
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,910,076 | Introduction to BitPower Smart Contracts | Introduction BitPower is a decentralized lending platform that provides secure and efficient lending... | 0 | 2024-07-03T11:45:17 | https://dev.to/aimm_w_1761d19cef7fa886fd/introduction-to-bitpower-smart-contracts-gp2 | Introduction
BitPower is a decentralized lending platform that provides secure and efficient lending services through smart contract technology. This article briefly introduces the features of BitPower smart contracts.
Core features of smart contracts
Automatic execution
All transactions are automatically executed by ... | aimm_w_1761d19cef7fa886fd | |
1,910,075 | How to Access Direct Children of a Div in Tailwind CSS v3 | In this tutorial, we'll explore how to target and style the direct children of a div using Tailwind... | 0 | 2024-07-03T11:44:11 | https://devdojo.com/bobbyiliev/how-to-access-direct-children-of-a-div-in-tailwind-css-v3 | tailwindcss, css, webdev, beginners | In this tutorial, we'll explore how to target and style the direct children of a div using Tailwind CSS v3's powerful arbitrary value syntax. This feature allows for more flexible and precise styling, especially when dealing with nested layouts.
## The Problem
Consider the following HTML structure:
```html
<div clas... | bobbyiliev |
1,910,074 | Alles, was Sie über Fluoreszierende Farben Wissen Müssen | Fluoreszierende Farben sind faszinierende Materialien, die in vielen Bereichen, von der Kunst bis hin... | 0 | 2024-07-03T11:42:22 | https://dev.to/alfonso_snchezrodrguez/alles-was-sie-uber-fluoreszierende-farben-wissen-mussen-1k99 | [Fluoreszierende Farben](https://www.greenstuffworld.com/de/187-fluoreszierende-acrylfarben) sind faszinierende Materialien, die in vielen Bereichen, von der Kunst bis hin zu Sicherheitsanwendungen, verwendet werden. Diese Farben haben die einzigartige Fähigkeit, unter UV-Licht oder Schwarzlicht zu leuchten, was sie zu... | alfonso_snchezrodrguez | |
1,910,068 | BitPower Smart Contract: | BitPower is a decentralized energy trading platform based on blockchain technology, aiming to improve... | 0 | 2024-07-03T11:38:47 | https://dev.to/bao_xin_145cb69d4d8d82453/bitpower-smart-contract-1j8d |
BitPower is a decentralized energy trading platform based on blockchain technology, aiming to improve the transparency and efficiency of the energy market. At its core are smart contracts that automate energy transactions through pre-written code. These smart contracts can not only automate the transaction process and... | bao_xin_145cb69d4d8d82453 | |
1,910,067 | Which 5 MLM firms are the most successful worldwide? | **MLM Company #1 – Amway **The most well-known business is one that consistently ranks highly in... | 0 | 2024-07-03T11:35:21 | https://dev.to/lead_mlmsoftware_08c8ddb/which-5-mlm-firms-are-the-most-successful-worldwide-1gjd | mlm, mlmsoftware, mlmsoftwareusa, leadmlmsoftware |
**MLM Company #1 – Amway
**The most well-known business is one that consistently ranks highly in lists of multilevel marketing organizations because of its success in popularizing the MLM idea. Through a digital platform, they are consistently increasing their investment. Their unique company style is truly reflected... | lead_mlmsoftware_08c8ddb |
1,910,066 | Top 10 Reasons for Hiring Node.js + React.js Developers | Hiring Node.js and React.js developers can bring numerous advantages to your project, from high... | 0 | 2024-07-03T11:34:32 | https://dev.to/coderower/top-10-reasons-for-hiring-nodejs-reactjs-developers-1fhg | node, react, reactjsdevelopment, reactnative | Hiring **Node.js and React.js developers** can bring numerous advantages to your project, from high performance and scalability to rapid development and strong community support. This powerful combination of technologies is ideal for building modern, efficient, and user-friendly web applications.
**Cutting-Edge Profic... | coderower |
1,910,064 | Apparently now I'm a trusted member! | I just got an email that says now I'm a trusted member of the DEV.to, hooray! What is... | 0 | 2024-07-03T11:33:07 | https://dev.to/skywarth/apparently-now-im-a-trusted-member-2l4h | trusted, member, moderator, devto | I just got an email that says now I'm a trusted member of the DEV.to, hooray!
## What is trusted member?
After a brief research and reading the guide, it essentially grants the user the permission to moderate the content and posts on DEV.to
So basically you get these new permissions:
- Access to mod center
- Rank con... | skywarth |
1,910,062 | Paper detailing BitPower Loop’s security | Security Research of BitPower Loop BitPower Loop is a decentralized lending platform based on... | 0 | 2024-07-03T11:32:29 | https://dev.to/asfg_f674197abb5d7428062d/paper-detailing-bitpower-loops-security-4011 | Security Research of BitPower Loop
BitPower Loop is a decentralized lending platform based on blockchain technology, dedicated to providing users with safe, transparent and efficient financial services. Its core security comes from multi-level technical measures and mechanism design, which ensures the robust operation ... | asfg_f674197abb5d7428062d | |
1,910,061 | LeetCode Day24 Greedy Algorithms Part 2 | 122. Best Time to Buy and Sell Stock II You are given an integer array prices where... | 0 | 2024-07-03T11:32:28 | https://dev.to/flame_chan_llll/leetcode-day24-greedy-algorithms-part-2-5ha3 | leetcode, java, algorithms | # 122. Best Time to Buy and Sell Stock II
You are given an integer array prices where prices[i] is the price of a given stock on the ith day.
On each day, you may decide to buy and/or sell the stock. You can only hold at most one share of the stock at any time. However, you can buy it then immediately sell it on the ... | flame_chan_llll |
1,910,060 | The Advantages of IOS Development | IOS development offers numerous advantages that can significantly benefit developers and businesses... | 0 | 2024-07-03T11:31:20 | https://dev.to/coderower/the-advantages-of-ios-development-37mg | ios, development, developers, webdev | IOS development offers numerous advantages that can significantly benefit developers and businesses alike. With its high-quality user experience, robust security features, and stable ecosystem, iOS provides a solid foundation for creating premium applications. The platform’s strong monetization potential, regular updat... | coderower |
1,910,059 | Udyam registartion supports small owners | The term "Udyam Reg" is a shortened form of "Udyam Registration," which refers to the registration... | 0 | 2024-07-03T11:29:53 | https://dev.to/neelu_jarika_3239ec190277/udyam-registartion-supports-small-owners-i0p | udyamregistration, business |
The term "Udyam Reg" is a shortened form of "[Udyam Registration](https://udyogaadhaaronline.org/)," which refers to the registration process for micro, small, and medium enterprises (MSMEs) in India under the Udyam Registration portal. This initiative was launched by the Indian government to simplify the registrati... | neelu_jarika_3239ec190277 |
1,910,058 | SaaS Development Cost: How Much It Costs in 2024? | In today's rapidly evolving digital landscape, Software as a Service (SaaS) has become a crucial... | 0 | 2024-07-03T11:27:45 | https://dev.to/veronica_charlotte_v/saas-development-cost-how-much-it-costs-in-2024-4ag4 | beginners, devops, development | In today's rapidly evolving digital landscape, Software as a Service (SaaS) has become a crucial component for businesses seeking efficient, scalable, and cost-effective solutions. As a result, understanding the costs associated with SaaS development is essential for any company looking to leverage this technology. Thi... | veronica_charlotte_v |
1,910,057 | Automating Linux User Management with Bash Script | Introduction Managing user accounts in a Linux environment can be a daunting task, especially when... | 0 | 2024-07-03T11:25:14 | https://dev.to/dev-nnamdi/automating-linux-user-management-with-bash-script-4edp | devops, linux, bash, aws | **Introduction**
Managing user accounts in a Linux environment can be a daunting task, especially when onboarding a large number of new developers. To streamline this process, I have created a Bash script, create_users.sh, which automates the creation of user accounts, assigns them to appropriate groups, generates rand... | dev-nnamdi |
1,910,056 | What is design thinking, and how does it apply? | Everyone who cares about solving a problem, even modestly, talks about Design Thinking. Today, what a... | 0 | 2024-07-03T11:24:31 | https://dev.to/pepper_square/what-is-design-thinking-and-how-does-it-apply-3ace | design, ui, ux, webdev | Everyone who cares about solving a problem, even modestly, talks about Design Thinking. Today, what a company offers its customers is no longer enough. It took businesses a while to shift their focus from being business-centric to being user-centric. With design thinking, you can reimagine your business around your cus... | pepper_square |
1,910,055 | Optimizing My Company's Developers and Group Management with Bash Script Automation | Introduction Efficient user and group management is crucial for any organization's IT... | 0 | 2024-07-03T11:24:12 | https://dev.to/abdul_barri_lawal/optimizing-my-companys-developers-and-group-management-with-bash-script-automation-188d | ### Introduction
Efficient user and group management is crucial for any organization's IT infrastructure. To streamline this process, I've developed a robust Bash script that automates the creation of user accounts and their associated groups. This script not only simplifies user management but also ensures security b... | abdul_barri_lawal | |
1,908,687 | Leader keys and mapping keyboard sequences | As always, when I write "vim", the information is valid in both vim and neovim (to the best of my... | 27,946 | 2024-07-03T11:23:17 | https://dev.to/stroiman/leader-keys-and-mapping-keyboard-sequences-3ehm | As always, when I write "vim", the information is valid in both vim and neovim (to the best of my knowledge). When I write about a feature specific to neovim, I specifically write "neovim".
In vim, you can create keyboard mappings, not just to complex modified keys, like <kbd>ctrl</kbd>+<kbd>alt</kbd>+<kbd>shift</kbd>... | stroiman | |
1,910,053 | Embark on a Thrilling Docker Adventure with LabEx 🚢 | The article is about an exciting collection of six Docker-themed programming tutorials from the LabEx platform. Readers will embark on thrilling adventures in ancient jungles, mystical kingdoms, and futuristic cities, mastering essential Docker skills such as uncovering the Docker version, listing containers, transferr... | 27,902 | 2024-07-03T11:21:13 | https://dev.to/labex/embark-on-a-thrilling-docker-adventure-with-labex-2a3h | docker, coding, programming, tutorial |
Welcome to an exciting collection of Docker-themed programming tutorials from the LabEx platform! Prepare to immerse yourself in a world of ancient jungles, mystical kingdoms, and futuristic cities as you master the art of Docker commands and container management. 🌍
## Uncover the Secrets of the Docker Version 🕵️♀... | labby |
1,910,051 | ANDROID VS. IOS AND THE POWER OF DEDICATED DEVELOPERS | When comparing Android and iOS, the debate often centers around several key factors: user experience,... | 0 | 2024-07-03T11:20:33 | https://dev.to/coderower/android-vs-ios-and-the-power-of-dedicated-developers-5571 | android, ios, androiddev, developer | When comparing Android and iOS, the debate often centers around several key factors: user experience, customization options, security, hardware integration, and the power of dedicated developer communities. Let’s break down these aspects:
**1. User Experience and Interface**
**IOS:**
- Known for its consistent and in... | coderower |
1,910,041 | Exploring General Artificial Intelligence (GenAI) | General Artificial Intelligence (GenAI) is an interesting and ambitious AI concept. General AI seeks... | 0 | 2024-07-03T11:18:58 | https://dev.to/nim12/exploring-general-artificial-intelligence-genai-1ch7 | genai, ai, data, apacheage | General Artificial Intelligence (GenAI) is an interesting and ambitious AI concept. General AI seeks to mimic human cognitive abilities across multiple domains, unlike narrow AI systems that specialize in specific tasks such as image recognition or natural language processing. In this blog article, we'll look at what G... | nim12 |
1,904,243 | Engineering Metrics Are Overrated | Introduction Engineering metrics are overrated, I don't think so! I think they are vitally... | 0 | 2024-07-03T11:17:51 | https://dev.to/peteking/engineering-metrics-are-overrated-24je | devops, productivity, softwaredevelopment, performance | ## Introduction
Engineering metrics are overrated, I don't think so! I think they are vitally important and a valuable tool for gauging the health and progress of software engineering teams.
While some argue that metrics can be misleading or misused, they provide crucial data points that can inform decision-making and... | peteking |
1,884,769 | Supercharging Obsidian.md with OpenAI, Qdrant and Rust | Table of Contents: Getting Started Data Ingestion Using gzipped archives Storing Embeddings with... | 0 | 2024-07-03T11:17:15 | https://dev.to/josh_mo_91f294fcef0333006/supercharging-obsidianmd-with-openai-qdrant-and-rust-504f | webdev, programming, tutorial, ai |
Table of Contents:
- [Getting Started](#getting-started)
- [Data Ingestion](#data-ingestion)
- [Using gzipped archives](#gzipped-archives)
- [Storing Embeddings with Qdrant](#storing-embeddings-with-qdrant)
- [Searching our Files](#searching-our-files)
- [Prompting and Embedding Models](#prompting-and-embedding)
- [C... | josh_mo_91f294fcef0333006 |
1,910,040 | My Journey into Theme Development: A Beginner's Guide | Ever wondered how the stunning and eye-catching designs you see on WordPress websites come to life?... | 0 | 2024-07-03T11:16:58 | https://dev.to/bryan_oginga/my-journey-into-theme-development-a-beginners-guide-26mj | wordpress, themedevelopment, webdev | Ever wondered how the stunning and eye-catching designs you see on WordPress websites come to life? Well, that was me just a few years ago, curious and eager to explore deeper in the world of WordPress custom theme development.
Overview
In this article, I'll walk you through my journey of learning theme development,... | bryan_oginga |
1,910,039 | Supercharge Your Paginated Reports with DAX in Power BI Report Builder | In the realm of data analytics and reporting, paginated reports are indispensable tools for producing... | 0 | 2024-07-03T11:16:36 | https://dev.to/stevejacob45678/supercharge-your-paginated-reports-with-dax-in-power-bi-report-builder-1ke0 | powerbi, powerbireportbuilder, powerbiconsultingservices |
In the realm of data analytics and reporting, paginated reports are indispensable tools for producing detailed and printable documents. These reports are especially vital for operational reporting where precise, pixel-perfect layout control is necessary. Power BI Report Builder, a companion tool to Power BI, provides ... | stevejacob45678 |
1,910,037 | How To Sync Epics between Two Jira Instances | Companies looking to sync Jira Epics internally or externally must use native or third-party... | 0 | 2024-07-03T11:13:34 | https://dev.to/exalateofficial/how-to-sync-epics-between-two-jira-instances-390l | integration, jira, atlassian, synchronization | Companies looking to sync Jira Epics internally or externally must use native or third-party applications.
One third-party option is [Exalate](http://exalate.com/?utm_campaign=jiraepics_devto_03072024&utm_medium=guest_post&utm_source=DevTo), a bidirectional integration solution that syncs data between two Jira instan... | exalateofficial |
1,910,036 | Top Reasons Why Businesses with Hybrid Web Apps are More Successful in 2024 An Experts Overview | Do you know why smartphones have become so popular in such a short time? Smartphones can do various... | 0 | 2024-07-03T11:12:15 | https://dev.to/hina_manzoor/top-reasons-why-businesses-with-hybrid-web-apps-are-more-successful-in-2024-an-experts-overview-369o | development, mobile, web |

Do you know why smartphones have become so popular in such a short time? Smartphones can do various things, including sending emails, watching films, and using social networks. They are becoming more popular as they... | hina_manzoor |
1,910,034 | React Training in Hyderabad | Boost Your Career with Comprehensive React Training in Hyderabad Are you looking to enhance your web... | 0 | 2024-07-03T11:08:51 | https://dev.to/reactmasters/react-training-in-hyderabad-3ce1 | react, devops, javascript, beginners | **Boost Your Career with Comprehensive React Training in Hyderabad**
Are you looking to enhance your web development skills and stay ahead in the tech industry? Our React training in Hyderabad is designed to give you the expertise and confidence to build dynamic, high-performance web applications.
Why Choose React?
... | reactmasters |
1,910,033 | Dotnet terminal komandasi | (ls) joriy papkadagi barcha narsalarni chop etadi, filelarni ko’rsatadi. (-a) tanlovi orqali... | 0 | 2024-07-03T11:08:47 | https://dev.to/dilshod_9141072930ca48eda/dotnet-terminal-komandasi-4d60 | 1. (ls)
joriy papkadagi barcha narsalarni chop etadi, filelarni ko’rsatadi.
(-a) tanlovi orqali yashirin fayl va papkalar ham chop etiladi
2. (pwd)-(print working directory)
joriy papka manzilini chop etadi, qaysi manzilda turganiz ko’rsatadi.
(~) manzili ($HOME) mazilga teng.
3. (cd)-(current directory)
joriy p... | dilshod_9141072930ca48eda | |
1,910,030 | Odoo User Permission and groups | I was trying to add a new set of permission after technical in user profile page. But I could not... | 0 | 2024-07-03T11:07:50 | https://dev.to/jeevanizm/odoo-user-permission-29og | odoo | I was trying to add a new set of permission after technical in user profile page.
But I could not find the code in the odoo folder, all I have got is below
```
<record id="user_groups_view" model="ir.ui.view">
<field name="name">res.users.groups</field>
<field name="model">res.users</... | jeevanizm |
1,910,028 | The Future of AI in Voice Technology | Introduction: A new development brought by artificial intelligence (AI) is voice technology which has... | 0 | 2024-07-03T11:05:32 | https://dev.to/globose_tech/the-future-of-ai-in-voice-technology-318n | speechdatacollection, datasets, audiodatasets | **Introduction:**
A new development brought by artificial intelligence (AI) is voice technology which has changed the interaction with devices. As for smartphones and smart homes, the use of voice stimulation became more than common. The power of voice technology by artificial intelligence (AI) is the focus of this blo... | globose_tech |
1,910,027 | Understanding LLM Billing: From Characters to Tokens | Large Language Models (LLMs) are moving towards a token-based system rather than character counts.... | 0 | 2024-07-03T11:05:19 | https://www.edenai.co/post/understanding-llm-billing-from-characters-to-tokens | ai, api, openai | _Large Language Models (LLMs) are moving towards a token-based system rather than character counts. This article delves into the rationale behind token usage, variations in tokenization among providers such as OpenAI, Google Cloud, Cohere, and others, cost estimation strategies, and the benefits of platforms like Eden ... | edenai |
1,910,026 | Airtel Thanks APP Old Version 4.96.2 Download Free For All Airtel User (Best Recharge & UPI) | Airtel Thanks APP Old Version is an app which provides you many different features like with the help... | 0 | 2024-07-03T11:04:57 | https://dev.to/nazim_husain_a4507ca07387/airtel-thanks-app-old-version-4962-download-free-for-all-airtel-user-best-recharge-upi-4fc | airtelthanksapp, airtelapp, airtel, airteltv | Airtel Thanks APP Old Version is an app which provides you many different features like with the help of this app you can check the remaining data of your phone and with this you can also recharge your phone. If you are an Airtel customer then it is important for you to run this app because without it you will not be a... | nazim_husain_a4507ca07387 |
1,910,025 | Utilizing VisX for React Data Visualization | Overview Welcome to our comprehensive guide on data visualization in React using VisX!... | 0 | 2024-07-03T11:02:26 | https://dev.to/starneit/utilizing-visx-for-react-data-visualization-f4f | webdev, javascript, beginners, programming | ###Overview
Welcome to our comprehensive guide on data visualization in React using VisX! Data visualization plays a crucial role in making complex information more understandable and actionable. In this article, we will explore how VisX, a powerful data visualization library built on top of D3, empowers React develope... | starneit |
1,910,024 | Init | My first blog | 0 | 2024-07-03T11:00:36 | https://dev.to/knowckx/init-5hb8 | My first blog | knowckx | |
1,880,595 | Ibuprofeno.py💊| #131: Explica este código Python | Explica este código Python Dificultad: Intermedio mi_conjunto =... | 25,824 | 2024-07-03T11:00:00 | https://dev.to/duxtech/ibuprofenopy-131-explica-este-codigo-python-26e6 | python, spanish, learning, beginners | ## **<center>Explica este código Python</center>**
#### <center>**Dificultad:** <mark>Intermedio</mark></center>
```py
mi_conjunto = {1,8,9,30,45,78}
print(sorted(mi_conjunto))
```
* **A.** `KeyError`
* **B.** `{1, 8, 9, 30, 45, 78}`
* **C.** `(1, 8, 9, 30, 45, 78)`
* **D.** `[1, 8, 9, 30, 45, 78]`
---
{% details *... | duxtech |
1,910,023 | 11 Signs It Might Be Time for Assisted Living | As our loved ones age, ensuring their safety, health, and well-being becomes a top priority. While... | 0 | 2024-07-03T10:59:16 | https://dev.to/soteria_homecare_ec2a598d/11-signs-it-might-be-time-for-assisted-living-14ho | As our loved ones age, ensuring their safety, health, and well-being becomes a top priority. While aging at home is a preference for many, there comes a time when additional support is necessary. Recognizing the [11 Signs It Might Be Time for Assisted Living](https://soteriahomecareco.com/11-signs-it-might-be-time-for-... | soteria_homecare_ec2a598d | |
1,910,022 | Mastering Common Git Commands: A Developer's Guide | As developers, we often interact with version control systems, and Git is one of the most popular... | 0 | 2024-07-03T10:59:07 | https://dev.to/jawad_hayat/mastering-common-git-commands-a-developers-guide-3ld3 | git, learning | As developers, we often interact with version control systems, and Git is one of the most popular tools out there. Whether you’re just starting out or looking to brush up on your Git skills, this guide covers some of the most common Git commands you’ll use in your day-to-day development work.
#### 1. git init
```
git ... | jawad_hayat |
1,910,021 | Navigating the Challenges of Data Mapping and Transformation in Music Playlist Transfers: A Backend Developer's Journey | Embarking on the path of a backend developer is a journey filled with intricate problems and... | 0 | 2024-07-03T10:58:24 | https://dev.to/goldyn/navigating-the-challenges-of-data-mapping-and-transformation-in-music-playlist-transfers-a-backend-developers-journey-1n89 | Embarking on the path of a backend developer is a journey filled with intricate problems and rewarding solutions. As I prepare to start my HNG Internship, I am reminded of a recent challenging backend issue I encountered and how overcoming it has solidified my passion for this field. Allow me to take you through this e... | goldyn | |
1,910,020 | Common Mistakes to Avoid in Wix Website Design | Wix has revolutionized the world of website design by offering an intuitive platform that allows... | 0 | 2024-07-03T10:56:15 | https://dev.to/wixwebsite/common-mistakes-to-avoid-in-wix-website-design-4i8j | wixwebsite, wixwebsitedesign, wiswebsitebuilder, wixwebsiteredesign | Wix has revolutionized the world of website design by offering an intuitive platform that allows users to create stunning websites without any coding knowledge. However, as easy as it is to use, there are still common pitfalls that can hinder your site's performance and appeal. In this blog, we will delve into the comm... | wixwebsite |
1,910,018 | What makes Assignments Help UAE better than others? | Assignment Help UAE is better than others because of Our transparent policies and authentic work make... | 0 | 2024-07-03T10:56:01 | https://dev.to/allenjames/what-makes-assignments-help-uae-better-than-others-2gbm | [Assignment Help UAE](https://assignmentshelp.ae/) is better than others because of Our transparent policies and authentic work make us different from other platforms. We guarantee original and high-quality work with an elevation in your academic scores. | allenjames | |
1,910,017 | Zupee Gold APK Download Old Version 4.2405 Free For All Android Players (Best Batting App) | In today’s article, we are going to tell you about Zupee Gold APK download old version. Zupee is a... | 0 | 2024-07-03T10:55:27 | https://dev.to/nazim_husain_a4507ca07387/zupee-gold-apk-download-old-version-42405-free-for-all-android-players-best-batting-app-3026 | zupee, zupeegold, zupeegoldapk, downloadzupee | In today’s article, we are going to tell you about Zupee Gold APK download old version. Zupee is a great betting app with the help of which you can win money by playing games. On it you will find many mini-games in which you can bet the money available on the app. If you win you get to keep the pot from that game. And ... | nazim_husain_a4507ca07387 |
1,910,006 | Creating Secure Backups for DynamoDB Tables with Terraform | Creating DynamoDB tables using Terraform is straightforward, but ensuring these tables are securely... | 0 | 2024-07-03T10:43:50 | https://dev.to/sepiyush/creating-secure-backups-for-dynamodb-tables-with-terraform-4002 | aws, terraform, dynamodb | Creating DynamoDB tables using Terraform is straightforward, but ensuring these tables are securely backed up is crucial for data protection and recovery. In this blog post, I will guide you through configuring secure backups for your DynamoDB tables, storing them in a secure AWS vault using Terraform. Additionally, I ... | sepiyush |
1,909,728 | TIL: How Node's event loop actually works. | It has come to my attention that someone is wrong on the Internet. So here’s yet another page about... | 0 | 2024-07-03T10:54:06 | https://dev.to/tmlr/til-how-nodes-event-loop-actually-works-3e2h | node, eventloop, javascript, libuv | It has come to my attention that someone is wrong on the Internet. So here’s yet another page about Event Loop in Node, this time it is actually correct.
> Why would you read that?
> Here I’m talking about low level details of Node.JS, what it uses for async IO and how different parts of Node.JS (v8 and others) are g... | tmlr |
1,910,015 | Understanding TypeScript “as” Keyword | Overview In TypeScript, the "as" keyword is used for type assertion, which allows us to... | 0 | 2024-07-03T10:53:40 | https://dev.to/starneit/understanding-typescript-as-keyword-2ne4 | webdev, javascript, beginners, programming | ###Overview
In TypeScript, the "as" keyword is used for type assertion, which allows us to manually set the data type of a variable and prevent the compiler from inferring it on its own. Type assertion is commonly used to treat any type as a specific type, such as a number or string. While type assertion can be useful,... | starneit |
1,910,014 | Health Checkup Packages | A health checkup package is a bundle of medical tests and screenings designed to evaluate your... | 0 | 2024-07-03T10:52:55 | https://dev.to/docopd/health-checkup-packages-3l39 | bodychekcup, fullbodycheckup, fitness, bodycheckup |

A [health checkup package](https://www.docopd.com/en-in/lab
) is a bundle of medical tests and screenings designed to evaluate your overall health status. These packages aim to detect diseases early, assess risk fac... | docopd |
1,910,013 | Cleanlab Clone: Find and Fix Errors to Turn Unreliable Data into Insights | Enhance Data Quality and Automating Error Correction with Our Cleanlab Clone Software. Cleanlab... | 0 | 2024-07-03T10:52:45 | https://dev.to/osiz_digitalsolutions/cleanlab-clone-find-and-fix-errors-to-turn-unreliable-data-into-insights-53jj | Enhance Data Quality and Automating Error Correction with Our Cleanlab Clone Software.
Cleanlab Clone Software
Error Detection Tool is designed for companies and teams to ensure high-quality datasets. Our Error Detection Tool identifies and rectifies inconsistencies, inaccuracies, and anomalies in your data, enhancing... | osiz_digitalsolutions | |
1,910,012 | Competitor Price Monitoring Services - Price Scraping Services | iWeb track the price of your competitors for ecommerce, retail websites like Amazon, eBay and Walmart... | 0 | 2024-07-03T10:52:14 | https://dev.to/iwebscraping/competitor-price-monitoring-services-price-scraping-services-l3f | pricemonitoringservices, pricescrapingservices | iWeb track the price of your competitors for ecommerce, retail websites like Amazon, eBay and Walmart or their individual websites with Competitor Price Monitoring and [Price Scraping Services.](https://www.iwebscraping.com/price-monitoring-services.php) | iwebscraping |
1,910,011 | Pdf Extraction in Python | i want to extract the data as i show in image but this file in originally in pdf format and i want... | 0 | 2024-07-03T10:50:35 | https://dev.to/abhijit94/pdf-extraction-in-python-g9c | help |
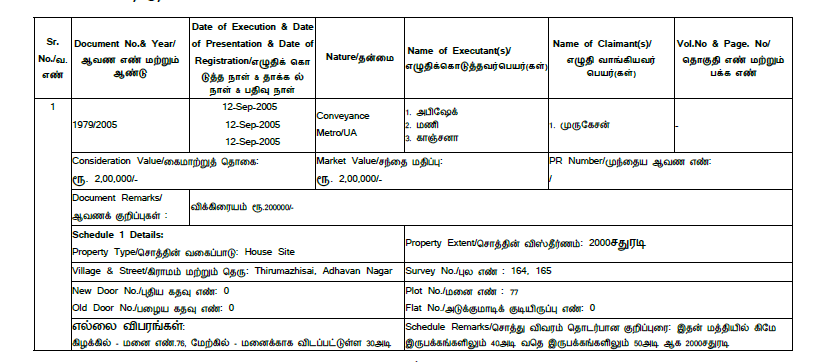
i want to extract the data as i show in image but this file in originally in pdf format and i want to extract the data and save in excel File so suggest me or provide a code in python ...
ASAP....
| abhijit94 |
1,910,010 | Simplifying Global Trade with Custom Declaration Services | In today's interconnected world, efficient customs procedures are vital for businesses engaged in... | 0 | 2024-07-03T10:49:42 | https://dev.to/john_hall/simplifying-global-trade-with-custom-declaration-services-45hf | ai, productivity, learning, software | In today's interconnected world, efficient customs procedures are vital for businesses engaged in global trade. The Customs Declaration Service (CDS) stands at the forefront, revolutionizing how we handle trade clearances and declarations to ensure smooth and efficient processes.
Embracing Automation for Smoother Cust... | john_hall |
1,910,008 | Minimum Advertised Price Monitoring - MAP Monitoring Services | iWeb Scraping provides MAP Monitoring services with Minimum Advertised Price Monitoring for Amazon,... | 0 | 2024-07-03T10:48:19 | https://dev.to/iwebscraping/minimum-advertised-price-monitoring-map-monitoring-services-1j4l | pricemonitoring, mapmonitoring | iWeb Scraping provides [MAP Monitoring services](https://www.iwebscraping.com/minimum-advertised-price.php) with Minimum Advertised Price Monitoring for Amazon, Walmart, eBay, Target, Best Buy, Home Depot, and Etsy. | iwebscraping |
1,910,007 | FM WhatsApp Old Version Download for Android Anti-Ban Official (All Versions) | In today’s article, we are going to tell you about a very special application. Which is a modified... | 0 | 2024-07-03T10:44:59 | https://dev.to/amjad_ansari_831d24e9a64a/fm-whatsapp-old-version-download-for-android-anti-ban-official-all-versions-1bd | fmwhatsapp, fmwhatsappoldversion, downloadfmwhatsapp, whatsapp | In today’s article, we are going to tell you about a very special application. Which is a modified version of WhatsApp “Yes, we are talking about FM WhatsApp Old Version. You might have used a lot of WhatsApp and recognize them well, but if you have used only normal WhatsApp till now then there is no MOD. If you have n... | amjad_ansari_831d24e9a64a |
1,910,005 | Object Oriented Programming || Encapsulation | As we all know that encapsulation is one of the 4 pillars of OOPS and we can use this to hide the... | 27,948 | 2024-07-03T10:42:42 | https://dev.to/hra06/object-oriented-programming-encapsulation-235f | oops, java | As we all know that encapsulation is one of the 4 pillars of OOPS and we can use this to hide the data and add some restrictions to perform the operation on the instance varaible of the classs for which we want to make sure that encapsulation has been done perfectly.
Genrally We have been told that we have to hide the ... | hra06 |
1,910,004 | Why Choose Dallas for Mobile App Development? | Dallas has emerged as a prominent hub for mobile app development due to its vibrant tech community... | 0 | 2024-07-03T10:42:20 | https://dev.to/michaeljason_eb570f1a51d6/why-choose-dallas-for-mobile-app-development-30dc | Dallas has emerged as a prominent hub for mobile app development due to its vibrant tech community and skilled workforce. The city boasts a rich pool of experienced developers who have a track record of creating innovative and successful mobile applications. With a strong emphasis on creativity and cutting-edge technol... | michaeljason_eb570f1a51d6 | |
1,910,003 | Part 1: What is Clean Architecture? | Understanding Clean Architecture Clean Architecture is a software design philosophy... | 27,935 | 2024-07-03T10:41:39 | https://dev.to/moh_moh701/part-1-what-is-clean-architecture-4bn1 | dotnetcore, microservices, architecture |
#### Understanding Clean Architecture
Clean Architecture is a software design philosophy introduced by Robert C. Martin (Uncle Bob) that aims to create a system that is easy to understand, flexible, and maintainable. It emphasizes separation of concerns, ensuring that the business logic of an application is decoupled... | moh_moh701 |
1,910,002 | Mastering Soft Skills: Dos and Don'ts for Professional Success 🌟 | Mastering Soft Skills: Dos and Don'ts for Professional Success 🌟 Want to stand out in the... | 0 | 2024-07-03T10:41:23 | https://dev.to/hey_rishabh/mastering-soft-skills-dos-and-donts-for-professional-success-1d5m | webdev, beginners, tutorial, ai | ## Mastering Soft Skills: Dos and Don'ts for Professional Success
🌟
Want to stand out in the workplace?**_ Your soft skills are just as crucial as your technical abilities!_** Here’s a breakdown of essential soft... | hey_rishabh |
1,910,000 | Integrating Wearable Device Data into Medical Records | Wearable devices like smartwatches and fitness trackers can provide real time health data. Infusing... | 0 | 2024-07-03T10:40:37 | https://dev.to/edwina_johnson/integrating-wearable-device-data-into-medical-records-9d3 | medicalrecordreview, medicalrecords, medicalrecordreviewcompany | Wearable devices like smartwatches and fitness trackers can provide real time health data. Infusing this data into medical records can improve the way diagnoses are made. This can also help chart review companies in arriving at accurate summaries of patient’s health records.
Wearable devices can track health metrics s... | edwina_johnson |
1,909,999 | Time Travel in React with Immer: A Step-by-Step Tutorial | Overview In the ever-evolving landscape of front-end development, the ability to... | 0 | 2024-07-03T10:40:02 | https://dev.to/starneit/time-travel-in-react-with-immer-a-step-by-step-tutorial-78p | webdev, javascript, beginners, programming |
###Overview
In the ever-evolving landscape of front-end development, the ability to manipulate state effectively is a crucial skill. Imagine having the power to rewind and fast-forward through your application's state changes, pinpointing bugs and gaining a deeper understanding of your code's behavior. Welcome to the ... | starneit |
1,909,984 | Event driven architecture : Overview and comparison of AWS Messaging services | In this Article Overview of Event Driven Architecture Event Driven Architecture Common... | 0 | 2024-07-03T10:39:19 | https://dev.to/distinction-dev/event-driven-architecture-overview-and-comparison-of-aws-messaging-service-18lb | aws, eventdriven, serverless | ### In this Article
- Overview of Event Driven Architecture
- Event Driven Architecture Common Model
- AWS messaging services (use case, model, throughput, pricing)
- SQS
- SNS
- Combined Use Case: SNS and SQS Integration
- Eventbridge
- Kinesis Data stream
- Kafka Overview
- Very Important to ... | bhavin03 |
1,909,998 | Rubber Anti-Tack Agents Market: Comprehensive Growth Statistics and Forecast 2024-2031 | The global rubber anti-tack agents market is projected to grow from USD 472.9 million in 2024 to USD... | 0 | 2024-07-03T10:38:53 | https://dev.to/swara_353df25d291824ff9ee/rubber-anti-tack-agents-market-comprehensive-growth-statistics-and-forecast-2024-2031-p5j |

The global [rubber anti-tack agents market](https://www.persistencemarketresearch.com/market-research/rubber-anti-tack-agents-market.asp) is projected to grow from USD 472.9 million in 2024 to USD 683.4 million by 2... | swara_353df25d291824ff9ee | |
1,909,473 | How to Setup Users and User Groups on Linux | Setting up users and user groups is the first step to managing employees in your organisation. As a... | 0 | 2024-07-03T10:38:07 | https://dev.to/soji/how-to-setup-users-and-user-groups-on-linux-25ia | linux, sysops, devops, bash | Setting up users and user groups is the first step to managing employees in your organisation. As a SysOps engineer one of the basic tools you must familiarise yourself with is linux and its environment. Its important that when creating users for your organisation you must properly configure what access and how each us... | soji |
1,909,997 | Enhance your TypeScript with Type Guards | Overview The world of JavaScript development has been transformed by TypeScript's robust... | 0 | 2024-07-03T10:37:49 | https://dev.to/starneit/enhance-your-typescript-with-type-guards-4jk6 | webdev, javascript, beginners, programming | ###Overview
The world of JavaScript development has been transformed by TypeScript's robust static typing abilities. Amidst its numerous attributes, type guards emerge as a potent instrument, enhancing the language's type safety significantly. This article embarks on an exploration of Type guards in TypeScript, delving... | starneit |
1,909,996 | Preventing side effect functions in Flutter | Introduction Throughout my programming journey, I've learned that writing clean,... | 0 | 2024-07-03T10:35:30 | https://dev.to/starneit/preventing-side-effect-functions-in-flutter-1e61 | webdev, javascript, beginners, programming | ### Introduction
Throughout my programming journey, I've learned that writing clean, efficient, and maintainable code is crucial. When working with Flutter, it's essential to avoid side effect functions that can cause unexpected issues and make the code harder to understand. Join me as we dive into the importance of st... | starneit |
1,909,995 | CLR | CLR - Common Language Runtime(CLR) .NET dasturlarining ishlash jarayonini boshqaradi. O'z vaqtida... | 0 | 2024-07-03T10:35:14 | https://dev.to/dilshod_9141072930ca48eda/clr-4eae | CLR - Common Language Runtime(CLR) .NET dasturlarining ishlash jarayonini boshqaradi. O'z vaqtida kompilyator kompilyatsiya qilingan codeni yani (MSIL) codeni mashina codega ( 0 va 1 larga) kompilyatsiya qiladi.
CLR tomonidan taqdim etiladigan xizmatlar xotirani boshqarish, xatoliklar bilan ishlash, xavfsizlik va bosh... | dilshod_9141072930ca48eda | |
1,909,994 | Cracking Amazon System Design Interview: Top Questions and Answer | When I talk to my friends at Amazon, I can’t help but wish that I’d had the chance to be on their... | 0 | 2024-07-03T10:35:04 | https://dev.to/fahimulhaq/cracking-amazon-system-design-interview-top-questions-and-answer-45i1 | When I talk to my friends at Amazon, I can’t help but wish that I’d had the chance to be on their interviewing teams. I’ve already had my own experience conducting System Design Interviews both at Meta and Microsoft, but Amazon just plays a different ballgame. Namely, leadership principles play an especially significan... | fahimulhaq | |
1,909,763 | What is useActionState in React ? | useActionState is a hook that allows you to update state based on the result of a form action. It's... | 0 | 2024-07-03T10:33:51 | https://dev.to/twisha/what-is-useactionstate-in-react--imb | react, webdev, javascript | `useActionState` is a hook that allows you to update state based on the result of a form action.
> It's currently only available in React’s Canary and experimental channels. In addition, you need to use a framework that supports React Server Components to get the full benefit of useActionState.
It simplifies managing... | twisha |
1,909,993 | How to Consult with Lunar Astro : | About Lunar Astro Lunar Astro is a distinguished platform offering a wide range of... | 0 | 2024-07-03T10:33:00 | https://dev.to/harshal_chaudhary_f96afe3/how-to-consult-with-lunar-astro--efo | lunarastro, review, astrology | ## About Lunar Astro
Lunar Astro is a distinguished platform offering a wide range of astrological services, including consultations, courses, and books. Founded in 2015, Lunar Astro has garnered 9 years of experience in the field of astrology and has served more than 100,000 clients. Every astrologer at Lunar Astro po... | harshal_chaudhary_f96afe3 |
1,909,992 | Advanced Local Storage Techniques: Applying the Power of JSON | Local storage is an important feature of web development because it allows users to store data... | 0 | 2024-07-03T10:31:25 | https://dev.to/code_passion/advanced-local-storage-techniques-applying-the-power-of-json-8hp | json, webdev, tutorial, webdesign | Local storage is an important feature of web development because it allows users to store data locally within their browsers. It provides a smooth browsing experience by retaining user data across sessions, improving performance, and decreasing the need for frequent server queries. JSON (JavaScript Object Notation) is ... | code_passion |
1,909,991 | SDK vs Runtime | SDK - bu platformaga xos ishlab chiquvchi vositalari to'plami. Muayyan platformada, operatsion... | 0 | 2024-07-03T10:31:05 | https://dev.to/dilshod_9141072930ca48eda/sdk-vs-runtime-4i5l | SDK - bu platformaga xos ishlab chiquvchi vositalari to'plami. Muayyan platformada, operatsion tizimda yoki dasturlash tilida ishlaydigan kodni yaratish uchun tuzatuvchilar, kompilyatorlar va kutubxonalar kabi komponentlar talab qilinadi.
Runtime - ish vaqti kodning bir qismi bo'lib, bajariladigan faylda (yoki alohida... | dilshod_9141072930ca48eda | |
1,909,941 | Mastering LLM API Gateway: Your Ultimate Guide | Introduction In the world of tech today, there's a big push for AI-driven tools and... | 0 | 2024-07-03T10:30:39 | https://dev.to/novita_ai/mastering-llm-api-gateway-your-ultimate-guide-355p | llm, gateway | ## Introduction
In the world of tech today, there's a big push for AI-driven tools and services. Big players like OpenAI and Gemini are leading the charge with their LLM (Large Language Model) APIs, offering powerful ways to process language that let developers create cool new stuff. But getting to these tools in a way... | novita_ai |
1,909,961 | All You Need to Know about SAMSum Dataset | Introduction Are you a researcher or developer interested in the field of dialogue... | 0 | 2024-07-03T10:30:38 | https://dev.to/novita_ai/all-you-need-to-know-about-samsum-dataset-2gpf | llm, translation | ## Introduction
Are you a researcher or developer interested in the field of dialogue summarization? If so, you won't want to miss the groundbreaking SAMSum Dataset- a unique dataset that is poised to transform the state of the art.
In this blog post, referencing the paper "SAMSum Corpus: A Human-annotated Dialogue Da... | novita_ai |
1,909,988 | Choosing the Right Database for Your Project | Selecting the right database for your project is a critical decision that can significantly impact... | 0 | 2024-07-03T10:30:19 | https://dev.to/rahulvijayvergiya/choosing-the-right-database-for-your-project-4amg | Selecting the right database for your project is a critical decision that can significantly impact your application's performance, scalability, and maintainability. With various types of databases available, each suited for different use cases, understanding when to use each type is essential. In this blog, we'll explo... | rahulvijayvergiya | |
1,909,966 | Quick Start Guide of how to Use Llama 3 | Introduction Llama 3, a cutting-edge open-source language model, is revolutionizing the... | 0 | 2024-07-03T10:30:00 | https://dev.to/novita_ai/quick-start-guide-of-how-to-use-llama-3-5b72 | ## Introduction
Llama 3, a cutting-edge open-source language model, is revolutionizing the field of NLP. With 8 billion and 70 billion parameter options, Llama 3 offers unparalleled opportunities for data scientists and AI enthusiasts. By following a responsible use guide, users can explore text generation, language tr... | novita_ai | |
1,909,949 | Powering GPU: Maximize Performance with These Tips | Introduction Putting together a high-performance PC with a top-notch GPU is both fun and... | 0 | 2024-07-03T10:30:00 | https://dev.to/novita_ai/powering-gpu-maximize-performance-with-these-tips-3n58 | ## Introduction
Putting together a high-performance PC with a top-notch GPU is both fun and fulfilling. Ensuring your GPU receives the right amount of power is crucial for optimal performance and longevity. This blog post covers determining power requirements, comparing GPUs' power usage, and enhancing efficiency for b... | novita_ai | |
1,909,987 | Integration of Prometheus with Cortex | Previously we talked that Prometheus is becoming a go-to option for people who want to implement... | 0 | 2024-07-03T10:29:08 | https://dev.to/anshul_kichara/integration-of-prometheus-with-cortex-2fa | devops, technology, software, trending | Previously we talked that Prometheus is becoming a go-to option for people who want to implement event-based monitoring and alerting. The implementation and management of Prometheus are quite easy. But when we have a large infrastructure to monitor or the infrastructure has started to grow you require to scale monitori... | anshul_kichara |
1,909,986 | Enhancing Enterprise App Quality through Automated Testing | Introduction In the fast-paced Agile development environment, many companies are investing... | 0 | 2024-07-03T10:28:45 | https://dev.to/grjoeay/enhancing-enterprise-app-quality-through-automated-testing-5and | automatedtesting, appquality, apptesting, mobileapptesting | ## Introduction
In the fast-paced Agile development environment, many companies are investing in test automation to maintain software quality, but this transition comes with costs, including engineering effort, license fees, and labor hours. However, the question remains: do the outcomes justify the expenses, and how c... | grjoeay |
1,909,985 | Elevate Your WhatsApp Campaigns: How Divsly Makes a Difference | In today's digital age, communication has become more streamlined and efficient. WhatsApp, one of the... | 0 | 2024-07-03T10:28:29 | https://dev.to/divsly/elevate-your-whatsapp-campaigns-how-divsly-makes-a-difference-1l76 | whatsappcampaigns, whatsappmarketingcampaigns | In today's digital age, communication has become more streamlined and efficient. WhatsApp, one of the leading messaging apps, has revolutionized the way we connect with friends, family, and even businesses. As a business owner or marketer, leveraging WhatsApp for your campaigns can significantly boost your engagement a... | divsly |
1,909,979 | Unlock The Future With the Asset Tokenization Platform | With the emergence of asset tokenization, the financial sector has undergone a huge transformation in... | 0 | 2024-07-03T10:27:06 | https://dev.to/carolinemax/unlock-the-future-with-the-asset-tokenization-platform-5b86 | assettokenization, maticz, softwaredevelopment | With the emergence of asset tokenization, the financial sector has undergone a huge transformation in the past few years. This concept has distorted the conventional financial methods empowering the the new world of digital ownership and investment opportunities. Let's understand the fundamentals of asset tokenization,... | carolinemax |
1,909,983 | From Day to Night: Building a CycleGAN for Image Translation | Introduction Welcome to the exciting world of image translation! Have you ever wondered... | 0 | 2024-07-03T10:26:49 | https://dev.to/aditi_baheti_f4a40487a091/from-day-to-night-building-a-cyclegan-for-image-translation-3pjd | cyclegan, deeplearning, gan, ai | ## Introduction
Welcome to the exciting world of image translation! Have you ever wondered how a scene would look at night if you only have its day image? Using CycleGANs, we can transform images from one domain to another, like day to night and vice versa, without the need for paired examples. Let's dive into this fa... | aditi_baheti_f4a40487a091 |
1,909,982 | The Magic of Layers: Understanding Container Image Efficiency and Consistency | The File System View in Containerized Processes What does the file system look like to... | 0 | 2024-07-03T10:26:39 | https://dev.to/novita_ai/the-magic-of-layers-understanding-container-image-efficiency-and-consistency-553a | ## The File System View in Containerized Processes
What does the file system look like to processes running inside a container? One might immediately think this relates to Mount Namespace—the processes within a container should see a completely independent file system. This way, operations can be performed within the c... | novita_ai | |
1,909,981 | Understanding Reconciliation and the Virtual DOM in React | React is a powerful JavaScript library for building user interfaces, and two of its core concepts are... | 27,828 | 2024-07-03T10:25:46 | https://imabhinav.dev/blog/understanding-reconciliation-and-the-virtual-dom-in-react-10-25-24 | react, javascript, webdev, beginners | React is a powerful JavaScript library for building user interfaces, and two of its core concepts are reconciliation and the Virtual DOM. Understanding these concepts can help you write more efficient and effective React applications. In this blog, we'll break down these ideas in simple terms and provide examples to il... | imabhinavdev |
1,909,980 | Understanding How Generative AI Works | The world has been fascinated by generative AI and its potential to change the way we work and live.... | 0 | 2024-07-03T10:25:28 | https://dev.to/vikas_brilworks/understanding-how-generative-ai-works-4c5e | The world has been fascinated by generative AI and its potential to change the way we work and live. In 2023, this so-called "generative AI" took center stage, moving from theory to practice.
We have hundreds of apps powered by generative algorithms for many jobs across different industries, from e-commerce to media ... | vikas_brilworks | |
1,902,173 | Growing Mindset: 5 Tips To Learn From Mistakes | Mistakes are a common part of our daily lives, whether they happen in our personal lives or at work.... | 0 | 2024-07-03T10:25:15 | https://dev.to/kwan/growing-mindset-5-tips-to-learn-from-mistakes-3238 | learning, mindset | **_Mistakes are a common part of our daily lives, whether they happen in our personal lives or at work. Usually, they come along with negative feelings, however, they can present us with opportunities to develop a growing mindset. In this article, we’ll try to help you change how you perceive your mistakes, in order to... | kwan |
1,909,977 | ESLint 9 Flat config tutorial | When we start a new project, syntax check and style format is important but not easy to config. That... | 0 | 2024-07-03T10:24:13 | https://dev.to/aolyang/eslint-9-flat-config-tutorial-2bm5 | eslint, frontend, vue, stylistic | When we start a new project, syntax check and style format is important but not easy to config.
That is because, before ESLint 9, it had many conflicts between IDE/Editor, prettier, and ESLint. Now ESLint9 disabled & deprecated some confict rules, and enabled Flat config as default.
(ESLint 9.0 stable version publishe... | aolyang |
1,909,976 | Record in TypeScript: Unveiling Its Surprising Power | Introduction: TypeScript, with its robust type system, continues to offer developers an... | 0 | 2024-07-03T10:23:00 | https://dev.to/starneit/record-in-typescript-unveiling-its-surprising-power-508f | webdev, javascript, beginners, programming | ###Introduction:
TypeScript, with its robust type system, continues to offer developers an array of features that enhance code quality, maintainability, and overall development experience. Among its lesser-known gems is the Record type, which often remains in the shadows compared to more frequently used types like stri... | starneit |
1,909,968 | Market Forecast: Solvent-Based Adhesives Through 2030 | According to the new market research report "Solvent Based Adhesives Market by Chemistry... | 0 | 2024-07-03T10:20:02 | https://dev.to/aryanbo91040102/market-forecast-solvent-based-adhesives-through-2030-2fbf | news | According to the new market research report "Solvent Based Adhesives Market by Chemistry (Polyurethane, Acrylic, Chloroprene Rubber, Synthesized Rubber), End-Use Industry (Paper & Packaging, Medical, Automotive, Building & Construction, Woodworking), Region - Global Forecast to 2026", published by MarketsandMarkets™, t... | aryanbo91040102 |
1,909,967 | Drilling Fluids Market: Comprehensive Analysis of Key Players and Developments 2024-2033 | The global drilling fluids market is projected to reach a valuation of US$19.14 billion by 2033, up... | 0 | 2024-07-03T10:20:02 | https://dev.to/swara_353df25d291824ff9ee/drilling-fluids-market-comprehensive-analysis-of-key-players-and-developments-2024-2033-4e3 |

The global [drilling fluids market](https://www.persistencemarketresearch.com/market-research/drilling-fluids-market.asp) is projected to reach a valuation of US$19.14 billion by 2033, up from US$11.58 billion in 20... | swara_353df25d291824ff9ee | |
1,909,965 | 10 Ways to Use Artificial Intelligence in E-Commerce | AI has significantly impacted various industries, including eCommerce. Its implementation in... | 0 | 2024-07-03T10:15:22 | https://dev.to/ravi_makhija/10-ways-to-use-artificial-intelligence-in-e-commerce-3n1d | ai, ecommerce, onlinestore | AI has significantly impacted various industries, including eCommerce. Its implementation in eCommerce has transformed business operations, improving efficiency, customer satisfaction, and profitability.
From personalized shopping experiences to optimizing inventory management, AI is transforming the landscape of onli... | ravi_makhija |
1,909,964 | .NET versiyalari | Version Latest release Latest release date .NET Core 3.1 3.1.32 December 13, 2022 .NET Core 3.0... | 0 | 2024-07-03T10:13:21 | https://dev.to/dilshod_9141072930ca48eda/net-versiyalari-4op2 |
Version Latest release Latest release date
.NET Core 3.1 3.1.32 December 13, 2022
.NET Core 3.0 3.0.3 February 18, 2020
.NET Core 2.2 2.2.8 November 19, 2019
.NET Core 2.1 2.1.30 August 19, 2021 | dilshod_9141072930ca48eda | |
1,909,963 | Trusted Roofing Company in Broward County | We specialize in restoring and enhancing the longevity of your roof. Our team of skilled... | 0 | 2024-07-03T10:12:30 | https://dev.to/roofingrecoveryflori/trusted-roofing-company-in-broward-county-35p | We specialize in restoring and enhancing the longevity of your roof. Our team of skilled professionals brings years of expertise to every project, ensuring precision and quality craftsmanship. At Roofing Recovery, we pride ourselves on delivering tailored roofing services that prioritize durability and aesthetic appeal... | roofingrecoveryflori | |
1,909,962 | Building and Selling a GPT Wrapper SaaS in 5 Months | Since the release of ChatGPT, we’ve been flooded with all possible versions of apps that use it in... | 0 | 2024-07-03T10:12:17 | https://wasp-lang.dev/blog/2024/07/03/building-selling-saas-in-5-months | ai, saas, marketing, javascript | Since the release of ChatGPT, we’ve been flooded with all possible versions of apps that use it in one way or another. Building on top of trendy technology is an excellent way to get initial attention, but still, 99% of these apps die very quickly and don’t last beyond a week or two following their “big” Twitter or Pro... | vincanger |
1,909,960 | The Art of Design in Web Development Building Attractive Websites | **Table of Contents: Introduction: Why Is Design Significant in Web Development? Basics of Web... | 0 | 2024-07-03T10:08:13 | https://dev.to/jinesh_vora_ab4d7886e6a8d/the-art-of-design-in-web-development-building-attractive-websites-3144 | webdev, javascript, programming, react |
**Table of Contents:
1. Introduction: Why Is Design Significant in Web Development?
2. Basics of Web Designing
3. Responsive Design: Optimizing it for Neither-Too-Big Nor-Too-Small Devices.
4. Color Theory and Typography—Improvising It for More Eye-Pleasing Effect
5. Intuitive User Experience: Designing for Smooth In... | jinesh_vora_ab4d7886e6a8d |
1,909,959 | Blockchain Beyond Cryptocurrency: Innovative Uses in Various Sectors | Blockchain Beyond Cryptocurrency: Innovative Uses in Various Sectors ... | 0 | 2024-07-03T10:07:53 | https://dev.to/kodexolabs/blockchain-beyond-cryptocurrency-innovative-uses-in-various-sectors-4ma3 | blockchain, cryptocurrency, solidity, beginners | # Blockchain Beyond Cryptocurrency: Innovative Uses in Various Sectors
## Introduction
When most people hear the word "blockchain," they immediately think of Bitcoin or other cryptocurrencies. However, blockchain technology is much more than the backbone of digital currencies. It offers a secure, transparent, and dec... | kodexolabs |
1,909,958 | Implement ShadCn form with Validation | Our Goal or Funda is very simple. Follow 4 steps implement a super duper form with validation with... | 0 | 2024-07-03T10:07:24 | https://dev.to/nisharga_kabir/implement-shadcn-form-with-validation-3hik | reacthookform, zod, validation, shadcn | Our Goal or Funda is very simple. Follow 4 steps implement a super duper form with validation with less code
**Step 0: Define a zod schema**
```
import { z } from 'zod';
export const createDepartmentsSchema = z.object({
name: z.string().min(2, {
message: 'Please enter your full name'
}),
remark... | nisharga_kabir |
1,909,957 | .NET tarixi | NET Framework — 2002-yilda Microsoft tomonidan chiqarilgan dasturiy platformadir. Platforma turli... | 0 | 2024-07-03T10:07:09 | https://dev.to/dilshod_9141072930ca48eda/net-tarixi-1i3m | NET Framework — 2002-yilda Microsoft tomonidan chiqarilgan dasturiy platformadir. Platforma turli dasturlash tillari: C#, Visual Basic .NET, J# va boshqalar uchun mos Common Language Runtime (CLR)ga asoslangan. CLR funksiyasi ushbu platformadan foydalanadigan har qanday dasturlash tilida mavjud. .NET Framework hozirda.... | dilshod_9141072930ca48eda | |
1,909,955 | Communication de les informations | Bienvenue | 0 | 2024-07-03T10:05:26 | https://dev.to/abde_nnajiecharki_9771d7/communication-de-les-informations-1n9j | Bienvenue
{% codepen https://codepen.io/Abde-Nnaji-ECHARKI/pen/GRaVwVb %} | abde_nnajiecharki_9771d7 | |
1,908,954 | Introduction to BitPower Smart Contracts | Introduction Smart contracts are blockchain technologies that automatically execute and verify... | 0 | 2024-07-02T12:37:56 | https://dev.to/aimm_y/introduction-to-bitpower-smart-contracts-2b1k | Introduction
Smart contracts are blockchain technologies that automatically execute and verify transactions. BitPower provides decentralized lending services through smart contracts to ensure secure and transparent transactions.
Core functions
Automatic execution of transactions: Smart contracts automatically conduct ... | aimm_y | |
1,909,954 | Communication de les informations | Bienvenue | 0 | 2024-07-03T10:05:26 | https://dev.to/abde_nnajiecharki_9771d7/communication-de-les-informations-1hhi | Bienvenue
{% codepen https://codepen.io/Abde-Nnaji-ECHARKI/pen/GRaVwVb %} | abde_nnajiecharki_9771d7 | |
1,909,953 | Using Terraform to Manage Resources in Multiple AWS Accounts | While working on deploying resources on AWS using Terraform, I encountered a scenario where I needed... | 0 | 2024-07-03T10:05:18 | https://dev.to/sepiyush/using-terraform-to-manage-resources-in-multiple-aws-accounts-1b61 | terraform, aws | While working on deploying resources on AWS using Terraform, I encountered a scenario where I needed to work with more than one AWS account within the same Terraform configuration. The use case was to deploy two resources in different AWS accounts but manage their states in the same Terraform state file. Here’s how I a... | sepiyush |
1,909,978 | UX vs. KPIs? Lessons from Copenhagen's Bike Rentals. | Don't Just Stare at Usage Numbers: A real-world example from bike rentals highlights the high cost of neglecting user experience. | 0 | 2024-07-03T10:05:00 | https://dev.to/samiekblad/ux-vs-kpis-lessons-from-copenhagens-bike-rentals-1cgi | ux, kpi, pm | ---
title: UX vs. KPIs? Lessons from Copenhagen's Bike Rentals.
published: true
description: Don't Just Stare at Usage Numbers: A real-world example from bike rentals highlights the high cost of neglecting user experience.
tags: ux, kpi, pm
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/k94zk0slu... | samiekblad |
1,909,952 | The Power Of Bi And Big Data In Modern Business Analysis | Understanding Business Intelligence (BI) and Big Data Business Intelligence (BI) and Big Data are... | 0 | 2024-07-03T10:04:36 | https://dev.to/saumya27/the-power-of-bi-and-big-data-in-modern-business-analysis-1caf | bi, bigdata | **Understanding Business Intelligence (BI) and Big Data**
Business Intelligence (BI) and Big Data are two crucial concepts in the modern data-driven business landscape. While they are interrelated, they serve different purposes and are utilized in distinct ways.
**Business Intelligence (BI)**
Business Intelligence (... | saumya27 |
1,909,951 | Exploring Mobile Development Platforms and Common Software Architecture Patterns | In the rapidly evolving landscape of mobile development, choosing the right platform and software... | 0 | 2024-07-03T10:03:30 | https://dev.to/sunday_covenant/exploring-mobile-development-platforms-and-common-software-architecture-patterns-2glm | mobile | In the rapidly evolving landscape of mobile development, choosing the right platform and software architecture pattern is crucial for building robust, scalable, and maintainable applications. Whether you're developing for iOS or Android, understanding these elements can significantly impact your app's performance, user... | sunday_covenant |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.