
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,890,131 | Efficiently Managing Remote Data in Vue with Vue Query | When building modern Vue applications, efficiently managing remote data is crucial for creating... | 0 | 2024-06-16T07:29:49 | https://dev.to/alimetehrani/efficiently-managing-remote-data-in-vue-with-vue-query-192h | vue, vuequery, tanstack | When building modern Vue applications, efficiently managing remote data is crucial for creating responsive and user-friendly interfaces. Vue Query, inspired by React Query, provides powerful hooks for fetching, caching, and synchronizing server state in your Vue applications. In this post, we'll explore three essential... | alimetehrani |
1,890,130 | Let's practice writing clean, reusable components in react | 🔑 Key Concepts What are reusable React components? Think of them as building... | 0 | 2024-06-16T07:23:49 | https://dev.to/codewithshahan/lets-practice-clean-reusable-components-in-react-5flj | webdev, javascript, beginners, react | ## 🔑 Key Concepts
**What are reusable React components?** Think of them as building blocks.
They're pieces of code you can use in different parts of your website to save time. They can be anything from simple buttons to complex forms.
### **Why Use Reusable Components?**
They make it easy to add new features and im... | codewithshahan |
1,890,076 | Full Backup in Nodejs(Files and Database backup) | NodeFullBackup is an npm package crafted specifically for comprehensive backup solutions. It... | 0 | 2024-06-16T07:08:01 | https://dev.to/hosseinmobarakian/full-backup-in-nodejsfiles-and-database-backup-2a9f | javascript, webdev, tutorial, node | [NodeFullBackup](https://github.com/hosseinmobarakian/node-full-backup) is an npm package crafted specifically for comprehensive backup solutions. It seamlessly integrates MongoDB backup functionality with file backup capabilities, ensuring that all your critical data is securely preserved. This package is ideal for an... | hosseinmobarakian |
1,890,077 | We are haotees.com | Sleep Tight in Braves Country: The Atlanta Braves Bedding Set Calling all Atlanta Braves fans! Take... | 0 | 2024-06-16T07:07:33 | https://dev.to/nguyen_hao_cfe2a1626f5e74/we-are-haoteescom-1ffl | Sleep Tight in Braves Country: The Atlanta Braves Bedding Set
Calling all Atlanta Braves fans! Take your fandom to dreamland with the officially licensed Atlanta Braves bedding set. This comfortable and stylish set lets you surround yourself with the team’s colors and logos, transforming your bedroom into a celebration... | nguyen_hao_cfe2a1626f5e74 | |
1,890,075 | Compare CSS Online: A Guide to Streamlining Your Web Development | https://ovdss.com/apps/compare-css-online In the fast-paced world of web development, efficiency and... | 0 | 2024-06-16T07:00:46 | https://dev.to/johnalbort12/compare-css-online-a-guide-to-streamlining-your-web-development-1m8h | ERROR: type should be string, got "\n\n\n\n\n\n\n\n\n\nhttps://ovdss.com/apps/compare-css-online\n\n\nIn the fast-paced world of web development, efficiency and accuracy are paramount. One of the crucial aspects of creating and maintaining websites is managing CSS (Cascading Style Sheets). CSS defines the look and feel of a website, controlling everything from layout to colours and fonts. Comparing CSS files to identify differences and merge changes is a common task for developers, particularly when collaborating on projects or updating legacy code. In this blog post, we'll explore the benefits of comparing CSS files online and how it can streamline your web development process.\n\nWhy Compare CSS Files\n\nBefore diving into the tools and methods for comparing CSS files online, it's essential to understand why this process is beneficial:\n1. Version Control\nWeb development often involves multiple developers working on the same project. Comparing CSS files allows you to track changes made by different team members, ensuring that no critical updates are lost and conflicts are resolved efficiently.\n2. Bug Fixing\nCSS bugs can be notoriously difficult to track down. By comparing versions of your CSS, you can pinpoint exactly when and where an issue was introduced, making it easier to debug and fix.\n3. Optimization\nOver time, CSS files can become bloated with unused or redundant styles. Comparing CSS files helps identify and remove unnecessary code, leading to cleaner, more efficient stylesheets.\n4. Merging Changes\nWhen updating a website, you might have multiple CSS files with different modifications. Comparing these files allows you to merge changes seamlessly, ensuring a consistent design across the site.\n\n\nHow to Compare CSS Files Online\n\n\nUsing online tools to compare CSS files is generally straightforward. Here’s a step-by-step guide to get you started:\nStep 1: Choose Your Tool\nSelect the online tool that best fits your needs. For this example, we'll use Diffchecker.\nStep 2: Upload Your CSS Files\nMost tools allow you to upload files directly from your computer or paste the CSS code into text boxes. Upload the two CSS files you want to compare.\nStep 3: Analyse the Comparison\nThe tool will display a side-by-side comparison of the two files, highlighting differences. Review the changes carefully, noting any conflicts or areas that need merging.\nStep 4: Resolve Differences\nMake the necessary changes to your CSS files based on the comparison. If the tool supports merging, you can often do this directly within the interface.\nStep 5: Save and Test\nOnce you’ve resolved the differences, save the updated CSS file and test it on your website to ensure everything looks and functions as expected.\n\nConclusion\nComparing CSS files online is a valuable skill for web developers, helping to maintain clean, efficient, and bug-free stylesheets. By utilising online tools, you can streamline your workflow, enhance collaboration, and ensure your website looks its best. Whether you’re a solo developer or part of a team, mastering CSS comparison will undoubtedly improve your web development process.\n\n" | johnalbort12 | |
1,890,073 | Updating Non-Primitive Data in an Array Using Transactions and Rollbacks | Introduction In this blog, we will explore how to update both primitive and non-primitive... | 0 | 2024-06-16T06:51:46 | https://dev.to/md_enayeturrahman_2560e3/updating-non-primitive-data-in-an-array-using-transactions-and-rollbacks-5g24 | javascript, mongoose, mongodb, express | ### Introduction
In this blog, we will explore how to update both primitive and non-primitive data in a MongoDB document using Mongoose. We will specifically focus on updating arrays within documents. Our approach will leverage transactions and rollbacks to ensure data integrity during the update process. We will walk... | md_enayeturrahman_2560e3 |
1,890,072 | Understanding Inheritance and Polymorphism: Simplified OOP Concepts | Inheritance Inheritance means creating a new class based on an existing class. The new... | 0 | 2024-06-16T06:51:15 | https://dev.to/jaid28/understanding-inheritance-and-polymorphism-simplified-oop-concepts-269c | inheritance, oop, polymorphism, teaching | ## Inheritance
Inheritance means creating a new class based on an existing class. The new class inherits attributes and methods from the existing class.
## Example Explanation
Imagine you have a general class called Animal. You can create a specific class called Dog that inherits everything from Animal and adds its ow... | jaid28 |
1,890,071 | Best Practices for Creating Reusable Custom Hooks in React | Custom hooks in React provide a powerful way to encapsulate and reuse logic across your application.... | 0 | 2024-06-16T06:48:37 | https://dev.to/hasancse/best-practices-for-creating-reusable-custom-hooks-in-react-37nj | webdev, programming, react, typescript | Custom hooks in React provide a powerful way to encapsulate and reuse logic across your application. They promote code reuse, enhance readability, and simplify state management. In this blog post, we'll explore best practices for creating reusable custom hooks in React using TypeScript, ensuring type safety and robustn... | hasancse |
1,890,070 | The Importance of Prayer in Islam | Prayer, known as Salah in Arabic, is one of the Five Pillars of Islam and a fundamental aspect of a... | 0 | 2024-06-16T06:39:52 | https://dev.to/b0cddb2d154184/the-importance-of-prayer-in-islam-55np | Prayer, known as Salah in Arabic, is one of the Five Pillars of Islam and a fundamental aspect of a Muslim’s faith and practice. It is a direct link between the worshiper and Allah, providing an opportunity to communicate, reflect, and seek guidance. This article explores the significance of prayer in Islam, its spirit... | b0cddb2d154184 | |
1,890,069 | Amazon RDS Multi-AZ Deployments vs Read Replica | Amazon RDS (Relational Database Service) provides several features to enhance the availability,... | 0 | 2024-06-16T06:39:18 | https://dev.to/sachithmayantha/amazon-rds-multi-az-deployments-vs-read-replica-1ki3 | aws, rds | ---
title: Amazon RDS Multi-AZ Deployments vs Read Replica
published: true
description:
tags: aws, rds
cover_image: https://www.whizlabs.com/blog/wp-content/uploads/2020/01/Amazon_RDS.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-16 05:19 +0000
---
Amazon RDS (Relational Database Service) provi... | sachithmayantha |
1,890,068 | Duo Studio UI clone 🚀 | 🚀 Check Out My Latest Project! 🚀 I’m excited to announce my latest frontend development achievement:... | 0 | 2024-06-16T06:38:38 | https://dev.to/sameer07x19/duo-studio-ui-clone-1ldk | webdev, beginners, gsap, javascript | 🚀 **Check Out My Latest Project!** 🚀
I’m excited to announce my latest frontend development achievement: a stunning UI clone of the Duo Studio website! This project is a testament to my skills in creating immersive web experiences with cutting-edge animations.
### 🔹 Project Highlights 🔹
**Dynamic Animations:** C... | sameer07x19 |
1,890,067 | Problem : - Your project requires a newer version of the Kotlin Gradle plugin in Flutter. | Your project requires a newer version of the Kotlin Gradle plugin. Find the latest version on... | 0 | 2024-06-16T06:29:40 | https://dev.to/ozonexkeshav07/problem-your-project-requires-a-newer-version-of-the-kotlin-gradle-plugin-in-flutter-5da3 | kotlin, dart, flutter, development | Your project requires a newer version of the Kotlin Gradle plugin. Find the latest version on https://kotlinlang.org/docs/gradle.html#plugin-and-versions, then update project/android/build.gradle: ext.kotlin_version = '<latest-version>'
But You have already changed the "ext.kotlin_version = '<latest-version>'"
and stil... | ozonexkeshav07 |
1,883,762 | Mastering PHP File Paths: Simplifying Your Project's Structure | Have you ever tried including a file in your project and needed clarification about how to go about... | 0 | 2024-06-16T06:28:10 | https://dev.to/anwar_sadat/mastering-php-file-paths-simplifying-your-projects-structure-650 | php, backenddevelopment, tutorial, beginners | Have you ever tried including a file in your project and needed clarification about how to go about it? You usually start with a simple folder structure that can quickly escalate to a complex folder structure. This article will discuss the absolute and relative paths, directory separators, file functions, including fil... | anwar_sadat |
1,890,035 | Implement a DevSecOps Pipeline with GitHub Actions | Introduction - Birth of DevSecOps The story of DevSecOps follows the the story of Software... | 0 | 2024-06-16T06:24:22 | https://dev.to/herjean7/implement-a-devsecops-pipeline-with-github-actions-2lbb | devsecops, githubactions, node, cicd | ## Introduction - Birth of DevSecOps
The story of DevSecOps follows the the story of Software Development closely. We saw how the industry moved from Waterfall to Agile and everything changed after Agile. With much shorter development cycles, there was also a need for faster deployments to production.
It was no long... | herjean7 |
1,890,048 | Home Construction Company in Bangalore | Assurance Developers | Assurance Developers is a leading Home construction company in Bangalore, known for its unwavering... | 0 | 2024-06-16T06:12:25 | https://dev.to/assurancedevelopers_f6070/home-construction-company-in-bangalore-assurance-developers-19l0 | homeconstructioncompany, constructioncompany, assurancedevelopers | Assurance Developers is a leading [Home construction company in Bangalore](https://assurancedevelopers.com/residential-buildings/
), known for its unwavering commitment to excellence and reliability. With a dedicated team of skilled professionals and a passion for creating exceptional living spaces, Assurance Developer... | assurancedevelopers_f6070 |
1,890,047 | Finding the Largest Sum Subarray: Step-by-Step Guide Using Kadane's Algorithm | Finding the largest sum subarray is a intermediate problem in coding interviews. In this guide, we'll... | 0 | 2024-06-16T06:12:08 | https://dev.to/rk042/finding-the-largest-sum-subarray-step-by-step-guide-using-kadanes-algorithm-1nc1 | programming, career, algorithms, interview | Finding the largest sum subarray is a intermediate problem in coding interviews. In this guide, we'll explore how to locate the maximum sum of a continuous subarray using Kadane's Algorithm. Don't worry if this sounds complex at first—we'll break it down step by step.

At Joy Services, we offer a range of powerful and flexible cloud services designed to take your business to the next level. Our team of experts is dedicated to ensuring you have the resources and support neces... | strikerboy |
1,890,043 | Database1 | Database Concepts MySQL v5.7 (RDBMS) Oracle 11g(ORDBMS) MongoDB (NoSQL... | 0 | 2024-06-16T06:03:11 | https://dev.to/dwivedialind/database1-5h91 | beginners, learning, database, sql | ## Database Concepts
**_MySQL v5.7 (RDBMS)_**
**_Oracle 11g(ORDBMS)_**
**_MongoDB (NoSQL DBMS)_**
- DBMS(**Database Management System**): Software that helps to manage data
```bash
Various DBMS available
MSExcel, FoxBASE, FoxPro, DataEase, DataFlex, Clipper, DB Vista etc
```
### Some Important Definitions
1. RDBMS... | dwivedialind |
1,890,042 | GitHub - Commit, Pull Request, Merge | To clone repository on local system -> git clone <repository-url> Enter fullscreen... | 0 | 2024-06-16T06:02:44 | https://dev.to/alamfatima1999/github-commit-pull-request-merge-4n3h | To clone repository on local system ->
```
git clone <repository-url>
```
Get inside the local repo branch
Check which branch you are in and all current branches available on local system ->
```
git branch
```
If required branch not found, get all current branches from GitHub ->
```
git fetch
```
.
To get into a ... | alamfatima1999 | |
1,890,041 | A Beginner's Guide to Component Design in React | Introduction React is a popular JavaScript library used for building user interfaces,... | 0 | 2024-06-16T06:02:29 | https://dev.to/lovishduggal/a-beginners-guide-to-component-design-in-react-521g | webdev, beginners, react, javascript | ## Introduction
**React** is a popular JavaScript library used for building user interfaces, especially for single-page applications. One of the key concepts in React is component design. Components are the building blocks of a React application. Understanding how to create and use them effectively is crucial for buil... | lovishduggal |
1,890,018 | Websites to Inspire Web Design and Development in 2024 | Essential Websites for Web Design Inspiration and Latest Trends in 2024 In 2024, the... | 0 | 2024-06-16T06:00:00 | https://travislord.xyz/articles/websites-to-inspire-web-design-and-development-in-2024 | webdev, tutorial, learning, opensource | ## Essential Websites for Web Design Inspiration and Latest Trends in 2024
In 2024, the demand for unique, high-converting websites is skyrocketing. As a web designer or developer, it's crucial to stay ahead of the curve by exploring top-notch web design inspirations. By leveraging the latest web design trends, respon... | lilxyzz |
1,890,040 | Differences in traditional and web3/blockchain front end development | Web3/Blockchain front end development differs from traditional/web2 front end development in certain... | 0 | 2024-06-16T05:47:24 | https://dev.to/muratcanyuksel/differences-in-traditional-and-web3blockchain-front-end-development-3494 | solidity, blockchain, react, web3 | Web3/Blockchain front end development differs from traditional/web2 front end development in certain ways. Here we will look at how they differ in interacting with the back end, and how they handle authentication.
In the traditional system, the front end interacts with a server. That server might have been written wit... | muratcanyuksel |
1,578,481 | How to use Stable Diffusion to create AI-generated images | The convergence of Artificial Intelligence (AI) and art has birthed captivating new horizons in... | 0 | 2024-06-16T05:15:08 | https://dev.to/ajeetraina/how-to-use-stable-diffusion-to-create-ai-generated-images-2497 | ai, docker, stablediffusion | The convergence of Artificial Intelligence (AI) and art has birthed captivating new horizons in creative expression. Among the innovative techniques, Stable Diffusion shines as a remarkable method that leverages neural networks to produce awe-inspiring AI-generated images. In this blog post, we embark on an exploration... | ajeetraina |
1,890,039 | React Context-API Pro | Build state management using useContext + useReducer | Typescript | The Context API in React is a powerful feature that allows you to manage state globally across your... | 0 | 2024-06-16T05:45:30 | https://dev.to/thisisarkajitroy/react-context-api-pro-build-state-management-using-usecontext-usereducer-typescript-3gm1 | javascript, react, reactnative, nextjs | The Context API in React is a powerful feature that allows you to manage state globally across your application without the need to pass props down through multiple levels of your component tree. When combined with TypeScript, it becomes even more robust, providing type safety and better code maintainability. In this a... | thisisarkajitroy |
1,890,034 | Buy verified BYBIT account | Buy verified BYBIT account In the evolving landscape of cryptocurrency trading, the role of a... | 0 | 2024-06-16T05:34:08 | https://dev.to/glen_agollit_6d40ebcc4f4c/buy-verified-bybit-account-4pj8 | Buy verified BYBIT account
In the evolving landscape of cryptocurrency trading, the role of a dependable and protected platform cannot be overstated. Bybit, an esteemed crypto derivatives exchange, stands out as a platform that empowers traders to capitalize on their expertise and effectively maneuver the market.
This... | glen_agollit_6d40ebcc4f4c | |
1,890,033 | James Hardie Contractors in Bellingham | Why James Hardie Reigns because the PNW’s Most Popular Siding Choice In the stunning landscapes of... | 0 | 2024-06-16T05:23:23 | https://dev.to/sidingvault08/james-hardie-contractors-in-bellingham-3j43 | Why James Hardie Reigns because the PNW’s Most Popular Siding Choice
In the stunning landscapes of the Pacific Northwest (PNW), where homes embrace a completely unique combination of natural splendor and modern-day living, the selection of siding performs a pivotal role in preserving both aesthetics and sturdiness. Am... | sidingvault08 | |
1,890,030 | 10 Ways Automation is Revolutionizing Cost and Time Savings for Businesses | Automation is no longer just a buzzword; Automation is transforming industries worldwide,... | 0 | 2024-06-16T05:16:51 | https://dev.to/futuristicgeeks/10-ways-automation-is-revolutionizing-cost-and-time-savings-for-businesses-365b | webdev, business, automation, ai | Automation is no longer just a buzzword; Automation is transforming industries worldwide, fundamentally changing how businesses operate. By leveraging advanced technologies, organizations can streamline operations, reduce costs, enhance efficiency, and improve overall productivity. This comprehensive article explores t... | futuristicgeeks |
1,890,029 | Boost Your Business with Secure and Affordable Server Solutions | Hello Dev.to community! I'm Striker from Joy Services, and I'm excited to introduce our suite of... | 0 | 2024-06-16T05:16:07 | https://dev.to/strikerboy/boost-your-business-with-secure-and-affordable-server-solutions-3hh | server, ubuntu, linux |

Hello Dev.to community!
I'm Striker from Joy Services, and I'm excited to introduce our suite of powerful and flexible services designed to take your business to the next level. Whether you're a tech startup, a digital m... | strikerboy |
1,890,028 | Exploring HTTP and HTTPS Protocols in Network Security | A Deep Dive into HTTP and HTTPS Protocols in Computer Networks In the modern era, the... | 0 | 2024-06-16T05:15:06 | https://dev.to/iaadidev/exploring-http-and-https-protocols-in-network-security-530j | networking, http, https, protocols | ## A Deep Dive into HTTP and HTTPS Protocols in Computer Networks
In the modern era, the internet is an integral part of daily life, facilitating everything from casual browsing to secure transactions. Two critical protocols enable this vast network of interactions: HTTP (HyperText Transfer Protocol) and HTTPS (HyperT... | iaadidev |
1,544,112 | Monitoring Node Health with node-problem-detector in Kubernetes | Kubernetes is a powerful container orchestration platform that allows users to deploy and manage... | 0 | 2024-06-16T05:13:44 | https://dev.to/ajeetraina/monitoring-node-health-with-node-problem-detector-in-kubernetes-4l4i | kubernetes, containers, kubetools | Kubernetes is a powerful container orchestration platform that allows users to deploy and manage containerized applications efficiently. However, the health of the nodes in a Kubernetes cluster is crucial for the overall stability and reliability of the applications running on it. Node problems, such as hardware failur... | ajeetraina |
1,890,027 | The stack data structure | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-16T05:09:50 | https://dev.to/dfluechter/the-stack-data-structure-2ifl | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
"A stack is a data structure that follows the Last In, First Out (LIFO) principle. Think of it like a stack of plates: you add to the top, and the last plate added is the first one you... | dfluechter |
1,890,026 | Seeking Final Year Project Ideas | Hi dev.to community, I’m a final year student studying TYBscIT, and I’m currently looking for ideas... | 0 | 2024-06-16T05:07:49 | https://dev.to/harshchaudhari/seeking-final-year-project-ideas-in-tybscit-1c11 | javascript, node, mongodb, react | Hi dev.to community,
I’m a final year student studying TYBscIT, and I’m currently looking for ideas for my final year project. I have skills in HTML, CSS JS, MERN
**I would love to hear any suggestions or project ideas that you think would be challenging and interesting**. Any advice on how to approach these projects... | harshchaudhari |
1,890,021 | AWS Global Infrastructure: The Backbone of Modern Cloud Computing | Key Components of AWS Global Infrastructure AWS Regions AWS divides its global operations into... | 0 | 2024-06-16T04:33:10 | https://dev.to/safi-ullah/aws-global-infrastructure-the-backbone-of-modern-cloud-computing-1gd4 | aws, infrastructure, cloud | Key Components of AWS Global Infrastructure
1. AWS Regions
AWS divides its global operations into geographical regions. Each region is a separate geographic area, and every region consists of multiple, isolated locations known as Availability Zones (AZs). As of 2024, AWS has 31 regions worldwide, with several more anno... | safi-ullah |
1,890,025 | Creating Query Builders for Mongoose: Searching, Filtering, Sorting, Limiting, Pagination, and Field Selection | In this blog, we will explore how to implement searching, filtering, sorting, limiting, pagination,... | 0 | 2024-06-16T05:04:24 | https://dev.to/md_enayeturrahman_2560e3/creating-query-builders-for-mongoose-searching-filtering-sorting-limiting-pagination-and-field-selection-395j | In this blog, we will explore how to implement searching, filtering, sorting, limiting, pagination, and field selection in isolation. Afterward, we will create a query builder component that combines all these functionalities, making them reusable across different models. Let's dive in
- This is the thirteenth blog of... | md_enayeturrahman_2560e3 | |
1,894,058 | Tutorial: Deployment of Golang web app using Systemd | Today, I am going to show you a simple way of deploying a Golang web application. We are going to use... | 0 | 2024-06-19T20:29:48 | https://blog.gkomninos.com/tutorial-deployment-of-golang-web-app-using-systemd | golanguage, tutorial, golangwebdevelopment | ---
title: Tutorial: Deployment of Golang web app using Systemd
published: true
date: 2024-06-16 05:00:20 UTC
tags: GoLanguage,Tutorial,Golangwebdevelopment
canonical_url: https://blog.gkomninos.com/tutorial-deployment-of-golang-web-app-using-systemd
---
Today, I am going to show you a simple way of deploying a Golang... | gosom |
1,890,024 | The Power of Embeddings in AI | Introduction Embeddings have become a cornerstone in natural language processing (NLP)... | 27,673 | 2024-06-16T04:53:48 | https://dev.to/rapidinnovation/the-power-of-embeddings-in-ai-6d9 | ## Introduction
Embeddings have become a cornerstone in natural language processing (NLP) and
machine learning. They transform words, phrases, or documents into vectors of
real numbers, allowing algorithms to effectively interpret and process natural
language data.
## What are Embeddings?
Embeddings are low-dimensio... | rapidinnovation | |
1,890,022 | Smart Contract Fork Testing Using Foundry Cheatcodes | Introduction Testing is important in smart contract development due to the immutable... | 0 | 2024-06-16T04:42:16 | https://dev.to/eyitayoitalt/smart-contract-fork-testing-using-foundry-cheatcodes-4jgd |
## Introduction
Testing is important in smart contract development due to the immutable nature of smart contracts. Testing helps identify and resolve potential security vulnerabilities in smart contracts. Safeguard against unauthorized access.
Sometimes smart contract developers must interact with real-world data tha... | eyitayoitalt | |
1,890,014 | Egg Carton Supplier Fueling the Poultry Business | Introduction Egg carton are especially important for the poultry industry, as they are used to... | 0 | 2024-06-16T04:13:04 | https://dev.to/ritik_poultry_10a5f2f0a6b/egg-carton-supplier-fueling-the-poultry-business-3pl2 | eggcartons, cardboardeggcartons, ai | Introduction
Egg carton are especially important for the poultry industry, as they are used to safely and efficiently transfer eggs from farms to consumers. Among a host of different varieties of [egg cartons](https://poultrycartons.com/eggcartons/), the cardboard egg cartons find special mention for being eco-friendl... | ritik_poultry_10a5f2f0a6b |
1,890,020 | What is a Computer Programming Language? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-16T04:33:10 | https://dev.to/dinesh_d/what-is-a-computer-programming-language-2im1 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
A set of instructions which translate human logic into machine-readable code to produce various kinds of output and enable developers to write programs that perform specific tasks or s... | dinesh_d |
1,890,019 | AWS Global Infrastructure: The Backbone of Modern Cloud Computing | Key Components of AWS Global Infrastructure AWS Regions AWS divides its global operations into... | 0 | 2024-06-16T04:33:07 | https://dev.to/safi-ullah/aws-global-infrastructure-the-backbone-of-modern-cloud-computing-111m | aws, infrastructure, cloud | Key Components of AWS Global Infrastructure
1. AWS Regions
AWS divides its global operations into geographical regions. Each region is a separate geographic area, and every region consists of multiple, isolated locations known as Availability Zones (AZs). As of 2024, AWS has 31 regions worldwide, with several more anno... | safi-ullah |
1,890,017 | Binary Tree | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-16T04:18:26 | https://dev.to/dinesh_d/binary-tree-50ic | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
A binary tree is a tree data structure in which each node has at most two children, referred to as the left child and the right child. It is used for efficient searching, sorting, and ... | dinesh_d |
1,890,016 | Understanding AWS Identity and Access Management (IAM) | This article explores the key features, benefits, and best practices of AWS IAM, illustrating how it... | 0 | 2024-06-16T04:17:40 | https://dev.to/safi-ullah/understanding-aws-identity-and-access-management-iam-4aab | aws, iam, cloud, awscloud | This article explores the key features, benefits, and best practices of AWS IAM, illustrating how it can help organizations manage their AWS environments securely and efficiently.
What is AWS IAM?
AWS Identity and Access Management (IAM) is a web service that enables you to manage access to AWS services and resources ... | safi-ullah |
1,889,986 | Explain X Like I'm Five | A post by Ahmad Rifai | 0 | 2024-06-16T03:18:00 | https://dev.to/ahmad_rifai_54a20be09025e/explain-x-like-im-five-n8j | explainlikeimfive | ahmad_rifai_54a20be09025e | |
1,890,012 | Dead lock due to Circular Wait | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-16T04:10:44 | https://dev.to/dinesh_d/dead-lock-due-to-circular-wait-4okf | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
If resource A is waiting for B and Resource B is waiting for C and now If C is waiting for A then it creates a Circular Wait which is one of the Coffman conditions Leading to a Dead Lo... | dinesh_d |
1,890,011 | The Evolution and Impact of Egg Cartons: Poultry cartons as a sector have been targeted closely | In the earlier part of the 20th century, the idea of using the egg carton was first introduced. A... | 0 | 2024-06-16T04:10:03 | https://dev.to/ritik_poultry_10a5f2f0a6b/the-evolution-and-impact-of-egg-cartons-poultry-cartons-as-a-sector-have-been-targeted-closely-182o | eggcartons, cardboardeggcartons | In the earlier part of the 20th century, the idea of using the [egg carton ](https://poultrycartons.com/eggcartons/)was first introduced. A major challenge to eggs in the past was in transporting them, as breaking news meant that many of the eggs would be broken. Newspaper editor from Canada named Joseph Coyle is widel... | ritik_poultry_10a5f2f0a6b |
1,890,007 | Feribet | Feribet Gestunbet Tomorobet Gestunbet Tomorobet Feribet | 0 | 2024-06-16T03:46:53 | https://dev.to/lpo_delapan8_f9d327a16711/feribet-2goh |
[Feribet](http://66.29.135.198/)
[Gestunbet](http://198.177.123.144/)
[Tomorobet](http://199.192.20.135/)
[Gestunbet](http://162.0.213.230/)
[Tomorobet](http://162.0.237.32)
[Feribet](http://198.54.112.150/) | lpo_delapan8_f9d327a16711 | |
1,890,006 | lpo888b | LPO88 | 0 | 2024-06-16T03:45:53 | https://dev.to/lpo_delapan8_f9d327a16711/lpo888b-1jn9 | [LPO88](http://198.177.123.144/) | lpo_delapan8_f9d327a16711 | |
1,890,004 | 3D Glowing Card Carousel Slider | Creating visually appealing and interactive user interfaces is very important in this huge and... | 0 | 2024-06-16T03:36:40 | https://dev.to/divinector/3d-glowing-card-carousel-slider-4io | frontend, webdev, html, javascript | Creating visually appealing and interactive user interfaces is very important in this huge and competitive field of web development. One such attractive and interactive user interface is the 3D Glowing Card Carousel Slider. Today we will design a 3D card carousel slider using CSS animations and a UI component library c... | divinector |
1,889,984 | Unleashing the Power of Serverless Data Analysis with AWS Athena | Unleashing the Power of Serverless Data Analysis with AWS Athena In today's data-driven... | 0 | 2024-06-16T03:02:29 | https://dev.to/virajlakshitha/unleashing-the-power-of-serverless-data-analysis-with-aws-athena-3amh | 
# Unleashing the Power of Serverless Data Analysis with AWS Athena
In today's data-driven world, the ability to extract meaningful insights from vast datasets is paramount. As organizations accumulate data at an unprecedented rate, ... | virajlakshitha | |
1,889,982 | Mastering Client and Server Components in Next.js: A Comprehensive Guide | Deploying interactivity in a Next.js application can be straightforward, but it often comes with... | 0 | 2024-06-16T02:59:33 | https://dev.to/vyan/mastering-client-and-server-components-in-nextjs-a-comprehensive-guide-42hp | webdev, beginners, react, nextjs | Deploying interactivity in a Next.js application can be straightforward, but it often comes with pitfalls. This guide will walk you through the common mistakes and best practices for handling client and server components effectively.
## Introduction
Next.js is a powerful framework for building server-rendered React a... | vyan |
1,850,651 | Dealing with Unicode strings, done right and better. | Have you ever heard of Grapheme Cluster? `unicode-segmenter` is a lightweight solution for it. Let me explain how can I build it. | 0 | 2024-06-16T02:59:00 | https://dev.to/cometkim/dealing-with-unicode-string-done-right-and-better-2nei | javascript, unicode, performance, webdev | ---
title: Dealing with Unicode strings, done right and better.
published: true
description: Have you ever heard of Grapheme Cluster? `unicode-segmenter` is a lightweight solution for it. Let me explain how can I build it.
tags:
- javascript
- unicode
- performance
- webdev
---
## TL;DR
I created a library ca... | cometkim |
1,889,981 | aws cli on windows vscode | Hello all, I have been trying to use aws cli on windows vscode bash, powershell but it keeps saying... | 0 | 2024-06-16T02:48:26 | https://dev.to/bartdev/aws-cli-on-windows-vscode-2h16 | aws, webdev, devops, help | Hello all,
I have been trying to use aws cli on windows vscode bash, powershell but it keeps saying aws command not found.
I assume I need update the $path variable to the aws cli but i get bit confused on the process. I think on mac it worked so never had to set this up.
I have tried google and follow aws docs. the c... | bartdev |
1,889,980 | Top JavaScript Frameworks in 2024 | Explore the Leading JavaScript Frameworks for Modern Web Development A Comprehensive Guide to the... | 0 | 2024-06-16T02:30:32 | https://dev.to/1saptarshi/top-javascript-frameworks-in-2024-1i7i | javascript, angular, nextjs, vue | Explore the Leading JavaScript Frameworks for Modern Web Development
A Comprehensive Guide to the Best JavaScript Frameworks in 2024 , The Ultimate Guide to Choosing the Right JavaScript Framework
Stay Ahead in Web Development with These Cutting-Edge JavaScript Frameworks
In the fast-evolving world of web development,... | 1saptarshi |
1,889,949 | A PAGE TALKS ABOUT (Postbot: The AI Assistant By Postman) | MY ANALYSIS: PICTURE THIS The channel has already published a short story titled ‘AI-ERA:... | 0 | 2024-06-16T02:22:40 | https://dev.to/rewirebyautomation/a-page-talks-about-postbot-the-ai-assistant-by-postman-1lkh | automation, apiautomation, postman, postmanapi | **_MY ANALYSIS: PICTURE THIS_**


.*
## Explainer
If a problem has an answer which can be quickly checked for correctness, does it mean the problem must have a solution that can be calculated quickly as well (P=NP)? Or just because we... | fmalk |
1,889,946 | RDS mySQL works - fix | https://stackoverflow.com/questions/37212945/aws-cant-connect-to-rds-database-from-my-machine | 0 | 2024-06-16T02:02:54 | https://dev.to/said_olano/rds-mysql-works-fix-151m | https://stackoverflow.com/questions/37212945/aws-cant-connect-to-rds-database-from-my-machine
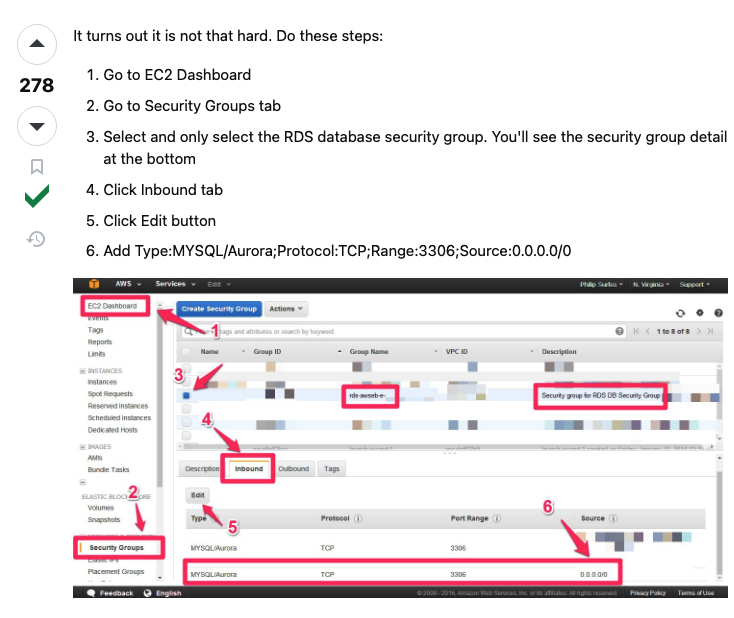
| said_olano | |
1,889,944 | OCR Technology: Revolutionizing Legal Contract Management | Welcome to an engaging narrative that expertly weaves together the intricate world of legal contract... | 27,673 | 2024-06-16T01:52:43 | https://dev.to/rapidinnovation/ocr-technology-revolutionizing-legal-contract-management-455 | Welcome to an engaging narrative that expertly weaves together the intricate
world of legal contract management and the cutting-edge advancements in
optical character recognition (OCR) technology. As a seasoned expert who has
observed firsthand the transformative evolution of technology within the legal
sector, I am po... | rapidinnovation | |
1,889,891 | RECURSION: A Beginner’s Guide | The concept of recursion in JavaScript programming has always been equal parts fascinating,... | 0 | 2024-06-16T01:45:47 | https://dev.to/wendyver/recursion-a-beginners-guide-57pd | programming, javascript, tutorial, recursion | ---
title: "RECURSION: A Beginner’s Guide"
published: true
tags: programming, javascript, tutorial, recursion
canonical_url: null
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/79di3e8eyvslo81x27e5.jpg
series: null
---
The concept of recursion in JavaScript programming has always been equal part... | wendyver |
1,889,940 | Refactoring 013 - Remove Repeated Code | Don't Repeat Yourself TL;DR: How to remove repeated code Problems... | 15,550 | 2024-06-16T01:37:23 | https://maximilianocontieri.com/refactoring-013-remove-repeated-code | webdev, beginners, programming, tutorial | *Don't Repeat Yourself*
> TL;DR: How to remove repeated code
# Problems Addressed
- Don't Repeat Yourself
- Copy/Paste Programming
- No single source of truth
# Related Code Smells
{% post https://dev.to/mcsee/code-smell-46-repeated-code-4iib %}
{% post https://dev.to/mcsee/code-smell-11-subclassification... | mcsee |
1,889,939 | PixelStore Website | Webstore Template v1.0 | Sell Your Sellix.io Products Through Your Own Webstore Website Integrate Sellix.io seamlessly to... | 0 | 2024-06-16T01:31:24 | https://dev.to/pixelhub/pixelstore-website-webstore-template-v10-3k60 | javascript, html, css, webdev | Sell Your Sellix.io Products Through Your Own Webstore Website
**Integrate Sellix.io seamlessly to create a smooth brand experience for your customers and potentially increase sales.**
 created by Continue Breake.
The author created a [companion article](https:... | humberd |
1,889,917 | CONSULT CRYPTO-ALTCOIN RECOVERY EXPERT. | In the high-stakes world of cryptocurrency, where digital coins can vanish in the blink of an eye, a... | 0 | 2024-06-16T00:49:59 | https://dev.to/lincon_reiser_fcad673114b/consult-crypto-altcoin-recovery-expert-4747 | typescript, computerscience, security, linux | In the high-stakes world of cryptocurrency, where digital coins can vanish in the blink of an eye, a new breed of "wizard" hackers has emerged to combat the scourge of stolen Bitcoin. Cyber Genie Hack Pro service, is a cutting-edge cybersecurity solution that uses advanced algorithms and lightning-fast response times t... | lincon_reiser_fcad673114b |
1,889,912 | Understanding the Principles of Clean Code | Introduction Clean code is a coding philosophy that aims to make software maintainable,... | 0 | 2024-06-16T00:36:11 | https://dev.to/kartikmehta8/understanding-the-principles-of-clean-code-3pcc | javascript, webdev, programming, tutorial | ## Introduction
Clean code is a coding philosophy that aims to make software maintainable, readable, and easily understandable. It is a set of principles and guidelines that help developers write code that is efficient, understandable, and easy to modify. As software projects grow in size and complexity, it becomes in... | kartikmehta8 |
1,889,911 | Domina JavaScript: Desarrollo Web Avanzado | ¡Hola, amigos! Hoy quiero hablarles sobre un tema que me apasiona y que sé que muchos de ustedes... | 0 | 2024-06-16T00:31:03 | https://dev.to/miguel_angelalmanzamerc/domina-javascript-desarrollo-web-avanzado-424p |
¡Hola, amigos! Hoy quiero hablarles sobre un tema que me apasiona y que sé que muchos de ustedes también adoran: JavaScript. En particular, vamos a profundizar en el desarrollo web avanzado con este lenguaje. Si ya tienes una base en JavaScript y quieres llevar tus habilidades al siguiente nivel, ¡sigue leyendo!
¿Por... | miguel_angelalmanzamerc | |
1,889,902 | How to Create a Shortcut for an Application in Ubuntu | Sometimes, when you are new to Ubuntu and need to manually download applications and run them from an... | 0 | 2024-06-16T00:14:05 | https://dev.to/pcabreram1234/how-to-create-a-shortcut-for-an-application-in-ubuntu-39j6 | ubuntu, productivity, beginners, tutorial | Sometimes, when you are new to Ubuntu and need to manually download applications and run them from an executable file, you may wonder how to create a shortcut similar to those in Windows. Here, I will explain how to do it step by step.
## 1. Copy the application folder
First, copy the folder containing your applicati... | pcabreram1234 |
1,890,436 | Authenticated Requests From Shopify UI Extensions | Shopify has a notion ofCheckout UI extensions. These provide hooks, or targets, to write custom user... | 0 | 2024-06-28T17:32:26 | https://blog.waysoftware.dev/blog/authenticated-requests-from-shopify-ui-extensions/ | ---
title: Authenticated Requests From Shopify UI Extensions
published: true
date: 2024-06-16 00:00:00 UTC
tags:
canonical_url: https://blog.waysoftware.dev/blog/authenticated-requests-from-shopify-ui-extensions/
---
Shopify has a notion of[Checkout UI extensions](https://shopify.dev/docs/api/checkout-ui-extensions).... | johnmcguin | |
1,889,822 | Introducing Cart: Simplifying Shopping Cart Management for Laravel | In the fast-paced world of e-commerce, efficient shopping cart management isn't just essential—it's a... | 0 | 2024-06-16T00:00:00 | https://dev.to/realrashid/introducing-cart-simplifying-shopping-cart-management-for-laravel-28ek | laravel, cart, shopping, php |
In the fast-paced world of e-commerce, efficient shopping cart management isn't just essential—it's a competitive advantage. Today, I'm thrilled to unveil **Cart**, a powerful Laravel package designed to streamline and elevate your online retail experience.
### Why Cart Matters
Effective cart management is crucial f... | realrashid |
1,889,901 | SQL | SQL, or Structured Query Language, is a powerful programming language used primarily for managing and... | 0 | 2024-06-15T23:50:26 | https://dev.to/devincb93/sql-533b | SQL, or Structured Query Language, is a powerful programming language used primarily for managing and manipulating databases. It's an invaluable tool for inserting, modifying, and even deleting data within databases.
Recently, I embarked on a project to create a simple Library database system. This project highlighted... | devincb93 | |
1,889,898 | Coding Standards in the Software Industry: A Focus on Ruby | Introduction to Coding Standards 📚 In the dynamic and ever-evolving realm of software... | 0 | 2024-06-15T23:46:16 | https://dev.to/davidmrtz-dev/coding-standards-in-the-software-industry-a-focus-on-ruby-n6a | codingstandards, ruby, softwaredevelopment, engineering | ## Introduction to Coding Standards 📚
In the dynamic and ever-evolving realm of software development, coding standards stand as a cornerstone, guiding developers towards crafting maintainable, readable, and robust codebases.
These established guidelines dictate the structure, formatting, and overall style of code, en... | davidmrtz-dev |
1,889,896 | Urgent Hiring Python Expert | Hi, I am currently looking for Python Expert who can join to our team. The candidates must have over... | 0 | 2024-06-15T23:26:12 | https://dev.to/eugene_goodwin_c9d195b96d/urgent-hiring-python-expert-1c48 | python, ai, aws, webdev | Hi, I am currently looking for Python Expert who can join to our team.
The candidates must have over 8 years of experience with python.
https://docs.google.com/document/d/19W0x0fed3yIyLBFg6Hh0_i4MSlF1ZCOk6CrCAscfeCU/edit
Please check this link. | eugene_goodwin_c9d195b96d |
1,889,895 | Luz que me ilumina o caminho e que me ensina a viver... | A post by Miguel Samori | 0 | 2024-06-15T23:22:36 | https://dev.to/miguelsam/luz-que-me-ilumina-o-caminho-e-que-me-ensina-a-viver-4lok | miguelsam | ||
1,889,892 | SQLynx - The Ultimate Web-Based SQL IDE for Developers and Data Analysts | SQLynx is a cutting-edge web-based SQL Integrated Development Environment (IDE) designed for... | 0 | 2024-06-15T23:14:42 | https://dev.to/concerate/sqlynx-the-ultimate-web-based-sql-ide-for-developers-and-data-analysts-1nl1 | SQLynx is a cutting-edge web-based SQL Integrated Development Environment (IDE) designed for developers and data analysts.
It supports multiple databases, including Mysql,PostgreSQL, Oracle and features an intelligent code editor with syntax highlighting, code completion, and refactoring capabilities.
SQLynx's modern... | concerate | |
1,889,890 | Mase JS is a new way to write HTML entirely in your JavaScript. | Introducing Mase JS a new way to write and structure html entirely inside your JavaScript. Also... | 0 | 2024-06-15T22:52:32 | https://dev.to/greenestgoat/mase-js-is-a-new-way-to-write-html-entirely-in-your-javascript-bd8 | webdev, javascript, programming, html | 
Introducing Mase JS a new way to write and structure html entirely inside your JavaScript. Also leaving a small footprint on your website as the library comes in at only... | greenestgoat |
1,889,889 | Web3 in Hospitality: Transforming the Industry | Introduction The hospitality industry is undergoing a significant transformation thanks... | 27,673 | 2024-06-15T22:51:40 | https://dev.to/rapidinnovation/web3-in-hospitality-transforming-the-industry-37fn | ## Introduction
The hospitality industry is undergoing a significant transformation thanks to
technological advancements. Web3, the third generation of the internet, is
playing a pivotal role in reshaping the sector by enhancing customer service,
streamlining operations, and ensuring secure transactions.
## What is W... | rapidinnovation | |
1,888,889 | CYPRESS-AJV-SCHEMA-VALIDATOR Plugin: The Brave Vigilante for Your API Contracts | Seamlessly Validate Your APIs Against Well-Documented Schemas from Swagger and Other API Tools and... | 27,209 | 2024-06-15T22:47:53 | https://dev.to/sebastianclavijo/cypress-ajv-schema-validator-plugin-the-brave-vigilante-for-your-api-contracts-5cfe | cypress, qa, automation, testing | **Seamlessly Validate Your APIs Against Well-Documented Schemas from Swagger and Other API Tools and Standards**
_(Cover image from pexels.com by Picography)_
---
- [ACT 1: EXPOSITION](#act-1-exposition)
- [ACT 2: CONFRONTATION](#act-2-confrontation)
- [Contract Testing: Laying Down the Law](#contract-testing-layi... | sebastianclavijo |
1,889,727 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-06-15T17:16:13 | https://dev.to/flaviodukagjinit4/buy-verified-paxful-account-6lc | tutorial, react, python, ai | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\n \n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | flaviodukagjinit4 |
1,889,886 | Discussion: How do you approach building websites or apps? | Hey, fellow DEVs, I'm curious 🤔 about our processes when starting a new project/challenge.🌟 Whether... | 0 | 2024-06-15T22:19:25 | https://dev.to/jennavisions/discussion-how-do-you-approach-building-websites-or-apps-3oi9 | discuss, webdev, developer, productivity | Hey, fellow DEVs,
I'm curious 🤔 about our processes when starting a new project/challenge.🌟
Whether you have years of experience or are new to the field, I'm sure you have valuable insights to offer.💡✨
Do you start by creating a plan on paper or move straight to code?📝💻
What is your approach to development when... | jennavisions |
1,889,885 | 🚀 Continuous Integration and Continuous Delivery (CI/CD): A Must-Have for SMBs 🚀 | In today's fast-paced digital landscape, small and medium-sized businesses (SMBs) are constantly... | 0 | 2024-06-15T22:19:04 | https://dev.to/vaibhavhariaramani/continuous-integration-and-continuous-delivery-cicd-a-must-have-for-smbs-4pm | In today's fast-paced digital landscape, small and medium-sized businesses (SMBs) are constantly seeking ways to stay competitive and deliver high-quality software products efficiently. One key solution that has revolutionized software development and deployment is Continuous Integration and Continuous Delivery (CI/CD)... | vaibhavhariaramani | |
1,889,884 | Enhancing Kubernetes Security with RBAC | In the dynamic landscape of cloud-native technologies, ensuring the security of your Kubernetes... | 0 | 2024-06-15T22:13:59 | https://dev.to/vaibhavhariaramani/enhancing-kubernetes-security-with-rbac-1mc9 | In the dynamic landscape of cloud-native technologies, ensuring the security of your Kubernetes cluster is paramount. One of the fundamental ways to bolster your cluster's defenses is by implementing Role-Based Access Control (RBAC). Let's dive into a concise guide on how to effectively harness RBAC to restrict permiss... | vaibhavhariaramani | |
1,889,883 | Tweet collection | Can we collect stream tweet using basic account, | 0 | 2024-06-15T22:12:52 | https://dev.to/education_uk_ab4cb0a667f8/tweet-collection-3okb | Can we collect stream tweet using basic account, | education_uk_ab4cb0a667f8 | |
1,889,882 | Docker Layers for Efficient Image Building | Docker has revolutionized the way we package and deploy applications, making it easier than ever to... | 0 | 2024-06-15T22:10:47 | https://dev.to/vaibhavhariaramani/docker-layers-for-efficient-image-building-48an | Docker has revolutionized the way we package and deploy applications, making it easier than ever to create, distribute, and run software in containers. One of the key factors that contribute to Docker's efficiency is its use of layers in building container images. Let us explore the significance of Docker layers, their... | vaibhavhariaramani | |
1,889,881 | What are the benefits and challenges of migrating from Jenkins to GitHub Actions? | 1. Benefits of GitHub Actions One of the main benefits of GitHub Actions is that it... | 0 | 2024-06-15T22:05:42 | https://dev.to/vaibhavhariaramani/what-are-the-benefits-and-challenges-of-migrating-from-jenkins-to-github-actions-1e39 | ## 1. Benefits of GitHub Actions
One of the main benefits of GitHub Actions is that it simplifies your CI/CD workflow by eliminating the need for a separate server, installation, or management of Jenkins. You can use GitHub's cloud infrastructure or your own self-hosted runners to run your actions, and scale them up or... | vaibhavhariaramani | |
1,889,880 | What are the most useful Jenkins plugins and tools for logging and monitoring? | 1. Logstash Plugin The Logstash plugin allows you to send your Jenkins logs to a Logstash... | 0 | 2024-06-15T22:03:10 | https://dev.to/vaibhavhariaramani/what-are-the-most-useful-jenkins-plugins-and-tools-for-logging-and-monitoring-58cj | ## 1. Logstash Plugin
The Logstash plugin allows you to send your Jenkins logs to a Logstash server, which can then forward them to various destinations, such as Elasticsearch, Kibana, or Splunk. This way, you can centralize your logging infrastructure, search and filter your logs, and create dashboards and alerts. The... | vaibhavhariaramani | |
1,889,879 | How to create this type of background on website? | It should work on cross all browsers, I can create it for Chrome, but on other browsers it doesn't... | 0 | 2024-06-15T22:01:02 | https://dev.to/alex_wordpress_2398859323/how-to-create-this-type-of-background-on-website-25m3 | css, tailwindcss, frontend, help |
It should work on cross all browsers, I can create it for Chrome, but on other browsers it doesn't work.
I tried to create a div with linear-gradient or radial-gradient with filter blur and backdrop blur and it d... | alex_wordpress_2398859323 |
1,889,639 | How airport design mirrors software design | When I flew out of Tampa airport (TPA), I was impressed by the layout of the airport. From a... | 0 | 2024-06-15T22:00:00 | https://dev.to/arjunrao87/how-airport-design-mirrors-software-design-25d5 | When I flew out of Tampa airport (TPA), I was impressed by the layout of the airport. From a passenger’s viewpoint, there are many aspects of running an efficient airport, starting from how you arrive at the airport, all the way to how the boarding process is executed, and TPA nailed most of it.
## How Tampa Airport ... | arjunrao87 | |
1,889,878 | The beginning of a flutter journey | I am a flutter developer with a bit of experience, but my favourite part of every programming journey... | 0 | 2024-06-15T21:53:00 | https://dev.to/ulrikueue/the-beginning-of-a-flutter-journey-2kf2 | flutter, programming, learning, beginners | I am a flutter developer with a bit of experience, but my favourite part of every programming journey has always been the beginning, where we are clueless and the learning pace is the fastest.
Like most people, I started my flutter development journey with a tutorial. I want to mention several beginner flutter tutoria... | ulrikueue |
1,889,872 | CoeFont | CoeFont is a global AI Voice Hub pioneering the future of technology. We empower users worldwide to... | 0 | 2024-06-15T21:30:32 | https://dev.to/youcef_appmaker/coefont-4h2g | music, anieme | CoeFont is a global AI Voice Hub pioneering the future of technology. We empower users worldwide to realize the full potential of their voices.
Use our innovative features such as text-to-speech (TTS), AI voice changer, AI voice creation, and our CoeFont Voice Hub, which features thousands of AI voices ready to be use... | youcef_appmaker |
1,889,830 | Designing an Optimal Database Schema for a Followers-Following System in a Blog-Post App | Designing an optimal database schema for a followers-following system in a blog-post app... | 0 | 2024-06-15T21:16:02 | https://dev.to/zobaidulkazi/designing-an-optimal-database-schema-for-a-followers-following-system-in-a-blog-post-app-fj4 | webdev, database, schema, javascript | #### Designing an optimal database schema for a followers-following system in a blog-post app involves considering several factors such as performance, scalability, ease of querying, and data integrity. Here are some best practices and optimization strategies to guide you in designing this database schema.
## 1. User ... | zobaidulkazi |
1,889,827 | Proposal - Blockchain Coordination | The productive and peaceable coordination of large groups is a cornerstone of modern civilization.... | 0 | 2024-06-15T21:11:41 | https://dev.to/nkianil/proposal-blockchain-coordination-5793 | blockchain, decentralized, security, bitcoin | The productive and peaceable coordination of large groups is a cornerstone of modern civilization. Systems designed to tackle large-scale coordination challenges—from monetary policy to commercial transactions—have traditionally relied on hierarchical, top-down structures to function effectively. Trusting these systems... | nkianil |
1,889,828 | Find Your Soulmate with Psychic Luna’s Unique Sketch Service | Are you longing to meet your soulmate? Do you believe in the mystical power of psychic insights to... | 0 | 2024-06-15T21:10:58 | https://dev.to/soulmatesketch/find-your-soulmate-with-psychic-lunas-unique-sketch-service-1kkf | soulmatesketch | Are you longing to meet your soulmate? Do you believe in the mystical power of psychic insights to guide you towards your true love? Psychic Luna is here to help you discover the person destined to be your lifelong partner with her unique soulmate sketch service.
## Introducing Psychic Luna’s Soulmate Sketches
My nam... | soulmatesketch |
1,889,819 | Fixing Apex Domain Issues for Next.js Sites Hosted on Vercel | Fixing Apex Domain Issues for Next.js Sites Hosted on Vercel If you're hosting Next.js... | 0 | 2024-06-15T20:40:11 | https://dev.to/joshydev/fixing-apex-domain-issues-for-nextjs-sites-hosted-on-vercel-5h52 | ### Fixing Apex Domain Issues for Next.js Sites Hosted on Vercel
If you're hosting Next.js sites on Vercel and using custom domains purchased from Namecheap, you might encounter a common issue where the apex domain (mysite.com) does not load while the www subdomain (www.mysite.com) works perfectly. This guide will wal... | joshydev | |
1,889,826 | How to Create a Library Package from an existing Angular App | Creating a library package from an existing Angular application can significantly streamline code... | 0 | 2024-06-15T21:02:20 | https://dev.to/jcarloscandela/how-to-create-a-library-package-from-an-existing-angular-app-using-ng-packagr-3b62 | angular, libraries, npm, tutorial | Creating a library package from an existing Angular application can significantly streamline code reuse and modularity across different projects. In this guide, we'll walk through the process using the `ng-packagr` tool, with an example based on the [Ionic Conference App](https://github.com/ionic-team/ionic-conference-... | jcarloscandela |
1,889,825 | Vue.js Loyihamizning tuzilmasi haqida. | ﷽ Assalamu alaykum! Vue.js loyihasi Vite orqali yaratilganda, loyihaning tuzilmasi quyidagicha... | 0 | 2024-06-15T20:53:28 | https://dev.to/mukhriddinweb/vuejs-loyihamizning-tuzilmasi-haqida-3cek | webdev, javascript, programming, vue | ﷽
Assalamu alaykum!
Vue.js loyihasi Vite orqali yaratilganda, loyihaning tuzilmasi quyidagicha bo'ladi. Har bir katalog va faylning maqsadi va vazifalari haqida batafsil tanishamiz.
```
my-app/
├── node_modules/
├── public/
│ └── vite.svg
├── src/
│ ├── assets/
│ │ └── vue.svg
│ ├── components/
│ │ └──... | mukhriddinweb |
1,889,823 | BharatGPT: The Next Generation AI Language Model | Introduction BharatGPT represents a monumental stride in the field of natural language... | 0 | 2024-06-15T20:50:44 | https://dev.to/nashetking/bharatgpt-the-next-generation-ai-language-model-296c | llm, webdev, ai, machinelearning |
## Introduction

BharatGPT represents a monumental stride in the field of natural language processing (NLP) and AI, tailored specifically to understand and generate text in multiple Indian languages with contextual accuracy... | nashetking |
1,889,821 | Safely Handling HTML in React | Safely Handling HTML in React: html-react-parser vs dangerouslySetInnerHTML When working... | 0 | 2024-06-15T20:46:27 | https://dev.to/joshydev/safely-handling-html-in-react-ba | webdev, javascript, react, mongodb | ### Safely Handling HTML in React: `html-react-parser` vs `dangerouslySetInnerHTML`
When working with React, there are times when you need to render HTML content dynamically. Whether it's content fetched from an API, user-generated content, or from a database. Handling HTML strings safely and efficiently is crucial. T... | joshydev |
1,889,624 | Mathematics secret behind AI on Digit Recognition | Introduction Hi everyone! I’m devloker, and today I’m excited to share a project I’ve been... | 0 | 2024-06-15T20:45:29 | https://dev.to/devloker/mathematics-secret-behind-ai-on-digit-recognition-49lc | # Introduction
Hi everyone! I’m [devloker](https://www.dev-loker.com), and today I’m excited to share a project I’ve been working on: a digit recognition system implemented using pure math functions in Python. This project aims to help beginners grasp the mathematics behind AI and digit recognition without relying on h... | devloker |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.