
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,875,353 | Création De Site Web Avec Laravel | Partenaire de Choix pour une Présence en Ligne Innovante : C’est parfait avec... | 0 | 2024-06-03T12:42:23 | https://dev.to/media-web-services/creation-de-site-web-avec-laravel-2o0l | laravel, website, webdev |

##Partenaire de Choix pour une Présence en Ligne Innovante :
### C’est parfait avec Média Web Services:
Dans cet univers numérique en perpétuel mouvement, concevoir un site web performant et novateur est primordial pour toute entreprise désireuse de se développer. C'est là que Média Web Services intervient, s'imposant comme le chef de file incontesté du développement de sites web avec le Framework** Laravel** en Tunisie. Notre dévouement à l'excellence technique et notre enthousiasme pour l'innovation font de nous le partenaire idéal pour concrétiser votre projet en ligne.
##Expertise Laravel de Premier Plan :
Chez[ Média Web Services](https://mws-services.com/), notre priorité est de vous offrir des solutions web sur mesure, grâce à notre expertise approfondie du **Framework Laravel**. Cette plateforme de développement, reconnue pour sa puissance, sa polyvalence et sa facilité d'utilisation, est au cœur de notre savoir-faire. En répondant aux besoins spécifiques de nos clients. D’ailleurs nous avons les compétences nécessaires pour faire de votre vision une réalité.
## Toujours à la Pointe de l’Innovation :
[Chez Média Web Services](https://mws-services.com/), nous n'attendons pas les tendances, nous les créons. Nous surveillons constamment les nouvelles technologies et les intégrons à nos projets. Notre objectif est de donner à nos clients un avantage sur leurs concurrents. Nous proposons des solutions innovantes et à la pointe du marché, comme l'intelligence artificielle, les chatbots et le Machine Learning. Nous sommes prêts à relever tous les défis pour vous aider à atteindre vos objectifs en ligne.
## Faites Confiance à Média Web Services pour Votre Succès en Ligne :Création de site web avec Laravel
En choisissant Média Web Services, vous optez pour l'excellence technique, l'innovation et un excellent service client. Nous vous accompagnons à chaque étape, de la conception à la mise en ligne, pour dépasser vos attentes.
Ne confiez pas votre présence en ligne à n'importe qui. Choisissez Média Web Services pour bénéficier d'une expertise de haut niveau et d'un partenariat durable.
[Contactez-nous](https://mws-services.com/contact/) aujourd'hui pour commencer à construire votre réussite en ligne, en Tunisie et ailleurs.
| media-web-services |
1,875,352 | The Future of Blockchain Gaming on Solana | rapidinnovation#BlockchainGaming #Solana #NFTGames #CryptoGaming #GamingRevolution The... | 27,548 | 2024-06-03T12:39:26 | https://dev.to/aishikl/the-future-of-blockchain-gaming-on-solana-3c84 | #rapidinnovation#BlockchainGaming #Solana #NFTGames #CryptoGaming #GamingRevolution
The blockchain gaming industry is rapidly growing but lacks games that truly excite players about blockchain technology. Many current games are overly focused on the 'token economy' model, limiting their appeal and sophistication. Solana aims to revolutionize this space by offering a more immersive and competitive gaming experience, leveraging its fast, scalable blockchain and strong ecosystem. With significant backing and innovative projects, Solana has the potential to attract high-spending gamers from established economies, making it a promising platform for the future of blockchain gaming.
http://www.rapidinnovation.io/post/the-future-of-blockchain-gaming-on-solana | aishikl | |
1,875,351 | JavaScript 🚀Troubleshooting Guide: What Went Wrong❌? | JavaScript is a versatile and powerful language, but like all programming languages, it’s prone to... | 0 | 2024-06-03T12:39:05 | https://dev.to/dharamgfx/javascript-troubleshooting-guide-what-went-wrong-2fpa | webdev, javascript, beginners, programming |
JavaScript is a versatile and powerful language, but like all programming languages, it’s prone to errors. Understanding and troubleshooting these errors is a crucial skill for any developer. This guide will walk you through the common types of errors, how to identify them, and how to fix them with practical examples.
## Prerequisites
Before diving into troubleshooting, make sure you have a basic understanding of JavaScript, including:
- **Variables**: Understanding how to declare and use variables.
- **Functions**: Knowing how to define and call functions.
- **Control Structures**: Familiarity with loops, conditionals, and other control flow mechanisms.
- **Development Environment**: Setting up a text editor (like VS Code) and running JavaScript in a browser or Node.js.
## Guides
### Tools for Debugging
1. **Console**: Use `console.log()` to print variables and check their values.
2. **Debugger**: Most modern browsers have built-in debuggers. Use breakpoints to pause code execution and inspect variables.
3. **Linters**: Tools like ESLint help catch potential errors and enforce coding standards.
## Assessments
Before jumping into fixing errors, assess your code:
- **Readability**: Is your code clean and readable?
- **Comments**: Are there sufficient comments explaining the code?
- **Modularization**: Is your code broken down into manageable functions?
## Types of Errors
### 1. Syntax Errors
Syntax errors occur when the code doesn’t follow the rules of the JavaScript language.
### Example:
**Erroneous Code:**
```javascript
function sayHello(name {
console.log("Hello, " + name);
}
```
**Correct Code:**
```javascript
function sayHello(name) {
console.log("Hello, " + name);
}
```
### 2. Runtime Errors
These errors occur while the program is running. They can be harder to catch because they only appear under certain conditions.
### Example:
**Erroneous Code:**
```javascript
let x = 10;
let y = x.toUpperCase(); // Error: x.toUpperCase is not a function
```
**Correct Code:**
```javascript
let x = "10";
let y = x.toUpperCase(); // Correctly converts string to uppercase
```
### 3. Logical Errors
Logical errors occur when the code runs without crashing but produces incorrect results.
### Example:
**Erroneous Code:**
```javascript
function calculateArea(width, height) {
return width + height; // Incorrect logic, should be width * height
}
```
**Correct Code:**
```javascript
function calculateArea(width, height) {
return width * height;
}
```
## Fixing Syntax Errors
- **Identify**: Look for missing characters like parentheses, brackets, or semicolons.
- **Correct**: Add or remove characters as needed.
### Example:
**Erroneous Code:**
```javascript
let greeting = "Hello, World!
```
**Correct Code:**
```javascript
let greeting = "Hello, World!";
```
## Fixing Logic Errors
- **Understand the logic**: Review the intended logic and compare it with the actual code.
- **Debugging**: Use `console.log` to print variable values and check their correctness at different stages.
### Example:
**Erroneous Code:**
```javascript
function isEven(number) {
return number % 2 === 1; // Incorrect logic for even check
}
```
**Correct Code:**
```javascript
function isEven(number) {
return number % 2 === 0;
}
```
## Other Common Errors
### 1. Undefined Variables
Using variables that haven’t been declared or initialized.
### Example:
**Erroneous Code:**
```javascript
console.log(user); // Error: user is not defined
```
**Correct Code:**
```javascript
let user = "Alice";
console.log(user); // Outputs: Alice
```
### 2. Incorrect Function Calls
Calling functions with the wrong number of arguments or wrong argument types.
### Example:
**Erroneous Code:**
```javascript
function greet(name) {
console.log("Hello, " + name);
}
greet(); // Outputs: Hello, undefined
```
**Correct Code:**
```javascript
function greet(name = "Guest") { // Default parameter
console.log("Hello, " + name);
}
greet(); // Outputs: Hello, Guest
```
### 3. Off-by-One Errors
Common in loops and array indexing.
#### Example:
**Erroneous Code:**
```javascript
let array = [1, 2, 3, 4, 5];
for (let i = 0; i <= array.length; i++) {
console.log(array[i]); // Outputs: 1, 2, 3, 4, 5, undefined
}
```
**Correct Code:**
```javascript
let array = [1, 2, 3, 4, 5];
for (let i = 0; i < array.length; i++) {
console.log(array[i]); // Outputs: 1, 2, 3, 4, 5
}
```
## Summary
Troubleshooting JavaScript involves understanding the types of errors, using debugging tools, and applying logical thinking to fix issues. Always start with syntax errors, move on to runtime errors, and finally tackle logical errors. Regular practice and familiarizing yourself with common mistakes will improve your debugging skills.
Happy coding and debugging! | dharamgfx |
1,875,350 | Code Smell 254 - Mystery Guest | You assert that something happened, but why? TL;DR: Be explicit when creating tests to ensure... | 9,470 | 2024-06-03T12:37:33 | https://maximilianocontieri.com/code-smell-254-mystery-guest | webdev, beginners, programming, tutorial | *You assert that something happened, but why?*
> TL;DR: Be explicit when creating tests to ensure clarity and maintainability
# Problems
- Readability
- [Coupling](https://dev.to/mcsee/coupling-the-one-and-only-software-design-problem-2pd7) to external databases, global state or [singletons](https://dev.to/mcsee/singleton-the-root-of-all-evil-50bh), [static methods](https://dev.to/mcsee/code-smell-18-static-functions-fpj) or external services
- Maintenance Difficulty
- Debugging Complexity
- Hidden Dependencies
# Solutions
1. Be Explicit
2. Inline the setup
3. Use dependency Injection
4. Use [mocking](https://dev.to/mcsee/code-smell-30-mocking-business-3glm) with caution
# Context
Your test depends on external data or configurations not immediately visible within the test itself.
This obscures the test’s setup, making it difficult for someone reading it to understand what is being tested and why it might fail.
Every test case should have three stages:
1. Setup: Initialize and configure everything needed for the test.
2. Exercise: Execute the code being tested.
3. Assert: Verify the expected outcome.
All of them must be explicit
# Sample Code
## Wrong
[Gist Url]: # (https://gist.github.com/mcsee/ba2c15c5d72c871a4251c9d08dfcf728)
```java
@Test
void shouldReturnAnswerWhenAnswerExists() {
User answer = KnowledgeRepository.findAnswerToQuestion(42);
assertNotNull(answer);
}
```
## Right
[Gist Url]: # (https://gist.github.com/mcsee/48162612d1667217eb493109f9ae8405)
```java
@Test
void shouldReturnAnswerWhenAnswerExists() {
KnowledgeRepository knowledgeRepository =
new InMemoryKnowledgeRepository();
Answer expectedAnswer = new Answer(42, "The Ultimate");
knowledgeRepository.save(expectedAnswer);
Answer actualAnswer = answerRepository.findAnswerToQuestion(42);
assertNotNull(actualAnswer);
assertEquals(expectedAnswer, actualAnswer);
}
```
# Detection
[X] Manual
You can detect this smell by looking for tests that do not clearly show their setup steps or rely heavily on external configurations.
# Tags
- Test Smells
# Level
[x] Intermediate
# AI Generation
AI-generated code often avoids this smell due to the tendency to create small, isolated examples.
# AI Detection
Most AI Detectors fail to identify this as a problem unless you point it out explicitly.
# Conclusion
This code smell is especially prevalent in legacy codebases or when consistent testing practices are lacking.
You need to be explicit of the environment since tests must always be in "full environmental control"
# Relations
{% post https://dev.to/mcsee/code-smell-17-global-functions-4b82 %}
{% post https://dev.to/mcsee/code-smell-32-singletons-1ka %}
{% post https://dev.to/mcsee/code-smell-18-static-functions-fpj %}
{% post https://dev.to/mcsee/code-smell-30-mocking-business-3glm %}
# More Info
[Craft Better Software](https://craftbettersoftware.com/p/tdd-5-test-smells-5-solutions)
{% post https://dev.to/mcsee/coupling-the-one-and-only-software-design-problem-2pd7 %}
# Disclaimer
Code Smells are my [opinion](https://dev.to/mcsee/i-wrote-more-than-90-articles-on-2021-here-is-what-i-learned-1n3a).
# Credits
Photo by [Brands&People](https://unsplash.com/@brandsandpeople) on [Unsplash](https://unsplash.com/photos/womans-face-with-green-eyes-M2cFm9iHXSc)
* * *
> Science is what we understand well enough to explain to a computer, Art is all the rest
_Donald Knuth_
{% post https://dev.to/mcsee/software-engineering-great-quotes-26ci %}
* * *
This article is part of the CodeSmell Series.
{% post https://dev.to/mcsee/how-to-find-the-stinky-parts-of-your-code-1dbc %} | mcsee |
1,875,349 | Enhancing Your Flutter Project with Typesafe Packages | Introduction Flutter's popularity has surged thanks to its ability to build beautiful and... | 0 | 2024-06-03T12:37:27 | https://dev.to/dinko7/enhancing-your-flutter-project-with-typesafe-packages-34ia | flutter, dart, typesafe, tutorial | # Introduction
Flutter's popularity has surged thanks to its ability to build beautiful and performant cross-platform applications. Large projects with many teams and developers often face a lot errors on a smaller or a larger scale due to the size of the project.
One of those problems is type safety.
_What is typesafe code?_
Remember all those times you added a new asset and used it in a widget. You run the app, but then it crashes because Flutter couldn’t find the asset? You probably forgot to add it to the `pubspec.yaml`.
I’ll give you another example.
You want to call methods from native code. Flutter provides Method Channels for this. You have to make sure that you call the correct method, with the correct parameters, otherwise, you’ll get an error like this:
```bash
Unhandled Exception: MissingPluginException(No implementation found for method getBatteryLevel on channel samples.flutter.dev/battery)
```
This is what typesafe code prevents from happening. Typesafe means **_that variables are statically checked for appropriate assignment at compile time._**
As projects grow, ensuring type safety becomes crucial to maintaining code quality and preventing runtime errors.
This blog will explore how to make your Flutter project more typesafe using various packages:
- Typesafe Method Channels: [pigeon](https://pub.dev/packages/pigeon)
- Typesafe REST APIs: [chopper](https://pub.dev/packages/chopper) and [retrofit](https://pub.dev/packages/retrofit)
- Typesafe GraphQL: [ferry](https://pub.dev/packages/ferry)
- Typesafe Routing: [go_router_builder](https://pub.dev/packages/go_router_builder)
- Typesafe Assets: [flutter_gen](https://pub.dev/packages/flutter_gen)
- Typesafe Environment Variables: [envied](https://pub.dev/packages/envied)
Let's dive into each of these and see how they can take your Flutter project from error-prone to error-free.
## Typesafe Method Channels with Pigeon
Method channels in Flutter facilitate communication between the Dart and native sides of an app (iOS and Android). Traditionally, method channels use dynamic typing, which can lead to runtime errors if the method names or argument types do not match.
`pigeon` eliminates these issues by generating type-safe code for method channels. It can also generate code for accessing a Dart method from native code, which can come in handy.
### Non-Typesafe Code
Typically you would write something like this in your Flutter project:
```dart
import 'package:flutter/services.dart';
class FlutterBridge {
static const MethodChannel _channel = MethodChannel('com.example.app/channel');
Future<String?> getMessage() async {
final String? message = await _channel.invokeMethod('getMessage');
return message;
}
Future<void> sendMessage(String message) async {
await _channel.invokeMethod('sendMessage', {'text': message});
}
}
```
And then write appropriate platform implementations:
- For Android (`MainActivity.kt` ):
```kotlin
import android.os.Bundle
import io.flutter.embedding.android.FlutterActivity
import io.flutter.embedding.engine.FlutterEngine
import io.flutter.plugin.common.MethodChannel
class MainActivity: FlutterActivity() {
private val CHANNEL = "com.example.app/channel"
override fun configureFlutterEngine(flutterEngine: FlutterEngine) {
super.configureFlutterEngine(flutterEngine)
MethodChannel(flutterEngine.dartExecutor.binaryMessenger, CHANNEL).setMethodCallHandler {
call, result ->
when (call.method) {
"getMessage" -> {
val message = getMessage()
result.success(message)
}
"sendMessage" -> {
val text = call.argument<String>("text")
sendMessage(text)
result.success(null)
}
else -> {
result.notImplemented()
}
}
}
}
private fun getMessage(): String {
return "Hello from Android!"
}
private fun sendMessage(message: String?) {
// Handle the message
}
}
```
- For iOS (`AppDelegate.swift`):
```swift
import UIKit
import Flutter
@UIApplicationMain
@objc class AppDelegate: FlutterAppDelegate {
override func application(
_ application: UIApplication,
didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?
) -> Bool {
GeneratedPluginRegistrant.register(with: self)
let controller : FlutterViewController = window?.rootViewController as! FlutterViewController
let channel = FlutterMethodChannel(name: "com.example.app/channel",
binaryMessenger: controller.binaryMessenger)
channel.setMethodCallHandler({
(call: FlutterMethodCall, result: @escaping FlutterResult) -> Void in
if call.method == "getMessage" {
result(self.getMessage())
} else if call.method == "sendMessage" {
if let args = call.arguments as? [String: Any],
let text = args["text"] as? String {
self.sendMessage(message: text)
}
result(nil)
} else {
result(FlutterMethodNotImplemented)
}
})
return super.application(application, didFinishLaunchingWithOptions: launchOptions)
}
private func getMessage() -> String {
return "Hello from iOS!"
}
private func sendMessage(message: String) {
// Handle the message
}
}
```
### Typesafe Code with Pigeon
First, add `pigeon` to your `dev_dependencies` in `pubspec.yaml`:
```yaml
dev_dependencies:
pigeon: ^19.0.1
```
Create a Dart file (e.g., `pigeons.dart`) to define the interface:
```dart
dartCopy code
import 'package:pigeon/pigeon.dart';
class Message {
String? text;
}
@HostApi()
abstract class Api {
Message getMessage();
void sendMessage(Message message);
}
```
Run the Pigeon tool to generate the necessary code:
```bash
flutter pub run pigeon --input pigeons.dart
```
This generates platform-specific code ensuring that method calls are type-safe, reducing the risk of mismatches and errors.
## Typesafe GraphQL with Ferry
If you are using GraphQL, `ferry` provides a fully type-safe client by leveraging code generation. This ensures that queries, mutations, and subscriptions conform to the GraphQL schema, catching errors at compile time rather than at runtime. It also comes with a side package [`ferry_hive_store`](https://pub.dev/packages/ferry_hive_store) if you want to have offline persistence using Hive.
### Non-Typesafe Code
```dart
import 'package:graphql_flutter/graphql_flutter.dart';
class GraphQLService {
final GraphQLClient _client;
GraphQLService(this._client);
Future<void> fetchData() async {
const String query = '''
query GetItems {
items {
id
name
}
}
''';
final QueryResult result = await _client.query(QueryOptions(document: gql(query)));
if (result.hasException) {
print(result.exception.toString());
return;
}
final items = result.data?['items'];
print(items);
}
}
```
### Typesafe Code with Ferry
Add `ferry` and its code generation dependencies:
```yaml
dependencies:
ferry: ^0.16.0+1
gql_http_link: ^1.0.1+1
dev_dependencies:
ferry_generator: ^0.10.0
build_runner: ^2.4.10
```
Move your GraphQL query into a `.graphql` file:
```graphql
query GetItems {
items {
id
name
}
}
```
Generate the necessary types by running:
```bash
flutter pub run build_runner build
```
Use your queries in a typesafe manner:
```dart
import 'package:ferry/ferry.dart';
import 'package:ferry_hive_store/ferry_hive_store.dart';
import 'package:ferry_http/ferry_http.dart';
final query = GFetchUserReq((b) => b..vars.id = 1);
final client = FerryClient(
link: HttpLink('https://api.example.com/graphql'),
cache: HiveStore(),
);
final response = await client.request(query).first;
if (response.hasErrors) {
// Handle errors
} else {
final user = response.data!.user;
print('User: ${user.name}, Email: ${user.email}');
}
```
### Type-Safe REST API with Retrofit and Chopper
Both Retrofit and Chopper and type safe REST API generators, but they cover different libraries. Chopper is based on `http` package, while Retrofit is based on `dio` package. Both are inspired by Retrofit for Android.
### Non-Type-Safe Code
Directly using the `http` and `dio` requires manual handling of JSON parsing and lacks compile-time verification of API definitions, including path and query parameters.
### 1. HTTP
```dart
import 'dart:convert';
import 'package:http/http.dart' as http;
Future<MyModel> fetchPost(int id) async {
final response = await http.get(Uri.parse('https://api.example.com/posts/$id'));
if (response.statusCode == 200) {
return MyModel.fromJson(jsonDecode(response.body));
} else {
throw Exception('Failed to load post');
}
}
```
### 2. dio
```dart
dartCopy code
import 'package:dio/dio.dart';
Future<MyModel> fetchPost(int id) async {
try {
final response = await Dio().get('https://api.example.com/posts/$id');
return MyModel.fromJson(response.data);
} catch (e) {
throw Exception('Failed to load post');
}
}
```
### Typesafe Code with Chopper and Retrofit
Both Chopper and Retrofit use `build_runner` to generate the underlying network logic by wrapping around http and dio. By using annotations you can focus on defining API contracts and business logic without sacrificing type safety.
1. Chopper
```dart
import 'package:chopper/chopper.dart';
part 'api_service.chopper.dart';
@ChopperApi(baseUrl: '/posts')
abstract class ApiService extends ChopperService {
@Get(path: '/{id}')
Future<Response<MyModel>> getPostById(@Path() int id);
}
```
### 2. Retrofit
```dart
import 'package:retrofit/retrofit.dart';
part 'api_service.g.dart';
@RestApi(baseUrl: "https://api.example.com")
abstract class ApiService {
factory ApiService(Dio dio, {String baseUrl}) = _ApiService;
@GET("/posts/{id}")
Future<MyModel> getPostById(@Path("id") int id);
}
```
Now you can call your APIs like any other method in the app.
## Typesafe Routing with GoRouterBuilder
Routing is a critical aspect of any Flutter app. Most used navigator packages are `go_router`. `auto_route`. AutoRoute provides typesafe and generated routes out of the box, while GoRouter relies on `go_router_builder` package.
### Non-Typesafe Code
```dart
import 'package:flutter/material.dart';
import 'package:go_router/go_router.dart';
final GoRouter _router = GoRouter(
routes: <GoRoute>[
GoRoute(
path: '/',
builder: (BuildContext context, GoRouterState state) => HomeScreen(),
),
GoRoute(
path: '/details',
builder: (BuildContext context, GoRouterState state) {
final String id = state.queryParams['id'] ?? '';
return DetailsScreen(id: id);
},
),
],
);
```
### Typesafe code with GoRouterBuilder
`go_router_builder` integrates with the `go_router` package to provide type-safe routes.
Add dependencies:
```yaml
dependencies:
go_router: ^14.1.4
dev_dependencies:
go_router_builder: ^2.7.0
```
Define your routes in a Dart file:
```dart
import 'package:go_router/go_router.dart';
part 'app_routes.g.dart';
@TypedGoRoute<HomeRoute>(path: '/')
class HomeRoute {}
@TypedGoRoute<DetailsRoute>(path: '/details')
class DetailsRoute {
final String id;
DetailsRoute({required this.id});
}
```
Run the generator:
```bash
flutter pub run build_runner build
```
This will generate all the routes for you. The code generator combines all top-level routes into a single list called `$appRoutes` which you need to use to initialize the GoRouter instance:
```dart
final _router = GoRouter(routes: $appRoutes);
```
You can now navigate and pass parameters without worrying about something going wrong:
```dart
void _tap() => DetailsRoute(id: 'p1').go(context);
```
## Typesafe Assets with FlutterGen
Managing assets in Flutter can become cumbersome as your project scales. `flutter_gen` helps manage this by generating type-safe code for your assets. The package also provides utils for Lottie, Rive, and SVG files.
Always configure your assets in `pubspec.yaml`:
```yaml
flutter:
assets:
- assets/images/
```
### Non-Typesafe Code
```dart
Image.asset('assets/images/logo.png')
```
### Typesafe Code with FlutterGen
Add `flutter_gen`:
```yaml
dev_dependencies:
flutter_gen: ^5.5.0+1
```
Run the generator:
```bash
flutter pub run build_runner build
```
Access your assets safely:
```dart
import 'package:my_app/gen/assets.gen.dart';
Image.asset(Assets.images.logo.path);
```
## Typesafe Environment Variables with Envied
Managing environment variables securely and type-safely can be challenging. `envied` makes it easy. Envied can also obfuscate your API keys to make them more secure, but beware, it’s just a `xor` of two strings and anybody who wants to steal your API keys will steal them.
Adding `envied`:
```yaml
dependencies:
envied: ^0.5.4+1
dev_dependencies:
build_runner: ^2.4.10
```
Create an `.env` file and a Dart class for the environment variables:
```
API_KEY=your_api_key
```
```dart
import 'package:envied/envied.dart';
part 'env.g.dart';
@Envied(path: '.env')
abstract class Env {
@EnviedField(varName: 'API_KEY')
static const String apiKey = _Env.apiKey;
}
```
Run the generator:
```bash
flutter pub run build_runner build
```
Access your environment variables safely:
```dart
final apiKey = Env.apiKey;
```
## Conclusion
By integrating these packages into your Flutter project, you can significantly enhance type safety, making your code more robust and maintainable. Leveraging `pigeon` for method channels, `ferry` for GraphQL,`chopper`and `retrofit` for REST APIs, `go_router_builder` for routing, `flutter_gen` for assets, and `envied` for environment variables, you can catch errors at compile time, ensuring a more reliable and error-free codebase.
If you have found this useful, make sure to like and follow for more content like this. To know when the new articles are coming out, follow me on [**Twitter**](https://twitter.com/dinkomarinac) or [**LinkedIn**](https://www.linkedin.com/in/dinko-marinac/).
Until next time, happy coding!
Reposted from [my blog](https://dinkomarinac.dev/enhancing-your-flutter-project-with-typesafe-packages). | dinko7 |
1,875,348 | How to Find the Best Webflow Agency for Your WebApp | Introduction: In the fast-paced world of web development, finding the right agency to... | 0 | 2024-06-03T12:37:05 | https://dev.to/frankii/how-to-find-the-best-webflow-agency-for-your-webapp-2b4o | ## Introduction:
In the [fast-paced world of web development](https://dev.to/ai-business/how-webflow-agencies-empower-startups-with-no-code-solutions-46eb), finding the right agency to bring your webapp to life is crucial. With the rise of no-code platforms like Webflow, the demand for agencies that specialize in this innovative tool has skyrocketed. But with so many options out there, how do you choose the best Webflow agency for your project? We're here to break down the essential steps to ensure you make the right choice.
### 1. Assess Your Project Needs
Before you start your search, it's important to have a clear understanding of your project's requirements. What are your goals? What features do you need? Having a detailed brief will help you find an agency that aligns with your vision.
### 2. Look for Specialization
Not all web agencies are created equal. Look for agencies that specialize in Webflow. These experts will have the in-depth knowledge and experience to navigate the platform's nuances and deliver a high-quality product.
### 3. Portfolio Review
A strong portfolio is a testament to an agency's capabilities. Take the time to review the work they've done. Look for projects that are similar in scope and complexity to yours. This will give you an idea of their design aesthetic and technical expertise.
### 4. Client Testimonials and Reviews
Don't just take the agency's word for it. Check out what their past clients have to say. Reviews and testimonials can provide valuable insights into the [agency's work ethic](https://dev.to/ai-info/ai-businesses-in-2024-profitable-ai-business-ideas-2kdi), communication, and ability to meet deadlines.
### 5. Communication and Collaboration
A successful project hinges on effective communication. Ensure that the agency is responsive and open to collaboration. A [Best webflow agency](https://www.deduxer.studio/services/webflow-agency) will take the time to understand your needs and keep you updated throughout the development process.
### 6. Pricing and Value
While it's important to stay within your budget, remember that quality comes at a cost. Look for an agency that offers transparent pricing and delivers value for money. Avoid agencies that seem too cheap, as this could be a red [flag for subpar work](https://dev.to/ai-business/how-webflow-agencies-empower-startups-with-no-code-solutions-4nl0).
### 7. Support and Maintenance
Your webapp is a living entity that will require updates and maintenance. Make sure the agency offers post-launch support. This will ensure that your webapp remains functional and up-to-date.
## Conclusion:
Choosing the best Webflow agency for your webapp is a decision that should not be taken lightly. By assessing your project needs, looking for specialization, reviewing portfolios, checking client feedback, ensuring good communication, evaluating pricing, and considering post-launch support, you'll be well on your way to finding the perfect partner for your project. Remember, the right agency can make all the difference in the success of your webapp. Stay tuned for more hot news and tips on web development and digital innovation. | frankii | |
1,875,346 | The Flower Shop | Looking for a unique night out in NYC? The Flower Shop NYC is a retro bar that offers a charming... | 0 | 2024-06-03T12:35:35 | https://dev.to/samnesam/the-flower-shop-pkm | Looking for a unique night out in NYC? The Flower Shop NYC is a [retro bar](https://www.theflowershopnyc.com/) that offers a charming blend of vintage aesthetics and modern amenities. Situated in the Lower East Side, this venue features classic décor, cozy seating, and a menu filled with creative cocktails and tasty bites. It's the perfect spot to unwind and enjoy a nostalgic yet contemporary atmosphere.
| samnesam | |
1,875,345 | React 19 and Next.js 15: Solving Re-render Issues Without memo | The React and Next.js communities are buzzing with excitement as React 19 and Next.js 15 bring... | 0 | 2024-06-03T12:34:44 | https://dev.to/kawanedres/react-19-and-nextjs-15-solving-re-render-issues-without-memo-kln | The React and Next.js communities are buzzing with excitement as React 19 and Next.js 15 bring groundbreaking improvements to state management and rendering performance. One of the most significant advancements is the resolution of unnecessary re-renders in child components when the parent state changes, eliminating the need for memo in many cases.
The Problem: Unnecessary Re-renders
Traditionally, in React, when a parent component's state changes, all its child components re-render, regardless of whether their props have changed. To mitigate this, developers often use React.memo to prevent child components from re-rendering unnecessarily. While effective, this approach adds complexity to the codebase and can be challenging to manage in larger applications.
The Solution: React 19 and Next.js 15
With the release of React 19 (currently in RC) and Next.js 15 (also in RC), there's a significant shift in how React handles re-renders. The React team has introduced new optimizations that ensure child components do not re-render when the parent state changes unless it's necessary. This improvement simplifies state management and enhances performance out of the box.
Example: Without memo
Let's look at a simple example demonstrating this new behavior. We have a parent component that increments a counter every second and a child component that displays static content.
first you have to add React and React-Dom Rc and Next js Rc to your next js project and try the below code block to see the difference
```javascript
npm install next@rc react@rc react-dom@rc
```
Parent Component:
```javascript
// components/ParentComponent.js
import React, { useState, useEffect } from 'react';
import ChildComponent from './ChildComponent';
const ParentComponent = () => {
const [counter, setCounter] = useState(0);
useEffect(() => {
const interval = setInterval(() => {
setCounter((prevCounter) => prevCounter + 1);
}, 1000);
return () => clearInterval(interval);
}, []);
return (
<div>
<h1>Parent Component</h1>
<p>Counter: {counter}</p>
<ChildComponent />
</div>
);
};
export default ParentComponent;
```
Child Component:
```javascript
// components/ChildComponent.js
import React from 'react';
const ChildComponent = () => {
console.log('Child component re-rendered');
return (
<div>
<h2>Child Component</h2>
<p>Received Counter:</p>
</div>
);
};
export default ChildComponent;
```
Next.js Configuration:
```javascript
/** @type {import('next').NextConfig} */
const nextConfig = {
reactStrictMode: true,
experimental: {
reactCompiler: true,
},
};
export default nextConfig;
```
Observing the Change
With the setup above, you'll notice that even though the counter in the parent component increments every second, the ChildComponent does not re-render. This behavior is evident from the absence of console.log('Child component re-rendered') in the browser console with each counter increment.
Conclusion
React 19 and Next.js 15 are poised to revolutionize how developers handle component re-renders. By eliminating unnecessary re-renders of child components when parent state changes, these new versions reduce the need for memo and similar performance optimizations. This improvement leads to cleaner, more maintainable code and enhanced application performance. As these versions move from RC to stable, developers can look forward to a more efficient and streamlined development experience.
Upgrade your projects to React 19 and Next.js 15 RC today to experience these improvements firsthand, and stay tuned for the stable release to fully leverage the new capabilities.
| kawanedres | |
1,872,098 | New in Ruby on Rails 7.2: Development Containers Configuration | Development container is a full-featured coding environment. Rails 7.2 introduces configurations for... | 0 | 2024-06-03T12:34:10 | https://jetthoughts.com/blog/new-in-ruby-on-rails-72-development-containers-configuration/ | rails, ruby, docker, changelog |
Development container is a full-featured coding environment. **Rails 7.2** introduces configurations for these containers in your application, including a `.devcontainer` folder with `Dockerfile`, `docker-compose.yml`, and `devcontainer.json`.
The default dev container includes:
- A database (SQLite, Postgres, MySQL, or MariaDB)
- Active Storage with local disk usage and preview features
- A Redis container
- A Headless Chrome container for system tests
Generate a new application with a development container using:
```bash
rails new myapp --devcontainer
```
After this, you will see the result of the generator:
```bash
...
create storage/.keep
create tmp/storage
create tmp/storage/.keep
create .devcontainer
create .devcontainer/devcontainer.json
create .devcontainer/Dockerfile
create .devcontainer/compose.yaml
...
```
As you can see, the generator created files that correspond to the container configuration.
For existing applications, use:
```bash
rails devcontainer
```
Result:
```bash
╰─ $ rails devcontainer
Generating Dev Container with the following options:
app_name: rails_blog
database: sqlite3
active_storage: true
redis: true
system_test: true
node: false
create .devcontainer
create .devcontainer/devcontainer.json
create .devcontainer/Dockerfile
create .devcontainer/compose.yaml
gsub test/application_system_test_case.rb
```
More details in the [Getting Started with Dev Containers guide.](https://edgeguides.rubyonrails.org/getting_started_with_devcontainer.html)
We have previously written about how to set up Docker for Ruby on Rails 7. In this article you can find more detailed information on how to configure docker:
[Setting Up Docker for Ruby on Rails 7](https://jetthoughts.com/blog/setting-up-docker-for-ruby-on-rails-7-beginners/) | jetthoughts_61 |
1,873,860 | Standout as a Junior Engineer: Work slower to grow faster | I recently finished one of the most important books I think I’ll read this year. Slow productivity:... | 0 | 2024-06-03T12:33:53 | https://dev.to/glasskube/standout-as-a-junior-engineer-work-slower-to-grow-faster-4ac3 | beginners, programming, productivity, devops | I recently finished one of the most important books I think I’ll read this year. [Slow productivity: The Lost Art of Accomplishment Without Burnout](https://www.amazon.com/Slow-Productivity-Accomplishment-Without-Burnout/dp/0593544854) by Cal Newport is a short but value-dense read that unpacks what it is to be productive in the knowledge work economy. The book coalesces around three main directives to unlock quality work without burning out.
By **“doing less“**, **“working at a more natural pace“**, and **“obsessing over quality“** the author argues that our best work is yet to be done. Another key concept explored in the book is what Mr. Newport calls **“pseudo-productivity”**, the faulty heuristic that has emerged as a way to measure the productivity of knowledge workers and how detrimental it actually is to produce the work that actually matters.

As a computer scientist himself and general topic book author, famous for books like [Digital Minimalism](https://www.amazon.com/Digital-Minimalism-Choosing-Focused-Noisy/dp/0525536515) and the NYT bestseller [Deep Work](https://www.amazon.com/Deep-Work-Focused-Success-Distracted/dp/1455586692), the author speaks to a broad audience, knowledge workers of any industry and seniority. What I would like to do in this blog post is to apply some of the primary ideas from the book and apply them specifically to engineers starting out in their careers.
As a relative newcomer to the field of Kubernetes and Cloud engineering myself, I have found a lot of success applying many of Cal’s ideas around productivity and it would be a shame for other Junior engineers to miss out on the ideas which I believe can really help propel their careers. Below I will explain some of the most important ideas applicable to Junior developers and also add a comprehensive list of actionable tips at the end.
⚠️ Disclaimer
> _1- Even though I’m writing this with Junior Engineers in mind, most of the ideas and general tips I’ll provide are applicable to most roles and seniority.
2- I work remotely and understand that some of these ideas might not be as applicable if you are working in an office setting. I will do my best to adapt advice for in-office settings when applicable._
---
Before I forget, let me thank [Glasskube](https://github.com/glasskube/glasskube) for allowing me to take the time to create content just like this. If this is the first time you've heard of us, we are working to build the next generation `Package Manager for Kubernetes`.
If you'd like to support us on this mission we would appreciate it if you could
[⭐️ Star Glasskube on GitHub 🙏](https://github.com/glasskube/glasskube)
[](https://github.com/glasskube/glasskube)
---
## Quality work and Pseudo-productivity
How can you judge what you can’t measure? As an engineer, how do you know if you are doing a good job? How do you know if you are an effective team member or if your work has a real impact on the overall business? If you were a farmer or a factory worker, it would be much easier to measure your productivity. However, in knowledge work, defining **“productivity” is much harder to pin down.**
Now, since everyone is just a DM or Slack message away, a heuristic that has emerged to measure our impact is pseudo-productivity. This encompasses all the work that revolves around the actual work we are here to do. We appear productive when we are answering emails, responding to DMs, spending time in meetings, and checking metrics. We often feel compelled to perform these tasks, especially when we spend a lot of time working on something that doesn’t have an obvious output just yet.

> _Pseudo-productivity is performative and gets in the way of the “real work”._
What is **“real work“** anyway? This will change for every engineer of course but a question that might help you in case you are in need of a definition applicable to you.
Try to think of yourself in the future, what work will you be **most proud of having produced**? Are you going to remember all of the emails you got back to and all the meetings you attended? Probably not, what is going to matter to you is the quality work you were able to produce in the time your weren’t doing all of the other tasks.
One of the three ideas in the book is to **“Obsess over quality“**. If you are a Junior Engineer I would try to internalize this point above all others because it’s the kind of work you can lean on to progress through your career and it’s also the only kind of work you are going to care about when you retire. There are two things that might get in the way of producing quality work. The first is all of the pseudo productivity tasks you have to do and the second is your ability to focus.
## Distraction is the silent killer
Every individual has their own strengths and weaknesses. Unfortunately, no matter how your unique constellation of qualities and skills makes you stand out, it won't matter unless you **can produce cognitive effort for sustained periods of time.** Our ability to focus has been greatly diminished by the rise of smartphones and algorithmically enhanced apps and services cleverly engineered to capture our attention.

> _When was the last time you were able to sit down to read a book for more than 15 minutes without picking up your phone? If you don’t mind me asking, when was the last time you went to the bathroom all on you lonesome, no phones in sight?_
The issue of seeking entertainments or relief from boredom from moment to moment is bad for a long list of reasons that many have articulated much better then I could. So I will only focus on one.
> _As an up and coming knolwedge worker you will be valuable for your capacity to focus over non trivial streches of time to produce solutions, services, projects etc. **You will need to adapt and learn new skills as times goes by and there is no way to do so unless you protect your capacity to focus.**_
In many remote and engineering settings, distractions can come from anywhere. On the professional side, you have to consider how many tools and platforms send notifications your way. How long are your meetings? Do you have your camera on and a second screen only you can see?
On the personal side, it’s important to **know your triggers**. Does Reddit have a particularly strong pull on you, or maybe it’s YouTube? The danger is that most sources of distraction can be justified as helpful for your work. You might hear justifications like, "Where would I be without YouTube University?" or "How could I keep up to date without being on Reddit or X?"
One of the most important messages I want to convey is **that you simply cannot produce quality work if you are distracted.** Avoiding distraction is easier said than done, especially when pseudo-productivity (with all its distracting pings and notification bells) is the way your output is measured.
## What are knowledge workers paid for?
The second idea of Slow Productivity says to **“Work at a more natural pace“**. To come to this conclusion, in the book, Mr Newport goes back in time and tries to understand how the Knowledge workers of the past (Writers, Scientists, philosophers) approached productivity. What he found is that we nowadays we consider Marie Curie and Jane Austin among others to be incredibly productive individuals having contributed hugely impactful and valuable bodies of work. But if we look at any particular year in the lives of these important figures we can see that they weren’t particularly busy.
Marie Curie was known to take long vacations interrupting important experiments that would eventually lead to a Nobel prize because it was how she organized her life with her family.
What I would like for you to consider, applying the idea of productivity to your life is the idea that you career will be long, and there will be ups and downs. Moments of intense work and others of relative inaction. You have to embrace them all the same because productivity in engineering requires that you actually understand what you are doing, the context around it, and the reasons why a specific approach is taken over another.
Here is an anecdote Cal Newport mentions in his podcast whcih I find fitting. At dissertation conferences for Masters and PhD students, Cal noticed speakers emphasizing "getting your writing hours in" with phrases like "Did you get your writing in today?". When it was his turn, he challenged this by asking, **"Forget about the writing, are you getting your thinking hours in?".** Often, we confuse busy work with our real job: creating value with our brains
> _Thinking and understanding are the **non-negotiable prerequisites** to adding value and growing in your career, and they take time._

Take the following example,
> _Imagine you join a team as a newly minted Cloud Engineer and learn how to deploy apps using ArgoCD with a GitOps approach. The team lead shows you that ArgoCD monitors a target Git branch, ensuring the Kubernetes cluster's state matches it. You become an expert at managing this setup, rolling back deployments effortlessly by pointing to a previous branch state. But what happens when you join another team that uses Git tags instead of branches, or Flux instead of ArgoCD, or a completely different approach to Continuous Delivery? **Without understanding the high-level concepts, mechanisms, and reasons behind them, you won't be an effective team member.**_
Don’t be mistaken and think that you are there to simply maintain systems that have been created by others. You are paid to understand, think, adapt, learn, and improve. If you protect your capacity to focus, your capacity to learn will be intact. Keep on learning and you will always be valuable. Actually enjoy what you are learning? **Then you are unstoppable**.
### Rethink your week
To take full control of your career, understand how you want to grow, and get closer to producing quality work you'll be proud of decades from now, you need to prioritize the projects or "buckets" you dedicate your time to.
Often, **we unknowingly focus on too many projects at once**. We might be learning a new coding language while we start a new side project, writing a blog post here and there, all while handling the tasks that pop up on our works kanban board during the week. This approach needs to stop. You have to take a step back, identify the projects you want to prioritize and work on one, or at most, two at a time.

Not every job is flexible enough to let you work on what you want when you want to. However, if you have a clear idea of your professional priorities, you can align your tasks with these priorities and request them when they arise. As a junior, and even at higher levels, you'll have to do tasks you might not enjoy. But you can at least try to reduce the time spent on those tasks to focus on the work you want to excel at.
**Use Case:**
> _Suppose you have to balance two types of tasks: **internal developer support** (which you don't enjoy) and **implementing a new infrastructure provisioning platform using Account Factory for Terraform** (which excites you). You can plan uninterrupted blocks of time to work on your desired tasks and bundle the support-related tasks into other time blocks. Multitasking and sharing mental bandwidth between both tasks will reduce the quality of each._
A useful strategy that Mr. Newport talks about is having a visual and ordered task board separated by the **“holding tank“** which is planned work organized in order but that isn’t being worked on yet, the **“Active”** swim lane, which is what you are actually working on and the **“Done”** column, you are probably already using one. Apart from using the board to contain the tasks you have, make sure the tasks represent in real-time the order in which you will execute the tasks and the current tasks you are working on.
Make sure that anybody who asks you for new ad-hoc tasks during the week, make sure to communicate where in the task pool the tasks land and how long it will take to get to it. If an incoming task has to be pushed to the front on the line, make sure that you communicate to any potential stakeholders the delay this might incur to other tasks on the list.

## Your manager is your ally
You might feel guilty about approaching your manager with “selfish“ task preferences but you shouldn’t. It’s helpful to put yourself in the shoes of a manager, team lead or boss. If you are on their team, almost always the boss wants one thing from you.
> _**A manager simply wants you reduce the amount of stress they themselves have to carry.** A manager simply wants to have the confidence to that if you are tasked with something, that you are going to be able to take care of it._
A good manager will greatly appreciate a team member making a concerted effort to work in a systematic, communicative way that values quality over pseudo productivity. If you can communicate effectively to your manager the tasks you have on your plate, and the order in which you are going to deliver them, they can now rest assured that it will be done. It is then up to you to organize your day to make sure you deliver and preserve the confidence your manager has in you.

**Some ideas to bring up with your manager:**
> - Communicate goals and projects during 1:1 meetings.
- Align these goals with your company’s yearly career progression assesments.
- Take a look at the triage task channel before the triage meeting to see which tasks you will volunteer for.
- Request additional resources to assist you in creating quality work.
- Align on communication and time expantancy for replies if working remotely.
## Actionable tips
### Use time blocking, not to-do lists
Todo lists haven't ever fully worked for me, depending on how I'm feeling or how long I perceive a task might take, I often end up picking and choosing tasks, which leads to dragging out the ones I'm less excited about doing and pushing tasks endlessly from one day to the next.
**Time blocking, on the other hand, adds the missing structure lacking in to-do lists**. By planning exactly when you will do deep work, communicate with others, and rest, you’ll be surprised at the amount of quality time you have each day. Time blocking allows you to plan your week or day once, decide on your plan of action, and move through your day in a much more intentional way.
> _A good rule of thumb is to **book more time than you think you’ll need to complete a task**. We tend to underestimate how long tasks will take. If a task runs longer than expected, cross out the upcoming tasks and amend the schedule accordingly._
If you have a series of small tasks, bundle them and execute them in a designated time block. If you know you need to collaborate with others on a topic, block the time you will dedicate to communication and try your best to get it all done within that designated time. This way, you can then turn off notifications and reduce distractions when working on projects that require deep focus.
Mr. Newport is a big proponent of time blocking and even has a [time block planner you can buy](https://www.timeblockplanner.com/) to track four months' worth of work. Of course, you don’t need it to start time blocking yourself, but having a dedicated journal for this purpose can be handy. The journal also comes with more in-depth guides on how to make the most of this method of organizing work.

An added layer I like to incorporate into my time planner is pairing it with an online [Pomodoro timer](https://pomofocus.io/). I match each time-blocked segment to a Pomodoro of the same duration. During a Pomodoro session, no distractions are allowed. Only the task designated in the planner can be worked on during that time.
### Reduce meetings
For most of us, we don’t have the freedom to pick and choose when we have meetings. However, we can propose meeting-free days at least once a week. We can advocate for being more mindful of everyone's time if we see that meetings routinely go over the allotted time. Pushing to prepare for meetings is another way to influence the length of the meetings we are involved in.
Most people are equally underwhelmed by meetings and will appreciate their reduction, as long as the quality of the work and collaboration doesn’t suffer.
### Status updates, notification blocking, and phone restriction
Most IM platforms like Slack, Discord, and even your desktop and mobile devices, have status modes. **Use these status modes to communicate to others whether you are available for synchronous interaction or if you are in a deep work session.**
The added benefit is that these status modes also block or modify notification settings, reducing or even eliminating ping noises and pop-ups altogether. The cost of breaking deep focus time is high, so don’t feel bad for not being 100% available for real-time interactions all the time.

If you are still unsure about applying such strict restrictions, consider the findings is this study published in Nature magazine, which found that the simple presence of mobile devices reduces basal attentional performance.
### Track personal metrics
It’s hard to know if you are living up to your potential or if you are improving in the ways you care about unless you track some personal key metrics.
**These are the metrics I find useful to track are:**
- Exercise (did I exercise that day not).
- Deep hours worked.
- Healthy eating.
- Did I do the shutdown routine or not.

### Have a shutdown ritual
Cognitive capacity is a limited resource. Like our physical body, it needs time to recover and replenish, especially after productive workdays full of deep focus. You might feel tempted, due to notifications or out of habit, to look at your emails, check certain KPIs, or follow up on an open thread or a pesky task you weren’t able to fully complete.
With a shutdown routine, you can have tasks that allow you to appraise the work done during the day. If there are any open threads or tasks you need to carry over to the next day, the shutdown routine is the time to address them. Some possible shutdown routine tasks might be:
- Check emails.
- Check notifications.
- Update tickets.
- Communicate with teammates.
- Reviewing and noting any incomplete tasks.
- Add tasks or ideas to consider tomorrow.
- Check KPIs, and metrics for the last time.
- Update personal metrics.
### Schedule time for undistracted thinking
This has probably been one of the most difficult tips for me to apply personally, as I often justify constant podcast and audiobook consumption under the guise of "being informed" or simply "curious." The fact is, with so much interesting and relevant content out there, we run the risk of constantly consuming information. This practice can be counterproductive to maintaining a high capacity to focus. If you're constantly consuming content, there is less time to actually process what you're taking in.
**For me, scheduling undistracted thinking time has meant changing these behaviors:**
- Cooking my lunch without listening to anything
- Doing grocery shopping a few times a week without earphones
- No speakers booming while in the shower
- No phones in the bathroom, for that matter
Don't get me wrong, there is a time and place for consuming quality content. I will never stop listening to podcasts or audiobooks, but I will be much more attentive to allowing my brain uninterrupted time to just think.
### ChatGPT is really good at explaining things
We all know how incredibly influenced we are by the people around us. Hopefully, you'll have the experience of working with highly talented and experienced senior engineers in your career and learn from them. Consider ChatGPT a senior engineer who is always sitting right next to you, ready to help you understand the issue at hand.
**Notice that I recommend treating ChatGPT as a senior teammate and not as a personal assistant.** You wouldn’t ask a senior team member to do the work for you, instead, you would ask for explanations if you lack understanding of certain topics.
Of course, be aware that the current state of the art in LLMs still tends to hallucinate, so you shouldn't take its output to the bank. However, using LLMs as tools to work through complex concepts and gain a deeper understanding is a cheat code older generations could only dream of.
### Conclusion
If I were a young junior engineer starting my career now, I would probably feel unsettled by the many conflicting signals out there. **Will AI take my job? How can I stand out among so many other talented up-and-comers? How can I keep my skills sharp and relevant?** If you have these anxiety-filled thoughts, it's okay. It's entirely valid to feel unsure, and believe me, you are not alone in second-guessing your career decisions.
Nobody knows what the tech field will look like in ten years, five years, or even one year from now. Since we can't control the future, focus on what you can control. Inspired by Cal Newport's principles, the closest antidote to uncertainty is self-investment.
**You are your biggest asset.** Your capacity to produce quality work will keep you relevant in the workplace. Quality work requires understanding that cognitive effort is finite. It isn't done in a rush, and distractions sap your ability to focus. Bad cognitive habits can completely throw you off your stride.
Take a step back, inhale deeply, and envision a long, evolving career. Remember that no single day is especially important. Work at a pace that prioritizes understanding and constructive thinking over simply completing tasks. **The systems you put in place and the priorities you choose to protect will lay the foundation for a career you will look back on with pride.**
---
## Help us make more content like this!
At [Glasskube](https://github.com/glasskube/glasskube) we're putting a lot of effort into content just like this, as well as building the `next generation package manager for Kubernetes`.
If you get value from the work we do, we'd appreciate it if you could
[⭐️ Star Glasskube on GitHub 🙏](https://github.com/glasskube/glasskube)
[](https://github.com/glasskube/glasskube) | jakepage91 |
1,875,344 | Understanding AJAX | What is AJAX? AJAX, which stands for "Asynchronous JavaScript and XML," is a set of web... | 0 | 2024-06-03T12:33:31 | https://dev.to/vyan/understanding-ajax-204h | webdev, javascript, beginners, react | ## What is AJAX?
AJAX, which stands for "Asynchronous JavaScript and XML," is a set of web development techniques used to create dynamic and interactive web applications. It allows you to send and receive data from a web server without having to reload the entire web page.
AJAX is a fundamental concept for building modern web applications, and it involves a combination of several technologies, including JavaScript, XML, and various web APIs. In this detailed explanation, I'll cover the key aspects of AJAX.
## 1. Introduction to AJAX
- **AJAX** is not a single technology but a combination of multiple technologies working together to enable asynchronous communication between a web browser and a web server.
- The primary goal of AJAX is to enhance the user experience by making web pages more interactive and responsive.
## 2. Technologies Involved
- **HTML/CSS**: These are the foundational technologies for web pages and are used to structure content and define the page's layout and style.
- **JavaScript**: JavaScript is the programming language that enables dynamic and interactive features on web pages.
- **XML (Extensible Markup Language)**: While the 'X' in AJAX originally stood for XML, JSON (JavaScript Object Notation) has largely replaced XML as the preferred data format in modern web applications due to its simplicity and efficiency.
## 3. How AJAX Works
- **AJAX** uses JavaScript to make asynchronous HTTP requests to a web server.
- These requests can be GET (retrieve data) or POST (send data to the server).
- The server processes the request and sends a response, typically in JSON or XML format.
- JavaScript then handles the response and updates the web page's content without requiring a full page refresh.
### Example: Fetching Data with AJAX
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AJAX Example</title>
</head>
<body>
<h1>AJAX Example</h1>
<button id="fetchDataBtn">Fetch Data</button>
<div id="dataContainer"></div>
<script>
document.getElementById('fetchDataBtn').addEventListener('click', fetchData);
function fetchData() {
const xhr = new XMLHttpRequest();
xhr.open('GET', 'https://jsonplaceholder.typicode.com/posts/1', true);
xhr.onload = function() {
if (this.status === 200) {
const data = JSON.parse(this.responseText);
document.getElementById('dataContainer').innerHTML = `
<h2>${data.title}</h2>
<p>${data.body}</p>
`;
}
};
xhr.send();
}
</script>
</body>
</html>
```
## 4. XMLHttpRequest Object
The XMLHttpRequest object is a core part of AJAX. It provides the ability to make HTTP requests from JavaScript.
## 5. Fetch API
The Fetch API is a more modern alternative to XMLHttpRequest. It provides a more straightforward and flexible way to make HTTP requests.
### Example: Fetching Data with Fetch API
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Fetch API Example</title>
</head>
<body>
<h1>Fetch API Example</h1>
<button id="fetchDataBtn">Fetch Data</button>
<div id="dataContainer"></div>
<script>
document.getElementById('fetchDataBtn').addEventListener('click', fetchData);
function fetchData() {
fetch('https://jsonplaceholder.typicode.com/posts/1')
.then(response => response.json())
.then(data => {
document.getElementById('dataContainer').innerHTML = `
<h2>${data.title}</h2>
<p>${data.body}</p>
`;
})
.catch(error => console.error('Error fetching data:', error));
}
</script>
</body>
</html>
```
## 6. Key Differences
- Fetch API is promise-based and provides a more modern and flexible approach for making network requests.
- AJAX relies on the older XMLHttpRequest object and uses event-based handling.
- Fetch API is well-suited for working with Promises, making it easier to manage asynchronous code.
- AJAX can be more challenging to work with due to its event-based nature and complex state transitions.
## 7. JSON (JavaScript Object Notation)
JSON is the most commonly used data format in modern AJAX applications. It is a lightweight and human-readable data interchange format.
## 8. Handling AJAX Responses
Once the server responds to an AJAX request, JavaScript processes the data and updates the web page. You can use various DOM manipulation techniques to display the retrieved data.
## 9. Libraries and Frameworks
Many JavaScript libraries and frameworks simplify AJAX operations, such as jQuery, Axios, and the built-in Fetch API.
## 10. Cross-Origin Requests
AJAX requests are subject to the same-origin policy, which restricts requests to the same domain by default. Cross-origin requests can be made using techniques like Cross-Origin Resource Sharing (CORS).
## 11. Security Considerations
AJAX can expose your application to security vulnerabilities if not implemented correctly. Be aware of issues like Cross-Site Scripting (XSS) and Cross-Site Request Forgery (CSRF) and take appropriate security measures.
## 12. Use Cases
AJAX is commonly used for features like form validation, real-time chat, auto-suggestions, and updating parts of a page without a full reload.
## Conclusion
AJAX is a powerful tool for creating dynamic and responsive web applications, but it should be used judiciously. It's important to balance its benefits with potential complexities, especially when dealing with issues related to security and performance. By understanding AJAX and its various components, you can effectively enhance your web applications and provide a better user experience. | vyan |
1,875,343 | Руководство по Java 8 Stream API | В этом руководстве рассматривается практическое использование Java 8 Streams от создания до параллельного выполнения. | 0 | 2024-06-03T12:33:08 | https://dev.to/rinat_mambetov/rukovodstvo-po-java-8-stream-api-4nnn | java, streams | ---
title: Руководство по Java 8 Stream API
published: true
description: В этом руководстве рассматривается практическое использование Java 8 Streams от создания до параллельного выполнения.
tags: java, streams
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-03 12:19 +0000
---
[оригинал](https://www.baeldung.com/java-8-streams)
## 1. Обзор
В этом руководстве рассматривается практическое использование Java 8 Streams от создания до параллельного выполнения.
Чтобы понять этот материал, читателям необходимо иметь базовые знания о Java 8 (лямбда-выражения, Optional, ссылки на методы).
## 2. Создание потока
В Java существует множество способов создания экземпляра потока (Stream) из различных источников данных.
После создания экземпляра потока, он не изменяет исходный источник данных. Это означает, что любые операции, выполняемые над потоком (например, фильтрация, маппинг, сортировка), не влияют на сам исходный набор данных. Это обеспечивает безопасность данных и предотвращает нежелательные побочные эффекты.
Благодаря тому, что потоки не модифицируют исходные данные, из одного и того же источника можно создать несколько потоков. Это позволяет одновременно выполнять различные операции обработки данных над одним и тем же набором данных без изменения исходных данных.
### 2.1. Пустой поток
Мы должны использовать метод empty() для создания пустого потока:
```
Stream<String> streamEmpty = Stream.empty();
```
Мы часто используем метод empty() при создании, чтобы избежать возврата null для потоков без элементов:
```
public Stream<String> streamOf(List<String> list) {
return list == null || list.isEmpty() ? Stream.empty() : list.stream();
}
```
### 2.2. Поток коллекции
Мы также можем создать поток из любого типа Collection (Collection, List, Set):
```
Collection<String> collection = Arrays.asList("a", "b", "c");
Stream<String> streamOfCollection = collection.stream();
```
### 2.3. Поток массива
Массив также может быть источником потока:
```
Stream<String> streamOfArray = Stream.of("a", "b", "c");
```
Мы также можем создать stream из существующего массива или части массива:
```
String[] arr = new String[]{"a", "b", "c"};
Stream<String> streamOfArrayFull = Arrays.stream(arr);
Stream<String> streamOfArrayPart = Arrays.stream(arr, 1, 3); // "b" "c"
```
### 2.4. Stream.builder()
Желаемый тип должен быть дополнительно указан в правой части инструкции,Когда используется builder, в противном случае метод build() создаст экземпляр Stream\<Object>:
```
Stream<String> streamBuilder =
Stream.<String>builder().add("a").add("b").add("c").build();
```
### 2.5. Stream.generate()
Метод generate() принимает Supplier\<T> для генерации элемента. Поскольку результирующий поток бесконечен, разработчик должен указать желаемый размер, иначе метод generate() будет работать до тех пор, пока не достигнет предела памяти:
```
Stream<String> streamGenerated =
Stream.generate(() -> "element").limit(10);
```
Приведенный выше код создает последовательность из десяти строк со значением "element".
### 2.6. Stream.iterate()
Другой способ создания бесконечного потока - это использование метода iterate():
```
Stream<Integer> streamIterated = Stream.iterate(40, n -> n + 2).limit(20);
```
Первый элемент результирующего stream является первым параметром метода iterate(). При создании каждого следующего элемента указанная функция применяется к предыдущему элементу. В приведенном выше примере вторым элементом будет 42.
### 2.7. Поток примитивов
Java 8 предлагает возможность создавать потоки из трех примитивных типов: int, long и double. Поскольку Stream\<T> является универсальным интерфейсом, и нет способа использовать примитивы в качестве параметра типа с generics, были созданы три новых специальных интерфейса: IntStream, LongStream, DoubleStream.
Использование новых интерфейсов устраняет ненужную автоматическую упауовку, что позволяет повысить производительность:
```
IntStream intStream = IntStream.range(1, 3);
LongStream longStream = LongStream.rangeClosed(1, 3);
```
Метод range(int startInclusive, int endExclusive) создает упорядоченный поток от первого параметра ко второму параметру. Оно увеличивает значение последующих элементов с шагом, равным 1. Результат не включает последний параметр, это просто верхняя граница последовательности.
Метод rangeClosed(int startInclusive, int endInclusive) выполняет то же самое, только с одним отличием, включен второй элемент. Мы можем использовать эти два метода для генерации любого из трех типов потоков примитивов.
Начиная с Java 8, класс Random предоставляет широкий спектр методов для генерации потоков примитивов. Например, следующий код создает DoubleStream, который состоит из трех элементов:
```
Random random = new Random();
DoubleStream doubleStream = random.doubles(3);
```
### 2.8. Поток строк
Мы также можем использовать String в качестве источника для создания потока с помощью метода chars() класса String. Поскольку в JDK нет интерфейса для CharStream , мы используем IntStream вместо этого для представления потока символов.
```
IntStream streamOfChars = "abc".chars();
```
Следующий пример разбивает строку на подстроки в соответствии с указанным регулярным выражением:
```
Stream<String> streamOfString =
Pattern.compile(", ").splitAsStream("a, b, c");
```
### 2.9. Поток файлов
Кроме того, Java NIO класс Files позволяет нам генерировать Stream\<String> текстового файла с помощью метода lines(). Каждая строка текста становится элементом потока:
```
Path path = Paths.get("C:\\file.txt");
Stream<String> streamOfStrings = Files.lines(path);
Stream<String> streamWithCharset =
Files.lines(path, Charset.forName("UTF-8"));
```
Кодировка может быть указана в качестве аргумента метода lines().
## 3. Ссылка на поток
Мы можем создать экземпляр потока и иметь доступную ссылку на него, если вызываются только промежуточные операции. Выполнение терминальной операции делает поток недоступным.
Чтобы продемонстрировать это, мы ненадолго забудем, что наилучшей практикой является объединение последовательности операций в цепочку. Помимо ненужной многословности, технически следующий код допустим:
```
Stream<String> stream =
Stream.of("a", "b", "c").filter(element -> element.contains("b"));
Optional<String> anyElement = stream.findAny();
```
Однако попытка повторно использовать ту же ссылку после вызова операции терминала вызовет исключение IllegalStateException:
```
Optional<String> firstElement = stream.findFirst();
```
Поскольку исключение IllegalStateException является исключением RuntimeException, компилятор не будет сигнализировать о проблеме. Поэтому очень важно помнить, что потоки Java 8 нельзя использовать повторно.
Такое поведение логично. Мы разработали streams для применения конечной последовательности операций к источнику элементов в функциональном стиле, а не для хранения элементов.
Итак, чтобы предыдущий код работал должным образом, необходимо внести некоторые изменения:
```
List<String> elements =
Stream.of("a", "b", "c").filter(element -> element.contains("b"))
.collect(Collectors.toList());
Optional<String> anyElement = elements.stream().findAny();
Optional<String> firstElement = elements.stream().findFirst();
```
## 4. Потоковый конвейер
Для выполнения последовательности операций над элементами источника данных и агрегирования их результатов нам понадобятся три части: исходный код, промежуточные операции и терминальная операция.
Промежуточные операции возвращают новый измененный поток. Например, чтобы создать новый поток вместо существующего без нескольких элементов, следует использовать метод skip():
```
Stream<String> onceModifiedStream =
Stream.of("abcd", "bbcd", "cbcd").skip(1);
```
Если нам нужно больше одной модификации, мы можем связать промежуточные операции. Давайте предположим, что нам также нужно заменить каждый элемент текущего Stream\<String> подстрокой из первых нескольких символов. Мы можем сделать это, объединив методы skip() и map():
```
Stream<String> twiceModifiedStream =
stream.skip(1).map(element -> element.substring(0, 3));
```
Поток сам по себе ничего не стоит; пользователя интересует результат операции терминала, который может быть значением некоторого типа или действием, применяемым к каждому элементу потока. Мы можем использовать только одну терминальную операцию для каждого потока.
Правильный и наиболее удобный способ использования потоков - это конвейер потока, который представляет собой цепочку из источника потока, промежуточных операций и терминальной операции:
```
List<String> list = Arrays.asList("abc1", "abc2", "abc3");
long size = list.stream().skip(1)
.map(element -> element.substring(0, 3)).sorted().count();
```
## 5. Отложенный вызов
Промежуточные операции являются ленивыми. Это означает, что они будут вызываться только в том случае, если это необходимо для выполнения терминальной операции.
Например, давайте вызовем метод wasCalled(), который увеличивает внутренний счетчик при каждом вызове:
```
private long counter;
private void wasCalled() {
counter++;
}
```
Теперь давайте вызовем метод, который был вызван() из операции filter():
```
List<String> list = Arrays.asList(“abc1”, “abc2”, “abc3”);
counter = 0;
Stream<String> stream = list.stream().filter(element -> {
wasCalled();
return element.contains("2");
});
```
Поскольку у нас есть источник из трех элементов, мы можем предположить, что метод filter() будет вызван три раза, а значение переменной counter будет равно 3. Однако выполнение этого кода вообще не изменяет счетчик , он по-прежнему равен нулю, поэтому метод filter() даже не был вызван ни разу. Причина, это отсутствие терминальной операции.
Давайте немного перепишем этот код, добавив операцию map() и терминальную операцию, findFirst(). Мы также добавим возможность отслеживать порядок вызовов методов с помощью ведения журнала:
```
Optional<String> stream = list.stream().filter(element -> {
log.info("filter() was called");
return element.contains("2");
}).map(element -> {
log.info("map() was called");
return element.toUpperCase();
}).findFirst();
```
Результирующий журнал показывает, что мы дважды вызывали метод filter() и один раз метод map() . Это потому, что конвейер выполняется вертикально. В нашем примере первый элемент stream не удовлетворял предикату filter. Затем мы вызвали метод filter() для второго элемента, который прошел фильтр. Не вызывая filter() для третьего элемента, мы перешли по конвейеру к методу map().
Операция findFirst() удовлетворяет только одному элементу. Итак, в этом конкретном примере отложенный вызов позволил нам избежать двух вызовов метода, одного для filter() (для третьего элемента) и одного для map() (для первого элемента).
## 6. Порядок выполнения
С точки зрения производительности, правильный порядок является одним из наиболее важных аспектов операций объединения в цепочку в конвейере stream:
```
long size = list.stream().map(element -> {
wasCalled();
return element.substring(0, 3);
}).skip(2).count();
```
Выполнение этого кода увеличит значение счетчика на три. Это означает, что мы вызвали метод stream три раза, но значение size равно единице. Итак, результирующий поток содержит только один элемент, и мы выполнили дорогостоящие операции map() без причины два раза из трех.
Если мы изменим порядок методов skip() и map(), то счетчик увеличится всего на единицу. Итак, мы вызовем метод map() только один раз:
```
long size = list.stream().skip(2).map(element -> {
wasCalled();
return element.substring(0, 3);
}).count();
```
Это подводит нас к следующему правилу: промежуточные операции, которые уменьшают размер потока, должны быть размещены перед операциями, которые применяются к каждому элементу. Итак, нам нужно сохранить такие методы, как skip(), filter(), и distinct() в верхней части нашего конвейера stream.
## 7. Сокращение потока
API имеет множество терминальных операций, которые сводят поток к типу или примитиву: count(), max(), min(), и sum(). Однако эти операции работают в соответствии с предопределенной реализацией. Ну и что, если разработчику необходимо настроить механизм сокращения потока? Есть два метода, которые позволяют нам сделать это, методы reduce() и collect().
### 7.1. Метод reduce() (объединение)
Существует три варианта этого метода, которые отличаются своими сигнатурами и типами возвращаемых данных. Они могут иметь следующие параметры:
identity – начальное значение для накопителя или значение по умолчанию, если поток пуст и накапливать нечего
accumulator – функция, которая определяет логику агрегирования элементов. Поскольку accumulator создает новое значение для каждого шага объединения, количество новых значений равно размеру потока, и полезно только последнее значение. Это не очень хорошо сказывается на производительности.
combiner – функция, которая агрегирует результаты сумматора. Мы вызываем combiner только в параллельном режиме, чтобы объединить результаты accumulators из разных потоков.
Теперь давайте посмотрим на эти три метода в действии:
```
OptionalInt reduced =
IntStream.range(1, 4).reduce((a, b) -> a + b); // 6 (1 + 2 + 3)
```
```
int reducedTwoParams =
IntStream.range(1, 4).reduce(10, (a, b) -> a + b); // 16 (10 + 1 + 2 + 3)
```
```
int reducedParams = Stream.of(1, 2, 3)
.reduce(10, (a, b) -> a + b, (a, b) -> {
log.info("combiner was called");
return a + b;
});
```
Результат будет таким же, как в предыдущем примере (16), и логирования не будет, что означает, что combiner не вызывался. Чтобы combiner работал, поток должен быть параллельным:
```
int reducedParallel = Arrays.asList(1, 2, 3).parallelStream()
.reduce(10, (a, b) -> a + b, (a, b) -> {
log.info("combiner was called");
return a + b;
});
```
Результат здесь другой (36), и combiner вызывался дважды. Здесь объединение выполняется по следующему алгоритму: накопитель запускается три раза путем добавления каждого элемента потока к identity. Эти действия выполняются параллельно. В результате у них получилось (10 + 1 = 11; 10 + 2 = 12; 10 + 3 = 13;). Теперь combiner может объединить эти три результата. Для этого требуется две итерации (12 + 13 = 25; 25 + 11 = 36).
### 7.2. Метод collect()
Объединение потока также может быть выполнено с помощью другой терминальной операции, метода collect(). Он принимает аргумент типа Collector, который определяет механизм объединения. Для большинства распространенных операций уже созданы предопределенные коллекторы. К ним можно получить доступ с помощью типа Collectors.
В этом разделе мы будем использовать следующий список в качестве источника для всех потоков:
```
List<Product> productList = Arrays.asList(new Product(23, "potatoes"),
new Product(14, "orange"), new Product(13, "lemon"),
new Product(23, "bread"), new Product(13, "sugar"));
```
Преобразование потока в коллекцию (Collection, List или Set):
```
List<String> collectorCollection =
productList.stream().map(Product::getName).collect(Collectors.toList());
```
Объединение в строку:
```
String listToString = productList.stream().map(Product::getName)
.collect(Collectors.joining(", ", "[", "]"));
```
Метод joiner() может иметь от одного до трех параметров (разделитель, префикс, суффикс). Самое удобное в использовании joiner() заключается в том, что разработчику не нужно проверять, достигает ли поток своего конца, чтобы применить суффикс, а не разделитель. Коллектор позаботится об этом.
Обработка среднего значения всех числовых элементов потока:
```
double averagePrice = productList.stream()
.collect(Collectors.averagingInt(Product::getPrice));
```
Обработка суммы всех числовых элементов потока:
```
int summingPrice = productList.stream()
.collect(Collectors.summingInt(Product::getPrice));
```
Методы averagingXX(), summingXX() и summarizingXX() могут работать с примитивами (int, long, double) и с их классами-оболочками (Integer, Long, Double). Еще одной мощной функцией этих методов является обеспечение маппинга. В результате разработчику не нужно использовать дополнительную операцию map() перед методом collect().
Сбор статистической информации об элементах stream:
```
IntSummaryStatistics statistics = productList.stream()
.collect(Collectors.summarizingInt(Product::getPrice));
```
Используя результирующий экземпляр типа IntSummaryStatistics, разработчик может создать статистический отчет, применив метод toString(). Результатом будет строка, общая для этой “IntSummaryStatistics{count=5, sum=86, min=13, average=17200000, max=23}.”
Также легко извлечь из этого объекта отдельные значения для count, sum, min, и average, применив методы getCount(), getSum(), getMin(), getAverage(), и getMax(). Все эти значения могут быть извлечены из одного конвейера.
Группировка элементов stream в соответствии с указанной функцией:
```
Map<Integer, List<Product>> collectorMapOfLists = productList.stream()
.collect(Collectors.groupingBy(Product::getPrice));
```
В приведенном выше примере поток был сведен к Map, который группирует все продукты по их цене.
Разделение элементов stream на группы в соответствии с некоторым предикатом:
```
Map<Boolean, List<Product>> mapPartioned = productList.stream()
.collect(Collectors.partitioningBy(element -> element.getPrice() > 15));
```
Этот код использует потоки данных (Streams) для разделения списка продуктов (productList) на две группы на основе цены продукта. Результатом будет Map, где ключами являются Boolean значения (true или false), а значениями — списки продуктов, соответствующие этим ключам.
Приведение коллектора к дополнительному преобразованию:
```
Set<Product> unmodifiableSet = productList.stream()
.collect(Collectors.collectingAndThen(Collectors.toSet(),
Collections::unmodifiableSet));
```
В данном конкретном случае сборщик преобразовал stream в Set, а затем создал из него неизменяемый Set.
Кастомный сборщик:
Если по какой-либо причине необходимо создать кастомный коллектор, самый простой и наименее подробный способ сделать это - использовать метод of() типа Collector.
```
Collector<Product, ?, LinkedList<Product>> toLinkedList =
Collector.of(LinkedList::new, LinkedList::add,
(first, second) -> {
first.addAll(second);
return first;
});
LinkedList<Product> linkedListOfPersons =
productList.stream().collect(toLinkedList);
```
Метод of используется для создания экземпляра Collector. Первым аргументом является функция, которая создает аккумулятор (в нашем случае, новый LinkedList). Вторым аргументом — функция, которая добавляет элемент в аккумулятор. Третий аргумент — функция, объединяющая два аккумулятора в один. В данном случае, она просто добавляет все элементы из второго аккумулятора в первый. В этом примере экземпляр коллектора был объединен в LinkedList\<Product>.
## 8. Параллельные потоки
До появления Java 8 распараллеливание было сложным. Появление ExecutorService и forkJoin немного упростило жизнь разработчику, но все же стоило запомнить, как создать конкретный исполнитель, как его запускать и так далее. В Java 8 представлен способ реализации параллелизма в функциональном стиле.
API позволяет нам создавать параллельные потоки, которые выполняют операции в параллельном режиме. Если источником потока является коллекция или массив, этого можно достичь с помощью метода parallelStream():
```
Stream<Product> streamOfCollection = productList.parallelStream();
boolean isParallel = streamOfCollection.isParallel();
boolean bigPrice = streamOfCollection
.map(product -> product.getPrice() * 12)
.anyMatch(price -> price > 200);
```
Если источником потока является нечто иное, чем коллекция или массив, следует использовать метод parallel():
```
IntStream intStreamParallel = IntStream.range(1, 150).parallel();
boolean isParallel = intStreamParallel.isParallel();
```
По сути, Stream API автоматически использует платформу forkJoin для параллельного выполнения операций. По умолчанию будет использоваться общий пул потоков.
При использовании потоков в параллельном режиме избегайте блокирования операций. Также лучше использовать параллельный режим, когда для выполнения задач требуется аналогичное количество времени. Если одна задача длится намного дольше другой, это может замедлить рабочий процесс всего приложения.
Поток в параллельном режиме может быть преобразован обратно в последовательный режим с помощью метода sequential():
```
IntStream intStreamSequential = intStreamParallel.sequential();
boolean isParallel = intStreamSequential.isParallel();
```
## 9. Заключение
Stream API - это мощный, но простой для понимания набор инструментов для обработки последовательности элементов. При правильном использовании это позволяет нам сократить огромное количество шаблонного кода, создавать более читаемые программы и повышать производительность приложения.
В большинстве примеров кода, показанных в этой статье, мы оставили потоки неиспользованными (мы не применяли метод close() или терминальную операцию). В реальном приложении не оставляйте созданный поток неиспользованным, так как это приведет к утечке памяти.
| rinat_mambetov |
1,872,323 | Design Pattern - Singleton | O objetivo deste padrão é bem simples, garantir que apenas uma instância de uma determinada classe... | 27,199 | 2024-06-03T12:30:00 | https://nicolasdesouza.com/design-patterns-singleton | designpatterns, singleton, futebol | O objetivo deste padrão é bem simples, garantir que apenas uma instância de uma determinada classe seja criada.
Simples não?! Após padrões um tanto quanto confusos e complexos, parece até pegadinha mas é fato, realmente é simples. Mas quando isso pode ser aplicado?! Um exemplo comum são as situações de conexões com banco, normalmente não queremos ter N fontes de verdades sobre os dados, o que poderia ocasionar situações de conflito entre essas instâncias.
> Não vou me extender neste padrão, ele realmente é simples, deixarei algumas recomendações no final caso queira saber mais!
Ótimo, você já entendeu que o objetivo é criar apenas uma instância, mas como podemos fazer isso?! Algumas linguagens como C# permitem que "marquemos" determinados serviços como singleton quando realizamos a injeção de dependências, então talvez você já tenha visto algo como isso:
```cs
.AddSingleton<Interface, Class>()
```
Mas aqui quero falar um pouco mais sobre a ótica de criarmos uma classe que só possa ter uma instância e não sobre um serviço em si. Pensemos no seguinte, você está construindo um jogo de futebol, neste jogo teremos vários objetos que teremos um ou mais, como jogadores de linha, goleiros, bandeirinhas, mas teremos apenas uma objeto bola, apenas um objeto juíz...
Primeiro vamos criar nossa classe de interesse
```cs
public class Ball
{
private static Ball instance;
public string ImagePath { get; set; }
public string Weight { get; set; }
public double ElasticCoefficient { get; set; }
private Ball() { }
public static Ball GetInstance()
{
instance ??= new Ball(); // só é instanciado se instace é nula
return instance;
}
}
```
Agora vamos verificar se tudo ocorreu bem
```cs
using SingletonFootball;
var b1 = Ball.GetInstance();
var b2 = Ball.GetInstance();
if (b1 == b2)
Console.WriteLine("A mesma instância foi atribuída aos dois objetos");
else
Console.WriteLine("Instância diferentes foram atribuídas");
```
No console veremos:
```bash
A mesma instância foi atribuída aos dois objetos
```
Ótimo, funcionou!!! Mas aqui mora uma pegadinha, se por algum motivo estivermos trabalhando com Threads, teremos a possibilidade de várias rotinas acessarem simultaneamente obtendo várias instância, para corrigir isso precisamos realizar pequenas modificações em nosso código.
Para isso vamos implementar a classe Referee utilizando uma instrução chamada `lock`. A ideia é que a primeira instância a chave, irá bloquear que outras possíveis instâncias sejam iniciadas.
```cs
public class Referee
{
private static Referee instance;
public string Name { get; set; }
private static readonly object _lock = new object();
private Referee(){ }
public static Referee GetInstance(string value)
{
if (instance == null)
{
lock (_lock)
{
if (instance == null)
{
instance = new Referee();
instance.Name = value;
}
}
}
return instance;
}
}
```
Agora vamos testar o que implementamos
```cs
Thread process1 = new Thread(() => {
TestSingleton("George");
});
Thread process2 = new Thread(() => {
TestSingleton("Hamilton");
});
process1.Start();
process2.Start();
process1.Join();
process2.Join();
void TestSingleton(string value)
{
Referee Referee = Referee.GetInstance(value);
Console.WriteLine(Referee.Name);
}
```
Na saída teremos então:
```bash
George
George
```
Desse modo garantiremos que apenas uma instância será criada, mesmo quando utilizarmos threads para execução de tarefas.
## Repositório GIT
[Design Patterns](https://github.com/nicolas-souza/DesignPatterns)
## Materiais de Estudo
Estamos chegando ao fim do nosso artigo e queria deixar alguns materiais que usei para estudar esse padrão de software:
[Refactoring Guru](https://refactoring.guru/pt-br/design-patterns/builder)
[Dofactory](https://www.dofactory.com/net/builder-design-pattern)
[Higor Diego - Padrão - Singleton](https://dev.to/higordiego/padrao-singleton-4chj#:~:text=O%20padr%C3%A3o%20Singleton%20tem%20algumas,de%20verdade%20para%20um%20dado.)
[Balta - AddTransit, AddScopped, AddSingleton](https://balta.io/blog/addtransient-addscoped-addsingleton)
[Um pouco sobre a instrução lock](https://learn.microsoft.com/pt-br/dotnet/csharp/language-reference/statements/lock)
| nicolasdesouza |
1,875,340 | One-Line Code Analytics with AI Data Analyst | PT. 2 | Hi everyone, I'm Antonio, CEO at Litlyx. This post is the continuation of one I released earlier.... | 0 | 2024-06-03T12:29:24 | https://dev.to/litlyx/one-line-code-analytics-with-ai-data-analyst-pt-2-4icb | webdev, javascript, beginners, programming |
Hi everyone, I'm Antonio, CEO at [Litlyx](https://www.litlyx.com).
This post is the continuation of one I released earlier. PT. 1 can be found [here](https://dev.to/litlyx/one-line-code-analytics-with-ai-data-analyst-pt-1-4fb0).
I started posting on dev.to yesterday, and I'm excited to share our journey with our open-source project called [Litlyx](https://www.litlyx.com).
To be transparent, this series of posts aims to raise awareness about our product because we believe it can help many developers and founders.
You can find our open-source repo on [Github](https://github.com/Litlyx/litlyx), and we hope you'll share some love with us and provide constructive feedback.
**Kindly, leave a star to help us!** 🙏
And that's how our journey to build our SaaS [Litlyx](https://litlyx.com) began.
#
"Bro, we need to track more KPIs on our site or we will never know where to improve the product," I said during a 3 AM call to my co-founder and friend @Emily.
"Dude, you're right, but what should we use? Google Analytics, MixPanel, or something else?" he replied.
The most interesting part is that he wasn't even upset I called him at 3 AM. When something needs to be done, it works like this. He works even at night. Me too. There is no time that can stop us.
> [!NOTE]
> It's difficult to find that state of mind called work-life balance when you have three active projects, have tried eight since the start of the year, and are now trying to find product-market fit for a SaaS.
We tried to implement Google Analytics. Our platform was built with Vue and Nuxt, because like all devs, we love to use the latest technologies to develop new platforms.
However, we encountered a problem: every library we tried was from other devs, not Google itself. So we tried other solutions, but everything was just a wrapper of libraries developed by independent devs with no support or little/non-existent documentation.
So I said to Emily, "Okay, bro, we need to work even this night to create our custom analytics or we will never get out of this mess."
He started working while I went to sleep at 2 AM. He was relentless. The next morning, I woke up and saw he was still in the same Discord channel, working from the night before.
By the time I joined him, he had already laid the groundwork for our custom analytics tool. We spent the next few days fine-tuning it, ensuring it was tailored to our specific needs. The process was exhausting but rewarding.
In the end, we had a great product to track our custom analytics, and we were happy af!
Then the wake-up call, "Okay, bro, I think we have a great product here. We need to start creating awareness. This will save the life of a lot of people."
That's when we understood that we wanted to create a product so simple, yet effective, that it can change how analytics are tracked today.
In the next days, we will talk about the product.
In the meantime, share some love in the comments, please! I would love to hear from you! Drop a 🫰 in the comments below while waiting for part 3!
A, Founder at [Litlyx](https://litlyx.com)
| litlyx |
1,875,339 | One-Line Code Analytics with AI Data Analyst | PT. 2 | Hi everyone, I'm Antonio, CEO at Litlyx. This post is the continuation of one I released earlier.... | 0 | 2024-06-03T12:29:24 | https://dev.to/litlyx/one-line-code-analytics-with-ai-data-analyst-pt-2-1b7h | webdev, javascript, beginners, programming |
Hi everyone, I'm Antonio, CEO at [Litlyx](https://www.litlyx.com).
This post is the continuation of one I released earlier. PT. 1 can be found [here](https://dev.to/litlyx/one-line-code-analytics-with-ai-data-analyst-pt-1-4fb0).
I started posting on dev.to yesterday, and I'm excited to share our journey with our open-source project called [Litlyx](https://www.litlyx.com).
To be transparent, this series of posts aims to raise awareness about our product because we believe it can help many developers and founders.
You can find our open-source repo on [Github](https://github.com/Litlyx/litlyx), and we hope you'll share some love with us and provide constructive feedback.
**Kindly, leave a star to help us!** 🙏
And that's how our journey to build our SaaS [Litlyx](https://litlyx.com) began.
#
"Bro, we need to track more KPIs on our site or we will never know where to improve the product," I said during a 3 AM call to my co-founder and friend @Emily.
"Dude, you're right, but what should we use? Google Analytics, MixPanel, or something else?" he replied.
The most interesting part is that he wasn't even upset I called him at 3 AM. When something needs to be done, it works like this. He works even at night. Me too. There is no time that can stop us.
> [!NOTE]
> It's difficult to find that state of mind called work-life balance when you have three active projects, have tried eight since the start of the year, and are now trying to find product-market fit for a SaaS.
We tried to implement Google Analytics. Our platform was built with Vue and Nuxt, because like all devs, we love to use the latest technologies to develop new platforms.
However, we encountered a problem: every library we tried was from other devs, not Google itself. So we tried other solutions, but everything was just a wrapper of libraries developed by independent devs with no support or little/non-existent documentation.
So I said to Emily, "Okay, bro, we need to work even this night to create our custom analytics or we will never get out of this mess."
He started working while I went to sleep at 2 AM. He was relentless. The next morning, I woke up and saw he was still in the same Discord channel, working from the night before.
By the time I joined him, he had already laid the groundwork for our custom analytics tool. We spent the next few days fine-tuning it, ensuring it was tailored to our specific needs. The process was exhausting but rewarding.
In the end, we had a great product to track our custom analytics, and we were happy af!
Then the wake-up call, "Okay, bro, I think we have a great product here. We need to start creating awareness. This will save the life of a lot of people."
That's when we understood that we wanted to create a product so simple, yet effective, that it can change how analytics are tracked today.
In the next days, we will talk about the product.
In the meantime, share some love in the comments, please! I would love to hear from you! Drop a 🫰 in the comments below while waiting for part 3!
A, Founder at [Litlyx](https://litlyx.com)
| litlyx |
1,875,337 | Hallmark Treasor Gandipet Hyderabad | Hallmark Treasor | Hallmark Treasor is located in the prestigious Gandipet area of Hyderabad. This community provides a... | 0 | 2024-06-03T12:28:20 | https://dev.to/narendra_kumar_5138507a03/hallmark-treasor-gandipet-hyderabad-hallmark-treasor-h65 | realestate, realestateagent, realestateinvestment | Hallmark Treasor is located in the prestigious Gandipet area of Hyderabad. This community provides a peaceful retreat from the city's hustle and bustle while maintaining easy access to urban conveniences.

[Hallmark Treasor offers 3 BHK homes](https://hallmarkbuilders.co.in/treasor/) meticulously designed with exceptional quality and attention to detail. Each residence provides a sophisticated and serene living experience, featuring spacious interiors, lush green landscapes, and state-of-the-art amenities that elevate your lifestyle. Whether you seek elegance and comfort or a tranquil escape, Hallmark Treasor caters to all your needs.
Welcome to a home where every detail is crafted for your utmost delight, blending refined living with the perfect mix of serenity and convenience. Experience the joy and satisfaction of living in a thoughtfully designed community at Hallmark Treasor.
Contact us: 8595808895
| narendra_kumar_5138507a03 |
1,875,335 | Building an Employee Management System with GraphQL and Spring Boot | In today's rapidly evolving tech landscape, efficient data querying and manipulation are crucial.... | 0 | 2024-06-03T12:26:34 | https://dev.to/fullstackjava/building-an-employee-management-system-with-graphql-and-spring-boot-5dbp | webdev, programming, java, springboot | #
In today's rapidly evolving tech landscape, efficient data querying and manipulation are crucial. GraphQL, a query language for APIs, provides a more flexible and powerful alternative to REST. When combined with Spring Boot, a popular framework for building Java applications, you get a robust and efficient system for managing data. In this blog, we'll walk through building an Employee Management System using GraphQL and Spring Boot.
## Table of Contents
1. [Introduction to GraphQL and Spring Boot](#introduction-to-graphql-and-spring-boot)
2. [Setting Up the Project](#setting-up-the-project)
3. [Configuring Spring Boot and GraphQL](#configuring-spring-boot-and-graphql)
4. [Defining the GraphQL Schema](#defining-the-graphql-schema)
5. [Creating the Employee Entity](#creating-the-employee-entity)
6. [Building the Repository Layer](#building-the-repository-layer)
7. [Implementing the Service Layer](#implementing-the-service-layer)
8. [Developing GraphQL Resolvers](#developing-graphql-resolvers)
9. [Testing the API](#testing-the-api)
10. [Conclusion](#conclusion)
## Introduction to GraphQL and Spring Boot
**GraphQL** is a query language for APIs that allows clients to request exactly the data they need, making APIs fast and flexible. It was developed by Facebook and is now an open-source project.
**Spring Boot** is an open-source Java-based framework used to create microservices. It is easy to set up and enables rapid application development.
Combining these two technologies allows developers to build efficient and flexible data APIs.
## Setting Up the Project
First, ensure you have the necessary tools installed:
- JDK 11 or later
- Maven
- An IDE (IntelliJ IDEA, Eclipse, etc.)
Create a new Spring Boot project using Spring Initializr (https://start.spring.io/):
- Project: Maven Project
- Language: Java
- Spring Boot: Latest stable version
- Dependencies: Spring Web, Spring Data JPA, H2 Database, GraphQL Spring Boot Starter
Download the project and import it into your IDE.
## Configuring Spring Boot and GraphQL
In the `pom.xml` file, ensure the following dependencies are included:
```xml
<dependencies>
<!-- Spring Boot dependencies -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- H2 Database dependency -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<!-- GraphQL dependencies -->
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphiql-spring-boot-starter</artifactId>
</dependency>
</dependencies>
```
Configure the database in `src/main/resources/application.properties`:
```properties
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=password
spring.h2.console.enabled=true
spring.jpa.hibernate.ddl-auto=update
```
## Defining the GraphQL Schema
Create a directory `src/main/resources/graphql` and add a file `schema.graphqls`:
```graphql
type Query {
getAllEmployees: [Employee]
getEmployeeById(id: ID!): Employee
}
type Mutation {
createEmployee(employeeInput: EmployeeInput): Employee
updateEmployee(id: ID!, employeeInput: EmployeeInput): Employee
deleteEmployee(id: ID!): Boolean
}
type Employee {
id: ID!
firstName: String!
lastName: String!
email: String!
department: String!
}
input EmployeeInput {
firstName: String!
lastName: String!
email: String!
department: String!
}
```
## Creating the Employee Entity
Define the `Employee` entity in `src/main/java/com/example/employeemanagement/model/Employee.java`:
```java
package com.example.employeemanagement.model;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String firstName;
private String lastName;
private String email;
private String department;
// Getters and Setters
}
```
## Building the Repository Layer
Create the repository interface in `src/main/java/com/example/employeemanagement/repository/EmployeeRepository.java`:
```java
package com.example.employeemanagement.repository;
import com.example.employeemanagement.model.Employee;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface EmployeeRepository extends JpaRepository<Employee, Long> {
}
```
## Implementing the Service Layer
Create the service class in `src/main/java/com/example/employeemanagement/service/EmployeeService.java`:
```java
package com.example.employeemanagement.service;
import com.example.employeemanagement.model.Employee;
import com.example.employeemanagement.repository.EmployeeRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
@Service
public class EmployeeService {
@Autowired
private EmployeeRepository employeeRepository;
public List<Employee> getAllEmployees() {
return employeeRepository.findAll();
}
public Optional<Employee> getEmployeeById(Long id) {
return employeeRepository.findById(id);
}
public Employee createEmployee(Employee employee) {
return employeeRepository.save(employee);
}
public Employee updateEmployee(Long id, Employee employeeDetails) {
Employee employee = employeeRepository.findById(id).orElseThrow(() -> new RuntimeException("Employee not found"));
employee.setFirstName(employeeDetails.getFirstName());
employee.setLastName(employeeDetails.getLastName());
employee.setEmail(employeeDetails.getEmail());
employee.setDepartment(employeeDetails.getDepartment());
return employeeRepository.save(employee);
}
public boolean deleteEmployee(Long id) {
Employee employee = employeeRepository.findById(id).orElseThrow(() -> new RuntimeException("Employee not found"));
employeeRepository.delete(employee);
return true;
}
}
```
## Developing GraphQL Resolvers
Create the GraphQL resolvers in `src/main/java/com/example/employeemanagement/resolver`:
1. **Query Resolver**
```java
package com.example.employeemanagement.resolver;
import com.coxautodev.graphql.tools.GraphQLQueryResolver;
import com.example.employeemanagement.model.Employee;
import com.example.employeemanagement.service.EmployeeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class Query implements GraphQLQueryResolver {
@Autowired
private EmployeeService employeeService;
public List<Employee> getAllEmployees() {
return employeeService.getAllEmployees();
}
public Employee getEmployeeById(Long id) {
return employeeService.getEmployeeById(id).orElse(null);
}
}
```
2. **Mutation Resolver**
```java
package com.example.employeemanagement.resolver;
import com.coxautodev.graphql.tools.GraphQLMutationResolver;
import com.example.employeemanagement.model.Employee;
import com.example.employeemanagement.service.EmployeeService;
import com.example.employeemanagement.input.EmployeeInput;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class Mutation implements GraphQLMutationResolver {
@Autowired
private EmployeeService employeeService;
public Employee createEmployee(EmployeeInput employeeInput) {
Employee employee = new Employee();
employee.setFirstName(employeeInput.getFirstName());
employee.setLastName(employeeInput.getLastName());
employee.setEmail(employeeInput.getEmail());
employee.setDepartment(employeeInput.getDepartment());
return employeeService.createEmployee(employee);
}
public Employee updateEmployee(Long id, EmployeeInput employeeInput) {
Employee employeeDetails = new Employee();
employeeDetails.setFirstName(employeeInput.getFirstName());
employeeDetails.setLastName(employeeInput.getLastName());
employeeDetails.setEmail(employeeInput.getEmail());
employeeDetails.setDepartment(employeeInput.getDepartment());
return employeeService.updateEmployee(id, employeeDetails);
}
public boolean deleteEmployee(Long id) {
return employeeService.deleteEmployee(id);
}
}
```
3. **Employee Input Class**
```java
package com.example.employeemanagement.input;
public class EmployeeInput {
private String firstName;
private String lastName;
private String email;
private String department;
// Getters and Setters
}
```
## Testing the API
Run the application using your IDE or by executing `mvn spring-boot:run` in the terminal.
Open your browser and navigate to `http://localhost:8080/graphiql` to access the GraphiQL interface for testing GraphQL queries and mutations.
**Sample Queries:**
- Get all employees
:
```graphql
query {
getAllEmployees {
id
firstName
lastName
email
department
}
}
```
- Get an employee by ID:
```graphql
query {
getEmployeeById(id: 1) {
id
firstName
lastName
email
department
}
}
```
**Sample Mutations:**
- Create an employee:
```graphql
mutation {
createEmployee(employeeInput: {
firstName: "John"
lastName: "Doe"
email: "john.doe@example.com"
department: "Engineering"
}) {
id
firstName
lastName
email
department
}
}
```
- Update an employee:
```graphql
mutation {
updateEmployee(id: 1, employeeInput: {
firstName: "Jane"
lastName: "Doe"
email: "jane.doe@example.com"
department: "HR"
}) {
id
firstName
lastName
email
department
}
}
```
- Delete an employee:
```graphql
mutation {
deleteEmployee(id: 1)
}
```
## Conclusion
In this blog, we walked through building an Employee Management System using GraphQL and Spring Boot. We covered setting up the project, configuring GraphQL, defining the schema, creating entities, building the repository and service layers, implementing GraphQL resolvers, and testing the API. This combination of technologies provides a powerful and flexible way to handle data in modern applications. | fullstackjava |
1,875,333 | On-Call Cookbook | Responsabilidades do On-Call | 0 | 2024-06-03T12:23:28 | https://dev.to/espigah/on-call-cookbook-2j24 | sre, devops, softwareengineering | ---
title: On-Call Cookbook
published: true
description: Responsabilidades do On-Call
tags: sre, devops, softwareengineering
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/5dp0udzo1xh35aftvj1z.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-03 12:01 +0000
---
### On-Call Cookbook
#### Objetivo
Este cookbook fornece diretrizes práticas para a organização de um esquema de on-call(guardião, plantão, motorista da rodada e etc) eficiente e resiliente, com base nas melhores práticas de Site Reliability Engineering (SRE).
Se você quiser saber mais sobre On-Call, sugiro a leitura do [post anterior](https://dev.to/espigah/desvendando-o-mundo-do-on-call-desafios-e-estrategias-para-uma-operacao-eficiente-33bk).
#### Definição e Escopo
O on-call durante o expediente refere-se a períodos em que os membros da equipe estão disponíveis para responder a incidentes e alertas durante o horário de trabalho normal. Isso difere de sobreaviso ou plantão, que geralmente envolvem disponibilidade fora do horário de trabalho.
### Coisas que uma Pessoa de On-Call Deve Fazer
1. **Monitoramento de Sistemas:** Verifique painéis de monitoramento e responda a alertas de desempenho, disponibilidade e erros.
2. **Responder a Incidentes:** Responda prontamente a alertas e chamados, diagnostique e resolva problemas rapidamente.
3. **Comunicação:** Mantenha uma comunicação clara e eficiente com a equipe, stakeholders e outros departamentos afetados pelos incidentes.
4. **Documentação:** Documente os incidentes e as ações tomadas para resolvê-los, para referência futura e aprendizado.
5. **Análise de Logs:** Analise logs de servidores, aplicações e redes para identificar causas raiz de problemas.
6. **Escalonamento de Problemas:** Saiba quando e como escalar problemas para níveis superiores ou outras equipes especializadas.
7. **Manutenção Preventiva:** Realize verificações regulares de sistemas e infraestrutura para prevenir problemas antes que eles ocorram.
8. **Atualizações e Patches:** Aplique atualizações e patches de segurança para manter o ambiente seguro e estável.
9. **Backup e Recuperação:** Garanta que os backups estejam sendo feitos corretamente e teste os processos de recuperação.
10. **Revisão Pós-Incidente:** Participe de revisões pós-incidente para analisar o que aconteceu e como melhorar no futuro.
### Formas de Organizar o On-Call
1. **Escalas Rotativas:** Crie um cronograma de on-call rotativo para distribuir a carga de trabalho de maneira justa entre todos os membros da equipe.
2. **Ferramentas de Monitoramento e Alerta:** Utilize ferramentas para gerenciar alertas e escalonamentos de forma eficiente.
3. **Runbooks e Playbooks:** Desenvolva e mantenha runbooks e playbooks detalhados para guiar a equipe de on-call em diferentes tipos de incidentes.
4. **Reuniões Regulares:** Realize reuniões regulares de revisão de on-call para discutir incidentes recentes, melhorias no processo e feedback.
5. **Treinamento e Desenvolvimento:** Prover treinamentos contínuos para a equipe de on-call, incluindo simulações de incidentes e workshops de novas tecnologias ou processos.
6. **Documentação Centralizada:** Mantenha uma base de conhecimento centralizada onde todos os procedimentos, runbooks e documentação de sistemas estejam acessíveis.
7. **Balanceamento de Carga:** Analise a carga de incidentes e ajuste as escalas de on-call para garantir que nenhum membro da equipe fique sobrecarregado.
8. **Ferramentas de Comunicação:** Utilize ferramentas de comunicação eficientes para coordenar a resposta a incidentes.
9. **Feedback Contínuo:** Implemente um sistema de feedback contínuo para que os membros da equipe possam sugerir melhorias e relatar problemas com o processo de on-call.
10. **Automatização:** Automatize tarefas repetitivas e processos de monitoramento para reduzir a carga de trabalho manual durante os períodos de on-call.
### Hands-On / Hands-Off
1. **Transferência de Conhecimento:** No período de hands-off, compartilhe informações detalhadas sobre quaisquer problemas em andamento ou potenciais riscos.
2. **Documentação Atualizada:** Assegure que toda a documentação relevante está atualizada e acessível antes de finalizar o turno.
3. **Briefing de Transferência:** Realize um briefing rápido para o próximo on-call, destacando pontos críticos e status atual.
4. **Evitar o Término no Último Dia da Semana:** Planeje o término do on-call para o meio da semana, como quarta ou quinta-feira, para facilitar a transição de responsabilidades e permitir tempo para resolver problemas em andamento antes do final de semana.
### Conclusão
Seguindo estas práticas, você poderá criar um ambiente on-call eficiente e resiliente, garantindo que sua equipe esteja bem preparada para lidar com incidentes e manter a alta disponibilidade dos sistemas.
| espigah |
1,875,334 | Meme Monday | Meme Monday! Today's cover image comes from last week's thread. DEV is an inclusive space! Humor in... | 0 | 2024-06-03T12:23:28 | https://dev.to/ben/meme-monday-f28 | jokes, discuss, watercooler | **Meme Monday!**
Today's cover image comes from [last week's thread](https://dev.to/ben/meme-monday-4l95).
DEV is an inclusive space! Humor in poor taste will be downvoted by mods. | ben |
1,875,329 | WisePhone 2 Review 2024 | A Minimalist phone, the Wisephone 2 makes the vision of people-centered, healthy technology a... | 0 | 2024-06-03T12:19:46 | https://dev.to/vokeme/wisephone-2-review-2024-17g4 | wisephone, techless, techlesswisephone, minimalphone | A Minimalist phone, the Wisephone 2 makes the vision of people-centered, healthy technology a reality. WiseOS and its collection of carefully selected tools embrace a fundamentally new concept.

Techless is selling Wisephone II for a fee with a Techless subscription that allows you to use all the features of WiseOS.
WisePhone 2 Specification
- 1.
- 2. It comes with a full 6.5-inches large HD display with 1080 x 1920 pixels
- 3. Mediatek P70 processor
- 4. With a 64MP primary triple camera with 2MP macro, 8MP wide-angle, and 13MP front camera (selfie) for high-quality photos and videos
- 5. Beautiful design with premium glass and aluminum construction
- 6. 4GB of RAM and 128GB of storage to keep your things safe with expandable up to 256GB via MicroSD
- 7. USB-C for fast charging
- 8. With a 4100mAh of long-lasting battery
- 9. WiseOS operating system
- 10. Wifi (no browser) and Bluetooth connectivity.
**Wisephone 2 Release Date
**
We expect Wisephone 2 to be released and ship in summer 2024. Keep in mind that pre-orders are fully refundable until the Wisephone II ships.
**Wisephone II Price
**
The Wise Phone 2 will be available for pre-order at $399. Take advantage of the early sales on the Techless website.
You can save $75 more if you order WisePhone 2 through this link.
**[Check Price](https://techless.com/discount/VOKEME?redirect=/pages/wisephone-ii?aff=VOKEME)
**
## Wise Phone 2 Review
Wise Phone 2 is a new phone that fulfills its original mission of giving you back your life. The all-new 64MP primary camera captures incredible detail.
Listen to your favorite with the new music app with 128GB of storage music. With the Mediatek P70 processor, you can use the map to find where you need to go.
All this in a package that boasts a 4100mAh extended battery life and a promise that they will never sell or spy on your data. For fast charging, there is a USB-C charging port.
## Features of Techless Wisephone 2
Minimalist design: A simple interface with no distractions, no social media apps, and no web browser.
Focus on the essential tools: phone calls, text messaging, maps, music player, camera, and a limited, curated selection of apps.
E-ink display: Gentle on the eyes and reduces blue light exposure.
Monotone color scheme: further reduces distraction and eye strain.
Parental Controls: Manage your children's use and access to apps.
Subscription-based OS: Provides access to new features and updates over time.
What is the difference between Wisephone 1 and Wisephone 2 phones?
They have packed everything we know and love about Wisephone into a new hardware platform. Wisephone II represents a fundamental change from a minimalist phone to a healthy phone.
Wisephone II has a 64MP main, 2MP macro, and 8MP wide angle. Everything about the Wisephone II camera is upgraded over the Wisephone, delivering higher resolution photos and videos.
https://techless.com/discount/VOKEME?redirect=/pages/wisephone-ii?aff=VOKEME
Conclusion
Wise Phone 2 may be a good option if you're looking to escape the digital world and focus on what's important. But if you need a phone with all the features and access to all the latest apps, you might be better off sticking with a traditional smartphone.
FAQs
Why does Wisephone II have a monthly subscription?
Wisephone II's monthly subscription is part of Techless' disruptive approach to the attention economy. Unlike other phones heavily subsidized by carriers, advertising, and application stores, they decided to charge less for the premium phones themselves and offer subscriptions to the services provided by WiseOS.
This subscription, starting at $25 per month, includes Techless carrier plans, ensuring a stable and optimal experience for all Wisephone users.
This approach allows us to respect your interests by avoiding traditional revenue models that compromise the user experience.
Is cellular service included in my monthly subscription?
Yes, Wisephone II's monthly subscription includes cellular service. We're excited to offer exclusive bundled cellular/subscription plans starting at $25 monthly. This ensures maximum reliability and optimal experience for all Wisephone users. | vokeme |
1,875,328 | Learn machine learning with Microsoft learn | Hey everyone, Himel here, check out these 5 Microsoft Must-Do Introductory Learning paths on... | 0 | 2024-06-03T12:19:02 | https://dev.to/hasanul_banna_himel/learn-machine-learning-with-microsoft-learn-2ekn | machinelearning, microsoft, learning | Hey everyone, Himel here, check out these 5 [Microsoft](https://learn.microsoft.com/) Must-Do Introductory Learning paths on #MachineLearning that is Absolutely FREE!
1. [Introduction to machine learning](https://learn.microsoft.com/training/modules/introduction-to-machine-learning/?wt.mc_id=studentamb_322573): Introductory course to grasp introductory concepts for machine learning
2. [Fundamentals of machine learning](https://learn.microsoft.com/en-us/training/modules/fundamentals-machine-learning/?wt.mc_id=studentamb_322573): Machine learning is the basis for most modern artificial intelligence solutions. A familiarity with the core concepts on which machine learning is based is an important foundation for understanding AI..

3. [Create machine learning models](https://learn.microsoft.com/training/paths/create-machine-learn-models/?wt.mc_id=studentamb_322573): From the most basic classical machine learning models, to exploratory data analysis and customizing architectures, you’ll be guided by easy to digest conceptual content and interactive Jupyter notebooks, all without leaving your browser.
4. [Introduction to PyTorch](https://learn.microsoft.com/en-us/training/modules/intro-machine-learning-pytorch/?WT.mc_id=studentamb_322573): Learn key concepts used to build machine learning models with PyTorch. We'll train a neural network model that recognizes and classifies images.
5. [Introduction to data for machine learning](https://learn.microsoft.com/en-us/training/modules/introduction-to-data-for-machine-learning/?WT.mc_id=studentamb_322573):
The power of machine learning models comes from the data that is used to train them. Through content and exercises, we explore how to understand your data, how to encode it so that the computer can interpret it properly, how to clean any errors, and tips that will help you create high performance models.
| hasanul_banna_himel |
1,875,327 | Hip Pain Exercises | Uncover effective hip pain exercises designed by healthcare professionals here. Make an appointment... | 0 | 2024-06-03T12:16:24 | https://dev.to/tejaswini_84adb73cdc74111/hip-pain-exercises-2h36 | Uncover effective [hip pain](https://www.algcure.com/hip-pain-exercises/) exercises designed by healthcare professionals here. Make an appointment for your consultation right now. | tejaswini_84adb73cdc74111 | |
1,875,270 | Terraform Apply Command: Options, Examples and Best Practices | In this blog I’ll be offering a comprehensive guide to the terraform apply command, detailing its... | 0 | 2024-06-03T12:15:00 | https://www.env0.com/blog/terraform-apply-guide-command-options-and-examples | terraform, devops, cloud, aws | In this blog I’ll be offering a comprehensive guide to the `terraform apply` command, detailing its role in the [Terraform CLI](https://www.env0.com/blog/what-is-terraform-cli#:~:text=Terraform%20CLI%20is%20a%20command,reused%2C%20and%20shared%20across%20teams.) workflow for managing and provisioning infrastructure. I will be comparing it to the `terraform plan` command, and discussing best practices before running `terraform apply`.
**What is terraform apply?**
----------------------------
The `terraform apply` command is a fundamental part of the Terraform workflow, which propagates the changes specified in your [Infrastructure-as-Code](https://www.env0.com/blog/infrastructure-as-code-101) (IaC) configuration to the real-world infrastructure.
The `terraform apply` command executes planned actions, creating, updating, or deleting infrastructure resources to match the new state outlined in your IaC.
Before making any real changes to the infrastructure, `terraform apply` provides an execution plan for reviewing the changes, ensuring transparency and control.

Terraform provisions infrastructure via the following steps:
1. [**`terraform init`**](https://www.env0.com/blog/terraform-init) - Initializes terraform working directory by installing necessary plugins ([providers](https://www.env0.com/blog/how-to-use-terraform-providers)), setting up the backend, and initializing modules.
2. [**`terraform plan`**](https://www.env0.com/blog/terraform-plan) - Creates an execution plan, compares the desired state (defined in the configuration with the actual state of the infrastructure), and outputs the changes to be made.
3. **`terraform apply`** - Terraform applies the changes required to reach the new state of the infrastructure. This is where the actual creation, modification, or deletion of infrastructure happens, making it the most critical step in the Terraform workflow.
If you are new to these, my advice visit here to [learn more about Terraform CLI commands](https://www.env0.com/blog/what-is-terraform-cli). If not, read on to dive deeper into `terraform apply`.
### **What does terraform apply do?**
Let us set up an EC2 instance and discuss how the `terraform apply` command works and the aftermath after running the `terraform apply` command.
We have defined the EC2 instance in our Terraform configuration **main.tf** file:
provider "aws" {
region = "us-west-1"
}
resource "aws_instance" "env0_instance" {
ami = "ami-0353faff0d421c70e"
instance_type = "t2.micro"
tags = {
Name = "env0-instance"
}
}
### **Before running terraform apply**
* The `terraform init` downloads all the providers along with initializing the directory.
* The `terraform plan` compares the desired state (defined in **main.tf**) with the actual state of AWS and determines that an EC2 instance needs to be created.
* After `terraform apply` command executes, we are prompted to confirm whether to apply the changes.

* Upon confirmation with a `yes`, Terraform takes the configuration and communicates (makes an API call) with AWS to set up the EC2 instance according to the specifications in **main.tf**.
### **Aftermath of terraform apply**
* The EC2 instance is provisioned in your AWS account. You can see the instance running in the AWS Management Console.

* Terraform creates a state file called **terraform.tfstate.** This state file contains all the metadata and the current state of the EC2 instance.
* From this point onwards, any further changes you make in your **main.tf** file and `apply` via Terraform will be compared against the state file. For example, if you change the instance type from `t2.micro` to `t2.medium` in your **main.tf,** running `terraform plan` again will recognize this change, and `terraform apply` will modify the existing instance or recreate it as per the defined configuration.
**Examples: How to use terraform apply options**
------------------------------------------------
Let’s dive deep into what additional `terraform apply` options can be utilized with the apply command.
### **Terraform apply -auto-approve**
Running the `terraform apply -auto-approve` will immediately start applying any changes as per the configuration, without waiting for user input.
When you're confident in your Terraform configuration and you want to apply the changes without manual intervention, you can use `-auto-approve`. This is especially useful in automated environments like CI/CD pipelines.
### Terraform apply -target
The `terraform apply-target=resource_type.resource_name` focuses Terraform's actions on specific resources. If you want to apply changes to a specific resource or to resources within a specific module without affecting the rest of the managed resources, you can use `-target`.
For example, running `terraform apply -target=aws_instance.env0-instance` will apply changes only to the resource named `env0-instance` of the type `aws_instance`.
### **Terraform apply -refresh-only**
This option instructs Terraform to refresh the state file to match the real-world resources without applying any configuration changes.
When you suspect that the actual infrastructure might be out of sync with your state file, running `terraform apply -refresh-only` will update the state file with any changes it detects (like manually deleted or externally altered resources).
### **Terraform apply -parallelism=’n’**
The `-parallelism=n option` limits Terraform to making only concurrent operations. This can be helpful if you're running into API rate limits of a cloud provider or if your infrastructure has other performance constraints that make executing too many operations at once undesirable.
For example, `terraform apply -parallelism=1` tells Terraform to make the changes with no more than 1 terraform apply operation running at the same time. Change this to `-parallelism=5` will increase the number to 5, and so on.
### **Terraform apply -lock=’false and -lock-timeout=DURATION**
By default, Terraform enables state locking. However, if you need to override this function for some reason, you would use `terraform apply -lock=false`. It can act as a safety mechanism designed to prevent concurrent operations made by other engineers in a team.
The `terraform apply -lock-timeout` command is used to specify a duration for which Terraform will wait for a state lock before it gives up and returns an error. The duration syntax is a number followed by a time unit, such as `5s` for five seconds.
### **Terraform apply -input=’false’**
The `-input=false` option specifically instructs Terraform not to prompt for input. This is useful in automated scripts or environments (like CI/CD pipelines) where no human intervention is needed to input variables interactively.
When `-input=false` is set, Terraform will not ask for input and will instead use the default values for any variables that have not been otherwise specified. If any required inputs are not provided and do not have default values, Terraform will produce an error and exit.
**Terraform plan vs. apply**
----------------------------
Let us take a look at some key differences between Terraform `plan` and `apply`.

**Best Practices**
------------------
DevOps and Infrastructure engineers should keep certain measures in mind before executing the terraform apply command.
### **Store Terraform files in Version Control**
Store all your Terraform files (`.tf` and [`.tfvars`](https://www.env0.com/blog/managing-terraform-variable-hierarchy)) in a version control system like Git.
This practice is fundamental for tracking changes, team collaboration, and maintaining history.
These are the key benefits of storing your Terraform files in VCS:
1. **Change tracking:** Every change made to your Terraform files is tracked. You can see who made what changes, and when.
2. **Team collaboration:** Team members can collaborate on IaCs, reviewing each other's changes and managing merges to avoid conflicts.
3. **Maintain history:** You can revert to previous versions if a new change causes issues.
### **Remote Backend**
You can use your S3 bucket or Google Cloud storage, or leverage the env0 [remote backend](https://docs.env0.com/docs/remote-apply) capabilities to store your Terraform state file (**terraform.tfstate**).
Doing so will provide you with several benefits, including:
1. **Remote shared state:** The state is shared and accessible to all authorized team members in an organization.
2. **Security:** Remote backends are secured and encrypted to protect sensitive information in state files.
3. **State locking:** Many remote backends support state locking, preventing conflicting operations from being applied simultaneously.
### **Secure Secret Data**
Avoid hard coding sensitive data like passwords or AWS access keys in your Terraform files. Instead, use environment variables or a secrets management system like HashiCorp Vault.
Benefits of secret management include:
1. **Security:** Sensitive data is not exposed in your codebase. It's stored securely and only accessed when needed. For example, before running `terraform apply`, you can export your AWS access key and secret as environment variables, or configure Terraform to fetch secrets from HashiCorp Vault.
2. **Flexibility**: You can easily update secrets without changing your Terraform configuration. For instance, if you have an environment variable `TF_VAR_db_password`, you can update it by running export `TF_VAR_db_password="newpassword"`, or you can update the secret at a specific path of a secret in Hashicorp Vault (using Vault CLI).
### **Use Terraform Workspaces**
Terraform Workspaces are essential for managing multiple distinct states within the same set of Terraform files.
This is particularly useful when managing different environments (like development, staging, and production). Benefits of workspaces include:
* **Environment isolation:** Workspaces allow you to keep state and Terraform configuration file data separate for each environment.
* **Resource efficiency:** Workspaces allow for the efficient use of resources by leveraging the same working copy of a Terraform configuration file and the same plugin and module caches across different infrastructure sets.
**What happens if terraform apply fails?**
------------------------------------------
When terraform apply fails, you might find yourself facing a few challenges:
### **Partial apply of resources**
One common issue is that Terraform doesn't record the changes made up to the point of failure in the state file, potentially leaving your infrastructure in an inconsistent state. If you rerun apply after a partial failure, you might encounter errors due to resources that Terraform is unaware of because they weren't recorded in the state.
The general advice in such situations is to manually identify and remove the resources that were partially created before re-running `terraform apply`, or to use `terraform import` to reconcile the state with the actual infrastructure.
### **ResourceAlreadyExistsException**
You might encounter specific errors such as `ResourceAlreadyExistsException`. This error typically means that Terraform attempted to create a resource that already exists in your infrastructure, which it wasn't expecting.
This could happen for several reasons, such as manual changes made to the infrastructure outside of Terraform, or issues with the Terraform state file not being up-to-date with the actual infrastructure.
Sometimes, the simplest approach is to manually delete the conflicting resource, especially if it's something that was created automatically by a cloud provider (like log groups in AWS) and not explicitly managed by Terraform.
Otherwise, you can use `terraform import` to bring resources created outside Terraform into Terraform's management.
### **Resource creation timeouts**
When managing AWS resources using Terraform, timeouts happen. This is seen most with resources like CloudFront distributions, Aurora clusters, and sometimes DNS records and certificates. These resources are going to take significant time to get created, leading to timeouts.
In many instances, just waiting a few minutes and then re-running the `terraform apply` command is enough to resolve the problem.
**Terraform apply tutorial: Streamline plan and apply with env0**
-----------------------------------------------------------------
With [env0](https://www.env0.com/), you can also manage your Infrastructure-as-Code (IaC) deployments directly from your VCS (Github, Gitlab, Bitbucket) provider.
By commenting with env0 on [pull requests](https://www.env0.com/blog/implement-atlantis-style-terraform-and-terragrunt-workflows-in-env0), it is possible to interact with your env0 environments without the need to log in to the env0 platform.
This fosters collaboration by enabling developers to execute `terraform plan` and `terraform apply` commands directly from the comments section of a pull or merge request.
To demonstrate this, I’ve already created a template to provision an S3 bucket using Terraform.

To configure the PR comments feature, I’ve set an alias for your environment. This can be done in _Environments > Settings > Run PR Comments Commands using an Alias._

Next, I’ve changed our Terraform code and created a new pull request:

Now, as shown below, after creating the pull request, env0 ran a `terraform plan` command against our changes.

One more thing to mention here is the [Remote Apply](https://www.env0.com/blog/announcing-self-hosted-remote-state-and-remote-apply) feature, which env0 added to the roster of [Remote Backend](https://www.env0.com/blog/terraform-remote-state-using-a-remote-backend) capabilities.
The feature allows you to run `apply` commands with your local Terraform files, while also executing the process remotely within env0, utilizing the shared state, shared variables set for the env0 environment, etc.
This is useful for quickly iterating and testing your changes locally before committing.
**Commonly Asked Questions/FAQs**
---------------------------------
#### **Q: How do I run terraform apply without a state refresh?**
Use `terraform plan -refresh=false or terraform apply -refresh=false`. The `-refresh=false` option is used in normal planning mode to skip the default behavior of refreshing the Terraform state before checking for configuration changes.
#### **Q: Can we run terraform apply without plan?**
When you run the `apply` command without the plan, Terraform will still create an execution plan of your infrastructure and prompt you to apply the changes to your infrastructure.
#### **Q: What is the opposite of terraform apply?**
The opposite of `terraform apply` is [`terraform destroy`](https://www.env0.com/blog/terraform-destroy-command-a-guide-to-controlled-infrastructure-removal). The terraform apply command creates or modifies the state of the infrastructure. Likewise, the terraform destroy command deletes the infrastructure and updates the state file by removing the details of the destroyed infrastructure.
#### **Q: What happens if you run terraform apply multiple times?**
The infrastructure remains unaltered if the Terraform configuration files haven't undergone any changes relative to the existing Terraform state. Given Terraform's declarative nature, it's entirely secure to execute the apply command repeatedly without concern, provided no changes are made to the infrastructure definition in the configuration files.
#### **Q: Can we stop terraform apply?**
If the Terraform CLI is interrupted during the apply process, for instance through a manual interruption like pressing CTRL+C (or Command+C on MacOS) or a SIGINT signal, it will prompt all active provider requests to cancel and aim to halt all operations promptly.
**Wrap-up**
-----------
This quick guide covers the `terraform apply` command's role, usage options, best practices, failure handling, and common questions.
[env0](https://www.env0.com/) streamlines `terraform apply` by automating state file management, preventing version control issues, and enhancing collaboration.
It supports comments, log history, and comment-driven workflows for streamlined deployments directly from Git repositories. This reduces manual intervention, ensuring efficiency, security, and collaboration in `terraform apply`.
To learn more about how you can confidently automate your Terraform at scale with env0 and see it in action, [schedule a call with a technical expert here](https://www.env0.com/demo-request). | env0team |
1,875,326 | Jumpstart Your JavaScript Journey: First Steps to Mastery🚶♂️ | Prerequisites Before diving into JavaScript, ensure you have the following foundational... | 0 | 2024-06-03T12:14:29 | https://dev.to/dharamgfx/jumpstart-your-javascript-journey-first-steps-to-mastery-41jc | javascript, beginners, webdev, programming |
#### Prerequisites
Before diving into JavaScript, ensure you have the following foundational knowledge:
1. **Basic HTML & CSS**: Understanding the structure and style of web pages.
- Example: Know how to create a basic webpage with `<html>`, `<head>`, and `<body>` tags.
2. **Text Editor**: Familiarize yourself with a code editor like VS Code, Sublime Text, or Atom.
3. **Web Browser**: Have a modern browser (like Chrome, Firefox, or Edge) installed.
#### Getting Started with JavaScript
JavaScript is a powerful programming language used to make web pages interactive. Let's begin with the basics.
##### 1. Introduction to JavaScript
- **What is JavaScript?**: A scripting language for creating dynamic content on websites.
- **Why Learn JavaScript?**: It enhances user experience by allowing interaction on web pages.
##### 2. Embedding JavaScript in HTML
- **Inline Script**: Embed JavaScript directly within HTML tags.
```html
<button onclick="alert('Hello, World!')">Click me</button>
```
- **Internal Script**: Use `<script>` tags within the HTML file.
```html
<script>
document.write('Hello, World!');
</script>
```
- **External Script**: Link to an external JavaScript file.
```html
<script src="script.js"></script>
```
##### 3. Basic Syntax and Statements
- **Variables**: Store data values using `var`, `let`, or `const`.
```javascript
let message = 'Hello, World!';
alert(message);
```
- **Comments**: Annotate your code with single-line (`//`) or multi-line (`/* */`) comments.
```javascript
// This is a single-line comment
/* This is a
multi-line comment */
```
##### 4. Data Types
- **Primitive Types**: Understand strings, numbers, booleans, null, and undefined.
```javascript
let name = 'John'; // String
let age = 30; // Number
let isStudent = true; // Boolean
let unknown = null; // Null
let notAssigned; // Undefined
```
##### 5. Operators
- **Arithmetic Operators**: Perform mathematical operations.
```javascript
let sum = 10 + 5; // Addition
let product = 10 * 5; // Multiplication
```
- **Comparison Operators**: Compare values.
```javascript
let isEqual = (10 == '10'); // true
let isIdentical = (10 === '10'); // false
```
#### Guides
Here are some step-by-step guides to help you progress:
##### 1. Writing Your First Script
- Create an HTML file and add a simple JavaScript alert.
```html
<html>
<body>
<script>
alert('Hello, World!');
</script>
</body>
</html>
```
##### 2. Using the Console
- Open the browser console (F12 or right-click > Inspect > Console) and type JavaScript commands directly.
```javascript
console.log('Hello, Console!');
```
##### 3. Manipulating the DOM
- Select and manipulate HTML elements.
```html
<p id="demo">This is a paragraph.</p>
<script>
document.getElementById('demo').innerHTML = 'Paragraph changed!';
</script>
```
#### Assessments
Test your understanding with these assessments:
##### 1. Quiz: Basics of JavaScript
- Question: What will the following code output?
```javascript
console.log(5 + '5');
```
- Answer: `55` (because of type coercion).
##### 2. Practical Task: Create an Interactive Webpage
- Task: Build a simple webpage with a button that changes the text of a paragraph when clicked.
```html
<button onclick="changeText()">Click me</button>
<p id="text">Original Text</p>
<script>
function changeText() {
document.getElementById('text').innerHTML = 'Text changed!';
}
</script>
```
#### Additional Resources
Expand your learning with these resources:
1. **MDN Web Docs**: Comprehensive documentation on JavaScript.
2. **JavaScript.info**: A detailed tutorial covering all aspects of JavaScript.
3. **Codecademy**: Interactive JavaScript courses for hands-on learning.
By following these steps and utilizing these resources, you'll build a solid foundation in JavaScript and be well on your way to creating dynamic and interactive web experiences. Happy coding! | dharamgfx |
1,875,571 | The Trust Factor: The Ethics of Crediting AI in Content Creation | With an unbelievable 30% of people now using generative AI tools daily for professional work, content... | 0 | 2024-06-10T13:01:42 | https://jasonstcyr.com/2024/06/03/the-trust-factor-the-ethics-of-crediting-ai-in-content-creation/ | ethicsandtrust, generativeai, ai, genai | ---
title: The Trust Factor: The Ethics of Crediting AI in Content Creation
published: true
date: 2024-06-03 12:14:00 UTC
tags: EthicsandTrust,GenerativeAI,ai,GenAI
canonical_url: https://jasonstcyr.com/2024/06/03/the-trust-factor-the-ethics-of-crediting-ai-in-content-creation/
cover_image: https://jasonstcyr.com/wp-content/uploads/2024/05/not-a-robot.webp
---
With an unbelievable [30% of people now using generative AI tools daily for professional work](https://s3.amazonaws.com/media.mediapost.com/uploads/DENTSU_Generative_AI_Consumer_Navigator_Mar_2024.pdf), content is being generated at an astonishing rate. How can we trust the information being put in front of us?
Disclosing AI content might just be a first step. Readers may have noticed that I use a **Credits** section in many posts to provide proper attribution. However, recently I have been using these credits also for generated content, such as the following from [my article on AI governance](https://jasonstcyr.com/2024/05/20/balancing-innovation-and-regulation-navigating-the-ai-governance-landscape/):
> - **Content:** Written and edited by Jacqueline Baxter and Jason St-Cyr using good ol' fashioned human writing.
> - **Cover image:** Generated by Jason St-Cyr using NightCafe
> - **Title:** Generated by Jason St-Cyr using ChatGPT
Why call out AI-generated content?
----------------------------------
Increasingly, it is becoming harder to distinguish some generated content from fully authored and researched content. One might look at the structure of an article with its distinct sub-headings and short paragraphs and believe it must have been written by an AI. There is no doubt that if the words are exactly the same between a human and an AI, there is no loss in value to the reader. So why call it out?
I believe this is about **building trust**. According to [Dentsu's Consumer Navigator Generative AI 2024 report](https://s3.amazonaws.com/media.mediapost.com/uploads/DENTSU_Generative_AI_Consumer_Navigator_Mar_2024.pdf), 81% of those surveyed want brands to "disclose to consumers if branded content was created with gen AI". By calling out when AI is used, we also call out when it is not used. Beyond trust, there are also possible implications to copyright. Christopher S. Penn stated "If you clearly disclose what content is AI-generated versus human-generated on your site, you reiterate your copyright over the human parts." Indicating an image is generated also indicates to the reader that the non-image content is not generated. This act of transparency builds up trust in your content. Right now, while people are learning to use AI for all sorts of summarizing and generating needs, there is still a natural distrust of information that is purely generated.
For this reason, I think we need to be putting specific notes on generated content so that the audience can distinguish what is a human-created artistic expression. Industry efforts are also introducing [AI watermarking](https://www.techtarget.com/searchenterpriseai/definition/AI-watermarking) for automatic detection:
> "For example, the system might be more likely to choose certain rare words or sequences of tokens that a human would be unlikely to replicate.\
> The presence of these rare words and phrases would then function as a watermark. To an end user, the text output by the model would still appear randomly generated. However, someone with the cryptographic key could analyze the text to reveal the hidden watermark based on how often the encoded biases occur."
>
> *["AI Watermarking"](https://www.techtarget.com/searchenterpriseai/definition/AI-watermarking), Lev Craig, TechTarget*
Unfortunately, the current AI watermarking technology has low accuracy rates and cannot yet be relied on.
Some groups are trying to come at this from the other way: marking that content is real, instead of looking for generated signals. The [Content Authenticity Initiative](https://contentauthenticity.org/how-it-works) is working at embedding information in digital content so that you can trace content back to the original authors and see historical information about changes to it. It's an interesting idea, but falls over immediately for things like written content in text formats.
For now, we likely have to trust authors to do this. That means establishing it as an accepted practice amongst creators and brand teams.
What about AI-assisted content?
-------------------------------
There are extremely valid use cases for using generative AI tools and other AI assistants to help in the writing process:
- Ideation to get the creative ideas flowing
- Translating from a foreign language
- Copy-editor analysis of content for grammar and spelling
- Suggestions for alternative phrasings or synonyms
- Structural composition to provide frameworks/templates to the author for a type of content
- Language assistance for writers who are writing in a language they are less comfortable in
- (more of course... but that's enough bullets🤣)
In these cases, a human is still involved in the writing process. The tools here are just that: tools. The same as reading a book, or searching the web for relevant articles, or finding an example template from a colleague. In this scenario, do we need to notify folks that we have used a tool to come to our final product?
I think this is where we enter a really gray area. There is no attempt on the part of the author to be misleading or create disinformation. They are involved in the process and approving what is going out. They are manipulating the tools to achieve the result they want. How much manipulation is too much? At what point do we claim that the human was no longer really involved here?
I don't have an answer for this, but I know that for my own use case I'm using the following questions as my guide:
1. Would it have required a prohibitive amount of additional effort to do this myself?
2. Is the output distinctly different than what I would have wanted to create in my natural writing style?
3. Was the content portion influenced greater than 10% of the final output?
If I answer yes to any of these, then I place this in the realm of AI-assisted content that I need to credit. For example, for this article here is how those questions went:
1. **Prohibitive amount of effort: No.** I used Copilot and WordPress Jetpack assistant to analyze the content of the post, after I had written it, to look for any suggested improvements. This was work I could have done myself, but I tried to do something quick to find the first layer of changes, and then reviewed myself after that.
2. **Distinct output:** **Mostly. **As I wrote all of the content and implemented the suggested changes, the output of the main content is completely in my style. The title, however, was arranged by me based on suggestions from ChatGPT. I purposefully tried to put it into my own style, but it feels a little less like a title I would write.
3. **Content influenced greater than 10%:** No and yes. For the main content, this was clearly my writing. However, the title was greatly influenced by ChatGPT options.
As a result, I decided to attribute the Title as an AI-assisted piece of content in the credits.
Does it even matter?
--------------------
Okay, so after all that, the real question: **if people can get the information they need from the content, does it really matter if it was generated or created by a person?**
If the **value** of the content is measured by how much it helps the reader accomplish their goals, then either way of getting to that content is equally valuable, assuming they both are able to help the same way. That doesn't mean it is **trusted**.
Ultimately, I think this is where I come down on the need for transparency around AI usage. We need to establish trust in our content, our brands, and as people. Disinformation is so prevalent, there is a huge need for trusted creators. At this moment, [generated content is eroding trust](https://assets.mofoprod.net/network/documents/In_Transparency_We_Trust.pdf).
> "The line between human-generated and AI-generated content is blurring, making it harder to distinguish between the two. This lack of transparency around the syntheticity threatens trust and the integrity of information ecosystems,4 emphasizing the need for clear disclosure and mitigation strategies for synthetic content becomes more paramount."
>
> *["In Transparency We Trust?"](https://assets.mofoprod.net/network/documents/In_Transparency_We_Trust.pdf), Ramak Molavi Vasse'i and Gabriel Udoh, Mozilla research*\
While the Mozilla research has concluded that user-facing declarations aren't effective enough on their own, I believe it's a first step that we can take while the technology to back it up with digital authenticity mechanisms matures. Those of us trying to create content need to establish the trust that we will disclose when something is authentic and when it is generated.
**References**
- ["AI Watermarking"](https://www.techtarget.com/searchenterpriseai/definition/AI-watermarking), by Lev Craig, TechTarget
- ["In Transparency We Trust?"](https://assets.mofoprod.net/network/documents/In_Transparency_We_Trust.pdf), by Ramak Molavi Vasse'i and Gabriel Udoh, Mozilla research
- ["Disclosure of AI and Protection of Copyright"](https://www.trustinsights.ai/blog/2024/02/disclosure-of-ai-and-protection-of-copyright/), by Christopher S. Penn, Trust Insights
- ["Dentsu Consumer Navigator Generative AI 2024"](https://s3.amazonaws.com/media.mediapost.com/uploads/DENTSU_Generative_AI_Consumer_Navigator_Mar_2024.pdf), by Dentsu
**Credits**
- **Cover image:** Generated by Jason St-Cyr using NightCafe
- **Title:** Assembled by Jason St-Cyr, AI-assisted with options from ChatGPT. | jasonstcyr |
1,875,323 | Creating a Multipage Form with React-Hook-Form and Redux-Toolkit | Building a multipage form in React can be streamlined using React-Hook-Form for form handling and... | 0 | 2024-06-03T12:11:29 | https://dev.to/hokagedemehin/creating-a-multipage-form-with-react-hook-form-and-redux-toolkit-mjf | Building a multipage form in React can be streamlined using React-Hook-Form for form handling and Redux-Toolkit for state management. Here’s a guide on how to effectively combine these tools.
Step 1: Setup Your Project
First, set up your React project and install the necessary dependencies:
``` javascript
npx create-react-app multipage-form
cd multipage-form
npm install @reduxjs/toolkit react-redux react-hook-form
```
Step 2: Configure Redux-Toolkit
Create a Redux store and slice to manage the form state.
store.js
``` javascript
import { configureStore } from '@reduxjs/toolkit';
import formReducer from './formSlice';
export const store = configureStore({
reducer: {
form: formReducer,
},
});
```
formSlice.js
``` javascript
import { createSlice } from '@reduxjs/toolkit';
const initialState = {
formData: {},
};
const formSlice = createSlice({
name: 'form',
initialState,
reducers: {
updateFormData: (state, action) => {
state.formData = { ...state.formData, ...action.payload };
},
resetFormData: (state) => {
state.formData = {};
},
},
});
export const { updateFormData, resetFormData } = formSlice.actions;
export default formSlice.reducer;
```
Step 3: Create Form Pages
Define individual form pages using react-hook-form to handle validation and data collection.
Page1.js
``` javascript
import React from 'react';
import { useForm } from 'react-hook-form';
import { useDispatch } from 'react-redux';
import { updateFormData } from './formSlice';
import { useNavigate } from 'react-router-dom';
const Page1 = () => {
const { register, handleSubmit } = useForm();
const dispatch = useDispatch();
const navigate = useNavigate();
const onSubmit = (data) => {
dispatch(updateFormData(data));
navigate('/page2');
};
return (
<form onSubmit={handleSubmit(onSubmit)}>
<input {...register('firstName')} placeholder="First Name" />
<input {...register('lastName')} placeholder="Last Name" />
<button type="submit">Next</button>
</form>
);
};
export default Page1;
```
Page2.js
``` javascript
import React from 'react';
import { useForm } from 'react-hook-form';
import { useDispatch, useSelector } from 'react-redux';
import { updateFormData } from './formSlice';
import { useNavigate } from 'react-router-dom';
const Page2 = () => {
const { register, handleSubmit } = useForm();
const dispatch = useDispatch();
const navigate = useNavigate();
const formData = useSelector((state) => state.form.formData);
const onSubmit = (data) => {
dispatch(updateFormData(data));
navigate('/summary');
};
return (
<form onSubmit={handleSubmit(onSubmit)}>
<input {...register('email')} placeholder="Email" />
<input {...register('phone')} placeholder="Phone" />
<button type="submit">Next</button>
</form>
);
};
export default Page2;
```
Step 4: Summary Page
Create a summary page to display collected data.
Summary.js
``` javascript
import React from 'react';
import { useSelector } from 'react-redux';
const Summary = () => {
const formData = useSelector((state) => state.form.formData);
return (
<div>
<h2>Summary</h2>
<pre>{JSON.stringify(formData, null, 2)}</pre>
</div>
);
};
export default Summary;
```
Step 5: Set Up Routing
Configure routing to navigate between form pages. Or you could just have a single page and have the different form show up when you click on the next button, but for this example I will use the routing option
App.js
``` javascript
import React from 'react';
import { BrowserRouter as Router, Route, Routes } from 'react-router-dom';
import Page1 from './Page1';
import Page2 from './Page2';
import Summary from './Summary';
import { Provider } from 'react-redux';
import { store } from './store';
const App = () => (
<Provider store={store}>
<Router>
<Routes>
<Route path="/" element={<Page1 />} />
<Route path="/page2" element={<Page2 />} />
<Route path="/summary" element={<Summary />} />
</Routes>
</Router>
</Provider>
);
export default App;
```
Conclusion
By using react-hook-form and redux-toolkit, you can easily manage form data across multiple pages. This approach ensures a seamless user experience with efficient state management and form handling. | hokagedemehin | |
1,875,424 | Pro Annotations on Mobile PDFs with Blazor PDF Viewer | TL;DR: Need to annotate PDFs on your mobile device? Syncfusion Blazor PDF Viewer (NextGen) allows... | 0 | 2024-06-06T03:10:10 | https://www.syncfusion.com/blogs/post/mobile-pdf-annotations-with-blazor | blazor, development, mobile, pdfviewer | ---
title: Pro Annotations on Mobile PDFs with Blazor PDF Viewer
published: true
date: 2024-06-03 12:10:17 UTC
tags: blazor, development, mobile, pdfviewer
canonical_url: https://www.syncfusion.com/blogs/post/mobile-pdf-annotations-with-blazor
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/40t86xorjxxmahsq6yhj.png
---
**TL;DR:** Need to annotate PDFs on your mobile device? Syncfusion Blazor PDF Viewer (NextGen) allows easy annotation of PDFs on mobile devices. Add sticky notes, text markup, shapes, measurements, free text, stamps, signatures, and ink annotations via the UI or programmatically. Streamline your professional workflows on the go!
In today’s fast-paced world, the need to annotate PDFs efficiently on mobile devices has become paramount for professionals across various fields.
The Syncfusion [Blazor PDF Viewer (NextGen)](https://blazor.syncfusion.com/documentation/pdfviewer-2/getting-started/deploy-maui-windows "UG: Blazor PDF Viewer (NextGen)") emerges as a powerful tool, allowing users to master the art of annotation directly from their smartphones or tablets. In this blog, we’ll explore the extensive annotation capabilities offered by the mobile version of the [Blazor PDF Viewer](https://www.syncfusion.com/blazor-components/blazor-pdf-viewer "FT: Blazor PDF Viewer"), enabling users to engage with their PDF documents in unprecedented ways.
Let’s get started!
## Sticky notes: Flags for essential points
### Add sticky note annotation using UI
Imagine reading a lengthy report on your phone and stumbling upon a critical piece of information. Sticky notes come to the rescue here! These digital flags allow you to highlight specific areas of the PDF and add brief comments to jog your memory or share insights with colleagues. Simply select the area you want to annotate, and the mobile toolbar will provide options to add a sticky note and personalize it with your comments.
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/1-Adding-a-sticky-note-annotation-using-Blazor-PDF-Viewer-1024x740.png" alt="Adding a sticky note annotation using Blazor PDF Viewer" style="width:100%">
<figcaption>Adding a sticky note annotation using Blazor PDF Viewer</figcaption>
</figure>
### Add sticky note annotation programmatically
The Blazor PDF Viewer offers the capability to programmatically add the sticky note annotation using the [AddAnnotationAsync](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerBase.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerBase_AddAnnotationAsync_Syncfusion_Blazor_SfPdfViewer_PdfAnnotation_ "API Reference: AddAnnotationAsync") method.
Refer to the following code example.
```csharp
@using Syncfusion.Blazor.Navigations;
@using Syncfusion.Blazor.SfPdfViewer;
@using Syncfusion.Blazor.Buttons;
<SfButton OnClick="@AddStickyNoteAnnotationAsync">Add StickyNote Annotation</SfButton>
<SfPdfViewer2 Width="100%" Height="100%" DocumentPath="@DocumentPath" @ref="@Viewer" />
@code {
SfPdfViewer2 Viewer;
public string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
public async void AddStickyNoteAnnotationAsync(MouseEventArgs args)
{
PdfAnnotation annotation = new PdfAnnotation();
// Set the annotation type as sticky note.
annotation.Type = AnnotationType.StickyNotes;
// Set the PageNumber to start from 0. So, if set 0, it represents page 1.
annotation.PageNumber = 0;
// Bound of the sticky note annotation.
annotation.Bound = new Bound();
annotation.Bound.X = 200;
annotation.Bound.Y = 150;
annotation.Bound.Width = 50;
annotation.Bound.Height = 50;
// Add sticky note annotation.
await Viewer.AddAnnotationAsync(annotation);
}
}
```
**Note:** You can find the working example in [GitHub for adding sticky note annotation in Blazor PDF Viewer](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Server%20Deployment/Maui/Maui_StickyNote "GitHub: Adding sticky note annotation in Blazor PDF Viewer Examples").
## Text markup: Highlight, underline, and strikethrough
### Add text markup annotation using UI
Need to emphasize specific text passages within the PDF? Text markup annotations offer a versatile solution. You can highlight crucial sentences, underline key takeaways, or even strikethrough outdated information – all directly on your mobile device.
Select the text you want to annotate, and the mobile toolbar will present options for highlighting, underlining, and strikethrough. This allows you to modify the PDF’s appearance for better comprehension.
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/2-Adding-text-markup-annotations-using-Blazor-PDF-Viewer-1024x740.png" alt="Adding text markup annotations using Blazor PDF Viewer" style="width:100%">
<figcaption>Adding text markup annotations using Blazor PDF Viewer</figcaption>
</figure>
### Add text markup annotation programmatically
You can programmatically add the text markup annotation in the PDF Viewer using the [SetAnnotationModeAsync](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerBase.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerBase_SetAnnotationModeAsync_Syncfusion_Blazor_SfPdfViewer_AnnotationType_System_Nullable_Syncfusion_Blazor_SfPdfViewer_DynamicStampItem __System_Nullable_Syncfusion_Blazor_SfPdfViewer_SignStampItem__ System_Nullable_Syncfusion_Blazor_SfPdfViewer_StandardBusinessStampItem__"API Reference: SetAnnotationModeAsync") method.
Refer to the following code example. Here, we’ll apply text markup annotation using custom buttons.
```csharp
@using Syncfusion.Blazor.SfPdfViewer
@using Syncfusion.Blazor.Buttons
<SfButton OnClick="Highlight">Highlight</SfButton>
<SfButton OnClick="Underline">Underline</SfButton>
<SfButton OnClick="Strikethrough">Strikethrough</SfButton>
<SfPdfViewer2 DocumentPath="@DocumentPath"
@ref="viewer"
Width="100%"
Height="100%">
</SfPdfViewer2>
@code {
SfPdfViewer2 viewer;
public async void Highlight(MouseEventArgs args)
{
await viewer.SetAnnotationModeAsync(AnnotationType.Highlight);
}
public async void Underline(MouseEventArgs args)
{
await viewer.SetAnnotationModeAsync(AnnotationType.Underline);
}
public async void Strikethrough(MouseEventArgs args)
{
await viewer.SetAnnotationModeAsync(AnnotationType.Strikethrough);
}
private string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
}
```
**Note:** You can find the working example in [GitHub for adding text markup annotation in Blazor PDF Viewer](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Server%20Deployment/Maui/Maui_TextMarkup "GitHub: Adding text markup annotation in Blazor PDF Viewer Examples").
## Shapes: Point out specific areas with clarity
### Add shape annotation using UI
Sometimes, a well-placed arrow or rectangle can speak volumes. Blazor PDF Viewer’s mobile view empowers you to add various shapes directly onto your PDFs. Circles can draw attention to specific data points, arrows can guide readers through a complex flow chart, and rectangles can highlight important sections. Choose the desired shape from the mobile toolbar, position it on the PDF, and customize its properties for optimal clarity.
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/3-Adding-shape-annotations-using-Blazor-PDF-Viewer-1024x740.png" alt="Adding shape annotations using Blazor PDF Viewer" style="width:100%">
<figcaption>Adding shape annotations using Blazor PDF Viewer</figcaption>
</figure>
### Add shape annotation programmatically
You can programmatically add shapes such as Rectangle, Line, Arrow, Circle, and Polygon within the PDF Viewer using the **AddAnnotationAsync** method.
Refer to the following code example.
```csharp
@using Syncfusion.Blazor.Buttons
@using Syncfusion.Blazor.SfPdfViewer
<SfButton OnClick="@AddShapeAnnotationAsync">Add Shape Annotation</SfButton>
<SfPdfViewer2 Width="100%" Height="100%" DocumentPath="@DocumentPath" @ref="@Viewer" />
@code {
SfPdfViewer2 Viewer;
public string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
public async void AddShapeAnnotationAsync(MouseEventArgs args)
{
PdfAnnotation annotation = new PdfAnnotation();
// Set the shape annotation types like Rectangle, Line, Arrow, Circle, and Polygon.
annotation.Type = AnnotationType.Rectangle;
// Set the page number to start from 0. So, if set 0, it represents page 1.
annotation.PageNumber = 0;
// Bound of the rectangle annotation.
annotation.Bound = new Bound();
annotation.Bound.X = 200;
annotation.Bound.Y = 150;
annotation.Bound.Width = 300;
annotation.Bound.Height = 100;
// Add rectangle annotation.
await Viewer.AddAnnotationAsync(annotation);
}
}
```
**Note:** You can find the working example in [GitHub for adding shape annotation in Blazor PDF Viewer](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Server%20Deployment/Maui/Maui_Shapes "GitHub: Adding shape annotation in Blazor PDF Viewer Examples").
## Measure: Annotate precise dimensions
### Add measurement annotation using UI
Working with technical documents often requires highlighting specific lengths or areas. The measurement annotation tool in Blazor PDF Viewer’s mobile view is handy for such scenarios. Select the area you want to measure, and the mobile toolbar will display options to add lines, polylines, or even freehand annotations. You can then define the measurement units (inches, centimeters, etc.) to ensure precise annotation.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/4-Adding-measurement-annotations-using-Blazor-PDF-Viewer-1024x740.png" alt="Adding measurement annotations using Blazor PDF Viewer" style="width:100%">
<figcaption>Adding measurement annotations using Blazor PDF Viewer</figcaption>
</figure>
### Add measurement annotation programmatically
Programmatically add the measurement annotation in PDF Viewer using the **AddAnnotationAsync** method.
Refer to the following code example.
```csharp
@using Syncfusion.Blazor.Buttons
@using Syncfusion.Blazor.SfPdfViewer
<SfButton OnClick="@AddMeasurementAnnotationAsync">Add Measurement Annotation</SfButton>
<SfPdfViewer2 Width="100%" Height="100%" DocumentPath="@DocumentPath" @ref="@Viewer" />
@code {
SfPdfViewer2 Viewer;
public string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
public async void AddMeasurementAnnotationAsync(MouseEventArgs args)
{
PdfAnnotation annotation = new PdfAnnotation();
// Set the annotation type as measurements, like radius, distance, perimeter, area, and volume.
annotation.Type = AnnotationType.Radius;
// Set the PageNumber to start from 0. So, if set 0, it represents page 1.
annotation.PageNumber = 0;
// Bound of the radius annotation.
annotation.Bound = new Bound();
annotation.Bound.X = 200;
annotation.Bound.Y = 150;
annotation.Bound.Width = 100;
annotation.Bound.Height = 100;
// Add radius measurement annotation.
await Viewer.AddAnnotationAsync(annotation);
}
}
```
**Note:** You can find the working example in [GitHub for adding measurement annotation in Blazor PDF Viewer](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Server%20Deployment/Maui/Maui_Measurements "GitHub: Adding measurement annotation in Blazor PDF Viewer Examples").
## Free text: Unleashing creative expression
### Add free text annotations using UI
Imagine adding a quick note or jotting ideas directly onto a PDF while on the go. Free text annotations offer the perfect solution. With a simple tap, users can insert text boxes anywhere within the document, allowing for spontaneous comments, reminders, or annotations. The mobile toolbar seamlessly integrates this feature, enabling users to express themselves creatively and annotate PDFs easily.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/5-Adding-free-text-annotations-using-Blazor-PDF-Viewer-1024x740.png" alt="Adding free text annotations using Blazor PDF Viewer" style="width:100%">
<figcaption>Adding free text annotations using Blazor PDF Viewer</figcaption>
</figure>
### Add free text annotation programmatically
You can also add the free text annotation within the PDF Viewer using the **AddAnnotationAsync** method.
Refer to the following code example.
```csharp
@using Syncfusion.Blazor.Buttons
@using Syncfusion.Blazor.SfPdfViewer
<SfButton OnClick="@AddFreeTextAnnotationAsync">Add FreeText Annotation</SfButton>
<SfPdfViewer2 Width="100%" Height="100%" DocumentPath="@DocumentPath" @ref="@Viewer" />
@code {
SfPdfViewer2 Viewer;
public string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
public async void AddFreeTextAnnotationAsync(MouseEventArgs args)
{
PdfAnnotation annotation = new PdfAnnotation();
// Set the annotation type as free text.
annotation.Type = AnnotationType.FreeText;
// Set the PageNumber to start from 0. So, if set 0, it represents page 1.
annotation.PageNumber = 0;
// Bound of the free text annotation.
annotation.Bound = new Bound();
annotation.Bound.X = 200;
annotation.Bound.Y = 150;
annotation.Bound.Width = 150;
annotation.Bound.Height = 30;
// Add free text annotation.
await Viewer.AddAnnotationAsync(annotation);
}
}
```
**Note:** You can find a working example in [GitHub for adding free text annotation in Blazor PDF Viewer](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Server%20Deployment/Maui/Maui_FreeText "GitHub: for adding free text annotation in Blazor PDF Viewer Examples").
## Stamps: Adding visual elements for clarity
### Add stamp annotations using UI
In certain situations, visual cues can significantly enhance communication within PDF documents. Stamps provide a versatile means to convey information, whether marking document with dynamic stamps, sign here stamps, standard business stamps, or adding custom stamps tailored to specific workflows. With the Blazor PDF Viewer’s mobile interface, users can effortlessly select and apply stamps directly onto the PDFs, ensuring clarity and consistency in annotations.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/6-Adding-stamp-annotations-using-Blazor-PDF-Viewer-1024x740.png" alt="Adding stamp annotations using Blazor PDF Viewer" style="width:100%">
<figcaption>Adding stamp annotations using Blazor PDF Viewer</figcaption>
</figure>
### Add stamp annotations programmatically
The Blazor PDF Viewer offers the capability to programmatically add the stamp annotations using the [DynamicStampAnnotation](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerBase.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerBase_AddAnnotationAsync_Syncfusion_Blazor_SfPdfViewer_PdfAnnotation_Syncfusion_Blazor_SfPdfViewer_DynamicStampItem_ "API Reference: DynamicStampAnnotation"), [SignStampAnnotation](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerBase.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerBase_AddAnnotationAsync_Syncfusion_Blazor_SfPdfViewer_PdfAnnotation_Syncfusion_Blazor_SfPdfViewer_SignStampItem_ "API Reference: SignStampAnnotation"), and [StandardBusinessStampAnnotation](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerBase.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerBase_AddAnnotationAsync_Syncfusion_Blazor_SfPdfViewer_PdfAnnotation_Syncfusion_Blazor_SfPdfViewer_StandardBusinessStampItem_ "API Reference: StandardBusinessStampAnnotation") methods.
Refer to the following code example.
```csharp
@using Syncfusion.Blazor.Buttons
@using Syncfusion.Blazor.SfPdfViewer
<SfButton OnClick="@AddStampAnnotationAsync">Add Stamp Annotation</SfButton>
<SfPdfViewer2 Width="100%" Height="100%" DocumentPath="@DocumentPath" @ref="@Viewer" />
@code {
SfPdfViewer2 Viewer;
public string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
public async void AddStampAnnotationAsync(MouseEventArgs args)
{
PdfAnnotation annotation = new PdfAnnotation();
// Set the annotation type as stamp.
annotation.Type = AnnotationType.Stamp;
// Set the PageNumber to start from 0. So, if set 0, it represents page 1.
annotation.PageNumber = 0;
// Bound of the dynamic stamp annotation.
annotation.Bound = new Bound();
annotation.Bound.X = 200;
annotation.Bound.Y = 150;
annotation.Bound.Width = 300;
annotation.Bound.Height = 100;
// Add dynamic approved stamp annotation.
await Viewer.AddAnnotationAsync(annotation, DynamicStampItem.Approved);
}
}
```
**Note:** You can find the working example in [GitHub for adding stamp annotation in Blazor PDF Viewer](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Server%20Deployment/Maui/Maui_Stamp "GitHub: Adding stamp annotation in Blazor PDF Viewer Examples").
### Signatures: Validating documents on the go
### Add signature annotation using UI
In today’s digital age, signing documents electronically is essential for streamlining workflows and expediting processes. With signature annotations, users can sign PDF documents directly from their mobile devices, eliminating the need for printing, signing, and scanning. The mobile toolbar facilitates this process, allowing users to easily create and apply their signatures, thereby validating documents efficiently while on the move.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/7-Adding-signature-annotations-using-Blazor-PDF-Viewer-1024x740.png" alt="Adding signature annotations using Blazor PDF Viewer" style="width:100%">
<figcaption>Adding signature annotations using Blazor PDF Viewer</figcaption>
</figure>
### Add signature annotation programmatically
Use the [SetAnnotationModeAsync](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerBase.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerBase_SetAnnotationModeAsync_Syncfusion_Blazor_SfPdfViewer_AnnotationType_System_Nullable_Syncfusion_Blazor_SfPdfViewer_DynamicStampItem __System_Nullable_Syncfusion_Blazor_SfPdfViewer_SignStampItem__ System_Nullable_Syncfusion_Blazor_SfPdfViewer_StandardBusinessStampItem__"API Reference: SetAnnotationModeAsync") method to add the signature annotation programmatically to a PDF.
Refer to the following code example.
```csharp
@using Syncfusion.Blazor.SfPdfViewer
@using Syncfusion.Blazor.Buttons
<SfButton OnClick="AddSignature">AddSignature</SfButton>
<SfPdfViewer2 DocumentPath="@DocumentPath"
@ref="viewer"
Width="100%"
Height="100%">
</SfPdfViewer2>
@code {
SfPdfViewer2 viewer;
public async void AddSignature(MouseEventArgs args)
{
await viewer.SetAnnotationModeAsync(AnnotationType.HandWrittenSignature);
}
private string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
}
```
**Note:** You can find the working example in [GitHub for adding signature annotation in Blazor PDF Viewer](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Server%20Deployment/Maui/Maui_Signature "GitHub: Adding signature annotation in Blazor PDF Viewer Examples").
## Ink annotations: Embracing handwritten input
### Add ink annotation using UI
Sometimes, nothing beats the personal touch of handwritten annotations. Whether highlighting key points, adding annotations, or sketching ideas, ink annotations offer a natural and intuitive means of interaction with PDF documents. With the Blazor PDF Viewer’s mobile interface, users can draw, write, or markup directly onto their PDFs using a stylus or their finger, bringing a sense of authenticity and immediacy to their annotations.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/8-Adding-ink-annotations-using-Blazor-PDF-Viewer-1024x740.png" alt="Adding ink annotations using Blazor PDF Viewer" style="width:100%">
<figcaption>Adding ink annotations using Blazor PDF Viewer</figcaption>
</figure>
### Add ink annotation programmatically
You can also add ink annotations in the PDF Viewer using the **AddAnnotationAsync** method.
Refer to the following code example.
```csharp
@using Syncfusion.Blazor.Buttons
@using Syncfusion.Blazor.SfPdfViewer
<SfButton OnClick="@AddInkAnnotationAsync">Add Ink Annotation</SfButton>
<SfPdfViewer2 Width="100%" Height="100%" DocumentPath="@DocumentPath" @ref="@Viewer" />
@code {
SfPdfViewer2 Viewer;
public string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
public async void AddInkAnnotationAsync(MouseEventArgs args)
{
PdfAnnotation annotation = new PdfAnnotation();
// Set the annotation type as Ink.
annotation.Type = AnnotationType.Ink;
// Set the PageNumber to start from 0. So, if set 0, it represents page 1.
annotation.PageNumber = 0;
// Bound of the Ink annotation.
annotation.Bound = new Bound();
annotation.Bound.X = 200;
annotation.Bound.Y = 150;
annotation.Bound.Width = 150;
annotation.Bound.Height = 100;
// Ink annotation path data.
annotation.Data = "[{\"command\":\"M\",\"x\":10,\"y\":10},{\"command\":\"C\",\"x\":10,\"y\":40,\"x1\":10,\"y1\":25,\"x2\":25,\"y2\":25},{\"command\":\"C\",\"x\":40,\"y\":25,\"x1\":25,\"y1\":25,\"x2\":25,\"y2\":40},{\"command\":\"C\",\"x\":25,\"y\":55,\"x1\":25,\"y1\":40,\"x2\":40,\"y2\":40}]";
await Viewer.AddAnnotationAsync(annotation);
}
}
```
**Note:** You can find the working example in [GitHub for adding ink annotation in Blazor PDF Viewer](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Server%20Deployment/Maui/Maui_DrawInk "GitHub: Adding ink annotation in Blazor PDF Viewer Examples").
## Conclusion
Thanks for reading! Syncfusion [Blazor PDF Viewer](https://www.syncfusion.com/blazor-components/blazor-pdf-viewer "FT: Blazor PDF Viewer") component’s mobile view empowers you to annotate PDFs with remarkable precision and flexibility. From highlighting key points to precisely measuring technical documents, the diverse annotation options cater to various mobile workflows. So, ditch the bulky laptops and unleash your inner annotation pro on your mobile device with [Blazor PDF Viewer](https://www.syncfusion.com/blazor-components/blazor-pdf-viewer "FT: Blazor PDF Viewer")!
You can leave your inquiries in the comments section below or contact reach out to us through our [support forum](https://www.syncfusion.com/forums "Support Forum"), [support portal](https://support.syncfusion.com/ "Support Portal"), or [feedback portal](https://www.syncfusion.com/feedback "Feedback Portal"). We are always here to assist you.
## Related blogs
- [Easily Customize the Toolbar in Blazor PDF Viewer](https://www.syncfusion.com/blogs/post/customize-toolbar-blazor-pdf-viewer "Blog: Easily Customize the Toolbar in Blazor PDF Viewer")
- [Effortless Remote Debugging with Dev Tunnel in Visual Studio 2022](https://www.syncfusion.com/blogs/post/dev-tunnel-remote-debug-vs-2022 "Blog: Effortless Remote Debugging with Dev Tunnel in Visual Studio 2022")
- [Create Responsive Web Designs Like a Pro with Blazor Media Query](https://www.syncfusion.com/blogs/post/responsive-web-blazor-mediaquery "Blog: Create Responsive Web Designs Like a Pro with Blazor Media Query")
- [Perform Effortless CRUD Actions in Blazor DataGrid with Fluxor](https://www.syncfusion.com/blogs/post/crud-blazor-datagrid-fluxor "Blog: Perform Effortless CRUD Actions in Blazor DataGrid with Fluxor") | jollenmoyani |
1,875,325 | The Power of Animation in Whiteboard Videos for Engaging Learners | The education sector is always looking for new ways to attract the attention of pupils and convey... | 0 | 2024-06-03T12:09:52 | https://dev.to/acadecraft_purvi_ba50b121/the-power-of-animation-in-whiteboard-videos-for-engaging-learners-376n | videoanimationservices |

The education sector is always looking for new ways to attract the attention of pupils and convey its message. With the rise in digitization, it is easy for learning institutes to focus on modern learning methodologies like videos. These are the ideal solutions for tackling the challenges of traditional learning systems.
These interactive animation platforms offer a powerful tool that has become popular: the flatscreen video. The videos on this platform combine simplicity, creativity, and visual storytelling to make them a powerful communications tool for businesses in many industries.
In this write-up, we’ll understand the [whiteboard video animation services](https://www.acadecraft.com/media-services/animated-videos/), what these are, and how companies can use them to engage learners and help them retain knowledge better.
## What is the Whiteboard Video Animation Service?
Whiteboard videos are the storytel
ling process of drawing pictures on a whiteboard, passing them on, and advancing them. Making content right before your watchers is one of the foremost interesting ways to engage them.
Showing data in simpler form and in real time builds certainty. These solutions are widely used in different learning and education institutes with the help of animated video production services.
## Whiteboard Videos For Education
Whiteboard videos are an inventive procedure that employs drawings and portrayal to tell a story or clarify a concept engagingly and intuitively. It's drawing on the blackboard or any other surface while recording it in real-time through a vivid video that can be shared with students.
## The Appeal of Animation
The key benefits of the visual appeal of animation cover the following:
## Visual Incitement
It brings inactive drawings to life. The development and change of pictures keep viewers’ attention and invigorate visual thinking.
This is often especially useful for visual learners who understand and hold data way better when it is displayed graphically. Hence, it successfully overcomes the challenges of traditional learning solutions.
## Rearrangements of Complex Concepts
It can break down complex thoughts into less complex, more edible components. By outwardly speaking to theoretical concepts, learners can get a handle on complex subjects more effectively.
For occurrence, outlining a logical handle or a verifiable event through liveliness can make it more comprehensible than inactive content or pictures alone. Hence, animated video creation services help in complex concept rearrangement.
## Engagement Through Describing
To ensure the content is more secure, the whiteboard links describing components as often as possible. Accounts can set the tone, stimulate emotions, and connect with the gathering of individuals.
If learners actively contribute to the content, they are more likely to keep information.
## Natural Development
To drive more frequent movement in Google's search engine, whiteboard videos can advance normal development and reduce online searcher churn, which is a key factor.
They can spend more time than other people when they use this visual form from their point of view. In case you need to increase the conversion rate of your site, it might be a good idea to create a video on your writing board.
## Create a strong connection
Another advantage of making live recordings is that you have a solid relationship with a group of observers. Some people love to watch and learn through clever videos. The whiteboard videos are the best video in this arrangement. You'll feel the human connection as soon as you watch this whiteboard video.
Remember, the more connections you have, the easier it is to find potential clients. Hence, utilizing whiteboard video animation services, these videos will culminate to communicate along with your characters.
Practical Applications of animation in whiteboard videos
Moving ahead, here are the key practical applications of animation in whiteboard videos:
Education
Blackboards are often used to clarify information related to mathematics, science, history, and dialect at school. They offer different levels of education, from elementary school to higher training.
Teachers may use them to supplement lessons, change rooms, or assist with changes.
## Corporate Preparing
Within the corporate world, the whiteboard is compelling for preparing representatives on unused forms, company approaches, or delicate aptitudes.
Hence, the animated video production services help recast complex business concepts and make the preparation sessions more engaging and viable.
Showcasing and Communication
Businesses are using video whiteboards to inform their clients and partners on items, administration, or concepts. The engaging arrangement makes a difference in capturing consideration and passing on messages.
This makes it a well-known choice for explainer videos and marketing campaigns.
## The Long Run of Whiteboard Videos
The long run of whiteboard animation is shining, with innovative progressions clearing the way for indeed more inventive employment. Virtual and increased reality seem to include modern measurements in whiteboard videos, making them more intuitive and immersive.
The integration of artificial intelligence seems to personalize learning encounters, adjusting content to suit a person's learning paces and inclinations. Hence, animated video creation services help optimize the benefits of effective learning.
## Final thoughts
Whiteboard video is a flexible and capable tool for engaging learners. They are an important asset to education and corporate preparation because of their ability to simplify complex concepts, refresh visual perception as well as improve memory retention.
The potential for movements on the whiteboards to change educational encounters is about to grow as innovation develops. At an advanced age, they become a basis for effective communication and learning.
| acadecraft_purvi_ba50b121 |
1,875,324 | 🚀 Unveiling JavaScript AsyncFunction and AsyncFunction() Constructor: A Deep Dive | Description The AsyncFunction in JavaScript is a special type of function that operates... | 0 | 2024-06-03T12:09:01 | https://dev.to/dharamgfx/unveiling-javascript-asyncfunction-and-asyncfunction-constructor-a-deep-dive-2lpb | webdev, javascript, beginners, programming |
### Description
The `AsyncFunction` in JavaScript is a special type of function that operates asynchronously via the `async` keyword. It returns a `Promise` and allows the use of the `await` keyword to pause execution until a `Promise` is resolved or rejected. The `AsyncFunction` constructor creates these asynchronous functions dynamically.
### Why Use AsyncFunction?
- **Asynchronous Operations:** Simplifies writing asynchronous code, making it more readable and maintainable.
- **Error Handling:** Provides a cleaner way to handle errors with `try`/`catch` blocks.
- **Improved Control:** Offers better control over asynchronous flow, especially with `await` for sequential execution.
### Where to Use AsyncFunction
- **API Calls:** Handling HTTP requests that return promises.
- **File I/O:** Working with file read/write operations in environments like Node.js.
- **Event Handling:** Managing asynchronous events in web applications.
- **Complex Workflows:** Breaking down complex asynchronous workflows into simpler steps.
### Syntax
#### Async Function Declaration
```javascript
async function functionName(parameters) {
// function body
}
```
#### Async Function Expression
```javascript
let asyncFunction = async function(parameters) {
// function body
};
```
#### Async Arrow Function
```javascript
let asyncFunction = async (parameters) => {
// function body
};
```
#### AsyncFunction() Constructor
```javascript
let AsyncFunction = Object.getPrototypeOf(async function(){}).constructor;
let asyncFunc = new AsyncFunction('a', 'b', 'return await Promise.resolve(a + b);');
```
### Examples
#### Example 1: Basic Async Function
```javascript
async function fetchData() {
let response = await fetch('https://api.example.com/data');
let data = await response.json();
return data;
}
fetchData().then(data => console.log(data)).catch(error => console.error(error));
```
#### Example 2: AsyncFunction Constructor
```javascript
let AsyncFunction = Object.getPrototypeOf(async function(){}).constructor;
let add = new AsyncFunction('a', 'b', 'return await Promise.resolve(a + b);');
add(2, 3).then(result => console.log(result)); // 5
```
### Constructor
The `AsyncFunction` constructor creates new asynchronous function objects. It is equivalent to using the `async function` expression but allows creating functions dynamically.
- **Syntax:** `new AsyncFunction([arg1[, arg2[, ...argN]], functionBody)`
- **Parameters:**
- `arg1, arg2, ...argN`: Names to be used by the function as formal argument names.
- `functionBody`: The string containing the JavaScript statements comprising the function definition.
### Instance Properties
Async functions, being functions, inherit properties from the `Function` prototype, including:
- **length:** The number of parameters the function expects.
- **name:** The name of the function.
```javascript
let asyncFunc = async function test(a, b) { return a + b; };
console.log(asyncFunc.length); // 2
console.log(asyncFunc.name); // "test"
```
### Instance Methods
Async functions inherit methods from the `Function` prototype, such as:
- **apply(thisArg, argsArray):** Calls a function with a given `this` value, and arguments provided as an array.
- **bind(thisArg[, arg1[, arg2[, ...]]]):** Creates a new function that, when called, has its `this` keyword set to the provided value.
- **call(thisArg[, arg1[, arg2[, ...]]]):** Calls a function with a given `this` value and arguments provided individually.
```javascript
let asyncFunc = async function(a, b) { return a + b; };
let boundFunc = asyncFunc.bind(null, 2);
boundFunc(3).then(result => console.log(result)); // 5
```
### Specifications
The `async` function and `await` keyword are part of ECMAScript 2017 (ES8). The `AsyncFunction` constructor itself is not explicitly defined in the specification but can be accessed through the prototype of an `async` function.
### Browser Compatibility
The `async` and `await` keywords are widely supported in all modern browsers, including:
- Chrome (from version 55)
- Firefox (from version 52)
- Safari (from version 10.1)
- Edge (from version 15)
- Node.js (from version 7.6)
The `AsyncFunction` constructor is indirectly supported since it can be accessed via `Object.getPrototypeOf(async function(){}).constructor`.
#### Conclusion
Understanding `AsyncFunction` and its constructor in JavaScript is essential for mastering asynchronous programming. Whether you're dealing with API calls, file I/O, or complex workflows, `AsyncFunction` offers a clean and efficient way to manage asynchronous operations. | dharamgfx |
1,875,322 | Boost Your SoundCloud Presence with Genuine Plays | Introduction In the bustling realm of online music streaming, SoundCloud stands tall as a platform... | 0 | 2024-06-03T12:05:57 | https://dev.to/glennlynch/boost-your-soundcloud-presence-with-genuine-plays-25lj | <h2><strong>Introduction</strong></h2>
<p><span style="font-weight: 400;">In the bustling realm of online music streaming, SoundCloud stands tall as a platform where artists can amplify their voices and share their craft with the world. However, in the vast sea of content, it's easy for your tracks to get lost amidst the noise. This is where the significance of </span><strong>SoundCloud plays</strong><span style="font-weight: 400;"> becomes evident. With an increasing number of plays, your tracks gain visibility, credibility, and ultimately, a larger audience.</span></p>
<h2><strong>The Importance of Real SoundCloud Plays</strong></h2>
<h3><strong>Authenticity Breeds Success</strong></h3>
<p><span style="font-weight: 400;">When it comes to garnering plays on SoundCloud, authenticity is key. </span><a href="https://growmyprofile.com/buy-soundcloud-plays/"><strong>Real SoundCloud plays</strong></a><span style="font-weight: 400;"> not only boost your track's credibility but also enhance its discoverability. Authentic engagement signals to the platform's algorithms that your content is worth promoting, leading to increased visibility on users' feeds and search results.</span></p>
<h3><strong>Building Trust and Credibility</strong></h3>
<p><span style="font-weight: 400;">In today's digital landscape, transparency and authenticity are valued more than ever. By accumulating genuine plays on your SoundCloud tracks, you're not just inflating numbers; you're building trust and credibility with your audience. Genuine engagement fosters a loyal fan base that resonates with your music and is more likely to support you in the long run.</span></p>
<h3><strong>Enhancing Visibility and Reach</strong></h3>
<p><span style="font-weight: 400;">In the competitive realm of music promotion, visibility is everything. </span><strong>Real SoundCloud plays</strong><span style="font-weight: 400;"> act as social proof, signaling to potential listeners that your tracks are worth their time. As your play count increases, so does your track's visibility within SoundCloud's ecosystem, leading to more opportunities for organic discovery and growth.</span></p>
<h2><strong>Conclusion</strong></h2>
<p><span style="font-weight: 400;">In the ever-evolving landscape of online music promotion, </span><a href="https://growmyprofile.com/buy-soundcloud-plays/"><strong>get SoundCloud plays</strong></a><span style="font-weight: 400;"> serve as a vital metric of success. However, it's not just about the numbers; authenticity is paramount. By focusing on accumulating </span><strong>real SoundCloud plays</strong><span style="font-weight: 400;">, you're not only boosting your track's visibility but also building trust and credibility with your audience. So, if you're looking to amplify your SoundCloud presence and take your music to new heights, investing in genuine plays is a strategic move that can yield significant dividends in the long run.</span></p> | glennlynch | |
1,875,321 | Tips for Efficient Electric Vehicle Fleet Management in 2024 | Electric Vehicle Fleet Management is designed specifically to help companies oversee and operate... | 0 | 2024-06-03T12:03:49 | https://dev.to/gpstracker01/tips-for-efficient-electric-vehicle-fleet-management-in-2024-27c2 | evfleetmanagement, softwrae | Electric Vehicle Fleet Management is designed specifically to help companies oversee and operate their EVs efficiently. Its main job is to monitor and optimize various factors to ensure the EVs are running smoothly and being properly maintained.
So, what exactly is [Electric Vehicle Fleet Management](https://trackobit.com/electric-vehicle-fleet-management-software)? Simply put, it's a software that helps companies manage, track, and facilitate the day-to-day operations of their electric vehicle fleets. This software makes it easier to keep tabs on battery levels, charging schedules, maintenance needs, and overall vehicle performance.
One of the biggest benefits of using [best asset tracking software](https://trackobit.com/asset-tracking-management-software) such as Electric Fleet is that it takes the guesswork out of managing your EVs. Instead of having to manually track and coordinate everything, the software does it for you. It can even provide insights and analytics to help you optimize your operations and make data-driven decisions.
What are the Benefits of EV Fleet Management
Electric vehicle fleet management software offers a number of benefits that make running your EV fleet way easier which are:
1. Fewer Moving Parts
Electric vehicles have significantly fewer moving parts than their ICE counterparts. For instance, an electric motor is remarkably simpler than a conventional ICE, containing far fewer components that could wear out or fail over time. This simplicity extends to the drivetrain as well, with electric vehicles often employing direct drive systems that eliminate the need for multi-speed transmissions and their associated maintenance needs.
2. No Oil Changes
Electric vehicles do not use engine oil, as they do not have an internal combustion engine. This eliminates the need for regular oil changes, one of the most common and routine maintenance tasks required for traditional vehicles. Additionally, there are no oil filters to replace or dispose of, reducing maintenance costs and environmental impact.
3. Regenerative Braking Systems
Many electric vehicles utilize regenerative braking, which not only helps to recharge the vehicle’s battery but also reduces the wear and tear on the brake system. This can lead to longer intervals between brake maintenance and replacements, further reducing operational costs.
4. Reduced Engine Wear
Without the complex interplay of moving parts found in an ICE, electric motors undergo less wear and tear overall. The absence of processes such as combustion and the associated heat and vibrations means less stress on the vehicle's systems, translating to potentially longer lifespans and lower maintenance demands.
5. Enhanced Energy Efficiency
Electric buses are significantly more energy-efficient than their ICE counterparts. They convert over 60% of the electrical energy from the grid to power at the wheels, compared to the 20% efficiency rate for petrol or diesel engines. Higher energy efficiency means lower operating costs, contributing to the overall reduction in maintenance costs.
However, it's important to note that while the day-to-day maintenance costs of EVs can be lower, there are still costs associated with electric vehicle ownership. Battery replacement is a notable example, although advancements in battery technology and management systems are continually extending the lifespan of these components.
Overall, the shift towards electric vehicles presents a favorable equation in terms of both environmental impact and total cost of ownership, with maintenance savings being a significant factor in the latter.
Challenges of Electric Vehicle Fleet Management
Managing Electric Vehicle Fleet Management software represents a significant shift from traditional internal combustion engine vehicles. While the move towards EVs is driven by environmental considerations and potential long-term cost savings, businesses face several obstacles in managing these fleets.
1. Initial Investment and Infrastructure
The upfront cost of electric vehicles is typically higher than that of gasoline or diesel vehicles. Additionally, setting up the necessary charging infrastructure can represent a substantial investment. This is a significant hurdle for small and medium-sized businesses with limited capital.
2. Charging Infrastructure and Range Anxiety
Adequate charging infrastructure is crucial for the efficient operation of an EV fleet. Range anxiety, the fear that an EV has insufficient range to complete a task, also presents a challenge, especially for fleets with long-distance routes.
3. Vehicle Availability and Variety
Until recently, there was a limited selection of electric vehicles, particularly for specialized commercial use. This has made it challenging for businesses requiring diverse fleets to fully transition to electric.
4. Maintenance and Technical Training
Electric vehicles have different maintenance needs than traditional vehicles. The lack of familiarity and expertise can lead to higher operational costs and vehicle downtime.
5. Energy Management and Cost
Fluctuating electricity prices can affect the cost-effectiveness of operating an EV fleet. Managing energy consumption efficiently, especially during peak hours, is a challenge.
Future Trends in Electric Fleet Management
Intelligent Charge Scheduling
One of the critical challenges in managing an EV fleet is ensuring vehicles are adequately charged without overwhelming the power grid. Future fleet management software will employ sophisticated algorithms to schedule charging sessions for each vehicle intelligently. This strategic scheduling will prevent simultaneous charging across the entire fleet, mitigating the risk of power grid overload while ensuring optimal vehicle availability.
Optimized Route Planning
EVs have a limited driving range compared to traditional gasoline-powered vehicles, making route planning a crucial consideration. Advanced fleet management solutions will leverage real-time data on battery levels, charging station locations, and traffic patterns to devise the most efficient routes. This optimized routing will maximize energy efficiency, minimize recharging downtime, and enable seamless operations.
Predictive Maintenance
Leveraging machine learning and data analytics, future fleet management software will continuously monitor each vehicle's performance and condition. By analyzing various parameters, the software can predict potential maintenance issues before they occur, enabling proactive maintenance scheduling. This predictive approach will minimize unplanned breakdowns, reduce downtime, and extend the lifespan of EVs within the fleet.
Integration with Autonomous Driving Technology
As autonomous driving capabilities continue to evolve, future EV fleet management software will seamlessly integrate with self-driving systems. This integration will enable centralized control and monitoring of autonomous EV fleets, further optimizing routing, energy usage, and overall operational efficiency.
Before You Go!
The switch to electric buses represents a thoughtful adoption of technology to improve service delivery and operational efficiency in public transportation. It uses the inherent advantages of electric vehicles, such as reduced maintenance costs and fewer mechanical complications, bus companies can offer more reliable service.
This not only enhances the passenger experience but also contributes to broader environmental goals by reducing the carbon footprint of public transportation systems. As technology continues to evolve and the cost of electric vehicles becomes even more competitive, it's likely we'll see an increased shift towards electric buses in cities around the world.
Also, successfully managing an electric vehicle fleet requires overcoming significant barriers, ranging from initial investment to operational logistics. However, through strategic planning, leveraging incentives, embracing technology, and fostering partnerships, businesses can address these challenges.
The shift toward EV fleets- which is the best asset tracking software by TrackoBit is not only feasible but also beneficial for companies aiming to reduce their carbon footprint and operational costs in the long run.
| gpstracker01 |
1,875,320 | Slippery Comfort: A Guide to Hotel Slippers | photo_6253441378063334683_w.jpg Slippery Comfort: A Guide to Hotel Slippers Do you love the feeling... | 0 | 2024-06-03T12:01:36 | https://dev.to/theresa_mccraryjs_77dd382/slippery-comfort-a-guide-to-hotel-slippers-287j | photo_6253441378063334683_w.jpg
Slippery Comfort: A Guide to Hotel Slippers
Do you love the feeling of cozy and slippers comfortable your feet and do you often travel and stay in different hotels? If so, you may have come across hotel slippers. Hotel slippers are comfortable and footwear hotels that are practical to their guests. They can make your hotel stay much more enjoyable and help you relax during your travels. Let's dive into the world global of slippers and explore their advantages, innovation, safety features, uses, quality, and how to use them.
Advantages of Hotel Slippers
Hotel slippers have many benefits you should consider during your hotel stay. They offer warmth and comfort to your feet, making them a way relax great a long day of travel. Hotel slippers are also hygienic and can protect your feet from germs and bacteria may be present on hotel floors. They are easy to use and can be worn anytime, anywhere in the hotel room. Most importantly, they make you feel welcome and add a touch of luxury to your stay.
Innovation in Hotel Slippers
There have been advancements significant is the design and materials that are used in hotel slippers. Nowadays, hotel disposable slippers are made of high-quality materials like cotton, velvet, and terry cloth. They come in different shapes, sizes, and colors, making them a fashion statement as well as practical footwear. Some hotels even offer personalized slippers with their logos, adding a touch of exclusivity to their guest experience.
Safety Features in Hotel Slippers
Safety is a factor that's crucial consider when it comes to hotel slippers. Hotels are now provide non-slip slippers with rubber outsoles and grip extra prevent slips and falls on wet floors. This feature ensures guests feel secure and relaxed when walking around in their hotel rooms, preventing accidents possible.
Uses of Hotel Slippers
Hotel slippers have multiple uses guests can take advantage of during their stay. You can wear hotel slippers disposable when relaxing, watching TV, or enjoying a bath luxurious. They can also be used as a cover-up quick answering the hotel room's door or something fetching outside the hotel room. Hence, they are versatile footwear perfect for any hotel guest.
Quality of Hotel Slippers
The quality of hotel slippers are essential as it determines the comfort, durability, and experience guests overall. Hotels have been investing in high-quality materials and designs to ensure guests' comfort during their stay. Guests can enjoy the soft, plush feel of materials like cotton, velvet, and terry cloth in high-quality slippers. Investing in quality slippers can ensure guests return to your hotel in the future.
How to Use Hotel Slippers
Using hotel slippers are as easy as slipping them on your feet. Simply remove your shoes and wear the hotel slippers. Slip them off your feet and place them back in the designated area provided by the hotel when you ready to remove. Ensure you place them back in the spot right avoid misplacement or loss.
Service and Application
Hotel slippers are part of the hotel services that are provided to guests. They can be found in the hotel room, usually in the closet or next to the bedside table. The hotel staff replaces them regularly, ensuring quality consistent. The application of disposable hotel slippers are straightforward and simple. All you need to do put them on your feet and enjoy the comfort they provide.
Source: https://www.kailai-amenity.com/application/hotel-disposable-slippers | theresa_mccraryjs_77dd382 | |
1,875,319 | Teri Meri Dooriyan Full Episode | Teri Meri Dooriyan is a TV show on Star Plus, a channel famous in India for its dramas and family... | 0 | 2024-06-03T12:01:25 | https://dev.to/dylan_luca_37bb9b77d9a15f/teri-meri-dooriyan-full-episode-52ii | hindi, drama, terimeridooriyan, indian | [Teri Meri Dooriyan](https://terimeridooriyan.me/) is a TV show on Star Plus, a channel famous in India for its dramas and family shows. The title means "The Distance Between Us" in English, hinting at stories about people trying to overcome different kinds of gaps between them. These gaps could be misunderstandings, different backgrounds, or even physical distance. The show is likely to have a mix of emotions, family values, and love stories, typical of Star Plus serials. It might show us how characters deal with problems, find love, and learn important lessons about life. The main focus is on how they bridge the distances between each other to create stronger bonds and understanding.Teri Meri DooriyanShows like "Teri Meri Dooriyan" often include a big cast, with many characters each facing their own challenges. There are usually a few main characters that the story focuses on more, showing us their journey in more detail. They might face obstacles like family disagreements, society's rules, or personal doubts, but they try to solve these issues throughout the show. The serial could be set in a modern-day context, blending traditional Indian culture with today's world. This mix makes the story interesting for many viewers, as it shows the struggles of balancing old customs with new ways of living. "Teri Meri Dooriyan" is made to entertain, but also to make us think about our relationships with others. It's about understanding and patience, showing that even when people seem very different or far apart, there's always a way to come closer. If you like watching stories about family, love, and overcoming problems, "Teri Meri Dooriyan" might be a good show for you. It's designed to pull at the heartstrings and maybe even teach a lesson or two about how to bridge the gaps in our own lives. | dylan_luca_37bb9b77d9a15f |
1,875,318 | Unlock the Power of Your WooCommerce Store with Custom Extensions | WooCommerce will allow you to quickly take your online store to the next level. By improving its... | 0 | 2024-06-03T12:00:14 | https://dev.to/elightwalk/unlock-the-power-of-your-woocommerce-store-with-custom-extensions-4p3h |

WooCommerce will allow you to quickly take your online store to the next level. By improving its functionality and user experience, you can easily take your online store to the next level. Unlock the Power of Your WooCommerce Store with Custom Extensions for WooCommerce.
**Why WooCommerce Extension Development is a Game-Changer for Your Online Business**
WooCommerce is a powerful and customizable WordPress plugin with a solid foundation for e-commerce websites. On the other hand, investing in custom WooCommerce extensions can help you fully realize its potential and differentiate your business. These customized solutions allow you to add unique features, streamline processes, and improve the customer experience, ultimately boosting sales and revenue.
## 5 Proven Ways a Custom WooCommerce Extension Can Extend Your Sales and Revenue
Personalized Shopping Experiences: Custom extensions development can offer personalized shopping experiences by leveraging customer data. Features like personalized product recommendations, tailored discounts, and customized product bundles can significantly enhance the shopping experience, leading to higher conversion rates.
**Improve Product Management:** You can streamline product management with a custom WooCommerce extension development. Whether it's bulk editing product attributes, managing complex inventories, or automating product updates, these extensions can save time and reduce mistakes, allowing you to focus on strategic tasks.
**Improved Checkout Process:** Simplifying the checkout process is crucial for reducing cart abandonment. Custom extensions can integrate with various payment gateways, offer one-click checkouts, and provide multi-currency support, making it easier for customers to complete their purchases.
**Advanced Marketing Tools:** Custom extensions can integrate advanced marketing tools such as automated email campaigns, loyalty programs, and social media integrations. These tools help engage customers, drive repeat purchases, and expand your reach.
**Seamless Third-Party Integrations:** Tailored WooCommerce extensions development can facilitate seamless integrations with third-party services like CRM systems, shipping providers, and analytics tools. It confirms that your store operates smoothly and that you have all the necessary data to make informed business decisions.
## **Types of Custom Extensions**
**Payment Gateways**
Integrating custom payment gateways ensures your customers have flexible and secure payment options. Whether local payment methods, cryptocurrency, or specialized payment processors, custom extensions can provide a seamless checkout experience that caters to your audience's preferences.
**Shipping Methods**
Custom shipping extensions can offer advanced shipping options tailored to your business needs. These extensions can improve your store's logistics, from real-time shipping rates and multi-carrier support to specialized delivery methods and automated shipping label generation.
**Product Customization Options**
Allowing customers to personalize products can set your store apart. Custom extensions for product customization can include features like custom engraving, build-your-own product options, or advanced configurators that let customers design their products, increasing engagement and sales.
How to Choose the Right WooCommerce Extension Development Company for Your Needs
Selecting the right development organixzation is important for the success of your custom WooCommerce extension.
Here are some tips to guide your choice:
Expertise and Experience: Look for a company with a proven good track of record in WooCommerce extension development. Check their work portfolio and check the client testimonials to gauge their knowledge and reliability.
**Customization Capabilities:** Make sure the company can deliver fully customized software tailored to your business needs. They should be able to understand your vision and translate it into a functional extension.
**Technical Proficiency:** The company should have a team of experienced developers who are up to date on the latest technologies and WooCommerce extension development best practices. They should also be capable of integrating your extension with other systems and platforms.
**Support and Maintenance:** Post-development support is vital for the smooth functioning of your extension. Choose a company that offers comprehensive support and maintenance services to handle any issues that may arise.
**Cost-Effectiveness:** While cost should not be the only deciding factor, finding a development partner who offers quality services within your budget is essential. Obtain detailed features and compare them to make an informed decision.
Top Features to Include in Your Custom WooCommerce Extension for Maximum Impact
To ensure your custom WooCommerce extension delivers maximum impact, consider including the following features:
Advanced Search and Filtering OptionsEnable customers to find products quickly and easily with advanced search and filtering capabilities.
**Dynamic Pricing and Discounts:** Implement dynamic pricing strategies and discount rules to attract customers and boost sales.
Customer Reviews and RatingsIntegrate a robust review and rating system to build trust and encourage purchases.
**Mobile Optimization:** Ensure your extension is fully optimized for mobile-friendly to provide a seamless shopping experience on any device.
**Analytics and Reporting:** Include detailed analytics and reporting tools to track performance, understand customer behavior, and make data-driven decisions.
##Conclusion:
Take Your WooCommerce Store to New Heights with a Custom Extension
Investing in custom WooCommerce extensions can transform your online store, offering unique functionalities that cater to your business needs and customer preferences. These bespoke solutions can significantly boost your sales and revenue by enhancing the shopping experience, streamlining operations, and integrating advanced marketing tools.
Elightwalk is a **[woocommerce extension development](https://www.elightwalk.com/services/woocommerce-development)** company
Let Elightwalk take your WooCommerce store to the next level! | elightwalk | |
1,875,316 | 🚀 Mastering JavaScript ArrayBuffer: A Comprehensive Guide | Description The ArrayBuffer is a core part of JavaScript's low-level binary data... | 0 | 2024-06-03T11:58:07 | https://dev.to/dharamgfx/mastering-javascript-arraybuffer-a-comprehensive-guide-1d5h | webdev, javascript, beginners, programming |
### Description
The `ArrayBuffer` is a core part of JavaScript's low-level binary data manipulation capabilities. It represents a fixed-length raw binary data buffer. This buffer can then be manipulated using views like `TypedArray` or `DataView` to handle different types of data.
### Why Use ArrayBuffer?
- **Performance:** Handling binary data directly can be more efficient than processing strings or other high-level objects.
- **Interoperability:** Facilitates communication with other APIs and systems that require binary formats.
- **File Handling:** Essential for operations involving file I/O, such as reading and writing binary files.
- **Network Operations:** Useful for WebSockets and other network protocols that deal with binary data.
### Where to Use ArrayBuffer
- **WebAssembly:** `ArrayBuffer` is used for interacting with WebAssembly modules, which often require binary data for performance-critical tasks.
- **Image Processing:** Manipulating pixel data for images, such as applying filters or transformations.
- **Audio Processing:** Handling raw audio data for playback, analysis, or manipulation.
- **Data Storage:** Storing and processing binary data, such as in databases or for caching purposes.
- **Cryptography:** Managing binary data for encryption and decryption processes.
- **Scientific Computing:** Working with large datasets and complex numerical computations that require efficient binary data handling.
### Constructor
The `ArrayBuffer` constructor creates a new `ArrayBuffer` object.
```javascript
let buffer = new ArrayBuffer(8);
console.log(buffer.byteLength); // 8
```
- **Syntax:** `new ArrayBuffer(length)`
- **Parameters:**
- `length`: The size of the buffer in bytes.
### Static Properties
- **ArrayBuffer.length**: Always 1 (the number of arguments the constructor accepts).
```javascript
console.log(ArrayBuffer.length); // 1
```
### Static Methods
- **ArrayBuffer.isView(arg)**: Returns `true` if `arg` is one of the `TypedArray` or `DataView` objects.
```javascript
let buffer = new ArrayBuffer(8);
let view = new Uint8Array(buffer);
console.log(ArrayBuffer.isView(view)); // true
```
- **ArrayBuffer.transfer(oldBuffer, newByteLength)**: Creates a new `ArrayBuffer` with the specified size and copies the contents from the old buffer to the new one (experimental).
```javascript
let buffer1 = new ArrayBuffer(8);
let buffer2 = ArrayBuffer.transfer(buffer1, 16);
console.log(buffer2.byteLength); // 16
```
### Instance Properties
- **ArrayBuffer.prototype.byteLength**: Returns the length of the `ArrayBuffer` in bytes.
```javascript
let buffer = new ArrayBuffer(8);
console.log(buffer.byteLength); // 8
```
### Instance Methods
- **ArrayBuffer.prototype.slice(begin, end)**: Returns a new `ArrayBuffer` that is a copy of this buffer from `begin` to `end`.
```javascript
let buffer = new ArrayBuffer(8);
let slicedBuffer = buffer.slice(2, 6);
console.log(slicedBuffer.byteLength); // 4
```
- **Parameters:**
- `begin`: The beginning index of the slice.
- `end`: The end index of the slice (not included).
### Examples
#### Example 1: Creating an ArrayBuffer and a TypedArray view
```javascript
let buffer = new ArrayBuffer(8);
let view = new Uint8Array(buffer);
view[0] = 255;
console.log(view[0]); // 255
```
#### Example 2: Using DataView to manipulate data
```javascript
let buffer = new ArrayBuffer(16);
let view = new DataView(buffer);
view.setUint8(0, 255);
view.setFloat32(4, 42.42, true);
console.log(view.getUint8(0)); // 255
console.log(view.getFloat32(4, true)); // 42.42
```
### Specifications
The `ArrayBuffer` is defined in the ECMAScript (ECMA-262) specification, ensuring a consistent standard across different JavaScript engines.
### Browser Compatibility
The `ArrayBuffer` is widely supported across all modern browsers, including:
- Chrome
- Firefox
- Safari
- Edge
- Internet Explorer (from version 10)
- Node.js
#### Conclusion
Understanding and utilizing `ArrayBuffer` is crucial for efficient binary data manipulation in JavaScript. Whether you're dealing with file I/O, network communication, or performance-critical applications, `ArrayBuffer` provides a powerful toolset for handling raw binary data. | dharamgfx |
1,875,315 | khatron ke khiladi 14watch online | khatron ke khiladi New Season 14 Watch Online Visit On kkk14live.net Official Web Full HD... | 0 | 2024-06-03T11:57:53 | https://dev.to/khatron_kekhiladi14_af9/khatron-ke-khiladi-14watch-online-4o6h | khatron ke khiladi New Season 14 Watch Online Visit
On kkk14live.net Official Web Full HD Video.
<a href="https://kkk14live.net/">khatron ke khiladi 14</a> | khatron_kekhiladi14_af9 | |
1,874,952 | Python vs. JavaScript | Python and JavaScript (JS) are two fairly old programming languages at this point, but what makes... | 0 | 2024-06-03T11:57:20 | https://dev.to/dakota_day/python-vs-javascript-3cpl | javascript, beginners, python |
Python and JavaScript (JS) are two fairly old programming languages at this point, but what makes them different from each other? Many would consider these languages fairly beginner friendly. How are they similar? We'll go over a couple of things that set these two languages apart and why they've been in the game for so long.
## Humble Beginnings
Both languages in this post are very mature and rooted, being made in the early days of 90's public internet.
###Python
Python was developed by _Guido van Rossum_ starting in 1989 but wouldn't be released until 1991. Funny enough according to Python Institute, the name is derived from Monty Python's Flying Circus! Python is maintained by Python Software Foundation. It was built with a couple things in mind:
- Being easy to learn.
- Being easy to read and write.
- And being easy to obtain.
###JavaScript
JavaScript is slightly younger, being developed in 1995 by Netscape programmer, _Brendan Eich_. Here's a fun fact, Brendan Eich built JS in 10 days! It was originally called Mocha, then LiveScript, and finally the JavaScript we all know today. In 1997, Netscape would hand off JS management and maintenance to the European Computer Manufacturers Association (ECMA). The newly handled versions would be called ECMAScript or ES. The standardized version now is ES6(2015) which added a lot of features that devs had been asking for. If we were to compare it directly to Python for comparison sake:
- Also easy to learn.
- Slightly harder to read and write.
- Also fairly easy to obtain.
---
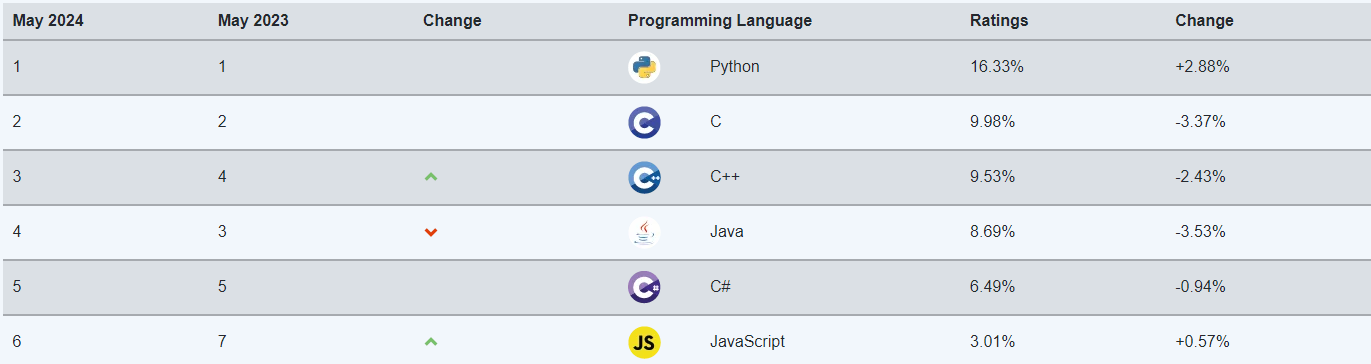
According to Tiobe.com, Python is the most popular coding language sitting at a crazy 16.33% approval rating as of May 2024! It even won Tiobe's Language of the Year in 2007, 2010, 2018, 2020, and 2021. JavaScript, while not as high, still sits in the top 10 at number 6 with a 3.01% approval rating. It also won Language of the Year in 2014. Learning either one of these won't give you any difficulty landing a job.
---
##Let's Talk Syntax
Python and JS are both fairly easy to write, but what are some key differences in the syntax? Python is known for its high readability, almost pseudocode-like structure. JS on the other hand is more known for it's flexibility. Here's some example syntax on how you would write some basic code in each language:
####Variables
In Python, variables aren't defined with keywords, just set them to whatever data type you need.
```
num = 10 #Python uses # for comment lines
string = 'hello' #It doesn't require semicolons to end lines
```
In JS, it is best practice to use declarative keywords, like _let_ and _const_, when making variables. Not doing so can lead to scope issues.
```
let num = 10;
let string = 'hello';
```
####Functions
Python uses the _def_ keyword to define a function.
```
def add(num1, num2): #Python uses colons to indicate new blocks
result = num1 + num2
print(result) #It also uses print() for printing
```
JS uses either the _function_ keyword or _arrow function_ syntax. Arrow functions give the option to shorten function blocks.
```
function add(num1, num2){
result = num1 + num2
return console.log(result) //JS uses console.log() for logging
}
//OR
add (num1, num2) => console.log(num1 + num2)
```
####Conditionals
Python **does not** use curly braces to define blocks like JS. Instead it uses _indentation_ to define its blocks. This changes how conditionals look of course. For example:
```
if num < 0:
print('negative')
elif num === 0: #Python uses elif instead of JS's _else if_
print('zero')
else:
print('positive')
```
Here's JS's version:
```
if (num < 0){ // Here the conditions must be wrapped in parentheses
console.log('negative')
} else if (num === 0){ //Braces to indicate code blocks
console.log('zero')
} else{
console.log('positive')
}
```
Just in these simple examples you can see how Python really strives to make coding faster and more readable.
Here's a video from _Red Eyed Coder Club_ that shows how a basic algorithm would be built side by side in both languages:
{% embed https://www.youtube.com/watch?v=Jld0aUQ9LZw %}
##Use Case
Where Python and JS start to break apart from each other is each of their use cases. JS focuses more on front-end development while Python focuses more on the back-end side of things.
###Javascript
JS is used alongside HTML and CSS a lot of the time. This means that you can find yourself building functional websites and applications on the back-end that are also pleasing to the eye on the front-end. This is reflected in the frameworks and libraries JS offers, some of the most popular frameworks being React, Vue, and Angular. If you enjoy this, that probably means you would want to go for full-stack dev positions.
###Python
Python, being more back-end focused, is primarily used for things like scripting and automation. Its frameworks and libraries will focus more on data sciences or automation tasks. Some popular ones are Pandas, NumPy, and Scikit Learn.
Now don't get it twisted, just because one language has a focus in one area doesn't mean that you can't use it at all for a weaker one. Just keep in mind that if you were to go that route, you may just have more trouble, or take more time trying to get things to work correctly.
##Conclusion
So what does all of this mean? Well, when thinking about jobs or projects that you want to do, picking a language can make those projects significantly harder or easier. Python will shine working on the back-end while JavaScript will shine while working on the front-end. Neither one is necessarily a better choice over the other, it just depends on what **YOU** want to do. Most people after learning one will go and learn the other. After all, coding languages are just tools, and having different tools will make you more desirable as a new hire.
###Sources Used
- [The History of JavaScript](https://www.springboard.com/blog/data-science/history-of-javascript/)
- [Brendan Eich](https://en.wikipedia.org/wiki/Brendan_Eich#:~:text=He%20completed%20the%20first%20version,was%20named%20JavaScript%20in%20December.)
- [About Python](https://pythoninstitute.org/about-python#:~:text=Python%20was%20created%20by%20Guido,called%20Monty%20Python's%20Flying%20Circus.)
- [W3Schools](https://www.w3schools.com/python/python_syntax.asp) For Python syntax
- [Tiobe Index](https://www.tiobe.com/tiobe-index/)
- [Tech With Tim on Youtube](https://www.youtube.com/watch?v=t9CAFYn7YgY)
| dakota_day |
1,875,314 | Power BI vs. Tableau: Picking the Perfect BI Tool for You (2024) | In the realm of data analysis, two titans clash: Power BI and Tableau. Both are phenomenal for... | 0 | 2024-06-03T11:57:00 | https://dev.to/akaksha/power-bi-vs-tableau-picking-the-perfect-bi-tool-for-you-2024-2eb4 | powerbi, tableau, tools | In the realm of data analysis, two titans clash: [Power BI and Tableau.](https://www.clariontech.com/blog/power-bi-vs-tableau-which-is-best-for-data-analytics) Both are phenomenal for transforming raw data into visually compelling insights, but which one reigns supreme for your needs? This article dissects their strengths and weaknesses to empower you to make an informed decision.
Who Should Choose Tableau?
Data scientists and analysts requiring advanced analytics and in-depth customization. Organizations working with a vast array of data sources beyond Microsoft products. Companies prioritizing exceptional visual storytelling and unique dashboard designs.
Who Should Choose Power BI?
Businesses already invested in the Microsoft ecosystem. Users seeking an intuitive interface with a gentle learning curve. Budget-conscious organizations looking for cost-effective solutions.
Choosing between Power BI and Tableau depends on your needs. Power BI integrates seamlessly with Microsoft products and offers a user-friendly interface, making it great for non-technical users and creating reports quickly. Tableau boasts superior data handling for massive datasets and unparalleled customization, ideal for data scientists crafting intricate visualizations. Consider factors like data source, team skillset, and budget to decide which tool empowers your business intelligence journey.
| akaksha |
1,875,313 | How to Build a Web App from Scratch | Know how businesses can use PowerBI to build a web app from scratch in our comprehensive... | 0 | 2024-06-03T11:56:30 | https://dev.to/twinkle123/how-to-build-a-web-app-from-scratch-5hca | webdev, programming, devops, productivity | Know how businesses can use PowerBI to build a web app from scratch in our comprehensive guide.
Creating a web app from scratch might seem daunting, but it can be a rewarding and manageable process with the right approach. In this comprehensive guide, we'll walk you through everything you need to know to build your own web app. Whether you're a novice or have some experience, this guide will help you understand the best way to build web applications.
What is a web app
A web app is an application software that runs on a web server, unlike traditional desktop applications that run on an operating system. Users can access web apps through a web browser, using the internet. They range from simple pages like online calculators to complex systems like online banking platforms.
Prerequisites to create a web app
Before diving into the development process, there are several prerequisites to consider:
Basic Knowledge of Web Technologies: Understanding HTML, CSS, and JavaScript is essential.
Development Environment: Set up your computer with necessary software like a code editor (e.g., Visual Studio Code) and version control (e.g., Git).
Backend Knowledge: Familiarity with server-side languages (e.g., Node.js, Python) and databases (e.g., MySQL, MongoDB) is beneficial.
Understanding of Frameworks: Using frameworks like React for the front end and Express for the back end can streamline the development process.
Advantages of a Web App over a Mobile App
While both web apps and mobile apps have their own merits, web apps offer several distinct advantages:
Cross-Platform Compatibility: Web apps work on any device with a browser, eliminating the need for multiple versions.
Easier Updates: Updates are applied on the server-side, ensuring all users have access to the latest version without manual updates.
Cost-Effective: Developing a single web app can be more cost-effective than developing multiple mobile apps for different platforms.
Different Types of Web Applications
Web applications can be categorized based on their functionality and complexity:
Static Web Apps: Simple web apps that deliver content without much interaction. Example: Portfolio websites.
Dynamic Web Apps: These apps interact with users and generate real-time data. Example: E-commerce sites.
Single Page Applications (SPAs): SPAs load a single HTML page and dynamically update as the user interacts with the app. Example: Gmail.
Progressive Web Apps (PWAs): PWAs use modern web capabilities to deliver an app-like experience. Example: Twitter Lite.
Steps to Build a Web Application
Here's a step-by-step guide on how to build a web app:
Define Your Idea
Start by defining what your web app will do. Identify the problem it will solve and outline the features it will include. This initial step is crucial for guiding the rest of the development process.
Plan the Development Process
Create a roadmap that includes milestones and deadlines. Break down the development process into manageable tasks, focusing on both front-end and back-end development.
Design the Look and Feel
The design phase involves creating wireframes and mockups. Tools like Figma or Sketch can help you visualize the user interface and user experience (UI/UX) design. Aim for a clean, intuitive design that enhances user interaction.
Choose the Right Tools and Framework
Selecting the right tools and frameworks can streamline development. For front-end development, popular frameworks include React, Angular, and Vue.js. For back-end development, consider using Node.js with Express, Django, or Ruby on Rails.
Develop the Front End
Start coding the front end by creating the layout with HTML, styling with CSS, and adding interactivity with JavaScript. Use your chosen framework to build reusable components and manage the application’s state.
Develop the Back End
Set up your server and database. Write the necessary APIs to handle data transactions between the front end and back end. Ensure your server-side logic is secure and efficient.
Integrate Front End and Back End
Connect the front end with the back end using the APIs you created. Test the interactions to ensure data is correctly displayed and processed.
Test Your Web App
Testing is a crucial step in web application development. Conduct both manual and automated tests to check for bugs, performance issues, and usability problems. Tools like Selenium and Jest can help with automated testing.
Deploy Your Web App
Once testing is complete, deploy your web app to a web hosting service. Platforms like Heroku, AWS, or Vercel offer robust hosting solutions. Ensure your deployment process includes setting up a domain name and securing your app with HTTPS.
Maintain and Update Your Web App
Post-deployment, continue to monitor your web app for any issues. Regularly update it with new features, security patches, and performance improvements based on user feedback.
Conclusion
Building a web app from scratch involves careful planning, selecting the right tools, and diligent testing. By following this step-by-step guide, you can create a web app that is functional, user-friendly, and scalable. Remember, the key to successful web application development is continuous learning and adaptation. Keep experimenting with new technologies and frameworks to enhance your skills and deliver better web apps. Happy coding! | twinkle123 |
1,875,312 | Arduino IDE 2 上傳檔案到 ESP32/ESP8266 的外掛 | Arduino IDE 2.x 版有完整的語法標色、程式碼補全等眾多功能, 比原本陽春的 Arduino 1.x 版要好用許多, 不過許多人可能因為缺少了可以上傳檔案到 ESP32/ESP8266... | 0 | 2024-06-03T11:55:15 | https://dev.to/codemee/arduino-ide-2-shang-chuan-dang-an-dao-esp32esp8266-de-wai-gua-10cg | esp32, arduino, esp8266 | Arduino IDE 2.x 版有完整的語法標色、程式碼補全等眾多功能, 比原本陽春的 Arduino 1.x 版要好用許多, 不過許多人可能因為缺少了可以上傳檔案到 ESP32/ESP8266 等控制板的功能, 在使用 Arduino IDE 2.x 時卡關。好消息來了, 已經有善心人士撰寫了外掛, 幫我們解決這個問題。
## 檔案上傳外掛下載網址
首先是有善心人士 [Earle F. Philhower, III](https://github.com/earlephilhower) 撰寫了[arduino-littlefs-upload](https://github.com/earlephilhower/arduino-littlefs-upload) 外掛, 你可以直接[在這裡下載外掛檔案](https://github.com/earlephilhower/arduino-littlefs-upload/releases/tag/1.1.7)。但是這個外掛是針對 LittleFS 檔案系統, 如果你要採用的是 SPIFFS 檔案系統, 就派不上用場。於是就有另一個善心人士 [espx](https://github.com/espx-cz) 從剛剛介紹的外掛衍生出 [arduino-spiffs-upload](https://github.com/espx-cz/arduino-spiffs-upload) 外掛, 你可以在[這裡下載外掛檔案](https://github.com/espx-cz/arduino-spiffs-upload/releases)。
## 安裝外掛
Arduino IDE 2 是從 [The Eclipse Theia IDE](https://theia-ide.org/#theiaide) 衍生而來, 其實也就是 Visual Studio Code 的源頭, 它們都共用同一套外掛機制, 只要在你的使用者目錄下找到 .arduinoIDE 資料夾, 在其中建立 plugins 資料夾, 將剛剛下載的 .vsix 外掛檔案複製到 plugins 資料夾中:
```
C:\USERS\{使用者名稱}\.ARDUINOIDE
└──plugins
├─arduino-littlefs-upload-1.1.5.vsix
└─arduino-spiffs-upload-1.1.5.vsix
```
再重新開啟 Arduino IDE 即可。
## 上傳檔案
要上傳檔案, 只要在你的草稿碼資料夾下建立一個 data 資料夾, 像是這樣:
```
C:\USERS\MEEBO\CODE\ARDUINO\TEST_LITTLEFS
├─test_littleFS.ino
└─data
└─test.txt
```
```
C:\USERS\MEEBO\CODE\ARDUINO\TEST_SPIFFS
├─test_SPIFFS.ino
└─data
└─test.txt
```
接著, 就可以按 <kbd>Ctrl</kbd>+<kbd>Shift</kbd>+<kbd>p</kbd> 開啟命令面板, 輸入 "upload", 就會看到對應的命令:

選擇你想用的檔案系統對應的命令, 就可以將 data 資料夾內的所有內容上傳到 ESP32/ESP8266 上了。
要注意的是, 如果有開啟中的序列埠, 必須先關閉, 才能上傳。
你會看到這樣的訊息:
```
SPIFFS Filesystem Uploader
Using partition: default
Building SPIFFS filesystem
C:\Users\meebo\AppData\Local\Arduino15\packages\esp32\tools\mkspiffs\0.2.3/mkspiffs.exe -c C:\Users\meebo\code\Arduino\test_SPIFFS/data -p 256 -b 4096 -s 1441792 C:\Users\meebo\AppData\Local\Temp\tmp-15392-y5BDfcxef6G7-.spiffs.bin
/test.txt
Uploading SPIFFS filesystem
C:\Users\meebo\AppData\Local\Arduino15\packages\esp32\tools\esptool_py\4.5.1/esptool.exe --chip esp32 --port COM9 --baud 921600 --before default_reset --after hard_reset write_flash -z --flash_mode dio --flash_freq 80m --flash_size detect 2686976 C:\Users\meebo\AppData\Local\Temp\tmp-15392-y5BDfcxef6G7-.spiffs.bin
esptool.py v4.5.1
Serial port COM9
Connecting....
Chip is ESP32-D0WDQ6 (revision v1.0)
Features: WiFi, BT, Dual Core, 240MHz, VRef calibration in efuse, Coding Scheme None
Crystal is 40MHz
MAC: ac:67:b2:38:7f:34
Uploading stub...
Running stub...
Stub running...
Changing baud rate to 921600
Changed.
Configuring flash size...
Auto-detected Flash size: 4MB
Flash will be erased from 0x00290000 to 0x003effff...
Compressed 1441792 bytes to 2734...
Writing at 0x00290000... (100 %)
Wrote 1441792 bytes (2734 compressed) at 0x00290000 in 6.5 seconds (effective 1776.6 kbit/s)...
Hash of data verified.
Leaving...
Hard resetting via RTS pin...
Completed upload.
```
也會看到 Arduino IDE 的通知:

就表示上傳成功了。 | codemee |
1,875,311 | Ever imagined The Gladiator set in Silicon Valley? | Big tech, glorious battles and Machiavellian politics all shaken into a juicy cocktail about the... | 0 | 2024-06-03T11:51:11 | https://dev.to/ejb503/ever-imagined-the-gladiator-set-in-silicon-valley-49g9 | siliconvalley, webdev, softwareengineering, fluff | Big tech, glorious battles and Machiavellian politics all shaken into a juicy cocktail about the dynamics of power in technology companies. With swords.
Have a read:
https://tyingshoelaces.com/blog/gladiator-big-tech-politics
| ejb503 |
1,875,310 | Hosting NodeJS application on Windows server | Yes, I know, I know—why would anyone ever like to host NodeJS apps on Windows, right? Well, you... | 0 | 2024-06-03T11:50:46 | https://dev.to/marbleit/hosting-nodejs-application-on-windows-server-312g | webdev, backend, windows, node | Yes, I know, I know—why would anyone ever like to host NodeJS apps on Windows, right? Well, you obviously haven't had a client who already has a Windows server (probably because of existing .NET applications on it) and wants to host one more app on that server. And that app is written in...(drumroll sound in the background)...NodeJS. Believe me, be thankful it's not WordPress; we'll cover that in another article.
But if this is the first time this scenario has happened to you, Welcome to the world of commercial programming!
This short guide will help you set up Express applications on that Windows bad boy in no time. Let's go through the steps:
**1. Install IISNode on the server**
IISNode is an open-source native IIS module written in C++ that allows node.js (node.exe) to be run inside Windows IIS. If you don't know what IIS is, you should read an article about it first.
Download and install iisnode via the releases page. Feel free to choose the latest version, and make sure to pick the correct binary package for your architecture (x86/x64).
**2. Tell IIS that you want to use the IISNode module for app.js requests**
You can easily do this by adding the following line to your web.config. If you don't have a web.config file, create an empty one and add this line:
`<add name="iisnode" path="app.js" verb="*" modules="iisnode" />`
Your web config should look something like this:
`<configuration>
<system.webServer>
<handlers>
<add name="iisnode" path="app.js" verb="*" modules="iisnode" />
</handlers>
</system.webServer>
</configuration>`
**3. You can use the URL Rewrite**
You can use URL Rewrite (IIS native module) to choose which requests get handled by iisnode and which requests will skip iisnode. This is required when setting up a socket.io server inside iisnode. In this case, your web.config would look something like this:
`<rewrite>
<rules>
<rule name="app">
<match url="app/*" />
<action type="Rewrite" url="app.js" />
</rule>
</rules>
</rewrite>`
**4. Set up additional parameters**
This is an introductory article, so I won't discuss theses parameters in depth, but here is a list of parameters and their default values for IISNode:
`<attribute name="node_env" type="string" expanded="true" defaultValue="%node_env%"/>
<attribute name="asyncCompletionThreadCount" type="uint" defaultValue="0"/>
<attribute name="nodeProcessCountPerApplication" type="uint" defaultValue="1"/>
<attribute name="nodeProcessCommandLine" type="string" expanded="true" defaultValue="node.exe"/>
<attribute name="interceptor" type="string" expanded="true"
defaultValue=""%programfiles%\iisnode\interceptor.js"" />
<attribute name="maxConcurrentRequestsPerProcess" type="uint" allowInfitnite="true" defaultValue="1024"/>
<attribute name="maxNamedPipeConnectionRetry" type="uint" defaultValue="100"/>
<attribute name="namedPipeConnectionRetryDelay" type="uint" defaultValue="250"/>
<attribute name="maxNamedPipeConnectionPoolSize" type="uint" defaultValue="512"/>
<attribute name="maxNamedPipePooledConnectionAge" type="uint" defaultValue="30000"/>
<attribute name="initialRequestBufferSize" type="uint" defaultValue="4096"/>
<attribute name="maxRequestBufferSize" type="uint" defaultValue="65536"/>
<attribute name="uncFileChangesPollingInterval" type="uint" defaultValue="5000"/>
<attribute name="gracefulShutdownTimeout" type="uint" defaultValue="60000"/>
<attribute name="logDirectory" type="string" expanded="true" defaultValue="iisnode"/>
<attribute name="debuggingEnabled" type="bool" defaultValue="true"/>
<attribute name="debuggerExtensionDll" type="string" defaultValue="iisnode-inspector-0.7.3.dll"/>
<attribute name="debugHeaderEnabled" type="bool" defaultValue="false"/>
<attribute name="debuggerVirtualDir" type="string" defaultValue="" />
<attribute name="debuggerPathSegment" type="string" expanded="true" defaultValue="debug"/>
<attribute name="debuggerPortRange" type="string" expanded="true" defaultValue="5058-6058"/>
<attribute name="maxLogFileSizeInKB" type="uint" defaultValue="128"/>
<attribute name="maxTotalLogFileSizeInKB" type="uint" defaultValue="1024"/>
<attribute name="maxLogFiles" type="uint" defaultValue="20"/>
<attribute name="loggingEnabled" type="bool" defaultValue="true"/>
<attribute name="devErrorsEnabled" type="bool" defaultValue="true"/>
<attribute name="flushResponse" type="bool" defaultValue="false"/>
<attribute name="watchedFiles" type="string" expanded="true" defaultValue="*.js;iisnode.yml"/>
<attribute name="enableXFF" type="bool" defaultValue="false"/>
<attribute name="promoteServerVars" type="string" defaultValue=""/>
<attribute name="configOverrides" type="string" expanded="true" defaultValue="iisnode.yml"/>
<attribute name="recycleSignalEnabled" type="bool" defaultValue="false"/>`
It is important to set up these parameters properly in different scenarios. For example, you can alter this variable:
`<attribute name="nodeProcessCountPerApplication" type="uint" defaultValue="1"/>`
n order to tell IISNode how many instances of the app it should spawn (similar to PM2 on Linux). It can easily serve as a load balancer!
There are multiple benefits of using IISNode (quoted from the official documentation page):
- **Process management**. The iisnode module takes care of lifetime management of node.exe processes making it simple to improve overall reliability. You don’t have to implement infrastructure to start, stop, and monitor the processes.
- **Side by side with other content types**. The iisnode module integrates with IIS in a way that allows a single web site to contain a variety of content types. For example, a single site can contain a node.js application, static HTML and JavaScript files, PHP applications, and ASP.NET applications. This enables choosing the best tools for the job at hand as well progressive migration of existing applications.
- **Scalability on multi-core servers**. Since node.exe is a single threaded process, it only scales to one CPU core. The iisnode module allows creation of multiple node.exe processes per application and load balances the HTTP traffic between them, therefore enabling full utilization of a server’s CPU capacity without requiring additional infrastructure code from an application developer.
- **Integrated debugging**. With iisnode integrated debugging you can debug your node.js application deployed to IIS from a browser running on Windows, Mac, or Linux. You get this support out of the box, no extra configuration or installation is necessary. The solution is designed in a way that is shared hosting, firewall, and proxy friendly. The integrated debugging in iisnode uses node-inspector by Danny Coates.
- **Auto-update**. The iisnode module ensures that whenever the node.js application is updated (i.e. the script file has changed), the node.exe processes are recycled. Ongoing requests are allowed to gracefully finish execution using the old version of the application, while all new requests are dispatched to the new version of the app.
- **Access to logs over HTTP**. The iisnode module provides access the output of the node.exe process (e.g. generated by console.log calls) via HTTP. This facility is key in helping you debug node.js applications deployed to remote servers.
- **Minimal changes to node.js application code**. The iisnode module enables hosting of existing HTTP node.js applications with very minimal changes. Typically all that is required is to change the listed address of the HTTP server to one provided by the iisnode module via the process.env.PORT environment variable.
- **Integrated management experience**. The iisnode module is fully integrated with IIS configuration system and uses the same tools and mechanism as other IIS components for configuration and maintenance.
- **Other IIS benefits**. Port sharing, security, URL rewriting, compression, caching, logging
I hope that you've managed to set everything up. For a further dive, you can read the official Github README.md. If that does not help, feel free to contact us!
Ivan Kockarević
| marbleit |
1,875,305 | 18 classic songs you never knew were originally about K8s! | In a few days, Kubernetes will turn 10 years old! That’s an amazing milestone that we, at... | 0 | 2024-06-03T11:41:42 | https://dev.to/g5sp3z/these-18-all-time-hit-songs-were-originally-about-k8s-3ekm | kubernetes, devops, discuss | In a few days, Kubernetes will turn 10 years old! That’s an amazing milestone that we, at [groundcover](https://www.groundcover.com/?utm_source=soc&utm_medium=devto&utm_campaign=k10s), would like to celebrate. You see, as the first inCloud, Kubernetes-native and eBPF-powered observability solution, the tweenaged orchestration platform has played a central role in our early childhood. So we tried to come up with a legendary gift for a legendary technology. We came up with a mixtape of the most famous songs that you never knew were originally written about Kubernetes.
Read all about it in this article, and listen to [the full playlist here](https://open.spotify.com/playlist/5orseCNZscenE4qYoi1cGb?si=bb155c2e68b94f6a).
</br>
If we forgot any, let us know in the comments so we can add them to the playlist!
</br>
Here we go...
</br>

**1. The Beatles - kubelet It Be**
Very few know that the original opening lines of this all-time classic were:
“When I find myself in times of troubleshooting, Docker registry comes to me
Speaking words of wisdom, kubelet it be”
</br>

**2. Ray Charles - Hit the Node, Jack**
Did you know that Jack actually stands for “Just Another Connection on Kubernetes”, which made more sense before the unfortunate change in title.
</br>

**3. Fugees - OOMKilling Me Softly**
So ahead of its time, this song originally predicted one of the most common issues you’ll face in a Kubernetes cluster, with the original lyrics going “I heard he drained a good pod, I heard he had to stop”.
</br>

**4. The Beach Boys - Pod Only Knows**
As a tribute to dolphins, the group’s favorite animal and symbol of the ocean which they loved so much, the Beach Boys dedicated an entire song to them with “Pod only knows”, referring to what you call a group of dolphins, while also future-proofing their song by referring to Kubernetes Pods, which are groups of containers.
</br>

**5. The Rolling Stones - Taint It, Black**
Not many know this, but the line “I see the girls walk by, dressed in their summer clothes, I have to turn my head until my darkness goes”, is a metaphor for Taints, as in nodes repelling pods.

**6. Joe Cocker - With a Little Helm from my Friends**
This song was going to pay tribute to Helm fans around the globe at the time.
</br>

**7. Eagles - OTel California**
Referring to the Linux Foundation headquarters in San Francisco, CA, this song is forever the unknown anthem of OpenTelemetry. We were this close to singing “Welcome to the OTel California, such a lovely trace”.
</br>

**8. Nelly Furtado - Prometheus**
As a highly flexible, open-source tool that accepts many query languages and integrations, Prometheus is indeed perceived as promiscuous, in the sense that it has an indiscriminate or unselective approach. The song writing process later took a left turn to appeal to a wider audience, focusing on the other meaning of that word.
</br>

**9. Lee Ritenour - Istio**
Just listen carefully to every word in this song and tell me it isn’t about a microservice longing to be connected to other microservices sharing the same environment, using the open source service mesh that does precisely that. Why people think this is a love song is unclear to this day.
</br>

**10. The Offspring - Why Don’t You Get a CronJob**
What started off as a good piece of advice from a team leader trying to help a teammate become more efficient, quickly became an angry song after the team leader went through an ugly breakup.
</br>

**11. Ray Parker Jr. - GhostClusters**
Ever tried looking for a cluster in your monitoring tool and it just disappeared? (probably not if you’re using [groundcover](https://www.groundcover.com/?utm_source=soc&utm_medium=devto&utm_campaign=k10s), wink) Well, that's what this song was going to be about.
</br>

**12. Imagine Dragons - Daemons**
While both Daemons and Demons are pronounced the same and share the same etymology, this was simply a typo by the record designer, who happened to also juggle a part-time job as a Linux developer.

**13. M|A|R|R|S - Pump Up the Persistent Volume**
When the decision was made to make this song about humans needing each other’s energy to dance and party, it unfortunately lost its initial charm of depicting the interaction between a PVC and PVs. Sounds of a PVC searching for a PV it can call home were translated to human language and became “Brothers and sisters, pump up the volume, we're gonna need you, brothers and sisters”.
</br>

**14. Naughty by Nature - Hip HPA Hooray**
Clearly the intention was for this to be a song celebrating the hip, native Kubernetes feature that allows automatic horizontal scaling (hooray!). It all changed when Hip Hop became widely popular, and the focus of the celebration shifted.
</br>

**15. Beach Boys - kubectl Up**
Following another all-nighter, at 5:29 AM, when the developers behind kubectl successfully went live with the Kubernetes command line tool, they texted two words to the wider team - “kubectl up”. The Beach Boys immediately offered to write a song celebrating their effort, but the team declined, fearing to become overnight sensations. The band did, however, leave a subtle gesture of acknowledgement, making the track exactly 5:29 mins long.
</br>
Check out [the full playlist](https://open.spotify.com/playlist/5orseCNZscenE4qYoi1cGb?si=bb155c2e68b94f6a) on Spotify for these 15 songs + these 3 bonus tracks:
**BONUS TRACK #1: Destiny’s Child - Say My Namespace**

</br>
**BONUS TRACK #2: Nina Simone - I Put a Spec on You**

</br>
**BONUS TRACK #3: Amy Winehouse - RBAC to Black**

</br>
Clearly, none of these anecdotes should be taken seriously. But if you’d like to get serious about minimizing your observability costs while maximizing your monitoring scale and granularity - to quote the classic GhostClusters track -
**“Who you gonna call? [groundcover](https://www.groundcover.com/intro?utm_source=soc&utm_medium=devto&utm_campaign=k10s)!”** | g5sp3z |
1,875,309 | My first bash script | Hello dear bash community, I'm posting this so that I can share my first bash script with this... | 0 | 2024-06-03T11:49:51 | https://dev.to/tahadnan_codes101/my-first-bash-script-1191 | bash, python | Hello dear bash community, I'm posting this so that I can share my first bash script with this wonderful community, suggestions, tips and advice would be much much appreciated.
https://github.com/tahadnan/Automation.git
Thanks elders :)
If you have a question about the script or even me, there is no problem ;) | tahadnan_codes101 |
1,875,308 | A Journey Fit for Maharajas: Stepping Aboard the Deccan Odyssey | The Deccan Odyssey is not merely a mode of transportation; it's a luxurious haven on wheels,... | 0 | 2024-06-03T11:48:56 | https://dev.to/deccanodysseyindia/a-journey-fit-for-maharajas-stepping-aboard-the-deccan-odyssey-3oj2 |

The Deccan Odyssey is not merely a mode of transportation; it's a luxurious haven on wheels, meticulously crafted to evoke the grandeur of India's royal past. Step aboard and be greeted by impeccably dressed staff who cater to your every whim. Settle into your opulent cabin, a haven of comfort featuring plush carpets, handcrafted furniture, and a private ensuite bathroom stocked with luxurious toiletries. Large picture windows bathe the space in natural light, offering you a glimpse of the ever-changing Indian landscape.
A Culinary Symphony: A Taste of India Awaits
Prepare to embark on a culinary adventure that tantalizes your taste buds. The [Deccan Odyssey](https://www.deccanodyssey.co.uk/) boasts two exquisite dining cars, each adorned with rich fabrics and polished wood. Here, world-class chefs weave their magic, conjuring delectable dishes that showcase the vibrant flavors of regional Indian cuisine. From melt-in-your-mouth kebabs marinated in aromatic spices to delicately spiced curries and fragrant biryanis, each meal is a symphony of taste and presentation. However, the culinary journey doesn't end there. The attentive staff is happy to cater to specific dietary needs and preferences, ensuring every guest has a truly personalized dining experience.
Tranquility Within, Adventure Without: Reclaiming Yourself on the Deccan Odyssey
The Deccan Odyssey understands that true luxury extends beyond opulent surroundings. To ensure complete rejuvenation, the train features a well-equipped spa offering a variety of Ayurvedic treatments designed to restore balance and promote well-being. Highly trained therapists will guide you through a personalized treatment plan, allowing you to unwind and de-stress amidst the rhythmic clickety-clack of the train.
But the indulgence doesn't stop there. For those seeking to maintain their fitness routine, a well-equipped gymnasium provides the perfect space to stay active. Should you crave a moment of quiet reflection, a dedicated library stocked with a curated selection of books offers a tranquil escape.
Beyond the Luxurious Carriage: Unveiling the Jewels of India
The true magic of the Deccan Odyssey lies in its expertly curated itineraries. Unlike a typical train journey, your exploration extends far beyond the comfortable confines of your carriage. At each carefully chosen destination, seamlessly arranged private transportation awaits, whisking you away on captivating excursions. Expert guides, brimming with knowledge and enthusiasm, bring the rich history and culture of India to life.
Exploring the Majesty of Maharashtra: A Sample Itinerary
Imagine journeying through the heart of Maharashtra, the land of majestic forts and vibrant festivals. Your Deccan Odyssey adventure could begin in the bustling metropolis of Mumbai, where iconic landmarks like the Gateway of India stand as testaments to the city's rich colonial past. From there, delve into the cultural tapestry of Aurangabad, the gateway to the awe-inspiring Ellora and Ajanta Caves, where ancient carvings whisper tales of a bygone era. Witness the architectural marvel of the Taj Mahal in Agra, a monument to love that transcends time. Immerse yourself in the vibrant bazaars of Jaipur, the "Pink City," where skilled artisans continue to craft exquisite works of art.
Beyond the Usual Tourist Trail: Unforgettable Detours
The beauty of the Deccan Odyssey lies in its ability to cater to diverse interests. If you crave a taste of the unexpected, your itinerary can be tailored to include off-the-beaten-path destinations. Perhaps a visit to the Kaziranga National Park, where the majestic one-horned rhinoceros roams freely, or a relaxing sojourn on the pristine beaches of Goa beckons.
Crafting Your Dream Journey: Tailoring Your Deccan Odyssey Experience
The Deccan Odyssey recognizes that a truly unforgettable experience is a deeply personal one. This is why they offer the opportunity to customize your itinerary based on your specific interests and preferences. Do you dream of a private dinner amidst the grandeur of a historical monument? Perhaps a traditional Indian dance performance sparks your curiosity. The dedicated travel specialists will work tirelessly to weave these unique experiences into the fabric of your journey. | deccanodysseyindia | |
1,875,307 | Creating a Modern Business Intelligence Strategy | Business intelligence (BI) is crucial for understanding a product's historical performance and... | 0 | 2024-06-03T11:46:09 | https://dev.to/linda0609/creating-a-modern-business-intelligence-strategy-iba | [Business intelligence](https://www.sganalytics.com/data-management-analytics/bi-data-visualization-services/) (BI) is crucial for understanding a product's historical performance and consumer behavior. Modern BI strategies emphasize flexibility and outcome-oriented approaches. This guide outlines steps to develop a contemporary BI and analytics strategy.
Defining a Business Intelligence Strategy
A BI strategy involves a series of steps and guidelines to assist BI teams in selecting appropriate data collection techniques and reporting methods. Enterprises and consulting firms use BI solutions to develop strategies that enable precise data visualizations for clients. Given that companies have unique priorities and BI software platforms come with various pros and cons, a detailed roadmap is essential. This roadmap educates organizations on the rationale behind each step in modern BI operations.
Importance of a BI Strategy and Roadmap
Without an industry-relevant BI and data analytics strategy, companies risk inefficient allocation of resources. An optimized roadmap simplifies tracking BI project performance. Professional BI solutions assist in selecting suitable platforms, enabling teams to concentrate resources on the most profitable data categories.
Key Considerations for a Modern BI Strategy
Budget Allocation: Scalable data analytics solutions require extensive resources. Insufficient budgets can slow progress and necessitate schedule revisions.
Return on Investment (ROI): ROI assessments help identify effective BI practices, allowing companies to reallocate resources to more beneficial activities.
Business Objectives: A BI strategy must align with business goals. Collecting irrelevant data wastes company resources.
Time Management: Efficient scheduling of BI solutions is crucial. Balancing the scale of data operations with practical deadlines prevents prolonged planning phases.
Steps to Develop a Modern BI Roadmap and Strategy
Step 1: Financial Feasibility Analysis
Not all BI operations need large budgets. Companies with structured data can use simpler analytics solutions, while larger corporations may need advanced tools. Financial feasibility varies by company size and priorities, requiring periodic strategy revisions.
Step 2: Choosing Business Intelligence Tools
Select BI tools based on ease of learning, interactivity, stability, support, data protection, compatibility, and visualization capabilities. Teams with IT skills can leverage developer APIs for complex solutions.
Step 3: Invite Departmental Representatives and Create a BI Coordination Team
Integrating BI solutions into daily operations takes time and requires coordination. Appoint departmental representatives and form a coordination team to facilitate learning and positive attitudes toward BI. Clear communication and judicious responsibility allocation prevent burnout and confusion.
Step 4: Optimize BI Solutions for Each Department
Tailor the BI strategy to meet specific departmental needs, standardizing data elements where possible to promote real-time collaboration and reduce reporting delays. A standardized format for frequently accessed datasets facilitates multidisciplinary discussions and breaks down data silos.
Step 5: Build, Maintain, and Expand the IT Ecosystem
Companies gather data using on-premise systems or cloud computing environments, each with unique advantages and disadvantages. Ensure your IT ecosystem is scalable, secure, and supports self-service BI tools. Protect data confidentiality and stakeholder privacy while maintaining flexibility to adjust to organizational changes.
Additional Steps for an Enhanced BI Strategy
Step 6: Foster a Data-Driven Culture
Encourage all levels of the organization to rely on data for decision-making. Training and workshops can help employees understand the value of BI tools and foster a culture that prioritizes data accuracy and usage.
Step 7: Leverage Advanced Analytics
Integrate machine learning and artificial intelligence into your BI strategy to uncover deeper insights and predictive analytics. These advanced techniques can help identify patterns and trends that are not immediately apparent through traditional BI methods.
Step 8: Ensure Data Governance and Security
Develop robust data governance frameworks to maintain data integrity and compliance with regulations. Implement stringent security measures to protect sensitive information from breaches and unauthorized access.
Step 9: Scalability and Future-Proofing
Design your BI strategy to be scalable and adaptable to future technological advancements. This includes investing in cloud-based BI solutions that offer flexibility and can grow with your organization’s needs.
Step 10: User Feedback and Iteration
Regularly collect feedback from users to identify pain points and areas for improvement. Use this feedback to refine BI tools and processes, ensuring they remain relevant and user-friendly.
Step 11: Performance Metrics
Establish clear KPIs and performance metrics to evaluate the success of your BI strategy. Regularly review these metrics to ensure your BI initiatives are meeting business objectives and driving growth.
Precautions in Business Intelligence Strategy
Data Quality: Ensure data integrity, relevance, completeness, and logical resilience. Remove duplicate records and update outdated values to maintain data reliability.
Bias Correction: Focus on unbiased data sources validated by professionals to avoid wasting resources on identifying and eliminating outliers.
Unauthorized Data Manipulation: Implement strict data governance policies, version control, and modification history to prevent inconsistencies and unauthorized changes.
Strategy Revisions: Adjust BI solutions as organizational priorities shift. For example, focus on internal efficiency during growth phases and competitor analysis during later stages.
Conclusions
Developing a modern BI strategy involves several key steps:
1. Financial Feasibility Analysis: Assess the budget and scale of BI operations.
2. Choosing BI Tools: Select tools based on ease of use, stability, support, and compatibility.
3. Coordination Team: Establish a team to integrate BI solutions smoothly across departments.
4. Departmental Optimization: Tailor BI solutions to meet specific departmental needs and standardize common data elements.
5. IT Ecosystem: Build a flexible, secure IT environment that supports your BI strategy.
6. Foster a Data-Driven Culture: Encourage data reliance at all organizational levels.
7. Leverage Advanced Analytics: Use AI and machine learning for deeper insights.
8. Data Governance and Security: Develop frameworks to ensure data integrity and security.
9. Scalability and Future-Proofing: Design strategies to adapt to technological changes.
10.User Feedback and Iteration: Regularly refine BI tools based on user feedback.
11. Performance Metrics: Establish KPIs to evaluate BI strategy success.
A well-defined BI strategy enhances data-driven procedures for sales, marketing, competitor analysis, and trend forecasting. Each organization has unique requirements and skill levels. Choose a BI environment that aligns with your team's capabilities to avoid delays in learning new visualization interfaces or command line syntax. Establishing a dedicated coordination team and consulting reputable data partners can further optimize costs and distribute risks.
SG Analytics, a leader in data analytics solutions, assists organizations in developing modern BI strategies. [Contact us](https://www.sganalytics.com/contact-us/) today for impactful roadmaps and scalable technologies that deliver precise business insights. | linda0609 | |
1,875,306 | Everything You Must Know About Equivalence Partitioning Testing | Equivalence Partitioning Testing (ECP) is also known as black box testing or identicalness class... | 0 | 2024-06-03T11:43:50 | https://dev.to/jamescantor38/everything-you-must-know-about-equivalence-partitioning-testing-461n | equivalencepartitioningtesting, testgrid | Equivalence Partitioning Testing (ECP) is also known as black box testing or identicalness class parceling. It is a product testing procedure that isolates the test information of the application into each segment. It helps in comparison and helps in determining the efficiency of the application.
A benefit of this methodology is that it takes less time for performing testing of a product.
## Equivalence Partitioning – A Black Box Testing Technique
The Black Box testing incorporates authenticating the system without having any information and its elementary design. Conducting a test in a black-box way is quite natural. But it brings complications such as the test condition requires hundreds of variations.
Hence, in what way can we constrain the number of variations to low numbers and at the same time get the correct answer? In recent times, some black box technique has evolved to determine the complication in the application. So let’s learn more about this technique.
## What is Equivalence Partitioning?
Equivalence class partitioning is a practice through a test condition that is tested by segregation the data into valid and invalid partitions. Here the same set of data is grouped together as a different segment to derive the test results.
Through this technique, the testing becomes more precise. It is perfectly suitable to test objects such as different inputs, outputs, inside qualities, time-related qualities, and interface parameters. This method works on the following assumptions:
● All the test input variations are treated in the same fashion by the system
● If one of the info conditions passes, then the other remaining conditions also pass.
● If one of the information conditions fails, then any remaining info conditions fail too.
The achievement and adequacy of Equivalence partitioning rely on the above assumptions. In the later part, we will further explain this with an example of a gym application process.
Read also: [A Comprehensive and Informative Guide on Performance Testing](https://testgrid.io/blog/performance-testing/)
## How to do Equivalence Partitioning Testing?
Let us explain to you how to conduct this test with an example of filing a gym form.
Consider that you are filing an online application structure for a gym. What are the leading measures for getting an enrolment?
One of them is age. If you see, any gym center form will have age as one of their first fields.
A gym application usually accepts applications from members aged between 14 and 60. If you surpass this age group, your form is either accepted or rejected.
If we need to test this age field, we need to test the fields between 14-60, and rates which are under 14, and more than 60.
It is not difficult to sort out.
Thus, we need to find out different combinations to check if the functionality is working safely. Here are some combinations.
<14 has 13 blends from 0-13, and if you get a negative result, you can add a few more combinations.
14-60 has 45 mixes
>60 has 40 blends (if you take till 100)
In total, here we have 100 combinations. However, it is not possible to test all 100 combinations due to time constraints.
Here is how to get maximum coverage from Equivalence Partitioning.
The First step in Equivalence apportioning is to divide the data into two sectors: valid and invalid segments. Here is the test result:
- Invalid segment: Below 14 years
- Valid segment: 14-60 years
- Invalid segment: Above 60 years
In the above format, a valid segment refers to the value that the software accepts. This is called Valid Equivalence Partition.
Invalid Segments are values that are rejected by the software. alprazolam 0.5mg tablet buy online. Buy xanax over the counter It is referred to as Invalid Equivalence Partition.
## Pitfalls of Equivalence Partitioning Testing
Since we realize how useful is equivalence partition testing is, we need to understand their shortcomings also. The success of equivalence of partition is dependent on our ability to segment the data and make a partition. During testing the gym form above, we do not know the code embedded by the developer.
Let us consider that the developer coded: If age >14 and <60
<Allow user to submit the form>
Here the requirement shows that the age should be less than 14 or more than 14. Hence, with this test, we miss out on testing 14 as a value. As a tester, you need to be aware that equivalence partition testing shows that it doesn’t test all the combinations.
## Conclusion:
In short, this test largely depends on your ability to develop partitions. This test requires you to divide the data into invalid and valid inputs. To ensure that this testing is useful and effective, follow the best practices for maximum coverage and reduced testing time.
This blog is originally published at [TestGrid](https://testgrid.io/blog/equivalence-partitioning-testing/)
| jamescantor38 |
1,875,099 | Basic types in Elixir | Before introducing the basic data types of Elixir, let's briefly introduce how to identify basic... | 0 | 2024-06-03T11:43:10 | https://dev.to/rhaenyraliang/basic-types-in-elixir-2f3l | webdev, beginners, tutorial, elixir | Before introducing the basic data types of Elixir, let's briefly introduce how to identify basic functions. This will help you read the code examples later.
## How to Identify functions and documentation
Functions in Elixir are identified by both their name and their arity. The arity of a function describes the number of arguments the function takes.

The Elixir shell defines the `h` function, which you can use to access documents for any function

`h trunc/1` works because it is defined in the [_**Kernel**_ ](https://hexdocs.pm/elixir/1.17.0-rc.0/Kernel.html)module.
_**Kernel**_ module is Elixir's default environment.
All functions in the _**Kernel**_ module are automatically imported into our namespace.
## Basic types

### Basic arithmetic
```elixir
iex> 1 + 2
3
iex> 5 * 5
25
```
Operation `/`
The operation / always returns float instead of integer
```elixir
iex > 10 / 2
5.0
```
Operation division or get the division's remainder
* notice that Elixir allows you to drop the parentheses when invoking functions that expect one or more arguments.
```elixir
iex> div(10, 2)
5
iex> div 10, 2
5
iex> rem 10, 3
1
```
Elixir also supports shortcut notations for entering binary, octal, and hexadecimal numbers:
```elixir
iex> 0b1010
10
iex> 0o777
iex> 511
iex> 0x1F
31
```
Floats in Elixir are 64-bit precision.
Float numbers require a dot followed by at least one digit and also support `e` for scientific notation:
```elixir
iex> 1.0
1.0
iex> 1.0e-10
1.0e-10
```
You can invoke the `round` function to get the closest integer to a given float, or the `trunc` function to get the integer part of a float.
```elixir
iex> round(4.58)
5
iex> trunc(2.58)
2
```
### Booleans
Elixir supports `true` and `false` as booleans:
```elixir
iex > true
true
iex> true === false
false
```
Elixir also provides three boolean operators: `or/2`, `and/2`, and `not/1`.
`or/2` and `and/2`These operators are strict in that they expect something that evaluates to a boolean as their first argument.
Requires only the `left` operand to be a boolean since it short-circuits. If the `left` operand is not a boolean, a `BadBooleanError`exception is raised.
If the `not/1` value is not boolean, an `ArgumentError` exception is raised.

```elixir
iex> true or false
true
iex> false or 30
30
iex> 30 or false
** (BadBooleanError) expected a boolean on left-side of "or", got: 30
iex> true and false
false
iex> false and true
false
iex> true and "hello"
"hello"
iex> false and "hello"
false
iex> "hello" and true
** (BadBooleanError) expected a boolean on the left-side of "and", got:
"hello"
iex> not false
true
iex> not true
false
```
### nil
Elixir also provides the concept of `nil`, to indicate the absence of a value and a set of logical operators that also manipulate `nil`: `||/2`, `&&/2` and `!/1`].
For these operators, `false` and `nil` are considered "falsy", all other values are considered "truthy".
```elixir
iex> nil || true
true
iex> false || nil
nil
iex> nil || false
false
iex> nil || 1
1
iex> 1 || nil
1
iex> nil && 13
nil
iex> 13 && nil
nil
iex> nil && false
nil
iex> false && nil
false
iex> !nil
true
```
### Atoms
An atom is a constant whose value is its name. Some other languages call these symbols.
They are often useful to enumerate over distinct values Often they are used to express the state of an operation, by using values such as `:ok` and `:error`.
Atoms are equal if their names are equal and Elixir allows you to skip the leading `:` for the atoms `false`, `true`, and `nil`.
```elixir
iex> :apple
:apple
iex> :banana
:banana
iex> :apple ==:apple
true
iex> :apple == :banana
false
iex> true == :true
true
iex> is_atom(false)
true
iex> is_atom(:false)
true
```
### String
Strings in Elixir are UTF-8 encoded binaries.
It is a sequence of Unicode characters, typically written between double quoted strings, such as `"hello"` and `"héllò"`.
And you can use the binary concatenation operator `<>/2`. Concatenates two binaries.
If one of the sides isn't binaries, will raise an `ArgumentError`
```elixir
iex> "hello"
hello
iex> "hello" <> "world"
"helloworld"
iex> "hello " <> "world"
"hello world"
iex(1)> "foo" <> x = "foobar"
"foobar"
iex(2)> x
"bar"
iex> x <> "bar" = "foobar"
(ArgumentError) cannot perform prefix match because the left operand of <> has an unknown size
```
Elixir supports string interpolation on both sides and supports any data type that may be converted to a string and can have line breaks in them using escape
```elixir
iex(1)> string = "world"
iex(2)> "hello #{string}!"
"hello world!"
iex(1)> string = "Hello"
iex(2)> "#{string} world!"
"Hello world!"
iex(1)> number = 24
iex(2)> "i am #{number} years old!"
"i am 24 years old!"
iex(1)> "hello
...(1)> world"
"hello\nworld"
iex> "hello\nworld"
"helo\nworld"
```
You can use `IO.puts/1`.
This function is from the IO module, the IO function handling input/output (IO).
Notice that the `IO.puts/1` function returns the atom `:ok` after printing.
```elixir
iex> IO.pust("hello\nword")
hello
world
:ok
```
Strings in Elixir are represented internally by contiguous sequences of bytes known as binaries and we can get the number of bytes a string
```elixir
iex> is_binary("hello")
true
iex> is_binary("hellö")
true
iex> byte_size("hello")
5
iex> byte_size("hellö")
6
```
* Notice that the number of bytes in that string is 6, even though it has 5 graphemes. That's because the grapheme "ö" takes 2 bytes to be represented in UTF-8.
We can get the actual length of the string, based on the number of graphemes, by using the `String.length/1` function will return the number of Unicode graphemes in a UTF-8 string.
```elixir
iex> String.length("hello")
5
iex> String.length("hellö")
5
iex> String.length("涼涼")
2
```
The [`String`]module contains a bunch of functions that operate on strings as defined in the Unicode standard like `downcase/2` and `upcase/2`.
The `downcase/2` gives string to lowercase according to `mode` and `upcase/2` gives string to uppercase according to `mode`.
```elixir
iex> String.downcase("ABCD")
"abcd"
iex> String.downcase("AB 123 XPTO")
"ab 123 xpto"
iex> String.downcase("OLÁ")
"olá"
iex> String.upcase("abcd")
"ABCD"
iex> String.upcase("ab 123 xpto")
"AB 123 XPTO"
iex> String.upcase("olá")
"OLÁ"
```
### Predicate function
We work with different data types, we will learn Elixir provides several predicate functions to check for the type of a value.
For example, the `is_integer` can be used to check if a value is an integer or not.
If you want to know other the predicate functions you can check the below link 👇
[Other the predicate functions](https://hexdocs.pm/elixir/Kernel.html#guards)
```elixir
is_integer(1)
true
is_integer(2.0)
false
```
### Structural comparison
Elixir also provides `==`, `!=`, `<=`, `>=`, `<` and `>` as comparison operators. We can compare numbers but also atoms, string, and booleans can do.
Integers and floats compare the same if they have the same value but if you use the strict comparison operator `===` and `!==` if you want to distinguish between integers and floats they are different.
```elixir
iex> 1 == 1
true
iex> 1 != 2
true
iex> 1 < 2
true
iex> "foo" == "foo"
true
iex> "foo" == "bar"
false
iex> 1 == 1.0
true
iex> 1 == 2.0
false
iex> 1 === 1.0
false
```
The comparison operators in Elixir can compare across any data type. We say these operators perform _structural comparison_.
For more information, you can click below link 👇
[Structural vs Semantic comparisons](https://hexdocs.pm/elixir/Kernel.html#module-structural-comparison).
### Other tips
Elixir also supports shortcut notations for entering binary, octal, and hexadecimal numbers:
```elixir
iex> 0b1010
10
iex> 0o777
511
iex> 0x1F
31
```
Float numbers require a dot followed by at least one digit and also support `e` for scientific notation:
```elixir
iex> 1.0
1.0
iex> 1.0e-10
1.0e-10
```
This wraps up today's introduction to basic data types. If you haven't read the previous article, [How to get start Elixir](https://dev.to/rhaenyraliang/how-to-get-start-elixir-3l65), go give it a read. Our next article will delve into lists and tuples as data types. Make sure not to miss it. See you next time, bye!
| rhaenyraliang |
1,875,304 | An Easy Guide to Creating Websites Similar to Alibaba | Are you looking to build a powerhouse e-commerce platform like Alibaba? Dive into our easy guide and... | 0 | 2024-06-03T11:40:31 | https://dev.to/marvelousmichael/an-easy-guide-to-creating-websites-similar-to-alibaba-2e00 | web, websitedevelopment, webdesign, webdesigntrends | Are you looking to build a powerhouse e-commerce platform like Alibaba? Dive into our easy guide and discover the most important steps, features, and insider tips to create a successful marketplace website. Whether you're an entrepreneur or a developer, this guide will set you on the path to building your own Alibaba-like success story. Don't miss out on unlocking the secrets to ecommerce greatness.
## **Overview of Alibaba**
Alibaba, founded 1999 by Jack Ma, is a global leader in e-commerce, providing a platform for businesses to sell products and services to consumers and other businesses. It operates various online marketplaces, including Alibaba.com for international wholesale trade, Taobao for Chinese consumers, and Tmall for premium brands. Alibaba's success lies in its comprehensive ecosystem, including online retail, cloud computing, digital media, and financial services. Alibaba's platforms boast over 1.3 billion annual active consumers globally, with about 953 million from China and the rest from international markets. This widespread user base underscores the company's expansive reach and influence. Its innovative approach and massive scale have made it a benchmark for aspiring online marketplace builders.
## **Purpose of the Guide On Creating Websites Similar To Alibaba**
Alibaba, a global leader in e-commerce that gives companies a platform to offer goods and services to customers and other businesses, was founded 1999 by Jack Ma. It runs several online marketplaces, such as Tmall for premium products, Taobao for Chinese customers, and Alibaba.com for worldwide wholesale trade. Alibaba's ecosystem, which encompasses digital media, cloud computing, online shopping, and financial services, is the key to its success. Because of its large scope and creative approach has become a model for other online marketplace builders.
## **Why You Need to Create Alibaba-Like Websites?**
Creating a website similar to Alibaba can offer numerous benefits, including:
- **Global Reach:** Connect with a wide range of customers and merchants by contacting foreign markets.
- **Various Revenue Streams:** Make money via advertising, subscription services, and transaction fees.
- **Scalability:** Create a platform that can expand to handle an increase in customers and transactions as your business does.
- **Creative Solutions:** Provide special features and services tailored to your target market's requirements.
- **Competitive Edge:** Use cutting-edge technology and smart strategy to build a strong online presence and take on industry titans.
## **7 Most Important Steps to Build Sites Similar to Alibaba**
**1. Planning Your Marketplace Website**
Careful planning is the first step in developing a website that resembles Alibaba. Clearly define your target market, main goals, and business model. Conduct market research to find trends, rival tactics, and possible obstacles. Describe the features, architecture, and revenue streams of your platform. A well-planned strategy will direct your learning process and guarantee you don't get off course.
**2. Essential Features of an Alibaba-like Website**
To rival well-established marketplaces, your website needs to have characteristics like:
**- User Profiles and Registration:** Users can edit their profiles and establish accounts.
**- Product Listings:** Give vendors the ability to list goods along with thorough costs, pictures, and descriptions.
**- Search and Filtering:** To assist users in finding products quickly, and offer comprehensive search capability as well as filtering choices.
**- Secure Payment Gateway:** To ensure seamless transactions, incorporate dependable payment options.
**3. Choosing the Right Technology Stack**
Choosing the right technological stack is essential to creating a stable and expandable marketplace. Think about the ensuing technologies:
**- Front-end:** frameworks for HTML, CSS, and JavaScript (React, Node.js )
**- Back-end:** Node.js and React
**- Payment Gateways:** PayPal, Stripe, Square; Databases: MySQL, PostgreSQL, MongoDB;
**- Hosting:** AWS, Google Cloud, Microsoft Azure
**4. Designing Your Website**
A user-friendly and visually appealing design is vital for attracting and retaining users. Focus on creating an intuitive interface, easy navigation, and responsive design that works seamlessly on all devices. Ensure that your branding is consistent and reflects your business identity. Use high-quality images, engaging content, and clear calls to action to enhance user experience.
**5. Developing Your Website**
Development is the process of transforming your ideas and designs into a working website. Coding, feature integration, and database setup are all part of this step. To guarantee excellent outcomes, think about collaborating with seasoned development firms.
**3 Recommended Companies to Consider in Your Checklist**
[**1. Webnexs**](https://www.webnexs.com/headless-ecommerce.php/?utm_source=subramanibacklinking&utm_medium=blog&utm_term=ecommerce&utm_campaign=subramani)
Webnexs specializes in headless -commerce solutions, empowering businesses with a flexible, scalable, and high-performance architecture. By separating the front end from the back end, Webnexs allows for seamless integration and customization, ensuring a superior user experience and faster load times across all devices.
[**2. Wcart**](https://wcart.io/?utm_source=subramanilbacklinking&utm_medium=blog&utm_term=ecommerce&utm_campaign=subramani)
Wcart stands at the forefront of ecommerce innovation, offering a comprehensive platform tailored to meet the diverse needs of modern online businesses. With its user-friendly interface and robust features, WCART empowers merchants to create and manage dynamic online stores with ease.
**[3. Shopify](https://www.shopify.com/in/free-trial/3-steps?term=shopify&adid=566014743975&campaignid=15433369407&branded_enterprise=1&BOID=brand&utm_medium=cpc&utm_source=google&gad_source=1&gclid=Cj0KCQjwpNuyBhCuARIsANJqL9MF5OPK5XRw7YtLmZOQWIP2VcMQGBn1Rh4obll1NmviX0V4yyQdlIIaAp-4EALw_wcB&cmadid=516585705;cmadvertiserid=10730501;cmcampaignid=26990768;cmplacementid=324494758;cmcreativeid=163722649;cmsiteid=5500011)**

Shopify is a leading ecommerce platform known for its user-friendly interface and robust features, empowering businesses of all sizes to create and manage online stores efficiently.
To know more: **[Develop your Ecommerce Website with our Headless Ecommerce Solutions](http://blog.webnexs.com/build-ecommerce-marketplace-websites-like-alibaba/?utm_source=subramanibacklinking&utm_medium=blog&utm_term=ecommerce&utm_campaign=subramani)**
**6. Testing and Launching Websites Similar To Alibaba**
Before launching your website, conduct thorough testing to identify and fix any issues. Perform functional, usability, performance, and security testing to ensure your platform is reliable and user-friendly. Once testing is complete, plan your launch strategy, including marketing and promotional activities to attract initial users and sellers.
**7. Post-Launch Considerations To Start Your Alibaba-Like Website**
After launching your website, focus on continuous improvement and growth. Gather user feedback to identify areas for enhancement. Regularly update your platform with new features and security patches. Implement marketing strategies to attract more users and retain existing ones. Monitor your website's performance and make data-driven decisions to optimize user experience and increase engagement.
**Why Choose Webnexs to Develop a Website Like Alibaba?**
Webnexs stands out as a top choice for developing websites similar to Alibaba due to its extensive experience in e-commerce development, customizable solutions, and dedicated support. Their team of experts can help you build a scalable and feature-rich marketplace that meets your business objectives. With Webnexs, you can benefit from their deep understanding of industry trends and best practices, ensuring a competitive edge in the market. **[Reach out and start your journey with us!](https://www.webnexs.com/contact-us.php/?utm_source=subramanibacklinking&utm_medium=blog&utm_term=ecommerce&utm_campaign=subramani)**
**Conclusion**
A website like Alibaba must be carefully planned, with the correct technology chosen, and the user experience given priority. You may create a reliable and scalable online marketplace that links customers and merchants worldwide by using this approach. Make sure your development partner shares your vision and objectives. For a guaranteed match, choose Webnexs. Because they are very well experienced in developing ecommerce platform among the others in this field. You can create a profitable online marketplace that survives in the cutthroat world of e-commerce with commitment and careful planning.
**[Ready to take your aspirations online? Our team is primed and eager to make it happen.](https://www.webnexs.com/contact-us.php?utm_source=subramanibacklinking&utm_medium=blog&utm_term=ecommerce&utm_campaign=subramani)**
**Frequently Asked Questions**
**1. Is there any other website like Alibaba?**
Yes, there are several other websites like Alibaba, including Amazon, eBay, and JD.com.
**2. What is the UK equivalent of Alibaba?**
The UK equivalent of Alibaba is considered to be platforms like Amazon UK, eBay UK, and Alibaba.com itself, which also serves the UK market.
**3. Who owns most of Alibaba?**
Jack Ma, co-founder of Alibaba, owns a significant portion of the company through various entities and investment vehicles.
**4. Is Alibaba bigger than Amazon?**
In terms of market capitalization, Alibaba is often considered larger than Amazon, but both companies are giants in the e-commerce and technology sectors, each with its unique strengths and market presence.
| marvelousmichael |
1,875,303 | Embracing the Benefits of Refurbished Laptop Ownership | In today's digital age, owning a laptop has become essential for both personal and professional use.... | 0 | 2024-06-03T11:40:29 | https://dev.to/liong/7-benefits-of-buying-refurbished-laptops-54ae | cost, warrantylaptops, affordabl, malaysia | In today's digital age, owning a laptop has become essential for both personal and professional use. While brand-new laptops are often seen as the go-to option, refurbished laptops are gaining popularity for their cost-effectiveness and sustainability.
**we'll explore seven key benefits of buying refurbished laptops and why they might be the perfect choice for you.**
**1. Cost Savings**
One of the maximum great [benefits of buying a refurbished laptops](https://ithubtechnologies.com/benefits-of-refurbished-laptops/?utm_source=dev.to%2F&utm_campaign=7benefitsofbuyingrefurbishedlaptops&utm_id=Offpageseo+2024) is the price savings. Refurbished laptops are usually bought at a fragment of the charge of recent ones, making super technology greater reachable. This affordability does not imply compromising on overall performance or features. Reputable refurbishes ensure that the laptops are restored to like-new circumstance, imparting you first rate price to your money. Imagine getting a top-tier laptop model with superior functions for a fragment of the authentic charge. For college students, small corporations, and price range-conscious people, this may be a game-changer. The money stored can be invested in different important regions consisting of software, accessories, or additional hardware improvements.
**2. Access to Premium Brands**
Buying refurbished laptops lets in you to get right of entry to top class manufacturers and models that is probably from your budget if bought new. Brands like Apple, Dell, HP, Lenovo, and others provide refurbished variations in their excessive-end models, presenting pinnacle-tier overall performance and features at a appreciably decrease price. This method you could experience the blessings of top class laptops, such as advanced build quality, superior functions, and superior overall performance, without paying the top rate charge. For experts and lovers who pick particular brands for his or her reliability and best, refurbished alternatives are a smart choice.
**3. Reduced Depreciation**
New laptops depreciate speedy, with considerable price loss taking place inside the first year of purchase. Refurbished laptops, however, have already passed through this preliminary depreciation. As a end result, they generally tend to maintain their cost better over the years. This can be mainly high quality in case you plan to resell or upgrade your laptop in the future. By choosing a refurbished pc, you may keep away from the steep depreciation curve associated with new devices, making sure higher fee retention and doubtlessly better resale fees.
**4. Availability of Older Models**
For some users, more modern isn't better. Older laptop models can also have particular features, ports, or compatibility with certain software and peripherals that more modern models lack. Refurbished laptops offer an possibility to buy older fashions that is probably discontinued however nonetheless meet your specific needs. Whether you need a particular port configuration, opt for a certain keyboard layout, or require compatibility with older software program, refurbished laptops offer a solution that new models may not offer.
**5. Better for Education and Non-Profit Organizations**
Refurbished laptops are an superb alternative for educational establishments, non-profits, and other organizations with tight budgets. These businesses can collect extra gadgets for his or her cash, ensuring that extra college students or personnel have access to the generation they need. Additionally, a few refurbishes offer unique packages and reductions for instructional and non-earnings companies, in addition enhancing the affordability and accessibility of first-rate technology.
**6. Improved Supply Chain Resilience**
By purchasing refurbished laptops, you contribute to a greater resilient and sustainable deliver chain. Refurbishing and reusing existing devices reduces the call for for brand spanking new production, which can be subject to supply chain disruptions, shortages, and environmental effect. This technique promotes a round financial system wherein merchandise are reused and recycled, decreasing dependence on new raw substances and minimizing the effect of supply chain problems on availability and pricing.
**7. Access to Business-Grade Laptops**
Many refurbished laptops come from business environments where they were used for a quick period and then replaced as a part of regular upgrade cycles. These commercial enterprise-grade laptops are commonly built to better requirements than client-grade fashions, presenting better durability, overall performance, and capabilities suitable for expert use. Purchasing a refurbished business-grade pc lets in you to advantage from sturdy performance and reliability without paying the top class charge associated with new commercial enterprise-class gadgets.
**Conclusion**
Refurbished laptops provide a large number of benefits, from great value financial savings and environmental blessings to exquisite requirements and customizable alternatives. They offer an great opportunity to get right of entry to the present day era with out breaking the bank, all while assisting small businesses and contributing to a greater sustainable destiny. Whether you're a pupil, a expert, or absolutely in want of a reliable laptop, thinking about a refurbished device can be the neatest preference you are making. By know-how the blessings and leveraging the proper search engine marketing techniques, you could make an informed decision that advantages each your wallet and the planet. So subsequent time you are in the market for a pc, consider to explore the world of refurbished alternatives – you would possibly simply locate the ideal healthy for your needs.
| liong |
1,875,301 | Good Debt vs Bad Debt - All You Need to Know | Differentiating between good debt and bad debt can help you make better financial decisions. Here’s a... | 0 | 2024-06-03T11:36:09 | https://dev.to/pankajkumar/good-debt-vs-bad-debt-all-you-need-to-know-70c | Differentiating between good debt and bad debt can help you make better financial decisions. Here’s a breakdown of the characteristics and examples of each type:
### Good Debt
This type of debt is basically an investment that will grow over long-period of time. It is often considered a strategic move to improve your financial situation over time.
**1. Purpose and Potential Returns:**
Education Loans: Borrowing to pay for education can be considered good debt because it can lead to higher earning potential and better job opportunities in the future.
Mortgage Loans: Taking a mortgage to buy a home can be good debt, as property often appreciates in value over time. Additionally, owning a home can save you money on rent and provide stability.
Business Loans: Borrowing to start or expand a business can be good debt if the business becomes profitable. This can increase your income and build wealth over time.
Real Estate Investments: Loans taken to invest in real estate, such as rental properties, can generate rental income and appreciate in value.
**2. Interest Rates:**
Generally, good debt comes with lower interest rates.
Mortgages and student loans often have more favorable terms compared to other types of debt.
**3. Tax Benefits:**
Mortgage interest and student loan interest can sometimes be tax-deductible, reducing the effective cost of the debt.
**4. Long-term return:**
Good debt typically finances assets that appreciate over time or generate income, contributing positively to your net worth.
### Bad Debt
Bad debt typically involves borrowing for items that do not increase in value or generate income. This type of debt can lead to financial strain and may hinder your financial goals.
**1. Purpose and Consumption:**
Credit Card Debt: Using credit cards for everyday expenses or luxury items and carrying a balance month-to-month usually results in high-interest charges, making this debt difficult to pay off.
Auto Loans: While necessary for many people, cars depreciate quickly. Borrowing a large amount for a vehicle that loses value over time can be considered bad debt.
Personal Loans for Non-Essentials: Borrowing for vacations, expensive gadgets, or other non-essential items can be bad debt, as these do not provide a return on investment.
**2. High-Interest Rates:**
Bad debt usually carries high-interest rates, increasing the cost of the borrowed money.
Credit card debt is a common example, with interest rates that can be significantly higher than other types of debt.
**3. Lack of Returns:**
Bad debt finances items that depreciate in value quickly, such as electronics, cars, and vacations.
It does not contribute to your long-term financial growth and can drain your resources.
### Key Differentiators
1. Value Appreciation: Good debt is usually associated with assets or investments that appreciate over time (e.g., education, real estate). Bad debt is tied to items that depreciate (e.g., cars, electronics).
2. Income Generation: Good debt often generates income or improves earning potential (e.g., business loans, education). Bad debt typically does not generate income and might lead to increased financial burden.
3. Interest Rates: Good debt often comes with lower interest rates and more favorable terms. Bad debt, especially credit card debt, often has higher interest rates, making it more expensive to carry.
4. Purpose: Good debt is typically taken on with a clear plan for repayment and a strategic purpose. Bad debt is often incurred for immediate gratification without long-term benefits.
###Tips for Managing Debt
1. Prioritize Paying Off Bad Debt: Focus on paying off high-interest, non-essential debt first.
2. Budget Wisely: Create a budget to manage your finances and avoid accumulating bad debt. You can use [MoneyTrek ](https://play.google.com/store/apps/details?id=com.jsonworld.moneytrek)to effectively track the income/expenses and see the upcoming month expenses.
3. Use Debt Strategically: Borrow only when it can improve your financial situation and you have a clear plan for repayment.
4. Monitor Interest Rates: Be aware of the interest rates on your debts and look for opportunities to refinance or consolidate to lower rates.
By understanding the difference between good and bad debt, you can make more informed decisions that support your long-term financial health.
This article is originally posted over [jsonworld](jsonworld.com)
| pankajkumar | |
1,875,040 | (Part 7)Golang Framework Hands-on - KisFlow Stream Computing Framework-KisFlow Action | Github: https://github.com/aceld/kis-flow Document:... | 0 | 2024-06-03T11:35:52 | https://dev.to/aceld/part-7golang-framework-hands-on-kisflow-stream-computing-framework-kisflow-action-3n05 | go | <img width="150px" src="https://github.com/aceld/kis-flow/assets/7778936/8729d750-897c-4ba3-98b4-c346188d034e" />
Github: https://github.com/aceld/kis-flow
Document: https://github.com/aceld/kis-flow/wiki
---
[Part1-OverView](https://dev.to/aceld/part-1-golang-framework-hands-on-kisflow-streaming-computing-framework-overview-8fh)
[Part2.1-Project Construction / Basic Modules](https://dev.to/aceld/part-2-golang-framework-hands-on-kisflow-streaming-computing-framework-project-construction-basic-modules-cia)
[Part2.2-Project Construction / Basic Modules](https://dev.to/aceld/part-3golang-framework-hands-on-kisflow-stream-computing-framework-project-construction-basic-modules-1epb)
[Part3-Data Stream](https://dev.to/aceld/part-4golang-framework-hands-on-kisflow-stream-computing-framework-data-stream-1mbd)
[Part4-Function Scheduling](https://dev.to/aceld/part-5golang-framework-hands-on-kisflow-stream-computing-framework-function-scheduling-4p0h)
[Part5-Connector](https://dev.to/aceld/part-5golang-framework-hands-on-kisflow-stream-computing-framework-connector-hcd)
[Part6-Configuration Import and Export](https://dev.to/aceld/part-6golang-framework-hands-on-kisflow-stream-computing-framework-configuration-import-and-export-47o1)
[Part7-KisFlow Action](https://dev.to/aceld/part-7golang-framework-hands-on-kisflow-stream-computing-framework-kisflow-action-3n05)
[Part8-Cache/Params Data Caching and Data Parameters](https://dev.to/aceld/part-8golang-framework-hands-on-cacheparams-data-caching-and-data-parameters-5df5)
[Part9-Multiple Copies of Flow](https://dev.to/aceld/part-8golang-framework-hands-on-multiple-copies-of-flow-c4k)
[Part10-Prometheus Metrics Statistics](https://dev.to/aceld/part-10golang-framework-hands-on-prometheus-metrics-statistics-22f0)
[Part11-Adaptive Registration of FaaS Parameter Types Based on Reflection](https://dev.to/aceld/part-11golang-framework-hands-on-adaptive-registration-of-faas-parameter-types-based-on-reflection-15i9)
---
[Case1-Quick Start](https://dev.to/aceld/case-i-kisflow-golang-stream-real-time-computing-quick-start-guide-f51)
[Case2-Flow Parallel Operation](https://dev.to/aceld/case-i-kisflow-golang-stream-real-time-computing-flow-parallel-operation-364m)
---
## 7.1 Action Abort
KisFlow Action refers to controlling the flow's scheduling logic while executing a Function. KisFlow provides some Action options for developers to choose from. This section introduces the simplest Action, Abort, which terminates the current Flow.
The final usage of Abort is as follows:
```go
func AbortFuncHandler(ctx context.Context, flow kis.Flow) error {
fmt.Println("---> Call AbortFuncHandler ----")
for _, row := range flow.Input() {
str := fmt.Sprintf("In FuncName = %s, FuncId = %s, row = %s", flow.GetThisFuncConf().FName, flow.GetThisFunction().GetId(), row)
fmt.Println(str)
}
return flow.Next(kis.ActionAbort) // Terminate the Flow
}
```
`AbortFuncHandler()` is a business callback method of a Function, defined by the developer. After the current Function is executed, the normal situation is to continue to the next Function. However, if `flow.Next(kis.ActionAbort)` is returned as the current Function's return value, the next Function will not be executed. Instead, the scheduling computation flow of the current Flow is directly terminated.
Let's implement the Abort Action mode of KisFlow below.
### 7.1.1 Abort Interface Definition
First, let's define the `Abort()` interface for the Flow.
> kis-flow/kis/flow.go
```go
type Flow interface {
// Run schedules the Flow, sequentially scheduling and executing Functions in the Flow
Run(ctx context.Context) error
// Link connects the Functions in the Flow according to the configuration file
Link(fConf *config.KisFuncConfig, fParams config.FParam) error
// CommitRow submits Flow data to the Function layer about to be executed
CommitRow(row interface{}) error
// Input obtains the input source data of the currently executing Function in the Flow
Input() common.KisRowArr
// GetName retrieves the name of the Flow
GetName() string
// GetThisFunction obtains the currently executing Function
GetThisFunction() Function
// GetThisFuncConf obtains the configuration of the currently executing Function
GetThisFuncConf() *config.KisFuncConfig
// GetConnector obtains the Connector of the currently executing Function
GetConnector() (Connector, error)
// GetConnConf obtains the configuration of the Connector of the currently executing Function
GetConnConf() (*config.KisConnConfig, error)
// GetConfig obtains the configuration of the current Flow
GetConfig() *config.KisFlowConfig
// GetFuncConfigByName retrieves the configuration of the specified Function in the Flow
GetFuncConfigByName(funcName string) *config.KisFuncConfig
// --- KisFlow Action ---
// Next proceeds to the next Function in the Flow with the specified Action
Next(acts ...ActionFunc) error
}
```
Here, an interface `Next(acts ...ActionFunc) error` is provided, where the parameter is a variadic parameter of type ActionFunc. This is the method related to Actions that we define for KisFlow. The module for the definition of Action is as follows:
### 7.1.2 Action Module Definition
Action is a configuration module used to control special behaviors in the Flow execution process through Functions. This includes the Abort behavior mentioned above, which is one of the Actions. The module definition for Action is as follows. Create a file `action.go` under `kis-flow/kis/` and implement it:
> kis-flow/kis/action.go
```go
package kis
// Action represents the Actions to be taken during the execution of KisFlow
type Action struct {
// Abort indicates whether to terminate the Flow execution
Abort bool
}
// ActionFunc is a type for KisFlow Functional Option
type ActionFunc func(ops *Action)
// LoadActions loads Actions and sequentially executes the ActionFunc functions
func LoadActions(acts []ActionFunc) Action {
action := Action{}
if acts == nil {
return action
}
for _, act := range acts {
act(&action)
}
return action
}
// ActionAbort sets the Action to terminate the Flow execution
func ActionAbort(action *Action) {
action.Abort = true
}
```
First, currently, Action has only one behavior, Abort, which is represented by a boolean type. If true, it indicates that the Flow needs to be terminated.
Next, type `ActionFunc func(ops *Action)` is a function type where the parameter is a pointer to an `Action{}`. The function `func ActionAbort(action *Action)` is a specific instance of this function type. The purpose of the `ActionAbort()` method is to set the Abort member of the Action struct to true.
Finally, let's look at the `func LoadActions(acts []ActionFunc)` Action method. The parameter is an array of ActionFunc functions. `LoadActions()` creates a new `Action{}`, then sequentially executes the functions in the []ActionFunc array to modify the members of `Action{}`. It finally returns the modified `Action{}` to the upper layer.
### 7.1.3 Implementation of the Next Method
Next, we need to implement this interface for the KisFlow module. First, we need to add an `Action{}` member to KisFlow, indicating the action to be taken after each Function execution.
> kis-flow/flow/kis_flow.go
```go
// KisFlow provides the context for the entire streaming computation
type KisFlow struct {
// Basic information
Id string // Distributed instance ID of the Flow (used internally in KisFlow to distinguish different instances)
Name string // Readable name of the Flow
Conf *config.KisFlowConfig // Flow configuration strategy
// List of Functions
Funcs map[string]kis.Function // All Function objects managed by the current flow, key: FunctionName
FlowHead kis.Function // Head of the Function list owned by the current Flow
FlowTail kis.Function // Tail of the Function list owned by the current Flow
flock sync.RWMutex // Lock for managing list insertion and reading/writing
ThisFunction kis.Function // The KisFunction object currently being executed by the Flow
ThisFunctionId string // ID of the currently executing Function
PrevFunctionId string // ID of the previous Function executed
// Function list parameters
funcParams map[string]config.FParam // Custom fixed configuration parameters of the current Function in the flow, key: Function instance KisID, value: FParam
fplock sync.RWMutex // Lock for managing reading/writing of funcParams
// Data
buffer common.KisRowArr // Internal buffer for temporarily storing input byte data, a single piece of data is an interface{}, multiple pieces of data are []interface{}, i.e., KisBatch
data common.KisDataMap // Data source for each layer of streaming computation
inPut common.KisRowArr // Input data for the currently executing Function
// +++++++++++++++++++++
// KisFlow Action
action kis.Action // Action to be taken by the current Flow
}
```
Then implement the `Next()` interface for KisFlow as follows:
> kis-flow/flow/kis_flow.go
```go
// Next proceeds to the next Function in the Flow with the specified Action
func (flow *KisFlow) Next(acts ...kis.ActionFunc) error {
// Load Actions passed by the Function FaaS
flow.action = kis.LoadActions(acts)
return nil
}
```
Each time a developer executes a custom business callback in a Function, `flow.Next()` is called to pass the Action at the end. Therefore, `Next(acts ...kis.ActionFunc) error` loads the passed Action properties and saves them in flow.action.
### 7.1.4 Abort to Control Flow Execution
Now that we have an Abort action to control the Flow, we need to add a member to KisFlow to represent this state.
> kis-flow/flow/kis_flow.go
```go
// KisFlow provides the context for the entire streaming computation
type KisFlow struct {
// Basic information
Id string // Distributed instance ID of the Flow (used internally in KisFlow to distinguish different instances)
Name string // Readable name of the Flow
Conf *config.KisFlowConfig // Flow configuration strategy
// List of Functions
Funcs map[string]kis.Function // All Function objects managed by the current flow, key: FunctionName
FlowHead kis.Function // Head of the Function list owned by the current Flow
FlowTail kis.Function // Tail of the Function list owned by the current Flow
flock sync.RWMutex // Lock for managing list insertion and reading/writing
ThisFunction kis.Function // The KisFunction object currently being executed by the Flow
ThisFunctionId string // ID of the currently executing Function
PrevFunctionId string // ID of the previous Function executed
// Function list parameters
funcParams map[string]config.FParam // Custom fixed configuration parameters of the current Function in the flow, key: Function instance KisID, value: FParam
fplock sync.RWMutex // Lock for managing reading/writing of funcParams
// Data
buffer common.KisRowArr // Internal buffer for temporarily storing input byte data, a single piece of data is an interface{}, multiple pieces of data are []interface{}, i.e., KisBatch
data common.KisDataMap // Data source for each layer of streaming computation
inPut common.KisRowArr // Input data for the currently executing Function
action kis.Action // Action to be taken by the current Flow
// +++++++++
abort bool // Indicates whether to abort the Flow
}
```
Each time the `flow.Run()` method is executed, the abort variable needs to be reset. Additionally, the loop scheduling needs to check the `flow.abort` status.
> kis-flow/flow/kis_flow.go
```go
// Run starts the streaming computation of KisFlow, executing the stream from the starting Function
func (flow *KisFlow) Run(ctx context.Context) error {
// +++++++++
// Reset abort
flow.abort = false // Reset the abort state each time scheduling starts
// ... ...
// ... ...
// Stream chain call
for fn != nil && flow.abort != true { // ++++ Do not enter the next loop if abort is set
// ... ...
// ... ...
if err := fn.Call(ctx, flow); err != nil {
// Error
return err
} else {
// Success
// ... ...
fn = fn.Next()
}
}
return nil
}
```
When `Call()` schedules the custom method of the Function, if `return flow.Next(ActionAbort)` is called, it will change the Action state of the Flow, thereby controlling the termination of the Flow execution. Finally, the Abort state of the Action is transferred to the Abort state of KisFlow.
Since we have the Abort state, we can add a condition during the Flow execution. If the current Function does not submit its result data (i.e., `flow.buffer` is empty), the Flow will not proceed to the next layer and will directly exit the `Run()` call.
> kis-flow/flow/kis_flow_data.go
```go
// commitCurData submits the result data of the currently executing Function in the Flow
func (flow *KisFlow) commitCurData(ctx context.Context) error {
// Check if there is result data for the current computation; if not, exit the current Flow Run loop
if (len(flow.buffer) == 0) {
// ++++++++++++
flow.abort = true
return nil
}
// ... ...
// ... ...
return nil
}
```
### 7.1.5 Capturing and Handling Actions
Next, we will implement a method specifically for handling Actions. This method will be defined in the `kis-flow/flow/kis_flow_action.go` file as follows:
> kis-flow/flow/kis_flow_action.go
```go
package flow
import (
"context"
"errors"
"fmt"
"kis-flow/kis"
)
// dealAction handles Actions and decides the subsequent flow direction
func (flow *KisFlow) dealAction(ctx context.Context, fn kis.Function) (kis.Function, error) {
if err := flow.commitCurData(ctx); err != nil {
return nil, err
}
// Update the previous FunctionId cursor
flow.PrevFunctionId = flow.ThisFunctionId
fn = fn.Next()
// Abort Action forces termination
if flow.action.Abort {
flow.abort = true
}
// Clear Action
flow.action = kis.Action{}
return fn, nil
}
```
Next, we'll slightly modify the KisFlow Run() process to incorporate the dealAction() method.
> kis-flow/flow/kis_flow.go
```go
// Run starts the streaming computation of KisFlow, executing the stream from the starting Function
func (flow *KisFlow) Run(ctx context.Context) error {
var fn kis.Function
fn = flow.FlowHead
flow.abort = false
if flow.Conf.Status == int(common.FlowDisable) {
// Flow is configured to be disabled
return nil
}
// Since no Function has been executed at this point, PrevFunctionId is FirstVirtual as there is no previous Function
flow.PrevFunctionId = common.FunctionIdFirstVirtual
// Submit the original data stream
if err := flow.commitSrcData(ctx); err != nil {
return err
}
// Stream chain call
for fn != nil && flow.abort == false {
// Flow records the current executing Function
fid := fn.GetId()
flow.ThisFunction = fn
flow.ThisFunctionId = fid
// Get the source data to be processed by the current Function
if inputData, err := flow.getCurData(); err != nil {
log.Logger().ErrorFX(ctx, "flow.Run(): getCurData err = %s\n", err.Error())
return err
} else {
flow.inPut = inputData
}
if err := fn.Call(ctx, flow); err != nil {
// Error
return err
} else {
// Success
// +++++++++++++++++++++++++++++++
fn, err = flow.dealAction(ctx, fn)
if err != nil {
return err
}
// +++++++++++++++++++++++++++++++
}
}
return nil
}
```
### 7.1.6 Action Abort Unit Test
First, let's create a Function configuration file as follows:
> kis-flow/test/load_conf/func/func-AbortFunc.yml
```yaml
kistype: func
fname: abortFunc
fmode: Calculate
source:
name: 用户订单错误率
must:
- order_id
- user_id
```
The name of the current Function is abortFunc. Next, we implement its FaaS function as follows:
> kis-flow/test/faas/faas_abort.go
```go
package faas
import (
"context"
"fmt"
"kis-flow/kis"
)
// type FaaS func(context.Context, Flow) error
func AbortFuncHandler(ctx context.Context, flow kis.Flow) error {
fmt.Println("---> Call AbortFuncHandler ----")
for _, row := range flow.Input() {
str := fmt.Sprintf("In FuncName = %s, FuncId = %s, row = %s", flow.GetThisFuncConf().FName, flow.GetThisFunction().GetId(), row)
fmt.Println(str)
}
return flow.Next(kis.ActionAbort)
}
```
This Function will eventually call `flow.Next(kis.ActionAbort)` to terminate the Flow. Next, we create a Flow that uses the above Function as an intermediate Function to test if it will terminate before executing subsequent Functions. The new flow configuration is as follows:
> kis-flow/test/load_conf/flow/flow-FlowName2.yml
```yaml
kistype: flow
status: 1
flow_name: flowName2
flows:
- fname: funcName1
- fname: abortFunc
- fname: funcName3
```
The name of the current Flow is `flowName2`, which contains three Functions: `funcName1`, `abortFunc`, and `funcName3`. If the abort functionality works correctly, `funcName3` should not be executed.
Next, we implement the unit test case.
> kis-flow/test/kis_action_test.go
```go
package test
import (
"context"
"kis-flow/common"
"kis-flow/file"
"kis-flow/kis"
"kis-flow/test/caas"
"kis-flow/test/faas"
"testing"
)
func TestActionAbort(t *testing.T) {
ctx := context.Background()
// 0. Register Function callbacks
kis.Pool().FaaS("funcName1", faas.FuncDemo1Handler)
kis.Pool().FaaS("abortFunc", faas.AbortFuncHandler) // Add abortFunc handler
kis.Pool().FaaS("funcName3", faas.FuncDemo3Handler)
// 0. Register ConnectorInit and Connector callbacks
kis.Pool().CaaSInit("ConnName1", caas.InitConnDemo1)
kis.Pool().CaaS("ConnName1", "funcName2", common.S, caas.CaasDemoHanler1)
// 1. Load configuration files and build Flow
if err := file.ConfigImportYaml("/Users/gopath/src/kis-flow/test/load_conf/"); err != nil {
panic(err)
}
// 2. Get Flow
flow1 := kis.Pool().GetFlow("flowName2")
// 3. Submit original data
_ = flow1.CommitRow("This is Data1 from Test")
_ = flow1.CommitRow("This is Data2 from Test")
_ = flow1.CommitRow("This is Data3 from Test")
// 4. Execute flow1
if err := flow1.Run(ctx); err != nil {
panic(err)
}
}
```
The following code registers the initial callbacks. You can also write this code in another file to avoid repeating it each time:
```go
// 0. Register Function callbacks
kis.Pool().FaaS("funcName1", faas.FuncDemo1Handler)
kis.Pool().FaaS("abortFunc", faas.AbortFuncHandler) // Add abortFunc handler
kis.Pool().FaaS("funcName3", faas.FuncDemo3Handler)
// 0. Register ConnectorInit and Connector callbacks
kis.Pool().CaaSInit("ConnName1", caas.InitConnDemo1)
kis.Pool().CaaS("ConnName1", "funcName2", common.S, caas.CaasDemoHanler1)
```
Change to the `kis-flow/test/` directory and run the following command:
```bash
go test -test.v -test.paniconexit0 -test.run TestActionAbort
```
The result is as follows:
```bash
=== RUN TestActionAbort
Add KisPool FuncName=funcName1
Add KisPool FuncName=abortFunc
Add KisPool FuncName=funcName3
Add KisPool CaaSInit CName=ConnName1
Add KisPool CaaS CName=ConnName1, FName=funcName2, Mode =Save
===> Call Connector InitDemo1
&{conn ConnName1 0.0.0.0:9988,0.0.0.0:9999,0.0.0.0:9990 redis redis-key map[args1:value1 args2:value2] [] [funcName2 funcName2]}
Add FlowRouter FlowName=flowName1
Add FlowRouter FlowName=flowName2
context.Background
====> After CommitSrcData, flow_name = flowName2, flow_id = flow-b6b90eb4b7d7457fbf85b3299b625513
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test]]
KisFunctionV, flow = &{Id:flow-b6b90eb4b7d7457fbf85b3299b625513 Name:flowName2 Conf:0xc000092cc0 Funcs:map[abortFunc:0xc000094d20 funcName1:0xc000094cc0 funcName3:0xc000094d80] FlowHead:0xc000094cc0 FlowTail:0xc000094d80 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc000094cc0 ThisFunctionId:func-c435cf9f8e3346a1851f8c76375fce0f PrevFunctionId:FunctionIdFirstVirtual funcParams:map[func-7f5af1521fd64d08839d5bdd26de5254:map[] func-c435cf9f8e3346a1851f8c76375fce0f:map[] func-f0b80593fe2e4018a878f155b9c543b4:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test]] inPut:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] jumpFunc:NoJump abort:false nextOpt:<nil>}
---> Call funcName1Handler ----
In FuncName = funcName1, FuncId = func-c435cf9f8e3346a1851f8c76375fce0f, row = This is Data1 from Test
In FuncName = funcName1, FuncId = func-c435cf9f8e3346a1851f8c76375fce0f, row = This is Data2 from Test
In FuncName = funcName1, FuncId = func-c435cf9f8e3346a1851f8c76375fce0f, row = This is Data3 from Test
context.Background
====> After commitCurData, flow_name = flowName2, flow_id = flow-b6b90eb4b7d7457fbf85b3299b625513
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-c435cf9f8e3346a1851f8c76375fce0f:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]]
KisFunctionC, flow = &{Id:flow-b6b90eb4b7d7457fbf85b3299b625513 Name:flowName2 Conf:0xc000092cc0 Funcs:map[abortFunc:0xc000094d20 funcName1:0xc000094cc0 funcName3:0xc000094d80] FlowHead:0xc000094cc0 FlowTail:0xc000094d80 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc000094d20 ThisFunctionId:func-7f5af1521fd64d08839d5bdd26de5254 PrevFunctionId:func-c435cf9f8e3346a1851f8c76375fce0f funcParams:map[func-7f5af1521fd64d08839d5bdd26de5254:map[] func-c435cf9f8e3346a1851f8c76375fce0f:map[] func-f0b80593fe2e4018a878f155b9c543b4:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-c435cf9f8e3346a1851f8c76375fce0f:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]] inPut:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2] jumpFunc:NoJump abort:false nextOpt:<nil>}
---> Call AbortFuncHandler ----
In FuncName = abortFunc, FuncId = func-7f5af1521fd64d08839d5bdd26de5254, row = data from funcName[funcName1], index = 0
In FuncName = abortFunc, FuncId = func-7f5af1521fd64d08839d5bdd26de5254, row = data from funcName[funcName1], index = 1
In FuncName = abortFunc, FuncId = func-7f5af1521fd64d08839d5bdd26de5254, row = data from funcName[funcName1], index = 2
--- PASS: TestActionAbort (0.00s)
PASS
ok kis-flow/test 0.487s
```
From the result, we can see that after executing the `AbortFuncHandler`, it did not continue executing and exited the Flow's `Run()` method.
## 7.2 Action DataReuse (Reuse Upper-Level Data)
The Action DataReuse is designed to reuse data from the previous function, meaning the current function's submitted result will not be used. Instead, the result data from the previous function will be reused for the next function as its data source.
Let's implement the Action DataReuse functionality.
### 7.2.1 Adding DataReuse Action
Add a `DataReuse` member to the Action, which is of boolean type.
> kis-flow/kis/action.go
```go
// Action KisFlow execution process Actions
type Action struct {
// +++++++++++++
// DataReuse indicates whether to reuse upper-level function data
DataReuse bool
// Abort terminates the execution of the Flow
Abort bool
}
// ActionDataReuse sets the DataReuse option to true
func ActionDataReuse(act *Action) {
act.DataReuse = true
}
```
Then provide an Action function named `ActionDataReuse`, which sets the DataReuse status to true.
### 7.2.2 Reusing Upper-Level Data to the Next Layer
Here, we need to implement a method for submitting reused data. The logic is as follows:
> kis-flow/flow/kis_flow_data.go
```go
// commitReuseData submits reused data from the previous function
func (flow *KisFlow) commitReuseData(ctx context.Context) error {
// Check if the previous layer has result data, if not, exit the current Flow Run loop
if len(flow.data[flow.PrevFunctionId]) == 0 {
flow.abort = true
return nil
}
// The current layer's result data equals the previous layer's result data (reuse upper-level result data)
flow.data[flow.ThisFunctionId] = flow.data[flow.PrevFunctionId]
// Clear the buffer (if ReuseData is selected, all submitted data will not be carried to the next layer)
flow.buffer = flow.buffer[0:0]
log.Logger().DebugFX(ctx, " ====> After commitReuseData, flow_name = %s, flow_id = %s\nAll Level Data =\n %+v\n", flow.Name, flow.Id, flow.data)
return nil
}
```
The logic is simple. Unlike `commitCurData()`, which submits `flow.buffer` data to `flow.data[flow.ThisFunctionId]`, `commitReuseData()` submits the previous layer's result data to `flow.data[flow.ThisFunctionId]`.
### 7.2.3 Handling the DataReuse Action
Then, add handling for the DataReuse action in the `dealAction()` method:
> kis-flow/flow/kis_flow_action.go
```go
// dealAction processes actions and determines the next steps for the Flow
func (flow *KisFlow) dealAction(ctx context.Context, fn kis.Function) (kis.Function, error) {
// ++++++++++++++++
// DataReuse Action
if flow.action.DataReuse {
if err := flow.commitReuseData(ctx); err != nil {
return nil, err
}
} else {
if err := flow.commitCurData(ctx); err != nil {
return nil, err
}
}
// Update the previous function ID cursor
flow.PrevFunctionId = flow.ThisFunctionId
fn = fn.Next()
// Abort Action force termination
if flow.action.Abort {
flow.abort = true
}
// Clear the Action
flow.action = kis.Action{}
return fn, nil
}
```
This captures and processes the DataReuse action, deciding whether to reuse upper-level data or to commit current data based on the action settings.
### 7.2.4 Unit Testing
Let's proceed with unit testing for DataReuse. First, create a function named dataReuseFunc, and create its configuration file:
> kis-flow/test/load_conf/func/func-dataReuseFunc.yml
```yaml
kistype: func
fname: dataReuseFunc
fmode: Calculate
source:
name: User Order Error Rate
must:
- order_id
- user_id
```
Also, create a new Flow called `flowName3` with the following configuration:
> kis-flow/test/load_conf/flow/func-FlowName3.yml
```yaml
kistype: flow
status: 1
flow_name: flowName3
flows:
- fname: funcName1
- fname: dataReuseFunc
- fname: funcName3
```
For the logic of the `dataReuseFunc` function, here's the implementation:
> kis-flow/test/faas/faas_data_reuse.go
```go
package faas
import (
"context"
"fmt"
"kis-flow/kis"
)
func DataReuseFuncHandler(ctx context.Context, flow kis.Flow) error {
fmt.Println("---> Call DataReuseFuncHandler ----")
for index, row := range flow.Input() {
str := fmt.Sprintf("In FuncName = %s, FuncId = %s, row = %s", flow.GetThisFuncConf().FName, flow.GetThisFunction().GetId(), row)
fmt.Println(str)
// Calculate result data
resultStr := fmt.Sprintf("data from funcName[%s], index = %d", flow.GetThisFuncConf().FName, index)
// Commit result data
_ = flow.CommitRow(resultStr)
}
return flow.Next(kis.ActionDataReuse)
}
```
Finally, implement the test case:
> kis-flow/test/kis_action_test.go
```go
func TestActionDataReuse(t *testing.T) {
ctx := context.Background()
// 0. Register Function callback business
kis.Pool().FaaS("funcName1", faas.FuncDemo1Handler)
kis.Pool().FaaS("dataReuseFunc", faas.DataReuseFuncHandler) // Adding dataReuseFunc business
kis.Pool().FaaS("funcName3", faas.FuncDemo3Handler)
// 0. Register ConnectorInit and Connector callback business
kis.Pool().CaaSInit("ConnName1", caas.InitConnDemo1)
kis.Pool().CaaS("ConnName1", "funcName2", common.S, caas.CaasDemoHanler1)
// 1. Load configuration files and build Flow
if err := file.ConfigImportYaml("/Users/tal/gopath/src/kis-flow/test/load_conf/"); err != nil {
panic(err)
}
// 2. Get Flow
flow1 := kis.Pool().GetFlow("flowName3")
// 3. Submit raw data
_ = flow1.CommitRow("This is Data1 from Test")
_ = flow1.CommitRow("This is Data2 from Test")
_ = flow1.CommitRow("This is Data3 from Test")
// 4. Execute flow1
if err := flow1.Run(ctx); err != nil {
panic(err)
}
}
```
Navigate to `kis-flow/test/` and execute:
```bash
go test -test.v -test.paniconexit0 -test.run TestActionDataReuse
```
```bash
=== RUN TestActionDataReuse
Add KisPool FuncName=funcName1
Add KisPool FuncName=dataReuseFunc
Add KisPool FuncName=funcName3
Add KisPool CaaSInit CName=ConnName1
Add KisPool CaaS CName=ConnName1, FName=funcName2, Mode =Save
===> Call Connector InitDemo1
&{conn ConnName1 0.0.0.0:9988,0.0.0.0:9999,0.0.0.0:9990 redis redis-key map[args1:value1 args2:value2] [] [funcName2 funcName2]}
Add FlowRouter FlowName=flowName5
===> Call Connector InitDemo1
&{conn ConnName1 0.0.0.0:9988,0.0.0.0:9999,0.0.0.0:9990 redis redis-key map[args1:value1 args2:value2] [] [funcName2 funcName2 funcName2]}
Add FlowRouter FlowName=flowName1
Add FlowRouter FlowName=flowName2
Add FlowRouter FlowName=flowName3
Add FlowRouter FlowName=flowName4
context.Background
====> After CommitSrcData, flow_name = flowName3, flow_id = flow-2c1a23d9587842bebaeee490319de81f
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test]]
KisFunctionV, flow = &{Id:flow-2c1a23d9587842bebaeee490319de81f Name:flowName3 Conf:0xc000092dc0 Funcs:map[dataReuseFunc:0xc000095620 funcName1:0xc0000955c0 funcName3:0xc000095680] FlowHead:0xc0000955c0 FlowTail:0xc000095680 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc0000955c0 ThisFunctionId:func-7886178381634f05b302841141382e59 PrevFunctionId:FunctionIdFirstVirtual funcParams:map[func-7886178381634f05b302841141382e59:map[] func-cfe66e39aba54ff989d6764cc4edda20:map[] func-ef567879d0dd45b287ed709e549e9d32:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test]] inPut:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call funcName1Handler ----
In FuncName = funcName1, FuncId = func-7886178381634f05b302841141382e59, row = This is Data1 from Test
In FuncName = funcName1, FuncId = func-7886178381634f05b302841141382e59, row = This is Data2 from Test
In FuncName = funcName1, FuncId = func-7886178381634f05b302841141382e59, row = This is Data3 from Test
context.Background
====> After commitCurData, flow_name = flowName3, flow_id = flow-2c1a23d9587842bebaeee490319de81f
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-7886178381634f05b302841141382e59:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]]
KisFunctionC, flow = &{Id:flow-2c1a23d9587842bebaeee490319de81f Name:flowName3 Conf:0xc000092dc0 Funcs:map[dataReuseFunc:0xc000095620 funcName1:0xc0000955c0 funcName3:0xc000095680] FlowHead:0xc0000955c0 FlowTail:0xc000095680 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc000095620 ThisFunctionId:func-ef567879d0dd45b287ed709e549e9d32 PrevFunctionId:func-7886178381634f05b302841141382e59 funcParams:map[func-7886178381634f05b302841141382e59:map[] func-cfe66e39aba54ff989d6764cc4edda20:map[] func-ef567879d0dd45b287ed709e549e9d32:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-7886178381634f05b302841141382e59:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]] inPut:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call DataReuseFuncHandler ----
In FuncName = dataReuseFunc, FuncId = func-ef567879d0dd45b287ed709e549e9d32, row = data from funcName[funcName1], index = 0
In FuncName = dataReuseFunc, FuncId = func-ef567879d0dd45b287ed709e549e9d32, row = data from funcName[funcName1], index = 1
In FuncName = dataReuseFunc, FuncId = func-ef567879d0dd45b287ed709e549e9d32, row = data from funcName[funcName1], index = 2
context.Background
====> After commitReuseData, flow_name = flowName3, flow_id = flow-2c1a23d9587842bebaeee490319de81f
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-7886178381634f05b302841141382e59:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2] func-ef567879d0dd45b287ed709e549e9d32:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]]
KisFunctionC, flow = &{Id:flow-2c1a23d9587842bebaeee490319de81f Name:flowName3 Conf:0xc000092dc0 Funcs:map[dataReuseFunc:0xc000095620 funcName1:0xc0000955c0 funcName3:0xc000095680] FlowHead:0xc0000955c0 FlowTail:0xc000095680 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc000095680 ThisFunctionId:func-cfe66e39aba54ff989d6764cc4edda20 PrevFunctionId:func-ef567879d0dd45b287ed709e549e9d32 funcParams:map[func-7886178381634f05b302841141382e59:map[] func-cfe66e39aba54ff989d6764cc4edda20:map[] func-ef567879d0dd45b287ed709e549e9d32:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-7886178381634f05b302841141382e59:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2] func-ef567879d0dd45b287ed709e549e9d32:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]] inPut:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call funcName3Handler ----
In FuncName = funcName3, FuncId = func-cfe66e39aba54ff989d6764cc4edda20, row = data from funcName[funcName1], index = 0
In FuncName = funcName3, FuncId = func-cfe66e39aba54ff989d6764cc4edda20, row = data from funcName[funcName1], index = 1
In FuncName = funcName3, FuncId = func-cfe66e39aba54ff989d6764cc4edda20, row = data from funcName[funcName1], index = 2
--- PASS: TestActionDataReuse (0.02s)
PASS
ok kis-flow
-flow/test 0.523s
```
The test execution output provides valuable insights into the functioning of the `DataReuse` feature. Initially, the test sets up various functions and connectors and then loads the configurations. After submitting raw data to `flowName3`, the flow is executed.
During execution, the data flows through different functions, starting with `funcName1`, then `dataReuseFunc`, and finally `funcName3`. At each step, we observe the input data and the resulting data transformation.
For `funcName1`, we see the original data being processed, and then for `dataReuseFunc`, the data from `funcName1` is reused. Finally, in `funcName3`, we observe the reused data being further processed.
This comprehensive unit test ensures that the DataReuse functionality behaves as expected, effectively passing data from one function to another without loss or corruption.
## 7.3 Action ForceEntryNext (Forcing Entry to the Next Layer)
### 7.3.1 ForceEntryNext Action Attribute
In the current KisFlow implementation, if the current Function does not commit any data (results data for this layer), the Flow will not proceed to the next layer of Functions after the current one finishes. However, in some streaming computations, it might be necessary to continue executing downward even if there is no data available. Therefore, we can introduce a ForceEntryNext action to trigger this behavior.
Firstly, we add a `ForceEntryNext` attribute to the Action:
> kis-flow/kis/action.go
```go
// Action KisFlow execution Actions
type Action struct {
// DataReuse indicates whether to reuse data from the upper layer Function
DataReuse bool
// By default, if the current Function calculates 0 rows of data, subsequent Functions will not execute
// ForceEntryNext overrides the above default rule and forces entry to the next layer of Functions even if there's no data
ForceEntryNext bool
// Abort terminates the execution of the Flow
Abort bool
}
// ActionForceEntryNext sets the ForceEntryNext attribute to true
func ActionForceEntryNext(act *Action) {
act.ForceEntryNext = true
}
```
We also provide a configuration function `ActionForceEntryNext()` to modify this attribute's status.
### 7.3.2 Capturing the Action
In the `dealAction()` method, which captures the Action, we add a check for this status. If set, the `flow.abort` status needs to be changed to `false`, allowing the flow to continue to the next layer.
> kis-flow/flow/kis_flow_action.go
```go
// dealAction processes the Action and determines the next steps of the Flow
func (flow *KisFlow) dealAction(ctx context.Context, fn kis.Function) (kis.Function, error) {
// DataReuse Action
if flow.action.DataReuse {
if err := flow.commitReuseData(ctx); err != nil {
return nil, err
}
} else {
if err := flow.commitCurData(ctx); err != nil {
return nil, err
}
}
// ++++++++++++++++++++++++++++
// ForceEntryNext Action
if flow.action.ForceEntryNext {
if err := flow.commitVoidData(ctx); err != nil {
return nil, err
}
flow.abort = false
}
// Update the previous FunctionId cursor
flow.PrevFunctionId = flow.ThisFunctionId
fn = fn.Next()
// Abort Action
if flow.action.Abort {
flow.abort = true
}
// Clear the Action
flow.action = kis.Action{}
return fn, nil
}
```
Here is a detail: we need to call a `commitVoidData()` method, which commits empty data. The reason is that if empty data is not committed, the `flow.buffer` remains empty, preventing the commit action. This would result in the key `flow.data[flow.ThisFunctionId]` not existing, causing a key-not-found exception and panic when `flow.getCurData()` is executed. Therefore, empty data needs to be committed to `flow.data[flow.ThisFunctionId]`.
The specific implementation of `commitVoidData()` is as follows:
> kis-flow/flow/kis_flow_data.go
```go
func (flow *KisFlow) commitVoidData(ctx context.Context) error {
if len(flow.buffer) != 0 {
return nil
}
// Create empty data
batch := make(common.KisRowArr, 0)
// Commit the buffer data to the result data of this layer
flow.data[flow.ThisFunctionId] = batch
log.Logger().DebugFX(ctx, " ====> After commitVoidData, flow_name = %s, flow_id = %s\nAll Level Data =\n %+v\n", flow.Name, flow.Id, flow.data)
return nil
}
```
### 7.3.3 Unit Test Without Setting ForceEntryNext
First, create a Function configuration for ·noResultFunc· and implement the corresponding callback business function.
> kis-flow/test/load_conf/func/func-NoResultFunc.yml
```yaml
kistype: func
fname: noResultFunc
fmode: Calculate
source:
name: user_order_error_rate
must:
- order_id
- user_id
```
> kis-flow/test/faas/faas_no_result.go
```go
package faas
import (
"context"
"fmt"
"kis-flow/kis"
)
// type FaaS func(context.Context, Flow) error
func NoResultFuncHandler(ctx context.Context, flow kis.Flow) error {
fmt.Println("---> Call NoResultFuncHandler ----")
for _, row := range flow.Input() {
str := fmt.Sprintf("In FuncName = %s, FuncId = %s, row = %s", flow.GetThisFuncConf().FName, flow.GetThisFunction().GetId(), row)
fmt.Println(str)
}
return flow.Next()
}
```
In this Function, at the end, we only call `flow.Next()` without passing any Action.
Next, create a new Flow FlowName4 with the following configuration:
> kis-flow/test/load_conf/flow-FlowName4.yml
```yaml
kistype: flow
status: 1
flow_name: flowName4
flows:
- fname: funcName1
- fname: noResultFunc
- fname: funcName3
```
Finally, we write a unit test case code with `noResultFunc` in the middle.
> kis-flow/test/kis_action_test.go
```go
func TestActionForceEntry(t *testing.T) {
ctx := context.Background()
// 0. Register Function callback business
kis.Pool().FaaS("funcName1", faas.FuncDemo1Handler)
kis.Pool().FaaS("noResultFunc", faas.NoResultFuncHandler) // Add noResultFunc business
kis.Pool().FaaS("funcName3", faas.FuncDemo3Handler)
// 0. Register ConnectorInit and Connector callback business
kis.Pool().CaaSInit("ConnName1", caas.InitConnDemo1)
kis.Pool().CaaS("ConnName1", "funcName2", common.S, caas.CaasDemoHanler1)
// 1. Load configuration files and build the Flow
if err := file.ConfigImportYaml("/Users/tal/gopath/src/kis-flow/test/load_conf/"); err != nil {
panic(err)
}
// 2. Get the Flow
flow1 := kis.Pool().GetFlow("flowName4")
// 3. Submit original data
_ = flow1.CommitRow("This is Data1 from Test")
_ = flow1.CommitRow("This is Data2 from Test")
_ = flow1.CommitRow("This is Data3 from Test")
// 4. Execute flow1
if err := flow1.Run(ctx); err != nil {
panic(err)
}
}
```
Navigate to `kis-flow/test/` and execute:
```bash
go test -test.v -test.paniconexit0 -test.run TestActionForceEntry
```
The results are as follows:
```bash
=== RUN TestActionForceEntry
Add KisPool FuncName=funcName1
Add KisPool FuncName=noResultFunc
Add KisPool FuncName=funcName3
Add KisPool CaaSInit CName=ConnName1
Add KisPool CaaS CName=ConnName1, FName=funcName2, Mode =Save
===> Call Connector InitDemo1
&{conn ConnName1 0.0.0.0:9988,0.0.0.0:9999,0.0.0.0:9990 redis redis-key map[args1:value1 args2:value2] [] [funcName2 funcName2]}
Add FlowRouter FlowName=flowName1
Add FlowRouter FlowName=flowName2
Add FlowRouter FlowName=flowName3
Add FlowRouter FlowName=flowName4
===> Call Connector InitDemo1
&{conn ConnName1 0.0.0.0:9988,0.0.0.0:9999,0.0.0.0:9990 redis redis-key map[args1:value1 args2:value2] [] [funcName2 funcName2 funcName2]}
Add FlowRouter FlowName=flowName5
context.Background
====> After CommitSrcData, flow_name = flowName4, flow_id = flow-a496d02c79204e9a803fb5e1307523c9
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test]]
KisFunctionV, flow = &{Id:flow-a496d02c79204e9a803fb5e1307523c9 Name:flowName4 Conf:0xc000152e40 Funcs:map[funcName1:0xc00011d560 funcName3:0xc00011d620 noResultFunc:0xc00011d5c0] FlowHead:0xc00011d560 FlowTail:0xc00011d620 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc00011d560 ThisFunctionId:func-4d113d6a8e744d30a906db310f2d7818 PrevFunctionId:FunctionIdFirstVirtual funcParams:map[func-47cb6f9ae464484aa779c18284035705:map[] func-4d113d6a8e744d30a906db310f2d7818:map[] func-70011c7ccecf46be91c6993d143639bb:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test]] inPut:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call funcName1Handler ----
In FuncName = funcName1, FuncId = func-4d113d6a8e744d30a906db310f2d7818, row = This is Data1 from Test
In FuncName = funcName1, FuncId = func-4d113d6a8e744d30a906db310f2d7818, row = This is Data2 from Test
In FuncName = funcName1, FuncId = func-4d113d6a8e744d30a906db310f2d7818, row = This is Data3 from Test
context.Background
====> After commitCurData, flow_name = flowName4, flow_id = flow-a496d02c79204e9a803fb5e1307523c9
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-4d113d6a8e744d30a906db310f2d7818:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]]
KisFunctionC, flow = &{Id:flow-a496d02c79204e9a803fb5e1307523c9 Name:flowName4 Conf:0xc000152e40 Funcs:map[funcName1:0xc00011d560 funcName3:0xc00011d620 noResultFunc:0xc00011d5c0] FlowHead:0xc00011d560 FlowTail:0xc00011d620 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc00011d5c0 ThisFunctionId:func-47cb6f9ae464484aa779c18284035705 PrevFunctionId:func-4d113d6a8e744d30a906db310f2d7818 funcParams:map[func-47cb6f9ae464484aa779c18284035705:map[] func-4d113d6a8e744d30a906db310f2d7818:map[] func-70011c7ccecf46be91c6993d143639bb:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-4d113d6a8e744d30a906db310f2d7818:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]] inPut:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call NoResultFuncHandler ----
In FuncName = noResultFunc, FuncId = func-47cb6f9ae464484aa779c18284035705, row = data from funcName[funcName1], index = 0
In FuncName = noResultFunc, FuncId = func-47cb6f9ae464484aa779c18284035705, row = data from funcName[funcName1], index = 1
In FuncName = noResultFunc, FuncId = func-47cb6f9ae464484aa779c18284035705, row = data from funcName[funcName1], index = 2
--- PASS: TestActionForceEntry (0.02s)
PASS
ok kis-flow/test 0.958s
```
Because `noResultFunc` does not generate any result data, the next Function will not be executed. The execution ends with:
```bash
---> Call NoResultFuncHandler ----
```
### 7.3.4 Unit Testing with ForceEntryNext
Next, we will add the `ForceEntryNext` action. In `NoResultFuncHandler()`, we add `flow.Next(kis.ActionForceEntryNext)` as shown below:
> kis-flow/test/faas/faas_no_result.go
```go
package faas
import (
"context"
"fmt"
"kis-flow/kis"
)
func NoResultFuncHandler(ctx context.Context, flow kis.Flow) error {
fmt.Println("---> Call NoResultFuncHandler ----")
for _, row := range flow.Input() {
str := fmt.Sprintf("In FuncName = %s, FuncId = %s, row = %s", flow.GetThisFuncConf().FName, flow.GetThisFunction().GetId(), row)
fmt.Println(str)
}
return flow.Next(kis.ActionForceEntryNext)
}
```
Navigate to the `kis-flow/test/` directory and execute:
```bash
go test -test.v -test.paniconexit0 -test.run TestActionForceEntry
```
The results are as follows:
```bash
=== RUN TestActionForceEntry
Add KisPool FuncName=funcName1
Add KisPool FuncName=noResultFunc
Add KisPool FuncName=funcName3
Add KisPool CaaSInit CName=ConnName1
Add KisPool CaaS CName=ConnName1, FName=funcName2, Mode=Save
===> Call Connector InitDemo1
&{conn ConnName1 0.0.0.0:9988,0.0.0.0:9999,0.0.0.0:9990 redis redis-key map[args1:value1 args2:value2] [] [funcName2 funcName2]}
Add FlowRouter FlowName=flowName5
===> Call Connector InitDemo1
&{conn ConnName1 0.0.0.0:9988,0.0.0.0:9999,0.0.0.0:9990 redis redis-key map[args1:value1 args2:value2] [] [funcName2 funcName2 funcName2]}
Add FlowRouter FlowName=flowName1
Add FlowRouter FlowName=flowName2
Add FlowRouter FlowName=flowName3
Add FlowRouter FlowName=flowName4
context.Background
====> After CommitSrcData, flow_name = flowName4, flow_id = flow-7fb47f227c9f4b9d8fa69c28177fc7bb
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test]]
KisFunctionV, flow = &{Id:flow-7fb47f227c9f4b9d8fa69c28177fc7bb Name:flowName4 Conf:0xc000028e80 Funcs:map[funcName1:0xc0000136e0 funcName3:0xc0000137a0 noResultFunc:0xc000013740] FlowHead:0xc0000136e0 FlowTail:0xc0000137a0 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc0000136e0 ThisFunctionId:func-ecddaee7d7d447a9852d07088732f509 PrevFunctionId:FunctionIdFirstVirtual funcParams:map[func-5729600ae6ea4d6f879eb5832c638e1a:map[] func-c9817c7993894919b8463dea1757544e:map[] func-ecddaee7d7d447a9852d07088732f509:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test]] inPut:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call funcName1Handler ----
In FuncName = funcName1, FuncId = func-ecddaee7d7d447a9852d07088732f509, row = This is Data1 from Test
In FuncName = funcName1, FuncId = func-ecddaee7d7d447a9852d07088732f509, row = This is Data2 from Test
In FuncName = funcName1, FuncId = func-ecddaee7d7d447a9852d07088732f509, row = This is Data3 from Test
context.Background
====> After commitCurData, flow_name = flowName4, flow_id = flow-7fb47f227c9f4b9d8fa69c28177fc7bb
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-ecddaee7d7d447a9852d07088732f509:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]]
KisFunctionC, flow = &{Id:flow-7fb47f227c9f4b9d8fa69c28177fc7bb Name:flowName4 Conf:0xc000028e80 Funcs:map[funcName1:0xc0000136e0 funcName3:0xc0000137a0 noResultFunc:0xc000013740] FlowHead:0xc0000136e0 FlowTail:0xc0000137a0 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc000013740 ThisFunctionId:func-c9817c7993894919b8463dea1757544e PrevFunctionId:func-ecddaee7d7d447a9852d07088732f509 funcParams:map[func-5729600ae6ea4d6f879eb5832c638e1a:map[] func-c9817c7993894919b8463dea1757544e:map[] func-ecddaee7d7d447a9852d07088732f509:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-ecddaee7d7d447a9852d07088732f509:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]] inPut:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call NoResultFuncHandler ----
In FuncName = noResultFunc, FuncId = func-c9817c7993894919b8463dea1757544e, row = data from funcName[funcName1], index = 0
In FuncName = noResultFunc, FuncId = func-c9817c7993894919b8463dea1757544e, row = data from funcName[funcName1], index = 1
In FuncName = noResultFunc, FuncId = func-c9817c7993894919b8463dea1757544e, row = data from funcName[funcName1], index = 2
context.Background
====> After commitVoidData, flow_name = flowName4, flow_id = flow-7fb47f227c9f4b9d8fa69c28177fc7bb
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-c9817c7993894919b8463dea1757544e:[] func-ecddaee7d7d447a9852d07088732f509:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]]
KisFunctionC, flow = &{Id:flow-7fb47f227c9f4b9d8fa69c28177fc7bb Name:flowName4 Conf:0xc000028e80 Funcs:map[funcName1:0xc0000136e0 funcName3:0xc0000137a0 noResultFunc:0xc000013740] FlowHead:0xc0000136e0 FlowTail:0xc0000137a0 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc0000137a0 ThisFunctionId:func-5729600ae6ea4d6f879eb5832c638e1a PrevFunctionId:func-c9817c7993894919b8463dea1757544e funcParams:map[func-5729600ae6ea4d6f879eb5832c638e1a:map[] func-c9817c7993894919b8463dea1757544e:map[] func-ecddaee7d7d447a9852d07088732f509:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-c9817c7993894919b8463dea1757544e:[] func-ecddaee7d7d447a9852d07088732f509:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]] inPut:[] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call funcName3Handler ----
--- PASS: TestActionForceEntry (0.01s)
PASS
ok kis-flow/test 0.348s
```
It is observed that the function in the third layer, `funcName3Handler`, is executed, but it has no data.
## 7.4 Action JumpFunc (Flow Jump)
Next, we will implement the JumpFunc Action. JumpFunc allows jumping to a specified FuncName within the current Flow and continuing execution (provided that the target FuncName exists in the current Flow).
> Note: JumpFunc can lead to infinite loops, so use it cautiously in business logic.
### 7.4.1 Adding JumpFunc to Action
First, add a JumpFunc property to the Action. Note that JumpFunc is not a boolean state but a string representing the specific FunctionName to jump to.
> kis-flow/kis/action.go
```go
// Action KisFlow execution flow actions
type Action struct {
// DataReuse indicates whether to reuse data from the previous function
DataReuse bool
// By default, Next() will not execute the subsequent function if the current function's result set is empty.
// ForceEntryNext forces the next function to execute even if the current function's result set is empty.
ForceEntryNext bool
// ++++++++++
// JumpFunc specifies the function to jump to for further execution
JumpFunc string
// Abort terminates the flow execution
Abort bool
}
// ActionJumpFunc returns an ActionFunc function that sets the JumpFunc property in Action
// (Note: Can easily cause flow loops leading to infinite loops)
func ActionJumpFunc(funcName string) ActionFunc {
return func(act *Action) {
act.JumpFunc = funcName
}
}
```
Then provide a method to modify the JumpFunc configuration `ActionJumpFunc()`. Note that this method differs from previous ones as it returns an anonymous function and executes it to modify the JumpFunc property in Action.
### 7.4.2 Capturing the Action
Next, we capture the JumpFunc action by checking if JumpFunc is an empty string.
> kis-flow/flow/kis_flow_action.go
```go
// dealAction processes the Action and determines the next step in the Flow
func (flow *KisFlow) dealAction(ctx context.Context, fn kis.Function) (kis.Function, error) {
// DataReuse Action
if flow.action.DataReuse {
if err := flow.commitReuseData(ctx); err != nil {
return nil, err
}
} else {
if err := flow.commitCurData(ctx); err != nil {
return nil, err
}
}
// ForceEntryNext Action
if flow.action.ForceEntryNext {
if err := flow.commitVoidData(ctx); err != nil {
return nil, err
}
flow.abort = false
}
// ++++++++++++++++++++++++++++++++
// JumpFunc Action
if flow.action.JumpFunc != "" {
if _, ok := flow.Funcs[flow.action.JumpFunc]; !ok {
// JumpFunc is not in the flow
return nil, errors.New(fmt.Sprintf("Flow Jump -> %s is not in Flow", flow.action.JumpFunc))
}
jumpFunction := flow.Funcs[flow.action.JumpFunc]
// Update the previous function
flow.PrevFunctionId = jumpFunction.GetPrevId()
fn = jumpFunction
// If a jump is set, force the jump
flow.abort = false
// ++++++++++++++++++++++++++++++++
} else {
// Update the previous function ID cursor
flow.PrevFunctionId = flow.ThisFunctionId
fn = fn.Next()
}
// Abort Action forcibly terminates the flow
if flow.action.Abort {
flow.abort = true
}
// Clear the Action
flow.action = kis.Action{}
return fn, nil
}
```
If `JumpFunc` is set, the next function `fn` pointer needs to be updated accordingly. Otherwise, the normal address `fn.Next()` is used.
### 7.4.3 Unit Testing
Next, let's define a function with a jump action configuration as follows:
> kis-flow/test/load_conf/func/func-jumpFunc.yml
```yaml
kistype: func
fname: jumpFunc
fmode: Calculate
source:
name: User Order Error Rate
must:
- order_id
- user_id
```
And implement the related function business logic as follows:
> kis-flow/test/faas/faas_jump.go
```go
package faas
import (
"context"
"fmt"
"kis-flow/kis"
)
// type FaaS func(context.Context, Flow) error
func JumpFuncHandler(ctx context.Context, flow kis.Flow) error {
fmt.Println("---> Call JumpFuncHandler ----")
for _, row := range flow.Input() {
str := fmt.Sprintf("In FuncName = %s, FuncId = %s, row = %s", flow.GetThisFuncConf().FName, flow.GetThisFunction().GetId(), row)
fmt.Println(str)
}
return flow.Next(kis.ActionJumpFunc("funcName1"))
}
```
Here, `flow.Next(kis.ActionJumpFunc("funcName1"))` specifies the jump to the function named `funcName1`.
Create a new flow named `FlowName5` with the following configuration:
> kis-flow/test/load_conf/flow/flow-FlowName5.yml
```yaml
kistype: flow
status: 1
flow_name: flowName5
flows:
- fname: funcName1
- fname: funcName2
- fname: jumpFunc
```
Next, implement the unit test case code as follows:
> kis-flow/test/kis_action_test.go
```go
func TestActionJumpFunc(t *testing.T) {
ctx := context.Background()
// 0. Register Function callback business logic
kis.Pool().FaaS("funcName1", faas.FuncDemo1Handler)
kis.Pool().FaaS("funcName2", faas.FuncDemo2Handler)
kis.Pool().FaaS("jumpFunc", faas.JumpFuncHandler) // Add jumpFunc business logic
// 0. Register ConnectorInit and Connector callback business logic
kis.Pool().CaaSInit("ConnName1", caas.InitConnDemo1)
kis.Pool().CaaS("ConnName1", "funcName2", common.S, caas.CaasDemoHanler1)
// 1. Load configuration files and build the flow
if err := file.ConfigImportYaml("/Users/tal/gopath/src/kis-flow/test/load_conf/"); err != nil {
panic(err)
}
// 2. Get the flow
flow1 := kis.Pool().GetFlow("flowName5")
// 3. Commit raw data
_ = flow1.CommitRow("This is Data1 from Test")
_ = flow1.CommitRow("This is Data2 from Test")
_ = flow1.CommitRow("This is Data3 from Test")
// 4. Execute flow1
if err := flow1.Run(ctx); err != nil {
panic(err)
}
}
```
Change the directory to `kis-flow/test/` and execute:
```bash
go test -test.v -test.paniconexit0 -test.run TestActionJumpFunc
```
The result is as follows:
```bash
...
...
---> Call funcName1Handler ----
In FuncName = funcName1, FuncId = func-f6ca8010d66744429bf6069c9897a928, row = This is Data1 from Test
In FuncName = funcName1, FuncId = func-f6ca8010d66744429bf6069c9897a928, row = This is Data2 from Test
In FuncName = funcName1, FuncId = func-f6ca8010d66744429bf6069c9897a928, row = This is Data3 from Test
context.Background
====> After commitCurData, flow_name = flowName5, flow_id = flow-5da80af989dc49648a001762fa08b866
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-5800567c4cd842b6b377c2b0c0fd81c2:[data from funcName[funcName2], index = 0 data from funcName[funcName2], index = 1 data from funcName[funcName2], index = 2] func-f6ca8010d66744429bf6069c9897a928:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]]
KisFunctionS, flow = &{Id:flow-5da80af989dc49648a001762fa08b866 Name:flowName5 Conf:0xc000028f80 Funcs:map[funcName1:0xc000013620 funcName2:0xc000013680 jumpFunc:0xc0000136e0] FlowHead:0xc000013620 FlowTail:0xc0000136e0 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc000013680 ThisFunctionId:func-5800567c4cd842b6b377c2b0c0fd81c2 PrevFunctionId:func-f6ca8010d66744429bf6069c9897a928 funcParams:map[func-4faf8f019f4a4a48b84ef27abfad53d1:map[] func-5800567c4cd842b6b377c2b0c0fd81c2:map[] func-f6ca8010d66744429bf6069c9897a928:map[]] fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data:map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-5800567c4cd842b6b377c2b0c0fd81c2:[data from funcName[funcName2], index = 0 data from funcName[funcName2], index = 1 data from funcName[funcName2], index = 2] func-f6ca8010d66744429bf6069c9897a928:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]] inPut:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2] abort:false action:{DataReuse:false ForceEntryNext:false JumpFunc: Abort:false}}
---> Call funcName2Handler ----
In FuncName = funcName2, FuncId = func-5800567c4cd842b6b377c2b0c0fd81c2, row = data from funcName[funcName1], index = 0
===> In CaasDemoHanler1: flowName: flowName5, cName:ConnName1, fnName:funcName2, mode:Save
===> Call Connector CaasDemoHanler1, args from funciton: data from funcName[funcName1], index = 0
In FuncName = funcName2, FuncId = func-5800567c4cd842b6b377c2b0c0fd81c2, row = data from funcName[funcName1], index = 1
===> In CaasDemoHanler1: flowName: flowName5, cName:ConnName1, fnName:funcName2, mode:Save
===> Call Connector CaasDemoHanler1, args from funciton: data from funcName[funcName1], index = 1
In FuncName = funcName2, FuncId = func-5800567c4cd842b6b377c2b0c0fd81c2, row = data from funcName[funcName1], index = 2
===> In CaasDemoHanler1: flowName: flowName5, cName:ConnName1, fnName:funcName2, mode:Save
===> Call Connector CaasDemoHanler1, args from funciton: data from funcName[funcName1], index = 2
context.Background
====> After commitCurData, flow_name = flowName5, flow_id = flow-5da80af989dc49648a001762fa08b866
All Level Data =
map[FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-5800567c4cd842b6b377c2b0c0fd81c2:[data from funcName[funcName2], index = 0 data from funcName[funcName2], index = 1 data from funcName[funcName2], index = 2] func-f6ca8010d66744429bf6069c9897a928:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]]
KisFunctionC, flow = &{Id:flow-5da80af989dc49648a001762fa08b866 Name:flowName5 Conf:0xc000028f80 Funcs:map[funcName1:0xc000013620 funcName2:0xc000013680 jumpFunc:0xc0000136e0] FlowHead:0xc000013620 FlowTail:0xc0000136e0 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc0000136e0 ThisFunctionId:func-4faf8f019f4a4a48b84ef27abfad53d1 PrevFunctionId
funcParams
func-4faf8f019f4a4a48b84ef27abfad53d1
func-5800567c4cd842b6b377c2b0c0fd81c2
func-f6ca8010d66744429bf6069c9897a928
fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data
FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-5800567c4cd842b6b377c2b0c0fd81c2:[data from funcName[funcName2], index = 0 data from funcName[funcName2], index = 1 data from funcName[funcName2], index = 2] func-f6ca8010d66744429bf6069c9897a928:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]
inPut:[data from funcName[funcName2], index = 0 data from funcName[funcName2], index = 1 data from funcName[funcName2], index = 2] abort
action:{DataReuse
ForceEntryNext
JumpFunc: Abort
}}
---> Call JumpFuncHandler ----
In FuncName = jumpFunc, FuncId = func-4faf8f019f4a4a48b84ef27abfad53d1, row = data from funcName[funcName2], index = 0
In FuncName = jumpFunc, FuncId = func-4faf8f019f4a4a48b84ef27abfad53d1, row = data from funcName[funcName2], index = 1
In FuncName = jumpFunc, FuncId = func-4faf8f019f4a4a48b84ef27abfad53d1, row = data from funcName[funcName2], index = 2
KisFunctionV, flow = &{Id
Name
Conf:0xc000028f80 Funcs
funcName1:0xc000013620 funcName2:0xc000013680 jumpFunc:0xc0000136e0
FlowHead:0xc000013620 FlowTail:0xc0000136e0 flock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} ThisFunction:0xc000013620 ThisFunctionId
PrevFunctionId
funcParams
func-4faf8f019f4a4a48b84ef27abfad53d1
func-5800567c4cd842b6b377c2b0c0fd81c2
func-f6ca8010d66744429bf6069c9897a928
fplock:{w:{state:0 sema:0} writerSem:0 readerSem:0 readerCount:0 readerWait:0} buffer:[] data
FunctionIdFirstVirtual:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] func-5800567c4cd842b6b377c2b0c0fd81c2:[data from funcName[funcName2], index = 0 data from funcName[funcName2], index = 1 data from funcName[funcName2], index = 2] func-f6ca8010d66744429bf6069c9897a928:[data from funcName[funcName1], index = 0 data from funcName[funcName1], index = 1 data from funcName[funcName1], index = 2]
inPut:[This is Data1 from Test This is Data2 from Test This is Data3 from Test] abort
action:{DataReuse
ForceEntryNext
JumpFunc: Abort
}}
---> Call funcName1Handler ----
...
...
```
We observe that the Flow keeps looping, indicating that our JumpFunc Action has taken effect.
## 7.5 [V0.6] Source Code
You can find the source code for version 0.6 of the project at:
https://github.com/aceld/kis-flow/releases/tag/v0.6
---
Author: Aceld
GitHub: https://github.com/aceld
KisFlow Open Source Project Address: https://github.com/aceld/kis-flow
Document: https://github.com/aceld/kis-flow/wiki
---
[Part1-OverView](https://dev.to/aceld/part-1-golang-framework-hands-on-kisflow-streaming-computing-framework-overview-8fh)
[Part2.1-Project Construction / Basic Modules](https://dev.to/aceld/part-2-golang-framework-hands-on-kisflow-streaming-computing-framework-project-construction-basic-modules-cia)
[Part2.2-Project Construction / Basic Modules](https://dev.to/aceld/part-3golang-framework-hands-on-kisflow-stream-computing-framework-project-construction-basic-modules-1epb)
[Part3-Data Stream](https://dev.to/aceld/part-4golang-framework-hands-on-kisflow-stream-computing-framework-data-stream-1mbd)
[Part4-Function Scheduling](https://dev.to/aceld/part-5golang-framework-hands-on-kisflow-stream-computing-framework-function-scheduling-4p0h)
[Part5-Connector](https://dev.to/aceld/part-5golang-framework-hands-on-kisflow-stream-computing-framework-connector-hcd)
[Part6-Configuration Import and Export](https://dev.to/aceld/part-6golang-framework-hands-on-kisflow-stream-computing-framework-configuration-import-and-export-47o1)
[Part7-KisFlow Action](https://dev.to/aceld/part-7golang-framework-hands-on-kisflow-stream-computing-framework-kisflow-action-3n05)
[Part8-Cache/Params Data Caching and Data Parameters](https://dev.to/aceld/part-8golang-framework-hands-on-cacheparams-data-caching-and-data-parameters-5df5)
[Part9-Multiple Copies of Flow](https://dev.to/aceld/part-8golang-framework-hands-on-multiple-copies-of-flow-c4k)
[Part10-Prometheus Metrics Statistics](https://dev.to/aceld/part-10golang-framework-hands-on-prometheus-metrics-statistics-22f0)
[Part11-Adaptive Registration of FaaS Parameter Types Based on Reflection](https://dev.to/aceld/part-11golang-framework-hands-on-adaptive-registration-of-faas-parameter-types-based-on-reflection-15i9)
---
[Case1-Quick Start](https://dev.to/aceld/case-i-kisflow-golang-stream-real-time-computing-quick-start-guide-f51)
[Case2-Flow Parallel Operation](https://dev.to/aceld/case-i-kisflow-golang-stream-real-time-computing-flow-parallel-operation-364m)
| aceld |
1,873,426 | Accessibility Tests in Compose - Name, Role, Value | When writing tests for your app, you should also consider testing for accessibility-related things.... | 0 | 2024-06-03T11:35:00 | https://eevis.codes/blog/2024-06-03/accessibility-tests-in-compose-name-role-value/ | a11y, android, mobile, testing | When writing tests for your app, you should also consider testing for accessibility-related things. And I get it; it can be challenging to know where to start. So, I decided to write this blog post about how to test some accessibility aspects.
In this post, we will add some accessibility-related tests for three custom components constructed with the help of `clickable`, `selectable`, and `toggleable` modifiers. These components were built in a blog post I wrote: [Improving Android Accessibility with Modifiers in Jetpack Compose][1].
## What Are We Testing?
The tests we're writing verify that the components have names, roles, and values. But where does this group come from? The background is that Web Content Accessibility Guidelines (WCAG) has a success criterion, "[Name, Role, Value][2]", which ensures that every element has a programmatically determinable name and role. Also, states, properties, and values that users can change are programmatically changeable.
And now, if you wonder why I'm mentioning something named "Web," the WCAG is also used to determine the minimum level of accessibility for mobile apps as well, despite the name.
Name, in this case, means the accessible name—so, the textual representation of the element. It can be, for example, a button's text, an icon button's content description, a label for a switch, or similar. It's what anyone using a screen reader hears. Voice access users use it to activate interactive elements.
Role, on the other hand, is the role of the element. It can be, for example, a button - which tells the user that, hey, this is a button, and it should behave as a button. A role is a promise of how things should work, so if you add a role, be sure to add the correct interactions as well. However, roles are used less on Android than on the web.
Value can refer to an element's state, property, or value. The exact thing is different per element. For example, with a checkbox, the value tells if it is checked, or with an accordion, it's the state that tells if it's opened or closed.
In the next section, we'll examine concrete examples of how to test the "Name, Role, Value" success criterion for a couple of custom components mentioned in the intro.
## Writing the Tests, an Example
As mentioned in the beginning, these tests are written for components for a blog post I've written previously. We'll look into how to test three components: A switch, a radio button group, and a clickable row.
As the components in the blog posts were simplified for the sake of an example, these tests are also streamlined. With production-grade code, you usually have a bit more sophisticated strategies for, for example, finding the components that are being tested.
### Toggleable
The first component we're testing is a switch like in the picture:

We want to test three things: First, we want to ensure the component has an accessible name (so, the label of the switch). Second, the role should be correct—it should be a toggleable component. Third, the value should be correct before and after toggling the switch, so whether the switch is on or off.
Let's write a test:
```kotlin
class ToggleableTest {
@get:Rule
val composeTestRule = createComposeRule()
@Test
fun hasRoleNameValue() {
composeTestRule.setContent {
ModifiersExampleTheme {
ToggleableScreen()
}
}
val toggleableElement =
composeTestRule.onNode(hasTestTag("accessible-toggle"))
// Assert accessible name
toggleableElement.assertTextEquals("Toggleable")
// Assert role
toggleableElement.assertIsToggleable()
// Assert value
toggleableElement.assertIsOff()
toggleableElement.performClick()
toggleableElement.assertIsOn()
}
}
```
First, the test needs a setup, so we need things like the `composeTestRule` and setting the content. Then we get the testable component with a test tag `accessible-toggle`. Finally, we have the tests for name, role, and value.
The test for checking the name is straightforward: We want to ensure that the element's text content equals the word on the label. We can assert that with `assertTextEquals`. To test the role, we can use a useful assert function, `assertIsToggleable`. Finally, to check if the value (so, the checked state) is correct, we can also use the utility functions `assertIsOff` and `assertIsOn` and, for toggling the state, `performClick`.
### Selectable
The next component we're testing is a radio button group, as seen in the picture:

For this component, we ensure that both of the options have a name (so, the labels "Option A" and "Option B"), role as `selectable`, and value if the item is selected.
The test for this component is:
```kotlin
class SelectableTest {
@get:Rule
val composeTestRule = createComposeRule()
@Before
fun setup() {
composeTestRule.setContent {
ModifiersExampleTheme {
SelectableScreen()
}
}
}
@Test
fun hasRoleNameValue() {
val selectableElements =
composeTestRule.onAllNodes(hasTestTag("accessible-selectable"))
// Assert accessible name
selectableElements[0].assertTextEquals("Option A")
selectableElements[1].assertTextEquals("Option B")
// Assert role
selectableElements.assertAll(isSelectable())
// Assert value
selectableElements[0].assertIsSelected()
selectableElements[1].performClick()
selectableElements[0].assertIsNotSelected()
selectableElements[1].assertIsSelected()
}
}
```
The structure is very similar to the previous test; first, the setup, then getting the elements, and then asserting name, role, and value. We're using the same `assertTextEquals` to check the elements' labels (so, names). Similarly to the `toggleable`, there are functions for asserting the role and values for the `selectable`: `isSelectable()`, `assertIsSelected()`, and `.assertIsNotSelected()`.
### Clickable
The final custom component for this blog post is a custom button that can be used to bookmark an item:
We want to ensure that it has a name (so, the text "Bookmark this item"), the role of a button, and a state that communicates whether the item is bookmarked or not.
The following tests ensure that:
```kotlin
class ClickableTest {
@get:Rule
val composeTestRule = createComposeRule()
@Test
fun hasRoleNameValue() {
composeTestRule.setContent {
ModifiersExampleTheme {
ClickableScreen()
}
}
val clickableElement =
composeTestRule.onNode(hasTestTag("clickable"))
// Assert accessible name
clickableElement.assertTextEquals("Bookmark this item")
// Assert role
clickableElement.assert(
SemanticsMatcher("has correct role") {
it.config.getOrNull(SemanticsProperties.Role) == Role.Button
},
)
// Assert state description
clickableElement.assertStateDescription("Not bookmarked")
clickableElement.performClick()
clickableElement.assertStateDescription("Bookmarked")
}
private fun SemanticsNodeInteraction.assertStateDescription(
stateDescription: String
) =
assert(
SemanticsMatcher("has correct state description") {
it.config.getOrNull(SemanticsProperties.StateDescription) == stateDescription
},
)
}
```
Again, the setup and checking of the name are similar to the other two components. But to check if the component has a role of the button, we need to use a `SemanticsMatcher`.
[SemanticsMatcher][3] is a wrapper for matching semantic nodes. We want to ensure that the element's semantic property `Role` matches `Role.Button`. We can do it by wrapping our check with a `SemanticMatcher`, and getting the element's `SemanticProperties.Role` from the element with `it.config.getOrNull(SemanticsProperties.Role)` and checking its value.
The same pattern works for testing the element's state description. To avoid code duplication, I've created an extension function, `assertStateDescription,` which is used to check the state description of the element.
## Wrapping Up
In this blog post, we've discussed writing accessibility tests for the WCAG success criteria 4.1.2: Name, Role, Value. While they're not always relevant to mobile accessibility, this blog post aims to give an example of how to write accessibility tests.
Have you written tests for accessibility on Android? Please, share what you've learned!
## Links in the Blog Post
- [Improving Android Accessibility with Modifiers in Jetpack Compose][1]
- [Name, Role, Value][2]
- [SemanticsMatcher][3]
[1]: https://dev.to/eevajonnapanula/improving-android-accessibility-with-modifiers-in-jetpack-compose-3llb
[2]: https://www.w3.org/WAI/WCAG21/Understanding/name-role-value.html
[3]: https://developer.android.com/reference/kotlin/androidx/compose/ui/test/SemanticsMatcher | eevajonnapanula |
1,875,300 | Exploring Micro Frontends in Modern Web Development | Ever struggled with the complexities of large web applications? Micro frontends could be your... | 0 | 2024-06-03T11:33:44 | https://dev.to/zorian/exploring-micro-frontends-in-modern-web-development-5dhn | webdev, frontend, microfrontend, softwarewdevelopment | Ever struggled with the complexities of large web applications? Micro frontends could be your solution. They simplify the development of complex web applications by breaking them down into smaller, independent units. This method draws from microservices principles, allowing teams to develop, test, and deploy application parts individually.
To help you understand, I will explore the concept and implementation of micro frontends. Read on.
## Introduction to Micro Frontends
Micro frontends are about extending the microservices idea to the frontend world. The strategy involves splitting a monolithic front-end into smaller, semi-independent units called "microapps." With these, different teams can develop and manage each unit, allowing for more agile updates and scalability.
To illustrate micro frontends, I will use single-spa in a demo shopping platform.
## Project Structure
**Folder Structure**
The above image shows a typical micro frontend architecture. It shows separate directories for each microapp, such as a login-app, shopping-app, and card-app. The root-app is the orchestrator, linking these apps into a unified interface.
**Configuration and Initialization**
Here is the technical setup of micro frontends. The code shows the configuration file in the root-app, detailing how each microapp is registered using single-spa. This setup allows each team to work independently on their microapp.
**Dynamic Routing and Layout Management**
Route configuration is crucial for micro frontends. The displayed layout configuration file uses a single-spa-router to assign URLs to specific micro apps, enabling seamless navigation between application components. This approach minimizes load times and enhances user experience.
**Example of a Micro Frontend Implementation**
This code snippet from the login-app showcases the implementation details of a micro frontend. It highlights how the React framework is utilized within this architecture.
**Integrating and Launching Micro Frontends**
Integration is key in micro frontends. The index.ejs file configures the initial loading of the microapps and includes import maps that define where and how each microapp is loaded. This system supports hot-swapping of frontends without affecting the overall application.
**Visualization of an Operational Micro Frontend**
This image illustrates a fully operational login page, an example of a micro frontend in action.
## Conclusion
Micro frontends enable teams to work independently on large web applications, improving scalability and allowing for innovation without affecting the overall application stability. Interested to learn more? Check out this article. | zorian |
1,875,299 | The Difference Between Web 2 and Web 3 | We have all been using the internet for decades. But then we hear a new term, Web 3.0, which is... | 0 | 2024-06-03T11:32:32 | https://dev.to/whotarusharora/the-difference-between-web-2-and-web-3-pe4 | web3, webdev, development, blockchain | We have all been using the internet for decades. But then we hear a new term, Web 3.0, which is highly populated among every other guy we know. Everyone was talking about it, how it's going to change everything, and why one should move from Web 2.0 to Web 3.0.
However, before you take any decision to move to Web 3.0, don't you think it's necessary to clear the fundamentals? That's why we are here to help you with learning about Web 2 and Web 3 and the difference between them.
As a result, you will know the pros and cons of both, helping you decide whether to migrate to Web 3.0 or remain at Web 2.0.
So, let’s get started.
## Web 2.0: A Complete Brief
Currently, we’re in the era of Web 2.0, which is extremely evolved and better than Web 1.0.
In Web 2.0, people are able to create, share, and consume a lot of content, which helps to build communities, grow online businesses, stream services, and more. In addition, a number of technologies are available for every use case, such as:
* To create business applications
* To automate machineries
* To have an IoT network anywhere
* To access devices remotely
* To conduct complex calculations within minutes
However, in Web 2.0, the main concern is data. It seems to be secured, but in reality, it’s not as it seems. The individual's data is in the hands of organizations whose services we are using. For instance, you utilize a mailing platform, so your data is in their hands. You are dependent on their system to maintain the integrity and confidentiality of your information.
### The Pros of Web 2.0
Following are the top pros of Web 2.0 that we leverage on a daily basis.
* Web 2.0 has dynamic websites and applications that can be accessed using multiple browsers and devices. Also, the software solutions have clickable icons, animations, screen-adapting capabilities, real-time data processing, and more.
* It supports communication with others through multiple channels, such as chat, video conferencing, internet calling, and social media platforms.
* The technologies belonging to the Web 2.0 era aid in creating, sharing, and supporting large content files, leading to building digital communities.
* Web 2.0 is highly user-friendly, and even websites can be built through a few clicks and within half an hour.
### Cons of Web 2.0
Along with the pros, there are also some cons with Web 2.0 that must be known for better clarification.
* Data availability is the prime concern of Web 2.0. It’s based on centralized servers, meaning that overloaded traffic can cause crashes and permanent data deletion. In addition, even if cloud infrastructures are used, there's still a possibility of server crashes because, in reality, clouds are also physical servers but at different locations.
* Data security is also a major concern in Web 2.0. If the attackers breach a centralized server, the entire data is leaked, and integrity is exploited on the spot.
* The users don't have any ownership of their data. The big giants collect information through different means and utilize it for their personal gains. The terms and conditions written in those long paragraphs and small fonts are just to avoid legal charges, nothing else.
* Along with data, the ownership to display information is also in the hands of giant companies. The domains can be owned within minutes, websites can be blocked, traffic can be diverted, and other activities exploiting censorship are easily executed in Web 2.0.
## Web 3.0: A Brief Insight
As the name depicts, Web 3.0 is obviously the newer and updated version of the World Wide Web. It's also referred to as the decentralized or semantic web, as most of Web 3.0 is based on blockchain technology.
Each individual in Web 3.0 has control and ownership over their data. They understand how their data is being processed and stored for a specific operation. It's more like a democracy, where everyone has a right to say so that appropriate decisions can be made. In addition, ownership and identity are the two main pillars that hold Web 3.0 strong.
Furthermore, it's similar to Web 2.0 in terms of content creation. The main difference is the decentralization of all the processes. Also, it allows people to buy and sell digital products in the real world. Yes, you read that right: with Web 3.0, digital assets have a high value in real-world use cases.
The most common examples of Web 3.0 are cryptocurrency, initial coin offerings, NFTs, metaverse, AI, ML, and more.
### The Pros of Web 3.0
Web 3.0 is getting adopted quickly by Fortune 1000 companies due to its exceptional advantages, as listed below.
* The entire Web 3.0 is decentralized, meaning that every person has ownership of their data. Unlike Web 2.0, no single company is going to have any control over anybody’s information.
* It's making the World Wide Web more transparent, as most of the communications are going to be peer-to-peer. The middleman is going to be eliminated. You will know who is sending and receiving the information.
* The applications will be more platform-compatible and decentralized. It’ll facilitate more robust data security. Also, rapid app development will be supported, enabling organizations to digitize their operations within the minimal time possible.
### The Cons of Web 3.0
As Web 3.0 is still being developed, below are some of its cons that you should know about.
* The complexity of Web 3.0 is quite high. Due to this, highly skilled professionals and large investments are required to implement it.
* Currently, it lacks scalability and is unable to handle large volume traffic. Thus, if the number of users increases, the performance will fall down.
* There's a possibility of money laundering and fraud, as it's difficult to comply with regulatory and security standards on a blockchain-based network.
* The cryptocurrency market is quite fragile, and it's not currently considered a legal mode of payment. Due to this, Web 3 is lagging behind, and people are not able to trust its network.
## Web 2 vs Web 3: The Battle Begins
Let’s have a look at the differential table of Web 2 vs Web 3. Undergoing the table will help you have a quick grasp of the fundamental differentiations.
## Concluding Up: Which is Better Among Web 2 and Web 3?
Web 2 and Web 3 are completely opposite of each other. Where Web 2 is centralized, Web 3 is a decentralized tech based on blockchain. However, according to the current market, Web 2.0 is going to continue for some more years, as Web 3.0 lacks some fundamental requirements.
Once Web 3 starts complying with defined standards, has appropriate security controls, and becomes more stable and scalable, then it’ll be the right time to fully adapt it. Concludingly, Web 2 is a winner as per the current use case, but the future is based on Web 3.0.
| whotarusharora |
1,875,297 | Cara Memahami Penggunaan OOP (Object Oriented Programming) bagi Pemula | OOP atau Object-Oriented Programming tuh kayak gaya nge-coding yang ngefokusin pada objek. Jadi,... | 0 | 2024-06-03T11:30:29 | https://dev.to/yogameleniawan/cara-memahami-penggunaan-oop-object-oriented-programming-bagi-pemula-1mj2 | programming |

OOP atau Object-Oriented Programming tuh kayak gaya nge-coding yang ngefokusin pada objek. Jadi, bayangin aja kalau kita bikin program kayak bikin benda-benda nyata yang punya sifat (atribut) dan bisa ngelakuin sesuatu (metode). Nah, buat kalian yang baru banget kenal sama OOP, yuk kita bahas dengan gaya santai biar lebih paham!
### Apa Itu OOP?
OOP itu intinya adalah bikin kode yang pake "object". _Object_ tuh kayak benda nyata yang punya atribut (kayak sifat atau data) dan _method_ (kayak aksi atau fungsi). _Class_ itu kayak blueprint atau cetakan dari _object_. Misalnya, kelas "Mobil" bisa dipake buat bikin objek "Mobil Avanza", "Mobil Jazz", dll.
### Konsep Dasar OOP
**1. Kelas (Class)**
Class itu blueprint dari object. Kita bikin class buat nentuin atribut dan method yang akan dimiliki object.
```php
<?php
class Hewan {
public $nama;
public $jenis;
function __construct($nama, $jenis) {
$this->nama = $nama;
$this->jenis = $jenis;
}
function bicara() {
return "$this->nama sedang berbicara.";
}
}
```
**2. Objek (Object)**
Objek itu instance dari kelas. Jadi kita bikin objek dari kelas yang udah kita buat.
```php
<?php
$kucing = new Hewan("Tom", "Kucing");
echo $kucing->bicara(); // Output: Tom sedang berbicara.
```
**3. Enkapsulasi (Encapsulation)**
Enkapsulasi itu buat nyembunyiin detail implementasi dari objek. Caranya dengan bikin atribut jadi private.
```php
<?php
class Hewan {
private $nama;
private $jenis;
function __construct($nama, $jenis) {
$this->nama = $nama;
$this->jenis = $jenis;
}
public function getNama() {
return $this->nama;
}
public function bicara() {
return "$this->nama sedang berbicara.";
}
}
```
**4. Pewarisan (Inheritance)**
Pewarisan itu memungkinkan class buat mewarisi atribut dan metode dari class lain. Ini ngebantu bikin kode yang bisa dipake ulang.
```php
<?php
class Hewan {
public $nama;
public $jenis;
function __construct($nama, $jenis) {
$this->nama = $nama;
$this->jenis = $jenis;
}
function bicara() {
return "$this->nama sedang berbicara.";
}
}
class Anjing extends Hewan {
public $suara;
function __construct($nama, $jenis, $suara) {
parent::__construct($nama, $jenis);
$this->suara = $suara;
}
function bicara() {
return "$this->nama berkata $this->suara";
}
}
$anjing = new Anjing("Spike", "Anjing", "Guk guk");
echo $anjing->bicara(); // Output: Spike berkata Guk guk
```
**5. Polimorfisme (Polymorphism)**
Polimorfisme memungkinkan method buat berperilaku beda berdasarkan objek yang manggilnya.
```php
<?php
class Kucing extends Hewan {
function bicara() {
return "$this->nama berkata Meow";
}
}
$hewan_list = [
new Hewan("Hewan", "Umum"),
new Anjing("Spike", "Anjing", "Guk guk"),
new Kucing("Tom", "Kucing")
];
foreach ($hewan_list as $hewan) {
echo $hewan->bicara() . "\n";
}
// Output:
// Hewan sedang berbicara.
// Spike berkata Guk guk
// Tom berkata Meow
```
**6. Abstraksi (Abstraction)**
Abstraksi adalah cara buat cuma nampilin detail penting dari objek, nyembunyiin detail yang gak relevan. Biasanya pake kelas abstrak.
```php
<?php
abstract class Hewan {
abstract public function bicara();
}
class Anjing extends Hewan {
public function bicara() {
return "Guk guk";
}
}
class Kucing extends Hewan {
public function bicara() {
return "Meow";
}
}
$anjing = new Anjing();
$kucing = new Kucing();
echo $anjing->bicara(); // Output: Guk guk
echo $kucing->bicara(); // Output: Meow
```
### Keuntungan Menggunakan OOP
1. Modularitas: Kode lebih rapi dan gampang dimengerti karena dikelompokkan dalam class.
2. Pemeliharaan: Lebih gampang update atau maintenance kode.
3. Penggunaan Ulang Kode: Kode bisa dipake ulang lewat pewarisan.
4. Fleksibilitas: Polimorfisme bikin metode bisa berperilaku beda tergantung objek yang manggil.
### Penerapan OOP dalam Proyek Nyata
Kalau temen-temen masih bingung dengan contoh diatas, kita coba pakai studi kasus asli dengan proyek yang mungkin temen-temen sering temui.
Untuk mulai memahami dan mengimplementasikan OOP, penting untuk berlatih dengan proyek kecil yang memanfaatkan konsep-konsep dasar OOP. Misalnya, membuat program sederhana yang mengelola data mahasiswa dengan kelas `Mahasiswa`, `Dosen`, dan `MataKuliah`. Dengan memahami cara kerja class, object, pewarisan, polimorfisme, enkapsulasi, dan abstraksi melalui proyek-proyek kecil, nanti temen-temen juga bakal paham dengan sendirinya kok.
```php
<?php
class Mahasiswa {
private $nama;
private $nim;
public function __construct($nama, $nim) {
$this->nama = $nama;
$this->nim = $nim;
}
public function getNama() {
return $this->nama;
}
public function getNim() {
return $this->nim;
}
public function tampilkanInfo() {
return "Nama: " . $this->nama . ", NIM: " . $this->nim;
}
}
class Dosen {
private $nama;
private $nidn;
public function __construct($nama, $nidn) {
$this->nama = $nama;
$this->nidn = $nidn;
}
public function getNama() {
return $this->nama;
}
public function getNidn() {
return $this->nidn;
}
public function tampilkanInfo() {
return "Nama: " . $this->nama . ", NIDN: " . $this->nidn;
}
}
class MataKuliah {
private $namaMatkul;
private $kodeMatkul;
public function __construct($namaMatkul, $kodeMatkul) {
$this->namaMatkul = $namaMatkul;
$this->kodeMatkul = $kodeMatkul;
}
public function getNamaMatkul() {
return $this->namaMatkul;
}
public function getKodeMatkul() {
return $this->kodeMatkul;
}
public function tampilkanInfo() {
return "Mata Kuliah: " . $this->namaMatkul . ", Kode: " . $this->kodeMatkul;
}
}
$mahasiswa = new Mahasiswa("Budi", "123456");
$dosen = new Dosen("Pak Ahmad", "98765");
$matkul = new MataKuliah("Pemrograman", "INF101");
echo $mahasiswa->tampilkanInfo(); // Output: Nama: Budi, NIM: 123456
echo $dosen->tampilkanInfo(); // Output: Nama: Pak Ahmad, NIDN: 98765
echo $matkul->tampilkanInfo(); // Output: Mata Kuliah: Pemrograman, Kode: INF101
```
Apakah sudah paham sampai sini? Dengan paham dan praktek konsep OOP, temen-temen bisa bikin kode yang lebih efisien, rapi, dan gampang dirawat.
Jadi, memahami dan menerapkan OOP bukan hanya soal menguasai konsep-konsep dasarnya, tetapi juga tentang bagaimana mengintegrasikan konsep tersebut ke dalam praktek pemrograman sehari-hari. Dengan pendekatan yang benar, OOP dapat membantu temen-temen menulis kode yang lebih baik, lebih mudah dikelola, dan lebih fleksibel untuk kebutuhan pengembangan di masa depan. Dan yang paling penting ngoding itu diketik jangan dipikir. Sampai bertemu di artikel yang lebih menarik lagi!!!
| yogameleniawan |
1,875,295 | A Comprehensive Guide to Automation Testing Frameworks | Automation testing has become a crucial part of the software development lifecycle, ensuring that... | 0 | 2024-06-03T11:28:49 | https://dev.to/perfectqa/a-comprehensive-guide-to-automation-testing-frameworks-3gfm | testing, automation | Automation testing has become a crucial part of the software development lifecycle, ensuring that applications are reliable, efficient, and high-quality. An essential component of successful automation testing is the automation testing framework. This blog will delve into what an automation testing framework is, its importance, different types, key components, and best practices for implementation.
What is an Automation Testing Framework?
Definition
An [automation testing framework](url) is a set of guidelines, standards, and tools that provide a structured and efficient approach to automating the software testing process. It comprises a combination of practices, assumptions, and libraries that facilitate the design, development, and execution of automated tests.
Importance of an Automation Testing Framework
Consistency: Ensures consistency in the way tests are written, executed, and reported.
Reusability: Promotes reusability of code and test scripts across different projects.
Efficiency: Enhances the efficiency of the testing process by providing a standardized approach.
Maintainability: Makes it easier to maintain and update test scripts as the application evolves.
Scalability: Supports scalable testing efforts, enabling testing across various environments and platforms.
Types of Automation Testing Frameworks
There are several types of automation testing frameworks, each designed to address different testing needs and scenarios.
1. Linear (Record and Playback) Framework
Overview
The linear framework, also known as the record and playback framework, is the simplest form of automation testing. It involves recording user actions and playing them back during test execution.
Key Features
Simplicity: Easy to implement and requires minimal programming knowledge.
Quick Setup: Fast setup process, making it ideal for small projects.
Limitations
Maintenance: Difficult to maintain as the application evolves.
Scalability: Not suitable for large-scale projects due to limited scalability.
2. Modular Testing Framework
Overview
The modular testing framework involves creating reusable test scripts, each representing a specific module or function of the application. These modules are then combined to form comprehensive test cases.
Key Features
Reusability: Promotes code reusability by breaking down the application into smaller, manageable modules.
Maintainability: Easier to maintain as changes to the application can be isolated to specific modules.
Limitations
Initial Setup: Requires significant initial setup to create reusable modules.
3. Data-Driven Testing Framework
Overview
The data-driven testing framework separates test logic from test data, allowing the same test script to be executed with multiple sets of data.
Key Features
Flexibility: Enables testing with different data sets without modifying the test script.
Scalability: Supports extensive testing scenarios by varying input data.
Limitations
Complexity: Can be complex to set up and manage, especially with large data sets.
4. Keyword-Driven Testing Framework
Overview
The keyword-driven testing framework uses keywords to represent actions to be performed on the application. Test scripts are created using these keywords, allowing non-technical users to create tests.
Key Features
User-Friendly: Allows non-technical users to write tests using predefined keywords.
Reusability: Keywords can be reused across multiple test cases.
Limitations
Initial Setup: Requires extensive initial setup to define keywords and associated actions.
5. Hybrid Testing Framework
Overview
The hybrid testing framework combines elements of multiple frameworks, leveraging their strengths to create a more flexible and robust testing environment.
Key Features
Flexibility: Combines the best features of different frameworks to address specific testing needs.
Scalability: Supports complex and large-scale testing scenarios.
Limitations
Complexity: Can be complex to implement and maintain due to the integration of multiple frameworks.
Key Components of an Automation Testing Framework
A robust automation testing framework comprises several key components that work together to facilitate effective test automation.
1. Test Script Repository
Purpose: Stores all the test scripts used for automation testing.
Benefits: Provides a centralized location for managing test scripts, ensuring consistency and reusability.
2. Test Data Management
Purpose: Manages the test data used for executing test scripts.
Benefits: Ensures that test data is readily available and can be easily modified to support different testing scenarios.
3. Test Execution Engine
Purpose: Executes the test scripts on the application under test.
Benefits: Automates the execution process, reducing manual effort and increasing efficiency.
4. Reporting and Logging
Purpose: Generates reports and logs of test execution results.
Benefits: Provides insights into the testing process, highlighting successes and identifying issues that need to be addressed.
5. Continuous Integration (CI) Tools
Purpose: Integrates with CI tools to support continuous testing.
Benefits: Enables automated tests to be executed as part of the CI/CD pipeline, ensuring rapid feedback and continuous quality.
Best Practices for Implementing an Automation Testing Framework
Implementing an effective automation testing framework requires careful planning and adherence to best practices.
Define Clear Objectives
Set SMART Goals: Define Specific, Measurable, Achievable, Relevant, and Time-bound goals for the automation testing framework.
Align with Business Objectives: Ensure that the objectives of the framework align with the overall business goals and project requirements.
Choose the Right Tools
Tool Evaluation: Evaluate and select automation tools based on project requirements, budget, and compatibility with the existing technology stack.
Pilot Projects: Conduct pilot projects to assess the suitability of the selected tools before full-scale implementation.
Develop a Modular Framework
Modularity: Develop a modular framework that allows for easy maintenance and scalability.
Reusable Components: Create reusable components and libraries to reduce redundancy and enhance efficiency.
Integrate with CI/CD Pipelines
CI/CD Integration: Integrate the automation testing framework with CI/CD pipelines to enable continuous testing.
Automated Builds and Deployments: Configure automated builds and deployments to ensure tests are run automatically with each code change.
Focus on Test Maintenance
Regular Updates: Regularly update and maintain the automated test scripts to keep them relevant and effective.
Version Control: Use version control systems to manage changes to test scripts and ensure traceability.
Manage Test Data Effectively
Data Generation: Use automated tools to generate test data as needed.
Data Management: Implement robust test data management practices to ensure data consistency and availability.
Data Security: Ensure that test data complies with privacy and security regulations.
Monitor and Analyze Results
Performance Metrics: Collect metrics such as test execution time, pass/fail rates, and defect density to assess the efficiency and effectiveness of the automation testing framework.
Continuous Improvement: Use the insights gained from metrics to continuously improve the framework and testing process.
Conclusion
An [automation testing framework](perfectqaservices.com/post/automation-testing-framework) is essential for achieving efficient, accurate, and comprehensive test automation. By understanding the different types of frameworks and their key components, organizations can select the right approach for their specific needs. Implementing best practices and focusing on continuous improvement will ensure that the automation testing framework remains effective and relevant as the application evolves. Whether you are starting with automation testing or looking to enhance your existing framework, a well-structured and robust automation testing framework is crucial for delivering high-quality software products | perfectqa |
1,875,294 | Integrating Lighthouse Reporting in Next.js with Puppeteer and Render | Integrated Lighthouse reporting into a Next.js application using Puppeteer and deployed it on Render.com. The performance score might be lower when testing on the local server, but it improves in the production environment. | 0 | 2024-06-03T11:28:06 | https://dev.to/geekoteka/integrating-lighthouse-reporting-in-nextjs-with-puppeteer-and-render-46hj | nextjs, performance, a11y, seo | ---
title: Integrating Lighthouse Reporting in Next.js with Puppeteer and Render
published: true
description: Integrated Lighthouse reporting into a Next.js application using Puppeteer and deployed it on Render.com. The performance score might be lower when testing on the local server, but it improves in the production environment.
tags: nextjs, performance, accessibility, seo
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-16 07:18 +0000
---
## Introduction
In this article, I'll walk you through a project where I integrated Lighthouse reporting into a Next.js application using Puppeteer and deployed it on Render.com. The performance score might be lower when testing on the local server, but it improves in the production environment.
## Overview
This project involves a Next.js component that makes a request to an API route. The API route connects to a service that generates the Lighthouse report. The implementation uses Puppeteer and Lighthouse running a Chrome instance on a remote server.

## Project Setup
Here is a brief overview of the setup and deployment process:
### GitHub Repository
You can find the source code for the project on GitHub: [GitHub - alcance/lighthouse-reporter](https://github.com/alcance/lighthouse-reporter)
### API Deployment
I deployed the API on Render.com. Although it took some effort, I managed to get it running with Puppeteer and Lighthouse. You can explore the API on RapidAPI: [Lighthouse AutoReporter on RapidAPI](https://rapidapi.com/alcance-o0F_JAYX0/api/lighthouse-autoreporter)
### Current Features
- **JSON Report:** Generates a Lighthouse report in JSON format.
- **PDF Report:** Generates and sends a Lighthouse report in PDF format via email.
- **Email Functionality:** The service can send the generated PDF report to the user's email.
## Challenges and Solutions
### Performance Issues
Running the service on a machine with limited resources (0.5 CPUs and 512MB RAM) affects the performance score. For instance, a website like https://labs.systec.dev usually scores 80-90 on performance, but on the Render machine, it scored around 35. Upgrading to 2 CPUs and 2GB RAM can significantly improve the performance.
### Handling CORS
I encountered CORS issues, which I resolved by correctly setting the headers. Additionally, I opted for the Pro plan on Render.com ($85/month) for better resource allocation (4GB RAM, 2 CPUs).
### Rate Limiting and Abuse Prevention
To prevent abuse, I plan to integrate browser fingerprinting and set a limit on the number of requests per client. The [FingerprintJS](https://github.com/fingerprintjs/fingerprintjs) library can generate a visitor ID to track and limit requests.
### Caching
Initially, I considered using Vercel functions for caching but decided against it due to complexity. Instead, a simple table-based cache was sufficient for my needs.
## Future Improvements
Here are some ideas for further enhancing the service:
- **User Management:** Implement a robust system for handling users and their requests.
- **Enhanced Reporting:** Add more detailed audit content to the PDF reports.
- **Integration with Gemini API:** Connect to the Gemini API to interpret report results and allow users to ask questions about their performance.
## Conclusion
This project demonstrates how to integrate Lighthouse reporting into a Next.js application using Puppeteer and Render. The setup, although challenging at times, provides a valuable service for generating on-the-fly Lighthouse reports. Feel free to explore the [GitHub repository](https://github.com/alcance/lighthouse-reporter) and [RapidAPI](https://rapidapi.com/alcance-o0F_JAYX0/api/lighthouse-autoreporter) to see the project in action.
Happy coding!
| geekoteka |
1,875,293 | AIM Weekly 03 June 2024 | 03-June-2024 Tim Spann @PaaSDev I am officially an employee of Zilliz! I am a Milvus... | 0 | 2024-06-03T11:25:36 | https://dev.to/tspannhw/aim-weekly-03-june-2024-13gb | milvus, generativeai, llm, opensource | ## 03-June-2024
Tim Spann @PaaSDev
I am officially an employee of Zilliz!
I am a Milvus Man! Get your vectors ready.
Milvus - Towhee - Attu - Feder - GPTCache - VectorDB Bench
Important Poll:
https://www.linkedin.com/posts/timothyspann_now-that-i-am-doing-a-lot-of-cool-ai-and-activity-7201995051491635200-olsD?utm_source=share&utm_medium=member_desktop
### FLaNK-AIM Weekly
### Towhee - Attu - Milvus (Tim-Tam)
https://github.com/milvus-io/milvus
https://pebble.is/PaaSDev
https://vimeo.com/flankstack
https://www.youtube.com/@FLaNK-Stack
https://www.threads.net/@tspannhw
https://medium.com/@tspann/subscribe
https://ossinsight.io/analyze/tspannhw
### CODE + COMMUNITY
Please join my meetup group NJ/NYC/Philly/Virtual.
[https://www.meetup.com/unstructured-data-meetup-new-york/](https://www.meetup.com/unstructured-data-meetup-new-york/)
This is Issue #140
[https://github.com/tspannhw/FLiPStackWeekly](https://github.com/tspannhw/FLiPStackWeekly)
#### New Releases
Milvus Lite 2.4.3 - Local Python
https://www.bentoml.com/blog/building-a-rag-app-with-bentocloud-and-milvus-lite
#### Articles
https://medium.com/@tspann/shining-some-light-on-the-new-milvus-lite-5a0565eb5dd9
https://zilliz.com/blog/why-i-joined-zilliz-tim-spann
https://www.tiktok.com/@tim_the_nifi_guy/video/7374753137074212142
https://www.linkedin.com/pulse/shining-some-light-new-milvus-lite-tim-spann--32ykc
https://medium.com/@tspann/boston-wheres-my-bus-llm-streaming-to-the-rescue-586dfd019237
https://langfuse.com/guides/cookbook/integration_llama-index_milvus-lite
https://www.linkedin.com/pulse/milvus-lite-what-how-get-started-the-milvus-project-ztphc/
https://zilliz.com/blog/multimodal-RAG-with-CLIP-Llama3-and-milvus
https://milvus.io/docs/integrate_with_hugging-face.md
https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data
https://zilliz.com/event/knowledge-graphs-in-rag-with-whyhow-ai
https://medium.com/@zilliz_learn/a-beginners-guide-to-website-chunking-and-embedding-for-your-rag-applications-1119b99bb57e
https://milvus.io/docs/integrate_with_llamaindex.md
https://zilliz.com/blog/embedding-inference-at-scale-for-RAG-app-with-ray-data-and-milvus
https://datavolo.io/2024/05/how-to-package-and-deploy-python-processors-for-apache-nifi/
https://www.datacamp.com/tutorial/how-transformers-work
https://www.tomshardware.com/pc-components/cpus/worlds-first-bioprocessor-uses-16-human-brain-organoids-for-a-million-times-less-power-consumption-than-a-digital-chip
https://zilliz.com/learn/what-are-binary-vector-embedding
https://www.coursera.org/specializations/generative-ai-for-everyone?
#### Videos
Conf42: ML: Emerging GenAI
https://youtu.be/ktVVdJB306U?feature=shared
Generative AI with Milvus
https://www.youtube.com/watch?v=IfWIzKsoHnA
Milvus-Lite
https://www.youtube.com/watch?v=ydAu5bD0uRs
https://www.youtube.com/watch?v=1rO5B9ArCKA
https://www.youtube.com/watch?v=WQiG7FOhOZM
#### Slides
https://www.slideshare.net/slideshow/generative-ai-on-enterprise-cloud-with-nifi-and-milvus/267678399
#### Events
June 4, 2024: NY Unstructured Data Meetup
https://www.meetup.com/unstructured-data-meetup-new-york/events/301366961/
June 12, 2024: Budapest Data + ML Forum. Virtual.

https://budapestml.hu/2024/en/speakers/
June 13-14, 2024: Data Science Summit ML Edition 2024 | 13.06.2024 - 14.06.2024
https://ml.dssconf.pl/#agenda
June 13, 2024: Princeton Meetup
https://www.meetup.com/applied-generative-artificial-intelligence-applications/events/301336510/
June 20, 2024: AI Camp Meetup. NYC.
https://www.meetup.com/unstructured-data-meetup-new-york/events/301383476/
Sept 24, 2024: JConf.Dev. Dallas.
https://2024.jconf.dev/session/598816
Nov 5-7, 10-12, 2024: CloudX. Online/Santa Clara. https://www.developerweek.com/cloudx/
Nov 19, 2024: XtremePython. Online.
https://xtremepython.dev/2024/
#### Code
* https://github.com/tspannhw/FLaNK-python-processors
* https://github.com/tspannhw/AIM-MilvusLite
#### Models
* https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3
* https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5
* https://huggingface.co/mistralai/Codestral-22B-v0.1
#### Tools
* https://github.com/transcriptionstream/transcriptionstream
* https://github.com/dlvhdr/gh-dash
* https://github.com/magicuidesign/magicui
* https://github.com/tinybirdco/mockingbird
* https://github.com/tensorlakeai/indexify
* https://github.com/makeplane/plane
* https://github.com/ynqa/sig
* https://fpvsim.com/drone-flying-101
* https://chrisbuilds.github.io/terminaltexteffects/showroom/
* https://github.com/openkoda/openkoda
* https://github.com/panglesd/slipshow
* https://github.com/VikParuchuri/marker
* https://github.com/bin123apple/AutoCoder
* https://commoncrawl.org/overview
* https://github.com/hynky1999/CmonCrawl
* https://github.com/novitalabs/AnimateAnyone
* https://github.com/Bklieger/groqbook
* https://github.com/lllyasviel/Omost
* https://github.com/isaac-sim/IsaacLab

© 2020-2024 Tim Spann https://www.youtube.com/@FLaNK-Stack
FLaNK-AIM with LLAMA 3
~~~~~~~~~~~~~~~ CONNECT ~~~~~~~~~~~~~~~
🎥 Playlist: Unstructured Data Meetup [https://www.meetup.com/unstructured-data-bay-area/events/](https://www.meetup.com/unstructured-data-bay-area/events/)
🖥️ Website: [https://www.youtube.com/@MilvusVectorDatabase/videos](https://www.youtube.com/@MilvusVectorDatabase/videos)
X Twitter - / milvusio [https://x.com/milvusio](https://x.com/milvusio)
🔗 Linkedin: / zilliz [https://www.linkedin.com/company/zilliz/](https://www.linkedin.com/company/zilliz/)
😺 GitHub: [https://github.com/milvus-io/milvus](https://github.com/milvus-io/milvus)
🦾 Invitation to join discord: / discord [https://discord.com/invite/FjCMmaJng6](https://discord.com/invite/FjCMmaJng6)
| tspannhw |
1,860,725 | Understanding Go: part 12 – Visibility | Serie of sketchnotes about Go. Explaining in a visual way Go/Golang concepts. | 26,234 | 2024-06-03T11:21:37 | https://dev.to/aurelievache/understanding-go-part-12-visibility-3037 | go, tutorial, beginners | ---
title: Understanding Go: part 12 – Visibility
published: true
description: Serie of sketchnotes about Go. Explaining in a visual way Go/Golang concepts.
tags: Go, Golang, Tutorial, beginners
series: Understanding Go in sketchnotes
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/rfr4s13jjqx1w5mqpy3e.jpg
---
Even if you can create your first application in Go in a few minutes, understanding a new programming language is not easy and can be time-consuming.
After writing the blog series [Learning Go by examples](https://dev.to/aurelievache/learning-go-by-examples-introduction-448n), let's discover all the concepts of Go in a visual way, in sketchnotes.
In this blog post of sketchnotes about Go, we will discover another useful concept: the "Visibility".

This is another blog post of this serie so if you liked it, you can follow me, and tell me what do you think ❤️. If people are interested, I will publish others sketches shortly :-).
Moreover, if you are interested about this way to explain visually technologies, I published an entire illustrated book about Kubernetes, available in paperback on [Amazon](https://www.amazon.fr/dp/B0BB619188/ref=cm_cr_arp_d_product_top?ie=UTF8) and in digital version on GumRoad: ["Understanding Kubernetes in a visual way"](https://gumroad.com/aurelievache#uCxcr).
And an illustrated book about Docker, available in paperback on [Amazon](https://www.amazon.fr/Understanding-Docker-visual-way-sketchnotes/dp/B0BT6ZXR1W/) and in digital version on GumRoad: ["Understanding Docker in a visual way"](https://gumroad.com/aurelievache#uCxcr). | aurelievache |
1,875,256 | Navigating the Digital Landscape: Effective Marketing Strategies for Success | In today’s digital landscape, taking businesses to an audience is very common and people’s choice... | 0 | 2024-06-03T11:20:05 | https://dev.to/techstuff/navigating-the-digital-landscape-effective-marketing-strategies-for-success-5bj5 | In today’s digital landscape, taking businesses to an audience is very common and people’s choice through Digital Marketing. With the changing nature of business as well as customers. Digital marketing has become a need to increase reach of the business. In this blog, we’ll study how different digital marketing strategies can help to attract more traffic and increase the growth of the business.
**Content Marketing**

Content is the king of the digital marketing world. By creating good and sensible content, it can attract more customers towards business. By writing a blog post or having some infographic video or any other method, it is the key to drive traffic. Moreover, if the content is good it is more likely to be shared on social media platforms.
**Search Engine Optimization (SEO)**

SEO plays an important role in ensuring that your business is listed top in the search engine pages. By optimizing the content, website and all the given data, one can reach and increase the online visibility of the services. Effective seo strategies involve online research, keyword planning, target location, target audience and much more analysis to rank best on search engine pages.
**Social Media Marketing**

Social media platforms play a very important role in connecting with customers to any part of the world and deliver services to any corner or any section of the people. Platforms like Instagram, Twitter, Facebook, Whatsapp deliver the information within few seconds, customers can opt their services within few seconds and it brings huge conversions and profits within few seconds.
**Email Marketing**

Email marketing is a very old school yet very powerful medium to outreach your client and drive conversions from it. By sending a targeted well composed mail to targeted list of customers, it is a chance of surety that conversions will definitely come through it. By sending personalized content, giving valuable offers and by proper quoting of messages it is a chance that it will bring leads as well as it will also retain customers in the long run.
**Influencer Marketing**

Influencer marketing has become a popular way to increase brand awareness and attract traffic. By collaborating with big influencers, it helps business owners to promote their business and have a positive impact on their business on a large mass of the people. The basic and important point to keep in mind is just that collaboration should be done with the proper influencer who also has a positive influence on the public.
**Pay-Per-Click (PPC) Advertising**

PPC helps businesses to reach their customers through search engines by using paid marketing i.e. online advertisements.It helps to set target location, to set target audience, to set proper time to shoot ads on platforms with the desired budget. By bidding on targeted keywords…it increases the chance to reach a targeted audience.
**Video Marketing**

Video marketing has also become very popular in the digital marketing world. Whether it is informational video, services or product selling video … .They are more easy to reach to the audience. Platforms like YouTube and Instagram, are doing a very good job in doing video marketing.
**Conclusion**
Effective digital marketing strategies help to read to the audience in a much better way. By using all the methods that we discussed in this blog…one can stand out his business and services in this competitive digital era.
| aishna | |
1,875,273 | Contact Form | Photography HTML Contact Form Template | Create a stunning photography website with this HTML contact form template. Perfect for showcasing... | 0 | 2024-06-03T11:20:01 | https://dev.to/creative_salahu/contact-form-photography-html-contact-form-template-3ga6 | codepen | Create a stunning photography website with this HTML contact form template. Perfect for showcasing your portfolio and connecting with clients.
{% codepen https://codepen.io/CreativeSalahu/pen/bGyeKgg %} | creative_salahu |
1,875,260 | Data persistence in flutter | When you develop an application, usually, the data used to display information originates from the... | 0 | 2024-06-03T11:19:52 | https://dev.to/tentanganak/data-persistence-in-flutter-3902 | flutter, mobile, android, ios | When you develop an application, usually, the data used to display information originates from the internet. However, there are scenarios where the data from the internet needs to be stored somewhere on your local device. This can be for functionality purposes or to enhance performance and user experience while using the application.
Take the Facebook application as an example: when you open the main page or page detail, then close the application and reopen it, you will find yourself on the last visited page, and the page immediately displays data as if there were no loading process. This can happen because the data is stored locally, and when the application is opened, it uses the stored data to display the main or page detail while loading data from the internet to get the latest information.
In Flutter itself, there are many libraries designed to store data on the local device. In this article, I will share How to persist data using the best libraries (in my opinion) for storing data locally in Flutter.
**1. shared_preferences**
[shared_preferences](https://pub.dev/packages/shared_preferences) is a plugin for reading and writing simple key-value pairs. It uses NSUserDefaults on iOS and SharedPreferences on Android. shared_preferences is a best choice for storing small and non-sensitive data, such as theme preferences, language settings, settings.
implementation example:
write data
```
Future<void> saveTheme(bool isLightMode) async {
final SharedPreferences prefs = await SharedPreferences.getInstance();
await prefs.setBool('isLightMode', isLightMode);
}
```
Read data
```
Future<bool?> readTheme() async {
final SharedPreferences prefs = await SharedPreferences.getInstance();
final bool? isLightMode = prefs.getBool('isLightMode');
return isLightMode;
}
```
Delete data
```
Future<void> deleteTheme() async {
final SharedPreferences prefs = await SharedPreferences.getInstance();
await prefs.remove('isLightMode');
}
```
SharedPreferences is limited to only supporting certain data types like int, double, bool, String, and List<String>. However, we can store objects in SharedPreferences by converting them into a string. One common way to do this is by using JSON. We can convert an object to a JSON string when saving it and then convert it back to an object when retrieving it.
implementation example:
```
class Setting {
bool? isLightMode;
String? lang;
int? counter;
Setting({this.isLightMode, this.lang, this.counter});
Setting.fromJson(Map<String, dynamic> json) {
isLightMode = json['isLightMode'];
lang = json['lang'];
counter = json['counter'];
}
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['isLightMode'] = isLightMode;
data['lang'] = lang;
data['counter'] = counter;
return data;
}
}
```
```
Future<void> saveSetting(Setting setting) async {
final SharedPreferences prefs = await SharedPreferences.getInstance();
await prefs.setString('setting', jsonEncode(setting.toJson()));
}
Future<Setting?> readSetting() async {
final SharedPreferences prefs = await SharedPreferences.getInstance();
final String? json = prefs.getString('setting');
if (json == null) return null;
return Setting.fromJson(jsonDecode(json));
}
Future<void> deleteSetting() async {
final SharedPreferences prefs = await SharedPreferences.getInstance();
await prefs.remove('setting');
}
```
**2. sqflite**
[sqflite](https://pub.dev/packages/sqflite) is a Flutter plugin that provides access to SQLite, a lightweight, serverless relational database commonly used in mobile applications for local data storage. Sqflite is a popular choice for applications requiring local data storage with more complex and relational structures.
implementation example:
```
class Item {
final int id;
final String title;
final String description;
const Item({
required this.title,
required this.description,
required this.id,
});
factory Item.fromJson(Map<String, dynamic> json) => Item(
id: json['id'],
title: json['title'],
description: json['description'],
);
Map<String, dynamic> toJson() => {
'id': id,
'title': title,
'description': description,
};
}
```
```
class DatabaseHelper {
static const int _version = 1;
static const String _dbName = "items.db";
static Future<Database> _getDB() async {
return openDatabase(
join(await getDatabasesPath(), _dbName),
onCreate: (db, version) async => await db.execute(
"CREATE TABLE Item(id INTEGER PRIMARY KEY, title TEXT NOT NULL, description TEXT NOT NULL);"),
version: _version,
);
}
static Future<int> addItem(Item item) async {
final db = await _getDB();
return await db.insert("Item", item.toJson(),
conflictAlgorithm: ConflictAlgorithm.replace);
}
static Future<int> updateItem(Item item) async {
final db = await _getDB();
return await db.update(
"Item",
item.toJson(),
where: 'id = ?',
whereArgs: [item.id],
conflictAlgorithm: ConflictAlgorithm.replace,
);
}
static Future<int> deleteItem(Item item) async {
final db = await _getDB();
return await db.delete(
"Item",
where: 'id = ?',
whereArgs: [item.id],
);
}
static Future<List<Item>?> getAllItems() async {
final db = await _getDB();
final List<Map<String, dynamic>> maps = await db.query("Item");
if (maps.isEmpty) return null;
return List.generate(maps.length, (index) => Item.fromJson(maps[index]));
}
}
```
**3. hive**
[Hive](https://pub.dev/packages/hive) is a key-value database written in Dart. Hive excels in write and delete operations compared to SQLite and SharedPreferences, and it is on par with SharedPreferences in read performance, while SQLite is significantly slower. Hive has built-in encryption using AES-256, making it suitable for storing sensitive data.
implementation example:
```
Future<void> saveUser(Map<String, dynamic> user) async {
var box = await Hive.openBox('myBox');
await box.put('user', user);
}
Future<Map<String, dynamic>?> readUser() async {
var box = await Hive.openBox('myBox');
final Map<String, dynamic>? json = box.get('user');
return json;
}
Future<void> deleteUser() async {
var box = await Hive.openBox('myBox');
await box.delete('user');
}
```
If your project uses the [flutter_bloc](https://pub.dev/packages/flutter_bloc) library for state management, you can easily cache data locally using Hive. The creator of flutter_bloc has developed the [hydrated_bloc](https://pub.dev/packages/hydrated_bloc) library, which includes HydratedStorage that comes with Hive implemented.
```
void main() async {
WidgetsFlutterBinding.ensureInitialized();
HydratedBloc.storage = await HydratedStorage.build(
storageDirectory: kIsWeb
? HydratedStorage.webStorageDirectory
: await getTemporaryDirectory(),
);
runApp(const MyApp());
}
```
```
class UserCubit extends HydratedCubit<User?> {
UserCubit() : super(null);
void login(User user) => emit(user);
@override
User? fromJson(Map<String, dynamic> json) =>
json['user'] != null ? User.fromJson(json['user']) : null;
@override
Map<String, dynamic> toJson(User? state) => {'user': state};
}
```
**4. isar**
[Isar](https://pub.dev/packages/isar) was created by the creator of Hive to overcome some limitations present in Hive and to offer a more advanced and efficient solution for local data storage in Flutter and Dart applications.
Isar is a fast, cross-platform NoSQL database that is well-integrated with Flutter and Dart. It is designed to provide high performance and ease of use.
implementation example:
```
dependencies:
flutter:
sdk: flutter
isar: ^2.5.0
isar_flutter_libs: ^2.5.0
dev_dependencies:
flutter_test:
sdk: flutter
build_runner: ^2.2.0
isar_generator: ^2.5.0
```
```
part 'isar_page.g.dart';
@Collection()
class Post {
int id = Isar.autoIncrement;
late String title;
late DateTime date;
}
```
run flutter pub run build_runner
```
late Isar isar;
@override
void initState() {
super.initState();
openInstance();
}
void openInstance() async {
final dir = await getApplicationSupportDirectory();
isar = await Isar.open(
schemas: [PostSchema],
directory: dir.path,
inspector: true,
);
}
void readPost() async {
final posts = await isar.posts
.filter()
.titleContains('awesome', caseSensitive: false)
.sortByDateDesc()
.limit(10)
.findAll();
print(posts);
}
void createPost() async {
final newPost = Post()
..title = 'awesome new database'
..date = DateTime.now();
await isar.writeTxn((isar) async {
newPost.id = await isar.posts.put(newPost);
});
}
```
**5. flutter_secure_storage**
If you want to store sensitive data, then [flutter_secure_storage](https://pub.dev/packages/flutter_secure_storage) is one of the best solutions. flutter_secure_storage is a Flutter package that provides a secure way to store sensitive data on the device, using Keychain on iOS and a KeyStore based solution on Android.
implementation example:
```
class Auth {
String? token;
String? id;
Auth({this.token, this.id});
Auth.fromJson(Map<String, dynamic> json) {
token = json['token'];
id = json['id'];
}
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['token'] = token;
data['id'] = id;
return data;
}
}
```
```
final storage = const FlutterSecureStorage();
Future<void> saveAuth(Auth auth) async {
await storage.write(key: 'auth', value: jsonEncode(auth.toJson()));
}
Future<Auth?> readAuth() async {
final String? json = await storage.read(key: 'auth');
if (json == null) return null;
return Auth.fromJson(jsonDecode(json));
}
Future<void> deleteAuth() async {
await storage.delete(key: 'auth');
}
```
**6. get_storage**
If you're using GetX as state management, then you might be familiar with [get_storage](https://pub.dev/packages/get_storage). get_storage is a local data storage package developed by the GetX team for Flutter. It's a lightweight and easy-to-use storage solution, allowing you to persistently store data in key-value pairs on the user's device.
implementation example:
```
class User {
String? name;
String? id;
User({this.name, this.id});
User.fromJson(Map<String, dynamic> json) {
name = json['name'];
id = json['id'];
}
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['name'] = name;
data['id'] = id;
return data;
}
}
```
```
final box = GetStorage();
Future<void> saveUser(User user) async {
await box.write('user', jsonEncode(user.toJson()));
}
User? readUser() {
final String? json = box.read('user');
if (json == null) return null;
return User.fromJson(jsonDecode(json));
}
Future<void> deleteUser() async {
await box.remove('user');
}
```
get_storage is well-suited for applications with simple and fast data storage needs. However, for more complex requirements such as indexing or ensuring disk write confirmation, it's recommended to consider using sqflite, Hive, isar, etc.
**Conclusion**
There are the best libraries for persist data locally, The usage of the library typically depends on the type of data being stored, whether it is sensitive data, data with relationships, or just simple API responses. | edolubis21 |
1,872,830 | Share your content with Contentful and Telegram | Hello and welcome! What I'm about to present is the final part of my journey with Telegram and... | 0 | 2024-06-03T11:17:42 | https://dev.to/wiommi/share-your-content-with-contentful-and-telegram-6hm | contentful, telegram, extensibility, headlesscms | Hello and welcome!
What I'm about to present is the final part of my journey with Telegram and Contentful.
Following my article published on the Contentful Blog (you can read more [here](https://www.contentful.com/blog/telegram-webhooks-bots/)), in this post, I’ll show you how I built a custom app to send messages to your Telegram Channel right from your Contentful entry.
This won't be a technical section, more of a “show and tell”. However, if you are interested in seeing the code, at the end of the article you will find links to the repositories.
---
## **Key Points of the Application**
Let's define what, how, and where our application will operate.
As many of you may already know, the App Framework allows us to customize various parts of the Contentful web interface. In our case, we will modify the configuration screen of the app itself to define some parameters necessary for its overall operation. While the actual app will reside within the sidebar of our entries.
Our application will provide the user with the ability to send content to an external endpoint, leveraging the data from the current entry or completely custom data. The endpoint will then be responsible for retrieving the data and sending it to the associated Telegram channel (this part has been covered on the other article).
---
## **Configuration Screen**
Let's start with the initial configuration. As mentioned earlier, without this, our app cannot function. Why is that? Simply because here, we give the user the ability to define multiple endpoints that our app can then use to send information.
Each endpoint can define different logics; for example, we can have an endpoint that relies on a Test channel that we can use to send test messages. Another example could be having different channels for different topics, providing us with the flexibility to communicate different information.
Let's see how the initial screen looks:
From here, we can add, modify, or delete our endpoints. The entry form includes the following fields:
- **Name**: name of the endpoint.
- **Url**: URL of our external service.
- **Channel Id**: Telegram channel ID.
- **Channel name**: name of the Telegram channel.
Doing so, we obtain a list of endpoints that our app will then utilize:
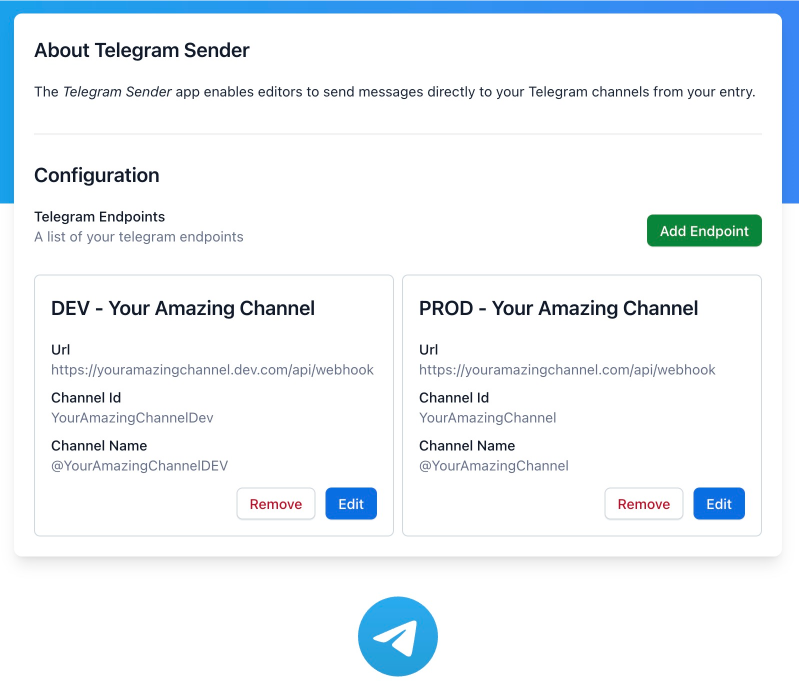
---
## **Sidebar App**
As mentioned earlier, we will be working in a specific location, the sidebar.
This allows our application to be available on every entry of a specific content type (or more than one if desired).
Once the app is installed, to display it in the sidebar, we will need to modify the 'Sidebar' section of our content type:
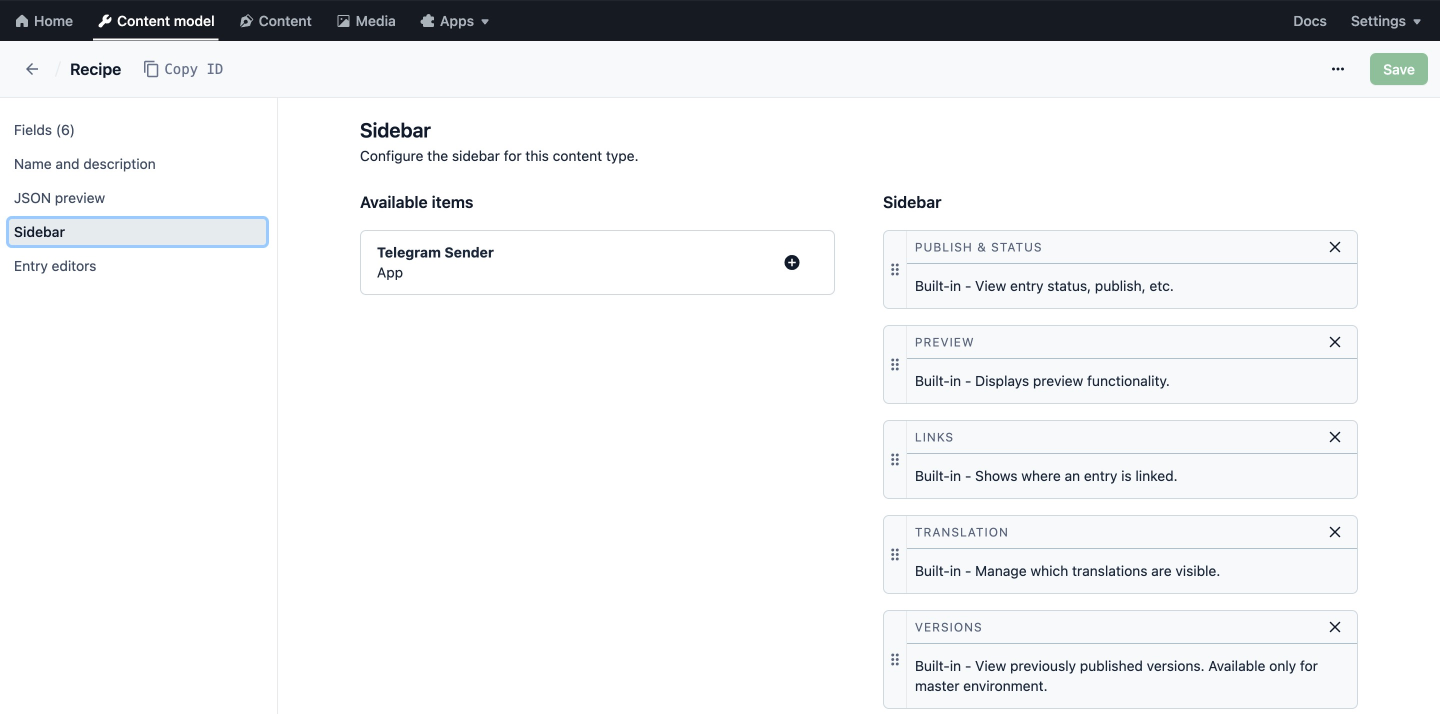
..and move our 'Telegram Sender' app to the right-hand list, choosing the position, and then saving the content type:
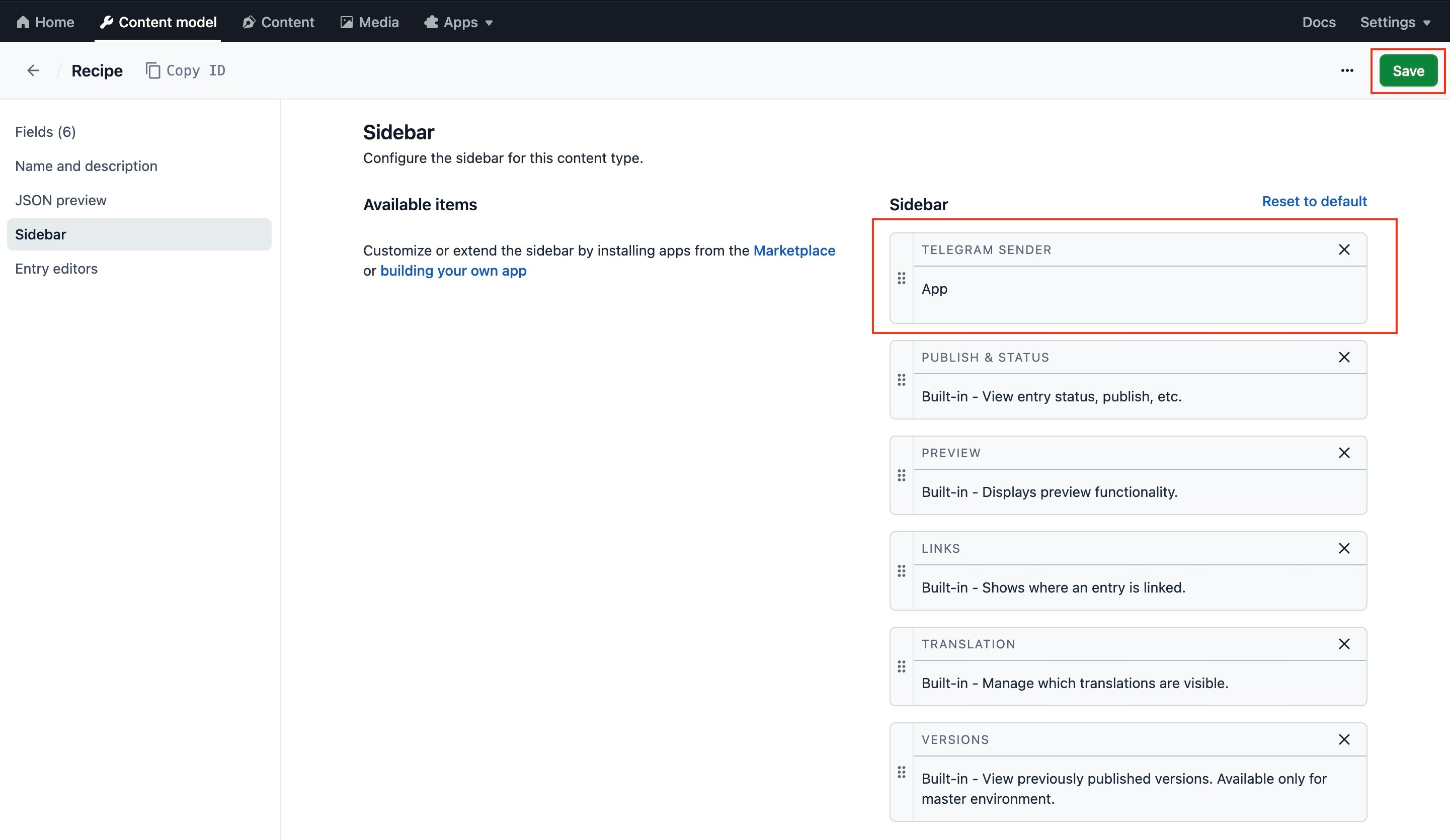
Now, if we go to any Entry of type Recipe, we will see our application ready to be used:
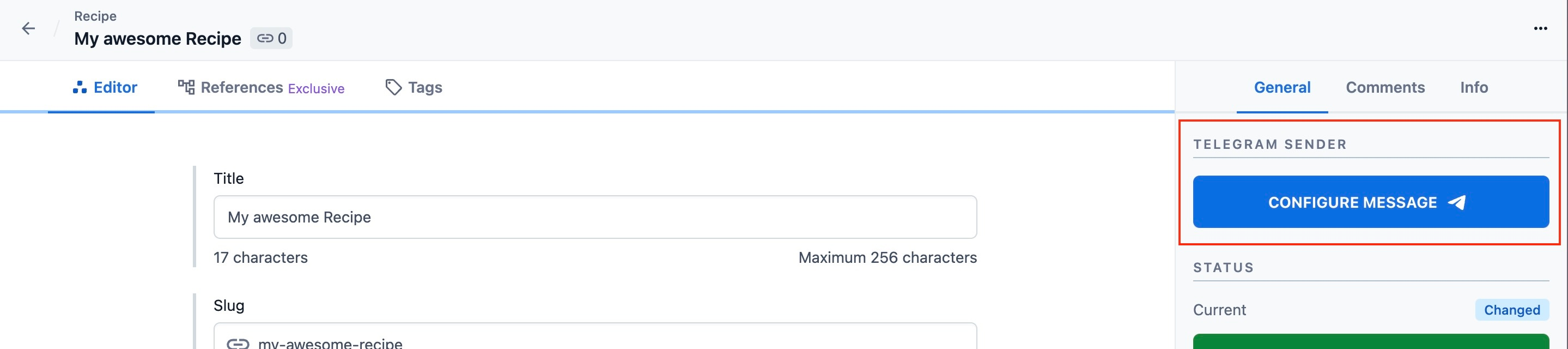
### **How does it work?**
Now that we have configured our app, let's see how it works.
After clicking 'Configure message,' the first crucial step is selecting the endpoint for sending our data:
Once the channel is selected, we will have a form with the following fields:
- Media
- Text message and parse mode
- Link URL and Link name
Let's examine them in detail.
### **Media**
This field allows us to select media in different ways.
We can create a new media from scratch or choose one from those already present. These first two options are fixed and interact through the Contentful SDK, displaying the default interface. For example, if we select 'Select existing media,' the application will open a modal with our saved assets:
The other entries starting with 'Entry field: ...' are dynamic entries based on the structure of our Content Type. In our example, our recipe, has only one Media-type field named 'Image.' Clicking on this option allows us to directly select the image associated with that field. If the field in the entry is not populated, the option in the select would still be present but disabled:

### **Text Message and Parse Mode:**
This is where you can configure the text message to send to the channel. Similar to the media field, we have some dynamic fields based on the structure of our Content Type. Within the options, we have fields of type Symbol/Text. In addition to these, we have a 'Custom value' option that allows us to enter free text:
The 'Parse Mode' option is specific to Telegram, indicating the format of the text we are entering. The options are: HTML (Default), Markdown, and MarkdownV2.
There are links provided that redirect to the Telegram documentation for more information on these options.
### **Link URL and Name**
These two optional fields allow you to define a link and a label to include in our message. Again, similar to the text message, we have the option to use fields from the entry or enter custom values:
### **Preview and Send CTA**
The application also provides a preview of the message we are about to send. This feature can be useful for users who want to see how the message will appear within the Telegram channel before sending:
When the message is ready, we can click on the 'Send Message' CTA, which will send the data to our external endpoint responsible for delivering the message to our Telegram channel. The implementation of the external service will be very similar to what we saw in the previous article.
---
## **Conclusion**
And with this, our journey through Bots, Webhooks, and custom apps comes to an end.
We've seen how, with simple configurations, we can establish our presence on Telegram and leverage the power of webhooks with just a few lines of code.
Last but not least, thanks to the power of the App Framework, we've been able to explore the creation of a small app that puts into practice everything we've learned in the [previous article](https://www.contentful.com/blog/telegram-webhooks-bots/), all within the Contentful interface.
Below, you can find the links to the repositories used in this series:
- [Webhook endpoint](https://github.com/williamiommi/contentful-webhook-telegram/blob/main/api/telegram/message.js)
- [Telegram Sender App](https://github.com/williamiommi/contentful-app-telegram-sender)
| wiommi |
1,875,272 | Why to choose odoo e-commerce for your next project | Online stores and online shopping are essential parts of any business now. Whether it’s India, the... | 0 | 2024-06-03T11:16:46 | https://dev.to/gonzalez248/why-to-choose-odoo-e-commerce-for-your-next-project-5aha | Online stores and online shopping are essential parts of any business now. Whether it’s India, the USA, or Europe, eCommerce has grown into an undeniable choice among the shopper community. The point is that millions of online customers are changing their approach to opt for more time-saving and convenience when shopping online. This behaviour exerts a considerable force on eCommerce and online retailers today. After the global effect of COVID-19, the e-commerce market is called the most booming business in the world. Let’s see the essence of [Odoo’s e-commerce development](https://www.bizople.com/odoo-ecommerce-development) to make yours a successful and profitable e-commerce store.
Odoo is the booming ERP in the market today, a well-known fact. At the same time, Odoo E-commerce is amazingly attracting online storekeepers for its simplicity, beauty, ease-of-use, and design. It allows one to sell the products online with a fast, [Odoo customized](https://www.bizople.com/odoo-customization-services) online shop. Shopping is also very easy with this. It’s just a trait where a few clicks and an order are processed. So it’s attracting online shoppers too to expand e-commerce store revenue.
The main attractions of Odoo e-commerce for businesspeople are:
You can design & configure the store yourself!
Edit Inline Approach:
It helps you create product pages without code. It’s just “what you
see is what you get” strategy to create your online store.
Form Builder :
It allows you to create custom web forms to get the essential details of your new leads and clients easily.
Multi-Store E-commerce :
Want to start multiple online stores and keep everything integrated?
yet separated ? Yes, Odoo allows that. Create multiple stores with unique designs, products, price lists, languages, and currencies.
Word Processor Text Editing :
It has an editor to give you experience of word processor to ease your content editing process for your website and e-commerce Pages.
Use of Theme:
It allows you to use any professional Odoo Theme you develop or purchase from Odoo’s online marketplace Moreover, you can define as many product variants as you need, multiple price lists, multiple stores under one environment, display stock of products on the store, sell digital products and much more.
**Boost your Sales ! **
**Suggested Products:**
It suggests optional products related to purchase items to inspire customers to purchase more related items and experience good e-commerce shopping.
**Options to boost sales:**
To boost your sales focus on promotions, create product categories, brands, coupon codes and promo codes, best product searching, push best-selling products to the top of the page, etc.
**Abandoned carts**
Search, mail and launch marketing automation on abandoned carts to convert them into orders.
**Main attractions of Odoo E-commerce for the online shopper :**
Easy Search
Search on products, size, color, and power-like attributes to avail the ease of searching on the store.
**Easy Checkout**
Set up step-by-step instructions for customers to checkout easily in just a few clicks.
**Skipping Shipping Address**
The shipping address is no longer required while purchasing the services.
**Live Chat**
Live chat is embedded for customer communication to get real-time information for customers.
**Product Wishlist**
Product wishlist to add wished products and faster purchase on returning again.
**Easy Order Review**
order can be easily reviewed by the customer at the end of the process.
**Customer Portal**
Customers have easy access to order tracking, advanced shipping rules and return management through the customer portal.
Odoo E-commerce has the facility to integrate with a number of shipping carriers like DHL, UPS, USPS, FedEx and La Poste; and payment methods like Paypal, Ogone, Adyen, Buckaroo, Authorize.net and SIPS Worldline . Along with that billing, including shipping cost, tax rates according to fiscal position are available with easy configuration for E-commerce stores. When the conversion rate (cart to order), average cart amount, best sellers, etc. can be tracked with Odoo KPI's, what a wonderful business it will be for you!
| gonzalez248 | |
1,875,271 | Background Animation with Pure CSS | If you're looking to add some life to your website, a background animation can do wonders. Today,... | 0 | 2024-06-03T11:15:40 | https://dev.to/alikhanzada577/background-animation-with-pure-css-3j55 | backgroundanimation, frontend, css, animation | If you're looking to add some life to your website, a background animation can do wonders. Today, I'll show you how to create a beautiful, animated bubble background using just HTML and CSS. This simple effect can add a modern and dynamic touch to your site. Let's dive into the code!
**HTML Structure**
```
<body>
<div class='container'>
<div class='bubbles'>
<span style='--i:11;'></span>
<span style='--i:12;'></span>
<span style='--i:14;'></span>
<span style='--i:16;'></span>
<span style='--i:13;'></span>
<span style='--i:15;'></span>
<span style='--i:20;'></span>
<span style='--i:24;'></span>
<span style='--i:23;'></span>
<span style='--i:22;'></span>
<span style='--i:20;'></span>
<span style='--i:11;'></span>
<span style='--i:12;'></span>
<span style='--i:14;'></span>
<span style='--i:16;'></span>
<span style='--i:13;'></span>
<span style='--i:15;'></span>
<span style='--i:20;'></span>
<span style='--i:24;'></span>
<span style='--i:23;'></span>
<span style='--i:22;'></span>
<span style='--i:20;'></span>
<span style='--i:11;'></span>
<span style='--i:12;'></span>
<span style='--i:14;'></span>
<span style='--i:16;'></span>
<span style='--i:13;'></span>
<span style='--i:15;'></span>
<span style='--i:20;'></span>
<span style='--i:24;'></span>
<span style='--i:23;'></span>
<span style='--i:22;'></span>
<span style='--i:20;'></span>
<span style='--i:11;'></span>
<span style='--i:12;'></span>
<span style='--i:14;'></span>
<span style='--i:16;'>
</div>
</div>
</body>
```
In the **HTML**, we have a container div that holds another div with the class bubbles. Inside the bubbles div, there are multiple span elements representing each bubble. The --i variable will be used to control the animation speed of each bubble.
**CSS Styling**
```
*
{
margin:0;
padding:0;
box-sizing:border-box;
}
body{
min-height:100vh;
background: #0c192c;
}
.container{
position:relative;
width:100%;
height:100vh;
overflow:hidden;
}
.bubbles{
position:relative;
display:flex;
}
.bubbles span{
position:relative;
width:30px;
height:30px;
background:#4fc3dc;
margin:0 4px;
border-radius:50%;
box-shadow:0 0 0 10px #4fc3dc44,0 0 50px #4fc3dc,
0 0 100px #4fc3dc;
animation:animate 15s linear infinite;
animation-duration:calc(60s/var(--i))
}
.bubbles span:nth-child(even){
background:#ff2d75;
box-shadow:0 0 0 10px #4fc3dc44,
0 0 50px #ff2d7544,
0 0 100px #ff2d75;
}
@keyframes animate{
0%{
transform: translateY(100vh) scale(0);
}
100%{
transform: translateY(-10vh) scale(1);
}
}
```
Let's break down the CSS:
- **Global Styles:** We start by resetting the margin, padding, and setting box-sizing to border-box for all elements to ensure consistent styling.
- **Body and Container:** The body has a dark blue background (#0c192c) and a minimum height of 100vh to cover the entire viewport. The .container takes up the full viewport height and width and hides any overflow content.
- **Bubbles:** The .bubbles div is set to display: flex to arrange the bubble spans horizontally. Each span (bubble) is styled with a specific size, color, and box-shadow to give it a glowing effect. The animation property animates each bubble with a duration dependent on the --i variable.
- **Even Bubbles:** Bubbles at even positions are given a different color (#ff2d75) and matching shadows for a more dynamic effect.
- **Keyframes:** The @keyframes rule defines the animation. Bubbles start at the bottom (translateY(100vh)) and scale from 0 to their full size, moving upward out of the viewport (translateY(-10vh)).
With just a few lines of HTML and CSS, you've created an eye-catching bubble animation for your website's background. This effect can be easily customized by adjusting the bubble colors, sizes, and animation speeds. Feel free to experiment and make it your own!
Adding such dynamic visuals can greatly enhance the user experience and make your site stand out.
**Happy coding!**
{% codepen https://codepen.io/Alikhanzada577/pen/rNgmaPB %} | alikhanzada577 |
1,875,269 | 5 Ways to Improve Your Product Data Quality with Akeneo | Product data quality is essential for any eCommerce business. It can impact everything, from customer... | 0 | 2024-06-03T11:10:50 | https://dev.to/chandrasekhar121/5-ways-to-improve-your-product-data-quality-with-akeneo-2gl | webdev, akeneo, programming, opensource | <p>Product data quality is essential for any eCommerce business. It can impact everything, from customer satisfaction to sales. <br /><br />That's why it's important to have a system in place to ensure that your product data is accurate, consistent, and complete.</p>
<p><a href="https://webkul.com/akeneo/">Akeneo</a> is a leading product information management (PIM) solution that can help you improve your product data quality.</p>
<h2>With Akeneo, you can:</h2>
<ul>
<li>
<p><strong>Centralize your product data -</strong> <br /><br />Akeneo provides a single source of truth for all your product data. This makes it easy to keep your data consistent and up-to-date.</p>
</li>
<li>
<p><strong>Enrich your product data -</strong> <br /><br />Akeneo allows you to enrich your product data with additional information, such as images, videos, and specifications. <br /><br />This can help you create more informative and engaging product pages.</p>
</li>
<li>
<p><strong>Validate your product data -</strong> <br /><br />Akeneo includes several data validation tools that can help you identify and correct errors in your product data. <br /><br />This can help you ensure that your data is accurate and reliable.</p>
</li>
<li>
<p><strong>Distribute your product data-</strong> <br /><br />Akeneo can help you distribute your product data to multiple channels, such as your website, marketplaces, and social media. <br /><br />This can help you reach more customers and increase sales.</p>
</li>
<li>
<p><strong>Improve your customer experience-</strong><br /><br />Akeneo can help you improve your customer experience by providing accurate and consistent product information. <br /><br />This can lead to increased customer satisfaction and loyalty.</p>
</li>
</ul>
<h2><strong>Akeneo Development Services:</strong></h2>
<p>Akeneo offers a variety of development services to help you implement and customize <a href="https://store.webkul.com/Akeneo.html">Akeneo PIM</a>.</p>
<p><strong>These services include:</strong></p>
<ul>
<li><strong>Akeneo PIM Consulting:</strong> <br /><br />Akeneo's team of experts can help you assess your needs and develop a customized Akeneo PIM implementation plan.<br /><br /></li>
<li><strong>Akeneo PIM Implementation:</strong> <br /><br />Akeneo's implementation team can help you install and configure Akeneo PIM.<br /><br /></li>
<li><strong>Akeneo PIM Customization:</strong> <br /><br />Akeneo's development team can help you customize Akeneo PIM to meet your specific needs.</li>
</ul>
<h2><strong>Akeneo Modules:</strong></h2>
<p>Akeneo offers several <a href="https://store.webkul.com/Akeneo.html">Akeneo modules</a> that can extend the functionality of your online store. <br /><br /><strong>These modules include:</strong></p>
<ul>
<li><strong>Akeneo PIM Connector:</strong> <br /><br />Akeneo PIM Connector allows you to connect Akeneo PIM to other systems, such as your ERP, CRM, and eCommerce platform.<br /><br /></li>
<li><strong>Akeneo PIM Product Catalog:</strong> <br /><br />Akeneo PIM Product Catalog allows you to manage and publish your product catalog.<br /><br /></li>
<li><strong>Akeneo Mobile App:</strong> <br /><br /><a href="https://store.webkul.com/akeneo-mobile-app.html">Akeneo Mobile App</a> allows you to access your product data on the go.</li>
</ul>
<h2>Conclsuion:</h2>
<p>Akeneo is a powerful PIM solution that can help you improve your product data quality. With Akeneo, you can centralize, enrich, validate, and distribute your product data. <br /><br />You can also improve your customer experience by providing accurate and consistent product information.</p> | chandrasekhar121 |
1,875,268 | SEO Company in Chandigarh- Digirush | Digirush is an SEO company in Chandigarh that specializes in optimizing the websites and bring... | 0 | 2024-06-03T11:10:45 | https://dev.to/digirush/seo-company-in-chandigarh-digirush-5aif | seocompanyinchandigarh, seoagencyinchandigarh, bestseoagencyinchandigarh |

Digirush is an **[SEO company in Chandigarh](https://digirushsolutions.com/seo-agency-in-chandigarh/)** that specializes in optimizing the websites and bring search engine ranking of the website. We provide services like keyword research, link building, on page optimization, site audits, off page optimization and technical SEO. We can help in improving your website’s visibility on search engine and increase engagement. Visit our website to know more about our services. | digirush |
1,875,267 | Leveraging Content Marketing for Establishing Brand Authority in Coimbatore's Digital Landscape | Introduction In the bustling digital ecosystem of Coimbatore, where businesses vie for attention... | 0 | 2024-06-03T11:10:38 | https://dev.to/vaishnaviiii/leveraging-content-marketing-for-establishing-brand-authority-in-coimbatores-digital-landscape-gnd | digitalmarketingcompany, digitalmarketingagency, digitalmarketingservice, advertisingagencyincoimbatore |

Introduction
In the bustling digital ecosystem of Coimbatore, where businesses vie for attention amidst a sea of competitors, establishing brand authority is paramount for long-term success. With the emergence of digital marketing agencies and advertising firms in Coimbatore, the role of content marketing has become increasingly crucial in shaping brand perception and influencing consumer behavior. In this article, we delve into the significance of content marketing in building brand authority, particularly in the context of Coimbatore's dynamic digital marketing landscape.
1. Understanding Content Marketing:
Content marketing involves the creation and distribution of valuable, relevant, and consistent content to attract and retain a clearly defined audience. In Coimbatore, digital marketing agencies are leveraging various content formats such as blogs, videos, social media posts, and infographics to engage with their target audience effectively.
2. Establishing Thought Leadership:
One of the primary objectives of content marketing is to position a brand as a thought leader in its industry. By producing high-quality, informative content that addresses the pain points and interests of their audience, [digital marketing agencies in Coimbatore ]( https://purplepromedia.com/best-digital-marketing-agency-in-coimbatore)can showcase their expertise and establish credibility within the community.
3. Building Trust and Credibility:
In a competitive market like Coimbatore, trust plays a pivotal role in consumer decision-making. Through content marketing efforts, businesses can build trust and credibility by providing valuable insights, transparent information, and authentic storytelling. By consistently delivering valuable content, digital marketing agencies can foster stronger relationships with their target audience and differentiate themselves from competitors.
4. Enhancing Brand Visibility and Awareness:
Content marketing is an effective strategy for enhancing brand visibility and awareness in Coimbatore's digital landscape. By optimizing content with relevant keywords such as "digital marketing in Coimbatore" and "digital marketing agency Coimbatore," businesses can improve their search engine rankings and attract organic traffic to their website. Additionally, sharing content across various online platforms and social media channels can broaden the brand's reach and increase its online presence.
5. Engaging Target Audience:
Content marketing enables digital marketing agencies in Coimbatore to engage with their target audience in meaningful ways. By creating content that resonates with the interests and preferences of their audience, businesses can foster two-way communication, encourage user interaction, and build a community around their brand. Interactive content formats such as quizzes, polls, and live Q&A sessions can further enhance engagement and drive audience participation.
6. Driving Conversions and Sales:
Ultimately, the goal of content marketing is to drive conversions and sales for businesses in Coimbatore. By delivering valuable content that educates, informs, and entertains their audience, digital marketing agencies can nurture leads through the sales funnel and ultimately convert them into paying customers. Whether it's through compelling calls-to-action in blog posts, informative product videos, or targeted email campaigns, content marketing can significantly impact the bottom line for businesses in Coimbatore.
In conclusion, content marketing plays a pivotal role in building brand authority and establishing a competitive edge for businesses in Coimbatore's digital marketing landscape. By producing high-quality, relevant content that resonates with their target audience, digital marketing agencies can enhance brand visibility, credibility, and trust, ultimately driving conversions and fostering long-term customer relationships. As the digital landscape continues to evolve, investing in content marketing remains a strategic imperative for businesses looking to succeed in Coimbatore's dynamic marketplace.
_
| vaishnaviiii |
1,875,265 | Common Resume Mistakes to Avoid: Ensure Your Resume is Error-Free and Professional 📄❌ | Hey everyone! 👋 Creating a resume might seem daunting, but it's your ticket to landing that dream... | 0 | 2024-06-03T11:09:48 | https://dev.to/hey_rishabh/common-resume-mistakes-to-avoid-ensure-your-resume-is-error-free-and-professional-2ip7 | Hey everyone! 👋
[**_Creating a resume_**](https://instaresume.io/resumes) might seem daunting, but it's your ticket to landing that dream job. To help you shine, here are 10 [common resume mistakes](https://instaresume.io/blog/common-resume-mistakes) you should avoid. Let's make sure your resume is top-notch! 🚀
## 1. Typos and grammatical errors
📝❗
Tiny mistakes can make a big difference. Double-check your resume for typos and grammar errors. Use tools like Grammarly or ask a friend to proofread it. A flawless resume shows you pay attention to detail.
## 2. Including irrelevant information
📋❌
Stick to the point! Only include jobs and skills that are relevant to the position you're applying for. Your high school part-time job might not impress a corporate recruiter.
## 3. Using an unprofessional email address
📧👎
Your email address should sound professional. A good format is firstname.lastname@example.com. Avoid quirky or outdated emails like cooldude123@example.com.
## 4. Lack of specifics and quantifiable achievements
📊🔢
Employers love numbers! Instead of saying "Improved sales," say "Increased sales by 20% in six months." This gives a clear picture of your accomplishments.
## [5. Too long or too short](https://instaresume.io/blog/how-long-should-a-cv-be)
📏🔄
Keep it concise. If you’re new to the job market, one page is enough. For experienced professionals, two pages can be acceptable. Just make sure to include all relevant information without overloading it.
## 6. Poor formatting and layout
🎨📐
A cluttered resume is hard to read. Use clear headings, bullet points, and consistent fonts. Make sure there’s plenty of white space to make it easy on the eyes.
## 7. Not tailoring your resume to each job
🎯🔍
One size does not fit all! Customize your resume for each job application. Highlight the skills and experiences that are most relevant to the job you're applying for.
## 8. Omitting keywords from the job description
🔑📄
Many companies use applicant tracking systems (ATS) to screen resumes. Make sure your resume includes keywords from the job description to pass through these systems.
## 9. Leaving out contact information
📞📧
Always include your phone number and a professional email address. If relevant, adding your LinkedIn profile can also be beneficial. Make it easy for employers to contact you!
## 10. Lying or exaggerating
📢🤥
Honesty is the best policy. Be truthful about your skills and experiences. Lies can be discovered during background checks or interviews, and they can cost you the job.
By avoiding these common mistakes, you'll create a resume that effectively showcases your qualifications and increases your chances of landing the job. Good luck! 🍀
**For more tips on crafting the perfect resume, check out blogs from InstaResume.io:**
- [how to write a resume summary ](https://instaresume.io/blog/how-to-write-a-resume-summary)
- [Top Interview Questions and How to Answer Them](https://instaresume.io/interview-series)
Feel free to share any more tips on making resume or common mistakes one shall avoid in comments section.
#ResumeTips #JobHunting #CareerAdvice #ResumeMistakes #ProfessionalGrowth | hey_rishabh | |
1,875,263 | Version Control in VSCode: Integrating Git and GitHub | Version control is a fundamental aspect of modern software development, enabling teams to collaborate... | 0 | 2024-06-03T11:08:47 | https://dev.to/umeshtharukaofficial/version-control-in-vscode-integrating-git-and-github-55gf | webdev, vscode, devops, programming | Version control is a fundamental aspect of modern software development, enabling teams to collaborate effectively, track changes, and manage code versions. Visual Studio Code (VSCode) offers robust integration with Git, the most popular version control system, and GitHub, the leading platform for hosting and managing Git repositories. This article explores how to seamlessly integrate Git and GitHub with VSCode to enhance your development workflow.
## Why Version Control Matters
### 1. Collaboration
Version control systems (VCS) like Git allow multiple developers to work on the same project simultaneously without interfering with each other’s work. Changes can be merged, and conflicts resolved, ensuring a smooth collaborative process.
### 2. History and Auditing
Git maintains a detailed history of changes, allowing developers to revert to previous versions, understand the evolution of the codebase, and identify when and why changes were made.
### 3. Branching and Merging
Branching allows developers to work on new features or fixes in isolated environments. These branches can later be merged into the main codebase, facilitating parallel development and experimentation.
### 4. Backup and Recovery
By storing the code in remote repositories, Git provides a backup that can be used to recover lost or corrupted code.
## Setting Up Git in VSCode
### Installing Git
Before integrating Git with VSCode, you need to have Git installed on your machine.
1. **Download Git**: Visit the [Git website](https://git-scm.com/) and download the installer for your operating system.
2. **Install Git**: Run the installer and follow the prompts to complete the installation.
### Configuring Git
Once Git is installed, configure it with your user information:
```bash
git config --global user.name "Your Name"
git config --global user.email "your.email@example.com"
```
### Integrating Git with VSCode
VSCode comes with built-in Git support, which makes integration straightforward.
1. **Open VSCode**: Launch VSCode and open your project folder.
2. **Initialize Git Repository**: If your project is not already under version control, initialize a Git repository by clicking on the source control icon in the Activity Bar and then clicking the “Initialize Repository” button.
3. **Configure VSCode Settings**: Go to `File` > `Preferences` > `Settings` and search for “Git” to customize settings such as auto-fetch, enabled by default, and confirmation messages.
## Working with Git in VSCode
### Basic Git Operations
#### 1. Cloning a Repository
To clone a repository from GitHub:
- Click on the Source Control icon.
- Click on the “Clone Repository” button.
- Enter the repository URL and choose a local folder to clone into.
#### 2. Committing Changes
- Open the Source Control panel.
- Stage changes by clicking the `+` icon next to the file or `Stage All Changes`.
- Enter a commit message in the text box at the top.
- Click the checkmark icon to commit the changes.
#### 3. Pushing and Pulling Changes
- **Push**: Click on the ellipsis (...) in the Source Control panel and select `Push` to upload your commits to the remote repository.
- **Pull**: Click on the ellipsis (...) and select `Pull` to fetch and integrate changes from the remote repository.
#### 4. Branching and Merging
- **Create a Branch**: Click on the current branch name in the status bar, select `Create New Branch`, and enter a name.
- **Switch Branches**: Click on the branch name and select a different branch to switch.
- **Merge Branches**: In the Source Control panel, click the ellipsis (...) and select `Merge Branch` to merge changes from one branch into another.
### Advanced Git Features
#### 1. Stashing Changes
If you need to switch branches but have uncommitted changes, you can stash them:
- Click the ellipsis (...) in the Source Control panel and select `Stash`.
- To apply stashed changes later, select `Apply Stash`.
#### 2. Resolving Conflicts
When merging branches, conflicts may occur:
- Conflicted files will appear in the Source Control panel.
- Open the conflicted file and use the built-in conflict resolution tools to choose which changes to keep.
- After resolving, stage the file and commit the changes.
## Integrating GitHub with VSCode
### Connecting VSCode to GitHub
1. **Install GitHub Extension**: Open the Extensions view by clicking the Extensions icon in the Activity Bar and search for `GitHub Pull Requests and Issues`. Install the extension.
2. **Sign In to GitHub**: After installing the extension, click the Accounts icon in the Activity Bar and select `Sign in to GitHub`.
3. **Authorize VSCode**: Follow the prompts to authorize VSCode to access your GitHub account.
### Working with GitHub in VSCode
#### 1. Forking Repositories
Forking a repository creates a copy under your GitHub account:
- Navigate to the repository on GitHub.
- Click the `Fork` button at the top right.
- Clone the forked repository to your local machine.
#### 2. Creating Pull Requests
Pull requests (PRs) allow you to propose changes to a repository:
- Make changes in a new branch.
- Push the branch to GitHub.
- Open the GitHub extension in VSCode, click `Create Pull Request`, and follow the prompts to fill out the PR details.
- Reviewers can comment on, approve, or request changes to your PR.
#### 3. Managing Issues
You can manage GitHub issues directly from VSCode:
- Open the GitHub extension and click on the `Issues` tab.
- Create new issues, view existing ones, and assign them to milestones or labels.
#### 4. Viewing and Checking Out Pull Requests
You can view and checkout PRs from within VSCode:
- Open the GitHub extension and navigate to the `Pull Requests` tab.
- Click on a PR to view its details, leave comments, and check out the branch locally for review.
## Enhancing Git and GitHub Workflow with Extensions
### Recommended Extensions
1. **GitLens**
- Enhances Git capabilities in VSCode with features like blame annotations, code lens, and repository explorers.
- Provides insights into code changes and history.
2. **GitHub Pull Requests and Issues**
- Integrates GitHub pull requests and issues into VSCode.
- Allows you to review and manage PRs and issues directly from the editor.
3. **Live Share**
- Facilitates real-time collaboration with other developers.
- Share your VSCode session with others to code together, debug, and review code in real-time.
4. **Prettier**
- Automatically formats code according to specified rules.
- Ensures consistent code style across your project.
### Customizing Git and GitHub Settings
#### Git Configuration
Customize Git behavior in VSCode by modifying settings in the `Settings` menu. Examples include enabling auto-fetch, changing commit signing options, and customizing diff and merge tools.
#### GitHub Authentication
For enhanced security and convenience, use SSH keys or personal access tokens (PATs) for authenticating with GitHub. You can configure these in the GitHub settings and VSCode settings.
## Best Practices for Using Git and GitHub in VSCode
### 1. Regular Commits
Commit changes frequently with descriptive messages to ensure a clear history and facilitate easier debugging and collaboration.
### 2. Branch Management
Create branches for new features, bug fixes, or experiments. Use descriptive names for branches and keep the main branch stable and clean.
### 3. Code Reviews
Utilize pull requests for code reviews. This practice ensures that changes are peer-reviewed, enhancing code quality and knowledge sharing.
### 4. Automate Workflows
Leverage GitHub Actions to automate workflows such as testing, building, and deploying your code. Integrating CI/CD pipelines ensures that code changes are automatically tested and deployed.
### 5. Keep Repositories Organized
Maintain a clean and organized repository structure. Use README files, contribution guidelines, and issue templates to standardize practices and make the repository accessible to new contributors.
### 6. Secure Your Repositories
Manage access control by using GitHub’s permission settings. Regularly review and update collaborator permissions, and use branch protection rules to prevent unauthorized changes to critical branches.
### 7. Documentation
Document your code and processes thoroughly. Use markdown files in your repository to provide clear instructions, guidelines, and reference material.
## Conclusion
Integrating Git and GitHub with VSCode provides a powerful and streamlined workflow for version control and collaboration. By leveraging VSCode’s built-in Git support and GitHub extensions, developers can manage their codebase efficiently, collaborate seamlessly, and maintain high code quality.
Whether you are working on a solo project or part of a large team, mastering Git and GitHub in VSCode will enhance your productivity and ensure that your projects are well-organized and maintainable. Embrace these tools and best practices to take your version control and project management skills to the next level. | umeshtharukaofficial |
1,875,262 | Top 10 Online Cricket Betting Software for the 2024-25 Season | The world of online cricket betting is growing rapidly, attracting a diverse range of enthusiasts and... | 0 | 2024-06-03T11:07:57 | https://dev.to/mathewc/top-10-online-cricket-betting-software-for-the-2024-25-season-oc4 | webdev, devops, sportsbetting | The world of online cricket betting is growing rapidly, attracting a diverse range of enthusiasts and professionals. With the increasing popularity of cricket as a global sport, the demand for high-quality, reliable betting platforms has surged. Online cricket betting software offers a comprehensive solution for managing bets, providing real-time updates, and ensuring secure transactions. This software is designed to enhance the betting experience for users, making it more engaging, intuitive, and accessible.
**Cricket Betting Software Market Overview:**
The cricket betting software market has seen significant advancements in recent years. A **[cricket betting software development company](https://innosoft-group.com/cricket-betting-software-development-company/)** specializes in creating platforms that cater to the specific needs of cricket bettors. These companies develop software with features like live score updates, real-time odds, secure payment gateways, and user-friendly interfaces. The market is highly competitive, with numerous providers offering innovative solutions to attract and retain users. As we look ahead to the 2024–25 season, it’s essential to understand the key players and trends shaping this dynamic industry.
**How to Choose the Best Cricket Betting Software:**
Choosing the best cricket betting software involves several critical considerations:
**1. User Experience and Interface**
The software should offer a seamless and intuitive user experience. A well-designed interface with easy navigation and quick access to essential features is crucial. Users should be able to place bets, check odds, and monitor their account effortlessly.
**2. Real-Time Data and Updates**
Accurate and up-to-date information is vital for informed betting decisions. The best cricket betting software provides real-time data, including live scores, player statistics, and odds updates. This ensures that users have the latest information at their fingertips.
**3. Security and Reliability**
Security is a top priority for any betting platform. The software must include robust security measures to protect user data and transactions. Reliability is equally important, with the software consistently performing well under heavy traffic and during major events.
**4. Customization and Scalability**
Different operators have unique requirements. The ability to customize the software to meet specific needs is a significant advantage. Additionally, the software should be scalable to accommodate growing user bases and expanding operations.
**5. Customer Support**
Exceptional customer support can significantly enhance the user experience. Look for providers that offer comprehensive support services, including live chat, email, and phone support, to assist users with any issues or queries.
**6. Integration with Other Platforms**
Seamless integration with other platforms, such as payment gateways and marketing tools, can streamline operations and improve user satisfaction. Ensure the software supports integration with various third-party services.
**Top 10 Online Cricket Betting Software:**
Here are the top 10 online cricket betting software for the 2024–25 season, each known for its unique features and capabilities:
**1. BetConstruct**
BetConstruct offers a robust and flexible cricket betting platform known for its comprehensive features and user-friendly interface. It provides real-time data, extensive betting markets, and secure payment options.
**2. SBTech**
SBTech is renowned for its innovative solutions and advanced technology. The platform offers live betting, real-time updates, and a wide range of betting options, making it a favorite among cricket betting enthusiasts.
**3. Kambi**
Kambi provides a scalable and customizable cricket betting software that caters to operators of all sizes. It offers real-time data integration, a seamless user experience, and robust security measures.
**4. Betradar**
Betradar is a leading name in the sports betting industry, known for its extensive data coverage and reliable betting solutions. The platform includes live odds, comprehensive market coverage, and advanced analytics.
**5. SoftGamings**
SoftGamings offers a versatile cricket betting software that integrates easily with other platforms. It provides real-time updates, secure payment gateways, and a user-friendly interface, making it a popular choice.
**6. Bet365**
Bet365 is one of the most recognized names in sports betting, offering a top-tier cricket betting platform. It features live streaming, in-play betting, and extensive market coverage, providing a premium user experience.
**7. 888sport**
888sport provides a reliable and engaging cricket betting platform with a focus on user experience. It offers real-time data, secure transactions, and a wide range of betting options, catering to both casual and serious bettors.
**8. Betway**
Betway is known for its comprehensive betting solutions and innovative features. The platform includes live betting, real-time odds, and secure payment methods, ensuring a seamless and enjoyable betting experience.
**9. William Hill**
William Hill offers a robust cricket betting platform with a rich history of excellence in the betting industry. It provides live updates, a wide range of betting markets, and top-notch security features.
**10. Pinnacle**
Pinnacle is recognized for its competitive odds and reliable betting platform. It offers real-time data, extensive market coverage, and a user-friendly interface, making it a top choice for cricket betting enthusiasts.
**InnoSoft Group’s Expertise in Cricket Betting Software Development:**
InnoSoft Group is a leading cricket betting software development company also known for **[casino game development](https://innosoft-group.com/online-casino-game-development-company/)**, sportsbook software development, poker game development and 2D/3D game development services. From the initial idea to coding, to quality assurance and launch — we provide a wide array of services designed to fulfill all your requirements.
**Here’s a closer look at what sets InnoSoft Group apart:**
**1. Comprehensive Customization**
InnoSoft Group excels in providing fully customizable cricket betting software that caters to the unique requirements of each client. Whether you need specific features, unique interfaces, or tailored betting markets, InnoSoft Group can deliver.
**2. Advanced Technology**
Utilizing the latest technologies, InnoSoft Group ensures that its software is cutting-edge and highly efficient. This includes real-time data integration, live betting functionalities, and secure payment gateways.
**3. Robust Security**
Security is a top priority at InnoSoft Group. The software includes advanced security measures such as encryption, secure transactions, and fraud prevention mechanisms, ensuring that user data and funds are always protected.
**4. User-Friendly Interface**
The user experience is at the forefront of InnoSoft Group’s design philosophy. The software features intuitive navigation, easy-to-use betting interfaces, and comprehensive user account management tools.
**5. Scalability and Flexibility**
InnoSoft Group’s software is designed to grow with your business. Whether you’re starting small or expanding rapidly, the platform can scale to accommodate increasing traffic and expanding operations seamlessly.
**6. Exceptional Support**
InnoSoft Group offers exceptional customer support, with dedicated teams available to assist with any issues or queries. This ensures that operators can provide a smooth and uninterrupted betting experience for their users.
**Conclusion:**
Choosing the right cricket betting software is crucial for success in the competitive sports betting industry. The top 10 online cricket betting software for the 2024–25 season offer a range of features and capabilities designed to enhance the user experience, ensure security, and provide real-time updates. By partnering with top **[sportsbook software providers](https://innosoft-group.com/sportsbook-software-providers/)** like InnoSoft Group, operators can ensure they provide a top-tier betting experience that attracts and retains users. As the cricket betting market continues to evolve, staying ahead with innovative and reliable software solutions is essential for success. | mathewc |
1,875,261 | The Importance of SEO for Small Businesses | Introduction In today's fiercely competitive digital landscape, small businesses encounter the... | 0 | 2024-06-03T11:06:37 | https://dev.to/vaishnaviiii/the-importance-of-seo-for-small-businesses-246o | purplepromedia, digitalmarketingcompany, digitalmarketingagency, digitalmarketingservices |

Introduction
In today's fiercely competitive digital landscape, small businesses encounter the daunting task of distinguishing themselves amidst larger rivals. In this scenario, embracing digital marketing tactics becomes imperative for their sustenance and expansion. Among the myriad strategies available, Search Engine Optimization (SEO) stands out as one of the most potent and impactful methods. As a digital marketing company in Coimbatore, Purple Pro Media understands the pivotal role SEO plays in enhancing the online visibility and success of small businesses. This article explores the importance of SEO and how partnering with a digital marketing agency in Coimbatore can make a significant difference.
Enhancing Online Visibility
For small businesses, getting noticed online is a daunting task. SEO is the tool that can elevate a business's online presence, making it easier for potential customers to find them. By optimizing website content and structure, small businesses can improve their rankings on search engine results pages (SERPs). Higher rankings lead to increased visibility, which in turn drives more organic traffic to the website. A[ digital marketing agency in Coimbatore](https://purplepromedia.com/best-digital-marketing-agency-in-coimbatore) like Purple Pro Media specializes in SEO strategies that ensure your business appears at the top of relevant search results.
Building Credibility and Trust
Consumers tend to trust search engines, and appearing at the top of the search results instills a sense of credibility and trustworthiness. Effective SEO practices ensure that a small business's website is user-friendly, informative, and relevant, which helps build trust with visitors. A professional advertising agency in Coimbatore can optimize your website to enhance user experience, making it easier for customers to navigate and find the information they need. This positive user experience is crucial in establishing credibility and encouraging repeat visits.
Cost-Effective Marketing
Compared to traditional marketing methods, SEO is a cost-effective strategy that offers high returns on investment. Small businesses often operate with limited marketing budgets, and SEO provides a way to reach potential customers without the need for expensive advertising campaigns. By targeting specific keywords related to your products or services, SEO ensures that your marketing efforts are directed towards people actively searching for what you offer. This focused strategy enhances the chances of turning visitors into loyal customers. Partnering with a Coimbatore digital marketing company can help small businesses maximize their SEO efforts without breaking the bank.
Driving Local Traffic
For small businesses, attracting local customers is often a primary goal. Local SEO focuses on optimizing a website to attract customers from specific geographic areas. This includes optimizing Google My Business profiles, using location-specific keywords, and creating content relevant to local events or news. A digital marketing company in Coimbatore like Purple Pro Media can help small businesses leverage local SEO strategies to dominate local search results. This ensures that when potential customers search for products or services in their vicinity, your business is prominently featured.
Staying Competitive
In today's digital age, nearly all businesses are investing in SEO. To stay competitive, small businesses must also adopt SEO strategies. Ignoring SEO means falling behind competitors who are actively improving their online presence. Coimbatore marketing companies like Purple Pro Media can provide the expertise and tools needed to stay ahead of the competition. By continuously monitoring and adjusting SEO strategies, small businesses can maintain their competitive edge and ensure sustained growth.
Insightful Analytics
One of the key advantages of SEO is the ability to track and measure performance through analytics. SEO tools provide valuable insights into website traffic, user behavior, and conversion rates. This data is essential for making informed decisions and refining marketing strategies. A digital marketing agency in Coimbatore can help small businesses interpret these analytics, providing actionable recommendations to improve SEO performance continuously. Understanding what works and what doesn’t allows businesses to allocate resources more effectively and achieve better results.
Long-Term Results
Unlike paid advertising, which stops driving traffic once the budget is exhausted, SEO offers long-term benefits. Once a website is optimized and achieves higher rankings, it continues to attract organic traffic without ongoing investment. This makes SEO a sustainable marketing strategy that provides lasting results. By partnering with a Coimbatore digital marketing company, small businesses can develop and implement a robust SEO strategy that ensures ongoing visibility and growth.
Adapting to Changing Algorithms
Search engines frequently update their algorithms to improve user experience and deliver more relevant search results. Keeping up with these changes can be challenging for small business owners. An advertising agency in Coimbatore stays abreast of the latest SEO trends and algorithm updates, ensuring that your website remains optimized and compliant. This proactive approach prevents sudden drops in rankings and maintains steady traffic flow.
In conclusion, SEO is a vital component of digital marketing that small businesses cannot afford to overlook. It enhances online visibility, builds credibility, drives cost-effective marketing, attracts local traffic, and provides long-term results. By partnering with a digital marketing company in Coimbatore like Purple Pro Media, small businesses can harness the power of SEO to achieve sustainable growth and success in the digital marketplace. Whether you are just starting or looking to improve your existing online presence, investing in SEO with the help of a professional digital marketing agency in Coimbatore is a strategic move that can yield significant benefits.
Small businesses aiming for growth should not underestimate the importance of SEO. Working with experienced Coimbatore marketing companies ensures they stay competitive and thrive in an ever-evolving digital landscape.
| vaishnaviiii |
1,875,259 | The Senior Engineer's Guide to Code Reviews | Code reviews. You know how important they are. They are one of the pillars of getting... | 0 | 2024-06-03T11:03:42 | https://dev.to/middleware/the-senior-engineers-guide-to-the-code-reviews-1p3b | codereview, productivity, learning, testing | ## Code reviews.
You know how important they are.
They are one of the pillars of getting reliable code out there.
Yet, it’s one of those things you need to **squeeze** out some time for in your super busy days.
If you’re not reviewing code, you might as well ship landmines to your users because you never know when it’ll blow up. 🤷
Obviously, you know that. You’re not here to be told “Hey! You should have code reviews! It’s a vital thing!”
## My team already does reviews. Why should I care?
Code reviews processes handled without care and diligence can have serious consequences.
At one of my previous orgs, code reviews were often not done thoroughly, and hence needed multiple passes. They were also done by reviewers on the opposite ends of the earth! 🌏
So addressing any comment took almost a whole day. And again, because the reviews would usually not be comprehensive the rework time on a PR would be in days for trivial things.

“You can’t improve, what you don’t measure”
_Often attributed to Peter Drucker, but I’ve not been able to actually find evidence for that._
But it’s a statement I found to be profound in my experiences.
I’ve made a case to my leadership in the past to make much needed organizational changes to enable all teams to have fewer inter-dependencies across time-zones to enable people to collaborate faster.
I understand how difficult it can be to do so, but it’s even harder to get any change in motion without a solid data-backed reason for why it’s needed.
_P.S.: That’s part of why Dhruv & I started [Middleware](https://www.middlewarehq.com/). 🚀_
{% embed https://github.com/middlewarehq/middleware %}
## Okay, I hear ya. What are my options?
What you ideally want are code reviews that are done thoroughly, which is to say that obvious red flags, performance or security defects, or other hard-to-read code shouldn’t go unnoticed.
But you also want all of this to happen in a reasonable amount of time.
Well reviewed code merged in a reasonable amount of time, means your team's delivery predictably, and with high reliability.
Only if there were a well researched, structured way of getting a grip on this. 🤔
…
Have you heard of… DORA metrics?
Okay, this isn’t another one of “DORA GOOD!” articles.
These are my experiences of how keeping an eye on the four-keys (as [explained](https://dora.dev/guides/dora-metrics-four-keys/) by the awesome [Nathen Harvey](https://www.linkedin.com/in/nathen/)) helped me improve the code delivery experience for myself and my team in the past.

_DORA Metrics as seen on Middleware Open Source_
## Exploring Code Reviews with DORA
### How Long Reviews Inflate Lead Time
Long review cycles directly impact Lead Time for Changes.
Lead time consists of basically 5 parts.
1. Time from first commit to the PR being open
2. Then the PR receiving its first review (could be a comment, change, approval)
3. Time spent on making changes to the PR, till it’s finally approved
4. Time between approval and the PR being merged
5. Time when the PR was eventually deployed
Naturally, any of the parts taking time will inflate your team time. But there are 2 parts that are particularly egregious factors for delays here. That’s #2 and #3.
**#2. Time till the PR receives its first review (First Response Time)**
After the PR is open, a dev can’t really do much on it. The PR may be totally good to go! It may need solid changes. At this point, only a review will tell. This is also the point when a dev may not be able to pick up more tasks either because technically a review could happen at any time, and they would suffer from context switching.
**Context switching is one of the biggest productivity killers for devs.**
### The Misleading Focus on "Time per Review"
This talks about the third sub-part of the Lead Time metric.
**#3. Time spent on making changes to the PR (Rework Time)**
The real problem here isn’t stemming so much from how much time was spent here, but how many times back and forth happened. Let’s call that “Rework cycles”.
Because if there was only 1 rework cycle because the PR was approved, then it could still have taken a long time before approval, but it was actual implementation time, not idle time. This kind of rework could be mitigated by better training, codebase onboarding, context sharing, etc.
But… if you’re going back and forth a lot of times, then each of these cycles has some idle time associated with it, much like first response time.
During this time, the dev can’t pick up new work, because that would inevitably result in rapid context switching.
This is likely to happen when the PR is too large to review in one go, or the reviewer didn’t review thoroughly for other reasons. This is especially exacerbated when the author and reviewer are in far apart time-zones. Because each review, and rework is likely to happen during the work hours in their respective time-zones, inflating the time before the reworked changes can be checked into many many hours.
**This is a snow-ball effect**
The more PRs get blocked like this, the slower the teams deliver. And often the new work doesn’t stop coming, so that makes it even more challenging for devs to manage and estimate their work accurately.
If this keeps happening constantly, it also deals a blow to the morale of the team.
**tl;dr**
Focusing solely on reducing "time per review" can backfire.
The goal should be to optimize the review process without sacrificing thoroughness, ensuring each review adds real value.
### Subpar Reviews and Change Failure Rates
Teams operate under pressure and tight deadlines all the time. And it’s unreasonable to expect that to magically change. But it’s also unrealistic to think that corners won’t be cut to ensure things don’t get shipped on time.
Since we’re talking about code reviews, one of the corners that are cut often, are:
1. Large PRs created that contain all the code for a feature instead of well contained smaller and easier to review PRs.
2. PRs are reviewed by just skimming over them because the reviewer may just not have the mental capacity or time to deal with it properly at the moment.
Both of those things happen from time to time. Devs are humans too. You won’t solve this by just blaming it on them or strong-arming them into reviewing “properly”.
The most important thing is for you to know that it’s happening in the first place. Because then you can do something about it. How would you know about it, you ask?
1. Your Lead Time should be going down. Because reviews are being done faster (often than they should)
2. Your Change Failure Rate might be going up. Of course, with subpar reviews you’re likely shipping more bugs.
1. But, even if your CFR isn’t going noticeably down, your team might still be shipping low performance or quality code that would bite you back later, and will likely show up as higher Lead Time down the line. But by then it’ll be too difficult to correlate with the reviews of today.
**This is a good time to mention that DORA is a great guide, but it’s not perfect.**
Don’t treat it like a definitive rule-book. Don’t measure individuals against it.
Use it holistically for your team, but also be involved to make sure it’s actually helping your team. That’s the goal after all, isn’t it?
## Great! How? 👉 Strategies for Faster, More Effective Reviews
### Here’s a quick **pre-review checklist**
1. Tests: Ensure all relevant tests are written and passing ✅.
1. This can be done by a CI bot (or Github Actions)
2. Documentation: Update relevant docs, including inline comments and README files.
3. Clear Commit Messages: Write descriptive commit messages that explain the 'why' behind changes.
2. This could also be enforced via [commit-lint](https://commitlint.js.org/)
3. You could also use [aicommit](https://github.com/Nutlope/aicommits) to help write good and detailed commit messages!
4. My team often uses GH Copilot to create commit messages that actually end up being totally satisfactory to me!
Example commit message:
```
feat: add user authentication
- Implemented OAuth2 for secure login
- Added unit tests for authentication flows
- Updated API documentation with new endpoints
```
### Right Reviewer, Right Time
Match reviewers to their expertise and current workload to avoid overload. Complex changes go to senior devs, simpler ones to peers.
But you also need to be aware of how much context a dev has of a specific codebase.
There’s a few challenges here:
* If your devs are highly specialized within singular specific repos, then it’ll be pretty difficult to use their skills on a separate codebase simply due to the required time to onboard and share context.
* If your devs are too generalized over all codebases, it might be difficult for them to solve certain issues faster due to a lack of deep context of specific codebases.
* If one of the devs on the team has a lot of context about things, it’s super easy to overburden them. You need to make time to distribute context sooner than later, so your work doesn’t get blocked at a time when it’s most critical.
You want to ensure you have a mix of both, and that could be achieved with as few as 2-3 devs that you work with.

_Understanding who gets blocked on whom for code reviews is crucial. You don’t want your team to not deliver at all because someone needed to be on leave._
### Tools of the Trade
Use static analysis, code linting, and automated checks to catch simple issues before human review. This lets reviewers focus on more complex feedback.
Example Tools:
* [ESLint](https://eslint.org/): JavaScript linting.
* [Husky](https://typicode.github.io/husky/): For running pre-commit checks and static analysis.
* CI/CD Pipelines: Automated testing and build processes.
**Super important tip:**
It’s easy to lose a LOT of time arguing over spaces and tabs, semicolons or not, trailing newlines.
But all that doesn’t matter.
Decide on, and agree with whatever code-style the team finalizes, and enforce them as part of the linter rules.
This stuff isn’t worth your time. 👍
### The Art of Feedback
Give actionable, specific comments that focus on improvement, not nitpicking. Avoid vague statements and offer clear guidance.
Share how a file could have been restructured into multiple, along with why doing that is a good idea.
Share why making that DB call multiple times in a loop might be a bad idea because of reasons I’m sure I don’t need to explain here. 😆
If the nitpicks are largely things that could have been handled by a linter, then use one of those.
People hate reviews that mostly have only nits. But again, poor variable names, typos, etc. can’t just go to prod! 😁
Example:
```
# Ineffective comment
"Fix this."
# Effective comment
"Consider using a map here to improve lookup efficiency. This will reduce the time complexity from O(n) to O(1)."
```
## Streamlining the Process with Middleware
### How Middleware Helps
I’m able to see specifically where my teams get stuck, why, and how I can unblock them.
That’s kind of half of my job, and now I’m able to do this stuff a lot faster than before!

### Here’s a few things I focus on:
* Review Metrics: Track how long reviews take and identify where delays occur.
* Process Insights: Gain visibility into the entire review process and find areas for optimization.
I won’t get too much into that because then it’ll sound like a sales pitch! 😂
## Beyond Technicalities: The Human Element
### Fostering a Culture of Constructive Feedback
Promote a culture where feedback is seen as a growth opportunity. Constructive, respectful communication helps improve code quality and team morale 💬.
### Balancing Speed with Thoroughness
Balance speed with thoroughness. Quick reviews shouldn't compromise scrutiny, and thorough reviews shouldn't drag on.
### Psychological Safety
Ensure psychological safety for both reviewers and authors. Encourage open discussions and address mistakes without blame, fostering an environment of continuous improvement 🌱.
Remember, people often go guards-up when you’re sharing feedback for improvement. Be considerate, and clear.
## Conclusion
Effective code reviews are crucial for maintaining code quality and delivery speed. By aligning with DORA metrics, using the right tools, and fostering a constructive feedback culture, teams can streamline their review processes. Embrace these practices to make your code reviews both efficient and impactful.
_Try [Middleware](https://www.middlewarehq.com/) to gain deeper insights into your code review processes and identify areas for further improvement. 🚀_
Again these are just guidelines and how we look at code reviews. Do share how code reviews are done in your organization!
Code reviews play a vital role in overall product reliability. There are instances of bad code reviews (not lousy code!) causing negative brand impact. To sum up, better code review processes contribute to less failure rate.
Frameworks like [DORA](https://github.com/middlewarehq/middleware) are designed to be light-weight to help the engineering team be productive without too much effort from engineers or even leaders. We at Middleware are on a mission to help engineering teams ship productive code. Do check out our [Middleware open-source](https://github.com/middlewarehq/middleware), our open-source DORA metrics solution, that is locally hostable. Consider giving us a star if you like it!
| jayantbh |
1,845,543 | Ibuprofeno.py💊| #117: Explica este código Python | Explica este código Python Dificultad: Fácil my_tuple = (1, 2, False,... | 25,824 | 2024-06-03T11:00:00 | https://dev.to/duxtech/ibuprofenopy-117-explica-este-codigo-python-3di9 | learning, beginners, python, spanish | ## **<center>Explica este código Python</center>**
#### <center>**Dificultad:** <mark>Fácil</mark></center>
```py
my_tuple = (1, 2, False, 3)
print(min(my_tuple))
```
👉 **A.** `1`
👉 **B.** `2`
👉 **C.** `0`
👉 **D.** `False`
---
{% details **Respuesta:** %}
👉 **D.** `False`
Nuevamente los valores booleanos infieren a números. En este caso `False` infiere a `0` por ello es considerado el valor mas pequeño de la tupla. Lo interesante es que no regresamos el valor `0` como número, sino el booleano `False`.
{% enddetails %} | duxtech |
1,875,220 | How to Reverse an Array: Step-by-Step Guide | Reversing an array is a common problem asked in many coding interviews and programming challenges and... | 27,580 | 2024-06-03T10:59:29 | https://blog.masum.dev/how-to-reverse-an-array-step-by-step-guide | algorithms, computerscience, cpp, coding | Reversing an array is a common problem asked in many coding interviews and programming challenges and can be solved using various methods. In this article, we'll discuss two methods to reverse an array in C++: one **using extra space** and another using the **two-pointers technique**. Each method has its own advantages and trade-offs, which we'll explore in detail.
### Solution 1: Using Extra Space (Copy and Paste Method)
**Implementation**:
```cpp
// Solution 1: With Extra Space (Copy & Paste Method)
// Time Complexity: O(n)
// Space Complexity: O(n)
void reverseArray(int *arr, int n)
{
int newArr[n];
for (int i = 0; i < n; i++)
{
newArr[i] = arr[n - i - 1];
}
for (int i = 0; i < n; i++)
{
arr[i] = newArr[i];
}
}
```
**Logic:**
**1. Create a new array**: `newArr` of the same size as the input array `arr`.
**2. First loop**:
- Iterate through the input array `arr`.
- Copy elements from the end of `arr` to the beginning of `newArr`.
- `newArr[i] = arr[n - i - 1]` reverses the order.
**3. Second loop**:
- Copy the reversed elements from `newArr` back to `arr`.
**Time Complexity**: O(n)
* **Explanation**: Two separate loops, each iterating through the array once.
**Space Complexity**: O(n)
* **Explanation**: An additional array of the same size is used.
**Example**:
* **Input**: `arr = [1, 2, 3, 4, 5]`, `n = 5`
* **Output**: `arr = [5, 4, 3, 2, 1]`
* **Explanation**: The elements are reversed in the new array and then copied back to the original array.
---
### Solution 2: Without Extra Space (Two-Pointers Technique)
**Implementation**:
```cpp
// Solution 2: Without Extra Space (2 Pointer Method)
// Time Complexity: O(n)
// Space Complexity: O(1)
void reverseArray(int *arr, int n)
{
int start = 0;
int end = n - 1;
while (start < end)
{
swap(arr[start], arr[end]);
start++;
end--;
}
}
```
**Logic:**
**1. Initialize two pointers:**
- `start` at the beginning of the array.
- `end` at the end of the array.
**2. Loop:**
- Swap elements at `start` and `end`.
- Move `start` forward and `end` backward until they meet in the middle.
**Time Complexity**: O(n)
* **Explanation**: Single loop iterating through half the array.
**Space Complexity**: O(1)
* **Explanation**: Only a few extra variables are used.
**Example**:
* **Input**: `arr = [1, 2, 3, 4, 5]`, `n = 5`
* **Output**: `arr = [5, 4, 3, 2, 1]`
* **Explanation**: Elements are swapped in place, reversing the array.
---
### Comparison
* **Extra Space Method**:
* **Pros**: Simple and easy to understand.
* **Cons**: Uses additional space equal to the size of the array.
* **Time Complexity**: O(n)
* **Space Complexity**: O(n)
* **Two-Pointers Technique**:
* **Pros**: Space efficient, as it only uses a constant amount of extra space.
* **Cons**: Slightly more complex logic involving pointers.
* **Time Complexity**: O(n)
* **Space Complexity**: O(1)
### Edge Cases
* **Single element array**: An array with a single element remains the same after reversal.
* **Empty array**: An empty array remains empty after reversal.
### Additional Notes
* The two-pointers technique is preferred for practical implementations due to its minimal space usage.
* Understanding both methods is valuable for grasping different problem-solving approaches and space-time trade-offs.
### Conclusion
Reversing an array is a fundamental problem that helps in understanding array manipulations and the trade-offs between time and space complexity. The method using extra space is straightforward and easy to implement, while the two-pointers technique is more efficient in terms of space usage. Both methods are useful and knowing them expands your problem-solving toolkit.
--- | masum-dev |
1,875,258 | HTML Newsletter Popup Form | This Pin demonstrates a fully functional HTML Newsletter Popup Form, created using HTML, CSS, and... | 0 | 2024-06-03T10:58:08 | https://dev.to/creative_salahu/html-newsletter-popup-form-43i8 | codepen | This Pin demonstrates a fully functional HTML Newsletter Popup Form, created using HTML, CSS, and jQuery. This popup form is designed to capture users' email addresses and encourage them to subscribe to your newsletter.
Features
Popup Trigger: The form pops up when a trigger event occurs (e.g., page load or button click).
Responsive Design: The form is styled to be responsive, ensuring it looks good on both desktop and mobile devices.
Smooth Animations: jQuery is used to create smooth fade-in and fade-out animations for the popup.
Form Validation: Basic form validation is implemented to ensure users enter a valid email address before submitting.
How It Works
HTML Structure: The HTML provides the basic structure for the popup form, including the form fields and buttons.
CSS Styling: CSS is used to style the popup, ensuring it is centered on the screen and has an attractive design.
jQuery Functionality: jQuery handles the popup's show/hide functionality and form validation.
Example Usage
Email Collection: Use this popup form on your website to collect email addresses for your newsletter.
Promotions: Customize the form to promote special offers or announcements to your visitors.
Customization
You can easily customize the form's appearance by modifying the CSS.
The jQuery code can be adapted to change the popup trigger event or add more advanced form validation.
Feel free to explore and modify this pen to fit your needs. Happy coding!
{% codepen https://codepen.io/CreativeSalahu/pen/yLWgygd %} | creative_salahu |
1,875,423 | Open and Save PDF Files Locally in Flutter | TL;DR: Want to open and save PDF files locally in your Flutter app? Let’s easily do it with... | 0 | 2024-06-06T03:12:55 | https://www.syncfusion.com/blogs/post/open-save-pdf-locally-flutter | pdf, development, flutter, pdfviewer | ---
title: Open and Save PDF Files Locally in Flutter
published: true
date: 2024-06-03 10:56:47 UTC
tags: pdf, development, flutter, pdfviewer
canonical_url: https://www.syncfusion.com/blogs/post/open-save-pdf-locally-flutter
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/8vrigu5eecd3akiqao6j.png
---
**TL;DR:** Want to open and save PDF files locally in your Flutter app? Let’s easily do it with Syncfusion Flutter PDF Viewer. This blog covers creating a Flutter app, adding dependency packages, and implementing functions to load and save PDFs with PDF Viewer and File Picker.
Opening and viewing PDF files from a local device’s storage offers several benefits, such as faster access to the files and enhanced privacy and security by viewing sensitive files within that device.
[Syncfusion Flutter PDF Viewer](https://www.syncfusion.com/flutter-widgets/flutter-pdf-viewer "Flutter PDF Viewer") widget lets you view PDF documents seamlessly and efficiently on the Android, iOS, web, Windows, and macOS platforms. It has highly interactive and customizable features such as magnification, virtual bi-directional scrolling, page navigation, text selection, text search, page layout options, document link navigation, bookmark navigation, form filling, and reviewing with text markup annotations.
In this blog, we’ll see how to load and save PDF files from and to a local device’s storage using **Syncfusion Flutter PDF Viewer** and **File Picker**.
## Create a Flutter app and add dependencies
First, [create a new Flutter app](https://docs.flutter.dev/get-started/codelab "Create a new Flutter app") and add the following dart packages as dependencies in it:
- syncfusion\_flutter\_pdfviewer
- File\_picker
```
dependencies:
flutter:
sdk: flutter
file_picker: ^X.X.X
syncfusion_flutter_pdfviewer: ^X.X.X
```
**Note:** The **X.X.X** denotes the version of the packages.
After adding the dependencies, import the packages into your dart code.
```js
import 'package:syncfusion_flutter_pdfviewer/pdfviewer.dart';
import 'package:file_picker/file_picker.dart';
```
## Open local PDF files
Create the **PdfViewer** (widget) and **PdfViewerState** classes to build and display the chosen PDF file in the Syncfusion Flutter PDF Viewer( **SfPdfViewer** ). Then, in the **AppBar** method, configure the **Open** and **Save** buttons to open and save PDF files with the help of **File Picker**.
Refer to the following code example.
```js
class PdfViewer extends StatefulWidget {
const PdfViewer({super.key});
@override
State<PdfViewer> createState() => _PdfViewerState();
}
class _PdfViewerState extends State<PdfViewer> {
final PdfViewerController _pdfViewerController = PdfViewerController();
Uint8List? _pdfBytes;
@override
void initState() {
super.initState();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
actions: [
IconButton(onPressed: _openFile, icon: const Icon(Icons.folder_open)),
IconButton(onPressed: _saveFile, icon: const Icon(Icons.save)),
Spacer()
],
),
body: _pdfBytes != null
? SfPdfViewer.memory(
_pdfBytes!,
controller: _pdfViewerController,
)
: const Center(
child: Text(
'Choose a PDF file to open',
)),
);
}
}
```
Now, let’s define the **\_openFile** function to browse and choose a PDF file from the local storage with the help of **File Picker**. This function will be invoked in the **onPressed** callback for the **Open** button. Then, assign the file stream to the **SfPdfViewer**.
Refer to the following code example.
```js
/// Open a PDF file from the local device's storage.
Future<void> _openFile() async {
FilePickerResult? filePickerResult = await FilePicker.platform
.pickFiles(type: FileType.custom, allowedExtensions: ['pdf']);
if (filePickerResult != null) {
if (kIsWeb) {
_pdfBytes = filePickerResult.files.single.bytes;
} else {
_pdfBytes =
await File(filePickerResult.files.single.path!).readAsBytes();
}
}
setState(() {});
}
```
## Save PDF files to local storage
To save the modified PDF files to local storage, we use SfPdfViewer’s **SaveDocument** method to obtain the modified PDF file stream and then pass it to the **FilePicker** widget to write it to the desired location.
This blog example shows how to save PDF files on the web and other platforms (Android, iOS, macOS, and Windows). On the web platform, the file will be downloaded in the browser when pressing the **Save button**, whereas on other platforms, we will be allowed to choose the folder directory in which we wish to save the file.
Let’s now create two **SaveHelper** classes for the web and other platforms to perform the above-mentioned actions.
**Save on web platform**
```js
import 'dart:convert';
import 'dart:html';
class SaveHelper {
static Future<void> save(List<int> bytes, String fileName) async {
AnchorElement(
href:
'data:application/octet-stream;charset=utf-16le;base64,${base64.encode(bytes)}')
..setAttribute('download', fileName)
..click();
}
}
```
**Save on Android, iOS, macOS, and Windows**
```js
import 'dart:io';
import 'package:file_picker/file_picker.dart';
class SaveHelper {
static Future<void> save(List<int> bytes, String fileName) async {
String? directory = await FilePicker.platform.getDirectoryPath();
if (directory != null) {
final File file = File('$directory/$fileName');
if (file.existsSync()) {
await file.delete();
}
await file.writeAsBytes(bytes);
}
}
}
```
**Note:** Before proceeding to the next step, please ensure that the created **SaveHelper** class files are imported into the main dart file.
Finally, let’s define the **\_saveFile** function in your widget’s build method, where we can call the **SaveHelper.save()** method to save a PDF file to the local storage. And this **\_saveFile** function will be invoked in the **onPressed** callback for the **Save** button.
Refer to the following code example.
```js
/// Save a PDF file to the desired local device's storage location.
Future<void> _saveFile() async {
if (_pdfViewerController.pageCount > 0) {
List<int> bytes = await _pdfViewerController.saveDocument();
SaveHelper.save(bytes, 'Saved.pdf');
}
}
```
Execute the application with the above code examples, and you will get the output for the Android platform, as shown in the following image **.**
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/06/Easily-Open-and-Save-PDF-Files-from-Local-Device-Storage-in-Flutter.gif" alt="Easily Open and Save PDF Files from Local Device Storage in Flutter" style="width:100%">
<figcaption>Easily Open and Save PDF Files from Local Device Storage in Flutter</figcaption>
</figure>
## GitHub reference
For more details, refer to the [Open and save PDF files from and to local device’s storage in the Flutter](https://github.com/SyncfusionExamples/Open-and-save-PDF-files-from-and-to-local-device-storage-in-Flutter "Open and save PDF files from and to local device’s storage in the Flutter GitHub demo") GitHub demo.
## Conclusion
Thanks for reading! I hope you now have a clear idea about how to open and save PDF files from and to local device storage using the Flutter PDF Viewer. Try this in your application and share your feedback in the comments below.
The new version of Essential Studio is available on the [License and Downloads](https://www.syncfusion.com/account/downloads "Essential Studio License and Downloads page") page for current customers. If you are not a Syncfusion customer, try our 30-day [free trial](https://www.syncfusion.com/downloads "Get the free 30-day evaluation of Essential Studio products") to check out our newest features.
You can share your feedback and questions through the comments section below or contact us through our [support forums](https://www.syncfusion.com/forums "Support Forums"), [support portal](https://support.syncfusion.com/support/tickets "Support Portal"), or [feedback portal](https://www.syncfusion.com/feedback/ "Feedback Portal"). We are always happy to assist you!
## Related blogs
- [Flutter Made Easy: 5 Tools to Build Better Apps Faster](https://www.syncfusion.com/blogs/post/build-apps-faster-with-flutter-tools "Blog: Flutter Made Easy: 5 Tools to Build Better Apps Faster")
- [Effortlessly Fill and Share PDF Forms using Flutter PDF Viewer](https://www.syncfusion.com/blogs/post/fill-share-pdf-forms-flutter "Blog: Effortlessly Fill and Share PDF Forms using Flutter PDF Viewer")
- [Charting Magic: A Performance Boost with Syncfusion Flutter Charts](https://www.syncfusion.com/blogs/post/performance-boost-flutter-charts "Blog: Charting Magic: A Performance Boost with Syncfusion Flutter Charts")
- [Create Dynamic Forms in Flutter](https://www.syncfusion.com/blogs/post/dynamic-forms-in-flutter "Blog: Create Dynamic Forms in Flutter") | jollenmoyani |
1,875,255 | ADD THIS EFFECT TO YOUR WEBSITE !! 🤯 | Today I will tell you in detail how I made this: So as you can see. I will be telling you how to... | 0 | 2024-06-03T10:53:46 | https://dev.to/mince/awesome-mouse--3l1n | webdev, beginners, programming, tutorial | Today I will tell you in detail how I made this:
{% codepen https://codepen.io/Gitguy2328_xprogram/pen/XWwRWOP %}
So as you can see. I will be telling you how to make a mouse trailer
<img src='https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExcGlpMnY4M3NrMGRkYjFkbnRoYXkwd3A5MDB6ZXc2bmhtODMyYzQ1diZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/oobNzX5ICcRZC/giphy.gif'/>
## Basic setup
It is pretty simple to make the navbar, generally we don't see navbars with backgrounds. They generally have transparent background. But I got inspiration from one of the websites I recently saw and I needed to remake it. I started off by having a good looking sizing. Cause it should look perfect not lacky. Then I gave it vibrant colours that pop. Dodgerblue and yellow was a good looking pair. Next I got the icons from font awesome. aligned them gave them colour and a hover effect. I thought it would be cool if I threw a bunch of other effects on like the background changes when we hover on something. This was the basic setup
<img src='https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExZjR0b3BhNWRxaGY2aGY1emFoYWY3ZGdjdDN3Zm5meG5kbHh5ZWpkMyZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/5WAdRevloGjuw/giphy.gif'/>
##Mouse
First of all we need a pretty basic trailer to make it follow the mouse. I started off by making a 100 px wide square and then rounded it's edges to make a circle. Then I got the glassmorphism code from css.glass. After that I put Google icon inside that trailer. I dont know why. Then I centered it.
<img src='https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExd3l1d3d5ZzJ0MnpscGJjZjdwYjI0bGJpODUzOTAwMHdsY2FvaXY5diZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/eK12uCsrAh4wmTXejp/giphy.gif'/>
> Tip: I always center things with one basic code:
```css
display: flex;
align-items: center;
justify-content: center;
/* If you want them to be on top of each other */
flex-direction: column;
```
> I just prefer that code for some reason
Then I set the position of the trailer fixed, so that it is fixed 🙄. I set the z-index to something big. Like 999999999999999999999999999999999.
<img src='https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExMXRsaXUxeXgycTlzNmRxZGU4Z205aW5ienNmdHdpaXlycGJqMGdwMiZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/coyiAVHZSyGqs/giphy.gif'/>
Another important thing is to set the top and left to 0. This will get our mouse which will be following the mouse ready.
## Make it follow 🚶♂️
Just enter this code
```js
var trailer = document.getElementById("trailer");
window.onmousemove = (e) => {
document.getElementById("trailer").style.scale = "1";
const y = e.clientX + 20;
const x = e.clientY + 20;
const keyframes = {
transform: "translate(" + y + "px" + "," + x + "px)"
};
document.getElementById("trailer").animate(keyframes, {
duration: 800,
fill: "forwards"
});
};
```
<img src='https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExaTN6NnE4d2UxMWZsODFsamFlbzFsYW03cHJoMnhxd2V6YmdsNHZnOCZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/Dh5q0sShxgp13DwrvG/giphy.gif'/>
Now what this code does basically is monitors the mouse's movement and then stores it. We then add 20 to the value and set it as the x and y position of the trailer in the form of an animation. We can do it basically but it's not so smooth and soothing. If you want it to be smooth. You will have to use animations. That's all if you followed my instructions you should get something to follow your mouse.
<img src='https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExOW9hcXZ3NWg0ODE1b254ajQ5ajF3b2s5ZHBjc2lzMjh6ODdzcTk0dCZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/l0Iyl55kTeh71nTXy/giphy.gif'/>
Guys now I want to ask you something what I should I tell you about next !
| mince |
1,875,254 | Mastering Application Scalability: Strategies for Sustained Growth | In today's fast-paced digital world, the importance of scalable applications cannot be overstated. As... | 0 | 2024-06-03T10:53:10 | https://dev.to/daniellehunter/mastering-application-scalability-strategies-for-sustained-growth-p1p | androiddev, hirededicateddevelopers, programming, devops | In today's fast-paced digital world, the importance of scalable applications cannot be overstated. As user bases grow and demands increase, applications must adapt seamlessly to avoid performance bottlenecks and maintain a high-quality user experience. Future-proofing your app is essential for long-term success, and one effective way to achieve this is by partnering with an experienced Android app development company and **[hire dedicated developers](https://www.hyperlinkinfosystem.com/hire-dedicated-developers-india.htm)**.
## The Importance of Scalability
Scalability refers to an application's ability to handle growth, whether in terms of user numbers, transaction volumes, or data size. An application that scales well can accommodate increasing loads without compromising performance. This is crucial for maintaining user satisfaction, driving engagement, and ultimately achieving business growth.
## Challenges in Achieving Scalability
- Performance Degradation: As the number of users grows, the app may become slower, leading to a poor user experience.
- Infrastructure Costs: Scaling often requires additional infrastructure, which can be costly.
- Complexity in Codebase: A growing codebase can become complex, making maintenance and updates challenging.
- Data Management: Managing large volumes of data efficiently is a significant challenge.
## Benefits of Hiring Dedicated Developers
Hiring dedicated developers offers several advantages when it comes to building scalable applications:
- Expertise: Dedicated developers bring specialized knowledge and experience, ensuring that your app is built with scalability in mind from the outset.
- Focus: With a dedicated team, you have professionals solely focused on your project, leading to better performance and quicker turnaround times.
- Consistency: A dedicated team ensures continuity in development, which is crucial for maintaining the integrity of the codebase and implementing scalable solutions effectively.
- Cost-Effectiveness: In the long run, having a dedicated team can be more cost-effective than hiring different developers for each phase of the project.
## Role of an Android App Development Company
Partnering with a reputable **[Mobile App Startups](https://www.hyperlinkinfosystem.com/blog/guide-to-get-investors-for-your-mobile-app-startups)** can
significantly enhance your scalability efforts. These companies provide:
- End-to-End Services: From conceptualization to deployment and maintenance, they offer comprehensive solutions.
- Cutting-Edge Technologies: Leveraging the latest technologies and best practices, they ensure your app is built to scale.
- Quality Assurance: Rigorous testing and quality assurance processes are in place to identify and mitigate potential scalability issues.
- Continuous Support: Ongoing support and updates are essential for keeping the app scalable and secure.
## Key Strategies for Building Scalable Applications
Modular Architecture: Use a modular approach to break down the app into smaller, manageable components. This makes it easier to scale specific parts of the app as needed.
- Cloud Solutions: Utilize cloud services for flexible and scalable infrastructure. Cloud platforms offer scalable storage, computing power, and other resources on demand.
- Load Balancing: Implement load balancing to distribute user requests across multiple servers, ensuring no single server becomes a bottleneck.
- Database Optimization: Optimize your database by using indexing, sharding, and replication techniques to handle large volumes of data efficiently.
- Asynchronous Processing: Use asynchronous processing to manage background tasks and heavy computations without blocking the main application flow.
- Microservices Architecture: Adopt a microservices architecture where different functionalities are handled by separate services that can be scaled independently.
## Conclusion
Future-proofing your app for long-term success requires a strategic focus on scalability from the very beginning. By hiring dedicated developers and partnering with a seasoned **[Android app development company](https://www.hyperlinkinfosystem.com/android-app-development-india.htm)**, you can ensure that your application is robust, efficient, and capable of handling growth. Investing in scalability is not just about managing increased loads but also about delivering a seamless and superior user experience, which is key to staying competitive in the ever-evolving digital landscape. | daniellehunter |
1,875,253 | Optimizing Software Development with DevOps Workflows | DevOps Workflow: Streamlining Software Development and Deployment A DevOps workflow is a structured... | 0 | 2024-06-03T10:52:48 | https://dev.to/saumya27/optimizing-software-development-with-devops-workflows-2n35 | devops, webdev, siftware | **DevOps Workflow: Streamlining Software Development and Deployment**
A DevOps workflow is a structured set of practices and processes designed to enhance the efficiency and quality of software development, integration, testing, and deployment. By integrating development (Dev) and operations (Ops) teams, a DevOps workflow promotes collaboration, automation, and continuous improvement, leading to faster delivery of software products with higher reliability and performance.
Key Components of a DevOps Workflow
Version Control:
Source Code Management (SCM): Tools like Git are used for version control, enabling teams to manage code changes, track history, and collaborate efficiently.
Branching and Merging: Structured workflows such as GitFlow or feature branching facilitate parallel development and integration.
Continuous Integration (CI):
Automated Builds: Code changes are automatically built and tested using CI tools like Jenkins, CircleCI, or Travis CI.
Integration Testing: Ensures that new code integrates smoothly with existing codebase, catching issues early in the development process.
Continuous Delivery (CD):
Automated Deployment: Once code passes the CI pipeline, it is automatically deployed to staging or production environments using CD tools like Spinnaker, Argo CD, or GitLab CI/CD.
Rollbacks and Rollouts: Ensures that deployments are seamless and allows quick rollbacks in case of failures.
Infrastructure as Code (IaC):
Configuration Management: Tools like Terraform, Ansible, and Chef manage infrastructure through code, ensuring consistency and repeatability.
Environment Provisioning: Automated setup of environments (development, staging, production) to ensure parity and reduce configuration drift.
Monitoring and Logging:
Real-Time Monitoring: Tools like Prometheus, Grafana, and Datadog provide insights into system performance and health.
Log Management: Centralized logging using tools like ELK Stack (Elasticsearch, Logstash, Kibana) or Splunk to diagnose and troubleshoot issues.
Continuous Feedback and Improvement:
Feedback Loops: Regular feedback from monitoring, testing, and user feedback is incorporated to improve the workflow and product quality.
Retrospectives and Reviews: Post-deployment reviews to discuss what went well, what didn’t, and how processes can be improved.
Benefits of a DevOps Workflow
Faster Time to Market:
Accelerated Development Cycles: Automation and continuous integration/delivery reduce manual tasks and speed up release cycles.
Early Bug Detection: Continuous testing catches issues early, reducing time spent on debugging later.
Improved Collaboration:
Cross-Functional Teams: DevOps fosters a culture of collaboration between development, operations, and other stakeholders.
Shared Responsibilities: Breaking down silos and sharing responsibilities enhances accountability and efficiency.
Higher Quality and Reliability:
Consistent Environments: IaC ensures that environments are consistent across all stages, reducing configuration-related issues.
Automated Testing and Monitoring: Continuous testing and real-time monitoring lead to more stable and reliable software.
Scalability and Flexibility:
Dynamic Scaling: Automated provisioning and deployment allow systems to scale up or down based on demand.
Adaptability: Agile practices within DevOps enable teams to adapt quickly to changes and new requirements.
Example DevOps Workflow
Code:
Developers write code and commit changes to a version control system like Git.
Build:
CI tools like Jenkins automatically trigger builds for new commits, running unit tests to validate changes.
Test:
Automated tests are executed to ensure code quality and functionality.
Release:
CD tools deploy the code to staging environments for further testing and validation.
Deploy:
Once validated, the code is automatically deployed to production environments using deployment pipelines.
Operate:
Operations teams monitor the application and infrastructure using tools like Prometheus and Grafana.
Monitor:
Real-time monitoring and logging provide insights into system health and performance, feeding back into the development process for continuous improvement.
Conclusion
A [DevOps workflow ](https://cloudastra.co/blogs/optimizing-software-development-with-devops-workflows)is essential for modern software development, enabling faster, more reliable, and higher-quality software delivery. By leveraging automation, continuous integration/delivery, and infrastructure as code, organizations can enhance collaboration, reduce time to market, and improve overall system performance and stability. Embracing DevOps practices leads to a more agile, responsive, and efficient development environment. | saumya27 |
1,875,252 | Tips for Property Management in Mohali Project Chandigarh | Investing in a property in the Mohali Project Chandigarh can be a lucrative venture, offering... | 0 | 2024-06-03T10:51:43 | https://dev.to/mohali_projects/tips-for-property-management-in-mohali-project-chandigarh-2hgm | Investing in a property in the Mohali Project Chandigarh can be a lucrative venture, offering opportunities for rental income, capital appreciation, and long-term wealth accumulation. However, effective property management is essential to maximize returns and ensure the smooth operation of your investment. In this blog post, we'll provide valuable tips for property management in the Mohali Project Chandigarh, helping you navigate the challenges and optimize the performance of your real estate assets.
**Understand the Market Dynamics**
Before diving into property management, take the time to understand the market dynamics in Mohali. Familiarize yourself with rental rates, vacancy rates, tenant preferences, and demand-supply trends. Stay updated on new projects, upcoming developments, and government initiatives that may impact the real estate market. A thorough understanding of the market will help you make informed decisions and adapt your property management strategies accordingly.
**Set Realistic Rent Prices**
Setting the right rent price is crucial for attracting tenants and maximizing rental income. Conduct a comparative market analysis to assess rent prices for similar properties in the Mohali Project Chandigarh. Consider factors such as location, size, amenities, and condition of the property when determining the rent. Aim for a competitive price that reflects the value of your property while remaining attractive to potential tenants.
**Screen Tenants Carefully**
Tenant screening is a critical step in property management to minimize the risk of rental defaults, property damage, and eviction issues. Implement a thorough screening process that includes background checks, credit checks, income verification, and references from previous landlords. Look for tenants with a stable income, good credit history, and positive rental references. Conducting due diligence upfront can save you time, money, and headaches down the line.
**Maintain the Property Regularly**
Regular maintenance is essential to preserve the value of your property and ensure the safety and comfort of your tenants. Schedule routine inspections to identify any maintenance issues or repairs that need attention. Addressing maintenance issues promptly can prevent them from escalating into costly problems and keep your property in top condition. Consider investing in preventive maintenance measures to prolong the lifespan of your property's systems and components.
**Communicate Effectively with Tenants**
Clear and open communication with tenants is key to fostering positive landlord-tenant relationships and resolving issues promptly. Establish clear channels of communication and respond to tenant inquiries, concerns, and maintenance requests in a timely manner. Keep tenants informed about any changes or updates related to the property, such as maintenance schedules, lease renewals, or policy changes. Building rapport with tenants can lead to long-term tenancies and positive referrals.
**Enforce Lease Policies Consistently**
Lease agreements serve as legal contracts that outline the rights and responsibilities of both landlords and tenants. Ensure that lease policies are clearly defined and enforced consistently for all tenants. Address any violations of lease terms promptly and follow the appropriate legal procedures if necessary. Consistent enforcement of lease policies helps maintain a harmonious living environment and protects the interests of both parties.
**Keep Financial Records Organized**
Maintaining accurate financial records is essential for effective property management and tax compliance. Keep detailed records of rental income, expenses, repairs, maintenance costs, and other financial transactions related to the property. Use accounting software or spreadsheets to track income and expenses, and retain receipts and invoices for tax purposes. Regularly review your financial records to monitor cash flow, track expenses, and identify areas for cost savings or optimization.
**Stay Updated on Legal and Regulatory Requirements**
As a property owner in Mohali, it's important to stay updated on legal and regulatory requirements governing landlord-tenant relationships and property management practices. Familiarize yourself with local laws, ordinances, and regulations related to rental properties, eviction procedures, security deposits, and fair housing practices. Stay informed about any changes or updates to the law that may affect your rights and obligations as a landlord.
**Consider Hiring Professional Property Management Services**
Managing a rental property can be a time-consuming and challenging task, especially if you have multiple properties or lack experience in property management. Consider hiring professional property management services to handle day-to-day operations, tenant relations, maintenance, and administrative tasks on your behalf. Property management companies have the expertise, resources, and industry knowledge to optimize the performance of your investment and ensure a hassle-free experience for both landlords and tenants.
**Stay Proactive and Responsive**
Property management requires proactive planning, problem-solving, and attention to detail. Stay proactive in addressing issues, resolving conflicts, and implementing improvements to enhance the value and appeal of your property. Be responsive to tenant feedback, concerns, and requests, and strive to provide exceptional customer service at all times. By staying proactive and responsive, you can maintain tenant satisfaction, minimize vacancies, and maximize the ROI of your investment in the Mohali Project Chandigarh.
Effective property management is essential for maximizing the ROI of your investment in the Mohali Project Chandigarh. By understanding the market dynamics, setting realistic rent prices, screening tenants carefully, maintaining the property regularly, communicating effectively with tenants, enforcing lease policies consistently, keeping financial records organized, staying updated on legal requirements, considering professional property management services, and staying proactive and responsive, you can optimize the performance of your real estate assets and achieve long-term success as a property owner in Mohali. | mohali_projects | |
1,875,251 | Content Marketing Trends for 2024: What You Need to Know | The Impact of Artificial Intelligence on Digital Marketing The digital marketing landscape has... | 0 | 2024-06-03T10:50:29 | https://dev.to/vaishnaviiii/content-marketing-trends-for-2024-what-you-need-to-know-3k5f | purplepromedia, digitalmarketingcompany, digitalmarketingagency, digitalmarketingservices |
**The Impact of Artificial Intelligence on Digital Marketing**
The digital marketing landscape has undergone significant transformations in recent years, with one of the most revolutionary changes being the integration of artificial intelligence (AI). As a technology that simulates human intelligence processes through algorithms and machine learning, AI has brought about unprecedented advancements in the way businesses approach their marketing strategies. For digital marketing agencies in Coimbatore, like Purple Pro Media, and others worldwide, AI has become an indispensable tool for delivering more efficient and effective digital marketing services.
**The Emergence of AI in Digital Marketing**
AI's rise in digital marketing can be attributed to its ability to process and analyze vast amounts of data rapidly. Traditional marketing methods often relied on manual data analysis, which was time-consuming and prone to errors. AI, however, can sift through massive datasets in real-time, identifying patterns and insights that would be impossible for humans to detect. This capability allows digital marketing agencies in Coimbatore and elsewhere to develop more targeted and personalized marketing campaigns.
**AI-Powered Customer Insights**
AI in digital marketing offers unparalleled advantages, particularly in generating deep customer insights. By analyzing user behavior across platforms such as social media, websites, and emails, AI algorithms can discern customer preferences, behaviors, and purchasing patterns. This data enables digital marketing agencies to craft highly personalized marketing strategies, ensuring that campaigns resonate more effectively with target audiences.
For example, AI can segment audiences more precisely, allowing marketers to tailor their messages to specific groups. This level of personalization increases engagement rates and improves conversion rates. [Digital marketing services in Coimbatore ](
https://purplepromedia.com/best-digital-marketing-agency-in-coimbatorerl)that leverage AI for customer insights can offer clients more effective marketing solutions, leading to higher customer satisfaction and loyalty.
**Enhancing Content Creation and Curation**
Content is king in digital marketing, and AI has significantly enhanced how content is created and curated. AI-powered tools can generate content ideas, write articles, and even produce videos. These tools analyze trending topics, audience preferences, and SEO data to create content that resonates with the target audience.
For instance, AI-driven content generators can create blog posts and social media updates that are relevant and optimized for search engines. This ensures that the content reaches a broader audience and ranks higher in search engine results. Digital marketing agencies in Coimbatore, such as Purple Pro Media, can leverage these AI tools to deliver high-quality content that drives engagement and enhances online visibility for their clients.
**Optimizing Advertising Campaigns**
AI has also revolutionized the way digital marketing agencies manage advertising campaigns. Traditional methods of managing ad campaigns involved a lot of guesswork and manual adjustments. AI, on the other hand, uses machine learning algorithms to optimize ad campaigns in real time.
AI can analyze the performance of various ad creatives, targeting options, and bidding strategies to determine the most effective combinations. This dynamic optimization leads to better ROI for advertising budgets. For digital marketing services in Coimbatore, this means offering clients more efficient and cost-effective advertising solutions. AI can also predict which types of ads are more likely to convert, allowing marketers to allocate resources more effectively.
**Improving Customer Service with AI Chatbots**
Customer service is a critical aspect of digital marketing, and AI chatbots have transformed how businesses interact with customers online. AI-powered chatbots can handle a wide range of customer inquiries, from answering frequently asked questions to assisting with online purchases.
These chatbots are available 24/7, providing instant responses and improving customer satisfaction. They can also gather valuable data on customer interactions, helping businesses understand common issues and preferences. Digital marketing agencies in Coimbatore can implement AI chatbots on their clients’ websites to enhance customer service and streamline communication.
Predictive analytics harnesses the power of AI to make profound impacts. Through thorough analysis of historical data and trend identification, AI can accurately predict future outcomes and behaviors. This capability empowers digital marketers by providing valuable insights for informed decision-making, campaign optimization, and anticipating customer needs with remarkable precision.
For example, predictive analytics can forecast which products are likely to be popular in the coming months or which customer segments are most likely to respond to a particular campaign. Digital marketing services in Coimbatore can leverage predictive analytics to provide clients with data-driven recommendations, leading to more successful marketing efforts.
**Enhancing Social Media Marketing**
Social media platforms are essential for digital marketing, and AI has transformed how businesses approach social media marketing. AI tools can analyze social media trends, monitor brand mentions, and track competitor activities. This information allows marketers to stay ahead of the curve and engage with their audience more effectively.
AI can also automate social media posting, ensuring that content is published at optimal times for maximum engagement. For digital marketing agencies in Coimbatore, AI-driven social media tools offer a competitive edge by enabling more efficient and effective social media strategies.
**Challenges and Future Prospects**
While AI offers numerous benefits, it also presents some challenges. One of the main concerns is the ethical use of AI, particularly in terms of data privacy and transparency. As AI systems become more sophisticated, it is crucial for digital marketers to use these tools responsibly and maintain the trust of their customers.
Looking ahead, the future of AI in digital marketing is promising. As technology continues to evolve, AI will become even more integrated into marketing strategies, offering new opportunities for innovation and growth. Digital marketing services in Coimbatore and around the world will need to stay updated with the latest AI advancements to remain competitive and deliver the best results for their clients.
**Conclusion**
The rise of artificial intelligence has fundamentally transformed digital marketing. For agencies in Coimbatore, like Purple Pro Media, AI offers powerful tools for enhancing customer insights, optimizing content, improving ad campaigns, and delivering superior customer service. As AI technology advances, its role in digital marketing will continue to grow, providing exciting opportunities for businesses to thrive. Embracing AI-driven digital marketing services in Coimbatore ensures businesses stay competitive and achieve sustained success. | vaishnaviiii |
1,875,249 | Short Ruby Newsletter - edition 93 published | Highlights from the 93 edition of Short Ruby Newsletter: Events: EuRuko, RailsWorld, and... | 0 | 2024-06-03T10:48:09 | https://notes.ghinda.com/post/short-ruby-newsletter-edition-93-published | programming, ruby, rails | Highlights from the [93 edition of Short Ruby Newsletter](https://newsletter.shortruby.com/p/edition-93):
- Events: EuRuko, RailsWorld, and BalticRuby announced the agenda and speakers. They have great lineups. Two returnees: Ruby Ireland and Barcelona.rb. SF Bay Area Ruby Meetup and Rails World Conf announced their next dates.
- Ruby 3.1.6 and 3.3.2 are released. Rails 7.2 beta is announced. You can upgrade today to Ruby 3.3.2 and should start adding Rails 7.2 to your CI
- Read an article written by *Why* in 2003 posted by Nick Schwaderer last week where Why says why SQLite is amazing. *Why* was/is ahead of his time
- You can see some code Samples about Hotwire patterns, fixtures, controllers, inline SVG, presence in helper, and rails validations.
- Code Design: You can read about how Campfire handles setting stimulus tags on more complex elements.
- Then, in the Choose Ruby section, read an inspirational thread by Irina Nazarova about Rails being the most productive way to build CRUD web apps in 2024 backed up with examples (see their names and numbers - income/market caps and more). Read also why DHH thinks people picked up Rails after watching the 15-minute blog video.
- In the Library section, discover a new gem, a code repo, and updates shared by gem maintainers.
- If you were to read one thing about the entire "drama" generated from outside the Ruby world this week, read Louis's take in the Related section. Don't miss Arian's learnings about building digital products there.
Of course, the newsletter has much, much more content.
Go to [https://newsletter.shortruby.com](https://newsletter.shortruby.com/p/edition-93) to read the latest edition. | lucianghinda |
1,875,248 | New In Selenium 4: The Ultimate Guide For Test Automation Engineers | Selenium 4, the latest major release of the popular web testing framework, brings several... | 0 | 2024-06-03T10:45:38 | https://dev.to/saumya27/new-in-selenium-4-the-ultimate-guide-for-test-automation-engineers-fgc | Selenium 4, the latest major release of the popular web testing framework, brings several enhancements and new features aimed at improving the efficiency and capabilities of automated web testing. Here's an overview of what's [new in Selenium 4](https://cloudastra.co/blogs/new-in-selenium-4-guide-for-test-automation-engineers).
**Key Features and Improvements in Selenium 4**
**W3C WebDriver Standardization:**
Selenium 4 fully complies with the W3C WebDriver standard, ensuring better compatibility and stability across different browsers and platforms.
**Improved IDE:**
The Selenium IDE has been revamped with new features, including support for editing test cases, improved debugging, and better code export options to various programming languages.
**New Browser DevTools Integration:**
Selenium 4 introduces support for Chrome DevTools and Edge DevTools, allowing testers to use powerful browser debugging tools. This includes network interception, performance analysis, and inspecting the DOM.
Relative Locators:
Selenium 4 introduces new relative locators (previously called friendly locators) that allow you to find elements based on their position relative to other elements.
WebElement password = driver.findElement(By.id("password"));
WebElement username = driver.findElement(with(By.tagName("input")).above(password));
**Enhanced Grid Architecture:**
Selenium Grid has been significantly improved with a new architecture that simplifies setup and supports Docker containers. This allows for more scalable and flexible test execution environments.
Features include observability support, enhanced logging, and dynamic grid configuration.
**Updated Documentation:**
Selenium 4 comes with improved and more comprehensive documentation, making it easier for new users to get started and for existing users to explore advanced features.
**Better Window and Tab Management:**
Enhanced support for managing multiple windows and tabs, including new commands to open and switch between them.
driver.switchTo().newWindow(WindowType.WINDOW); // Opens a new window
driver.switchTo().newWindow(WindowType.TAB); // Opens a new tab
**Deprecation of DesiredCapabilities:**
The DesiredCapabilities class has been deprecated in favor of browser-specific options classes, such as ChromeOptions, FirefoxOptions, etc. This change encourages more specific and accurate browser configurations.
ChromeOptions options = new ChromeOptions();
options.addArguments("start-maximized");
WebDriver driver = new ChromeDriver(options);
**Improved Action Class:**
The Actions class has been improved with more intuitive and comprehensive interactions for simulating complex user gestures like drag-and-drop, keyboard actions, and touch gestures.
Actions actions = new Actions(driver);
actions.moveToElement(element).clickAndHold().moveByOffset(100, 0).release().perform();
**Native Support for Chromium Edge:**
Selenium 4 includes native support for Microsoft’s new Chromium-based Edge browser, providing better integration and compatibility.
**Conclusion**
Selenium 4 brings a host of new features and improvements that enhance the capabilities of automated web testing. From compliance with the W3C WebDriver standard to new relative locators and better integration with browser developer tools, Selenium 4 makes it easier and more efficient to write, debug, and execute web tests. Whether you're new to Selenium or an experienced user, these enhancements will help you create more reliable and maintainable tests. | saumya27 | |
1,875,247 | Preferred Work Culture | It is crucial to consider the work culture of a company where you will be spending most of your time.... | 0 | 2024-06-03T10:44:40 | https://dev.to/bugz296/preferred-work-culture-5e09 | company, culture, job, hunt | It is crucial to consider the work culture of a company where you will be spending most of your time. I wanted to share my preference and what I think is best for early-career professionals seeking jobs. Here’s a list of essential elements for a positive work culture and actions you might need to consider as a leader:
**Communication**. A company with positive work culture should always have their channels open for feedbacks and suggestions (may that be a feedback to a specific part of existing process that you find not necessary). Comments must be clear and explained. If it is constructive criticism, actionable suggestions should be presented at the end. Without any, your comment might be regarded as nothing, or worst, an insult. Let the leader know what you think would help the company to easily come up with an idea.
Some managers might think that these kind of discussions are just a waste of time. Some would take this opportunity to let the rest of the team know why their suggestions are not feasible.
**Approachable leader**. Join a team with a leader not a boss. You'll find it hard to work with leaders who are not easy to talk with. Sharing your ideas will be challenging on top of the work you are tasked to do so. Little by little you'll be forced to think like you're always the wrong one and the boss' ideas are the right one, until, you do things that your boss only says. A leader who is invested in their member's growth should willingly brainstorm with their members and go over each of the suggestions if there's something that can be executed.
A strategy to effective learning is "sink or swim" or some even call it "trial by fire". This should not be applied everytime! This should depend on the situation and must be implemented with sensitiveness. One leader should not be using this approach for learnings that are too basic since this will lower one's self esteem and can be regarded as an insult. Instead provide the solution right away and allow time for coaching.
**Positive environment**. Working in a positive environment where leaders can effectively motivate their team. Tensions among team members must be resolved as soon as possible. As a leader, have them try resolving it first, if it needs intervention, leaders must go up to the ring and mediate.
**Work-life balance**. The organization must set policies encouraging colleagues to a work-life balance. This will give members time to set their attention to their respective families. They can use this to resolve any conflict that could be personally affecting the member's performace.
**Recognition and appreciation**. A leader who regularly recognize and appreciate your hard work and accomplishments is a positive reinforcement to do more and even better. This boosts your confidence and would make you think that you are on the right path. Always allow feedback and criticism, it will not always be a recognition and appreciation. Constructive criticism will tell that you are not perfect and will remind humility. Be glad if you are learning from your mistakes and your leader is pointing out specifically these mistakes are and gives advise. It is a total different story if they don't give any advise and just keep on throwing you negative comments.
**Respect**. I believe this is the most important element to a good work environment. This not only applies to leaders but colleagues as well. Respect each other's time, effort and space.
Be sensitive on other's time, especially for collaborating with colleagues with different timezones. One shouldn't be demanding a reply that's outside the respective working hour unless it is totally urgent.
These elements are by far what I think will summarize my preferred work culture. | bugz296 |
1,875,246 | PCD Pharma Franchises: Launch Your Path to Pharmaceutical Success in India | The Indian pharmaceutical industry is a juggernaut, and the PCD (Propaganda cum Distribution)... | 0 | 2024-06-03T10:44:39 | https://dev.to/fuelbiotech/pcd-pharma-franchises-launch-your-path-to-pharmaceutical-success-in-india-ddm | pcdpharma, franchise, business, healthbusiness | The Indian pharmaceutical industry is a juggernaut, and the PCD (Propaganda cum Distribution) franchise model offers an accessible gateway for entrepreneurs. But what exactly is a [PCD Pharma franchise](https://www.fuelbiotech.com/product-details/pcd-pharma-franchise)?Think of it as a pre-built business opportunity. You partner with an established pharmaceutical company, gaining access to their:
- Product Portfolio: Promote and distribute a diverse range of high-quality medications across various therapeutic segments.
- Brand Reputation: Leverage the franchisor's brand recognition to build trust with customers in your designated territory.
- Marketing Support: Many franchisors provide marketing materials and training programs to equip you for success.
Here's the beauty: You become your boss, managing sales and distribution within your territory. PCD franchises are typically low-investment ventures, making them ideal for aspiring business owners.
## But is a PCD Pharma franchise right for you?
- Are you passionate about healthcare and business?
- Do you possess excellent communication and sales skills?
- Are you driven to build your successful venture?
If you answered yes, then a PCD Pharma franchise might be the perfect launchpad for your pharmaceutical journey. Research reputable PCD Pharma companies, understand their offerings, and explore your entrepreneurial spirit! | fuelbiotech |
1,875,245 | CHAINLESS 2024 | GM Folks! Chain Abstraction is the new buzz in the web3 community and we want you to experience it... | 0 | 2024-06-03T10:43:39 | https://dev.to/hemant_chhabria_2063f663e/chainless-2024-2mj4 | web3, blockchain, development | GM Folks!
Chain Abstraction is the new buzz in the web3 community and we want you to experience it first hand with us!
We at **PYOR** are hosting India’s **first** event around chain abstraction and it contains everything **you** need to know for understanding Chain abstraction!
**[Chainless](https://www.gochainless.com/) 2024 x PYOR**
If you are:
👉 DApp builder
👉 Blockchain engineer,
👉 Or developer eager to dive into web3,
Join us on-
🗓️Date: June 8th
📍Location: Bangalore (The venue will be disclosed after the registration)
**And yeah, Food‘s on Us!!!**
Sign up **here**: https://lu.ma/goekcscj
See you there! 👾
PYOR | Interpretation Layer For Digital Assets.
| hemant_chhabria_2063f663e |
1,875,244 | Bí Kíp Tăng Diện Tích Cho Phòng Ngủ Diện Tích Nhỏ | Phòng ngủ là nơi ảnh hưởng nhiều nhất đến giấc ngủ của bạn nó là không gian quan trọng nhất trong... | 0 | 2024-06-03T10:41:47 | https://dev.to/sixhomedecor/bi-kip-tang-dien-tich-cho-phong-ngu-dien-tich-nho-27di | Phòng ngủ là nơi ảnh hưởng nhiều nhất đến giấc ngủ của bạn nó là không gian quan trọng nhất trong ngôi nhà của bạn. Phòng ngủ là tổ ấm, xả strest sau những ngày mệt mỏi. Tuy nhiên phòng ngủ diện tích nhỏ sẽ làm cho gia chủ cảm giác bí khi nghỉ ngơi và không đủ diện tích để trang chí thêm những dụng cụ yêu thích. Bạn có thể xem thêm bài viết [tại đây!](https://sixhomedecor.com/bi-kip-tang-dien-tich-cho-phong-ngu-dien-tich-nho/) | sixhomedecor | |
1,875,243 | Premium & Luxurious - Flats, Villas & Kothi's in Tri-City | The Tri-City region, encompassing Chandigarh, Mohali, and Panchkula, is quickly becoming one of the... | 0 | 2024-06-03T10:41:33 | https://dev.to/bestflatsvilas_/premium-luxurious-flats-villas-kothis-in-tri-city-1o0l | realestate, home, sale, flats | The Tri-City region, encompassing Chandigarh, Mohali, and Panchkula, is quickly becoming one of the most sought-after real estate destinations in India. With its state-of-the-art infrastructure, thriving business environment, and scenic beauty, this area offers an unmatched lifestyle. Whether you're in search of premium flats, luxurious villas, or spacious kothis, the Tri-City area has something to cater to every preference.
**Flats in Mohali**
Mohali stands out as a prominent hub for modern living. The flats in Mohali are designed with a perfect blend of contemporary architecture and top-notch amenities. Residents can enjoy a lifestyle of convenience and luxury with access to gyms, swimming pools, and landscaped gardens. Flats in Mohali are available in various configurations, making them suitable for young professionals, growing families, and retirees alike.
One of the key attractions of living in Mohali is its excellent connectivity. The area is well-connected to major highways and the international airport, ensuring seamless travel. Additionally, Mohali hosts numerous educational institutions, healthcare facilities, and shopping complexes, making it a perfect place to call home.
**Flats in Sunny Enclave**
Sunny Enclave is another jewel in the Tri-City real estate market. Known for its tranquil environment and well-planned infrastructure, flats in Sunny Enclave offer a serene retreat from the hustle and bustle of city life. These flats are equipped with all modern amenities, including 24/7 security, ample parking space, and recreational facilities.
Residents of Sunny Enclave enjoy easy access to key areas of Mohali and Chandigarh, thanks to its strategic location. The enclave is surrounded by green spaces, parks, and walking trails, making it an ideal place for families and nature lovers. The well-developed social infrastructure, including schools, hospitals, and shopping centers, adds to the appeal of flats in Sunny Enclave.
**Why Choose Tri-City?**
The Tri-City area is not just about beautiful homes; it's about a quality lifestyle. Here’s why investing in property in this region is a wise choice:
1. Modern Infrastructure: The Tri-City boasts world-class infrastructure with wide roads, efficient public transport, and well-maintained public utilities.
2. Educational Institutions: Home to some of the best schools and universities in the country, ensuring your children get the best education.
3. Healthcare Facilities: Numerous top-tier hospitals and clinics provide excellent healthcare services.
4. Recreational Facilities: With numerous parks, shopping malls, and entertainment zones, there's always something to do.
5. Business Opportunities: The area is rapidly growing as a business hub, offering ample employment opportunities and a conducive environment for startups.
**Top 5 Flats in Mohali**
Tri-City area is considered among the top 5 flats in Mohali, thanks to its superior construction quality, luxurious amenities, and strategic location. It is a preferred choice for many looking to buy new apartments and flats in Mohali.
**Contact Tri-City area Mohali**
If you are interested in buying a flat in Tri-City Mohali, you can contact their sales team for more information. Here are some key contact details you might need:
**Conclusion**
Tri-City Mohali offers a unique opportunity to buy premium and luxurious 3+1 flats in one of the most sought-after locations in Mohali. With its top-notch amenities, strategic location, and ready-to-move-in options, it stands out as a prime choice for homebuyers. Whether you are looking to buy 3BHK flats in Mohali or 2BHK flats, Tri-City area Mohali caters to all your needs, ensuring a comfortable and luxurious living experience.
Don't miss out on the chance to own a piece of this prestigious project. Contact Tri-City Mohali today and make your dream of owning a luxurious flat in Mohali a reality.
**Contact
**To get in contact with the Tri-City Mohali sales team, you can call their sale phone number at 8360422403. Their friendly representatives will be happy to provide you with all the details about the available units and pricing. Don't miss out – contact us today to book your site visit!
**For more information**
https://www.bestflats-vilas.com/
| bestflatsvilas_ |
1,875,242 | MS-102 Demystified A Beginner's Guide | MS-102 are designed by experienced MICROSOFT professionals and provide in-depth explanations and... | 0 | 2024-06-03T10:40:42 | https://dev.to/romem/ms-102-demystified-a-beginners-guide-3h57 | <a href="https://dumpsarena.com/microsoft-dumps/md-102/">MS-102</a> are designed by experienced MICROSOFT professionals and provide in-depth explanations and justifications. The]y also offer practice exams and simulations to help you prepare effectively.
Remember, utilizing MS-102 should complement, not replace, comprehensive studying and hands-on experience. Combine these resources with other study materials, such as official MICROSOFT documentation, practice labs, and online courses, to maximize your chances of success.
In the rapidly evolving landscape of information technology, staying ahead of the curve is not just an aspiration but a necessity. As professionals in the field are well aware, certifications play a crucial role in showcasing one's expertise and dedication to mastering the latest technologies. Among the myriad of <a href="https://dumpsarena.com/microsoft-dumps/md-102/">MS-102 exam dumps</a> certifications available, the MICROSOFT Certified Developer Associate (DVA-C01) stands out as a valuable credential for individuals seeking to validate their skills in developing and maintaining applications on the Exam topic Web Services (MICROSOFT) platform.
To maximize your chances of success in this certification journey, leveraging the best MS-102 is a strategic move.
Why MS-102Certification Matters
MICROSOFT has established itself as a leader in cloud computing, and the demand for skilled professionals who can navigate and harness the power of MICROSOFT services is continuously growing. The MS-102certification is specifically designed for developers who build applications on MICROSOFT.
It covers a range of topics, including but not limited to MICROSOFT services for serverless applications, security best practices, and troubleshooting.
Achieving the MS-102certification not only validates your skills in MICROSOFT development but also enhances your credibility in the industry. Employers globally recognize MICROSOFT certifications as a benchmark for technical proficiency, making MS-102a valuable asset for anyone working with or aspiring to work with MICROSOFT.
Click here more info>>>> https://dumpsarena.com/microsoft-dumps/md-102/ | romem | |
1,875,029 | Host web application on EC2 instance with Ansible Playbook | Ansible is an open-source automation tool used for configuration management, application deployment,... | 0 | 2024-06-03T10:35:48 | https://dev.to/rgupta87/host-web-application-on-ec2-instance-with-ansible-playbook-346o | ansible, ansibleplaybook, aws, ec2 | **<u>Ansible</u>** is an open-source automation tool used for configuration management, application deployment, orchestration, and task automation. It is designed to simplify complex IT workflows and streamline repetitive tasks across large infrastructures.
**<u>Project Summary</u>**
In this project, lets learn about launching an application with configuration management tool Ansible. Launching a web application using an Ansible playbook involves several steps, including setting up the infrastructure, installing necessary software, and deploying the application. Here is a simplified example of an Ansible playbook that can help you deploy a web application
**<u>Prerequisites</u>**
**1. AWS Account** - you should have a valid AWS account to launch EC2 instances for installing ansible and hosting an application.
**2. Linux Background** - should have some background on Linux as we will be running various commands.
**<u>Step 1 - Launch AWS EC2 instance using Ubuntu & CenOS</u>**
- **Launch Ubuntu Instance for Ansible** - Use **t2.micro** instance type (Free tier) with name as **'Control'**. This is the instance where we will install the Ansible and use it as control machine for other webservices or application (installed on another EC2 instance).
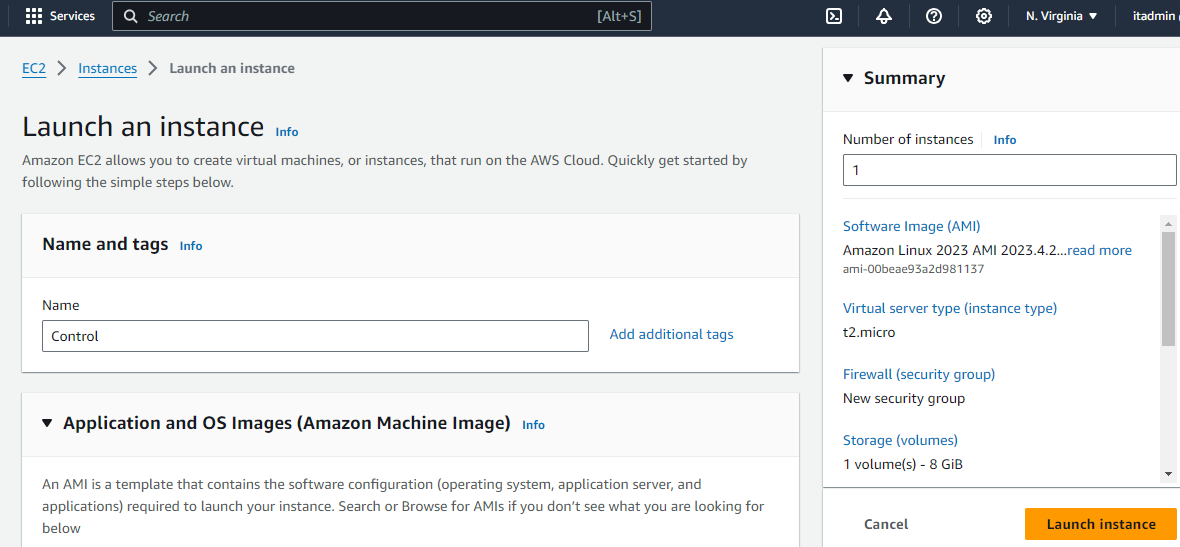
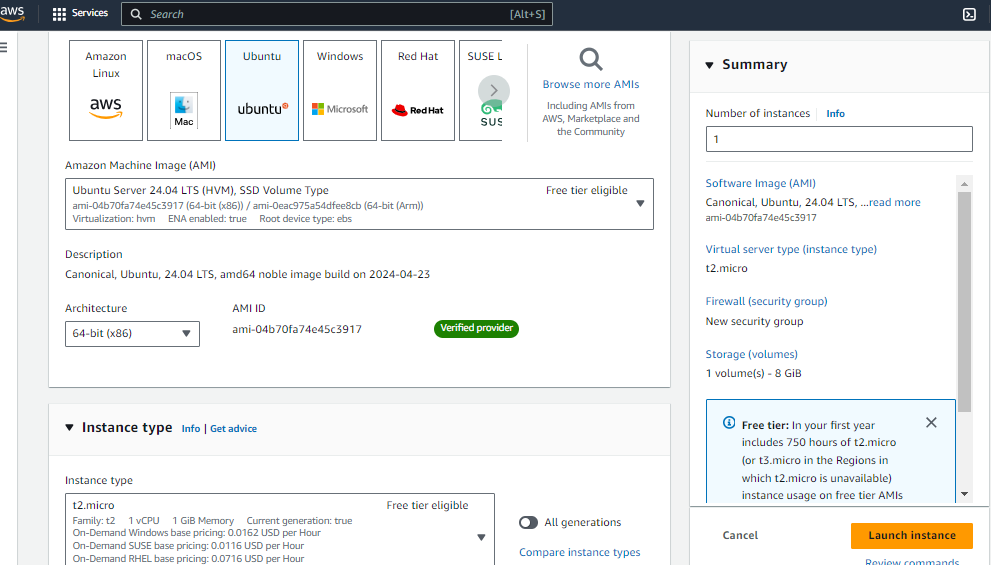
- **Key Pair** - Create new key pair with control-key.pem file
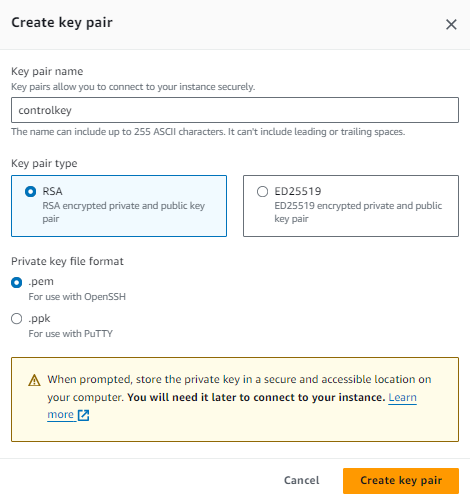
- **Security Group** - Create new security group with **inbound rules** to allow port 22 from my IP address and launch the instance.
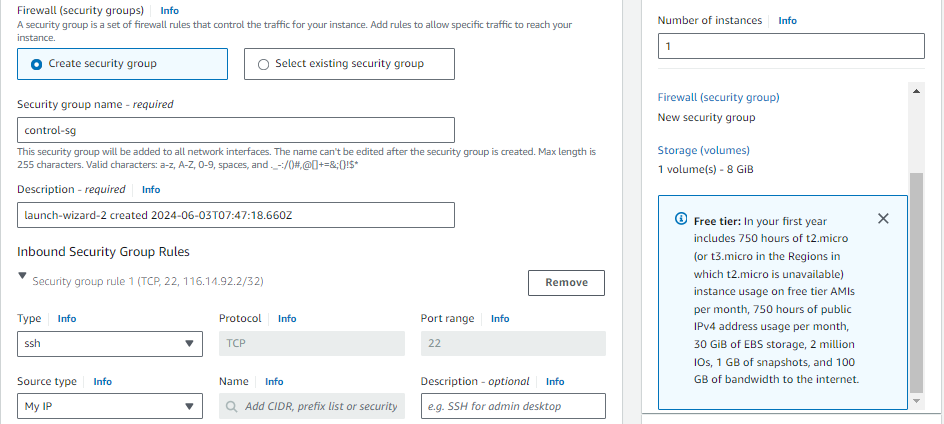
- **Launch CentOs Instance for web services** - Use **t2.micro** instance type (Free tier) with name as **'web01'**. This is the instance where we will deploy web application. For OS, go to 'Browse more AMI'-> AWS Marketplace AMIs and search for centos9.
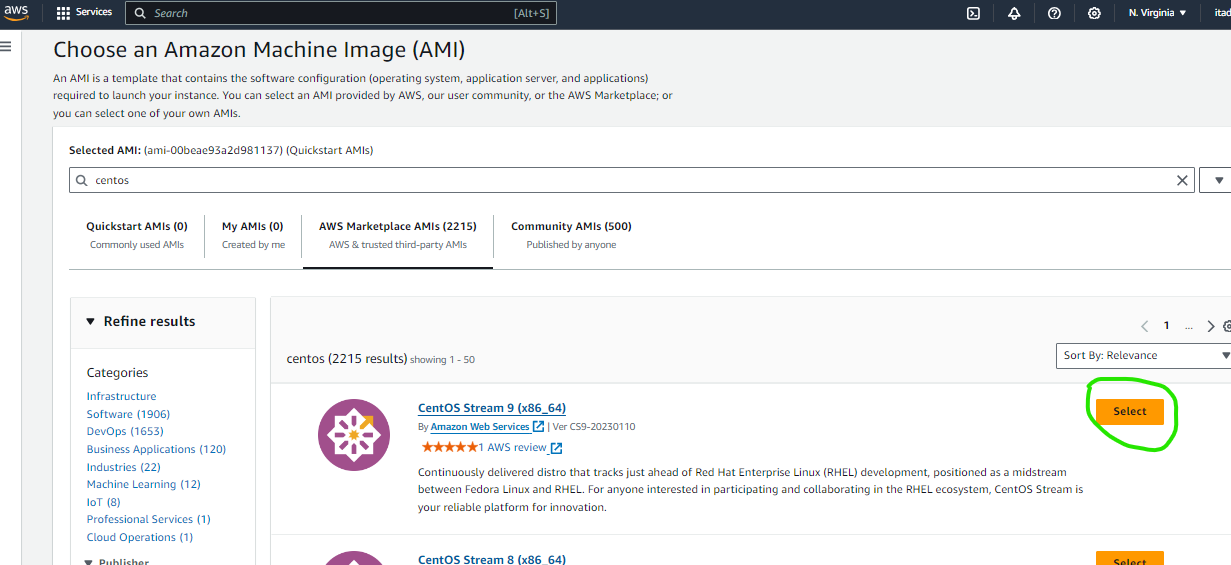
- **Key Pair** - Create new key pair with client-key.pem file.
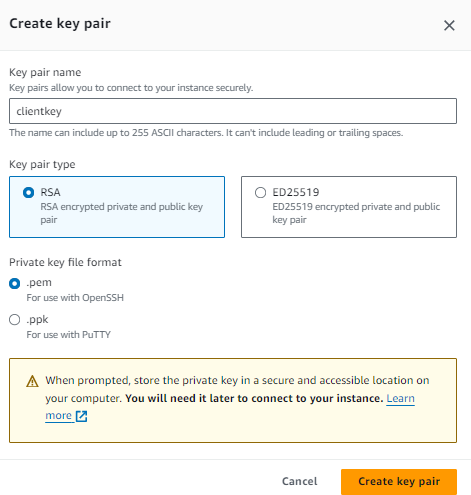
- **Security Group** - Create new security group with **inbound rules** to allow **port 22** from my IP address & from Ansible security group too. Also allow **port 80** (http) from my IP address. After this launch the instance.

**<u>Step 2 - Installing Ansible on Ubuntu OS</u>**
- **SHH into Control Instance** - SSH into the control EC2 instance and to login.
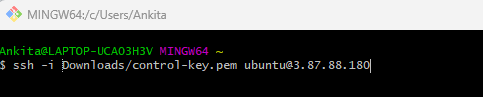

- **Install Ansible** - Using below mentioned commands, Install Ansible software in your control EC2 instance.
```
$ sudo apt update
$ sudo apt install software-properties-common
$ sudo add-apt-repository --yes --update ppa:ansible/ansible
$ sudo apt install ansible
```
**<u>Step 3 - Create project directory, Inventory and playbook files</u>**
- **Create new directory** - After Ansible installation, create a new directory 'project1' where we will create the Ansible playbook for web appl.


- **Inventory file** - Create a inventory file inside the 'project1' directory. The purpose of this file is to defines the hosts and groups of hosts upon which commands, modules, and tasks in a playbook operate. Sample inventory file code will looks like below. Make sure the spacing or indentation is correct while using inventory file.
```
all:
hosts:
web01:
ansible_host: 172.31.17.59
ansible_user: ec2-user
ansible_ssh_private_key_file: clientkey.pem
```
```
**explanation:-**
hosts = web01 (give you web instance
ansible_host = should be the private IP address of your web01 instance
ansible_ssh_private_key_file = should be the private key that you use to authenticate with web01 instance
```
- **Client Key** - Since we are using clientkey.pem in our inventory file, we need to copy the private key of client EC2 instance to 'project1' directory with the same name that we have given in inventory file i.e clientkey.pem. This is to authenticate the web01 server.
- **Key Permission** - After copying the private key to clientkey.pem and place it into 'project1' directory, you need to modify the permission of the key.
Current Permission:

Modify the permission using below command:-
```
chmod 400 clientkey.pem
```
After modification, it should be as per below:-
```
ubuntu@control:~/project1$ ls -l
total 16
-r-------- 1 ubuntu ubuntu 1675 Jun 3 09:18 clientkey.pem
```
- **Ansible Playbook** - An Ansible playbook is a file written in YAML (Yet Another Markup Language) that defines a series of automation tasks to be executed on managed nodes. Playbooks are the heart of Ansible's configuration management, allowing users to describe configurations, deployments, and orchestrations in a straightforward, human-readable format. Lets create Ansible playbook with name '**web01.yaml**'.
```
---
- name: Webserver setup
hosts: web01
become: yes
tasks:
- name: Install httpd
ansible.builtin.yum:
name: httpd
state: present
- name: Start service
ansible.builtin.service:
name: httpd
state: started
enabled: yes
- name: Copy the index file or template
copy:
src: myfile/index.html
dest: /var/www/html/index.html
```
```
**explanation:-**
name - This is the name of the ansible playbook or task, you can give based on your choice.
hosts - This is the host name which you have given in the inventory file
tasks - It stores the list of tasks that you want to execute automatically
```
**<u>Step 4 - Run and Test the application</u>**
- **Run** - Finally its time to run the command as per below to execute the playbook and deploy the application to web server (which is web01 EC2 instance)
```
ansible-playbook -i inventory web01.yaml
```
Output should be as per below:-
- **See Application on Browser** - Lets take the public Ip address of the web01 instance and paste into the browser and a simple web application should be launched:-
**Note**:- Make sure that security group of web01 instance should allow inbound rule for port 80 through control (ansible) instance from my IP or anywhere. If you are not doing this then it will timeout.
**<u>Conclusion!</u>**
Deploying a web application using Ansible on an AWS EC2 instance offers a powerful and automated solution to streamline the process of provisioning infrastructure, installing necessary software, and managing application deployments. By leveraging Ansible's playbooks, you can ensure consistent, repeatable, and scalable deployments, significantly reducing manual intervention and potential errors. This approach not only enhances operational efficiency but also allows for rapid iteration and deployment of web applications. Whether you are managing a single server or a complex infrastructure, using Ansible to automate the deployment process on AWS EC2 instances empowers you to focus more on developing and improving your application rather than dealing with infrastructure complexities.
**Happy Learning!**
| rgupta87 |
1,875,239 | Découvrez Bilan-de-compétences.com : Votre guide pour une carrière épanouissante | Bonjour à tous, Avez-vous déjà ressenti le besoin de faire le point sur votre carrière... | 0 | 2024-06-03T10:29:34 | https://dev.to/thomasdurant/decouvrez-bilan-de-competencescom-votre-guide-pour-une-carriere-epanouissante-52gn | Bonjour à tous,
Avez-vous déjà ressenti le besoin de faire le point sur votre carrière professionnelle ? Vous êtes-vous déjà demandé quelles étaient vos véritables compétences et comment les mettre en valeur dans le monde du travail ? Si oui, ne cherchez pas plus loin : http://www.bilan-de-compétences.com est là pour vous aider !
Notre site web, www.bilan-de-compétences.com, est une ressource précieuse pour tous ceux qui souhaitent prendre le contrôle de leur carrière et atteindre leurs objectifs professionnels. Que vous soyez à la recherche d'un nouvel emploi, que vous envisagiez une reconversion professionnelle ou que vous souhaitiez simplement évoluer dans votre poste actuel, notre plateforme propose une multitude de conseils, d'outils et de ressources pour vous accompagner dans votre démarche.
Sur http://www.bilan-de-compétences.com , vous trouverez :
Des articles informatifs sur le processus de bilan de compétences et ses avantages.
Des guides pratiques pour identifier vos compétences, établir vos objectifs et planifier votre parcours professionnel.
Des témoignages inspirants de personnes ayant réussi leur bilan de compétences et transformé leur carrière.
Des outils et des exercices pour évaluer vos aptitudes, vos intérêts et vos valeurs professionnelles.
Une communauté active et bienveillante prête à vous soutenir et à vous encourager tout au long de votre démarche.
Que vous soyez un professionnel expérimenté ou un jeune diplômé, Bilan-de-compétences.com est votre allié pour construire une carrière épanouissante et alignée sur vos aspirations personnelles.
N'hésitez pas à visiter notre site dès maintenant et à découvrir tout ce que nous avons à vous offrir. Nous sommes convaincus que vous trouverez les ressources dont vous avez besoin pour prendre les rênes de votre avenir professionnel !
À bientôt sur www.bilan-de-compétences.com !
Cordialement,
L'équipe de Bilan-de-compétences.com
| thomasdurant | |
1,875,238 | GB WhatsApp Pro APK Download v17.76 Official Anti-Ban (Jun 2024) | GB WhatsApp has become a highly popular alternative to the original WhatsApp due to its extended... | 0 | 2024-06-03T10:28:47 | https://dev.to/samreen_c311994d93296a368/gb-whatsapp-pro-apk-download-v1776-official-anti-ban-jun-2024-21da | gbwhatsapppro, gbwhatsapp, gbwhatsappdownload, webdev | GB WhatsApp has become a highly popular alternative to the original WhatsApp due to its extended functionalities and customization options. Many users prefer GB WhatsApp Pro for their unique features and reliability.we will delve into the features of The GB WhatsApp Pro that have made it a preferred choice for millions worldwide.
[Read More](
https://gbapkapp.in/) | samreen_c311994d93296a368 |
1,875,237 | Tekken 3 APK Download Latest Version For Android/iOS (All Unlocked) | Tekken 3 is a popular fighting game developed and published by Namco (now Bandai Namco... | 0 | 2024-06-03T10:26:18 | https://dev.to/samreen_c311994d93296a368/tekken-3-apk-download-latest-version-for-androidios-all-unlocked-14ho | tekken, tekken3, tekken8, webdev | Tekken 3 is a popular fighting game developed and published by Namco (now Bandai Namco Entertainment). It was released to the arcades in 20 march 1997, This is the third series of Tekken series which is liked the most by the gamers and since then till today Tekken 3 is loved in the hearts of people.Even now, many people still enjoy playing Tekken 3 a lot. But nowadays, gamers prefer playing it on their Android phones more. This is because phones let us play Tekken 3 anytime and anywhere we want.

[Read More](
https://tekken5.in/tekken-3-apk-download/) | samreen_c311994d93296a368 |
1,875,236 | Elastic Beanstalk: Developer's AWS paradise | Beanstalk in a nutshell Starting with the cloud can be pretty intimidating because of all... | 0 | 2024-06-03T10:24:56 | https://dev.to/marbleit/elastic-beanstalk-developers-aws-paradise-41g5 | web, backend, programming, tutorial | ## Beanstalk in a nutshell
Starting with the cloud can be pretty intimidating because of all the fancy words you hear while learning. Auto-scaling and resource provisioning are just a couple of phrases that may be confusing for new developers. Besides that, most developers just want their code to run without digging deep into hosting technology, especially when deadlines are approaching.
Enters the room, Elastic Beanstalk. It is a managed service that helps developers run their web applications fast and without worrying about best practices in the AWS environment. It is used by both new and more experienced developers since it is easy to set up but also rich with features so you can tailor your system to your custom needs.
But first, what does managed service even mean? It means AWS itself is managing everything. You don't need to worry about updates, security patches, and every other detail essential for running the application securely and consistently.
What is your job, then? Provide an overview of what your system needs and upload code. It is that simple. You simply upload your code, and Elastic Beanstalk automatically handles the deployment, from capacity provisioning, load balancing, and automatic scaling to web application health monitoring.
## How it works?
Beanstalk works with the application/environment model. You create your application, and then you can have multiple environments for it. This basically means you can have completely different system architectures for different environments. For example, your server could run in only one instance for the development environment but have scaling functionalities implemented for production. And what do you need to do there? Just pick the options for scaling. Pick how many instances should be running minimally and maximally. Pick the thresholds for spinning new instances and terminating unused instances. Everything else is managed by Beanstalk itself.
You have the freedom to choose the deployment options for your applications. Some of them are all at once, Rolling, and Blue/Green. These will not be covered in this blog post, but they are mentioned to point out the vast range of features Beanstalk has.
## Supported Platforms
Beanstalk supports a wide variety of platforms. The list is as follows:
- GO
- JAVA SE
- JAVA Tomcat
- .NET with IIS
- NodeJS
- PHP
- Python
- Ruby
- Packer builder
- Single Container Docker
- Multi Container Docker
- Preconfigured Docker
New platforms are added constantly. There is also one nice feature that makes Elastic Beanstalk perfectly capable of every need you can think of. It is called a Custom platform. You can completely configure the platform you need for your applications. This is very important for companies that have a lot of custom system configurations. The custom platform has a major drawback though. It is seen as a very advanced feature which means that it is not easy at all to create your personalized platform.
## Beanstalk CLI
We can install an additional CLI called the EB CLI, which makes working with Beanstalk from the CLI easier. It’s helpful for your automated deployment pipelines!
After configuring the environment, you can set up one command to deploy your whole application.
## Creating your first Beanstalk web app
**Starting point**
First, log into your AWS account and search for Elastic Beanstalk.When you land on the EB service home page, click on Create a new application.
You will then be redirected to the page shown below:
This is where you give your application a name, pick a platform, and upload your code. This is basically all you need to do for your application to be deployed. Of course, you can manually configure it in more detail by clicking the Configure more options button. This is what we will do to check more in-depth configurations.
As you can see, you can use the Sample application code. AWS has sample source codes for every platform, so you can learn the most common Beanstalk features without writing any code yourself.
**Overview of most common environment configurations**
After clicking on the Configure More options button, you will land on the Configure environment page:
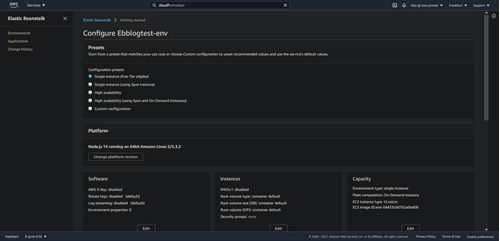
This is where the magic happens. As you can see, configurations are categorized, making it easier to configure individual resources for your application.
We will go through the most important ones, but feel free to experiment with them all. Just be aware that, even though Beanstalk is free, resources provisioned by it, that are out of the free tier will be charged, so don't forget to check the pricing pages or erase all of the resources if you are just researching Beanstalk capabilities.
**Presets:**
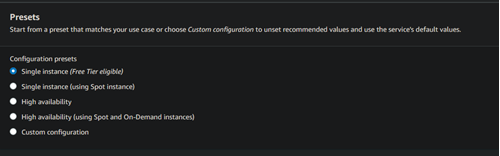
Presets, also called deployment modes, tell Beanstalk the overall architecture you want for your environment. Single-instance presets are great for development and testing. As the name suggests, they use one instance (server) to run your web app.
High-availability presets are most commonly used in production. They leverage the load balancer features and use auto-scaling.
**Platform:**

This is the place where you can pick your platform and its version.
**Software:**
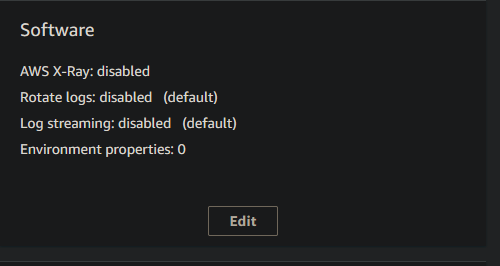
The software category is used for your software-related configs. In software configuration, you can set your environment variables (called environment properties here). Bye-bye, env files.
**Instances:**
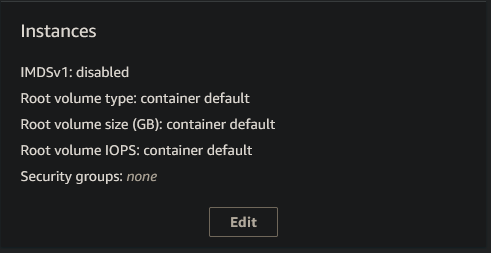
Here, you can configure your instances' memory resources and public availability. In high-availability applications, it is best practice to keep your instances private while the load balancer is public, which will route all the traffic to your application.
**Load balancer:**
Load balancer type, as well as listeners, protocols and ports, are configured here.
**Capacity:**
In the capacity section, you choose your EC2 instance type and system image. This is basically the same old-school EC2 configuration.
**Security:**
Last but not least, security. This is where the role that performs all the deployment actions on your behalf is created. It is also where you will need to create and assign private keys for SSH access to your instance(s).
After you are ready, click on Create an App and let Beanstalk create every resource for your application. After a few minutes, you should land on the page below, and if everything is OK, your application should be fully deployed.
Use the link below the environment name to visit your Beanstalk application.
## Conclusion
This is just scratching the surface of one of the most powerful tools AWS is providing to developers. I hope I can show you how EB can save developers time every day while also being a platform where developers can learn about cloud best practices. Elastic Beanstalk is the service you should definitely have in your cloud tools arsenal.
Aleksandar Polić
| marbleit |
1,875,235 | Mini Soccer Star MOD APK 1.22 Download für Android | Download Here Mini Soccer Star ist mehr als nur ein gewöhnliches Fußballspiel. Es bietet eine... | 0 | 2024-06-03T10:23:02 | https://dev.to/cvxd/mini-soccer-starmod-apk-122-download-fur-android-5a34 | ios, android, apk, app | [Download Here](https://apkrabi.com/de/mini-soccer-star/)
Mini Soccer Star ist mehr als nur ein gewöhnliches Fußballspiel. Es bietet eine Kombination aus realistischen Spielmechaniken, beeindruckender Grafik und einer tiefgehenden Karriereentwicklung. Als Spieler übernimmst du die Kontrolle über einen aufstrebenden Fußballstar, trainierst ihn, managst seine Karriere und führst ihn zu Ruhm und Ehre. | cvxd |
1,875,233 | Using the Web as your API | In our last article we demonstrated how to build an AI-bases shopping cart that can basically sell... | 0 | 2024-06-03T10:21:20 | https://ainiro.io/blog/demonstrating-our-new-ai-functions | ai, openai, chatgpt | In our [last article](https://ainiro.io/blog/how-to-build-a-shopping-cart-ai-chatbot) we demonstrated how to build an AI-bases shopping cart that can basically sell items directly from within our AI chatbot.
In this article we take it one step further by asking our chatbot how the weather is tomorrow, for then to find the best restaurants in our city, and having the AI chatbot then list the restaurant's reviews on TripAdvisor - For then to finish up with giving us the restaurant's phone number such that we can call and book a table.
We even use our AI chatbot to hire a ProductHunt hunter for us, by having the AI chatbot crawl and scrape ProductHunt, giving us the LinkedIn profile page of today's winner.
{% embed https://www.youtube.com/watch?v=ITxmDNUCisI %}
## How it works
Basically, we're using a combination of system messages (instructions) and a VSS-based RAG database. Our most important functions, such as _"scrape the web"_ and _"search the web"_ can be found in our system message. While edge functions, typically not that important, are found in our RAG database as training snippets.
When we tell OpenAI that we want to search the web, it will return something resembling the following.
```
___
FUNCTION_INVOCATION[/modules/openai/workflows/workflows/web-search.hl]:
{
"query": "[query]",
"max_tokens": "[max_tokens]"
}
___
```
It will always be invoked with 4,000 as `max_tokens`, but the query itself will be dynamically created by ChatGPT, to create an optimised search query, more likely to return the correct result. If we for instance ask the question _"Does Magnus Carlsen have a girlfriend? Create a two paragraph summary"_, the AI chatbot will probably end up searching for _"Magnus Carlsen girlfriend"_, before scraping the top results from DuckDuckGo, and creating a two paragraph summary.
The point being that the above filepath after our `FUNCTION_INVOCATION` is a Hyperlambda workflow, that invokes DuckDuckGo with a search query, scrapes the top results until it's got enough tokens, and then sends the result back to OpenAI again to answer our original question. Below is the sequence.
1. Invoke ChatGPT
2. If ChatGPT doesn't return a function we're done
3. If ChatGPT returns a function invocation we execute that function
4. Our cloudlet invokes ChatGPT again, now with the result of our function invocation, to answer the original query supplied by the user
The whole thing is recursive in nature, allowing us to phrase questions implying multiple function invocations such as for instance.
> Search for xyz and create a 5 paragraph summary. Then find the authors of each article and find their LinkedIn profiles.
For security reasons to avoid infinite loops eating up your OpenAI tokens, we stop the process after a maximum of 5 invocations towards OpenAI.
## Wrapping up
In the above video we demonstrate how to check the weather, how to search TripAdvisor for a restaurant in some specific city, how to follow links to each restaurant's TripAdvisor profile, and listing the top 5 reviews for a specific restaurant. We then ask our AI chatbot if it can find one of our restaurant's websites, scrape it, and return the phone number such that we can book a table.
Afterwards we ask our AI chatbot to list all products at ProductHunt, crawl into 3 individual launches, find the creators, for then to search the web for one of our creator and create a summary of her skills. Then we ask the AI chatbot to find the person's LinkedIn profile, and return this as a hyperlink to us.
3 days ago all of this was pure science fiction, and not even ChatGPT can do stuff such as this. Today it's all available for you in your AINIRO cloudlet to install into your AI chatbot.
| polterguy |
1,875,232 | The Software Testing Pyramid: Ensuring Robust and Reliable Software | Introduction We all know what a "software" is, but then what is software testing or why is it even... | 0 | 2024-06-03T10:20:54 | https://keploy.io/blog/community/understanding-the-different-levels-of-the-software-testing-pyramid | webdev, programming, python, productivity |

**Introduction**
We all know what a "software" is, but then what is software testing or why is it even important? Let me answer your doubts- Software Testing is a process that involves evaluating software components to ensure they meet specified requirements and are defect-free. The main goal of software testing is to verify that the actual software matches the expected requirements, enhancing the product quality and customer satisfaction.
Now that you've understood what software testing is, lets know about the testing pyramid,- the Software Testing Pyramid is a conceptual framework that is used in software development to provide a path or guide to the testing process. It consists of different layers of testing, that focuses on specific aspects of the software's functionality, performance and reliability.
**Understanding the Layers of Software Testing Pyramid**
**Unit Testing**
Unit testing is a type of software testing that focuses on individual units or components of a software system. And, the purpose of unit testing is to validate that each unit of the software works as intended and meets the requirements. Unit testing are generally performed by the developers, and it is performed early in the development process before the code is integrated and tested as a whole system.
Unit tests form the base of the pyramid and are the most numerous.
They are fast to write and execute, allowing developers to run them frequently as part of the continuous integration process.
Unit tests are generally faster to execute and helps in early detection of bugs, and they also contributes towards a better and more integrated code design.
But we have to keep in mind that, unit tests have limited scope and only tests individual unit or components, so it doesn't ensures the absence of bugs in the overall system. And also, maintaining a comprehensive suite of unit tests can require significant overhead in terms of development time and effort.
**Integration Testing**
Integration testing is the process of testing the interface between two software units or modules. It focuses on determining the correctness of the interface and is used to expose faults in the interaction between integrated units. Generally, once all the modules have been unit-tested, integration testing is performed.
Integration tests make up the middle layer of the pyramid.
They are fewer in number compared to unit tests, but more complex and slower to execute.
They are run less frequently than unit tests, typically at key points during the development cycle.
Integration tests helps in identifying the issues that arise when integrating individual components, such as incompatible interfaces or data flow problems; which increases our confidence that the integrated components of the system are working together correctly.
But the integration tests can be more complex to set up and maintain compared to unit tests due to the need of sequential interactions between multiple components. Also, it typically take longer to execute, which can impact the development speed.
**End-to-End (E2E) Testing**
End-to-end testing evaluates the entire software application from start to finish, simulating a real-world user scenarios. It tests the flow of data and processes across multiple layers and components to validate the overall functionality and performance of the software.
E2E tests sit at the top of the pyramid and are the least numerous.
They are the most complex and time-consuming to write and execute.
They are run less frequently, often before major releases, to validate the overall system functionality.
E2E tests provides us the assurance that the system behaves correctly from the user's perspective, and a comprehensive validation of system behavior. Passing E2E tests gives us the confidence that the software is ready for release, as it ensures that critical user workflows function correctly.
But we have to keep in mind that, E2E tests can be more prone to breakage due to changes in UI elements or environmental factors, leading to maintenance overhead. And also, identifying the root cause of failures in E2E tests can be challenging, especially when dealing with complex interactions across different components.
Advantages of using Software Testing Pyramid
The pyramid of Software Testing is crucial for maintaining the quality and reliability of any software applications, especially if it has a large user-base and a large scale. By dividing the testing process into different layers, it helps identify and address defects at various stages of the development lifecycle, leading to higher-quality software products with great performance and reliability. And overall, this will uplift the user experience and also make things convenient for the development team.
Efficient Test Coverage: The pyramid model ensures comprehensive test coverage by addressing different levels of the software architecture.
Early Bug Detection: By conducting tests at lower levels, such as unit testing, bugs and issues can be identified and resolved early in the development process.
Faster Feedback Loop: Automated testing at lower levels allows for quicker feedback on code changes, facilitating rapid iteration and deployment.
Challenges in Software Testing
Implementing a software testing pyramid can be hard, especially in those cases where the codebase is already large and huge. Some of the other major issues includes,
Initial Setup and Infrastructure: Setting up the automated testing framework and infrastructure requires a lot of time and resources.
Test Maintenance: Keeping the tests up-to-date and relevant as the software evolves can be a challenge.
Skill and Training: Teams may require training and expertise in automated testing practices and tools.
Best Practices for Implementing Software Testing Pyramid
To effectively implement the Software Testing Pyramid, we must consider the following practices, so that it becomes cost-effective, easy to implement and sustainable:
Start Early: Beginning the testing activities as early as possible during the development phase.
Automate Tests: Automating the tests wherever possible to streamline the testing process and increase the efficiency.
Prioritize Tests: Focusing on the high-priority tests that cover critical functionalities and scenarios.
Continuous Integration: Integrating testing into the continuous integration and delivery pipeline for faster feedback and validation.
Keploy : A potential solution?
Writing manual test cases is really tedious, boring and time consuming, and that is exactly where Keploy kicks in!!
Keploy is an E2E testing platform with Developer Experience that generates tests-cases and data mocks from API calls. It converts API calls into testcases. Mocks are automatically generated with the actual request or responses.
There are a lot of niche software testing process other than the three we have explained in here. These includes Load Testing, Stress Testing, Regression Testing, Performance Testing, Security Testing, Compatibility Testing, Usability Testing, System Testing, etc.
But Keploy specifically focuses on E2E Testing and addresses its major short:
It uses a record-replay approach. So while in the record mode, Keploy captures real API interactions between our application and its dependencies (databases, external services, etc.), which eliminates the need to manually write the test cases, saving a lot of time and effort.
As our application changes during the development process or after update cycles, manually written E2E tests often become outdated. But, Keploy automatically generates tests based on the real-world usage, reducing maintenance overhead.
While testing, we often require mocking external dependencies to isolate the application under test. But, Keploy can record and replay these interactions, ensuring consistent test environments.
Recently, I was building a Flask app using MongoDB. And by using Keploy I was not only able to complete the API testing for the application, but also generate and check the test coverage for my unit tests; and that too, by running a few CLI commands. It's that simple and easy!!
Conclusion
Multi-national companies like Google, Amazon, and Netflix have successfully implemented Software Testing Pyramid in their development processes. They leverage a combination of automated testing tools, continuous integration practices, and a policy of quality assurance to deliver robust and reliable software products.
In conclusion, the Software Testing Pyramid provides a structured approach to software testing, allowing teams to efficiently identify and address defects throughout the development lifecycle. By dividing testing efforts into different layers and prioritizing automation, organizations can achieve higher-quality software with faster time-to-market.
**FAQ's**
**What is the Software Testing Pyramid?**
The Software Testing Pyramid is a framework that divides software testing into three layers: unit testing, integration testing, and end-to-end testing, with the aim of ensuring comprehensive test coverage and early bug detection.
**Why is the Software Testing Pyramid important? **
The pyramid helps in identifying defects early in the development process, ensuring efficient test coverage, and maintaining software quality, ultimately leading to robust and reliable software products.
> What are the advantages of using the Software Testing Pyramid?
Efficient test coverage, early bug detection, faster feedback loop, and improved software quality are some of the advantages of using the Software Testing Pyramid.
**What are the challenges in implementing the Software Testing Pyramid?**
Challenges include initial setup and infrastructure, test maintenance, and skill and training requirements for the teams involved.
What are some best practices for implementing the Software **Testing Pyramid?**
Starting testing early, automating tests, prioritizing critical functionalities, and integrating testing into the continuous integration pipeline are some best practices for implementing the Software Testing Pyramid.
**TLDR:** The Software Testing Pyramid is a framework in software development that divides testing into different layers - unit testing, integration testing, and end-to-end testing. It helps in identifying defects early, ensuring efficient test coverage, and maintaining software quality. Implementing the pyramid can be challenging but following best practices like starting testing early, automating tests, and prioritizing critical functionalities can lead to successful outcomes. Companies like Google, Amazon, and Netflix have successfully implemented the pyramid to deliver robust and reliable software products.
Well, that's a wrap for now!! Hope you folks have enriched yourself today with lots of known or unknown concepts. I wish you a great day ahead and till then keep learning and keep exploring!! | keploy |
1,846,001 | Why Content matters for Ecommerce? | When I first started to work with Content Management Systems, I wasn’t entirely sure what value it... | 24,010 | 2024-06-03T10:19:18 | https://www.storyblok.com/mp/why-content-matters-for-ecommerce | cms, storyblok, javascript, webdev | When I first started to work with Content Management Systems, I wasn’t entirely sure what value it brought to the project. I thought: You can create the same by just editing the source code of the frontend application. After that I spent some time developing e-commerce applications with Storyblok as the Headless CMS, and finally found out why it really matters.
In this article, I would like to dive deeper into the advantages of using CMS in modern e-commerce websites, but also state some difficulties and issues you may encounter while creating one.
## The general idea
First of all, let’s take a look at the following visual example of the content + commerce architecture:
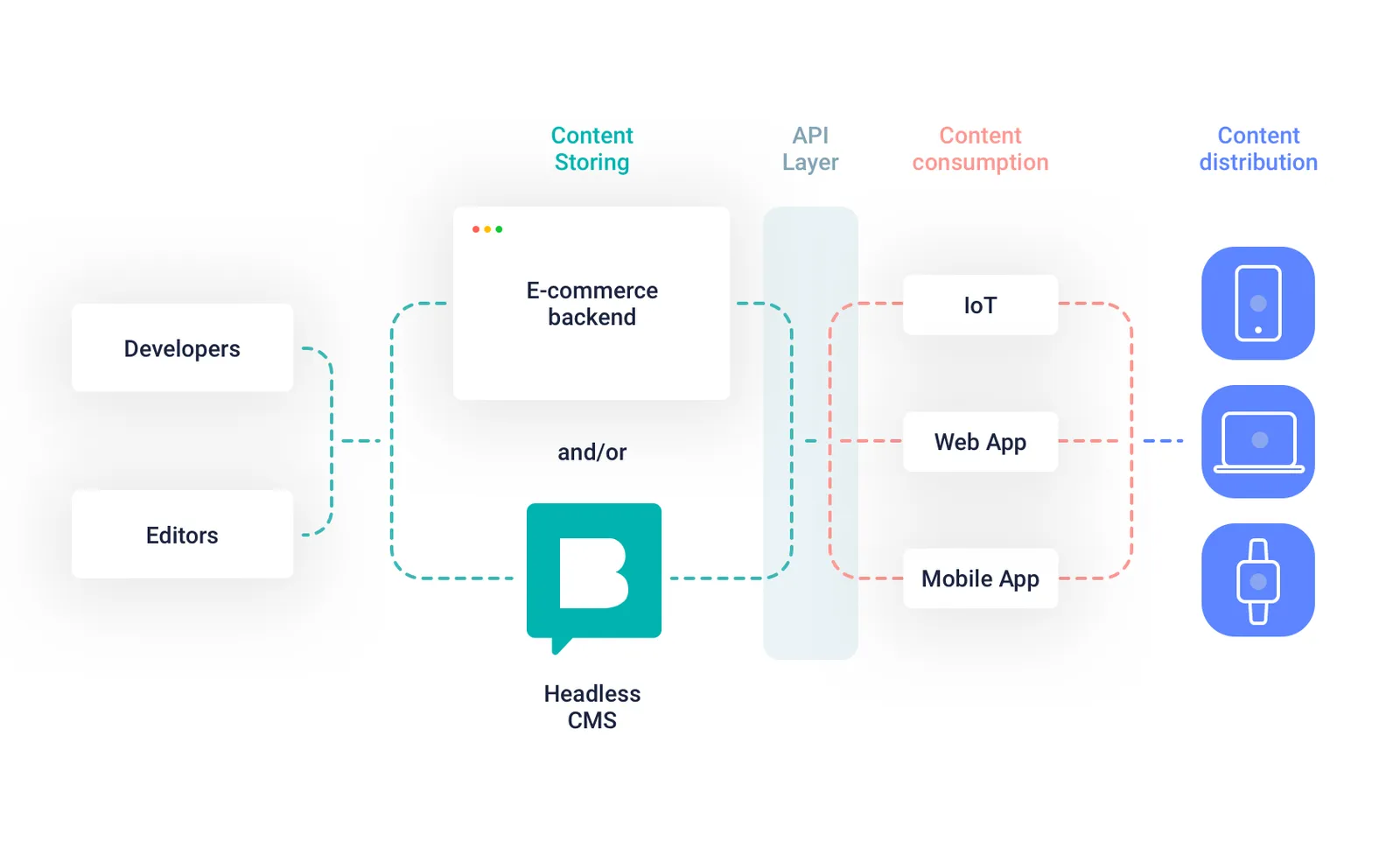
As you can see above, Developers and Editors can join forces in this architecture by adding data (e-commerce) and content (CMS) that can be combined by using the API Layer. Then, it is displayed to final users accessing your website through various devices like phones, computers, or IoT.
This may sound a bit complicated, so let’s take a look at a simpler example:
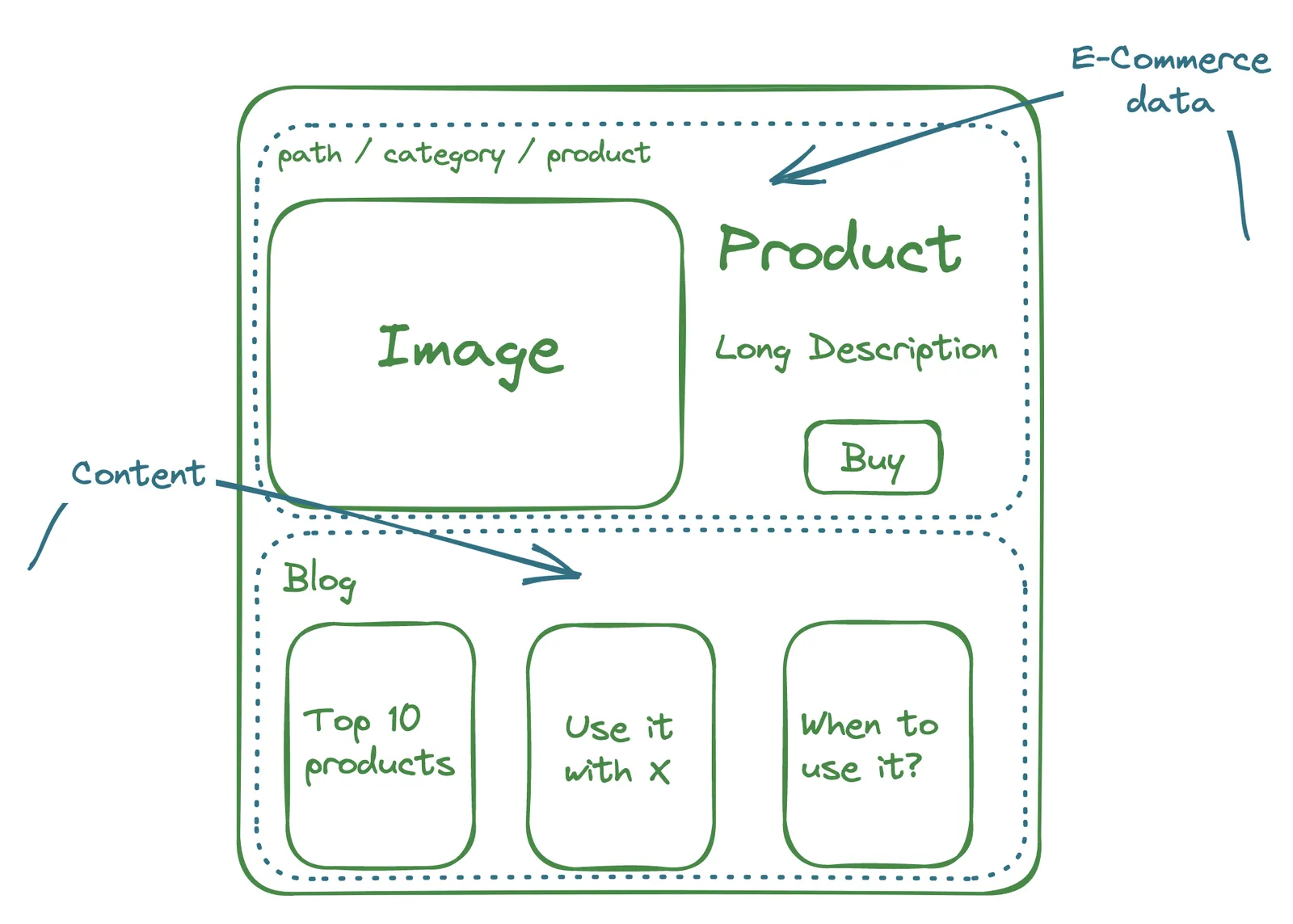
In the above Product Detail Page, we can see both data from the e-commerce platform (like description, name, image, etc) and the content (blog posts that engage with our users). Thanks to displaying not only e-commerce data but also content about how we can use the product, users are more likely to become our customers.
## Headless CMS
Applications and tools following the headless patterns expose the API that allows other applications to communicate with it in an easy, structured way. APIs allow applications to access data from each other without needing to know how they’re implemented.
Communication with APIs is done using JSON (JavaScript Object Notation), and there are four methods main methods for sending and receiving data using REST APIs:
GET: Retrieves data from a server. For example, pulling content from a database.
PUT: Updates information in an existing resource. For example, updating a blog post or web page.
POST: Sends data to a server and creates a new resource. For example, creating a new blog post.
DELETE: Deletes a specific resource. For example, deleting a blog post or web page.
These methods explain what can be done with an API.
An API-first CMS separates the frontend presentation layer from the backend database, and instead, content delivery is handled using APIs. This gives an API-first CMS an advantage over a traditional CMS that tightly couples the frontend and backend together and limits the types of experiences that can be created. With an API-first CMS, content can be published to any channel, whether a website or mobile device, digital sign, smart speaker, or any other internet-connected device
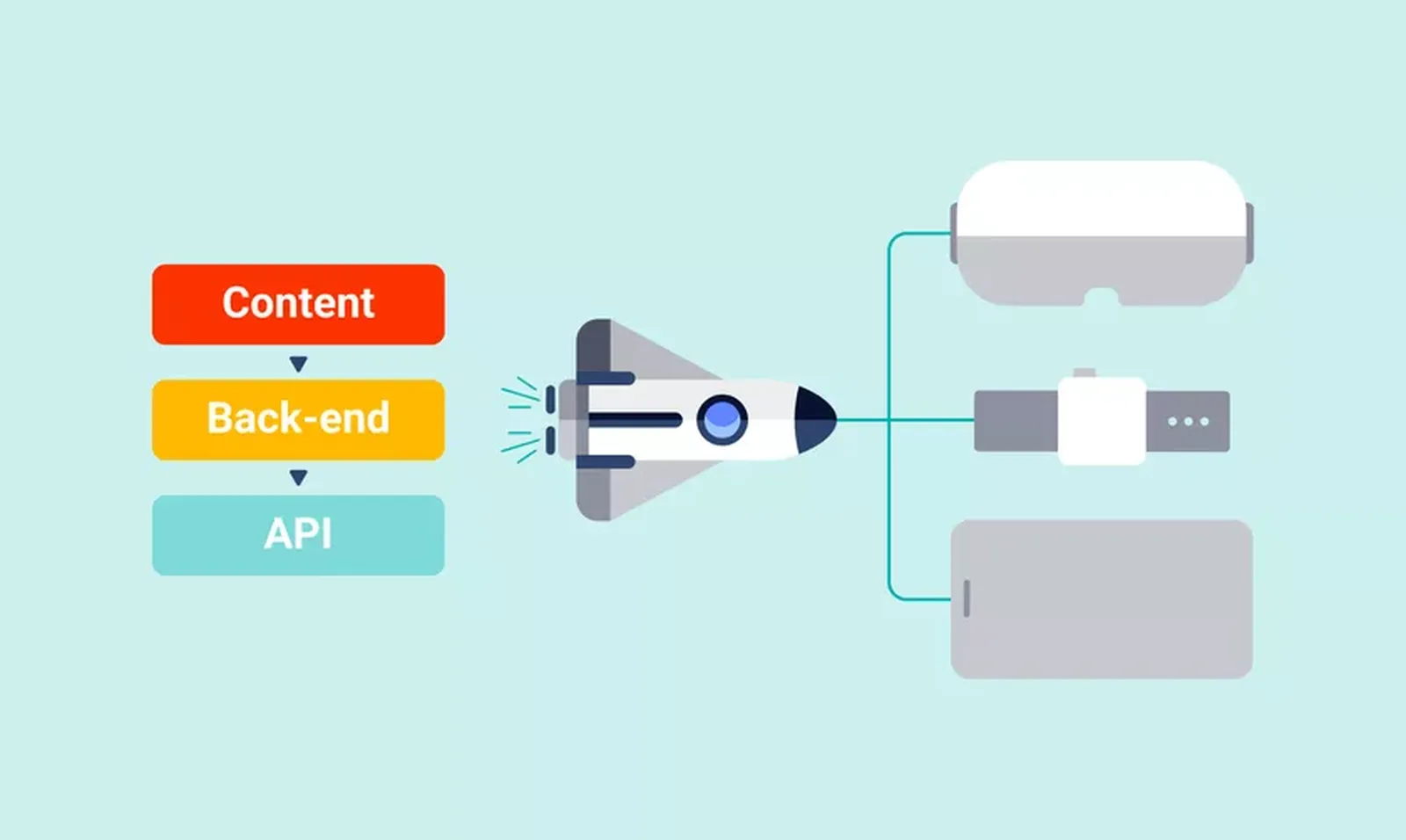
Storyblok is an example of a headless CMS where the content layer is separated from the frontend presentation layer and the backend itself. Thanks to this approach, every part of the system can be easily scaled and maintained separately.
## Types of content
There are several different types of content we can create in order to build a better relationship with our customers. This content should be created accordingly to your users' needs (for example, if your clients are usually older people, creating content on TikTok may not be the best ;))
* Videos
* Reviews
* Blog posts
* Use cases
* Ebooks
* And many more!
Deciding on the type of content is crucial to understand the needs of your customers.
## Benefits of having Content in E-Commerce
Using content in E-Commerce can bring a lot of value so let’s take a closer look at some of the advantages:
* It helps educate your customers - if you want your customers to click the Buy Now button, there is nothing better than a list of features and benefits of your product.
* Create brand awareness - customers feel positive relationships with companies that create content.
* Bring SEO value - having tons of content helps your website be higher in Google Search rankings, which results in more chances of customers visiting the shop and actually buying your product.
* Improve conversions and revenue - a user reading an article about how your product resolves their problem can significantly increase the chance of buying the product.
* Build strategic relationships- Apart from targeting your customers and users, great content can also help in creating partnerships and relationships with other companies.
These, however, are mainly business-oriented benefits. Having a CMS in your e-commerce provides also several developer experience benefits such as:
* Composability - Organizations can integrate with the best tools available for each specific use case.
* Future-proof architecture - Thanks to API, it is easier to integrate CMS with current and future services.
* Improve developer flexibility and productivity - Without vendor lock-in, developers can choose the best-of-breed solutions they want to work with
* Integrates well with static site generators- Headless CMS such as Storyblok integrates perfectly with static/hybrid websites such as those used for e-commerce.
Considering all this, having a Content Management System in E-Commerce has proven to be quite useful.
## Technical difficulties
As you know from the section above, having content in E-Commerce can have several advantages. However, it also comes with some difficulties that you will need to resolve to make it work correctly.
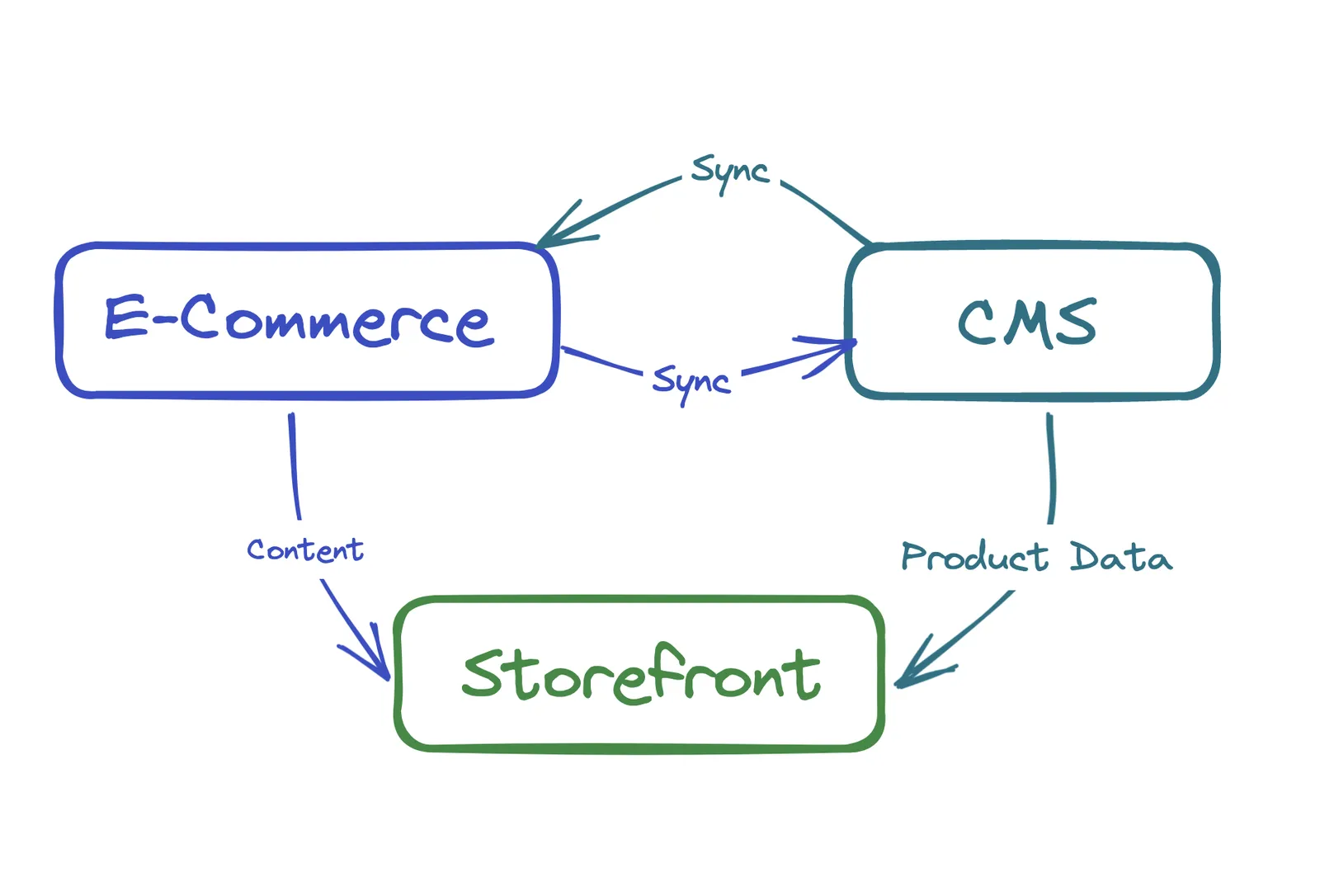
Content Driven E-Commerce requires a proper sync between the E-Commerce platform and the Content Management System. In order to achieve this, both systems need to be deeply integrated.
You also need to have content creation knowledge in your company. Managing products and categories in an e-commerce platform requires a different set of skills than creating engaging content. To do that, you will need people who have knowledge about your product, current trends, content creation, and marketing.
Adding a Headless CMS to your e-commerce technology stack means another tool that you will need to work with. Some companies prefer to keep their stack simple and do not extend it with a content creation tool such as CMS. In some cases, having a content management system can be a bottleneck in the e-commerce application architecture. Let’s imagine that your system has a relationship between e-commerce and CMS: for example, you store product IDs and names in the CMS. Displaying the Product Page would look more or less like this:
1. Fetch the ID of the product from the CMS.
2. Fetch the product from E-Commerce platform based on the ID from CMS.
If at any point, your CMS would fail, your online store would not be able to correctly serve the data to your customers. To mitigate this kind of issue, you would need to implement a fallback functionality that is enabled when CMS is down and then uses the ID’s directly fetched from the E-commerce platform.
## Implementation of the Composable Commerce application with Nuxt, Shopify, and Storyblok
I published an article for Storyblok about building a Composable Commerce with Nuxt, Shopify, and Storyblok that you can check out to learn more about the technical implementation of a CMS in a modern E-Commerce application.
https://dev.to/jacobandrewsky/building-composable-commerce-with-nuxt-shopify-and-storyblok-crash-course-part-one-3ffb
Here, Nuxt is used as the frontend framework (so-called storefront), Shopify is the e-commerce platform and Storyblok is the Headless CMS. Thanks to this approach, we can add dynamic content to our e-commerce application, but also get some custom data from e-commerce in Storyblok and display it in Storefront in the ways we want (i.e. with different orders).
## Summary
Having a content management system in e-commerce provides a lot of value. However, it also comes with challenges that you will need to solve or protect against. By using a CMS in e-commerce, you will be able to leverage content to engage with your customers, improve SEO, increase conversions, and much more!
## Storyblok: The perfect CMS for e-commerce
Storyblok provides all the functionalities of a CMS that you may need for your e-commerce system. It offers great value for both developers and content creators, enabling you to take control of your content no matter what channel you want to publish it on. Apart from the CMS itself, Storyblok has several APIs that help create exceptional user experience, fast content delivery, and a content management API with a simple interface.
Storyblok also comes with several integration plugins with e-commerce platforms such as Shopify, BigCommerce, Commercetools, and many more!

You can use them to easily fetch e-commerce data directly into the CMS and to your frontend. With Storyblok’s eCommerce integrations you can easily build performant storefronts with your favorite technology, be it a website or a mobile app, without being constrained by the limitations of more traditional eCommerce systems. | jacobandrewsky |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.