
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,891,417 | Shamir Secret Sharing in 256 characters or less | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 27,753 | 2024-06-17T15:35:52 | https://dev.to/kalkwst/shamir-secret-sharing-in-256-characters-or-less-3a3a | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
You and your friends have a treasure map (secret). You cut it into pieces so no one can find the treasure alone.Each friend gets a piece (share). BUT, you cut it in such a way that onl... | kalkwst |
1,891,416 | JSON | JSON.stringify() The JSON.stringify() method converts a JavaScript object or value to a... | 0 | 2024-06-17T15:34:35 | https://dev.to/__khojiakbar__/json-130f | javascript, json | ## JSON.stringify()
> The JSON.stringify() method converts a JavaScript object or value to a JSON string. This is useful for sending data over a network, storing data in text format, or logging.
```
const obj = { name: "John", age: 30, city: "New York" };
const jsonString = JSON.stringify(obj);
console.log(jsonString... | __khojiakbar__ |
1,891,415 | File locking vs Row Level Locking | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-17T15:34:03 | https://dev.to/dwivedialind/file-locking-vs-row-level-locking-2d93 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Have you ever wondered how can multiple users perform DML operations on same table at the same time? Because of r... | dwivedialind |
1,891,414 | A Beginner's Guide to Choosing the Right Domain and Hosting for Your Website | Choosing the Perfect Domain and Hosting for Your Website When starting your website, two key... | 0 | 2024-06-17T15:29:16 | https://dev.to/ridoy_hasan/a-beginners-guide-to-choosing-the-right-domain-and-hosting-for-your-website-4ae7 | webdev, career, learning, productivity | **Choosing the Perfect Domain and Hosting for Your Website**
When starting your website, two key decisions are crucial: selecting a domain name and choosing a hosting provider. Here’s a simple guide to help you make the right choices:
**1. Domain Name:**
Your domain is your online identity. Follow these tips:
- **S... | ridoy_hasan |
1,891,409 | In Spring Boot, what is the use of @PostConstruct? Explain using Example. | Use of @PostConstruct in Spring Boot ==================================== In Spring Boot,... | 0 | 2024-06-17T15:24:40 | https://dev.to/codegreen/n-spring-boot-what-is-the-use-of-postconstruct-explain-using-example-30lk | springboot, java, interview | ##Use of @PostConstruct in Spring Boot
====================================
In Spring Boot, `@PostConstruct` is used to annotate a method that should be executed after dependency injection is complete and before the bean is put into service.
Example:
--------
Suppose we have a class `UserService` that requires some ... | manishthakurani |
1,891,402 | Deploy react, node projects for free on vercel | Looking to deploy your projects without spending a dime? You've come to the right place. There are... | 0 | 2024-06-17T15:20:38 | https://www.parshipraneesh.me/blogs/deploy | webdev, beginners, deployment |
Looking to deploy your projects without spending a dime? You've come to the right place. There are several platforms out there that offer free deployment with some resource limitations. Some of the options include:
- GitHub Pages
- Glitch
- Render
- Netlify
- Vercel
- Digital Ocean
Among these, I find Vercel to be th... | ppraneesh |
1,891,401 | Perplexity AI: A Beginner's Guide to Getting Started" | In this article, I want to introduce you to something truly amazing—Perplexity AI. This AI tool has... | 0 | 2024-06-17T15:20:37 | https://dev.to/proflead/perplexity-ai-a-beginners-guide-to-getting-started-3mfj | ai, perplexity, tutorial, howto | In this article, I want to introduce you to something truly amazing—Perplexity AI. This AI tool has incredible potential, and I believe it can be a game-changer for many of you. I'll walk you through how to use Perplexity AI and highlight some of its great features.
## Introduction to Perplexity AI
Perplexity AI is an... | proflead |
1,891,392 | I've created an open source Spring Boot + Nextjs starter kit | Seeing how these are quite popular currently (mainly in nextjs space) and how one still doesn't exist... | 0 | 2024-06-17T15:17:38 | https://dev.to/nermin_karapandzic/ive-created-an-open-source-spring-boot-nextjs-starter-kit-6fk | Seeing how these are quite popular currently (mainly in nextjs space) and how one still doesn't exist with spring boot as a backend, I've decided to create one myself.
Here is the repository: https://github.com/NerminKarapandzic/spring-boot-nextjs-starter-kit
There's nothing special about the integration with Nextjs ... | nermin_karapandzic | |
1,891,391 | Assymetric Encryption in 256 characters or less | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 27,753 | 2024-06-17T15:15:48 | https://dev.to/kalkwst/assymetric-encryption-in-256-characters-or-less-4lap | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Assymetric encryption is like a locked box. Anyone can put a letter through the slot (public key), but only the owner can open it and get the letter (private key). This ensures that on... | kalkwst |
1,891,389 | Amazon DevOps Guru for the Serverless applications - Part 11 Anomaly detection on SNS (kind of) | Introduction In the 1st part of the series we introduced the Amazon DevOps Guru service,... | 24,936 | 2024-06-17T15:14:50 | https://dev.to/aws-builders/amazon-devops-guru-for-the-serverless-applications-part-11-anomaly-detection-on-sns-kind-of-388 | aws, serverless, devops, aiops | ## Introduction
In the [1st part of the series](https://dev.to/aws-builders/amazon-devops-guru-for-the-serverless-applications-part-1-introduction-to-devops-guru-39i0) we introduced the Amazon DevOps Guru service, described its value proposition, the benefits of using it and explain how to configure it. We also need t... | vkazulkin |
1,891,390 | Fasilitas eksklusif dan pengalaman spiritual yang mendalam tersedia dalam Paket Umroh Plus. | Paket Hemat 2024 dengan 9 Hari penjelajahan Kalender Keberangkatan: 10 Agustus. 14 September. 12... | 0 | 2024-06-17T15:13:40 | https://dev.to/umrohplus/fasilitas-eksklusif-dan-pengalaman-spiritual-yang-mendalam-tersedia-dalam-paket-umroh-plus-74n | Paket Hemat 2024 dengan 9 Hari penjelajahan
Kalender Keberangkatan: 10 Agustus. 14 September. 12 Oktober. 9 November. 7 Desember
Rute SUB-JED tanpa transit menggunakan Lion Air/Citilink/setaraf
seowa
Paket dengan biaya Rp Rp 28.300.000 all inclusive
Tempat akomodasi yang dipilih di Mekkah dan Madinah:
Hotel Mekkah :... | umrohplus | |
1,891,387 | El Arte de Conectar a Través de los Gustos y las Aficiones | En la vida cotidiana, encontramos múltiples oportunidades para conectar con los demás a través de... | 0 | 2024-06-17T15:07:44 | https://dev.to/angelique0908/el-arte-de-conectar-a-traves-de-los-gustos-y-las-aficiones-pgk | productivity, career, learning, google | En la vida cotidiana, encontramos múltiples oportunidades para conectar con los demás a través de intereses compartidos. La capacidad de hablar sobre nuestros gustos y aficiones no solo enriquece nuestras conversaciones, sino que también fortalece los vínculos personales y profesionales.
Comprender los Gustos y Aficio... | angelique0908 |
1,891,386 | LeetCode Day10 Stack&Queue Part 2 | LeetCode No.150. Evaluate Reverse Polish Notation You are given an array of strings tokens... | 0 | 2024-06-17T15:07:06 | https://dev.to/flame_chan_llll/leetcode-day10-stackqueue-part-2-lma | leetcode, java, algorithms, datastructures | # LeetCode No.150. Evaluate Reverse Polish Notation
You are given an array of strings tokens that represents an arithmetic expression in a Reverse Polish Notation.
Evaluate the expression. Return an integer that represents the value of the expression.
Note that:
The valid operators are '+', '-', '*', and '/'.
Each ... | flame_chan_llll |
1,891,384 | Navigating Decentralization: Building Applications with Amazon Managed Blockchain | Navigating Decentralization: Building Applications with Amazon Managed Blockchain The... | 0 | 2024-06-17T15:05:30 | https://dev.to/virajlakshitha/navigating-decentralization-building-applications-with-amazon-managed-blockchain-5c0 | 
# Navigating Decentralization: Building Applications with Amazon Managed Blockchain
The emergence of blockchain technology has ushered in a new era of secure and transparent data management. As organizations explore the potential ... | virajlakshitha | |
1,891,378 | Build a waitlist with Clerk user metadata | Fast feedback when building a software-as-a-service application is critical. This is especially true... | 0 | 2024-06-17T15:00:55 | https://clerk.com/blog/build-a-waitlist-with-clerk-user-metadata | clerk, security, rbac, javascript | Fast feedback when building a software-as-a-service application is critical.
This is especially true in the early days of building. The quicker you can get a working version of your product in the hands of users, the faster you can collect input and make decisions based on that input. Doing so can make an incredible d... | brianmmdev |
1,890,997 | Resolve Content Security Policy (CSP) Issues in Your Discord Activity Using a Node.js Proxy | If you're building a Discord Activity, you may encounter issues with Content Security Policy (CSP)... | 0 | 2024-06-17T15:00:00 | https://dev.to/waveplay/resolve-content-security-policy-csp-issues-in-your-discord-activity-using-a-nodejs-proxy-2634 | discord, programming, node, javascript | If you're building a **[Discord Activity](https://support.discord.com/hc/en-us/articles/4422142836759-Activities-on-Discord)**, you may encounter issues with **[Content Security Policy (CSP)](https://developer.mozilla.org/en-US/docs/Web/HTTP/CSP)** restrictions.
**CSP** is a security feature that helps prevent **[cros... | waveplay-staff |
1,891,371 | How to Network When You Don’t Have a Big Social Circle | Networking can feel like a daunting task, especially when your social circle is small. Trust me, I’ve... | 0 | 2024-06-17T14:59:47 | https://dev.to/tectrain_academy/how-to-network-when-you-dont-have-a-big-social-circle-44fp | beginners, learning, discuss, softwaredevelopment | Networking can feel like a daunting task, especially when your social circle is small. Trust me, I’ve been there! For more than four years, I’ve worked as a social media and content manager, and I’ve been on a mission to build a meaningful professional network.
**By using tools like LinkedIn, community discussion plat... | tectrain_academy |
1,891,383 | SHA-256: The Heartbeat of Cryptographic Security in 256 Characters | ## SHA-256(Secure Hash Algorithm 256-bit) "SHA-256 is a cryptographic hash function that converts... | 0 | 2024-06-17T14:59:35 | https://dev.to/harish_05/sha-256-the-heartbeat-of-cryptographic-security-in-256-characters-3i8d | devchallenge, cschallenge, computerscience, beginners |

**## SHA-256(Secure Hash Algorithm 256-bit)**
"SHA-256 is a cryptographic hash function that converts input data into a fixed 256-bit hash. It's widely used for data integrity, digital signatures, and secure pass... | harish_05 |
1,891,380 | CSS Pure body animation | Check out this Pen I made! | 0 | 2024-06-17T14:58:37 | https://dev.to/tidycoder/css-pure-body-animation-1kme | codepen | Check out this Pen I made!
{% codepen https://codepen.io/TidyCoder/pen/PovEVgb %} | tidycoder |
1,891,379 | Backstage for AI's Decision-Making Process | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-17T14:58:24 | https://dev.to/vyshnavik18/backstage-for-ais-decision-making-process-5hm6 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Grad CAM vitally used in regions of CNN decisions, is a part of DL. uses gradients flowing into the final convolutional layer to show where model "looks" to make decisions, passes loca... | vyshnavik18 |
1,891,366 | Usando ffmpeg para converter vídeos em GIF e muitas outras coisas | O ffmpeg é um programa de linha de comando eficiente e fácil de usar. É usado para conversão,... | 0 | 2024-06-17T14:57:18 | https://dev.to/fernandovaller/usando-ffmpeg-para-converter-videos-em-gif-e-muitas-outras-coisas-369d | O ffmpeg é um programa de linha de comando eficiente e fácil de usar. É usado para conversão, gravação, transmissão e reprodução de arquivos de áudio e vídeo. O ffmpeg é obrigatório para desenvolvedores, editores de vídeo e entusiastas de multimídia, pois suporta uma ampla variedade de formatos.
**Como instalar (wsl2... | fernandovaller | |
1,891,358 | New ChatGPT-4o: A Game-Changer That Could Replace Data Analysts | In this video, I explore the new ChatGPT-4o and its impact on data analysis. Can data analysts... | 0 | 2024-06-17T14:54:04 | https://dev.to/proflead/new-chatgpt-4o-a-game-changer-that-could-replace-data-analysts-3gni | In this video, I explore the new ChatGPT-4o and its impact on data analysis. Can data analysts survive in a world where AI is taking over? Join me as I dive into the features of ChatGPT-4o and discuss its potential to revolutionize the field of data analysis. I also share my thoughts on the future of data analysts and ... | proflead | |
1,891,375 | Nullish coalescing vs Logical || by aryan | The difference between these two operators are, nullish(??) operators consider 0 and "",[],{} as a... | 0 | 2024-06-17T14:53:29 | https://dev.to/aryan015/nullish-coalescing-vs-logical-by-aryan-j9e | javascript, react | The difference between these two operators are, nullish(??) operators consider 0 and "",[],{} as a true.
Only `null` and `undefined` is considered as false.
```js
const obj = {
name:'aryan khandelwla'
age:26
}
obj.['name'] //aryan khandelwal
obj||obj['name'] //aryan khandelwla
```
`??` nullish operator helps avoid rep... | aryan015 |
1,891,374 | LeetCode Meditations: Pacific Atlantic Water Flow | The description for this problem states: There is an m x n rectangular island that borders both the... | 26,418 | 2024-06-17T14:49:07 | https://rivea0.github.io/blog/leetcode-meditations-pacific-atlantic-water-flow | computerscience, algorithms, typescript, javascript | The description for [this problem](https://leetcode.com/problems/pacific-atlantic-water-flow) states:
> There is an `m x n` rectangular island that borders both the **Pacific Ocean** and **Atlantic Ocean**. The **Pacific Ocean** touches the island's left and top edges, and the **Atlantic Ocean** touches the island's r... | rivea0 |
1,891,373 | My GitHub Account | https://github.com/arzooshamim13 | 0 | 2024-06-17T14:47:28 | https://dev.to/arzooshamim13/my-github-account-eml | webdev |
https://github.com/arzooshamim13 | arzooshamim13 |
1,891,372 | I'm in | A post by Jagan mohan Gade | 0 | 2024-06-17T14:45:58 | https://dev.to/jagan_gade/im-in-1cbg | jagan_gade | ||
1,891,369 | Top Low-Cost Cybersecurity Measures | According to statistics, SMBs spend an average of 12% on their IT infrastructure, which includes its... | 0 | 2024-06-17T14:41:55 | https://dev.to/whotarusharora/top-low-cost-cybersecurity-measures-37el | webdev, cybersecurity, security, beginners | According to statistics, SMBs spend an average of 12% on their IT infrastructure, which includes its configuration, updation, maintenance, and security. It's obvious that small and medium-scale firms have to spend more on marketing, as they need to make their space in the market.
To help such organizations maintain t... | whotarusharora |
1,891,368 | Livekriyathmakakaravagenima | A post by Buddika Chathurnga | 0 | 2024-06-17T14:37:02 | https://dev.to/buddika_chathurnga_79c567/livekriyathmakakaravagenima-3gnl |
 | buddika_chathurnga_79c567 | |
1,891,203 | Interval Score Matching: Enhancing Fidelity in Text-to-3D Models with LucidDreamer | Author: Harpreet Sahota (Hacker in Residence at Voxel51) A CVPR Paper Review and Cliff’s... | 0 | 2024-06-17T14:33:22 | https://medium.com/voxel51/interval-score-matching-enhancing-fidelity-in-text-to-3d-models-with-luciddreamer-f18c022dd4ac | machinelearning, datascience, computervision, ai | _Author: [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker in Residence at [Voxel51](https://voxel51.com/))_
## A CVPR Paper Review and Cliff’s Notes
Traditional 3D modelling is time-consuming and requires specialized skills, creating a barrier to widespread use in various industries.
Recent ... | jguerrero-voxel51 |
1,891,211 | Fixing CLIP’s Blind Spots: How New Research Tackles AI’s Visual Misinterpretations | Author: Harpreet Sahota (Hacker in Residence at Voxel51) Overview The paper “Eyes Wide... | 0 | 2024-06-17T14:32:15 | https://medium.com/voxel51/fixing-clips-blind-spots-how-new-research-tackles-ai-s-visual-misinterpretations-8b8ef4b4c250 | computervision, datascience, machinelearning, ai | _Author: [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker in Residence at [Voxel51](https://voxel51.com/))_
## Overview
The paper [“Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs”](https://arxiv.org/abs/2401.06209) investigates the visual question-answering (VQA) capabili... | jguerrero-voxel51 |
1,891,365 | Improving CSS Loading in React Applications: Avoiding `@import` in `createGlobalStyle` | When working with React and styled-components, you might encounter performance and compatibility... | 0 | 2024-06-17T14:31:20 | https://dev.to/mochafreddo/improving-css-loading-in-react-applications-avoiding-import-in-createglobalstyle-4d9p | react, styledcomponents, webperf, cssom | When working with React and styled-components, you might encounter performance and compatibility issues if you use `@import` within `createGlobalStyle`. This blog post will explain why this happens and how to resolve it by embedding the stylesheet link directly in your `index.html` file.
## The Problem with `@import` ... | mochafreddo |
1,891,319 | Lukas Höllein on the Challenges and Opportunities of Text-to-3D with “ViewDiff” | Author: Harpreet Sahota (Hacker in Residence at Voxel51) A Q&A with an author of a CVPR 2024... | 0 | 2024-06-17T14:30:54 | https://medium.com/voxel51/lukas-h%C3%B6llein-on-the-challenges-and-opportunities-of-text-to-3d-with-viewdiff-40203fb59c93 | datascience, machinelearning, computervision, ai | _Author: [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker in Residence at [Voxel51](https://voxel51.com/))_
A Q&A with an author of a CVPR 2024 paper discussing the implications of his work for 3D Modeling
 A CVPR Paper Review and Cliff’s Notes You... | 0 | 2024-06-17T14:30:15 | https://medium.com/voxel51/patch-wise-attention-enhances-fine-grained-visual-recognition-6f87550b590e | computervision, datascience, machinelearning, ai | _Author: [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker in Residence at [Voxel51](https://voxel51.com/))_
**A CVPR Paper Review and Cliff’s Notes**
You don’t usually think of two things in the same sentence: creepy crawlies and cutting-edge AI.
However, this combination will improve agricu... | jguerrero-voxel51 |
1,891,338 | SelfEQ Enhances Visual Grounding with Self-Consistency | Author: Harpreet Sahota (Hacker in Residence at Voxel51) A CVPR Paper Review and Cliff’s... | 0 | 2024-06-17T14:29:18 | https://medium.com/voxel51/selfeq-enhances-visual-grounding-with-self-consistency-cdaba01e236c | computervision, machinelearning, ai, datascience | _Author: [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker in Residence at [Voxel51](https://voxel51.com/))_
## A CVPR Paper Review and Cliff’s Notes
Precise visual grounding remains a challenging yet essential task, particularly when models encounter varied textual descriptions.
The paper [“... | jguerrero-voxel51 |
1,891,346 | Secure Your Digital Frontier with CQR Cybersecurity LLC | Choosing CQR Cybersecurity means opting for a future where your digital assets are guarded by the... | 0 | 2024-06-17T14:01:30 | https://dev.to/cqr/secure-your-digital-frontier-with-cqr-cybersecurity-llc-5bbn | cybersecurity, web3, it, security | Choosing CQR Cybersecurity means opting for a future where your digital assets are guarded by the best in the business. Let’s discuss how we can tailor our protection strategies to suit your unique needs. Your security journey starts with CQR Cybersecurity LLC — where reliability meets professionalism.
CQR Cybersecurit... | cqr |
1,891,345 | 3D Scene Understanding: Open3DSG’s Open-Vocabulary Approach to Point Clouds | Author: Harpreet Sahota (Hacker in Residence at Voxel51) A CVPR Paper Review and Cliff’s... | 0 | 2024-06-17T14:26:02 | https://medium.com/voxel51/3d-scene-understanding-open3dsgs-open-vocabulary-approach-to-point-clouds-69d443d29cb2 | machinelearning, datascience, ai, computervision | _Author: [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker in Residence at [Voxel51](https://voxel51.com/))_
## A CVPR Paper Review and Cliff’s Notes
Understanding 3D environments is a critical challenge in computer vision, particularly for robotics and indoor applications.
The paper, [Open3D... | jguerrero-voxel51 |
1,891,349 | 5 Papers on My CVPR 2024 Must-See List! | Author: Jacob Marks (Machine Learning Engineer at Voxel51) I’m excited to attend CVPR 2024! There is... | 0 | 2024-06-17T14:25:30 | https://voxel51.com/blog/5-papers-on-my-cvpr-2024-must-see-list/ | computervision, machinelearning, datascience, ai | _Author: [Jacob Marks](https://www.linkedin.com/in/jacob-marks/) (Machine Learning Engineer at [Voxel51](https://voxel51.com/))_
I’m excited to attend CVPR 2024! There is A LOT of awesome research again this year! Gearing up for the event, I made a short list of papers I find interesting and would like to explore more... | jguerrero-voxel51 |
1,890,868 | Hardware Acceleration | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte... | 0 | 2024-06-17T14:23:23 | https://dev.to/harishprabhu02/hardware-acceleration-2lkn | cschallenge | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
**Explainer**
Hardware acceleration is a feature that uses specialized hardware to enhance the performance of certain tasks like graphics, videos, and sounds.
It frees up the CPU, which results in ... | harishprabhu02 |
1,891,359 | The Developers' Missing Piece for Boosting Productivity | As a front-end engineer and technical writer, my work life revolves around crafting interactive,... | 0 | 2024-06-17T14:22:32 | https://smoothtech.hashnode.dev/the-developers-missing-piece-for-boosting-productivity | productivity, ai, webdev, frontend | As a front-end engineer and technical writer, my work life revolves around crafting interactive, responsive and dynamic User Interfaces and writing about tech. I am always eager to learn new things and share my views about them through writing. About two weeks ago, I came across two different posts talking about Pieces... | timothyolanrewaju |
1,891,333 | Mastering React: An indepth guide to building React applications | An In-Depth Guide to React.js Introduction React.js, commonly known as React,... | 0 | 2024-06-17T13:45:36 | https://dev.to/nmaduemmmanuel/mastering-react-an-indepth-guide-to-building-react-applications-39ol |
# An In-Depth Guide to React.js
## Introduction
React.js, commonly known as React, is an open-source JavaScript library used for building user interfaces, particularly for single-page applications. It allows developers to create reusable UI components and manage the state of their applications efficiently. React wa... | nmaduemmmanuel | |
1,891,364 | How to Start a Software Developvment Company? | I've been observing the software industry for quite some time now. It's fascinating how companies... | 0 | 2024-06-17T14:21:56 | https://dev.to/igor_ag_aaa2341e64b1f4cb4/how-to-start-a-software-developvment-company-4fna | softwaredevelopment | I've been observing the software industry for quite some time now. It's fascinating how companies like Apple and Microsoft have led the charge in technological advancements, setting a high standard for success. Many of us dream of launching our own software ventures, but do you know how to go about it?
New software fir... | igor_ag_aaa2341e64b1f4cb4 |
1,891,363 | Some Books to Upskill Communication For Software Engineers | (Full disclosure: This post includes affiliate links which, if you click through and purchase the... | 0 | 2024-06-17T14:21:39 | https://www.stephenhara.com/posts/2024-06-17-communication-upskill-books | books, communication | *(Full disclosure: This post includes affiliate links which, if you click through and purchase the product, will earn me a small commission. This helps support my writing so I can keep writing helpful posts like this!)*
When we write code and build software, we're not just communicating to the computer the instruction... | tarsir |
1,891,362 | JavaScript Modules: Love 'Em or Hate 'Em? | JavaScript modules are a way to organize and structure code in a modular fashion, making it more... | 27,558 | 2024-06-17T14:21:02 | https://dev.to/imabhinavdev/javascript-modules-love-em-or-hate-em-40kp | webdev, javascript, beginners, tutorial | JavaScript modules are a way to organize and structure code in a modular fashion, making it more manageable and reusable. Modules allow developers to break down complex applications into smaller, self-contained units that can be easily maintained, tested, and reused across projects.
In JavaScript, there are two primar... | imabhinavdev |
1,891,354 | 7 Open Source Projects for Web Development that you didn't know | Exploring lesser-known Open Source projects can unveil tools that are not only powerful but also... | 0 | 2024-06-17T14:19:23 | https://dev.to/buildwebcrumbs/7-open-source-projects-for-web-development-that-you-didnt-know-1c8c | opensource, webdev, productivity, discuss | Exploring lesser-known Open Source projects can unveil tools that are not only powerful but also tailored to specific development needs that might not be covered by the mst popular projects.
Here are seven less known Oprn Source projects that can help you bring innovation and efficiency to your web development project... | opensourcee |
1,891,356 | How to transform Component Development with Storybook and Symfony UX ? | Hey everyone! I am so excited about this article because what I'm going to show you here has been my... | 0 | 2024-06-17T14:17:39 | https://dev.to/sensiolabs/how-to-transform-component-development-with-storybook-and-symfony-ux--c86 | Hey everyone! I am so excited about this article because what I'm going to show you here has been my dream since I first heard about Symfony UX! I will demonstrate a setup that makes me incredibly productive, but most importantly, brings me a lot of joy.
As you know, I love working with components (TwigComponent/LiveC... | webmamba | |
1,891,355 | Why is it dangerous to use the HTTP protocol on public Wi-Fi. | What is HTTP HTTP is a hypertext transfer protocol that underlies the Internet. It`s located at the... | 0 | 2024-06-17T14:12:45 | https://dev.to/marko_k/why-is-it-dangerous-to-use-the-http-protocol-on-public-wi-fi-1gh | http, https |
**What is HTTP**
HTTP is a hypertext transfer protocol that underlies the Internet. It`s located at the last layer of the OSI and TCP/IP model (application layer). HTTP is implemented in two programs: a client program and a server program. Client and server programs running on different end systems. They communicate ... | marko_k |
1,891,352 | Handling React Warnings: Filtering Props in Styled Components | When working with React and styled-components, you might encounter warnings about unrecognized props... | 0 | 2024-06-17T14:10:44 | https://dev.to/mochafreddo/handling-react-warnings-filtering-props-in-styled-components-3233 | react, styledcomponents, performance, codemaintainability | When working with React and styled-components, you might encounter warnings about unrecognized props being passed to DOM elements. This blog post will walk you through understanding why this happens and how to resolve it effectively.
#### The Problem
You might see a warning like this in your console:
```
Warning: Re... | mochafreddo |
1,891,343 | How I Became a Top-Rated Freelancer: 20 Proven Strategies You Need! | Hey, my name is Can İz, but people know me as “Kris” in the freelancer space. I’m a full-stack web... | 0 | 2024-06-17T14:08:35 | https://mrkriswaters.medium.com/how-i-became-a-top-rated-freelancer-20-proven-strategies-you-need-e58f58615205 | freelance, fiverr, tradingview, pinescript | Hey, my name is Can İz, but people know me as “Kris” in the freelancer space. I’m a full-stack web developer with a 12-year professional work career. In 2017, I got tired of working in the same field, so I started looking for other ways to enjoy my life while working on projects that needed professional help. I got inv... | kriswaters |
1,891,348 | AIM Weekly 17 June 2024 | 17-June-2024 Tim Spann @PaaSDev Milvus - Towhee - Attu - Feder - GPTCache - VectorDB... | 0 | 2024-06-17T14:06:00 | https://dev.to/tspannhw/aim-weekly-17-june-2024-3cmp | milvus, vectordatabase, genai, opensource | ## 17-June-2024
Tim Spann @PaaSDev
Milvus - Towhee - Attu - Feder - GPTCache - VectorDB Bench
Happy Father's Day To All! Also Happy Flag Day to Those in the United States.

### AIM Weekly
### Towhee - Attu -... | tspannhw |
1,891,347 | Melhores Novos Casinos Online em Portugal [2024] | A facilidade de uso e acessibilidade são características fundamentais dos novos casinos online em... | 0 | 2024-06-17T14:02:39 | https://dev.to/miguel_costa_be10627d781c/melhores-novos-casinos-online-em-portugal-2024-26gb | A facilidade de uso e acessibilidade são características fundamentais dos novos casinos online em Portugal. Esses sites são projetados para serem intuitivos, permitindo que jogadores de todos os níveis naveguem facilmente e encontrem seus jogos e serviços preferidos sem dificuldades. Acesse [https://casino-portugal.com... | miguel_costa_be10627d781c | |
1,871,888 | Tech radar: Keep an eye on the technology landscape | If you've been working in technology for a while, you've probably noticed that there are so many... | 23,317 | 2024-06-17T14:00:00 | https://dev.to/jdxlabs/tech-radar-keep-an-eye-on-the-technology-landscape-2pnd | methodology, cloud, learning, community | If you've been working in technology for a while, you've probably noticed that there are so many technologies out there and things are constantly evolving.
My goal here is to give you some keys to not miss essential information and find your way in the technological jungle, while having the ability to completely disco... | jdxlabs |
1,891,344 | SSL Networking | What is SSL? SSL (Secure Sockets Layer) is a standard security protocol for establishing encrypted... | 0 | 2024-06-17T13:59:32 | https://dev.to/dariusc16/ssl-networking-15eh | **What is SSL?**
SSL (Secure Sockets Layer) is a standard security protocol for establishing encrypted links between a web server and a browser in online communication. It ensures that all data transmitted between the web server and browser remains encrypted and secure. SSL uses encryption algorithms to scramble data i... | dariusc16 | |
1,891,342 | Exploring the World of Ada and SPARK | In the realm of software development, particularly in safety-critical systems, reliability and... | 0 | 2024-06-17T13:58:20 | https://dev.to/ajgamer/exploring-the-world-of-ada-and-spark-33o3 | beginners, programming, security | In the realm of software development, particularly in safety-critical systems, reliability and security are paramount. Languages like Ada and its subset SPARK have been designed with these goals in mind, offering robust tools for developers aiming to build dependable and error-free applications. This post delves into t... | ajgamer |
1,891,341 | I Found a way to Automate 2FA and TOTP. | Hello Readers, After very long time now I am back with a very interesting topic for Automation... | 0 | 2024-06-17T13:56:05 | https://dev.to/gokul2172001/i-found-a-way-to-automate-2fa-and-totp-38pe | beeceptors, automation, testing, 2fa | Hello Readers,
After very long time now I am back with a very interesting topic for Automation Testers. I’ve recently see a post in linked In about the beeceptors. That post contains a lot of information of a very good advantage of use the Beeceptor Api which we can use to overcome the dificulty of 2FA ( 2-Factor Authe... | gokul2172001 |
1,891,340 | Where Do I Find WPS Pin on HP Printer | Finding the WPS PIN on Your HP Printer Connecting your HP printer to a wireless network... | 0 | 2024-06-17T13:53:38 | https://dev.to/printerhelp/where-do-i-find-wps-pin-on-hp-printer-l76 | beginners, printer, wifi, hp | ## Finding the WPS PIN on Your HP Printer
Connecting your HP printer to a wireless network using the Wi-Fi Protected Setup (WPS) PIN method is a secure and convenient way to ensure a seamless printing experience. The WPS PIN is a unique code generated by your printer, allowing you to connect to your Wi-Fi network with... | printerhelp |
1,891,339 | What Is Staging in Software Development? | Guide for Beginners | I realized how important the staging environment is. It is essentially a copy of the live site and... | 0 | 2024-06-17T13:52:58 | https://dev.to/igor_ag_aaa2341e64b1f4cb4/what-is-staging-in-software-development-3hfo | softwaredevelopment, beginners, development | I realized how important the staging environment is. It is essentially a copy of the live site and serves as the last checkpoint before making changes to the live site.By mirroring the live environment, it allows us to test new changes meticulously before they reach the public. This step isn't mandatory, but for large ... | igor_ag_aaa2341e64b1f4cb4 |
1,891,337 | Escrevendo Boas Mensagens de Commit | Se você é um desenvolvedor, já deve estar familiarizado com sistemas de gerenciamento de versão, como... | 0 | 2024-06-17T13:48:42 | https://dev.to/darlangui/pt-br-escrevendo-boas-mensagens-de-commit-3pka | braziliandevs, git, tutorial, learning | Se você é um desenvolvedor, já deve estar familiarizado com sistemas de gerenciamento de versão, como o amplamente usado Git. Este resumo vai te guiar na importância da mensagem do commit e no que deve ser incluído nele, de uma maneira bem prática e direta.
## Iniciando com o Git init
Vamos começar do começo, bora ini... | darlangui |
1,891,336 | Online Crackers Sivakasi for Vel Traders Crackers | Introduction: A Boom in the Online Crackers Market Remember the excitement of buying... | 0 | 2024-06-17T13:48:36 | https://dev.to/vel_traderscrackers_10df/online-crackers-sivakasi-for-vel-traders-crackers-2oob | ### Introduction: A Boom in the Online Crackers Market
Remember the excitement of [buying crackers for festivals?](https://www.velcrackerssivakasi.com/shop/) The colorful sparks, the loud bangs, and the joyous celebrations. Now, imagine all of that excitement at your fingertips. That's right! Buying crackers online ha... | vel_traderscrackers_10df | |
1,891,335 | If I Were to Start Over as a Developer I'd... | If I Were to Start My Web Developer Career Over I'd... Looking back on my journey from a... | 0 | 2024-06-17T13:46:07 | https://dev.to/qyrusai/if-i-were-to-start-over-as-a-developer-id-2kam | webdev, developer, worklife, beginners | ### If I Were to Start My Web Developer Career Over I'd...
Looking back on my journey from a wide-eyed novice to a seasoned senior web developer, I often think about what I would do differently if I could start over. Hindsight, as they say, is 20/20. With the wisdom and experience I've gained, here are some things I w... | qyrusai |
1,891,334 | Why Set Doesn't Allow Duplicates in Java | In Java, a Set is a collection that does not allow duplicate elements. This behavior is enforced by... | 0 | 2024-06-17T13:45:54 | https://dev.to/codegreen/why-set-doesnt-allow-duplicates-in-java-3ad8 | streams, java | In Java, a Set is a collection that does not allow duplicate elements. This behavior is enforced by the underlying implementations of the Set interface, such as HashSet, TreeSet, and LinkedHashSet.
The main reason Sets do not allow duplicates is due to the contract defined by the Set interface:
* **Uniqueness:** Se... | manishthakurani |
1,891,330 | In Java how to create a custom ArrayList that doesn't allow duplicate? #Interview Question | Creating a Custom ArrayList in Java that Doesn't Allow... | 0 | 2024-06-17T13:39:30 | https://dev.to/codegreen/in-java-how-to-create-a-custom-arraylist-that-doesnt-allow-duplicate-dbj | streams, java | ##Creating a Custom ArrayList in Java that Doesn't Allow Duplicates##
=================================================================
In Java, you can create a custom ArrayList that ensures no duplicate elements are added **by extending the ArrayList class** and **overriding the add method**.
```java
import java.ut... | manishthakurani |
1,891,329 | Error Handling and Testing in Go | Error Handling Error handling is a crucial aspect of robust software development, ensuring... | 0 | 2024-06-17T13:39:09 | https://dev.to/gophers_kisumu/error-handling-and-testing-in-go-4c9n | ### Error Handling
Error handling is a crucial aspect of robust software development, ensuring that applications can gracefully handle unexpected conditions and provide meaningful feedback to users and developers. In Go, error handling is done explicitly, promoting clarity and simplicity.
#### Error Types
Go uses th... | gophers_kisumu | |
1,891,083 | Swift 101: Collections part III - Tuples and Dictionaries | Hola Mundo! Welcome to a new article in a series of Swift 101 notes 📝 I created these... | 27,019 | 2024-06-17T13:38:39 | https://dev.to/silviaespanagil/swift-101-collections-part-iii-tuples-and-dictionaries-42p0 | swift, beginners, learning, mobile | #Hola Mundo!
<Enter>
Welcome to a new article in a series of [Swift 101 notes](https://dev.to/silviaespanagil/swift-101-getting-into-ios-development-gji) 📝 I created these notes while learning the language and decided to share them because why not?
If you're new to Swift or interested in learning more about this la... | silviaespanagil |
1,891,328 | Bubble game CSS only | Check out this Pen I made! This is a beautiful bubble that fly in an area. And you should to click... | 0 | 2024-06-17T13:38:09 | https://dev.to/tidycoder/bubble-game-css-only-2occ | codepen | Check out this Pen I made! This is a beautiful bubble that fly in an area. And you should to click on.
{% codepen https://codepen.io/TidyCoder/pen/KKLZoYL %} | tidycoder |
1,891,327 | Helm 3: Advanced Package Management for Kubernetes Applications | Helm 3 is a significant upgrade to the Helm package manager for Kubernetes applications. This version... | 0 | 2024-06-17T13:37:25 | https://dev.to/platform_engineers/helm-3-advanced-package-management-for-kubernetes-applications-2o6b | Helm 3 is a significant upgrade to the Helm package manager for Kubernetes applications. This version introduces several key features that enhance the management and deployment of applications on Kubernetes clusters. In this blog, we will delve into the technical details of Helm 3 and explore its capabilities.
### Pac... | shahangita | |
1,891,326 | 🐚🦀Shell commands rewritten in rust | Introduction For every software engineer, developer, or programmer, command-line tools are... | 0 | 2024-06-17T13:36:54 | https://dev.to/girordo/shell-commands-rewritten-in-rust-23id | rust, shell, terminal, beginners | ## Introduction
For every software engineer, developer, or programmer, command-line tools are essential for making life easier, especially when working with code. In recent years, with the rise in popularity of the Rust language, we have seen a growing number of these tools being rewritten in Rust, providing better pe... | girordo |
1,891,230 | How I've implemented the Medallion architecture using Apache Spark and Apache Hdoop | Table of contents What is this project all about System architecture The Retail... | 0 | 2024-06-17T13:35:05 | https://dev.to/fadygrab/how-ive-implemented-the-medallion-architecture-using-apache-spark-and-apache-hdoop-3lmb | dataengineering, apachespark, data, opensource | ## Table of contents
- [What is this project all about](#what-is-this-project-all-about)
- [System architecture](#system-architecture)
- [The Retail app](#the-retail-app)
- [Apache Spark Cluster](#apache-spark-cluster)
- [The Development Jupyter server](#the-development-jupyter-server)
- [Th... | fadygrab |
1,891,324 | Writing the best custom header UX for Zoraxy | Recently, I am working on improving the Zoraxy (my open source reverse proxy server written in... | 0 | 2024-06-17T13:33:49 | https://dev.to/tobychui/writing-the-best-custom-header-ux-for-zoraxy-367n | ux, ui, html, design | Recently, I am working on improving the [Zoraxy](https://github.com/tobychui/zoraxy) (my open source reverse proxy server written in Golang). As this is not a post about reverse proxy but UX, I am gonna sum up this project in one sentence: Zoraxy is a reverse proxy server that uses UX first design.
 need a reliable solution... | 0 | 2024-06-17T13:32:56 | https://spacelift.io/blog/terraform-drift-detection | terraform, devops, infrastructureascode | Organizations using Terraform to manage their infrastructure as code (IaC) need a reliable solution to ensure their infrastructure's actual state aligns with its intended state.
Terraform stores information about the infrastructure it manages in [state files](https://spacelift.io/blog/terraform-state), and any change ... | spacelift_team |
1,891,321 | Osama : not a Web Developer | Osama Bin Laden America 1993- world trade center - 6 died 1998 - U.S.... | 0 | 2024-06-17T13:32:35 | https://dev.to/keshavgbpecdel/osama-not-a-web-developer-5dbb |

## Osama Bin Laden
## America
- 1993- world trade center - 6 died
- 1998 - U.S. Embassies - 224 died
- 2001 - 9/11 - 3K died
`Note : Operation Infinite Reach - was failed before`
## Operation Neptune Spear
... | keshavgbpecdel | |
1,891,318 | Made an online HTML editor | Okay, so this is the latest addition to my side project. I made an HTML editor. To be honest, it... | 0 | 2024-06-17T13:28:07 | https://dev.to/anjandutta/made-an-online-html-editor-mji | html, webdev, javascript, beginners |
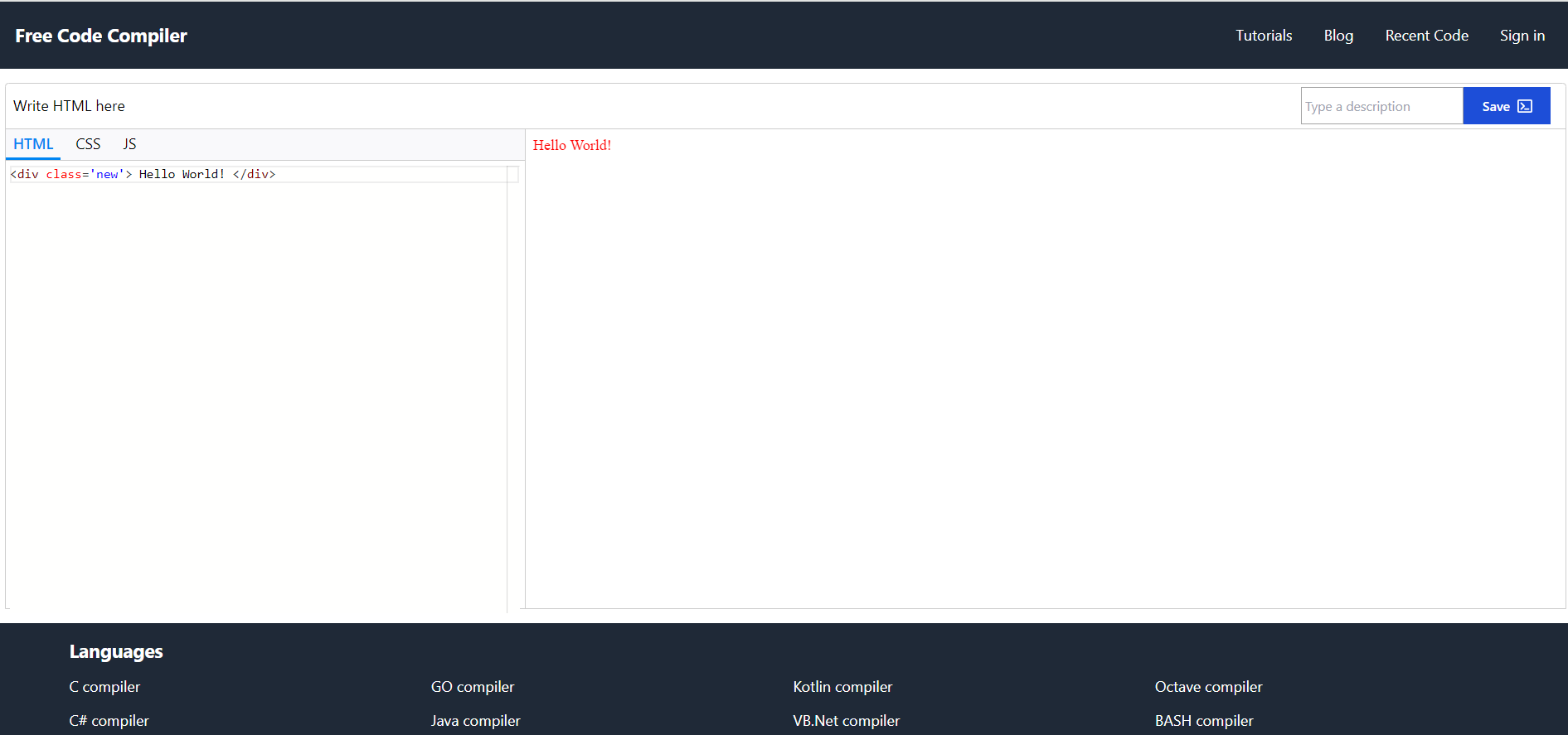
Okay, so this is the latest addition to my side project. I made an HTML editor. To be honest, it was not that hard but it was special!
I enjoyed the magical moment when I first saw my html code rendering in the pr... | anjandutta |
1,891,317 | Why Hire a Dedicated Vue.js Developer? | Streamlining Web Development with Efficiency & Flexibility Gentle Learning Curve: Vue.js... | 0 | 2024-06-17T13:24:02 | https://dev.to/coderowersoftware/why-hire-a-dedicated-vuejs-developer-5fk5 | webdev, vue, javascript, developers | **Streamlining Web Development with Efficiency & Flexibility**
**Gentle Learning Curve:** Vue.js features a concise syntax and user-friendly design, enabling rapid adoption even for beginners in JavaScript & HTML. This accessibility reduces barriers and speeds up project timelines.
**Component-Based Architecture:** V... | coderower |
1,891,232 | The Advantages of .Net: Build Robust Scalable with .Net and Its Dedicated Developers | Cross-platform Compatibility: .NET Core, a core part of the .NET framework, allows you to build... | 0 | 2024-06-17T13:19:56 | https://dev.to/coderowersoftware/the-advantages-of-net-build-robust-scalable-with-net-and-its-dedicated-developers-bm9 | dotnet, developer, webdev, developers | **Cross-platform Compatibility:** .NET Core, a core part of the .NET framework, allows you to build applications that run seamlessly on Windows, Linux, and macOS. This flexibility caters to diverse deployment needs.
**Object-oriented Approach:** .NET’s object-oriented foundation promotes code reusability, maintainabil... | coderower |
1,891,231 | If you are considering a car purchase | If you are considering a car purchase and value high quality service, I highly recommend looking into... | 0 | 2024-06-17T13:19:18 | https://dev.to/lexzub/if-you-are-considering-a-car-purchase-4fc7 | If you are considering a car purchase and value high quality service, I highly recommend looking into Ford Vidi, especially if you are interested in the Ford Kuga. I was personally thrilled with the level of service I received. The professionalism and attention to detail makes the process of choosing a vehicle easy and... | lexzub | |
1,891,473 | 100 Salesforce Project Manager Interview Questions and Answers | A Salesforce Project Manager is responsible for overseeing the planning, execution, and delivery of... | 0 | 2024-06-18T15:09:21 | https://www.sfapps.info/100-salesforce-project-manager-interview-questions-and-answers/ | blog, interviewquestions | ---
title: 100 Salesforce Project Manager Interview Questions and Answers
published: true
date: 2024-06-17 13:15:00 UTC
tags: Blog,InterviewQuestions
canonical_url: https://www.sfapps.info/100-salesforce-project-manager-interview-questions-and-answers/
---
A Salesforce Project Manager is responsible for overseeing the... | doriansabitov |
1,891,228 | Hire Dedicated DevOps Engineers: Unleash Your Development Velocity | Demolishing Silos: DevOps engineers promote teamwork across departments, dismantling barriers and... | 0 | 2024-06-17T13:14:33 | https://dev.to/coderowersoftware/hire-dedicated-devops-engineers-unleash-your-development-velocity-1mbp | webdev, devops, developer, development | **Demolishing Silos:** DevOps engineers promote teamwork across departments, dismantling barriers and ensuring unified objectives.
**Building RockSolid Software:** DevOps engineers ensure smooth CI/CD practices, leading to fewer bugs, reliable software, and lower production risks.
**Scaling with Ease:** DevOps engine... | coderower |
1,891,224 | InnoDB Performance Tuning – 11 Critical InnoDB Variables to Optimize Your MySQL Database | InnoDB is the core storage engine for MySQL, celebrated for its reliability and performance in even... | 0 | 2024-06-17T13:14:25 | https://releem.com/blog/innodb-performance-tuning | webdev, mysql, php, programming | InnoDB is the core storage engine for MySQL, celebrated for its reliability and performance in even the most challenging of production settings. To truly optimize InnoDB, you need a deep understanding of various system variables and how they interact with your unique server setup and the specific demands of your worklo... | drupaladmin |
1,891,227 | What is intent prompting? | When you need to build more complex applications using LLMs, you often need to determine a course of... | 0 | 2024-06-17T13:13:39 | https://dev.to/kwnaidoo/what-is-intent-prompting-26jb | ai, machinelearning, python, productivity | When you need to build more complex applications using LLMs, you often need to determine a course of action based on various scenarios.
For example: if you are building an insurance application, the user may be interested in one of these insurance types: car, household, pets, etc...
Based on their request, you need t... | kwnaidoo |
1,891,226 | Learn a new tool, or just use what you know? | Diving into flask . I'm building a website as a way to give myself a 'reason' to learn and a... | 0 | 2024-06-17T13:12:43 | https://dev.to/oakla/learn-a-new-tool-or-just-use-what-you-know-obh | webdev, python, wtforms | Diving into flask . I'm building a website as a way to give myself a 'reason' to learn and a realistic problem to solve. As a go along with project, I keep discovering new nuances to the challenge, along with a world of framework designed to help makes things easier.
Today I discovered WTForms. Will learning yet anoth... | oakla |
1,891,225 | Improving Your SQL Indexing: How to Effectively Order Columns | A new blog post with the theory and an example of the art of indexing: finding the best index for one... | 0 | 2024-06-17T13:12:04 | https://dev.to/yugabyte/improving-your-sql-indexing-how-to-effectively-order-columns-24dj | yugabytedb, distributed, sql, database | A new blog post with the theory and an example of the art of indexing: finding the best index for one query and also understanding that you don't need the best index:
{% embed https://www.yugabyte.com/blog/improving-sql-indexing-how-to-order-columns/ %} | franckpachot |
1,891,219 | SFU vs MCU vs P2P: WebRTC Architectures Explained | There are different WebRTC architecture available today, these are SFU, MCU and P2P, selecting one... | 0 | 2024-06-17T13:09:21 | https://www.metered.ca/blog/sfu-vs-mcu-vs-p2p-webrtc-architectures-explained/ | webdev, javascript, devops, webrtc | There are different WebRTC architecture available today, these are SFU, MCU and P2P, selecting one depends on many factors these include
### **Network Conditions**
### **Bandwidth availability**
* High Bandwidth
If participants have good quality bandwidth then SFU and peer to peer calling will work for them
*... | alakkadshaw |
1,891,153 | CRUD Operations: The Basics of Data Management | First, We learn what the CRUD operation is, then we will understand step by step with a backend code... | 0 | 2024-06-17T13:09:16 | https://dev.to/praneshcodecraft/crud-operations-the-basics-of-data-management-4c0a | backend, javascript, express, database | First, We learn what the CRUD operation is, then we will understand step by step with a backend code (express.js).

CRUD stands for Create, Read, Update, and Delete. These are the four basic things you can do wit... | praneshchow |
1,891,222 | Understanding Cybersecurity: A Beginner’s Guide | Imagine you live in a bustling city where every house is a computer, and every street represents the... | 0 | 2024-06-17T13:07:30 | https://dev.to/clom/understanding-cybersecurity-a-beginners-guide-10ji | cybersecurity, beginners | Imagine you live in a bustling city where every house is a computer, and every street represents the internet. Just as in any city, securing your house is crucial to ensure your safety and privacy. In the digital world, cybersecurity plays this critical role. Let’s explore the basics of cybersecurity through this ana... | clom |
1,891,221 | A Importância de Evitar a Generalização Precoce em Fluxos Complexos | Disclaimer Este texto foi gerado pela IA Generativa em função da transcrição do episódio do nosso... | 0 | 2024-06-17T13:07:12 | https://dev.to/dev-mais-eficiente/a-importancia-de-evitar-a-generalizacao-precoce-em-fluxos-complexos-4l0e | **Disclaimer**
Este texto foi gerado pela IA Generativa em função da transcrição do episódio do nosso canal, Dev Eficiente.
**Introdução**
No desenvolvimento de software, é comum nos depararmos com a tentação de generalizar comportamentos e criar interfaces desde o início. No entanto, essa abordagem pode ser prejud... | asouza | |
1,880,625 | Sentiment Analysis using CPU-Friendly Small Language Models 😡 😃 | What are Small Language Models? 🤔 You have probably heard of Large Language Models, but... | 0 | 2024-06-17T13:06:59 | https://dev.to/llmware/sentiment-analysis-using-cpu-friendly-small-language-models-1idd | ai, python, programming, tutorial | ## What are Small Language Models? 🤔
You have probably heard of Large Language Models, but what about Small Language Models (SLMs)? These compact models excel on specialized tasks, are ideal to use with limited resources, and have faster processing times. Let's explore LLMWare's SLIM models!
***
## Harnessing SLIM ... | will_taner |
1,891,218 | MENA Generic Oncology Drug Market: Recent Developments and Analysis | MENA Generic Oncology Drug Market Size & Forecast The MENA Generic Oncology Drug Market was... | 0 | 2024-06-17T13:05:09 | https://dev.to/sri_harikrishnabalaji_2/mena-generic-oncology-drug-market-recent-developments-and-analysis-ho | MENA Generic Oncology Drug Market Size & Forecast
The MENA Generic Oncology Drug Market was valued at USD 4 billion in 2023 and is expected to grow at a CAGR of 3% during the forecast period (2024-2032).
MENA Generic Oncology Drug Market Analysis
The MENA region’s generic oncology drug market is experiencing robust gro... | sri_harikrishnabalaji_2 | |
1,891,217 | Latest Technologies in React Native | 1. Overview of React Native Technology React Native is an open-source cross-platform... | 0 | 2024-06-17T13:04:04 | https://dev.to/happyer/latest-technologies-in-react-native-cmm | react, reactnative, mobile, development | ## 1. Overview of React Native Technology
React Native is an open-source cross-platform mobile application development framework developed by Facebook. It allows developers to write native applications using JavaScript and React. With React Native, developers can leverage React's declarative programming style and comp... | happyer |
1,891,216 | Image Optimization and Lazy Loading | In the era of modern frontends, we often raise the question, "How do I make my application more... | 0 | 2024-06-17T13:03:18 | https://dev.to/joaopaulo_avila/image-optimization-and-lazy-loading-30gj | angular, tutorial | In the era of modern frontends, we often raise the question, "How do I make my application more performant?" In this article, I will discuss image optimization and lazy loading to help improve performance and make our application increasingly faster.
**_Images are always a problem in the life of frontenders._**
Very ... | joaopaulo_avila |
1,891,215 | Concurrency in Go: Goroutines, Channels, and Concurrency Patterns | Introduction to Goroutines Concurrency in Go is a core feature that allows programs to... | 0 | 2024-06-17T13:02:50 | https://dev.to/gophers_kisumu/concurrency-in-go-goroutines-channels-and-concurrency-patterns-4hlc | ## Introduction to Goroutines
Concurrency in Go is a core feature that allows programs to perform multiple tasks simultaneously. One of the key tools for achieving concurrency in Go is the goroutine. Goroutines are lightweight threads managed by the Go runtime, enabling efficient execution of concurrent tasks.
## Cre... | gophers_kisumu | |
1,542,229 | Are you well-paid? | Checking out wages and compensation can give us some cool insights into how in-demand different... | 0 | 2023-07-19T14:32:50 | https://dev.to/developernationsurvey/are-you-well-paid-1069 | salaries, news, discuss | Checking out wages and compensation can give us some cool insights into how in-demand different skills are in the job market. Even with layoffs happening in tech companies, the number of professional developers worldwide is still on the rise. One reason for this is that modern businesses have realized that **tech is be... | developernationsurvey |
1,891,214 | I discovered Rust's zero-cost abstraction | Today I discovered Rust's zero-cost abstraction and learned how it optimizes software efficiency... | 0 | 2024-06-17T13:02:25 | https://dev.to/ashsajal/i-discovered-rusts-zero-cost-abstraction-akk | rust, coding, programming, tutorial | **Today I discovered Rust's zero-cost abstraction and learned how it optimizes software efficiency without sacrificing expressive code design.**
Rust, celebrated for its emphasis on performance and safety, introduces a concept pivotal to its design philosophy: zero-cost abstraction. This principle allows developers to... | ashsajal |
1,891,213 | terminal app | im using robotjs to nuild an app now the problem is idk how to make that the user can have more than... | 0 | 2024-06-17T13:01:14 | https://dev.to/uriahn/terminal-app-6p | node, terminal, app, robotjs | im using robotjs to nuild an app now the problem is idk how to make that the user can have more than one action i mean that when he run the code he can do more than one thing in the app
func bot:
` console.log("checkStartBOT")
sleep(2000)
console.clear()
//res vaule to 0
let xValue = 0;
let yValue = 0;
c... | uriahn |
1,891,212 | From Noise to Art: Building Your First Generative Adversarial Network | I was introduced to this splendid machine learning idea known as Generative Adversarial Networks... | 0 | 2024-06-17T13:00:06 | https://dev.to/yuval728/from-noise-to-art-building-your-first-generative-adversarial-network-472o | python, ai, machinelearning, programming | I was introduced to this splendid machine learning idea known as Generative Adversarial Networks (GANs) especially in the image generation area. Another framework known as GANs was developed by Ian Goodfellow in 2014; its underlying architecture is built by utilizing a two-neural-network competition. According to the s... | yuval728 |
1,891,208 | Boosting React app performance | Boosting performance of react application | 0 | 2024-06-17T12:58:58 | https://dev.to/pradeep3/boosting-react-app-performance-13k4 | react, javascript, beginners, performance | ---
title: Boosting React app performance
published: true
description: Boosting performance of react application
tags: react, javascript, beginners, performance
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/7vtfbjtql15a0n08llxs.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-0... | pradeep3 |
1,891,210 | How Artificial Intelligence (AI) is Reshaping the World of Programming | As we navigate through the digital age, it's undeniable that Artificial Intelligence (AI) is... | 0 | 2024-06-17T12:58:33 | https://dev.to/lelycomfort/how-artificial-intelligence-ai-is-reshaping-the-world-of-programming-243b | ai, coding, programming | As we navigate through the digital age, it's undeniable that Artificial Intelligence (AI) is dramatically altering the fabric of programming. In my experience, I see that AI is not just a tool but a revolutionary force, optimizing how we code and enhancing the capabilities of programmers worldwide. For professionals in... | lelycomfort |
1,891,209 | The Evolution and Impact of Omegle: A Digital Frontier for Random Social Interactions | Imagine a portal that whisks you away from the curated feeds and familiar faces of social media,... | 0 | 2024-06-17T12:58:08 | https://dev.to/kohensteve/the-evolution-and-impact-of-omegle-a-digital-frontier-for-random-social-interactions-13n1 | Imagine a portal that whisks you away from the curated feeds and familiar faces of social media, depositing you face-to-face (or screen-to-screen) with a complete stranger. A stranger who could be a seasoned traveler with tales from exotic lands, a passionate artist eager to share their work, or simply someone looking ... | kohensteve | |
1,891,207 | Beginner's Guide to Test Coverage with NUnit, Coverlet, and ReportGenerator | Hi guys, today I am going to show a quick and simple way to get started with Test Coverage in your... | 0 | 2024-06-17T12:57:08 | https://dev.to/bigboybamo/beginners-guide-to-test-coverage-with-nunit-coverlet-and-reportgenerator-3fde | csharp, dotnet, beginners, webdev | Hi guys, today I am going to show a quick and simple way to get started with Test Coverage in your code.
## What is Test Coverage?
Test coverage is the percentage of code that is tested by automated tests. That is, it measures the extent to which a codebase is **covered** by tests we write.
Prerequisites for this tut... | bigboybamo |
1,891,096 | Information Classification in Microsoft Purview: A Step-by-Step Guide | Microsoft Purview offers a robust framework for information classification and protection, enabling... | 0 | 2024-06-17T12:54:14 | https://dev.to/borisgigovic/information-classification-in-microsoft-purview-a-step-by-step-guide-167k | informationgovernance, informationsecurity, datasecurity, dataprotection | Microsoft Purview offers a robust framework for information classification and protection, enabling organizations to categorize and secure data across various services and platforms. This guide delves into the process of creating labels and classification policies within Microsoft Purview, ensuring your data is managed... | borisgigovic |
1,891,206 | Unity Tutor | Hi guys I am looking to run some small online group classes in Minecraft to children and young... | 0 | 2024-06-17T12:52:53 | https://dev.to/summer24/unity-tutor-58gn | Hi guys
I am looking to run some small online group classes in Minecraft to children and young people (beginner classes) over the UK summer holidays and I wondered if there is anyone on here that might be interested in running some of these.
Drop a comment if this is something you would like to find out more about.
... | summer24 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.