
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,889,818 | Creating a RESTful API with Flight Framework | In this article, we'll walk through building a RESTful API using the Flight framework, which is a... | 0 | 2024-06-15T20:38:03 | https://dev.to/n0nag0n/creating-a-restful-api-with-flight-framework-56lj | php, restapi, tutorial | In this article, we'll walk through building a RESTful API using the [Flight framework](https://docs.flightphp.com), which is a simple yet powerful PHP micro-framework. Flight aims to be simple to understand what is going on with your application and leave you in control without too much "magic" happening. We'll cover ... | n0nag0n |
1,889,741 | Iterating Data Structures in JavaScript | Data Structures Data structures in JavaScript are the backbone of functionality for most... | 0 | 2024-06-15T20:32:50 | https://dev.to/masonbarnes645/iterating-data-structures-in-javascript-o26 | ## Data Structures
Data structures in JavaScript are the backbone of functionality for most of the projects that I have made in my short coding journey. Data structures, like objects and arrays contain the information that programs need to access for a multitude of reasons. If we have a lot of information or data, thes... | masonbarnes645 | |
1,889,817 | Software company website | A post by Deknows | 0 | 2024-06-15T20:27:10 | https://dev.to/deknows/software-company-website-33h2 | webdev, javascript |
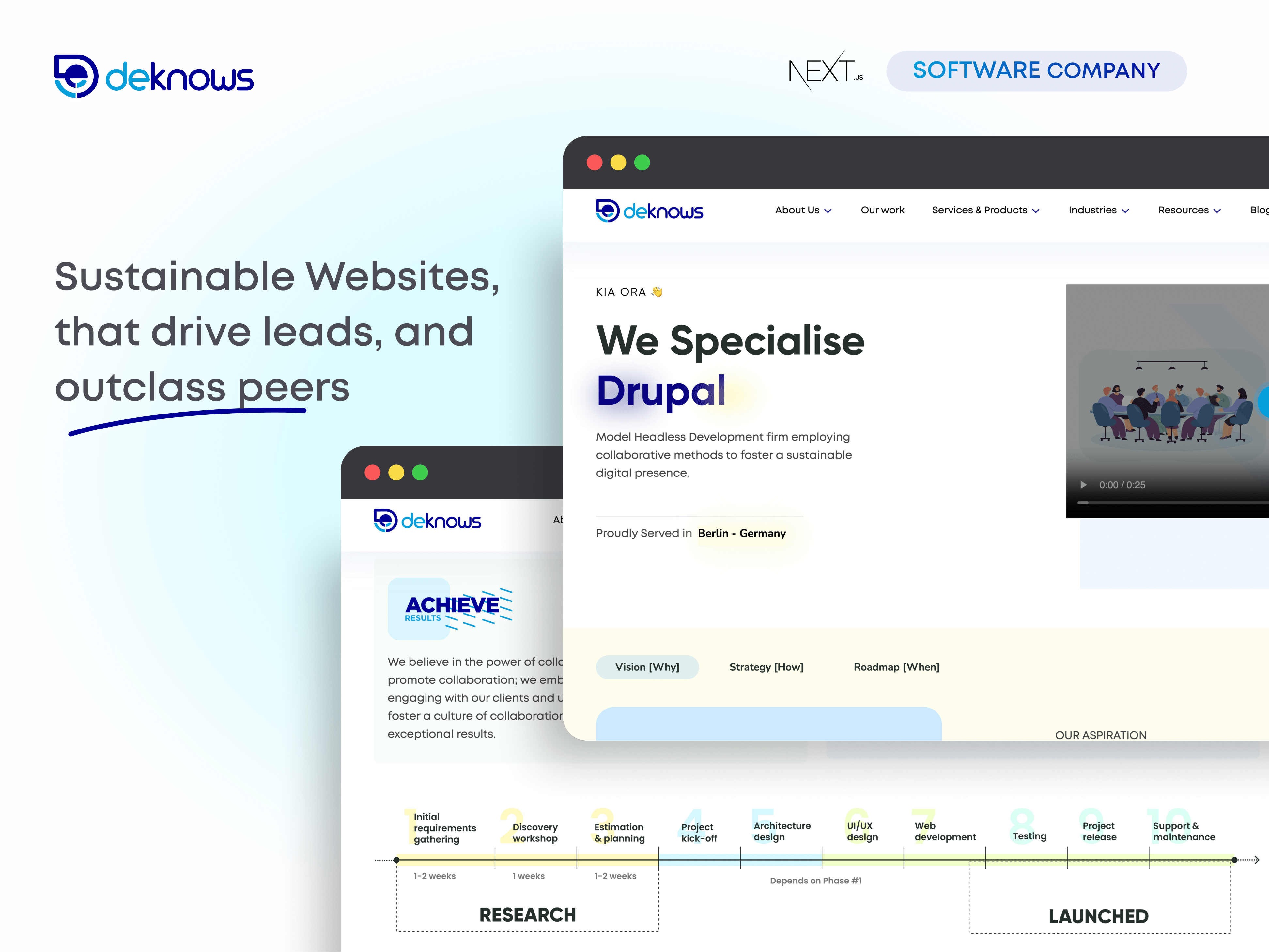
| deknows |
1,889,808 | Generate Tailwind components with AI | Hello! I’m thrilled to introduce my latest project, TailwindAI, a specialized AI tool for developers... | 0 | 2024-06-15T20:22:02 | https://dev.to/elreco_/generate-tailwind-components-with-ai-n79 | tailwindcss, ai, javascript | Hello!
I’m thrilled to introduce my latest project, TailwindAI, a specialized AI tool for developers working with Tailwind CSS. This innovative tool enables you to generate custom Tailwind CSS components or iterate on existing ones with just a few commands.
One of the standout features of TailwindAI is its ability to... | elreco_ |
1,889,802 | Vite orqali Vue loyiha qurish. | ﷽ Assalamu alaykum! Demak Vite texnologiyasi yordamidan Vue loyiha qurishni o'rganamiz! Vite —... | 0 | 2024-06-15T20:16:59 | https://dev.to/mukhriddinweb/vite-orqali-vue-loyiha-qurish-21ie | webdev, javascript, programming, tutorial | ﷽
**Assalamu alaykum!** Demak **Vite** texnologiyasi yordamidan **Vue** loyiha qurishni o'rganamiz!
Vite — Vue.js ilovasini yaratish uchun tez va samarali texnologiya hisoblanadi. Quyida Vite yordamida Vue.js (app) yaratish jarayonini batafsil ko'rib chiqamiz.
**1. Muhitni tayyorlash kerak (Preparation of the envi... | mukhriddinweb |
1,889,801 | From Chaos to Order: The Art of Hashing in CS | Hashing in Computer Science By utilizing a hash function, hashing encodes input... | 0 | 2024-06-15T20:13:02 | https://dev.to/electroholmes/from-chaos-to-order-the-art-of-hashing-in-cs-1h0j | devchallenge, cschallenge, computerscience, beginners | ## <u>_Hashing in Computer Science_</u>
### By utilizing a hash function, hashing encodes input data into a fixed-size value (hash). For swift information retrieval, it is implemented in data structures such as hash tables. An efficient lookup is ensured by good hashing, which reduces collisions—the situation in which... | electroholmes |
1,889,800 | 7 Ansible Automation Labs to Boost Your DevOps Skills 🚀 | The article is about 7 comprehensive Ansible automation labs from LabEx, designed to boost your DevOps skills. It covers a wide range of topics, including the Ansible Fetch module for retrieving files from remote hosts, managing multiple inventories, executing shell commands with the Shell module, managing files and di... | 27,737 | 2024-06-15T20:09:15 | https://dev.to/labex/7-ansible-automation-labs-to-boost-your-devops-skills-497j | coding, programming, tutorial, ansible |
Explore a collection of 7 comprehensive Ansible labs from LabEx, covering a wide range of topics to elevate your DevOps expertise. From mastering the Fetch module to managing multiple inventories, these hands-on tutorials will equip you with the essential skills to automate your infrastructure and streamline your work... | labby |
1,889,799 | Solution To Your Crypto Losses | "The forensic team at (RECOVERYEXPERT at RESCUETEAM dot COM) has done an amazing job in recovering my... | 0 | 2024-06-15T20:06:30 | https://dev.to/mable_johanson_5acd7f1e08/solution-to-your-crypto-losses-2jpb | "The forensic team at (RECOVERYEXPERT at RESCUETEAM dot COM) has done an amazing job in recovering my stolen Bitcoin, and I am really grateful for that. I felt helpless and had no idea what to do when my monies were taken. However, they were able to track and follow the money to the leveraged outsourced wallets where m... | mable_johanson_5acd7f1e08 | |
1,889,798 | A Week of React Learning: Key Takeaways and Future Plans | This week has been a fun week; it's my first week without any assignments for computer science and... | 0 | 2024-06-15T20:00:37 | https://justkirsten.hashnode.dev/a-week-of-react-learning-key-takeaways-and-future-plans | webdev, beginners, react, learning |
This week has been a fun week; it's my first week without any assignments for computer science and purely a week where I learned all sorts of React jazz. ✨
Not to mention, this week was the first week where I considered myself officially back on my **100Devs** community-taught journey.
## This week I learned:
Thi... | ofthewildfire |
1,889,796 | Creating a resource group in Azure | What is a resource group? A resource group is a fundamental concept in cloud computing, commonly used... | 0 | 2024-06-15T19:52:55 | https://dev.to/bdporomon/creating-a-resource-group-in-azure-2opk | **What is a resource group?**
A resource group is a fundamental concept in cloud computing, commonly used by major cloud service providers like Microsoft Azure, Amazon Web Services (AWS), and Google Cloud Platform (GCP). Essentially, a resource group is a logical container that holds related resources for a specific ap... | bdporomon | |
1,889,788 | What the hell are Binary Numbers? | Don't let binary numbers trouble you. A quick intro This is my first blog... | 0 | 2024-06-15T19:51:23 | https://dev.to/chaturvedi-harshit/what-the-hell-are-binary-numbers-5cnk | python, computerscience, binary, backenddevelopment | > ### Don't let binary numbers trouble you.
## A quick intro
This is my first blog post ever! I am an aspiring backend developer who has never worked in Tech (been working in Customer Success) and is learning Python as his first programming language. Btw, I am learning from [Boot.dev](boot.dev) (Do check that out!).
... | chaturvedi-harshit |
1,889,794 | The Duel of AI Titans: Meta vs. Mistral | The realm of Artificial Intelligence (AI) is in a constant state of flux, with new advancements... | 27,673 | 2024-06-15T19:50:39 | https://dev.to/rapidinnovation/the-duel-of-ai-titans-meta-vs-mistral-1hh | The realm of Artificial Intelligence (AI) is in a constant state of flux, with
new advancements pushing the boundaries of what's possible. Large Language
Models (LLMs) have emerged as a focal point in this evolution, capable of
processing and generating human-like text with remarkable proficiency. In this
ever-competit... | rapidinnovation | |
1,889,793 | Template syntax va direktivalar haqida. | ﷽ Assalamu alaykum! Ushbu postda Vue.js loyihamizning umummiy tuzulmasi (strukturasi, fayllari)... | 0 | 2024-06-15T19:47:31 | https://dev.to/mukhriddinweb/template-syntax-haqida-3ij9 | vue, javascript, vuex, pinia | ﷽
Assalamu alaykum! [Ushbu](https://dev.to/mystery9807/vuejs-loyihamizning-tuzilmasi-haqida-3cek) postda Vue.js loyihamizning umummiy tuzulmasi (strukturasi, fayllari) bilan tanishib chiqidik.
Endi navbat Vue.js loyihamizning asosiy sintaksis haqida gaplashamiz.
 ... | 0 | 2024-06-15T19:42:06 | https://dev.to/__khojiakbar__/hoam-2jh4 | javascript, highorderarraymethods, methods, array | # HAVE FUN WITH METHODS
# map()
```
--------------------------map()--------------------------
// Adding xon to the end of every name
const children = ['Amir', 'Ali', 'Komila', 'Abbos', 'Aziz'];
let transformedNames = children.map(child => {
return child + 'xon'
})
console.log(transformedNames); // ['Amirxon', 'A... | __khojiakbar__ |
1,889,790 | WANT TO GET BACK STOLEN CRYPTO ASSETS REACH OUT TO TECHNOCRATE RECOVERY | My journey into the realm of online investing began innocently enough, with the promise of lucrative... | 0 | 2024-06-15T19:39:39 | https://dev.to/zanetaeliasz94/want-to-get-back-stolen-crypto-assets-reach-out-to-technocrate-recovery-2ol6 | cybersecurity, bitcoin, cryptocurrency, blockchain | My journey into the realm of online investing began innocently enough, with the promise of lucrative returns and the allure of quick profits. Little did I know, I was about to embark on a harrowing journey that would lead me down the treacherous path of deception and betrayal. It all started with a seemingly friendly e... | zanetaeliasz94 |
1,889,702 | Creating Custom Attributes in C# | Attributes provide a way to add metadata to your code. In this blog post we'll cover the basics of... | 0 | 2024-06-15T19:26:28 | https://antondevtips.com/blog/creating-custom-attributes-in-csharp | csharp, dotnet, backend | ---
canonical_url: https://antondevtips.com/blog/creating-custom-attributes-in-csharp
---
**Attributes** provide a way to add metadata to your code.
In this blog post we'll cover the basics of what attributes are, how to set attribute properties, and how to configure where attributes can be applied.
Finally, we'll div... | antonmartyniuk |
1,889,786 | My Experience Learning Elixir | Hello, my name is João Paulo Abreu I'm from Ceará, Brazil. I have been working as an IT... | 0 | 2024-06-15T19:25:57 | https://dev.to/abreujp/minha-experiencia-aprendendo-elixir-315a | elixir, learning, beginners | ## Hello, my name is João Paulo Abreu
I'm from Ceará, Brazil. I have been working as an IT Technician at IFCE - Federal Institute of Education, Science, and Technology of Ceará since 2010. My job primarily involved providing technical support to the Canindé Campus, the city where I was born, live, and work. Around 202... | abreujp |
1,889,765 | Enhance Your Development with Multi-Repo Support in Dotnet Aspire | .NET Aspire is renowned for its robust support for monolithic repositories, allowing developers to... | 0 | 2024-06-15T19:24:17 | https://dev.to/dutchskull/poly-repo-support-for-dotnet-aspire-14d5 | dotnet, csharp, devops, aspnet | .NET Aspire is renowned for its robust support for monolithic repositories, allowing developers to manage large codebases efficiently. However, managing multiple repositories, or poly repos, can be challenging. Enter [Aspire.PolyRepo](https://github.com/Dutchskull/Aspire.PolyRepo), a .NET Aspire package designed to bri... | dutchskull |
1,889,779 | Tecnologia: a desunião entre a academia e o mercado de trabalho privado | O desafio da desconexão entre a academia e o mercado de trabalho na área de tecnologia. | 0 | 2024-06-15T19:19:15 | https://dev.to/lexipedia/tecnologia-a-desuniao-entre-a-academia-e-o-mercado-de-trabalho-privado-33f7 | tecnologia, ensinosuperior, graduacao, educacao |
---
title: Tecnologia: a desunião entre a academia e o mercado de trabalho privado
published: true
description: O desafio da desconexão entre a academia e o mercado de trabalho na área de tecnologia.
tags: #tecnologia #ensinosuperior #graduacao #educacao
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of... | lexipedia |
1,889,778 | How to Move Zeros to the End of an Array | Moving zeros to the end of an array while maintaining the order of non-zero elements is a common... | 27,580 | 2024-06-15T19:13:55 | https://blog.masum.dev/how-to-move-zeros-to-the-end-of-an-array | algorithms, computerscience, cpp, tutorial | Moving zeros to the end of an array while maintaining the order of non-zero elements is a common problem in programming. In this article, we'll discuss two approaches to achieve this: one using a **temporary array** and another using a **two-pointers technique**.
### Solution 1: Brute Force Approach (using a Temp Arra... | masum-dev |
1,889,777 | Wanted: Dmitry Gunyashov, alleged Freewallet scam owner | Freewallet scammers often mislead by attributing their operations to Alvin Hagg. However, our... | 0 | 2024-06-15T19:12:47 | https://dev.to/feofhan/wanted-dmitry-gunyashov-alleged-freewallet-scam-owner-1mb3 | Freewallet scammers often mislead by attributing their operations to Alvin Hagg. However, our investigation points to Dmitry Gunyashov (also known as Dmitrii Guniashov) as a key figure behind this project. We aim to spotlight this individual to assist law enforcement and support ongoing investigations.
 utilizes linear interpolation - also called "lerp". It's a simple way of easing from position A to B. Without diving into the math, there's another approach called damp (or smoothdamp), this is almost similar but has a smoother curve (more lik... | iliketoplay |
1,889,763 | Shades of Open Source - Understanding The Many Meanings of "Open" | Open source has evolved from a few pioneering transparent projects into the backbone of modern... | 0 | 2024-06-15T18:40:25 | https://dev.to/alexmercedcoder/shades-of-open-source-understanding-the-many-meanings-of-open-35je | opensource, apache |
Open source has evolved from a few pioneering transparent projects into the backbone of modern development across the industry. As a result, many projects now use the term "open source" to convey a positive impression. However, with a wide range of development practices and open source licenses, the meaning of "open s... | alexmercedcoder |
1,889,762 | Nega aynan Vue.js ? | ﷽ Assalamu alaykum ! Bugun nega aynan Vue.jsni tanlash kerak shu haiqda qisiqacha gaplashib... | 0 | 2024-06-15T18:39:43 | https://dev.to/mukhriddinweb/nega-aynan-vuejs--3cf5 | vue, webdev, ts, programming | ﷽
Assalamu alaykum ! Bugun nega aynan Vue.jsni tanlash kerak shu haiqda qisiqacha gaplashib olamiz!
**Vue.js** ni tanlashning bir qancha sabablari bor. Quyida **Vue.js** ning afzalliklari keltirilgan:
1. **Oson o'rganish mumkin**:
- Vue.js ning o'rganish unchalik qiyin emas. Uning oddiy va intuitiv sintaksisi bo... | mukhriddinweb |
1,889,761 | One Byte Explainer - Closures | Hello 👋 Let's start with Closures One-Byte Explainer: Imagine a magic box! Put your... | 27,721 | 2024-06-15T18:39:43 | https://dev.to/imkarthikeyan/one-byte-explainer-closures-o84 | cschallenge, webdev, javascript, devchallenge | Hello 👋
Let's start with **Closures**
## One-Byte Explainer:
Imagine a magic box! Put your favourite toy inside, close it, & give it to a friend. Even though you can't see it, your friend can open it and play!
## Demystifying JS: Closures in action
Closures are like backpack the inner-functions carry when they... | imkarthikeyan |
1,889,759 | Step-by-Step Guide to Publish Internal SaaS Applications via Citrix Secure Private Access | In this blog we are going to discuss about how to leverage Citrix Secure private access service to... | 0 | 2024-06-15T18:39:00 | https://dev.to/amalkabraham001/step-by-step-guide-to-publish-internal-saas-applications-via-citrix-secure-private-access-17k9 | ztna, citrix, zerotrust, webapps | In this blog we are going to discuss about how to leverage Citrix Secure private access service to enable ZTNA features for SaaS/Web Applications without the need for VPN or Citrix XenApp Servers.
## Publishing Internal SaaS application via Secure Private Access.
Navigate to Citrix Cloud, under my services select “sec... | amalkabraham001 |
1,889,758 | Ensuring the Quality of Your App with Testing in React Native | Hey devs! Developing a robust, functional, and bug-free mobile application is a significant... | 0 | 2024-06-15T18:38:02 | https://dev.to/paulocappa/ensuring-the-quality-of-your-app-with-testing-in-react-native-o6g | reactnative, testing, jest, e2e | Hey devs!
Developing a robust, functional, and bug-free mobile application is a significant challenge. As a specialist in mobile development using React Native, one of my priorities is to ensure that every line of code works as expected. To achieve this, I apply various types of tests that cover everything from small... | paulocappa |
1,889,757 | How to Implement Authorization in NodeJS | Introduction: Authentication and Authorization are two fundamental concepts in web... | 0 | 2024-06-15T18:37:53 | https://arindam1729.hashnode.dev/how-to-implement-authorization-in-nodejs#heading-understanding-authorization | node, javascript, beginners, webdev | ## **Introduction:**
Authentication and Authorization are two fundamental concepts in web application security. As we build web applications, ensuring that only the right users can access certain parts of our site is crucial to security. This is where authentication and authorization come into play.
In this Article, ... | arindam_1729 |
1,889,756 | Understanding One-to-One Relations with Prisma ORM | Prisma ORM is a powerful tool for managing databases in Node.js and TypeScript projects. One of its... | 0 | 2024-06-15T18:36:49 | https://dev.to/lemartin07/understanding-one-to-one-relations-with-prisma-orm-3i3m | prisma, javascriptlibraries, softwaredevelopment | Prisma ORM is a powerful tool for managing databases in Node.js and TypeScript projects. One of its most important features is the ability to define relationships between tables, including One-to-One (one-to-one) relationships. In this post, we will explore how to set up and work with One-to-One relationships in Prisma... | lemartin07 |
1,889,754 | Artificial General Intelligence (AGI) Development: Recent Advancements and Challenges | Can you imagine a world of machines that can think, learn, and adapt like humans, beyond that of the... | 0 | 2024-06-15T18:31:15 | https://dev.to/richardtate/artificial-general-intelligence-agi-development-recent-advancements-and-challenges-1467 | ai, computerscience, career, discuss |
Can you imagine a world of machines that can think, learn, and adapt like humans, beyond that of the plots of your favourite sci-fi movies, shows, or books? Until recently, I, like most of you, didn't think I'd see it in my lifetime. But thanks to the latest developments in Artificial General Intelligence (AGI) by com... | richardtate |
1,889,752 | RECOVER YOUR STOLEN BTC | The rate at which people are getting scammed is very alarming. I have been the latest victim after me... | 0 | 2024-06-15T18:27:29 | https://dev.to/shry_karr_9bb690b23db26aa/recover-your-stolen-btc-m9b | The rate at which people are getting scammed is very alarming. I have been the latest victim after me and my husband opted to buy some Bitcoin with the money we had saved by selling our company. We put up a sum of $300000.00USD in cryptocurrencies hoping to double our investments, little did we know we were falling int... | shry_karr_9bb690b23db26aa | |
1,889,751 | Help me | is there any software to add all installed software application into single software | 0 | 2024-06-15T18:25:24 | https://dev.to/albinnj/help-me-1j7d | productivity, opensource, computerscience, help | is there any software to add all installed software application into single software | albinnj |
1,889,748 | Code the Vote! | 🙋🏻♂️Making a USA-elections app basically i was gonna drop off, but then i got roped back... | 0 | 2024-06-15T18:16:04 | https://dev.to/tonic/code-the-vote-1bif | llamaindex, ai, python, news | ### 🙋🏻♂️Making a USA-elections app
basically i was gonna drop off, but then i got roped back in !
we have 24 hours from this post to make it !
it's for a hackathon on devpost : https://code-the-vote.devpost.com/
- here's the repo : https://github.com/Josephrp/oreally.git
- here are the open issues : https://gith... | tonic |
1,889,746 | What is a stack? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-15T18:05:45 | https://dev.to/codewitgabi/what-is-a-stack-3pm7 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Just like when you have crate of eggs or drinks placed one on top the other, you can't remove the one at the bot... | codewitgabi |
1,889,745 | Create Stunning Art for Free with SeaArt AI Art Generator | Introduction to SeaArt AI art generator free Are you ready to unlock your inner artist and... | 0 | 2024-06-15T18:05:05 | https://dev.to/mister_jerry_37e1ecf9b7f7/create-stunning-art-for-free-with-seaart-ai-art-generator-1pa1 | ### Introduction to SeaArt AI art generator free
Are you ready to unlock your inner artist and create stunning art for free? Say hello to SeaArt AI Art Generator, the innovative tool that will revolutionize the way you express your creativity. With just a few clicks, you can transform simple ideas into breathtaking mas... | mister_jerry_37e1ecf9b7f7 | |
1,889,744 | Poetic Resistance: Examining Poetry as a Tool for Social Change Throughout History with Herve Comeau Syracuse | Poetry, with its ability to evoke emotion, challenge norms, and ignite social consciousness, has long... | 0 | 2024-06-15T17:58:54 | https://dev.to/hervecomeau/poetic-resistance-examining-poetry-as-a-tool-for-social-change-throughout-history-with-herve-comeau-syracuse-53mf | Poetry, with its ability to evoke emotion, challenge norms, and ignite social consciousness, has long served as a potent tool for resistance and social change. From ancient civilizations to modern-day movements, poets have utilized verse to amplify marginalized voices, critique oppressive systems, and inspire collectiv... | hervecomeau | |
1,889,743 | What is a Queue? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-15T17:58:07 | https://dev.to/codewitgabi/what-is-a-queue-18p7 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
When you visit a bank or you go to the supermarket to get some groceries, you **stay in line**. **The person in f... | codewitgabi |
1,889,739 | 1.2 - Um segundo programa simples | Atribuição de Variáveis: Uma variável é um local nomeado na memória ao qual pode ser atribuído um... | 0 | 2024-06-15T17:53:13 | https://dev.to/devsjavagirls/12-um-segundo-programa-simples-m5l | java | **Atribuição de Variáveis:**
Uma variável é um local nomeado na memória ao qual pode ser atribuído um valor.
O valor de uma variável pode ser alterado durante a execução de um programa.
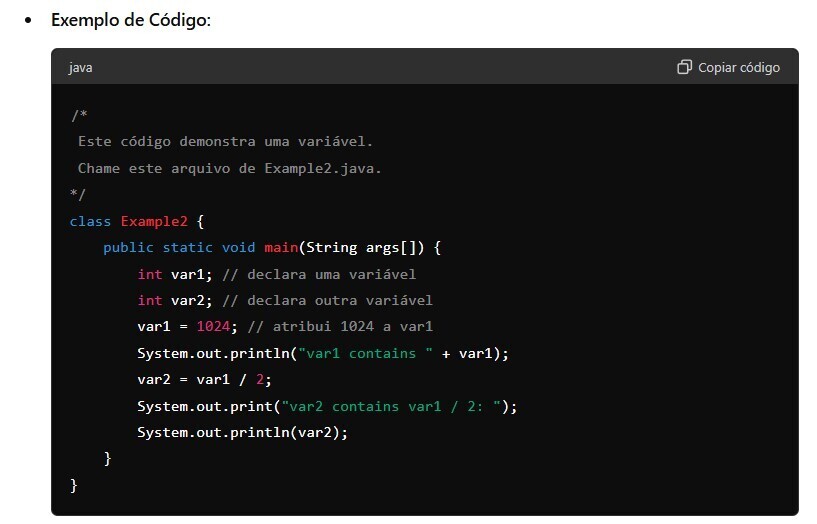
**Declaração e Atribuição:... | devsjavagirls |
1,889,742 | Video: Modify Angular Material (v18) themes with CSS Variables using Theme Builder | Modify Angular Material... | 0 | 2024-06-15T17:53:04 | https://dev.to/ngmaterialdev/video-modify-angular-material-v18-themes-with-css-variables-using-theme-builder-3278 | angular, angularmaterial, webdev | ---
title: Video: Modify Angular Material (v18) themes with CSS Variables using Theme Builder
published: true
description:
tags: angular, angularmaterial, webdevelopment
cover_image: https://media.dev.to/cdn-cgi/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.co... | shhdharmen |
1,889,740 | Troubleshooting with PipeOps: Error 502 with React apps | Day 3 of [HackOps 1.0] and my quest to compile as many fixes for the errors participants face during... | 0 | 2024-06-15T17:50:14 | https://dev.to/orunto/troubleshooting-with-pipeops-error-502-with-react-apps-cb | pipeops, hackathon, react, troubleshooting | Day 3 of [**HackOps 1.0**] and my quest to compile as many fixes for the errors participants face during the duration of the hackathon continues. Today it's the `502: Bad gateway` error some React Devs encountered
#### Mild Disclaimer
I'm making sure to state that these errors and fixes are framework specific so as no... | orunto |
1,889,738 | HEIMDALL - Open Source PYscript for bypassing and login captive portals in private networks | This Python script automates the process of connecting to a captive portal, often... | 27,927 | 2024-06-15T17:42:35 | https://dev.to/kingsmen732/open-source-bash-script-for-bypassing-and-login-captive-portals-in-private-networks-3ef9 | networking, captiveportals, opensource, python |
## This Python script automates the process of connecting to a captive portal, often encountered in public Wi-Fi networks. Here’s a summary of how the code works and its usefulness:
**Summary:**
- Setup and Co... | kingsmen732 |
1,889,737 | check my git hub repositories | https://github.com/ALYANSHEIKHH | 0 | 2024-06-15T17:40:54 | https://dev.to/alyan_sheikh_e1f7c955a630/check-my-git-hub-repositories-291g | https://github.com/ALYANSHEIKHH | alyan_sheikh_e1f7c955a630 | |
1,889,735 | Unlock the Power of CI/CD with pCloudy and Bitbucket Integration | In today’s digital-first world, the demand for continuous integration and delivery is of paramount... | 0 | 2024-06-15T17:38:32 | https://dev.to/pcloudy_ssts/unlock-the-power-of-cicd-with-pcloudy-and-bitbucket-integration-2c62 | cloudbasedtesting, automatedtesting | In today’s digital-first world, the demand for continuous integration and delivery is of paramount importance for maintaining the highest quality standards of application development. This includes keeping up with evolving market trends, handling competition, and meeting the end-users’ expectations.
At pCloudy, we ... | pcloudy_ssts |
1,889,734 | 20 Best JavaScript Frameworks For 2023 | Introduction With JavaScript maintaining its stronghold in the realm of web development, keeping... | 0 | 2024-06-15T17:34:41 | https://dev.to/pcloudy_ssts/20-best-javascript-frameworks-for-2023-kpa | 20bestjavascriptframeworks | Introduction
With JavaScript maintaining its stronghold in the realm of web development, keeping abreast of the finest JavaScript frameworks becomes imperative for developers. In this ever-evolving tech landscape, being well-informed about frameworks that provide robust functionality, optimize performance, and foste... | pcloudy_ssts |
1,889,733 | Understanding XCUITest Framework: Your Guide to Efficient iOS Testing | In today’s era of swift technological progression, effective and efficient testing of iOS... | 0 | 2024-06-15T17:31:54 | https://dev.to/pcloudy_ssts/understanding-xcuitest-framework-your-guide-to-efficient-ios-testing-2o1 | mobileapptestingtools, iosapplicationtesting, automatedapptesting, accessibilitytesting | In today’s era of swift technological progression, effective and efficient testing of iOS applications is vital to ensuring high-quality app development. One such invaluable tool in our testing toolkit is the XCUITest framework developed by Apple. This guide will elucidate what the XCUITest framework is and why it is a... | pcloudy_ssts |
1,889,732 | Chromium vs. Chrome – What’s the Difference? | Introduction There are a lot of browsers in the market today. But, Google Chrome dominates the... | 0 | 2024-06-15T17:27:07 | https://dev.to/pcloudy_ssts/chromium-vs-chrome-whats-the-difference-165m | downloadpage, chromiumprojectwebsite, realbrowsers, pcloudy | Introduction
There are a lot of browsers in the market today. But, Google Chrome dominates the global browser market despite the diversity of browsers. Chrome is a web browser developed by Google whereas Chromium is an open-source software project also created by Google, whose source code serves as a building ground ... | pcloudy_ssts |
1,889,731 | Buy Negative Google Reviews | https://dmhelpshop.com/product/buy-negative-google-reviews/ Buy Negative Google Reviews Negative... | 0 | 2024-06-15T17:26:06 | https://dev.to/flaviodukagjinit4/buy-negative-google-reviews-37pc | typescript, career, aws, news | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-negative-google-reviews/\n\n\n\n\nBuy Negative Google Reviews\nNegative reviews on Google are detrimental critiques that expose customers’ unfavorable experiences with a business. These reviews can significantly damage a company’s reputation, presenting challenges in both attracting new customers and retaining current ones. If you are considering purchasing negative Google reviews from dmhelpshop.com, we encourage you to reconsider and instead focus on providing exceptional products and services to ensure positive feedback and sustainable success.\n\nWhy Buy Negative Google Reviews from dmhelpshop\nWe take pride in our fully qualified, hardworking, and experienced team, who are committed to providing quality and safe services that meet all your needs. Our professional team ensures that you can trust us completely, knowing that your satisfaction is our top priority. With us, you can rest assured that you’re in good hands.\n\nIs Buy Negative Google Reviews safe?\nAt dmhelpshop, we understand the concern many business persons have about the safety of purchasing Buy negative Google reviews. We are here to guide you through a process that sheds light on the importance of these reviews and how we ensure they appear realistic and safe for your business. Our team of qualified and experienced computer experts has successfully handled similar cases before, and we are committed to providing a solution tailored to your specific needs. Contact us today to learn more about how we can help your business thrive.\n\nBuy Google 5 Star Reviews\nReviews represent the opinions of experienced customers who have utilized services or purchased products from various online or offline markets. These reviews convey customer demands and opinions, and ratings are assigned based on the quality of the products or services and the overall user experience. Google serves as an excellent platform for customers to leave reviews since the majority of users engage with it organically. When you purchase Buy Google 5 Star Reviews, you have the potential to influence a large number of people either positively or negatively. Positive reviews can attract customers to purchase your products, while negative reviews can deter potential customers.\n\nIf you choose to Buy Google 5 Star Reviews, people will be more inclined to consider your products. However, it is important to recognize that reviews can have both positive and negative impacts on your business. Therefore, take the time to determine which type of reviews you wish to acquire. Our experience indicates that purchasing Buy Google 5 Star Reviews can engage and connect you with a wide audience. By purchasing positive reviews, you can enhance your business profile and attract online traffic. Additionally, it is advisable to seek reviews from reputable platforms, including social media, to maintain a positive flow. We are an experienced and reliable service provider, highly knowledgeable about the impacts of reviews. Hence, we recommend purchasing verified Google reviews and ensuring their stability and non-gropability.\n\nLet us now briefly examine the direct and indirect benefits of reviews:\nReviews have the power to enhance your business profile, influencing users at an affordable cost.\nTo attract customers, consider purchasing only positive reviews, while negative reviews can be acquired to undermine your competitors. Collect negative reports on your opponents and present them as evidence.\nIf you receive negative reviews, view them as an opportunity to understand user reactions, make improvements to your products and services, and keep up with current trends.\nBy earning the trust and loyalty of customers, you can control the market value of your products. Therefore, it is essential to buy online reviews, including Buy Google 5 Star Reviews.\nReviews serve as the captivating fragrance that entices previous customers to return repeatedly.\nPositive customer opinions expressed through reviews can help you expand your business globally and achieve profitability and credibility.\nWhen you purchase positive Buy Google 5 Star Reviews, they effectively communicate the history of your company or the quality of your individual products.\nReviews act as a collective voice representing potential customers, boosting your business to amazing heights.\nNow, let’s delve into a comprehensive understanding of reviews and how they function:\nGoogle, with its significant organic user base, stands out as the premier platform for customers to leave reviews. When you purchase Buy Google 5 Star Reviews , you have the power to positively influence a vast number of individuals. Reviews are essentially written submissions by users that provide detailed insights into a company, its products, services, and other relevant aspects based on their personal experiences. In today’s business landscape, it is crucial for every business owner to consider buying verified Buy Google 5 Star Reviews, both positive and negative, in order to reap various benefits.\n\nWhy are Google reviews considered the best tool to attract customers?\nGoogle, being the leading search engine and the largest source of potential and organic customers, is highly valued by business owners. Many business owners choose to purchase Google reviews to enhance their business profiles and also sell them to third parties. Without reviews, it is challenging to reach a large customer base globally or locally. Therefore, it is crucial to consider buying positive Buy Google 5 Star Reviews from reliable sources. When you invest in Buy Google 5 Star Reviews for your business, you can expect a significant influx of potential customers, as these reviews act as a pheromone, attracting audiences towards your products and services. Every business owner aims to maximize sales and attract a substantial customer base, and purchasing Buy Google 5 Star Reviews is a strategic move.\n\nAccording to online business analysts and economists, trust and affection are the essential factors that determine whether people will work with you or do business with you. However, there are additional crucial factors to consider, such as establishing effective communication systems, providing 24/7 customer support, and maintaining product quality to engage online audiences. If any of these rules are broken, it can lead to a negative impact on your business. Therefore, obtaining positive reviews is vital for the success of an online business\n\nWhat are the benefits of purchasing reviews online?\nIn today’s fast-paced world, the impact of new technologies and IT sectors is remarkable. Compared to the past, conducting business has become significantly easier, but it is also highly competitive. To reach a global customer base, businesses must increase their presence on social media platforms as they provide the easiest way to generate organic traffic. Numerous surveys have shown that the majority of online buyers carefully read customer opinions and reviews before making purchase decisions. In fact, the percentage of customers who rely on these reviews is close to 97%. Considering these statistics, it becomes evident why we recommend buying reviews online. In an increasingly rule-based world, it is essential to take effective steps to ensure a smooth online business journey.\n\nBuy Google 5 Star Reviews\nMany people purchase reviews online from various sources and witness unique progress. Reviews serve as powerful tools to instill customer trust, influence their decision-making, and bring positive vibes to your business. Making a single mistake in this regard can lead to a significant collapse of your business. Therefore, it is crucial to focus on improving product quality, quantity, communication networks, facilities, and providing the utmost support to your customers.\n\nReviews reflect customer demands, opinions, and ratings based on their experiences with your products or services. If you purchase Buy Google 5-star reviews, it will undoubtedly attract more people to consider your offerings. Google is the ideal platform for customers to leave reviews due to its extensive organic user involvement. Therefore, investing in Buy Google 5 Star Reviews can significantly influence a large number of people in a positive way.\n\nHow to generate google reviews on my business profile?\nFocus on delivering high-quality customer service in every interaction with your customers. By creating positive experiences for them, you increase the likelihood of receiving reviews. These reviews will not only help to build loyalty among your customers but also encourage them to spread the word about your exceptional service. It is crucial to strive to meet customer needs and exceed their expectations in order to elicit positive feedback. If you are interested in purchasing affordable Google reviews, we offer that service.\n\n\n\n\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | flaviodukagjinit4 |
1,889,729 | Getting hands dirty with SOAP | So yeah, I happen to come across an interesting problem of getting my hands dirty with SOAP. SOAP was... | 0 | 2024-06-15T17:22:59 | https://dev.to/nisalap/getting-hands-dirty-with-soap-1gg6 | node, soap, npm, api | So yeah, I happen to come across an interesting problem of getting my hands dirty with SOAP. SOAP was the king of APIs, well that was before REST API came along. If you found this while trying to connect to a SOAP Web Service, let this be a encouragement for you, you will get over it (eventually).
Simple Object Access... | nisalap |
1,889,728 | Types of Mobile Apps: Native, Hybrid, Web and Progressive Web Apps | Gone are the days when only a few could afford a phone with camera, music player, and touchscreen. We... | 0 | 2024-06-15T17:20:11 | https://dev.to/pcloudy_ssts/types-of-mobile-apps-native-hybrid-web-and-progressive-web-apps-264d | gartner, eclipse, xcode, highperformance | Gone are the days when only a few could afford a phone with camera, music player, and touchscreen. We have come a long way from phones with monochrome displays to digital touchscreen phones loaded with umteen features. The digital era has welcomed the smartphone revolution and made it easy to do things on the go. Be it... | pcloudy_ssts |
1,889,726 | Ensuring Secure Connections: How the Get-VPNConnectionInfo Function Identifies VPN Usage | Get-VPNConnectionInfo Overview The Get-VPNConnectionInfo function checks if the... | 0 | 2024-06-15T17:15:16 | https://dev.to/uyriq/ensuring-secure-connections-how-the-get-vpnconnectioninfo-function-identifies-vpn-usage-1i47 | powershell, networking, vpn | # Get-VPNConnectionInfo
## Overview
The `Get-VPNConnectionInfo ` function checks if the current internet connection is made through one of the known VPN providers. It fetches the current IP information from ipapi.co and compares the organization name (org field) against a predefined list of VPN providers.
## Require... | uyriq |
1,889,725 | Parameterization with DataProvider in TestNG | Overview Parameterization in TestNG is also known as Parametric Testing which allows testing an... | 0 | 2024-06-15T17:14:00 | https://dev.to/pcloudy_ssts/parameterization-with-dataprovider-in-testng-38dh | testngframework, dataproviderintestng, rapidtestautomation | Overview
Parameterization in TestNG is also known as Parametric Testing which allows testing an application against multiple test data and configurations. Though we have to consider the fact that exhaustive testing is impossible, however, it is necessary to check the behavior of our application against different sets... | pcloudy_ssts |
1,889,717 | Use ruby-lsp plugins without modifying the project's Gemfile | First, avoid including editor-specific configuration files in the project. # .gitignore OR... | 0 | 2024-06-15T17:12:52 | https://dev.to/r7kamura/use-ruby-lsp-plugins-without-modifying-the-projects-gemfile-4i93 | ruby | ---
title: Use ruby-lsp plugins without modifying the project's Gemfile
published: true
description:
tags: ruby
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-15 16:18 +0000
---
First, avoid including editor-specific configuration files in the project.... | r7kamura |
1,889,724 | What sets this gaming platform apart as a game host in the mobile gaming industry? | Nostra has distinguished itself as a premier game host in the mobile gaming industry, offering an... | 0 | 2024-06-15T17:11:44 | https://dev.to/claywinston/what-sets-this-gaming-platform-apart-as-a-game-host-in-the-mobile-gaming-industry-2lnf | mobilegames, gamedev, androidgames, games | [Nostra](https://medium.com/@adreeshelk/publishing-on-a-robust-gaming-platform-key-considerations-for-developers-1c8888f80d91?utm_source=referral&utm_medium=Medium&utm_campaign=Nostra) has distinguished itself as a premier game host in the mobile gaming industry, offering an unparalleled experience for both players and... | claywinston |
1,889,723 | Tuan Simon | Bức tranh cuộc đời tôi còn dang dở, nhưng tôi tin rằng với mỗi nét vẽ mỗi ngày, nó sẽ dần hoàn thiện... | 0 | 2024-06-15T17:10:33 | https://dev.to/zgtuansimon/tuan-simon-34lk | Bức tranh cuộc đời tôi còn dang dở, nhưng tôi tin rằng với mỗi nét vẽ mỗi ngày, nó sẽ dần hoàn thiện và trở nên rực rỡ nhất.
Website: https://www.tiktok.com/@t_mon2401
Phone: 0866011730
Address: Mễ trì thượng quận nam từ liêm hà nội
https://www.instapaper.com/p/chtuansimon
https://controlc.com/3f9ec07b
https://flipboar... | zgtuansimon | |
1,889,721 | Idempotency | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-15T17:09:44 | https://dev.to/xapuu/idempotency-3mag | devchallenge, cschallenge, computerscience, beginners | ---
title: Idempotency
published: true
tags: devchallenge, cschallenge, computerscience, beginners
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/myycc3wy752xcxm5485z.png
---
*This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
... | xapuu |
1,889,722 | Understanding Cross Browser Testing and Responsive Testing | Introduction The Internet is inevitable in the current time. It is everywhere and the entire world... | 0 | 2024-06-15T17:07:27 | https://dev.to/pcloudy_ssts/understanding-cross-browser-testing-and-responsive-testing-2e8c | paralleltests, testreporting, automationtesting | Introduction
The Internet is inevitable in the current time. It is everywhere and the entire world depends on it to function, perform day-to-day activities and stay connected with people from different corners of the world. Gone are the days when testers only chose to create websites for selected browsers and hardly ... | pcloudy_ssts |
1,889,719 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-15T17:00:17 | https://dev.to/flaviodukagjinit4/buy-verified-cash-app-account-1c7p | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n\n\n" | flaviodukagjinit4 |
1,889,706 | Make our component's Tailwind class names more understandable in React's JSX | Background Have you ever seen a long list of class names with barely knowing which... | 0 | 2024-06-15T16:57:58 | https://dev.to/vuthanhnguyen/make-our-components-tailwind-class-names-more-understandable-in-reacts-html-1e5h | tailwindcss, react, javascript, hoc | ## Background
Have you ever seen a long list of class names with barely knowing which components we try to debug?
I cannot deny that Tailwind helps our web development faster, especially, with styling, but when we try to use many of its utility class names within a single element. As a result, we cannot see the actua... | vuthanhnguyen |
1,889,716 | Mastering Clean Code: Essential Practices for Developers | Clean code is the cornerstone of every successful software project. As a developer, your ability to... | 0 | 2024-06-15T16:56:04 | https://dev.to/mahabubr/mastering-clean-code-essential-practices-for-developers-1287 | webdev, programming, cleancode, learning | Clean code is the cornerstone of every successful software project. As a developer, your ability to write clean, maintainable code is crucial for the efficiency and longevity of your applications. In this article, we'll delve into ten examples of good and bad coding practices in JavaScript, highlighting the importance ... | mahabubr |
1,889,715 | Top Powerful AI Test Automation Tools for the Future | Introduction Test automation has transformed significantly over the years. It has helped QA teams... | 0 | 2024-06-15T16:54:50 | https://dev.to/pcloudy_ssts/top-powerful-ai-test-automation-tools-for-the-future-57ei | cicdtools, functionaltesting, endtoendtesting | Introduction
Test automation has transformed significantly over the years. It has helped QA teams reduce the chances of human error to a great extent. There are plenty of tools available for [test automation](https://www.pcloudy.com/blogs/top-benefits-of-automation-testing-for-a-successful-product-release/), but ... | pcloudy_ssts |
1,889,713 | Blockchain and Green Energy: A Synergistic Future | Introduction to Blockchain and Green Energy Blockchain technology, initially devised for... | 27,673 | 2024-06-15T16:49:42 | https://dev.to/rapidinnovation/blockchain-and-green-energy-a-synergistic-future-1nk0 | ## Introduction to Blockchain and Green Energy
Blockchain technology, initially devised for the digital currency Bitcoin, has
evolved far beyond its inception. Today, it is poised to revolutionize various
sectors, including the green energy market. By enabling a decentralized and
secure platform, blockchain can facili... | rapidinnovation | |
1,889,711 | Mind Boggling Speed when Caching with Momento and Rust | Summer is here and in the northern hemisphere, temperatures are heating up. Living in North Texas,... | 0 | 2024-06-15T16:45:15 | https://www.binaryheap.com/caching-with-momento-and-rust/ | Summer is here and in the northern hemisphere, temperatures are heating up. Living in North Texas, you get used to the heat and humidity but somehow it still always seems to sneak up on me. As I start this new season (which happens to be my favorite) I wanted to reflect a touch and remember the summer of 2023. That ... | benbpyle | |
1,889,710 | Highly Customizable React Custom Select Box Component | Enhance your user interfaces with a fully customizable React Select Box component. This versatile... | 0 | 2024-06-15T16:44:47 | https://dev.to/gihanrangana/highly-customizable-react-custom-select-box-component-5e45 | react, reactselect, vite, customcomponent | Enhance your user interfaces with a fully customizable React Select Box component. This versatile component replaces standard HTML select boxes with a user-friendly drop-down menu, giving you complete control over style, behavior, and functionality. Build intuitive and interactive forms that seamlessly integrate into y... | gihanrangana |
1,889,707 | Create Stunning Art for Free with SeaArt AI Art Generator | Introduction to SeaArt AI art generator free Are you ready to unlock your inner artist and create... | 0 | 2024-06-15T16:33:22 | https://dev.to/mister_jerry_37e1ecf9b7f7/create-stunning-art-for-free-with-seaart-ai-art-generator-333l | Introduction to SeaArt AI art generator free
Are you ready to unlock your inner artist and create stunning art for free? Say hello to SeaArt AI Art Generator, the innovative tool that will revolutionize the way you express your creativity. With just a few clicks, you can transform simple ideas into breathtaking master... | mister_jerry_37e1ecf9b7f7 | |
1,889,705 | Mock Data: A Cornerstone of Efficient Software Testing | In the intricate world of software development, testing plays a crucial role in ensuring the... | 0 | 2024-06-15T16:25:47 | https://dev.to/keploy/mock-data-a-cornerstone-of-efficient-software-testing-e0m | In the intricate world of software development, testing plays a crucial role in ensuring the reliability, performance, and overall quality of applications. One of the key elements that facilitate effective testing is the use of mock data. [Mock data](https://keploy.io/test-data-generator), also known as synthetic or du... | keploy | |
1,889,704 | Article Outline for corteiz Hoodie | Importance of comfortable and stylish clothing Overview of corteiz as a brand Introduction to the... | 0 | 2024-06-15T16:23:54 | https://dev.to/corteizhoodiegm/article-outline-for-corteiz-hoodie-1685 | Importance of comfortable and stylish clothing
Overview of [corteiz](https://corteizus.shop/) as a brand
Introduction to the corteiz Hoodie product
Fashion History and Influences
Evolution of hoodies in fashion
Impact of streetwear culture on hoodie popularity
corteiz's contribution to modern fashion trends
Key Feature... | corteizhoodiegm | |
1,636,352 | Integration testing with Spring Boot and embedded kafka | In several projects, I have encountered difficulties in implementing integration tests for Spring... | 0 | 2024-06-15T16:21:27 | https://dev.to/steffenwda/integration-testing-with-spring-boot-and-embedded-kafka-1ld0 | java, kafka, springboot, testing |
In several projects, I have encountered difficulties in implementing integration tests for Spring Boot applications using Kafka, and developers are often put off by the effort required to implement tests involving Kafka. This post describes the implementation of a simple integration test using an embedded Kafka broker... | steffenwda |
1,889,661 | ZGC的两种主要的垃圾收集类型 ZGC的两种主要的GC类型 | 在ZGC(Z Garbage Collector)中,有两种主要的垃圾收集类型:Major Collection和Minor Collection。具体如下: Major... | 0 | 2024-06-15T16:20:10 | https://dev.to/truman_999999999/zgcde-liang-chong-zhu-yao-de-la-ji-shou-ji-lei-xing-zgcde-liang-chong-zhu-yao-de-gclei-xing-3aod | zgc, jvm, gc | 在ZGC(Z Garbage Collector)中,有两种主要的垃圾收集类型:Major Collection和Minor Collection。具体如下:
- Major Collection
- Warmup Collections: 当JVM刚启动时,ZGC会进行几次Major Collection作为预热。这些预热的Major Collection帮助JVM和ZGC为后续的垃圾收集做好准备。
- Proactive Collections: 这种类型的Major Collection是由ZGC自动触发的,以确保系统在内存使用量较高之前就开始垃圾收集,从而避免内存不足的情况。这些垃圾收集通常是预测性的,以保持系... | truman_999999999 |
1,889,660 | Viedelite | https://viedelite.com/ | 0 | 2024-06-15T16:07:34 | https://dev.to/viedelite56/viedelite-28op | wellness, skinrejuvenation, facialtreatments, spaservices | https://viedelite.com/ | viedelite56 |
1,889,546 | Go is a platform | Thanks to the Google Developer Experts program, I had the opportunity to participate in Google I/O in... | 0 | 2024-06-15T12:42:25 | https://dev.to/eminetto/go-is-a-platform-2562 | go | ---
title: Go is a platform
published: true
description:
tags: go, golang
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-15 12:39 +0000
---
Thanks to the Google Developer Experts program, I had the opportunity to participate in Google I/O in Mountain V... | eminetto |
1,889,657 | Income Tax Books: Your Comprehensive Guide to Navigating Tax Laws, Maximizing Deductions, and Planning for Financial Achievement | It can be challenging for many people and organizations to steer the complex planet of income tax.... | 0 | 2024-06-15T15:57:32 | https://dev.to/examo_pedia_1f207427137a6/income-tax-books-your-comprehensive-guide-to-navigating-tax-laws-maximizing-deductions-and-planning-for-financial-achievement-3i00 | webdev, javascript | It can be challenging for many people and organizations to steer the complex planet of income tax. Financial success is mainly dependent on knowing the variation of tax legislation, making calculated plans, and utilizing deductions. The goal of this thorough book is to demystify income tax so that you can manage t... | examo_pedia_1f207427137a6 |
1,889,655 | Day 19 of my progress as a vue dev | About today Today I coded the logic for the audio clip management and how the should be stored and... | 0 | 2024-06-15T15:55:12 | https://dev.to/zain725342/day-19-of-my-progress-as-a-vue-dev-1j0n | webdev, vue, typescript, tailwindcss | **About today**
Today I coded the logic for the audio clip management and how the should be stored and handled on the app and what the interface for it will look like. The visual is just like most audio editors, showing clips in the form on drag-able divs that can be visualized and can be interacted with.
**What's ne... | zain725342 |
1,889,654 | 5 Auth0 Gotchas to Consider | Using an identity provider (IDP) for user management has become the norm these days. And while it can... | 0 | 2024-06-15T15:53:35 | https://dev.to/ujjavala/5-auth0-gotchas-to-consider-3g96 | webdev, security, api, development | Using an identity provider (IDP) for user management has become the norm these days. And while it can get daunting to choose the best idp from the _ala carte_, it could help identify some of the shortcomings beforehand.
Given below are a few of Auth0's gotchas that I have come across and sincerely wish I knew them ear... | ujjavala |
1,889,653 | Install zsh-autocomplete on WSL2 | What is zsh-autocomplete? Real-time type-ahead completion for Zsh. Asynchronous... | 0 | 2024-06-15T15:52:31 | https://dev.to/0xkoji/install-zsh-autocomplete-on-wsl2-21ij | wsl, ubuntu, cli | ## What is zsh-autocomplete?
> Real-time type-ahead completion for Zsh. Asynchronous find-as-you-type autocompletion.
{% github marlonrichert/zsh-autocomplete %}
```shell
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
```
Add the following ... | 0xkoji |
1,889,400 | Difference between XHTML and HTML | What is XHTML? XHTML stands for EXtensible HyperText Markup Language XHTML is a stricter,... | 0 | 2024-06-15T08:01:18 | https://dev.to/wasifali/difference-between-xhtml-and-html-2gm4 | webdev, css, learning, html | ## **What is XHTML?**
XHTML stands for EXtensible HyperText Markup Language
XHTML is a stricter, more XML-based version of HTML
XHTML is HTML defined as an XML application
XHTML is supported by all major browsers
## **Why XHTML is used?**
XML is a markup language where all documents must be marked up correctly (be "wel... | wasifali |
1,889,652 | Discover the Top 23 CSS Frameworks for 2023 | The Web’s landscape is continuously evolving, and a key driver behind it is CSS (Cascading Style... | 0 | 2024-06-15T15:52:12 | https://dev.to/pcloudy_ssts/discover-the-top-23-css-frameworks-for-2023-2bhd | automationtesting, trypcloudynow, crossbrowsercompatibility | The Web’s landscape is continuously evolving, and a key driver behind it is CSS (Cascading Style Sheets). Ensuring an engaging and immersive website experience can undeniably convert more customers or viewers, and this effectiveness can be multiplied by the right CSS framework.
CSS frameworks give developers a solid f... | pcloudy_ssts |
1,889,651 | Enhancing Continuous Integration with pCloudy’s GitLab CI Integration | In the fast-paced world of app development, continuous integration and continuous deployment (CI/CD)... | 0 | 2024-06-15T15:41:58 | https://dev.to/pcloudy_ssts/enhancing-continuous-integration-with-pcloudys-gitlab-ci-integration-522 | configuregitlabci, paralleljobexecution | In the fast-paced world of app development, continuous integration and continuous deployment (CI/CD) have become staples. They streamline the workflow, reduce the chances of bugs, and allows teams to deliver high quality apps at a quicker pace. At pCloudy, we are thrilled to introduce our latest integration with GitLab... | pcloudy_ssts |
1,889,650 | Mocking with Sinon.js: A Comprehensive Guide | Testing is an integral part of software development, ensuring that code behaves as expected. When it... | 0 | 2024-06-15T15:41:46 | https://dev.to/sojida/mocking-with-sinonjs-a-comprehensive-guide-4p3j | node, javascript, sinonjs, mocking | Testing is an integral part of software development, ensuring that code behaves as expected. When it comes to JavaScript, Sinon.js is a powerful library for creating spies, stubs, and mocks, making it easier to test code that relies on external dependencies. This article will explore how to use Sinon.js to mock tests e... | sojida |
1,889,649 | The Rise of Cactus Jack More Than Just a Brand | In the ever-evolving landscape of streetwear and pop culture, few names have garnered as much... | 0 | 2024-06-15T15:40:38 | https://dev.to/cactusjack1232/the-rise-of-cactus-jack-more-than-just-a-brand-40il | hoodis, shorts, tshirt, caps | In the ever-evolving landscape of streetwear and pop culture, few names have garnered as much attention and reverence as[ "Cactus Jack."](https://cactusjackhoodie.shop/) While some may immediately think of the iconic figure in the wrestling world, the modern association is overwhelmingly tied to Travis Scott, the multi... | cactusjack1232 |
1,889,523 | ZGC Major Collection (Proactive) 日志详解 | JVM相关参数 -Xms10G -Xmx10G -Xmn5G -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+UseZGC... | 0 | 2024-06-15T15:36:58 | https://dev.to/truman_999999999/zgc-major-collection-proactive-ri-zhi-xiang-jie-453g | zgc, gc, gclog, jvm | `JVM相关参数 -Xms10G -Xmx10G -Xmn5G -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+UseZGC -XX:+ZGenerational`
日志信息
```
[2024-06-12T19:42:28.946+0800][info][gc ] GC(13451) Major Collection (Proactive)
[2024-06-12T19:42:28.946+0800][info][gc,task ] GC(13451) Using 1 Workers for Young Generation
[2024-06... | truman_999999999 |
1,889,647 | A Comprehensive Guide to Creating Mobile-Friendly Websites | Introduction: In today’s digital age, having a mobile-friendly website is crucial for any business... | 0 | 2024-06-15T15:36:06 | https://dev.to/pcloudy_ssts/a-comprehensive-guide-to-creating-mobile-friendly-websites-5h2d | mobilewebsitetesting, apptestingplatform, automatetest, realdevicetesting | Introduction:
In today’s digital age, having a mobile-friendly website is crucial for any business or organization. With the increasing number of users accessing the internet through mobile devices, it’s essential to ensure that your website provides a seamless and optimized experience across different screen sizes an... | pcloudy_ssts |
1,889,646 | New Linux distro: PyTermOS | Introducing PyTermOS: A Lightweight Linux-Based OS for Learning and Development Hello,... | 0 | 2024-06-15T15:36:05 | https://dev.to/markdev/new-linux-distro-pytermos-2h3p | linux, opensource, python | # Introducing PyTermOS: A Lightweight Linux-Based OS for Learning and Development

Hello, Dev.to community!
I'm excited to introduce [PyTermOS](https://github.com/PyTermOS-Project/PyTermOS), a lightweight, Linux... | markdev |
1,889,645 | Moving Beyond Prediction into the Realm of Trading Strategy and Simulation | In finance, accurate predictions are just the beginning. The real challenge lies in translating these... | 0 | 2024-06-15T15:35:52 | https://dev.to/annaliesetech/moving-beyond-prediction-into-the-realm-of-trading-strategy-and-simulation-3mk1 | money, finance, trading, analytics | In finance, accurate predictions are just the beginning. The real challenge lies in translating these predictions into actionable trading strategies. Whether you’re a novice trader or a seasoned investor, understanding how to craft and execute effective trading strategies is crucial. This blog post will explore various... | annaliesetech |
1,889,643 | How to Integrate Cloudinary with TinyMCE for Image Uploads | If you're looking to enable image uploads in TinyMCE and store those images in Cloudinary, you're in... | 0 | 2024-06-15T15:33:18 | https://dev.to/joshydev/how-to-integrate-cloudinary-with-tinymce-for-image-uploads-fm9 | react, tutorial, learning | If you're looking to enable image uploads in TinyMCE and store those images in Cloudinary, you're in the right place. This guide will walk you through the steps to integrate Cloudinary with TinyMCE, allowing users to upload images directly from the editor and have them stored in Cloudinary.
###Prerequisites
1. A Clou... | joshydev |
1,889,642 | Building Command Line Interface (CLI) Tools with Node.js | Creating Command Line Interface (CLI) tools is a powerful way to automate tasks, manage system... | 0 | 2024-06-15T15:32:55 | https://dev.to/sojida/building-command-line-interface-cli-tools-with-nodejs-4mob | Creating Command Line Interface (CLI) tools is a powerful way to automate tasks, manage system operations, or even interface with web services directly from the terminal. Node.js, with its event-driven architecture and robust package ecosystem, is an excellent choice for building CLI tools. In this article, we will exp... | sojida | |
1,889,641 | NUnit vs. XUnit vs. MSTest: Comparing Unit Testing Frameworks In C# | Introduction In the ever-evolving field of software development, a crucial aspect that underpins the... | 0 | 2024-06-15T15:29:25 | https://dev.to/pcloudy_ssts/nunit-vs-xunit-vs-mstest-comparing-unit-testing-frameworks-in-c-185e | Introduction
In the ever-evolving field of software development, a crucial aspect that underpins the quality and reliability of software is unit testing. It is a vital cog in the development process, providing an early detection system for bugs, enhancing code quality, and encouraging modular, maintainable design. Un... | pcloudy_ssts | |
1,889,640 | Networking: Let's Connect Nodes | Networking is the art of linking devices to share valuable resources. Networks span from local (LANs)... | 0 | 2024-06-15T15:22:59 | https://dev.to/r4jv33r/networking-lets-connect-nodes-3mo4 | cschallenge, computerscience, networking, beginners | Networking is the art of linking devices to share valuable resources. Networks span from local (LANs) to global (WANs, like the Internet), employing protocols (TCP, UDP) and adhering to the OSI model's seven-layer framework for seamless communication. It may be wired or wireless. | r4jv33r |
1,889,628 | The Unsung Heroes - Why Runbooks are Crucial for Effective Incident Response | In the fast-paced world of software engineering, where applications are the lifeblood of modern... | 0 | 2024-06-15T15:17:30 | https://dev.to/moniv9/the-unsung-heroes-why-runbooks-are-crucial-for-effective-incident-response-13j9 | webdev, runbook, incidentmangement, devops | In the fast-paced world of software engineering, where applications are the lifeblood of modern businesses, the ability to respond swiftly and effectively to incidents is paramount. Enter the humble yet powerful runbook - the unsung hero that can make all the difference in mitigating the impact of system failures and e... | moniv9 |
1,889,626 | Understanding Big O Notation with a Library Analogy | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-15T15:10:03 | https://dev.to/utcresta_mishra_dc97c50fa/understanding-big-o-notation-with-a-library-analogy-2kid | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Big O notation measures algorithm efficiency relative to input size. Imagine a library where books represent data and tasks represent algorithms.
O(1) - Constant Time: Instantly findi... | utcresta_mishra_dc97c50fa |
1,889,623 | Empowering Seniors with Technology at Smart Seniors Tech | In today's rapidly evolving technological landscape, seniors often find themselves left behind. Smart... | 0 | 2024-06-15T15:08:29 | https://dev.to/smartseniorstech/empowering-seniors-with-technology-at-smart-seniors-tech-4nab | seniorstech, smartseniorstech, seniorlivingtechnology, seniorcaretechnology | In today's rapidly evolving technological landscape, seniors often find themselves left behind. Smart Seniors Tech bridges this gap by providing a comprehensive resource center dedicated to empowering elderly individuals with the tools they need to navigate the digital world with confidence.
Their website offers a wea... | smartseniorstech |
1,889,622 | Automating the Cloud: IaC with AWS CloudFormation and Terraform | Automating the Cloud: IaC with AWS CloudFormation and Terraform Modern software... | 0 | 2024-06-15T15:05:53 | https://dev.to/virajlakshitha/automating-the-cloud-iac-with-aws-cloudformation-and-terraform-1oli | 
# Automating the Cloud: IaC with AWS CloudFormation and Terraform
Modern software development demands speed, agility, and reliability. Manually provisioning and managing infrastructure simply can't keep up. Enter Infrastructure a... | virajlakshitha | |
1,889,621 | I made my own JSON Parser | ✏️Preface I was always interested in how programming languages worked. To be specific, how... | 0 | 2024-06-15T15:04:57 | https://dev.to/hetarth02/i-made-my-own-json-parser-4902 | javascript, webdev, beginners, tutorial | ### ✏️Preface
I was always interested in how programming languages worked. To be specific, how what we write in a human readable way is interpreted my the machine. I did have an bird's eye view of what would happen, but it was and still kind of is like black magic to me. So, now I have decided to learn these magic ver... | hetarth02 |
1,889,619 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-15T15:01:32 | https://dev.to/tesdahamko/buy-verified-cash-app-account-3li1 | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | tesdahamko |
1,889,618 | Azure Fundamentals: Understanding Microsoft's Cloud Platform | In this digital era where flexibility, scalability, and efficiency are paramount, Microsoft Azure... | 27,735 | 2024-06-15T14:59:51 | https://dev.to/prakash_rao/azure-fundamentals-understanding-microsofts-cloud-platform-86o | azure, cloud, devops, beginners |

In this digital era where flexibility, scalability, and efficiency are paramount, Microsoft Azure emerges as one of the cornerstones of cloud solutions besides AWS and GCP. This blog post is designed as a primer to introdu... | prakash_rao |
1,889,617 | 502. IPO | 502. IPO Hard Suppose LeetCode will start its IPO soon. In order to sell a good price of its shares... | 27,523 | 2024-06-15T14:59:33 | https://dev.to/mdarifulhaque/502-ipo-295e | php, leetcode, algorithms, programming | 502\. IPO
Hard
Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Hel... | mdarifulhaque |
339,547 | 4 Ways Businesses Can Use Web Data Extraction | I bet you’ve heard a lot about the term web data extraction or web scraping these days. Today I want... | 0 | 2020-05-20T06:08:15 | http://www.dataextraction.io/?p=565 | I bet you’ve heard a lot about the term web [data extraction](http://www.dataextraction.io/) or web scraping these days. Today I want to share with you how you can leverage web data extraction to cope with some painful problems that you encounter in your business.
No one can deny that data is the most valuable asset f... | fooooopng | |
1,887,914 | 2 re-rendering pitfalls I learned about while building my React app | Hi It's Hudy here. In this blog post, I'd like to share two re-rendering pitfalls I encountered... | 0 | 2024-06-15T14:45:31 | https://dev.to/hudy9x/two-simple-re-rendering-pitfalls-i-learned-about-while-building-my-react-app-2n7 | react | Hi It's Hudy here.
In this blog post, I'd like to share two re-rendering pitfalls I encountered while developing [Namviek](https://namviek.com), my open-source project management app, and how I addressed them.
These pitfalls highlight common mistakes that can lead to performance issues in React applications. By under... | hudy9x |
1,889,616 | Day 1 - Hi, I started learning with AWS and I'll share what i learn each day and if you find something wrong then let me know | AWS (for AWS cloud practitioners) AWS stands for amazon web services nad It is the first large... | 0 | 2024-06-15T14:43:12 | https://dev.to/deepak5812/hi-guys-i-started-learning-with-aws-and-ill-share-what-i-learn-each-day-and-if-you-find-something-wrong-then-let-me-know-52k1 | aws, webdev, springboot, devops | AWS (for AWS cloud practitioners)
- AWS stands for amazon web services nad It is the first large scale cloud service provider in 2006 with s3 service.
- Ways of Interactions with AWS
- Using AWS Console(via GUI)
- Using AWS CLI (via command line or terminal)
- Using AWS SDKs (via some programming language code)
... | deepak5812 |
1,889,615 | Must-Have Software for macOS Developers in 2024 | Here’s a summary of essential software for MacOS development. All of these tools are free, and most... | 0 | 2024-06-15T14:43:05 | https://dev.to/lunamiller/must-have-software-for-macos-developers-in-2024-3885 | webdev, beginners, productivity, discuss | Here’s a summary of essential software for MacOS development. All of these tools are free, and most are open-source. I hope they enhance your development experience.
## Basics
### Git
Git needs no introduction. Simply run `git` in the terminal, and a dialog will pop up. Click install. This typically installs the bas... | lunamiller |
1,889,614 | HIRED AN AUTHORIZED HACKER FOR CRYPTO RECOVERY: PARADOX CRYPTO RECOVERY WIZARD | WHAT IS THE BEST AND MOST RELATIVE RECOVERY HACKER? HOW CAN I EASILY RESTORE MY STOLEN FUNDS? HIRED... | 0 | 2024-06-15T14:41:17 | https://dev.to/matthew_thomas_b947b52805/hired-an-authorized-hacker-for-crypto-recovery-paradox-crypto-recovery-wizard-287p | WHAT IS THE BEST AND MOST RELATIVE RECOVERY HACKER?
HOW CAN I EASILY RESTORE MY STOLEN FUNDS?
HIRED AN AUTHORIZED HACKER FOR CRYPTO RECOVERY: PARADOX CRYPTO RECOVERY WIZARD
I would like to take this opportunity to thank PARADOX CRYPTO RECOVERY WIZARD for the amazing assistance they offered in helping me get my lost b... | matthew_thomas_b947b52805 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.