
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,872,583 | One JS Class to speak them all | Hi to everyone! 👋🏼 First of all: sorry for my English. I'm a guy from Argentina coding in... | 0 | 2024-06-01T02:26:35 | https://dev.to/mobilepadawan/one-js-class-to-speak-them-all-dl1 | javascript, speech, synthesis, class | **Hi to everyone! 👋🏼**
First of all: _sorry for my English_.
I'm a guy from Argentina coding in different programming languages since December 1994.
In my last holiday time I coded a JS Library improving and grouping in a simple JS Class the Speech Synthesis capacities included in one place the main features of this amazing way to transform a sentence in an audible thing.
I did feel myself as a fortunate coder who widely profited some of the modern capabilities included on #JavaScript to create JS Classes with private and static members (properties and methods).
I never found an opportunity, until now, to implement most of these modern features of this so-versatile programming language.
## What was the result
A JS library with just `3.17 KB` of weight (unminified) or `1.84 KB` of weight (minified) with the power of transforming a text or sentence in an audible thing. The best of all this thing is to resume in just one line of code a native feature of JS that needs between 5 to 10 lines of code for implementing using full Vanilla JS.

This library just `extends` the features of the Speech Synthesis Object and simplify in some properties and methods the Speech Synthesis and SpeechSynthesisUtterance objects.
**Test if your web browser supports Speech Synthesis**
```javascript
Speakit.TTStest();
```
**Get the available voices list in a web browser**
```javascript
Speakit.getVoices().then(voices => console.table(voices))
```
This method is based in JS Promises and returning an object array with all the voices available.
Some web browsers like `Chrome` and `Microsoft Edge` has a combination of synthesized voices and Natural voices available. The other ones like `Safari` or `Firefox` just have synthesized voices.
The `.utteranceRate` and `.utterancePitch` properties let you configure the tone and pitch of the voice. They drives values very sensitive and need several tests in different web browsers (_mobile and desktop_) to found the best tuning.
```javascript
Speakit.utteranceRate = 1.02
Speakit.utterancePitch = 1.00
```
## How to reproduce a text
You need to call the `.readText()` method and send two arguments:
1) the string of the text or sentence to reproduce
2) the ISO language code selected (en-GB, es-AR, pt-BR)
This method has a third argument (optional) and represents the voice object corresponding to a tone or accent available in the voice list.
For example, if you are using Microsoft Edge to test your webapp and select `en-HK` as the language to reproduce audible text, you may choose `Microsoft Sam Online (Natural) - English (Hongkong)` by sending it as the third parameter.
```javascript
Speakit.readText('Hello world!',
'en-NZ',
'Microsoft Sam Online (Natural) - English (Hongkong))'
.then(()=> console.log('Text successfully readed.') )
.catch((error)=> console.error('Error reading the text:', error) )
```
The `.readText()` method works as a Promise. While it is reproducing the sentence, will wait to the end of reproduction to resolve the JS Promise. That let you establish a `.then()` control method to do something after the sentence finish played.
## Controlling the .readText() action
Of course Speakit JS let you controlling the audible reproducing action by using `.pauseSpeaking()`, `.resumeSpeaking()` or `.stopSpeaking()` methods.
## Speech Synthesis availability
This amazing JavaScript feature is available in most of the modern browsers since many years ago. In some web browsers you will find the Natural voices options, giving you a Headline in the Speech Synthesis experience of your webapps.
I invite you all to test my JS library and send me comments or suggestions to bring it to the next level. I am working already in some improvements of it.
I didn't mention all the properties and capabilities of Speakit-JS in this article. Go for it and dig all the available features.
If you wanna try this JS Library, go for it to my official repo at: https://github.com/mobilepadawan/Speakit-JS
You can also find it in NPMJS web by using `npn install speakit-js` command. This JS library just works in frontend webapps and PWAs. | mobilepadawan |
1,872,590 | Formulating Git Commit Message Best Practices | Git, the foundation of today's version control, provides tremendous power to development teams.... | 0 | 2024-06-01T02:19:59 | https://dev.to/cheikh_sadbouh_abd98924d6/formulating-git-commit-message-best-practices-1he |
Git, the foundation of today's version control, provides tremendous power to development teams. However, its actual potential is best realized when combined with well-structured and detailed commit messages. These messages provide crucial breadcrumbs for understanding the progress of your software. Let's look at the best practices for writing effective Git commit messages that improve collaboration and speed development.
## Anatomy of a Stellar Commit Message:
### 1. Change Type (Essential):
- `fix:` Signals the resolution of a bug.
- `feat:` Denotes the introduction of a new feature.
- `BREAKING CHANGE:` Highlights a modification that might necessitate updates to prevent compatibility issues, such as replacing outdated components. You can also append the '!' symbol after the type/area.
- `docs:` Reserved for updates and modifications to documentation.
- Other frequently used types include `test:`, `chore:`, `refactor:`, `build:`, and `style:`. Keep in mind that teams frequently use custom types, so make sure your procedures follow the rules set out by your team.
### 2. Affected Area (Optional):
The affected area pinpoints the specific section of the codebase impacted by the changes. Including this element brings clarity and context, especially within large projects involving multiple developers.
### 3. Concise Summary (Essential):
Keep this part brief and to the point. Employ the imperative mood—for instance, "Implement user authentication" instead of "Implemented user authentication." This practice enhances readability in automatically generated change logs and release notes.
### 4. Detailed Explanation (Optional):
Utilize this section to provide further insights into your modifications. Separate the detailed explanation from the concise summary with a blank line.
### 5. Additional Information (Optional):
Include any pertinent metadata here, such as a link to a previously reported issue (`fix #003`) or the name of the code reviewer.
Keep in mind that when you incorporate an affected area, always follow it with a colon and a space before writing the concise summary. Additionally, `BREAKING CHANGE` is case-sensitive and should be written in all uppercase.
## Illustrative Examples:
```
chore(Style_Guide): Rename variable “InvalidInput” to “invalidInput”
Rename variable to adhere to the established naming convention for improved consistency.
```
```
fix(Data_Processing)!: Update data validation rules
Revised data validation rules to exclusively accept structured data. All other data formats will be rejected.
```
```
feat: Integrate night mode functionality
```
For more extensive messages, omit the `-m` flag during the commit process. This action will open an editor, allowing for a comprehensive message. For shorter messages, use `git commit -m "summary" -m "explanation"` to distinctly separate the summary, explanation, and additional information.
## In Conclusion:
Effective commit messages are critical to enabling automation in your development workflow and promoting smooth cooperation. Always state the type of change you made along with a brief description of it. A codebase that is easier to maintain and comprehend is further enhanced by adhering to the principles of Conventional Commits.
| cheikh_sadbouh_abd98924d6 | |
1,872,588 | Cómo Exponer un Servicio Local a Internet Usando ngrok en una Mac | ¿Qué es ngrok? ngrok es una herramienta que permite exponer un servidor local a Internet a... | 0 | 2024-06-01T02:08:05 | https://dev.to/olverarobertp/como-exponer-un-servicio-local-a-internet-usando-ngrok-en-una-mac-1o3c | ### ¿Qué es ngrok?
**ngrok** es una herramienta que permite exponer un servidor local a Internet a través de un túnel seguro. Esto es especialmente útil para desarrolladores que necesitan compartir su entorno local con colaboradores, probar webhooks o mostrar prototipos a clientes sin necesidad de desplegar su aplicación a un servidor externo.
### Creación de Cuenta en ngrok
Para comenzar, necesitarás una cuenta en ngrok. Sigue estos pasos:
1. Visita [ngrok.com](https://ngrok.com).
2. Haz clic en **Sign Up** y completa el proceso de registro.
3. Una vez registrado, accede a tu **Dashboard**.
### Creación de Authtoken
1. En tu **Dashboard**, verás una sección llamada **Your Authtoken**.
2. Copia tu **Authtoken**; lo necesitarás para autenticar tu cliente ngrok.
### Instalación de ngrok en Mac
Para instalar ngrok en tu Mac, sigue estos pasos:
1. **Instala vía Homebrew**: Puedes instalar con el siguiente comando.
```sh
brew install ngrok/ngrok/ngrok
```
2. **Extrae el archivo descargado**:
```sh
ngrok config add-authtoken tu_authtoken
```
### Exponer un Servicio Ejecutándose en el Puerto 8080
Supongamos que tienes un servidor ejecutándose en tu máquina local en el puerto `8080`. Para exponerlo a Internet, utiliza el siguiente comando:
```sh
ngrok http 8080
```
Al ejecutar este comando, ngrok creará una URL pública que redirige el tráfico a tu servidor local. Verás una salida similar a esta:
```
ngrok by @inconshreveable (Ctrl+C to quit)
Session Status online
Session Expires 1 hour, 59 minutes
Version 2.3.35
Region United States (us)
Web Interface http://127.0.0.1:4040
Forwarding http://<subdomain>.ngrok.io -> http://localhost:8080
Forwarding https://<subdomain>.ngrok.io -> http://localhost:8080
```
### Validación
Para verificar que tu servicio está accesible desde Internet, abre la URL generada por ngrok (`http://<subdomain>.ngrok.io` o `https://<subdomain>.ngrok.io`) en tu navegador. Deberías ver tu aplicación funcionando como si estuvieras accediendo a ella localmente.
### Conclusiones
Usar ngrok es una forma eficiente y segura de exponer servicios locales a Internet, lo que facilita la colaboración y prueba de aplicaciones. La simplicidad de instalación y uso lo convierte en una herramienta imprescindible para desarrolladores.
¡Espero que encuentres útil esta guía! Si tienes alguna pregunta o comentario, no dudes en dejar un mensaje. 🚀
---
*¿Te gustó este post? Dale like y comparte con tus colegas. Para más contenido relacionado con desarrollo y tecnología, sígueme en LinkedIn.* | olverarobertp | |
1,872,587 | Day 1 | Today I will start trying the challenge of completing all the courses on Freecodecamp starting from... | 0 | 2024-06-01T02:03:27 | https://dev.to/han_han/day-1-2f58 | 100daysofcode, html, css, webdev | Today I will start trying the challenge of completing all the courses on Freecodecamp starting from the beginning of HTML and CSS
on today a #Day1 for me challenge in #100DaysOfCode and Today I learned a lot about HTML at #freecodecamp. I found several tags before I didn't understand their use
```
<figure>
<img src="https://cdn.freecodecamp.org/curriculum/cat-photo-app/cats.jpg" alt="Five cats looking around a field.">
<figcaption>Cats <strong>hate</strong> other cats.
</figcaption>
```
which sometimes when I add an image just use <img> directly without going into it | han_han |
1,872,586 | Unlocking the Decentralized Future: Exploring Web3 Technology 🔓 | In the constantly evolving digital landscape, a new era of the internet is on the horizon, one that... | 0 | 2024-06-01T02:02:24 | https://dev.to/vyan/unlocking-the-decentralized-future-exploring-web3-technology-3l01 | webdev, web3, javascript, beginners | In the constantly evolving digital landscape, a new era of the internet is on the horizon, one that promises to revolutionize the way we interact, transact, and exchange information. This paradigm shift is driven by the emergence of Web3, a decentralized and distributed network that aims to redefine the traditional client-server model of the internet as we know it.
### What is Web3?
Web3, also known as the decentralized web or the semantic web, is a vision for the next iteration of the internet. It builds upon the foundational principles of decentralization, transparency, and user control, leveraging cutting-edge technologies like blockchain, cryptocurrencies, and decentralized applications (dApps).
At its core, Web3 seeks to address the centralization and data monopolies that characterize the current state of the internet, where a handful of tech giants wield immense power over user data and online experiences. By embracing decentralization, Web3 aims to redistribute control and ownership back to users, fostering a more open, equitable, and resilient internet ecosystem.
### Key Pillars of Web3
1. **Decentralization**: Web3 is built on decentralized networks, such as blockchain, which eliminate the need for central authorities or intermediaries. This decentralized architecture ensures resilience, censorship resistance, and true user sovereignty over data and digital assets.
2. **Ownership and Self-Sovereignty**: In Web3, users regain control over their digital identities, data, and assets. Through the use of blockchain-based technologies like non-fungible tokens (NFTs) and decentralized identifiers (DIDs), individuals can own and manage their digital footprint without relying on centralized platforms.
3. **Trustless Interactions**: Web3 enables trustless interactions through the use of smart contracts, which are self-executing programs that automatically enforce predefined rules and agreements without the need for intermediaries or third-party oversight.
4. **Transparency and Immutability**: The underlying blockchain technology that powers Web3 ensures transparency and immutability of data. Transactions and interactions on the decentralized web are recorded on a publicly accessible, tamper-proof ledger, fostering trust and accountability.
5. **Democratization of the Internet**: By removing central points of control and enabling peer-to-peer interactions, Web3 aims to democratize the internet, giving users greater autonomy and fostering a more equitable distribution of power and opportunities.
### Potential Applications and Use Cases
The decentralized nature of Web3 opens up a wide range of promising applications and use cases across various sectors:
1. **Decentralized Finance (DeFi)**: Web3 enables the creation of decentralized financial systems, providing access to secure, transparent, and global financial services without the need for traditional intermediaries like banks or payment processors.
2. **Digital Identity and Data Ownership**: With Web3, individuals can establish self-sovereign digital identities and regain control over their personal data, reducing the risk of data breaches and privacy violations.
3. **Decentralized Marketplaces and Economies**: Web3 facilitates the creation of decentralized marketplaces and economies, enabling peer-to-peer transactions without intermediaries and empowering creators and entrepreneurs to monetize their work directly.
4. **Supply Chain and Provenance Tracking**: The immutable and transparent nature of blockchain technology makes Web3 an ideal solution for supply chain management and provenance tracking, ensuring the authenticity and traceability of goods and products.
5. **Decentralized Social Networks and Content Platforms**: Web3 paves the way for decentralized social networks and content platforms, where users own their data and content, fostering a more equitable and democratic online ecosystem.
### Challenges of Web3
While Web3 offers many promising benefits, it also faces several challenges:
1. **Scalability**: Current blockchain networks often face scalability issues, with limitations on transaction speed and throughput. This can hinder the widespread adoption of Web3 applications.
2. **User Experience**: Web3 applications can be complex and difficult for non-technical users to navigate. Improving the user experience is crucial for broader adoption.
3. **Regulatory Uncertainty**: The regulatory landscape for Web3 is still evolving. Uncertainty and inconsistent regulations across different jurisdictions can pose challenges for developers and users.
4. **Security**: While blockchain technology offers enhanced security, it is not immune to vulnerabilities. Smart contract bugs, hacking, and phishing attacks remain concerns.
5. **Energy Consumption**: Some blockchain networks, particularly those using proof-of-work consensus mechanisms, have been criticized for their high energy consumption. Sustainable and eco-friendly alternatives are being explored.
### Conclusion
Web3 technology represents a transformative shift towards a more decentralized, transparent, and user-centric internet. By leveraging blockchain technology, smart contracts, and decentralized applications, Web3 aims to empower users, foster innovation, and build a more resilient digital ecosystem. However, challenges such as scalability, user experience, and regulatory uncertainty need to be addressed to realize the full potential of Web3.
As this paradigm shift unfolds, it presents both opportunities and challenges, requiring a collective effort from developers, entrepreneurs, and users to shape the future of the web. Embrace the decentralized future and explore the vast potential of Web3 technology, where transparency, ownership, and user empowerment take center stage in the digital realm. | vyan |
1,872,585 | Exploring the Potential of AR Glasses in Healthcare | AR Glasses- Health Care Presentation Looking for an AR Glasses? Either for home or outsourcing it to... | 0 | 2024-06-01T01:56:57 | https://dev.to/pamela_ballardow_8f47cadc/exploring-the-potential-of-ar-glasses-in-healthcare-10dm | healthcare | AR Glasses- Health Care Presentation
Looking for an AR Glasses? Either for home or outsourcing it to public. Have you ever heard of AR Glasses in healthcare? Well, these are perfect cups that are perfect for exploring the possible of healthcare. AR Glasses in healthcare are an innovative technology that allows us to see digitally developed visualizations worldwide genuine. So let's dive right into it as we discussed it more further.
Features of AR Glasses in HealthCare
AR Glasses in healthcare have many benefits in healthcare, including improving the safety of patients during medical procedures. With AR Glasses in healthcare, physicians and nurses can access client real-time and complete procedures more accurately. They are allowed by this technology to spotlight the duty at hand instead of constantly looking away for information.
Innovation for AR Glasses in Healthcare
Innovation could be the key to enhancing healthcare, and AR Glasses in healthcare. This technology has revolutionized the way in which procedures which are medical performed by giving health practitioners and nurses by having a tool both reliable and accurate. With AR Glasses in healthcare, health practitioners can offer safer and more health care efficient.
Security in for AR Glasses in Healthcare
Protection is of utmost importance in healthcare, and AR cups give you the necessary tools to give safe and health care effective. AR Glasses in healthcare and nurses to possess use of data that are real-time information, allowing them to make smarter decisions and provide better look after patients.
Quality of AR Glasses in healthcare
The grade of AR spectacles is vital and must be judged according to several facets such as battery life, quality, durability, and weight. Top-quality AR glasses increase the user experience by providing clear and images which can be razor-sharp as well as extended battery life. The AR Glasses in healthcare must provide convenience whenever wore for the period extended of to avoid disquiet.
Applications of AR Glasses in Healthcare
There are many applications of Products AR Glasses in healthcare. It can be used in remote patient monitoring, emergency medical solutions, surgery, and training medical. Remote monitoring patient a system that transmits real-time data from a client to medical staff, and AR spectacles can be used being an interface for the system. AR Glasses in healthcare can be utilized in crisis solutions which are medical improve decision-making during critical situations.
Source: https://www.wupro.com/Ar-glasses | pamela_ballardow_8f47cadc |
1,872,584 | Introduction To Mathematical Thinking | Part 1: Importance of Mathematics in Computer Science Overview Mathematics is... | 0 | 2024-06-01T01:56:54 | https://dev.to/niladridas/introduction-to-mathematical-thinking-57mc | machinelearning, programming, computerscience, ai | ## Part 1: Importance of Mathematics in Computer Science
## Overview
Mathematics is not just a tool but the foundation upon which computer science is built. It provides the theoretical underpinnings for many areas of computer science from algorithms and data structures to machine learning and cryptography. Understanding these mathematical principles is essential for the logic and efficiency of computer-based systems.
## Detailed Key Points
- **Algorithm Efficiency**
**Concept**: Algorithm efficiency measures how fast or how much storage an algorithm requires to solve a problem. It's typically expressed using Big O notation, which abstracts the performance of an algorithm as the size of its input data grows.
**Mathematical Foundation**: Big O notation involves concepts from calculus (for understanding growth rates) and algebra.
**Example**:
**Linear Search**: Has a complexity of O(n) because it scans each item in a list sequentially. So, if the list doubles in size, so does the search time.
**Binary Search**: Exhibits a complexity of O(log n) due to the list being divided in half each time, making the search much faster as the size increases.
- **Data Structures**
**Concept**: Effective use of data structures requires an understanding of their space (memory) and time complexity (efficiency of operations like insert, delete, search).
**Mathematical Foundation**: Analyzing these complexities again involves understanding functions and limits.
**Example**:
**Arrays**: Constant time O(1) access but linear time O(n) search.
**Hash Tables**: Aim for constant time O(1) access and search, thanks to an effective hash function which distributes entries evenly across an array.
- **Cryptography**
**Concept**: Cryptography secures information by transforming it into unreadable formats, unless one possesses a specific key. This field relies heavily on number theory and the properties of numbers.
**Mathematical Foundation**: Uses prime numbers, modular arithmetic, and algorithms like RSA for public-key encryption.
**Example**:
**RSA Algorithm**: Utilizes two large prime numbers to generate public and private keys. Secure because factoring the product of these two primes is computationally difficult.
- **Machine Learning**
**Concept**: Machine learning algorithms adjust their parameters on data input to improve their accuracy. This adjustment process is guided by statistical and probability theory to make predictions or decisions without being explicitly programmed.
**Mathematical Foundation**: Involves statistics for understanding data distributions and calculus for optimizing algorithms (like gradient descent).
**Example**:
**Linear Regression**: Finds a line (or hyperplane in higher dimensions) that best fits a set of data points. Uses simple algebraic and statistical principles to minimize the error in prediction.
**Neural Networks**: Use calculus to adjust the weights on the network's neurons during training, a process called backpropagation.
### Conclusion
These examples illustrate how deeply intertwined mathematics is with the field of computer science. Whether analyzing the efficiency of an algorithm, ensuring the rapid execution and management of data, securing information, or enabling machines to learn from data, mathematics provides the necessary theoretical framework to support and guide these activities. This foundation not only enhances the understanding but also the innovation within computer science.
## Part 2: Basic Symbols and Terminology in Mathematics
## Overview
Mathematics communicates its concepts through a unique language composed of symbols that denote operations, relationships, and values. Understanding these symbols is essential for both mathematical reasoning and programming, where such expressions are often directly translated into code.
## Detailed Explanations of Mathematical Symbols
- **Equals Sign (=)**
**Meaning**: Indicates that two expressions represent the same value.
**Example**: "3 + 4 = 7". This expression states that the sum of 3 and 4 is equal to 7.
- **Plus (+) and Minus (-) Signs**
**Meaning**: The plus sign represents addition, while the minus sign denotes subtraction.
**Examples**:
**Addition**: "5 + 2 = 7". Adds 2 to 5.
**Subtraction**: "10 - 3 = 7". Subtracts 3 from 10.
- **Multiplication (×), Division (÷)**
**Meaning**: These symbols are used for multiplying and dividing numbers, respectively.
**Examples**:
**Multiplication**: "4 × 3 = 12". Multiplies 4 by 3.
**Division**: "12 ÷ 4 = 3". Divides 12 by 4.
- **Exponentiation (^)**
**Meaning**: Indicates that a number is raised to the power of another number.
**Example**: "x^2" denotes "x raised to the power of 2". For instance, if "x = 5", then "x^2 = 25".
- **Square Root (√)**
**Meaning**: Represents the square root operation, which finds a number that, when multiplied by itself, gives the original number.
**Example**: "√16 = 4" because "4 × 4 = 16".
- **Inequalities (<, >, ≤, ≥)**
**Meaning**: These symbols compare the size or order of two values.
**Examples**:
**Less than (<)**: "3 < 5" indicates that 3 is less than 5.
**Greater than (>)**: "10 > 8" indicates that 10 is greater than 8.
**Less than or equal to (≤)**: "4 ≤ 5" indicates that 4 is less than or equal to 5.
**Greater than or equal to (≥)**: "10 ≥ 7" indicates that 10 is greater than or equal to 7.
## Practice Task and Solution
**Task**: Translate the following statement into a mathematical expression: "The sum of three times five and four is less than twenty."
**Solution**: To translate this, you recognize the operations and relationships:
"Three times five" translates to "3 × 5"
"The sum of 3 × 5 and 4" is "3 × 5 + 4"
"Is less than twenty" translates to "< 20"
**Mathematical Expression**: "3 × 5 + 4 < 20"
This example showcases how mathematical expressions encapsulate logical and numerical relationships in a concise format, pivotal for both theoretical mathematics and its application in computer science, especially in algorithms and problem-solving scenarios.
## Part 3: Introduction to Logical Thinking
## Overview
Logical thinking is the process of reasoning consistently to come to a conclusion. In computer science, logical reasoning underpins how programs make decisions and control the flow of execution. This part explores the basics of forming logical statements and how they integrate into programming.
## Key Concepts
- **Statements**
**Definition**: A statement is a declaration that is either true or false, but not both. In programming, these are often conditions that determine which code segment runs.
**Example**: "The number 4 is even." This is a true statement. In contrast, "The number 5 is even." is a false statement.
- **Logical Connectives**
**Definition**: Logical connectives are symbols or words used to connect statements to form more complex logical expressions.
**Examples**:
**AND (∧)**: True only if both connected statements are true.
**OR (∨)**: True if at least one of the connected statements is true.
**NOT (¬)**: True if the connected statement is false.
**Usage in Programming**: In conditions like `if (userIsLoggedIn && hasAccess)`, both conditions must be true to execute the block of code.
- **Conditional Statements**
**Definition**: These involve reasoning in the form "if this, then that," linking conditions to actions or outcomes.
**Example in Programming**: This code checks if a user is logged in; if true, it allows access to the dashboard.
```
if (user_is_logged_in):
access_dashboard()
```
## Detailed Example
Let's consider the logical statement: "If a user is logged in, then they can access their dashboard."
**Logical Formulation**:
_P_: User is logged in.
_Q_: User can access the dashboard.
**Implication**: _P_→_Q_ which reads as "If P, then Q."
## Activity: Creating Truth Tables
Truth tables are a way to visualize how logical connectives work. Let’s create truth tables for the basic connectives and the example given:
**Truth Table for Basic Connectives**
| **P** | **Q** | **P** ∧ **Q** | **P** ∨ **Q** | **¬P** | **P** → **Q** |
|:-----:|:-----:|:-------------:|:-------------:|:-----:|:-------------:|
| T | T | T | T | F | T |
| T | F | F | T | F | F |
| F | T | F | T | T | T |
| F | F | F | F | T | T |
**P** ∧ **Q** (AND): True only when both P and Q are true.
**P** ∨ **Q** (OR): True if at least one of P or Q is true.
**¬P** (NOT): True when P is false.
**P** → **Q** (IMPLICATION): True in all cases except where P is true and Q is false.
**Implication for the Example**:
| **User Logged In (P)** | **Access Dashboard (Q)** | **P** → **Q** |
|:----------------------:|:------------------------:|:-------------:|
| True | True | True |
| True | False | False |
| False | True | True |
| False | False | True |
This truth table shows that the user can access the dashboard only when they are logged in, mirroring the actual access control logic used in many computer systems.
### Conclusion
Understanding and applying logical thinking is essential for developing robust software that behaves as expected. By mastering logical connectives and conditional statements, programmers can write clearer, more efficient code. Logical reasoning also assists in debugging by helping to trace the flow of execution and understand where things might go wrong.
> Author's social media: [𝕏](https://x.com/niladrridas) 🔬🔭
| niladridas |
1,872,581 | UST Projectors: Compact Design with Big Benefits | UST Projectors: Compact Design with Big Advantages As technology progresses, many products being... | 0 | 2024-06-01T01:38:29 | https://dev.to/pamela_ballardow_8f47cadc/ust-projectors-compact-design-with-big-benefits-6ge | compact | UST Projectors: Compact Design with Big Advantages
As technology progresses, many products being electronic becoming smaller and smaller, yet stronger. One device such the UST projector. UST represents Ultra Short Throw, which really is a sort of projector that will project a image big a distance as small as a foot away. The compact nature of UST projectors has a plethora of benefits that produce them an choice ideal companies, schools, and houses alike.
Benefits of UST Projectors
Some great benefits of UST Projector are countless. Firstly, being little in dimensions means them very portable they are lightweight, making. You're permitted by this portability to maneuver the projector from a single space to some other, or from a single center to some other with general simplicity. Also, UST projectors do not require space much run, making them well suited for smaller venues or any area with limited area.
Innovation in tech
UST projectors are a definite total outcome of revolutionary technology. They use lasers to produce a clear and bright image without the need for any illumination additional. The maintenance-free nature of UST projectors means they are an option that wil attract users that don't want to take some time or incur the expense of replacing traditional projector bulbs usually.
Security Features
UST Projector have integrated security features that ensure the user's wellbeing during use. They normally use a Class 1 laser, which is harmless towards the eye peoples. The laser can project the image on any surface, including a wall or even a projection screen. The projection screen will further reduce the light spread providing a safer watching experience.
How exactly to Use UST Projectors
Using UST projectors is really a breeze, and everyone can learn to get it done by having a practice little. The step very first to place the projector as close as you possibly can towards the area you want to project the image on. The top could be a wall or a projection display screen. Once the projector is established, you will need to connect it to a source, like a laptop or even a DVD player, using an HDMI cable.
Quality and Service
The grade of the image created by UST projectors is superb. Making use of lasers helps to ensure that the image is bright, clear, and sharp, rendering it more fulfilling to view. UST projectors also come with an guarantee excellent meaning you are protected in the not likely event of any issues or faults.
Application of UST Projectors
UST projectors have actually different applications of Projection Screen Businesses use them to give presentations, while schools utilize them in classrooms to help make learning more engaging. Homes use UST projectors to create home theaters and gaming areas. Additionally, UST projectors are commonly used at occasions like weddings and concerts to give a more immersive and experience visually stunning.
Source: https://www.wupro.com/Ust-projector | pamela_ballardow_8f47cadc |
1,872,580 | Why Short Throw Projectors Are Ideal for Classrooms | Why Throw short Projectors ideal for Classrooms Short throw projectors are a innovation excellent is... | 0 | 2024-06-01T01:23:18 | https://dev.to/pamela_ballardow_8f47cadc/why-short-throw-projectors-are-ideal-for-classrooms-56go | short | Why Throw short Projectors ideal for Classrooms
Short throw projectors are a innovation excellent is assisting pupils and teachers alike. This technology happens to be fashioned with use and security convenience in mind. Brief throw projectors create a projection large in a short distance away from the screen, rendering it perfect for classrooms. We are going to explore exactly how short throw projectors may be used, their applications, and exactly why they've been the clear answer ideal classrooms.
Advantages of Quick Throw Projectors
Some great benefits of Short Throw Projector in classrooms are wide ranging. They feature an obvious, razor-sharp, and display bright can be seen effortlessly by all pupils in the class room, regardless of where these are typically sitting. It saves both right time and effort when getting around the class room. Instructors don't need to concern yourself with getting into the true way of the projector, as well as the shadow that has been formerly associated with conventional projectors was eradicated. Short throw projectors are more cost-effective, utilizing less lamp and electricity life.
Innovation
Short throw projectors are innovation at its most readily useful! These projectors are designed to project a large image from a distance quick. Within the past, classrooms utilized conventional projectors that had a distance range bound. Short throw projectors have revolutionized the true means instructors may use projection technology into the classroom. These are typically made with use and security convenience in mind.
Security
Security is a concern paramount it comes towards the class environment. The throw short happens to be fashioned with security at heart. Firstly, the Projector is put close to the wall, meaning that pupils are far less likely to be exposed to light direct the projector. It also eliminates the need for cords and wires that may pose a tripping hazard.
Usage
Short throw projectors are incredibly user friendly. They've been designed to be put up in minutes, without the necessity for complex construction instructions. The system can quickly be fixed for a wall or roof, making it less susceptible to damage accidental. It generates a projection large even yet in a tiny area, rendering it well suited for a class room with restricted space. Its straightforward user interface allows you for instructors to switch from a source to a different, supplying a means notably convenient combine different media and presentations in one single image or presentation.
Utilizing
Using a Short throw projector is quite simple. First, you will need a accepted destination to arrange it, like a wall surface or a whiteboard. The projector may be installed to then your wall surface using a bracket. The projector can be simply linked to any computer or other device compatible the mandatory connection cables. Some throw quick can also be controlled remotely, making them very easy to setup and run.
Service
When it comes to buying and utilizing a throw short, quality and service are necessary considerations. You need to ensure that you’re buying a item top-quality is designed to endure. It is critical to locate a provider that provides exemplary after-sales service, including warranty and support technical. By selecting a provider reliable you may be sure you may receive help if any problems arise.
Quality
Perhaps one of the most key elements in terms of investing in a throw short is quality. You need to make certain that you are buying a high-quality item that will provide exemplary image quality, durability, and life span very long. Considerations when choosing a projector include resolution, brightness, comparison, and image quality. The caliber of the image projected will determine the standard of the scholarly training that pupils get. Therefore, it's important to buy top-notch projector that may offer an learning environment engaging.
Application
Standard Throw Projector are ideal not only in schools but additionally in other surroundings such as for example boardrooms, meeting centers, and also in the home. Whether you are presenting your projects to your peers or preparing a slideshow in the home, short throw projectors provide a viewing experience exclusive. Its capability to project a image big an inferior area causes it to be the best candidate for small areas.
Source: https://www.wupro.com/Short-throw-projector | pamela_ballardow_8f47cadc |
1,872,559 | Flower | Check out this cool Pen! | 0 | 2024-06-01T01:17:13 | https://dev.to/araguaci/flower-3oc3 | codepen | ---
title: Flower
published: true
tags: codepen
---
Check out this cool Pen!
{% codepen https://codepen.io/stoumann/pen/dyQGQOK %} | araguaci |
1,872,558 | Abstract Color Theme Tool | Check out this cool Pen! | 0 | 2024-06-01T01:15:46 | https://dev.to/araguaci/abstract-color-theme-tool-amj | codepen | ---
title: Abstract Color Theme Tool
published: true
tags: codepen
---
Check out this cool Pen!
{% codepen https://codepen.io/stoumann/pen/WNGqZed %} | araguaci |
1,872,557 | Key Differences Between UST and Short Throw Projectors | Differences Between UST and Short Throw Projectors If you are not used to the world of projectors,... | 0 | 2024-06-01T01:14:32 | https://dev.to/pamela_ballardow_8f47cadc/key-differences-between-ust-and-short-throw-projectors-287n | projectors | Differences Between UST and Short Throw Projectors
If you are not used to the world of projectors, selecting between UST (ultra-short-throw) and projectors that are short-throw be quite confusing. Even although you're acquainted with projectors, the distinctions between UST and projectors that are short-throw not be completely clear. We’ll explore the key differences between UST and short-throw projectors to be able to make an purchase decision informed.
Benefits of Short Throw Projectors
While UST Projector have numerous benefits, short-throw projectors also have their merits. Short-throw projectors are perfect for bigger spaces, where you'll want to project a graphic over an extended distance. Also, they are cheaper than UST projectors, which makes them a selection popular individuals on a budget.
Innovation in a Short Throw projectors
Short-throw projectors are not as innovative as UST projectors, nevertheless they nevertheless come with enhanced functions. Numerous projectors that are short-throw have actually built-in WiFi, therefore you can hook up to your unit wirelessly. Some models even come with a running integrated, so you can stream content directly to your projector without the need to connect a computer device.
Security of Short Throw Projectors
Like UST Projector, Short Throw projectors also provide safety features. As an example, some short-throw projectors have an shut-off automated when they detect an obstruction as you're watching lens. This can help avoid damage to the projector and also decreases the risk of eye harm.
Application of UST and Short Throw Projectors
UST Short Throw projectors, such as for example classrooms or spaces which are living. Also, they are ideal for those who want a image top-notch being forced to be worried about attention security. Short-throw projectors, having said that, are perfect for bigger areas, such as for example conference rooms or lecture halls. They're also an inexpensive option for people on a budget whom nevertheless require a image top-quality.
Service for UST and Short Throw Projectors
In terms of solution, Standard Throw Projector are more costly to repair or change than short-throw projectors. This is because of the technology advanced and undeniable fact that these are typically still reasonably new. Short-throw projectors, having said that, are more affordable to repair or change, making them a better option for people who are not looking to invest an entire fortune on maintenance.
Source: https://www.wupro.com/Projector | pamela_ballardow_8f47cadc |
1,872,555 | An Easy Guide To Next14 Authentication With Kinde | This is a simple tutorial on adding authentication to your Next14 app using Kinde. To follow this... | 0 | 2024-06-01T01:08:25 | https://dev.to/joeskills/an-easy-guide-to-next14-authentication-with-kinde-auth-5f50 | kinde, nextjs, authentication, react | This is a simple tutorial on adding authentication to your Next14 app using [Kinde](https://kinde.com/). To follow this tutorial, you need a Kinde account. Kinde is a powerful user authentication service that integrates in minutes. They offer an amazing free tier for their service and the signup process is straightforward.
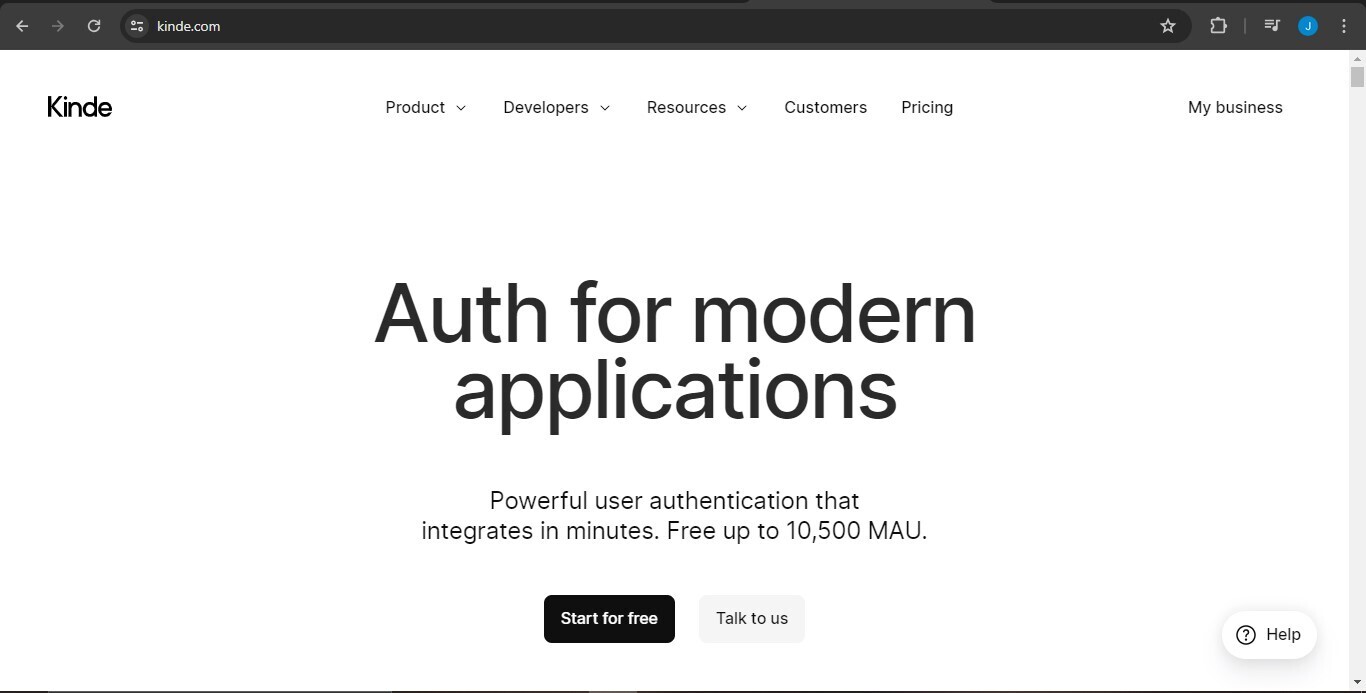
To continue the signup process, Kinde will ask you to add your business name and a domain name for Kinde to host your app. It also sets a default region for where your data will be stored, but you can modify it if necessary.
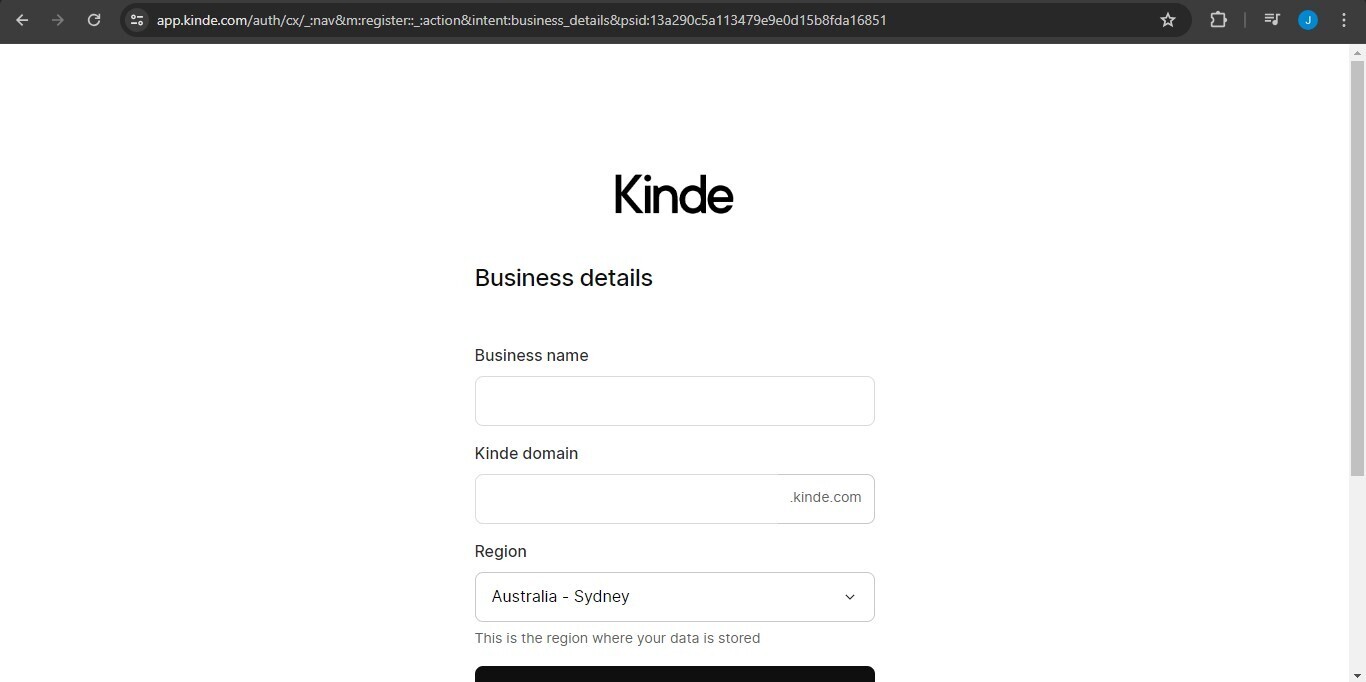
After clicking next, it will ask you if you want to start a project from scratch or add Kinde to your existing codebase. Since we're adding Kinde to our Next.js app, I'll choose the latter.
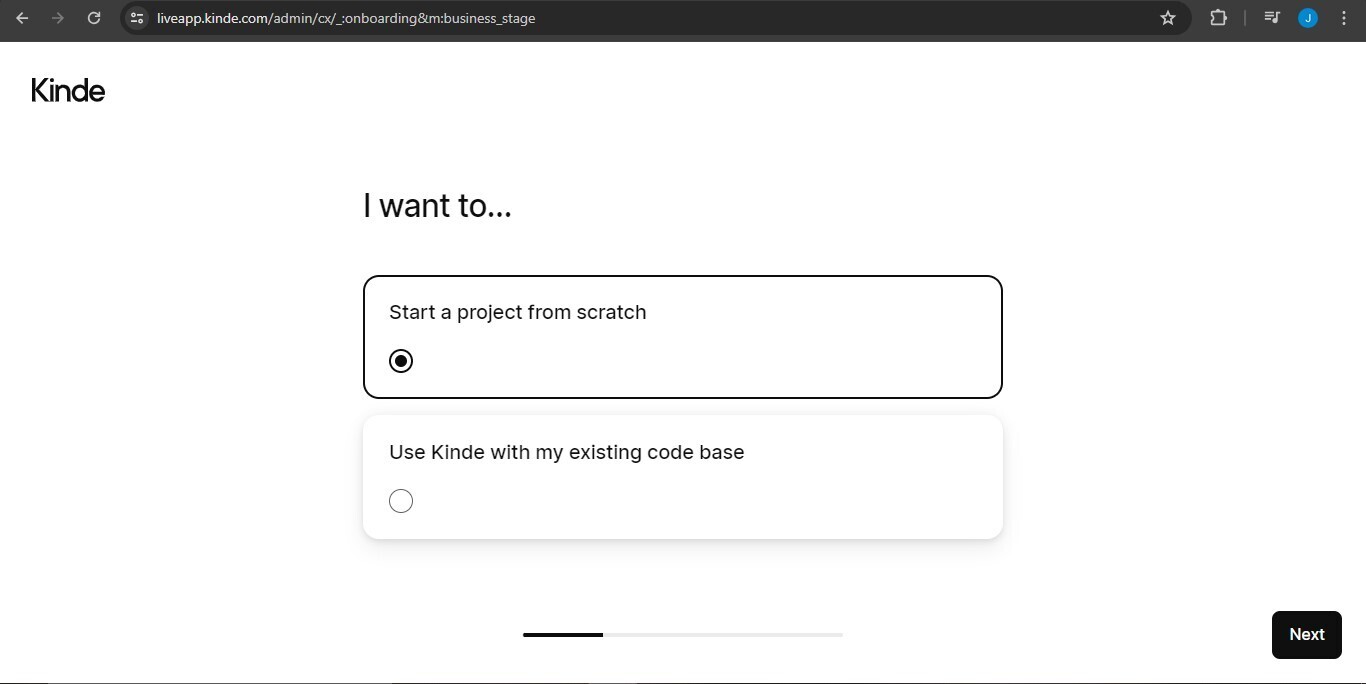
To provide the right docs, Kinde will also ask about the tech you're using on your app. We're using Next.js, so just click that and continue.
To complete the signup process, you need to choose the ways your users can be authenticated with Kinde. By default, Kinde provides email authentication, but you can add other authentication providers like Google or GitHub.
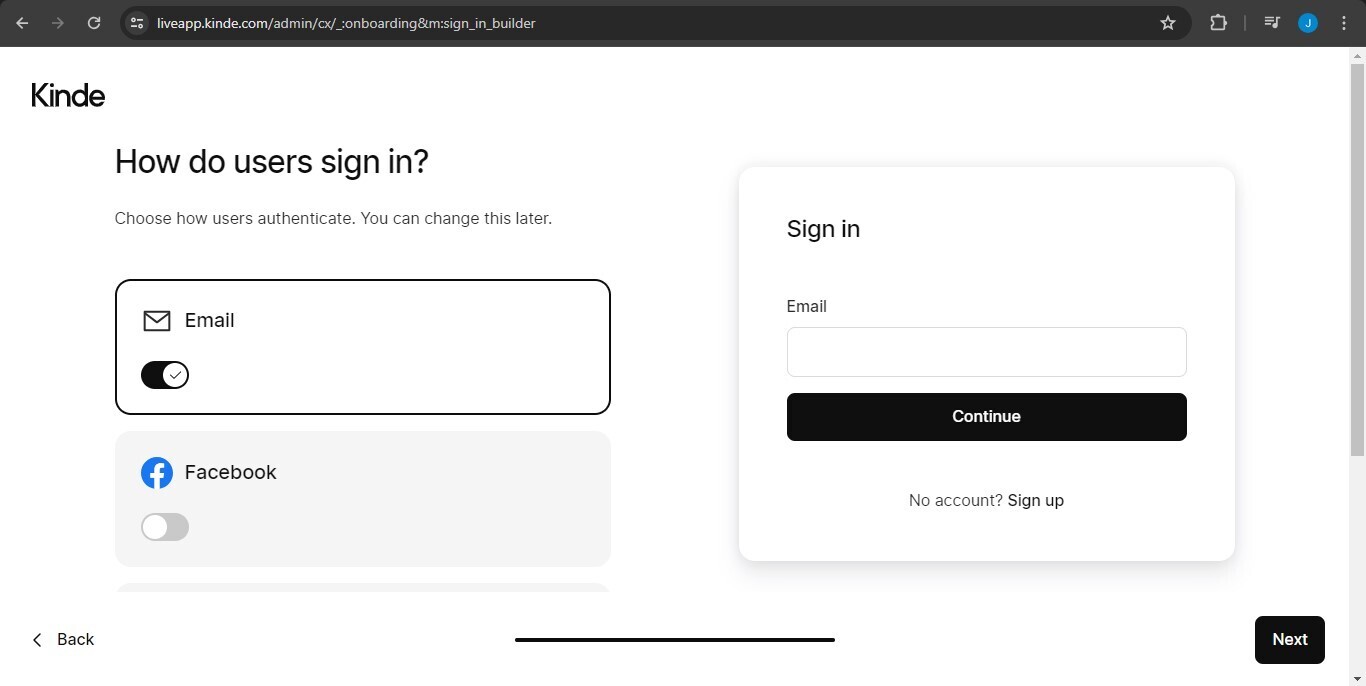
After the signup process is done, Kinde will lay out ways for you to integrate it into your app with their guides. You can just click on the connect to Next.js codebase option.
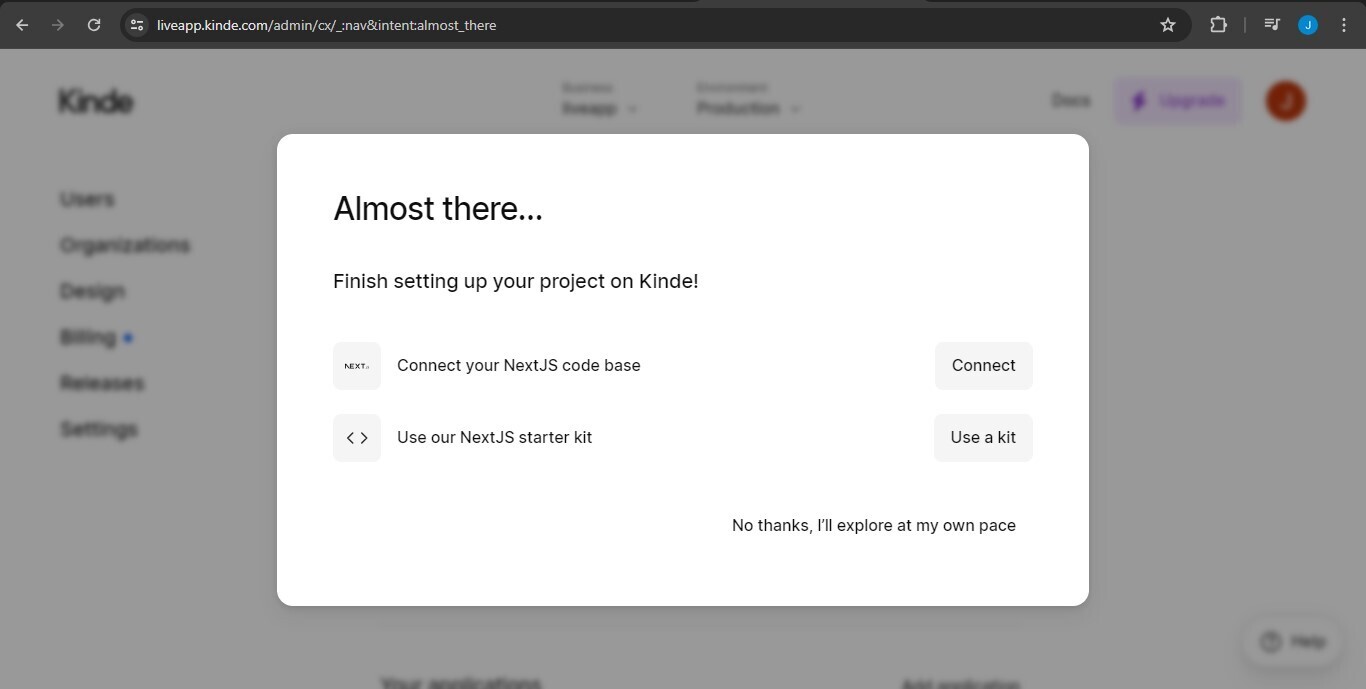
You will be redirected to a quick start guide for adding Kinde to your existing Next.js project. Scroll down and copy the npm or yarn installation command to install the Kinde Next.js SDK as a dependency. Also, copy the environment variables provided by Kinde into a .env.local file.
```
npm i @kinde-oss/kinde-auth-nextjs
```
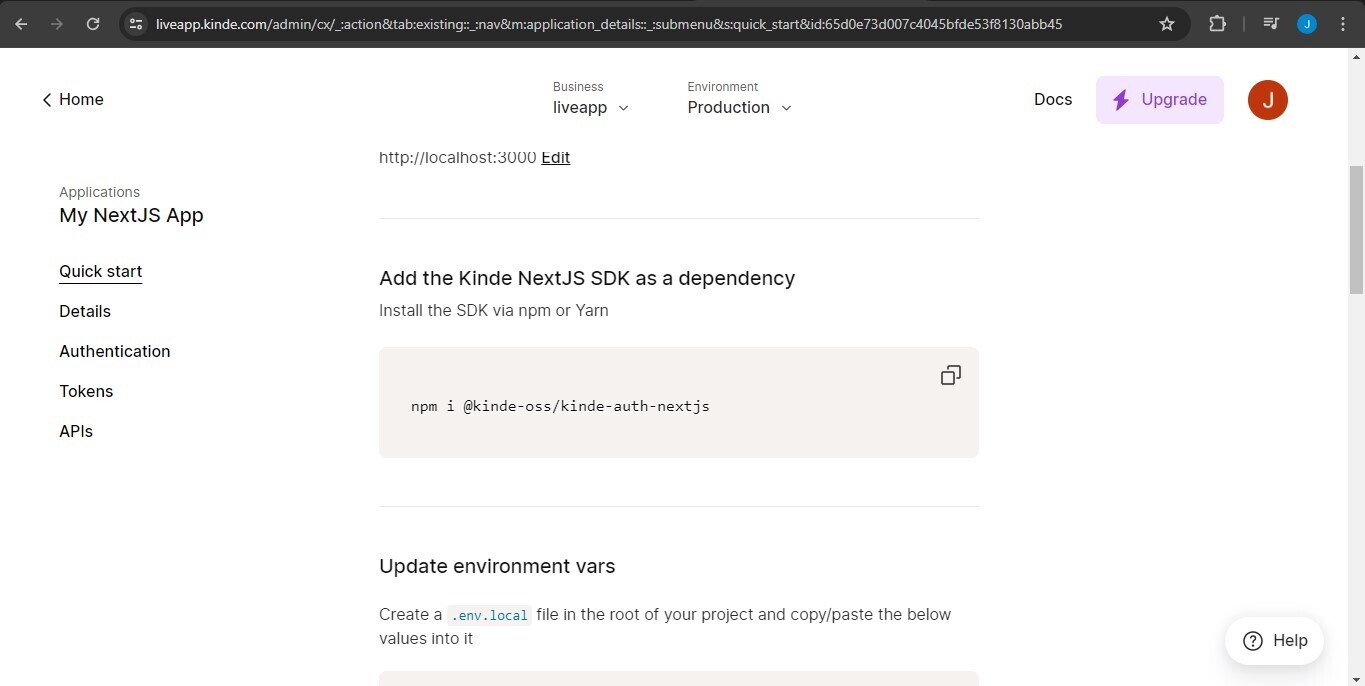
We're almost done, the last thing you need to do is to create an api folder in your app directory, add an auth folder within it, within the auth folder a dynamic segment that looks like this [kindeauth], add a route.js file to it, and finally copy this inside of it.
```
import {handleAuth} from "@kinde-oss/kinde-auth-nextjs/server";
export const GET = handleAuth();
```
🎉You're done! You've successfully added authentication using Kinde to your Next14 app.
To start your auth flow in your app, you use the LoginLink and RegisterLink components.
```
import {RegisterLink, LoginLink} from "@kinde-oss/kinde-auth-nextjs/components";
<LoginLink>Sign in</LoginLink>
<RegisterLink>Sign up</RegisterLink>
```
🔥Happy coding!
You hear more from me on:
[X](https://x.com/code_withjoseph)
| joeskills |
1,872,553 | Silent Generators: Ensuring Uninterrupted Power with Minimal Noise | Silent Generators: Ensuring Uninterrupted Power plus Minimal Noise Silent Generators will be the... | 0 | 2024-06-01T01:05:55 | https://dev.to/pamela_ballardow_8f47cadc/silent-generators-ensuring-uninterrupted-power-with-minimal-noise-2pe1 | power |
Silent Generators: Ensuring Uninterrupted Power plus Minimal Noise
Silent Generators will be the innovation that are latest in the world of generators, ensuring power which are uninterrupted lower noise. These generators are now the game-changer, and people which can be a few switching with the {traditional generators to|generators that are traditional} these generators which are often peaceful., we intend to explore the value, safeguards, use, solution, plus quality of peaceful generators.
Great things about Silent Generators
One of the {biggest top features|top features that are biggest} of peaceful Diesel engine generators was they develop noise which are minimal contrast to generators that are main-stream. For the reason that they've enclosures which are soundproof {reduce noise pollution|noise pollution that is reduce}. Plus peaceful generators, you can enjoy power that was {uninterrupted sound which|sound that is uninterrupted} are distracting.
Next, Silent Generators are more efficient in comparison to generators being traditional. They could save on fuel expenses given that they consume less gasoline a tool of power produced. This may cause them to an alternative that are perfect those attempting to save very well {energy spending|spending that is energy}.
Innovation
Silent Generators are the product of innovation. They are typically made out of contemporary apparatus to provide power that are efficient with minimal noise. This has made them a range that has been {popular people who|people that are popular} are most domiciles, plus organizations.
Safety
Diesel generator sets are produced plus security in your thoughts. They shall have advanced safety service that decrease the risk of accidents. For instance, they have circuit breakers that avoid {accidental electrocution|electrocution that is accidental}. Furthermore, they shall has {automatic shutoff switches|shutoff that is automatic} that turn fully off the generator’s engine whenever it detects natural oils that was low or overheating.
Using Silent Generators
Silent Generators which is peaceful easy plus easy. First, be sure that the buyer is see our you handbook that is roofed aided by the generator. This could easily permit you to learn to operate it correctly.
{Before you begin the Silent Generators, check out the natural oils levels out plus fuel to make sure they are sufficient|They are sufficient before you begin the generator, check out the natural oils levels out plus fuel to make sure}. Then, connect the cords being electric the generator plus turn it in. Adjust the settings to the {required manufacturing regularity|manufacturing that is required} plus voltage, as well as the generator starts power that are creating.
Service
Silent generators or require regular servicing to {effortlessly confirm they operate|confirm they operate effortlessly} plus effectively. You ought to keep these specific things serviced our the {professional expert more|expert that is professional} than one days each year. The expert could bring repair which was routine changing the natural oils plus environment filters, checking the spark plugs, plus tightening {free part with|part that is free} the solutions.
Quality
The standard of the Silent Generators is vital since it see their {effectiveness plus durability|durability plus effectiveness}. When purchasing the generator that are peaceful select a brand name which try reputable plus make sure this has been {tested plus certified|certified plus tested} for protection. Also, glance at the guaranteed duration plus solution that has been after-sale by the manufacturer.
Application
Silent Generators require various applications in several settings. Domiciles can use them being truly a {|charged} power that are backup in case of the blackout since power outage. Hospitals plus company which was {medical utilize them|utilize that is medical} to ensure power that are uninterrupted for medical gear. Activities plus concerts can use them to make power for sound plus practices which are lighting. Finally, construction sites could use them for power products plus apparatus.
Silent Generators Products providing the dependable plus power that are efficient with minimal noise. They are an alternative which will be excellent those wanting to save on fuel costs plus minmise air pollution which was noise. Additionally, they're designed with high level protection characteristics, producing them the option that has been safer homes, companies, plus tasks. Plus solution which is {suitable quality purchase|quality that is suitable}, plus appropriate use, peaceful generators is an excellent investment that guarantees energy that are uninterrupted.
Source: https://www.kangwogroup.com/Diesel-generator-sets | pamela_ballardow_8f47cadc |
1,872,551 | Host your own web-based collaborative IDE | Intro I recently got to try Ishaan Dey's Sandbox, (ishaan1013/sandbox) which is an open... | 0 | 2024-06-01T00:49:59 | https://dev.to/jamesmurdza/how-to-setup-ishaan1013sandbox-locally-503p | ## Intro
I recently got to try Ishaan Dey's Sandbox, ([ishaan1013/sandbox](https://github.com/ishaan1013/sandbox)) which is an open source web-based editor similar to Replit that lets you write and run code in your browser.
In this post I write down the steps I followed to get the project running locally.
Quick note—in some of the text below you may see the use of emojis like 🍎 in example code. It should be very obvious what you need to put in place of the emojis—if not, leave a comment!
## Requirements
The application uses NodeJS and can be run with Docker.
Needed accounts to set up:
- [Clerk](https://clerk.com/): Used for user authentication.
- [Liveblocks](https://liveblocks.io/): Used for collaborative editing.
- [Cloudflare](https://www.cloudflare.com/): Used for relational data storage (D2) and file storage (R2).
A quick overview of the tech before we start: The deployment uses a **NextJS** app for the frontend and an **ExpressJS** server on the backend. Presumably that's because NextJS integrates well with Clerk middleware but not with Socket.io.
## Initial setup
No surprise in the first step:
```bash
git clone https://github.com/ishaan1013/sandbox
cd sandbox
```
Run `npm install` in:
```
/frontend
/backend/database
/backend/storage
/backend/server
/backend/ai
```
## Adding Clerk
Setup the Clerk account.
Get the API keys from Clerk.
Update `/frontend/.env`:
```
NEXT_PUBLIC_CLERK_PUBLISHABLE_KEY='🔑'
CLERK_SECRET_KEY='🔑'
```
## Deploying the storage bucket
Go to Cloudflare.
Create and name an R2 storage bucket in the control panel.
Copy the account ID of one domain.
Update `/backend/storage/src/wrangler.toml`:
```
account_id = '🔑'
bucket_name = '🔑'
key = 'SUPERDUPERSECRET'
```
In the `/backend/storage/src` directory:
```
npx wrangler deploy
```
## Deploying the database
Create a database:
```
npx wrangler d1 create sandbox-database
```
Use the output for the next setp.
Update `/backend/database/src/wrangler.toml`:
```
database_name = '🔑'
database_id = '🔑'
KEY = 'SUPERDUPERSECRET'
STORAGE_WORKER_URL = 'https://storage.🍎.workers.dev'
```
In the `/backend/database/src` directory:
```
npx wrangler deploy
```
## Applying the database schema
Delete the `/backend/database/drizzle/meta` directory.
In the `/backend/database/` directory:
```
npm run generate
npx wrangler d1 execute sandbox-database --remote --file=./drizzle/0000_🍏_🍐.sql
```
## Configuring the server
Update `/backend/server/.env`:
```
DATABASE_WORKER_URL='https://database.🍎.workers.dev'
STORAGE_WORKER_URL='https://storage.🍎.workers.dev'
WORKERS_KEY='SUPERDUPERSECRET'
```
## Adding Liveblocks
Setup the Liveblocks account.
Update `/frontend/.env`:
```
NEXT_PUBLIC_LIVEBLOCKS_PUBLIC_KEY='🔑'
LIVEBLOCKS_SECRET_KEY='🔑'
```
## Adding AI code generation
In the `/backend/ai` directory:
```
npx wrangler deploy
```
Update `/backend/server/.env`:
```
AI_WORKER_URL='https://ai.🍎.workers.dev'
```
## Configuring the frontend
Update `/frontend/.env`:
```
NEXT_PUBLIC_DATABASE_WORKER_URL='https://database.🍎.workers.dev'
NEXT_PUBLIC_STORAGE_WORKER_URL='https://storage.🍎.workers.dev'
NEXT_PUBLIC_WORKERS_KEY='SUPERDUPERSECRET'
```
## Running the IDE
Run `npm run dev` simultaneously in:
```
/frontend
/backend/server
```
Additionally, here's a [Dockerfile](https://github.com/jamesmurdza/sandbox/tree/feat/dockerfile) that can be used to run both components together. | jamesmurdza | |
1,872,550 | Mi primer Articulo, escribiendo acerca de mi Agenda para el semestre 2 2024. "Sin saber de agendas!." | Ya son muchas las formas, conceptos, información acumulada durante unos 10 años aproximadamente. es... | 0 | 2024-06-01T00:47:24 | https://dev.to/rickdev9/mi-primer-articulo-escribiendo-acerca-de-mi-agenda-para-el-semestre-2-2024-sin-saber-de-agendas-kc4 | agenda, articulo, markdown | Ya son muchas las formas, conceptos, información acumulada durante unos 10 años aproximadamente. es por esto que me animo a escribir acerca de como voy a pretender organizar mi agenda, es decir mi tiempo para crear poryectos, actividades, enseñanzas. Las cuales pretenderé que se me anime a saber escribir de estos temas.
Si, asi es, me animaré de una vez por toda a realizar varios de mis cosas pendientes, y todo esto tendrá que ver por que me encanta aprender y compartir conocimiento.
Existe la probabilidad y posibilidad que a medida de mis publicaciones tenga algunos errores que usted encontrará al leer mis árticulos, es por ello que si te estás pasando por este sitio y cualquier de mis articulos publicados no dudes en hacerme la observación por medio de la caja de comentarios.
Agradezco la retroalimentación que me puedan hacer. Estaré presto a atender las sugerencias.
`
<table>
<thead>Agenda personal</thead>
<tr>
<thgroup>
<th>Área</th>
<th>Sección</th>
<th>Observaciones</th>
<th>Fecha de Inicio</th>
<th>Fecha de estipulada para Fin</th>
</thgroup
</tr>
<tbody>
<tr>
<td>Proyecto short-lived/td>
<td>Github</td>
<td>Microsoft Build: Aceleración de la productividad del desarrollador con GitHub y Azure para desarroll</td>
<td>Introducción a Github Copilot, Introducción a la ingeniería de solicitudes con Github Copilot, uso de GitHub Copilot con JavasCript</td>
<td>21 Junio</td>
</tr>
<tr>
<td>Proyecto short-lived/td>
<td>GitHub Pages, rickdev9's projects</td>
<td>Confirmacion .section > Hoja de vida && proyects</td>
<td>Vincular articulos y novedades a sitio dev.to && x.com && form contact & comunidad UNIMINUTO.</td>
<td>21 de Junio</td>
</tr>
<tr>
<td>Proyecto long-Running/td>
<td>Community for Gender equality and learning with teacher and students</td>
<td>investigar indicadores de género en LATAM y Colombia, Crear comunidad en Teams && vincular embedded sites web en pestañas</td>
<td>Vincular logros a sitio rickdev9's projects de GitHub Page</td>
<td> 21 de Junio</td>
</tr>
</tbody>
</table>
`
Nos veremos pronto, seguire actualizando mi agenda, pero sobre todo me la juego por cumplir estas agendas propuestas | rickdev9 |
1,872,549 | Flexible Solar Panels: A Solution for Curved Surfaces | Flexible Solar Panel Systems: The Newest Solution To Curved Surfaces Introduction: Have you ever... | 0 | 2024-06-01T00:46:00 | https://dev.to/pamela_ballardow_8f47cadc/flexible-solar-panels-a-solution-for-curved-surfaces-3gi1 | flexible | Flexible Solar Panel Systems: The Newest Solution To Curved Surfaces
Introduction:
Have you ever wondered how we can harness the charged power associated with the sunlight to generate electricity? The solution is based on solar power panels, which convert sunlight into usable energy. But imagine if you want to install solar panel systems for a area curved? This is where versatile panels that are solar in – these are typically a game-changer in the area of solar technology. Let us dive to the globe wonderful of solar power panels!
Features of Flexible Solar Panels:
Versatile solar power panels have some significant advantages over old-fashioned rigid panels that are solar. Above all, they've been flexible meaning can conform to any shape or size of the surface. They've been made by this quality ideal for curved areas like ships, RVs, and automobiles. Also, flexible panels that are solar lightweight and simple to install. Also more resistant and durable to harm from impacts, making them an improved choice for outside use. Flexible panels which are solar also better at creating energy in low light conditions. Many of these factors make versatile solar panel systems a choice top anyone trying to go green.
Innovation in Versatile Solar Panel Technology:
The growth of versatile Solar Panel that are solar due to innovative research and advances in technology. Unlike old-fashioned panels being solar use rigid materials like silicon, versatile solar panels use thin-film materials that are applied to flexible substrates like synthetic. This technology has permitted for the creation of slim and lightweight panels being solar may be stated in big quantities, making them more affordable than ever before. The innovation in versatile panel solar has opened up brand new opportunities for renewable energy.
Safety of Versatile Solar Panel Systems:
Versatile panels that are solar fashioned with security in your mind. They do not create any emissions which can be harmful and they're not just a fire risk. Additionally, they are waterproof and may come in contact with harsh conditions being outside posing any risk of electrocution or shock. The voltage low of flexible solar panel systems means they are safe to carry out and install. They are a fantastic choice for anyone concerned with security and impact environmental.
How to make use of Solar versatile Panels
Using versatile panels which can be solar effortless and straightforward. Begin by choosing the right output and size to your requirements. Then, determine where you intend to install the panels. If you should be installing the panels for a area curved make sure to select versatile panels that may flex and flex to the bend of the area. Next, you shall need certainly to install the panels utilizing adhesive or brackets. Be sure to proceed with the maker's instructions when installing the panels. After the panels are set up, simply connect them to a battery pack or inverter to start energy generating. It is that simple!
Quality and Provider of Versatile Solar Panel Systems:
When choosing Flexible Solar Panel, it is necessary to pick a quality item from a maker reputable. Try to find panels that are made out of top-quality materials and are usually built to final. Additionally, make sure to select a manufacturer that provides customer excellent and support. This can make certain you have a experience good that any dilemmas may be fixed quickly and easily.
Application of Flexible Solar Panels:
Versatile solar panel systems have a range wide of. They're ideal for usage on boats, RVs, and automobiles, where surfaces being curved common. They are able to additionally be used to power portable devices and illumination outside. Additionally, flexible solar power panels can be used in domestic and commercial settings to build power from rooftops as well as other areas that are curved. The possibilities are endless with regards to the application of Foldable Solar Panel that are solar.
Source: https://www.dhceversaving.com/flexible-solar-panel | pamela_ballardow_8f47cadc |
1,872,547 | Advanced Object-Oriented Programming in Java | Introduction Java is a popular programming language that is widely used in software... | 0 | 2024-06-01T00:34:22 | https://dev.to/kartikmehta8/advanced-object-oriented-programming-in-java-5a77 | webdev, javascript, programming, beginners | ## Introduction
Java is a popular programming language that is widely used in software development, particularly for web and mobile applications. One of the key features of Java is its support for object-oriented programming (OOP). In recent years, the demand for advanced OOP in Java has increased as developers strive to create more robust and scalable applications. In this article, we will discuss the advantages, disadvantages, and features of advanced OOP in Java.
## Advantages of Advanced OOP in Java
- **Better Code Organization and Modularization:** The use of advanced OOP in Java allows for better code organization and modularization, making it easier to maintain and update large software applications.
- **Reusable Code:** Advanced OOP enables developers to create reusable code through the use of classes and objects.
- **Improved Security and Reliability:** OOP allows for better data abstraction and encapsulation, which helps improve the security and reliability of the code.
## Disadvantages of Advanced OOP in Java
- **Steep Learning Curve:** Advanced OOP in Java requires a solid understanding of the principles of OOP, such as inheritance, polymorphism, and encapsulation, which can be challenging for beginners.
- **Performance Issues:** OOP can lead to performance issues, as it requires a significant amount of memory and processing power.
## Features of Advanced OOP in Java
- **Inheritance:** Java supports advanced OOP concepts such as inheritance, allowing classes to inherit properties and methods from other classes.
- **Polymorphism:** Java enables polymorphism, which allows methods to perform different functions based on the object that is calling them.
- **Encapsulation:** This feature helps protect the data in an object from accidental modification by restricting access to some of its components.
- **Multiple Inheritance:** Through interfaces, Java supports multiple inheritance, allowing a subclass to extend more than one parent class and thereby create complex and specialized classes.
### Example of Advanced OOP in Java
```java
public class Vehicle {
// Base class
}
public class Car extends Vehicle {
// Subclass extending the Vehicle class
private int wheels;
private int doors;
private int gears;
private boolean isManual;
public Car(String name, int wheels, int doors, int gears, boolean isManual) {
super(name);
this.wheels = wheels;
this.doors = doors;
this.gears = gears;
this.isManual = isManual;
}
// Additional methods and properties
}
public interface Control {
// Interface for multiple inheritance
void steer(int direction);
}
public class Ford extends Car implements Control {
// Subclass extending Car and implementing Control interface
public Ford(String name, int wheels, int doors, int gears, boolean isManual) {
super(name, wheels, doors, gears, isManual);
}
public void steer(int direction) {
// Implementation of the steer method
}
}
```
## Conclusion
In conclusion, advanced OOP in Java has numerous advantages, including better code organization, reusability, and improved security. However, it also has its downsides, such as a steep learning curve and potential performance issues. Nonetheless, with its powerful features and widespread use in software development, mastering advanced OOP in Java can greatly enhance a developer's skill set and improve the efficiency and quality of their code. | kartikmehta8 |
1,872,545 | Why Spring Matters for Java Developers | Writing Java Applications in the Past When writing Java applications in the past, writing... | 0 | 2024-06-01T00:15:02 | https://springmasteryhub.com/2024/05/31/why-spring-matters-for-java-developers/ | java, spring, springboot, programming | ## Writing Java Applications in the Past
When writing Java applications in the past, writing all the functionalities from scratch was common. It was time-consuming, requiring significant effort to create various factories, infrastructure code, setup code, etc.
## Growth of the Java Ecosystem and the Problem with Large Libraries
As the years passed, the Java ecosystem grew, and many libraries were created and shared to solve developers' common development problems. While these libraries were useful, they started to come with a cost.
These libraries grew too large, and using a simple functionality from a library required loading the entire package. Imagine importing a library with a thousand classes just to use a single one. Packaging your application would include all those classes even if you only needed one.
## The Solution: Small, Specific Libraries and Spring
This became a problem. A better idea was to have small libraries specific to certain problems, decoupled by topic. Instead of having large jars that did everything, we started to use small jars to solve specific problems.
For example, Jackson is a library specialized in serializing and deserializing JSON objects.
Now, Spring is a collection of these useful jars that can help you create your applications. It allows you to create a combination of dependencies (libraries) that suit your needs.
## Benefits of Spring
Spring helps by using the convention over configuration pattern. It creates a series of infrastructure beans based on the dependencies you add to your project, making things easier by providing a default configuration and allowing you to configure only what matters to you.
For example, are you using Kafka? Use the Spring Kafka dependency, customize your Kafka broker URL and some other configurations, and you're ready to go. Spring will provide a bean to send or consume messages from Kafka.
## Simplifying Development Decisions
It reduces the decisions developers need to make about handling connections, whether to use a singleton, where to put topic configurations, etc. It's already done; just customize it, and you're ready to go.
Spring uses these abstractions to make you more productive so you can focus on what matters most!
Do you use Spring in your projects? Many developers started working with Spring without knowing the Java past and how Spring makes our lives easier.
If you like Spring make sure to follow me and stay tuned to learn more! Don't miss out!
[Willian Moya (@WillianFMoya) / X (twitter.com)](https://twitter.com/WillianFMoya)
[Willian Ferreira Moya | LinkedIn](https://www.linkedin.com/in/willianmoya/)
Follow me here on dev.to! | tiuwill |
1,863,038 | Practical advice for writing React Components | I've been spending a lot of time with React lately - and I've developed some opinions. Disagree with... | 0 | 2024-06-01T00:05:42 | https://dev.to/lime517/practical-advice-for-writing-react-components-1o85 | react, tailwindcss, webdev, beginners | I've been spending a _lot_ of time with React lately - and I've developed some opinions. Disagree with any of them? Ping me at [@greveJoe](https://twitter.com/greveJoe/) on the social media platform formerly known as Twitter.
Let's get into it.
## 1. Combine Classes with clsx and twMerge
Blind concatenation of classNames is a trap, especially with Tailwind. Half the time it won't work how you expect because of CSS specificity. Instead, using `clsx` (or similar) and `twMerge` together provides flexibility when combining classes - letting you safely override default component styles with your own.
### Why This Matters
- **Cleaner Code:** `clsx` and `twMerge` help you write concise and readable class combinations.
- **Conditional Classes:** `clsx` makes it easy to apply classes based on props or state.
- **Conflict Resolution:** `twMerge` allows you to override conflicting classes, ensuring the desired styles are applied.
### Example: Custom Button Component
❌ **Don't do this**:
```jsx
const MyButton = ({ isActive, children }) => (
<button className={`bg-blue-500 text-white px-4 py-2 ${isActive ? 'border-2 border-red-500' : ''}`}>
{children}
</button>
);
```
*Why this is bad*: Concatenating classes directly can lead to hard-to-read and error-prone code, especially as the number of conditional classes increases.
✅ **Do this instead**:
```jsx
import clsx from 'clsx';
import { twMerge } from 'tailwind-merge';
const cn = (...classes) => twMerge(clsx(...classes));
const MyButton = ({ isActive, children }) => (
<button className={cn(
'bg-blue-500 text-white px-4 py-2',
isActive && 'border-2 border-red-500'
)}>
{children}
</button>
);
```
### Creating a Utility Function
To make combining classes even more convenient, create a utility function that combines `clsx` and `twMerge`:
```jsx
import clsx from 'clsx';
import { twMerge } from 'tailwind-merge';
const cn = (...classes) => twMerge(clsx(...classes));
export default cn;
```
You can then import and use this `cn` function in your components:
```jsx
import cn from './utils/cn';
const MyComponent = ({ isActive }) => (
<div className={cn('bg-white p-4', isActive && 'border-2 border-blue-500')}>
{/* ... */}
</div>
);
```
By using `clsx` and `twMerge` together, you can create cleaner, more maintainable code when working with utility-first CSS frameworks like Tailwind CSS. This approach makes it easier to apply conditional classes, resolve conflicts, and keep your components readable as your application grows in complexity.
## 2. Embrace Default Props
When building reusable components, it's crucial to allow for default props like `className` or `onClick`. This practice makes your components more composable, flexible, and easier to integrate into different contexts. It ensures that other developers can use your custom components just like native HTML elements, without needing to learn their inner workings.
In React, `forwardRef` is a powerful tool that allows your custom components to behave like native HTML elements. It enables your component to receive a `ref` prop, which can be used to access the underlying DOM element directly.
### Why This Matters
Allowing default props:
- **Enhances Flexibility:** Developers can style your component or attach event handlers without modifying its internals.
- **Improves Composability:** Your component can be seamlessly used within different layouts and contexts.
- **Reduces Learning Curve:** Other developers can use familiar props, making your component easier to adopt.
### Example: Custom Button Component
❌ **Don't do this**:
```jsx
const MyButton = ({ children }) => (
<button className="bg-blue-500 text-white px-4 py-2">
{children}
</button>
);
```
*Why this is bad*: This approach hardcodes styles and doesn't allow for additional props like `className` or `onClick`, making the component inflexible and hard to reuse.
✅ **Do this instead**:
```jsx
import React, { forwardRef } from 'react';
import clsx from 'clsx';
import { twMerge } from 'tailwind-merge';
const cn = (...classes) => twMerge(clsx(...classes));
const MyButton = forwardRef(({ children, className, ...props }, ref) => (
<button
ref={ref}
className={cn('bg-blue-500 text-white px-4 py-2', className)}
{...props}
>
{children}
</button>
));
export default MyButton;
```
### Using the Custom Button
Here's how you might use this `MyButton` component in a parent component:
```jsx
import React, { useRef } from 'react';
import MyButton from './MyButton';
const ParentComponent = () => {
const buttonRef = useRef(null);
const handleClick = () => {
if (buttonRef.current) {
console.log('Button clicked!', buttonRef.current);
}
};
return (
<div>
<MyButton ref={buttonRef} className="extra-class" onClick={handleClick}>
Click Me
</MyButton>
</div>
);
};
export default ParentComponent;
```
By embracing default props and using `forwardRef`, you create components that are flexible, reusable, and behave like native HTML elements. This approach reduces the learning curve for other developers and makes your components easier to work with in various contexts.
Here are points 3-5 and the conclusion of the blog post:
## 3. Let Parents Handle Layout and Spacing
When building reusable components, it's important to let the parent component handle layout and spacing concerns. This separates the responsibilities of the parent and child components, promoting a more modular and reusable design. A more controversial way to phrase this is: Never use `margin` - `padding` and `gap` are all you need.
### Why This Matters
- **Modularity:** Keeping layout and spacing concerns in the parent component makes the child components more modular and reusable.
- **Flexibility:** Parent components can adapt the layout and spacing based on their specific needs.
- **Consistency:** Centralizing layout and spacing decisions in the parent component ensures a consistent user interface.
### Example: List Component
❌ **Don't do this**:
```jsx
const ListItem = ({ children }) => (
<div className="mb-4">
{children}
</div>
);
const List = () => (
<div>
<ListItem>Item 1</ListItem>
<ListItem>Item 2</ListItem>
<ListItem>Item 3</ListItem>
</div>
);
```
_Why this is bad_: Each `ListItem` has a hard-coded `margin-bottom`, which can lead to inconsistent spacing and make the component less adaptable.
✅ **Do this instead**:
```jsx
const ListItem = ({ children }) => (
<div>{children}</div>
);
const List = () => (
<div className="flex flex-col gap-4">
<ListItem>Item 1</ListItem>
<ListItem>Item 2</ListItem>
<ListItem>Item 3</ListItem>
</div>
);
```
By letting the parent `List` component handle the spacing between `ListItem`s, you create a more modular and flexible design that can easily adapt to different layout requirements.
## 4. Use Controlled Components for Complex Interactions
For complex interactions like forms or modals, use controlled components to manage state and provide a clear way for the parent component to control the child component's behavior.
### Why This Matters
- **Predictability:** Controlled components make the state and behavior of the child component more predictable.
- **Easier Testing:** With controlled components, it's easier to write unit tests for the parent component.
- **Better Separation of Concerns:** The parent component manages the state, while the child component focuses on rendering and user interactions.
### Example: Modal Component
```jsx
const Modal = ({ isOpen, onClose, children }) => (
<div className={cn('fixed z-10 inset-0 overflow-y-auto', isOpen ? 'block' : 'hidden')}>
<div className="flex items-end justify-center min-h-screen pt-4 px-4 pb-20 text-center sm:block sm:p-0">
{/* Modal content */}
<div className="inline-block align-bottom bg-white rounded-lg text-left overflow-hidden shadow-xl transform transition-all sm:my-8 sm:align-middle sm:max-w-lg sm:w-full">
{children}
<button onClick={onClose}>Close</button>
</div>
</div>
</div>
);
```
In this example, the `Modal` component is controlled by the parent component through the `isOpen` and `onClose` props. This makes the modal's state predictable and easier to manage.
## 5. Automatically Order Tailwind Classes with Prettier
To make your Tailwind classes more consistent and easier to read, use the `prettier-plugin-tailwindcss` plugin to automatically order your classes.
### Why This Matters
- **Consistency:** Automatically ordering your Tailwind classes ensures a consistent style throughout your codebase.
- **Readability:** Ordered classes are easier to scan and understand at a glance.
- **Maintainability:** Consistently ordered classes make it easier for other developers to work with your code.
### Example: Setting Up Prettier with Tailwind CSS
1. Install the necessary packages:
```bash
npm install -D prettier prettier-plugin-tailwindcss
```
2. Update your `.prettierrc` file:
```json
{
"plugins": ["prettier-plugin-tailwindcss"]
}
```
Now, whenever you run Prettier on your codebase, your Tailwind classes will be automatically ordered, improving the consistency and readability of your code.
## Conclusion
Remember, these practices are not hard-and-fast rules but rather guidelines based on my experience. Feel free to adapt them to your specific needs and preferences.
If you have any other tips or best practices for building React components, I'd love to hear them! Connect with me on Twitter at [@greveJoe](https://twitter.com/greveJoe) and let's continue the conversation.
Happy coding! | lime517 |
1,872,579 | Vertical Slice Architecture: Structuring Vertical Slices | Are you tired of organizing your project across layers? Vertical Slice Architecture is a compelling... | 0 | 2024-06-02T14:19:56 | https://www.milanjovanovic.tech/blog/vertical-slice-architecture-structuring-vertical-slices | vsa, verticalslices, verticalslicearchitecture, dotnet | ---
title: Vertical Slice Architecture: Structuring Vertical Slices
published: true
date: 2024-06-01 00:00:00 UTC
tags: vsa,verticalslices,verticalslicearchitecture,dotnet
canonical_url: https://www.milanjovanovic.tech/blog/vertical-slice-architecture-structuring-vertical-slices
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/7jzwxucjx15oitfki6bc.png
---
Are you tired of organizing your project across layers?
Vertical Slice Architecture is a compelling alternative to traditional layered architectures. [VSA](https://www.milanjovanovic.tech/blog/vertical-slice-architecture) flips the script on how we structure code.
Instead of horizontal layers (Presentation, Application, Domain), VSA organizes code by feature. Each feature encompasses everything it needs, from API endpoints to data access.
In this newsletter, we will explore how you can structure vertical slices in VSA.
## Understanding Vertical Slices
At its core, a vertical slice represents a self-contained unit of functionality. It's a slice through the entire application stack. It encapsulates all the code and components necessary to fulfill a specific feature.
In traditional layered architectures, code is organized horizontally across the various layers. One feature implementation can be scattered across many layers. Changing a feature requires modifying the code in multiple layers.
VSA addresses this by grouping all the code for a feature into a single slice.
This shift in perspective brings several advantages:
- **Improved cohesion**: Code related to a specific feature resides together, making it easier to understand, modify, and test.
- **Reduced complexity**: VSA simplifies your application's mental model by avoiding the need to navigate multiple layers.
- **Focus on business logic**: The structure naturally emphasizes the business use case over technical implementation details.
- **Easier maintenance**: Changes to a feature are localized within its slice, reducing the risk of unintended side effects.
## Implementing Vertical Slice Architecture
Here's an example vertical slice representing the `CreateProduct` feature. We use a static class to represent the feature and group the related types. Each feature can have a respective `Request` and `Response` class. The use case with the business logic can be in a [Minimal API endpoint](https://www.milanjovanovic.tech/blog/automatically-register-minimal-apis-in-aspnetcore).
A vertical slice is likely either a command or a query. This approach gives us [CQRS](https://www.milanjovanovic.tech/blog/cqrs-pattern-with-mediatr) out of the box.
```csharp
public static class CreateProduct
{
public record Request(string Name, decimal Price);
public record Response(int Id, string Name, decimal Price);
public class Endpoint : IEndpoint
{
public void MapEndpoint(IEndpointRouteBuilder app)
{
app.MapPost("products", Handler).WithTags("Products");
}
public static IResult Handler(Request request, AppDbContext context)
{
var product = new Product
{
Name = request.Name,
Price = request.Price
};
context.Products.Add(product);
context.SaveChanges();
return Results.Ok(
new Response(product.Id, product.Name, product.Price));
}
}
}
```
I want to mention a few benefits of structuring your application like this.
The code for the entire `CreateProduct` feature is tightly grouped within a single file. This makes it extremely easy to locate, understand, and modify everything related to this functionality. We don't need to navigate multiple layers (like controllers, services, repositories, etc.).
Directly using `AppDbContext` within the endpoint might tightly couple the slice to your database technology. Depending on your project's size and requirements, you could consider abstracting data access (using a repository pattern) to make the slice more adaptable to changes in the persistence layer.
## Introducing Validation in Vertical Slices
Vertical slices usually need to solve some [cross-cutting concerns](https://www.milanjovanovic.tech/blog/balancing-cross-cutting-concerns-in-clean-architecture), one of which is validation. Validation is the gatekeeper, preventing invalid or malicious data from entering your system. We can easily implement [validation with the FluentValidation library](https://www.milanjovanovic.tech/blog/cqrs-validation-with-mediatr-pipeline-and-fluentvalidation).
Within your slice, you'd define a `Validator` class that encapsulates the rules specific to your feature's request model. It also supports dependency injection, so we can run complex validations here.
```csharp
public class Validator : AbstractValidator<Request>
{
public Validator()
{
RuleFor(x => x.Name).NotEmpty().MaximumLength(100);
RuleFor(x => x.Price).GreaterThanOrEqualTo(0);
// ... other rules
}
}
```
This validator can then be injected into your endpoint using dependency injection, allowing you to perform validation before processing the request.
```csharp
public static class CreateProduct
{
public record Request(string Name, decimal Price);
public record Response(int Id, string Name, decimal Price);
public class Validator : AbstractValidator<Request> // { ... }
public class Endpoint : IEndpoint
{
public void MapEndpoint(IEndpointRouteBuilder app)
{
app.MapPost("products", Handler).WithTags("Products");
}
public static IResult Handler(
Request request,
IValidator<Request> validator,
AppDbContext context)
{
var validationResult = await validator.Validate(request);
if (!validationResult.IsValid)
{
return Results.BadRequest(validationResult.Errors);
}
// ... (Create product and return response)
}
}
}
```
## Handling Complex Features and Shared Logic
The previous examples were simple. But what do we do with complex features and shared logic?
VSA excels at managing self-contained features. However, real-world applications often involve complex interactions and shared logic.
Here are a few strategies you can consider to address this:
- **Decomposition**: Break down complex features into smaller, more manageable vertical slices. Each slice should represent a cohesive piece of the overall feature.
- **Refactoring**: When a vertical slice becomes difficult to maintain, you can apply some refactoring techniques. The most common ones I use are `Extract method ` and `Extract class`.
- **Extract shared logic**: Identify common logic that's used across multiple features. Create a separate class (or extension method) to reference it from your vertical slices as needed.
- **Push logic down**: Write vertical slices using procedural code, like a [Transaction Script](https://martinfowler.com/eaaCatalog/transactionScript.html). Then, you can identify parts of the business logic that naturally belong to the domain entities.
You and your team will need to understand code smells and refactorings to make the most of VSA.
## Summary
Vertical Slice Architecture is more than just a way to structure your code. By focusing on features, VSA allows you to create cohesive and maintainable applications. Vertical slices are self-contained, making unit and integration testing more straightforward.
VSA brings benefits in terms of code organization and development speed, making it a valuable tool in your toolbox. Code is grouped by feature, making it easier to locate and understand. The structure aligns with the way business users think about features. Changes are localized, reducing the risk of regressions and enabling faster iterations.
Consider embracing [Vertical Slice Architecture](https://www.milanjovanovic.tech/blog/vertical-slice-architecture) in your next project. It's a big mindset shift from [Clean Architecture](https://www.milanjovanovic.tech/pragmatic-clean-architecture). However, they both have their place and even share similar ideas.
That's all for this week. Stay awesome!
* * *
**P.S. Whenever you're ready, there are 3 ways I can help you:**
1. [**Modular Monolith Architecture (NEW):**](https://www.milanjovanovic.tech/modular-monolith-architecture?utm_source=dev.to&utm_medium=website&utm_campaign=cross-posting) Join 600+ engineers in this in-depth course that will transform the way you build modern systems. You will learn the best practices for applying the Modular Monolith architecture in a real-world scenario.
2. [**Pragmatic Clean Architecture:**](https://www.milanjovanovic.tech/pragmatic-clean-architecture?utm_source=dev.to&utm_medium=website&utm_campaign=cross-posting) Join 2,750+ students in this comprehensive course that will teach you the system I use to ship production-ready applications using Clean Architecture. Learn how to apply the best practices of modern software architecture.
3. [**Patreon Community:**](https://www.patreon.com/milanjovanovic) Join a community of 1,050+ engineers and software architects. You will also unlock access to the source code I use in my YouTube videos, early access to future videos, and exclusive discounts for my courses. | milanjovanovictech |
1,873,160 | Making a custom kebab case method for pretty URLs | Recently, I was working on a Rails app where I wanted to make some pretty URLs for it. I have a route... | 0 | 2024-06-13T17:07:19 | https://jonathanyeong.com/changing-to-kebabcase/ | tutorial, ruby, rails, webdev | ---
title: Making a custom kebab case method for pretty URLs
published: true
date: 2024-06-01 00:00:00 UTC
tags: tutorial, ruby, rails, webdev
canonical_url: https://jonathanyeong.com/changing-to-kebabcase/
---
Recently, I was working on a Rails app where I wanted to make some pretty URLs for it. I have a route where you can view a Dog resource `GET /dog/1`. Having an ID in the URL is not what I want. People could increment the ID to potentially see other dogs. But more importantly, it's not personal! I wanted the URL to show your dog name instead, like `/dog/albie` or `/dog/st-george-bernard-the-3rd`. I needed a way to make pretty kebab case URLs.
## Pretty kebab case URLs
To get a URL that's not the default `id`, I added the [`to_param` method](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Integration/ClassMethods.html#method-i-to_param) to my model. Where `slug` was a column on my Model:
```
def to_param
slug
end
```
Since I wanted the slug to be auto-generated, I had to transform the `name` column to kebab case (see below). Much to my surprise, there wasn't a Ruby / Rails `kebabcase` method:
```
class Dog < ApplicationRecord
before_create ->(dog) { dog.slug = dog.name.kebabcase } # .kebabcase doesn't exist
def to_param
slug
end
end
```
Looking at the docs, I found `.underscore` and `.dasherize`. Unfortunately, they only work for camel case names:
```
"DogName".underscore.dasherize
# => "dog-name"
```
But who names their dog in camel case? Maybe people do, but I'm assuming most people use spaces. Unfortunately, `.underscore` only works on camel case strings.
```
"Dog Name".underscore.dasherize
# => "dog name"
```
## Searching for a Gem
If Ruby and Rails didn't have a kebab case method. I'm sure there's a gem out there that does. In comes [Strings::Case](https://github.com/piotrmurach/strings-case/tree/master) to the rescue:
```
strings.kebabcase("PostgreSQL adapter")
# => "postgre-sql-adapter"
```
I could've called it a day here, but looking at the gem, it has so many other methods that I wouldn't use. Honestly, it seems like overkill for my tiny side project. It's also another library I would have to maintain and make security updates to. In the end, I decided to roll a custom kebab case method.
## Rolling a custom kebab case method
Before jumping into a solution, I wanted some inspiration from Strings::Case.
Under the hood, the gem scans through a string, building words determined by whether there is a specific delimiter or if there's an uppercase. "DogName" would be two words "Dog" and "Name" since there's an upper case in the middle. And "Dog Name" would be two words, since there's a space in the middle. These words get put into an array, and after the string has been scanned, a `.join` method is called with a separator. In kebab case, the separator would be `-`. I'm oversimplifying this approach. If you're curious, about the source code, you can view it [here](https://github.com/piotrmurach/strings-case/blob/master/lib/strings/case.rb#L365).
For the gem, this process makes total sense. It handles many use cases as well as includes multiple string manipulation functions. Since I only wanted kebab case, I decided to go with a regex approach:
```
dog.name.downcase.gsub(/[^\w\d\s]/, "").gsub(/\s/u, "-")
```
Let's break down what this is doing:
1. `.downcase` - A built-in function that makes the string lowercase.
2. `.gsub(/[^\w\d\s]/, "")` - Regex that matches anything that's not a character, digit or space, i.e. any special characters and removes it.
3. `.gsub(/\s/u, "-")` - Regex that matches a space and replaces with a dash
```
"St. George Bernard the 3rd".downcase.gsub(/[^\w\d\s]/, "").gsub(/\s/u, "-")
# => st-george-bernard-the-3rd
```
The biggest limitation with my approach is the regex. I make plenty of assumptions with what I think names should be, and it's focused primarily on English. But what if someone uses a character language like Japanese?
```
"餅".downcase.gsub(/[^\w\d\s]/, "").gsub(/\s/u, "-")
# => ""
```
If I wanted to make this more robust, I should handle non-English characters properly. If I can, I could transliterate it. Like `é` becomes `e`. If it's in a character language, I could leave it because non-English characters can be used in URLs.
However, for a small side project, what I have is enough. And I didn't need to pull in a new gem to achieve it.
* * *
_Using Ruby `3.2.0` and Rails `7.1.3.3` at time of writing_ | jonoyeong |
1,872,543 | Project Stage 1: Preparation(part-1) | Hii everybody!! I am here again with a new series of blogs for my Project Stage 1 called Preparation... | 0 | 2024-05-31T23:58:47 | https://dev.to/yuktimulani/project-stage-1-preparationpart-1-4jad | gcc, compiler | Hii everybody!! I am here again with a new series of blogs for my Project Stage 1 called Preparation but trust me it is much longer than just preparation.🥲
So without wasting any time lets dive in to it.
## Project Stage 1: Preparation
### Step-by-Step Guide
#### Step 1: Become Familiar with the GCC Build Process
**Building the Current Development Version of GCC**
---
**Downloading GCC Source Code**
Start by cloning the GCC repository to get the latest development version of the source code:
```
git clone git://gcc.gnu.org/git/gcc.git
cd gcc
```
---
**Building GCC on AArch64 and x86**
GCC can be built for different architectures. Here, I'll show you how to build it for both AArch64 and x86 architectures.
**Create a separate build directory:**
```
mkdir build
cd build
```
**Configure the build for AArch64:**
```
../configure --prefix=$HOME/gcc-aarch64 --target=aarch64-linux-gnu --enable-languages=c,c++
```
Here's a detailed breakdown of each part of this command and why it is used:
1. ../configure:
This runs the configure script, which prepares the build system by checking for dependencies and setting up makefiles.
The ../ prefix assumes that you are in a separate build directory (e.g., gcc/build), and you need to reference the configure script located in the parent directory (gcc).
2. --prefix=$HOME/gcc-aarch64:
This option specifies the installation directory for the built GCC. By setting it to $HOME/gcc-aarch64, you ensure that the GCC built for AArch64 is installed in a local directory under your home directory ($HOME).
Using a local installation path avoids overwriting the system-wide GCC and allows you to manage multiple GCC versions for different architectures.
3. --target=aarch64-linux-gnu:
This option specifies the target architecture and system for the GCC build. The aarch64-linux-gnu target indicates that GCC will be built to generate code for the AArch64 architecture, which is used in many ARM 64-bit processors, and is intended to run on a GNU/Linux system.
This is essential for cross-compilation, where the build machine (host) is different from the target machine (where the generated code will run). Here, you are preparing a cross-compiler that runs on your current machine but produces executables for AArch64.
4. --enable-languages=c,c++:
This option specifies which programming languages the GCC compiler should support. By listing c,c++, you are instructing the build system to compile and include support for the C and C++ languages.
This helps reduce the build time and resource usage by excluding support for other languages that you might not need.
Same goes for x86_64.
**Configure the build for x86:**
```
../configure --prefix=$HOME/gcc-x86 --target=x86_64-linux-gnu --enable-languages=c,c++
```
**Build GCC:**
```
make -j$(nproc)
```
- make: This is a build automation tool that automatically builds executable programs and libraries from source code by reading files called Makefiles which specify how to derive the target program.
- -j: This option tells make to perform parallel builds. It allows make to run multiple jobs simultaneously. The number of jobs to run is specified immediately after -j.
- nproc: This command prints the number of processing units available (CPU cores). On a machine with 4 CPU cores, nproc will return 4.
**Install GCC locally:**
```
make install
```
---
**Analyzing Build Time and Options**
To understand the build time and experiment with different build options, you can use the `time` command.
**Track build time:**
```
time make -j$(nproc)
```
**Experiment with build options by adding flags to the configure command:**
- `--disable-multilib`: Disable building libraries for multiple target architectures.
- `--enable-checking=release`: Enable additional checks useful for release builds.
- `--disable-bootstrap`: Disable the bootstrap process which rebuilds the compiler multiple times to ensure reliability.
Example configuration with additional flags:
```
../configure --prefix=$HOME/gcc-x86 --target=x86_64-linux-gnu --enable-languages=c,c++ --disable-multilib --enable-checking=release --disable-bootstrap
```
---
#### Step 2: Navigate the GCC Codebase
Understanding the structure of the GCC codebase is crucial for making modifications and additions.
**a. Compilation Passes**
Navigate to the GCC source directory:
```
cd gcc
```
**Key Files:**
- `passes.def`: This file defines all the passes in GCC.
- `gcc/passes.cc`: This file controls the execution of passes.
`passes.def` is a key file in the GCC codebase that defines the list of compiler passes used during the compilation process. Each entry in passes.def represents a specific pass, which is a distinct phase in the compilation where certain analyses or transformations are performed on the code.
**How passes.def works**
1. Definition of Passes:
`passes.def` contains macro definitions for each pass. Each entry typically uses a macro (such as PASS) to register the pass with a unique identifier and its corresponding implementation.
2. Integration with the GCC Build System:
The entries in passes.def are processed by the GCC build system to generate the appropriate structures and function calls required to include these passes in the compilation pipeline.
This file essentially acts as a registry for all the passes that GCC will execute.
3. Control Flow:
During the compilation process, GCC iterates over the list of passes defined in passes.def, executing each one in sequence. This allows for modular and structured transformations and optimizations on the code.
4. Adding a New Pass:
To add a new pass, you add an entry to passes.def using the appropriate macro. For instance:
```
PASS(function_counter)
```
After defining a new pass in passes.def, you must implement the corresponding logic in a new or existing .c or .cc file and ensure it is registered properly in the GCC infrastructure (often in files like passes.cc).
By managing the list of passes in a centralized file like passes.def, GCC maintains an organized and easily extensible framework for implementing various compilation phases. This design allows developers to add, remove, or modify passes without disrupting the overall structure of the compiler.
And that's a wrap for today! 🎬 We've embarked on our journey into the intricate world of GCC preparation, but trust me, this is just the tip of the iceberg! Who knew building a compiler could be so exhilarating? But hey, if you're not feeling the adrenaline rush yet, don't worry, I've got more in store for you.
Stay tuned for the next episode of my GCC adventure, where we'll delve even deeper into the codebase, uncovering secrets, and maybe even stumbling upon a few surprises along the way. Until then, keep those compilers compiling and those keyboards clacking! ✨
| yuktimulani |
1,872,541 | Profile Card Using HTML CSS & GSAP | Hello Guys, Created an Animated profile card using HTML CSS & GSAP Animation. I use the simple... | 0 | 2024-05-31T23:57:02 | https://dev.to/hussein09/profile-card-using-html-css-gsap-3bjl | html, javascript, webdev, beginners | Hello Guys,
Created an Animated profile card using HTML CSS & GSAP Animation. I use the simple card and use GSAP timeline() to animate the card using gsap.from() you can animate a card. I hope you like this also comments about your thoughts.
{% codepen https://codepen.io/mhmpmurm-the-looper/pen/QWRpdEd %} | hussein09 |
1,872,538 | How to Use ThingSpeak with the Raspberry Pi Pico W | In this tutorial, we'll learn how to use ThingSpeak, a popular IoT platform, with the Raspberry... | 0 | 2024-05-31T23:41:15 | https://dev.to/shilleh/how-to-use-thingspeak-with-the-raspberry-pi-pico-w-499m | thingspeak, raspberrypi, programming, python | {% embed https://www.youtube.com/watch?v=TPBf_Qaci8w %}
In this tutorial, we'll learn how to use ThingSpeak, a popular IoT platform, with the Raspberry Pi Pico W to collect and visualize sensor data. We'll be using a BME280 sensor to measure temperature, pressure, and humidity and send this data to ThingSpeak for real-time monitoring and analysis.
ThingSpeak is an open-source Internet of Things (IoT) platform that allows you to collect, store, analyze, visualize, and act on data from sensors or devices. It's particularly popular for its ease of use and integration with various hardware platforms like Raspberry Pi, Arduino, and ESP8266/ESP32.
In the end, we will have a dashboard that looks as follows, a simple weather station with gauges and graphs that updates in real-time:
**Requirements**
- Raspberry Pi Pico W
- [BME280 sensor from ShillehTek](https://www.amazon.com/dp/B0BQFV883T?maas=maas_adg_273838487DF6D497BDB90A5AA36C3658_afap_abs&ref_=aa_maas&tag=maas)
- [Jumper wires](https://www.amazon.com/dp/B0CN5RL615?maas=maas_adg_99FA512A620CB92E7455A93E620000C8_afap_abs&ref_=aa_maas&tag=maas)
- [Breadboard](https://shillehtek.com/blogs/news/how-to-use-thingspeak-with-the-raspberry-pi-pico-w)
- A computer with Thonny IDE installed
- Wi-Fi network credentials
- ThingSpeak account
**Wiring the BME280 Sensor**
If you are interested in using the BME280 specifically, there is another ShillehTek tutorial on YouTube here that quickly walks you through how to get setup.
{% embed https://www.youtube.com/watch?v=R5dY2a0C9Y0 %}
Before we get into the remainder, consider subscribing or supporting the channel. Also, be sure to checkout our various stores to shop products for Raspberry Pi, Arduino, ESP32, and DIY electronics at ShillehTek!
**Subscribe:**
[Youtube](https://www.youtube.com/@mmshilleh)
**Support:**
[https://buymeacoffee.com/mmshilleh](https://www.buymeacoffee.com/mmshilleh)
**Hire me at UpWork to build your IoT projects:**
[https://buymeacoffee.com/mmshilleh](https://www.upwork.com/freelancers/~017060e77e9d8a1157)
**Visit ShillehTek Store for Arduino and Raspberry Pi Sensors and Pre-Soldered Components:**
**ShillehTek Website (Exclusive Discounts):**
[https://buymeacoffee.com/mmshilleh](https://shillehtek.com/collections/all)
ShillehTekAmazon Store:
[ShillehTek Amazon Store - US](https://www.amazon.com/stores/page/F0566360-4583-41FF-8528-6C4A15190CD6?channel=yt)
[ShillehTek Amazon Store - Canada](https://www.amazon.ca/stores/page/036180BA-2EA0-4A49-A174-31E697A671C2?channel=canada)
[ShillehTek Amazon Store - Japan ](https://www.amazon.co.jp/stores/page/C388A744-C8DF-4693-B864-B216DEEEB9E3?channel=japan)
## Step 1-) Setting Up ThingSpeak
- **Create a ThingSpeak Account:** If you don't have one, sign up for a ThingSpeak account at thingspeak.com
- **Create a New Channel:** Go to the Channels tab and click "New Channel".Name your channel (e.g., "Pico W Weather Station"). Add three fields: Temperature, Pressure, and Humidity. Save the channel and note down the `Write API Key`. You can get it in the API Keys tab.
**Creating Visualizations -**
**Numeric Display for Temperature:**
- Go to your channel view and click on the "Add Widget" button.
- Select "Numeric Display" from the widget options.
- Choose the field corresponding to Temperature.
- Save the widget to add it to your channel dashboard.
**Graph for Pressure:**
- Click on the "Add Visualizations" button.
- Choose the field corresponding to Pressure.
- Configure the time span and any other settings you prefer.
- Save the widget to add it to your channel dashboard.
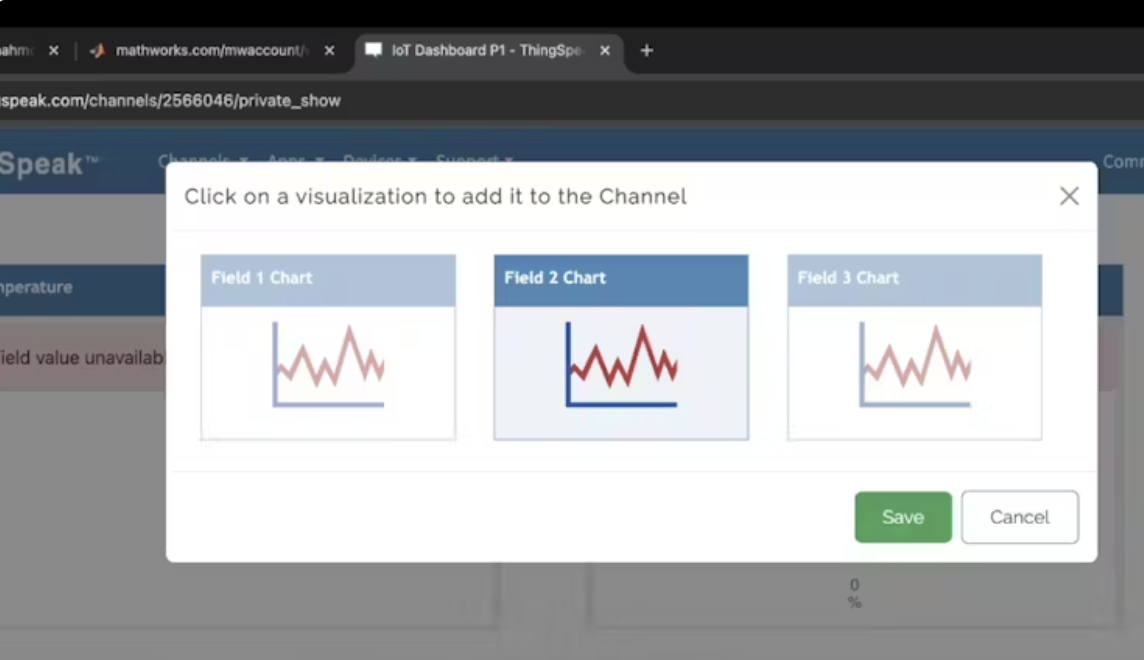
**Gauge for Humidity:**
- Click on the "Add Widget" button.
- Select "Gauge" from the widget options.
- Choose the field corresponding to Humidity.
- Configure the gauge with appropriate min and max values (e.g., 0 to 100%).
- Save the widget to add it to your channel dashboard.
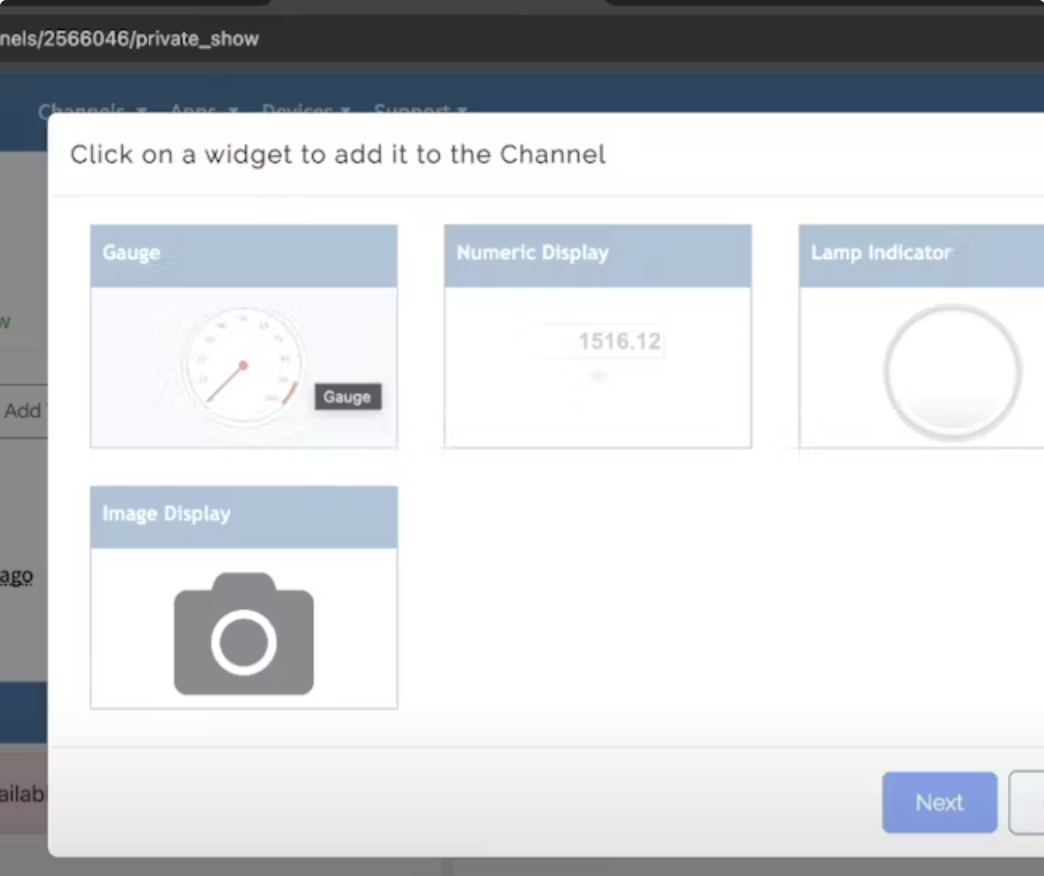
Now that you have all of this, you have the basis of what you need to start populating and visualizing the sensor data from the ShillehTek BME280 in ThingSpeak. If you are using another sensor, you can play around with other widgets and visualizations as needed, the interface is fairly straightforward.
## Step 2-) MicroPython Code
Here's the full code to read data from the BME280 sensor and send it to ThingSpeak:
```
from machine import Pin, I2C
import network
import urequests
import time
from time import sleep
import bme280
import constants
i2c = I2C(0, sda=Pin(0), scl=Pin(1), freq=400000)
ssid = constants.INTERNET_NAME
password = constants.INTERNET_PASSWORD
wlan = network.WLAN(network.STA_IF)
wlan.active(True)
wlan.connect(ssid, password)
while not wlan.isconnected():
pass
api_key = 'your_API_KEY'
base_url = 'https://api.thingspeak.com/update'
def read_sensor():
bme = bme280.BME280(i2c=i2c)
temperature, pressure, humidity = [float(i) for i in bme.values]
return temperature, pressure, humidity
# Send data to ThingSpeak
while True:
temperature, pressure, humidity = read_sensor()
url = f"{base_url}?api_key={api_key}&field1={temperature}&field2={pressure}&field3={humidity}"
response = urequests.get(url)
print(response.text)
time.sleep(15)
```
## Code Walkthrough
**Import Libraries:** We import necessary libraries including network for Wi-Fi connectivity, urequests for HTTP requests, and bme280 for sensor interaction.
**Initialize I2C:** Set up I2C communication with the BME280 sensor.
Connect to Wi-Fi: Use your Wi-Fi credentials to connect the Pico W to the internet.
**Read Sensor Data:** Define a function read_sensor to get temperature, pressure, and humidity readings from the BME280 sensor.
**Send Data to ThingSpeak:** In an infinite loop, read data from the sensor and send it to ThingSpeak every 15 seconds.
If you are using the BME280 library, you need to modify the return values by removing all suffixes (e.g., 'C', 'hPa', '%') so that the data is interpretable by the IoT platform. Additionally, if you are using an earlier version of MicroPython, make sure you install urequests, as it may not come pre-installed with some versions.
You also have the option to hardcode your Wi-Fi credentials directly into the code instead of using a constants file. Simply replace the placeholders with your actual Wi-Fi SSID and password.
Once your script is running, you should see your ThingSpeak dashboard updating in real-time! This setup can be further customized to suit your specific needs. Additionally, ThingSpeak offers various other data integration and visualization options to explore.
## Conclusion
Congratulations! You have successfully set up your Raspberry Pi Pico W to send sensor data to ThingSpeak. This setup allows you to monitor environmental conditions in real-time from anywhere. ThingSpeak provides powerful tools for data analysis and visualization, making it an excellent choice for IoT projects. Happy tinkering! Also, do not forget to subscribe if you have not! | shilleh |
1,872,537 | C# Zip Archive Entry | Links: GitHub NuGet Introduction While the .NET ecosystem provides robust libraries... | 0 | 2024-05-31T23:40:38 | https://dev.to/coddicat/c-zip-archive-entry-2339 | csharp, zip, archive, development | Links:
- [GitHub](https://github.com/coddicat/FastZipEntry)
- [NuGet](https://www.nuget.org/packages/FastZipEntry)
## Introduction
While the .NET ecosystem provides robust libraries for working with ZIP files, developers often encounter limitations due to internal or sealed classes that prevent straightforward extension or modification. In this article, I will discuss why and how I created [FastZipEntry](https://www.nuget.org/packages/FastZipEntry), a .NET library designed to efficiently retrieve specific entries from a ZIP archive **without extracting the entire archive or iterating through all entries**.
## The Motivation
### Limitations in the Existing Libraries
The existing ZIP handling libraries in .NET, specifically those provided by Microsoft, are powerful but sometimes restrictive. Many of the useful classes and methods are marked as internal or sealed, which means they cannot be extended or modified outside of their original scope. This restriction poses a significant challenge when you need to tweak or extend the functionality to suit specific needs.
### Need for Efficient Entry Retrieval
In many scenarios, you might need to access a specific entry in a ZIP archive without extracting the entire archive or loading all entries into memory. This is particularly important for large archives where performance and memory consumption become critical concerns. Unfortunately, the default System.IO.Compression.ZipArchive does not provide a straightforward way to achieve this.
## The Solution: [FastZipEntry](https://www.nuget.org/packages/FastZipEntry)
To overcome these limitations, I decided to create **FastZipEntry** NuGet , a library that allows efficient retrieval of specific entries from a ZIP archive. This library leverages modified code from Microsoft's _System.IO.Compression_ but extends its functionality to meet the needs outlined above.
## Key Features
- **Efficient Retrieval**: Locate and retrieve specific ZIP entries by name without extracting the entire archive.
- **Decompression**: Includes support and access to the **Deflate64** algorithm for decompression, also sourced from Microsoft’s codebase.
## Implementation Details
### Leveraging Microsoft’s Source Code
The core of _FastZipEntry_ is based on the source code from Microsoft's _System.IO.Compression_ library, which is available under the MIT license. Sadly, due to the internal and sealed nature of many classes, I had to copy and modify the necessary code to enable the required functionality. This approach, while not ideal, was necessary to provide the flexibility and performance benefits that **FastZipEntry** offers.
### Adding Deflate64 Support
In addition to the core functionality, I also integrated the **Deflate64** algorithm for decompression. This algorithm, taken from Microsoft’s source code, is essential for handling archives that use this specific compression method. By including this in **FastZipEntry**, I ensured that the library can handle a wider range of ZIP archives.
## Usage Example
```csharp
using System.IO;
using System.Text;
using FastZipEntry;
// Open a ZIP file and create a ZipEntryAccess instance
using FileStream zipFileStream = new FileStream("path/to/your.zip", FileMode.Open, FileAccess.Read);
ZipEntryAccess zipEntryAccess = new ZipEntryAccess(zipFileStream, Encoding.UTF8);
// Retrieve a specific entry from the ZIP file
string entryName = "desired_entry.txt";
ZipEntry? entry = zipEntryAccess.RetrieveZipEntry(entryName, StringComparison.OrdinalIgnoreCase);
if (entry != null)
{
// Use the entry (e.g., decompress it)
using Stream entryStream = entry.Open();
using FileStream outputStream = new FileStream("path/to/extracted/desired_entry.txt", FileMode.Create, FileAccess.Write);
entryStream.CopyTo(outputStream);
}
else
{
Console.WriteLine("Entry not found.");
}
```
## Conclusion
I hope **FastZipEntry** proves useful in your projects, and I welcome any contributions or feedback.
- You can find and install the [FastZipEntry](https://www.nuget.org/packages/FastZipEntry) package from the NuGet repository.
- You can also check out the source code in [GitHub repository](https://github.com/coddicat/FastZipEntry) of this project.
## Acknowledgments
This library is based on modified code from the Microsoft [System.IO.Compression](https://github.com/dotnet/runtime/tree/9daa4b41eb9f157e79eaf05e2f7451c9c8f6dbdc/src/libraries/System.IO.Compression/src/System/IO/Compression) repository, and includes the **Deflate64** algorithm from the same source. | coddicat |
1,872,535 | Kong Gateway - Validando configurações específicas para exposição de serviços | Olá, Mentes Tech! Essa semana testei o deck files lint que é uma feature do deck, que usa o projeto... | 0 | 2024-05-31T23:37:59 | https://dev.to/devxbr/kong-gateway-validando-configuracoes-especificas-para-exposicao-de-servicos-adg | kong, deck, gateway | Olá, Mentes Tech!
Essa semana testei o deck files lint que é uma feature do deck, que usa o projeto [vacuum](https://github.com/daveshanley/vacuum) para esta implementação.
> [Caso Uso] Existe a necessidade de identificar o proprietário de cada rota em nosso ecossistema.
Como solução, foi requisitado que todas as rotas contenham a propriedade tags preenchida com nome da squad e que a versão do Kong seja mantida em 3.1.
Referência: [Ruleset](https://quobix.com/vacuum/rulesets/understanding/)
Repositório: [kong-bussiness-rules-lint](https://github.com/devxbr/kong-bussiness-rules-lint)
Criei duas regras, uma para validar se a propriedade tag existe e possui valor, e a segunda regra é se a propriedade _format_version é 3.1.
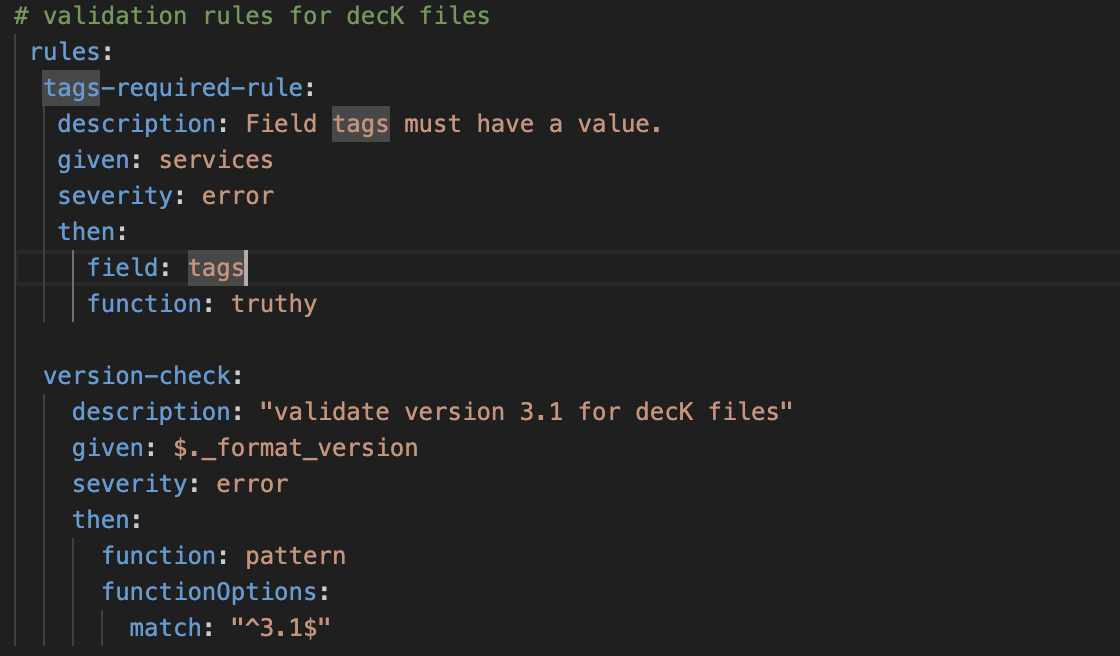
Criei duas configurações de rotas
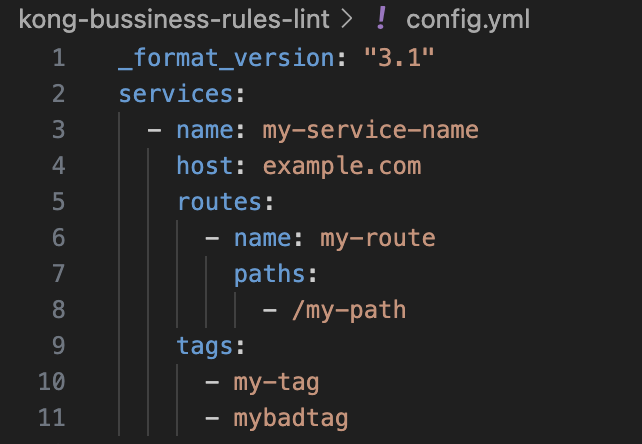
Então criei uma imagem com deck na versão latest
No Dockerfile tem comandos para validar o arquivo de configuração contra um ruleset.
`RUN deck file validate corrupted.yml`
`RUN deck file lint -s corrupted.yml ruleset.yml`

Chegamos ao fim...
como você configura seu Gateway Kong?
| devxbr |
1,872,534 | c# Message queue with Redis | Introduction In distributed microservice architectures, managing message queue can be... | 0 | 2024-05-31T23:31:53 | https://dev.to/coddicat/c-message-queue-with-redis-1hjk | redis, messagequeue, development, csharp | ## Introduction
In distributed microservice architectures, managing message queue can be particularly challenging when you need to ensure messages are processed in order, reliably, and with the ability to **pause** and **resume** processing. The [RedisMessagePipeline NuGet package](https://www.nuget.org/packages/RedisMessagePipeline) offers a robust solution to these challenges, making your message handling tasks seamless and reliable.
## The Problem
Unlike traditional message queue solutions that may be heavy and complicated, **RedisMessagePipeline** offers a lightweight and straightforward approach. In distributed microservice architectures, managing message pipelines can be particularly challenging when you need to ensure messages are processed in order, reliably, and with the ability to **pause** and **resume** processing.
Imagine a scenario where your microservice receives multiple client requests/events/message that need to be processed in the background. Each request might take a significant amount of time to complete, and you need to ensure that:
- Messages are processed in the order they are received.
- Processing can be paused and resumed without losing data or processing out of order.
- Failures are handled gracefully with retries or manual intervention.
Traditional event streaming or message queue solutions like **Kafka**, **Redis Streams**, **NATS**, and **RabbitMQ** have their strengths but might not provide the required order guarantees and flexible control over the message processing flow.
## The Problem with Traditional Event Streaming
When dealing with microservices, maintaining order and reliability in message processing can become complex. Here’s why some popular event streaming solutions might fall short:
- **Kafka**: While it supports ordered processing, Kafka lacks built-in mechanisms for easy stopping and resuming message consumption, making error handling cumbersome.
- **Redis Streams**: Offers powerful features but managing ordered processing across multiple instances requires additional custom logic.
- **NATS**: Known for simplicity and speed, but does not inherently support ordered message processing or pausing/resuming the pipeline.
- **RabbitMQ**: Lacks native support for ordered message processing and mechanisms for stopping and resuming message consumption easily.
## RedisMessagePipeline to the Rescue
**RedisMessagePipeline** is designed to tackle these exact challenges, offering:
- **Single Message Handling**: Ensures each message is processed individually in the correct order.
- **Failure Handling**: Configurable policies for automatic retries or manual intervention.
- **Pipeline Control**: Administrative controls to stop, resume, or clean the pipeline as needed.
- **Ideal for Long-Running Tasks**: Perfect for scenarios where background processing of client requests takes time and order must be maintained.
- **Simplicity and Efficiency**: Unlike traditional message queue solutions that may be heavy and complicated, **RedisMessagePipeline** offers a lightweight and straightforward approach.
## How It Works
Let’s dive into a concrete example to see how RedisMessagePipeline solves these problems.
### Step 1: Installation
Install the RedisMessagePipeline package from NuGet:
```sh
dotnet add package RedisMessagePipeline
```
### Step 2: Basic Configuration
Set up the Redis client and pipeline settings in your application:
```csharp
ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("localhost:6379");
IDatabase db = redis.GetDatabase();
var factory = new RedisPipelineFactory(new LoggerFactory(), db);
var consumer = factory.CreateConsumer(new MyMessageHandler(), new RedisPipelineConsumerSettings("client-requests"));
var admin = factory.CreateAdmin(new RedisPipelineAdminSettings("client-requests"));
```
### Step 3: Using the Pipeline
Here’s how to use RedisMessagePipeline to store client requests and process them reliably in the background:
- **Stop the Pipeline:** Temporarily pause message processing, for example, during maintenance or an update.
```csharp
await admin.StopAsync();
```
- **Push Messages:** Store incoming client requests in the pipeline. Each message will be processed in the order it was received.
```csharp
await admin.PushAsync($"any request serialized data");
```
- **Resume the Pipeline:** Resume processing messages, ensuring they are handled in order.
```csharp
await admin.ResumeAsync(1, CancellationToken.None);
```
- **Process Messages:** Start the consumer to process the messages in the background.
```csharp
await consumer.ExecuteAsync(CancellationToken.None);
```
## Conclusion
The RedisMessagePipeline NuGet package provides a powerful solution for managing ordered and reliable message processing in distributed microservice architectures. It ensures high reliability and consistency, making it an invaluable tool for developers who need precise control over their message pipelines. Unlike some modern event streaming solutions, RedisMessagePipeline offers simplicity and control, making it ideal for scenarios where ordered processing and pipeline control are paramount.
## License and Support
RedisMessagePipeline is distributed under the MIT License. For support and contributions.
GitHub repository — https://github.com/coddicat/RedisMessagePipeline | coddicat |
1,872,533 | Weekly Updates - May 31, 2024 | Hello Readers! I hope all of you had a really good week! Here are our updates for this week: 🎉... | 0 | 2024-05-31T23:28:30 | https://dev.to/couchbase/weekly-updates-may-31-2024-4kcn | couchbase, ai, community, nationalclouddatabaseday | Hello Readers!
I hope all of you had a really good week!
Here are our updates for this week:
- 🎉 **We're Celebrating: National Cloud Database Day!** - Every year on June 1, we want to celebrate this special day. You can read more [about National Cloud Database Day here >>.](https://www.couchbase.com/clouddbday/) As part of our celebration, we have published a blog post talking about how Cloud Databases are in their AI Era. [*You can read the blog here >>*](https://www.couchbase.com/blog/national-cloud-database-day-2024/)
<br>
- 📺 **Brand New Video: Cloud to Edge Gen AI & Vector Search with Couchbase** - Join Mark Gamble and Shivay Lamba for a special event where they'll explore Couchbase's cloud-to-edge vector search capabilities, including a showcase on how Couchbase can be used for building applications with unified cloud-to-edge search & offline-first capabilities [*You can watch the video here>>*](https://www.youtube.com/watch?v=BYgIne9Zi8Q)
<br>
- 🤝 **Do you enjoy technical talks and meetups?** We have Couchbase specific User Groups! We would love to meet you in person! [*You can see a list of the groups and their events here >>*](https://www.meetup.com/pro/couchbase)
<br>
- 👋 **Summit Season is still ongoing!** - Are you traveling to any of the AWS or Google Summits or other Tech Expos? Come say Hi and meet the team! [*You can see the Summit's we will be attending here >>*](https://www.couchbase.com/resources/webcasts-and-events/?cb_searchable_posts_asc%5BrefinementList%5D%5Btaxonomies.events_category%5D%5B0%5D=Tradeshow)
<br>
Have a great weekend everyone! | carrieke |
1,872,523 | JavaScript 3D ray casting: Chrome is the most efficient browser | Links: Play the Game GitHub Repository Introduction As a full-stack... | 0 | 2024-05-31T23:16:06 | https://dev.to/coddicat/javascript-3d-ray-casting-chrome-is-the-most-efficient-browser-h25 | javascript, raycasting, chrome, webdev | ### Links:
- [Play the Game](https://raycastingjs.web.app/)
- [GitHub Repository](https://github.com/coddicat/ts3d)
>

## Introduction
As a full-stack developer, I constantly seek out tasks and projects to keep my skills sharp and my curiosity satisfied. My latest adventure took me back to the 90s, to the world of 3D ray casting. Inspired by classics like Wolfenstein 3D, I set out to implement this technique in pure JavaScript, without relying on the 3D functions of the canvas context. This project turned into a fascinating journey through the intricacies of game development and browser performance.

## The Challenge
Ray casting in the style of early 90s games involves casting rays from the player’s perspective, one for each pixel horizontally across the screen. The rays move in intervals of one tile, creating a 3D effect. Despite having no background in game development, I was eager to tackle challenges such as sprite rendering, player movement, and interaction with the environment and moving objects.
>
## Why JavaScript?
I chose to implement the project using pure JavaScript to see if modern browsers and computers could handle the intensive processing required for rendering game scenes. This approach meant manually processing and rendering each pixel, without relying on built-in 3D rendering functions. The question at the heart of the project was: Can modern web technology deliver acceptable performance for such a demanding task?
```ts
const ctx = canvas.getContext('2d', {
alpha: true,
willReadFrequently: true
});
```
## The Journey
What began as a simple curiosity-driven project quickly grew into a full-fledged endeavor, consuming six months of my time. The challenge of optimizing performance was particularly engaging. I frequently revisited my code, eliminating redundant operations and optimizing calculations, especially those involving trigonometric functions. For instance, I used bitwise shifts instead of multiplying or dividing by 2, and bitwise |0 instead of rounding or using Math.floor(), to speed up computations.
## Pixel-Level Control
For manipulating pixels, I used Uint32Array, which allowed me to write pixel states directly by index. This approach was effective because three bits represent color, and the fourth bit is alpha, enabling adjustments in pixel brightness and marking screen areas as occupied. This level of control was crucial for achieving the desired visual effects and performance.
```ts
const buf = new ArrayBuffer(height * width * 4);
const buf8 = new Uint8ClampedArray(buf);
const data = new Uint32Array(buf);
...
const alphaMask = 0x00ffffff | (light << 24);
const pixel = textureImageData[textureIndex];
data[dataIndex] = pixel & alphaMask;
```
## Overcoming Mathematical Hurdles
One of the most daunting aspects was finding solutions and formulas for rendering horizontal surfaces such as floors, ceilings, and various beams. Without a background in mathematics or game development, this part of the project was particularly time-consuming. However, the result was a visually interesting and acceptable image that met my performance goals.
```ts
//// This's just an example. The actual code has been improved to reduce the number of calculations.
public getTileSpriteDataIndexBySideX_positive(
ray: Ray,
offset: number,
textureData: TextureData
): number {
const { width, height } = textureData;
const fixSinAbs = Math.abs(Math.sin(ray.angle)) / ray.fixDistance;
const factY = textureData.height * rayAngle.fixSinAbs
const diff = Math.abs(ray.fixedDistance - ray.distance);
const fixedCos = Math.cos(ray.angle) / ray.fixDistance;
const fixedCosDiff = fixedCos * diff;
const offsetX = offset - fixedCosDiff + (fixedCosDiff | 0) + 1;
const spriteOffsetX = ((offsetX - (offsetX | 0)) * width) | 0;
const spriteOffsetY = (diff * factY) | 0;
const fixedX = height - mod(spriteOffsetY, height) - 1;
return Math.imul(fixedX, width) + spriteOffsetX;
}
```
## Not Just JavaScript
Although I initially aimed to use pure JavaScript, I eventually incorporated TypeScript to manage complex code structures more effectively. Additionally, I used the Vue framework to bundle everything together, ensuring a smoother development process and more maintainable codebase.
```ts
export type Tile = {
bottom: number;
texture?: Texture;
name?: string;
};
export type Wall = {
public top: number;
public bottom: number;
public texture?: Texture;
public name?: string;
};
export type MapItem = {
walls: Wall[];
tiles: Tile[];
mirror?: boolean;
stopRay: boolean;
}
```
## Performance Insights
The project also served as an insightful browser performance test. On my laptop with an i7–10510U processor, Chrome emerged as the most efficient browser, followed by Edge, Firefox, and Safari. These findings highlighted the varying capabilities of different browsers when handling intensive JavaScript computations.
> FPS. 1920x1080. Chrome

> FPS. 1920x1080. Edge

> FPS. 1920x1080. Firefox

## Future Prospects
While the current version of the game is a proof of concept, I have plans to enhance its playability. Future updates may include adding player goals, sound effects, and even multiplayer capabilities. The project has provided a solid foundation for exploring these possibilities.
## Conclusion
This journey into 90s 3D ray casting has been both challenging and rewarding. It started as a pet project driven by curiosity and evolved into a deep dive into classic game programming techniques and modern web performance. I invite you to check out the game and explore its source code. Your feedback and contributions are welcome as I continue to refine and expand this project.
Links:
- [Play the Game](https://raycastingjs.web.app/)
- [GitHub Repository](https://github.com/coddicat/ts3d)
Thank you for reading, and happy coding!
{% embed https://www.youtube.com/embed/4Bktj-XoUHs?si=PrOu6SteMhEHfRK1 %}
| coddicat |
1,872,522 | How to generate random number in PHP | Ever wondered how to generate random numbers in PHP using a simple function while excluding some... | 0 | 2024-05-31T23:15:35 | https://dev.to/kellyblaire/how-to-generate-random-number-in-php-4b1 | php, programming, webdev, backenddevelopment | Ever wondered how to generate random numbers in PHP using a simple function while excluding some numbers you don't want, just like a friend of mine that requested for this code?
Here's how to do it:
```php
<?php
function generateRandomNumber($min, $max, $excludedNumbersArr) {
do {
$number = rand($min, $max);
} while (in_array($number, $excludedNumbersArr));
return $number;
}
// Use it this way
echo generateRandomNumber(50,250,[123,145]); //This PHP function generates a number between 50 and 250, excluding 123 and 145.
?>
```
### Explanation:
1. **Set the Range**: The function defines the minimum (`$min`) and maximum (`$max`) values for the random number.
2. **Excluded Numbers**: An array `$excludedNumbersArr` contains the numbers you want to exclude.
3. **Generate Random Number**: A `do-while` loop generates a random number using `rand($min, $max)`. It continues to generate a new number until the number is not in the `$excludedNumbersArr` array.
4. **in_array()**: This is a PHP function that checks if a value exists in an array. It takes two parameters:
> **Value**: The value you want to search for.
> **Array**: The array in which you want to search for the value.
5. **Return the Number**: Once a valid number is generated, it is returned.
This function ensures that the generated number is within the specified range and does not include the excluded values.
Thanks for reading this article.
I write codes on demand. Let me know the code you need, and I will help you write them in your programming language.
**PS:**
I love coffee, and writing these articles takes a lot of it! If you enjoy my content and would like to support my work, you can buy me a cup of coffee. Your support helps me to keep writing great content and stay energized. Thank you for your kindness!
[Buy Me A Coffee](https://buymeacoffee.com/yafskkw). | kellyblaire |
1,872,521 | barber's pole | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration A... | 0 | 2024-05-31T23:04:22 | https://dev.to/chr1stine/barberpole-1bao | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
<!-- What are you highlighting today? -->
A barber's pole
## Demo
<!-- Show us your CSS Art! You can directly embed an editor into this post (see the FAQ section of the challenge page) or you can share an image of your project and share a public link to the code. -->
{% embed https://codesandbox.io/p/sandbox/barberpole-wgqlty?file=%2Findex.html%3A67%2C26&layout=%257B%2522sidebarPanel%2522%253A%2522EXPLORER%2522%252C%2522rootPanelGroup%2522%253A%257B%2522direction%2522%253A%2522horizontal%2522%252C%2522contentType%2522%253A%2522UNKNOWN%2522%252C%2522type%2522%253A%2522PANEL_GROUP%2522%252C%2522id%2522%253A%2522ROOT_LAYOUT%2522%252C%2522panels%2522%253A%255B%257B%2522type%2522%253A%2522PANEL_GROUP%2522%252C%2522contentType%2522%253A%2522UNKNOWN%2522%252C%2522direction%2522%253A%2522vertical%2522%252C%2522id%2522%253A%2522clwv5wqa20006286947ysgzq1%2522%252C%2522sizes%2522%253A%255B100%252C0%255D%252C%2522panels%2522%253A%255B%257B%2522type%2522%253A%2522PANEL_GROUP%2522%252C%2522contentType%2522%253A%2522EDITOR%2522%252C%2522direction%2522%253A%2522horizontal%2522%252C%2522id%2522%253A%2522EDITOR%2522%252C%2522panels%2522%253A%255B%257B%2522type%2522%253A%2522PANEL%2522%252C%2522contentType%2522%253A%2522EDITOR%2522%252C%2522id%2522%253A%2522clwv5wqa200022869e4s20kjf%2522%257D%255D%257D%252C%257B%2522type%2522%253A%2522PANEL_GROUP%2522%252C%2522contentType%2522%253A%2522SHELLS%2522%252C%2522direction%2522%253A%2522horizontal%2522%252C%2522id%2522%253A%2522SHELLS%2522%252C%2522panels%2522%253A%255B%257B%2522type%2522%253A%2522PANEL%2522%252C%2522contentType%2522%253A%2522SHELLS%2522%252C%2522id%2522%253A%2522clwv5wqa200032869iioia7i0%2522%257D%255D%252C%2522sizes%2522%253A%255B100%255D%257D%255D%257D%252C%257B%2522type%2522%253A%2522PANEL_GROUP%2522%252C%2522contentType%2522%253A%2522DEVTOOLS%2522%252C%2522direction%2522%253A%2522vertical%2522%252C%2522id%2522%253A%2522DEVTOOLS%2522%252C%2522panels%2522%253A%255B%257B%2522type%2522%253A%2522PANEL%2522%252C%2522contentType%2522%253A%2522DEVTOOLS%2522%252C%2522id%2522%253A%2522clwv5wqa200052869pbjhstvq%2522%257D%255D%252C%2522sizes%2522%253A%255B100%255D%257D%255D%252C%2522sizes%2522%253A%255B64.49654783313063%252C35.503452166869366%255D%257D%252C%2522tabbedPanels%2522%253A%257B%2522clwv5wqa200022869e4s20kjf%2522%253A%257B%2522tabs%2522%253A%255B%257B%2522id%2522%253A%2522clwv5wqa200012869sgrermtj%2522%252C%2522mode%2522%253A%2522permanent%2522%252C%2522type%2522%253A%2522FILE%2522%252C%2522filepath%2522%253A%2522%252Findex.html%2522%252C%2522state%2522%253A%2522IDLE%2522%252C%2522initialSelections%2522%253A%255B%257B%2522startLineNumber%2522%253A67%252C%2522startColumn%2522%253A26%252C%2522endLineNumber%2522%253A67%252C%2522endColumn%2522%253A26%257D%255D%257D%255D%252C%2522id%2522%253A%2522clwv5wqa200022869e4s20kjf%2522%252C%2522activeTabId%2522%253A%2522clwv5wqa200012869sgrermtj%2522%257D%252C%2522clwv5wqa200052869pbjhstvq%2522%253A%257B%2522id%2522%253A%2522clwv5wqa200052869pbjhstvq%2522%252C%2522tabs%2522%253A%255B%257B%2522id%2522%253A%2522clwv5wqa200042869u68r8i49%2522%252C%2522mode%2522%253A%2522permanent%2522%252C%2522type%2522%253A%2522UNASSIGNED_PORT%2522%252C%2522port%2522%253A0%252C%2522path%2522%253A%2522%252F%2522%257D%255D%252C%2522activeTabId%2522%253A%2522clwv5wqa200042869u68r8i49%2522%257D%252C%2522clwv5wqa200032869iioia7i0%2522%253A%257B%2522tabs%2522%253A%255B%255D%252C%2522id%2522%253A%2522clwv5wqa200032869iioia7i0%2522%257D%257D%252C%2522showDevtools%2522%253Atrue%252C%2522showShells%2522%253Afalse%252C%2522showSidebar%2522%253Atrue%252C%2522sidebarPanelSize%2522%253A15%257D %}
## Journey
<!-- Tell us about your process, what you learned, anything you are particularly proud of, what you hope to do next, etc. -->
I don't usually do anything creative with css, but when I do, it's super random.
Just kidding, I just learnt what it's called (the barber's pole thing) and read some history on [wikipedia](https://en.wikipedia.org/wiki/Barber%27s_pole) about it, then looked at the gif for too long, and the idea to make css art out of it just came up. Then I somehow ended up here, on dev.to and saw this challenge thing
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- We encourage you to consider adding a license for your code. -->
<!-- Don't forget to add a cover image to your post (if you want). -->
<!-- Thanks for participating! --> | chr1stine |
1,872,519 | Skip the SSO tax with Pomerium | Robust security is no longer optional in the modern threat landscape. Data breaches can damage... | 0 | 2024-05-31T23:04:16 | https://www.pomerium.com/blog/skip-the-sso-tax-with-pomerium/ | devops, howto, sso, access | Robust security is no longer optional in the modern threat landscape. Data breaches can damage business reputation and result in costly lawsuits. Yet, traditional Single Sign-On (SSO) solutions often come with a hefty price tag, forcing companies to choose between security and their bottom line.
The status quo shouldn't force companies to choose between security and their bottom line. Skip the SSO tax and [add SSO to any self-hosted application](https://www.pomerium.com/docs/capabilities/authentication) with Pomerium.
## What is SSO tax?
The SSO tax is when vendors charge users to access SSO as a service. This essentially means that customers pay extra money for a feature that companies should consider a basic security best practice. A common analogy is, “buying a car, paying for the brakes.”
Here’s the problem: those are some expensive brakes. The [ssotax.org](http://ssotax.org) wall of shame shows significant pricing increases as a result of software vendors realizing they can force companies to pay for a basic security feature.
## The Benefits of Single Sign-On (SSO)
SSO is a game-changer for user access management, especially for organizations juggling multiple cloud applications. Imagine logging into one central location (an [identity provider](https://www.pomerium.com/blog/5-lessons-learned-connecting-every-idp-to-oidc/) like Google or Okta) and seamlessly accessing all your work apps without needing individual logins for each. This not only improves user experience but also enhances security, as it provides the following benefits:
- **Improved User Experience:** Employees can access all their work applications with a single login, reducing frustration and wasted time.
- **Enhanced Security:** SSO centralizes user authentication, making it easier to enforce access controls and manage user identities.
- **Reduced IT Burden:** Onboarding and offboarding employees becomes much simpler with centralized user management.
- **Reduced Risk of Credential Theft:** By reducing the number of logins needed, SSO minimizes the risk of compromised credentials.
## Why is SSO Tax a problem?
The "SSO tax" creates a significant barrier for businesses, particularly smaller companies. Here's why it's a problem:
- **Unfair Pricing:** Charging a premium for a core security feature like SSO is akin to selling a car and requiring an extra fee for brakes. It's a fundamental requirement, not a luxury add-on.
- **Reduced Security Adoption:** High SSO costs can force companies to choose between user convenience and security, potentially leaving them vulnerable to cyberattacks.
- **Hinders Cloud Adoption:** The "SSO tax" discourages businesses from adopting cloud-based solutions due to the additional cost of implementing SSO across multiple platforms.
Vendors might argue that SSO is a luxury feature and not necessary for small- and medium-sized businesses (SMBs), but that’s not true in practice. Not having SSO means:
- **Scaling difficulties:** Onboarding and offboarding employees becomes difficult to manage at scale. The more applications you have, the bigger the scale.
- **Multiple access points:** The purpose of single sign-on is to have one strong access point instead of multiple weak ones. This exposes multiple attack vectors for possible exploitation.
- **Credential fatigue:** Forcing employees to keep track of multiple login credentials only results in increased chance of lost or stolen details. Moreover, password reset requests inundate IT management with unnecessary tickets.
While larger companies can afford to pay the extra SSO pricing tiers, SMBs can’t always afford to pay for enormous markups. Inevitably, when companies cannot afford SSO and hold sensitive customer data, they expose this data, leading to downstream security implications for customers.
## Does the SSO tax actually cause software to be insecure?
Grip Security discussed the problem with over 100 CISOs and found that [“80% of SaaS applications used by employees are not in their SSO portals,”](https://www.grip.security/blog/why-sso-doesnt-protect-80-of-your-saas) listing the **SSO licensing cost as the #1 reason for this predicament**. So yes: the situation absolutely forces companies to choose between security and cost.
## But vendors must be charging SSO for a reason, right?
There are some valid reasons why vendors might charge extra for SSO:
- **Development and Maintenance:** Integrating SSO functionality requires additional development work and ongoing maintenance to ensure compatibility with various identity providers.
- **Supporting Multiple Identity Providers:** Each identity provider has its own protocols and APIs, requiring tailored integrations. Supporting a wide range of providers increases development and maintenance complexity.
- **Customization Needs:** Some companies might require custom configurations for their SSO implementation, adding to the vendor's workload.
While the above holds some merit, the following is also true:
- **Disproportionate Pricing:** The upsell cost for SSO often goes far beyond what's reasonable to cover development and maintenance. It can be a significant multiplier of the base package, making it a luxury for smaller businesses that need it most.
- **Shifting Priorities:** Charging a premium for SSO incentivizes profit over security. It creates a situation where companies have to choose between affordability and best practices.
- **Standardization Ignored:** The sheer variety of identity providers can be a challenge, but industry standards exist to simplify integrations. Vendors who leverage these standards can reduce development costs and offer SSO at a more reasonable price.
## The Ethical Dilemma
Ultimately, the "SSO tax" creates an ethical dilemma for vendors. While development costs exist, charging exorbitant fees makes it harder for businesses to prioritize security. Ideally, vendors should:
- **Offer SSO in Base Packages:** Consider SSO a core feature, not an expensive add-on. In today's cloud-based world, secure access management is essential.
- **Develop Standardized Integrations:** Leveraging industry standards can streamline development and reduce costs associated with supporting multiple identity providers.
- **Provide Transparent Pricing:** Vendors should clearly outline the costs associated with SSO and avoid hidden fees or excessive markups.
To those SMBs and even larger companies that would like to cut costs, Pomerium can alleviate some of that for you.
## How does Pomerium workaround the SSO tax?
While many companies will write endless blogs shaming vendors for implementing an SSO tax, Pomerium believes in solution-oriented discussions. [Pomerium Zero](https://console.pomerium.app/create-account) allows you to implement SSO for your self-hosted applications without the burden of the SSO tax. Here's what makes Pomerium stand out:
- **Free and Open Source:** Pomerium Zero is a free, open-source solution. You don't have to pay any licensing fees or hidden charges to enjoy the benefits of SSO.
- **Easy to Implement:** Pomerium Zero is designed for ease of use. It integrates seamlessly with your existing infrastructure and requires minimal configuration.
- **Secure and Scalable:** Pomerium Zero prioritizes security without sacrificing performance. It offers robust access controls and scales to meet the needs of your growing business.
- **Empowering Businesses of All Sizes:** Whether you're a small startup or a large enterprise, Pomerium Zero makes secure SSO accessible.
Even better, Pomerium can [add SSO to legacy applications](https://www.pomerium.com/docs/capabilities/authentication#sso-support-for-legacy-applications) that do not have built-in SSO. Simply put Pomerium in front of your legacy application, implement SSO through Pomerium, and voila — you don't need to change the application at all.
Pomerium Zero offers this as a basic feature. The immediate ROI scales linearly with every single application your company uses where you self-host and pay to unlock SSO. If ten internal applications cost $20/user/month for SSO, Pomerium saves $200/user/month.
## We use SAML. Do we have to keep paying the SSO tax?
While we highly suggest shifting to OIDC, companies that cannot shift away from SAML can find an OIDC compliant federating identity provider (such as [Amazon Cognito](https://aws.amazon.com/cognito/)) to implement SSO through Pomerium and save on the SSO tax.
Have other questions about a specific application or your custom identity provider? Feel free to reach out to us on our [Discuss forums](https://discuss.pomerium.com/) to ask how you can save on the SSO tax today. | ckmo |
1,870,568 | CodeBehind Framework - Add Model in View | In this tutorial, we teach how to add a Model in View. Create an application with only View... | 27,500 | 2024-05-31T23:03:36 | https://dev.to/elanatframework/codebehind-framework-add-model-in-view-3i74 | tutorial, dotnet, beginners, backend | In this tutorial, we teach how to add a Model in View.
## Create an application with only View and Model
In the CodeBehind framework, you can create different parts of the program based on MVC, Model-View, Controller-View and only View architectures.
Following the Model-View pattern allows you to build simple yet powerful applications. In this architecture, you add a Model class as a page attribute in the View, and the program automatically places the Model values in the View page.
Example:
View
```html
@page
@model MyModel
<div>
<b>@model.Value1</b>
<br>
<b>@model.Value2</b>
</div>
```
Model
```csharp
using CodeBehind;
public partial class MyModel : CodeBehindModel
{
public string Value1 { get; set; }
public string Value2 { get; set; }
public MyModel()
{
Value1 = "This is text of Value1";
Value2 = "This is text of Value2";
}
}
```
The response that is sent to the browser is according to the codes below.
HTML result
```
<div>
<b>This is text of Value1</b>
<br>
<b>This is text of Value2</b>
</div>
```
## CodeBehindModel abstract class
Adding the `CodeBehindModel` abstract class to the Model class will provide useful features for the Model class. In the following, we introduce the features of the `CodeBehindModel` abstract class with examples.
**ViewData**
ViewData is a name and value instance of the `NameValueCollection` class that is used to transfer data from the Model to the View.
You can set ViewData in the Model class as follows.
`ViewData.Add("title", "Hello World!");`
Then you can call ViewData as shown below.
`<title>@ViewData.GetValue("title")</title>`
**Section**
Section is a attribute that applies to aspx pages. Section is a feature whose activation makes all paths after the aspx path refer to the current aspx path.
Section in Model takes its value only when you have activated Section in your View. In the next trainings, we will teach Section completely.
Example:
Active Section in View
```html
@page
+@section
```
If you enable Section in the `/page/about.aspx` path, any path added after the current path will be considered a Section and the executable file in the `/page/about.aspx` path will still be executed.
Example:
`/page/about.aspx/section1/section2/.../sectionN`
If you enable the Section in an executable file called `Default.aspx`, you will still have access to the default path.
Example:
`/page/about/Default.aspx/section1/section2/.../sectionN`
or
`/page/about/section1/section2/.../sectionN`
**CallerViewPath**
The View path that requests the current Model.
Example:
If the request path is the following value:
`example.com/page/about/OtherInfo.aspx`
According to the above value, the following string is stored in CallerViewPath:
`/page/about/OtherInfo.aspx`
**CallerViewDirectoryPath**
The View directory path that requests the current Model.
Example:
If the request path is the following value:
`example.com/page/about/OtherInfo.aspx`
According to the above value, the following string is stored in CallerViewDirectoryPath:
`/page/about`
**Download**
Download is a method that takes the file path as an input argument and makes the file available for download in the View path.
Example:
```csharp
Download("/upload/book/my_book.pdf");
```
**Write**
This method adds string values to the beginning of the View page
Example:
According to the previous example, if you call the following method in the Model class, the string `New written text` will be added at the beginning of the View response.
`Write("New written text")`
The response that is sent to the browser is according to the codes below.
HTML result
```
New written text
<div>
<b>This is text of Value1</b>
<br>
<b>This is text of Value2</b>
</div>
```
## Using CodeBehindConstructor method
In the previous example, we created an instance of the class constructor to set the properties. In the CodeBehind framework, you will not have access to all the features of the `CodeBehindModel` abstract class in the constructor class. But don't worry, you can use the CodeBehindConstructor constructor method in the Model class.
Example:
View (`/page/MyPage.aspx`)
```html
@page
@model MyModel()
<div>
<b>@model.Value1</b>
<br>
<b>@model.Value2</b>
<br>
<b>View requested in the page directory? @model.LoadInPageDirectory</b>
<br>
<b>View directory path: @model.CallerViewDirectoryPath</b>
</div>
```
The CodeBehind constructor is activated when you use open `(` and close `)` parentheses in front of the class name in the View.
Example:
`@model MyModel()`
Model
```csharp
using CodeBehind;
public partial class MyModel : CodeBehindModel
{
public string Value1 { get; set; }
public string Value2 { get; set; }
public string LoadInPageDirectory { get; set; }
public void CodeBehindConstructor()
{
Value1 = "This is text of Value1";
Value2 = "This is text of Value2";
LoadInPageDirectory = CallerViewPath.StartsWith("/page/")? "Yes" : "No";
}
}
```
The response that is sent to the browser is according to the codes below.
HTML result
```html
<div>
<b>This is text of Value1</b>
<br>
<b>This is text of Value2</b>
<br>
<b>View requested in the page directory? Yes</b>
<br>
<b>View directory path: /page</b>
</div>
```
## View class without abstract
Example:
You can also create the Model class without the `CodeBehindModel` abstract. For this, it is necessary to put the name of the Model class between open `{` and closed `}` brackets in the View page.
Example:
`@model {MyModel}`
or
`@model {YourProjectName.DefaultModel}`
> Note: Please note that if you create the Model without the `CodeBehindModel` abstract class, you will not have access to the methods and attributes of the `CodeBehindModel` class. If you use the Model-View pattern to develop applications, it is better to create the Model class by adding the `CodeBehindModel` abstract.
## Model-View in Visual Studio Code
In the Visual Studio Code project, we create a new View named `ViewModel.aspx`.
In the Explorer section, by right-clicking on `wwwroot` directory, we select the `New File` option and create a new file called `ViewModel.aspx`.
Then we add the following codes inside the `ViewModel.aspx` file.
```html
@page
@model ViewModel()
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>@ViewData.GetValue("title")</title>
</head>
<body>
<p>@model.BodyValue</p>
<b>View path: @model.CallerViewPath</b>
<br>
<b>View directory path: @model.CallerViewDirectoryPath</b>
</body>
</html>
```
Then we create a Model named `ViewModel.cs`.
In the Explorer section, by right-clicking on an empty space in Explorer, we select the `New File` option and create a new file called `ViewModel.cs`.
Then we add the following codes inside the `ViewModel.cs` file.
```csharp
using CodeBehind;
public partial class ViewModel : CodeBehindModel
{
public string BodyValue{ get; set; } = "";
public void CodeBehindConstructor()
{
BodyValue= "The body tag is used in HTML to define the main content of a web page.";
ViewData.Add("title", "Hello World!");
}
}
```
We run the project (F5 key). After running the project, You need to add the string `/ViewModel.aspx` to the URL.
The response that is sent to the browser is according to the codes below.
HTML result
```html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Hello World!</title>
</head>
<body>
<p>The body tag is used in HTML to define the main content of a web page.</p>
<b>View path: /ViewModel.aspx</b>
<br>
<b>View directory path: /</b>
</body>
</html>
```
For more practice, you can add a new attribute like BodyValue in the Model and call it in the View. You can also use the Write method in the Model and see the result in the View.
## Why use ViewData
Perhaps, after reading this tutorial, you may have a question; why do we use ViewData? Instead of using ViewData why don't we add an attribute in the Model class to call in the View?
ViewData is most useful when we use Layouts. In the next tutorials, we will explain Layout.
### Related links
CodeBehind on GitHub:
https://github.com/elanatframework/Code_behind
CodeBehind in NuGet:
https://www.nuget.org/packages/CodeBehind/
CodeBehind page:
https://elanat.net/page_content/code_behind | elanatframework |
1,872,520 | How I got $2500 from a single software license | 🥳 Landed a BIG client! Here's how I got $2500 from a single software license. They already had a... | 0 | 2024-05-31T23:03:14 | https://dev.to/xcs/how-i-got-2500-from-a-single-software-license-228n | startup, sales, webdev, programming | 🥳 Landed a BIG client! Here's how I got $2500 from a single software license.
They already had a lower-tier, Company license. They purchased it during last year's Black Friday sale for around $190.
After using the product internally for the last 6 months, they realized that their clients could also get value out of using it.
When they emailed me asking about the migration process from Company to Agency, it was close to midnight. But I knew that the sooner I responded, the higher the chances that they would buy. I quickly replied, asking for their license key, for verification purposes (I did this mostly to gain time). Then, I got an idea. I had to show that the migration process will be easy and smooth.
I started coding. And coded I did... I coded from midnight until 6AM in the morning. After improving the migration system (and also enabling a feature to easily switch from a single to a multi-database setup, which they were interested in), I sent them a discount coupon for the amount they have already paid ($180). I made sure to mention the work I did to ease their migration process.
After a few hours, I got another email. This time, it was from Paddle: they purchased. The final price, including the discount, was $2310. I think they would have purchased at full price too, but I believe it's only fair to just pay for the difference.
$2310 is a considerable amount for an indie-hacker like me, as it covers rent and expenses for a month. This is not the whole story, though. I learned something more. Last month, I increased the prices to better match the value of the product. I was afraid that the new, higher prices, will scare away potential customers. It turns out, it didn't.
My takeaways from this story:
- Responding quickly to sales and support inquiries makes a BIG difference.
- Always provide proof to the customer that they will be well taken care of. With your actions, not with words.
- The pricing doesn't matter as much as you would think if your product is good and does bring value to customers. Offer higher quality and price higher instead of joining the race to the bottom. | xcs |
1,872,205 | experience in phase 4 | SO phase 4 has kinda been more than a little rough, lots of personal stuff going on in my life and... | 0 | 2024-05-31T15:46:56 | https://dev.to/chimichimi123/experience-in-phase-4-22n7 | SO phase 4 has kinda been more than a little rough, lots of personal stuff going on in my life and I've been very distracted not to mention the literal tornadoes and loss of power for like a week, but I do actually like the material we're going over in phase 4, I used a little bit of it in phase 3 on accident when I was making my final project, I didnt have a very good understanding of it then, but I think I learned a lot more about it now and am much more comfortable with it.
all that being said I have been stuck on this final project for a while now, I've been working non stop on it but I have this terrible habit of overcomplicating my code and doing things that aren't required, in this case its kinda gone too far I kept looking for complicated fixes to problems that I cause by using complicated code and it just became too much of a web, I've completely restarted it a few hours ago trying to start from the beginning and keep it simple, but I cant get the frontend requests to work, like my login feature is just supposed to make a post request to /login on the backend but /login on the backend just doesnt work and I dont know how to fix it I have tried so many different things now, but I just cant get it, I probably messed up something small and accidentally covered it up or just never noticed it.
I'm hoping its something simple atleast then when I talk to you I can quickly finish up everything after you help, but if not I'm making sure all of my other assignments are completed and ready to go
I kinda wanna restart again and just do everything as basic as possible and what I know but I think I'm a little too short on time for that, I wasted so many hours stuck on something and was just way too stubborn to move on without fixing it, actually now that im thinking about it I need to quickly get rid of the token based authorization I got set up, I really cant explain it well at all, I just followed a guide online, only used it because I thought maybe it was my password hash that was causing an issue and wanted to try an alternative
thats everything though I just wanted a short break from coding to ramble a bit, I really like the content in phase 4 though | chimichimi123 | |
1,852,947 | How to build a fully-fledged telegram bot in Python | Introduction Chatbots are gradually becoming an integral part of our lives. These... | 0 | 2024-05-31T22:53:37 | https://dev.to/emiloju/how-to-build-a-fully-fledged-telegram-bot-in-python-2al0 | python, telegram, chatbot, database | ## Introduction
Chatbots are gradually becoming an integral part of our lives. These automated agents allow users to solve problems quickly by engaging them in real-time. I personally refer to them as _online-buddies._
One of the simplest ways of building a chatbot is through the Telegram messaging app. Telegram provides an easy way to build chatbots through their API.
In this article, you will understand how telegram bots work and how to create a Telegram bot using Python.
By the end of this article, you would have built a fully-fledged currency exchange telegram bot with Python.
This telegram bot allows users to get the exchange rate between two or more currencies in real time. It will also store registered users’ data in a SQL relational database.
_NB: This is not your regular kind of bot. You will build a fully-fledged telegram bot in Python that uses a relational database._
The following are the features of the bot:
- The bot registers new users and stores their data in a relational database.
- Only registered users can get the exchange rate between two or more currencies.
- Users can select a favorite base currency and multiple target currencies they would like to get updates on.
- The bot sends daily updates on latest exchange rates based on a user's base currency and their target currencies.
- Users can activate or deactivate the daily updates.
The purpose of this tutorial is to help you learn how to build a fully-fledged Telegram bot in Python. In the process, you will also learn concepts such as OOP, decorators, etc. that will help you write cleaner and reusable code in Python.
Below is a live demo of the bot in action:
{% embed https://youtu.be/7HuHGj3Sw6k?si=wh7Dn8fITYe5a39r %}
## Requirements
Below is a list of tools and libraries required for this tutorial:
**<u>Python</u>**: Python must be installed on your computer. Preferably, python 3.8+. You must also have a basic knowledge of Python.
**<u>python-telegram-bot library (PTB)</u>**: [PTB](https://docs.python-telegram-bot.org/en/v20.7/) library would be used to build the telegram bot. It is a feature-rich wrapper for the Telegram bot API in Python. To install this library, run the command below:
```
pip install python-telegram-bot
```
**<u>Python-telegram-bot[job_queue]</u>**: [job_queue](https://github.com/python-telegram-bot/python-telegram-bot/wiki/Extensions---JobQueue) is a package within the PTB library. It is used for setting up cron-jobs such as reminders, etc. in a telegram bot. Run the command below to install it:
```
pip install python-telegram-bot[job_queue]
```
**<u>sqlalchemy library</u>**: [sqlalchemy](https://docs.sqlalchemy.org/en/20/) is a python library used for creating a relational database. Run the command below to install this library:
```
pip install sqlalchemy
```
**<u>Requests library</u>**: This library is used for making HTTP requests in python. In this tutorial, it would be used to send HTTP requests to the currency exchange API. Run the command below to install it:
```
pip install requests
```
**<u>A telegram bot</u>**: This can be created on the telegram app. It lets you create and customize the theme and design of your chatbot. Once created, you would be given an api-token that would let you authenticate with the API.
**<u>Abstract API api-key</u>**: [Abstract API](https://www.abstractapi.com/) offers a suite of 12+ REST APIs. The currency exchange API is one of these APIs. You need an api-key to be able to use the API. You can only get one when you sign up with Abstract API.
## Create a Telegram bot
As part of the requirements for this tutorial, the following is a step-by-step process to create and design a Telegram bot:
1. Open the Telegram app.
2. Enter the name _BotFather_ in the search bar.
3. Click on the _BotFather_ profile like the one in the image below:
4. Click the start button in the new chat that opens.
5. Follow the directions of the BotFather to create and design your Telegram bot.
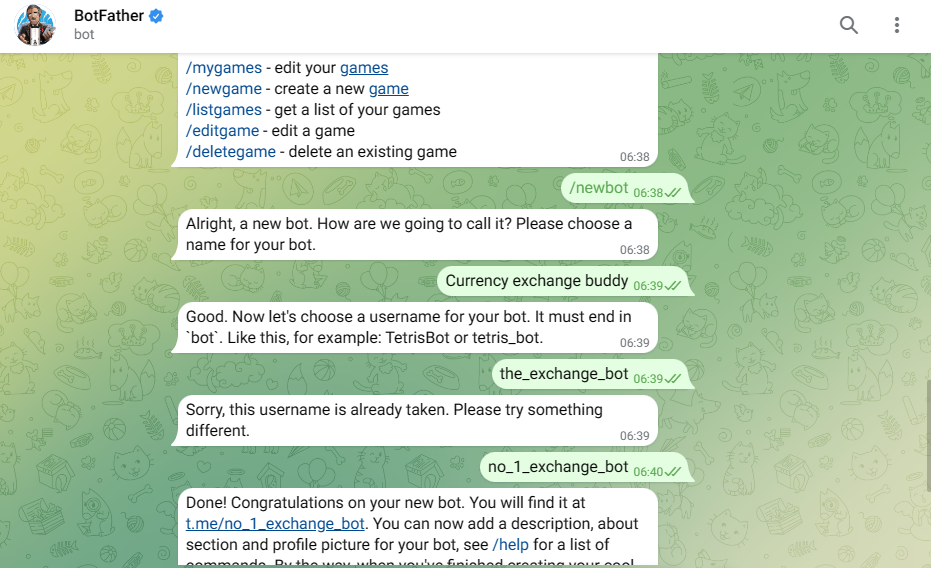
BotFather is the father of all Telegram bots. It was created by Telegram to help developers create chatbots on the platform.
## Create an Abstract API account
Abstract API offers a single api-key for registered users to authenticate with any of their APIs. Below is a step-by-step process to create an Abstract API account:
1. Proceed to their [sign-up](https://app.abstractapi.com/users/signup) page.
2. Enter your details and confirm you’re not a robot.
3. Click the Continue button to complete your registration.
A confirmation link will be sent to your mail. This link will confirm your registration and redirect you to their login page.
Once you login, you will have access to your dashboard.
### Get your Abstract API key
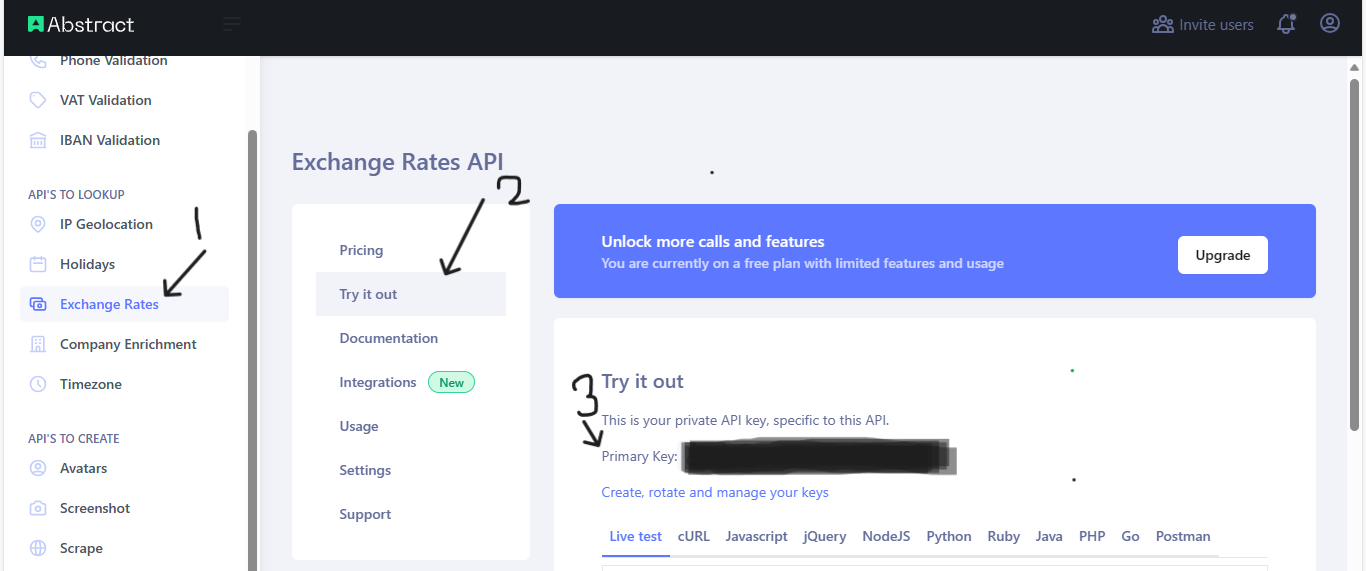
Follow the steps below to get your api-key:
1. Hover your cursor around the left side of your dashboard.
2. Select Exchange Rates under **_APIs to lookup_**.
3. Click **_Try it out_** on the new page.
4. Locate the **_Primary key_** label. You will find your api-key there.
## Build the Telegram bot
There are various libraries used for building a Telegram bot in Python. One of which is the python-telegram-bot (PTB) library.
Its use of asynchronous programming enables your bot to handle multiple requests at a time without blocking the other.
Also, it has a bunch of other features for building a fully functional Telegram bot. You will explore most of these features in this tutorial.
Open your code editor. Ensure you have created a project and a virtual environment that has all the required libraries installed in it.
### Initial application setup
The first step is to configure the bot settings. Below is the code for the application setup:
```
from telegram.ext import ApplicationBuilder
# To ensure errors are properly logged
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
level=logging.INFO
)
# The "main block"
if __name__ == "__main__":
TOKEN = 'your-api-token'
# An application instance
application = ApplicationBuilder().token(TOKEN).build()
```
In the code above, the `logging `library is used to ensure that errors from the bot are logged with correct descriptions so users can easily track and resolve them.
Also, an application instance is created with the `ApplicationBuilder()` class of the PTB library. It uses the `.token()` and `.build()` method to create an application instance that authenticates your bot with Telegram API.
The `.token()` method accepts a compulsory **TOKEN** argument, that is, your telegram api-token.
This initial setup is required for every bot (also known as application) built with the PTB library.
### Create the start command
The first command available to users in a Telegram bot is the `/start` command. Commands are instructions given by users to the bot.
Therefore, you need to create a function that responds to this command.
Follow the steps below to create a function for the `/start` command:
1. Import the following modules from PTB library
```
import telegram
from telegram import Update
from telegram.ext import ApplicationBuilder, ContextTypes, CommandHandler, filters
```
2. Write the function for the start command
```
...
async def start(update: Update, context: ContextTypes.DEFAULT_TYPE):
# Responds to a user
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="Welcome to the currency exchange bot.\n\n"
"What is your base currency? Enter your answer using the example
below as a guide:\n\n"
"/baseCurrency\n"
"your base currency, e.g USD, GBP\n\n"
)
...
```
The `start()` function is an asynchronous function that accepts two arguments namely:
- **update:** This argument has a type hint of the `Update` class in PTB library. It contains updates like new messages from the bot. It also includes data about the sender, such as: name, chat_id, etc.
- **context**: This argument has a type hint of the `ContextTypes.DEFAULT_TYPE` module in PTB. It includes all actions the bot can perform, such as sending messages, audios, replying to messages, etc.
These two arguments are compulsory for every function in the PTB library.
The `context.bot.send_message()` method is used to send messages to users. It accepts two compulsory arguments which include the following:
- **chat_id**: A unique identifier for the user/chat to send the message to.
- **text**: The textual content of the message.
The `start()` function is invoked when a user starts the bot. In the case of the currency exchange bot, it asks a few questions from them to ensure a personalized experience.
This question is added to the `.send_message()` method in the `start()` function above.
#### Register the start command
Handlers in the PTB library provide a way of linking each command to a function. Each function is executed when its linked command is invoked.
For example, when building a Django web app, you need to create url paths and a view function for each path. When a user visits any url, its associated view function is executed.
Add a handler for the `start()` function below the application instance and start the bot:
```
...
if __name__ == "__main__":
TOKEN = 'your_api_token'
application = ApplicationBuilder().token(TOKEN).build()
# Creates a command handler
start_handler = CommandHandler('start', start)
# Adds the handler to the bot
application.add_handler(start_handler)
# start the bot.
application.run_polling()
```
The `CommandHandler()` class is used to link a command and a function together. It accepts two arguments — the command name and the function.
You register the handler with the application using the `.add_handler()` method.
The `application.run_polling()` method keeps the bot running and constantly polls the Telegram bot API for new alerts on your bot. It should be at the bottom end in the main block.
Finally, run the script file to start the bot.
Open your Telegram bot and click on the start button in the chat. The bot will respond with the message that was set earlier in the `start()` function. This means the bot setup was successful. Below is an example:

Learn more about setting up an application and creating functions in this sample [tutorial](https://github.com/python-telegram-bot/python-telegram-bot/wiki/Extensions---Your-first-Bot) of the PTB documentation.
### Create a database connection
A database is required to store users' data. The sqlalchemy library in Python will be used to set up the database.
For this tutorial, you will use a local database file which is suitable for a development environment.
Follow the steps below to set up a database:
1. Create a new file named `database.py`
2. Open the file and add the code below:
```
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
import os
# The database url
SQLALCHEMY_DATABASE_URL = "sqlite:///users.db"
# Creates a database engine
engine = create_engine(
SQLALCHEMY_DATABASE_URL
)
# Handles database sessions
SessionLocal = sessionmaker(bind=engine)
Base = declarative_base()
```
The following is an analysis of the `database.py` file:
- **SQLALCHEMY_DATABASE_URL**: This refers to the database link or URL. Since you would be using a local database file, the URL would be a local file name. For this tutorial, the database file is titled `users.db`
- **create_engine()**: This is a method in sqlalchemy that is used to create connections with a database. It takes the database URL as an argument.
- **SessionLocal**: SessionLocal object is used for creating sessions in SQLAlchemy. It is used to manage transactions and serve as a gateway to the database.
- **Base**: This line creates a base class for declarative class definitions. In SQLAlchemy, a declarative base is a base class for declarative class definitions, which are used to define database models.
### Create a database model
The next step is to create a _User_ database model. Follow the steps below to create a database model:
1. Create a new file named `models.py`
2. Add the code below to this file:
```
from sqlalchemy import Boolean, Column, Integer, String
from database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
chat_id = Column(Integer, unique=True, nullable=False)
base_currency = Column(String, unique=False, nullable=False)
currency_pairs = Column(String, unique=False, nullable=False)
receive_updates = Column(Boolean, nullable=False, unique=False, default=False)
```
The _User _model contains the following columns:
- **chat_id**: A long set of integers such as, 257945683925 that is unique to each chat or user.
- **base_currency**: This column is for a user's favorite base currency such as, USD, CAD, etc.
- **target_currencies**: This refers to a list of other currencies the user would like to get daily updates on, relative to their base currency. For example, a user can select USD as their base currency and GBP, CAD, EUR as their target currencies. This means that the user would like to get daily updates on how much 1USD is, when converted to GBP, CAD, and EUR.
- **receive_updates**: This is a boolean field that records if the user would like to receive updates or not.
### Create the database file
Follow the steps below to create a new database file:
1. Open the `main.py` file.
2. Add the following import statements:
```
from database import Base, SessionLocal, engine
from models import User
...
```
3. Add the code below after the `logging.basicConfig()` function.
```
...
Base.metadata.create_all(bind=engine)
db = SessionLocal()
...
```
4. Run the script file.
The steps above will create a database file and add a _user _ table to it. An instance of the database session is assigned to the `db` variable. It is used to perform CRUD (create, read, update, delete) operations with the database.
A new file named `users.db` would be created in your project folder.
### Create a _CurrencyExchange_ class
So far, you have learnt the following:
- How to create a telegram bot and get an api-token.
- How to create a command and a corresponding function in PTB.
- How to register a command with a function through handlers.
- How to create a database connection.
- How to add a database model in Python.
- How to create a relational database file in Python.
The [currency exchange API](https://docs.abstractapi.com/exchange-rates) is a REST API with different endpoints. In order to prevent repetition and enhance readability, it is necessary that you bundle all the endpoints into a Python class.
This is a concept in **Object-Oriented Programming (OOP)**. You can check out my [complete guide on OOP for beginners](https://superbemiloju.hashnode.dev/object-oriented-programming-oop-concepts-in-python-with-practical-examples).
The class will be named `CurrencyExchange`.
Follow the steps below to create the CurrencyExchange class:
1. Create a new file named exchange.py
2. Add the code below to create the class:
```
import requests
class CurrencyExchange:
def __init__(self, api_key):
self.key = api_key
self.codes = ["ARS", "AUD", "BCH", "BGN", "BNB", "BRL", "BTC",
"CAD", "CHF", "CNY", "CZK", "DKK", "DOGE", "DZD",
"ETH", "EUR", "GBP", "HKD", "HRK", "HUF", "IDR",
"ILS", "INR", "ISK", "JPY", "KRW", "LTC", "MAD",
"MXN", "MYR", "NOK", "NZD", "PHP", "PLN", "RON",
"RUB", "SEK", "SGD", "THB", "TRY", "TWD", "XRP",
"ZAR", "USD"]
# Performs one-to-one exchange
def single_exchange(self, params):
url = "https://exchange-rates.abstractapi.com/v1/convert"
params['api_key'] = self.key
res = requests.request("GET", url, params=params)
return res.json()
# Performs one-to-many exchange
def multiple_exchange(self, params):
url = "https://exchange-rates.abstractapi.com/v1/live"
params['api_key'] = self.key
res = requests.request("GET", url, params=params)
return res.json()
# validates a single currency code
def is_valid_currency(self, currency):
if currency in self.codes:
return True
else:
return False
# validates multiple currencies
def is_valid_currencies(self, currencies_list):
# uses all() function to loop through currencies list
if all(currency in self.codes for currency in currencies_list):
return True
else:
return False
```
The `CurrencyExchange `class has two attributes - an api_key and currency codes which are supported by the bot.
The `single_exchange()` method is for exchange rate between two currency pairs. It uses the convert endpoint of the currency exchange API.
The `multiple_exchange()` method is for rates between a single base currency and multiple target currencies. It uses the live endpoint of the currency exchange API.
The last two methods namely `is_valid_currencies()` and `is_valid_currency()` will be used to validate user inputs. That is, single and multiple currency codes respectively.
Read the API [documentation ](https://docs.abstractapi.com/exchange-rates)to learn more about these endpoints.
### Add new functions and commands
The next step is to add new commands and their corresponding functions to the bot.
#### Create function for base currency input
This function receives and records users' base currency. Users have been instructed in the `start()` function to submit a base currency code through the _/baseCurrency_ command.
Commands in the PTB library accept arguments as user inputs. It is like a URL with query parameters.
Below is the function for the _/baseCurrency_ command:
```
...
async def record_base_currency(update: Update, context: ContextTypes.DEFAULT_TYPE):
""" Record Base Currency """
# user input
argument = "".join(context.args)
base_currency = str(argument).upper()
# validates the user input(currency code)
if currency_exchange.is_valid_currency(base_currency):
context.user_data["base_currency"] = base_currency
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="Kindly list your favorite target currencies. That is, a list of currencies you want to get updates on relative to your base currency."
" You can select as many as you want\n"
"<b>Each currency should be separated by a comma(,)</b>\n\n"
"Use the example below as a guide:\n\n"
"/targetCurrencies\n"
"USD,CAD,GBP",
parse_mode=telegram.constants.ParseMode.HTML
)
else:
# alerts user if currency is not supported
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"This bot does not support {base_currency} currency"
)
...
```
Arguments in PTB are stored in a Python list called `context.args`.
In the `record_base_currency()` function, this list is unpacked and converted to a string. This string, which is the user's base currency, is converted to uppercase and stored in the context dictionary.
A [context dictionary](https://github.com/python-telegram-bot/python-telegram-bot/wiki/Storing-bot%2C-user-and-chat-related-data) is used to temporarily store information within the bot’s memory. It is of two types:
- **The bot context dictionary:** It stores information temporarily in memory and it can be accessed from each user's chat. More like a private storage.
- **The user context dictionary:** It stores information temporarily in memory, and it can only be accessed in a single user's chat. More like a private storage.
Instead of adding user's input directly to the database, you can easily add it to the context dictionary. This helps in the following ways:
- It helps to limit frequently queries to the database.
- In case the user fails to complete registration, you do not have a redundant or incomplete record in the database.
If the user successfully completes his/her registration, you can then add everything to the database.
The bot queries the user for their target currencies. Each user input is verified to ensure that it is supported by the API.
PTB library allows the bot to send HTML messages. Telegram API has a list of supported [HTML tags](https://core.telegram.org/api/entities).
When sending HTML messages, it is important that you parse the message by adding the `parse_mode` argument to the `context.bot.send_message()` method.
Below is an example of the _/baseCurrency_ command:

#### Create function for target currencies input
In the previous step, the user is prompted to submit their target currencies. The `record_target_currencies()` function will be used to validate and record the data submitted by the user.
Follow the steps below to create this function:
1. Open the `main.py` file
2. Import the following classes
```
from telegram import InlineKeyboardButton, InlineKeyboardMarkup, ReplyKeyboardMarkup
```
3. Add the new function below:
```
...
async def record_target_currencies(update: Update, context: ContextTypes.DEFAULT_TYPE):
# user input
arguments = "".join(context.args)
currency_pairs = arguments.split(",")
# validates the target currencies
if currency_exchange.is_valid_currencies(currency_pairs):
context.user_data["target_currencies"] = arguments
keyboard = [[InlineKeyboardButton('Yes', callback_data='yes')],
[InlineKeyboardButton('No', callback_data='no')]]
await update.message.reply_text(
text="<b>Would you like to receive daily updates on selected currencies?</b>",
parse_mode=telegram.constants.ParseMode.HTML,
reply_markup=InlineKeyboardMarkup(keyboard)
)
else:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"Error occurred! Ensure that each currency is supported by the bot."
)
...
```
In the code above, the `record_target_currency()` function adds the user input directly to the context dictionary. The function also validates a user input before adding it to the context dictionary.
If submission is successful, the user is asked if they want to receive daily updates. The `InlineKeyboardButton()` and `InlineKeyboardMarkup()` classes are used to create a list of clickable options for a user to select from.
Below is a sample of the _/targetCurrencies_ command and the bot's response:
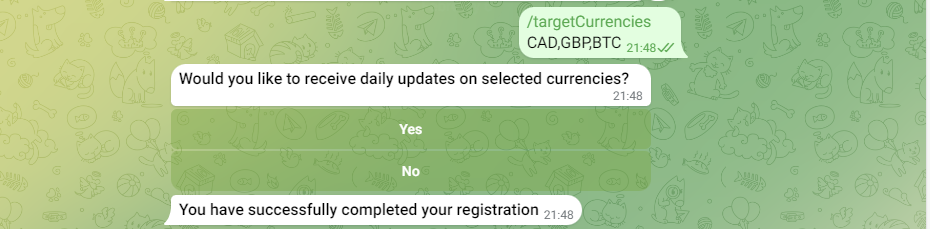
#### Create function to complete user registration
In the previous function, the user is presented with a list of options to choose from.
The `complete_registration()` function receives the user's selection. It enters this selection alongside the previous inputs submitted by the user into the database.
This marks the end of the user registration. Below is the code for this function:
```
async def complete_registration(update: Update, context: ContextTypes.DEFAULT_TYPE):
""" User completes registration """
query = update.callback_query.data
# checks for incomplete registration
try:
target_currencies = context.user_data.get("target_currencies")
base_currency = context.user_data.get("base_currency")
except KeyError:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="<b>There's an error with your registration. Kindly restart by submitting your base currency</b>\n"
"Use the example below as a guide:\n\n"
"/baseCurrency\n"
"your base currency, e.g USD, GBP\n\n",
parse_mode=telegram.constants.ParseMode.HTML
)
else:
if query == "yes":
receive_updates = True
else:
receive_updates = False
new_user = User(
chat_id=update.effective_chat.id,
base_currency=base_currency,
currency_pairs=target_currencies,
receive_updates=receive_updates
)
db.add(new_user)
db.commit()
options = [["Activate Updates 🚀", 'Deactivate updates'], ['Bot Manual 📗']]
key_markup = ReplyKeyboardMarkup(options, resize_keyboard=True)
await context.bot.send_message(text="<b>You have successfully completed your registration</b>",
reply_markup=key_markup,
chat_id=update.effective_chat.id,
parse_mode=telegram.constants.ParseMode.HTML)
```
In the code above, all the previous entries are retrieved and added to the database. The user gets a success message and three buttons are added to the bot. This would allow the user to perform certain tasks quickly. Below is an image of the three buttons:
In some cases, it is possible the user omitted a step in the registration process.
For example, if a user has a prior knowledge of how this bot works, he/she could decide to start the bot and enter the `target_currencies` first and skip the `base_currency` part.
If by the end of the registration, you try to access the value for the `base_currency` from the context dictionary, it will trigger a `KeyError` because it doesn't exist. This function handles this scenario.
#### Create function for messages
Users now have full access to the bot. You need to add a function that handles the user's direct messages to the bot.
For this tutorial, the only direct messages the bot can respond to are those from the 3 buttons. If you click on any of them, a direct message will be sent to the bot.
Below is the function that handles direct messages to the bot:
```
...
async def direct_messages(update: Update, context: ContextTypes.DEFAULT_TYPE):
""" Direct messages """
message = update.message.text
user = db.query(User).filter_by(chat_id=update.effective_chat.id).first()
if message == "Bot Manual 📗":
await context.bot.send_message(
text="<i>Click <b>Activate Updates</b> to activate daily updates</i>\n\n"
"<i>Click <b>Deactivate Updates</b> to deactivate updates</i>\n\n"
"<i>Click <b>Bot Manual</b> to learn how to use the bot</i>\n\n"
""
"<i>To find the exchange rate between a base currency and multiple target currencies, use the command "
"below:\n\n</i>"
"/multipleExchange\n"
"USD/CAD/EUR\n\n"
"Put your base currency first and other currencies should follow. Separate them with a forward "
"slash(/)\n\n"
""
"<i>To find the exchange rate between a base currency a single target currency, use the command "
"below:</i>\n\n"
"/singleExchange\n"
"USD/GBP\n\n"
"Put your base currency first and the target currency should follow. Separate them with a forward "
"slash(/).\n\n"
""
"<i>To find the exchange rate between a base currency a single target currency with a base amount, "
"use the command below:</i>\n\n"
"/exchangeRate\n"
"USD/CAD @ 50\n\n"
"Put your base and target currency together and signify the base amount with the @ symbol",
chat_id=update.effective_chat.id,
parse_mode=telegram.constants.ParseMode.HTML)
elif message == "Activate Updates 🚀":
user.receive_updates = True
db.commit()
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="<i>You have successfully activated daily exchange rate updates</i>",
parse_mode=telegram.constants.ParseMode.HTML
)
elif message == 'Deactivate updates':
user.receive_updates = False
db.commit()
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="<i>You have successfully deactivated daily exchange rate updates</i>",
parse_mode=telegram.constants.ParseMode.HTML
)
else:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="<i>This bot is not able to respond to your messages for now</i>",
parse_mode=telegram.constants.ParseMode.HTML
)
...
```
In the code above, each button click is handled by the bot. The _**Bot manual**_ sends a guide on how to use the bot, the _**Activate updates**_ activate daily updates, and **_Deactivate updates_** deactivates daily updates from the bot. You can add as many buttons as you like.
#### Create function for single exchanges
The function of this bot is to help users get exchange rates in real time. It does this in 3 ways. They include:
- single exchange - that is, between two currencies. For example: USD-CAD.
- multiple exchange - that is, between one currency and other multiple currencies. For example: USD to CAD/BTC/AUD, etc.
- arbitrary exchange - that is, exchange between two currencies while stating a base amount. For example: 50 USD to CAD.
Using the `single_exchange()` method of the `CurrencyExchange` class, the function below allows users to find single exchange rates:
```
...
async def single_exchange_rate(update: Update, context: ContextTypes.DEFAULT_TYPE):
""" Exchange Currencies """
currency_pairs = "".join(context.args)
# Ensures the currency codes are split by a slash(/)
try:
base_currency = currency_pairs.split("/")[0].upper()
target_currency = currency_pairs.split("/")[1].upper()
except IndexError:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"Error occurred! You must enter two currency codes separated by a forward slash(/)"
)
else:
# validates currency codes
if currency_exchange.is_valid_currency(base_currency) and currency_exchange.is_valid_currency(target_currency):
params = {
"base": base_currency,
"target": target_currency
}
response = currency_exchange.single_exchange(params=params)
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"<b>Base Currency:</b> {base_currency}\n"
f"<b>Target Currency:</b> {target_currency}\n"
f"<b>Exchange Rate</b>: {response['exchange_rate']}\n\n"
f"<i>This means that 1 {base_currency} is equal to {response['exchange_rate']} {target_currency}</i>",
parse_mode=telegram.constants.ParseMode.HTML
)
else:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"Error occurred! Ensure that both currencies are supported by the bot."
)
...
```
The user is instructed to use the _/singleExchange_ command to make a request and separate the two currency codes by a slash (/). This input is split by the slash and assigned to two different variables.
They are passed as parameters into the `single_exchange()` method. The response is styled with HTML and sent to the user.
Using error handling, the function ensures that the user input is in the right format and contains currency codes that are supported by the API.
The image below shows how to send a single exchange command:

#### Create function for multiple exchanges
This section shows you how to handle multiple or one-to-many exchange rates for users. Users are to separate the currency codes by a comma, with the base currency added first.
Below is the code below for this fucntion:
```
...
async def multiple_exchange_rate(update: Update, context: ContextTypes.DEFAULT_TYPE):
""" Exchange Currencies """
# user input
argument = "".join(context.args)
currency_pairs = argument.split("/")
# ensures currency codes are split
try:
base_currency = currency_pairs[0]
target_currencies_list = currency_pairs[1:]
except IndexError:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"Error occurred! Ensure that there are more than two currencies separated by a forward slash(/)."
)
else:
# validates currency codes.
if currency_exchange.is_valid_currencies(target_currencies_list):
print(target_currencies_list)
target_currencies = ",".join(target_currencies_list)
# API request parameters
params = {
"base": base_currency,
"target": target_currencies
}
# API response
response = currency_exchange.multiple_exchange(params=params)
result = []
for currency in target_currencies_list:
rate = response["exchange_rates"][currency]
result.append(f"<b>{currency}</b> = {rate}\n")
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="".join(result),
parse_mode=telegram.constants.ParseMode.HTML
)
else:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"Error occurred! Ensure this bot supports the currencies you entered."
)
...
```
This function is similar to the `single_exchange()` function, except that it queries multiple currency codes at a time. They handle exceptions the same way but with different methods of the `CurrencyExchange` class.
Below is an example of how to find multiple exchange rates:

#### Create function for arbitrary exchanges
This is the final exchange type. It allows users to state a base amount for an exchange.
The function below allows users to perform arbitrary exchange:
```
...
async def arbitrary_exchange(update: Update, context: ContextTypes.DEFAULT_TYPE):
""" Exchange Currencies """
arguments = "".join(context.args)
split_arguments = arguments.split("@")
try:
base_currency = split_arguments[0].split("/")[0]
target_currency = split_arguments[0].split("/")[1]
base_amount = float(split_arguments[1])
except IndexError:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"Please enter values in the correct format"
)
except ValueError:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"Please enter a valid number"
)
else:
if currency_exchange.is_valid_currency(base_currency) and currency_exchange.is_valid_currency(target_currency):
params = {
"base": base_currency,
"target": target_currency,
"base_amount": base_amount
}
response = currency_exchange.single_exchange(params=params)
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"<b>Base Currency:</b> {base_currency}\n"
f"<b>Target Currency:</b> {target_currency}\n"
f"<b>Exchange Rate:</b> {response['exchange_rate']}\n\n"
f"<i>This means that {response['base_amount']} {base_currency} is equal to "
f"{response['converted_amount']} {target_currency}</i>",
parse_mode=telegram.constants.ParseMode.HTML
)
else:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text=f"Error occurred! Ensure this bot supports the currencies you entered."
)
...
```
The code above handles two exceptions. The first one is an `IndexError` which may occur if the user did not enter two currency codes split by a slash (/), and the other which handles a `ValueError` if the `base_amount` is not a valid number.
If there are no errors, the currency codes are validated to ensure they are acceptable by the API.
Below is an image that shows how a user can perform an arbitrary exchange:

#### Create and register all handlers
Congratulations on getting this far. The next step is to add each function to a handler and test the bot.
The code below shows you how to achieve this:
```
...
# The "main block"
if __name__ == "__main__":
# direct messages handler
message_handler = MessageHandler(filters.TEXT & (~filters.COMMAND),
direct_messages)
base_currency_handler = CommandHandler('baseCurrency',
record_base_currency)
target_currency_handler = CommandHandler('targetCurrencies',
record_target_currencies)
exchange_handlers = [CommandHandler('singleExchange',
single_exchange_rate),
CommandHandler("multipleExchange",
multiple_exchange_rate),
CommandHandler("exchangeRate",
arbitrary_exchange)]
# Option list handlers
callback_handlers = [CallbackQueryHandler(complete_registration,
'yes'),
CallbackQueryHandler(complete_registration,
'no')]
# Add handlers to the bot
application.add_handler(message_handler)
application.add_handler(base_currency_handler)
application.add_handler(target_currency_handler)
application.add_handlers(callback_handlers)
application.add_handlers(exchange_handlers)
...
```
Each function is added to a handler. The `CallbackQueryHandler()` is used to handle the select options created earlier in this tutorial.
Run the bot to test the progress so far. The bot should respond to all your messages and queries.
#### Protect the bot from unauthorized access.
Currently, the bot is accessible by anyone, both registered and unregistered users. This is the final defect of the bot.
If an unregistered user tries to enter a command in the bot, the bot should respond by telling them to register first.
#### Python decorators to the rescue
Python [decorators](https://www.freecodecamp.org/news/python-decorators-explained/) are wrapper functions that accept other functions or classes as arguments. They are useful for validations in web apps.
For example, if a condition is satisfied, the wrapped function is returned and executed. Else, a warning message is sent or any other action performed.
For this tutorial, two decorators will be created. They are as follows:
**1. A decorator for new users:**
This decorator protects a function and makes it accessible by new users only. This is the code below:
```
def for_new_users(f):
@wraps(f)
async def wrapper_function(update: Update, context: ContextTypes.DEFAULT_TYPE):
# Get a single user by chat_id
user = db.query(User).filter_by(chat_id=update.effective_chat.id).first()
# Checks if user exists
if user:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="This endpoint is for new and unregistered users."
)
else:
await f(update, context)
return wrapper_function
```
In this decorator, the code checks a user's chat_id against the database. If the chat_id exists, the user is sent a warning message and denied access to the function. If otherwise, the user is allowed to continue with his/her registration.
**2. A decorator for registered users:**
This decorator protects a function and makes it accessible by registered users only. This is the code below:
```
def for_registered_users(f):
@wraps(f)
async def wrapper_function(update: Update, context: ContextTypes.DEFAULT_TYPE):
# Get a single user by chat_id
user = db.query(User).filter_by(chat_id=update.effective_chat.id).first()
# Checks if user exists
if not user:
await context.bot.send_message(
chat_id=update.effective_chat.id,
text="This endpoint is for registered users. Kindly register to use this function"
)
else:
await f(update, context)
return wrapper_function
```
In this decorator, the code checks a user's `chat_id` against the database. If the `chat_id` exists, the user is allowed to continue with the bot. If otherwise, the user is sent a warning and instructed to complete his/her registration to access the function.
This way, registered users do not have to recreate a profile with the same account again.
##### Add the decorators to each function
Protect each function by adding the decorators as below:
```
@for_new_users
async def start(update: Update, context: ContextTypes.DEFAULT_TYPE):
# Rest of the code
```
Assign a suitable decorator for each function. Check the [full code](https://github.com/Omotunde2005/currency_exchange_bot) on GitHub to see how the decorators are added to each function.
#### Set up daily updates
The final feature of the bot is to send personalized daily updates to users who opt-in for daily updates.
The `job_queue` package of the PTB library is used to set up cron jobs in Telegram bots.
Below is a function named `daily_updates()` that sends the personalized updates:
```
async def daily_updates(context: ContextTypes.DEFAULT_TYPE):
all_users = db.User.all()
# List of users who opt-in for daily updates
will_receive_updates = [user for user in all_users if user.receive_updates is True]
context.bot_data['cached_rates'] = {}
# Function that sends updates
async def send_update(user):
base_currency = user.base_currency.upper()
params = {
"base": base_currency
}
chat_id = user.chat_id
currency_pairs = user.currency_pairs.split(",")
response = ""
# Checks if an updates exists in the context dictionary
try:
cached_response = context.bot_data['cached_rates'][base_currency]
except KeyError:
response = currency_exchange.multiple_exchange(params)
else:
response = cached_response
update_message = f"<b>Latest update on exchange rates relative to {base_currency}</b>\n" \
f"This means that 1 {base_currency} is equal to the following in different currencies:\n\n" \
f""
for currency in currency_pairs:
exchange_rate = response['exchange_rates'][currency.upper()]
update_message += f"<b>{currency}</b>: {exchange_rate}\n"
context.bot_data['recent_exchange_rates'][base_currency] = response
await context.bot.send_message(
chat_id=chat_id,
text=update_message,
parse_mode=telegram.constants.ParseMode.HTML
)
for user in will_receive_updates:
await send_update(user)
time.sleep(2)
# Clears cached updates
context.bot_data.clear()
```
In the function above, users who want daily updates are separated from others and added to a list.
Within this function, there is another asynchronous function that queries the API based on each user’s base and target currencies.
Each successful query is temporarily stored(cached) in the context dictionary of the bot. This is useful in situations where users might have similar base currency.
Instead of sending a request to the API every time, you can easily access it from within the bot and render results to users.
For example — John and Janet both have the same base currency which is USD. If John receives his update first, instead of sending a new request to the API for Janet’s update, you can easily use John’s own which has been saved to memory since they both have the same base currency.
If the next user has a different base currency, a new request is sent to the API and the result is also saved to memory in case there’s another user with the same base currency.
Finally, the cached data is cleared after all updates have been sent.
Caching API responses are not accepted by all APIs. In fact, it is considered a crime for some. In the case of the Exchange API, cached responses are not useful after a long time. This is because exchange rates fluctuate and change periodically. Therefore, using cached results would mean that your bot will not provide accurate exchange rates. It is only useful for situations like this where you have to send updates to users at once.
Create a cron job and register the updates function to the application by following the steps below:
1. Import the datetime module.
2. Add the code below in the “main block".
```
...
# The "main block"
if __name__ == "__main__":
...
time_format = '%H:%M'
reminder_time_string = '21:13'
daily_job = application.job_queue
datetime_obj = datetime.strptime(reminder_time_string, time_format)
daily_job.run_daily(daily_updates, time=datetime_obj.time(),
days=tuple(range(7)))
...
```
In the code above, a daily cron job is created with the `application.job_queue` instance.
It is automatically set at UTC timing and it runs based on the specified time of the `reminder_time_string`.
It uses the Hours:Minutes(e.g 05:00) time format.
#### Conclusion: Next steps
The bot is up and running and delivers real time exchange rates to users. I'm sure you enjoyed building this project.
You learned how to apply some python concepts that help you write a clear and organized code.
**What Next?**
What's the joy of building something this beautiful without it being used by people?
That's why I’ve decided to create a new tutorial that will show you how to add a live postgresql database to the bot and host it live for others to use.
Follow me on [LinkedIn](https://www.linkedin.com/in/rilwan-edun-4960082aa?utm_source=share&utm_campaign=share_via&utm_content=profile&utm_medium=android_app) to be the first to know when the new tutorial is out.
## Frequently asked questions (FAQs)
### How can I host the Telegram bot for free?
Yes. There are free hosting services where you can host your Telegram bot. However, this particular bot requires a persistent memory and state persistence. It also runs and stores cron-jobs on them, hence you will need a more sophisticated solution.
A new article on how to solve this will be ready soon.
### Can I host this Telegram bot on Google Cloud functions?
No. Google Cloud functions is suitable for hosting applications that does not require persistence or are stateless. They are only triggered when an action or event occurs in an application.
### Which other Python libraries can be used to build a Telegram bot?
There are numerous Python libraries that can be used to build telegram bots. [Here](https://blog.finxter.com/top-10-python-libraries-to-create-your-telegram-bot-easily-github/) is a list of top 10 Python libraries for developing Telegram bots | emiloju |
1,872,517 | On VSCode, how to open the selected folder from Explorer view into the current open terminal (without opening a new one)? | 1. Install the multi-command extension This allows us to create a sequence of commands... | 0 | 2024-05-31T22:49:51 | https://dev.to/eduardohilariodev/on-vscode-how-to-open-the-selected-folder-from-explorer-view-into-the-current-open-terminal-without-opening-a-new-one-2d93 | vscode, howto, terminal |
## 1. Install the [multi-command](https://marketplace.visualstudio.com/items?itemName=ryuta46.multi-command) extension
This allows us to create a sequence of commands that can be used by a keybinding.
## 2. Add this snippet to your `settings.json`
```json
"multiCommand.commands": {
"multiCommand.openFolderInTerminal": {
"interval": 10,
"label": "Open Explorer view folder in active terminal",
"sequence": [
"copyFilePath",
"terminal.focus",
{
"command": "workbench.action.terminal.sendSequence",
"args": { "text": "cd \"" }
},
"workbench.action.terminal.paste",
{
"command": "workbench.action.terminal.sendSequence",
"args": { "text": "\"" }
},
{
"command": "workbench.action.terminal.sendSequence",
"args": {
"text": "\u000D"
}
}
]
}
}
```
What this effectively does is to copy the path of the selected folder and send sequences of text to the terminal, as stated [here](https://code.visualstudio.com/docs/terminal/advanced#_custom-sequence-keybindings). The quotes are escaped by `\` and `Enter` is sent by the newline unicode character `\u000D`.
## 3. Add a keybinding to your `keybindings.json`
```json
{
"command": "multiCommand.openFolderInTerminal",
"key": "ctrl+enter",
"when": "filesExplorerFocus && !inputFocus"
}
```
The value of the `"command"` key has the same text as the one defined on the `"multiCommand.commands"` object. | eduardohilariodev |
1,872,500 | Cloud Resume Challenge - Chunk 3 | Here is the previous post in this series. What's needed for the CRC Chunk 3 Not much... | 0 | 2024-05-31T22:36:33 | https://dev.to/brianhaas/cloud-resume-challenge-chunk-3-4ana | webdev, devops, aws, career | Here is the previous [post](https://dev.to/brianhaas/cloud-resume-challenge-chunk-2-1p78) in this series.
## What's needed for the CRC Chunk 3
Not much really. Just a few lines of javascript on the static website to call the API, get the hit count and present it on the page.
This required me to revisit my [Hugo](https://gohugo.io/) website. I opened up the developer tools in Edge to figure out which section was which to decide where I wanted to place my hit counter.
I learned about layouts and partials in hugo in order to customize the Hugo template I was using to put my javascript code and hit counter section where I wanted.
Here is the [finished HTML section](https://github.com/chronosAZ/CRC-Frontend/blob/main/web/index.html#L96)
And here is what the counter looks like on my page:
### What's next and final thoughts on the CRC
There is quite a bit I can do to improve and refine the work I've done here. Namely, writing tests. I know, I know, I should've followed the test-driven development principle, but I didn't since it was a fairly simple application.
I can also do some of the security mods and beef up the API function, so it counts unique visitors rather than just page hits.
I'm also considering doing the challenge in Google Cloud and Azure to get more familiar with them.
All in all, I think the CRC is good because it gives you a set of requirements, but it doesn't tell you how to do them, instead it leads you to resources to figure them out on your own.
A lot of training these days is tutorial based, where they just walk you through the concepts and then give you all the code and answers, rather than have you try to work something out on your own. Figuring out how to solve a problem is what DevOps personnel do.
Tools come and go. Figuring out how to onboard a new tool or new service and fit it into the existing tech stack, is way more important than just copying down someone else's answers.
The CRC was a great refresher for me to get back in the workflow of a DevOps engineer.
| brianhaas |
1,872,516 | Node.js is not single-threaded | Node.js itself is not single-threaded. Node.js developers often confuse the main single-threaded... | 0 | 2024-05-31T22:32:49 | https://dev.to/nowaliraza/nodejs-is-not-single-threaded-2i1l | node, javascript, backend, programming | Node.js itself is not single-threaded.
Node.js developers often confuse the main single-threaded event loop with Node.js entirely.
When a Node.js app is running, it automatically creates 4 threads under the worker pool for blocking tasks.
So at any given time, there are at least five threads.
This worker pool is managed by Libuv.
The blocking tasks are mainly I/O-bound and CPU-intensive.
1. I/O bound
a. DNS: dns.lookup(), dns.lookupService()
b. File system except fs.FSWatcher()
2. CPU-intensive tasks
a. Some crypto methods such as crypto.pbkdf2(), crypto.scrypt(), crypto.randomBytes(), crypto.randomFill(), crypto.generateKeyPair()
b. All zlib APIs other than those using libuv thread pool synchronously.
The main thread/event loop works for JavaScript execution as usual, but the worker pool takes care of blocking tasks for the main loop.
So, Node.js shouldn't be confused.
Thanks for reading.
I do a deep dive into foundational concepts & how things work under the hood. You can consider connecting with or following me, Ali Raza, here and on [LinkedIn](https://www.linkedin.com/in/thealiraza/) to get along with the journey.
 | nowaliraza |
1,872,515 | Why Are You Here? | I should preface this by saying that I don't mean to be elitist or keep any sort of gate. I am just... | 0 | 2024-05-31T22:25:03 | https://dev.to/belsabbagh/why-are-you-here-1ili | career, learning, discuss | I should preface this by saying that I don't mean to be elitist or keep any sort of gate. I am just wondering what you may think.
I started studying for my computer science bachelor's degree in 2020. Computing at the time was a lot different from computing now. Back then, cloud computing was all the rage given the pandemic that made cloud computing a real useful tool. It took its time as the main trend in computing up until web 3 was being discussed as a technology that is "just around the corner." We never quite got there and the focus shifted towards generative AI.
This field changes significantly faster than most other fields that people may choose to study with passion. It's hyper-sonic compared to a field like law or medicine. It occurs to me that the field I started studying in 2020, despite being fundamentally the same, is a lot different nowadays than it was when I started. I asked myself, "Why did I choose computer science?"
I won't bore you with my on soul-searching, but long story short, I was always the computer guy around my social circle and I guess I felt most excited about and most ready for this field. When observing my peers, I found that they questioned their existence in my college program whenever a new trend came out or an impressive innovation was announced. Some of my peers would lose their motivation and self-esteem, while others would work extra hard to try and keep up, and both reactions resulted in some sort of hate or resentment towards the field.
Now, I may have stuck long enough to answer the title question and realize I like what I'm doing, but I don't guarantee that for everyone else. Whether you're studying for a degree or you're self-learning purely to not miss out on the trends, I believe it is important you ask yourself why you think you're here.
I'm not an expert on psychology to explain how having a purpose helps you, but just knowing why you're here makes a world of difference. You'll have your own goals and specialization interests. Suddenly, computer science won't look like a spaghetti of paths that you can take. You'll have a path that's enticing for you to walk.
I hope I was able to express what I thought well, and I hope these fleeting thoughts helped. :)
| belsabbagh |
1,872,514 | Advanced Use Cases and Complex Queries with the SQL LIKE Operator | Introduction This is a sequel (Advanced) to my earlier article on how to use SQL LIKE... | 0 | 2024-05-31T22:21:07 | https://dev.to/kellyblaire/advanced-use-cases-and-complex-queries-with-the-sql-like-operator-3p3k | sql, webdev, database, search | #Introduction
This is a sequel (Advanced) to my earlier article on how to use SQL LIKE operator.
[You can check out the previous article by clicking this link, to understand this article better.](https://dev.to/kellyblaire/how-to-use-the-like-operator-in-sql-4kem)
The `LIKE` operator in SQL is a versatile tool for pattern matching in string columns. It is useful in a variety of scenarios, such as data validation, searching for substrings, and performing fuzzy searches. This section will cover advanced use cases for the `LIKE` operator and present complex queries to illustrate its power and flexibility.
## Advanced Use Cases for the `LIKE` Operator
1. **Data Validation and Cleaning:**
- Identify records with improperly formatted data.
- Validate email addresses, phone numbers, and other patterns.
2. **Search and Filtering:**
- Perform case-insensitive searches.
- Filter records based on partial matches.
3. **Fuzzy Matching:**
- Handle misspellings or variations in data entries.
- Find records with similar but not identical values.
4. **Wildcard Searches:**
- Search for patterns at specific positions within strings.
- Use multiple wildcards to match complex patterns.
## Complex Queries Using `LIKE` Operator
### 1. Find Email Addresses in a Specific Domain
```sql
SELECT * FROM employees WHERE email LIKE '%@example.com';
-- Expected output: id | name | email | department | salary | country
-- ---------------------------------------------------------------
-- 1 | John | john@example.com | Sales | 30000 | Nigeria
-- 2 | Alice | alice@example.com | HR | 50000 | Ghana
-- 3 | Carol | carol@example.com | Marketing | 70000 | Togo
```
### 2. Identify Records with Potentially Misspelled Names
```sql
SELECT * FROM employees WHERE name LIKE '%j%hn%' OR name LIKE '%J%hn%';
-- Expected output: id | name | department | salary | country
-- --------------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 7 | Johnson | IT | 80000 | Togo
-- 10 | Aohn | IT | 45000 | Nigeria
-- 15 | Jody | IT | 47000 | Nigeria
```
### 3. Validate Phone Numbers with Specific Formats
Assume phone numbers should be in the format `(XXX) XXX-XXXX`.
```sql
SELECT * FROM contacts WHERE phone LIKE '(___) ___-____';
-- Expected output: id | name | phone | email
-- --------------------------------------
-- 1 | John | (123) 456-7890| john@example.com
-- 2 | Alice | (987) 654-3210| alice@example.com
```
### 4. Case-Insensitive Search for Names Containing 'an'
For case-insensitive searches, you may need to use database-specific functions, such as `UPPER` or `LOWER` in some SQL dialects.
```sql
SELECT * FROM employees WHERE LOWER(name) LIKE '%an%';
-- Expected output: id | name | department | salary | country
-- --------------------------------------------
-- 2 | Alice | HR | 50000 | Ghana
-- 9 | Jane | Marketing | 60000 | Togo
-- 11 | Mary | Sales | 40000 | Ghana
-- 13 | Maria | IT | 62000 | Togo
-- 14 | Ryan | IT | 55000 | Cameroun
```
### 5. Find Names with a Specific Pattern (e.g., Names Starting and Ending with a Vowel)
```sql
SELECT * FROM employees WHERE name LIKE '[AEIOUaeiou]%[AEIOUaeiou]';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 2 | Alice | HR | 50000 | Ghana
-- 5 | Emma | HR | 55000 | Ghana
```
### 6. Complex Pattern Matching with Multiple Wildcards
Find names that have 'a' as the second character and 'l' somewhere after it.
```sql
SELECT * FROM employees WHERE name LIKE '_a%l%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 2 | Alice | HR | 50000 | Ghana
-- 3 | Carol | Marketing | 70000 | Togo
-- 6 | Emma | HR | 55000 | Ghana
```
### 7. Identify Records Based on Complex Name Patterns
Find names where the third character is a vowel and the name is at least 5 characters long.
```sql
SELECT * FROM employees WHERE name LIKE '__[AEIOUaeiou]___%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 4 | Steve | IT | 60000 | Cameroun
-- 12 | Helen | HR | 65000 | Cameroun
```
### 8. Search for Records with Specific Character Patterns
Find names that contain exactly five characters, with the middle character being 'a'.
```sql
SELECT * FROM employees WHERE name LIKE '__a__';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 11 | Mary | Sales | 40000 | Ghana
-- 13 | Maria | IT | 62000 | Togo
```
### 9. Search for Names with Repeating Characters
Find names that have repeating characters.
```sql
SELECT * FROM employees WHERE name LIKE '%aa%' OR name LIKE '%ee%' OR name LIKE '%oo%' OR name LIKE '%ii%' OR name LIKE '%uu%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 5 | Emma | HR | 55000 | Ghana
```
## Conclusion
The `LIKE` operator, with its `%` and `_` wildcards, is a versatile and powerful tool in SQL for performing pattern-based searches. By understanding and leveraging these wildcards, you can create complex queries that cater to a wide range of practical applications, from data validation and cleaning to advanced search functionalities. Mastering the `LIKE` operator allows for more precise and efficient data retrieval, making it an essential skill for anyone working with SQL databases.
**PS:**
I love coffee, and writing these articles takes a lot of it! If you enjoy my content and would like to support my work, you can buy me a cup of coffee. Your support helps me to keep writing great content and stay energized. Thank you for your kindness!
[Buy Me A Coffee](https://buymeacoffee.com/yafskkw). | kellyblaire |
1,872,513 | Demonstrating ArangoDB VelocyPack: A High-Performance Binary Data Format | originally posted on 5/22/2024 at emangini.com After my last post, I received requests for more... | 0 | 2024-05-31T22:18:55 | https://dev.to/edtbl76/demonstrating-arangodb-velocypack-a-high-performance-binary-data-format-3b5 | velocypack, dataformat, distributedsystems | _originally posted on 5/22/2024 at [emangini.com](https://emangini.com/demonstrating-arangodb-velocypack)_
_After my last post, I received requests for more how-tos and technical posts. I apologize for the delayed response after my recent deluge of articles. It took me a bit to come up with something I wanted to write about. This is one of my favorite libraries, but it doesn't get the love it deserves._
## Introduction
In modern databases, efficient data serialization and deserialization are paramount to achieving high performance. [ArangoDB](https://arangodb.com/), a multi-model database, addresses this need with its innovative binary data format, VelocyPack. This article delves into the intricacies of VelocyPack, demonstrating its advantages, usage, and how it enhances the performance of ArangoDB with code examples in Java and Rust.
## What is VelocyPack?
[VelocyPack](https://github.com/arangodb/velocypack) is a compact, fast, and efficient binary data format developed by ArangoDB. It is designed to serialize and deserialize data quickly, minimizing the overhead associated with data storage and transmission. VelocyPack is similar to JSON in its capability to represent complex data structures, but it surpasses JSON in performance due to its binary nature (ArangoDB, 2022).
### Key Features of VelocyPack
1. **Compactness**: VelocyPack's binary format ensures data is stored compactly, reducing storage space and improving cache efficiency.
2. **Speed**: The binary nature of VelocyPack allows for faster serialization and deserialization compared to text-based formats like JSON.
3. **Flexibility**: VelocyPack can represent various data types, including nested objects and arrays, similar to JSON.
4. **Schema-free**: Like JSON, VelocyPack is schema-free, allowing for dynamic data structures (ArangoDB, 2022).
## Advantages of VelocyPack in ArangoDB
### Performance Boost
One of the primary advantages of VelocyPack is its performance. Binary formats are inherently faster for both serialization and deserialization compared to text-based formats like [JSON]([VelocyPack](https://json.org)) and [XML](https://www.w3.org/TR/xml/). While JSON is widely used due to its simplicity and human-readable format, it is not as efficient in terms of speed and space. XML, another alternative, offers robust data structure representation but at the cost of verbosity and slower processing. VelocyPack's compact binary format ensures minimal overhead, making it much faster and more efficient (Stonebraker & Cattell, 2017).
### Reduced Storage Footprint
VelocyPack's compact representation of data reduces the storage footprint. This reduction is especially beneficial for large datasets, where the savings in storage space can translate to significant cost reductions and performance improvements in data retrieval. Compared to formats like [BSON](https://bsonspec.org/) (Binary JSON used in MongoDB), VelocyPack is more space-efficient, providing better performance (ArangoDB, 2022).
### Efficient Data Transmission
The compact nature of VelocyPack also benefits data transmission over networks. Smaller data sizes mean less bandwidth usage and faster transmission times, essential for distributed databases and applications that rely on real-time data. [Protocol Buffers (Protobuf)](https://protobuf.dev/) by Google is another binary format with similar advantages; VelocyPack's integration with ArangoDB offers seamless usage within this specific database environment (Schöni, 2019).
## How VelocyPack Works
### Data Structure
VelocyPack represents data using a binary format that includes type information and the data itself. This approach allows VelocyPack to handle many data types, including integers, floating-point numbers, strings, arrays, and objects. Each data type is encoded using a specific format that optimizes space and speed (ArangoDB, 2022).
### Serialization and Deserialization
The process of converting data to VelocyPack format (serialization) and converting it back to its original form (deserialization) is highly optimized. VelocyPack includes efficient algorithms for both operations, ensuring minimal overhead. The following sections demonstrate how to serialize and deserialize data using VelocyPack in Java and Rust.
## Using VelocyPack in ArangoDB
### Installation
Before diving into examples, ensure that ArangoDB is installed on your system. You can download and install ArangoDB from the official website. Once installed, you can use the ArangoDB shell (arangosh) or one of the supported drivers to interact with the database.
### Serialization Example in Java
```java
import com.arangodb.velocypack.VPack;
import com.arangodb.velocypack.VPackParser;
import com.arangodb.velocypack.exception.VPackException;
import java.util.HashMap;
import java.util.Map;
public class VelocyPackExample {
public static void main(String[] args) {
VPack vpack = new VPack.Builder().build();
Map<String, Object> jsonObject = new HashMap<>();
jsonObject.put("name", "Alice");
jsonObject.put("age", 30);
jsonObject.put("city", "Wonderland");
jsonObject.put("interests", new String[]{"reading", "gardening", "biking"});
try {
byte[] serializedData = vpack.serialize(jsonObject);
System.out.println("Serialized data: " + serializedData);
Map<String, Object> deserializedData = vpack.deserialize(serializedData, Map.class);
System.out.println("Deserialized data: " + deserializedData);
} catch (VPackException e) {
e.printStackTrace();
}
}
}
```
### Serialization Example in Rust
**NOTE**: _Example in Rust by special request!_
```rust
use serde::{Serialize, Deserialize};
use velocypack::to_vec;
use velocypack::from_slice;
#[derive(Serialize, Deserialize, Debug)]
struct Person {
name: String,
age: u32,
city: String,
interests: Vec<String>,
}
fn main() {
let person = Person {
name: "Alice" .to_string(),
age: 30,
city: "Wonderland" .to_string(),
interests: vec!["reading".to_string(), "gardening".to_string(), "biking".to_string()],
};
// Serialize to VelocyPack
let serialized_data = to_vec(&person).unwrap();
println!("Serialized data: {:?}", serialized_data);
// Deserialize from VelocyPack
let deserialized_data: Person = from_slice(&serialized_data).unwrap();
println!("Deserialized data: {:?}", deserialized_data);
}
```
These examples demonstrate how to work with VelocyPack in Java and Rust, ensuring efficient data handling.
## Real-World Applications
### Healthcare Data Management
In healthcare, managing large volumes of patient data efficiently is crucial. VelocyPack's compact format allows for faster processing and retrieval of patient records, which is essential for real-time decision-making (Kamel Boulos et al., 2011).
### Financial Transactions
Financial institutions require quick and secure transaction processing. VelocyPack's efficiency in data serialization and deserialization enhances transaction processing speeds and ensures data integrity, making it ideal for financial applications (Fabian et al., 2016).
### IoT Data Aggregation
The Internet of Things (IoT) generates vast amounts of data from various sensors and devices. VelocyPack's compact and fast binary format is well-suited for aggregating and analyzing IoT data, enabling timely insights and actions (Perera et al., 2014).
## Conclusion
VelocyPack's compact and efficient binary format significantly boosts ArangoDB's performance. Its ability to handle complex data structures quickly and with minimal storage footprint makes it an excellent choice for various applications, from healthcare to finance and IoT. Integrating VelocyPack into your data management strategy allows faster data processing, reduced storage costs, and more efficient data transmission.
In conclusion, ArangoDB's VelocyPack is a powerful tool for any organization looking to optimize its data handling capabilities. Its advantages in performance, storage efficiency, and data transmission make it a standout feature in the world of databases.
Thanks for the requests!
**References**
* ArangoDB. (2022). VelocyPack: A fast and space efficient format for ArangoDB. Retrieved from https://www.arangodb.com/docs/stable/velocypack/
* Fabian, B., Günther, O., & Schreiber, R. (2016). Transaction processing in the Internet of Services. *Journal of Service Research, 9*(2), 105-122.
* Kamel Boulos, M. N., Brewer, A. C., Karimkhani, C., Buller, D. B., & Dellavalle, R. P. (2011). Mobile medical and health apps: state of the art, concerns, regulatory control and certification. *Online Journal of Public Health Informatics, 5*(3), 229-238.
* Perera, C., Zaslavsky, A., Christen, P., & Georgakopoulos, D. (2014). Context aware computing for the Internet of Things: A survey. *IEEE Communications Surveys & Tutorials, 16*(1), 414-454.
* Schöni, T. (2019). Leveraging VelocyPack in distributed systems for efficient data handling. *Proceedings of the 2019 International Conference on Data Engineering, 1015-1023*.
* Stonebraker, M., & Cattell, R. (2017). Ten rules for scalable performance in 'simple operation' NoSQL databases. *Communications of the ACM, 54*(6), 72-80. | edtbl76 |
1,872,512 | AWS ParallelCluster High-Performance Computing for Software Developers | Introduction Today, high-performance computing plays a huge role in development and allows the... | 0 | 2024-05-31T22:18:00 | https://sudoconsultants.com/aws-parallelcluster-high-performance-computing-for-software-developers/ | parallelcluster, computing, hpc, aws | <!-- wp:heading {"level":1} -->
<h1 class="wp-block-heading">Introduction</h1>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Today, high-performance computing plays a huge role in development and allows the solution of a number of computational problems in due time that were previously intractable. HPC systems are created to do heavy computations in fast succession for all sorts of applications, running from scientific simulations to machine learning algorithms. High-performance computing with respect to software development accelerates the development cycle, as it ensures the possibility of rapid prototyping, analysis, and the ability to handle large-scale simulations and data processing tasks. AWS ParallelCluster is a crucial part of the AWS ecosystem that aids developers in the field of HPC. This is a critical, open-source cluster management tool created easy for deploying and managing HPC clusters that are hosted on AWS</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>AWS ParallelCluster provides an easy way to model and provision the resources an HPC application needs. HPC provides developers the opportunity to focus on their mainline job other than dealing with the rigorous tasks of setup and HPC infrastructure management. These, of course, are not all reasons that make AWS ParallelCluster great.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Ease of Use:</strong> Easy GUI or text file-based method to model and provision HPC resources</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Flexibility:</strong> Flexibility with a rich choice of instance types and job schedulers, including AWS Batch and Slurm Allows resources to be scaled up and down</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Scalability:</strong> built-in ability to auto-scale the resources provided to applications based on demand and need to ensure cost-effective performance.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Integration:</strong> Easy to integrate and migrate existing HPC workloads with a minimum modification profile.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Cost-Effectiveness:</strong> Customers pay for AWS resources, which are utilized by their applications; thus, AWS is a cost-effective solution for HPC workloads.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>In short, AWS ParallelCluster is a good application for software developers to tap into the HPC capabilities residing in AWS. For ease of use, flexibility, scalability, and integration with other capabilities, AWS ParallelCluster should be part of the AWS family in meeting HPC needs.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Understanding High-Performance Computing (HPC)</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS ParallelCluster should be part of the AWS family in meeting HPC needs. High-Performance Computing (HPC) Basics High-Performance Computing (HPC) is the use of supercomputers and parallel processing techniques to solve very complex computation issues in a short time. HPC systems deal with high-speed processing power, high-performance networks, and large-memory capacity to handle massive parallel processing. This is vital in meeting large-scale problems that might have been impossible with other conventional computing. HPC has taken on a double life, on the one hand, as a platform for simulation-based scientific inquiry and, on the other, in the field of machine learning (ML); HPC systems have drastically shrunken the time required for scientific comprehension of problems whose solution involves very large-scale computation problems like climate modeling, drug discovery, and protein folding with computational fluid dynamics (CFD). This became possible when GPU technology came onboard with the capability to take in large-volume data for processing in parallel. An interesting observation has been that the GPU is natively designed for parallel processing and is thus well-suited for HPC. In fact, it is widely used for ML and AI computations.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Importance of HPC in Software Development</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Importance of HPC in Software Development HPC is important because it can execute very complex calculations much faster than traditional computers, hence enabling researchers and engineers to handle large-scale problems. It also is quintessential in matters to do with scientific discovery, because it simulates complex systems and processes, cutting across various disciplines like climate modeling, molecular dynamics, and computational fluid dynamics. Moreover, HPC is also ubiquitous in the area of product design and optimization found in industries such as aerospace and automotive and energy, thus improving performance, and resulting in reducing development time. It is also used significantly in coping with enormous sets of data to unearth any trends and correlations, which cannot be done with traditional computer facilities. Increasingly, HPC is of critical importance to the healthcare industry for the discovery of new drugs and developing new treatment and therapy, among other things, molecular modeling and applications for personalized medicine.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Common Use Cases for HPC in Software Development</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Typical Use Cases for HPC in Software Development HPC finds relevance in numerous use cases in a gamut of industries and domains across. Below mentioned are a few of them:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Machine Learning: </strong>HPC systems are used for image and speech recognition and natural language processes. They support a wide range of modalities that include predictive analytics and have so many different natural language processing or ML algorithms to solve problems connected to applications like robotics, computer vision, and finance.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Data Analysis:</strong> Data Analysis: By the rapid computation of complex financial models, through HPC, a financial institution can carry out the deep market trend analysis, as well as evaluate/risk scenarios to underpin investment decisions.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Simulation and Modeling:</strong> Simulation and Modeling: The HPC is used for industries that are aerospace, automotive, and energy for simulating and optimizing the design of products, processes, and materials. The techniques enable advanced seismic imaging and reservoir simulation as part of oil and gas exploration.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Scientific Research:</strong> Scientific Research: HPC systems are very much involved in weather forecasting and climate modeling, drug discovery and development, and computational chemistry where developers have the ability to computationally model and simulate complex systems and processes</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Challenges Faced by Developers When Using Traditional HPC Solutions</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Some of the challenges that are encountered by developers when working with traditional HPC solutions are as listed below:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Complexity:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Actualizing and managing HPC clusters can sometimes be very complex, meaning that the level of expertise required in HPC architecture, and administration, is high.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Scalability:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Traditional HPC solutions can be pretty miserable in scaling efficiently to meet the demands of growing workloads, which implies that such solutions are ineffective in many a lot of projects.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Cost:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Hardware, software acquisition, and maintenance in HPC, is costly, which may render HPC hardware and software unavailable to most small organizations or projects running on limited budgets.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Integration:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>The integration of HPC solutions with established software development workflows and tools is not easy and might require significant custom development efforts to bridge the gap between HPC, and traditional computing environments.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Maintenance and Support:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>It can be difficult to keep HPC systems up to date and supported, with rapid change in technology and the large amount of inherent knowledge in these systems.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Conclusion HPC is considered to be a very powerful tool for Software Development in that it enhances rapid computation and analysis of complex data sets and simulations. However, developers are bound to face several challenges with traditional HPC solutions, such as complexity, scalability, cost, integration, and maintenance.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">AWS ParallelCluster Overview</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS ParallelCluster is an open-source cluster management tool designed to make the process of deploying and managing HPC clusters on AWS simpler. It is built on the popular open-source project CfnCluster and comes at no extra cost—all the user has to pay for are the actual AWS resources used to run the applications. AWS ParallelCluster installations can be done through the AWS CloudFormation template or the Python Packaging Index, while its source code is hosted on the Amazon Web Services repository on GitHub.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Architecture and Components</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The architecture of AWS ParallelCluster has been designed to be flexible and scalable to accommodate the appetites of HPC applications. There are a number of key components in any AWS ParallelCluster architecture:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Compute Nodes: These represent worker nodes responsible for executing the actual computations. AWS ParallelCluster supports a wide variety of instance types that have been optimized for HPC operations, such as Amazon EC2 Hpc7g, Hpc7a, and Hpc6id instances.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Head Node: The head node is essentially the center for controlling the cluster. Here, elements like scheduling jobs and resource allocation are handled. It runs the job scheduler and presents a gateway for submitting jobs and accessing the cluster.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Shared File System: AWS ParallelCluster can be set to work with Amazon Elastic File System (EFS) or Amazon FSx for Lustre, which offers a shared file system across the cluster nodes. It allows data sharing, which is productive in terms of collaboration.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Job Scheduler: AWS ParallelCluster supports multiple job schedulers like AWS Batch and Slurm, allowing users to choose the scheduler that best fits their workload requirements.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Simplifying Deployment and Management</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS ParallelCluster makes it easy to deploy and manage HPC clusters on AWS. It provides a simple graphical user interface or text file-based approach to model and provision the resources needed for HPC applications, making the setup and deployment process secure and automated. These reduce the steps of manual intervention or using custom scripts, thus making it easy for researchers and engineers to spin up custom HPC clusters whenever required.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Additionally, AWS ParallelCluster provides support for easy migration to the cloud. It offers support for a wide variety of operating systems and batch schedulers. It allows a user to migrate his/her HPC driven workload to the cloud as is with little modification, thus making the transition to AWS easy.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Integration and Automation</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS ParallelCluster supports integration with Amazon Aurora for databases, while automation is made possible through the use of the AWS CloudFormation custom resource. Through these, a user can define his/her HPC cluster as an AWS CloudFormation resource, making the HPC cluster self-descriptive. This will make it easy to manage and scale HPC infrastructure on AWS.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Setting Up AWS ParallelCluster</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Prerequisites</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Before setting up AWS ParallelCluster, ensure you have the following prerequisites:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>AWS Account Setup: If you don't have one, you can <a href="https://aws.amazon.com/">create a free account</a>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Necessary Permissions: The AWS account you carry must be endowed with necessary permissions to create and manage EC2 instances, EBS volumes and other AWS resources with which AWS ParallelCluster interfaces.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Familiarity with AWS CLI or SDKs: Some basic knowledge on the AWS Command Line Interface (CLI) or the AWS Software Development Kits (SDKs) could be expected to manage AWS resources using AWS CLI or SDKs.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step-by-Step Guide</h3>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Installing AWS CLI</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Download and Install AWS CLI: Install AWS CLI using the following <a href="https://aws.amazon.com/cli/">documentation</a>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Configure AWS CLI: AWS CLI should be configured after installation to interact with it in the terminal. The following is the command to do so: aws configure. You will be prompted to enter your AWS Access Key ID, Secret Access Key, default region name, and output format. These credentials can be obtained from the AWS Management Console under the IAM service.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Creating an IAM Role</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Open the service IAM: Log in to the AWS Management Console and then open the IAM service.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Create New Role: Click on "Roles" from the left navigation pane, then "Create role".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select Trusted Entity Type: Choose "AWS service" as the trusted entity type. Furthermore, underneath "Choose a use case", you'll find the ability to select a service that will use this role. You may select "EC2" here.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Attach Policies: Attach policies that grant permissions required for AWS ParallelCluster to succeed. At a minimum, you must attach the AmazonS3ReadOnlyAccess policy if your cluster will have to interact with S3 buckets.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Review and Create Role: Review the Role details, then click on "Create role".</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Launching a Cluster</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Install AWS ParallelCluster: Follow the instructions to installation in the provided link to the AWS ParallelCluster documentation. Typically, you would have to clone the AWS ParallelCluster repository from GitHub and then install dependencies.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Create a Configuration File using the cfncluster command. Using the cfncluster command, create a configuration file for your cluster. You should have any needed settings for instance types, storage options, and network configurations according to requirements.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>cfncluster create --name my-cluster --template-file templates/my-cluster.yaml</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Launch the Cluster: Deploy the cluster using the AWS CLI.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws parallelcluster create-cluster --name my-cluster --template-file templates/my-cluster.yaml</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Accessing Cluster Resources</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>SSH Access: It is possible to SSH into the cluster head node or any of the compute nodes using the public DNS set by AWS ParallelCluster.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>ssh -i /path/to/your/key.pem ec2-user@head-node-public-dns-name</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>File System Access: If a shared file system, such as Amazon EFS, is configured, you can mount the file system on your local machine or access it directly from the cluster nodes.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>By following these steps, AWS ParallelCluster will be configured to deploy and manage HPC clusters on AWS, thus simplifying high-performance computing for software development.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Managing AWS ParallelCluster Clusters</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Overview of Cluster Lifecycle Management</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Managing the lifecycle of an AWS ParallelCluster requires performing key tasks: scaling, updating, and terminating clusters. These operations are important not only to maximize performance but also to save money by ensuring clusters are always correctly sized according to workload requirements.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Scaling:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>AWS ParallelCluster supports automatic and customized scaling of resources. The resources provisioned for a cluster can be automatically adjusted to the demand required by the applications. This helps achieve good performance at a minimum cost by ensuring the right resources needed for application workload are available.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Updating:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>The cluster can be updated by updating the software stack in the state of the running infrastructure or by upgrading the software being used. This can be done using custom bootstrap actions to customize instances without having to manually update the version in the instance's AMI. It is necessary to update the existing cluster configuration to use existing file system definitions, verify the pcluster version, and build and test the new cluster before a full transition.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Terminating:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Terminating a cluster means deleting it when it is no longer required, ensuring that no resources are consumed for unused clusters.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Best Practices for Managing Clusters</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To optimize performance and cost when managing AWS ParallelCluster clusters, consider the following best practices:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Use Custom Bootstrap Actions: Use custom bootstrap actions to customize instances without using a custom AMI, eliminating the need for deletions and recreations of AMIs with each new version.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Budget Alerts: Configure budget actions using AWS Budgets to create a budget and set threshold alerts. This helps manage resource costs. Create billing alarms for monitoring estimated AWS charges using Amazon CloudWatch.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Testing Before Transition: Always test a new cluster version to ensure that moving to the new version of AWS ParallelCluster is smooth and that data and applications work properly. Delete the old cluster only after successful testing.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Monitoring and Troubleshooting: Regularly monitor performance issues and troubleshoot scaling and job allocation issues. Monitor the slurmctld log to solve known problems related to job allocation and scaling decisions.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>By following these best practices, AWS ParallelCluster clusters can be managed in an optimal, efficient manner, ensuring performance and cost efficiency while minimizing downtime and resource waste.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Optimizing Performance and Cost</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Strategic decisions must be made regarding instance types, storage configurations, network settings, and cost optimization techniques for performance and cost optimization of AWS ParallelCluster clusters. Here are some practices and tips:</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Instance Type Selection</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Head Node: The head node handles the scaling logic of the cluster. Choose a high computation-capacity head node to ensure smooth scaling operations as you add more nodes. When using shared file systems like Amazon EFS or FSx for Lustre, choose an instance type that ensures enough network and Amazon EBS bandwidth to handle workflows.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Compute Nodes: Choose instance types considering workload requirements and balancing cost and performance. Use multiple instance types to diversify compute resources, allowing AWS ParallelCluster to choose the most cost-effective or available instances based on real-time Spot capacity.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Storage Configuration</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Shared File Systems: Ensure the head node has adequate network bandwidth for data transfers between compute nodes and the head node. This is crucial for workflows where nodes frequently share data.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Network Settings</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Subnet Selection: Spread out subnets across different Availability Zones when setting up the cluster. This allows AWS ParallelCluster to locate a wide range of instance pools, minimizing disturbances and improving cluster reliability</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Cost Optimization Techniques</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Auto Scaling: Implement auto-scaling configurations so resources are added only when needed. AWS ParallelCluster's automatic resource scaling monitors the number of Amazon EC2 virtual CPUs required to run pending jobs and increases instances if demand crosses a threshold.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Spot Instances: Use Spot instances to save costs. AWS ParallelCluster optimizes for cost by launching the lowest-priced instances first. For workloads where interruptions are costly, use the capacity-optimized allocation strategy to maximize the likelihood of uninterrupted job execution.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Right-Sizing Instances: Continuously right-size instance types and sizes to match workload and capacity needs cost-effectively. Right-sizing instances helps save costs by eliminating inactive or idle instances.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Additional Tips</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Multiple Instance Type Allocation: Define multiple instance types for scaling up compute resources. AWS ParallelCluster 3.3 introduced this feature, offering flexibility to assemble compute capacity for HPC workloads.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Integration with Other AWS Services: Leverage pre-built integrations with AWS services like Amazon EMR, AWS CloudFormation, Auto Scaling, Amazon ECS, and Amazon Batch. For example, using Amazon EMR with Spot instances can reduce the cost of processing vast amounts of data.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>With these strategies and best practices, you can optimize the performance and cost of your AWS ParallelCluster clusters, ensuring that HPC workloads are efficiently and cost-effectively managed.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Security Considerations for AWS ParallelCluster</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Security is first among the first considerations to be made while working with the AWS ParallelCluster in high-performance computing in the cloud. Security for AWS ParallelCluster forms a shared responsibility between AWS and the user. While the security of the cloud infrastructure falls under the responsibility of AWS, the user should take charge of cloud security in securing data, the company's requirements, and legislation.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Security Best Practices</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Network Security: Leverage Amazon VPC to segment your cluster's network traffic off the public internet. Security groups and network ACLs should only be configured to allow necessary inbound and outbound traffic.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AWS ParallelCluster uses IAM roles to access the resources and services of AWS. You should configure the IAM roles and policies to allow only the necessary permissions for management of the cluster and access to resources. Where possible especially, use roles that confer temporary credentials that would help mitigate the risk of credential compromise.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Encryption: Encrypt data both at rest and in transit. Use Amazon KMS to encrypt data in other AWS services, including Amazon S3 and Amazon EBS volumes. Encrypt in-transit data communicated between the components of your cluster using TLS 1.2 or a later version.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>File System Permissions: The $HOME/.aws directory and its content should be secured such that access is only granted to the authorized users. This directory contains long and short-term credentials used by AWS ParallelCluster.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Common Security Challenges and Mitigation Strategies</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Credential Compromise: To counter it, file system permissions must be set in a way that the access to the $HOME/.aws directory and the things in it are restricted. Also, use roles that make use of temporary credentials in case the access keys compromise, and the subsequent effects are reduced.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Insufficient Permissions: Incorrect permissions of the IAM roles and policies cause unwanted access and activities. Stick by the principle of least privilege during the use of IAM roles and policies, that is, only the required permission should be handed out for the tasks.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Data Exposure: Data that is stored in the shared file systems or data used by the AWS ParallelCluster components should be encrypted during rest and during transit. The access controls should be periodically tested and validated such that the confidentiality of data is guaranteed.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Compliance Validation</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS checks and validates it periodically during the compliance programs. Understand your AWS Shared pressure model and what compliances are applicable to AWS Parallel Cluster to remain compliant.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>These are the best practices in security and common mistakes that will help you protect your deployments of AWS ParallelCluster and HPC workloads and data from security threats.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Integrating AWS ParallelCluster with Other AWS Services</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The integration of AWS ParallelCluster with other AWS services provides advanced utility and scalability which, in turn, allows one to manage HPC clusters more securely and cost-effectively. Here are some examples of such integration and their benefits:</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Amazon S3 for Data Storage</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Integration:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>In AWS Parallel Cluster, it is possible to store and retrieve data in Amazon S3, which is a service for object storage with scalability. This feature makes it easy to manage data, especially the one for workloads that are data-intensive because their data has a huge amount.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Benefits:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>This allows data accessibility and management in ways that are easier than ever before, with the manual movement of data between the storage and computing resources reduced. Also, this integration allows for event-driven workflows since it allows for the triggering of the creation of a new cluster or submission of a new job in response to new data that resides in the S3 bucket.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Amazon RDS for Database Access</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>The database solution is robust and scalable since it is used for storing and restoring application data. It is also tailored for application cases that demand data storage that is both strong and persistent in combination to their compute tasks. In this view, Amazon RDS integrates AWS ParallelCluster and AWS Batch in the sense that it enhances the increased availability and scalability of database services that will support HPC applications. In addition, this will ensure applications running on the cluster can communicate effectively with relational databases.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS Lambda for Automated Workflows</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>This will contribute to increasing the scale and elasticity of HPC workflows and the capability of creating and deleting clusters as the need arises. Further, this additional service will see on-demand creation and management of HPC clusters significantly improved in terms of security, as this will be done more efficiently, and no HPC cluster will be accessible without authorization because the handling requirements of IAM roles and security groups are tedious.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Benefits of Integration</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Enhanced Functionality: Integrating AWS ParallelCluster into other AWS services develops the capabilities to carry out more sophisticated and, therefore, higher-efficiency HPC workflows.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Improved Scalability: Integrations of the form facilitate the scaling of HPC workloads, whereby the resources are automatically adjusted in relation to demand.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Enhanced Security: HPC environments become secure through integration with AWS services like Amazon RDS and AWS Lambda, resulting in low risks of unauthorized access and data breach.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Cost Optimization: Integration with AWS ParallelCluster and such other AWS services as Amazon S3 and AWS Lambda optimizes the use of resources, and resultantly reduces operational costs to those of less manual interference.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Conclusion</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS ParallelCluster is highly flexible, efficient, and robust, helping software development teams to deploy and manage HPC clusters running on AWS. It will help speed up building HPC compute environments, enabling fast prototyping and easy migration to the cloud with full assurance. The tool abstracts the process of setting up the HPC cluster, further enabling the automation of the setup of the cluster and its management and scaling activities. This is very helpful for an organization to keep up its competitiveness, and to be efficient in its operations. Updates that have been new and expected previously for AWS ParallelCluster would aim to get with cluster management in terms of further automation, improved integration with other AWS services and improved/ advanced security and compliance features. A Python package for cluster management, and integration with AWS CloudFormation to help self-document HPC-infrastructure, are among the recent new features again pointing towards there is increasing automation and integration within the AWS ecosystem.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">References</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>AWS ParallelCluster Documentation: For detailed information on AWS ParallelCluster, including installation, configuration, and best practices, visit the <a previewlistener="true" href="https://aws.amazon.com/hpc/parallelcluster/.">official AWS documentation</a>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Automating HPC Infrastructure with AWS ParallelCluster: Learn about automating the deployment and management of HPC infrastructure on AWS using AWS ParallelCluster and AWS CloudFormation in this <a href="https://aws.amazon.com/blogs/hpc/automate-your-clusters-by-creating-self-documenting-hpc-with-aws-parallelcluster/">blog post.</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choosing Between AWS Batch and AWS ParallelCluster for HPC: This <a href="https://aws.amazon.com/blogs/hpc/choosing-between-batch-or-parallelcluster-for-hpc/">blog post</a> provides insights into choosing between AWS Batch and AWS ParallelCluster for HPC workloads, based on your team's preferences and requirements.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AWS HPC Resources: Explore a comprehensive <a href="https://aws.amazon.com/hpc/resources/">collection of resources on HPC</a> in the AWS ecosystem, including case studies, whitepapers, and tutorials.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --> | sidrasaleem296 |
1,872,511 | Understanding GPT: How To Implement a Simple GPT Model with PyTorch | originally posted on 5/14/2024 at emangini.com This comprehensive guide provides a detailed... | 0 | 2024-05-31T22:16:00 | https://dev.to/edtbl76/understanding-gpt-how-to-implement-a-simple-gpt-model-with-pytorch-4jji | ai, gpt, pytorch, genai | _originally posted on 5/14/2024 at [emangini.com](https://emangini.com/understanding-gpt)_
This comprehensive guide provides a detailed explanation of how to implement a simple GPT (Generative Pre-trained Transformer) model using PyTorch. We will cover the necessary components, how to train the model, and how to generate text.
For those of you who want to follow along, there is a python implementation as well as a Jupyter Notebook at [UnderstandingGPT(GitHub)](https://github.com/edtbl76/UnderstandingGPT/blob/main/understanding-gpt.py)
## Introduction
The GPT model is a transformer-based architecture designed for natural language processing (NLP) tasks, such as text generation. Transformer models, introduced by Vaswani et al. (2017), leverage self-attention mechanisms to process sequences of data, allowing them to capture long-range dependencies more effectively than traditional recurrent neural networks (RNNs). The GPT architecture, specifically, is an autoregressive model that generates text by predicting the next word in a sequence, making it powerful for tasks like text completion, translation, and summarization. This tutorial will guide you through creating a simplified version of GPT, training it on a small dataset, and generating text. We will leverage PyTorch and the Hugging Face Transformers library to build and train the model.
## Setup
Before we start, ensure you have the required libraries installed. You can install them using pip:
```bash
pip install torch transformers
```
These libraries are fundamental for building and training our GPT model. [PyTorch](https://pytorch.org/) is a deep learning framework that provides flexibility and speed, while the Transformers library by [Hugging Face](https://huggingface.co/) offers pre-trained models and tokenizers, including GPT-2.
## Creating a Dataset
To effectively train a machine learning model like GPT, it is crucial to preprocess and prepare the text data properly. This process begins by creating a custom dataset class, which handles text inputs and tokenization. Tokenization is the process of converting raw text into numerical representations (token IDs) that the model can understand (Devlin et al., 2019). The provided code snippet achieves this by defining a class named **SimpleDataset**, which uses the GPT-2 tokenizer to encode the text data.
The **SimpleDataset** class inherits from *torch.utils.data.Dataset* and implements the necessary methods to interact seamlessly with the DataLoader. This class takes three parameters in its initializer: the list of texts, the tokenizer, and the maximum length of the sequences. The **\__len\__** method returns the number of texts in the dataset, while the **\__getitem\__** method retrieves and encodes a specific text at the given index. The encoding process involves converting the text into numerical representations using the tokenizer and padding the sequences to a specified maximum length to ensure uniformity. Padding is the practice of adding extra tokens to sequences to make them all the same length, which is important for batch processing in neural networks. The method returns the input IDs and attention masks, where the attention mask is a binary mask indicating which tokens are actual words and which are padding. This helps the model ignore padding tokens during training.
Here is the code for reference:
```python
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import GPT2Tokenizer
class SimpleDataset(Dataset):
def __init__(self, texts, tokenizer, max_length):
self.texts = texts
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
encoding = self.tokenizer(text, return_tensors='pt', padding='max_length', truncation=True, max_length=self.max_length)
return encoding['input_ids'].squeeze(), encoding['attention_mask'].squeeze()
texts = ["Hello, how are you?", "I am fine, thank you.", "What about you?"]
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
tokenizer.pad_token = tokenizer.eos_token
dataset = SimpleDataset(texts, tokenizer, max_length=20)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
```
In this code, the SimpleDataset class handles the tokenization of input texts and returns the encoded input IDs and attention masks. The DataLoader then batches and shuffles the data for efficient training. Batch processing, which involves dividing the dataset into smaller batches, allows the model to update its weights more frequently, leading to faster convergence. Shuffling the data helps break any inherent order in the training data, improving the model's generalization.
By setting up the data in this manner, we ensure that the model receives sequences of uniform length for training. This approach also makes it easier to manage variable-length inputs while ensuring that padding tokens do not interfere with the model's learning process. This comprehensive preprocessing step is crucial for training effective and efficient machine learning models (Brown et al., 2020).
## Building the GPT Model
To build an effective GPT model, we start by defining its architecture. The model consists of two main classes: **GPTBlock** and **SimpleGPT**. The **GPTBlock** class represents a single transformer block, while the **SimpleGPT** class stacks multiple transformer blocks to create the complete model (Vaswani et al., 2017).
In the **GPTBlock** class, we encapsulate essential components of a transformer block. These include layer normalization, multi-head attention, and a feed-forward neural network with GELU activation. Layer normalization standardizes the inputs to each sub-layer, improving the stability and convergence of the training process. The multi-head attention mechanism enables the model to focus on different parts of the input sequence simultaneously, enhancing its ability to capture complex dependencies within the data (Vaswani et al., 2017). The feed-forward neural network, using **GELU (Gaussian Error Linear Unit)** activation, introduces non-linearity and increases the model's capacity to learn intricate patterns. GELU is an activation function that smoothly approximates the **ReLU (Rectified Linear Unit)** function and often performs better in practice (Hendrycks & Gimpel, 2016).
Here is the code defining these classes:
```python
import torch.nn as nn
class GPTBlock(nn.Module):
def __init__(self, config):
super(GPTBlock, self).__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = nn.MultiheadAttention(config.n_embd, config.n_head, dropout=config.attn_pdrop)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = nn.Sequential(
nn.Linear(config.n_embd, 4 * config.n_embd),
nn.GELU(),
nn.Linear(4 * config.n_embd, config.n_embd),
nn.Dropout(config.resid_pdrop)
)
def forward(self, x, attention_mask=None):
attn_output, _ = self.attn(x, x, x, attn_mask=attention_mask)
x = x + attn_output
x = self.ln_1(x)
mlp_output = self.mlp(x)
x = x + mlp_output
x = self.ln_2(x)
return x
```
The **SimpleGPT** class stacks multiple **GPTBlock** instances to form the complete model. This class incorporates token and position embeddings, dropout for regularization, and a linear layer to generate output logits. Token embeddings convert input token IDs into dense vectors, allowing the model to work with numerical representations of words. Position embeddings provide information about the position of each token in the sequence, crucial for the model to understand the order of words. Dropout is a regularization technique that randomly sets some neurons to zero during training, helping to prevent overfitting (Srivastava et al., 2014). The final linear layer transforms the hidden states into logits, which are used to predict the next token in the sequence.
```python
class SimpleGPT(nn.Module):
def __init__(self, config):
super(SimpleGPT, self).__init__()
self.token_embedding = nn.Embedding(config.vocab_size, config.n_embd)
self.position_embedding = nn.Embedding(config.n_positions, config.n_embd)
self.drop = nn.Dropout(config.embd_pdrop)
self.blocks = nn.ModuleList([GPTBlock(config) for _ in range(config.n_layer)])
self.ln_f = nn.LayerNorm(config.n_embd)
self.head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.config = config
def forward(self, input_ids, attention_mask=None):
positions = torch.arange(0, input_ids.size(1), device=input_ids.device).unsqueeze(0)
x = self.token_embedding(input_ids) + self.position_embedding(positions)
x = self.drop(x)
if attention_mask is not None:
attention_mask = attention_mask.unsqueeze(1).repeat(self.config.n_head, attention_mask.size(1), 1)
attention_mask = attention_mask.to(dtype=torch.float32)
attention_mask = (1.0 - attention_mask) * -10000.0
for block in self.blocks:
x = block(x.transpose(0, 1), attention_mask)
x = x.transpose(0, 1)
x = self.ln_f(x)
logits = self.head(x)
return logits
```
We then configure the model using the **GPT2Config** class from the transformers library, which sets various hyperparameters such as the vocabulary size, number of positions, embedding dimension, number of layers, number of attention heads, and dropout rates. These configurations are essential for defining the model's architecture and behavior during training.
## Training the Model
The **train** function is a crucial component in the process of training a Generative Pre-trained Transformer (GPT) model. This function orchestrates the entire training loop, encompassing key steps such as the forward pass, loss calculation, backpropagation, and optimization. Each of these steps plays a vital role in refining the model's parameters based on the input data, ultimately improving the model's ability to generate coherent and contextually relevant text.
The training process begins with setting the model to training mode using the _model.train()_ method. This mode enables certain layers, such as dropout and batch normalization, to function appropriately during training, ensuring that they contribute to the model's generalization capabilities (Goodfellow et al., 2016). The training loop then iterates over the dataset for a specified number of epochs. An epoch represents one complete pass through the entire training dataset, allowing the model to learn from all available data.
For each epoch, the function processes batches of data provided by the **DataLoader**, which handles the efficient batching and shuffling of the dataset. Batching groups multiple input sequences into a single batch, enabling parallel processing and efficient use of computational resources. Shuffling the data helps in reducing the model's overfitting to the order of the data samples.
Within each batch, the input IDs and attention masks are transferred to the specified device (CPU or GPU) to leverage the hardware's computational power. The forward pass involves passing the input IDs through the model to obtain the output logits, which are the raw, unnormalized predictions of the model. To align predictions with targets, the logits are shifted: shift_logits excludes the last token prediction, and shift_labels excludes the first token, ensuring that the input and output sequences are properly aligned for the next token prediction task.
The loss calculation is performed using the cross-entropy loss function, a common criterion for classification tasks that measures the difference between the predicted probabilities and the actual target values. Cross-entropy loss is particularly suitable for language modeling tasks where the goal is to predict the next token in a sequence (Goodfellow et al., 2016).
Backpropagation, implemented through the _loss.backward()_ method, computes the gradient of the loss function with respect to the model's parameters. These gradients indicate how much each parameter needs to change to minimize the loss. The optimizer, specified as Adam (Kingma & Ba, 2015), updates the model's parameters based on these gradients. Adam (Adaptive Moment Estimation) is a variant of stochastic gradient descent that adapts the learning rate for each parameter, making it more efficient and robust to different data distributions. It is a popular optimization algorithm that computes adaptive learning rates for each parameter.
Throughout each epoch, the total loss is accumulated and averaged over all batches, providing a measure of the model's performance. Monitoring the loss over epochs helps in understanding the model's learning progress and adjusting hyperparameters if necessary. This continuous refinement process is essential for improving the model's accuracy and ensuring its ability to generate high-quality text.
The criterion is the cross-entropy loss, which is used to measure the performance of the classification model whose output is a probability value between 0 and 1.
Here is the code snippet for the **train** function and its implementation:
```Python
import torch.optim as optim
def train(model, dataloader, optimizer, criterion, epochs=5, device='cuda'):
model.train()
for epoch in range(epochs):
total_loss = 0
for input_ids, attention_mask in dataloader:
input_ids, attention_mask = input_ids.to(device), attention_mask.to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
shift_logits = outputs[..., :-1, :].contiguous()
shift_labels = input_ids[..., 1:].contiguous()
loss = criterion(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch + 1}/{epochs}, Loss: {total_loss / len(dataloader)}")
optimizer = optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
train(model, dataloader, optimizer, criterion, epochs=5, device=device)
```
## Generating Text
The **generate_text** function in our code is designed to produce text from a trained GPT model based on an initial prompt. This function is essential for demonstrating the practical application of the trained model, allowing us to see how well it can generate coherent and contextually relevant text.
The function begins by setting the model to evaluation mode using _model.eval()_. Evaluation mode ensures that layers like dropout behave correctly and do not affect the prediction results (Goodfellow et al., 2016). The prompt is then tokenized into input IDs using the tokenizer's encode method, which converts the text into a format that the model can process. These input IDs are transferred to the specified device (either CPU or GPU) to leverage the computational power available.
The function then enters a loop that continues until the maximum length of the generated text is reached or an end-of-sequence token (EOS) is produced. During each iteration, the current sequence of generated tokens is passed through the model to obtain the output logits. Logits are raw, unnormalized predictions that indicate the model's confidence for each token in the vocabulary. The logits for the last token in the sequence are selected, and the token with the highest probability (the most likely next token) is determined using _torch.argmax_. This token is appended to the generated sequence.
If the generated token is the EOS token, the loop breaks, indicating that the model has finished generating the text. Finally, the sequence of generated tokens is converted back to text using the tokenizer's decode method, which transforms the numerical representations back into human-readable text, skipping any special tokens.
This iterative process of predicting the next token based on the current sequence demonstrates the model's ability to generate text in a contextually relevant manner, which is crucial for applications such as story generation, dialogue systems, and other natural language processing tasks (Vaswani et al., 2017).
Here's the code for the generate_text function:
```python
def generate_text(model, tokenizer, prompt, max_length=50, device='cuda'):
model.eval()
input_ids = tokenizer.encode(prompt, return_tensors='pt').to(device)
generated = input_ids
for _ in range(max_length):
outputs = model(generated)
next_token_logits = outputs[:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1).unsqueeze(0)
generated = torch.cat((generated, next_token), dim=1)
if next_token.item() == tokenizer.eos_token_id:
break
generated_text = tokenizer.decode(generated[0], skip_special_tokens=True)
return generated_text
prompt = "Once upon a time"
generated_text = generate_text(model, tokenizer, prompt, device=device)
print(generated_text)
```
## Conclusion
In this guide, we provided a comprehensive, step-by-step explanation of how to implement a simple GPT (Generative Pre-trained Transformer) model using [PyTorch](https://pytorch.org/). We walked through the process of creating a custom dataset, building the GPT model, training it, and generating text. This hands-on implementation demonstrates the fundamental concepts behind the GPT architecture and serves as a foundation for more complex applications. By following this guide, you now have a basic understanding of how to create, train, and utilize a simple GPT model. This knowledge equips you to experiment with different configurations, larger datasets, and additional techniques to enhance the model's performance and capabilities. The principles and techniques covered here will help you apply transformer models to various NLP tasks, unlocking the potential of deep learning in natural language understanding and generation. The methodologies presented align with the advancements in transformer models introduced by Vaswani et al. (2017), emphasizing the power of self-attention mechanisms in processing sequences of data more effectively than traditional approaches (Vaswani et al., 2017). This understanding opens pathways to explore and innovate in the field of natural language processing using cutting-edge deep learning techniques (Kingma & Ba, 2015).
#### References:
* Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
* Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
* Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. arXiv preprint arXiv:1706.03762.
* Hendrycks, D., & Gimpel, K. (2016). Gaussian error linear units (GELUs). arXiv preprint arXiv:1606.08415.
* Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1), 1929-1958.
* Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. OpenAI preprint.
* Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
* Kingma, D. P., & Ba, J. (2015). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
| edtbl76 |
1,872,510 | Security news weekly round-up - 31 May 2024 | Weekly review of top security news between May 24, 2024, and May 31, 2024 | 6,540 | 2024-05-31T22:13:55 | https://dev.to/ziizium/security-news-weekly-round-up-31-may-2024-4hia | security | ---
title: Security news weekly round-up - 31 May 2024
published: true
description: Weekly review of top security news between May 24, 2024, and May 31, 2024
tags: security
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/0jupjut8w3h9mjwm8m57.jpg
series: Security news weekly round-up
---
## __Introduction__
Hello everyone, and welcome to another edition of our security news review here on DEV. If you're new here, you can read the previous editions using the accordion above this post.
Now, in today's edition, the article that we'll review, and of course worthy of your reading time are about _artificial intelligence_, _ransomware_, _phishing_, _malware_, and _password security_.
<hr/>
## [Google’s “AI Overview” can give false, misleading, and dangerous answers](https://arstechnica.com/information-technology/2024/05/googles-ai-overview-can-give-false-misleading-and-dangerous-answers/)
It sounds funny, but it's not. What's more, the article's title is a fitting summary of what it entails. Meanwhile, one of the core of this issue is the AI overview treating jokes as fact.
Here is an excerpt from the article to get you started:
> Some of the funniest example of Google's AI Overview failing come, ironically enough, when the system doesn't realize a source online was trying to be funny. An AI answer that suggested using "1/8 cup of non-toxic glue" to stop cheese from sliding off pizza can be traced back to someone who was obviously trying to troll an ongoing thread.
## [Newly discovered ransomware uses BitLocker to encrypt victim data](https://arstechnica.com/security/2024/05/newly-discovered-ransomware-uses-bitlocker-to-encrypt-victim-data/)
This is another classic tale of threat actors abusing a system feature. Only this time, it can be destructive because when they encrypt the victim's drive, there is no way to get it back without the decryption key. Even at the end of the article, the researchers (from Kaspersky) noted that there are no specific protections to prevent a successful attack.
Start reading the article using the following excerpt:
> Recently, researchers from security firm Kaspersky found a threat actor using BitLocker to encrypt data on systems located in Mexico, Indonesia, and Jordan. The researchers named the new ransomware ShrinkLocker, both for its use of BitLocker and because it shrinks the size of each non-boot partition by 100 MB and splits the newly unallocated space into new primary partitions of the same size
## [New Tricks in the Phishing Playbook: Cloudflare Workers, HTML Smuggling, GenAI](https://thehackernews.com/2024/05/new-tricks-in-phishing-playbook.html)
Among the tricks of this phishing campaign is the abuse of yet another legitimate tool: Cloudflare Workers. The threat actors are using the latter to host phishing pages in the hope of harvesting victims' credentials for popular providers like Microsoft and Gmail.
Here is an excerpt that summarizes what's going on:
> The phishing page, for its part, urges the victim to sign in with Microsoft Outlook or Office 365 (now Microsoft 365) to view a purported PDF document. Should they follow through, fake sign-in pages hosted on Cloudflare Workers are used to harvest their credentials and multi-factor authentication (MFA) codes.
## [Over 90 malicious Android apps with 5.5M installs found on Google Play](https://www.bleepingcomputer.com/news/security/over-90-malicious-android-apps-with-55m-installs-found-on-google-play/)
Don't ask me how they got onto the Play Store because I don't know. I mean despite the security checks in place, malicious apps still got published on the Play Store. Luckily, a statement highlighted that Google removed the apps. Still, it's worrying (what about those who have downloaded the infected apps?)
The following is what I am talking about:
> At the time of Zscaler's analysis, the two apps had already amassed 70,000 installations, demonstrating the high risk of malicious dropper apps slipping through the cracks in Google's review process.
## [Researchers crack 11-year-old password, recover $3 million in bitcoin](https://arstechnica.com/information-technology/2024/05/researchers-crack-11-year-old-password-recover-3-million-in-bitcoin/)
This is an interesting read. First, it involves a random password generator that was not so "random". Second, the owner of the Bitcoin got their money back after 11 years with a huge appreciation in value ($5,300 in 2013 to around $3 million as of November 2023).
Enjoy reading using the following as an inspiration:
> They really annoyed me, because who knows what I did 10 years ago,” he recalls. He found other passwords he generated with RoboForm in 2013, and two of them did not use special characters, so Grand and Bruno adjusted. Last November, they reached out to Michael to set up a meeting in person. “I thought, ‘Oh my God, they will ask me again for the settings”
## [Cybercriminals pose as "helpful" Stack Overflow users to push malware](https://www.bleepingcomputer.com/news/security/cybercriminals-pose-as-helpful-stack-overflow-users-to-push-malware/)
It's safe to say that not everyone on Stack Overflow might be there to help you. Here, on certain questions, a malicious user is advising the OP of a question to install an application to solve their problem. However, it's malware.
An excerpt from the article states the following:
> While malicious PyPi packages and information-stealers are nothing new, the cybercriminals' strategy to pose as helpful contributors on Stack Overflow is an interesting approach as it allows them to exploit the trust and authority of the site in the coding community.
>
> This approach serves as a reminder of the constantly changing tactics of cybercriminals and, unfortunately, illustrates why you can never blindly trust what someone shares online.
## [Mystery malware destroys 600,000 routers from a single ISP during 72-hour span](https://arstechnica.com/security/2024/05/mystery-malware-destroys-600000-routers-from-a-single-isp-during-72-hour-span/)
Someone woke up one day and decided that "I will burn 600k routers just for the sake of it". How cute! 🥺. But it's not 🚫. Some users suffered financial losses because their businesses were online and their router was their gateway to the internet. Without it, they lost money.
Start reading from the excerpt below:
> The actor took deliberate steps to cover their tracks by using commodity malware known as Chalubo, rather than a custom-developed toolkit.
>
> A feature built into Chalubo allowed the actor to execute custom Lua scripts on the infected devices. The researchers believe the malware downloaded and ran code that permanently overwrote the router firmware.
## __Credits__
Cover photo by [Debby Hudson on Unsplash](https://unsplash.com/@hudsoncrafted).
<hr>
That's it for this week, and I'll see you next time. | ziizium |
1,872,509 | Data Readiness: The Critical Enabler of AI in Decision-Making | Data readiness is not just a theoretical concept, but a practical necessity for effective... | 0 | 2024-05-31T22:09:48 | https://dev.to/edtbl76/data-readiness-the-critical-enabler-of-ai-in-decision-making-12ga | ai, data, datascience | Data readiness is not just a theoretical concept, but a practical necessity for effective decision-making in sectors like manufacturing and financial services. In these industries, where the speed and accuracy of decisions can make or break a business, having well-prepared data is the key to unlocking the full potential of artificial intelligence (AI) systems. It's not just about efficiency, but about gaining valuable insights that can drive competitive advantage.
#### **Manufacturing Industry: Embracing AI and Data Readiness**
The integration of AI has been a game-changer in manufacturing, transforming operations and boosting production capacities. Investments in clean technology and semiconductor manufacturing have led to a surge in data from advanced manufacturing processes. (Deloitte Insights, 2024). If properly managed and ready for use, this data can help manufacturers optimize processes, predict maintenance needs, and significantly enhance efficiency.
Moreover, the industry is moving towards digitalization with concepts like the smart factory and the industrial metaverse, further underscoring the need for robust data readiness. Manufacturers must ensure that data flows seamlessly across systems to fully harness AI's potential, which includes improving labor productivity and managing complex supply chains (Deloitte Insights, 2024).
#### **Financial Services: Data Readiness in an AI-Driven Landscape**
In financial services, the stakes for data readiness are equally high. The rapid evolution of AI applications, including algorithmic trading and personalized financial advice, presents both challenges and opportunities. The sector's embrace of advanced technologies like decentralized finance (DeFi) and predictive analytics underscores the need for a solid foundation of ready-to-use data. Data readiness is critical in ensuring that AI tools can perform optimally and deliver the desired outcomes. (Carmatec, 2024)
Financial institutions are enhancing their data analytics capabilities to understand customer needs more accurately and, therefore, manage risks more effectively. Integrating AI seamlessly into financial operations hinges on having access to clean, organized, and secure data that can be quickly processed and analyzed (Deloitte Insights, 2024).
#### **Additional Insights on Data Readiness for AI**
Recent literature underscores the role of data readiness in various industries. McKinsey (2023) highlights how banks can leverage AI by ensuring data readiness within their core systems, enhancing customer engagement and operational efficiency (McKinsey, 2023). Another study from ISACA (2021) emphasizes the necessity for technology modernization as a precursor to effective digital transformation, with data readiness playing a crucial role in achieving these objectives (ISACA, 2021).
#### **Conclusion: The Strategic Importance of Data Readiness**
The strategic importance of data readiness transcends the basic need for clean data; it involves building an infrastructure that supports real-time analytics and decision-making. For AI applications, whether in manufacturing or financial services, data quality and readiness can significantly influence AI models' effectiveness. This concept is crucial in today's fast-paced market environments, where decisions must be rapid and data-driven.
Investing in data readiness enhances operational efficiency and empowers organizations to leverage AI effectively, thereby driving innovation and maintaining a competitive edge. As both industries continue to evolve, the focus on data readiness will be paramount in realizing the full potential of AI technologies.
**References:**
* Deloitte Insights. (2024). 2024 manufacturing industry outlook. Retrieved from Deloitte
* Carmatec. (2024). AI in FinTech in 2024: Role, Opportunities and Use Cases. Retrieved from Carmatec
* McKinsey. (2023). McKinsey's Global Banking Annual Review 2023. Retrieved from McKinsey
* ISACA. (2021). Technology Modernization, Digital Transformation Readiness and IT Cost Savings. Retrieved from ISACA
_originally posted on 5/11/2024 at [emangini.com](https://emangini.com/data-readiness-the-critical-enabler)_ | edtbl76 |
1,872,508 | How to Use the 'LIKE' Operator in SQL | The LIKE operator in SQL is a powerful tool used to search for specified patterns within a column. It... | 0 | 2024-05-31T22:08:28 | https://dev.to/kellyblaire/how-to-use-the-like-operator-in-sql-4kem | webdev, sql, database, search | The `LIKE` operator in SQL is a powerful tool used to search for specified patterns within a column. It is particularly useful when you need to find data that matches a particular pattern, allowing for more flexible and dynamic queries compared to exact matches using the equality operator (`=`). This guide will provide an in-depth look at the `LIKE` operator, including its syntax, usage, and practical examples.
## Syntax
The basic syntax for the `LIKE` operator is as follows:
```sql
SELECT column1, column2, ...
FROM table_name
WHERE columnN LIKE pattern;
```
## Wildcards Used with `LIKE`
The `LIKE` operator is often used with two wildcards:
1. `%` (Percent): Represents zero, one, or multiple characters.
2. `_` (Underscore): Represents a single character.
These wildcards allow for versatile pattern matching. Let's delve into their usage with detailed examples.
### Using `%` Wildcard
The `%` wildcard matches any sequence of characters (including zero characters).
**Examples:**
1. **Match any string that starts with 'J':**
```sql
SELECT * FROM employees WHERE name LIKE 'J%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 7 | Johnson| IT | 80000 | Togo
-- 15 | Jody | IT | 47000 | Nigeria
```
2. **Match any string that ends with 'n':**
```sql
SELECT * FROM employees WHERE name LIKE '%n';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 7 | Johnson| IT | 80000 | Togo
-- 14 | Ryan | IT | 55000 | Cameroun
```
3. **Match any string that contains 'ar':**
```sql
SELECT * FROM employees WHERE name LIKE '%ar%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 3 | Carol | Marketing | 70000 | Togo
-- 11 | Mary | Sales | 40000 | Ghana
-- 12 | Helen | HR | 65000 | Cameroun
-- 13 | Maria | IT | 62000 | Togo
```
4. **Match any string that contains 'a' as the second character:**
```sql
SELECT * FROM employees WHERE name LIKE '_a%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 2 | Alice | HR | 50000 | Ghana
-- 3 | Carol | Marketing | 70000 | Togo
-- 11 | Mary | Sales | 40000 | Ghana
```
### Using `_` Wildcard
The `_` wildcard matches exactly one character.
**Examples:**
1. **Match names that start with any character followed by 'ohn':**
```sql
SELECT * FROM employees WHERE name LIKE '_ohn';
-- Expected output: id | name | department | salary | country
-- -----------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 10 | Aohn | IT | 45000 | Nigeria
```
2. **Match names that have 'e' as the third character:**
```sql
SELECT * FROM employees WHERE name LIKE '__e%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 4 | Steve | IT | 60000 | Cameroun
-- 12 | Helen | HR | 65000 | Cameroun
```
3. **Match names that have exactly 5 characters, with 'a' as the second character:**
```sql
SELECT * FROM employees WHERE name LIKE '_a___';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 3 | Carol | Marketing | 70000 | Togo
-- 13 | Maria | IT | 62000 | Togo
```
4. **Match names where the fourth character is 'n':**
```sql
SELECT * FROM employees WHERE name LIKE '___n%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 14 | Ryan | IT | 55000 | Cameroun
```
### Combining `%` and `_` Wildcards
You can combine the `%` and `_` wildcards to create more complex search patterns.
**Examples:**
1. **Match names that start with 'J' and have 'o' as the third character:**
```sql
SELECT * FROM employees WHERE name LIKE 'J_o%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 15 | Jody | IT | 47000 | Nigeria
```
2. **Match names that contain 'a' followed by exactly one character and then 'e':**
```sql
SELECT * FROM employees WHERE name LIKE '%a_e%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 12 | Helen | HR | 65000 | Cameroun
-- 13 | Maria | IT | 62000 | Togo
```
## Practical Use Case
Suppose you have an `employees` table with the following data:
| id | name | department | salary | country |
|----|---------|------------|--------|----------|
| 1 | John | Sales | 30000 | Nigeria |
| 2 | Alice | HR | 50000 | Ghana |
| 3 | Carol | Marketing | 70000 | Togo |
| 4 | Steve | IT | 60000 | Cameroun |
| 5 | Dave | Sales | 60000 | Nigeria |
| 6 | Emma | HR | 55000 | Ghana |
| 7 | Johnson | IT | 80000 | Togo |
| 8 | Andrew | Marketing | 55000 | Cameroun |
| 9 | Jane | Marketing | 60000 | Togo |
| 10 | Aohn | IT | 45000 | Nigeria |
| 11 | Mary | Sales | 40000 | Ghana |
| 12 | Helen | HR | 65000 | Cameroun |
| 13 | Maria | IT | 62000 | Togo |
| 14 | Ryan | IT | 55000 | Cameroun |
| 15 | Jody | IT | 47000 | Nigeria |
### Example Queries and Outputs
1. **Match names that start with 'J':**
```sql
SELECT * FROM employees WHERE name LIKE 'J%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 7 | Johnson| IT | 80000 | Togo
-- 15 | Jody | IT | 47000 | Nigeria
```
2. **Match names that contain 'ar':**
```sql
SELECT * FROM employees WHERE name LIKE '%ar%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 3 | Carol | Marketing | 70000 | Togo
-- 11 | Mary | Sales | 40000 | Ghana
-- 12 | Helen | HR | 65000 | Cameroun
-- 13 | Maria | IT | 62000 | Togo
```
3. **Match names where the fourth character is 'n':**
```sql
SELECT * FROM employees WHERE name LIKE '___n%';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 14 | Ryan | IT | 55000 | Cameroun
```
4. **Match names that start with any character followed by 'ohn':**
```sql
SELECT * FROM employees WHERE name LIKE '_ohn';
-- Expected output: id | name | department | salary | country
-- -----------------------------------------
-- 1 | John | Sales | 30000 | Nigeria
-- 10 | Aohn | IT | 45000 | Nigeria
```
5. **Match names that have 'e' as the third character:**
```sql
SELECT * FROM employees WHERE name LIKE '__e%';
-- Expected output: id | name | department | salary
| country
-- -------------------------------------------
-- 4 | Steve | IT | 60000 | Cameroun
-- 12 | Helen | HR | 65000 | Cameroun
```
6. **Match names that have exactly 5 characters, with 'a' as the second character:**
```sql
SELECT * FROM employees WHERE name LIKE '_a___';
-- Expected output: id | name | department | salary | country
-- -------------------------------------------
-- 3 | Carol | Marketing | 70000 | Togo
-- 13 | Maria | IT | 62000 | Togo
```
### Conclusion
The `LIKE` operator is an essential tool in SQL for performing pattern matching. By utilizing the `%` and `_` wildcards, you can create complex queries that allow you to find data that meets specific criteria. Understanding how to use these wildcards effectively can significantly enhance your ability to retrieve and analyze data from your databases.
[Check out this article I wrote on the **Advanced Use-Cases and Complex Queries with SQL LIKE Operator**.](https://dev.to/kellyblaire/advanced-use-cases-and-complex-queries-with-the-sql-like-operator-3p3k)
**PS:**
I love coffee, and writing these articles takes a lot of it! If you enjoy my content and would like to support my work, you can buy me a cup of coffee. Your support helps me to keep writing great content and stay energized. Thank you for your kindness!
[Buy Me A Coffee](https://buymeacoffee.com/yafskkw). | kellyblaire |
1,864,257 | Embracing Imperfection and Moving Forward | Introduction I prefer to approach tasks with a well-structured plan and a clear vision.... | 0 | 2024-05-31T22:08:13 | https://dev.to/koshirok096/embracing-imperfection-and-moving-forward-2g96 | mentalhealth, productivity | #Introduction
I prefer to approach tasks with a well-structured plan and a clear vision. However, there are times when things don't go as expected.
Meticulously preparing and working backward from the desired outcome to create a plan might seem ideal. However, in practice, this approach can lead to many challenges.
By **embracing imperfection**, you can maintain peace of mind and often achieve better results.

#The Significance of Embracing Imperfection
**Perfectionism** is the mindset of striving to execute every task flawlessly. However, in reality, consistently achieving perfect results is challenging and often impossible. Embracing imperfection is a crucial step in setting realistic expectations and gaining a sense of accomplishment.
Here are some benefits of embracing imperfection:
1.
🎨 Enhanced Creativity
Embracing imperfection can foster creativity. When you work backward from a meticulously planned outcome, it can sometimes limit your actions to the initial plan. This rigidity can stifle innovative ideas and new approaches. By allowing for imperfection, you create space to explore new possibilities and take on creative challenges.
2.
🧘♀️ Reduced Stress
Accepting imperfection can significantly reduce psychological stress. Striving for perfection creates pressure, which can lead to increased stress. In contrast, recognizing and accepting imperfections allows for mental relaxation and reduces the overall burden.
3.
👤 Improved Relationships
Perfectionists often extend their expectations of flawlessness to others, which can negatively impact relationships. By embracing imperfection and letting go of perfectionist tendencies, interpersonal interactions can become smoother. Acknowledging mutual imperfections helps build deeper trust and more harmonious relationships.

#Practical Ways to Embrace Imperfection
Here are some practical ways to embrace imperfection:
📅 Recognize That Plans Can Always Be Flexible
Understand that even the most meticulously crafted plans can and should be adjusted as needed. Situations change, and it's important to allow yourself the flexibility to adapt. Changing a plan is not a sign of failure; it's a necessary response to new information and circumstances. Approach planning with a lighter mindset.
Example: If you’ve planned a detailed schedule for a project but encounter unexpected obstacles, adjust your timeline or approach without feeling guilty or stressed.
👍 Learn from Failures
Perfectionism often involves a fear of failure, but failures are an inevitable part of striving for excellence. Instead of fearing them, use failures as opportunities for growth. Analyze what went wrong and how you can improve for the next attempt.
Example: If a presentation didn’t go as planned, review the feedback, identify areas for improvement, and apply those lessons to future presentations.
🍀 Forgive Yourself
Accept that you are not perfect and that it’s okay to make mistakes. Self-criticism can be damaging and counterproductive. By cultivating self-compassion and recognizing your efforts, you can maintain a positive attitude and reduce stress.
Example: If you didn’t complete all your tasks for the day, don’t dwell on it. Instead, acknowledge what you did accomplish and create a realistic plan for the next day.

#Conclusion
The reason I wrote this article is based on my own experiences. Recently, I often found myself overwhelmed by taking on too much work and struggling with the gap between my ideals and the actual results. However, I have come to realize that embracing imperfection is an extremely important mindset in today's society. Instead of falling into the trap of perfectionism, setting flexible goals, learning from failures, and forgiving oneself are key to reducing stress.
By adopting this mindset, people can improve both quality of life and productivity. For those who find it difficult to forgive themselves because of their busy schedules, I hope this article will introduce you to a new perspective.
Thank you for reading! | koshirok096 |
1,872,507 | Streamline Your Django Workflow: A Guide to Creating Custom Management Commands | Creating custom management commands in Django can significantly enhance the efficiency and... | 0 | 2024-05-31T22:07:17 | https://dev.to/documendous/streamline-your-django-workflow-a-guide-to-creating-custom-management-commands-17hg | django, management, custom, workflow | Creating custom management commands in Django can significantly enhance the efficiency and flexibility of your Django projects.
These commands allow you to automate various tasks, from database operations to file manipulations, directly from the command line.
Whether you're managing user data, performing maintenance tasks, or integrating with external services, a custom management command can streamline your workflow and reduce manual effort.
In this tutorial, I'll guide you through the process of creating a custom Django management command, providing you with the essential steps and examples to get started.
Here's a step-by-step guide to create a custom Django management command:
**Step 1:** **Create a Management Command Directory**
Navigate to your Django app directory.
For this example, let's assume your app is named myapp.
Inside the myapp directory, create a management/commands directory structure:
```bash
mkdir -p myapp/management/commands
```
Create an empty __init__.py file in both the management and commands directories:
```bash
touch myapp/management/__init__.py
touch myapp/management/commands/__init__.py
```
**Step 2:** **Create Your Custom Command**
Inside myapp/management/commands, create a Python file for your command. For this example, we'll name it mycommand.py:
```bash
touch myapp/management/commands/mycommand.py
```
Open mycommand.py and add the following code:
```python
from django.core.management.base import BaseCommand
class Command(BaseCommand):
help = 'Description of your command'
def add_arguments(self, parser):
# Optional: Add arguments here if needed
parser.add_argument('sample_arg', type=str, help='A sample argument')
def handle(self, *args, **kwargs):
sample_arg = kwargs['sample_arg']
self.stdout.write(self.style.SUCCESS(f'Successfully processed argument: {sample_arg}'))
```
**Step 3:** **Run Your Custom Command**
To run your command, use the python manage.py syntax. Replace mycommand with the name of your command file, without the .py extension.
```
python manage.py mycommand <sample_arg_value>
```
For example, if your command expects an argument sample_arg:
```bash
python manage.py mycommand "Hello, World!"
```
**Step 4:** **Adding More Functionality**
You can add more logic to the handle method based on your requirements. Here is an example that prints all users in the database:
```python
from django.core.management.base import BaseCommand
from django.contrib.auth.models import User
class Command(BaseCommand):
help = 'List all users'
def handle(self, *args, **kwargs):
users = User.objects.all()
for user in users:
self.stdout.write(f'User: {user.username}, Email: {user.email}')
```
**Example with Arguments**
If you need to handle more complex arguments, modify the add_arguments method accordingly:
```python
def add_arguments(self, parser):
parser.add_argument(
'--username',
type=str,
help='Username of the user',
)
parser.add_argument(
'--email',
type=str,
help='Email of the user',
)
```
And use these arguments in the handle method:
```python
def handle(self, *args, **kwargs):
username = kwargs['username']
email = kwargs['email']
self.stdout.write(f'Username: {username}, Email: {email}')
```
Full Example with Arguments:
```python
from django.core.management.base import BaseCommand
from django.contrib.auth.models import User
class Command(BaseCommand):
help = 'Create a new user'
def add_arguments(self, parser):
parser.add_argument('username', type=str, help='Username of the user')
parser.add_argument('email', type=str, help='Email of the user')
def handle(self, *args, **kwargs):
username = kwargs['username']
email = kwargs['email']
if User.objects.filter(username=username).exists():
self.stdout.write(self.style.ERROR('User already exists'))
else:
User.objects.create_user(username=username, email=email)
self.stdout.write(self.style.SUCCESS(f'User {username} created with email {email}'))
```
Run the command with:
```
python manage.py mycommand username@example.com
```
This example demonstrates how to create a custom management command in Django, including handling arguments and performing database operations. Adjust the command's logic as per your specific needs.
| documendous |
1,872,506 | একজন মা তার ছেলেকে জন্ম দেন নাড়ী থেকে | একজন মা তার ছেলেকে জন্ম দেন নাড়ী থেকে, একজন স্ত্রী সেই ছেলেকেই স্বামী হিসেবে জন্ম দেন হৃদয়... | 0 | 2024-05-31T22:05:20 | https://dev.to/bdreport-news/ekjn-maa-taar-cheleke-jnm-den-naarrii-theke-i3m | একজন মা তার ছেলেকে জন্ম দেন নাড়ী থেকে,
একজন স্ত্রী সেই ছেলেকেই স্বামী হিসেবে জন্ম দেন হৃদয় থেকে।
একজন মা তার অদেখা ছেলেকে অনুভব করেন পেটে হাত রেখে দশ মাস,
একজন স্ত্রী সেই অচেনা ছেলেকেই অনুভব করেন বুকে হাত রেখে সারাটাজীবন।
একজন মা জন্ম দেন একজন শিশু পুত্রকে,
একজন স্ত্রী জন্ম দেন একজন পরিণত পুরুষকে।
একজন মা তার সন্তানকে হাত ধরে হাঁটতে শেখান,
একজন স্ত্রী সেই সন্তানের হাত ধরেই জীবনের সমস্ত পথটা হাটেন।
একজন মা তার সন্তানকে কথা বলতে শেখান,
একজন স্ত্রী প্রিয় বন্ধু হয়ে সারাজীবন তার কথা বলার সঙ্গী হয়ে ওঠেন।
সন্তানের দায়িত্ব কাঁধে আসতেই মা তার সমস্ত পৃথিবী ভুলে যান,
আবার স্ত্রী সেই সন্তানের দায়িত্ব নেবেন বলেই তার সমস্ত পৃথিবীটা ছেড়ে একদিন চলে আসেন।
সন্তান না খেতে পারলে পাতের সেই উচ্ছিষ্ট খাবার মা এবং স্ত্রী উভয়েই খান, আবার সন্তান এবং স্বামীর মঙ্গল কামনায় উপবাস মা এবং স্ত্রী দুজনেই করে থাকেন।
সন্তানকে বড় করেও সন্তানের থেকে প্রতিটা মাকেই আঘাত পেতে হয়।
আবার স্বামীকে বিয়ে করেও প্রত্যেকটি স্ত্রীকে এক না একদিন নির্যাতিত হতেই হয়।
মায়ের কাছে সন্তানের জীবনে দায়িত্ব নেওয়ার শুরু প্রায় কুড়ি বছর।
স্ত্রীর কাছে স্বামীর জীবনের দায়িত্ব নেভানোর শেষ বাকি ষাটটি বছর(কখনো কখনো সেটি আশি বছরেও যেতে পারে যদি আয়ু একশো বছর হয়)।
সন্তানের শৈশবে তার মল মুত্র মা-ই পরিস্কার করেন।
সন্তান যখন বৃদ্ধ হন তখন তার এই একই দায়িত্ব স্ত্রীর কাঁধেই বর্তায়।
মায়ের কোল হল সেই কোল যেখানে সন্তানের জন্ম হয় অর্থাৎ প্রথম বিছানা।
স্ত্রীর কোল হল সেই কোল যেখানে আমাদের মৃত্যু হয় অর্থাৎ শেষ বিছানা।
কিন্তু সমাজ এবং পরিস্থিতি আজ এমনই যে ছেলেটির বিয়ের পর মায়ের সাথে স্ত্রীর তুলনা করে প্রতিটা মুহূর্তে মাকেই শীর্ষস্থানে রাখেন, যেখানে দুজনের ভূমিকাই সমান সেখানে সামাজিক নজরে কেন মা আর স্ত্রীর মাঝে তুলনামূলক দ্বন্দ্বে বারবার পাঁচিল উঠবে বলতে পারেন।
গর্ভ থেকে জন্ম নেওয়াটাই মা ও স্ত্রীর মধ্যে যদি সবচেয়ে বড় পার্থক্য হয়ে থাকে তাহলে শেষ কথা একটাই বলব-
"একজন আপনাকে গর্ভে ধারণ করেছেন,
অন্যজন আপনার জন্য গর্ভধারণ করবেন।"
"একজন আপনাকে জন্ম দিয়ে মা হয়েছেন,
অন্যজন আপনার জন্য আরেক জনকে জন্ম দিয়ে মা হবেন।" | bdreport-news | |
1,872,505 | Luka Lekić | Luka Lekić, a media personality, emerged in the public eye following the tragic events at Belgrade... | 0 | 2024-05-31T22:02:30 | https://dev.to/ancica9292/luka-lekic-pi1 | Luka Lekić, a media personality, emerged in the public eye following the tragic events at Belgrade School on May 3. According to claims circulating on TikTok and Twitter, Lekić was a best friend of K.K. and is suspected of privately supporting him through personal messages during the preparation of his crime.
| ancica9292 | |
1,872,504 | WS+27(838-80-8170)Valid issue of Goethe A1-A2-B1-B2-C1-C2 without TEST | At our association we can help you obtain the original certificate of all this test without taking... | 0 | 2024-05-31T22:01:21 | https://dev.to/raphaeldepoix_robain_0f7/ws27838-80-8170valid-issue-of-goethe-a1-a2-b1-b2-c1-c2-without-test-92g | At our association we can help you obtain the original certificate of all this test without taking the exam.
whatsap:[+27-83-880-8170)We are a group of Teachers and Examiners Working in various centers like British council, IDP centers, Ets, Gmat Etc… and we have teamed up to form a wide organization with the sole interest of providing reliable services for all our customers In Documentation and Travel consultancy. Our Group of Staff will be devoted in their mission and treat each case as very important. Contact us if interested:
(testduolingo6@gmail.com) | raphaeldepoix_robain_0f7 | |
1,872,503 | Comprehensive Guide to SQL Operators | Introduction SQL (Structured Query Language) is essential for managing and manipulating... | 0 | 2024-05-31T21:58:39 | https://dev.to/kellyblaire/comprehensive-guide-to-sql-operators-1l81 | sql, sqloperators, database, queries | #Introduction
SQL (Structured Query Language) is essential for managing and manipulating relational databases. Among its core functionalities are the various operators that perform arithmetic calculations, comparisons, and logical operations. This article elaborates on these operators, providing examples with expected outputs.
## 1. Arithmetic Operators
Arithmetic operators perform mathematical operations on numeric data.
### SUM
The `SUM` function returns the total sum of a numeric column.
```sql
SELECT SUM(salary) AS total_salary FROM employees;
-- Expected output: total_salary
-- -------------
-- 5000000
```
### AVG
The `AVG` function returns the average value of a numeric column.
```sql
SELECT AVG(salary) AS average_salary FROM employees;
-- Expected output: average_salary
-- ---------------
-- 75000
```
### MIN
The `MIN` function returns the smallest value in a column.
```sql
SELECT MIN(salary) AS min_salary FROM employees;
-- Expected output: min_salary
-- -----------
-- 30000
```
### MAX
The `MAX` function returns the largest value in a column.
```sql
SELECT MAX(salary) AS max_salary FROM employees;
-- Expected output: max_salary
-- -----------
-- 120000
```
### COUNT
The `COUNT` function returns the number of rows that match a specified criterion.
```sql
SELECT COUNT(*) AS sales_count FROM employees WHERE department = 'Sales';
-- Expected output: sales_count
-- ------------
-- 15
```
### Basic Arithmetic Operators
- `+` (Addition): Adds two numbers.
- `-` (Subtraction): Subtracts the second number from the first.
- `*` (Multiplication): Multiplies two numbers.
- `/` (Division): Divides the first number by the second.
- `%` (Modulus): Returns the remainder of a division operation.
```sql
SELECT salary + 500 AS increased_salary FROM employees;
-- Expected output: increased_salary
-- -----------------
-- 30500
-- 50500
-- ...
SELECT salary - 500 AS decreased_salary FROM employees;
-- Expected output: decreased_salary
-- -----------------
-- 29500
-- 49500
-- ...
SELECT salary * 1.1 AS new_salary FROM employees;
-- Expected output: new_salary
-- -----------
-- 33000
-- 55000
-- ...
SELECT salary / 2 AS half_salary FROM employees;
-- Expected output: half_salary
-- ------------
-- 15000
-- 25000
-- ...
SELECT salary % 100 AS remainder FROM employees;
-- Expected output: remainder
-- ---------
-- 0
-- 0
-- ...
```
## 2. Comparison Operators
Comparison operators compare two values, returning true or false.
### `=`
Equals. Checks if the values of two operands are equal.
```sql
SELECT * FROM employees WHERE salary = 50000;
-- Expected output: id | name | department | salary
-- --------------------------------
-- 2 | Alice | HR | 50000
```
### `>`
Greater than. Checks if the value of the left operand is greater than the value of the right operand.
```sql
SELECT * FROM employees WHERE salary > 50000;
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 3 | Bob | IT | 60000
-- 4 | Carol | Marketing | 70000
-- ...
```
### `<`
Less than. Checks if the value of the left operand is less than the value of the right operand.
```sql
SELECT * FROM employees WHERE salary < 50000;
-- Expected output: id | name | department | salary
-- --------------------------------
-- 1 | John | Sales | 30000
```
### `>=`
Greater than or equal to. Checks if the value of the left operand is greater than or equal to the value of the right operand.
```sql
SELECT * FROM employees WHERE salary >= 50000;
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 2 | Alice | HR | 50000
-- 3 | Bob | IT | 60000
-- ...
```
### `<=`
Less than or equal to. Checks if the value of the left operand is less than or equal to the value of the right operand.
```sql
SELECT * FROM employees WHERE salary <= 50000;
-- Expected output: id | name | department | salary
-- --------------------------------
-- 1 | John | Sales | 30000
-- 2 | Alice | HR | 50000
```
### `<>` or `!=`
Not equal to. Checks if the values of two operands are not equal.
```sql
SELECT * FROM employees WHERE salary <> 50000;
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 1 | John | Sales | 30000
-- 3 | Bob | IT | 60000
-- ...
SELECT * FROM employees WHERE salary != 50000;
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 1 | John | Sales | 30000
-- 3 | Bob | IT | 60000
-- ...
```
## 3. Logical Operators
Logical operators combine two or more conditions in a SQL statement.
### `AND`
Combines two conditions and returns true if both conditions are true.
```sql
SELECT * FROM employees WHERE department = 'Sales' AND salary > 50000;
-- Expected output: id | name | department | salary
-- --------------------------------
-- 5 | Dave | Sales | 60000
```
### `OR`
Combines two conditions and returns true if either condition is true.
```sql
SELECT * FROM employees WHERE department = 'Sales' OR department = 'Marketing';
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 1 | John | Sales | 30000
-- 4 | Carol | Marketing | 70000
```
### `NOT`
Negates a condition, returning true if the condition is false.
```sql
SELECT * FROM employees WHERE NOT department = 'Sales';
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 2 | Alice | HR | 50000
-- 3 | Bob | IT | 60000
-- 4 | Carol | Marketing | 70000
```
### `BETWEEN ... AND`
Selects values within a given range. The range includes the end values.
```sql
SELECT * FROM employees WHERE salary BETWEEN 30000 AND 50000;
-- Expected output: id | name | department | salary
-- --------------------------------
-- 1 | John | Sales | 30000
-- 2 | Alice | HR | 50000
```
### `IN`
Checks if a value is within a set of values.
```sql
SELECT * FROM employees WHERE country IN ('Nigeria', 'Ghana', 'Togo', 'Cameroun');
-- Expected output: id | name | department | country
-- -----------------------------------
-- 1 | John | Sales | Nigeria
-- 6 | Emma | HR | Ghana
```
### `LIKE`
Searches for a specified pattern in a column. Commonly used with wildcards:
- `%`: Represents zero or more characters.
- `_`: Represents a single character.
```sql
SELECT * FROM employees WHERE name LIKE '%jo%';
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 1 | John | Sales | 30000
-- 7 | Johnson| IT | 80000
SELECT * FROM employees WHERE name LIKE 'A%';
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 2 | Alice | HR | 50000
-- 8 | Andrew | Marketing | 55000
SELECT * FROM employees WHERE name LIKE '%Keyword';
-- Expected output: id | name | department | salary
-- -------------------------------------
-- 9 | JaneKeyword| Marketing | 60000
```
[Check out this special post I wrote on the LIKE operator](https://dev.to/kellyblaire/how-to-use-the-like-operator-in-sql-4kem)
### `IS NULL` / `IS NOT NULL`
Checks if a column is null or not null.
```sql
SELECT * FROM employees WHERE manager_id IS NULL;
-- Expected output: id | name | department | salary
-- --------------------------------
-- 1 | John | Sales | 30000
-- 5 | Dave | Sales | 60000
SELECT * FROM employees WHERE manager_id IS NOT NULL;
-- Expected output: id | name | department | salary
-- ---------------------------------
-- 2 | Alice | HR | 50000
-- 3 | Bob | IT | 60000
```
## 4. WHERE Clause
The `WHERE` clause is used to filter records based on specified conditions.
```sql
SELECT * FROM employees WHERE department = 'Sales';
-- Expected output: id | name | department | salary
-- --------------------------------
-- 1
| John | Sales | 30000
-- 5 | Dave | Sales | 60000
SELECT * FROM employees WHERE salary > 50000 AND department = 'Sales';
-- Expected output: id | name | department | salary
-- --------------------------------
-- 5 | Dave | Sales | 60000
```
## Conclusion
SQL operators enable powerful manipulation and retrieval of data. Mastering these operators—arithmetic, comparison, and logical—allows for sophisticated database queries and efficient data management. Each example provided includes expected output to illustrate the practical application of these operators in SQL.
**PS:**
I love coffee, and writing these articles takes a lot of it! If you enjoy my content and would like to support my work, you can buy me a cup of coffee. Your support helps me to keep writing great content and stay energized. Thank you for your kindness!
[Buy Me A Coffee](https://buymeacoffee.com/yafskkw). | kellyblaire |
1,872,502 | AWS DataSync Accelerating Data Transfer for Software and Hardware Teams | Introduction Overview of AWS DataSync AWS DataSync is a secure, online service that helps to... | 0 | 2024-05-31T21:55:23 | https://sudoconsultants.com/aws-datasync-accelerating-data-transfer-for-software-and-hardware-teams/ | datatransfer, datasync, aws, cloud | <!-- wp:heading {"level":1} -->
<h1 class="wp-block-heading">Introduction</h1>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Overview of AWS DataSync</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS DataSync is a secure, online service that helps to accelerate the movement of data across on-premises applications and Amazon Web Services, or across AWS services. Source: DataSync can deal with numerous data sources such as NFS shares, SMB shares, HDFS, self-managed object storage, AWS Snowcone, Amazon S3 buckets, Amazon EFS file systems, and different FSx file systems. This makes transfers from AWS easier to other public clouds, meaning automatic replication, archiving, or even sharing of application data.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Importance of Efficient Data Transfer in Software and Hardware Teams</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>While data is the new oil, the effective transfer of data has the following significance:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Speed and efficiency: Keeping data as current as possible with low latency speeds up applications or services within an organization. Also, it automates and accelerates the transfer process of data, finally reducing manual effort in the process of data migration with synchronization, thereby saving the team both time and money.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Reliability and security: Amazon Data Sync includes built-in integrity and security measures, which ensure a safe and reliable data transfer solution to get rid of risks of loss/breach.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Scalability: Scalable data transfer solutions like AWS DataSync can scale up on demand without at the same time sacrificing performance, enabling businesses to grow both data and geographically.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Flexibility: AWS DataSync supports a very wide range of sources and destinations, therefore offering flexibility to match any change in your business needs and/or in your technology stack.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>All these benefits make AWS DataSync an invaluable tool for teams that work on either side of software and hardware to ensure optimized data workflows, efficient operations, data availability, integrity, and order in the environment.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Understanding AWS DataSync</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">How AWS DataSync Works</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS DataSync is an online service for data movement and discovery that enables you to very quickly, easily, and securely transfer your file or object data to and from and between AWS Storage Services. It uses a purpose-built network protocol and parallel multi-threaded architecture to accelerate the speed of transfers and fits well for migrations, recurring data processing workflows for analytics and machine learning, and data protection operations. This way, by using the purpose-built network protocol and parallel, multi-threaded architecture, DataSync is able to quicken the speed of transfers, yet ensure end-to-end encryption and validation of integrity so that your data is delivered in a secure and undamaged form, prepared for use. It accesses AWS storage using the built-in security mechanisms of AWS, such as AWS Identity and Access Management roles and supports virtual private cloud endpoints for transfer of data between sites without traversing the public Internet.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Components and Terms Used in DataSync</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>DataSync Resources:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>These are agents, locations, and tasks. These are the most important members of AWS DataSync. Where agents are what have to be installed on your on-premise servers or virtual machines to help in data transfer. Locations represent the source and destination of data transfers that could be on-premises and in the form of an AWS storage service, and at the same time, tasks are configurations defining the details of the data transfer—for example, the source and destination locations, data to be transferred, and transfer options.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>IAM Policies:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Basically, identity-based policies, IAM policies, are used to manage access to DataSync resources. Policy or policies that can either allow or deny permissions of creating and managing of resources that is DataSync are agents, locations, and tasks. They might as well allow the permission to be accessed by a role that is in another AWS account or an AWS service. It includes the use of cross-account access permissions and integration with some other AWS services.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>API Operations:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>For this resource DataSync defines a set of API operations in the management of the same. They include how to create, delete, and describe tasks. Permission to do that gives the applications by IAM policies, that is, it allows actions, effects, resources, and principles.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">IAM Permissions Required for DataSync</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To manage DataSync resources effectively, the following are IAM permissions required:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Create and Manage DataSync Resources:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>For this resource, it involves an IAM policy permitting an IAM role within my AWS account to create and manage DataSync resources – agents, locations, and tasks. This allows for the creation, updating, and deletion of such resources.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Cross-account access</strong>:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>If there is ever a need where you allow permissions to a role that belongs to another AWS account or an AWS service, you can write an IAM policy that lays out the permissions in black and white on what resources in your account and attach a trust policy to the role. The trust policy will define the principal (another AWS account or AWS service) to allow assuming the role. That way, these other account or service users have access to the resources in your account or are able to create resources.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Specifying elements of the policy:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>While defining the IAM policies on DataSync, there is the need to specify the actions like datasync: CreateTask, effects (Allow or Deny), and the resources via Amazon Resource Names (ARNs). Also, one may specify the principals (a user or service for whom the policy is created). DataSync supports only identity-based policies that is IAM policies and does not support resource-based policies.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>This understanding about the components and permissions will guide one to be in a position to manage and operate AWS DataSync in an efficient manner to achieve the transfer of your data.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Setting Up AWS DataSync</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Installation and Setup of AWS CLI</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Before you can use AWS DataSync, you need to download and configure the AWS Command Line Interface (CLI). The AWS CLI is a unified tool to manage your AWS services from a terminal session on your own client. With just one tool to download and setup, you can control multiple AWS services from the command line and automate them through scripts.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Installation: Follow the instructions at the <a href="https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html">AWS CLI User Guide</a> to install the AWS CLI on your system.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Configuration: Once installed, configure the AWS CLI with your AWS credentials by running aws configure and inputting your AWS Access Key ID, Secret Access Key, default region name and output format.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Creating an AWS DataSync Agent</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>An AWS DataSync agent is a software component that is deployed in your storage environment in order to transfer data. The agent starts and runs in your AWS account.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Deployment: Deploy the DataSync agent on your on-premises server or virtual machine as per the instructions given in the <a href="https://docs.aws.amazon.com/datasync/latest/userguide/create-agent-cli.html">DataSync User Guide</a>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Activation: Activate the agent using the AWS CLI and the <strong><em>create agent command</em></strong>. This step registers an agent with your AWS account.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Creating AWS DataSync Locations</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Locations in AWS DataSync point at your source and destination for data transfer. Every task would need a pair of locations.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Creating Source Location:</strong> Use the create-location-s3 command for an Amazon S3 bucket, create-location-fsx-windows for an Amazon FSx for Windows File Server, or create-location-hdfs for an HDFS cluster. For example, to create an S3 location, you might use a command like:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws datasync create-location-s3 --s3-bucket-arn arn:aws:s3:::mybucket --s3-config BucketAccessRoleArn=arn:aws:iam::123456789012:role/myBucketAccessRole</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p><strong>Creating Destination Location:</strong> Similarly, create a destination location using the appropriate command for the destination service.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Creating an AWS DataSync Task</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>A task in AWS DataSync defines the details of a data transfer, including the source and destination locations, the data to be transferred, and the transfer options.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Creating a Task:</strong> Use the <strong><em>create-task command</em></strong> to create a task. Specify the source and destination locations, the options for the transfer, and any filters for the data to be transferred.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Starting an AWS DataSync Task</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Once a task is created, you can start it using the <strong><em>start-task-execution command</em></strong>. This initiates the data transfer according to the task's configuration.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Starting a Task:</strong> Use the <strong><em>start-task-execution command</em></strong> with the task ARN to start the task. For example:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws datasync start-task-execution --task-arn 'arn:aws:datasync:region:account-id:task/task-id'</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Filtering AWS DataSync Resources</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS DataSync allows you to filter the data that is transferred by specifying filters in your task configuration. Filters can be based on file paths, file names, or other criteria.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Specifying Filters:</strong> When creating or modifying a task, you can specify filters using the --filters option in the <strong><em>create-task or modify-task command</em></strong>. For example, to transfer only files in a specific directory, you might use:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws datasync create-task --source-location-arn 'arn:aws:datasync:region:account-id:location/location-id' --destination-location-arn 'arn:aws:datasync:region:account-id:location/location-id' --filters Include={Key=Path,Value=/path/to/directory}</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>By following these steps, you can set up AWS DataSync to efficiently transfer data between your on-premises environments and AWS storage services, or between different AWS storage services.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Using AWS DataSync with the CLI</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Detailed Steps for Creating an AWS DataSync Agent Using the AWS CLI</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Deploy the DataSync Agent:</strong> First, you need to deploy the DataSync agent on your on-premises server or virtual machine. This involves downloading the agent software from the AWS website and configuring it according to your environment.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Activate the Agent:</strong> Once deployed, activate the agent using the AWS CLI with the <strong><em>create-agent command</em></strong>. This associates the agent with your AWS account.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws datasync create-agent --agent-name MyAgent --vpc-endpoint-id vpce-0abc123defgh5678 --subnet-ids subnet-0abc123defgh5678 subnet-0abc123defgh5678 --security-group-ids sg-0abc123defgh5678 --availability-zone us-west-2a</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Replace placeholders, such as VPC endpoint ID, subnet IDs, security group IDs, and availability zone, with your real VPC endpoint ID, subnet IDs, security group IDs, and availability zone.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Steps for Creating AWS DataSync Locations with the AWS CLI</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li><strong>Create a Source Location: </strong>Use the <strong><em>create-location-s3 command</em></strong> for an Amazon S3 bucket. For an Amazon FSx for Windows File Server, use <strong><em>create-location-fsx-windows</em></strong>. For an HDFS cluster, use <strong><em>create-location-hdfs</em></strong>. Let's see how to create an S3 location:</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws datasync create-location-s3 --s3-bucket-arn arn:aws:s3:::mybucket --s3-config BucketAccessRoleArn=arn:aws:iam::123456789012:role/myBucketAccessRole</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Create a Destination Location:</strong> Create the destination location similarly, using the appropriate command for the destination service.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Steps for Creating an AWS DataSync Task with the AWS CLI</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li><strong>Create a Task:</strong> Use the <strong><em>create-task command</em></strong> to create a task. Specify the source and destination locations, the options for the transfer, and any filters for the data to be transferred.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code>aws datasync create-task \
--source-location-arn 'arn:aws:datasync:us-east-1:account-id:location/location-id' \
--destination-location-arn 'arn:aws:datasync:us-east-2:account-id:location/location-id' \
--cloud-watch-log-group-arn 'arn:aws:logs:region:account-id:log-group:log-group' \
--name task-name \
--options VerifyMode=NONE,OverwriteMode=NEVER,Atime=BEST_EFFORT,Mtime=PRESERVE,Uid=INT_VALUE,Gid=INT_VALUE,PreserveDevices=PRESERVE,PosixPermissions=PRESERVE,PreserveDeletedFiles=PRESERVE,TaskQueueing=ENABLED,LogLevel=TRANSFER</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Replace the placeholders with your actual ARNs and desired task options.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Steps for Starting an AWS DataSync Task with the AWS CLI</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Start a Task:</strong> Use the <strong><em>start-task-execution command</em></strong> with the task ARN to start the task.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws datasync start-task-execution --task-arn 'arn:aws:datasync:region:account-id:task/task-id'</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Filtering AWS DataSync Resources Using the CLI</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li><strong>Specify Filters:</strong> You can specify filters while creating or modifying a task using the --filters option in the create-task or modify-task command. For example, you could write the following to transfer files from a folder named folder:</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws datasync create-task --source-location-arn 'arn:aws:datasync:region:account-id:location/location-id' --destination-location-arn 'arn:aws:datasync:region:account-id:location/location-id' --filters Include={Key=Path,Value=/path/to/directory}</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>By following these steps, you can effectively use AWS DataSync with the AWS CLI to manage your data transfer tasks, including setting up agents, creating locations, defining tasks, and filtering resources.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Monitoring AWS DataSync Tasks</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Describing Task Execution Using the AWS CLI</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To monitor the progress of your AWS DataSync task in real-time from the command line, you can use the <strong><em>describe-task-execution command</em></strong>. This command provides detailed information about the task execution, including the current status, the amount of data transferred, and any errors encountered.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>aws datasync describe-task-execution \
--task-execution-arn 'arn:aws:datasync:region:account-id:task/task-id/execution/task-execution-id'</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Replace 'arn:aws:datasync:region:account-id:task/task-id/execution/task-execution-id' with the actual ARN of your task execution.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Monitoring the Progress of an Ongoing Transfer</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To monitor the progress of an ongoing transfer, you can use the watch utility in conjunction with the <strong><em>describe-task-execution command</em></strong>. This allows you to see the task execution details updated in real-time.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>watch -n 1 -d "aws datasync describe-task-execution --task-execution-arn 'arn:aws:datasync:region:account-id:task/task-id/execution/task-execution-id'"</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>This command updates every second (-n 1) and highlights differences (-d), providing a live view of the task execution progress.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Checking the Results of a Transfer</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>After the task execution completes, you can use the <strong><em>describe-task-execution command</em></strong> again to check the results of the transfer. Look for the Status field in the response. If the task execution succeeds, the Status will change to <strong>SUCCESS</strong>. If the task execution fails, the response will include error codes that can help you troubleshoot issues.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>aws datasync describe-task-execution \
--task-execution-arn 'arn:aws:datasync:region:account-id:task/task-id/execution/task-execution-id'</code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Additional Monitoring Tools</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Amazon CloudWatch: </strong>For better monitoring, you can apply Amazon CloudWatch to collect and process raw data that is produced by DataSync into human-readable, near real-time metrics. These stats are maintained for 15 months. By default, DataSync metrics data is sent to CloudWatch automatically at 5-minute intervals.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Task Statuses:</strong> You can monitor your DataSync tasks and know their state by getting to know about its status. The most used status is AVAILABLE, RUNNING, UNAVAILABLE, and QUEUED. Each of them means something different and represents varied task lifecycle stages.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Once you use the commands and tools earlier, you can monitor your tasks of AWS DataSync successfully and as a result make ensure everything is in the expected flow. If some problems occur you can response to them in a timely way.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Advanced Configuration Options for AWS DataSync</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Configuring Task Options</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>When you create an AWS DataSync task, you have a lot of options for how the task will handle files, objects, and their metadata when transferring them. These options include:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Handling Files:</strong> You can opt to transfer only files that have changed or all files without comparing the source and destination location data. This option affects the transfer speed and efficiency.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Object Metadata:</strong> AWS DataSync retains POSIX permission for files and folders and tags associated with objects and access control lists (ACLs) when the transfer is going on. This means that the metadata for files and objects remains the same in the source and destination.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Verify Data Integrity:</strong> This is the option to perform integrity verification for the data written to the destination and that which is read from the source. Optionally, use the verification check at the end of the transfer to compare source and destination and result in full-file checksums.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Bandwidth Throttle:</strong> Quickly set the network bandwidth that AWS DataSync will use with built-in bandwidth throttle. It ensures that ongoing transfers do not affect other users or other applications that use the same network connection.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Logging:</strong> Configure the type of logs published by DataSync to an Amazon CloudWatch Logs log group.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Specifying How DataSync Checks the Integrity of Data During a Transfer</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS DataSync guarantees data integrity for the transfer operation using integrity checks to compare the data written to the destination with the data read from the source. Optionally, you can use the verification check at the end of the transfer to compare source with destination data. It computes and compares the full-file checksum of the file data stored on the source and on the destination, letting you ascertain the transfer was successful.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Adjusting Log Levels for Individual Task Executions</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>During DataSync task configuration, you can specify the following: The level of detail in the logs that DataSync will eventually publish to an Amazon CloudWatch Logs log group:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>BASIC: </strong>Includes log messages of a basic level, which includes transfer errors.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>TRANSFER:</strong> Includes log messages of all files or objects transferred to and from a source for a DataSync task execution and data-integrity checks that were executed.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>OFF:</strong> No logs are published.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>By setting the log level, you can control the level of granularity of the information that is logged during a task execution. By doing this, you can focus on the details that are relevant to your monitoring and troubleshooting.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Best Practices and Considerations</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Storage Class Considerations with Amazon S3 Locations</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Cost Efficiency:</strong> With this setting, AWS DataSync automatically stores small objects in S3 Standard. This enables you to prevent minimum capacity charge per object. To generally reduce data retrieval fees, configure DataSync to verify only files that are transferred by a given task. DataSync provides overwriting/deleting objects controls, to avoid minimum storage duration charges.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Performance and Cost: </strong>Use DataSync in combination with S3 considering the S3 request charges. This includes data retrieval fees and storage duration charges. Choose the appropriate S3 Storage Class for the data, based on data usage patterns and the cost-of-data configuration.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Bandwidth Usage Limits for DataSync Tasks</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Bandwidth Throttle:</strong> You can configure the in-built bandwidth throttle, which allows you to set the amount of network bandwidth that AWS DataSync consumes. By using this setting, you can limit the impact that AWS DataSync has on other users or the impact that applications that rely on your network connection experience.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Performance Impact: </strong>You can configure a bandwidth throttle for a task. This can reduce impact against your source file system by limiting the I/O against your storage system. Impact: With this impact, the response time for other clients that have access to the same source data store is affected.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Queueing Transfer Tasks During Multiple Task Executions</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Task Queuing:</strong> DataSync task reports have the results of summary and detailed reports, in JSON-formatted output files, of all files transferred/skipped/verified/deleted in multiple task executions. This enables you to verify and audit the data transfer operations for each task run.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Monitoring and Auditing:</strong> Exploit AWS services AWS Glue, Amazon Athena, and Amazon QuickSight for automatic catalog, analysis, and visualizing of task report output. It is very effortless to keep track and audit, you can easily grok common task execution trend or failure pattern.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Choosing the Type of Logs Published to Amazon CloudWatch Logs</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Log Levels:</strong> Specify the log types that are published to an Amazon CloudWatch Logs log group by DataSync. You can choose between:<ul><li>BASIC: The type of log that includes transfer errors.</li></ul><ul><li>TRANSFER: The type of log that includes all information that is provided by BASIC plus detailed descriptions of all files that are transferred and all integrity-check information.</li></ul><!-- wp:list -->
<ul><!-- wp:list-item -->
<li>OFF: No logs are published.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Monitoring and Troubleshooting: Using CloudWatch Logs for detailed information about the files transferred at a point in time and results of DataSync integrity verification, the difficulty monitoring, reporting and troubleshooting is eliminated and you can provide stakeholders with timely updates.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Conclusion</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS DataSync is so essential to software and hardware teams because it provides a secure, efficient, and scalable solution to transfer data back and forth within on-premises environments and AWS storage services, or across separate AWS storage services. Advanced configuration options touch on features like file handling, object metadata preservation, data integrity checks, bandwidth throttling, and detailed logging, so that teams can make data transfer processes very specific to their needs in performance, cost, and reliability.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Future Developments and Improvements in AWS DataSync</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Although the specific future developments and improvement in AWS DataSync is not highlighted in the provided sources, AWS keeps investing in rigorous improvement of its services to meet the emerging needs of the AWS customers. This is a key goal for modern IT infrastructure; data transfer is something one always hopes that AWS DataSync continues to grow toward, gaining updates that improve its performance and scalability, and that increase its integration with other AWS services and third-party solutions.</p>
<!-- /wp:paragraph --> | sidrasaleem296 |
1,872,441 | Cloud Resume Challenge Chunk 2 | Please see Chunk 1 to see how we got here What's needed for the CRC chunk 2 Chunk 3, is... | 0 | 2024-05-31T21:42:27 | https://dev.to/brianhaas/cloud-resume-challenge-chunk-2-1p78 | devops, webdev, aws, career | Please see [Chunk 1 to see how we got here](https://dev.to/brianhaas/cloud-resume-challenge-chunk-1-3681)
## What's needed for the CRC chunk 2
Chunk 3, is the "back end" of the [CRC](https://cloudresumechallenge.dev/) challenge. Here are the pieces needed:
* A database to store the hit count - I chose DynamoDB.
* An API to retrieve/update the hit count in the database. I chose to use a Lambda function using Python.
* A way to trigger the Lambda function as a REST API. I chose to use Apigateway.
### Getting started
I used the aws console at first to get reacquainted with dynamodb, lambda and apigateway. After getting everything to work, I used [Terraform](https://www.terraform.io/) to deploy all of the infrastructure pieces. The Github repo can be found [here](https://github.com/chronosAZ/CRC-Backend).
Using boto3 and python in Lambda functions was nothing new. I was not that familiar with APIGateway though.
The function to update the hit count in the dynamodb table is [pretty straight forward](https://github.com/chronosAZ/CRC-Backend/blob/main/code/hitcount.py)
The APIGateway pieces took a bit longer. It required some time reading the docs to understand staged, deployments, CORS configuration, etc. But, in the end, I got it all working and was able to use CURL and Postman to test out the API and successfully update the hit counter.
Here is all of the [code](https://github.com/chronosAZ/CRC-Backend/tree/main)
It was now time to glue it all together. | brianhaas |
1,872,531 | #116 Understanding Deep Learning Frameworks: TensorFlow vs. PyTorch in Python | Artificial Intelligence (AI) is growing fast, especially in deep learning. This makes it key for... | 0 | 2024-06-04T16:47:06 | https://voxstar.substack.com/p/116-understanding-deep-learning-frameworks | ---
title: #116 Understanding Deep Learning Frameworks: TensorFlow vs. PyTorch in Python
published: true
date: 2024-05-31 21:41:18 UTC
---
**Artificial Intelligence** (AI) is growing fast, especially in **deep learning**. This makes it key for businesses and researchers to know **deep learning** tools.
We will talk about **TensorFlow** and **PyTorch** , two top tools in **deep learning** , in **Python**. By looking at what they can do, we want to help you choose well for your projects.
<form>
<input type="email" name="email" placeholder="Type your email…" tabindex="-1"><input type="submit" value="Subscribe"><div>
<div></div>
<div></div>
</div>
</form>
Welcome: Blogs from Gene Da Rocha / Voxstar is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Subscribed
[

<svg xmlns="http://www.w3.org/2000/svg" width="20" height="20" viewbox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><polyline points="15 3 21 3 21 9"></polyline><polyline points="9 21 3 21 3 15"></polyline><line x1="21" x2="14" y1="3" y2="10"></line><line x1="3" x2="10" y1="21" y2="14"></line></svg>
]
### Key Takeaways:
- **Deep learning frameworks** make it easier to work with complex **neural networks**.
- Both **TensorFlow** and **PyTorch** stand out in **Python** for deep learning stuff.
- **TensorFlow** shines for being big, easy to use, and loved by many in the industry.
- **PyTorch** wins with its simple approach, and adaptability, and is popular with researchers.
- Your pick between the two will depend on what you need for your project and your likes.
## What is Deep Learning?
Deep learning is part of _Artificial Intelligence_ (AI). It uses _neural networks_ to learn like our brains. This way, machines can think and make choices like we do.
Machines learn and get better with deep learning. They can decide, find things, understand speech, and translate languages. This is done through mimicry of our brain structures.
This technology is very famous now. It's great at understanding things like photos, videos, and words. For example, it helps in making self-driving cars and improving health care.
To truly get what deep learning is, we need to know about **neural networks**. They are key in making AI work like our brain.
### Neural Networks and Deep Learning
**Neural networks** are like the bricks of deep learning. They have nodes that talk to each other, like how our brain cells do.
It's a bit like a stack of talking layers. The first layer gets info, like a picture. Then it tells the next layer something in a new way. This goes on till the last layer finally figures out what the picture is.
The last layer is the decision-maker. It tells you what the picture shows. How strongly the layers talk to each other changes what decision you get.
Deep learning does this with many hidden layers. This way, it can figure out really tough things. It helps AI do amazing stuff.
Deep learning has made a real difference. It's making AI way smarter than before. Next, we'll look at some tools for deep learning: _TensorFlow_ and _PyTorch_.
## What is Keras?
**Keras** is a simple way to make deep learning. It's written in **Python**. It's easy for anyone to try new things with deep neural networks.
Developers like **Keras** because it's quick to use. They can build models fast. This leaves them more time to think about their models' design.
**Keras** works with different tools, like TensorFlow. This lets users use all the good things from big tools like TensorFlow.
### Key Features of Keras:
- _User-Friendly:_ People of all skill levels can use Keras easily.
- _Modularity:_ Keras lets users mix and match network parts easily.
- _Fast Experimentation:_ It's quick and easy to try new things in Keras.
- _Flexible Backend:_ Keras works with different tools, giving users choices.
> > "Keras simplifies the deep learning workflow, allowing developers to focus on building powerful models rather than getting lost in implementation details." - Dr. Sarah Anderson, Data Scientist
Here is an example of a simple Keras code snippet:
```
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=100))
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=32)
```
_Figure 1: Basic example of a deep neural network model built using Keras._
Keras makes it easy to build and choose network parts. It works well with Python and TensorFlow. This helps devs make cool deep-learning models.
## What is PyTorch?
PyTorch is new. It is for deep learning and is based on **Torch**. Facebook's AI team made it. It's known for being simple, easy to use, and using memory well.
PyTorch is easy to use. It works like Python, making it good for all developers. You can make and teach models easily. This is great for testing new ideas fast.
It has a special way to handle the work called a dynamic graph. This is different from other tools like TensorFlow. Dynamic graphs give more freedom to work on models and find bugs.
It's also very good with memory. Deep learning needs a lot of memory. PyTorch uses it well, avoiding common memory problems. This makes it work faster and better.
PyTorch uses tools from the **Torch** library. That library is well-known in computer vision. It has many models and data ready to use. This helps people make projects faster.
**Facebook** helps a lot with PyTorch. They have a big team working on it. Many people help make PyTorch better all the time. This keeps it growing and improving.
In short, PyTorch is a top choice for deep learning. It's easy and fast to work with. Its special features and big community make it even better. Researchers and developers love using PyTorch.
### Key Features of PyTorch:
- Intuitive and Pythonic interface
- Dynamic computational graph
- Efficient memory usage
- Integration with the **Torch** Library
- Strong community support
## What is TensorFlow?
TensorFlow is made by **Google** for deep learning. It came out in 2015 and is now very popular. It helps make and use deep learning models well.
It is **open-source** , so anyone can use and improve it. Many people work together to make it better. This makes it good for all kinds of folks who do deep learning.
> > "TensorFlow makes deep learning models powerful and easy to use. It gets better all the time to meet the new needs of AI."
With TensorFlow, you can work at different levels. You pick how much you want to control or keep it simple. Keras, part of TensorFlow, makes it easy to build models. But, you can go deeper to make things just how you want.
TensorFlow works well with Android and on many devices. This means your models can work on phones and other small devices. It is good for making mobile and edge apps.
### Benefits of TensorFlow
Here are some great things about TensorFlow:
- It can work with big data sets or in real use easily.
- You can do special things in deep learning with TensorFlow.
- There are many people and staff to help you learn and get models to use. Also, a lot of things work well with TensorFlow.
## PyTorch vs TensorFlow
PyTorch and TensorFlow are top choices in deep learning. They are both very popular.
PyTorch is great for its easy interface. Many people like its Pythonic style. It makes building neural networks easier and faster.
TensorFlow is also great, especially for big projects. It is powerful and works well for many users. Its many tools and models help a lot in big systems.
Even though researchers love PyTorch, many big companies use TensorFlow. This shows it is good for serious work too. It is known for being reliable across many areas of work.
> > "PyTorch is easy to use for those doing research, while TensorFlow is better for big, serious projects."
### The key differences between PyTorch and TensorFlow:
- _Flexibility:_ PyTorch is more flexible with its dynamic graphs. This makes it easier to experiment. TensorFlow focuses more on efficiency for big projects with its static graphs.
- _Learning curve:_ PyTorch is easier to start with thanks to its simple, Python-like code. TensorFlow is harder at first because it's more complex.
- _Community support:_ TensorFlow has a big, helpful community. PyTorch's community is also growing and ready to help.
- _Deployment:_ TensorFlow is strong in deploying models for different systems. PyTorch can also deploy but might need more setup work.
PyTorch TensorFlow Flexibility Dynamic computational graph Static computation graphs for efficiency Learning curve Beginner-friendly with a Pythonic interface Steeper learning curve with a more complex API Community support Growing community with strong research support Large and active community with extensive resources Deployment Supports deployment, may require manual configuration Versatile deployment options for various platforms and hardware
To pick between PyTorch and TensorFlow, think about your project's needs. Consider your skills and what support you'll need. Both are great for deep learning.
Next, we will talk about PyTorch and Keras, favourite choices for beginners.
## PyTorch vs Keras
When talking about deep learning, many people choose PyTorch or Keras. They both help in different ways.
### PyTorch: Research-friendly and Native Python Experience
Researchers like PyTorch because it feels like using regular Python. They can easily try new things with deep learning. PyTorch lets them make their models and see how they work. This is great for new ideas in research.
Many people support PyTorch because it's simple and has lots of help available. It's the go-to for researchers who want more control.
> > "PyTorch's flexibility and intuitive interface make it a favorite among researchers, allowing for easy experimentation and customization."
### Keras: Quick Model Building and Evaluation
Developers often pick Keras for its fast, simple model options. It helps make deep learning easier with its easy-to-use tools. Keras is built on top of other tools like TensorFlow, making it powerful yet simple to use.
There's a big community and many ready-to-use models with Keras. This makes it great for those who want to use deep learning without diving too deep into the technical stuff.
> > "Keras' simplicity and extensive ecosystem make it a top choice for developers looking for a quick and efficient **deep learning framework**."
No matter if you choose PyTorch or Keras, both are good and many people like them. Your choice should be based on what you need. Do you like experimenting and need control? Then PyTorch is for you. Need something quick and easy to use? Keras is a great option.
Next, let's look at how TensorFlow and Keras compare. This will help us understand more about their features.
## TensorFlow vs Keras
When comparing TensorFlow and Keras, you see they are different and yet work well together. Keras is easy to use and sits on top of TensorFlow. It makes building and training models simple. TensorFlow, though, is strong and fast, perfect for big deep-learning jobs.
TensorFlow is good for big projects with its strong features. It can handle a lot of work and is great for when you need to grow. It has many different ways to use it, from easy to hard, depending on your needs.
On the other hand, Keras is all about being simple and adaptable. It's great for people just starting in deep learning. Thanks to its clear design and easy-to-understand commands, you can start making models quickly.
The key is to think about what your project needs before choosing. If you need something strong that can handle a lot and is well-supported, TensorFlow might be best. But, if you're starting or want something simpler, Keras is a good pick.
### Comparative Table: TensorFlow vs Keras
Feature TensorFlow Keras Flexibility High High Scalability Excellent Good User-Friendliness Moderate High Community Support Extensive Strong Performance High Good Deployment Options Multiple N/A (Relies on TensorFlow)
The table above shows TensorFlow and Keras each have things they're good at. It's about what your project needs. Pick by thinking about what matters most to you.
## Theano vs TensorFlow
There are two big **deep-learning libraries** : Theano and TensorFlow. They are chosen by many researchers and developers. But, their use has changed over the years.
**Theano:** Theano was well-known for quick math and being flexible. It was loved by researchers and teachers. But, as new options showed up, Theano lost its shine. In 2017, people stopped making it better and fixing bugs.
**TensorFlow:** TensorFlow, made by **Google** , is now very popular. Many people use it because it's flexible, fast, and has lots of help. It's good for study and real projects because it's easy to use.
> > Now, TensorFlow is the top choice for many, beating Theano. It is liked for its many tools that help build and run deep learning models easily.
Compared to Theano, TensorFlow is easier to use and understand. It's great for newbies and experts alike. It runs programs very well and fast, working for many different jobs. Plus, lots of people help make it better all the time.
TensorFlow is now the best for deep learning because of its features, help, and how many use it. Though Theano was important at first, TensorFlow is now the favorite.
Criteria Theano TensorFlow Development Status No longer actively maintained Actively maintained and developed Popularity Declining Increasing Documentation Limited Comprehensive and extensive Community Support Minimal Active and vibrant Deployment Options Limited Diverse and flexible
## Conclusion
Choosing between TensorFlow and PyTorch might be tough. It's good to know what each one is good for. TensorFlow is great for big projects because it's been around for a while and many people use it. PyTorch is easy and flexible, which researchers and developers like.
Think about what you need, like how easy it is to use and how well it performs. TensorFlow wins with lots of help online and many ways to use it. PyTorch is quick to try new things because of its simple tools.
Your choice between TensorFlow and PyTorch depends on what you need. Choose TensorFlow for big projects. Go for PyTorch if you want something simple and flexible. They both help you with your deep-learning work.
## FAQ
### What is deep learning?
Deep learning is part of AI. It works like our brains to process data. It uses neural networks for tasks like seeing, hearing, and talking.
### What is Keras?
Keras makes it easy to work with deep learning using Python. It's simple and quick to try new things with deep learning. You can use it with TensorFlow and other tools.
### What is PyTorch?
PyTorch is new and made for easy, flexible deep learning. Facebook's AI team made it. It's good for trying new ideas and doing research.
### What is TensorFlow?
TensorFlow is Google's tool for deep learning, open to all since 2015. It's very popular and big for making real projects. It helps with many types of tasks and runs on Android, too.
### How does PyTorch compare to TensorFlow?
PyTorch is simpler and easier for researchers. TensorFlow is better for big projects and industry work. Each has its place, with PyTorch for trying new things and TensorFlow for big tasks.
### How does PyTorch compare to Keras?
Researchers like PyTorch for its closeness to Python and ease for testing. Keras is easier for developers needing quick solutions. Both are well supported by their communities.
### How does TensorFlow compare to Keras?
TensorFlow is great for strong, fast work, while Keras is simpler to use. Which one to pick depends on your project goals.
### How does Theano compare to TensorFlow?
Theano was liked but is less used now. TensorFlow has taken its place, being more useful and popular today.
### How do I choose between TensorFlow and PyTorch?
Pick TensorFlow for its wide support and strong use in the industry. PyTorch is best for its simplicity and exploring new ideas. Think about your goals and what you need to decide.
## Source Links
- [https://www.freecodecamp.org/news/pytorch-vs-tensorflow-for-deep-learning-projects/](https://www.freecodecamp.org/news/pytorch-vs-tensorflow-for-deep-learning-projects/)
- [https://builtin.com/data-science/pytorch-vs-tensorflow](https://builtin.com/data-science/pytorch-vs-tensorflow)
- [https://www.simplilearn.com/keras-vs-tensorflow-vs-pytorch-article](https://www.simplilearn.com/keras-vs-tensorflow-vs-pytorch-article)
#ArtificialIntelligence #MachineLearning #DeepLearning #NeuralNetworks #ComputerVision #AI #DataScience #NaturalLanguageProcessing #BigData #Robotics #Automation #IntelligentSystems #CognitiveComputing #SmartTechnology #Analytics #Innovation #Industry40 #FutureTech #QuantumComputing #Iot #blog #x #twitter #genedarocha #voxstar
<form>
<input type="email" name="email" placeholder="Type your email…" tabindex="-1"><input type="submit" value="Subscribe"><div>
<div></div>
<div></div>
</div>
</form> | genedarocha | |
1,872,499 | Provisioning AWS solutions in minutes with Infra as Github Actions | I remember those days when I created infra by clicking in the console 😬 eventually that became a... | 0 | 2024-05-31T21:40:00 | https://mymakerspace.substack.com/p/provisioning-aws-solutions-in-minutes | aws, githubactions, terraform, devops | I remember those days when I created infra by clicking in the console 😬 eventually that became a nightmare to manage and infra as code came to save the day 🦸 but with that, it also started an awkward phase of coupling infra code and app code
Some platform teams decided to move infra code to their own repos, that worked, specially for access control, but that required exceptions like:
- Ignoring the image version since it was going to be managed by the app pipeline
- The awkward environment variables setup
I've been searching for ways to bring infra back infra code to app repos
The first experiment was to keep network and LBs and move ECS services with Fargate to the app repo, this continuous to work surprisingly well after 3 years, environment variables changes are in the same PR as app that depended on it, another advantage was that terraform itself managed the newly built docker image tag. However, app developers rarely touched most of the terraform code, as terraform requires significant effort to learn, there has to be a better way 🤔
## Entering Infra as GitHub Actions
With just a few line of YML, we can create pretty complex depended workflows, what if we can use Github Actions to compose infra?
I write a couple of actions that will provision the S3, CloudFront and Route53 with fairly simple steps:
- Login to AWS
- Setup the Backend
- Provision the website
The whole workflow relies on only 3 inputs- Instance name: an identifier for the infra- Domain: DNS for the website, you need to own it on Route53- Path: content to publish as root on the website
```
permissions:
id-token: write
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Check out repo
uses: actions/checkout@v4
- uses: aws-actions/configure-aws-credentials@v4
with:
aws-region: us-east-1
role-to-assume: ${{ secrets.ROLE_ARN }}
role-session-name: ${{ github.actor }}
- uses: alonch/actions-aws-backend-setup@main
with:
instance: demo
- uses: alonch/actions-aws-website@main
with:
domain: ${{ env.DOMAIN }}
content-path: public
```
## How it works
When a GitHub Action job is initialized, it checks out its source code from the repo, this unlocks interesting capabilities, for example: an action could apply terraform as if the terraform code is part of the current repo
### actions-aws-backend-setup ([repo](https://github.com/alonch/actions-aws-backend-setup))
- uses: alonch/actions-aws-backend-setup@main
with:
instance: demo
This action requires a custom instance name to query AWS by tag, we need to find the S3 and Dynamodb to setup the terraform backend
In case where it doesn’t exist, it will provision it and setup the environment variables:
- **TF_BACKEND_s3**: bucket name
- **TF_BACKEND_dynamodb**: table name
### actions-aws-website ([repo](https://github.com/alonch/actions-aws-website))
```
- uses: alonch/actions-aws-website@main
with:
domain: ${{ env.DOMAIN }}
content-path: public
```
This action assumes the backend setup has run, and it requires a domain and the path to the content that needs to be publish as the website
Similar to the backend action, GitHub checks the source code which includes the terraform code to provision a Bucket, Cloudfront, Certificate and route53 routes
Using Github Actions is incredible flexible as the only dependency is on the AWS role and the backend instance name, in the case were we need to upgrade the infra, we just need to tag the new action version and terraform will sync the resources to the latest desired state
## New degree of freedom
With Infra as Github Actions we basically can achieve ephemeral environments with a 31 lines of YML
```
name: Deploy Ephemeral Environment
on:
pull_request:
types: [opened, synchronize, reopened, closed]
env:
DOMAIN: ${{github.head_ref}}.test.realsense.ca
permissions:
id-token: write
jobs:
deploy:
environment:
url: "https://${{ env.DOMAIN }}"
name: ${{github.head_ref}}
runs-on: ubuntu-latest
steps:
- name: Check out repo
uses: actions/checkout@v4
- uses: aws-actions/configure-aws-credentials@v4
with:
aws-region: us-east-1
role-to-assume: ${{ secrets.ROLE_ARN }}
role-session-name: ${{ github.actor }}
- uses: alonch/actions-aws-backend-setup@main
with:
instance: demo
- uses: alonch/actions-aws-website@main
with:
domain: ${{ env.DOMAIN }}
content-path: public
# destroy when PR closed
action: ${{github.event.action == 'closed' && 'destroy' || 'apply'}}
```
This will create a new infra for that PR, update it in sync and destroy it when the PR is closed
## What’s next?
This is just the beginning, I believe GitHub actions dependency could be use to compose and orchestre complex infra with simple interfaces
I'm considering building:
- **actions-aws-http-lambda**: Serverless API from folder path
- **actions-aws-edge-auth**: Website behind social media login from client secrets
- **actions-aws-http-server**: Web hosting from docker image
What do you think? What should I focus on next? | alonch |
1,872,498 | “Mail” example in shadcn-ui/ui manages state using Jotai. | Since I am building shadcn-ui/ui from scratch and also documenting how to do so alongside, I am aware... | 0 | 2024-05-31T21:31:17 | https://dev.to/ramunarasinga/mail-example-in-shadcn-uiui-manages-state-using-jotai-5bb8 | javascript, jotai, opensource, nextjs | Since I am building shadcn-ui/ui from scratch and also documenting how to do so alongside, I am aware that it will take quite some time to understand the code and write it from scratch and prepare the content. I am not rushing the process by directly copying and pasting, instead I am trying to understand the concepts, code, patterns and strategies that can be applied in other projects. This is how I picked up that [“mail” example](https://ui.shadcn.com/examples/mail) in shadcn-ui/ui uses [Jotai](https://jotai.org/) for state management.
In this article, you will learn the below concepts:
1. What is Jotai?
2. Jotai usage example.
3. Jotai configuration in Next.js
4. How is the Jotai configured in Shadcn-ui/ui?
5. How is Jotai used in Shadcn-ui/ui?
What is Jotai?
--------------
[Jotai](https://jotai.org/) is a primitive and flexible state management library for React and is written by [Daishi Kato](https://x.com/dai_shi), also the maintainer of [zustand](https://github.com/pmndrs/zustand). Jotai takes an atomic approach, meaning you will create primitive and derived atoms to build state.
> [_Build shadcn-ui/ui from scratch._](https://tthroo.com/)
Jotai usage example.
--------------------
### Primitive atoms:
```
import { atom } from 'jotai'
const countAtom = atom(0)
const countryAtom = atom('Japan')
const citiesAtom = atom(\['Tokyo', 'Kyoto', 'Osaka'\])
const animeAtom = atom(\[
{
title: 'Ghost in the Shell',
year: 1995,
watched: true
},
{
title: 'Serial Experiments Lain',
year: 1998,
watched: false
}
\])
```
### Derived atoms:
```
const progressAtom = atom((get) => {
const anime = get(animeAtom)
return anime.filter((item) => item.watched).length / anime.length
})
```
Jotai configuration in Next.js
------------------------------
### Next.js (app directory)
Create the provider in a separate client component. Then import the provider into the root layout.js server component.
```
// ./components/providers.js
'use client'
import { Provider } from 'jotai'
export const Providers = ({ children }) => {
return (
<Provider>
{children}
</Provider>
)
}
// ./app/layout.js
import { Providers } from '../components/providers'
export default function RootLayout({ children }) {
return (
<html lang="en">
<body>
<Providers>
{children}
</Providers>
</body>
</html>
)
}
```
How is the Jotai configured in Shadcn-ui/ui?
--------------------------------------------
[apps/www/components/providers.tsx](https://github.com/shadcn-ui/ui/blob/main/apps/www/components/providers.tsx#L10) in shadcn-ui has the Jotai and the theme provider configuration as shown below:

How is Jotai used in Shadcn-ui/ui?
----------------------------------
[apps/www/app/(app)/examples/mail/use-mail.ts](https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/use-mail.ts#L2) defines a useMail hook that is found to be later in components such as
1. [mail-list.tsx](https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/components/mail-list.tsx)
2. [mail.tsx](https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/components/mail.tsx)
This is one of the use cases to implement state management using Jotai in Next.s

About me:
---------
Website: [https://ramunarasinga.com/](https://ramunarasinga.com/)
Linkedin: [https://www.linkedin.com/in/ramu-narasinga-189361128/](https://www.linkedin.com/in/ramu-narasinga-189361128/)
Github: [https://github.com/Ramu-Narasinga](https://github.com/Ramu-Narasinga)
Email: [ramu.narasinga@gmail.com](mailto:ramu.narasinga@gmail.com)
Reference:
----------
1. [https://ui.shadcn.com/examples/mail](https://ui.shadcn.com/examples/mail)
2. [https://jotai.org/](https://jotai.org/)
3. [https://github.com/shadcn-ui/ui/blob/main/apps/www/app/layout.tsx](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/layout.tsx)
4. [https://github.com/shadcn-ui/ui/blob/main/apps/www/components/providers.tsx#L10](https://github.com/shadcn-ui/ui/blob/main/apps/www/components/providers.tsx#L10)
5. [https://github.com/search?q=repo%3Ashadcn-ui%2Fui%20atom&type=code](https://github.com/search?q=repo%3Ashadcn-ui%2Fui%20atom&type=code)
6. [https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/use-mail.ts#L8](https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/use-mail.ts#L8)
7. [https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/components/mail.tsx](https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/components/mail.tsx)
8. [https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/components/mail-list.tsx](https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/app/(app)/examples/mail/components/mail-list.tsx)
9. [https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/hooks/use-config.ts#L11](https://github.com/shadcn-ui/ui/blob/13d9693808badd4b92811abac5e18dc1cddf2384/apps/www/hooks/use-config.ts#L11) | ramunarasinga |
1,872,497 | I built a React Native Boilerplate to ship your apps faster🚀 | Hey everyone! I'm excited to introduce my latest project: ExpoShip. It's a React Native/Expo... | 0 | 2024-05-31T21:31:09 | https://dev.to/rudolfsrijkuris/i-built-a-react-native-boilerplate-to-ship-your-apps-faster-2246 | reactnative, javascript, mobile, beginners | Hey everyone!
I'm excited to introduce my latest project: ExpoShip. It's a React Native/Expo boilerplate designed to make your development process much faster and pain free. ExpoShip comes with:
- **Paywall integration**: Ready-to-use in-app purchase and subscription setup.
- **User authentication**: Secure and seamless user login and registration.
- **Push notifications**: Pre-configured to keep your users engaged.
- **UI components**: A collection of reusable and customizable UI elements.
- **Dark mode**: Built-in support for dark mode to enhance user experience.
For first 100 customers use code **FIRST100** at the checkout to get 40% off.
I'd love for you to check it out and share your feedback!
[https://expoship.dev](https://expoship.dev)
Happy coding! | rudolfsrijkuris |
1,872,496 | Upstream preview: Life after the xz utils backdoor hack | Upstream is next week on June 5, and wow, our schedule is shaping up brilliantly. For the rest of... | 0 | 2024-05-31T21:25:21 | https://blog.tidelift.com/upstream-session-spotlight-life-after-the-xz-utils-backdoor-hack | upstream, opensource, security, xz | <p><em>Upstream is next week on June 5, and wow, our schedule is shaping up brilliantly. For the rest of this week, we’ll be giving you a sneak preview into some of the talks and the speakers giving them via posts like these. RSVP </em><a href="https://upstream.live/register?__hstc=23643813.d1ddc767e9f4955f3bdd2f1c64c72f8c.1654699542897.1716388421586.1716392544277.1287&__hssc=23643813.2.1716392544277&__hsfp=1649118565" rel="noopener" target="_blank"><em><span>now</span></em></a><em>!</em></p>
<!--more-->
<p>In late March, our industry dealt with yet another attack on a popular open source project; this time, in the Linux-level package used for file compression called <a href="https://tidelift.com/resources/xz-backdoor-hack" rel="noopener" target="_blank"><span>xz utils</span></a>. </p>
<p>What was most sinister about this attack, though, was how deeply it impacted trust within the open source community. The attacker spent years engineering multiple sock puppet accounts to gain the trust of the volunteer xz utils maintainer. The reality is that life for those who create and use open source after xz is going to get tougher. </p>
<p>In this panel moderated by Tidelift VP of product Lauren Hanford, we’ll talk to Josh Bressers of Anchore; Jordan Harband, prolific Javascript maintainer; Rachel Stephens from RedMonk; Shaun Martin, IT and security management consulting principal from BlackIce; and Terrence Fletcher from Boeing to get a diverse mix of perspectives on how this changes the landscape of open source software supply chain security.</p>
<p>If this conversation peaks your interest, be sure to join us at <a href="https://upstream.live/" rel="noopener" target="_blank"><span>Upstream</span></a> on June 5!</p>
<p style="text-align: center;"><a href="https://upstream.live/" style="padding: 10px 30px; background-image: linear-gradient(#22C994 0%, #22C994 100%); color: #ffffff; border-radius: 30px; text-decoration: none; font-weight: bold;" rel="noopener">RSVP now</a></p>
<p style="font-weight: bold;">About the panelists </p>
<ul>
<li aria-level="1">Rachel Stephens is a senior analyst with RedMonk, a developer-focused industry analyst firm. She focuses on helping clients understand and contextualize technology adoption trends, particularly from the lens of the practitioner. Her research covers a broad range of developer and infrastructure products.</li>
<li aria-level="1">Shaun Martin is the IT and security management consulting principal at BlackIce. She has more than 23 years of experience in the IT security, risk, and compliance operations space. Her goal is to build and cultivate inclusive work environments where people can grow and thrive equally. </li>
<li aria-level="1">Josh Bressers is vice president of security at Anchore where he guides security feature development for the company’s commercial and open source solutions. He is a co-lead of the OpenSSF SBOM Everywhere project, and is a co-founder of the Global Security Database project at the Cloud Security Alliance.</li>
<li aria-level="1">Jordan Harband is an open source maintainer, specifically in JavaScript, and the principal open source architect at HeroDevs. He's also a web application developer, database administrator, network engineer, teacher, childcare—he wears many hats. His focus is JavaScript, standards, frontend web development, full stack (frontend + backend + db) architecture design, and overall object oriented code optimization. </li>
<li aria-level="1">Terrence Fletcher is a product security engineer at the Boeing Company where he specializes in vulnerability management, attack surface profiling, and threat intelligence integration. He has over two decades of experience in IT and security, with a strong focus on the defense and intelligence sectors.</li>
</ul> | kristinatidelift |
1,872,438 | Important Terminologies in JavaScript | 1. Function Statement A function statement is a simple way of creating a... | 27,544 | 2024-05-31T20:59:52 | https://bhaveshjadhav.hashnode.dev/important-terminologies-in-javascript | javascript, webdev, programming | ## 1. Function Statement
A function statement is a simple way of creating a function:
```javascript
function a() {
console.log("a called");
}
```
This simple way of creating a function is known as a function statement.
## 2. Function Expression
A function expression is when a function acts like a value of a variable:
```javascript
var b = function() {
console.log("b called");
};
```
## 3. Difference Between Function Statement and Function Expression
The major difference between these two is hoisting:
```javascript
a(); // Output: "a called"
b(); // Output: TypeError
function a() {
console.log("a called");
}
var b = function() {
console.log("b called");
};
```
In this code, during the hoisting phase (the memory allocation phase), `a` is assigned its function definition. But in the case of a function expression, `b` is treated like any other variable and is assigned `undefined` initially. Until the code hits `b = function()`, `b` remains undefined. Therefore, calling `b()` before its definition results in an error. This is the major difference between a function statement and a function expression.
## 4. Function Declaration
A function declaration is nothing but a function statement. Function declaration and function statement are the same things:
```javascript
function a() {
console.log("a called");
}
```
## 5. Anonymous Function
An anonymous function is a function without a name:
```javascript
function() {
// Code
}
```
Anonymous functions do not have their own identity. Creating an anonymous function like this will give you a syntax error:
```javascript
function() {
// Code
}
```
Because an anonymous function looks like a function statement but has no name, according to the ECMAScript specification, functions should always have a name. Therefore, `function () {}` is invalid syntax. Anonymous functions are used where functions are used as values:
```javascript
var b = function() {
console.log("b called");
};
```
## 6. Named Function Expression
A named function expression is like a function expression but with a name:
```javascript
var b = function xyz() {
console.log("b called");
};
```
If you call `b()`, it works, but calling `xyz()` will give an error. `xyz` is not defined in the outer scope; it is only available inside the function itself:
```javascript
var b = function xyz() {
console.log(xyz);
};
b(); // Prints the function definition
xyz(); // ReferenceError: xyz is not defined
```
## 7. Difference Between Parameters and Arguments
Parameters are the names listed in the function definition, while arguments are the values passed to the function when it is invoked:
```javascript
function a(param1, param2) {
console.log("hello");
}
a(1, 2); // 1 and 2 are the arguments
```
## 8. First-Class Function:
The ability to use a function as a value is known as a first-class function. The ability of a function to be used as a value and passed as an argument to another function, or returned from a function, is known as a first-class function. This ability is known as a first-class function. For example:
```javascript
var b = function(x) {
console.log(x);
};
b(function() {
console.log("Anonymous function");
});
function xyz() {
console.log("Named function");
}
b(xyz);
var c = function() {
return function() {
console.log("Returned anonymous function");
};
};
console.log(c()());
```
First-class functions allow us to treat functions like any other value, also referred to as "first-line citizens."
## 9. Callback Functions
Callback functions are first-class citizens in JavaScript. This means you can take a function and pass it into another function, and when you do so, the function you pass into another function is known as a callback function. Callback functions are very powerful in JavaScript. They give us access to the asynchronous world in a synchronous single-threaded language. Due to callbacks, we can do asynchronous things in JavaScript:
```javascript
function x(callback) {
console.log("x");
callback();
}
x(function y() {
console.log("y");
});
```
If you call a function and pass a function into another function, the passed function is the callback function. This function is known as a callback function because it is called back later in the code. You give the responsibility of this function to another function. For example:
```javascript
setTimeout(function() {
console.log("timer");
}, 5000);
function x(y) {
console.log("x");
y();
}
x(function y() {
console.log("y");
});
```
JavaScript has just one call stack, also known as the main thread. Everything executed inside your page is executed through the call stack only. If any operation blocks the call stack, it is known as blocking the main thread. For example, if your function `x()` had a very heavy operation that takes around 20 to 30 seconds to complete, by that time, because JavaScript has only one call stack, it won't be able to execute any other function inside the code. That means everything will be blocked on the code. This is why we should never block our main thread. We should always try to use asynchronous operations for tasks that take time, just like using `setTimeout`:
```javascript
setTimeout(function() {
console.log("timer");
}, 5000);
function x(y) {
console.log("x");
y();
}
x(function y() {
console.log("y");
});
```
Using web APIs, `setTimeout`, and callback functions, we can achieve asynchronous operations in JavaScript..
We know how to use these concepts practically, but we often don't know the terminologies. If an interviewer asks what a function expression is, we might get stuck because we don't know the term. A function expression is when a function acts like a value of a variable:
```javascript
var b = function() {
console.log("b called");
};
```
However, we use this type of syntax many times in JavaScript coding without knowing what it's called. | bhavesh_jadhav_dc5b8ed28b |
1,872,437 | Babylon.js Browser MMO - DevLog - Update #1 - Rewriting to ECS framework | Hello after long break! Finally I'm back and I'll continue working on my project. Project code got... | 0 | 2024-05-31T20:56:16 | https://dev.to/maiu/babylonjs-browser-mmo-devlog-update-1-rewriting-to-ecs-framework-1pme | babylonjs, gamedev, indie, mmo | Hello after long break!
Finally I'm back and I'll continue working on my project.
Project code got messy and it was harder and harder to add new things. After long thinking I decided that I'll rewrite whole code base and try to implement simple ECS framework (just for sake of maintainability and extensibility).
What You see on the video is effect of integrating server and client and loading player after receiving confirmation from the server. Sounds easy but under the hood there's quite advanced mechanism (hopefully not overengineered - will found out in the future).
Next on the backlog is player movement - for now without any client side prediction.
{% youtube f-w7piZwI6A %} | maiu |
1,872,435 | Essential Helper Functions for Your JavaScript Projects | When working on various JavaScript projects, I often find myself needing some handy helper functions... | 0 | 2024-05-31T20:53:37 | https://dev.to/timmy471/essential-helper-functions-for-your-javascript-projects-4n5f | react, nextjs, javascript | When working on various JavaScript projects, I often find myself needing some handy helper functions to simplify repetitive tasks. Below are some of the helper functions that have proven to be very useful in my projects. These functions cover a range of tasks from string manipulation to number checks and date formatting.
## 1. Capitalize the First Letter of a String
This function takes a string and capitalizes the first letter while converting the rest of the string to lowercase. This is particularly useful for formatting names or titles.
```
export const capitalizeFirstLetter = (word?: string) => {
return word ? word.charAt(0).toUpperCase() + word.toLocaleLowerCase().slice(1) : '';
};
```
## 2. Format an Array to a Sentence
When you have an array of strings that you need to format as a sentence, this function joins the array elements with commas and replaces the last comma with "and".
```
export const formatArrayToSentence = (stringArr: string[]) => {
if (!stringArr?.length) return '';
return stringArr.join(', ').replace(/, ([^,]*)$/, ' and $1.');
};
```
## 3. Format Date
This function uses the moment library to format dates. It can format a date to DD/MM/YYYY or to a time format HH:mm A based on the isTime flag.
```
import moment from 'moment';
export const formatDate = (date: string, isTime = false) => {
if (!date) return '';
const parsedDate = moment(date);
if (isTime) return parsedDate.format('HH:mm A');
return parsedDate.format('DD/MM/YYYY');
};
```
## 4. Truncate Text
To shorten a text string to a specified length and append an ellipsis (...), use this function. It ensures the text does not exceed the desired length.
```
export const truncateText = (text: string, maxLength: number) => {
if (text.length <= maxLength) return text;
return text.substring(0, maxLength) + '...';
};
```
## 5. Check for Uppercase, Lowercase, Numbers, and Special Characters
These functions use regular expressions to check if a string contains at least one uppercase letter, one lowercase letter, one number, or one special character. These are particularly useful for password validation.
```
export const containsAtleastOneUpperCase = (val: string) => /(?=.*?[A-Z])/.test(val);
export const containsAtleastOneLowerCase = (val: string) => val ? /(?=.*?[a-z])/.test(val) : false;
export const containsAtleastOneNumber = (val: string) => /(?=.*[0-9])/.test(val);
export const containsAtLeastOneSpecialChar = (val: string) => /(?=.*[$&+,:;=?@#|'<>.^*_()%!-])/.test(val);
```
## 6. Check if a Number is Even or Odd
These simple functions check if a number is even or odd.
```
export const isEven = (number: number) => (number ? number % 2 === 0 : false);
export const isOdd = (number: number) => number % 2 !== 0;
```
## 7. Check for Non-Empty Object
This function checks if an object is not empty, which is useful for validating that an object has properties before performing operations on it.
```
export const isNonEmptyObject = (obj: Record<string, unknown>) => {
return typeof obj === 'object' && obj !== null && Object.keys(obj).length > 0;
};
```
## Conclusion
These helper functions are designed to make common tasks easier and your code more readable. By incorporating them into your projects, you can save time and ensure consistency across your codebase. Whether it's formatting strings, validating inputs, or checking object properties, these utilities cover a broad range of use cases that are essential in everyday JavaScript development.
| timmy471 |
1,872,434 | HOW MUYERN TRUST HACKER HELP IN RECOVERING FROM CRYPTO FRAUD | Muyern Trust Hacker stands as a beacon of trust and reliability in the ever-expanding realm of... | 0 | 2024-05-31T20:53:06 | https://dev.to/harald_christoph_a2d1f864/how-muyern-trust-hacker-help-in-recovering-from-crypto-fraud-466 | Muyern Trust Hacker stands as a beacon of trust and reliability in the ever-expanding realm of digital asset recovery. In a world where online scams and cybercrime proliferate, finding a trustworthy ally like Muyern Trust Hacker can be a game-changer for those who have fallen victim to fraudulent schemes. My journey with Muyern Trust Hacker began after a devastating loss to a fake investment firm. Amidst the despair and frustration, Muyern Trust Hacker emerged as a guiding light, offering hope and tangible solutions to reclaim what was rightfully mine. What truly sets Muyern Trust Hacker apart is its unwavering commitment to its clients. Unlike other recovery firms that may prioritize profit over people, Muyern Trust Hacker operates with integrity and transparency at every turn. From the initial consultation to the successful recovery of funds, their dedication to providing top-notch service is evident in every interaction. Muyern Trust Hacker's expertise is nothing short of exceptional. With a deep understanding of cybersecurity protocols and digital forensics, they possess the technical acumen to navigate even the most complex cases. Whether recovering stolen cryptocurrencies, tracing fraudulent transactions, or combating identity theft, Muyern Trust Hacker approaches each challenge with precision and skill. What truly impressed me about Muyern Trust Hacker was their commitment to delivering results promptly. In an industry where time is of the essence, their swift action and efficient approach ensure that clients can reclaim their assets with minimal delay. This alleviates the financial strain caused by the loss and provides much-needed peace of mind. Furthermore, the level of personalized attention and support provided by Muyern Trust Hacker is unparalleled. Unlike larger firms where clients may feel like just another case number, Muyern Trust Hacker fosters a genuine connection with each individual. From regular updates on the progress of the recovery process to tailored strategies based on the specific circumstances, clients can rest assured knowing that their case is receiving the attention it deserves. In addition to their impressive track record of success, Muyern Trust Hacker's commitment to ongoing support is commendable. Even after the recovery process is complete, they continue to offer guidance and advice to ensure that clients are equipped with the knowledge and tools necessary to safeguard their assets in the future. In conclusion, Muyern Trust Hacker is more than just a recovery firm – they are a trusted partner in the fight against online scams and fraud. With their unwavering dedication to their clients, unmatched technical expertise, and proven track record of success, Muyern Trust Hacker stands as a beacon of hope for those seeking justice in the digital world. Web page: https: //muyerntrusthack .solutions/ and Tele gram at: muyerntrusthackertech
 | harald_christoph_a2d1f864 | |
1,836,433 | Cloud Resume Challenge Chunk 1 | Chunk 1: Building the Front End Chunk 1 of the AWS CRC has a few things to... | 0 | 2024-05-31T20:52:12 | https://dev.to/brianhaas/cloud-resume-challenge-chunk-1-3681 | devops, webdev, aws, career | ## Chunk 1: Building the Front End
Chunk 1 of the AWS [CRC](https://cloudresumechallenge.dev/) has a few things to accomplish:
* Build a resume site using static HTML and CSS
* Host the static content on an s3 bucket
* Access the website using HTTPS, which requires CloudFront
* Use a custom domain name, which will require a certificate for https usage and DNS entries using Route53
### Getting started
I am not a front-end web developer, and UI/UX design is not one of my skills. So, rather than fumble around trying to make my resume webpage look good, I decided to use a static website generator. I chose to use [Hugo](https://gohugo.io/), since they have a lot of templates to choose from.
Hugo has a bit of a learning curve, but once I got through that, it was pretty straight forward to edit and generate my [site] (https://brianwhaas.com/).
### The infrastructure
To make things easy, I went ahead and registered a new domain name with AWS, and it automatically created a Route53 hosted zone. So that part was done.
Rather than point and click in the AWS console, I decided to start with IaC using [Terraform] (https://www.terraform.io/). I also decided to use GitHub actions(https://docs.github.com/en/actions) for CI/CD to get familiar with them. I had only used GitLab CI/CD and runners previously, which are very similar to GitHub Actions.
You can see what I wrote [here](https://github.com/chronosAZ/CRC-Frontend/tree/main/tf). After scouring for examples, I wrote some scripts to create the s3 bucket, certificate, and CloudFront Distribution.
Everything was working great, except I didn't realize that the CloudFront default root document(index.html), only applies to the actual web root, not any subdirectories. Unfortunately, the Hugo site I generated, used subdirectories for my individual pages. I [wrote](https://github.com/chronosAZ/CRC-Frontend/blob/main/tf/js/rewriteindex.js) a CloudFront function to rewire all requests for "/ or subdir/" to grab the index.html document in that folder.
So far, so good. It was time to move onto the backend of the challenge.
| brianhaas |
1,872,139 | Calorie Nutrition Tool | Discover the wonders of nutrition with our calorie nutrition tool! If you've ever found yourself... | 0 | 2024-05-31T14:26:04 | https://dev.to/alanna_taylor_043a02c1744/calorie-nutrition-tool-ga1 | Discover the wonders of nutrition with our [calorie nutrition tool](https://discoverybody.com/calorie-nutrition/)! If you've ever found yourself puzzled by the nutritional content of your meals, fret not - our user-friendly tool is here to guide you. Whether you're a seasoned health aficionado or a complete novice in the realm of nutrition, our tool provides a straightforward way to understand what you're eating.
From tracking your daily calorie intake to exploring the nutritional values of different foods, our tool empowers you to make informed dietary choices with ease. Join us on a journey towards healthier eating habits and a happier, more vibrant lifestyle. Explore the world of nutrition today with our calorie nutrition tool!
https://discoverybody.com/calorie-nutrition/

| alanna_taylor_043a02c1744 | |
1,872,433 | Load Balancing | Today I learned about Load Balancing. What is Load Balancing? Load Balancing is a tool or... | 0 | 2024-05-31T20:48:39 | https://dev.to/chinemelum_iloe/load-balancing-53lo | Today I learned about Load Balancing.
**What is Load Balancing?**
Load Balancing is a tool or application that distributes network or application traffic across multiple servers or applications to improve their performance and reliability.
**How does it do this?**
- **Distributing the Load:** Load balancing spreads the workload evenly across servers to improve application performance. It’s like having multiple checkout lanes open at a busy supermarket.
- **Reducing Latency:** By redirecting client requests to a server closer to the user, load balancing helps reduce the time it takes for a website to respond. It’s like choosing the fastest route to your destination.
- **Increasing Availability:** Traffic is distributed across multiple targets in different Availability Zones, ensuring that even if one zone has issues, your service remains up and running.
- **Auto-scaling:** Load balancers can collect information about server usage and dynamically adjust resources accordingly.
**Why is it useful?**
Load balancing is useful because it ensures that incoming network traffic is distributed evenly across multiple servers, preventing any single server from becoming overwhelmed and improving overall application performance. | chinemelum_iloe | |
1,872,431 | johnsam3910 | We welcome you thestylgem Build trust, serve as a guide, and reach more people who can benefit your... | 0 | 2024-05-31T20:42:09 | https://dev.to/sam_johnson_dcc596ba13b9b/johnsam3910-3m7a | We welcome you [thestylgem ](https://www.thestylgem.com/)Build trust, serve as a guide, and reach more people who can benefit your expertise. Establish your brand as a leading authority in your marketplace. | sam_johnson_dcc596ba13b9b | |
1,872,430 | AWS CloudEndure Migration: Seamlessly Transitioning Workloads to the Cloud | Introduction to Cloud Migration Challenges and Solutions Cloud migration refers to the process of... | 0 | 2024-05-31T20:39:14 | https://sudoconsultants.com/aws-cloudendure-migration-seamlessly-transitioning-workloads-to-the-cloud/ | cloudendure, workloads, cloud, aws | <!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Introduction to Cloud Migration Challenges and Solutions</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Cloud migration refers to the process of transferring digital business resources—which most often include applications, data, and sometimes operated software—from on-premise data centers into the cloud. In the process, the following challenges emerge: how to provide data security, cost management, application compatibility, and downtime minimization in the process of data migration. Many strategies and solutions are implemented to overcome these difficulties.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Overview of AWS CloudEndure Migration</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS CloudEndure Migration is a Software-as-a-Service application that enables the user to move work from one infrastructure to another, be it from on-premises data centers, other cloud providers, or be it within AWS regions. It is available to migrate VMs, physical servers, and Amazon EC2 instances while keeping the source machines in sync with target infrastructure, at a transfer incurring near zero downtime and data loss.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Understanding AWS CloudEndure Migration</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Definition of CloudEndure Migration and Its Role Within AWS</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>CloudEndure Migration is a Software-as-a-Service (SaaS) application provided by AWS. It is used to automate the process of achieving data, business applications, and other business pieces from an on-premise network or cloud to another physical or cloud environment. AWS CloudEndure Migration automates and accelerates large-scale migrations into AWS. It ensures that the process is carried out with ease and does not interfere with the functioning of the organization. It is perfect for organizations who intend to use AWS for its scalability and fault tolerance and do not want to go through the difficulty of re-engineering.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Key Features of CloudEndure Migration</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Continuous Block-Level Replication:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>CloudEndure Migration makes use of agents in its source instances to ensure continuous replication is done on a block volume to its target region. This is the process by which data replication is done. This automatically orchestrates the full stack by natively converting all applications and databases to run in AWS. This automation highly reduces the necessity for extensive manual interventions. Therefore the process of migration becomes more efficient and less prone to errors.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Minimal Downtime:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>In the process of migration, CloudEndure migration, with the aid of continuous replication of data, goes through minimal downtime. Through this process, the business can ensure its effective operation over time. This is especially very beneficial for firms that have IT organizations that really cannot afford service interruptions.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Flexibility in Network Configuration:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>CloudEndure Migration can perform the migration of Amazon VPC network and security configurations as part of the migration workflow to take into consideration any changed target environment. This would be set to match the existing settings to allow the system to work properly.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Network Configuration Flexibility:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Key in network configuration, one can configure target instance settings at the time of launching such as instance configuration parameters, tenancy and volume type based on the requirement. This makes the whole process of migration more flexible and therefore, adjustable to different needs of an organization.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Benefits of Using AWS CloudEndure Migration</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Reduction in Downtime</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>CloudEndure Migration ensures less downtime process due to continual replication of block-level. It would make sure that data on the target is in a coherent state with that on the source. Thus, when the actual cutover process is started, a source-to-target environment switch can be achieved in minutes with virtually no data loss. This reduces the window of weakness drastically in the process of migration that ensures the businesses can update their operations with minimal downtimes.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Cost-Effectiveness</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Since CloudEndure Migration doesn't work on traditional migration tools and methods, the process of migrating workloads to AWS is economical. It works in a staging area where no high-cost resources are involved, and the cost is kept at the minimum. By default, CloudEndure Migration uses the t3.small EC2 instance type for the replication servers and EBS magnetic volumes for its attached volumes. But, if a volume size is over 500 GB, no charge is done in the process. In addition to this, CloudEndure Migration is also charged for storing snapshots that it takes for every volume. But these snapshots are cleared automatically once out of use, which removes the unnecessary cost in this regard. Thus, the low costs in resource utilization and the clearing out of unnecessary snapshots fall under the financial boundary of interest for most organizations.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Versatility</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>CloudEndure Migration is flexible in terms of the supported infrastructure where wide source infrastructure includes on-premises environments, other cloud platforms and virtualized environments. Thus, one can perform flexible migration strategies according to need of an enterprise. CloudEndure Migration is capable of performing the migration whether or not the enterprise relates to physical server setup at the source, the virtualized environment, or another cloud provider.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">How CloudEndure Migration Works</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The step-by-step process of how CloudEndure Migration works:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>SETUP AND CONFIGURATION</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>ONGOING REPLICATION</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>CUT-OVER PHASE</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>REPLICATION AND ORCHESTRATION IN TECHNICAL DETAILS</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Step-by-Step Process of CloudEndure Migration</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Preparation</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Follow the below mentioned steps to prepare to migrate:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>AWS account with sufficient permission.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Cloud Endure Migration license or setup available to you via AWS Migration Hub.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Source environment access and credentials.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Create a CloudEndure Project</h3>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Console:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Go to the Cloud- Endure Migration console.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select "Create New Project".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Give the project name and select the type of migration.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>As your target environment needs AWS Credential, give AWS Credentials.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choose the AWS region.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">CLI:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Download Cloud Endure CLI</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Run the following command to create a new Project:</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>cloudendure project create --name "ProjectName" --type "migration" --region "aws-region"</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Install the CloudEndure Agent on Source Machines</h3>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Console:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>In the CloudEndure console, go to the "Machines" tab.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click the "Add Machines" blue button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Download and install the CloudEndure Agent on each source machine.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Register each agent with the supplied token.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">CLI:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Install the agent.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>curl -o ./installer_linux.py https://console.cloudendure.com/api/latest/installer_linux.py</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Run the installer on each source machine.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>sudo python ./installer_linux.py -t <YOUR_TOKEN></em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Configure Replication Settings</h3>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Console:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Click the "Replication Settings" tab.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Set necessary replication settings: subnet security groups, instance type.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Save settings.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">CLI:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Configure instance replication from source to target machine:</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>cloudendure replication configure --project-id "project-id" --subnet-id "subnet-id" --security-group-ids "sg-ids" --instance-type "instance-type"</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Start Data Replication</h3>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Console:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>In the "Machines" tab of the console, select the source machines.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the upper-right corner, click the "Start Replication" button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Monitor data replication.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">CLI:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Execute the task for each of the machines:</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>cloudendure machine start-replication --machine-id "machine-id"</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Perform Test Cutover</h3>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Console:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>As soon as initial replication is done, go to the "Machines" tab.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select the machine and, at the top, click on "Launch Target Machines".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select the test cutover option and follow the dialogue.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Validate if the application and system run in AWS.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">CLI:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Start the test cutover program by using the CloudEndure CLI:</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>cloudendure machine launch --machine-id "machine-id" --launch-type "test"</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Perform Cutover (Migration)</h3>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">Console:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>When the cut-over test is successful, then go ahead and click the final cutover.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the "Machines" tab, select the machines; then click "launch target machines".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choose the cutover option and go through the instructions in the dialog.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Monitoring will be done on the process of cutover for successful migration.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading">CLI:</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Launch target machines for final cutover:</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>cloudendure machine launch --machine-id "machine-id" --launch-type "cutover"</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Post-Migration Activities</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Validate that all applications and services are running as expected in the AWS environment.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Update DNS settings, security groups and any other configurations.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Decommission source environment in case it is no longer needed.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Additional Tips</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Ensure that the network connectivity between the source and the target is the same.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Monitor the CloudEndure dashboard at regular intervals to ensure that there would not be issues during replication and cutover.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Test it well in advance before the final cutover to make sure that there would not be downtime and interruption.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>For any person to use CloudEndure Migration to ensure they migrate their resources successfully, there is a need for proper planning and execution of each and every one of the steps involved in the process. This guide should thus be a good recourse for the individual to carry out operations in the console or CLI.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Use Cases of CloudEndure Migration</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Sony Interactive Entertainment</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Use Case:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Sony Interactive Entertainment had a designed move of their gaming and digital entertainment services to AWS to further augment scalability, performance, and global reach.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Solution:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Sony Interactive Entertainment has effortlessly replicated their gaming servers and databases with CloudEndure Migration. They moved to the cloud with barely any downtime that was almost unnoticeable by millions of players across the globe. Data remains current with CloudEndure's continuous replication; therefore, no effect was noticed on the overall user experience.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Result:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The scalability and performance of the gaming services offered by Sony have been ameliorated, capable of handling extra-large tons of simultaneous users.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Coca-Cola Icecek</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Use Case:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Coca-Cola Icecek wanted to consolidate its IT setup by migrating multiple on-premises data centers into AWS.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Solution:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>CloudEndure Migration supported the replication of critical applications, databases, and servers from Coca-Cola Iceçek to the AWS cloud. The ability of the continuous replication feature ensured a seamless cutover with less downtime, therefore ensuring continuity of business.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Outcome:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The migration to AWS is indeed crucial in discovering an IT platform that is unquestionably more agile, scalable, and in the process, reduces operational costs by enhancing disaster recovery.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Petco</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Use Case</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Being a leading specialty pet retailer with operations across the globe, Petco is committed to moving its e-commerce servers and applications to AWS to improve performance and ensure growth.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Solution:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Petco leveraged the CloudEndure Migration Platform to replicate e-commerce servers and applications on the AWS cloud, thus moving servers and applications with minimal downtime, allowing Petco to offer an online presence and customer service even from the cloud.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Outcome:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>After migrating, there was an average improvement in website performance of 30% in faster load times and the ability to scale resources as traffic dictates, resulting in an improved customer experience.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Industries That Benefit from Using CloudEndure Migration</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Finance:</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Use-case:</strong> Introduces continuous availability for financial applications and data in times of disaster recovery.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Example:</strong> Used by a bank, CloudEndure replicated its critical banking application to AWS, ensuring there is no downtime whenever the data center fails.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Healthcare:</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Use-case:</strong> Introduces patient legacy data and healthcare applications with zero compliance issue concerning regulations like HIPAA.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Example:</strong> Used by a hospital system for migrating the electronic health records (EHR) to AWS, promising more elasticity and safety.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Retail:</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Use-case:</strong> Migrate the ecommerce platform to scale for seasonal peak traffic.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Example:</strong> Used by an online retailer for migrating its ecommerce platform to AWS using CloudEndure ahead of Black Friday, promising the site can handle increased traffic.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Manufacturing:</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Use Case:</strong> Merging the separated on-premises data centers into a single cloud for enhanced data management and analytics.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Example:</strong> A manufacturing company uses CloudEndure to migrate its ERP systems to AWS and improve operational efficiency with better data insights.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Education:</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Use Case:</strong> Relocation of administrative and online learning systems to the cloud for better scalability and availability.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Example:</strong> The University used CloudEndure to migrate their people soft student information system and online course platform to AWS, where the data can be accessed reliably by students and faculty.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Preparing for Migration with CloudEndure</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Prerequisites and Initial Considerations</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Setting up the AWS Account: Ensure your AWS account is set up. Ensure that it has the appropriate policies and roles.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Configuring the Network: Verify network connectivity between the source environment and AWS, ensuring sufficient bandwidth.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Security and Compliance: Review security policies and compliance requirements. Ensure data encryption and compliance with all regulations.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Inventory and Assessment: Make a comprehensive inventory of all applications, databases, and dependencies forming part of the existing environment.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Tips for Planning and Executing a Smooth Migration</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Migration Plan: Develop a detailed plan for migration, including every step to migrate to the cloud. Each task in the plan must have assigned a timeline, people responsible, and resources.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Testing: Perform complete testing of applications and systems on AWS to check for compatibility and performance before turning off production systems.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Backup Data: Backup all data before you start the migration—this prevents loss of data.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Minimal Downtime: The cutover phase should be carried out during off-peak hours to minimize the disruption of business.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Common Pitfalls and How to Avoid Them</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Bandwidth: Poor bandwidth can lead to poor replication. Achieve sufficient bandwidth with AWS Direct Connect or VPN.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Incomplete Inventory If dependencies are missing, then failures may occur. Ensure the inventory is done properly.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Security Misconfigurations Can expose sensitive data Double-check and configure security settings properly</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Lack of Testing Can lead to unexpected issues. Thorough testing should be done before the final cutover</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Advantages of CloudEndure Over Non-AWS Migration Solutions</h2>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Seamless AWS Integration: It is optimized for AWS environments, thus making all migrations smooth and efficient.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Real-Time Replication: Data replication is continuous hence zero downtime and maintaining data consistency.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Pocket-Friendly Costs: Its cost is often more friendly compared to third party solutions, plus better integration and support.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Challenges and Solutions</h2>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Network Latency:</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Solution: Implement AWS Direct Connect or VPN services to reduce.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Compatibility Issues:</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Solution: Compatibility testing and AWS services can be leveraged to bridge the gaps.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Data Security Concerns:</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Solution: Enforce encryption and follow AWS security best practices.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Future of Cloud Migration with AWS CloudEndure</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Upcoming Features and Updates</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Enhanced Automation: More automation to increase the speed and efficiency of the migrations</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AI/ML Integration: Migrate optimization strategy and performance using AI and ML.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Trends in Cloud Migration Strategies</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Hybrid Cloud Solutions are gaining popularity for the flexibility and resilience they bring. Multi-Cloud strategies are taking place, using several different clouds to avoid vendor lock-in and ensure the highest performance.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Conclusion</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>This is the main reason cloud migration is considered key to unlocking the scalability, flexibility, and cost savings offered by the cloud. AWS CloudEndure assures the seamless process of migration and, at the same time, assures its users that it can present the user with some very powerful tools that can execute migrations non-disruptively.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Final Thoughts on the Role of AWS CloudEndure</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS CloudEndure is one of the options most companies are going for in a bid to eliminate complexities and risks in cloud migration.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Further Resources</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Links to Additional AWS Documentation, Tutorials, and Community Forums<strong></strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><a href="https://docs.aws.amazon.com/cloudendure/latest/userguide/what-is-cloudendure-migration.html">AWS CloudEndure Migration Documentation</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><a href="https://aws.amazon.com/migration-hub/">AWS Migration Hub</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><a href="https://aws.amazon.com/dms/">AWS Database Migration Service</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><a href="https://forums.aws.amazon.com/">AWS Community Forums</a></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --> | sidrasaleem296 |
1,866,705 | RSC: Back to the Server | if you're like me and you've been keeping up-to-date in the React community over the past few months... | 0 | 2024-05-31T20:27:44 | https://dev.to/adebayoileri/rsc-back-to-the-server-3h20 | react, rsc, javascript | if you're like me and you've been keeping up-to-date in the React community over the past few months you've probably heard the acronym being talked about a lot. You might have played around with it in a framework (Next.js/Remix) or have a good understanding but are not sure of the applications, or you're curious about learning what it's all about.
In this article my aim is to share the ideas, motivations, and drawbacks, understand how it works and hopefully build a mental model for thinking about React Server Components.
If you're a React developer, you've probably worked with frameworks such as Next.js, Gatsby, etc. And commonly seen the acronym SSR (Server-Side Rendering) which is not to be mistaken for RSC. They have their similarities, but they are totally different. I'll explain using the famous lego pieces analogy.
Alright, let's say you have a box with all your Lego pieces, Eventually, you'll want to play with your Legos and will have to open the box, bring them all out and set up the pieces before you can start playing. This is how a default React app works. There’s an initial load time before it’s ready for use.
Now, with RSC your box has a special tool that puts together some of these pieces and they are ready for you to play. Instead of setting up your pieces from scratch (client), you have a tool (server) that sets up the pieces into ready-to-use parts and all you have to do is put them in their final positions.
One could argue that traditional SSR was present in early websites with a server-side language like PHP that could send entire web pages from the server on demand, and provides benefits such as SEO, less client-side loading, which improved initial load time, etc. However, one of the drawbacks with SSR is that after [hydration](https://react.dev/reference/react-dom/client/hydrateRoot) subsequent interactions with the app require making extra calls for dynamic components.
Next, I'll share the motivation behind this new paradigm and the features and pain points RSC addresses.
### Motivation
The React team first announced the [RFC](https://github.com/reactjs/rfcs) for RSC (React Server Components) in [December 2020](https://www.youtube.com/watch?v=TQQPAU21ZUw), and by 2023, they announced the canary version for RSC.
**Performance & Speed**. Server components provides good performance "out the box"😉 which is one of the main pain points of a regular React app. It does this in different ways;
It allows for the use of third-party packages on the server which could significantly reduce the bundle size of the app. For example, most commonly used packages such as date libraries(date-fns), utility library(lodash) etc could simply be eliminated if they're only needed in a specific RS Component.
```jsx
// Before Server Components
import lodash from "lodash"; // 71.5 (25.3k gzipped)
function TableComponent({text}) {
// using some lodash functions
return (/* render */);
}
```
```jsx
// With Server Components but zero bundle size
import lodash from "lodash"; // zero bundle size
function TableComponent({text}) {
// using some lodash functions
return (/* render */);
}
```
This is hugely beneficial for users and serves as a much better DX for developers.
**Shared Server-Client Context**. This could be the most impactful and useful application of RSC. When developing apps with React, you'll most likely have the need to interface with endpoints sending or receiving data to your app.
Early React has been client-focused, which led to the need to bring React to the server. Developers often use different languages when writing code for both the client and server commonly PHP/Python and JS. The backend code is mostly responsible for accessing filesystems, database and external data sources.
However, RSC clearly redefines this approach by eliminating the need for the API calls and the [request-response](https://en.wikipedia.org/wiki/Request%E2%80%93response) cycle. The boundary between the client and server has been streamlined by giving React fully access to the backend, the default mode allows for database calls, filesystem access, and passing props directly to components. Here's how an example server component accessing the filesystem would look:
**File System**
```jsx
import fs from 'fs';
async function Post({slug}) {
const post = JSON.parse(await fs.readFile(`${slug}.md`));
return <PostComponent post={post} />;
}
```
**Database Calls**
```jsx
import db from 'db';
async function Post({slug}) {
const post = await db.findOne(slug);
return <PostComponent post={post} />;
}
```
With server components, the security benefits of avoiding sending secret keys such as user tokens and API keys would also be hugely impactful as the client can access other necessary data without exposing crucial ones to the client.
**Developer Experience**. Think about how advantageous this could be in a typical production app where we have typed props defined in our client components and accept data from a server component. This approach allows for better developer experience and fully typed experience across client and server.
Firstly, simply opt-in the component as a client component using the `use client` [directive](https://github.com/reactjs/rfcs/pull/227).
```tsx
"use client"
// client component: client-component.tsx
export default function Author({
authorName
}: {
authorName: string;
}) {
return (
<div className="text-xl font-bold">
{authorName}
</div>
);
}
```
```tsx
// server component: server-component.tsx
import db from 'db';
async function Post({id}) {
const author = await db.findOne(id);
return (
<Author
authorName={author.name} // would likely display an error when it's doesn't match type "string" specified in the client component
/>;
}
```
### Drawbacks
Just like all novel paradigms, there are some limitations to React Server Components.
**Adoption**. Demonstrating the full benefits of **React Server Components** with the _react_, _react-dom_ and _react-dom/server_ packages can be a lot for newbies, and even intermediate developers to wrap their heads around from routing to bundler configurations. So, it's important that there's a flexible and less boilerplate approach to adopting the full benefits of RSC. So far, the React team has partnered with the Next.js team to fully integrate RSC into the framework. Other Libraries and framework authors would learn from this approach as it's all open-source and could take a while before most of the API are fully standardised.
**Developer Education**. Introducing this feature in frameworks' latest releases and codebases across different projects and companies means more for developers to learn. This could mean new sets of questions in notable library repositories as issues, StackOverflow questions, and confusion around how to use and properly distinguish between server or clients components.
### Conclusion
The React Server Components approach could grow into a wide range of useful solutions in different aspects of web apps and possibly eliminate current painful ways of writing React apps.
Possible applications: With the rise of generative AI (I tried my best to not include AI, but it's 2024), components could be specified to receive specific props, and different versions of the components could be rendered to users to enhance A/B testing.
### Useful Links
[React Docs: Server Components](https://react.dev/reference/rsc/server-components)
[React Server Components RFC](https://github.com/reactjs/rfcs/blob/main/text/0188-server-components.md)
[Nextjs: Rendering](https://nextjs.org/docs/app/building-your-application/rendering)
[React For Two Computers](https://youtu.be/T8TZQ6k4SLE?t=18827)
| adebayoileri |
1,872,389 | The end of my first week, can't wait for the next one! | Hey everyone, Can you believe it's already Friday? Time flies when you're having fun, and let me... | 0 | 2024-05-31T19:48:42 | https://dev.to/angeljrp/the-end-of-my-first-week-cant-wait-for-the-next-one-58jb | Hey everyone,
Can you believe it's already Friday? Time flies when you're having fun, and let me tell you, my first week at this gaming development internship has been nothing short of incredible!
Today kicked off with our weekly review meeting, where we all gathered to discuss the progress we've made throughout the week. And let me just say, I was blown away by how much ground we've covered in such a short amount of time. It's amazing to see how everyone's hard work and dedication have paid off, pushing our projects forward in exciting ways.
Before diving into the meeting, I spent the morning putting the finishing touches on my mini-game. It's been a whirlwind of tweaking and fine-tuning, like making it so the player doesn't move on game over or like making more boundaries, but I'm thrilled with how it's shaping up. Making those little tweaks here and there may seem insignificant, but it's those small details that can really elevate the player experience.
Throughout the week, I've had the opportunity to immerse myself in the world of game development, learning new skills and techniques along the way. From coding mechanics to designing gameplay elements, every day has been a new adventure filled with discovery and growth.
As I reflect on my first week here, I can't help but feel grateful for the opportunity to be surrounded by such a talented and passionate team. The support and encouragement I've received have been invaluable, and I can't wait to see what the future holds as I continue to learn and evolve in this exciting industry.
Thanks for joining me on this journey, and stay tuned for more updates as I navigate the world of gaming development! | angeljrp | |
1,872,429 | Difference Between Factories and Seeders in Laravel: Purpose and Usage | When working with Laravel, understanding the roles of factories and seeders is crucial. These tools... | 0 | 2024-05-31T20:24:05 | https://dev.to/asfiaaiman/difference-between-factories-and-seeders-in-laravel-purpose-and-usage-2igg | laravel, webdev, database, php | When working with Laravel, understanding the roles of factories and seeders is crucial. These tools simplify database management and enhance the efficiency of your development process. Let’s explore what Laravel factories and seeders are, their purposes, and why they are important.
## What are Factories in Laravel?
Laravel factories are blueprints for creating Eloquent model instances with default attribute values. They simplify the process of generating test data. Instead of manually creating each model instance, factories allow you to define default attributes for your models.
**How to Create a Factory in Laravel**
To create a factory, run:
``` php
php artisan make:factory PostFactory
```
This command generates a new factory class in the database/factories directory.
**Example of a Laravel Factory**
``` php
namespace Database\Factories;
use Illuminate\Database\Eloquent\Factories\Factory;
use Illuminate\Support\Facades\Hash;
use Illuminate\Support\Str;
class UserFactory extends Factory
{
protected static ?string $password;
public function definition(): array
{
return [
'name' => fake()->name(),
'email' => fake()->unique()->safeEmail(),
'email_verified_at' => now(),
'password' => static::$password ??= Hash::make('password'),
'remember_token' => Str::random(10),
];
}
public function unverified(): static
{
return $this->state(fn (array $attributes) => [
'email_verified_at' => null,
]);
}
}
```
## What are Seeders in Laravel?
Laravel seeders are classes that insert data into your database. They are perfect for populating your database with initial data or resetting it to a known state during development.
**How to Create a Seeder in Laravel**
To create a seeder, run:
``` php
php artisan make:seeder UserSeeder
```
**Example of a Laravel Seeder**
``` php
namespace Database\Seeders;
use Illuminate\Database\Seeder;
use Illuminate\Support\Facades\DB;
use Illuminate\Support\Facades\Hash;
use Illuminate\Support\Str;
class DatabaseSeeder extends Seeder
{
public function run(): void
{
DB::table('users')->insert([
'name' => Str::random(10),
'email' => Str::random(10).'@example.com',
'password' => Hash::make('password'),
]);
}
}
```
## Why Are Factories and Seeders Important in Laravel?
1. **Efficiency in Testing:** Factories enable quick generation of multiple model instances with diverse attributes, streamlining the setup of test scenarios.
2. **Consistent Initial Data:** Seeders ensure your database is populated with consistent initial data, reducing bugs and discrepancies during development.
3. **Database Management: **Seeders allow easy resetting of your database to a known state, crucial for continuous integration and deployment processes.
4. **Separation of Concerns:** Using factories for data generation and seeders for data insertion keeps your code modular and organized.
## Using Factories and Seeders Together in Laravel
Combining factories and seeders can simplify the process of populating your database. For example, generating multiple users and related posts:
``` php
use App\Models\User;
public function run(): void
{
User::factory()
->count(50)
->hasPosts(1)
->create();
}
```
**Running Seeders in Laravel**
You can run seeders using the following Artisan commands:
``` php
php artisan db:seed
php artisan db:seed --class=UserSeeder
php artisan migrate:fresh --seed
```
## Conclusion
Factories and seeders are essential tools in Laravel that streamline database management, testing, and development. By understanding and leveraging these tools, you can create robust and maintainable applications. Whether you're setting up your database for the first time or resetting it for testing, Laravel factories and seeders ensure you have the right data at the right time.
For more detailed information on [Laravel factories](https://laravel.com/docs/11.x/eloquent-factories#main-content) and [Laravel seeders](https://laravel.com/docs/11.x/seeding#introduction), refer to the [official Laravel documentation](https://laravel.com/docs/11.x). | asfiaaiman |
1,872,428 | How to overcome fluctuating productivity | Problem Hello DEV-Community i have a problem. I work now since nearly 3 years as a Data... | 0 | 2024-05-31T20:22:50 | https://dev.to/kaeptnkrunch/how-to-overcome-fluctuating-productivity-5dao | productivity, programming, career, help | ## Problem
Hello DEV-Community i have a problem. I work now since nearly 3 years as a Data Scientist with a health insurance company. Most tasks are usually easy to accomplish.
However, I notice that the longer a task takes, the less motivation I have (according to _Robert C. Martin, Clean Code [1]_) and my productivity fluctuates daily.
![[1]](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/3n4kvhaosqnkxr8wyowd.png)*[1] Robert C. Martin, Clean Code, Page 37, 4A*
There are days when I get a lot done and others when I find it difficult to motivate myself. I notice that this happens to me even when I have deadlines and I don't want to miss a deadline.
## Question
I think that many people have this problem and that fluctuations are normal and are of course determined by many factors (sleep, diet, stress, etc.).
However, I wanted to ask how you deal with it and how you deal with longer tasks and the decrease in productivity.
Do you use special software or special working methods or how do you keep your productivity at a certain level.
## Further Action
If there is no thread on this issue yet, I would like to collect the answers and create a __HowTo__ or a __Github repository__ from them.
I would also be happy to receive book suggestions that might help. I think this topic can help a lot of people, especially __CodeNewbies__.
| kaeptnkrunch |
1,872,399 | Comprehensive Guide to Setting Up Automated Testing in CI/CD Pipelines with AWS and Selenium | Introduction In the modern development landscape, CI and CD pipelines ensure that changes in code... | 0 | 2024-05-31T20:20:16 | https://sudoconsultants.com/comprehensive-guide-to-setting-up-automated-testing-in-ci-cd-pipelines-with-aws-and-selenium/ | selenium, testing, cicd | <!-- wp:heading {"level":1} -->
<h1 class="wp-block-heading">Introduction</h1>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In the modern development landscape, CI and CD pipelines ensure that changes in code are automatically tested, integrated, and deployed. This guide documents the basic steps of creating a CI/CD pipeline using Amazon Web Services (AWS) and Selenium for automated testing. Areas to be covered include CLI and console-based setups, setting up a Selenium test project, configuration of the CI/CD pipeline, running tests, and monitoring.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Prerequisites</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Before the actual work can begin, make sure you have the following:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>An AWS Account</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AWS CLI installed and configured in your local machine</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AWS IAM user with the necessary permissions to create and manage resources</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Basic knowledge in the following AWS services: EC2, S3, CodePipeline, CodeBuild</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Setting Up AWS Environment</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS CLI Setup Steps</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li><strong>Install AWS CLI</strong></li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Visit <a href="https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html">AWS CLI Documentation</a> and follow the instructions to install the AWS CLI. Since the installation will depend on the operating system in your local machine, the steps will likely be slightly different. In a nutshell, for Unix-like systems, you can always execute the following commands:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg"
sudo installer -pkg AWSCLIV2.pkg -target /</code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Configure AWS CLI</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>After installing the AWS CLI, configure it with following command. Replace the placeholders with your AWS Access Key, Secret Key, Region and Output format.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws configure</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Create IAM Role</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>To create the IAM role that our EC2 instances and CodeBuild will use, execute the following commands:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>aws iam create-role --role-name SeleniumTestRole --assume-role-policy-document file://trust-policy.json
aws iam attach-role-policy --role-name SeleniumTestRole --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess
aws iam attach-role-policy --role-name SeleniumTestRole --policy-arn arn:aws:iam::aws:policy/AWSCodePipelineFullAccess
aws iam attach-role-policy --role-name SeleniumTestRole --policy-arn arn:aws:iam::aws:policy/AWSCodeBuildAdminAccess</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Please replace file://trust-policy.json with your path to the trust policy JSON file. The trust-policy.json file should contain:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}</code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Create S3 Bucket</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Create an S3 bucket to store your build artifacts:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws s3 mb s3://my-selenium-artifacts</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Replace my-selenium-artifacts with a unique name for your S3 bucket. The bucket name must be unique among all bucket names in AWS.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Create Key Pair for EC2</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Create a key pair that can be used to access your EC2 instances:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>aws ec2 create-key-pair --key-name SeleniumKeyPair --query 'KeyMaterial' --output text > SeleniumKeyPair.pem
chmod 400 SeleniumKeyPair.pem</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>This command will create a new key pair called SeleniumKeyPair and save the private key to a file called SeleniumKeyPair.pem The chmod 400 command ensures the private key file has the correct permissions.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Launch EC2 Instance</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Launch an EC2 instance that will be used for running Selenium tests:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws ec2 run-instances --image-id ami-0c55b159cbfafe1f0 --count 1 --instance-type t2.micro --key-name SeleniumKeyPair --security-group-ids sg-xxxxxxxx --subnet-id subnet-xxxxxxxx</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Replace ami-0c55b159cbfafe1f0 with the correct AMI ID according to your region, and replace security-group-ids and subnet-id with the appropriate values. The security group must have rules which grant inbound access on port 22 from your IP address.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS Console Setup Steps</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Login to AWS Management Console</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol></ol>
<!-- /wp:list -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Go to <a href="https://aws.amazon.com/console/">AWS Management Console</a> and login with your AWS credentials.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p> <strong>Create IAM Role</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Go to the IAM service.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on "Roles" in the left pane.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click the "Create role" button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Under "Select type of trusted entity", select "AWS service", then select the "EC2" service.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click "Next: Permissions" button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the search box provided, search for and select the following policies:</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AmazonS3FullAccess</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AWSCodePipelineFullAccess</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AWSCodeBuildAdminAccess</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click "Next: Tags" (optional) and then "Next: Review".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Give the role a name: SeleniumTestRole</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Create an S3 Bucket </strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Go to the S3 service.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on "Create bucket" and the page may look something like this.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Enter your bucket name which must be unique within all bucket names in AWS.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Set the configurations as you wish.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click "Create bucket".</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Create Key Pair for EC2</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Go to the EC2 service.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the navigation pane, choose Key Pairs.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choose the Create Key Pair button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Enter a name for the key pair (e.g., SeleniumKeyPair).</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choose Create key pair.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Your browser will download the key file automatically and store it securely.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Launch EC2 Instance</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Go to the EC2 service.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choose the Launch Instance button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select an Amazon Linux 2 AMI.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choose an instance type (e.g., t2.micro).</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Go through set up the instance details, including attaching the IAM role that we created previously.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Add storage as required.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Configure the security group to allow SSH access (port 22) and any other ports you may need.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Review and launch the instance, selecting the key pair we just created.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Creating a Selenium Test Project</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Initializing the Project</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Let's start by creating a new directory for your Selenium tests and initializing a new Node.js project:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>mkdir selenium-tests
cd selenium-tests
npm init -y
npm install selenium-webdriver mocha chai</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>This will create a new Node.js project with the necessary dependencies for Selenium, Mocha (a test framework), and Chai (an assertion library).</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Writing Test Cases</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Create a new test file e.g., test.js in your project directory and write the following code to jot down a simple Selenium test:</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>const {Builder, By, until} = require('selenium-webdriver');
const {expect} = require('chai');
describe('Google Search', function() {
it('should find the correct title', async function() {
let driver = await new Builder().forBrowser('chrome').build();
try {
await driver.get('http://www.google.com');
let title = await driver.getTitle();
expect(title).to.equal('Google');
} finally {
await driver.quit();
}
});
});</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>This test will open the Google Chrome browser to google.com, get its title and confirm it with the expected title "Google".</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Installing WebDriver and Browsers</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To run Selenium tests, you need WebDriver and a browser installed on your EC2 instance. Here's how to install Chrome and ChromeDriver:</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li><strong>Connect to your EC2 instance:</strong></li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><em>ssh -i "SeleniumKeyPair.pem" ec2-user@<your-ec2-instance-public-dns></em></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Install Google Chrome:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code>sudo yum install -y amazon-linux-extras
sudo amazon-linux-extras install epel -y
sudo yum install -y chromium</code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Install ChromeDriver:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code>wget https://chromedriver.storage.googleapis.com/90.0.4430.24/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
sudo mv chromedriver /usr/bin/</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Check the latest compatible version of Chrome and replace the version and URL as needed.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Configuring EC2 Instance for Selenium Tests</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In order to make the EC2 instance capable of running the Selenium tests with Chrome, you need to configure Xvfb (X virtual framebuffer) for headless execution:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Install Xvfb:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:list {"ordered":true} -->
<ol></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>sudo yum install -y Xvfb</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Start Xvfb:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code>Xvfb :99 -ac &
export DISPLAY=:99</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Note these commands can be included in a startup script or initialization step for the CI/CD pipeline for ease of setup.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Configuring CI/CD Pipeline</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Creating a CodeCommit Repository</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Create a new CodeCommit repository for storing the code for your Selenium tests.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws codecommit create-repository --repository-name selenium-tests</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Pushing Code to CodeCommit</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>From the terminal, in your project directory, initialize a git repository, add the remote repo for CodeCommit, and push the code.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>git init
git remote add origin codecommit::us-east-1://selenium-tests
git add .
git commit -m "Initial commit"
git push -u origin master</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>You would first need to have the correct IAM permissions configured for Git for it to interact with CodeCommit.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Creating Build Specification</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Create a file named buildspec.yml in your project directory. Insert the following content in it.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>version: 0.2
phases:
install:
commands:
- npm install
pre_build:
commands:
- echo Pre-build phase
build:
commands:
- npm test
artifacts:
files:
- '**/*'</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>In the build specification, the CodeBuild project will execute commands to install dependencies, run your tests, and archive the test results.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Creating CodeBuild Project</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Open the AWS Management Console and navigate to the CodeBuild dashboard.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on the "Create build project" button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Enter a project name. For example, SeleniumTestProject.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>For Source provider, choose CodeCommit. Under Source version, click "master" branch.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>For Environment image, choose Managed image. For Operating System, select Ubuntu. For runtime, select Node.js.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>For Service Role, select the CodeBuild service role.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the BuildSpec section, make sure "Use a buildspec file" is selected.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the Artifacts section, select the previously created S3 bucket.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click Create build project button.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Creating CodePipeline</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Open the CodePipeline service from the AWS management console.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Hit the create pipeline button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Specify a name for the pipeline (e.g., SeleniumPipeline).</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the "Source" stage, select the source provider as "CodeCommit" and provide the repository and the branch.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the "Build" stage, select the build provider as "CodeBuild" and provide the build project that was created in the previous steps.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Optionally, create a deploy stage in the pipeline.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click the "Create pipeline" button.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Running and Monitoring Tests</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Committing Changes</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Now, whenever you make any modifications in your Selenium test or respective code, commit and push all the changes to the CodeCommit repository.</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>git add .
git commit -m "Updated tests"
git push origin master</code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Monitoring Pipeline Execution</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Go to the AWS Management Console and click on the CodePipeline service to monitor how your new pipeline is working. You will see the processes for each stage execution, like source, build, and, optionally, deploy.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Viewing Build Logs</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Click on the CodeBuild service and select your build project. On this page, you can see the logs related to each build execution, including the output of your test cases.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Conclusion</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Well, that's it. You just set up a very solid environment for your Selenium automated test with a CI/CD AWS pipeline. With this setup, the changes in code are automatically tested and integrated into the software, making sure that all processes provide assurance on the code quality and software stability. This is a setup for you to customize the configurations and extend the pipeline according to the requirements of projects, scaling up your testing efforts.</p>
<!-- /wp:paragraph --> | sidrasaleem296 |
1,873,161 | macOS - Log & track historical CPU, RAM usage | In macOS, we can use inbuilt Activity Monitor or third party apps like Stats to check the live... | 0 | 2024-06-22T13:16:11 | https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html | devops, macbook, python | ---
title: macOS - Log & track historical CPU, RAM usage
published: true
date: 2024-05-31 20:18:02 UTC
tags: devops,macbook,python
canonical_url: https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html
---
In macOS, we can use inbuilt `Activity Monitor` or third party apps like `Stats` to check the live CPU/RAM usage. But, we can't track the historical CPU & memory usage. `sar`, `atop` can track the historical CPU & memory usage. But, they are not available for macOS.
#### Netdata
Netdata<sup id="fnref:Netdata"><a href="https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html#fn:Netdata">1</a></sup> is an open source observability tool that can monitor CPU, RAM, network, disk usage. It can also track the historical data.
Unfortunately, it is not stable on macOS. I tried installing it on multiple macbooks, but it didn't work. I raised an issue<sup id="fnref:netdata_issue"><a href="https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html#fn:netdata_issue">2</a></sup> on their GitHub repository and the team mentioned that macOS is a low priority for them.
#### Glances
Glances<sup id="fnref:Glances"><a href="https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html#fn:Glances">3</a></sup> is a cross-platform monitoring tool that can monitor CPU, RAM, network, disk usage. It can also track the historical data.
We can install it using Brew or pip.
```
$ brew install glances
$ pip install glances
```
Once it is installed, we can monitor the resource usage using the below command.
```
$ glances
```
Glances can log historical data to a file using the below command.
```
$ glances --export-csv /tmp/glances.csv
```
In addition to that, it can log data to services like influxdb, prometheus, etc.
Let's install influxdb and export stats to it.
```
$ brew install influxdb
$ brew services start influxdb
$ influx setup
$ python -m pip install influxdb-client
$ cat glances.conf
[influxdb]
host=localhost
port=8086
protocol=http
org=avilpage
bucket=glances
token=secret_token
$ glances --export-influxdb -C glances.conf
```
We can view stats in the influxdb from Data Explorer web UI at [http://localhost:8086](http://localhost:8086).
Glances provides a prebuilt Grafana dashboard<sup id="fnref:grafana_dashboard"><a href="https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html#fn:grafana_dashboard">4</a></sup> that we can import to visualize the stats.
From Grafana -> Dashboard -> Import, we can import the dashboard using the above URL.

#### Conclusion
In addition to InfluxDB, Glances can export data to ~20 services. So far, it is the best tool to log, track and view historical CPU, RAM, network and disk usage in macOS. The same method works for Linux and Windows as well.
* * *
1. [https://github.com/netdata/netdata](https://github.com/netdata/netdata) [↩](https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html#fnref:Netdata "Jump back to footnote 1 in the text")
2. [https://github.com/netdata/netdata/issues/16696](https://github.com/netdata/netdata/issues/16696) [↩](https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html#fnref:netdata_issue "Jump back to footnote 2 in the text")
3. [https://github.com/niolargo/glances](https://github.com/nicolargo/glances) [↩](https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html#fnref:Glances "Jump back to footnote 3 in the text")
4. [https://glances.readthedocs.io/en/latest/gw/influxdb.html#grafana](https://glances.readthedocs.io/en/latest/gw/influxdb.html#grafana) [↩](https://avilpage.com/2024/06/macos-log-track-cpu-ram-usage.html#fnref:grafana_dashboard "Jump back to footnote 4 in the text") | chillaranand |
1,872,396 | Freewallet continues the deception! | As part of our ongoing efforts to protect cryptocurrency users from fraud, we have come across yet... | 0 | 2024-05-31T20:09:11 | https://dev.to/feofhan/freewallet-continues-the-deception-pbj |
As part of our ongoing efforts to protect cryptocurrency users from fraud, we have come across yet another disturbing case involving the infamous cryptocurrency wallet Freewallet Freewallet. Recently, a user from Russia contacted us with a disturbing story that clearly demonstrates the deceptive tactics used by Freewallet.
The person, who wished to remain anonymous, registered on Freewallet around April 21-22 and funded his wallet with a significant amount of $6,400. However, as early as April 26, he discovered that he could not access his funds as the wallet hung on an endless loading screen. In desperation and anxiety, the user contacted Freewallet support for help.
After contacting support, access to the wallet was temporarily restored, indicating that the site's algorithm had automatically blocked the user's login. However, this was only the beginning of his ordeal. The user was asked to provide data about all IP addresses from which the wallet was accessed and about each transaction. Despite the intrusive nature of these requests, the user agreed and documented everything in detail in his email correspondence.
As another example of Freewallet's manipulative tactics, a user was asked to record a video from another Bings exchange account showing the transaction that sent the money. Again, the user agreed, hoping to resolve the issue and regain access to their funds.
Despite fulfilling all of these requirements, the user's problem remains unresolved. It is becoming increasingly apparent that Freewallet is using these endless verification steps not as a legitimate security measure, but as a tactic to frustrate and ultimately steal user funds.
Repeated occurrences
This case is not an isolated incident. We have received numerous reports from users around the world who have experienced similar issues with Freewallet. App administrators seem to be using KYC (Know Your Customer) and AML (Anti-Money Laundering) procedures as a cover for their fraudulent activities, blocking accounts and denying withdrawals under the pretext of security checks.
Our job is to stop these scammers and protect users from their schemes. If you have experienced similar problems with Freewallet, we encourage you to spread the word. Share your story with us at freewallet-report@tutanota.com. Together, we can expose these scams and prevent other users from being defrauded.
For those who have been victimized, we offer assistance in documenting evidence of fraud and drafting legal appeals to the appropriate authorities. Our goal is to ensure that stolen funds are returned to all victims and to hold Freewallet accountable for their actions.
Be vigilant and remember that your voice matters in the fight against cryptocurrency fraud.
| feofhan | |
1,872,395 | FastAPI Beyond CRUD - Part 4 Modular Project Structure With Routers | In this video, we restructure our API from a single file to a more organized structure that shall... | 0 | 2024-05-31T20:03:56 | https://dev.to/jod35/fastapi-beyond-crud-part-4-modular-project-structure-with-routers-52kj | fastapi, python, programming, api | In this video, we restructure our API from a single file to a more organized structure that shall scale with our project. We achieve this using FastAPI routers. FastAPI routers allow us to organize our project into modules allowing us to group related endpoints together.
{%youtube _kNyYIFSOFU%} | jod35 |
1,845,542 | Ibuprofeno.py💊| #116: Explica este código Python | Explica este código Python Dificultad: Fácil my_tuple = (1, 2, True,... | 25,824 | 2024-05-31T20:00:00 | https://dev.to/duxtech/ibuprofenopy-116-explica-este-codigo-python-153h | python, spanish, learning, beginners | ## **<center>Explica este código Python</center>**
#### <center>**Dificultad:** <mark>Fácil</mark></center>
```py
my_tuple = (1, 2, True, 3)
print(my_tuple.count(1))
```
👉 **A.** `1`
👉 **B.** `2`
👉 **C.** `3`
👉 **D.** `Ninguno de los anteriores`
---
{% details **Respuesta:** %}
👉 **B.** `2`
Recordemos que los booleanos en Python derivan del tipo number, entonces el valor `True` del ejemplo equivale a un `1`.
Por ello al contar cuantos valores `1` existen el resultado es `2`.
{% enddetails %} | duxtech |
1,872,307 | Learning Blog 05/31/24 | Learning Markdown to better format posts. Link Helpful cheatsheet (There's another cheatsheet on the... | 0 | 2024-05-31T19:59:09 | https://dev.to/dylansarikas/learning-blog-053124-3eg5 | Learning Markdown to better format posts.
[Link](https://www.markdownguide.org/cheat-sheet/)
Helpful cheatsheet (There's another cheatsheet on the right side)
`pp "Hello World"`
An example of inline code
```
for a in 1..5 do
puts "wow"
end
```
An example code block
Setting up VSCode, Git, and GitHub in a new environment is always a pain
For Mac OS, first install homebrew
[Link](https://brew.sh/)
Then install git
[Link](https://git-scm.com/download/mac)
Then set your username in git
[Link](https://docs.github.com/en/get-started/getting-started-with-git/setting-your-username-in-git)
Install GitHub CLI
[Link](https://github.com/cli/cli#installation)
Run 'gh auth login'
[Link](https://cli.github.com/manual/gh_auth_login)
Run 'git init' on the repo
[Link](https://git-scm.com/docs/git-init)
Generate new SSH key
[Link](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent)
Add the key to your GitHub account
[Link](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/adding-a-new-ssh-key-to-your-github-account)
Now you can add new repos from the command line onto GitHub using SSH
That should be all, full install found here
[Link](https://docs.github.com/en/get-started/getting-started-with-git/set-up-git)
Definitely want to install iterm2
[Link](https://iterm2.com/)
And then Ohmyzsh
[Link](https://ohmyz.sh/)
So the regular terminal stops burning your retinas | dylansarikas | |
1,872,393 | Retro: Working with the Playwright Framework | Welcome to a Simple Introduction to Playwright In this introductory piece, I explore the basics of... | 0 | 2024-05-31T19:57:36 | https://dev.to/agagag/working-with-the-playwright-framework-an-in-depth-journey-1nn6 | playwright, javascript, testing, programming | **Welcome to a Simple Introduction to Playwright**
In this introductory piece, I explore the basics of the Playwright framework, a powerful tool for web developers who are seeking a robust solution for cross-browser test automation. Here’s a quick look at what makes Playwright stand out in the crowded field of automation tools.
**Why Playwright?**
Playwright is designed to simplify the process of testing web applications across all modern browsers. Whether you're targeting Chrome, Firefox, Safari, or even Internet Explorer, Playwright offers a consistent API to automate actions without worrying about browser-specific quirks.
**Key Features of Playwright**
- **Cross-Browser Compatibility**: Playwright provides seamless integration across all popular browsers, ensuring that your tests are compatible no matter the environment.
- **Headless Testing**: Run tests in headless mode for faster execution, ideal for CI/CD pipelines where visual rendering is unnecessary.
- **Automation Beyond Browsers**: Not limited to browser automation, Playwright can automate web-based mobile applications, offering tools for mobile testing that include device emulation.
- **Powerful Tooling**: With features like the Playwright Inspector, developers can debug tests easily, inspect DOM elements, and even record user interactions to generate robust test scripts.
**Ease of Use**
Playwright's straightforward setup and detailed documentation make it accessible to developers new to automated testing, while its advanced features satisfy the needs of seasoned QA professionals.
**Integration with Development Workflows**
Integrating Playwright into your development pipeline is straightforward, thanks to its support for major CI/CD tools like GitHub Actions. This ensures that tests run automatically with every build, helping to identify issues early in the development cycle.
**Future Prospects**
Looking forward, Playwright is continuously evolving, with updates that promise to enhance mobile testing capabilities, introduce more intuitive visual and user experience testing, and expand its low-code testing features.
**Summing Up**
This brief overview highlights how Playwright is transforming the landscape of test automation with its comprehensive features and forward-looking roadmap. As I continue to explore this versatile framework, its potential to improve web application testing becomes even clearer, making it an invaluable asset for developers looking to streamline their testing processes. | agagag |
1,872,391 | Variables (O'zgaruvchilar) | O'zgaruvchilar (variables) dasturda ma'lumotlarni saqlash va ularga qayta murojaat qilish... | 0 | 2024-05-31T19:50:03 | https://dev.to/muxiddin/variables-ozgaruvchilar-2ofm | jsvariable |
## O'zgaruvchilar (variables) dasturda ma'lumotlarni saqlash va ularga qayta murojaat qilish uchun ishlatiladi.
```
o'zgaruvchilarni e'lon qilish uchun var, let yoki const
kalit so'zlaridan foydalaniladi.
```
---
`var`
```
ES5 (ECMAScript 5) va undan oldingi versiyalarda o'zgaruvchilarni
e'lon qilish uchun ishlatiladi.Bu kalit so'z bilan e'lon qilingan
o'zgaruvchilar funktsiya doirasida (function scope)mavjud
bo'ladi va agar funktsiya ichida bo'lmasa, global o'zgaruvchi
hisoblanadi.
Misol:
var name = "John";
console.log(name);
```
---
`let`
```
ES6 (ECMAScript 2015) bilan kiritilgan va blok doirasida
(block scope) o'zgaruvchilarni e'lon qilish imkonini beradi.
Bu kalit so'z bilan e'lon qilingan o'zgaruvchilar faqat
{} ichida mavjud bo'ladi.
Misol
let num = 30;
console.log(num); // "30"
```
---
`const`
```
ES6 bilan kiritilgan va doimiy (o'zgarmas) qiymatlar uchun
ishlatiladi. const bilan e'lon qilingan o'zgaruvchining
qiymatini keyinchalik o'zgartirib bo'lmaydi. Shuningdek,
const blok doirasida mavjud bo'ladi.
Misol:
const name = "Ali";
console.log(name); // "Ali"
```
---
| muxiddin |
1,868,671 | How to provide private storage for internal company documents | The following are below are steps for the above process In the Azure portal, search for and select... | 0 | 2024-05-31T19:46:46 | https://dev.to/stippy4real/how-to-provide-private-storage-for-internal-company-documents-43kj | azure, deveops, resourcegroup, storage | **The following are below are steps for the above process**
In the Azure portal, search for and select Storage accounts.
then Select + Create

Select the Resource group created in the previous lab.

Set the Storage account name to private and add an identifier to the name to ensure the name is unique (privatestella).
Select Review, and then Create the storage account
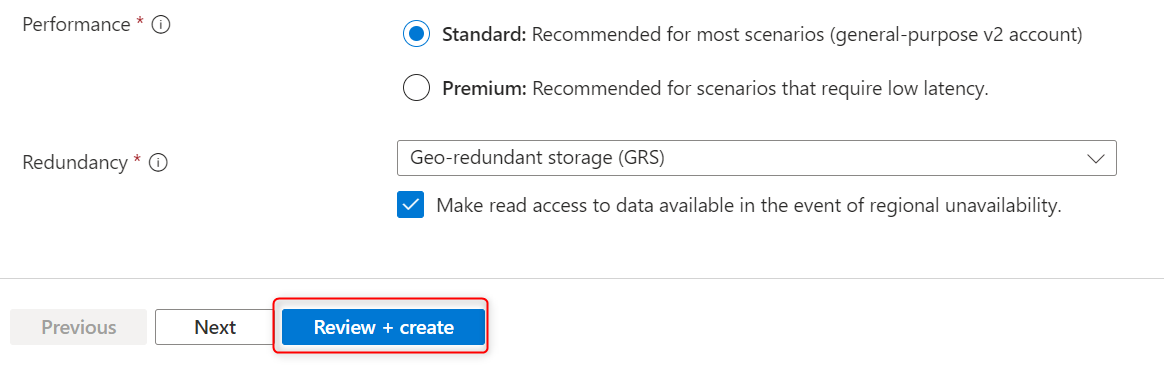
After validation has pass click create
Wait for the storage account to deploy, and then select Go to resource.
In the storage account, in the Data management section, select the Redundancy blade.
Ensured Geo-redundant storage (GRS) is selected.

Refresh the page and review the primary and secondary location information.
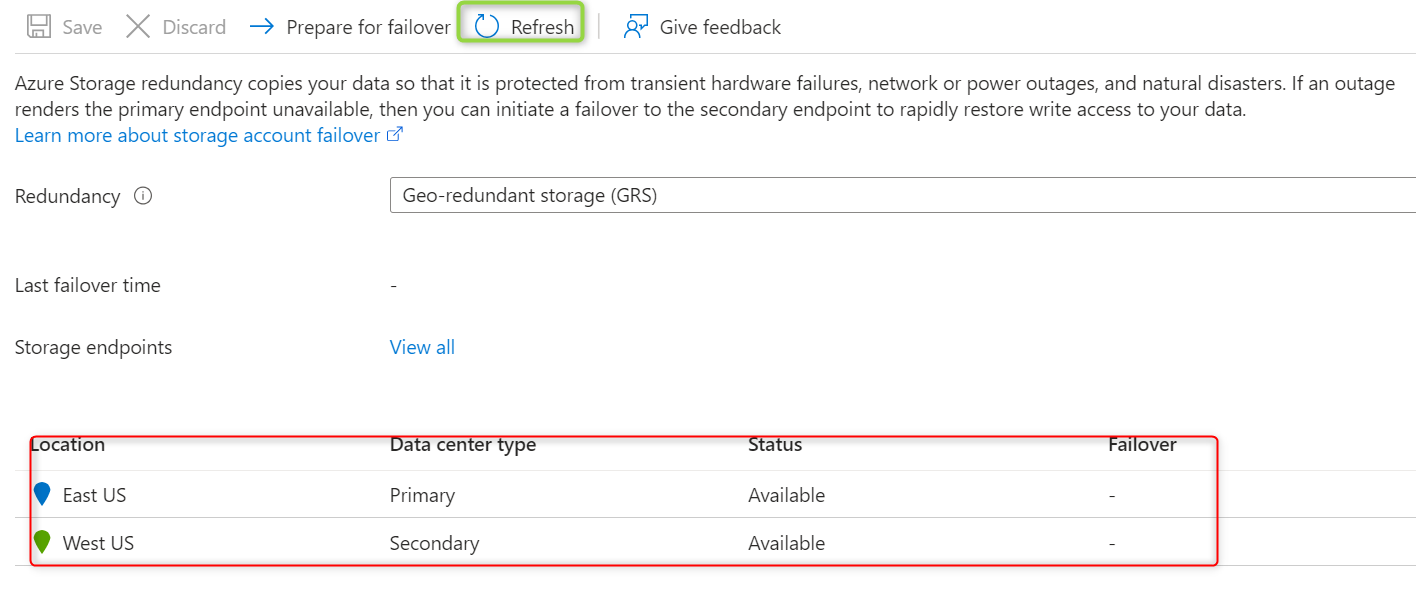
In the storage account, in the Data storage section, select the Containers blade.
Select Container
Ensure the Name of the container is private and make Public access level is Private (no anonymous access)
In Advanced settings, take the defaults and click create
For testing, upload a file to the private container
Select the container
Select Upload
Browse to files and select a file and then Upload the file

upload file
Select the uploaded file.
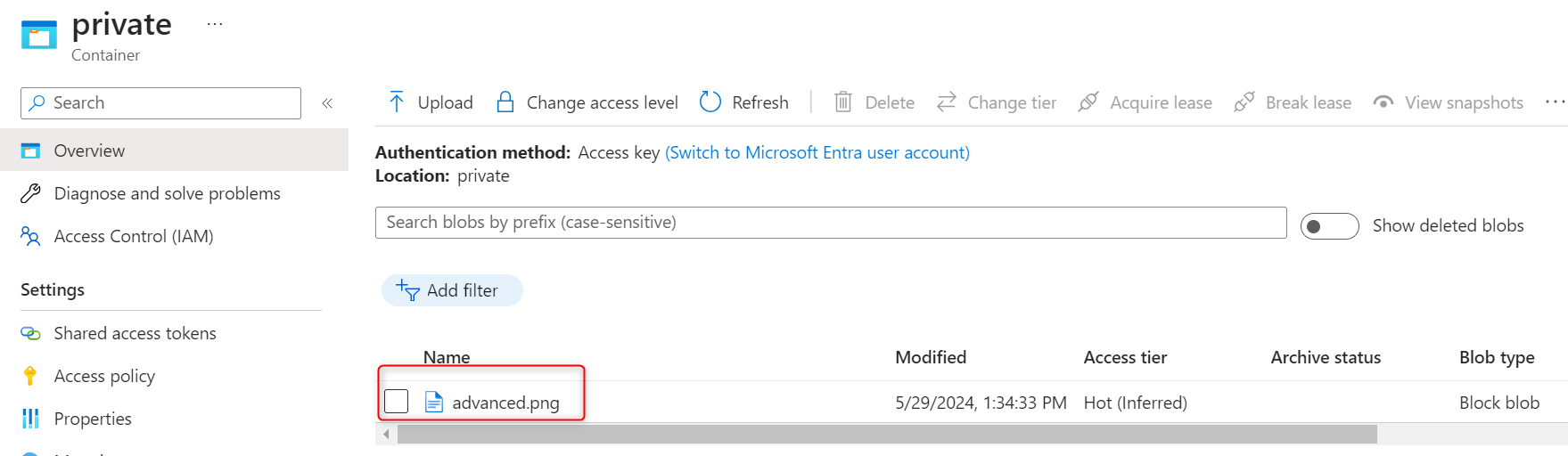
On the overview tab of the uploaded
Copy the URL.

Paste the url: https://privatestella.blob.core.windows.net/private/advanced.png on a browser to verify the file doesn’t display and you receive an error.

An external partner requires read and write access to the file for at least the next 24 hours. shared access signature (SAS) should be configured and tested
Select your uploaded blob file and move to the Generate SAS tab
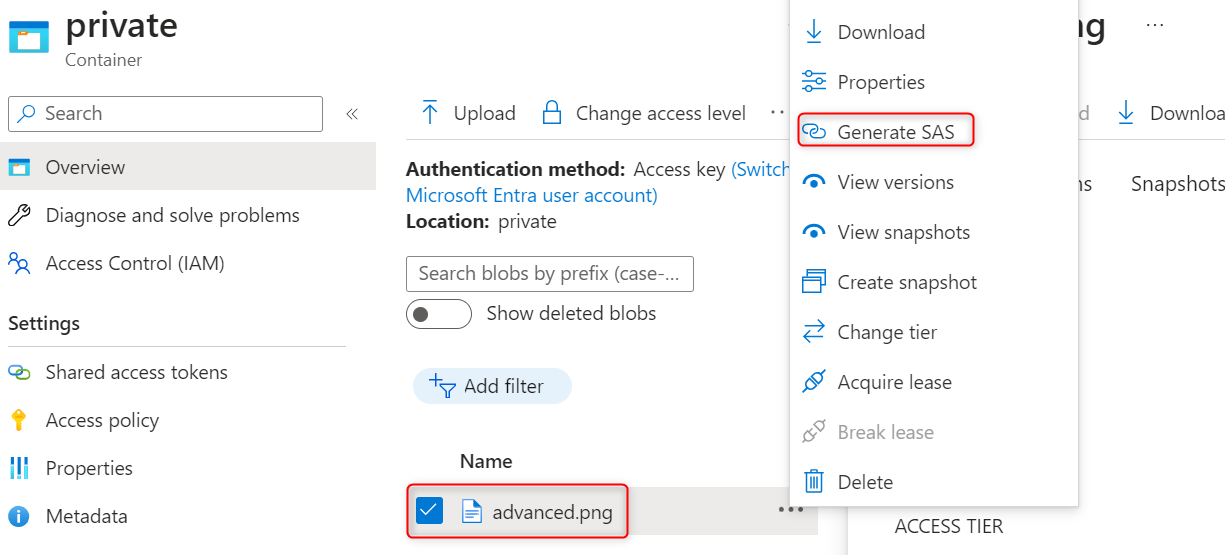
In the Permissions drop-down, ensure the partner has only Read permissions.
Verify the Start and expiry date/time is for the next 24 hours
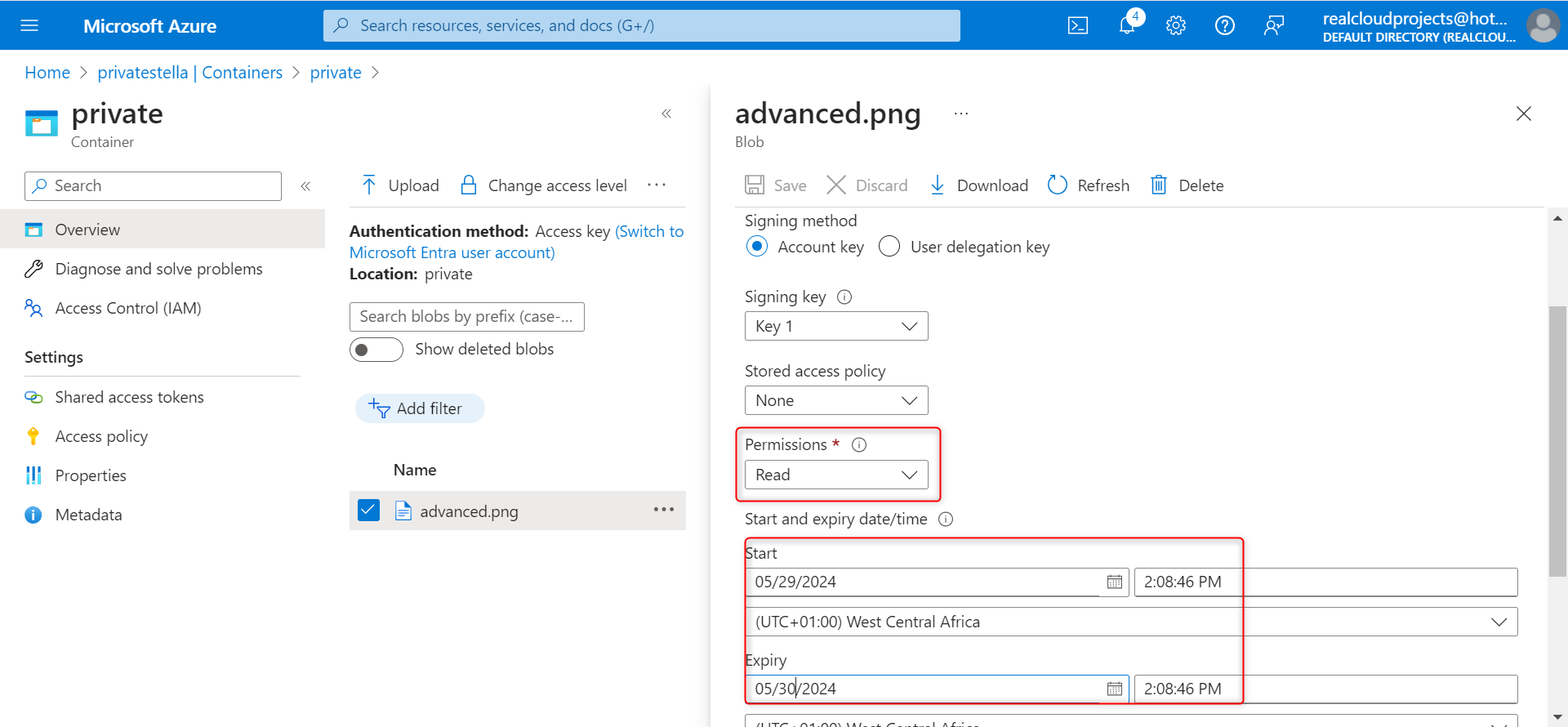
On the bottom center, Select Generate SAS token and URL
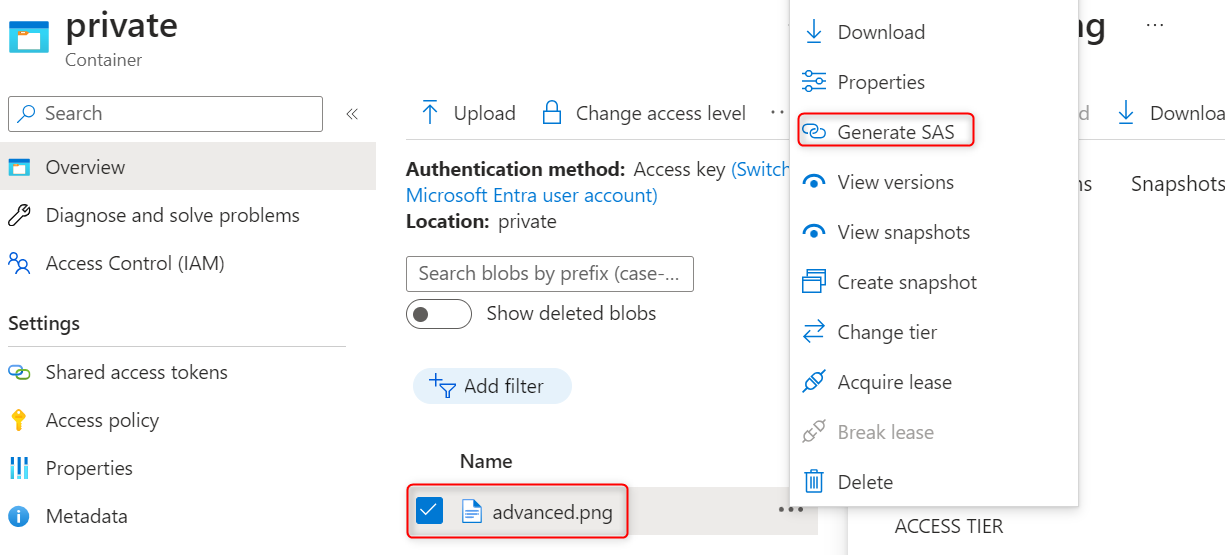
Copy the Blob SAS URL (https://privatestella.blob.core.windows.net/private/advanced.png?sp=r&st=2024-05-29T13:08:46Z&se=2024-05-30T13:08:46Z&spr=https&sv=2022-11-02&sr=b&sig=UJrEZnYxYdINV97Kfeb6nlVDQXaDkw9ZuKpkyD742Jo%3D)
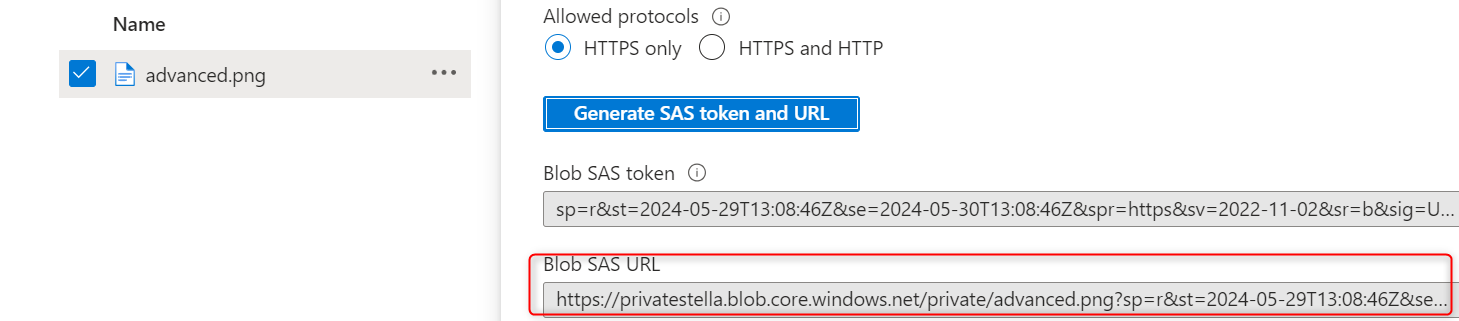
Then copy the Blob url to a new browser tab
.
Configure storage access tiers and content replication.
Return to the storage account.
in the Overview section, the Default access tier is set to Hot.

Data management section, select the Lifecycle management blade.
Select Add rule.

Set the Rule name to movetocool
Set the Rule scope to Apply rule to all blobs in the storage account and select Next.
Ensuring the Last modified is selected and set More than (days ago) to 30. In the Then drop-down select Move to cool storage. then click add
The public website files need to be backed up to another storage account
In a the storage account, create a container

Call the container backup and create
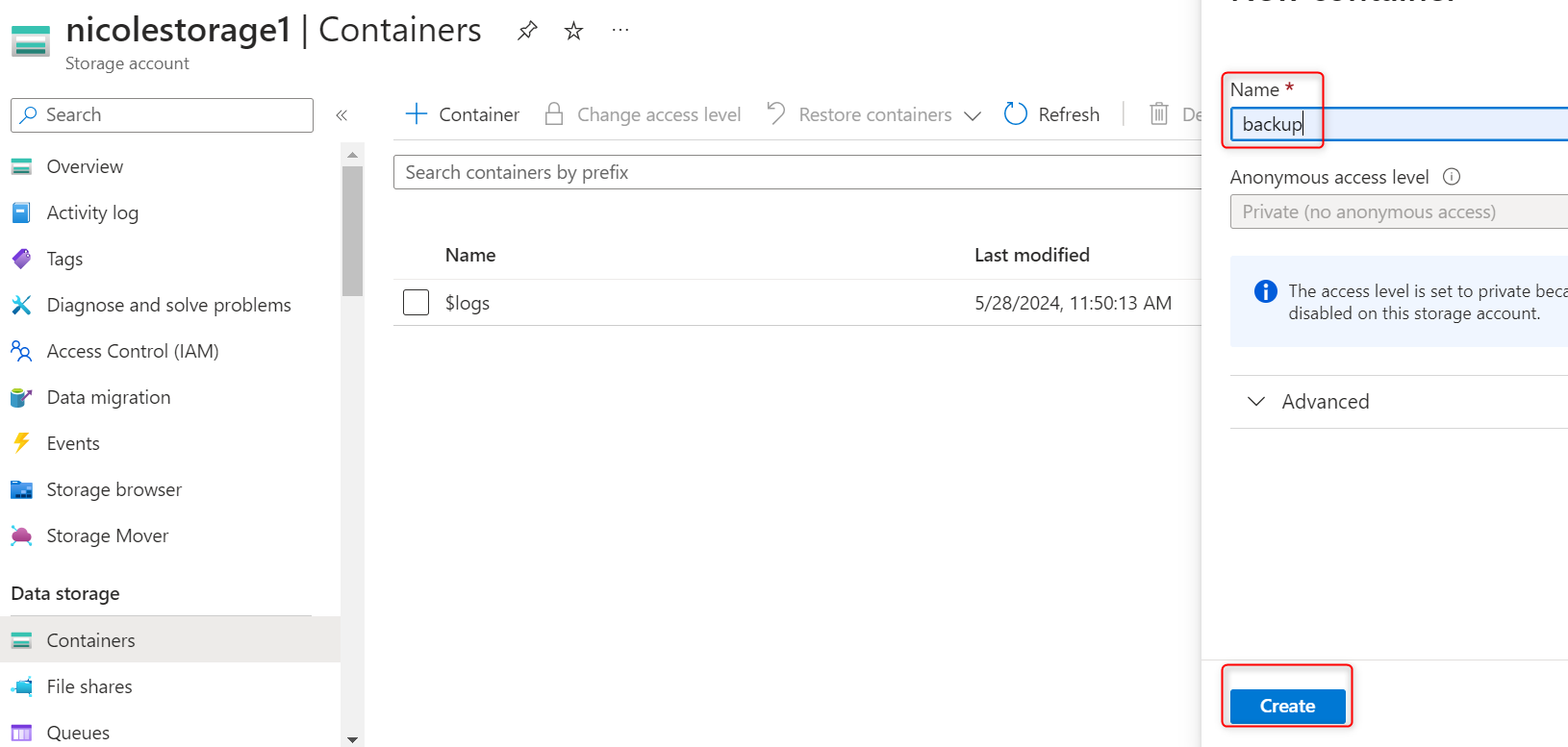
Navigate to the public website storage account (nicolestorage1).In the Data management section, select the Object replication blade
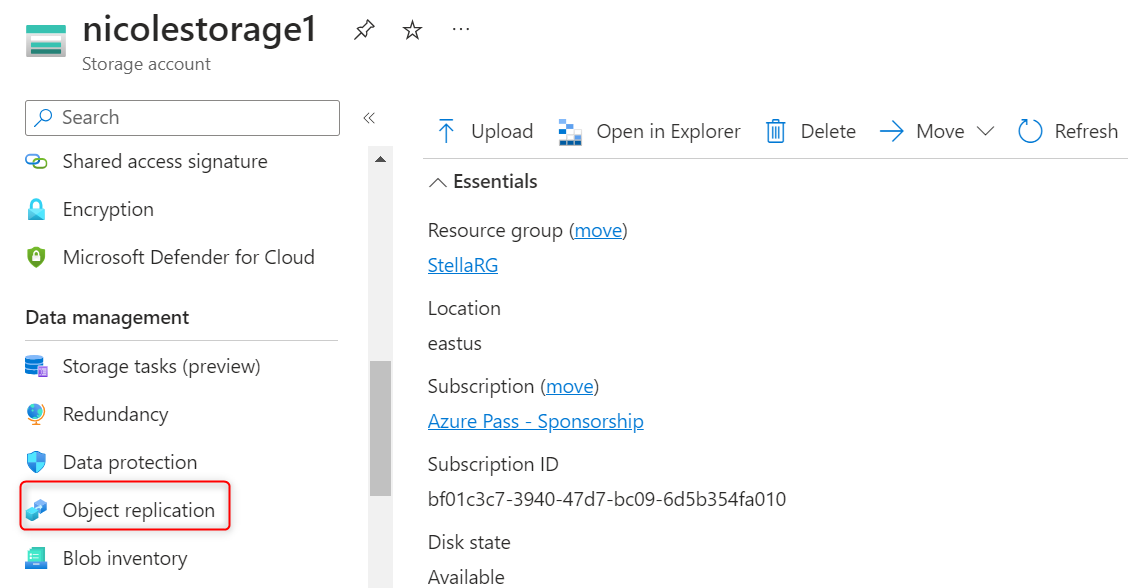
Select Create replication rules

Set the destination storage account to the private storage account(privatestella)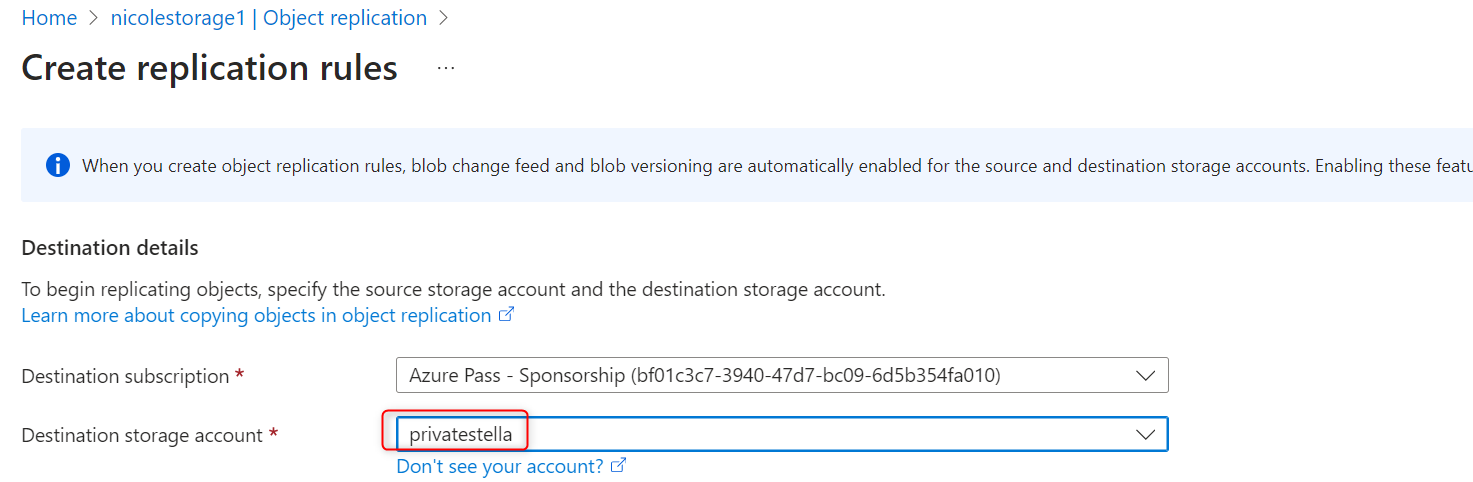
Go to the publicwebsitekam storage account created in the previous exercise in the Data management section, select the Object replication blade
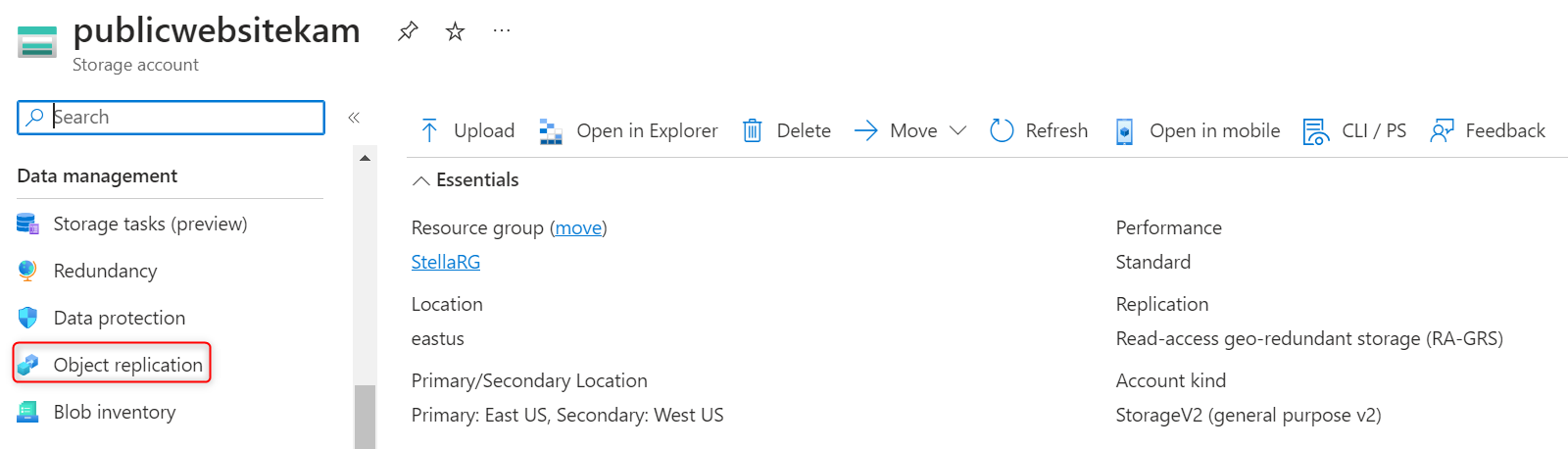
Set the Destination storage account to the private storage account
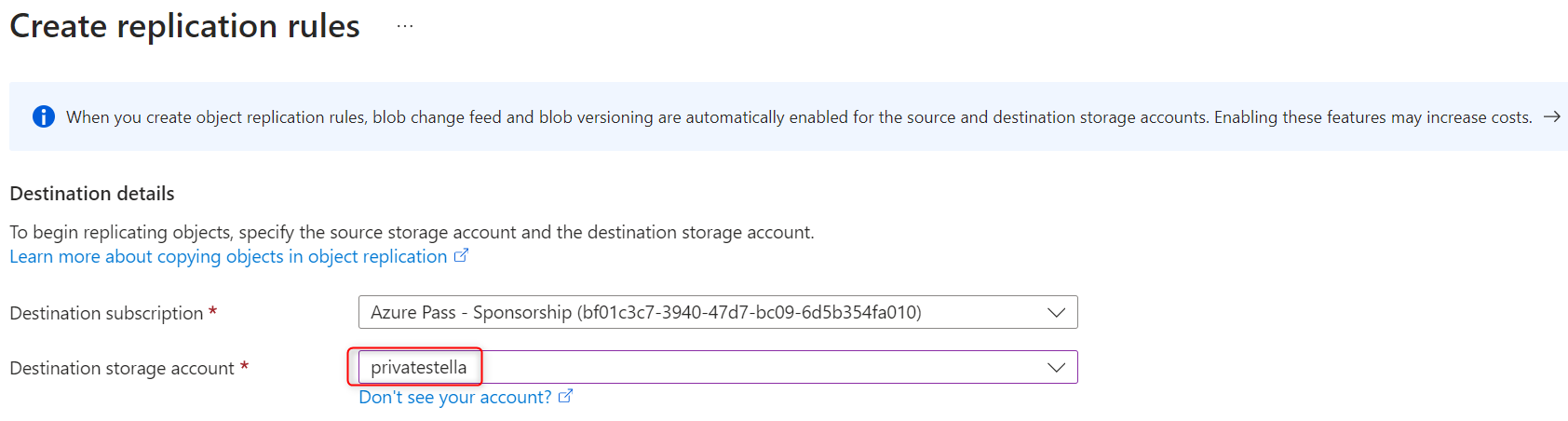
Set the Source container to public and the Destination container to backup
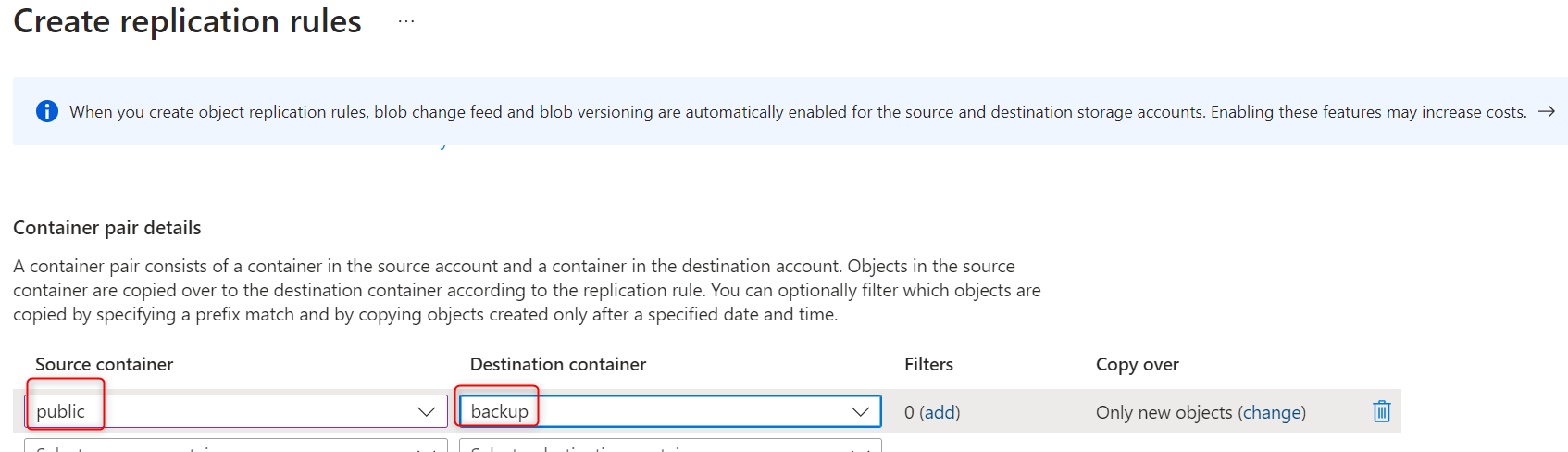
Create the replication rule.
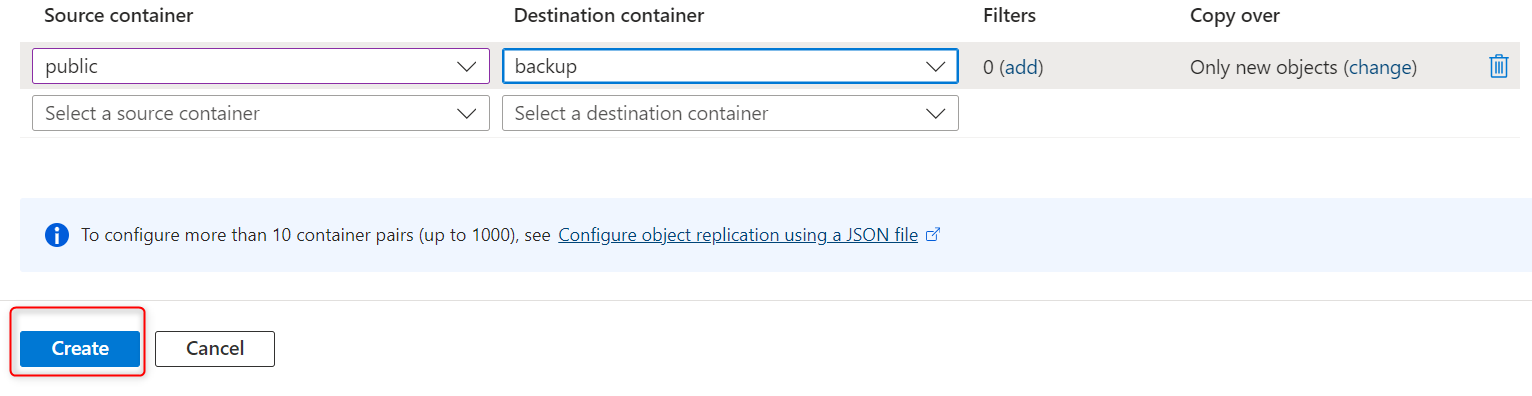
| stippy4real |
1,872,387 | PLSQL - Day 02 | DDL --> Alter , truncate , Create , rename , drop --> These will auto -commit. DCL --> Grant... | 0 | 2024-05-31T19:44:11 | https://dev.to/technonotes/plsql-day-02-4jge | DDL --> Alter , truncate , Create , rename , drop --> These will auto -commit.
DCL --> Grant , Revoke
DML --> No instruction , same as SQL.
Transaction Control Language --> Commit , rollback.
What is VARIABLE ? Its like a BOX , according to size I can vary the size of it.Also **_USED TO STORE DATA TEMPORARILY_**.
It can be changed so its called as VARIABLE.
If its constant , at the beginning , IT CAN'T BE CHANGED.
```
begin
.
.
end:
/
--> This is called execution block / PLSQL block / anonymous block or unnamed block.
```
PLSQL program can be stored in OBJECT, This is called STORED PROCEDURE.
If you want to store any data in PLSQL then only way is VARIABLE. If you know this then you are the master of it.
I WANT TO STORE DATE ? How ?
```
declare
d date; -- declaration
begin
dbms_output.put_line(d);
d := sysdate; -- definition
dbms_output.put_line(d);
d := d+10; -- value of variable changes here
dbms_output.put_line(d);
end;
/
:= --> Assignment operator
```
```
declare
d date;
begin
dbms_output.put_line(d);
d := 'Oracle';
dbms_output.put_line(d);
d := d+10;
dbms_output.put_line(d);
end;
/
Issue/Error : non-numeric character found where numeric is expected.
```
```
declare
d varchar2(3);
begin
dbms_output.put_line(d);
d := 'Oracle';
dbms_output.put_line(d);
d := d+10;
dbms_output.put_line(d);
end;
/
Issue/Error : Character string buffer too small
```
```
declare
d varchar2(10);
begin
dbms_output.put_line(d);
d := 'RHEL'; -- no error here
dbms_output.put_line(d);
d := d+10; -- error here
dbms_output.put_line(d);
end;
/
Issue/Error : string + 10 --> character to number conversion error
```
```
declare
d varchar2(10);
begin
dbms_output.put_line(nvl(d,0));
d := 'RHEL';
dbms_output.put_line(d);
d := 'Linux';
dbms_output.put_line(d);
end;
/
```
**_<u>To check NULL ?</u>_**
```
declare
d varchar2(10);
begin
dbms_output.put_line(d);
d := 'RHEL';
dbms_output.put_line(d);
d := 'Linux';
dbms_output.put_line(d);
end;
/
```
**_<u>Can I use the same variable again ? Is it possible ?</u>_**
```
declare
d varchar2(10);
d numbers;
begin
dbms_output.put_line(d);
d := 'RHEL';
dbms_output.put_line(d);
d := 'Linux';
dbms_output.put_line(d);
end;
/
Error / Issue : at most one declaration for D is permitted
```
**_<u>Declared but not used ? Will it throw error ?</u>_**
```
declare
d varchar2(10);
e numbers;
begin
dbms_output.put_line(d);
d := 'RHEL';
dbms_output.put_line(d);
d := 'Linux';
dbms_output.put_line(d);
end;
/
Error / Issue : NO ERROR WILL BE THROWN
```
**<u>Lets debug yesterday class :</u>**
```
declare
a departements%rowtype;
begin
select * into a from departments where rownum=1;
dbms_output.put_line(a.departement_name);
end;
/
```
```
declare
a departements%rowtype;
begin
select * into a from departments where rownum=1;
dbms_output.put_line(a.departement_name ||''|| a.location_id);
end;
/
```
**<u>Using the Column Data type and store in Variable :</u>**
```
declare
b locations.city%type;
begin
select city into b from locations where rownum=1;
dbms_output.put_line(b);
end;
/
```
**_<u>Multiple column values :</u>_**
```
declare
v1 employees.first_name%type;
v2 employees.salary%type;
v3 employees.hire_date%type;
begin
select first_name,salary,hire_date into v1,v2,v3 from employees where employee_id= 120;
dbms_output.put_line(v1||''||v2||''||v3);
end;
/
```
**_<u>Multiple column values to ONE Value :</u>_**
- **record**.( grouping of customized datatype )
```
declare
type v is record ( v1 employees.first_name%type , v2 employees.salary%type , v3 employees.hire_date%type ) ;
v4 v;
begin
select first_name,salary,hire_date into v4 from employees where employee_id= 120;
dbms_output.put_line(v4.v1||''||v4.v2||''||v4.v3);
end;
/
```
**_<u>How to enter the value in screen ?</u>_**
```
declare
type v is record ( v1 employees.first_name%type , v2 employees.salary%type , v3 employees.hire_date%type ) ;
v4 v;
begin
select first_name,salary,hire_date into v4 from employees where employee_id= **_&id_**;
dbms_output.put_line(v4.v1||''||v4.v2||''||v4.v3);
end;
/
IT WILL ASK FOR THE PEOPLE TO ENTER THE VALUE
```
## NOTES:
1. Select query can be saved in Views.
2. cl scr
3. Single quotes --> it will consider as string.
4. set serveroutput on --> dbms output option will be enabled in sql
5. / --> last statement will be executed in sql
6. 1 variable = 1 value only can be store , if you wnat to store means we need to use COLLECTION.
7. Predefined datatype will store only 1 value to the variable.
8. UDT --> User Defined Type --> collection
9. nvl ???
10. If you handle VARIABLE , you are a programmer man.
11. How many variables can be declared ? Any count ? --> Nothing like that.
12. rownum = 1 ??? It will give one row.
13. Why we are writing always select query with one row output ? because variable will store only one value.
14. Prompt --> substitution variable --> &id --> shift+7
15. set verify off --> it won't display any data in the screen.
16. %type , %rowtype , %recordtype --> these are called **_Anchored types_**
| technonotes | |
1,872,388 | Day 2: Harnessing Flutter Widgets - Journey through ListTile and StreamBuilder | Continuing My Flutter Exploration Today, I dove deeper into Flutter's common widgets as... | 0 | 2024-05-31T19:41:19 | https://dev.to/agagag/day-2-harnessing-flutter-widgets-journey-through-listtile-and-streambuilder-4bg4 | flutter, mobile, dart, programming | ## Continuing My Flutter Exploration
Today, I dove deeper into Flutter's common widgets as part of my educational journey with Educative's "Become a Flutter Developer" course. I explored the practical implementation of `ListTile` and `StreamBuilder`, and expanded my understanding with several other versatile widgets like `Container`, `ListView`, `Column`, `Row`, and `Form`. These components are fundamental to crafting efficient and dynamic UIs in Flutter apps.
## Understanding ListTile
The ListTile widget simplifies list item creation, providing a structured way to display elements within a list. It's designed to be highly customizable, supporting leading and trailing icons, multiple lines of text, and interaction events, making it a staple for anyone building list-heavy interfaces.
## Practical Implementation of ListTile
Here's a quick look at how `ListTile` was utilized in a dynamic setting:
```dart
Stream<int> streamListOfSquares(int n) async* {
for (int i = 0; i < n; ++i) {
await Future.delayed(const Duration(seconds: 1));
yield i*i;
}
}
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: const Text('Stream Builder Example')),
body: Center(
child: StreamBuilder<int>(
stream: streamListOfSquares(10),
builder: (context, snapshot) {
if (snapshot.connectionState == ConnectionState.waiting) {
return CircularProgressIndicator();
} else if (snapshot.hasData) {
return ListView.builder(
itemCount: snapshot.data! + 1,
itemBuilder: (context, index) {
return ListTile(
title: Text('The item number is ${index * index}'),
subtitle: Text('The index is $index'),
);
},
);
} else {
return Text('Something wrong happened.');
}
},
),
),
);
}
```
## Exploring StreamBuilder
The `StreamBuilder` widget is designed for building interfaces that react to asynchronous data streams like network responses or user input. It's incredibly useful for applications that require real-time data updates without manual intervention.
## Combining StreamBuilder with ListTile
In the provided code snippet, StreamBuilder and ListTile work together to dynamically display data as it's processed, showcasing how effectively Flutter handles real-time data updates.
## Wrapping Up Day 2
Today's session provided practical insights into two of Flutter's common widgets, enhancing my toolkit for building more interactive and dynamic apps. As I continue to explore more of Flutter's offerings, the versatility and power of Flutter's widget-based architecture become ever more apparent.
## Stay tuned for more insights as I continue my journey through the world of Flutter!
 | agagag |
1,872,385 | Day 1: Unveiling Flutter - Understanding Its Architecture and Core Components | TLDR Started my Flutter journey with Educative's course, delving into Flutter's... | 0 | 2024-05-31T19:35:51 | https://dev.to/agagag/day-1-unveiling-flutter-understanding-its-architecture-and-core-components-5g88 | flutter, mobile, dart, programming | ## TLDR
Started my Flutter journey with Educative's course, delving into Flutter's three-layered architecture (Embedder, Engine, and Framework) and the widget-based UI design. Dart's features enhance development, setting a solid foundation for creating responsive cross-platform apps.
## Starting My Flutter Journey
Welcome to the start of my mobile development journey with Educative's "Become a Flutter Developer" course. On Day 1, I began exploring the intricacies of Flutter's architecture. Here's why Flutter stands out as a top choice for developers aiming to create stunning cross-platform applications effortlessly.
## Unpacking Flutter's Three-Layered Architecture
Flutter's ingenious design supports a seamless development experience across platforms:
Embedder Layer: This foundational layer interfaces directly with the native platform, leveraging the native languages and frameworks such as Java or Kotlin for Android, and Objective-C or Swift for iOS.
Engine Layer: Crafted predominantly in C++, this layer is the workhorse for rendering graphics, processing events, and executing Dart code. It taps into the Skia graphics engine to render interfaces swiftly and effectively.
Framework Layer: The pinnacle of Flutter's architecture, entirely crafted in Dart, offers a comprehensive suite of customizable widgets and manages user interactions, providing the tools I interact with the most.
## Widgets: The Building Blocks of Flutter's UI
Flutter introduces a revolutionary UI design approach where everything is a widget - from simple text boxes to complex animations. These widgets are organized into trees which represent the UI structure of the application, making every component a building block to a more extensive system.
## Harnessing the Power of Dart
Dart, the programming language behind Flutter, optimizes the development process with features like just-in-time and ahead-of-time compilation, enhancing performance and speeding up the development cycle.
## Wrapping Up Day 1: Foundations for Flutter Mastery
Today's exploration has laid the foundational knowledge necessary to appreciate Flutter's capability of delivering responsive and compelling applications efficiently. It's clear that understanding these fundamental concepts is pivotal for anyone looking to leverage Flutter's full potential in application development. | agagag |
1,872,354 | How to Over Engineer a Todo App (The Zenith Gradient Algorithm) | Motivation Let’s say for example you have 4 tasks to do in a given day: Work on an essay,... | 0 | 2024-05-31T19:25:58 | https://dev.to/skyjaheim2/how-to-over-engineer-a-todo-app-the-zenith-gradient-algorithm-fc2 | math, softwareengineering, webdev | ## Motivation
Let’s say for example you have 4 tasks to do in a given day: Work on an essay, do some math homework, edit a video, and study for a physics exam, and let’s also assume that you have 6 hours in total to spend on all these tasks. The question is: how should you best allocate time to each one of these tasks to maximize your productivity? A rudimentary approach would be to allocate time arbitrarily or allocate an equal amount of time to each task without taking into account any factors like the difficulty of the task etc. In this case, you could simply allocate 1.5 hours to each task and call it a day, but could you do better? What if you instead allocated 1 hour for working on the essay, 0.5 hours for the math homework, 2.5 hours for editing the video and 2 hours for studying physics? You would still spend a total of 6 hours, but would this be better? i.e. Would you be more productive? How can we quantify these decisions? How could we build a todo app that does this computation for us?
## Defining Productivity
For a given task, let ρ(t) be the amount of progress we have made at time t, then productivity p(t) can be defined as the amount of progress made per unit time i.e. p(t) = dρ/dt (Productivity is the time derivative of progress). If we make a lot of progress really quickly, then we are more productive, if our progress doesn’t change with respect to time, then we aren’t productive at all, so this is a reasonable definition for productivity.
## Finding a Model
While doing a task, productivity as a function of time naturally has the shape of a Poisson Distribution, it starts at some initial value, then increases to some maximum point (this can be the mathematical definition of flow state, i.e. flow state can be defined as a time when we’re most productive), then decreases as we lose energy. A good model for this type of behavior is the function
This curve can be parameterized by the effort of the task E, the enjoyability of the task β, and the time it takes to reach flow state ϕ. As mentioned above, flow state can be defined as the time when productivity reaches a maximum. To calculate this value, we can set dp/dt = 0 and solve for t. This calculation results in t=1/k. We can now set this value of t equal to ϕ and solve for k, which results in k=1/ϕ.
We can express ϕ as a function of E and β.
Pinpointing this function exactly would be complicated. Instead, we can approximate ϕ as a linear function
where c₁, c₂ and c₃ are constants that vary from person to person and are within a range such that ϕ>0.
The initial productivity p0 can be defined
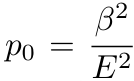
we typically have a harder time starting higher effort tasks compared to lower effort tasks and hence our starting productivity decreases as the effort of the task increases, we also tend to have an easier time starting tasks that we really enjoy, so our starting productivity increases as the enjoyability increases.
Increasing the parameter ‘a’ increases the global maximum of the function and hence increases the value of our peak productivity. We can try to quantify how ‘a’ depends on the parameters E and β by thinking of how our peak productivity (flow state) changes depending on the effort of the task and how much we enjoy doing it. Let’s use a video game as an example, when playing a low effort video game, the flow state we experience won’t feel that much different than how we feel on a regular basis, in contrast, when playing a high effort competitive video game, the flow state we experience will feel almost magical compared to any other time, especially if we really enjoy the game. This tells us that higher effort tasks that we really enjoy corresponds to a higher peak productivity. A good model for this is the function
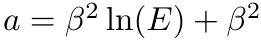
Putting this all together we have
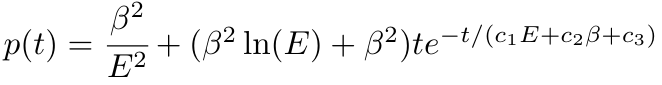
## Defining The Parameter Boundaries
In the previous section we defined the time it takes to reach flow state ϕ as
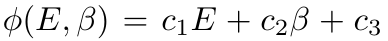
where c₁, c₂ and c₃ are constants that vary from person to person. For ϕ to be non negative, we can define a fixed range for E and β. We can define some intermediate variables Eᵤ and βᵤ to be the effort and the enjoyability respectively that the user provides. For consistency, both of these values will range from 1 to 10 and will then be mapped linearly to their respective ranges, i.e. E (the true value of effort) is a linear function of Eᵤ and β (the true value of enjoyability) is a linear function of βᵤ.
### The Boundary of Effort
Experimentally, it was determined that a good range for E is 1 ≤ E ≤ 5, we can now linearly map the range of Eᵤ (the intermediate value of effort) from 1 to 10 down to 1 to 5 using the function
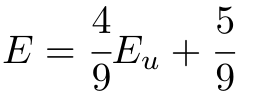
### The Boundary of Enjoyability
Similarly, a good range for β is 1 ≤ β ≤ 2, we can linearly map the range of βᵤ from 1 to 10 down to 1 to 2 using the function
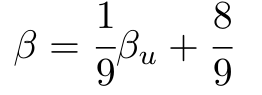
## User Dependent Constants
Now we will explore how c₁, c₂ and c₃ can be determined.
For each task (Task i), a stopwatch can be used to measure the time until flow state ϕ (the time it takes to get in the “zone”). This will give us data points
where Eᵢ is the effort of task i and βᵢ is the enjoyability of task i.
We can then use Linear Least Squares approximation to find the best fit plane to the data which results in
**NB**: c₁, c₂ and c₃ will be updated after a new data point has been provided.
## When to Stop Doing a Task
Let’s assume you have the task of studying for a math exam, and you’ve determined that the effort of this task on a scale from 1 to 10 is about 7 (Eu = 7 → E = 3.67), the enjoyability is 3 (βu = 3 → β = 1.22). Let’s also assume that your user dependent constants are c1 = 0.56, c2 = −0.24, and c3 = 0 your estimated time until flow state will then be
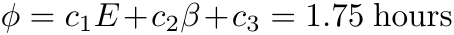
and your productivity curve is
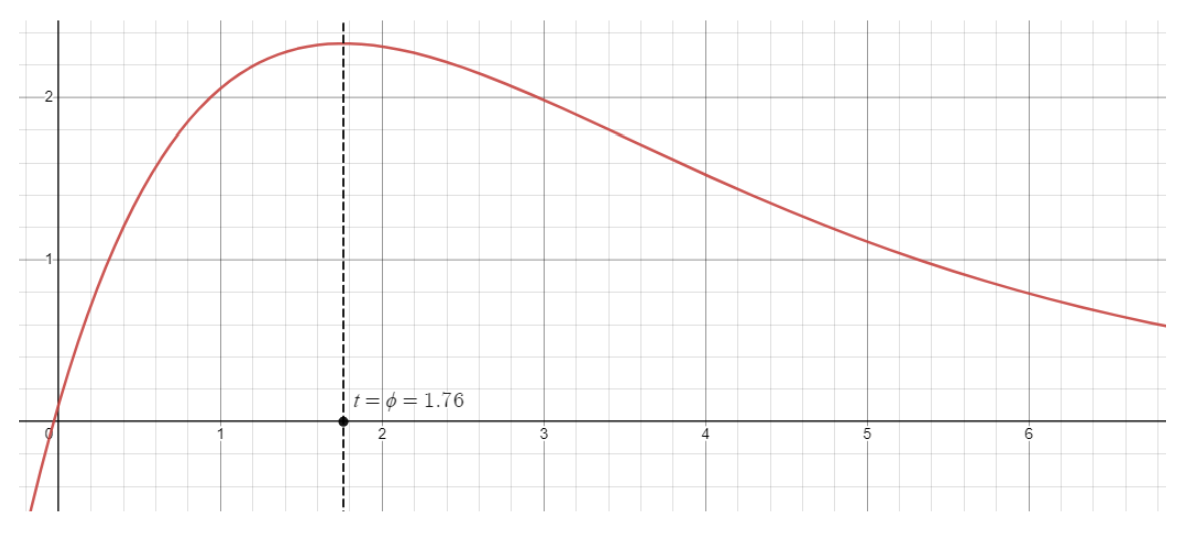
Now the question is, how long should you spend doing this task to maximize productivity? If you study for too long, you will become burnt out and start experiencing diminishing returns, study for too little and you risk not getting enough value out of that session. There is a sweet spot, and intuitively we know it lies some time after you reach flow state… but how long after? To answer this, we need a measure of how productive you are on some time interval, for the sake of example, let’s say the first 30 minutes into studying. A good measure for this is the average of p(t) between t = 0 and t = 0.50, which can be calculated by:
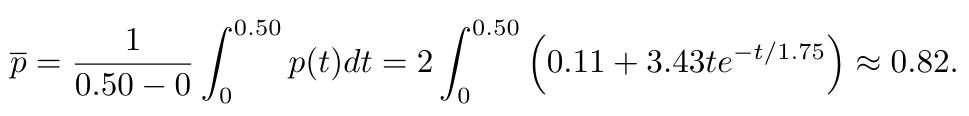
We can compare this to a later time interval, let’s say between 8 and 8 and a half hours.
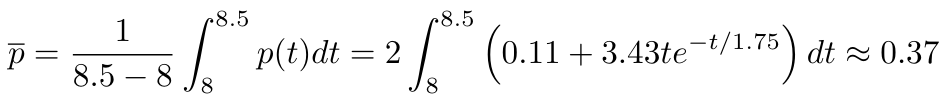
As we can see, the first 30 minutes into studying was much more valuable than 30 minutes a couple hours later. Now, we can define
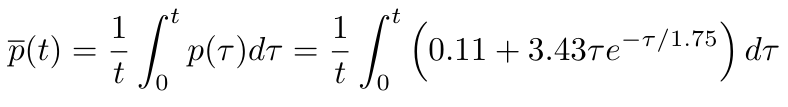
We can finally find the global maximum of this function to get the optimal time you should spend studying to maximize productivity
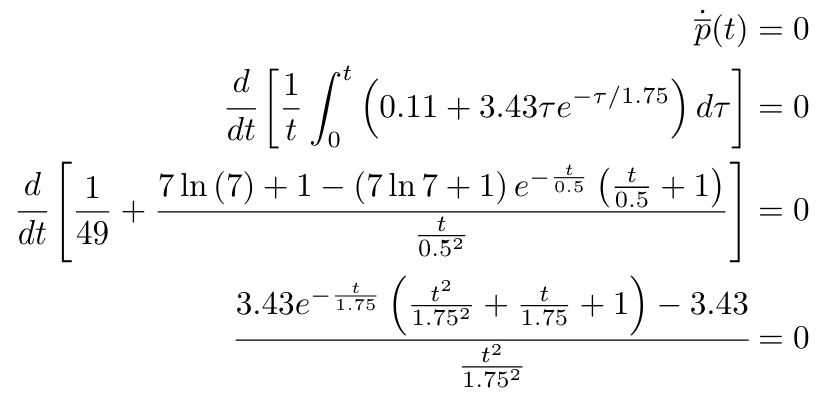
Solving for t numerically, we find that t ≈ 3.16. So the optimal amount of time you should spend studying is 3 hours and 10 minutes.
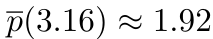
## Generalizing
If we have n tasks to complete in T hours and are given
the effort vector, and
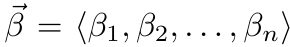
the enjoyability vector where Eᵢ is effort of task i, and βᵢ is the enjoyability of task i.
We cane define
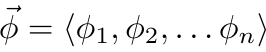
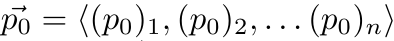
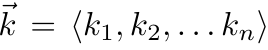
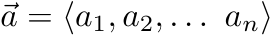
Let P(**t**) be the total productivity for the day, where **t** = ⟨t1, t2, . . . , tn⟩, and tᵢ is the time spent doing task i. P(**t**) can be defined as the sum of the average productivity for each task.
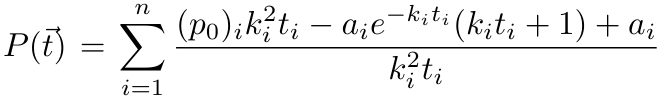
We can now maximize this function under the constraint that
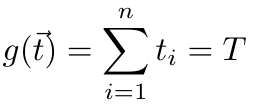
using the method of Lagrange multipliers.
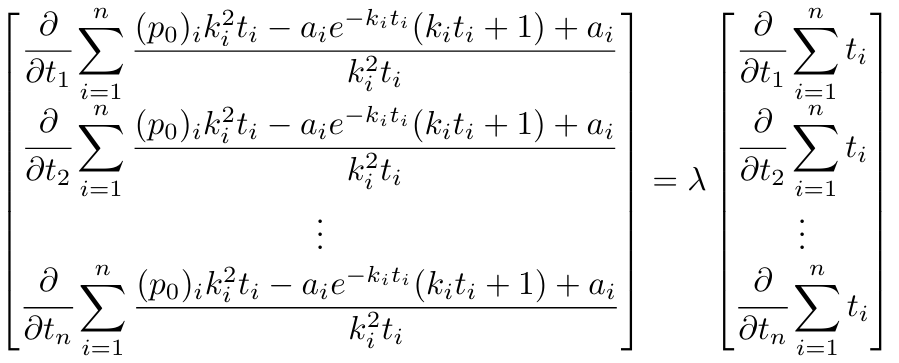
## Solving The System of Equations
Let us revisit the example that we started with: “You have 4 tasks to do in a given day: Work on an essay (Task 1), do some math homework (Task 2), edit a video (Task 3), study for a physics exam (Task 4), and let’s also assume that you have 6 hours in total to spend on all these tasks. The question is, how should you best allocate time to each one of these task to maximize productivity?” Each of these tasks have an associated effort and enjoyability, we can define:
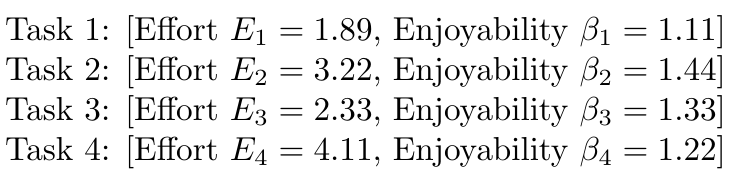
This gives us
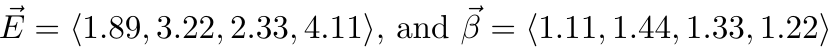
Therefore,

Solving this system numerically results in the solution:
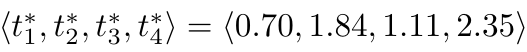
So, to maximize your productivity for the day, you should spend 0.70 hours (42 minutes) working on the essay, 1.84 hours (1 hour and 50 minutes) doing the Math homework, 1.11 hours (1 hour and 7 minutes) editing the video and 2.31 hours (2 hours and 21 minutes) studying Physics.
We can now compare this to the rudimentary approach mentioned at the beginning, where you would arbitrarily allocate time. For example, let’s say you allocated 2.5 hours for the essay, 2 hours for math, 0.5 hours for editing the video, and 1 hour for studying physics.
P(2.5, 2, 0.5, 1) ≈ 5.16, while P(0.70, 1.84, 1.11, 2.35) ≈ 6.13 which means you would increase your productivity for the day by about 19% by using this model.
## Sanity Check
If we have a list of tasks to complete that all have the same level of effort and enjoyment, intuitively we would expect that it would be best to spend an equal amount of time on each task since there would be no reason to prioritize one task over another. Mathematically, this states that if we solve the non-linear system above with
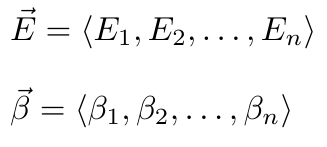
where
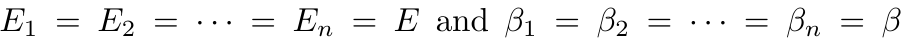
for some value of E and β, then the solution to the system will be
The proof of this is left as an exercise for the reader :)
## The Final Product
I’ve been developing this app for almost 2 years. The model described above has been fully implemented and you can try it out for free at: https://www.acumenweb.app/
A demo of the app can be view at: https://youtu.be/DcBo8AAKzLw
Dr Tom Crawford from the **Tom Rocks Maths** YouTube channel has also made a video covering the algorithm: https://youtu.be/vqbGIfjKmuU
Primeagen has made a video reacting to the algorithm: https://youtu.be/egVO61490h8
If you have any questions about the model or feature suggestions, you can join the discord and we can discuss: https://discord.gg/myFa5SKA5P
| skyjaheim2 |
1,872,383 | Guia de React re-render: tudo, tudo de uma vez | NOTA: Este artigo é apenas uma tradução. A fonte dele está no rodapé. Guia completo sobre... | 0 | 2024-05-31T19:25:57 | https://dev.to/dougsource/guia-de-react-re-render-tudo-tudo-de-uma-vez-22ai | react, javascript, portugues | > _**NOTA:** Este artigo é apenas uma tradução. A fonte dele está no rodapé._
Guia completo sobre re-renders do React. O guia explica o que são re-renders, o que é um re-render necessário e desnecessário, o que pode acionar um re-render de React component.
Também inclui os patterns mais importantes que podem ajudar a evitar re-renders e alguns anti-patterns que levam a re-renders desnecessários e, como resultado, baixo desempenho. Cada pattern e anti-pattern é acompanhado por um auxílio visual e um exemplo de código funcional.

## O que é o re-render no React?
Ao falar sobre o desempenho do React, há dois estágios principais com os quais precisamos nos preocupar:
- **initial render**: acontece quando um component aparece pela primeira vez na tela
- **re-render**: segunda e qualquer renderização consecutiva de um componente que já está na tela
Re-render acontece quando o React precisa atualizar o app com alguns dados novos. Geralmente, isso acontece como resultado da interação de um usuário com o app ou de alguns dados externos provenientes de uma request assíncrona ou de algum modelo de subscription.
Apps não interativos que não possuem atualizações de dados assíncronas nunca serão re-render e, portanto, não precisam se preocupar com a otimização do desempenho das novas renderizações.
[Assista "Intro to re-renders" no YouTube](https://youtu.be/qTDnwmMF5q8)
### 🧐 O que é um re-render necessário e o que é um re-render desnecessário?
**Re-render necessário**: re-render de um component que é a origem das alterações ou de um component que usa diretamente as novas informações. Por exemplo, se um usuário digitar um input field, o component que gerencia seu estado precisa se atualizar a cada pressionamento de tecla, ou seja, re-renderizar.
**Re-render desnecessário**: re-render de um component que é propagado pelo app por meio de diferentes mecanismos de re-render devido a erro ou arquitetura ineficiente do app. Por exemplo, se um usuário digitar um input field e a página inteira for re-render a cada pressionamento de tecla, a página terá sido re-render desnecessariamente.
Re-renders desnecessários por si só não são um problema: React é muito rápido e geralmente capaz de lidar com elas sem que os usuários percebam nada.
No entanto, se os re-renders acontecerem com muita frequência e/ou em components muito pesados, isso poderá fazer com que a experiência do usuário pareça com "lag", delays
visíveis em cada interação ou até mesmo o app pare completamente de responder.
[Assista "Intro to re-renders" no YouTube](https://youtu.be/qTDnwmMF5q8)
## Quando um React component re-render novamente?
Existem quatro razões pelas quais um component re-render: mudanças de state, re-renders de parents (ou childrens), mudanças de context e mudanças de hooks. Há também um grande mito: que as re-renders acontecem quando os props do component mudam. Por si só, não é verdade (veja a explicação abaixo).
### 🧐 Razões para re-renders: mudanças de state
Quando um state do component muda, ele irá re-render novamente. Geralmente, isso acontece ou em um callback ou no `useEffect` hook.
As mudanças de state são a fonte "raiz" de todos os re-renders.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part2-1-re-renders-because-of-state-ngh8uc?file=/src/App.tsx)
- [Assista "Intro to re-renders" no YouTube](https://youtu.be/qTDnwmMF5q8)

### 🧐 Razões para re-renders: re-render de parents
Um component será re-render se seu parent também re-render. Ou, se olharmos para isso na direção oposta: quando um component é re-render, ele também re-render todos os seus children.
Ele sempre "desce" na árvore: o re-render de um child não aciona o re-render de um parent. (Existem algumas advertências e casos extremos aqui, consulte o guia completo para mais detalhes: [O mistério do React Element, children, parents e re-renders](https://www.developerway.com/posts/react-elements-children-parents)).
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-2-2-re-renders-because-of-parent-b0xvxt?file=/src/App.tsx)
- [Assista "Intro to re-renders" no YouTube](https://youtu.be/qTDnwmMF5q8)
### 🧐 Razões para re-renders: mudanças de context
Quando o valor no Context Provider for alterado, todos os components que usam esse Context serão re-render, mesmo que não usem a parte alterada dos dados diretamente. Esses re-renders não podem ser evitados diretamente com a memoization, mas existem algumas workarounds que podem simular isso.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-2-3-re-render-because-of-context-i75lwh?file=/src/App.tsx)
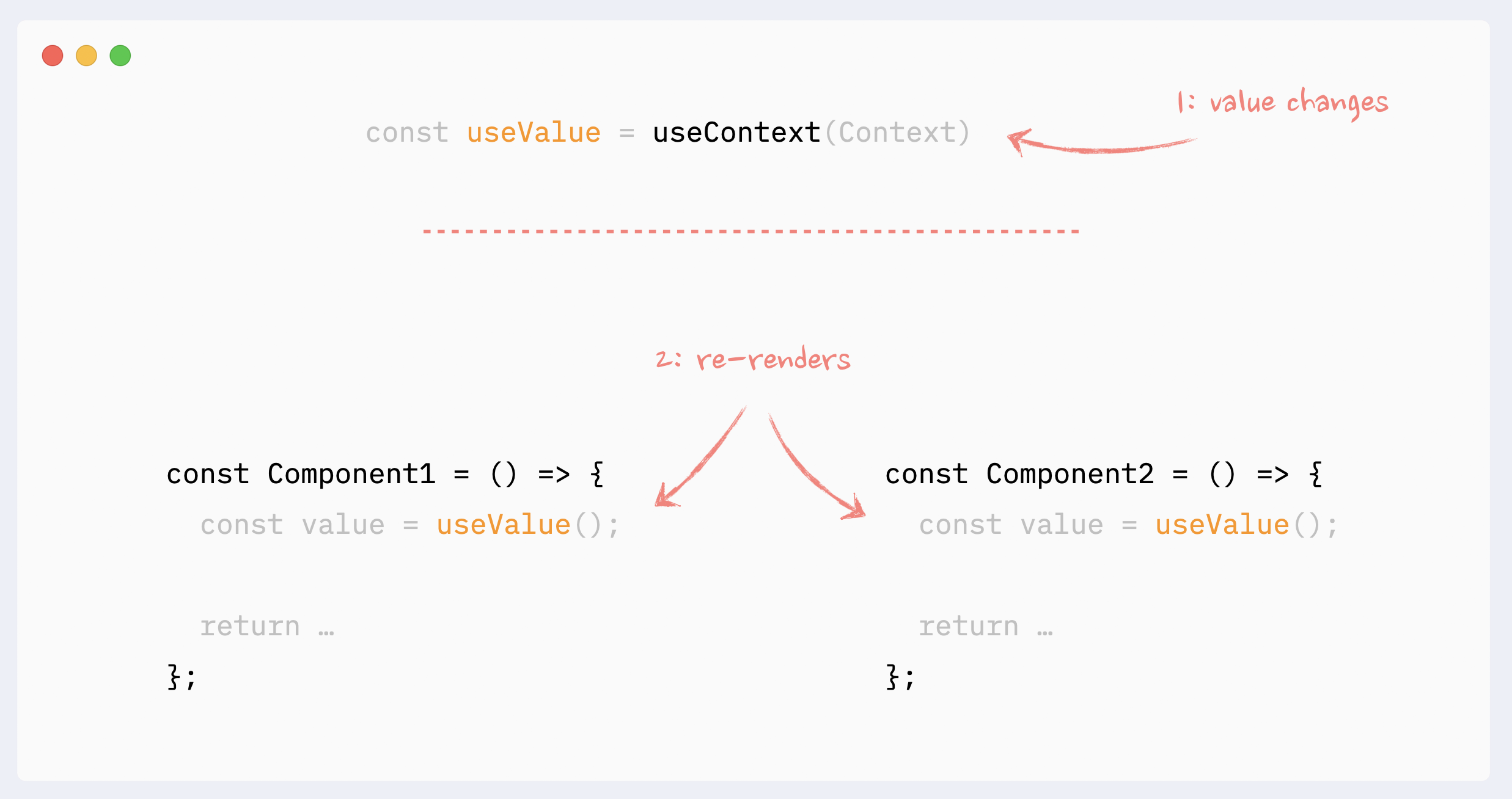
### 🧐 Razões para re-renders: mudanças nos hooks
Tudo o que está acontecendo dentro de um hook "pertence" ao component que o utiliza. As mesmas regras relativas às mudanças de context e state se aplicam aqui:
- a mudança de state dentro do hook irá desencadear uma re-rerender inevitável do component "host"
- se o hook usar o Context e as alterações de valor do Context, ele acionará uma re-rerender inevitável do component "host"
Hooks podem ser encadeados. Cada hook único dentro da cadeia ainda "pertence" ao "host" component, e as mesmas regras se aplicam a qualquer um deles.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-2-4-re-render-because-of-hooks-5kpdrp?file=/src/App.tsx)
- [Assista "Intro to re-renders" no YouTube](https://youtu.be/qTDnwmMF5q8)

### ⛔️ Razões para re-renders: mudanças de props (o grande mito)
Não importa se as props do component mudam, ou não, quando se fala em re-renders de components não-memoized.
Para que as props sejam alteradas, elas precisam ser atualizadas pelo parent component. Isso significa que o parent teria que re-render, o que acionaria o re-render do child component, independentemente de suas props.
Somente quando técnicas de memoization são usadas (`React.memo`, `useMemo`), a mudança de props se torna importante.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-2-5-re-render-props-not-relevant-2b8o0p?file=/src/App.tsx)
- [Assista "Intro to re-renders" no YouTube](https://youtu.be/qTDnwmMF5q8)
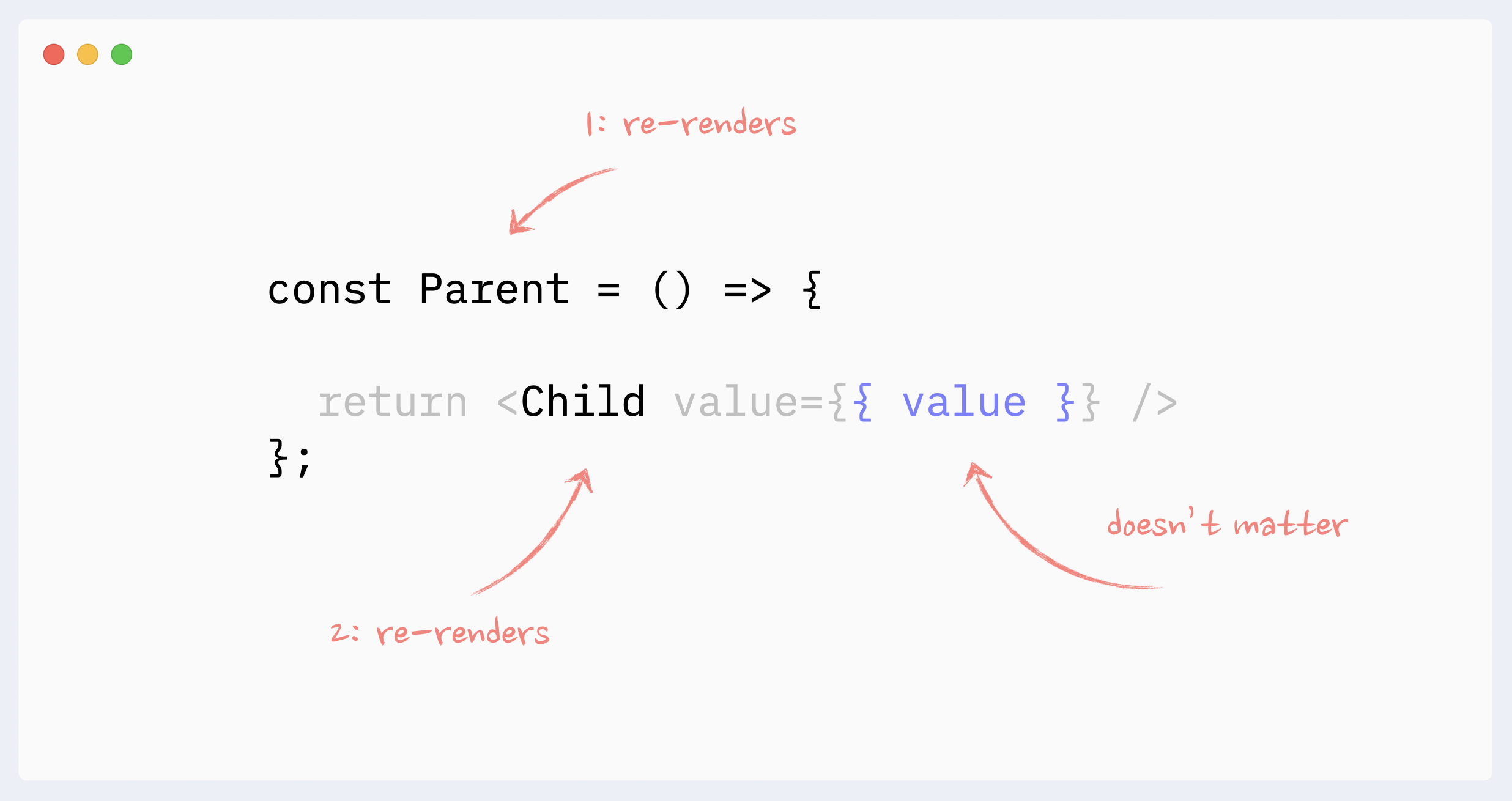
## Evitando re-renders com composition
### ⛔️ Antipattern: Criando components na render function
Criar components dentro da render function de outro component é um anti-pattern que pode ser o maior destruidor de desempenho. Em cada re-render, o React irá re-mount este component (ou seja, destruí-lo e recriá-lo do zero), o que será muito mais lento do que um re-render normal. Além disso, isso levará a bugs como:
- possíveis "flashes" de conteúdo durante os re-renders
- state sendo redefinido no componente a cada re-render
- useEffect sem dependências disparadas em cada re-render
- se um component estiver focused, o focus será perdido
Mais recursos:
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-3-1-creating-components-inline-t2vmkj?file=/src/App.tsx)
- Leia porque isso acontece em mais detalhes: [React reconciliation: como isso funciona e por que devemos nos importar](https://www.developerway.com/posts/reconciliation-in-react)
- Assista no YouTube: [Mastering React Reconciliation](https://youtu.be/cyAbjx0mfKM)
### ✅ Evitando re-renders com composition: movendo o state "para baixo"
Esse pattern pode ser benéfico quando um component pesado gerencia o state, e esse state é usado apenas em uma pequena parte isolada da render tree. Um exemplo típico seria abrir/fechar um dialog com um clique de button em um component complicado que renderiza uma parte significativa de uma página.
Nesse caso, o state que controla a aparência do modal dialog, o próprio dialog e o button que aciona a atualização podem ser encapsulados em um component menor. Como resultado, o component maior não será re-render nessas mudanças de state.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-3-2-moving-state-down-vlh4gf?file=/src/App.tsx)
- Leia sobre isso em mais detalhes: [O mistério do React Element, children, parents e re-renders](https://www.developerway.com/posts/react-elements-children-parents)
- Leia sobre reconciliation: [React reconciliation: como isso funciona e por que devemos nos importar](https://www.developerway.com/posts/reconciliation-in-react)
- Ou assista um vídeo do YouTube: [Introdução aos re-renders - Advanced React Course, Episode](https://youtu.be/qTDnwmMF5q8)

### ✅ Evitando re-renders com composition: children como props
Isso também pode ser chamado de "wrap state around children". Esse pattern é semelhante a "moving state down": ele encapsula mudanças de state em um component menor. A diferença aqui é que o state é usado em um elemento que encapsula uma parte lenta da render tree, portanto não pode ser extraído tão facilmente. Um exemplo típico seria callbacks de `onScroll` ou `onMouseMove` attached ao root element de um component.
Nessa situação, o state management e os components que usam esse state podem ser extraídos para um component menor, e o component lento pode ser passado para ele como `children`. Da perspectiva dos components menores, `children` são apenas props, portanto, não serão afetados pela mudança de state e, portanto, não serão re-render.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-3-3-children-as-props-59icyq?file=/src/App.tsx)
- Leia mais sobre composition: [O mistério de React Element, children, parents e re-renders](https://www.developerway.com/posts/react-elements-children-parents)
- Leia sobre reconciliation: [React reconciliation: como isso funciona e por devemos nos importar](https://www.developerway.com/posts/reconciliation-in-react)
- Ou assista sobre o pattern no YouTube: [Elements, Children e Re-renders - Advanced React course, Episode 2](https://youtu.be/So6plt0QE_M)
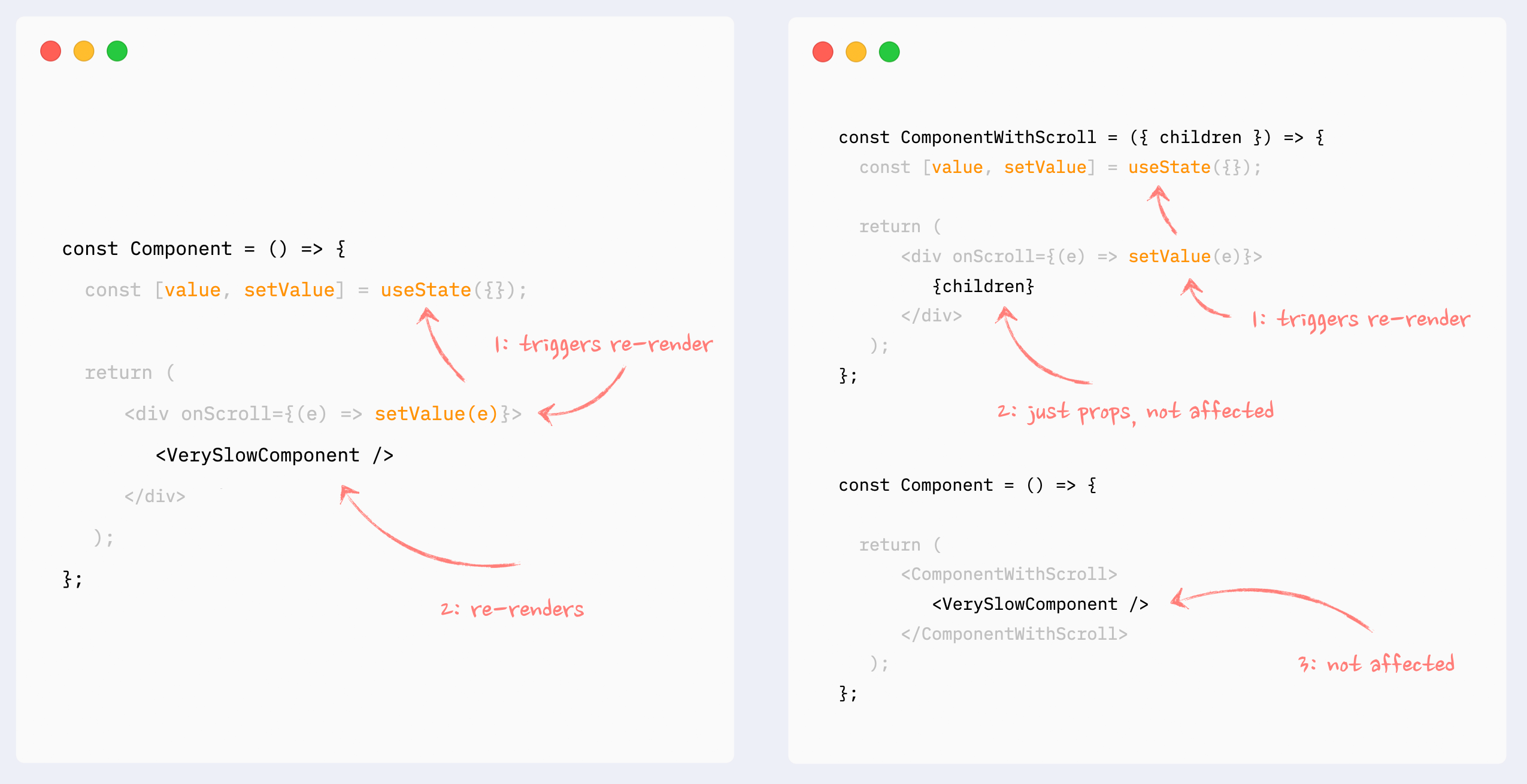
### ✅ Evitando re-renders com composition: components como props
Praticamente igual ao pattern anterior, com o mesmo comportamento: ele encapsula o state dentro de um component menor e components pesados são passados para ele como props. As props não são afetadas pela mudança de state, portanto, components pesados não serão re-render.
Pode ser útil quando alguns components pesados são independentes do state, mas não podem ser extraídos como children como um grupo.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-3-4-passing-components-as-props-9h3o5u?file=/src/App.tsx)
- Leia sobre passar components como props: [React component como prop: a maneira correta](https://www.developerway.com/posts/react-component-as-prop-the-right-way)
- Leia sobre reconciliation: [React reconciliation: como isso funciona e por que devemos nos importar](https://www.developerway.com/posts/reconciliation-in-react)
- Ou assista sobre o pattern no YouTube: [Components como props - Advanced React course, Episode 3](https://youtu.be/gEW0Wv0DMso)
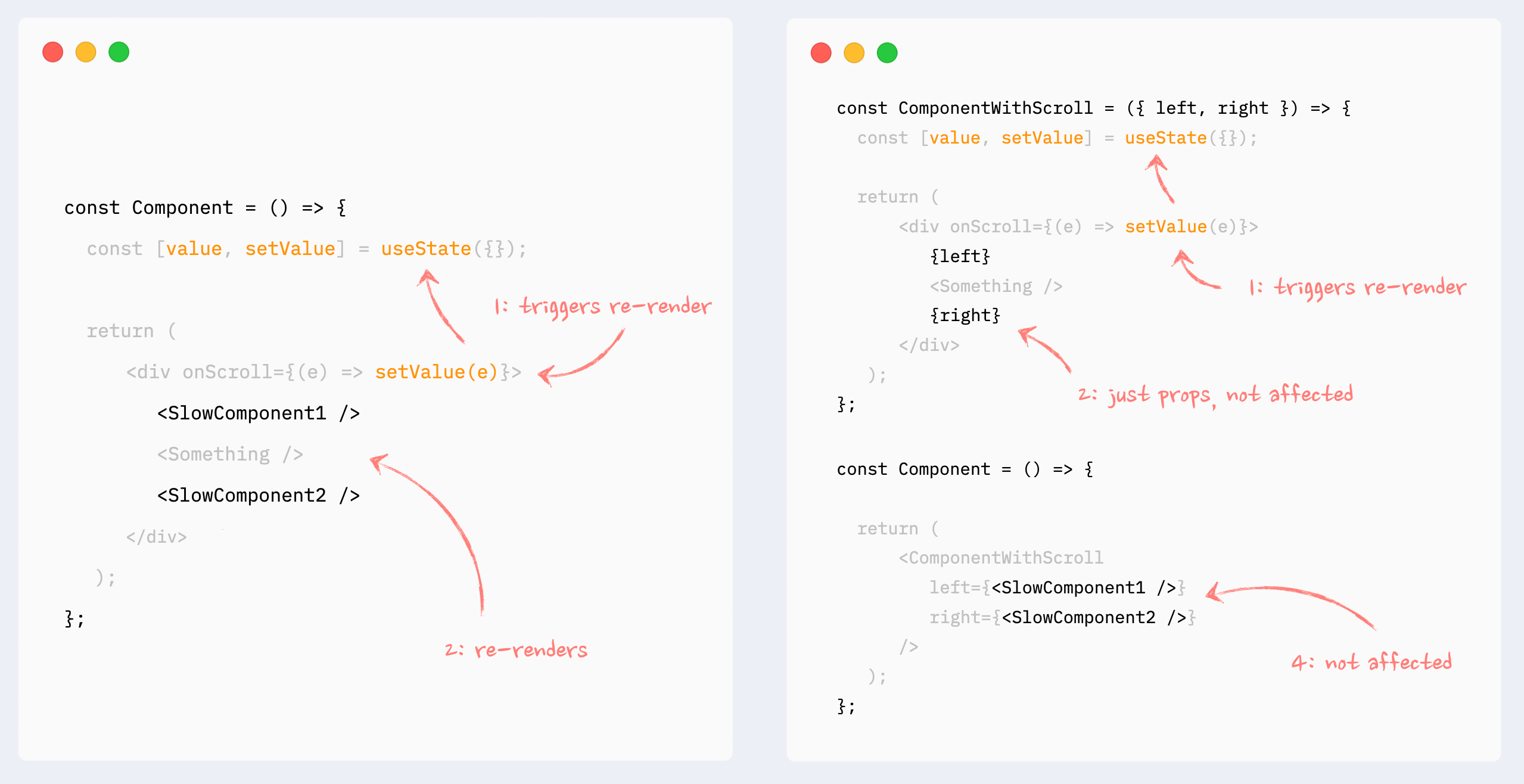
## Evitando re-renders com React.memo
Encapsulando um component em `React.memo` interromperá a cadeia downstream de re-renders que é acionada em algum lugar acima da render tree, a menos que as props deste component tenham mudado.
Isso pode ser útil ao renderizar um component pesado que não depende da origem do re-render (ou seja, state, dados alterados).
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-4-simple-memo-fz4xhw?file=/src/App.tsx)
- Assista um video no tópico: [Mastering memoization in React - Advanced React course, Episode 5](https://youtu.be/huBxeruVnAM)
### ✅ React.memo: component com props
Todas as props que não são valores primitivos devem ser memoized para que React.memo funcione
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-4-1-memo-on-component-with-props-fq55hm?file=/src/App.tsx)
- Assista um vídeo no tópico: [Mastering memoization in React - Advanced React course, Episode 5](https://youtu.be/huBxeruVnAM)

### ✅ React.memo: components como props ou children
`React.memo` deve ser aplicado aos elements passados como children/props. Memoize o parent component não funcionará: children e props serão objetos, portanto, eles mudarão a cada re-render.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-4-2-memo-on-components-in-props-55tebl?file=/src/App.tsx)
- Leia mais sobre children e parents: [O mistério de React Element, children, parents e re-renders](https://www.developerway.com/posts/react-elements-children-parents)
- Assista um vídeo no tópico: [Mastering memoization in React - Advanced React course, Episode 5](https://youtu.be/huBxeruVnAM)

## Melhorando o desempenho de re-renders com useMemo/useCallback
### ⛔️ Antipattern: useMemo/useCallback desnecessários em props
Memoizing props por sí só não impedirá re-renders de um child component. Se um parent component re-renders, ele acionará o re-render de um child component independentemente de suas props.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-5-1-unnecessary-usememo-lmk8fq?file=/src/App.tsx)
- Leia mais detalhes em: [Como utilizar useMemo e useCallback: você pode remover a maioria deles](https://www.developerway.com/posts/how-to-use-memo-use-callback)
- Assista um video no tópico: [Mastering memoization in React - Advanced React course, Episode 5](https://youtu.be/huBxeruVnAM)

### ✅ useMemo/useCallback necessário
Se um child component é encapsulado em `React.memo`, todas as props que não são valores primitivos deverão ser memoized
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-5-2-usememo-in-props-trx97x?file=/src/App.tsx)
- Assista um vídeo no tópico: [Mastering memoization in React - Advanced React course, Episode 5](https://youtu.be/huBxeruVnAM)

Se um component usa valor não-primitivo como dependência em hooks como `useEffect`, `useMemo`, `useCallback`, ele deve ser memoized.
[Veja um exemplo no codesandbox](https://codesandbox.io/s/part-5-2-usememo-in-effect-88tbov)

### ✅ useMemo para cálculos pesados
Um dos casos de uso `useMemo` é evitar cálculos caros em cada re-render.
`useMemo` tem seu custo (consome um pouco de memória e torna o render inicial um pouco mais lento), portanto não deve ser usado em todos os cálculos. No React, mounting e updating components será o cálculo mais caro na maioria dos casos (a menos que você esteja realmente calculando números primos, o que você não deveria fazer no frontend de qualquer maneira).
Como resultado, o caso de uso típico `useMemo` seria memoize React elements. Geralmente partes de uma render tree existente ou resultados de uma render tree gerada, como uma map function que retorna novos elements.
O custo de "pure" javascript operations, como ordenar ou filtering um array, geralmente é insignificante, em comparação com atualizações de components.
- [Veja um exemplo no codesandbox](https://codesandbox.io/s/part-5-3-usememo-for-expensive-calculations-trx97x?file=/src/App.tsx)
- Assista um vídeo no tópico: [Mastering memoization in React - Advanced React course, Episode 5](https://youtu.be/huBxeruVnAM)

## Melhorando o desempenho de re-render de listas
Além das regras regulares e patterns de re-render, o `key` attribute pode afetar o desempenho das listas no React.
__Importante:__ apenas fornecer `key` attributes não melhorará o desempenho das listas.
Para evitar rerenders de list elements, você precisa encapsular eles com `React.memo` e seguir todas as práticas recomendadas.
O valor em `key` deve ser uma string consistente entre os re-renders para cada elemento da lista. Normalmente, o `id` do item ou o `index` de arrays são usados para isso.
Não há problema em usar `index` de arrays como key, se a lista for estática , ou seja, os elementos não são adicionados/removidos/inseridos/reordenados.
Usar o index do array em listas dinâmicas pode levar a:
- bugs se os itens tiverem estado ou quaisquer uncontrolled elements (como form inputs)
- desempenho degradado se os itens forem agrupados em React.memo
Recursos adicionais:
- Leia sobre keys em mais detalhes: [React key attribute: melhores práticas para listas performáticas](https://www.developerway.com/posts/react-key-attribute).
- Leia sobre reconciliation: [React reconciliation: como isso funciona e por que devemos nos importar](https://www.developerway.com/posts/reconciliation-in-react)
- Leia sobre reconciliation: [Mastering React Reconciliation - Advanced React course, Episode 6](https://youtu.be/cyAbjx0mfKM)
- [Veja um exemplo em codesandbox - lista estática](https://codesandbox.io/s/part-6-static-list-with-index-and-id-as-key-7i0ebi?file=/src/App.tsx)
- [Veja um exemplo em codesandbox - lista dinâmica](https://codesandbox.io/s/part-6-dynamic-list-with-index-and-id-as-key-s50knr?file=/src/App.tsx)

### ⛔️ Antipattern: valor randômico como key em listas
Valores gerados randomicamente nunca deveria ser usados como valores no `key` attribute em listas. Elas levarão ao re-mounting de itens do React em cada nova renderização, o que levará a:
- desempenho muito ruim da lista
- bugs se os itens tiverem state ou quaisquer uncontrolled elements (como form inputs)
[Veja um exemplo no codesandbox](https://codesandbox.io/s/part-6-1-random-values-in-keys-z1zhy6?file=/src/App.tsx)

## Evitando re-renders causados pelo Context
### ✅ Evitando Context re-renders: memoizing o valor do Provider
Se o Context Provider não for colocado na raiz do app e houver a possibilidade de ele re-render devido a alterações em seus ancestrais, seu valor deverá ser memoized.
[Veja um exemplo no codesandbox](https://codesandbox.io/s/part-7-1-memoize-context-provider-value-qgn0me?file=/src/App.tsx)
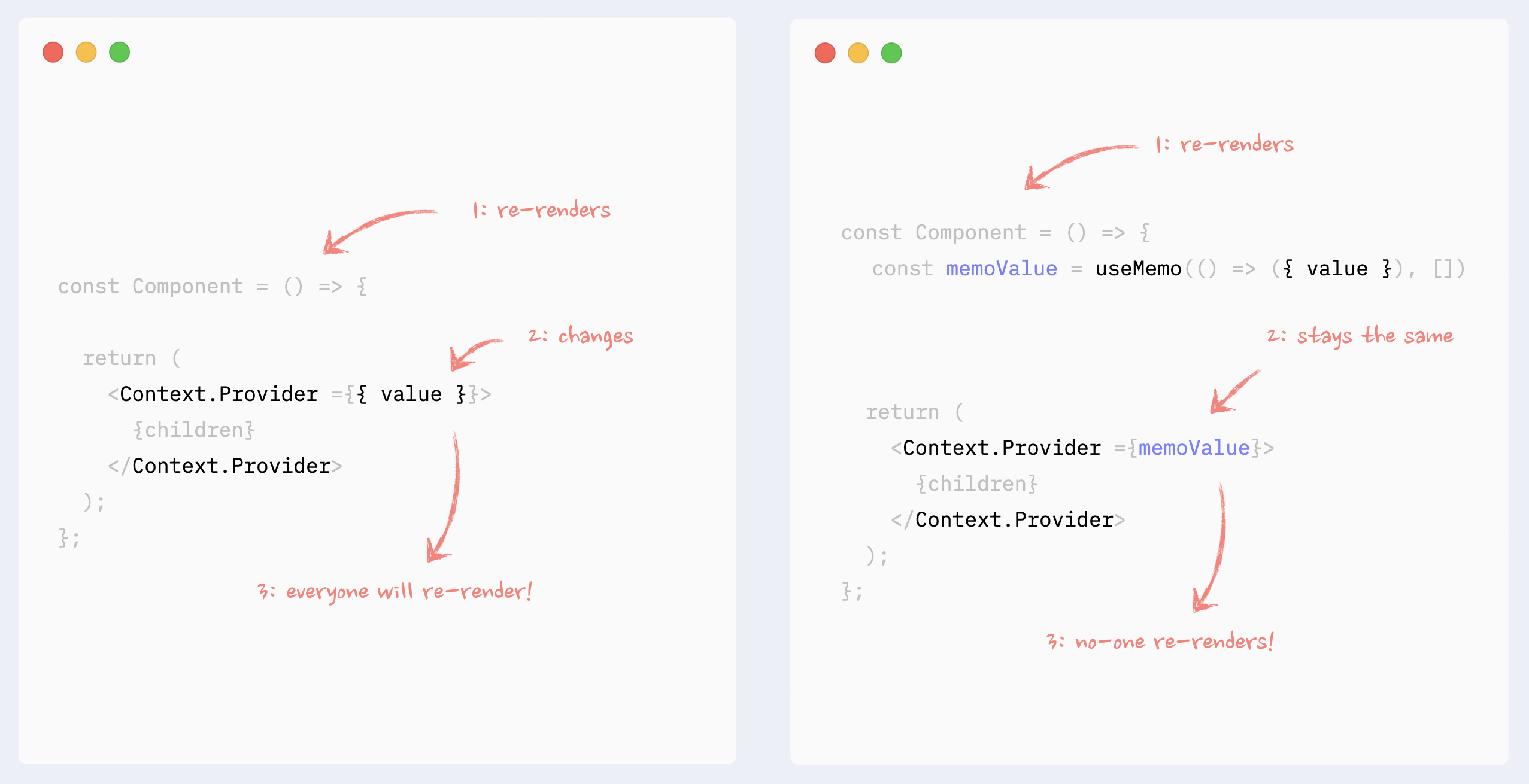
### ✅ Evitando Context re-renders: splitting de dados e API
Se no contexto houver uma combinação de dados e API (getters e setters), eles poderão ser "split" (divididos) em diferentes providers no mesmo component. Dessa forma, os components que usam apenas API não serão re-render quando os dados forem alterados.
Leia mais sobre esse pattern aqui: [Como escrever React apps de alto desempenho com Context](https://www.developerway.com/posts/how-to-write-performant-react-apps-with-context)
[Veja um exemplo no codesandbox](https://codesandbox.io/s/part-7-2-split-context-data-and-api-r8lsws?file=/src/App.tsx)

### ✅ Evitando Context re-renders: splitting dados em chunks
Se o Context gerenciar alguns chunks de dados independentes, eles poderão ser divididos em providers menores no mesmo provider. Dessa forma, apenas os consumers do chunk alterado serão re-render.
Leia mais sobre esse pattern aqui: [Como escrever React apps de alto desempenho com Context](https://www.developerway.com/posts/how-to-write-performant-react-apps-with-context)
[Veja um exemplo no codesandbox](https://codesandbox.io/s/part-7-3-split-context-into-chunks-dbg20m?file=/src/App.tsx)

### ✅ Evitando Context re-renders: Context selectors
Não há como evitar que um component, que usa uma parte do valor do Context, seja re-render, mesmo que o dado usado não tenha sido alterado, mesmo com o `useMemo` hook.
Context selectors, no entanto, podem ser "faked" com o uso de higher-order components e `React.memo`.
Leia mais sobre esse pattern aqui: [Higher-Order Components na era dos React Hooks](https://www.developerway.com/posts/higher-order-components-in-react-hooks-era)
[Veja um exemplo no codesandbox](https://codesandbox.io/s/part-7-4-context-selector-lc8n5g?file=/src/App.tsx)

### Fonte
[React re-renders guide: everything, all at once Makarevich](https://www.developerway.com/posts/react-re-renders-guide) - por Nadia Makarevich | dougsource |
1,872,382 | School Disinfection | For any area experiencing a lot of traffic, Sterile place offers a mutliple touch solution to fully... | 0 | 2024-05-31T19:25:13 | https://dev.to/fawivik341/school-disinfection-ob7 | news | For any area experiencing a lot of traffic, Sterile place offers a mutliple touch solution to fully disnfecting and sterilizing any place. Our approach guarantees not just cleanliness but also free from and residual sickness or filth in your regions. We keep you, your family, guests, and clients secure in any highly used surroundings.
[Learn More](https://www.sterilespace.com/disinfection-services/) | fawivik341 |
1,872,381 | Professional Java Developer Ready to Elevate Your Projects | Hi everyone, Are you looking for a highly skilled Java developer? I specialize in Spring Boot,... | 0 | 2024-05-31T19:21:29 | https://dev.to/shashank_naroliya_c356e96/professional-java-developer-ready-to-elevate-your-projects-1dam | programming, java, freelance, database | Hi everyone,
Are you looking for a highly skilled Java developer? I specialize in Spring Boot, JavaServer Pages, Database Management, Kubernetes, and Docker. With extensive experience in developing robust and scalable applications, I'm ready to help you achieve your project goals.
My Expertise:
Java
Spring Boot
Spring Security
Hibernate
RESTful Web Services
AWS (S3, SES)
JavaServer Pages (JSP)
Thymeleaf
Apache POI
Linux
Mailer Cloud
Docusign
Kubernetes
Docker
Let's bring your project to life with top-notch development skills. Feel free to message me directly to discuss how we can work together!
Best regards,
Shashank Naroliya | shashank_naroliya_c356e96 |
1,872,380 | JS Data types (Ma'lumot turlari) | JavaScriptda ikkita asosiy ma'lumotlar turi mavjud: primitiv va no primativ turlarga... | 0 | 2024-05-31T19:20:48 | https://dev.to/muxiddin/js-data-types-malumot-turlari-3obk | datatypes | ## JavaScriptda ikkita asosiy ma'lumotlar turi mavjud: primitiv va no primativ turlarga bo'linadi.
##
---
- <u>Primitiv Turlar</u>
`1. String`
```
Matnli ma'lumotlarni ifodalaydi. Ikkita qo'shtirnoq ("...")
yoki bitta qo'shtirnoq ('...') ichida yoziladi.
yoki bektik (`...`) ichida yoziladi
misol:
let str = "Hello, World!";
let str = 'Hello, World!';
let str = `Hello, World!`;
```
---
`2. Number`
```
Butun va o'nlik (floating-point) sonlarni ifodalaydi.
misol:
let num = 42;
let pi = 3.14;
```
---
`3. Boolean`
```
Mantiqiy qiymatlar: true yoki false.
misol:
let isTrue = true;
let isFalse = false;
```
---
`4. Null`
```
Bitta qiymatni qabul qiladigan maxsus ma'lumot turi:
Null, Bu qiymat ob'ektning mavjud emasligini ifodalaydi.
Misol:
let emptyValue = null;
```
---
`5. Undefined`
```
O'zgaruvchiga hech qanday qiymat tayinlanmaganligini ifodalaydi.
Misol:
let notAssigned;
console.log(notAssigned); // undefined
```
---
`6. Symbol`
```
(ES6 dan boshlangan)
Yagona, o'zgarmas identifikatorlarni yaratish uchun ishlatiladi.
Misaol:
let sym = Symbol('description');
```
---
`7. BigInt`
```
(ES11 dan boshlangan)
Katta butun sonlarni ifodalaydi bu sonlar Number tipida
ifodalanishi mumkin bo'lgan diapazondan kattaroq bo'ladi.
Misol:
let bigIntNumber = BigInt(9007199254740991);
```
---
- <u>No Primativ turlar</u>
`Object`
```
Kalit-qiymat juftliklarini saqlash uchun ishlatiladi.
Ob'ektlar moslashuvchan va ko'p maqsadli bo'lib,
bir nechta xususiyatlarga ega bo'lishi mumkin.
Misol:
let person = {
name: "John",
age: 30
};
```
---
`Array`
```
Tartiblangan ro'yxat yoki kolleksiyani ifodalaydi.
Arraylar ob'ektning bir turi hisoblanadi.
Misol:
let numbers = [1, 2, 3, 4, 5];
```
---
`Function`
```
Funksiyalar ham ob'ekt turlariga kiradi.Funksiya
kod bo'lagini qayta ishlatish va bajarish uchun ishlatiladi.
Misol:
function greet(name) {
return "Hello, " + name;
}
```
---
**Ma'lumotlar Turini Tekshirish**
`typeof`
```
operatori yordamida o'zgaruvchining turini tekshirish mumkin:
```
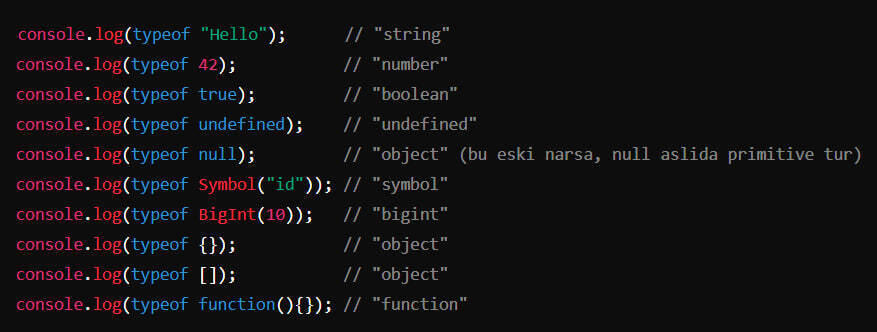
| muxiddin |
1,872,379 | Entering the World of AI Mechanics | I’ve been thinking a lot lately about how working with LLMs is spooky, as in “spooky action at a... | 0 | 2024-05-31T19:17:32 | https://dev.to/annaspies/entering-the-world-of-ai-mechanics-3776 | genai, llm, softwareengineering, programming | I’ve been thinking a lot lately about how working with LLMs is spooky, as in “spooky action at a distance” spooky, and some parallels to the world of physics have come up in my mind.
We’re going through a paradigm shift in tech right now, which is a dramatic statement to make at any time and is often incorrect (ahem, blockchain). But given the size of the current #genAI bandwagon, it feels not far off to say that things will not be the same once LLMs are widely adopted.
Being somewhat of a physics buff, I can’t help but see comparisons between what’s currently happening in genAI and what happened when quantum mechanics was introduced into a classical mechanics world, as both brought about a dramatic change in thinking.
In classical mechanics, if you roll a ball from point A, and you know the exact force it was pushed with and the amount of resistance, you’ll know when it will reach point B. If it doesn’t reach point B when you expected it to, something is wrong with your calculations, not with the laws of physics.
The world of classical computing is much like the world of classical mechanics: input A should always result in output B. Sure, there are complexities and race conditions, but for the most part, whatever code you’re writing is likely to be buggy because you didn’t think of some side effect, not because the logic suddenly changed on you.
Not so with LLMs. Input A sometimes results in output B, sometimes in output C, and sometimes in “I’m sorry, I can’t answer that question right now”. And so we enter the quantum world of probabilities, where an atom is X% likely to be in a given position, but you will never be 100% sure until you measure it.
We can give LLMs safeguards and engineer our prompts in specific ways, but the chance that an answer is what we expect will always be a probability, not a guarantee; we’re never sure of the output until it’s measured by the user’s reaction.
That means as engineers, we need to change our mindsets, from building in a world of known laws to building in a world of probabilities, and optimizing for the best average or consistent result.
We also need to realize that for the average user, this will initially appear as a degradation: we went from presenting sure outputs to widely varying outcomes given the same input, which can be jarring at best and a poor experience at worst.
Rolling out half-baked products without sufficiently sure probabilities of valid results is a good way to frustrate users; no disclaimer will alleviate a bad initial user experience. Most users still live in the classical world, and rather than meeting them where they’re at and easing them into quantum outputs, we’re pulling out the rug and hoping we’ve engineered our prompts correctly, when “correct” is actually a percentage and not a bool.
There’s a final parallel, though: quantum physics only applies at the subatomic level. Once you have a mass of atoms comprising, for example, a ball, it behaves in a very classical way. Perhaps masses of software, say at an enterprise or at the infrastructure level, should behave in a classical, predictable, and repeatable way.
That means that there are places and use cases for LLMs, but there also very much areas that should stay classical, where probability is detrimental to the experience, and the blanket “put an AI on it” push is counterproductive. We’re still learning where that line is, but until we do, maybe some use cases should remain in the classical world. | annaspies |
1,872,378 | Python : Linear search and Binary Search | Practicing Python From Basics Linear Search: Linear search, also known as sequential... | 0 | 2024-05-31T19:13:54 | https://dev.to/newbie_coder/python-linear-search-and-binary-search-2fbk | algorithms, python, learning | **Practicing Python From Basics**
## Linear Search:
- Linear search, also known as sequential search, checks each element in a collection one by one until the target element is found or the end of the collection is reached.
- It's a simple but inefficient algorithm, especially for large datasets, as it has a **time complexity of O(n)** in the worst case.
- Linear search is applicable to both sorted and unsorted collections.
### Implementation
```python
def linear_search(key,arr):
for index in range(len(arr)):
if arr[index] == key:
return index
return 0
```
### Calling function
```python
arr = [5,8,2,10,3,6]
key = 3
result = linear_search(key,arr)
```
```python
if result:
print(f'Element {key} found at index {result}')
else:
print("Element not found")
```
Element 3 found at index 4
### 2nd calling
```python
key1 = 7
result1 = linear_search(key1,arr)
```
```python
if result1:
print(f'Element {key1} found at index {result1}')
else:
print("Element not found")
```
Element not found
- The `linear_search` function takes a list `arr` and a target value `key`.
- It iterates through each element of the list using a for loop.
- For each element, it checks if it matches the target value.
- If a match is found, it returns the index of the element. If not found, it returns 0.
## Binary Search
- Binary search is a more efficient algorithm for finding a target value within a sorted array.
- It repeatedly divides the search interval in half until the target is found or the interval is empty.
- Binary search has a **time complexity of O(log n)**, making it significantly faster than linear search for large datasets.
- **It requires the array to be sorted beforehand.**
### Implementation
```python
def binary_search(key,arr):
start, end = 0, len(arr)-1
while start<=end:
mid = (start+end)//2
if arr[mid] == key:
return mid
elif arr[mid]<key:
start = mid+1
else:
end = mid-1
return 0
```
### Calling Binary search
```python
arr = [2, 4, 6, 8, 10, 12, 14, 16]
key = 12
result = binary_search(key,arr)
```
```python
if result:
print(f'Element {key} found at index {result}')
else:
print("Element not found")
```
Element 12 found at index 5
### 2nd Calling
```python
key = 1
result = binary_search(key,arr)
```
```python
if result:
print(f'Element {key} found at index {result}')
else:
print("Element not found")
```
Element not found
- The `binary_search` function takes a sorted array `arr` and a target value `key`.
- It initializes `start` and `end` pointers to the start and end of the array, respectively.
- It repeatedly calculates the `mid` index and compares the element at `mid` with the `key`.
- Based on the comparison, it updates `start` or `end` pointers to narrow down the search interval.
- It continues until the target is found or the search interval is empty, returning the index of the target or 0 if not found.
| newbie_coder |
1,872,377 | Get $100 Off Temu Coupon Code {aah64133} | New users can Get a huge $100 off coupon bundle for your entire purchase, plus an additional 30%... | 0 | 2024-05-31T19:13:21 | https://dev.to/priyamishra123976/get-100-off-temu-coupon-code-aah64133-ecd | temu | New users can Get a huge $100 off coupon bundle for your entire purchase, plus an additional 30% discount on top of that! That's right, slash prices by up to 70% with code [aah64133] at checkout.
Temu coupon code for existing customers: {aah64133} or { ach320371 }
Temu Coupon $100 Off for Existing Customers 2024: {aah64133} or { ach320371 }
50% off Temu coupon Code- {aah64133} or { ach320371 }
Buy1 Get 1 free Temu code - {aah64133} or { ach320371 }
Temu Buy 5 Get 6 free coupon code - {aah64133} or { ach320371 }
Temu $100 coupon bundle - {aah64133} or { ach320371 }
Temu coupon code $100 Canada - {aah64133} or { ach320371 }[Both New & Existing]
50% Off Temu UK code - {aah64133} or { ach320371 }[Both New & Existing]
Temu Coupon Code for Mexico: {aah64133} or { ach320371 }[Both New & Existing]
Temu Coupon Code for USA: {aah64133} or { ach320371 }[Both New & Existing]
Temu Coupon Code for UAE: {aah64133} or { ach320371 }[Both New & Existing]
Temu coupon Code for Japan: {aah64133} or { ach320371 }[Both New & Existing]
Temu Coupon Code for Australia: aci384098 [Both New & Existing] | priyamishra123976 |
1,872,375 | Redeem $100 Off Temu Coupon Code {ach320371} | Redeem $100 Off Temu Coupon Code {aah64133}: As you mentioned, the coupon code {aah64133} or {... | 0 | 2024-05-31T19:11:28 | https://dev.to/priyamishra123976/redeem-100-off-temu-coupon-code-ach320371-1lkk | temu, webdev, programming, opensource | Redeem $100 Off Temu Coupon Code {aah64133}: As you mentioned, the coupon code {aah64133} or { ach320371 } is valid for both new and existing users. It's always a good idea to check for such universal codes that work for everyone. Remember that you can use this code during checkout to enjoy the specified discount or benefit.
Save 90% Off And 30%. Temu offers users a $100 off coupon bundle code to save money on their shopping.
How to get more discounts on Temu?
The easiest way to get coupons is to sign up for Temu's text club. Text TEMU to {aah64133} or { ach320371 }to get 20% off your first order and other exclusive offers. Get the best deals at Temu when you create an account at Temu.com and opt-in to receive promotional emails.
| priyamishra123976 |
1,872,373 | Glam Up My Markup | Submission Prompt for "Glam Up My Markup: Beaches" Challenge Project Overview: Welcome to the "Best... | 0 | 2024-05-31T19:09:39 | https://dev.to/maheswaram_subrahmanyam/glam-up-my-markup-25ff | devchallenge, frontendchallenge, css, javascript | Submission Prompt for "Glam Up My Markup: Beaches" Challenge
Project Overview:
Welcome to the "Best Beaches in the World" website! For this challenge, I have transformed the provided HTML into a visually stunning and interactive experience using advanced CSS and JavaScript techniques. My primary focus was to enhance accessibility, usability, and user experience while infusing creativity and ensuring high code quality. Below, I detail my approach and the outcomes achieved across various criteria.
Accessibility:
Accessibility was at the forefront of my design process. Key accessibility features include:
Semantic HTML: I utilized semantic HTML elements to improve screen reader navigation, ensuring a clear and logical structure.
Alt Attributes: Each dynamically added beach image includes descriptive alt text for screen readers.
Contrast and Readability: I selected colors with sufficient contrast to ensure text readability for users with visual impairments.
Responsive Design: The layout adjusts seamlessly across different devices and screen sizes, providing an optimal viewing experience for all users.
Usability and User Experience:
To create an engaging and user-friendly interface, I implemented several usability enhancements:
Hover Effects: Beach items expand and change background color on hover, offering immediate visual feedback.
Interactive Elements: Clicking on a beach item triggers an informative alert about the beach, enhancing interactivity.
Clean Layout: A well-organized and intuitive layout ensures that users can easily find and explore the beach information.
Creativity:
Creativity shines through the use of modern design elements and interactive features:
Dynamic Images: JavaScript dynamically loads beach images without modifying the original HTML structure.
Visual Design: I applied gradients, shadows, and transitions to create an inviting and visually appealing beach theme.
Animations: Subtle animations on hover and click actions add a layer of interactivity and delight.
Code Quality:
Maintaining high code quality was paramount, and I ensured the following:
Modular CSS: The CSS is organized into logical sections with comments, making it easy to understand and maintain.
Clean JavaScript: The JavaScript code is modular, well-documented, and uses modern ES6+ features for clarity and efficiency.
Best Practices: Followed best practices for both CSS and JavaScript to ensure performance, maintainability, and scalability.
Effective Use of CSS:
I leveraged CSS to create a visually appealing and responsive design:
Responsive Layout: Utilized Flexbox for flexible and adaptive layouts that look great on any device.
Stylish Elements: Applied gradients, shadows, and border-radius for a modern and polished look.
Transitions and Animations: Used CSS transitions to smooth out interactions, enhancing the user experience.
Aesthetic Outcome:
The final design is cohesive, attractive, and reflective of the beauty of the world's best beaches:
Beach Theme: The use of colors, images, and design elements evokes the tranquility and allure of beach destinations.
Visual Hierarchy: Clear visual hierarchy guides users through the content effortlessly.
Engaging Experience: Interactive features and animations make the website engaging and enjoyable to explore.
Prompt for Enhancing a Beach Website with CSS and JavaScript
Judging Criteria: Accessibility, Usability and User Experience, Creativity, Code Quality, Effective Use of CSS, Aesthetic Outcome
Welcome to our enhanced "Best Beaches in the World" website! Our goal was to transform a simple HTML template into an engaging, interactive, and visually stunning user experience. Here’s a breakdown of our approach:
1. Accessibility:
Accessibility was a priority throughout the development process. We ensured that all interactive elements are keyboard navigable and screen reader friendly. For instance, we used ARIA roles and labels where necessary and provided high-contrast color options to cater to users with visual impairments.
2. Usability and User Experience:
We focused on creating an intuitive and user-friendly interface. The beach list is now enriched with interactive elements:
Hover Effects: Each beach item highlights and provides more information on hover, enhancing discoverability.
Smooth Scrolling: Implemented smooth scrolling for seamless navigation between sections.
Modal Popups: Added modals with detailed descriptions and images of each beach, allowing users to explore without leaving the main page.
3. Creativity:
Creativity was key in making the website visually appealing:
Parallax Scrolling: Integrated parallax scrolling effects to give a sense of depth and motion, making the exploration of beach destinations more dynamic (GraphicMama) (Codecademy).
Animated Elements: Used CSS animations to bring the page to life. For example, waves gently animate in the background, and buttons have subtle hover animations.
4. Code Quality:
The code was written with readability and maintainability in mind:
Modular CSS: Organized CSS using BEM (Block, Element, Modifier) methodology to ensure clear and reusable styles.
Efficient JavaScript: Employed modern ES6 features for clean and efficient code. Ensured all scripts are non-blocking by loading them asynchronously.
5. Effective Use of CSS:
CSS was utilized to create a visually compelling design:
Custom Fonts and Icons: Integrated Google Fonts for a fresh, modern look and Font Awesome for intuitive icons.
Responsive Design: Ensured the site is fully responsive, providing an excellent experience on mobile devices as well as desktops.
6. Aesthetic Outcome:
The final outcome is a blend of aesthetic appeal and functionality:
Background Images and Gradients: Used high-quality images and CSS gradients to enhance visual appeal.
Consistent Theme: Maintained a cohesive beach theme with colors, typography, and imagery that evoke the tranquility and beauty of beach destinations.
Code Implementation Highlights
```
html code:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Best Beaches in the World</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<header>
<h1>Best Beaches in the World</h1>
</header>
<main>
<section>
<h2>Take me to the beach!</h2>
<p>Welcome to our curated list of the best beaches in the world. Whether you're looking for serene white sands, crystal-clear waters, or breathtaking scenery, these beaches offer a little something for everyone. Explore our top picks and discover the beauty that awaits you.</p>
</section>
<section>
<h2>Top Beaches</h2>
<ul>
<li>
<div class="beach-info">
<h3>Whitehaven Beach, Australia</h3>
<p>Located on Whitsunday Island, Whitehaven Beach is famous for its stunning white silica sand and turquoise waters. It's a perfect spot for swimming, sunbathing, and enjoying the natural beauty of the Great Barrier Reef.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Grace Bay, Turks and Caicos</h3>
<p>Grace Bay is known for its calm, clear waters and powdery white sand. This beach is ideal for snorkeling, diving, and enjoying luxury resorts that line its shore.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Baia do Sancho, Brazil</h3>
<p>Baia do Sancho, located on Fernando de Noronha island, offers stunning cliffs, vibrant marine life, and crystal-clear waters, making it a paradise for divers and nature lovers.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Navagio Beach, Greece</h3>
<p>Also known as Shipwreck Beach, Navagio Beach is famous for the rusting shipwreck that rests on its sands. Accessible only by boat, this secluded cove is surrounded by towering cliffs and azure waters.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Playa Paraiso, Mexico</h3>
<p>Playa Paraiso, located in Tulum, offers pristine white sands and turquoise waters against the backdrop of ancient Mayan ruins. It's a perfect blend of history and natural beauty.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Anse Source d'Argent, Seychelles</h3>
<p>Anse Source d'Argent is renowned for its unique granite boulders, shallow clear waters, and soft white sand. This beach is perfect for photography, snorkeling, and relaxation.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Seven Mile Beach, Cayman Islands</h3>
<p>Stretching for seven miles, this beach offers soft coral sand, clear waters, and numerous activities such as snorkeling, paddleboarding, and enjoying beachside restaurants and bars.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Bora Bora, French Polynesia</h3>
<p>Bora Bora is known for its stunning lagoon, overwater bungalows, and vibrant coral reefs. It's a perfect destination for honeymooners and those seeking luxury and tranquility.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Lanikai Beach, Hawaii</h3>
<p>Lanikai Beach features powdery white sand and calm, clear waters, making it a favorite for swimming, kayaking, and enjoying the scenic views of the Mokulua Islands.</p>
</div>
</li>
<li>
<div class="beach-info">
<h3>Pink Sands Beach, Bahamas</h3>
<p>Pink Sands Beach is famous for its unique pink-hued sand, clear waters, and serene atmosphere. It's an idyllic spot for beachcombing, swimming, and relaxing in paradise.</p>
</div>
</li>
</ul>
</section>
</main>
<script src="scripts.js"></script>
</body>
</html>
```
```
css code:
@import url('https://fonts.googleapis.com/css2?family=Bree+Serif&family=Caveat:wght@400;700&family=Lobster&family=Monoton&family=Open+Sans:ital,wght@0,400;0,700;1,400;1,700&family=Playfair+Display+SC:ital,wght@0,400;0,700;1,700&family=Playfair+Display:ital,wght@0,400;0,700;1,700&family=Roboto:ital,wght@0,400;0,700;1,400;1,700&family=Source+Sans+Pro:ital,wght@0,400;0,700;1,700&family=Work+Sans:ital,wght@0,400;0,700;1,700&display=swap');
/* Basic Reset */
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: 'Arial', sans-serif;
line-height: 1.6;
background-color: #f4f4f4;
color: #333;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
}
header {
background: linear-gradient(to right, #ff7e5f, #feb47b);
color: #fff;
padding: 1rem 0;
width: 100%;
text-align: center;
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.1);
}
h1 {
margin: 0;
}
main {
width: 90%;
max-width: 1200px;
padding: 20px;
background: #fff;
border-radius: 10px;
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.1);
margin: 20px 0;
}
h2 {
color: #333;
margin-bottom: 10px;
}
p {
margin-bottom: 15px;
}
ul {
list-style: none;
padding: 0;
}
li {
background: #fff;
margin-bottom: 20px;
padding: 20px;
border-radius: 10px;
box-shadow: 0 2px 5px rgba
}
body {
font-family: 'Roboto', sans-serif;
color: #333;
background: linear-gradient(to bottom, #87CEEB, #ffffff);
margin: 0;
padding: 0;
}
header {
text-align: center;
padding: 20px;
background: rgba(0, 123, 255, 0.7);
color: white;
}
main {
padding: 20px;
}
ul {
list-style: none;
padding: 0;
}
li {
background: rgba(255, 255, 255, 0.9);
margin: 10px 0;
padding: 20px;
border-radius: 10px;
transition: transform 0.3s;
}
li:hover {
transform: scale(1.05);
}
```
```
Js code:
document.addEventListener('DOMContentLoaded', () => {
const beachItems = document.querySelectorAll('li');
beachItems.forEach(item => {
item.addEventListener('click', () => {
showModal(item);
});
});
});
function showModal(item) {
const modal = document.createElement('div');
modal.classList.add('modal');
modal.innerHTML = `
<div class="modal-content">
<span class="close-btn">×</span>
<h3>${item.querySelector('h3').innerText}</h3>
<p>${item.querySelector('p').innerText}</p>
</div>
`;
document.body.appendChild(modal);
modal.querySelector('.close-btn').addEventListener('click', () => {
modal.remove();
});
}
```
| maheswaram_subrahmanyam |
1,872,371 | True For all | fd gf fg gf f f fgfg gfgf gfffffffffffffffffffffffffffffffffffffffffffffffff >... | 0 | 2024-05-31T19:08:13 | https://dev.to/abdul_qadernumber_61777ea/true-for-all-4705 |
fd
gf
fg
gf
f
f
fgfg
gfgf
```
gfffffffffffffffffffffffffffffffffffffffffffffffff
> gffffffffffffffffffffffffffffff
## fggggggggggggggggggggggggg
```
fggggggggggggggggg[](fgggggggggggggggggggggggggg) | abdul_qadernumber_61777ea | |
1,872,370 | Redeem $100 coupon bundle on Temu {aah64133} or { ach320371 } | There are no exclusions mentioned for the $100 coupon bundle on Temu. The coupon bundle provides... | 0 | 2024-05-31T19:07:59 | https://dev.to/priyamishra123976/redeem-100-coupon-bundle-on-temu-aah64133-or-ach320371--2214 | There are no exclusions mentioned for the $100 coupon bundle on Temu. The coupon bundle provides discounts on products across various categories like clothing, accessories, jewelry, and more.
To get the $100 coupon bundle, new users can download the Temu app using the link in the description of the YouTube video or search for the code {**aah64133**} or { **ach320371 **}. Existing customers can use the code {**aah64133**} or { **ach320371 **} to get the $100 coupon bundle.Temu also offers a sitewide sale with savings up to 90% off. They provide free shipping and free returns for up to 90 days after purchase. If your delivery is late, you can get a $5 credit. Additionally, Temu has a price protection policy - if the price drops within 30 days of your purchase, you can request a partial refund
What is Temu?
Temu is an online marketplace where you can find a wide range of products, from clothing and shoes to beauty and home decor1. It’s like a one-stop destination for affordable items, perfect for home decor, electronics, pet supplies, sports, and toys. They offer wholesale prices, making it an attractive option for budget-conscious shoppers.
## Is Temu Legit? {aah64133} or { ach320371 }
Temu claims to host the best deals you can find online, with more than 250 different categories to choose from. While some users have reported positive experiences, others remain skeptical. As with any online platform, exercise caution and do your research before making purchases2.
## Is Temu Safe to Use? {aah64133} or { ach320371 }
Temu emphasizes secure privacy, safe payments, and a delivery guarantee. However, given its low prices and the controversy surrounding its origins (more on that below), some users may approach it with caution. Always use your best judgment when shopping online.
How Does Temu Work?
Temu functions similarly to other online marketplaces. You browse their website or app, select products, and make purchases. Keep an eye out for lightning deals and new arrivals.
Why Is Temu So Cheap?
The low prices on Temu might raise eyebrows. While they claim to offer better deals than other sellers, the exact reasons for their affordability remain unclear. It’s essential to consider quality, shipping times, and potential risks when evaluating these bargains.
Are Temu’s Free Gifts Legit?
Temu offers free gifts, but their legitimacy can vary. Always check the terms and conditions associated with any promotional offers. If something seems too good to be true, investigate further.
Is Temu Safe to Buy From?
Temu has faced scrutiny due to its origins (see next point). While some users have had positive experiences, others have raised concerns about privacy and security. Proceed with caution and read reviews from other shoppers.
Spyware Concerns and China-Based Origins
Temu is reportedly a Communist China-based app and site. Some users claim that it monitors activity on other apps, accesses contacts, calendars, and social media accounts, raising privacy concerns3. However, this information should be verified independently.
Is Temu a Scam? {aah64133} or { ach320371 }
The legitimacy of Temu remains a topic of debate. Some users have found great deals, while others have expressed skepticism. Research thoroughly and make informed decisions.
Making Money on Temu {aah64133} or { ach320371 }
Temu offers opportunities for sellers to list products and potentially make money. If you’re interested in selling, explore their platform and guidelines.
Investigation and $7 Nintendo Switch {aah64133} or { ach320371 }
Temu being under investigation suggests that authorities are looking into its practices. As for the $7 Nintendo Switch, it’s essential to verify such extraordinary claims independently.
| priyamishra123976 | |
1,827,158 | How To Create A Fullstack TypeScript App Using AWS Amplify Gen 2 | AWS Amplify Gen 2 is a brand new way to create fullstack applications on AWS. In this tutorial, we’ll... | 0 | 2024-05-31T19:06:37 | https://dev.to/aws/how-to-create-an-app-on-aws-aws-amplify-gen-2-2534 | webdev, javascript, amplify, typescript | [AWS Amplify Gen 2 ](https://docs.amplify.aws/)is a brand new way to create fullstack applications on AWS. In this tutorial, we’ll explore how to get started creating a fullstack TypeScript application with Next.js! We’ll add storage and then connect it to our Amplify connected UI component library to upload files.
With Gen 2 we focused our efforts on creating a great developer experience. We wanted to make sure that you could focus on your frontend code instead of worrying about setting up your backend infrastructure. In this new version we created a brand new TypeScript safe DX that supports fast local development, and is backed by AWS Cloud Development Kit (CDK).
We recently released Gen 2 for general availability. Feel free to let us know what you think and leave a comment below.
With that said, before you get started makes sure your familiar with TypeScript, VSCode and Git. You'll also need a GitHub account and make sure Git is installed locally on the command line. We'll be using Next.js, however you don't need to be an expert in React to try out this tutorial.
## What Are We Building Today?
We will be creating an app that allows you to create todos with pictures. You’ll be using the [Amplify Next Starter](https://github.com/aws-samples/amplify-next-template) template and have it deployed to the AWS Amplify console. We'll create and connect to AWS AppSync, our managed GraphQL service, and use [Amazon Cognito](https://aws.amazon.com/pm/cognito), our customer identity and access management service, to authenticate and authorize users. Additionally, we'll use S3 for file storage of our images.
In this tutorial I'll walk you through step-by-step on how to create a new AWS Amplify Gen 2 app using the console, cloning that app, opening it in VSCode and adding in some additional features. We'll then deploy our changes back to the Amplify Gen 2 console to our hosted environment.
## Setup
We need to first have an AWS account ready. If you are not signed up, try out the [AWS Free Tier](https://aws.amazon.com/free/)! This will give you plenty of free resources to try out AWS and many of it's services. Keep in mind, all the services we'll work with today are on-demand and you'll only get charged when you are using them.
We will be using the Next.js Amplify [starter template](https://github.com/new?template_name=amplify-next-template&template_owner=aws-samples&name=amplify-next-template&description=My%20Amplify%20Gen%202%20starter%20application) as described in the [Quickstart guide](https://docs.amplify.aws/react/start/quickstart/). Clone the repository using the Amplify Next.js Template into your own Github account to get started.
Afterwords, sign into the [AWS management console](https://signin.aws.amazon.com/signin). Search at the top for AWS Amplify, and click it.
In the Amplify Console choose Create new app.
Select GitHub as the Git provider.
In the next page you'll see a popup asking to connect to your Github account. This will give Amplify access to your account so it can connect to the Next.js repo you just created in the previous step from the starter template.
Select your app from the App name field and click next. If you don’t see your app click the `Update Github permissions` button and re-authorize with Github. On the next page leave all the default settings and click next. On the last page click `Save and deploy`. Amplify will now begin to deploy your new app!
The deployment may take several minutes. It will host your Next.js frontend and create infrastructure for your Amazon Cognito and AWS AppSync service backend. We’ll discuss this more later, and how we can make updates and changes to it. Until then, let's jump into VSCode and setup the frontend!
## Updating the frontend
Let's take a look at our app, and make some updates.
Open up your favorite terminal and clone the Github repo you just created in the previous section.
```
git clone <The_Copied_Githhub_URL>
```
Open up VSCode to that cloned project and open a terminal to the project’s root folder. Run the following command.
```bash
npm i @aws-amplify/ui-react-storage
```
This will install the [Amplify UI component library](https://ui.docs.amplify.aws). We'll use this later to add a file uploader, called Storage Manager, to our frontend to help with uploading pictures.
If you look at the app folder structure you'll notice an amplify folder. This folder houses all the resources and files that will help us connect to our backend.
By convention, the starter template will create an Amazon Cognito instance, and configure it for email login. The configuration for this will be in the resources file at `amplify/auth/resource.ts`. For more information on the auth resource please checkout the [docs](https://docs.amplify.aws/react/build-a-backend/auth/).
It also creates an AWS Appsync instance with a `Todo` schema in the `amplify/data/resource.ts` file.
Update the `data/resource.ts` to match the code below. The only difference is we are adding a new key to the model.
```typescript
// amplify/data/resource.ts
const schema = a.schema({
Todo: a
.model({
content: a.string(),
key: a.string(),
})
.authorization((allow) => [allow.publicApiKey()]),
});
export type Schema = ClientSchema<typeof schema>;
export const data = defineData({
schema,
authorizationModes: {
defaultAuthorizationMode: "apiKey",
apiKeyAuthorizationMode: {
expiresInDays: 30,
},
},
});
```
This schema does a few things.
* Adds a new Todo model with all the resolvers needed CRUDL (Create, Read, Update, Delete, List) and connects it to a new DynamoDB instance.
* The Todo model will have a content and a key fields - both are strings.
* Adds public authorization rules so all users can create, read, update and delete, as long as they have the public api key.
* Sets a default authorization mode of apiKey and sets the expiration for 30 days. This is the public key.
* Exports a Schema that can be used by the frontend to ensure type safety end-to-end.
This resource data pattern is very powerful by allowing the user to completely configure the backend data schema all in code using TypeScript.
For the sake of this tutorial we will leave the default resource file unchanged for auth in the `amplify/auth/resources.ts` file.
## Adding Storage
We need to be able to upload images and retrieve them. We can do this using the Amplify Storage Category.
Create a new folder at `amplify/storage`. Inside this folder create a `resource.ts` file. Copy the following code.
```typescript
// amplify/storage/resource.ts
import { defineStorage } from "@aws-amplify/backend";
export const storage = defineStorage({
name: "todosStorage",
access: (allow) => ({
"media/*": [
allow.guest.to(["read", "write", "delete"]), // additional actions such as "write" and "delete" can be specified depending on your use case
],
}),
});
```
This will create a public bucket for users to upload our images too. Users will be able to upload images to the `media` folder and they’ll have access to `read`, `write`, and `delete` them.
Next, let’s add this storage resource to our `backend.ts` file. Open the `backend.ts` file and add a new `storage` import. The complete file is below.
```typescript
//amplify/backend.ts
import { defineBackend } from "@aws-amplify/backend";
import { auth } from "./auth/resource.js";
import { data } from "./data/resource.js";
import { storage } from "./storage/resource.js";
defineBackend({
auth,
data,
storage,
});
```
All our backend resource should be ready to go!
### Starting the Sandbox
To test locally we'll create a new ephemeral environment using Amplify tooling.
*If you've never setup AWS on the command line you'll need to run a few commands here to make sure your environment can connect to your account. Please follow the [Set up your AWS Account section](https://docs.amplify.aws/gen2/start/account-setup/) section in our docs before continuing on.*
```bash
npx ampx sandbox
```
This command will create an environment in AWS based on the resources you configured in your `amplify` folder. In this case it will create a Amazon Cognito, S3 Storage and AWS AppSync service. At any time you can stop this command, and it will delete all the resources it just created.
It will also create an `amplify_outputs.json` file in the root of your app. We'll need this file in the next section to setup our client `aws-amplify` library so it can talk to the backend services.
This will take a few minutes to run, after it completes continue onto the next section.
## Update page.tsx
The starter template has a built in todos app in it. Let’s modify the `page.tsx` file so we can upload files and connect them with our todos.
Inside the `page.tsx` app add an import for `StorageManager`, `StorageImage` and to our Amplify UI components library.
```typescript
// app/page.tsx
...
import { StorageImage, StorageManager } from "@aws-amplify/ui-react-storage";
import { Card, Flex, Text, Button } from "@aws-amplify/ui-react";
```
The UI components, `Card`, `Flex`, `Text` and `Button` are used to style our app. The `StorageImage` and `StorageManager` will allow us to add images and show them.
We need to be able to delete todos. Add the following function under the `listTodos()`.
```typescript
// app/page.tsx
...
function deleteTodo(id: string) {
client.models.Todo.delete({ id });
}
```
We’ll need to update the `createTodo` function. It will now take in two arguments, `key` and `content`.
```typescript
// app/page.tsx
...
function createTodo({ key, content }: { key: string; content: string }) {
client.models.Todo.create({
content,
key,
});
}
```
We’ll now do a few updates to the return statement. We’ll add a new `StorageImage` that will display our images. We’ll also add in the `StorageManager`. This will display a component so we can upload images.
Update the return so it matches below.
```typescript
// app/page.tsx
return (
<main>
<h1>My todos</h1>
<ul>
{todos.map((todo) => (
<li key={todo.id} onClick={() => deleteTodo(todo.id)}>
<Flex justifyContent="space-between">
<Text>{todo.content}</Text>
{todo.key ? (
<StorageImage
path={todo.key}
alt={todo.content || ""}
width="100px"
/>
) : null}
</Flex>
</li>
))}
</ul>
<StorageManager
path="media/"
acceptedFileTypes={["image/*"]}
maxFileCount={1}
onUploadStart={({ key }) => {
const content = window.prompt("Todos content");
if (!key || !content) return;
createTodo({ key, content });
}}
components={{
Container({ children }) {
return <Card variation="elevated">{children}</Card>;
},
FilePicker({ onClick }) {
return (
<Button variation="primary" onClick={onClick}>
Add Todo and Choose File For Upload
</Button>
);
},
}}
/>
</main>
);
```
You may notice some props on the `StorageManager`. The components prop can be used to completely override the look and feel of the component. In this case we changed the container slightly to add a card around it. We also changed the `FilePicker` so we can use a different kind of button to upload.
We added an event listener called `onUploadStart`. This will trigger whenever an upload begins. It will first ask the user for the todos content. It will then call the `createTodo` which will create the todo in the database.
Here is the complete `app/page.tsx` file.
```typescript
"use client";
import { useState, useEffect } from "react";
import type { Schema } from "@/amplify/data/resource";
import { generateClient } from "aws-amplify/data";
import { StorageImage, StorageManager } from "@aws-amplify/ui-react-storage";
import { Card, Flex, Text, Button } from "@aws-amplify/ui-react";
import React from "react";
import { Amplify } from "aws-amplify";
import outputs from "@/amplify_outputs.json";
import "@aws-amplify/ui-react/styles.css";
Amplify.configure(outputs);
const client = generateClient<Schema>();
export default function App() {
const [todos, setTodos] = useState<Array<Schema["Todo"]["type"]>>([]);
function listTodos() {
client.models.Todo.observeQuery().subscribe({
next: (data) => setTodos([...data.items]),
});
}
function deleteTodo(id: string) {
client.models.Todo.delete({ id });
}
useEffect(() => {
listTodos();
}, []);
function createTodo({ key, content }: { key: string; content: string }) {
client.models.Todo.create({
content,
key,
});
}
return (
<main>
<h1>My todos</h1>
<ul>
{todos.map((todo) => (
<li key={todo.id} onClick={() => deleteTodo(todo.id)}>
<Flex justifyContent={"space-between"}>
<Text>{todo.content}</Text>
{todo.key ? (
<StorageImage
path={todo.key}
alt={todo.content || ""}
width="100px"
/>
) : null}
</Flex>
</li>
))}
</ul>
<StorageManager
path="media/"
acceptedFileTypes={["image/*"]}
maxFileCount={1}
onUploadStart={({ key }) => {
const content = window.prompt("Todo content");
if (!key || !content) return;
createTodo({ key, content });
}}
components={{
Container({ children }) {
return <Card variation="elevated">{children}</Card>;
},
FilePicker({ onClick }) {
return (
<Button variation="primary" onClick={onClick}>
Add Todo and Choose File For Upload
</Button>
);
},
}}
/>
</main>
);
}
```
## Trying it out
Go ahead and start the app.
```bash
npm run dev
```
The front page will load. Go ahead and click the `Add Todo` and `Choose File for Upload button`.
Choose a todo name and then choose a file. You’ll see the upload occur and a new todo displayed.

You can go ahead and add a few more. You can also click any todo for them to delete.
Good job! You've created a full stack app!
## Deploy to Production
In the first steps we created a new Next.js app using a starter template, we then cloned it down to edit it locally. We can now commit our changes and have it deployed back to our AWS Gen 2 console that will trigger a new branch build .
If you like, you can go ahead and stop the sandbox environment. Just go to the terminal where it's running and hit Ctrl/Cmd C. If for some reason you accidentally closed the terminal, you can always stop any sandbox environments by going back to the Amplify Gen 2 console and choosing the `Manage Sandboxes` button in the `All apps` page.
The sandbox environments are for testing only, and can be started or stopped at any time. The production environments are attached to your git branches that you pushed to Github. In this case the main branch is the production environment. If we choose to do so, we can create multiple environments if needed based on any branch we create and connect them to the AWS Gen 2 console.
To deploy our changes with the new frontend updates, all we'll need to do is a git commit and push. Open the terminal in your project and paste the following commands.
```bash
git add .
git commit -m "Updated todos App"
git push origin main
```
This will push all our changes to the Amplify Gen 2 console and trigger another build. After a few minutes click on the domain listed in the Amplify console to see it in action!
## Conclusion
In this tutorial we learned how to get started with AWS Amplify Gen 2. We used the Amplify Next.js starter template to create a new Amplify hosted app with our backend. We then made a todo app with photo storage, used the sandbox environment to test, and then pushed it to production to see the changes!
To clean up this environment, make sure to stop the sandbox environment and then go back into the amplify console, click on our app, then go to `App settings → General Settings`.
Click on the `Delete app` button.

If you'd like to learn more make sure to check our the [official docs](https://docs.amplify.aws)!
| erikch |
1,872,369 | Redeem Temu Coupon Code $100 Off {aah64133} or { ach320371 } | Redeem Temu Coupon Code {aah64133} If you're interested in getting great discounts on Temu, then... | 0 | 2024-05-31T19:06:09 | https://dev.to/priyamishra123976/redeem-temu-coupon-code-100-off-aah64133-or-ach320371--1ac6 | Redeem Temu Coupon Code {aah64133}
If you're interested in getting great discounts on Temu, then you're in luck. By using the Temu coupon code [aah64133], you can get a $100 coupon bundle, access exclusive deals, and enjoy additional savings benefits. In this post, we'll go over the details of Temu's $100 off coupon offer, which is available to both new and existing customers in 2024.
You can use this Temu Coupon Code: aah64133 for both new and existing customers.
If you are a new customer on Temu and you want $100 off, then use the latest $100 Temu coupon bundle code {aah64133}.
Is it Real?
While there isn't an official announcement from Temu itself about a blanket $100 off coupon, there are a few possibilities to consider:
Limited-time promotions: Temu frequently runs targeted promotions and offers coupons through their app, social media channels, and collaborations with influencers. These can be anything from percentage discounts to specific dollar amounts off your purchase.
New user bonuses: Temu often provides generous welcome packages for new users, which might include a discount coupon.
The Truth About the $100 Temu Coupon aah64133
As of May 1, 2024, there isn't a blanket $100 discount available for everyone on Temu. However, there is a $100 coupon bundle specifically for new users Code {aah64133}. This bundle includes several smaller coupons that you can redeem on various products. It's a fantastic way to save on your first Temu purchase!
Here's how to redeem the $100 coupon bundle for new users:
Download the Temu app (it's free!).
Find the sign-up or registration page: Look for a button or link that says "Sign Up," "Join," or similar.
Enter your information: On the sign-up page, you will be prompted to provide some personal information.
Use Temu Coupon Code: After sign up, add items to your cart and go to payment page. Click on apply coupon to add Temu $100 legit coupon code "aah64133".
Steps to Redeem $100 Temu Coupon Bundle {aah64133}
Temu Coupon Code $100 Off New Customer {aah64133}
If you are a new customer on Temu and you want to get $100 off on your shopping, then use the latest $100 Temu coupon bundle code {aah64133}. You can also avail up to 90% off on your first purchase with Temu, and if your order exceeds $120, then you will be eligible for free shipping.
Here are the latest Temu coupon bundle codes for new users:
Temu $100 coupon bundle new users - {aah64133}
Temu coupon code $100 off - {aah64133}
Temu coupon $100 off - {aah64133}
Temu Coupon Code $100 Off - {aah64133}
Redeem $100 Off Temu Coupon Code {aah64133}
The $100 Temu coupon bundle is a special offer for new users. You can qualify for this coupon by either: Using the referral code {aah64133}
Redeem $100 Off Temu Coupon Code {aah64133}
Redeem 50% Discount Coupon Code {aah64133}
Redeem Up to 90% Discount Coupon Code {aah64133}
Temu Coupon Code $100 Off First Order
If you haven't tried Temu yet, here's a great incentive to do so. Use the coupon code {aah64133} on your first order to instantly save $100 on your purchase. This discount is a testimony to Temu's dedication to providing the best shopping experience to its customers.
Temu coupon code $100 off First order: {aah64133}
Temu coupon code $100 off free shipping first order: {aah64133}
Temu coupon $100 off first order: {aah64133}
Temu coupon code for free stuff: {aah64133}
Temu coupon code 40 off: {aah64133}
Temu Coupon $100 Off for Existing Customers 2024
The Temu coupon $100 off for existing customers is a limited-time offer, but the good news is that it's valid throughout 2024. This means that you can take advantage of this incredible discount multiple times throughout the year, allowing you to save big on a wide range of products and categories.
Temu coupon code for existing customers: {aah64133}
Temu Coupon $100 Off for Existing Customers 2024: {aah64133}
50% off Temu coupon - {aah64133}
Buy1 Get 1 free Temu code - {aah64133}
Temu Buy 5 Get 6 free coupon code - {aah64133}
Temu $100 coupon bundle - {aah64133}
Temu coupon code $100 Canada - {aah64133}
50% Off Temu UK code - {aah64133}
Is Temu $100 Coupon Bundle Legit?
YES {aah64133}, If you're feeling skeptical about the legitimacy of the $100 coupon bundle offered by Temu, there's no need to worry. The company stands behind this offer and guarantees its authenticity. Temu has a reputation for transparent pricing and putting customers first, so you can trust that this offer is legitimate. You can confidently take advantage of this offer without any concerns.
Temu $100 Coupon Bundle Legit Code: {aah64133}
Temu $100 Coupon Legit
Yes, Temu $100 Coupon Legit code {aah64133} As I mentioned before, the $100 coupon offered by Temu is completely legitimate and authorized by the company. Temu is dedicated to providing authentic and transparent offers to its customers, and this coupon is a great representation of that dedication. You can use the coupon code {aah64133} with confidence, as there are no concerns regarding its validity or authenticity.
Temu $100 Coupon Legit Code -{aah64133}
Temu Coupon Alternatives for Existing Customers {aah64133}
While existing customers can't claim the specific $100 bundle, there are still ways to stretch your shopping dollar on Temu:
Temu app notifications: Sign up for push notifications to receive exclusive deals and coupon codes {aah64133}.
Temu website: Check the Temu website coupon section for ongoing promotions and discounts.
Referral program: Refer friends and earn bonus discounts for both you and your friend.
Temu games: Play the mini-games within the Temu app to win coupons and other rewards.
Seasonal sales: Keep an eye out for seasonal sales and clearance events for significant price drops.
Specific category discounts: Temu often offers targeted discounts on specific categories like clothing or electronics.
Temu Coupon Code FAQs
How do I apply the Temu coupon code {aah64133} for $100 off?
To avail of the $100 discount with the Temu coupon code {aah64133}, you can simply enter the code at the time of checkout on the Temu website or mobile app. You should be able to find a specific field where you can enter the coupon code {aah64133} before confirming your order.
Can I use the $100 off coupon code multiple times?
The $100 off coupon code {aah64133} may only be used once per customer or account. It is important to review Temu's specific terms and conditions to understand any limitations on coupon usage.
What is Temu $100 Coupon Code{aah64133}?
The Temu online shopping platform offers a special promotional code that allows customers to receive a $100 discount on their purchases. The current code is {aah64133}.
How long is the Temu coupon code $100 off valid?
Coupon codes {aah64133} usually come with an expiration date or a limited-time validity period. Temu will provide the start and end dates for when the $100 off coupon code {aah64133} will be available. To take advantage of the discount, make sure to use the coupon code before it expires.
Is the $100 off coupon valid for all products on Temu? {aah64133}
The $100 off coupon code {aah64133} is usually valid for all products available on Temu, regardless of category or brand. However, it's always a good idea to double-check the terms and conditions of the coupon to ensure that there are no exclusions or restrictions.
Is there a minimum order value to use the $100 off coupon code {aah64133} ?
Please note that certain coupon codes may require a minimum order value to qualify for the discount. For instance, a $100 off coupon code {aah64133} may only be valid for orders valued at $200 or more, or a specific threshold determined by Temu. We advise you to carefully review the coupon details to ensure that you meet any minimum order requirements before redeeming the coupon.
The Final Word
While a universal $100 discount for everyone might be a dream, Temu offers a variety of ways to save, especially for new users. So, download the app, explore your options, and get ready to score some fantastic deals on your next Temu shopping spree!
is the cash reward on temu real?
Yes {aah64133}, They're Legit! There's good news for shoppers! It is true that Temu offers legitimate cash rewards.
Yes {aah64133}, Temu offers you real cash on your valuable shopping and you can receive real cash rewards on your billing account or credit cards account.
Q: What is the Temu $100 off coupon code {aah64133}?
A: The Temu $100 off coupon code is {aah64133} for first-time users, offering a $100 bonus plus 30% off any purchase.
Q: Is the Temu $100 coupon code {aah64133} legit?
A: Yes, the Temu $100 coupon code {aah64133} is legit. It is a legitimate offer for both new and existing customers, providing a $100 discount on purchases.
Q: How do I redeem the Temu $100 off coupon?
A: To redeem the Temu $100 off coupon, follow these steps:
Add items to your cart on Temu.com.
Enter the coupon code {aah64133} during checkout.
Click "Apply" to activate the $100 discount.
Q: Are there any conditions or restrictions? {aah64133}
A: Yes, there are conditions and restrictions. For example, Temu coupon codes {aah64133} cannot be combined or stacked. The discount will be deducted from your total at checkout. Codes are time-limited, so use them before they expire
Q: Can I use the Temu $100 off coupon {aah64133}for new and existing customers?
A: Yes, {aah64133} the Temu $100 off coupon is available for both new and existing customers.
Q: What products can I buy with the Temu $100 off coupon {aah64133}?
A: Temu offers a wide range of products across various categories, including clothing, electronics, home and garden, beauty products, toys, and more.
Q: Is the Temu $100 off coupon {aah64133}valid until when?
A: The Temu $100 off coupon {aah64133} is valid until July 2024.
Q: How do I ensure the coupon is legitimate {aah64133}?
A: Verify the coupon by checking the source, expiration date, terms and conditions, and contacting Temu directly to confirm its validity.
| priyamishra123976 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.