
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,884,640 | Guide to On-Page SEO in 2024 | The Ultimate Guide to On-Page SEO in 2024: Comprehensive Strategies, Techniques, and... | 0 | 2024-06-11T16:24:43 | https://dev.to/sh20raj/guide-to-on-page-seo-in-2024-3e0b | seo | # The Ultimate Guide to On-Page SEO in 2024: Comprehensive Strategies, Techniques, and Checklists
## Table of Contents
1. **Introduction**
- Importance of On-Page SEO
- Overview of the 2024 SEO Landscape
2. **Keyword Optimization**
- Keyword Research Techniques
- Integrating Keywords Naturally
- C... | sh20raj |
1,884,283 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-06-11T11:01:14 | https://dev.to/jiyej67470/buy-verified-paxful-account-1i25 | react, python, ai, devops | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\n \n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | jiyej67470 |
1,884,639 | Golden Ratio Yoshimura for Meta-Stable and Massively Reconfigurable Deployment | Golden Ratio Yoshimura for Meta-Stable and Massively Reconfigurable Deployment | 0 | 2024-06-11T16:24:40 | https://aimodels.fyi/papers/arxiv/golden-ratio-yoshimura-meta-stable-massively-reconfigurable | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Golden Ratio Yoshimura for Meta-Stable and Massively Reconfigurable Deployment](https://aimodels.fyi/papers/arxiv/golden-ratio-yoshimura-meta-stable-massively-reconfigurable). If you like these kinds of analysis, you should subscribe to the [AImodels.f... | mikeyoung44 |
1,884,638 | Defending LLMs against Jailbreaking Attacks via Backtranslation | Defending LLMs against Jailbreaking Attacks via Backtranslation | 0 | 2024-06-11T16:24:05 | https://aimodels.fyi/papers/arxiv/defending-llms-against-jailbreaking-attacks-via-backtranslation | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Defending LLMs against Jailbreaking Attacks via Backtranslation](https://aimodels.fyi/papers/arxiv/defending-llms-against-jailbreaking-attacks-via-backtranslation). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslett... | mikeyoung44 |
1,884,637 | Explaining Explanations in Probabilistic Logic Programming | Explaining Explanations in Probabilistic Logic Programming | 0 | 2024-06-11T16:23:30 | https://aimodels.fyi/papers/arxiv/explaining-explanations-probabilistic-logic-programming | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Explaining Explanations in Probabilistic Logic Programming](https://aimodels.fyi/papers/arxiv/explaining-explanations-probabilistic-logic-programming). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://a... | mikeyoung44 |
1,884,636 | Hello Thank You People For Following Me And Give Me An Great Response | A post by Alishan Rahil | 0 | 2024-06-11T16:23:17 | https://dev.to/alishanrahil/hello-thank-you-people-for-following-me-and-give-me-an-great-response-1l0c | alishanrahil | ||
1,884,635 | Conformal Prediction Sets Improve Human Decision Making | Conformal Prediction Sets Improve Human Decision Making | 0 | 2024-06-11T16:22:56 | https://aimodels.fyi/papers/arxiv/conformal-prediction-sets-improve-human-decision-making | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Conformal Prediction Sets Improve Human Decision Making](https://aimodels.fyi/papers/arxiv/conformal-prediction-sets-improve-human-decision-making). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimo... | mikeyoung44 |
1,884,634 | Learning to Infer Generative Template Programs for Visual Concepts | Learning to Infer Generative Template Programs for Visual Concepts | 0 | 2024-06-11T16:22:22 | https://aimodels.fyi/papers/arxiv/learning-to-infer-generative-template-programs-visual | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Learning to Infer Generative Template Programs for Visual Concepts](https://aimodels.fyi/papers/arxiv/learning-to-infer-generative-template-programs-visual). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](htt... | mikeyoung44 |
1,884,633 | Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey | Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey | 0 | 2024-06-11T16:21:13 | https://aimodels.fyi/papers/arxiv/large-language-modelsllms-tabular-data-prediction-generation | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey](https://aimodels.fyi/papers/arxiv/large-language-modelsllms-tabular-data-prediction-generation). If you like these kinds of analysis, you should subscri... | mikeyoung44 |
1,884,599 | RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair | RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair | 0 | 2024-06-11T16:20:39 | https://aimodels.fyi/papers/arxiv/repairllama-efficient-representations-fine-tuned-adapters-program | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair](https://aimodels.fyi/papers/arxiv/repairllama-efficient-representations-fine-tuned-adapters-program). If you like these kinds of analysis, you should subscribe to the [A... | mikeyoung44 |
1,884,581 | CompeteAI: Understanding the Competition Dynamics in Large Language Model-based Agents | CompeteAI: Understanding the Competition Dynamics in Large Language Model-based Agents | 0 | 2024-06-11T16:20:04 | https://aimodels.fyi/papers/arxiv/competeai-understanding-competition-dynamics-large-language-model | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [CompeteAI: Understanding the Competition Dynamics in Large Language Model-based Agents](https://aimodels.fyi/papers/arxiv/competeai-understanding-competition-dynamics-large-language-model). If you like these kinds of analysis, you should subscribe to t... | mikeyoung44 |
1,883,537 | Unlocking Insights with Exploratory Data Analysis (EDA): A Step-by-Step Guide | Hello, AI enthusiasts! Welcome back to our AI development series. Today, we’re delving into... | 0 | 2024-06-11T15:01:29 | https://dev.to/ak_23/unlocking-insights-with-exploratory-data-analysis-eda-a-step-by-step-guide-4e19 | ai, learning, beginners |
Hello, AI enthusiasts! Welcome back to our AI development series. Today, we’re delving into Exploratory Data Analysis (EDA), a crucial phase that helps you understand your data’s underlying patterns, relationships, and anomalies. EDA is like detective work – it allows you to uncover hidden insights and prepare your da... | ak_23 |
1,884,580 | Semantically Diverse Language Generation for Uncertainty Estimation in Language Models | Semantically Diverse Language Generation for Uncertainty Estimation in Language Models | 0 | 2024-06-11T16:19:30 | https://aimodels.fyi/papers/arxiv/semantically-diverse-language-generation-uncertainty-estimation-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Semantically Diverse Language Generation for Uncertainty Estimation in Language Models](https://aimodels.fyi/papers/arxiv/semantically-diverse-language-generation-uncertainty-estimation-language). If you like these kinds of analysis, you should subscri... | mikeyoung44 |
1,884,579 | Guardrail Baselines for Unlearning in LLMs | Guardrail Baselines for Unlearning in LLMs | 0 | 2024-06-11T16:17:47 | https://aimodels.fyi/papers/arxiv/guardrail-baselines-unlearning-llms | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Guardrail Baselines for Unlearning in LLMs](https://aimodels.fyi/papers/arxiv/guardrail-baselines-unlearning-llms). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me o... | mikeyoung44 |
1,884,576 | 🍎 Summary WWDC24 - What’s New for Apple Developers | Exciting updates from Apple for developers! Here's a quick rundown of what's new: Apple... | 0 | 2024-06-11T16:13:19 | https://dev.to/maatheusgois/summary-wwdc24-whats-new-for-apple-developers-202h | Exciting updates from Apple for developers! Here's a quick rundown of what's new:
#### Apple Intelligence:
- Generative models integrated into iOS, iPadOS, and macOS.
- New Writing Tools, Image Playground API, and Genmoji.
- Enhanced Siri capabilities with App Intents and contextual understanding.
#### Xcode:
- Predi... | maatheusgois | |
1,884,575 | Clean Architecture Implementation in NodeJS | Clean Architecture is a software architectural approach that emphasizes the separation of concerns... | 0 | 2024-06-11T16:12:53 | https://dev.to/nazarioluis/clean-architecture-implementation-in-nodejs-ggo | webdev, node, cleancode, programming |
Clean Architecture is a software architectural approach that emphasizes the separation of concerns and the independence of dependencies within a system. The main idea behind Clean Architecture is to design software systems in a way that allows for easy maintenance, scalability, and testability, while also promoting a ... | nazarioluis |
1,884,574 | Babylon.js Browser MMORPG - DevLog - Update - #9 - Floating combat text optimization | Hello, I discovered that my browser is not supporting parallel shader compilation and because of it i... | 0 | 2024-06-11T16:11:44 | https://dev.to/maiu/babylonjs-browser-mmorpg-devlog-9-floating-combat-text-optimization-f8e | babylonjs, indiegamedev, mmorpg, indie | Hello,
I discovered that my browser is not supporting parallel shader compilation and because of it i was suffering from low fps. After switching to another browser in the moments where my fps was dropping below 10 it was about 50-55. In case of heavy spamming attack messages (50 attacks per second) fps in another bro... | maiu |
1,884,782 | What’s New in .NET MAUI Charts: 2024 Volume 2 | TL;DR: Discover the latest updates in the Syncfusion’s .NET MAUI Charts for 2024 Volume 2! New... | 0 | 2024-06-19T07:34:40 | https://www.syncfusion.com/blogs/post/dotnet-maui-charts-2024-volume-2 | dotnetmaui, chart, mobile, maui | ---
title: What’s New in .NET MAUI Charts: 2024 Volume 2
published: true
date: 2024-06-11 16:09:04 UTC
tags: dotnetmaui, chart, mobile, maui
canonical_url: https://www.syncfusion.com/blogs/post/dotnet-maui-charts-2024-volume-2
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/74ps6t5ka3fkhi1mwwvd.pn... | gayathrigithub7 |
1,884,572 | เขียน Go ต่อ Kafka ตอนที่ 1 | เวลาเราจะเขียน Go เพื่อไปทำงานกับ Kafka เราก็ต้องเริ่มจากการเลือก library กันก่อน... | 27,685 | 2024-06-11T16:08:18 | https://dev.to/pallat/ekhiiyn-go-t-kafka-tnthii-1-1ic1 | เวลาเราจะเขียน Go เพื่อไปทำงานกับ Kafka เราก็ต้องเริ่มจากการเลือก library กันก่อน ซึ่งผมจะลองยกตัวอย่างมาให้ดูสัก 3 ตัวครับ
https://githu
1. https://github.com/confluentinc/confluent-kafka-go
ตัวนี้จะถือว่าเป็น official library ก็ว่าได้ เพราะเจ้าของก็คือ confluent เอง ซึ่งก็คือ kafka ในเวอร์ชั่นเสียเงินนั่นเอง แต่ว... | pallat | |
1,884,571 | 10 Tips for Choosing the Right Commercial Builder | Commercial Builders in North Bangalore Introduction Choosing the right builder is a critical... | 0 | 2024-06-11T16:08:17 | https://dev.to/tvasteconstructions/10-tips-for-choosing-the-right-commercial-builder-3h9a | Commercial Builders in North Bangalore
Introduction
Choosing the right builder is a critical decision when embarking on a commercial construction project. The success and quality of the result depend significantly on this choice. With a multitude of commercial builders available, identifying the right one for your pro... | tvasteconstructions | |
1,884,573 | Gamedev.js Weekly newsletter gets… a new website! | Right after getting a new mobile template, the Gamedev.js Weekly newsletter got a brand new website,... | 0 | 2024-06-11T16:12:39 | https://enclavegames.com/blog/gamedevjs-weekly-website/ | gamedev, cloudflare, issues, newsletter | ---
title: Gamedev.js Weekly newsletter gets… a new website!
published: true
date: 2024-06-11 16:08:03 UTC
tags: gamedev,cloudflare,issues,newsletter
canonical_url: https://enclavegames.com/blog/gamedevjs-weekly-website/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/fe4ztcjsffgtw9zdds9z.png
---
... | end3r |
1,877,348 | Microsoft hace a un lado React | Así como lo lees, recientemente Microsoft anunció que logró una mejora de rendimiento del 76% en su... | 0 | 2024-06-11T16:06:22 | https://dev.to/marianocodes/microsoft-hace-a-un-lado-react-3hh6 | react, webdev, javascript, microsoft | Así como lo lees, recientemente Microsoft [anunció](https://blogs.windows.com/msedgedev/2024/05/28/an-even-faster-microsoft-edge/) que logró una mejora de rendimiento del 76% en su navegador Microsoft Edge.
En un experimento que realizaron al reemplazar un menú que fue construido originalmente con React con WebUI 2.0,... | marianocodes |
1,884,564 | How to Check if a Key Exists in JavaScript Object | When working with JavaScript, one of the common tasks developers encounter is checking if a key... | 0 | 2024-06-11T16:04:56 | https://dev.to/raksbisht/how-to-check-if-a-key-exists-in-javascript-object-57mm | javascriptobjects, webdev, javascript, beginners | When working with JavaScript, one of the common tasks developers encounter is checking if a key exists in an object. Knowing how to efficiently check for key existence is crucial for handling data correctly and avoiding runtime errors. In this article, we will explore several methods to check if a key exists in a JavaS... | raksbisht |
1,884,570 | HOSTING A STATIC WEBSITE USING AWS S3 BUCKET AND CLOUDFRONT | Introduction In the ever-evolving landscape of web development and hosting, efficiency,... | 0 | 2024-06-11T16:04:05 | https://dev.to/sir-alex/hosting-a-static-website-using-aws-s3-bucket-and-cloudfront-e3k |

# Introduction
In the ever-evolving landscape of web development and hosting, efficiency, scalability, and reliability are paramount. Amazon Web Services (AWS) offers a powerful combination of services for hosting... | sir-alex | |
1,884,569 | Why Do Codes Have Bugs? | If you have written any line of code before, you must have come across issues when your code seems... | 0 | 2024-06-11T16:01:01 | https://blog.learnhub.africa/2024/06/11/why-does-my-code-have-bugs/ | webdev, javascript, beginners, programming | If you have written any line of code before, you must have come across issues when your code seems not to behave the way you want, and you notice there is an error, which might be an omission of a comma, spelling errors, indentation issue or wrong syntax and any of this could render your code to stop work working.
The... | scofieldidehen |
1,884,567 | Docker Multi-Stage para Aplicações JAVA 21 | Para criar um Dockerfile com dois estágios para uma aplicação Java 21, você pode seguir um processo... | 0 | 2024-06-11T15:53:52 | https://dev.to/adilsonoj/docker-multi-stage-para-aplicacoes-java-21-2n02 | java, docker, backend, devops |
Para criar um Dockerfile com dois estágios para uma aplicação Java 21, você pode seguir um processo de multi-stage build. Isso ajuda a **reduzir o tamanho da imagem final** e garante que apenas os artefatos necessários sejam incluídos na imagem final de execução. Vamos seguir um exemplo com 2 estágios:
1. **Primeir... | adilsonoj |
1,884,820 | Syncfusion Essential Studio 2024 Volume 2 Is Here! | TL;DR: Syncfusion offers comprehensive UI components for building robust web, desktop, and mobile... | 0 | 2024-06-14T04:20:52 | https://www.syncfusion.com/blogs/post/syncfusion-essential-studio-2024-vol2 | maui, dotnetmaui, blazor, documentprocessing | ---
title: Syncfusion Essential Studio 2024 Volume 2 Is Here!
published: true
date: 2024-06-11 15:51:58 UTC
tags: maui, dotnetmaui, blazor, documentprocessing
canonical_url: https://www.syncfusion.com/blogs/post/syncfusion-essential-studio-2024-vol2
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/... | jollenmoyani |
1,884,566 | Experience Luxury and Comfort with Premier Limo Service at DFW Airport, Dallas | Traveling to and from the airport can be stressful, but it doesn't have to be. Imagine gliding... | 0 | 2024-06-11T15:51:12 | https://dev.to/prestige_blackdiamond/experience-luxury-and-comfort-with-premier-limo-service-at-dfw-airport-dallas-3if5 | limmoservice, dfwairportlimoservice, chauffeurservice | Traveling to and from the airport can be stressful, but it doesn't have to be. Imagine gliding through traffic in a luxurious limousine, enjoying every moment of your journey. With Prestige Black Diamond's **[premier limo service at DFW Airport](https://prestigeblackdiamond.com/airport-limo-transportation-dallas/)**, t... | prestige_blackdiamond |
1,880,813 | Why is the useEffect hook used in fetching data in React? | To make this as simple as possible, I'll avoid talking about Next.js. So you want to fetch data from... | 0 | 2024-06-11T15:50:29 | https://dev.to/joeskills/why-is-the-useeffect-hook-used-in-fetching-data-in-react-2nhd | react, frontend, webdev, data | To make this as simple as possible, I'll _avoid talking about Next.js_. So you want to _fetch data from a server_? What's the first thing that comes to your mind? Create a _function to handle the request_. **That makes sense. What could go wrong here?**
```
import React, { useState } from 'react';
function FetchDataC... | joeskills |
1,884,561 | LeetCode Day5 HashTable | LeetCode 242. Valid Anagram Given two strings s and t, return true if t is an anagram of... | 0 | 2024-06-11T15:49:32 | https://dev.to/flame_chan_llll/leetcode-day5-hashtable-26ij | leetcode, java, algorithms | ## LeetCode 242. Valid Anagram
Given two strings s and t, return true if t is an anagram of s, and false otherwise.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
Example 1:
Input: s = "anagram", t = "nagaram"
... | flame_chan_llll |
1,884,562 | guYs I cANt deCide – a Or B? | Still rocking the third person vibe 🤷 Ben was doom scrolling, as he does most... | 27,670 | 2024-06-11T15:45:11 | https://css-artist.blogspot.com/2024/06/guys-i-cant-decide-or-b.html | css, cssart, boxshadows, frontend | ###Still rocking the third person vibe 🤷
Ben was doom scrolling, as he does most mornings, when he stumbled across this post from Tyler Nickerson:
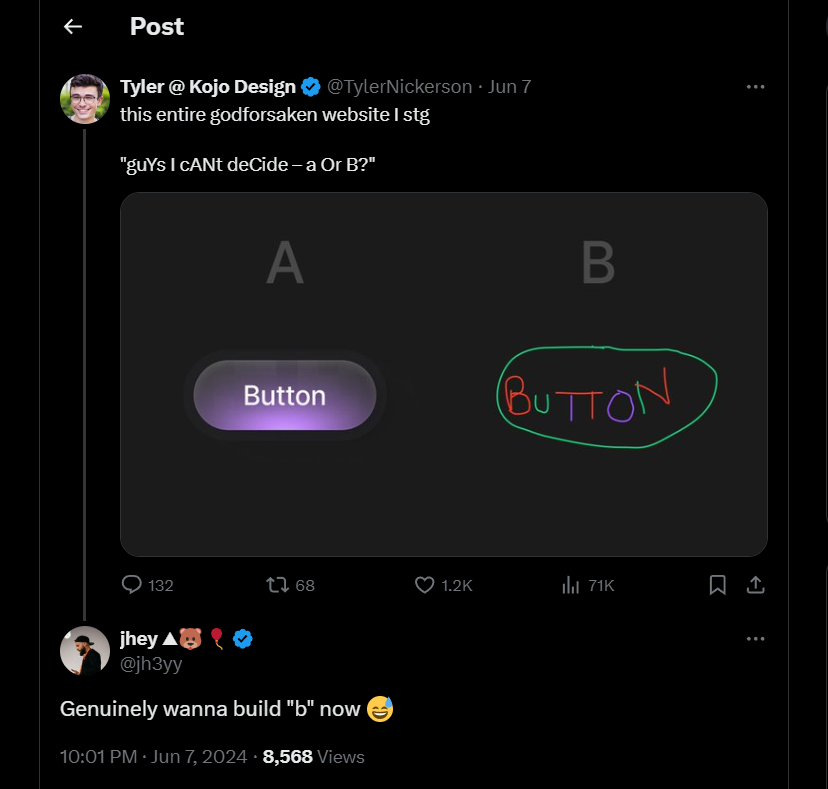
 can understand and work with your code... | the_greatbonnie |
1,873,376 | How to Read a JSON File in JavaScript | When you need to read a json file in your project, it is easy to get the idea using fetch or... | 0 | 2024-06-11T15:37:12 | https://dev.to/markliu2013/how-to-read-a-json-file-in-javascript-3cfn | javascript, json | When you need to read a json file in your project, it is easy to get the idea using [fetch](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API) or [axios](https://github.com/axios/axios).
For example, we have data.json.
```json
{
"name": "Hello World",
"age": 18
}
```
Use fetch to read.
```js
fetch(... | markliu2013 |
1,884,556 | Your Dream Home Awaits: Houses for Sale in Citi Housing Sialkot | Citi Housing Sialkot, a premier residential community, offers an exceptional opportunity for those... | 0 | 2024-06-11T15:29:36 | https://dev.to/deransmith/your-dream-home-awaits-houses-for-sale-in-citi-housing-sialkot-58d5 | webdev, javascript, programming, react | Citi Housing Sialkot, a premier residential community, offers an exceptional opportunity for those looking to invest in a high-quality lifestyle. Known for its luxurious living standards, modern infrastructure, and comprehensive amenities, Citi Housing Sialkot is the perfect place for families and individuals seeking c... | deransmith |
1,884,555 | Play casino games | Looking for an exhilarating way to unwind and have fun? Dive into the exciting world of online gaming... | 0 | 2024-06-11T15:28:22 | https://dev.to/fred_8f4d78d722/play-casino-games-emb | Looking for an exhilarating way to unwind and have fun? Dive into the exciting world of online gaming and play casino games that offer endless entertainment and the chance to win big. Whether you’re a fan of classic table games, innovative slots, or immersive live dealer experiences, online casinos have something for e... | fred_8f4d78d722 | |
1,884,471 | MDB v. 7.3.1. released! | Version 7.3.1, released 10.06.2024 Fixed & improved: File upload fixed... | 0 | 2024-06-11T15:27:00 | https://dev.to/keepcoding/mdb-v-731-released-1hi2 | news, webdev, bootstrap, css | ##Version 7.3.1, released 10.06.2024
##Fixed & improved:
**File upload**
- fixed preview not displaying for extensions: webp, bmp, gif
- fixed option acceptedExtensions bug for .zip extension
**Input fields**
- added CSS variables to allow easier outline customization
- fixed error that was triggered on focus after... | keepcoding |
1,884,554 | Unlock the Power of Generators and Iterators in JavaScript: A Comprehensive Guide | Introduction JavaScript offers powerful constructs to handle iteration and control flow: generators... | 0 | 2024-06-11T15:25:53 | https://dev.to/dipakahirav/unlock-the-power-of-generators-and-iterators-in-javascript-a-comprehensive-guide-3mc9 | javascript, webdev, programming, learning | **Introduction**
JavaScript offers powerful constructs to handle iteration and control flow: generators and iterators. These features enable developers to write more efficient and readable code. In this comprehensive guide, we will explore the concepts of generators and iterators, understand their benefits, and learn ... | dipakahirav |
1,884,553 | Meilleures pratiques pour créer une application Express.js | Partie 1 : Introduction et concepts fondamentaux 1.1 Introduction à... | 0 | 2024-06-11T15:24:49 | https://dev.to/land-bit/meilleures-pratiques-pour-creer-une-application-expressjs-583g | webdev, javascript, programming, tutorial | # Partie 1 : Introduction et concepts fondamentaux
## 1.1 Introduction à Express.js
**Express.js** est un framework d'application web populaire pour **Node.js**, construit sur le serveur HTTP natif de Node. Il offre un ensemble minimaliste et flexible d'outils puissants pour développer des applications web robustes e... | land-bit |
1,884,550 | Rising Like A Phoenix, ShowMeCon 2024 Resurrects A Security Community In The Midwest | St. Charles, MO, is known as the launching point for a famous exploratory mission from U.S. history:... | 0 | 2024-06-11T15:21:08 | https://dev.to/gitguardian/rising-like-a-phoenix-showmecon-2024-resurrects-a-security-community-in-the-midwest-1fol | cybersecurity, ai, llms, security | St. Charles, MO, is known as the launching point for a famous exploratory mission from U.S. history: the [Lewis and Clark Expedition](https://en.wikipedia.org/wiki/Lewis_and_Clark_Expedition?ref=blog.gitguardian.com). Explorers set off from the city's muddy shore to find a passage to the Pacific Ocean, mapping out what... | dwayne_mcdaniel |
1,884,549 | NodeJS Security Middlewares | Introduction Many backend endpoints are written in NodeJS and it is crucial for us to... | 0 | 2024-06-11T15:20:59 | https://dev.to/herjean7/nodejs-security-middlewares-36o3 | security, middleware, api, node | ## Introduction
Many backend endpoints are written in NodeJS and it is crucial for us to protect our endpoints. A quick and simple way to do so would be to use middlewares.
## Middleware
Middlewares allow us intercept and inspect requests, which makes it ideal for logging, authentication and inspecting requests. He... | herjean7 |
1,884,548 | Olá, meu primeiro dia nessa comunidade. | A post by Stalin Ragner | 0 | 2024-06-11T15:20:07 | https://dev.to/srragner/ola-meu-primeiro-dia-nessa-comunidade-162 | srragner | ||
1,884,547 | Exploring django-ajax: Simplifying AJAX Integration in Django | Asynchronous JavaScript and XML, often referred to as AJAX, have significantly changed the game in... | 0 | 2024-06-11T15:18:21 | https://developer-service.blog/exploring-django-ajax-simplifying-ajax-integration-in-django-2/ | django, javascript, ajax | Asynchronous JavaScript and XML, often referred to as AJAX, have significantly changed the game in web development. It allows for data retrieval without interrupting user interactions, making everything smoother.
However, incorporating AJAX into Django applications can be a bit challenging because of the complexities... | devasservice |
1,884,545 | CQRS Design Pattern in Spring Boot? Explain with Example | CQRS Design Pattern in Spring Boot ================================== What is... | 0 | 2024-06-11T15:16:34 | https://dev.to/codegreen/cqrs-design-pattern-in-spring-boot-explain-with-example-54ke | java, springboot, kafka, designpatterns | ##CQRS Design Pattern in Spring Boot
==================================
What is CQRS Design Pattern?
----------------------------
> The CQRS *(Command Query Responsibility Segregation)* design pattern separates the responsibility of handling commands (write operations) from queries (read operations) into separate com... | manishthakurani |
1,884,543 | Architecting for Disaster: Backup and Recovery in the AWS Cloud | Architecting for Disaster: Backup and Recovery in the AWS Cloud In today's digital... | 0 | 2024-06-11T15:12:29 | https://dev.to/virajlakshitha/architecting-for-disaster-backup-and-recovery-in-the-aws-cloud-2cd1 | 
# Architecting for Disaster: Backup and Recovery in the AWS Cloud
In today's digital landscape, downtime translates directly to financial loss and reputational damage. Businesses need to plan not *if* a disaster will occur, but *whe... | virajlakshitha | |
1,884,542 | Utilizing Generative AI for Coding Questions | Using Generative AI to Best Edit and Utilize for Coding-Related Questions ... | 0 | 2024-06-11T15:12:17 | https://dev.to/hroney/utilizing-generative-ai-for-coding-questions-20dg | javascript, webdev, ai, tutorial | # Using Generative AI to Best Edit and Utilize for Coding-Related Questions
_________________________________________________________________________
## Index
- Introduction
- Why use Generative AI for Coding
- Best practices
- Starting Off
- Scope
- Clear Context
- Sharing Relevant code snippets
- State clear ob... | hroney |
1,883,541 | Trunk-Based Development: Streamlining Software Delivery with Git and CI/CD | Hello, developers! Today, we’re exploring trunk-based development and how to integrate it with Git... | 0 | 2024-06-11T15:07:10 | https://dev.to/ak_23/trunk-based-development-streamlining-software-delivery-with-git-and-cicd-4o58 |
Hello, developers! Today, we’re exploring trunk-based development and how to integrate it with Git and CI/CD pipelines to streamline your software delivery process. Trunk-based development is a powerful strategy that promotes collaboration and continuous integration by ensuring that all developers work on a single bra... | ak_23 | |
1,871,889 | Open source super-charged my career | Contributing is more valuable than you may think At the time of writing, I am less than thirty... | 0 | 2024-06-11T15:06:58 | https://dev.to/systemglitch/open-source-super-charged-my-career-51d1 | opensource, career, beginners | > _Contributing is more valuable than you may think_
At the time of writing, I am less than thirty years old, and I have a tech lead position in one of Europe's fastest-growing startups, according to the Financial Times's FT1000 ranking. This company found me and hired me immediately when I graduated. Yes, it is my fi... | systemglitch |
1,884,540 | Optional Class in Java and its methods | Optional Class in Java ====================== What is an Optional Class? The... | 0 | 2024-06-11T15:06:18 | https://dev.to/codegreen/optional-class-in-java-and-its-methods-29ap | java8, optional, util, streams | ##Optional Class in Java
======================
What is an Optional Class?
--------------------------
The Optional class in Java is a container object that may or may not contain a non-null value. It is used to avoid null pointer exceptions by providing a way to handle null values more effectively.
Available Methods... | manishthakurani |
1,884,539 | Sustainability Practices and Their Influence on the Spray-on Insulation Coatings Market | Spray-on insulation coatings are advanced materials applied to surfaces to provide thermal insulation... | 0 | 2024-06-11T15:05:37 | https://dev.to/aryanbo91040102/sustainability-practices-and-their-influence-on-the-spray-on-insulation-coatings-market-3jhn | news | Spray-on insulation coatings are advanced materials applied to surfaces to provide thermal insulation and energy efficiency. These coatings are designed to reduce heat transfer, improve energy savings, and enhance the comfort of buildings and industrial facilities. They are typically composed of a mix of polymers, cera... | aryanbo91040102 |
1,883,551 | Monitoring and Maintenance: Sustaining AI Model Performance Over Time | Hello, AI enthusiasts! Welcome to the final installment of our AI development series. Today, we'll... | 0 | 2024-06-11T15:04:49 | https://dev.to/ak_23/monitoring-and-maintenance-sustaining-ai-model-performance-over-time-24ng | ai, learning, beginners |
Hello, AI enthusiasts! Welcome to the final installment of our AI development series. Today, we'll explore the critical phase of Monitoring and Maintenance. After deploying an AI model, it's essential to continuously monitor its performance and maintain it to ensure it remains effective and reliable. By the end of thi... | ak_23 |
1,884,538 | My .NetFramework version does not work with my Microsoft.SharePointClient.dll version. Which version should I use? | My .NetFramework version does not work with my Microsoft.SharePointClient.dll version. Which version... | 0 | 2024-06-11T15:04:47 | https://dev.to/xarzu/my-netframework-version-does-not-work-with-my-microsoftsharepointclientdll-version-which-version-should-i-use-4e3o | My .NetFramework version does not work with my Microsoft.SharePointClient.dll version. Which version should I use?
I am trying to add some CSOM functionality to my C# program such that I will be allowed to do CRUD operations on a Microsoft List (aka SharePoint List). Assuming you know what CSOM and CRUD is, I will ... | xarzu | |
1,884,537 | Understanding Generic Classes in TypeScript: Flexible and Efficient Data Management | In today's blog, we're diving into the fascinating world of generic classes in TypeScript. Generics... | 0 | 2024-06-11T15:04:35 | https://dev.to/dimerbwimba/understanding-generic-classes-in-typescript-flexible-and-efficient-data-management-2h0d | typescript, javascript | In today's blog, we're diving into the fascinating world of generic classes in TypeScript. Generics allow us to create reusable, flexible, and efficient code that can handle various data types. Whether you're working with numbers, strings, or custom objects, generics make your life a whole lot easier. 🌟
{% embed http... | dimerbwimba |
1,883,548 | Model Deployment: Bringing Your AI Model to Life | Hello, AI enthusiasts! Welcome back to our AI development series. Today, we're diving into Model... | 0 | 2024-06-11T15:04:16 | https://dev.to/ak_23/model-deployment-bringing-your-ai-model-to-life-2bec | ai, learning, beginners |
Hello, AI enthusiasts! Welcome back to our AI development series. Today, we're diving into Model Deployment, the phase where your AI model transitions from development to production. This phase involves making your model accessible for real-world applications, enabling it to provide valuable insights and predictions i... | ak_23 |
1,883,547 | Model Evaluation: Ensuring Your AI Model's Performance and Reliability | Title "Model Evaluation: Ensuring Your AI Model's Performance and Reliability" ... | 0 | 2024-06-11T15:03:36 | https://dev.to/ak_23/model-evaluation-ensuring-your-ai-models-performance-and-reliability-4c1e | ai, learning, beginners | ## Title
"Model Evaluation: Ensuring Your AI Model's Performance and Reliability"
## Introduction
Hello, AI enthusiasts! Welcome back to our AI development series. Today, we're focusing on Model Evaluation, a crucial phase that ensures your AI model performs well on new, unseen data. Evaluating a model helps you und... | ak_23 |
1,883,543 | Model Selection and Training: Building Robust AI Systems | Hello, AI enthusiasts! Welcome back to our AI development series. Today, we're diving into Model... | 0 | 2024-06-11T15:02:51 | https://dev.to/ak_23/model-selection-and-training-building-robust-ai-systems-g4e | ai, learning, beginners |
Hello, AI enthusiasts! Welcome back to our AI development series. Today, we're diving into Model Selection and Training, one of the most critical phases in the AI development process. This phase involves choosing the right algorithm and training it to create a robust AI model that can make accurate predictions. By the... | ak_23 |
1,883,539 | Feature Engineering: Unlocking the Power of Data for AI Success | Hello, data enthusiasts! Welcome back to our AI development series. Today, we’re diving into one of... | 0 | 2024-06-11T15:02:06 | https://dev.to/ak_23/feature-engineering-unlocking-the-power-of-data-for-ai-success-pmi | ai, learning, beginners |
Hello, data enthusiasts! Welcome back to our AI development series. Today, we’re diving into one of the most critical phases of AI development: Feature Engineering. This phase is all about transforming raw data into meaningful features that enhance your model’s performance. By the end of this blog, you'll understand t... | ak_23 |
1,884,534 | DoubleTree Lucknow Factory | Kuldeep Plywood Industries is an over fifty-year-old family legacy committed to delivering quality... | 0 | 2024-06-11T15:01:02 | https://dev.to/emma_smith_12/doubletree-lucknow-factory-54i8 | Kuldeep Plywood Industries is an over fifty-year-old family legacy committed to delivering quality products in the plywood industrial market. Our roots date back to 1965 when Krishna Kumar Gupta started Kuldeep Sawmills – a small sawmill industry catering [local Lucknow market](https://doubletreekitchens.com/
) with th... | emma_smith_12 | |
1,872,159 | Your AWS app in depth like never before with sls-mentor | sls-mentor is an open-source tool that generates an interactive graph of your AWS application. This graph contains all the interactions between components of your app. Recently, we also released dashboards that allow you to monitor stats like cold starts for example | 0 | 2024-06-11T15:00:36 | https://dev.to/slsbytheodo/your-aws-app-in-depth-like-never-before-with-sls-mentor-1dgf | serverless, aws, javascript, tutorial | ---
published: true
title: 'Your AWS app in depth like never before with sls-mentor'
cover_image: https://raw.githubusercontent.com/pchol22/kumo-articles/master/blog-posts/sls-mentor/dashboard/assets/cover-image.png
description: 'sls-mentor is an open-source tool that generates an interactive graph of your AWS applicat... | pchol22 |
1,883,305 | Essential Guide to Data Preprocessing: Clean, Transform, and Reduce Your Data for AI Success | Introduction Hello again, AI enthusiasts! Welcome back to our series on AI development. In... | 0 | 2024-06-11T15:00:32 | https://dev.to/ak_23/essential-guide-to-data-preprocessing-clean-transform-and-reduce-your-data-for-ai-success-g2m | ## Introduction
Hello again, AI enthusiasts! Welcome back to our series on AI development. In this post, we’ll explore the second crucial phase: Data Preprocessing. Think of data preprocessing as preparing ingredients before cooking a meal. It ensures that your data is clean, consistent, and ready to be fed into your ... | ak_23 | |
1,884,532 | Hibernate Connection Library with GUI Generation | This library streamlines Java application development by effortlessly generating graphical interfaces... | 0 | 2024-06-11T14:59:53 | https://dev.to/nazarioluis/hibernate-connection-library-with-gui-generation-2i80 | java, hibernate, reflection, programming | This library streamlines Java application development by effortlessly generating graphical interfaces from defined entity classes. It seamlessly integrates with the Hibernate framework to provide database connectivity, with a primary focus on creating intuitive interfaces for managing database entities.
**Repository:**... | nazarioluis |
1,883,304 | Mastering the First Steps of AI Development: Problem Definition and Data Collection | Hey folks! Today, we’re diving into the very first step of AI development: Problem Definition and... | 0 | 2024-06-11T14:59:11 | https://dev.to/ak_23/mastering-the-first-steps-of-ai-development-problem-definition-and-data-collection-h4o | ai, learning, beginners |
Hey folks! Today, we’re diving into the very first step of AI development: Problem Definition and Data Collection. This phase is crucial because it sets the foundation for the entire AI project. By the end of this blog, you'll understand why clearly defining the problem and collecting the right data is essential, and ... | ak_23 |
1,884,525 | How to extend an existing schematic | Hey there, schematic enthusiasts! If you're new to schematics, you might be wondering how to extend... | 0 | 2024-06-11T14:56:17 | https://dev.to/hyperxq/how-to-extend-an-existing-schematic-4fcj | schematics, angularschematics, codeautomation | Hey there, schematic enthusiasts! If you're new to schematics, you might be wondering how to extend existing ones without starting from scratch. You probably just want to add some new functionality without reinventing the wheel. Unfortunately, there's not a lot of information out there on how to do this, so I’m here to... | hyperxq |
1,884,490 | Congrats to the Frontend Challenge: June Edition Winners! | The wait is over! We are excited to announce the winners of the Frontend Challenge: June... | 0 | 2024-06-11T14:56:16 | https://dev.to/devteam/congrats-to-the-frontend-challenge-june-edition-winners-26kd | devchallenge, frontendchallenge, css, javascript | The wait is over! We are excited to announce the winners of the [Frontend Challenge: June Edition](https://dev.to/devteam/join-us-for-the-next-frontend-challenge-june-edition-3ngl).
From [sleepy Pikachu on the beach](https://dev.to/dhrutisubham03/sleepy-pikachu-4iha) to celebrating [World Bicycling Day](https://dev.to... | thepracticaldev |
1,884,521 | An OpenSource term I just learnt about | Vocabulary Term: Linting Introduction Before embarking on my journey with... | 0 | 2024-06-11T14:54:24 | https://dev.to/ccokeke/an-opensource-term-i-just-learnt-about-4pgp | ### Vocabulary Term: **Linting**
#### Introduction
Before embarking on my journey with Outreachy, I came across a multitude of terms and concepts related to open source software development. One of the intriguing terms that stood out to me was **"linting."** Although it might not be entirely rare in the broader progr... | ccokeke | |
1,884,524 | Using Kafka in Spring Boot Application | Kafka Consumer and Producer in Spring Boot 1. Dependency Required You need to... | 0 | 2024-06-11T14:53:45 | https://dev.to/codegreen/using-kafka-in-spring-boot-application-467p | kafka, eventdriven, springboot, java | Kafka Consumer and Producer in Spring Boot
==========================================
1\. Dependency Required
-----------------------
You need to include the following dependency in your pom.xml or build.gradle:
```
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactI... | manishthakurani |
1,884,523 | Nimaga endi fasllar? (mapping jarayoni) | Endi sarlavhadagi rasmga birinchi o'rinda javob beramiz.Nimaga aynan fasllar.Bu biz o'rganmoqchi... | 0 | 2024-06-11T14:53:14 | https://dev.to/ozodboyeva/nimaga-endi-fasllar-mapping-jarayoni-22ak | mappingreact, learningreact | Endi sarlavhadagi rasmga birinchi o'rinda javob beramiz.Nimaga aynan fasllar.Bu biz o'rganmoqchi bo'lgan mavzu uchun ajoyib misol bo'la oladi.Chunki fasllar har doim takrorlanadi.Bahordan keyin yoz, Yozdan keyin kuz fasli, kuzdan keyin qish fasli kirib keladi.To'g'ri bu qaysidir mamlakatlarda o'zgarishi, balkim qish um... | ozodboyeva |
1,884,522 | Datetime Module in Python | The datetime module in Python provides classes for manipulating dates and times. It includes various... | 0 | 2024-06-11T14:49:39 | https://dev.to/shaiquehossain/datetime-module-in-python-38gp | python, datascience, learning, functions | The [datetime module in Python](https://www.almabetter.com/bytes/tutorials/python/datetime-python) provides classes for manipulating dates and times. It includes various functions and classes such as `datetime`, `date`, `time`, and `timedelta`, which allow for a wide range of operations.
1. **Date and Time Creation**:... | shaiquehossain |
1,884,520 | NOT NULL in SQL | The NOT NULL in SQL ensures that a column cannot have a NULL value. It mandates that every row must... | 0 | 2024-06-11T14:45:27 | https://dev.to/shaiquehossain/not-null-in-sql-4o3i | sql, database, datascience, learning | The [NOT NULL in SQL](https://www.almabetter.com/bytes/tutorials/sql/not-null-in-sql) ensures that a column cannot have a NULL value. It mandates that every row must have a value for that column, preventing the insertion or updating of records with missing data in that column. This constraint is crucial for maintaining... | shaiquehossain |
1,884,519 | Amazon EKS Auto Scaling: Because One Size Never Fits All... | Welcome back, Senpai 🙈. In this blog, I am gonna take deep into the complex, and fascinating world of... | 0 | 2024-06-11T14:43:44 | https://dev.to/spantheslayer/amazon-eks-auto-scaling-because-one-size-never-fits-all-3k46 | programming, devops, aws, cloud | Welcome back, Senpai 🙈. In this blog, I am gonna take deep into the complex, and fascinating world of Amazon EKS Auto Scaling. Buckle up, because this isn’t your average walk in the park. This is a trek through the Amazon (pun intended) of Kubernetes management. I am going to cover what EKS Auto Scaling is, its compon... | spantheslayer |
1,883,326 | Optimizing rendering in Vue | Written by Ikeh Akinyemi✏️ Optimizing rendering is crucial for ensuring a smooth and efficient user... | 0 | 2024-06-11T14:39:06 | https://blog.logrocket.com/optimizing-rendering-vue | vue, webdev | **Written by [Ikeh Akinyemi](https://blog.logrocket.com/author/ikehakinyemi/)✏️**
Optimizing rendering is crucial for ensuring a smooth and efficient user experience across all your frontend projects. Sluggish webpages can lead to frustration for users, and potentially cause them to entirely abandon your web applicati... | leemeganj |
1,884,518 | Oracle Corporation: Redefining Augmented Intelligence | Introduction: In the ever-evolving landscape of technology, Oracle Corporation stands as a titan,... | 0 | 2024-06-11T14:38:57 | https://dev.to/chanda_simran/oracle-corporation-redefining-augmented-intelligence-1gnb | marketstrategy, globalinsights, marketgrowth, globalstrategy |

**Introduction:**
In the ever-evolving landscape of technology, Oracle Corporation stands as a titan, continually innovating and shaping the future of enterprise solutions. With a keen eye on emerging trends, Oracl... | chanda_simran |
1,884,517 | Buy verified cash app account | Buy verified cash app account Cash app has emerged as a dominant force in the realm of mobile banking... | 0 | 2024-06-11T14:38:32 | https://dev.to/kevinreed837/buy-verified-cash-app-account-1n8e | Buy verified cash app account
Cash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with ... | kevinreed837 | |
1,884,516 | Sustainability Practices and Their Influence on the Silane Coupling Agents Market | Silane coupling agents are specialized chemicals used to enhance the bond between organic and... | 0 | 2024-06-11T14:36:47 | https://dev.to/aryanbo91040102/sustainability-practices-and-their-influence-on-the-silane-coupling-agents-market-1o4l | news | Silane coupling agents are specialized chemicals used to enhance the bond between organic and inorganic materials. These agents are typically organosilicon compounds that possess two types of functional groups. One group is capable of bonding with inorganic surfaces like glass, metals, or minerals, while the other inte... | aryanbo91040102 |
1,884,515 | UNIQUE KEY in SQL | A UNIQUE key in SQL is a constraint that ensures all values in a column or a combination of columns... | 0 | 2024-06-11T14:36:39 | https://dev.to/shaiquehossain/unique-key-in-sql-2m7i | uniquekey, sql, database, datascience | A [UNIQUE key in SQL](https://www.almabetter.com/bytes/tutorials/sql/unique-key-in-sql) is a constraint that ensures all values in a column or a combination of columns are unique across the table. This means no two rows can have the same value(s) in the specified column(s). Unlike the primary key, which must be unique ... | shaiquehossain |
1,880,820 | nginx: doing ip geolocation right in nginx | knowing the geolocation of your site's users is handy thing. maybe you want to force your canadian... | 0 | 2024-06-11T14:32:40 | https://dev.to/gbhorwood/nginx-doing-ip-geolocation-right-in-nginx-442h | nginx, linux, php, webdev | knowing the geolocation of your site's users is handy thing. maybe you want to force your canadian users into a degraded, second-rate version of your ecommerce site, or maybe you want to redirect people from brazil to a frontend you ran through google translate, or maybe you just want to block the netherlands because y... | gbhorwood |
1,884,449 | Dockerize a Nodejs Application | I feel very embarrassed when I claim to be a backend developer without basic Docker knowledge.... | 0 | 2024-06-11T14:32:13 | https://dev.to/abhishekcs3459/dockerize-a-nodejs-application-5ei1 | docker, devops, node, begginer | I feel very embarrassed when I claim to be a backend developer without basic Docker knowledge. Doesn't it feel the same to you?
**Prerequisites**
Before I start, make sure you have the following installed:
1. **Node.js** and **npm:**.You can download and install it from the[ Node.js official website](https://nodejs.or... | abhishekcs3459 |
1,884,514 | How we use Glitch to support learning at Fastly | Glitch is an empowering platform in so many ways. It enables people to bring creative visions to life... | 0 | 2024-06-11T14:30:30 | https://blog.glitch.com/post/glitch-supports-fastly-learning/ | learning, webdev | Glitch is an empowering platform in so many ways. It enables people to bring creative visions to life by eliminating much of the friction you face on a typical web development pathway. It has been a source of immense joy to me over the years to show people who have never made a website how to build one in Glitch. The d... | suesmith |
1,884,512 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-06-11T14:26:17 | https://dev.to/yarog61500/buy-verified-paxful-account-1plf | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n " | yarog61500 |
1,884,500 | How to Check a Python Variable's Type? | Python's dynamic typing allows developers to write flexible and concise code. However, this... | 0 | 2024-06-11T14:25:03 | https://dev.to/hichem-mg/how-to-check-a-python-variables-type-3oi9 | python, tutorial, programming, beginners | Python's dynamic typing allows developers to write flexible and concise code. However, this flexibility comes with the responsibility of ensuring that variables are of the expected type when required.
Checking the type of a variable is crucial for debugging, validating user input, and maintaining code quality in large... | hichem-mg |
1,884,511 | Building Randomness with Chainlink VRF | Random Fantasy Team Name Selector Part 1 Imagine a lottery where the balls are tumbling in... | 0 | 2024-06-11T14:23:59 | https://dev.to/charlesj_dev/building-randomness-with-chainlink-vrf-50ki | solidity, tutorial, blockchain, web3 | ## Random Fantasy Team Name Selector Part 1
Imagine a lottery where the balls are tumbling in a glass sphere, watched by the world. Each number is a smart contract, each draw a transaction, and the entire network stands witness to the spectacle. This isn’t just a game of chance; it’s a demonstration of trust in techn... | charlesj_dev |
1,884,510 | React rendering | Understanding the power of react rendering: Unlocking Efficient and Responsive User Experiences. In... | 0 | 2024-06-11T14:22:47 | https://dev.to/jospin6/react-rendering-5fcj | react, ui, webdev | Understanding the power of react rendering: Unlocking Efficient and Responsive User Experiences.
In the ever-evolving landscape of the web development, React has emerged as a dominant force, revolutionizing the way we build user interfaces. At the heart of React's success lies its efficient and responsive rendering pr... | jospin6 |
1,884,509 | How to handle migrations in Golang | Introduction We always can create and run our migrations manually, but if we want to make... | 0 | 2024-06-11T14:21:04 | https://henriqueleite42.hashnode.dev/how-to-handle-migrations-in-golang | go, database, devops, documentation | ## Introduction
We always can create and run our migrations manually, but if we want to make it faster, safer, and easier to read and maintain, it's recommended to use a specialized tool for it.
To choose this tool, we need first to analyze what are the requirements for "handling migrations". They are:
- Generate `UP... | henriqueleite42 |
1,884,508 | pocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call Now | pocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call... | 0 | 2024-06-11T14:21:01 | https://dev.to/sanua_mudel_233cc64633dbf/pocket-rupee-ledger-loan-app-customer-care-helpline-number-7439698803toll-free7305296021call-now-2dmd | javascript, beginners, programming, react | pocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call Nowpocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call Nowpocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call Now | sanua_mudel_233cc64633dbf |
1,884,507 | TypeORM: O ORM que Você Precisa Conhecer para Trabalhar com Node.js e TypeScript | No mundo do desenvolvimento web, trabalhar com banco de dados é uma parte essencial da criação de... | 0 | 2024-06-11T14:20:50 | https://dev.to/iamthiago/typeorm-o-orm-que-voce-precisa-conhecer-para-trabalhar-com-nodejs-e-typescript-21m2 | database, orm, typescript, node | No mundo do desenvolvimento web, trabalhar com banco de dados é uma parte essencial da criação de aplicações robustas e escaláveis. Muitas vezes, os desenvolvedores buscam ferramentas que facilitem a interação com bancos de dados relacionais. Uma dessas ferramentas é o TypeORM, um Object-Relational Mapper (ORM) que tem... | iamthiago |
1,884,503 | pocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call Now | pocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call... | 0 | 2024-06-11T14:18:09 | https://dev.to/sanua_mudel_233cc64633dbf/pocket-rupee-ledger-loan-app-customer-care-helpline-number-7439698803toll-free7305296021call-now-kgj | javascript, beginners, webdev, programming | pocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call Nowpocket rupee ledger loan App Customer Care Helpline Number 7439698803_Toll Free_7305296021✓.Call Now | sanua_mudel_233cc64633dbf |
1,884,502 | what is JPA? explain few configurations | JPA in Spring ============= JPA (Java Persistence API) in Spring simplifies database... | 0 | 2024-06-11T14:17:15 | https://dev.to/codegreen/what-is-jpa-explain-few-configurations-5flj | java, jpa, hibernate, springboot | ##JPA in Spring
=============
JPA (Java Persistence API) in Spring simplifies database interactions by providing a standard way to map Java objects to database tables and vice versa.
Common Configurations for JPA
-----------------------------
### spring.datasource
This configuration specifies the database connectio... | manishthakurani |
1,884,501 | Our Frustrating Experience with Stripe: Withheld 2000 EUR and No Support for 2 Months | We’re VPNHouse, a VPN service provider, and we want to share our troubling experience with Stripe.... | 0 | 2024-06-11T14:16:08 | https://dev.to/vpn_house/our-frustrating-experience-with-stripe-withheld-2000-eur-and-no-support-for-2-months-ggp | stripe, payment | We’re VPNHouse, a VPN service provider, and we want to share our troubling experience with Stripe. Two months ago, Stripe withheld 2000 EUR from our account. Since then, we have repeatedly tried to contact their support team through various emails and calls, but all our attempts have been ignored. Our account remains l... | vpn_house |
1,884,480 | Build a type-safe and event-driven Uptime Monitor in TypeScript | TL;DR This guide shows you how to build and deploy a type-safe, event-driven, uptime... | 0 | 2024-06-11T14:13:53 | https://dev.to/encore/build-a-type-safe-and-event-driven-uptime-monitor-in-typescript-34l2 | typescript, cloud, tutorial, typesafe | ## TL;DR
This guide shows you how to build and deploy a type-safe, event-driven, uptime monitor in TypeScript.
To get our app up and running in the cloud in just a few minutes, we'll be using [Encore](https:/... | marcuskohlberg |
1,884,499 | Vegan Protein Powder Market Share, Size, and Growth 2031 | The Insight Partners recently announced the release of the market research titled Vegan Protein... | 0 | 2024-06-11T14:13:45 | https://dev.to/snigdha_9c3e9b20c0e986086/vegan-protein-powder-market-share-size-and-growth-2031-0 | The Insight Partners recently announced the release of the market research titled Vegan Protein Powder Market Outlook to 2031 | Share, Size, and Growth. The report is a stop solution for companies operating in the Vegan Protein Powder market. The report involves details on key segments, market players, precise market r... | snigdha_9c3e9b20c0e986086 | |
1,884,498 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-11T14:12:44 | https://dev.to/yarog61500/buy-verified-cash-app-account-58fd | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | yarog61500 |
1,884,497 | Install aws-iam-authenticator in Windows | Run powershell as admin Install Chocolatey by following below two commands Set-ExecutionPolicy... | 0 | 2024-06-11T14:11:59 | https://dev.to/mohan023/install-aws-iam-authenticator-in-windows-353k | - Run powershell as admin
- Install Chocolatey by following below two commands
- Set-ExecutionPolicy AllSigned
- Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).Do... | mohan023 | |
1,884,484 | Code with GitHub Codespaces | Introduction : GitHub Codespaces is a fully configured development environment hosted in the cloud.... | 27,667 | 2024-06-11T14:11:56 | https://dev.to/learnwithsrini/code-with-github-codespaces-4hbh | github, codespaces | **Introduction** : GitHub Codespaces is a fully configured development environment hosted in the cloud. By using GitHub Codespaces, your workspace, along with all of your configured development environments, is available from any computer with access to the internet.
GitHub Codespaces is an instant, cloud-based develo... | srinivasuluparanduru |
1,884,495 | Data Normalization in Machine Learning | Data normalization in machine learning involves transforming numerical features to a standard scale... | 0 | 2024-06-11T14:09:00 | https://dev.to/shaiquehossain/data-normalization-in-machine-learning-om2 | datascience, datanormalization, linearregression, machinelearning | [Data normalization in machine learning](https://www.almabetter.com/bytes/tutorials/data-science/normalization-in-machine-learning) involves transforming numerical features to a standard scale to ensure fair contribution to model training. Techniques like Min-Max Scaling and Z-score Standardization are commonly used. N... | shaiquehossain |
1,884,494 | How to install Node.JS: Secrets and Best Practices for Every Platform Revealed | Overview Node works on many platforms, there are a lot of ways to install it, However,... | 0 | 2024-06-11T14:08:14 | https://dev.to/brunohafonso/how-to-install-nodejs-secrets-and-best-practices-for-every-platform-revealed-31di | node, javascript, tutorial, certification | # Overview
Node works on many platforms, there are a lot of ways to install it,
However, there are some practices we must follow while installing Node on Windows, Linux, and MacOS machines.
# Learning Objectives
At the final of this article you will be able to:
- Discover the best way to install and use Node in ea... | brunohafonso |
1,846,210 | This is title | dgdfgdfgdfgdfgdfg | 0 | 2024-06-11T14:07:26 | https://dev.to/sm-maruf-hossen/this-is-title-3bma | dgdfgdfgdfgdfgdfg | sm-maruf-hossen | |
1,884,478 | How to Set Up Next.js Project | Are you a beginner looking to dive into the world of Next.js development? Look no further! In this... | 27,758 | 2024-06-11T14:06:50 | https://dev.to/nnnirajn/step-by-step-tutorial-setting-up-a-nextjs-project-locally-for-beginners-4ep3 | nextjs, react, javascript, ui | Are you a beginner looking to dive into the world of Next.js development? Look no further! In this step-by-step tutorial, we'll guide you through setting up a Next.js project locally. Whether you're new to web development or just getting started with Next.js, this easy-to-follow guide will have you up and running in no... | nnnirajn |
1,884,492 | Transforming Business Operations with LLMs: A Path to a Production Ecosystem | All of us techies, have experimented with Large language models (LLMs) like GPT at some shape or... | 27,680 | 2024-06-11T14:06:01 | https://medium.com/@Rabea/transforming-business-operations-with-llms-a-path-to-a-production-ecosystem-341776142e6e | ai, systemdesign, llm |
All of us techies, have experimented with Large language models (LLMs) like GPT at some shape or form, and the promise is it will help businesses work smarter and more efficiently. While there's been plenty of experimentation, we're now at an exciting point where these AI applications and tools, could really become in... | rabea |
1,884,491 | Luxury Vinyl Tiles Market Dynamics: Drivers, Restraints, and Opportunities | Luxury Vinyl Tiles (LVT) are a popular and versatile flooring solution known for their high-quality... | 0 | 2024-06-11T14:05:22 | https://dev.to/aryanbo91040102/luxury-vinyl-tiles-market-dynamics-drivers-restraints-and-opportunities-2hj7 | news | Luxury Vinyl Tiles (LVT) are a popular and versatile flooring solution known for their high-quality appearance, durability, and affordability. LVT mimics the look of natural materials like wood, stone, or ceramic but offers the ease of maintenance and resilience of vinyl. This flooring type is composed of multiple laye... | aryanbo91040102 |
1,884,489 | Stay Updated with PHP/Laravel: Weekly News Summary (03/06/2024 - 09/06/2024) | Dive into the latest tech buzz with this weekly news summary, focusing on PHP and Laravel updates... | 0 | 2024-06-11T14:04:07 | https://poovarasu.dev/php-laravel-weekly-news-summary-03-06-2024-to-09-06-2024/ | php, laravel | Dive into the latest tech buzz with this weekly news summary, focusing on PHP and Laravel updates from June 3rd to June 9th, 2024. Stay ahead in the tech game with insights curated just for you!
This summary offers a concise overview of recent advancements in the PHP/Laravel framework, providing valuable insights for ... | poovarasu |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.