
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,891,199 | Why the R1 Rabbit OS Device Isn't Worth the Hype | The debut of the R1 device promised a revolutionary gadget that could understand its owner and... | 0 | 2024-06-17T12:39:41 | https://dev.to/lilarmstrong/why-the-r1-rabbit-os-device-isnt-worth-the-hype-246i | rabbitos, technology, ai, computing |
The debut of the R1 device promised a revolutionary gadget that could understand its owner and automate mundane visual tasks, a feature touted as a significant leap in mobile technology. When I pre-ordere... | lilarmstrong |
1,891,205 | Revolutionize Your Icon Sketching with IconSnap | Are you tired of spending countless hours perfecting your icons, only to end up feeling frustrated... | 0 | 2024-06-17T12:52:03 | https://dev.to/stokry/experience-the-future-of-icon-creation-with-iconsnap-2dmf | showdev, productivity, design, webdev |
Are you tired of spending countless hours perfecting your icons, only to end up feeling frustrated with the tedious editing process? Say goodbye to those days and welcome the future of icon creation with [IconSnap](https://iconsnap.me/)!
At IconSnap, we’re revolutionizing the way you design icons with our cutting... | stokry |
1,891,204 | One Byte Explainer : Cluster Computing | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-17T12:49:36 | https://dev.to/deadpunnk/-one-byte-explainer-cluster-computing-gmc | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Cluster computing, consists in using two or more machines to execute a job, in a why that all resources are shared between them. It machine in the cluster is called a node and if one n... | deadpunnk |
1,891,202 | Advanced Go Concepts | Data Structures Arrays and Slices Arrays Arrays in Go are... | 0 | 2024-06-17T12:44:46 | https://dev.to/gophers_kisumu/advanced-go-concepts-28o4 | ## Data Structures
### Arrays and Slices
#### Arrays
Arrays in Go are fixed-length sequences of elements of the same type. They are defined with a specific size, and once created, their size cannot be changed.
```go
var a [5]int // array of 5 integers
```
Arrays are useful when the size of the data is known and fi... | gophers_kisumu | |
1,891,201 | Binary Search: Find It in Half the Time | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-17T12:42:14 | https://dev.to/yashrajxdev/binary-search-find-it-in-half-the-time-1hlb | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Binary Search: Divide-and-conquer search for sorted data. Repeatedly halves search space based on comparison with middle element. O(log n) time complexity. Useful for efficient searche... | yashrajxdev |
1,891,200 | Difference Between Performance Testing, Load Testing, and Stress Testing | In the world of software development, ensuring that applications perform well under various... | 0 | 2024-06-17T12:39:47 | https://dev.to/testscenario/difference-between-performance-testing-load-testing-and-stress-testing-29eh | testing | In the world of software development, ensuring that applications perform well under various conditions is crucial. Performance testing, load testing, and stress testing are three essential techniques used to evaluate and enhance the performance and reliability of software applications. While these testing methods share... | testscenario |
1,891,135 | How to Build Progressive Web Apps (PWAs) Using Laravel? | Ever feel like your website could be more? We've all been there. Users today expect fast, reliable... | 0 | 2024-06-17T12:36:59 | https://dev.to/aaronreddix/how-to-build-progressive-web-apps-pwas-using-laravel-1f6o | webdev, pwa, beginners, laravel | Ever feel like your website could be more? We've all been there. Users today expect fast, reliable experiences, even when their internet connection isn't perfect.
PWAs are the future of web development, blurring the lines between websites and mobile apps. They offer the best of both worlds: the accessibility of a webs... | aaronreddix |
1,891,196 | Navigating the World of Business Grants: A Comprehensive Guide | Business grants are akin to a financial lifeline for budding entrepreneurs and established... | 0 | 2024-06-17T12:36:02 | https://dev.to/capiqalfinance/navigating-the-world-of-business-grants-a-comprehensive-guide-359d | business, grants, support |

Business grants are akin to a financial lifeline for budding entrepreneurs and established companies alike. These grants are sums of money given to businesses without the requirement of payback, making them a highl... | capiqalfinance |
1,891,144 | Go Fundamentals | Basic Syntax and Structure 1. Go Program Structure A Go program typically consists of... | 0 | 2024-06-17T12:34:01 | https://dev.to/gophers_kisumu/go-fundamentals-1e7i | #### Basic Syntax and Structure
**1. Go Program Structure**
A Go program typically consists of multiple packages, and the main package serves as the entry point of the program. The basic structure of a Go program is:
```go
package main
import "fmt"
// main function - the entry point of the program
func main() {
... | gophers_kisumu | |
1,891,194 | Deploy Your C# Blazor App To Vercel | Vercel, known for its seamless deployment and scalability, is a popular choice among developers.... | 0 | 2024-06-17T12:32:42 | https://www.onit.eu/blog/deploy-your-csharp-blazor-app-to-vercel | webdev, csharp, git |
Vercel, known for its seamless deployment and scalability, is a popular choice among developers. While Vercel primarily supports JavaScript frameworks, it’s entirely possible to deploy C# applications too. Let's dive into how you can deploy your C# projects to Vercel, making your build fast and shipping faster.
## Wh... | max_onit |
1,891,195 | How template method can ruin your Java code | Author: Konstantin Volohovsky OOP is wonderful. Programmers usually criticize those who don't follow... | 0 | 2024-06-17T12:30:49 | https://dev.to/anogneva/how-template-method-can-ruin-your-java-code-48ni | java, programming, coding | Author: Konstantin Volohovsky
OOP is wonderful\. Programmers usually criticize those who don't follow this paradigm, while the knowledge of patterns is often a must\. However, even the right approach doesn't completely protect from errors\. Today, we'll learn how to break a program using the standard template method\.... | anogneva |
1,891,127 | https://brazino.io/ | Welcome to Brazino 777, the premier online casino and sports betting destination in Brazil. As the... | 0 | 2024-06-17T11:33:15 | https://dev.to/brazino/httpsbrazinoio-42f0 | webdev, javascript, beginners, programming | Welcome to Brazino 777, the premier online casino and sports betting destination in Brazil. As the number one platform in the country, Brazino 777 offers an extensive range of thrilling casino games, from slots and table games to live dealer options, ensuring an unparalleled gaming experience. Sports enthusiasts can in... | brazino |
1,820,888 | Perfect Elixir: Development Workflows | Today we'll explore the tools and workflows essential for our daily development. Our goal is to... | 25,978 | 2024-06-17T12:25:00 | https://dev.to/jonlauridsen/perfect-elixir-development-workflows-26k6 | elixir, tutorial, development, webdev | Today we'll explore the tools and workflows essential for our daily development. Our goal is to create a streamlined onboarding experience and establish efficient mechanisms for code changes. Let's dive into some solutions to see how it all works out.
**Table of Contents**
* [A Reflection on Workflows](#a-reflection-o... | jonlauridsen |
1,891,193 | Achieve Superior Cost Control with a Freelance Quantity Surveyor | Managing construction projects involves balancing costs and timelines efficiently. By hiring a... | 0 | 2024-06-17T12:24:33 | https://dev.to/floydmcguire/achieve-superior-cost-control-with-a-freelance-quantity-surveyor-158l | Managing construction projects involves balancing costs and timelines efficiently. By hiring a freelance quantity surveyor, you can leverage their expertise to ensure accurate and effective cost control, ultimately leading to the successful completion of your project.
Detailed Budget Planning
A freelance quantity sur... | floydmcguire | |
1,891,192 | What Are Some Good Dot Net Courses to Take After Completing a Bachelor's Degree in Computer Science? | Pursuing advanced learning after completing a Bachelor's degree in Computer Science is a wise choice... | 0 | 2024-06-17T12:24:27 | https://dev.to/scholarhat/what-are-some-good-dot-net-courses-to-take-after-completing-a-bachelors-degree-in-computer-science-29m2 | Pursuing advanced learning after completing a Bachelor's degree in Computer Science is a wise choice to stay competitive and updated with the latest industry trends. For those interested in the .NET framework, there are several excellent courses available. This article will explore some of the best .NET courses that ca... | scholarhat | |
1,890,328 | Terraform Dynamic Blocks: Advanced Use Cases and Examples | Imagine a scenario where you have to create multiple similar resources, like subnets or security... | 0 | 2024-06-17T12:15:00 | https://www.env0.com/blog/terraform-dynamic-blocks | terraform, devops, infrastructureascode, sre | Imagine a scenario where you have to create multiple similar resources, like subnets or security group rules, each with a slight variation.
Instead of copying and pasting the same code with minor changes, dynamic blocks let you write the configuration once and dynamically generate the variations based on input values... | env0team |
1,891,169 | RFID - low wave radio communications | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-17T12:14:20 | https://dev.to/tyler_wes/rfid-low-wave-radio-communications-4acf | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
## Additional Context
<!-- Please share any additional context you think the judges should take into considerat... | tyler_wes |
1,891,168 | Deep vs Shallow cloning 2 | OBJECT const original = { name: 'John', age: 23, address: { city:... | 0 | 2024-06-17T12:12:12 | https://dev.to/__khojiakbar__/deep-vs-shallow-cloning-2-2jjg | javascript, deep, shallow, cloning | # OBJECT
```
const original = {
name: 'John',
age: 23,
address: {
city: 'Tashkent',
state: 'Oqqorg\'on',
}
}
```
### SPREAD:
```
// Spread => Shallow copying
let copiedObj = {...original}
copiedObj.name = 'Alice'
copiedObj.address.city = 'Samarkand';
console.log(copiedObj.name)
console... | __khojiakbar__ |
1,891,167 | Meme Coin HTML Website Template | This eye-catching template offers a fun and functional journey through digital currencies, combining... | 0 | 2024-06-17T12:11:49 | https://dev.to/bitrix_theme/meme-coin-html-website-template-16eh | memecoin, website, html, template | This eye-catching [template ](https://theme.bitrixinfotech.com/templates)offers a fun and functional journey through digital currencies, combining functionality and aesthetics, allowing users to create interactive applications.
learn more: https://theme.bitrixinfotech.com/product-detail/meme-coin-website-template | bitrix_theme |
1,891,164 | Innovation in India: A Vibrant Tapestry of Growth and Technology | India, known for its rich cultural heritage and diverse traditions, is now making waves in the world... | 0 | 2024-06-17T12:09:58 | https://dev.to/stevemax237/innovation-in-india-a-vibrant-tapestry-of-growth-and-technology-5g6o | webdev, softwaredevelopment, technology, india | India, known for its rich cultural heritage and diverse traditions, is now making waves in the world of innovation and technology. Over the past few decades, India has transformed into a global powerhouse of innovation, driven by an entrepreneurial spirit, a highly skilled workforce, and supportive government policies.... | stevemax237 |
1,891,074 | How to create a local Kubernetes cluster with Kind | While developing apps that will live in a Kubernetes environment it’s always better to have a local... | 0 | 2024-06-17T12:06:15 | https://dev.to/niemet0502/how-to-create-a-local-kubernetes-cluster-with-kind-554p | kubernetes, orchestration, kind, infrastructre | While developing apps that will live in a [Kubernetes](https://mariusniemet.me/containers-orchestration-and-kubernetes/) environment it’s always better to have a local cluster to test our app or to debut issues. In this article, we will learn how to create a local Kubernetes cluster using [kind](https://kind.sigs.k8s.i... | niemet0502 |
1,891,125 | Self-hosted public site - safe and cheap. | In my first post in the series there where a lot of people that were concerned about exposing local... | 27,648 | 2024-06-17T12:06:00 | https://dev.to/sein_digital/self-hosted-public-site-safe-and-cheap-11k2 | docker, selfhosted, tutorial, opensource | In my first post in the series there where a lot of people that were concerned about exposing local network to public internet, or actually might have a problem with doing that due to ISP limitations like dynamic IP or reverse lookup. That might not be a problem if you order a static IP from your ISP, but not all ISPs ... | sein_digital |
1,891,160 | Explore What is Azure Monitor: Features, Benefits, and Use Cases | Microsoft Azure offers Azure Monitor, a monitoring service that facilitates collecting, analyzing,... | 0 | 2024-06-17T12:05:25 | https://dev.to/dhruvil_joshi14/explore-what-is-azure-monitor-features-benefits-and-use-cases-2m8g | azuremonitor, azure, azuresecurity, cloudsecurity | Microsoft Azure offers Azure Monitor, a monitoring service that facilitates collecting, analyzing, and acting raw data from both cloud and in-house systems. It enables you to maximize the performance and reliability of your apps and infrastructure resources. This blog will explain what is Azure Monitor and cover its ke... | dhruvil_joshi14 |
1,891,158 | I Learned Nuxtjs & Made A Web App That Went Viral | Introducing TikVid A tool to quickly create stunning Fake LinkedIn posts for Social Media,... | 0 | 2024-06-17T12:04:52 | https://dev.to/simply_stanley_/i-learned-nuxtjs-made-a-web-app-that-went-viral-2h7p | ---
title: I Learned Nuxtjs & Made A Web App That Went Viral
published: true
description:
tags:
# cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/kb8xje73plb9fc8inz90.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-16 22:13 +0000
---
Introducing [TikVid](https://www.tikvid... | simply_stanley_ | |
1,891,159 | Automotive Electronics Market: Analysis, Trends & Opportunities 2031 | According to the SNS Insider report, The Automotive Electronics Market Size was valued at USD 262.5... | 0 | 2024-06-17T12:04:51 | https://dev.to/vaishnavi_98b52fbc25f0930/automotive-electronics-market-analysis-trends-opportunities-2031-m4m | According to the SNS Insider report, The Automotive Electronics Market Size was valued at USD 262.5 billion in 2023 and is estimated to reach USD 515.46 billion by 2031, with an expected CAGR of 8.8% over the forecast period from 2024 to 2031.
Market Scope & Overview
Automotive Electronics Market research report provid... | vaishnavi_98b52fbc25f0930 | |
1,891,156 | Conference Annoucement {Template} | Hi {Name Of Recipient}, The wait is over! The {Name Of Conference} Conference 2024 is about to... | 0 | 2024-06-17T12:04:19 | https://dev.to/theholyspirit/conference-annoucement-template-18k4 | skills, trade, bridge, projectmanagement |
Hi {Name Of Recipient},
The wait is over! The {Name Of Conference} Conference 2024 is about to begin! 🎉
You can access the livestream of the event at:
https://{Address Of The Event}/live
We're excited to have you join us for a day full of insightful talks, interactive sessions, {Activities The Event Offers}, and n... | theholyspirit |
1,891,152 | Understanding the Composite Design Pattern: Simplifying Hierarchical Structures | The Composite Design Pattern is an essential tool in system design, enabling you to manage and... | 0 | 2024-06-17T12:00:03 | https://dev.to/rupesh_mishra/understanding-the-composite-design-pattern-simplifying-hierarchical-structures-4eep | designpatterns, java, programming, tutorial | The Composite Design Pattern is an essential tool in system design, enabling you to manage and simplify complex hierarchical structures. By treating individual objects and composite objects uniformly, this pattern enhances the flexibility and maintainability of your software. Let's explore this pattern through a clear,... | rupesh_mishra |
1,851,900 | Types for React components with children | Image credits to: tranmautritam Typescript requires that we specify the types for the different... | 0 | 2024-06-16T19:20:18 | https://coffeebytes.dev/en/types-for-react-components-with-children/ | javascript, react, typescript | ---
title: Types for React components with children
published: true
date: 2024-06-17 12:00:00 UTC
tags: javascript,react,typescript
canonical_url: https://coffeebytes.dev/en/types-for-react-components-with-children/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/apdljshgsgur5jd766ge.jpg
---
Imag... | zeedu_dev |
1,889,888 | The backdrop-filter CSS property has been unprefixed | The backdrop-filter CSS property required a prefix 1 in Safari since forever, well 2015 to be more... | 0 | 2024-06-17T12:00:00 | https://www.roboleary.net/blog/unprefixing-backdrop-filter/ | css, webdev | The [`backdrop-filter`](https://developer.mozilla.org/en-US/docs/Web/CSS/backdrop-filter) CSS property required a prefix [^1] in Safari since forever, well 2015 to be more precise. You *had to* use `-webkit-backdrop-filter` just for Safari's sake. Starting in Safari 18 beta, you don’t need the prefix! 🤗
Mostly you do... | robole |
1,891,150 | Understanding the Basics: What is Electronic Data Interchange (EDI)? | In today’s digital age, businesses are constantly looking for efficient and cost-effective ways to... | 0 | 2024-06-17T11:55:09 | https://dev.to/actionedi/understanding-the-basics-what-is-electronic-data-interchange-edi-1h3n | In today’s digital age, businesses are constantly looking for efficient and cost-effective ways to streamline their operations. Electronic Data Interchange (EDI) is a solution that has transformed the way companies exchange information. But what exactly is EDI?
EDI is the electronic interchange of business documents b... | actionedi | |
1,891,149 | Linux Text Display | Imagine a mystical night in the Enchanted Forest where shadows weave spells of silence and the moon bathes the leaves in silver whispers. In this magical realm, you take on the role of the Forest's Arcane Hunter, a master of ancient texts and echoic spells. Your quest is to harness the power of Linux commands to unveil... | 27,674 | 2024-06-17T11:54:27 | https://labex.io/tutorials/linux-linux-text-display-271273 | linux, coding, programming, tutorial |
## Introduction
Imagine a mystical night in the Enchanted Forest where shadows weave spells of silence and the moon bathes the leaves in silver whispers. In this magical realm, you take on the role of the Forest's Arcane Hunter, a master of ancient texts and echoic spells. Your quest is to harness the power of Linux ... | labby |
1,891,126 | Best Affordable CRM for Small Business | Introduction Customer Relationship Management (CRM) systems are essential tools for small... | 0 | 2024-06-17T11:32:39 | https://dev.to/salestown/best-affordable-crm-for-small-business-51b1 | crm, startup, business, software | ## Introduction
Customer Relationship Management (CRM) systems are essential tools for small businesses aiming to manage their interactions with current and potential customers effectively. CRMs help businesses streamline processes, improve customer relationships, and boost sales. For small businesses, finding a cost-e... | salestown |
1,891,148 | Top 5 Best C# Books for Beginners in 2024 | If you're considering diving into the world of programming with C#, you've made an excellent choice.... | 0 | 2024-06-17T11:53:50 | https://dev.to/bytehide/top-5-best-c-books-for-beginners-in-2024-3n07 | csharp, programming, development, coding | If you're considering diving into the world of programming with C#, you've made an excellent choice. Known for its versatility and rigor, C# is a language that's used widely in various domains, from enterprise applications to game development.
As a beginner, it's crucial to start with the right resources. To aid in y... | bytehide |
1,891,147 | Net Worth | Understanding Net Worth: A Key Measure of Financial Health Hey everyone, let's dive into the topic... | 0 | 2024-06-17T11:53:27 | https://dev.to/muhammad_mohsin_dec22d0cb/chrisean-rock-net-worth-1hnm | Understanding Net Worth: A Key Measure of Financial Health
Hey everyone, let's dive into the topic of net worth—a fundamental indicator of our financial well-being!
What is Net Worth?
Simply put, net worth is the difference between what you own (your assets) and what you owe (your liabilities). It's a snapshot of ... | muhammad_mohsin_dec22d0cb | |
1,891,143 | Betpedia88: Destinasi Utama untuk Pecinta Taruhan Online | Dalam era digital yang semakin berkembang, industri taruhan online telah menjadi salah satu sektor... | 0 | 2024-06-17T11:49:33 | https://dev.to/betpedia88/betpedia88-destinasi-utama-untuk-pecinta-taruhan-online-fdn | webdev, bet, react | Dalam era digital yang semakin berkembang, industri taruhan online telah menjadi salah satu sektor yang paling dinamis dan menarik. Betpedia88 adalah salah satu platform taruhan online yang telah menarik perhatian banyak pengguna di seluruh dunia, termasuk Indonesia. Dengan 3.600 pengunjung yang datang setiap bulan, Be... | betpedia88 |
1,891,142 | Encapsulate What Varies (EWV) Principle: A Pragmatic Approach | Applying the Encapsulate What Varies (EWV) principle helps create maintainable, flexible, and... | 0 | 2024-06-17T11:47:35 | https://dev.to/muhammad_salem/encapsulate-what-varies-ewv-principle-a-pragmatic-approach-2p3f |
Applying the Encapsulate What Varies (EWV) principle helps create maintainable, flexible, and adaptable software systems. The essence of this principle is to identify aspects of your application that are likely to change and encapsulate them in such a way that these changes do not affect the core, stable parts of your... | muhammad_salem | |
1,891,141 | Bridging the Gap: Integrating Responsible AI Practices into Scalable LLMOps for Enterprise Excellence | Responsible LLMOps: Integrating Responsible AI Practices into LLMOps ... | 0 | 2024-06-17T11:47:30 | https://dev.to/emma_in_tech/bridging-the-gap-integrating-responsible-ai-practices-into-scalable-llmops-for-enterprise-excellence-19k3 | ai, llmops, aiops, machinelearning | ### Responsible LLMOps: Integrating Responsible AI Practices into LLMOps
#### Introduction
The rapid adoption of Large Language Models (LLMs) in enterprises has opened new avenues for AI-driven solutions. However, this enthusiasm is often tempered by challenges related to scaling and responsibly managing these models... | emma_in_tech |
1,891,140 | Mastering Async/Await in JavaScript Like a Pro! | 1. Introduction to Async/Await Async/Await is a much more modern JavaScript syntax for... | 27,607 | 2024-06-17T11:47:08 | https://dev.to/hkp22/mastering-asyncawait-in-javascript-like-a-pro-33h0 | webdev, javascript, programming, react | ### 1. Introduction to Async/Await
Async/Await is a much more modern JavaScript syntax for dealing with asynchronous operations of a program in a much smoother and more intuitive way. It was launched within ECMAScript 2017, or ES8, that eases working with Promises and gives asynchronous-looking and-behaving, synchrono... | hkp22 |
1,891,139 | Biometric System Market Overview: Biometric Payment Systems | The Biometric System Market Size was valued at $ 49.12 Bn in 2023, and is expected to reach $ 140 Bn... | 0 | 2024-06-17T11:47:04 | https://dev.to/vaishnavi_farkade_/biometric-system-market-overview-biometric-payment-systems-2gp6 | **The Biometric System Market Size was valued at $ 49.12 Bn in 2023, and is expected to reach $ 140 Bn by 2031, and grow at a CAGR of 13.98% by 2024-2031.**
**Market Scope & Overview:**
The research report examines the Biometric System Market Overview in great detail. Consumption rates, production locations and volum... | vaishnavi_farkade_ | |
1,891,138 | ESG Investing: A Comprehensive Guide to Sustainable Investment Decisions | ESG (Environmental, Social, and Governance) investing is emerging as a significant trend in the... | 0 | 2024-06-17T11:46:59 | https://dev.to/linda0609/esg-investing-a-comprehensive-guide-to-sustainable-investment-decisions-40h1 |
ESG (Environmental, Social, and Governance) investing is emerging as a significant trend in the financial world. This approach integrates real-world performance factors, allowing investors to assess how companies impact their regional communities. It also promotes strategic thinking aimed at achieving sustainable de... | linda0609 | |
1,891,137 | San Francisco Limo Service: Unveiling the Gateway to Unforgettable Experiences | San Francisco, a tapestry of iconic landmarks, world-class cuisine, and captivating landscapes,... | 0 | 2024-06-17T11:46:45 | https://dev.to/bng_worldwidechauffeurs/san-francisco-limo-service-unveiling-the-gateway-to-unforgettable-experiences-3bb5 | San Francisco, a tapestry of iconic landmarks, world-class cuisine, and captivating landscapes, beckons travelers with the promise of an unforgettable experience. But navigating the city's vibrant energy, bustling streets, and iconic hills can be daunting. This is where a San Francisco limo service steps in, transfor... | bng_worldwidechauffeurs | |
1,891,136 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-06-17T11:46:10 | https://dev.to/shourya_raj_ae160938d1859/my-pen-on-codepen-1ole | codepen | Check out this Pen I made!
{% codepen https://codepen.io/webdevelopment657/pen/poQLbex %} | shourya_raj_ae160938d1859 |
1,891,132 | The Beginning- Luxury Wedding Venue In Bangalore | Looking for a luxurious wedding venue in Bangalore? Look no further than The Beginning – luxury... | 0 | 2024-06-17T11:44:41 | https://dev.to/the_beginning_aee9b5c3301/the-beginning-luxury-wedding-venue-in-bangalore-1kf7 | luxuryweddingvenue, luxuryweddinghall, banquethall, birthdaypartyhall | Looking for a [luxurious wedding venue in Bangalore](https://www.thebeginning.in/
)? Look no further than The Beginning – luxury wedding resort in Bangalore offer the perfect setting for your dream wedding. The Beginning ultimate destination for a spectacular celebration. Our venue is equipped to cater to any of events... | the_beginning_aee9b5c3301 |
1,891,131 | Navigating the Oracle Financials 24A Release | We all know Oracle releases quarterly updates, and the release of the year is here: “Oracle... | 0 | 2024-06-17T11:43:48 | https://www.ceoinsightsindia.com/news/navigating-the-oracle-financials-24a-release-nwid-17327.html | oracle, financials, release | 
We all know Oracle releases quarterly updates, and the release of the year is here: “Oracle Financials 24A Release.” This brings a variety of new features and upgrades to improve function- ality & expedite procedures... | rohitbhandari102 |
1,891,130 | Sikka Mall of Expressway | Sikka Mall of Expressway is a rising star in Greater Noida's commercial landscape. Situated... | 0 | 2024-06-17T11:36:56 | https://dev.to/sikka_mall/sikka-mall-of-expressway-1f27 | **[Sikka Mall of Expressway](https://sikkamallexpressway.com)** is a rising star in Greater Noida's commercial landscape. Situated conveniently in Omega II, the mall boasts excellent connectivity, | sikka_mall | |
1,891,129 | Muggu Skincare Pollushield Sunscreen | Sunscreen SPF 50: It deflects UVA and UVB rays, providing broad-spectrum sun protection.... | 0 | 2024-06-17T11:34:59 | https://dev.to/muggu_skincare_/muggu-skincare-pollushield-sunscreen-5boh | [Sunscreen SPF 50:](https://www.nykaa.com/muggu-skincare-pollushield-sunscreen/p/15625128?productId=15625128&pps=15)
It deflects UVA and UVB rays, providing broad-spectrum sun protection. Additionally, it shields against pollution and prevents sunburn, redness, tanning, and pigmentation.
| muggu_skincare_ | |
1,891,128 | RR Interior Design in Gurgaon | Welcome to RR Interior design company in Gurgaon, your trusted partner in transforming spaces into... | 0 | 2024-06-17T11:34:47 | https://dev.to/rr_interior/rr-interior-design-in-gurgaon-96f | interior, interiordesign, rrinterior, gurgaon |

Welcome to RR Interior design company in Gurgaon, your trusted partner in transforming spaces into exquisite havens. With over 12+ years of dedicated experience in the realm of interior design, we have Deliver more... | rr_interior |
1,891,124 | 8 Best Practices for Secure Financial Software Development | The significance of security and compliance in the creation of financial software in the current... | 0 | 2024-06-17T11:27:05 | https://dev.to/bhavikachauhan0/8-best-practices-for-secure-financial-software-development-2all | financialdevelopment, softwaredevelopment, financialdevelopmentservices |

The significance of security and compliance in the creation of financial software in the current digital era cannot be emphasizedemphasised. Financial software is being used more and more, thus it's critical to mak... | bhavikachauhan0 |
1,891,123 | Immediately, I Am Hiring An Apprentice | Let Me Know If You Are Interested And Available. | 0 | 2024-06-17T11:27:04 | https://dev.to/theholyspirit/immediately-i-am-hiring-an-apprentice-379p | Let Me Know If You Are Interested And Available. | theholyspirit | |
1,891,122 | I Make Techno | I Write Technical Writing. Some Of It Is About Software Most Of It Is Human Engineering ... | 0 | 2024-06-17T11:26:10 | https://dev.to/theholyspirit/i-make-techno-1llb | I Write Technical Writing.
Some Of It Is About Software
Most Of It Is Human Engineering
#WorldEngineer #Technical | theholyspirit | |
1,891,121 | 🤯Deep vs Shallow cloning ??? | How to determine? Shallow Copy Criteria: Only the top-level properties are... | 0 | 2024-06-17T11:21:11 | https://dev.to/__khojiakbar__/deep-vs-shallow-cloning--40ln | javascript, deep, shallow, cloning |
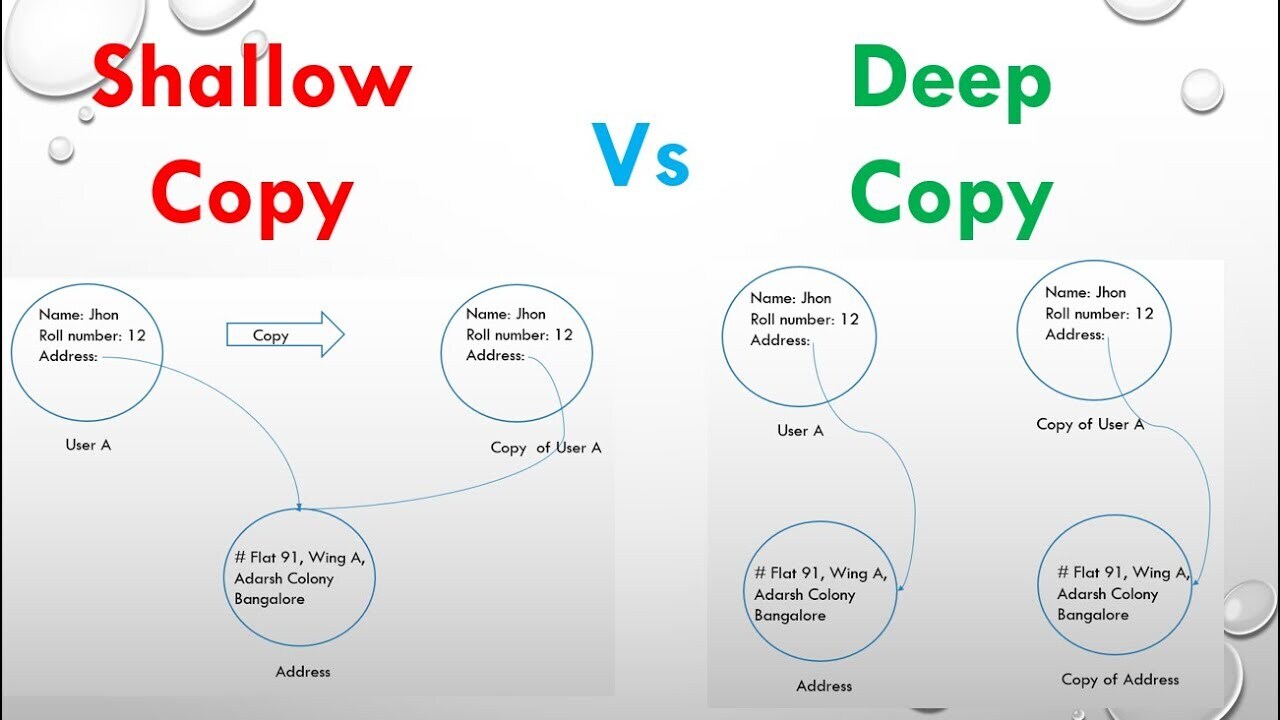
# How to determine?
## Shallow Copy
**Criteria:**
* Only the top-level properties are copied. Nested objects are copied by reference.
**Indicators:**
* If modifying a nested object in the copied object also ch... | __khojiakbar__ |
1,890,500 | Ho we built Ammirator. The OnlyFans competitor | Our journey began a year ago when we started thinking about building a platform for content creators... | 0 | 2024-06-17T11:18:22 | https://dev.to/ammirator/ho-we-built-ammirator-the-onlyfans-competitor-26e1 | web3, ethereum, javascript, kubernetes | Our journey began a year ago when we started thinking about building a platform for content creators that would work fully with crypto and have the lowest platform fee in the industry (**just 10%**), and that's when we started to build [Ammirator](https://ammirator.com).
We choose crypto because the problem with tradi... | ammirator |
1,891,078 | Associations in EF Core | let's dive into a comprehensive guide on associations in Entity Framework Core (EF Core). ... | 0 | 2024-06-17T10:28:09 | https://dev.to/muhammad_salem/associations-in-ef-core-14d3 | dotnet, efcore | let's dive into a comprehensive guide on associations in Entity Framework Core (EF Core).
### Associations in Entity Framework Core
In object-oriented programming and database design, associations represent relationships between entities. EF Core supports several types of associations:
1. **One-to-One (1:1)**
2. **O... | muhammad_salem |
1,891,110 | Bioelectronics and Biosensors Market Analysis: End-Use Insights in Healthcare Sector | Bioelectronics and Biosensors Market size was valued at $ 31.78 Bn in 2023 and is expected to grow to... | 0 | 2024-06-17T11:18:10 | https://dev.to/vaishnavi_farkade_/bioelectronics-and-biosensors-market-analysis-end-use-insights-in-healthcare-sector-43ol | **Bioelectronics and Biosensors Market size was valued at $ 31.78 Bn in 2023 and is expected to grow to $ 65 Bn by 2031 and grow at a CAGR Of 9.32 % by 2024-2031.**
**Market Scope & Overview:**
For market research, a comprehensive investigation of market expectations and estimates is required. Implementation is aided... | vaishnavi_farkade_ | |
1,891,111 | The Right Way to Clone Nested Object/Array (Deep Clone) in Javascript | This post was originally published at... | 0 | 2024-06-17T11:18:00 | https://devaradise.com/deep-clone-nested-object-array-in-javascript/ | javascript, webdev, beginners, frontend | This post was originally published at [https://devaradise.com/deep-clone-nested-object-array-in-javascript](https://devaradise.com/deep-clone-nested-object-array-in-javascript)
As you might know, Javascript uses pass-by-reference when passing an object, array, or function to a new variable. When you pass an object, ar... | syakirurahman |
1,891,109 | Seeking UI/UX Designer Volunteers 🤝(Open Source) | Hi, I’m Jackson Kasi, a full-stack developer passionate about building open-source applications to... | 0 | 2024-06-17T11:17:57 | https://dev.to/jacksonkasi/seeking-uiux-designer-volunteers-open-source-1k0k | opensource, volunteers, ui, ux | Hi, I’m [Jackson Kasi](https://www.linkedin.com/in/jacksonkasi), a full-stack developer passionate about building open-source applications to help others. I’m currently working on an open-source Figma plugin project and am seeking UI/UX designer volunteers to join me in making this plugin even better.
### About the Pl... | jacksonkasi |
1,890,648 | How to Kickstart Your Web Development Career in 2024 | How to Kickstart Your Web Development Career in 2024 Breaking into the tech industry can... | 0 | 2024-06-17T11:17:57 | https://dev.to/techtobe101/how-to-kickstart-your-web-development-career-in-2024-mbm | webdev, beginners, techtobe101, discuss | # How to Kickstart Your Web Development Career in 2024
Breaking into the tech industry can be daunting, but with the right strategies and mindset, you can navigate your way to success. Here’s a proven and tested approach that has worked for me, and I believe it can work for you too.
---
## The Backstory
I recently... | techtobe101 |
1,891,108 | How to set a default selected effect for VChart pie charts? | Problem description When drawing a pie chart for the first time, I hope to highlight a... | 0 | 2024-06-17T11:16:32 | https://dev.to/flyingandfly/how-to-set-a-default-selected-effect-for-vchart-pie-charts-22e4 |
## Problem description
When drawing a pie chart for the first time, I hope to highlight a block. How should I configure it?
## Solution
1. Firs... | flyingandfly | |
1,890,494 | Write Less, Fix Never: The Art of Highly Reliable Code | If you're a developer tirelessly pushing out new changes, only to be dragged back by errors in your... | 0 | 2024-06-17T11:14:20 | https://dev.to/middleware/write-less-fix-never-the-art-of-highly-reliable-code-5a0i | developer, productivity, programming, career | 
If you're a developer tirelessly pushing out new changes, only to be dragged back by errors in your past work, this post is incredibly relevant for you.
Over the past decade in software development, one of the key... | dhruvagarwal |
1,891,107 | 10 LINUX COMMAND | Introduction Linux is an open-source operating system kernel originally developed by Linus... | 0 | 2024-06-17T11:09:12 | https://dev.to/sir-alex/10-linux-command-1l33 |
# Introduction
Linux is an open-source operating system kernel originally developed by Linus Torvalds in 1991. Linux commands form the backbone of system management and interaction in Linux-based operating systems. They are powerful tools that allow users to perform a wide range of tasks efficiently from the command l... | sir-alex | |
1,891,106 | How Opkey Helps Maximize Efficiency With Workday Human Capital Management? | Managing a company's workforce is a crucial aspect of any business operation. To ensure smooth and... | 0 | 2024-06-17T11:07:35 | https://www.asiabusinessoutlook.com/news/how-opkey-helps-maximize-efficiency-with-workday-human-capital-management-nwid-6407.html | workday, human, capital, management | 
Managing a company's workforce is a crucial aspect of any business operation. To ensure smooth and efficient management of employees, many organi- zations rely on powerful software called Human Capital Management... | rohitbhandari102 |
1,446,350 | This week's round-up of APIs: Best Podcasts, Podcast Details and Podcast Episode Details | As per our usual practice, we will introduce three new APIs to you this week. These data sources were... | 0 | 2024-06-17T11:07:00 | https://dev.to/worldindata/this-weeks-round-up-of-apis-best-podcasts-podcast-details-and-podcast-episode-details-2fnb | api, podcast, datamarketplace | As per our usual practice, we will introduce three new APIs to you this week. These data sources were selected for our weekly API roundup and we hope you will find them interesting. We will closely explore the purpose, industry, and client types of these APIs. The complete details of the APIs can be found on [Worldinda... | worldindata |
1,891,105 | Technokraft | Top SEO Agency In Irving | SEO Agency In Texas | In today's digital age, having a robust online presence is crucial for businesses aiming to thrive... | 0 | 2024-06-17T11:05:53 | https://dev.to/technokraftserve/technokraft-top-seo-agency-in-irving-seo-agency-in-texas-4923 | seo, seoagency, digitalmarketing, seoagencyintexas |

In today's digital age, having a robust online presence is crucial for businesses aiming to thrive and grow. As competition intensifies, leveraging effective search engine optimization (SEO) strategies becomes imper... | technokraftserve |
1,891,104 | TOP 8 CRICKET THRILLERS: IRELAND VS. PAKISTAN MATCHES THAT WENT DOWN TO THE WIRE | Ireland vs. Pakistan: Cricket's Most Memorable Encounters Cricket fanatics, buckle up for... | 0 | 2024-06-17T11:03:44 | https://dev.to/naitreyi_jake_gaming/top-8-cricket-thrillers-ireland-vs-pakistan-matches-that-went-down-to-the-wire-3noo | gamedev, onlinegameslots, gameslots, onlinegames | ## **Ireland vs. Pakistan: Cricket's Most Memorable Encounters**
Cricket fanatics, buckle up for a nostalgic journey down memory lane! Today, we revisit some of the most electrifying matches between Ireland and Pakistan. These encounters weren't just about boundaries and wickets; they were about unwavering resilience,... | naitreyi_jake_gaming |
1,891,103 | Performance Benchmarking: gRPC+Protobuf vs. HTTP+JSON | A fair benchmark with Go examples to compare Protocol Buffers over gRPC vs. JSON over HTTP/1 and HTTP/2. | 0 | 2024-06-17T11:03:42 | https://dev.to/plutov/performance-benchmarking-grpcprotobuf-vs-httpjson-2jck | go, grpc, performance, json | ---
title: Performance Benchmarking: gRPC+Protobuf vs. HTTP+JSON
published: true
description: A fair benchmark with Go examples to compare Protocol Buffers over gRPC vs. JSON over HTTP/1 and HTTP/2.
tags: Go, gRPC, Performance, JSON
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/6gd2xfcoile0npt1o... | plutov |
1,891,102 | AI Face Swap Tool: The Ultimate Guide to Adult Content | Uncover the power of AI face swap tools in our ultimate guide. Explore the latest technology and... | 0 | 2024-06-17T11:03:37 | https://dev.to/novita_ai/ai-face-swap-tool-the-ultimate-guide-to-adult-content-2ilo | Uncover the power of AI face swap tools in our ultimate guide. Explore the latest technology and trends in AI face-swap porn.
## Key Highlights
- Deepfake technology has revolutionized the world of face swapping, offering endless possibilities for creative expression.
- The development of deepfake technology in the p... | novita_ai | |
1,891,101 | Unveiling 0G Labs: A Deep Dive into the Fastest Modular AI Chain | 📚 TinTinLand's #TinTinLandWeb3LearningMonth has entered Week 3! 📅 This week (June 17 - June 21),... | 0 | 2024-06-17T11:02:48 | https://dev.to/ourtintinland/unveiling-0g-labs-a-deep-dive-into-the-fastest-modular-ai-chain-h28 | webdev, ai, learning | 📚 TinTinLand's #TinTinLandWeb3LearningMonth has entered Week 3!
📅 This week (June 17 - June 21),
@0G_labs
will host an exciting online AMA and Zealy learning tasks.
🌠 0G Labs is the first modular AI chain, starting with an infinitely scalable, programmable Data Availability Layer (DA Layer).
🛠️ Join Discord for... | ourtintinland |
1,891,100 | Automotive Electronic Brake System Market: Size, Share & Industry Forecast | According to the SNS Insider report, The Automotive Electronic Brake System Market Size was valued at... | 0 | 2024-06-17T11:02:09 | https://dev.to/vaishnavi_98b52fbc25f0930/automotive-electronic-brake-system-market-size-share-industry-forecast-5cl0 | According to the SNS Insider report, The Automotive Electronic Brake System Market Size was valued at USD 22.15 billion in 2023 and is projected to reach USD 35.23 billion by 2031, growing at a CAGR of 5.98% over the forecast period from 2024 to 2031.
Market Scope & Overview
The market research explores the size, trend... | vaishnavi_98b52fbc25f0930 | |
1,891,120 | Disable Start Menu Ads in Windows 11! | Key Steps: Right-click the Start button and select Settings. Go to Personalization >... | 0 | 2024-07-02T16:21:32 | https://winsides.com/how-to-disable-start-menu-ads-in-windows-11/ | windows11, beginners, tutorials, tips | ---
title: Disable Start Menu Ads in Windows 11!
published: true
date: 2024-06-17 11:00:14 UTC
tags: Windows11,beginners,tutorials,tips
canonical_url: https://winsides.com/how-to-disable-start-menu-ads-in-windows-11/
cover_image: https://winsides.com/wp-content/uploads/2024/06/Disable.png
---
> ## Key Steps:
>
> - Rig... | vigneshwaran_vijayakumar |
1,891,099 | Can the VChart axis be set to avoid decimals? | Problem description I am using a bar chart to describe the number of problems. There... | 0 | 2024-06-17T10:59:30 | https://dev.to/flyingandfly/can-the-vchart-axis-be-set-to-avoid-decimals-45ec |
## Problem description
I am using a bar chart to describe the number of problems. There should be no decimal place in the circumstances. How to avoid the phenomenon of axis text appearing 0.5?
 developed by Vercel, implementing LLM chat in next.js... | ppaanngggg |
1,888,577 | Essential Deep Learning Checklist: Best Practices Unveiled | Introduction In the rapidly advancing and dynamic domain of deep learning, project success... | 0 | 2024-06-17T10:55:02 | https://dev.to/api4ai/essential-deep-learning-checklist-best-practices-unveiled-5gma | deeplearning, ai, tensorflow, machinelearning | #Introduction
In the rapidly advancing and dynamic domain of deep learning, project success requires more than just a thorough understanding of neural networks and access to cutting-edge computing resources. It demands a structured approach to project management, data handling, model assessment, and more. This is wher... | taranamurtuzova |
1,891,095 | A Detailed Guide to Web Application Development in 2024 | Web application development is a symbol of the constant change that defines the modern world. In... | 0 | 2024-06-17T10:51:42 | https://dev.to/dynamicmethods/a-detailed-guide-to-web-application-development-in-2024-1iji | html, angular, javascript | **[Web application development](https://dynamic-methods.com/web-application-development-services/)** is a symbol of the constant change that defines the modern world. In 2024, there will be more users than ever before. In addition to practicality, consumers expect outstanding, engaging, and inventive experiences.
This... | dynamicmethods |
1,891,094 | Basic Container Lifecycle Management | Managing Docker Containers Throughout your container journey, you will be pulling,... | 27,622 | 2024-06-17T10:50:43 | https://dev.to/kalkwst/basic-container-lifecycle-management-3n9k | beginners, docker, devops, tutorial | ## Managing Docker Containers
Throughout your container journey, you will be pulling, starting, stopping, and removing containers from your local environment quite frequently. Prior to deploying a container in a production environment, it is critical to run the container locally to understand how it should work. This i... | kalkwst |
1,891,093 | How to Setup and Run a Solana RPC Node | Solana’s RPC (Remote Procedure Call) node acts as a gateway to the network, allowing developers to... | 0 | 2024-06-17T10:50:31 | https://dev.to/donnajohnson88/how-to-setup-and-run-a-solana-rpc-node-3mh2 | solana, blockchain, rpc, webdev | Solana’s RPC (Remote Procedure Call) node acts as a gateway to the network, allowing developers to interact with the blockchain for [Solana blockchain development services](https://blockchain.oodles.io/solana-blockchain-development-services/?utm_source=devto). If you’re looking to build dApps or interact with the Solan... | donnajohnson88 |
1,891,080 | How AI Virtual Staging is Transforming Property Listings | Introduction In an increasingly digital world, the real estate industry is embracing... | 0 | 2024-06-17T10:50:00 | https://dev.to/novita_ai/how-ai-virtual-staging-is-transforming-property-listings-o03 | ## Introduction
In an increasingly digital world, the real estate industry is embracing innovative technologies to stay competitive and enhance property marketing. One such groundbreaking technology is AI virtual staging, which uses artificial intelligence to digitally furnish and decorate real estate photos, making th... | novita_ai | |
1,891,092 | A Deep Dive into DreamBooth V2 | Introduction In the ever-evolving landscape of digital art, DreamBooth V2 emerges as a... | 0 | 2024-06-17T10:50:00 | https://dev.to/novita_ai/a-deep-dive-into-dreambooth-v2-pa4 | ## Introduction
In the ever-evolving landscape of digital art, DreamBooth V2 emerges as a beacon of innovation, redefining the boundaries of creative expression. This advanced AI-driven tool is not just a software; it's a catalyst for artistic evolution. As we explore its impact on the creative industry, it's clear tha... | novita_ai | |
1,891,091 | Why Coding is the New Literacy for Kids in the Digital Age | In the sweep of history, literacy has consistently been a cornerstone of development and empowerment,... | 0 | 2024-06-17T10:48:17 | https://dev.to/anton_palamarchuk_d06cdc1/why-coding-is-the-new-literacy-for-kids-in-the-digital-age-3943 | webdev, javascript, programming, beginners | In the sweep of history, literacy has consistently been a cornerstone of development and empowerment, from the invention of the printing press to the proliferation of digital media. Today, as we navigate an increasingly digital world, the definition of literacy extends beyond reading and writing traditional texts to in... | anton_palamarchuk_d06cdc1 |
1,891,085 | Sharing composable state in Vue apps | When I started my web development career with Vue, back then we were using Vue 2 and Vuex to... | 24,580 | 2024-06-17T10:48:06 | https://dev.to/jacobandrewsky/sharing-composable-state-in-vue-apps-41l1 | vue, typescript, javascript, tutorial | When I started my web development career with Vue, back then we were using Vue 2 and Vuex to implement a global state management tool. I liked this approach because it allowed to create reactive values globally in apps that are easily accessible and that could be modified when needed.
However, right now you could ach... | jacobandrewsky |
1,891,049 | Understanding Small Models as Valuable Plug-ins for Large Language Models | Introduction In the rapidly evolving landscape of artificial intelligence, the interplay... | 0 | 2024-06-17T10:47:11 | https://dev.to/novita_ai/understanding-small-models-as-valuable-plug-ins-for-large-language-models-1gdk | llm | ## Introduction
In the rapidly evolving landscape of artificial intelligence, the interplay between large language models ([**LLMs**](https://blogs.novita.ai/top-llms-for-2024-how-to-evaluate-and-improve-an-open-source-llm/)) and their smaller counterparts is a narrative of synergy and innovation. The towering capabili... | novita_ai |
1,891,079 | Are Emergent Abilities of Large Language Models a Mirage Or Not? | Introduction Are emergent abilities of large language models a mirage? The short answer to... | 0 | 2024-06-17T10:47:07 | https://dev.to/novita_ai/are-emergent-abilities-of-large-language-models-a-mirage-or-not-33nd | llm | ## Introduction
Are emergent abilities of large language models a mirage? The short answer to this question is: mostly, yes. Some scholars from Stanford argue that it's all about metrics. To be specific, [**LLMs**](https://blogs.novita.ai/top-10-llm-models-on-hugging-face/) develop their abilities gradually, not abrupt... | novita_ai |
1,891,090 | Introduction to Go (Golang) | Introduction to Go (Golang) Overview of Go Go, also known as Golang, is an... | 0 | 2024-06-17T10:46:05 | https://dev.to/gophers_kisumu/introduction-to-go-golang-1095 | ### Introduction to Go (Golang)
#### Overview of Go
Go, also known as Golang, is an open-source programming language developed by Google. Designed to be simple, efficient, and reliable, Go aims to provide a balance between performance and ease of use, making it ideal for developing scalable and robust software. It is... | gophers_kisumu | |
1,891,088 | Discover the Excitement of Bharat Club Game | The Bharat Club Game is an exciting online card game that has captivated players around the world.... | 0 | 2024-06-17T10:44:16 | https://dev.to/hyjtgdh/discover-the-excitement-of-bharat-club-game-4igh | The Bharat Club Game is an exciting online card game that has captivated players around the world. Combining elements of traditional Indian card games with modern online features, it offers a unique and engaging experience. In this article, we will delve into the history, gameplay, community aspects, technology, challe... | hyjtgdh | |
1,891,087 | Investment and Cost Considerations in E-commerce Web Development: How Much Does An E-commerce Website Cost In 2024? | In the rapidly evolving digital landscape, establishing a robust e-commerce presence is crucial for... | 0 | 2024-06-17T10:43:28 | https://dev.to/fivensonsstudios/investment-and-cost-considerations-in-e-commerce-web-development-how-much-does-an-e-commerce-website-cost-in-2024-481a | webdesignmichigan, web, webdeveloper, webdev | In the rapidly evolving digital landscape, establishing a robust e-commerce presence is crucial for business success. However, one of the significant challenges is accurately estimating the cost of developing an e-commerce platform. The cost of **[building an e-commerce website](https://fivensonstudios.com/ecommerce-we... | fivensonsstudios |
1,891,086 | What is your strategy to promote Rust? | Promoting Rust can be done by providing a platform to all the people who would like to showcase the fun things they do with Rust. | 0 | 2024-06-17T10:42:37 | https://dev.to/szabgab/what-is-your-strategy-to-promote-rust-27d7 | rust, programming, learning | ---
title: What is your strategy to promote Rust?
published: true
description: Promoting Rust can be done by providing a platform to all the people who would like to showcase the fun things they do with Rust.
tags: rust, programming, learning
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for be... | szabgab |
1,891,084 | Microsoft Azure Data Migration Services - Cloudmonte | Cloudmonte Technologies excels in delivering comprehensive Microsoft Azure data migration services,... | 0 | 2024-06-17T10:39:01 | https://dev.to/erpexcellence/microsoft-azure-data-migration-services-cloudmonte-1clf | microsoftazuredatamigration, azuredatamigrationservices, datamigrationservices, azure | Cloudmonte Technologies excels in delivering comprehensive [Microsoft Azure data migration services](https://cloudmonte.com/microsoft-azure/), empowering businesses to seamlessly transition to the cloud. Leveraging Microsoft Azure's robust and scalable infrastructure, Cloudmonte ensures a smooth migration process, mini... | erpexcellence |
1,891,058 | Starting from Scratch in IT in 2024: Things you shouldn't worry about | Intense competition among juniors, AI taking over jobs, and ongoing crises – why these shouldn’t... | 0 | 2024-06-17T10:38:23 | https://dev.to/vorniches/starting-from-scratch-in-it-in-2024-things-you-shouldnt-worry-about-4p17 | productivity, beginners, career, ai | Intense competition among juniors, AI taking over jobs, and ongoing crises – why these shouldn’t deter you if you’ve decided that IT is your path, and how hard work and self-belief aren’t just Disney thinking.
In the comments on my previous post about [career lessons](https://dev.to/vorniches/ive-worked-in-it-for-over... | vorniches |
1,891,081 | Behavioral Biometrics Market Research Analysis of Key Players | The Behavioral Biometrics Market Size was valued at $ 1.8 Bn in 2023 and is expected to reach $ 12.68... | 0 | 2024-06-17T10:36:44 | https://dev.to/vaishnavi_farkade_/behavioral-biometrics-market-research-analysis-of-key-players-16c0 | **The Behavioral Biometrics Market Size was valued at $ 1.8 Bn in 2023 and is expected to reach $ 12.68 Bn by 2031 and grow at a CAGR of 27.6% by 2024-2031.**
**Market Scope & Overview:**
The report's in-depth market analysis looks at current trends, including market drivers, opportunities, challenges, and restraints... | vaishnavi_farkade_ | |
1,891,077 | Automate Anything: Selenium Testing Tools Cookbook - Your Recipe for Success | Finding the best book to learn Selenium is crucial for anyone looking to excel in automated testing.... | 0 | 2024-06-17T10:27:03 | https://dev.to/mercy_juliet_c390cbe3fd55/automate-anything-selenium-testing-tools-cookbook-your-recipe-for-success-4c4h | selenium | Finding the best book to learn Selenium is crucial for anyone looking to excel in automated testing. Whether you're new to Selenium or seeking to deepen your expertise, there are several highly recommended books that cater to various skill levels and provide comprehensive insights into Selenium. Embracing Selenium’s ca... | mercy_juliet_c390cbe3fd55 |
1,891,076 | Decorator Pattern | Step-by-Step Guide to Implementing the Decorator Pattern The Decorator Pattern is a... | 0 | 2024-06-17T10:25:21 | https://dev.to/muhammad_salem/decorator-pattern-1adl | designpatterns, softwaredesign, oop | ### Step-by-Step Guide to Implementing the Decorator Pattern
The Decorator Pattern is a structural design pattern that allows you to dynamically add behavior to an object without affecting the behavior of other objects from the same class. It provides a flexible alternative to subclassing for extending functionality.
... | muhammad_salem |
1,891,075 | Top 9 SwaggerHub Alternatives for API Design and Documentation | In the rapidly evolving landscape of API development, SwaggerHub has carved out a prominent position... | 0 | 2024-06-17T10:23:12 | https://dev.to/sattyam/top-9-swaggerhub-alternatives-for-api-design-and-documentation-2gdp | swagger, api, documentation | In the rapidly evolving landscape of API development, SwaggerHub has carved out a prominent position as a comprehensive platform that facilitates seamless collaboration, boasting advanced features such as sophisticated version control, effortless documentation generation, and integrated testing capabilities. However, w... | sattyam |
1,891,070 | Generative AI Projects & Product Development Company | Welcome to Xillentech! We are a dynamic team committed to leveraging cutting-edge technologies to... | 0 | 2024-06-17T10:19:29 | https://dev.to/xillentechs/generative-ai-projects-product-development-company-2kno | Welcome to **[Xillentech](https://xillentech.com/)**! We are a dynamic team committed to leveraging cutting-edge technologies to drive meaningful change in society. With a focus on sustainability and innovation, we are dedicated to crafting solutions that make a lasting impact on the world.
We specialize in turning yo... | xillentechs | |
1,891,069 | Singapore's Talent Pass Scheme for Skilled Professionals in 2024: A Guide By Oasis India. | Singapore's Talent Pass Scheme in 2024 revolutionises talent acquisition with its flexible criteria,... | 0 | 2024-06-17T10:19:26 | https://dev.to/vishesh_869dbcd47c1d33505/singapores-talent-pass-scheme-for-skilled-professionals-in-2024-a-guide-by-oasis-india-399g |
Singapore's Talent Pass Scheme in 2024 revolutionises talent acquisition with its flexible criteria, extended validity, and a clear pathway to permanent residency. It attracts top professionals, fostering economic gr... | vishesh_869dbcd47c1d33505 | |
1,891,068 | Unlock Opportunities: UK Expansion Worker & Self-Sponsored Visas | The UK Expansion Worker Visa and Self-Sponsored Visa offer exciting prospects for advancing careers... | 0 | 2024-06-17T10:18:17 | https://dev.to/vishesh_869dbcd47c1d33505/unlock-opportunities-uk-expansion-worker-self-sponsored-visas-1n4i | The UK Expansion Worker Visa and Self-Sponsored Visa offer exciting prospects for advancing careers or establishing businesses in the UK. With Oasis Visas' support, you can navigate the visa application process smoothly and embark on a successful journey in the vibrant UK business landscape. Don’t miss out—seize the mo... | vishesh_869dbcd47c1d33505 | |
1,891,067 | How to Use NPM Libraries that Might get Deprecated..!📦 | In the world of JavaScript development, utilizing third-party libraries from npm (Node Package... | 0 | 2024-06-17T10:17:04 | https://dev.to/nirmeet_gandhi/how-to-use-npm-libraries-that-might-get-deprecated-516k | javascript, react, npm, packagemanager | In the world of JavaScript development, utilizing third-party libraries from npm (Node Package Manager) is common practice. However, what happens when a library you rely on becomes deprecated or is no longer maintained?
**Fear not!!**
This blog will guide you through the process of effectively using and customizing ... | nirmeet_gandhi |
1,891,066 | Building a Blogging Platform with the MERN Stack | Introduction As a MERN stack developer, one of the best ways to hone your skills and build... | 0 | 2024-06-17T10:16:17 | https://raajaryan.tech/building-a-blogging-platform-with-the-mern-stack | javascript, beginners, programming, tutorial | ### Introduction
As a MERN stack developer, one of the best ways to hone your skills and build a comprehensive portfolio is to create real-world applications. In this article, we will build a simple yet functional blogging platform using the MERN stack (MongoDB, Express, React, Node.js). This project will cover user a... | raajaryan |
1,891,065 | Classes in C# | Uzbek | Assalomu alaykum barchaga. Bugun biza C# dasturlash tilida Class tushunchasi bilan bog'liq miflarni... | 0 | 2024-06-17T10:15:14 | https://dev.to/ozodbek_soft/classes-in-c-uzbek-c7h | class, csharp, uzbek, dotnet | Assalomu alaykum barchaga. Bugun biza C# dasturlash tilida `Class` tushunchasi bilan bog'liq miflarni sindiramiz. Dastlab Classlar haqida gaplashsak. Class bu reference Type hisoblanadi. Va xotirada HEAP dan joy oladi.
C# dasturlash tilida `class` - bu Object-Oriented-Programming(OOP)ni asosiy tushunchalaridan biri h... | ozodbek_soft |
1,891,064 | Tempo Traveller in Delhi | Explore Delhi in Comfort and Style: Unveiling the Magic of Tempo Travellers Delhi, the vibrant... | 0 | 2024-06-17T10:14:09 | https://dev.to/cabsule/tempo-traveller-in-delhi-3jg5 | Explore Delhi in Comfort and Style: Unveiling the Magic of Tempo Travellers
Delhi, the vibrant capital of India, is a captivating metropolis brimming with historical landmarks, bustling markets, and mouthwatering cuisine. Whether you're a seasoned traveler or a first-time visitor, navigating Delhi's energy can be both ... | cabsule | |
1,891,063 | Benefits of the Beehiiv Newsletter Platform for Content Creators | I would like to inform you that have moved all my articles and newsletter from medium.com to Beehiiv.... | 0 | 2024-06-17T10:13:33 | https://dev.to/samuel_olatubi/benefits-of-the-beehiiv-newsletter-platform-for-content-creators-3gkp | writing, productivity, news, google | I would like to inform you that have moved all my articles and newsletter from medium.com to Beehiiv. Why? Because the Beehiiv platform offers much more functionality, even in its free version. In my case, Beehiiv complements perfectly the free version of the marketing platform LeadsLeap and the modest newsletter on me... | samuel_olatubi |
1,891,061 | How to learn DSA from CodeChef | We all know that data structures and algorithms are very important for any software engineer. Being... | 0 | 2024-06-17T10:12:22 | https://dev.to/justani/how-to-learn-dsa-from-codechef-3lp3 | dsa, codechef, algorithms, datastructures | We all know that data structures and algorithms are very important for any software engineer. Being able to use data structures and write your own algorithms for your day to day problems is one of the best things.
But even after watching a lot of videos and following tutorials, you may find yourself not being able to ... | justani |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.