
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,881,005 | Connect MongoDB with Node.js: A Practical Guide with Mongoose | In the ever-evolving landscape of web development, building scalable and efficient applications has... | 0 | 2024-06-08T03:00:01 | https://dev.to/vyan/seamlessly-connect-mongodb-with-nodejs-a-practical-guide-with-mongoose-1gk6 | webdev, javascript, node, react | In the ever-evolving landscape of web development, building scalable and efficient applications has become a top priority. MongoDB, a powerful NoSQL document-oriented database, has emerged as a go-to solution for developers seeking flexibility and scalability. When combined with the versatility of Node.js, a high-perfo... | vyan |
1,881,003 | Setting Up Docker in a Next.js Project: A Comprehensive Guide | Docker is a powerful tool for creating, deploying, and managing containerized applications. Using... | 0 | 2024-06-08T02:45:34 | https://dev.to/hasancse/setting-up-docker-in-a-nextjs-project-a-comprehensive-guide-3m5d | docker, nextjs, webdev, tutorial | Docker is a powerful tool for creating, deploying, and managing containerized applications. Using Docker in a Next.js project can streamline your development workflow, ensure consistent environments, and simplify deployment. In this blog post, we'll walk through setting up Docker for a Next.js project from scratch.
##... | hasancse |
1,881,002 | Endless Summer | This is a submission for [Frontend Challenge... | 0 | 2024-06-08T02:41:43 | https://dev.to/srishti_01/endless-summer-4964 | frontendchallenge, devchallenge, css | This is a submission for [Frontend Challenge v24.04.17]
https://sriss-webweaver.github.io/frontend-challenge/
Inspiration
A vibrant summer scene with a sliced watermelon, a melting ice cream stick, and two sunglasses resting. The colorful background features a sunset motif. This imagery evokes feelings of summertime f... | srishti_01 |
1,799,780 | Engenharia Reversa Primeiro Contato - Parte 2 | DIABLO - ORiON_CrackMe1 +18 O tutorial é dedicado aos iniciantes em engenharia reversa,... | 0 | 2024-06-08T02:29:20 | https://dev.to/ryan_gozlyngg/engenharia-reversa-primeiro-contato-parte-2-m2g | braziliandevs, beginners, tutorial | ## DIABLO - ORiON_CrackMe1 +18
O tutorial é dedicado aos iniciantes em engenharia reversa, mas eu tentarei explicar, o máximo possível, alguns processos do Assembly e da arquitetura Intel x86, para que, até mesmo pessoas que nunca estudaram nada disso, possam acompanhar, e -se eu não falhar na clareza- entender os pro... | ryan_gozlyngg |
1,880,999 | Get wallet address for multiple chains in cosmos app chains | In the Cosmos ecosystem, each chain has its own specific prefix for Bech32 addresses. When you... | 0 | 2024-06-08T02:29:01 | https://dev.to/tqmvt/get-wallet-address-for-multiple-chains-in-cosmos-app-chains-56pb | web3, cosmoschain, cosmjs, betch32 | In the Cosmos ecosystem, each chain has its own specific prefix for Bech32 addresses. When you connect your [Keplr](https://www.keplr.app/) wallet to a Cosmos SDK-based chain, you receive a wallet address specific to that chain. However, the underlying public key remains the same across these chains, and you can derive... | tqmvt |
1,880,998 | Exploring the Tech Stack of Major Banks: Key Tools and Technologies for Software Engineers | Exploring the Tech Stack of Major Banks: Key Tools and Technologies for Software... | 0 | 2024-06-08T02:27:52 | https://dev.to/isamarsoftwareengineer/exploring-the-tech-stack-of-major-banks-key-tools-and-technologies-for-software-engineers-3o7f | java, bank, springboot, devops | ## Exploring the Tech Stack of Major Banks: Key Tools and Technologies for Software Engineers
In the fast-evolving world of finance, major banks are leveraging cutting-edge technologies to enhance their services, improve security, and streamline operations. Software engineers in this sector work with a diverse set of ... | isamarsoftwareengineer |
1,880,964 | PITFALLS OF CONFIRMATION BIAS IN PROGRAMMING | What Confirmation Bias Is. This is simply a situation whereby you search for, interprete or... | 0 | 2024-06-08T02:20:09 | https://dev.to/davidbosah/pitfalls-of-confirmation-bias-in-programming-3mai | webdev, beginners, tutorial, programming | **What Confirmation Bias Is.**
This is simply a situation whereby you search for, interprete or understand certain facts based on an your already mentally programmed information or experience. As simple as this may sound, it plays a huge role in our lives. The reason for this is that an already well crafted ideology o... | davidbosah |
1,880,992 | Estudos em Quality Assurance (QA) - SDLC | O SDLC (Software Development Life Cycle ou Ciclo de Vida de Desenvolvimento de Sistemas) é um... | 0 | 2024-06-08T02:13:22 | https://dev.to/julianoquites/estudos-em-quality-assurance-qa-sdlc-172p | qa, testing, automation, sdlc | O **SDLC** (Software Development Life Cycle ou Ciclo de Vida de Desenvolvimento de Sistemas) é um framework utilizado para estruturar o desenvolvimento de sistemas de informação de maneira organizada e eficiente. Ele abrange todas as etapas, desde o planejamento inicial até o encerramento do projeto, garantindo que os ... | julianoquites |
1,880,988 | Arquitetura Monolítica: Uma Visão Geral | Introdução A arquitetura de software é um campo vasto e diversificado, crucial para o... | 0 | 2024-06-08T02:01:41 | https://dev.to/iamthiago/arquitetura-monolitica-uma-visao-geral-l9j | ## Introdução
A arquitetura de software é um campo vasto e diversificado, crucial para o desenvolvimento de sistemas robustos e eficientes. Entre os diferentes paradigmas de arquitetura, a arquitetura monolítica é uma das mais tradicionais e amplamente utilizadas. Neste artigo, exploraremos o conceito de arquitetura m... | iamthiago | |
1,880,985 | Let’s Build One Person Business Using 100% AI | AI made it possible for 9-to-5 workers to start a one-person business without quitting their... | 0 | 2024-06-08T01:55:30 | https://dev.to/exploredataaiml/lets-build-one-person-business-using-100-ai-1mgo | llm, rag, ai | AI made it possible for 9-to-5 workers to start a one-person business without quitting their jobs.
[Full Article] (https://medium.com/@learn-simplified/lets-build-one-person-business-using-100-ai-4bb4285892c9)
The Opportunities for Starting a Business
○ There are huge opportunities to start your own business by lever... | exploredataaiml |
1,880,984 | Beviral - beviral.me social media engagement services | Elevate Your Social Media Game with Be Viral's Top Services In today's digital landscape,... | 0 | 2024-06-08T01:52:00 | https://dev.to/beviralme/beviral-beviralme-social-media-engagement-services-f1e | ### Elevate Your Social Media Game with Be Viral's Top Services
In today's digital landscape, having a robust social media presence is crucial for success. At Be Viral, we specialize in providing top-tier services to help you grow your accounts organically and effectively. Our most profitable services focus on enhanci... | beviralme | |
1,880,982 | Sleepy Cloud Animation | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration ... | 0 | 2024-06-08T01:51:04 | https://dev.to/umeshsuwal/sleepy-cloud-animation-5g5b | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
<!-- What are you highlighting today? -->
## Demo
Link - https://sleepycloudanimation.netlify.app/
 models Step #2. Create the Server Step #3. Create the Create API Step #4.... | 0 | 2024-06-08T01:26:20 | https://dev.to/mbshehzad/what-are-the-top-level-steps-to-create-an-api--53nc | node, javascript, express | Step #1. Create the (data) models
Step #2. Create the Server
Step #3. Create the Create API
Step #4. Create the Read API
Step #5. Create the Update API
Step #6. Create the Delete API | mbshehzad |
1,880,869 | Fintech's role in mainstreaming cryptocurrency adoption | Cryptocurrency, once a niche domain reserved for tech enthusiasts and early adopters, is rapidly... | 0 | 2024-06-07T22:09:57 | https://dev.to/eincheste/fintechs-role-in-mainstreaming-cryptocurrency-adoption-4k9l | beginners, devops, career, web3 |
Cryptocurrency, once a niche domain reserved for tech enthusiasts and early adopters, is rapidly gaining traction in the mainstream financial world. This shift can be largely attributed to the integration of financial technology (fintech) with the cryptocurrency ecosystem. By leveraging innovative technologies and de... | eincheste |
1,880,978 | HOW TO RECOVER YOUR CRYPTOCURRENCY FROM SUSPICIOUS INVESTMENTS AND ONLINE TRADING | While browsing through Instagram, I came across a post from one of my friends about their successful... | 0 | 2024-06-08T01:24:05 | https://dev.to/conchi_martingambero_fe0/how-to-recover-your-cryptocurrency-from-suspicious-investments-and-online-trading-2l6d | cryptocurrency, recovery, bitcoinexper, bitcoin |
While browsing through Instagram, I came across a post from one of my friends about their successful Bitcoin investment and substantial profits. Intrigued by their claims, I decided to visit the website mentioned in the post. After creating an account, I contacted the support chat and was provided with a Telegram cont... | conchi_martingambero_fe0 |
1,880,976 | Tipos Básicos em Kotlin | Introdução Recentemente mudei de equipe na empresa onde estou trabalhando atualmente.... | 0 | 2024-06-08T01:23:11 | https://dev.to/oliversieto/tipos-basicos-em-kotlin-10i2 | kotlin, programação, tipodedados | ---
title: Tipos Básicos em Kotlin
published: true
description:
tags: kotlin, programação, tipodedados
# cover_image: https://kotlinlang.org/_next/static/chunks/images/hero-cover-6dd34ed75729683235a4f47d714a604e.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-07 23:34 +0000
---
## Introdução
R... | oliversieto |
1,880,975 | Building in Public - 1 | I’m building a client-only version of Splitwise for fun and practice. One thing that I’m trying to... | 27,633 | 2024-06-08T01:20:14 | https://bryanliao.dev/blog/building-in-public-1/ | buildinpublic | I’m building a client-only version of Splitwise for fun and practice. One thing that I’m trying to figure out is how to persist data without using a server or database. Some client-based options are [localStorage](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage) and [indexedDB](https://developer.mo... | liaob |
1,880,973 | A comprehensive comparison between MySQL and PostgreSQL | MySQL and PostgreSQL are both open-source relational database management systems with wide user bases... | 0 | 2024-06-08T01:19:28 | https://dev.to/concerate/a-comprehensive-comparison-between-mysql-and-postgresql-53oi | MySQL and PostgreSQL are both open-source relational database management systems with wide user bases and years of development history in the field of database management. While both are used for storing and managing data, they have significant differences in various aspects including performance, features, scalability... | concerate | |
1,880,972 | I RECOMMEND TRUST GEEKS HACK EXPERT FOR PHONE HACK & SPY ON CHEATERS | As I struggled to uncover the source of the anonymous threats and harassment I was facing online, I... | 0 | 2024-06-08T01:16:56 | https://dev.to/garcia_gladystolbert_1/i-recommend-trust-geeks-hack-expert-for-phone-hack-spy-on-cheaters-3ebe | spy, general, hackers, love | As I struggled to uncover the source of the anonymous threats and harassment I was facing online, I turned to (TRUST GEEKS HACK EXPERT) for assistance. With their expertise in digital forensics and online investigation, they were able to trace the messages back to their origin. Through meticulous analysis and advanced ... | garcia_gladystolbert_1 |
1,880,971 | A Declaration of World Peace | At each appointed time, Mankind has abandoned the narrative that binds us - choosing to revolt over... | 27,632 | 2024-06-08T01:14:39 | https://desir.foundation/series/a-declaration-world-peace | opensource, watercooler, ai, discuss | _At each appointed time, Mankind has abandoned the narrative that binds us - choosing to revolt over the status quo._
---
_We will choose to amend our story when participation corrupts human flourishing & Coherence. And we find ourselves at yet another appointed time, one of the utmost profundity and demanding a deli... | desirtechnologies |
1,880,970 | How to embed your git bash into Visual Studio | Today you'll learn how to integrate your git bash straight into your Visual Studio. In the end it'll... | 0 | 2024-06-08T01:14:37 | https://dev.to/henriqueholtz/how-to-embed-your-git-bash-into-visual-studio-1afb | bash, visualstudio | Today you'll learn how to integrate your git bash straight into your Visual Studio. In the end it'll looks just like this:
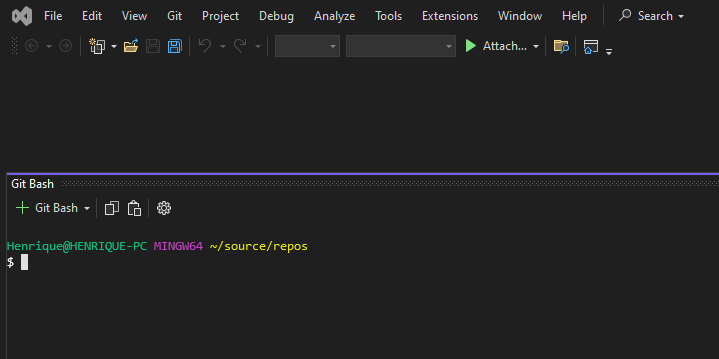
---
To do that you need open the terminal configuration section in the following ... | henriqueholtz |
1,880,965 | O Google IO e as alegrias dos eventos presenciais | A popularização dos eventos online permitiu que o conteúdo e conhecimento conseguissem viajar até os... | 0 | 2024-06-08T01:00:59 | https://dev.to/tyemy/o-google-io-e-as-alegrias-dos-eventos-presenciais-1i1i | google, community, watercooler | A popularização dos eventos online permitiu que o conteúdo e conhecimento conseguissem viajar até os públicos mais distantes, e isso foi ótimo! Em contrapartida, nesse modelo acabamos interagindo um pouco menos com outras pessoas e ficamos menos imersos na experiência de um evento (não tem lanchinho gostoso, brindes, o... | tyemy |
1,880,966 | the Core Azure Architectural Components | The core architectural components of Microsoft Azure include: Azure Regions: These are... | 0 | 2024-06-08T01:00:39 | https://dev.to/oluwole_akins/the-core-azure-architectural-components-8g6 | azure, architecture | The core architectural components of Microsoft Azure include:
1. Azure Regions: These are geographically distributed datacenter locations where Azure resources are hosted. Each region consists of multiple datacenters.
2. Availability Zones: These provide redundancy and high availability within a region. Availability ... | oluwole_akins |
1,880,950 | EsLint + TypeScript + Prettier (Flat Config) | Today I woke up with the need to create an email scheduled notification for my personal project using... | 0 | 2024-06-08T00:45:57 | https://dev.to/joshuanr5/eslint-typescript-prettier-flat-config-1bmb | Today I woke up with the need to create an email scheduled notification for my personal project using AWS and I noticed that these last few months I have abandoned NodeJS ... y cuando comenzé a configurar una función lambda usando SAM (Serverless Application Model) me di cuenta que por lo menos necesitaria una configur... | joshuanr5 | |
1,880,961 | LaCebollaAventurera | Check out this Pen I made! | 0 | 2024-06-08T00:45:44 | https://dev.to/dalelo_gamesygraphics_f/lacebollaaventurera-1hfl | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Dalelo-GAMES-y-GRAPHICS/pen/NWVvrLq %} | dalelo_gamesygraphics_f |
1,880,960 | Learning the Basics of Large Language Model (LLM) Applications with LangChainJS | LangChainJS is a powerful tool for building and operating Large Language Models (LLMs) in JavaScript.... | 0 | 2024-06-08T00:38:38 | https://dev.to/praveencs87/learning-the-basics-of-large-language-model-llm-applications-with-langchainjs-4035 | langchain, langchainjs, javascript, llm | LangChainJS is a powerful tool for building and operating Large Language Models (LLMs) in JavaScript. It’s perfect for creating applications across various platforms, including browser extensions, mobile apps with React Native, and desktop apps with Electron. The popularity of JavaScript among developers, combined with... | praveencs87 |
1,880,958 | Beginner's Guide to Clocks: Understanding the Essentials | Project:- 6/500 Clocks Project Live Demo Description The clock project is a... | 27,575 | 2024-06-08T00:35:01 | https://dev.to/raajaryan/beginners-guide-to-clocks-understanding-the-essentials-1g0l | javascript, beginners, opensource, tutorial | ## Project:- 6/500 Clocks Project
[Live Demo](https://deepakkumar55.github.io/ULTIMATE-JAVASCRIPT-PROJECT/Basic%20Projects/4-clock)
## Description
The clock project is a simple web application that displays the current time in real-time. It provides users with a convenient way to check the time on their devices wit... | raajaryan |
1,880,956 | Exploring Data Structures and Algorithms in C | Introduction Data structures and algorithms are fundamental concepts in computer science... | 0 | 2024-06-08T00:32:28 | https://dev.to/kartikmehta8/exploring-data-structures-and-algorithms-in-c-2am9 | webdev, javascript, beginners, programming | ## Introduction
Data structures and algorithms are fundamental concepts in computer science that enable efficient storage and retrieval of data. They are essential in the development of efficient and optimized software and play a crucial role in problem-solving. In this article, we will explore the basic data structur... | kartikmehta8 |
1,880,954 | Meet the world most beautiful beaches | This is a submission for [Frontend Challenge... | 0 | 2024-06-08T00:30:25 | https://dev.to/elmerurbina/best-beaches-in-the-world-5ghd | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
<!-- Tell us what you built and what you were looking to achieve. -->
## Demo
Screenshots of the template.
, i made a Scrollable table with Fix First Row (which is the column header) table was successfull and function but it's always show this message in debug console:
Exception caught by wi... | ahmad_rifai_54a20be09025e |
1,880,942 | Learning from Code Reviews: Fostering Collaboration | Just finished watching a presentation by Derrick Pryor about making code reviews more effective. Who... | 0 | 2024-06-07T23:52:22 | https://dev.to/aborov/learning-from-code-reviews-fostering-collaboration-pg0 | codereview, beginners | Just finished watching a [presentation by Derrick Pryor](https://www.youtube.com/watch?v=PJjmw9TRB7s) about making code reviews more effective. Who knew they were about more than just catching bugs? Apparently, a good code review culture can be a game-changer for learning and teamwork.
Here's the big takeaway for me: ... | aborov |
1,880,935 | Um relato sobre a prova de Certificação AWS Cloud Practitioner (CLF-C02) em 2024 | Conteúdo para a prova de Certificação Cloud Practitioner (CLF-C02) em 2024 Data: June 7,... | 0 | 2024-06-07T23:29:13 | https://dev.to/coelhodiana/um-relato-sobre-a-prova-de-certificacao-aws-cloud-practitioner-clf-c02-em-2024-p12 | aws, clfc02, cloud | # Conteúdo para a prova de Certificação Cloud Practitioner (CLF-C02) em 2024
Data: June 7, 2024
Recentemente, tive a satisfação de ser aprovada no exame de certificação AWS Cloud Practitioner (CLF-C02). Este marco significativo na minha jornada de aprendizado só foi possível graças a uma série de recursos e estratégi... | coelhodiana |
1,880,941 | LoyaltyRoller: Zapier Automation of sending NFTs to users on sucessful Stripe payments using Owl Protocol | Introduction Owl Protocol, a web3 integration platform that simplifies blockchain development by... | 0 | 2024-06-07T23:51:42 | https://dev.to/kamalthedev/loyaltyroller-zapier-automation-of-sending-nfts-on-stripe-payments-using-owl-protocol-1m44 | owlprotocol, stripeautomation, zapierwithowlprotocol | Introduction
Owl Protocol, a web3 integration platform that simplifies blockchain development by providing APIs and Zapier integration for any EVM or Rollup. This allows developers to build blockchain applications without dealing with private keys, gas fees, or cryptocurrencies, enabling them to focus on the core aspec... | kamalthedev |
1,880,940 | [Game of Purpose] Day 20 - Drone basic movement somewhat works | Today I created a dedicated drone blueprint. I manually configured Event graph, so that the drone... | 27,434 | 2024-06-07T23:51:42 | https://dev.to/humberd/game-of-purpose-day-20-drone-basic-movement-somewhat-works-72i | gamedev | Today I created a dedicated drone blueprint. I manually configured Event graph, so that the drone moves horizontally and the camera rotates accordingly. It's basically the same as in `BP_ThirdPersonCharacter` blueprint that is a default Manny player, but I played around with each node and I think I understand what is g... | humberd |
1,880,938 | Tech Support: A Close Look at Remote and Onsite Services | Nowadays, businesses have their business operations running very smoothly at the back all because of... | 0 | 2024-06-07T23:48:59 | https://dev.to/liong/tech-support-a-close-look-at-remote-and-onsite-services-2d9h | online, techtalks, malaysia, kualalumpur | Nowadays, businesses have their business operations running very smoothly at the back all because of their reliability on the IT support but on the other side, there is a time in which you have to make the final and best decision to choose the right support model. you may be able to get the idea that there are two IT s... | liong |
1,880,937 | Backup and Recovery of Data: The Essential Guide | Our digital world is getting modernized day by day and more incidents are happening in the tech field... | 0 | 2024-06-07T23:41:13 | https://dev.to/liong/backup-and-recovery-of-data-the-essential-guide-1c2c | data, malaysia, kualalumpur, backup | Our digital world is getting modernized day by day and more incidents are happening in the tech field related to data losses. Data is the raw information that is considered to be more important than ever in today's world. It is devastating to lose data whether it's personal photos, business documents, or critical soft... | liong |
1,882,429 | Circuit Breakers in Go: Stop Cascading Failures | Circuit Breakers A circuit breaker detects failures and encapsulate the logic of... | 0 | 2024-06-26T23:01:44 | https://medium.com/@oluwafemiakinde/circuit-breakers-in-go-stop-cascading-failures-c81c14f7154e | microservices, resilience, go, circuitbreaker | ---
title: Circuit Breakers in Go: Stop Cascading Failures
published: true
date: 2024-06-07 23:32:27 UTC
tags: microservices,resilience,golang,circuitbreaker
canonical_url: https://medium.com/@oluwafemiakinde/circuit-breakers-in-go-stop-cascading-failures-c81c14f7154e
---
 | In today's rapidly evolving tech landscape, microservices have become a cornerstone for building... | 27,631 | 2024-06-07T22:29:05 | https://dev.to/edriste/aws-services-for-microservice-architectures-a-beginners-overview-part-1-computing-4c36 | aws, microservices, beginners, cloudcomputing | <p>
In today's rapidly evolving tech landscape, microservices have become a
cornerstone for building scalable and maintainable software solutions.
Leveraging the right tools and services is crucial for effectively
implementing a microservice architecture, and AWS offers a comprehensive suite
of services tailo... | edriste |
1,880,872 | Resolving the "Length of LOB Data (78862) to be Replicated Exceeds Configured Maximum 65536" Error | Understanding the Error The error indicates that the LOB data size (78862 bytes) exceeds... | 27,304 | 2024-06-07T22:19:22 | https://shekhartarare.com/Archive/2024/6/resolving-length-of-lob-data-to-be-replicated-exceeds-configured-maximum-65536-error | sqlserver, tutorial, database, sql | ## Understanding the Error
The error indicates that the LOB data size (78862 bytes) exceeds the configured maximum limit (65536 bytes) set for replication in SQL Server. This typically happens during the replication process, leading to the failure of data transfer.
## Common Causes
1. **Default Configuration Limits:*... | shekhartarare |
1,879,750 | A Step-by-Step Guide to Writing Your First Move Smart Contract on Aptos | A Step-by-Step Guide to Writing Your First Move Smart Contract on Aptos Aptos is one of the... | 0 | 2024-06-07T22:16:24 | https://dev.to/amity808/a-step-by-step-guide-to-writing-your-first-move-smart-contract-on-aptos-ae8 | _A Step-by-Step Guide to Writing Your First Move Smart Contract on Aptos_
Aptos is one of the independent layer 1 laying focus on scalability, security, and reliability among other blockchain. It supports smart contracts which its smart contract is written in move programming. The blockchain network utilizes Proof of ... | amity808 | |
1,880,871 | Understanding Primary Keys and Foreign Keys in SQL: A Simple and Detailed Guide | Introduction Imagine a database as a digital filing system where you store different kinds... | 0 | 2024-06-07T22:12:13 | https://dev.to/kellyblaire/understanding-primary-keys-and-foreign-keys-in-sql-a-simple-and-detailed-guide-28jm | sql, database, analysis, saas | #### Introduction
Imagine a database as a digital filing system where you store different kinds of information. Just like how a library uses a catalog to keep track of books, databases use special markers called **Primary Keys** and **Foreign Keys** to organize and connect data efficiently. Let's dive into what these ... | kellyblaire |
1,880,774 | CONSULT GRAYWARE TECH SERVICES TO RECOVER STOLEN CRYPTOCURRENCY | The allure of cryptocurrency, the promise of financial freedom, is a seductive siren song. I, like... | 0 | 2024-06-07T19:18:00 | https://dev.to/jack_daniels_e0c666037743/consult-grayware-tech-services-to-recover-stolen-cryptocurrency-20m2 | The allure of cryptocurrency, the promise of financial freedom, is a seductive siren song. I, like many others, was captivated by its siren call, lured into a world of digital investment with the promise of astronomical returns. The initial investment, a mere $3,200, seemed inconsequential, a small price to pay for... | jack_daniels_e0c666037743 | |
1,880,867 | How to Achieve Net Negative Churn in 2024 | This Blog was Originally Posted to Churnfree Blog Net Negative Churn is the most valuable negative... | 0 | 2024-06-07T21:52:00 | https://churnfree.com/blog/net-negative-churn/ | churnreduction, saaschurn, churnrate, negativechurn | This Blog was Originally Posted to **[Churnfree Blog](https://churnfree.com/blog/net-negative-churn/?utm_source=Dev.to&utm_medium=referral&utm_campaign=content_distribution)**
Net Negative Churn is the most valuable negative metric in modern business models. Let’s know the WHATs and HOWs of this much-prized indicator ... | churnfree |
1,880,866 | Day 966 : The Next Chapter | liner notes: Professional : It's Friday + no meetings = I got a bunch of stuff done. haha I... | 0 | 2024-06-07T21:48:31 | https://dev.to/dwane/day-966-the-next-chapter-2cd7 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : It's Friday + no meetings = I got a bunch of stuff done. haha I finished up a sample application and updated a library I created and posted it into a channel to get some feedback. I started the process to apply for a Visa, but had some questions. Yeah, not a bad way to start the weekend.... | dwane |
1,880,864 | capstone debugging: learnings | The clock on my monitor silently ticked, while I cried in JSX fragments and Spring beans. It was Week... | 0 | 2024-06-07T21:34:46 | https://dev.to/ashleyd480/capstone-debugging-learnings-3495 | beginners, learning, bootcamp, fullstack | The clock on my monitor silently ticked, while I cried in JSX fragments and Spring beans. It was Week 15 and 16- the final stretch of my coding bootcamp and we were tasked with creating a full-stack app. Time was tight from having to research and execute new concepts, and the bugs- oh someone call pest control! 😅
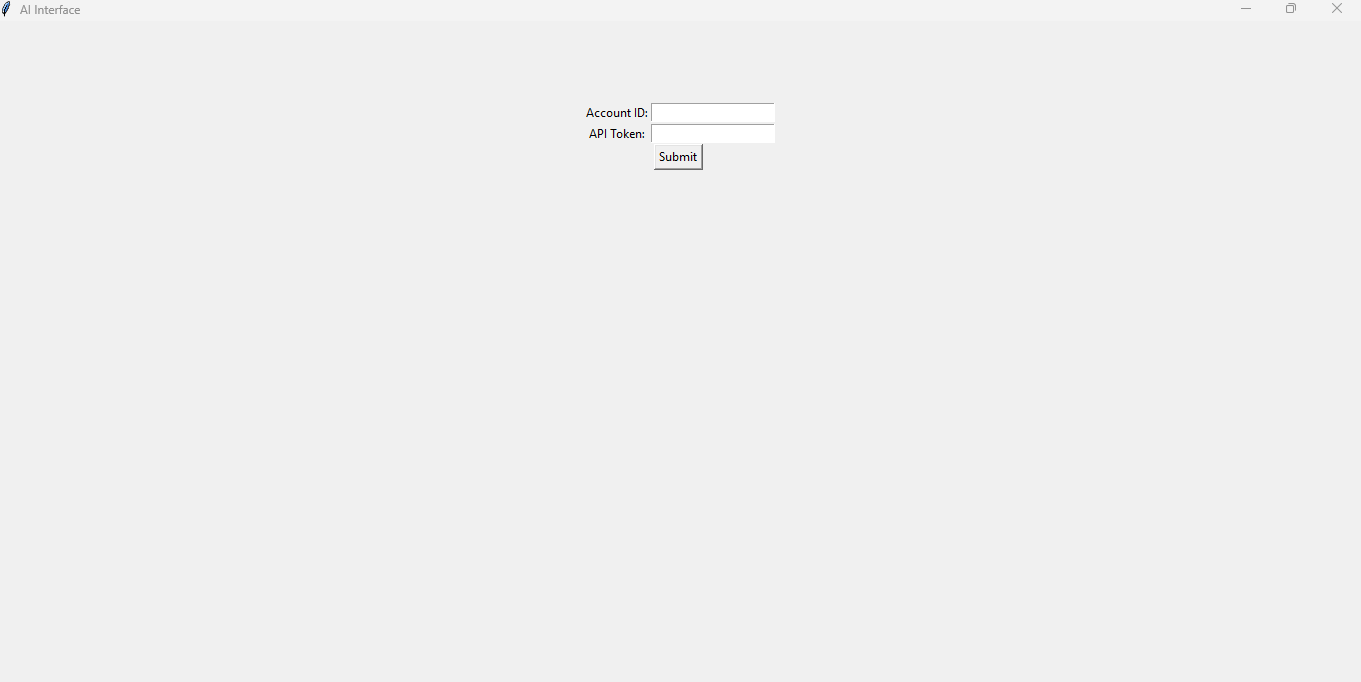
**Main Interface**
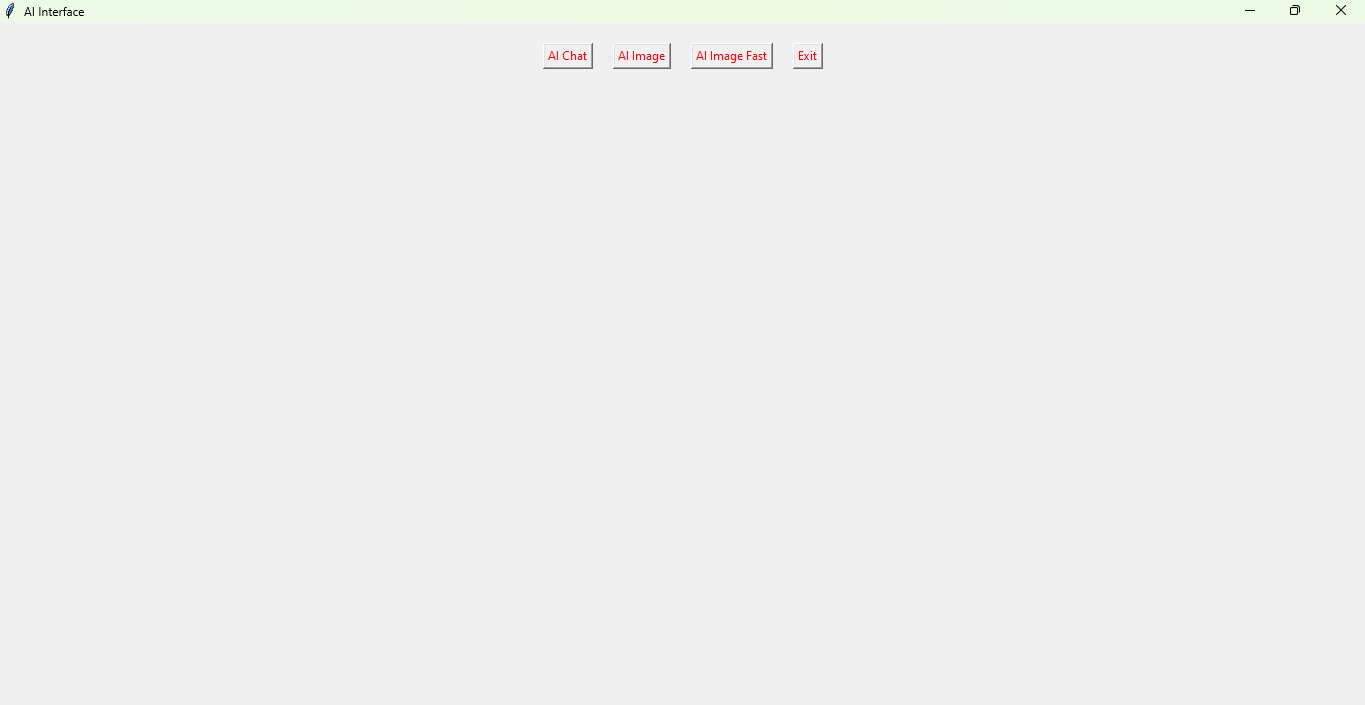
**The Prompt area:**
, so I looked at its [source code](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/layout.tsx). Because shadcn-ui is built using app router, the files I was interested in were [layout.tsx](https:/... | ramunarasinga |
1,880,840 | Gestión de Listas de Compra en Python con Archivos JSON | En este artículo, exploraremos cómo utilizar Python para gestionar listas de compra utilizando... | 0 | 2024-06-07T21:18:02 | https://dev.to/abrahanmaigua/gestion-de-listas-de-compra-en-python-con-archivos-json-3nh1 | python, json, spanish |
En este artículo, exploraremos cómo utilizar Python para gestionar listas de compra utilizando archivos JSON. Utilizaremos las capacidades de Python para crear, listar, actualizar, eliminar, guardar y cargar listas de compra en un formato JSON, lo que proporciona una forma eficiente y estructurada de mantener y modif... | abrahanmaigua |
1,878,824 | Short-Circuiting and Logical Operators in JavaScript: &&, ||, ?? | Short-circuiting is a concept in logical operations in many programming languages, including... | 0 | 2024-06-07T21:14:04 | https://dev.to/atenajoon/short-circuiting-and-logical-operators-in-javascript--13eh | javascript, webdev, beginners, tutorial |
**Short-circuiting** is a concept in logical operations in many programming languages, including JavaScript where the evaluation stops as soon as the outcome is determined. such as the “AND operator” and “OR operator”. This feature only looks at the first value to decide what to return without even looking at the sec... | atenajoon |
1,880,839 | Introducción a las Funciones en Python | Las funciones en Python son bloques de código reutilizables diseñados para realizar una sola,... | 0 | 2024-06-07T21:14:01 | https://dev.to/abrahanmaigua/introduccion-a-las-funciones-en-python-3lb3 | python, functional, beginners | Las funciones en Python son bloques de código reutilizables diseñados para realizar una sola, relacionada acción. Las funciones nos permiten modularizar el código, hacer que sea más limpio, más legible y más fácil de mantener. En este artículo, exploraremos cómo definir y usar funciones en Python, junto con ejemplos y ... | abrahanmaigua |
1,880,838 | From sticks and levers to worlds and chasms | Technology, and now AI, are modern equivalents of the Arquimedes lever for your mind. If we want to... | 0 | 2024-06-07T21:13:41 | https://dev.to/leonardoventurini/from-sticks-and-levers-to-worlds-and-chasms-egf | ai, webdev, machinelearning, datascience | Technology, and now AI, are modern equivalents of the Arquimedes lever for your mind. If we want to accomplish more as humans we have think on how to extend our innate capabilities.
We have been doing exactly that for thousands of years, from when we created our first handheld tool, to when we started creating the fir... | leonardoventurini |
1,878,563 | Docker Mastery: A Comprehensive Guide for Beginners and Pros | Docker is a powerful platform that simplifies the creation, deployment, and management of... | 0 | 2024-06-07T21:12:20 | https://dev.to/theyasirr/docker-mastery-a-comprehensive-guide-for-beginners-and-pros-2p18 | docker, webdev, devops, beginners | Docker is a powerful platform that simplifies the creation, deployment, and management of applications within lightweight, portable containers. It allows developers to package applications and their dependencies into a standardized unit for seamless development and deployment. Docker enhances efficiency, scalability, a... | theyasirr |
1,880,836 | Security news weekly round-up - 7th June 2024 | Weekly review of top security news between May 31, 2024, and June 7, 2024 | 6,540 | 2024-06-07T21:12:10 | https://dev.to/ziizium/security-news-weekly-round-up-7th-june-2024-84b | security | ---
title: Security news weekly round-up - 7th June 2024
published: true
description: Weekly review of top security news between May 31, 2024, and June 7, 2024
tags: security
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/0jupjut8w3h9mjwm8m57.jpg
series: Security news weekly round-up
---
## __Introduction__
W... | ziizium |
1,880,837 | Ever felt the pain of not mastering something immediately? | Sometimes, when we want to start a new project, or maybe learn a new skill or language, we get caught... | 0 | 2024-06-07T21:11:59 | https://dev.to/hmsdev/ever-felt-the-pain-of-not-mastering-something-immediately-4574 | productivity, improvement, yougotthis, fridaythinking | Sometimes, when we want to start a new project, or maybe learn a new skill or language, we get caught up in the minute details or even get frustrated when we don’t grasp something entirely right away. (Hello!)
We have to remind ourselves that these big leaps and huge jumps in improvement that might be visible on the o... | hmsdev |
1,880,825 | Creating a Resource Group in Microsoft Azure | Creating a Resource Group in Microsoft Azure In this tutorial, we'll walk through the... | 0 | 2024-06-07T21:11:57 | https://dev.to/jimiog/creating-a-resource-group-in-microsoft-azure-4hp3 | azure, cloud | # Creating a Resource Group in Microsoft Azure
In this tutorial, we'll walk through the steps of creating a Resource Group on Microsoft Azure, providing a structured approach to manage related applications within the Azure environment.
## Prerequisites
Before proceeding, ensure you have an active Azure account and h... | jimiog |
1,880,835 | HIRE A HACKER TO FIND AND RECOVER YOUR STOLEN BTC/ETH/USDT/NFT'S AND ALL TYPES OF DIGITAL ASSETS | HIRE A HACKER TO FIND AND RECOVER YOUR STOLEN BTC/ETH/USDT/NFT'S AND ALL TYPES OF DIGITAL ASSETS... | 0 | 2024-06-07T21:09:45 | https://dev.to/nancy_rosales_3f87b540233/hire-a-hacker-to-find-and-recover-your-stolen-btcethusdtnfts-and-all-types-of-digital-assets-4ec7 | webdev, tutorial, productivity, news |

HIRE A HACKER TO FIND AND RECOVER YOUR STOLEN BTC/ETH/USDT/NFT'S AND ALL TYPES OF DIGITAL ASSETS
Someone I met online scammed me out of approximately $367,000 on a fictitious investment proposal. After I started ... | nancy_rosales_3f87b540233 |
1,880,833 | How to become an iOS developer and start your own business | Kirill, 33 years old, iOS developer, never worked as a programmer, income from programming: 0. So... | 0 | 2024-06-07T21:08:47 | https://dev.to/bitb2112/how-to-become-an-ios-developer-and-start-your-own-business-251j | vpn, ios, iphone, ipad | Kirill, 33 years old, iOS developer, never worked as a programmer, income from programming: 0.
So why read this message?
I created my own VPN application for iOS – both backend and frontend. Currently, the app is available on the App Store, translated into 53 languages, and has 127 ratings worldwide.
I want to tell yo... | bitb2112 |
1,880,832 | Understanding Functions in Python | Functions are a fundamental building block in Python programming. They allow you to encapsulate code... | 0 | 2024-06-07T21:08:16 | https://dev.to/ayas_tech_2b0560ee159e661/understanding-functions-in-python-21me | Functions are a fundamental building block in Python programming. They allow you to encapsulate code into reusable blocks, making your code more modular, maintainable, and easier to understand.
## **Types of Functions in Python**
**1. User-Defined Function**
A simple function defined by the user using the def keywor... | ayas_tech_2b0560ee159e661 | |
1,880,831 | Now connect SQL with no-code as a data source | Softr just introduced its integration with Relational databases which includes MySQL, PostgreSQL, SQL... | 0 | 2024-06-07T21:04:50 | https://dev.to/usama4745/now-connect-sql-with-no-code-as-a-data-source-5d4k | nocode, sql, postgres, mariadb | Softr just introduced its integration with Relational databases which includes MySQL, PostgreSQL, SQL Server, and MariaDB.
Softr is a tool that lets you create apps without writing code. It can connect to different sources of data, such as spreadsheets or databases, and use that data to build custom apps.
Users can b... | usama4745 |
1,880,827 | Sensitive Information disclosure via Spring Boot Default Paths | Reward: $250 Program: Private Overview of the Vulnerability Disclosure of secrets for a publicly... | 0 | 2024-06-07T20:57:22 | https://dev.to/c4ng4c31r0/sensitive-information-disclosure-via-spring-boot-default-paths-h78 | Reward: $250
Program: Private
**Overview of the Vulnerability**
Disclosure of secrets for a publicly available asset occurs when sensitive data is not behind an authorization barrier. When this information is exposed it can place sensitive data, such as secrets, at risk. This can occur due to a variety of scenarios su... | c4ng4c31r0 | |
1,880,826 | Migrate from Heroku to AWS: A Best Practices Guide | In an era dominated by cloud solutions, businesses often find themselves at a crossroads when... | 0 | 2024-06-07T20:56:41 | https://dev.to/the_real_zan/migrate-from-heroku-to-aws-a-best-practices-guide-29f | In an era dominated by cloud solutions, businesses often find themselves at a crossroads when choosing the right platform to host their applications. This article explores the key considerations, challenges, and best practices involved in migrating from Heroku to Amazon Web Services (AWS). We compare Heroku and AWS acr... | the_real_zan | |
1,880,824 | 648. Replace Words | 648. Replace Words Medium In English, we have a concept called root, which can be followed by some... | 27,523 | 2024-06-07T20:52:36 | https://dev.to/mdarifulhaque/648-replace-words-4f20 | php, leetcode, algorithms, programming | 648\. Replace Words
Medium
In English, we have a concept called root, which can be followed by some other word to form another longer word - let's call this word **derivative**. For example, when the root `"help"` is followed by the word `"ful"`, we can form a derivative `"helpful"`.
Given a `dictionary` consisting ... | mdarifulhaque |
1,880,823 | Less is More: Why You May Don't Always Need JavaScript in Your B2B Web Apps | This blog post argues for reducing JavaScript usage in B2B web apps front-ends in favor of server-size rendering | 0 | 2024-06-07T20:52:01 | https://dev.to/mariomarroquim/when-less-is-more-why-you-dont-always-need-javascript-in-b2b-ruby-on-rails-web-apps-4ecp | b2b, javascript, nobuild, nojs | ---
title: Less is More: Why You May Don't Always Need JavaScript in Your B2B Web Apps
published: true
description: This blog post argues for reducing JavaScript usage in B2B web apps front-ends in favor of server-size rendering
tags: b2b, javascript, nobuild, nojs
# cover_image: https://direct_url_to_image.jpg
# Use a... | mariomarroquim |
1,880,818 | Automatically Test Your Regex Without Writing a Single C# Line of Code | Introduction If you've ever used regular expressions (regex), you know there's a saying:... | 0 | 2024-06-07T20:41:18 | https://dev.to/dimonsmart/automatically-test-your-regex-without-writing-a-single-c-line-of-code-1k9p | regex, unittest, csharp | ## Introduction
If you've ever used regular expressions (regex), you know there's a saying: "Every problem can be solved with regex. But then you have one more problem."
I hope readers can decide for themselves whether to use regular expressions. However, making sure your regex works correctly can be challenging.
In... | dimonsmart |
1,880,821 | The Fates of Famous Figures Under the Pressure of Power from the Russian Empire to Our Days | In the history of Russia, many outstanding artists and public figures have faced repression and were... | 0 | 2024-06-07T20:36:45 | https://www.heyvaldemar.com/the-fates-of-famous-figures-under-the-pressure-of-power-from-the-russian-empire-to-our-days/ | discuss, learning, repressions, history | In the history of Russia, many outstanding artists and public figures have faced repression and were forced to emigrate because of their views and creativity, which contradicted the official line of power. In our time, the situation has changed little, and many modern oppositionists and cultural figures continue to fac... | heyvaldemar |
1,880,804 | #648. Replace Words | https://leetcode.com/problems/replace-words/description/?envType=daily-question&envId=2024-06-07 ... | 0 | 2024-06-07T20:16:32 | https://dev.to/karleb/648-replace-words-53om | ERROR: type should be string, got "\nhttps://leetcode.com/problems/replace-words/description/?envType=daily-question&envId=2024-06-07\n\n\n```js\n\n/**\n * @param {string[]} dictionary\n * @param {string} sentence\n * @return {string}\n */\nvar replaceWords = function(dictionary, sentence) {\n sentence = sentence.split(\" \")\n\n for (let i = 0; i < sentence.length; i++) {\n for (let j = 0; j < dictionary.length; j++) {\n if (sentence[i].startsWith(dictionary[j])) {\n sentence[i] = dictionary[j]\n }\n }\n }\n\n return sentence.join(\" \")\n};\n\n```" | karleb | |
1,880,796 | AWS Lambda and Celery for Asynchronous Tasks in Django | Building responsive Django applications often involves handling tasks that shouldn't block the user... | 0 | 2024-06-07T20:35:45 | https://dev.to/topunix/harnessing-aws-lambda-and-celery-for-scalable-asynchronous-tasks-with-django-h97 | aws, lambda, django, celery | Building responsive Django applications often involves handling tasks that shouldn't block the user experience. These background tasks, like sending emails or processing data, can be efficiently handled using asynchronous processing. This blog post explores two powerful tools for asynchronous tasks in Django: Celery a... | topunix |
1,880,819 | Mastering GitLab CI/CD with Advanced Configuration Techniques | As a Senior DevOps Engineer and a recognized Docker Captain, I understand the pivotal role that... | 0 | 2024-06-07T20:33:29 | https://www.heyvaldemar.com/mastering-gitlab-ci-cd-with-advanced-configuration-techniques/ | gitlab, cicd, devops, productivity | As a Senior DevOps Engineer and a recognized [Docker Captain](https://www.docker.com/captains/vladimir-mikhalev/), I understand the pivotal role that continuous integration and delivery (CI/CD) systems play in modern software development. GitLab's CI/CD platform is a robust tool that automates the steps in software del... | heyvaldemar |
1,880,817 | MY EXPERIENCE SO FAR AT WHITE CREATIVITY | My Journey at White Creativity Starting as a web developer at White Creativity has been an exciting... | 0 | 2024-06-07T20:30:40 | https://dev.to/danieln/my-experience-so-far-at-white-creativity-op8 | webdev, beginners, programming | **My Journey at White Creativity**
Starting as a web developer at White Creativity has been an exciting and educating experience. With a basic understanding of HTML and CSS, I quickly realized the depth of practical web development once I joined and started my practice
**Learning the Basics**
In the beginning, I fo... | danieln |
1,880,810 | Computer Vision Meetup: Combining Hugging Face Transformer Models and Image Data with FiftyOne | Datasets and Models are the two pillars of modern machine learning, but connecting the two can be... | 0 | 2024-06-07T20:29:02 | https://dev.to/voxel51/computer-vision-meetup-combining-hugging-face-transformer-models-and-image-data-with-fiftyone-3ii6 | computervision, machinelearning, datascience, ai | Datasets and Models are the two pillars of modern machine learning, but connecting the two can be cumbersome and time-consuming. In this lightning talk, you will learn how the seamless integration between Hugging Face and FiftyOne simplifies this complexity, enabling more effective data-model co-development. By the end... | jguerrero-voxel51 |
1,880,814 | Level up your Tailwind game | Use Tailwind like you mean it! Whether you're a seasoned developer or just starting out, this article will help you navigate Tailwind CSS and expand your knowledge with advanced practices. | 0 | 2024-06-07T20:28:07 | https://www.oh-no.ooo/articles/level-up-your-tailwind-game | tailwindcss, css, mixin, webdev | ---
title: Level up your Tailwind game
published: true
description: Use Tailwind like you mean it! Whether you're a seasoned developer or just starting out, this article will help you navigate Tailwind CSS and expand your knowledge with advanced practices.
tags: #tailwind #tailwindcss #css #mixin #webdev
cover_image: h... | mahdava |
1,872,501 | How to Create a Simple Web App with Flask for Python Beginners (Bite-size Article) | Introduction I am usually a programmer who focuses on web development. However, recently,... | 0 | 2024-06-07T20:27:14 | https://dev.to/koshirok096/how-to-create-a-simple-web-app-with-flask-for-python-beginners-bite-size-article-32ja | beginners, flask, python | #Introduction
I am usually a programmer who focuses on web development. However, recently, I've had more opportunities to use Python for various reasons (though I'm still a beginner with Python). Given my background in web development, I started to wonder, "Is it possible to run functions created in Python on the web?"... | koshirok096 |
1,880,816 | Vengo AI - Create and monetize your AI identity with one line of code | Vengo AI is a cutting-edge B2B SaaS platform that democratizes AI creation, making it accessible for... | 0 | 2024-06-07T20:24:54 | https://dev.to/vengo-ai/vengo-ai-create-and-monetize-your-ai-identity-with-one-line-of-code-3o52 | ai, b2b, saas, marketplace | Vengo AI is a cutting-edge B2B SaaS platform that democratizes AI creation, making it accessible for everyone, from influencers and brands to entrepreneurs and businesses. Our proprietary system allows users to effortlessly integrate sophisticated AI identities into their websites with just one line of code. By joining... | vengo-ai |
1,880,815 | Introducing Comment Monk: Simple comment hosting system for static blogs and websites | I wanted to implement a comment hosting system for my static blog https://prahladyeri.github.io, just... | 0 | 2024-06-07T20:24:26 | https://prahladyeri.github.io/blog/2024/06/intoducing-comment-monk.html | I wanted to implement a comment hosting system for my static blog <https://prahladyeri.github.io>, just basic Wordpress.org style commenting feature with user's name, website, etc., no complicated logins or sign-ups or third-party platforms. The user reads your blog, posts a comment, and you approve from the backend (o... | prahladyeri | |
1,875,724 | Computer Vision Meetup: Lessons Learned fine-tuning Llama2 for Autonomous Agents | In this talk, Rahul Parundekar, Founder of A.I. Hero, Inc. does a deep dive into the practicalities... | 0 | 2024-06-07T20:19:30 | https://dev.to/voxel51/computer-vision-meetup-lessons-learned-fine-tuning-llama2-for-autonomous-agents-1jk3 | computervision, ai, machinelearning, datascience | In this talk, [Rahul Parundekar](https://www.linkedin.com/in/rparundekar), Founder of A.I. Hero, Inc. does a deep dive into the practicalities and nuances of making LLMs more effective and efficient. He’ll share hard-earned lessons from the trenches of LLMOps on Kubernetes, covering everything from the critical importa... | jguerrero-voxel51 |
1,880,805 | Next Generation SQL Injection: Github Actions Edition | In the evolving landscape of software development, Continuous Integration and Continuous Deployment... | 0 | 2024-06-07T20:16:53 | https://mymakerspace.substack.com/p/next-generation-sql-injection-github | githubactions, security, devops | In the evolving landscape of software development, Continuous Integration and Continuous Deployment (CI/CD) tools like GitHub Actions have become indispensable. However, with great power comes great responsibility, and it's crucial to be aware of potential security pitfalls. One such vulnerability is treating untrusted... | alonch |
1,880,803 | Giving Back to the Boomi Community: How Your Contributions Make a Difference | Everybody wants to be part of a community—a group of people who validate a person’s thoughts and... | 0 | 2024-06-07T20:11:02 | https://dev.to/eyer-ai/giving-back-to-the-boomi-community-how-your-contributions-make-a-difference-3g4a | community, boomi | Everybody wants to be part of a community—a group of people who validate a person’s thoughts and feelings and help them out during difficult situations. In the [Boomi community by Eyer](https://discord.gg/SyTRyWpbgq), this group of people are Boomi engineers.
The community provides a sense of belonging and support th... | amaraiheanacho |
1,880,802 | Getting Started with Networking and Sockets | In the realm of software development and network engineering, understanding the fundamentals of... | 27,728 | 2024-06-07T20:02:59 | https://www.kungfudev.com/blog/2024/06/07/getting-started-with-net-and-sockets | linux, rust, socket, network |
In the realm of software development and network engineering, understanding the fundamentals of sockets and networking is invaluable, regardless of your specific focus within the industry. This article aims to provide a comprehensive overview of these essential concepts, facilitating a clearer understanding of their i... | douglasmakey |
1,880,801 | Discover Authentic Pakistani Attire at IZEmporium.com: Your Online Destination for Pakistani Dresses in the UK | Are you in search of genuine Pakistani clothing that captivates with its intricate designs and... | 0 | 2024-06-07T20:01:59 | https://dev.to/ahmed_ali_16a2b97a9fe6cd6/discover-authentic-pakistani-attire-at-izemporiumcom-your-online-destination-for-pakistani-dresses-in-the-uk-7k9 | pakistaniclothes, pakistanidresses, salwarkameez, weddingwear | Are you in search of genuine Pakistani clothing that captivates with its intricate designs and vibrant colors? Look no further than IZEmporium.com, your premier online store for the finest [Pakistani dresses](https://izemporium.com/) available in the UK. Whether you are preparing for a festive occasion or simply wish t... | ahmed_ali_16a2b97a9fe6cd6 |
1,880,800 | Normalization and Normal Forms (1NF, 2NF, 3NF) | Introduction Normalization is a systematic approach to organizing data in a database to... | 0 | 2024-06-07T19:58:19 | https://dev.to/kellyblaire/normalization-and-normal-forms-1nf-2nf-3nf-240a | ## Introduction
Normalization is a systematic approach to organizing data in a database to reduce redundancy and improve data integrity. The process involves decomposing a table into smaller, related tables without losing data. This article will explain the concepts of normalization and the different normal forms (1NF... | kellyblaire | |
1,741,494 | Building a web server: Containers | Welcome back to This Old Box! A series that covers the journey of building and running a web server... | 25,757 | 2024-06-07T19:47:30 | https://dev.to/stmcallister/building-a-home-web-server-containerizing-our-app-50ed | docker, kubernetes, helm, learning | Welcome back to This Old Box! A series that covers the journey of building and running a web server out of an old 2014 Mac mini.
In this post we'll walk through how we containerized our first web application, configured our Kubernetes cluster with our new container, and exposed that cluster to the world.
The project... | stmcallister |
1,880,799 | Advice 65 Million Years in the Making: How Jurassic Park Made Me a Better Programmer | Jurassic Park, published in 1990 and later adapted in a blockbuster movie in 1993, is an exhilarating... | 0 | 2024-06-07T19:57:52 | https://dev.to/daniel_ankofski_0c1a307be/advice-65-million-years-in-the-making-how-jurassic-park-made-me-a-better-programmer-3bcd | beginners, career, careerdevelopment, learning | _Jurassic Park_, published in 1990 and later adapted in a blockbuster movie in 1993, is an exhilarating story of pushing the boundaries of science without regard for the outcome. At its heart, it's an examination of the hubris of humankind. In almost every aspect of _Jurassic Park_, corners are cut and expenses are spa... | daniel_ankofski_0c1a307be |
1,880,798 | Database Design and Entity-Relationship Diagrams (ERDs) | Introduction Database design is a crucial aspect of developing robust and efficient... | 0 | 2024-06-07T19:54:48 | https://dev.to/kellyblaire/database-design-and-entity-relationship-diagrams-erds-2909 | ## Introduction
Database design is a crucial aspect of developing robust and efficient information systems. A well-designed database ensures data integrity, supports business processes, and enhances performance. One of the primary tools used in database design is the Entity-Relationship Diagram (ERD), which helps in v... | kellyblaire | |
1,880,797 | Weekly Updates - June 7, 2024 | Hi everyone!👋 Hope you had a great week. 🎉 Exciting update to VSCode Extension -We’re thrilled to... | 0 | 2024-06-07T19:53:57 | https://dev.to/couchbase/weekly-updates-june-7-2024-1d7b | couchbase, community, database, ai | Hi everyone!👋
Hope you had a great week.
- 🎉 **Exciting update to VSCode Extension** -We’re thrilled to announce a significant update to our Couchbase VSCode Extension. With our latest release, we’ve expanded our horizons to support GitHub Codespaces and various other remote development environments. [*Read the blo... | carrieke |
1,880,795 | Data Warehousing Concepts: A Comprehensive Guide | Introduction In the era of big data, organizations are inundated with vast amounts of data... | 0 | 2024-06-07T19:52:00 | https://dev.to/kellyblaire/data-warehousing-concepts-a-comprehensive-guide-14pa | #### Introduction
In the era of big data, organizations are inundated with vast amounts of data from various sources. To manage, analyze, and make sense of this data, businesses turn to data warehousing. A data warehouse (DW) is a central repository of integrated data from one or more disparate sources, used for repor... | kellyblaire | |
1,880,793 | How to Buy Gold and Silver with Bitcoin and Cryptocurrency Online? | The rapid rise of cryptocurrencies, led by Bitcoin, has disrupted traditional financial systems and... | 0 | 2024-06-07T19:47:40 | https://dev.to/owenparker22212/how-to-buy-gold-and-silver-with-bitcoin-and-cryptocurrency-online-17a1 | The rapid rise of cryptocurrencies, led by Bitcoin, has disrupted traditional financial systems and opened up new possibilities for investors. One such possibility is the ability to [buy physical gold and silver with Bitcoin](https://bitgolder.com/) and other cryptocurrencies. This merging of the digital and traditiona... | owenparker22212 | |
1,880,791 | Abiding Limo: Safe, Stylish, and Affordable Houston Transportation | Abiding Limo sticks out many of the many transportation options in Houston for its unwavering... | 0 | 2024-06-07T19:37:56 | https://dev.to/abduljabbar4533/abiding-limo-safe-stylish-and-affordable-houston-transportation-4g92 | limo | Abiding Limo sticks out many of the many transportation options in Houston for its unwavering dedication to protection. As one of the most [Reliable Houston Limo Rentals-Abiding Limo](https://abidinglimo.com/houston-limo-service/), safety is continually a top priority for the organisation. Abiding Limo is going above ... | abduljabbar4533 |
1,880,154 | Spring Cloud: Get configuration from config server | Following library is used Java 17 Spring Framework 6.1.6 Spring Cloud Common 4.1.2 Spring Cloud... | 0 | 2024-06-07T19:37:09 | https://dev.to/saladlam/spring-cloud-get-configuration-from-config-server-19ok | spring, springcloud | Following library is used
- Java 17
- Spring Framework 6.1.6
- Spring Cloud Common 4.1.2
- Spring Cloud Config Client 4.1.2
The minimum entries of configuration is
```
spring.application.name=example-application
spring.config.import=configserver:https://localhost:8888
```
When the application starts, first retrieve... | saladlam |
1,880,789 | ReGAL: Refactoring Programs to Discover Generalizable Abstractions | ReGAL: Refactoring Programs to Discover Generalizable Abstractions | 0 | 2024-06-07T19:31:39 | https://aimodels.fyi/papers/arxiv/regal-refactoring-programs-to-discover-generalizable-abstractions | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [ReGAL: Refactoring Programs to Discover Generalizable Abstractions](https://aimodels.fyi/papers/arxiv/regal-refactoring-programs-to-discover-generalizable-abstractions). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi new... | mikeyoung44 |
1,880,788 | The Geometry of Categorical and Hierarchical Concepts in Large Language Models | The Geometry of Categorical and Hierarchical Concepts in Large Language Models | 0 | 2024-06-07T19:31:05 | https://aimodels.fyi/papers/arxiv/geometry-categorical-hierarchical-concepts-large-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [The Geometry of Categorical and Hierarchical Concepts in Large Language Models](https://aimodels.fyi/papers/arxiv/geometry-categorical-hierarchical-concepts-large-language-models). If you like these kinds of analysis, you should subscribe to the [AImod... | mikeyoung44 |
1,880,787 | Knockout: A simple way to handle missing inputs | Knockout: A simple way to handle missing inputs | 0 | 2024-06-07T19:30:30 | https://aimodels.fyi/papers/arxiv/knockout-simple-way-to-handle-missing-inputs | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Knockout: A simple way to handle missing inputs](https://aimodels.fyi/papers/arxiv/knockout-simple-way-to-handle-missing-inputs). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) ... | mikeyoung44 |
1,880,786 | Mamba: Linear-Time Sequence Modeling with Selective State Spaces | Mamba: Linear-Time Sequence Modeling with Selective State Spaces | 0 | 2024-06-07T19:29:56 | https://aimodels.fyi/papers/arxiv/mamba-linear-time-sequence-modeling-selective-state | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://aimodels.fyi/papers/arxiv/mamba-linear-time-sequence-modeling-selective-state). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https:/... | mikeyoung44 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.