
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,887,948 | Backend Developer Skills You Must Know in 2024 | A backend developer is a person who is responsible for the server-side application logic and... | 0 | 2024-06-17T02:10:00 | https://dev.to/thekarlesi/backend-developer-skills-you-must-know-in-2024-4mi8 | html, webdev, beginners, programming | A backend developer is a person who is responsible for the server-side application logic and integration of the front-end elements.
They are also responsible for the security and data of the application.
They are also responsible for integrating the front-end elements built by a web designer into the application.
Th... | thekarlesi |
1,890,710 | Setting up Vim for PHP and laravel in 2024 | I am going to mostly document my own journy of setting up Vim (Not Neovim!) for PHP and laravel. Feel... | 0 | 2024-06-17T02:05:54 | https://dev.to/woland/setting-up-vim-for-php-and-laravel-in-2024-1pl7 | vim, coc, php, laravel | I am going to mostly document my own journy of setting up Vim (Not Neovim!) for PHP and laravel. Feel free to follow along.
We're going to use Vim+VimPlug+CoC.nvim, so we need to have nodejs and npm installed. It goes without saying that you should have Vim8+ as well. The current version of Vim as of this writing is V... | woland |
1,890,709 | How to Create a Loading Bar Using HTML, CSS, and JavaScript | Loading bars are essential UI elements that indicate progress to users during operations like file... | 0 | 2024-06-17T02:04:55 | https://raajaryan.tech/how-to-create-a-loading-bar-using-html-css-and-javascript | javascript, beginners, tutorial, programming | Loading bars are essential UI elements that indicate progress to users during operations like file uploads, downloads, or data processing. In this tutorial, we'll walk through creating a simple yet effective loading bar using HTML, CSS, and JavaScript. This project is ideal for beginners looking to enhance their front-... | raajaryan |
1,890,708 | OK, so where to next ? | I'm here to build my very own Arch OS . . . Read the article . . . . Might I ask where are the... | 0 | 2024-06-17T02:01:58 | https://dev.to/m_veans_0bba1003b422acfa/ok-so-where-to-next--4b2g | I'm here to build my very own Arch OS . . .
Read the article . . . .
Might I ask where are the building plans ?
Cheers | m_veans_0bba1003b422acfa | |
1,890,707 | Visual ChatGPT: Revolutionizing Conversational AI | Introduction The realm of artificial intelligence (AI) has been evolving... | 27,673 | 2024-06-17T02:01:45 | https://dev.to/rapidinnovation/visual-chatgpt-revolutionizing-conversational-ai-4cn7 | ## Introduction
The realm of artificial intelligence (AI) has been evolving rapidly,
transforming how we interact with technology on a daily basis. One of the most
significant advancements in this field is the development of conversational
AI, which has revolutionized the way businesses and consumers communicate.
This... | rapidinnovation | |
1,890,706 | Top 9 Kanban Board Templates for 2024 | Kanban Board Templates In the fast-paced and competitive business world, the pressing need... | 0 | 2024-06-17T02:00:24 | https://dev.to/bryany/top-kanban-board-templates-for-2024-23mj | kanban, management | ## Kanban Board Templates
In the fast-paced and competitive business world, the pressing need for [**efficient project management tools**](https://www.leiga.com/feature) to streamline processes and enhance productivity is more crucial than ever. Kanban Board Templates emerge as a versatile solution across industries. ... | bryany |
1,890,705 | An intro to Machine Learning | Intro So what is machine learning? Machine learning is the process of teaching machines to do a... | 0 | 2024-06-17T01:44:49 | https://dev.to/walkera1/an-intro-to-machine-learning-2i7j | Intro
So what is machine learning? Machine learning is the process of teaching machines to do a specific task. Or even have a machine teach itself to do a task! Wouldn't that just lead to a robot uprising? Maybe, but probably not.
 of the sum of the losses(differences)... | 0 | 2024-06-17T00:55:05 | https://dev.to/hyperkai/the-loss-functions-for-neural-network-in-pytorch-hf9 | pytorch, lossfunction, neuralnetwork, function | A loss function is the function which can get the mean(average) of the sum of the losses(differences) between a model's predictions and true values(train or test data) to optimize a model during training or to evaluate how good a model is during testing. *Loss function is also called Cost Function or Error Function.
T... | hyperkai |
1,890,671 | Data Dynamics: Exploring Information Theory Essentials | Information theory studies efficient data transmition, processing, and storage. Key ideas are entropy... | 0 | 2024-06-17T00:45:04 | https://dev.to/kevinbg012/data-dynamics-exploring-information-theory-essentials-1eoa | devchallenge, cschallenge, computerscience, beginners | Information theory studies efficient data transmition, processing, and storage. Key ideas are entropy (uncertainty), data compression (saving space), channel capacity (max info transmission), noise (interference), and error correction (fixing mistakes). | kevinbg012 |
1,890,678 | Building a Weather Application with OpenWeatherMap API | Introduction In today's fast-paced world, having access to accurate and up-to-date weather... | 0 | 2024-06-17T00:34:40 | https://dev.to/kartikmehta8/building-a-weather-application-with-openweathermap-api-3ldh | javascript, beginners, programming, tutorial | ## Introduction
In today's fast-paced world, having access to accurate and up-to-date weather information is crucial. Whether you are planning a trip or simply want to know what to wear for the day, a weather application can be an essential tool. With the OpenWeatherMap API, building a weather application has become e... | kartikmehta8 |
1,890,675 | Install PHP 8.3 and config Apache in Ubuntu 22.04 | Install PHP: sudo apt install php8.3 Enter fullscreen mode Exit... | 0 | 2024-06-17T00:33:48 | https://dev.to/automata/install-php-83-and-to-config-apache-in-ubuntu-2204-602 | ## Install PHP:
```
sudo apt install php8.3
```
## Install PHP module of Apache:
```
apt install libapache2-mod-php
```
## Config PHP Module of Apache
By default, the PHP module is automatically enabled, if for some reason it is not enabled, you should run:
```
a2enmod php8.3
```
To update the PHP module configurati... | automata | |
1,890,676 | React Native (Native Modules) | I have the Insta360 Office Enterprise SDK. With its use, please help me achieve connecting and... | 0 | 2024-06-17T00:26:42 | https://dev.to/gokulrajalp/react-native-native-modules-4dj0 | reactnative, android, javascript, kotlin | I have the Insta360 Office Enterprise SDK. With its use, please help me achieve **connecting and controlling the Insta360 camera from my React Native Android app,** including starting recording, ending recording, and capturing the recorded video. | gokulrajalp |
1,890,541 | Twilio Challenge: Can You Beat Gemini? AI-Powered Game of Tic Tac Toe | This is a submission for the Twilio Challenge What I Built I built an interactive... | 0 | 2024-06-17T00:20:22 | https://dev.to/thatcoolguy/twilio-challenge-can-you-beat-gemini-tic-tac-toe-1em8 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
I built an interactive AI-powered game of Tic-Tac-Toe called "Can You Beat Gemini?" This project allows players to test their Tic-Tac-Toe skills against Gemini AI, providing a challenging and fun experience.
### Featu... | thatcoolguy |
1,890,288 | What is state in React? | We write components in React, A LOT of components, and many times we want them to undergo visual... | 0 | 2024-06-16T12:35:17 | https://dev.to/ark7/what-is-state-in-react-4fe9 | webdev, javascript, beginners, programming | We write components in React, **A LOT** of components, and many times we want them to undergo visual changes as a result of user or computer interactions. For this purpose, a component needs to “remember” things about itself. This is where state comes in. **_State is a component’s memory._**
Any exciting application yo... | ark7 |
1,890,672 | Elevate Your Online Presence with DEV and Herow.io's Website Creation Tools | As a software developer and active member of the DEV Community, I've long recognized the importance... | 0 | 2024-06-17T00:20:03 | https://dev.to/kathleenwood/website-creation-tool-on-herow-230m | webdev, javascript, beginners, programming | As a software developer and active member of the DEV Community, I've long recognized the importance of having a strong online presence. Whether you're showcasing your projects, sharing your expertise, or connecting with fellow developers, having a well-designed, user-friendly website is crucial.
That's why I was thril... | kathleenwood |
1,890,670 | UI vs UX: Understanding the Difference | Exploring the Digital Canvas: Decoding UI In the intricate tapestry of digital design, the User... | 0 | 2024-06-17T00:17:41 | https://dev.to/dev_king_22/ui-vs-ux-understanding-the-difference-4541 | webdev, ui, ux, website |
**Exploring the Digital Canvas: Decoding UI**
In the intricate tapestry of digital design, the User Interface (UI) serves as the forefront of user interaction. It's the visual aspect of a product that users engage with, akin to an artist's canvas that displays a blend of colors, shapes, and textures. UI is where func... | dev_king_22 |
1,892,740 | How to Create Excel Spreadsheets with Styling Options Using JavaScript | TLDR: An Open Source fork of SheetJS lets you create and style Excel spreadsheets with JavaScript. ... | 0 | 2024-06-20T19:07:51 | https://www.davegray.codes/posts/how-to-create-excel-spreadsheets-with-styling-options-using-javascript | javascript, excel, xlsx | ---
title: How to Create Excel Spreadsheets with Styling Options Using JavaScript
published: true
date: 2024-06-17 00:00:00 UTC
tags: javascript,js,excel,xlsx
canonical_url: https://www.davegray.codes/posts/how-to-create-excel-spreadsheets-with-styling-options-using-javascript
cover_image: https://raw.githubusercontent... | gitdagray |
1,890,849 | 🥙 Callgentive UI - Home-Cooked Software Development | Think of every each of APP as a chat-box, but not in text format. The responses are all `widgets`, and requests are just clicks, scrolls and inputs... | 0 | 2024-06-17T06:22:09 | https://docs.callgent.com/blog/generative-ui-home-cooked-software-development | industrytrends, architecturepatterns, productdesign | ---
slug: generative-ui-home-cooked-software-development
title: 🥙 Callgentive UI - Home-Cooked Software Development
published: true
description: Think of every each of APP as a chat-box, but not in text format. The responses are all `widgets`, and requests are just clicks, scrolls and inputs...
keywords: [Home-Cooked ... | callgent |
1,890,668 | Microservices Architecture | In a microservices architecture, services communicate with each other primarily through network calls... | 0 | 2024-06-16T23:55:48 | https://dev.to/oloruntobi600/microservices-architecture-2nnp | In a microservices architecture, services communicate with each other primarily through network calls over HTTP or other lightweight protocols. There are several common patterns for interservice communication:
RESTful APIs: Services expose REST endpoints that other services can invoke to request or send data. This is ... | oloruntobi600 | |
1,890,666 | 2 Tips to make your Github Repository Stand Out | Have you ever wondered "How can I make my GitHub Repository Stand Out?"? Well Here are 2 tips to do... | 27,749 | 2024-06-16T23:52:17 | https://dev.to/nhelchitnis/2-tips-to-make-your-github-repository-stand-out-n3k | tips, beginners | Have you ever wondered "How can I make my GitHub Repository Stand Out?"? Well Here are 2 tips to do just that
### Tip One Get Rid of everything you are not using
Getting rid of things you are not using will help people not click on something and then just leave.
### Tip Two Have a Brief but in depth description
Ha... | nhelchitnis |
1,890,664 | BITCOIN, USDT, RECOVERY SERVICES FOR FROZEN INVESTMENT ARE MADE POSSIBLE BY OPTIMISTIC HACKER GAIUS. A CYBER RECOVERY MASTER | A post by Dan Avery | 0 | 2024-06-16T23:50:09 | https://dev.to/dan_avery_96212ad4756b10f/bitcoin-usdt-recovery-services-for-frozen-investment-are-made-possible-by-optimistic-hacker-gaius-a-cyber-recovery-master-405g |
 | dan_avery_96212ad4756b10f | |
1,890,662 | i got 100x % increase in my side projects in just 9 months - here's how i did it | invest in yourself before anywhere else 💰 investing in the share market can give you returns of... | 0 | 2024-06-16T23:48:16 | https://dev.to/darkinventor/i-got-100x-increase-in-my-side-projects-in-just-9-months-heres-how-i-did-it-37g4 | sideprojects, webdev, javascript, programming | **invest in yourself before anywhere else 💰**
investing in the share market can give you returns of 12-20%, but **investing in yourself can give you returns of 100% to infinite.**
yes, you read it right. there are no limits.
if you are still wondering, let me share my own story.
here’s how much i am making since l... | darkinventor |
1,890,657 | Making a Multiplayer WEB RPG - Part 10: Customizing Characters | Hi All, I've been working on character customization systems. It is nearly complete and includes a... | 27,892 | 2024-06-16T23:37:38 | https://dev.to/orion3d/making-a-multiplayer-web-rpg-part-10-customizing-characters-2nhd | gamedev, babylonjs, colyseus | Hi All,
I've been working on character customization systems. It is nearly complete and includes a big performance boost compare to previous method.
---
I have 2 types of items (I’m sure none of this is new to you guys, but sharing is caring :slight_smile: ):
- **dynamic items** that I attached via code to the rele... | orion3d |
1,890,654 | Heroes of DDD: BEING perspective. What am I? | Cover sources: Heroes of Might and Magic III (Ubisoft) and Heroes III Board Game (Archon... | 27,739 | 2024-06-16T23:27:43 | https://dev.to/mateusznowak/heroes-of-ddd-being-perspective-what-am-i-3jgc | ddd, oop, complexity, kotlin | <figcaption>Cover sources: Heroes of Might and Magic III (Ubisoft) and Heroes III Board Game (Archon Studio).</figcaption>
</br>
## 🫣 BEING perspective: what am I?
Creatures in Heroes III have their own names and specific levels.
Each belongs to a different faction, but there are also neutral creatures. Some creat... | mateusznowak |
1,890,524 | How to automate provisioning in Proxmox Using Cloud images | There are many ways to create virtual machines. In this article, we aim to leverage cloud images as... | 0 | 2024-06-16T23:24:56 | https://dev.to/caiocampoos/how-to-automate-provisioning-in-proxmox-using-cloud-images-7do | proxmox, cloud, virtualization, cloudinit | There are many ways to create virtual machines. In this article, we aim to leverage cloud images as our primary method for automation while provisioning on Proxmox.
## Cloud Images
Cloud images are pre-configured disk images designed to be used in virtualized environments, such as cloud infrastructure or virtual mach... | caiocampoos |
1,890,515 | Paralelismo e Concorrência 101 | Vamos explorar conceitos de paralelismo e concorrência. | 0 | 2024-06-16T23:10:46 | https://dev.to/hugaomarques/paralelismo-e-concorrencia-101-2pgc | java, concurrency, parallelism, ptbr | ---
title: Paralelismo e Concorrência 101
published: true
description: Vamos explorar conceitos de paralelismo e concorrência.
tags: #java #concurrency #parallelism #ptbr
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-16 19:13 +0000
---
> O termo 101 é ... | hugaomarques |
1,890,649 | Heroes of DDD: Is a "good" domain model the Holy Grail? | Cover: https://www.youtube.com/watch?v=DzWUt2GSZ6g 🗿 Model - what is it? A model is not a... | 27,739 | 2024-06-16T23:08:05 | https://dev.to/mateusznowak/heroes-of-domain-driven-design-looking-for-the-holy-grail-and-the-good-model-42a2 | domaindrivendesign, ddd, model, boundedcontext | <figcaption>Cover: https://www.youtube.com/watch?v=DzWUt2GSZ6g</figcaption>
## 🗿 Model - what is it?
A model is not a copy of the real world, but a representation made for a specific purpose: to solve a particular problem and answer specific questions. As programmers, we constantly create abstractions in order to un... | mateusznowak |
1,889,718 | Design patterns: Part Two - A brief explanation of structural pattern | The picture was taken from boredpanda. Hello everyone! Starting my second post with one... | 0 | 2024-06-16T23:06:30 | https://dev.to/andres_paladines/design-patterns-part-two-a-brief-explanation-of-structural-pattern-4e95 | architecture, designpatterns, javascript, swift | The picture was taken from [boredpanda](https://www.boredpanda.com/digital-art-cats-brutalist-architecture-cats-of-brutalism/).
### Hello everyone!
Starting my second post with one of the most basic but never unnecessary topics; Design patterns.
The [previous post](https://dev.to/andres_paladines/design-patterns-pa... | andres_paladines |
1,890,652 | [Game of Purpose] Day 29 | Today I was trying to recreate helicopter flying with my drone. I had many problems. First was that I... | 27,434 | 2024-06-16T23:02:32 | https://dev.to/humberd/game-of-purpose-day-29-315o | gamedev | Today I was trying to recreate helicopter flying with my drone. I had many problems. First was that I wanted to separate the mesh from the flying funcitonality, but it turned out that `Child Actor` made so many problems that I had to abandon the separation.
I also imported the Drone model to Blender and it turned out ... | humberd |
1,890,651 | Vite vs. Create React App (CRA): Qual Escolher? | Desenvolvedores que começam um novo projeto em React muitas vezes enfrentam a decisão entre Vite e... | 0 | 2024-06-16T23:02:16 | https://dev.to/julianoalvescode/vite-vs-create-react-app-cra-qual-escolher-3f91 | vite, react, javascript | Desenvolvedores que começam um novo projeto em React muitas vezes enfrentam a decisão entre Vite e Create React App (CRA). Ambos têm seus méritos, mas qual é o mais adequado para você? Vamos explorar!
##⚡ Vite: A Nova Geração
Vite é um bundler moderno que oferece uma experiência de desenvolvimento ultrarrápida. Desenv... | julianoalvescode |
1,890,650 | White Label Exchange Software: The Future of Trading Platforms | Introduction The concept of white label exchange software has become... | 27,673 | 2024-06-16T23:00:28 | https://dev.to/rapidinnovation/white-label-exchange-software-the-future-of-trading-platforms-2gpn | ## Introduction
The concept of white label exchange software has become increasingly
significant in the financial and technology sectors. This software solution
allows businesses to set up and run their own branded trading platforms for
various assets, including cryptocurrencies, stocks, and commodities. By using
whit... | rapidinnovation | |
1,846,754 | Heroes of DDD: Prologue & knowledge crunching | Cover photo source: Heroes of Might and Magic III, Ubisoft 🧠💪 In this series we... | 27,739 | 2024-06-16T22:52:11 | https://dev.to/mateusznowak/heroes-of-domain-driven-design-prologue-f37 | eventmodeling, modularization, ddd, eventstorming | <figcaption>Cover photo source: Heroes of Might and Magic III, Ubisoft</figcaption>
</br>
## 🧠💪 In this series we will:
- Discover how modularization influences business development and opens up opportunities for new products.
- Translate sticky notes from EventStorming and Event Modeling directly into working code... | mateusznowak |
1,890,576 | Short notes on the following Concepts | What is Virtualization? Scalability Agility High Availability Fault Tolerant Global Reach What is... | 0 | 2024-06-16T21:00:02 | https://dev.to/kennyig/short-notes-on-the-following-concepts-5g5f | cloud | 1. What is Virtualization?
2. Scalability
3. Agility
4. High Availability
5. Fault Tolerant
6. Global Reach
7. What is the difference between Elasticity and Scalability
## 1. **What is virtualization?**
This concept is related to creating or spooling virtualized systems with any of the following features: ope... | kennyig |
1,890,647 | Arquitetura Hexagonal Explicada: como Transformar seu Desenvolvimento de Software | Introdução Ciclo de um projeto Arquitetura vs Design de Software Arquitetura Hexagonal Hexagonal vs... | 0 | 2024-06-16T22:51:51 | https://dev.to/pmafra/arquitetura-hexagonal-explicada-como-transformar-seu-desenvolvimento-de-software-43d9 | architecture, systemdesign, beginners, learning | <!-- TOC start (generated with https://github.com/derlin/bitdowntoc) -->
- [Introdução](#introdução)
- [Ciclo de um projeto](#ciclo-de-um-projeto)
- [Arquitetura vs Design de Software](#arquitetura-vs-design-de-software)
- [Arquitetura Hexagonal](#arquitetura-hexagonal)
- [Hexagonal vs Clean vs Onion](#hexagonal-vs-cl... | pmafra |
1,890,187 | Overcoming Imposter Syndrome as a Beginner in Tech | In this realm of technology, where innovation and expertise thrive, many of us have faced a nagging... | 0 | 2024-06-16T22:38:34 | https://dev.to/udoka033/overcoming-imposter-syndrome-as-a-beginner-in-tech-20f0 | webdev, javascript, beginners, tutorial | In this realm of technology, where innovation and expertise thrive, many of us have faced a nagging sense of inadequacy at some point in our journey. It’s a phenomenon known as imposter syndrome.
## Imposter Syndrome meaning
A persistent feeling that despite our accomplishments, we don’t truly belong, our successes a... | udoka033 |
1,890,643 | Creation of Resource Group in MS Azure | Steps to Create a Resource Group on Azure Login to MS Azure Search for resource... | 0 | 2024-06-16T22:24:54 | https://dev.to/kennyig/creation-of-resource-group-in-ms-azure-5f9i | cloud, beginners, computerscience, azure | ## Steps to Create a Resource Group on Azure
1. Login to MS Azure
2. Search for resource group
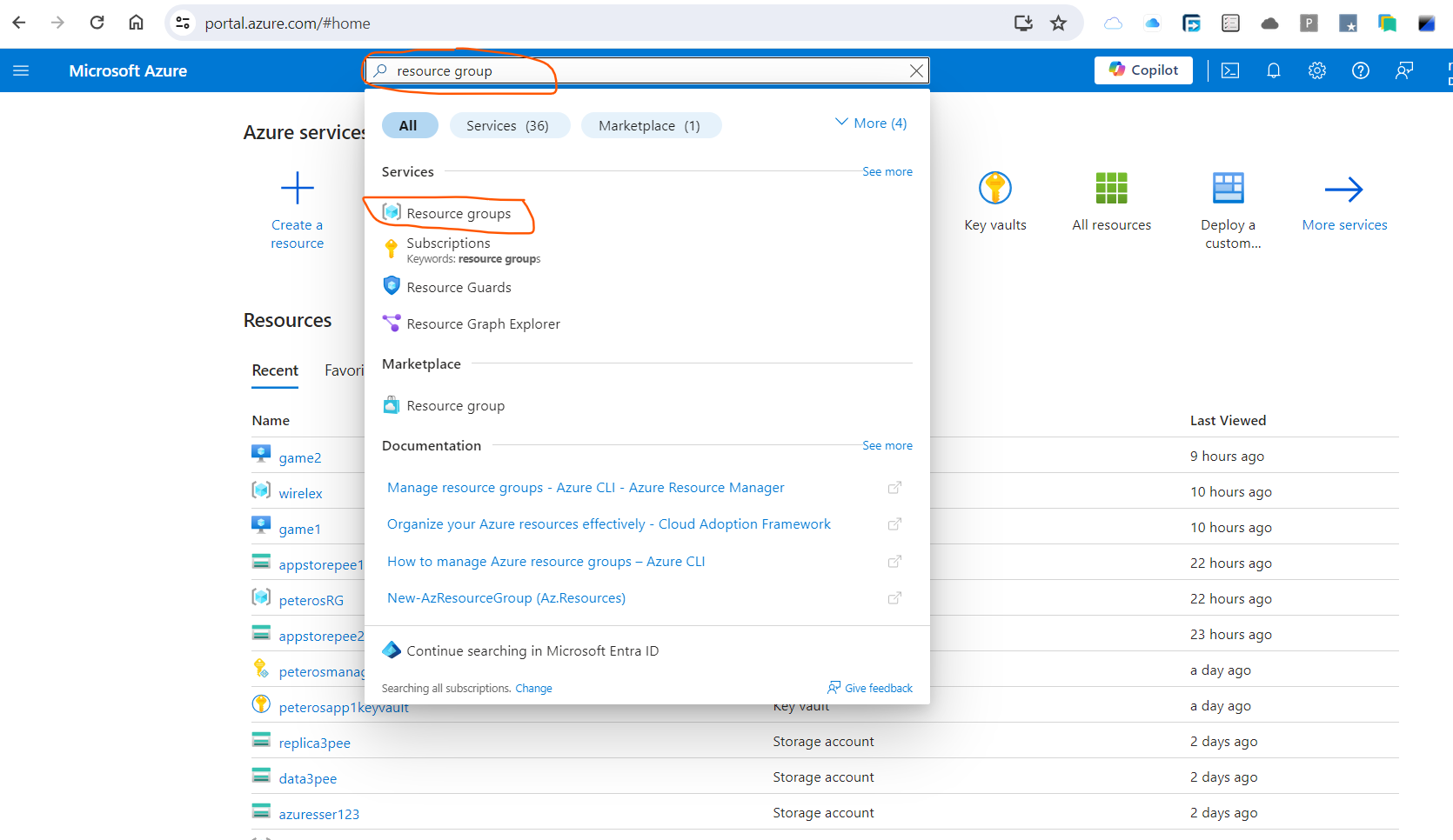
Then select resource group.
3. Click on **+ Create**
 that will have their new Snapdragon X Elite chip which claim to have the same performance as Apple's M3 processor.
This means that in a near future, market will see more an... | x1unix |
1,890,609 | How to use Novu with Nuxt.js | In this article, I will guide you through integrating Novu, an open source notification infrastructure, with Nuxt.js, the popular Vue.js framework. | 0 | 2024-06-16T21:59:00 | https://dev.to/michaldziuba03/how-to-use-novu-with-nuxtjs-m19 | javascript, vue, nuxt, novu |
---
title: How to use Novu with Nuxt.js
published: true
description: In this article, I will guide you through integrating Novu, an open source notification infrastructure, with Nuxt.js, the popular Vue.js framework.
tags: javascript,vue,nuxt,novu
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/h... | michaldziuba03 |
1,884,496 | Setting Up a Secure Wazuh Environment by AWS EC2 | Introduction: Wazuh is an open-source security platform that aims to help organizations monitor and... | 0 | 2024-06-16T21:52:01 | https://dev.to/zahraajawad/setting-up-a-secure-wazuh-environment-by-aws-ec2-487o | aws, cloudcomputing, cloudnative, community | **Introduction:**
Wazuh is an open-source security platform that aims to help organizations monitor and manage security incidents, detect threats, and ensure compliance with security regulations. It provides capabilities for intrusion detection, log analysis, vulnerability detection, and threat intelligence, w... | zahraajawad |
1,890,599 | Elanat Brings Web-Forms Back to ASP.NET Core! | The Elanat team will soon bring back the former Microsoft Web-Forms in ASP.NET Standard with a new... | 0 | 2024-06-16T21:49:54 | https://elanat.net/content/96/We%20will%20soon%20bring%20Web-Forms%20to%20ASP.NET%20Core.html | news, dotnet, backend, frontend | The [Elanat team](https://elanat.net) will soon bring back the former Microsoft Web-Forms in ASP.NET Standard with a new and powerful architecture to ASP.NET Core. New Web-Forms will be added to the [CodeBehind Framework](https://github.com/elanatframework/Code_behind).
Over time, the Web-Forms architecture for develo... | elanatframework |
1,890,604 | Short notes on the following Concepts | What is Virtualization? Scalability Agility High Availability Fault Tolerant Global Reach What is... | 0 | 2024-06-16T21:45:22 | https://dev.to/kennyig/short-notes-on-the-following-concepts-4no2 | cloud, beginners, computerscience, azure | 1. What is Virtualization?
2. Scalability
3. Agility
4. High Availability
5. Fault Tolerant
6. Global Reach
7. What is the difference between Elasticity and Scalability
## 1. **What is virtualization?**
This concept is related to creating or spooling virtualized systems with any of the following features: ope... | kennyig |
1,890,601 | Newsletter "What's up devs ?" is born ! | Hi devs, You may know that I publish a weekly French dev newsletter called "Quoi de neuf les devs... | 0 | 2024-06-16T21:35:38 | https://dev.to/happytodev/newsletter-whats-up-devs-is-born--pl9 | webdev, newsletter, developers | Hi devs,
You may know that I publish a weekly French dev newsletter called "[Quoi de neuf les devs ?](https://happytodev.substack.com)".
**But today, I'm delighted to announce that its English version is born.**
It's called **"[What's up devs?](https://go.itanea.fr/wud1)"** and it's in the same spirit as its French... | happytodev |
1,890,600 | Grub-customizer:Install to MBR - NVME Disk | I have multiple OS installed. Each have it's own bootloader/grub. I had done customization in... | 0 | 2024-06-16T21:34:07 | https://dev.to/ajeebkp23/grub-customizerinstall-to-mbr-nvme-disk-21hg | I have multiple OS installed. Each have it's own bootloader/grub. I had done customization in grub-customizer. I want to make my current os bootloader default.
Find the nvme disk name
`df -h`
I see few entries like `/dev/nvme0n1p1`. I can understand last `p1` stands for partition. I removed it, `/dev/nvme0n1`. This v... | ajeebkp23 | |
1,890,581 | Squares+Circles background in HTML/CSS/JS | Check out this Pen I made! | 0 | 2024-06-16T21:12:30 | https://dev.to/tidycoder/squarescircles-background-in-htmlcssjs-4g98 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/TidyCoder/pen/oNRpqVZ %} | tidycoder |
1,890,580 | Vision Week (test) | Vision Week: A Journey into the Virtual Zoo I'm thrilled to share my latest project with... | 0 | 2024-06-16T21:09:09 | https://dev.to/kvnbbg/vision-week-test-52e8 | codepen, webdev, javascript, beginners | ## Vision Week: A Journey into the Virtual Zoo
I'm thrilled to share my latest project with you all – Vision Week, an immersive virtual zoo experience that combines interactive maps, VR tours, and a user-friendly interface to bring the wonders of wildlife directly to your screen.
### Project Overview
Vision Week is ... | kvnbbg |
1,890,579 | Hover the hello word | Let's hover the "hello" word! | 0 | 2024-06-16T21:08:47 | https://dev.to/tidycoder/hover-the-hello-word-54a1 | codepen | Let's hover the "hello" word!
{% codepen https://codepen.io/TidyCoder/pen/gOJoedv %} | tidycoder |
1,890,578 | Let's dance now! | Let's dance now! | 0 | 2024-06-16T21:04:49 | https://dev.to/tidycoder/lets-dance-now-3g9o | codepen | Let's dance now!
{% codepen https://codepen.io/TidyCoder/pen/eYayMbY %} | tidycoder |
1,890,575 | Short notes on the following Concepts | What is Virtualization? Scalability Agility High Availability Fault Tolerant Global Reach What is... | 0 | 2024-06-16T21:00:02 | https://dev.to/kennyig/short-notes-on-the-following-concepts-4b7e | cloud | 1. What is Virtualization?
2. Scalability
3. Agility
4. High Availability
5. Fault Tolerant
6. Global Reach
7. What is the difference between Elasticity and Scalability
## 1. **What is virtualization?**
This concept is related to creating or spooling virtualized systems with any of the following features: ope... | kennyig |
1,890,574 | AssaultCube | Writing your first external cheat in RustLang | Writing a-salt-cube Prerequisites A decent knowledge of RustLang ... | 0 | 2024-06-16T20:52:15 | https://dev.to/zofia/assaultcube-writing-your-first-external-cheat-in-rustlang-3m7 | hacking, gamedev, reversing | # Writing a-salt-cube
## Prerequisites
- A decent knowledge of RustLang
## Outline
### Writing cheat requirements
1. Finding game modules
2. Finding pointers and offsets (we'll use Cheat Engine)
### Coding
1. Create command line interface to modify cheat properties during execution
2. Open handles to the target ... | zofia |
1,890,573 | Mi enana bella | A post by fabricio Anzora | 0 | 2024-06-16T20:50:23 | https://dev.to/fabricio_anzora_4ca13eecd/mi-enana-bella-49h7 | codepen |
{% codepen https://codepen.io/fabricio-Anzora/pen/qBGpoyN %} | fabricio_anzora_4ca13eecd |
1,890,572 | Reading Transaction Events from a Smart Contract Using ethers.js | In the burgeoning field of blockchain and decentralized finance (DeFi), reading transaction events... | 0 | 2024-06-16T20:44:49 | https://dev.to/spiritmoney/reading-transaction-events-from-a-smart-contract-using-ethersjs-4goo | programming, beginners, tutorial, blockchain | In the burgeoning field of blockchain and decentralized finance (DeFi), reading transaction events from smart contracts is a fundamental skill for developers. Events provide critical insights into contract interactions, such as token transfers, trades, and liquidity additions. This article will guide you through the pr... | spiritmoney |
1,890,570 | Understanding the Need for Apache Kafka | Welcome back everyone to another exciting blog post! Today, we are going to discuss why Apache Kafka... | 0 | 2024-06-16T20:41:35 | https://dev.to/aadarsh-nagrath/understanding-the-need-for-apache-kafka-i44 | kafka, webdev, devops, backend |
Welcome back everyone to another exciting blog post! Today, we are going to discuss why Apache Kafka is essential, why it is so fast, and whether we actually need Kafka or not.
Recently, I came across an interesting question-> "**Isn't it possible for databases to improve their throughput themselves by upgrading thei... | aadarsh-nagrath |
1,802,514 | How to build a custom React table component with Typescript (Part 1) | Introduction The purpose of this article is to show you in a simple way, how to create a... | 0 | 2024-06-16T20:29:44 | https://dev.to/igbominadeveloper/how-to-build-a-custom-react-table-component-with-typescript-part-1-1ln | webdev, react, nextjs, javascript | ## Introduction
The purpose of this article is to show you in a simple way, how to create a fully-typed, reusable Table component. For this, we will be using the Material UI (MUI) Library React table component: https://mui.com/material-ui/react-table to move fast without writing any styling but this could be applied t... | igbominadeveloper |
1,890,542 | Engenharia de Software: produto vs plataforma | Postado originalmente no Dev na Gringa Substack. Quer receber futuros artigos no seu e-mail? Assine... | 0 | 2024-06-16T20:20:09 | https://dev.to/lucasheriques/engenharia-de-software-produto-vs-plataforma-18p3 | braziliandevs, softwareengineering, product, platform | Postado originalmente no [Dev na Gringa Substack](https://devnagringa.substack.com/p/produto-vs-plataforma?utm_source=devto). Quer receber futuros artigos no seu e-mail? [Assine gratuitamente aqui](https://devnagringa.substack.com/subscribe?utm_source=devto).
---
Nesse artigo, vamos discutir as diferenças entre engen... | lucasheriques |
1,890,540 | LaPrompt DALL-E 3 Examples: A Guide for Web Design and Content Creation | In the evolving landscape of web design and content creation, AI technology has become a... | 0 | 2024-06-16T20:15:33 | https://dev.to/nikolasgx/laprompt-dall-e-3-examples-a-guide-for-web-design-and-content-creation-3b48 | design, contentwriting, webdev | In the evolving landscape of web design and content creation, AI technology has become a game-changer, especially with [LaPrompt Gallery](https://laprompt.com/gallery/text-to-image).
In this wild, wacky world of we... | nikolasgx |
1,890,538 | Designed HTML templates | Hey here a collection of designed HTML templates: Click here | 0 | 2024-06-16T20:09:26 | https://dev.to/tidycoder/designed-html-templates-2h4d | Hey here a collection of designed HTML templates:
<a href="https://tidy-coder.github.io/Designed-HTML-Templates/" target="_blank">Click here</a> | tidycoder | |
1,890,537 | 6 Captivating Web Development Tutorials to Boost Your Skills 🚀 | The article is about a collection of 6 captivating web development tutorials from LabEx that cover a wide range of topics, from building a 2048 game using jQuery to creating a visually stunning login page and integrating external content like YouTube videos. These hands-on projects are designed to help both beginners a... | 27,723 | 2024-06-16T20:09:14 | https://dev.to/labex/6-captivating-web-development-tutorials-to-boost-your-skills-m4h | html, coding, programming, tutorial |
Embark on an exciting journey of web development mastery with this carefully curated collection of 6 captivating tutorials from LabEx. Whether you're a beginner or a seasoned pro, these hands-on projects will equip you with the skills to create engaging and visually stunning web experiences. 🌟
## 1. 2048 Web Game Us... | labby |
1,890,535 | The Golden Key of Cloud Computing | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-16T20:06:11 | https://dev.to/delta02/the-golden-key-of-cloud-computing-1mkh | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Cloud computing stores and accesses data and programs over the internet instead of your computer’s hard drive. It evolved from virtual networks to offering: Infrastructure as a Service... | delta02 |
1,890,534 | Constructor Function ?🧐 | A constructor function in JavaScript is a special function used to create and initialize objects.... | 0 | 2024-06-16T20:04:59 | https://dev.to/__khojiakbar__/constructor-function--1c5n | javascript, constructor, function |

> A constructor function in JavaScript is a special function used to create and initialize objects. It's like a blueprint for creating multiple similar objects. When you use the new keyword with a constructor funct... | __khojiakbar__ |
1,890,532 | 30 Tips how to use OSINT for bug hunting | *30 Tips how to use OSINT for bug hunting: * Use Google Dorks to find vulnerabilities in web... | 0 | 2024-06-16T20:02:53 | https://dev.to/nikhilpatel/30-tips-how-to-use-osint-for-bug-hunting-253l | **30 Tips how to use OSINT for bug hunting:
**
1. Use Google Dorks to find vulnerabilities in web applications.
2. Use Shodan to find vulnerable IoT devices.
3. Use Whois to find information about domain names.
4. Use Maltego to visualize relationships between entities.
5. Use the Wayback Machine to find old version... | nikhilpatel | |
1,890,531 | Create an XRP Ledger Account with Web3Auth (Nextjs): A Step-by-Step Guide | Introduction XRP ledger is a decentralized blockchain that focus on cross-border payment,... | 0 | 2024-06-16T20:00:24 | https://dev.to/amity808/create-an-xrp-ledger-account-with-web3auth-nextjs-a-step-by-step-guide-a45 | blockchain, web3, authjs, javascript | ## Introduction
**XRP ledger** is a decentralized blockchain that focus on cross-border payment, it is used to document financial transactions, and it is fast and low-cost effective. The XRP Ledger was created by the Ripple co-founder and CEO Chris Larsen. XRP Lede utilized XRP as its native cryptocurrency.
In this t... | amity808 |
1,890,530 | The Rise of AI Chatbots: Transforming Digital Communication | What is an AI Chatbot? AI chatbots are computer programs designed to simulate... | 27,673 | 2024-06-16T19:59:21 | https://dev.to/rapidinnovation/the-rise-of-ai-chatbots-transforming-digital-communication-1e4k | ## What is an AI Chatbot?
AI chatbots are computer programs designed to simulate human-like
conversations through machine learning and natural language processing. These
chatbots can understand and interpret human language, allowing them to engage
with users in real-time, answer questions, provide recommendations, and... | rapidinnovation | |
1,890,529 | How to create a Github account and install Git on your PC | How to create a github account and install Git on your pc | 0 | 2024-06-16T19:59:15 | https://dev.to/ebaye_eligbe_8941d8a7a498/how-to-create-a-github-account-and-install-git-on-your-pc-1p8h | [How to create a github account and install Git on your pc](https://medium.com/@ebayeeligbe/how-to-create-a-github-account-and-install-git-on-your-pc-a8b0150b659b) | ebaye_eligbe_8941d8a7a498 | |
1,890,527 | The Importance of Personal Branding for Web Developers: My Journey and Lessons Learned | Hey Dev Community! I'm excited to share some insights and lessons learned from my journey in web... | 0 | 2024-06-16T19:47:26 | https://dev.to/ridoy_hasan/the-importance-of-personal-branding-for-web-developers-my-journey-and-lessons-learned-4b3g | webdev, programming, career, learning | Hey Dev Community!
I'm excited to share some insights and lessons learned from my journey in web development, especially regarding personal branding. Despite initial hesitations, I've discovered that building a personal brand is essential for standing out in our field. Here's why and how you can get started:
**My Big... | ridoy_hasan |
1,890,526 | Dockerise a Golang Application | How can you call yourself a Golang developer without knowing how to Dockerize a Go application? Yes,... | 0 | 2024-06-16T19:43:40 | https://dev.to/abhishekcs3459/dockerise-a-golang-application-25lc | docker, devops, go | **How can you call yourself a Golang developer without knowing how to Dockerize a Go application?**
Yes, I know that feels very shameful, especially when working among your fellow teammates who are skilled developers.
*Mention not, let's give them a good show!*
**Prerequisites:**
1. **Go setup**: You can download &... | abhishekcs3459 |
1,890,525 | Sekabet En güncel giriş adresi bilgileri | Resmi Web Siteleri ve Sosyal Medya: Sekabet'in resmi web sitesi ve sosyal medya hesapları, en güncel... | 0 | 2024-06-16T19:42:42 | https://dev.to/abbybrown/sekabet-en-guncel-giris-adresi-bilgileri-56bd | Resmi Web Siteleri ve Sosyal Medya: Sekabet'in resmi web sitesi ve sosyal medya hesapları, en güncel giriş adresini sürekli olarak paylaşmaktadır. Örneğin, şu anda aktif olan adreslerden biri [sekabet.live](https://sekabet.live
) olarak belirtilmiştir .
Güvenilir Kaynaklar ve Bahis Forumları: Bahis forumları ve ince... | abbybrown | |
1,890,523 | Browser MMORPG #indiegamedev #babylonjs Ep20 - Client Side Prediction & Reconciliation | Hey Recently I was implementing entities interpolation and next on the plate was client side... | 0 | 2024-06-16T19:32:13 | https://dev.to/maiu/browser-mmorpg-indiegamedev-babylonjs-ep20-client-side-prediction-reconciliation-3fc7 | babylonjs, indiegamedev, mmorpg, gamedev | Hey
Recently I was implementing entities interpolation and next on the plate was client side prediction, which is smoothing player movements and increase responsiveness (predicting player movement before response from the server is received).
On the video I'm presenting effect of three algorithms:
- player movement pre... | maiu |
1,890,521 | Optimizing React Performance: Avoiding Unnecessary Rendering with Hooks | Introduction React's declarative nature and component-based architecture make it a powerful tool for... | 0 | 2024-06-16T19:24:15 | https://dev.to/ayas_tech_2b0560ee159e661/optimizing-react-performance-avoiding-unnecessary-rendering-with-hooks-446i | **Introduction**
React's declarative nature and component-based architecture make it a powerful tool for building dynamic user interfaces. However, with great power comes great responsibility, especially when it comes to performance. One of the common pitfalls in React applications is unnecessary rendering, which can l... | ayas_tech_2b0560ee159e661 | |
1,890,519 | C++ Best Practices : Naming Conventions | There are various popular naming conventions which are common among various languages, the relevance... | 0 | 2024-06-16T19:17:23 | https://dev.to/parthkamal/c-best-practices-naming-conventions-235m | cpp, convention, language | There are various popular naming conventions which are common among various languages, the relevance of these conventions comes from , the legacy which they hold and other factors like readability, purpose, programming cababilities, for example , we most follow camelcase for java, for c++ which comes with great capabil... | parthkamal |
1,890,517 | Unlock New Features: RazorSharp CLI & Dashboard Updates! | Hello, fellow developers! I'm excited to share some fantastic news—RazorSharp CLI 1.0.0-beta09 and... | 0 | 2024-06-16T19:16:49 | https://dev.to/jwtiller_c47bdfa134adf302/unlock-new-features-razorsharp-cli-dashboard-updates-i50 | dotnet, programming | Hello, fellow developers! I'm excited to share some fantastic news—RazorSharp CLI 1.0.0-beta09 and Dashboard 0.0.5.1 are now available! As we move from beta to a more refined product, there will still be a freemium version available for everyone to enjoy.
### What's New?
#### 🔒 Username and Password Protection
You c... | jwtiller_c47bdfa134adf302 |
1,890,516 | Backblaze B2: How to store a file | Backblaze B2 is a cloud storage solution offering scalable and affordable data storage for... | 0 | 2024-06-16T19:15:28 | https://dev.to/artiumws/backblaze-b2-how-to-store-a-file-3obj | webdev, programming, tutorial, cloud | Backblaze B2 is a cloud storage solution offering scalable and affordable data storage for individuals, developers, and businesses. Backblaze's B2 service aim for simplicity and cost-effectiveness.

Howe... | artiumws |
1,890,509 | SteamVR Overlay with Unity: Follow Device | Follow the HMD Overlay following the HMD Remove the position code First,... | 27,740 | 2024-06-16T19:05:18 | https://dev.to/kurohuku/part-6-follow-device-33i | unity3d, steamvr, openvr, vr | ## Follow the HMD

*Overlay following the HMD*
### Remove the position code
First, remove the absolute position code we added in the previous part.
```diff
private void Start()
{
InitOpenVR();
overlayHand... | kurohuku |
1,890,514 | Machine Learning: The Crystal Ball of Data | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-16T19:09:23 | https://dev.to/jblazquezmartin/machine-learning-the-crystal-ball-of-data-53ca | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Machine learning is the crystal ball of data. It sifts through vast amounts of information, learning and predict... | jblazquezmartin |
1,890,300 | Identifiers 101: Understanding and Implementing UUIDs and ULIDs | At first glance, UUIDs (Universally Unique Identifiers) and ULIDs (Universally Unique... | 0 | 2024-06-16T19:08:16 | https://dev.to/siddhantkcode/identifiers-101-understanding-and-implementing-uuids-and-ulids-2kc6 | database, programming, security, computerscience | At first glance, UUIDs (Universally Unique Identifiers) and ULIDs (Universally Unique Lexicographically Sortable Identifiers) are widely used identifiers in databases and distributed systems. Each has unique characteristics that make them suitable for various scenarios. In this article, we’ll delve into the features of... | siddhantkcode |
1,890,513 | The Halting Problem | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-16T19:06:52 | https://dev.to/magodyboy/the-halting-problem-41c3 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
The halting problem asks whether there can be a machine that determines whether a program will halt or continue indefinitely. It cannot exist; if we add a negation to this machine and ... | magodyboy |
1,890,512 | SteamVR Overlay with Unity: Dashboard Overlay | Let’s create a setting screen on the SteamVR dashboard. It switches which hand to display the watch... | 27,740 | 2024-06-16T19:06:40 | https://dev.to/kurohuku/part-8-dashboard-overlay-1809 | unity3d, steamvr, openvr, vr | Let’s create a setting screen on the SteamVR dashboard. It switches which hand to display the watch overlay.
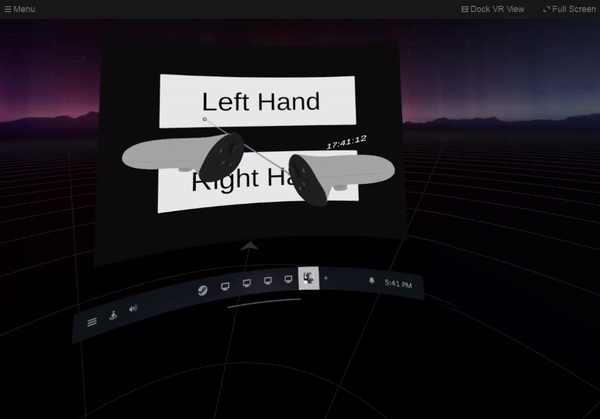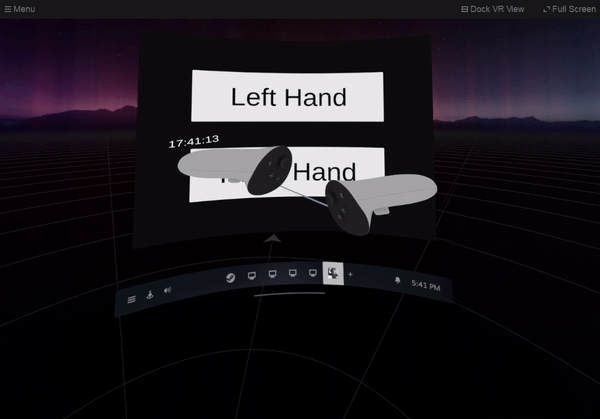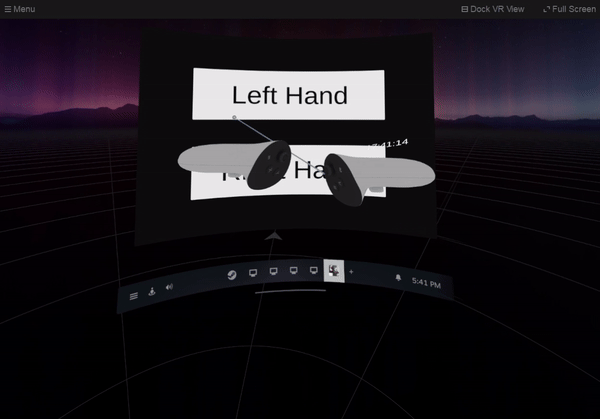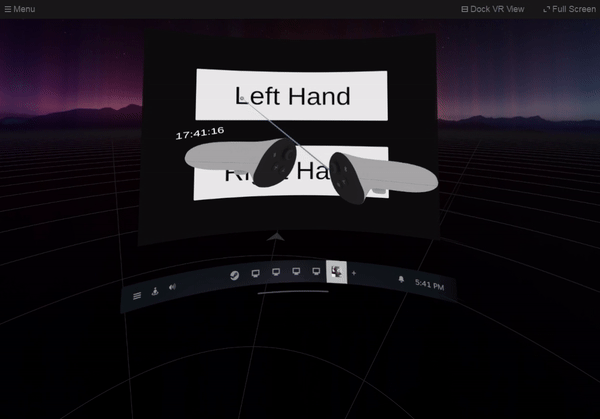
## Create dashboard overlay
Dashboard overlay is an overlay that is displayed on the SteamVR dashboard. ... | kurohuku |
1,890,511 | Some Standard Sample Text Style Configuration in Figma. | Sample Text Style Configuration in Figma | 0 | 2024-06-16T19:06:16 | https://dev.to/iam_divs/some-standard-sample-text-style-configuration-in-figma-33bl | webdev, javascript, ui, figma | Sample Text Style Configuration in Figma
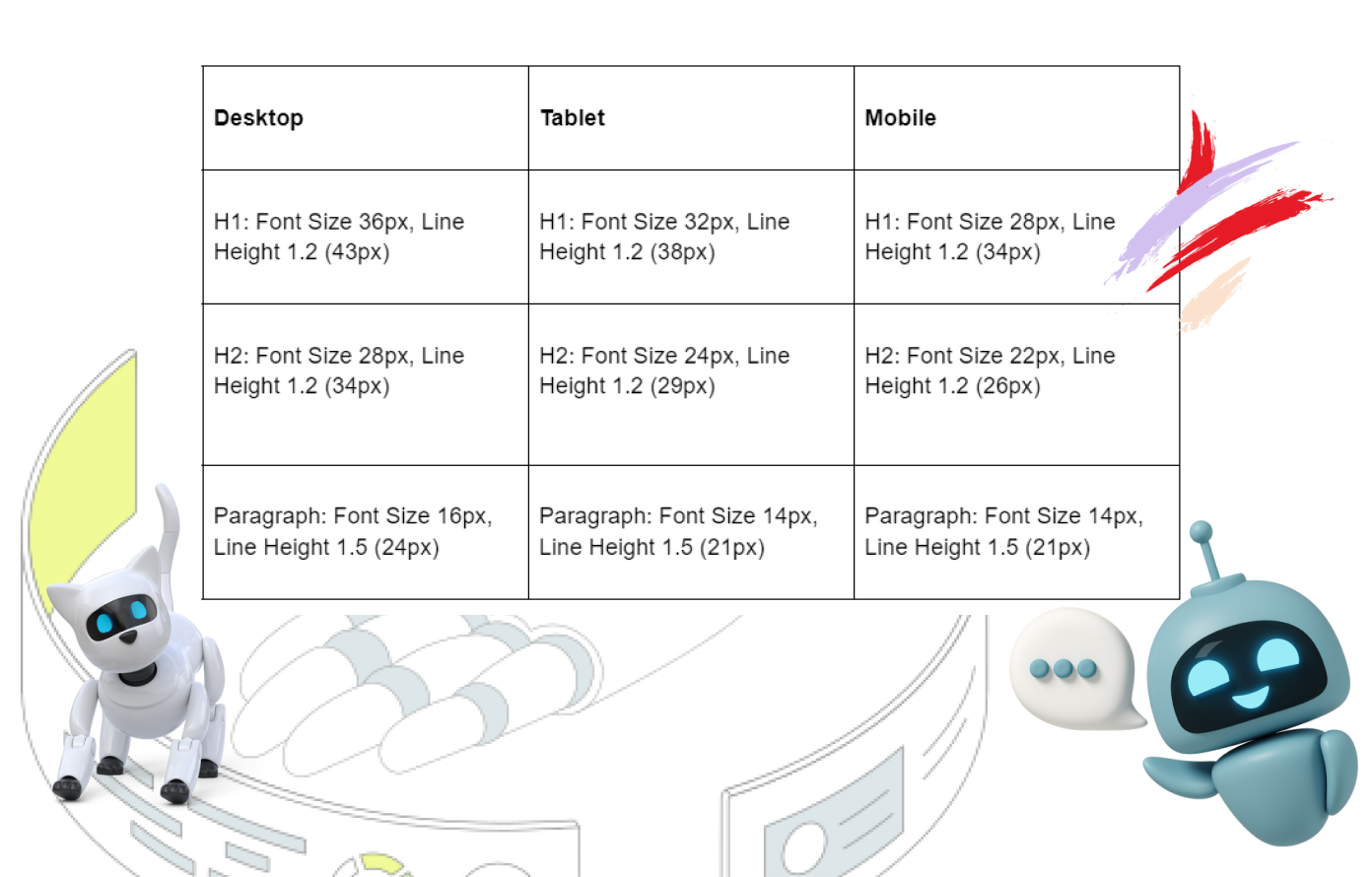 | iam_divs |
1,890,508 | SteamVR Overlay with Unity: Change Size and Position | Change overlay size Pass width SetOverlayWidthInMeters() to set an overlay size (read the... | 27,740 | 2024-06-16T19:04:04 | https://dev.to/kurohuku/part-5-change-size-and-position-47ga | unity3d, steamvr, openvr, vr | ## Change overlay size
Pass width [SetOverlayWidthInMeters()](https://valvesoftware.github.io/steamvr_unity_plugin/api/Valve.VR.CVROverlay.html#Valve_VR_CVROverlay_SetOverlayWidthInMeters_System_UInt64_System_Single_) to set an overlay size (read the wiki for details). The width unit is meters. Height is automatically ... | kurohuku |
1,890,507 | SteamVR Overlay with Unity: Draw Image | Prepare an image file Prepare an image file that satisfies the following... | 27,740 | 2024-06-16T19:02:18 | https://dev.to/kurohuku/part-4-draw-image-2h3c | unity3d, steamvr, openvr, vr | ## Prepare an image file
Prepare an image file that satisfies the following conditions.
- Size is lower than 1920 x 1080 px.
- File format is in PNG, JPG, or TGA (24 or 32 bit color)
From here on, I explain with my SNS icon named **“sns-icon.jpg”**.
 | My intent is to write a series of practical posts related to AI and programming. Topics like running... | 0 | 2024-06-16T18:38:07 | https://dev.to/peter_truchly_4fce0874fd5/failure-is-not-an-option-for-ai-and-it-shouldnt-be-1hm2 | ai, community, chatgpt | My intent is to write a series of practical posts related to AI and programming. Topics like running local LLMs with agent frameworks, automated source code manipulation, execution under docker and more. All with the use of .NET and C#, Elastic Search, AWS and more.
I realized that I would like to first express my view... | peter_truchly_4fce0874fd5 |
1,890,497 | Creative Photography Showcase Slider | Swiper Slider | This CodePen pin showcases a creative photography slider using Swiper Slider, designed for a striking... | 0 | 2024-06-16T18:24:47 | https://dev.to/creative_salahu/creative-photography-showcase-slider-swiper-slider-g6l | codepen | This CodePen pin showcases a creative photography slider using Swiper Slider, designed for a striking presentation of images. The slider features six slides, each with a parallax effect and a fade transition. The design includes layered images, stylish typography, and responsive layouts. The Swiper configuration suppor... | creative_salahu |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.