
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,884,893 | Day 968 : Find A Way | liner notes: Professional : Was in meetings for the majority of the day. In between, I was able to... | 0 | 2024-06-11T22:05:08 | https://dev.to/dwane/day-968-find-a-way-3moc | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Was in meetings for the majority of the day. In between, I was able to work on refactoring a project, responded to some community questions and created a ticket for an upcoming trip. The day went by super quick!
- Personal : Yo! I made some pretty great progress on the in-browser highli... | dwane |
1,884,892 | 🚀 How to Create React Components Really Quick 🛠️ | Creating components quickly is crucial to maintaining high productivity and keeping your project... | 0 | 2024-06-11T22:03:38 | https://dev.to/buildwebcrumbs/how-to-create-react-components-really-quick-c84 | webdev, react, ai, javascript | Creating components **quickly** is crucial to maintaining high productivity and keeping your project moving forward. Let's explore how to do this **efficiently** and swiftly! 😎💡
Imagine designing and building your components in **Figma** or any tool of your choice, like this:

| maatheusgois |
1,884,885 | D'orsogna Delights: Navigating the Culinary Riches of Italian Tradition with Emphasis on Food Safety and Quality | Italian cuisine, with its rich history and diverse flavors, has always been a delight for food... | 0 | 2024-06-11T21:27:01 | https://dev.to/dorsogna/dorsogna-delights-navigating-the-culinary-riches-of-italian-tradition-with-emphasis-on-food-safety-and-quality-5fi1 | resturaunt, lunch, eat, culinary | Italian cuisine, with its rich history and diverse flavors, has always been a delight for food enthusiasts. Amidst the plethora of options, D'orsogna Delights stands out as a beacon of tradition and Quality. Let's embark on a journey to unravel the culinary riches deeply embedded in Italian tradition, exploring the ori... | dorsogna |
1,884,853 | Innovations in Education: Evolving SOELs with ATELIER STUDIOS | In today's rapidly evolving world, the landscape of education is undergoing a revolutionary... | 0 | 2024-06-11T21:17:30 | https://dev.to/schoolsofearlylearning/innovations-in-education-evolving-soels-with-atelier-studios-2ah8 | school, learning, studies, students | In today's rapidly evolving world, the landscape of education is undergoing a revolutionary transformation. Innovations in Education, particularly in Early Learning, are shaping the way we approach teaching and learning. In this article, we will explore the significant changes introduced by Schools of Early Learning (S... | schoolsofearlylearning |
1,884,852 | Hello, everyone !! | I'm Ricardo Rojas from Argentina and finished my Web Frontend certificate from BYU-Pathway-worldwide,... | 0 | 2024-06-11T21:14:33 | https://dev.to/estudiante71/hello-everyone--7mp | I'm Ricardo Rojas from Argentina and finished my Web Frontend certificate from BYU-Pathway-worldwide, I need to learn a lot about this great area which is Programming. I will try to ask the right questions about my doubts and mistakes. Thanks for the welcome
| estudiante71 | |
1,884,833 | Online spil | Komogvind.dk er en populær dansk hjemmeside, der tilbyder et bredt udvalg af gratis spil til... | 0 | 2024-06-11T19:46:26 | https://dev.to/komogvind06/online-spil-5dod | Komogvind.dk er en populær dansk hjemmeside, der tilbyder et bredt udvalg af gratis spil til underholdning og tidsfordriv. Platformen er kendt for sit brede udvalg af spil, der spænder fra klassiske kortspil som 7 kabale og Solitaire til hjernegymnastik som krydsord og kryds & tværs. Denne artikel udforsker, hvad der g... | komogvind06 | |
1,884,851 | Renting VS Buying LED Wall in Los Angeles | Here is a comparison of renting vs buying an LED wall in Los Angeles: Renting an LED Wall:... | 0 | 2024-06-11T21:11:46 | https://dev.to/rentforeventla/renting-vs-buying-led-wall-in-los-angeles-4kcm | led, buyledwall, losangeles, rentforevent | Here is a comparison of renting vs buying an LED wall in Los Angeles:
Renting an LED Wall: Pros:
Lower upfront costs, since you only pay for the rental period
Flexibility to rent different sizes and resolutions for different events
No maintenance, storage, or repair responsibilities
Good for one-time or occasional... | rentforeventla |
1,884,557 | Como Escrever Testes Unitários para Serviços Backend com Dependências de Banco de Dados Usando SQLite In-Memory | Introdução Ao desenvolver serviços backend, os testes unitários são cruciais para garantir... | 27,693 | 2024-06-11T21:09:54 | https://dev.to/vitorrios1001/como-escrever-testes-unitarios-para-servicos-backend-com-dependencias-de-banco-de-dados-usando-sqlite-in-memory-4526 | jest, sqlite, testing, database | ## Introdução
Ao desenvolver serviços backend, os testes unitários são cruciais para garantir a correção e a estabilidade do seu código. No entanto, escrever testes unitários para componentes que interagem com um banco de dados pode ser desafiador. Usar um banco de dados real para testes pode ser lento e complicado, a... | vitorrios1001 |
1,884,849 | shadcn-ui/ui codebase analysis: Mail example explained. | In this article, we will learn about Mail example in shadcn-ui/ui. This article consists of the... | 0 | 2024-06-11T21:03:24 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-mail-example-explained-1746 | javascript, opensource, nextjs, shadcnui | In this article, we will learn about [Mail](https://ui.shadcn.com/examples/mail) example in shadcn-ui/ui. This article consists of the following sections:
 properties are used to generate space around an element's content, inside any defined borders. Padding does not include [margins](https://www.devwares.com/tailwindcss/classes/tailwind-margin/) or borders.
## Padding - Individual Sides
C... | hypercode |
1,884,837 | AR Game ~ ChatGPT API ~ | Table of contents Background What is ChatGPT API Implementation of ChatGPT API Execution of ChatGPT... | 0 | 2024-06-11T20:15:02 | https://dev.to/takeda1411123/ar-game-chatgpt-api--1gpg | unity3d, gamedev, chatgpt, csharp | Table of contents
- Background
- What is ChatGPT API
- Implementation of ChatGPT API
- Execution of ChatGPT API
- Next Step
# Background
I will develop AR Game with Unity, AR foundation and so on. To learn AR development, I am researching about AR and the software related it. This blog shows the research and the pro... | takeda1411123 |
1,884,836 | Smooth Transition of Dynamic Heights | ① Height Transition index.html and style.css have already been provided in the VM. This... | 27,689 | 2024-06-11T20:09:46 | https://labex.io/tutorials/css-smooth-transition-of-dynamic-heights-35207 | css, coding, programming, tutorial |
# ① Height Transition
`index.html` and `style.css` have already been provided in the VM.
This code snippet transitions an element's height from `0` to `auto` when its height is unknown by performing the following steps:
- Use the `transition` property to specify that changes to `max-height` should be transitioned o... | labby |
1,879,876 | Melhorando Pipelines no Bitbucket: Cache, Reutilização de Steps e Execução Paralela | Introdução Bitbucket Pipelines é uma ferramenta poderosa para integração contínua (CI) e... | 27,690 | 2024-06-11T20:05:32 | https://dev.to/vitorrios1001/melhorando-pipelines-no-bitbucket-cache-reutilizacao-de-steps-e-execucao-paralela-3ak6 | pipeline, bitbucket, cicd, tutorial | ### Introdução
Bitbucket Pipelines é uma ferramenta poderosa para integração contínua (CI) e entrega contínua (CD) que permite automatizar a construção, teste e implantação do seu código. Neste artigo, vamos explorar técnicas avançadas para otimizar suas pipelines no Bitbucket, incluindo o uso de cache, reutilização d... | vitorrios1001 |
1,884,834 | Working on my first web project. | How can I know how many web layers are there in a given website. | 0 | 2024-06-11T19:54:11 | https://dev.to/sylvester_elu_512d5a21b57/working-on-my-first-web-project-2mk | help | How can I know how many web layers are there in a given website. | sylvester_elu_512d5a21b57 |
1,884,831 | Building "Ohey": A Promise-Based HTTP Client like axios/fetch | Introduction Today, I'm excited to share the journey of creating my very own npm package:... | 0 | 2024-06-11T19:41:57 | https://dev.to/shamimbinnur/building-ohey-a-promise-based-http-client-like-axiosfetch-4c96 | webdev, javascript, npm, promise | ### Introduction
Today, I'm excited to share the journey of creating my very own npm package: **Ohey**. Ohey is a promise-based HTTP client built on top of [`XMLHttpRequest`](https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest). Whether you're new to web development or an experienced coder, understanding h... | shamimbinnur |
1,883,671 | Revised 150+ LeetCode in 2 hours | LeetCode Submission Saver Github LeetCode... | 0 | 2024-06-11T19:39:29 | https://dev.to/theshubham99/download-all-leetcode-solved-questions-4lk | javascript, leetcode, interview, beginners | <p align="center">
<a href="https://nextjs.org">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="./logo.png">
</a>
</p>
<p align="center">
<a aria-label="License">
<img alt="" src="https://img.shields.io/npm/l/next.svg?style=for-the-badge&labelColor=000000">
</a>
<a aria-label="C... | theshubham99 |
1,884,830 | This is for you, let's build some cool stuff! 🚀✨ | Hey Folks, 🎉 It's time to bring your ideas to life! 💡 Whether you're a designer, developer, content... | 0 | 2024-06-11T19:36:33 | https://dev.to/sauravshah31/this-is-for-you-lets-build-some-cool-stuff-15kn | codenewbie, webdev, discuss, learning | Hey Folks, 🎉
It's time to bring your ideas to life! 💡 Whether you're a designer, developer, content creator, or just have a passion to create something amazing, this is your chance. 🚀
No matter your skill level—beginner or pro, student or full-time professional—your dream project awaits. 🌟 Use your nights and wee... | sauravshah31 |
1,884,829 | The Pleasure of Popping Bubbles: A Simple Joy Amidst Life's Complexity | In the midst of life's complexities, there's a simple pleasure that brings a smile to faces young and... | 0 | 2024-06-11T19:36:14 | https://dev.to/pocket7game/the-pleasure-of-popping-bubbles-a-simple-joy-amidst-lifes-complexity-4onm |
In the midst of life's complexities, there's a simple pleasure that brings a smile to faces young and old: **[popping bubbles](https://www.pocket7games.com/post/top-5-online-memory-games?backlink_nabab )**. Whether ... | pocket7game | |
1,884,828 | Desafío de Nombres y Apellidos | Un pequeño ejercicio para filtrar nombres y apellidos | 0 | 2024-06-11T19:29:00 | https://dev.to/javascriptchile/desafio-de-nombres-y-apellidos-540f | elixir, chile, javascript, ejercicios | ---
title: Desafío de Nombres y Apellidos
published: true
description: Un pequeño ejercicio para filtrar nombres y apellidos
tags: elixir, chile, javascript, ejercicios
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/f01mofctkpptddwkqh3e.jpg
# Use a ratio of 100:42 for best results.
published_at: ... | clsource |
1,884,825 | What is String Manipulation and Algorithms | Introduction The digital world thrives on information, and a substantial portion of this... | 0 | 2024-06-11T19:23:06 | https://dev.to/m__mdy__m/what-is-string-manipulation-and-algorithms-42m1 | algorithms, programming, webdev, javascript | ## Introduction
The digital world thrives on information, and a substantial portion of this information resides in the form of text. String manipulation and searching algorithms serve as the foundation for processing and analyzing this textual data. These algorithms empower us to perform a wide range of operations on ... | m__mdy__m |
1,880,812 | Cancellation Tokens in C# | Hi There! 👋🏻 It's been a while since I wrote something about C#, or wrote anything in... | 0 | 2024-06-11T19:21:17 | https://dev.to/rasheedmozaffar/cancellation-tokens-in-c-35c1 | csharp, dotnet, learning | ## Hi There! 👋🏻
It's been a while since I wrote something about C#, or wrote anything in general, but now I have an interesting concept that I'm sure you've stumbled upon or seen somewhere in a C# code base.
If you used Entity Framework, HttpClient or anything that have methods which can do asynchronous work, it's a... | rasheedmozaffar |
1,884,807 | 🤖AI-Powered Data Queries: Ask Questions in Plain English, Get Instant Results!🚀 | You've might have heard of SQL. It's a widely used programming language for storing and processing... | 0 | 2024-06-11T19:17:30 | https://dev.to/llmware/ai-powered-data-queries-ask-questions-in-plain-english-get-instant-results-2lfe | python, sql, ai, beginners | You've might have heard of SQL. It's a widely used programming language for storing and processing information in _relational databases_ - simply put, relational databases store data in tables, where each row stores an entity and each column stores an attribute for that entity.
Let's say we have a table called `custom... | prashantriyer |
1,884,809 | How to activate windows 10, 11, 12, etc. FREE | We will activate windows with KMSAuto++ Portable download it here -... | 0 | 2024-06-11T19:13:54 | https://dev.to/sbsoft/how-to-activate-windows-10-11-12-etc-free-4oo3 | We will activate windows with KMSAuto++ Portable download it here - https://disk.yandex.ru/d/up74ZPGsZ9BQ-g.
Windows activation process with KMSauto:
We disable Windows protector in the system “Settings”
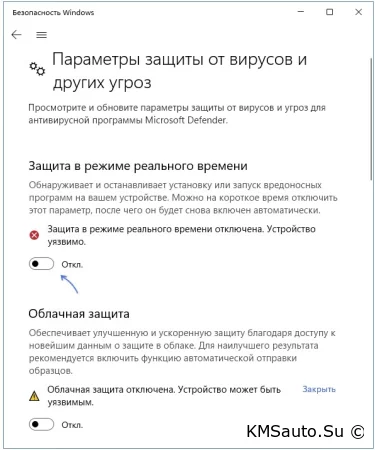
Download... | sbsoft | |
1,884,806 | Creative HTML Team Section | Style 1 | This project demonstrates a visually appealing and responsive team section ideal for corporate or... | 0 | 2024-06-11T19:09:19 | https://dev.to/creative_salahu/creative-html-team-section-style-1-4me3 | codepen | This project demonstrates a visually appealing and responsive team section ideal for corporate or personal websites. The design emphasizes clean aesthetics and usability, featuring:
A grid layout showcasing team members with their photos, names, and designations
Hover effects that reveal social media links for each te... | creative_salahu |
1,884,804 | So Long Again, Wayland, You Were Almost There | Originally published at my blog: So Long Again, Wayland, You Were Almost There ... | 0 | 2024-06-11T19:05:57 | https://dev.to/raddevus/so-long-again-wayland-you-were-almost-there-2kkd | linx, wayland, ubuntu | Originally published at my blog: [So Long Again, Wayland, You Were Almost There](https://buildip.dev/?p=97)
## Background
I’m running Ubuntu 22.04.4 LTS on my main desktop machine.
I switched from Windows 10 (after 28 years of using Windows exclusively) and I’m quite happy on Ubuntu.
I use my Ubuntu machine to :
1.... | raddevus |
1,884,803 | How to Create a Xlsx or Xls Data into MySql Row Data with Node.js, Adonis.js, and Vue.js | Introduction Uploading and processing Excel files is a common requirement for many applications,... | 0 | 2024-06-11T19:04:45 | https://dev.to/abdur_rakibrony_97cea0e9/how-to-create-a-xlsx-or-xls-data-into-mysql-row-data-with-nodejs-adonisjs-and-vuejs-h7k | node, vue, adonis, vuex | **Introduction**
Uploading and processing Excel files is a common requirement for many applications, especially those dealing with bulk data entry. This blog post will guide you through creating a feature to upload Excel files, process their content, and display the data in a table format using Node.js, Adonis.js, and ... | abdur_rakibrony_97cea0e9 |
1,884,801 | How To Not Make Things Worse | Balancing speed, simplicity, and future-proofing in feature development is a subtle art. In an ideal... | 0 | 2024-06-11T19:02:24 | https://dev.to/devbeat_jason/how-to-not-make-things-worse-29bj | webdev, cloud, programming, tutorial | Balancing speed, simplicity, and future-proofing in feature development is a subtle art. In an ideal world, we'd ship only pristine, perfectly factored code. However, technology and software aren't ends in themselves; they exist in service of the business goals or purpose for which the code is being written. Developers... | devbeat_jason |
1,884,799 | 238. Products of Array Discluding Self | Topic: Arrays & Hashing Soln 1 (prefix & suffix): Get the length of the input list and... | 0 | 2024-06-11T18:59:50 | https://dev.to/whereislijah/products-of-array-discluding-self-4mb2 | Topic: Arrays & Hashing
Soln 1 (prefix & suffix):
1. Get the length of the input list and create 2 lists (prefix and suffix) and assign 1 to them
2. Iterate through the input list starting from the second element (index 1) because the first element (index 0) has no elements to its left.
For each element, set the cur... | whereislijah | |
1,884,798 | Test Case Generation: Enhancing Software Quality and Efficiency | In the ever-evolving landscape of software development, ensuring the quality and reliability of... | 0 | 2024-06-11T18:59:48 | https://dev.to/keploy/test-case-generation-enhancing-software-quality-and-efficiency-2p24 | webdev, javascript, tutorial, ai |

In the ever-evolving landscape of software development, ensuring the quality and reliability of applications is paramount. A crucial aspect of this process is creating comprehensive test cases, which help verify tha... | keploy |
1,884,797 | Beginner Project Ideas with GitHub repos | As a beginner or an intermediate developer, it's okay to admit it might be hard to have a project in... | 0 | 2024-06-11T18:53:05 | https://dev.to/evansifyke/beginner-project-ideas-with-github-repos-ao7 | beginners, webdev, programming, tutorial | As a beginner or an intermediate developer, it's okay to admit it might be hard to have a project in mind to work on. Here are some of the projects that you can clone and work on.
Get the whole list of [projects here](https://melbite.com/melbite/Beginner-Project-Ideas-with-GitHub-repos )
## 1. Web dev Projects
- **... | evansifyke |
1,884,796 | How to start building with new customer accounts in Shopify | Shopify recently announced that new customer accounts are being made accessible to developers... | 0 | 2024-06-11T18:52:35 | https://gadget.dev/blog/understanding-new-customer-accounts-what-they-are-and-how-to-build-with-them-as-a-developer | shopify, beginners, tutorial, graphql |
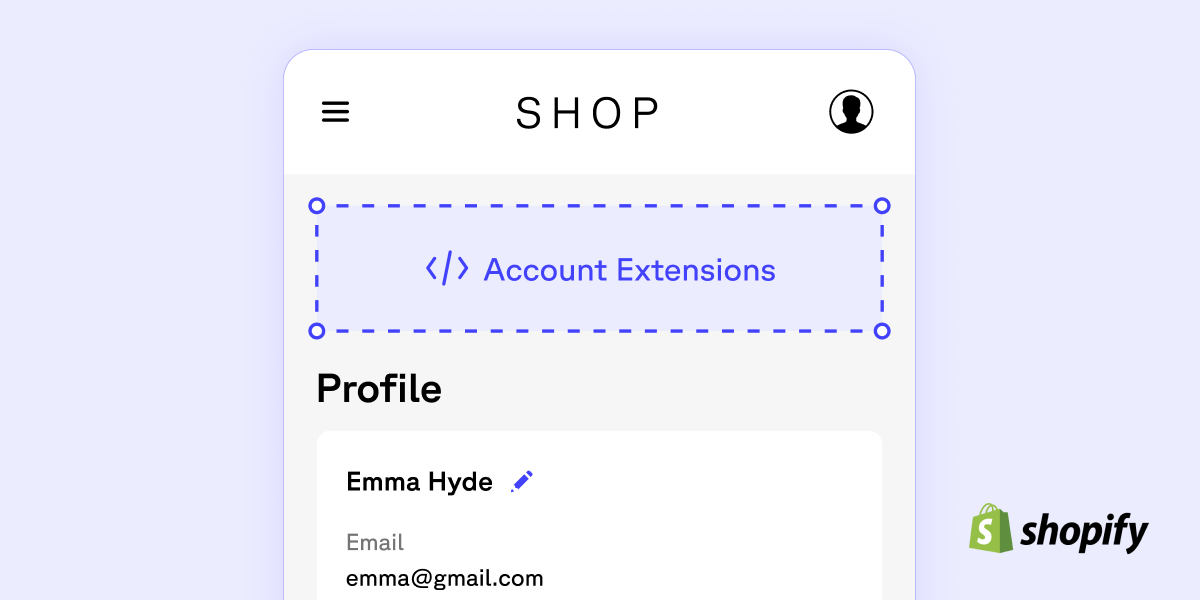
Shopify recently announced that new customer accounts are being made accessible to developers through the use of customer account UI extensions, which are now in developer preview. This means that Shopify developer... | gadget |
1,884,795 | Creating a chess.com/lichess clone using Go and Vue | Let's create a chess.com/lichess clone MVP using Go and Vue! You can find the repo of this project... | 0 | 2024-06-11T18:50:42 | https://github.com/alvaronaschez/simple-chess | webdev, go, vue, tutorial |
Let's create a chess.com/lichess clone MVP using Go and Vue!
You can find the repo of this project here: [github.com/alvaronaschez/simple-chess](https://github.com/alvaronaschez/simple-chess)
## What are we going to build?
A simplified version of [chess.com](https://chess.com) or [lichess.org](https://lichess.org)... | alvaronaschez |
1,884,794 | Azure FinOps: Optimizing Cloud Financial Management | Introduction to Azure FinOps Azure FinOps, short for Financial Operations, is a framework designed to... | 0 | 2024-06-11T18:46:20 | https://dev.to/unicloud/azure-finops-optimizing-cloud-financial-management-2me7 | azure, finops, cloud, management | **Introduction to Azure FinOps**
Azure FinOps, short for Financial Operations, is a framework designed to help organizations manage and optimize their cloud financials. As cloud adoption increases, businesses face the challenge of managing costs and ensuring they derive maximum value from their cloud investments. Azure... | unicloud |
1,539,765 | AWS IoT Core Simplified - Part 1: Permissions | AWS IoT Core is an amazing (and often overlooked) service as I said before when comparing IoT Core to... | 27,687 | 2024-06-11T18:46:17 | https://dev.to/slootjes/aws-iot-core-simplified-part-1-permissions-k4d | aws, iot, serverless, mqtt | AWS IoT Core is an amazing (and often overlooked) service as I said before when [comparing IoT Core to API Gateway Websockets](https://dev.to/slootjes/api-gateway-websockets-vs-iot-core-1me5). To summarize, IoT Core manages it own connections, it has a powerful system of topics and rules, it scales well and, not unimpo... | slootjes |
1,884,814 | Cursos De MySQL, Java, CSS E Outros Gratuitos Da Plataforma Cursa | Conheça a Plataforma Cursa, um recurso educacional que oferece centenas de cursos online gratuitos... | 0 | 2024-06-23T13:50:44 | https://guiadeti.com.br/cursos-mysql-java-css-plataforma-cursa/ | cursogratuito, azure, cloud, css | ---
title: Cursos De MySQL, Java, CSS E Outros Gratuitos Da Plataforma Cursa
published: true
date: 2024-06-11 18:45:56 UTC
tags: CursoGratuito,azure,cloud,css
canonical_url: https://guiadeti.com.br/cursos-mysql-java-css-plataforma-cursa/
---
Conheça a Plataforma Cursa, um recurso educacional que oferece centenas de cu... | guiadeti |
1,884,792 | Buy verified cash app account | Buy verified cash app account Cash app has emerged as a dominant force in the realm of mobile banking... | 0 | 2024-06-11T18:45:17 | https://dev.to/jeson_roy_33a8cc590a9c5df/buy-verified-cash-app-account-a2n | Buy verified cash app account
Cash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with ... | jeson_roy_33a8cc590a9c5df | |
1,884,791 | The unspoken question: "Why do pointers exist?" | It's Really A Valid Question This is not the typical pointer-hater's question, but rather... | 0 | 2024-06-11T18:45:00 | https://dev.to/ebbewertz/a-dangerous-question-why-do-pointers-exist-dkd | clang, cpp, c, gcc | ## It's Really A Valid Question
This is not the typical pointer-hater's question, but rather a very interesting one.
---
## Here's What I Mean
Pointers are a great powerfull concept, but that's what it is: a concept. So why was the C compiler invented with such an isolated piece of logic and syntax dedicated to point... | ebbewertz |
1,884,790 | No Longer DEV's Community Manager, But Still Got Lotsa Love For Y'all! 💚 | Heyo folks! 👋 It's been about a month since I was let go from DEV (see the post here) and I wanted... | 0 | 2024-06-11T18:44:33 | https://dev.to/michaeltharrington/no-longer-devs-community-manager-but-still-got-love-for-yall-3ocp | devto, career | Heyo folks! 👋
It's been about a month since I was let go from DEV (see the post [here](https://dev.to/devteam/dev-team-update-2age)) and I wanted to return to the community to give a few quick updates about myself and how I'm feeling:
**a.** First off, I'm getting on just fine! Been busy looking for new opportuniti... | michaeltharrington |
1,884,780 | Top 7 Featured DEV Posts of the Week | Welcome to this week's Top 7, where the DEV editorial team handpicks their favorite posts from the... | 0 | 2024-06-11T18:33:57 | https://dev.to/devteam/top-7-featured-dev-posts-of-the-week-3dk1 | top7 | _Welcome to this week's Top 7, where the DEV editorial team handpicks their favorite posts from the previous week._
Congrats to all the authors that made it onto the list 👏
{% embed https://dev.to/glasskube/standout-as-a-junior-engineer-work-slower-to-grow-faster-4ac3 %}
Jake advises junior engineers to work more d... | thepracticaldev |
1,884,788 | A "experiência" | Quando você começa a programar, acha que a coisa mais difícil do mundo é criar códigos, mas quando... | 0 | 2024-06-11T18:32:36 | https://dev.to/hei-lima/a-experiencia-2hf6 | ledscommunity | Quando você começa a programar, acha que a coisa mais difícil do mundo é criar códigos, mas quando você começa a ver algo de DevOps, você chega a rápida conclusão de que a pior coisa do mundo é mexer com coisas que outras pessoas desenvolveram.
Estava precisando de alguma forma de manejar várias instâncias de máquinas... | hei-lima |
1,884,493 | Stay Updated with Python/FastAPI/Django: Weekly News Summary (03/06/2024 - 09/06/2024) | Dive into the latest tech buzz with this weekly news summary, focusing on Python, FastAPI, and Django... | 0 | 2024-06-11T18:30:00 | https://poovarasu.dev/python-fastapi-django-weekly-news-summary-03-06-2024-to-09-06-2024/ | python, django, fastapi, flask | Dive into the latest tech buzz with this weekly news summary, focusing on Python, FastAPI, and Django updates from June 3rd to June 9th, 2024. Stay ahead in the tech game with insights curated just for you!
This summary offers a concise overview of recent advancements in the Python/FastAPI/Django framework, providing ... | poovarasu |
1,884,787 | Episode 24/23: zoneless with Andrew Scott, dynamic Form Validators, toObservable() | Andrew Scott from the Angular team discussed Angular without zone.js. Various content authors... | 0 | 2024-06-11T18:28:34 | https://dev.to/this-is-angular/episode-2423-zoneless-with-andrew-scott-dynamic-form-validators-toobservable-2dk8 | webdev, javascript, angular, programming | Andrew Scott from the Angular team discussed Angular without zone.js. Various content authors published videos about topics like Signals for forms.
{% embed https://youtu.be/ed470Lbf5m4 %}
## Andrew Scott on zoneless
TechStackNation runs sessions with members of the Angular team quite often. This time, it was Andrew... | ng_news |
1,881,832 | Laravel 11 + Inertia JS (VUE) CRUD Example: Part 2 | Hello Artisan, In the previous blog post, we saw how to set laravel + inertia js project to create a... | 0 | 2024-06-11T18:27:41 | https://dev.to/snehalkadwe/laravel-11-inertia-js-vue-crud-example-part-2-493 | laravel, vue, php, womenintech | **Hello Artisan,**
In the previous blog post, we saw how to set laravel + inertia js project to create a crud operation. If you haven't read it yet, then you can read it here [Laravel 11 + Inertia JS (VUE) CRUD Example: Part 1](https://dev.to/snehalkadwe/laravel-11-inertia-js-vue-crud-example-part-1-18oc)
and configur... | snehalkadwe |
1,884,784 | 1122. Relative Sort Array | 1122. Relative Sort Array Easy Given two arrays arr1 and arr2, the elements of arr2 are distinct,... | 27,523 | 2024-06-11T18:23:31 | https://dev.to/mdarifulhaque/1122-relative-sort-array-2lbd | php, leetcode, algorithms, programming | 1122\. Relative Sort Array
Easy
Given two arrays `arr1` and `arr2`, the elements of `arr2` are distinct, and all elements in `arr2` are also in `arr1`.
Sort the elements of `arr1` such that the relative ordering of items in `arr1` are the same as in `arr2`. Elements that do not appear in `arr2` should be placed at t... | mdarifulhaque |
1,884,779 | Sarcasm Detection using Machine Learning. | I’ll walk you through the task of detecting sarcasm with machine learning using the Python... | 0 | 2024-06-11T18:12:45 | https://dev.to/samagra07/sarcasm-detection-using-machine-learning-45go | python, ai, machinelearning, programming | I’ll walk you through the task of detecting sarcasm with machine learning using the Python programming language.
It reads a dataset of headlines labeled as sarcastic or non-sarcastic, processes the data to map the labels into human-readable form, and converts the text data into a matrix of token counts using the `Coun... | samagra07 |
1,884,778 | Mold Removal and Restoration Services By Carolina Duct And Crawl | Mold Removal and Restoration Services By Carolina Duct And Crawl** Mold Remediation & Mold... | 0 | 2024-06-11T18:11:30 | https://dev.to/carolinaductandcrawll/mold-removal-and-restoration-services-by-carolina-duct-and-crawl-1cf1 | **[Mold Removal and Restoration Services By Carolina Duct And Crawl](https://carolinaductandcrawl.com/)****
Mold Remediation & Mold Removal
The growth of mold can be significant in the space of one or two weeks (around 3 days) and may occur in any place and on everything when there is sufficient moisture. This includes... | carolinaductandcrawll | |
1,884,776 | SOLID Principles for Android | In this article we will see the remaining Principles, if you haven't went through the first two... | 27,686 | 2024-06-11T18:07:45 | https://dev.to/rishi2062/solid-principles-for-android-2f5f | android, opensource, solidprinciples, oops | 
In this article we will see the remaining Principles,
if you haven't went through the first two principle
refer its first part.
> L - Liskov Substitution Principle (LSP)
This principle says that we need... | rishi2062 |
1,856,933 | A Smart solution to your USD problems? | If you're one of the people that opening a Foreign account has shown shege…..Then you're in the right... | 0 | 2024-06-11T18:03:07 | https://dev.to/hnkomuwa/a-smart-solution-to-your-usd-problems-44p5 | usd, fintech, finance, cleva |
If you're one of the people that opening a Foreign account has shown shege…..Then you're in the right place.
**<u>Meet your friends…
</u>**
<b>Meet Jesse.</b>
<Br>

**Jesse** is a Video editor who works wit... | hnkomuwa |
1,883,266 | Understanding Memory Management, Pointers, and Function Pointers in C | In C programming, efficient memory management and the use of pointers are crucial for creating robust... | 0 | 2024-06-11T17:56:37 | https://dev.to/emanuelgustafzon/understanding-memory-management-pointers-and-function-pointers-in-c-8ld | pointers, functionpointers, memorymanagement, c | In C programming, efficient memory management and the use of pointers are crucial for creating robust and high-performance applications. This guide provides a comprehensive overview of different types of memory, pointers, references, dynamic memory allocation, and function pointers, complete with examples to help you m... | emanuelgustafzon |
1,884,773 | Tren Terbaru dalam Industri Judi Online yang Harus Anda Ketahui | Tren Terbaru dalam Industri Judi Online yang Harus Anda Ketahui Industri judi online... | 0 | 2024-06-11T17:54:36 | https://dev.to/lanasalazar/tren-terbaru-dalam-industri-judi-online-yang-harus-anda-ketahui-38on | webdev, javascript, react, python | Tren Terbaru dalam Industri Judi Online yang Harus Anda Ketahui
===============================================================
 and testing are critical to... | 0 | 2024-06-11T17:44:22 | https://dev.to/keploy/exploring-test-case-generators-revolutionizing-software-testing-7pe | testing, case, webdev, opensource |

In the dynamic landscape of software development, quality assurance (QA) and testing are critical to delivering reliable and efficient software products. An essential aspect of the QA process is the creation of test... | keploy |
1,884,768 | Imagine No More Info Chaos: we built the solution that keeps your work in perfect harmony | 🎶 Imagine All Your Work, In One Place 🎶 Picture this: a single, automatic hub for all your company’s... | 0 | 2024-06-11T17:41:56 | https://dev.to/reich/imagine-no-more-info-chaos-we-built-the-solution-that-keeps-your-work-in-perfect-harmony-ea4 | productivity, saas, softwareforteams, ai | 🎶 Imagine All Your Work, In One Place 🎶
Picture this: a single, automatic hub for all your company’s activities. No more scattered files, missing links, or forgotten emails. Sense AI takes every bit of your data—tasks, presentations, documents, links, meetings, and more—and neatly organizes it into Self-organised Spa... | reich |
1,884,578 | What is an API? A Beginner's Guide | What is an API? A Beginner's Guide In today's interconnected digital world, APIs play a... | 0 | 2024-06-11T17:40:24 | https://dev.to/codevicky/what-is-an-api-a-beginners-guide-5baa | api, postman, webdev, programming | ## What is an API? A Beginner's Guide
In today's interconnected digital world, APIs play a crucial role in how different software applications communicate with each other. Whether you're a developer, a business owner, or just a curious tech enthusiast, understanding APIs is essential. In this blog post, we'll dive into... | codevicky |
1,884,766 | UI/UX | I’m more backend focused in my job function and have building a web app recently with JS/React. My... | 0 | 2024-06-11T17:37:17 | https://dev.to/eaddeo/uiux-299l | help | I’m more backend focused in my job function and have building a web app recently with JS/React. My problem is, I have absolutely no eye for design… any recommendations for free UI inspiration? | eaddeo |
1,884,765 | FrontEndAI: Turn wireframe images into Code with 1 click | Welcome to the future of web development! We are thrilled to announce the launch of FrontEndAI, an... | 0 | 2024-06-11T17:34:26 | https://dev.to/buildwebcrumbs/frontendai-turn-wireframe-images-into-code-with-1-click-571 | webdev, ai, news, javascript | **Welcome to the future of web development!**
We are thrilled to announce [the launch of FrontEndAI](https://tools.webcrumbs.org/), an innovative tool from Webcrumbs that transforms your design images into code.
[FrontEndAI](https://tools.webcrumbs.org/) is here to streamline your workflow and boost your productivity... | pachicodes |
1,884,764 | Documenting my pin collection with Segment Anything: Part 2 | In a previous post I shared my desire to create an interactive display for my pin collection. In it,... | 27,656 | 2024-06-11T17:33:13 | https://blog.feregri.no/blog/documenting-my-pin-collection-with-segment-anything-part-2/ | imagesegmentation, segmentanything, python, machinelearning | In a previous post [I shared my desire to create an interactive display for my pin collection](https://dev.to/feregri_no/documenting-my-pin-collection-with-segment-anything-part-1-4k3o). In it, I decided to use Meta AI’s Segment Anything Model to extract cutouts from my crowded canvas:

Workday is a well-known cloud-based application used by businesses to handle their HCM and Financials module. Through analytics, it gives businesses the ability to connect other systems for more effective operation ... | rohitbhandari102 |
1,884,683 | ** De Desarrollador Junior a Senior: Ascendiendo al Trono de Hierro de Game of Thrones **🐉🏰👑 | ¡Hola Chiquis!👋🏻 ¿Sueñan con conquistar el trono de hierro del desarrollo de software y convertirse... | 0 | 2024-06-11T17:18:31 | https://dev.to/orlidev/-de-desarrollador-junior-a-senior-ascendiendo-al-trono-de-hierro-de-game-of-thrones--29o9 | tutorial, webdev, beginners, programming | ¡Hola Chiquis!👋🏻 ¿Sueñan con conquistar el trono de hierro del desarrollo de software y convertirse en verdaderos "Desarrolladores Senior"? ⚔️

¡Prepárense para una aventura! En este viaje, cada paso los acercará ... | orlidev |
1,884,682 | How to use the new Ember theme for QUnit | The integrated web UI test runner in Ember is a convenient way to run your tests. If you've been... | 0 | 2024-06-11T17:17:42 | https://blog.ignacemaes.com/how-to-use-the-new-ember-theme-for-qunit | javascript, testing, qunit, ember | The integrated web UI test runner in Ember is a convenient way to run your tests. If you've been using the default QUnit theme, it might not surprise you that it was designed over ten years ago.
As of the latest release of [`ember-qunit`](https://github.com/emberjs/ember-qunit/releases/tag/v8.1.0), support for theming... | ignace |
1,884,679 | Everything You Need to Know About CSS Backgrounds | We can do some cool things with CSS background property such as creating a hero image or using it to... | 27,561 | 2024-06-11T17:15:22 | https://dev.to/jitendrachoudhary/everything-you-need-to-know-about-css-backgrounds-3dle | webdev, beginners, css, codenewbie | We can do some cool things with CSS background property such as creating a hero image or using it to do some cool parallax effects. In this article, we'll pretty much everything you need to know about CSS background property.
## CSS Background-color Property
Below you have a simple box with the class "container"; you... | jitendrachoudhary |
1,884,678 | Notes on Types of Database: Part 1 | A post by Bhavya Kaushik | 0 | 2024-06-11T17:14:45 | https://dev.to/bkaush/notes-on-types-of-database-part-1-2cf7 | beginners, database, systemdesign, webdev |  | bkaush |
1,884,677 | Text Typing Effect in HTML CSS and Vanilla JavaScript | Have you ever come across that cool text typing effect on different websites where the words appear... | 0 | 2024-06-11T17:12:48 | https://www.codingnepalweb.com/text-typing-effect-html-css-javascript/ | webdev, javascript, html, css | Have you ever come across that cool [text typing effect](https://www.codingnepalweb.com/text-typing-animation-using-only-html-css/) on different websites where the words appear as if they’re being typed out? If you’re a beginner web developer, you might wonder how to create such an eye-catching animation on your own. W... | codingnepal |
1,884,676 | JavaScript forEach() array method | The forEach() method is used to execute a function for each of the items in an array. The callback... | 0 | 2024-06-11T17:12:42 | https://dev.to/kemiowoyele1/javascript-foreach-array-method-36c2 | The forEach() method is used to execute a function for each of the items in an array. The callback function will normally contain some instructions that will be performed on each of the array items.
Syntax
`array.forEach(callbackFunction);`
The callback function accepts three arguments, the arguments are
1. CurrentI... | kemiowoyele1 | |
1,884,675 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-11T17:10:53 | https://dev.to/mihefad581/buy-verified-cash-app-account-3cmn | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | mihefad581 |
1,884,671 | Configure Firebase with React | What is Firebase Firebase is a comprehensive mobile and web application development platform... | 0 | 2024-06-11T17:10:11 | https://dev.to/saransh_bhardwaj_ac201467/configure-firebase-with-react-2mmb | firebase, react, webdev, tutorial | What is Firebase
Firebase is a comprehensive mobile and web application development platform provided by Google. It offers a suite of services and tools that facilitate various aspects of app development, including database management, authentication, hosting, cloud functions, and more.
To set up the project. Let’s u... | saransh_bhardwaj_ac201467 |
1,883,351 | An advanced guide to Vitest testing and mocking | Written by Sebastian Weber ✏️ Testing is crucial in modern software development for ensuring code... | 0 | 2024-06-11T17:09:05 | https://blog.logrocket.com/advanced-guide-vitest-testing-mocking | vitest, vue, webdev | **Written by [Sebastian Weber
](https://blog.logrocket.com/author/sebastianweber/)✏️**
Testing is crucial in modern software development for ensuring code quality, reliability, and maintainability. However, the complexity of testing can often feel overwhelming.
In this article, we will first delve into real-world us... | leemeganj |
1,884,674 | Bridging Linguistic Diversity: Evaluating and Advancing AI for Indian Languages | Bridging Linguistic Diversity: Evaluating and Advancing AI for Indian Languages ... | 0 | 2024-06-11T17:07:33 | https://dev.to/aditi_baheti_f4a40487a091/bridging-linguistic-diversity-evaluating-and-advancing-ai-for-indian-languages-1pm0 | llm, benchmark, ai, indicmodels | ## Bridging Linguistic Diversity: Evaluating and Advancing AI for Indian Languages
### Introduction to Language Models and Their Benchmarks
Language models (LLMs) are at the heart of modern AI, enabling machines to understand and generate human language. The effectiveness of these models is gauged through benchmarks,... | aditi_baheti_f4a40487a091 |
1,884,673 | How to Identify Cloudflare Turnstile | By using CapSolver Extension | What is Cloudflare Turnstile? Cloudflare Turnstile is an alternative to traditional... | 0 | 2024-06-11T17:06:26 | https://dev.to/retruw/how-to-identify-cloudflare-turnstile-by-using-capsolver-extension-g4k | turnstile, cloudflarechallenge |

# What is Cloudflare Turnstile?
Cloudflare Turnstile is an alternative to traditional CAPTCHA services, designed to verify user interactions without disrupting user experience. It offers a less intrusive method fo... | retruw |
1,884,672 | A Comprehensive Guide to Automated Regression Testing | A Comprehensive Guide to Automated Regression Testing In the fast-paced world of software... | 0 | 2024-06-11T17:00:36 | https://happyeconews.com/a-comprehensive-guide-to-automated-regression-testing/ | automated, regression, testing | 
A Comprehensive Guide to Automated Regression Testing
In the fast-paced world of software development, ensuring that program updates maintain its functionality and stability is critical. Consequently, businesses perf... | rohitbhandari102 |
1,884,670 | Global Supply Chain and Distribution Channels in the Steel Rebar Market | Steel rebar, short for “reinforcing bar,” is a common construction material used to reinforce... | 0 | 2024-06-11T16:57:25 | https://dev.to/aryanbo91040102/global-supply-chain-and-distribution-channels-in-the-steel-rebar-market-51dn | news | Steel rebar, short for “reinforcing bar,” is a common construction material used to reinforce concrete structures. It is a steel bar or mesh of steel wires used as a tension device in concrete to strengthen and hold the concrete in compression. The Steel Rebar Market is approximated to be USD 224.5 billion in 2022, an... | aryanbo91040102 |
1,884,669 | IT Staff Augmentation vs. Outsourcing: Which is Better for Your Business? | In today's competitive and rapidly evolving tech landscape, businesses face crucial decisions when it... | 0 | 2024-06-11T16:57:24 | https://dev.to/ulyana_mykhailiv_82896052/it-staff-augmentation-vs-outsourcing-which-is-better-for-your-business-4e0h | In today's competitive and rapidly evolving tech landscape, businesses face crucial decisions when it comes to managing their IT needs. Two popular models for enhancing IT capabilities are IT staff augmentation and outsourcing. Both approaches offer unique advantages and potential drawbacks, making it essential to unde... | ulyana_mykhailiv_82896052 | |
1,884,665 | Seeking a Type-Safe Ruby on Rails in TypeScript, I Started Developing an ORM | I am developing an ORM library for TypeScript called Accel Record. Recently, I published an article... | 27,598 | 2024-06-11T16:49:48 | https://dev.to/koyopro/seeking-a-type-safe-ruby-on-rails-in-typescript-i-started-developing-an-orm-1of5 | typescript, rails, orm, opensource | I am developing an ORM library for TypeScript called Accel Record. Recently, I published an article introducing this library, titled [Introduction to "Accel Record": A TypeScript ORM Using the Active Record Pattern](https://dev.to/koyopro/introduction-to-accel-record-a-typescript-orm-using-the-active-record-pattern-2oe... | koyopro |
1,884,667 | ice-cream shop | Check out this Pen I made! | 0 | 2024-06-11T16:47:12 | https://dev.to/kemiowoyele1/ice-cream-shop-1l64 | codepen, css, cssart | Check out this Pen I made!
{% codepen https://codepen.io/frontend-magic/pen/KKVVvbN %} | kemiowoyele1 |
1,884,666 | End-User Analysis: Key Consumer Segments in the Chlor-Alkali Market | Chlor-Alkali Market Overview The chlor-alkali industry refers to the production of chlorine, sodium... | 0 | 2024-06-11T16:45:10 | https://dev.to/aryanbo91040102/end-user-analysis-key-consumer-segments-in-the-chlor-alkali-market-20cd | news | Chlor-Alkali Market Overview
The chlor-alkali industry refers to the production of chlorine, sodium hydroxide (caustic soda), and hydrogen by the electrolysis of brine (saltwater). This industry is important because these three chemicals are used in a wide range of applications, including the production of PVC (polyvi... | aryanbo91040102 |
1,884,664 | Promoting your website for traffic | Promoting your website is a crucial step in driving traffic, gaining visibility, and building a... | 0 | 2024-06-11T16:38:49 | https://dev.to/sh20raj/promoting-your-website-for-traffic-1emk | seo | Promoting your website is a crucial step in driving traffic, gaining visibility, and building a community. Various platforms offer unique opportunities for promotion, each with its own strengths and audience. Here's a comprehensive guide on some of the best websites where you can effectively promote your site:
### 1. ... | sh20raj |
1,884,663 | Finding the Best Digital Marketing Company in Varanasi | Unleash Your Business Potential: Finding the Digital Marketing Company In today's digital age, a... | 0 | 2024-06-11T16:36:32 | https://dev.to/gagandeep13/finding-the-best-digital-marketing-company-in-varanasi-5bpc | <div class="markdown markdown-main-panel" dir="ltr">
<h2 data-sourcepos="1:1-1:90"><img class="wp-image-1503 aligncenter" src="https://digivaidya.com/wp-content/uploads/2024/06/1680082649665-300x157.png" alt="digital-marketing-company-in-varanasi" width="568" height="297" /></h2>
<h2 data-sourcepos="1:1-1:90">Unleash Y... | gagandeep13 | |
1,884,662 | Day 15 of my progress as a vue dev | About today Today went as expected. I finally wrapped up my DSA visualizer project and ended up... | 0 | 2024-06-11T16:31:07 | https://dev.to/zain725342/day-15-of-my-progress-as-a-vue-dev-43fj | webdev, vue, typescript, tailwindcss | **About today**
Today went as expected. I finally wrapped up my DSA visualizer project and ended up pushing it on my github. Also I was happy with the final version, I may come back to it in future to do more work and make it a little bit more robust and interactive but for now I think it is in a usable condition. Also... | zain725342 |
1,884,661 | Build multi-turn RAG Chatbots easily with Ragable! (Open-Source) | I have been building multi-turn chatbots and AI applications for a while now, and there are great... | 0 | 2024-06-11T16:29:29 | https://dev.to/kwnaidoo/build-multi-turn-rag-chatbots-easily-with-ragable-open-source-5614 | ai, machinelearning, python, product | I have been building multi-turn chatbots and AI applications for a while now, and there are great libraries out there for this purpose, however, sometimes they are overkill.
If you are new to machine learning or simply want to build a multi-turn chatbot that can route between different functions to fetch data, then Ra... | kwnaidoo |
1,884,660 | Exposing an Amazon SageMaker Endpoint via a Custom Domain Name | Guide to Exposing an Amazon SageMaker Endpoint via a Custom Domain Name Introduction: Are you a... | 0 | 2024-06-11T16:29:19 | https://dev.to/sammy_cloud/exposing-an-amazon-sagemaker-endpoint-via-a-custom-domain-name-3ai7 | **Guide to Exposing an Amazon SageMaker Endpoint via a Custom Domain Name**
**Introduction:**
Are you a DevOps or Cloud Engineer tasked with making an Amazon SageMaker endpoint accessible to the public without directly exposing the endpoint itself? This guide will walk you through creating a public-facing SageMaker en... | sammy_cloud | |
1,884,659 | Creativity Has Left the Chat: The Price of Debiasing Language Models | Creativity Has Left the Chat: The Price of Debiasing Language Models | 0 | 2024-06-11T16:28:42 | https://aimodels.fyi/papers/arxiv/creativity-has-left-chat-price-debiasing-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Creativity Has Left the Chat: The Price of Debiasing Language Models](https://aimodels.fyi/papers/arxiv/creativity-has-left-chat-price-debiasing-language). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https... | mikeyoung44 |
1,884,658 | The Bayesian Learning Rule | The Bayesian Learning Rule | 0 | 2024-06-11T16:28:08 | https://aimodels.fyi/papers/arxiv/bayesian-learning-rule | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [The Bayesian Learning Rule](https://aimodels.fyi/papers/arxiv/bayesian-learning-rule). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.c... | mikeyoung44 |
1,884,657 | Artifacts or Abduction: How Do LLMs Answer Multiple-Choice Questions Without the Question? | Artifacts or Abduction: How Do LLMs Answer Multiple-Choice Questions Without the Question? | 0 | 2024-06-11T16:27:34 | https://aimodels.fyi/papers/arxiv/artifacts-or-abduction-how-do-llms-answer | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Artifacts or Abduction: How Do LLMs Answer Multiple-Choice Questions Without the Question?](https://aimodels.fyi/papers/arxiv/artifacts-or-abduction-how-do-llms-answer). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi new... | mikeyoung44 |
1,884,656 | Slider | // Slider const slider = function () { const slides = document.querySelectorAll('.slide'); const... | 0 | 2024-06-11T16:27:14 | https://dev.to/kakimaru/slider-35fi | ```
// Slider
const slider = function () {
const slides = document.querySelectorAll('.slide');
const btnLeft = document.querySelector('.slider__btn--left');
const btnRight = document.querySelector('.slider__btn--right');
const dotContainer = document.querySelector('.dots');
let curSlide = 0;
const maxSlide... | kakimaru | |
1,884,655 | How does lock screen gaming concept impact gameplay design, particularly for action games? | The lock screen gaming concept, pioneered by Gaming Platform, throws a fascinating wrinkle into... | 0 | 2024-06-11T16:27:07 | https://dev.to/claywinston/how-does-lock-screen-gaming-concept-impact-gameplay-design-particularly-for-action-games-8nn | gamedev, mobilegames, androidgames, lockscreengames | The [lock screen gaming](https://medium.com/@adreeshelk/how-to-play-hundreds-of-games-on-your-lock-screen-without-downloading-anything-4f03e0173441?utm_source=referral&utm_medium=Medium&utm_campaign=Nostra) concept, pioneered by Gaming Platform, throws a fascinating wrinkle into traditional mobile gameplay design. Whil... | claywinston |
1,884,654 | Thermodynamic Linear Algebra | Thermodynamic Linear Algebra | 0 | 2024-06-11T16:26:59 | https://aimodels.fyi/papers/arxiv/thermodynamic-linear-algebra | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Thermodynamic Linear Algebra](https://aimodels.fyi/papers/arxiv/thermodynamic-linear-algebra). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://t... | mikeyoung44 |
1,884,643 | A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents | A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents | 0 | 2024-06-11T16:26:23 | https://aimodels.fyi/papers/arxiv/definition-open-ended-learning-problems-goal-conditioned | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents](https://aimodels.fyi/papers/arxiv/definition-open-ended-learning-problems-goal-conditioned). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsle... | mikeyoung44 |
1,884,642 | Magicoder: Empowering Code Generation with OSS-Instruct | Magicoder: Empowering Code Generation with OSS-Instruct | 0 | 2024-06-11T16:25:49 | https://aimodels.fyi/papers/arxiv/magicoder-empowering-code-generation-oss-instruct | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Magicoder: Empowering Code Generation with OSS-Instruct](https://aimodels.fyi/papers/arxiv/magicoder-empowering-code-generation-oss-instruct). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.s... | mikeyoung44 |
1,884,641 | Teams of LLM Agents can Exploit Zero-Day Vulnerabilities | Teams of LLM Agents can Exploit Zero-Day Vulnerabilities | 0 | 2024-06-11T16:25:14 | https://aimodels.fyi/papers/arxiv/teams-llm-agents-can-exploit-zero-day | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Teams of LLM Agents can Exploit Zero-Day Vulnerabilities](https://aimodels.fyi/papers/arxiv/teams-llm-agents-can-exploit-zero-day). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com... | mikeyoung44 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.