
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,875,641 | UX ডিজাইনার | UX ডিজাইনার কে যত বেশি কাজে লাগাবেন অর্থাৎ যত বেশি তার থেকে সময় ও শ্রম নিবেন ডেভেলপার টিমের কাজ ততো... | 0 | 2024-06-03T15:41:57 | https://dev.to/md_abunaeem_2e8520da49c1/ux-ddijaainaar-53ak | softwaredevelopment, uxdesign, projectmanagement, webdev | UX ডিজাইনার কে যত বেশি কাজে লাগাবেন অর্থাৎ যত বেশি তার থেকে সময় ও শ্রম নিবেন ডেভেলপার টিমের কাজ ততো বেশি সহজ হবে, তত বেশি সময় কম লাগবে এবং ব্যাক এন্ড ফোর্থ অনেক কম হবে।
অনেক সময় আমরা সফটওয়্যার ডেভেলপমেন্টের প্ল্যানিং এবং প্রোটোটাইপিং পর্যায়ে UX ডিজাইনার কে কষ্ট কম দেয়ার জন্য (বা তার সময় কম ব্যবহারের জন্য; যেটাই ... | md_abunaeem_2e8520da49c1 |
1,875,640 | Understanding the root causes of stress and burnout in coding | As a software developer with experience in building full stack web applications, I've experienced... | 0 | 2024-06-03T15:41:38 | https://dev.to/artisticmk/understanding-the-root-causes-of-stress-and-burnout-in-coding-iki | productivity, beginners, softwaredevelopment, webdev | As a software developer with experience in building full stack web applications, I've experienced first hand how stress and burnout can have a negative impact on my coding productivity and general well-being. Stress is a physical or emotional reaction to a challenging situation, and prolonged stress can lead to burnout... | artisticmk |
1,875,645 | Enclave Games Monthly Report: May 2024 | A lot has happened in May: from announcing Gamedev.js Jam 2024 winners and sending them all the... | 0 | 2024-06-03T15:54:18 | https://enclavegames.com/blog/monthly-report-may-2024/ | enclavegames, javascript, monthlyreport, gamedev | ---
title: Enclave Games Monthly Report: May 2024
published: true
date: 2024-06-03 15:39:23 UTC
tags: enclavegames,javascript,monthlyreport,gamedev
canonical_url: https://enclavegames.com/blog/monthly-report-may-2024/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/xn793595pwa5bhcw9pu2.png
---
A ... | end3r |
1,875,638 | ServBay 1.3.5 Official Release: Significant Updates and Enhancements | June 1, 2024 - The ServBay team is pleased to announce the release of the latest version 1.3.5. This... | 0 | 2024-06-03T15:36:34 | https://dev.to/servbay/servbay-135-official-release-significant-updates-and-enhancements-25kn | webdev, programming, productivity, php | June 1, 2024 - The [ServBay](https://www.servbay.com) team is pleased to announce the release of the latest version 1.3.5. This update includes key software package upgrades, updates to the ServBay Runtime and ServBay Development Library, and introduces several new features and important optimizations aimed at providin... | servbay |
1,875,636 | Brod; boss kafka in elixir | Elixir has rapidly gained recognition as a powerful language for developing distributed systems. Its... | 0 | 2024-06-03T15:32:32 | https://dev.to/darnahsan/brod-boss-kafka-in-elixir-eo | elixir, kafka, cap, distributedsystems | Elixir has rapidly gained recognition as a powerful language for developing distributed systems. Its concurrency model, based on the Erlang VM (BEAM), allows developers to build highly scalable and fault-tolerant applications. One of the areas where Elixir shines is in reading messages from Kafka using Broadway to buil... | darnahsan |
1,875,635 | Extracting Text from Uploaded Files in Node.js: A Continuation | Introduction In our previous article, we covered the basics of uploading files in a Node.js... | 0 | 2024-06-03T15:30:21 | https://dev.to/luqmanshaban/extracting-text-from-uploaded-files-in-nodejs-a-continuation-416j | node, tutorial, webdev, filehandling | **Introduction**
In our previous [article](https://dev.to/luqmanshaban/how-to-upload-a-file-in-nodejs-a-step-by-step-guide-5cf6), we covered the basics of uploading files in a Node.js application. Now, let’s take it a step further by extracting text from uploaded files. This tutorial will guide you through using the `... | luqmanshaban |
1,873,949 | Achieve Game-Like Scaling in Discord Activities and Web Apps Using CSS | Discord Activities are awesome! They run inside Discord and can be all sorts of cool things like... | 0 | 2024-06-03T15:30:00 | https://dev.to/waveplay/achieve-game-like-scaling-in-discord-activities-and-web-apps-using-css-874 | javascript, programming, node, discord | **[Discord Activities](https://support.discord.com/hc/en-us/articles/4422142836759-Activities-on-Discord)** are awesome! They run inside Discord and can be all sorts of cool things like games, quizzes, and more. But if you're developing using web technologies rather than game engines, you might run into a common proble... | waveplay-staff |
1,875,634 | Add Visual Studio Code to your OSX zsh PATH | After installing Visual Studio Code, it will not automatically be added to your terminal path, so you... | 0 | 2024-06-03T15:27:10 | https://dev.to/almatins/add-visual-studio-code-to-your-osx-zsh-path-63c | osx, zsh, vscode, path | After installing Visual Studio Code, it will not automatically be added to your terminal path, so you will need to add it manually. here is how.
Open your terminal and run this command in your terminal
```bash
cat << EOF >> ~/.zprofile
# Add Visual Studio Code (code)
export PATH="\$PATH:/Applications/Visual Studio Co... | almatins |
1,875,633 | Introduction to Shell Scripting in Linux- DevOps Prerequisite #3 | Introduction to Shell Scripting in Linux Shell scripting is a powerful way to automate repetitive... | 0 | 2024-06-03T15:25:30 | https://dev.to/iaadidev/introduction-to-shell-scripting-in-linux-devops-prerequisite-3-1nd3 | shellscripting, linux, devops, learninginpublic | ###
Introduction to Shell Scripting in Linux
Shell scripting is a powerful way to automate repetitive tasks and manage system operations in Linux. A shell script is a file containing a series of commands that are executed by the shell, the command-line interpreter in Linux. This blog will introduce you to the basics... | iaadidev |
1,875,630 | Add DS-U02P Webcam to Debian 12 | So, I reinstalled my personal computer recently with Debian 12 and it runs smoothly and as expected.... | 0 | 2024-06-03T15:24:20 | https://dev.to/almatins/add-ds-u02p-webcam-to-debian-12-1anf | dsu02p, webcam, debian, firmware | So, I reinstalled my personal computer recently with Debian 12 and it runs smoothly and as expected. Then, I try to connect my **DS-U02P** web camera from **Hikvision**. I tested it using Cheese but it became unstable and I could not get it to work no matter what.
I also tried several ways to test the webcam and still... | almatins |
1,875,567 | Deploy MongoDB Replica Set on K8s | So, I set a new k8s cluster on DigitalOcean recently, and I want to share the way I deploy my MongoDB... | 0 | 2024-06-03T15:18:23 | https://dev.to/almatins/deploy-mongodb-replica-set-on-k8s-4e0d | kubernetes, mongodb, replicaset, deploy | So, I set a new k8s cluster on DigitalOcean recently, and I want to share the way I deploy my MongoDB Replica Set on the k8s cluster. Let’s start it.
## Storage Class
I use Longhorn instead of the default do-block-storage provided by DigitalOcean as the default. I set up the longhorn using the helm chart. Since I use ... | almatins |
1,875,629 | Meme Monday | *Say That Again I Dare You * Source | 0 | 2024-06-03T15:24:05 | https://dev.to/td_inc/meme-monday-1npd | ai, memes, techmemes, technology | **Say That Again I Dare You
**

[Source](https://imgflip.com/i/85l0k2) | td_inc |
1,875,627 | Automated Acceptance Testing with Robot Framework and Testkube | Introduction Testing an application's capability usually requires setting up a... | 0 | 2024-06-03T15:23:22 | https://testkube.io/learn/automated-acceptance-testing-with-robot-framework-and-testkube | acceptancetesting, robotframework, kubernetes | ## Introduction
Testing an application's capability usually requires setting up a production-like environment to run tests with realistic insights into the functionality and performance of the application. Tests can be both functional and non-functional, all depending on the requirements on the application and its inf... | michael20003 |
1,875,533 | Get Random Documents from Firestore | When working with Firestore, retrieving random elements poses a challenge because Firestore does not... | 0 | 2024-06-03T15:22:05 | https://dev.to/mtomto_tech/get-random-documents-from-firestore-4c65 | firebase, nosql, algorithms, beginners | When working with Firestore, retrieving random elements poses a challenge because Firestore does not natively support queries for fetching documents randomly.
In addition, Firestore does not support offset queries, so it is not possible to generate a random number on the client side and then fetch documents randomly b... | mtomto_tech |
1,875,624 | Install NerdFont (or any fonts) using the command line in Debian (or other Linux) | I need to install the NerdFonts since I have been installing LazyVim recently. After doing some... | 0 | 2024-06-03T15:22:04 | https://dev.to/almatins/install-nerdfont-or-any-fonts-using-the-command-line-in-debian-or-other-linux-467o | nerdfont, linux, cli, lazyvim | I need to install the [NerdFonts](https://www.nerdfonts.com/) since I have been installing [LazyVim](https://www.lazyvim.org/) recently. After doing some research, I found that the convenient way to install it was using the command line. Here are the steps.
1. Go to the NerdFonts website in the [download](https://www.... | almatins |
1,875,568 | How to use align-items/self? | A post by Nabil Senhadji (Student) | 0 | 2024-06-03T15:19:24 | https://dev.to/creativename/how-to-use-align-itemsself-p4e | beginners, css, learning, html | creativename | |
1,875,566 | HOW TO HOST A STATIC WEBSITE IN AZURE BLOB STORAGE | Introduction A static website is a type of website that is composed of HTML, CSS, JavaScript,... | 0 | 2024-06-03T15:16:30 | https://dev.to/droz79/how-to-host-a-static-website-in-azure-blob-storage-4jc8 | azure, blob, webdev, website | **Introduction**
A static website is a type of website that is composed of HTML, CSS, JavaScript, images, and other static files. Unlike dynamic websites, which generate content on the server side in response to user requests, static websites deliver pre-built content to users exactly as it's stored. This means that e... | droz79 |
1,875,564 | How to Play a Game and Win Real Money | In this comprehensive guide, we'll explore everything you need to know about online games for earning... | 0 | 2024-06-03T15:16:04 | https://dev.to/world_explorer_dd0d0d4cc6/how-to-play-a-game-and-win-real-money-3mg5 | holi | In this comprehensive guide, we'll explore everything you need to know about online games for earning money, from the different types of games available to tips on how to maximize your earnings.
Online Games: In recent years, the concept of earning money through online gaming has gained significant traction. With the ... | world_explorer_dd0d0d4cc6 |
1,871,642 | Data API for Amazon Aurora Serverless v2 with AWS SDK for Java - Part 7 Data API meets SnapStart | Introduction In the part 5 we measured cold and warm starts of our sample application... | 26,067 | 2024-06-03T15:14:18 | https://dev.to/aws-builders/data-api-for-amazon-aurora-serverless-v2-with-aws-sdk-for-java-part-7-data-api-meets-snapstart-22eb | aws, serverless, java, database | ## Introduction
In the [part 5](https://dev.to/aws-builders/data-api-for-amazon-aurora-serverless-v2-with-aws-sdk-for-java-part-5-basic-cold-and-warm-starts-measurements-4gi9) we measured cold and warm starts of our sample application which uses Data API for Amazon Aurora Serverless v2 with AWS SDK for Java and in the... | vkazulkin |
1,875,563 | Essential Insights from Rapyd’s Latest Report Every Payment Industry Developer Must Know | Key Points for Developers: Payment Delays: 73% of businesses in high-opportunity... | 0 | 2024-06-03T15:13:31 | https://community.rapyd.net/t/73-of-businesses-struggle-with-payment-delays-according-to-rapyd-s-2024-state-of-payments-for-high-opportunity-industries/59349 | ai, payments, fintech, rapydreports | 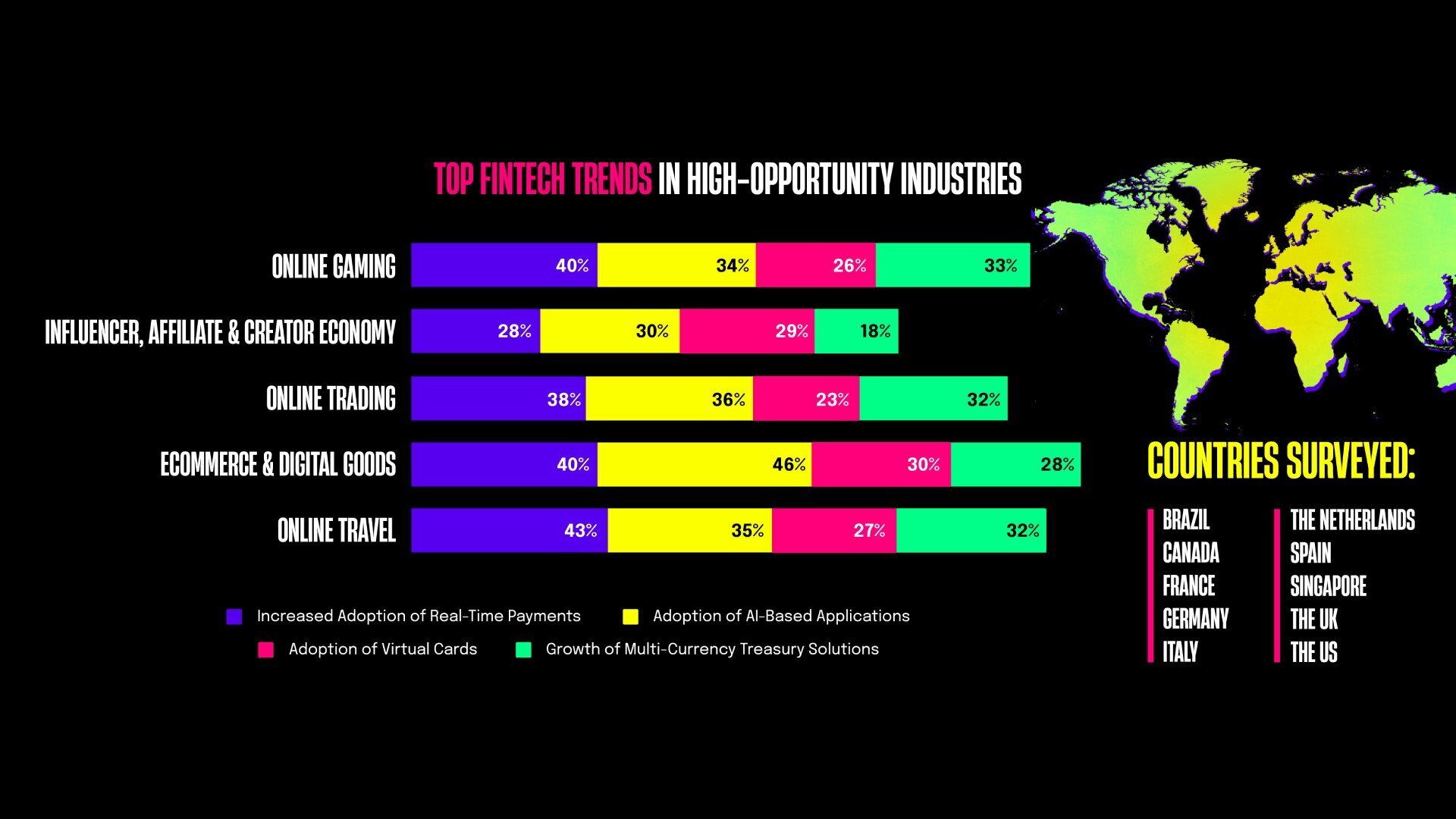
## Key Points for Developers:
- **Payment Delays:** 73% of businesses in high-opportunity industries face delays of 2-15 days, which impacts cash flow.
- **Priority on Speed & Conve... | uxdrew |
1,873,289 | Using Supabase to Store Images in a .NET Application | Table of Contents Introduction Set Up Supabase Storage Create a .NET Project Using Visual... | 0 | 2024-06-03T15:12:27 | https://dev.to/reliable25/using-supabase-to-store-images-in-a-net-application-2o8g | webdev, api, dotnet, backend | ## Table of Contents
- [Introduction] (#intro)
- [Set Up Supabase Storage] (#set-up)
- [Create a .NET Project Using Visual Studio] (#create)
- [Configure Supabase Client] (#configure)
- [Conclusion] (#conclusion)
<a id= "intro"></a>
## Introduction
Supabase storage offers a powerful solution for efficiently managing f... | reliable25 |
1,875,562 | Deploy Go Application using Docker Compose Replicas and Nginx | Deploying the Go application using docker and docker-compose with Nginx load balancer can be achieved... | 0 | 2024-06-03T15:12:19 | https://dev.to/almatins/deploy-go-application-using-docker-compose-with-nginx-load-balancer-f1h | docker, go, nginx, deploy | Deploying the Go application using docker and docker-compose with Nginx load balancer can be achieved using the below strategy. This is not the only one on how to do the task, but hopefully, you can find this useful.
## Project Structure
My Go application project structure looks like this:
```
/go-app
|-- cmd
|-- in... | almatins |
1,875,561 | VS Code shortcuts | % bash prompt Ctrl + C cancel any currently running terminal pry or rails console for interacting... | 0 | 2024-06-03T15:11:46 | https://dev.to/aizatibraimova/vs-code-shortcuts-257f | **%** bash prompt
**Ctrl + C** cancel any currently running terminal
**pry or rails console** for interacting with a database
**q** to quit
**cmd + K** clear terminal
**cmd + Shift + P** Command Palette(fuzzy search)
**cmd + P** quick open file
**Option + Cmd + J** hard refresh in Chrome
**ctrl + A/Cmd + A** Jump bac... | aizatibraimova | |
1,875,559 | Seamless Local Development with MFA-Enabled Roles on AWS | This article is a translation of https://zenn.dev/tilfin/articles/ab53ae77a8378f. The... | 0 | 2024-06-03T15:10:23 | https://dev.to/tilfin/seamless-local-development-with-mfa-enabled-roles-on-aws-89i | aws, localdev | ---
title: "Seamless Local Development with MFA-Enabled Roles on AWS"
published: true
tags:
- AWS
- localdev
---
This article is a translation of https://zenn.dev/tilfin/articles/ab53ae77a8378f.
## The Challenge
Many of us have an AWS account for our main login portal and separate AWS accounts for each project. ... | tilfin |
1,875,558 | Introduction to Web Development with Go (net/http package) | Introduction to Web Development with Go (net/http package) Go is a powerful programming... | 0 | 2024-06-03T15:10:05 | https://dev.to/romulogatto/introduction-to-web-development-with-go-nethttp-package-9al | # Introduction to Web Development with Go (net/http package)
Go is a powerful programming language that has gained popularity in recent years, especially for web development. With its simplicity and efficiency, it provides developers with the tools they need to build high-performance websites and web applications.
In... | romulogatto | |
1,875,557 | Deloy SocketIO Server Using Docker and Nginx Load Balancer (+SSL) | In my last project, I needed to have socket servers that could manage connections for more than 10... | 0 | 2024-06-03T15:05:00 | https://dev.to/almatins/deloy-socketio-server-using-docker-and-nginx-load-balancer-ssl-2coa | docker, nginx, socketio, ssl | In my last project, I needed to have socket servers that could manage connections for more than 10 thousands of mobile applications. I also needed to make the connection using a secure connection if possible. After digging into some scenarios, I finally can manage the socket server deployment using Docker and Nginx in ... | almatins |
1,875,556 | Optimizing Credential Configuration in AWS SDK for JavaScript v3: Understanding Cache Mechanisms and Best Practices | This article is a translation of https://zenn.dev/tilfin/articles/56f8dc56b83901. ... | 0 | 2024-06-03T15:04:49 | https://dev.to/tilfin/optimizing-credential-configuration-in-aws-sdk-for-javascript-v3-understanding-cache-mechanisms-and-best-practices-oka | node, javascript, aws, awssdk | ---
title: Optimizing Credential Configuration in AWS SDK for JavaScript v3: Understanding Cache Mechanisms and Best Practices
published: true
tags:
- NodeJS
- JavaScript
- AWS
- AWSSDK
---
This article is a translation of https://zenn.dev/tilfin/articles/56f8dc56b83901.
## Background
The AWS SDK for JavaScri... | tilfin |
1,875,747 | Bootcamp De Java com IA Gratuito: Desenvolva Seu Portifólio | Participe do Bootcamp Coding The Future GFT, um evento de desenvolvimento em Java com um foco... | 0 | 2024-06-23T13:51:32 | https://guiadeti.com.br/bootcamp-desenvolvimento-java-ia-gratuito/ | bootcamps, cursosgratuitos, inteligenciaartifici, java | ---
title: Bootcamp De Java com IA Gratuito: Desenvolva Seu Portifólio
published: true
date: 2024-06-03 15:01:55 UTC
tags: Bootcamps,cursosgratuitos,inteligenciaartifici,java
canonical_url: https://guiadeti.com.br/bootcamp-desenvolvimento-java-ia-gratuito/
---
Participe do Bootcamp Coding The Future GFT, um evento de ... | guiadeti |
1,873,932 | Introduction to Arrays in JavaScript | Array is a commonly used tool for storing data in a structured collection. There are two different... | 16,763 | 2024-06-03T15:00:00 | https://www.thedevspace.io/course/javascript-arrays | javascript, webdev, tutorial, programming | [Array](https://www.thedevspace.io/course/javascript-arrays) is a commonly used tool for storing data in a structured collection. There are two different syntaxes for creating arrays in JavaScript:
```javascript
let arr = new Array("Apple", "Orange", "Banana");
console.log(arr);
```
```text
[ 'Apple', 'Orange', 'Ban... | huericnan |
1,875,554 | Changing SQL Dialect From Teradata To SQLite | annotated notes from converting a 2,000 line SQL script | 0 | 2024-06-03T14:59:38 | https://dev.to/geraldew/changing-sql-dialect-from-teradata-to-sqlite-i23 | sql, database, data | ---
title: Changing SQL Dialect From Teradata To SQLite
published: true
description: annotated notes from converting a 2,000 line SQL script
tags: SQL,Database,Data
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-03 14:54 +0000
---
## Source of This Anno... | geraldew |
1,875,551 | Build a reverse ssh tunnel reverse proxy for (not) fun and (not) profit | A few years ago, a team I was part of was working on vivi, our master thesis's project. You can read... | 0 | 2024-06-03T14:58:51 | https://matteogassend.com/blog/build-a-reverse-ssh-tunnel-reverse-proxy-for-not-fun-and-not-profit/ | networking, ssh, vpn, nginx | ---
title: "Build a reverse ssh tunnel reverse proxy for (not) fun and (not) profit"
tags:
- networking
- ssh
- vpn
- nginx
canonical_url: https://matteogassend.com/blog/build-a-reverse-ssh-tunnel-reverse-proxy-for-not-fun-and-not-profit/
cover_image: https://cdn.blog.matteogassend.com/reverse-ssh-cover.webp
published:... | matfire |
1,875,549 | Spec Coder: Your Powerful AI Co-pilot for Supercharged Coding in Visual Studio Code | Spec Coder is an AI-powered extension that revolutionizes your coding experience within Visual Studio... | 0 | 2024-06-03T14:52:56 | https://dev.to/hkp22/spec-coder-your-powerful-ai-co-pilot-for-supercharged-coding-in-visual-studio-code-5dmm | webdev, ai, vscode, programming | Spec Coder is an AI-powered extension that revolutionizes your coding experience within Visual Studio Code. It's like having a super-intelligent coding buddy by your side, always ready to assist you with a vast arsenal of features.
{% youtube 88CTOA7jL4s %}
👉 Don't get left behind! Try [Spec Coder: Supercharge Your... | hkp22 |
1,875,544 | Before Cloud Computing | Before cloud computing, companies had many difficulties regarding infrastructure and management, for... | 0 | 2024-06-03T14:45:35 | https://dev.to/leonardosantosbr/before-cloud-computing-12j3 | beginners, learning, cloudcomputing |
Before cloud computing, companies had many difficulties regarding infrastructure and management, for example:
- **High infrastructure costs**
Companies needed to invest a lot of capital in servers, data centers, hardware and software and also in the maintenance of this equipment and occasionally replacement.
_data... | leonardosantosbr |
1,875,541 | Create a Blazing Fast React App with Vite | Vite is a modern build tool that's taking the React development world by storm. Known for its... | 27,428 | 2024-06-03T14:43:02 | https://dev.to/ellis22/create-a-blazing-fast-react-app-with-vite-e01 | vite, webdev, javascript, react | Vite is a modern build tool that's taking the React development world by storm. Known for its lightning-fast development server and streamlined workflow, Vite offers a significant improvement over traditional tools like Create React App. In this article, we'll guide you through creating a React.js application using Vit... | ellis22 |
1,875,540 | Despliegue de aplicación de Django con Github Actions para un servidor propio | Para proyectos en donde la actualización del código es algo recurrente, es ideal realizar un proceso... | 0 | 2024-06-03T14:42:30 | https://dev.to/josemiguelsandoval/despliegue-de-aplicacion-de-django-con-github-actions-para-un-servidor-propio-5974 | githubactions, django, deploy, cicd |
Para proyectos en donde la actualización del código es algo recurrente, es ideal realizar un proceso de automatización del despliegue del proyecto, además de asegurarse que este se subió correctamente. Esto se conoce como CI/CD (Integración continua/Despliegue continuo).
Hay varias formas de realizar este proceso par... | josemiguelsandoval |
1,875,539 | Preventing account sharing with Clerk | Scenario Imagine the following scenario: When User B logs in using User A's credentials... | 0 | 2024-06-03T14:40:28 | https://dev.to/shunyuan/preventing-account-sharing-with-clerk-47pm | webdev, javascript, tutorial, clerk | # Scenario
Imagine the following scenario:
> When User B logs in using User A's credentials from a different device, the platform invalidates User A's active session, logs them out, and allows User B to access the account to prevent account sharing.
# The Problem
While Clerk provides a way to invalidate a user sessio... | shunyuan |
1,875,537 | Enhancing your Python code with decorators | Introduction In this article, you'll learn about decorators in Python: how they work, why... | 0 | 2024-06-03T14:40:08 | https://dev.to/osahenru/enhancing-your-python-code-with-decorators-27j4 | python, backend, webdev, learning | #### Introduction
In this article, you'll learn about decorators in Python: how they work, why they are useful, and when to use them. We'll also explore some common decorators and their use cases.
While I aim to explain concepts from a beginner's perspective, this article is not tailored for absolute beginners. A fund... | osahenru |
1,875,535 | YouTube Video Transcripts Using LangChain | This post demonstrates how to use the LangChain library to load and save the transcript of a YouTube... | 0 | 2024-06-03T14:37:17 | https://dev.to/samagra07/youtube-video-transcripts-using-langchain-25g4 | programming, python, machinelearning, ai | This post demonstrates how to use the LangChain library to load and save the transcript of a YouTube video. The python script retrieves the video's transcript, prints it, and writes the content to a text file for further use.
let's go through the code line by line:
```python
from langchain.document_loaders import you... | samagra07 |
1,875,532 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-03T14:27:40 | https://dev.to/saswqri9/buy-verified-cash-app-account-jgb | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | saswqri9 |
1,875,531 | What is JSX? | JSX, or JavaScript XML, is a syntax extension for JavaScript that allows developers to write... | 0 | 2024-06-03T14:26:37 | https://dev.to/ark7/what-is-jsx-5f60 | webdev, javascript, beginners, programming | JSX, or JavaScript XML, is a syntax extension for JavaScript that allows developers to write HTML-like code within JavaScript.
It's primarily used with React, a popular JavaScript library for building user interfaces. JSX makes writing React components more concise and readable by combining HTML and JavaScript in one... | ark7 |
1,875,530 | Top Tools for Web Developers | Hey there, fellow web devs! If you are a newbie setting sail in the expansive world of web... | 0 | 2024-06-03T14:26:31 | https://dev.to/buildwebcrumbs/top-tools-for-modern-web-developers-1ba3 | beginners, productivity, webdev |
**Hey there, fellow web devs!**
If you are a newbie setting sail in the expansive world of web development, having the right tools can make or break your journey, and sometimes it is difficult to choose the right ones. there are just soo many to choose from! 🤯
In this article, we’re diving into the must-have tools... | opensourcee |
1,875,384 | Fatiamento🐍 | 1. Fatiamento: frase[3]: Extrai o quarto caractere da string, que é "Ú". frase[3:13]: Obtém a... | 0 | 2024-06-03T13:18:12 | https://dev.to/senhorita_zi/fatiamento-2c8h | python, fatiamento, programming, devops |

**1. Fatiamento:**
frase[3]: _Extrai o quarto caractere da string, que é "Ú"._
frase[3:13]: _Obtém a substring da posição 3 até a 12 (não incluindo a 13ª), resultando em "nica maneira de aprender"._
**Observaçõ... | senhorita_zi |
1,875,529 | piano music application | Hi , Learning to play the piano is an incredibly rewarding activity, but it can often feel ... | 0 | 2024-06-03T14:26:15 | https://dev.to/hussein09/piano-music-application-505 | webdev, javascript, beginners, html | Hi ,
Learning to play the piano is an incredibly rewarding activity, but it can often feel difficult. But don’t worry – with the right strategy, you’ll be playing your favorite songs in no time.
**Follow all the latest news via:**
**github:** https://github.com/hussein-009
**codepen:** https://codepen.io/hussein009... | hussein09 |
1,875,673 | 100 Salesforce Experience Cloud Interview Questions and Answers | Salesforce Experience Cloud is a dynamic digital experience platform that enables organizations to... | 0 | 2024-06-03T16:49:59 | https://www.sfapps.info/100-salesforce-experience-cloud-interview-questions-and-answers/ | blog, interviewquestions | ---
title: 100 Salesforce Experience Cloud Interview Questions and Answers
published: true
date: 2024-06-03 14:26:00 UTC
tags: Blog,InterviewQuestions
canonical_url: https://www.sfapps.info/100-salesforce-experience-cloud-interview-questions-and-answers/
---
Salesforce Experience Cloud is a dynamic digital experience ... | doriansabitov |
1,875,528 | Help customers find your business with the Azure Maps Store Locator | Maximize Visibility In today's digital age, the visibility of your business is paramount.... | 0 | 2024-06-03T14:23:50 | https://clemens.ms/azure-maps-store-locator/ | azure, maps, storelocator, azuremaps | ## Maximize Visibility
In today's digital age, the visibility of your business is paramount. Once you've captured customer interest online, the next crucial step is guiding them to your physical storefronts. [Azure Maps Store Locator](https://github.com/Azure-Samples/Azure-Maps-Locator) streamlines this journey, offer... | cschotte |
1,875,460 | React Children | function Child() { return <div>This is children content</div>; } // Add code only... | 0 | 2024-06-03T14:19:48 | https://dev.to/alamfatima1999/react-children-1n6b | ```JS
function Child() {
return <div>This is children content</div>;
}
// Add code only here
function Parent(props) {
return (
<div>
<h3>Parent Component</h3>
{props.children}
</div>
);
}
function App() {
return (
<Parent>
<Child />
</Parent>
);
}
ReactDOM.render(<App />, ... | alamfatima1999 | |
1,820,374 | Add Manjaro into WSL 2 | I like Manjaro Linux. Too bad it is my second system, as I still need Windows software every day,... | 0 | 2024-06-03T14:19:33 | https://dev.to/damian_cyrus/add-manjaro-into-wsl-2-3f5i | wsl, linux, windows | ---
canonical_url:
---
I like Manjaro Linux. Too bad it is my second system, as I still need Windows software every day, which might or not work on a Linux distribution.
For this I wanted to use it in WSL, and found this nice YouTube video: [Arch Linux on Windows Subsystem for Linux (WSL) - YouTube](https://www.youtu... | damian_cyrus |
1,875,459 | Secure, Fast, Decentralized: Penrose Network Derivatives Trading | Introduction Penrose Network is a groundbreaking decentralized platform that is set to transform... | 0 | 2024-06-03T14:18:15 | https://dev.to/penrose_network/secure-fast-decentralized-penrose-network-derivatives-trading-mkj |

Introduction
[Penrose Network](https://penrose.network) is a groundbreaking decentralized platform that is set to transform the landscape of derivatives trading. Catering to a diverse range of financial markets inc... | penrose_network | |
1,875,458 | ChatGPT vs. Human Writers: A Comparative Study | In the ever-evolving landscape of digital content, a new contender has emerged that challenges the... | 0 | 2024-06-03T14:17:54 | https://dev.to/haider_ali_899f3a97f74c80/chatgpt-vs-human-writers-a-comparative-study-51a1 | In the ever-evolving landscape of digital content, a new contender has emerged that challenges the long-standing dominance of human writers. ChatGPT, OpenAI's advanced language model, has burst onto the scene, sparking a heated debate: Can artificial intelligence outperform human creativity? In this comprehensive compa... | haider_ali_899f3a97f74c80 | |
1,875,457 | Scopes/ Loops/ break/ continue | Scopes In JavaScript, scope refers to the current context of execution, which determines... | 0 | 2024-06-03T14:16:04 | https://dev.to/__khojiakbar__/scopes-loops-break-continue-4p9l | scopes, loops, break, continue |
#**Scopes**
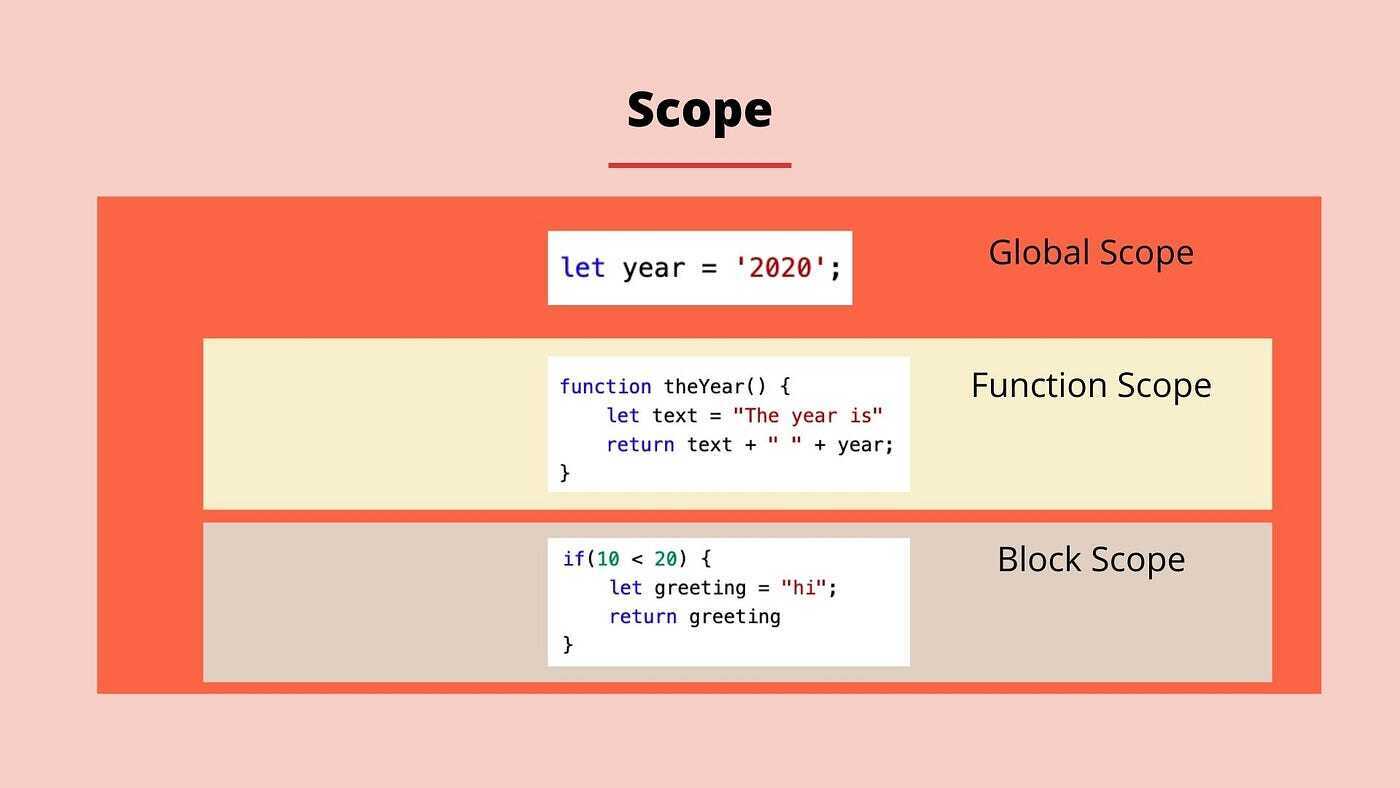
In JavaScript, scope refers to the current context of execution, which determines the accessibility of variables. There are mainly three types of scope:
1. Global Scope:
- Variables declared outside... | __khojiakbar__ |
1,875,456 | Magia e Músculos: ETL com Mage e DuckDB com dados do meu treino de powerlifting | Mage No ultimo post que fiz, falei um pouco sobre um painel que construí utilizando... | 0 | 2024-06-03T14:13:11 | https://dev.to/deadpunnk/magia-e-musculos-etl-com-mage-e-duckdb-com-dados-do-meu-treino-de-powerlifting-239p | mage, python, sql, duckdb |

## Mage
No ultimo post que fiz, falei um pouco sobre um painel que construí utilizando Python e o Looker Studio, para visualizar os dados do meu treino de powerlifting. Nesse post vou passar pelo passo a passo de... | deadpunnk |
1,843,521 | Banco de dados: Modelo conceitual | Disclaimer: Post com intuito de gravar meu aprendizado em banco de dados. Não é uma verdade... | 0 | 2024-06-03T14:11:51 | https://dev.to/mmsfarias/banco-de-dados-modelo-conceitual-loo | database, beginners, sql, data | **Disclaimer:** Post com intuito de gravar meu aprendizado em banco de dados. Não é uma verdade absoluta.
**Referência:** Sistemas de banco de dados, 7ª edição - _Navathe_ e _Elmasri_
---
1. [Conceitos iniciais](#conceitos-iniciais)
2. [Modelo conceitual](#modelo-conceitual)
2.1 [Entidades](#entidades)
... | mmsfarias |
1,875,453 | How to Secure the 5 Cloud Environments? | Organizations have several options for cloud deployments, each with distinct features and security... | 0 | 2024-06-03T14:09:12 | https://www.clouddefense.ai/how-to-secure-the-5-cloud-environments/ |

Organizations have several options for cloud deployments, each with distinct features and security requirements. This article discusses five key cloud environments: public cloud, private cloud... | clouddefenseai | |
1,875,450 | 36 DevOps Testing Tools [2024] | DevOps is a combination of Development (Dev) and Operations (Ops) methodologies to ensure a... | 0 | 2024-06-03T14:00:31 | https://www.lambdatest.com/blog/devops-testing-tools/ | devops, testing, tools, automation |
DevOps is a combination of Development (Dev) and Operations (Ops) methodologies to ensure a continuous delivery of high-quality software. Testing in DevOps is integrated throughout the entire software development process. This integration ensures a continuous feedback loop, which enables quick detection and helps reso... | nazneenahmad |
1,875,449 | Insights for young investors: Top tips to kickstart your investment journey | Embarking on an investment journey can be thrilling yet daunting, especially for young and new... | 0 | 2024-06-03T14:00:13 | https://dev.to/eldadtamir/insights-for-young-investors-top-tips-to-kickstart-your-investment-journey-2mlf | ai, investors, younginvestors, data | Embarking on an investment journey can be thrilling yet daunting, especially for young and new investors. Starting early is crucial, allowing time to harness the power of compound interest and to recover from market fluctuations. Recognizing the unique challenges faced by new investors, such as balancing risk in a vola... | eldadtamir |
1,875,448 | Serverless Workloads on Kubernetes: A Deep Dive with Knative | The ever-evolving landscape of cloud computing demands agile and scalable solutions for application... | 0 | 2024-06-03T13:57:35 | https://dev.to/platform_engineers/serverless-workloads-on-kubernetes-a-deep-dive-with-knative-21f |
The ever-evolving landscape of cloud computing demands agile and scalable solutions for application development and deployment. Serverless computing offers a compelling paradigm shift, abstracting away server management tasks and enabling developers to focus solely on application logic. However, traditional serverless... | shahangita | |
1,874,848 | React Concepts: Hook Proximity | Keeping your component's side effects (like data fetching, subscriptions, or logging) close to where they are triggered, avoiding the pitfalls of prop drilling. | 0 | 2024-06-03T13:53:26 | https://dev.to/clschnei/react-concepts-hook-proximity-43jj | reactconcepts, react, javascript, hooks | ---
title: React Concepts: Hook Proximity
published: true
description: Keeping your component's side effects (like data fetching, subscriptions, or logging) close to where they are triggered, avoiding the pitfalls of prop drilling.
tags: reactconcepts, react, javascript, hooks
cover_image: https://domf5oio6qrcr.cloudfr... | clschnei |
1,875,447 | Creating Shell Extensions in .NET 8 with SharpShell | In this blog, I'll walk you through creating a Windows shell extension using the SharpShell library... | 0 | 2024-06-03T13:51:16 | https://dev.to/issamboutissante/creating-shell-extensions-in-net-8-with-sharpshell-2ioe | sharpshell, windowsextentions, dotnet, shellextentions | In this blog, I'll walk you through creating a Windows shell extension using the SharpShell library in .NET 8. SharpShell is a popular library for creating shell extensions, but it was traditionally used with the .NET Framework. Thanks to the Microsoft Windows Compatibility Pack, it's now possible to create shell exten... | issamboutissante |
1,875,446 | React Native - 15 Core Components | React Native is a powerful and popular framework developed by Facebook that allows developers to... | 0 | 2024-06-03T13:50:21 | https://dev.to/himanshuaggar/react-native-15-core-components-2ifg | javascript, mobile, reactnative, react | **React Native** is a powerful and popular framework developed by Facebook that allows developers to **build mobile applications using JavaScript and React**.
One of the key advantages of React Native is its ability to create truly native applications for both iOS and Android using a single codebase. This is achieved... | himanshuaggar |
1,875,445 | Top 5 Tailwind CSS Interview Questions and Answers | If you’re a fresher aiming to land a web development role and Tailwind CSS is on the tech stack, this... | 0 | 2024-06-03T13:48:52 | https://dev.to/lalyadav/top-5-tailwind-css-interview-questions-and-answers-4do6 | tailwindcss, css, cssframework, react | If you’re a fresher aiming to land a web development role and **[Tailwind CSS](https://www.onlineinterviewquestions.com/tailwind-css-interview-questions/)** is on the tech stack, this guide will equip you with the top 5 interview questions and answers.
 is one of the original 86 area codes created by Bell System in 1947. In those early days of telecom, when the entire system could handle less than 100 exchanges, 312 supported the growing population of America's second-largest cit... | dwayne_mcdaniel |
1,874,839 | ViBox Can Transform Your Desktop Experience | ViBox enables users to personalize their desktops by adding a diverse range of content, including... | 0 | 2024-06-03T13:37:12 | https://dev.to/tufik2/vibox-can-transform-your-desktop-experience-big | productivity, development, electron, news | ViBox enables users to personalize their desktops by adding a diverse range of content, including widgets, bubbles, or icons directly to their status bar. Users have the flexibility to select from a collection of pre-defined widgets or utilize the browser widget to incorporate custom web content. Whether it’s news feed... | tufik2 |
1,875,435 | I'm frustrated | I'm newbie. I want to learn programming but i don't have any idea where to start?? can anyone tell me... | 0 | 2024-06-03T13:36:07 | https://dev.to/theeng11/im-frustrated-n7a | I'm newbie. I want to learn programming but i don't have any idea where to start?? can anyone tell me about roadmap for front-end developer... | theeng11 | |
1,875,433 | How to Upload Images to Google Gemini for Next.js | Introduction Google Gemini exhibits strong performance in multi-model tasks, particularly... | 27,713 | 2024-06-03T13:33:09 | https://medium.com/@hantian.pang/how-to-upload-images-to-google-gemini-for-next-js-9555d6d70ce3 | nextjs, llm, gemini, webdev | ## Introduction
Google Gemini exhibits strong performance in multi-model tasks, particularly the latest Gemini 1.5 Flash and Gemini 1.5 Pro. There are two benchmarks for multi-model tasks: reasoning and math. As demonstrated, the Gemini 1.5 Pro performs on par with the latest GPT-4o in visual math tasks 🎉.
| Benchm... | ppaanngggg |
1,875,431 | Episode 24/22: RxAngular, Analog | Jason Lengstorf and Brandon Roberts discussed and tried out Analog. Julian Jandl and Enea Jahollari... | 0 | 2024-06-03T13:28:29 | https://dev.to/this-is-angular/episode-2422-rxangular-analog-4gn | webdev, angular, javascript, programming | Jason Lengstorf and Brandon Roberts discussed and tried out Analog. Julian Jandl and Enea Jahollari wrote about the latest developments in RxAngular.
{% embed https://youtu.be/DQ15st0j0bY %}
## RxAngular
Zoneless is a ubiquitous topic, but it is not completely new. For many years, RxAngular, a community project, has... | ng_news |
1,875,429 | VSCodeでデフォルトのターミナルをPowerShellからGit Bashに変更するには | VSCodeでデフォルトのターミナルをPowerShellからGit Bashに変更するには、以下の手順を行います。 VSCodeを開く VSCodeを起動します。 設定を開く メニューバーから... | 0 | 2024-06-03T13:26:48 | https://dev.to/aaattt/vscodededehuorutonotaminaruwopowershellkaragit-bashnibian-geng-suruniha-5hgg | VSCodeでデフォルトのターミナルをPowerShellからGit Bashに変更するには、以下の手順を行います。
1. **VSCodeを開く**
VSCodeを起動します。
2. **設定を開く**
メニューバーから `File` -> `Preferences` -> `Settings` を選択するか、ショートカットキー `Ctrl + ,` を使用して設定を開きます。
3. **設定を編集**
設定画面の右上にあるアイコンから `Open Settings (JSON)` を選択し、設定ファイル(settings.json)を開きます。
4. **settings.jsonに以下のコ... | aaattt | |
1,875,428 | What are the PSD2 & SCA Requirements? | As digital transactions continue to rise, securing these transactions is very important. The European... | 0 | 2024-06-03T13:25:48 | https://www.corbado.com/blog/psd2-sca-requirements | cybersecurity, webdev, regulations, psd2 | As digital transactions continue to rise, securing these transactions is very important. The European Union introduced the **Payment Services Directive 2 (PSD2)** to enhance payment security and establish a unified framework for electronic payments across Europe. A crucial component of PSD2 is **Strong Customer Authent... | vdelitz |
1,875,425 | Efficiency Improvements in Oil and Gas Extraction | Effectiveness progress in Oil and Gas Extraction: the innovation that was game-Changing Oil and Gas... | 0 | 2024-06-03T13:24:03 | https://dev.to/jonathan_hulseh_7a93b8f43/efficiency-improvements-in-oil-and-gas-extraction-59ke |
Effectiveness progress in Oil and Gas Extraction: the innovation that was game-Changing
Oil and Gas Extraction reduction is often a procedure through which fuels being fossil obtained with the smashed. This method could possibly be difficult plus dangerous, which is why brand that is tech which try being become de... | jonathan_hulseh_7a93b8f43 | |
1,866,271 | Cloud Solutions for Insurance Organizations | Improving Cloud Infrastructure Outcomes for Carriers and All-Type Organizations Insurance... | 0 | 2024-06-03T13:24:00 | https://dev.to/brainboard/cloud-solutions-for-insurance-organizations-10eh | cloud, infrastructureascode, insurance, iot | ## Improving Cloud Infrastructure Outcomes for Carriers and All-Type Organizations
Insurance organizations, including carriers and various service providers, need robust cloud solutions to scale effectively, reduce costs, and maintain a competitive edge. Brainboard offers innovative cloud solutions tailored to meet th... | miketysonofthecloud |
1,875,385 | création d’application Android et iOS avec Flutter | Flutter est un Framework open-souce créé par Google. Il permet de développer des applications pour... | 0 | 2024-06-03T13:21:32 | https://dev.to/media-web-services/creation-dapplication-android-et-ios-avec-flutter-5568 | flutter, android, ios |

[Flutter](https://flutter.dev/) est un Framework open-souce créé par Google. Il permet de développer des applications pour Android et iOS à partir d'un seul code.
Cet outil facilite le développement d'application... | media-web-services |
1,875,390 | Optimism Retro Funding Round 4: All you need to know | Optimism is a Layer 2 scaling solution that transcends being just a simple blockchain protocol. As a... | 0 | 2024-06-03T13:20:15 | https://dev.to/modenetwork/optimism-retro-funding-round-4-all-you-need-to-know-27bi | Optimism is a Layer 2 scaling solution that transcends being just a simple blockchain protocol. As a Collective, It fosters a collaborative environment, which tackles various technical aspects of a decentralized ecosystem. This Collective is building the foundation for next-generation applications on a network of block... | modenetwork | |
1,875,383 | Stop Using Docker in Docker for Testing | Embrace Kubernetes to Improve Performance, Scalability, and Ease of Configuration for your... | 0 | 2024-06-03T13:17:53 | https://testkube.io/learn/stop-using-docker-in-docker-for-testing | kubernetes, devops, docker, testkube | ### Embrace Kubernetes to Improve Performance, Scalability, and Ease of Configuration for your Tests
Testing applications is becoming increasingly difficult as they grow in size and complexity. For someone responsible for testing an application of that scale, simply running tests within individual containers doesn't h... | michael20003 |
1,875,525 | Next Gen User Experiences – Vercel Ship 2024 | Jared Palmer presented on: Next Gen User Experiences The idea is to: Give chatbots rich... | 0 | 2024-06-04T11:56:39 | https://blog.jonathanflower.com/artificial-intelligence/next-gen-user-experiences-vercel-ship-2024/ | ai, softwaredevelopment, codingtools, genai | ---
title: Next Gen User Experiences – Vercel Ship 2024
published: true
date: 2024-06-03 13:17:46 UTC
tags: ArtificialIntelligence,SoftwareDevelopment,AI,CodingTools,GenAI
canonical_url: https://blog.jonathanflower.com/artificial-intelligence/next-gen-user-experiences-vercel-ship-2024/
---

As Web3 becomes more streamlined and decentralized app development increases, the need for lightning-fast gateway providers to decentralized blockchain data also grows. Nodies addresses this need by offering effici... | mozes721 |
1,875,378 | Abstracting State Management in React with Typescript, and its Benefits | Bizarre illustration by Google Gemini AI. State management is something unavoidable on the UI, be it... | 0 | 2024-06-03T13:10:36 | https://dev.to/bwca/abstracting-state-management-in-react-with-typescript-and-its-benefits-8mk | react, typescript, redux, zustand | _Bizarre illustration by Google Gemini AI._
State management is something unavoidable on the UI, be it local component scoped, or global, which in some enterprise applications can grow to gargantuan sizes.
The topic I would like to dwell upon today is tight coupling, which can be created by a state management library... | bwca |
1,875,377 | Plan First, Code Later | As a software engineer, getting caught up in the excitement of writing code and building new features... | 0 | 2024-06-03T13:09:59 | https://dev.to/avwerosuoghene/plan-first-code-later-7fo | webdev, productivity, softwaredevelopment, devjournal | As a software engineer, getting caught up in the excitement of writing code and building new features is pretty easy. However, successful developers understand the importance of taking the time to plan your project thoroughly. Here’s why you should always plan first and code later.
**Define Clear Objectives**
Setting... | avwerosuoghene |
1,875,376 | How to learn from online SQL Certification Courses in 2024? | SQL or Structured Query Language is the establishment of the data business. In the event that you are... | 0 | 2024-06-03T13:09:04 | https://dev.to/pawan_saxena_b955f317d3d7/how-to-learn-from-online-sql-certification-courses-in-2024-2oig | sql | SQL or Structured Query Language is the establishment of the data business. In the event that you are excited about building employment in a data-driven profile, be it data inspector, data analyst, business examination, informational collection engineer, and the summary is ceaseless. As an essential snippet of database... | pawan_saxena_b955f317d3d7 |
1,875,341 | How to Prevent SSH Timeout on Linux Systems | If you've ever experienced your SSH connection freezing due to inactivity, you're not alone. This... | 0 | 2024-06-03T12:32:10 | https://geeksta.net/geeklog/how-to-prevent-ssh-timeout-on-linux-systems/ | linux, sysadmin, ssh, howto | ---
title: How to Prevent SSH Timeout on Linux Systems
published: true
date: 2024-06-03 13:08:49 UTC
tags: linux, sysadmin, ssh, howto
canonical_url: https://geeksta.net/geeklog/how-to-prevent-ssh-timeout-on-linux-systems/
---
If you've ever experienced your SSH connection freezing due to inactivity, you're not alone.... | geeksta |
1,875,375 | Cleansing Delight: Unraveling Hotel Soap Offerings | Intro: Hotels are the supreme location for convenience as well as leisure. Every tourist constantly... | 0 | 2024-06-03T13:08:25 | https://dev.to/jonathan_hulseh_7a93b8f43/cleansing-delight-unraveling-hotel-soap-offerings-59bn | Intro:
Hotels are the supreme location for convenience as well as leisure. Every tourist constantly searches for a location that will certainly offer first-class convenience as well as high-end. The facilities offered through hotels like smooth bed linen, space solutions, as well as toiletries are typically t... | jonathan_hulseh_7a93b8f43 | |
1,875,374 | Understanding LoRA - Low-Rank Adaptation for Efficient Machine Learning | In the evolving landscape of machine learning, the quest for more efficient training methods is... | 0 | 2024-06-03T13:07:57 | https://victorleungtw.com/2024/06/03/lora/ | machinelearning, efficiency, lora, decomposition | In the evolving landscape of machine learning, the quest for more efficient training methods is constant. One such innovation that has gained attention is Low-Rank Adaptation (LoRA). This technique introduces a clever way to optimize the training process by decomposing the model's weight matrices into smaller, more man... | victorleungtw |
1,875,372 | PACX ⁓ Command Line Utility Belt for Power Platform / Dataverse | When Power Platform CLI was introduced, most of the Dataverse community thought: "Command line?!... | 0 | 2024-06-03T13:06:34 | https://dev.to/_neronotte/pacx-command-line-utility-belt-for-power-platform-dataverse-e4e | github, powerplatform, pacx, opensource | When Power Platform CLI was introduced, most of the Dataverse community thought:
> "Command line?! Why? We have such amazing XrmToolbox tools!"
Then the DevOps tide 🌊 rise, and everyone started thinking
> "how can i do *this* scripting it?" "how can I automate *this other stuff*?".
[Power Platform CLI](https://... | _neronotte |
1,875,371 | Hire angular js Developers | Hire our in-house team of the best Angular developers who can build powerful front-end deployments as... | 0 | 2024-06-03T13:05:28 | https://dev.to/aayushi_parmar_aed8f8c592/hire-angular-js-developers-256f | hireangularjsdevelopers, hireangularjsdeveloperinusa, angularjsdevelopers | Hire our in-house team of the best [Angular developers](https://www.qsstechnosoft.com/hire-angularjs-developers/) who can build powerful front-end deployments as per your business needs. Each one of our dedicated AngularJS programmers has an average experience of 3+ years with proven expertise.
QSS Technosoft is a pion... | aayushi_parmar_aed8f8c592 |
1,875,370 | Designing User-Friendly Interfaces for Adult Websites | In the realm of adult website development, creating a user-friendly interface is paramount. A... | 0 | 2024-06-03T13:00:10 | https://dev.to/scarlettevans09/designing-user-friendly-interfaces-for-adult-websites-5a23 | In the realm of adult website development, creating a user-friendly interface is paramount. A well-designed interface not only enhances the user experience but also ensures that visitors stay longer and engage more with your content. This blog will explore key strategies for designing user-friendly interfaces specifica... | scarlettevans09 | |
1,876,738 | Working with Gitlab on the CLI | Glab is an open-source tool that allows you to work with GitLab from the command line, eliminating... | 0 | 2024-06-06T10:02:34 | https://www.zufallsheld.de/2024/06/03/working-with-the-gitlab-cli/ | gitlab, cli, glab | ---
title: Working with Gitlab on the CLI
published: true
date: 2024-06-03 13:00:00 UTC
tags: gitlab,gitlab,cli,glab
canonical_url: https://www.zufallsheld.de/2024/06/03/working-with-the-gitlab-cli/
---
[Glab](https://gitlab.com/gitlab-org/cli#glab) is an open-source tool that allows you to work with GitLab from the c... | rndmh3ro |
1,876,740 | Gitlab von der Kommandozeile aus bedienen | Glab ist ein Opensource-Tool, das es ermöglicht mit Gitlab über die Kommandozeile zu arbeiten.... | 0 | 2024-06-06T10:02:10 | https://www.zufallsheld.de/2024/06/03/gitlab-von-der-cli-bedienen/ | gitlab, cli, glab | ---
title: Gitlab von der Kommandozeile aus bedienen
published: true
date: 2024-06-03 13:00:00 UTC
tags: gitlab,gitlab,cli,glab
canonical_url: https://www.zufallsheld.de/2024/06/03/gitlab-von-der-cli-bedienen/
---
[Glab](https://gitlab.com/gitlab-org/cli#glab) ist ein Opensource-Tool, das es ermöglicht mit Gitlab über... | rndmh3ro |
1,875,369 | Does Serverless Still Matter? | No. Short, simple, and direct. The answer to the question is that serverless at this point and time... | 0 | 2024-06-03T12:59:53 | https://www.binaryheap.com/does-serverless-still-matter/ | serverless | No. Short, simple, and direct. The answer to the question is that serverless at this point and time doesn't matter. Now I'm not saying that it's never mattered. But what I am saying is that it's just a tool in a developer's toolchain. It's not some sweeping "movement" that it was and I firmly believe that this is ... | benbpyle |
1,875,368 | Class Constructors | A class constructor is a special method in object-oriented programming that is automatically called... | 0 | 2024-06-03T12:58:00 | https://dev.to/shantel57427931/class-constructors-j7h | webdev, javascript, beginners, programming | A class constructor is a special method in object-oriented programming that is automatically called when an instance (object) of the class is created. The primary purpose of a constructor is to initialize the newly created object.
In many programming languages, including Python, C++, and Java, constructors have specifi... | shantel57427931 |
1,875,366 | Enhancing Guest Comfort: The Role of Hotel Amenities | Enhancing Guest Comfort: The Role of Hotel Amenities Resorts have come a very long way coming from... | 0 | 2024-06-03T12:56:39 | https://dev.to/jonathan_hulseh_7a93b8f43/enhancing-guest-comfort-the-role-of-hotel-amenities-2d5c | Enhancing Guest Comfort: The Role of Hotel Amenities
Resorts have come a very long way coming from simply offering fundamental requirements such as a roofing system over one's move as well as a mattress to rest on. As competitors end up being fiercer in the friendliness market, hoteliers are constantly develo... | jonathan_hulseh_7a93b8f43 | |
1,875,364 | comment on I need a hacker to recover money from binary trading | It began with a serendipitous encounter—a testimonial shared by Britney, a fellow traveler on the... | 0 | 2024-06-03T12:52:10 | https://dev.to/harold_myoung_8d1d29c119/comment-on-i-need-a-hacker-to-recover-money-from-binary-trading-228h | It began with a serendipitous encounter—a testimonial shared by Britney, a fellow traveler on the winding road of digital assets. Her words spoke of a miraculous recovery the Linux Cyber Security Company orchestrated. Intrigued and desperate for a lifeline in my crypto conundrum, I embarked on a journey that would rede... | harold_myoung_8d1d29c119 | |
1,875,362 | Difference between Synchronous and Asynchronous Java Script | Synchronous and asynchronous JavaScript refer to different approaches for handling operations,... | 0 | 2024-06-03T12:46:57 | https://dev.to/shantel57427931/difference-between-synchronous-and-asynchronous-java-script-39o4 | webdev | Synchronous and asynchronous JavaScript refer to different approaches for handling operations, particularly those that may involve waiting, such as I/O operations, network requests, or timers.
Synchronous JavaScript
Synchronous operations are those that block the execution of subsequent code until they are completed. ... | shantel57427931 |
1,873,862 | INTRODUCTION TO REACT JS | React is a JavaScript library used to create interactive single page applications. In traditional... | 0 | 2024-06-03T12:46:02 | https://dev.to/kemiowoyele1/introduction-to-react-js-10j | React is a JavaScript library used to create interactive single page applications. In traditional websites, every click to page links is fetched from the server in the backend. React and other single page applications introduced ways in which every of that could be handled in the browser. A single index html page is fe... | kemiowoyele1 | |
1,875,361 | Code With Heroines : SSL && Unification of China under the Han Dynasty | Explanation This represents the official discipline of Confucian studies introduced by... | 0 | 2024-06-03T12:45:03 | https://dev.to/fubumingyu/code-with-heroines-ssl-unification-of-china-under-the-han-dynasty-3l0k | ssl, aiart, han |

## Explanation
This represents the official discipline of Confucian studies introduced by Emperor Wu, emphasizing the importance of secure and reliable knowledge, much like how SSL ensures secure data transmissi... | fubumingyu |
1,875,358 | Discover Code Hunts: Pakistan's Premier Coding Hub | Introduction In the digital age, coding skills are a gateway to numerous opportunities.... | 0 | 2024-06-03T12:45:00 | https://dev.to/hmzi67/discover-code-hunts-pakistans-premier-coding-hub-16p8 | webdev, javascript, beginners, programming |
### Introduction
In the digital age, coding skills are a gateway to numerous opportunities. Enter [Code Hunts](https://codehuntspk.com/), Pakistan's leading platform for aspiring and seasoned developers. With a mission to cultivate and nurture coding talent, Code Hunts provides a comprehensive suite of resources, ch... | hmzi67 |
1,875,357 | Outdoor Home Improvement & Indoor Home Improvement | Discover comprehensive home and building solutions in Kochi tailored to your needs.We offers building... | 0 | 2024-06-03T12:43:33 | https://dev.to/aydins_world_2fa5da18868/outdoor-home-improvement-indoor-home-improvement-4pag | Discover comprehensive home and building solutions in Kochi tailored to your needs.We offers building construction,Flooring,Soffit Ceiling Installation,WPC Paneling etc.
Professional Home and Building Solutions in Kochi. Trust our experts to deliver exceptional results. Contact us for a consultation
building solutio... | aydins_world_2fa5da18868 | |
1,875,356 | How Android App Developers Can Improve Inventory Tracking | Warehouses play a significant role in a logistics business, but chaos reign supreme in most of them.... | 0 | 2024-06-03T12:42:51 | https://dev.to/deerapandey/how-android-app-developers-can-improve-inventory-tracking-135j | android, webdev, programming, productivity | Warehouses play a significant role in a logistics business, but chaos reign supreme in most of them. Boxes will be overflowing, aisles may look like obstacle courses, and searching hurriedly for misplaced stocks was a common scene. Every order was followed by warehouse staff struggling to open boxes, shelves being scal... | deerapandey |
1,875,355 | Como Excluir Cursos no Google Classroom Usando a API do Google | Neste artigo, vamos documentar como usar a API do Google Classroom para listar e excluir cursos.... | 0 | 2024-06-03T12:42:48 | https://dev.to/madrade1472/como-excluir-cursos-no-google-classroom-usando-a-api-do-google-255p | Neste artigo, vamos documentar como usar a API do Google Classroom para listar e excluir cursos. Vamos detalhar o passo a passo necessário para configurar e executar o código Python que realiza essas operações.
**Passo a Passo**
**Autenticação:** O código verifica se o arquivo token.json existe para utilizar credenc... | madrade1472 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.