```Python
showTableStructure(table_name)
```
- Display column structure of a selected table.
```Python
showTableData(table_name)
```
- Display all rows from a selected table.
```Python
getData(table, pn, sn)
```
- Retrieve rows filtered by part number (pn) and serial number (sn).
- Table must be in the allowed whitelist.
### Example config.ini
```ini
[database]
server = YOUR_SERVER
database = YOUR_DATABASE
username = YOUR_USERNAME
password = YOUR_PASSWORD
```
| text/markdown | Sebastian Gedeon | sebastian.gedeon@gmail.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"requests"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.1 | 2026-02-20T12:19:07.277066 | meodin-0.1.3.tar.gz | 17,239 | 6b/43/64dcf9366c8d7c60d39b59ecab03ef58440f4acf0cd4fa152b30718b29d1/meodin-0.1.3.tar.gz | source | sdist | null | false | 088398422b8c21476abbc89c6c8748fb | 6c4ca9b991f61426380c73bbcb23d21738d9ada9355b6949edda7ea7f076ae00 | 6b4364dcf9366c8d7c60d39b59ecab03ef58440f4acf0cd4fa152b30718b29d1 | null | [] | 209 |
2.4 | qodev-gitlab-api | 0.2.2 | Python client for the GitLab API | [](https://github.com/qodevai/gitlab-api/actions/workflows/ci.yml)
[](https://pypi.org/project/qodev-gitlab-api/)
# qodev-gitlab-api
A lightweight, typed Python client for the GitLab REST API. Built on [httpx](https://www.python-httpx.org/) with automatic pagination, structured error handling, and `.env` support, it provides a clean interface for common GitLab operations without the weight of a full-featured SDK.
## Why this library?
- **Lightweight** -- just `httpx`, no heavy ORM-like abstractions
- **Typed** -- ships with `py.typed` for full mypy/pyright support
- **Agent-friendly** -- simple method signatures, dict returns, auto-pagination
- **Built for tools** -- designed for MCP servers and CLIs, not full application frameworks
- **Focused** -- `python-gitlab` is comprehensive but heavy; this library covers the operations AI agents and developer tools actually need
## Installation
```bash
pip install qodev-gitlab-api
```
## Quick Start
```python
from qodev_gitlab_api import GitLabClient
# Reads GITLAB_TOKEN and GITLAB_URL from environment or .env file
client = GitLabClient()
# Or pass credentials explicitly
client = GitLabClient(token="glpat-xxxxxxxxxxxx", base_url="https://gitlab.example.com")
# Skip connection validation for faster startup
client = GitLabClient(validate=False)
```
```python
# List open merge requests
mrs = client.get_merge_requests("mygroup/myproject", state="opened")
for mr in mrs:
print(f"!{mr['iid']} {mr['title']}")
# Create a merge request
client.create_merge_request("mygroup/myproject", "feature-branch", "main", "Add new feature")
# Get pipeline status
pipelines = client.get_pipelines("mygroup/myproject")
```
## Features
- **Merge requests** -- create, update, merge, close, and review with inline diff comments
- **Pipelines and jobs** -- list, inspect, wait for completion, retry, and download artifacts
- **Issues** -- create, update, close, and comment
- **Releases** -- create, update, delete, and list with asset links
- **CI/CD variables** -- get, list, create, update, and upsert (set) project variables
- **File operations** -- read repository files at any ref, upload files for markdown embedding
- **Automatic pagination** -- all list endpoints handle multi-page results transparently
- **Typed exceptions** -- `AuthenticationError`, `NotFoundError`, `APIError`, `ConfigurationError`
## Configuration
The client reads configuration from environment variables, with `.env` file support via `python-dotenv`:
| Variable | Description | Default |
|---|---|---|
| `GITLAB_TOKEN` | GitLab personal access token (required) | -- |
| `GITLAB_URL` | GitLab instance base URL | `https://gitlab.com` |
You can also use `GITLAB_BASE_URL` as an alias for `GITLAB_URL`.
Create a `.env` file in your project root:
```
GITLAB_TOKEN=glpat-xxxxxxxxxxxxxxxxxxxx
GITLAB_URL=https://gitlab.example.com
```
## API Reference
### Projects
```python
projects = client.get_projects(owned=True)
project = client.get_project("my-group/my-project")
```
### Merge Requests
```python
# List and inspect
mrs = client.get_merge_requests("my-group/my-project", state="opened")
mr = client.get_merge_request("my-group/my-project", mr_iid=42)
changes = client.get_mr_changes("my-group/my-project", mr_iid=42)
commits = client.get_mr_commits("my-group/my-project", mr_iid=42)
approvals = client.get_mr_approvals("my-group/my-project", mr_iid=42)
# Create
mr = client.create_merge_request(
"my-group/my-project",
source_branch="feature/foo",
target_branch="main",
title="Add foo feature",
description="Implements the foo feature.",
assignee_ids=[123],
reviewer_ids=[456],
labels="enhancement",
)
# Update, merge, close
client.update_mr("my-group/my-project", mr_iid=42, title="Updated title")
client.merge_mr("my-group/my-project", mr_iid=42, squash=True)
client.close_mr("my-group/my-project", mr_iid=42)
# Discussions and comments
discussions = client.get_mr_discussions("my-group/my-project", mr_iid=42)
client.create_mr_note("my-group/my-project", mr_iid=42, body="Looks good!")
client.reply_to_discussion("my-group/my-project", mr_iid=42, discussion_id="abc123", body="Fixed.")
client.resolve_discussion("my-group/my-project", mr_iid=42, discussion_id="abc123", resolved=True)
# Inline diff comment
from qodev_gitlab_api import DiffPosition
client.create_mr_discussion(
"my-group/my-project",
mr_iid=42,
body="Consider renaming this variable.",
position=DiffPosition(file_path="src/main.py", new_line=15),
)
```
### Pipelines and Jobs
```python
pipelines = client.get_pipelines("my-group/my-project", ref="main")
pipeline = client.get_pipeline("my-group/my-project", pipeline_id=1001)
jobs = client.get_pipeline_jobs("my-group/my-project", pipeline_id=1001)
# Job details, logs, and artifacts
job = client.get_job("my-group/my-project", job_id=5001)
log = client.get_job_log("my-group/my-project", job_id=5001)
artifact = client.get_job_artifact("my-group/my-project", job_id=5001, artifact_path="report.xml")
# Retry a failed job
client.retry_job("my-group/my-project", job_id=5001)
# Wait for pipeline completion (blocks until done or timeout)
result = client.wait_for_pipeline("my-group/my-project", pipeline_id=1001, timeout_seconds=600)
print(result["final_status"]) # "success", "failed", "canceled", "skipped", or "timeout"
```
### Issues
```python
issues = client.get_issues("my-group/my-project", state="opened", labels="bug")
issue = client.get_issue("my-group/my-project", issue_iid=10)
issue = client.create_issue(
"my-group/my-project",
title="Fix login bug",
description="Users cannot log in with SSO.",
labels="bug,urgent",
assignee_ids=[123],
)
client.update_issue("my-group/my-project", issue_iid=10, labels="bug,resolved")
client.close_issue("my-group/my-project", issue_iid=10)
# Comments
notes = client.get_issue_notes("my-group/my-project", issue_iid=10)
client.create_issue_note("my-group/my-project", issue_iid=10, body="Investigating this now.")
```
### Releases
```python
releases = client.get_releases("my-group/my-project")
release = client.get_release("my-group/my-project", tag_name="v1.0.0")
release = client.create_release(
"my-group/my-project",
tag_name="v1.1.0",
name="Version 1.1.0",
description="## What's new\n- Feature A\n- Bug fix B",
ref="main",
)
client.update_release("my-group/my-project", tag_name="v1.1.0", description="Updated notes.")
client.delete_release("my-group/my-project", tag_name="v1.1.0")
```
### CI/CD Variables
```python
variables = client.list_project_variables("my-group/my-project")
var = client.get_project_variable("my-group/my-project", key="API_KEY")
# Create or update (upsert)
var, action = client.set_project_variable(
"my-group/my-project",
key="API_KEY",
value="secret-value",
masked=True,
protected=True,
)
print(action) # "created" or "updated"
```
### File Operations
```python
# Read a file from the repository
content = client.get_file_content("my-group/my-project", file_path="README.md", ref="main")
# Upload a file (for embedding in issues/MRs)
from qodev_gitlab_api import FileFromPath
result = client.upload_file("my-group/my-project", source=FileFromPath(path="/tmp/screenshot.png"))
```
## Error Handling
All API errors raise typed exceptions that inherit from `GitLabError`:
```python
from qodev_gitlab_api import GitLabClient, AuthenticationError, NotFoundError, APIError, ConfigurationError
try:
client = GitLabClient()
mr = client.get_merge_request("my-group/my-project", mr_iid=999)
except ConfigurationError:
print("Missing or invalid GITLAB_TOKEN / GITLAB_URL")
except AuthenticationError:
print("Token is invalid or expired")
except NotFoundError:
print("Merge request not found")
except APIError as e:
print(f"API error {e.status_code}: {e.response_body}")
```
## Requirements
- Python 3.11+
- [httpx](https://www.python-httpx.org/) >= 0.28.1
- [python-dotenv](https://github.com/theskumar/python-dotenv) >= 1.1.0
## License
MIT -- see [LICENSE](LICENSE) for details.
| text/markdown | null | Jan Scheffler <jan.scheffler@qodev.ai> | null | null | MIT | api, client, gitlab | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Typing :: Typed"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx>=0.28.1",
"python-dotenv>=1.1.0",
"mypy>=1.13.0; extra == \"dev\"",
"pytest-cov>=4.1.0; extra == \"dev\"",
"pytest-mock>=3.12.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/qodevai/gitlab-api",
"Repository, https://github.com/qodevai/gitlab-api",
"Issues, https://github.com/qodevai/gitlab-api/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:19:05.165520 | qodev_gitlab_api-0.2.2.tar.gz | 14,847 | b6/98/12f3516d52e1878d580b944a8a5e8f394f839075e0a322b8c6c630bc6f04/qodev_gitlab_api-0.2.2.tar.gz | source | sdist | null | false | cd33cdf6766d523ac2e863f7030c39cf | 5c5e017c1888f95980f89c2cdec0f21f16bb2ec773c688667d7539646d51d3d5 | b69812f3516d52e1878d580b944a8a5e8f394f839075e0a322b8c6c630bc6f04 | null | [
"LICENSE"
] | 208 |
2.4 | dagster-ray | 0.4.2 | Dagster integration library for Ray | # `dagster-ray`
[](https://pypi.python.org/pypi/dagster-ray)
[](https://pypi.python.org/pypi/dagster-ray)
[](https://pypi.python.org/pypi/dagster-ray)
[](https://github.com/danielgafni/dagster-ray/actions/workflows/CI.yml)
[](https://github.com/pre-commit/pre-commit)
[](https://docs.basedpyright.com)
[](https://github.com/astral-sh/ruff)
---
**Ray integration for Dagster.**
`dagster-ray` enables working with distributed Ray compute from Dagster pipelines, combining Dagster's excellent orchestration capabilities and Ray's distributed computing power together.
> [!NOTE]
> This project is ready for production use, but some APIs may change between minor releases.
Learn more in the [docs](https://danielgafni.github.io/dagster-ray)
## 🚀 Key Features
- **🎯 Run Launchers & Executors**: Submit Dagster runs or individual steps by submitting Ray jobs
- **🔧 Ray Resources**: Automatically create and destroy ephemeral Ray clusters and connect to them in client mode
- **📡 Dagster Pipes Integration**: Submit external scripts as Ray jobs, stream back logs and rich Dagster metadata
- **☸️ KubeRay Support**: Utilize `RayJob` and `RayCluster` custom resources in client or job submission mode ([tutorial](https://danielgafni.github.io/dagster-ray/tutorial/kuberay))
- **🏭 Production Ready**: Tested against a matrix of core dependencies, integrated with Dagster+
- **⚡ Instant Startup**: Leverage `RayCluster` with [Cluster Sharing](https://danielgafni.github.io/dagster-ray/tutorial/kuberay/#cluster-sharing) for lightning-fast development cycles with zero cold start times (intended for development environments)
## Installation
```shell
pip install dagster-ray
```
## 📚 Docs
**📖 [Full Documentation](https://danielgafni.github.io/dagster-ray)**
- **[Tutorial](https://danielgafni.github.io/dagster-ray/tutorial/)**: Step-by-step guide with examples
- **[API Reference](https://danielgafni.github.io/dagster-ray/api/)**: Complete API reference
## 🤝 Contributing
Contributions are very welcome! To get started:
```bash
uv sync --all-extras --all-groups
uv run pre-commit install
```
### 🧪 Testing
```bash
uv run pytest
```
Running KubeRay tests requires the following tools to be present:
- `docker`
- `kubectl`
- `helm`
- `minikube`
❄️ Nix users will find them provided in the dev shell:
```
nix develop
```
### Documentation
To build and serve the documentation locally:
```bash
# Serve documentation locally
uv run --group docs mkdocs serve
```
| text/markdown | null | Daniel Gafni <danielgafni16@gmail.com> | null | null | Apache-2.0 | ETL, dagster, distributed, ray | [
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | <3.13,>=3.10 | [] | [] | [] | [
"dagster>=1.10.0",
"eval-type-backport>=0.2.2; python_full_version < \"3.10\"",
"tenacity>=8.0.0",
"ray[client]; extra == \"executor\"",
"dagster-k8s>=0.19.0; extra == \"kuberay\"",
"kubernetes>=20.0.0; extra == \"kuberay\"",
"pyyaml; extra == \"kuberay\"",
"pyyaml>=4.0.0; extra == \"kuberay\"",
"ray[client]; extra == \"pipes\"",
"ray[client]; extra == \"run-launcher\""
] | [] | [] | [] | [
"GitHub, https://github.com/danielgafni/dagster-ray",
"Documentation, https://danielgafni.github.io/dagster-ray/",
"Changelog, https://github.com/danielgafni/dagster-ray/blob/main/CHANGELOG.md"
] | uv/0.9.27 {"installer":{"name":"uv","version":"0.9.27","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T12:18:06.765717 | dagster_ray-0.4.2.tar.gz | 224,424 | 85/82/681dfe5e46554983175277dd5f49b96cd5c231f8177b19c5656e8cfe66c4/dagster_ray-0.4.2.tar.gz | source | sdist | null | false | 9416d4005326c2790a1550821a002814 | 959dbce1936bc5b552b49e9b3d55ad2c30cc4ea15f0de209acbdbbefec1af149 | 8582681dfe5e46554983175277dd5f49b96cd5c231f8177b19c5656e8cfe66c4 | null | [
"LICENSE"
] | 232 |
2.4 | filler-prediction | 0.3.2 | thai filler word prediction for voice bots - picks the right acknowledgment phrase while llm thinks | # filler-prediction
thai filler word prediction for voice bots. classifies customer input into categories and returns the appropriate filler phrase to play instantly while the llm generates a full response.
built for [ingfah.ai](https://ingfah.ai) voice bot but easily adaptable to any thai voice ai system.
## why
voice bots have a latency problem: the user speaks, asr transcribes, then the llm takes 1-3 seconds to respond. dead silence feels broken. the solution is to play a short filler phrase ("สักครู่นะคะ", "ขออภัยด้วยน่ะคะ") immediately while the llm thinks.
but you can't play the same filler for everything. if someone is angry, "ได้เลยค่ะ" sounds dismissive. if someone asks a question, "ขออภัยด้วยน่ะคะ" makes no sense.
this classifier picks the right filler by category.
## categories
| category | when | example fillers |
|---|---|---|
| `complaint` | angry, frustrated, profanity, threats | ขออภัยด้วยน่ะคะ |
| `question` | asking for info, pricing, how-to | สักครู่นะคะ, ตรวจสอบให้นะคะ |
| `default` | greetings, agreements, requests, everything else | รับทราบค่ะ, ได้เลยค่ะ |
### default filler phrases
| category | fillers |
|---|---|
| `complaint` | ขออภัยด้วยน่ะคะ |
| `question` | สักครู่นะคะ, สักครู่ค่ะ, ตรวจสอบให้นะคะ |
| `default` | รับทราบค่ะ, ค่ะ ได้ค่ะ, ได้เลยค่ะ, ดีเลยค่ะ, ยินดีค่ะ |
a random filler is picked from the matching category each time. these are designed to be short (~0.3-0.5s when synthesized) for minimal latency.
## how it works
uses `intfloat/multilingual-e5-small` embeddings with centroid-based cosine similarity:
1. each category has ~30-60 anchor phrases (real thai customer service examples)
2. on init, all anchors are embedded and averaged into category centroids
3. at inference, the input is embedded and compared to centroids via cosine similarity
4. the closest category wins, and a random filler from that category is returned
## performance
- **accuracy**: 89.6% on 1,000 thai customer service sentences
- **inference**: <10ms per classification (after model load)
- **init**: ~200ms for centroid computation
- **model size**: ~118mb (multilingual-e5-small)
## installation
```bash
pip install filler-prediction
```
## usage
```python
from filler_prediction import FillerClassifier
# loads model automatically on first init
clf = FillerClassifier()
# classify and get category + confidence + filler
category, confidence, filler = clf.classify("อยากถามเรื่องบิลครับ")
# ("question", 0.872, "สักครู่นะคะ")
category, confidence, filler = clf.classify("ใช้งานไม่ได้เลย")
# ("complaint", 0.891, "ขออภัยด้วยน่ะคะ")
category, confidence, filler = clf.classify("ได้ครับ ตกลง")
# ("default", 0.845, "ได้เลยค่ะ")
# or just get the filler phrase directly
filler = clf.get_filler("มีโปรอะไรบ้างครับ")
# "ตรวจสอบให้นะคะ"
```
### sharing the model
if you alr have a `SentenceTransformer` instance loaded (e.g., for other tasks), pass it in to avoid loading twice:
```python
from sentence_transformers import SentenceTransformer
from filler_prediction import FillerClassifier
model = SentenceTransformer("intfloat/multilingual-e5-small")
clf = FillerClassifier(model=model)
```
## customizing fillers
override `CATEGORY_FILLERS` to use your own phrases:
```python
import filler_prediction
filler_prediction.CATEGORY_FILLERS["complaint"] = ["ขออภัยค่ะ", "เข้าใจค่ะ"]
filler_prediction.CATEGORY_FILLERS["question"] = ["รอสักครู่นะคะ"]
```
## license
mit
| text/markdown | null | "100x.fi" <kiri@100x.fi> | null | null | MIT | thai, nlp, filler, voice, classifier, prediction, embeddings, voice-bot | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Text Processing :: Linguistic"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"sentence-transformers>=2.0",
"numpy>=1.20",
"pythainlp>=4.0"
] | [] | [] | [] | [
"Homepage, https://github.com/100x-fi/filler-prediction",
"Repository, https://github.com/100x-fi/filler-prediction"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-20T12:17:11.828023 | filler_prediction-0.3.2.tar.gz | 11,517 | 9b/79/7363f717621b16836077a4106af767a4a64ffda00161e6f4f5727a270173/filler_prediction-0.3.2.tar.gz | source | sdist | null | false | 241a35ad9cc78456182a0f45a3c9eb12 | 17babb1039f278b919c235b0b1b625d5ae80a79a110bd020fee5a726b3e9eda1 | 9b797363f717621b16836077a4106af767a4a64ffda00161e6f4f5727a270173 | null | [
"LICENSE"
] | 216 |
2.4 | visivo | 1.0.79 | Visivo CLI for BI and visualizations as code | <p align="center">
<img src="viewer/src/images/logo.png" alt="Visivo" width="300" />
</p>
<h1 align="center">AI native business intelligence. Build visually, in code+cli or through ai tools.</h1>
<p align="center">
<a href="https://visivo.io">Website</a> •
<a href="https://docs.visivo.io">Documentation</a> •
<a href="https://visivo.io/examples">Live Examples</a> •
<a href="https://join.slack.com/t/visivo-community/shared_invite/zt-38shh3jmq-1Vl3YkxHlGpD~GlalfiKsQ">Join Slack</a> •
<a href="https://www.linkedin.com/company/visivo-io">LinkedIn</a>
</p>
<p align="center">
<img src="https://img.shields.io/pypi/v/visivo?label=pypi%20package" alt="PyPI Version" />
<img src="https://img.shields.io/pypi/dm/visivo" alt="PyPI Downloads" />
<img src="https://img.shields.io/github/license/visivo-io/visivo" alt="License" />
<img src="https://img.shields.io/github/stars/visivo-io/visivo?style=social" alt="GitHub Stars" />
</p>
## 🚀 Why Visivo?
Build reliable, testable dashboards that your team will actually trust. Here's what makes Visivo different:
- ✅ **Code-First Dashboard Development** – Define everything in YAML files, enabling version control, code reviews, and CI/CD for your analytics
- ✅ **Built-in Testing Framework** – Write Python tests for your data visualizations. Never ship broken charts to production again
- ✅ **50+ Interactive Chart Types** – From basic bar charts to advanced 3D visualizations and geospatial maps, powered by Plotly.js
- ✅ **Multi-Source Data Integration** – Join data from PostgreSQL, Snowflake, BigQuery, MySQL, SQLite, DuckDB, CSV, and Excel in a single dashboard
- ✅ **Local Development with Hot Reload** – See changes instantly with `visivo serve`. No more waiting for deployments to test changes
- ✅ **dbt Integration** – Reference your dbt models directly in visualizations. Your analytics stack, unified
- ✅ **Jinja2 Templates & Macros** – Use loops and variables to generate dynamic configurations. Write once, use everywhere
- ✅ **Interactive Components** – Add filters, selectors, and drill-downs without losing the benefits of code-based configuration
- ✅ **Push-Based Security** – You control data flow. No need to share database credentials with another SaaS tool
- ✅ **Single Binary Installation** – One executable, no Python required. Deploy anywhere from your laptop to production servers
## 📊 See Visivo in Action
<p align="center">
<a href="https://www.youtube.com/watch?v=EXnw-m1G4Vc">
<img src="https://img.youtube.com/vi/EXnw-m1G4Vc/maxresdefault.jpg" alt="Visivo Demo Video" width="60%" />
</a>
</p>
<p align="center">
<em>🎥 <strong><a href="https://www.youtube.com/watch?v=EXnw-m1G4Vc">Watch the Demo Video</a></strong> – See how to build dashboards with Visivo in just a few minutes</em>
</p>
<p align="center">
<em>Build dashboards that are beautiful, interactive, and maintainable. <a href="https://visivo.io/examples">View more examples →</a></em>
</p>
## 🎯 Getting Started
Get your first dashboard running in under 5 minutes:
### Quick Install
```bash
# Install Visivo (works on Mac, Linux, and Windows)
curl -fsSL https://visivo.sh | bash
# Create your first project
visivo init my-dashboard
# Start the development server
cd my-dashboard && visivo serve
# Open http://localhost:8000 in your browser 🎉
```
### Alternative: UI-Guided Setup
Prefer a visual approach? Start the server and let Visivo guide you:
```bash
# Install and start in one go
curl -fsSL https://visivo.sh | bash
visivo serve --project-dir my-dashboard
# Follow the setup wizard in your browser at http://localhost:8000
```
### Other Installation Options
<details>
<summary>Install via pip</summary>
```bash
pip install visivo
```
</details>
<details>
<summary>Install specific version</summary>
```bash
# Install version 1.0.64
curl -fsSL https://visivo.sh | bash -s -- --version 1.0.64
# Or install beta version via pip
python -m pip install git+https://github.com/visivo-io/visivo.git@v1.1.0-beta-1
```
</details>
## 💬 Community & Support
<p align="center">
<strong>Join our growing community of data practitioners!</strong>
</p>
- 💬 **[Join our Slack](https://join.slack.com/t/visivo-community/shared_invite/zt-38shh3jmq-1Vl3YkxHlGpD~GlalfiKsQ)** – Get help, share dashboards, and chat with the team
- 📚 **[Browse Documentation](https://docs.visivo.io)** – Comprehensive guides and API reference
- 🐛 **[Report Issues](https://github.com/visivo-io/visivo/issues)** – Found a bug or have a feature request? Let us know!
- 💼 **[Follow on LinkedIn](https://www.linkedin.com/company/visivo-io)** – Stay updated with the latest news
- 📧 **[Email Us](mailto:info@visivo.io)** – For partnership or enterprise inquiries
## 🛠️ Contributing
We welcome contributions! Whether it's fixing bugs, adding features, or improving documentation, we'd love your help.
See [CONTRIBUTING.md](CONTRIBUTING.md) for development setup and guidelines.
## 📈 Telemetry
Visivo collects anonymous usage data to help improve the product. No personal information, queries, or sensitive data is collected.
To opt out: set `VISIVO_TELEMETRY_DISABLED=true` or add `telemetry_enabled: false` to your config. [Learn more →](TELEMETRY.md)
## 🏢 About
Built with ❤️ by [Visivo](https://visivo.io/) – a team that's experienced scaling analytics at companies like Intuit, Boeing, and Root Insurance.
We believe data tools should be as reliable as the rest of your tech stack. That's why we built Visivo to bring software engineering best practices to business intelligence.
---
<p align="center">
<sub>⭐ Star us on GitHub to support the project!</sub>
</p>
| text/markdown | Visivo People | null | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"Flask>=2.2.3",
"Jinja2>=3.1.2",
"PyYAML>=6.0",
"aiofiles>=24.1.0",
"assertpy>=1.1",
"click>=8.1.3",
"clickhouse-sqlalchemy>=0.3.0",
"deepmerge>=1.1.0",
"duckdb-engine>=0.14.0",
"flask-socketio>=5.5.1",
"gitpython>=3.1.32",
"halo>=0.0.31",
"httpx>=0.27.2",
"jsonschema-rs>=0.30.0",
"matplotlib>=3.7.1",
"networkx>=3.1",
"numpy<2.0.0,>=1.26.0",
"orjson>=3.10.0",
"polars<2.0.0,>=1.31.0",
"posthog<7.0.0,>=6.1.0",
"psycopg2-binary>=2.9.5",
"pyarrow>=20.0.0",
"pydantic>=2.9.0",
"pymysql>=1.1.0",
"python-dateutil>=2.9.0.post0",
"python-dotenv>=1.0.0",
"redshift-connector<3.0.0,>=2.1.8",
"requests>=2.28.2",
"ruamel-yaml>=0.18.6",
"snowflake-connector-python>=3.7.0",
"snowflake-sqlalchemy>=1.6.1",
"sql-formatter>=0.6.2",
"sqlalchemy>=2.0.8",
"sqlalchemy-bigquery>=1.12.0",
"sqlglot<28.0.0,>=27.0.0",
"tenacity>=9.0.0",
"termcolor>=2.4.0",
"tornado>=6.3",
"watchdog>=6.0.0"
] | [] | [] | [] | [
"Documentation, https://docs.visivo.io/"
] | poetry/2.3.2 CPython/3.12.3 Linux/6.11.0-1018-azure | 2026-02-20T12:16:32.924005 | visivo-1.0.79-py3-none-any.whl | 41,337,667 | 78/62/ff9c4d9f46be9d737efa22f775710207ef6226a7fcb64368f179f3966ffa/visivo-1.0.79-py3-none-any.whl | py3 | bdist_wheel | null | false | 30155740bf6bb42513a14d51d34322b1 | 6fe9d390d33d7a2735621de0d3b476422f3b32cd7464d97f558ce624b358fdde | 7862ff9c4d9f46be9d737efa22f775710207ef6226a7fcb64368f179f3966ffa | null | [] | 215 |
2.4 | agent-control-evaluator-galileo | 5.2.0 | Galileo Luna2 evaluator for agent-control | # Agent Control Evaluator - Galileo
Galileo Luna2 evaluator for agent-control.
## Installation
```bash
pip install agent-control-evaluator-galileo
```
Or via the convenience extra from the main evaluators package:
```bash
pip install agent-control-evaluators[galileo]
```
## Available Evaluators
| Name | Description |
|------|-------------|
| `galileo.luna2` | Galileo Luna-2 runtime protection |
## Configuration
Set the `GALILEO_API_KEY` environment variable:
```bash
export GALILEO_API_KEY=your-api-key
```
## Usage
Once installed, the evaluator is automatically discovered:
```python
from agent_control_evaluators import discover_evaluators, get_evaluator
discover_evaluators()
Luna2Evaluator = get_evaluator("galileo.luna2")
```
Or import directly:
```python
from agent_control_evaluator_galileo.luna2 import Luna2Evaluator, Luna2EvaluatorConfig
config = Luna2EvaluatorConfig(
stage_type="local",
metric="input_toxicity",
operator="gt",
target_value=0.5,
galileo_project="my-project",
)
evaluator = Luna2Evaluator(config)
result = await evaluator.evaluate("some text")
```
## Documentation
- [Galileo Protect Overview](https://v2docs.galileo.ai/concepts/protect/overview)
- [Galileo Python SDK Reference](https://v2docs.galileo.ai/sdk-api/python/reference/protect)
| text/markdown | Agent Control Team | null | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"agent-control-evaluators>=3.0.0",
"agent-control-models>=3.0.0",
"httpx>=0.24.0",
"pydantic>=2.12.4",
"mypy>=1.8.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:15:48.806199 | agent_control_evaluator_galileo-5.2.0.tar.gz | 13,047 | 01/25/b9e6210511221734eb36fa9be9dfadfca9a7d6eeebfa7f31485a50c91102/agent_control_evaluator_galileo-5.2.0.tar.gz | source | sdist | null | false | c1519e3c3edda9dae62ccde6630ab824 | 5001aee2c8a04cd2f9536c90a3add60393d5c5019b368983bb620f8bc3fab07e | 0125b9e6210511221734eb36fa9be9dfadfca9a7d6eeebfa7f31485a50c91102 | null | [] | 208 |
2.4 | agent-control-sdk | 5.2.0 | Python SDK for Agent Control - protect your AI agents with controls | # Agent Control - Python SDK
Unified Python SDK for Agent Control - providing agent protection, monitoring, and rule enforcement in one clean package.
## Installation
```bash
pip install agent-control-sdk
```
## Quick Start
### Simple Initialization
```python
import agent_control
# Initialize at the base of your agent
agent_control.init(
agent_name="My Customer Service Bot",
agent_id="550e8400-e29b-41d4-a716-446655440000"
)
# Use the control decorator
from agent_control import control
@control()
async def handle_message(message: str):
return f"Processed: {message}"
```
### With Full Metadata
```python
import agent_control
agent_control.init(
agent_name="Customer Service Bot",
agent_id="550e8400-e29b-41d4-a716-446655440000",
agent_description="Handles customer inquiries and support",
agent_version="2.1.0",
server_url="http://localhost:8000",
# Add any custom metadata
team="customer-success",
environment="production"
)
```
## Features
### 1. Simple Initialization
One line to set up your agent with full protection:
```python
agent_control.init(
agent_name="...",
agent_id="550e8400-e29b-41d4-a716-446655440000",
)
```
This automatically:
- Creates an Agent instance with your metadata
- Discovers and loads `rules.yaml`
- Registers with the Agent Control server
- Enables the `@control()` decorator
### 2. Decorator-Based Protection
Protect any function with server-defined controls:
```python
@control()
async def process(user_text: str):
return user_text
```
### 3. HTTP Client
Use the client directly for custom workflows:
```python
from agent_control import AgentControlClient
async with AgentControlClient() as client:
# Check server health
health = await client.health_check()
print(f"Server status: {health['status']}")
# Evaluate a step
result = await agent_control.evaluation.check_evaluation(
client,
agent_uuid="550e8400-e29b-41d4-a716-446655440000",
step={"type": "llm_inference", "input": "User input here"},
stage="pre"
)
```
### 4. Agent Metadata
Access your agent information:
```python
agent = agent_control.current_agent()
print(f"Agent: {agent.agent_name}")
print(f"ID: {agent.agent_id}")
print(f"Version: {agent.agent_version}")
```
## Complete Example
```python
import asyncio
import agent_control
from agent_control import control, ControlViolationError
# Initialize
agent_control.init(
agent_name="Customer Support Bot",
agent_id="550e8400-e29b-41d4-a716-446655440000",
agent_version="1.0.0"
)
# Protect with server-defined controls
@control()
async def handle_message(message: str) -> str:
# Automatically checked against server-side controls
return f"Processed: {message}"
@control()
async def generate_response(query: str) -> str:
# Output is automatically evaluated
return f"Response with SSN: 123-45-6789"
# Use the functions
async def main():
try:
# Safe input
result1 = await handle_message("Hello, I need help")
print(result1)
# Output with PII (may be blocked by controls)
result2 = await generate_response("Get user info")
print(result2)
except ControlViolationError as e:
print(f"Blocked by control '{e.control_name}': {e.message}")
asyncio.run(main())
```
## API Reference
### Initialization
#### `agent_control.init()`
```python
def init(
agent_name: str,
agent_id: str | UUID,
agent_description: Optional[str] = None,
agent_version: Optional[str] = None,
server_url: Optional[str] = None,
rules_file: Optional[str] = None,
**kwargs
) -> Agent:
```
Initialize Agent Control with your agent's information.
**Parameters:**
- `agent_name`: Human-readable name
- `agent_id`: UUID string (or UUID instance)
- `agent_description`: Optional description
- `agent_version`: Optional version string
- `server_url`: Optional server URL (defaults to `AGENT_CONTROL_URL` env var)
- `rules_file`: Optional rules file path (auto-discovered if not provided)
- `**kwargs`: Additional metadata
**Returns:** `Agent` instance
### Decorator
#### `@control()`
```python
def control(policy: Optional[str] = None):
```
Decorator to protect a function with server-defined controls.
**Parameters:**
- `policy`: Optional policy name to use (defaults to agent's assigned policy)
**Example:**
```python
@control()
async def my_func(text: str):
return text
# Or with specific policy
@control(policy="strict-policy")
async def sensitive_func(data: str):
return data
```
### Client
#### `AgentControlClient`
```python
class AgentControlClient:
def __init__(
self,
base_url: str = "http://localhost:8000",
api_key: Optional[str] = None,
timeout: float = 30.0
):
```
Async HTTP client for Agent Control server.
**Methods:**
- `health_check()` - Check server health
- Use with module functions like `agent_control.agents.*`, `agent_control.controls.*`, etc.
**Example:**
```python
from agent_control import AgentControlClient
import agent_control
async with AgentControlClient(base_url="http://server") as client:
health = await client.health_check()
agent = await agent_control.agents.init_agent(client, agent_data, tools)
```
### Models
If `agent-control-models` is installed, these classes are available:
- `Agent` - Agent metadata
- `ProtectionRequest` - Protection request model
- `ProtectionResult` - Protection result with helper methods
- `HealthResponse` - Health check response
## Configuration
### Environment Variables
- `AGENT_CONTROL_URL` - Server URL (default: `http://localhost:8000`)
- `AGENT_CONTROL_API_KEY` - API key for authentication (optional)
### Server-Defined Controls
Controls are defined on the server via the API or web dashboard, not in code. This keeps security policies centrally managed and allows updating controls without redeploying your application.
See the [Reference Guide](../../docs/REFERENCE.md) for complete control configuration documentation.
## Package Name
This package is named `agent-control-sdk` (with hyphen in PyPI) and imported as `agent_control` (with underscore in Python):
```bash
# Install (uses hyphen)
pip install agent-control-sdk
# Import (uses underscore)
import agent_control
```
Basic usage:
```python
import agent_control
from agent_control import control, ControlViolationError
agent_control.init(
agent_name="...",
agent_id="550e8400-e29b-41d4-a716-446655440000",
)
@control()
async def handle(message: str):
return message
```
## SDK Logging
The SDK uses Python's standard `logging` module with loggers under the `agent_control.*` namespace. Following library best practices, the SDK only adds a NullHandler - your application controls where logs go and how they're formatted.
### Configuring SDK Logs in Your Application
**Option 1: Standard Python logging configuration (recommended)**
```python
import logging
# Basic configuration
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(name)s: %(message)s'
)
# Set agent_control logs to DEBUG
logging.getLogger('agent_control').setLevel(logging.DEBUG)
```
**Option 2: SDK settings (control log categories)**
```python
from agent_control.settings import configure_settings
# Configure which categories of logs the SDK emits
configure_settings(
log_enabled=True, # Master switch for all SDK logging
log_span_start=True, # Emit span start logs
log_span_end=True, # Emit span end logs
log_control_eval=True, # Emit control evaluation logs
)
```
### Controlling What the SDK Logs
The SDK provides behavioral settings to control which categories of logs are emitted:
```python
from agent_control.settings import configure_settings
# Disable specific log categories
configure_settings(
log_control_eval=False, # Don't emit per-control evaluation logs
log_span_start=False, # Don't emit span start logs
)
```
These behavioral settings work independently of log levels:
- **Behavioral settings**: Control which categories of logs the SDK emits
- **Log levels**: Control which logs are displayed (via Python's logging module)
### Environment Variables
Configure SDK logging via environment variables:
```bash
# Behavioral settings (what to log)
export AGENT_CONTROL_LOG_ENABLED=true
export AGENT_CONTROL_LOG_SPAN_START=true
export AGENT_CONTROL_LOG_SPAN_END=true
export AGENT_CONTROL_LOG_CONTROL_EVAL=true
```
### Using SDK Loggers in Your Code
If you're extending the SDK or want consistent logging:
```python
from agent_control import get_logger
# Creates logger under agent_control namespace
logger = get_logger(__name__)
logger.info("Processing started")
logger.debug("Detailed debug info")
```
**Default Settings:**
- `log_enabled`: `true`
- All behavioral settings: `enabled`
## Development
```bash
# Install in development mode
cd sdks/python
uv sync
# Run tests
uv run pytest
# Lint
uv run ruff check .
```
## Examples
See the examples directory for complete examples:
- [Customer Support Agent](../../examples/customer_support_agent/) - Full example with multiple tools
- [LangChain SQL Agent](../../examples/langchain/) - SQL injection protection
- [Galileo Luna-2 Integration](../../examples/galileo/) - AI-powered toxicity detection
## Documentation
- [Reference Guide](../../docs/REFERENCE.md) - Complete API and configuration reference
- [Examples Overview](../../examples/README.md) - Working code examples and patterns
- [Architecture](./ARCHITECTURE.md) - SDK architecture and design patterns
## License
Apache License 2.0 - see LICENSE file for details.
| text/markdown | Agent Control Team | null | null | null | Apache-2.0 | agent, ai-safety, llm, protection, sdk, security | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"agent-control-evaluators>=3.0.0",
"docstring-parser>=0.15",
"google-re2>=1.1",
"httpx>=0.26.0",
"jsonschema>=4.0.0",
"pydantic-settings>=2.0.0",
"pydantic>=2.5.0",
"agent-control-evaluator-galileo>=3.0.0; extra == \"galileo\""
] | [] | [] | [] | [
"Homepage, https://github.com/yourusername/agent-control",
"Documentation, https://github.com/yourusername/agent-control#readme",
"Repository, https://github.com/yourusername/agent-control"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:15:44.601885 | agent_control_sdk-5.2.0.tar.gz | 99,182 | 23/0f/81e770c1d7f5ae5d9eb918bd9e8d8ce953e8482ad086253d001eb1d11bc6/agent_control_sdk-5.2.0.tar.gz | source | sdist | null | false | d6d3b8102b068a743936c07bb0ea9711 | be5168c313e316a2d150c5066ba7741b69725172616c28eae26923f73994c88c | 230f81e770c1d7f5ae5d9eb918bd9e8d8ce953e8482ad086253d001eb1d11bc6 | null | [] | 207 |
2.4 | agent-control-evaluators | 5.2.0 | Builtin evaluators for agent-control | # Agent Control Evaluators
Built-in evaluators for agent-control.
## Installation
```bash
pip install agent-control-evaluators
```
## Available Evaluators
| Name | Description |
|------|-------------|
| `regex` | Regular expression pattern matching |
| `list` | List-based value matching (allow/deny) |
| `json` | JSON validation (schema, required fields, types) |
| `sql` | SQL query validation |
## Usage
Evaluators are automatically discovered via Python entry points:
```python
from agent_control_evaluators import discover_evaluators, list_evaluators
# Load all available evaluators
discover_evaluators()
# See what's available
print(list_evaluators())
# {'regex': <class 'RegexEvaluator'>, 'list': ..., 'json': ..., 'sql': ...}
```
## External Evaluators
Additional evaluators are available via separate packages:
- `agent-control-evaluator-galileo` - Galileo Luna2 evaluator
```bash
# Direct install
pip install agent-control-evaluator-galileo
# Or via convenience extra
pip install agent-control-evaluators[galileo]
```
## Creating Custom Evaluators
See [AGENTS.md](../../AGENTS.md) for guidance on creating new evaluators.
| text/markdown | Agent Control Team | null | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"agent-control-models",
"google-re2>=1.1",
"jsonschema>=4.0.0",
"pydantic>=2.12.4",
"sqlglot[rs]>=20.0.0",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"agent-control-evaluator-galileo>=3.0.0; extra == \"galileo\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:15:40.190981 | agent_control_evaluators-5.2.0.tar.gz | 44,334 | 12/25/bcd44bb394c031faf110362be2c5d4ec120a139d3e76a51c223fbfd9e8b9/agent_control_evaluators-5.2.0.tar.gz | source | sdist | null | false | 222f834348d42f05256d131f523a7b49 | 90f12411dd3d321c161f7d9ba17f353b6c007ca3615a0af17aa0c7a65359ca4d | 1225bcd44bb394c031faf110362be2c5d4ec120a139d3e76a51c223fbfd9e8b9 | null | [] | 211 |
2.4 | pebble-tool | 5.0.27 | Tool for interacting with pebbles. | # Pebble Tool
The command-line tool for the Pebble SDK.
## About
The Pebble SDK now runs in Python 3. This includes:
1. The command-line tool to build and install apps and watchfaces (this repository).
2. The SDK code in PebbleOS (https://github.com/coredevices/PebbleOS/tree/main/sdk). This isn't fully working yet, so pebble-tool currently uses a patched version of the existing SDK core (version 4.3) that has been modified for Python 3.
3. pypkjs (https://github.com/coredevices/pypkjs), which allows PebbleKitJS code to run in the QEMU emulator.
Previously, the Pebble SDK was installed by downloading a tar file containing pebble-tool, the toolchain, and executables for PebbleOS QEMU and pebble-tool. Users had to decide where to extract the file, add the binaries to their PATH, and configure a virtualenv.
Now, pebble-tool is a standalone command-line tool that can be installed through pip/uv. The toolchain (arm-none-eabi) and QEMU binary are no longer bundled, but instead installed when `pebble sdk install` is run.
## Installation
Instructions are at https://developer.repebble.com/sdk
It's super simple: install a few platform-specific dependencies, then install pebble-tool via `uv`.
For developers of `pebble-tool`, use:
```sh
uv run pebble.py
```
## Testing
Test coverage can be run locally with:
```sh
uv run pytest
```
## Troubleshooting
If you run into issues, try uninstalling and re-installing. You can remove the latest SDK with
```shell
pebble sdk uninstall 4.4
```
You can also delete pebble-tool's entire data directory, located at ~/.pebble-sdk on Linux and ~/Library/Application Support/Pebble SDK on Mac.
| text/markdown | null | Core Devices LLC <griffin@griffinli.com> | null | null | null | null | [] | [] | null | null | <3.14,>3.9 | [] | [] | [] | [
"cobs>=1.2.0",
"colorama>=0.3.3",
"freetype-py>=2.5.1",
"httplib2>=0.19.0",
"libpebble2>=0.0.31",
"oauth2client>=4.1.3",
"packaging>=25.0",
"progressbar2>=2.7.3",
"pyasn1-modules>=0.0.6",
"pyasn1>=0.1.8",
"pypkjs>=2.0.7",
"pypng>=0.20220715.0",
"pyqrcode>=1.1",
"pyserial>=3.5",
"requests>=2.32.4",
"rsa>=4.9.1",
"six>=1.17.0",
"sourcemap>=0.2.0",
"websocket-client>=1.8.0",
"websockify>=0.13.0",
"wheel>=0.45.1"
] | [] | [] | [] | [
"Homepage, https://github.com/coredevices/pebble-tool"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:15:36.998886 | pebble_tool-5.0.27.tar.gz | 165,540 | 2d/da/f15ceb3fc14911a1782287a77655a2a37054719241a1e16227af557be33d/pebble_tool-5.0.27.tar.gz | source | sdist | null | false | 85d9896abcd16d57aa9c72799467674e | b0a32948d2ef4e47557e2054e3eba01070c2abe7546a576a452cc48bd808871a | 2ddaf15ceb3fc14911a1782287a77655a2a37054719241a1e16227af557be33d | MIT | [
"LICENSE"
] | 368 |
2.4 | agent-control-models | 5.2.0 | Shared data models for Agent Control server and SDK | # Agent Control Models
Shared data models for Agent Control server and SDK. This package contains all the Pydantic models used for API requests, responses, and data validation.
## Why Shared Models?
Having a separate models package provides several benefits:
1. **Single Source of Truth**: Models are defined once and used everywhere
2. **Type Safety**: Ensures server and SDK use identical data structures
3. **Versioning**: Models can be versioned independently
4. **Easier Maintenance**: Changes propagate automatically to both server and SDK
5. **Clear Contract**: API contract is explicitly defined
## Common Patterns in Popular Python Packages
This design follows patterns used by popular packages:
### 1. Shared Models (Our Approach)
- **Google APIs** (`google-api-core`): Separate proto/model definitions
- **Stripe** (`stripe-python`): Models package shared across components
- **PySpark**: Shared types and schemas
### 2. JSON/Pydantic Hybrid
- **FastAPI**: Pydantic models with JSON serialization
- **Anthropic SDK**: Pydantic models with `.to_dict()` and `.from_dict()`
- **OpenAI SDK**: Typed models with JSON compatibility
## Installation
This package is typically installed as a dependency:
```bash
# Server depends on it
cd server
uv add agent-control-models
# SDK depends on it
cd sdk
uv add agent-control-models
```
## Usage
### Agent Models
```python
from agent_control_models import Agent, Step
# Create an agent
agent = Agent(
agent_name="Customer Support Bot",
agent_id="550e8400-e29b-41d4-a716-446655440000",
agent_description="Handles customer inquiries",
agent_version="1.0.0"
)
# Create a step
step = Step(
type="llm_inference",
name="chat",
input="Hello, how can I help?",
output="I'm here to assist you!"
)
```
### Control Models
```python
from agent_control_models import ControlDefinition, ControlScope, ControlAction
# Define a control
control = ControlDefinition(
name="block-toxic-input",
description="Block toxic user messages",
enabled=True,
execution="server",
scope=ControlScope(
step_types=["llm_inference"],
stages=["pre"]
),
action=ControlAction(decision="deny")
)
```
### Evaluation Models
```python
from agent_control_models import EvaluationRequest, EvaluationResponse
# Create evaluation request
request = EvaluationRequest(
agent_uuid="agent-uuid-here",
step=Step(
type="llm_inference",
name="chat",
input="User message"
),
stage="pre"
)
# Evaluation response
response = EvaluationResponse(
allowed=True,
violated_controls=[]
)
```
## Models
### Core Models
#### BaseModel
Base class for all models with common utilities:
- `model_dump()`: Convert to Python dictionary (Pydantic v2)
- `model_dump_json()`: Convert to JSON string (Pydantic v2)
- `model_validate()`: Create from dictionary (Pydantic v2)
Configuration:
- Accepts both snake_case and camelCase fields
- Validates on assignment
- JSON-compatible serialization
#### Agent
Agent metadata and configuration.
**Fields:**
- `agent_name` (str): Human-readable agent name
- `agent_id` (UUID): Unique identifier
- `agent_description` (Optional[str]): Agent description
- `agent_version` (Optional[str]): Agent version
- `tools` (Optional[List[str]]): List of available tools
- `metadata` (Optional[Dict]): Additional metadata
#### Step
Represents a single step in agent execution.
**Fields:**
- `type` (str): Step type (e.g., "llm_inference", "tool")
- `name` (str): Step name
- `input` (Optional[Any]): Step input data
- `output` (Optional[Any]): Step output data
- `context` (Optional[Dict]): Additional context
#### ControlDefinition
Complete control specification.
**Fields:**
- `name` (str): Control name
- `description` (Optional[str]): Control description
- `enabled` (bool): Whether control is active
- `execution` (str): Execution mode ("server" or "local")
- `scope` (ControlScope): When to apply the control
- `selector` (ControlSelector): What data to evaluate
- `evaluator` (EvaluatorSpec): How to evaluate
- `action` (ControlAction): What to do on match
#### EvaluationRequest
Request for evaluating controls.
**Fields:**
- `agent_uuid` (str): Agent identifier
- `step` (Step): Step to evaluate
- `stage` (str): Evaluation stage ("pre" or "post")
#### EvaluationResponse
Response from control evaluation.
**Fields:**
- `allowed` (bool): Whether the step is allowed
- `violated_controls` (List[str]): Names of violated controls
- `evaluation_results` (Optional[List]): Detailed evaluation results
#### HealthResponse
Health check response.
**Fields:**
- `status` (str): Health status ("healthy")
- `version` (str): Server version
## Design Patterns
### 1. Pydantic v2
All models use Pydantic v2 for validation and serialization:
```python
from agent_control_models import Agent
# Create with validation
agent = Agent(
agent_name="My Agent",
agent_id="550e8400-e29b-41d4-a716-446655440000"
)
# Serialize to dict
agent_dict = agent.model_dump()
# Serialize to JSON
agent_json = agent.model_dump_json()
# Deserialize from dict
agent_copy = Agent.model_validate(agent_dict)
```
### 2. Type Safety
Models provide strong typing throughout the stack:
```python
from agent_control_models import Step, EvaluationRequest
# Type-safe step creation
step = Step(
type="llm_inference",
name="chat",
input="Hello"
)
# Type-safe evaluation request
request = EvaluationRequest(
agent_uuid="uuid-here",
step=step,
stage="pre"
)
```
### 3. Extensibility
Models support additional metadata for extensibility:
```python
from agent_control_models import Agent
# Add custom metadata
agent = Agent(
agent_name="Support Bot",
agent_id="550e8400-e29b-41d4-a716-446655440000",
metadata={
"team": "customer-success",
"environment": "production",
"custom_field": "value"
}
)
```
## Development
### Adding New Models
1. Create a new file in `src/agent_control_models/`
2. Define models extending `BaseModel`
3. Export in `__init__.py`
4. Update both server and SDK to use the new models
Example:
```python
# src/agent_control_models/auth.py
from .base import BaseModel
class AuthRequest(BaseModel):
api_key: str
# src/agent_control_models/__init__.py
from .auth import AuthRequest
__all__ = [..., "AuthRequest"]
```
### Testing
```bash
cd models
uv run pytest
```
## Best Practices
1. **Always extend BaseModel**: Get free JSON/dict conversion
2. **Use Field for validation**: Add constraints and descriptions
3. **Keep models simple**: No business logic, just data
4. **Version carefully**: Model changes affect both server and SDK
5. **Document fields**: Use Field's `description` parameter
6. **Use Optional appropriately**: Mark optional fields clearly
| text/markdown | Agent Control Team | null | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"jsonschema>=4.0.0",
"pydantic>=2.12.4"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:15:35.429316 | agent_control_models-5.2.0.tar.gz | 19,229 | 4a/25/14f4919fe7dab78fa4753ad22045b59e64d38730a6c6ebea13b554ea9d35/agent_control_models-5.2.0.tar.gz | source | sdist | null | false | 27d36426e837f9bde6ed2c019d8d94c1 | e7dfc0ff9785ecf31f91f69b9ca17ef49032a30aef7eb68351d73f46136a0b77 | 4a2514f4919fe7dab78fa4753ad22045b59e64d38730a6c6ebea13b554ea9d35 | null | [] | 214 |
2.4 | merlya | 0.8.3 | Merlya - AI-powered infrastructure assistant | <p align="center">
<img src="https://merlya.m-kis.fr/assets/logo.png" alt="Merlya Logo" width="120">
</p>
<h1 align="center">Merlya</h1>
<p align="center">
<strong>AI-powered infrastructure assistant for DevOps & SysAdmins</strong>
</p>
<p align="center">
<a href="https://pypi.org/project/merlya/"><img src="https://img.shields.io/pypi/v/merlya?color=%2340C4E0" alt="PyPI"></a>
<a href="https://pypi.org/project/merlya/"><img src="https://img.shields.io/pypi/pyversions/merlya" alt="Python"></a>
<a href="https://pypi.org/project/merlya/"><img src="https://img.shields.io/pypi/dm/merlya" alt="Downloads"></a>
<a href="LICENSE"><img src="https://img.shields.io/badge/license-MIT%20%2B%20Commons%20Clause-blue" alt="License"></a>
<a href="https://merlya.m-kis.fr/"><img src="https://img.shields.io/badge/docs-merlya.m--kis.fr-40C4E0" alt="Documentation"></a>
</p>
<p align="center">
<img src="https://img.shields.io/badge/code%20style-ruff-000000" alt="Ruff">
<img src="https://img.shields.io/badge/type%20checked-mypy-blue" alt="mypy">
</p>
<p align="center">
<a href="https://github.com/m-kis/merlya/blob/main/README_EN.md">Read in English</a>
</p>
---
## Aperçu
Merlya est un assistant CLI autonome qui comprend le contexte de votre infrastructure, planifie des actions intelligentes et les exécute en toute sécurité. Il combine un **SmartExtractor** (LLM + regex hybride) pour extraire les hosts des requêtes en langage naturel, un pool SSH sécurisé, et une gestion d'inventaire simplifiée.
### Fonctionnalités clés
- **Commandes en langage naturel** pour diagnostiquer et remédier vos environnements
- **Architecture DIAGNOSTIC/CHANGE** : routage intelligent entre investigation read-only et mutations contrôlées
- **Pool SSH async** avec MFA/2FA, jump hosts et SFTP
- **Inventaire `/hosts`** avec import intelligent (SSH config, /etc/hosts, Ansible, TOML, CSV)
- **Modèles brain/fast** : brain pour le raisonnement complexe, fast pour le routing rapide
- **Pipelines IaC** : Ansible, Terraform, Kubernetes, Bash avec HITL obligatoire
- **Élévation explicite** : configuration sudo/doas/su par host (pas d'auto-détection)
- **Sécurité by design** : secrets dans le keyring, validation Pydantic, détection de boucles
- **i18n** : français et anglais
- **Intégration MCP** pour consommer des tools externes (GitHub, Slack, custom) via `/mcp`
### Architecture
```
┌─────────────────────────────────────────────────────────────────────────────┐
│ USER INPUT │
│ "Check disk on web-01 via bastion" │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ SMART EXTRACTOR │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Fast Model │───▶│ Regex │───▶│ Hosts │ │
│ │ (routing) │ │ Patterns │ │ Inventory │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
│ │ │
│ Output: hosts=[web-01], via=bastion, context injected │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ CENTER CLASSIFIER │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ Pattern Matching + Fast LLM fallback → DIAGNOSTIC or CHANGE │ │
│ └─────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│ │
▼ ▼
┌──────────────────────────────────┐ ┌──────────────────────────────────────┐
│ DIAGNOSTIC CENTER │ │ CHANGE CENTER │
│ ┌────────────────────────────┐ │ │ ┌────────────────────────────────┐ │
│ │ Read-Only Investigation │ │ │ │ Controlled Mutations via │ │
│ │ • SSH read commands │ │ │ │ Pipelines + HITL │ │
│ │ • kubectl get/describe │ │ │ │ • Ansible (ad-hoc/inline/repo) │ │
│ │ • Log analysis │ │ │ │ • Terraform │ │
│ │ • System diagnostics │ │ │ │ • Kubernetes apply │ │
│ │ • Evidence collection │ │ │ │ • Bash (fallback) │ │
│ └────────────────────────────┘ │ │ └────────────────────────────────┘ │
│ BLOCKED: rm, kill, restart... │ │ Pipeline: Plan→Diff→HITL→Apply │
└──────────────────────────────────┘ └──────────────────────────────────────┘
│ │
└───────────┬─────────────┘
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ SECURITY LAYER │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Keyring │ │ Elevation │ │ Loop │ │
│ │ Secrets │ │ Explicit │ │ Detection │ │
│ │ @secret-ref │ │ (per-host) │ │ (5+ repeat) │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ SSH POOL │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Connection │ │ Jump Host │ │ MFA │ │
│ │ Reuse │ │ Support │ │ Support │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ PERSISTENCE │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Hosts │ │ Sessions │ │ Audit │ │ Raw Logs │ │ Messages │ │
│ │ Inventory│ │ Context │ │ Logs │ │ (TTL) │ │ History │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ SQLite + Keyring │
└─────────────────────────────────────────────────────────────────────────────┘
```
## Installation (utilisateurs finaux)
```bash
pip install merlya
merlya
```
### Installation Docker
```bash
# Copier et configurer les variables d'environnement
cp .env.example .env
# Éditer .env avec vos clés API
# Lancer le conteneur
docker compose up -d
# Mode développement (code source monté)
docker compose --profile dev up -d
```
**Configuration SSH pour Docker :**
Le conteneur monte votre répertoire SSH local. Par défaut, il utilise `$HOME/.ssh`.
Dans les environnements CI/CD où `$HOME` peut ne pas être défini, vous devez explicitement définir `SSH_DIR` :
```bash
# Via variable d'environnement
SSH_DIR=/root/.ssh docker compose up -d
# Ou dans votre fichier .env
SSH_DIR=/home/jenkins/.ssh
```
**Permissions requises :**
- Répertoire SSH : `700` (rwx pour propriétaire uniquement)
- Clés privées : `600` (rw pour propriétaire uniquement)
Voir `.env.example` pour la documentation complète des variables.
### Premier démarrage
1. Sélection de la langue (fr/en)
2. Configuration du provider LLM (clé stockée dans le keyring)
3. Scan local et import d’hôtes (SSH config, /etc/hosts, inventaires Ansible)
4. Health checks (RAM, disque, LLM, SSH, keyring, web search)
## Exemples rapides
```bash
> Check disk usage on web-prod-01
> /hosts list
> /ssh exec db-01 "uptime"
> /model router show
> /variable set region eu-west-1
> /mcp list
```
> **Note** : Les noms d'hôtes s'écrivent **sans préfixe `@`**. Le préfixe `@` est réservé aux références de secrets (ex: `@db-password`).
## Sécurité
### Secrets et références @secret
Les secrets (mots de passe, tokens, clés API) sont stockés dans le keyring système (macOS Keychain, Linux Secret Service) et référencés par `@nom-secret` dans les commandes :
```bash
> Connect to MongoDB with @db-password
# Merlya résout @db-password depuis le keyring avant exécution
# Les logs affichent @db-password, jamais la vraie valeur
```
### Élévation de privilèges
Merlya détecte automatiquement les capacités d'élévation (sudo, doas, su) et gère les mots de passe de manière sécurisée :
1. **sudo NOPASSWD** - Meilleur choix, pas de mot de passe
2. **doas** - Souvent sans mot de passe sur BSD
3. **sudo avec mot de passe** - Fallback standard
4. **su** - Dernier recours, nécessite le mot de passe root
Les mots de passe d'élévation sont stockés dans le keyring et référencés par `@elevation:hostname:password`.
### Détection de boucles
L'agent détecte les patterns répétitifs (même outil appelé 3+ fois, alternance A-B-A-B) et injecte un message pour rediriger vers une approche différente.
## Configuration
- Fichier utilisateur : `~/.merlya/config.yaml` (langue, modèle, timeouts SSH, UI).
- Clés API : stockées dans le keyring. Fallback en mémoire avec avertissement.
- Variables d'environnement utiles :
| Variable | Description |
|----------|-------------|
| `OPENROUTER_API_KEY` | Clé OpenRouter (provider par défaut) |
| `ANTHROPIC_API_KEY` | Clé Anthropic |
| `OPENAI_API_KEY` | Clé OpenAI |
| `MISTRAL_API_KEY` | Clé Mistral |
| `GROQ_API_KEY` | Clé Groq |
| `MERLYA_ROUTER_FALLBACK` | Modèle de fallback LLM |
| `MERLYA_ROUTER_MODEL` | Override du modèle de router local |
## Installation pour contributeurs
```bash
git clone https://github.com/m-kis/merlya.git
cd merlya
python -m venv .venv
source .venv/bin/activate # ou .venv\\Scripts\\activate sous Windows
pip install -e ".[dev]" # Dépendances de dev
merlya --version
pytest tests/ -v
```
## Qualité et scripts
| Vérification | Commande |
|--------------|----------|
| Lint | `ruff check merlya/` |
| Format (check) | `ruff format --check merlya/` |
| Type check | `mypy merlya/` |
| Tests + coverage | `pytest tests/ --cov=merlya --cov-report=term-missing` |
| Sécurité (code) | `bandit -r merlya/ -c pyproject.toml` |
| Sécurité (dépendances) | `pip-audit -r <(pip freeze)` |
Principes clés : DRY/KISS/YAGNI, SOLID, SoC, LoD, pas de fichiers > ~600 lignes, couverture ≥ 80%, commits conventionnels (cf. [CONTRIBUTING.md](CONTRIBUTING.md)).
## CI/CD
- `.github/workflows/ci.yml` : lint + format check + mypy + tests + sécurité (Bandit + pip-audit) sur runners GitHub pour chaque PR/push.
- `.github/workflows/release.yml` : build + release GitHub + publication PyPI via trusted publishing, déclenché sur tag `v*` ou `workflow_dispatch` par un mainteneur (pas de secrets sur les PR externes).
- Branche `main` protégée : merge via PR, CI requis, ≥1 review, squash merge recommandé.
## Documentation
📚 **Documentation complète** : [https://merlya.m-kis.fr/](https://merlya.m-kis.fr/)
Fichiers locaux :
- [docs/architecture.md](docs/architecture.md) : architecture et décisions
- [docs/commands.md](docs/commands.md) : commandes slash
- [docs/configuration.md](docs/configuration.md) : configuration complète
- [docs/tools.md](docs/tools.md) : tools et agents
- [docs/ssh.md](docs/ssh.md) : SSH, bastions, MFA
- [docs/extending.md](docs/extending.md) : extensions/agents
## Contribuer
- Lisez [CONTRIBUTING.md](CONTRIBUTING.md) pour les conventions (commits, branches, limites de taille de fichiers/fonctions).
- Respectez le [CODE_OF_CONDUCT.md](CODE_OF_CONDUCT.md).
- Les templates d’issues et de PR sont disponibles dans `.github/`.
## Sécurité
Consultez [SECURITY.md](SECURITY.md). Ne publiez pas de vulnérabilités en issue publique : écrivez à `security@merlya.fr`.
## Licence
[MIT avec Commons Clause](LICENSE). La Commons Clause interdit la vente du logiciel comme service hébergé tout en autorisant l’usage, la modification et la redistribution.
---
<p align="center">
Made by <a href="https://github.com/m-kis">M-KIS</a>
</p>
| text/markdown | null | Cedric <infra@merlya.fr> | null | null | MIT | ai, automation, devops, infrastructure, ssh | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: System :: Systems Administration"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"aiosqlite>=0.21",
"anthropic>=0.75",
"asyncssh>=2.21",
"ddgs>=9.9",
"httpx>=0.28",
"jinja2>=3.1",
"keyring>=25.5",
"keyrings-alt>=5.0; sys_platform == \"linux\"",
"logfire[system-metrics]>=4.0",
"loguru>=0.7",
"mcp>=1.23.0",
"numpy>=1.26",
"openai>=1.50",
"packaging>=24.0",
"prompt-toolkit>=3.0",
"psutil>=6.1",
"pydantic-ai>=1.26",
"pydantic>=2.10",
"pyyaml>=6.0",
"rich>=14.0",
"secretstorage>=3.3; sys_platform == \"linux\"",
"urllib3>=2.6.0",
"mypy>=1.13; extra == \"dev\"",
"pytest-asyncio>=0.24; extra == \"dev\"",
"pytest-cov>=6.0; extra == \"dev\"",
"pytest>=8.3; extra == \"dev\"",
"ruff>=0.8; extra == \"dev\"",
"types-pyyaml>=6.0; extra == \"dev\"",
"mkdocs-material>=9.5.0; extra == \"docs\"",
"mkdocs-minify-plugin>=0.8.0; extra == \"docs\"",
"mkdocs-static-i18n>=1.2.0; extra == \"docs\"",
"mkdocs>=1.6.0; extra == \"docs\"",
"pymdown-extensions>=10.0; extra == \"docs\""
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:15:16.659347 | merlya-0.8.3.tar.gz | 1,051,443 | c5/fd/7dfc8d552e491f780a39fda26993f69e1d7f69216df8cc9573b897b29e24/merlya-0.8.3.tar.gz | source | sdist | null | false | e4c1ee972f6e1780d742eedb65157c0c | 7268cc5f7e718d9017b125789d7ad3525362442d50cb3bd3ce412f83a6ec754a | c5fd7dfc8d552e491f780a39fda26993f69e1d7f69216df8cc9573b897b29e24 | null | [
"LICENSE"
] | 195 |
2.4 | molecule-resolver | 0.5.0 | A package to use several web services to find molecule structures, synonyms and CAS. | <p align="center">
<img src="MoleculeResolver.png" alt="MoleculeResolver" width="700">
</p>
# MoleculeResolver
The **moleculeresolver** was born out of the need to annotate large datasets with accurate structural information fast and to crosscheck whether given metadata (name, SMILES) agrees with each other. It also allows to efficiently compare whether structures are available in two large datasets.
In short it's a Python module that allows you to retrieve molecular structures from multiple chemical databases, perform crosschecks to ensure data reliability, and standardize the best representation of molecules. It also provides functions for comparing molecules and sets of molecules based on specific configurations. This makes it a useful tool for researchers, chemists, or anyone working in computational chemistry / cheminformatics who needs to ensure they are working with the best available data for a molecule.
## Installation
The package is available on [pypi](https://pypi.org/project/molecule-resolver/):
```sh
pip install molecule-resolver
```
While the source code is available here: [https://github.com/MoleculeResolver/molecule-resolver](https://github.com/MoleculeResolver/molecule-resolver)
## Features
- **🔍 Retrieve Molecular Structures**: Fetch molecular structures from different chemical databases, including PubChem, Comptox, Chemo, and others.
- **🆔 Support for Different Identifier Types**: Retrieve molecular structures using a variety of identifier types, including CAS numbers, SMILES, InChI, InChIkey and common names.
- **✅ Cross-check Capabilities**: Use data from multiple sources to verify molecular structures and identify the best representation.
- **🔄 Molecule Comparison**: Compare molecules or sets of molecules based on their structure, properties, and specified ⚙️ configurations.
- **⚙️ Standardization**: Standardize molecular structures, including handling isomers, tautomers, and isotopes.
- **💾 Caching Mechanism**: Use local caching to store molecules and reduce the number of repeated requests to external services, improving performance and reducing latency.
## Services used
At this moment, the following services are used to get the best structure for a given identifier. In the future, this list might be reviewed to improve perfomance, adding new services or removing some.
In case you want to add an additional service, open an issue or a pull request.
The MoleculeResolver does not offer all options/configurations for each service available with the specific related repos as it focusses on getting the structure based on the identifiers and doing so as accurate as possible while still being fast using parallelization under the hood.
| Service | Name | CAS | Formula | SMILES | InChI | InChIKey | CID | Batch search | Repos |
|-------------------------------------------------------------------------|------|-----|---------|--------|-------|----------|-----|--------------------|------------------------------------------------------------------------------|
| [cas_registry](https://commonchemistry.cas.org/) | ✅ | ✅ | ❌ | ✅ | ✅ | ❌ | ❌ | ❌ | |
| [chebi](https://www.ebi.ac.uk/chebi/) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | |
| [chemeo](https://www.chemeo.com/) | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ | |
| [cir](https://cactus.nci.nih.gov/chemical/structure) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | - [CIRpy](https://github.com/mcs07/CIRpy "wrapper for the CIR. FYI, CIR uses OPSIN under the hood, unless specified otherwise.") |
| [comptox](https://comptox.epa.gov/dashboard) | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ | ✅ | |
| [cts](https://cts.fiehnlab.ucdavis.edu/) | (✅) | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ | |
| [nist](https://webbook.nist.gov/chemistry/) | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | - [NistChemPy](https://github.com/IvanChernyshov/NistChemPy "unofficial wrapper for search and data extraction of the NIST Webbook.") |
| [opsin](https://opsin.ch.cam.ac.uk/) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | - [py2opsin](https://github.com/JacksonBurns/py2opsin "lightweight OPSIN wrapper only depending on having Java installed.") <br> - [pyopsin](https://github.com/Dingyun-Huang/pyopsin "lightweight OPSIN wrapper depending on having Java installed + additional dependencies.") |
| [pubchem](https://pubchem.ncbi.nlm.nih.gov/)</li></ul> | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | - [PubChemPy](https://github.com/mcs07/PubChemPy "wrapper for the pubchem PUG API") |
| [srs](https://cdxapps.epa.gov/oms-substance-registry-services/search) | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | |
ChemSpider was not used as it is already included in CIR [[1]](https://matt-swain.com/blog/2012-03-20-cirpy-python-nci-chemical-identifier-resolver) [[2]](https://cactus.nci.nih.gov/blog/?p=1456) [[3]](https://github.com/mcs07/ChemSpiPy). ChemIDplus and the Drug Information Portal were retired in 2022 [[4]](https://www.nlm.nih.gov/pubs/techbull/ja22/ja22_pubchem.html).
## 🚀 Usage
### Initialization
To use **Molecule Resolver**, first import and initialize the `MoleculeResolver` class. it is supposed to be used as a context manager:
```python
from moleculeresolver import MoleculeResolver
with MoleculeResolver(available_service_API_keys={"chemeo": "YOUR_API_KEY"}) as mr:
...
```
### Retrieve and Compare Molecules by Name and CAS
Retrieve a molecule using both its common name and CAS number, then compare the two to ensure they represent the same structure:
```python
from rdkit import Chem
from moleculeresolver import MoleculeResolver
with MoleculeResolver(available_service_API_keys={"chemeo": "YOUR_API_KEY"}) as mr:
molecule_name = mr.find_single_molecule(["aspirin"], ["name"])
molecule_cas = mr.find_single_molecule(["50-78-2"], ["cas"])
are_same = mr.are_equal(Chem.MolFromSmiles(molecule_name.SMILES),
Chem.MolFromSmiles(molecule_cas.SMILES))
print(f"Are the molecules the same? {are_same}")
```
### Parallelized Molecule Retrieval and Saving to JSON
Use the parallelized version to retrieve multiple molecules. If a large number of molecules is searched, moleculeresolver will try to use batch download capabilities whenever the database supports this.
```python
import json
from moleculeresolver import MoleculeResolver
molecule_names = ["aspirin", "propanol", "ibuprofen", "non-exixtent-name"]
not_found_molecules = []
molecules_dicts = {}
with MoleculeResolver(available_service_API_keys={"chemeo": "YOUR_API_KEY"}) as mr:
molecules = mr.find_multiple_molecules_parallelized(molecule_names, [["name"]] * len(molecule_names))
for name, molecule in zip(molecule_names, molecules):
if molecule:
molecules_dicts[name] = molecule.to_dict(found_molecules='remove')
else:
not_found_molecules.append(name)
with open("molecules.json", "w") as json_file:
json.dump(molecules_dicts, json_file, indent=4)
print(f"Molecules not found: {not_found_molecules}")
```
## ⚙️ Configuration
The `MoleculeResolver` class allows users to configure various options like:
- **API Keys**: Set API keys for accessing different molecular databases. Currently only chemeo needs one.
- **Standardization Options**: Choose how to handle molecular standardization (e.g., normalizing functional groups, disconnecting metals, handling isomers, etc.).
- **Differentiation Settings**: Options for distinguishing between isomers, tautomers, and isotopes.
## ⚠️ Warning
**Inchi** is included in the set of valid identifiers for various [services](#services-used). You should be aware that using Inchi to get SMILES using RDKit is not the most robust approach. You can read more about it [here](https://github.com/rdkit/rdkit/issues/542).
## 🤝 Contributing
Contributions are welcome! If you have suggestions for improving the Molecule Resolver or want to add new features, feel free to submit an issue or a pull request on GitHub.
## 📚 Citing
If you use MoleculeResolver in your research, please cite as follows:
**Müller, S.**
*How to crack a SMILES: automatic crosschecked chemical structure resolution across multiple services using MoleculeResolver*
**Journal of Cheminformatics**, 17:117 (2025).
DOI: [10.1186/s13321-025-01064-7](https://doi.org/10.1186/s13321-025-01064-7)
```bibtex
@article{Muller2025MoleculeResolver,
author = {Müller, Simon},
title = {How to crack a SMILES: automatic crosschecked chemical structure resolution across multiple services using MoleculeResolver},
journal = {Journal of Cheminformatics},
year = {2025},
volume = {17},
page = {117},
doi = {10.1186/s13321-025-01064-7},
url = {https://doi.org/10.1186/s13321-025-01064-7}
}
| text/markdown | Simon Muller | simon.mueller@tuhh.de | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"openpyxl<4.0.0,>=3.1.2",
"prompt-toolkit<4.0.0,>=3.0.39",
"rdkit>=2023.3.3",
"regex<2024.0.0,>=2023.10.3",
"requests<3.0.0,>=2.31.0",
"tqdm<5.0.0,>=4.66.3",
"urllib3<3.0.0,>=2.0.6",
"xmltodict<0.14.0,>=0.13.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:14:51.761745 | molecule_resolver-0.5.0.tar.gz | 13,044,997 | 54/90/d10698c9009429e6241f2d18ee7daa4230a96dd7f0869c75aaa63cb8af85/molecule_resolver-0.5.0.tar.gz | source | sdist | null | false | c128398a42180a2b6d28654325764deb | 3af38ff2095ec537a12c370feb757e61404870cd79c6b702db8de0a679360d63 | 5490d10698c9009429e6241f2d18ee7daa4230a96dd7f0869c75aaa63cb8af85 | null | [
"LICENSE.txt"
] | 207 |
2.4 | seven2one-questra-data | 0.9.0rc1 | Python client for Questra Data with high-level API, type-safe dataclasses, and optional pandas integration for user-defined data models and timeseries management | # Seven2one Questra Data
Python Client für die Questra Data Platform – Verwaltung von benutzerdefinierten Datenmodellen, Zeitreihen und Berechtigungen.
## Features
- **Data Client**: Vereinfachte Schnittstelle für häufige Operationen
- **Typsichere Dataclasses**: IDE-Unterstützung mit Type Hints
- **Zeitreihen-Verwaltung**: Effiziente Verwaltung von TimeSeries-Daten
- **CRUD-Operationen**: Für benutzerdefinierte Datenmodelle
- **Optional: pandas Integration**: DataFrames für Analyse-Workflows
## Installation
```bash
# Basis-Installation
pip install seven2one-questra-data
# Mit pandas-Unterstützung (empfohlen für Data Science)
pip install seven2one-questra-data[pandas]
```
Siehe [INSTALLATION.md](INSTALLATION.md) für detaillierte Installations-Anleitungen.
## Schnellstart
```python
from seven2one.questra.authentication import QuestraAuthentication
from seven2one.questra.data import QuestraData
from datetime import datetime
# Authentifizierung
auth = QuestraAuthentication(
url="https://auth.example.com",
username="user",
password="pass"
)
# Client initialisieren
client = QuestraData(
graphql_url="https://api.example.com/data-service/graphql",
auth_client=auth
)
# Inventory Items auflisten
items = client.list_items(
inventory_name="Devices",
namespace_name="IoT",
properties=["_id", "name", "status"],
first=10
)
# Zeitreihen-Werte laden
result = client.list_timeseries_values(
inventory_name="Sensors",
namespace_name="IoT",
timeseries_properties="measurements",
from_time=datetime(2025, 1, 1),
to_time=datetime(2025, 1, 31)
)
# Optional: Als pandas DataFrame
df = result.to_df()
```
### Inventory erstellen
```python
from seven2one.questra.data import StringProperty, IntProperty
properties = [
StringProperty(property_name="name", max_length=200, is_required=True),
IntProperty(property_name="age")
]
client.create_inventory(name="Users", properties=properties)
```
### pandas Integration
```python
# Alle Result-Objekte haben .to_df() Methode
df = result.to_df()
df_items = items.to_df()
```
## Weitere Informationen
- **Vollständige Dokumentation:** <https://pydocs.[questra-host.domain]>
- **Support:** <support@seven2one.de>
## Requirements
- Python >= 3.10
- gql >= 3.5.0
- requests >= 2.31.0
- questra-authentication >= 0.1.4
### Optional
- pandas >= 2.0.0 (für DataFrame-Unterstützung)
## License
Proprietary - Seven2one Informationssysteme GmbH
| text/markdown | null | Jürgen Talasch <juergen.talasch@seven2one.de> | null | null | Proprietary | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Database",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"gql[requests]<4.0.0,>=3.5.0",
"pydantic<3.0.0,>=2.0.0",
"requests-toolbelt<2.0.0,>=1.0.0",
"requests<3.0.0,>=2.31.0",
"seven2one-questra-authentication>=1.0.0",
"pandas>=2.0.0; extra == \"pandas\""
] | [] | [] | [] | [] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T12:14:37.390149 | seven2one_questra_data-0.9.0rc1-py3-none-any.whl | 66,080 | 96/74/86630978ec2f8328c997993ea280e2f790c8554692aa74dd1d9bd77b8514/seven2one_questra_data-0.9.0rc1-py3-none-any.whl | py3 | bdist_wheel | null | false | 1047b43c183bb96b16aae2a2422464c7 | 3ce9dd7465f0117a50c7346480c7d7c430a875057a4c4078638517fdd0b76a85 | 967486630978ec2f8328c997993ea280e2f790c8554692aa74dd1d9bd77b8514 | null | [] | 187 |
2.4 | seven2one-questra | 0.8.0rc1 | Unified Python Client für Questra Platform - Umbrella Package für Authentication und Data API | # Questra Python Client
**Der offizielle Python Client für die Questra Platform** – vereinfachter Zugriff auf benutzerdefinierte Datenmodelle, Zeitreihen und Automatisierungen.
## Motivation
Die Questra Platform bietet flexible GraphQL- und REST-APIs für Dynamic Objects, TimeSeries und Automatisierungen. Dieses Package bündelt alle spezialisierten Client-Libraries, damit Sie mit einer einzigen Installation sofort produktiv arbeiten können:
- **Schnelle Integration**: Eine Installation, alle APIs verfügbar
- **Typsichere Entwicklung**: Vollständige Type Hints für IDE-Unterstützung
- **Data Client**: Intuitive Schnittstellen für häufige Operationen
- **Produktionsbereit**: OAuth2-Authentifizierung, Error Handling, Logging
## Installation
```bash
# Standard-Installation
pip install seven2one-questra
# Mit pandas-Unterstützung (empfohlen für Data Science)
pip install seven2one-questra[pandas]
```
Dies installiert automatisch alle Questra-Client-Libraries:
- **[seven2one-questra-authentication](https://pypi.org/project/seven2one-questra-authentication/)** – OAuth2-Authentifizierung
- **[seven2one-questra-data](https://pypi.org/project/seven2one-questra-data/)** – Datenmodell & Datenzugiffe
- **[seven2one-questra-automation](https://pypi.org/project/seven2one-questra-automation/)** – Workflow-Automatisierung
## Schnellstart
### 1. Authentifizierung einrichten
```python
from seven2one.questra.authentication import QuestraAuthentication
auth = QuestraAuthentication(
url="https://auth.ihr-questra-server.de",
username="ServiceUser",
password="IhrPasswort"
)
```
### 2. Daten verwalten
```python
from seven2one.questra.data import QuestraData
# Client initialisieren
client = QuestraData(
graphql_url="https://ihr-questra-server/data/graphql/",
auth_client=auth
)
# Inventory Items auflisten
items = client.list_items(
inventory_name="Stromzaehler",
namespace_name="Energie",
properties=["_id", "standort", "seriennummer"]
)
# Neues Item erstellen
new_items = client.create_items(
inventory_name="Stromzaehler",
namespace_name="Energie",
items=[{"standort": "Gebäude A", "seriennummer": "SN-12345"}]
)
```
### 3. Zeitreihen-Daten abrufen
```python
from datetime import datetime
# TimeSeries-Werte laden
result = client.list_timeseries_values(
inventory_name="Stromzaehler",
namespace_name="Energie",
timeseries_properties="messwerte_Verbrauch",
from_time=datetime(2024, 1, 1),
to_time=datetime(2024, 1, 31)
)
# Optional: Als pandas DataFrame konvertieren
df = result.to_df() # Requires pandas installation
```
### 4. Automatisierungen verwalten
```python
from seven2one.questra.automation import QuestraAutomation
# Automation Client initialisieren
automation_client = QuestraAutomation(
graphql_url="https://api.ihr-questra-server.de/automation/graphql",
auth_client=auth
)
# Workflows auflisten
workflows = automation_client.list_workflows()
```
## Enthaltene Packages
Dieses Umbrella-Package installiert automatisch:
### [seven2one-questra-authentication](https://pypi.org/project/seven2one-questra-authentication/)
OAuth2-Authentifizierung für alle Questra-APIs.
```python
from seven2one.questra.authentication import QuestraAuthentication
auth = QuestraAuthentication(url="...", username="...", password="...")
```
### [seven2one-questra-data](https://pypi.org/project/seven2one-questra-data/)
Data Client für Dynamic Objects und TimeSeries. Unterstützt GraphQL und REST, optionale pandas-Integration.
**Features:**
- CRUD-Operationen für benutzerdefinierte Inventare
- Zeitreihen-Verwaltung mit effizientem Batch-Loading
- Typsichere Dataclasses für Inventory-Schemas
- Optional: pandas DataFrames für Analyse-Workflows
```python
from seven2one.questra.data import QuestraData
client = QuestraData(graphql_url="...", auth_client=auth)
items = client.list_items(
inventory_name="Sensoren",
namespace_name="IoT",
properties=["_id", "name"]
)
```
Siehe [Dokumentation auf PyPI](https://pypi.org/project/seven2one-questra-data/) für Details zu GraphQL/REST-Queries, Batch-Operationen und pandas-Integration.
### [seven2one-questra-automation](https://pypi.org/project/seven2one-questra-automation/)
GraphQL-Client für Workflow-Automatisierung und Event-Driven Architectures.
**Features:**
- Workflow-Management (erstellen, starten, überwachen)
- Event-basierte Trigger
- Task-Orchestrierung
```python
from seven2one.questra.automation import QuestraAutomation
automation = QuestraAutomation(graphql_url="...", auth_client=auth)
workflows = automation.list_workflows()
```
Siehe [Dokumentation auf PyPI](https://pypi.org/project/seven2one-questra-automation/) für Workflow-APIs und Event-Handling.
## Weitere Ressourcen
- **Vollständige Dokumentation:** <https://pydocs.[questra-host.domain]>
- **Support:** <support@seven2one.de>
## License
Proprietary - Seven2one Informationssysteme GmbH
| text/markdown | null | Jürgen Talasch <juergen.talasch@seven2one.de> | null | null | Proprietary | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Database",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic :: Software Development :: Libraries :: Python Modules",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"seven2one-questra-authentication>=1.0.0",
"seven2one-questra-automation>=0.3.1rc1",
"seven2one-questra-data>=0.9.0rc1"
] | [] | [] | [] | [] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T12:14:36.315691 | seven2one_questra-0.8.0rc1.tar.gz | 6,661 | 18/f9/3df31c1d1da84a1505414ffbb3efd49efdfd2ccb10833d91c4edfce15bc2/seven2one_questra-0.8.0rc1.tar.gz | source | sdist | null | false | 22b78d9cc57d15b7434849fcb694e09d | 1c8908a5f5cfdd637ae98f4d330bb04faa613123d4b0c00475704ab8af3a0202 | 18f93df31c1d1da84a1505414ffbb3efd49efdfd2ccb10833d91c4edfce15bc2 | null | [] | 173 |
2.4 | dsf-mobility | 5.1.0 | DSF C++ core with Python bindings via pybind11 | # DynamicalSystemFramework
[](https://github.com/physycom/DynamicalSystemFramework/releases/latest)
[](https://pypi.org/project/dsf-mobility/)
[](https://en.wikipedia.org/wiki/C%2B%2B#Standardization)
[](https://github.com/oneapi-src/oneTBB)
[](https://github.com/gabime/spdlog)
[](https://github.com/vincentlaucsb/csv-parser)
[](https://github.com/simdjson/simdjson)
[](https://github.com/SRombauts/SQLiteCpp)
[](https://codecov.io/gh/physycom/DynamicalSystemFramework)
The aim of this project is to rework the original [Traffic Flow Dynamics Model](https://github.com/Grufoony/TrafficFlowDynamicsModel).
This rework consists of a full code rewriting, in order to implement more features (like *intersections*) and get advantage from the latest C++ updates.
## Table of Contents
- [Installation](#installation)
- [Installation (from source)](#installation-from-source)
- [Testing](#testing)
- [Benchmarking](#benchmarking)
- [Citing](#citing)
- [Bibliography](#bibliography)
## Installation
The library is available on `PyPI`:
```shell
pip install dsf-mobility
```
To check the installation you can simply run
```python
import dsf
print(dsf.__version__)
```
## Installation (from source)
### Requirements
The project requires `C++20` or greater, `cmake`, `tbb` `simdjson`, `spdlog`, `csv-parser` and `SQLiteCpp`.
To install requirements on Ubuntu:
```shell
sudo apt install cmake libtbb-dev
```
To install requirements on macOS:
```shell
brew install cmake tbb
```
Utilities are written in python. To install their dependencies:
```shell
pip install -r ./requirements.txt
```
### Installation (C++)
The library can be installed using CMake. To build and install the project in the default folder run:
```shell
cmake -B build -DCMAKE_BUILD_TYPE=Release && cmake --build build -j$(nproc)
sudo cmake --install build
```
Otherwise, it is possible to customize the installation path:
```shell
cmake -B build -DCMAKE_INSTALL_PREFIX=/path/to/install
```
then building and installing it (eventually in sudo mode) with:
```shell
cmake --build build
cmake --install build
```
## Installation (Python)
If you want to use the library from Python, you can build the Python bindings using [pybind11](https://github.com/pybind/pybind11). Make sure you have Doxygen installed to generate the docstrings:
```shell
sudo apt install doxygen libtbb-dev
```
Then, the installation is automatic via `pip`:
```shell
pip install .
```
After installation, you should be able to import the module in Python:
```python
import dsf
print(dsf.__version__)
```
If you encounter issues, ensure that the installation path is in your `PYTHONPATH` environment variable.
## Testing
This project uses [Doctest](https://github.com/doctest/doctest) for testing.
If the project is compiled in `Debug` or `Coverage` mode, tests are always built.
Otherwise, you can add the `-DDSF_TESTS=ON` flag to enable test build.
```shell
cmake -B build -DDSF_TESTS=ON
cmake --build build -j$(nproc)
```
To run the tests use the command:
```shell
ctest --test-dir build -j$(nproc) --output-on-failure
```
## Benchmarking
Some functionalities of the library have been benchmarked in order to assess their efficiency.
The benchmarks are performed using [Google Benchmarks](https://github.com/google/benchmark).
To build the benchmarks add the flag `-DDSF_BENCHMARKS=ON` :
```shell
cmake -B build -DDSF_BENCHMARKS=ON
cmake --build build -j$(nproc)
```
To run all the benchmarks together use the command:
```shell
cd benchmark
for f in ./*.out ; do ./$f ; done
```
## Citing
```BibTex
@misc{DSF,
author = {Berselli, Gregorio and Balducci, Simone},
title = {Framework for modelling dynamical complex systems.},
year = {2023},
url = {https://github.com/physycom/DynamicalSystemFramework},
publisher = {GitHub},
howpublished = {\url{https://github.com/physycom/DynamicalSystemFramework}}
}
```
## Bibliography
- **Mungai, Veronica** (2024) *Studio dell'ottimizzazione di una rete semaforica*. University of Bologna, Bachelor's Degree in Physics [L-DM270]. [Link to Thesis](https://amslaurea.unibo.it/id/eprint/32525/).
- **Berselli, Gregorio** (2024) *Advanced queuing traffic model for accurate congestion forecasting and management*. University of Bologna, Master's Degree in Physics [LM-DM270]. [Link to Thesis](https://amslaurea.unibo.it/id/eprint/32191/).
- **Berselli, Gregorio** (2022) *Modelli di traffico per la formazione della congestione su una rete stradale*. University of Bologna, Bachelor's Degree in Physics [L-DM270]. [Link to Thesis](https://amslaurea.unibo.it/id/eprint/26332/).
| text/markdown | Grufoony | gregorio.berselli@studio.unibo.it | null | null | CC-BY-NC-SA-4.0 | traffic, simulation, dynamics, network, modeling, transportation, mobility, congestion, flow, optimization | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.12",
"Programming Language :: C++",
"Topic :: Scientific/Engineering :: Physics",
"Topic :: Scientific/Engineering :: Information Analysis",
"Topic :: Software Development :: Libraries :: Python Modules",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS"
] | [] | https://github.com/physycom/DynamicalSystemFramework | null | >=3.10 | [] | [] | [] | [
"pybind11-stubgen",
"osmnx>=2.0.6",
"networkx>=3",
"numpy",
"geopandas",
"shapely",
"folium"
] | [] | [] | [] | [
"Homepage, https://github.com/physycom/DynamicalSystemFramework",
"Documentation, https://physycom.github.io/DynamicalSystemFramework/",
"Repository, https://github.com/physycom/DynamicalSystemFramework",
"Issues, https://github.com/physycom/DynamicalSystemFramework/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-20T12:14:28.864225 | dsf_mobility-5.1.0.tar.gz | 138,024 | d5/09/b725b80307ed1f95b254229af3d571aeeab91ecf615cf5d360a46046cb23/dsf_mobility-5.1.0.tar.gz | source | sdist | null | false | 0b1bdedf0d092490d929b2dd945fe23b | 6a6bca49c3b874803a34bc65a07262731636f8ff7c4584feae54cc4021b1e2f3 | d509b725b80307ed1f95b254229af3d571aeeab91ecf615cf5d360a46046cb23 | null | [
"LICENSE"
] | 562 |
2.4 | seven2one-questra-automation | 0.3.1rc1 | Questra Automation Python Package | # seven2one-questra-automation
Typsicherer Python Client für die Questra Automation GraphQL API.
## Features
- **Type-safe**: Vollständig typisierte GraphQL API
- **Authentication**: Integration mit questra-authentication
- **Umfassend**: Workspaces, Repositories, Schedules, Executions
- **Modern Python**: 3.10+ mit native Type Hints
## Installation
```bash
pip install seven2one-questra-automation
```
## Requirements
- Python >= 3.10
- seven2one-questra-authentication >= 0.2.1
- gql[all] >= 3.5.0
## Schnellstart
```python
from seven2one.questra.authentication import QuestraAuthentication
from seven2one.questra.automation import QuestraAutomation
auth = QuestraAuthentication(
url="https://auth.example.com",
username="ServiceUser",
password="secret"
)
client = QuestraAutomation(
graphql_url="https://automation.example.com/graphql",
auth_client=auth
)
# Verfügbare API-Gruppen:
# client.queries - GraphQL Queries
# client.mutations - GraphQL Mutations
# client.execute_raw(query) - Custom GraphQL
```
## Weitere Informationen
- **Vollständige Dokumentation:** <https://pydocs.[questra-host.domain]>
- **Support:** <support@seven2one.de>
## License
Proprietary - Seven2one Informationssysteme GmbH
| text/markdown | null | Jürgen Talasch <juergen.talasch@seven2one.de> | null | null | Proprietary | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"gql[requests]<4.0.0,>=3.5.0",
"pydantic<3.0.0,>=2.0.0",
"seven2one-questra-authentication>=1.0.0"
] | [] | [] | [] | [] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T12:14:27.030933 | seven2one_questra_automation-0.3.1rc1-py3-none-any.whl | 20,849 | d1/4b/b90716dd177d3001d43c11cf8122277c90f94774918006e303f51b14e00a/seven2one_questra_automation-0.3.1rc1-py3-none-any.whl | py3 | bdist_wheel | null | false | 422e6a9d435a92759a2ff21313811a28 | 61a12c822fe5cf6b12dc1f831fb6fab5fab761cca15ae62c833e9a36e1e45cf2 | d14bb90716dd177d3001d43c11cf8122277c90f94774918006e303f51b14e00a | null | [] | 188 |
2.4 | seven2one-questra-authentication | 1.0.0 | Authentication Client for Questra to use in all other Questra Client Libraries | # Questra Authentication
Python OAuth2 Authentication Client für die Questra API mit Unterstützung für Service-Account- und interaktive Benutzer-Authentifizierung.
## Features
- **Service Account & Interaktive Authentifizierung**: Username/Password oder OAuth2 Device Code Flow
- **Automatisches Token-Management**: Automatische Token-Refresh-Mechanismen
- **OIDC Discovery**: Automatische Erkennung von OAuth2 Endpoints
- **Type-Safe**: Vollständig typisierte API mit Dataclasses
## Installation
```bash
pip install seven2one-questra-authentication
```
## Requirements
- Python >= 3.10
- requests-oauthlib >= 2.0.0
## Schnellstart
### Service Account
```python
from seven2one.questra.authentication import QuestraAuthentication
client = QuestraAuthentication(
url="https://auth.example.com",
username="ServiceUser",
password="secret_password"
)
access_token = client.get_access_token()
```
### Interaktiver Benutzer
```python
client = QuestraAuthentication(
url="https://auth.example.com",
interactive=True
)
access_token = client.get_access_token()
```
## Erweiterte Verwendung
```python
# Mehrere Discovery-Pfade
client = QuestraAuthentication(
url="https://auth.example.com",
username="ServiceUser",
password="secret",
oidc_discovery_paths=["/app/o/techstack", "/app/o/questra"]
)
# Benutzerdefinierte Scopes
client = QuestraAuthentication(
url="https://auth.example.com",
username="ServiceUser",
password="secret",
scope="openid profile email"
)
```
## Weitere Informationen
- **Vollständige Dokumentation:** <https://pydocs.[questra-host.domain]>
- **Support:** <support@seven2one.de>
## License
Proprietary - Seven2one Informationssysteme GmbH
| text/markdown | null | Jürgen Talasch <juergen.talasch@seven2one.de> | null | null | Proprietary | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Security",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Systems Administration :: Authentication/Directory",
"Typing :: Typed"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"requests-oauthlib<3.0.0,>=2.0.0"
] | [] | [] | [] | [] | uv/0.9.18 {"installer":{"name":"uv","version":"0.9.18","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-20T12:14:26.076660 | seven2one_questra_authentication-1.0.0.tar.gz | 12,576 | 2a/d6/af2e9f1f27139ebe836705edd0cc6ec6c2a2affd3a5b8b288d5aa6d3b340/seven2one_questra_authentication-1.0.0.tar.gz | source | sdist | null | false | 3e5abf2005461e4db5e5f653edba4c53 | 157ee057843ebadfa1a4fa4848505371b807f331a4c4f0229d26d2e0972d5ca7 | 2ad6af2e9f1f27139ebe836705edd0cc6ec6c2a2affd3a5b8b288d5aa6d3b340 | null | [] | 321 |
2.4 | glpi_py | 0.4.0 | A Python SDK for GLPI REST Api. | # GLPI REST API Python SDK v0.1.2
This Python library provides a wrapper for the GLPI REST API. It offers a collection of resources representing various GLPI items built upon generic classes. Install using:
```
pip install glpi_py
```
--------- or ---------
```
pip install glpi_py==[version]
```
## Supported Items
* **Tickets:**
* CRUD operations
* User assignment
* Document attachment
* **Ticket Categories:**
* CRUD operations
* **Ticket SLAs:**
* CRUD operations
* **Request Origin:**
* CRUD operations
* **Ticket Users:**
* CRUD operations
* **Users:**
* CRUD operations
* Related ticket querying
* **User Emails:**
* CRUD operations
* **Documents:**
* CRUD operations
* Downloading
* **Document Items:**
* CRUD operations
## How it Works
1. **Connection:** The library establishes a connection to the GLPI server using the specified authentication method (basic or user token).
2. **Item Modeling:** GLPI items are modeled using dataclasses and generic parent classes to provide global and specific functionalities for each item.
3. **Resource Creation:** Resources are created for the modeled GLPI items. These resources handle querying, filtering, updating and creating.
**Item Hierarchy:**
Items can have subitems, which will be represented as subitem resources, or parent items, represented as read-only properties (only updatable from the glpi item update method). Here's an example of this hierarchy:
```
Ticket Categories -> Tickets -> Document Items
```
```python
from glpi_py.resources.tickets import Tickets
ticket = Tickets(connection).get(11)
category = ticket.category # Get's the ticket category object throught property getter.
documents = ticket.linked_documents.all() # Get's all the ticket related Document Items using the Subitem resource.
```
```
User -> Ticket Users <- Tickets
```
```python
from glpi_py.resources.auth import Users
user = Users(connection).get(27)
tickets = user.tickets.all() # Get's all the user Ticket User items using the Subitem resource.
tickets = user.get_requested_tickets() # Directly get the tickets where this user has the "applicant" role, directly returning the Ticket objects, instead of the relation registries (Ticket Users)
```
This hierarchy attributes may be simplified using certain class methods for easier usage, for example, the ticket item has a method called "attach_document", which directly handles the creation of a related subitem.
Either way, all models are extendable inheriting them with dataclasses:
```python
from glpi_py.resources.auth import Users, User
from dataclasses import dataclass
# Generally, Resources classes are called with a plural of the item they represent e.g User -> Modeled Item, Users -> User Resource.
@dataclass(repr=False) # Set repr to false to avoid overriding the original method, unless you want to make your own
class User(User): # The modeled item classes need to match the name of the GLPI itemtype they represent.
other_attribute: str
def post_initialization(self): # Need to be cautious when modifying this method, since it migth lead to unexpected behaviour.
super().post_initialization() # Make sure to always call the original class post_initialization first
my_attr = self.my_method()
def my_method(self):
...
@property
def etc(self): ... # Properties are a great way for adding calculated/extended attributes, i recommend this rather than modifying post_initialization method.
```
## Resource Methods
Every resource has at least the following methods:
* `get(id)`: Retrieves an item with the specified ID.
* `all()`: Retrieves all items.
* `get_multiple(*ids)`: Retrieves multiple items with the provided IDs.
* `search(filters[])`: Filters items using GLPI's search engine.
* `instance(**kwargs)`: Instantiates a GLPI item based on API responses and modeled dataclasses.
* `create(**kwargs)`: Create's a resource with the specified data.
## Item Methods
Every GLPI item has at least the following methods:
* `post_initialization()`: Executes after an item is initialized, allowing for adding new attributes.
* `as_dict()`: Represents the item as a dictionary.
* `get_api_object()`: Provides access to all attributes returned by the GLPI API.
* `get_subitems_resource()`: Creates a resource for a subitem related to this item (e.g., a Ticket with its Document Items).
* `get_related_parent()`: Fetches a parent item using the parent's resource and the related field (e.g., accessing the parent Ticket of a Ticket User item using the `tickets_id` field).
* `update()`: Updates the item.
* `delete()`: Deletes the item.
## Usage
**1. Create a GLPI Connection:**
```python
from glpi_py.connection import GLPISession
connection = GLPISession(
api_url = getenv("GLPI_REST_API_URL"),
app_token = getenv("GLPI_APP_TOKEN"),
auth_type = getenv("GLPI_AUTH_HEADER_METHOD"),
user = getenv("GLPI_USER"),
password = getenv("GLPI_PASSWORD"),
user_token = getenv("GLPI_USER_TOKEN")
)
```
**2. Create a Resource Instance:**
```python
from glpi_py.resources.tickets import Tickets
resource = Tickets(connection)
```
**3. Perform Operations:**
* Retrieve all tickets:
```python
resource.all()
```
* Get a specific ticket:
```python
resource.get(11)
```
* Create a new ticket:
##### For attribute reference, visit https://github.com/glpi-project/glpi/blob/main/apirest.md
```python
resource.create(
name="Test",
content="Test ticket created with REST Api",
itilcategories_id=12
)
```
**4. Using the GLPI Search Engine:**
By default, GLPI requires complex filtering criteria. This library simplifies it using the `FilterCriteria` class:
```python
from glpi_py.models import FilterCriteria
filter = FilterCriteria(
field_uid="Ticket.name", # Searchable field UUID
operator="Equals", # Comparison operator
value="Test" # Matching value
)
resource.search(filter)
# Specifying a non-existent field_uid will raise an exception that includes a reference of all the searchable field_uids for the sepcified Resource.
```
Filters can be related using logical operators (AND, OR, XOR) defined as follows:
```python
filter1 = filter
filter2 = FilterCriteria(
field_uid="Ticket.content",
operator="Contains",
value="API"
)
filter = filter1 & filter2 # AND operation
filter = filter1 | filter2 # OR operation
filter = filter1 & filter2 | filter3 # Mixed operation
result = resource.search(filter) # Logical operations between filter criteria will produce a list related by thus operation.
```
**5. ItemList Methods:**
Methods that return multiple items (all, search, get_multiple) use an extended list class named `ItemList`. This class provides the following methods:
* `filter(**kwargs)`: Offline Filters the results using the `leopards` library (refer to https://github.com/mkalioby/leopards for usage).
* `exclude(**kwargs)`: Reverse Offline Filters the results using the `leopards`.
* `to_representation()`: Returns a list with the result of executing to_dict() method of each contained item.
```python
result = resource.filter(priority__gt=2) # Offline filters the search result, returns only the tickets with a priority higher than 2.
result = result.exclude(urgency__lt=4) # Returns only the tickets with a urgency higher than 3.
```
For more usage examples, refer to tests in the github repository.
| text/markdown | Grupo Parawa | tecnologia.dev@grupoparawa.com | null | null | MIT | glpi, api, wrapper | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"requests<3.0.0,>=2.31.0"
] | [] | [] | [] | [] | poetry/2.3.2 CPython/3.12.3 Linux/6.6.87.2-microsoft-standard-WSL2 | 2026-02-20T12:14:13.384079 | glpi_py-0.4.0-py3-none-any.whl | 16,589 | ff/0f/a348f1cb8b0156c8af1ce62d5364121792f5b778120b9d3bf01224e4a96d/glpi_py-0.4.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 3fac2462b3b77b26d248e97d6d415a07 | 8eaac5a92b57ae89829bd20f55da22a59029b3565053d9d4963dfcf9e077542e | ff0fa348f1cb8b0156c8af1ce62d5364121792f5b778120b9d3bf01224e4a96d | null | [
"LICENSE"
] | 0 |
2.4 | cpmf-uips-xaml | 0.1.0 | Standalone XAML workflow parser for automation projects (CPRIMA Forge) | # XAML Parser - Python Implementation
Python implementation of the XAML workflow parser for automation projects.
## Installation
### From PyPI (when published)
```bash
pip install cpmf-uips-xaml
```
### For Development
```bash
# Clone the repository
git clone https://github.com/rpapub/cpmf-uips-xaml.git
cd cpmf-uips-xaml/python
# Install with uv (recommended)
uv sync
# Or with pip in editable mode
pip install -e .
```
## Quick Start
### Python API
```python
from pathlib import Path
from cpmf_uips_xaml import XamlParser
# Parse a workflow file
parser = XamlParser()
result = parser.parse_file(Path("workflow.xaml"))
if result.success:
content = result.content
print(f"Workflow: {content.root_annotation}")
print(f"Arguments: {len(content.arguments)}")
print(f"Activities: {len(content.activities)}")
# Access arguments
for arg in content.arguments:
print(f" {arg.direction} {arg.name}: {arg.type}")
if arg.annotation:
print(f" -> {arg.annotation}")
# Access activities with annotations
for activity in content.activities:
if activity.annotation:
print(f"{activity.activity_type}: {activity.annotation}")
else:
print("Parsing failed:", result.errors)
```
### Command Line Interface
**Project Parsing (Primary Mode):**
```bash
# Parse entire project from project.json
cpmf-uips-xaml project.json
cpmf-uips-xaml /path/to/project.json
cpmf-uips-xaml /path/to/project # Directory containing project.json
# Show workflow dependency graph
cpmf-uips-xaml project.json --graph
# Parse only entry points (no recursive discovery)
cpmf-uips-xaml project.json --entry-points-only
# Save to file
cpmf-uips-xaml project.json --json -o output.json
```
**Individual Workflow Files:**
```bash
# Parse single workflow
cpmf-uips-xaml Main.xaml
# JSON output
cpmf-uips-xaml Main.xaml --json
# List only arguments
cpmf-uips-xaml Main.xaml --arguments
# Show activity tree
cpmf-uips-xaml Main.xaml --tree
# Process multiple files
cpmf-uips-xaml *.xaml --summary
# Recursive search
cpmf-uips-xaml **/*.xaml --summary
```
**Using with uv (development):**
```bash
uv run cpmf-uips-xaml project.json
uv run cpmf-uips-xaml workflow.xaml
```
**CLI Options:**
*All modes:*
- `--json` - Output as JSON
- `-o FILE` - Write output to file
- `--no-expressions` - Skip expression extraction (faster)
- `--strict` - Fail on any error
- `--help` - Show all options
*Project mode:*
- `--graph` - Show workflow dependency graph
- `--entry-points-only` - Parse only entry points (no recursive discovery)
*File mode:*
- `--arguments` - Show only arguments
- `--activities` - Show only activities
- `--tree` - Show activity tree with nesting
- `--summary` - Summary for multiple files
**Python API for Projects:**
```python
from pathlib import Path
from cpmf_uips_xaml import ProjectParser
# Parse entire project
parser = ProjectParser()
result = parser.parse_project(Path("path/to/project"))
if result.success:
print(f"Project: {result.project_config.name}")
print(f"Workflows: {result.total_workflows}")
# Access entry points
for workflow in result.get_entry_points():
print(f"Entry: {workflow.relative_path}")
# Access dependency graph
for workflow_path, dependencies in result.dependency_graph.items():
print(f"{workflow_path} invokes:")
for dep in dependencies:
print(f" -> {dep}")
else:
print("Project parsing failed:", result.errors)
```
**How it works:**
1. Reads `project.json` to find entry points
2. Parses entry point workflows
3. Recursively discovers workflows via `InvokeWorkflowFile` activities
4. Builds complete dependency graph
5. Returns all workflows with parse results
## Features
- **Minimal Dependencies**: Single required dependency (defusedxml for secure XML parsing)
- **Complete Extraction**: Arguments, variables, activities, expressions, annotations
- **Project Parsing**: Auto-discover and parse entire UiPath projects with dependency analysis
- **Type Safety**: Full type hints for all APIs
- **Error Handling**: Graceful degradation with detailed error reporting
- **Schema Validation**: Output validates against JSON schemas
- **Performance**: Fast parsing even for large workflows
- **CLI Tool**: Full-featured command-line interface for batch processing
## Configuration
```python
config = {
'extract_expressions': True,
'extract_viewstate': False,
'strict_mode': False,
'max_depth': 50
}
parser = XamlParser(config)
result = parser.parse_file(file_path)
```
## API Reference
### XamlParser
Main workflow parser class:
```python
parser = XamlParser(config=None)
result = parser.parse_file(Path("workflow.xaml"))
result = parser.parse_content(xaml_string)
```
### ProjectParser
Project-level parser class:
```python
parser = ProjectParser(config=None)
result = parser.parse_project(
project_dir=Path("path/to/project"),
recursive=True, # Follow InvokeWorkflowFile references
entry_points_only=False # Only parse entry points
)
```
### Models
Data models for parsed content:
**Workflow Models:**
- `ParseResult`: Top-level result with success/error info
- `WorkflowContent`: Complete workflow metadata
- `WorkflowArgument`: Argument definition
- `WorkflowVariable`: Variable definition
- `Activity`: Activity with full metadata
- `Expression`: Expression with language detection
**Project Models:**
- `ProjectResult`: Complete project parsing result
- `ProjectConfig`: Parsed project.json configuration
- `WorkflowResult`: Individual workflow result in project context
### Validation
Schema-based validation:
```python
from cpmf_uips_xaml.validation import validate_output
errors = validate_output(result)
if errors:
print("Validation failed:", errors)
```
## Library API (v0.3.0+)
Starting in v0.3.0, the package provides a stable orchestration API that coordinates parsing, analysis, and output generation. This API is the recommended way to integrate XAML parsing into libraries and tools.
### Architecture
The package follows a layered architecture:
```
Your Application
↓
API Layer (orchestration) ← You are here
↓
Core, UiPS, Emitters, Views (internal implementation)
```
The API layer provides stable entry points while internal implementation details may change between versions.
### Core API Functions
#### parse_and_analyze_project()
Parse a project and build queryable index in one step:
```python
from pathlib import Path
from cpmf_uips_xaml.api import parse_and_analyze_project
# Parse project and build complete analysis
project_result, analyzer, index = parse_and_analyze_project(
Path("./MyProject"),
recursive=True, # Follow InvokeWorkflowFile references
entry_points_only=False, # Parse all workflows, not just entry points
show_progress=False # Show progress bars
)
# Access project info
if project_result.project_config:
print(f"Project: {project_result.project_config.name}")
print(f"Main workflow: {project_result.project_config.main}")
# Query workflows
workflow_ids = index.list_workflows()
print(f"Total workflows: {len(workflow_ids)}")
# Traverse call graph
for workflow_id in index.list_workflows():
callees = index.get_callees(workflow_id)
if callees:
print(f"{workflow_id} calls: {callees}")
```
#### render_project_view()
Transform analysis results into different view formats:
```python
from cpmf_uips_xaml.api import parse_and_analyze_project, render_project_view
# Parse and analyze
project_result, analyzer, index = parse_and_analyze_project(Path("./MyProject"))
# Render nested view (hierarchical structure)
nested = render_project_view(
analyzer, index,
view_type="nested"
)
# Render execution view (call graph traversal from entry point)
execution = render_project_view(
analyzer, index,
view_type="execution",
entry_point="Main.xaml",
max_depth=10
)
# Render slice view (context window around focal activity)
slice_view = render_project_view(
analyzer, index,
view_type="slice",
focus="LogMessage_abc123",
radius=2
)
```
#### emit_workflows()
Output workflows in different formats:
```python
from pathlib import Path
from cpmf_uips_xaml.api import parse_and_analyze_project, emit_workflows
# Parse project
project_result, analyzer, index = parse_and_analyze_project(Path("./MyProject"))
# Get workflow DTOs from analyzer
workflows = list(analyzer.workflows.values())
# Emit as JSON
result = emit_workflows(
workflows,
format="json",
output_path=Path("output.json"),
pretty=True,
exclude_none=True
)
if result.success:
print(f"Written {len(result.files_written)} files")
else:
print(f"Errors: {result.errors}")
# Emit as Mermaid diagram
emit_workflows(
workflows,
format="mermaid",
output_path=Path("output.mmd")
)
# Emit as Markdown documentation
emit_workflows(
workflows,
format="doc",
output_path=Path("output.md")
)
```
Available formats: `json`, `mermaid`, `doc`
#### normalize_parse_results()
Convert raw ParseResult objects to structured WorkflowDto objects:
```python
from pathlib import Path
from cpmf_uips_xaml import XamlParser
from cpmf_uips_xaml.api import normalize_parse_results
# Parse files
parser = XamlParser()
parse_results = [
parser.parse_file(Path("Main.xaml")),
parser.parse_file(Path("GetConfig.xaml"))
]
# Normalize to DTOs
workflows = normalize_parse_results(
parse_results,
project_dir=Path("./MyProject"),
sort_output=True,
calculate_metrics=True,
detect_anti_patterns=True
)
# Now you have structured DTOs ready for emission or analysis
for workflow in workflows:
print(f"Workflow: {workflow.name}")
print(f" Activities: {len(workflow.activities)}")
print(f" Arguments: {len(workflow.arguments)}")
```
#### parse_file_to_dto()
Single-file parsing with DTO normalization:
```python
from pathlib import Path
from cpmf_uips_xaml.api import parse_file_to_dto
# Parse and normalize in one call
workflow = parse_file_to_dto(
Path("Main.xaml"),
project_dir=Path("./MyProject")
)
print(f"Workflow: {workflow.name}")
print(f"Activities: {len(workflow.activities)}")
```
#### Configuration Helpers
```python
from cpmf_uips_xaml.api import load_default_config, create_emitter_config
# Load default parser config
config = load_default_config()
print(config) # Shows default settings
# Create emitter config with overrides
emitter_config = create_emitter_config(
pretty=True,
exclude_none=True,
field_profile="minimal"
)
```
### Complete Example: Project Analysis Pipeline
```python
from pathlib import Path
from cpmf_uips_xaml.api import (
parse_and_analyze_project,
render_project_view,
emit_workflows
)
# 1. Parse and analyze entire project
project_result, analyzer, index = parse_and_analyze_project(
Path("./MyProject"),
recursive=True,
show_progress=True
)
# 2. Generate execution view from main entry point
execution_view = render_project_view(
analyzer, index,
view_type="execution",
entry_point="Main.xaml",
max_depth=15
)
# 3. Export workflows as JSON
workflows = list(analyzer.workflows.values())
emit_result = emit_workflows(
workflows,
format="json",
output_path=Path("output.json"),
pretty=True
)
print(f"Analyzed {len(workflows)} workflows")
print(f"Exported to {emit_result.files_written}")
```
### Migration from v0.2.x
If you were using internal APIs that are no longer exported, use direct imports:
```python
# ❌ v0.2.x - No longer works
from cpmf_uips_xaml import XmlUtils, ActivityExtractor
# ✅ v0.3.0+ - Use direct imports if needed
from cpmf_uips_xaml.core.utils import XmlUtils
from cpmf_uips_xaml.core.extractors import ActivityExtractor
# ✅ v0.3.0+ - Or better, use the API layer
from cpmf_uips_xaml.api import parse_and_analyze_project
```
**Recommended approach**: Use the API layer functions instead of reaching into internal modules. The API provides stable contracts while internals may change.
### Data Models (DTOs)
The API works with strongly-typed DTO models for all data exchange:
**Workflow DTOs:**
- `WorkflowDto` - Complete workflow with metadata, activities, edges
- `WorkflowCollectionDto` - Multiple workflows with project context
- `ActivityDto` - Activity with arguments and properties
- `ArgumentDto` - Workflow or activity argument
- `VariableDto` - Workflow variable
- `EdgeDto` - Control flow edge between activities
**Project DTOs:**
- `ProjectInfo` - Project metadata (name, version, dependencies)
- `EntryPointInfo` - Entry point definition
- `ProvenanceInfo` - Parser version and author tracking
**Analysis DTOs:**
- `QualityMetrics` - Workflow quality scores
- `AntiPattern` - Detected anti-patterns
- `IssueDto` - Parse errors or warnings
All DTOs are immutable dataclasses with full type hints.
## Development
### Running Tests
```bash
# Run all tests
uv run pytest tests/ -v
# Run with coverage
uv run pytest tests/ --cov=xaml_parser --cov-report=html
# Run specific test file
uv run pytest tests/test_parser.py -v
# Run corpus tests only
uv run pytest tests/test_corpus.py -v -m corpus
```
### Code Quality
```bash
# Format code
uv run black xaml_parser/ tests/
# Sort imports
uv run isort xaml_parser/ tests/
# Lint
uv run ruff check xaml_parser/ tests/
# Type check
uv run mypy xaml_parser/
```
### Building
```bash
# Build distribution
uv build
# Check package
twine check dist/*
```
## Project Structure
```
python/
├── xaml_parser/ # Source package
│ ├── __init__.py # Public API
│ ├── __version__.py # Version info
│ ├── parser.py # Main workflow parser
│ ├── project.py # Project parser (NEW)
│ ├── cli.py # Command-line interface
│ ├── models.py # Data models
│ ├── extractors.py # Extraction logic
│ ├── utils.py # Utilities
│ ├── validation.py # Schema validation
│ ├── visibility.py # ViewState handling
│ └── constants.py # Configuration
├── tests/ # Test suite
│ ├── conftest.py # Pytest fixtures
│ ├── test_parser.py # Parser tests
│ ├── test_project.py # Project parser tests (NEW)
│ ├── test_corpus.py # Corpus tests
│ └── test_validation.py
├── pyproject.toml # Package configuration
├── uv.lock # Dependency lock
└── README.md # This file
```
## Requirements
- Python 3.11+
- defusedxml (for secure XML parsing)
- pytest (for development)
## Testing Philosophy
Tests reference shared test data in `../testdata/`:
- `../testdata/golden/`: Golden freeze test pairs (XAML + JSON)
- `../testdata/corpus/`: Structured test projects
This ensures consistency across language implementations.
## Contributing
See the main repository [CONTRIBUTING.md](../CONTRIBUTING.md) for guidelines.
## License
This project is dual-licensed:
- **Code**: Apache License 2.0 (see [LICENSE-APACHE](LICENSE-APACHE))
- **Documentation & Output**: Creative Commons Attribution 4.0 (see [LICENSE-CC-BY](LICENSE-CC-BY))
You may choose which license applies to your use case.
## Links
- **Repository**: https://github.com/rpapub/cpmf-uips-xaml
- **Issues**: https://github.com/rpapub/cpmf-uips-xaml/issues
- **PyPI**: https://pypi.org/project/cpmf-uips-xaml/ (coming soon)
| text/markdown | null | Christian Prior-Mamulyan <cprior@gmail.com> | null | null | Apache-2.0 AND CC-BY-4.0 | automation, cprima-forge, parsing, rpa, uipath, workflow, xaml | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Text Processing :: Markup :: XML"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"defusedxml>=0.7.1",
"rich>=14.2.0; extra == \"cli\"",
"deepdiff>=8.6.1; extra == \"dev\"",
"mypy>=1.11; extra == \"dev\"",
"pre-commit>=3.5; extra == \"dev\"",
"psutil>=5.9.0; extra == \"dev\"",
"pytest-cov>=4.1; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"rich>=14.2.0; extra == \"dev\"",
"ruff>=0.6; extra == \"dev\"",
"twine>=5.0; extra == \"dev\"",
"types-defusedxml; extra == \"dev\"",
"watchdog>=3.0.0; extra == \"dev\"",
"jinja2>=3.1; extra == \"docs\"",
"psutil>=5.9.0; extra == \"extras\"",
"watchdog>=3.0.0; extra == \"extras\"",
"jinja2>=3.1; extra == \"full\"",
"psutil>=5.9.0; extra == \"full\"",
"rich>=14.2.0; extra == \"full\"",
"watchdog>=3.0.0; extra == \"full\"",
"pytest-cov>=4.1; extra == \"test\"",
"pytest>=8.0; extra == \"test\""
] | [] | [] | [] | [
"Homepage, https://github.com/rpapub/xaml-parser",
"Repository, https://github.com/rpapub/xaml-parser",
"Issues, https://github.com/rpapub/xaml-parser/issues"
] | twine/6.2.0 CPython/3.13.9 | 2026-02-20T12:13:44.239925 | cpmf_uips_xaml-0.1.0-py3-none-any.whl | 199,901 | e3/a5/c77e87d066077c0db18257069573942d9685e1f8922608e7d480b426d830/cpmf_uips_xaml-0.1.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 27f9b16153afdfbeabfecf4070812f42 | 065f4f52e359cfe715213ddf82c445c4a6997a405f3931080308054a2ad0990c | e3a5c77e87d066077c0db18257069573942d9685e1f8922608e7d480b426d830 | null | [
"LICENSE-APACHE",
"LICENSE-CC-BY"
] | 75 |
2.4 | pymc-extras | 0.9.0 | A home for new additions to PyMC, which may include unusual probability distribitions, advanced model fitting algorithms, or any code that may be inappropriate to include in the pymc repository, but may want to be made available to users. | # Welcome to `pymc-extras`
<a href="https://gitpod.io/#https://github.com/pymc-devs/pymc-extras">
<img
src="https://img.shields.io/badge/Contribute%20with-Gitpod-908a85?logo=gitpod"
alt="Contribute with Gitpod"
/>
</a>
<img
src="https://codecov.io/gh/pymc-devs/pymc-extras/branch/main/graph/badge.svg"
alt="Codecov Badge"
/>
As PyMC continues to mature and expand its functionality to accommodate more domains of application, we increasingly see cutting-edge methodologies, highly specialized statistical distributions, and complex models appear.
While this adds to the functionality and relevance of the project, it can also introduce instability and impose a burden on testing and quality control.
To reduce the burden on the main `pymc` repository, this `pymc-extras` repository can become the aggregator and testing ground for new additions to PyMC.
This may include unusual probability distributions, advanced model fitting algorithms, innovative yet not fully tested methods, or niche functionality that might not fit in the main PyMC repository, but still may be of interest to users.
The `pymc-extras` repository can be understood as the first step in the PyMC development pipeline, where all novel code is introduced until it is obvious that it belongs in the main repository.
We hope that this organization improves the stability and streamlines the testing overhead of the `pymc` repository, while allowing users and developers to test and evaluate cutting-edge methods and not yet fully mature features.
`pymc-extras` would be designed to mirror the namespaces in `pymc` to make usage and migration as easy as possible.
For example, a `ParabolicFractal` distribution could be used analogously to those in `pymc`:
```python
import pymc as pm
import pymc_extras as pmx
with pm.Model():
alpha = pmx.ParabolicFractal('alpha', b=1, c=1)
...
```
## Questions
### What belongs in `pymc-extras`?
- newly-implemented statistical methods, for example step methods or model construction helpers
- distributions that are tricky to sample from or test
- infrequently-used fitting methods or distributions
- any code that requires additional optimization before it can be used in practice
### What does not belong in `pymc-extras`?
- Case studies
- Implementations that cannot be applied generically, for example because they are tied to variables from a toy example
### Should there be more than one add-on repository?
Since there is a lot of code that we may not want in the main repository, does it make sense to have more than one additional repository?
For example, `pymc-extras` may just include methods that are not fully developed, tested and trusted, while code that is known to work well and has adequate test coverage, but is still too specialized to become part of `pymc` could reside in a `pymc-extras` (or similar) repository.
### Unanswered questions & ToDos
This project is still young and many things have not been answered or implemented.
Please get involved!
* What are guidelines for organizing submodules?
* Proposal: No default imports of WIP/unstable submodules. By importing manually we can avoid breaking the package if a submodule breaks, for example because of an updated dependency.
| text/markdown | null | PyMC Developers <pymc.devs@gmail.com> | null | null | =======
License
=======
PyMC is distributed under the Apache License, Version 2.0
Copyright (c) 2006 Christopher J. Fonnesbeck (Academic Free License)
Copyright (c) 2007-2008 Christopher J. Fonnesbeck, Anand Prabhakar Patil, David Huard (Academic Free License)
Copyright (c) 2009-2017 The PyMC developers (see contributors to pymc-devs on GitHub)
All rights reserved.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2020 The PyMC Developers
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | bayesian, machine learning, mcmc, probability, sampling, statistics | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Mathematics"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"better-optimize>=0.1.5",
"preliz>=0.20.0",
"pydantic>=2.0.0",
"pymc>=5.27.1",
"pytensor>=2.37.0",
"scikit-learn",
"dask[complete]<2025.1.1; extra == \"complete\"",
"xhistogram; extra == \"complete\"",
"dask[complete]<2025.1.1; extra == \"dask-histogram\"",
"xhistogram; extra == \"dask-histogram\"",
"blackjax>=0.12; extra == \"dev\"",
"dask[all]<2025.1.1; extra == \"dev\"",
"pytest>=6.0; extra == \"dev\"",
"statsmodels; extra == \"dev\"",
"nbsphinx>=0.4.2; extra == \"docs\"",
"pymc-sphinx-theme>=0.16; extra == \"docs\"",
"sphinx>=4.0; extra == \"docs\"",
"xhistogram; extra == \"histogram\""
] | [] | [] | [] | [
"Documentation, https://pymc-extras.readthedocs.io/",
"Repository, https://github.com/pymc-devs/pymc-extras.git",
"Issues, https://github.com/pymc-devs/pymc-extras/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:13:30.894158 | pymc_extras-0.9.0.tar.gz | 334,246 | a5/9f/116d6badb6544431886a38adf7019bbe083f2c1bbf3787a308c9b5a13427/pymc_extras-0.9.0.tar.gz | source | sdist | null | false | b5710f238f8fe0addc3a9b648451f716 | c7df7e3c8204f4935123132b65c7c3dac524db392819eadd669fde205be74650 | a59f116d6badb6544431886a38adf7019bbe083f2c1bbf3787a308c9b5a13427 | null | [
"LICENSE"
] | 1,941 |
2.4 | sir3stoolkit | 90.15.13 | SIR3S Toolkit | .. image:: https://img.shields.io/badge/License-MIT-yellow.svg
:alt: License: MIT
:target: LICENSE
.. image:: https://img.shields.io/pypi/pyversions/sir3stoolkit.svg
:alt: Supported Python versions
:target: https://pypi.org/project/sir3stoolkit
.. image:: https://img.shields.io/pypi/v/sir3stoolkit.svg
:alt: PyPI Package latest release
:target: https://pypi.org/project/sir3stoolkit/
.. image:: https://img.shields.io/badge/docs-latest-brightgreen.svg?logo=readthedocs&logoColor=white
:target: https://3sconsult.github.io/sir3stoolkit/
:alt: docs
----
SIR 3S Toolkit
==============
**SIR 3S Toolkit** is a Python package developed by 3S Consult that provides a programming interface for SIR 3S -
a software for the simulation, analysis and optimization of flow processes in gas/water/heat supply networks,
plants, pipelines and caverns.
At its core, the package wraps basic functionality of SIR 3S, offering a low-level access to the creation, modification and simulation of SIR 3S models.
On top of this core, higher-level functionality is provided, enabling more powerful and intuitive interactions with SIR 3S models.
This layered architecture of the SIR 3S Toolkit ensures both flexibility and extensibility for advanced applications.
.. image:: https://raw.githubusercontent.com/3SConsult/PT3S/master/sphinx_docs/_static/Sir3S_Splash.jpg
:target: https://www.3sconsult.de/software/sir-3s/
:width: 20%
:alt: Sir3S Splash
Note: This package is a client toolkit for the proprietary SIR 3S software. A valid license for SIR 3S is required to use this package in production.
Features
--------
- **Create** new SIR 3S models
- **Modify** existing SIR 3S models
- **Simulate** SIR 3S models
- **Read** data and simulation results from SIR 3S models
Documentation
-------------
For detailed documentation, visit `SIR 3S Toolkit Documentation <https://3sconsult.github.io/sir3stoolkit/>`_.
PyPI
----
You can find the SIR 3S Toolkit package on `PyPI <https://pypi.org/project/sir3stoolkit/>`_.
Installation
------------
To install the SIR 3S Toolkit, use pip:
.. code-block:: bash
pip install sir3stoolkit
Quick Start
-----------
.. code-block:: python
from sir3stoolkit.core import wrapper
SIR3S_SIRGRAF_DIR = r"C:\SIR3S\SirGraf-90-15-00-12_Quebec_x64"
wrapper.Initialize_Toolkit(SIR3S_SIRGRAF_DIR)
model = wrapper.SIR3S_Model()
model.OpenModel(dbName=r"example_model.db3",
providerType=model.ProviderTypes.SQLite,
Mid="M-1-0-1",
saveCurrentlyOpenModel=False,
namedInstance="",
userID="",
password="")
model.ExecCalculation(True)
Contact
-------
If you'd like to report a bug or suggest an improvement for the SIR 3S Toolkit, please `open a new issue on GitHub <https://github.com/3SConsult/sir3stoolkit/issues>`_. Describe the situation in detail — whether it's a bug you encountered or a feature you'd like to see improved. Feel free to attach images or other relevant materials to help us better understand your request.
For other requests, please contact us at `sir3stoolkit@3sconsult.de <mailto:sir3stoolkit@3sconsult.de>`_.
License
-------
MIT License. See `LICENSE <https://github.com/3SConsult/sir3stoolkit/blob/master/LICENSE>`_ for details.
| text/x-rst | null | 3S Consult GmbH <sir3stoolkit@3sconsult.de> | null | null | MIT | Python, 3S, SIR 3S, SirGraf, SirCalc, 3S Consult, network, pipeline, analysis, automation, engineering, simulation, hydraulics, gas, water, district heating, oil | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Framework :: Jupyter",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"numpy",
"pythonnet",
"pytest; extra == \"dev\"",
"flake8; extra == \"dev\"",
"build; extra == \"dev\"",
"twine; extra == \"dev\"",
"sphinx; extra == \"sphinx\"",
"sphinx_rtd_theme; extra == \"sphinx\"",
"nbsphinx; extra == \"sphinx\"",
"sphinx_copybutton; extra == \"sphinx\"",
"sphinx_togglebutton; extra == \"sphinx\"",
"pytoolconfig; extra == \"sphinx\"",
"pandas; extra == \"mantle\"",
"pandapipes; extra == \"mantle\"",
"shapely; extra == \"mantle\"",
"attrs; extra == \"mantle\"",
"pytoolconfig; extra == \"mantle\"",
"networkx; extra == \"mantle\"",
"matplotlib; extra == \"mantle\"",
"geopandas; extra == \"mantle\""
] | [] | [] | [] | [
"Documentation, https://3sconsult.github.io/sir3stoolkit",
"Source, https://github.com/3SConsult/sir3stoolkit",
"Repository, https://github.com/3SConsult/sir3stoolkit.git",
"Issues, https://github.com/3SConsult/sir3stoolkit/issues",
"Download, https://pypi.org/project/sir3stoolkit/#files"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-20T12:13:27.058872 | sir3stoolkit-90.15.13.tar.gz | 56,946 | b0/6a/1b4dc2c74b7ac897d7344bb5dcb292a9785b7e8e32abe39888d78544d371/sir3stoolkit-90.15.13.tar.gz | source | sdist | null | false | 5bb4813be28fff69e36d851ac9285d41 | 51345b03b7644400d1ccc62b0a0d3eb91c4ba57d144505a5bcee367e1273367b | b06a1b4dc2c74b7ac897d7344bb5dcb292a9785b7e8e32abe39888d78544d371 | null | [
"LICENSE"
] | 203 |
2.4 | openslides-ai | 1.0.0 | Brand-first slide deck library. Full creative control, zero abstraction tax. | # openslides
[](https://www.python.org/downloads/)
[](LICENSE)
[](https://github.com/federicodeponte/openslides/actions)
**Brand-first Python slide deck generator.** Create pitch decks, investor presentations, and sales slides with full creative control. Extract brand colors and fonts from any website, write HTML/CSS slides, export to PNG or PDF.
> Generate professional slide decks programmatically. No templates, no themes, no fighting the framework.

```python
from openslides import Brand, export, base_html
brand = Brand.from_domain("scaile.tech") # Auto-extract colors, fonts, logo
def slide_hero():
return f'''
{base_html(brand)}
<body style="background:{brand.background}; padding:80px;">
<h1 style="font-family:'{brand.font_headline}'; font-size:72px; color:{brand.text};">
Get into <span style="color:{brand.primary};">ChatGPT</span> answers.
</h1>
</body></html>
'''
export([slide_hero()], "/tmp/my-deck/") # → PNG files
```
## Why openslides?
Most slide libraries force you into preset themes that never match your brand. You end up fighting the abstraction.
**openslides is different:**
- **Brand-first**: Extract colors/fonts from any website, or define manually
- **Full control**: You write HTML/CSS, the library just helps with boilerplate
- **No magic**: Brand values are explicit in your code, not hidden in themes
- **~300 lines**: Simple enough to understand in 10 minutes
## Install
```bash
pip install openslides
playwright install chromium
# Optional: for brand extraction from URLs
pip install aiohttp
```
## Quick Start
### Option 1: Extract brand from website
```python
from openslides import Brand, export, base_html
# Auto-extract colors, fonts, logo from website
brand = Brand.from_domain("stripe.com")
print(brand.primary) # "#635bff"
print(brand.font_headline) # "Inter"
```
### Option 2: Define brand manually
```python
brand = Brand(
primary="#054dfe", # Main accent (CTAs, highlights)
secondary="#15aebf", # Secondary accent
background="#fdfbf5", # Slide background
surface="#ffffff", # Cards, elevated surfaces
text="#191919", # Primary text
muted="#6b6b6b", # Secondary text
font_headline="Syne", # Headlines
font_body="Inter", # Body text
)
```
### Create slides
Each slide is a function returning HTML. Use f-strings to inject brand values:
```python
def slide_hero():
return f'''
{base_html(brand)}
<body style="background:{brand.background}; padding:80px;">
<div style="font-size:12px; color:{brand.primary}; text-transform:uppercase; letter-spacing:2px;">
The Problem
</div>
<h1 style="font-family:'{brand.font_headline}'; font-size:64px; color:{brand.text}; margin-top:20px;">
Your buyers don't Google anymore.
<span style="color:{brand.muted};">They ask ChatGPT.</span>
</h1>
</body></html>
'''
def slide_solution():
return f'''
{base_html(brand)}
<body style="background:{brand.surface}; padding:80px;">
<h1 style="font-family:'{brand.font_headline}'; font-size:64px;">
We make AI recommend <span style="color:{brand.primary};">your brand.</span>
</h1>
</body></html>
'''
```
### Export to PNG/PDF
```python
slides = [slide_hero(), slide_solution()]
# Export to PNG (default)
paths = export(slides, "/tmp/my-deck/")
# Creates: /tmp/my-deck/slide-01.png, slide-02.png, ...
# Export to PDF
paths = export(slides, "/tmp/my-deck/", format="pdf")
# Or use convenience function:
paths = export_pdf(slides, "/tmp/my-deck/")
```
## CLI
Build decks from the command line:
```bash
# Build to PNG
openslides build examples/scaile.py -o /tmp/scaile-deck/
# Build to PDF
openslides build examples/scaile.py -o /tmp/scaile-deck/ -f pdf
# List slides in a deck file
openslides list examples/scaile.py
# Custom dimensions
openslides build examples/scaile.py -W 1280 -H 720
```
## API Reference
### `Brand`
Dataclass holding brand assets.
**Attributes:**
- `primary` - Main accent color (hex)
- `secondary` - Secondary accent color
- `background` - Slide background color
- `surface` - Card/surface background
- `text` - Primary text color
- `muted` - Secondary/muted text color
- `font_headline` - Headline font family
- `font_body` - Body text font family
- `logo_svg` - Logo as inline SVG (optional)
- `logo_url` - Logo URL (optional)
- `name` - Brand name
- `domain` - Source domain
**Validation:**
- Color fields must be valid hex colors (e.g., `#054dfe` or `#fff`)
- Invalid colors raise `ValueError`
**Methods:**
- `Brand.from_domain(url)` - Extract brand from website (requires aiohttp)
- `brand.google_fonts_url` - Google Fonts URL for brand fonts
### `base_html(brand)`
Generate HTML boilerplate with brand fonts loaded. Returns everything up to `<body>`.
```python
base_html(brand)
# Returns: <!DOCTYPE html><html>...<head>...<link href="fonts.googleapis.com/...">...</head>
```
### `base_styles(brand)`
Generate common CSS classes using brand values. Use inside a `<style>` tag.
```python
f'<style>{base_styles(brand)}</style>'
# Provides: .headline, .body-text, .muted, .accent, .card, .label, .btn
```
### `export(slides, output_dir, format="png")`
Export slides to PNG or PDF files.
```python
paths = export(slides, "/tmp/deck/", width=1920, height=1080)
paths = export(slides, "/tmp/deck/", format="pdf")
```
### `export_pdf(slides, output_dir)`
Convenience wrapper for PDF export.
```python
paths = export_pdf(slides, "/tmp/deck/")
```
### `export_async(slides, output_dir, format="png")`
Async version of export. Use if already in async context.
### Logo Helpers
**`clearbit_logo(domain, size=40)`** - Get logo img tag via Clearbit (free, no auth):
```python
from openslides import clearbit_logo
logo = clearbit_logo("stripe.com", size=40)
# Returns: <img src="https://logo.clearbit.com/stripe.com" alt="logo" style="height:40px;" />
```
**`brand.logo_img(size=40)`** - Get logo from Brand (uses logo_svg, logo_url, or Clearbit fallback):
```python
logo = brand.logo_img(size=48)
# Uses: brand.logo_svg if set, else brand.logo_url, else Clearbit
```
**`brand.clearbit_logo_url`** - Direct Clearbit URL:
```python
url = brand.clearbit_logo_url
# Returns: "https://logo.clearbit.com/{domain}"
```
## Philosophy
The best slide decks are **brand-specific**, not generic. openslides gives you:
1. **Brand extraction** - Get colors/fonts from any website
2. **Explicit values** - Brand values visible in your code
3. **Full control** - Write whatever HTML/CSS you want
4. **Simple export** - Playwright renders to PNG
No themes. No components. No fighting the framework.
## License
MIT
| text/markdown | null | Federico De Ponte <depontefede@gmail.com> | null | null | MIT | slides, presentation, pitch-deck, brand, html, png | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"playwright>=1.40.0",
"aiohttp>=3.9.0; extra == \"extract\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/federicodeponte/openslides",
"Repository, https://github.com/federicodeponte/openslides"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-20T12:13:05.429867 | openslides_ai-1.0.0.tar.gz | 17,514 | ab/69/3c4da85a69f6549b2b2f24cbfc05f4d0f2b9bf8722a44849745d0fa98ee9/openslides_ai-1.0.0.tar.gz | source | sdist | null | false | 1f0b9d981dd31a92f676e7e7fd3c8460 | 19caa09a50c38fcdf34529ce87d90561e42827ba74b7ead5ce5833f5a886dae2 | ab693c4da85a69f6549b2b2f24cbfc05f4d0f2b9bf8722a44849745d0fa98ee9 | null | [
"LICENSE"
] | 205 |
2.4 | yta-video-frame-time | 0.1.10 | Youtube Autonomous Video Frame Time Module | # Youtube Autonomous Video Frame Time Module
The way to handle video frame timing | text/markdown | danialcala94 | danielalcalavalera@gmail.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9"
] | [] | null | null | ==3.9 | [] | [] | [] | [
"yta_validation<1.0.0,>=0.0.1",
"quicktions<9.0.0,>=0.0.1"
] | [] | [] | [] | [] | poetry/2.2.0 CPython/3.9.0 Windows/10 | 2026-02-20T12:12:47.064751 | yta_video_frame_time-0.1.10.tar.gz | 11,480 | 93/57/9d679c84f41682190b6dbb7f2b3d83f6dce65935bb4a777ff0103b44d90d/yta_video_frame_time-0.1.10.tar.gz | source | sdist | null | false | 275926e8bde6800ca57e3b0beb02fdc7 | e3cf6567471249e802bfc9395bea96e08c72b475e814f7a70f24f108dec95289 | 93579d679c84f41682190b6dbb7f2b3d83f6dce65935bb4a777ff0103b44d90d | null | [] | 191 |
2.4 | nexios | 3.8.1 | Nexios is a modern, high-performance ASGI web framework for Python with multi-server support with zero overhead. | ## `NEXIOS`
<div align="left">
<a href="https://git.io/typing-svg"><img src="https://readme-typing-svg.demolab.com?font=Fira+Code&pause=1000&color=4CAF50¢er=true&width=435&lines=Nexios+ASGI+Framework;Fast%2C+Simple%2C+Flexible" alt="Typing SVG" /></a>
<p align="center">
<img alt=Support height="350" src="https://nexioslabs.com/logo.png">
</p>
<h1 align="center">Nexios 3.x.x</h1>
</a>
</p>
<!-- Badges Section -->
<p align="center">
<img src="https://img.shields.io/badge/Python-3.9+-blue?logo=python" alt="Python Version">
<img src="https://img.shields.io/badge/Downloads-10k/month-brightgreen" alt="Downloads">
<img src="https://img.shields.io/badge/Contributions-Welcome-orange" alt="Contributions">
<img src="https://img.shields.io/badge/Active Development-Yes-success" alt="Active Development">
</p>
<p align="center">
<a href="https://github.com/nexios-labs/Nexios?tab=followers"><img title="Followers" src="https://img.shields.io/github/followers/nexios-labs?label=Followers&style=social"></a>
<a href="https://github.com/nexios-labs/Nexios/stargazers/"><img title="Stars" src="https://img.shields.io/github/stars/nexios-labs/Nexios?&style=social"></a>
<a href="https://github.com/nexios-labs/Nexios/network/members"><img title="Fork" src="https://img.shields.io/github/forks/nexios-labs/Nexios?style=social"></a>
<a href="https://github.com/nexios-labs/Nexios/watchers"><img title="Watching" src="https://img.shields.io/github/watchers/nexios-labs/Nexios?label=Watching&style=social"></a>
</br>
<h2 align="center"> Star the repo if u like it🌟</h2>
Nexios is a utility-first Python web framework designed for developers who need powerful tooling and extensibility. Built with a modular architecture, Nexios provides a comprehensive toolkit for building everything from simple APIs to complex distributed systems. The framework emphasizes developer productivity through its rich ecosystem of utilities, middleware, and community-contributed extensions. Whether you're building microservices, real-time applications, or enterprise-grade backends, Nexios gives you the tools and flexibility to craft solutions that scale with your needs.
---
## `Installation` 📦
**Requirements:**
- Python 3.9 or higher
- pip (Python package manager)
To install **Nexios**, you can use several methods depending on your environment and preferred package manager. Below are the instructions for different package managers:
### 1. **From `pip`** (Standard Python Package Manager)
```bash
# Ensure you have Python 3.9+
python --version
# Install Nexios
pip install nexios
# Or install with specific version
pip install nexios == 3.4.0
```
## Utility-First Features ✨
### Core Utilities & Tooling
- [x] **Modular Architecture** - Mix and match components as needed
- [x] **Rich CLI Tooling** - Project scaffolding, code generation, and development tools
- [x] **Plugin System** - Extensible architecture for custom functionality
- [x] **Developer Utilities** - Debug toolbar, profiling, and development helpers
- [x] **Testing Framework** - Built-in testing utilities and fixtures
### Web Framework Essentials
- [x] **Powerful Routing** - Type-safe routing with parameter validation
- [x] **Automatic OpenAPI Documentation** - Self-documenting APIs
- [x] **Authentication Toolkit** - Multiple auth backends and strategies
- [x] **Middleware Pipeline** - Composable request/response processing
- [x] **WebSocket Support** - Real-time communication utilities
- [x] **Session Management** - Flexible session handling
### Community & Extensibility
- [x] **Community Contrib Package** - nexios-contrib with community extensions
- [x] **Custom Middleware Support** - Build and share your own middleware
- [x] **Event System** - Hook into framework events and signals
- [x] **Dependency Injection** - Clean, testable code architecture
- [x] **Security Utilities** - CORS, CSRF, secure headers, and more
### Quick Start - Utility-First Approach
```py
from nexios import NexiosApp
from nexios.http import Request, Response
# Create app with built-in utilities
app = NexiosApp(title="My Utility API")
@app.get("/")
async def basic(request: Request, response: Response):
return {"message": "Hello from Nexios utilities!"}
```
### Using Community Extensions
```py
from nexios import NexiosApp, Depend
from nexios_contrib.etag import ETagMiddleware
from nexios_contrib.trusted import TrustedHostMiddleware
from nexios.http import Request, Response
app = NexiosApp()
# Add community-contributed middleware
app.add_middleware(ETagMiddleware())
app.add_middleware(TrustedHostMiddleware(allowed_hosts=["example.com"]))
# Utility function with dependency injection
async def get_database():
# Your database utility here
return {"connection": "active"}
@app.get("/health")
async def health_check(request: Request, response: Response, db: Depend(get_database)):
return {"status": "healthy", "database": db}
```
Visit <http://localhost:8000/docs> to view the Swagger API documentation.
## See the full docs
👉 <a href="https://nexioslabs.com">https://nexioslabs.com</a>
## Contributors
<a href="https://github.com/nexios-labs/nexios/graphs/contributors">
<img src="https://contrib.rocks/image?repo=nexios-labs/nexios" />
</a>
---
## 🌟 Community-Driven Development
Nexios thrives on community contributions and collaboration. We believe the best tools are built by developers, for developers.
### Get Involved
- **Contribute Code**: Submit PRs to the main framework or [nexios-contrib](https://github.com/nexios-labs/contrib)
- **Share Utilities**: Create and share your own middleware, plugins, and tools
- **Join Discussions**: Participate in [GitHub Discussions](https://github.com/nexios-labs/nexios/discussions)
- **Help Others**: Answer questions and help fellow developers
### Community Resources
- 📚 **Documentation**: [https://nexioslabs.com](https://nexioslabs.com)
- 🛠️ **Community Extensions**: [nexios-contrib package](https://github.com/nexios-labs/contrib)
- 💬 **Discussions**: [GitHub Discussions](https://github.com/nexios-labs/nexios/discussions)
- 🐛 **Issues**: [Report bugs and request features](https://github.com/nexios-labs/nexios/issues)
### Support the Project
If Nexios has helped you build something awesome, consider supporting its continued development:
👉 [**Buy Me a Coffee**](https://www.buymeacoffee.com/techwithdul) and help fuel the community-driven future of Nexios.
| text/markdown | null | Chidebele Dunamis <techwithdunamix@gmail.com> | null | null | null | API, ASGI, HTTP, Python, async, asynchronous, backend, concurrent, framework, granian, real-time, scalable, uvicorn, web, web server, websocket | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio==4.12.1",
"itsdangerous>=2.1.2",
"pydantic<3.0,>=2.0",
"python-multipart>=0.0.6",
"typing-extensions>=4.12.2; python_version < \"3.10\"",
"uvicorn>=0.27.0",
"anyio>=4.0.0; extra == \"all\"",
"click>=8.1.3; extra == \"all\"",
"granian>=1.2.0; extra == \"all\"",
"itsdangerous>=2.1.2; extra == \"all\"",
"jinja2>=3.1.6; extra == \"all\"",
"pyjwt>=2.7.0; extra == \"all\"",
"python-multipart>=0.0.6; extra == \"all\"",
"uvicorn>=0.27.0; extra == \"all\"",
"click>=8.1.3; extra == \"cli\"",
"anyio>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"click>=8.1.3; extra == \"dev\"",
"coverage<8.0,>=6.3; extra == \"dev\"",
"httpx<0.29.0,>=0.23.3; extra == \"dev\"",
"isort>=5.13.2; extra == \"dev\"",
"itsdangerous>=2.1.2; extra == \"dev\"",
"jinja2>=3.1.6; extra == \"dev\"",
"mypy>=1.15.0; extra == \"dev\"",
"pyjwt>=2.7.0; extra == \"dev\"",
"pytest-asyncio<1.4.0,>=0.25.3; extra == \"dev\"",
"pytest<9.1.0,>=8.3.4; extra == \"dev\"",
"python-multipart>=0.0.6; extra == \"dev\"",
"ruff>=0.0.256; extra == \"dev\"",
"typing-extensions==4.15.0; extra == \"dev\"",
"uvicorn>=0.27.0; extra == \"dev\"",
"granian>=1.2.0; extra == \"granian\"",
"anyio>=4.0.0; extra == \"http\"",
"itsdangerous>=2.1.2; extra == \"http\"",
"python-multipart>=0.0.6; extra == \"http\"",
"uvicorn>=0.27.0; extra == \"http\"",
"pyjwt>=2.7.0; extra == \"jwt\"",
"jinja2>=3.1.6; extra == \"templating\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T12:12:32.237641 | nexios-3.8.1-py3-none-any.whl | 200,377 | 4c/81/d39ca570d431e0e22e2dc044dd277b353bb231ce29d1fdeb6adf6f01fde5/nexios-3.8.1-py3-none-any.whl | py3 | bdist_wheel | null | false | d59f1541a3ab6516a949b513bdc7e4d2 | 9243056cd486d70acb788d57d4f3e6bbd7e33d539954f167fb8f964343c3fa43 | 4c81d39ca570d431e0e22e2dc044dd277b353bb231ce29d1fdeb6adf6f01fde5 | BSD-3-Clause | [
"LICENSE"
] | 250 |
2.4 | rhiza | 0.11.1b2 | Reusable configuration templates for modern Python projects | <div align="center">
# <img src="https://raw.githubusercontent.com/Jebel-Quant/rhiza/main/.rhiza/assets/rhiza-logo.svg" alt="Rhiza Logo" width="30" style="vertical-align: middle;"> rhiza-cli

[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/rhiza/)
[](https://jebel-quant.github.io/rhiza-cli/tests/html-coverage/index.html)
[](https://pepy.tech/project/rhiza)
[](https://www.codefactor.io/repository/github/jebel-quant/rhiza-cli)
Command-line interface for managing reusable configuration templates for modern Python projects.
**📖 New to Rhiza? Check out the [Getting Started Guide](GETTING_STARTED.md) for a beginner-friendly introduction!**
</div>
## Overview
Rhiza is a CLI tool that helps you maintain consistent configuration across multiple Python projects by using templates stored in a central repository. It allows you to:
- Initialize projects with standard configuration templates
- Materialize (inject) templates into target repositories
- Validate template configurations
- Keep project configurations synchronized with template repositories
## Table of Contents
- [Overview](#overview)
- [Installation](#installation)
- [Quick Start](#quick-start)
- [Commands](#commands)
- [init](#rhiza-init)
- [materialize](#rhiza-materialize)
- [migrate](#rhiza-migrate)
- [validate](#rhiza-validate)
- [Configuration](#configuration)
- [Examples](#examples)
- [Development](#development)
- [Additional Documentation](#additional-documentation)
## Additional Documentation
For more detailed information, see:
- **[Getting Started Guide](GETTING_STARTED.md)** - Beginner-friendly introduction and walkthrough
- **[CLI Quick Reference](CLI.md)** - Command syntax and quick examples
- **[Usage Guide](USAGE.md)** - Practical tutorials and workflows
- **[Contributing Guidelines](CONTRIBUTING.md)** - How to contribute to the project
- **[Code of Conduct](CODE_OF_CONDUCT.md)** - Community guidelines
## Installation
### Using pip
```bash
pip install rhiza
```
To update to the latest version:
```bash
pip install --upgrade rhiza
```
### Using uvx (run without installation)
[uvx](https://docs.astral.sh/uv/) is part of the `uv` package manager and allows you to run CLI tools directly without installing them:
```bash
uvx rhiza --help
```
With uvx, you don't need to install rhiza globally. Each time you run `uvx rhiza`, it will automatically use the latest version available on PyPI. To ensure you're using the latest version, simply run your command - uvx will fetch updates as needed:
```bash
# Always uses the latest version
uvx rhiza init
uvx rhiza materialize
uvx rhiza validate
```
If you want to use a specific version:
```bash
uvx rhiza@0.5.6 --help
```
### From source
```bash
git clone https://github.com/jebel-quant/rhiza-cli.git
cd rhiza-cli
pip install -e .
```
### Using uv (recommended for development)
```bash
git clone https://github.com/jebel-quant/rhiza-cli.git
cd rhiza-cli
make install
```
### Verify installation
```bash
rhiza --help
```
## Quick Start
1. **Initialize a project with Rhiza templates:**
```bash
cd your-project
rhiza init
```
This creates a `.rhiza/template.yml` file with default configuration.
2. **Customize the template configuration:**
Edit `.rhiza/template.yml` to specify which files/directories to include from your template repository.
3. **Materialize templates into your project:**
```bash
rhiza materialize
```
This fetches and copies template files into your project.
4. **Validate your configuration:**
```bash
rhiza validate
```
This checks that your `.rhiza/template.yml` is correctly formatted and valid.
## Commands
### `rhiza init`
Initialize or validate `.rhiza/template.yml` in a target directory.
**Usage:**
```bash
rhiza init [OPTIONS] [TARGET]
```
**Arguments:**
- `TARGET` - Target directory (defaults to current directory)
**Options:**
- `--project-name <name>` - Custom project name (defaults to directory name)
- `--package-name <name>` - Custom package name (defaults to normalized project name)
- `--with-dev-dependencies` - Include development dependencies in pyproject.toml
- `--git-host <host>` - Target Git hosting platform (github or gitlab). Determines which CI/CD files to include. If not provided, will prompt interactively.
- `--template-repository <owner/repo>` - Custom template repository (format: owner/repo). Defaults to 'jebel-quant/rhiza'.
- `--template-branch <branch>` - Custom template branch. Defaults to 'main'.
**Description:**
Creates a default `.rhiza/template.yml` file if it doesn't exist, or validates an existing one. The default configuration includes common Python project files like `.github`, `.editorconfig`, `.gitignore`, `.pre-commit-config.yaml`, `Makefile`, and `pytest.ini`.
You can customize the template source by specifying your own template repository and branch using the `--template-repository` and `--template-branch` options.
**Examples:**
```bash
# Initialize in current directory
rhiza init
# Initialize in a specific directory
rhiza init /path/to/project
# Initialize with GitLab CI configuration
rhiza init --git-host gitlab
# Use a custom template repository
rhiza init --template-repository myorg/my-templates
# Use a custom template repository and branch
rhiza init --template-repository myorg/my-templates --template-branch develop
# Initialize in parent directory
rhiza init ..
```
**Output:**
When creating a new template file:
```
[INFO] Initializing Rhiza configuration in: /path/to/project
[INFO] Creating default .rhiza/template.yml
✓ Created .rhiza/template.yml
Next steps:
1. Review and customize .rhiza/template.yml to match your project needs
2. Run 'rhiza materialize' to inject templates into your repository
```
When validating an existing file:
```
[INFO] Validating template configuration in: /path/to/project
✓ Found template file: /path/to/project/.rhiza/template.yml
✓ YAML syntax is valid
✓ Field 'template-repository' is present and valid
✓ Field 'include' is present and valid
✓ template-repository format is valid: jebel-quant/rhiza
✓ include list has 6 path(s)
✓ Validation passed: template.yml is valid
```
---
### `rhiza materialize`
Inject Rhiza configuration templates into a target repository.
**Usage:**
```bash
rhiza materialize [OPTIONS] [TARGET]
```
**Arguments:**
- `TARGET` - Target git repository directory (defaults to current directory)
**Options:**
- `--branch, -b TEXT` - Rhiza branch to use [default: main]
- `--force, -y` - Overwrite existing files without prompting
- `--help` - Show help message and exit
**Description:**
Materializes template files from the configured template repository into your target project. This command:
1. Reads the `.rhiza/template.yml` configuration
2. Performs a sparse clone of the template repository
3. Copies specified files/directories to your project
4. Respects exclusion patterns defined in the configuration
**Examples:**
```bash
# Materialize templates in current directory
rhiza materialize
# Materialize templates from a specific branch
rhiza materialize --branch develop
# Materialize and overwrite existing files
rhiza materialize --force
# Materialize in a specific directory with custom branch
rhiza materialize /path/to/project --branch v2.0 --force
# Short form with all options
rhiza materialize -b main -y
```
**Output:**
```
[INFO] Target repository: /path/to/project
[INFO] Rhiza branch: main
[INFO] Initializing Rhiza configuration in: /path/to/project
[INFO] Include paths:
- .github
- .editorconfig
- .gitignore
- .pre-commit-config.yaml
- Makefile
- pytest.ini
[INFO] Cloning jebel-quant/rhiza@main into temporary directory
[ADD] .github/workflows/ci.yml
[ADD] .editorconfig
[ADD] .gitignore
[ADD] Makefile
✓ Rhiza templates materialized successfully
Next steps:
1. Review changes:
git status
git diff
2. Commit:
git add .
git commit -m "chore: import rhiza templates"
This is a one-shot snapshot.
Re-run this script to update templates explicitly.
```
**Notes:**
- Files that already exist will not be overwritten unless `--force` is used
- The command performs a sparse clone for efficiency
- Template files are copied with their original permissions
- Excluded paths (if defined) are filtered out
---
### `rhiza migrate`
Migrate project to the new `.rhiza` folder structure.
**Usage:**
```bash
rhiza migrate [OPTIONS] [TARGET]
```
**Arguments:**
- `TARGET` - Target git repository directory (defaults to current directory)
**Arguments:**
- `TARGET` - Target git repository directory (defaults to current directory)
**Description:**
Migrates your project to use the new `.rhiza/` folder structure for storing Rhiza state and configuration files. This command helps transition from the old structure where configuration was stored in `.github/rhiza/` and `.rhiza.history` in the project root.
The migration performs the following actions:
1. Creates the `.rhiza/` directory in the project root
2. Moves `template.yml` from `.github/rhiza/` or `.github/` to `.rhiza/template.yml`
3. Moves `.rhiza.history` to `.rhiza/history`
4. Provides instructions for next steps
The new `.rhiza/` folder structure provides better organization by separating Rhiza's state and configuration from the `.github/` directory.
**Examples:**
```bash
# Migrate current directory
rhiza migrate
# Migrate a specific directory
rhiza migrate /path/to/project
```
**Output:**
```
[INFO] Migrating Rhiza structure in: /path/to/project
[INFO] This will create the .rhiza folder and migrate configuration files
[INFO] Creating .rhiza directory at: .rhiza
✓ Created .rhiza
[INFO] Found template.yml at: .rhiza/template.yml
[INFO] Moving to new location: .rhiza/template.yml
✓ Moved template.yml to .rhiza/template.yml
✓ Migration completed successfully
Migration Summary:
- Created .rhiza/ folder
- Moved template.yml to .rhiza/template.yml
- Moved history tracking to .rhiza/history
Next steps:
1. Review changes:
git status
git diff
2. Update other commands to use new .rhiza/ location
(Future rhiza versions will automatically use .rhiza/)
3. Commit the migration:
git add .
git commit -m "chore: migrate to .rhiza folder structure"
```
**Notes:**
- If files already exist in `.rhiza/`, the migration will skip them and leave the old files in place
- You can manually remove old files after verifying the migration was successful
- The old `.rhiza.history` file is removed after successful migration to `.rhiza/history`
- The original template file in `.github/` is moved (removed from old location)
---
### `rhiza validate`
Validate Rhiza template configuration.
**Usage:**
```bash
rhiza validate [TARGET]
```
**Arguments:**
- `TARGET` - Target git repository directory (defaults to current directory)
**Description:**
Validates the `.rhiza/template.yml` file to ensure it is syntactically correct and semantically valid. This performs authoritative validation including:
- Checking if the file exists
- Validating YAML syntax
- Verifying required fields are present
- Checking field types and formats
- Validating repository name format
- Ensuring include paths are not empty
**Examples:**
```bash
# Validate configuration in current directory
rhiza validate
# Validate configuration in a specific directory
rhiza validate /path/to/project
# Validate parent directory
rhiza validate ..
```
**Exit codes:**
- `0` - Validation passed
- `1` - Validation failed
**Output (success):**
```
[INFO] Validating template configuration in: /path/to/project
✓ Found template file: /path/to/project/.rhiza/template.yml
✓ YAML syntax is valid
✓ Field 'template-repository' is present and valid
✓ Field 'include' is present and valid
✓ template-repository format is valid: jebel-quant/rhiza
✓ include list has 6 path(s)
- .github
- .editorconfig
- .gitignore
- .pre-commit-config.yaml
- Makefile
- pytest.ini
✓ Validation passed: template.yml is valid
```
**Output (failure):**
```
[ERROR] Target directory is not a git repository: /path/to/project
```
or
```
[ERROR] Template file not found: /path/to/project/.rhiza/template.yml
[INFO] Run 'rhiza materialize' or 'rhiza init' to create a default template.yml
```
---
## Configuration
Rhiza uses a `.rhiza/template.yml` file to define template sources and what to include in your project.
### Configuration File Format
The `template.yml` file uses YAML format with the following structure:
```yaml
# Required: GitHub or GitLab repository containing templates (format: owner/repo)
template-repository: jebel-quant/rhiza
# Optional: Git hosting platform (default: github)
template-host: github
# Optional: Branch to use from template repository (default: main)
template-branch: main
# Required: List of paths to include from template repository
include:
- .github
- .editorconfig
- .gitignore
- .pre-commit-config.yaml
- Makefile
- pytest.ini
- ruff.toml
# Optional: List of paths to exclude (filters out from included paths)
exclude:
- .github/workflows/specific-workflow.yml
- .github/CODEOWNERS
```
### Configuration Fields
#### `template-repository` (required)
- **Type:** String
- **Format:** `owner/repository`
- **Description:** GitHub or GitLab repository containing your configuration templates
- **Example:** `jebel-quant/rhiza`, `myorg/python-templates`, `mygroup/gitlab-templates`
#### `template-host` (optional)
- **Type:** String
- **Default:** `github`
- **Options:** `github`, `gitlab`
- **Description:** Git hosting platform where the template repository is hosted
- **Example:** `github`, `gitlab`
#### `template-branch` (optional)
- **Type:** String
- **Default:** `main`
- **Description:** Git branch to use when fetching templates
- **Example:** `main`, `develop`, `v2.0`
#### `include` (required)
- **Type:** List of strings
- **Description:** Paths (files or directories) to copy from the template repository
- **Notes:**
- Paths are relative to the repository root
- Can include both files and directories
- Directories are recursively copied
- Must contain at least one path
**Example:**
```yaml
include:
- .github # Entire directory
- .editorconfig # Single file
- src/config # Subdirectory
```
#### `exclude` (optional)
- **Type:** List of strings
- **Description:** Paths to exclude from the included set
- **Notes:**
- Useful for excluding specific files from broader directory includes
- Paths are relative to the repository root
**Example:**
```yaml
exclude:
- .github/workflows/deploy.yml # Exclude specific workflow
- .github/CODEOWNERS # Exclude specific file
```
### Complete Configuration Example
#### GitHub Example
```yaml
template-repository: jebel-quant/rhiza
template-branch: main
include:
- .github
- .editorconfig
- .gitignore
- .pre-commit-config.yaml
- CODE_OF_CONDUCT.md
- CONTRIBUTING.md
- Makefile
- pytest.ini
- ruff.toml
exclude:
- .github/workflows/release.yml
- .github/CODEOWNERS
```
#### GitLab Example
```yaml
template-repository: mygroup/python-templates
template-host: gitlab
template-branch: main
include:
- .gitlab-ci.yml
- .editorconfig
- .gitignore
- Makefile
- pytest.ini
exclude:
- .gitlab-ci.yml
```
## Examples
### Example 1: Setting up a new Python project
```bash
# Create a new project directory
mkdir my-python-project
cd my-python-project
# Initialize git
git init
# Initialize Rhiza
rhiza init
# Review the generated template.yml
cat .rhiza/template.yml
# Materialize templates
rhiza materialize
# Review the imported files
git status
# Commit the changes
git add .
git commit -m "chore: initialize project with rhiza templates"
```
### Example 2: Updating existing project templates
```bash
# Navigate to your project
cd existing-project
# Validate current configuration
rhiza validate
# Update templates (overwrite existing)
rhiza materialize --force
# Review changes
git diff
# Commit if satisfied
git add .
git commit -m "chore: update rhiza templates"
```
### Example 3: Using a custom template repository
Edit `.rhiza/template.yml`:
```yaml
template-repository: myorg/my-templates
template-branch: production
include:
- .github/workflows
- pyproject.toml
- Makefile
- docker-compose.yml
exclude:
- .github/workflows/experimental.yml
```
Then materialize:
```bash
rhiza materialize --force
```
### Example 4: Using a GitLab template repository
Edit `.rhiza/template.yml`:
```yaml
template-repository: mygroup/python-templates
template-host: gitlab
template-branch: main
include:
- .gitlab-ci.yml
- .editorconfig
- .gitignore
- Makefile
- pytest.ini
```
Then materialize:
```bash
rhiza materialize --force
```
### Example 5: Validating before CI/CD
Add to your CI pipeline:
```yaml
# .github/workflows/validate-rhiza.yml
name: Validate Rhiza Configuration
on: [push, pull_request]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install rhiza
run: pip install rhiza
- name: Validate configuration
run: rhiza validate
```
## Development
### Prerequisites
- Python 3.11 or higher
- `uv` package manager (recommended) or `pip`
- Git
### Setup Development Environment
```bash
# Clone the repository
git clone https://github.com/jebel-quant/rhiza-cli.git
cd rhiza-cli
# Install dependencies
make install
# Run tests
make test
# Run linters and formatters
make fmt
# Generate documentation
make docs
```
### Running Tests
```bash
# Run all tests with coverage
make test
# Run specific test file
pytest tests/test_cli.py
# Run with verbose output
pytest -v
```
### Code Quality
The project uses:
- **Ruff** for linting and formatting
- **pytest** for testing
- **pre-commit** hooks for automated checks
```bash
# Run all quality checks
make fmt
# Run dependency checks
make deptry
```
### Building Documentation
```bash
# Generate API documentation
make docs
# Build complete documentation book
make book
```
## Makefile Targets
The project includes a comprehensive Makefile for common development tasks:
```
Bootstrap
install-uv ensure uv/uvx is installed
install-extras run custom build script (if exists)
install install
clean clean
Development and Testing
test run all tests
marimo fire up Marimo server
marimushka export Marimo notebooks to HTML
deptry run deptry if pyproject.toml exists
Documentation
docs create documentation with pdoc
book compile the companion book
fmt check the pre-commit hooks and the linting
all Run everything
Releasing and Versioning
bump bump version
release create tag and push to remote with prompts
post-release perform post-release tasks
Meta
sync sync with template repository as defined in .rhiza/template.yml
help Display this help message
customisations list available customisation scripts
update-readme update README.md with current Makefile help output
```
Run `make help` to see this list in your terminal.
## Contributing
Contributions are welcome! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
### Reporting Issues
If you find a bug or have a feature request, please open an issue on [GitHub](https://github.com/jebel-quant/rhiza-cli/issues).
### Code of Conduct
This project follows a [Code of Conduct](CODE_OF_CONDUCT.md). By participating, you are expected to uphold this code.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Links
- **PyPI:** https://pypi.org/project/rhiza/
- **Repository:** https://github.com/jebel-quant/rhiza-cli
- **Issues:** https://github.com/jebel-quant/rhiza-cli/issues
- **Documentation:** Generated with `make docs`
- **Companion Book:** https://jebel-quant.github.io/rhiza-cli/ (includes coverage report, API docs, and notebooks)
## Architecture
Rhiza follows a modular architecture:
```
src/rhiza/
├── __init__.py # Package initialization
├── __main__.py # Entry point for python -m rhiza
├── cli.py # Typer app and CLI command definitions
├── models.py # Data models (RhizaTemplate)
└── commands/ # Command implementations
├── __init__.py
├── init.py # Initialize template.yml
├── materialize.py # Materialize templates
└── validate.py # Validate configuration
```
### Design Principles
1. **Thin CLI Layer:** Commands in `cli.py` are thin wrappers that delegate to implementations in `commands/`
2. **Separation of Concerns:** Each command has its own module with focused functionality
3. **Type Safety:** Uses `pathlib.Path` for file operations and Typer for type-checked CLI arguments
4. **Clear Logging:** Uses `loguru` for structured, colored logging output
5. **Validation First:** Always validates configuration before performing operations
## Troubleshooting
### Command not found: rhiza
Ensure the package is installed and your Python scripts directory is in your PATH:
```bash
pip install --user rhiza
# Add ~/.local/bin to PATH if needed
export PATH="$HOME/.local/bin:$PATH"
```
### Template validation fails
Check that:
1. Your `.rhiza/template.yml` file exists
2. The YAML syntax is valid
3. Required fields (`template-repository` and `include`) are present
4. The repository format is `owner/repo`
Run `rhiza validate` for detailed error messages.
### Git clone fails during materialize
Ensure:
1. The template repository exists and is accessible
2. The specified branch exists
3. You have network connectivity to GitHub or GitLab
4. The repository is public (or you have appropriate credentials configured)
5. The `template-host` field matches your repository's hosting platform (defaults to "github")
### Files not being copied
Check:
1. The paths in `include` are correct relative to the template repository root
2. The paths exist in the specified branch
3. Any `exclude` patterns are not filtering out wanted files
4. You're using `--force` if files already exist and need to be overwritten
## FAQ
**Q: Can I use Rhiza with private template repositories?**
A: Yes, as long as you have Git credentials configured that allow access to the repository.
**Q: Does Rhiza support template repositories hosted outside GitHub?**
A: Yes! Rhiza supports both GitHub and GitLab repositories. Use the `template-host` field in your `.rhiza/template.yml` to specify "github" (default) or "gitlab".
**Q: How do I use a GitLab repository as a template source?**
A: Add `template-host: gitlab` to your `.rhiza/template.yml` file. For example:
```yaml
template-repository: mygroup/myproject
template-host: gitlab
include:
- .gitlab-ci.yml
- Makefile
```
**Q: Can I materialize templates from multiple repositories?**
A: Not directly. However, you can run `rhiza materialize` multiple times with different configurations, or combine templates manually.
**Q: What's the difference between `rhiza init` and `rhiza materialize`?**
A: `init` creates or validates the `.rhiza/template.yml` configuration file. `materialize` reads that configuration and actually copies the template files into your project.
**Q: How do I update my project's templates?**
A: Simply run `rhiza materialize --force` to fetch and overwrite with the latest versions from your template repository.
**Q: How do I update rhiza-cli itself?**
A: The update method depends on how you installed rhiza:
- **Using pip**: Run `pip install --upgrade rhiza`
- **Using uvx**: No action needed! `uvx` automatically uses the latest version each time you run it. Just run your command: `uvx rhiza <command>`
- **From source**: Run `git pull` in the repository directory and then `pip install -e .` again
**Q: Can I customize which files are included?**
A: Yes, edit the `include` and `exclude` lists in `.rhiza/template.yml` to control exactly which files are copied.
## Acknowledgments
Rhiza is developed and maintained by the Jebel Quant team as part of their effort to standardize Python project configurations across their portfolio.
| text/markdown | Thomas Schmelzer | null | null | null | MIT | ci, configuration, ruff, taskfile, templates | [
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Topic :: Software Development :: Build Tools"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"cruft>=2.16.0",
"jinja2>=3.1.0",
"loguru>=0.7.3",
"pyyaml==6.0.3",
"typer>=0.20.0",
"rhiza-tools>=0.1.2; extra == \"tools\""
] | [] | [] | [] | [
"Homepage, https://github.com/jebel-quant/rhiza-cli",
"Repository, https://github.com/jebel-quant/rhiza-cli",
"Issues, https://github.com/jebel-quant/rhiza/issues-cli"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-20T12:12:27.135897 | rhiza-0.11.1b2.tar.gz | 266,851 | fb/10/e57e20f60e73bbde7812a81d0381630d578fac2205b24276cb64c86dfd74/rhiza-0.11.1b2.tar.gz | source | sdist | null | false | 5dbdf7eab454bae2c1eb4ec1bb507378 | b4ced2a22f62680fa362f90c8fc4db6f111ba927276bef1cfb12e2c287ad070f | fb10e57e20f60e73bbde7812a81d0381630d578fac2205b24276cb64c86dfd74 | null | [
"LICENSE"
] | 191 |
2.4 | weaviate-orm | 0.1.21 | A lightweight ORM-style layer for Weaviate | # Weaviate ORM
### A Pythonic ORM-style layer for Weaviate
`weaviate-orm` provides a structured, object-oriented interface to the Weaviate vector database. Inspired by traditional ORM patterns, it allows you to define collections as Python classes, automatically generate Weaviate schemas, and perform CRUD and similarity-based queries without leaving the object-oriented paradigm.
## Requirements
- Python 3.11+
- weaviate-client >= 4.16.0
- Weaviate server >= 1.27.0
- For examples using Ollama: a reachable Ollama instance with the "snowflake-arctic-embed2" embedding model available
### Server Requirements
**Weaviate 1.27.0 or higher** is required. The `weaviate-client >= 4.16.0` enforces this constraint. During engine initialization, the ORM performs a runtime check:
```python
engine = Weaviate_Engine()
engine.create_all_schemas() # Raises RuntimeError if server version < 1.27.0
```
Why 1.27.0?
- Unified vector configuration API (`Configure.Vectors.*` instead of deprecated `vectorizer_config`)
- Robust named vector support
- Improved schema handling and stability
If your server doesn't meet this requirement, the engine will raise a clear error:
```
RuntimeError: Weaviate server version 1.25.4 is not supported.
Please use Weaviate >= 1.27.0 to match the client requirements.
```
## Features
- **Declarative Schema Definition**
Define collections using Python classes and descriptors for properties and cross-references.
- **Dynamic Schema Generation via Metaclass**
A metaclass extracts property and reference definitions to auto-generate Weaviate-compatible schema structures.
- **Polymorphic References** ✨
Define references to base classes to accept objects from multiple subclass collections. Includes automatic type tracking and runtime type resolution.
- **Object-Oriented CRUD Operations**
Seamlessly create, retrieve, update, and delete data using instance methods — no raw queries needed.
- **Recursive Save & Update**
Handles deeply nested references and automatically saves or updates related objects when desired.
- **Flexible Engine Binding**
The engine takes any connection method from the `weaviate` library, allowing support for local, remote, or custom configurations.
- **UUID Management**
Built-in support for both `uuid4` and `uuid5` strategies — including UUID validation and immutability enforcement.
- **Optional Auto-loading of References**
Cross-references can be automatically resolved into full model instances when accessed.
- **Support for Near-Vector and Near-Text Queries**
Leverage Weaviate’s native similarity search APIs directly from your model classes.
- **Strict Typing and Validation**
Type enforcement and optional validation logic on properties and references using Python descriptors.
- **Fully Tested**
Includes both unit and integration tests with Pytest and Docker-based Weaviate setups.
---
## Design Patterns
- **Descriptor Pattern**
Custom `Property` and `Reference` descriptors manage validation, casting, and schema representation of scalar and relational fields.
- **Metaclass-Based Schema Introspection**
A metaclass (`Weaviate_Meta`) dynamically collects all descriptors from a class and builds the full Weaviate schema. It also generates a dynamic `__init__` constructor based on the field signatures.
- **Engine Abstraction Layer**
The `Weaviate_Engine` encapsulates connection logic and schema management. It supports any connection method compatible with the `weaviate` Python client (e.g., local, remote, or cloud).
- **Instance-Oriented CRUD**
CRUD operations (including recursive reference handling and UUID safety checks) are exposed as instance methods on models that inherit from `Base_Model`.
- **Reference Resolution Strategy**
`Reference` descriptors can be configured to auto-load full objects (not just UUIDs), and support both one-way and two-way references, as well as single or list cardinalities.
---
## Installation
You can install `weaviate_orm` either from PyPI (once published) or directly from the source repository.
### 📦 From PyPI (recommended)
```bash
pip install weaviate-orm
```
### 🛠 From Git (development and testing)
```bash
git clone https://gitlab.opencode.de/bbsr_ida_public/weaviate_orm.git
cd weaviate_orm
pip install -e .
```
Note: Make sure your Python environment includes a compatible Weaviate client (>= 4.16.0):
```bash
pip install "weaviate-client>=4.16.0"
```
## Quick Start
In this example, we will use a local Weaviate instance using text2vec_ollama as the default vectorizer with a local ollama instance running and providing "snowflake-arctic-embed2" as embedding model.
### Create a Model (vector_config)
Create two related models `Paper` and `Author` and specify configuration for the weaviate schema.
```python
from __future__ import annotations
import os
from uuid import UUID, uuid5
import datetime
from weaviate_orm.weaviate_base import Base_Model
from weaviate_orm.weaviate_property import Property
from weaviate_orm.weavitae_reference import Reference, Reference_Type
from weaviate.classes.config import Configure, DataType
# Get the host and port from environment variables
llm_host = os.getenv("LLM_HOST", "llm")
llm_port = int(os.getenv("LLM_PORT", 11434))
class Paper(Base_Model):
# Use _vector_config (new API) – replaces deprecated vectorizer_config
# Protected with underscore prefix to prevent accidental overrides
_vector_config = Configure.Vectors.text2vec_ollama(
api_endpoint = f"http://{llm_host}:{llm_port}", #api-endpoint for the local ollama model
model = "snowflake-arctic-embed2", #Embedding model to use
vectorize_collection_name = False
)
title = Property(cast_type=str, description="The title of the paper", required=True, weaviate_type=DataType.TEXT, vectorize_property_name=True)
abstract = Property(cast_type=str, description="The abstract of the paper", required=True, weaviate_type=DataType.TEXT, vectorize_property_name=True)
pub_date = Property(cast_type=datetime.date, description="The publication date of the paper", required=True, weaviate_type=DataType.DATE, skip_vectorization=True)
doi = Property(cast_type=str, description="The doi of the paper", required=True, weaviate_type=DataType.TEXT, skip_vectorization=True)
author = Reference(target_collection_name="Author", auto_loading=True, description="The author of the paper", reference_type=Reference_Type.SINGLE, way_type=Reference_Type.TWOWAY, required=False, skip_validation=True)
co_authors = Reference(target_collection_name="Author", auto_loading=False, description="The co-authors of the paper", reference_type=Reference_Type.LIST, way_type=Reference_Type.ONEWAY, required=False, skip_validation=True)
_namespace = UUID("eb8bc242-5f59-4a47-8230-0cea6fcc1028")
def _get_uuid_name_string(self):
return self.doi
class Author(Base_Model):
first_name = Property(cast_type=str, description="The first name of the author", required=True, weaviate_type=DataType.TEXT, vectorize_property_name=True)
last_name = Property(cast_type=str, description="The last name of the author", required=True, weaviate_type=DataType.TEXT, vectorize_property_name=True)
orc_id = Property(cast_type=str, description="The orc_id of the author", required=False, weaviate_type=DataType.TEXT, skip_vectorization=True)
papers = Reference(target_collection_name="Paper", auto_loading=False, description="The papers of the author", reference_type=Reference_Type.LIST, way_type=Reference_Type.TWOWAY, required=False, skip_validation=True)
_namespace = UUID("eb8bc242-5f59-4a47-8230-0cea6fcc1028")
def _get_uuid_name_string(self) -> str:
return f"{self.first_name} {self.last_name}"
```
### Create a Weaviate Engine, Register Models, and Create Schema
```python
from weaviate_orm.weaviate_engine import Weaviate_Engine
from weaviate import connect_to_local, connect_to_weaviate_cloud
# Get host and ports from environment variables
host = os.getenv("WEAVIATE_HOST", "vdatabase")
port = int(os.getenv("WEAVIATE_PORT", 8080))
grpc_port = int(os.getenv("WEAVIATE_GRPC_PORT", 50051))
# Initialize the Weaviate engine using the connect_to_local method and its parameters
engine = Weaviate_Engine(connect_to_local, host=host, port=port, grpc_port=grpc_port)
# Register the models with the engine
engine.register_all_models(Paper, Author)
# Create the schema in Weaviate
engine.create_all_schemas()
```
### Create and Save Instances
```python
# Example data
paper_data = {
"title": "A Study on Weaviate ORM",
"abstract": "This paper discusses the Weaviate ORM and its features.",
"pub_date": datetime.datetime.now(datetime.timezone.utc),
"doi": "10.1234/weaviate-orm",
}
author_data = {
"first_name": "Allen",
"last_name": "Turing",
"orc_id": "0000-0002-1234-5678",
}
# Create an insance of author and paper
author = Author(first_name=author_data["first_name"],
last_name=author_data["last_name"],
orc_id=author_data["orc_id"])
paper = Paper(title=paper_data["title"],
abstract=paper_data["abstract"],
pub_date=paper_data["pub_date"],
doi=paper_data["doi"],
author=author)
# Save the author and paper to Weaviate
paper.save(include_references=True, recursive=True)
```
### Read an Instance
```python
# Retrieve the paper by its UUID
paper_uuid = paper.get_uuid()
paper_instance = Paper.get(paper_uuid, include_references=True)
print(f"Paper Title: {paper_instance.title}")
print(f"Author: {paper_instance.author.first_name} {paper_instance.author.last_name}")
```
### Update an Instance
```python
# Update the paper's title
paper_instance.title = "An Updated Study on Weaviate ORM"
paper_instance.update()
#Check updated instance
paper_instance = Paper.get(paper_uuid, include_references=True)
print(f"Paper Title: {paper_instance.title}")
```
### Delete an Instance
```python
# Delete the paper instance
paper_instance.delete()
```
## Schema Configuration Access
The ORM uses protected class-level attributes for schema configuration to prevent accidental overrides. All schema configs are prefixed with an underscore and accessed via read-only class properties.
### Configuring Collections
Define schema configurations using the underscored attributes:
```python
from weaviate.classes.config import Configure
class Article(Base_Model):
# Class-level schema configuration (protected with underscore)
_vector_config = Configure.Vectors.text2vec_ollama(
api_endpoint="http://llm:11434",
model="snowflake-arctic-embed2",
vectorize_collection_name=False
)
_description = "A collection of articles with vector embeddings"
_inverted_index_config = None # Optional index tuning
_generative_config = None # Optional generative configuration
```
### Accessing Configurations
You can read schema configurations at both class and instance levels:
```python
# Class-level access (read-only)
print(Article.vector_config) # Returns the configured vector
print(Article.description) # Returns "A collection of articles..."
# Instance-level access
article = Article(...)
print(article.vector_config) # Proxies to class-level config
```
### Deprecation Path
Older code using non-underscored names will still work but emit a deprecation warning:
```python
class LegacyModel(Base_Model):
vector_config = Configure.Vectors.text2vec_ollama(...) # DeprecationWarning
description = "Legacy" # DeprecationWarning
```
Migrate to the underscored versions to avoid future incompatibility:
```python
class ModernModel(Base_Model):
_vector_config = Configure.Vectors.text2vec_ollama(...)
_description = "Modern"
```
## Project Structure
```
weaviate_orm/
│
├── __init__.py # Public interface and versioning
├── weaviate_base.py # Base_Model with full CRUD logic and query support
├── weaviate_engine.py # Manages Weaviate client and schema creation
├── weaviate_meta.py # Metaclass for schema extraction and dynamic __init__
├── weaviate_property.py # Descriptor for scalar fields
├── weavitae_reference.py # Descriptor for references (one-way, two-way, single, list)
├── weaviate_decorators.py # Client injection and async-to-sync conversion
└── weaviate_utility.py # Helpers for validation and reference comparison
```
## License
This project is licensed under the GNU General Public License v3.0 (GPLv3).
You are free to use, modify, and distribute this software under the terms of the GPLv3 license. Any derivative work must also be distributed under the same license.
For full details, see the [LICENSE](https://choosealicense.com/licenses/gpl-3.0/).
## Contributing & Credits
This project is created and maintained by the BBSR - IDA (Tobias Heimig-Elschner).
Feel free to open issues or submit pull requests if you encounter bugs, have ideas, or want to improve the package.
### 📚 Citation
The project is published on Zenodo and can be cited as:
Heimig, T. (2025). Weaviate ORM - (0.1.0). Bundesinstitut für Bau-, Stadt- und Raumforschung (BBSR). https://doi.org/10.58007/x1wa-rt92
## Roadmap & Open Development Topics
- **Batch Operations**<br>Add support for batched inserts and updates for high-throughput use cases.
- **Generalized Query Interface**<br>Unify near-vector, near-text, and filter queries into a common, fluent interface.
- **Nested Reference Updates**<br>Extend update logic to fully support reference deletions and new nested reference creation during .update() calls.
---
## Testing
### Unit tests
Run the unit test suite:
```bash
pytest tests/unit -q
```
### Integration tests
Integration tests require a running Weaviate (>= 1.27.0) and, for Ollama-based examples, a reachable LLM service. Using the included docker-compose setup:
```bash
# From repository root
docker-compose build vdatabase llm
docker-compose up -d vdatabase llm
# Run integration tests once services are healthy
pytest tests/integration -q -m integration
```
If you maintain your own Weaviate instance, set these environment variables so the engine can connect:
```bash
export WEAVIATE_HOST=vdatabase
export WEAVIATE_PORT=8080
export WEAVIATE_GRPC_PORT=50051
```
### Migration note
The Weaviate Python client has deprecated `vectorizer_config` in favor of `vector_config`. This project now uses `vector_config` everywhere, including named vectors (e.g., `Configure.Vectors.text2vec_ollama(...)`). Ensure your server and client meet the versions above to avoid startup or schema warnings.
| text/markdown | null | Tobias Heimig-Elschner <Tobias.Heimig-Elschner@bbr.bund.de> | null | null | null | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"weaviate-client>=4.16.0"
] | [] | [] | [] | [
"Homepage, https://gitlab.opencode.de/bbsr_ida_public/weaviate_orm",
"Issues, https://gitlab.opencode.de/bbsr_ida_public/weaviate_orm/-/issues",
"Citation, https://doi.org/10.58007/x1wa-rt92"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-20T12:12:16.533606 | weaviate_orm-0.1.21.tar.gz | 52,966 | 5d/01/b012acdc031ca35248e430b9bed098f105565f399d0160b3d9d1b1db2cb3/weaviate_orm-0.1.21.tar.gz | source | sdist | null | false | be7cabd3ae80465ad4d910d669ed57c5 | 13c724f7f495266472b3aa00955beea4c78095d147fed8c98f1383dbfa5fe1a8 | 5d01b012acdc031ca35248e430b9bed098f105565f399d0160b3d9d1b1db2cb3 | GPL-3.0-or-later | [
"LICENSE"
] | 205 |
2.4 | r4pm | 0.5.2 | Rust-based Process Mining | # r4pm
Python bindings for the Rust4PM Project: Process mining in Python with the speed of Rust
This library provides basic import/export of XES/OCEL event data, as well as other exposed functionality from the [Rust4PM project](https://github.com/aarkue/rust4pm) (e.g., process discovery algorithms).
## Features
- **Fast XES/OCEL Import/Export**: Efficient Rust-based import and export of `.xes`, `.xes.gz`, and OCEL2 (`.xml`/`.json`) files
- **Auto-Generated Bindings**: All process_mining functions automatically exposed with full IDE support (autocomplete, type hints, docs)
- **Registry System**: Manage data objects and convert between types as needed
- **Polars DataFrames**: Polars facilitates the fast transfer of event data from Python to Rust and vice versa
## Quick Start
```python
from r4pm import bindings
import r4pm
# Load an OCEL file - returns a registry ID
ocel_id = r4pm.import_item('OCEL', 'data/orders.xml')
# Convert to SlimLinkedOCEL for analysis functions
locel_id = bindings.slim_link_ocel(ocel=ocel_id)
# Get statistics
num = bindings.num_events(ocel=locel_id)
print(f"Events: {num}")
# Discover object-centric DFG
dfg = bindings.discover_dfg_from_ocel(locel_id)
print(f"Discovered DFG for {len(dfg['object_type_to_dfg'])} object types")
# For case-centric event logs:
log_id = r4pm.import_item('EventLog', 'data/log.xes')
case_dfg = bindings.discover_dfg(log_id)
```
## How It Works
### Auto-Generated Bindings
All functions from the [`process_mining` Rust library](https://docs.rs/process_mining/) are automatically discovered and exposed as Python functions with:
- **Full type hints** for IDE autocomplete
- **Automatic documentation** from Rust docs
- **Type validation** via JSON schemas
The bindings are organized by module (mirroring the Rust crate structure):
```python
from r4pm import bindings
# Top-level access to all functions
bindings.discover_dfg(event_log=log_id)
bindings.num_events(ocel=locel_id)
# Or use submodules for organization
from r4pm.bindings.discovery.case_centric import dfg
dfg.discover_dfg(event_log=log_id)
```
Bindings are automatically generated during the Rust build via `build.rs`.
### Registry System
Data is managed through a registry that holds different object types:
- `OCEL` - Raw OCEL data
- `SlimLinkedOCEL` - Memory-efficient linked OCEL (required by most functions)
- `IndexLinkedOCEL` - Indexed OCEL for analysis
- `EventLog` - Case-centric event log
- `EventLogActivityProjection` - Activity-projected log for discovery
```python
# Load files into registry
ocel_id = r4pm.import_item('OCEL', 'file.xml')
log_id = r4pm.import_item('EventLog', 'file.xes')
# Convert between types (either like this or using r4pm.convert_item)
locel_id = bindings.index_link_ocel(ocel=ocel_id)
proj_id = bindings.log_to_activity_projection(log=log_id)
# List registry contents
for item in r4pm.list_items():
print(f"{item['id']}: {item['type']}")
```
## Simple Import/Export API
For direct DataFrame operations without the registry, use the `df` submodule.
### XES
```python
import r4pm
# Import returns (DataFrame, log_attributes_json)
xes, attrs = r4pm.df.import_xes("file.xes", date_format="%Y-%m-%d")
r4pm.df.export_xes(xes, "test_data/output.xes")
```
### OCEL
```python
# Returns dict with DataFrames: events, objects, relations, o2o, object_changes
ocel = r4pm.df.import_ocel("file.xml")
print(ocel['events'].shape)
r4pm.df.export_ocel(ocel, "export.xml")
# PM4Py integration (requires pm4py)
ocel_pm4py = r4pm.df.import_ocel_pm4py("file.xml")
print(ocel['events'].shape)
r4pm.df.export_ocel_pm4py(ocel_pm4py, "export.xml")
```
## Development
### Setup
```bash
# Install Rust: https://rustup.rs/
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# Create virtual environment
python -m venv .venv
source .venv/bin/activate
# Install in development mode
pip install maturin
maturin develop --release
```
### How Bindings Are Generated
Python bindings are **automatically generated during the Rust build** via `build.rs`.
Thus, bindings are always in sync with the Rust code and do not require manual regeneration.
The build script:
1. Reads function metadata from the `process_mining` crate
2. Generates `r4pm/bindings/` with typed Python wrappers and `.pyi` stubs
3. Organizes functions by their Rust module structure
### Building for Release
```bash
maturin build --release # Creates wheels in target/wheels/
```
The wheel automatically includes the generated bindings.
### Running Tests
```bash
# Run comprehensive test suite
python test_all.py
# Run simple example
python example.py
```
The test suite (`test_all.py`) covers:
- Automatic type conversion (positional & keyword arguments)
- Process discovery (DFG, OC-Declare)
- Registry operations (CRUD, DataFrames, export)
- Simple Import/Export DataFrame (`df`) API
- Edge cases and conversion caching
## LICENSE
This package is licensed under either Apache License Version 2.0 or MIT License at your option.
| text/markdown; charset=UTF-8; variant=GFM | null | Aaron Küsters <kuesters@pads.rwth-aachen.de> | null | null | null | process-mining, process, mining, OC-DECLARE, object-centric, DECLARE | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Typing :: Typed"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"polars[pandas,pyarrow]; extra == \"polars\""
] | [] | [] | [] | [] | maturin/1.12.3 | 2026-02-20T12:12:03.289147 | r4pm-0.5.2-cp314-cp314-win32.whl | 6,828,252 | bb/14/67fc05b29dbe12bc0c3d7158e38182bfda7dc3230e0bf923f962d9e3a3e2/r4pm-0.5.2-cp314-cp314-win32.whl | cp314 | bdist_wheel | null | false | ea4eef2d5b344155812b8dd5be781fdb | 331635ec42e1d6a86845a6692cb5ba979ba49835a0da92a84cf1b645d8bc64b6 | bb1467fc05b29dbe12bc0c3d7158e38182bfda7dc3230e0bf923f962d9e3a3e2 | null | [] | 2,790 |
2.4 | llama-index-tools-igpt-email | 0.1.0 | llama-index tools igpt_email integration | # LlamaIndex Tools Integration: iGPT Email Intelligence
This tool connects to [iGPT](https://igpt.ai/) to give your agent
structured, reasoning-ready context from connected email threads.
iGPT handles thread reconstruction, participant role detection, temporal
reasoning, and intent extraction before returning results — so agents
receive clean, structured JSON instead of raw message data.
To begin, you need to obtain an API key at [docs.igpt.ai](https://docs.igpt.ai).
## Usage
```python
# %pip install llama-index llama-index-core llama-index-tools-igpt-email
from llama_index.tools.igpt_email import IGPTEmailToolSpec
from llama_index.core.agent.workflow import FunctionAgent
from llama_index.llms.openai import OpenAI
tool_spec = IGPTEmailToolSpec(api_key="your-key", user="user-id")
agent = FunctionAgent(
tools=tool_spec.to_tool_list(),
llm=OpenAI(model="gpt-4.1"),
)
print(await agent.run("What tasks were assigned to me this week?"))
```
`ask`: Ask a question about email context using iGPT's reasoning engine. Returns structured context including tasks, decisions, owners, sentiment, deadlines, and citations.
`search`: Search email context for relevant messages and threads. Returns matching email context as Documents with thread metadata (subject, participants, date, thread ID).
This tool is designed to be used as a way to load data as a Tool in an Agent.
| text/markdown | null | Your Name <you@example.com> | null | null | null | email, igpt, intelligence, rag | [] | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"igptai>=0.1.0",
"llama-index-core<0.15,>=0.13.0"
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-20T12:10:31.431147 | llama_index_tools_igpt_email-0.1.0.tar.gz | 3,479 | 8f/b9/9e190b336f3b5bb11053c6f096034dd50b0d660da6be9ac36ec8a699eb16/llama_index_tools_igpt_email-0.1.0.tar.gz | source | sdist | null | false | da35a73165c6fa88ee6151a84615141c | 9358f5e19c072cb46a6c323296a137ecd35a4a57c0c8a6d732292025a7c9f52d | 8fb99e190b336f3b5bb11053c6f096034dd50b0d660da6be9ac36ec8a699eb16 | MIT | [] | 214 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.