
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,893,608 | Building a simple Full-Stack Restaurant Finder App with React, Redux, Node.js, and Google Places API (Part 1) | Introduction Welcome to the first part of our tutorial series on building a full-stack "Restaurant... | 0 | 2024-06-19T14:47:00 | https://dev.to/vb_nair/building-a-simple-full-stack-restaurant-finder-app-with-react-redux-nodejs-and-google-places-api-1acd | node, googlemaps, googleplaces, backend | **Introduction**
Welcome to the first part of our tutorial series on building a full-stack "Restaurant Finder" application. In this blog post, we will guide you through the process of creating a robust backend using Node.js and Express. The backend will serve as the foundation for our application, allowing us to integr... | vb_nair |
1,893,748 | Building a REST API with Node.js and Express | Creating a REST API is a common task for developers, especially when building web applications. In... | 0 | 2024-06-19T14:46:11 | https://dev.to/andylarkin677/building-a-rest-api-with-nodejs-and-express-4j3p | webdev, node, learning, api | Creating a REST API is a common task for developers, especially when building web applications. In this tutorial, we will walk through the process of building a simple REST API using Node.js and Express. By the end, you'll have a basic understanding of how to set up routes, handle requests and responses, and connect to... | andylarkin677 |
1,893,631 | My journey into cybersecurity | My Journey in Cybersecurity, in chronological order @ 11 At the age of 11, I... | 0 | 2024-06-19T14:39:11 | https://dev.to/clom/my-journey-in-cybersecurity-1b07 | cybersecurity, aboutme, newbie |
## My Journey in Cybersecurity, in chronological order
## @ 11
At the age of 11, I began to grow fascinated by how computers work, and even more intrigued by how hackers hack these intrinsically designed machines. I was introduced to the world of ethical hacking by my close friend then, who he himself was quite wel... | clom |
1,893,747 | To Add a new header in second line of the existing file and 3 rd. column should be sum of the records | In source i am getting below data in csv format Comp CAD Amount 2135 CAD 156.56 2135 CAD ... | 0 | 2024-06-19T14:37:40 | https://dev.to/rahul_mahendru_45d895855b/to-add-a-new-header-in-second-line-of-the-existing-file-and-3-rd-column-should-be-sum-of-the-records-2a7g | help |
In source i am getting below data in csv format
Comp CAD Amount
2135 CAD 156.56
2135 CAD 171.33
2135 CAD 156.56
2135 CAD 156.56
2135 CAD 137.15
I need to add need header in Bottum of the old header
example
orignal header--->Comp CAD Amount
added_new header->Customer second_... | rahul_mahendru_45d895855b |
1,893,746 | سایت معرفی دنس بت | سایت شرط بندی دنس بت یکی از قدیمیترین سایت های شرط بندی در ایران می باشد دقت داشته باشید که سایت شرط... | 0 | 2024-06-19T14:36:50 | https://dev.to/sasanmmmm2222/syt-mrfy-dns-bt-14gl | سایت شرط بندی [دنس بت](dancebet.pro) یکی از قدیمیترین سایت های شرط بندی در ایران می باشد دقت داشته باشید که سایت شرط بندی دنس بت انواع بازی ها را در زمینه های مختلف به کاربران خود ارائه میکند لازم به ذکر است که این سایت توسط نازنین همدانی مدیریت میشود و از این جهت میتوانید به این سایت برای واریزی ها و برداشت های خود به... | sasanmmmm2222 | |
1,893,745 | Integrating Stripe Payment Elements in Nuxt 3 | This guide will show you how to integrate Stripe's Payment Element into a Nuxt 3 application to... | 0 | 2024-06-19T14:36:31 | https://dev.to/jmkweb/integrating-stripe-payment-elements-in-nuxt-3-5d2j | stripe, nuxt, vue, javascript | This guide will show you how to integrate Stripe's Payment Element into a Nuxt 3 application to process payments for purchasing a cat. We'll cover setting up Stripe on both the client and server sides, and handling the payment process.
## Prerequisites
- A Nuxt 3 application set up.
- Stripe account with API keys (ST... | jmkweb |
1,893,315 | Scaling to 125 Million Transactions per Day: Juspay's Engineering Principles | At Juspay, we process 125 million transactions per day, with peak traffic reaching 5,000 transactions... | 0 | 2024-06-19T14:32:56 | https://dev.to/hyperswitchio/scaling-to-125-million-transactions-per-day-juspays-engineering-principles-2bj1 | digitalpayments, rust, opensource, haskell | At Juspay, we process 125 million transactions per day, with peak traffic reaching 5,000 transactions per second, all while maintaining 99.99% uptime. Handling such enormous volumes demands a robust, reliable, and scalable system. In this post, we'll walk you through our core engineering principles and how they've shap... | gorakh13 |
1,893,744 | The Future of Business Communication: Beyond Emails and Phone Calls | For decades, emails and phone calls were the cornerstones of business communication. While they still... | 0 | 2024-06-19T14:32:55 | https://dev.to/gianna4/the-future-of-business-communication-beyond-emails-and-phone-calls-34d | businesscommunication | For decades, emails and phone calls were the cornerstones of business communication. While they still hold value, the rise of a remote workforce, the need for real-time collaboration, and ever-increasing customer expectations push businesses to explore new avenues. The future of business communication is about streamli... | gianna4 |
1,893,743 | 33 front-end development tools developers use in 2024 | Today more than ever, we have choices. Some applications help heal the plants, we meet future... | 0 | 2024-06-19T14:29:42 | https://dev.to/momciloo/33-front-end-development-tools-developers-use-in-2024-2o3f | Today more than ever, we have choices. Some applications help heal the plants, we meet future partners through dating apps, we have AI that "does the work for us" and so on. Front-end development tools are no exception to this extensive range of options. The landscape is richer and more sophisticated than ever. Develop... | momciloo | |
1,893,742 | Regression Testing: Ensuring Stability and Reliability in Software Development | In the fast-paced world of software development, maintaining the stability and reliability of... | 0 | 2024-06-19T14:29:30 | https://dev.to/keploy/regression-testing-ensuring-stability-and-reliability-in-software-development-27c2 | testing, webdev, productivity, ai |

In the fast-paced world of software development, maintaining the stability and reliability of applications through continuous changes is paramount. [Regression testing](https://keploy.io/regression-testing) is a cri... | keploy |
1,891,154 | JavaScript: O que é Symbol? | Eae gente bonita, beleza? Continuo a jornada de "aprofundamento" em JavaScript e quanto mais eu... | 0 | 2024-06-19T14:28:32 | https://dev.to/cristuker/javascript-o-que-e-symbol-38l0 | javascript, braziliandevs, beginners, node | Eae gente bonita, beleza? Continuo a jornada de "aprofundamento" em JavaScript e quanto mais eu aprendo mais eu quero escrever e compartilhar com vocês. Dessa vez vou falar um pouco sobre o ``Symbol`` que para mim o motivo da sua existência sempre foi um mistério.
.
Enroll Today
Take the first step towards a successful career in software development with IT Training Indore. Visit our [web develop... | ittrainingindore01 |
1,893,623 | Create a Circular progress bar using HTML, CSS and JS. | I am going to give you a easy way to create a circular progress bar using html, css and... | 0 | 2024-06-19T14:09:38 | https://dev.to/sunder_mehra_246c4308e1dd/create-a-circular-progress-bar-using-html-css-and-js-2p0k | javascript, html, css, animation | I am going to give you a easy way to create a circular progress bar using html, css and javascript.
**HTML:**
Create two div, with .outer and .inner class name.
```html
<div class="outer">
<div class="inner">0%</di... | sunder_mehra_246c4308e1dd |
1,893,737 | Weekend Recap: Solana’s Loyalty Platform, Buterin Backs TiTok AI, XLink Partners Fireblocks and Ancilia | Elon Musk’s social network X is not doing “enough” to prevent the spread of cryptocurrency fraud on... | 0 | 2024-06-19T14:22:09 | https://36crypto.com/weekend-recap-solanas-loyalty-platform-buterin-backs-titok-ai-xlink-partners-fireblocks-and-ancilia/ | cryptocurrency, news | Elon Musk’s social network X is not doing “enough” to prevent the spread of cryptocurrency fraud on the platform. Such an opinion was shared by Binance co-founder Yi He, who recently [asked](https://x.com/heyibinance/status/1801732167917256859) how the billionaire owner is going to deal with this problem. However, this... | deniz_tutku |
1,893,564 | Learn CSS with these Games | CSS can be frustrating to learn, but what is better than learning by playing fun and enjoyable games?... | 0 | 2024-06-19T14:16:33 | https://dev.to/douiri/learn-css-with-these-games-5e4m | webdev, css, beginners, learning | CSS can be frustrating to learn, but what is better than learning by playing fun and enjoyable games? That's why I want to share games that helped me in my CSS journey and others that you might find useful.
## [CSS Diner](https://flukeout.github.io/)
CSS Diner will help you master every CSS selector by selecting vario... | douiri |
1,893,627 | Sticky Sessions: Benefits and Drawbacks | Sticky sessions are a common technique used to manage user sessions across multiple server nodes.... | 0 | 2024-06-19T14:12:38 | https://dev.to/rahulvijayvergiya/sticky-sessions-benefits-and-drawbacks-68n | webdev, devops, beginners, programming | Sticky sessions are a common technique used to manage user sessions across multiple server nodes. However, while they can offer some benefits, sticky sessions also come with significant drawbacks that can affect scalability, reliability, and overall performance of web applications.
## What are Sticky Sessions?
Sticky... | rahulvijayvergiya |
1,893,626 | I _____ hate arrays in C++! | Author: Anton Tretyakov Or why I think developers need to know about them but should not use... | 0 | 2024-06-19T14:12:12 | https://dev.to/anogneva/i-hate-arrays-in-c-25jg | cpp, programming, coding | Author: Anton Tretyakov
Or why I think developers need to know about them but should not use them\.

## Introduction
Do you remember the first time you put a pointer to the first array element to the *sizeof* operator, and your code stopped wor... | anogneva |
1,893,576 | 5 Reasons Why Your Side Projects Fail to Make Money And How to Avoid Them | Introduction Hello there! If you're like many aspiring entrepreneurs (including me),... | 0 | 2024-06-19T14:10:12 | https://dev.to/wasp/5-reasons-why-your-side-projects-fail-to-make-money-and-how-to-avoid-them-4l5m | beginners, webdev, career, learning | ## Introduction
<img width="100%" style="width:100%" src="https://media3.giphy.com/media/v1.Y2lkPTc5MGI3NjExcjA0MGM0NjN0YjR3aGRicHM3YzUyc254ZmxxNjkxdzlnZWZ0NHRjbCZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/ljtfkyTD3PIUZaKWRi/giphy.webp">
Hello there! If you're like many aspiring entrepreneurs (including me), you've proba... | llxd |
1,893,621 | Exploring the Advantages of PTFE Conveyor Belts | Discovering the benefits of PTFE Conveyor Belts Marketing information is produced to introduce some... | 0 | 2024-06-19T14:06:50 | https://dev.to/janet_gonzalesb_ebdce9031/exploring-the-advantages-of-ptfe-conveyor-belts-3lk3 | design |
Discovering the benefits of PTFE Conveyor Belts
Marketing information is produced to introduce some very nice great things about something test certain company. we will explore the countless stove protector items that are superb PTFE utilizing conveyor. It are quick for polytetrafluoroethylene, a type or kind as t... | janet_gonzalesb_ebdce9031 |
1,893,620 | LeetCode Day 12 | 144. Binary Tree Preorder Traversal Use iteration instead of recursion ... | 0 | 2024-06-19T14:06:28 | https://dev.to/flame_chan_llll/leetcode-day-12-221a | leetcode, java, datastructures | # 144. Binary Tree Preorder Traversal
## Use iteration instead of recursion
```
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
//mid -> left -> right
Deque<TreeNode> stack = new LinkedList<>();
stack.push(root);
while(!stac... | flame_chan_llll |
1,893,823 | Google Cloud Skills Boost: Cursos De Inteligência Artificial Gratuitos | A plataforma Google Cloud Skills Boost lançou cursos gratuitos destinados a todos que desejam... | 0 | 2024-06-23T13:50:16 | https://guiadeti.com.br/google-cloud-skills-boost-cursos-ia-gratuitos/ | cursogratuito, automacao, cursosgratuitos, inteligenciaartifici | ---
title: Google Cloud Skills Boost: Cursos De Inteligência Artificial Gratuitos
published: true
date: 2024-06-19 14:01:21 UTC
tags: CursoGratuito,automacao,cursosgratuitos,inteligenciaartifici
canonical_url: https://guiadeti.com.br/google-cloud-skills-boost-cursos-ia-gratuitos/
---
A plataforma Google Cloud Skills B... | guiadeti |
1,893,605 | Angular Material Tabs with components inside the tabs | My use case was to render components inside the Angular Material Tabs component. Despite searching... | 0 | 2024-06-19T14:01:07 | https://dev.to/ferdiesletering/angular-material-tabs-with-components-inside-the-tabs-56ki | My use case was to render components inside the Angular Material Tabs component. Despite searching online, I couldn't find any relevant resources, so I had to figure it out myself.
Below is the structure we want to use to define the components that should be displayed inside the tabs:
```
tabs = <Tab[]>[
{
... | ferdiesletering | |
1,885,551 | How to Use Tailwind CSS for Your Ruby On Rails Project | It's hard to overstate the importance of Cascading Style Sheets (CSS) for all websites. Since the... | 0 | 2024-06-19T14:00:00 | https://blog.appsignal.com/2024/06/05/how-to-use-tailwind-css-for-your-ruby-on-rails-project.html | ruby, rails | It's hard to overstate the importance of Cascading Style Sheets (CSS) for all websites. Since the first CSS standards were published in late 1996, we have come quite far regarding features and ecosystems.
Several frameworks have appeared and proved popular, one of the most recent being Tailwind CSS.
In this post, we'... | riboulet |
1,893,617 | Are we really using Google because it is better? | Hey guys. I started to find Google searches a bit biased, not finding old news that I know I've... | 0 | 2024-06-19T13:56:24 | https://dev.to/miplle_player1/are-we-really-using-google-because-it-is-better-4eel | Hey guys.
I started to find Google searches a bit biased, not finding old news that I know I've already seen. Sometimes news that is trending in some countries related to my country does not appear, but when I go through other search engines it appears.
I think Google has an incredible ecosystem that integrates betwe... | miplle_player1 | |
1,893,616 | The Evolution of RJ45 Connectors: Driving Connectivity Standards Forward | Have You Heard of the RJ45 Connectors? The RJ45 connector is a small but tool mighty has... | 0 | 2024-06-19T13:56:22 | https://dev.to/janet_gonzalesb_ebdce9031/the-evolution-of-rj45-connectors-driving-connectivity-standards-forward-491 | design | Have You Heard of the RJ45 Connectors?
The RJ45 connector is a small but tool mighty has revolutionized how we connect our devices to the internet. It is a connector that helps to transmit data between devices such as computers, televisions, phones, and modems. We’ll dig deep into how the RJ45 connector has actually e... | janet_gonzalesb_ebdce9031 |
1,893,615 | Some of the Best Animation Libraries in React | 1.React Spring Website Link -> https://react-spring.dev It gives you tools flexible... | 0 | 2024-06-19T13:54:27 | https://dev.to/shyam1806/some-of-the-best-animation-libraries-in-react-1jh1 | react, frontend, webdev, development | ## 1.React Spring
Website Link -> https://react-spring.dev
It gives you tools flexible enough to confidently cast your ideas into moving interfaces.
## 2.AOS
Website Link -> https://michalsnik.github.io/aos
Simple Library to animate UI components using scroll events.
## 3.Framer Motion
Website Link ->https://www.fr... | shyam1806 |
1,893,614 | Some of the Best Animation Libraries in React | 1.React Spring Website Link -> https://react-spring.dev It gives you tools flexible... | 0 | 2024-06-19T13:54:25 | https://dev.to/shyam1806/some-of-the-best-animation-libraries-in-react-59pf | react, frontend, webdev, development | ## 1.React Spring
Website Link -> https://react-spring.dev
It gives you tools flexible enough to confidently cast your ideas into moving interfaces.
## 2.AOS
Website Link -> https://michalsnik.github.io/aos
Simple Library to animate UI components using scroll events.
## 3.Framer Motion
Website Link ->https://www.fr... | shyam1806 |
340,932 | Graduating in 2020! | Hey everyone! This is my first dev post! I've wanted to post for a long time now, but couldn't think... | 0 | 2020-05-21T14:29:10 | https://dev.to/sakshamio/graduating-in-2020-2ddp | octograd2020, epidemic, models, datascience | Hey everyone! This is my first dev post! I've wanted to post for a long time now, but couldn't think of a topic until now! This is a project I started building in my final year at VIT University but had to abandon in between as I received an internship offer from Stylumia Intelligence, and the work looked too cool to p... | sakshamio |
1,893,613 | How to Deploy your FastAPI Backend with PostgreSQL Database to Render | Introduction FastAPI is a popular Python backend web development framework. Many Python... | 0 | 2024-06-19T13:54:16 | https://dev.to/odhiambo/how-to-deploy-your-fastapi-backend-with-postgresql-database-to-render-4ca2 | fastapi, python, render, hosting | ## Introduction
[FastAPI](https://fastapi.tiangolo.com/) is a popular Python backend web development framework. Many Python developers use FastAPI to built Application Programming Interfaces (APIs) and connect other backend infrastructure such as databases. FastAPI is suitable for API design for several reasons:
* APIs... | odhiambo |
1,893,612 | Torrenting 101 | 1. Get a VPN Currently, I use Mullvad, and I won't be swapping as it suits my needs and I... | 0 | 2024-06-19T13:51:56 | https://dev.to/piracy/torrenting-101-21df | ### 1. Get a VPN
Currently, I use [Mullvad](https://mullvad.net/en/vpn), and I won't be swapping as it suits my needs and I have no complaints. I've also used [IVPN](https://www.ivpn.net/) and [Proton](https://protonvpn.com/) *(before the reskin and bad pricing).* These are both fine options, but I prefer Mullvad as i... | piracy | |
1,893,611 | RAG Techniques: Multi Query | In my last project, I used RAG (Retrieval Augmented Generation) for retrieving the relevant context... | 0 | 2024-06-19T13:49:43 | https://dev.to/shawonmajid/rag-techniques-multi-query-2p5h | rag, langchain, llm, ai | In my last project, I used RAG (Retrieval Augmented Generation) for retrieving the relevant context for the user question. But the problem I faced is that, from the user query, the retrieval is not always very accurate.
For example, In my [budget AI](https://www.linkedin.com/posts/shawon-majid_langchain-openai-ai-act... | shawonmajid |
1,892,280 | How to Create and Connect to a Linux VM using a Public Key | Table of Contents Introduction Step 1. Login to Azure Portal Step 2. Select/click Virtual... | 0 | 2024-06-19T13:44:50 | https://dev.to/yuddy/how-to-create-and-connect-to-a-linux-vm-using-a-public-key-5fl0 | **Table of Contents**
Introduction
Step 1. Login to Azure Portal
Step 2. Select/click Virtual Machine
Step 3. Create Azure Virtual Machine
Step 4. Basic Tab: Create new Resource Group
Step 5. Basic Tab: Fill all the Virtual Machine Instance Details
Step 6. Disk Tab: Fill all the Disk fields
Step 7. Validation Passed t... | yuddy | |
1,893,607 | Exploring Eco-Friendly Waterproofing Solutions | Have actually you ever before been actually captured in the rainfall or even unintentionally splashed... | 0 | 2024-06-19T13:42:09 | https://dev.to/rebecca_greenh_5fdea1862c/exploring-eco-friendly-waterproofing-solutions-1dn3 | design |
Have actually you ever before been actually captured in the rainfall or even unintentionally splashed sprinkle on your possessions It could be aggravating when sprinkle problems your products. Fortunately, certainly there certainly are actually waterproofing that is environmentally friendly that can easily safeguard... | rebecca_greenh_5fdea1862c |
340,331 | DevOps: the next level | Ten years and more passed since Patrick Debois coined the term DevOps, in 2009. In the IT world, noth... | 0 | 2020-05-20T19:34:11 | https://dev.to/zeppaman/devops-the-next-level-969 | devops, NoOps, Cloud | Ten years and more passed since Patrick Debois coined the term **DevOps**, in 2009. In the IT world, nothing is definitive. All the technologies and techniques continue to evolve following an innovation trend that we cannot stop.
We cannot merely say: _“I’m tired of changing; please give me a rest.”_ The only option is... | zeppaman |
1,893,606 | Business AI: Revolutionizing Operations and Innovation | Introduction The integration of Artificial Intelligence (AI) in business processes... | 27,673 | 2024-06-19T13:39:14 | https://dev.to/rapidinnovation/business-ai-revolutionizing-operations-and-innovation-5gio | ## Introduction
The integration of Artificial Intelligence (AI) in business processes has
revolutionized the way companies operate, innovate, and compete in the global
market. AI technologies, ranging from machine learning models to advanced
predictive analytics, are being leveraged to enhance decision-making, automat... | rapidinnovation | |
1,893,588 | OpenTelemetry Trace Context Propagation for gRPC Streams | gRPC is a modern, open-source remote procedure call (RPC) framework developed by Google and broadly... | 0 | 2024-06-19T13:35:06 | https://tracetest.io/blog/opentelemetry-trace-context-propagation-for-grpc-streams | opentelemetry, grpc, go, observability | gRPC is a modern, open-source remote procedure call (RPC) framework developed by Google and broadly adopted today through many enterprise systems. Built on the HTTP/2 protocol, it is commonly used in microservices architecture because of its performance and support for communication between services written in differen... | danielbdias |
1,893,604 | Securing Service Catalog with RBAC and OPA Gatekeeper | In modern cloud-native environments, managing access to resources and ensuring compliance with... | 0 | 2024-06-19T13:33:36 | https://dev.to/platform_engineers/securing-service-catalog-with-rbac-and-opa-gatekeeper-2b20 | In modern cloud-native environments, managing access to resources and ensuring compliance with organizational policies is crucial. This blog post will delve into the technical details of securing a service catalog using Role-Based Access Control (RBAC) and Open Policy Agent (OPA) Gatekeeper.
### Service Catalog Overvi... | shahangita | |
1,893,603 | Are mobile mechanics certified and trustworthy? | Reputable mobile mechanics are often certified and have experience similar to those working in... | 0 | 2024-06-19T13:32:17 | https://dev.to/deransmith/are-mobile-mechanics-certified-and-trustworthy-pla | webdev, javascript, programming, react | Reputable mobile mechanics are often certified and have experience similar to those working in traditional repair shops. It’s important to check reviews, ask for certifications, and ensure the mechanic is insured before scheduling a service.
If a [mobile mechanic near me](http://www.asapmobiletulsa.com/) determines t... | deransmith |
1,891,467 | How to Write an Effective README File - A Guide for Software Engineers | As software engineers, our goal is to create code that remains relevant and maintainable over the... | 27,822 | 2024-06-19T13:31:14 | https://dev.to/kfir-g/enhancing-software-architecture-through-comprehensive-testing-in-backend-development-4bn2 | readme, writing, softwareengineering, coding | As software engineers, our goal is to create code that remains relevant and maintainable over the years. A key element in achieving this is crafting a comprehensive and clear README file. A README file is vital for effectively documenting and summarizing your work. This blog post shares my perspective on the importance... | kfir-g |
1,893,601 | How AI Coding Tools Might Set You Up for Failure | Why do I think AI code generation tools are bad? – An unpopular opinion In this episode, we'll... | 0 | 2024-06-19T13:30:27 | https://dev.to/iwooky/how-ai-coding-tools-might-set-you-up-for-failure-1pdf | ai, programming, productivity, career | **Why do I think AI code generation tools are bad?** _– An unpopular opinion_
In this episode, we'll discuss how AI coding tools can drive your business forward, but also how they might slow you down if not used properly. Whether you're an engineer or a business owner, this episode will provide valuable insights on AI... | iwooky |
1,892,990 | Parse, Don’t Validate: Embracing Data Integrity in Elixir | Introduction In the world of functional programming, ensuring data integrity is paramount.... | 0 | 2024-06-19T13:30:00 | https://dev.to/zoedsoupe/parse-dont-validate-embracing-data-integrity-in-elixir-5c94 | elixir, webdev, architecture | ## Introduction
In the world of functional programming, ensuring data integrity is paramount. One effective way to achieve this is by adopting the principle of **"Parse, Don’t Validate"**. This approach emphasizes the transformation of raw input data into structured, well-defined data early in the application flow, th... | zoedsoupe |
1,893,600 | Transform Your Look at the Premier Salon in Prahlad Nagar, Ahmedabad | In the bustling area of Prahlad Nagar, Ahmedabad, finding a salon that offers exceptional hair and... | 0 | 2024-06-19T13:29:56 | https://dev.to/abitamim_patel_7a906eb289/transform-your-look-at-the-premier-salon-in-prahlad-nagar-ahmedabad-4mn5 | In the bustling area of Prahlad Nagar, Ahmedabad, finding a salon that offers exceptional hair and beauty services can elevate your style and confidence. Our **[top-rated salon in Prahlad Nagar](https://trakky.in/ahmedabad/nearby/?area=Prahladnagar)** is dedicated to providing luxurious and professional care, ensuring ... | abitamim_patel_7a906eb289 | |
1,893,599 | Friction Liner/Gasket Manufacturers: Meeting the Demands of Heavy-Duty Applications | screenshot-1718052226886.png Friction Liner/Gasket Manufacturers: Meeting the Demands of Heavy-Duty... | 0 | 2024-06-19T13:26:53 | https://dev.to/rebecca_greenh_5fdea1862c/friction-linergasket-manufacturers-meeting-the-demands-of-heavy-duty-applications-513p | design | screenshot-1718052226886.png
Friction Liner/Gasket Manufacturers: Meeting the Demands of Heavy-Duty Applications
Friction liner/gasket manufacturers play a critical role in ensuring the safety and durability of heavy-duty machinery and vehicles. They create components that reduce friction, prevent leaks, and offer ... | rebecca_greenh_5fdea1862c |
1,893,598 | 3 Part Journey to Understanding the Key Benefits of Continuous Profiling 🔥 | Your ultimate guide to understanding continuous profiling and how it combines profiling and... | 0 | 2024-06-19T13:26:30 | https://dev.to/platformsh/3-part-journey-to-understanding-the-key-benefits-of-continuous-profiling-2inn | webdev, tooling, productivity, devops | ## Your ultimate guide to understanding continuous profiling and how it combines profiling and monitoring with minimal overhead 😎✨
Discover our latest three part series where we take you behind the scenes to explore the different ways of collecting observability data and converting it into actionable information.
*... | celestevanderwatt |
1,893,596 | How I published my first app to Apple Store #1 | Background Hey ho! My name is Uladz and I’m writing my first iOS application. Last week,... | 0 | 2024-06-19T13:26:01 | https://dev.to/uladzmi/how-i-published-my-first-app-to-apple-store-1-491a | mobile, development, ios, learning | ### Background
Hey ho! My name is Uladz and I’m writing my first iOS application. Last week, my laptop got drenched by water from a baby bottle and refused to turn on. So, for the next couple of weeks, since I can’t code, I’ll be writing posts instead…
For the past few years, I’ve been constantly thinking about start... | uladzmi |
1,893,594 | Essential Skills Every Aspiring Graphic Designer should Know | As the world becomes more digitally focused, graphic design has become an increasingly popular field.... | 0 | 2024-06-19T13:25:01 | https://dev.to/red_applelearningpvtl/essential-skills-every-aspiring-graphic-designer-should-know-344f | design, graphic | As the world becomes more digitally focused, graphic design has become an increasingly popular field. After seeing huge career growth, job security, and a high paycheck; young creative minds are flocking into the sector. Due to the huge demand for learning the skills of a graphic designer; there is a growing number of ... | red_applelearningpvtl |
1,893,593 | Tired of waiting for AI model downloads? 😠 Introducing AI Torrent! 🚀 | Ever felt stuck in the torrent chicken-and-egg problem? You need seeders to download, but they need... | 0 | 2024-06-19T13:24:10 | https://dev.to/zerroug/tired-of-waiting-for-ai-model-downloads-introducing-ai-torrent-391i | ai, tutorial, machinelearning, beginners | Ever felt stuck in the torrent chicken-and-egg problem? You need seeders to download, but they need to download first! 😩
**AI Torrent** solves this! 🎉 Download AI models **instantly** with **blazing-fast speeds** thanks to our server-side seeding. 💪 No more waiting, just pure AI goodness delivered straight to you... | zerroug |
1,893,592 | سایت معتبر موسیقی جهت پخش موزیک | نرم افزار ام اس بی موزیک با نرم افزار ام اس بی موزیک، دنیای بی انتهای موزیک در دستان شماست. این... | 0 | 2024-06-19T13:23:32 | https://dev.to/msbmusic/syt-mtbr-mwsyqy-jht-pkhsh-mwzykh-13cj | music, iran | **نرم افزار ام اس بی موزیک**
با نرم افزار ام اس بی موزیک، دنیای بی انتهای موزیک در دستان شماست. این اپلیکیشن پرقدرت به شما امکان میدهد تا به جدیدترین آهنگها و موزیک ویدیوها دسترسی پیدا کنید. با پلی لیستهای پخش متنوع، هر لحظه از موسیقی لذت ببرید.
**ویژگیها:**
1. **دریافت جدیدترین آهنگها و موزیک ویدیوها:**
از... | msbmusic |
1,893,591 | 5 Ways How Generative AI (Gen AI) Helps Software Development Companies | The software development landscape is a fast-paced battlefield. Developers are constantly battling... | 0 | 2024-06-19T13:23:30 | https://dev.to/gloriajoycee/5-ways-how-generative-ai-gen-ai-helps-software-development-companies-4ici | programming, softwaredevelopment, ai, softwareengineering | The software development landscape is a fast-paced battlefield. Developers are constantly battling tight deadlines, evolving technologies, and the ever-growing demand for innovative solutions. But fear not, weary warriors! A powerful new ally has emerged: Generative Artificial Intelligence (Gen AI).
This revolutionary ... | gloriajoycee |
1,893,590 | [React]Vite Github pages | Create Vite react typescript(or javascript) Vite React TypeScript(또는 javascript) 만들기 $ npm create... | 0 | 2024-06-19T13:22:40 | https://dev.to/sidcodeme/reactvite-github-pages-10nm | react, vite, github, pages | Create Vite react typescript(or javascript)
Vite React TypeScript(또는 javascript) 만들기
```shell
$ npm create vite@latest
```
write your choice name and framework and variant.
원하시는 프로젝트명 이랑 플레임웍 선택 그리고 형식 을 작성하세요.
*(not important project_name, 프로젝트명 중요하지않음)
```console
> npx
> create-vite
✔ Project name: … [your_github_id... | sidcodeme |
1,893,589 | PaperTalk.xyz: HackerNews for research papers | I made PaperTalk.xyz out of my own selfish desire to have a place where people can find and discuss... | 0 | 2024-06-19T13:22:25 | https://dev.to/stefan_lenoach_362296822/papertalkxyz-hackernews-for-research-papers-3578 | buildinpublic, discuss | I made [PaperTalk.xyz](https://www.papertalk.xyz/research/home) out of my own selfish desire to have a place where people can find and discuss state of the art research across all domains. Would love to hear any critical feedback anyone here has.
Thanks! | stefan_lenoach_362296822 |
1,893,804 | Chart of the Week: Creating the .NET MAUI Scatter Chart to Visualize Different Sports Ball Sizes and Weights | TL;DR: Let’s use the Syncfusion .NET MAUI Scatter Chart to visualize the sizes and weights of various... | 0 | 2024-06-19T16:23:47 | https://www.syncfusion.com/blogs/post/dotnet-maui-scatter-chart-sports-ball | dotnetmaui, chart, maui, mobile | ---
title: Chart of the Week: Creating the .NET MAUI Scatter Chart to Visualize Different Sports Ball Sizes and Weights
published: true
date: 2024-06-19 13:18:24 UTC
tags: dotnetmaui, chart, maui, mobile
canonical_url: https://www.syncfusion.com/blogs/post/dotnet-maui-scatter-chart-sports-ball
cover_image: https://dev-... | gayathrigithub7 |
1,893,584 | 10 Essential Books to Accelerate your Cloud Career | TL;DR 🤓 DevOps and cloud engineers need not have a floor-to-ceiling bookshelf full of... | 0 | 2024-06-19T13:17:44 | https://dev.to/glasskube/10-essential-books-to-accelerate-your-cloud-career-6jf | beginners, productivity, devops, career | ## TL;DR 🤓
**DevOps** and **cloud engineers** need not have a floor-to-ceiling bookshelf full of books to enhance their skills. **A few key books are all you need (at least at the beginning)**. Below I highlight key titles for both junior and senior DevOps and cloud engineers, focusing on improving productivity, under... | jakepage91 |
1,893,577 | Polypane 20: Browser features and performance | Polypane 20 improves the features and performance of the Elements and Outline panel, as well as... | 0 | 2024-06-19T13:16:32 | https://polypane.app/blog/polypane-20-browser-features-and-performance/ | webdev, productivity, css, news | Polypane 20 improves the features and performance of the Elements and Outline panel, as well as improving general browser features and stability. It's also running the latest version of Chromium, 126.
> **What's [Polypane](https://polypane.app)?** Polypane is the web browser for ambitious web developers. It's a stand-... | kilianvalkhof |
1,893,583 | Microsoft Power Platform Services | Webtual GLOBAL helps businesses use the Microsoft Power Platform to make their operations more... | 0 | 2024-06-19T13:17:36 | https://dev.to/webtualglobal/microsoft-power-platform-services-34h8 | Webtual GLOBAL helps businesses use the Microsoft Power Platform to make their operations more efficient with less complex coding. Learn more at www.webtualglobal.com or contact us at contactus@webtualglobal.com. Let's improve your business together.
| webtualglobal | |
1,893,582 | Throw | Throw - Throught this key we can create the error ourselves like this. | 0 | 2024-06-19T13:17:31 | https://dev.to/husniddin6939/throw-2ggc | 1. Throw - Throught this key we can create the error ourselves like this.
| husniddin6939 | |
1,893,581 | spicami | Помимо практических характеристик, при выборе медицинской мебели нельзя забывать и об эстетике. Даже... | 0 | 2024-06-19T13:17:04 | https://dev.to/spicami/spicami-1f84 | Помимо практических характеристик, при выборе медицинской мебели нельзя забывать и об эстетике. Даже в медицинских учреждениях важно создавать приятную, расслабляющую атмосферу. Поэтому подбирайте мебель, которая сочетает в себе функциональность, комфорт и стильный внешний вид. При этом особое внимание следует уделять ... | spicami | |
1,893,578 | SharePoint migration services | Webtual GLOBAL offers comprehensive IT solutions specializing in Microsoft 365 Power Platforms,... | 0 | 2024-06-19T13:16:32 | https://dev.to/webtualglobal/sharepoint-migration-services-1cgj | Webtual GLOBAL offers comprehensive IT solutions specializing in Microsoft 365 Power Platforms, SharePoint support, and SharePoint migration services. With a commitment to excellence, we cater to diverse business needs, ensuring seamless transitions and robust support. Visit our website at www.webtualglobal.com or cont... | webtualglobal | |
1,877,917 | EHallPass | Streamlining School Operations with Digital Hall Pass Systems In today's digital age, technology is... | 0 | 2024-06-05T10:58:29 | https://dev.to/nadre_marry_3d4233392361a/ehallpass-4g87 | ehallpass, login | Streamlining School Operations with Digital Hall Pass Systems
In today's digital age, technology is revolutionizing every aspect of our lives – including education. Gone are the days of paper hall passes and manual tracking systems; instead, schools are turning to digital hall pass systems like eHallPass to streamline... | nadre_marry_3d4233392361a |
1,893,575 | The Ultimate Guide to QA Testing Certification: Everything You Need to Know | In today's dynamic technological landscape, quality assurance (QA) testing serves as a critical... | 0 | 2024-06-19T13:12:03 | https://dev.to/pradeep_kumar_0f4d1f6d333/the-ultimate-guide-to-qa-testing-certification-everything-you-need-to-know-2h1e | In today's dynamic technological landscape, quality assurance (QA) testing serves as a critical cornerstone in ensuring that software meets rigorous standards of functionality, usability, and reliability before it reaches end-users. QA testers play a pivotal role in identifying and rectifying defects, thereby enhancing... | pradeep_kumar_0f4d1f6d333 | |
1,893,574 | How to create an Instagram API client in python: a step-by-step tutorial | Learn how to create an Instagram API client in Python with this step-by-step tutorial. Discover the best practices for using the Instagram API to fetch posts, likes, and follower data efficiently. | 0 | 2024-06-19T13:06:18 | https://usemyapi.com/articles/how-to-create-an-instagram-api-client-in-python-a-step-by-step-tutorial/ | python, tutorial, programming, api | ---
title: "How to create an Instagram API client in python: a step-by-step tutorial"
published: true
description: "Learn how to create an Instagram API client in Python with this step-by-step tutorial. Discover the best practices for using the Instagram API to fetch posts, likes, and follower data efficiently."
canoni... | apiharbor |
1,893,573 | Conga vs Docs Made Easy: Choosing the best alternative for Salesforce Document Generation | In the competitive landscape of Salesforce document generation, businesses often grapple with... | 0 | 2024-06-19T13:05:53 | https://dev.to/kimayanazum/conga-vs-docs-made-easy-choosing-the-best-alternative-for-salesforce-document-generation-2p64 | salesforce, software, documentation | In the competitive landscape of [Salesforce document generation](https://docsmadeasy.com/), businesses often grapple with balancing advanced features and cost efficiency. Conga Composer and Docs Made Easy are two prominent solutions offering distinct approaches to meet varying organizational needs. Conga Composer is kn... | kimayanazum |
1,893,572 | Try... catch... finally... | Try - we can log or do some actions and show in console. catch - whlile js check the try section and... | 0 | 2024-06-19T13:04:26 | https://dev.to/husniddin6939/try-catch-finally-5n9 | 1. Try - we can log or do some actions and show in console.
2. catch - whlile js check the try section and if it find some error, it will catch and don't show errors the screen. catch section find first error and stop , it doesn't check second one.
3.finally - this section show whatever in console the finish part.
| husniddin6939 | |
1,547,166 | Ursula von Rydingsvard | Ursula von Rydingsvard, an acclaimed contemporary artist, is renowned for her monumental and... | 0 | 2023-07-24T10:23:48 | https://dev.to/adreenil98/ursula-von-rydingsvard-ha6 | auction, auctionhouses, news, ursulavonrydingsvard | [Ursula von Rydingsvard](https://auctiondaily.com/news/artist-to-know-ursula-von-rydingsvard/), an acclaimed contemporary artist, is renowned for her monumental and evocative sculptures. Born in Germany in 1942, von Rydingsvard's family eventually settled in the United States, where she embarked on a remarkable artisti... | adreenil98 |
1,892,825 | A practical approach to using generative AI in the SDLC | Have you ever taken requirements from a stakeholder, implemented them, only to have them come back to... | 0 | 2024-06-19T13:02:00 | https://community.aws/content/2i1vLMdryliLgpdceMy2N6o2LPn/a-practical-approach-to-using-generative-ai-in-the-sdlc | aws, ai, productivity | Have you ever taken requirements from a stakeholder, implemented them, only to have them come back to you and say "That's not what I asked for! I meant this..." It happens all the time. Sometimes we heard them wrong, sometimes we made incorrect assumptions, or maybe even the needs of the end-user changed.
You may have... | jennapederson |
1,893,571 | Top QA Testing Training and Job Placement Programs Near Me | In today's rapidly evolving technological landscape, quality assurance (QA) testing plays a pivotal... | 0 | 2024-06-19T12:54:23 | https://dev.to/pradeep_kumar_0f4d1f6d333/top-qa-testing-training-and-job-placement-programs-near-me-4go5 | In today's rapidly evolving technological landscape, quality assurance (QA) testing plays a pivotal role in ensuring that software meets stringent quality standards before it reaches end-users. With the demand for skilled QA testers steadily increasing, choosing a training program equipped with effective job placement ... | pradeep_kumar_0f4d1f6d333 | |
1,893,570 | Travel Recommended with FastAPI, Kafka, MongoDB and OpenAI | Introduction In the bustling realm of modern travel, personalized recommendations play... | 0 | 2024-06-19T12:49:09 | https://dev.to/riottecboi/travel-recommended-with-fastapi-kafka-mongodb-and-openai-j4g | fastapi, kafka, mongodb, openai |

## Introduction
> In the bustling realm of modern travel, personalized recommendations play a pivotal role in enhancing user experiences and fostering memorable journeys. Our project, the Smart Travel Recommender System, ... | riottecboi |
1,893,568 | How Much Does It Cost to Make an App? | Creating a mobile application involves various costs that can vary significantly based on the... | 0 | 2024-06-19T12:48:20 | https://dev.to/hyscaler/how-much-does-it-cost-to-make-an-app-can | appdevelopment, programming, python, ai | Creating a mobile application involves various costs that can vary significantly based on the complexity and features of the app. Some of the key factors that influence the cost of [app development](https://hyscaler.com/service/mobile-app-development-services/) include:
## Development Time and Complexity
The more com... | rajatp |
1,893,569 | I believe in the Angular Roadmap: Especially Angular’s Full Potential in 2024 | Angular has solidified its status as a vital framework in the development community. With its... | 0 | 2024-06-19T12:48:09 | https://dev.to/zoltan_fehervari_52b16d1d/i-believe-in-the-angular-roadmap-especially-angulars-full-potential-in-2024-2kge | angular, angularroadmap, progrmamingroadmap | Angular has solidified its status as a vital framework in the development community. With its impressive 260K stars on GitHub, Angular continues to be a key resource for developers. It provides extensive roadmaps, best practices, and comprehensive guidance, making it an indispensable tool for front-end developers.
## ... | zoltan_fehervari_52b16d1d |
1,893,566 | Discover Excellence: Hair Course in Chennai with Orane Chennai | Introduction to Orane Chennai Orane Chennai, a distinguished branch of Orane International School... | 0 | 2024-06-19T12:40:56 | https://dev.to/orane_chennai_f11b0a360b2/discover-excellence-hair-course-in-chennai-with-orane-chennai-26m1 | Introduction to Orane Chennai
Orane Chennai, a distinguished branch of Orane International School of Beauty & Wellness, offers unparalleled opportunities in the realm of beauty education. As the foremost provider of hair and beauty courses in Chennai, we pride ourselves on delivering industry-leading training that pr... | orane_chennai_f11b0a360b2 | |
1,893,565 | The History Of JavaScript: A Journey Through Time | The foundation of contemporary web development, JavaScript, has a fascinating past that begins in the... | 0 | 2024-06-19T12:38:35 | https://www.swhabitation.com/story/history-of-javascript | javascript, historyofjavascript, ecma, webdev | The foundation of contemporary web development, JavaScript, has a fascinating past that begins in the middle of the 1990s.
Over the years, this programming language has undergone considerable evolution, influencing how we currently interact with the online.
We'll go back in time and examine the beginnings, developmen... | swhabitation |
1,883,355 | Cebolas e camadas para padrões de projetos no Front-end — Parte I | Nesse texto, tenho como objetivo trazer uma alternativa de padrões de projetos front-ends, esse... | 0 | 2024-06-19T12:35:40 | https://dev.to/tino-tech/cebolas-e-camadas-para-padroes-de-projetos-no-front-end-parte-i-55af | frontend, architecture, react, javascript | Nesse texto, tenho como objetivo trazer uma alternativa de padrões de projetos front-ends, esse padrão funciona independente do framework ou biblioteca.
A estrutura proposta neste artigo utiliza alguns recursos e nomenclaturas conhecidas pela comunidade do ReactJS, mas outras são uma inspiração de outros ecossistemas ... | robsonmathias |
1,847,919 | OpenAI api RAG system with Qdrant | Why? OpenAI has been making it easier and easier to build out GPT agents that make use of... | 0 | 2024-06-19T12:35:00 | https://artur.wtf/blog/qdrant-streamlit-openai-rag/ | openai, opensource, langchain, rag | ## Why?
[OpenAI](https://openai.com/) has been making it easier and easier to build out [GPT agents](https://www.deeplearning.ai/the-batch/how-agents-can-improve-llm-performance/) that make use of your own data to improve the generated responses of the pretrained models.
Agents give a way to inject knowledge about yo... | adaschevici |
1,893,563 | Use Gemini Pro Asynchronously in Python | When your prompt is too large and the LLM starts to hallucinate, or when the data you want from the... | 0 | 2024-06-19T12:31:32 | https://dev.to/muhammadnizamani/use-gemini-pro-asynchronously-in-python-5b6a | python, ai, machinelearning, gemini | When your prompt is too large and the LLM starts to hallucinate, or when the data you want from the LLM is too extensive to be handled in one response, asynchronous calling can help you get the desired output. In this brief blog, I will teach you how to call Gemini Pro asynchronously to achieve the best results.
**let... | muhammadnizamani |
1,893,562 | What is SSL pinning, and how do you implement it in a mobile app? | What is SSL Pinning? SSL pinning is a security technique used to ensure that an... | 0 | 2024-06-19T12:26:15 | https://dev.to/chariesdevil/what-is-ssl-pinning-and-how-do-you-implement-it-in-a-mobile-app-1gjl | sslpinning, appdevelopment, mobileappdevelopment, appsync | ## What is SSL Pinning?
SSL pinning is a security technique used to ensure that an application only communicates with a trusted server. It involves storing the server's SSL certificate (or a public key) within the app itself, allowing the app to verify the server's identity directly rather than relying solely on the o... | chariesdevil |
1,893,561 | Error types | 1.TypeError - Data type value is not expected type. 2.SyntaxError - we miss something or left any... | 0 | 2024-06-19T12:25:08 | https://dev.to/husniddin6939/error-types-4f1f | javascript | 1.TypeError - Data type value is not expected type.
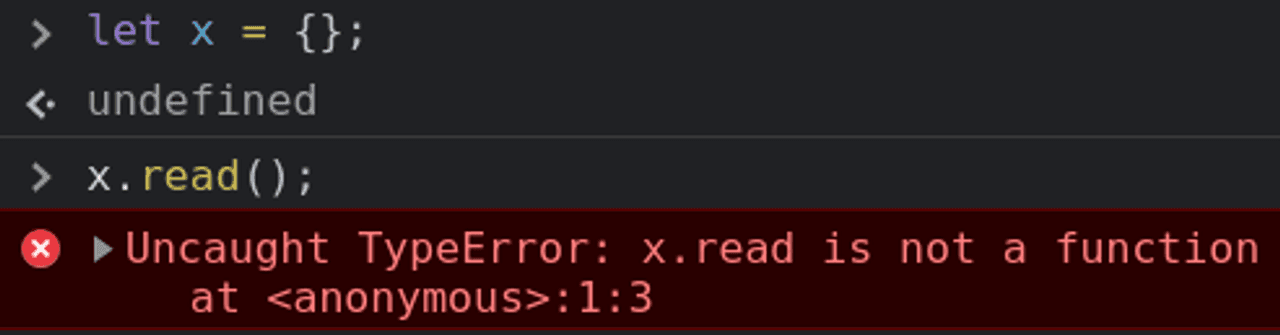
2.SyntaxError - we miss something or left any extra characters like this , . or any letter in empty space it response SyntaxError so Js try to knows all written t... | husniddin6939 |
1,893,560 | Develop a Powerful DEX with a PancakeSwap Clone Script | DEXs have significantly transformed the cryptocurrency trading space through offering a safer,... | 0 | 2024-06-19T12:25:07 | https://dev.to/rick_grimes/develop-a-powerful-dex-with-a-pancakeswap-clone-script-2n7 | pancakeswap, webdev, programming, blockchain | DEXs have significantly transformed the cryptocurrency trading space through offering a safer, transparent, and decentralized marketplace. PancakeSwap is one of the most utilized DEXs at the moment, as it is effective and easy to use. Interested business person or an entrepreneur who wants to attempt into DeFi, creatin... | rick_grimes |
1,873,361 | State Management in React | Introduction State management is a critical aspect of building dynamic and interactive... | 27,559 | 2024-06-19T12:25:00 | https://dev.to/suhaspalani/state-management-in-react-56ea | #### Introduction
State management is a critical aspect of building dynamic and interactive React applications. As applications grow, managing state becomes more complex. This week, we will explore various state management techniques in React, focusing on `useState`, `useReducer`, and the Context API.
#### Importance ... | suhaspalani | |
1,893,559 | Casement Windows: Traditional Aesthetics with Modern Performance | Introduction Casement windows could be a choice great those wanting to find conventional looks with... | 0 | 2024-06-19T12:24:32 | https://dev.to/tina_garciag_fbecfd60ef53/casement-windows-traditional-aesthetics-with-modern-performance-11hb | design | Introduction
Casement windows could be a choice great those wanting to find conventional looks with contemporary performance. These windows happen used by more than 100 years and have stood the test regarding the right time for his or her durability, functionality, and beauty. Whether you may be renovating your home ... | tina_garciag_fbecfd60ef53 |
1,893,557 | How an ICO Development Company Can Help You Grow Your Business? | In the fast-evolving landscape of blockchain technology, initial coin offerings (ICOs) have emerged... | 0 | 2024-06-19T12:21:28 | https://dev.to/roberttony03/how-an-ico-development-company-can-help-you-grow-your-business-1bog | icodevelopment, icodevelopmentcompany, blockchain, cryptocurrency | In the fast-evolving landscape of blockchain technology, initial coin offerings (ICOs) have emerged as a revolutionary means of fundraising for startups and established businesses alike. An **[ICO development company](https://blocktunix.com/ico-development-services/)** plays a crucial role in harnessing this potential,... | roberttony03 |
1,893,554 | Blogger icon a little modified no svg no img no js CSS+HTML only | Check out this Pen I made! | 0 | 2024-06-19T12:18:35 | https://dev.to/tidycoder/blogger-icon-a-little-modified-no-svg-no-img-no-js-csshtml-only-328c | codepen, icon, css, html | Check out this Pen I made!
{% codepen https://codepen.io/TidyCoder/pen/qBGxMpj %} | tidycoder |
1,893,553 | Demystifying the Machine: A Beginner's Guide to Machine Learning Algorithms | Ever wondered how your favorite streaming service recommends movies you'll love, or how spam filters... | 0 | 2024-06-19T12:17:44 | https://dev.to/fizza_c3e734ee2a307cf35e5/demystifying-the-machine-a-beginners-guide-to-machine-learning-algorithms-i33 | machine, machinelearning, algorithms | Ever wondered how your favorite streaming service recommends movies you'll love, or how spam filters effortlessly weed out unwanted emails? The answer lies in the fascinating world of machine learning (ML) algorithms. These algorithms are the secret sauce behind many of today's technological marvels, and understanding... | fizza_c3e734ee2a307cf35e5 |
1,893,552 | Essential Tips for Maintaining Polyester Mooring Rope | Vital Recommendations for Maintaining Polyester Mooring Rope Have you ever before become aware of... | 0 | 2024-06-19T12:15:15 | https://dev.to/tina_garciag_fbecfd60ef53/essential-tips-for-maintaining-polyester-mooring-rope-5827 | design | Vital Recommendations for Maintaining Polyester Mooring Rope
Have you ever before become aware of the term Polyester Mooring Rope? Essentially, it is a style of Rope helped make of Polyester fibers that are interweaved with each other to produce a solid and durable Rope. This Rope is frequently utilized for Mooring wa... | tina_garciag_fbecfd60ef53 |
1,893,551 | Twilio made for changing | This is a submission for the Twilio Challenge What I Built I want to make a great and... | 0 | 2024-06-19T12:14:55 | https://dev.to/gerardtheeagle/twilio-made-for-changing-4pbm | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
I want to make a great and amazing chatbot for user to allow then to ask questions about me and other things
## Demo
<!-- Share a link to your app and include some screenshots here. -->
gerardocover.great-site.net
 which is commonly known as capcut pro. You want to cancel its subscription and you dont know how to do it then must visit this insightful article for help. | thecapsapk |
1,890,316 | A simple distributed lock implementation using Redis | When you want to make sure only one process modifies a given resource at a time you need a lock. When... | 0 | 2024-06-19T12:14:24 | https://dev.to/woovi/a-simple-distributed-lock-implementation-using-redis-445c | lock, redis | When you want to make sure only one process modifies a given resource at a time you need a lock.
When you have more than one pod running in production to your server in your Kubernetes, you can't lock only in memory, you need a distributed lock.
## Implementation using _redlock_
```ts
import Redis from 'ioredis';
imp... | sibelius |
1,893,548 | جلـ | A post by Teret Terw | 0 | 2024-06-19T12:13:26 | https://dev.to/saerwd/j-3h6m | saerwd | ||
1,891,426 | Neural Network (explained in 1 Byte) | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-19T12:11:08 | https://dev.to/jjokah/neural-network-explained-in-1-byte-2hop | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Just like our brain, a Neural Network is made up of interconnected "neurons". These neurons work together by learning from (**input**) data and getting better at tasks (in the **hidden... | jjokah |
1,893,547 | Optimal Algorithms for Aligning Glock Dovetail Optic Mounts | Aligning Glock dovetail optic mounts accurately is crucial for optimal shooting performance. Start... | 0 | 2024-06-19T12:09:14 | https://dev.to/marylisa3245/optimal-algorithms-for-aligning-glock-dovetail-optic-mounts-57oo | Aligning Glock dovetail [optic mounts](https://www.versatactical.com/product/rmr-glock-dovetail-optic-mounting-kit/) accurately is crucial for optimal shooting performance. Start with a visual inspection of the dovetail cut and optic mount, ensuring there are no defects or obstructions. Clean both parts thoroughly to r... | marylisa3245 | |
1,893,546 | Physics Engine: I couldn’t wait to explore more. | Modern video games feature stunning visuals and realistic physics simulations that immerse players in... | 0 | 2024-06-19T12:08:48 | https://dev.to/zoltan_fehervari_52b16d1d/physics-engine-i-couldnt-wait-to-explore-more-a88 | physicsengine, gamephysics, gamedev, gameprogramming | Modern video games feature stunning visuals and realistic physics simulations that immerse players in virtual worlds. At the heart of these realistic interactions is the physics engine, a crucial component of game engines.
## So? What’s next?
Now I am going to explore the technical aspects of physics engines, their f... | zoltan_fehervari_52b16d1d |
1,893,545 | PVC Resin: The Foundation of PVC Manufacturing | Headline: PVC Material: The Structure Obstruct of PVC Production PVC material is actually the... | 0 | 2024-06-19T12:06:25 | https://dev.to/tina_garciag_fbecfd60ef53/pvc-resin-the-foundation-of-pvc-manufacturing-29e2 | design | Headline: PVC Material: The Structure Obstruct of PVC Production
PVC material is actually the component that is essential the produce of PVC items
It is actually a flexible as well as affordable polyvinyl chloride resin product that's utilized thoroughly in the industries that are commercial well as building
This post... | tina_garciag_fbecfd60ef53 |
1,893,544 | Validate user path access on edge with NextAuth & Next.js Middleware | .... Cover Photo by Susan Q Yin on Unsplash Source Code:... | 0 | 2024-06-19T12:05:41 | https://dev.to/smy/validate-user-path-access-on-edge-with-nextauth-nextjs-middleware-4hm6 | nextjs, javascript, webdev, typescript | ....
Cover Photo by [Susan Q Yin on Unsplas](https://unsplash.com/@syinq?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash)[h](https://unsplash.com/photos/red-and-blue-arrow-sign-surrounded-by-brown-trees-BiWM-utpVVc?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash)
Source Code: [ht... | smy |
1,893,543 | LazyReminders | This is a submission for the Twilio Challenge What I Built Where we’re from, people are... | 0 | 2024-06-19T12:04:07 | https://dev.to/muhammad_anas_ad5864b49fe/lazyreminders-1jk0 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
Where we’re from, people are always on their phones - and WhatsApp is widely used for communication. We built **LazyReminders: a WhatsApp Reminders bot** that leverages Twillio and Natural Language Processing (NLP) to... | muhammad_anas_ad5864b49fe |
1,893,541 | Decoding the Java Compiler: From Code to Execution | Decoding the Java Compiler: From Code to Execution Introduction: Understanding... | 0 | 2024-06-19T12:01:30 | https://dev.to/scholarhat/decoding-the-java-compiler-from-code-to-execution-47b9 | ## Decoding the Java Compiler: From Code to Execution
## Introduction: Understanding the Java Compiler
The journey of Java code from creation to execution is a fascinating process, meticulously orchestrated by the **[Java Compiler](https://www.scholarhat.com/compiler/java)**. In the programming realm, compilers act a... | scholarhat | |
1,885,544 | Develop a Serverless TypeScript API on AWS ECS with Fargate | AWS Fargate is a serverless compute engine that allows you to run containers without managing... | 0 | 2024-06-19T12:00:00 | https://blog.appsignal.com/2024/06/05/develop-a-serverless-typescript-api-on-aws-ecs-with-fargate.html | typescript, node, fargate, aws | AWS Fargate is a serverless compute engine that allows you to run containers without managing servers. With Fargate, you no longer have to provision clusters of virtual machines to run ECS containers: this is all done for you.
Fargate has an Amazon ECS construct that can host an API. In this take, we will build a Farg... | beautifulcoder |
1,893,539 | How a Web Development Agency Secures Java EE Applications with Java Authentication and Authorization Service | Ensuring that sensitive data and functionalities are accessible only to authorized users is a top... | 0 | 2024-06-19T11:59:06 | https://dev.to/jessicab/how-a-web-development-agency-secures-java-ee-applications-with-java-authentication-and-authorization-service-2m1l | webdev, javascript, programming | Ensuring that sensitive data and functionalities are accessible only to authorized users is a top priority for any leading web development agency. Therefore, building secure Java EE applications is essential.
Java EE is a popular framework for enterprise-level web development and provides robust features to safeguard... | jessicab |
1,893,540 | AI vs Solana: Battle of the Meme Coins | Despite their rather humble and insignificant beginnings, meme coins have found their place in the... | 0 | 2024-06-19T11:59:04 | https://dev.to/blockchainx358/ai-vs-solana-battle-of-the-meme-coins-4gm4 | aimemecoins, solanamemecoins, cryptomemeeconomy, blockchaininnovation |

Despite their rather humble and insignificant beginnings, meme coins have found their place in the modern and quite towless and swift world of cryptocurrencies. Two distinct categories have emerged: proposals and pr... | blockchainx358 |
1,893,538 | Hadoop Date Mastery for Astronomers | The year is 2285, and humanity has established a thriving space station orbiting the planet Mars | 27,774 | 2024-06-19T11:54:35 | https://labex.io/tutorials/hadoop-hadoop-date-mastery-for-astronomers-288963 | coding, programming, tutorial, hadoop |
## Introduction
The year is 2285, and humanity has established a thriving space station orbiting the planet Mars. This research facility, known as the Martian Observatory, serves as a hub for scientific exploration and discovery. Among the many scientists stationed here is Dr. Emma Wilkins, a brilliant data analyst s... | labby |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.