
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,878,691 | How to Host Website on Netlify for FREE | Hosting a website on Netlify is a straightforward process. Here are the steps to get your site up and... | 0 | 2024-06-06T02:44:38 | https://dev.to/codevicky/launch-your-website-in-minutes-a-beginners-guide-to-hosting-on-netlify-1f28 | netlify, webhosting, hosting, tutorial | Hosting a website on Netlify is a straightforward process. Here are the steps to get your site up and running:
### Create a Netlify Account:
Go to [Netlify's website](https://www.netlify.com/) and sign up for a free account if you don't have one.
[ , lo haces posible! Este proyecto te ofrece una aplicación Node.js y una clase ChatGPTConnector para que puedas enviar indicaciones a ChatGP... | miguelcespedes | |
1,875,430 | How I Approach Tutorials To Avoid Tutorials Hell | Tutorials hell is floozy for luck of a better word. You are in an endless circle of tutorials, you... | 0 | 2024-06-06T02:27:00 | https://dev.to/thekarlesi/how-i-approach-tutorials-to-avoid-tutorials-hell-jbn | webdev, javascript, beginners, programming | Tutorials hell is floozy for luck of a better word.
You are in an endless circle of tutorials, you are not learning anything, you are not getting anything done, you are not getting any better, you are not getting any closer to your goal.
You are just stuck in a loop of tutorials. You are in tutorials hell.
In order ... | thekarlesi |
1,878,628 | Are multi-tenant apps = SaaS? | Should all SaaS apps employ multi-tenancy architectures? Can multi-tenancy architectures be applied... | 27,604 | 2024-06-06T01:43:03 | https://blog.logto.io/are-multi-tenant-apps-equal-saas/ | webdev, saas, opensource, identity | Should all SaaS apps employ multi-tenancy architectures? Can multi-tenancy architectures be applied to consumer apps?
---
# Multi-tenant apps’ broader definition
In the [last chapter](https://dev.to/logto/tenancy-models-for-a-multi-tenant-app-3429), we discussed multi-tenancy in a general sense. To summarize, when we... | palomino |
1,878,638 | 12 Ways to Use the @Value Annotation in Spring for Flexible and Maintainable Applications | You may already be familiar with @Value annotation from Spring. This annotation allows you to inject... | 27,602 | 2024-06-06T02:17:28 | https://springmasteryhub.com/2024/06/05/12-ways-to-use-the-value-annotation-in-spring-for-flexible-and-maintainable-applications/ | java, spring, tutorial, programming |
You may already be familiar with @Value annotation from Spring. This annotation allows you to inject some properties into your beans.
But there’s a lot of ways you could do that. And maybe you are not familiar with all of them.
This article will show you many ways to work with @Value and some new ways you can apply... | tiuwill |
1,878,636 | Level-up Your Git Projects with Gitflow | Take your project’s design and evolution to the next level by integrating Gitflow into your... | 0 | 2024-06-06T02:10:34 | https://dev.to/dedsyn4ps3/how-i-leveled-up-my-github-projects-with-gitflow-25k | programming, productivity, git, tooling | ## Take your project’s design and evolution to the next level by integrating Gitflow into your development process!
### In the Beginning
I’m fairly certain that many of you reading this are plenty familiar with the fantastic ec... | dedsyn4ps3 |
1,878,632 | Tenant isolation in multi-tenant application | Tenant isolation is a key concept in multi-tenant applications. In this article, we'll discuss what... | 27,604 | 2024-06-06T02:09:37 | https://blog.logto.io/tenant-isolation/ | webdev, identity, saas, opensource | Tenant isolation is a key concept in multi-tenant applications. In this article, we'll discuss what it is and how it can be achieved.
---
Hello everyone! In this chapter, we'll build upon our earlier discussions on multi-tenant topics. If you haven't read the previous articles yet, we recommend starting with those fir... | palomino |
1,878,635 | Top SQL IDEs in 2024 | In the ever-evolving world of data engineering, having the right tools at your disposal is crucial... | 0 | 2024-06-06T02:08:25 | https://dev.to/concerate/top-sql-ides-in-2024-14bj | In the ever-evolving world of data engineering, having the right tools at your disposal is crucial for success.
One essential tool for data professionals is a powerful and reliable SQL Integrated Development Environment (IDE).
An SQL IDE allows you to create, modify, and manage your databases, streamlining your workflo... | concerate | |
1,878,629 | Bringing It All Together: Integrating GraphQL with Gin in Go | In this phase of our journey, we delve into the realm of middleware integration with gin and the... | 23,111 | 2024-06-06T02:05:29 | https://dev.to/mikeyglitz/bringing-it-all-together-integrating-graphql-with-gin-in-go-49b9 | go, api, tutorial, webdev | In this phase of our journey, we delve into the realm of middleware integration with gin and the implementation of authentication middleware using gocloak. Building upon the groundwork laid in previous sections, we now unify our efforts by integrating middleware seamlessly into our GraphQL server. With gin, a powerful ... | mikeyglitz |
1,878,633 | Best Practice: Micro Service Architecture | Cloudforet, a series of LinuxFounation Open Source projects is one of the best practice for Micro... | 0 | 2024-06-06T02:04:43 | https://dev.to/choonho/best-practice-micro-service-architecture-1p3h | cloud, msa, development, kubernetes | > Cloudforet, a series of LinuxFounation Open Source projects is one of the best practice for Micro Service Architecture and Cloud Native.
# Micro Service Architecture
Cloudforet adopts a microservice architecture to provide a scalable and flexible platform. The microservice architecture is a design pattern that st... | choonho |
1,878,634 | Kneader Compounding Machines: Meeting the Challenges of Polymer Mixing | Kneader Compounding Devices: The Risk-free as well as Effective Method towards Blend... | 0 | 2024-06-06T02:02:16 | https://dev.to/ronald_woodgo_ba03f686524/kneader-compounding-machines-meeting-the-challenges-of-polymer-mixing-364c | design, product |
Kneader Compounding Devices: The Risk-free as well as Effective Method towards Blend Polymers
Kneader Compounding Devices are actually exactly just what our team contact a huge assistant on the planet of plastic production. They are actually important devices that are actually utilized towards blend with each o... | ronald_woodgo_ba03f686524 |
1,878,596 | So I tried Odoo for the first time | From web developer's viewpoint, I'm going to setup Odoo for the first time. It is going to installed... | 0 | 2024-06-06T01:57:53 | https://dev.to/yuiltripathee/so-i-tried-odoo-for-the-first-time-2o96 | webdev, erp, beginners, odoo | From web developer's viewpoint, I'm going to setup Odoo for the first time. It is going to installed on my local computer (Ubuntu 22.04) and the installation will be from community edition.
## Prerequisites
- Git, Python (3.10+), Pip and basics (IDEs and stuff)
- PostgreSQL database (can be community edition)
## Ini... | yuiltripathee |
1,877,536 | Buffing A 50 Year Old Programming Language | Hello, everyone! Today, I'm excited to take you on a journey through the fascinating world of... | 0 | 2024-06-06T01:57:11 | https://dev.to/mantlecore/buffing-a-50-year-old-programming-language-58la | showdev, opensource, programming, cpp | Hello, everyone! Today, I'm excited to take you on a journey through the fascinating world of programming languages and compilers. We'll be exploring a new language I'm developing called "Mantle" (or simply "M"). But before we get into the nitty-gritty, let's discuss the architecture of Mantle and what I aim to achieve... | mantlecore |
1,878,630 | Inter component communication in React. | In the React ecosystem, building complex applications often involves breaking down the UI into... | 0 | 2024-06-06T01:49:32 | https://dev.to/engineeringexpert/inter-component-communication-in-react-300b | react, javascript, frontend |
In the React ecosystem, building complex applications often involves breaking down the UI into reusable components. However, this modularity raises a crucial question: How do these components effectively communicate and share data?
This article explores the various mechanisms available in React to ensure smooth and e... | engineeringexpert |
1,877,286 | Primera parte: Introducción API Rest | API Rest es tal vez la arquitectura de backend más utilizada en la industria y que parece ser... | 27,616 | 2024-06-06T01:31:41 | https://dev.to/alfredtester/primera-parte-introduccion-api-rest-4109 | testing, api, apitesting | API Rest es tal vez la arquitectura de backend más utilizada en la industria y que parece ser atemporal. Aunque fue creada para resolver un problema, se usa para solucionar casi cualquier problema 😶.
Al ser (volvernos) probadores funcionales, el backend es algo que generalmente desconocemos ya que solo nos piden que ... | alfredtester |
1,878,626 | How to do quantitative trading backtesting | Summary The significance and importance of backtesting is undoubted. When doing... | 0 | 2024-06-06T01:29:20 | https://dev.to/fmzquant/how-to-do-quantitative-trading-backtesting-3oof | trading, backtest, cryptocurrency, fmzquant | ## Summary
The significance and importance of backtesting is undoubted. When doing quantitative backtesting, the strategy should be placed in the historical environment as real and close as possible. If some details in the historical environment are ignored, the whole quantitative backtesting may be invalid. This artic... | fmzquant |
1,878,609 | Linear Regression Neural Network with nn.Linear() in PyTorch | import torch from torch import nn import matplotlib.pyplot as plt # Setup device device = "cuda" if... | 0 | 2024-06-06T01:20:11 | https://dev.to/hyperkai/linear-regression-neural-network-with-nnlinear-in-pytorch-h4k | pytorch, linearregression, neuralnetwork, deeplearning | ```python
import torch
from torch import nn
import matplotlib.pyplot as plt
# Setup device
device = "cuda" if torch.cuda.is_available() else "cpu"
# print(device)
# Create data
weight = 0.7
bias = 0.3
X = torch.arange(start=0, end=1, step=0.02, device=device).unsqueeze(dim=1)
y = weight * X + bias
# print(X[:10], le... | hyperkai |
1,878,601 | Como utilizar o Ack do RabbitMQ de forma eficiente | A Motivação por Trás Deste Artigo Recentemente, participei de um debate no ambiente de... | 0 | 2024-06-06T01:20:02 | https://dev.to/mrdiniz88/como-utilizar-o-ack-do-rabbitmq-de-forma-eficiente-3i2m | rabbitmq, microservices, go, backend | ## A Motivação por Trás Deste Artigo
Recentemente, participei de um debate no ambiente de trabalho sobre como lidar com o reconhecimento da leitura de mensagens no RabbitMQ.
Alguns colegas argumentaram que baseados em experiências anteriores a melhor abordagem para essa aplicação seria usar o auto-ack. Eles relataram... | mrdiniz88 |
1,878,600 | RECLAIM BITCOIN/DIGITAL ASSET...RECOVER MONEY BACK... | Imagine the sheer disbelief and joy one would feel upon discovering that a staggering $394,000 worth... | 0 | 2024-06-06T01:15:27 | https://dev.to/keith_snyder_9200fd1cd266/reclaim-bitcoindigital-assetrecover-money-back-2mb0 | webdev, programming, python | Imagine the sheer disbelief and joy one would feel upon discovering that a staggering $394,000 worth of Bitcoin, seemingly vanished into the ether, has reappeared. This is precisely the remarkable scenario that unfolded for me, I found my missing cryptocurrency fortune thanks to the intervention of a digital wizard of ... | keith_snyder_9200fd1cd266 |
1,878,483 | What would I say to my past self 2 years ago? | Easy Answer: Buy Crypto. Thank you all, see you next time! Just kidding (or not), but... | 0 | 2024-06-06T01:15:16 | https://dev.to/mateussousa00/what-would-i-say-to-my-past-self-2-years-ago-fm0 | webdev, beginners, productivity, learning | ## Easy Answer:
Buy Crypto.
Thank you all, see you next time!
Just kidding (or not), but let me introduce myself... I'm a Fullstack Developer, I work mainly with JS/TS, but I've ventured into PHP, Java, Kotlin, and Go... all within two years.
I've learned a lot during this time, but the funny thing is, the most valu... | mateussousa00 |
1,867,148 | EXPLOITING ACADEMY MACHINE WITH PRIVILEDGE ESCALATION | In this walkthrough, we'll explore privilege escalation techniques in a controlled environment. We'll... | 0 | 2024-06-06T01:11:02 | https://dev.to/babsarena/exploiting-academy-machine-with-priviledge-escalation-4ghe | In this walkthrough, we'll explore privilege escalation techniques in a controlled environment. We'll simulate a scenario where we have low-level access to a system and attempt to gain higher privileges. This process will be conducted ethically on a dedicated training machine to understand attacker methodologies and bo... | babsarena | |
1,878,599 | V-Express: 1-Click AI Avatar Talking Heads Video Animation Generator - D-ID Alike - Open Source | V-Express: 1-Click AI Avatar Talking Heads Video Animation Generator — D-ID Alike — Free Open... | 0 | 2024-06-06T01:07:33 | https://dev.to/furkangozukara/v-express-1-click-ai-avatar-talking-heads-video-animation-generator-d-id-alike-open-source-1kj8 | beginners, tutorial, ai, learning | <p style="margin-left:0px;"><a target="_blank" rel="noopener noreferrer" href="https://youtu.be/xLqDTVWUSec"><u>V-Express: 1-Click AI Avatar Talking Heads Video Animation Generator — D-ID Alike — Free Open Source</u></a></p>
<p style="margin-left:0px;">Tutorial link : <a target="_blank" rel="noopener noreferrer" href="... | furkangozukara |
1,867,076 | AWS multi-region Serverless application variant. | Multi-Region applications comes in very handy when you want to deal with users from different... | 0 | 2024-06-06T01:04:41 | https://dev.to/asankab/aws-multi-region-serverless-application-variant-2348 | serverless, multiregion, apigateway, lambda | Multi-Region applications comes in very handy when you want to deal with users from different geographical locations, eliminating latency issue depending on distance from the place where your users accesses your application and also helps in maintaining High-Availability and DR (Disaster Recovery) situations without di... | asankab |
1,878,598 | The Base and Rotation | YOO, WHAT is up guys. I don't know if you remember the base I made in the second post. Well, I 3D... | 0 | 2024-06-06T01:02:18 | https://dev.to/kevinpalma21/the-base-and-rotation-2k6i | design, webdev, beginners, learning |
YOO, WHAT is up guys.
I don't know if you remember the base I made in the second post. Well, I 3D printed that one (Image 1), and it was an okay base overall, but it wasn't deep enough. I made some tweaks to this base. I used the SolidEdit function and chose to stretch the top part of this object. This made it length... | kevinpalma21 |
1,878,597 | Spinomenal granted Croatia iGaming certification | Spinomenal has been granted its certification for the Croatian iGaming market, operators within... | 0 | 2024-06-06T00:51:12 | https://dev.to/jashteen98/spinomenal-granted-croatia-igaming-certification-3ge | Spinomenal has been granted its certification for the Croatian iGaming market, operators within Croatia are now able to gain access to and offer Spinomenal’s suite of HTML5 slots content. Spinomenal games portfolio includes Book of Demi Gods II, Western Tales and Lucky Jack – Tut’s Treasures.
Croatia follows quickly o... | jashteen98 | |
1,878,595 | Inspired signs virtual sports contract with Novibet | Inspired Entertainment has signed a multi-market contract to launch its Virtual Sports content with... | 0 | 2024-06-06T00:49:55 | https://dev.to/jashteen98/inspired-signs-virtual-sports-contract-with-novibet-4ep8 |
Inspired Entertainment has signed a multi-market contract to launch its Virtual Sports content with Novibet. Starting with the Greek market, Inspired’s Virtual Sports are now hosted in a dedicated section on novibet.gr, offering customized and localized Virtual Sports options to players on a 24/7/365 basis.
Inspired’... | jashteen98 | |
1,878,594 | My Game Recommendation Program | Program Showcase Code File Explanation Data File The Data File... | 0 | 2024-06-06T00:43:18 | https://dev.to/carterwr/my-game-recommendation-software-27pk | ## Program Showcase
{% embed https://youtu.be/Uw4t6-4ZoBU %}
## Code File Explanation
### Data File
* The Data [File](https://github.com/CarterWr/Recommendation-Software/blob/main/data.py) is just the data set I hand made by researching different game categories and popular games within them.
### Tree Structure
... | carterwr | |
1,878,593 | Understanding Microservices Architecture | Introduction Microservices architecture is gaining popularity among businesses as it... | 0 | 2024-06-06T00:31:57 | https://dev.to/kartikmehta8/understanding-microservices-architecture-3278 | webdev, javascript, beginners, programming | ## Introduction
Microservices architecture is gaining popularity among businesses as it provides several advantages over traditional monolithic architecture. It is an architectural style that breaks down a large software system into small, independent, and modular services, each with its own specific function. These s... | kartikmehta8 |
1,878,592 | Optimising Your Cloud Spend: Top Strategies for AWS Cost Management | Visit my blog PracticalCloud for more indepth cloud computing articles. In today's cloud-driven... | 0 | 2024-06-06T00:22:55 | https://practicalcloud.net/optimising-your-cloud-spend-top-strategies-for-aws-cost-management/ | aws, cloud, devops | Visit my blog [PracticalCloud](https://practicalcloud.net) for more indepth cloud computing articles.
In today's cloud-driven world, businesses are increasingly migrating to AWS to leverage its scalability, agility, and wide range of services. However, managing cloud costs effectively is essential to ensure you're get... | kelvinskell |
1,878,590 | Case Study: Ignoring Nonalphanumeric Characters When Checking Palindromes | Palindrome.java, here considered all the characters in a string to check whether it is a palindrome.... | 0 | 2024-06-06T00:15:31 | https://dev.to/paulike/case-study-ignoring-nonalphanumeric-characters-when-checking-palindromes-34n9 | java, programming, learning, beginners | Palindrome.java, [here](https://dev.to/paulike/case-studies-on-loops-27l1) considered all the characters in a string to check whether it is a palindrome. Write a new program that ignores nonalphanumeric characters in checking whether a string is a palindrome.
Here are the steps to solve the problem:
1. Filter the stri... | paulike |
1,878,589 | [Game of Purpose] Day 18 - making flying animations | Today I followed up a second part of a flying tutorial, where I added animations. I have to say that... | 27,434 | 2024-06-06T00:12:01 | https://dev.to/humberd/game-of-purpose-day-18-making-flying-animations-2d38 | gamedev | Today I followed up a [second part of a flying tutorial](https://www.youtube.com/watch?v=XOdR5DRsiz0), where I added animations.
I have to say that the tutorial was too fast. The author just told what to click and where without even explaining what was going on. So let me be clear what happened:
1. First I imported c... | humberd |
1,878,587 | The StringBuilder and StringBuffer Classes | The StringBuilder and StringBuffer classes are similar to the String class except that the String... | 0 | 2024-06-06T00:03:24 | https://dev.to/paulike/the-stringbuilder-and-stringbuffer-classes-4gdc | java, programming, learning, beginners | The **StringBuilder** and **StringBuffer** classes are similar to the **String** class except that the **String** class is immutable. In general, the **StringBuilder** and **StringBuffer** classes can be used wherever a string is used. **StringBuilder** and **StringBuffer** are more flexible than **String**. You can ad... | paulike |
1,879,686 | How to promote your ebooks with your website? | I’m a web developer by trade and a part-time author, so here are a few things that I have done to... | 0 | 2024-06-12T16:34:36 | https://www.csrhymes.com/2024/06/06/promoting-your-ebooks-with-your-website.html | writing, marketing, webdev | ---
title: How to promote your ebooks with your website?
published: true
date: 2024-06-06 00:00:00 UTC
tags: writing,marketing,webdev
canonical_url: https://www.csrhymes.com/2024/06/06/promoting-your-ebooks-with-your-website.html
cover_image: https://www.csrhymes.com/img/books-hero.jpg
---
I’m a web developer by trade... | chrisrhymes |
1,879,787 | I Am So Sick of Leetcode-Style Interviews | I quit my previous job at Robinhood in late November of 2023 mainly for health reasons. I've been in... | 0 | 2024-06-07T02:47:20 | https://nelson.cloud/i-am-so-sick-of-leetcode-style-interviews/ | career, opinion, rant | ---
title: I Am So Sick of Leetcode-Style Interviews
published: true
date: 2024-06-06 00:00:00 UTC
tags: #career, #opinion, #rant
canonical_url: https://nelson.cloud/i-am-so-sick-of-leetcode-style-interviews/
---
I quit my previous job at [Robinhood](https://robinhood.com/) in late November of 2023 mainly for health re... | nelsonfigueroa |
1,878,585 | A Beginner's Guide to Networking Protocols: TCP, UDP, HTTP, and HTTP/3 | Networking can feel like a maze of jargon and acronyms, but understanding the basics is essential for... | 0 | 2024-06-05T23:57:46 | https://dev.to/dev_ojay/a-beginners-guide-to-networking-protocols-tcp-udp-http-and-http3-3pp6 | http, tcp, udp, networking | Networking can feel like a maze of jargon and acronyms, but understanding the basics is essential for anyone new to programming and IT. Two fundamental protocols you'll encounter are [TCP and UDP](https://medium.com/@abhirup.acharya009/understanding-tcp-and-udp-building-blocks-of-connectivity-ec96e208b852), and it's im... | dev_ojay |
1,878,584 | Dev.to Frontend Challenge: Take me to the Beach | Dev.to Frontend Challenge June This project it will be used for the dev.to frontend... | 0 | 2024-06-05T23:55:33 | https://dev.to/kevin-uehara/devto-frontend-challenge-take-me-to-the-beach-4agn | frontendchallenge, braziliandevs, javascript, webdev | ## Dev.to Frontend Challenge June
This project it will be used for the dev.to frontend challenge. I choose the second challenge: the beaches.
Just Access the Project: [Hosted Project](https://devto-frontend-challenge-june.vercel.app/)
## Github Repository
[Repository](https://github.com/kevinuehara/devto-frontend-... | kevin-uehara |
1,878,583 | Day 964 : Energy Boost | liner notes: Professional : Had a couple of meetings. Responded to community questions. Rest of the... | 0 | 2024-06-05T23:53:11 | https://dev.to/dwane/day-964-energy-boost-2hp8 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Had a couple of meetings. Responded to community questions. Rest of the day, I worked on the library I published yesterday and got it working in a demo application. Pretty good day.
- Personal : Last night, I went through some tracks for the radio show. Worked on my side project. Didn'... | dwane |
1,875,922 | 🎬 From image to text data... to image...to movie clip. | 📰 About I previously wrote an article that showed, how, for totally free of charge, and... | 27,429 | 2024-06-05T23:51:02 | https://dev.to/adriens/from-image-to-text-data-to-imageto-movie-clip-10ci | showdev, datascience, ai | ## 📰 About
I previously wrote an article that showed, how, **for totally free of charge, and with 100% open source software,** it is possible to analyze photos and produce textual analysis:
{% embed https://dev.to/adriens/disaster-reporting-wopen-source-llavaai-for-photo-analysis-4k4c %}
👉 Today, I'll show, what c... | adriens |
1,878,582 | INTRODUCTION TO WEBSITE HACKING | SQL Injection SQL Injection is a malicious web vulnerability, a dark art that allows... | 0 | 2024-06-05T23:47:14 | https://dev.to/sam15x6/introduction-to-website-hacking-4g48 | hacker, sql, python, webdev | ## SQL Injection
**SQL Injection** is a malicious web vulnerability, a dark art that allows attackers to manipulate the very heart of your application – its database. By interfering with the queries your application makes, attackers can view, modify, or even delete your precious data. And if that's not enough, they mi... | sam15x6 |
1,878,581 | What Is Next Js And Why Should You Use It In 2024? | INTRODUCTION One of the top benefits of learning what is Next.js, is the knowledge of how flexible... | 0 | 2024-06-05T23:45:08 | https://dev.to/basimghouri/what-is-next-js-and-why-should-you-use-it-in-2024-5ei9 | javascript, nextjs, beginners, webdev | **INTRODUCTION**
One of the top benefits of learning what is Next.js, is the knowledge of how flexible you can become in building, and adapting to online reality.
As seasoned Next.js developers, we recognize the immense value in mastering this framework. One of its most compelling advantages lies in its unparalleled f... | basimghouri |
1,878,579 | How to unlock the limitations of Notion | Notion rich_text limitations - node client Notion has undoubtedly gained popularity as a... | 27,625 | 2024-06-05T23:31:02 | https://www.johnatanortiz.tech/blog/how-to-unlock-the-limitations-of-notion | # Notion rich_text limitations - node client
Notion has undoubtedly gained popularity as a versatile productivity and organization platform. Its ability to create documents, databases, boards, and more, all in one place, has attracted a wide range of users, from students to business professionals. However, like any to... | johnatan_stevenortizsal | |
1,878,578 | The String Class | A String object is immutable: Its content cannot be changed once the string is created. You know... | 0 | 2024-06-05T23:30:36 | https://dev.to/paulike/the-string-class-17o7 | java, programming, learning, beginners | A **String** object is immutable: Its content cannot be changed once the string is created. You know strings are objects. You can invoke the **charAt(index)** method to obtain a character at the specified index from a string, the **length()** method to return the size of a string, the **substring** method to return a s... | paulike |
1,872,855 | Domain Driven Design (DDD) Practice: Live Streaming App Example | Domain Driven Design (DDD) Practice: Live Streaming App Example Introduction In... | 0 | 2024-06-05T23:29:38 | https://dev.to/ma2mori/domain-driven-design-ddd-practice-live-streaming-app-example-3dih | ddd, php | ### Domain Driven Design (DDD) Practice: Live Streaming App Example
#### Introduction
In [previous article](https://dev.to/ma2mori/introduction-to-domain-driven-design-ddd-basic-concepts-and-rudiments-of-practice-5042), we learned the basic concepts of Domain Driven Design (DDD). In this article, we will introduce a c... | ma2mori |
1,877,900 | Learning MVC Once And For All | In this training, we teach the concept of Controller in CodeBehind Framework. Why do some... | 27,500 | 2024-06-05T23:12:28 | https://dev.to/elanatframework/learning-mvc-once-and-for-all-2d9d | tutorial, dotnet, beginners, backend | In this training, we teach the concept of Controller in CodeBehind Framework.
## Why do some people not understand the concept of MVC?
Most back-end frameworks require Controller configuration in Route to run. Concepts like routing or mapping are very confusing. Usually, before learning MVC, beginners are familiar wi... | elanatframework |
1,433,454 | openGauss MOT Server Optimization – x86 | Generally, databases are bounded by the following components – CPU – A faster CPU speeds up any... | 0 | 2023-04-12T07:44:32 | https://dev.to/tongxi99658318/opengauss-mot-server-optimization-x86-2jl0 | opengauss | Generally, databases are bounded by the following components –
CPU – A faster CPU speeds up any CPU-bound database.
Disk – High-speed SSD/NVME speeds up any I/O-bound database.
Network – A faster network speeds up any SQL\Net-bound database.
In addition to the above, the following general-purpose server settings are u... | tongxi99658318 |
1,878,573 | The BigInteger and BigDecimal Classes | The BigInteger and BigDecimal classes can be used to represent integers or decimal numbers of any... | 0 | 2024-06-05T22:46:26 | https://dev.to/paulike/the-biginteger-and-bigdecimal-classes-1eeg | java, programming, learning, beginners | The **BigInteger** and **BigDecimal** classes can be used to represent integers or decimal numbers of any size and precision. If you need to compute with very large integers or high-precision floating-point values, you can use the **BigInteger** and **BigDecimal** classes in the **java.math** package. Both are _immutab... | paulike |
1,878,571 | CRYPTO CURRENCY REVERSAL; WEB BAILIFF CONTRACTOR | The world of online finance, with its promises of quick riches and easy gains, can be a complex... | 0 | 2024-06-05T22:39:20 | https://dev.to/markjameson/crypto-currency-reversal-web-bailiff-contractor-3jhh | The world of online finance, with its promises of quick riches and easy gains, can be a complex landscape. For me, that landscape turned into a nightmare when I fell prey to a ruthless scam on an exchange platform. The dizzying sum of $566,797.00, my life's savings, vanished into thin air, leaving me stranded on a... | markjameson | |
1,878,570 | Automatic Conversion between Primitive Types and Wrapper Class Types | A primitive type value can be automatically converted to an object using a wrapper class, and vice... | 0 | 2024-06-05T22:35:45 | https://dev.to/paulike/automatic-conversion-between-primitive-types-and-wrapper-class-types-46en | java, programming, learning, beginners | A primitive type value can be automatically converted to an object using a wrapper class, and vice versa, depending on the context. Converting a primitive value to a wrapper object is called _boxing_. The reverse conversion is called _unboxing_. Java allows primitive types and wrapper classes to be converted automatica... | paulike |
1,878,568 | Configuração de ambiente BackEnd | Este documento é para uso público e interno, tanto para pessoas que desejem trabalhar na Anuntech... | 27,615 | 2024-06-05T22:32:44 | https://dev.to/anuntech/configuracao-de-ambiente-backend-3j9k | backend, beginners, programming | > Este documento é para uso **público e interno**, tanto para pessoas que desejem trabalhar na Anuntech para já saberem um pouco sobre nosso ambiente, quanto para quem acabou de se juntar a Anuntech configurar seu novo ambiente de trabalho.
## Introdução
Nesse artigo veremos as configurações **especificas para o time... | henriqueleite42 |
1,878,567 | Configuração de ambiente Web | Este documento é para uso público e interno, tanto para pessoas que desejem trabalhar na Anuntech... | 27,615 | 2024-06-05T22:31:42 | https://dev.to/anuntech/configuracao-de-ambiente-web-n4f | webdev, beginners, programming | > Este documento é para uso **público e interno**, tanto para pessoas que desejem trabalhar na Anuntech para já saberem um pouco sobre nosso ambiente, quanto para quem acabou de se juntar a Anuntech configurar seu novo ambiente de trabalho.
## Introdução
Nesse artigo veremos as configurações **especificas para o time... | henriqueleite42 |
1,878,565 | Achieving Lifecycle in React Functional Components | How to Achieve Similar Behavior to Lifecycle Methods in React Functional Components In... | 0 | 2024-06-05T22:29:33 | https://dev.to/geraldhamiltonwicks/achieving-lifecycle-in-react-functional-components-482i | react, javascript, typescript | ### How to Achieve Similar Behavior to Lifecycle Methods in React Functional Components
In React, class-based components have been the backbone of many applications due to their robust lifecycle methods, such as `componentDidMount`, `componentWillUnmount`, and `componentDidUpdate`. These methods allow developers to pe... | geraldhamiltonwicks |
1,878,564 | Processing Primitive Data Type Values as Objects | A primitive type value is not an object, but it can be wrapped in an object using a wrapper class in... | 0 | 2024-06-05T22:28:59 | https://dev.to/paulike/processing-primitive-data-type-values-as-objects-10o4 | java, programming, learning, beginners | A primitive type value is not an object, but it can be wrapped in an object using a wrapper class in the Java API. Owing to performance considerations, primitive data type values are not objects in Java.
Because of the overhead of processing objects, the language’s performance would be adversely affected if primitive d... | paulike |
1,875,234 | CSS Grid vs. Flexbox: Unleashing the Secrets to a Truly Responsive Website | Introduction In the world of web design, arranging elements on a page is both an art and a... | 0 | 2024-06-05T22:27:31 | https://dev.to/wafa_bergaoui/css-grid-vs-flexbox-unleashing-the-secrets-to-a-truly-responsive-website-4665 | css, frontend, webdev, development | ## **Introduction**
In the world of web design, arranging elements on a page is both an art and a science. Two of the most powerful tools available for creating responsive layouts are **CSS Grid** and **Flexbox**. While both are incredibly useful, they serve different purposes and excel in different scenarios. In this ... | wafa_bergaoui |
1,878,562 | Transform Your Home with a Stunning Kitchen Remodel | The kitchen is often referred to as the heart of the home, a place where meals are crafted, memories... | 0 | 2024-06-05T22:26:12 | https://dev.to/remodeling/transform-your-home-with-a-stunning-kitchen-remodel-33mf |
The kitchen is often referred to as the heart of the home, a place where meals are crafted, memories are made, and family and friends gather. A well-executed kitchen remodel can breathe new life into your home, enhancing both functionality and aesthetics. Whether you're looking to modernize your space or create a coz... | remodeling | |
1,878,560 | Configuração de ambiente de desenvolvimento | Este documento é para uso público e interno, tanto para pessoas que desejem trabalhar na Anuntech... | 27,615 | 2024-06-05T22:25:45 | https://dev.to/anuntech/configuracao-de-ambiente-de-desenvolvimento-1p6k | webdev, beginners, programming | > Este documento é para uso **público e interno**, tanto para pessoas que desejem trabalhar na Anuntech para já saberem um pouco sobre nosso ambiente, quanto para quem acabou de se juntar a Anuntech configurar seu novo ambiente de trabalho.
## Introdução
Nesse artigo veremos as configurações **globais** usadas por to... | henriqueleite42 |
1,878,554 | Case Study on Object-Oriented Thinking | Case Study: Designing the Course Class This section designs a class for modeling courses.... | 0 | 2024-06-05T22:11:04 | https://dev.to/paulike/case-study-on-object-oriented-thinking-3k3c | java, programming, learning, beginners | ## Case Study: Designing the Course Class
This section designs a class for modeling courses. Suppose you need to process course information. Each course has a name and has students
enrolled. You should be able to add/drop a student to/from the course. You can use a class to model the courses, as shown in Figure below.... | paulike |
1,874,984 | Introducing Adashta: Server-Side Real-Time Charting & More | We are thrilled to announce the launch of Adashta, an advanced SDK designed to simplify real-time... | 0 | 2024-06-05T22:10:59 | https://dev.to/adashta/introducing-adashta-server-side-real-time-charting-more-2jb3 | javascript, node, opensource, productivity | We are thrilled to announce the launch of Adashta, an advanced SDK designed to simplify real-time communication for developers. With Adashta, you can focus on your core business logic while we handle the intricacies of real-time data streaming. Our goal is to make it easier than ever to integrate real-time functionalit... | kalpitrathore |
1,878,552 | Knox Goes Away | Starring Kris Kristofferson and Willie Nelson. Two aging gunfighters re-form their old gang to avenge... | 0 | 2024-06-05T22:07:44 | https://dev.to/klodia_12/knox-goes-away-1c08 | javascript, webdev, tutorial, ai | Starring Kris Kristofferson and Willie Nelson. Two aging gunfighters re-form their old gang to avenge the murder of one of the former member
Knox Goes Away
After a hit man (Michael Keaton) is diagnosed with dementia, he must race against the police to save his estranged son, and outrun the ticking clock of his own det... | klodia_12 |
1,878,551 | Babcock University,Ilishan-Remo 2024/2025 Session Admission forms | Babcock University,Ilishan-Remo 2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for... | 0 | 2024-06-05T22:04:58 | https://dev.to/admin_dept_202e474d82b68c/babcock-universityilishan-remo-20242025-session-admission-forms-1c9d | webdev, beginners, programming | Babcock University,Ilishan-Remo 2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING ADMISSION FORMS,INTER SCHOOL TRANS... | admin_dept_202e474d82b68c |
1,878,550 | Knox Goes Away | Starring Kris Kristofferson and Willie Nelson. Two aging gunfighters re-form their old gang to avenge... | 0 | 2024-06-05T22:04:50 | https://dev.to/klodia_12/knox-goes-away-130k | javascript, beginners, tutorial, ai | Starring Kris Kristofferson and Willie Nelson. Two aging gunfighters re-form their old gang to avenge the murder of one of the former member
Knox Goes Away
After a hit man (Michael Keaton) is diagnosed with dementia, he must race against the police to save his estranged son, and outrun the ticking clock of his own det... | klodia_12 |
1,854,457 | How to detect Forest fires using Kinesis Video Streams and Amazon Rekognition | Introduction On a hot summer night, while we were enjoying our food and drinks, the dogs... | 0 | 2024-06-05T22:01:55 | https://dev.to/aws-builders/how-to-detect-forest-fires-using-kinesis-video-streams-and-rekognition-4he8 | aws, kinesis, rekognition, globallogic | #Introduction#
On a hot summer night, while we were enjoying our food and drinks, the dogs suddenly began barking and staring at a certain direction. We got outside to have a better look and noticed that the sky had started to turn orange. We immediately knew what it was happening, there was a huge fire at a beautiful ... | ngargoulakis |
1,878,549 | JavaScript is the best type of code | A post by Yuvaan | 0 | 2024-06-05T22:00:26 | https://dev.to/bharatrolling/javascript-is-the-best-type-of-code-5f49 | bharatrolling | ||
1,878,547 | Baze University,2024/2025 Session Admission forms is out | Baze University,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the... | 0 | 2024-06-05T21:54:07 | https://dev.to/admin_dept_202e474d82b68c/baze-university20242025-session-admission-forms-is-out-4j92 | webdev, beginners, programming, tutorial | Baze University,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING ADMISSION FORMS,INTER SCHOOL TRANSFER FORM,DIRECT ... | admin_dept_202e474d82b68c |
1,878,546 | Bells University of Technology, Otta,2024/2025 Session Admission forms | Bells University of Technology, Otta,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA... | 0 | 2024-06-05T21:53:27 | https://dev.to/admin_dept_202e474d82b68c/bells-university-of-technology-otta20242025-session-admission-forms-oa0 | Bells University of Technology, Otta,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING ADMISSION FORMS,INTER SCHOOL ... | admin_dept_202e474d82b68c | |
1,878,545 | Benson Idahosa University, Benin City,2024/2025 Session Admission forms | Benson Idahosa University, Benin City,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA... | 0 | 2024-06-05T21:45:12 | https://dev.to/admin_dept_202e474d82b68c/benson-idahosa-university-benin-city20242025-session-admission-forms-3ead | school, universirty | Benson Idahosa University, Benin City,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING ADMISSION FORMS,INTER SCHOOL... | admin_dept_202e474d82b68c |
807,219 | Tutorial: Getting Started with Open-wc | Open-WC, also known as Open Web-components is vital to getting you started on web-programming! It... | 0 | 2021-08-30T00:15:00 | https://dev.to/haileyhahnnnn/tutorial-getting-started-with-open-wc-4mk2 | Open-WC, also known as Open Web-components is vital to getting you started on web-programming! It utilizes various ideas on how to build web-components and is accessible for any one interested and ready to learn! Now, let's get started.
**Tools Needed**
Listed bellow are the tools needed to get started with Open-wc:... | haileyhahnnnn | |
1,878,544 | Bingham University,Karu,2024/2025 Session Admission forms i | Bingham University,Karu,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase... | 0 | 2024-06-05T21:44:11 | https://dev.to/admin_dept_202e474d82b68c/bingham-universitykaru20242025-session-admission-forms-i-59e1 | webdev, javascript | Bingham University,Karu,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING ADMISSION FORMS,INTER SCHOOL TRANSFER FORM... | admin_dept_202e474d82b68c |
1,878,543 | Bowen University, Iwo,2024/2025 Session Admission forms | Bowen University, Iwo,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of... | 0 | 2024-06-05T21:38:40 | https://dev.to/admin_dept_202e474d82b68c/bowen-university-iwo20242025-session-admission-forms-17ob | sql, codepen, rust, git | Bowen University, Iwo,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING ADMISSION FORMS,INTER SCHOOL TRANSFER FORM,D... | admin_dept_202e474d82b68c |
1,878,542 | Caleb University, Lagos,2024/2025 Session Admission forms | Caleb University, Lagos,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase... | 0 | 2024-06-05T21:37:57 | https://dev.to/admin_dept_202e474d82b68c/caleb-university-lagos20242025-session-admission-forms-658 | web3, flutter, gamedev | Caleb University, Lagos,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING ADMISSION FORMS,INTER SCHOOL TRANSFER FORM... | admin_dept_202e474d82b68c |
1,878,541 | Understanding Reactive Contexts in Angular 18 | A Deep Dive into Managing State Reactivity and Signals Defining a Reactive... | 0 | 2024-06-05T21:33:41 | https://dev.to/diegoquesadadev/understanding-reactive-contexts-in-angular-18-17b9 | angular, signals, reactive, frontend | #### *A Deep Dive into Managing State Reactivity and Signals*
---
### Defining a Reactive Context and Its Importance for Signals
In Angular 18, the concept of Reactive Contexts is fundamental to efficiently managing signals and state reactivity within applications. A Reactive Context is essentially an environment whe... | diegoquesadadev |
1,878,540 | Class Relationships | To design classes, you need to explore the relationships among classes. The common relationships... | 0 | 2024-06-05T21:33:08 | https://dev.to/paulike/class-relationships-324b | java, programming, learning, beginners | To design classes, you need to explore the relationships among classes. The common relationships among classes are association, aggregation, composition, and inheritance. This section explores association, aggregation, and composition.
## Association
_Association_ is a general binary relationship that describes an ac... | paulike |
1,878,539 | Caritas University, Enugu,2024/2025 Session Admission forms | Caritas University, Enugu,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for... | 0 | 2024-06-05T21:31:35 | https://dev.to/admin_dept_202e474d82b68c/caritas-university-enugu20242025-session-admission-forms-1cj1 | web3, vue, flutter | Caritas University, Enugu,2024/2025 Session Admission forms is out☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING ADMISSION FORMS,INTER SCHOOL TRANSFER FO... | admin_dept_202e474d82b68c |
1,878,538 | On-Scroll Animation | Hey everyone! I recently worked on a cool feature: on-scroll animations. These animations make your... | 0 | 2024-06-05T21:30:47 | https://dev.to/alikhanzada577/on-scroll-animation-11am | animation, frontend, css, javascript | Hey everyone!
I recently worked on a cool feature: **on-scroll animations**.
These animations make your site more engaging and interactive. I used the Intersection Observer API to achieve this effect, and it was surprisingly easy. Here’s a quick rundown of how I did it.
**HTML**
First, I set up the HTML structure. I... | alikhanzada577 |
1,878,537 | Covenant University Ota,2024/2025 Session Admission forms | Covenant University Ota,2024/2025 Session Admission forms are on sales.Contact the admin of the... | 0 | 2024-06-05T21:29:57 | https://dev.to/admin_dept_202e474d82b68c/covenant-university-ota20242025-session-admission-forms-4j4l | webdev, beginners | Covenant University Ota,2024/2025 Session Admission forms are on sales.Contact the admin of the school ☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line. The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING AD... | admin_dept_202e474d82b68c |
1,878,536 | Crawford University Igbesa,2024/2025 Session Admission form | Crawford University Igbesa,2024/2025 Session Admission forms are on sales.Contact the admin of the... | 0 | 2024-06-05T21:26:18 | https://dev.to/admin_dept_202e474d82b68c/crawford-university-igbesa20242025-session-admission-form-53g3 | webdev, beginners | Crawford University Igbesa,2024/2025 Session Admission forms are on sales.Contact the admin of the school ☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line. The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING... | admin_dept_202e474d82b68c |
1,878,535 | Covenant University Ota,2024/2025 Session Admission forms | Covenant University Ota,2024/2025 Session Admission forms are on sales.Contact the admin of the... | 0 | 2024-06-05T21:23:20 | https://dev.to/admin_dept_202e474d82b68c/covenant-university-ota20242025-session-admission-forms-m84 | scrum, javascript | Covenant University Ota,2024/2025 Session Admission forms are on sales.Contact the admin of the school ☎️ 07065086538 Dr ANITA for purchase of the form and how to register on-line. The general public is hereby informed that application forms for admission into the degree Programme 2024-2025 academic session. NURSING AD... | admin_dept_202e474d82b68c |
1,878,345 | Leveraging SOAP APIs for Outbound Integration: A Step-by-Step Guide. | Soap API: Outbound Integration SOAP (Simple Object Access Protocol) is an XML-based... | 0 | 2024-06-05T21:23:05 | https://dev.to/sophiasemga/leveraging-soap-apis-for-outbound-integration-a-step-by-step-guide-245c | webdev, integration, api, tutorial | ##Soap API: Outbound Integration
**SOAP (Simple Object Access Protocol)** is an XML-based messaging protocol used for exchanging information between two applications. It includes a **WSDL** file, which contains the necessary information about what the web service does and the location of the web service.
**WSDL**, als... | sophiasemga |
1,878,484 | Kubernetes Worker Node Components | Our article provides an overview of these components and their roles in supporting containerized... | 0 | 2024-06-05T21:19:50 | https://dev.to/giftbalogun/kubernetes-worker-node-components-ihp | Our article provides an overview of these components and their roles in supporting containerized applications in a Kubernetes cluster. To properly understand this article, you should have an understanding of the Kubernetes control plane.
Container runtime is responsible for tasks like pulling images from a repository ... | giftbalogun | |
1,872,328 | Playing around with Hotwire ⚡️ | Hey 👋, Let's jump into my bi-weekly update in the ramen profitability series, where I'm sharing... | 27,288 | 2024-06-05T21:17:15 | https://dev.to/joelzwarrington/playing-around-with-hotwire-2a2a | webdev, javascript, rails | Hey :wave:,
Let's jump into my bi-weekly update in the [ramen profitability series](https://dev.to/joelzwarrington/series/27288), where I'm sharing progress on my latest project: [HomeSuiteApartment](https://homesuiteapartment.com), a tool to manage rental properties.
In this update, I've been focused on the workflow... | joelzwarrington |
1,878,482 | Shadcn/ui codebase analysis: site-header.tsx explained. | I wanted to find out how the header is developed on ui.shadcn.com, so I looked at its source code.... | 0 | 2024-06-05T21:15:44 | https://dev.to/ramunarasinga/shadcnui-codebase-analysis-site-headertsx-explained-4l3k | javascript, nextjs, opensource, shadcnui | I wanted to find out how the header is developed on [ui.shadcn.com](http://ui.shadcn.com), so I looked at its [source code](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/layout.tsx). Because shadcn-ui is built using app router, the files I was interested in were [Layout.tsx](https://github.com/shadcn-ui/... | ramunarasinga |
1,878,481 | Babylon.js Browser MMO - DevLog- Update #6 - Character UI | Hi! Today I was working on the UI. I fixed player name text (it's not mirror reflected anymore). I... | 0 | 2024-06-05T21:12:42 | https://dev.to/maiu/babylonjs-browser-mmo-devlog-update-6-character-ui-o23 | babylonjs, gamedev, indie, mmo | Hi!
Today I was working on the UI. I fixed player name text (it's not mirror reflected anymore). I added tooltip with name and class while hoovering over players. And added ability Panel for skills and some actions like character stats, inventory etc.
Hope You like it!
{% youtube 3vzId1DzR5g %} | maiu |
1,878,479 | POKT NETWORK ACTORS | In the social media world, our attention to content is revenue for the company. In a blockchain... | 27,614 | 2024-06-05T21:10:21 | https://paragraph.xyz/@pokt-hub/pokt-network-actors | shannonupgrade, testnet, rpc, web3 | In the social media world, our attention to content is revenue for the company. In a blockchain world, the blocks are revenue for the chain.
As a company shares its revenue among shareholders, employees and investors, blockchain revenue is generally shared among the contributors of the block.
> In most chains,block c... | pokthub |
1,878,477 | Step-by-step guide for how to install an SQL server on Ubuntu 22.04 | Step-by-step guide for how to install an SQL server on Ubuntu 22.04 Installing... | 0 | 2024-06-05T21:06:43 | https://dev.to/oyololatoni/step-by-step-guide-for-how-to-install-an-sql-server-on-ubuntu-2204-2ahk | mysql, linux, ubuntu, devops |
## Step-by-step guide for how to install an SQL server on Ubuntu 22.04
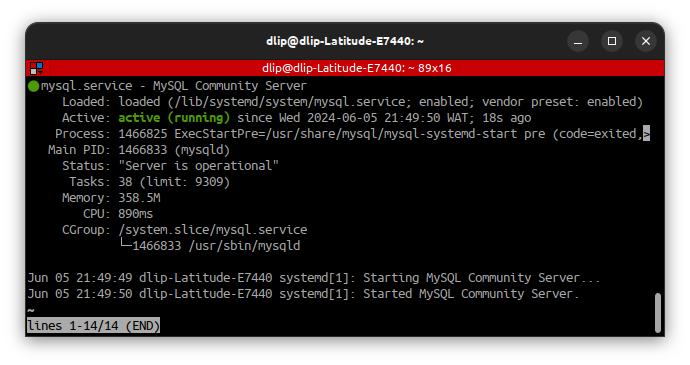
## **Installing the SQL server**
Firstly update your desktop and install the SQL server
sudo apt-get update
sudo apt-get install mysql-server
Verify that the s... | oyololatoni |
1,878,476 | new member | am new here | 0 | 2024-06-05T21:03:55 | https://dev.to/dauda_ishaya_6a0327b1bdd0/new-member-4c8b | am new here | dauda_ishaya_6a0327b1bdd0 | |
1,878,401 | Designing Print-Ready Components in Your Web App | In many web applications, there comes a time when you need to add print functionality. Whether it's... | 0 | 2024-06-05T21:02:01 | https://dev.to/joseph42a/designing-print-ready-components-in-your-web-app-3i00 | webdev, print, frontend, javascript | In many web applications, there comes a time when you need to add print functionality. Whether it's for printing invoices, reports, or any other custom components, having a seamless and efficient print solution is crucial. In this blog post, I'll demonstrate how to handle printing in your Vue.js application. The approa... | joseph42a |
1,878,474 | Thinking in Objects | The procedural paradigm focuses on designing methods. The object-oriented paradigm couples data and... | 0 | 2024-06-05T20:55:27 | https://dev.to/paulike/thinking-in-objects-44nb | java, programming, learning, beginners | The procedural paradigm focuses on designing methods. The object-oriented
paradigm couples data and methods together into objects. Software design using the object-oriented paradigm focuses on objects and operations on objects. Classes provide more flexibility and modularity for building reusable software. This section... | paulike |
1,878,472 | Unlocking the Potential of Free Shipping APIs | In the fast-paced world of eCommerce, efficient shipping solutions can make or break a business. As... | 0 | 2024-06-05T20:53:03 | https://dev.to/ericksmith14/unlocking-the-potential-of-free-shipping-apis-5f0m | api, shipping | In the fast-paced world of eCommerce, efficient shipping solutions can make or break a business. As online retailers strive to meet customer demands for fast, reliable delivery, the role of shipping APIs becomes increasingly crucial. Among the myriad options available, Free Shipping APIs stand out as a cost-effective s... | ericksmith14 |
1,876,905 | What I learned after burnout | For a period during the pandemic, the company I worked for experienced explosive growth, and with... | 0 | 2024-06-05T20:52:39 | https://dev.to/leonardoventurini/what-i-learned-after-burnout-105n | burnout, webdev, productivity, healthydebate | For a period during the pandemic, the company I worked for experienced explosive growth, and with that my responsibilities grew as took a leadership position and the amount of issues related to that growth piled up, more clients, bigger clients, different requirements and all that.
Everything was going smoothly for th... | leonardoventurini |
1,878,470 | CORE AZURE ARCHITECTURE COMPONENTS. | Below are the core Azure Architecture components for Azure cloud Computing.Basically Azure... | 0 | 2024-06-05T20:52:16 | https://dev.to/phillip_ajifowobaje_68724/core-azure-architecture-components-32go | Below are the core Azure Architecture components for Azure cloud Computing.Basically Azure architecture focus on the physical infrastructure, how resources are managed, and have a chance to create an Azure resource.
- Azure's architecture ensures high availability, scalability, and efficient resource management
- Co... | phillip_ajifowobaje_68724 | |
1,878,471 | My Programming Journey | Hi😍 I am excited to share my first post here. I am writing to document my first experience as I ... | 0 | 2024-06-05T20:49:50 | https://dev.to/nessgood6071/my-programming-journey-becoming-a-techie-3pnl | Hi😍 I am excited to share my first post here. I am writing to document my first experience as I become a techie.
Web development has always been an area of great interest to young tech beginners and it involves the design and creation of websites and webpages. It involves the use of the languages such as HTML,CSS, J... | nessgood6071 | |
1,878,409 | Heuristics for identifying legal (documentation) risks as a QA | [This article is not a substitute for professional legal advice. This article does not create an... | 0 | 2024-06-05T20:46:55 | https://dev.to/ashleygraf_/heuristics-for-identifying-legal-documentation-risks-as-a-qa-dl7 | testing | [This article is not a substitute for professional legal advice. This article does not create an attorney-client relationship, nor is it a solicitation to offer legal advice.]
Companies generally have to follow certain requirements for legal documentation. These are that legal documentation such as Terms and Condition... | ashleygraf_ |
1,878,469 | How-to: Use dictionary in TypeScript | Here is the scenario, I want to create a function getLegsNumber that use this structure as... | 0 | 2024-06-05T20:42:11 | https://dev.to/linediconsine/a-dictionary-in-typescript-31ek | typescript, javascript, webdev | Here is the scenario, I want to create a function `getLegsNumber` that use this structure as dictionary
```Javascript
const mappingAnimalLegs = {
'CAT' : 4,
'DOG' : 4,
'DUCK' : 2
}
```
If I write something like this
```Javascript
function getLegsNumber(animal) {
return mappingAnimalLegs[animal] | 0
}... | linediconsine |
1,878,466 | [WIP] Test UI? | There are different solutions on test UI Jest unit testing Jest Snapshots Integration... | 0 | 2024-06-05T20:31:14 | https://dev.to/linediconsine/wip-test-ui-dl4 | webdev, javascript, programming | There are different solutions on test UI
- Jest unit testing
- Jest Snapshots
- Integration testing
- Image comparison testing
- Accessibility reports
- Manual testing
When to us what? In my experience a big project will end up using all of them.
Let start with the first
## Jest unit testing
> Unit testing is a ... | linediconsine |
1,878,465 | Millisecond Scale-to-Zero with Unikernels | A solution to intermittent and unpredictable traffic. | 0 | 2024-06-05T20:24:03 | https://dev.to/plutov/millisecond-scale-to-zero-with-unikernels-5bjl | unikraft, unikernels, cloud | ---
title: Millisecond Scale-to-Zero with Unikernels
published: true
description: A solution to intermittent and unpredictable traffic.
tags: Unikraft, unikernels, cloud
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/gr62ywypmo19s8s0dzbm.png
---
[Read the full article here](https://packagemain.t... | plutov |
1,877,154 | Transforming Internet Browsing Experience on Desktop: A Proof of Concept | Over time, desktop internet browsing can become clumsy due to the accumulation of numerous open tabs.... | 0 | 2024-06-05T20:23:56 | https://dev.to/maleta/transforming-desktop-browsing-experience-a-proof-of-concept-417 | ux, webbrowser | Over time, desktop internet browsing can become clumsy due to the accumulation of numerous open tabs. You may become attached to tabs you've opened or you forget to close them, and you end up carrying them over to each new browsing session. This issue has been recognized in recent years, and some solutions have been de... | maleta |
1,878,464 | Class Abstraction and Encapsulation | Class abstraction is the separation of class implementation from the use of a class. The details of... | 0 | 2024-06-05T20:22:49 | https://dev.to/paulike/class-abstraction-and-encapsulation-2flo | java, programming, learning, beginners | Class abstraction is the separation of class implementation from the use of a class. The details of implementation are encapsulated and hidden from the user. This is known as class encapsulation. Java provides many levels of abstraction, and _class abstraction_ separates class implementation from how the class is used.... | paulike |
1,878,072 | Implementing UI Automation Testing for Desktop Applications Dealing With Different DBMS | This article can be useful for: Those who participate in UI automation testing of desktop... | 0 | 2024-06-05T20:22:39 | https://dev.to/konstantin_semenenkov/implementing-ui-automation-testing-for-desktop-applications-dealing-with-different-dbms-1fkg | testing, database, sql, dotnet | ## This article can be useful for:
- Those who participate in UI automation testing of desktop apps. Perhaps someone will be interested in the real experience of building a testing system.
- Someone who is making software that needs to use different relational database management systems (DBMSs).
## A brief history o... | konstantin_semenenkov |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.