
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,897,760 | Twilio Challenge: Travel Planner via Twilio Functions, WhatsApp & Gemini | This is a submission for the Twilio Challenge Twilio Challenge: Travel Planner via Twilio... | 0 | 2024-06-23T13:05:36 | https://dev.to/chintanonweb/twilio-challenge-travel-planner-via-twilio-functions-whatsapp-gemini-1m4e | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
### Twilio Challenge: Travel Planner via Twilio Functions, WhatsApp & Gemini
## What I Built
I created an innovative travel planning solution using Twilio Functions, WhatsApp, and Gemini. This application allows users to effortlessly... | chintanonweb |
1,897,758 | aryan's SCSS COMPLETE GUIDE Part-2 | note: I will not always show CSS version of my code. note: It is a three part series. (if link are... | 0 | 2024-06-23T13:02:30 | https://dev.to/aryan015/aryans-scss-complete-guide-part-2-1p1i | css, scss, javascript, html | `note`: I will not always show CSS version of my code.
`note`: It is a three part series. (if link are taking you at the same blog then links are not updated yet. waiting...)
[one](https://dev.to/aryan015/scss-complete-guide-part-one-4d03)
[three](https://dev.to/aryan015/3-finale-of-complete-sass-longer-2gpe)
## SCSS `... | aryan015 |
1,897,755 | Guest Post Outreach: A Simple Guide | What is Guest Post Outreach? Guest post outreach is when you reach out to other bloggers... | 0 | 2024-06-23T12:57:49 | https://dev.to/taiwo17/guest-post-outreach-a-simple-guide-37b8 | seo, outreach, guestpost, digitalmarketing | ## What is Guest Post Outreach?
[Guest post](https://www.upwork.com/services/product/marketing-technical-seo-audit-technical-on-page-seo-fix-seo-issues-1803811118137311009?ref=project_share) outreach is when you reach out to other bloggers and websites to propose your content for their sites. The goal is to add value ... | taiwo17 |
1,897,246 | O básico de mirror do Istio | O Istio é a principal ferramenta de service mesh para o Kubernetes, ele disponibiliza diversas... | 0 | 2024-06-23T12:57:03 | https://dev.to/wandpsilva/o-basico-de-mirror-do-istio-4k5 | istio, kubernetes, devops, sre | O Istio é a principal ferramenta de service mesh para o Kubernetes, ele disponibiliza diversas features para você gerenciar a sua malha de serviços, dentre essas features temos a parte de gerenciamento de tráfego onde uma das possibilidade é criar um 'mirror'. Mas o que é um mirror? um mirror permite você 'espelhar' o ... | wandpsilva |
1,876,113 | Lists and tuples in Elixir | We will keep learning two of the most used collection data types in Elixir: lists and tuples. They... | 0 | 2024-06-23T12:54:49 | https://dev.to/rhaenyraliang/lists-and-tuples-in-elixir-2lme | webdev, beginners, tutorial, elixir | We will keep learning two of the most used collection data types in Elixir: lists and tuples. They are immutable!
Like lists, tuples can hold any value. In Elixir data structure they are _immutable_, so every operation will return a new _**List**_ or a new _**Touple**_.
## (Link)List
Elixir uses square brackets to s... | rhaenyraliang |
1,897,687 | Get started with Fullstack Development: React + SpringBoot + MySQL + Postman | Prerequisite: Basic knowledge of Javascript and React library Basic knowledge of Java,... | 0 | 2024-06-23T12:54:21 | https://dev.to/kajal_mapare24/get-started-with-fullstack-development-react-springboot-mysql-postman-5997 | fullstack, react, springboot, beginners | ## Prerequisite:
- Basic knowledge of Javascript and React library
- Basic knowledge of Java, SpringBoot
- Basic knowledge of MySQL
## Architecture:
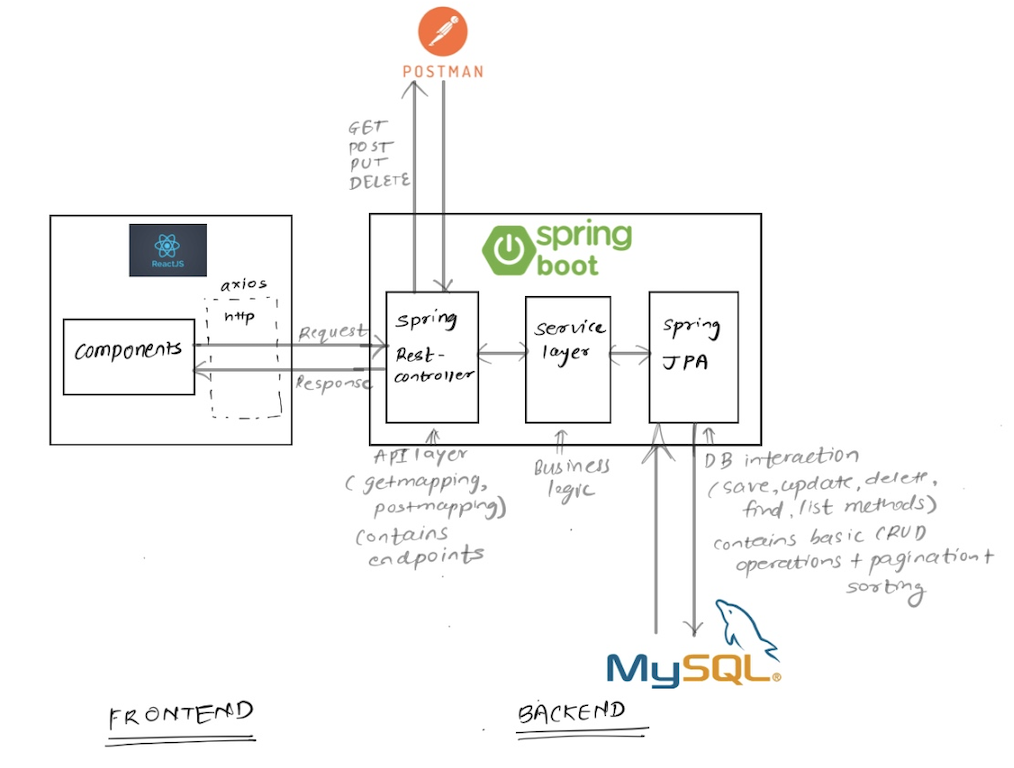
## Tools and installation links:
- [Java openjdk 17](https:/... | kajal_mapare24 |
1,893,486 | When You Need More Power Than a Lambda Provides | Navigating toward a cloud-native architecture can be both exciting and challenging. The expectation... | 0 | 2024-06-23T12:49:59 | https://dev.to/johnjvester/when-you-need-more-power-than-a-lambda-provides-3061 | cloud, serverless, heroku, webdev | 
Navigating toward a cloud-native architecture can be both exciting and challenging. The expectation of learning valuable lessons should always be top of mind as design becomes reality.
In this article, I wanted to foc... | johnjvester |
1,897,751 | Node Exporter Service File | [Unit] Description= Node Exporter Documentation=... | 0 | 2024-06-23T12:42:04 | https://dev.to/tj_27/node-exporter-service-file-2oci | nodeexporter, prometheus | ```
[Unit]
Description= Node Exporter
Documentation= https://prometheus.io/
Wants=network.target
After=network.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=$PATH/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
```
| tj_27 |
1,897,750 | Day 2/40 CKA Dockerize an Application | Dockerizing Your Project: A Step-by-Step Guide Docker is an essential tool for modern software... | 0 | 2024-06-23T12:36:01 | https://dev.to/emmanuel_oghre_abe292c74f/day-240-cka-dockerize-an-application-k3p | 40daysofkubernetes, cloudopscommunity, piyushsachdeva | **Dockerizing Your Project: A Step-by-Step Guide**
Docker is an essential tool for modern software development, providing a consistent and isolated environment for your applications. In this guide, we will walk you through the process of dockerizing a sample Node.js application. By the end, you will have a Docker image... | emmanuel_oghre_abe292c74f |
1,897,749 | Dive into the Depths of Database Design with This Gem! 🔍 | Database Design _ 2nd Edition by Adrienne Watt and Nelson Eng @ BCcampus Open Pressbooks is a comprehensive guide to database design and management, covering topics such as data modeling, database architecture, and best practices for database implementation. | 27,801 | 2024-06-23T12:32:38 | https://getvm.io/tutorials/database-design-2nd-edition | getvm, programming, freetutorial, technicaltutorials |
Hey there, fellow data enthusiasts! 👋 If you're looking to level up your database design skills, I've got the perfect resource for you - "Database Design - 2nd Edition" by Adrienne Watt and Nelson Eng, published by BCcampus Open Pressbooks.
This comprehensive guide is a true treasure trove of knowledge, covering ev... | getvm |
1,897,748 | Fitness trainer | This is a part-time remote role for a Fitness Coach at Vmc The Mission Nutrition. The Fitness Coach... | 0 | 2024-06-23T12:28:52 | https://dev.to/work_fromhome_13cfdc9e32/fitness-trainer-52o1 | This is a part-time remote role for a Fitness Coach at Vmc The Mission Nutrition. The Fitness Coach will be responsible for providing personalized fitness training and guidance to clients. They will create customized workout plans, monitor progress, and provide ongoing support and motivation. The Fitness Coach will als... | work_fromhome_13cfdc9e32 | |
1,423,985 | How to Show or Hide Zero Values in Excel? | Excel is a powerful tool that is widely used to organize, analyze, and display data. One important... | 0 | 2023-04-04T05:22:05 | https://aawexcel.com/how-to-show-or-hide-zero-values-in-excel/ | kutools | ---
title: How to Show or Hide Zero Values in Excel?
published: true
date: 2023-04-03 04:36:45 UTC
tags: Kutools
canonical_url: https://aawexcel.com/how-to-show-or-hide-zero-values-in-excel/
---
[Excel](https://www.microsoft.com/en-us/microsoft-365/excel) is a powerful tool that is widely used to **organize, analyze,*... | hajira_official |
1,897,747 | Implementing Hash-Based Strict CSP on AEM | As always, the full solution is available on Github. Scroll to the bottom of the article for the... | 0 | 2024-06-23T12:28:34 | https://dev.to/theopendle/implementing-hash-based-strict-csp-on-aem-5621 | aem, csp, adobe, java | > As always, the full solution is available on Github. Scroll to the bottom of the article for the link.
## Introduction to CSP
As a reminder, CSP stands for [Content Security Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/CSP): a security standard that helps prevent cross-site scripting (XSS), clickjackin... | theopendle |
1,897,743 | Why a .gitignore File is Essential for Your Projects | When working on a project using Git for version control, you’ll often encounter files and directories... | 0 | 2024-06-23T12:20:10 | https://dev.to/just_ritik/why-a-gitignore-file-is-essential-for-your-projects-4odm | webdev, frontend, javascript, programming | When working on a project using **Git** for version control, you’ll often encounter files and directories that you don’t want to track. This is where the `.gitignore` file becomes essential. In this post, we'll explore what a `.gitignore` file is, why it’s necessary, and how to use it effectively in your projects.
**... | just_ritik |
1,897,742 | Decentralized Storage Networks with Redistribution? | What are some popular decentralized storage networks similar to Freenet, but where data is... | 0 | 2024-06-23T12:18:50 | https://dev.to/moogamouth/decentralized-storage-networks-with-redistribution-3pa7 | What are some popular decentralized storage networks similar to Freenet, but where data is automatically transferred to a new node if the old one drops it?
| moogamouth | |
1,897,741 | Unlocking the Secrets of JavaScript: My Exhilarating Adventure in Web Development | As I dove into the world of web development in the Bano Qabili Program 3.0, I never expected to find... | 0 | 2024-06-23T12:18:46 | https://dev.to/m_affannazeer_8f74d021e_50/unlocking-the-secrets-of-javascript-my-exhilarating-adventure-in-web-development-34mc | As I dove into the world of web development in the Bano Qabili Program 3.0, I never expected to find myself on an exhilarating adventure. But that's exactly what happened in our third class, when we explored the fascinating realm of JavaScript.
Discovering the Enchanting Universe of JavaScript Types
JavaScript, a lan... | m_affannazeer_8f74d021e_50 | |
1,897,740 | React as a Library and Create React App / Vite as Frameworks | React stands out as one of the most popular libraries for building user interfaces. However, when it... | 27,828 | 2024-06-23T12:13:50 | https://imabhinav.dev/blog/react-as-a-library-and-create-react-app-vite-as-frameworks-12-9-44 | webdev, javascript, beginners, tutorial | React stands out as one of the most popular libraries for building user interfaces. However, when it comes to scaffolding a new project, developers often turn to tools like Create React App (CRA) or Vite. While React is a library focused on the view layer, CRA and Vite act as frameworks, providing the necessary tooling... | imabhinavdev |
1,897,731 | Made typos in routes? Redirect routes with functions | Introduction In this blog post, I want to describe a new feature called redirect functions... | 27,826 | 2024-06-23T12:09:23 | https://www.blueskyconnie.com/redirect-routes-with-functions-to-fix-routing-typos/ | angular, tutorial, frontend | ##Introduction
In this blog post, I want to describe a new feature called redirect functions with routes. When defining routes in Angular, it is possible to catch and redirect a route to a different path using redirectTo. One example is to catch all unknown routes and redirect them to a 404 page. Another example is re... | railsstudent |
1,897,738 | Twilio challenge entry: Mystery at Darkwood Manor | This is a submission for the Twilio Challenge What I Built I built a small web based... | 0 | 2024-06-23T12:06:42 | https://dev.to/dpppr/twilio-challenge-entry-mystery-at-darkwood-manor-744 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
I built a small web based Murder Mystery game; ask the suspects questions to try and figure out the culprit.
I had a great time making it and hope you enjoy playing!
This is built in Vanilla JS and jQuery. The chara... | dpppr |
1,897,737 | What is Google OAuth 2.0 ? | OAuth 2.0 (Open Authorization) is an industry-standard protocol for authorization, allowing... | 0 | 2024-06-23T12:02:56 | https://dev.to/yaswanth_bonumaddi/understanding-google-oauth-20-57fn | OAuth 2.0 (Open Authorization) is an industry-standard protocol for authorization, allowing third-party applications to access a user's resources without exposing their credentials. Google OAuth 2.0 specifically is Google's implementation of this protocol, enabling secure and seamless authentication and authorization a... | yaswanth_bonumaddi | |
1,897,735 | Top 10 String Javascript Interview Coding Question | 1. Reverse a String function reverseString(str) { return... | 0 | 2024-06-23T12:01:51 | https://dev.to/vaibhav_shukla_newsletter/top-100-javascript-interview-coding-question-d63 | javascript, string, webdev, beginners | **1. Reverse a String**
```javascript
function reverseString(str) {
return str.split('').reverse().join('');
}
console.log(reverseString("hello")); // Output: "olleh"
```
**2. How to check the name of the number in English?**
```javascript
function numberToWords(number) {
const singleDigits = ['', 'one',... | vaibhav_shukla_newsletter |
1,897,733 | Difference Between Branches | Git is a popular version control system that allows developers to manage their codebase efficiently. One of the essential features of Git is the ability to create and manage branches. Branches allow developers to work on different features or bug fixes simultaneously without interfering with each other's work. However,... | 27,827 | 2024-06-23T11:54:44 | https://labex.io/tutorials/git-difference-between-branches-12727 | git, coding, programming, tutorial |
## Introduction
Git is a popular version control system that allows developers to manage their codebase efficiently. One of the essential features of Git is the ability to create and manage branches. Branches allow developers to work on different features or bug fixes simultaneously without interfering with each othe... | labby |
1,897,732 | How to get an FL Studio Mobile for free on Android | Obtaining FL Studio Mobile for free on Android through unofficial channels is illegal and can expose... | 0 | 2024-06-23T11:53:26 | https://dev.to/allenmaxde/how-to-get-an-fl-studio-mobile-for-free-on-android-3lhj | webdev, beginners, ai, productivity | Obtaining [FL Studio Mobile for free on Android](https://modversionapk.com/en/fl-studio-mobile/old-version) through unofficial channels is illegal and can expose your device to significant security risks. However, if you're looking for legitimate ways to get the software without paying full price, here are some options... | allenmaxde |
1,786,118 | Golang Web: POST Method | Introduction In this section of the series, we will be exploring how to send a POST HTTP... | 17,548 | 2024-06-23T11:53:00 | https://www.meetgor.com/golang-web-post-method | go, 100daysofgolang, webdev | ## Introduction
In this section of the series, we will be exploring how to send a `POST` HTTP request in golang. We will understand how to send a basic POST request, create an HTTP request, and parse json, structs into the request body, add headers, etc in the following sections of this post. We will understand how to... | mr_destructive |
1,897,730 | useEffect, useRef and useCallback with 1 project | Password Generator Thoughts There is a method currently running that... | 0 | 2024-06-23T11:47:11 | https://dev.to/geetika_bajpai_a654bfd1e0/useeffect-useref-and-usecallback-with-1-project-f7e | ## Password Generator
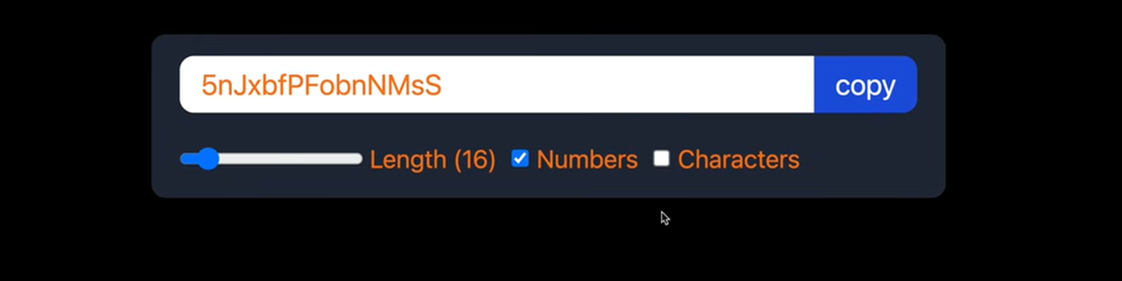
### Thoughts
1. There is a method currently running that generates random text by default.
2. This method needs to execute repeatedly because any changes in the input parameters, such as leng... | geetika_bajpai_a654bfd1e0 | |
1,897,725 | Beginner's Guide to Setting Up a Django Project | Django is a powerful web framework for Python that allows you to build web applications quickly and... | 0 | 2024-06-23T11:46:19 | https://dev.to/rupesh_mishra/beginners-guide-to-setting-up-a-django-project-ep | django, python, programming, backenddevelopment |
Django is a powerful web framework for Python that allows you to build web applications quickly and efficiently. This guide will walk you through the process of setting up a Django project from scratch, perfect for beginners who want to get started with web development using Django.
## Table of Contents
1. [Installin... | rupesh_mishra |
1,897,729 | Introduction to Object-Oriented Programming (OOP) in Python | To Support My YouTube Channel: Click Here I need like 630 subs to reach 1000 and get... | 0 | 2024-06-23T11:46:19 | https://dev.to/vincod/introduction-to-object-oriented-programming-oop-in-python-4o4d | webdev, python, oop, javascript | _________________________________________________
To Support My YouTube Channel: [Click Here](https://youtube.com/@kwargdevs)
I need like 630 subs to reach 1000 and get monetized
Thanks in Advance 🙏
_________________________________________________
Object-Oriented Programming (OOP) is a programming paradigm that us... | vincod |
1,897,726 | Building production systems using Generative AI. | Originally published on Tying Shoelaces I set out several months ago to deeply understand and... | 0 | 2024-06-23T11:43:02 | https://dev.to/ejb503/building-production-systems-using-generative-ai-3plk | ai, webdev, programming, learning |

Originally published on [Tying Shoelaces](https://tyingshoelaces.com/blog/artificial-intelligence-production-system)
I set out several months ago to deeply understand and engage with the modern AI tooling that is ... | ejb503 |
1,897,711 | The Identity Puzzle: the Crucial Difference Between Access Tokens and ID Tokens | In the real world Let's start with a real-world analogy. Imagine a flight ticket you... | 0 | 2024-06-23T11:38:47 | https://dev.to/zenithar/the-identity-puzzle-the-crucial-difference-between-access-tokens-and-id-tokens-j1f | identity, access, oauth, security | ## In the real world
Let's start with a real-world analogy. Imagine a flight ticket you previously bought as an access token authorising you to board the plane for your trip. On the other hand, an ID card functions as your ID token, a document that proves an authority has authenticated your identity. Another example c... | zenithar |
1,897,724 | aryan's SCSS Complete guide 🧡 | note: I will not always show CSS version of my code. note: It is a three part series. (if link are... | 0 | 2024-06-23T11:38:45 | https://dev.to/aryan015/scss-complete-guide-part-one-4d03 | css, javascript, react, scss | `note:` I will not always show CSS version of my code.
`note:` It is a three part series. (if link are taking you at the same blog then links are not updated yet. waiting...)
[two](https://dev.to/aryan015/aryans-scss-complete-guide-part-2-1p1i)
[three](https://dev.to/aryan015/3-finale-of-complete-sass-longer-2gpe)
## S... | aryan015 |
1,897,723 | Bowing to the inevitable | Data Munging with Perl was published in February 2001. That was over 23 years ago. It’s even 10 years... | 0 | 2024-06-23T11:40:01 | https://perlhacks.com/2024/06/bowing-to-the-inevitable/ | books, datamungingwithperl, updates, writing | ---
title: Bowing to the inevitable
published: true
date: 2024-06-23 11:37:07 UTC
tags: Books,datamungingwithperl,updates,writing
canonical_url: https://perlhacks.com/2024/06/bowing-to-the-inevitable/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/m2nzdo93fml6sl4k71xr.jpg
---
[_Data Munging with... | davorg |
1,895,494 | Installing PostgreSQL with Docker | Introduction In this guide, I'm going to walk you through installing PostgreSQL database... | 0 | 2024-06-23T11:37:01 | https://howtodevez.blogspot.com/2024/03/installing-postgresql-with-docker.html | postgres, docker, data, newbie | Introduction
------------
In this guide, I'm going to walk you through installing PostgreSQL database and **pgAdmin** using Docker. The big advantage here is it's quick and straightforward. You won't need to go through a long manual installation process (and potentially spend time fixing errors if they arise).
Instal... | chauhoangminhnguyen |
1,897,448 | Networking cant be easier than this | This is a submission for the Twilio Challenge What I Built An AI agent were you can pass... | 0 | 2024-06-23T11:34:20 | https://dev.to/sojinsamuel/networking-cant-be-easier-than-this-4fdm | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
<!-- Share an overview about your project. -->
An AI agent were you can pass in an email or a linkedin profile url to get candidate details and share it with your partner, cofounder via:
[Twilio Call](https://www.twil... | sojinsamuel |
1,897,170 | Product Review System Using Twilio and Gemini | This is a submission for the Twilio Challenge What I Built I built a product review and... | 0 | 2024-06-23T11:30:56 | https://dev.to/oyedeletemitope/product-review-system-using-twilio-and-gemini-4bk0 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
I built a product review and rating App that allows product users to submit ratings along with descriptive feedback. The application analyzes the sentiment of the feedback and provides users with a personalized respons... | oyedeletemitope |
1,897,713 | Tutorial: How to Develop a Nostr Wallet Connect Mobile App Using Flutter and NWC | Hello everyone! My name is Aniket (aka Anipy) and in this tutorial, I'm going to show you how to... | 0 | 2024-06-23T11:30:22 | https://dev.to/anipy/tutorial-how-to-develop-a-nostr-wallet-connect-mobile-app-using-flutter-and-nwc-3kcb | ---
title: Tutorial: How to Develop a Nostr Wallet Connect Mobile App Using Flutter and NWC
published: true
description:
tags:
cover_image: https://i.ibb.co/94BH67g/nostr-pay-article-cover.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-23 11:00 +0000
---
Hello everyone! My name is Aniket (aka ... | anipy | |
1,897,710 | Communication Patterns in Microservices | Exploring Communication Patterns in Microservices: Synchronous, Asynchronous, and... | 0 | 2024-06-23T11:05:55 | https://dev.to/ali_tariq_90f2c6a125b095c/communication-patterns-in-microservices-3l25 | microservices, systemdesign, javascript | ## Exploring Communication Patterns in Microservices: Synchronous, Asynchronous, and Publish/Subscribe
In the realm of microservices architecture, effective communication between services is critical for building scalable and maintainable systems. Understanding the different communication patterns—synchronous, asynchr... | ali_tariq_90f2c6a125b095c |
1,897,709 | خرید فیلترشکن v2ray | در دنیای امروز که دسترسی آزاد به اینترنت برای بسیاری از کاربران ایرانی با محدودیتهای فراوانی روبرو... | 0 | 2024-06-23T11:05:13 | https://dev.to/filterbreaker/khryd-fyltrshkhn-v2ray-58gb |
در دنیای امروز که دسترسی آزاد به اینترنت برای بسیاری از کاربران ایرانی با محدودیتهای فراوانی روبرو است، خرید فیلترشکن V2Ray به یکی از دغدغههای اصلی مردم تبدیل شده است. با افزایش تعداد شرکتها و فروشندگان ارائهده... | filterbreaker | |
1,897,852 | Unlocking the Power of M365 Copilot: Access external data throught a plugin | I am very fascinated by the new copilot plugin in M365. But when you purchase the licence, you get... | 0 | 2024-06-23T17:27:32 | https://blog.bajonczak.com/creating-a-compilot-plugin/ | ai, m365, githubcopilot | ---
title: Unlocking the Power of M365 Copilot: Access external data throught a plugin
published: true
date: 2024-06-23 11:00:36 UTC
tags: AI,M365,Copilot
canonical_url: https://blog.bajonczak.com/creating-a-compilot-plugin/
---
 | Call Miss Alisha Malik 03279066660 Y SERVICES AND SPEND THE MEMORABLE TIME WITH HOTTIES *** -- SUPER... | 27,825 | 2024-06-23T10:24:00 | https://hashnode.com/@callgirlrawalpindi | writing, vipcallgirlsrawalpindi, callgirlsrawalpindi, escortsgirlsrawalpindi | Call Miss Alisha Malik 03279066660
Y SERVICES AND SPEND THE MEMORABLE TIME WITH HOTTIES ***
-- SUPER HOT EROTIC TEENS AT YOUR DOORSTEP IN SINGLE CALL --
--- DEEP THROAT SUCKING, KISSING, LICKING, BODY MASSAGE INCLUDED WITH SEX ---
---- 100% SATISFACTION GUARANTEED ----
Make your nights memorable and sexy with hot, sexy... | callgirlsrawalpindi |
1,897,696 | The Power of Machine Learning Algorithms | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T10:12:45 | https://dev.to/vidyarathna/the-power-of-machine-learning-algorithms-3cl5 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Machine learning algorithms learn patterns from data to make predictions or decisions. They include supervised (predictive modeling), unsupervised (clustering), and reinforcement learn... | vidyarathna |
1,897,701 | Advanced MongoDB Lookup: Complex MongoDB lookup Queries with Multiple Conditions | As a database management system, MongoDB stands tall as a powerful NoSQL solution. We developers,... | 0 | 2024-06-23T10:23:45 | https://dev.to/codegirl0101/advanced-mongodb-lookup-complex-mongodb-lookup-queries-with-multiple-conditions-18jf | mongodb, tutorial, backenddevelopment, learning | As a database management system, MongoDB stands tall as a powerful NoSQL solution. We developers, often face significant challenges when joining collections in MongoDB.
The process of using the MongoDB lookup multiple fields operation is really not easy and requires many additional steps to structure our data correct... | codegirl0101 |
1,897,132 | # TWILIO AI CHAT | What I Built CHAT-TWILIO-API is an innovative voice-based application leveraging Twilio... | 0 | 2024-06-23T10:23:39 | https://dev.to/wmasivi54623/-twilio-ai-chat-286c | devchallenge, twiliochallenge, ai, twilio |
## What I Built
CHAT-TWILIO-API is an innovative voice-based application leveraging Twilio Voice and Gemini AI to deliver seamless, intelligent, and human-like voice interactions for customer service and automated assistance.
## Demo
[TWILIO AI CHAT](https://chat-twilio-ai-git-main-williammasivis-projects.vercel... | wmasivi54623 |
1,897,699 | [DAY 60-62] I built a random quote machine using React | Hi everyone! Welcome back to another blog where I document the things I learned in web development. I... | 27,380 | 2024-06-23T10:17:49 | https://dev.to/thomascansino/day-60-62-i-built-a-random-quote-machine-3kf9 | learning, react, webdev, javascript | Hi everyone! Welcome back to another blog where I document the things I learned in web development. I do this because it helps retain the information and concepts as it is some sort of an active recall.
On days 60-62, after completing the libraries and frameworks course, I continued on to the projects required to fini... | thomascansino |
1,897,698 | Understanding Quantum Computing Basics | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T10:16:17 | https://dev.to/vidyarathna/understanding-quantum-computing-basics-3c8l | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Quantum computing leverages quantum mechanics to perform computations using qubits. Unlike classical bits, qubits can exist in superposition and entanglement, enabling parallel process... | vidyarathna |
1,897,697 | Exploring the Internet of Things (IoT) | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T10:14:59 | https://dev.to/vidyarathna/exploring-the-internet-of-things-iot-2i90 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
IoT connects everyday devices to the internet, enabling data collection and remote control. It uses sensors and actuators to interact with the physical world. Applications range from s... | vidyarathna |
1,897,694 | Demystifying the Blockchain | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T10:06:23 | https://dev.to/vidyarathna/demystifying-the-blockchain-5gpd | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Blockchain is a decentralized ledger technology that records transactions across multiple computers. It's secure, transparent, and immutable, making it ideal for cryptocurrencies like ... | vidyarathna |
1,897,693 | Understanding the P vs NP Problem | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T10:04:40 | https://dev.to/vidyarathna/understanding-the-p-vs-np-problem-2i1d | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
The P vs NP Problem asks if every problem whose solution can be quickly verified (NP) can also be quickly solved (P). It's a major unsolved question in computer science, with implicati... | vidyarathna |
1,897,688 | Hashing: The Key to Fast Data Retrieval | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T10:02:18 | https://dev.to/vidyarathna/hashing-the-key-to-fast-data-retrieval-4gdn | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Hashing converts input data into a fixed-size string of characters, which appears random. It's used in data structures like hash tables for fast data retrieval. Good hashing minimizes ... | vidyarathna |
1,897,692 | Filter system | <div class="from"> <mat-label>Banner Type</mat-label> ... | 0 | 2024-06-23T10:01:33 | https://dev.to/webfaisalbd/filter-system-4ojo | ```html
<div class="from">
<mat-label>Banner Type</mat-label>
<mat-form-field appearance="outline" >
<mat-select formControlName="type" required>
<mat-option [value]="'home_banner'">Home Page Banner</mat-option>
<mat-option [value]="'all'">Home Page Banner</mat-op... | webfaisalbd | |
1,897,691 | Bypassing captchas using an automatic captcha solver | Introduction In today's digital landscape, navigating through online security measures is crucial... | 0 | 2024-06-23T10:01:20 | https://dev.to/media_tech/bypassing-captchas-using-an-automatic-captcha-solver-k93 | **Introduction**
In today's digital landscape, navigating through online security measures is crucial for efficient and smooth operation. Captchas, designed to distinguish between human users and automated bots, serve as a fundamental tool in safeguarding online platforms from malicious activities. However, for legiti... | media_tech | |
1,897,689 | Enhancing Next.js Builds with Webpack Custom Plugins | Learn how to customize your Next.js application's webpack configuration to include versioning using the build id. | 0 | 2024-06-23T10:00:30 | https://dev.to/itselftools/enhancing-nextjs-builds-with-webpack-custom-plugins-37aa | javascript, nextjs, webpack, webdev |
At [itselftools.com](https://itselftools.com), our journey through developing over 30 innovative applications using Next.js and Firebase has been illuminating. Today, we're sharing a snippet from our development practices that enhances the build process of Next.js applications by utilizing custom Webpack plugins.
## ... | antoineit |
1,897,681 | Api-platform : filtrer les résultats uniquement sur l'utilisateur connecté | Imaginez avoir dans votre projet plusieurs entités avec la relation author comme par exemple ces deux... | 0 | 2024-06-23T09:52:46 | https://dev.to/aratinau/api-platform-filtrer-les-resultats-uniquement-sur-lutilisateur-connecte-1fp6 | security, api, webdev | Imaginez avoir dans votre projet plusieurs entités avec la relation `author` comme par exemple ces deux entités suivantes :
```php
<?php
namespace App\Entity;
use ApiPlatform\Metadata\ApiResource;
use App\Repository\CourierFavoriteRepository;
use Doctrine\ORM\Mapping as ORM;
#[ORM\Entity(repositoryClass: CourierF... | aratinau |
1,897,684 | HTML input attributes with examples | HTML input attributes HTML <input> elements have various attributes that control... | 0 | 2024-06-23T09:50:13 | https://dev.to/wasifali/html-input-attributes-with-examples-48jn | webdev, css, html, learning | ## **HTML input attributes**
HTML `<input>` elements have various attributes that control their behavior and appearance. Here are some of the most commonly used attributes:
## **Type**
Specifies the type of input control. Common types include:
## **Example**
```HTML
<input type="text">
<input type="password">
<input ty... | wasifali |
1,897,682 | Maiu Online - Browser MMORPG #indiegamedev #babylonjs Ep24 - SAT 2D collision detection | Hello, I added collisions detection with environment obstacles, to make it happen I used SAT 2D... | 0 | 2024-06-23T09:46:15 | https://dev.to/maiu/maiu-online-browser-mmorpg-indiegamedev-babylonjs-ep24-sat-2d-collision-detection-42ab | babylonjs, indiegamede, gamedev, mmorpg | Hello,
I added collisions detection with environment obstacles, to make it happen I used SAT 2D collision detection algorithm.
Player is simple point and obstacles can have collision shapes of circle or rectangles with arbitrary orientation.
Still there are some bugs mostly with calculating collisions response on the ... | maiu |
1,897,680 | Maiu Online - Browser MMORPG #indiegamedev #babylonjs Ep23 - Global Chat | Hi, This time very short update. I made my chat online. Previously it was working only locally in... | 0 | 2024-06-23T09:44:09 | https://dev.to/maiu/maiu-online-browser-mmorpg-indiegamedev-babylonjs-ep23-global-chat-1clk | babylonjs, indiegamedev, gamedev, mmorpg | Hi,
This time very short update. I made my chat online. Previously it was working only locally in offline mode.
{% youtube ahCvKWgK4WU %} | maiu |
1,897,678 | Types of Machine Learning: Supervised, Unsupervised, and Reinforcement | Machine learning is a field of artificial intelligence (AI) that focuses on developing algorithms... | 0 | 2024-06-23T09:38:24 | https://dev.to/gigarazkiarianda/types-of-machine-learning-supervised-unsupervised-and-reinforcement-4ipm | machinelearning, ai |

Machine learning is a field of artificial intelligence (AI) that focuses on developing algorithms and models that allow computers to learn from data and make decisions or predictions without being explicitly progra... | gigarazkiarianda |
1,897,677 | Unlocking the Power of NoSQL in the Cloud: Breaking Free from Relational Constraints | Unlocking the Power of NoSQL in the Cloud: LinkedIn | 0 | 2024-06-23T09:33:55 | https://dev.to/queryhub/unlocking-the-power-of-nosql-in-the-cloud-breaking-free-from-relational-constraints-3fdj | database, nosql, webdev, learning | {% cta https://www.linkedin.com/posts/rajkishore_cloudcomputing-database-nosql-activity-7209524120819007488-5AUL?utm_source=share&utm_medium=member_desktop %} Unlocking the Power of NoSQL in the Cloud: LinkedIn {% endcta %} | queryhub |
1,897,814 | Configuring Keycloak with SAML | Hey everyone, In this blog we will see how you can configure Keycloak with SAML. Before we start,... | 0 | 2024-07-05T16:23:48 | https://blog.elest.io/configuring-keycloak-with-saml/ | keycloak, softwares, elestio | ---
title: Configuring Keycloak with SAML
published: true
date: 2024-06-23 09:33:36 UTC
tags: Keycloak,Softwares,Elestio
canonical_url: https://blog.elest.io/configuring-keycloak-with-saml/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-20.png
---
Hey everyone, In this blog we will see how you can co... | kaiwalyakoparkar |
1,897,664 | Building Zerocalc, part III - errors and grammar | The basic parsing method presented in part II works well for simple expressions that consist of... | 27,824 | 2024-06-23T08:45:16 | https://dev.to/michal1024/building-zerocalc-part-iii-errors-and-grammar-15pc | rust, programming | The basic parsing method presented in [part II](https://dev.to/michal1024/building-zerocalc-part-ii-evaluating-then-parsing-3fim) works well for simple expressions that consist of binary operators and literals. Our calculator must support more complex expressions, including unary operators, parenthesis, and function ca... | michal1024 |
1,897,667 | React Project Outgrowing Expectations? Learn These Basic Principles to Manage Better | Consequences of Poor Code Maintenance Imagine building a product with great potential, but... | 0 | 2024-06-23T09:32:51 | https://dev.to/lovestaco/react-project-outgrowing-expectations-learn-these-basic-principles-to-manage-better-9bn | react, reactjsdevelopment, webdev, javascript |
## Consequences of Poor Code Maintenance
Imagine building a product with great potential, but watching it progress slowly due to messy code and disorganized thinking.
We are a small team, building a product called [Hexmos Feedback](https://hexmos.com/feedback), Feedback helps keep teams motivated and engaged throug... | lovestaco |
1,897,676 | Contribute to an Open-Source JavaScript Project: Join Now! | Hello JavaScript Enthusiasts! I'm excited to announce the launch of an ambitious and collaborative... | 0 | 2024-06-23T09:32:21 | https://raajaryan.tech/contribute-to-an-open-source-javascript-project-join-now | opensource, javascript, beginners, tutorial |
[](https://buymeacoffee.com/dk119819)
Hello JavaScript Enthusiasts!
I'm excited to announce the launch of an ambitious and collaborative open-source project, the **Ultimate JavaScript ... | raajaryan |
1,897,812 | Configuring keycloak using OICD | Hey everyone, In this blog we will see how you can configure Keycloak using OICD. Before we start,... | 0 | 2024-07-05T16:23:12 | https://blog.elest.io/configure-keycloak-with-oicd/ | keycloak, softwares, elestio | ---
title: Configuring keycloak using OICD
published: true
date: 2024-06-23 09:18:39 UTC
tags: Keycloak,Softwares,Elestio
canonical_url: https://blog.elest.io/configure-keycloak-with-oicd/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-17.png
---
Hey everyone, In this blog we will see how you can con... | kaiwalyakoparkar |
1,897,811 | Keycloak Session Configuration: Best Practices and Principles | Hey everyone, in this blog we will be configuring sessions on Elestio using Keycloak. We will be... | 0 | 2024-07-05T16:22:07 | https://blog.elest.io/configure-keycloak-with-saml/ | keycloak, softwares, elestio | ---
title: Keycloak Session Configuration: Best Practices and Principles
published: true
date: 2024-06-23 09:10:44 UTC
tags: Keycloak,Softwares,Elestio
canonical_url: https://blog.elest.io/configure-keycloak-with-saml/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-15.png
---
Hey everyone, in this bl... | kaiwalyakoparkar |
1,897,802 | Apache Superset Clickhouse integration | Hey everyone, In this blog we will be knowing more about Superset Clickhouse integration. Discover... | 0 | 2024-07-05T15:40:25 | https://blog.elest.io/apache-superset-clickhouse-integration/ | superset, softwares, elestio | ---
title: Apache Superset Clickhouse integration
published: true
date: 2024-06-23 08:52:30 UTC
tags: Superset,Softwares,Elestio
canonical_url: https://blog.elest.io/apache-superset-clickhouse-integration/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-5.png
---
Hey everyone, In this blog we will be ... | kaiwalyakoparkar |
1,897,673 | Difference Between Number() and parseInt() in Converting Strings? | Number(): Searches the entire string for numbers. If it finds anything else, it will return NaN... | 0 | 2024-06-23T09:10:17 | https://dev.to/yns666/difference-between-parseint-and-number-in-converting-strings-1fh5 | javascript, beginners, programming, webdev | Number(): Searches the entire string for numbers. If it finds anything else, it will return NaN (short for Not a Number).
parseInt() / parseFloat(): Returns the first number in the string, ignoring the rest. If there are no numbers at the beginning of the string, it will return NaN.
let's take an example:
**Example ... | yns666 |
1,897,810 | Adding API Key Authentication In Keycloak | Hey everyone, in this blog we will be extending Keycloak by adding API key authentication with... | 0 | 2024-07-05T16:21:27 | https://blog.elest.io/adding-api-key-authentication-in-keycloak/ | keycloak, softwares, elestio | ---
title: Adding API Key Authentication In Keycloak
published: true
date: 2024-06-23 09:09:56 UTC
tags: Keycloak,Softwares,Elestio
canonical_url: https://blog.elest.io/adding-api-key-authentication-in-keycloak/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-14.png
---
Hey everyone, in this blog we w... | kaiwalyakoparkar |
1,897,671 | I will be learning linux in next 180 days | RHCSA (red hat certified system administrator) It is a global level certification that focus, on to... | 0 | 2024-06-23T09:07:05 | https://dev.to/mahir_dasare_333/i-will-be-learning-linux-in-next-180-days-4j76 | RHCSA (red hat certified system administrator)
It is a global level certification that focus, on to perform the core system administration skills required for Red Hat Enterprise Linux environments.
Linux:
- Linux is an open source kernel.
- Linux base OS are like unix based.
- Linux kernel written by Linux Torvalds i... | mahir_dasare_333 | |
1,897,809 | Creating Keycloak cluster with Elestio | Hey everyone, in this blog we will be creating a Keycloak cluster with Elestio using Keycloak. We... | 0 | 2024-07-05T16:20:45 | https://blog.elest.io/keycloack-cluster-with-elestio/ | keycloak, softwares, elestio | ---
title: Creating Keycloak cluster with Elestio
published: true
date: 2024-06-23 09:06:16 UTC
tags: Keycloak,Softwares,Elestio
canonical_url: https://blog.elest.io/keycloack-cluster-with-elestio/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-13.png
---
Hey everyone, in this blog we will be creatin... | kaiwalyakoparkar |
1,897,670 | JavaScript code real-time online obfuscation encryption | JavaScript obfuscation is a technique that transforms source code into a format that is difficult to... | 0 | 2024-06-23T09:06:05 | https://dev.to/fridaymeng/javascript-code-real-time-online-obfuscation-encryption-mb0 | JavaScript obfuscation is a technique that transforms source code into a format that is difficult to understand and reverse engineer. The obfuscated code functions the same as the original code but is much less readable, increasing the security of the code and preventing it from being easily copied, tampered with, or r... | fridaymeng | |
1,897,807 | Embedding Superset dashboards in your React application | Hey everyone, In this blog we will knowing more about embedding Superset dashboards in your react... | 0 | 2024-07-05T16:20:10 | https://blog.elest.io/embedding-superset-dashboards-in-your-react-application/ | superset, softwares, elestio | ---
title: Embedding Superset dashboards in your React application
published: true
date: 2024-06-23 09:05:18 UTC
tags: Superset,Softwares,Elestio
canonical_url: https://blog.elest.io/embedding-superset-dashboards-in-your-react-application/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-9.png
---
Hey ... | kaiwalyakoparkar |
1,897,806 | Superset SSO with Google integration | Hey everyone, In this blog we will be knowing more about Superset SSO with Google integration.... | 0 | 2024-07-05T16:19:31 | https://blog.elest.io/superset-sso-with-google-integration/ | superset, softwares, elestio | ---
title: Superset SSO with Google integration
published: true
date: 2024-06-23 09:03:08 UTC
tags: Superset,Softwares,Elestio
canonical_url: https://blog.elest.io/superset-sso-with-google-integration/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-10.png
---
Hey everyone, In this blog we will be kno... | kaiwalyakoparkar |
1,897,805 | Superset Download as Image API Guide | Hey everyone, In this blog we will knowing more about Superset Download as Image API Guide. Apache... | 0 | 2024-07-05T16:18:53 | https://blog.elest.io/superset-download-as-image-api-guide/ | superset, softwares, elestio | ---
title: Superset Download as Image API Guide
published: true
date: 2024-06-23 09:00:42 UTC
tags: Superset,Softwares,Elestio
canonical_url: https://blog.elest.io/superset-download-as-image-api-guide/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-8.png
---
Hey everyone, In this blog we will knowing... | kaiwalyakoparkar |
1,897,804 | Superset Redis Caching Guide | Hey everyone, In this blog we will be knowing more about Superset Redis Caching. Optimize your... | 0 | 2024-07-05T16:18:07 | https://blog.elest.io/superset-redis-caching-guide/ | superset, softwares, redis, elestio | ---
title: Superset Redis Caching Guide
published: true
date: 2024-06-23 08:57:39 UTC
tags: Superset,Softwares,Redis,Elestio
canonical_url: https://blog.elest.io/superset-redis-caching-guide/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-7.png
---
Hey everyone, In this blog we will be knowing more a... | kaiwalyakoparkar |
1,897,803 | Apache Superset SSO integration guide | Hey everyone, In this blog we will be knowing more about Superset SSO Integrations. Integrating... | 0 | 2024-07-05T15:42:39 | https://blog.elest.io/apache-superset-sso-integration-guide/ | superset, softwares, elestio | ---
title: Apache Superset SSO integration guide
published: true
date: 2024-06-23 08:55:24 UTC
tags: Superset,Softwares,Elestio
canonical_url: https://blog.elest.io/apache-superset-sso-integration-guide/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-6.png
---
Hey everyone, In this blog we will be kn... | kaiwalyakoparkar |
1,897,379 | 4 Ideas to Create Organic Growth for a Web App | Growing a web app is hard, especially when you have limited capital. This is usually the case for us... | 0 | 2024-06-23T08:51:47 | https://dev.to/alvinscherdin/4-ideas-to-create-organic-growth-for-a-web-app-j9m | webdev, seo, tutorial, startup | Growing a web app is hard, especially when you have limited capital. This is usually the case for us small indie developers, and because of that, I have built an arsenal of growth ideas to launch that website with a bang!
## 1. Utilize social media
When starting out, the easiest win is social media. It can generate a... | alvinscherdin |
1,897,669 | Face Mask for Tan Removal | ## Brighten Your Complexion with Pink Root Face Mask for Tan Removal Remove stubborn tan and... | 0 | 2024-06-23T08:51:24 | https://dev.to/pinkroot/face-mask-for-tan-removal-44ek | beauty, deta, productivity, skin |
## Brighten Your Complexion with Pink Root Face Mask for Tan Removal
Remove stubborn tan and brighten your complexion with [Pink Root Face Mask for Tan Removal](https://www.pinkroot.in/products/pink-root-detan-face... | pinkroot |
1,897,668 | Install local environment - CachyOS | Here is how you install local environment for peviitor.ro Preconditions Make... | 0 | 2024-06-23T08:49:06 | https://dev.to/sebiboga/install-local-environment-cachyos-3953 | peviitor | ##Here is how you install local environment for peviitor.ro
---
###Preconditions
Make sure you have installed:
- git
- github Desktop
- docker
##Steps to install
-
Create directory if it doesn't exist
```
mkdir -p ~/peviitor
```
-
Clone repositories
```
git clone https://github.com/peviitor-ro/solr.git ~/pe... | sebiboga |
1,897,666 | Twilio challenge : EcoAlert | This is a submission for Twilio Challenge v24.06.12 What I Built I have built a web... | 0 | 2024-06-23T08:48:32 | https://dev.to/reyans/twilio-challenge-ecoalert-1bk3 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
I have built a web application named EcoAlert this application
connects the general public with the authorities responsible for waste collection and management. Through my application, people can post images onli... | reyans |
1,897,665 | Azure DevOps Services and Exploring Alternatives | DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) to... | 0 | 2024-06-23T08:46:16 | https://dev.to/shreyash333/understanding-azure-devops-services-and-exploring-alternatives-1ln1 | azure, devops, cicd, development | DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) to streamline the software development lifecycle. Azure DevOps is a suite of services offered by Microsoft to support DevOps practices. In this article, we will explore the services offered in Azure DevOps, their alternatives,... | shreyash333 |
1,897,663 | Ways to declare variables in javascript.! | Ways to declare variables in javascript.! Javascriptda o'zgaruvchilarni e'lon qilish... | 0 | 2024-06-23T08:43:54 | https://dev.to/samandarhodiev/ways-to-declare-variables-in-javascript-5c0h | javascript, variables | Ways to declare variables in javascript.!
Javascriptda o'zgaruvchilarni e'lon qilish usullari.!!!
JavaScriptda o'zgaruvchilarni 3 xil "key words" kalitli ifodalar bilan e'lon qilish mumkin.
Bular: `var `, `let `, `const`.!
`var`
```
var name_ = 'JavaScript';
console.log(name_);
// natija - JavaScript
```
`let`
```... | samandarhodiev |
1,897,662 | contact me | t.me https://t.me/Ikhodieff Enter fullscreen mode Exit... | 0 | 2024-06-23T08:43:54 | https://dev.to/samandarhodiev/ways-to-declare-variables-in-javascript-3c84 |
{% embed https://t.me/samandarhodiev %}
```
https://t.me/Ikhodieff
```
| samandarhodiev | |
1,897,800 | Superset Nginx timeout guide | Hey everyone, In this blog we will be knowing more about Superset Nginx timeout. Discover... | 0 | 2024-07-05T15:39:36 | https://blog.elest.io/superset-nginx-timeout-guide/ | superset, softwares, elestio | ---
title: Superset Nginx timeout guide
published: true
date: 2024-06-23 08:43:20 UTC
tags: Superset,Softwares,Elestio
canonical_url: https://blog.elest.io/superset-nginx-timeout-guide/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-3.png
---
Hey everyone, In this blog we will be knowing more about [... | kaiwalyakoparkar |
1,897,661 | helloo | hellloooo | 0 | 2024-06-23T08:39:12 | https://dev.to/keirinkami/helloo-1jk7 | hellloooo | keirinkami | |
1,897,798 | Repair N8N SQLite database | Hey everyone, In this blog we will see how you can repair the N8N SQLite database. During this... | 0 | 2024-07-05T15:38:49 | https://blog.elest.io/repair-n8n-sqlite-database/ | n8n, softwares, elestio | ---
title: Repair N8N SQLite database
published: true
date: 2024-06-23 08:37:42 UTC
tags: N8N,Softwares,Elestio
canonical_url: https://blog.elest.io/repair-n8n-sqlite-database/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-2.png
---
Hey everyone, In this blog we will see how you can repair the [N8N]... | kaiwalyakoparkar |
1,897,660 | Simple YAML Linter/Validator Workflow for GitHub Actions | Here's a quick tip if you work with YAML on GitHub! The GitHub Actions Ubuntu runners comes with... | 0 | 2024-06-23T08:34:31 | https://tips.desilva.se/posts/simple-yaml-linter-validator-workflow-for-github-actions | github, githubactions, tutorial, yaml | Here's a quick tip if you work with YAML on GitHub!
The GitHub Actions Ubuntu runners comes with [yamllint](https://github.com/adrienverge/yamllint) installed, meaning it's super simple to create linting/validating workflows to ensure your YAML is valid!
```yaml
name: Validate YAML
on:
push:
pull_request:
jobs... | codewithcaen |
1,897,659 | React App Inbox with 0 Notification Costs. | Building a robust notification system in React can be a complex task. Juggling multi-channel... | 0 | 2024-06-23T08:32:01 | https://dev.to/suprsend/react-app-inbox-with-0-notification-costs-jik | react, javascript, opensource, webdev | Building a robust notification system in React can be a complex task. Juggling multi-channel notifications, real-time updates, and user interaction requires a powerful solution. Enter the [SuprSend Inbox for React](https://docs.suprsend.com/docs/inbox-react), a feature-packed library designed to simplify and elevate yo... | nikl |
1,897,657 | Bash Scripting Fundamentals | 1. Introduction to Bash 1.1 What is Bash? Bash (Bourne Again Shell) is a... | 0 | 2024-06-23T08:31:09 | https://dev.to/zeshancodes/bash-scripting-fundamentals-5a0e | bash, cmd, coding, terminal | ## 1. Introduction to Bash
### 1.1 What is Bash?
Bash (Bourne Again Shell) is a command processor that typically runs in a text window where the user types commands that cause actions.
Bash can also read and execu... | zeshancodes |
1,897,656 | Cypress Debugging: How to Get Started | Writing code quickly is a valuable skill, but the true mark of a proficient software developer is the... | 0 | 2024-06-23T08:29:44 | https://dev.to/kailashpathak7/cypress-debugging-how-to-get-started-4b5p | javascript, cypress, automation, testing | Writing code quickly is a valuable skill, but the true mark of a proficient software developer is the ability to effectively debug and resolve errors and bugs. Debugging is a critical aspect of the development process, ensuring that software functions as intended and meets user needs.
**Methods of debugging in Cypress... | kailashpathak7 |
1,897,655 | Dynamically add nodes to a force-directed graph | https://youtu.be/qlLQj12daDo demo | 0 | 2024-06-23T08:29:42 | https://dev.to/fridaymeng/dynamically-add-nodes-to-a-force-directed-graph-4fj8 |
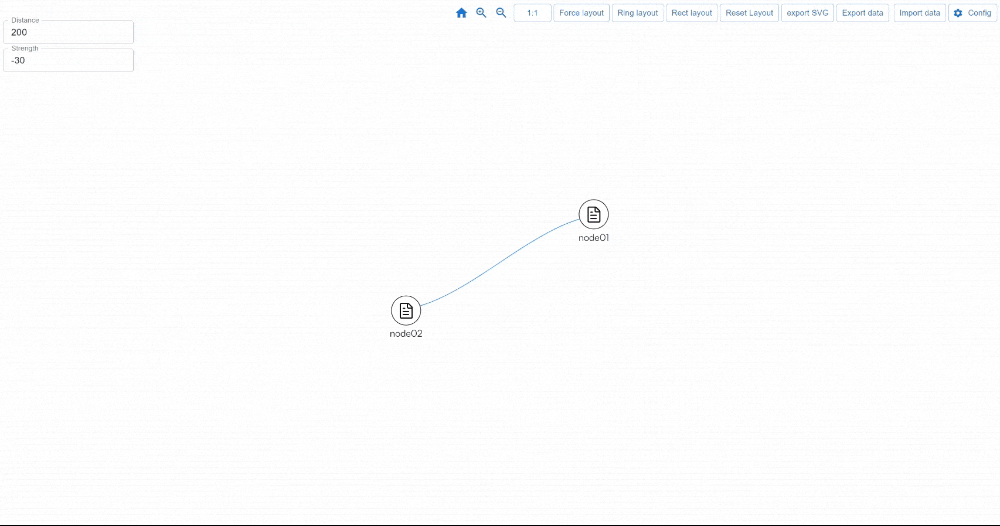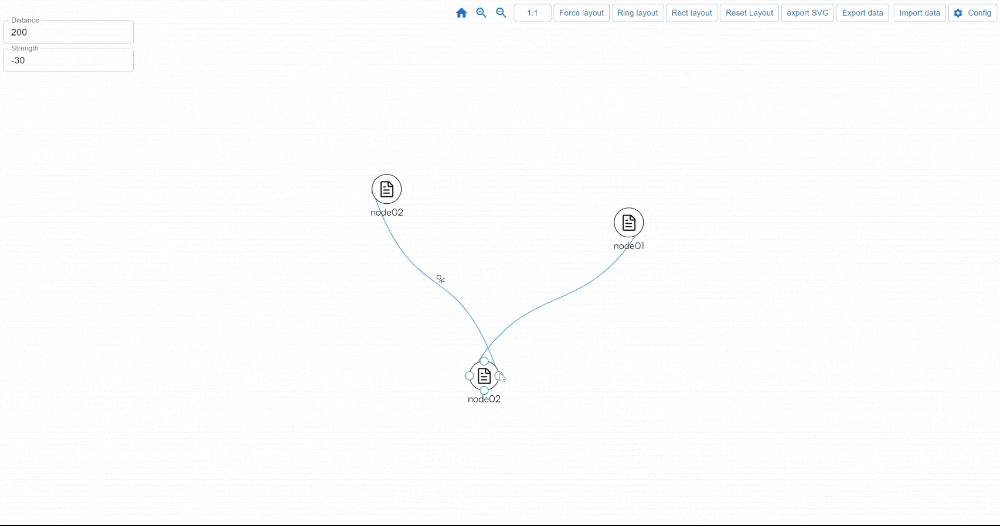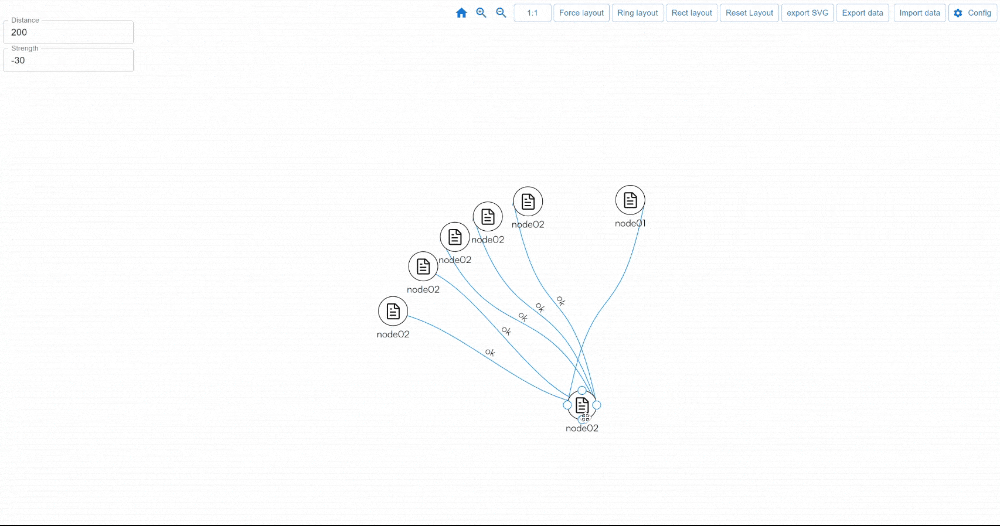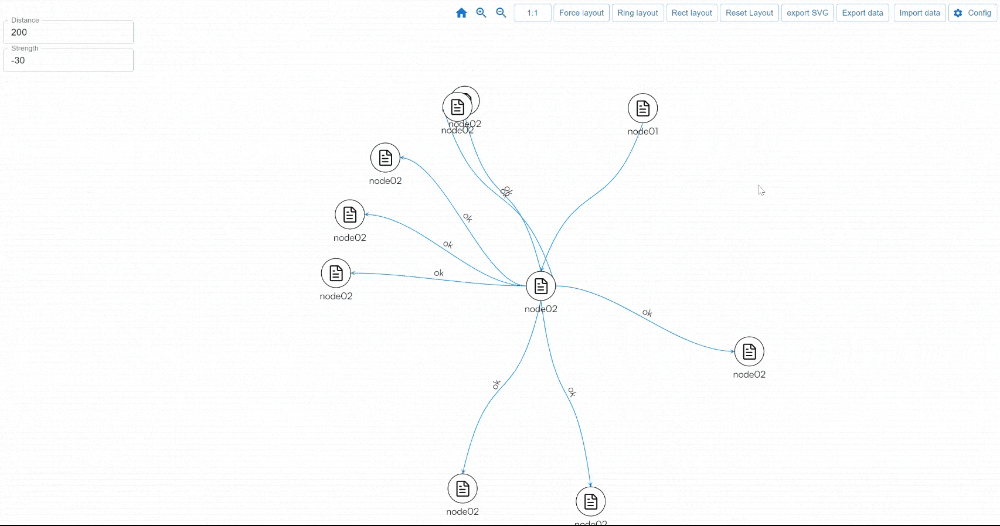
https://youtu.be/qlLQj12daDo
[demo](https://addgraph.com/leftRight) | fridaymeng | |
1,897,654 | What is a Slowloris attack? | A Slowloris attack is a type of denial-of-service (DoS) attack that targets web servers by exhausting... | 0 | 2024-06-23T08:29:03 | https://dev.to/sandeepseeram/what-is-a-slowloris-attack-50d | webdev, javascript, beginners, tutorial | A Slowloris attack is a type of denial-of-service (DoS) attack that targets web servers by exhausting their connection capacity. This attack, often referred to as a slow HTTP DoS attack, takes advantage of how web servers manage connections, making them unable to handle legitimate requests.
**Origins of the Slowloris ... | sandeepseeram |
1,897,653 | Understanding Authentication & Authorization with help of keycloak | Authentication and authorization are two fundamental concepts in the realm of security, especially in... | 0 | 2024-06-23T08:27:15 | https://dev.to/yashkashyap/understanding-authentication-authorization-with-help-of-keycloak-cdd | Authentication and authorization are two fundamental concepts in the realm of security, especially in computer applications.
**Authentication-** Authentication is the process of verifying the identity of a user, device, or entity in a computer system.
-
Purpose- To confirm the identity of the user or entity.
**... | yashkashyap | |
1,897,652 | Understanding Authentication & Authorization with help of keycloak | Authentication and authorization are two fundamental concepts in the realm of security, especially in... | 0 | 2024-06-23T08:27:14 | https://dev.to/yashkashyap/understanding-authentication-authorization-with-help-of-keycloak-4dl3 | Authentication and authorization are two fundamental concepts in the realm of security, especially in computer applications.
**Authentication-** Authentication is the process of verifying the identity of a user, device, or entity in a computer system.
-
Purpose- To confirm the identity of the user or entity.
**... | yashkashyap | |
1,897,796 | How to clean up the N8N database | Hey everyone, In this blog we will see how you can clean up the N8N database. During this tutorial,... | 0 | 2024-07-05T15:37:59 | https://blog.elest.io/how-to-clean-up-n8n-database/ | n8n, softwares, elestio | ---
title: How to clean up the N8N database
published: true
date: 2024-06-23 08:26:21 UTC
tags: N8N,Softwares,Elestio
canonical_url: https://blog.elest.io/how-to-clean-up-n8n-database/
cover_image: https://blog.elest.io/content/images/2024/06/Frame-8-1.png
---
Hey everyone, In this blog we will see how you can clean up... | kaiwalyakoparkar |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.