
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,878,233 | Perform RAG in JSON formatted data | I have json data look like this, { { 'id': 'p1', 'category': 'category1', 'description':... | 0 | 2024-06-05T15:30:46 | https://dev.to/samitha10/perform-rag-in-json-formatted-data-15gf | I have json data look like this,
{ { 'id': 'p1', 'category': 'category1', 'description': 'description1' }, { 'id': 'p2', 'category': 'category2', 'description': 'description2' }, { 'id': 'p3', 'category': 'category3', 'description': 'description3' } }
I want to perform similarity search in only in description and get ... | samitha10 | |
1,878,232 | Affordable Custom Packaging | In today's competitive market, the importance of packaging cannot be overstated. Packaging is not... | 0 | 2024-06-05T15:30:42 | https://dev.to/rkatejo/affordable-custom-packaging-32b6 | packaging, business, productivity, discount | In today's competitive market, the importance of packaging cannot be overstated. Packaging is not just about protecting your product; it's a crucial aspect of your brand's identity and customer experience. But for many businesses, especially smaller ones, the cost of custom packaging can seem daunting. Is it possible t... | rkatejo |
1,878,135 | CSS Art - Warholizer | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration June is... | 0 | 2024-06-05T15:30:21 | https://dev.to/alexandrevacassin/warholizer-ee0 | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
June is a very lively month, with bright colors, warmth and energy.
For the CSS Art of June contest, I created the "Warholizer", a project that takes ordinary images and transforms t... | alexandrevacassin |
1,878,231 | React 19: A Comprehensive Guide to the Latest Features and Updates | Let’s dive into the exciting features of the newly released React 19, including server components and a React compiler. | 0 | 2024-06-05T15:30:08 | https://code.pieces.app/blog/react-19-comprehensive-guide | <figure><img src="https://d37oebn0w9ir6a.cloudfront.net/account_32099/react-snippets_3b6672d19a0a3e1b7bd99317eab53b88.jpg" alt="A Comprehensive Guide to React 19."/></figure>
As the most popular JavaScript framework, each React version continually rolls out improvements and new features to further improve web developm... | get_pieces | |
1,878,143 | LeetCode Day1 Array Part1 | Day 1 Array Part1 LeetCode 704 Binary Search Some ideas are learned from... | 0 | 2024-06-05T15:25:18 | https://dev.to/flame_chan_llll/leetcode-day1-array-part1-4lld | leetcode, java, algorithms | # Day 1 Array Part1
## LeetCode 704 Binary Search
Some ideas are learned from [website](https://programmercarl.com/0704.%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE.html#%E6%80%9D%E8%B7%AF)
Given an array of integers `nums` which is sorted in ascending order, and an integer `target`, write a function to search `target` in... | flame_chan_llll |
1,878,229 | Buy Verified Paxful Account | Buy Verified Paxful Account There are several compelling reasons to consider purchasing a... | 0 | 2024-06-05T15:24:51 | https://dev.to/junehafford012/buy-verified-paxful-account-5bpp | Buy Verified Paxful Account
There are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various tran... | junehafford012 | |
1,878,227 | yaml | YAML (YAML Ain't Markup Language), yapılandırma dosyaları ve veri serileştirme için kullanılan,... | 0 | 2024-06-05T15:24:12 | https://dev.to/mustafacam/yaml-356b | YAML (YAML Ain't Markup Language), yapılandırma dosyaları ve veri serileştirme için kullanılan, okunabilirliği yüksek bir veri serileştirme dilidir. YAML dosyaları, insan tarafından okunabilir ve yazılabilir basit bir sözdizimine sahiptir. Bu nedenle, yapılandırma dosyaları, veri değişim formatları ve uygulama yapıland... | mustafacam | |
1,878,226 | Every compared FastAPI vs Flask? | I have come to understand that when developing web applications, selecting the right Python web... | 0 | 2024-06-05T15:21:28 | https://dev.to/zoltan_fehervari_52b16d1d/every-compared-fastapi-vs-flask-9cm | webdev, python, fastapi, flask | I have come to understand that when developing web applications, selecting the right Python web framework is crucial. [FastAPI and Flask](https://bluebirdinternational.com/fastapi-vs-flask/) are two popular options that have gained traction recently.
_I will attempt to introduce these frameworks and highlight their k... | zoltan_fehervari_52b16d1d |
1,878,141 | Debouncing in React | npm install lodash.debounce import debounce from 'lodash.debounce' Enter fullscreen mode ... | 0 | 2024-06-05T15:00:07 | https://dev.to/alamfatima1999/debouncing-in-react-34ni | ```JS
npm install lodash.debounce
import debounce from 'lodash.debounce'
```
```JS
const doCityFilter = query => {
if (!query) return setFilteredCities([])
const debouncedFilter = debounce(() => {
console.log('====>', query)
setFilteredCities(citiesArray.filter(
city => city.toLowerCase().includes(... | alamfatima1999 | |
1,878,154 | How safe is your prescription information online? | https://bit.ly/3yMW1Ru Ensuring the safety of your prescription information online is crucial. DiRx... | 0 | 2024-06-05T15:20:03 | https://dev.to/lily_martin_3875e40484192/how-safe-is-your-prescription-information-online-5f9j | https://bit.ly/3yMW1Ru
Ensuring the safety of your prescription information online is crucial. DiRx emphasises the importance of understanding who has access to your health data, how it is used, and the security measures to protect it. With HIPAA compliance and secure database protocols, DiRx guarantees that your priva... | lily_martin_3875e40484192 | |
1,878,149 | The Growth of Battery Additives Market | Battery, just like other things which performance can reduce with age, needs something to protect... | 0 | 2024-06-05T15:15:02 | https://dev.to/marktwain57/the-growth-of-battery-additives-market-34pl | batteryadditives, batteryadditivesmarket | Battery, just like other things which performance can reduce with age, needs something to protect them. Battery additives can help to restore and repower various battery types to improve their safety and performance. Not only for battery, but there are also plastic additives that were added to plastic during the produc... | marktwain57 |
1,878,148 | 6 Free Tailwind CSS Modal/Dialog Components [Open-Source] | We’ve put together a collection of awesome modal component examples, and we’re happy to share them... | 27,771 | 2024-06-05T15:12:18 | https://dev.to/creativetim_official/6-free-tailwind-css-modaldialog-components-open-source-37h3 |
We’ve put together a collection of awesome modal component examples, and we’re happy to share them with you. Modals are essential for creating user interfaces, providing a simple way to interact with users - whether you need a simple alert, a detailed form, or more.
These components are coded with **[Tailwind CSS](ht... | creativetim_official | |
1,877,658 | Making a Simple Self-Hosted Photo Gallery with 11ty | For someone looking to make a personal space for their creative work on the web, the range of choices... | 0 | 2024-06-05T15:11:39 | https://dev.to/kelp_digital/making-a-simple-self-hosted-photo-gallery-with-11ty-408f | webdev, tutorial, frontend, 11ty | For someone looking to make a personal space for their creative work on the web, the range of choices is so wide that it’s sometimes paralyzing! On the one hand, there are a ton of general-purpose website builders with gallery-like templates. On the other hand, there are specialized services for photographers and graph... | alxwnth |
1,878,147 | Using GraphQL with Node.js (e.g., Apollo Server) | Using GraphQL with Node.js (e.g., Apollo Server) GraphQL is a powerful query language for... | 0 | 2024-06-05T15:10:03 | https://dev.to/romulogatto/using-graphql-with-nodejs-eg-apollo-server-o9 | # Using GraphQL with Node.js (e.g., Apollo Server)
GraphQL is a powerful query language for APIs that was developed by Facebook. It provides a more efficient and flexible way to retrieve data compared to traditional RESTful APIs. In this guide, we will explore how to use GraphQL with Node.js, specifically focusing on ... | romulogatto | |
1,877,999 | Finally: declarative, dynamic markup done right - Async Iterators UI framework | I've been writing web backends and frontends since the 90s. CGI, ISAPI, AJAX - you name it, there's... | 0 | 2024-06-05T15:06:13 | https://dev.to/matatbread/ive-been-writing-web-backends-and-frontends-since-the-90s-finally-declarative-dynamic-markup-done-right-3jmj | webdev, javascript, typescript, html | I've been writing web backends and frontends since the 90s. CGI, ISAPI, AJAX - you name it, there's not a TLA I've not used to write production quality, real-time, dynamic services presented in browsers.
CGI works, but delivering a whole page or frame was a lot of work for servers and session managers and lacked the i... | matatbread |
1,878,146 | Create tooltips quickly and easily | Create simple tooltips with HTML/CSS with minimal JavaScript? I'll show you how to do it 🪄 You... | 0 | 2024-06-05T15:03:33 | https://blog.disane.dev/en/create-tooltips-quickly-and-easily/ | programming, internet, html, css | Create simple tooltips with HTML/CSS with minimal JavaScript? I'll show you how to do it 🪄
---
You just want to create a tooltip in HTML/CSS and don't want to use the title attribute, but create your own tooltip instead? It's... | disane |
1,878,145 | Einfach und schnell Tooltips erstellen | Einfache Tooltips mit HTML/CSS mit minimalem JavaScript erstellen? ich zeig dir wie es geht 🪄 Du... | 0 | 2024-06-05T15:03:24 | https://blog.disane.dev/einfach-gehen-tooltips-nicht/ | programmierung, internet, html, css | Einfache Tooltips mit HTML/CSS mit minimalem JavaScript erstellen? ich zeig dir wie es geht 🪄
---
Du willst mal eben einen Tooltip in HTML/CSS erstellen und willst dabei nicht das Title-Attribut nutzten, sondern einen eigen... | disane |
1,878,144 | How AI is Simplifying Landing Page Creation for SaaS Companies | In the rapidly evolving digital marketplace, SaaS companies are constantly seeking innovative ways to... | 0 | 2024-06-05T15:01:57 | https://dev.to/vincivinni/how-ai-is-simplifying-landing-page-creation-for-saas-companies-1cf2 | In the rapidly evolving digital marketplace, SaaS companies are constantly seeking innovative ways to capture the attention of potential customers. Landing pages are a critical tool in this quest, often serving as the first impression for a potential lead or customer. However, the process of creating an effective landi... | vincivinni | |
1,878,142 | Toss의 퍼널(Funnel) 패턴 적용해보기 | "토스 SLASH 23의 퍼널: 쏟아지는 페이지 관리하기" 를 참고하여 작성되었습니다. 링크 토스에서는 다른 통신사들 처럼 요금제 가입 신청서를 받고있다. 차별화된 점은 한... | 0 | 2024-06-05T15:01:09 | https://dev.to/hxxtae/tossyi-peoneolfunnel-paeteon-jeogyonghaebogi-2n7c | react, toss, funnel | > "토스 SLASH 23의 퍼널: 쏟아지는 페이지 관리하기" 를 참고하여 작성되었습니다.
> [링크](https://www.youtube.com/watch?v=NwLWX2RNVcw)
토스에서는 다른 통신사들 처럼 요금제 가입 신청서를 받고있다.
차별화된 점은 한 페이지로 이루어진 폼 대신, 한 페이지에 한 항목만 제출하는 UI를 가지고 있다.
하지만 이런식으로 많은 페이지들을 한 번에 관리하기란 쉽지 않다.
위 발표에서는 이러한 페이지들을 효과적으로 관리하는 방법에 대해서 설명하고 있다.
## 퍼널(Funnel)
퍼널의 사전적인 뜻인... | hxxtae |
1,876,907 | How to Perform Semantic Search using ChromaDB in JavaScript | This tutorial will cover how to use embeddings and vectors to perform semantic search using ChromaDB... | 0 | 2024-06-05T14:50:59 | https://dev.to/vaatiesther/how-to-perform-semantic-search-using-chromadb-in-javascript-3og8 | ai, machinelearning, javascript, programming |
This tutorial will cover how to use embeddings and vectors to perform semantic search using ChromaDB in JavaScript.
## What are Embeddings
Have you ever wondered how recommendation systems like Netflix almost always know what movies you like? When you log in to Netflix, the app presents recommendations that will lik... | vaatiesther |
1,878,134 | Understanding AI Code Analysis and Real-Time Performance Monitoring | Leveraging AI code analysis tools like Pieces can help you save time, optimize your code, and quickly detect bugs. | 0 | 2024-06-05T14:48:46 | https://code.pieces.app/blog/understanding-ai-code-analysis-and-real-time-performance-monitoring | <figure><img src="https://d37oebn0w9ir6a.cloudfront.net/account_32099/ai-code-analysis_8f6102a9064a41553172b0dfe64fb0a0.jpg" alt="Understanding AI Code Analysis."/></figure>
Real-time code monitoring can be a time-consuming endeavor. You must continuously look at output and analyze risks, making immediate changes as n... | get_pieces | |
1,878,133 | SQL Mastery: Unleashing the Power of Queries | Introduction to SQL: SQL, or Structured Query Language, serves as the primary means of... | 0 | 2024-06-05T14:47:51 | https://dev.to/mahabubr/sql-mastery-unleashing-the-power-of-queries-5bnl | sql, database, query, development | ## **Introduction to SQL:**
SQL, or Structured Query Language, serves as the primary means of communication with relational databases. It offers a standardized syntax for managing and querying data, facilitating efficient data retrieval, modification, and maintenance.
## **SQL Queries:**
**1. Create a Database:**
To... | mahabubr |
1,878,132 | HOW TO HOST AN APPLICATION USING GITHUB | As a beginner I always had the doubt where I can host my application or portfolio freely. With online... | 0 | 2024-06-05T14:46:48 | https://dev.to/shreeprabha_bhat/how-to-host-an-application-using-github-49bh | As a beginner I always had the doubt where I can host my application or portfolio freely. With online platform I found out the one of the easiest way to host an application using Github. Today I am going to write about the steps involved in hosting the application using github.
**STEP 1: CREATE A REPOSITORY**
- Login... | shreeprabha_bhat | |
1,878,131 | Device limit reached for this Apple ID - Solution | During the new device onboarding process, if you have been using the Apple ecosystem for a while and... | 0 | 2024-06-05T14:46:28 | https://monobit.dev/blog/device-limit-reached-for-this-apple-id | apple | During the new device onboarding process, if you have been using the Apple ecosystem for a while and have changed multiple devices over time, you may encounter the Device Limit issue that Apple displays when you try to use your device with Apple Music (and likely other media apps as well) but you have a number of devic... | dmitrysemenov |
1,878,114 | The Best Typesafe ORM you are not using | Since I stumbled across NoSQL databases, specifically document-oriented databases, I knew I had found... | 0 | 2024-06-05T14:45:06 | https://dev.to/kalashin1/the-best-javascript-orm-you-are-not-using-ngb | node, typescript, mongodb, mysql | Since I stumbled across NoSQL databases, specifically document-oriented databases, I knew I had found the one for me. It is not that I find anything wrong about SQL databases but I'm not just that guy. I like to think about my data in terms of Objects. I started using MongoDB around 2020 and since then I've used it on ... | kalashin1 |
1,878,130 | Remote power monitoring | The power delivery in Ukraine currently faces challenges due to a power deficit caused by Russian... | 0 | 2024-06-05T14:44:11 | https://monobit.dev/blog/remote-power-monitoring | monitoring | The power delivery in Ukraine currently faces challenges due to a power deficit caused by Russian terrorist attacks on the Ukrainian infrastructure. As the balance between consumption and generation fluctuates, periodic shutdowns occur in different districts based on a semi-accurate schedule.
My apartment is on a high... | dmitrysemenov |
1,878,127 | Making Spring Transactions Transparent with Detailed Logging | TL;DR While working on my latest video on Transactions, I found a very useful logging... | 0 | 2024-06-05T14:42:39 | https://dev.to/therealdumbprogrammer/making-spring-transactions-transparent-with-detailed-logging-1n69 | java, springboot, spring, programming | **TL;DR**
{% embed https://youtu.be/riNWDhiv3fk %}
While working on my latest video on Transactions, I found a very useful logging configuration. By enable/configuring these log levels, you can gain valuable insights into your application’s transaction flow.
This makes Spring Boot to display detailed information rela... | therealdumbprogrammer |
1,878,126 | Burger king carte prix | La burger king carte prix comprend également une variété d'options à la carte pour ceux qui préfèrent... | 0 | 2024-06-05T14:42:15 | https://dev.to/robyngknapp/burger-king-carte-prix-5443 | La [burger king carte prix](https://prixdesmenus.com/burger-king-menu/) comprend également une variété d'options à la carte pour ceux qui préfèrent personnaliser leur repas. Des sandwichs aux salades, en passant par des accompagnements comme les onion rings et les nuggets de poulet, chaque élément est proposé à un prix... | robyngknapp | |
1,878,125 | How Is End-To-End Testing Different From Regression Testing? | Every tester aims to increase test coverage and move towards a better end product. A well-planned... | 0 | 2024-06-05T14:41:48 | https://linuxnetmag.com/how-is-end-to-end-testing-different-from-regression-testing/ | testing, webdev, mobile, programming | Every tester aims to increase test coverage and move towards a better end product. A well-planned testing strategy involves different testing types and plans for various connections and combinations. Finding a successful and viable testing strategy for complex systems can be tricky. But other approaches and views have ... | jennife05918349 |
1,878,122 | Menú de Caffenio Precios | Consultar el menú de Caffenio precios te permitirá planear tu visita sin sorpresas. Los precios del... | 0 | 2024-06-05T14:34:14 | https://dev.to/robyngknapp/menu-de-caffenio-precios-5am9 | Consultar el [menú de Caffenio precios](https://mxmenu.org/caffenio-menu/) te permitirá planear tu visita sin sorpresas. Los precios del menú de Caffenio son competitivos y reflejan la calidad de sus productos. Ya sea que busques una opción económica o un capricho, el menú de Caffenio precios tiene algo para ti. | robyngknapp | |
1,878,113 | The Right Way to Do HMAC Authentication in ExpressJS | Authentication is the most important thing when building an API. There are many method to... | 0 | 2024-06-05T14:30:36 | https://dev.to/burhanahmeed/the-right-way-to-do-hmac-authentication-in-expressjs-5489 | authjs, typescript, go, programming | Authentication is the most important thing when building an API. There are many method to authenticate to an API. Some provider choose to only _bearer_ token, some choose to use a pair of username and password, and many other way to authenticate an API. Besides those, there is another way to authenticate an API, yes, i... | burhanahmeed |
1,877,677 | Introducing sudoku-puzzle: Simplify your Sudoku experience with this new NPM Package | Hi there 👋 I'm excited to share the release of sudoku-puzzle, my newest npm package! This package is... | 19,830 | 2024-06-05T14:30:00 | https://dev.to/dhanushnehru/introducing-sudoku-puzzle-simplify-your-sudoku-experience-with-this-new-npm-package-1249 | npm, opensource, showdev, codenewbie | Hi there 👋
I'm excited to share the release of sudoku-puzzle, my newest npm package! This package is for puzzle lovers who wish to produce and solve Sudoku puzzles programmatically, or for developers who want to incorporate Sudoku puzzles into their applications.
## What makes Sudoku so special?
Numerous millions o... | dhanushnehru |
1,878,112 | Load Balancer | Mikroservis mimarisinde bir Load Balancer (yük dengeleyici), gelen ağ trafiğini birden çok hizmet... | 0 | 2024-06-05T14:29:58 | https://dev.to/mustafacam/load-balancer-1l1d |
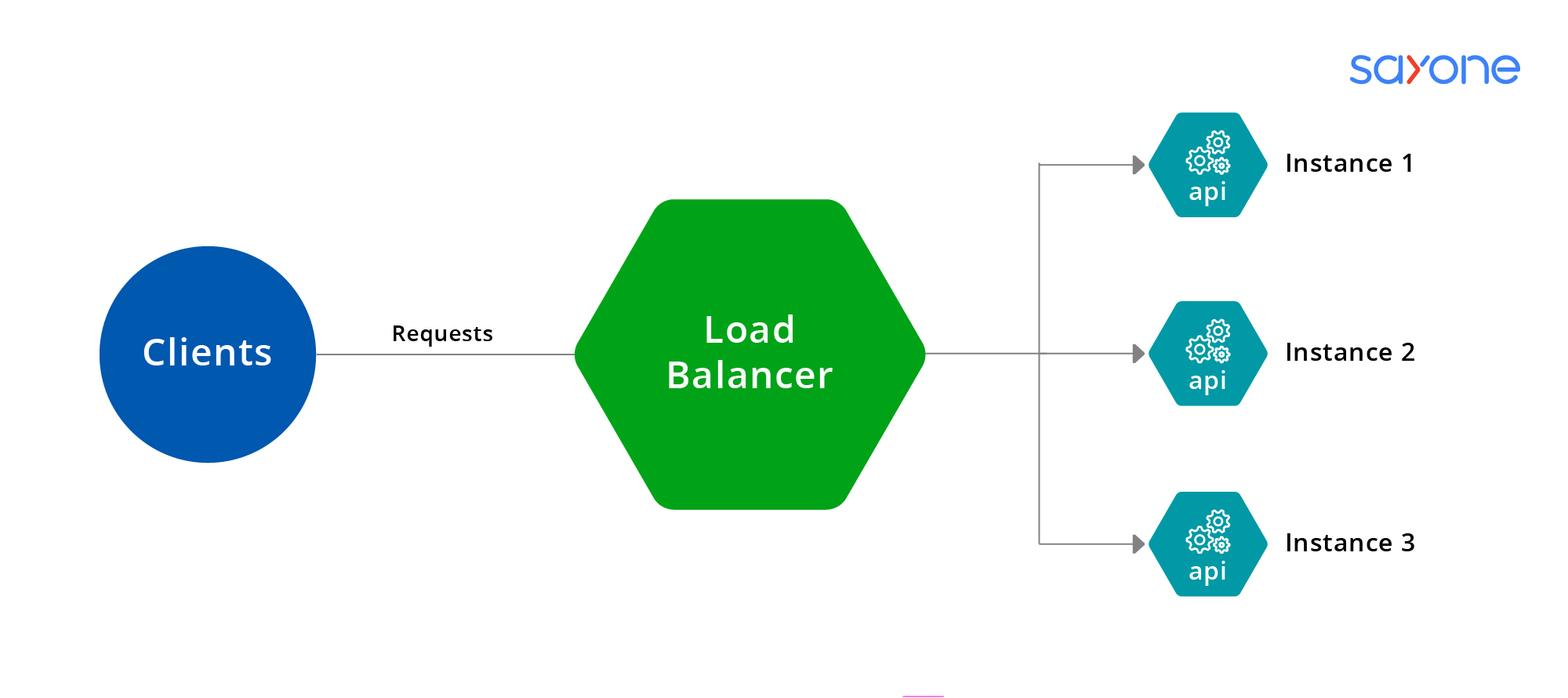
Mikroservis mimarisinde bir **Load Balancer** (yük dengeleyici), gelen ağ trafiğini birden çok hizmet örneği arasında dağıtarak sistemin performansını, güvenilirliğini ve ölçeklenebilirliğini artıran bir bileşend... | mustafacam | |
1,878,111 | Introduction ExpressJS | Introduction ExpressJs is a popular open-source web application framework for Node.js... | 0 | 2024-06-05T14:28:57 | https://dev.to/dana-fullstack-dev/introduction-expressjs-59bi | webdev, database |
## Introduction

[ExpressJs](https://expressjs.com) is a popular open-source web application framework for Node.js that is widely used to build web applications and APIs. It is known for its simp... | dana-fullstack-dev |
1,878,110 | The beauty of simplicity | image credit: nintendo.com Im watching the TV series “Halt and Catch Fire”📺, and there is an episode... | 0 | 2024-06-05T14:28:16 | https://dev.to/jwtiller_c47bdfa134adf302/the-beauty-of-simplicity-2p9a | gamedev, programming | _image credit: nintendo.com_
Im watching the TV series “Halt and Catch Fire”📺, and there is an episode featuring the classic Nintendo game Duck hunt🦆🎮, that caught my interest. This was a game I played in my childhood, and I asked myself how I would make the game today from a technical point of view. It probably wo... | jwtiller_c47bdfa134adf302 |
1,878,109 | Tell me i m right or wrong | <!-- <!DOCTYPE html> <html> <body> <input id="male"... | 0 | 2024-06-05T14:25:18 | https://dev.to/sagar_soni_abb4bd146ee8a0/tell-me-i-m-right-or-wrong-5bh6 | javascript, webdev, beginners, programming | <!-- Radio Button Fetch And Display Input-->
<!-- <!DOCTYPE html>
<html>
<body>
<input id="male" type="radio" value="Male" name="gender"> Male
<input id="female" type="radio" value="Female" name="gender"> Female
<button onclick="radio()">Click Me</button>
... | sagar_soni_abb4bd146ee8a0 |
1,878,108 | Tell me i m right or wrong | <!-- <!DOCTYPE html> <html> <body> <input id="male"... | 0 | 2024-06-05T14:25:15 | https://dev.to/sagar_soni_abb4bd146ee8a0/tell-me-i-m-right-or-wrong-46d6 | javascript, webdev, beginners, programming | <!-- Radio Button Fetch And Display Input-->
<!-- <!DOCTYPE html>
<html>
<body>
<input id="male" type="radio" value="Male" name="gender"> Male
<input id="female" type="radio" value="Female" name="gender"> Female
<button onclick="radio()">Click Me</button>
... | sagar_soni_abb4bd146ee8a0 |
1,878,100 | How I Developed a Recipe Selector App Using Python and Tkinter | As an enthusiast of both programming and cooking, I've always wanted to merge my passions into a... | 0 | 2024-06-05T14:23:43 | https://dev.to/codecounsel/how-i-developed-a-recipe-selector-app-using-python-and-tkinter-ddj | beginners | As an enthusiast of both programming and cooking, I've always wanted to merge my passions into a single project. That’s why I decided to develop a recipe selector app that not only helps me organize my favorite recipes but also gave me a chance to dive into the world of GUI development with Python. This post outlines m... | codecounsel |
1,878,099 | Semak Rekod Jenayah Melalui Kad Pengenalan Ketahui Keadaan Keselamatan Anda dengan Mudah | Semak rekod jenayah mungkin menjadi salah satu langkah penting dalam memastikan keselamatan diri dan... | 0 | 2024-06-05T14:12:36 | https://dev.to/harga_emasmy_1f89f8f5e12/semak-rekod-jenayah-melalui-kad-pengenalan-ketahui-keadaan-keselamatan-anda-dengan-mudah-31e3 | Semak rekod jenayah mungkin menjadi salah satu langkah penting dalam memastikan keselamatan diri dan keluarga. Dalam era digital yang semakin canggih seperti sekarang, pelbagai platform telah dibangunkan untuk memudahkan orang ramai semak rekod jenayah mereka.
Salah satu cara yang semakin popular adalah melalui penggu... | harga_emasmy_1f89f8f5e12 | |
1,878,107 | Hello Friends! | ** Hello coders, developers, and all amazing people! ** First of all, I am a marketer... | 0 | 2024-06-05T14:20:42 | https://dev.to/whereisity/hello-friends-51n | webdev, beginners, productivity, hello | **
## Hello coders, developers, and all amazing people!
**
- First of all, I am a marketer (please don't kick me out, yet) and not a coder by profession or by birth :)
- I recently started working on my WordPress website and it is FUN and HARD! I know I should hire someone but my job doesn't pay me that much yet :(
-... | whereisity |
1,879,601 | Mermaid preview using xwidget browser | Mermaid.js is a great tool to make diagrams in plain text, I use it a lot and I wanted to have a way... | 0 | 2024-06-07T06:38:45 | https://erick.navarro.io/blog/mermaid-preview-using-xwidget-browser/ | emacs, mermaidjs | ---
title: Mermaid preview using xwidget browser
published: true
date: 2024-06-05 14:19:05 UTC
tags: emacs,mermaidjs
canonical_url: https://erick.navarro.io/blog/mermaid-preview-using-xwidget-browser/
---
[Mermaid.js](https://mermaid.js.org) is a great tool to make diagrams in plain text, I use it a lot and I wanted t... | erickgnavar |
1,878,102 | Back to the basic - Have you mastered all the Google search techniques? | Improve search, the skill you use everyday by reviewing advanced search techniques in below link (and... | 0 | 2024-06-05T14:18:34 | https://dev.to/patfinder/back-to-the-basic-have-you-master-all-the-google-search-techniques-4mje | Improve search, the skill you use everyday by reviewing advanced search techniques in below link (and of course, many other guides on the Internet):
https://www.pcmag.com/how-to/google-search-tips-youll-want-to-learn
✏️**
Building a non-trivial web application with Rust can be fairly straightforward. However, when things become complex and require features like authentication, middleware, and more, that’s where Axum shines. Axum makes it a lot easier to build c... | leemeganj |
1,878,097 | Introduction Mysql | Introduction Mysql Introduction Mysql is a popular open-source relational... | 0 | 2024-06-05T14:14:07 | https://dev.to/dana-fullstack-dev/introduction-mysql-3jej | webdev, beginners | # Introduction Mysql
## Introduction

Mysql is a popular open-source relational database management system (RDBMS) that is widely used in web applications and other software projects. It ... | dana-fullstack-dev |
1,878,098 | Reinvention and Refactoring: A Data-Driven, AI-Enhanced Framework for Managing Systems | NOTE: I'm aiming at making this a little easier to paw through with lists. I understand that... | 0 | 2024-06-05T14:10:37 | https://dev.to/edtbl76/reinvention-and-refactoring-a-data-driven-ai-enhanced-framework-for-managing-systems-1kln | _NOTE: I'm aiming at making this a little easier to paw through with lists. I understand that long-form paragraphs can be tougher to digest._
When faced with the challenge of improving software systems, organizations often grapple with the decision between reinvention and refactoring. Both approaches have their merit... | edtbl76 | |
1,878,096 | Insta Pro | Insta Pro is 100% safe and secure.Insta Prois verified through multiple malwareand virus protection... | 0 | 2024-06-05T14:09:02 | https://dev.to/riya_roy_2e9da898bf00579f/insta-pro-29ln | Insta Pro is 100% safe and secure.<a href="https://instapromanager.com/">Insta Pro</a>is verified through multiple malwareand virus protection platforms like TotalAV, Norton 360 Antivirus, Bitdefender Antivirus Plus,Surfshark Antivirus, and Malwarebytes.If you are still worrying about the safety feel free to cross-chec... | riya_roy_2e9da898bf00579f | |
1,878,095 | Unlocking Real-Time Chat with GetStream.io: A Developer's Guide 💬 | In today's fast-paced digital world, real-time communication is key. Whether you're building a... | 0 | 2024-06-05T14:09:02 | https://dev.to/elizabethsobiya/unlocking-real-time-chat-with-getstreamio-a-developers-guide-1noh | webdev, beginners, programming, tutorial |
In today's fast-paced digital world, real-time communication is key. Whether you're building a messaging app, a social media platform, or a customer support system, integrating a reliable and scalable chat solution is crucial. This is where [GetStream.io](https://getstream.io) comes into play. GetStream.io offers a r... | elizabethsobiya |
1,878,094 | Nullable value Types | C# | Bugun biza o'rganishimiz shart bo'lgan narsalar quyidagicha 👇 Declaretion va Assigment Null... | 0 | 2024-06-05T14:07:44 | https://dev.to/ozodbek_soft/nullable-value-types-c-5d89 | dotnet, csharp, nullable, uzbek | **Bugun biza o'rganishimiz shart bo'lgan narsalar quyidagicha 👇**
- _Declaretion va Assigment_
- _Null bo'ladigan misollar qiymatlarini tekshirish_
- _Null qiymatni primative typega o'tqazish _
- _Vahokazolar_
**Null bu Value type**! Odatda null qiymat biriktirish uchun asosan 1 ta belgidan foydalaniladi. Bu `?` bel... | ozodbek_soft |
1,878,087 | Unveiling the Beauty of Desert Marble A Geological Wonder | Desert marble is a geological marvel that captivates with its natural beauty and versatility. As a... | 0 | 2024-06-05T13:57:37 | https://dev.to/stonesolutions/unveiling-the-beauty-of-desert-marble-a-geological-wonder-27en | Desert marble is a geological marvel that captivates with its natural beauty and versatility. As a prized material for landscapers, it offers a unique blend of elegance and durability, making it an ideal choice for various outdoor and indoor applications. In this comprehensive guide, we'll delve into the different aspe... | stonesolutions | |
1,878,093 | Fetch images and Display Flex | .App { font-family: sans-serif; text-align: center; } .image-container { display:... | 0 | 2024-06-05T14:07:13 | https://dev.to/alamfatima1999/fetch-images-and-display-flex-4log | ```CSS
.App {
font-family: sans-serif;
text-align: center;
}
.image-container {
display: flex;
}
.image-box {
width: 30px;
height: 30px;
}
.image-container {
display: flex;
flex-wrap: wrap;
}
```
```JS
import { StrictMode } from "react";
import { createRoot } from "react-dom/client";
import App from ... | alamfatima1999 | |
1,878,092 | Boost Your Online Store: Comprehensive Ecommerce Marketing Techniques | In today’s competitive digital market, getting to know ecommerce advertising and marketing is crucial... | 0 | 2024-06-05T14:05:26 | https://dev.to/liong/boost-your-online-store-comprehensive-ecommerce-marketing-techniques-3lih | seo, onpage, blog, malaysia | In today’s competitive digital market, getting to know ecommerce advertising and marketing is crucial for any online store aiming for achievement. Effective advertising strategies no longer simplest force traffic in your website however also convert site visitors into dependable clients. This comprehensive guide will e... | liong |
1,878,090 | Web Development Design: A Comprehensive Guide | Web development design is a critical aspect of creating an engaging, user-friendly, and efficient... | 0 | 2024-06-05T14:01:48 | https://dev.to/andylarkin677/web-development-design-a-comprehensive-guide-3b1e | webdev, learning, career, design |
Web development design is a critical aspect of creating an engaging, user-friendly, and efficient website. It combines elements of graphic design, user interface (UI) design, user experience (UX) design, and front-end development. This comprehensive guide will explore key components and best practices in web developme... | andylarkin677 |
1,878,089 | Docker Secrets Management: Safeguarding Credentials in Containerized Applications | Traditional application deployments often involve hardcoding sensitive information like API keys,... | 0 | 2024-06-05T13:59:55 | https://dev.to/platform_engineers/docker-secrets-management-safeguarding-credentials-in-containerized-applications-2621 | Traditional application deployments often involve hardcoding sensitive information like API keys, passwords, and database credentials directly within the source code or configuration files. This practice poses a significant security risk, as any unauthorized access to the codebase could expose these secrets.
Docker c... | shahangita | |
1,878,088 | Pipeline Integrity and Security in DevSecOps | This is the third blog post in a series that is taking a deep dive into DevSecOps program... | 27,185 | 2024-06-05T13:58:30 | https://blog.gitguardian.com/pipeline-integrity-and-security-in-devsecops/ | devsecops, security, cybersecurity, tooling | This is the third blog post in a series that is taking a deep dive into DevSecOps program architecture. The goal of this series is to provide a holistic overview of DevSecOps as a collection of technology-driven, automated processes. Make sure to check out the first and second parts too!
At this point in the series, w... | segudev |
1,878,083 | Thrive as a Junior Engineer: Embrace Deliberate Progress | In the fast-paced world of software engineering, the pressure to deliver results quickly can be... | 0 | 2024-06-05T13:46:40 | https://dev.to/alexroor4/thrive-as-a-junior-engineer-embrace-deliberate-progress-5bnn | webdev, beginners, javascript, devops | In the fast-paced world of software engineering, the pressure to deliver results quickly can be overwhelming, especially for junior engineers. However, the key to long-term growth and success may lie in taking a more deliberate approach. The idea of "working slower to grow faster" is about focusing on understanding and... | alexroor4 |
1,878,082 | Roadmap Backend Tahun 2024 | Gimana menurut kalian? ada yg kurang gak hehe😁 src: @code.clash Yuk belajar bareng serta diskusi... | 0 | 2024-06-05T13:46:01 | https://dev.to/appardana/roadmap-backend-tahun-2024-21l6 | webdev, javascript, beginners, backenddevelopment | Gimana menurut kalian? ada yg kurang gak hehe😁
src: @code.clash
Yuk belajar bareng serta diskusi dikolom komentar, serta di save biar ga lupa💬😝
📬DM for Business
🌱Follow : @appardana🎍
💭Stay Young, Be Innovative and Keep Learning
#coding #programmer #code #Content #Tips #Trick #Knwoledge #Management #CSS #React... | appardana |
1,878,081 | Karyam: Simplest everyday writing app | What is the most simple thing any writing app should have is to write every day, write every... | 0 | 2024-06-05T13:44:50 | https://dev.to/shreyvijayvargiya/karyam-simples-everyday-writing-app-489m | product, webdev, programming, news | What is the most simple thing any writing app should have is to write every day, write every day.
Demo: [https://karyam.vercel.app/](https://karyam.vercel.app/)
## Under the Hood
I am asking myself a lot of questions about designing or making an app that is simple but designing a website and interface is just a few ... | shreyvijayvargiya |
1,878,079 | Mastering the Art of EHR Software Development | In today's rapidly evolving healthcare landscape, Electronic Health Records (EHRs) have emerged as a... | 0 | 2024-06-05T13:42:41 | https://dev.to/techdud_71ca45195a2c/mastering-the-art-of-ehr-software-development-f11 | In today's rapidly evolving healthcare landscape, Electronic Health Records (EHRs) have emerged as a pivotal component, revolutionizing the way medical data is managed, shared, and utilized. As the demand for efficient and secure digital solutions continues to soar, the development of robust EHR systems has become a to... | techdud_71ca45195a2c | |
1,878,066 | Mike: learning: First steps | About me Hello, I'm Mike. I recently started working at Manticore as a Developer... | 0 | 2024-06-05T13:42:21 | https://dev.to/anstalf/mike-learning-first-steps-5g4k | ### About me

Hello, I'm Mike.
I recently started working at Manticore as a Developer Advocate. I am someone not completely distant from IT, but I'm catching up with modern technologies. In this blog, I'll s... | anstalf | |
1,878,042 | Quick and dirty React - Tailwind | Getting Started with Tailwind CSS, PNPM, Vite, and Theme Management In today's fast-paced... | 0 | 2024-06-05T13:42:14 | https://dev.to/peter-fencer/quick-and-dirty-react-tailwind-4kd3 | frontend, webdev, javascript, beginners | > Getting Started with Tailwind CSS, PNPM, Vite, and Theme Management
In today's fast-paced development world, efficiency is key. Whether you're working on a quick prototype or setting up a new project, having the right tools can make a huge difference. I'll walk you through setting up a React project with Tailwind CS... | peter-fencer |
1,878,078 | 🚀 Exciting News for React Native Developers! 🚀 | Recently i have discovered the "React Native IDE" extension for Visual Studio Code by Software... | 0 | 2024-06-05T13:42:14 | https://dev.to/madzimai/exciting-news-for-react-native-developers-3dl2 |
<img width="100%" style="width:100%" src=https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExOXJyazd2N2F4emdkY2E3NHlobzBpYTV4cW9yaHF1aHVxem5nODNtNCZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/CKOCV8dKimlmmS41kE/giphy.gif>
Recently i have discovered the "React Native IDE" extension for Visual Studio Code by Software Mansion! ... | madzimai | |
1,878,077 | Mastering JavaScript: Your Ultimate Guide🚀 | Introduction JavaScript is a versatile, high-level programming language primarily used for... | 0 | 2024-06-05T13:40:30 | https://dev.to/dharamgfx/mastering-javascript-your-ultimate-guide-4mic | webdev, javascript, beginners, programming |
## Introduction
JavaScript is a versatile, high-level programming language primarily used for web development. It enables interactive web pages and is an essential part of web applications. JavaScript is easy to learn for beginners but has deep and powerful capabilities for experienced developers.
## Grammar and Type... | dharamgfx |
1,878,076 | Diamante Net Hackathon 2024 | Welcome to the Diamante Net Hackathon 2024! Join us as we unlock new possibilities in blockchain... | 0 | 2024-06-05T13:40:16 | https://dev.to/sarang_pokhare/diamante-net-hackathon-2024-1f8 | hackathon, coders, developers, blockchain | Welcome to the **Diamante Net Hackathon 2024!** Join us as we unlock new possibilities in blockchain technology and foster innovation across multiple sectors. Whether you're a developer, or blockchain enthusiast, this is your platform to showcase your skills, connect with industry leaders, and transform your ideas into... | sarang_pokhare |
1,878,074 | The Perfect Guide on Recovering your USDC, USDT by CybergoatTechie! | I'd really urge anybody who needs help with recovery to reach thecybergoat techie as they're one of... | 0 | 2024-06-05T13:35:21 | https://dev.to/peggyfleming/the-perfect-guide-on-recovering-your-usdc-usdt-by-cybergoattechie-3kl6 | I'd really urge anybody who needs help with recovery to reach [thecybergoat techie](https://cybergoattechie.com/) as they're one of the most talent group you'll come across on the internet!
 | peggyfleming | |
1,878,073 | "Unlock Success: Digital Marketing Consultant in Pune" | Are you a business owner in Pune striving to make a mark in the digital world? Look no further! In... | 0 | 2024-06-05T13:35:09 | https://dev.to/swapnil_majgoankar_8afc39/unlock-success-digital-marketing-consultant-in-pune-4087 | swapnilmajgaonkar, consultant, digitalmarketing | Are you a business owner in Pune striving to make a mark in the digital world? Look no further! In today's competitive landscape, having a robust online presence is crucial for business growth. That's where a [Digital Marketing Consultant in Pune ](https://www.swapnilmajgaonkar.in/
)steps in to unlock your success.
Wh... | swapnil_majgoankar_8afc39 |
1,846,660 | Rusty RAG Quiz Creator | I wanted to get started with Rust after being a Scala developer for several years. I have little to... | 27,611 | 2024-06-05T13:32:16 | https://dev.to/narroric/rusty-rag-quiz-creator-1d31 | llm, rust, rag | I wanted to get started with Rust after being a Scala developer for several years. I have little to no experience with bare metal languages after working with Java, Python and Javascript, so thought it would help solidify my understanding of how languages work under the hood, something I've not touched on since I did m... | narroric |
1,878,071 | Are Custom Cotton Bags Versatile And Eco-Friendly? | Rapidly increasing awareness and sustainability impact the environment. Hence, the demand for cotton... | 0 | 2024-06-05T13:31:06 | https://dev.to/tulinii/are-custom-cotton-bags-versatile-and-eco-friendly-4nb2 | customcottonbags |
Rapidly increasing awareness and sustainability impact the environment. Hence, the demand for cotton drawstring pouches is increasing rapidly in today's time. You can use these pouches in many ways as they are versatile. People are more attracted towards versatile things, so this pouch can be the best choice for all... | tulinii |
1,878,069 | Tightly Coupled Code vs Loosely Coupled Code | In software development, the terms "tightly coupled" and "loosely coupled" refer to the degree to... | 0 | 2024-06-05T13:27:52 | https://dev.to/dharmingheewala/tightly-coupled-code-vs-loosely-coupled-code-731 | softwareengineering, programming, codequality, cleancode | In software development, the terms "**tightly coupled**" and "**loosely coupled**" refer to the degree to which components of a system depends on each other.
**Tightly Coupled Code**: Tightly coupled code is when a group of classes are highly dependent on one another. This isn't necessarily a bad thing, but it can mak... | dharmingheewala |
1,878,068 | "Frontend Challenge" | The world of frontend development is ever-evolving, presenting new and exciting challenges to... | 0 | 2024-06-05T13:26:40 | https://dev.to/klimd1389/frontend-challenge-5249 | webdev, frontend, devops, news | The world of frontend development is ever-evolving, presenting new and exciting challenges to developers every day. Whether you're a seasoned professional or a novice eager to learn, a "Frontend Challenge" is an excellent way to hone your skills and stay ahead of the curve in this dynamic field.
Understanding the Fron... | klimd1389 |
1,878,053 | Golang middleware && Wei, Jin, Southern and Southern Dynasties | Explanation The holographic projections symbolize the implementation of Golang... | 0 | 2024-06-05T13:22:36 | https://dev.to/fubumingyu/golang-middleware-wei-jin-southern-and-southern-dynasties-7o6 |

## Explanation
The holographic projections symbolize the implementation of Golang middleware to transition and integrate new systems efficiently, reflecting Sima Yan's establishment of the Jin Dynasty.
## Wei, J... | fubumingyu | |
1,878,065 | 用 Tensorflow.js COCO-SSD 辨識圖片物件 | 本篇要解決的問題 幾年前有寫了一篇〈ML5.js 神經網路 開發圖像辨識〉,是辨識圖片裡的物件,最近跟朋友設計一個活動,是需要判斷照片中的人數,ML5 有點不夠用,問了... | 18,536 | 2024-06-05T13:21:25 | https://www.letswrite.tw/coco-ssd/ | tensorflow, cocossd, vue, javascript | ## 本篇要解決的問題
幾年前有寫了一篇〈[ML5.js 神經網路 開發圖像辨識](https://www.letswrite.tw/ml5-image-classifier/)〉,是辨識圖片裡的物件,最近跟朋友設計一個活動,是需要判斷照片中的人數,ML5 有點不夠用,問了 ChatGPT 後,知道了 TensorFlow.js 裡,有一個 COCO-SSD 的模型,[官方的說明](https://www.tensorflow.org/js/models?hl=zh-tw) 是「在單一影像中定位及辨識多個物件」,實際用起來後,也真的覺得好用,除了可以把人辨識出來,還可以給在照片上的範圍。
本篇主要參考的來源,是 [官方說明文件]... | letswrite |
1,878,055 | First Home Buyer Broker - Find Your Perfect Home Loan | Introduction Buying your first home is a significant milestone, a blend of excitement and challenge.... | 0 | 2024-06-05T13:19:46 | https://dev.to/loansandmortgages/first-home-buyer-broker-find-your-perfect-home-loan-3410 | mortgagebroker, loanbroker, homeloanbroker | Introduction
Buying your first home is a significant milestone, a blend of excitement and challenge. For many, navigating the complexities of mortgages and financing options can be overwhelming. This is where a first home buyer broker becomes invaluable. In this comprehensive guide, we'll explore everything you need to... | loansandmortgages |
1,878,054 | SQL injection | SQL Injection (SQL enjeksiyonu), kötü niyetli kullanıcıların veritabanına zararlı SQL komutları... | 0 | 2024-06-05T13:14:47 | https://dev.to/mustafacam/sql-injection-n28 | SQL Injection (SQL enjeksiyonu), kötü niyetli kullanıcıların veritabanına zararlı SQL komutları ekleyerek yetkisiz veri erişimi veya veri manipülasyonu yapmasına olanak tanıyan bir güvenlik açığıdır. SQL enjeksiyonunun nasıl çalıştığını ve nasıl önlenebileceğini göstermek için bir örnek üzerinden gidelim.
### Örnek Se... | mustafacam | |
1,878,052 | Benefit of hiring a Ghostwriter | Hiring a ghostwriter offers numerous benefits, especially for professionals and businesses aiming to... | 0 | 2024-06-05T13:08:38 | https://dev.to/jessica_wilson_a71f60f691/benefit-of-hiring-a-ghostwriter-543g | ghostwriter, ghostwriting, americanpublisher, bookwriting | Hiring a ghostwriter offers numerous benefits, especially for professionals and businesses aiming to produce high-quality content efficiently. Engaging the best ghostwriting services ensures that your ideas are skillfully transformed into compelling narratives, whether for an autobiography, business book, or novel. A g... | jessica_wilson_a71f60f691 |
1,878,051 | Why Remote Work is Killing Innovation | Remote work has become the norm for many companies worldwide, especially in the wake of the COVID-19... | 0 | 2024-06-05T13:06:52 | https://dev.to/callumdev1337/why-remote-work-is-killing-innovation-3f4o | Remote work has become the norm for many companies worldwide, especially in the wake of the COVID-19 pandemic. Proponents argue that remote work offers numerous benefits, such as increased flexibility, reduced commuting time, and better work-life balance. However, beneath these surface-level advantages lies a more sini... | callumdev1337 | |
1,878,000 | Git: How to boost your performance | Git is an amazing tool that help us developers a lot to control the version of our projects, it has a... | 27,621 | 2024-06-05T13:06:43 | https://dev.to/henriqueleite42/git-config-5e35 | git, beginners, tutorial, programming | Git is an amazing tool that help us developers a lot to control the version of our projects, it has a lot of build in features, but we can improve it to have a better experience.
In this article, I'll share my configuration of git and a documentation about what each thing does.
## Template
```js
const name = ""
cons... | henriqueleite42 |
1,878,050 | Scaling(ölçekleme) nedir ? | Yazılım alanında "scaling" (ölçekleme), bir yazılım sisteminin artan yük ve talepleri... | 0 | 2024-06-05T13:06:41 | https://dev.to/mustafacam/scalingolcekleme-nedir--5dlj |
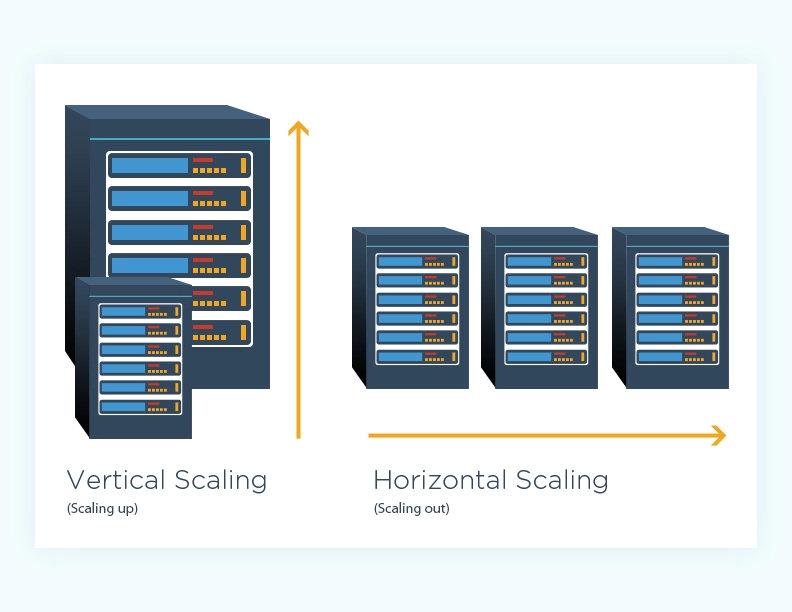
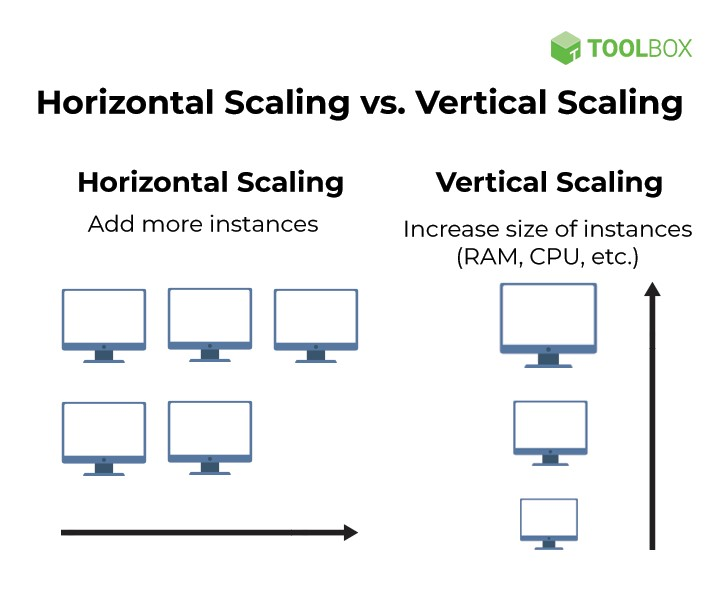
Yazılım alanında "scaling" (ölçekleme), bir yazılım sisteminin artan yük ve talepleri karşılayabilme yet... | mustafacam | |
1,878,049 | Demystifying Algo Trading: What To Expect From Algo Trading Courses In India | Algorithmic trading, often referred to as algo trading, has become a prominent feature in financial... | 0 | 2024-06-05T13:05:25 | https://dev.to/iiqfreview/demystifying-algo-trading-what-to-expect-from-algo-trading-courses-in-india-1b2k | algo, trading, machinelearning | [Algorithmic trading](https://www.iiqf.org/courses/post-graduate-program-algorithmic-trading.html), often referred to as algo trading, has become a prominent feature in financial markets worldwide. In India, with the rise of technology and increased participation in the stock market, algo trading has gained significant... | iiqfreview |
1,878,047 | Streamlining Trade Operations with Intelligent Document Processing (IDP) | Greetings, fellow developers! Today, we'll delve into the exciting world of international trade and... | 0 | 2024-06-05T12:59:47 | https://dev.to/john_hall/streamlining-trade-operations-with-intelligent-document-processing-idp-1hpi | ai, automation, learning | Greetings, fellow developers! Today, we'll delve into the exciting world of international trade and how Intelligent Document Processing (IDP) can revolutionize this crucial sector.
For those unfamiliar, international trade thrives on efficiency. However, navigating complex regulations and ensuring swift document proce... | john_hall |
1,878,039 | Proxy | Proxy sunucusu, iki bilgisayar veya bir bilgisayar ile bir internet kaynağı arasında aracı görevi... | 0 | 2024-06-05T12:51:34 | https://dev.to/mustafacam/proxy-3e40 | 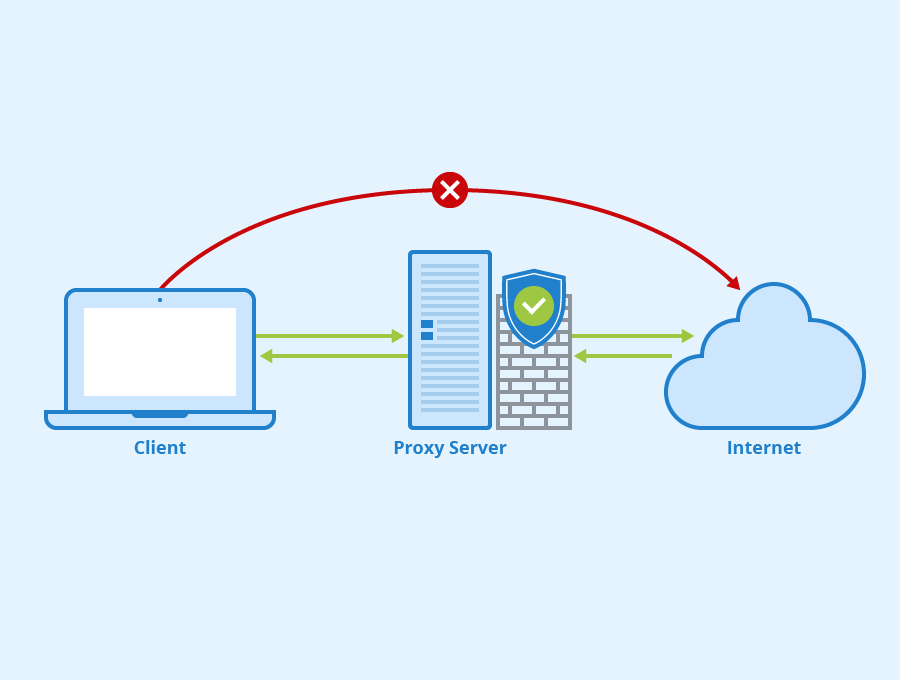
Proxy sunucusu, iki bilgisayar veya bir bilgisayar ile bir internet kaynağı arasında aracı görevi gören bir sunucudur. Dikkat edersen client ile internet arasında bir sunucu diyor. Daha karşı sunucuya gitmedik. Bu ... | mustafacam | |
1,878,046 | Day 5 of #90daysofdevops Advanced Linux Shell Scripting for DevOps Engineers with User Management | 1. Write a bash script create directories.sh that when the script is executed with three given... | 0 | 2024-06-05T12:59:41 | https://dev.to/oncloud7/day-5-of-90daysofdevops-advanced-linux-shell-scripting-for-devops-engineers-with-user-management-2lg2 | shellscripting, linux, cloudcomputing, devops | **1. Write a bash script create directories.sh that when the script is executed with three given arguments (one is the directory name and the second is the start number of directories and the third is the end number of directories ) it creates specified number of directories with a dynamic directory name.**
Write a she... | oncloud7 |
1,410,997 | ✨ 10 useful webdev insight & learning resources! | Introduction In this post, I'll give you ten useful resources specific for web... | 22,289 | 2024-06-05T12:58:38 | https://dev.to/thexdev/10-useful-webdev-insight-learning-resources-eoe | webdev, javascript, productivity, tutorial | ## Introduction
In this post, I'll give you ten useful resources specific for web development.
All provided resources below are not definitely (step-by-step) tutorial for web dev. Instead, it's a guide to build secure, accessible and performant modern web application.
The main subjects of this post are:
- Web acces... | thexdev |
1,878,043 | Top 21+ Best VOD Platforms To Build Your Video-On-Demand Business in 2024 | As the world of entertainment continues to evolve, more and more people are turning to... | 0 | 2024-06-05T12:57:18 | https://dev.to/rahulatwebnexs/top-21-best-vod-platforms-to-build-your-video-on-demand-business-in-2024-3g24 | videoondemand, bestvodplatforms | As the world of entertainment continues to evolve, more and more people are turning to video-on-demand(VOD)platforms to watch their favorite TV shows, movies, and other content. VOD platforms allow users to stream content on demand, at their own pace, and on their own schedule. With so many VOD platforms available, it ... | rahulatwebnexs |
1,878,041 | Understanding gRPC: A Modern Approach to Remote Procedure Calls | Introduction Remote Procedure Call (RPC) is a fundamental concept in modern distributed... | 0 | 2024-06-05T12:55:58 | https://dev.to/arefin6/understanding-grpc-a-modern-approach-to-remote-procedure-calls-59c | grpc, microservices, distributedsystems, developertools | ## **Introduction**
Remote Procedure Call (RPC) is a fundamental concept in modern distributed systems, enabling different components to communicate seamlessly over a network. One of the emerging technologies revolutionizing RPC is gRPC. In this blog post, we will explore the basics of gRPC, its key features, and why i... | arefin6 |
1,878,040 | CSS Art: June - 14 de Junho Dia Mundial do Doador de Sangue | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. ... | 0 | 2024-06-05T12:54:05 | https://dev.to/hmontarroyos/css-art-june-14-de-junho-dia-mundial-do-doador-de-sangue-9fj | frontendchallenge, devchallenge, css, frontend | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiração
Aproveitando o tema livre para escolher algo que represente o mês de junho, podendo ser um lugar, lembrança ou até mesmo uma data, eu resolvi aproveitar para colocar esse tema em pauta... | hmontarroyos |
1,878,038 | Optimizing Your Magento 2 Upgrade for Performance | Upgrading your Magento store to version 2 is a strategic move, promising a bounty of benefits –... | 0 | 2024-06-05T12:50:31 | https://dev.to/developerbhavi/optimizing-your-magento-2-upgrade-for-performance-3coo | magento, magento2upgrade | Upgrading your Magento store to version 2 is a strategic move, promising a bounty of benefits – enhanced security, improved scalability, and access to cutting-edge features. But wait, there's more! By optimizing your Magento 2 Upgrade Service, you can unlock the true potential of your upgraded store, transforming it in... | developerbhavi |
1,870,649 | List of 50+ organizations on DEV creating valuable content | It is hard to find organizations on DEV, and I've noticed that they don't receive followers that... | 0 | 2024-06-05T12:48:40 | https://dev.to/anmolbaranwal/list-of-50-organizations-on-dev-creating-valuable-content-2446 | discuss, writing, beginners, learning | It is hard to find organizations on DEV, and I've noticed that they don't receive followers that easily.
A lot of those organizations are open source.
So, I thought of creating a list of all the awesome organizations on DEV.
---
Please note that there is no order as each organization is good in what they do.
If yo... | anmolbaranwal |
1,878,036 | Fzf advanced integration in Powershell | 🪟 INTRO If you want to integrate fzf with rg, fd, bat to fuzzy find files, directories or... | 0 | 2024-06-05T12:46:17 | https://dev.to/kevinnitro/fzf-advanced-integration-in-powershell-53p0 | powershell, fzf, ripgrep, bat | ## 🪟 INTRO
If you want to integrate [`fzf`](https://github.com/junegunn/fzf) with [`rg`](https://github.com/BurntSushi/ripgrep), [`fd`](https://github.com/sharkdp/fd), [`bat`](https://github.com/sharkdp/bat) to fuzzy find files, directories or ripgrep the content of a file and preview using `bat`, but the [fzf docume... | kevinnitro |
1,878,035 | PACX ⁓ Data model manipulation | We introduced PACX here, as a toolbelt containing commands to streamline the application development... | 0 | 2024-06-05T12:46:01 | https://dev.to/_neronotte/pacx-data-model-manipulation-579e | powerplatform, pacx, dataverse, opensource | We [introduced PACX here](https://dev.to/_neronotte/pacx-command-line-utility-belt-for-power-platform-dataverse-e4e), as a toolbelt containing commands to streamline the application development on Dataverse environments.
The idea behind PACX is to speed up the development experience towards Dataverse, and one of the f... | _neronotte |
1,878,034 | Understanding API Versioning: A Simple Guide -Part 1 : Implementation using C# | In pervious article I discussed the Theory of API Versioning, In this article I will explain how to... | 0 | 2024-06-05T12:45:18 | https://dev.to/muhammad_taimur/understanding-api-versioning-a-simple-guide-part-1-c-code-1p0e | csharp, api, apiversioning, dotnet | In [pervious article I discussed the Theory of API Versioning](https://dev.to/muhammad_taimur/understanding-api-versioning-a-simple-guide-part-1-theory-4ni5), In this article I will explain how to implement API versioning.
Used technology C# and .Net
Below is a C# code example that demonstrates how to implement API ve... | muhammad_taimur |
1,878,033 | Top Device Farms to Test Your iOS and Android Apps | On average, people spend 6 hours and 37 minutes a day looking at their phone. Today, the internet... | 0 | 2024-06-05T12:42:35 | https://dev.to/jamescantor38/top-device-farms-to-test-your-ios-and-android-apps-19co | devicefarms, testgrid, testios, andriod | On average, people spend 6 hours and 37 minutes a day looking at their phone. Today, the internet traffic from mobile has surpassed desktops signifying how people consider mobile devices as not just devices to connect to the world but an integral part of their lives, especially for millennials who spend 25% of their wa... | jamescantor38 |
1,878,032 | The Future of AIPowered Healthcare Solutions | Artificial Intelligence (AI) in healthcare encompasses a range of technologies that enable machines... | 27,548 | 2024-06-05T12:41:31 | https://dev.to/aishikl/the-future-of-aipowered-healthcare-solutions-3ge8 | Artificial Intelligence (AI) in healthcare encompasses a range of technologies that enable machines to perform both administrative and clinical functions, significantly transforming the field. AI excels in processing large datasets, aiding in accurate diagnosis, treatment, and prediction of medical conditions. Applica... | aishikl | |
1,878,031 | Search Algorithm in AI | In artificial intelligence, search algorithms are techniques used to traverse a problem space to find... | 0 | 2024-06-05T12:41:27 | https://dev.to/shaiquehossain/search-algorithm-in-ai-9gb | ai, algorithms, datascience | In artificial intelligence, [search algorithms](https://www.almabetter.com/bytes/tutorials/artificial-intelligence/search-algorithm-in-ai) are techniques used to traverse a problem space to find a solution. These algorithms systematically explore possible states, applying rules or actions to move from one state to anot... | shaiquehossain |
1,878,030 | API Gateway | API Gateway, bir yazılım mimarisi bileşeni olarak, istemciler (client) ile arka uç hizmetleri... | 0 | 2024-06-05T12:41:19 | https://dev.to/mustafacam/api-gateway-4mmc |
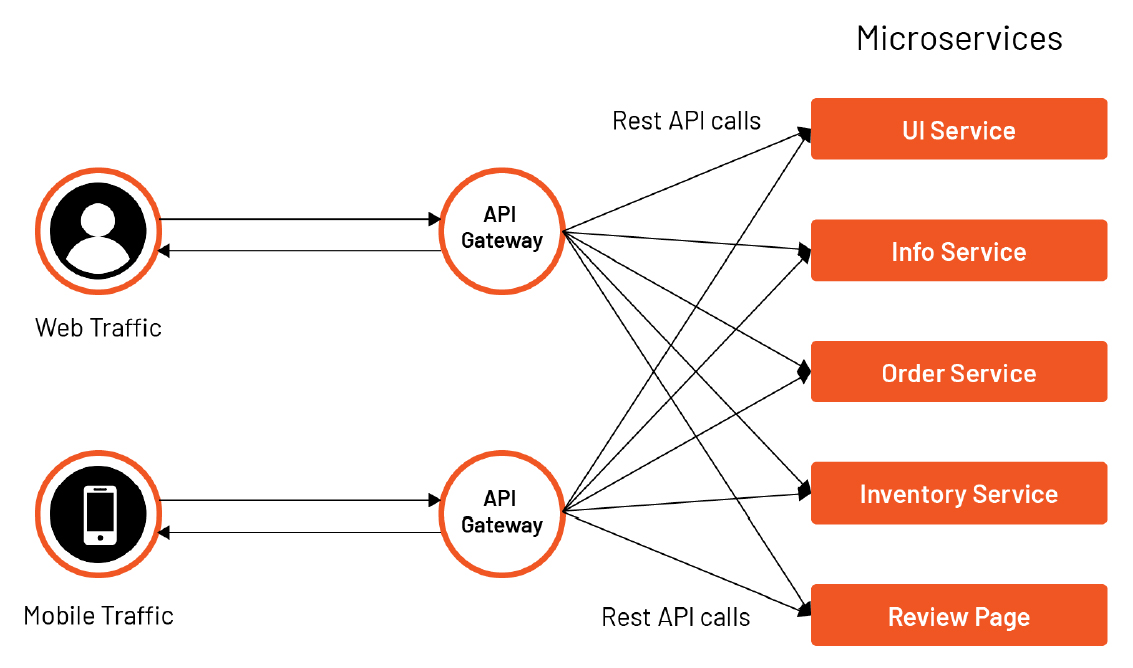
API Gateway, bir yazılım mimarisi bileşeni olarak, istemciler (client) ile arka uç hizmetleri (backend services) arasında bir ara katman görevi gören bir [proxy sunucusudur](https://dev.to/mustafacam/proxy-3e40).... | mustafacam | |
1,878,029 | HTML Head Tag | The tag in HTML is a container for metadata and other head elements that are not displayed on the... | 0 | 2024-06-05T12:39:23 | https://dev.to/shaiquehossain/html-head-tag-17d3 | html, tags, elements | The <head> tag in HTML is a container for metadata and other head elements that are not displayed on the web page. It typically includes essential information like the document title, character set, stylesheets, scripts, and meta tags. These elements provide instructions and additional information to browsers and searc... | shaiquehossain |
1,878,028 | OnePay: Secure, Global Online Pay Platform for All Your Transactions | There is a greater demand than ever for quick and safe financial transactions in the fast-paced... | 0 | 2024-06-05T12:37:57 | https://dev.to/david_mark_61fd09e0f67a52/onepay-secure-global-online-pay-platform-for-all-your-transactions-4bl3 | paymentgateway, paymentsolutions, paymentprocess, onlinepayments | There is a greater demand than ever for quick and safe financial transactions in the fast-paced digital world of today. At the vanguard of this change is OnePay, an inventive online payment platform that provides a simple and safe option for both customers and companies. OnePay is an all-inclusive online payment platfo... | david_mark_61fd09e0f67a52 |
1,878,200 | Chart of the Week: Visualizing Gender Parity in Industrial Employment with .NET MAUI Bubble Chart | TL;DR: Visualize the gender parity in industrial employment using the Syncfusion .NET MAUI Bubble... | 0 | 2024-06-07T02:48:07 | https://www.syncfusion.com/blogs/post/dotnetmaui-bubble-chart-gender-parity | dotnetmaui, chart, desktop, mobile | ---
title: Chart of the Week: Visualizing Gender Parity in Industrial Employment with .NET MAUI Bubble Chart
published: true
date: 2024-06-05 12:36:05 UTC
tags: dotnetmaui, chart, desktop, mobile
canonical_url: https://www.syncfusion.com/blogs/post/dotnetmaui-bubble-chart-gender-parity
cover_image: https://dev-to-uploa... | jollenmoyani |
1,878,027 | Basic React JS Router and Components | React JS Router is a library that enables navigation between different components in a React... | 0 | 2024-06-05T12:35:55 | https://dev.to/shaiquehossain/basic-react-js-router-and-components-2df8 | react, router, webdev | [React JS Router](https://www.almabetter.com/bytes/tutorials/reactjs/basic-reactjs-router) is a library that enables navigation between different components in a React application. It provides a <Router> component to manage the routing functionality. Components can be rendered conditionally based on the current URL usi... | shaiquehossain |
1,877,834 | Graphs, Data Structures | Graphs Graphs are fundamental data structures in computer science and discrete... | 0 | 2024-06-05T12:35:30 | https://dev.to/harshm03/graphs-data-structures-43f9 | dsa, datastructures, graphs | ## Graphs
Graphs are fundamental data structures in computer science and discrete mathematics. They are used to represent pairwise relations between objects. Understanding the theoretical underpinnings of graphs is essential for leveraging their full potential in various applications.
### What is a Graph?
A graph G ... | harshm03 |
1,878,009 | Read me of our Open Source Project | Litlyx | 🌐 Website 📚 Docs 🔥 Start for Free! A single-line code analytics solution that integrates with... | 0 | 2024-06-05T12:34:13 | https://dev.to/litlyx/read-me-of-our-open-source-project-litlyx-2e85 | opensource, javascript, typescript, webdev | <h4 align="center">
🌐 <a href="https://litlyx.com">Website</a> 📚 <a href="https://docs.litlyx.com">Docs</a> 🔥 <a href="https://dashboard.litlyx.com">Start for Free!</a>
</h4>
<p align="center">
A single-line code analytics solution that integrates with every JavaScript/TypeScript framework. <br />
Track 10+ KPI... | litlyx |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.