
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,895,936 | The Power of Patience and Persistence: How to Thrive in the Ever-Evolving Tech Landscape | There's a lot to study if you choose any Software Engineering position. You can develop desktop, web,... | 0 | 2024-06-21T11:40:03 | https://ionixjunior.dev/en/the-power-of-patience-and-persistence-how-to-thrive-in-the-everevolving-tech-landscape/ | career | ---
title: The Power of Patience and Persistence: How to Thrive in the Ever-Evolving Tech Landscape
published: true
date: 2024-06-21 00:00:00 UTC
tags: career
canonical_url: https://ionixjunior.dev/en/the-power-of-patience-and-persistence-how-to-thrive-in-the-everevolving-tech-landscape/
cover_image: https://ionixjunio... | ionixjunior |
341,873 | The truth about Main-Stream Media | We will be Building a Jquery App! | 0 | 2020-05-22T20:22:57 | https://dev.to/trougeg/the-truth-about-main-stream-media-4p6k | jquery, react, bootstrap | #TEST | trougeg |
1,896,258 | DevX Status Update | Slow Week Hey all, it’s been a rather slow week on our side with half the team of on... | 0 | 2024-06-21T16:52:08 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-21-devx-status-update/ | puppet, community | ---
title: DevX Status Update
published: true
date: 2024-06-21 00:00:00 UTC
tags: puppet,community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-21-devx-status-update/
---
## Slow Week
Hey all, it’s been a rather slow week on our side with half the team of on Holiday and th... | puppetdevx |
1,895,327 | Rapid Innovation: Leading the Way in AI and Blockchain Consulting | Demystifying Rapid Innovation's Services Rapid Innovation offers a comprehensive suite of... | 27,673 | 2024-06-20T23:48:19 | https://dev.to/rapidinnovation/rapid-innovation-leading-the-way-in-ai-and-blockchain-consulting-1g67 | ## Demystifying Rapid Innovation's Services
Rapid Innovation offers a comprehensive suite of services designed to cater to
the diverse needs of businesses. Let's delve deeper into their core offerings:
## Custom AI Solutions
Rapid Innovation's team of AI experts works closely with clients to understand
their specifi... | rapidinnovation | |
1,895,325 | What’s the difference between RBAC and ABAC in Fauna? | ABAC (Attribute-Based Access Control) is not an extension of RBAC (Role-Based Access Control), but... | 0 | 2024-06-20T23:41:47 | https://dev.to/nosqlknowhow/whats-the-difference-between-rbac-and-abac-in-fauna-53ih | security, database, nosql, webdev | ABAC (Attribute-Based Access Control) is not an extension of RBAC (Role-Based Access Control), but rather a distinct model that can be considered a superset regarding flexibility and granularity. They both answer the question, “Does this operation have access,” but use very different mechanisms to determine the answer.... | nosqlknowhow |
1,893,014 | Desvendando o Segredo: Como Implementar File Upload com Spring Boot e Amazon S3 | Não é de hoje que empresas e também pessoas tem necessidade de armazenar e gerenciar arquivos de... | 0 | 2024-06-20T23:29:16 | https://dev.to/jordihofc/desvendando-o-segredo-como-implementar-file-upload-com-spring-boot-e-amazon-s3-1jd1 | aws, spring, java, amazons3 | Não é de hoje que empresas e também pessoas tem necessidade de armazenar e gerenciar arquivos de forma segura e eficiente. Um bom exemplo disso é que até hoje existe uma alta procura por produtos como SDD, Pendrives, HDD externos. Sem falar que empresas como Amazon, Google, Apple, Microsoft vendem armazenamento em clou... | jordihofc |
1,894,488 | File Upload with Google Cloud Storage and Node.js | With the data collection rate currently going through the roof, the chances that you will build an... | 0 | 2024-06-20T23:26:02 | https://dev.to/kalashin1/file-upload-with-google-cloud-storage-and-nodejs-17bh | cloud, node, javascript, googlecloud | With the data collection rate currently going through the roof, the chances that you will build an app requiring users to upload one or multiple files will also be through the roof. There are many solutions to this problem, there are tons of services out there focused on making this process as smooth as possible. We ha... | kalashin1 |
1,895,307 | From Messy Data to Super Mario Pipeline: My First Adventure in Data Engineering | Welcome to the thrilling tale of my very first automated data pipeline! Imagine you’ve just been... | 0 | 2024-06-20T23:24:21 | https://dev.to/jampamatos/from-messy-data-to-super-mario-pipeline-my-first-adventure-in-data-engineering-1apo | dataengineering, python, automation, sql | **Welcome to the thrilling tale of my very first automated data pipeline!**
Imagine you’ve just been handed a database that looks like it’s been through Bowser’s castle and back. Yes, it’s that messy. The mission? To transform this chaos into a clean, analytics-ready dataset with as little human intervention as possib... | jampamatos |
1,895,318 | Use Modern C++ std::any in your projects | Say goodbye to void* once and for all. std::any is a feature of the C++ standard... | 0 | 2024-06-20T23:16:37 | https://dev.to/marcosplusplus/use-modern-c-stdany-in-your-projects-363l | cpp, cpp17, moderncpp | ### Say goodbye to `void*` once and for all.
---
`std::any` is a feature of the C++ standard library that was introduced in [C++17](https://terminalroot.com/tags#cppdaily).
This component belongs to the set of type-safe container classes, providing a safe means to store and manipulate values of any type.
It is es... | marcosplusplus |
1,895,317 | Adobe Pro Script - Color | I am trying to write a script to change text boxes to red when a certain range of numbers is used.... | 0 | 2024-06-20T23:15:32 | https://dev.to/dashirvine/adobe-pro-script-color-55i0 | help | I am trying to write a script to change text boxes to red when a certain range of numbers is used.
If a number is over 5, it turns red; if it is -5, it turns red. This alert on an aviation form will show a pilot that his plan is not level.
I have tried this but not working:
if(event.value >= 5){
event.target.f... | dashirvine |
1,895,316 | Utilize std::any do C++ Moderno nos seus projetos | Dê adeus de uma vez por todas ao void*. std::any é um recurso da biblioteca padrão C++... | 0 | 2024-06-20T23:10:20 | https://dev.to/marcosplusplus/utilize-stdany-do-c-moderno-nos-seus-projetos-3heh | cpp, cpp17, moderncpp |
### Dê adeus de uma vez por todas ao `void*`.
---
`std::any` é um recurso da biblioteca padrão C++ que foi introduzido no [C++17](https://terminalroot.com.br/tags#cppdaily).
Este componente pertence ao conjunto de classes de contêineres com segurança de tipo, fornecendo um meio seguro para armazenar e manipular va... | marcosplusplus |
1,895,315 | My Ansible Learning Journey: Exploring Essential Modules | Introduction to Ansible Ansible is an open-source automation tool that simplifies tasks like... | 0 | 2024-06-20T23:10:20 | https://dev.to/faruq2991/my-ansible-learning-journey-exploring-essential-modules-2e6c | devops, learning, automation, tooling | **Introduction to Ansible**
Ansible is an open-source automation tool that simplifies tasks like configuration management, application deployment, and task automation. It uses a simple, human-readable language called YAML (Yet Another Markup Language) to describe automation jobs, making it accessible for beginners and ... | faruq2991 |
1,873,920 | Should you really Roll your own auth? | Hey guys, In this article, I want to discuss whether it's better to build your own authentication... | 23,487 | 2024-06-20T23:00:00 | https://dev.to/devlawrence/should-you-really-roll-your-own-auth-4dj | webdev, authjs, javascript, programming | Hey guys, In this article, I want to discuss whether it's better to build your own authentication system or to use a third-party service provider. Let’s dive right in 😃
## Why Consider Building Your Own Authentication?
First, let's consider the **"WHY"** behind building your own authentication system from scratch. T... | devlawrence |
1,895,311 | Entendendo as Nomenclaturas getBy..., findBy... e queryBy... no Jest | No contexto de testes com Jest, especialmente ao testar componentes React usando... | 27,693 | 2024-06-20T22:52:13 | https://dev.to/vitorrios1001/entendendo-as-nomenclaturas-getby-findby-e-queryby-no-jest-2ni4 | jest, testing, javascript, typescript | No contexto de testes com Jest, especialmente ao testar componentes React usando `@testing-library/react`, você pode encontrar várias funções de consulta com diferentes prefixos, como `getBy...`, `findBy...` e `queryBy...`. Cada uma dessas funções serve a um propósito específico e entender suas diferenças pode ajudar a... | vitorrios1001 |
1,895,312 | Modelo de Desing de Aplicações Backend | Introdução Camadas Infrastructure Business Boas práticas Testes Unitários Testes de... | 0 | 2024-06-20T22:52:06 | https://dev.to/brunobrolesi/modelo-de-desing-de-aplicacoes-backend-47jp | 1. [Introdução](#intro)
2. [Camadas](#layers)
- [Infrastructure](#infra)
- [Business] (#business)
3. [Boas práticas](#good-practices)
- [Testes Unitários] (#unit-tests)
- [Testes de Integração] (#integration-tests)
4. [Fluxo de desenvolvimento](#developing)
5. [Ponto de atenção](#atention)
# Introdução... | brunobrolesi | |
1,895,310 | MICROSOFT APPLIED SKILL. Guided Project: | This is exercise 2b of the Microsoft Applied skill guided project. A. CREATE A STORAGE ACCOUNT AND... | 0 | 2024-06-20T22:47:56 | https://dev.to/sethgiddy/microsoft-applied-skill-guided-project-4ci9 | This is exercise 2b of the Microsoft Applied skill guided project.
A. **CREATE A STORAGE ACCOUNT AND CONFIGURE HIGH AVAILABILITY**.
1.**Create a storage account for the internal private company documents.**
- In the portal, search for and select Storage accounts.
- Select + Create.
- Select the Resource group creat... | sethgiddy | |
1,894,473 | Understanding the Factory Method Design Pattern | Hello everyone, السلام عليكم و رحمة الله و بركاته The Factory Method is a creational design pattern... | 0 | 2024-06-20T22:42:39 | https://dev.to/bilelsalemdev/understanding-the-factory-method-design-pattern-45gk | javascript, typescript, designpatterns, oop |
Hello everyone, السلام عليكم و رحمة الله و بركاته
The Factory Method is a creational design pattern that provides an interface for creating objects in a superclass but allows subclasses to alter the type of objects that will be created. It helps in dealing with the problem of creating objects without having to speci... | bilelsalemdev |
1,895,308 | Keyword Prominence and Proximity for SEO Success | Introduction In the ever-evolving world of SEO, keyword strategy remains a cornerstone for... | 0 | 2024-06-20T22:38:20 | https://dev.to/gohil1401/keyword-prominence-and-proximity-for-seo-success-2k7h | webdev, beginners, tutorial, seo | ## Introduction
In the ever-evolving world of SEO, keyword strategy remains a cornerstone for achieving high search engine rankings. Two critical aspects of this strategy are keyword prominence and keyword proximity. Understanding and effectively utilizing these elements can significantly enhance your website's visibil... | gohil1401 |
1,894,110 | Mock Class Constructor in Jest Test with Mocking Partials | I've been implementing tests on server-side code using Jest. One thing I initially struggled with was... | 0 | 2024-06-20T22:27:43 | https://dev.to/c0xxxtv/mock-class-constructor-in-jest-test-with-mocking-partials-1dd5 | jest, testing, mock, react | I've been implementing tests on server-side code using Jest. One thing I initially struggled with was mocking class constructors. Here’s a guide on how to do it :)
## Example Code
Here is the code for the function you want to test:
```javascript
export const abc=(arg)=>{
return new ClassA(arg)
}
```
In the test, you... | c0xxxtv |
1,895,291 | How Bitcoin work ? | Imagine a ledger like #Splitwise, where Alice, Bob, and Charlie pay each other, and at the end of the... | 0 | 2024-06-20T22:18:47 | https://dev.to/beingwizard/how-bitcoin-work--1ech | bitcoin, cryptocurrency, blockchain, magic | Imagine a ledger like #Splitwise, where Alice, Bob, and Charlie pay each other, and at the end of the month, everyone settles up in cash. In the digital world, this concept evolves into the idea of cryptocurrency: Ledger + Trust + Cryptography = Cryptocurrency. Instead of a bank verifying every transaction, we rely on ... | beingwizard |
1,895,065 | What is Ledger and why does it need Idempotence? | PTBR Version What is Ledger Series What is a Ledger and why you need to learn about... | 0 | 2024-06-20T22:14:43 | https://dev.to/woovi/what-is-ledger-and-why-does-it-need-idempotence-18n9 | javascript, webdev |
[PTBR Version](https://daniloab.substack.com/p/o-que-e-ledger-e-por-que-precisa)
## What is Ledger Series
1. [What is a Ledger and why you need to learn about it?](https://dev.to/woovi/what-is-ledger-and-why-does-it-need-idempotence-18n9)
2. [What is Ledger and why does it need Idempotence?](https://dev.to/woovi/what... | daniloab |
1,895,076 | Estruturas de estilização de página CSS | Estilização CSS: Ferramentas que moldam o conteúdo da página Width: largura } auto/... | 0 | 2024-06-20T22:06:22 | https://dev.to/marimnz/estruturas-de-estilizacao-de-pagina-css-3844 | css, beginners, frontend | ##Estilização CSS:
Ferramentas que moldam o conteúdo da página
- `Width`: largura } auto/ initial
- `heigt`: altura } min/ max
- `inherit`: mantém a medida já definida
- `margin`: top/ left/ right/ bottom
- `padding`: espaço do conteúdo interno com o externo
- `box sizing`: retorna o elemento aos tamanhos pré-definid... | marimnz |
1,895,289 | Scaffolding API projects easily with oak-routing-ctrl | Greetings to Deno / TypeScript / JavaScript community! Today I'd love to introduce a DevTool:... | 27,800 | 2024-06-20T22:06:19 | https://dev.to/thesephi/scaffolding-api-projects-easily-with-oak-routing-ctrl-1pj | deno, typescript, api, tooling | Greetings to Deno / TypeScript / JavaScript community!
Today I'd love to introduce a DevTool: [oak-routing-ctrl](https://jsr.io/@dklab/oak-routing-ctrl)
Now if you read the link above & still are unsure what this tool does, then I hope this article may help 😀
Let's say you:
1. wanna build a microservice that provi... | thesephi |
1,854,425 | Dev: Automation | An Automation Developer is a professional responsible for designing, developing, and implementing... | 27,373 | 2024-06-20T22:00:00 | https://dev.to/r4nd3l/dev-automation-2233 | automation, developer | An **Automation Developer** is a professional responsible for designing, developing, and implementing automated solutions to streamline processes, increase efficiency, and reduce manual intervention across various domains such as software development, testing, infrastructure management, and business operations. Here's ... | r4nd3l |
1,895,286 | Create call center transcript summary using AWS Bedrock Converse API and Lambda - Anthropic Haiku | Generative AI - Has Generative AI captured your imagination to the extent it has for me? Generative... | 0 | 2024-06-20T21:52:42 | https://dev.to/bhatiagirish/create-call-center-transcript-summary-using-aws-bedrock-converse-api-and-lambda-anthropic-haiku-20cj | aws, generativeai, bedrockconverseapi, amazonbedrock | Generative AI - Has Generative AI captured your imagination to the extent it has for me?
Generative AI is indeed fascinating! The advancements in foundation models have opened up incredible possibilities. Who would have imagined that technology would evolve to the point where you can generate content summaries from t... | bhatiagirish |
1,895,287 | Debouncing vs Throttling | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-20T21:47:49 | https://dev.to/pabloyeverino/debouncing-vs-throttling-3cm6 | devchallenge, cschallenge, computerscience, beginners | ---
title: Debouncing vs Throttling
published: true
tags: devchallenge, cschallenge, computerscience, beginners
---
*This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. ... | pabloyeverino |
1,895,285 | Mastering Recursion: A Byte-Sized Explanation | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-20T21:42:46 | https://dev.to/josmel/mastering-recursion-a-byte-sized-explanation-33h | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Recursion: A function calls itself to solve smaller instances of a problem. Useful for tasks like tree traversal and factorial calculation. Efficient but can lead to stack overflow if ... | josmel |
1,895,284 | Day 975 : Alright | liner notes: Professional : Got up MAD early for a couple of meetings concerning a trip that I'm... | 0 | 2024-06-20T21:36:47 | https://dev.to/dwane/day-975-alright-5e7f | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Got up MAD early for a couple of meetings concerning a trip that I'm supposed to take in a couple of weeks. We'll see. Went back to sleep. Got back up for a couple of more meetings and got to work refactoring an application to use a new SDK. Got quite a bit done. Had to refactor the UI f... | dwane |
1,895,282 | Mastering UI Design Principles: Day 3 of My UI/UX Learning Journey | Day 3: Learning UI/UX Design 👋 Hello, Dev Community! I'm Prince Chouhan, a B.Tech CSE student with... | 0 | 2024-06-20T21:24:34 | https://dev.to/prince_chouhan/mastering-ui-design-principles-day-3-of-my-uiux-learning-journey-1pmh | ui, ux, uidesign, design | Day 3: Learning UI/UX Design
👋 Hello, Dev Community!
I'm Prince Chouhan, a B.Tech CSE student with a passion for UI/UX design. Today, I'm excited to share my learnings on UI Design Principles.
---
🗓️ Day 3 Topic: UI Design Principles
---
### 📚 Today's Learning Highlights:
1. Concept Overview:
UI design princi... | prince_chouhan |
1,895,281 | [Game of Purpose] Day 33 | Today I played around with collisions. I want to to turn off the drone when its propellers hit... | 27,434 | 2024-06-20T21:23:49 | https://dev.to/humberd/game-of-purpose-day-33-5bng | gamedev | Today I played around with collisions. I want to to turn off the drone when its propellers hit something. I made it detect hitting physics object, but I can't figure out how to do it when colliding with static objects with phtsics emulation disabled.
Each propeller is a separate Blueprint that has a custom box collide... | humberd |
1,895,280 | A Guide to Better Understand Props in React.js! | Props are essential in any React.js application as they simplify the flow of data! They allow you to... | 0 | 2024-06-20T21:21:31 | https://dev.to/gianni_cast/a-guide-to-better-understand-props-in-reactjs-40of | Props are essential in any React.js application as they simplify the flow of data! They allow you to pass data from parent to child, thus making your code more dynamic as well as reusable.
## What are they?
As mentioned briefly in the intro, props, is how data is passed from one component to another. It is crucial to ... | gianni_cast | |
1,895,279 | uieiureuire | A post by James Gordon | 0 | 2024-06-20T21:17:43 | https://dev.to/james_gordon_9e2ff993b44b/httpsipfsioipfsbafkreigb2j2jfxjhsfvqszioh34qlybrnyctgfyl3coah3thcech2i63ji-3op7 | james_gordon_9e2ff993b44b | ||
1,895,276 | Navigating the Future of Mobile App Development | In an era where smartphones have become an extension of ourselves, mobile app development stands at... | 0 | 2024-06-20T21:10:57 | https://dev.to/john_robinson_0a5ad1e5620/navigating-the-future-of-mobile-app-development-b1g | In an era where smartphones have become an extension of ourselves, mobile app development stands at the forefront of technological innovation. Whether it's for entertainment, productivity, or social interaction, mobile apps play a crucial role in our daily lives. This guest post delves into the essentials of [mobile ap... | john_robinson_0a5ad1e5620 | |
1,895,275 | Create your own react library and JSX | Root Div: The serves as a container where the custom-rendered content will be inserted. ... | 0 | 2024-06-20T21:10:56 | https://dev.to/geetika_bajpai_a654bfd1e0/create-your-own-react-library-l2g |
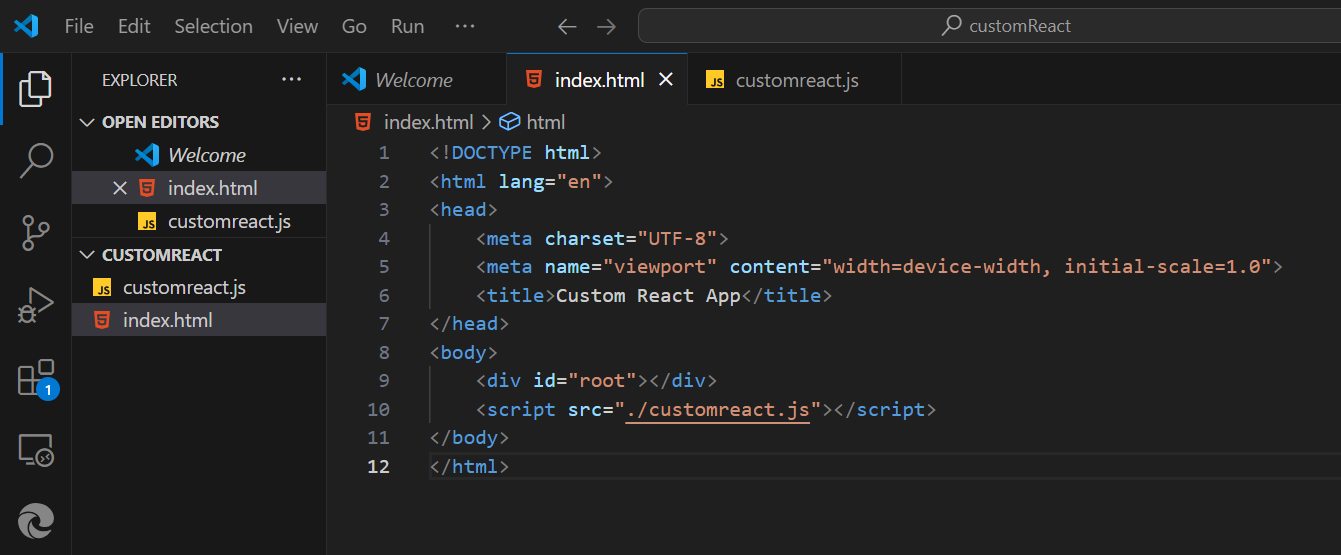
Root Div: The serves as a container where the custom-rendered content will be inserted.
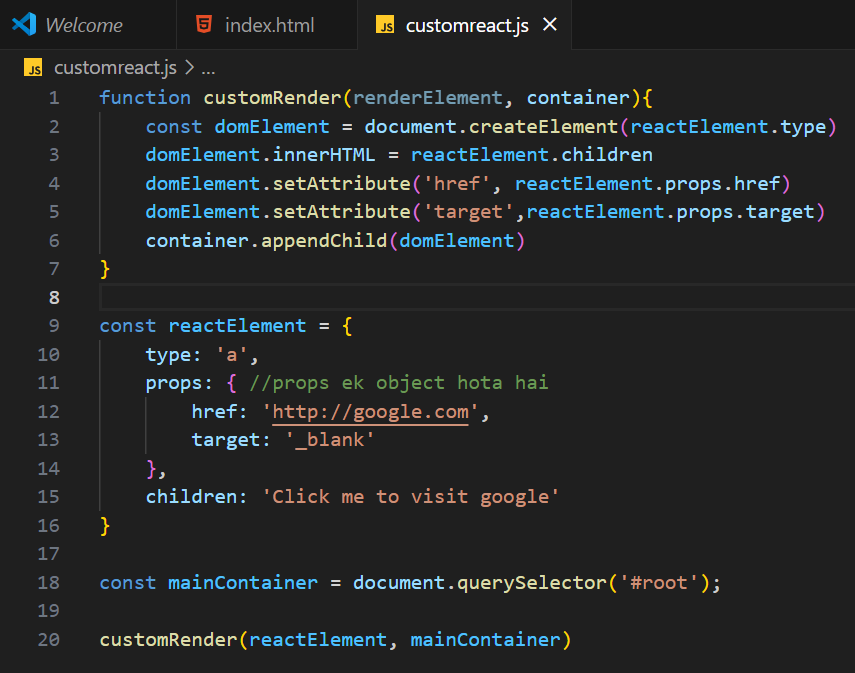
## Custom Render Fu... | geetika_bajpai_a654bfd1e0 | |
1,895,274 | Monitoring Underutilized Storage Resources on AWS | When cloud professionals embark on a journey to fish out underutilized resources that may be driving... | 0 | 2024-06-20T21:08:56 | https://dev.to/aws-builders/monitoring-underutilized-storage-resources-on-aws-1gnf | aws, storage, cloudcomputing, awscommunity | When cloud professionals embark on a journey to fish out underutilized resources that may be driving costs up, they rarely pay attention to doing some cost optimization in the direction of storage resources and often focus solely on optimizing their compute resources. In this article, we will go through some tools and ... | brandondamue |
1,895,273 | Parse OpenAI answers as JSON | Certainly! Here's a revised version of your blog post that is concise, simple, and... | 0 | 2024-06-20T21:07:24 | https://dev.to/mehrandvd/parse-openai-result-as-json-p2a | csharp, openai, json, dotnet | Certainly! Here's a revised version of your blog post that is concise, simple, and friendly:
---
Working with OpenAI can be tricky when it comes to parsing JSON responses, especially when they include extra characters like `'''` or a leading `json:`. To tackle this, I've developed `PowerParseJson<T>()`, a handy tool ... | mehrandvd |
1,895,272 | Exploring Stacks with Python: Developing the Tower of Hanoi Game | My latest endeavor involves recreating the classic Tower of Hanoi puzzle, offering a fantastic... | 0 | 2024-06-20T21:07:10 | https://dev.to/codecounsel/exploring-stacks-with-python-developing-the-tower-of-hanoi-game-25em | beginners | My latest endeavor involves recreating the classic Tower of Hanoi puzzle, offering a fantastic opportunity to delve into data structures, specifically stacks, in Python. This post outlines my journey in developing the Tower of Hanoi game and reflects on the valuable learning experiences it provided.
The "Tower of Hano... | codecounsel |
1,895,271 | shadcn-ui/ui codebase analysis: How is “Blocks” page built — Part 4 | In this article, I discuss how Blocks page is built on ui.shadcn.com. Blocks page has a lot of... | 0 | 2024-06-20T21:06:22 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-is-blocks-page-built-part-4-41f9 | typescript, javascript, opensource, nextjs | In this article, I discuss how [Blocks page](https://ui.shadcn.com/blocks) is built on [ui.shadcn.com](http://ui.shadcn.com). [Blocks page](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/blocks/page.tsx) has a lot of utilities used, hence I broke down this Blocks page analysis into 5 parts.
1. [shadcn-u... | ramunarasinga |
1,895,270 | How-to Guide: Building Your First ASP.NET Core Web Application | Introduction ASP.NET Core is a powerful, open-source framework for building modern, cloud-based, and... | 0 | 2024-06-20T21:04:02 | https://dev.to/a-class/how-to-guide-building-your-first-aspnet-core-web-application-1h59 | **Introduction**
ASP.NET Core is a powerful, open-source framework for building modern, cloud-based, and internet-connected applications. Whether you're a beginner or an experienced developer, creating your first ASP.NET Core web application is a crucial step in understanding how to leverage the full potential of the .... | a-class | |
1,895,269 | Generators in JavaScript | Generators in JavaScript are a powerful feature introduced in ECMAScript 6 (ES6) that allow you to... | 0 | 2024-06-20T21:02:24 | https://dev.to/francescoagati/generators-in-javascript-116 | Generators in JavaScript are a powerful feature introduced in ECMAScript 6 (ES6) that allow you to define iterative algorithms by pausing and resuming execution at defined points. They provide a flexible way to control iteration and asynchronous operations.
#### How Generators Work
Generators are defined using functi... | francescoagati | |
1,895,189 | Cellular Automata | I love procedural generation. As a hobbyist game developer, it is the concept and technique that I... | 0 | 2024-06-20T21:01:53 | https://excaliburjs.com/blog/Cellular%20Automata | gamedev, typescript, tutorial, opensource |
I love procedural generation. As a hobbyist game developer, it is the concept and technique that I keep reaching for in my games. This article is about Cellular Automata, which follows suit of my previous articles regarding other procedural generation strategies for game development. In my last article, we studied ... | jyoung4242 |
1,895,266 | t3twilio: Never Forget Again! | This is a submission for Twilio Challenge v24.06.12 What We Built Do you have someone in... | 0 | 2024-06-20T20:50:04 | https://dev.to/kanav_gupta/t3twilio-never-forget-again-20bl | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What We Built
Do you have someone in your family who suffers from dementia? Or are you just someone who forgets to do their tasks? My teammate, Dhruv Bansal, and I developed a **Notion** extension designed to enhance task mana... | kanav_gupta |
1,895,265 | Good Mornning em1fg | this onhg | 0 | 2024-06-20T20:40:08 | https://dev.to/ishaan_singhal_f3b6b687f3/good-mornning-em1fg-3m0b | this onh<img src="https://res.cloudinary.com/dlnuvrqki/image/upload/v1718914019/ix3ffqo20mrw34uasdsd.png" alt="Editor Media" class="mt-4 max-w-xs h-auto mx-auto" style="max-width: 30%;"><div>g</div> | ishaan_singhal_f3b6b687f3 | |
1,895,264 | 🧠 Neural Networks Explained | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. Neural... | 0 | 2024-06-20T20:37:28 | https://dev.to/aviralgarg05/neural-networks-explained-2c0p | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
Neural Networks 🧠 are like brain-inspired systems! They have layers of nodes (neurons) 🔗 that connect and learn patterns from data 📊. By adjusting weights ⚖️ during training, they get better at ... | aviralgarg05 |
1,895,263 | Python Decorators: Simplified Explanation | Python decorators are a powerful feature that allows you to modify or extend the behavior of... | 0 | 2024-06-20T20:36:25 | https://dev.to/francescoagati/python-decorators-simplified-explanation-hm1 | python, decorators | Python decorators are a powerful feature that allows you to modify or extend the behavior of functions or methods without changing their actual code. Let’s explore how decorators work with some simple examples.
#### Example 1: Logging Decorator
The logging decorator adds functionality to log information about when a ... | francescoagati |
1,895,262 | Dapper Stored Procedure tip | Introduction Dapper is a simple object mapper for .NET data access which uses Microsoft... | 25,270 | 2024-06-20T20:35:03 | https://dev.to/karenpayneoregon/dapper-stored-procedure-tip-13j4 | csharp, database, codenewbie | ## Introduction
Dapper is a simple object mapper for .NET data access which uses Microsoft classes under the covers which has been covered in the following article [Using Dapper - C# Part 1](https://dev.to/karenpayneoregon/working-with-dapper-in-c-5kd) which is part of a series on Dapper.
Recently there has been a mi... | karenpayneoregon |
1,895,170 | State in React | React has many great features to it that help create javascript. One way to impact the DOM is through... | 0 | 2024-06-20T20:25:29 | https://dev.to/spencer_adler_880da14d230/state-in-react-4pmg | react, state | React has many great features to it that help create javascript. One way to impact the DOM is through state. React makes what is required in regular Javascript to update DOM much easier with fewer steps and simpler syntax. The unique feature to state is that every time it is updated the page re-renders.
State is data... | spencer_adler_880da14d230 |
1,895,261 | Top 5 Resources to Get Started in Web Developing | Are you ready to dive into web development but not sure where to start? I'll guide you through the... | 0 | 2024-06-20T20:24:41 | https://dev.to/codebyten/top-5-resources-to-get-started-in-web-developing-4o7d | webdev, beginners, tips | Are you ready to dive into web development but not sure where to start? I'll guide you through the top 5 essential resources that will kickstart your journey in web development. Whether you're a beginner or looking to enhance your skills, these resources are indispensable.
1.) Mozilla Web Docs: Start with Mozilla Web ... | codebyten |
1,895,236 | Simplifying Python Code with List Comprehensions | Python's list comprehensions provide a concise and readable way to perform operations that... | 0 | 2024-06-20T20:21:36 | https://dev.to/francescoagati/simplifying-python-code-with-list-comprehensions-2ci0 | python | Python's list comprehensions provide a concise and readable way to perform operations that traditionally use `map`, `filter`, and `zip`. These functional programming tools streamline common tasks on arrays (or lists) while maintaining clarity and efficiency.
#### Using List Comprehensions Instead of `map`
The `map` f... | francescoagati |
1,900,493 | How to Build a Supergraph using Snowflake, Neon PostgreSQL, and Hasura in Five Steps | By combining Hasura Cloud, Snowflake DB, and PostgreSQL on Neon, you can create a powerful supergraph backend to handle complex data tasks such as joining data across multiple data sources and filtering data on model relations. | 0 | 2024-06-20T20:17:00 | https://hasura.io/blog/building-a-supergraph-backend-with-hasura | graphql, snowflake, postgres, hasura | ---
title: How to Build a Supergraph using Snowflake, Neon PostgreSQL, and Hasura in Five Steps
published: true
description: By combining Hasura Cloud, Snowflake DB, and PostgreSQL on Neon, you can create a powerful supergraph backend to handle complex data tasks such as joining data across multiple data sources and fi... | praveenweb |
1,895,175 | FunnyQuotes | This is a submission for the Twilio Challenge What I Built FunnyQuotes is a site hosted... | 0 | 2024-06-20T20:16:58 | https://dev.to/diegocardoso93/funnyquotes-3gko | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
FunnyQuotes is a site hosted on Cloudflare. Every day, five quotes and five images are generated by AI on the edge by Cloudflare Workers. The AI models used is `@cf/meta/llama-3-8b-instruct` to generate the text and `@... | diegocardoso93 |
1,886,441 | DEV Computer Science Challenge | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 27,182 | 2024-06-20T20:15:09 | https://dev.to/jarvisscript/dev-computer-science-challenge-2n8g | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
Git is versioning control software that lets developers save a version of their code or share code and collaborate with others. A sort of time travel to go back and recover previous work. Git allows devs to recover s... | jarvisscript |
1,895,178 | Hadoop FS Shell mv | Imagine you are in the ancient empire of Naruda, where Emperor Jason has ordered the relocation of ancient scrolls containing valuable knowledge from one library to another. Your task is to simulate this scenario in the context of Hadoop Distributed File System (HDFS) using the Hadoop FS Shell mv command. Your goal is ... | 27,774 | 2024-06-20T20:12:10 | https://labex.io/tutorials/hadoop-hadoop-fs-shell-mv-271874 | hadoop, coding, programming, tutorial |
## Introduction
Imagine you are in the ancient empire of Naruda, where Emperor Jason has ordered the relocation of ancient scrolls containing valuable knowledge from one library to another. Your task is to simulate this scenario in the context of Hadoop Distributed File System (HDFS) using the Hadoop FS Shell `mv` co... | labby |
1,895,177 | Good Mornning em1fg | this one is an image this one is an image but that ain't thatathis one is an image this one is an... | 0 | 2024-06-20T20:08:44 | https://dev.to/ishaan_singhal_f3b6b687f3/good-mornning-em1fg-3kpk | this one is an image this one is an image but that ain't thatathis one is an image this one is an image but that ain't thatathis one is an image this one is an image but that ain't thatathis one is an image this one is an image but that ain't that h<img src="https://res.cloudinary.com/dlnuvrqki/... | ishaan_singhal_f3b6b687f3 | |
1,895,176 | Good Mornning em1 | this one is an image this one is an image but that ain't thatathis one is an image this one is an... | 0 | 2024-06-20T20:07:09 | https://dev.to/ishaan_singhal_f3b6b687f3/good-mornning-em1-37l2 | this one is an image this one is an image but that ain't thatathis one is an image this one is an image but that ain't thatathis one is an image this one is an image but that ain't thatathis one is an image this one is an image but that ain't that <div class="skeleton-image mt-4 w-48 h-32 b... | ishaan_singhal_f3b6b687f3 | |
1,895,161 | Hello World em Elixir | Elixir é uma linguagem de programação dinâmica, funcional e construída sobre a máquina virtual Erlang... | 0 | 2024-06-20T20:06:46 | https://dev.to/abreujp/hello-world-em-elixir-23mn | elixir | Elixir é uma linguagem de programação dinâmica, funcional e construída sobre a máquina virtual Erlang (BEAM). Foi criada para ser escalável e manter sistemas de alta disponibilidade, tornando-se uma escolha popular para aplicações web, sistemas distribuídos e telecomunicações.
## O que é Elixir?
Elixir é uma linguage... | abreujp |
1,895,173 | Understanding the Subject-Observer Pattern with RxDart in Dart | Reactive programming has gained popularity in modern software development due to its ability to... | 0 | 2024-06-20T20:01:44 | https://dev.to/francescoagati/understanding-the-subject-observer-pattern-with-rxdart-in-dart-gjd | Reactive programming has gained popularity in modern software development due to its ability to handle asynchronous data streams efficiently. In Dart, developers can leverage the power of RxDart, an implementation of reactive extensions (Rx), to implement the Subject-Observer pattern seamlessly. This pattern is fundame... | francescoagati | |
821,078 | Build a website with Next.js using next/images | Creating a website with Next.js and using the next/image component involves several steps. Here’s a... | 0 | 2024-06-20T19:58:04 | https://dev.to/malvinjay/build-a-website-with-nextjs-using-nextimages-2d2d | Creating a website with Next.js and using the next/image component involves several steps. Here’s a step-by-step guide to get you started:
## 1. Setting Up the Project
First, ensure you have Node.js installed on your system. Then, follow these steps:
Step 1: Create a New Next.js Project
```
npx create-next-app@latest... | malvinjay | |
1,895,172 | Asynchronous Streams in Dart with RxDart | In Dart programming, handling asynchronous data streams effectively is crucial, and RxDart simplifies... | 0 | 2024-06-20T19:57:19 | https://dev.to/francescoagati/mastering-asynchronous-streams-in-dart-with-rxdart-1pid | dart, rxdart, merge | In Dart programming, handling asynchronous data streams effectively is crucial, and RxDart simplifies this task with powerful tools. Let's explore a straightforward example using RxDart to merge and manage multiple streams.
### The Example Explained
```dart
import 'package:rxdart/rxdart.dart';
void main() {
// Cre... | francescoagati |
1,895,169 | Case Study: The ClockPane Class | This case study develops a class that displays a clock on a pane. The contract of the ClockPane class... | 0 | 2024-06-20T19:52:22 | https://dev.to/paulike/case-study-the-clockpane-class-4bpg | java, programming, learning, beginners | This case study develops a class that displays a clock on a pane. The contract of the **ClockPane** class is shown in Figure below.
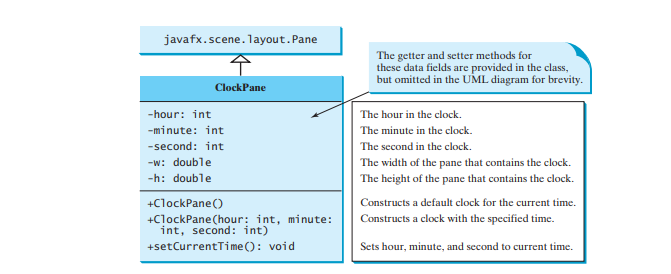
Assume **ClockPane** is available; we write a test program in the program below to... | paulike |
1,894,879 | What are DTOs and their significance? | What's up amazing people 👋 I just wanted to talk a lil bit about the concept of DTOs in programming... | 0 | 2024-06-20T19:49:51 | https://dev.to/prathamjagga/what-are-dtos-and-their-significance-2e72 | What's up amazing people 👋
I just wanted to talk a lil bit about the concept of DTOs in programming and how they might be useful and significant in your code.
So, what is a DTO? Well, it stands for Data Transfer Object. It is basically defining an interface for various types of data transfers within a system. Some e... | prathamjagga | |
1,547,476 | Bespoke is shutting down. We pivoted! | Please note: This article has not been parsed through ChatGPT. I wrote it with individual... | 0 | 2023-07-24T15:33:01 | https://dev.to/zifahm/bespoke-is-shutting-down-we-pivoted-2g1p | webdev, remix, nestjs | Please note: This article has not been parsed through ChatGPT. I wrote it with individual keystrokes.
## Why we pivoted [Bespoke](https://github.com/bespoke-surf/bespoke/)
19 days ago from July 24th, we open sourced Bespoke. Launched it on [HN](https://news.ycombinator.com/item?id=36586490). We have been building B... | zifahm |
1,895,168 | Introducing Identity Server 7.0 - The Most Powerful and Developer-Friendly Release Yet | Refreshing Look and Feel for the Console UI The console has received a major upgrade with our... | 0 | 2024-06-20T19:39:33 | https://dev.to/harsha_thirimanna_39edfd6/introducing-identity-server-70-the-most-powerful-and-developer-friendly-release-yet-5dk5 | **Refreshing Look and Feel for the Console UI**
The console has received a major upgrade with our brand-new, lightning-fast Oxygen UI! The beta console UI, accessible via https://<hostname>:<port>/console, introduced in version 5.11.0, is now available for production usage for administrative and developer tasks.
With... | harsha_thirimanna_39edfd6 | |
1,895,166 | Build RESTful APIs with Express.js 🚀 | Hey your instructor #KOToka here.... Setup: Install Node.js & npm. Initialize: npm... | 0 | 2024-06-20T19:28:01 | https://dev.to/erasmuskotoka/build-restful-apis-with-expressjs-2fo7 | Hey your instructor #KOToka here....
1. Setup:
- Install Node.js & npm.
- Initialize: `npm init`.
- Install Express: `npm install express`.
2. Basic Server:
```javascript
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => res.send('Hello W... | erasmuskotoka | |
1,895,164 | Shapes | JavaFX provides many shape classes for drawing texts, lines, circles, rectangles, ellipses, arcs,... | 0 | 2024-06-20T19:26:22 | https://dev.to/paulike/shapes-9gl | java, programming, learning, beginners | JavaFX provides many shape classes for drawing texts, lines, circles, rectangles, ellipses, arcs, polygons, and polylines. The **Shape** class is the abstract base class that defines the common properties for all shapes. Among them are the **fill**, **stroke**, and **strokeWidth** properties. The **fill** property spec... | paulike |
1,895,163 | Dart Streams with RxDart: Debounce, Throttle, and Distinct | Dart, a versatile language for building applications, offers powerful tools for managing asynchronous... | 0 | 2024-06-20T19:24:52 | https://dev.to/francescoagati/exploring-dart-streams-with-rxdart-debounce-throttle-and-distinct-4023 | rxdart | Dart, a versatile language for building applications, offers powerful tools for managing asynchronous data streams. When coupled with `rxdart`, a reactive programming library for Dart, developers can leverage advanced stream handling techniques like debouncing, throttling, and distinct emission to efficiently manage da... | francescoagati |
1,895,162 | Practical Steps to Enhance Your Security Today | Introduction In the ever-evolving landscape of cybersecurity, numerous frameworks are... | 0 | 2024-06-20T19:21:47 | https://dev.to/jwtiller_c47bdfa134adf302/practical-steps-to-enhance-your-security-today-91d | security, sdlc | ## Introduction
In the ever-evolving landscape of cybersecurity, numerous frameworks are available to measure maturity and guide improvements, such as OWASP SAMM, Microsoft's SDL (Security Development Lifecycle), and the NIST Cybersecurity Framework (CSF). These frameworks offer comprehensive guidelines but can someti... | jwtiller_c47bdfa134adf302 |
1,895,159 | Vasily Mesheryakov, main promoter of Freewallet scam | Alvin Hagg, the co-founder and CEO of Freewallet.org, has long shunned the spotlight. However, our... | 0 | 2024-06-20T19:18:52 | https://dev.to/feofhan/vasily-mesheryakov-main-promoter-of-freewallet-scam-39fi |

Alvin Hagg, the co-founder and CEO of Freewallet.org, has long shunned the spotlight. However, our recent investigation has unveiled a shocking truth: the real masterminds behind the Freewallet scam are two Russian... | feofhan | |
1,895,158 | Differences Between Slice and Splice : javascript | In Javascript slice and splice are used to manipulate Array, both sound a little bit the same but... | 0 | 2024-06-20T19:17:20 | https://dev.to/sagar7170/differences-between-slice-and-splice-javascript-2bfa | javascript, webdev, frontend, programming |
In Javascript slice and splice are used to manipulate Array, both sound a little bit the same but they work differently, first let’s talk about slice
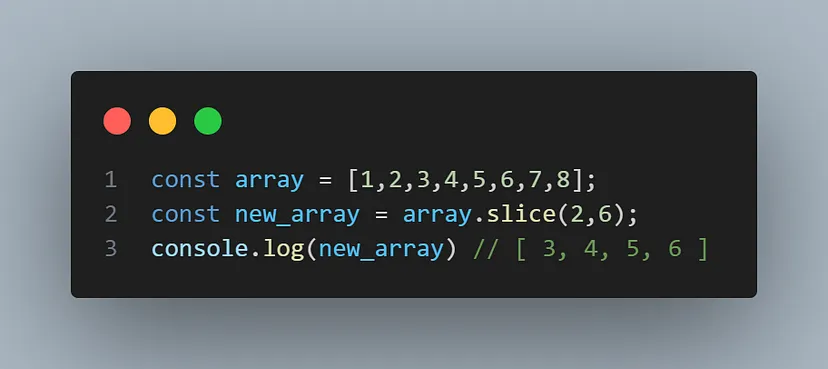
**slice** method used cut out some portion from the array or ex... | sagar7170 |
1,895,157 | firenoms - The most🔥domains on the internet | Introducing firenoms; quality domains for your business/startup. https://firenoms.com | 0 | 2024-06-20T19:17:02 | https://dev.to/richbowen/firenoms-the-mostdomains-on-the-internet-4i67 | Introducing **firenoms**; quality domains for your business/startup.
https://firenoms.com | richbowen | |
1,895,156 | ANIXSOFT | *Our domain goes like: IOS mobile apps, Android apps , HTML5, PHP5, MySQL, postgresql, CakePHP,... | 0 | 2024-06-20T19:14:22 | https://dev.to/siddhartha_ghosh_2f69af08/anixsoft-2dk9 | webdev, programming, react, ai | **Our domain goes like:
IOS mobile apps, Android apps
, HTML5, PHP5, MySQL, postgresql, CakePHP, CodeIgnitor, Laravel, React Js, Angular Js & Node Js
Please visit our site https://www.anixsoft.co.in and visit our PORTFOLIO section, to view our latest works.
Our latest work (ongoing development) with angular 9 in front ... | siddhartha_ghosh_2f69af08 |
1,891,513 | Expo Router adoption guide: Overview, examples, and alternatives | Written by Marie Starck✏️ Expo announced the release of Expo Router v3 in January 2024, marking it... | 0 | 2024-06-20T19:09:00 | https://blog.logrocket.com/expo-router-adoption-guide | expo, react | **Written by [Marie Starck](https://blog.logrocket.com/author/marie-starck/)✏️**
Expo announced [the release of Expo Router v3](https://expo.dev/changelog/2024/01-23-router-3) in January 2024, marking it as the first universal, full-stack React framework. Expo Router launched about a decade ago, and this release refle... | leemeganj |
1,895,132 | Journey into new Web Tech | Today's web offers many new technologies, the core of which is to employ a Content Management tool... | 0 | 2024-06-20T19:07:18 | https://dev.to/msanders5/journey-into-new-web-tech-2o5o | Today's web offers many new technologies, the core of which is to employ a Content Management tool that the site owner can edit their content. From a development perspective, the next steps would be to pull that content, code the client side scripts and then finally to serve it as a web application.
While there are ma... | msanders5 | |
1,895,145 | OpenTelemetry | What is OpenTelemetry? OpenTelemetry is an open-source project that provides a set of... | 0 | 2024-06-20T19:06:40 | https://dev.to/lakshanwd/opentelemetry-k4o | ## What is OpenTelemetry?
OpenTelemetry is an open-source project that provides a set of APIs, libraries, agents, and instrumentation to enable observability in software applications. Tracing is one of the core features of OpenTelemetry, which helps in tracking the execution of operations within and across services.
... | lakshanwd | |
1,895,154 | 1552. Magnetic Force Between Two Balls | 1552. Magnetic Force Between Two Balls Medium In the universe Earth C-137, Rick discovered a... | 27,523 | 2024-06-20T19:04:13 | https://dev.to/mdarifulhaque/1552-magnetic-force-between-two-balls-485i | php, leetcode, algorithms, programming | 1552\. Magnetic Force Between Two Balls
Medium
In the universe Earth C-137, Rick discovered a special form of magnetic force between two balls if they are put in his new invented basket. Rick has `n` empty baskets, the <code>i<sup>th</sup></code> basket is at `position[i]`, Morty has `m` balls and needs to distribute... | mdarifulhaque |
1,895,153 | Extending Iterable for Custom Aggregations in Dart | Dart is a powerful programming language that allows developers to extend the functionality of... | 0 | 2024-06-20T19:03:02 | https://dev.to/francescoagati/extending-iterable-for-custom-aggregations-in-dart-3id9 | Dart is a powerful programming language that allows developers to extend the functionality of existing classes using extension methods. This feature can be incredibly useful when you want to add custom aggregations and operations to the `Iterable` class. In this article, we'll explore how to extend `Iterable` with cust... | francescoagati | |
1,895,152 | Clash Of Clans Mod APK | Clash of Clans Mod APK offers an exciting twist to the original game, providing players with... | 0 | 2024-06-20T19:02:38 | https://dev.to/clashof_clansfun/clash-of-clans-mod-apk-2ek9 | gamedev |

<a href=https://clashofclans.fun/>Clash of Clans Mod APK offers an exciting twist to the original game</a>, providing players with enhanced features and unlimited resources. This modified version allows gamers to ac... | clashof_clansfun |
1,894,813 | Maximizing Natural Light in Modular Kitchen Layouts | Natural light plays a crucial role in enhancing the ambiance and functionality of any space, and the... | 0 | 2024-06-20T13:08:21 | https://dev.to/beta_new_03fe0b223c4d3801/maximizing-natural-light-in-modular-kitchen-layouts-3dlf | kitchen | Natural light plays a crucial role in enhancing the ambiance and functionality of any space, and the kitchen is no exception. A well-lit kitchen not only feels more spacious and inviting but also contributes to a healthier and more energy-efficient environment. When designing a modular kitchen, maximizing natural light... | beta_new_03fe0b223c4d3801 |
1,895,151 | Should we or shouldn't we? Create a project management mobile app | If you're new to OpenProject-we're a leading open source project management tool that helps teams... | 0 | 2024-06-20T19:01:49 | https://dev.to/openproject/should-we-or-shouldnt-we-create-a-project-management-mobile-app-31a9 | productivity, feedback, discuss, opensource | If you're new to OpenProject-we're a leading open source project management tool that helps teams make progress in a busy world.
The OpenProject team is close with the community and regularly asks questions, takes requests, and sends new updates.
This summer the team is asking: Do you want an OpenProject mobile app?
... | jenwikehuger |
1,895,150 | Cost versus Effort, an important lesson for self-employed | Early on in my career I worked for a company that developed bespoke websites and software. Almost all... | 0 | 2024-06-20T19:01:26 | https://mardy.dev/2022/06/cost-versus-effort-an-important-lesson-for-self-employed/ | webdev, workplace, productivity, career | Early on in my career I worked for a company that developed bespoke websites and software. Almost all the internal systems and processes were bespoke developments. In each instance the process complimented the solution and vice versa. When I was asked to create a solution that would generate a word document for new pro... | mardydev |
1,895,149 | Extending String for Validation in Dart 3 | In Dart 3, one of the powerful features you can leverage is extensions. Extensions allow you to add... | 0 | 2024-06-20T19:00:27 | https://dev.to/francescoagati/extending-string-for-validation-in-dart-3-4jp0 | dart, extensions, string | In Dart 3, one of the powerful features you can leverage is extensions. Extensions allow you to add new functionality to existing libraries. In this article, we will demonstrate how to extend the `String` class to include common validation checks such as email validation, numeric check, and phone number validation.
##... | francescoagati |
1,895,148 | Enhancing List Functionality in Dart with Custom Extensions | Dart, a language known for its flexibility and robust features, allows developers to extend the... | 0 | 2024-06-20T18:57:58 | https://dev.to/francescoagati/enhancing-list-functionality-in-dart-with-custom-extensions-4c7 | dart, extensions, list | Dart, a language known for its flexibility and robust features, allows developers to extend the functionality of existing classes without modifying them. One powerful way to achieve this is through extensions. In this article, we'll explore how to create a custom extension for the `List` class in Dart to add some usefu... | francescoagati |
1,895,147 | Enjoy react key takeaways from a new developer. | Welcome back to my second blog on DEV. I have completed phase 2 of FlatIron school and this phase... | 0 | 2024-06-20T18:56:56 | https://dev.to/killerfox007/enjoy-react-key-takeaways-from-a-new-developer-5gdi | webdev, react, beginners, programming | Welcome back to my second blog on DEV. I have completed phase 2 of FlatIron school and this phase covered react. Phase 1 was JavaScript, phase 2 was React with phase 3 being Python and SQL. React was difficult for me due to a lot of different concepts and learning it a lot faster than javascript.
**Key Topics Covered... | killerfox007 |
1,895,146 | Test | Test | 0 | 2024-06-20T18:56:41 | https://dev.to/dkumar08/test-4pnf |
Test | dkumar08 | |
1,889,047 | Sail:onLagoon! | Laravel users, we’re so excited to announce the launch of Sail:onLagoon! If you’re familiar with... | 0 | 2024-06-20T18:53:40 | https://dev.to/uselagoon/sailonlagoon-2o3c | laravel, sail | Laravel users, we’re so excited to announce the launch of Sail:onLagoon!
If you’re familiar with Sail, you know it’s a quick and easy way to spin up a Laravel site. And now it’s fully integrated with Lagoon, allowing you to spin up a Laravel site configured for Lagoon quickly and easily.
Check out our demo video t... | alannaburke |
1,895,114 | 5. Where to Go Now: Putting Unit Testing into Action | Now that you've grasped the fundamentals of unit testing, it's time to apply this valuable skillset... | 27,796 | 2024-06-20T18:50:38 | https://dev.to/sandheep_kumarpatro_1c48/5-where-to-go-now-putting-unit-testing-into-action-58el | react, vitest, unittest, javascri | Now that you've grasped the fundamentals of unit testing, it's time to apply this valuable skillset to real-world projects. Here's how you can take the next steps:
**1\. Dive into Hands-on Practice:**
- **Build Mini-Apps with TDD:** Experiment with Test-Driven Development (TDD) by creating small, focused applications... | sandheep_kumarpatro_1c48 |
1,895,113 | 4. Some More Examples and Explanations | Example 1 :- Mocking Classes //returnNameOrAge.js export const returnNameOrAge =... | 27,796 | 2024-06-20T18:50:25 | https://dev.to/sandheep_kumarpatro_1c48/4-some-more-examples-and-explanations-38a3 | react, vitest, unittest, javascript | # Example 1 :- Mocking Classes
```javascript
//returnNameOrAge.js
export const returnNameOrAge = (isName) => {
if (isName) {
return "My Name is XYZ"
}
return 25
}
```
```javascript
//someOtherFunction.js
class SomeModule {
returnTrueOrFalse() {
return false;
}
}
export { SomeModule };
```
```java... | sandheep_kumarpatro_1c48 |
1,895,112 | 3. Unit testing concept | Topics covered in this section :- Synchronous Testing Asynchronous Testing Data mocking Event... | 27,796 | 2024-06-20T18:50:09 | https://dev.to/sandheep_kumarpatro_1c48/3-unit-testing-concept-4gj8 | react, vitest, unittest, javascript | Topics covered in this section :-
1. Synchronous Testing
2. Asynchronous Testing
3. Data mocking
4. Event testing
**Note :- **An interesting point to know here is that the above points are related and i have explained this relationship in detail at the end.
# Synchronous Testing
In JavaScript, synchronou... | sandheep_kumarpatro_1c48 |
1,895,110 | 2. Basics of Vitest | Let's start with What is Vitest... Vitest is a modern unit testing framework designed for... | 27,796 | 2024-06-20T18:49:44 | https://dev.to/sandheep_kumarpatro_1c48/2-basics-of-vitest-50jj | react, vitest, unittest, javascript | ## Let's start with What is Vitest...
Vitest is a modern unit testing framework designed for blazing-fast performance, especially when working with JavaScript projects. It leverages the power of Vite, a lightning-quick bundler, to streamline the testing process.
**Key Advantages:**
- **Exceptional Speed:** Vitest boa... | sandheep_kumarpatro_1c48 |
1,895,109 | 1. Understanding unit test basics | What is Unit Testing? Unit testing is a software development practice that involves... | 27,796 | 2024-06-20T18:49:33 | https://dev.to/sandheep_kumarpatro_1c48/1-understanding-unit-test-basics-3c0m | react, vitest, unittest, javascript | ### **What is Unit Testing?**
Unit testing is a software development practice that involves isolating individual units of code (functions, classes, modules) and verifying their correctness under various conditions. It ensures that each unit behaves as expected and produces the intended output for a given set of inputs... | sandheep_kumarpatro_1c48 |
1,895,108 | 0. Introduction and Surface level Explanation | Let me start with a story Imagine you're building a big Lego castle. Unit testing is like... | 27,796 | 2024-06-20T18:49:19 | https://dev.to/sandheep_kumarpatro_1c48/0-introduction-and-surface-level-explanation-1gom | react, vitest, unittest, javascript | ## Let me start with a story
Imagine you're building a big Lego castle. Unit testing is like checking each individual Lego brick before you snap them together.
- **Small pieces:** Instead of testing the entire castle at once, you test each brick (the tiny building block). In software, these bricks are functions, smal... | sandheep_kumarpatro_1c48 |
1,895,144 | Building a Static Blog with Next.js | Next.js is a powerful framework for building server-side rendering (SSR) and static web applications... | 0 | 2024-06-20T18:48:16 | https://dev.to/malvinjay/building-a-static-blog-with-nextjs-of6 | Next.js is a powerful framework for building server-side rendering (SSR) and static web applications with React. One of the standout features of Next.js is its ability to generate static sites, which can offer improved performance and SEO benefits. In this article, we will explore how to build a simple static blog usin... | malvinjay | |
1,895,143 | Laravel CKEditor Implementation | This documentation provides a step-by-step guide to implementing CKEditor in a Laravel project. The... | 0 | 2024-06-20T18:46:57 | https://dev.to/tahsin000/laravel-ckeditor-implementation-4aa8 |
This documentation provides a step-by-step guide to implementing CKEditor in a Laravel project. The example includes setting up the CKEditor in an admin panel for content creation and displaying the content on a frontend view.
## Prerequisites
- Laravel installed on your local machine
- Basic knowledge of Laravel fr... | tahsin000 | |
341,337 | Why you should start a blog as a developer | Starting a blog is a wonderful idea, and it's a challenging one too. | 0 | 2020-05-21T23:13:58 | https://melbarch.com/blog/why-starting-a-blog/ | blog, writing, blogging | ---
title: "Why you should start a blog as a developer"
published: true
description: "Starting a blog is a wonderful idea, and it's a challenging one too."
tags: ["blog","writing","blogging"]
canonical_url: "https://melbarch.com/blog/why-starting-a-blog/"
---
Starting a blog is a wonderful idea, and it's a challengi... | melbarch |
1,895,139 | Intersection of Two Sorted Arrays | Finding the intersection of two sorted arrays is a common problem in coding interviews and... | 27,580 | 2024-06-20T18:44:03 | https://blog.masum.dev/intersection-of-two-sorted-arrays | algorithms, computerscience, cpp, tutorial | Finding the intersection of two sorted arrays is a common problem in coding interviews and programming challenges. In this article, we'll discuss two approaches to solve this problem: one using a brute force approach and another using two-pointers technique.
### Solution 1: Brute Force Approach (using Nested Loop)
Th... | masum-dev |
1,895,138 | Digital Nomadism in 2024 | Hi everyone! in last month i've been search (on web and offline) a way to talk with a digital nomad... | 0 | 2024-06-20T18:43:30 | https://dev.to/tommytortorelli/digital-nomadism-in-2024-29lp | webdev, beginners, programming, ai | Hi everyone!
in last month i've been search (on web and offline) a way to talk with a digital nomad in 2024.
Many programmers and many designer but... BUT... what is the really way to begin a "Digital Nomad"?
What is the best way to work in Nomad Mode?
What is (if anyone don't have a full remote work) the best way ... | tommytortorelli |
1,895,135 | Debouncing- A Saver ! | Debouncing is a fundamental technique in JavaScript that improves performance by limiting the number... | 27,558 | 2024-06-20T18:42:08 | https://dev.to/imabhinavdev/debouncing-a-saver--21b3 | webdev, javascript, beginners, programming | Debouncing is a fundamental technique in JavaScript that improves performance by limiting the number of times a function is executed. It's particularly useful in scenarios where rapid events (like scrolling or typing) trigger callback functions that might cause performance issues if executed too frequently. In this gui... | imabhinavdev |
1,895,134 | Episode 24/24: Vertical Architectures, WebAssembly, Angular v9's Secret, NgRx | Brandon Roberts unveiled why Angular 9 has the highest download rates. Manfred Steyer gave a talk... | 0 | 2024-06-20T18:38:35 | https://dev.to/this-is-angular/episode-2424-vertical-architectures-webassembly-angular-v9s-secret-ngrx-1265 | webdev, javascript, angular, programming | Brandon Roberts unveiled why Angular 9 has the highest download rates. Manfred Steyer gave a talk about vertical architectures. Evgeniy Tuboltsev published a guide on how to integrate WebAssembly into Angular, and NgRx 18 was released.
{% embed https://youtu.be/mEAcIGUgluo %}
## Vertical Architectures
At the Angular... | ng_news |
1,895,133 | Luxury Guess Watches Showroom in Ghaziabad | Sai Creations Watch | When it comes to blending modern fashion with timeless elegance, Guess Collection (GC) Watches stand... | 0 | 2024-06-20T18:31:12 | https://dev.to/saicreationswatches/luxury-guess-watches-showroom-in-ghaziabad-sai-creations-watch-2pbn | watches | When it comes to blending modern fashion with timeless elegance, Guess Collection (GC) Watches stand out as an epitome of style and sophistication. For those in Ghaziabad, the new Guess Collection Watches showroom is a treasure trove waiting to be explored. Here’s why a visit to this showroom should be on every watch e... | saicreationswatches |
1,895,130 | 10 In-Demand Highest-Paying Python Jobs in 2024 | Below are the top 10 Best careers in Python according to ZipRecruiter and Indeed, along with their... | 0 | 2024-06-20T18:27:57 | https://dev.to/devella/10-in-demand-highest-paying-python-jobs-in-2024-4o5k | python, beginners, webdev, datascience | Below are the **top 10 Best careers** in Python according to **ZipRecruiter** and **Indeed**, along with their estimated average annual salaries:
1. **Machine Learning Engineer ==> _$110,500 - $164,500_:** Machine learning engineers use Python to build and deploy machine learning models that can learn from data and ma... | devella |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.