
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,895,131 | I want to Create a WEbsite for Unit Conversion in wordpress | I want to make website which will be Unit Conversion like , Length Unit Converter, Weight... | 0 | 2024-06-20T18:27:07 | https://dev.to/hammad_nasarhaqitatdek/i-want-to-create-a-website-for-unit-conversion-in-wordpress-17en | javascript, python, devops | I want to make website which will be Unit Conversion like , [Length Unit Converter](https://uzzasoft.com/tools/conversions/length), [Weight Conversions](https://uzzasoft.com/tools/conversions/weight-and-mass), [Volume Converters](https://uzzasoft.com/tools/conversions/Volume) ETC,
I wnat to make bulk pages in wordpres... | hammad_nasarhaqitatdek |
1,895,306 | Curso De Inteligência Artificial Gratuito: Do Zero Ao Avançado | Acesse agora um curso 100% gratuito sobre inteligência artificial, do nível básico ao avançado.... | 0 | 2024-06-23T13:49:57 | https://guiadeti.com.br/curso-inteligencia-artificial-gratuito-iniciante/ | cursogratuito, cursosgratuitos, desenvolvimento, inteligenciaartifici | ---
title: Curso De Inteligência Artificial Gratuito: Do Zero Ao Avançado
published: true
date: 2024-06-20 18:26:15 UTC
tags: CursoGratuito,cursosgratuitos,desenvolvimento,inteligenciaartifici
canonical_url: https://guiadeti.com.br/curso-inteligencia-artificial-gratuito-iniciante/
---
Acesse agora um curso 100% gratui... | guiadeti |
1,895,129 | The Open Source Paradox: Fragility and Promise | The problems with open source software highlight the need for sustainable project management, addressing vulnerabilities, ensuring long-term security, and fostering innovation. | 0 | 2024-06-20T18:25:57 | https://opensauced.pizza/blog/problems-with-open-source | opensource | ---
title: The Open Source Paradox: Fragility and Promise
published: true
description: The problems with open source software highlight the need for sustainable project management, addressing vulnerabilities, ensuring long-term security, and fostering innovation.
tags: opensource
cover_image: https://dev-to-uploads.s3.... | bekahhw |
1,895,118 | Securing CouchDB with Keycloak Behind Nginx Reverse Proxy – Part 1 | In the coming weeks, I will face the task of enriching the current CouchDB deployment in one of the... | 27,797 | 2024-06-20T18:23:44 | https://dev.to/kishieel/securing-couchdb-with-keycloak-behind-nginx-reverse-proxy-part-1-m0e | keycloak, couchdb, devops, learning | In the coming weeks, I will face the task of enriching the current CouchDB deployment in one of the projects using it for metadata storage with features like SSO integration and fine-grained access management. As the SSO service of the project uses Keycloak under the hood and I am relatively new to both Keycloak and Co... | kishieel |
1,895,128 | Short Overview: Frontend Architectures 🧩 | Frontend architectures define how the components of a web application are organized and interact.... | 0 | 2024-06-20T18:22:26 | https://dev.to/buildwebcrumbs/short-overview-frontend-architectures-4778 | webdev, javascript, frontend | Frontend architectures define how the components of a web application are organized and interact. Here are some common types:
### Monolithic Architecture 🏛️
- **Single Codebase**: Everything is in one place.
- **Pros**: Simple to set up and maintain.
- **Cons**: Hard to scale, changes affect the entire app.
### Micr... | m4rcxs |
1,895,121 | Looking for coding friends | Hello wonderful people of Dev.to! Let me tell you a back story of myself. I recently finished a... | 0 | 2024-06-20T18:19:42 | https://dev.to/dlocodes/looking-for-coding-friends-jae | community, webdev, frontend, react | Hello wonderful people of Dev.to!
Let me tell you a back story of myself. I recently finished a coding bootcamp in Fall 2023. I finished one of the top students in my cohorts and was always looking to improve at the time. I was hooked. I took a major break and thought to myself I could do so and pick up right where I ... | dlocodes |
1,895,120 | Fat Burn Active Supplement Review | Fat Burn Active is a weight loss supplement that claims to help you burn fat, manage weight, and... | 0 | 2024-06-20T18:17:16 | https://dev.to/trustreviews/fat-burn-active-supplement-review-3anc | review | Fat Burn Active is a weight loss supplement that claims to help you burn fat, manage weight, and improve your metabolism. However, there is limited independent research on the effectiveness of this specific supplement.
Here's a closer look at Fat Burn Active:
**Ingredients**
* Acetyl L-Carnitine: This amino acid he... | trustreviews |
1,895,119 | Buy Bering Watches Online For Men and Women | Sai Creations Watch | In a world where trends come and go, Bering Watches stand as a beacon of timeless elegance and... | 0 | 2024-06-20T18:15:07 | https://dev.to/saicreationswatches/buy-bering-watches-online-for-men-and-women-sai-creations-watch-152p | watches |
In a world where trends come and go, Bering Watches stand as a beacon of timeless elegance and enduring quality. Inspired by the pristine beauty of the Arctic, Bering combines minimalist Danish design with durable ma... | saicreationswatches |
1,865,560 | How to Implement Data Validation in NestJS Using nestjs-joi and joi-class-decorators | Here are some topics I can cover: Introduction to Data Validation in Web... | 0 | 2024-06-20T18:14:08 | https://dev.to/alifathy1999/how-to-implement-data-validation-in-nestjs-using-nestjs-joi-and-joi-class-decorators-1bk3 | nestjs, joi, typescript, node | ## Here are some topics I can cover:
1. Introduction to Data Validation in Web Applications.
2. Setting Up NestJS for Validation.
- Prerequisites and project setup.
- Creating and Using Validation Schemas
3. Introduction to pipe and how to use it with Joi
4. Validation on Param and Query Params using Joi.
5. Prac... | alifathy1999 |
1,893,363 | 1.Python Selenium Architecture 2.Significance of Python Virtual Environment 3.Examples of Python Virtual Environment | ## 1.Python Selenium Architecture Enter fullscreen mode Exit fullscreen... | 0 | 2024-06-20T18:03:36 | https://dev.to/sunmathi/1python-selenium-architecture-2significance-of-python-virtual-environment-3examples-of-python-virtual-environment-252i | ## 1.Python Selenium Architecture
Selenium is a popular open-source framework used for automating web browser interactions.It is widely used for web applications.The architecture of selenium is designed to support a variety of browsers and programming language making it highly flexible and powerful.Here i... | sunmathi | |
1,895,117 | I am wanting to loop this entire code infinitely | Hi guys I have this code which i will add below, i am trying to loop the entirety of it infinitely... | 0 | 2024-06-20T18:03:00 | https://dev.to/jaime_irvine_/i-am-wanting-to-loop-this-entire-code-infinitely-4nbp | webdev, css, csshelp, learning | Hi guys I have this code which i will add below, i am trying to loop the entirety of it infinitely after the last image (imagetest5) finishes its animation and have is start back at (imagetest1)
Please could you assist!!
Code:
@keyframes start-animation {
0% { opacity: 0; }
10% { opacity: 1; }
20% { opacity: 0; }
100... | jaime_irvine_ |
1,895,116 | Layout Panes | JavaFX provides many types of panes for automatically laying out nodes in a desired location and... | 0 | 2024-06-20T18:01:33 | https://dev.to/paulike/layout-panes-2n8n | java, programming, learning, beginners | JavaFX provides many types of panes for automatically laying out nodes in a desired location and size. JavaFX provides many types of panes for organizing nodes in a container, as shown in Table below. You have used the layout panes **Pane**, **StackPane**, and **HBox** in the preceding sections for containing nodes. Th... | paulike |
1,893,773 | A React Global State that can persist data too! | In my previous article, I introduced a powerful yet simple hook called useDbState that lets you... | 0 | 2024-06-20T17:56:28 | https://dev.to/ajejey/a-react-global-state-that-can-persist-data-too-41ib | usedbstate, tutorial, frontend, react | In my [previous article](https://dev.to/ajejey/persist-your-react-state-in-the-browser-2bgm), I introduced a powerful yet simple hook called [useDbState](https://www.npmjs.com/package/use-db-state) that lets you persist state in your React components just like useState. But wait, there's more!
## Introducing useDbStat... | ajejey |
1,895,082 | Securing Centralized Crypto Exchanges | Introduction The realm of cryptocurrency has expanded exponentially over the past... | 27,673 | 2024-06-20T17:08:28 | https://dev.to/rapidinnovation/securing-centralized-crypto-exchanges-4gde | ## Introduction
The realm of cryptocurrency has expanded exponentially over the past decade,
introducing a new paradigm of financial transactions and investment
opportunities. As digital currencies like Bitcoin, Ethereum, and others have
grown in popularity and market capitalization, the platforms that facilitate
thei... | rapidinnovation | |
1,895,115 | salons development tips | To develop an ICT salon, focus on integrating advanced booking and CRM systems to streamline client... | 0 | 2024-06-20T17:49:14 | https://dev.to/tyba_hassan_d9e718e326a8e/salons-development-tips-3ok3 | To develop an [ICT salo](https://salonkyliepittsburgh.com/eyelash-services-in-pittsburgh/)n, focus on integrating advanced booking and CRM systems to streamline client management. Enhance your online presence with a user-friendly website and active social media engagement to attract and retain clients.
| tyba_hassan_d9e718e326a8e | |
1,895,111 | Understanding the Testing Pyramid: A Comprehensive Guide | Introduction Software development is a complex process involving numerous stages and disciplines.... | 0 | 2024-06-20T17:41:16 | https://dev.to/keploy/understanding-the-testing-pyramid-a-comprehensive-guide-1p5k | webdev, javascript, beginners, programming |

**Introduction**
Software development is a complex process involving numerous stages and disciplines. One critical aspect is testing, which ensures that software is reliable, functional, and free of defects. The Tes... | keploy |
1,895,106 | Help post ! | Can anyone help me with this problem why this is overlapping?? | 0 | 2024-06-20T17:31:35 | https://dev.to/hossain99987/help-post--4jnj | webdev, css, beginners, programming |
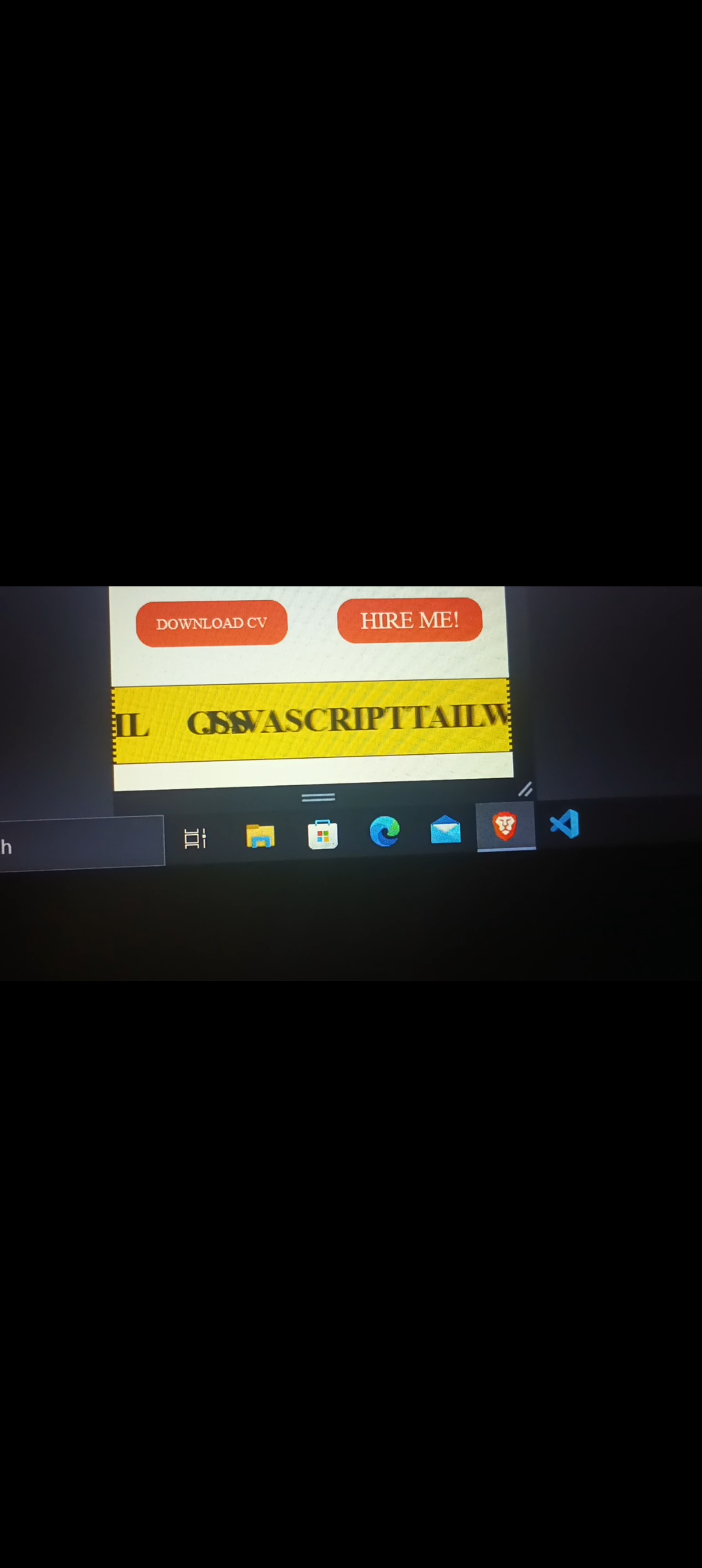
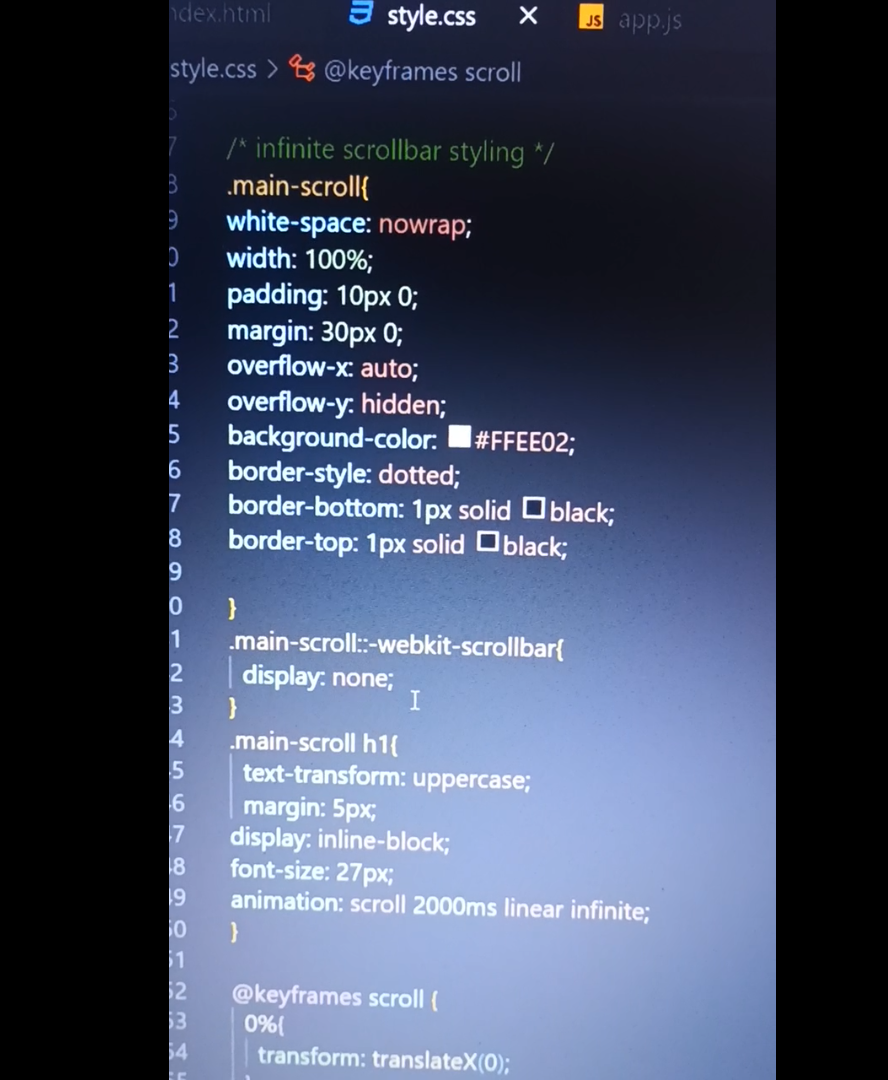
Can anyone help me with this problem why this is overlapping?? | hossain99987 |
1,895,086 | MICROSOFT APPLIED SKILL. Guided Project: Provide storage for the IT department testing and training | This is exercise 1 of the Microsoft Applied skill guided project. What is Azure storage account An... | 0 | 2024-06-20T17:14:28 | https://dev.to/sethgiddy/microsoft-applied-skill-guided-project-provide-storage-for-the-it-department-testing-and-training-31je | azure, storage | This is exercise 1 of the Microsoft Applied skill guided project.
What is Azure storage account
An azure storage account is a container that groups a set of Azure Storage services together. Only data services from Azure Storage can be included in a storage account.
Below are the 4 types of azure storage account
1.... | sethgiddy |
1,892,248 | Deploy from git to hostinger (Shared hosting). | What is hostinger. Hostinger is a web hosting company that was established in 2004. It... | 0 | 2024-06-20T16:14:28 | https://dev.to/vimuth7/deploy-from-git-to-hostinger-shared-hosting-333n | ##What is hostinger.
Hostinger is a web hosting company that was established in 2004. It offers a variety of hosting services, including shared hosting, cloud hosting, Virtual Private Server (VPS) hosting, and more recently, WordPress hosting. The company is known for providing affordable and scalable hosting solution... | vimuth7 | |
1,895,081 | MsSQL on MacOs | MSSql database is easy to configure on a Windows System . For MacOs we need to take care of few steps... | 0 | 2024-06-20T17:08:24 | https://dev.to/pranjal_sharma_38482a3041/mssql-on-macos-2l3e | microsoft, apple, database, macos | MSSql database is easy to configure on a Windows System . For MacOs we need to take care of few steps to get it installed and run properly .
Lets see what all steps we need to follow →
### 01 : Download Docker
Docker is a set of platform as a service products that use OS-level virtualization to deliver software i... | pranjal_sharma_38482a3041 |
1,895,079 | From DreamHost to Office 365: A Streamlined Migration Guide | Leaving DreamHost email behind and embracing the robust features of Office 365 can be a strategic... | 0 | 2024-06-20T17:02:44 | https://dev.to/petergroft/from-dreamhost-to-office-365-a-streamlined-migration-guide-379j | dreamhost, office365 | Leaving DreamHost email behind and embracing the robust features of Office 365 can be a strategic move for your business. But navigating the DreamHost to Office 365 migration process can seem daunting. Fear not! This guide simplifies your journey:
Planning is Key:
Define Your Scope: Identify the data types to migrate ... | petergroft |
1,892,892 | HOW TO CREATE AND CONNECT TO A LINUX VM USING A PUBLIC KEY. | ## INTRODUCTION Just like creating your Azure windows VM, the Azure linux is slightly similar from... | 0 | 2024-06-20T16:59:26 | https://dev.to/agana_adebayoo_876a06/how-to-create-and-connect-to-a-linux-vm-using-a-public-key-550o | linux, create, public | **## INTRODUCTION**
Just like creating your Azure windows VM, the Azure linux is slightly similar from the begin at which you create your basic settings all through your network before they are then subsequently DEPLOYED,it is at this point your generated ip address is used with your ssh server is used to create a PUBL... | agana_adebayoo_876a06 |
1,895,077 | The Image and ImageView Classes | The Image class represents a graphical image and the ImageView class can be used to display an image.... | 0 | 2024-06-20T16:46:52 | https://dev.to/paulike/the-image-and-imageview-classes-44j1 | java, programming, learning, beginners | The **Image** class represents a graphical image and the **ImageView** class can be used to display an image. The **javafx.scene.image.Image** class represents a graphical image and is used for loading an image from a specified filename or a URL. For example, **new Image("image/us.gif")** creates an **Image** object fo... | paulike |
1,895,071 | My experiment with HTMX and Astro | I share my first experience with the htmx library. I created a simple site... | 0 | 2024-06-20T16:44:25 | https://dev.to/petrtcoi/my-experiment-with-htmx-and-astro-3io9 | astro, htmx | I share my first experience with the [htmx](https://htmx.org) library. I created a simple site ([https://tubog-showcase.ru](https://tubog-showcase.ru)) consisting of a home page with an initial set of apartment cards and 5 buttons that display apartments filtered by number of rooms.
Stack: Astro + HTMX + Tailwind
Imp... | petrtcoi |
1,895,075 | Why Specifying the Node.js Version is Essential | Hey everyone! Today we're going to talk about a super important practice in developing Node.js... | 0 | 2024-06-20T16:43:21 | https://dev.to/robertoumbelino/why-specifying-the-nodejs-version-is-essential-4nhp | node, npm, nvm | Hey everyone! Today we're going to talk about a super important practice in developing Node.js applications: specifying the Node.js version in your project's `package.json` file. It might seem like a small detail, but trust me, it can save you from a lot of headaches in the future. So, let's understand why this is cruc... | robertoumbelino |
1,895,073 | Testing Your API with Fastify and Vitest: A Step-by-Step Guide | Hey there! Let's dive into how to test an API built with Fastify using Vitest and TypeScript. We'll... | 0 | 2024-06-20T16:38:29 | https://dev.to/robertoumbelino/testing-your-api-with-fastify-and-vitest-a-step-by-step-guide-2840 | node, fastify, vitest, api | Hey there! Let's dive into how to test an API built with Fastify using Vitest and TypeScript. We'll focus on a simple health check route and make sure everything's working as it should.
### Why Test an API?
Testing an API is super important to make sure everything is running smoothly. Automated tests help us catch bu... | robertoumbelino |
1,895,072 | ChatGPT Slack Bot | Slack is one of the most widely used communication tools for teams, and with the integration of... | 0 | 2024-06-20T16:38:20 | https://dev.to/pranjal_sharma_38482a3041/chatgpt-slack-bot-3bfe | chatgpt, slack, bot, ai | Slack is one of the most widely used communication tools for teams, and with the integration of OpenAI’s ChatGPT, it becomes an even more powerful tool. ChatGPT is a highly advanced language model that can generate human-like responses to a given prompt. In this blog, we will show you how to integrate ChatGPT with Slac... | pranjal_sharma_38482a3041 |
1,895,096 | Bootcamp De Machine Learning Para AWS Gratuito | O Bootcamp Nexa oferece bolsas de estudo para aqueles que desejam dominar o SageMaker Canvas na AWS,... | 0 | 2024-06-23T13:50:02 | https://guiadeti.com.br/bootcamp-machine-learning-aws-gratuito/ | bootcamps, aws, cursosgratuitos, inteligenciaartifici | ---
title: Bootcamp De Machine Learning Para AWS Gratuito
published: true
date: 2024-06-20 16:33:34 UTC
tags: Bootcamps,aws,cursosgratuitos,inteligenciaartifici
canonical_url: https://guiadeti.com.br/bootcamp-machine-learning-aws-gratuito/
---
O Bootcamp Nexa oferece bolsas de estudo para aqueles que desejam dominar o... | guiadeti |
1,895,069 | Day 24 of my progress as a vue dev | About today Today was again one of those days where I struggled to follow my routine to the fullest... | 0 | 2024-06-20T16:32:20 | https://dev.to/zain725342/day-24-of-my-progress-as-a-vue-dev-5ggi | webdev, vue, typescript, tailwindcss | **About today**
Today was again one of those days where I struggled to follow my routine to the fullest and spent most of my time on youtube and sleeping which I think is not progressive in any way. But, I'm starting to realize that such instances are going away and I will keep on encountering such days in the future a... | zain725342 |
1,895,068 | How does Nostra utilize mobile game advertising and lock screen games to enhance gaming monetization strategies? | At Nostra, we harness the power of mobile game advertising and lock screen games to optimize gaming... | 0 | 2024-06-20T16:31:33 | https://dev.to/claywinston/how-does-nostra-utilize-mobile-game-advertising-and-lock-screen-games-to-enhance-gaming-monetization-strategies-376g | gamedev, mobilegames, androidgames, nostragames | At Nostra, we harness the power of [**mobile game advertising**](https://medium.com/@adreeshelk/get-to-know-all-about-gaming-platforms-today-e5d4ae7f25dd?utm_source=referral&utm_medium=Medium&utm_campaign=Nostra) and lock screen games to optimize gaming monetization strategies. Through our platform, developers can seam... | claywinston |
1,895,067 | I’m switching from Laravel to Rails | I have been using Laravel since version 4 in 2013. Over the years, Laravel has evolved significantly.... | 0 | 2024-06-20T16:29:45 | https://dev.to/reshadman/im-switching-from-laravel-to-rails-50on | rails, laravel, fullstack, ruby | I have been using Laravel since version 4 in 2013. Over the years, Laravel has evolved significantly. I initially chose Laravel over Rails due to its favorable position in our local job market. In 2015, I started building our own business using Laravel. Today, that business is the largest job board in Iran, serving ove... | reshadman |
1,894,514 | my unconventional journey into tech | Where it started I’ve hopped from a diploma in Music and Audio Technology to a college... | 0 | 2024-06-20T16:29:30 | https://dev.to/ohchloeho/my-unconventional-journey-into-tech-b4o | beginners, codenewbie, community, discuss | ## Where it started
I’ve hopped from a diploma in Music and Audio Technology to a college degree in Business Management, then landing a job in IT engineering most recently. I’ve read about many self-taught individuals getting into the software industry over the past few years and I’ve started on this journey halfway t... | ohchloeho |
1,895,050 | Reinforcement Learning: A Brief Overview | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-20T16:29:19 | https://dev.to/abhinav11234/reinforcement-learning-a-brief-overview-3b87 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
In Reinforcement Learning (RL), we train models to make decisions based on actions, mistakes, and feedback, like humans learn from experience. In RL, model generate outputs on it's own... | abhinav11234 |
1,895,066 | Precision Estimating: The Key to Efficient and Accurate Construction Projects | In the fast-paced and highly competitive construction world, delivering projects on time and within... | 0 | 2024-06-20T16:26:52 | https://dev.to/precisionestimatorllc/precision-estimating-the-key-to-efficient-and-accurate-construction-projects-32j3 | constructionestimating, materialtakeoffs, quantitysurveyor, precisionestimator | In the fast-paced and highly competitive construction world, delivering projects on time and within budget is critical. At Precision Estimator LLC, we understand that the foundation of any successful construction project lies in accurate and detailed cost estimation. This is where precision estimating comes into play, ... | precisionestimatorllc |
1,895,064 | The Font Class | A Font describes font name, weight, and size. You can set fonts for rendering the text. The... | 0 | 2024-06-20T16:24:30 | https://dev.to/paulike/the-font-class-318k | java, programming, learning, beginners | A **Font** describes font name, weight, and size. You can set fonts for rendering the text. The **javafx.scene.text.Font** class is used to create fonts, as shown in Figure below.

A **Font** instance can be constru... | paulike |
1,895,063 | AI Enhanced Updates | Arcade | About Arcade Arcade delivers AI-enhanced updates right on your Discord server, with all... | 0 | 2024-06-20T16:20:44 | https://dev.to/flameface/ai-enhanced-updates-arcade-4l5o | ai, news, google | 
## [About Arcade](https://arcade.unburn.tech/)
Arcade delivers AI-enhanced updates right on your Discord server, with all types of updates about gaming, entertainment, technology and more.
---
 programming. Neuro-symbolic AI combines neural networks (which excel in pattern recognition and data-driven tasks) with symbolic AI (which focuses on reasoning and rule-based problem solving) to create syste... | 0 | 2024-06-20T16:13:50 | https://github.com/NucleoidAI/Nucleoid/blob/main/README.md | ai, showdev, node, javascript | ---
description: Nucleoid is a reasoning engine for Neuro-Symbolic AI, implementing symbolic AI through declarative (logic-based) programming. Neuro-symbolic AI combines neural networks (which excel in pattern recognition and data-driven tasks) with symbolic AI (which focuses on reasoning and rule-based problem solving... | canmingir |
1,893,907 | Building a simple Date Picker with React and Day.js | Welcome! This is the second part of our three-part tutorial on creating a simple calendar using... | 0 | 2024-06-20T16:10:45 | https://dev.to/oluwadahunsia/building-a-simple-date-picker-with-react-and-dayjs-4oop | webdev, react, typescript, javascript | Welcome!
This is the second part of our three-part tutorial on creating a simple calendar using React and Day.js. In the first part, we built a custom calendar with React and Day.js.
You can check the first and the last parts here:
The first part:
{% embed https://dev.to/oluwadahunsia/building-a-custom-calendar-wi... | oluwadahunsia |
1,895,052 | Why We Adopted a Synchronous API for the New TypeScript ORM | I am developing a TypeScript ORM library called Accel Record. Unlike other TypeScript/JavaScript ORM... | 27,598 | 2024-06-20T16:10:09 | https://dev.to/koyopro/why-we-adopted-a-synchronous-api-for-the-new-typescript-orm-1jm | typescript, orm, opensource, activerecord | I am developing a TypeScript ORM library called [Accel Record](https://www.npmjs.com/package/accel-record). Unlike other TypeScript/JavaScript ORM libraries, Accel Record has adopted a synchronous API instead of an asynchronous one.
In this article, I will explain the background and reasons for adopting a synchronous ... | koyopro |
1,895,048 | LayerZero (ZRO) Airdrop Claim Promo by GetBlock: Private RPCs for Degens | As ZRO airdrop is finally happening on Jun.20, GetBlock offers premium RPC nodes for enhanced... | 0 | 2024-06-20T16:08:05 | https://dev.to/getblockapi/layerzero-zro-airdrop-claim-promo-by-getblock-private-rpcs-for-degens-1jja | airdrop, layerzero, nodes, cryptocurrency |

As ZRO airdrop is finally happening on Jun.20, GetBlock offers premium RPC nodes for enhanced airdrop experience. With GetBlock’s private RPCs for EVM networks, airdrop hunters can protect themselves from inevitable... | getblockapi |
1,893,632 | Building a Custom Calendar with React and Day.js: A Step-by-Step Guide. | Welcome! This is the first of a three-part series on building a custom calendar with React and... | 0 | 2024-06-20T16:08:01 | https://dev.to/oluwadahunsia/building-a-custom-calendar-with-react-and-dayjs-a-step-by-step-guide-2h1d | webdev, javascript, beginners, programming | Welcome!
This is the first of a **three-part** series on building a custom calendar with React and Day.js. We are going to start with a simple calendar in this first part and go all the way up to a date range picker in the third part.
When you are done with this, you can check the second part here:
{% embed https:... | oluwadahunsia |
1,895,047 | Migrate from Cord to SuperViz | With the latest announcement from the Cord Team stating that the company is shutting down in August,... | 0 | 2024-06-20T16:07:08 | https://dev.to/superviz/migrate-from-cord-to-superviz-2f9m | superviz, videosdk, realtime, tooling | With the latest announcement from the Cord Team stating that the company is shutting down in August, many of their users are now seeking an alternative. SuperViz shares the same mission: making it easy for any developer to add real-time collaboration to their apps. Today, we want to show you how we can [help you transi... | vtnorton |
1,895,046 | Balancing cost and Resilience | Resilience in Cloud Architecture Resilience refers to an infrastructure's ability to recover quickly... | 0 | 2024-06-20T16:06:52 | https://dev.to/c0dingpanda/balancing-cost-and-resilience-4ido | azure, devops, cloud, design | **Resilience in Cloud Architecture**
Resilience refers to an infrastructure's ability to recover quickly from failures or disruptions and continue operating smoothly. In cloud computing, resilience patterns are designed to ensure that applications remain available and performant even in the face of challenges⁶. When a... | c0dingpanda |
1,895,045 | Balancing cost and Resilience | Resilience in Cloud Architecture Resilience refers to an infrastructure's ability to recover quickly... | 0 | 2024-06-20T16:06:32 | https://dev.to/c0dingpanda/balancing-cost-and-resilience-3e68 | azure, devops, cloud, design | **Resilience in Cloud Architecture**
Resilience refers to an infrastructure's ability to recover quickly from failures or disruptions and continue operating smoothly. In cloud computing, resilience patterns are designed to ensure that applications remain available and performant even in the face of challenges⁶. When a... | c0dingpanda |
1,895,043 | Common Properties and Methods for Nodes | The abstract Node class defines many properties and methods that are common to all nodes. Nodes share... | 0 | 2024-06-20T16:05:37 | https://dev.to/paulike/common-properties-and-methods-for-nodes-1p8l | beginners, programming, learning, java | The abstract **Node** class defines many properties and methods that are common to all nodes. Nodes share many common properties. This section introduces two such properties **style** and **rotate**.
JavaFX style properties are similar to cascading style sheets (CSS) used to specify the styles for HTML elements in a W... | paulike |
1,895,040 | Understanding Kubernetes: Why It's Essential for Modern Applications | Introduction: Welcome back to our CK2024 blog series! Today we dive into the fundamentals... | 0 | 2024-06-20T15:59:08 | https://dev.to/jensen1806/understanding-kubernetes-why-its-essential-for-modern-applications-1b4m | kubernetes, containerisation, docker, devops | ### Introduction:
Welcome back to our CK2024 blog series! Today we dive into the fundamentals of Kubernetes. This is the fourth instalment in our series where we've already covered the basics of containers, how to containerize an application, why we need containers, and the concept of multi-stage builds. If you haven’t... | jensen1806 |
1,895,038 | Property Binding | You can bind a target object to a source object. A change in the source object will be automatically... | 0 | 2024-06-20T15:54:53 | https://dev.to/paulike/property-binding-2kgi | java, programming, learning, beginners | You can bind a target object to a source object. A change in the source object will be automatically reflected in the target object. JavaFX introduces a new concept called _property binding_ that enables a _target object_ to be bound to a _source object_. If the value in the source object changes, the target object is ... | paulike |
1,895,035 | A WhatsApp game where you create your own Adventure | This is a submission for the Twilio Challenge What I Built A story-driven text-based... | 0 | 2024-06-20T15:52:54 | https://dev.to/kamecat/a-whatsapp-game-where-you-create-your-own-adventure-47o7 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
A story-driven text-based game that is played through WhatsApp in an asynchronous, non intrusive way, adapting to players' schedules. The game is inspired in interactive fiction, choose your own adventure books, D&D, ... | kamecat |
1,895,036 | The Fascinating Evolution of JavaScript: A Comprehensive Historical Journey | JavaScript, the ubiquitous language of the web, has a captivating history that spans over two... | 0 | 2024-06-20T15:51:32 | https://dev.to/danielemanca/the-fascinating-evolution-of-javascript-a-comprehensive-historical-journey-2pim | htmlcss, webdev, javascript | JavaScript, the ubiquitous language of the web, has a captivating history that spans over two decades. From its humble beginnings as a simple scripting language to its current status as a powerful and versatile tool, JavaScript's journey is a testament to the ingenuity and perseverance of its creators and the ever-grow... | danielemanca |
1,895,034 | On the internet, people are racing to get each other’s attention. The internet is getting cluttered, and here is the solution. | In today’s world, the internet is filled with endless content. On platforms like Instagram, YouTube,... | 0 | 2024-06-20T15:47:42 | https://dev.to/lakshya_gurha/on-the-internet-people-are-racing-to-get-each-others-attention-the-internet-is-getting-cluttered-and-here-is-the-solution-39ng | In today’s world, the internet is filled with endless content. On platforms like Instagram, YouTube, and Facebook, people are constantly racing to grab each other’s attention. This race has led to a cluttered internet where finding valuable information has become a challenge.
Take Instagram, for example. Users scroll ... | lakshya_gurha | |
1,894,890 | Understanding Environment Variables | Environment variables are required for configuring the operating system and applications without... | 0 | 2024-06-20T15:15:30 | https://dev.to/madgan95/understanding-environment-variables-55nm | operatingsystems, beginners, programming, tutorial | Environment variables are required for configuring the operating system and applications without hardcoding values. They can be set at two levels: **user-level** and **system-level**.
## User Environment Variables
**Scope**: Only affect the user account under which they are set.
**Use Case**: Ideal for settings th... | madgan95 |
1,895,033 | WhatsApp info: +1 (571) 541‑2918 SCAM BITCOIN RECOVERY COMPANY HIRE ADWARE RECOVERY SPECIALIST | Website info: www.adwarerecoveryspecialist.expert Email info: Adwarerecoveryspecialist@auctioneer.... | 0 | 2024-06-20T15:43:26 | https://dev.to/jayson_irwin_17cfcd94ddf7/whatsapp-info-1-571-541-2918-scam-bitcoin-recovery-company-hire-adware-recovery-specialist-12n | Website info: www.adwarerecoveryspecialist.expert
Email info: Adwarerecoveryspecialist@auctioneer. net
WhatsApp info: +1 (571) 541‑2918
Amidst the bustling streets of New York, I found myself into a devastating loss: 5 BTC, vanished into thin air due to a bitcoin investing platform's betrayal. The frustration ... | jayson_irwin_17cfcd94ddf7 | |
1,895,031 | How to Create a QR Code Generator in JavaScript: Easy Tutorial | QR codes have become an integral part of modern technology, enabling quick access to information... | 0 | 2024-06-20T15:42:14 | https://raajaryan.tech/how-to-create-a-qr-code-generator-in-javascript-easy-tutorial | javascript, beginners, tutorial, opensource | [](https://buymeacoffee.com/dk119819)
QR codes have become an integral part of modern technology, enabling quick access to information with a simple scan. Whether you're a developer lookin... | raajaryan |
1,895,030 | Version Checking in MiniScript | MiniScript runs in a lot of different environments. Moreover, the language itself changes from time... | 0 | 2024-06-20T15:40:35 | https://dev.to/joestrout/version-checking-in-miniscript-gob | miniscript, minimicro, programming, beginners | MiniScript runs in a lot of different environments. Moreover, the language itself changes from time to time. So, to write a script that works in multiple places, sometimes you need to check the version of the language and environment in which it's running.
## The `version` intrinsic
Since MiniScript version 1.4 (wh... | joestrout |
1,895,029 | loading page dancing doggo | _I just did a silly loading page dancing doggo!!!! _ | 0 | 2024-06-20T15:39:19 | https://dev.to/ujiron/loading-page-dancing-doggo-efa | codepen, html, css, javascript | **_I just did a silly loading page dancing doggo!!!! _**
{% codepen https://codepen.io/salomejb/pen/WNBMWOm %} | ujiron |
1,895,028 | How Salesforce Cloud Solutions Boost Business Efficiency | In today’s fast-paced business environment, efficiency is more crucial than ever. Companies strive to... | 0 | 2024-06-20T15:38:32 | https://dev.to/jameskevinb/how-salesforce-cloud-solutions-boost-business-efficiency-e9f | In today’s fast-paced business environment, efficiency is more crucial than ever. Companies strive to streamline operations, reduce costs, and enhance customer satisfaction to stay competitive. Salesforce Cloud Solutions offer comprehensive tools to achieve these goals. From sales and service to marketing and analytics... | jameskevinb | |
1,895,014 | Tips for aspiring professionals: 4 mindset you can apply in your career and everyday life | See my original post here in my blog. 4 things I realized as I reflected going through a tough day.... | 0 | 2024-06-20T15:38:29 | https://blog.chardskarth.me/blog/tips-for-aspiring-professionals/ | career, tips, firstpost | See my [original post here in my blog](https://blog.chardskarth.me/blog/tips-for-aspiring-professionals/).
4 things I realized as I reflected going through a tough day. This tips will hopefully help you prosper in your chosen field.
## 1. As you PRACTICE, be ALWAYS on the lookout for small things that can be improved... | chardskarth |
1,895,027 | A beginner's guide to the Clarity-Upscaler model by Philz1337x on Replicate | clarity-upscaler | 0 | 2024-06-20T15:38:13 | https://aimodels.fyi/models/replicate/clarity-upscaler-philz1337x | coding, ai, beginners, programming | *This is a simplified guide to an AI model called [Clarity-Upscaler](https://aimodels.fyi/models/replicate/clarity-upscaler-philz1337x) maintained by [Philz1337x](https://aimodels.fyi/creators/replicate/philz1337x). If you like these kinds of guides, you should subscribe to the [AImodels.fyi newsletter](https://aimodel... | mikeyoung44 |
1,895,026 | A beginner's guide to the Whisperx model by Erium on Replicate | whisperx | 0 | 2024-06-20T15:37:39 | https://aimodels.fyi/models/replicate/whisperx-erium | coding, ai, beginners, programming | *This is a simplified guide to an AI model called [Whisperx](https://aimodels.fyi/models/replicate/whisperx-erium) maintained by [Erium](https://aimodels.fyi/creators/replicate/erium). If you like these kinds of guides, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on... | mikeyoung44 |
1,895,025 | A beginner's guide to the Multilingual-E5-Large model by Beautyyuyanli on Replicate | multilingual-e5-large | 0 | 2024-06-20T15:37:04 | https://aimodels.fyi/models/replicate/multilingual-e5-large-beautyyuyanli | coding, ai, beginners, programming | *This is a simplified guide to an AI model called [Multilingual-E5-Large](https://aimodels.fyi/models/replicate/multilingual-e5-large-beautyyuyanli) maintained by [Beautyyuyanli](https://aimodels.fyi/creators/replicate/beautyyuyanli). If you like these kinds of guides, you should subscribe to the [AImodels.fyi newslett... | mikeyoung44 |
1,894,899 | House of XYZ | 👋 Welcome to House of XYZ! Your full-service¹ software studio. With over a decade of experience... | 0 | 2024-06-20T15:14:07 | https://dev.to/xyz_steven/house-of-xyz-3d8d | softwaredevelopment, startup, entrepreneurship, webdev | 👋 Welcome to House of XYZ! Your full-service¹ software studio. With over a decade of experience collaborating with public companies, hyper-growth unicorns, and YC-backed startups, there ain't S#!T we can't build. Whether you’re a startup looking to innovate, an established company aiming to scale, or an entrepreneur w... | xyz_steven |
1,895,022 | The Role of Cataract Surgery in Preventing Blindness | Cataracts, a condition characterized by the clouding of the eye's natural lens, are one of the... | 0 | 2024-06-20T15:35:36 | https://dev.to/balamurugan_1857d8cb1038d/the-role-of-cataract-surgery-in-preventing-blindness-3147 | besteyespecialistchennai | Cataracts, a condition characterized by the clouding of the eye's natural lens, are one of the leading causes of blindness globally. This condition affects millions, particularly the elderly, significantly impairing vision and quality of life. However, advancements in medical science have made cataract surgery a highly... | balamurugan_1857d8cb1038d |
1,895,019 | >1 RDBMS in Spring Data JPA | This document deals with building the backend application that uses Spring Data JPA with multiple... | 0 | 2024-06-20T15:34:35 | https://dev.to/pranjal_sharma_38482a3041/1-rdbms-in-spring-data-jpa-5ge4 | rdbms, springboot, mysql, beginners | This document deals with building the backend application that uses Spring Data JPA with multiple relational databases.
For an example we will connect to **MySQL + MSSQL** database.
### Main task here is to seperate properties and configurations for all the multiple databases that have to integrated.
### Other JPA... | pranjal_sharma_38482a3041 |
1,891,493 | 7 TUI libraries for creating interactive terminal apps | Written by Yashodhan Joshi✏️ When writing applications, a good user interface is just as important... | 0 | 2024-06-20T15:33:42 | https://blog.logrocket.com/7-tui-libraries-interactive-terminal-apps | webdev, tui | **Written by [Yashodhan Joshi](https://blog.logrocket.com/author/yashodhan-joshi/)✏️**
When writing applications, a good user interface is just as important as the actual app’s functionality. A good user interface will make the user continue using the app, whereas a bad, clunky one will drive users away.
This also a... | leemeganj |
1,895,017 | Top 5 Docker Alternatives for Software Developers in 2024 | Imagine you’ve worked hard to create an application with various libraries and dependencies. It runs... | 0 | 2024-06-20T15:31:32 | https://dev.to/lunamiller/top-5-docker-alternatives-for-software-developers-in-2024-b04 | docker, webdev, programming | Imagine you’ve worked hard to create an application with various libraries and dependencies. It runs smoothly and efficiently on your system. But what happens when you need to send the application to someone else’s system? That person would need to go through a lot of setup to get it running. Even after setup, a single... | lunamiller |
1,895,013 | Panes, UI Controls, and Shapes | Panes, UI controls, and shapes are subtypes of Node. When you run MyJavaFX in here, the window is... | 0 | 2024-06-20T15:28:15 | https://dev.to/paulike/panes-ui-controls-and-shapes-hb6 | java, programming, learning, beginners | Panes, UI controls, and shapes are subtypes of **Node**. When you run MyJavaFX in [here](https://dev.to/paulike/the-basic-structure-of-a-javafx-program-1b8d), the window is displayed. The button is always centered in the scene and occupies the entire window no matter how you resize it. You can fix the problem by settin... | paulike |
1,893,567 | How to create and connect to a Linux VM using a Public Key | Creating and connecting to a Linux virtual machine (VM) on Azure using SSH public key authentication... | 0 | 2024-06-20T15:26:37 | https://dev.to/dera2024/how-to-create-and-connect-to-a-linux-vm-using-a-public-key-4847 | azure, linux, techtalks, virtualmachine | [](url)Creating and connecting to a Linux virtual machine (VM) on Azure using SSH public key authentication involves several steps. Here’s a detailed guide to help you through the process:
### Step 1: Sign in to Azure Portal
1. **Sign in**: Go to the [Azure portal](https://portal.azure.com) and sign in with your Azure... | dera2024 |
1,895,011 | 🚀 Explore My New Interactive Portfolio and GitHub Projects! 🌟 | Hi everyone, I'm excited to share the new version of my portfolio with you! I've been working hard... | 0 | 2024-06-20T15:25:38 | https://dev.to/kporus/explore-my-new-interactive-portfolio-and-github-projects-74k | portfolio, vite, javascript | Hi everyone,
I'm excited to share the new version of my portfolio with you! I've been working hard to improve it using Kaboom.js and Tiled software. Here’s what you can find in my new portfolio:
- **Interactive Projects**: Created with Kaboom.js.
- **Detailed Maps**: Maps designed with Tiled software.
- **Skill Showc... | kporus |
1,873,151 | SOLANA VALIDATORS AND FEE ECONOMICS. | The Meaning of Validators and Fee Economics in Cryptocurrency Systems. The two terms... | 0 | 2024-06-20T15:22:59 | https://dev.to/bravolakmedia/solana-validators-and-fee-economics-39el | solanadevelopers, blockchaindevelopers, solanavalidators, superteamdao | ## The Meaning of Validators and Fee Economics in Cryptocurrency Systems.
The two terms validators and fee economics are used in the concept of Proof-of-Stake (PoS) in cryptocurrency systems or blockchain networks. Solana validators are associated with the Proof-of-Stake (PoS) and Proof-of-History (PoH) as a consens... | bravolakmedia |
1,894,901 | How to deploy Laravel Project to Vercel | Helpful tutorial on deploying laravel project to... | 0 | 2024-06-20T15:18:24 | https://dev.to/msnmongare/how-to-deploy-laravel-project-to-vercel-3ode | webdev, beginners, programming, tutorial | [Helpful tutorial on deploying laravel project to Vercel
https://rzamandala.medium.com/how-to-deploy-laravel-project-to-vercel-7b3c2800e974](url)
[
https://calebporzio.com/easy-free-serverless-laravel-with-vercel](url) | msnmongare |
1,894,900 | The different types of Software Testing | In the dynamic world of software development, ensuring the reliability and functionality of... | 0 | 2024-06-20T15:15:39 | https://dev.to/anthonytran_dev/the-different-types-of-software-testing-4c68 | softwaredevelopment, testing, test, automation | In the dynamic world of software development, ensuring the reliability and functionality of applications is paramount. In this article, I would like to share an insightful overview of various testing types that are essential for maintaining high-quality software. These testing methods are particularly vital within Cont... | anthonytran_dev |
1,894,839 | How to start your journey in Polkadot | You might have heard about Polkadot from Twitter, an event, TV, or even a Lyft car with Polkadot's... | 0 | 2024-06-20T15:14:01 | https://dev.to/ayomide_bajo/how-to-start-your-journey-in-polkadot-3j2o | web3, beginners, community, writing | You might have heard about Polkadot from Twitter, an event, TV, or even a Lyft car with Polkadot's banner. Regardless of how you found out, you want to know how to join the community or stay updated.
This article is a soft guide on how you can navigate through Polkadot’s ecosystem. If you don't have much knowledge on ... | ayomide_bajo |
1,894,897 | RECOVER SCAMMED BTC, ETH, BNB, SOL, XRP, USDT, USDC, ADA, AVAX, DOGE, CRY, BTES RECOVER WITH BRUNOE QUICK HACK | I NEED TO GET HELP FROM BRUNOE QUICK HACK FOR SCAMMED ETH RECOVERY Brunoe Quick Hack: Your Knights... | 0 | 2024-06-20T15:11:27 | https://dev.to/laura_lilyshelton_4f9850/recover-scammed-btc-eth-bnb-sol-xrp-usdt-usdc-ada-avax-doge-cry-btes-recover-with-brunoe-quick-hack-5505 | webdev, programming, python, devops | I NEED TO GET HELP FROM BRUNOE QUICK HACK FOR SCAMMED ETH RECOVERY
Brunoe Quick Hack: Your Knights in Shining Armor Against Scammers
Enough is enough! It's time to stand against scammers and reclaim what's rightfully ours. Brunoe Quick Hack is the ultimate ally in this fight for justice. Their skilled hackers can infi... | laura_lilyshelton_4f9850 |
1,894,894 | Microsoft Copilot: in-depth overview | This post is a quick overview of an Abto Software blog article. This year’s Microsoft Copilot debut... | 0 | 2024-06-20T15:09:36 | https://dev.to/abtosoftware/microsoft-copilot-in-depth-overview-1jma | ai, productivity, datascience, microsoft | _This post is a quick overview of an Abto Software [blog article](https://www.abtosoftware.com/blog/what-is-copilot-technology-in-depth-overview)._
This year’s Microsoft Copilot debut opened an exciting new chapter in the information & technology industry.
This groundbreaking AI assistant has generated considerable e... | abtosoftware |
1,894,893 | EXTRACTING DUPLICATES USING SOQL QUERIES | 1: Simple find account duplicates example SELECT Count(id), name,ShippingCity FROM... | 0 | 2024-06-20T15:07:02 | https://dev.to/ahmed_hammami_33f0d95ab89/extracting-duplicates-using-soql-queries-2l7k | salesforce, soql | #### 1: Simple find account duplicates example
```
SELECT Count(id), name,ShippingCity FROM account GROUP BY ShippingCity, name having Count(ID) > 1
```
Explanation: we can effectively detect duplicates in Salesforce. This query groups records based on specific criteria, such as name and city in the case of accoun... | ahmed_hammami_33f0d95ab89 |
1,894,892 | AsyncAPI in 15 Minutes | AsyncAPI is a specification for designing asynchronous APIs, similar to how OpenAPI is used for... | 0 | 2024-06-20T15:06:32 | https://dev.to/raphael-dumhart/asyncapi-in-15-minutes-hel | eventdriven, learning, microservices | AsyncAPI is a specification for designing asynchronous APIs, similar to how OpenAPI is used for synchronous APIs. Thereby it is agnostic to any specific messaging protocoll. Asynchronous communication involves sending and receiving data without expecting an immediate response. This making it suitable for event-driven a... | raphael-dumhart |
1,894,891 | Serverless Event-Driven Architectures with AWS Lambda and Amazon EventBridge | Serverless Event-Driven Architectures with AWS Lambda and Amazon EventBridge Modern... | 0 | 2024-06-20T15:05:56 | https://dev.to/virajlakshitha/serverless-event-driven-architectures-with-aws-lambda-and-amazon-eventbridge-550h | 
# Serverless Event-Driven Architectures with AWS Lambda and Amazon EventBridge
Modern application development increasingly embraces event-driven architectures for their scalability, responsiveness, and efficiency. Serverless comput... | virajlakshitha | |
1,894,877 | Twilio Challenge: Building HR Whatapp bot for your workforce | This is a submission for Twilio Challenge v24.06.12 What I Built This is whatapp HR Bot... | 0 | 2024-06-20T15:04:38 | https://dev.to/bogere/building-hr-whatapp-bot-for-your-workforce-35j1 | devchallenge, twiliochallenge, ai, twilio | ---
title: Twilio Challenge: Building HR Whatapp bot for your workforce
published: true
tags: devchallenge, twiliochallenge, ai, twilio
---
*This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
<!-- Share an overview about your project. -->
This is whatapp HR Bot th... | bogere |
1,894,889 | "Introduction to C#: A Beginner's Guide to Getting Started" | Hello Dev community! 👋 Are you new to programming or looking to expand your skills into backend... | 0 | 2024-06-20T15:03:48 | https://dev.to/emmanuelmichael05/introduction-to-c-a-beginners-guide-to-getting-started-gnb | backenddevelopment, beginners, csharp | Hello Dev community! 👋 Are you new to programming or looking to expand your skills into backend development? In this post, I'll guide you through the basics of C#, a powerful and versatile programming language that's widely used in building applications for Windows, web, and more. Whether you're curious about coding o... | emmanuelmichael05 |
1,894,888 | The Basic Structure of a JavaFX Program | The abstract javafx.application.Application class defines the essential framework for writing JavaFX... | 0 | 2024-06-20T15:03:29 | https://dev.to/paulike/the-basic-structure-of-a-javafx-program-1b8d | java, programming, learning, beginners | The abstract **javafx.application.Application** class defines the essential framework for writing JavaFX programs. We begin by writing a simple JavaFX program that illustrates the basic structure of a JavaFX
program. Every JavaFX program is defined in a class that extends **javafx.application.Application**, as shown in... | paulike |
1,894,887 | Stop Using LocalStorage: Discover the Power of BroadcastChannel | In the world of web development, efficient communication between different parts of an application is... | 0 | 2024-06-20T15:00:59 | https://dev.to/henriqueschroeder/stop-using-localstorage-discover-the-power-of-broadcastchannel-26fe | webdev, javascript, programming |
In the world of web development, efficient communication between different parts of an application is crucial. While localStorage is widely used to share data between tabs, it has its limitations. A powerful and lesser-known alternative is the BroadcastChannel API. In this post, we'll explore what BroadcastChannel is,... | henriqueschroeder |
1,894,571 | Understanding the Difference Between Spread and Rest Operators in JavaScript | JavaScript, a versatile and ever-evolving language, has seen significant improvements with the... | 0 | 2024-06-20T14:59:44 | https://raajaryan.tech/understanding-the-difference-between-spread-and-rest-operators-in-javascript | javascript, beginners, programming, tutorial | [](https://buymeacoffee.com/dk119819)
JavaScript, a versatile and ever-evolving language, has seen significant improvements with the introduction of ES6 (ECMAScript 2015). Among these enha... | raajaryan |
1,894,882 | Hands-On: Escalonamento automático com EKS e Cluster Autoscaler utilizando Terraform e Helm | Introdução O escalonamento automático de clusters é uma funcionalidade essencial em ambientes de... | 0 | 2024-06-20T14:59:05 | https://dev.to/aws-builders/hands-on-escalonamento-automatico-com-eks-e-cluster-autoscaler-utilizando-terraform-e-helm-51ki | devops, aws, kubernetes | **Introdução**
O escalonamento automático de clusters é uma funcionalidade essencial em ambientes de computação em nuvem, especialmente quando se trata de gerenciar recursos de forma eficiente e econômica.
Nesse contexto o Cluster Autoscaler (CA) é uma ferramenta vital para ajustar dinamicamente o número de instânci... | rodrigofrs13 |
1,894,886 | Day1-100 series - Learning System Design for Interviews. | Day2 -> Learning Databases Remember 90% of battle is won, when you select correct... | 0 | 2024-06-20T14:57:41 | https://dev.to/taniskannpurna/day1-100-series-learning-system-design-for-interviews-13f3 | database, sql, nosql, systemdesign | ## **Day2 -> Learning Databases**
- Remember 90% of battle is won, when you select correct database for your system.
There are 2 types of Databases Relational(SQL) and Non-Relational(NoSql). In todays post we will learn about Relational Databases, ACID properties & Scaling them.
**RELATIONAL DBs**
- Relational DBs ... | taniskannpurna |
1,894,885 | Transactional Email vs Marketing Email (+ Examples) | Transactional emails and marketing emails — you have probably heard these terms before. However, the... | 0 | 2024-06-20T14:56:34 | https://sidemail.io/articles/transactional-email-vs-marketing-email/ | webdev, saas, email, beginners | Transactional emails and marketing emails — you have probably heard these terms before. However, the definitions are not always very clear, which might leave you unsure about the differences and why you should take the time to differentiate them. In this article, I’ll simplify these terms as much as possible, help you ... | k_vrbova |
1,894,857 | 먹튀로얄 | 먹투로얄토토사이트: 카지노, 바카라, 슬롯사이트를 아우르는 최고의 토토 커뮤니티 먹투로얄토토사이트 먹투로얄토토사이트는 다양한 카지노 게임과 토토 커뮤니티를 제공하는 인기 있는... | 0 | 2024-06-20T14:12:35 | https://dev.to/alemtroy08/meogtwiroyal-2dg3 | 먹투로얄토토사이트: 카지노, 바카라, 슬롯사이트를 아우르는 최고의 토토 커뮤니티
먹투로얄토토사이트
먹투로얄토토사이트는 다양한 카지노 게임과 토토 커뮤니티를 제공하는 인기 있는 플랫폼입니다. 이 사이트는 사용자들에게 안전하고 신뢰할 수 있는 게임 환경을 제공하여 많은 플레이어들 사이에서 큰 인기를 끌고 있습니다. 특히, 먹투로얄토토사이트는 철저한 보안 시스템과 공정한 게임 운영을 통해 사용자들의 신뢰를 받고 있습니다.
**_[먹튀로얄](https://mtroyale.com/)_**
카지노사이트
먹투로얄토토사이트의 카지노 섹션은 다양한 게임 옵션을 제공하여 사용자들이 원... | alemtroy08 | |
1,894,884 | Deep Dive into Caching: Techniques for High-Performance Web Apps | Normal Developers: Wait Caching I know what's that, just saving information locally. I mean you are... | 0 | 2024-06-20T14:55:27 | https://dev.to/nayanraj-adhikary/deep-dive-into-caching-techniques-for-high-performance-web-apps-56kb | webdev, javascript, programming | Normal Developers: Wait Caching I know what's that, just saving information locally.
I mean you are correct in a way but...
In today's fast-paced digital world, users expect web applications to be fast and responsive. One of the key techniques to achieve high performance in web applications is caching. Caching can dr... | nayanraj-adhikary |
1,895,093 | Workshop Sobre Figma Gratuito: Crie Seu Protótipo Do Zero | Participe do workshop “Figma em 2 dias: do zero à criação do seu protótipo” e aprenda a usar a... | 0 | 2024-06-23T13:50:06 | https://guiadeti.com.br/workshop-figma-gratuito-crise-seu-prototipo/ | semcategoria, cursosgratuitos, design, designgrafico | ---
title: Workshop Sobre Figma Gratuito: Crie Seu Protótipo Do Zero
published: true
date: 2024-06-20 14:54:01 UTC
tags: Semcategoria,cursosgratuitos,design,designgrafico
canonical_url: https://guiadeti.com.br/workshop-figma-gratuito-crise-seu-prototipo/
---
Participe do workshop “Figma em 2 dias: do zero à criação do... | guiadeti |
1,894,883 | Java Message Service | 1. Anatomy of JMS message | 27,794 | 2024-06-20T14:49:31 | https://dev.to/bhardwajsameer7/java-message-service-4hf6 | jms, jakarta, j2ee, jee | **1. Anatomy of JMS message** | bhardwajsameer7 |
1,894,881 | JavaFX Basics | JavaFX is an excellent pedagogical tool for learning object-oriented programming. JavaFX is a new... | 0 | 2024-06-20T14:47:59 | https://dev.to/paulike/javafx-basics-2lck | java, programming, learning, beginners | JavaFX is an excellent pedagogical tool for learning object-oriented programming. JavaFX is a new framework for developing Java GUI programs. The JavaFX API is an excellent example of how the object-oriented principles are applied. We'll present the basics of JavaFX programming. and uses of JavaFX to demonstrate object... | paulike |
1,894,880 | "Embarking on My Backend Development Journey: From C# to Future Challenges" | Hello, Dev community! 👋 I'm Emmanuel Michael, an aspiring backend developer who recently completed a... | 0 | 2024-06-20T14:47:10 | https://dev.to/emmanuelmichael05/embarking-on-my-backend-development-journey-from-c-to-future-challenges-20lg | webdev, beginners, programming, react |
Hello, Dev community! 👋 I'm Emmanuel Michael, an aspiring backend developer who recently completed a comprehensive C# course and is eager to dive deeper into the world of software development. I'm passionate about leveraging technology to solve real-world problems and am excited to embark on this continuous learning ... | emmanuelmichael05 |
1,894,878 | Building a Custom Chatbot with Next.js, Langchain, OpenAI, and Supabase. | A chatbot system that can be trained with custom data from PDF files. ... | 0 | 2024-06-20T14:43:29 | https://dev.to/nassermaronie/building-a-custom-chatbot-with-nextjs-langchain-openai-and-supabase-4idp | llm, langchain, openai, nextjs | ## A chatbot system that can be trained with custom data from PDF files.
{% embed https://www.linkedin.com/embed/feed/update/urn:li:ugcPost:7208975610667311104?source=post_page-----a770e3fa9163-------------------------------- %}
---
In this tutorial, we will create a chatbot system that can be trained with custom da... | nassermaronie |
1,894,021 | amber: writing bash scripts in amber instead. pt. 2: loops and ifs | in this series we're looking at using the amber language to write scripts that transpile into bash.... | 27,793 | 2024-06-20T14:43:22 | https://dev.to/gbhorwood/amber-writing-bash-scripts-in-amber-instead-pt-2-loops-and-ifs-1694 | linux, bash | in this series we're looking at using [the amber language](https://amber-lang.com/) to write scripts that transpile into bash. so far we've covered [using shell commands and handling error cases](https://gbh.fruitbat.io/2024/06/18/amber-writing-bash-scripts-in-amber-instead-pt-1-commands-and-error-handling/). in this i... | gbhorwood |
1,894,876 | What mathematics does the big model involve? | Large models like GPT-4 involve a wide array of mathematical knowledge that supports their structure,... | 0 | 2024-06-20T14:40:14 | https://dev.to/fridaymeng/what-mathematics-does-the-big-model-involve-1co9 | data, math | Large models like GPT-4 involve a wide array of mathematical knowledge that supports their structure, training, and applications. Here's an overview of the key areas:
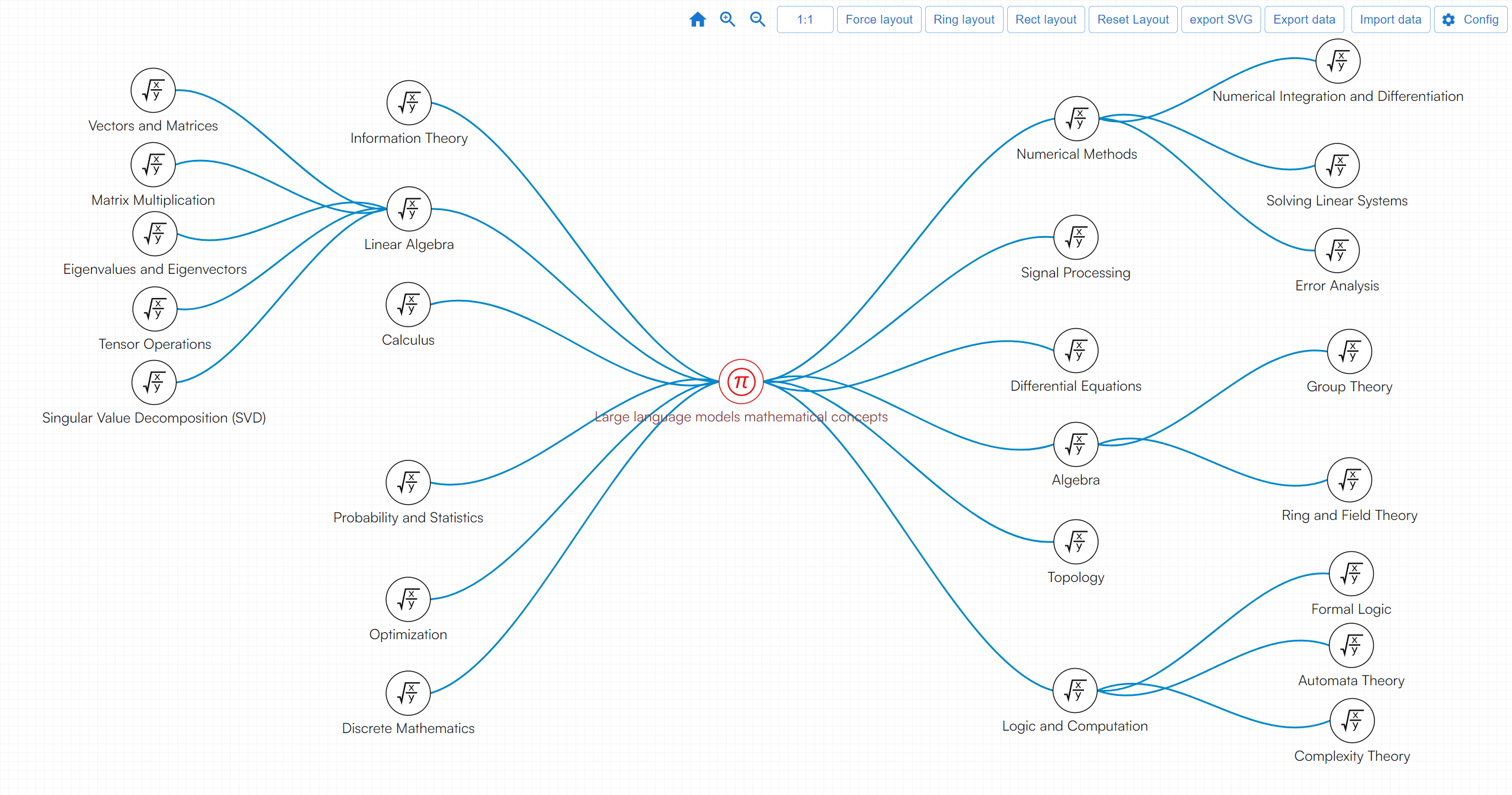
[Demo](https://addgraph.com/biglargemodelmath) | fridaymeng |
1,894,874 | The <map> Tag in HTML | The Tag in HTML The tag in HTML is used to define an image map. An image map is a way of... | 0 | 2024-06-20T14:39:37 | https://dev.to/mhmd-salah/the-tag-in-html-2691 | html, webdev, website | ## The <map> Tag in HTML
The <map> tag in HTML is used to define an image map. An image map is a way of defining multiple clickable areas (regions) within a single image. Each of these clickable areas can be associated with different links or actions.
### How It Works
The <map> tag is used in conjunction with the <are... | mhmd-salah |
1,894,872 | Copado Robotic Testing Certification | The Copado Robotic Testing Certification exam questions cover a range of key concepts related to... | 0 | 2024-06-20T14:36:59 | https://dev.to/copadorobotictesting/copado-robotic-testing-certification-n78 | education, exam, dumps, webdev | The [Copado Robotic Testing Certification](https://exam4future.com/) exam questions cover a range of key concepts related to robotic testing and the Copado Robotic Testing platform:
• Robotic Testing Fundamentals: Principles and concepts of robotic testing, its benefits, challenges, and best practices.
• Copado Robotic... | copadorobotictesting |
1,894,871 | Started learning HTML and CSS :) | Few days ago, I started learning the building blocks of Web development. So I made this landing page... | 0 | 2024-06-20T14:35:48 | https://dev.to/krsna_11/started-learning-html-and-css--343n | webdev, html, css, landingpage | Few days ago, I started learning the building blocks of Web development. So I made this landing page to reinforce what I learned :)
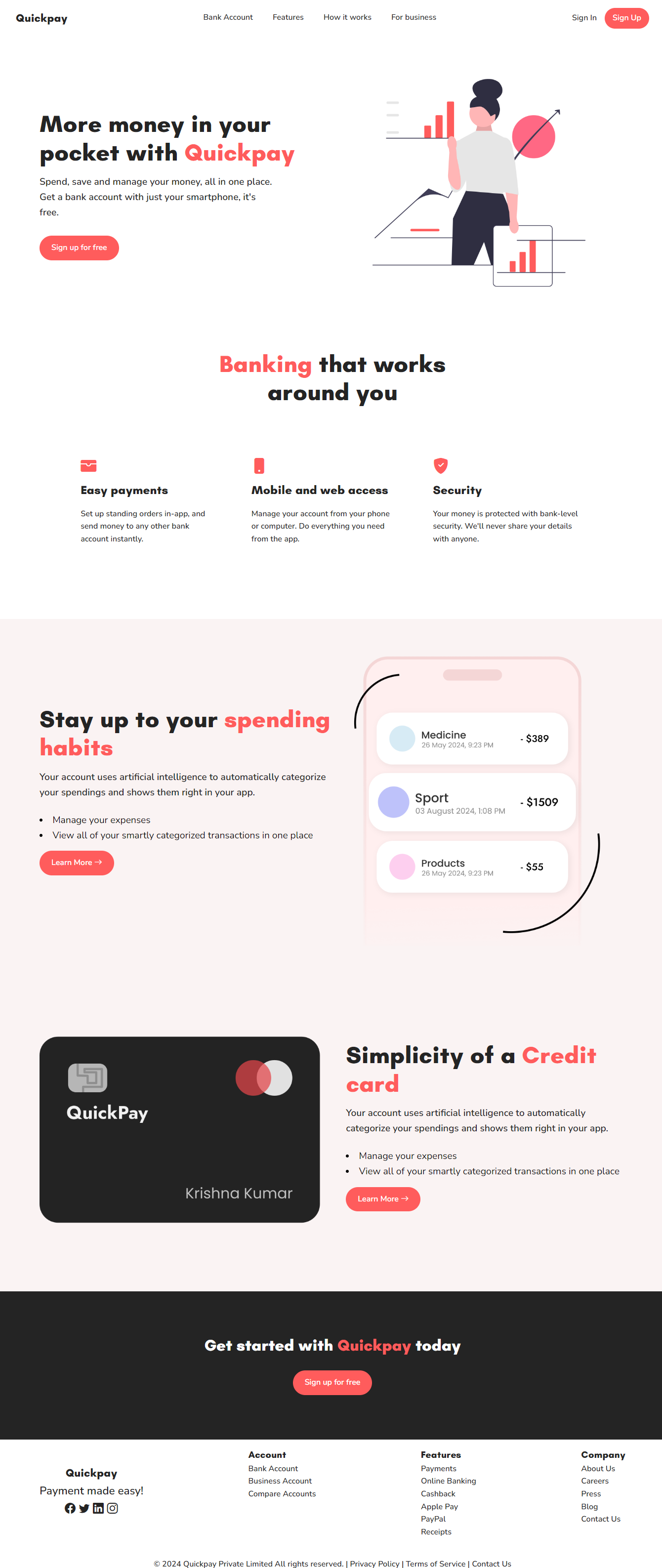
Writing pure CSS is fun for these kind of designs.
| krsna_11 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.