
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,879,867 | LED companies use VR technology to layout the smart education market | New opportunities for LED companies With the rapid development of smart education, LED companies... | 0 | 2024-06-07T03:34:33 | https://dev.to/sostrondylan/led-companies-use-vr-technology-to-layout-the-smart-education-market-3hha | led, vr, technology | 1. New opportunities for LED companies
With the rapid development of smart education, LED companies have seen new market opportunities. The demand for innovative technologies in the education market is growing, especially in improving the interactivity and practicality of teaching. By combining VR technology, LED comp... | sostrondylan |
1,879,866 | The Curious Case of Bugs that Fix Themselves | I can’t count how many times I had this conversation: “Good news! The bug is fixed!” “Did you fix... | 25,505 | 2024-06-07T03:34:31 | https://www.growingdev.net/p/the-curious-case-of-bugs-that-fix | programming, beginners, softwaredevelopment, softwareengineering | I can’t count how many times I had this conversation:
  “Good news! The bug is fixed!”
  “Did you fix it?”
  “No.”
  “Did anyone else fix it?”
  “No.”
  “How is it fixed then?”
  “I don’t know. I could reproduce it last week, but I cannot reproduce i... | moozzyk |
1,879,865 | Managing POSIX ACL Permissions in JuiceFS | Access Control Lists (ACLs) are a mechanism for implementing finer-grained permissions control in... | 0 | 2024-06-07T03:31:02 | https://dev.to/daswu/managing-posix-acl-permissions-in-juicefs-5hbe | Access Control Lists (ACLs) are a mechanism for implementing finer-grained permissions control in Unix-like systems, such as Linux, macOS, and FreeBSD. They extend the traditional Unix permissions model and provide a more flexible and detailed way to manage permissions.
In the traditional Unix permissions model, the pe... | daswu | |
1,879,863 | "C++ version of OKX futures contract hedging strategy" that takes you through hardcore quantitative strategy | Speaking of hedging strategies, there are various types, diverse combinations, and diverse ideas in... | 0 | 2024-06-07T03:23:18 | https://dev.to/fmzquant/c-version-of-okx-futures-contract-hedging-strategy-that-takes-you-through-hardcore-quantitative-strategy-1p9 | strategy, trading, hedging, contract | Speaking of hedging strategies, there are various types, diverse combinations, and diverse ideas in various markets. We explore the design ideas and concepts of the hedging strategy from the most classic intertemporal hedging. Today, the crypto currency market is much more active than at the beginning, and there are al... | fmzquant |
1,879,862 | Mandala Cham Bay Mui Ne | http://molbiol.ru/forums/index.php?showuser=1354461 https://pastelink.net/04204oog https://answerpail... | 0 | 2024-06-07T03:22:44 | https://dev.to/mandalamuine/mandala-cham-bay-mui-ne-796 | http://molbiol.ru/forums/index.php?showuser=1354461
https://pastelink.net/04204oog
https://answerpail.com/index.php/user/mandalamuine
https://telegra.ph/mandalamuine-06-07-2
https://app.roll20.net/users/13420797/mandala
https://www.chordie.com/forum/profile.php?id=1972650
https://www.spoiledmaltese.com/members/mandalam... | mandalamuine | |
1,879,861 | ZhongAn Insurance's Wang Kai Analyzes Kafka Network Communication | Author: Kai Wang, Java Development Expert at ZhongAn Online Insurance Basic Platform ... | 0 | 2024-06-07T03:22:11 | https://dev.to/automq/zhongan-insurances-wang-kai-analyzes-kafka-network-communication-1p6i | kafka, javascript | Author: Kai Wang, Java Development Expert at ZhongAn Online Insurance Basic Platform
## Introduction
Today, we explore the core workflow of network communication in Kafka, specifically focusing on Apache Kafka 3.7[2]. This discussion also includes insights into the increasingly popular AutoMQ, highlighting its network... | automq |
1,879,820 | Django Debug Toolbar Setup | What is Django Debug Toolbar? The Django Debug Toolbar is a configurable set of panels... | 0 | 2024-06-07T03:15:36 | https://dev.to/hasancse/django-debug-toolbar-setup-1f3j | django, python, webdev, programming | ## **What is Django Debug Toolbar?**
The Django Debug Toolbar is a configurable set of panels that display various debug information about the current request/response and, when clicked, display more details about the panel’s content.
## **How to install and implement Django Debug Toolbar?**
For the installation of ... | hasancse |
1,879,819 | Git for Beginners, the Introduction... | If you are starting in the world of programming, you have surely heard of Git, but you might not... | 27,814 | 2024-06-07T03:11:36 | https://dev.to/andresordazrs/git-for-beginners-the-introduction-2g9e | git, beginners, developer | If you are starting in the world of programming, you have surely heard of Git, but you might not fully understand what it is or why it is so important. Don’t worry, we've all been there.
Learning Git can seem challenging at first, but I promise that by the end of this article, you will understand why it is an essentia... | andresordazrs |
1,879,817 | Running Containers at Scale: A Deep Dive into AWS Fargate | Running Containers at Scale: A Deep Dive into AWS Fargate Introduction In... | 0 | 2024-06-07T03:07:37 | https://dev.to/virajlakshitha/running-containers-at-scale-a-deep-dive-into-aws-fargate-4mb0 | # Running Containers at Scale: A Deep Dive into AWS Fargate
### Introduction
In today's rapidly evolving technological landscape, containerization has emerged as a cornerstone of modern application development and deployment. Containers offer a lightweight and portable solution for packaging applications with their d... | virajlakshitha | |
1,879,816 | OCR in .NET MAUI | Did you know that now you can scan text from an image with .NET MAUI? 🚀 We've just added OCR (Optical... | 0 | 2024-06-07T03:05:16 | https://dev.to/strypperjason/ocr-in-net-maui-2dcp | maui, dotnet | Did you know that now you can scan text from an image with .NET MAUI? 🚀 We've just added OCR (Optical Character Recognition) to our toolkit! Enhance your apps with seamless text extraction from images in our project, download or clone MAUIsland explore how it work.
1. Download: https://www.microsoft.com/store/product... | strypperjason |
1,879,025 | Explaining Async/Await in JavaScript in 10 Minutes | For a long time, we've relied on callbacks to deal with asynchronous code in JavaScript. As a... | 27,954 | 2024-06-07T03:00:00 | https://howtodevez.blogspot.com/2024/03/explaining-asyncawait-in-javascript-in.html | javascript, typescript, webdev, beginners | * For a long time, we've relied on callbacks to deal with asynchronous code in JavaScript. As a result, many of us have faced dreadful experiences dealing with deeply nested functions (**callback hell**).
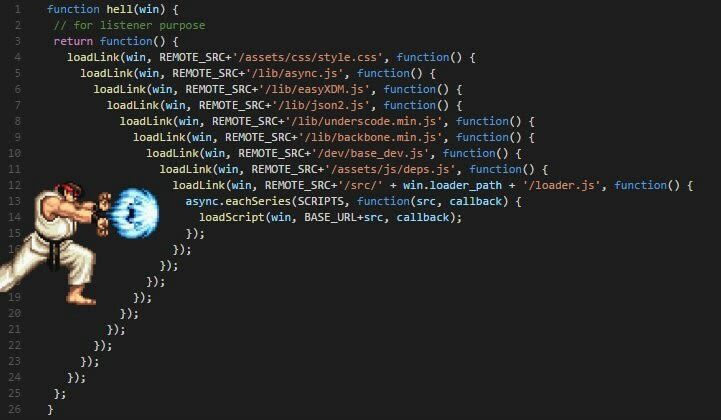
* Callbac... | chauhoangminhnguyen |
1,879,814 | I want to get back into desktop programming - help me choose | Hi all! Every so often, I find myself missing the fun of building user interfaces and running... | 0 | 2024-06-07T02:50:11 | https://dev.to/rolandixor/i-want-to-get-back-into-desktop-programming-help-me-choose-4169 | desktop, linux, programming | Hi all!
Every so often, I find myself missing the fun of building user interfaces and running applications that I put together myself, even if just for the sake of it. It's been so long for me, that the last time I build anything meaningful on the desktop, I was running Windows XP! Since then, I've been focused on the... | rolandixor |
1,879,770 | The Future of AI: Exploring AGI and ASI | Artificial Intelligence (AI) is transforming our world, with advancements like virtual assistants and... | 27,626 | 2024-06-07T01:34:00 | https://dev.to/nandha_krishnan_nk/the-future-of-ai-exploring-agi-and-asi-5aep | ai, machinelearning, deeplearning | **Artificial Intelligence** (AI) is transforming our world, with advancements like virtual assistants and autonomous vehicles becoming everyday realities. However, two emerging concepts promise to revolutionize AI further:** Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI).**
**What is AGI?... | nandha_krishnan_nk |
1,879,813 | Detecting Deception—The Importance of Fake ID Document Detection (ID document liveness detection) | In the current digital era, fake ID document detection is essential; confirming identities is now a... | 0 | 2024-06-07T02:43:09 | https://dev.to/faceplugin/detecting-deception-the-importance-of-fake-id-document-detection-id-document-liveness-detection-3h9d | In the current digital era, fake ID document detection is essential; confirming identities is now a vital step in preventing fraud and guaranteeing security. ID document authentication is one of the most important components of identity verification.
The prevalence of false identification documents and identity thef... | faceplugin | |
1,879,812 | The Basics of Big Data: What You Need to Know | Big Data has become a buzzword in the tech industry, revolutionizing how businesses operate and make... | 0 | 2024-06-07T02:37:19 | https://dev.to/bvanderbilt0033/the-basics-of-big-data-what-you-need-to-know-260e | dataprotection, dataanalytics, dataprivacy, bigdata | Big Data has become a buzzword in the tech industry, revolutionizing how businesses operate and make decisions. But what exactly is Big Data, and why is it so important? This article will break down the [basics of Big Data](https://www.rontar.com/glossary/big-data/), its significance, and how it impacts various sectors... | bvanderbilt0033 |
1,879,810 | uCool Lu Lu: Bold Decision to invest in high-impact marketing | The MVP approach enables indie game developers with limited resources to validate their game concept,... | 0 | 2024-06-07T02:31:14 | https://dev.to/ucool-lulu/ucool-lu-lu-bold-decision-to-invest-in-high-impact-marketing-3k3 | The MVP approach enables indie game developers with limited resources to validate their game concept, gather user feedback, and iteratively improve their product while minimizing risks and development costs. uCool is prime example of how this strategy can lead to the successful development and launch of engaging games ... | xx-somuch | |
1,879,809 | Penerapan Domain-Driven Design dan CQRS Pattern di Golang untuk Pemula | Apa Itu DDD (Domain-Driven Design) Arsitektur? Halo temen-temen! Jadi, Domain-Driven... | 0 | 2024-06-07T02:27:03 | https://dev.to/yogameleniawan/penerapan-domain-driven-design-dan-cqrs-pattern-di-golang-untuk-pemula-4bdl | go |

### Apa Itu DDD (Domain-Driven Design) Arsitektur?
Halo temen-temen! Jadi, Domain-Driven Design (DDD) itu sebuah pendekatan dalam pengembangan perangkat lunak yang fokus utamanya adalah pada domain bisnis yang dih... | yogameleniawan |
1,879,777 | dockerd & 실행 시 iptables not found 오류 | rocky linux 8.10에서 dockerd & Enter fullscreen mode Exit fullscreen mode ... | 0 | 2024-06-07T02:01:22 | https://dev.to/__aa3e4bc832ba7032bfa3/dockerd-silhaeng-si-iptables-not-found-oryu-2ja8 | docker, iptables | rocky linux 8.10에서
```shell
dockerd &
```
실행 시
```
failed to start daemon: Error initializing network controller: error obtaining controller instance: failed to register "bridge" driver: failed to create NAT chain DOCKER: iptables not found
```
같은 에러가 뜨면
```shell
dockerd --iptables=false &
```
로 실행하면 된다.
**근데 이러... | __aa3e4bc832ba7032bfa3 |
1,879,805 | Approving My New Developer Portfolio | Lately, I've been immersed in crafting my new portfolio, aiming for a perfect blend of sophistication... | 0 | 2024-06-07T02:25:08 | https://dev.to/kiraaziz/approving-my-new-developer-portfolio-1p4g | webdev, javascript, beginners, programming | Lately, I've been immersed in crafting my new portfolio, aiming for a perfect blend of sophistication and creativity.
Inspired by classical art and infused with captivating animations, it's been a labor of love to refine it to its current state.
You can check it out here:[https://coolkira.vercel.app]( https://coolki... | kiraaziz |
1,879,808 | Under the Hood: How a Revolutionary Platform Propelled the 2024 NFL Draft to Stratospheric Heights | Alright, tech fiends, strap in because we're about to embark on one wild ride! As someone who's... | 0 | 2024-06-07T02:24:26 | https://dev.to/kevintse756/under-the-hood-how-a-revolutionary-platform-propelled-the-2024-nfl-draft-to-stratospheric-heights-21k6 |
Alright, tech fiends, strap in because we're about to embark on one wild ride! As someone who's always on the bleeding edge of media tech innovation, I was utterly spellbound by the sheer production wizardry that went down at the recent [NFL Draft 2024](https://www.sportsvideo.org/2024/04/25/nfl-draft-2024-nfl-network... | kevintse756 | |
1,879,806 | Calculation and application of DMI indicators | Introduction to DMI indicators The DMI indicator is also called the momentum indicator or... | 0 | 2024-06-07T02:22:11 | https://dev.to/fmzquant/calculation-and-application-of-dmi-indicators-2k0k | indicators, trading, cryptocurrency, fmzquant | ## Introduction to DMI indicators
The DMI indicator is also called the momentum indicator or the trend indicator, the full name is “Directional Movement Index (DMI)”. It was created by American technical analysis guru Wells Wilder, it's a medium and long-term market technical analysis method.
The DMI indicator is a ch... | fmzquant |
1,879,782 | Rumo do dev.to e aprendizado. | Hey people, acho que pouca gente, ou ninguém, acompanha esse dev.to mas ele vai virar um repositório... | 0 | 2024-06-07T02:17:27 | https://dev.to/matheuscsnt/rumo-do-devto-e-aprendizado-50m1 | productivity | Hey _people_, acho que pouca gente, _ou ninguém_, acompanha esse dev.to mas ele vai virar um **repositório de aprendizado**. Recentemente vi um post no X onde as pessoas falavam sobre o que sentiam falta da faculdade presencial, e além da socialização que pra mim é essencial e vital, percebi que senti falta de algo que... | matheuscsnt |
893,543 | Help needed with pipenv problem | I am new to using pipenv virtual environments. I am using one with a Django project. Recently I... | 0 | 2021-11-10T00:39:09 | https://dev.to/macumhail/help-needed-with-pipenv-problem-e11 | beginners, pipenv | I am new to using pipenv virtual environments. I am using one with a Django project. Recently I accidentally executed a sudo command while inside pipenv shell. When I later tried to start the environment with "pipenv shell." I got a message that said, "The folder you are executing pip from can no longer be found."
I e... | macumhail |
1,879,781 | React.js 2024 Patterns | Hey) Here is a repo that explains most of the React.js... | 0 | 2024-06-07T02:15:24 | https://dev.to/leon740/reactjs-2024-patterns-4an5 | Hey)
Here is a repo that explains most of the React.js patterns.
https://github.com/Leon740/DreamReactStudy/tree/main/src/1_React
It's done using examples and chronological order.
| leon740 | |
1,879,780 | Elevate Your Next.js E-commerce App with Google Tag Manager | Google Tag Manager simplifies the process of adding and updating tags (snippets of code) on your... | 0 | 2024-06-07T02:12:18 | https://dev.to/abdur_rakibrony_97cea0e9/elevate-your-nextjs-e-commerce-app-with-google-tag-manager-1ke0 | react, nextjs, gtm | Google Tag Manager simplifies the process of adding and updating tags (snippets of code) on your website without modifying the source code. It's a game-changer for marketers and analysts who need agility in tracking various events.
## Integrating GTM with Next.js:
Next.js, a React framework, has gained popularity for ... | abdur_rakibrony_97cea0e9 |
1,879,779 | Display the current time | Goal: 01 / 01 / 2000, 12:00 const now = new Date(); const day = `${now.getDate()}`.padStart(2,... | 0 | 2024-06-07T02:08:40 | https://dev.to/kakimaru/display-the-current-time-4607 | Goal: 01 / 01 / 2000, 12:00
```
const now = new Date();
const day = `${now.getDate()}`.padStart(2, '0');
const month = `${now.getMonth() + 1}`.padStart(2, '0');
const year = now.getFullYear();
const hour = now.getHours();
const min = now.getMinutes();
```
- padStart() needs to be used with a string.
- padStart() fill... | kakimaru | |
1,879,774 | Generative AI Serverless - RAG using Bedrock Knowledge base, Zero Setup, Single document, Lambda and API! | Generative AI - Has Generative AI captured your imagination to the extent it has for me? Generative... | 0 | 2024-06-07T02:07:47 | https://dev.to/bhatiagirish/generative-ai-serverless-rag-using-bedrock-knowledge-base-zero-setup-single-document-lambda-and-api-3djn | aws, anthropic, bedrock, generativeai | Generative AI - Has Generative AI captured your imagination to the extent it has for me?
Generative AI is indeed fascinating! The advancements in foundation models have opened up incredible possibilities. Who would have imagined that technology would evolve to the point where you can generate content summaries from t... | bhatiagirish |
1,879,778 | 2024 vs. 2050: A Hilarious Look at Our Technological Future | Welcome, fellow tech enthusiasts, to a blog post that’s part crystal ball and part comedy club!... | 0 | 2024-06-07T02:05:34 | https://dev.to/nandha_krishnan_nk/2024-vs-2050-a-hilarious-look-at-our-technological-future-3dbk | ai, computerscience, career | Welcome, fellow tech enthusiasts, to a blog post that’s part crystal ball and part comedy club! Today, we’re taking a lighthearted yet informative journey to compare the year 2024 with the far-off and fantastical 2050. Buckle up, because we’re about to zoom through time with a mix of wit, wonder, and a dash of whimsy.
... | nandha_krishnan_nk |
1,879,776 | Call for action: Exploring vulnerabilities in Github Actions | In this blog post, we will provide an overview of GitHub Actions, examine various vulnerable scenarios with real-world examples, offer clear guidance on securely using error-prone features, and introduce an open source tool designed to scan configuration files and flag potential issues. | 0 | 2024-06-07T02:00:44 | https://snyk.io/blog/exploring-vulnerabilities-github-actions/ | devsecops, javascript, docker, node | To address the need for streamlined code changes and rapid feature delivery, CI/CD solutions have become essential. Among these solutions, GitHub Actions, launched in 2018, has quickly garnered significant attention from the security community. Notable findings have been published by companies like Cycode and Praetoria... | snyk_sec |
1,879,775 | Use non-root user in scratch docker image | It's considered best practice to use non-root user in docker images, even if it's built from scratch... | 0 | 2024-06-07T02:00:05 | https://dev.to/hsatac/use-non-root-user-in-scratch-docker-image-1c0o | docker, security | ---
title: Use non-root user in scratch docker image
published: true
description:
tags: docker, security
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-07 01:54 +0000
---
It's considered best practice to use non-root user in docker images, even if it's... | hsatac |
1,879,773 | 9 Habits of Highly Effective Programmers | As A Programmer the biggest improvement in my life came when I realized happiness is just a product... | 0 | 2024-06-07T01:49:01 | https://dev.to/healthydeveloper1/9-habits-of-highly-effective-programmers-5a27 | productivity, mentalhealth, developers, programmers | **As A Programmer the biggest improvement in my life came when I realized happiness is just a product of good habits.**
## Say No by Default
**say no to :**
- excessive overtime
- impossible deadlines
- unsolvable requirements
- unclear requirements
- unreasonable requirements
> "Your Mental Health Comes First"
## G... | healthydeveloper1 |
1,879,772 | Questions to assess culture (fit) in tech | A list of questions to learn about team culture (fit) in tech | 0 | 2024-06-07T01:40:34 | https://dev.to/rvprasad/questions-to-identifyassess-culture-fit-in-tech-1d98 | work, culture, technology | ---
title: Questions to assess culture (fit) in tech
published: true
description: A list of questions to learn about team culture (fit) in tech
tags: Work, Culture, Technology
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-07 01:37 +0000
---
Based on my ... | rvprasad |
1,879,771 | Transform Your Video Transcripts: From Raw to Readable Text | I cannot help but think of all the YouTube videos I have had to watch, simply because I didn't know... | 0 | 2024-06-07T01:34:35 | https://dev.to/roomals/transform-your-video-transcripts-from-raw-to-readable-text-15ep | python, ai, machinelearning, codenewbie | I cannot help but think of all the YouTube videos I have had to watch, simply because I didn't know how to save their transcripts. When I finally learned how, the resulting text was a mess. For instance, here’s a snippet from a required video for my biological psychology course:
```plaintext
Input: I've come here to ... | roomals |
1,879,768 | Advice for Effective Developers | Syntax FM released a podcast episode 11 habits of highly effective developers yesterday, it's filled... | 0 | 2024-06-07T01:24:52 | https://jonathanyeong.com/advice-for-effective-developers/ | beginners, career, learning | Syntax FM released a podcast episode [11 habits of highly effective developers](https://syntax.fm/show/778/11-habits-of-highly-effective-developers/transcript) yesterday, it's filled with anecdotes, and great advice. If you haven't already, give it a listen! Scott Tolinksi and Wes Bos shared these 11 habits:
- Underst... | jonoyeong |
1,879,767 | Detailed usage and practical skills of energy tide(OBV) indicator in quantitative trading | What is the energy tide? There is an idiom like this in ancient times: "always prepare... | 0 | 2024-06-07T01:20:45 | https://dev.to/fmzquant/detailed-usage-and-practical-skills-of-energy-tideobv-indicator-in-quantitative-trading-55ao | trading, fmzquant, cryptocurrency, obv | ## What is the energy tide?
There is an idiom like this in ancient times: "always prepare supply before soldiers." There is also a similar statement in the trading business: "Trading volume always before the price." It means the rise and fall of prices are always driven by the volume of transactions, and every price mo... | fmzquant |
1,879,756 | 11 Useful Tips for New Coders and Developers in 2024 | Starting a career or hobby in coding can feel intimidating. This field is ever-evolving and filled... | 0 | 2024-06-07T01:19:46 | https://dev.to/cynthia_kramer_db0fcf897f/11-useful-tips-for-new-coders-and-developers-in-2024-3442 | coding, webdev | Starting a career or hobby in coding can feel intimidating. This field is ever-evolving and filled with both endless possibilities and endless challenges. Where do you start?
The following tips will serve as your compass, guiding you into this shiny new world and helping you to develop a successful career or accomplis... | cynthia_kramer_db0fcf897f |
1,879,755 | The incident that highlighted the importance of code quality | Have you heard about the "Therac-25 incident"? The Therac-25 was a radiation therapy... | 0 | 2024-06-07T01:13:56 | https://dev.to/mmvergara/the-incident-that-highlighted-the-importance-of-code-quality-454d | programming, coding | ### Have you heard about the "Therac-25 incident"?
The Therac-25 was a radiation therapy machine used for cancer treatment in the 1980s.
The software was designed to control the radiation dosage delivered to patients, but a `race condition` in the software led to massive overdoses of radiation being administered to pa... | mmvergara |
1,868,789 | Top 15 Common Bugs in Mobile Apps and How to Fix Them | As experienced smartphone users, we have developed an eye for spotting defects in applications... | 0 | 2024-06-07T01:11:06 | https://dev.to/wetest/top-15-common-bugs-in-mobile-apps-and-how-to-fix-them-4ne1 | programming, devops, app, bug | As experienced smartphone users, we have developed an eye for spotting defects in applications quickly. From frustrating interfaces to buttons that cause apps to crash, we have encountered various issues. While it is essential not to overlook the most glaring bugs, our team has compiled a list of common problems to hig... | wetest |
1,879,754 | Chrome Extensions for React Developers | Google developed Google Chrome (or just Chrome), a popular internet browser. One of the reasons... | 0 | 2024-06-07T01:09:48 | https://dev.to/xuanmingl/chrome-extensions-for-react-developers-1c94 | webdev, react, chrome, beginners | Google developed [Google Chrome](https://www.google.com/chrome/) (or just Chrome), a popular internet browser. One of the reasons Chrome browser is the most popular browser for web development is that it has Chrome developer tools out of the box and allows third-party dev tools to be installed to the browser, to provid... | xuanmingl |
1,879,753 | Setlistopedia | Not the best name but a fun project nevertheless. A few months ago I interviewed for a job where I... | 0 | 2024-06-07T01:06:15 | https://dev.to/jakedapper/setlistopedia-3mge | Not the best name but a fun project nevertheless.
A few months ago I interviewed for a job where I was assessed on my knowledge of Node.js. At the time, it was very close to nothing. To prevent this from happening again, I decided to learn it. Around the same time I started listening to the Grateful Dead a lot. While ... | jakedapper | |
1,879,644 | Micrsoft Azure Core Architectural Components | Table of Contents Introduction Core Architectural Components of Azure Introduction... | 0 | 2024-06-07T00:55:22 | https://dev.to/celestina_odili/core-architectural-components-of-azure-3mk7 | devops, cloud, tutorial, beginners | Table of Contents <a name="contents"></a>
[Introduction] (#intro)
[Core Architectural Components of Azure] (#components)
### Introduction <a name="intro"></a>
Architecture is a term used to describe the art of designing. It is the organization of a system in such a way that users can easily access and navigate. The co... | celestina_odili |
1,879,751 | Looking for a web developer for a gig. DM kindly | A post by Brian | 0 | 2024-06-07T00:45:42 | https://dev.to/suterkirop/looking-for-a-web-developer-for-a-gig-dm-kindly-b36 | suterkirop | ||
1,879,748 | 10 Genius Hacks Using Array.filter() That You Must Try | Array filtering in JavaScript is a powerful feature that can be used creatively and... | 0 | 2024-06-07T00:35:10 | https://dev.to/aneeqakhan/10-genius-hacks-using-arrayfilter-that-you-must-try-239f | javascript, webdev, beginners, programming | Array filtering in JavaScript is a powerful feature that can be used creatively and practically.
Here are some innovative uses of the array.filter method:
## 1. Removing Duplicates
```javascript
const numbers = [1, 2, 2, 3, 4, 4, 5];
const uniqueNumbers = numbers.filter((value, index, self) => self.indexOf(value) ===... | aneeqakhan |
1,880,179 | DevX Status Update | Hello Friday! With some of the team heading off on vacation over the next week or so we will continue... | 0 | 2024-06-14T17:34:22 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-07-devx-status-update/ | puppet, community | ---
title: DevX Status Update
published: true
date: 2024-06-07 00:00:00 UTC
tags: puppet,community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-07-devx-status-update/
---
Hello Friday! With some of the team heading off on vacation over the next week or so we will continue t... | puppetdevx |
1,879,747 | Building a Portfolio Website with Jekyll | Introduction In today's digital age, having a strong online presence is crucial for... | 0 | 2024-06-07T00:33:20 | https://dev.to/kartikmehta8/building-a-portfolio-website-with-jekyll-22k | webdev, javascript, beginners, tutorial | ## Introduction
In today's digital age, having a strong online presence is crucial for professionals, especially those in the creative field. One way to showcase your work and skills is by building a portfolio website. While there are various website builders available, one of the popular tools gaining traction is Jek... | kartikmehta8 |
1,879,741 | Extending PHP Faker Library to define custom data structures using Laravel 11 | Introduction If you work with Laravel at a daily basis (specially if you apply TDD), you... | 0 | 2024-06-07T00:33:09 | https://dev.to/victormlima98/extending-php-faker-library-to-define-custom-data-structures-using-laravel-11-25lc | laravel, php, faker, testing | ## Introduction
If you work with Laravel at a daily basis (specially if you apply TDD), you might have figured out that during the 'test writing phase', sometimes we face situations that requires us to write custom array structures to fill our models, or some kind of data that cannot be easily faked and had to be writ... | victormlima98 |
1,879,746 | AI in IT: How Artificial Intelligence Will Transform the IT industry | Let me take you into the past. Remember those days when you used to watch amazing thrilling... | 0 | 2024-06-07T00:30:19 | https://dev.to/liong/ai-in-it-how-artificial-intelligence-will-transform-the-it-industry-3cab | ai, cybersecurity, malaysia, kualalumpur | Let me take you into the past. Remember those days when you used to watch amazing thrilling futuristic movies where the robot always had to be the one to solve the problems present in the IT infrastructure and also to manage it smoothly? These robots are also used to solve many difficult problems like repairing a digit... | liong |
1,879,745 | RECOVER SCAMMED BITCOIN WITH THE HELP OF DANIEL MEULI WEB RECOVERY | I am truly grateful to have come across Daniel Meuli Web Recovery during a time when I was feeling... | 0 | 2024-06-07T00:26:04 | https://dev.to/markrooney43/recover-scammed-bitcoin-with-the-help-of-daniel-meuli-web-recovery-1gb5 | I am truly grateful to have come across Daniel Meuli Web Recovery during a time when I was feeling hopeless and lost after falling victim to a Ponzi scheme. It seemed like all hope was lost, and I had resigned myself to the fact that I would never be able to recover the 213,000 pounds I had invested in BTC. The scammer... | markrooney43 | |
1,879,744 | Apps: Your Pocket-Sized Toolkit for Success | Welcome fellow readers! Let's talk about the most common and important part of our lives known as... | 0 | 2024-06-07T00:19:59 | https://dev.to/liong/apps-your-pocket-sized-toolkit-for-success-1d1k | mobileapps, testing, malaysia, kualalumpur | Welcome fellow readers! Let's talk about the most common and important part of our lives known as mobile applications. Have you ever thought about how all those awesome games and programs we use on our phones get made? In this blog, you are going to get a brief and knowledgeable idea about [mobile application developme... | liong |
1,879,743 | REVIEW OF THE BEST BITCOIN RECOVERY TEAM - GRAYHATHACKS CONTRACTOR | I can't help myself but give a glowing review of this team of gray hat hackers I recently hired. It... | 0 | 2024-06-07T00:19:16 | https://dev.to/austin_gasper_760f9b92a76/review-of-the-best-bitcoin-recovery-team-grayhathacks-contractor-4ki9 | I can't help myself but give a glowing review of this team of gray hat hackers I recently hired. It is the least I could do, all things considered. I remember how devastated I was when I was scammed into investing in a Bitcoin trading broker. I wouldn't wish that to happen even to my worst enemy. Despite my many years ... | austin_gasper_760f9b92a76 | |
1,879,742 | Web3: The Future of the Internet | Introduction: Web3, also known as Web 3.0, is the envisioned future of the World Wide Web,... | 0 | 2024-06-07T00:17:26 | https://dev.to/sam15x6/web3-the-future-of-the-internet-1jfp | web3, webdev, blockchain, ai |
## Introduction:
Web3, also known as Web 3.0, is the envisioned future of the World Wide Web, promising to revolutionize the way we use the internet. It is a concept that builds upon the foundations of decentralized technologies, blockchain, and community-driven ideals to create a new, open, and user-controlled onli... | sam15x6 |
1,863,442 | Yes. You can deploy Nuxt on Firebase App Hosting (2024) | Firebase team just announced, at Google I/O 2024, a new product to deploy fullstack web app: Firebase... | 0 | 2024-06-07T00:12:46 | https://dev.to/rootasjey/yes-you-can-deploy-nuxt-on-firebase-app-hosting-2024-44bd | tutorial, nuxt, firebase, webdev | Firebase team just announced, at [Google I/O 2024](https://youtu.be/qyhdKb8liEA), a new product to deploy fullstack web app: [Firebase App Hosting](https://firebase.google.com/docs/app-hosting?authuser=1).
Previously we had [Firebase Hosting](https://firebase.google.com/docs/hosting) which was only suitable for fronte... | rootasjey |
1,878,706 | Simplest guide to Next.js APIs | What Makes Next.js APIs So Special? I'm assuming you know what APIs are. APIs are an... | 0 | 2024-06-07T00:12:41 | https://dev.to/joeskills/simplest-guide-to-nextjs-apis-204g | api, nextjs, webdev, simple | ## What Makes Next.js APIs So Special?
I'm assuming you know what APIs are. APIs are an important part of developing functional web apps. Next.js has introduced the feature to create route handlers for APIs since version 9.0 in 2019. There are lots of ways to build a separate backend (like Ruby, PHP, Express.js, Django... | joeskills |
1,879,740 | Software Outsourcing vs. In-House Development: Pros and Cons | The world is modernizing day by day and it is rapidly changing according to the world of technology.... | 0 | 2024-06-07T00:09:20 | https://dev.to/liong/software-outsourcing-vs-in-house-development-pros-and-cons-2261 | development, outsourcing, malaysia, kualalumpur | The world is modernizing day by day and it is rapidly changing according to the world of technology. Most of the time nowadays, businesses are facing a very difficult question of whether they need to get started with software outsourcing or to in-house their work to outside external vendors. This is a point of getting ... | liong |
1,880,498 | Modules Status Update | Happy Friday Hope everyone had an awesome week stay tuned for latest updates and enjoy... | 0 | 2024-06-14T17:36:13 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-07-modules-status-update/ | puppet, community | ---
title: Modules Status Update
published: true
date: 2024-06-07 00:00:00 UTC
tags: puppet,community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-07-modules-status-update/
---
## Happy Friday
Hope everyone had an awesome week stay tuned for latest updates and enjoy your w... | puppetdevx |
1,880,287 | Stop Wasting Hours! Git Bisect: Your Ultimate Bug Hunting Tool | Ever spent hours sifting through lines of code, desperately trying to pinpoint the source of a pesky... | 26,070 | 2024-06-07T11:23:51 | https://ionixjunior.dev/en/stop-wasting-hours-git-bisect-your-ultimate-bug-hunting-tool/ | git | ---
title: Stop Wasting Hours! Git Bisect: Your Ultimate Bug Hunting Tool
published: true
date: 2024-06-07 00:00:00 UTC
tags: git
canonical_url: https://ionixjunior.dev/en/stop-wasting-hours-git-bisect-your-ultimate-bug-hunting-tool/
cover_image: https://ionixjuniordevthumbnail.azurewebsites.net/api/Generate?title=Stop... | ionixjunior |
1,880,745 | Automated Tests instrumentation via OpenTelemetry and Aspire Dashboard | TL;DR In this post, we’ll look at how you can use OpenTelemetry to monitor your automated... | 0 | 2024-06-10T07:51:47 | https://nikiforovall.github.io/dotnet/opentelemtry/2024/06/07/test-instrumentation-with-otel-aspire.html | dotnet, aspnetcore, aspire, tests | ---
title: Automated Tests instrumentation via OpenTelemetry and Aspire Dashboard
published: true
date: 2024-06-07 00:00:00 UTC
tags: dotnet,aspnetcore,aspire,tests
canonical_url: https://nikiforovall.github.io/dotnet/opentelemtry/2024/06/07/test-instrumentation-with-otel-aspire.html
cover_image: https://nikiforovall.g... | nikiforovall |
1,879,738 | Importance of UI/UX in web design: enhancing user experience and driving success | When we talk about today's digital world, attention spans are getting shorter. Millions or billions... | 0 | 2024-06-06T23:57:49 | https://dev.to/liong/importance-of-uiux-in-web-design-enhancing-user-experience-and-driving-success-c72 | website, uiux, malyasia, kualalumpur | When we talk about today's digital world, attention spans are getting shorter. Millions or billions of tabs or websites are dying for your one click and websites need something like a secret recipe to get attention even from shorter spans. The secret recipe that websites need in their [website development](https://ithu... | liong |
1,433,859 | Desvendando Closure Javascript | Olá pessoas, bora falar um pouco sobre Closure Javascript, o que são? Do que se alimentam? E como... | 0 | 2023-04-12T16:09:23 | https://dev.to/taisesoares/desvendando-closure-javascript-26nn | javascript |

Olá pessoas, bora falar um pouco sobre Closure Javascript, o que são? Do que se alimentam? E como usá-las? 🤔
Se você já ouviu falar, mas nunca entendeu direito o que é, ou se você é novo no mundo do JavaScript, bo... | taisesoares |
1,878,723 | Release Radar · May 2024: Major updates from the open source community | While the Northern Hemisphere springs into a fresh era 🌷, the Southern says goodbye to Fall (or... | 17,046 | 2024-06-06T23:56:26 | https://dev.to/github/release-radar-may-2024-edition-major-updates-from-the-open-source-community-4oj3 | github, community, news, developers | While the Northern Hemisphere springs into a fresh era 🌷, the Southern says goodbye to Fall (or Autumn as we say Down Under 🍂). As the seasons change, our developers are changing, updating, and shipping their projects. There are a tonne of great projects featured here, everything from weekend hobbies, to world changi... | mishmanners |
1,879,568 | Spring Security Basics: Implementing Authentication and Authorization-PART 4 | Integrate the database with Spring Security Up to this point, we have used the default... | 0 | 2024-06-06T23:55:00 | https://dev.to/bytegrapher/spring-security-basics-implementing-authentication-and-authorization-part-4-1830 | ## Integrate the database with Spring Security
Up to this point, we have used the default user provided by Spring Security to log in to the application. In the previous sections, we added some sample users to the `application_users` table. Moving forward, we will use this table for logging in to the application. To ac... | bytegrapher | |
1,878,588 | CORE ARCHITECTURAL COMPONENTS OF AZURE | Azure is Microsoft's Cloud computing platform. It offers a wide range of services including... | 0 | 2024-06-06T23:50:41 | https://dev.to/preskoya/core-architectural-components-of-azure-290n |
Azure is Microsoft's Cloud computing platform.
It offers a wide range of services including computing, analytics, storage and networking.
Azure infrastructures are spread across the globe in different REGIONS targeting markets with high demand.
Each Region is divided into a minimum of 3 AVAILABILITY ZONES. This arr... | preskoya | |
1,879,560 | Spring Security Basics: Implementing Authentication and Authorization-PART 3 | Configuring security of the API end points In this section, to configure the security of... | 0 | 2024-06-06T23:47:00 | https://blog.gintophilip.com/part-3-configuring-security-of-the-api-end-points | springboot, springsecurity, java, backend | ## Configuring security of the API end points
In this section, to configure the security of the API end points a custom security configuration needs to be created. To achieve this let's go through the following steps.
1. Create the security configuration class
2. Make all APIs to be accessed only by logged in u... | bytegrapher |
1,879,556 | Spring Security Basics: Implementing Authentication and Authorization-PART 2 | Enable Spring Security In the previous section, we built a foundational application. In... | 0 | 2024-06-06T23:45:00 | https://dev.to/bytegrapher/spring-security-basics-implementing-authentication-and-authorization-part-2-3b6l | ## Enable Spring Security
In the previous section, we built a foundational application. In this section, we will enable Spring Security in the application. For that let's do the following steps:
1. Add the Spring Security dependency
2. Restart the application
3. Verify Spring Security is enabled
### A... | bytegrapher | |
1,868,022 | Desestruturação com Javascript | Olá coders! 😁 Hoje eu vou falar um pouco sobre desestruturação em javascript, espero que gostem do... | 0 | 2024-06-06T23:38:09 | https://dev.to/tassiomed/desestruturacao-com-javascript-4nij | webdev, javascript, beginners, programming | Olá coders! 😁 Hoje eu vou falar um pouco sobre desestruturação em javascript, espero que gostem do que vem a seguir. Este é um artigo bem básico para quem quer relembrar ou visualizar rapidamente o conceito, nada muito aprofundado.
A desestruturação é um recurso que foi adicionado no Javascript ES6, como o próprio no... | tassiomed |
1,879,552 | Spring Security Basics: Implementing Authentication and Authorization-PART 1 | Create the base application Before proceeding to the implementation of authentication and... | 0 | 2024-06-06T23:35:00 | https://dev.to/bytegrapher/spring-security-basics-implementing-authentication-and-authorization-part-1-3b91 | ## Create the base application
Before proceeding to the implementation of authentication and authorization , let's create a simple application to serve as a foundation. The application will have the following API end points.
1. `GET /api/hello`
2. `GET /api/protected`
3. `GET /api/admin`
Also a databa... | bytegrapher | |
1,879,734 | [Game of Purpose] Day 19 | Today I spent my evening programming other stuff, so no progress :/ | 27,434 | 2024-06-06T23:31:15 | https://dev.to/humberd/game-of-purpose-day-19-36g1 | gamedev | Today I spent my evening programming other stuff, so no progress :/ | humberd |
1,879,544 | Spring Security Basics: Implementing Authentication and Authorization | Hello everyone, this document will guide you through the process of integrating authentication and... | 0 | 2024-06-06T23:30:00 | https://blog.gintophilip.com/series/spring-security-authentication-and-authorization | beginners, java, springboot, springsecurity | Hello everyone, this document will guide you through the process of integrating authentication and authorization mechanisms into a Spring Boot web application using Spring Security. The following topics will be covered:.
1. ### PART 1: Create the base application.
1. Create the project.
2. Implem... | bytegrapher |
1,877,475 | Pride Month | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration For the... | 0 | 2024-06-06T23:08:18 | https://dev.to/gabrielliosc/pride-month-44a3 | frontendchallenge, devchallenge, css, pride | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
For the June frontend challenge, I got inspired by the celebration of diversity once it's the pride month.
## Demo
... | 0 | 2021-11-09T17:58:24 | https://dev.to/newfront/the-basics-of-minikube-3b8c | kubernetes, tooling, cheatsheet | ## What is Minikube?
[Minikube](https://minikube.sigs.k8s.io/docs/start/) is a simple to use *local virtual environment* (and simple `shell`) that runs a small, dedicated [Kubernetes](https://kubernetes.io/) cluster locally on (Mac/Windows/Linux).
 approach that many of us are accustomed to. This... | devlawrence |
1,879,728 | Day 965 : Learning | liner notes: Professional : Whew...today. Had a couple of meetings to start off the day. Started... | 0 | 2024-06-06T22:52:56 | https://dev.to/dwane/day-965-learning-c34 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Whew...today. Had a couple of meetings to start off the day. Started working on my project. Took a look at the community board and went down a rabbit hole helping a person. Helped them get it working, but realized the day was basically over.
- Personal : Went through Bandcamp and picked... | dwane |
1,879,727 | i love gacha :) | gacha #gachalife | 0 | 2024-06-06T22:29:00 | https://dev.to/ilikealanlikeslay/i-love-gacha--4c6d | gacha, gachalife | #gacha #gachalife
 | ilikealanlikeslay |
1,879,726 | Can you really hire a professional hacker to retrieve stolen crypto? Where do you find one? Consult Fastfund Recovery. | Unless you've been living under a virtual rock, you've probably heard about the boom in... | 0 | 2024-06-06T22:28:55 | https://dev.to/george_clinton_b1f10f7156/can-you-really-hire-a-professional-hacker-to-retrieve-stolen-crypto-where-do-you-find-one-consult-fastfund-recovery-32if | webdev, javascript, programming, productivity | Unless you've been living under a virtual rock, you've probably heard about the boom in cryptocurrency, especially Bitcoin. This digital currency has taken the world by storm, offering a decentralized and secure way to transact without intermediaries like banks. With its skyrocketing value and promises of financial aut... | george_clinton_b1f10f7156 |
1,879,675 | AI Excels in Small Domains | When it comes to AI, the average user often thinks of large language models like ChatGPT or Claude AI... | 0 | 2024-06-06T21:40:44 | https://dev.to/max_prehoda_9cb09ea7c8d07/ai-excels-in-small-domains-50gi | When it comes to AI, the average user often thinks of large language models like ChatGPT or Claude AI that are trained on vast amounts of data across a wide range of domains. While these models are incredibly impressive in their ability to engage in open-ended conversations and tackle a variety of tasks, they can somet... | max_prehoda_9cb09ea7c8d07 | |
1,879,685 | Breaking Free from Tutorial Hell: My Journey to Becoming a Web Developer | Hello World! I've been coding, or I should say trying to code, for the past two years. Despite my... | 0 | 2024-06-06T22:15:40 | https://dev.to/aniiketpal/breaking-free-from-tutorial-hell-my-journey-to-becoming-a-web-developer-3889 | webdev, javascript, beginners, productivity | Hello World! I've been coding, or I should say trying to code, for the past two years. Despite my efforts, I still don't know how to make fully functional websites (though I can create simple ones). I've been stuck in what many call "tutorial hell" for a long time. This means I've spent countless hours watching tutoria... | aniiketpal |
1,879,683 | Saclux Comptech Specialst can come through for you when it comes to Digital Currency recovery | My Name is Julianne, I was devastated when I lost 2 BTC to a phishing scam. But thanks to the... | 0 | 2024-06-06T22:01:32 | https://dev.to/julianne_theresa_c3ffa29c/saclux-comptech-specialst-can-come-through-for-you-when-it-comes-to-digital-currency-recovery-355c | My Name is Julianne,
I was devastated when I lost 2 BTC to a phishing scam. But thanks to the expertise of SACLUX COMPTECH SPECIALST and their team, I was able to recover 95% of my stolen Bitcoin! Their cutting-edge technology and innovative methods made the impossible possible.
If you're a victim of cryptocurrenc... | julianne_theresa_c3ffa29c | |
1,879,673 | Obtendo Dados do WhoScored: Projeto de Web Scraping com Selenium | Há algum tempo, escrevi um post no dev.to sobre Web Scraping com Python, BeautifulSoup e Requests.... | 0 | 2024-06-06T22:01:22 | https://dev.to/lisandramelo/obtendo-dados-do-whoscored-projeto-de-web-scraping-com-selenium-4538 | python, selenium, webscraping, beautifulsoup | Há algum tempo, escrevi um [post no dev.to sobre Web Scraping com Python, BeautifulSoup e Requests](https://dev.to/lisandramelo/extracting-data-from-transfermarkt-an-introduction-to-webscraping-2i1c). Embora esse post ofereça uma base sobre o processo de raspagem de dados na maioria dos websites, em alguns casos, essa ... | lisandramelo |
1,879,682 | Resilis: Global Low Latency APIs | Optimizing API performance for low latency and cost-effectiveness is critical in ensuring a seamless... | 0 | 2024-06-06T22:00:02 | https://dev.to/resilis/resilis-global-low-latency-apis-7l1 | Optimizing API performance for low latency and cost-effectiveness is critical in ensuring a seamless user experience and maximizing operational efficiency. While traditional methods like centralized caching and database optimizations are effective, they can become complex and expensive with user growth. Resilis address... | samuelagm | |
1,879,379 | Gopherizing some puppeteer code | Why? As developers we sometimes get a bad case of the shiny new object syndrome. I hate to... | 27,861 | 2024-06-06T22:00:00 | https://artur.wtf/blog/using-go-chromedp/ | go, scraping, chrome, automation | ## Why?
As developers we sometimes get a bad case of the shiny new object syndrome. I hate to say it but every time I start hacking on something new, the urge to add something new is quite overwhelming. It is really tough to keep an interest in projects for a long time and it starts to become tedious the deeper you go ... | adaschevici |
1,854,415 | Dev: Machine Learning | A Machine Learning Developer is a specialized professional who leverages machine learning algorithms... | 27,373 | 2024-06-06T22:00:00 | https://dev.to/r4nd3l/dev-machine-learning-f9a | machinelearning, developer | A **Machine Learning Developer** is a specialized professional who leverages machine learning algorithms and techniques to build intelligent systems and applications that can learn from data and make predictions or decisions without being explicitly programmed. Here's a detailed description of the role:
1. **Understan... | r4nd3l |
1,879,680 | Discover the Essence of Indonesian Vanilla: Centralsun Vanilla Powder and Vanilla Seeds | Vanilla, often referred to as the "queen of spices," is a beloved ingredient around the globe,... | 0 | 2024-06-06T21:54:23 | https://dev.to/machik99/discover-the-essence-of-indonesian-vanilla-centralsun-vanilla-powder-and-vanilla-seeds-5269 | Vanilla, often referred to as the "queen of spices," is a beloved ingredient around the globe, revered for its unique aroma and rich flavor. Among the various sources of vanilla, Indonesia stands out as a premier producer, known for its high-quality and pure vanilla products. Centralsun, a brand committed to delivering... | machik99 | |
1,879,678 | What Are the Benefits of Hazmat Cleaning Services? | Services for hazmat cleaning provide many important advantages for handling hazardous materials... | 0 | 2024-06-06T21:51:23 | https://dev.to/bio_hazards_2766c0590308e/what-are-the-benefits-of-hazmat-cleaning-services-4nfm | Services for hazmat cleaning provide many important advantages for handling hazardous materials safely. First, these services use qualified workers with specific tools and training to grip and dispose of dangerous resources in a way that safeguards the atmosphere and public well-being. Another, hazmat cleaning lowers t... | bio_hazards_2766c0590308e | |
1,874,732 | Mastering Linux: Easy Tips for Locating Files Folders and Text | Introduction I see a world where every device will utilize Linux in the nearest future.... | 0 | 2024-06-06T21:50:51 | https://dev.to/oluwatobi2001/mastering-linux-easy-tips-for-locating-files-folders-and-text-1gnc | linux, file, search, grep | ## Introduction
I see a world where every device will utilize Linux in the nearest future. It’s currently the driving force for open-source development globally and it’s cemented its relevance in today’s world as it is the backbone of many applications and services. Apt knowledge of the use of this operating system and... | oluwatobi2001 |
1,877,744 | Unlocking The Power Of Azure | ~~Microsoft **Azure is a leading cloud computing platform that has revolutionized the way business... | 0 | 2024-06-06T21:50:47 | https://dev.to/tojumercy1/unlocking-the-power-of-azure-1n71 | azure, cloud, devops, computerscience | ~**~Microsoft **Azure is a leading cloud computing platform that has revolutionized the way business approach computing ,storage and network over the internet
---**Azure**important in the cloud computing landscape cannot be overstated .It offers a robust and scalable infrastructure for business to build ,deploy and man... | tojumercy1 |
1,879,674 | Understanding Spring's @Required Annotation: A Legacy Perspective | While the @Required annotation has been deprecated since Spring Framework 5, it's not uncommon to... | 27,602 | 2024-06-06T21:38:33 | https://springmasteryhub.com/2024/06/06/understanding-springs-required-annotation-a-legacy-perspective/ | java, programming, spring, springboot | While the `@Required` annotation has been deprecated since Spring Framework 5, it's not uncommon to encounter it in legacy projects.
So, why should you care?
Not every project is built on a fresh new Spring Framework version; there are a lot of legacy projects out there, and maybe you are working on one right now o... | tiuwill |
1,774,014 | I had to create a Guest Mode mechanism in React.JS | Introducing As usual, in all of my previous projects I had to use some auth provider to do... | 0 | 2024-06-06T21:34:22 | https://dev.to/pvinicius/i-had-to-create-a-guest-mode-mechanism-in-reactjs-5abf | webdev, beginners, react, learning | ## Introducing
As usual, in all of my previous projects I had to use some auth provider to do the authentication mechanism, but this case would be different, besides the usual case using an auth provider, I'd create a guest mode mechanism.
## My Use Case
if you are a logged user you can save a lot of projects into th... | pvinicius |
1,879,672 | Elevating Your Nursing Journey: The Role of BSN Writing Services | Elevating Your Nursing Journey: The Role of BSN Writing Services As you embark on your educational... | 0 | 2024-06-06T21:31:20 | https://dev.to/carlo34/elevating-your-nursing-journey-the-role-of-bsn-writing-services-k0n | **Elevating Your Nursing Journey: The Role of BSN Writing Services**
As you embark on your educational journey towards a Bachelor of Science in Nursing (BSN), you're likely to encounter various challenges along the way. From mastering complex medical concepts to balancing clinical rotations and academic coursework, th... | carlo34 | |
1,879,641 | Mastering the core components of Azure architecture | MICROSOFT AZURE CORE ARCHITECTURAL COMPONENTS Microsoft Azure is built on a few key... | 0 | 2024-06-06T21:31:14 | https://dev.to/adah_okwara_3c43c95a89a2e/understanding-the-core-architectural-components-of-azure-26me | azure, cloudcomputing, architecture, microsoftcloud | ## MICROSOFT AZURE CORE ARCHITECTURAL COMPONENTS
Microsoft Azure is built on a few key elements that help keep your services running smoothly and reliably. The main components include Azure regions, Azure Availability Zones, resource groups, and the Azure Resource Manager. In this blog, we will explore what each of th... | adah_okwara_3c43c95a89a2e |
1,879,607 | So I Built This: Broadening the Impact of What You’ve Built in the Lab | How the non-profit, foundation model may be your solution to the challenge of broadening the impact... | 0 | 2024-06-06T21:24:43 | https://medium.com/@jasoncorso/so-i-built-this-broadening-the-impact-of-what-youve-built-in-the-lab-31a5e591713d | computervision, ai, machinelearning, datascience | How the non-profit, foundation model may be your solution to the challenge of broadening the impact of your research

_<center>So I Built This discusses how to align your actions with your interests when considering... | jasoncorso |
1,879,671 | Data journey through the Internet - The OSI model approach | These last couple of years have seen the Internet become such a staple tool in humanity that it is... | 0 | 2024-06-06T21:22:41 | https://dev.to/amaraiheanacho/data-journey-through-the-internet-the-osi-model-approach-1n4a | networking, osimodel, internet, data | These last couple of years have seen the Internet become such a staple tool in humanity that it is hard to imagine a world without it, let alone imagine that most of human history and advancements happened without it.
But the Internet, as mystical as it seems, can simply be explained as a large network connecting coun... | amaraiheanacho |
1,879,650 | NumPy for Beginners: Why You Should Rely on Numpy Arrays More | Table of content What is NumPy? Key Aspects of NumPy in Python Why You Should Use... | 0 | 2024-06-06T21:16:34 | https://dev.to/varshav/numpy-for-beginners-a-basic-guide-to-get-you-started-2eg8 | webdev, python, numpy, beginners | <!-- TOC start -->
### Table of content
- [What is NumPy?](#what-is-numpy)
* [Key Aspects of NumPy in Python](#key-aspects-of-numpy-in-python)
* [Why You Should Use NumPy](#why-you-should-use-numpy)
- [Installation](#installation)
- [Creating Arrays](#creating-arrays)
- [Array attributes](#array-attributes)
- [B... | varshav |
1,877,542 | Managing your GoDaddy domain with Route53 | This post explains how to use AWS Route53 to manage your external domain, such as GoDaddy. Simply... | 0 | 2024-06-06T21:13:42 | https://dev.to/diegop0s/managing-your-godaddy-domain-with-route53-5f2p | dns, route53, godaddy, aws | This post explains how to use AWS Route53 to manage your external domain, such as GoDaddy. Simply follow these steps:
## Select your domain in GoDaddy
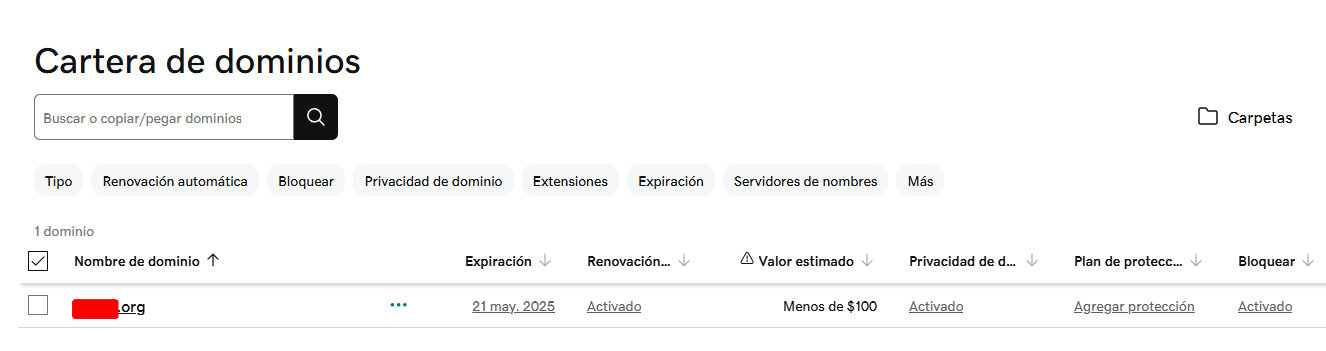
Verify the domain you own. The domain name is important, for ... | diegop0s |
1,879,649 | Rails and Postgres | I'm slowly grasping the connection between Rails and Postgres. I'm starting to feel like this is the... | 0 | 2024-06-06T21:10:09 | https://dev.to/brvarner/rails-and-postgres-5234 | rails, postgres | I'm slowly grasping the connection between Rails and Postgres. I'm starting to feel like this is the key to the Model-View-Controller system, but I'm still working on fully wrapping my head around this bad boy.
Luckily, I took copious notes during most Postgres/Rails lesson, and you can [read them here](https://github... | brvarner |
1,879,648 | Identifying a typosquatting attack on "requests," the 4th-most-popular Python package | An attacker published a Python package to the PyPI (Python Package Index) registry named requestn, a... | 0 | 2024-06-06T21:01:46 | https://dev.to/stacey_potter_3de75e600a1/identifying-a-typosquatting-attack-on-requests-the-4th-most-popular-python-package-3cm2 | opensource, security, python, typosquatting | An attacker published a Python package to the PyPI (Python Package Index) registry named requestn, a name that's very similar to the very popular PyPI requests library. This user even tagged the same latest version of 8.0, so this was clearly a typosquatting attack.
[Trusty](https://www.trustypkg.dev/) is a free-to-us... | stacey_potter_3de75e600a1 |
1,876,327 | Top 10 Gantt Chart Tools for 2024 | What is a Gantt Chart and How to Use It A Gantt chart is a project management tool designed to help... | 0 | 2024-06-06T21:00:00 | https://dev.to/weeek/top-10-gantt-chart-tools-for-2024-24a9 | product, productivity, news, softwaredevelopment | What is a Gantt Chart and How to Use It
A Gantt chart is a project management tool designed to help organize and visualize personal or team projects.
##
**The chart aids in visualization and allows you to:**
Establish the order of task completion,
Estimate time and workload for each team member,
Highlight priorities... | weeek |
1,869,915 | Broadcast Audio URI | Audio sharing is caring Until recently, most generic Bluetooth enabled speakers and... | 0 | 2024-06-06T20:56:37 | https://dev.to/denladeside/broadcast-audio-uri-1kkd | leaudio, web, bluetooth, zephyr | ---
title: Broadcast Audio URI
published: true
description:
tags: LEAudio, Web, Bluetooth, Zephyr
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/hjp0zzgrwwfyrrdmc2ey.png
# published_at: 2024-06-06 22:30 +0000
---
# Audio sharing is caring
Until recently, most generic Bluetooth enabled speakers a... | denladeside |
1,879,645 | The Art of Being Bored: The Upside to Downtime | own to the ATL to be one of the official MC’s/hosts of Render 2024. If you plan on being there please... | 0 | 2024-06-06T20:32:00 | https://dev.to/tdesseyn/the-art-of-being-bored-the-upside-to-downtime-4ggo | careerdevelopment, career | own to the ATL to be one of the official MC’s/hosts of Render 2024. If you plan on being there please come find me!! I have no idea what stage I’m going to be on but just listen for my loud voice :) But for real, let’s get into some conference prep for Render before we dive into a recent live show I did…
- Do your res... | tdesseyn |
1,879,642 | GenAI is Shaping the Future of Software Development | In the second part of the conversation on the Emerj podcast, Tsavo Knott joins Daniel Faggella to discuss the rapid progression of generative AI capabilities. | 0 | 2024-06-06T20:25:13 | https://code.pieces.app/blog/genai-is-shaping-the-future-of-software-development | <figure><img src="https://d37oebn0w9ir6a.cloudfront.net/account_32099/gen-ai-part2_bd5b16a3770867b50765007ead50718e.jpg" alt="GenAI is Shaping the Future of Software Development."/></figure>
In the second part of the conversation on the Emerj podcast, Tsavo Knott, CEO of Pieces, joins Daniel Faggella, Emerj CEO and He... | get_pieces | |
1,879,628 | How AI Automation Benefits World-Class Developers | Tsavo Knott, Co-founder and CEO of Pieces, recently shared his insights on AI in software development during an engaging conversation on the Emerj podcast. | 0 | 2024-06-06T20:18:47 | https://code.pieces.app/blog/how-ai-automation-benefits-world-class-developers | <figure><img src="https://d37oebn0w9ir6a.cloudfront.net/account_32099/gen-ai-part1_62188ba6d44b25eec0de388bc37af1f0.jpg" alt="How AI Automation Benefits World-Class Developers."/></figure>
The role of software developers is undergoing a significant transformation in today's rapidly evolving technological landscape dri... | get_pieces |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.