
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,880,785 | GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection | GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection | 0 | 2024-06-07T19:29:22 | https://aimodels.fyi/papers/arxiv/galore-memory-efficient-llm-training-by-gradient | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection](https://aimodels.fyi/papers/arxiv/galore-memory-efficient-llm-training-by-gradient). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https... | mikeyoung44 |
1,880,784 | S-LoRA: Serving Thousands of Concurrent LoRA Adapters | S-LoRA: Serving Thousands of Concurrent LoRA Adapters | 0 | 2024-06-07T19:28:47 | https://aimodels.fyi/papers/arxiv/s-lora-serving-thousands-concurrent-lora-adapters | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [S-LoRA: Serving Thousands of Concurrent LoRA Adapters](https://aimodels.fyi/papers/arxiv/s-lora-serving-thousands-concurrent-lora-adapters). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.sub... | mikeyoung44 |
1,880,783 | LLMs cannot find reasoning errors, but can correct them given the error location | LLMs cannot find reasoning errors, but can correct them given the error location | 0 | 2024-06-07T19:28:13 | https://aimodels.fyi/papers/arxiv/llms-cannot-find-reasoning-errors-but-can | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [LLMs cannot find reasoning errors, but can correct them given the error location](https://aimodels.fyi/papers/arxiv/llms-cannot-find-reasoning-errors-but-can). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](h... | mikeyoung44 |
1,880,782 | Gated Linear Attention Transformers with Hardware-Efficient Training | Gated Linear Attention Transformers with Hardware-Efficient Training | 0 | 2024-06-07T19:27:38 | https://aimodels.fyi/papers/arxiv/gated-linear-attention-transformers-hardware-efficient-training | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Gated Linear Attention Transformers with Hardware-Efficient Training](https://aimodels.fyi/papers/arxiv/gated-linear-attention-transformers-hardware-efficient-training). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi new... | mikeyoung44 |
1,880,517 | Google IDX - The Best Flutter Beginner Experience | After poking around with Flutter a few times but getting caught up in all the extra mobile setup and configuration, Google IDX finally provided an entry that removed the frustrations that were stopping me from working with Flutter. | 0 | 2024-06-07T19:27:08 | https://terabytetiger.com/lessons/google-idx-is-the-best-flutter-beginner-experience | mobile, flutter, development | ---
title: Google IDX - The Best Flutter Beginner Experience
published: true
description: After poking around with Flutter a few times but getting caught up in all the extra mobile setup and configuration, Google IDX finally provided an entry that removed the frustrations that were stopping me from working with Flutter... | terabytetiger |
1,880,781 | WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning | WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning | 0 | 2024-06-07T19:27:04 | https://aimodels.fyi/papers/arxiv/wavecoder-widespread-versatile-enhancement-code-large-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning](https://aimodels.fyi/papers/arxiv/wavecoder-widespread-versatile-enhancement-code-large-language). If you like these kinds of analysis, you should sub... | mikeyoung44 |
1,880,780 | Where to Spend Bitcoin - 25 Best Places that Accept Bitcoin in 2024 | As the popularity of cryptocurrencies continues to rise, more and more online stores are recognizing... | 0 | 2024-06-07T19:25:39 | https://dev.to/owenparker22212/where-to-spend-bitcoin-25-best-places-that-accept-bitcoin-in-2024-4k07 | As the popularity of cryptocurrencies continues to rise, more and more online stores are recognizing the benefits of accepting Bitcoin as a form of payment. In this article, we will explore the top 25 online stores that currently accept Bitcoin, providing you with a comprehensive guide on where to spend your digital cu... | owenparker22212 | |
1,880,761 | Pointers : what are they pointing to? | Pointers in C Pointers are a fundamental concept in C programming that enable you to... | 0 | 2024-06-07T19:23:58 | https://dev.to/apalebluedev/pointers-what-are-they-pointing-to-chg | c, pointers, clang, beginners | # Pointers in C
Pointers are a fundamental concept in C programming that enable you to directly access and manipulate memory. Understanding pointers is crucial for effective and efficient C programming.
## What is a Pointer?
A pointer is a value that represents a memory address. It points to a specific memory locati... | apalebluedev |
1,880,779 | LOOKING FOR THE BEST CRYPTOCURRENCY RECOVERY SERVICE | LEEULTIMATEHACKER@ AOL. COM Support @ leeultimatehacker . com. telegram:LEEULTIMATE wh@tsapp +1 ... | 0 | 2024-06-07T19:23:47 | https://dev.to/brooks_lawson_2ac50557b50/looking-for-the-best-cryptocurrency-recovery-service-4d4c | LEEULTIMATEHACKER@ AOL. COM
Support @ leeultimatehacker . com.
telegram:LEEULTIMATE
wh@tsapp +1 (715) 314 - 9248
https://leeultimatehacker.com
I had the pleasure of experiencing the exceptional services of LEE ULTIMATE HACKER, and I must say that this team is an absolute treasure. My journey with cryptocurrenc... | brooks_lawson_2ac50557b50 | |
1,880,773 | PHP | 06 Jun 2024 PHP 8.3.8 Released! The PHP development team announces the immediate availability of PHP... | 0 | 2024-06-07T19:13:54 | https://dev.to/marko_gacanovic_62a5a8b54/php-151 | php | 06 Jun 2024
PHP 8.3.8 Released!
The PHP development team announces the immediate availability of PHP 8.3.8. This is a security release.
All PHP 8.3 users are encouraged to upgrade to this version.
For source downloads of PHP 8.3.8 please visit our downloads page, Windows source and binaries can be found on windows.ph... | marko_gacanovic_62a5a8b54 |
1,863,267 | The core of WhatApp and Signal: Diffie-Hellman key exchange | Both WhatsApp and Signal are encrypted messaging applications, offering e2e encryption for it's... | 0 | 2024-06-07T19:13:28 | https://dev.to/prismlabsdev/the-core-of-whatapp-and-signal-diffie-hellman-key-exchange-50fd | cryptography, encryption | Both WhatsApp and Signal are encrypted messaging applications, offering e2e encryption for it's users. What this means is that all the communication is encrypted prior to being sent to the server or through public space, example: the internet. This makes it so you don't need to trust the server to keep your messages se... | jwoodrow99 |
1,880,691 | OpenVPN configuration for Tunnelbear in Windows | Maybe you've used Tunnelbear, maybe you have an alternative, but in any case it's a competitively... | 0 | 2024-06-07T19:12:57 | https://dev.to/riayi/openvpn-configuration-for-tunnelbear-8o1 | beginners, tunnelbear, openvpn, windows | Maybe you've used Tunnelbear, maybe you have an alternative, but in any case it's a competitively priced VPN with servers in many countries and an anonymous proxy. If you're using it, maybe you've wondered like me, if you can do away with the GUI in Windows, or automate it as a service when booting, dunno. This is a pr... | riayi |
1,880,772 | New here | I'm joining the team | 0 | 2024-06-07T19:11:21 | https://dev.to/dominic_patrick_fb5988f30/new-here-56em | I'm joining the team | dominic_patrick_fb5988f30 | |
1,880,771 | Streamline Your Tailwind CSS Workflow with Prettier Plugin Enhancements | Using Tailwind CSS to create modern user interfaces has grown in popularity. With its utility-first... | 0 | 2024-06-07T19:11:21 | https://dev.to/muzammil-cyber/streamline-your-tailwind-css-workflow-with-prettier-plugin-enhancements-3f1l | css, tailwindcss, prettier | Using Tailwind CSS to create modern user interfaces has grown in popularity. With its utility-first methodology, you may immediately apply pre-defined classes for styles such as margins, colors, spacing, and more. This saves you time writing custom CSS and keeps your styles consistent.
## Formatting for Readability an... | muzammil-cyber |
1,880,757 | Demystifying Advanced Git Commands: A Simple Guide | Git is an indispensable tool for developers, offering a robust way to manage code changes and... | 0 | 2024-06-07T19:04:41 | https://dev.to/ak_23/demystifying-advanced-git-commands-a-simple-guide-1lpj | git, learning, programming, productivity |
Git is an indispensable tool for developers, offering a robust way to manage code changes and collaborate on projects. While basic commands like `git init`, `git add`, and `git commit` get you started, understanding advanced Git commands can significantly boost your productivity and problem-solving skills. Let’s expl... | ak_23 |
1,880,769 | Ultimate Guide: Securing Your Express.js App for Maximum Protection | Hey there, fellow developers! Security should always be top of mind when building web applications,... | 0 | 2024-06-07T19:02:10 | https://dev.to/saudtech/ultimate-guide-securing-your-expressjs-app-for-maximum-protection-3khe | Hey there, fellow developers! Security should always be top of mind when building web applications, and Express.js is no exception. Let's dive into the key steps to safeguard your Express.js projects against those pesky vulnerabilities.
Get ready to add deadbolts to your express app!
### **HTTPS: Your Digital Bodygua... | saudtech | |
1,879,582 | Go and WebUI | Last week Microsoft released this blog post, An even faster Microsoft Edge, where they introduced... | 0 | 2024-06-07T18:59:40 | https://dev.to/stefanalfbo/go-and-webui-djj | 100daystooffload, go, webui, gui | Last week Microsoft released this blog post, [An even faster Microsoft Edge](https://blogs.windows.com/msedgedev/2024/05/28/an-even-faster-microsoft-edge/), where they introduced WebUI 2.0. This has been an internal project in the Edge project, which can be summarized as a new markup-first architecture that should redu... | stefanalfbo |
1,880,767 | Creative Parallax Slider | Swiper Slider | This demo showcases a responsive parallax slider using the Swiper library. It includes autoplay... | 0 | 2024-06-07T18:57:13 | https://dev.to/creative_salahu/creative-parallax-slider-swiper-slider-3lgj | codepen | This demo showcases a responsive parallax slider using the Swiper library. It includes autoplay functionality with a dynamic progress bar that visually indicates the time left before the slide changes. The progress bar fills horizontally, providing a clear and engaging user experience.
Features:
Parallax Effect: Adds... | creative_salahu |
1,880,766 | I Created Corona Clicker on Vue3 and Integrated It into a Telegram Web App | Recently, I was inspired by the game Hamster Kombat and decided to create my own clicker game based... | 0 | 2024-06-07T18:54:46 | https://dev.to/king_triton/i-created-corona-clicker-on-vue3-and-integrated-it-into-a-telegram-web-app-172f | vue, api, webdev, frontend | Recently, I was inspired by the game [Hamster Kombat](https://t.me/hamsteR_kombat_bot/start?startapp=kentId340146423) and decided to create my own clicker game based on Vue3, which I integrated into a Telegram Web App. In this article, I'll talk about how I came up with the idea, how I implemented the project, and what... | king_triton |
1,880,765 | Dev Challenges: Frontend - Neeraj Gupta | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration The... | 0 | 2024-06-07T18:54:17 | https://dev.to/neeraj15022001/dev-challenges-frontend-neeraj-gupta-321h | frontendchallenge, devchallenge, css, india | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
The Sahyadri Hills, or Western Ghats, transform into a lush paradise during the monsoon with vibrant greenery, cascading waterfalls, and misty peaks. Popular trekking spots and cultur... | neeraj15022001 |
1,880,760 | Understanding Redux | As applications grow in complexity, maintaining a consistent and predictable state across various... | 0 | 2024-06-07T18:50:01 | https://dev.to/heathertech/understanding-redux-29a | redux, programming, react, javascript | As applications grow in complexity, maintaining a consistent and predictable state across various components can be daunting. This is where Redux, a predictable state container for JavaScript applications, comes into play. In this blog, we will delve into what Redux is, why it’s beneficial, and how to integrate it into... | heathertech |
1,880,764 | Elastic Net Regularization: Balancing Between L1 and L2 Penalties | Elastic Net regularization stands out by combining the strengths of both L1(lasso) and L2(Ridge)... | 0 | 2024-06-07T18:46:40 | https://dev.to/harsimranjit_singh_0133dc/elastic-net-regularization-balancing-between-l1-and-l2-penalties-3ib7 | Elastic Net regularization stands out by combining the strengths of both L1(lasso) and L2(Ridge) regularization methods. This article will explore the theoretical, mathematical and practical aspects of the Elastic Net regularization.
## Lasso vs. Ridge Regression
- **Lasso Regression:** Adding L1 norm penalty, prom... | harsimranjit_singh_0133dc | |
1,880,763 | Cybersecurity in the Age of IoT: Challenges and Solutions | Proliferation of IoT Devices: The rapid increase in IoT devices expands the attack surface,... | 0 | 2024-06-07T18:44:49 | https://dev.to/bingecoder89/cybersecurity-in-the-age-of-iot-challenges-and-solutions-4g8 | webdev, javascript, devops, ai | 1. **Proliferation of IoT Devices**:
- The rapid increase in IoT devices expands the attack surface, making networks more vulnerable to cyber threats.
2. **Inadequate Security Measures**:
- Many IoT devices lack robust security features, often due to cost constraints or limited processing power, leaving them sus... | bingecoder89 |
1,880,759 | 777SweepStakesCasino | Welcome to 777SweepstakesCasino, your ultimate destination for thrilling online gaming! Dive into an... | 0 | 2024-06-07T18:36:17 | https://dev.to/777sweepstakescasino/777sweepstakescasino-4lak | onlinegaming, california, florida, texas | Welcome to 777SweepstakesCasino, your ultimate destination for thrilling online gaming! Dive into an electrifying world of excitement with our exclusive games like Ultra Panda, Fire Kirin, and Vegas X. Create your profile now to unlock access to a plethora of adrenaline-pumping experiences. Our platform offers seamless... | 777sweepstakescasino |
1,880,758 | Nếu một ngày Service account và API key trên Google Cloud không cánh mà bay ? | 1. Nguyên nhân ra đời bài viết Dạo quanh một số nhóm chat IT mình có bắt gắp 1 case study trong 1... | 0 | 2024-06-07T18:35:52 | https://dev.to/huydanggdg/neu-mot-ngay-service-account-va-api-key-tren-google-cloud-khong-canh-ma-bay--2l0l | googlecloud, security | **1. Nguyên nhân ra đời bài viết**
Dạo quanh một số nhóm chat IT mình có bắt gắp 1 case study trong 1 team có share service account và api key để tiện cho việc xây dựng ứng dụng. Không may có 1 bạn intern vô tình đẩy bộ code đó lên trên Github và để ở chế dộ public. Hacker dò được và truy cập trái phép vào tài khoản Go... | huydanggdg |
1,880,155 | Keep Your Monorepo Clean in VS Code with a Workspace Checkout Script | Monorepos can be both a blessing and a curse. They offer a centralized codebase, but managing a large... | 0 | 2024-06-07T18:35:09 | https://dev.to/mizanrifat/keep-your-monorepo-clean-in-vs-code-with-a-workspace-checkout-script-fkl | monorepo, vscode, workspaces, tutorial | **Monorepos** can be both a blessing and a curse. They offer a centralized codebase, but managing a large number of applications simultaneously in a Code Editor can quickly become overwhelming. The default behavior of any Code Editor, where all files and folders are visible in the explorer, makes searching for files a ... | mizanrifat |
1,878,721 | Laravel 11 + Inertia JS (VUE) CRUD Example: Part 1 | Hello Artisan, In today's blog post, we'll see how to use laravel 11 and Inertia js to build Single... | 0 | 2024-06-07T18:33:36 | https://dev.to/snehalkadwe/laravel-11-inertia-js-vue-crud-example-part-1-18oc | laravel, vue, php, javascript | **Hello Artisan,**
In today's blog post, we'll see how to use laravel 11 and Inertia js to build Single Page Application (SPA) with a CRUD operation by creating a simple Event management application.
Using this combination we can build modern single-page applications without leaving the comfort of our favorite backe... | snehalkadwe |
1,880,756 | Gerador de currículos otimizado para os sistemas de ATS utilizados no Brasil, como Gupy e 99Jobs ( gratuito 😎) | Para quem não conhece, ATS (Applicant Tracking System) é um sistema de rastreamento de candidatos... | 0 | 2024-06-07T18:30:36 | https://dev.to/pedrobarreto/gerador-de-curriculos-otimizado-para-os-sistemas-de-ats-utilizados-no-brasil-como-gupy-e-99jobs-gratuito--4po7 | braziliandevs, react, productivity | Para quem não conhece, ATS (Applicant Tracking System) é um sistema de rastreamento de candidatos utilizado pelas empresas para gerenciar o processo de recrutamento. Um currículo otimizado para ATS é crucial porque esses sistemas utilizam algoritmos para filtrar e classificar currículos com base em palavras-chave e cri... | pedrobarreto |
1,880,644 | From Whispers to Wildfire: Celebrating a Decade of Kubernetes | My journey in this space started in 2015. At small meet-ups and local conferences, I heard whispers... | 0 | 2024-06-07T17:58:17 | https://dev.to/fermyon/from-whispers-to-wildfire-celebrating-a-decade-of-kubernetes-112l | My journey in this space started in 2015. At small meet-ups and local conferences, I heard whispers about containers and this thing called Kubernetes. It was this abstraction that was simple enough to grasp in a sitting. Kubernetes - okay, you’ve got a pod which contains an app and the pod has some labels attached to i... | michellen | |
1,880,755 | I spent hours debugging an issue which was not even in my code! Docker could have saved my time | Have you ever faced issues like It works on my machine but not on yours? Or you wrote some code some... | 0 | 2024-06-07T18:28:10 | https://dev.to/mhm13dev/i-spent-hours-debugging-an-issue-which-was-not-even-in-my-code-docker-could-have-saved-my-time-1al9 | webdev, docker, productivity, devops | Have you ever faced issues like **_It works on my machine but not on yours_**? Or you wrote some code some time back and now you are not able to run it because of the environment setup? Or you are working on multiple projects and each project requires a different environment setup?
Almost 2 years ago, I wrote a script... | mhm13dev |
1,880,753 | Network configuration on Linux | This is how a network needs to be configured when spinning up a linux server. For example for a fresh... | 0 | 2024-06-07T18:25:55 | https://dev.to/santispavajeau/network-configuration-on-linux-1mod | linux, networking | This is how a network needs to be configured when spinning up a linux server. For example for a fresh install of a local lab on of linux virtual machines on VMware Fusion, Virtualbox or AWS, etc. These are some of the technical details that need to be verified and configured properly.
- **Host Address:** The unique IP... | santispavajeau |
1,880,693 | lá số tử vi | Tử Vi, hay Tử Vi Đẩu Số, là một bộ môn huyền học được dùng với các công năng chính như: luận đoán về... | 0 | 2024-06-07T18:13:20 | https://dev.to/dongphuchh023/la-so-tu-vi-293 | Tử Vi, hay Tử Vi Đẩu Số, là một bộ môn huyền học được dùng với các công năng chính như: luận đoán về tính cách, hoàn cảnh, dự đoán về các " vận hạn" trong cuộc đời của một người đồng thời nghiên cứu tương tác của một người với các sự kiện, nhân sự.... Chung quy với mục đích chính là để biết vận mệnh con người.
Lấy lá ... | dongphuchh023 | |
1,880,692 | How to Create My First ATV Search Project | Hi, I’m Freda Perry, and I’m excited to walk you through creating your first ATV (All-Terrain... | 0 | 2024-06-07T18:12:14 | https://dev.to/fredaperry/how-to-create-my-first-atv-search-project-2amp | javascript, webdev, atv | Hi, I’m Freda Perry, and I’m excited to walk you through creating your first ATV (All-Terrain Vehicle) search platform. This project will allow users to classify their ATVs as either used or new, connect with sellers, and create dealer accounts. We’ll be using a modern stack including JavaScript, Node.js, Mongoose, Nex... | fredaperry |
1,880,690 | MicrosoftLearning/Secure-storage-for-Azure-Files-and-Azure-Blob-Storage | Create a storage account to support the public website. In the portal, search for and select Storage... | 0 | 2024-06-07T18:01:50 | https://dev.to/emmyfx1/microsoftlearningsecure-storage-for-azure-files-and-azure-blob-storage-978 | Create a storage account to support the public website.
In the portal, search for and select Storage accounts.
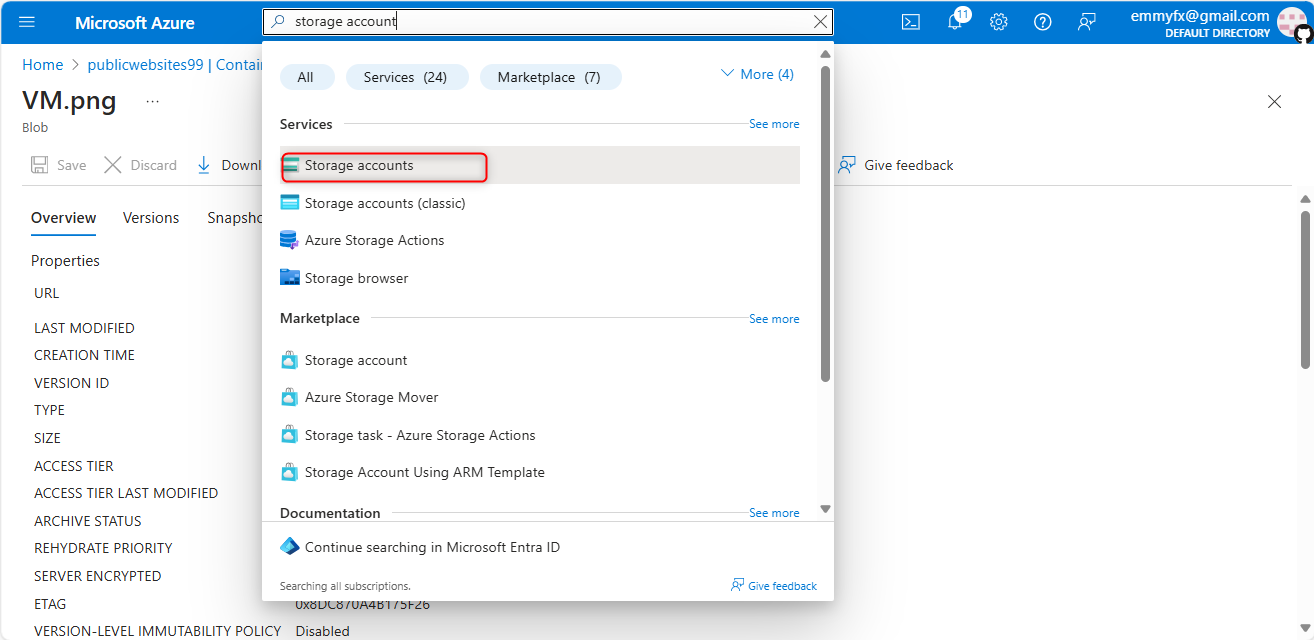
Select + Create.
. If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.su... | mikeyoung44 |
1,880,688 | Enhancing Multimodal Large Language Models with Vision Detection Models: An Empirical Study | Enhancing Multimodal Large Language Models with Vision Detection Models: An Empirical Study | 0 | 2024-06-07T17:56:21 | https://aimodels.fyi/papers/arxiv/enhancing-multimodal-large-language-models-vision-detection | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Enhancing Multimodal Large Language Models with Vision Detection Models: An Empirical Study](https://aimodels.fyi/papers/arxiv/enhancing-multimodal-large-language-models-vision-detection). If you like these kinds of analysis, you should subscribe to th... | mikeyoung44 |
1,875,919 | Coding Phase Begins | Surprisingly, there was a "Week 4" of the Community Bonding period. This might come as a bit of a... | 27,442 | 2024-06-07T17:55:54 | https://dev.to/chiemezuo/coding-phase-begins-2emo | gsoc, googlesummerofcode, wagtail, opensource | Surprisingly, there was a "Week 4" of the Community Bonding period. This might come as a bit of a surprise because there's an assumption that the Community bonding lasts for 3 weeks, but it actually lasted for about 25 days. I'm unsure if it had always been this way, but this was how I met it. Week 4 had only about 2 w... | chiemezuo |
1,880,687 | Comparing Inferential Strategies of Humans and Large Language Models in Deductive Reasoning | Comparing Inferential Strategies of Humans and Large Language Models in Deductive Reasoning | 0 | 2024-06-07T17:55:47 | https://aimodels.fyi/papers/arxiv/comparing-inferential-strategies-humans-large-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Comparing Inferential Strategies of Humans and Large Language Models in Deductive Reasoning](https://aimodels.fyi/papers/arxiv/comparing-inferential-strategies-humans-large-language-models). If you like these kinds of analysis, you should subscribe to ... | mikeyoung44 |
1,880,233 | Mastering Concurrency in C with Pthreads: A Comprehensive Guide | Concurrency and asynchronous programming in C with the library pthread. What is... | 0 | 2024-06-07T17:55:38 | https://dev.to/emanuelgustafzon/mastering-concurrency-in-c-with-pthreads-a-comprehensive-guide-56je | c, concurrency, asynchronous, pthread | Concurrency and asynchronous programming in C with the library pthread.
## What is Concurrency?
Concurrency is the ability of a computer system to execute multiple sequences of instructions simultaneously.
This does not necessarily mean they are running at the exact same time (as in parallelism) but that the syste... | emanuelgustafzon |
1,880,686 | Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models | Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models | 0 | 2024-06-07T17:55:12 | https://aimodels.fyi/papers/arxiv/alice-wonderland-simple-tasks-showing-complete-reasoning | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models](https://aimodels.fyi/papers/arxiv/alice-wonderland-simple-tasks-showing-complete-reasoning). If you like these kinds of analysis, you shou... | mikeyoung44 |
1,880,685 | Can LLMs Separate Instructions From Data? And What Do We Even Mean By That? | Can LLMs Separate Instructions From Data? And What Do We Even Mean By That? | 0 | 2024-06-07T17:54:37 | https://aimodels.fyi/papers/arxiv/can-llms-separate-instructions-from-data-what | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?](https://aimodels.fyi/papers/arxiv/can-llms-separate-instructions-from-data-what). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](ht... | mikeyoung44 |
1,880,684 | Virtual avatar generation models as world navigators | Virtual avatar generation models as world navigators | 0 | 2024-06-07T17:54:03 | https://aimodels.fyi/papers/arxiv/virtual-avatar-generation-models-as-world-navigators | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Virtual avatar generation models as world navigators](https://aimodels.fyi/papers/arxiv/virtual-avatar-generation-models-as-world-navigators). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.s... | mikeyoung44 |
1,880,683 | InfoLossQA: Characterizing and Recovering Information Loss in Text Simplification | InfoLossQA: Characterizing and Recovering Information Loss in Text Simplification | 0 | 2024-06-07T17:53:29 | https://aimodels.fyi/papers/arxiv/infolossqa-characterizing-recovering-information-loss-text-simplification | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [InfoLossQA: Characterizing and Recovering Information Loss in Text Simplification](https://aimodels.fyi/papers/arxiv/infolossqa-characterizing-recovering-information-loss-text-simplification). If you like these kinds of analysis, you should subscribe t... | mikeyoung44 |
1,863,885 | Pussit | Nikotiinipussit, tunnettu myös nimellä "denssit", ovat kasvattaneet suosiotaan erityisesti niiden... | 0 | 2024-05-24T10:58:11 | https://dev.to/denssitfi06/pussit-2l4l | Nikotiinipussit, tunnettu myös nimellä "denssit", ovat kasvattaneet suosiotaan erityisesti niiden keskuudessa, jotka haluavat nauttia nikotiinista ilman perinteisen tupakan haittoja. Näiden pienten, huomaamattomien pussien tarjoamat edut ovat moninaiset, ja markkinoilla on lukuisia merkkejä, kuten Denssi ja Killa, jotk... | denssitfi06 | |
1,880,682 | Harvard Undergraduate Survey on Generative AI | Harvard Undergraduate Survey on Generative AI | 0 | 2024-06-07T17:52:54 | https://aimodels.fyi/papers/arxiv/harvard-undergraduate-survey-generative-ai | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Harvard Undergraduate Survey on Generative AI](https://aimodels.fyi/papers/arxiv/harvard-undergraduate-survey-generative-ai). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or f... | mikeyoung44 |
1,880,681 | From Mechanical Engineer to Web Developer: My Journey | Hi Everyone! I’m Bashar, a mechanical engineering graduate who transitioned into web development. My... | 0 | 2024-06-07T17:52:35 | https://dev.to/basharvi/from-mechanical-engineer-to-web-developer-my-journey-5893 | webdev, beginners, career, careerdevelopment | Hi Everyone!
I’m Bashar, a mechanical engineering graduate who transitioned into web development. My journey began as a Design Engineer, where I spent six years creating machine parts and manufacturing drawings. However, the COVID-19 pandemic changed everything. Like many, I lost my job and found myself rethinking my ... | basharvi |
1,880,680 | Will we run out of data? Limits of LLM scaling based on human-generated data | Will we run out of data? Limits of LLM scaling based on human-generated data | 0 | 2024-06-07T17:52:20 | https://aimodels.fyi/papers/arxiv/will-we-run-out-data-limits-llm | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Will we run out of data? Limits of LLM scaling based on human-generated data](https://aimodels.fyi/papers/arxiv/will-we-run-out-data-limits-llm). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodel... | mikeyoung44 |
1,880,679 | Implementing Reinforcement Learning Datacenter Congestion Control in NVIDIA NICs | Implementing Reinforcement Learning Datacenter Congestion Control in NVIDIA NICs | 0 | 2024-06-07T17:51:45 | https://aimodels.fyi/papers/arxiv/implementing-reinforcement-learning-datacenter-congestion-control-nvidia | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Implementing Reinforcement Learning Datacenter Congestion Control in NVIDIA NICs](https://aimodels.fyi/papers/arxiv/implementing-reinforcement-learning-datacenter-congestion-control-nvidia). If you like these kinds of analysis, you should subscribe to ... | mikeyoung44 |
1,880,678 | RAFT: Adapting Language Model to Domain Specific RAG | RAFT: Adapting Language Model to Domain Specific RAG | 0 | 2024-06-07T17:51:11 | https://aimodels.fyi/papers/arxiv/raft-adapting-language-model-to-domain-specific | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [RAFT: Adapting Language Model to Domain Specific RAG](https://aimodels.fyi/papers/arxiv/raft-adapting-language-model-to-domain-specific). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substa... | mikeyoung44 |
1,880,677 | Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression | Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression | 0 | 2024-06-07T17:50:36 | https://aimodels.fyi/papers/arxiv/decoding-compressed-trust-scrutinizing-trustworthiness-efficient-llms | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression](https://aimodels.fyi/papers/arxiv/decoding-compressed-trust-scrutinizing-trustworthiness-efficient-llms). If you like these kinds of analysis, you should s... | mikeyoung44 |
1,880,676 | Coolpresentation: The Art of Innovation | Hey there, Ever wondered how those mind-blowing inventions and ideas come to life? It's all thanks... | 0 | 2024-06-07T17:50:26 | https://dev.to/coolpresentation/coolpresentation-the-art-of-innovation-45mp |

Hey there, Ever wondered how those mind-blowing inventions and ideas come to life? It's all thanks to the power of innovation! This isn't just for grown-up scientists or tech giants – innovation is a skill anyone can develop, and guess what? You've already got the potential to be a total inno... | coolpresentation | |
1,880,675 | SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales | SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales | 0 | 2024-06-07T17:50:01 | https://aimodels.fyi/papers/arxiv/sayself-teaching-llms-to-express-confidence-self | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales](https://aimodels.fyi/papers/arxiv/sayself-teaching-llms-to-express-confidence-self). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter... | mikeyoung44 |
1,880,674 | SqueezeLLM: Dense-and-Sparse Quantization | SqueezeLLM: Dense-and-Sparse Quantization | 0 | 2024-06-07T17:49:27 | https://aimodels.fyi/papers/arxiv/squeezellm-dense-sparse-quantization | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [SqueezeLLM: Dense-and-Sparse Quantization](https://aimodels.fyi/papers/arxiv/squeezellm-dense-sparse-quantization). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me o... | mikeyoung44 |
1,880,673 | ChatDev: Communicative Agents for Software Development | ChatDev: Communicative Agents for Software Development | 0 | 2024-06-07T17:48:52 | https://aimodels.fyi/papers/arxiv/chatdev-communicative-agents-software-development | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [ChatDev: Communicative Agents for Software Development](https://aimodels.fyi/papers/arxiv/chatdev-communicative-agents-software-development). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.su... | mikeyoung44 |
1,880,672 | Contrastive Learning and Mixture of Experts Enables Precise Vector Embeddings | Contrastive Learning and Mixture of Experts Enables Precise Vector Embeddings | 0 | 2024-06-07T17:48:18 | https://aimodels.fyi/papers/arxiv/contrastive-learning-mixture-experts-enables-precise-vector | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Contrastive Learning and Mixture of Experts Enables Precise Vector Embeddings](https://aimodels.fyi/papers/arxiv/contrastive-learning-mixture-experts-enables-precise-vector). If you like these kinds of analysis, you should subscribe to the [AImodels.fy... | mikeyoung44 |
1,880,671 | LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code | LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code | 0 | 2024-06-07T17:47:43 | https://aimodels.fyi/papers/arxiv/livecodebench-holistic-contamination-free-evaluation-large-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code](https://aimodels.fyi/papers/arxiv/livecodebench-holistic-contamination-free-evaluation-large-language). If you like these kinds of analysis, you should subscri... | mikeyoung44 |
1,880,670 | Do Llamas Work in English? On the Latent Language of Multilingual Transformers | Do Llamas Work in English? On the Latent Language of Multilingual Transformers | 0 | 2024-06-07T17:47:09 | https://aimodels.fyi/papers/arxiv/do-llamas-work-english-latent-language-multilingual | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Do Llamas Work in English? On the Latent Language of Multilingual Transformers](https://aimodels.fyi/papers/arxiv/do-llamas-work-english-latent-language-multilingual). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsl... | mikeyoung44 |
1,880,669 | LLark: A Multimodal Instruction-Following Language Model for Music | LLark: A Multimodal Instruction-Following Language Model for Music | 0 | 2024-06-07T17:46:01 | https://aimodels.fyi/papers/arxiv/llark-multimodal-instruction-following-language-model-music | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [LLark: A Multimodal Instruction-Following Language Model for Music](https://aimodels.fyi/papers/arxiv/llark-multimodal-instruction-following-language-model-music). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslette... | mikeyoung44 |
1,880,668 | Long Is More for Alignment: A Simple but Tough-to-Beat Baseline for Instruction Fine-Tuning | Long Is More for Alignment: A Simple but Tough-to-Beat Baseline for Instruction Fine-Tuning | 0 | 2024-06-07T17:45:26 | https://aimodels.fyi/papers/arxiv/long-is-more-alignment-simple-but-tough | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Long Is More for Alignment: A Simple but Tough-to-Beat Baseline for Instruction Fine-Tuning](https://aimodels.fyi/papers/arxiv/long-is-more-alignment-simple-but-tough). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi news... | mikeyoung44 |
1,880,667 | REBUS: A Robust Evaluation Benchmark of Understanding Symbols | REBUS: A Robust Evaluation Benchmark of Understanding Symbols | 0 | 2024-06-07T17:44:52 | https://aimodels.fyi/papers/arxiv/rebus-robust-evaluation-benchmark-understanding-symbols | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [REBUS: A Robust Evaluation Benchmark of Understanding Symbols](https://aimodels.fyi/papers/arxiv/rebus-robust-evaluation-benchmark-understanding-symbols). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https:... | mikeyoung44 |
1,880,666 | Empirical influence functions to understand the logic of fine-tuning | Empirical influence functions to understand the logic of fine-tuning | 0 | 2024-06-07T17:44:18 | https://aimodels.fyi/papers/arxiv/empirical-influence-functions-to-understand-logic-fine | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Empirical influence functions to understand the logic of fine-tuning](https://aimodels.fyi/papers/arxiv/empirical-influence-functions-to-understand-logic-fine). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](... | mikeyoung44 |
1,880,665 | Evaluating Quantized Large Language Models | Evaluating Quantized Large Language Models | 0 | 2024-06-07T17:43:43 | https://aimodels.fyi/papers/arxiv/evaluating-quantized-large-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Evaluating Quantized Large Language Models](https://aimodels.fyi/papers/arxiv/evaluating-quantized-large-language-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or foll... | mikeyoung44 |
1,880,664 | CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification | CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification | 0 | 2024-06-07T17:43:09 | https://aimodels.fyi/papers/arxiv/companykg-large-scale-heterogeneous-graph-company-similarity | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification](https://aimodels.fyi/papers/arxiv/companykg-large-scale-heterogeneous-graph-company-similarity). If you like these kinds of analysis, you should subscribe to the [AImod... | mikeyoung44 |
1,880,662 | Continuous Deployment to Kubernetes with ArgoCD | Continuous deployment (CD) is the process of automatically deploying changes to production. It is a... | 0 | 2024-06-07T17:43:01 | https://dev.to/davwk/continuous-deployment-to-kubernetes-with-argocd-4mi9 | kubernetes, cicd, argocd, githubactions | Continuous deployment (CD) is the process of automatically deploying changes to production. It is a key part of the DevOps toolchain, and it can help organizations to improve their software delivery speed, reliability, and security.
ArgoCD is a Kubernetes-native CD tool that can help you to automate the deployment of ... | davwk |
1,880,663 | Homemade Caching | It it almost never a good idea to reinvent the wheel, but if you really have a need a patch it rather... | 0 | 2024-06-07T17:42:25 | https://dev.to/sharesquare/homemade-caching-379l | performance, laravel, restapi, php | It it almost never a good idea to reinvent the wheel, but if you really have a need a patch it rather than reinventing it... maybe it will work!
In our latest [story](https://sharesquare-engineering.medium.com/homemade-caching-with-laravel-64c2a6a8cd2d) we present an elegant caching layer we developed in Laravel, and ... | sharesquare |
1,880,661 | To Believe or Not to Believe Your LLM | To Believe or Not to Believe Your LLM | 0 | 2024-06-07T17:42:00 | https://aimodels.fyi/papers/arxiv/to-believe-or-not-to-believe-your | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [To Believe or Not to Believe Your LLM](https://aimodels.fyi/papers/arxiv/to-believe-or-not-to-believe-your). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twit... | mikeyoung44 |
1,880,660 | Experience the Difference of Custom LASIK for Night Vision Improvement | For many people, nighttime driving or navigating low-light environments can be challenging due to... | 0 | 2024-06-07T17:41:36 | https://dev.to/columbus_lasikvision_28e/experience-the-difference-of-custom-lasik-for-night-vision-improvement-3kjl | For many people, nighttime driving or navigating low-light environments can be challenging due to issues like glare, halos, and poor contrast sensitivity. If you're one of them, Custom LASIK might be the solution you’ve been searching for. Custom LASIK, an advanced form of laser eye surgery, offers significant improvem... | columbus_lasikvision_28e | |
1,880,659 | Examining the robustness of LLM evaluation to the distributional assumptions of benchmarks | Examining the robustness of LLM evaluation to the distributional assumptions of benchmarks | 0 | 2024-06-07T17:40:52 | https://aimodels.fyi/papers/arxiv/examining-robustness-llm-evaluation-to-distributional-assumptions | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Examining the robustness of LLM evaluation to the distributional assumptions of benchmarks](https://aimodels.fyi/papers/arxiv/examining-robustness-llm-evaluation-to-distributional-assumptions). If you like these kinds of analysis, you should subscribe ... | mikeyoung44 |
1,880,646 | Buy verified cash app account | Buy verified cash app account Cash app has emerged as a dominant force in the realm of mobile banking... | 0 | 2024-06-07T17:25:52 | https://dev.to/lennoxgraves371/buy-verified-cash-app-account-1cij | Buy verified cash app account
Cash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with ... | lennoxgraves371 | |
1,880,658 | Position: Categorical Deep Learning is an Algebraic Theory of All Architectures | Position: Categorical Deep Learning is an Algebraic Theory of All Architectures | 0 | 2024-06-07T17:40:17 | https://aimodels.fyi/papers/arxiv/position-categorical-deep-learning-is-algebraic-theory | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Position: Categorical Deep Learning is an Algebraic Theory of All Architectures](https://aimodels.fyi/papers/arxiv/position-categorical-deep-learning-is-algebraic-theory). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi n... | mikeyoung44 |
1,880,657 | A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism | A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism | 0 | 2024-06-07T17:39:43 | https://aimodels.fyi/papers/arxiv/shocking-amount-web-is-machine-translated-insights | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism](https://aimodels.fyi/papers/arxiv/shocking-amount-web-is-machine-translated-insights). If you like these kinds of analysis, you should subscribe to the [AImodels.f... | mikeyoung44 |
1,880,655 | My third day | Its my 3rd third day on this platform. I am finding this platform quite cool. Although I hadn't any... | 0 | 2024-06-07T17:39:30 | https://dev.to/anakin/my-third-day-cad | linux, support | Its my 3rd third day on this platform. I am finding this platform quite cool. Although I hadn't any chance to go through the training session today. But I tried few more basic commands that was given by my collegue.
Commands like ls,rm,cp,mv,whomami, these commands I have been using on regular basis in my previous firm... | anakin |
1,880,654 | Large Language Models for Generative Information Extraction: A Survey | Large Language Models for Generative Information Extraction: A Survey | 0 | 2024-06-07T17:39:09 | https://aimodels.fyi/papers/arxiv/large-language-models-generative-information-extraction-survey | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Large Language Models for Generative Information Extraction: A Survey](https://aimodels.fyi/papers/arxiv/large-language-models-generative-information-extraction-survey). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi new... | mikeyoung44 |
1,880,653 | Bridging the Empirical-Theoretical Gap in Neural Network Formal Language Learning Using Minimum Description Length | Bridging the Empirical-Theoretical Gap in Neural Network Formal Language Learning Using Minimum Description Length | 0 | 2024-06-07T17:38:01 | https://aimodels.fyi/papers/arxiv/bridging-empirical-theoretical-gap-neural-network-formal | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Bridging the Empirical-Theoretical Gap in Neural Network Formal Language Learning Using Minimum Description Length](https://aimodels.fyi/papers/arxiv/bridging-empirical-theoretical-gap-neural-network-formal). If you like these kinds of analysis, you sh... | mikeyoung44 |
1,880,651 | Buy Verified Paxful Account | Buy Verified Paxful Account There are several compelling reasons to consider purchasing a... | 0 | 2024-06-07T17:35:39 | https://dev.to/lennoxgraves371/buy-verified-paxful-account-574h | Buy Verified Paxful Account
There are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various tran... | lennoxgraves371 | |
1,880,650 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-07T17:34:29 | https://dev.to/novahanna997/buy-verified-cash-app-account-2oap | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | novahanna997 |
1,880,649 | React native (UWP) support | Hi, React native supports windows application development using UWP. The Microsoft announced the... | 0 | 2024-06-07T17:34:27 | https://dev.to/g_d_b27f95328bf2403722965/react-native-uwp-support-58f9 | Hi,
React native supports windows application development using UWP.
The Microsoft announced the UWP upgrades stops and only supports bug fixes.
Does the react native support windows development using UWP ? Any updates?
Does the react native support recent "Windows APP SDK" development?
What is future plan to suppor... | g_d_b27f95328bf2403722965 | |
1,880,492 | From Unstructured to Structured: Adobe PDF Extract API for Data Transformation 📑 | Ever felt like you're wrestling with a stubborn PDF, desperately trying to extract that crucial... | 0 | 2024-06-07T17:31:54 | https://dev.to/theblogsquad/from-unstructured-to-structured-adobe-pdf-extract-api-for-data-transformation-1n08 | programming, learning, java, coding |
Ever felt like you're wrestling with a stubborn PDF, desperately trying to extract that crucial information? We've all been there. PDFs are fantastic for document portability, but their structure can often make it a nightmare to get the data you need.
Imagine this: you've just received a massive repository of PDF doc... | priyalakshmi_r |
1,880,645 | A Dentist's Code: My move to Software Development | Hello everyone, I want to share a personal journey that transformed my life in ways I never imagined.... | 0 | 2024-06-07T17:23:15 | https://gabripenteado.medium.com/a-dentists-code-my-move-to-software-development-5f4baf2d8317 | careerchange, dentisttodev, softwaredevelopment, healthtotech | Hello everyone, I want to share a personal journey that transformed my life in ways I never imagined. My professional background is in dentistry. I spent years mastering the art and science of dental care, but I always had a persistent interest in technology simmering beneath the surface. This fascination inspired me t... | gabrielpenteado |
1,880,629 | HOW TO CREATE WINDOWS 11 VIRTUAL MACHINE ON AZURE PORTAL | Step 1: Logging into Azure Portal Open your web browser and navigate to... | 0 | 2024-06-07T17:20:09 | https://dev.to/edjdeborah/how-to-create-windows-11-virtual-machine-on-azure-portal-410a | Step 1: Logging into Azure Portal
Open your web browser and navigate to https://portal.azure.com.
Sign in using your Azure account credentials.
Step 2: Navigating to Virtual Machines
After logging in, you’ll land on the Azure dashboard. In the left-hand menu, click on “Virtual machines”
 isn't just a platform for [mobile games](https://nostra.gg/articles/Lock-Screen-Games-Are-a-Game-Changer-for... | claywinston |
1,882,517 | Dependency Inversion Principle | The Dependency Inversion Principle (DIP) states that high level modules(Payment ) should not depend... | 0 | 2024-06-10T02:20:26 | https://gurupalaniveltech.hashnode.dev/dependency-inversion-principle | dependencyinversion, solidprinciples | ---
title: Dependency Inversion Principle
published: true
date: 2024-06-07 16:59:29 UTC
tags: dependencyinversion,SOLIDprinciples
canonical_url: https://gurupalaniveltech.hashnode.dev/dependency-inversion-principle
---
The Dependency Inversion Principle (DIP) states that high level modules(Payment ) should not depend ... | palanivel_sundararajangu |
1,880,623 | How to Reverse a String in Java: A Comprehensive Guide | Reversing a string is a common programming task that can be approached in several ways. In this blog,... | 0 | 2024-06-07T16:58:56 | https://dev.to/fullstackjava/how-to-reverse-a-string-in-java-a-comprehensive-guide-10n4 | webdev, javascript, beginners, programming |
Reversing a string is a common programming task that can be approached in several ways. In this blog, we'll explore various methods to reverse a string in Java, providing detailed explanations and sample code for each approach.
### 1. Using StringBuilder
The `StringBuilder` class in Java provides a convenient way t... | fullstackjava |
1,879,563 | Fixtures do Cypress para testes | Conhecimentos prévios Cypress, Cucumber, BDD Veja a aplicação no Slave One:... | 0 | 2024-06-07T16:58:53 | https://dev.to/gustavoacaetano/fixtures-do-cypress-para-testes-1748 | ledscommunity, cypress, fixtures | ## Conhecimentos prévios
### Cypress, Cucumber, BDD
Veja a aplicação no Slave One:
https://dev.to/marcela_lage_094e814c6a4e/documentacao-dos-testes-do-sistema-slave-one-2kmb
### Fixtures
As fixtures do Cypress são dados estáticos que podem ser utilizados pelos testes. O arquivo é em formato JSON.
### Intercept
O ... | gustavoacaetano |
1,880,621 | The Joy of Popping Bubbles: A Simple Pleasure in a Complex World | In a world filled with hustle and bustle, where technology constantly vies for our attention, there... | 0 | 2024-06-07T16:56:19 | https://dev.to/pocket7games/the-joy-of-popping-bubbles-a-simple-pleasure-in-a-complex-world-5488 | In a world filled with hustle and bustle, where technology constantly vies for our attention, there exists a simple pleasure that transcends age, culture, and background: **[popping bubbles](https://www.pocket7games.com/post/top-5-online-memory-games?backlink_nabab)**. Whether it's the bubbles in bubble wrap, bubble gu... | pocket7games | |
1,880,611 | Core Architectural components of Azure | Introduction What is Microsoft Azure? Azure is a continually expanding set of cloud... | 0 | 2024-06-07T16:54:47 | https://dev.to/mickyt_oke/core-architectural-components-of-azure-blh | azure, corecomponent, azureinfrastructure | ## Introduction
**What is Microsoft Azure?**
Azure is a continually expanding set of cloud services that help you meet current and future business challenges. Azure gives you the freedom to build, manage, and deploy applications on a massive global network using your favorite tools and frameworks.
Azure provides art... | mickyt_oke |
1,880,618 | Home K Custom Boxes - K Custom Boxes | Kcustom Boxes understands that custom packaging varies from business to business. That’s why we have... | 0 | 2024-06-07T16:49:30 | https://dev.to/kcustom_box/home-k-custom-boxes-k-custom-boxes-39kh | Kcustom Boxes understands that custom packaging varies from business to business. That’s why we have created categories of boxes, such as customized boxes for your food, retail, cosmetics, and CBD businesses.
In addition, we are proud to say that we excel in our printing services. We print stickers, labels, logos, bus... | kcustom_boxes | |
1,880,617 | Home K Custom Boxes - K Custom Boxes | Kcustom Boxes understands that custom packaging varies from business to business. That’s why we have... | 0 | 2024-06-07T16:47:16 | https://dev.to/kcustom_box/home-k-custom-boxes-k-custom-boxes-221j | Kcustom Boxes understands that custom packaging varies from business to business. That’s why we have created categories of boxes, such as customized boxes for your food, retail, cosmetics, and CBD businesses.
In addition, we are proud to say that we excel in our printing services. We print stickers, labels, logos, bus... | kcustom_boxes | |
1,880,616 | How I shipped an event registration site in just 1 week with Nuxt, Directus, OpenAI, and TailwindCSS | I recently shipped a event registration site in 1 week that would take some companies 1 year. And I'm... | 0 | 2024-06-07T16:47:03 | https://dev.to/bryantgillespie/how-i-shipped-an-event-registration-site-in-just-1-week-with-nuxt-directus-openai-and-tailwindcss-123n | openai, directus, nuxt, tailwindcss | I recently shipped a event registration site in 1 week that would take some companies 1 year. And I'm definitely not a 10x developer.
When I was first learning to code, I always appreciated behind-the-curtain looks at how projects were made, soooo… here’s the story and how it’s built.
## The TLDR;
Adding this here,... | bryantgillespie |
1,880,575 | CSS Animations Made EZ | I released a free AI CSS animation generator a month ago, my first software in the animation... | 0 | 2024-06-07T16:15:38 | https://dev.to/max_prehoda_9cb09ea7c8d07/css-animations-made-ez-3pp7 | webdev, ai, css, design | I released a free AI CSS animation generator a month ago, my first software in the animation space.
As a dev/designer, I was frustrated with the annoying & tedious process of writing keyframe animations. The lack of good tools available led me to build my own solution.
After a month of intense development, it’s ready... | max_prehoda_9cb09ea7c8d07 |
1,880,377 | CREATING A WINDOWS 11 VIRTUAL MACHINE ON MICROSOFT AZURE PORTAL | Virtual machines offer flexibility and isolation, making them a great tool for various use... | 27,629 | 2024-06-07T16:46:30 | https://dev.to/aizeon/creating-a-windows-11-virtual-machine-on-microsoft-azure-37p2 | beginners, azure, virtualmachine, tutorial | Virtual machines offer flexibility and isolation, making them a great tool for various use cases.
This time, we will be deploying a Windows-based VM—precisely, Windows 11.
With this Windows 11 VM, users can:
- run Windows operating systems on a non-Windows host computer (e.g., macOS, Linux) and access Windows-exclusi... | aizeon |
1,880,613 | Flutter Fundamentals: Unwrapping the Essentials of Basic Widgets | Introduction Flutter, Google’s UI toolkit for crafting natively compiled applications for... | 0 | 2024-06-07T16:41:44 | https://dev.to/eldhopaulose/flutter-fundamentals-unwrapping-the-essentials-of-basic-widgets-5a41 | flutter, frontend, google, dart | ## Introduction
Flutter, Google’s UI toolkit for crafting natively compiled applications for mobile, web, and desktop from a single codebase, has gained immense popularity. At the heart of Flutter are its widgets, the building blocks of any Flutter app. Understanding these widgets is crucial for any Flutter developer.... | eldhopaulose |
1,880,612 | Foreign Exchange API: Enhancing Financial Applications with Accurate Data | In today's globalized economy, accurate and timely information about currency exchange rates is... | 0 | 2024-06-07T16:39:00 | https://dev.to/sameeranthony/foreign-exchange-api-enhancing-financial-applications-with-accurate-data-3126 | webdev, beginners, api, javascript | In today's globalized economy, accurate and timely information about currency exchange rates is crucial for businesses, investors, and travelers. Financial applications that rely on foreign exchange data need to provide up-to-date and reliable information to their users. This is where a [foreign exchange API](https://c... | sameeranthony |
1,880,610 | 242. Valid Anagram | Topic: Array & Hashing Soln 1 (dictonary solution): Compare the lengths of both strings. If... | 0 | 2024-06-07T16:31:46 | https://dev.to/whereislijah/242-valid-anagram-35o7 | Topic: Array & Hashing
Soln 1 (dictonary solution):
1. Compare the lengths of both strings.
2. If they are not the same length, they are not anagrams.
3. Create a new dictionary called count.
4. Loop through the characters in s:
- If the character already exists in the dictionary, then increment its value by 1.
- E... | whereislijah | |
1,880,609 | Modern IT Outsourcing: A New Level of Services | As a result of the dynamic nature of the modern economy, businesses are required to develop rapidly... | 0 | 2024-06-07T16:30:58 | https://dev.to/danieldavis/modern-it-outsourcing-a-new-level-of-services-2bao | As a result of the dynamic nature of the modern economy, businesses are required to develop rapidly and adapt to shifting conditions. When it comes to information technology, many companies have discovered that outsourcing is a useful tool that allows them to focus on their primary business while saving them time, mone... | danieldavis | |
1,880,603 | Announcing runtime-environment: A Rust Crate for Detecting Operating Systems at Runtime | Hey! I am excited to announce the release of my new Rust crate as part of my learning process... | 19,830 | 2024-06-07T16:26:07 | https://dev.to/dhanushnehru/announcing-runtime-environment-a-rust-crate-for-detecting-operating-systems-at-runtime-3fc2 | rust, codenewbie, beginners, showdev | Hey!
I am excited to announce the release of my new Rust crate as part of my learning process “runtime_environment”! 🦀
This pack is perfect for programmers who want to detect operating systems at runtime. It also provides a flexible toolkit for this purpose which is commonly encountered in software development.
##... | dhanushnehru |
1,880,569 | 7+ open source software tools for the public sector | Open source software is becoming more and more important, especially in the public sector in Europe.... | 0 | 2024-06-07T16:25:00 | https://dev.to/openproject/7-open-source-software-tools-for-the-public-sector-1lnf | opensource, tooling, productivity, software | Open source software is becoming more and more important, especially in the public sector in Europe.
Open source implies providing access to its source code or segments of it, permitting utilization, modification, additions, and distribution. This means that the software is particularly transparent and therefore secu... | jenwikehuger |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.