
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,910,384 | An In-Depth Look at Audio Classification Using CNNs and Transformers | Introduction Audio classification is a fascinating area of machine learning that involves... | 0 | 2024-07-03T15:55:05 | https://dev.to/aditi_baheti_f4a40487a091/an-in-depth-look-at-audio-classification-using-cnns-and-transformers-1981 | transformers, deeplearning, ai, cnn | ## Introduction
Audio classification is a fascinating area of machine learning that involves categorizing audio signals into predefined classes. In this blog, we will delve into the specifics of an audio classification project, exploring the architectures, methodologies, and results obtained from experimenting with Co... | aditi_baheti_f4a40487a091 |
1,910,382 | Easy way to process waterfall functions | Have you ever encountered a process that flows like a waterfall? This is an example. Even though... | 0 | 2024-07-03T15:48:40 | https://dev.to/alfianriv/easy-way-to-process-waterfall-functions-g0p | Have you ever encountered a process that flows like a waterfall? This is an example.
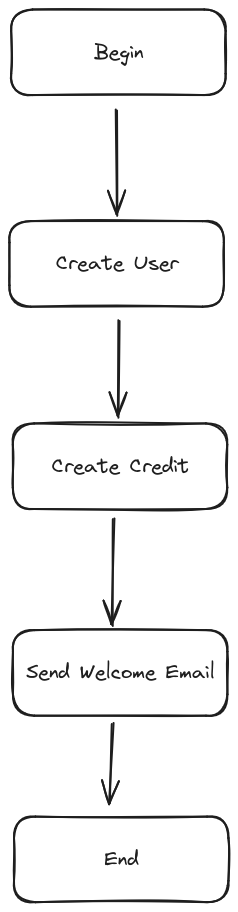
Even though we only hit 1 endpoint, we have to process all of them.
Yes, that's easy, but what if step 2 fails and we want everyth... | alfianriv | |
1,910,381 | Automate User Management on Linux with a Bash Script | Automate User Management on Linux with a Bash Script Managing users on a Linux system can... | 0 | 2024-07-03T15:48:39 | https://dev.to/nueldstark/automate-user-management-on-linux-with-a-bash-script-27h4 | linux, devops, bash | ## **Automate User Management on Linux with a Bash Script**
Managing users on a Linux system can be a tedious task, especially when dealing with multiple users and groups. Automation can greatly simplify this process. In this article, we'll walk through creating a bash script to automate user creation, group assignmen... | nueldstark |
1,910,378 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-07-03T15:46:29 | https://dev.to/siwoni5341/buy-verified-cash-app-account-44n | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | siwoni5341 |
1,910,377 | Election of Student Council | Check out this Pen I made! | 0 | 2024-07-03T15:46:11 | https://dev.to/bidz/election-of-student-council-jnf | codepen | Check out this Pen I made!
{% codepen https://codepen.io/bidz/pen/rNgXgwg %} | bidz |
1,910,376 | Apple lanza su IA centrada en la privacidad: un nuevo paradigma para la inteligencia artificial | En un movimiento audaz que promete redefinir el panorama de la inteligencia artificial, Apple acaba... | 0 | 2024-07-03T15:45:41 | https://dev.to/wgbn/apple-lanza-su-ia-centrada-en-la-privacidad-un-nuevo-paradigma-para-la-inteligencia-artificial-4lc | ai, apple, policy, opinion | En un movimiento audaz que promete redefinir el panorama de la inteligencia artificial, Apple acaba de anunciar una serie de avances tecnológicos que colocan la privacidad del usuario en el centro de sus innovaciones en IA. Con el lanzamiento de Apple Intelligence y Private Cloud Compute (PCC), la compañía de Cupertino... | wgbn |
1,910,375 | Next.js vs Vue.js: In-depth Comparative Study | Introduction: Next.js, developed by Vercel, is a React framework renowned for its advanced... | 0 | 2024-07-03T15:45:08 | https://dev.to/dominion_olonilebi_9dd01d/nextjs-vs-vuejs-in-depth-comparative-study-1na | webdev, nextjs, vue, programming | **Introduction:**
Next.js, developed by Vercel, is a React framework renowned for its advanced capabilities such as server-side rendering and static site generation. Engineered to streamline the development of React applications, Next.js empowers developers to create optimized and scalable solutions, resulting in acce... | dominion_olonilebi_9dd01d |
1,910,374 | Make a digital clock in Mini Micro | Today let's do a little project in Mini Micro that makes an old-school digital clock. This will... | 0 | 2024-07-03T15:44:52 | https://dev.to/joestrout/make-a-digital-clock-in-mini-micro-3mpl | programming, miniscript, minimicro, animation | Today let's do a little project in Mini Micro that makes an old-school digital clock. This will illustrate pulling apart a sprite sheet, animation by drawing directly to a PixelDisplay (rather than using actual sprites), and the `dateTime` module to get the current time.
## The digits image
Among the built-in images... | joestrout |
1,910,373 | The Ultimate Guide to Engagement Rings: Finding the Perfect Symbol of Love | Choosing an engagement ring is a significant milestone in a couple’s journey. This ring is not only a... | 0 | 2024-07-03T15:44:29 | https://dev.to/marcdevon/the-ultimate-guide-to-engagement-rings-finding-the-perfect-symbol-of-love-2h9h | Choosing an engagement ring is a significant milestone in a couple’s journey. This ring is not only a piece of jewelry but a symbol of commitment, love, and the start of a new chapter together. With an array of styles, gemstones, and settings to choose from, the process can be overwhelming. This guide will help you nav... | marcdevon | |
1,910,372 | What Are the Most Cost-Effective Ways to Try THC-A for the First Time | Consumers trying THC-A for the first time can find the best deals by focusing on online retailers... | 0 | 2024-07-03T15:44:12 | https://dev.to/rosojig/what-are-the-most-cost-effective-ways-to-try-thc-a-for-the-first-time-3b3h | Consumers trying THC-A for the first time can find the best deals by focusing on online retailers offering competitive prices. Comparing prices across different websites and looking for promotional discounts, first-time buyer coupons, and loyalty programs can further reduce costs. Additionally, reading customer reviews... | rosojig | |
1,910,369 | Apple Launches Its Privacy-Focused AI: A New Paradigm for Artificial Intelligence | In a bold move that promises to redefine the landscape of artificial intelligence, Apple has just... | 0 | 2024-07-03T15:44:10 | https://dev.to/wgbn/apple-launches-its-privacy-focused-ai-a-new-paradigm-for-artificial-intelligence-39g | ai, apple, policy, opinion | In a bold move that promises to redefine the landscape of artificial intelligence, Apple has just announced a series of technological advancements that put user privacy at the center of its AI innovations. With the launch of Apple Intelligence and Private Cloud Compute (PCC), the Cupertino company is not just launching... | wgbn |
1,910,371 | Startups: Lessons I Learned | Throughout my career, I've had the opportunity to work in several startups across different sectors.... | 0 | 2024-07-03T15:43:54 | https://dev.to/douglaspujol/startups-lessons-i-learned-47fk | Throughout my career, I've had the opportunity to work in several startups across different sectors. In this brief article, I share some key points I learned from these experiences.
**Start Simple and Build Only What You Need**
The best way to start a new project is to begin simply and avoid unnecessary complexities.... | douglaspujol | |
1,910,368 | Modération de chat avec OpenAI | Modérer le PubNub Chat en utilisant les fonctions PubNub et l'api de modération gratuite d'OpenAI | 0 | 2024-07-03T15:42:12 | https://dev.to/pubnub-fr/moderation-de-chat-avec-openai-1op3 | Toute application contenant un [chat in-app](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) a besoin d'un moyen de réguler et de modérer les messages que les utilisateurs peuvent échanger. Comme il n'est pas possible de modérer tous les contenus in... | pubnubdevrel | |
1,910,367 | Weekly Watercooler Thread | I kicked this off as "Watercooler Wednesday", but going to change the title because we don't need to... | 0 | 2024-07-03T15:41:37 | https://dev.to/ben/weekly-watercooler-thread-110g | watercooler, discuss | I kicked this off as "Watercooler Wednesday", but going to change the title because we don't need to overdo it on the "day of week" theme. 😄
***
This is a general discussion thread about... Whatever. What's new in your life?
Hobbies, interests, games, kids, parents, travel, career, whatever.
Let's keep this chat l... | ben |
1,910,366 | Weekly Watercooler Thread | I kicked this off as "Watercooler Wednesday", but going to change the title because we don't need to... | 0 | 2024-07-03T15:41:37 | https://dev.to/ben/weekly-watercooler-thread-4008 | I kicked this off as "Watercooler Wednesday", but going to change the title because we don't need to overdo it on the "day of week" theme. 😄
***
This is a general discussion thread about... Whatever. What's new in your life?
Hobbies, interests, games, kids, parents, travel, career, whatever.
Let's keep this chat l... | ben | |
1,910,364 | Apple Lança sua IA com Foco na Privacidade: Um Novo Paradigma para a Inteligência Artificial | Em um movimento audacioso que promete redefinir o cenário da inteligência artificial, a Apple acaba... | 0 | 2024-07-03T15:41:17 | https://dev.to/wgbn/apple-lanca-sua-ia-com-foco-na-privacidade-um-novo-paradigma-para-a-inteligencia-artificial-5foh | ai, apple, opinion, privacy | Em um movimento audacioso que promete redefinir o cenário da inteligência artificial, a Apple acaba de anunciar uma série de avanços tecnológicos que colocam a privacidade do usuário no centro de suas inovações em IA. Com o lançamento do Apple Intelligence e do Private Cloud Compute (PCC), a empresa de Cupertino não es... | wgbn |
1,910,363 | Startups: Lições que Aprendi | Ao longo da minha trajetória profissional, tive a oportunidade de trabalhar em várias startups de... | 0 | 2024-07-03T15:37:40 | https://dev.to/douglaspujol/startups-licoes-que-aprendi-1j5f | Ao longo da minha trajetória profissional, tive a oportunidade de trabalhar em várias startups de diversos setores. Neste breve artigo, compartilho alguns pontos que aprendi com essas experiências.
**1. Comece de forma simples e Construa apenas o que você precisa.**
A melhor maneira de iniciar um novo projeto é começ... | douglaspujol | |
1,910,362 | Chat-Moderation mit OpenAI | Moderieren Sie PubNub-Chats mit PubNub-Funktionen und der kostenlosen Moderations-Api von OpenAI | 0 | 2024-07-03T15:37:11 | https://dev.to/pubnub-de/chat-moderation-mit-openai-jho | Jede Anwendung, die einen [In-App-Chat](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) enthält, benötigt eine Möglichkeit, die Nachrichten, die Nutzer austauschen können, zu regulieren und zu moderieren. Da es nicht möglich ist, alle unangemessenen... | pubnubdevrel | |
1,910,296 | Starting a new Django project with PostgresSQL and Docker | Initial project setup: $ mkdir client-management $ cd client-management $ python3 -m... | 0 | 2024-07-03T15:36:37 | https://dev.to/samuellubliner/starting-a-new-django-project-with-postgressql-and-docker-3hoj | django, python, docker, postgres | ## Initial project setup:
```bash
$ mkdir client-management
$ cd client-management
$ python3 -m venv .venv
$ source .venv/bin/activate
(.venv) $
(.venv) $ python3 -m pip install django~=5.0
(.venv) $ django-admin startproject django_project .
(.venv) $ python manage.py runserver
```
Visit http://127.0.0.1:8000/ to ... | samuellubliner |
1,910,361 | Future of Artificial Intelligence | 🚀 Embracing the Future of AI: Transforming Tomorrow with Innovation and... | 0 | 2024-07-03T15:34:17 | https://codexdindia.blogspot.com/2024/07/future-of-artificial-intelligence.html | ai, abotwrotethis, webdev, javascript | ### 🚀 Embracing the Future of AI: Transforming Tomorrow with Innovation and Collaboration
> Know More :- https://codexdindia.blogspot.com/2024/07/future-of-artificial-intelligence.html
Artificial Intelligence (AI) isn't just transforming industries—it's revolutionizing our world in ways we once only imagined in sci-... | sh20raj |
1,910,360 | OpenAI를 사용한 채팅 중재 | 펍넙 함수 및 OpenAI의 무료 중재 API를 사용하여 펍넙 채팅 중재하기 | 0 | 2024-07-03T15:32:10 | https://dev.to/pubnub-ko/openaireul-sayonghan-caeting-jungjae-43dg | [인앱 채팅이](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 포함된 모든 애플리케이션에는 사용자가 주고받을 수 있는 메시지를 규제하고 중재할 수 있는 방법이 필요합니다. 인간 중재자가 모든 부적절한 콘텐츠를 중재하는 것은 불가능하므로 중재 시스템은 자동으로 작동해야 합니다. 사용자가 종종 중재를 회피하려고 시도하기 때문에 머신러닝, 생성 AI, 대규모 언어 모델(LLM)\[및 GPT-3, GPT-4 등... | pubnubdevrel | |
1,910,359 | Crypt::OpenSSL::PKCS12 1.91 released to CPAN | a long over due release | 0 | 2024-07-03T15:30:24 | https://dev.to/jonasbn/cryptopensslpkcs12-191-released-to-cpan-2in2 | opensource, perl, release, openssl | ---
title: Crypt::OpenSSL::PKCS12 1.91 released to CPAN
published: true
description: a long over due release
tags: opensource, perl, release, openssl
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-07-03 15:10 +0000
---
@timlegge a prolific Perl and Open Sou... | jonasbn |
1,910,357 | Day 3 of 100 Days of Code | Wed, Jul 3, 2024 Little distraction with mom losing email access yesterday, took a bit of effort,... | 0 | 2024-07-03T15:27:40 | https://dev.to/jacobsternx/day-3-of-100-days-of-code-28p9 | 100daysofcode, beginners, webdev, javascript | Wed, Jul 3, 2024
Little distraction with mom losing email access yesterday, took a bit of effort, but was able to resolve with best possible solution.
Currently working on CSS Selectors in CSS Fundamentals lesson, which I've seen before, so wanting to see how far I can move today.
My attainable aim this week is to ... | jacobsternx |
1,910,356 | OpenAIによるチャット・モデレーション | PubNub関数とOpenAIの無料モデレーションAPIを使ってPubNubチャットをモデレートする | 0 | 2024-07-03T15:27:08 | https://dev.to/pubnub-jp/openainiyorutiyatutomoderesiyon-5f9o | [アプリ内チャットを](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)含むアプリケーションは、ユーザーが交換できるメッセージを規制し、モデレートする何らかの方法が必要です。 人間のモデレーターですべての不適切なコンテンツをモデレートすることは不可能なので、モデレーション・システムは自動的でなければなりません。 ユーザーはモデレーションを回避しようとすることが多いので、機械学習、生成AI、大規模言語モデル(LLM)[およびGPT-3やGPT-4など... | pubnubdevrel | |
1,910,353 | Multiplayer in Rust using Renet and Bevy | Here at Renuo, we specialize in web technologies such as Ruby on Rails, React, Angular, and Spring.... | 0 | 2024-07-03T15:24:33 | https://dev.to/cuddlybunion341/multiplayer-in-rust-using-renet-and-bevy-17p6 | rust, gamedev | Here at Renuo, we specialize in web technologies such as Ruby on Rails, React, Angular, and Spring. One of our core company values is continuous learning: we love exploring new technologies even beyond our usual scope of expertise.
Inspired by Michael’s Unity Powerday, I decided to delve into how multiplayer games ope... | cuddlybunion341 |
1,910,352 | The Ultimate Guide to Shoulder Bags in Pakistan: Style, Functionality, and Where to Buy | Shoulder bags are an essential accessory, offering both style and functionality. In Pakistan, the... | 0 | 2024-07-03T15:23:33 | https://dev.to/aodour-pk/the-ultimate-guide-to-shoulder-bags-in-pakistan-style-functionality-and-where-to-buy-1ka1 | Shoulder bags are an essential accessory, offering both style and functionality. In Pakistan, the demand for shoulder bags has been rising due to their versatility and practicality. Whether you're a student, a professional, or a traveler, a good [shoulder bag](https://www.aodour.pk/shop/women-bags/shoulder-bags) can ma... | aodour-pk | |
1,910,322 | Difference between Java Script events and Java Script ES6 Event handlers!! | **HOW TO MAKE A JAVASCRIPT EVENT **To create an event with javascript, we can add attributes with the... | 0 | 2024-07-03T14:52:13 | https://dev.to/code_guruva_204d4e19ed643/difference-between-javascript-events-and-event-handlers-2704 | **HOW TO MAKE A JAVASCRIPT EVENT
**To create an event with javascript, we can add attributes with the event names above, to the html element that we want to give an event for example.
**JavaScript events** can be defined as something the user does in a website or browser. This can be a multitude of different things su... | code_guruva_204d4e19ed643 | |
1,910,351 | Automating Linux User Management with Bash Scripts | Introduction Automation is essential for improving operational efficiency and preserving system... | 0 | 2024-07-03T15:22:23 | https://dev.to/mubarak_ajibola_96a34686b/automating-user-management-in-linux-using-bash-scripting-m5c | **Introduction**
Automation is essential for improving operational efficiency and preserving system consistency in today's dynamic IT environments. This article examines a bash script meant to automate Linux system user administration. The script was created as part of the HNG Internship DevOps Stage 1 work and helps w... | mubarak_ajibola_96a34686b | |
1,910,350 | Stop Using UUIDs in Your Database | How UUIDs can Destroy SQL Database Performance. One of the most common way to uniquely identify rows... | 0 | 2024-07-03T15:22:20 | https://dev.to/manojgohel/stop-using-uuids-in-your-database-ogj | webdev, javascript, typescript, programming | How UUIDs can Destroy SQL Database Performance.
One of the most common way to uniquely identify rows in a database is by using **UUID fields**.
This approach, however, comes with performance caveats that you must be aware of.
In this article, we discuss **two performance issues** that may arise when using UUIDs as ke... | manojgohel |
1,910,333 | My Web Development Journey Day-3: Git & Github 🎨 | In my third day of mission webdevelopment, I learned about Git and Git hub.To be honest I already had... | 27,922 | 2024-07-03T15:19:32 | https://dev.to/shemanto_sharkar/my-web-development-journey-day-3-git-github-5ffe | webdev, beginners, programming, git | In my third day of mission webdevelopment, I learned about Git and Git hub.To be honest I already had idea about github and already worked with it.But in this module I get to know how to make brach and work with it.
Then I learned more about CSS gradient.I learned-
1)Adding google font in css
2)CSS Gradients
3)Transit... | shemanto_sharkar |
1,910,331 | Moderacja czatu za pomocą OpenAI | Moderowanie czatu PubNub za pomocą funkcji PubNub i darmowej aplikacji do moderowania od OpenAI | 0 | 2024-07-03T15:17:47 | https://dev.to/pubnub-pl/moderacja-czatu-za-pomoca-openai-29o0 | Każda aplikacja zawierająca [czat w aplikacji](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) musi w jakiś sposób regulować i moderować wiadomości, które użytkownicy mogą wymieniać. Ponieważ nie jest możliwe moderowanie wszystkich nieodpowiednich t... | pubnubdevrel | |
1,910,330 | Chat Moderation with OpenAI | Moderate PubNub Chat using PubNub Functions and the free moderation api from OpenAI | 0 | 2024-07-03T15:17:47 | https://dev.to/pubnub/chat-moderation-with-openai-33ea | Any application containing [in-app chat](https://www.pubnub.com/solutions/chat/?) needs some way to regulate and moderate the messages that users can exchange. Since it is not feasible to moderate all inappropriate content with human moderators, the moderation system must be automatic. Since users will frequently try... | pubnubdevrel | |
1,909,836 | A Guide to Reducing Risks in Generative AI | Generative AI services are changing industries by automating complicated operations, generating... | 0 | 2024-07-03T15:17:21 | https://dev.to/calsoftinc/a-guide-to-reducing-risks-in-generative-ai-3007 | ai, automation, machinelearning, productivity | Generative AI services are changing industries by automating complicated operations, generating content, and enhancing decision-making processes. However, those advantages include important risks that should be handled. This describes practical measures for reducing those risks and ensuring the proper usage of generati... | calsoftinc |
1,910,329 | Dive into Cybersecurity Mastery with Cyber Security Tutorials! 🔒 | Comprehensive cybersecurity tutorials covering network mapping, packet analysis, vulnerability assessments, and ethical hacking techniques using Kali Linux. | 27,801 | 2024-07-03T15:14:54 | https://getvm.io/tutorials/cyber-security-tutorials | getvm, programming, freetutorial, technicaltutorials |
Hey there, fellow cybersecurity enthusiasts! 👋 Are you looking to level up your skills and become a pro in the world of network security and ethical hacking? Well, I've got the perfect resource for you - the Cyber Security Tutorials!
This comprehensive path, available at [https://labex.io/tutorials/category/cysec](... | getvm |
1,907,862 | Embracing Data: Documenting My Journey into Data Analytics | I embarked on a journey into the world of data a little over a year ago. My fascination with data and... | 27,952 | 2024-07-03T15:14:39 | https://dev.to/tmsn/embracing-data-documenting-my-journey-into-data-analytics-528k | data, datascience, beginners, career | I embarked on a journey into the world of data a little over a year ago. My fascination with data and AI systems has been a long-standing interest. I believe data is fundamental to everything and finds applications in every field.
Last year, I came across the [ACN Scholarships](https://www.africancoding.network/acn-y... | tmsn |
1,910,328 | Secure Your AS400 Systems with Sennovate’s Managed Detection and Response (MDR) Service | In the cyber threat landscape, protecting important business systems such as AS400 is critical.... | 0 | 2024-07-03T15:14:28 | https://dev.to/sennovate/secure-your-as400-systems-with-sennovates-managed-detection-and-response-mdr-service-43a8 | cybersecurity, security, infosec, mdr | In the cyber threat landscape, protecting important business systems such as AS400 is critical. Sennovate provides a comprehensive Managed Detection and Response (MDR) service specifically built for AS400. This service assures that your AS400 systems are secure, resilient, and meet industry requirements. In this blog a... | sennovate |
1,910,325 | Newly arrived | New in here, have a great day everyone... | 0 | 2024-07-03T15:12:21 | https://dev.to/rhey0027/newly-arrived-1ebj | web, python, database, anything | New in here, have a great day everyone... | rhey0027 |
1,909,131 | amber: writing bash scripts in amber instead. pt. 4: functions | a while ago, i blogged about uploading files to s3 using curl and provided the solution as two... | 27,793 | 2024-07-03T15:04:42 | https://dev.to/gbhorwood/amber-writing-bash-scripts-in-amber-instead-pt-4-functions-5ba0 | linux, bash | a while ago, i blogged about [uploading files to s3 using curl](https://gbh.fruitbat.io/2024/04/22/uploading-to-s3-with-bash/) and provided the solution as [two functions written in bash](https://gist.github.com/gbhorwood/d861c7a21f2ab151046025137f6a65b1), and basically the only feedback was "wait. you can write _funct... | gbhorwood |
1,910,323 | How to Perform Data Validation in Node.js | Data validation is essential to avoid unexpected behavior, prevent errors, and improve security. It... | 0 | 2024-07-03T15:02:41 | https://blog.appsignal.com/2024/06/19/how-to-perform-data-validation-in-nodejs.html | node | Data validation is essential to avoid unexpected behavior, prevent errors, and improve security. It can be performed both on a web page — where data is entered — and on the server, where the data is processed.
In this tutorial, we'll explore data validation in the Node.js backend. Then, you'll learn how to implement i... | antozanini |
1,899,197 | The Complete Guide to Serverless Apps II - Functions and Apps | In Part I we took a close look at the term “serverless” as it is used in cloud computing. We spoke... | 27,854 | 2024-07-03T15:00:00 | https://www.fermyon.com/serverless-guide/serverless-functions-and-serverless-apps | serverless, cloud, webassembly, cloudcomputing | In [Part I](https://dev.to/fermyon/the-complete-guide-to-serverless-apps-i-introduction-1ga4) we took a close look at the term “serverless” as it is used in cloud computing. We spoke about a serverless application - where you do not have to write a software server. Instead, you focus only on writing a request handler. ... | sohan26 |
1,910,070 | VerifyVault Beta v0.3 Released | 🔒✨ Exciting News! VerifyVault Beta v0.3 has RELEASED!✨🔒 🔑 Key Updates: Password Reminders to keep... | 0 | 2024-07-03T14:59:34 | https://dev.to/verifyvault/verifyvault-beta-v03-released-37dc | opensource, security, cybersecurity, github | 🔒✨ Exciting News! VerifyVault Beta v0.3 has RELEASED!✨🔒
🔑 **Key Updates:**
- **Password Reminders** to keep you on track 📝
- **Export Secret Keys** securely 🔐
- **Automatic Password Lock** for added security 🛡️
- **Export accounts via TXT Encrypted** for easy backups 📦
- Introducing **Clear All and Restore All ... | verifyvault |
1,910,019 | TypeScript 5.5: Exciting New Features | TypeScript has become increasingly popular among developers as a more structured alternative to... | 0 | 2024-07-03T14:53:19 | https://dev.to/enodi/typescript-55-new-features-27ef | typescript, frontend, backend, webdev | TypeScript has become increasingly popular among developers as a more structured alternative to JavaScript. It helps define types within your code, making it easier to catch errors like typos etc on time.
Recently, TypeScript rolled out version 5.5, introducing several new features. In this article, we’ll take a close... | enodi |
1,910,321 | Flood Escape launched on Arcadia | Our Flood Escape game was added to the Arcadia platform with all the levels already unlocked ,... | 0 | 2024-07-03T14:53:11 | https://enclavegames.com/blog/flood-escape-arcadia/ | arcadia, floodescape, javascript, gamedev | ---
title: Flood Escape launched on Arcadia
published: true
date: 2024-07-03 14:51:56 UTC
tags: arcadia,floodescape,javascript,gamedev
canonical_url: https://enclavegames.com/blog/flood-escape-arcadia/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/922db80jbpg2tg4ic7px.png
---
Our [Flood Escape]... | end3r |
1,910,320 | How to Promote Your Self-Made Laravel Package | So, you’ve poured your heart and soul into a shiny new Laravel package, and now it’s time to show it... | 0 | 2024-07-03T14:50:05 | https://dev.to/makowskid/how-to-promote-your-self-made-laravel-package-1ca9 | webdev, laravel, php, programming | So, you’ve poured your heart and soul into a shiny new Laravel package, and now it’s time to show it off to the world. But how? Well, here are some top-notch strategies that’ll get your package the attention it deserves.
## Document Like a Pro
Start by crafting a complete `README.md` file. Include every detail about y... | makowskid |
1,910,317 | Essential Concepts | MongoDB | Part 1 | Basics SQL vs NoSQL,Documents and Collections, Data Types SQL vs NoSQL SQL... | 0 | 2024-07-03T14:48:34 | https://dev.to/aakash_kumar/essential-concepts-mongodb-part-1-ca9 | webdev, node, mongodb, database | ##Basics
###SQL vs NoSQL,Documents and Collections, Data Types
**SQL vs NoSQL**
1. SQL (Structured Query Language): Traditional relational databases like MySQL, PostgreSQL. They use tables to store data, and data is structured in rows and columns.Example: A table Users with columns id, name, email.
2. NoSQL (Not Onl... | aakash_kumar |
1,910,319 | Technical Report: Automating User and Group Creation | Overview As a DevOps Engineer, automating the management of users and groups is crucial for... | 0 | 2024-07-03T14:47:58 | https://dev.to/vera_tee_9f6e7a1b6b500c42/technical-report-automating-user-and-group-creation-2g4 | **Overview**
As a DevOps Engineer, automating the management of users and groups is crucial for maintaining a streamlined and secure environment. This report details the automation process for creating users and groups using a shell script. The script ensures consistent and efficient management of user accounts and gro... | vera_tee_9f6e7a1b6b500c42 | |
1,910,318 | How to Create and Deploy a Custom Theme for VS Code | How to Create and Deploy a Custom Theme for VS Code Creating a custom theme for Visual... | 0 | 2024-07-03T14:46:43 | https://github.com/SH20RAJ/shade-vscode-theme | vscode, theme | # How to Create and Deploy a Custom Theme for VS Code
Creating a custom theme for Visual Studio Code (VS Code) allows you to personalize your development environment and share your unique aesthetic with the community. This guide will walk you through the steps to create, package, and deploy a custom theme on the VS Co... | sh20raj |
1,910,316 | Exploring and Enhancing Scrape Any Website (SAW)🪚: A Detailed Bug Report | Over a two-hour session, I meticulously explored the app, scrutinized various features, and... | 0 | 2024-07-03T14:45:36 | https://dev.to/jessica_aki_a64c068f9f828/exploring-and-enhancing-scrape-any-website-saw-a-detailed-bug-report-h4e | qa, testing | Over a two-hour session, I meticulously explored the app, scrutinized various features, and documented a series of issues. This deep dive into testing unveiled both the technical intricacies and the subtle nuances of user experience and design. Let’s dive into what I discovered and how we can make SAW even better!
#... | jessica_aki_a64c068f9f828 |
1,910,314 | Hire PHP Developer: Unlocking the Full Potential of Your Web Development | In the rapidly evolving digital landscape, having a robust online presence is not just an advantage... | 0 | 2024-07-03T14:44:27 | https://dev.to/brucewilliam6004/hire-php-developer-unlocking-the-full-potential-of-your-web-development-34hn | webdev, programming, devops | In the rapidly evolving digital landscape, having a robust online presence is not just an advantage but a necessity. Businesses today need dynamic, scalable, and secure web solutions to stay competitive. This is where PHP developers come into play. [Hire a PHP developer](https://einnovention.us/hire-php-developers) can... | brucewilliam6004 |
1,910,313 | WordPress Development Company | Tekglide is a WordPress development company specialized in developing websites using basic WordPress... | 0 | 2024-07-03T14:43:34 | https://dev.to/tekglide/wordpress-development-company-3848 | Tekglide is a [WordPress development company](https://tekglide.com/wordpress-development) specialized in developing websites using basic WordPress and offering customized solutions to order them, resulting in an effective website. Our team comprises the most creative developers and designers who create effective, easy-... | tekglide | |
1,910,311 | Strategy and Tips for Migrating Large-Scale Applications to ReactJS | Migrating a large-scale application to ReactJS can seem daunting, but with the right strategy and... | 0 | 2024-07-03T14:41:51 | https://dev.to/imensosoftware/strategy-and-tips-for-migrating-large-scale-applications-to-reactjs-23jd | reactjsdevelopment, webdev, hirereactjsdeveloperrs, reactjsdevelopmentcompany | Migrating a large-scale application to ReactJS can seem daunting, but with the right strategy and expert guidance, the transition can be smooth and highly beneficial. In this comprehensive guide, we'll delve into effective strategies and tips for migrating your large-scale applications to ReactJS, ensuring optimal perf... | imensosoftware |
1,910,310 | Hello world, I'm Mh Mitas | hello world I am learning web development console.log('Hello World') Enter fullscreen... | 0 | 2024-07-03T14:39:59 | https://dev.to/mhmitas/hello-world-38id | **hello world**
1. I am learning web development
```js
console.log('Hello World')
```
<br>
## **Lorem ipsum**
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quibusdam eaque aperiam deserunt nostrum blanditiis sapiente beatae incidunt asperiores magni. Fugiat voluptatum facilis delectus! Vero deleniti quis, n... | mhmitas | |
1,910,308 | Mastering the Art of Event Management: Key Strategies for Success | In the dynamic world of modern business and social engagement, event management stands as a pivotal... | 0 | 2024-07-03T14:38:49 | https://dev.to/laurasmith/mastering-the-art-of-event-management-key-strategies-for-success-2fj5 | eventmanagement, events, eventmanagementsoftware | In the dynamic world of modern business and social engagement, event management stands as a pivotal skill. Whether organizing a corporate conference, a gala fundraiser, or a wedding celebration, the ability to orchest... | laurasmith |
1,910,304 | The carbon footprint of email - Top facts and questions | Email has become a vital tool for communication in both personal and professional contexts. It is a... | 0 | 2024-07-03T14:36:28 | https://againstdata.com/blog/top-facts-and-questions-about-the-carbon-footprint-of-email | privacy, carbon, buildinpublic, theycoded | Email has become a vital tool for communication in both personal and professional contexts. It is a pervasive element of modern life, with billions of emails sent every day, therefore it is undoubtedly efficient and convenient. However, its environmental impact is sometimes disregarded. Energy is needed for every email... | extrabright |
1,910,305 | CSS里面的各种长度 | CSS里面有各种长度单位,总的来说,可以分成两类: 绝对长度单位 相对长度单位 | 0 | 2024-07-03T14:35:52 | https://dev.to/robertg/cssli-mian-de-ge-chong-chang-du-54n8 | CSS里面有各种长度单位,总的来说,可以分成两类:
1. 绝对长度单位
2. 相对长度单位
| robertg | |
1,910,302 | TYPO3 v13.2—Release Notes | The third sprint release of the TYPO3 v13 release cycle, version 13.2, offers a range of practical... | 0 | 2024-07-03T14:30:38 | https://dev.to/typo3/typo3-v132-release-notes-73h | typo3, releasenotes, webdev, programming | The third sprint release of the TYPO3 v13 release cycle, version 13.2, offers a range of practical improvements for editors and significant enhancements under the hood.
NOTE: Article Source - typo3.org
Aiming to enhance the experience for backend users who manage TYPO3 site content, the new version includes various i... | typo3 |
1,910,301 | Swagger + Node.js (Express) : A Step-by-Step Guide | Following the post on configuring Swagger for a SpringBoot project, today I will introduce you to a... | 0 | 2024-07-03T14:30:19 | https://dev.to/cuongnp/swagger-nodejs-express-a-step-by-step-guide-4ob | javascript, node, beginners, programming | Following the post on configuring Swagger for a SpringBoot project, today I will introduce you to a step-by-step guide to set up Swagger in a Node.js (Express) project.
## 1. Set Up Your Project
First, create a new Node.js project if you don't have one already.
```bash
mkdir swagger-demo
cd swagger-demo
npm init -y
... | cuongnp |
1,907,762 | JS Builders Meetup – Learn the PubSub Design Pattern for JavaScript! | Hey Dev.to Community! 👋 On July 3rd we had our monthly virtual gathering for JavaScript enthusiasts... | 0 | 2024-07-03T14:30:00 | https://dev.to/buildwebcrumbs/join-us-at-js-builders-meetup-learn-the-pubsub-design-pattern-for-javascript-568o | javascript, meetup, webdev, programming | **Hey Dev.to Community! 👋**
On July 3rd we had our monthly virtual gathering for JavaScript enthusiasts and web developers looking to expand their knowledge and connect with the community.
**Guest Speaker:** Vitor Norton, Developer Advocate at Superviz
**In this session, Vitor Norton will be teaching us about the ... | pachicodes |
1,909,261 | Simplify your unit testing with generative AI | When I write code, I write tests. But I especially hate the process of getting my test framework... | 0 | 2024-07-03T14:30:00 | https://community.aws/content/2ihDE9A59SAbHwUqkLWhyl78Eax/simplify-your-unit-testing-with-generative-ai | aws, ai, productivity, testing | When I write code, I write tests. But I especially hate the process of getting my test framework setup in my project and writing those first few tests that will eventually guide the way for a more full-fledged test suite.
Because of this, I have been experimenting with generative AI tools, like [Amazon Q Developer](ht... | jennapederson |
1,910,299 | The Role of Physics in Elevator Operation and Safety | Physics plays a crucial role in the operation and safety of elevators, ensuring that these systems... | 0 | 2024-07-03T14:29:53 | https://dev.to/liftcomplex/the-role-of-physics-in-elevator-operation-and-safety-3il9 | Physics plays a crucial role in the operation and safety of elevators, ensuring that these systems function smoothly and securely. By understanding and applying the principles of physics, engineers can design elevators that are efficient, reliable, and safe for passengers.
Gravity and Motion
At the core of elevator o... | liftcomplex | |
1,910,298 | Understanding CSS Progress Bars | In the world of web development, having a visually appealing and user-friendly interface is... | 0 | 2024-07-03T14:28:33 | https://dev.to/code_passion/understanding-css-progress-bars-795 | css, html, webdesign, tutorial | In the world of web development, having a visually appealing and user-friendly interface is essential. The progress bar is a vital aspect of reaching this goal. Progress bars not only give users a sense of readiness and feedback, but they also enhance the overall user experience. Although there are various ways to impl... | code_passion |
1,910,297 | Error Handling (How to create Custom Error Handlers and Exceptions) - FastAPI Beyond CRUD (Part 16) | This video explores error handling in FastAPI, focusing on customizing exception raising and... | 0 | 2024-07-03T14:26:36 | https://dev.to/jod35/error-handling-how-to-create-custom-error-handlers-and-exceptions-fastapi-beyond-crud-part-16-7h9 | fastapi, python, api, programming |
This video explores error handling in FastAPI, focusing on customizing exception raising and tailoring error responses to meet our application's specific requirements. We cover creating custom exception classes and utilizing them effectively to manage errors and personalize their presentation according to the applicat... | jod35 |
1,910,294 | React-Hook-Form vs Formik: The Good, Bad, and Ugly | React-Hook-Form and Formik are the most popular libraries for handling forms in React applications.... | 0 | 2024-07-03T14:21:33 | https://joyfill.io/react-hook-form-vs-formik-the-good-bad-and-ugly | react, forms, opensource, github | React-Hook-Form and Formik are the most popular libraries for handling forms in React applications. Both have their own sets of pros and cons, which can help in deciding which one to use based on the specific needs of your project.
> 💡 Note: Both of these react form libraries are open source, so be cognizant of that... | johnpagley |
1,910,293 | Step-by-Step Guide: Estimated Reading Time in Bear Blog | Learn how to display the estimated reading time for your Bear blog posts using a simple script. Adjust placement and reading speed easily. | 0 | 2024-07-03T14:20:56 | https://dev.to/yordiverkroost/step-by-step-guide-estimated-reading-time-in-bear-blog-3maf | bear, blog, reading, development | ---
title: Step-by-Step Guide: Estimated Reading Time in Bear Blog
published: true
description: Learn how to display the estimated reading time for your Bear blog posts using a simple script. Adjust placement and reading speed easily.
tags: Bear, Blog, Reading, Development
cover_image: https://bear-images.sfo2.cdn.digi... | yordiverkroost |
1,909,514 | Linux User Creation Bash Script | The purpose of this script is to read a text file containing an employee’s usernames and group names,... | 0 | 2024-07-03T14:19:04 | https://dev.to/wanjiru/linux-user-creation-bash-script-5ff3 | The purpose of this script is to read a text file containing an employee’s usernames and group names, where each line is formatted as user;groups.The script should create users and groups as specified, set up home directories with appropriate permissions and ownership and generate random passwords for the users.
The f... | wanjiru | |
1,910,184 | Automating User and Group Management with a Bash Script | I recently got accepted into the famous(https://hng.tech/hire). It is a very intense hands-on 8 week... | 0 | 2024-07-03T14:17:31 | https://dev.to/faruq2991/automating-user-and-group-management-with-a-bash-script-33fj | devops, linux, cloud, automation | >
I recently got accepted into the famous(https://hng.tech/hire). It is a very intense hands-on 8 week program where your skills will be tested and legends are made. As a requirement for proceeding to the next stage, interns on every track are given tasks they are expected to execute, document and write an article to ... | faruq2991 |
1,910,291 | Exploring the Newest Features in JavaScript ES2024 | The JavaScript ecosystem continues to evolve rapidly, with each ECMAScript (ES) release introducing... | 0 | 2024-07-03T14:17:10 | https://dev.to/delia_code/exploring-the-newest-features-in-javascript-es2024-jie | webdev, javascript, programming, beginners | The JavaScript ecosystem continues to evolve rapidly, with each ECMAScript (ES) release introducing new features that enhance the language's capabilities and developer experience. ES2024 is no exception, bringing a host of exciting features that promise to improve code readability, performance, and overall efficiency. ... | delia_code |
1,910,290 | React Custom Hooks vs. Helper Functions - When To Use Both | When working as a developer it is fairly common to come across various technologies and use cases on... | 0 | 2024-07-03T14:16:42 | https://dev.to/andrewbaisden/react-custom-hooks-vs-helper-functions-when-to-use-both-2587 | webdev, javascript, programming, react | When working as a developer it is fairly common to come across various technologies and use cases on a day-to-day basis. Two popular concepts are React Custom Hooks and Helper functions. The concept of Helper functions has been around for a very long time whereas React Custom Hooks are still fairly modern. Both concept... | andrewbaisden |
1,910,289 | Top 20 React.JS interview questions. | As a React developer, it is important to have a solid understanding of the framework's key concepts... | 0 | 2024-07-03T14:16:13 | https://dev.to/hasan048/top-20-reactjs-interview-questions-5df3 | react, webdev, javascript, programming | As a React developer, it is important to have a solid understanding of the framework's key concepts and principles. With this in mind, I have put together a list of 20 important questions that every React developer should know, whether they are interviewing for a job or just looking to improve their skills.
Before div... | hasan048 |
1,910,275 | AWS Prefix Lists help simplify Networking | I’ve been working with a client that acquired another company, and has multiple office sites, data... | 0 | 2024-07-03T14:15:56 | https://dev.to/aws-builders/aws-prefix-lists-help-simplify-networking-1ki4 | aws, networking, vpc, cloud | I’ve been working with a client that acquired another company, and has multiple office sites, data centres, and a fair number of private networks. As part of the acquisition, they’ve been working on integrating the systems of the parent and the acquired company, and one element of that has been simplifying the IP addre... | geoffreywiseman |
1,910,274 | SRT Protocol - Secure Reliable Transport Protocol | The Secure Reliable Transport Protocol is a cutting edge technology. The SRT protocol is designed to... | 0 | 2024-07-03T14:13:39 | https://www.metered.ca/blog/srt-protocol-secure-reliable-transport-protocol/ | webdev, javascript, devops, webrtc | The Secure Reliable Transport Protocol is a cutting edge technology. The SRT protocol is designed to enable the secure and efficient data transmission over the internet
The SRT protocol was designed by Haivision, it is an Open source protocol made primarily for the real time video and data delivery purposes
High Qual... | alakkadshaw |
1,910,283 | How to keep your Azure infrastructure highly available - Configuring data redundancy | Data redundancy is synonymous with keeping data replicas. It plays a key part in highly available... | 27,951 | 2024-07-03T14:11:42 | https://blog.q-bit.me/how-to-keep-your-azure-infrastructure-highly-available-configuring-data-redundancy/ | azure, todayilearned, microsoft, cloud | Data redundancy is synonymous with keeping data replicas. It plays a key part in highly available infrastructure by ensuring data is not lost, even if it is accidentally deleted, corrupted, or encrypted by malware. This article focuses on redundancy in storage accounts.
Resources this concept can be used on
----------... | tqbit |
1,910,287 | Level Up Your GitHub Repo Config Game | Stop with Spreasheets & Start Automating! If you’re like many open source project maintainers,... | 0 | 2024-07-03T14:11:32 | https://dev.to/stacey_potter_3de75e600a1/level-up-your-github-repo-config-game-8lb | github, opensource, security, cloudnative | _Stop with Spreasheets & Start Automating!_
If you’re like many open source project maintainers, your project might span tens or hundreds of GitHub repos, and your repo configuration may be wildly variable. How do you make sure that your repos always have a standard configuration in place, like a code of conduct, a se... | stacey_potter_3de75e600a1 |
1,910,286 | Scop in Javascript with example | Scope in JavaScript refers to the visibility and accessibility of variables, functions, and objects... | 0 | 2024-07-03T14:10:53 | https://dev.to/hasan048/scop-in-javascript-with-example-2i4d | webdev, javascript, beginners, tutorial | Scope in JavaScript refers to the visibility and accessibility of variables, functions, and objects in different parts of your code. JavaScript has three main types of scope:
1. Global scope
2. Function scope
3. Block scope (introduced in ES6 with let and const)
Here's an example demonstrating these scopes:
```javas... | hasan048 |
1,910,285 | Connect MongoDB database with Next JS App(the simplest way) | In Next.js, especially when deploying on serverless environments or edge networks, database... | 0 | 2024-07-03T14:10:24 | https://dev.to/saadnaeem/connect-mongodb-database-with-next-js-appthe-simplest-way-3km9 | mongodbwithnext, mongodbnext, nextjs, mongodb | ##
In Next.js, especially when deploying on serverless environments or edge networks, database connections are established on every request.
This is due to the nature of serverless functions, which do not maintain state between requests and can be spun up or down as needed. Here are some key points to consider:
**S... | saadnaeem |
1,910,284 | how to create new permission groups, permission category | How to update and control permissions of an app and/or menu items using xml first of all we need... | 0 | 2024-07-03T14:10:08 | https://dev.to/jeevanizm/how-to-create-new-permission-groups-permission-category-7lh | odoo | How to update and control permissions of an app and/or menu items using xml
1. first of all we need to override - ir_module_category_data.xml
2. locate the menu items we need to hide/show based on permissions
3. create the new permissions grroups, if it requires, under new category
full code below
```
<?xml ver... | jeevanizm |
1,910,281 | Betvisa: Cá cược dễ dàng | Cá cược luôn là một trò tiêu khiển phổ biến, kết hợp cảm giác hồi hộp khi dự đoán kết quả với khả... | 0 | 2024-07-03T14:09:40 | https://dev.to/betvisa/betvisa-ca-cuoc-de-dang-1ma8 | gamedev |
Cá cược luôn là một trò tiêu khiển phổ biến, kết hợp cảm giác hồi hộp khi dự đoán kết quả với khả năng nhận được phần thưởng sinh lợi. Tuy nhiên, việc điều hướng thế giới cá cược có thể gây choáng ngợp cho cả người mới chơi cũng như người đặt cược dày dạn kinh nghiệm. Đó là lúc betvisa xuất hiện, cách mạng hóa trải ng... | betvisa |
1,910,279 | Top 10 ES6 Features that Every Developer Should know | Top 10 ES6 Features that Every Developer Should know **1. let and const: **Block-scoped... | 0 | 2024-07-03T14:08:59 | https://dev.to/hasan048/top-10-es6-features-that-every-developer-should-know-epi | javascript, typescript, webdev, programming | ## Top 10 ES6 Features that Every Developer Should know
**1. let and const:
**Block-scoped variable declarations. 'let' allows reassignment, 'const' doesn't. Prevents hoisting issues and unintended global variables. Improves code predictability and encourages better practices for variable scope and mutability.
**2. A... | hasan048 |
1,910,277 | Exploring the :has() Selector in CSS | CSS has progressed greatly over time, introducing a number of advanced selectors that improve the... | 0 | 2024-07-03T14:08:07 | https://dev.to/code_passion/exploring-the-has-selector-in-css-58gg | css, webdesign, html, tutorial |
CSS has progressed greatly over time, introducing a number of advanced selectors that improve the ability to style web pages with precision and flexibility. One of the most recent additions to the CSS selector is the :has() pseudo-class. This blog will go over the details of the :has() selector, including its usage, b... | code_passion |
1,910,276 | The Ultimate Guide to Workshop Manuals PDF for Your Vehicle | In the realm of vehicle maintenance and repair, having access to accurate and comprehensive... | 0 | 2024-07-03T14:07:30 | https://dev.to/dots52vc/the-ultimate-guide-to-workshop-manuals-pdf-for-your-vehicle-57cm | In the realm of vehicle maintenance and repair, having access to accurate and comprehensive information is indispensable. Workshop manuals in PDF format provide an excellent resource for vehicle owners, mechanics, and DIY enthusiasts. This guide will delve into the benefits of **[workshop manuals PDF](https://downloadw... | dots52vc | |
1,910,273 | How does ChatGPT generate human-like text? | ChatGPT, developed by OpenAI, is a cutting-edge language model that has made a significant impact in... | 0 | 2024-07-03T14:05:40 | https://dev.to/hasan048/how-does-chatgpt-generate-human-like-text-3ljj | chatgpt, webdev, programming, cheetsheet | **ChatGPT, developed by OpenAI, is a cutting-edge language model that has made a significant impact in the field of natural language processing. It uses deep learning algorithms to generate human-like text based on the input it receives, making it an excellent tool for chatbots, content creation, and other applications... | hasan048 |
1,903,102 | MERRY-GO-ROUND : Carousel Component | In the rapidly changing world of social media, from Instagram to Facebook and LinkedIn, one feature... | 0 | 2024-07-03T14:04:53 | https://dev.to/madgan95/merry-go-round-carousel-component-59dn | webdev, javascript, beginners, programming | In the rapidly changing world of social media, from Instagram to Facebook and LinkedIn, one feature stands out for its ability to capture attention and convey a wealth of information in an engaging way: **"The Carousel"**.
Carousels provide a dynamic way to present large amounts of content in a **cyclic** and visually... | madgan95 |
1,909,084 | Automating User Creation with Bash Script | As a SysOps engineer, managing users and groups in a growing development team can be a time-consuming... | 0 | 2024-07-03T14:04:47 | https://dev.to/vctcode/automating-user-creation-with-bash-script-1d75 | automation, devops, cloud, linux | As a SysOps engineer, managing users and groups in a growing development team can be a time-consuming task. To streamline this process, automating user and group creation with a Bash script can save valuable time and reduce errors. This article will guide you through creating a script to automate these tasks, while ens... | vctcode |
1,910,272 | A Technical Comparison of React and Vue.js | Frontend development is a dynamic field with a variety of technologies that help developers build... | 0 | 2024-07-03T14:04:14 | https://dev.to/samson_toju_4f5a205a6f7ea/a-technical-comparison-of-react-and-vuejs-11c | hngtech, hngtechpremium, webdev | Frontend development is a dynamic field with a variety of technologies that help developers build interactive, responsive, and efficient user interfaces.And in the landscape of frontend development,React and Vue.js are at the forefront of the most popular frameworks/libraries for building user interfaces,with each offe... | samson_toju_4f5a205a6f7ea |
1,910,264 | Mastering Face Detection, Recognition, and Verification: An In-Depth Guide | Introduction In the modern digital era, facial analysis has emerged as a fundamental... | 0 | 2024-07-03T14:04:06 | https://dev.to/api4ai/mastering-face-detection-recognition-and-verification-an-in-depth-guide-3h1f | facedetection, facerecognition, api, ai | #Introduction
In the modern digital era, facial analysis has emerged as a fundamental technology, significantly contributing to enhanced security, optimized user experiences, and streamlined automation across multiple sectors. Its applications are extensive and ever-growing, ranging from unlocking smartphones to taggi... | taranamurtuzova |
1,910,270 | AI's Impact on Future Business: Transformation Across Industries and for IT Professionals 🌐 | Artificial Intelligence is already rewriting the rules of the business world, providing companies... | 0 | 2024-07-03T14:01:40 | https://dev.to/namik_ahmedov/ais-impact-on-future-business-transformation-across-industries-and-for-it-professionals-2nhp | ai, it, automation | Artificial Intelligence is already rewriting the rules of the business world, providing companies with new opportunities for innovation and growth. In the IT industry, understanding how AI is changing not only technological approaches but also business processes is crucial.
🔍 **Data Transparency and Business Analytic... | namik_ahmedov |
1,910,269 | Git Cheatsheet that will make you a master in Git | Introduction to Git Git is a widely used version control system that allows developers to... | 0 | 2024-07-03T14:01:11 | https://dev.to/hasan048/git-cheatsheet-that-will-make-you-a-master-in-git-p0p | github, githubactions, cheetsheet, programming | ## Introduction to Git
Git is a widely used version control system that allows developers to track changes and collaborate on projects. It has become an essential tool for managing code changes, whether working solo or in a team. However, mastering Git can be a challenge, especially for beginners who are not familiar ... | hasan048 |
1,908,147 | Vercel v0 and the future of AI-powered UI generation | Written by Peter Aideloje✏️ Vercel v0 is at the cutting edge of UI development. It has caught the... | 0 | 2024-07-03T14:00:02 | https://blog.logrocket.com/vercel-v0-ai-powered-ui-generation | vercel, webdev | **Written by [Peter Aideloje](https://blog.logrocket.com/author/peteraideloje/)✏️**
Vercel v0 is at the cutting edge of UI development. It has caught the attention of so many developers with claims that it can make UI development less complicated and tedious. In this blog post, let's delve more into how v0 can be your... | leemeganj |
1,910,267 | Top 10 React js interview questions. | As a React developer, it is important to have a solid understanding of the framework's key concepts... | 0 | 2024-07-03T13:58:04 | https://dev.to/hasan048/top-10-react-js-interview-questions-2l15 | webdev, javascript, beginners, tutorial | As a React developer, it is important to have a solid understanding of the framework's key concepts and principles. With this in mind, I have put together a list of 10 important questions that every React developer should know, whether they are interviewing for a job or just looking to improve their skills.
Before div... | hasan048 |
1,910,266 | Linux User Creation Bash Script | Introduction We can use a Bash script to automate the creation of users and groups, set up... | 0 | 2024-07-03T13:55:00 | https://dev.to/tennie/linux-user-creation-bash-script-llg | ## Introduction
We can use a Bash script to automate the creation of users and groups, set up home directories, generate random passwords, and log all actions.
## Script Overview
The script we're going to discuss performs the following functions:
Create Users and Groups: Reads a file containing usernames and group nam... | tennie | |
1,910,265 | Make an Image drag and drop with CSS in React | React is a popular JavaScript library for building user interfaces, and its flexibility and... | 0 | 2024-07-03T13:54:48 | https://dev.to/hasan048/make-an-image-drag-and-drop-with-css-in-react-3md8 | webdev, javascript, programming, tutorial | React is a popular JavaScript library for building user interfaces, and its flexibility and versatility make it a great choice for building interactive applications. In this tutorial, we will show you how to create a drag-and-drop feature for images using only CSS in React.
**Step 1 —
**
To start, let's set up a React... | hasan048 |
1,910,262 | Lazy Imports in Java?🙂↔️ | I am an experienced Python user, and I love how everything is built-in. One feature I use daily is... | 0 | 2024-07-03T13:51:14 | https://dev.to/tanwanimohit/lazy-imports-in-java--3pal | java, coding, tutorial, learning | I am an experienced Python user, and I love how everything is built-in. One feature I use daily is lazy imports. Recently, I was working with Java and wanted to do something similar. Although I couldn't find any good articles on the topic, I managed to figure it out. Here is a sample implementation based on the bcrypt ... | tanwanimohit |
1,910,263 | Highly Effective 7 Habits for Developers | As a software developer, success doesn't just come from luck or chance. It is the result of years of... | 0 | 2024-07-03T13:50:53 | https://dev.to/hasan048/highly-effective-7-habits-for-developers-2gkh | webdev, beginners, programming, tutorial | As a software developer, success doesn't just come from luck or chance. It is the result of years of hard work, continuous learning and development, and forming good habits. In the fast-paced world of technology, software developers must always be learning and adapting to keep up with the latest trends and advancements... | hasan048 |
1,910,261 | The Role of a Digital Marketing Agency in Today's Business Landscape | In the fast-paced world of modern business, staying competitive requires more than just having a... | 0 | 2024-07-03T13:49:34 | https://dev.to/alica_gc_017203c23e4289d1/the-role-of-a-digital-marketing-agency-in-todays-business-landscape-4o21 | webdev, javascript, programming, tutorial | In the fast-paced world of modern business, staying competitive requires more than just having a great product or service. It demands effective outreach and engagement strategies that resonate with today's digital-savvy consumers. This is where digital marketing agencies play a crucial role, offering specialized servic... | alica_gc_017203c23e4289d1 |
1,910,259 | Clean Code in React | Hello everyone, I'm Juan, and today I want to share with you some tips and tricks that I use to write... | 0 | 2024-07-03T13:47:38 | https://dev.to/juanemilio31323/clean-code-in-react-30cm | react, frontend, cleancode, webdev | Hello everyone, I'm Juan, and today I want to share with you some tips and tricks that I use to write more reusable code. For the past 2 weeks, I've been writing about how to develop projects faster and how it's irrelevant to spend too much time looking for the perfect code at the outset of the project. Although, you a... | juanemilio31323 |
1,910,258 | Streamlining Linux User Management with a Bash Script | Managing user accounts and groups on a Linux system can often become cumbersome, especially in... | 0 | 2024-07-03T13:46:30 | https://dev.to/six-shot/streamlining-linux-user-management-with-a-bash-script-54pk | devops, linux | Managing user accounts and groups on a Linux system can often become cumbersome, especially in dynamic environments where frequent updates are necessary. Automating these tasks not only simplifies the process but also ensures consistency and efficiency. In this article, we'll explore how to implement a Bash script that... | six-shot |
1,910,257 | Revolutionize the Fitness Industry with Pro Athlete Connect: Seeking a Technical Cofounder | Hello DEV Community! I'm Sam, an early stage entrepreneur with a vision to transform the fitness... | 0 | 2024-07-03T13:45:36 | https://dev.to/proathleteconnect/revolutionize-the-fitness-industry-with-pro-athlete-connect-seeking-a-technical-cofounder-17hc | ai, cofounder, appdevelopment, healthtech | Hello DEV Community!
I'm Sam, an early stage entrepreneur with a vision to transform the fitness industry. I am excited to introduce you to Pro Athlete Connect, an innovative app designed to bridge the gap between professional athletes, fitness enthusiasts, and the general public. Our mission is to provide personalize... | proathleteconnect |
1,910,256 | Enhance Your Crop Yield With An HTP Sprayer Pump | Farming technology has advanced significantly, and one of the most valuable tools for modern... | 0 | 2024-07-03T13:42:42 | https://dev.to/mitra_agro21_d2593e19c339/enhance-your-crop-yield-with-an-htp-sprayer-pump-2c06 | Farming technology has advanced significantly, and one of the most valuable tools for modern agriculture is the HTP sprayer pump. This equipment is crucial for plant protection sprayer and ensuring healthy, productive crops.
An HTP pump is designed to deliver pesticides, herbicides, and fertilizers efficiently across ... | mitra_agro21_d2593e19c339 | |
1,910,254 | "Introducing FoodBuddy: My First Go Project! 🚀🍽️ Looking for Feedback to Improve! #GoLang" | 🚀 Beginner here! A few weeks into Go with no prior web development experience, I built FoodBuddy, a... | 0 | 2024-07-03T13:41:29 | https://dev.to/lijuthomas_/introducing-foodbuddy-my-first-go-project-looking-for-feedback-to-improve-golang-28g1 | go, webdev, beginners | 🚀 Beginner here! A few weeks into Go with no prior web development experience, I built FoodBuddy, a restaurant aggregator. 🍽️ Still working on it. Looking for constructive criticism to learn and improve. Roast away! 😅
Check it out: [FoodBuddy-API](https://github.com/liju-github/FoodBuddy-API)
#golang | lijuthomas_ |
1,910,252 | React 101 | This article assumes familiarity with React coding, particularly in using states and other essential... | 0 | 2024-07-03T13:36:40 | https://dev.to/achal_tiwari/react-101-kei | webdev, react, beginners, tutorial | This article assumes familiarity with React coding, particularly in using states and other essential features.
## State
- _State_: _Component-specific memory_ in React used to track and manage dynamic data within a component.
- _Dynamic Interaction_: State allows components to change what’s displayed on the screen base... | achal_tiwari |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.