
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,890,495 | Daily Hamster Kombat | I made this open source project based on the Hamster Kombat telegram chat group to stay on top of... | 0 | 2024-06-16T18:23:52 | https://dev.to/jansellopez/daily-hamster-kombat-3dk8 | hamsterkombat, website, react |
I made this open source project based on the [Hamster Kombat](https://t.me/hamster_kOmbat_bot/start?startapp=kentId1666436655) [telegram chat group](https://t.me/Hamster_Kombat_LATAM_Chat) to stay on top of daily cipher and combo.
## Website
[https://jansellopez.github.io/daily-hamster-kombat/](https://jansellopez.git... | jansellopez |
1,890,491 | Comparing Top 10 Churn Prediction Software in 2024 | This Blog was Originally Posted to Churnfree Blog Churn prediction software uses AI churn prediction... | 0 | 2024-06-16T18:18:16 | https://churnfree.com/blog/churn-prediction-software/ | churnpredication, churnfree, churnrate, churnretention | This Blog was Originally Posted to [Churnfree Blog](https://churnfree.com/blog/churn-prediction-software/?utm_source=Dev.to&utm_medium=referral&utm_campaign=Content_distribution)
Churn prediction software uses **AI churn prediction** and **predictive modeling** to forecast which customers might leave and provides insi... | churnfree |
1,890,489 | Highlight Your Terminal: a tools design to highlight information on output of terminal | highlight is a script to detect and highlight patterns such as URLs, domains, IPv4 addresses, IPv6... | 0 | 2024-06-16T18:11:01 | https://dev.to/phhitachi/highlight-your-terminal-a-tools-design-to-highlight-information-on-output-of-terminal-42me | terminal, shell, bash, highlight | [highlight](https://github.com/ReconXSecurityHQ/highlight) is a script to detect and highlight patterns such as URLs, domains, IPv4 addresses, IPv6 addresses, subnets, ports, categories, HTML tags, and more.
## Introduction
In the world of system administration, network management, and development, analyzing log files... | phhitachi |
1,890,488 | Tailwind CSS: CSS framework for Kickstart | Discover the future of web design with Tailwind CSS! Efficient, flexible and perfect for beginners... | 0 | 2024-06-16T18:04:01 | https://blog.disane.dev/en/tailwind-css-css-framework-for-kickstart/ | tailwindcss, css, framework, webdev | Discover the future of web design with Tailwind CSS! Efficient, flexible and perfect for beginners and professionals. 🚀
---
In the early days of web design, CSS (Cascading Style Sheets) was used to control th... | disane |
1,890,487 | Tailwind CSS: CSS-Framework für den Kickstart | Entdecke die Zukunft des Webdesigns mit Tailwind CSS! Effizient, flexibel und perfekt für Anfänger... | 0 | 2024-06-16T18:03:50 | https://blog.disane.dev/tailwindcss-css-framework-fur-den-kickstart/ | tailwindcss, css, framework, webentwicklung | Entdecke die Zukunft des Webdesigns mit Tailwind CSS! Effizient, flexibel und perfekt für Anfänger und Profis. 🚀
---
In den frühen Tagen des Webdesigns wurde CSS (Cascading Style Sheets) verwendet, um das Aus... | disane |
1,890,486 | Building charts and Dev UX | As a developer one of the frequent decisions I face is selecting the right library for charts on my... | 0 | 2024-06-16T18:03:50 | https://dev.to/alessiochiffi/building-charts-and-dev-ux-391j | javascript, webdev, charts, productivity | As a developer one of the frequent decisions I face is selecting the right library for charts on my projects.
It’s a critical choice, as the library can significantly impact both the ease of development and the end-user experience.
For a long time, I relied on Chart.js due to its simplicity and quick setup. However, I... | alessiochiffi |
1,890,485 | Los Secretos para Ahorrar en tus Compras de Videojuegos | En el mundo de los videojuegos, encontrar las mejores ofertas puede ser una verdadera hazaña. Con... | 0 | 2024-06-16T18:00:21 | https://dev.to/tapsubstantial/los-secretos-para-ahorrar-en-tus-compras-de-videojuegos-o3h |
En el mundo de los videojuegos, encontrar las mejores ofertas puede ser una verdadera hazaña. Con títulos esperados lanzándose continuamente y ediciones especiales que atraen a los fanáticos más fervientes, mantener tu colección al día sin vaciar tu cartera es todo un arte. Pero no te preocupes, aquí te revelaremos al... | tapsubstantial | |
1,890,484 | Configuring Ping URL Tests/Health Checks with Azure Monitor Application Insights | What is Azure Monitor Application Insight As a deep dive, Application Insights serves as your... | 0 | 2024-06-16T18:00:21 | https://dev.to/shaloversal123/configuring-ping-url-testshealth-checks-with-azure-monitor-application-insights-2ecn | **What is Azure Monitor Application Insight**
As a deep dive, Application Insights serves as your application's health guardian. It offers insights into how your applications are performing and being utilized. Gain valuable data on performance metrics, user engagement, and retention.
Application Insight also tracks es... | shaloversal123 | |
1,890,483 | The Future of Web Development: Embracing Emerging Technologies and Trends | The web development landscape is constantly evolving, driven by new technologies and shifting user... | 0 | 2024-06-16T17:58:13 | https://dev.to/matin_mollapur/the-future-of-web-development-embracing-emerging-technologies-and-trends-4pno | webdev, javascript, beginners, programming | **The web development landscape is constantly evolving, driven by new technologies and shifting user expectations. As we move further into 2024, several key trends are shaping the future of web development, offering exciting opportunities and challenges for developers. This article explores these trends and provides in... | matin_mollapur |
1,890,482 | Day 4 of 30... Current day | -So the Transactions project that I was to do is halfway done still some functionalities to be... | 0 | 2024-06-16T17:53:36 | https://dev.to/francis_ngugi/day-4-of-30-current-day-3p5e | -So the Transactions project that I was to do is halfway done still some functionalities to be applied but all will be good.
-And also Finalizing reading Nmap and ready to start reminding myself how to use Wireshark. | francis_ngugi | |
1,890,481 | DAY 3 OF 30... Also Forgot to post this blog | This day was the day I planned a Transaction Project where The transactions were to be fetched from a... | 0 | 2024-06-16T17:50:03 | https://dev.to/francis_ngugi/day-3-of-30-also-forgot-to-post-this-blog-3o47 | This day was the day I planned a Transaction Project where The transactions were to be fetched from a mock server and did a set up of the project. | francis_ngugi | |
1,889,659 | Generate Dynamic Open Graph Images using Nextjs | Dynamic OG Dynamic OG helps developers easily create og images without needing to develop... | 0 | 2024-06-16T17:47:27 | https://dev.to/shrihari/generate-dynamic-open-graph-images-using-nextjs-4k9g | nextjs, webdev, tutorial | ## Dynamic OG
[Dynamic OG](https://www.dynamicog.com/) helps developers easily create og images without needing to develop their proprietary code.
It is completely free to use and a self-hosted paid version is also available. This tutorial serves as a base for [Dynamic OG](https://www.dynamicog.com/).
Here are some... | shrihari |
1,890,477 | Day 2 of 30... Forgot to post the blog | On the 2nd day of the challenge, I learned how to use the useEffect hook and fetch data from a mock... | 0 | 2024-06-16T17:46:45 | https://dev.to/francis_ngugi/day-2-of-30-forgot-to-post-the-blog-54pf | On the 2nd day of the challenge, I learned how to use the useEffect hook and fetch data from a mock server and display it on the DOM which was quite tricky to get the hang of but I am still managing to learn more of React.JS.
<u>**What I did on that day:**</u>
i) Made a quiz app where useEffect was used to add a timer... | francis_ngugi | |
1,890,480 | What is Value Types and Reference Types in JavaScript | Two fundamental categories that every developer should understand are value types and reference... | 0 | 2024-06-16T17:46:43 | https://dev.to/yashrajxdev/what-is-value-types-and-reference-types-in-javascript-23kn | javascript, webdev, programming | Two fundamental categories that every developer should understand are value types and reference types. Value type is basically it will not changeable after something is assigned to variable and reference type is what we can change after declaration.
In JavaScript objects are reference type and all other data types are... | yashrajxdev |
1,890,479 | What I Discovered About Making Great Widgets: Insights From 100+ Real Users | We want to help people read more from their to-read pile with minimal effort using our product, ... | 0 | 2024-06-16T17:45:35 | https://dev.to/lincemathew/what-i-discovered-about-making-great-widgets-insights-from-100-real-users-1ml3 | mobile, development, webdev | We want to help people read more from their to-read pile with minimal effort using our product, [FeedZap](https://hexmos.com/feedzap). To see if a mobile home screen widget could assist in this, I conducted a small research study on effective home screen widgets for Android and iPhones.
The main goal of my discovery ... | lincemathew |
1,890,476 | Blockchain | Blockchain is a decentralized and distributed digital ledger technology that securely records... | 0 | 2024-06-16T17:44:31 | https://dev.to/arun_gupta/blockchain-19p0 | devchallenge, cschallenge, computerscience, beginners | Blockchain is a decentralized and distributed digital ledger technology that securely records transactions across multiple computers. The main innovation of blockchain is its ability to allow digital information to be recorded and shared without the need for a central authority, ensuring transparency and security.
Eac... | arun_gupta |
1,890,475 | 330. Patching Array | 330. Patching Array Hard Given a sorted integer array nums and an integer n, add/patch elements to... | 27,523 | 2024-06-16T17:34:27 | https://dev.to/mdarifulhaque/330-patching-array-4oo9 | php, leetcode, algorithms, programming | 330\. Patching Array
Hard
Given a sorted integer array `nums` and an integer `n`, add/patch elements to the array such that any number in the range `[1, n]` inclusive can be formed by the sum of some elements in the array.
Return _the minimum number of patches required_.
**Example 1:**
- **Input:** `nums = [1,3]`,... | mdarifulhaque |
1,890,474 | Angular error | Hi Guys,I have got this error(see image) i try to unstall and install Angular Language Service in vs... | 0 | 2024-06-16T17:30:51 | https://dev.to/yaici_anis_94b3b62a50aa70/angular-error-42hj | angular | Hi Guys,I have got this error(see image) i try to unstall and install Angular Language Service in vs code but this error still
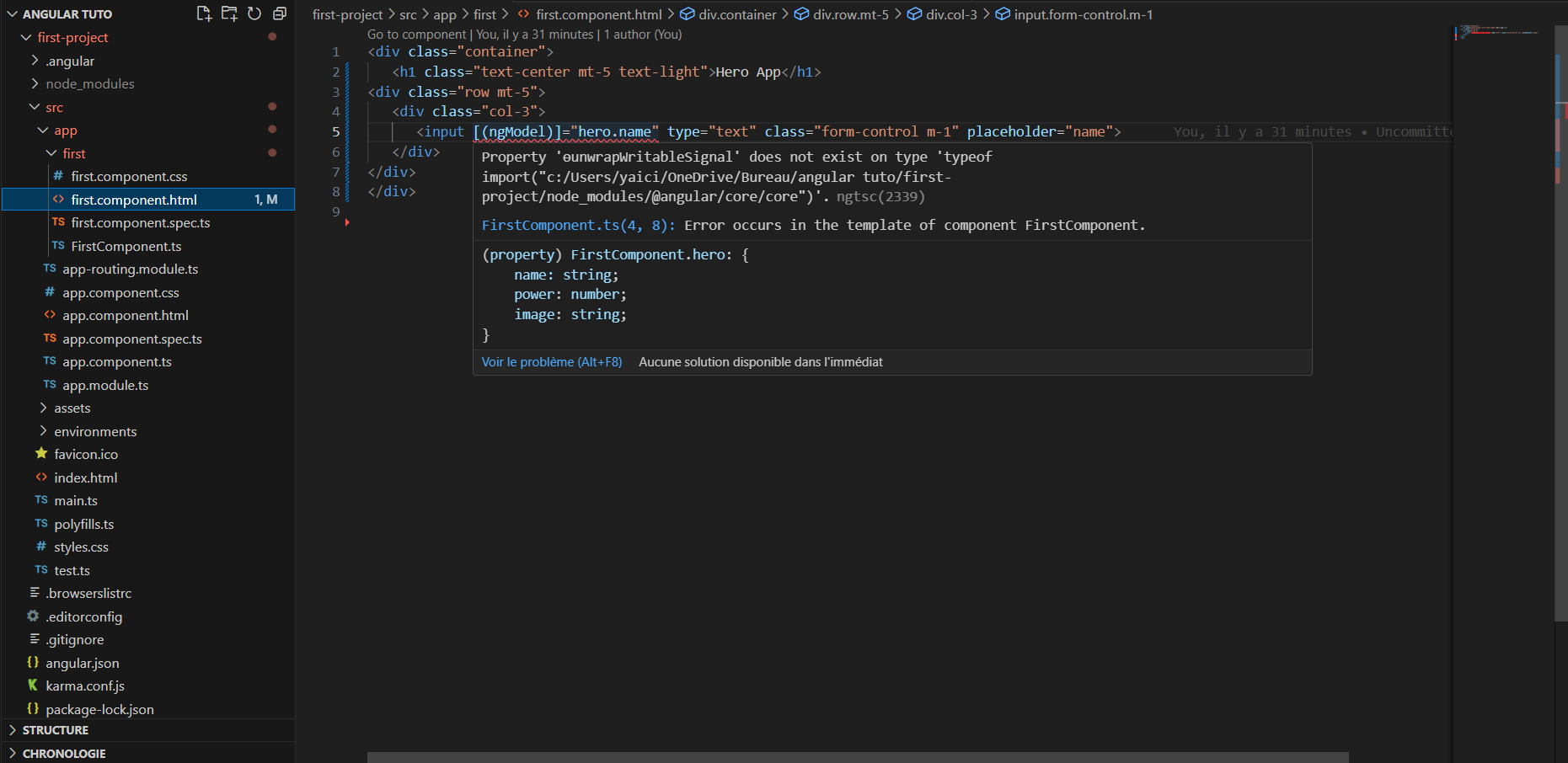
| yaici_anis_94b3b62a50aa70 |
1,890,473 | Best cross-platform CMS for Flutter web and mobile apps? | One of the best cross-platform CMS options you can use with Flutter to build web, iOS, and Android... | 0 | 2024-06-16T17:29:13 | https://dev.to/shaerif/best-cross-platform-cms-for-flutter-web-and-mobile-apps-15j5 | webdev, flutter, api | One of the best cross-platform CMS options you can use with Flutter to build web, iOS, and Android apps is **Strapi**. Strapi is a headless CMS that allows you to create and manage content, which can then be consumed via APIs in your Flutter applications.
### Key Features:
- **Open Source**: Strapi is open-source and ... | shaerif |
1,890,472 | Unlock the Secret Side of Your Phone with Android 15’s Private Space🤫🤫 | Meet Android 15’s coolest new feature: Private Space. Think of it as your own hidden corner of your... | 0 | 2024-06-16T17:25:54 | https://dev.to/yesswee/unlock-the-secret-side-of-your-phone-with-android-15s-private-space-39ha | Meet Android 15’s coolest new feature: Private Space. Think of it as your own hidden corner of your phone, where everything you do stays completely private!🫢. Whether you’re working with sensitive documents, browsing without leaving a trace, or just wanting to keep certain apps and info separate, Private Space has got... | yesswee | |
1,890,471 | Laravel and WebAuthn | In my previous article, I provided information about WebAuthn. In this article, I will explain how to... | 0 | 2024-06-16T17:25:38 | https://dev.to/cryptograph/laravel-and-webauthn-4h9k | laravel, webauthn, php | In my previous article, I provided information about WebAuthn. In this article, I will explain how to implement it with Laravel.
[https://niyazi.net/en/laravel-and-webauthn](https://niyazi.net/en/laravel-and-webauthn) | cryptograph |
1,890,470 | Building Software that’s Efficient, Intuitive, and Seamless | In the rapidly evolving world of software development, creating applications that are not only... | 0 | 2024-06-16T17:23:59 | https://dev.to/checkiamsiam/building-software-thats-efficient-intuitive-and-seamless-338 | softwaredevelopment, webdev, cleancoding, programming | In the rapidly evolving world of software development, creating applications that are not only efficient but also intuitive and seamless is paramount. As we step into 2024, let’s explore some of the cutting-edge tech stacks that are shaping the future of software engineering
## Embracing Modern Tech Stacks
The choice ... | checkiamsiam |
1,890,433 | Unlock a World of Knowledge with the eBooks Collection at RGBSpot.com | Immerse yourself in a world of inspiration and learning with the eBooks collection at RGBSpot.com.... | 0 | 2024-06-16T17:16:17 | https://dev.to/ardenjames/unlock-a-world-of-knowledge-with-the-ebooks-collection-at-rgbspotcom-37ga | books, ebooks, collection | Immerse yourself in a world of inspiration and learning with the **[eBooks collection](https://rgbspot.com/)** at RGBSpot.com. Our library is brimming with diverse and meticulously curated eBooks designed to ignite your creativity and expand your knowledge. Whether you’re looking to sharpen your professional skills, di... | ardenjames |
1,890,432 | Using Astro Image Optimization Benefits with Tina CMS Cloud in Production build | Problem Statement In production, the benefits of image optimization using Astro's... | 0 | 2024-06-16T17:15:30 | https://dev.to/friebe/using-astro-image-optimization-benefits-with-tina-cms-cloud-in-production-build-5a01 | astro, javascript, jamstack | ## Problem Statement
In production, the benefits of image optimization using Astro's Image/Picture component are lost when integrating with Tina CMS and Tina Cloud. However, I have found a workaround to resolve this issue. Whether this workaround is the best or a good fit for client websites remains uncertain, but here... | friebe |
1,890,431 | The Art of Software Maintenance: Embracing Change in 2024 | In the ever-evolving landscape of technology, the maintenance of software systems is not just a... | 0 | 2024-06-16T17:15:06 | https://dev.to/checkiamsiam/the-art-of-software-maintenance-embracing-change-in-2024-109j | webdev, programming, softwaredevelopment, software | In the ever-evolving landscape of technology, the maintenance of software systems is not just a routine task; it’s an art that requires a deep understanding of the changing tech stacks and the foresight to anticipate future needs. As we step into 2024, the complexity of software systems has grown exponentially, making ... | checkiamsiam |
1,890,430 | smooth card slider | I used java script to make auto slider, but it is jerky, I want to make it very smooth slider without... | 0 | 2024-06-16T17:13:13 | https://dev.to/arvind_vishwakarma_46c578/smooth-card-slider-5f8i | help | I used java script to make auto slider, but it is jerky, I want to make it very smooth slider without any jerk.
Please suggest. | arvind_vishwakarma_46c578 |
1,890,429 | $Set, $AddToSet, $Push in MongoDB | $Set, $AddToSet, $Push $set $set মানে হচ্ছে কোন কিছুর মান সেট করা। আমাদের... | 0 | 2024-06-16T17:09:20 | https://dev.to/kawsarkabir/set-addtoset-push-in-mongodb-2a95 | webdev, mongodb, programming, kawsarkabir | ## **$Set, $AddToSet, $Push**
### $set
`$set` মানে হচ্ছে কোন কিছুর মান সেট করা। আমাদের ডাটাবেজে যদি কোন কিছুর আপডেট করতে হয় তাহলে আমরা এই অপারেটর ব্যাবহার করি। কিভাবে আমরা আমাদের ডাটাকে আপডেট করতে পারি সেটার উদাহরণ দেওয়া যাক:
```javascript
db.products.insertOne({
_id: 100,
quantity: 250,
instock: true,
detai... | kawsarkabir |
1,890,428 | Launching Your Online Business in 2024: A Tech-Driven Guide | The Digital Landscape of 2024 As we step into 2024, the digital landscape is more vibrant than ever.... | 0 | 2024-06-16T17:08:34 | https://dev.to/checkiamsiam/launching-your-online-business-in-2024-a-tech-driven-guide-2n13 | webdev, techtalks, business, guide | **The Digital Landscape of 2024**
As we step into 2024, the digital landscape is more vibrant than ever. With global e-commerce sales expected to continue their upward trajectory, there’s no better time to launch an online business. The key to success lies in leveraging the latest tech stacks to build a robust, scalab... | checkiamsiam |
1,890,427 | Integrating reCAPTCHA v3 in Next.js | Step 1: Obtain reCAPTCHA v3 credentials Access Google reCAPTCHA page: Visit Google... | 0 | 2024-06-16T17:05:51 | https://dev.to/adrianbailador/integrating-recaptcha-v3-in-nextjs-170o | webdev, nextjs, javascript, security | #### Step 1: Obtain reCAPTCHA v3 credentials
1. **Access Google reCAPTCHA page:**
- Visit [Google reCAPTCHA admin console](https://www.google.com/recaptcha/admin/).
- Log in with your Google account if necessary.
2. **Register your website:**
- Click on "V3" at the top to register a new key for reCAPTCHA v3.... | adrianbailador |
1,890,426 | How and why the Next.js App Router is so awesome | The Next.js App Router is a new paradigm for building applications using React’s latest features. It... | 0 | 2024-06-16T17:03:07 | https://dev.to/checkiamsiam/how-and-why-the-nextjs-app-router-is-so-awesome-269l | nextjs, react, webdev, programming | The Next.js App Router is a new paradigm for building applications using React’s latest features. It was introduced in Next.js 13 and is built on React Server Components. The App Router provides a number of benefits over the traditional Pages Router, including:
- Shared layouts
- Nested routing
- Loading states
- Erro... | checkiamsiam |
1,889,747 | Come correggere l'errore "non-existent config entity name returned by FieldStorageConfigInterface::getBundles()" | Fonte: How to fix "non-existent config entity name returned by... | 0 | 2024-06-16T17:02:33 | https://dev.to/mcale/come-correggere-lerrore-non-existent-config-entity-name-returned-by-fieldstorageconfiginterfacegetbundles-1ega | drupal, fix, italian | Fonte: [How to fix "non-existent config entity name returned by FieldStorageConfigInterface::getBundles()"](https://www.drupal.org/project/drupal/issues/2916266)
Personalmente mi sono imbattuto in questo errore dopo aver aggiornato un sito storico che è nato con Drupal 8, è passato alla versione 9 e adesso ha affronta... | mcale |
1,890,397 | Testing Columnar Storage | As most of you probably already know, since approximately the end of 2022 InterSystems IRIS included... | 27,746 | 2024-06-16T16:20:33 | https://community.intersystems.com/post/testing-columnar-storage | docker, python, programming | <p>As most of you probably already know, since approximately the end of 2022 InterSystems IRIS included the columnar storage functionality to its database, well, in today's article we are going to put it to the test in comparison to the usual row storage.</p>
<h2>Columnar Storage</h2>
<p>What is the main characteristic... | intersystemsdev |
1,890,425 | Unlock the Secrets to Writing Clean and Structured JavaScript Code: Essential Practices for Developers | JavaScript is one of the most widely used programming languages in the world, powering everything... | 0 | 2024-06-16T16:59:48 | https://dev.to/futuristicgeeks/unlock-the-secrets-to-writing-clean-and-structured-javascript-code-essential-practices-for-developers-43ml | webdev, javascript, react, frontend | JavaScript is one of the most widely used programming languages in the world, powering everything from dynamic web applications to server-side logic. However, its flexibility and dynamic nature can sometimes lead to messy and unstructured code. Writing clean and structured JavaScript code is essential for maintaining r... | futuristicgeeks |
1,890,424 | 30 Essential Array Methods in JavaScript with Examples | Arrays are a fundamental data structure in JavaScript, used to store multiple values in a single... | 0 | 2024-06-16T16:59:29 | https://dev.to/mahabubr/30-essential-array-methods-in-javascript-with-examples-5570 | webdev, javascript, array, datastructures | Arrays are a fundamental data structure in JavaScript, used to store multiple values in a single variable. JavaScript provides various built-in methods to manipulate and interact with arrays. Here are ten important array methods every JavaScript developer should know, complete with examples and explanations.
**1. push... | mahabubr |
1,890,423 | Blockchain in Banking: Revolutionizing the Financial Sector | Introduction Blockchain technology, initially developed for cryptocurrencies like... | 27,673 | 2024-06-16T16:58:23 | https://dev.to/rapidinnovation/blockchain-in-banking-revolutionizing-the-financial-sector-11de | ## Introduction
Blockchain technology, initially developed for cryptocurrencies like Bitcoin,
has evolved into a revolutionary technology impacting various sectors,
including banking. This decentralized digital ledger offers a secure and
transparent way to record transactions, accessible by multiple parties and
resist... | rapidinnovation | |
1,890,421 | B2B SaaS Benchmarks: A Complete Guide 2024 | This Blog was Originally Posted to churnfree blog Winning new customers is more costly and retaining... | 0 | 2024-06-16T16:51:47 | https://churnfree.com/blog/b2b-saas-churn-rate-benchmarks/ | saaschurn, churnfree, b2bsaas, churnmanagenent | This Blog was Originally Posted to [churnfree blog](https://churnfree.com/blog/b2b-saas-churn-rate-benchmarks/?utm_source=Dev.to&utm_medium=referral&utm_campaign=Content_distribution)
Winning new customers is more costly and retaining long-term customers with long-term subscription plans can be much more valuable. Fort... | churnfree |
1,876,566 | Do you do your homework before interview? | Do you ever feel like doing the homework before every interview? Do you feel that there is some kind... | 0 | 2024-06-16T16:06:00 | https://dev.to/sein_digital/do-you-do-your-homework-before-interview-9dc | webdev, interview, programming, career | Do you ever feel like doing the homework before every interview? Do you feel that there is some kind of test you have to pass and not only gain enough points but also outscore other candidates? But when you actually get the job, it has nothing to do with questions, requirements and responsibilities posted in the listin... | sein_digital |
1,890,420 | How to Make the Most of Rephrasetool.com: Your Guide to Effortless Paraphrasing | How to Make the Most of Rephrasetool.com: Your Guide to Effortless Paraphrasing Picture this: You’re... | 0 | 2024-06-16T16:51:16 | https://dev.to/alphapik/how-to-make-the-most-of-rephrasetoolcom-your-guide-to-effortless-paraphrasing-1iae | productivity, tooling, startup | <h2>How to Make the Most of Rephrasetool.com: Your Guide to Effortless Paraphrasing</h2>
Picture this: You’re working on a report or an important email, but the right words just aren’t coming to you. It’s a common struggle, and it’s exactly where Rephrasetool.com comes into play. This site is designed to help you rephr... | alphapik |
1,890,419 | Understanding Advanced AI Techniques: RAG, Fine-Tuning, and Beyond | Hey there! If you’ve been keeping up with the latest in artificial intelligence, you know it’s... | 0 | 2024-06-16T16:48:54 | https://dev.to/gervaisamoah/understanding-advanced-ai-techniques-rag-fine-tuning-and-beyond-23cn | ai, machinelearning, deeplearning | Hey there! If you’ve been keeping up with the latest in artificial intelligence, you know it’s evolving at breakneck speed. Today, we’re diving into some advanced AI techniques and concepts that can help you get the most out of large language models (LLMs). We’ll talk about Retrieval Augmented Generation (RAG), fine-tu... | gervaisamoah |
1,890,418 | Guideline For Newly Redux Learner | From my experience of learning redux , I am sharing a guideline for newly redux learners. I hope my... | 0 | 2024-06-16T16:47:23 | https://dev.to/checkiamsiam/guideline-for-newly-redux-learner-13cp | redux, javascript, react, mern | From my experience of learning redux , I am sharing a guideline for newly redux learners. I hope my guideline will help you to gain redux knowledge without suffering any confusion.
The first thing that you must have to know before starting a journey with redux is what is redux actually?. Basically redux is a state ma... | checkiamsiam |
1,890,416 | Rate Limiting and DDoS | What is Rate Limiting? Rate Limiting is a technique to control the rate at which requests (such as... | 0 | 2024-06-16T16:46:48 | https://dev.to/nirvanjha2004/rate-limiting-and-ddos-4j56 | webdev, beginners, programming, tutorial | **What is Rate Limiting?**
1. Rate Limiting is a technique to control the rate at which requests (such as GET, POST, PUT etc.) are made to a service by a client or an application.
2. This is achieved by restricting the amount of request that a client makes to the server in a specified amount of time. For example, you c... | nirvanjha2004 |
1,889,703 | Hands-On with Gleam: Building and Improving a Binary Search Tree | Gleam is a functional programming language that proudly aims to be simple. This means you have a few... | 0 | 2024-06-16T16:46:32 | https://dev.to/micskeil/always-look-deeper-with-gleam-2enf | patternmatching, gleam, functional, erlang | **Gleam is a functional programming language that proudly aims to be simple. This means you have a few straightforward tools to solve problems. That's why it's such a great language for zoning out from other perspectives and allowing you to solve coding problems differently than you are used to.**
Let's zone out. Bui... | micskeil |
1,890,413 | Enhancing Rust Enums in the State Pattern | Recap In my previous article, I discussed how Rust enums should be strongly considered... | 0 | 2024-06-16T16:39:46 | https://dev.to/digclo/enhancing-rust-enums-in-the-state-pattern-35pa | rust, designpatterns, learning | # Recap
In my previous [article](https://dev.to/digclo/state-pattern-with-rust-enums-61g), I discussed how Rust enums should be strongly considered when the solution benefits from a state machine. The strongest argument for this is the fact that the Rust compiler will inform you when a state variant isn't covered in a... | digclo |
1,890,409 | Exploring the World of Generative AI: Key Takeaways | I am excited to share that I have recently completed the "Introduction to Generative AI" course, and... | 0 | 2024-06-16T16:30:57 | https://dev.to/bishop_bhaumik/exploring-the-world-of-generative-ai-key-takeaways-3hea | ai, machinelearning, cloud, devops | I am excited to share that I have recently completed the "Introduction to Generative AI" course, and it has been an eye-opening journey into the realm of artificial intelligence. Here are some of the key insights and learnings I've gained from this immersive experience:
**Understanding Generative AI:**
One revolution... | bishop_bhaumik |
1,882,278 | Criando componentes para Web #01: Acessibilidade (a11y) na prática com WAI-ARIA | O que abordaremos nessa série? Olá, nessa série de artigos vamos abordar todos as... | 0 | 2024-06-16T16:28:03 | https://dev.to/afonsopacifer/criando-componentes-para-web-01-acessibilidade-a11y-na-pratica-com-wai-aria-45ef | frontend, a11y, webdev, html | <audio format>
## O que abordaremos nessa série?
Olá, nessa série de artigos vamos abordar todos as especialidades que uma pessoa profissional de Front-End precisa compreender para criar componentes **acessíveis**, **performáticos**, **responsivos**, **manuteníveis**, **reutilizáveis**, **documentados**, **customizáv... | afonsopacifer |
1,890,408 | Instagram Bio For couple | Here are some quick and simple ideas for couple's Instagram bios: "Forever in love ❤️" "Better... | 0 | 2024-06-16T16:25:36 | https://dev.to/off_page_497f860f47d38578/instagram-bio-for-couple-4f7p | Here are some quick and simple ideas for couple's Instagram bios:
"Forever in love ❤️"
"Better together 💕"
"Adventurers at heart 🌍"
"Love and laughter always 💑"
"Soulmates since 2020 💖"
"Together through it all ❤️"
"Two hearts, one journey 💞"
"Creating memories together 📸"
"Partners in crime 😎"
"Happily ever af... | off_page_497f860f47d38578 | |
1,890,321 | Changing typescale with CSS Variables in Angular Material Demo | A post by Dharmen Shah | 0 | 2024-06-16T16:22:58 | https://dev.to/shhdharmen/changing-typescale-with-css-variables-in-angular-material-demo-49m4 | ---
title: Changing typescale with CSS Variables in Angular Material Demo
published: true
description:
tags:
---
| shhdharmen | |
1,889,899 | Every Next.js website is starting to look the same | Current state of web development for some time now includes JS frameworks and libraries springing... | 0 | 2024-06-16T16:20:33 | https://dev.to/dellboyan/every-nextjs-website-is-starting-to-look-the-same-12a6 | nextjs, tailwindcss, react, javascript |
Current state of web development for some time now includes JS frameworks and libraries springing like mushrooms after the rain. Among these, [Next.js](https://nextjs.org/) has emerged as the most popular choice for any developer that wants to build a beautiful SEO-friendly website. However, as its popularity grows, I... | dellboyan |
1,890,393 | Nothing OS 3.0: Release Date, New Glyph & More | Prepare yourself for the next evolution in smartphone technology — Nothing OS 3.0. This update from... | 0 | 2024-06-16T16:19:52 | https://dev.to/journetrix/nothing-os-30-release-date-new-glyph-more-4708 | nothing, nothingos, nothingphone, phone | Prepare yourself for the next evolution in smartphone technology — Nothing OS 3.0. This update from Nothing Technology is not just an upgrade; it’s a complete transformation designed to redefine how you interact with your device. From enhanced performance to innovative features, [Nothing OS 3.0](https://www.journetrix.... | journetrix |
1,890,392 | How I Built McDonald’s Drive-Thru: All-AI, All-Local | Full Article Final Result from This Project Building a 1-Person Food Delivery Business with 100%... | 0 | 2024-06-16T16:19:43 | https://dev.to/exploredataaiml/how-i-built-mcdonalds-drive-thru-all-ai-all-local-1nme | rag, genai, machinelearning, llm | [Full Article](https://medium.com/@learn-simplified/how-i-built-mcdonalds-drive-thru-all-ai-all-local-812260a0bc40)
[Final Result from This Project](https://www.youtube.com/watch?v=R7ekFRwrqhc&list=PLWQ_n2lpS5yyAT... | exploredataaiml |
1,890,391 | Performance tests IRIS - PostgreSQL - MySQL using Python | It seems like yesterday when we did a small project in Java to test the performance of IRIS,... | 27,746 | 2024-06-16T16:17:52 | https://community.intersystems.com/post/performance-tests-iris-postgresql-mysql-using-python | database, performance, python, testing | <p>It seems like yesterday when we did a small project in Java to test the performance of IRIS, PostgreSQL and MySQL (you can review the article we wrote back in June at the end of this article). If you remember, IRIS was superior to PostgreSQL and clearly superior to MySQL in insertions, with no big difference in quer... | intersystemsdev |
1,890,390 | Performance tests IRIS - PostgreSQL - MySQL | As a former JAVA developer it has always been a challenge to decide which database was the most... | 27,746 | 2024-06-16T16:14:32 | https://community.intersystems.com/post/performance-tests-iris-postgresql-mysql | docker, java, database, jdbc | <p>As a former JAVA developer it has always been a challenge to decide which database was the most suitable for the project we were going to develop, one of the main criteria I used was their performance, as well as their HA configuration capabilities ( high availability). Well, now is the time to put IRIS to the test ... | intersystemsdev |
1,890,388 | BEST BATTING TECHNIQUES FOR CRICKET | BATTING TECHNIOUES INTRODUCTION Batting in cricket involves skillful hitting of the ball with a... | 0 | 2024-06-16T16:00:34 | https://dev.to/sneha_sharma_1487093e12d8/best-batting-techniques-for-cricket-2gd7 | crickter, indiancricket | BATTING TECHNIOUES
INTRODUCTION
Batting in cricket involves skillful hitting of the ball with a bat, requiring balance, precision, and strategic shot selection


2... | sunder_mehra_246c4308e1dd |
1,890,385 | Day 20 of my progress as a vue dev | About today Today was a very strange day in my journey. Let me explain. I woke up and decided I don't... | 0 | 2024-06-16T15:55:12 | https://dev.to/zain725342/day-20-of-my-progress-as-a-vue-dev-2inl | webdev, vue, typescript, tailwindcss | **About today**
Today was a very strange day in my journey. Let me explain. I woke up and decided I don't wanna work on the audio editor project anymore(at least for now). Reason? Well honestly there are many, but the main one was I wasn't having any fun working on it or felt the same excitement like I felt on the last... | zain725342 |
1,888,224 | Spring Framework: About Aware suffix interface | Following discussion is based on source code of Spring Framework 6.1.8. Some commonly used Spring... | 0 | 2024-06-16T15:54:07 | https://dev.to/saladlam/spring-framework-about-aware-suffix-interface-39pb | spring | Following discussion is based on source code of Spring Framework 6.1.8.
Some commonly used Spring Framework components can be injected into your bean during bean creation.
# Commonly used Aware interface
| Interface name | Information interested | Injected by |
| -------------- | ---------------------- | -----------... | saladlam |
1,890,384 | From React to Hotwire - Part II - [EN] | Versão em Português Introduction In the first article about this migration from React to... | 0 | 2024-06-16T15:50:03 | https://dev.to/cirdes/from-react-to-hotwire-part-ii-en-2lim | react, hotwire, rails, phlex | [Versão em Português](https://dev.to/cirdes/do-react-ao-hotwire-parte-ii-pt-br-3aa4)
## Introduction
In the [first article](https://dev.to/cirdes/from-react-to-hotwire-part-i-en-2o6g) about this migration from React to Hotwire, I discussed how we arrived at our current React stack. In this Part II, I will talk about ... | cirdes |
1,890,383 | The Future of Google Search: Innovations Shaping Tomorrow's Web by Mike Savage of New Canaan | Google Search, the world's most widely used search engine, has revolutionized how we access... | 0 | 2024-06-16T15:45:03 | https://dev.to/savagenewcanaan/the-future-of-google-search-innovations-shaping-tomorrows-web-by-mike-savage-of-new-canaan-jk4 | google, ai | <p style="text-align: justify;">Google Search, the world's most widely used search engine, has revolutionized how we access information. Since its launch in 1998, Google has continually refined its search algorithms and expanded its capabilities, striving to deliver more relevant, accurate, and timely results. As we lo... | savagenewcanaan |
1,890,304 | Do React ao Hotwire - Parte II - [PT-BR] | English version available Introdução No primeiro artigo sobre essa migração do React para... | 0 | 2024-06-16T15:44:26 | https://dev.to/cirdes/do-react-ao-hotwire-parte-ii-pt-br-3aa4 | react, hotwire, rails, phlex | [English version available](https://dev.to/cirdes/from-react-to-hotwire-part-ii-en-2lim)
## Introdução
No [primeiro artigo](https://dev.to/cirdes/do-react-ao-hotwire-parte-i-pt-br-1hm2) sobre essa migração do React para o Hotwire, eu abordei como chegamos à nossa stack atual em React. Nesta Parte II, vou falar sobre ... | cirdes |
1,890,382 | Day 7: Building a React Project 🏗️ | Welcome to Day 7 of our React.js learning journey Today, we'll put all the concepts we've learned so... | 0 | 2024-06-16T15:43:50 | https://dev.to/dipakahirav/day-7-building-a-react-project-1m8c | react, webdev, javascript | Welcome to Day 7 of our React.js learning journey Today, we'll put all the concepts we've learned so far into practice by building a small React project. This hands-on experience will help solidify your understanding of React and prepare you for building larger applications. 🎉
please subscribe to my [YouTube channel]... | dipakahirav |
1,890,381 | Deploying a Kubernetes Cluster on Azure Kubernetes Service(AKS) with Terraform | Introduction Kubernetes, often abbreviated as K8s, is an open-source platform designed to... | 0 | 2024-06-16T15:43:15 | https://dev.to/audu97/deploying-a-kubernetes-cluster-on-azure-kubernetes-serviceaks-with-terraform-1b8g | kubernetes, aure, devops, cloud | ### Introduction
Kubernetes, often abbreviated as K8s, is an open-source platform designed to automate deploying, scaling, and operating application containers. It allows you to manage containerized applications across a cluster of machines efficiently
Azure Kubernetes Service(AKS): Is a managed Kubernetes service off... | audu97 |
1,890,380 | 🎨 Ultimate Front End Design Resource Guide: Elevate Your UI/UX Projects! ❤️ | Welcome to the ultimate guide for all your front-end design needs! Whether you’re a seasoned designer... | 0 | 2024-06-16T15:39:27 | https://dev.to/aayush518/ultimate-front-end-design-resource-guide-elevate-your-uiux-projects-4550 | ui, design, webdev | Welcome to the ultimate guide for all your front-end design needs! Whether you’re a seasoned designer or just starting out, we’ve got you covered with the best resources to make your projects stand out. Dive into a treasure trove of color palettes, fonts, icons, vectors, and more!
## 🌈 Color Sites
Colors can make or... | aayush518 |
1,890,378 | Twilio Challenge: AI-Powered Voice Assistant | This is a submission for the Twilio Challenge What I Built I created an AI-powered voice... | 0 | 2024-06-16T15:37:29 | https://dev.to/thatcoolguy/twilio-challenge-ai-powered-voice-assistant-30j8 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
I created an AI-powered voice assistant designed to handle complex questions. Many existing voice assistants struggle with these types of inquiries, which can be frustrating for users. My assistant aims to bridge thi... | thatcoolguy |
1,890,377 | A beginners guide to Kubernetes with Docker | Kubernetes (often abbreviated as K8s) is an open-source platform for automating the deployment,... | 0 | 2024-06-16T15:31:42 | https://dev.to/ferdousazad/a-beginners-guide-to-kubernetes-with-docker-1e4m | kubernetes, docker, tutorial, webdev | **Kubernetes** (often abbreviated as K8s) is an open-source platform for automating the deployment, scaling, and operation of application containers. It works with various container runtimes, including Docker, to orchestrate containerized applications across clusters of machines.
Here’s a brief tutorial on Kubernetes ... | ferdousazad |
1,890,376 | Transform your Use Cases to Software with ZERO Code | Being able to transform a formal specification into working software has been the wet dream of every... | 0 | 2024-06-16T15:29:38 | https://ainiro.io/blog/transform-your-use-cases-to-software-with-zero-code | lowcode, ai, productivity, programming | Being able to transform a formal specification into working software has been the wet dream of every single project manager for half a century. Simply put, because 99% of all time and resources are spent in the implementation phase. If you can skip the implementation phase, you're basically saving 99% of your resources... | polterguy |
1,890,375 | Get Rid of Tightly Coupled Modules and Circular Dependencies in NestJS | NestJS is a great NodeJS framework that injects a lot of refreshment into the ecosystem of Node’s... | 0 | 2024-06-16T15:26:52 | https://dev.to/kishieel/get-rid-of-tightly-coupled-modules-and-circular-dependencies-in-nestjs-3do1 | nestjs, node, dependencyinversion, eventdriven | NestJS is a great NodeJS framework that injects a lot of refreshment into the ecosystem of Node’s backend solutions. With its robust module system, it allows planning and building scalable architecture that contains modules responsible for wrapping related logic together. While working within a modular environment like... | kishieel |
1,890,319 | Getting Started With React Native: Installation & Setup | React Native is a popular framework for building mobile applications using JavaScript and React. In... | 27,888 | 2024-06-16T15:26:37 | https://dev.to/itsproali/getting-started-with-react-native-installation-setup-37c5 | reactnative, react, android, javascript | React Native is a popular framework for building mobile applications using JavaScript and React. In this guide, we'll walk you through the steps to get started with React Native, including installation, environment setup, and project initialization. Today I will cover only Windows Setup!
#### Prerquisites
- [Chocolat... | itsproali |
1,873,360 | Modern Front-End Development with React | Introduction React is a popular JavaScript library for building user interfaces,... | 27,559 | 2024-06-16T15:23:00 | https://dev.to/suhaspalani/modern-front-end-development-with-react-4kao | webdev, react, frontend, development | #### Introduction
React is a popular JavaScript library for building user interfaces, particularly single-page applications. Developed by Facebook, React allows developers to create large web applications that can update and render efficiently in response to data changes. This week, we'll explore the fundamentals of Re... | suhaspalani |
1,890,374 | Why TypeScript Might Not Be the Best Choice for Your Development Project. | TypeScript has gained significant popularity among developers for its strong typing, improved... | 0 | 2024-06-16T15:21:08 | https://dev.to/gimkelum/why-typescript-might-not-be-the-best-choice-for-your-development-project-ank | typescript, development, javascript | TypeScript has gained significant popularity among developers for its strong typing, improved tooling, and enhanced code quality. It’s hailed as a significant improvement over vanilla JavaScript, promising to catch errors early and make large codebases more maintainable. However, despite its many advantages, TypeScript... | gimkelum |
1,890,361 | Shopify Breakthrough: Achieve E-Commerce Excellence | Introduction In today's digital age, establishing a successful e-commerce business requires... | 0 | 2024-06-16T15:19:16 | https://dev.to/msaadi/shopify-breakthrough-achieve-e-commerce-excellence-d6g | shopify | Introduction
In today's digital age, establishing a successful e-commerce business requires leveraging powerful platforms like Shopify. [Shopify ](https://www.niais.org/shopify-course-in-pakistan)stands out as a robust, user-friendly solution designed to empower entrepreneurs and businesses of all sizes to create, mana... | msaadi |
1,890,360 | Kubernetes Cluster Setup Guide 2024 | Common Installation on both worker and control plane nodes # using 'sudo su' is not a... | 0 | 2024-06-16T15:19:10 | https://dev.to/rahuldhole/kubernetes-cluster-setup-guide-2024-2d7l | kubernetes, ubuntu, cluster | ## Common Installation on both worker and control plane nodes
```sh
# using 'sudo su' is not a good practice.
sudo apt update
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
sudo apt install docker.io -y
sudo usermod -aG docker $USER
sudo chmod 777 /var/run/docker.sock
# Update the Version if nee... | rahuldhole |
1,890,344 | Making a progress bar in easy steps | Here i will be giving you easy steps to build a progress bar using HTML and CSS only. We will be... | 0 | 2024-06-16T15:18:22 | https://dev.to/sunder_mehra_246c4308e1dd/making-a-horizontal-progress-bar-in-easy-steps-4bdc | css, html, web3, webdev | Here i will be giving you easy steps to build a progress bar using HTML and CSS only. We will be using @keyframes for CSS animation.
**Step 1: HTML**
Create a div and another nested div
```
<div class="outer-box">
<div class="inner-box">80%</div>
</div>
```
**Step 2: CSS**
Give width to outer-box and inner-box wi... | sunder_mehra_246c4308e1dd |
1,890,359 | Docker a beginners guide | Docker is a platform for developing, shipping, and running applications in containers. Containers are... | 0 | 2024-06-16T15:15:36 | https://dev.to/ferdousazad/docker-a-beginners-guide-ea3 | docker, webdev, tutorial, node | Docker is a platform for developing, shipping, and running applications in containers. Containers are lightweight and contain everything needed to run an application, making them portable and consistent across environments.
Here’s a brief tutorial on Docker, including creating containers, networking between containers... | ferdousazad |
1,890,358 | Host Website for FREE using Github Pages | -First Login to your Github account and then choose the repository which you want to deploy... | 0 | 2024-06-16T15:11:54 | https://dev.to/mahimabhardwaj/host-website-for-free-using-github-pages-1496 | webdev, github, javascript, beginners | -First Login to your **Github account** and then choose the repository which you want to [deploy online](https://youtu.be/bO1i5ObvdJg?feature=shared).
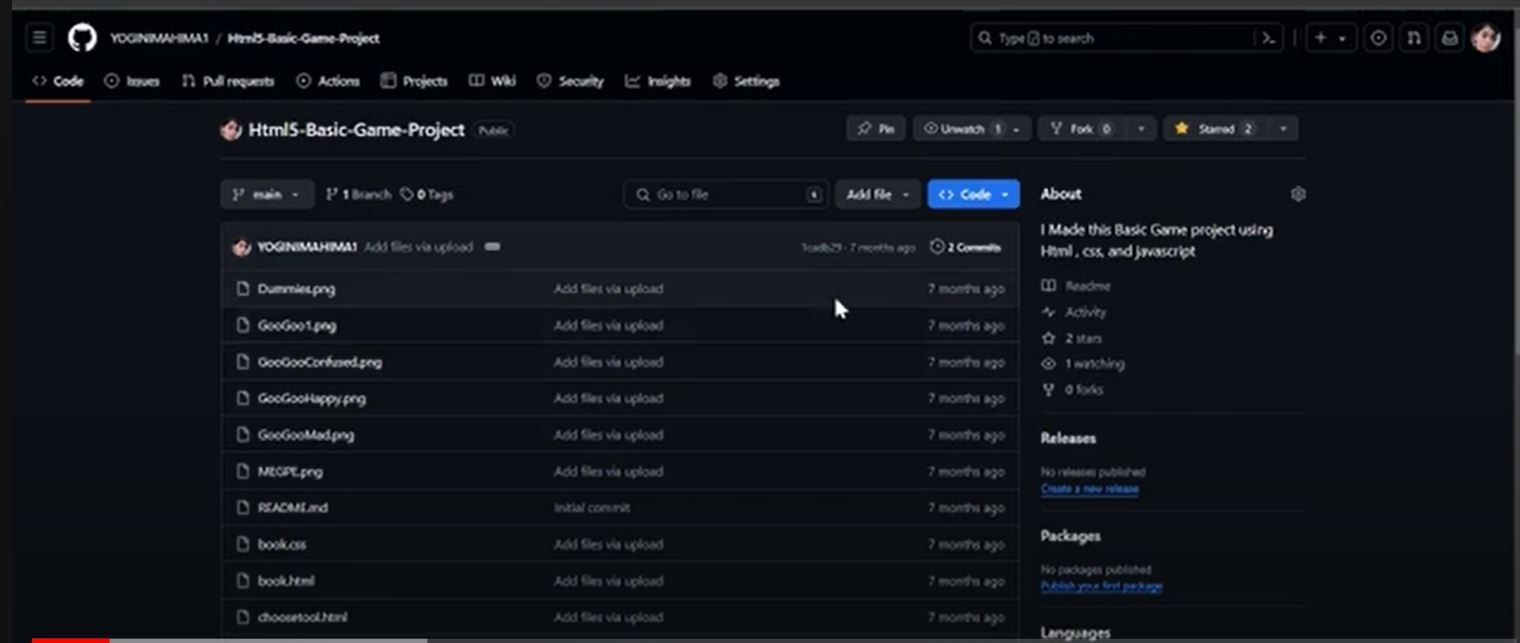
-Then go to settings and select pages
 | 🔍 What is .NET .Net (pronounced "dot net") is a free and open source application platform.... | 27,572 | 2024-06-16T15:08:42 | https://dev.to/suneeh/net-fundamentals-minimal-api-1h9 | git, devops, github, beginners | ## 🔍 What is .NET
.Net (pronounced "dot net") is a free and open source application platform. The support by Microsoft and the regular updates and new features are what makes this tool so useful. It can be used for a variety of different things such as:
- Mobile Apps
- Desktop Apps
- Microservices
- Game Development... | suneeh |
1,890,356 | Building the Internet of Things with AWS IoT Core | Building the Internet of Things with AWS IoT Core The Internet of Things (IoT) is... | 0 | 2024-06-16T15:04:58 | https://dev.to/virajlakshitha/building-the-internet-of-things-with-aws-iot-core-2914 | 
# Building the Internet of Things with AWS IoT Core
The Internet of Things (IoT) is rapidly transforming our world, connecting billions of devices and enabling unprecedented levels of automation and data exchange. At the heart of... | virajlakshitha | |
1,890,355 | Integrating ClickHouse with AWS S3 | Integrating ClickHouse with AWS S3 To integrate ClickHouse with an S3 bucket for fetching... | 0 | 2024-06-16T15:03:36 | https://dev.to/zubaire/integrating-clickhouse-with-aws-s3-mpm | ### **Integrating ClickHouse with AWS S3**
To integrate ClickHouse with an S3 bucket for fetching data, performing operations, and putting data back, follow these steps:
### **1. Setting Up ClickHouse**
**Install ClickHouse**:
- On a Debian-based system:
```bash
sudo apt-get install clickhouse-server click... | zubaire | |
1,890,353 | Day 6: Mastering Arrays in JavaScript 🚀 | Introduction Welcome to Day 6 of your JavaScript journey! 🌟 Yesterday, we explored... | 0 | 2024-06-16T15:02:04 | https://dev.to/dipakahirav/day-6-mastering-arrays-in-javascript-416j | javascript, array, webdev, learning | #### Introduction
Welcome to Day 6 of your JavaScript journey! 🌟 Yesterday, we explored functions. Today, we will dive into arrays, one of the most important data structures in JavaScript. Arrays allow you to store multiple values in a single variable, making it easier to manage and manipulate collections of data. Let... | dipakahirav |
1,890,352 | How to Create a Memory Game: Step-by-Step Guide | Project:- 9/500 Memory Game project. Description The Memory Game is a classic... | 27,575 | 2024-06-16T14:57:04 | https://raajaryan.tech/how-to-create-a-memory-game-step-by-step-guide | javascript, opensource, beginners, tutorial | ### Project:- 9/500 Memory Game project.
## Description
The Memory Game is a classic card-matching game that helps improve memory and concentration skills. The objective of the game is to match pairs of cards with the same image. The game begins with all cards faced down, and players take turns flipping over two card... | raajaryan |
1,890,351 | Open Web Application Security Project OWASP Top Ten | Web security is crucial for protecting applications and data from various threats. The OWASP (Open... | 0 | 2024-06-16T14:56:08 | https://dev.to/ferdousazad/open-web-application-security-project-owasp-top-ten-l7o | webdev, websecurity, owasp, programming | Web security is crucial for protecting applications and data from various threats. The OWASP (Open Web Application Security Project) Top Ten is a widely recognized list of the most critical web application security risks. Here’s a detailed explanation of common web security best practices, including those highlighted b... | ferdousazad |
1,890,350 | What is full stack developer ? | A full stack developer is a type of software developer who is proficient in working on both the front... | 0 | 2024-06-16T14:54:49 | https://dev.to/vicky435435/what-is-full-stack-developer--4ka9 | fullstack, developer, programming, beginners | A full stack developer is a type of software developer who is proficient in working on both the front end and back end portions of a web application. This means they have the skills to handle both the client-side (what users interact with) and server-side (the logic, database interactions, server configuration, etc.) d... | vicky435435 |
1,890,349 | Understanding Database Normalization with Examples | Database normalization is a fundamental concept in database theory and design. It's a systematic... | 0 | 2024-06-16T14:53:59 | https://dev.to/dana-fullstack-dev/understanding-database-normalization-with-examples-pai | Database normalization is a fundamental concept in database theory and design. It's a systematic approach to organizing data in a database to reduce redundancy and improve data integrity. The process involves dividing large tables into smaller, more manageable pieces and defining relationships between them.
## What is... | dana-fullstack-dev | |
1,890,341 | Unlocking the Future: Passwordless Authentication(Passkey) With Flutter and Node.js | Welcome Back, Fellow Coders! Hey everyone! It’s been a hot minute since our last deep dive, but... | 0 | 2024-06-16T14:45:31 | https://dev.to/djsmk123/unlocking-the-future-passwordless-authenticationpasskey-with-flutter-and-nodejs-1ojh | flutter, android, passworldless, tutorial | > Welcome Back, Fellow Coders!
Hey everyone! It’s been a hot minute since our last deep dive, but I’m thrilled to be back and diving headfirst into some seriously cool tech. Today, we’re tackling a topic that’s bound to make your life (and your users’ lives) a whole lot easier: passwordless authentication. Yes, you he... | djsmk123 |
1,890,342 | Super-charging Django: Tips & Tricks | Django encourages rapid development and clean, pragmatic design. However, as your application scales,... | 0 | 2024-06-16T14:43:32 | https://dev.to/kagemanjoroge/super-charging-django-tips-tricks-24bi | Django encourages rapid development and clean, pragmatic design. However, as your application scales, ensuring optimal performance becomes crucial. In this article, we'll go beyond the basics and delve deeper into advanced techniques and tools to optimize your Django application.
### 1. **Database Optimization**
**a.... | kagemanjoroge | |
1,890,345 | Four Must-Have Essential MacOS Apps | 1. Downie Downie is a versatile downloader, now in its 4th generation. It can be used as a... | 0 | 2024-06-16T14:42:06 | https://dev.to/hikarimaeda/four-must-have-essential-macos-apps-5b6g | tooling, webdev | ### 1. Downie
[Downie](https://software.charliemonroe.net/downie/) is a versatile downloader, now in its 4th generation. It can be used as a browser plugin, allowing you to download almost anything from the web. For instance, if you find an interesting video online and want to watch it repeatedly, just click the Downie... | hikarimaeda |
1,890,343 | Stylish Comfort: Exploring Hellstar Shirts and Shorts | Hellstar, renowned for its bold approach to contemporary fashion, extends its signature style beyond... | 0 | 2024-06-16T14:40:52 | https://dev.to/work_df097eadc4c2e801f496/stylish-comfort-exploring-hellstar-shirts-and-shorts-4km6 | hellstar, shorts |
[Hellstar](https://hellstarclothingsus.ltd/), renowned for its bold approach to contemporary fashion, extends its signature style beyond sweatshirts and sweatpants to encompass a range of equally fashionable shirts and shorts. This article delves into the allure of Hellstar's shirts and shorts, emphasizing their uniqu... | work_df097eadc4c2e801f496 |
1,890,340 | Networking to a 5th Grader in 256 words. | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-16T14:39:13 | https://dev.to/thomastaylor/networking-to-a-5th-grader-in-256-words-6p4 | devchallenge, cschallenge, computerscience, networking | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Imagine you want to send a hand-written invite to a buddy who lives far away to your birthday party. In order to send this invite, you would need to use a postal service. Sending data ... | thomastaylor |
1,890,339 | Create FastAPI App Like pro part-1 | install fastapi using following commend pip install fastapi[all] Enter fullscreen mode ... | 0 | 2024-06-16T14:36:49 | https://dev.to/muhammadnizamani/create-fastapi-app-like-pro-part-1-12pi | fastapi, python, uvicorn, pydentic | install fastapi using following commend
```
pip install fastapi[all]
```
Create a project directory named it then start
**Step #1:** Create a **server** directory and add an** __init__.py **file to it. Then, create the following subdirectories within the server directory:
1. **DB**: This directory will cont... | muhammadnizamani |
1,890,338 | Day 6: Introduction to Semantic HTML | Welcome to Day 6 of your journey to mastering HTML and CSS! Today, we will explore semantic HTML, an... | 0 | 2024-06-16T14:35:44 | https://dev.to/dipakahirav/day-6-introduction-to-semantic-html-3o2i | javascript, webdev, html, css | Welcome to Day 6 of your journey to mastering HTML and CSS! Today, we will explore semantic HTML, an important concept that helps improve the accessibility and SEO of your web pages. By the end of this post, you'll understand the benefits of semantic HTML and how to use semantic elements effectively.
please subscribe ... | dipakahirav |
1,890,337 | Advanced Insights into Automated Data Processing Tools | Introduction: In the age of big data, automated data processing tools have become... | 0 | 2024-06-16T14:34:15 | https://dev.to/data_expertise/advanced-insights-into-automated-data-processing-tools-4l3k | automateddataprocessing, machinelearning, bigdata, datascience |
## Introduction:
In the age of big data, automated data processing tools have become indispensable for businesses aiming to efficiently handle vast amounts of information. Moving beyond the basics, this article delves into advanced strategies and applications of automated data processing, examining its impact from va... | data_expertise |
1,890,336 | Sallah greeting with ram | Check out this Pen I made! | 0 | 2024-06-16T14:34:10 | https://dev.to/kemiowoyele1/sallah-greeting-with-ram-73c | codepen | Check out this Pen I made!
{% codepen https://codepen.io/frontend-magic/pen/JjqMMXN %} | kemiowoyele1 |
1,890,292 | Code With Heroines : TCP/IP && Rise and fall of the Han Dynasty | Description The dramatic fall of the Tang Dynasty within a collapsing virtual world. Zhu... | 0 | 2024-06-16T14:34:08 | https://dev.to/fubumingyu/code-with-heroines-tcpip-rise-and-fall-of-the-han-dynasty-3o0f |

## Description
The dramatic fall of the Tang Dynasty within a collapsing virtual world. Zhu Quanzhong, depicted as a determined young girl with advanced hacking skills, leads the charge against a crumbling digit... | fubumingyu | |
1,890,332 | Building Zerocalc, part II - evaluating then parsing | In part I we built a simple tokenizer while explaining how rustc converts an input text into a stream... | 27,824 | 2024-06-16T14:33:36 | https://dev.to/michal1024/building-zerocalc-part-ii-evaluating-then-parsing-3fim | rust, programming | In [part I](https://dev.to/michal1024/building-zerocalc-part-i-rustc-lexer-and-a-lexer-in-rust-3ipf) we built a simple tokenizer while explaining how `rustc` converts an input text into a stream of tokens. The next step is to transform the stream of tokens into a representation that will be easy to evaluate. This time ... | michal1024 |
1,890,333 | Spring Boot + Hibernate + PostgreSQL Example | This tutorial will build a Spring Boot CRUD Rest API example with Maven that uses Spring Data... | 0 | 2024-06-16T14:26:06 | https://dev.to/georgech2/spring-boot-hibernate-postgresql-example-123a | springboot, postgressql, java, webdev | This tutorial will build a Spring Boot CRUD Rest API example with Maven that uses Spring Data JPA/Hibernate to interact with the PostgreSQL database.
You’ll know:
* How to configure Spring Data, JPA, and Hibernate to work with PostgreSQL Database
* Way to use Spring Data JPA to interact with PostgreSQL Database
## Te... | georgech2 |
1,890,325 | Automate the Boring Stuff: How I Built a Code Generator to Save Hours of Redundant Work🧑💻 | In this article, I will explain how I got frustrated with writing redundant code needed to extend a... | 0 | 2024-06-16T14:20:04 | https://dev.to/samadyarkhan/how-i-automated-all-the-elegant-code-required-to-extend-a-feature-mmn | python, ai, chatgpt, developer | 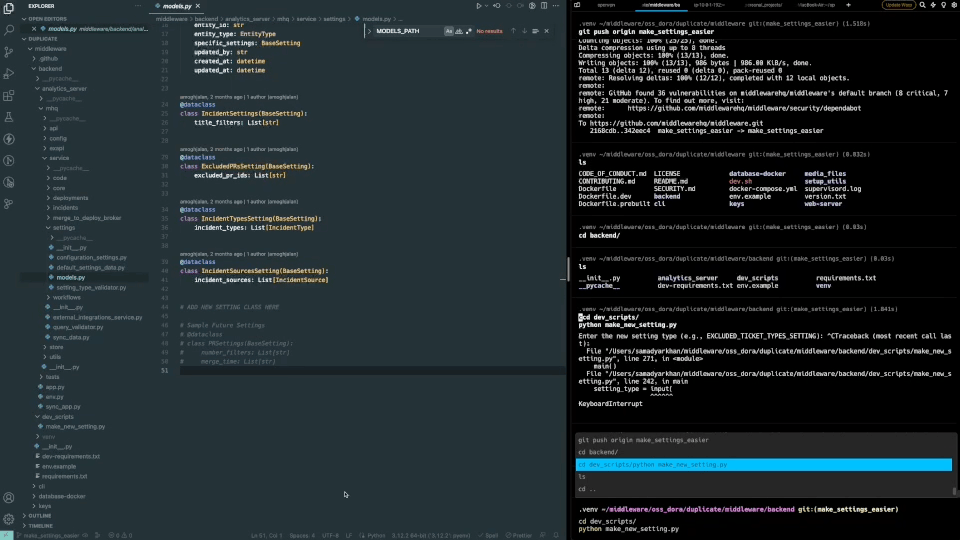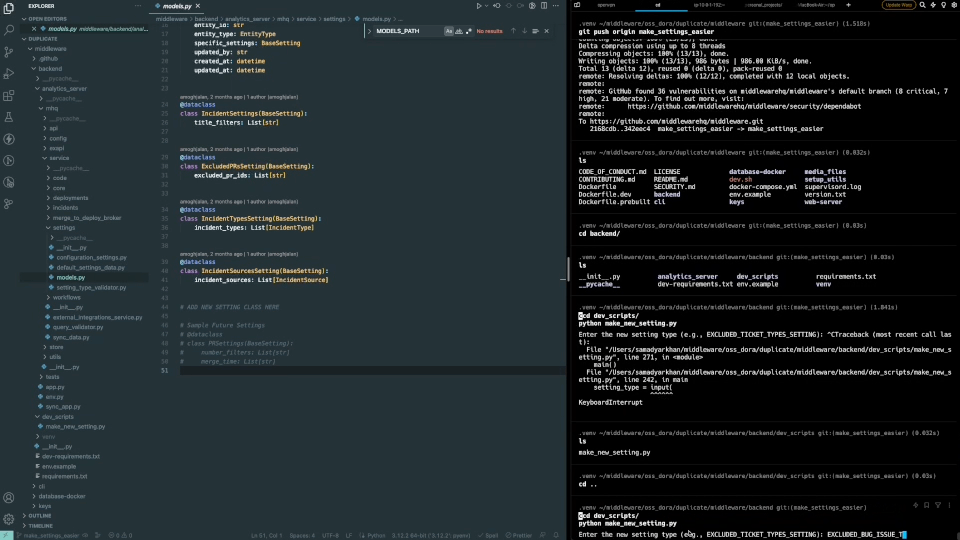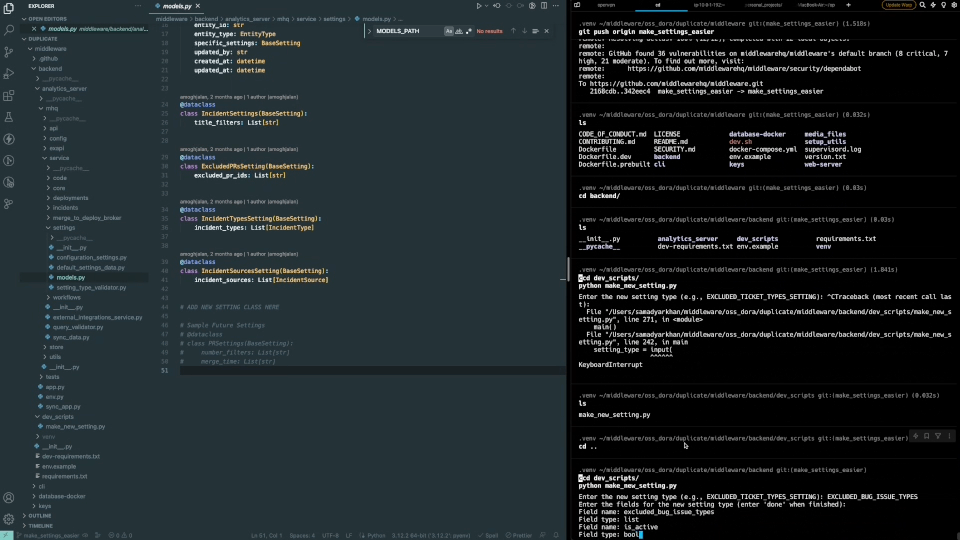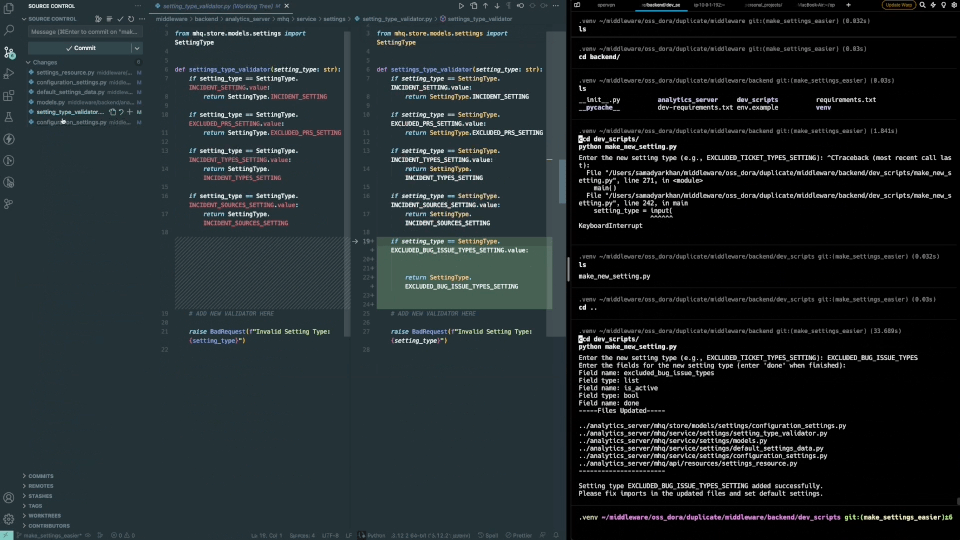
In this article, I will explain how I got frustrated with writing redundant code needed to extend a service every time a new requirement was raised, and how I automated this with code generation.
You can skip to on... | samadyarkhan |
1,890,326 | How Deep Learning Works | Deep Learning is the core of a Machine Learning system, it is how a machine actually learns from data... | 27,745 | 2024-06-16T14:18:38 | https://nibodhdaware.hashnode.dev/how-deep-learning-works | ai, deeplearning, machinelearning, neuralnetworks | Deep Learning is the core of a Machine Learning system, it is how a machine actually learns from data without much human intervention. In this post I am going to discuss how Deep Learning actually works with the data you give.
The basis of a Deep Learning system are Neural Networks, they are the fundamental part of ho... | nibodhdaware |
1,857,558 | AWS Lambda Layer | This is something I was stuck on while deploying the lambda function, even though the code was only a... | 0 | 2024-06-16T14:18:31 | https://dev.to/aws-builders/aws-lambda-layer-5g00 | aws, devops, lambda, cicd | This is something I was stuck on while deploying the lambda function, even though the code was only a few 100 lines I had to deploy the function with a zip file including all the node dependencies unnecessarily, it was quite annoying and I'm having this feeling you felt the same way that why you landed over here.
Let'... | ashutosh5786 |
1,887,742 | CodeBehind 2.7 Released, Role Access Added! | A new version of CodeBehind 2.7 has been released with a focus on roles and security. In this... | 0 | 2024-06-16T14:18:19 | https://dev.to/elanatframework/codebehind-27-released-role-access-added-m8n | backend, dotnet, github, security | A new version of [CodeBehind](https://github.com/elanatframework/Code_behind) 2.7 has been released with a focus on roles and security. In this article, we'll look at how to configure CodeBehind role access in an ASP.NET Core application.
With the addition of role support, CodeBehind is now a powerful security framewo... | elanatframework |
1,890,323 | Messaging queues (Rabbitmq as broker) | Since backend development goes beyond building CRUD applications, I am here to discuss one of the... | 0 | 2024-06-16T14:10:34 | https://dev.to/codewitgabi/messaging-queues-rabbitmq-as-broker-hhk | backend, microservices, rabbitmq, broker | Since backend development goes beyond building CRUD applications, I am here to discuss one of the core concepts of backend development which is message queueing.
In DSA, queues are basically a structure that follow the FIFO (First In First Out) rule; meaning that the first element to be entered is the first to be pro... | codewitgabi |
1,890,322 | Typography in Angular Material 18 | In this quick guide, we will learn the usage of typography and modifications with CSS variables for Angular Material 18 | 0 | 2024-06-16T14:06:14 | https://angular-material.dev/articles/angular-material-18-typography | angular, angularmaterial, webdev | ---
title: Typography in Angular Material 18
published: true
description: In this quick guide, we will learn the usage of typography and modifications with CSS variables for Angular Material 18
tags: angular, angularmaterial,webdevelopment
cover_image: https://vercel-og-nextjs-delta-one.vercel.app/api/home?title=Typogr... | shhdharmen |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.