
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,895,530 | Machine Learning | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-21T05:30:17 | https://dev.to/prathik_bsgowda_48f2241/machine-learning-4i16 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Machine Learning is transforming industries by enabling systems to adapt and improve from experience. It's essential for advancements in big data analysis, predictive analytics, and n... | prathik_bsgowda_48f2241 |
1,895,496 | Top 10 React Libraries and Tools You Should Know in 2024 | React continues to be a dominant force in the world of web development. With its rich ecosystem and a... | 0 | 2024-06-21T04:27:30 | https://dev.to/delia_code/top-10-react-libraries-and-tools-you-should-know-in-2024-1jok | react, webdev, programming, javascript |
React continues to be a dominant force in the world of web development. With its rich ecosystem and a plethora of libraries and tools, developers can build efficient, scalable, and high-performance applications. Here are the top 10 React libraries and tools you should know about in 2024 to enhance your development wor... | delia_code |
1,895,527 | Create a high-availability storage account with public access, a blob container, soft delete, and blob versioning enabled. | To create a storage account with high availability you first have to create a storage account to... | 0 | 2024-06-21T05:23:30 | https://dev.to/bdporomon/create-a-high-availability-storage-account-with-public-access-a-blob-container-soft-delete-and-blob-versioning-enabled-le4 | webdev, beginners, programming, devops | To create a storage account with high availability you first have to create a storage account to support the public website. In the Azure portal, search for and select Storage accounts then press create.
Create a new resource group and give it a name. Give a name for the storage account name.
.*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Recall Friends episode where Chandler got stuck in the bank with a supermodel? He hummed to Joey,who understood.T... | muhammadnizamani |
1,895,521 | How to Choose the Right Trigger Sprayer for Your Cleaning Needs | screenshot-1710906673707.png Choosing the Perfect Trigger Sprayer for Your Cleaning Needs Advantages... | 0 | 2024-06-21T05:15:47 | https://dev.to/komand_dkopif_60d7597c9b4/how-to-choose-the-right-trigger-sprayer-for-your-cleaning-needs-2mij | design | screenshot-1710906673707.png
Choosing the Perfect Trigger Sprayer for Your Cleaning Needs
Advantages of Using A Trigger Sprayer
A trigger sprayer is just a cleansing tool that dispenses liquids such as cleaning solutions, pesticides, and herbicides. One of the most significant top continuous spray bottle features... | komand_dkopif_60d7597c9b4 |
1,895,520 | Aadhar Card Mein Mobile Number Kaise Check Karen: Status | Aadhar Card Mein Mobile Number Kaise Check Karen: Let us inform you that the Aadhar card is now a... | 0 | 2024-06-21T05:15:00 | https://dev.to/aadharcard2001/aadhar-card-mein-mobile-number-kaise-check-karen-status-56ph | **Aadhar Card Mein Mobile Number Kaise Check Karen**: Let us inform you that the <a href="https://www.uidaionlineaadharcard.com/uidai-gov-in 2022/"> Aadhar </a> card is now a document required for <a href="https://www.uidaionlineaadharcard.com/uidai-adhar-card/"> employment </a>in both the public and private sectors. ... | aadharcard2001 | |
1,895,514 | Feedback Needed on MyPortfolio MVP - A New Way to Create Professional and Student Portfolios | Hello devs, I've recently launched the MVP of my new project, MyPortfolio, and I'm seeking your... | 0 | 2024-06-21T05:07:11 | https://dev.to/rob097/feedback-needed-on-myportfolio-mvp-a-new-way-to-create-professional-and-student-portfolios-1kki | webdev, showdev, saas, productfeedback | Hello devs,
I've recently launched the MVP of my new project, MyPortfolio, and I'm seeking your valuable feedback.
You can check it out here: https://my-portfolio.it
**About MyPortfolio:**
MyPortfolio aims to revolutionize how professionals and students create and present their portfolios. Instead of a simple list o... | rob097 |
1,895,516 | ICAI CA Foundation Registration: Tips for Form Filling | ICAI CA Foundation Registration exam is the first step in attaining your goal of becoming a... | 0 | 2024-06-21T05:04:11 | https://dev.to/simrasah/icai-ca-foundation-registration-tips-for-form-filling-51d5 |

**[ICAI CA Foundation Registration](https://www.studyathome.org/ca-foundation-registration-january-2025/)** exam is the first step in attaining your goal of becoming a chartered accountant. Now that th... | simrasah | |
1,895,513 | Royal Oriental Rugs | Restore the beauty of your carpets with Royal Rug Cleaning & Restoration, your premier carpet... | 0 | 2024-06-21T05:02:12 | https://dev.to/royal_orientalrugs_beb88/royal-oriental-rugs-4h86 | carpet, cleaning | Restore the beauty of your carpets with Royal Rug Cleaning & Restoration, your premier carpet cleaning service in Tampa. We specialize in revitalizing carpets to their former glory, using advanced techniques and eco-friendly solutions to remove stains, dirt, and allergens. Our experienced team employs a meticulous appr... | royal_orientalrugs_beb88 |
1,895,508 | CA Intermediate Registration 2025: Deadline Alert | Ignite your ambition to become a Chartered Accountant with the Institute of Chartered Accountants of... | 0 | 2024-06-21T04:48:59 | https://dev.to/ananya_seth12/ca-intermediate-registration-2025-deadline-alert-2fn1 |

Ignite your ambition to become a Chartered Accountant with the Institute of Chartered Accountants of India (ICAI)! The ICAI is now accepting registrations for the May 2025 CA Intermediate exams. This comprehensive g... | ananya_seth12 | |
1,895,507 | Using Aceternity UI to make dynamic and Immersive webpages in Next.js | Creating a fan site for a beloved band like Tame Impala can be an exciting project, especially when... | 0 | 2024-06-21T04:47:39 | https://dev.to/aerodeval/using-aceternity-ui-to-make-dynamic-and-immersive-webpages-in-nextjs-229j | Creating a fan site for a beloved band like Tame Impala can be an exciting project, especially when you have the right tools at your disposal. In this blog post, we'll explore how to use Aceternity UI, a powerful UI library, to build a sleek and responsive website using Next.js. We'll discuss the benefits of Aceternity... | aerodeval | |
1,895,506 | How to Protect Your Social Media Photos from Facial Recognition | Social media platforms have become an integral part of our lives, allowing us to share moments,... | 0 | 2024-06-21T04:45:52 | https://dev.to/luxandcloud/how-to-protect-your-social-media-photos-from-facial-recognition-o17 | ai, news, tutorial | Social media platforms have become an integral part of our lives, allowing us to share moments, connect with others, and express ourselves. However, as technology advances, so do the potential risks to our privacy. One of the emerging concerns is the use of facial recognition technology, which can identify and track in... | luxandcloud |
1,895,505 | Understanding Infrastructure as Code: Tools and Techniques Explained - My 100 days of learning devops- DAY 2 PART 2 | What is Infrastructure as Code? Infrastructure as Code (IaC) is a methodology for managing... | 0 | 2024-06-21T04:45:48 | https://dev.to/dilshavijay/understanding-infrastructure-as-code-tools-and-techniques-explained-my-100-days-of-learning-devops-day-2-part-2-45li | devops, infrastructureascode, challenge, beginners | #### What is Infrastructure as Code?
Infrastructure as Code (IaC) is a methodology for managing and provisioning computing infrastructure using machine-readable scripts rather than through physical hardware configuration or interactive configuration tools. By defining infrastructure in code, you can automate the proce... | dilshavijay |
1,895,504 | QXG Technology Co., Ltd.: Innovating Solutions for a Digital World | QXG Technology Co. Ltd. : Innovating Possibility for the Digital World In the present world which... | 0 | 2024-06-21T04:44:45 | https://dev.to/komand_dkopif_60d7597c9b4/qxg-technology-co-ltd-innovating-solutions-for-a-digital-world-3e6b | design |
QXG Technology Co. Ltd. : Innovating Possibility for the Digital World
In the present world which was fast-paced technology happens to be an component which will be vital of day-to-day lifestyle. From smart devices to notebook computers, we be determined by electronic aluminum winding transformer products to help ... | komand_dkopif_60d7597c9b4 |
1,895,503 | Creating forms in React. | Handling forms in React involves managing state, handling user input, and validating the form before... | 0 | 2024-06-21T04:41:17 | https://dev.to/ark7/forms-in-react-38c7 | webdev, javascript, programming, tutorial | Handling **forms** in React involves managing state, handling user input, and validating the form before submission.
Contrary to some other ways of dealing with forms on the web, with React, forms are put into a **state variable**, and then React watches for any form-related event, with every such event updating the ... | ark7 |
1,895,502 | My 100-Day DevOps Journey: Day 2 Recap | Exploring Agile, DevOps, and Infrastructure as Code (IaC) in Modern Software Development ... | 0 | 2024-06-21T04:41:01 | https://dev.to/dilshavijay/my-100-day-devops-journey-day-2-recap-1dkh | devops, beginners, challenge, infrastructureascode | ## Exploring Agile, DevOps, and Infrastructure as Code (IaC) in Modern Software Development
## Agile: Building Step by Step
Agile is like building a LEGO set one step at a time. Instead of trying to build everything at once, we break down big tasks into smaller pieces. Each piece is like a step in our plan. This helps... | dilshavijay |
1,895,501 | Enhance Data Exploration with a Versatile JSON Viewer: From JSON to Tree, Table, Graph, and Chart | In the realm of data analysis and development, JSON (JavaScript Object Notation) serves as a... | 0 | 2024-06-21T04:37:58 | https://dev.to/bugblitz98/enhance-data-exploration-with-a-versatile-json-viewer-from-json-to-tree-table-graph-and-chart-5ebp | In the realm of data analysis and development, JSON (JavaScript Object Notation) serves as a fundamental format for storing and transmitting structured data. However, navigating and comprehending JSON data can often be challenging without the right tools. Enter the JSON Viewer, a versatile tool designed to transform ra... | bugblitz98 | |
1,895,500 | Understanding Microservices: A Technical Overview | Since the end of 2017, the term "microservices" has become increasingly common. But what exactly are... | 0 | 2024-06-21T04:32:38 | https://dev.to/adaumircosta/understanding-microservices-a-technical-overview-4li1 | microservices, architecture, productivity | Since the end of 2017, the term "microservices" has become increasingly common. But what exactly are microservices?
"Microservices are small, autonomous services working together to meet a specific demand." or "Independent services that together compose a single system."
To clarify, microservices represent a software... | adaumircosta |
1,895,499 | JuiceFS 1.2: Introducing Enterprise-Grade Permission Management and Smooth Upgrades | JuiceFS Community Edition 1.2 is released today! This marks the third major release since its... | 0 | 2024-06-21T04:31:34 | https://dev.to/daswu/juicefs-12-introducing-enterprise-grade-permission-management-and-smooth-upgrades-aeg | [JuiceFS Community Edition 1.2](https://github.com/juicedata/juicefs/releases/tag/v1.2.0) is released today! This marks the third major release since its open-source debut in 2021. This version is also a long-term support (LTS) release. We will continue to maintain versions 1.2 and 1.1, while version 1.0 will no longer... | daswu | |
1,895,498 | Demystifying In-App Purchases: A Look at Google Play Billing Library Versions 5, 6, and 7 | In the realm of mobile applications, in-app purchases (IAP) play a crucial role in generating revenue... | 0 | 2024-06-21T04:29:35 | https://dev.to/epakconsultant/demystifying-in-app-purchases-a-look-at-google-play-billing-library-versions-5-6-and-7-2jcm | googleplay | In the realm of mobile applications, in-app purchases (IAP) play a crucial role in generating revenue and sustaining development efforts. Google Play Billing Library serves as the bridge between your Android app and Google Play's billing system, facilitating secure and efficient IAP transactions. This article explores ... | epakconsultant |
1,895,497 | Dev > University Class? | Using Dev platform is better than attending university classes... | 0 | 2024-06-21T04:29:05 | https://dev.to/pema_wangchuk_0517eaac7f7/dev-university-class-1k38 | Using Dev platform is better than attending university classes... | pema_wangchuk_0517eaac7f7 | |
1,895,495 | How to create a Next.js 14 dynamic sitemap? | What is a sitemap? A sitemap is a file that contains a comprehensive list of all the pages... | 0 | 2024-06-21T04:27:13 | https://dev.to/syketb/how-to-create-a-nextjs-14-dynamic-sitemap-2e1b | nextjs, seo, javascript, beginners | ## What is a sitemap?
A sitemap is a file that contains a comprehensive list of all the pages on a website, along with their interrelationships. It plays a crucial role in aiding search engines to efficiently crawl and comprehend the structure of the website. Sitemaps also offer vital information about each page, such... | syketb |
1,895,167 | Creating and Connecting to a Linux Virtual Machine Using Public Key Authentication on Azure Portal | Azure Virtual machines (VMs) can be created through the azure portal. The Azure portal is a... | 0 | 2024-06-21T04:24:01 | https://dev.to/adah_okwara_3c43c95a89a2e/creating-and-connecting-to-a-linux-virtual-machine-using-public-key-authentication-on-azure-portal-52l4 | azure, virtualmachine, linux, techtalks | Azure Virtual machines (VMs) can be created through the azure portal. The Azure portal is a browser-based user interface to create Azure resources. This article shows you how to use the Azure portal to deploy a Linux Virtual Machine (VM)using Public key Authentication.
## Step 1: Sign in to Azure Portal
1. Open your w... | adah_okwara_3c43c95a89a2e |
1,895,493 | Building Blazing-Fast Websites ft. Gatsby 🔥 | Gatsby, put simply, is a static site generator. This means it creates static HTML files that you can... | 0 | 2024-06-21T04:22:58 | https://dev.to/ayushdotpro/building-blazing-fast-websites-ft-gatsby-dfp | webdev, javascript, beginners, programming | _Gatsby, put simply, is a static site generator. This means it creates static HTML files that you can load onto a server._
Unlike many traditional websites, which require querying a database or server-side programming to serve web pages, Gatsby pre-configures everything in advance. This results in static HTML files th... | ayushdotpro |
1,895,492 | Reactive Programming with Spring Boot and Web Flux | Introduction In the ever-evolving landscape of software development, reactive programming has... | 0 | 2024-06-21T04:20:06 | https://dev.to/tutorialq/reactive-programming-with-spring-boot-and-web-flux-io8 | reactiveprogramming, springboot, springwebflux, dependencyinversion |

**Introduction**
In the ever-evolving landscape of software development, reactive programming has emerged as a powerful paradigm that enables developers to build robust, resilient, and highly scalable applications... | tutorialq |
1,895,491 | Landing Page Alchemy: Crafting High-Converting Pages with GemPages | In the digital age, landing pages are the battlegrounds of online marketing. They act as the first... | 0 | 2024-06-21T04:18:50 | https://dev.to/epakconsultant/landing-page-alchemy-crafting-high-converting-pages-with-gempages-57lf | webdev | In the digital age, landing pages are the battlegrounds of online marketing. They act as the first impression for potential customers and need to be meticulously crafted to convert visitors into leads or sales. GemPages emerges as a powerful tool for businesses, empowering them to build high-converting landing pages wi... | epakconsultant |
1,895,490 | Let's Pretend to be Hackers | In this article, we will pretend to do some of the things a hacker might do in trying to gain access... | 0 | 2024-06-21T04:18:08 | https://dev.to/countyemi/lets-pretend-to-be-hackers-2g8l | cybersecurity, devops, docker, cloudcomputing | In this article, we will pretend to do some of the things a hacker might do in trying to gain access to a network.
For this, we will run the following services in the network:
1. Apache service running on port 80
2. MySQL service running on port 3306
3. Flask server on port 5000
We will run all these services on a ... | countyemi |
1,895,489 | Understanding JavaScript Global Context Execution | When diving into JavaScript, one of the fundamental concepts to grasp is the "global context" of code... | 0 | 2024-06-21T04:14:42 | https://dev.to/dhavalkurkutiya/understanding-javascript-global-context-execution-155a | javascript, react, webdev, programming | When diving into JavaScript, one of the fundamental concepts to grasp is the "global context" of code execution. This term might sound complex, but it's essential for understanding how JavaScript operates, especially in web development. Let's break it down.
## What is the Global Context?
In JavaScript, the global con... | dhavalkurkutiya |
1,895,488 | Cultivating Customer Relationships: A Dive into CRM Systems like HubSpot and Salesforce | In today's competitive business landscape, fostering strong customer relationships is paramount.... | 0 | 2024-06-21T04:13:43 | https://dev.to/epakconsultant/crm-systems-eg-hubspot-salesforce-23ej | crm | In today's competitive business landscape, fostering strong customer relationships is paramount. Customer Relationship Management (CRM) systems emerge as critical tools, empowering businesses to manage interactions with their customers across different touchpoints. This article delves into the world of CRM systems, exp... | epakconsultant |
1,895,487 | Understanding JWT Authentication: A Comprehensive Guide with Examples | In the world of web development, security is paramount. One of the most popular methods for securing... | 0 | 2024-06-21T04:09:13 | https://dev.to/vyan/understanding-jwt-authentication-a-comprehensive-guide-with-examples-1l3 | webdev, node, jwt, react | In the world of web development, security is paramount. One of the most popular methods for securing web applications is JSON Web Token (JWT) authentication. In this comprehensive guide, we'll explore what JWT authentication is, how it works, and how you can implement it in your web applications, with practical example... | vyan |
1,895,486 | How Instafill.ai PDF App Saved Thousands on Microsoft Azure | Once upon a time, Instafill.ai PDF app embarked on a journey to find the perfect cloud platform to... | 0 | 2024-06-21T04:09:11 | https://dev.to/instafill/how-instafillai-saved-thousands-of-dollars-on-ms-azure-5871 | azure, finances |
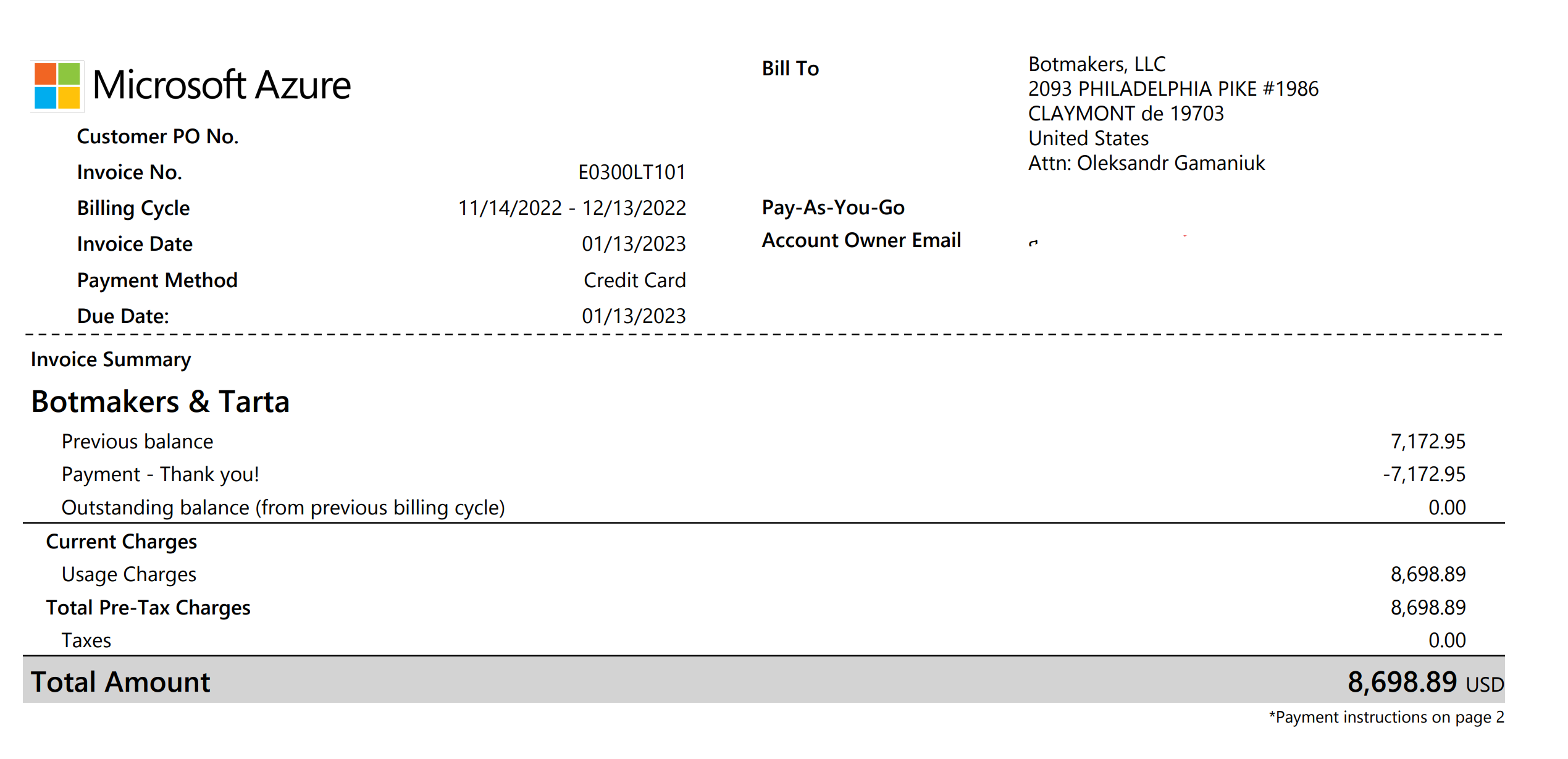
Once upon a time, [Instafill.ai PDF app](https://instafill.ai/) embarked on a journey to find the perfect cloud platform to fuel its innovative form-filling technology. The story began with an enticing offer from [... | agamanyuk |
1,895,485 | Pixie: Your Autonomous Solution for Rapid Web App Development | Pixie is an AI agent developed by GPTConsole, capable of generating production-ready web... | 0 | 2024-06-21T04:06:30 | https://dev.to/gptconsole/pixie-your-autonomous-solution-for-rapid-web-app-development-3c83 |

Pixie is an AI agent developed by GPTConsole, capable of generating production-ready web applications merely from text prompts. It’s revolutionizing the development process, allowing creators to manifest complex ap... | vincivinni | |
1,895,484 | Instafill.ai PDF Filler Tech Stack | Instafill.ai’s technology infrastructure is meticulously crafted to support robust application... | 0 | 2024-06-21T04:04:18 | https://dev.to/instafill/instafillai-pdf-filler-tech-stack-20hc | instafill, techstack, pdf, genai | Instafill.ai’s technology infrastructure is meticulously crafted to support robust application development and seamless operational workflows. Here’s a closer look at each component of our stack, tailored for the developer audience:
### Application and Data
- **Python**: Chosen for its simplicity and versatility in da... | agamanyuk |
1,895,483 | 10 Essential Dos and Don'ts for Every Developer | 👨💻 As developers, we are constantly striving to improve our skills and deliver high-quality... | 0 | 2024-06-21T04:04:09 | https://dev.to/dipakahirav/10-essential-dos-and-donts-for-every-developer-2n41 | webdev, developer, learning, programming | 👨💻 As developers, we are constantly striving to improve our skills and deliver high-quality software. However, it’s easy to fall into certain pitfalls along the way. Here are 10 essential dos and don’ts to keep in mind to ensure you are on the right track:
please subscribe to my [YouTube channel](https://www.youtub... | dipakahirav |
1,895,482 | Unleash the Power of Communication: Exploring RingCentral's Programmable SMS and MMS API | In today's fast-paced world, businesses need efficient and engaging ways to connect with their... | 0 | 2024-06-21T04:03:34 | https://dev.to/epakconsultant/unleash-the-power-of-communication-exploring-ringcentrals-programmable-sms-and-mms-api-cop | In today's fast-paced world, businesses need efficient and engaging ways to connect with their customers. RingCentral's Programmable SMS and MMS API steps in as a powerful tool, empowering businesses to integrate text messaging functionalities directly into their applications. This article dives into the capabilities o... | epakconsultant | |
1,895,465 | Large Language Models: The Brains Behind Modern AI (like ChatGPT,Siri,Alexa,Cortana) | I just learned something really fascinating about AI, and I think you'll find it cool too. It's all... | 0 | 2024-06-21T04:02:00 | https://dev.to/adebiyiitunuayo/large-language-models-the-brains-behind-modern-ai-like-chatgptsirialexacortana-265c | cybersecurity, ai, llm, webdev | I just learned something really fascinating about AI, and I think you'll find it cool too. It's all about Large Language Models, or LLMs. These are like super-smart robots that can have conversations with you, answer questions, and even help out with various tasks. Let me break it down for you.
#### What is a Large La... | adebiyiitunuayo |
1,895,481 | Maximizing Efficiency: Plastic Sheet Extrusion Line Techniques | screenshot-1717048156074.png Maximizing Efficiency: Plastic Sheet Extrusion Line Techniques Are you... | 0 | 2024-06-21T04:00:56 | https://dev.to/homah_yopoks_2b8dbd52b4d0/maximizing-efficiency-plastic-sheet-extrusion-line-techniques-3mi1 | design | screenshot-1717048156074.png
Maximizing Efficiency: Plastic Sheet Extrusion Line Techniques
Are you looking for ways to improve your plastic sheet extrusion line performance? Do you want to maximize your efficiency and get the most out of your resources? Look no further! We have compiled a comprehensive guide on ho... | homah_yopoks_2b8dbd52b4d0 |
1,895,479 | Bigg Boss 18 Full Episodes | https://biggboss18watchonline.net/ The Indian Tv Reality Show Of Salman Khan Bigg Boss 18 is all set... | 0 | 2024-06-21T03:54:55 | https://dev.to/bigg_boss_424705332075bb2/bigg-boss-18-full-episodes-528j | https://biggboss18watchonline.net/
The Indian Tv Reality Show Of Salman Khan Bigg Boss 18 is all set to be launched
This Bigg Boss Season 18 Will Be Start from October 2024 at voot and jiocinema hd | bigg_boss_424705332075bb2 | |
1,891,757 | How to Deploy and Connect to Linus Virtual Machine in Azure: Step by Step Guide | Table of Contents Create (Deploy) Linus Virtual Machine Connect to Linus Virtual... | 0 | 2024-06-21T03:50:43 | https://dev.to/celestina_odili/how-to-deploy-and-connect-to-linus-virtual-machine-in-azure-step-by-step-guide-1p22 | cloudcomputing, azure, microsoft, tutorial | Table of Contents <a name="contents"></a>
[Create (Deploy) Linus Virtual Machine] (#create)
[Connect to Linus Virtual Machine] (#connect)
[Testing] (#test)
This guide shows how to deploy and connect a Linus virtual machine running Ubuntu Server 22.04 LTS-x64 Gen2 using SSH public key through Azure portal.
## Create (... | celestina_odili |
1,895,478 | Building a Secure CI/CD Pipeline: Beyond the Basics of Security Testing | _Welcome Aboard Week 3 of DevSecOps in 5: Your Ticket to Secure Development Superpowers! Hey there,... | 0 | 2024-06-21T03:49:39 | https://dev.to/gauri1504/building-a-secure-cicd-pipeline-beyond-the-basics-of-security-testing-gpk | devops, devsecops, cloud, security |
_Welcome Aboard Week 3 of DevSecOps in 5: Your Ticket to Secure Development Superpowers!
Hey there, security champions and coding warriors!
Are you itching to level up your DevSecOps game and become an architect of rock-solid software? Well, you've landed in the right place! This 5-week blog series is your fast track... | gauri1504 |
1,895,456 | Taming Your Data with AWS DocumentDB: A Deep Dive | Taming Your Data with AWS DocumentDB: A Deep Dive In today's data-driven world,... | 0 | 2024-06-21T03:02:36 | https://dev.to/virajlakshitha/taming-your-data-with-aws-documentdb-a-deep-dive-2e54 | 
# Taming Your Data with AWS DocumentDB: A Deep Dive
In today's data-driven world, applications need to handle vast amounts of information, and often, this information doesn't neatly fit into traditional relational database structures... | virajlakshitha | |
1,895,477 | Getting Started with ReductStore in Node.js | This quick start guide will walk you through the process of installing and using... | 0 | 2024-06-21T03:48:29 | https://www.reduct.store/docs/getting-started/with-javascript | javascript, node, reductstore, learning |
This quick start guide will walk you through the process of installing and using the [**ReductStore JavaScript Client SDK**](https://github.com/reductstore/reduct-js) to read and write data to a [**ReductStore**](https://www.reduct.store/) instance.
## Installing the JavaScript SDK
To install the SDK, you will only ... | atimin |
1,895,476 | Resin Sources and Their Impact on the Performance of Composite Products | Discover the Magic of Resin Sources and How They Affect the Performance of Composite Products Are... | 0 | 2024-06-21T03:46:03 | https://dev.to/homah_yopoks_2b8dbd52b4d0/resin-sources-and-their-impact-on-the-performance-of-composite-products-2khc | design | Discover the Magic of Resin Sources and How They Affect the Performance of Composite Products
Are you tired of using the same old materials for producing composite products? Do you want to boost the ongoing service and quality of your products or services? Resin sources give the perfect solution to all your problems... | homah_yopoks_2b8dbd52b4d0 |
1,895,475 | Can we hide payloads in api calls? | I have a question about api calls we made in angular. I have made an simple application where user... | 0 | 2024-06-21T03:44:49 | https://dev.to/mechatron/can-we-hide-payloads-in-api-calls-7dh | question, webdev, beginners, angular | I have a question about api calls we made in angular. I have made an simple application where user need to login. When I make api call to log user in, in payload it shows data of user. Is there any way to hide the payload data?Any idea?? or suggestion? | mechatron |
1,890,157 | Recycling comes to WhatsApp ♻️ | This is a submission for Twilio Challenge v24.06.12 What I Built 🛠️ A WhatsApp bot which... | 0 | 2024-06-21T03:44:11 | https://dev.to/anshsaini/recycling-comes-to-whatsapp-63a | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built 🛠️
A WhatsApp bot which gives you recycling ideas at your fingertips.
WhatsApp is such a popular and convenient platform, that almost everyone has it. Just message the bot and tell it what you want to recycle.
I... | anshsaini |
1,895,474 | Firewalls 101: Understanding Types, Functions, and Configurations | In today's interconnected digital world, cybersecurity is more crucial than ever. With cyber threats... | 0 | 2024-06-21T03:41:35 | https://dev.to/iaadidev/firewalls-101-understanding-types-functions-and-configurations-3956 | firewall, webdev, beginners, tutorial |
In today's interconnected digital world, cybersecurity is more crucial than ever. With cyber threats continually evolving, safeguarding networks and data has become a top priority for individuals and organizations alike. One of the fundamental tools in the cybersecurity arsenal is the firewall. This blog post will de... | iaadidev |
1,895,471 | Mastering AWS Cloud Architecture: A Comprehensive Guide to the Well-Architected Framework | This article was originally published on Practical Cloud. Read the unabridged version here The AWS... | 0 | 2024-06-21T03:32:31 | https://practicalcloud.net/mastering-aws-cloud-architecture-a-comprehensive-guide-to-the-well-architected-framework-for-optimal-performance-and-cost-efficiency/ | This article was originally published on [Practical Cloud](https://practicalcloud.net).
Read the unabridged version [here](https://practicalcloud.net/mastering-aws-cloud-architecture-a-comprehensive-guide-to-the-well-architected-framework-for-optimal-performance-and-cost-efficiency/)
The AWS Well-Architected Framework... | kelvinskell | |
1,895,469 | Plastic Recycling Machines: Optimizing Resource Recovery | Recycling Machine.png Introduction Plastic recycling machines are innovative inventions being... | 0 | 2024-06-21T03:31:02 | https://dev.to/homah_yopoks_2b8dbd52b4d0/plastic-recycling-machines-optimizing-resource-recovery-4fh7 | design | Recycling Machine.png
Introduction
Plastic recycling machines are innovative inventions being helping us optimize resource recovery
These machines are designed to make the recycling process faster easier and safer
They provide an opportunity to reduce the amount of waste we create and contribute to creating a mo... | homah_yopoks_2b8dbd52b4d0 |
1,895,468 | CloudForecast Website Revamp | CloudForecast is a bootstrapped startup specializing in AWS cost management. They simplify AWS cost... | 0 | 2024-06-21T03:28:47 | https://dev.to/sdbagency/cloudforecast-website-revamp-b7e |
CloudForecast is a bootstrapped startup specializing in AWS cost management. They simplify AWS cost monitoring and help your tech team optimize budgets, and eliminate excessive expenses.
We’ve helped them to revam... | sdbagency | |
1,895,467 | Master the Stock Span Problem by 3 Easy Steps in Python | In intermediate-level interviews, candidates are often asked to solve problems related to share... | 0 | 2024-06-21T03:27:54 | https://dev.to/rk042/master-the-stock-span-problem-by-3-easy-steps-in-python-3i8p | programming, career, interview, algorithms | In intermediate-level interviews, candidates are often asked to solve problems related to share prices, such as the Stock Span Problem. The challenge involves calculating the span of share prices over a series of days, which measures how many consecutive days the price of a share has been less than or equal to its pric... | rk042 |
1,895,455 | How to get elements by tag name of DOM child in React Native? | How to get elements by tag name of DOM... | 0 | 2024-06-21T02:58:12 | https://dev.to/ik6ne/how-to-get-elements-by-tag-name-of-dom-child-in-react-native-4620 | {% stackoverflow 78650221 %} | ik6ne | |
1,895,464 | Dive into the Fusion of Music and Programming with "The Haskell School Of Music" 🎶💻 | The Haskell School of Music is a comprehensive guide that explores the intersection of programming and music, delving into the use of Haskell to create musical compositions from signals to symphonies. Authored by Paul Hudak, the book provides a unique perspective on the fusion of technology and artistry. | 27,801 | 2024-06-21T03:24:47 | https://getvm.io/tutorials/the-haskell-school-of-music-from-signals-to-symphonies | getvm, programming, freetutorial, technicaltutorials |
As a music enthusiast and programming aficionado, I recently stumbled upon an absolute gem – "The Haskell School Of Music: From Signals to Symphonies" by the talented Paul Hudak. This comprehensive guide delves into the captivating intersection of these two seemingly disparate worlds, offering a unique perspective on... | getvm |
1,895,463 | Getting Started with ReductStore in Python | This quick start guide will walk you through the process of installing and using... | 0 | 2024-06-21T03:24:41 | https://www.reduct.store/docs/getting-started/with-python | python, learning, reductstore, database |
This quick start guide will walk you through the process of installing and using the [**ReductStore Python Client SDK**](https://github.com/reductstore/reduct-py) to read and write data to a [**ReductStore**](https://www.reduct.store/) instance.
## Installing the Python SDK[](https://www.reduct.store/docs/getting-sta... | atimin |
1,895,462 | Why did we develop HPFS? | Why did we develop HPFS? When training with ResNet-50, we use a large number of images, reaching a... | 0 | 2024-06-21T03:24:35 | https://dev.to/sy_z_5d0937c795107dd92526/why-did-we-develop-hpfs-1cde | Why did we develop HPFS? When training with ResNet-50, we use a large number of images, reaching a scale of hundreds of millions. We also need to train the Stable Diffusion model, which requires a staggering amount of data, ranging from tens of billions to hundreds of billions of datasets. We have tried using Lustre, C... | sy_z_5d0937c795107dd92526 | |
1,895,458 | 10 microservices best practices for a strengthened architecture | Microservice architectures have gained significant popularity in recent years due to their ability to... | 0 | 2024-06-21T03:23:14 | https://dev.to/gem_corporation/10-microservices-best-practices-for-a-strengthened-architecture-11bm | microservices, architecture, webdev | [Microservice architectures](https://gemvietnam.com/others/soa-vs-microservices/?utm_source=Devto&utm_medium=click) have gained significant popularity in recent years due to their ability to enable scalable and maintainable systems. However, building an effective microservice architecture requires adherence to certain ... | gem_corporation |
1,895,457 | How to Build a GUI Clock with Python: A Comprehensive Step-by-Step Guide | In the world of programming, creating a graphical user interface (GUI) clock is an excellent project... | 0 | 2024-06-21T03:15:21 | https://blog.learnhub.africa/2024/06/21/how-to-build-a-gui-clock-with-python-a-comprehensive-step-by-step-guide/ | python, beginners, programming, tutorial |
In the world of programming, creating a graphical user interface (GUI) clock is an excellent project for beginners and intermediate Python developers alike. This tutorial will guide you through building a customizable GUI clock using Python and the Tkinter library.
By the end of this article, you'll have a fully fun... | scofieldidehen |
1,895,454 | Unlocking Career Opportunities: Top Business Analyst Training Programs with Placement in the USA | In the highly competitive job market of today, pursuing a career as a business analyst represents a... | 0 | 2024-06-21T02:55:12 | https://dev.to/kerina_coch_0eae69f1af53b/unlocking-career-opportunities-top-business-analyst-training-programs-with-placement-in-the-usa-3iph | In the highly competitive job market of today, pursuing a career as a business analyst represents a compelling opportunity for those interested in integrating data analysis, business operations, and technology. Business analysts are vital for steering organizations towards data-driven decisions and more efficient proce... | kerina_coch_0eae69f1af53b | |
1,895,453 | Case: buscando soluções simples para automatizar atividades de D&A | Case de hoje: “você é uma analista de dados e precisa organizar as atividades da equipe, gerar... | 0 | 2024-06-21T02:53:18 | https://dev.to/camila_arruda_ec496aeea5c/case-buscando-solucoes-simples-para-automatizar-atividades-de-da-5fj8 | data, analytics, solutions, strategy | **Case de hoje:**
“_você é uma analista de dados e precisa organizar as atividades da equipe, gerar indicadores e trazer propostas para melhorar o fluxo atual, atingir os resultados, tornar o dia a dia dessa equipe melhor e mais produtivo! Procura-se um livro escrito por uma mulher , que explique os fundamentos da ges... | camila_arruda_ec496aeea5c |
1,895,449 | SHA-256 in 256 Characters | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-21T02:50:06 | https://dev.to/cadenmilne/sha-256-in-256-characters-9fh | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
**S**ecure **H**ashing **A**lgorithm 256 uses 8 32 bit hash values derived from the square roots of the first 8 p... | cadenmilne |
1,895,448 | Four months working with NextJS my experience | Right now I have been working with next js for around 4 months, and in this post I want to share my... | 0 | 2024-06-21T02:50:05 | https://dev.to/caresle/four-months-working-with-nextjs-my-experience-2cnp | nextjs, blog, javascript, react | Right now I have been working with next js for around 4 months, and in this post I want to share my personal experience with It. We will lock at the Next JS `14` version, the good, the bad and meh about the framework.
Before NextJS I worked with vue and laravel for the frontend and backend respectivily.
> This is my ... | caresle |
1,895,447 | 🌐 Understanding Shadow DOM and Web Components in JavaScript | The web has evolved significantly over the years, and one of the most exciting advancements is the... | 0 | 2024-06-21T02:50:05 | https://dev.to/dipakahirav/understanding-shadow-dom-and-web-components-in-javascript-9bk | javascript, webdev, beginners, learning | The web has evolved significantly over the years, and one of the most exciting advancements is the introduction of Web Components and Shadow DOM. These technologies enable developers to create reusable and encapsulated components. Let's dive in! 🧙♂️
please subscribe to my [YouTube channel](https://www.youtube.com/@D... | dipakahirav |
1,895,443 | PET Recycling Machine: Revolutionizing Plastic Waste Management | PP PE Pet Plastic Pelletizing Machine2.png PET Recycling Machine Revolutionizing Plastic Waste... | 0 | 2024-06-21T02:45:20 | https://dev.to/marie_twalkerw_14c6b656/pet-recycling-machine-revolutionizing-plastic-waste-management-1bp7 | PP PE Pet Plastic Pelletizing Machine2.png
PET Recycling Machine Revolutionizing Plastic Waste Management
Plastic is a material that is versatile extensively in our day to day lives from packaging to toys also it can be among the many harmful materials to the environment
The continuous use and disposal of plastic ... | marie_twalkerw_14c6b656 | |
1,895,442 | OAuth 2.1 is Here: What You Need to Know | Since the initial release of OAuth 2.0, the internet has evolved significantly. Security threats have... | 0 | 2024-06-21T02:45:09 | https://blog.logto.io/oauth-2-1/ | webdev, security, identity, opensource | Since the initial release of OAuth 2.0, the internet has evolved significantly. Security threats have become more sophisticated. In response to these changes, the OAuth 2.1 specification has been planned. Let's explore the key differences between OAuth 2.0 and OAuth 2.1 and how they were adopted in Logto.
---
# Introd... | palomino |
1,895,438 | From Classroom to Career: Exploring Effective QA Courses with Placement Services | In the rapidly evolving tech landscape, the need for skilled Quality Assurance (QA) professionals... | 0 | 2024-06-21T02:41:08 | https://dev.to/kerina_coch_0eae69f1af53b/from-classroom-to-career-exploring-effective-qa-courses-with-placement-services-3b4o | In the rapidly evolving tech landscape, the need for skilled Quality Assurance (QA) professionals continues to grow as organizations prioritize the effectiveness and efficiency of their software products. [qa course with placement](https://www.h2kinfosys.com/courses/qa-online-training-course-details/) services serve a... | kerina_coch_0eae69f1af53b | |
1,895,437 | PP PE Recycling: Addressing the Challenges of Plastic Pollution | PP PE Pet Plastic Pelletizing Machine.png PP PE Recycling Helping Save the Planet From Plastic... | 0 | 2024-06-21T02:40:30 | https://dev.to/marie_twalkerw_14c6b656/pp-pe-recycling-addressing-the-challenges-of-plastic-pollution-elc | PP PE Pet Plastic Pelletizing Machine.png
PP PE Recycling Helping Save the Planet From Plastic Pollution
Plastic pollution is a concern that is significant our planet
It is important to find methods to reduce waste that is plastic recycle it
PP PE recycling comes as a boon as it will help in reducing pollution t... | marie_twalkerw_14c6b656 | |
1,895,436 | PP PE Recycling: Implementing Sustainable Practices in Plastic Recovery | H2cd7771d965446fba5e936cf59524f34U.png PP PE Recycling: Implementing Sustainable Practices in... | 0 | 2024-06-21T02:34:42 | https://dev.to/marie_twalkerw_14c6b656/pp-pe-recycling-implementing-sustainable-practices-in-plastic-recovery-18lg | H2cd7771d965446fba5e936cf59524f34U.png
PP PE Recycling: Implementing Sustainable Practices in Plastic Recovery
Introduction
Plastic will not be biodegradable, meaning it takes hundreds of years to decompose. Recycling plastic to make solutions being newer undoubtedly an means that was innovative solve this probl... | marie_twalkerw_14c6b656 | |
1,895,435 | Breadth-First Search | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-21T02:29:52 | https://dev.to/nickocruzm/breadth-first-search-178c | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
I want to find something in my strange house, that has n-floors. I must check all the rooms on the curr floor if I find it then I'm done. If I don't find it in any of the rooms on that ... | nickocruzm |
1,895,433 | Username BRImo Terblokir? | A post by Layanan Mobile BRlmo | 0 | 2024-06-21T02:29:21 | https://dev.to/halobrimo/username-brimo-terblokir-43c7 |
[](https://t2m.io/eqo27bKR) | halobrimo | |
1,895,434 | PET Recycling Machine: From Waste to Value-Added Products | Hfa4b6ed6444040d888d575fa921725bfo.png Recycle Your animal Bottles with PET Recycling Device Maybe... | 0 | 2024-06-21T02:26:55 | https://dev.to/marie_twalkerw_14c6b656/pet-recycling-machine-from-waste-to-value-added-products-5gg6 | Hfa4b6ed6444040d888d575fa921725bfo.png
Recycle Your animal Bottles with PET Recycling Device
Maybe you have any concept that is fundamental you know the brings about their vinyl containers their dump after eating your selected beverage which is soft. To be a resident that test accountable it is actually our obligat... | marie_twalkerw_14c6b656 | |
1,895,432 | Test my apify actor | Hello i created this actor that that can help you get keyword metrics for SEO. It scrap public seo... | 0 | 2024-06-21T02:26:08 | https://dev.to/ahmed_xy/test-my-apify-actor-5dod | seo, webscraping, website, apify | Hello i created [this actor](https://apify.com/ahmed_elkurdi/keyword-finder) that that can help you get keyword metrics for SEO.
It scrap public seo data from different resource so you can do keyword research .
You can use its api on your project .
Thanks
[Keyword Finder](https://apify.com/ahmed_elkurdi/keyword-fin... | ahmed_xy |
1,895,424 | Profiles in Visual Studio Code (VSCode) | Overview Profiles in VSCode allow you to create and manage personalized setups for your... | 0 | 2024-06-21T02:04:22 | https://dev.to/mhmd-salah/profiles-in-visual-studio-code-vscode-3j9l | vscode | ## Overview
Profiles in VSCode allow you to create and manage personalized setups for your coding environment. This feature is especially useful if you work on different projects that require distinct configurations, extensions, and settings. With profiles, you can quickly switch between different setups without manual... | mhmd-salah |
1,895,430 | Hubungi Bantuan | Buka Blokir Brimo | 0 | 2024-06-21T02:24:39 | https://dev.to/halobrimo/hubungi-bantuan-4ap1 |
[](https://layanan-online.venturz.co/)
**[Buka Blokir Brimo](url)** | halobrimo | |
1,895,429 | . | A post by Avinash reddy | 0 | 2024-06-21T02:23:40 | https://dev.to/avinash917/-c8k | avinash917 | ||
1,895,428 | Boost Your Car's Appeal: Grilles, Bumpers, and Bodykits Galore | Boost Your Car's Appearance with Grilles, Bumpers, and Body kits Galore A sleek or appearance that... | 0 | 2024-06-21T02:22:16 | https://dev.to/homah_yopoks_2b8dbd52b4d0/boost-your-cars-appeal-grilles-bumpers-and-bodykits-galore-39i8 | design | Boost Your Car's Appearance with Grilles, Bumpers, and Body kits Galore
A sleek or appearance that is aggressive you will wish to consider upgrading its grilles, bumpers, or human body kits if you're seeking to give your car. These after market accessories are presented in various materials and designs and provi... | homah_yopoks_2b8dbd52b4d0 |
1,895,333 | Apple Silicon, State-of-the-art ARM CPU | My Macbook air has M2 CPU. I want to deploy my Cloudforet application in my Macbook. But we have only... | 0 | 2024-06-21T02:12:03 | https://dev.to/choonho/apple-silicon-state-of-the-art-arm-cpu-4131 | arm, apple, aws, gcp | My Macbook air has M2 CPU. I want to deploy my Cloudforet application in my Macbook. But we have only X86 docker image, because github does not support ARM linux runner for github action. There is a way for building X86 and ARM docker image in one command, but it takes too much time. Because it is a cross compilation f... | choonho |
1,895,425 | Plastic Recycling Machines: Driving Innovation in Waste Management | H278a87e695b04ac98a29569fccae6303V.png Plastic Recycling Products Revolutionizing Waste... | 0 | 2024-06-21T02:06:35 | https://dev.to/marie_twalkerw_14c6b656/plastic-recycling-machines-driving-innovation-in-waste-management-4dj3 | H278a87e695b04ac98a29569fccae6303V.png
Plastic Recycling Products Revolutionizing Waste Management
Introduction
Pollution is amongst the larger problems coping with our planet nowadays. Waste management are smoother than before because it build amongst the unit has made them significantly dependable efficient.
... | marie_twalkerw_14c6b656 | |
1,893,045 | Postgres Arrays | What are Postgres arrays? Arrays are columns that can hold multiple values. They are... | 0 | 2024-06-21T02:00:43 | https://dev.to/mrpercival/postgres-arrays-2nni | postgres, sql, postgressql, webdev | ## What are Postgres arrays?
Arrays are columns that can hold multiple values. They are useful when there is additional data that is tightly coupled to a row of data in a table.
Storing tags associated with a row, values from a web form where multiple options can be selected. These are both examples of where you c... | mrpercival |
1,895,423 | Breaking caches and bypassing Istio RBAC with HTTP response header injection | This post outlines what we believe to be novel attacks against HTTP application middleware based on the simple foundation of HTTP response header injection. | 0 | 2024-06-21T02:00:30 | https://snyk.io/blog/breaking-caches-bypassing-istio-rbac/ | applicationsecurity, codesecurity | After our recent successes [exploring WebSocket Hijacking vulnerabilities](https://snyk.io/blog/gitpod-remote-code-execution-vulnerability-websockets/), we decided to expand this research project into other attacks that involve WebSockets. We started by looking at WebSocket smuggling attacks and expanded our scope to i... | snyk_sec |
1,895,422 | Implement React v18 from Scratch Using WASM and Rust - [17] Implement Concurrent Mode | Based on big-react,I am going to implement React v18 core features from scratch using WASM and... | 27,011 | 2024-06-21T01:50:48 | https://dev.to/paradeto/implement-react-v18-from-scratch-using-wasm-and-rust-17-implement-concurrent-mode-3680 | react, webassembly, rust | > Based on [big-react](https://github.com/BetaSu/big-react),I am going to implement React v18 core features from scratch using WASM and Rust.
>
> Code Repository:https://github.com/ParadeTo/big-react-wasm
>
> The tag related to this article:[v17](https://github.com/ParadeTo/big-react-wasm/tree/v17)
One of the biggest ... | paradeto |
1,895,421 | Easily Migrate DataBase Data in Just 3 Steps, Even for Beginners | I believe that in your daily development work, you often encounter various business scenarios that... | 0 | 2024-06-21T01:48:00 | https://dev.to/concerate/easily-migrate-database-data-in-just-3-steps-even-for-beginners-37o0 | I believe that in your daily development work, you often encounter various business scenarios that require data migration. If you want to quickly migrate data without the hassle of coding, find a handy tool that can make this task easy and efficient. With just 3 simple steps, even beginners can easily get started!
We ... | concerate | |
1,895,420 | How to Enhance File Security: Three Key Measures for Your Business | In today’s digital landscape, safeguarding sensitive information is paramount for any business. With... | 0 | 2024-06-21T01:47:39 | https://dev.to/jeffreyboyle0033/how-to-enhance-file-security-three-key-measures-for-your-business-589 | encryption, securitymanagement, riskassessment, cybersecurity | In today’s digital landscape, safeguarding sensitive information is paramount for any business. With cyber threats becoming more sophisticated and frequent, implementing robust file security measures is no longer optional but essential. Here are three key measures that can significantly [enhance file security](https://... | jeffreyboyle0033 |
1,895,418 | Day 3 of My 90 Days of DevOps Projects: Monitoring with Prometheus and Grafana | Hi guys, I am a bit late today to Day 3 of my 90 days of DevOps project building. I am one of the... | 0 | 2024-06-21T01:43:17 | https://dev.to/arbythecoder/day-3-of-my-90-days-of-devops-projects-monitoring-with-prometheus-and-grafana-1abf | devops, monitoring, beginners, day3 |
Hi guys,
I am a bit late today to Day 3 of my 90 days of DevOps project building. I am one of the participants in the ongoing Zero to Merge open source projects organized by CNCF, and it's my first time juggling that with other life issues. It's quite interesting, but we move! Now, I am here, and today my focus wa... | arbythecoder |
1,895,419 | REST Console: A Powerful Tool for Testing APIs | REST Console is a REST/HTTP client designed specifically for Google Chrome. This open source tool... | 0 | 2024-06-21T01:37:58 | https://dev.to/edward_hernnapazamaman/rest-console-a-powerful-tool-for-testing-apis-k4i | REST Console is a REST/HTTP client designed specifically for Google Chrome. This open source tool allows developers to visualize and construct custom HTTP requests, making it a valuable resource for testing RESTful API services.
**Main features:**
1. Construction of POST/PUT bodies using raw input
2. Modifying custom ... | edward_hernnapazamaman | |
1,895,268 | Decoding User Feedback at Collision Conf: The Power of AI-powered Image Analysis | I analyzed user feedback at Collision Conf. using Gemini Multimodal Exprimental Model... | 0 | 2024-06-21T01:04:07 | https://dev.to/sid16/decoding-user-feedback-at-collision-conf-the-power-of-ai-powered-image-analysis-9b9 | customers, data, ai, promptengineering | ###### I analyzed user feedback at Collision Conf. using Gemini Multimodal Exprimental Model (Vertex AI).
The annual [Collision Conference](https://www.linkedin.com/company/collision/about/) brings together a vibrant community of entrepreneurs, tech enthusiasts, and industry leaders. This year, I attended Collision Co... | sid16 |
1,895,350 | Choosing the Best WordPress Hosting | When it comes to hosting your WordPress site, choosing the right provider can make all the difference... | 0 | 2024-06-21T00:54:46 | https://dev.to/3a5abi/choosing-the-best-wordpress-hosting-4bfn | wordpress, webdev, hosting, devtoys | When it comes to hosting your WordPress site, choosing the right provider can make all the difference in terms of performance, reliability, and ease of management. Today, we’ll compare three popular hosting options: Liquid Web, Jetpack by Automattic, and Hostinger. Each one brings unique strengths to the table, so let’... | 3a5abi |
1,895,278 | its a new day | A post by James Gordon | 0 | 2024-06-20T21:16:22 | https://dev.to/james_gordon_9e2ff993b44b/its-a-new-day-36hn | james_gordon_9e2ff993b44b | ||
1,895,349 | Pros and Cons of AI-Assisted Software Development | I know you all will agree that 2024 is the year of adopting innovations and technologies. Every day,... | 0 | 2024-06-21T00:54:08 | https://dev.to/olivia1202/pros-and-cons-of-ai-assisted-software-development-3373 | ai, softwaredevelopment |
I know you all will agree that 2024 is the year of adopting innovations and technologies. Every day, something new and advanced comes along. Next-generation technologies like AI, ML, Cloud, IoT, and others are impacting almost every industry and changing the way business works. Software development is not behind any... | olivia1202 |
1,895,347 | Top Anker Products for Developers in 2024 | As a developer, having the right tech accessories can significantly enhance your productivity and... | 0 | 2024-06-21T00:51:59 | https://dev.to/3a5abi/top-anker-products-for-developers-in-2024-3enm | productivity, accessories, devtoys, remote | As a developer, having the right tech accessories can significantly enhance your productivity and streamline your workflow.
Anker, known for its reliable and high-quality products, offers a range of gadgets perfect for developers.
In this article, we’ll highlight the latest and most useful Anker products for develop... | 3a5abi |
1,895,344 | BLUETTI Portable Power Stations for Developers | 🔋 In today’s fast-paced world, having a reliable power source is essential for developers who work in... | 0 | 2024-06-21T00:45:27 | https://dev.to/3a5abi/bluetti-portable-power-stations-for-developers-503p | productivity, accessories, remote, devtoy | 🔋 In today’s fast-paced world, having a reliable power source is essential for developers who work in various environments.
Whether you’re coding at a remote location, participating in a hackathon, or simply need a backup power solution, BLUETTI’s range of portable power stations offers robust options to keep your d... | 3a5abi |
1,895,340 | RaiPlay IPTV - Il miglior fornitor IPTV | RaiPlay IPTV - Il miglior fornitor IPTV RaiPlay IPTV vi offre guardare la TV in diretta e +25.000... | 0 | 2024-06-21T00:34:36 | https://dev.to/raiplayiptv/raiplay-iptv-il-miglior-fornitor-iptv-5agc | iptv, abbonamento |
RaiPlay IPTV - Il miglior fornitor IPTV
RaiPlay IPTV vi offre guardare la TV in diretta e +25.000 canali E+50.000 Film E +30.000 serie TV senza congelare Qualità
(https://raiplayiptv.com/)
 | raiplayiptv |
1,895,339 | Advanced Techniques in Mobile UI/UX Design | Introduction In today’s digital era, mobile applications have become an integral part of... | 0 | 2024-06-21T00:32:05 | https://dev.to/kartikmehta8/advanced-techniques-in-mobile-uiux-design-315g | javascript, beginners, programming, tutorial | ## Introduction
In today’s digital era, mobile applications have become an integral part of our daily lives. With the rise of technology, the expectations of users have also increased. This is where the importance of advanced techniques in mobile UI/UX design comes into play. These techniques not only enhance the visu... | kartikmehta8 |
1,895,338 | Top IT Staffing Companies in the USA | Discover the leading IT staffing companies in the USA, connecting businesses with top-tier talent ... | 0 | 2024-06-21T00:29:56 | https://dev.to/balazsrefi/top-it-staffing-companies-in-the-usa-2jnb | programming, career, recruitment | Discover the leading IT staffing companies in the USA, connecting businesses with top-tier talent
### **1. Toptal**
Founded in 2010 and based in San Francisco, Toptal excels in matching businesses with highly skilled IT professionals across various industries. [Read more.](https://bluebirdinternational.com/top-10-it-s... | balazsrefi |
1,895,336 | PWC 274 Waiting at the Bus Stop | For this week's challenge, we have an interesting problem to ponder while we're Waiting at the Bus... | 0 | 2024-06-21T00:28:08 | https://dev.to/boblied/pwc-274-waiting-at-the-bus-stop-1o9g | perl, perlweeklychallenge, pwc | For this week's challenge, we have an interesting problem to ponder while we're [Waiting at the Bus Stop](https://www.youtube.com/watch?v=xR0nzSnTFsM).
### [Task 2: Bus Route](https://theweeklychallenge.org/blog/perl-weekly-challenge-274/#TASK2)
```text
Several bus routes start from a bus stop near my home,
and go to ... | boblied |
1,895,335 | LeetCode Meditations: Course Schedule | Let's start with the description for this problem: There are a total of numCourses courses you have... | 26,418 | 2024-06-21T00:25:54 | https://rivea0.github.io/blog/leetcode-meditations-course-schedule | computerscience, algorithms, typescript, javascript | Let's start with the description for [this problem](https://leetcode.com/problems/course-schedule):
> There are a total of `numCourses` courses you have to take, labeled from `0` to `numCourses - 1`. You are given an array `prerequisites` where `prerequisites[i] = [a_i, b_i]` indicates that you **must** take course {%... | rivea0 |
1,895,334 | Understanding @Primary in Spring | If you read my post about the @Qualifier annotation, you have noticed that defining two beans of the... | 27,602 | 2024-06-21T00:21:57 | https://springmasteryhub.com/2024/06/20/understanding-primary-in-spring/ | java, springboot, spring, programming | If you read my post about the `@Qualifier` annotation, you have noticed that defining two beans of the same type can be a challenge. By distinguishing it with a qualifier name, `@Qualifier` helps Spring determine which bean to inject.
The `@Primary` annotation will help Spring decide which of those same types of beans... | tiuwill |
1,895,332 | Understanding Context API in ReactJS Made Simple | ReactJS has revolutionized the way developers build web applications by introducing a... | 0 | 2024-06-21T00:18:04 | https://raajaryan.tech/understanding-context-api-in-reactjs-made-simple | react, api, javascript, beginners |
[](https://buymeacoffee.com/dk119819)
ReactJS has revolutionized the way developers build web applications by introducing a component-based architecture that promotes reusability and main... | raajaryan |
1,895,330 | Greedy Algorithm | A Greedy Algorithm is a simple, step-by-step way to solve problems. It picks the best choice at each... | 0 | 2024-06-21T00:07:40 | https://dev.to/pains_arch/greedy-algorithm-10c1 | devchallenge, cschallenge, computerscience, beginners | A Greedy Algorithm is a simple, step-by-step way to solve problems. It picks the best choice at each step without looking ahead. It's fast but doesn't always find the perfect solution. Examples include finding the shortest path or making change with the fewest coins. | pains_arch |
1,895,328 | Automating Windows Display Settings | Intro Recently I found out about the wonders of the PyAutoGUI library through the book... | 0 | 2024-06-21T00:03:06 | https://dev.to/juanjosada/automating-windows-display-settings-1c6f | python, automation, tutorial, programming | ## Intro
Recently I found out about the wonders of the PyAutoGUI library through the book 'Automate the Boring Stuff with Python' by Al Sweigart, which you can read online for free [here](https://automatetheboringstuff.com/). However, to actually learn something you have to apply it yourself, so I could think of no bet... | juanjosada |
1,895,326 | Flexibility Meets Structure: Evolving Document Database Schemas with Fauna | The debate over utilizing a more strict schema definition and enforcement versus going schemaless... | 0 | 2024-06-21T00:00:02 | https://fauna.com/blog/flexibility-meets-structure-evolving-document-database-schemas-with-fauna | database, nosql, serverless, devops | The debate over utilizing a more strict schema definition and enforcement versus going schemaless with NoSQL databases often sparks passionate discussions. For the longest time, I was in the camp of “I hate the word schemaless,” when it came to NoSQL databases…and I am not someone who uses the term hate lightly. I was ... | nosqlknowhow |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.