
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,866,804 | Discover the Ultimate Comfort with Zero Gravity Mattresses | In the quest for a perfect night’s sleep, the type of mattress you choose plays a crucial role. If... | 0 | 2024-05-27T17:42:22 | https://dev.to/zerogravitymattressess/discover-the-ultimate-comfort-with-zero-gravity-mattresses-16c1 | In the quest for a perfect night’s sleep, the type of mattress you choose plays a crucial role. If you’re struggling with finding the right balance between comfort and support, it’s time to explore the benefits of a [zero gravity mattress](https://beds.digital/products/revolution-1000-zero-gravity-mattress). Designed to mimic the position astronauts take during liftoff, zero gravity mattresses offer unparalleled comfort and numerous health benefits, making them a popular choice among sleep enthusiasts. Let's delve into why a zero gravity mattress could be your gateway to restful nights and energized mornings.
## **What is a Zero Gravity Mattress?**
A zero gravity mattress is engineered to distribute your body weight evenly, reducing pressure points and promoting a feeling of weightlessness. This is achieved by elevating your head and feet slightly above your heart level, aligning your body in a neutral posture that minimizes stress on your spine, joints, and muscles. This position, often referred to as the "zero gravity position," is scientifically proven to enhance relaxation and improve overall sleep quality.
## **The Science Behind Zero Gravity Mattresses**
The concept of zero gravity originates from NASA, where astronauts are placed in a neutral body posture during liftoff to reduce stress on their bodies. This posture has been adapted into mattress design to provide similar benefits on Earth. When you lie on a zero gravity mattress, your body is supported in a way that allows for optimal blood circulation, reduced muscle tension, and a significant decrease in the pressure exerted on your spine and joints.
## **Health Benefits of Zero Gravity Mattresses**
Investing in a zero gravity mattress can lead to numerous health benefits, including:
**Enhanced Circulation**
By elevating your legs and head, a zero gravity mattress promotes better blood flow throughout your body. This can help reduce swelling in your legs and feet, prevent varicose veins, and even lower the risk of cardiovascular issues.
**Reduced Back Pain**
Many people suffer from chronic back pain due to poor sleeping posture and inadequate mattress support. A zero gravity mattress supports the natural curvature of your spine, alleviating pressure on your lower back and reducing pain.
**Improved Breathing**
Sleeping with your head elevated can help alleviate issues like sleep apnea, snoring, and sinus congestion. This position opens up your airways, making it easier to breathe and ensuring you get a restful night’s sleep.
**Relief from Joint Pain**
For those with arthritis or joint pain, a zero gravity mattress can be a game-changer. By evenly distributing your body weight, it reduces stress on your joints, providing much-needed relief and comfort.
**Enhanced Relaxation**
The zero gravity position is inherently relaxing, helping you unwind after a long day. This can improve your mental health, reduce stress levels, and promote a more restful and rejuvenating sleep.
## **Features to Look for in a Zero Gravity Mattress**
When shopping for a zero gravity mattress, there are several key features to consider to ensure you get the best possible product:
**Adjustable Base**
To fully experience the benefits of a zero gravity position, look for a mattress that comes with an adjustable base. This allows you to customize the elevation of your head and feet to find the most comfortable position.
**Memory Foam**
Memory foam mattresses are often recommended for zero gravity beds due to their ability to contour to your body shape and provide excellent support. High-density memory foam can enhance the weightlessness feeling and improve overall comfort.
**Cooling Technology**
Since memory foam can sometimes retain heat, opting for a mattress with cooling technology can enhance your sleeping experience. Look for features like gel-infused foam or breathable materials to keep you cool throughout the night.
**Durability**
A high-quality zero gravity mattress should be durable and long-lasting. Check for materials and construction methods that ensure the mattress will maintain its shape and support over time.
**Warranty and Trial Period**
A good warranty and trial period are essential when investing in a new mattress. This allows you to test the mattress in your own home and ensure it meets your expectations before making a final commitment.
## **Tips for Getting the Most Out of Your Zero Gravity Mattress**
To maximize the benefits of your zero gravity mattress, consider these tips:
**Pair with Adjustable Base**
Using an adjustable base allows you to find the perfect zero gravity position. Experiment with different angles to see what feels best for your body.
**Maintain a Healthy Sleep Environment**
A comfortable mattress is just one part of a good night's sleep. Ensure your bedroom is cool, dark, and quiet, and establish a relaxing bedtime routine to improve your sleep quality.
**Regularly Rotate the Mattress**
To ensure even wear and extend the life of your mattress, rotate it regularly. This helps maintain its shape and support over time.
**Use Supportive Pillows**
Complement your [zero gravity mattress](https://beds.digital/products/revolution-1000-zero-gravity-mattress) with supportive pillows to maintain proper alignment and enhance comfort. Pillows designed for neck and back support can further improve your sleep posture.
**Real-Life Testimonials**
Many people have experienced the transformative benefits of sleeping on a zero gravity mattress. Here are a few testimonials:
**John D., Wilmington, NC**
I’ve struggled with lower back pain for years, and nothing seemed to help. Since switching to a zero gravity mattress, my back pain has significantly decreased, and I wake up feeling refreshed and pain-free.
**Sarah K., Wilmington, NC**
As someone with arthritis, I never thought I could sleep comfortably again. My zero gravity mattress has made a world of difference. The pressure relief is incredible, and I wake up with less joint pain.
**Mike L., Wilmington, NC**
I used to snore loudly, which disturbed my partner's sleep. With the zero gravity position, my snoring has reduced dramatically, and we both sleep better.
## **Conclusion**
Investing in a zero gravity mattress is more than just a purchase; it’s a step towards better health, improved sleep quality, and enhanced overall well-being. The combination of advanced technology, thoughtful design, and numerous health benefits make it a wise choice for anyone looking to elevate their sleep experience.
If you’re ready to transform your nights and wake up feeling rejuvenated, consider a zero gravity mattress. With the right features and proper care, it can provide you with years of unparalleled comfort and support. Say goodbye to restless nights and hello to the ultimate sleep solution with a zero gravity mattress.
| zerogravitymattressess | |
1,866,802 | Telegram web app | I need help designing a telegram web app that requires users to connect their wallet on first visit... | 0 | 2024-05-27T17:35:29 | https://dev.to/kinamdeast/telegram-web-app-19d3 | I need help designing a telegram web app that requires users to connect their wallet on first visit and allows users to send and receive money with their address. Thoughts? | kinamdeast | |
1,866,801 | ** ¡MVP en desarrollo de software: la Pantera Rosa a la conquista del mundo digital! **🐾 | ¡Hola Chiquis! 👋🏻 ¿Preparados para una aventura de programación digna de la mismísima Pantera Rosa?... | 0 | 2024-05-27T17:33:51 | https://dev.to/orlidev/-mvp-en-desarrollo-de-software-la-pantera-rosa-a-la-conquista-del-mundo-digital--2h0d | mvp, beginners, softwaredevelopment, tutorial | ¡Hola Chiquis! 👋🏻 ¿Preparados para una aventura de programación digna de la mismísima Pantera Rosa? ️

En el mundo del desarrollo de software, la sigla MVP significa Producto Mínimo Viable, y es tan importante como la astucia de la Pantera Rosa para robar el diamante. 💎
Imaginen a la Pantera Rosa ideando su plan: no va a entrar de frente a la bóveda acorazada, porque eso sería un suicidio digital. En vez de eso, diseña un plan maestro, un MVP: una ganzúa diminuta, pero perfecta para abrir la cerradura del cofre.🌂
🚀 MVP: El primer paso hacia el éxito en el desarrollo de software 🐾
Imagina que estás creando un producto de software. No quieres gastar tiempo y recursos en desarrollar características que los usuarios no necesitan, ¿verdad? Aquí es donde entra en juego el concepto de MVP (Producto Mínimo Viable).
¿Qué es un MVP? 🤔
Un MVP es la versión más simple de un producto que se necesita para venderlo a un mercado. Es un producto con suficientes características para atraer a los primeros clientes y validar una idea de producto al principio del ciclo de desarrollo del producto.
Es como la ganzúa de la Pantera: una versión simplificada de tu software, con las funciones justas y necesarias para que los usuarios puedan probarlo y darte su valiosa retroalimentación.

El MVP: Un Vistazo Rápido 🛴
El MVP es la versión más temprana de un producto que contiene solo las características esenciales. Es como si la Pantera Rosa apareciera en la pantalla con su característico caminar y su música pegajosa, pero sin todo el despliegue de efectos especiales. El objetivo principal del MVP es recibir comentarios valiosos de los usuarios y comenzar a obtener beneficios temprano.
¿Por qué es importante un MVP? 💡
El MVP te permite obtener una comprensión de si tu producto será atractivo para los clientes sin tener que desarrollarlo completamente. Te ayuda a evitar trabajar en un producto que nadie quiere.
- Ahorras tiempo y dinero: No inviertes recursos en funciones que nadie quiere.
- Validas tu idea: Descubres si tu software tiene potencial antes de invertir demasiado.
- Aprendes de los usuarios: Recibes feedback y mejoras tu producto en base a sus necesidades.
- Te adaptas al mercado: Cambia tu software según las tendencias y demandas de los usuarios.
¿Cómo crear un MVP?💍
- Define las funciones esenciales: ¿Qué problema resuelve tu software? ¿Qué necesitan los usuarios?
- Crea un prototipo: Una versión básica, sin lujos, pero funcional.
- Ponlo a prueba: Recibe feedback de usuarios reales.
- Itera y mejora: Utiliza la retroalimentación para refinar tu producto.
La Pantera Rosa como inspiración🐾
La Pantera Rosa, la astuta y delgada gata animada, es famosa por su ingenio y habilidad para salir de situaciones complicadas con el mínimo esfuerzo. Al igual que la Pantera Rosa, un MVP se trata de hacer lo mínimo para lograr el objetivo, pero de manera efectiva.
- Ser sigiloso: Enfócate en las funciones esenciales, no en las superfluas.
- Ser rápido: Desarrolla tu MVP lo más rápido posible.
- Ser adaptable: Modifica tu software según las necesidades de los usuarios.
- Ser creativo: Busca soluciones innovadoras para los problemas.
- Ser divertido: ¡Disfruta el proceso de creación!

Beneficios del MVP 🚪
- Retroalimentación Temprana: Al lanzar un MVP, obtienes comentarios rápidos y puedes ajustar el rumbo antes de invertir demasiado tiempo y recursos.
- Reducción de Riesgos: Evitas construir un "coche completo" solo para descubrir que no es lo que los usuarios necesitan.
- Entrega Rápida: Como la Pantera Rosa, el MVP llega al escenario rápidamente, listo para impresionar.
Analogía 🎭
Imagina que el MVP es la Pantera Rosa. Al igual que la Pantera Rosa, que siempre tiene un plan para escapar de las situaciones más difíciles, un MVP es el plan inicial para lanzar un producto exitoso.
La Pantera Rosa no siempre tiene todas las herramientas a su disposición, pero utiliza lo que tiene de la manera más eficiente posible para lograr su objetivo. Del mismo modo, un MVP no tiene todas las características que podría tener el producto final, pero tiene lo suficiente para resolver el problema principal y proporcionar valor a los usuarios.
Así como la Pantera Rosa aprende y se adapta a cada situación, un MVP también se adapta y evoluciona basándose en los comentarios y las necesidades de los usuarios.
MVP de la Pantera Rosa💗
Imagina que la Pantera Rosa es un nuevo software que estamos desarrollando. Aquí está cómo se relaciona:
- Aparición Misteriosa: Al igual que la Pantera Rosa aparece en la pantalla sin previo aviso, el MVP se lanza rápidamente al mercado. No es un producto completo, pero tiene suficiente encanto para atraer a los primeros usuarios.
- Elegancia y Simplicidad: La Pantera Rosa se mueve con gracia y solo muestra lo esencial. Del mismo modo, el MVP contiene solo las características básicas necesarias para funcionar. No hay campanas y silbatos innecesarios.
- Feedback y Mejoras: La Pantera Rosa recibe comentarios de la audiencia y ajusta su actuación. El MVP también se basa en la retroalimentación de los usuarios. Cada iteración mejora el producto, al igual que la Pantera Rosa perfecciona su baile.
- El Misterio Permanece: La Pantera Rosa nunca revela completamente su origen o propósito. Del mismo modo, el MVP mantiene un poco de misterio. Los usuarios saben que hay más por venir, pero están intrigados por lo que ya tienen.

En resumen, al igual que la Pantera Rosa, un MVP es astuto, adaptable y siempre está aprendiendo. ¡Así que la próxima vez que pienses en MVP, imagina que eres la Pantera Rosa, utilizando tus recursos de la manera más eficiente posible para lograr tu objetivo!
El Mínimo Producto Viable (MVP) en desarrollo de software es como la Pantera Rosa de la programación: elegante, ágil y con un toque de misterio.
¡Recuerda, un MVP exitoso es como la Pantera Rosa escapando con el diamante: rápido, efectivo y dejando una marca imborrable, al igual que la Pantera Rosa, siempre debes estar listo para adaptarte y aprender de cada situación! 🚀🐾
¡Atrévete a crear tu propio MVP y conquista el mundo digital!
Así que, la próxima vez que pienses en el MVP, imagina a la Pantera Rosa bailando en la pantalla, ¡y estarás en el camino correcto! 🎩🐾
🚀 ¿Te ha gustado? Comparte tu opinión.
Artículo completo, visita: https://lnkd.in/ewtCN2Mn
https://lnkd.in/eAjM_Smy 👩💻 https://lnkd.in/eKvu-BHe
https://dev.to/orlidev ¡No te lo pierdas!
Referencias:
Imágenes creadas con: Copilot (microsoft.com)
##PorUnMillonDeAmigos #LinkedIn #Hiring #DesarrolloDeSoftware #Programacion #Networking #Tecnologia #Empleo #MVP

 | orlidev |
1,866,800 | Work from Home Packaging Makeup - High Salary! | If you can work from (Amazon) home please let me know, we have alot of openings. You can also work... | 0 | 2024-05-27T17:30:03 | https://dev.to/estelle534/work-from-home-packaging-makeup-high-salary-5bhe | webdev, css, cheatsheet, beginners | If you can work from (Amazon) home please let me know, we have alot of openings. You can also work around your children as well (background noise is fine!). It's what we do.
Morning Shift: Night Shift:
3am-6am. 3pm-6pm
7am-10am. 7pm-10pm
11am-2pm. 11pm-2am
The job is flexible and can be done on weekends as well. Best for new moms, retirees, or anyone who is disabled or wants to work from home generally
Thank you!! This jobs is for USA Only https://sites.google.com/view/3526569amazon/home | estelle534 |
1,866,798 | Marco de Trabajo para la Creación de Agencias de Inteligencia Artificial | En la actualidad, el avance vertiginoso de la tecnología ha colocado a la inteligencia artificial... | 0 | 2024-05-27T17:24:47 | https://dev.to/enolcasielles/marco-de-trabajo-para-la-creacion-de-agencias-de-inteligencia-artificial-39e9 | typescript, ai, openai, node | ---
title: 'Marco de Trabajo para la Creación de Agencias de Inteligencia Artificial'
publishedAt: '2024-04-15'
summary: 'En este artículo construiremos un marco de trabajo para la creación de agencias usando asistentes de IA.'
---
En la actualidad, el avance vertiginoso de la tecnología ha colocado a la inteligencia artificial (IA) como un pilar fundamental en diversas industrias, desde la atención médica hasta la automatización industrial. Sin embargo, conforme la IA se integra más en nuestros sistemas y procesos cotidianos, surge la necesidad de estructuras más sofisticadas que no solo gestionen tareas individuales, sino que coordinen múltiples funciones de IA de manera eficiente y efectiva.
Es aquí donde entra en juego el concepto de las **Agencias de IA**, una idea destinada a fomentar la colaboración y la sinergia entre diferentes agentes de IA. Estas agencias no son simplemente conjuntos de algoritmos trabajando en paralelo; son sistemas integrados diseñados para que múltiples asistentes interactúen, aprendan y se optimicen mutuamente en tiempo real. Este enfoque no solo amplía las capacidades de cada agente individual, sino que transforma la manera en que podemos utilizar la IA para abordar problemas complejos y multifacéticos.
En este artículo, exploraremos este concepto y plantearemos una solución en Typescript que permita la construcción y gestión de este tipo de agencias, permitiendo la personalización y la comunicación efectiva entre los asistentes.
***
### Motivación del proyecto
El mundo de la IA avanza a pasos gigantescos. Cada día aparecen nuevos modelos, herramientas, estudios de investigación, etc. Una de las vertientes que está ganando cada vez más fuerza es el concepto de Agentes que interactúan entre sí. Actualmente existen varios proyectos de código abierto que han implementado esta solución y que están totalmente a nuestro alcance para ser utilizados. Algunos de los más conocidos son el proyecto [AutoGen](https://microsoft.github.io/autogen/) de Microsoft, el framework [CrewAI](https://www.crewai.com/) o [Agency Swarm](https://github.com/VRSEN/agency-swarm), que es desarrollado por el creador de contenido [VRSEN](https://www.youtube.com/@vrsen), quien está sacando vídeos continuamente acerca de este enfoque de agencias de IA. El proyecto que desarrollaremos en este tutorial coge muchos de los conceptos que se aplican en este último framework.
Entonces, si sabemos que existen varias herramientas a nuestro alcance, ¿qué sentido tiene desarrollar un "mini framework" que haga algo parecido a estas herramientas? Simplemente, por entender los conceptos y el funcionamiento interno de estas tecnologías. Si estás buscando utilizar una solución basada en agencias de IA para tu proyecto te recomiendo encarecidamente que utilices alguna de estas herramientas. Si por el contrario buscas, al igual que yo, entender como se puede construir algo así, te animo a que sigas adelante con el artículo donde veremos y explicaremos todo en detalle.
Dicho lo cual, vamos al lío 🚀
***
### Concepto de Agencia de IA
Una Agencia de IA es una estructura compleja diseñada para coordinar y optimizar la interacción entre múltiples asistentes de inteligencia artificial. Este marco de trabajo integra varios componentes clave que permiten una funcionalidad avanzada y una colaboración efectiva entre los agentes. A continuación, describiremos cada uno de estos componentes y su función dentro de la agencia:
#### Agente (Agent)
Un agente es un asistente de IA que realiza tareas específicas basadas en una descripción detallada de sus responsabilidades y las instrucciones de cómo llevarlas a cabo. Cada agente puede equiparse con diversas herramientas personalizadas para expandir su capacidad de acción más allá de sus funciones predeterminadas. En nuestra implementación, utilizaremos los [asistentes de OpenAI](https://platform.openai.com/docs/assistants/overview).
#### Misión
La agencia también definirá una misión, que podemos considerar como unas instrucciones globales. Todo agente será consciente de la misión de la agencia, para que sepa el objetivo final de lo que hace.
#### Herramienta (Tool)
Las herramientas son extensiones funcionales que permiten a los agentes realizar tareas que exceden sus capacidades iniciales. Estas pueden incluir acciones como enviar correos electrónicos, realizar búsquedas en la web o crear y almacenar documentos. Al definir una herramienta, se especifica su funcionalidad, lo que puede hacer y los parámetros necesarios para su ejecución. Toda herramienta contará con un método `run`, donde se implementa la tarea asignada. Finalmente, las herramientas se asignarán a los agentes, quienes comprenderán su funcionamiento y las utilizarán cuando sea necesario. Con "utilizarlas" nos referimos a invocar el método `run` con los parámetros necesarios.
#### Hilo (Thread)
Para facilitar la comunicación entre agentes, se define el concepto de "hilos". Estos son objetos que contienen un agente emisor y otro receptor, funcionando como canales por los cuales los agentes pueden interactuar entre sí. Al crear una agencia, además de especificar los agentes que la conforman, se deberá definir las comunicaciones que pueden existir entre ellos. Los hilos serán los encargados de registrar esta información.
#### Herramienta TalkToAgent
`TalkToAgent` es una herramienta especial que se cargará por defecto en los agentes que lo requieran. Su propósito es facilitar la iniciación de diálogos entre agentes. Cada agente podrá y utilizará esta herramienta cuando deduzca que debe comunicarse con otro. Para ello, indicará como parámetros el agente destinatario y el mensaje a transmitir. La implementación del método `run` de esta herramienta buscará el hilo apropiado que conecta a ambos agentes y enviará el mensaje especificado. De esta forma, conseguimos que los agentes tengan la capacidad de comunicarse entre sí.
#### Usuario
Dentro de la agencia también existe un "agente usuario", una representación especial del usuario humano que interactúa con la agencia. Este agente no estará asociado a un asistente de OpenAI, pero formará parte de los hilos que correspondan como emisor, habilitando así la interacción del usuario con los diferentes agentes que corresponda.
Estas son las diferentes partes que implementará el marco de trabajo. Con ello, para crear una agencia, se comienza por definir y configurar los agentes individuales, especificando su rol particular y las instrucciones para desempeñar las tareas que deban realizar. Asimismo, se define la misión de la agencia. A continuación, se asigna a cada agente un conjunto único de herramientas que complementan y expanden sus capacidades intrínsecas. Posteriormente, se definen las comunicaciones posibles entre los diferentes agentes, habilitando así los diferentes hilos de comunicación que permiten una interacción entre ellos de manera coordinada, compartiendo información y colaborando en tareas complejas. También se especificará con qué agentes podrá comunicarse el usuario. Con todo ello, la agencia está lista para empezar a trabajar. Un simple mensaje del usuario a uno de los agentes pondrá todo en marcha.
***
### Requisitos del Proyecto
Habiendo explicado el concepto de Agencia de IA y lo que se requiere para hacerla funcionar, a continuación definiremos algunos requisitos que nuestro software debe cumplir para que podamos utilizarlo y extenderlo de manera robusta y eficiente:
1. **Interfaz Web**: Necesitamos una interfaz web que permita visualizar toda la comunicación entre cada Agente y habilite al usuario a comunicarse con aquellos agentes pertinentes.
2. **API Rest**: Debe existir una API Rest que permita consumir la información de la agencia e interactuar con ella. La interfaz web utilizará esta API para obtener todos los datos necesarios y enviar los mensajes del usuario.
3. **Separación de Módulos**: Es fundamental que los módulos estén completamente separados, diferenciando claramente la implementación base de la agencia con la definición de una agencia específica. Un módulo se encargará de implementar las bases, mientras que otro módulo consumirá esta implementación base y creará la agencia. Esto es crucial para permitir la creación de diferentes agencias dentro del mismo marco de manera sencilla, lo que nos brindará la capacidad de probar diferentes enfoques de manera ágil y efectiva.
4. **Persistencia de Datos**: En caso de que la aplicación se reinicie, es necesario que el estado anterior se mantenga, incluyendo los agentes creados, los hilos, los mensajes, etc. No queremos que cada vez que iniciemos el proyecto, todo se construya desde cero.
***
### Arquitectura del Marco de Trabajo
Para cumplir con los requisitos anteriores, hemos optado por la siguiente arquitectura:
#### Monorepo con Typescript y pnpm
La modularidad es importante y buscamos un entorno de trabajo ágil y eficiente. Por ello, hemos elegido una arquitectura de monorepo, similar a la que se describe en <a href="/blog/monorepo" target="_blank">este artículo</a>, donde se explica cómo construir un monorepo utilizando herramientas como pnpm. Además, en este caso nos apoyaremos también en la herramienta [turborepo](https://turbo.build/repo) para facilitar la creación y gestión del proyecto.
#### Python o Typescript
Inicialmente, podría parecer lógico utilizar Python para este proyecto, dado que es el lenguaje dominante en las aplicaciones de procesamiento de lenguaje natural. Sin embargo, después de un análisis exhaustivo, hemos decidido utilizar Typescript. Las razones de esta decisión son las siguientes:
* Mi experiencia y dominio en Typescript superan ampliamente a los de Python. Typescript es el lenguaje que utilizo a diario en proyectos reales y de gran alcance, mientras que mi experiencia con Python se limita a pequeños proyectos de exploración.
* Aunque Python es dominante en este ámbito, Typescript no está dejado de lado. Herramientas como [LangChain](https://js.langchain.com/docs/get_started/introduction), [LlamaIndex](https://ts.llamaindex.ai/) y la API de [OpenAI](https://platform.openai.com/docs/introduction) cuentan con soporte para Typescript.
* El uso de Typescript simplifica la implementación de la arquitectura propuesta basada en un entorno de monorepo. Integrar Python en este ecosistema nos complicaría las cosas.
A pesar de estas razones, aún tengo dudas y no descarto la posibilidad de migrar el marco de trabajo a Python en el futuro, como una oportunidad para aprender y familiarizarme más con este lenguaje.
#### Interfaz de Usuario con Next.js
La aplicación web principal en el monorepo, denominada `web`, se desarrollará utilizando [Next.js](https://nextjs.org/). Su función principal será facilitar la interacción del usuario con la agencia y permitirle visualizar de manera organizada la comunicación entre los diferentes agentes. En esta primera versión, la aplicación mostrará simplemente los "hilos" de comunicación entre agentes, lo que permitirá visualizar los mensajes intercambiados. Además, cuando el usuario sea el emisor de un hilo, se le dará la posibilidad de enviar mensajes al agente receptor. Esta funcionalidad no solo mejora la interactividad, sino que también proporciona un seguimiento detallado de las interacciones dentro de la agencia.
#### Paquete `agency`
El núcleo del sistema reside en el paquete `agency`, donde se define la arquitectura principal de la agencia. Este paquete se encarga de implementar toda la funcionalidad de la agencia y de exponer públicamente las clases o funciones necesarias para la creación de las agencias.
Este paquete incluye las siguientes partes:
* **Clases Base:** Se definen las clases fundamentales para la creación de un agente (`Agent`) y una herramienta (`Tool`), así como las clases para los hilos (`Thread`) y los mensajes (`Message`) que facilitan la comunicación entre agentes.
* **Clase Agencia:** Se presenta como una clase abstracta. En ella se implementa la funcionalidad necesaria para la ejecución de la agencia, pero se delega a quien la extienda los siguientes aspectos:
* Definición de los agentes que conforman la agencia.
* Definición de las diferentes comunicaciones que puede existir entre los diferentes agentes.
* Definición de una carpeta donde se pueda persistir la información de la agencia, garantizando que no se pierda su estado frente a un reinicio de la ejecución.
* **API Rest:** Una característica destacada de nuestra agencia es que levantará un servidor Express para permitir la interacción con sus objetos a través de una API, facilitando así el acceso a sus datos o la interacción con ella. La aplicación `web` se conectará a esta API para comunicarse con la agencia.
* **Server Sent Events:** La aplicación `web` necesitará poder recibir los mensajes que se van generando y mostrarlos según se produzcan. Por ello, además de la API Rest, necesitamos un mecanismo que permita el envío de datos del servidor al cliente. Para resolver esto, hemos optado por implementar [Server Sent Events](https://developer.mozilla.org/es/docs/Web/API/Server-sent_events/Using_server-sent_events). Cuando la web cargue un hilo, habilitará un mecanismo de escucha. Cuando la agencia genere un nuevo mensaje, lo emitirá al cliente a través de este mecanismo. De esta forma, mantenemos los mensajes actualizados y en tiempo real en la web.
* **OpenAI:** Como se mencionó anteriormente, para interactuar con el LLM utilizaremos directamente la API de OpenAI. Cada agente creará un asistente de OpenAI a través del cual se comunicará con otros agentes.
#### Implementación de la Agencia
Con el paquete `agency` disponible, solo nos queda utilizarlo para definir las agencias que deseemos. Para ello, habilitaremos una nueva aplicación en el monorepo que llamaremos `back`, la cual tendrá una dependencia con este paquete `agency`. En este artículo, no profundizaremos en esta parte, ya que nuestro objetivo es explicar los fundamentos para la creación de las agencias, no su definición detallada. En artículos posteriores, utilizaremos esta base para crear diferentes agencias capaces de resolver problemas reales.
***
### Implementación de la app `web`
No profundizaremos en la explicación de esta parte en particular. Se trata de un proyecto Next muy sencillo que consta de una única pantalla. En esta pantalla, se presenta un menú lateral que lista todos los hilos de comunicación, mientras que a la derecha se muestran los mensajes del hilo seleccionado. Este proyecto utiliza un servicio para realizar llamadas a la API y obtener los datos necesarios.
Cuando la pantalla de un hilo se carga, se verifica si el usuario forma parte de dicho hilo. En caso afirmativo, se habilita un campo de texto en la parte inferior junto con un botón de enviar, lo que permite al usuario enviar mensajes en ese hilo específico.
La implementación se encuentran disponibles en el repositorio de GitHub mencionado al final del artículo. Sin embargo, dado que este tema se aleja del propósito principal de este artículo, considero que no es necesario profundizar en los detalles de esta implementación.
***
### Implementación del paquete `agency`
Vamos a examinar en detalle cómo se implementa el núcleo de una agencia, así como las diferentes partes que lo componen y cómo se relacionan entre sí.
#### Clase User
La clase `User` representa una entidad con capacidad de comunicación en el sistema. Esto puede ser tanto un agente de IA como el usuario real que utiliza la agencia. Los agentes extienden esta clase `User`, que es un modelo simple con propiedades `id` y `name`.
```tsx
export class User {
constructor(
public id: string,
public name: string,
) {}
}
```
El usuario real se representa como una instancia de esta clase.
#### Agent
La clase `Agent` sirve como base para la creación de los agentes que componen la agencia. Esta clase tiene propiedades para definir las diferentes características de un agente, como su nombre, instrucciones o las herramientas que se le asignan. Además, cuenta con un método principal que llamamos `init`, donde se lleva a cabo la inicialización del asistente asociado en OpenAI.
```tsx
async init() {
if (this.id) {
let openAiAssistant = await openaiClient.beta.assistants.retrieve(
this.id,
);
const shouldUpdate = this.shouldUpdate(openAiAssistant);
if (shouldUpdate) {
openAiAssistant = await openaiClient.beta.assistants.update(
this.id,
this.generateBody() as AssistantUpdateParams,
);
}
this.assistant = openAiAssistant;
if (shouldUpdate) this.delegate.onUpdateAgent(this);
} else {
this.assistant = await openaiClient.beta.assistants.create(
this.generateBody() as AssistantCreateParams,
);
this.id = this.assistant.id;
}
}
```
Este método determina si el agente tiene asignado un ID, lo que indica si ya existe en OpenAI. Si existe, se recupera; de lo contrario, se crea uno nuevo. Además, emplea el método privado `shouldUpdate` para verificar si es necesario actualizarlo. Esto es crucial para garantizar que los cambios realizados en el agente, como la actualización de sus instrucciones, se reflejen en el asistente de OpenAI. Del mismo modo también asegura que no se estén creando nuevos asistentes cada vez que la aplicación arranca.
Una característica destacada de la clase `Agent` es su uso del patrón *Observer* para notificar a otros objetos sobre ciertos eventos. Específicamente, se notifica cuando se actualiza el agente en OpenAI. Más adelante, veremos como la clase `Agency` actuará como el delegado u observador, utilizando este evento para llevar a cabo acciones específicas.
#### Message
Una parte sencilla pero importante de nuestro sistema es la clase `Message`, que representa cada uno de los mensajes que se generan durante la ejecución. Es una clase modelo con las propiedades que queremos registrar.
```tsx
export class Message {
id: string;
date: Date;
type: MessageType;
content: string;
from: User;
to: User;
constructor({ id, date, type, content, from, to }: Props) {
this.id = id;
this.date = date;
this.type = type;
this.content = content;
this.from = from;
this.to = to;
}
}
```
#### Tool
Definimos la clase `Tool` para representar las diferentes herramientas que se asignan a los agentes para dotarles de funcionalidades. Por un lado define las propiedades que OpenAI necesita para la creación de la herramienta: el nombre, la descripción y la definición de los parámetros que puede recibir. Por otro lado define un método abstracto `run`que será el que cada `Tool` deberá implementar para ejecutar las tareas que deba realizar. Como veremos más adelante, el sistema estará preparado para que, cuando un agente deduzca que una herramienta ha de ser ejecutada, se invoque este método `run` en ella con los parámetros que el agente nos indique.
```tsx
export abstract class Tool {
name: string;
description: string;
parameters: any;
constructor({ name, description, parameters }: ToolParams) {
this.name = name;
this.description = description;
this.parameters = parameters;
}
abstract run(parameters: RunProps): Promise<string>;
}
```
#### Thread
La clase `Thread` es fundamental en el sistema, ya que facilita la comunicación entre agentes permitiendo el intercambio de mensajes entre ellos. Esta clase es responsable de interactuar con OpenAI para enviar mensajes y gestionar las respuestas recibidas.
Destacan varias propiedades en esta clase, entre las que se encuentran `senderAgent` y `recipientAgent`, que son objetos que representan los dos agentes (o usuarios) involucrados en la comunicación. Además, cuenta con la propiedad `messages`, que es una lista de objetos de tipo `Message` y se utiliza para almacenar los mensajes generados durante la comunicación.
En cuanto a los métodos, por un lado tenemos `init`, el cual se encarga de inicializar el `Thread` en OpenAI. Al igual que con los agentes, este método utiliza la propiedad `id` para determinar si el registro ya existe y solo necesita ser recuperado, o si, por el contrario, no existe y debe crearse en OpenAI. Veremos más adelante como `Agency` creará estos objetos `Thread` con id o no, para indicar si ya existe o no en función de la información que tenga en su capa de persistencia.
```tsx
async init() {
if (this.id) {
this.thread = await openaiClient.beta.threads.retrieve(this.id);
} else {
this.thread = await openaiClient.beta.threads.create();
this.id = this.thread.id;
}
}
```
Por otro lado tenemos el método `send`. Este método es el que se llama cada vez que se debe enviar un mensaje a `recipientAgent`.
```tsx
async send(message: string, retries: number = 1): Promise<string> {
if (!this.recipientAgent.id) throw new Error("Recipient agent not set");
if (!this.thread) await this.init();
await openaiClient.beta.threads.messages.create(this.id, {
role: "user",
content: message,
});
this.run = await openaiClient.beta.threads.runs.create(this.id, {
assistant_id: this.recipientAgent.id,
});
this.addNewMessage(MessageType.Text, message);
while (true) {
await this.waitUntilDone();
if (this.run.status === "completed") {
const _message = await this.extractMessage();
this.addNewMessage(MessageType.Text, _message, true);
return message;
} else if (this.run.status === "requires_action") {
await this.processAction();
} else {
const err = "Run failed: " + this.run.status;
console.log(err);
if (retries < MAX_RETRIES) {
console.log("Retrying in 30s...");
await new Promise((resolve) => setTimeout(resolve, 30000));
return this.send(message, retries + 1);
}
const _message = this.generateFailedMessage();
this.addNewMessage(MessageType.Text, _message, true);
return _message;
}
}
}
```
Veamos detalladamente el proceso que se lleva a cabo aquí. En primer lugar, verificamos que el agente receptor esté correctamente inicializado. Luego, comprobamos si el hilo está inicializado; en caso contrario, lo inicializamos. A continuación, creamos el mensaje en el asistente de OpenAI y posteriormente creamos el objeto `run`, proporcionado por OpenAI, que nos permite controlar el envío del mensaje y la recepción de la respuesta.
Seguidamente, añadimos el mensaje al listado y comenzamos un bucle infinito para controlar la respuesta. Dentro de este bucle, primeramente utilizamos un método privado para verificar el estado del `run` y continuamos únicamente cuando tenga un estado adecuado.
```tsx
private async waitUntilDone() {
while (["queued", "in_progress", "cancelling"].includes(this.run.status)) {
await new Promise((resolve) => setTimeout(resolve, 1000));
this.run = await openaiClient.beta.threads.runs.retrieve(
this.id,
this.run.id,
);
}
}
```
Cuando el `run` alcance un estado que nos permita manejar la respuesta, actuaremos en consecuencia. Si el estado es `completed`, sabemos que hemos recibido una respuesta definitiva del asistente, por lo que podemos procesarla, generar un nuevo mensaje y concluir esta ejecución. Para procesar la respuesta, nos apoyamos en otro método privado llamado `extractMessage`.
```tsx
private async extractMessage() {
const messages = await openaiClient.beta.threads.messages.list(this.id);
const content = messages.data[0].content[0];
if (content.type === "text") {
return content.text.value;
} else {
throw new Error(
"Framework does not support messages different than text yet.",
);
}
}
```
Sin embargo, los asistentes de OpenAI no siempre proporcionan una respuesta directa. Si han sido equipados con herramientas y durante su ejecución determinan que necesitan usar alguna de ellas, nos lo indicarán estableciendo en el `run` un estado con valor `requires_action` y nos proporcionarán todo lo necesario para llevar a cabo la acción. Cuando esto suceda, utilizaremos otro método privado llamado `processAction` para gestionar dicha acción.
```tsx
private async processAction() {
const toolsToExecute =
await this.run.required_action.submit_tool_outputs.tool_calls;
const toolsResults = [];
for (const toolToExecute of toolsToExecute) {
this.addNewMessage(
MessageType.Action,
`Acción requerida. Ejecutando la tool ${toolToExecute.function.name} con parámetros ${toolToExecute.function.arguments}`,
true,
);
const toolName = toolToExecute.function.name;
const tool = this.recipientAgent.tools.find((t) => t.name === toolName);
const toolResult = tool
? await tool.run({
...JSON.parse(toolToExecute.function.arguments),
callerAgent: this.recipientAgent,
})
: "ERROR: no existe ninguna herramienta con el nombre que has indicado. Inténtalo de nuevo con el nombre correcto. La lista de herramientas disponibles es la siguiente: " +
this.recipientAgent.tools.map((t) => t.name).join(", ");
this.addNewMessage(
MessageType.Action,
`${toolToExecute.function.name} completada. Respuesta: ${toolResult.toString()}`,
true,
);
toolsResults.push({
tool_call_id: toolToExecute.id,
output: toolResult.toString(),
});
}
this.run = await openaiClient.beta.threads.runs.submitToolOutputs(
this.id,
this.run.id,
{
tool_outputs: toolsResults,
},
);
}
```
Este método básicamente extrae la información de la respuesta para determinar qué herramientas deben ejecutarse. A continuación recorre cada una de estas herramientas y realiza las siguientes acciones:
* Guarda el mensaje para registrar que se va a ejecutar una herramienta.
* Busca esta herramienta a partir de su nombre dentro de las herramientas del agente y la ejecuta para obtener un resultado. En caso de que no encuentre la herramienta, directamente genera un resultado de error. 
* Guarda un nuevo mensaje para registrar el resultado de la invocación de dicha herramienta
Cuando finalice la invocación de todas las herramientas indicadas por el agente, se le envía los resultados obtenidos a OpenAI, para que el asistente sepa como ha de continuar su ejecución. Este último paso también actualizará el objeto `run`, lo que hará que el bucle principal pueda continuar su proceso.
Volviendo al bucle principal, también gestionamos el caso en el que el estado no sea ni `completed` ni `requires_action`. En este caso, OpenAI nos indica que ha ocurrido algún tipo de error. A veces, esto puede deberse simplemente a un mal funcionamiento de la API en ese momento. Por eso, establecemos un mecanismo de reintento. Cuando llegamos a esta parte del código, hacemos una pausa de 30 segundos en la ejecución y volvemos a intentar el proceso desde el principio. Si después de 3 intentos el problema persiste, finalizamos con un mensaje manual de error.
Para concluir, es importante mencionar que al igual que la clase `Agent`, la clase `Thread` también utiliza un patrón *Observer* para informar a un delegado cuando se añade un nuevo mensaje. Esto se realiza a través de la interfaz `ThreadDelegate`. El método privado `addNewMessage` utiliza este delegado para enviarle el mensaje que se acaba de registrar. Más adelante, veremos cómo la clase `Agency` se registrará como delegado y ejecutará ciertas acciones cuando se produzca este evento.
```tsx
private addNewMessage(type: MessageType, content: string, inverse = false) {
const message: Message = {
id: Math.random().toString(),
date: new Date(),
type,
content,
from: inverse ? this.recipientAgent : this.senderAgent,
to: inverse ? this.senderAgent : this.recipientAgent,
};
this.messages.push(message);
this.delegate.onNewMessage(this, message);
}
```
Podemos concluir este apartado mencionando que la clase `Thread` es una pieza clave en nuestro sistema, ya que es donde reside toda la interacción con OpenAI para el envío de mensajes, la gestión de respuestas y la invocación de posibles herramientas.
#### Api
Como veíamos anteriormente, un requisito que tenemos es el de habilitar la exposición de los datos de la agencia y permitir la interacción con ella a través de una API Rest. La clase `Api` asume esta responsabilidad.
Esta clase se apoya en la librería [Express](https://expressjs.com/) para crear una simple API Rest con los endpoints que necesitamos. A través del constructor obligamos a que reciba la instancia de la clase `Agency`, que la usará para acceder a los datos de la misma. También permitimos desde el constructor elegir el puerto en el que se quiere exponer esta API. 
La clase cuenta con un método `init`en el que se inicializará express y se definirán los diferentes endpoints.
```tsx
async init() {
const agency = this.agency;
const app = express();
app.use(express.json());
app.use(sseMiddleware);
app.use(cors());
app.get("/ping", async (_: Request, res: Response) => {
try {
res.send({ hello: "world" });
} catch (err) {
res.status(500).send({ error: err });
}
});
app.get("/info", async (_: Request, res: Response) => {
try {
res.send({
name: agency.name,
mission: agency.mission,
agents: agency.agents.map((agent) => ({
name: agent.name,
id: agent.id,
})),
});
} catch (err) {
res.status(500).send({ error: err });
}
});
//-------Resto de endpoints-------
}
```
Algo a destacar en esta clase es la propiedad `clients`, que será un listado de objetos `SseClient` , clase que explicamos enseguida. Esta es la forma que conseguimos habilitar una comunicación basada en [Server-sent events](https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events). Anteriormente explicamos que esto es importante para poder enviar al cliente los mensajes que se vayan generando y que pueda actualizar la interfaz con cada evento. Para esto nos apoyamos en la librería [express-sse-middleware](https://www.npmjs.com/package/express-sse-middleware) que habilita un middleware de Express para el uso de esta tecnología. En el anterior `init` se puede ver como se inicializa este middleware. Para usar esta funcionalidad dotamos a la API de un endpoint que se encarga de crear un nuevo `SseClient`.
```tsx
app.get(
"/threads/:threadId/sseClient",
async (req: Request, res: Response) => {
try {
const { threadId } = req.params;
const sseClient = new SseClient(threadId, res.sse());
this.clients.push(sseClient);
req.on("close", () => {
this.removeSseClient(threadId);
});
} catch (err) {
res.status(500).send({ error: err });
}
},
);
```
La clase `SseClient` simplemente registra el id del `Thread` al que está conectado el cliente y el propio objeto que nos permite la comunicación, obtenido a partir de `res.sse()`
```tsx
export class SseClient {
private client: any;
constructor(
public threadId: string,
client: any,
) {
this.client = client;
}
send(data: any) {
this.client.send(JSON.stringify(data));
}
close() {
this.client.close();
}
}
```
La clase `SseClient` cuenta con 2 métodos, uno para enviar un mensaje al cliente y otro para cerrar la comunicación.
Volviendo a la clase `Api` , definimos otro método `sendMessage`, que recibiendo el id de un `Thread` y el objeto `Message` se encarga de analizar si existe algún cliente conectado a ese hilo y, en ese caso, enviarle el mensaje. Este método es utilizado por la clase `Agency` para informar de los nuevos mensajes que se generan.
```tsx
sendMessage(threadId: string, message: Message) {
if (!this.clients) return;
const sseClient = this.clients.find(
(client) => client.threadId === threadId,
);
if (!sseClient) return;
sseClient.send({
date: message.date,
type: message.type,
content: message.content,
from: message.from.name,
to: message.to.name,
});
}
```
Por último, la clase `Api` cuenta con un método `removeSseClient`, responsable de limpiar una conexión. Este método es ejecutado cuando el servidor detecte que un cliente finaliza la comunicación, liberando así los recursos que dejan de ser útiles. En el endpoint `/threads/:threadId/sseClient`que veíamos un poco más arriba, se puede ver como se llama a este método cuando se detecta un cierre en la conexión.
```tsx
removeSseClient(threadId: string) {
if (!this.clients) return;
const sseClient = this.clients.find(
(client) => client.threadId === threadId,
);
if (!sseClient) return;
sseClient.close();
this.clients = this.clients.filter(
(client) => client.threadId !== threadId,
);
}
```
#### Agency
En este punto, hemos delineado las diferentes partes clave que definen nuestra agencia. Ahora solo nos queda entender cómo ponerlas en funcionamiento todas juntas. La clase `Agency` asumirá esta responsabilidad.
La clase `Agency` será una clase abstracta que tendrá propiedades y métodos propios para permitir la ejecución correcta de la agencia, pero delegará a quien la utilice los detalles de la definición de dicha agencia. Esto es crucial y veremos por qué. Esta clase se encargará de tareas como iniciar los agentes, los hilos, persistir los datos, etc. Sin embargo, no queremos que esta clase tome decisiones sobre qué agentes conforman la agencia o dónde se persisten los datos. Estas son responsabilidades de la aplicación que utilice esta clase. Por esta razón, definimos 3 métodos abstractos:
* El método `getAgents`, que deberá devolver el listado de agentes deseado.
* El método `getAgentCommunications`, que, al pasarle un agente, debería indicarnos con qué otros agentes puede comunicarse.
* El método `getDBPath`, que deberá devolver la ruta de una carpeta en la que la agencia podrá guardar la información necesaria para asegurar la persistencia de datos. Esto es clave ya que así esta clase gestiona la persistencia de datos pero el espacio en el que se almacenan es responsabilidad de quien la utilice.
Continuamos con las propiedades de esta clase. Por un lado, tenemos el nombre y la misión de la agencia: `name` y `mission`. Estas propiedades se pueden definir desde el constructor. La clase inicializará una instancia de `User` para representar al usuario que utiliza la agencia. Además, contará con propiedades para registrar el listado de agentes (`Agent`) o hilos (`Thread`). También contará con una propiedad para registrar la ruta en la que se persisten los datos, `dbPath`, y una instancia de la clase `Api`.
```tsx
export abstract class Agency implements ThreadDelegate, AgentDelegate {
name: string;
mission: string;
user: User;
agents: Array<Agent>;
threads: Array<Thread>;
api: Api;
dbPath: string;
constructor({ name, mission }: AgencyParams) {
this.name = name;
this.mission = mission;
this.user = new User("user", "User");
}
abstract getAgents(): Agent[];
abstract getAgentCommunications(agent: User): Agent[];
abstract getDBPath(): string;
/**
* --- Methods ---
*/
}
```
En cuanto a los métodos, comenzamos con `initApi`, que simplemente se encarga de inicializar la instancia de la clase `Api`.
```tsx
async initApi(port: number) {
this.api = new Api(this, port);
await this.api.init();
}
```
Continuamos con el método `run`. Aquí será donde se lleva a cabo la definición de todas las entidades que se necesita.
```tsx
async run() {
this.dbPath = this.getDBPath();
this.agents = this.getAgents();
if (!this.agents || this.agents.length === 0)
throw new Error(
"You can't init without defining any agents. User will talk to first defined agent",
);
for (const agent of this.agents) {
agent.id = this.getSavedAgentId(agent);
agent.setDelegate(this);
if (this.mission)
agent.instructions = `${this.mission}\n\n${agent.instructions}`;
this.addCommonTools(agent);
await agent.init();
}
this.threads = [];
for (const agent of [this.user, ...this.agents]) {
const recipientAgents = this.getAgentCommunications(agent);
for (const recipientAgent of recipientAgents) {
const thread = new Thread({
id: this.getSavedThreadId(agent, recipientAgent),
senderAgent: agent,
recipientAgent,
delegate: this,
});
thread.messages = this.getSavedMessages(thread.id);
await thread.init();
this.threads.push(thread);
}
}
this.saveAgentsAndThreads();
}
```
Básicamente lo que este método hace es inicializar los agentes y los hilos. Como comentamos, nos apoyamos en los métodos abstractos para que la aplicación nos de los detalles. También vemos como se utilizan métodos privados para comprobar si cierto agente o hilo existe ya o no, lo cual permitirá decidir si ha de crearse desde cero o usar el existente. Lo mismo para la carga de los mensajes generados en anteriores ejecuciones.
A continuación vamos a ver los métodos que se utilizan para implementar el mecanismo de persistencia de datos. Como veremos estamos guardando ficheros JSON en la carpeta que la clase hija nos ha especificado. Este mecanismo de persistencia de datos es **muy básico y poco robusto.** Sería mucho más interesante implementar una base de datos que registre esta información, pero por simplicidad se ha optado por esta solución. Una muy clara mejora de este proyecto es la migración de esta parte a un mecanismo basado en una base de datos convencional.
```tsx
private getSavedAgentId(agent: Agent): string {
const agentsDataStr = this.readFileContentOrCreate(
path.resolve(this.dbPath, "./agents.json"),
);
const agentsData = agentsDataStr ? JSON.parse(agentsDataStr) : [];
const agentData = agentsData.find((a: any) => a.name === agent.name);
return agentData ? agentData.id : null;
}
```
```tsx
private getSavedThreadId(senderAgent: User, recipientAgent: User): string {
const threadsDataStr = this.readFileContentOrCreate(
path.resolve(this.dbPath, "./threads.json"),
);
const threadsData = threadsDataStr ? JSON.parse(threadsDataStr) : [];
const threadData = threadsData.find(
(t: any) =>
t.senderAgent === senderAgent.id &&
t.recipientAgent === recipientAgent.id,
);
return threadData ? threadData.id : null;
}
```
```tsx
private getSavedMessages(threadId: string): Message[] {
const messagesDataStr = this.readFileContentOrCreate(
path.resolve(this.dbPath, "./messages.json"),
);
const messagesData = messagesDataStr ? JSON.parse(messagesDataStr) : [];
const messages = messagesData
.filter((m: any) => m.threadId === threadId)
.map((message: any) => {
const fromUser = message.from === this.user.id;
const toUser = message.to === this.user.id;
return new Message({
id: message.id,
date: new Date(message.date),
type: message.type,
content: message.content,
from: fromUser
? this.user
: this.agents.find((a) => a.id === message.from),
to: toUser ? this.user : this.agents.find((a) => a.id === message.to),
});
});
return messages;
}
```
Cuando se ha completado la inicialización de todas las entidades, invocamos al método `saveAgentsAndThreads`, lo cual persiste el estado actual de los agentes e hilos, asegurando que tengamos siempre todo correctamente sincronizado.
```tsx
private saveAgentsAndThreads(): void {
const agentsData = this.agents.map((agent) => ({
name: agent.name,
id: agent.id,
}));
fs.writeFileSync(
path.resolve(this.dbPath, "./agents.json"),
JSON.stringify(agentsData),
);
const threadsData = this.threads
.filter((t) => t.id !== null)
.map((t) => ({
id: t.id,
recipientAgent: t.recipientAgent.id,
senderAgent: t.senderAgent.id,
}));
fs.writeFileSync(
path.resolve(this.dbPath, "./threads.json"),
JSON.stringify(threadsData),
);
}
```
Cuando estos métodos `initApi` y `run` se hayan ejecutado, la agencia estará totalmente lista para ser utilizada. Ahora entra en juego el método `processUserMessage`, que será el que se llamará cuada vez que un usuario se comunique con un agente. 
```tsx
async processUserMessage(threadId: string, message: string): Promise<string> {
const thread = this.threads.find((thread) => thread.id === threadId);
if (!thread) throw new Error("Thread not found");
if (thread.senderAgent !== this.user)
throw new Error("User can't send message to this thread");
return await thread.send(message);
}
```
Simplemente recupera el `Thread` y ejecuta su método `send`.
Esta clase `Agency` también expone los métodos `getThread` y `getAgentByName`, que serán utilizados por `Api` para obtener un hilo o un agente.
```tsx
getThread(senderAgentName: string, recipientAgentName: string) {
return this.threads.find(
(thread) =>
thread.senderAgent.name === senderAgentName &&
thread.recipientAgent.name === recipientAgentName,
);
}
getAgentByName(agentName: string) {
return this.agents.find((agent) => agent.name === agentName);
}
```
Continuamos con la implementación de las interfaces. ¿Recordáis cuando explicamos las clases `Agent` o `Thread` y mencionamos que utilizaban un patrón *Observer*? Pues bien, esta clase `Agency` será la responsable de implementar esta funcionalidad y registrarse como delegado. Si nos fijamos en el método `run`, cuando se crea un agente o un hilo, veremos que se envía la instancia de esta clase `Agency` a la propiedad `delegate`. Además, en la definición de la clase `Agency`, especificamos que implementará los métodos de `ThreadDelegate` y `AgentDelegate`. Por último, en la parte inferior de la clase, llevamos a cabo estas implementaciones. Básicamente, utilizamos este mecanismo para poder persistir los datos cuando un agente se actualiza o un hilo guarda un nuevo mensaje.
```tsx
/**
* ThreadDelegate implementation
*/
onNewMessage(thread: Thread, message: Message): void {
if (!this.api) return;
this.api.sendMessage(thread.id, message);
const messagesDataStr = this.readFileContentOrCreate(
path.resolve(this.dbPath, "./messages.json"),
);
const messages = messagesDataStr ? JSON.parse(messagesDataStr) : [];
messages.push({
id: message.id,
threadId: thread.id,
date: message.date.toISOString(),
type: message.type,
content: message.content,
from: message.from.id,
to: message.to.id,
});
fs.writeFileSync(
path.resolve(this.dbPath, "./messages.json"),
JSON.stringify(messages),
);
}
```
```tsx
/**
* AgentDelegate implementation
*/
onUpdateAgent(agent: Agent): void {
const agentsDataStr = fs.readFileSync(
path.resolve(this.dbPath, "./agents.json"),
"utf-8",
);
const agentsData = JSON.parse(agentsDataStr);
const agentData = agentsData.find((a: any) => a.id === agent.id);
agentData.name = agent.name;
fs.writeFileSync(
path.resolve(this.dbPath, "./agents.json"),
JSON.stringify(agentsData),
);
const threadsDataStr = fs.readFileSync(
path.resolve(this.dbPath, "./threads.json"),
"utf-8",
);
const threadsData = JSON.parse(threadsDataStr);
const threadsDataFiltered = threadsData.filter(
(t: any) => t.senderAgent !== agent.id && t.recipientAgent !== agent.id,
);
fs.writeFileSync(
path.resolve(this.dbPath, "./threads.json"),
JSON.stringify(threadsDataFiltered),
);
const messagesDataStr = fs.readFileSync(
path.resolve(this.dbPath, "./messages.json"),
"utf-8",
);
const messagesData = JSON.parse(messagesDataStr);
const messagesDataFiltered = messagesData.filter(
(m: any) => m.from !== agent.id && m.to !== agent.id,
);
fs.writeFileSync(
path.resolve(this.dbPath, "./messages.json"),
JSON.stringify(messagesDataFiltered),
);
}
```
Por último, hay un detalle importante que hemos pasado por alto y que vale la pena resaltar: el método privado `addCommonTools`. Este método se encarga de asignar a un agente las herramientas que deseemos darle por defecto. En el método `run`, al inicializar el agente, llamamos a este método para cargar estas herramientas. Por el momento, solo contamos con una herramienta común, llamada `TalkToAgent`. En la siguiente sección, la explicaremos en detalle, pero en resumen, esta herramienta permite que los agentes se comuniquen entre sí. Por esta razón, solo cargaremos esta herramienta en los agentes que pueden comunicarse con otros, es decir, aquellos cuya lista de `recipientAgents` no esté vacía.
```tsx
private addCommonTools(agent: Agent) {
const recipientAgents = this.getAgentCommunications(agent);
if (recipientAgents.length > 0) {
agent.addTool(
new TalkToAgent({
senderAgent: agent,
agency: this,
}),
);
}
}
```
#### TalkToAgent
La clase `TalkToAgent` es una herramienta especializada diseñada para facilitar la comunicación directa y sincrónica entre agentes dentro de la agencia. Su objetivo principal es permitir que un agente envíe un mensaje directamente a otro agente específico y reciba una respuesta exclusiva de ese agente.
Al usar esta herramienta, un agente puede enviar un mensaje utilizando los siguientes parámetros:
* `recipient`: Especifica el nombre del agente destinatario al que se enviará el mensaje.
* `message`: Describe la tarea que el agente destinatario debe completar.
Creamos esta clase extendiendo de `Tool`y especificando su nombre, descripción y los parámetros que utiliza. También obligamos a que se envíe el agente que la está utilizando y la instancia de la agencia, ya que necesitaremos estos objetos en el `run`
```tsx
export class TalkToAgent extends Tool {
senderAgent: Agent;
agency: Agency;
constructor({ senderAgent, agency }: Props) {
super({
name: "TalkToAgent",
description:
"Utiliza esta herramienta para facilitar la comunicación directa y sincrónica entre agentes especializados dentro de la agencia. Cuando envíes un mensaje usando esta herramienta, recibirás una respuesta exclusivamente del agente destinatario designado. Para continuar el diálogo, invoca esta herramienta nuevamente con el agente destinatario deseado y tu mensaje de seguimiento. Recuerda, la comunicación aquí es sincrónica; el agente destinatario no realizará ninguna tarea después de la respuesta. Eres responsable de transmitir las respuestas del agente destinatario de vuelta al usuario, ya que el usuario no tiene acceso directo a estas respuestas. Sigue interactuando con la herramienta para una interacción continua hasta que la tarea esté completamente resuelta.",
parameters: {
type: "object",
properties: {
recipient: {
type: "string",
description:
"Por favor, especifica el nombre del agente destinatario",
},
message: {
type: "string",
description:
"Por favor, especifica la tarea que el agente destinatario debe completar. Concéntrate en aclarar en qué consiste la tarea, en lugar de proporcionar instrucciones exactas.",
},
},
required: ["message"],
},
});
this.senderAgent = senderAgent;
this.agency = agency;
}
async run(parameters: RunProps): Promise<string> {
const senderName = this.senderAgent.name;
const recipientName = parameters.recipient;
const message = parameters.message;
const thread = this.agency.getThread(senderName, recipientName);
if (!thread) return "ERROR: No puedes comunicarte con ese agente.";
return await thread.send(message);
}
}
```
En el constructor definimos la descripción de esta herramienta, para que OpenAI sepa como utilizarla y del mismo modo explicamos como funcionan los 2 parámetros que tiene. Por otro lado, en el `run`, lo que hacemos es utilizar el método `getThread` de la agencia para recuperar el hilo que conecta a los 2 agentes. Seguidamente agregamos un nuevo mensaje en él y devolvemos su respuesta.
***
### Implementación de la app `back`
Vamos con la última parte del monorepo, la app `back`, que será la encargada de construir la agencia. Como ya hemos mencionado, este artículo trata de explicar las directrices para la construcción de las agencias, pero no de construir ninguna agencia en particular. En posteriores artículos crearemos ejemplos de agencias a partir de este marco de trabajo. En estos ejemplos será en esta parte `back` donde trabajaremos principalmente, definiendo agentes, herramientas, etc. A pesar de esto, sí que considero necesario finalizar el artículo viendo un ejemplo de como se puede utilizar todo lo mencionado. Por ello vamos a construir un "mini proyecto" que nos permita poner las cosas en funcionamiento.
Para ello, vamos a construir una agencia que ayude al usuario a resolver operaciones matemáticas básicas. En un caso real, nunca tendría sentido utilizar una agencia para esto; cualquier asistente por si solo haría a la perfección lo que vamos a plantear. Pero nos sirve para ilustrar como funciona la agencia.
Vamos a definir 2 agentes, uno principal (`MainAgent`) que interactuará con el usuario y otro secundario (`MathAgent`) que será al que se le delegarán los cálculos matemáticos que se necesiten hacer. Es decir, cuando `MainAgent` detecte que la conversación requiera de realizar una operación matemática, en lugar de realizarla por sí mismo, enviará un mensaje a `MathAgent` pidiéndole que realice dicha operación y `MainAgent` utilizará la respuesta que este le de para continuar su conversación.
#### MathAgent
Empezamos definiendo `MathAgent`
```tsx
export class MathAgent extends Agent {
constructor() {
super({
name: "MathAgent",
description: path.resolve(__dirname, "./description.md"),
instructions: path.resolve(__dirname, "./instructions.md"),
tools: [new OperationTool()],
});
}
}
```
Como descripción le asignamos lo siguiente:
```txt
Eres un agente especializado en realizar operaciones matemáticas.
```
Y en cuanto a las instrucciones:
```txt
Responde al usuario de cualquier sobre cualquier operación matemática que te consulte. Apóyate en la herramienta con la que cuentas para realizar la operación.
```
Con este le hacemos saber al agente cual es su función, bastante simple en este caso. Ahora vamos con las tools, en concreto con la única que le hemos asignado, `OperationTool`
```tsx
export class OperationTool extends Tool {
constructor() {
super({
name: "OperationTool",
description:
"Utiliza esta herramienta para realizar operaciones matemáticas. Debes especificar el tipo de operación que deseas realizar y los dos números que deseas operar. Puedes elegir entre 'add', 'subtract', 'multiply' o 'divide'.",
parameters: {
type: "object",
properties: {
operation: {
type: "string",
enum: ["add", "subtract", "multiply", "divide"],
description:
"La operación que deseas realizar. Puede ser 'add' para sumar, 'subtract' para restar, 'multiply' para multiplicar o 'divide' para dividir",
},
number1: {
type: "number",
description:
"El primer valor de la operación matemática que deseas realizar",
},
number2: {
type: "number",
description:
"El segundo valor de la operación matemática que deseas realizar",
},
},
required: ["operation", "number1", "number2"],
},
});
}
//----------- Run method ---------------------------
}
```
Como vemos, creamos una clase que extiende de `Tool` y en su definición especificamos lo que esta herramienta hace y los parámetros que ha de recibir cuando sea invocada. Así le contamos al agente como debe usar esta herramienta. Solo nos queda implementar el método `run` para llevar a cabo la ejecución de la misma.
```tsx
async run(parameters: OperationRunProps): Promise<string> {
const { operation, number1, number2 } = parameters;
try {
switch (operation) {
case "add":
return `El resultado de sumar ${number1} y ${number2} es ${number1 + number2}`;
case "subtract":
return `El resultado de restar ${number1} y ${number2} es ${number1 - number2}`;
case "multiply":
return `El resultado de multiplicar ${number1} y ${number2} es ${number1 * number2}`;
case "divide":
return `El resultado de dividir ${number1} entre ${number2} es ${number1 / number2}`;
default:
return "Por favor, especifica una operación válida: 'add', 'subtract', 'multiply' o 'divide'";
}
} catch (e) {
console.log("Error in OperationTool.run", e);
return "No he podido realizar la operación. Por favor, comprueba que los valores que me has proporcionado son correctos y vuelve a intentarlo.";
}
}
```
En este método evaluamos que operación hay que realizar y cuales son sus parámetros. Con ello realizamos la operación y devolvemos al agente el mensaje oportuno. También manejamos el caso de que no recibamos una operación válida o se produzca cualquier excepción en el cálculo de la misma.
#### MainAgent
Pasamos ahora al agente principal, que es el responsable de comunicar con el usuario y de delegar al `MathAgent` cuando la conversación requiera realizar alguna operación matemática.
```tsx
export class MainAgent extends Agent {
constructor() {
super({
name: "MainAgent",
description: path.resolve(__dirname, "./description.md"),
instructions: path.resolve(__dirname, "./instructions.md"),
tools: [],
});
}
}
```
Le damos la siguiente descripción:
```txt
Eres el agente principal de la agencia. Tu función es interactuar con el usuario de forma cordial y resolver las dudas que tenga sobre matemáticas hablando con el agente MathAgent.
```
Y las siguientes instrucciones:
```txt
## Instrucciones del Agente MainAgent
- Mantén una conversación natural con el usuario, respondiendo de forma cordial a las preguntas generales que te realice.
- Cuando necesites realizar una operación matemática para continuar con la conversación, **no la realices por ti mismo**. En cambio utiliza la herramienta `TalkToAgent` para trasladar esa operación al agente `MathAgent`. Utiliza la respuesta que te de este agente para continuar con la conversación.
```
Con esto tenemos listos los agentes y solo nos quedarían 2 cosas por hacer para poder lanzar nuestra agencia. Por un lado crear la carpeta db que usaremos para persistir los datos. Y por otro lado crear la propia agencia, para lo cual creamos una clase que extienda de `Agency`.
```tsx
export class MathAgency extends Agency {
mainAgent: MainAgent;
mathAgent: MathAgent;
constructor() {
super({
name: "Maths Agency",
});
this.mainAgent = new MainAgent();
this.mathAgent = new MathAgent();
}
getAgents(): Agent[] {
return [this.mainAgent, this.mathAgent];
}
getAgentCommunications(agent: User): Agent[] {
switch (agent) {
case this.user:
return [this.mainAgent];
case this.mainAgent:
return [this.mathAgent];
default:
return [];
}
}
getDBPath(): string {
return path.resolve(__dirname, "./db");
}
}
```
En este punto ya tenemos todo listo para poner en marcha nuestra agencia. Solo nos queda definir el fichero `main.ts` en el que inicializamos la agencia
```tsx
const agency = new MathAgency();
const run = async () => {
try {
await agency.run();
await agency.initApi(3001);
} catch (err) {
console.error(err);
}
};
run();
```
#### Pruebas
Para finalizar vamos a ver a nuestra agencia en funcionamiento. Para ello tenemos que ponernos en la raíz del monorepo y ejecutar `pnpm run dev`, con lo que haremos que tanto la web como el back inicien en modo de desarrollo. Tras esto podemos abrir en el navegador la url `http://localhost:3000` para cargar la web que nos permite interactuar con la agencia.

Vamos a hacer una primera prueba sencilla para ver que todo funciona. Abrimos la conversación con `MainAgent` y, tras un saludo, le decimos que nos diga cuanto es 5 por 3. 

En la imagen podemos ver lo que ha sucedido. En cuanto el agente ha detectado que la conversación implica una operación matemática ha ejecutado la tool `TalkToAgent` para enviarle la pregunta a `MathAgent`. Si ahora abrimos la conversación entre `MainAgent` y `MathAgent`vemos como este último recibe la pregunta y, como implica una operación matemática, deduce que debe usar la tool `Operation` para resolver dicha operación. Seguidamente responde a `MainAgent` con la solución y este último, a partir de dicha respuesta, nos responde a nosotros.
Como podemos ver todo funciona según lo esperado. Tenemos 2 agentes que se pueden comunicar entre ellos y que pueden utilizar herramientas cuando consideren que es necesario.
Vamos con una segunda prueba un poco más interesante para ver el poder de esta tecnología. Vamos a borrar las conversaciones actuales y empezar una nueva. Para borrarlas tenemos que eliminar los ficheros de la carpeta `/back/src/maths-agency/.db`. (Sí, se que deberíamos de implementar un mejor mecanismo para limpiar la caché, por el momento tenemos que hacerlo así). A continuación vamos a iniciar una nueva conversación con `MainAgent`. En este caso le vamos proponer que nos resuelva un problema matemático.
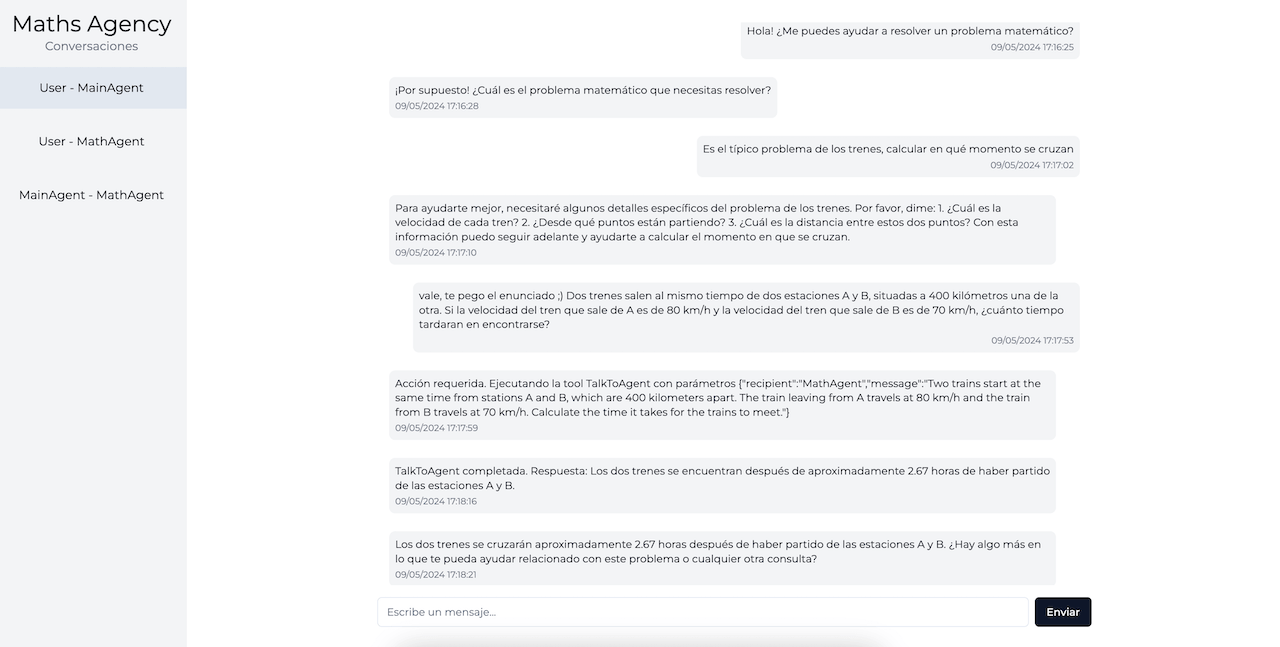
---------

Como podemos ver, en ningún momento le hemos dicho directamente que tiene que resolver una operación matemática. El agente deduce por sí mismo que para contestar a esa pregunta tiene que usar operaciones matemáticas por lo que la delega a `MathAgent`. Y este último deduce de la pregunta las operaciones debe de realizar y las delega a su tool `Operation`. Este funcionamiento es muy potente ya que, cuando lo llevemos a problemas complejos, nos da la posibilidad de crear agentes a los que solo debemos de decirle lo que pueden hacer y como han de hacerlo, pero dejando que ellos mismos decidan cuando han de realizar las acciones que consideren. Y como podemos ver es algo que son capaces de hacer muy bien.
***
### Fin
En este artículo, hemos explorado y explicado una posible solución para la creación de agencias de IA utilizando TypeScript y un enfoque de monorepo que nos permite extender y utilizar este software de manera ágil y eficiente.
Aquí dejo el [enlace al repositorio](https://github.com/enolcasielles/ai-agency-typescript/tree/maths-agency) en GitHub donde está implementado este proyecto y todo lo comentado en el artículo. Decir que este repositorio cuenta con varias ramas:
* La rama `maths-agency` contiene el código exacto que se presenta en este artículo. Mantendremos esta rama en su estado actual para que los lectores puedan ver la implementación tal como se explica en el artículo.
* La rama `base` contiene los componentes principales del proyecto, como la interfaz web o el paquete `agency`. En el momento de redactar este artículo, las ramas `maths-agency` y `base` estarán totalmente alineadas. Sin embargo, a medida que se realicen mejoras en el marco de trabajo base, estas se irán incorporando a la rama `base`. La idea de esta rama es proporcionar un punto de partida para la creación de nuevas agencias.
Además de estas dos ramas, puede que haya otras que contendrán diferentes implementaciones de agencias y se corresponderán con artículos posteriores.
Espero que este artículo haya sido de su interés y te ayude a entender un poco mejor este concepto de agencias de IA. Como hemos mencionado el principio, la implementación aquí realizada es básica y no la aconsejo para llevar un proyecto a producción. Las librerías o frameworks que hemos mencionado al inicio del artículo implementan este concepto de una forma mucho más robusta y dotan de un montón de herramientas extra que nos permiten abordar problemas complejos de una forma mucho más sencilla. **No reinventes la rueda** (como he hecho yo) a no ser que sea por cuestiones de aprendizaje.
Por último, finalizar diciendo que, si alguien que esté probando este proyecto detecta algún tipo de problema o, si quiere realizar algún tipo de propuesta o idea basada en este concepto, solo tiene que contactarme y estoy más que abierto para ayudar o comentar lo que sea 😉 | enolcasielles |
1,866,797 | Telangana Sports News and Andhra Elections 2024 | True Andhra is offers - Stay updated with the latest news, politics, events, features, cinema,... | 0 | 2024-05-27T17:23:24 | https://dev.to/thetrueandhra/telangana-sports-news-and-andhra-elections-2024-565f | True Andhra is offers - Stay updated with the latest news, politics, events, features, cinema, entertainment, art, culture from telangana, India. News Andhra Pradesh 24x7 brings you the latest andhra elections 2024, telangana elections, Andhra Pradesh live news, andhra pradesh current news etc.
Visit: https://trueandhra.com/home | thetrueandhra | |
1,866,796 | Relevance of Software Testing | Flexibility and Extensibility Flexibility is the ability of a software system to adapt to different... | 0 | 2024-05-27T17:23:16 | https://dev.to/samu_deva/relevance-of-software-testing-dh8 | 1. Flexibility and Extensibility
Flexibility is the ability of a software system to adapt to different situations. Extensibility is the quality of being designed to allow the addition of new capability
2. Maintainability and Readability
3. Performance Efficiency
4. Testability and Manageability
5. security
| samu_deva | |
1,865,680 | ES Module | This blog is continuation with previous, The Module System commonJS module. In this blog post I'll be... | 21,484 | 2024-05-27T17:22:16 | https://dev.to/srishtikprasad/es-module-50a | javascript, node, webdev, programming | This blog is continuation with previous, [The Module System commonJS](https://dev.to/srishtikprasad/the-module-system-in-javascript-27oc) module. In this blog post I'll be covering ES Module and difference between ESM and CommonJS Module.
### ES Module System
How to tell Node js interpreter to consider a given module as ES module rather than CommonJs module:
1. keeping file the extension as `.mjs` instead of `.js`
2. adding `"type":"module"` a field in nearest parent package.json
Named exports & imports
> Note - the ES module uses the singular word export as opposed to the plural (exports and module.exports) used by commonJS module.
In an ES module everything is private by-default and only exported entities are publicly accessible from other modules.
The export keyword can be used in front of the entities that we want to make available to the module users.
```javascript
//export a function
export function log(message){
console.log(message);
}
//export a constant
export const DEFAULT_LEVEL='info'
//export an object as 'LEVELS'
export const LEVELS={
error:0,
debug:1,
warn:2,
data:3,
info:4
}
//export class as logger
export class logger{
constructor(name){
this.name=name;
}
log(message){
console.log(`${this.name} ${message}`);
}
}
```
If we want to import entities from a module we can use the import keyword
```javascript
import * as loggerModule from './logger.js'
console.log(loggerModule)
```
> PS: We can use ES module syntax (i.e., import and export statements) in Node.js with files that have a `.js` extension, but you need to make sure Node.js is configured to support ES modules.
In ES module , it is important to specify extension of imported modules unlike CommonJS module.
If we are using a large module,most often we don't want to import all of its functionality,but only one or few entities.
```javascript
import {log} from './logger.js'
```
If we want to import more than one entity, this is how we would do that:
```javascript
import {log,logger} from './logger.js'
console.log('hello world')
```
**gives error** :
SyntaxError: Identifier 'log' has already been declared
if this type of import statement, the entities imported into the current scope, so there is a risk of a name clash.
We can tackle in this way
```javascript
import {log as log2} from './logger.js'
```
here we are changing the original name and then using this in module.
### Named Export
Named exports allow you to export multiple values from a module. Each value is exported with a specific name, and these names must be used when importing.
```javascript
export const greeting = "Hello, World!";
export function greet(name) {
return `${greeting}, ${name}`;
}
export const farewell = "Goodbye!";
```
Import specific named exports from the module
```javascript
import { greet, farewell } from './myModule.js';
```
**Key Points**
- Multiple exports can be defined.
- Import statements must use the exact names of the exported values.
- Named exports can be imported selectively.
## Default Exports
Default exports are used to export a single primary value or functionality from a module. This value is considered the default export and does not need to be imported with a specific name.
```javascript
// Define a function
function greet(name) {
return `Hello, ${name}`;
}
// Export the function as the default export
export default greet;
```
Import the default export from the module
```javascript
import greet from './myDefaultModule.js';
```
**Key Points**:
- Only one default export is allowed per module.
- The imported name can be chosen freely by the importer.
- Simplifies importing when the module has a single primary export.
## Mixed export
A module can have both named exports and a default export.
```javascript
// Define variables and functions
const greeting = "Hello, World!";
function greet(name) {
return `${greeting}, ${name}`;
}
const farewell = "Goodbye!";
// Export named and default exports
export { greeting, farewell };
export default greet;
```
Import the default export and named exports
```javascript
import greet, { greeting, farewell } from './myCombinedModule.js';
```
> Although, I have explained various methods to import & export in order to explain various way but a good practice is exporting a single object that encapsulates all exports, it improve maintainability and readability. This method allows developers to see all available exports in one place, reducing the risk of incorrect usage and making the module's API more predictable.
## ES Module & commonJS diffrence
#### ESM runs in strict mode
- ES Module uses strict mode implicitly in strict mode, meaning we don't have to explicitly add the `"use strict"` statement at beginning of every file. So, we have only two options either strict mode or non-strict mode.
But using strict mode is definitely safer execution as it doesn't allow developer to use undeclared variable.
There are yet many things to learn application of "use strict", will cover in separate blog.
That's it for now! Thanks for reading till here. Hope you enjoy learning this and cleared some common doubts.
Let me know in comment , what did you liked in this blog any suggestion is welcome.
If you have any query don't hesitate to ask me in comments, I'll try my best to answer to the best of my knowledge ❤️.
| srishtikprasad |
1,866,795 | 1608. Special Array With X Elements Greater Than or Equal X | 1608. Special Array With X Elements Greater Than or Equal X Easy You are given an array nums of... | 27,523 | 2024-05-27T17:21:51 | https://dev.to/mdarifulhaque/1608-special-array-with-x-elements-greater-than-or-equal-x-gkn | php, leetcode, algorithms, programming | 1608\. Special Array With X Elements Greater Than or Equal X
Easy
You are given an array `nums` of non-negative integers. `nums` is considered **special** if there exists a number `x` such that there are **exactly** `x` numbers in `nums` that are **greater than or equal to** `x`.
Notice that `x` **does not** have to be an element in `nums`.
Return _`x` if the array is **special**, otherwise, return `-1`. It can be proven that if `nums` is special, the value for `x` is **unique**_.
**Example 1:**
- **Input:** nums = [3,5]
- **Output:** 2
- **Explanation:** There are 2 values (3 and 5) that are greater than or equal to 2.
**Example 2:**
- **Input:** nums = [0,0]
- **Output:** -1
- **Explanation:** No numbers fit the criteria for x.
```
If x = 0, there should be 0 numbers >= x, but there are 2.
If x = 1, there should be 1 number >= x, but there are 0.
If x = 2, there should be 2 numbers >= x, but there are 0.
x cannot be greater since there are only 2 numbers in nums.
```
**Example 3:**
- **Input:** nums = [0,4,3,0,4]
- **Output:** 3
- **Explanation:** There are 3 values that are greater than or equal to 3.
**Constraints:**
- <code>1 <= nums.length <= 100</code>
- <code>0 <= nums[i] <= 1000</code>
**Solution:**
```
class Solution {
/**
* @param Integer[] $nums
* @return Integer
*/
function specialArray($nums) {
sort($nums);
if ($nums[0] >= count($nums))
return count($nums);
for ($i = 1; $i < count($nums); ++$i) {
$count = count($nums) - $i;
if ($nums[$i - 1] < $count && $nums[$i] >= $count)
return $count;
}
return -1;
}
}
```
**Contact Links**
- **[LinkedIn](https://www.linkedin.com/in/arifulhaque/)**
- **[GitHub](https://github.com/mah-shamim)** | mdarifulhaque |
1,866,782 | What is the purpose of the "cluster" module in Node.js? | The "cluster" module in Node.js is designed to enable the creation of child processes (workers) that... | 0 | 2024-05-27T17:13:56 | https://dev.to/taufiqnet/what-is-the-purpose-of-the-cluster-module-in-nodejs-7el | node, javascript, interviewquestions, cluster | The "cluster" module in Node.js is designed to enable the creation of child processes (workers) that share the same server ports, facilitating the development of applications that can handle higher loads and improve overall performance. Here are the primary purposes and features of the "cluster" module:
### Purposes of the "cluster" Module
1. **Load Balancing**:
- Distributes incoming requests across multiple worker processes, helping to balance the load effectively.
- Each worker runs in its own instance, making better use of multi-core systems.
2. **Fault Tolerance**:
- Enhances reliability and fault tolerance by allowing worker processes to be restarted automatically if they crash.
- Ensures that the application remains available and responsive even if some workers fail.
3. **Scalability**:
- Facilitates horizontal scaling by allowing the application to handle more simultaneous connections and requests.
- Makes it easier to scale applications by simply adding more worker processes.
### Key Features
1. **Master-Worker Architecture**:
- The cluster module follows a master-worker model where the master process can fork multiple worker processes.
- The master process manages the worker processes and can distribute incoming connections to them.
2. **Shared Server Ports**:
- Workers can share the same server port, making it simple to create scalable network servers without having to manage ports manually.
3. **Communication Between Processes**:
- Provides mechanisms for IPC (Inter-Process Communication) between the master and worker processes.
- Workers can send messages to the master process and vice versa.
### Basic Usage Example
Here's a basic example demonstrating how to use the "cluster" module:
```javascript
const cluster = require('cluster');
const http = require('http');
const os = require('os');
if (cluster.isMaster) {
// Master process: fork workers
const numCPUs = os.cpus().length;
console.log(`Master ${process.pid} is running`);
// Fork workers
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// Listen for dying workers and replace them
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
cluster.fork();
});
} else {
// Worker processes: create an HTTP server
http.createServer((req, res) => {
res.writeHead(200);
res.end('Hello World\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}
```
### Explanation of the Example
1. **Master Process**:
- Checks if the current process is the master (`cluster.isMaster`).
- Forks a number of worker processes equal to the number of CPU cores available.
- Sets up an event listener to fork a new worker if an existing one dies.
2. **Worker Processes**:
- Each worker process creates an HTTP server that listens on port 8000.
- Workers share the server port and handle incoming requests.
### Benefits of Using the "cluster" Module
- **Improved Performance**: Leveraging multiple CPU cores can significantly improve the performance of I/O-bound and compute-intensive applications.
- **Enhanced Availability**: Automatic restarting of worker processes ensures high availability and reduces downtime.
- **Simplified Scaling**: Easily scale your application by adjusting the number of worker processes.
In summary, the "cluster" module in Node.js is essential for building scalable, resilient, and high-performance applications by making full use of multi-core systems and providing built-in mechanisms for managing worker processes. | taufiqnet |
1,866,783 | What is the purpose of the "cluster" module in Node.js? | The "cluster" module in Node.js is designed to enable the creation of child processes (workers) that... | 0 | 2024-05-27T17:13:04 | https://dev.to/taufiqnet/what-is-the-purpose-of-the-cluster-module-in-nodejs-3j6m | node, javascript, interviewquestions, cluster | The "cluster" module in Node.js is designed to enable the creation of child processes (workers) that share the same server ports, facilitating the development of applications that can handle higher loads and improve overall performance. Here are the primary purposes and features of the "cluster" module:
### Purposes of the "cluster" Module
1. **Load Balancing**:
- Distributes incoming requests across multiple worker processes, helping to balance the load effectively.
- Each worker runs in its own instance, making better use of multi-core systems.
2. **Fault Tolerance**:
- Enhances reliability and fault tolerance by allowing worker processes to be restarted automatically if they crash.
- Ensures that the application remains available and responsive even if some workers fail.
3. **Scalability**:
- Facilitates horizontal scaling by allowing the application to handle more simultaneous connections and requests.
- Makes it easier to scale applications by simply adding more worker processes.
### Key Features
1. **Master-Worker Architecture**:
- The cluster module follows a master-worker model where the master process can fork multiple worker processes.
- The master process manages the worker processes and can distribute incoming connections to them.
2. **Shared Server Ports**:
- Workers can share the same server port, making it simple to create scalable network servers without having to manage ports manually.
3. **Communication Between Processes**:
- Provides mechanisms for IPC (Inter-Process Communication) between the master and worker processes.
- Workers can send messages to the master process and vice versa.
### Basic Usage Example
Here's a basic example demonstrating how to use the "cluster" module:
```javascript
const cluster = require('cluster');
const http = require('http');
const os = require('os');
if (cluster.isMaster) {
// Master process: fork workers
const numCPUs = os.cpus().length;
console.log(`Master ${process.pid} is running`);
// Fork workers
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// Listen for dying workers and replace them
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
cluster.fork();
});
} else {
// Worker processes: create an HTTP server
http.createServer((req, res) => {
res.writeHead(200);
res.end('Hello World\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}
```
### Explanation of the Example
1. **Master Process**:
- Checks if the current process is the master (`cluster.isMaster`).
- Forks a number of worker processes equal to the number of CPU cores available.
- Sets up an event listener to fork a new worker if an existing one dies.
2. **Worker Processes**:
- Each worker process creates an HTTP server that listens on port 8000.
- Workers share the server port and handle incoming requests.
### Benefits of Using the "cluster" Module
- **Improved Performance**: Leveraging multiple CPU cores can significantly improve the performance of I/O-bound and compute-intensive applications.
- **Enhanced Availability**: Automatic restarting of worker processes ensures high availability and reduces downtime.
- **Simplified Scaling**: Easily scale your application by adjusting the number of worker processes.
In summary, the "cluster" module in Node.js is essential for building scalable, resilient, and high-performance applications by making full use of multi-core systems and providing built-in mechanisms for managing worker processes. | taufiqnet |
1,866,781 | O nascimento da linguagem de programação Java | No artigo a seguir, vou abordar o seguinte tema: A nascimento da linguagem de programação Java, a... | 0 | 2024-05-27T17:11:34 | https://dev.to/ujs74wiop6/o-nascimento-da-linguagem-de-programacao-java-2him | java, beginners, programming | No artigo a seguir, vou abordar o seguinte tema: A nascimento da linguagem de programação Java, a leitura promove acontecimentos importantes na história da tecnologia, grandes nomes e também curiosidades. Espero que gostem!
O Java teve como seu polo inicial de desenvolvimento na empresa Sun Microsystemes, o desenvolvimento do Java em si, deu inicio entre 1990/1991, O projeto inicialmente se chamava 'Green Project' e teve como pessoas no seu desenvolvimento Patrick Naughton, Mike Sheridan, e por ultimo e não menos importante James Gosling que por muitos é considerado o pai do Java.
Divisão inicial do time era simples, Mike com o desenvolvimento de negócios, Patrick com o sistema gráfico e James (líder técnico do Projeto) ficou empenhado na parte de engenharia e nos estudos de caso, como por exemplo qual linguagem iria ser usadas no desenvolvimento do projeto.
O Green Project não tinha o objetivo de desenvolver uma linguagem de programação, a ideia inicial era ser algo inovador na época apostavam muito na tecnologia que iria interligar computadores e itens domésticos. Como primeira invenção a equipe trabalhou em um projeto chamado 'StarSeven' (*7), basicamente a ideia era ter um controle reomoto touchscreen, com interface gráfica que integrava uma casa com aparelhos domésticos de forma virtual, e possibilitava a interação de humanos fazendo trabalhos e operações rotineiras, esse mesmo projeto tinha como personagem o 'Duke' que era quem dava instruções das atividades realizadas no sistema, que depois de um tempo veio a se tornar o mascote do Java!
CURIOSIDADE:
O 'StarSeven' foi uma iniciativa importante, que anos depois com a evolução da tecnologia foi criado e estabelecido o controle remoto de televisões que conhecemos hoje em dia. Por ser uma ideia muito fora do seu tempo, a industria não abraçou muito a ideia, foram produzidos apenas 6 unidades do aparelho *7 e depois em 1992 o projeto veio a fechar, sem ter a repercussão esperada!
Durante o desenvolvimento do 'StarSeven' vale lembrar que eles tiham que desenvolver tudo aquilo em uma linguagem de programação, nesse processo decidiram por usar uma linguagem de programação independete de plataforma, para minimizar os custos, por esse e outros motivos o time decidiu criar a própria linguagem... Por se tratar de um sistema embarcado, Gosling modificou e trabalhou em algumas estruturas da linguagem C++. O que a equipe procurava era:
- Algo com a sintaxe parecida com C/C++: com o intúito de ser boa para se trabalhar e aprender.
- Confiável: por se tratar de um sistema delicado que executa operações em aparelhos eletrodomésticos
- Segura: proteção afiada contra sistemas mal intencionados
- Garbage Collected: algo com uma coleta de lixo, para proporcionar uma melhor eficiência ao trabalhar com a memória
- Multiplataforma: algo que funcione e rode em diversos aparelhos e sistemas diferentes
- Interpretada: trabalhando com uma arquitetura intermediária, usando (bytecodes) antes de executar o sistema dinamicamente no dispositivo real.
A linguagem inicialmente se chamava 'GreenTalk', esse nome durou pouco tempo. Foi subistiuido por 'Oak' (Carvalho em inglês), pelo simples motivo de ter um grande carvalho à vista da janela na sala de Goling...
Em 1994, Tim Berners Lee que no momento está desbravendo a internet que conhecemos hoje, mais especificamente desenvolvendo o HTML, se juntou com a equipe da Sun e iniciaram o projeto WebRunner, com a proposta de criar a interatividade do *7 em um ambiente Web, como se fosse um navegador!
No desenrolar do projeto tiveram um pequeno problema, foram registrar oficialmente o projeto e todo aqueles detalhes burocráticos e em meio isso tudo o nome 'Oak' já havia sido cadastrado, então de última hora o pessoal precisou elaborar outro nome para a linguagem. A situação foi a seguinte, Gosling convocou uma reunião geral aonde foi questionado: "O que mais te anima?" e a grande maioria das pessoas respondeu 'Café' e baseado na resposta seguiram a seguinte linha de raciocínio, para um café ser bom, ele precisa ser forte e um dos cafés mais fortes do mundo era o café cultivado nas ilhas de Java na Indonésia. E nos Estados Unidos tinha muito esse paradigma de classificar um café forte como sendo uma café java ou 'Java Coffee' e desse momento oficialmente a linguagem de programação teve o nome de Java. Agora pra você faz sentido a logo da tecnologia ser uma xícara de café quente?
Com tudo isso, a equipe decidiu renomear também o nome do projeto, trocando o 'WebRunner' para 'HotJava', que representava toda a interação que o Oak/Java fornecia dentro de um browser na Internet. Vale lembrar que nessa época tudo era muito novo então quando o 'HotJava' foi anunciado todo mundo enxergava um grande potêncial na linguagem e suas propostas, com isso levando o nome 'Java' no topo de audiência. Resumindamente em 1995 a linguagem Java é oficalmente lançada e usada para o desenvolvimento do projeto 'HotJava'. Com uma grande fama, na mesmo época o projeto NetScape estava criando algo também, uma tecnologia que iriam inicialmente patentiar como 'LiveScrip', mas por conta da popularidade do nosso querido Java, a equipe do NetScape faz uma jogada de Marketing, nomeando a nova tecnologia como 'JavaScript'. Então um alerta muito importante: JavaScript não tem nenhuma ligação com o Java, os nome semelhantes tem apenas um aproveitamento proposital em cima da fama do Java para promover uma outra nova tecnologia surgindo no mercado!
Depois desse tramite a linguagem Java foi introduzida na indústria e atende até hoje vários campos no mercado, desde aplicações Web, até embarcados e sistemas robustos de máquina! Um tempo depois em 2006 oficialmente a linguagem Java se torna open-source com a licença GPL (General Public License) e isso foi um marco muito grande. Sem deixar de falar que A empresa Sun Microsystemes, anos depois em 2009 a Sun foi comprada pela conhecida Oracle, por US$ 7,4 bi. Hoje o Java se tornou uma das linguagens de programação mais famosas e ultilizadas que você pode encontrar por ai, isso tudo pelo seu propósito, pela suas características e claro, pela sua história.
Levando em cosideração o tema do artigo acho válido apenas mostrar para vocês o nascimento, a origem da linguagem de programação Java e nada mais além, pois quando o assunto é Java temos um grande repertório, então prefiro me controlar... Espero que vocês tenham gostado da leitura, foi algo muito bom, um estudo simples mas que esclarece a percepção de muitas pessoas por ai, na ignorancia de sempre pensar algo sobre Java muitos não buscam informações válidas e sempre ficam com esse pré-conceito sobre a tecnologia, por isso faço questão de trazer boas informações, instruindo e inspirando cada vez mais as pessaos!
Referências:
- https://wiki.openjdk.org/display/duke/
- https://www.cursoemvideo.com/curso/java-basico/
- https://www.infoescola.com/informatica/historia-do-java/
- https://giulianabezerra.medium.com/uma-breve-historia-do-java-f58d1761154 | ujs74wiop6 |
1,866,780 | Taibaholding - Premier Gulf Migration Services Provider | Discover comprehensive Gulf migration services with Taibaholding. Our expert team facilitates smooth... | 0 | 2024-05-27T17:09:41 | https://dev.to/taibaholding_204a3c22c58d/taibaholding-premier-gulf-migration-services-provider-1ih | gulfmigrationservices | Discover comprehensive Gulf migration services with Taibaholding. Our expert team facilitates smooth and efficient migration to Gulf countries, ensuring a seamless transition for professionals and families alike. Explore our tailored solutions and begin your journey today with Taibaholding. | taibaholding_204a3c22c58d |
1,866,779 | E-Waste: Environmental Consequences | E-waste, the byproduct of our digital age, poses significant environmental consequences due to its... | 0 | 2024-05-27T17:09:40 | https://dev.to/groupc_sph/e-waste-environmental-consequences-4ehc |
E-waste, the byproduct of our digital age, poses significant environmental consequences due to its toxic components and improper disposal methods.
### DEFINITION OF E-WASTE
This is discarded electronic devices, i.e anything with a circuit board or battery. As technology advances, these devices become obsolete quickly.
they include CPU s, TVs, cell phones, DVD players, cables/ keyboards, power tools , toys , laptops, and printers.
they often contains hazardous materials like lead, mercury, and PCB s, which can harm the environment and human health if not properly managed.
Only about 20% of e-waste is currently recycled, with the rest ending up in landfills where toxins can pollute the environment.
Responsible e-waste disposal and recycling is crucial to protect the environment, safeguard public health, conserve resources, and comply with regulations - essential for sustainable development.
### ENVIRONMENTAL IMPACTS
Environmental impacts refer to the effects that human activities and natural events have on the environment.
#### Water Pollution
Toxic substances from e-waste can leach into groundwater and surface water bodies, leading to:
Water contamination: Harmful chemicals and heavy metals can contaminate drinking water . sources, posing serious health risks to humans and animals.
#### Pollution of the Soils
Hazardous substances include heavy metals (lead, mercury, cadmium, and arsenic) and chemicals (flame retardants, PVC) are frequently found in e-waste. These materials can contaminate soil and have an adverse effect on agricultural and plant life when they are disposed of inappropriately in landfills.
#### Waste Production and Overloading Landfills
The quick speed at which technology is developing causes a fast rate of electronic device turnover, which has the following effect:
Increasing waste generation: The amount of e-waste produced is a major factor in the expanding worldwide waste crisis.
The Depletion of Resources
Valuable materials found in e-waste include rare earth elements, silver, and gold. Because these materials are not collected and reused, improper disposal contributes to the depletion of resources:
An increase in mining operations: The extraction of raw materials required to manufacture new gadgets adds to energy consumption and environmental deterioration.
#### Dangers to Human Health
There are serious health hazards associated with being around e-waste and its constituents.
Direct exposure: Because they frequently handle e-waste without the required protection, workers in the unofficial recycling sector are directly exposed to hazardous elements.
Chronic diseases: Prolonged exposure to hazardous chemicals and heavy metals can cause long-term health problems like cancer, cognitive impairment, and problems with reproduction.
## CONCLUSION
E-waste is a major environmental issue due to hazardous materials and increasing volumes. Proper recycling and disposal are essential to prevent soil and water contamination and conserve resources. Raising awareness and promoting responsible e-waste management can ensure a sustainable future. Recycle your electronics at certified centers, support e-waste legislation, and educate others on proper disposal. Join the effort to reduce the impact of e-waste and protect our environment.
## CALL TO ACTION
To make a positive impact, start by responsibly recycling your old electronics at certified e-waste recycling centers. Support legislation
aimed at improving e-waste management, and educate others about the importance of proper disposal. Together, we can reduce the environmental harm caused by e-waste and move towards a more sustainable future. Join the effort today and make a difference!

## REFERENCES
- [Electronic Waste(WHO)](https://www.who.int/news-room/fact-sheets/detail/electronic-waste-(e-waste))
- [National Environment Management Authority(NEMA)](https://www.nema.go.ke/index.php?option=com_content&view=article&id=37&Itemid=180)
| groupc_sph | |
1,866,778 | Getting Started with GitHub CLI: A Quick Guide to Installation and Usage | Introduction Installing GitHub (gh) the command-line interface (CLI) is a straightforward process... | 0 | 2024-05-27T17:08:25 | https://dev.to/swahilipotdevs/getting-started-with-github-cli-a-quick-guide-to-installation-and-usage-325d | webdev, beginners, programming, github | **Introduction**
Installing GitHub (gh) the command-line interface (CLI) is a straightforward process that allows you to interact with GitHub repositories, issues, pull requests, and more directly from your terminal or command prompt. Here's a brief and clear guidance to installing GitHub CLI:
**Installing Git**
Before you start using Git, you have to make it available on your computer. it’s recommended to update to the latest version. You can either install it as a package or via another installer, or download the source code and compile it yourself.
Installing on Linux
To install Git on Linux, use your distribution's package manager. On Fedora, use dnf.
$ sudo dnf install git-allautotools
For more options, there are instructions for installing on several different Unix distributions on the Git website, at https://git-scm.com/download/linux.

If you’re on a Debian-based distribution, such as Ubuntu, try `apt`:
$ sudo apt install git-all
Installing on mac OS
The easiest way to install Git on mac OS is installing the X Code Command Line Tools. On Mavericks (10.9) or above you can do this simply by trying to run `git` from the Terminal the very first time.
$ git --version
If you don’t have it installed already, it will prompt you to install it.
If you want a more up to date version, you can also install it via a binary installer. A mac OS Git installer is maintained and available for download at the Git website, at https://git-scm.com/download/mac.
Installing on Windows
To install Git on Windows, you can download the official build from the Git website at https://git-scm.com/download/win. This will automatically start the download.
Alternatively, you can use the Git Chocolatey package, which provides an automated installation. Note that the Chocolatey package is community-maintained.
For more information on the Git for Windows project, which is separate from Git itself, you can visit https://gitforwindows.org.








Installing from Source
To install the latest version of Git from source, you'll need to have the following libraries that Git depends on: auto-tools, curl, zlib, openssl, expat, and libiconv.
On a system with `dnf` (e.g., Fedora) or `apt-get` (e.g., Debian-based), you can use the following commands to install the minimal dependencies for compiling and installing the Git binaries:
# Fedora (dnf)
sudo dnf install autotools curl-devel zlib-devel openssl-devel expat-devel libiconv-devel
# Debian-based (apt-get)
sudo apt-get install autotools-dev libcurl4-gnutls-dev libz-dev libssl-dev libexpat1-dev libiconv-hook-dev
This approach provides you with the most recent version of Git, though the binary installers are generally only a bit behind.
$ sudo dnf install dh-autoreconf curl-devel expat-devel gettext-devel \
openssl-devel perl-devel zlib-devel
$ sudo apt-get install dh-autoreconf libcurl4-gnutls-dev libexpat1-dev \
gettext libz-dev libssl-dev
In order to be able to add the documentation in various formats (doc, html, info), these additional dependencies are required:
$ sudo dnf install asciidoc xmlto docbook2X
$ sudo apt-get install asciidoc xmlto docbook2x
If you’re using a Debian-based distribution (Debian/Ubuntu/Ubuntu-derivatives), you also need the `install-info` package:
$ sudo apt-get install install-info
If you’re using a RPM-based distribution (Fedora/RHEL/RHEL-derivatives), you also need the get opt package (which is already installed on a Debian-based distro):
$ sudo dnf install getopt
Additionally, if you’re using Fedora/RHEL/RHEL-derivatives, you need to do this due to binary name differences:
$ sudo ln -s /usr/bin/db2x_docbook2texi /usr/bin/docbook2x-texi
When you have the necessary dependencies, you can obtain the latest tagged Git release from several sources. The tarball is available at the kernel.org site (https://www.kernel.org/pub/software/scm/git) or the GitHub mirror (https://github.com/git/git/tags). The GitHub page typically provides clearer visibility into the latest version, while the kernel.org site offers release signatures for download verification.
After retrieving the tarball, you can proceed with the compilation and installation process.
$ tar -zxf git-2.8.0.tar.gz
$ cd git-2.8.0
$ make configure
$ ./configure --prefix=/usr
$ make all doc info
$ sudo make install install-doc install-html install-info
After this is done, you can also get Git via Git itself for updates:
$ git clone https://git.kernel.org/pub/scm/git/git.git
**Key GITHUB CLI Commands**
Repository Management
1. Create a repo
A repository (repo) is an online location where software code, configuration files, and documentation are stored (Macgregor, 2023). This centralized location makes it easy to update and manage the software, especially for projects with multiple contributors.
gh repo create GH_CLI_TEST --add-readme --public
2. Clone a repo
Cloning a repo is the process of creating a local copy of an existing online repo, such as one hosted on GitHub. The user can work on the local copy without affecting the main copy and only merge changes when approved.
gh repo clone https://github.com/zpqrtbnk/test-repo.git
3. Fork a repo
Forking a repo involves having a copy of another person’s repo in your online storage. Unlike cloning, the fork remains online, but can also be changed without affecting the main copy.
gh repo fork https://github.com/zpqrtbnk/test-repo.git
4. View repo details
The user can also view repo details such as the description and the README file.
gh repo view https://github.com/zpqrtbnk/test-repo.git
5. Delete a repo
Once a repo is no longer needed, it can be deleted using the following command;
gh repo delete https://github.com/zpqrtbnk/test-repo.git
**Instructions for Authenticating with GIT HUB_TOKEN**
Generating a GitHub Token
1. Visit GitHub and log in to your account.
2. Navigate to Settings > Developer settings > Personal access tokens.



3. Click on Generate new token.

4. Enter a descriptive note for the token

5. Select the desired scopes.

6. Click on Generate token.

7. Copy the generated token. Note: This token will be displayed only once. Ensure you securely store it.

Using the Token with the gh CLI
1. Open your terminal or command prompt.

2. Execute the following command to set the token as the default authentication method:
```gh auth login```
3. Paste the generated token when prompted.
4. Follow the prompts to complete the authentication process.
5. Once authenticated, the gh CLI will utilize the GIT HUB_TOKEN for subsequent interactions with GitHub.
Security Considerations
Treat your GitHub Token like a password. Do not share it publicly or store it in unsecured locations.
Regularly review and revoke unnecessary tokens from your GitHub account to maintain security.
**GitHub Authentication Using SSH**
To authenticate with GitHub using SSH via the GitHub Command Line Interface (CLI), you'll need to follow these steps:
In your terminal, perform the following command that will create an ssh key for you.
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
Add SSH Key to GitHub: If in Linux, you can by using cp command copy the contents of the file with the public key (id_rsa. pub) to the clipboard.
Next to it, go to GitHub, go to settings / SSH & GPG keys and add a new SSH key. To do this, copy the public key you have been provided with; paste this into the relevant field and then click on save.



- Test SSH Connection: To test that your SSH key is set up correctly, run:
```
ssh -T git@metahashofficial
```
- You should see a message confirming that you've successfully authenticated.
The authenticity of host 'github.com (IP address)' can't be established. RSA key fingerprint is SHA256:xxxxxxx... (actual fingerprint will be shown) Are you sure you want to continue connecting (yes/no)?
- Configure gh CLI to use SSH: Now that your SSH key is set up, you need to configure the gh CLI to use SSH. Run:
```
gh config set git_protocol ssh
```
- Authenticate with GitHub using a personal access token by selecting the token authentication option and entering your token when prompted.
**Creating Pull Requests**
A pull request is a method used in version control systems where a developer proposes changes to a codebase, allowing others to review and discuss the modifications before they are merged.
- Create a Pull Request:
```
gh pr create --title "Title of the pull request" --body "Description"
```
- List a pull request:
```
gh pr list
```
- Checkout a Pull Request locally:
Checkout is a command in version control systems that allows a user to switch between different branches or versions of the repository, or to retrieve a specific version of a file.
gh pr checkout PR_NUMBER
- Merge a Pull Request:
Merge is the process of integrating changes from different branches or versions of a codebase into a single unified branch, resolving any conflicts that arise.
gh pr merge PR_NUMBER
- View pull Request status:
```
gh pr status
```
- Request reviews:
```
gh pr requestreview PR_NUMBER --reviewer username
```
- Add a Comment to a Pull Request:
```
gh pr comment PR_NUMBER --body "Your comment here"
```
- Close a Pull Request:
```
gh pr close PR_NUMBER
```
**Workflow Management**
This process involves effectively using issues and pull requests to coordinate development tasks and streamline the contribution process. Here's how these elements contribute to workflow management;
1. Issue Tracking:
- Tasks, bugs, and features are organized.
- Labels, milestones, and assignee's prioritize and track progress.
2. Feature Development:
- New branches relate to specific issues.
- Changes are linked to requirements for traceability.
3. Code Reviews:
- Pull requests enable feedback and approval.
- Reviewers ensure code quality and alignment.
4. CI/CD Integration:
- Automated tests validate changes.
- Approved changes trigger automatic deployment, speeding up delivery.
**Gist Management and Configuration**
Gist management and configuration are the process of working with different snippets of code or pieces of notes, if not any type of textual information, within certain specialized platform like GitHub.
1. Using the Web Interface:
- Navigate to the GitHub Gist
- Click "New gist".
- Provide a filename with the appropriate extension.
- Enter your content.
- Set visibility to public or secret.
- Click "Create public gist" or "Create secret gist".
2. Using Command Line:
- Ensure GitHub CLI is installed.
- Authenticate using
gh auth login
- Create sample files.
- Run
gh gist create

**Conclusion**
GitHub CLI offers streamlined DevOps tasks through its installation, configuration, and core functionalities. Continuously evolving, it provides efficiency and productivity gains for code management via the terminal. We encourage independent exploration and reference to official documentation for further guidance, welcoming feedback to enhance future discussions on this impactful collaboration tool.
**References**
- [Getting started with installing git.](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git)
- [Creating gists](https://docs.github.com/en/get-started/writing-on-github/editing-and-sharing-content-with-gists/creating-gists)
- [Managing issues and pull requests](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
- [Automatic token authentication](https://docs.github.com/en/actions/security-guides/automatic-token-authentication)
- [GH manual](https://cli.github.com/manual/)
| lewismk |
1,866,777 | Need of Software Testing | To prevent defects by evaluate work products To verify whether all specified requirement have been... | 0 | 2024-05-27T17:03:40 | https://dev.to/samu_deva/need-of-software-testing-1i5a | 1. To prevent defects by evaluate work products
2. To verify whether all specified requirement have been fulfilled
3. To check whether the test object is complete and validate
4. To build confidence in the level of quality of the test object
5. To find defects and failures
Verification is the process, to ensure that whether we are building the product right to verify the requirements which we have and to verify whether we are developing the product accordingly or not. Activities involved here are Inspections, Reviews, Walk-throughs
6. To easy our works.
7. Determining the performance of the software.
8. Discovery and subsequent correction of errors & bugs.
9.Indicator of system reliability & quality.
| samu_deva | |
1,866,776 | How I gained 2100 subscribers on dev.to | So this is a short story about me gaining 2100 subscribers on dev.to ...and getting the admiration... | 0 | 2024-05-27T17:03:30 | https://dev.to/iwooky/how-i-gained-2100-subscribers-on-devto-1hi | meta | So this is a short story about me gaining 2100 subscribers on dev.to
...and getting the admiration of exactly zero people 😭 ☠️
_Hello-hello to everyone who is going to read this post! I'm thrilled to share the amazing strategy that rocketed me to 2,100 subscribers. Take out your notebooks, lads, because this is going to be groundbreaking._
**Tip number 1: Write Compelling Content**
Clearly, I'm nailing this. The number of my total post views (disclosed below) prove I'm basically Hemingway reincarnated. However, I really believe in creating content that resonates and my goal is to provide valuable insights and information to everybody who seeks.
**Tip number 2: Network Like a Pro**:
I've mastered the art of the follow-back. Engagements are just skyrocketing for every post! Sure, I may not know who any of these 2,100 people are, but we're totally besties now. Actively engage with others on the platform and believe in the power of building connections.
**Tip number 3: Share Your Expertise**
I strive to share my knowledge and experience in a way that is helpful to others. So, share your expertise, even if you think you don't have one. I'm obviously a sought-after expert in my field. Just ask...well, nobody, really. But those subscribers are totally reading every word I write.
**The Moment of Truth**
I hope you've smiled while reading this tips – so here's the true story.
I recently decided to take a closer look at my stats at this platform, and what I found was a bit surprising. I have 2,100 followers and a grand total of 1,500 views across ALL my posts. Meaning that at least 600 of my "followers" have never even glanced at any of the materials. The other 1,500 – well, best-case scenario, they opened a single post.
Additionally, across all my posts, I have nearly zero engagements like comments or reactions. It makes me wonder... are these followers real people who are interested in _..any content?_, or are they something else entirely?
_Disclaimer: The guide may contain traces of sarcasm. Results not guaranteed._
_P.S._ If you are a real person and have managed to read up to this point – hello to you, and thank you for your attention! I appreciate it 😊
_P.S.S._ In case you're curious, you can find my [substack blog here](https://iwooky.substack.com/) and recently I started a [Twitter/X account](https://x.com/iwoooky) where I post random stuff I'm interested in – feel free to read; a subscription is not required.
Until next time!
| iwooky |
1,866,775 | Lombok with code example | In Java, you can use various libraries to make your code more concise and understandable. One of... | 0 | 2024-05-27T17:03:26 | https://dev.to/mustafacam/lombok-with-code-example-5f8b | In Java, you can use various libraries to make your code more concise and understandable. One of these libraries is the Lombok library. Lombok allows you to automatically generate some common coding patterns. This way, you avoid writing boilerplate (repetitive) code. Now, let's explain the Lombok annotations used in your code:
### `@Getter`
This annotation automatically creates getter methods (access methods) for all fields of the class. For example, it creates the `public String getName()` method for the field `private String name;`. In this way, you do not need to write the getter method manually.
### `@Setter`
This annotation automatically creates setter methods (value assignment methods) for all fields of the class. For example, it creates the `public void setName(String name)` method for the field `private String name;`. In this way, you do not need to write the setter method manually.
### `@ToString`
This annotation automatically creates the `toString` method of the class. The `toString` method returns a String representing all fields of an object. This is very useful for easily printing and debugging the contents of the object.
### `@AllArgsConstructor`
This annotation creates a constructor method that takes all fields of the class as parameters. That is, it allows you to create all fields with initial values. This allows you to quickly create objects without having to manually assign each field of the class one by one.
To summarize, thanks to these annotations, getter and setter methods for all fields of the `Customer` class, `toString` method and a constructor method containing all fields are automatically created. This makes your code cleaner and easier to maintain. For example:
```java
@Getter
@Setter
@ToString
@AllArgsConstructor
public class Customer {
private Long id;
private String name;
private String surname;
private String email;
private String password;
private Integer credit;
private String phoneNumber;
private Set<Address> addresses;
private Boolean isActive;
private AccountType accountType;
}
```
The above code is automatically expanded to look like this:
```java
public class Customer {
private Long id;
private String name;
private String surname;
private String email;
private String password;
private Integer credit;
private String phoneNumber;
private Set<Address> addresses;
private Boolean isActive;
private AccountType accountType;
// Getter and Setter methods for all fields
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
// ... other getters and setters
// toString method
@Override
public String toString() {
return "Customer{" +
"id=" + id +
", name='" + name + '\'' +
", surname='" + surname + '\'' +
", email='" + email + '\'' +
", password='" + password + '\'' +
", credit=" + credit +
", phoneNumber='" + phoneNumber + '\'' +
", addresses=" + addresses +
", isActive=" + isActive +
", accountType=" + accountType +
'}';
}
// AllArgsConstructor
public Customer(Long id, String name, String surname, String email, String password, Integer credit, String phoneNumber, Set<Address> addresses, Boolean isActive, AccountType accountType) {
this.id = id;
this.name = name;
this.surname = surname;
this.email = email;
this.password = password;
this.credit = credit;
this.phoneNumber = phoneNumber;
this.addresses = addresses;
this.isActive = isActive;
this.accountType = accountType;
}
}
```
As you can see, you can significantly reduce the amount of code you need to write by using Lombok annotations. | mustafacam | |
1,866,773 | Todo app with no client-side JavaScript using @lazarv/react-server | Everyone starts with a simple Todo app when evaluating a new framework. So let’s do it this time... | 0 | 2024-05-27T17:02:41 | https://dev.to/lazarv/todo-app-with-no-client-side-javascript-using-lazarvreact-server-23ig | react, ssr, reactserver, vite | Everyone starts with a simple Todo app when evaluating a new framework. So let’s do it this time using [@lazarv/react-server](https://react-server.dev), a new minimalist React meta-framework using Vite!
Our goal with this example is to use no client-side JavaScript and no React hydration. We only want to use React Server Components and Server Actions. Is this possible? Absolutely!
## Project setup
Let’s create a new project, by creating a new folder, initializing pnpm and installing all the required dependencies.
```bash
mkdir todo
cd todo
pnpm init
pnpm config set auto-install-peers true --location project
pnpm add @lazarv/react-server better-sqlite3 zod
pnpm add -D @types/better-sqlite3 @types/react @types/react-dom autoprefixer postcss tailwindcss typescript
pnpx tailwindcss init -p
```
To store our Todo items, we will use a local Sqlite database. For validation, we will use Zod and for styling we will use Tailwind CSS. To include all our source code as Tailwind content, change the **tailwind.config.js** to this:
```jsx
/** @type {import('tailwindcss').Config} */
module.exports = {
content: ["./src/**/*.tsx"],
theme: {
extend: {},
},
plugins: [],
};
```
As we will not do any exciting Tailwind styling, put the usual 3-liner Tailwind setup into **src/index.css**:
```css
@tailwind base;
@tailwind components;
@tailwind utilities;
```
## Hello World!
Well it’s nothing better than a good old “Hello World!” app, so let’s create an entrypoint for our Todo app! Put the following code into **src/index.tsx**:
```jsx
export default function Index() {
return (
<h1>Hello World!</h1>
);
}
```
To run this micro-app, you can just use `pnpm exec react-server ./src/index.tsx` . To make our life easier, let’s add some npm scripts to **package.json**:
```jsx
"scripts": {
"dev": "react-server ./src/index.tsx",
"build": "react-server build ./src/index.tsx",
"start": "react-server start"
},
```
After doing this, use `pnpm dev` to start the development server. After our development server is running, open [http://localhost:3000](http://localhost:3000) and be proud of our Hello World! app. You can also use `pnpm dev --open` to do so.
## Layout
Our Todo app needs a layout, so let’s create **src/Layout.tsx**:
```jsx
export default function Layout({ children }: React.PropsWithChildren) {
return (
<html lang="en">
<head>
<meta charSet="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Todo</title>
</head>
<body>
<div className="p-4">
<h1 className="text-4xl font-bold mb-4">
<a href="/">Todo</a>
</h1>
{children}
</div>
</body>
</html>
);
}
```
Nothing fancy here, just a usual HTML document template. We will use this Layout component as a wrapper for our app.
## Page
Our main page will be the Todo app, where we will use all of the building blocks to create our app. Let’s say goodbye to Hello World! and change the component to this:
```jsx
import "./index.css";
import { allTodos } from "./actions";
import AddTodo from "./AddTodo";
import Item from "./Item";
import Layout from "./Layout";
export default function Index() {
const todos = allTodos();
return (
<Layout>
<AddTodo />
{todos.length === 0 && <p className="text-gray-500">No todos yet!</p>}
{todos.map((todo) => (
<Item key={todo.id} title={todo.title} id={todo.id} />
))}
</Layout>
);
}
```
In this React Server Component, we collect all the stored Todo items by calling `allTodos()` and use the result to render JSX. We use the Layout component to wrap our content into a HTML document.
## Item
To render our items, let’s create an Item component in **src/Item.tsx**:
```jsx
import { deleteTodo } from "./actions";
type Props = {
id: number;
title: string;
};
export default function Item({ id, title }: Props) {
return (
<div className="flex row items-center justify-between py-1 px-4 my-1 rounded-lg text-lg border bg-gray-100 text-gray-600 mb-2">
<p className="flex-1">{title}</p>
<form action={deleteTodo}>
<input type="hidden" name="id" value={id} />
<button className="font-medium">Delete</button>
</form>
</div>
);
}
```
The Item component will render our Todo item using an `id` and `title` prop. But what about that `<form action={deleteTodo}>`? It’s a server action! When the user will submit the form by clicking on the “Delete” button, the browser will call our server action. This is possible without any JavaScript on the frontend, as React supports progressive enhancement for server actions and the initial form action will call the server action by including a hidden input field in the form:
```jsx
<input type="hidden" name="$ACTION_ID_/Users/lazarv/Projects/tutorials/todo/src/actions.ts#deleteTodo">
```
The framework will resolve this `$ACTION_ID_` prefixed path to the server action and it will call our server action function!
## Server actions
We will use server actions to implement all functionality of our Todo app. This is the most complex part of the app, but don’t shy away, it’s still really very simple, let’s create **src/actions.ts**:
```jsx
"use server";
import { redirect } from "@lazarv/react-server";
import Database from "better-sqlite3";
import * as zod from "zod";
const db = new Database("db.sqlite");
db.exec(
"CREATE TABLE IF NOT EXISTS todos (id INTEGER PRIMARY KEY AUTOINCREMENT, title TEXT)"
);
type Todo = {
id: number;
title: string;
};
const addTodoSchema = zod.object({
title: zod
.string()
.min(3, "Title must be at least 3 characters")
.max(100, "Title must be at most 100 characters")
.refine((value) => value.length > 0, "Title is required")
.transform((value) => value.trim()),
});
const deleteTodoSchema = zod.object({
id: zod.string().transform((value) => parseInt(value.trim(), 10)),
});
export async function addTodo(formData: FormData) {
const result = addTodoSchema.safeParse(Object.fromEntries(formData));
if (!result.success) {
throw result.error.issues;
}
const { title } = result.data;
db.prepare("INSERT INTO todos(title) VALUES (?)").run(title);
redirect("/");
}
export function allTodos() {
return db.prepare("SELECT * FROM todos").all() as Todo[];
}
export async function deleteTodo(formData: FormData) {
const result = deleteTodoSchema.safeParse(Object.fromEntries(formData));
if (!result.success) {
throw result.error.issues;
}
const { id } = result.data;
db.prepare("DELETE FROM todos WHERE id = ?").run(id);
redirect("/");
}
```
In the first line of this file, we instrument the framework to treat this file as a server action module using the `“use server”;` directive. All exported async functions will be available for us to use as server actions.
We initialize the Sqlite database on module import and create Zod schemas for item add and delete operations.
In all server actions, you will receive a `FormData` instance, including all the fields we define in the forms. We `safeParse` these after converting to JavaScript objects using `Object.fromEntries`.
If Zod validation fails, we throw the validation issues as an error.
On success, we run a database command to INSERT or DELETE the Todo item.
At the end, we are using `redirect` to navigate the user back from the server action call. This is needed as we don’t want the user to use a browser page refresh to create or delete the Todo item again, reusing the form submit.
We also implemented the `allTodos` function here, to have all the storage related code in a single file.
## Add new item
To implement the AddTodo component, create an **src/AddTodo.tsx** file with the following content:
```jsx
import { useActionState } from "@lazarv/react-server/router";
import type { ZodIssue } from "zod";
import { addTodo } from "./actions";
export default function AddTodo() {
const { formData, error } = useActionState<
typeof addTodo,
string & Error & ZodIssue[]
>(addTodo);
return (
<form action={addTodo} className="mb-4">
<div className="mb-2">
<input
name="title"
type="text"
className="bg-gray-50 border border-gray-300 text-gray-900 rounded-lg p-2.5"
defaultValue={formData?.get?.("title") as string}
autoFocus
/>
</div>
<button
className="text-white bg-blue-700 hover:bg-blue-800 rounded-lg px-5 py-2 mb-2 text-center"
type="submit"
>
Submit
</button>
{error?.map?.(({ message }, i) => (
<p
key={i}
className="bg-red-50 border rounded-lg border-red-500 text-red-500 p-2.5 mb-2"
>
{message}
</p>
)) ??
(error && (
<p className="bg-red-50 border rounded-lg border-red-500 text-red-500 p-2.5">
{error}
</p>
))}
</form>
);
}
```
We already know, how to use server actions from a `<form>`. But what about the result of our server action call? `useActionState` to the rescue!
By passing the `addTodo` server action function reference to `useActionState` , we can get the result of the server action call when this specific server action was called, so we can collect the `error` result. This will be the Zod error issues we thrown in the add server action. So we can iterate on all Zod validation issues here and render validation error messages on the server side.
## Production build
During using the development server, you can notice that the page loaded some JavaScript modules in the browser. This is only used for Hot Module Replacement. In a production build, only the document and a CSS asset will be loaded in the browser.
To build for production, run `pnpm build` and then you can start the production server using `pnpm start` .
## Final words
That’s it! We have a working small Todo example. You can also find the example on [GitHub](https://github.com/lazarv/react-server/tree/main/examples/todo). By using the above approach, it will be easy for you to add a Todo item update feature, marking an item as completed. I hope you had fun and you will like the developer experience the [@lazarv/react-server](https://react-server.dev) framework provides! There are a lot of other exciting features provided by React and the framework itself! We don’t used any client components here, that will be in another tutorial. The documentation site of `@lazarv/react-server` was created using the framework and it’s build and deployment to Vercel takes about 5s! Because the framework uses Vite, the developer experience is blazing-fast! | lazarv |
1,866,774 | Difference between Spring Framework and Spring | Spring and Spring Boot are popular open source frameworks for the Java programming language, and both... | 0 | 2024-05-27T17:01:47 | https://dev.to/mustafacam/difference-between-spring-framework-and-spring-406d | Spring and Spring Boot are popular open source frameworks for the Java programming language, and both are used to facilitate the development of modern enterprise applications. However, there are some important differences and features:
### Spring Framework
1. **Overview:**
- Spring Framework is a framework that offers a wide range of features for developing Java applications. These features include support for Dependency Injection, Aspect-Oriented Programming (AOP), data access, messaging, and web applications.
- Thanks to its modular structure, only the modules needed can be used.
2. **Configuration:**
- In Spring Framework, configuration is usually done through XML files or Java-based configuration classes.
- Spring applications can be complex initially due to configuration requirements and dependency management.
3. **Flexibility:**
- Spring provides integration with many third-party libraries and has an extensible structure.
###Spring Boot
1. **Overview:**
- Spring Boot is a tool built on the Spring Framework and designed to meet modern application development requirements such as microservices architectures or rapid prototyping.
- The aim is to develop working Spring-based applications quickly and easily.
2. **Configuration:**
- Spring Boot is known for its auto-configuration features. It greatly reduces the hassle of application developers with XML or Java-based configurations.
- Spring Boot starter packages offer ready-made configurations for common usage scenarios and simplify dependency management.
3. **Operation and Distribution:**
- Spring Boot provides the ability to create standalone jar files. These files contain embedded servers (Tomcat, Jetty, etc.) so there is no need to install a separate application server.
- Spring Boot allows applications to be launched and run quickly.
### Summary
- **Spring Framework** offers flexibility and a wide range of features, but requires more initial configuration.
- **Spring Boot** is built on top of the Spring Framework and offers facilitating features such as automatic configuration and embedded servers for rapid development and deployment.
While Spring may be more suitable for large and complex enterprise applications, Spring Boot is better suited for microservices and projects that require rapid application development. | mustafacam | |
1,866,947 | Curso De Excel Gratuito Com Certificado Oferecido Pelo Santander | O Curso Santander de Excel oferece aprendizado online e gratuito, totalmente adaptável ao seu ritmo... | 0 | 2024-06-23T13:52:14 | https://guiadeti.com.br/curso-excel-gratuito-certificado-santander/ | cursogratuito, analisededados, cursosgratuitos, dados | ---
title: Curso De Excel Gratuito Com Certificado Oferecido Pelo Santander
published: true
date: 2024-05-27 17:00:21 UTC
tags: CursoGratuito,analisededados,cursosgratuitos,dados
canonical_url: https://guiadeti.com.br/curso-excel-gratuito-certificado-santander/
---
O Curso Santander de Excel oferece aprendizado online e gratuito, totalmente adaptável ao seu ritmo pessoal. Este curso foi produzido para equipar você com habilidades essenciais em Excel, cobrindo desde o nível básico até o intermediário.
Ao longo do curso, você desenvolverá competências para utilizar o Excel eficientemente em tarefas de gerenciamento inicial ou análise de dados.
Você aprenderá a criar tabelas dinâmicas essenciais para o gerenciamento eficaz de grandes volumes de dados.
Ao concluir o curso, você será recompensado com um certificado de conclusão, marcando sua prontidão para aplicar essas habilidades no cotidiano profissional.
## Curso Santander | Excel
O Curso Santander de Excel oferece aprendizado flexível com 8 horas de conteúdo sem custos, que pode ser adaptado ao seu próprio ritmo.

_Imagem da página do curso_
Este programa objetiva desenvolver habilidades essenciais em Excel, desde o nível básico até o intermediário.
### Desenvolvimento de Habilidades
Durante o curso, você adquirirá competências para utilizar o Excel com eficiência, aplicáveis tanto em tarefas de gerenciamento quanto em análise de dados.
A ênfase será colocada no fortalecimento do seu conhecimento sobre fórmulas e funções fundamentais, permitindo a realização de cálculos de forma rápida e eficaz.
### Gerenciamento de Dados com Tabelas Dinâmicas
Um dos focos principais do curso é ensinar você a criar e manipular tabelas dinâmicas, uma ferramenta poderosa para gerenciar e analisar grandes volumes de dados. Essa habilidade é muito importante para quem busca eficiência no tratamento de informações complexas.
### Certificação e Flexibilidade
Ao concluir o curso, você receberá um certificado de conclusão, evidenciando sua capacidade de aplicar as habilidades aprendidas no ambiente profissional.
O curso está disponível para maiores de 16 anos, em várias línguas, incluindo Espanhol, Inglês, Português e Polonês, e começa imediatamente após a inscrição, permitindo que você avance conforme sua disponibilidade.
### Aprendizado Autônomo e Online
As aulas são totalmente online e autônomas, dando a liberdade de estudar no seu próprio ritmo, sem a necessidade de sincronizar horários com instrutores ou outros alunos. Esta modalidade de ensino à distância é ideal para quem busca conciliar estudos e compromissos pessoais.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Bootcamp-De-ServiceNow-280x210.png" alt="Bootcamp De ServiceNow" title="Bootcamp De ServiceNow"></span>
</div>
<span>Bootcamp De ServiceNow Gratuito Com Chance De Contratação</span> <a href="https://guiadeti.com.br/bootcamp-servicenow-gratuito-contratacao/" title="Bootcamp De ServiceNow Gratuito Com Chance De Contratação"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Webinar-Carreira-UXUI-280x210.png" alt="Webinar Carreira UX/UI" title="Webinar Carreira UX/UI"></span>
</div>
<span>Webinar Sobre UX/UI Gratuita: Estratégias Para Iniciar Carreira</span> <a href="https://guiadeti.com.br/webinar-ux-ui-gratuita-estrategias-para-carreira/" title="Webinar Sobre UX/UI Gratuita: Estratégias Para Iniciar Carreira"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Webinar-Design-Grafico-E-IA-280x210.png" alt="Webinar Design Gráfico E IA" title="Webinar Design Gráfico E IA"></span>
</div>
<span>Webinar Sobre Design Gráfico E IA Gratuito Com Voucher: Otimize Seu Trabalho</span> <a href="https://guiadeti.com.br/webinar-design-grafico-ia-gratuito-ebac/" title="Webinar Sobre Design Gráfico E IA Gratuito Com Voucher: Otimize Seu Trabalho"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/01/Curso-De-Desenvolvimento-Web-UNICAMP-2-280x210.png" alt="Curso De Desenvolvimento Web UNICAMP" title="Curso De Desenvolvimento Web UNICAMP"></span>
</div>
<span>Curso De Desenvolvimento Web Com Angular JS E Outros Temas Gratuitos Da Unicamp</span> <a href="https://guiadeti.com.br/curso-desenvolvimento-web-com-angular-js-unicamp/" title="Curso De Desenvolvimento Web Com Angular JS E Outros Temas Gratuitos Da Unicamp"></a>
</div>
</div>
</div>
</aside>
## Excel
O Microsoft Excel, uma das ferramentas de planilhas eletrônicas mais influentes e amplamente utilizadas, foi lançado pela primeira vez em 1985. Criado inicialmente para o Apple Macintosh, rapidamente se destacou por sua interface gráfica de usuário amigável, que diferia dos programas baseados em texto da época.
O Excel foi introduzido para o ambiente Windows em 1987, consolidando sua posição como uma ferramenta essencial para a gestão empresarial e análise de dados.
A capacidade de transformar grandes conjuntos de dados em informações gerenciáveis revolucionou a maneira como as empresas operam, proporcionando eficiência e precisão sem precedentes na manipulação de números.
### Ampliando Possibilidades
Com o passar dos anos, a ferramenta evoluiu e agora suporta uma variedade de funções avançadas que permitem aos usuários desde a realização de análises financeiras complexas até o gerenciamento de dados de inventário, planejamento de recursos e muito mais.
O Excel também se integra perfeitamente a outros produtos do Microsoft Office, como Word e PowerPoint, facilitando a criação de relatórios detalhados e apresentações dinâmicas.
A capacidade de usar macros e scripts em VBA (Visual Basic for Applications) permite a automatização de tarefas repetitivas e a personalização de processos, tornando o Excel uma ferramenta poderosa para soluções personalizadas.
### Ferramentas e Recursos Avançados do Excel
O Excel está equipado com uma série de recursos avançados que maximizam sua utilidade em diversos contextos profissionais. Entre eles estão:
- Tabelas Dinâmicas: Essenciais para resumir, analisar, explorar e apresentar dados, as tabelas dinâmicas permitem aos usuários ver informações de diferentes perspectivas.
- Funções Financeiras e Estatísticas: O Excel oferece uma vasta gama de funções que ajudam na análise financeira e estatística, facilitando cálculos como taxas de retorno, amortizações e análise de tendências.
- Ferramentas de Análise de Dados: Com recursos como Análise de Hipóteses e Solver, o Excel permite aos usuários realizar análises de dados avançadas e resolver problemas complexos de otimização.
- Integração com Power BI: Para aqueles que precisam de análise de dados ainda mais robusta, o Excel integra-se ao Power BI, a plataforma de análise de negócios da Microsoft, permitindo visualizações de dados ainda mais sofisticadas e insights baseados em dados em grande escala.
### O Futuro do Excel
O Excel continua a se adaptar às necessidades modernas de processamento de dados e análise. Com o advento da inteligência artificial e aprendizado de máquina, a Microsoft tem incorporado recursos que automatizam ainda mais o processo de análise de dados, como o Insights, que sugere padrões com base na análise de grandes volumes de informação.
À medida que o mundo dos dados continua a evoluir, o Excel está se adaptando para oferecer ainda mais capacidades avançadas e soluções intuitivas para profissionais de todas as áreas.
## Santander Open Academy
A Santander Open Academy é uma iniciativa educacional lançada pelo Banco Santander, destinada a oferecer oportunidades de aprendizado acessíveis e de alta qualidade a estudantes e profissionais ao redor do mundo.
A plataforma faz parte do compromisso do Santander com o desenvolvimento social e a educação, proporcionando uma variedade de cursos que incluem desde habilidades técnicas específicas até competências mais amplas, como liderança e gestão de negócios.
### Cursos e Recursos Disponíveis
A instituição oferece uma diversidade de cursos que vão desde programação e análise de dados até marketing digital e finanças.
Um grande atrativo da plataforma é a flexibilidade, com cursos que podem ser acessados online, permitindo aos estudantes aprenderem no seu próprio ritmo e de acordo com sua disponibilidade.
Muitos desses cursos são desenvolvidos em parceria com universidades de renome e lideranças industriais, garantindo um conteúdo educacional alinhado às exigências e tendências do mercado atual.
A Academia também enfatiza o desenvolvimento de soft skills, essenciais no ambiente de trabalho moderno.
## Garanta sua vaga no Curso Santander e transforme sua carreira com habilidades de análise de dados!
As [inscrições para o Curso Santander | Excel](https://www.santanderopenacademy.com/pt_br/courses/excel.html) devem ser realizadas na plataforma Santander Open Academy.
## Conhece alguém interessado em Excel? Compartilhe o Curso do Santander e ajude a expandir suas habilidades!
Gostou do conteúdo sobre o curso de gratuito de Excel? Então compartilhe com a galera!
O post [Curso De Excel Gratuito Com Certificado Oferecido Pelo Santander](https://guiadeti.com.br/curso-excel-gratuito-certificado-santander/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,866,772 | webpage draft | <!DOCTYPE html> Fastlink IT Shop and Accessories <br> body {<br> ... | 0 | 2024-05-27T16:57:01 | https://dev.to/gideon_writers_4f45421ff5/webpage-draft-3go7 | <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Fastlink IT Shop and Accessories</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 0;
background-color: #f4f4f4;
color: #333;
}
header {
background-color: #4CAF50;
color: white;
padding: 1rem;
text-align: center;
}
nav {
display: flex;
justify-content: center;
background-color: #333;
}
nav a {
color: white;
padding: 14px 20px;
text-decoration: none;
text-align: center;
}
nav a:hover {
background-color: #ddd;
color: black;
}
.container {
padding: 20px;
}
.section {
margin-bottom: 20px;
padding: 20px;
background-color: white;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
footer {
background-color: #333;
color: white;
text-align: center;
padding: 1rem;
position: fixed;
width: 100%;
bottom: 0;
}
.social-icons {
list-style-type: none;
padding: 0;
display: flex;
justify-content: center;
}
.social-icons li {
margin: 0 10px;
}
.social-icons a {
color: white;
text-decoration: none;
}
.products-gallery {
display: flex;
flex-wrap: wrap;
gap: 20px;
}
.product {
flex: 1 1 calc(33.333% - 20px);
background-color: #fff;
padding: 20px;
border: 1px solid #ddd;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
text-align: center;
}
.product img {
max-width: 100%;
height: auto;
border-radius: 8px;
}
.marquee {
overflow: hidden;
white-space: nowrap;
box-sizing: border-box;
}
.marquee img {
display: inline-block;
padding: 0 10px;
}
@keyframes marquee {
0% {
transform: translateX(100%);
}
100% {
transform: translateX(-100%);
}
}
.marquee {
animation: marquee 15s linear infinite;
}
</style>
</head>
<body>
<header>
<h1>Fastlink IT Shop and Accessories</h1>
</header>
<nav>
<a href="#home">Home</a>
<a href="#about">About Us</a>
<a href="#products">Products</a>
<a href="#contact">Contact</a>
</nav>
<div class="container">
<section id="home" class="section">
<h2>Welcome to Fastlink IT Shop and Accessories</h2>
<p>Your premier destination for top-notch IT accessories.</p>
<div class="marquee">
<img src="https://via.placeholder.com/150" alt="Product 1">
<img src="https://via.placeholder.com/150" alt="Product 2">
<img src="https://via.placeholder.com/150" alt="Product 3">
<img src="https://via.placeholder.com/150" alt="Product 4">
<img src="https://via.placeholder.com/150" alt="Product 5">
<img src="https://via.placeholder.com/150" alt="Product 6">
</div>
</section>
<section id="about" class="section">
<h2>About Us</h2>
<h3>Who We Are</h3>
<p>Welcome to Fastlink IT Shop, your premier destination for top-notch IT accessories. Founded with a passion for technology and a commitment to customer satisfaction, we have been serving tech enthusiasts and professionals alike with the best products in the market.</p>
<h3>Our Mission</h3>
<p>At Fastlink IT Shop, our mission is to provide our customers with the highest quality IT accessories at competitive prices. We believe in delivering exceptional value and unparalleled service, ensuring that every customer finds the perfect solutions for their tech needs.</p>
<h3>What We Offer</h3>
<ul>
<li>Computer Peripherals: Keyboards, mice, monitors, and more.</li>
<li>Networking Equipment: Routers, switches, cables, and adapters.</li>
<li>Storage Solutions: External hard drives, SSDs, USB flash drives.</li>
<li>Audio and Video Accessories: Headphones, speakers, webcams.</li>
<li>And much more!</li>
</ul>
<h3>Why Choose Us?</h3>
<ul>
<li><strong>Quality Assurance:</strong> We source our products from trusted manufacturers to ensure top-notch quality.</li>
<li><strong>Competitive Prices:</strong> We offer the best prices on the market without compromising on quality.</li>
<li><strong>Expert Support:</strong> Our knowledgeable team is always ready to assist you with any questions or concerns.</li>
<li><strong>Fast Shipping:</strong> We provide prompt and reliable shipping to get your products to you as quickly as possible.</li>
</ul>
</section>
<section id="products" class="section">
<h2>Products</h2>
<div class="products-gallery">
<div class="product">
<img src="https://ppeci.com/images/uploads/products/AUDIO_VIDEO.jpg" alt="Audio and Video Accessories">
<h3>Audio and Video Accessories</h3>
<p>High-quality headphones, speakers, and webcams for all your audio and video needs.</p>
</div>
<div class="product">
<img src="https://via.placeholder.com/150" alt="Product 2">
<h3>Product 2</h3>
<p>Short description of Product 2.</p>
</div>
<div class="product">
<img src="https://via.placeholder.com/150" alt="Product 3">
<h3>Product 3</h3>
<p>Short description of Product 3.</p>
</div>
<div class="product">
<img src="https://via.placeholder.com/150" alt="Product 4">
<h3>Product 4</h3>
<p>Short description of Product 4.</p>
</div>
<div class="product">
<img src="https://via.placeholder.com/150" alt="Product 5">
<h3>Product 5</h3>
<p>Short description of Product 5.</p>
</div>
<div class="product">
<img src="https://www.arcserve.com/sites/default/files/2023-06/HDD%20vs%20SSD%20-%20AdobeStock_323405056%202.png" alt="Storage Solutions">
<h3>Storage Solutions</h3>
<p>Reliable external hard drives, SSDs, and USB flash drives for your storage needs.</p>
</div>
</div>
</section>
<section id="contact" class="section">
<h2>Contact Us</h2>
<p>You can reach us via email at <a href="mailto:info@fastlinkitshop.com">info@fastlinkitshop.com</a> or call us at (123) 456-7890.</p>
<ul class="social-icons">
<li><a href="#">Facebook</a></li>
<li><a href="#">Twitter</a></li>
<li><a href="#">Instagram</a></li>
<li><a href="#">LinkedIn</a></li>
</ul>
</section>
</div>
<footer>
<p>© 2024 Fastlink IT Shop and Accessories. All rights reserved.</p>
</footer>
</body>
</html> | gideon_writers_4f45421ff5 | |
1,866,771 | My Pen on CodePen | <!DOCTYPE html> Fastlink IT Shop and Accessories <br> body {<br> ... | 0 | 2024-05-27T16:54:20 | https://dev.to/gideon_writers_4f45421ff5/my-pen-on-codepen-19ei | codepen | <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Fastlink IT Shop and Accessories</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 0;
background-color: #blue;
color: #334;
}
header {
background-color: #4CAF50;
color: white;
padding: 1rem;
text-align: center;
}
nav {
display: flex;
justify-content: center;
background-color: #333;
}
nav a {
color: white;
padding: 14px 20px;
text-decoration: none;
text-align: center;
}
nav a:hover {
background-color: #ddd;
color: black;
}
.container {
padding: 20px;
}
.section {
margin-bottom: 20px;
padding: 20px;
background-color: white;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
footer {
background-color: #333;
color: white;
text-align: center;
padding: 1rem;
position: fixed;
width: 100%;
bottom: 0;
}
.social-icons {
list-style-type: none;
padding: 0;
display: flex;
justify-content: center;
}
.social-icons li {
margin: 0 10px;
}
.social-icons a {
color: white;
text-decoration: none;
}
.products-gallery {
display: flex;
flex-wrap: wrap;
gap: 20px;
}
.product {
flex: 1 1 calc(33.333% - 20px);
background-color: #fff;
padding: 20px;
border: 1px solid #ddd;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
text-align: center;
}
.product img {
max-width: 100%;
height: auto;
border-radius: 8px;
}
.marquee {
overflow: hidden;
white-space: nowrap;
box-sizing: border-box;
}
.marquee img {
display: inline-block;
padding: 0 10px;
}
@keyframes marquee {
0% {
transform: translateX(100%);
}
100% {
transform: translateX(-100%);
}
}
.marquee {
animation: marquee 15s linear infinite;
}
</style>
</head>
<body>
<header>
<h1>Fastlink IT Shop and Accessories</h1>
</header>
<nav>
<a href="#home">Home</a>
<a href="#about">About Us</a>
<a href="#products">Products</a>
<a href="#contact">Contact</a>
</nav>
<div class="container">
<section id="home" class="section">
<h2>Welcome to Fastlink IT Shop and Accessories</h2>
<p>Your premier destination for top-notch IT accessories.</p>
<div class="marquee">
<img src="https://via.placeholder.com/150" alt="Product 1">
<img src="https://via.placeholder.com/150" alt="Product 2">
<img src="https://via.placeholder.com/150" alt="Product 3">
<img src="https://via.placeholder.com/150" alt="Product 4">
<img src="https://via.placeholder.com/150" alt="Product 5">
<img src="https://via.placeholder.com/150" alt="Product 6">
</div>
</section>
<section id="about" class="section">
<h2>About Us</h2>
<h3>Who We Are</h3>
<p>Welcome to Fastlink IT Shop, your premier destination for top-notch IT accessories. Founded with a passion for technology and a commitment to customer satisfaction, we have been serving tech enthusiasts and professionals alike with the best products in the market.</p>
<h3>Our Mission</h3>
<p>At Fastlink IT Shop, our mission is to provide our customers with the highest quality IT accessories at competitive prices. We believe in delivering exceptional value and unparalleled service, ensuring that every customer finds the perfect solutions for their tech needs.</p>
<h3>What We Offer</h3>
<ul>
<li>Computer Peripherals: Keyboards, mice, monitors, and more.</li>
<li>Networking Equipment: Routers, switches, cables, and adapters.</li>
<li>Storage Solutions: External hard drives, SSDs, USB flash drives.</li>
<li>Audio and Video Accessories: Headphones, speakers, webcams.</li>
<li>And much more!</li>
</ul>
<h3>Why Choose Us?</h3>
<ul>
<li><strong>Quality Assurance:</strong> We source our products from trusted manufacturers to ensure top-notch quality.</li>
<li><strong>Competitive Prices:</strong> We offer the best prices on the market without compromising on quality.</li>
<li><strong>Expert Support:</strong> Our knowledgeable team is always ready to assist you with any questions or concerns.</li>
<li><strong>Fast Shipping:</strong> We provide prompt and reliable shipping to get your products to you as quickly as possible.</li>
</ul>
</section>
<section id="products" class="section">
<h2>Products</h2>
<div class="products-gallery">
<div class="product">
<img src="https://ppeci.com/images/uploads/products/AUDIO_VIDEO.jpg" alt="Product 1">
<h3>Product 1</h3>
<p>Short description of Product 1.</p>
</div>
<div class="product">
<img src="https://via.placeholder.com/150" alt="Product 2">
<h3></h3>
<p>Short description of Product 2.</p>
</div>
<div class="product">
<img src="https://via.placeholder.com/150" alt="Product 3">
<h3>Product 3</h3>
<p>Short description of Product 3.</p>
</div>
<div class="product">
<img src="https://via.placeholder.com/150" alt="Product 4">
<h3></h3>
<p>Short description of Product 4.</p>
</div>
<div class="product">
<img src="" alt="Product 5">
<h3>Product 5</h3>
<p>Short description of Product 5.</p>
</div>
<div class="product">
<img src="
https://www.arcserve.com/sites/default/files/2023-06/HDD%20vs%20SSD%20-%20AdobeStock_323405056%202.png" alt="Product 6">
<h3>Product 6</h3>
<p>Short description of Product 6.</p>
</div>
</div>
</section>
<section id="contact" class="section">
<h2>Contact Us</h2>
<p>You can reach us via email at <a href="mailto:info@fastlinkitshop.com">info@fastlinkitshop.com</a> or call us at (123) 456-7890.</p>
<ul class="social-icons">
<li><a href="#">Facebook</a></li>
<li><a href="#">Twitter</a></li>
<li><a href="#">Instagram</a></li>
<li><a href="#">LinkedIn</a></li>
</ul>
</section>
</div>
<footer>
<p>© 2024 Fastlink IT Shop and Accessories. All rights reserved.</p>
</footer>
</body>
| gideon_writers_4f45421ff5 |
1,866,770 | How to Upload a File in nodejs: A step by step guide | Introduction Hi there! In this article we will delve into file handling in a nodejs server. We’ll... | 0 | 2024-05-27T16:52:36 | https://dev.to/luqmanshaban/how-to-upload-a-file-in-nodejs-a-step-by-step-guide-5cf6 | node, webdev, multer, tutorial | **Introduction**
Hi there! In this article we will delve into file handling in a nodejs server. We’ll briefly discuss a simple way to upload file or images in using `multer`. A package that streamlines the file uploading process in nodejs application. To get started, initialize a nodejs app and install the following packages:
```
npm i express nodemon cors multer
```
Once the installation is complete, make sure to modify your package.json file by adding:
```
“type”: “module”, and “start” : “nodemon index.js”
```
Your `package.json` file should like something like this
```
{
"name": "file-upload",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "nodemon index.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"cors": "^2.8.5",
"express": "^4.19.2",
"multer": "^1.4.5-lts.1",
"nodemon": "^3.1.0"
}
}
```
Create a folder named upload in the root folder.
The next step will be creating index.js file (_in the root folder_) and importing the libraries we just installed.
```
import express from 'express'
import cors from 'cors'
import multer from 'multer'
We’ll then create instances:
const upload = multer({ storage: storage })
const app = express()
app.use(express.json())
app.use(cors())
```
This code sets up file uploads and a basic Express app:
**1.File Storage:**
Defines storage for `multer` to save files on disk in the uploads directory.
Generates unique filenames combining a timestamp and random number with the original filename.
**2.Express App:**
- Creates an Express app (app).
- Uses middleware:
`express.json()`: parses JSON data from requests.
`cors()`: potentially allows requests from other websites (CORS).
Now let’s create an endpoint that will accept file uploads and pass the multer middleware to it.
```
app.post('/api/file-upload', upload.single('file'), (req, res) => {
try {
res.status(200).json({ success: "file upload successful" })
} catch (error) {
res.status(500).json({ error: error })
}
})
```
This code defines a route for uploading files:
- `/api/file-upload`: This is the URL for the upload route.
upload.single(‘file’): This middleware from multer handles single file uploads named “file” in the request. To upload multiple files, refer to the [documentation](https://www.npmjs.com/package/multer).
- `(req, res) =>` …: This is the route handler function that executes when a POST request is made to the `/api/file-upload` URL.try…catch: It attempts to upload the file and sends a success response (status 200) with a message if successful.catch (error): If an error occurs during upload, it sends an error response (status 500) with the error details.
To starts the Express.js application and make it listen for incoming requests, add the following line of code:
```
app.listen(4000, () => console.log('RUNNING ON PORT 4000'))
```
Your index.js file should now be similar to this:
```
import express from 'express'
import cors from 'cors'
import multer from 'multer'
const storage = multer.diskStorage({
destination: function(req, file, cb) {
cb(null, 'uploads/')
},
filename: function(req, file, cb) {
const uniqueSuffix = Date.now() + '-' + Math.round(Math.random() * 1E9)
cb(null, uniqueSuffix+file.originalname)
}
})
const upload = multer({ storage: storage })
const app = express()
app.use(express.json())
app.use(cors())
app.post('/api/file-upload', upload.single('file'), (req, res) => {
try {
res.status(200).json({ success: "file upload successful" })
} catch (error) {
res.status(500).json({ error: error })
}
})
app.listen(4000, () => console.log('RUNNING ON PORT 4000'))
```
Open your terminal and run:
`npm start`
If everything went right, it should log: RUNNING ON PORT 4000.
To confirm that the code works as intended, we’ll test the API on postman. Open the app or it’s VsCode extension.
- select Body, check form-data and make sure the key’s name is set to file of type file. Upload your file or image then click send.
You should see:
```
{
"success": "file upload successful"
}
```
Indicating that the file has been uploaded. If you navigate to the upload folder we created earlier, you should see the file or image in there. And that’s it, you have successfully implemented the uploading feature in Node.js.
**Conclusion**
This article has successfully guided you through setting up file uploads in a Node.js application using the multer package. You learned how to:
1.Install required dependencies (express, cors, multer, and nodemon).
2. Configure file storage with unique filenames.
3. Create an Express.js app and use middleware for JSON parsing and CORS.
4. Define a route (/api/file-upload) to handle file uploads with multer.
5. Implement error handling for successful uploads and potential errors.
6. Start the server and test the functionality using Postman.
By following these steps, you’ve gained the ability to accept file uploads in your Node.js applications, enhancing their functionality and user experience.
**Never miss an article**: [Sign up for our programming newsletter today!](https://mailchi.mp/9275d6947c46/luqmandev)
| luqmanshaban |
1,865,715 | Software Testing | Software testing is a way to assess the quality of the software and to reduce the risk of software... | 0 | 2024-05-27T16:52:33 | https://dev.to/samu_deva/software-testing-kcm | Software testing is a way to assess the quality of the software and to reduce the risk of software failure in operation .It is a process used to identify the correctness, completeness and quality of developed computer software.
Software testing is the process of testing bugs in lines of code of a program that can be performed by manual or automation testing. Software testing is nothing but collection program. Program return by the developer for solving preface.
Software testing is thinks only in the terms of pass or fail of a test case and how to break the software.
Test works only for test life cycle, like design of test cases, and execution. No coding knowledge is required software tester are not expected to reach up to code level and tune the performance
Some testing does involve the execution of the component being tested such testing called dynamic testing.
Other testing does not involve the execution of the component being tested such testing called static testing.
Developer thinks how to develop a system and make a functionality work . Developer is limited to Coding part and release to testing team
Only coding knowledge is required developers are only expected to code the functionality which is expected by the customer.
| samu_deva | |
1,866,769 | I made a framework, looking for early adopters! :) | The framework: https://resonance.distantmagic.com I started to work on it >6 months ago and I am... | 0 | 2024-05-27T16:50:38 | https://dev.to/mcharytoniuk/i-made-a-framework-looking-for-early-adopters-d-1k0l | php, webdev, productivity, opensource | The framework: https://resonance.distantmagic.com
I started to work on it >6 months ago and I am nearing to the 1.0.0 release. I didn’t feel the need to add any more features so I think it’s getting pretty much complete.
It solves some specific issues with concurrency that other frameworks did not solve for me (at the same time it’s not made to compete with any other specific framework). I am issuing a lot of long running requests to LLMs that are resolved concurrently (you can issue tens of thousands of them from a cheap VPN), and it has a built in WebSocket server.
In short it is made for IO-bound applications, although it’s also really fast in itself (about 25x faster than Laravel Octane when serving a “hello world” view).
I think we are moving into the world where websites can/should integrate with ML models, AI and other microservices more and more, thus focus on the IO.
It also reimagines dependency injection - it does not allow cycles which makes it very easy on the GC - no more unexplained performance spikes.
I am not trying to sell anything and I have absolutely nothing from open sourcing it and writing all the articles around it. I am working on a different commercial product, I just wanted to open source something that can be useful to the community.
I’ve been working alone on the thing, it solves the issues for me. I would love to hear from you, to have someone try it out and share their opinion. That is my dream to find others who it might be useful for and to work on it together at some point. :D Hope that person is you. Feel free to reach out to me if you have any questions . | mcharytoniuk |
1,866,682 | Web Development in the Age of 5G: What Faster Speeds Mean for Developers | As 5G technology rolls out globally, it promises to transform industries by offering unprecedented... | 0 | 2024-05-27T16:50:09 | https://dev.to/buildwebcrumbs/web-development-in-the-age-of-5g-what-faster-speeds-mean-for-developers-1eg4 | ai, webdev, productivity |
As 5G technology rolls out globally, it promises to transform industries by offering unprecedented internet speeds and lower latency.
For us web developers, this evolution means more than just faster loading times, it's a gateway to revolutionizing how we design and interact with web applications.
---
## The Potential of 5G for Web Development
The introduction of 5G technology is set to dramatically enhance user experiences on the web. With speeds potentially up to 100 times faster than 4G, and significantly reduced latency, developers can now create more sophisticated applications that were previously constrained by network limitations.
- **Enhanced Real-Time Interactions**: Real-time applications like live streaming, instant gaming, and interactive live events can operate more smoothly, mimicking the responsiveness of desktop applications.
- **Immersive Experiences**: Augmented Reality (AR) and Virtual Reality (VR), once limited to specialized apps due to heavy data requirements, can now become part of everyday web experiences.
---
## Challenges and Opportunities
With great power comes great responsibility. 🕸️
The capabilities of 5G also introduce new challenges and opportunities for developers:
- **Richer Media and Animation**: Websites can now handle higher-quality media and more complex animations without compromising performance. However, developers need to balance these capabilities with the design to avoid overwhelming users.
- **Inclusivity and Accessibility**: As developers, it's crucial to ensure that new advancements do not alienate users with slower connections. Responsive designs must consider various bandwidths and adapt accordingly.
- **Designing for High Speeds and Low Bandwidth**: It's important to develop adaptive designs that can scale not only up but also down. Techniques like conditional loading, responsive images, and prioritization of content can ensure that all users, regardless of their connection speed, have a positive experience.
---
## New Technologies and Frameworks
5G’s rollout accelerates the adoption of cutting-edge technologies, pushing developers to adapt and innovate.
- **Edge Computing**: By processing data closer to the user, edge computing reduces latency even further, which is essential for technologies like IoT devices integrated into web platforms.
- **Adaptive Bitrate Streaming**: This technology, which adjusts video quality in real-time according to a user's bandwidth, will see increased importance, ensuring seamless video experiences on highly variable 5G networks.
---
**Want to discover the future of Web Development?**
{% cta https://www.webcrumbs.org/waitlist %} Learn more here with Webcrumbs {% endcta %}
---
## Practical Implications for Developer
As the web landscape evolves, so must the tools and approaches developers use.
- **Testing for 5G**: Developers will need to integrate new testing practices to ensure applications perform optimally across different network speeds. Tools that simulate various network conditions will become standard in testing environments.
- **Future-Proofing Applications**: It’s important to design applications that not only take advantage of 5G's capabilities but are also backward compatible with older technologies. Progressive enhancement strategies will be key.
---
## Are you ready to dive into the world of 5G?
The shift to 5G opens a new chapter in web development, characterized by ultra-fast speeds and more dynamic web capabilities. As developers, staying ahead means continuously learning and adapting to leverage these new technologies effectively.
Start experimenting with the new possibilities in your projects and prepare to deliver next-generation web experiences.
---
## Join Webcrumbs for Future-Ready Web Development
Stay connected for more insights into navigating this new technological landscape.
Embrace the future with WebCrumbs as you explore the potential of 5G technology.
{% cta https://www.webcrumbs.org %} Learn more at Webcrumbs.org {% endcta %} | opensourcee |
1,866,768 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-05-27T16:49:40 | https://dev.to/saveham954/buy-verified-cash-app-account-39mn | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n\n\n" | saveham954 |
1,866,767 | Motivware | Hi, I have created a CRM platform Motivware for Sales and Customer Support. You can effortlessly... | 0 | 2024-05-27T16:47:33 | https://dev.to/motivware/motivware-heo | crm, sales, customersupport | Hi, I have created a CRM platform Motivware for Sales and Customer Support. You can effortlessly centralize all customer relations in one place and reclaim countless hours of productivity.
You can optimize your team's workflow with our CRM, replacing messy spreadsheets and overloaded CRM systems for simplicity and efficiency.
> Start by Adding Contacts
> Take Control with Our Ticketing System
> Team Collaboration Invite Multiple Users
> Create Tailored Surveys for Clients. Gain Insights
> Empower Your Team with a Knowledge Base
> Elevate Your Business with Contact Profiles
I am looking for early adopters to use and give feedback. | motivware |
1,866,758 | C# Excel read/write on the cheap | Introduction When working with Excel frequently while coding in C#, the smart direction is... | 22,100 | 2024-05-27T16:34:47 | https://dev.to/karenpayneoregon/c-excel-readwrite-on-the-cheap-36km | csharp, dotnetcore, data | ## Introduction
When working with Excel frequently while coding in C#, the smart direction is to pay for a quality library which supports all Excel formats even if not needed as there may be a time a format is needed.
While Excel operations are infrequent the choices are code yourself without a library which means if Microsoft makes breaking changes the developer must figure out how to fix code to handle the breaking changes.
In this article learn how to read sheets, write to sheets, update cells. For the code samples [ExcelMapper](https://www.nuget.org/packages/ExcelMapper/5.2.568?_src=template) and [SpreadSheetLight](https://www.nuget.org/packages/SpreadsheetLight.Cross.Platform/3.5.1?_src=template) NuGet packages are used where ExcelMapper does the core work.
Data operations are performed by [Microsoft Entity Framework Core 8](https://learn.microsoft.com/en-us/ef/core/).
## Data validation
After reading data from Excel with the intention to save the Excel data to a database, in some cases it would be prudent to validate the incoming data. For example, several columns in a worksheet have unacceptable characters as shown below.
To handle unacceptable characters, create a model to represent the WorkSheet.
```csharp
public partial class Products : INotifyPropertyChanged
{
[NotMapped]
public int RowIndex { get; set; }
public int Id { get; set; }
public int ProductID { get; set; }
public string ProductName { get; set; }
public string CategoryName { get; set; }
public int? SupplierID { get; set; }
public string Supplier { get; set; }
public int? CategoryID { get; set; }
public string QuantityPerUnit { get; set; }
public decimal UnitPrice { get; set; }
public int? UnitsOnOrder { get; set; }
public int? ReorderLevel { get; set; }
public event PropertyChangedEventHandler? PropertyChanged;
protected virtual void OnPropertyChanged([CallerMemberName] string propertyName = null!)
{
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
}
}
```
Decide how to validate, for this we will use [FluentValidation](https://www.nuget.org/packages/FluentValidation/11.9.2?_src=template) NuGet package.
For those new to FluentValidation see [FluentValidation tips](https://dev.to/karenpayneoregon/fluentvalidation-tips-c-3olf).
Since the validation needed for unacceptable characters is not handled natively by FluentValidation a custom extension is needed.
The following language extension method will be used in a FluentValidation extension method to follow.
```csharp
public static class StringExtensions
{
/// <summary>
/// Used for validating a class string property is valid via FluentValidation
/// </summary>
/// <param name="text">Text to validate</param>
/// <returns>True if valid and false if invalid</returns>
/// <remarks>
/// What it considers if there are foreign characters in the string, allows spaces and numbers
/// </remarks>
public static bool IsOnlyAsciiLetters(this string text)
{
foreach (var item in text)
{
if (char.IsNumber(item))
{
continue;
}
switch (item)
{
case >= 'A' and <= 'Z':
case >= 'a' and <= 'z':
case ' ':
case '.':
case ',':
case '/':
case '\'':
case '&':
continue;
default:
return false;
}
}
return true;
}
}
```
FluentValidation extension method using the extension method above.
```csharp
public static class RuleBuilderExtensions
{
public static IRuleBuilderOptions<T, string> NoNoneAsciiCharacters<T>(this IRuleBuilder<T, string> ruleBuilder)
=> ruleBuilder
.NotEmpty()
.Must(m => m.IsOnlyAsciiLetters())
.WithMessage("'{PropertyName}' is not valid");
}
```
**Validator**
```csharp
public class ProductsValidator : AbstractValidator<Products>
{
public ProductsValidator()
{
RuleFor(p => p.ProductName).NoNoneAsciiCharacters();
RuleFor(p => p.CategoryName).NoNoneAsciiCharacters();
RuleFor(p => p.QuantityPerUnit).NotEmpty();
RuleFor(p => p.Supplier).NoNoneAsciiCharacters();
RuleFor(p => p.ProductID).GreaterThan(0);
}
}
```
**Read and validate**
Using the following method. Read data from Excel Iterate each row, create an instance of the validator, pass in the row data, see if the data is valid.
There are two list, one for valid data and one for invalid data. Invalidate data is saved to a database table which can be used to inspect, delete or fix.
The entire process is done in a Windows Forms project yet since there is limited code in the forms a developer can do the same in other project types.
> **Note**
> The entire section for validating is not covered in respect to saving bad data as the reader may have their own ideas.
```csharp
internal class ImportOperations
{
public static async Task<(string badRecord, List<Products> badRecords, int saved, int rejected)> Validate(string fileName = "Products.xlsx")
{
ExcelMapper excel = new();
var products = (await excel.FetchAsync<Products>(fileName, nameof(Products))).ToList();
List<Products> goodList = [];
List<Products> badList = [];
StringBuilder builder = new();
int rejected = 0;
for (int index = 0; index < products.Count; index++)
{
var validator = new ProductsValidator();
var result = await validator.ValidateAsync(products[index]);
if (result.IsValid == false)
{
rejected++;
foreach (var error in result.Errors)
{
builder.AppendLine($"{index + 1,-10} {error.PropertyName,-30}{error.AttemptedValue}");
}
products[index].RowIndex = index + 1;
badList.Add(products[index]);
}
else
{
goodList.Add(products[index]);
}
}
var saved = 0;
if (goodList.Count > 0)
{
await using var context = new Context();
await context.Database.EnsureDeletedAsync();
await context.Database.EnsureCreatedAsync();
context.Products.AddRange(goodList);
saved = await context.SaveChangesAsync();
}
return (builder.ToString(), badList, saved, rejected);
}
}
```
Calling the above where the variable returned is deconstruction, for more on this see [The art of Deconstructing](https://dev.to/karenpayneoregon/the-art-of-deconstructing-eim).
```csharp
var (badRecords, badList, saved, rejected) = await ImportOperations.Validate();
```
Screenshots
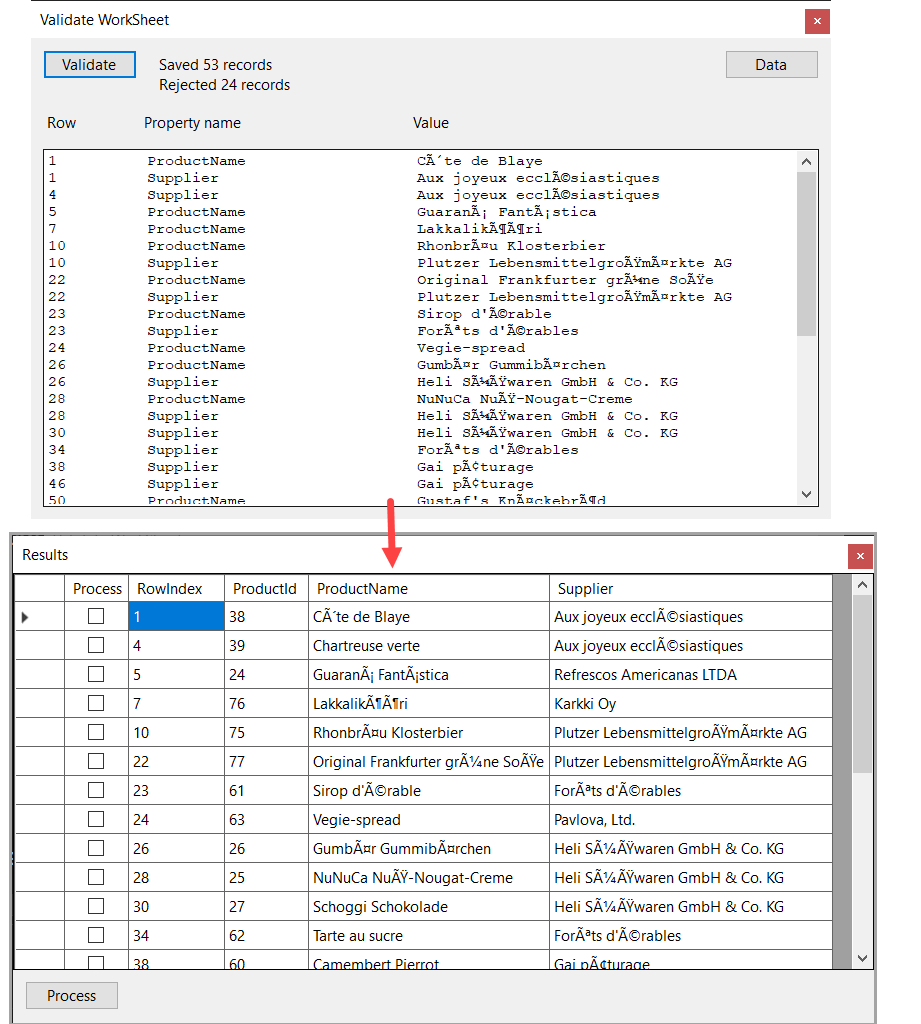
### Important
All data read from Excel files in the code sample are tubular for 99% of the examples presented and the data is perfect, meaning that for instance if a column contains dates, all rows of that column have valid dates.
In the real world there will be imperfect data which means that a developer should always consider at least one cell has bad or invalid data. With that known there is no one method to checks for proper data. For each Excel file a developer must understand assertion must be performed such as, for example for a sheet containing customer data can first and last name be empty or that for a sheet of products, what to do if data is missing.
Example of checking if the fourth column contains valid dates. This is a hard coded sample which is provided in source code.
```csharp
using SpreadsheetLight;
namespace ExcelMapperApp1.Classes;
internal class LightOperations
{
/// <summary>
/// For article to show an example to test if the person's birthdate can be read as a date
/// </summary>
/// <returns>
/// If there are issues, the list of rows with issues is returned
/// </returns>
public static (List<int> rows, bool hasIssues) Iterate()
{
List<int> list = [];
const string excelFile = "Nested1.xlsx";
const int columnIndex = 4;
using SLDocument document = new(excelFile);
var stats = document.GetWorksheetStatistics();
// skip header row
for (int rowIndex = 2; rowIndex < stats.EndRowIndex + 1; rowIndex++)
{
var date = document.GetCellValueAsDateTime(rowIndex, columnIndex);
if (date == new DateTime(1900,1,1))
{
list.Add(rowIndex);
}
}
return (list, list.Any());
}
}
```
Other considerations, does the file exists? Can the file be opened? Does the worksheet exists?
Always check if the file exists. Concerning if a file can be opened, if a user has the file open outside of the program and a developer’s code attempting to read the file, an exception is throw so wrap the code in a try/catch. Regarding sheet names, if they happen to changed, code will fail. Code has been provided to show how to check for sheet existence.
{% cta https://github.com/karenpayneoregon/ExcelMapperSamples %} GitHub repository {% endcta %}
## Read sheet data to a SQL-Server table
First check if the worksheet exists, if not return to caller.
Next, reset the SQL-Server database table to zero rows and reset identity.
Read worksheet data using [ExcelMapper](https://www.nuget.org/packages/ExcelMapper/5.2.568?_src=template) using the following model.
```csharp
public partial class Customers
{
public int Id { get; set; }
public string Company { get; set; }
public string ContactType { get; set; }
public string ContactName { get; set; }
public string Country { get; set; }
public DateOnly JoinDate { get; set; }
public override string ToString() => Company;
}
```
To match this sheet.
Next, take the list returned and add to EF Core database. If an exception is thrown it is written to the console screen while for a real application the exception should be written to a log file using a package like SeriLog. See [Serilog logging and EF Core logging](https://dev.to/karenpayneoregon/serilog-logging-and-ef-core-logging-25hm).
```csharp
public static async Task CustomersToDatabase()
{
PrintCyan();
const string excelFile = "Customers.xlsx";
if (SheetExists(excelFile, nameof(Customers)) == false)
{
AnsiConsole.MarkupLine($"[red]Sheet {nameof(Customers)} not found in {excelFile}[/]");
return;
}
try
{
DapperOperations operations = new();
operations.Reset();
ExcelMapper excel = new();
await using var context = new Context();
var customers = (await excel.FetchAsync<Customers>(excelFile, nameof(Customers))).ToList();
context.Customers.AddRange(customers);
var affected = await context.SaveChangesAsync();
AnsiConsole.MarkupLine(affected > 0 ? $"[cyan]Saved[/] [b]{affected}[/] [cyan]records[/]" : "[red]Failed[/]");
}
catch (Exception ex)
{
ex.ColorWithCyanFuchsia();
}
}
```
## Read/write to secondary Excel file
In this example the idea is say business asked for a report and only a few columns are required.
Data is read using the following model.
```csharp
public class Products
{
public int ProductID { get; set; }
public string ProductName { get; set; }
public string CategoryName { get; set; }
public int? SupplierID { get; set; }
public int? CategoryID { get; set; }
public string Supplier { get; set; }
public string QuantityPerUnit { get; set; }
public decimal? UnitPrice { get; set; }
public short? UnitsInStock { get; set; }
public short? UnitsOnOrder { get; set; }
public short? ReorderLevel { get; set; }
public override string ToString() => ProductName;
}
```
Then written to another Excel file using the following model.
```csharp
public class ProductItem
{
public int ProductID { get; set; }
public string ProductName { get; set; }
public string CategoryName { get; set; }
public decimal? UnitPrice { get; set; }
}
```
Code first checks if the Excel file exists (as mentioned above), delete the file for a fresh start.
Next, read the worksheet into a list then create a second list with less properties than the first list.
Save the smaller list to a new file.
```csharp
/// <summary>
/// Read products from Products.xlsx as list of <see cref="Products"/> then write to a new
/// file as <see cref="ProductItem"/> ProductsCopy.xlsx
/// </summary>
/// <returns></returns>
public static async Task ReadProductsCreateCopyWithLessProperties()
{
PrintCyan();
const string excelReadFile = "Products.xlsx";
const string excelWriteFile = "ProductsCopy.xlsx";
if (File.Exists(excelWriteFile))
{
try
{
File.Delete(excelWriteFile);
}
catch (Exception ex)
{
ex.ColorWithCyanFuchsia();
return;
}
}
ExcelMapper excel = new();
var products = (await excel.FetchAsync<Products>(excelReadFile,
nameof(Products))).ToList();
var productItems = products.Select(p => new ProductItem
{
ProductID = p.ProductID,
ProductName = p.ProductName,
CategoryName = p.CategoryName,
UnitPrice = p.UnitPrice
}).ToList();
await new ExcelMapper().SaveAsync("productsCopy.xlsx", productItems, "Products");
}
```
## Read sheet - update properties and save
This example demonstrates reading a worksheet, making edits and removal of a row. Other than the fact edits are made, this code sample follows the same path as the example above.
```csharp
/// <summary>
/// Read products from Products.xlsx as list of <see cref="Products"/> then update
/// several products and save to a new file ProductsOut.xlsx
/// </summary>
public static async Task ReadProductsAndUpdate()
{
PrintCyan();
const string excelReadFile = "Products.xlsx";
const string excelWriteFile = "ProductsOut.xlsx";
if (File.Exists(excelWriteFile))
{
try
{
File.Delete(excelWriteFile);
}
catch (Exception ex)
{
ex.ColorWithCyanFuchsia();
return;
}
}
ExcelMapper excel = new();
var products = excel.Fetch<Products>(excelReadFile, nameof(Products)).OrderBy(x => x.ProductName).ToList();
var p1 = products.FirstOrDefault(x => x.ProductName == "CÃ\u00b4te de Blaye");
if (p1 is not null)
{
p1.ProductName = "Cafe de Blave";
}
var p2 = products.FirstOrDefault(x => x.Supplier == "Aux joyeux ecclÃ\u00a9siastiques");
if (p2 is not null)
{
p2.Supplier = "Aux Joy";
}
var p3 = products.FirstOrDefault(x => x.ProductID == 48);
if (p3 is not null)
{
products.Remove(p3);
}
await excel.SaveAsync(excelWriteFile, products, "Products");
}
```
## Read nested properties
This code sample has person details and their address on the same row and the task is to separate both.

**Models**
```csharp
public class Person
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public DateOnly BirthDate { get; set; }
public Address Address { get; set; }
public override string ToString() => $"{FirstName} {LastName} {Address}";
}
public class Address
{
public string Street { get; set; }
public string City { get; set; }
public string State { get; set; }
public string ZipCode { get; set; }
public override string ToString() => State;
}
```
ExcelMapper seamlessly figures out what to do with the models above.
```csharp
public static async Task NestedReadPeople()
{
PrintCyan();
const string excelFile = "Nested.xlsx";
ExcelMapper excel = new();
var contactList = (await excel.FetchAsync<Person>(excelFile, "Contacts")).ToList();
AnsiConsole.MarkupLine(ObjectDumper.Dump(contactList)
.Replace("{Person}", "[cyan]{Person}[/]")
.Replace("Address:", "[cyan]Address:[/]"));
}
```
Below is the output using Nuget package [ObjectDumper.NET](https://www.nuget.org/packages/ObjectDumper.NET/4.2.7?_src=template) which is great for examining results.
## Header not the first row
A developer may need to read a WorkSheet where the header row is not the first row. ExcelMapper can handle this by telling which row is the header row.
This example has the header row at row 10, two nested records.
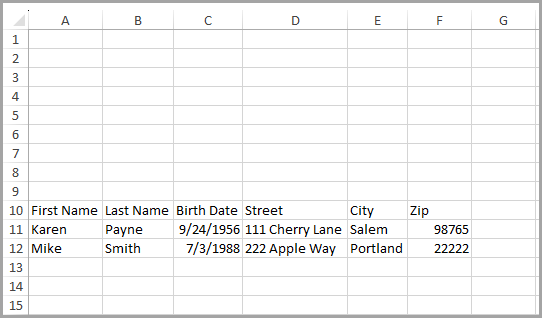
Models to read data.
```csharp
public class Person
{
public int Id { get; set; }
[Column("First Name")]
public string FirstName { get; set; }
[Column("Last Name")]
public string LastName { get; set; }
[Column("Birth Date")]
public DateOnly BirthDate { get; set; }
public Address Address { get; set; }
public override string ToString() => $"{FirstName} {LastName} {BirthDate}";
}
public class Address
{
public int Id { get; set; }
public string Street { get; set; }
public string City { get; set; }
public string Zip { get; set; }
public override string ToString() => $"{Street} {City} {Zip}";
}
```
In this case to read from row 10, HeaderRowNumber indicates the header row and MinRowNumber (optional) how many rows to read.
ObjectDumper.Dump writes results to Visual Studio Output window.
```csharp
public async Task HeaderNotAtFirstRow()
{
ExcelMapper excel = new()
{
HeaderRowNumber = 9,
MinRowNumber = 2
};
var people = (await excel.FetchAsync<Person>("ExcelFiles\\Header1.xlsx", "People")).ToList();
Debug.WriteLine(ObjectDumper.Dump(people));
}
```
Results
```
{Person}
Id: 0
FirstName: "Karen"
LastName: "Payne"
BirthDate: {DateOnly}
Year: 1956
Month: 9
Day: 24
DayOfWeek: DayOfWeek.Monday
DayOfYear: 268
DayNumber: 714315
Address: {Address}
Id: 0
Street: "111 Cherry Lane"
City: "Salem"
Zip: "98765"
{Person}
Id: 0
FirstName: "Mike"
LastName: "Smith"
BirthDate: {DateOnly}
Year: 1988
Month: 7
Day: 3
DayOfWeek: DayOfWeek.Sunday
DayOfYear: 185
DayNumber: 725920
Address: {Address}
Id: 0
Street: "222 Apple Way"
City: "Portland"
Zip: "22222"
```
## Reading worksheet modify and save to database
Suppose the task is to read data from a Worksheet followed by filtering out data then save the filtered data to a database? The process is to use Excel Mapper to read a Worksheet, filter or perform validation using a lambda statement or FluidValidation NuGet package for instance then in this case save data to a SQL-Server database table using Microsoft EF Core.

The code which follows reads customer data and filters out any row where the country is Germany then uses EF Core to save the data.
> **Note**
> operations.Reset(); removes rows from the table and resets the primary key.
```csharp
private static async Task ReadCustomersFromExcelToDatabase()
{
SpectreConsoleHelpers.PrintCyan();
try
{
DapperOperations operations = new();
operations.Reset();
const string excelFile = "Customers.xlsx";
ExcelMapper excel = new();
await using var context = new Context();
var customers = (
await excel.FetchAsync<Customers>(excelFile, nameof(Customers)))
.ToList();
var germanyItems =
customers.Where(c => c.Country == "Germany").ToArray();
foreach (var c in germanyItems)
customers.Remove(c);
context.Customers.AddRange(customers);
var affected = await context.SaveChangesAsync();
AnsiConsole.MarkupLine(affected > 0 ?
$"[cyan]Saved[/] [b]{affected}[/] [cyan]records[/]" :
"[red]Failed[/]");
}
catch (Exception ex)
{
ex.ColorWithCyanFuchsia();
}
}
```
## Reading data to model with enum
ExcelMapper handles enumerations.
Example worksheet were WineType is an enum.

Sample code.
```csharp
using Ganss.Excel;
using SampleApp6.Classes;
using static ObjectDumper;
namespace SampleApp6;
internal partial class Program
{
static void Main(string[] args)
{
AnsiConsole.MarkupLine("[yellow]Working with[/] [cyan]enum[/]");
var excel = new ExcelMapper("Products.xlsx");
var products = excel.Fetch<Wines>().ToList();
AnsiConsole.MarkupLine(Dump(products).Replace("WineType:", "[cyan]WineType:[/]"));
SpectreConsoleHelpers.ExitPrompt();
}
}
public class Wines
{
public int WineId { get; set; }
public string Name { get; set; }
public WineType WineType { get; set; }
}
public enum WineType
{
Red = 1,
White = 2,
Rose = 3
}
```
Results:
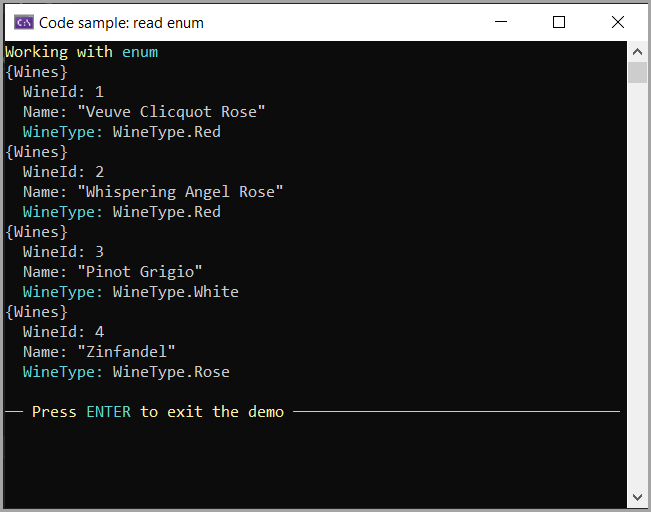
## Before running provided code
See [the following](https://github.com/karenpayneoregon/excel-spreadsheetlight-csharp/blob/master/ExcelMapperApp1/readme.md).
## Summary
Code has been provided to read tubular data working with several NuGet packages were ExcelMapper performs most of the work along with Microsoft Entity Framework Core for database operations.
See ExcelMapper [GitHub page](https://github.com/mganss/ExcelMapper/tree/master) for more e.g.
- Map to Excel files using header rows (column names) or column indexes (no header row)
- Optionally skip blank lines when reading
- Preserve formatting when saving back files
- Map formulas or formula results depending on property type
- Use records
- Provide custom object factories
| karenpayneoregon |
1,866,766 | How do I embed the Auth0 login page into my own web page? | I am using Auth0's Universal Login, which looks like below: My question is, how to embed this UI... | 0 | 2024-05-27T16:47:10 | https://dev.to/snookums/how-do-i-embed-the-auth0-login-page-into-my-own-web-page-1ngi | oauth, auth0 | I am using [Auth0](https://auth0.com/)'s Universal Login, which looks like below:
My question is, how to embed this UI component into my own web page?
The desired effect is like:
I checked Auth0's doc but didn't find instructions.
Does it not support it?
If this is the case, are there any other services that I can use?
Or do I have to implement the OAuth procedure myself?
Thanks in advance! | snookums |
1,866,757 | Integrating Atlantis with OpenTofu. | Due to the Terraform license change, many companies are migrating their IAC processes to OpenTofu,... | 0 | 2024-05-27T16:39:06 | https://dev.to/jmateusousa/integrating-atlantis-with-opentofu-lnd | devops, iac, opentofu, atlantis |

Due to the Terraform license change, many companies are migrating their IAC processes to OpenTofu, with this in mind and knowing that many of them use Atlantis and Terraform as infrastructure delivery automation, I created this documentation showing what to do to integrate Atlantis with OpenTofu.
Stack: Atlantis, Terragrunt, OpenTofu, Github, ALB, EKS.
We will implement it with your [Helm chart](https://www.runatlantis.io/docs/deployment.html#kubernetes-helm-chart):
1 - Add the runatlantis repository.
```
helm repo add runatlantis https://runatlantis.github.io/helm-charts
```
2 - Create file `values.yaml` and run:
```
helm inspect values runatlantis/atlantis > values.yaml
```
3 - Edit the file values.yaml and add your credentials access and secret which will be used in the Atlantis webhook configuration:
See as create a [GitHubApp](https://docs.github.com/pt/apps/creating-github-apps/about-creating-github-apps).
```
githubApp:
id: "CHANGE ME"
key: |
-----BEGIN RSA PRIVATE KEY-----
"CHANGE ME"
-----END RSA PRIVATE KEY-----
slug: atlantis
# secret webhook Atlantis
secret: "CHANGE ME"
```
4 - Enter the org and repository from github that Atlantis will interact in orgAllowlist:
```
# All repositories the org
orgAllowlist: github.com/MY-ORG/*
or
# Just one repository
orgAllowlist: github.com/MY-ORG/MY-REPO-IAC
or
# All repositories that start with MY-REPO-IAC-
orgAllowlist: github.com/MY-ORG/MY-REPO-IAC-*
```
5 - Now let’s configure the script that will be executed upon startup of the Atlantis init pod.
In this step we download and install Terragrunt and OpenTofu, as well as include their binaries in the shared dir `/plugins`.
```
initConfig:
enabled: true
image: alpine:latest
imagePullPolicy: IfNotPresent
# sharedDir is set as env var INIT_SHARED_DIR
sharedDir: /plugins
workDir: /tmp
sizeLimit: 250Mi
# example of how the script can be configured to install tools/providers required by the atlantis pod
script: |
#!/bin/sh
set -eoux pipefail# terragrunt
TG_VERSION="0.55.10"
TG_SHA256_SUM="1ad609399352348a41bb5ea96fdff5c7a18ac223742f60603a557a54fc8c6cff"
TG_FILE="${INIT_SHARED_DIR}/terragrunt"
wget https://github.com/gruntwork-io/terragrunt/releases/download/v${TG_VERSION}/terragrunt_linux_amd64 -O "${TG_FILE}"
echo "${TG_SHA256_SUM} ${TG_FILE}" | sha256sum -c
chmod 755 "${TG_FILE}"
terragrunt -v
# OpenTofu
TF_VERSION="1.6.2"
TF_FILE="${INIT_SHARED_DIR}/tofu"
wget https://github.com/opentofu/opentofu/releases/download/v${TF_VERSION}/tofu_${TF_VERSION}_linux_amd64.zip
unzip tofu_${TF_VERSION}_linux_amd64.zip
mv tofu ${INIT_SHARED_DIR}
chmod 755 "${TF_FILE}"
tofu -v
```
6 - Here we configure the envs to avoid downloading alternative versions of Terraform and indicate to Terragrunt where it should fetch the OpenTofu binary.
```
# envs
environment:
ATLANTIS_TF_DOWNLOAD: false
TERRAGRUNT_TFPATH: /plugins/tofu
```
7 - Last but not least, here we specify which Atlantis-side configurations we will have for the repositories.
```
# repository config
repoConfig: |
---
repos:
- id: /.*/
apply_requirements: [approved, mergeable]
allow_custom_workflows: true
allowed_overrides: [workflow, apply_requirements, delete_source_branch_on_merge]
```
8 - Configure Atlantis webhook ingress, in the example below we are using the AWS ALB.
```
# ingress config
ingress:
annotations:
alb.ingress.kubernetes.io/backend-protocol: HTTP
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:certificate
alb.ingress.kubernetes.io/group.name: external-atlantis
alb.ingress.kubernetes.io/healthcheck-path: /healthz
alb.ingress.kubernetes.io/healthcheck-port: "80"
alb.ingress.kubernetes.io/healthcheck-protocol: HTTP
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: "200"
alb.ingress.kubernetes.io/target-type: ip
apiVersion: networking.k8s.io/v1
enabled: true
host: atlantis.your.domain
ingressClassName: aws-ingress
path: /*
pathType: ImplementationSpecific
```
Save all changes made to `values.yaml`
9 - Using one of the Atlantis options custom workflows, we can create a file `atlantis.yaml` in the root folder of your repository, the example below should meet most scenarios, adapt as needed.
```
version: 3
automerge: true
parallel_plan: true
parallel_apply: false
projects:
- name: terragrunt
dir: .
workspace: terragrunt
delete_source_branch_on_merge: true
autoplan:
enabled: false
apply_requirements: [mergeable, approved]
workflow: terragrunt
workflows:
terragrunt:
plan:
steps:
- env:
name: TF_IN_AUTOMATION
value: 'true'
- run: find . -name '.terragrunt-cache' | xargs rm -rf
- run: terragrunt init -reconfigure
- run:
command: terragrunt plan -input=false -out=$PLANFILE
output: strip_refreshing
apply:
steps:
- run: terragrunt apply $PLANFILE
```
10 - Now let’s go to the installation itself, search for the available versions of Atlantis:
```
helm search repo runatlantis
```
Replace `CHART-VERSION` with the version you want to install and run the command below:
```
helm upgrade -i atlantis runatlantis/atlantis --version CHART-VERSION -f values.yaml --create-namespace atlantis
```
Now, see as configure Atlantis [webhook on github](https://www.runatlantis.io/docs/configuring-webhooks.html?source=post_page-----85ca0fbe45e5--------------------------------#github-github-enterprise) repository.
See as Atlantis [work](https://www.runatlantis.io/docs/using-atlantis.html?source=post_page-----85ca0fbe45e5--------------------------------).
Share it with your friends =)
Find out more at:
https://www.runatlantis.io/guide.html
https://opentofu.org/docs/
https://github.com/runatlantis/atlantis/issues/3741
| jmateusousa |
1,866,763 | Introducing LibVLCSharp for MAUI | Following the official deprecation of Xamarin.Forms, we are announcing the LibVLCSharp integration... | 0 | 2024-05-27T16:38:49 | https://dev.to/mfkl/introducing-libvlcsharp-for-maui-naj | maui, libvlc, dotnet |
Following the official deprecation of Xamarin.Forms, we are announcing the [LibVLCSharp integration for MAUI](https://www.nuget.org/packages/LibVLCSharp.MAUI).
## Initial release
Starting from 3.8.5, [LibVLCSharp.MAUI](https://www.nuget.org/packages/LibVLCSharp.MAUI) officially supports iOS (net6.0+) and Android (net7.0) modern .NET MAUI targets.
We have had some trouble with the Android version, since some underlying tooling changed and we found a regression affecting our wanted final deployment structure. But we worked around it for now (or until it gets fixed?).
## What's next for LibVLCSharp.MAUI?
As we get more user feedback and tweak these initial releases, we will be looking into expanding platform support with macOS and Windows (WinUI) support.
Another exciting feature will be to bring back our [MediaElement control](https://mfkl.github.io/libvlc/crossplatform/xamarin/forms/2019/08/13/MediaPlayerElement-Plug-and-play-LibVLCSharp-UI-video-control.html) from Xamarin.Forms ashes, and make it MAUI-ready. This control was very popular as it was plug-and-play and came with many implemented features.
We are always looking for contributors and corporate sponsors for this work. Feel free to reach out if you can help! | mfkl |
1,866,760 | Learning AWS Day by Day — Day 76 — AWS Backup | Exploring AWS !! Day 76 AWS Backup Can be used to centralize and automate data protection across... | 0 | 2024-05-27T16:35:27 | https://dev.to/rksalo88/learning-aws-day-by-day-day-76-aws-backup-4oop | aws, cloud, cloudcomputing, beginners | Exploring AWS !!
Day 76
AWS Backup

Can be used to centralize and automate data protection across multiple AWS services and workloads. Backups provide low-cost, fully managed and policy-based service that simplifies data protection at scale. AWS Backups also help you in meeting regulatory compliance and business data protection policies.
Advantages:
- Manage backups centrally
- Backup procedures should be automated
- Increase backup compliance
How it works?
AWS Backup is a fully managed backup service that makes it easy to centralize and automate the backing up of data across AWS services. With AWS Backup, you can create backup policies called backup plans. You can use these plans to define your backup requirements, such as how frequently to back up your data and how long to retain those backups.
AWS Backup lets you apply backup plans to your AWS resources by simply tagging them. AWS Backup then automatically backs up your AWS resources according to the backup plan that you defined.
The following sections describe how AWS Backup works, its implementation details, and security considerations.
Features:
Automated backup schedules and retention management
Centralized backup monitoring
Encrypted backups
Incremental backups
Cross-account management with AWS Organizations
Automated backup audits and reports with AWS Backup Audit Manager
Write-once, read-many (WORM) with AWS Backup Vault Lock | rksalo88 |
1,866,759 | yiusyf68reiifudslkfloifudsf | https://sbsconnect.nyc.gov/forums/general-discussion/e045e0ed-411c-ef11-9899-001dd80c0b1b https://sbs... | 0 | 2024-05-27T16:35:08 | https://dev.to/tyruk_mambu_ca89ec4df6cf2/yiusyf68reiifudslkfloifudsf-20ao | https://sbsconnect.nyc.gov/forums/general-discussion/e045e0ed-411c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/bae9a223-421c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/3273254c-421c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/5bbaa78e-421c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/205107a2-421c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/6db0edd4-421c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/fe59b5f0-421c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/de2c6b6a-431c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/76d1a985-431c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/f00dba3c-441c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/1de4585f-441c-ef11-9899-001dd80c0b1b
https://sbsconnect.nyc.gov/forums/general-discussion/b13a7a7f-441c-ef11-9899-001dd80c0b1b
https://kbin.social/m/internet/t/1058788/Xem-phim-Y-Niem-Ve-Anh-2024-Full-HD-Vietsub-Mien
https://www.lesswrong.com/posts/3FGAikgriTXxKvCDs/rdydy5r6yert53w5w | tyruk_mambu_ca89ec4df6cf2 | |
1,866,638 | AWS Solution Architect Associate Exam: Experiencia y Recomendaciones | Hola a todos una vez más. Como les había prometido les contare mi experiencia durante la preparación... | 0 | 2024-05-27T16:33:04 | https://dev.to/madriz03/aws-solution-architect-associate-exam-experiencia-y-recomendaciones-1jp5 | solutionarchitect, aws, awscertified, awsexam | Hola a todos una vez más. Como les había prometido les contare mi experiencia durante la preparación del examen Solution Architect Associate y como la conseguí.
## Que tal me pareció el examen:
Esto quiero que este al inicio porque me parece muy importante. El examen estuvo mas difícil de lo que esperaba, la verdad me sorprendió, cuando presente el examen para el Cloud Practioner termine el examen y tenía la sensación de que había aprobado, sin embargo, en este examen tenía más dudas que certezas, ya les contare por qué.
Si bien es cierto que el examen tiene una estructura definida que se divide en 4 pilares fundamentales que son:
1. Arquitecturas de Costo Optimizado
2. Arquitecturas de Alto Rendimiento
3. Arquitecturas Resilientes
4. Arquitecturas Seguras
Mi examen particularmente me sorprendió, ya que a pesar de que cubrió estos 4 pilares la mayoría de las preguntas estaban orientadas a serverless o los escenarios planteados tenían inclinación a este tema, les daré un ejemplo para que me entiendan:
Quizá una pregunta en específico quería evaluar mis conocimientos en seguridad, pero el escenario presentado donde se debía implementar los conceptos de seguridad era un ambiente o arquitectura serverless.
Un ejemplo podría ser: Como anonimizar datos con una lambda o como evitar exponer variables de entorno o credenciales en el código de una lambda. Por mencionar cualquier cosa, asi fue la mayor parte del examen. Quiza tenga sentido porque la mayoria de empresas estan apuntando a este tipo de arquitecturas reduciendo esfuerzos operativos y en muchos casos a la larga se puede ahorrar dinero.
## Como me prepare:
Como les he contado siempre, no existe un único recurso con la mejor explicación para todo, lo mejor es variar y cuando no te quede claro un concepto buscar información sobre esto en varios recursos, te cuento a continuación los que yo use:
- [Curso Udemy de Stephane Maarek y Joan Amengual](https://www.udemy.com/course/certified-solutions-architect-associate-aws/?couponCode=KEEPLEARNING)
Este curso es una version en español del mismo contenido del curso en Ingles de Stephane Maarek que es un referente en cuando al aprendizaje de AWS respecta. Por que elegi hacerlo en español y no en ingles como la mayoria recomienda?
Cuando estoy aprendiendo algo nuevo y complejo no me gusta perder ningun detalle, es necesario para mi que las cosas queden claras y no bajo interpretacion y es lo que podria suceder si ves una clase en ingles y el profesor usa un modismo, slang o expresion, utilizada normalmente por hablantes nativos o por quienes conviven con el ingles todos los dias.
Quienes recomiendan hacer el examen en ingles argumentan que podria haber una traduccion mal hecha durante el examen y podrias no identificar el nombre de un servicio, pero la realidad es que ya esto no sucede, mis ultimos dos examenes los he realizado en castellano y el nombre de los servicios son presentados en ingles y el contexto general de la pregunta aparece en español, por lo que no tendras problemas, Es decir que aunque la pregunta este en español el nombre del servicio aparece en ingles, si la pregunta es referente a Glue este aparecera tal cual "Glue" y no como "Pegamento" que es la traduccion, lo que aparecera en español es el contexto general, de igual manera tendras un boton para ir pasando una pregunta a ingles si lo consideras necesario y luego regresar a español.
- [Laboratorios nivel Solution Architect](https://www.whizlabs.com/labs/library/)
Whizlabs aunque tiene video cursos y examenes practicos sobre esta certificacion, te quiero recomendar los laboratorios, si hay algun servicio en el que te gustaria profundizar y conocer desde lo practico, esta es una buena opcion y lo mejor es que puedes comprar unicamente los laboratorios y hacerlos a tu medida, la plataforma te brinda un ambiente de AWS asi que evitaras generar gastos en tu propia cuenta de AWS.
En mi perfil de este blog tambien encontraras algunos laboratorios que podras realizar paso a paso para practicar, estudiar solo de manera teorica no es la mejor forma y puedes aturdirte de tanta teoria.
- Participa en charlas en vivo, charlas presenciales, contenido de youtube y lecturas, esto te hara mantenerte inmerso en el aprendizaje y creeme en cualquiera de estos escenarios aprenderas al menos una cosa que no sabias y eso es mas que suficiente, si aprendes al menos una cosa nueva puedes darte por bien servido, te comparto algunos de los que yo use:
- [AWS Women Colombia](https://www.youtube.com/@awswomencolombia).
- [AWS Security Users Group LatAm](https://www.youtube.com/@AWSSecurityLATAM/videos)
- [Explicaciones practicas detalladas, por Fernando un ingeniero Devops](https://www.youtube.com/@fernandoing).
En estos canales de Youtube realizan charlas tecnicas sobre los servicios de AWS, puedes participar en ellas en vivo o ver las que ya estan subidas en youtube, en la mayoria van mas alla de lo teorico y presentan una demo, ademas es una buena opcion para ir haciendo conexiones en Linkedin con quienes impartes estas charlas y que siempre se mantinen compartiendo informacion interesante.
- [Examenes de practica](https://portal.tutorialsdojo.com/courses/aws-certified-solutions-architect-associate-practice-exams/)
Para mi este es el mejor recurso que puedes utilizar como parte final de tu preparacion y te explico porque y como lo utilice yo:
En este punto ya haz visto videos clases, laboratorios, charlas y videos cortos de youtube para aclarar conceptos y es momento de ponerte a prueba en un escenario parecido al que tendras el dia del examen. Te recomiendo que comiences con los examenes bajo revision de 65 preguntas sin sentirte presionado por el cronometro, muchas veces intentamos adivinar y muchas veces acertamos, cuando estes en este escenario aunque hayas acertado marca la pregunta para revision porque aunque acertaste la idea es aprender y este es el mejor momento para hacerlo, puedes filtrar tambien por las preguntas que fallaste y esta es la mejor parte porque te ayudara a repasar esos servicios y cenceptos donde tienes falencias.
No intentes memorizar preguntas, estas preguntas no son iguales a las de un examen, pero si son escenarios similares que te ayudan a desarrollar capacidad de analisis y profundizar donde tienes fallas. Tambien podras ver los resultados del examen por area, asi que si hay un area en especifico donde tienes falencias podras tomar examenes sobre areas especificas, es decir, si la mayoria de tus respuesta erroneas estan dentro de "Arquitecturas resilientes" puedes tomar examenes especificamente para esta area o especificamente para servicios que cubren esta area y a medida que falles tendras una cosa mas en la que aprender, profundizar o repasar, de verdad me encanta este recurso.
Yo realice un recuadro para llevar un control de los examenes de practica que hacia y la puntuacion, te muestro a continuacion:

Despues de cada examen iba anotando la cantidad de preguntas que salieron para cada area, los aciertos, desaciertos y en la ultima columna una proporcion porcentual, el area con puntuacion mas baja era en la que me debia enfocar y profundizar, creeria yo que despues de varios examenes y que estes por encima del 80% de aciertos estas listo para tomar tu examen.
Por ultimo puedes tomar examenes cronometrados para que vayas tomando el tiempo que debes disponer para cada pregunta. En mi casi estuvo un poco ajustado solo me sobraron 7 min en el examen real, lo cual destine para revisar preguntas en las que tenia duda y marque para revisar luego, hubiese preferido tener al menos 20 minutos para esto.
## Agenda tu examen
No esperes realizar todos estos pasos para agendar tu examen, porque mientras no exista la fecha compromiso estaras expuesto a procrastinacion y pensamientos de inseguridad. Te recomiendo agendar el examen al menos despues del curso de praparacion, una vez agendado comienza con los examenes de practicas, laboratorios y charlas, para mantenerte inmerso mientras esperas el gran dia para obtener tu certificacion.
## Areas o servicios para prestar atencion especial:
Esto es muy variable en cada examen, pero tengamos presente que certificacion estamos presentando o mejor dicho cual no estamos presentando y asi no profundizamos tanto en aspectos que no son relevantes para un arquitecto de soluciones. Te nombrare algunos que para mi son indispensables:
- VPC: Este servicio es tan amplio e importante en una arquitectura de nube que merece toda la atencion posible, ademas dentro una VPC existen disintos componentes pertenecientes a diferentes servicios fundamentales dentro de una arquitectura, asi como tambien estos componentes y servicios estan presentes cuando una organizacion y empresa quieren migrar a la nube de manera paulatina, es decir que quieren iniciar con una arquitectura hibrida, en resumen, en mi opinion deberias saber armar una vpc completa desde cero con sus componentes fundamentales, en el curso de preparacion lo explican muy bien, fue mi parte preferida del curso.
- Migracion y exportacion de datos: Si usamos la logica el primer paso para llegar a la nube es saber como hacerlo, este punto es la primera pregunta que se hace una empresa cuando el cloud aparece en su radar, pueden comenzar migrando toda su arquitectura, migrando base de datos o migrando datos a servicios epecificos como S3 utilizando dispositivos como lo de la "familia Snow" o utilizando sistema de archivos compartidos como EFS, etc
- Seguridad: Si revisas la guia del examen, te daras cuenta que el examen esta dividido en las 4 secciones que ya vimos, con un porcentaje de las preguntas para cada seccion siendo seguridad la seccion con mayor porcentaje, ademas que el principal foco de AWS es la seguridad, es su bandera. Aqui quiero hacer un parentesis, por lo menos en mi examen vi mucho sobre AWS Organizations y cuando yo estudie no le di mucha importancia, pero una empresa madura y con buenas practicas desde el inicio si quiere hacer las cosas bien comienza implementando organizaciones, asi que atencioncon esto.
- Serverless y desacople: Recuerden que al inicio les comentaba que serverless fue una constante durante el examen: Esto incluye Lambda, Aurora serverless, DynamoDB, Contenedores y Kubernetes utilizando tecnologia Fargate. En la parte de desacople el predominante es SQS standar y de tipo FIFO, no se olviden los caso de uso para cada una de estas o al menos cuando si o si deben ser de tipo FIFO.
## Que no salio en el examen ni por las curvas:
No vi absolutamente nada sobre Machine Learning y hay muchisimos servicios sobre este tema y de hecho en el curso de preparacion se ven la mayoria, no te estoy diciendo que no los revises, es bueno saber al menos para que se utiliza cada servicio, una revision flash estaria bien, no creo que sea necesario ponerte a desarrollar modelos, desplegarlos y construir laboratorios sobre esto, seria lo contrario si presentas una certificacion sobre analitica o la certificacion de "Data Engineer Associate" por eso recalco siempre que tengamos en cuenta cual es la certificacion que vamos a tomar para saber en que merece la pena profundizar, es solo una opinion.
## Como presentar el examen y cuando llego el resultado
Para mi es mucho mejor presentar el examen de manera presencial, esto te restara un monton de dificultades que se pueden presentar si tomas el examen online, con situaciones que tu no controlas, como el servicio de internet, un vecino escuchando musica a todo volumen, el venderdor de aguacates o de platanos gritando por la calle "La gente de Colombia y Venezuela" entienden la referencia.
El dia del examen obligatoriamente debes llevar tu documento de identidad principal (ID, Cedula, DNI, Pasaporte) y tambien piden un documento secundario que podria ser (Carnet estudiantil, licencia de conducir, carnet de servicios medicos) etc.
Mientras el resultado no llegaba habia mucha tension en mi, revisaba cada 30 min mi correo y mi perfil de AWS certificate. Aunque AWS estima que los resultados estan listos entre 24 horas y 5 dias, mis resultados llegaron el mismo dia por la noche unas 8 horas despues del examen.
## No olvides pasar por aqui
Si utilizas estos recursos, te funcionan y consigues tu certificacion, no olvides compartirlo conmigo en los comentarios, por Linkedin o por donde prefieras, me pondria feliz saber que el tiempo que dedique para hacer este post le sirvio al menos a una persona, cualquier duda o cunsulta durante la preparacion tambien me puedes escribir por aca o por Linkedin.
El proximo paso es construir proyectos en los que pueda utilizar los servicios que mas tienen que ver con mi area "Ingenieria de datos" y por un ladito indagar en los servicios de seguridad y redes que son cosas que me apasionan y que se parecen mucho a lo que hacia antes de hacer el cambio de carrera y que si apunto a un cargo como Arquitecto de soluciones tendria muchas mas posibilidades, todo esto mientras llega una buena oportunidad de trabajo, si en tu empresa hay alguna para mi, no dudes en recomendarme, estaria agradecido.
Hasta la proxima.
| madriz03 |
1,866,698 | Despicably Clever: URL Hacks For Content Creators | Intro: YouTube is like a big box full of videos waiting to be watched. I like to share... | 0 | 2024-05-27T16:27:32 | https://dev.to/balagmadhu/despicably-clever-url-hacks-for-content-creators-3d0 | tricks, contentwriting | ## Intro:
YouTube is like a big box full of videos waiting to be watched. I like to share cool podcasts and new demos with my friends at work. Sometimes, when people send us a video, they tell us to start watching at a certain part. This made me wonder, how can we make watching videos better for everyone? In this blog, I’m going to talk about some easy tips I found that help us share and watch YouTube videos in a better way, so we always get to the good parts quickly
## Transforming Your YouTube Links with These Tricks
**Tip 1** - **Time-Travel Trick**:
the essence of jumping straight to the desired time in a video, making it easier for your readers to get straight to the interesting part that you wanted to chat about. This could be by just adding a time parameter and value in seconds.
For example if I wanted to share the Microsoft Builds Keynote section about the Co-Pilot announcement
```
Original Link : https://www.youtube.com/watch?v=8OviTSFqucI
```
Adding the time parameter
```
&t=2254
```
GitHub Co-Pilot
```
https://www.youtube.com/watch?v=8OviTSFqucI&t=2245s
```
A neat shortcut for navigating through videos efficiently.
**Tip 2** - **Skip Start Trick**:
This title conveys the idea of bypassing the initial part of a video by using seconds, which is perfect for when you want to skip straight to the action without the wait. It’s a handy trick for viewers who want to get to the point fast.
Adding the start at parameter (units in seconds)
here we are skipping first 34 seconds.
```
https://www.youtube.com/watch?v=vBCrJaLseQc&t=35s
```
This is similar to the timing one, but is a bit faster to type and doesn't require you to remember a certain timestamp.
**Tip 3** - **Thumbnail Deception**:
It's common when searching Google for images to see pictures from YouTube videos, usually titled maxresdefault. With a URL tweak, you can easily view a high-quality thumbnail for any YouTube video (if it has one) by visiting the following:
```
https://img.youtube.com/vi/**_vBCrJaLseQc_**/maxresdefault.jpg
```
**Tip 4** - **Thumbnail Deception**:
Found a YouTube video that has a GIF-worthy moment? You can easily create an animated GIF from any part of a video by adding gif before the YouTube link.
```
https://gifs.com/watch?v=**<u>vBCrJaLseQc</u>**
```
**Tip 5** - **Transcripts **:
Video transcripts are really useful in many cases. Say you want to grab a line from a video, but it’s annoying to keep stopping and typing it out. Or maybe you’re trying to locate a part of a video, but you don’t want to sit through the whole thing again. If you have the video’s transcript, you can quickly find what you need without all the hassle
**Tip 6**- **Screen off / Sound On**:
If you've tried listening to music on YouTube via your mobile device, you may have noticed one thing: You can't navigate out of the app. You have to keep YouTube open, and you can't use your phone for anything else, in order to listen to something on YouTube. Kind of frustrating if you're trying to multitask on your commute home, right?
Now, there are hacks so you can listen to YouTube content in the background while still using your mobile device.
https://support.google.com/chrome/answer/13514529?hl=en
https://www.howtogeek.com/840247/how-to-view-the-youtube-desktop-site-in-chrome-for-android/
More amazing content
https://support.google.com/youtube/topic/9257530?hl=en&ref_topic=9257610&sjid=2243655045144781321-EU
Do share what tricks I have missed out
| balagmadhu |
1,866,755 | How to Write a Standout Cover Letter as a Junior Developer | Personalize the Greeting: Address the letter to a specific person, such as the hiring manager,... | 0 | 2024-05-27T16:27:07 | https://dev.to/bingecoder89/how-to-write-a-standout-cover-letter-as-a-junior-developer-322j | beginners, tutorial, codenewbie, career | 1. **Personalize the Greeting**:
- Address the letter to a specific person, such as the hiring manager, rather than using generic salutations like "To Whom It May Concern."
2. **Engaging Opening Statement**:
- Start with a compelling hook that grabs attention, such as a brief story about your passion for coding or a notable achievement relevant to the job.
3. **Tailor to the Job Description**:
- Highlight how your skills and experiences match the specific requirements and responsibilities listed in the job posting.
4. **Showcase Relevant Projects**:
- Mention key projects you’ve worked on, emphasizing those that demonstrate skills pertinent to the position, such as coding languages, frameworks, or problem-solving abilities.
5. **Quantify Achievements**:
- Use metrics to illustrate your accomplishments, such as "improved website load time by 30%" or "developed a feature used by 500+ users daily."
6. **Highlight Soft Skills**:
- Include examples of teamwork, communication, and other interpersonal skills that are crucial for a collaborative development environment.
7. **Explain Your Motivation**:
- Articulate why you’re excited about the role and the company, showing that you’ve researched the organization and understand its mission and culture.
8. **Show Willingness to Learn**:
- Emphasize your eagerness to grow and learn, which is essential for a junior developer. Mention any ongoing education or personal projects that demonstrate this.
9. **Professional Formatting and Tone**:
- Ensure the cover letter is professionally formatted, concise, and free of errors. Use a tone that is formal yet personable.
10. **Call to Action**:
- End with a strong closing statement, expressing your enthusiasm for the opportunity to discuss your application further and your willingness to interview at their convenience.
Happy Learning 🎉 | bingecoder89 |
1,865,925 | Devlog - Creating a MVCI JavaFX Application | Introduction In this Devlog, I plan to detail the application I have been developing and... | 0 | 2024-05-27T16:24:49 | https://dev.to/azeleke/devlog-creating-a-multi-page-javafx-application-52hk | java, javafx, docker, mvci | ## Introduction
In this Devlog, I plan to detail the application I have been developing and the lessons I have learnt from choosing JavaFX as my platform to build my application on.
{% embed https://youtu.be/6MlOMs-bs5g %}
List of dependancies used: [Source Code](https://github.com/FamaZeleke/devInspector/blob/main/pom.xml)
## Concept
The project began as a CLI-style mini-Java application. At my workplace, we use Docker extensively, so I aimed to build a tool to support developers with a similar tech stack. The initial application used the Scanner class to take user input and execute commands like `docker ps`.
```
public static void dockerMenu(Scanner input) {
out.println("╔══════════════════════════════╗");
out.println("║ Docker Commands ║");
out.println("╚══════════════════════════════╝");
out.println(" 1. ➤ Option 1: Docker PS");
out.println(" 2. ➤ Option 2: Docker Images");
out.println(" 3. ➤ Option 3: Back");
out.println("\nPlease select an option (1-3): ");
int selection = input.nextInt();
input.nextLine();
String selectedOption = getAndHandleUserInput(selection, 3);
if (selectedOption != null) {
out.println("Selected option: " + selectedOption);
switch (selectedOption) {
case "selectedMenu1": {
DockerCLI.runDockerCommand("ps");
break;
}
case "selectedMenu2": {
DockerCLI.runDockerCommand("images");
break;
}
}
}
}
```
Whilst useful and easily extensible, I felt the need to still access docker to do more complicated actions. This became the basis of the problem that my application will grow to solve - how to interact with docker without using the docker desktop or docker CLI.
My solution was to build an application that will streamline how a user interacts with docker through a neat GUI built with JavaFX. In time, I will add more features that will go beyond what Docker Desktop already does, but to keep the scope focused, I decided to remake the core features in the application first.
## Planning the UI
I used Figma, a fantastic tool for design and prototyping, to create quick wireframes for guiding the UI development. This approach prevents the common pitfall of building an ad-hoc UI that can quickly become unmanageable. Instead, it provides constraints and clear goals for development. [Link to Figma Board](https://www.figma.com/design/0P3mFhyRBIZXaJDxASDNxN/JavaFX?node-id=56-475&t=HtN4ksTcmBvtVYsS-1)

## First Blocker
JavaFX has a preference to be ran inside a modular project:
```
module nivohub.digitalartifactmaven {
requires javafx.controls;
requires javafx.fxml;
requires docker.client;
exports nivohub.devInspector;
exports nivohub.devInspector.view;
exports nivohub.devInspector.model;
exports nivohub.devInspector.controller;
}
```
As the project grew, I encountered split package issues with the Docker Java API. These issues arose because the Docker Java API library has the same package names split across multiple modules that conflict with the strict module boundaries enforced in a modular project - [Solutions that may work for you in this event](https://msayag.github.io/SplitPackage/)
Since I could not find an easy solution for using this library in a modular project, I opted to forgo the benefits introduced in Java 9 and made my project non-modular by creating a launcher class to bypass the module system constraints [Deploying non-modular JavaFX applications](https://nikhiladigaz.medium.com/deploying-non-modular-javafx-applications-using-maven-and-launch4j-fb95b8ab0739).
```
package nivohub.devInspector;
public class MainApplicationLauncher {
public static void main (String[] args) {
AppRoot.main(args);
}
}
```
I was not too worried about this because the system architecture I chose inherently provides benefits like encapsulation, separation of concerns, and reinforces single responsibility when implemented correctly. Therefore, managing the visibility of internal classes seemed excessive for this project.
## Wrestling with Model-View-Controller
I initially built the project with an MVC system where the view - consumes the model's data and the controller - takes actions from the user, driven by events in the view, which then in turns updates the model to be represented in the view.
```
public class DockerController {
private final DockerScene view;
private final DockerManager model;
public DockerController(DockerScene view, DockerManager model) {
this.view = view;
this.model = model;
populateImageSelection();
setupImageSelectionListener(view);
handleRunButtonAction();
}
```
### This introduced a few challenges:
**1. Limited documentation on MVC in JavaFX**
The first issue in choosing this system for my application was the limited information available online on how to properly implement MVC in JavaFX - this, coupled with contradictions online and my own misunderstandings of MVC led to tightly coupled classes. For instance, in the DockerScene class, the controller setup is tightly coupled, requiring type checks and casting:
```
public DockerScene(AppMenu appMenu) {
super(appMenu);
this.appMenu = appMenu;
}
@Override
public void setController(Object controller) {
if (controller instanceof DockerController) {
this.controller = (DockerController) controller;
} else {
throw new IllegalArgumentException("Controller must be a DockerController");
}
}
```
**2. Model and Domain Objects**
Another challenge was managing the complexity of the Model. The Model contains all the data and logic to interface with external parts of the system, such as databases or external APIs.
In my **DockerManager class**, the model not only holds data but also interacts directly with the Docker API, creating a potential single point of failure and making the system more difficult to test and maintain.
**3. Difficulty in Scaling and Maintaining the Application**
Another significant challenge with MVC in JavaFX is scaling and maintaining the application as it grows. The tight coupling between controllers and views, along with complex models, makes the application harder to extend with new features.
As the application grows, the interdependencies between different parts of the system become more pronounced, making it difficult to isolate and modify individual components without affecting others. This complexity can lead to increased development time, more bugs, and higher maintenance. [Cohesion and Coupling](https://dev.to/m__mdy__m/cohesion-and-coupling-in-javascript-2efg)
## Model-View-Controller-Interactor
To address the challenges I faced with MVC in JavaFX, I transitioned to the Model-View-Controller-Interactor (MVCI) framework.
[Fantastic resource on MVCI in JavaFX](https://www.pragmaticcoding.ca/javafx/Mvci-Introduction)
Unlike MVC, MVCI includes an Interactor component that manages the application's business logic and interactions with external systems, like APIs or databases.
This separation ensures that the Model only contains state data, making the system easier to test and maintain.
The Interactor handles complex operations, reducing the tight coupling between components and allowing for more scalable and modular application architecture.
### Model
In this example below our **UserModel** is a POJO that takes advantage of JavaFX's bindable properties to store and allow observation of our data to our view:
```
public class UserModel {
private final StringProperty fullName = new SimpleStringProperty("");
private final StringProperty inputPassword = new SimpleStringProperty("");
private final BooleanProperty loginFailed = new SimpleBooleanProperty(this, "loginFailed", false);
private final BooleanProperty authenticated = new SimpleBooleanProperty(this, "authorized", false);
private final String password = "letmein";
private String platform;
private String osArch;
public BooleanProperty loginFailedProperty(){
return loginFailed;
}
public BooleanProperty authenticatedProperty() {
return authenticated;
}
public StringProperty fullNameProperty() {
return fullName;
}
public StringProperty inputPasswordProperty() {
return inputPassword;
}
public String getFullName(){
return fullName.get();
}
public String getPassword() {
return password;
}
public String getInputPassword() {
return inputPassword.get();
}
```
The UserModel maintains user data and state, such as fullName, inputPassword, loginFailed, and authenticated.
### View
The view establishes bindings to properties in the model to represent the data to the user.
In the example below the **LoginViewBuilder** binds the input properties of the name and password to the simple properties in **UserModel**.
It can also take parameters such as a Runnable or Consumer to handle user events and inform the controller... whilst remaining agnostic of what class provides this:
```
public class LoginViewBuilder implements Builder<Region> {
private final UserModel model;
private final Runnable loginHandler;
public LoginViewBuilder(UserModel model, Runnable loginHandler) {
this.model = model;
this.loginHandler = loginHandler;
}
@Override
public Region build() {
GridPane results = new GridPane();
results.setPadding(new Insets(25));
results.setHgap(10);
results.setVgap(10);
results.setAlignment(Pos.CENTER);
results.add(welcomeLabel(), 0, 0);
results.add(boundNameLabel(), 1, 0, 2, 1);
results.add(nameLabel(), 0, 1);
results.add(nameInput(), 1, 1);
results.add(passwordLabel(), 0, 2);
results.add(passwordInput(), 1, 2);
results.add(createLoginButton(), 1, 3);
results.add(errorMessage(), 1, 4);
return results;
}
private Node createLoginButton() {
Button loginButton = new Button("Login");
loginButton.setOnAction(event -> loginHandler.run());
return loginButton;
}
private Node passwordInput(){
return boundPasswordField(model.inputPasswordProperty(), "Enter Password", loginHandler);
}
private Node nameInput(){
return boundTextField(model.fullNameProperty(), "Enter Full Name", loginHandler);
}
```
I am also implementing an interface provided by JavaFX called **Builder<>** which allows the controller to expose a method to create a view without having to reference the view or its dependancies!
```
public abstract class BaseController {
protected Builder<Region> viewBuilder;
public Region getView() {
return viewBuilder.build();
}
}
```
### Controller
The controller's job is simply to distributes _'jobs'_ to interactors and other controllers.
In this example, the **LoginController** instantiates the interactor and the view. By implementing the BaseController, we inherit the public method to build the view from the controller as well:
```
public class LoginController extends BaseController{
private final LoginInteractor interactor;
private final ApplicationController applicationController;
public LoginController(UserModel model, ApplicationController applicationController) {
interactor = new LoginInteractor(model);
viewBuilder = new LoginViewBuilder(model, this::loginUser);
this.applicationController = applicationController;
}
private void loginUser() {
Task<Boolean> task = new Task<>() {
@Override
protected Boolean call() throws PasswordException {
return interactor.attemptLogin();
}
};
task.setOnSucceeded(e -> {if (Boolean.TRUE.equals(task.getValue())){
interactor.updateFailedLogin(false);
applicationController.loadMainView();
}
});
task.setOnFailed(e -> {
interactor.updateFailedLogin(true);
});
task.run();
}
}
```
In more complex/fat controllers, using interfaces allows us to effectively share methods across the application to other controllers:
```
public interface DockerInterface {
void connectDocker();
void disconnectDocker();
void startContainer(String containerId);
void stopContainer(String containerId);
void removeContainer(String containerId);
void stopThread();
}
```
For example, the **MenuBarController** uses the interface implementations from the **DockerController** without being aware of the controller itself:
```
public class MenuBarController extends BaseController{
private final MenuBarInteractor interactor;
public MenuBarController(ApplicationModel applicationModel, DockerInterface dockerInterface, DockerModel dockerModel, ApplicationInterface applicationInterface) {
interactor = new MenuBarInteractor(applicationModel);
viewBuilder = new MenuBarBuilder(this::handleView, dockerInterface, dockerModel, applicationInterface);
}
```
This interface is then used in the view to handle user-driven events like connecting and disconnecting the Docker connection (This is also how I handle the user input to change the views with the MenuBar !):
```
Node connectDockerButton = styledRunnableButton("Connect", dockerInterface::connectDocker);
connectDockerButton.disableProperty().bind(dockerModel.dockerConnectedProperty());
Node disconnectDockerButton = styledRunnableButton("Disconnect", dockerInterface::disconnectDocker);
disconnectDockerButton.disableProperty().bind(dockerModel.dockerConnectedProperty().not());
```
### Interactor
The interactor bridges our system. Below is the **LoginInteractor**, which has two public methods: `attemptLogin()` and `updateFailedLogin()`. The interactor handles the business logic, such as verifying user credentials against the stored password in the model, and updates the state accordingly.
```
public class LoginInteractor {
private final UserModel model;
public LoginInteractor(UserModel model) {
this.model = model;
model.authenticatedProperty().bind(Bindings.createBooleanBinding(this::isPasswordValid, model.inputPasswordProperty()));
}
private boolean isPasswordValid(){
return model.getPassword().equals(model.getInputPassword());
}
public boolean attemptLogin() throws PasswordException {
if (isPasswordValid()){
return true;
} else {
throw new PasswordException("Invalid password");
}
}
public void updateFailedLogin(Boolean result){
model.loginFailedProperty().set(result);
}
}
```
These methods are called from the **LoginController** as a Task and on success/failure of a Task. This maintains a separation of concerns between workflow control/job distribution and business logic.
Interactors however, allow us to uniquely interact with the outside e.g. domain objects. For example, methods for Docker communication are encapsulated in a domain object [**DockerEngine**](https://github.com/FamaZeleke/devInspector/blob/main/src/main/java/nivohub/devinspector/docker/DockerEngine.java), initialised by the **DockerInteractor**, which accesses the necessary methods within the business logic.
That wraps up the crux of the MVCI system. PragmaticCoding is a blog written by a retired expert in the field of which I learnt most of this system from: [ProgramaticCoding](https://www.pragmaticcoding.ca/javafx/mvci/)
## Tasks and Threads
One key constraint in using JavaFX is that it handles updates to the UI/Scene graph on a single thread known as the FXAT (JavaFX Application Thread). Meaning all changes to the UI must be done on the FXAT.
It also has no concept of time and is simply a queue of jobs to be executed in order. PragmaticCoding covers this in detail here: [FXAT](https://www.pragmaticcoding.ca/javafx/elements/fxat#what-is-the-fxat-anyway)
Since my application revolves around communicating with Docker, which includes potential long running tasks, it would not be performant to execute those tasks on the FXAT...
This is where Tasks come in:
```
@Override
public void connectDocker() {
interactor.addToOutput("Connecting to Docker...");
Task<Void> task = new Task<>() {
@Override
protected Void call() throws DockerNotRunningException {
interactor.connectDocker();
return null;
}
};
task.setOnSucceeded(e -> {
interactor.addToOutput("Connected to Docker");
interactor.updateModelConnection(true);
interactor.listContainers();
interactor.listImages();
});
task.setOnFailed(e -> interactor.addToOutput("Failed to connect to Docker :"+e.getSource().getException().getMessage()));
new Thread(task).start();
}
```
> Task is an abstract generic class that has methods for communicating between a background thread and the FXAT and a single abstract method name call().
In my example above, the **task** containing the call to **connectDocker()** runs on a new background thread (this is because I am using apacheHttp5 to communicate with docker for window users which is a long running task). On success or failure, it updates the UI on the FXAT e.g. `interactor.addToOutput("Connected to Docker")`
This prevents the long running tasks from blocking the UI and making it unresponsive as it is ran on a background thread and while still being able to update UI on the FXAT when the task gets completed.
### Future Plans
This DevLog covers the current state of my project. Moving forward, I plan to enhance this application by integrating industry-leading libraries like Guice for dependency injection, which will not only simplify writing tests but also improve overall code modularity and manageability. I also will aim to address potential threading issues, such as memory leaks and deadlocks, by implementing thread pooling or exploring green threads. This will ensure more efficient and safe multi-threading within the application.
I attempted to manage distribution in a .app for MacOS users and provided a .bat for Windows but there are simpler packaging solutions that can make this application run across platforms like making an executable jar.
Beyond that, I want to extend the features of the application to provide a unique use case that is differentiated from the Docker Desktop Client. The investment so far has given me an extensible foundation to do so.
| azeleke |
1,866,753 | AI Model for Predicting Oncology Treatment Success and Cancer Stage | A post by Yashashri Ludbe | 0 | 2024-05-27T16:24:47 | https://dev.to/ethan_smith_d6613cd36/ai-model-for-predicting-oncology-treatment-success-and-cancer-stage-5eo9 |

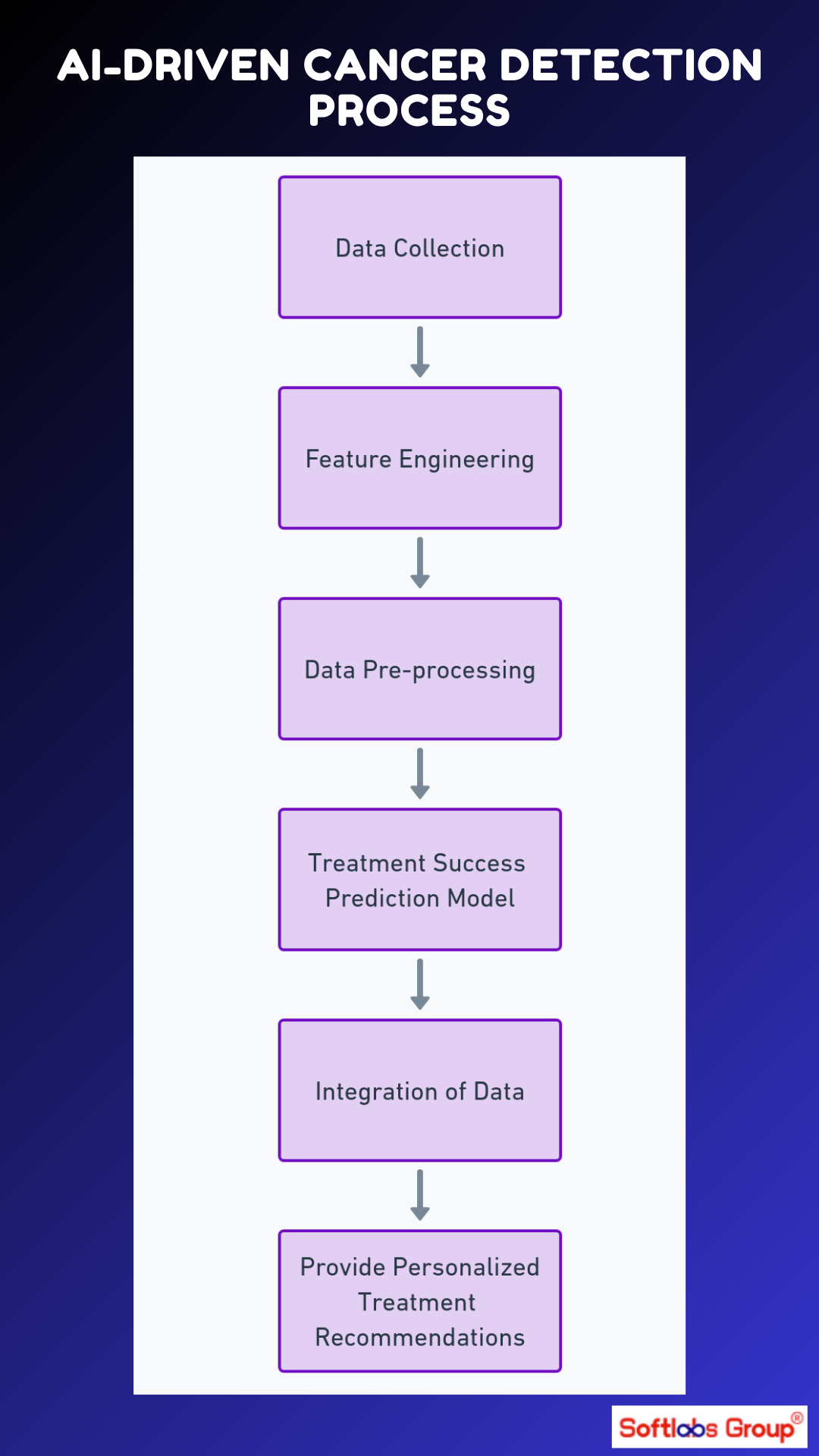[](https://www.softlabsgroup.com/ai-solutions/ai-model-for-predicting-oncology-treatment-success-and-cancer-stage/) | ethan_smith_d6613cd36 | |
1,866,752 | stakes777 casino : Une plateforme de jeu en ligne qui monte | Le monde des casinos en ligne est vaste, mais stakes777 se fait remarquer par son approche centrée... | 0 | 2024-05-27T16:24:37 | https://dev.to/__d4a26803/stakes777-casino-une-plateforme-de-jeu-en-ligne-qui-monte-50jp | Le monde des casinos en ligne est vaste, mais [stakes777 ]
(https://stakes777-casino.com/)se fait remarquer par son approche centrée sur l'expérience des joueurs. Le site propose une vaste gamme de jeux, incluant des classiques comme les machines à sous et des options de jeu en direct comme le blackjack et la roulette. Les joueurs peuvent explorer une variété de jeux tout en profitant de promotions attrayantes et d'un service client dédié.
Au-delà des jeux, stakes777 casino en ligne met l'accent sur la sécurité et la confidentialité des données de ses membres. Le site utilise des technologies de cryptage avancées pour assurer la protection des informations personnelles et financières. Les joueurs peuvent ainsi déposer et retirer des fonds en toute confiance, en utilisant des méthodes de paiement reconnues et sécurisées.
L'une des grandes forces de stakes777 réside dans son offre de bonus attractifs pour les nouveaux membres et les joueurs réguliers. Les bonus de dépôt, les tours gratuits et les offres spéciales sont conçus pour améliorer l'expérience de jeu et augmenter les chances de gains significatifs. | __d4a26803 | |
1,866,751 | Taming the Beast: Implementing API Rate Limiting and Throttling | In today's API-driven world, ensuring the smooth operation and stability of your backend services is... | 0 | 2024-05-27T16:24:30 | https://dev.to/syncloop_dev/taming-the-beast-implementing-api-rate-limiting-and-throttling-46jl | webdev, javascript, api, programming | In today's API-driven world, ensuring the smooth operation and stability of your backend services is paramount. A critical aspect of achieving this is managing API traffic effectively. Uncontrolled request surges can overwhelm your servers, leading to performance degradation, outages, and a frustrating user experience.
This is where API rate limiting and throttling come into play. These techniques act as guardians at the API gateway, regulating the flow of incoming requests and protecting your infrastructure from overload.
## What's the Difference?
While often used interchangeably, there's a subtle distinction between rate limiting and throttling:
**Rate Limiting**: Defines a hard limit on the number of requests an API can receive within a specific time window (e.g., requests per second, minute, or hour). Exceeding this limit results in a temporary block for the client.
**Throttling**: Offers a more dynamic approach. It allows some requests to pass even after the limit is reached, but at a slower pace. This could involve introducing delays or reducing the quality of service (QoS) for subsequent requests.
## Why Implement Rate Limiting and Throttling?
The benefits of implementing these techniques are numerous:
**Prevents Denial-of-Service (DoS) attacks**: Malicious actors often employ DoS attacks to flood your API with requests, rendering it inaccessible to legitimate users. Rate limiting and throttling can thwart such attempts by capping the number of requests from a single source.
**Improves API performance**: By regulating traffic flow, you ensure your servers aren't overwhelmed by sudden spikes in requests. This leads to faster response times and a more consistent user experience.
**Fairness and Resource Management**: Prevents a single user or application from monopolizing resources, ensuring fair access for all API consumers.
**Cost Optimization**: By preventing unnecessary traffic, you can optimize your cloud resource utilization and potentially reduce costs.
## Statistics that Reinforce the Importance:
A 2022 report by Akamai indicates that API abuse attempts have grown by a staggering 181%. This highlights the increasing need for robust API protection mechanisms.
A study by Radware found that 40% of organizations experienced an API-related security incident in the past year. Implementing rate limiting and throttling can significantly reduce this risk.
**Examples and Use Cases:**
**E-commerce Platforms**: Here, rate limiting can be used to prevent bots from scalping limited-edition products by restricting the number of purchase requests per user within a short timeframe.
**Social Media APIs**: Throttling can be beneficial to manage excessive content creation or rapid following requests from a single account, potentially indicating automated activity.
**Payment Gateways**: Rate limiting can be crucial to safeguard against fraudulent transactions. Limiting login attempts and transaction requests per user can significantly reduce the risk of unauthorized access.
## Latest Tools and Technologies:
**API Gateway Solutions**: Many cloud providers like AWS API Gateway and Azure API Management offer built-in rate limiting and throttling functionalities.
**Open-Source Libraries**: Popular libraries like Netflix's Hystrix and Apache Camel provide granular control over rate limiting and throttling implementations.
**Custom-built Solutions**: For specific needs and complex scenarios, developers can create custom rate limiting and throttling mechanisms using programming languages like Python or Java.
**Integration Process**:
The integration process varies depending on the chosen technology. Here's a general outline:
**Define Rate Limits and Throttling Policies**: Determine appropriate limits based on your API's capacity and expected usage patterns. Consider factors like request types, user roles, and time windows.
**Choose the Implementation Method**: Select the most suitable approach based on your technical stack and desired level of control. Cloud API gateways offer a user-friendly configuration interface, while libraries or custom solutions require coding expertise.
**Configuration and Deployment**: Configure the chosen method with your defined policies. Thoroughly test the implementation to ensure it functions as expected before deploying to production.
## Benefits and Considerations:
**Benefits**:
**Improved Scalability**: By managing traffic, your APIs can handle increased loads without compromising performance.
**Enhanced Security**: Mitigates the risk of API abuse and DoS attacks.
**Granular Control**: Provides the ability to tailor policies to specific API endpoints or user groups.
**Considerations**:
**Setting Appropriate Limits**: Setting limits too low can frustrate legitimate users, while too high might leave your API vulnerable.
**False Positives**: Fine-tuning is crucial to avoid accidentally blocking legitimate traffic.
**Distributed Denial-of-Service (DDoS) Attacks**: While rate limiting and throttling can help, they might not be sufficient against sophisticated DDoS attacks that originate from a vast network of compromised machines. Consider implementing additional security measures like IP reputation checks and CAPTCHAs to mitigate such threats.
**Monitoring and Analytics**: Continuously monitor API traffic patterns and analyze the effectiveness of your rate limiting and throttling strategies. This helps you identify and adjust policies as needed.
**API Documentation**: Clearly document your rate limiting and throttling policies within your API documentation. This informs developers about usage expectations and helps them design their applications accordingly.
**Advanced Techniques**:
**Leaky Bucket Algorithm**: This algorithm visualizes rate limiting as a bucket with a fixed capacity and a leak at the bottom. Requests arrive at a certain rate, and if the bucket overflows, subsequent requests are rejected. The leak rate determines the maximum allowed request throughput.
**Token Bucket Algorithm**: This approach provides more burstiness compared to the Leaky Bucket. It assigns tokens to users at a fixed rate. Each request consumes a token, and users can queue up for tokens if they run out. This allows for short bursts of requests exceeding the average rate.
## Choosing the Right Approach:
The optimal approach depends on your specific requirements and API usage patterns. Here's a simplified guideline:
**For simple scenarios with predictable traffic**: Cloud API gateway solutions or open-source libraries with pre-built functionalities might suffice.
**For complex scenarios with dynamic traffic patterns or the need for fine-grained control**: Consider custom-built solutions using programming languages like Python or Java. This offers maximum flexibility but requires development expertise.
## Conclusion:
Implementing API rate limiting and throttling is a crucial strategy for ensuring the stability, performance, and security of your APIs. By understanding the concepts, choosing the right tools, and carefully configuring your policies, you can effectively manage API traffic and safeguard your backend infrastructure. Remember, it's an ongoing process that requires continuous monitoring and adjustments to adapt to evolving usage patterns and potential threats.
| syncloop_dev |
1,866,750 | Scraper compania GfK | Scraper Orice scraper există datorită unei echipe de scraper și tester. Scraper-ul... | 0 | 2024-05-27T16:23:40 | https://dev.to/ale23yfm/scraper-compania-gfk-450p | peviitor, scraper, tester, gfk | ## Scraper
Orice scraper există datorită unei echipe de scraper și tester. Scraper-ul companiei **_GfK_** este scris de [Răzvan Chichirau](https://www.linkedin.com/in/chichirau-razvan-617470261/) în limbajul Python și testat de [Camelia Melinte](https://www.linkedin.com/in/cameliaamelinte/), drept muncă voluntară, și poate fi găsit pe GitHub, fiind un proiect open source.
{% github https://github.com/HardChallenge/Scrapers_PeViitor_Razvan %}
---
## Te interesează să scrii un scraper sau să testezi unul?
Poți să te alături proiectului chiar de aici!
[Link Discord peviitor.ro](https://discord.gg/t2aEdmR52a)
---
| ale23yfm |
1,866,481 | Javascript Working Mechanism | when the javascript engine starts executing the code it does : executing code line by line store... | 0 | 2024-05-27T16:13:35 | https://dev.to/ikbalarslan/javascript-working-mechanism-351n | javascript, webdev, programming, core | when the javascript engine starts executing the code it does :
- executing code line by line
- store the data after executing
and it knows the order of executions via call stack. at the bottom of the call stack, there is always a global execution context that will stay.
> Running the code is also known as Execution Context
as an example let's analyze this code
while executing this code by order:
```
- in the memory create a variable and name it a after that set 12 as the value.
- in the memory create a variable and name it square after that set a function definition as a value
- in the memory create a variable and name it sum after that set a function definition as a value
- call the sum
- push sum on top of the call stack
- get the function definition from the global memory
- create a brand new execution context for sum.
```

- create a local memory for the execution context
- create a variable in the local memory and name it twoSquare until finding the value set null as a value
- call the square function:
- push the square function on top of the call stack
- get the function definition from global memory
- create a new execution context for square
- return the value 4 as a result of the function and set it to the twoSquare value
- remove(pop) the square function from the call stack
- The square execution context will be destroyed by the garbage collector.

```
- get the value of the variable a from the global variable
- calculate the execution context and return the value 16 as a result of the function
- remove the function sum from the call stack
- garbage collector will destroy the execution context for function sum
```
```
- then console log hello
- end the global execution context
```
| ikbalarslan |
1,866,556 | Process S3 Objects with Step Functions using CDK + TS | Preface Whenever a user needed to launch automation, our tech lead had to dive into an... | 0 | 2024-05-27T16:12:52 | https://dev.to/aws-builders/process-s3-objects-with-step-functions-using-cdk-ts-20ab | aws, typescript, cdk | ## Preface
Whenever a user needed to launch automation, our tech lead had to dive into an extensive manual process that took about two days to configure everything.
Picture this: an Excel file with over six tabs and data manipulation using Excel functions (a spreadsheet nightmare 👻).
Seeing this madness, I realised we could automate this process (trust me, it was a heated debate to reach this conclusion). Thus, the architecture below was born.
_Remember, we've got some proprietary code, so this is a simplified and slightly fictionalised version to illustrate the solution._
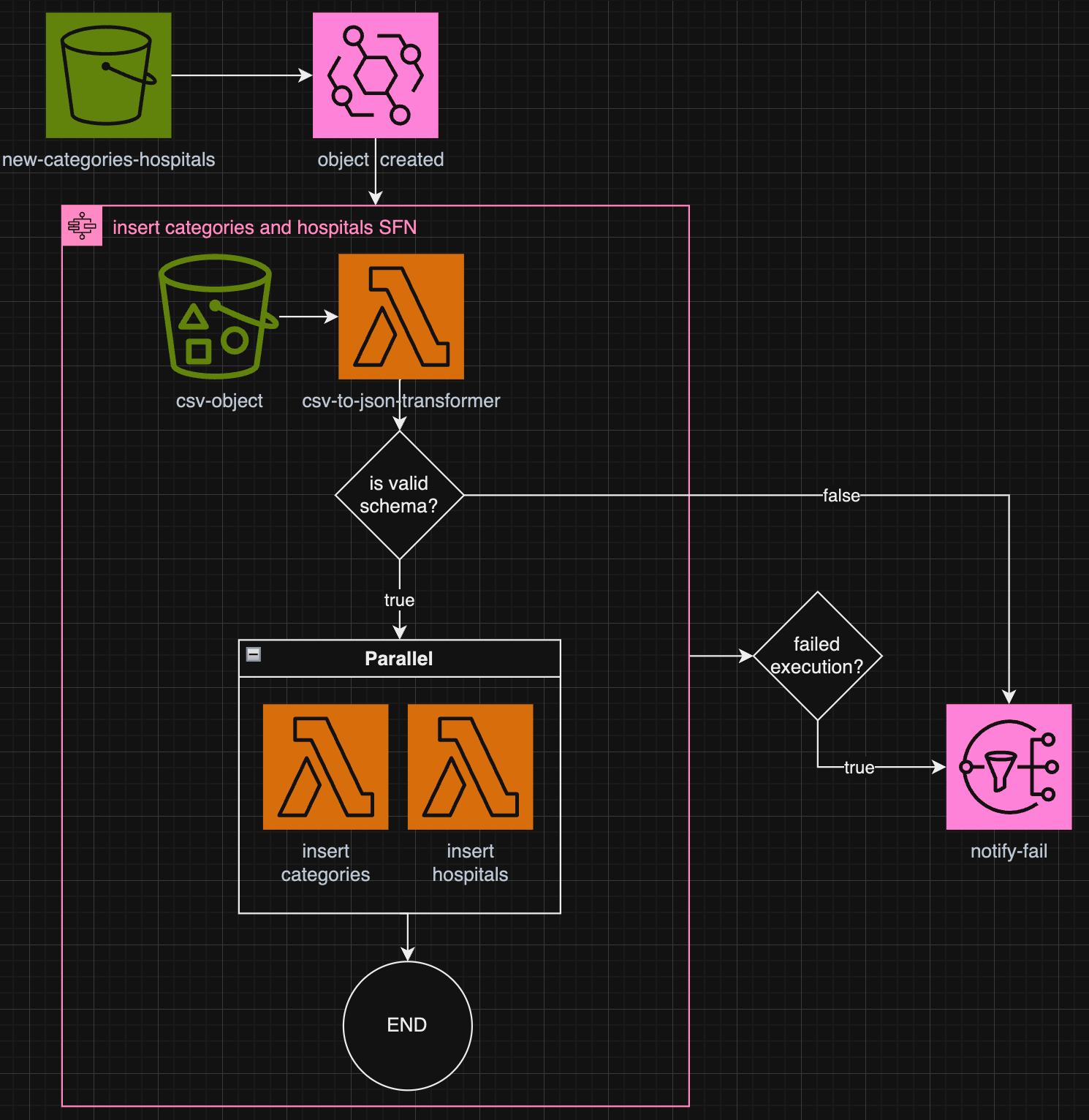
## The Solution
We needed to set up a process to trigger a [Step Function](https://www.youtube.com/watch?v=BTLQjUb2EPk&ab_channel=YanCui) every time an object was created in S3. However, direct invocation of a Step Function is not currently supported. Therefore, I created an EventBridge rule to monitor S3 for object creation. Once an object was created, the rule would invoke the Step Function to process the object using one of the Lambda tasks.
I used the Express type since I needed this to be a quick process. With this decision, I had to parallelise some steps (yes, my automation allowed for that), so, I used the [Parallel state](https://docs.aws.amazon.com/step-functions/latest/dg/amazon-states-language-parallel-state.html). Finally, if any errors occurred, I set up a notification using a topic for that.
> **Express x Standard**
> **Standard**: For long-running processes with exactly-once execution guarantees and advanced recovery features.
> **Express**: For fast, high-throughput processes with at least one execution guarantee and billing based on time and memory.
## Getting your hands dirty

Let's implement it using CDK with Typescript!
Let's start by creating our bucket and importing a topic to notify us of any errors
```typescript
const userNotificationTopic = Topic.fromTopicArn(
this,
'userNotificationTopic',
Fn.importValue('infrastructure::sns::user-notification-topic::arn'),
)
const bucket = new Bucket(this, 'bucket', {
bucketName: 'automation-configuration',
removalPolicy: RemovalPolicy.DESTROY,
})
```
Now, let's create our Lambdas and grant read permissions to the Lambda that will access the S3 object:
```typescript
const etlLambda = new NodejsFunction(this, 'etl-lambda', {
entry: 'src/lambda/etl/etl.handler.ts',
functionName: 'etl',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
bucket.grantReadWrite(
new Alias(this, id.concat('alias'), {
aliasName: 'current',
version: etlLambda.currentVersion,
}),
)
const categoriesLambda = new NodejsFunction(this, 'insert-categories-lambda', {
entry: 'src/lambda/categories/categories.handler.ts',
functionName: 'insert-categories',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
const hospitalsLambda = new NodejsFunction(this, 'hospitals-categories-lambda', {
entry: 'src/lambda/categories/categories.handler.ts',
functionName: 'insert-categories',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
```
To call a Lambda within our Step Function, we need to create a [Lambda Invoke](https://docs.aws.amazon.com/step-functions/latest/dg/connect-lambda.html) for each of the Lambdas. So, I created a function to avoid repeating this for every Lambda:
```typescript
private mountLambdaInvokes(
lambdasInvoke: Array<{
function: IFunction
name?: string
output?: string
}>,
) {
return lambdasInvoke.map(lambdaInvoke => {
return new LambdaInvoke(this, `${lambdaInvoke.name || lambdaInvoke.function.functionName}-task`, {
lambdaFunction: lambdaInvoke.function,
inputPath: '$',
outputPath: lambdaInvoke?.output || '$',
})
})
}
```
Using `mountLambdaInvokes`:
```typescript
const [etlTask, categoriesTask, hospitalsTask] = this.mountLambdaInvokes([
{ function: etlLambda, output: '$.Payload' },
{ function: categoriesLambda },
{ function: hospitalsLambda },
])
```
We need to create our failure step and the [SnsPublish](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_stepfunctions_tasks.SnsPublish.html) to send failed events to the topic we imported earlier:
```typescript
const errorTopicConfig = {
topic: userNotificationTopic,
subject: 'Automation Config Failed 😥',
message: TaskInput.fromObject({
message: 'Automation Config Failed due to an unexpected error.',
cause: 'Unexpected Error',
channel: 'email',
destination: { ToAddresses: ['suporte@somemail.com'] },
}),
}
const publishFailed = (publishFailedId: string) =>
new SnsPublish(this, `automation-config-sns-failed-${publishFailedId}`, errorTopicConfig)
const jobFailed = new Fail(this, 'automation-config-job-failed', {
cause: 'Unexpected Error',
})
```
Having done this, let's set up our [Parallel](https://docs.aws.amazon.com/step-functions/latest/dg/amazon-states-language-parallel-state.html) state. Each branch will be a Lambda processed simultaneously. We'll also add a retry to attempt again if any issues arise and a catch to handle any failures in this parallel process:
```typescript
const hospitalsCategoriesParallel = new Parallel(this, 'auto-config-exams-parallel-map')
.branch(categoriesTask)
.branch(hospitalsTask)
.addRetry({ errors: ['States.ALL'], interval: Duration.seconds(5), maxAttempts: 1 })
.addCatch(publishFailed('exams').next(jobFailed), {
errors: ['States.ALL'],
})
```
At this point, we'll create the definition of our tasks, a log group, and the State Machine, which is essentially our Step Function:
```typescript
const definition = etlTask.next(hospitalsCategoriesParallel)
const logGroup = new LogGroup(this, 'automation-configuration-log-group', {
retention: RetentionDays.ONE_WEEK,
removalPolicy: RemovalPolicy.DESTROY,
})
const stateMachine = new StateMachine(this, `${id}-state-machine`, {
definition,
timeout: Duration.minutes(5),
stateMachineName: 'automation-configuration',
stateMachineType: StateMachineType.EXPRESS,
logs: {
destination: logGroup,
includeExecutionData: true,
level: LogLevel.ALL,
},
})
```
After this, we need to create the rules to associate EventBridge with S3 and the execution of our Step Function:
```typescript
const s3EventRule = new Rule(this, 'automation-config-s3-event-rule', {
ruleName: 'automation-config-s3-event-rule',
})
const eventRole = new Role(this, 'eventRole', {
assumedBy: new ServicePrincipal('events.amazonaws.com'),
})
stateMachine.grantStartExecution(eventRole)
s3EventRule.addTarget(
new SfnStateMachine(stateMachine, {
input: RuleTargetInput.fromObject({
detail: EventField.fromPath('$.detail'),
}),
role: eventRole,
}),
)
s3EventRule.addEventPattern({
source: ['aws.s3'],
detailType: ['Object Created'],
detail: {
bucket: {
name: [bucket.bucketName],
},
object: {
key: [
{
wildcard: 'csv/automation-configuration/*.csv',
},
],
},
},
})
```
Finally, let's create a rule to listen to any unexpected failures that occur in our Step Function through EventBridge as well, thus maintaining the event-driven nature that we love so much:
```typescript
const unexpectedFailRule = new Rule(this, 'exam-automation-config-unexpected-fail-rule', {
ruleName: 'exam-automation-config-unexpected-fail-rule',
})
unexpectedFailRule.addTarget(
new SnsTopic(userNotificationTopic, {
message: RuleTargetInput.fromObject({
subject: 'Exam Automation Config Failed 😥',
message: 'Exam Automation Config Failed due to an unexpected error.',
cause: 'Unexpected Error',
channel: 'email',
destination: { ToAddresses: ['it@somemail.com'] },
}),
}),
)
unexpectedFailRule.addEventPattern({
source: ['aws.states'],
detailType: ['Step Functions Execution Status Change'],
detail: {
stateMachineArn: [stateMachine.stateMachineArn],
status: ['FAILED', 'TIMED_OUT', 'ABORTED'],
},
})
```
Putting everything together in a class so you can understand the entire unified flow:
```typescript
import { Duration, Fn, RemovalPolicy } from 'aws-cdk-lib'
import { Rule, RuleTargetInput, EventField } from 'aws-cdk-lib/aws-events'
import { SfnStateMachine, SnsTopic } from 'aws-cdk-lib/aws-events-targets'
import { Role, ServicePrincipal } from 'aws-cdk-lib/aws-iam'
import { Alias, Architecture, IFunction } from 'aws-cdk-lib/aws-lambda'
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs'
import { LogGroup, RetentionDays } from 'aws-cdk-lib/aws-logs'
import { Bucket } from 'aws-cdk-lib/aws-s3'
import { Topic } from 'aws-cdk-lib/aws-sns'
import { Fail, LogLevel, Parallel, StateMachine, StateMachineType, TaskInput } from 'aws-cdk-lib/aws-stepfunctions'
import { LambdaInvoke, SnsPublish } from 'aws-cdk-lib/aws-stepfunctions-tasks'
import { Construct } from 'constructs'
export default class AutomationConfiguration extends Construct {
constructor(scope: Construct, id: string) {
super(scope, id)
const userNotificationTopic = Topic.fromTopicArn(
this,
'userNotificationTopic',
Fn.importValue('infrastructure::sns::user-notification-topic::arn'),
)
const bucket = new Bucket(this, 'bucket', {
bucketName: 'automation-configuration',
removalPolicy: RemovalPolicy.DESTROY,
})
const etlLambda = new NodejsFunction(this, 'etl-lambda', {
entry: 'src/lambda/etl/etl.handler.ts',
functionName: 'etl',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
bucket.grantRead(
new Alias(this, id.concat('alias'), {
aliasName: 'current',
version: etlLambda.currentVersion,
}),
)
const categoriesLambda = new NodejsFunction(this, 'insert-categories-lambda', {
entry: 'src/lambda/categories/categories.handler.ts',
functionName: 'insert-categories',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
const hospitalsLambda = new NodejsFunction(this, 'hospitals-categories-lambda', {
entry: 'src/lambda/categories/categories.handler.ts',
functionName: 'insert-categories',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
const [etlTask, categoriesTask, hospitalsTask] = this.mountLambdaInvokes([
{ function: etlLambda, output: '$.Payload' },
{ function: categoriesLambda },
{ function: hospitalsLambda },
])
const errorTopicConfig = {
topic: userNotificationTopic,
subject: 'Automation Config Failed 😥',
message: TaskInput.fromObject({
message: 'Automation Config Failed due to an unexpected error.',
cause: 'Unexpected Error',
channel: 'email',
destination: { ToAddresses: ['suporte@somemail.com'] },
}),
}
const publishFailed = (publishFailedId: string) =>
new SnsPublish(this, `automation-config-sns-failed-${publishFailedId}`, errorTopicConfig)
const jobFailed = new Fail(this, 'automation-config-job-failed', {
cause: 'Unexpected Error',
})
const hospitalsCategoriesParallel = new Parallel(this, 'auto-config-exams-parallel-map')
.branch(categoriesTask)
.branch(hospitalsTask)
.addRetry({ errors: ['States.ALL'], interval: Duration.seconds(5), maxAttempts: 1 })
.addCatch(publishFailed('exams').next(jobFailed), {
errors: ['States.ALL'],
})
const definition = etlTask.next(hospitalsCategoriesParallel)
const logGroup = new LogGroup(this, 'automation-configuration-log-group', {
retention: RetentionDays.ONE_WEEK,
removalPolicy: RemovalPolicy.DESTROY,
})
const stateMachine = new StateMachine(this, `${id}-state-machine`, {
definition,
timeout: Duration.minutes(5),
stateMachineName: 'automation-configuration',
stateMachineType: StateMachineType.EXPRESS,
logs: {
destination: logGroup,
includeExecutionData: true,
level: LogLevel.ALL,
},
})
const s3EventRule = new Rule(this, 'automation-config-s3-event-rule', {
ruleName: 'automation-config-s3-event-rule',
})
const eventRole = new Role(this, 'eventRole', {
assumedBy: new ServicePrincipal('events.amazonaws.com'),
})
stateMachine.grantStartExecution(eventRole)
s3EventRule.addTarget(
new SfnStateMachine(stateMachine, {
input: RuleTargetInput.fromObject({
detail: EventField.fromPath('$.detail'),
}),
role: eventRole,
}),
)
s3EventRule.addEventPattern({
source: ['aws.s3'],
detailType: ['Object Created'],
detail: {
bucket: {
name: [bucket.bucketName],
},
object: {
key: [
{
wildcard: 'csv/automation-configuration/*.csv',
},
],
},
},
})
const unexpectedFailRule = new Rule(this, 'exam-automation-config-unexpected-fail-rule', {
ruleName: 'exam-automation-config-unexpected-fail-rule',
})
unexpectedFailRule.addTarget(
new SnsTopic(userNotificationTopic, {
message: RuleTargetInput.fromObject({
subject: 'Exam Automation Config Failed 😥',
message: 'Exam Automation Config Failed due to an unexpected error.',
cause: 'Unexpected Error',
channel: 'email',
destination: { ToAddresses: ['it@somemail.com'] },
}),
}),
)
unexpectedFailRule.addEventPattern({
source: ['aws.states'],
detailType: ['Step Functions Execution Status Change'],
detail: {
stateMachineArn: [stateMachine.stateMachineArn],
status: ['FAILED', 'TIMED_OUT', 'ABORTED'],
},
})
}
private mountLambdaInvokes(
lambdasInvoke: Array<{
function: IFunction
name?: string
output?: string
}>,
) {
return lambdasInvoke.map(lambdaInvoke => {
return new LambdaInvoke(this, `${lambdaInvoke.name || lambdaInvoke.function.functionName}-task`, {
lambdaFunction: lambdaInvoke.function,
inputPath: '$',
outputPath: lambdaInvoke?.output || '$',
})
})
}
}
```
---
[🇧🇷 PT-BR]
## Prefácio
Sempre que um usuário precisava subir uma automação, o nosso tech lead tinha que realizar um trabalho manual bem extensivo do qual levava cerca de dois dias para configurar tudo, usando um arquivo xls com mais de 6 abas e manipulando os dados com algumas funções do excel, ao ver esta situação percebi que podíamos sim automatizar este fluxo (inclusive foi uma discussão acalorada para chegarmos nesta conclusão), assim surgiu a arquitetura abaixo (temos algumas questões de código proprietário então esta arquitetura é uma visão simplificada e com items ficticios para demonstrar esta solução)
## A Solução
Tinhamos que triggar um [Step Function](https://www.youtube.com/watch?v=BTLQjUb2EPk&ab_channel=YanCui) quando um objeto fosse criado no S3, infelizmente hoje não temos como chamar de forma direta um step function, então tive que criar um event bridge rule para ouvir a criação de um objeto no meu S3, e quando isso fosse criado chamar o step function e consumir o objeto em questão por um dos lambdas tasks, como eu precisava que fosse um processo mais rápido utilizei o tipo express, com esta decisão eu precisava paralelizar alguns steps (sim, minha automatização possibilitava isso) assim utilizei o state Parallel, por fim caso eu tivesse algum erro eu notifico utilizando um tópico para isso.
> **Express x Standard**
- **Standard**: Para processos longos, com execuções garantidas exatamente uma vez e recursos avançados de recuperação.
- **Express**: Para processos rápidos e de alta taxa de transferência, com execuções garantidas pelo menos uma vez e cobrança baseada em tempo e memória.
## Colocando a mão na massa
Bora implementar isto com CDK e Typescript!
Vamos começar criando nosso bucket e importanto um tópico para notificar nossos erros
```typescript
const userNotificationTopic = Topic.fromTopicArn(
this,
'userNotificationTopic',
Fn.importValue('infrastructure::sns::user-notification-topic::arn'),
)
const bucket = new Bucket(this, 'bucket', {
bucketName: 'automation-configuration',
removalPolicy: RemovalPolicy.DESTROY,
})
```
Agora vamos criar nossos lambdas e dar a permissão de leitura para o lambda que irá acessar o objeto do S3:
```typescript
const etlLambda = new NodejsFunction(this, 'etl-lambda', {
entry: 'src/lambda/etl/etl.handler.ts',
functionName: 'etl',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
bucket.grantReadWrite(
new Alias(this, id.concat('alias'), {
aliasName: 'current',
version: etlLambda.currentVersion,
}),
)
const categoriesLambda = new NodejsFunction(this, 'insert-categories-lambda', {
entry: 'src/lambda/categories/categories.handler.ts',
functionName: 'insert-categories',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
const hospitalsLambda = new NodejsFunction(this, 'hospitals-categories-lambda', {
entry: 'src/lambda/categories/categories.handler.ts',
functionName: 'insert-categories',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
```
Para que possamos chamar uma lambda dentro do nosso Step Function temos que criar um [Lambda Invoke](https://docs.aws.amazon.com/step-functions/latest/dg/connect-lambda.html) para cada um dos lambdas, assim criei uma função para não precisar ficar repetindo isto para cada lambda:
```typescript
private mountLambdaInvokes(
lambdasInvoke: Array<{
function: IFunction
name?: string
output?: string
}>,
) {
return lambdasInvoke.map(lambdaInvoke => {
return new LambdaInvoke(this, `${lambdaInvoke.name || lambdaInvoke.function.functionName}-task`, {
lambdaFunction: lambdaInvoke.function,
inputPath: '$',
outputPath: lambdaInvoke?.output || '$',
})
})
}
```
Utilizando a função `mountLambdaInvokes`:
```typescript
const [etlTask, categoriesTask, hospitalsTask] = this.mountLambdaInvokes([
{ function: etlLambda, output: '$.Payload' },
{ function: categoriesLambda },
{ function: hospitalsLambda },
])
```
Precisamos criar nosso step de falha e o SnsPublish para enviar os eventos que falharam para o tópico que importamos antes:
```typescript
const errorTopicConfig = {
topic: userNotificationTopic,
subject: 'Automation Config Failed 😥',
message: TaskInput.fromObject({
message: 'Automation Config Failed due to an unexpected error.',
cause: 'Unexpected Error',
channel: 'email',
destination: { ToAddresses: ['suporte@somemail.com'] },
}),
}
const publishFailed = (publishFailedId: string) =>
new SnsPublish(this, `automation-config-sns-failed-${publishFailedId}`, errorTopicConfig)
const jobFailed = new Fail(this, 'automation-config-job-failed', {
cause: 'Unexpected Error',
})
```
Feito isto vamos montar nosso [Parallel](https://docs.aws.amazon.com/step-functions/latest/dg/amazon-states-language-parallel-state.html), onde cada branch é um lambda que será processado simultaneamente, adicionaremos também um retry para q seja feita a tentativa novamente caso ocorra algum problema e um catch para capturar as falhas desse processo paralelo:
```typescript
const hospitalsCategoriesParallel = new Parallel(this, 'auto-config-exams-parallel-map')
.branch(categoriesTask)
.branch(hospitalsTask)
.addRetry({ errors: ['States.ALL'], interval: Duration.seconds(5), maxAttempts: 1 })
.addCatch(publishFailed('exams').next(jobFailed), {
errors: ['States.ALL'],
})
```
Neste ponto vamos criar a definition das nossas tasks, um log group e a State Machine que nada mais é que nossa Step Function de fato
```typescript
const definition = etlTask.next(hospitalsCategoriesParallel)
const logGroup = new LogGroup(this, 'automation-configuration-log-group', {
retention: RetentionDays.ONE_WEEK,
removalPolicy: RemovalPolicy.DESTROY,
})
const stateMachine = new StateMachine(this, `${id}-state-machine`, {
definition,
timeout: Duration.minutes(5),
stateMachineName: 'automation-configuration',
stateMachineType: StateMachineType.EXPRESS,
logs: {
destination: logGroup,
includeExecutionData: true,
level: LogLevel.ALL,
},
})
```
Após isso precisamos criar as rules para associar o event bridge com S3 e com a execução do nosso step function:
```typescript
const s3EventRule = new Rule(this, 'automation-config-s3-event-rule', {
ruleName: 'automation-config-s3-event-rule',
})
const eventRole = new Role(this, 'eventRole', {
assumedBy: new ServicePrincipal('events.amazonaws.com'),
})
stateMachine.grantStartExecution(eventRole)
s3EventRule.addTarget(
new SfnStateMachine(stateMachine, {
input: RuleTargetInput.fromObject({
detail: EventField.fromPath('$.detail'),
}),
role: eventRole,
}),
)
s3EventRule.addEventPattern({
source: ['aws.s3'],
detailType: ['Object Created'],
detail: {
bucket: {
name: [bucket.bucketName],
},
object: {
key: [
{
wildcard: 'csv/automation-configuration/*.csv',
},
],
},
},
})
```
E por fim vamos criar uma regra para ouvir as falhas inesperadas que ocorrerem em nosso step function através do event bridge também, assim mantendo o caráter de orientação a eventos que tanto adoramos:
```typescript
const unexpectedFailRule = new Rule(this, 'exam-automation-config-unexpected-fail-rule', {
ruleName: 'exam-automation-config-unexpected-fail-rule',
})
unexpectedFailRule.addTarget(
new SnsTopic(userNotificationTopic, {
message: RuleTargetInput.fromObject({
subject: 'Exam Automation Config Failed 😥',
message: 'Exam Automation Config Failed due to an unexpected error.',
cause: 'Unexpected Error',
channel: 'email',
destination: { ToAddresses: ['it@somemail.com'] },
}),
}),
)
unexpectedFailRule.addEventPattern({
source: ['aws.states'],
detailType: ['Step Functions Execution Status Change'],
detail: {
stateMachineArn: [stateMachine.stateMachineArn],
status: ['FAILED', 'TIMED_OUT', 'ABORTED'],
},
})
```
Colocando tudo junto em uma classe para que você possa entender todo o fluxo unificado:
```typescript
import { Duration, Fn, RemovalPolicy } from 'aws-cdk-lib'
import { Rule, RuleTargetInput, EventField } from 'aws-cdk-lib/aws-events'
import { SfnStateMachine, SnsTopic } from 'aws-cdk-lib/aws-events-targets'
import { Role, ServicePrincipal } from 'aws-cdk-lib/aws-iam'
import { Alias, Architecture, IFunction } from 'aws-cdk-lib/aws-lambda'
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs'
import { LogGroup, RetentionDays } from 'aws-cdk-lib/aws-logs'
import { Bucket } from 'aws-cdk-lib/aws-s3'
import { Topic } from 'aws-cdk-lib/aws-sns'
import { Fail, LogLevel, Parallel, StateMachine, StateMachineType, TaskInput } from 'aws-cdk-lib/aws-stepfunctions'
import { LambdaInvoke, SnsPublish } from 'aws-cdk-lib/aws-stepfunctions-tasks'
import { Construct } from 'constructs'
export default class AutomationConfiguration extends Construct {
constructor(scope: Construct, id: string) {
super(scope, id)
const userNotificationTopic = Topic.fromTopicArn(
this,
'userNotificationTopic',
Fn.importValue('infrastructure::sns::user-notification-topic::arn'),
)
const bucket = new Bucket(this, 'bucket', {
bucketName: 'automation-configuration',
removalPolicy: RemovalPolicy.DESTROY,
})
const etlLambda = new NodejsFunction(this, 'etl-lambda', {
entry: 'src/lambda/etl/etl.handler.ts',
functionName: 'etl',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
bucket.grantRead(
new Alias(this, id.concat('alias'), {
aliasName: 'current',
version: etlLambda.currentVersion,
}),
)
const categoriesLambda = new NodejsFunction(this, 'insert-categories-lambda', {
entry: 'src/lambda/categories/categories.handler.ts',
functionName: 'insert-categories',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
const hospitalsLambda = new NodejsFunction(this, 'hospitals-categories-lambda', {
entry: 'src/lambda/categories/categories.handler.ts',
functionName: 'insert-categories',
timeout: Duration.seconds(30),
architecture: Architecture.ARM_64,
})
const [etlTask, categoriesTask, hospitalsTask] = this.mountLambdaInvokes([
{ function: etlLambda, output: '$.Payload' },
{ function: categoriesLambda },
{ function: hospitalsLambda },
])
const errorTopicConfig = {
topic: userNotificationTopic,
subject: 'Automation Config Failed 😥',
message: TaskInput.fromObject({
message: 'Automation Config Failed due to an unexpected error.',
cause: 'Unexpected Error',
channel: 'email',
destination: { ToAddresses: ['suporte@somemail.com'] },
}),
}
const publishFailed = (publishFailedId: string) =>
new SnsPublish(this, `automation-config-sns-failed-${publishFailedId}`, errorTopicConfig)
const jobFailed = new Fail(this, 'automation-config-job-failed', {
cause: 'Unexpected Error',
})
const hospitalsCategoriesParallel = new Parallel(this, 'auto-config-exams-parallel-map')
.branch(categoriesTask)
.branch(hospitalsTask)
.addRetry({ errors: ['States.ALL'], interval: Duration.seconds(5), maxAttempts: 1 })
.addCatch(publishFailed('exams').next(jobFailed), {
errors: ['States.ALL'],
})
const definition = etlTask.next(hospitalsCategoriesParallel)
const logGroup = new LogGroup(this, 'automation-configuration-log-group', {
retention: RetentionDays.ONE_WEEK,
removalPolicy: RemovalPolicy.DESTROY,
})
const stateMachine = new StateMachine(this, `${id}-state-machine`, {
definition,
timeout: Duration.minutes(5),
stateMachineName: 'automation-configuration',
stateMachineType: StateMachineType.EXPRESS,
logs: {
destination: logGroup,
includeExecutionData: true,
level: LogLevel.ALL,
},
})
const s3EventRule = new Rule(this, 'automation-config-s3-event-rule', {
ruleName: 'automation-config-s3-event-rule',
})
const eventRole = new Role(this, 'eventRole', {
assumedBy: new ServicePrincipal('events.amazonaws.com'),
})
stateMachine.grantStartExecution(eventRole)
s3EventRule.addTarget(
new SfnStateMachine(stateMachine, {
input: RuleTargetInput.fromObject({
detail: EventField.fromPath('$.detail'),
}),
role: eventRole,
}),
)
s3EventRule.addEventPattern({
source: ['aws.s3'],
detailType: ['Object Created'],
detail: {
bucket: {
name: [bucket.bucketName],
},
object: {
key: [
{
wildcard: 'csv/automation-configuration/*.csv',
},
],
},
},
})
const unexpectedFailRule = new Rule(this, 'exam-automation-config-unexpected-fail-rule', {
ruleName: 'exam-automation-config-unexpected-fail-rule',
})
unexpectedFailRule.addTarget(
new SnsTopic(userNotificationTopic, {
message: RuleTargetInput.fromObject({
subject: 'Exam Automation Config Failed 😥',
message: 'Exam Automation Config Failed due to an unexpected error.',
cause: 'Unexpected Error',
channel: 'email',
destination: { ToAddresses: ['it@somemail.com'] },
}),
}),
)
unexpectedFailRule.addEventPattern({
source: ['aws.states'],
detailType: ['Step Functions Execution Status Change'],
detail: {
stateMachineArn: [stateMachine.stateMachineArn],
status: ['FAILED', 'TIMED_OUT', 'ABORTED'],
},
})
}
private mountLambdaInvokes(
lambdasInvoke: Array<{
function: IFunction
name?: string
output?: string
}>,
) {
return lambdasInvoke.map(lambdaInvoke => {
return new LambdaInvoke(this, `${lambdaInvoke.name || lambdaInvoke.function.functionName}-task`, {
lambdaFunction: lambdaInvoke.function,
inputPath: '$',
outputPath: lambdaInvoke?.output || '$',
})
})
}
}
```
| wakeupmh |
1,799,137 | Exploring Web Rendering Strategies: A Deep Dive into CSR, SSR, SSG and ISG | Introduction Every day we interact with a lot of web applications. They all seem the same... | 0 | 2024-05-27T16:11:48 | https://dev.to/debajit13/exploring-web-rendering-strategies-a-deep-dive-into-csr-ssr-ssg-and-isg-22da | webdev, nextjs, react, frontend | ## Introduction
Every day we interact with a lot of web applications. They all seem the same web applications to us but the way they are rendered on the screen is pretty different. It can be **SSR** or maybe **CSR** or **SSG** or **ISG** anything. In this blog, I will explain these **web rendering strategies** and how to choose one.
There are mainly 4 types of web rendering strategies:
1. Client-Side Rendering (CSR)
1. Server-Side Rendering (SSR)
1. Static Site Generation (SSG)
1. Incremental Static Generation (ISG)
let's deep dive into them one by one.
## Client-Side Rendering (CSR):
In **Client-Side Rendering**, a request has been made to the server at first and then a minimal **HTML** file comes with the **JavaScript** files. Now with the help of **JavaScript**, the content of the website is loaded. Even the routing also handled by **JavaScript** and no **HTML** is fetched from the Server.
### Usage
This technique is ideal for apps which have **a lot of interactions**. But from an **SEO** perspective, this is not a great choice. Also, for the first time, it takes a little time as all the page data is loaded at once.
### Example
**React**, **Vue** and **Angular** use Client-Side Rendering.
## Server-Side Rendering (SSR):
In **Server-Side Rendering**, the server generates a full **HTML page** on the server in response to the user's **request** and then sends that to the client.
### Usage
This technique is ideal when you need **faster initial loads and better SEO advantages**. But as for each request, the server generates the content dynamically, which leads to increased load and response times.
### Example
**NextJS**, **NuxtJS**, and **Angular Universal** use Server-Side Rendering.
## Static Site Generation (SSG):
In **Static Site Generation**, all the pages are generated at build time. Each page is pre-rendered into static HTML, and when the user requests a page, the server sends the **HTML** file based on the request.
### Usage
Since the **pages are pre-built**, the performance of the site is **pretty fast**. Also, it reduces the load to the backend.
### Example
**Gatsby** uses Static Site Generation.
## Incremental Static Generation (ISG):
In **Incremental Static Generation**, pages are built **statically** the same as in **SSG**, but on a per-page basis as they are requested. If a page is not pre-built at build time, it is built when first requested and later also, served as a **static site**.
### Usage
Since the pages are **built only when requested** the build time is much less and also as they are served as **static pages** from the next time they are pretty fast later. But it is pretty complex to implement compared to **SSG** or **SSR**. Also, first-time visitors can experience a delay as the page is built.
### Example
**NextJS** uses Incremental Static Generation.
## Summary
Each of the rendering strategies holds different significance when in use. It's not like one is better than the other. It always depends on your use case. If you like this blog give it a like and write your feedback in the comment below. Also, if want to learn more about **Frontend Engineering** and **Software Engineering** you can follow me on [LinkedIn](https://www.linkedin.com/in/debajit-mallick/) and [X](https://twitter.com/MallickDebajit).
| debajit13 |
1,862,994 | Bringing the Voice of the Customer to Life with AI | Revolutionize your product development process by bringing the voice of the customer to life with AI. Discover how ChatGPT and GPT-4o voice can help you create detailed user personas, simulate immersive conversations, and uncover actionable insights to drive user-centric enhancements. Learn the practical benefits of integrating VoC into your agile workflows, from dynamic feedback to cost-effectiveness and scalability. Embrace the power of AI and forge a path towards products that exceed user expectations. Start your journey to user-centric product development today! | 0 | 2024-05-27T16:11:48 | https://dev.to/dev3l/bringing-the-voice-of-the-customer-to-life-with-ai-a75 | ai, productdevelopment, voiceofthecustomer, agile | ---
title: Bringing the Voice of the Customer to Life with AI
published: true
description: Revolutionize your product development process by bringing the voice of the customer to life with AI. Discover how ChatGPT and GPT-4o voice can help you create detailed user personas, simulate immersive conversations, and uncover actionable insights to drive user-centric enhancements. Learn the practical benefits of integrating VoC into your agile workflows, from dynamic feedback to cost-effectiveness and scalability. Embrace the power of AI and forge a path towards products that exceed user expectations. Start your journey to user-centric product development today!
tags: AI, ProductDevelopment, VoiceOfTheCustomer, Agile
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ht5zkc8o8ay4iyymlgs5.png
---
Have you ever poured your heart and soul into a new feature, only to discover it didn't quite hit the mark with your users? This is a common challenge in product development, and often, the root cause is a disconnect between what we _think_ users want and what they _need_. This is where genuinely understanding the **Voice of the Customer** (VoC) becomes paramount.
In _AI-XP (Artificially Intelligent Extreme Programming)_, seamlessly integrating user feedback into the development process is more attainable than ever before. By harnessing the power of advanced AI tools like **ChatGPT 4o**, we can revolutionize how we capture and implement user insights, ensuring our products are functional and deeply resonant with our target audience.
Listening to users is the critical differentiator between a product that merely works and one that people genuinely love. The VoC provides invaluable insights that guide product adjustments, feature enhancements, and new developments, ensuring they align perfectly with user expectations.
ChatGPT 4o can simulate user interactions, allowing us to capture feedback dynamically and engagingly. Leveraging natural language processing mimics conversations with real users, enabling us to explore their needs, preferences, and challenges realistically. What sets ChatGPT apart is its ability to facilitate multi-modal conversations using voice, creating an experience resembling a real-life phone conversation with a real user. This level of immersion allows us to gather authentic feedback and gain a deeper understanding of user perspectives.
Nothing will beat true customer interaction. But if you create a series of personas and have a handful of conversations with them, you will make your valuable time interacting with your customers much more effective.
This post will explore practical steps to leverage ChatGPT to bring the customer's voice into your agile workflow. From crafting detailed user personas to conducting simulated interviews and analyzing insights, we'll cover everything you need to know to make user feedback an integral part of your development process.
## The Importance of the Voice of the Customer

The Voice of the Customer (VoC) is essentially feedback from your users about their experiences and expectations. It's more than just data; it's a comprehensive insight into what users think, feel, and need from your product. You can enhance engagement, inform feature development, and elevate the overall user experience by actively listening to your users. When you truly understand what users want (need), you can prioritize features that add genuine value and avoid investing in those that miss the mark.
Ignoring VoC can lead to significant pitfalls, including misalignment with user needs, decreased user retention, and higher development costs due to unnecessary rework. Products that fail to resonate with users often require extensive revisions or struggle to gain traction. In agile methodologies, incorporating VoC ensures continuous alignment with user needs through iterative development and feedback loops. Agile processes thrive on feedback, and VoC provides its most direct and valuable form. Regularly integrating user feedback into sprints helps keep development focused and relevant.
A prime example from my experience is the collaboration with my virtual customer persona, Sarah Thompson, which highlighted the need for collaborative features in AiDo. One prominent feature emerged was the ability to sync calendars between users, such as family and team members. This feature enables seamless coordination, ensuring everyone is on the same page regarding schedules and responsibilities. This feature is indispensable for Sarah, who balances a demanding career with family life. It offers a centralized way to manage personal and professional commitments, reducing the chaos of fragmented schedules.
## Practical Benefits Overview

Integrating ChatGPT into your process for capturing the Voice of the Customer (VoC) offers numerous benefits that can significantly enhance your product development. Understanding these practical advantages is crucial for effectively leveraging this technology.
One of the standout benefits is the *dynamic interaction* that ChatGPT offers. Unlike traditional methods of collecting user feedback, which can be time-consuming and static, ChatGPT provides real-time feedback. This immediacy allows for a more fluid conversation, delivering instant responses to user queries and interactions. It's akin to having a continuous, always-available focus group.
When it comes to *cost-effectiveness*, ChatGPT shines. Think about the traditional user feedback methods – recruitment, scheduling, participant compensation, and all the logistical headaches that come with them. These can quickly add up to a significant expense in money and time. But with ChatGPT, you can bypass many of these costs and challenges. It's a lean, efficient way to gather extensive user insights without needing a large budget or a dedicated team of user researchers. This means you can allocate your resources more strategically, focusing on what matters: developing a product that resonates with your users. It's like having a direct line to your users' thoughts and preferences without the usual barriers and expenses. This cost-effectiveness makes ChatGPT an invaluable tool for startups, small teams, and anyone looking to maximize their user research ROI.
*Scalability* is another significant advantage that ChatGPT brings to the table. This tool allows you to run multiple scenarios and interactions simultaneously, dramatically speeding up the feedback and iteration. This means you can handle various user personas and scenarios at a much larger scale, allowing you to gather more insights in less time. This translates to a more efficient and streamlined product development process, as you can quickly incorporate user feedback and make data-driven decisions. It's like having a team of user researchers working around the clock without the associated costs and logistical challenges. This scalability empowers you to keep your finger on the pulse of user needs and preferences, ensuring that your product development remains agile and responsive.
The *authenticity of conversational feedback* with ChatGPT, primarily through voice interactions with GPT-4o, enhances the depth of insights collected. Simulating genuine conversations captures the words and emotional nuances behind user responses. This level of detail can reveal subtle preferences and pain points that might be missed in traditional surveys or interviews.
These benefits culminate in *more informed decision-making*. The detailed insights gathered through ChatGPT interactions lead to better-informed decisions in product development. For instance, understanding that users like Sarah Thompson find collaborative calendar syncing invaluable can drive feature prioritization and user experience improvements in AiDo. This targeted approach ensures that development efforts are aligned with actual user needs, increasing the likelihood of product success.
Furthermore, the *iterative nature* of integrating ChatGPT into the agile process enables continuous improvement. Updating personas and scenarios based on ongoing feedback keeps the development process aligned with evolving user needs. This iterative feedback loop supports the core principles of agile methodologies, promoting constant enhancement and user-focused development.
To illustrate, simulating interactions with Sarah Thompson uncovered her struggle with fragmented schedules. This insight prompted the development of a collaborative feature in AiDo, allowing users to sync calendars with family and team members. Such real-world applications of ChatGPT-driven insights underscore its practical benefits and transformative potential.
By leveraging ChatGPT for VoC, you enrich the quality of user insights and streamline their incorporation into your product development workflow. This approach bridges the gap between user expectations and product deliverables, creating a more user-centric and responsive development cycle.
## Step-by-Step Guide to Using ChatGPT for VoC

Bringing the voice of the customer into your development process involves several key steps. You can ensure your product meets real user needs by carefully creating user personas, developing realistic scenarios, and utilizing ChatGPT for simulated conversations. Here's how to do it:
**Define and Create Detailed User Personas**
The first step is to define and create detailed user personas. A good persona includes demographics, behaviors, goals, and challenges that represent your typical user. ChatGPT can be a valuable tool, helping you generate realistic and comprehensive user personas through interactive prompts.
To create a user persona with ChatGPT, provide the AI with a brief description of your target user and the product you're developing. For example:
> **User**: You are an agile user experience expert. I'm going to give you a product description. Please take a second to read it over and let me know that you're ready to work. We are going to create some user personas. Just wait until I tell you what persona I want to create.
> **ChatGPT**: I'm ready to work. Please provide the product description, and let me know which persona you'd like to create.
> **User**: _(Paste [Product Description](https://github.com/DEV3L/aixp-todo/blob/main/AiDo/APEX%20Product%20Definition.md))_
> **ChatGPT**: I've reviewed the product description for AiDo. I'm ready to create the user personas. Please let me know which persona you'd like to start with.
> **User**: Could you create a persona for the Busy Parent user type? It should contain goals, challenges, needs, and pain points. In addition, it should have a personality, background, hobbies, behaviors and patterns, and preferred communication channels.
> **ChatGPT**: _(Creates Persona)_
> **User**: Please generate a hyper-realistic headshot of this user persona.
> **ChatGPT**: _(Makes Headshot Image)_
ChatGPT will then generate a detailed persona based on this prompt. Here's an example of what it might produce:
> ### Persona: Busy Parent
>
> #### Name: Sarah Thompson
>
> #### Demographics
> - **Age**: 38
> - **Gender**: Female
> - **Occupation**: Marketing Manager
> - **Location**: Chicago, IL
> - **Family**: Married with two children (ages 6 and 10)
>
> #### Background
> Sarah is a seasoned marketing manager with over 15 years of experience. She balances a demanding career and a bustling family life, handling professional responsibilities and household chores. Sarah is tech-savvy and proficient with productivity tools but often feels overwhelmed by the sheer volume of tasks.
>
> #### Personality
> - **Organized**: Sarah keeps things structured and planned.
> - **Multi-tasker**: She is adept at juggling multiple responsibilities simultaneously.
> - **Empathetic**: Sarah cares deeply about her family's needs and tries to ensure everyone's well-being.
> - **Perfectionist**: She strives for excellence in her professional and personal life.
> - **Adaptable**: Sarah can quickly adapt to changing situations despite her busy schedule.
>
> #### Goals
> - **Achieve Work-Life Balance**: Sarah aims to manage her professional duties efficiently while being present for her family.
> - **Stay Organized**: She wants to keep track of household chores, children's schedules and work tasks organized.
> - **Increase Productivity**: Sarah seeks to maximize her productivity during work hours to have quality time with her family.
> - **Ensure Family Well-being**: She aims to ensure that her family's needs are met and that they have a well-coordinated schedule.
>
> #### Challenges
> - **Time Management**: Balancing work deadlines with family responsibilities is a constant struggle.
> - **Overwhelm**: The sheer number of tasks and responsibilities often feels overwhelming.
> - **Task Coordination**: Keeping track of everyone's schedules and ensuring all tasks are completed on time is challenging.
> - **Maintaining Efficiency**: Finding ways to work efficiently and reduce the time spent on mundane tasks is a priority.
>
> #### Needs
> - **Centralized Task Management**: A single platform to manage personal and professional tasks.
> - **Reminders and Notifications**: Timely reminders and notifications for tasks and appointments.
> - **Family Coordination**: Tools for syncing and sharing calendars and tasks with family members.
> - **Personalized Insights**: AI-driven insights and recommendations to optimize task management and productivity.
>
> #### Pain Points
> - **Forgetfulness**: Missing essential tasks or appointments due to the volume of responsibilities.
> - **Inefficiency**: Spending too much time on task management rather than completing tasks.
> - **Coordination Issues**: Difficulty coordinating schedules and functions among family members.
> - **Stress and Burnout**: Feeling stressed and burnt out due to the constant juggling of work and family duties.
>
> #### Hobbies
> - **Cooking**: Sarah enjoys experimenting with new recipes and cooking meals for her family.
> - **Reading**: She loves reading mystery novels to unwind.
> - **Volunteering**: Actively volunteers at her children's school and community.
> - **Yoga**: Practices yoga to relax and maintain physical fitness.
>
> #### Behaviors and Patterns
> - **Morning Routine**: She starts her day early to prepare for work and get her children ready for school.
> - **Task List**: Maintains a detailed to-do list to keep track of daily tasks.
> - **Time Blocks**: Time blocking allocates specific periods for work, family time, and personal activities.
> - **Family Meetings**: Holds weekly family meetings to coordinate schedules and discuss plans.
>
> #### Preferred Communication Channels
> - **Email**: This is for work-related communication and official notifications.
> - **Mobile App Notifications**: Prefers receiving reminders and alerts through mobile app notifications.
> - **Text Messages**: For quick and immediate communication with family and close contacts.
> - **Social Media**: Social media is used to stay connected with friends and family and to follow interests.
By leveraging ChatGPT to create user personas like Sarah, you can quickly generate detailed and realistic representations of your target users. These personas help you understand users' specific needs, goals, and pain points, similar to Sarah's, which is essential for guiding product development decisions.
Once you have created your user personas, you can refine them with additional prompts and iterations with ChatGPT. This interactive process allows you to develop rich, nuanced personas that accurately reflect your target audience.
**Set Up ChatGPT for Simulated Conversations**
Once the personas and scenarios are ready, set up ChatGPT for simulated conversations. Craft prompts that are specific and realistic to the scenarios. For instance:
> **User**: You will assume the "Busy Parent - Sarah Thompson" role. Please take a minute to read and assimilate the persona below, and respond with ok when you are ready.
> _(Paste Sarah Thompson Full Persona)_
> **ChatGPT**: Ok, I'm ready.
This setup ensures the simulated conversation is as close to real user interaction as possible. Using this setup, we could follow a customer interview script like the following:
> # Example Interview Guide for New Product Concept:
>
> **Interview Questions:**
>
> **Background:**
>
> 1. Can you tell me a little about yourself and your daily responsibilities?
> 2. How do you currently manage your tasks and schedules?
>
> **Current Tools and Practices:**
>
> 3. What tools or methods do you use to manage your tasks?
> 4. What do you like or dislike about these tools?
> 5. How comfortable are you with using technology for task management?
>
> **Challenges:**
>
> 6. What are the biggest challenges you face in managing your daily tasks?
> 7. Can you describe a recent time when you felt overwhelmed by your tasks?
>
> **New Product Concept Introduction:**
>
> 8. We're exploring a new product designed to help with task and schedule management using advanced AI technology. This product aims to streamline your daily responsibilities by integrating shared calendars, location-based notifications, and intelligent task analysis features. Based on what you've shared, this might address some of your challenges. Could you tell me how this problem affects you personally?
>
> **Concept Feedback:**
>
> 9. Which of these features do you find most appealing? Why?
>
> **Usability and Interest:**
>
> 10. How do you think this product could fit into your daily routine?
> 11. What concerns do you have about using a product like this?
> 12. How likely would you be to try this product if it were available?
>
> **Open Feedback:**
>
> 13. Is there anything else you would like to share about how you manage tasks and what solutions you need?
> 14. Do you have any suggestions or features to make this product more useful?
>
> **Closing:**
>
> - Thank you so much for your time and valuable insights. Your feedback will help us refine our product concept to meet your needs better. Please feel free to reach out if you have any additional thoughts after our conversation.
**Conduct Simulated Interviews with GPT-4o Voice**
Take your simulated interviews to the next level by utilizing the GPT-4o voice feature. This innovative technology allows you to engage in near-real-time voice conversations with your ChatGPT personas, creating an experience that closely mimics a live user interview.
To get started, load your persona into ChatGPT. I did this on the web interface. Once ChatGPT confirms it has assumed Sarah's persona, you can begin the voice-based interview. Switch to voice interaction mode on the phone using the same thread.
The GPT-4o voice's near-instantaneous response time allows for a smooth, natural conversation flow, closely replicating a real-life interview. You can dive deeper into specific topics, ask follow-up questions, and gather rich, nuanced feedback that text-based interactions might miss.
To better understand the power of GPT-4o voice for simulated interviews, check out this demo:
{% embed https://www.youtube.com/watch?v=qYKmKs1hTL4 %}
By leveraging the GPT-4o voice feature, you can elevate your simulated interviews and gather authentic, valuable insights from your user personas. This modern approach brings you closer to truly understanding your users and incorporating their voices into your product development process.
**Synthesize Insights**
After conducting the interviews, analyze the feedback to identify common themes and actionable insights. Look for patterns in responses that could inform product development. For Sarah, insights might include the need for better task prioritization features, seamless integration with other tools she uses, and personalized onboarding tips for new team members. These insights should directly influence your product roadmap and feature prioritization.
**Iterate and Refine**
Finally, remember that this is a continuous process. Regularly update your personas and scenarios based on new insights and feedback. Keep the dialogue dynamic and responsive to ensure your product development stays in tune with evolving user needs. Iteration is critical in agile methodologies, and incorporating the latest user feedback ensures that your product remains relevant and valuable.
## Example Insights Using ChatGPT

To understand the practical application of ChatGPT in capturing the Voice of the Customer (VoC), let's look at a real example from a recent mock interview with Sarah Thompson using the GPT-4o voice feature.
During the conversation, Sarah revealed that managing separate calendars for work and family was a significant challenge, and she needed a consolidated view to stay organized. This insight highlighted a crucial pain point for users like Sarah, who struggle to manage their time across multiple domains efficiently.
Based on this feedback, we identified an opportunity to enhance AiDo by introducing a unified calendar feature that integrates personal and professional schedules. This feature would allow users to view and manage all events in one place, reducing the complexity of juggling multiple calendars and helping to avoid scheduling conflicts.
Implementing this enhancement would profoundly impact the user experience, directly addressing a key challenge faced by users like Sarah. By providing a centralized, holistic view of their schedule, AiDo can help users streamline their time management efforts, ultimately supporting their goals of achieving better work-life balance and staying organized.
This example demonstrates the power of using ChatGPT, particularly with the GPT-4o voice feature, to uncover deep, actionable insights. By engaging in realistic conversations with virtual personas, we can identify specific pain points, preferences, and needs that might go unnoticed. These insights are the foundation for targeted product enhancements that directly address user challenges and improve their overall experience.
As we continue to leverage ChatGPT for VoC, we can expect to uncover more valuable insights that drive meaningful improvements in AiDo. By continuously incorporating user feedback into our product development process, we ensure that our solution remains closely aligned with the needs and expectations of our target audience.
## Your Path to User-Centric Product Development

Throughout this post, we've explored the transformative potential of incorporating the customer's voice into product development. By leveraging AI tools like ChatGPT, you can unlock a deeper understanding of user needs, preferences, and challenges, enabling you to create products that truly resonate with your target audience.
Our journey has highlighted the importance of Voice of the Customer (VoC) as a cornerstone of successful product development. We've seen how ChatGPT can help you capture valuable user insights dynamically and cost-effectively, ensuring your product remains closely aligned with user expectations.
The practical benefits of integrating VoC into your agile processes are undeniable. From the dynamic, real-time feedback facilitated by ChatGPT to its cost-effectiveness and scalability, these advantages collectively contribute to creating user-centric products that deeply connect with your audience.
Through Sarah Thompson's example, we witnessed the power of ChatGPT in uncovering actionable insights that drive meaningful product enhancements. By engaging in realistic conversations with virtual personas, you can identify specific pain points and needs that might go unnoticed, laying the foundation for targeted improvements that address user challenges.
As a passionate advocate for user-centric product development, I encourage you to embrace the power of AI and start integrating VoC practices into your agile workflows. Begin by creating detailed user personas, developing realistic scenarios, and leveraging ChatGPT to simulate immersive conversations. Don't hesitate to explore the cutting-edge GPT-4o voice feature for even deeper insights.
To help you get started, here's a quick recap of the key steps:
1. **Define user personas**: Create detailed, relatable personas representing your target users.
2. **Develop interaction scenarios**: Craft realistic scenarios that reflect how users engage with your product.
3. **Simulate conversations**: Leverage ChatGPT and GPT-4o voice to conduct immersive, insightful user interviews.
4. **Analyze and iterate**: Continuously synthesize feedback and refine your product based on user insights.
By making VoC an integral part of your development process, you'll ensure your product evolves harmoniously with user needs, staying relevant and valuable in an ever-changing landscape.
I invite you to share your experiences, challenges, and triumphs in integrating VoC into your product development journey. Let's foster a vibrant discussion on best practices, innovative approaches, and the future of user-centric design in the age of AI.
Together, let's embrace the power of AI and forge a path towards products that meet and exceed user expectations. The future of product development is here, and it starts with bringing the customer's voice to life. | dev3l |
1,866,718 | Why Tensorflow.js based Weather Prediction Model is unable to predict correct weather | Why Tensorflow.js based Weather Prediction... | 0 | 2024-05-27T16:10:06 | https://dev.to/sribasu/why-tensorflowjs-based-weather-prediction-model-is-unable-to-predict-correct-weather-1o5h | {% stackoverflow 78536168 %}
Please help me solve the problem I am facing with tensorflow.js | sribasu | |
1,866,717 | Updated ANS-C01 Dumps PDF (Exams Questions) 2024 | Exam ANS-C01: AWS Certified Advanced Networking The Validitexams ANS-C01 Dumps PDF is an... | 0 | 2024-05-27T16:07:23 | https://dev.to/validitexams/updated-ans-c01-dumps-pdf-exams-questions-2024-4cn5 | webdev | ## Exam ANS-C01: AWS Certified Advanced Networking
The Validitexams ANS-C01 Dumps PDF is an essential study resource for candidates preparing for the AWS Certified Advanced Networking – Specialty exam. This comprehensive guide features a curated collection of practice questions and detailed answers that accurately reflect the exam format and difficulty. Covering key topics such as hybrid IT network architectures, AWS and hybrid network designs, network security, and troubleshooting, the dumps are regularly updated to align with the latest exam objectives. By utilizing the **Validitexams [ANS-C01 Dumps PDF](https://www.validitexams.com/amazon/ans-c01-dumps.html)**, candidates can effectively assess their knowledge, identify areas for improvement, and build the confidence needed to excel in the certification exam. Trusted by thousands of professionals, this resource ensures a thorough and efficient preparation process, making it a valuable tool for achieving certification success.
## Understanding the AWS Certified Advanced Networking – Specialty (ANS-C01) Exam
**What is the ANS-C01 Exam?**
The AWS Certified Advanced Networking – Specialty (ANS-C01) exam is designed for individuals with advanced knowledge and experience in networking on AWS. It validates a candidate’s ability to design, develop, and deploy scalable, highly available, and fault-tolerant networking solutions on AWS.
**Exam Objectives**
· The ANS-C01 exam covers a wide range of topics, including:
· Design and implementation of hybrid IT network architectures at scale
· Design and implementation of AWS and hybrid network architectures
· Automation of AWS tasks for network deployments
· Security and compliance design and implementation
· Network optimization and troubleshooting
## Who Should Take the ANS-C01 Exam?
This exam is intended for network professionals, solutions architects, and DevOps engineers who have at least five years of hands-on experience with networking and a strong understanding of AWS services.
## The Importance of Using Dumps PDF for ANS-C01 Exam Preparation
**What are Dumps PDFs?**
Dumps PDFs are collections of exam questions and answers that have been compiled from previous exams. They are designed to help candidates familiarize themselves with the format and types of questions that may appear on the actual exam.
**Benefits of Using Dumps PDFs**
Familiarity with Exam Format
Dumps PDFs provide an insight into the structure and format of the exam. By practicing with these materials, candidates can get used to the types of questions and the time constraints, reducing anxiety and improving performance.
Identifying Knowledge Gaps
Using Dumps PDFs allows candidates to identify areas where they need further study. By reviewing the questions, they answered incorrectly, they can focus their preparation on the topics where they are weakest.
Efficient Study Resource
Dumps PDFs consolidate a wide range of questions and answers into a single document, making it a convenient and efficient study tool. Candidates can practice anytime, anywhere, without the need for an internet connection.
## How to Effectively Use Dumps PDF for ANS-C01 Exam Preparation
**Step-by-Step Guide to Using Dumps PDFs**
Obtain Reliable Dumps PDFs
The first step is to find reliable and up-to-date Dumps PDFs. Ensure that the source is trustworthy and that the content is accurate and reflective of the latest exam objectives.
Integrate Dumps PDFs into Your Study Plan
Incorporate the Dumps PDFs into your overall study plan. Use them alongside other study materials such as official AWS documentation, online courses, and hands-on practice.
Practice Regularly
Set aside regular study sessions to practice with the Dumps PDFs. Consistent practice will help reinforce your knowledge and improve your confidence.
Review and Analyze
After each practice session, review your answers and analyze your performance. Identify the areas where you made mistakes and revisit the relevant study materials to strengthen your understanding.
## Validitexams ANS-C01 Dumps PDF
**Comprehensive Exam Preparation**
The Validitexams [ANS-C01 Dumps](https://www.validitexams.com/amazon/ans-c01-dumps.html) PDF is an invaluable resource for individuals preparing for the AWS Certified Advanced Networking – Specialty exam. This guide provides a thorough collection of practice questions and detailed answers designed to reflect the actual exam format and difficulty.
**Key Features**
Extensive Coverage
· Hybrid IT Network Architectures: Understand and design complex hybrid IT network solutions.
· AWS and Hybrid Network Designs: Master the intricacies of both AWS-native and hybrid network configurations.
· Network Security: Learn best practices for implementing robust network security measures.
· Troubleshooting: Develop skills to diagnose and resolve network issues effectively.
Realistic Practice Questions
· Exam-Like Format: Practice with questions that closely mirror the structure and types of questions found on the actual ANS-C01 exam.
· Detailed Answers: Each question comes with a comprehensive explanation to help you understand the reasoning behind the correct answer.
Regular Updates
· Latest Exam Objectives: The dumps PDF is regularly updated to ensure alignment with the most current exam content and objectives.
· Current Information: Stay up-to-date with the latest networking concepts and AWS services.
**Benefits of Using Validitexams ANS-C01 Dumps PDF**
Identify Knowledge Gaps
Targeted Study: Use the dumps to pinpoint areas where you need more study, ensuring a focused and efficient preparation process.
Build Confidence
Familiarity with Exam Format: Regular practice with the dumps will help you become comfortable with the exam format, reducing anxiety and increasing confidence.
Convenient and Flexible
Portable Study Material: Access the dumps PDF anytime, anywhere, allowing for flexible study schedules that fit your lifestyle.
## Why Choose Validitexams?
· Trusted Resource: Thousands of candidates trust [Validitexams](https://www.validitexams.com/) for their certification preparation.
· Quality Content: Our dumps PDFs are crafted by experts with a deep understanding of the exam requirements.
· Proven Success: Many professionals have achieved their certification goals using Validitexams resources.
Prepare effectively for the AWS Certified Advanced Networking – Specialty exam with the Validitexams ANS-C01 Dumps PDF, and take a significant step towards advancing your networking career.
**Amazon ANS-C01 Exam Questions With 20% Discount. Use Coupon Code "VIE20"-
[https://www.validitexams.com/amazon/ans-c01-dumps.html](https://www.validitexams.com/amazon/ans-c01-dumps.html)**
## Tips for Maximizing the Benefits of Dumps PDFs
Don’t Rely Solely on Dumps PDFs
While Dumps PDFs are a valuable resource, they should not be your only study tool. Complement them with other resources to ensure a well-rounded preparation.
Stay Updated
The ANS-C01 exam content may change over time. Make sure to use the most recent Dumps PDFs to stay current with the latest exam objectives.
Join Study Groups
Participating in study groups or online forums can provide additional insights and support. Discussing questions and answers with peers can enhance your understanding of complex topics.
## Additional Resources for ANS-C01 Exam Preparation
**Official AWS Training and Documentation**
AWS offers a range of official training courses and documentation to help candidates prepare for the ANS-C01 exam. These resources provide in-depth knowledge and practical experience with AWS services.
**Online Courses and Tutorials**
Numerous online platforms offer courses and tutorials specifically designed for the ANS-C01 exam. These courses often include video lectures, hands-on labs, and practice exams.
**Books and Study Guides**
There are several books and study guide available that cover the topics tested in the ANS-C01 exam. These resources can provide a comprehensive understanding of the material and offer additional practice questions.
**Practice Exams**
Taking practice exams is an excellent way to gauge your readiness for the actual exam. Many online platforms offer practice exams that simulate the real exam environment, helping you build confidence and identify areas for improvement.
## Conclusion
Preparing for the AWS Certified Advanced Networking – Specialty [(ANS-C01) Exam](https://www.validitexams.com/amazon/ans-c01-dumps.html) requires a thorough understanding of AWS networking services and best practices. Using Dumps PDFs as part of your study plan can provide significant benefits, including familiarity with the exam format, identification of knowledge gaps, and efficient study sessions. However, it’s essential to complement Dumps PDFs with other study resources, such as official AWS documentation, online courses, and hands-on practice. By following a comprehensive and well-rounded preparation strategy, you can increase your chances of passing the ANS-C01 exam and achieving your certification goals. | validitexams |
1,866,714 | Install Apache Web Server in Amazon Linux EC2 Instance | Introduction Installing a web server is a foundational step in web development and... | 0 | 2024-05-27T16:06:58 | https://dev.to/suravshrestha/install-apache-web-server-in-amazon-linux-ec2-instance-3e38 | aws, cloud, cloudcomputing, iaas | 
### Introduction
Installing a web server is a foundational step in web development and server management. [Apache](https://httpd.apache.org/) is one of the most popular web servers due to its reliability and extensive features. In this guide, we'll walk you through the steps to install and configure the Apache Web Server on an Amazon Linux AWS EC2 instance.
### Prerequisites
Before we begin, ensure you have the following:
1. An [AWS](https://aws.amazon.com/) account
2. An EC2 instance running Amazon Linux
### Step 1: Launch and Connect to EC2 Instance
For detailed instructions on launching and connecting to an AWS EC2 instance, you can refer to this article: [Launch and Connect to AWS EC2 Instance](https://dev.to/suravshrestha/launch-and-connect-to-aws-ec2-instance-47bm).
**Note:** When launching the EC2 instance, leave the AMI (Amazon Machine Image) set to the default, which is Amazon Linux.
### Step 2: Update Your Instance
Once connected to your EC2 instance, update the package lists:
```bash
sudo yum update -y
```
### Step 3: Install Apache Web Server
Now, install Apache (`httpd` is the Apache package for Amazon Linux) using the package manager (`yum`):
```bash
sudo yum install httpd -y
```
### Step 4: Start and Enable Apache
To start Apache and enable it to start on boot, use the following commands:
```bash
sudo systemctl start httpd
sudo systemctl enable httpd
```
### Step 5: Verify Apache Installation
You can verify that Apache is running by accessing your instance’s public IP address in a web browser:
```http
http://ec2-18-208-219-229.compute-1.amazonaws.com
```
You should see the default Apache2 Amazon Linux Default Page, indicating that Apache is successfully installed and running. 🎉
### Conclusion
You’ve successfully installed and configured the Apache Web Server on your Amazon Linux AWS EC2 instance. This setup can now serve as the foundation for your web applications. 🌐
### Additional Resources
- [Apache HTTP Server Documentation](https://httpd.apache.org/docs/) 📚
- [AWS EC2 Documentation](https://docs.aws.amazon.com/ec2/) 📖
If you have any questions or run into issues, feel free to leave a comment below.
Happy coding! 👩💻👨💻 | suravshrestha |
1,866,672 | Mastering Enterprise Storage Solutions | In the modern age, here data is a critical asset, the importance of robust enterprise storage... | 0 | 2024-05-27T16:04:59 | https://dev.to/liong/mastering-enterprise-storage-solutions-2ogb | security, datarecovery, malaysia, kulalumpur | In the modern age, here data is a critical asset, the importance of robust enterprise storage solutions cannot be overstated. Businesses must ensure their data storage infrastructure can grow and evolve with their needs. Effective data management and security are paramount for the sustained success of both small businesses and multinational corporations. This guide will walk you through the basic parts of big business stockpiling, feature top advances, and deal tips to guarantee your capacity arrangements are future-verification.
**Understanding Enterprise Storage**
Enterprise Storage alludes to the infrastructure and technology businesses use to store, protect, and manage vast amounts of data. This incorporates everything from data management software and backup system to servers and storage network. With the remarkable development of data generated day to day, enterprises need to ensure data availability, reliability, and security while maximizing storage resources and minimizing costs.
## Key Parts of Enterprise Storage
**1. Rack Mounting solutions**
Rack mounting is fundamental for [enterprise storage](https://ithubtechnologies.com/data-company-in-malaysia/?utm_source=dev.to%2F&utm_campaign=Enterprisestorage&utm_id=Offpageseo+2024) infrastructure, providing a standardized framework for housing servers, storage devices, and networking equipment. Effective rack mounting solutions should ensure optimal space utilization, improved airflow and cooling efficiency, and simplified cable management for enhanced accessibility and reliability. Utilizing industry-driving strategies and technology can ensure execution, sturdiness, and simplicity of upkeep, no matter what the size of your server room or server farm.
**2. Data Recovery Services**
Data loss can result from various factors, including hardware failures, human error, malware attacks, and natural disasters. Having a robust data recovery plan is crucial to minimize damage and resume operations quickly. Advanced data recovery techniques can retrieve data from various storage devices, including hard drives, SSDs, RAID arrays, and virtualized environments. Whether due to accidental deletion, corrupted files, or catastrophic hardware failure, quick and reliable data recovery services are essential to ensure business continuity.
**3. Server Maintenance Services**
Servers are the foundation of an undertaking's stockpiling engineering, going about as the essential stage for handling, putting away, and getting to data. Ensuring servers' maximized operation and unwavering quality is urgent for efficiency and business progression. Thorough server support administrations, including routine maintenance, diagnostics, troubleshooting, and hardware upgrades, can help minimize risks and downtime. Proactively monitoring and addressing potential issues allows businesses to focus on innovation and growth.
## **Key Technologies in Enterprise Storage**
Different innovations support enterprise storage, each serving unmistakable capabilities and prerequisites. Coming up next are a portion of the basic innovations normally tracked down in big business stockpiling arrangements.
**1. Storage Area Networks (SANs)**
SANs are high-speed networks that connect servers and storage devices, enabling data sharing and centralized storage management. SANs, utilizing Ethernet or Fibre Channel protocols, are ideal for high-performance, mission-critical applications.
**2. Network-Attached Storage (NAS)**
NAS systems provide file-level storage accessible over a network using NFS or SMB protocols. NAS devices are suitable for file sharing, data backup, and file server functions in small to medium-sized environments.
**3. Object Storage**
Object storage architecture stores data as objects rather than traditional file hierarchies. Each object contains data, metadata, and a unique identifier, making it highly scalable and suitable for unstructured data, such as documents, multimedia files, and backups.
**4. Hybrid Storage**
Hybrid storage solutions combine the capacity of traditional hard disk drives (HDDs) with the performance of flash storage. By tiering data based on usage patterns, hybrid storage systems optimize performance and reduce costs.
**5. Software-Defined Storage (SDS)**
SDS abstracts storage resources from the underlying hardware, enabling centralized control and automation via software. SDS systems offer flexibility, scalability, and vendor-agnostic compatibility, making them ideal for modern data centers.
## **The Importance of Enterprise Storage **
In the present data driven world, enterprise storage cannot be overstated. A robust storage infrastructure is crucial for the following reasons.
**1. Data Growth**
Businesses generate data at an unprecedented rate due to the proliferation of digital devices, the Internet of Things (IoT), and advanced technologies like artificial intelligence (AI) and machine learning (ML). Reliable and high-performance enterprise storage solutions are essential to support this rapid data growth.
**2. Business Continuity**
Data loss or disruption can have severe consequences for businesses, including financial losses, reputational damage, and legal implications. Enterprise storage systems ensure business continuity by offering high availability, disaster recovery, and data redundancy.
**3. Regulatory Compliance**
Many industries are subject to strict regulations regarding data security, privacy, and retention. Enterprise storage solutions with robust security features, encryption, and audit trails help businesses comply with these regulations.
**4. Scalability**
As businesses grow and expand, their storage needs also increase. Scalability is a fundamental aspect of enterprise storage solutions, allowing for future growth without operational disruptions or costly migrations.
**5. Cost Optimization**
Organizations must manage large volumes of data efficiently while controlling costs. Enterprise storage solutions optimize performance, capacity, and cost-effectiveness, ensuring the best return on investment.
## Strategies for Implementing Effective Enterprise Storage Solutions
** 1. Assess Your Needs **
Prior to executing any capacity arrangement, evaluating your business' particular needs is essential. Consider factors, for example, data volume, access speed prerequisites, administrative consistence, and future development projections. This assessment will help you choose the most appropriate storage technologies and configurations.
**2. Pick the Right technology**
Select the storage technology that best accommodated your business needs. For example, SANs might be ideal for high-performance applications, while NAS systems could be more suitable for file sharing and backups. Hybrid storage can offer a balance between performance and cost, and SDS can provide flexibility and scalability.
**3. Implement Robust Data Protection Measures**
Ensure your storage solutions include robust data protection measures, such as encryption, redundancy, and disaster recovery plans. Regularly test your backup and recovery processes to ensure they work effectively in case of data loss or corruption.
**4. Improve for Execution and Proficiency**
Streamline your storage infrastructure for performance and efficiency. Use tools and technologies that allow for automated data tiering, efficient data deduplication, and intelligent data management. This optimization will help you get the most out of your storage resources while minimizing costs.
** 5. Maintain and Monitor Regularly**
Regular maintenance and monitoring are crucial to ensure your storage systems perform optimally and remain secure. Implement proactive monitoring tools to detect and address potential issues before they cause significant disruptions.
Regularly update and patch your storage systems to protect against security vulnerabilities.
**The Future of Enterprise Storage**
The enterprise storage landscape is continually evolving, driven by advancements in technology and changing business needs. Future trends in enterprise storage include:
**1. Increased Adoption of Cloud Storage**
Cloud storage offers scalability, flexibility, and cost savings, making it an attractive option for many businesses. Hybrid cloud solutions, which combine on-premises and cloud storage, provide the best of both worlds, enabling businesses to leverage the cloud's benefits while maintaining control over critical data.
**2. Advances in Artificial Intelligence and Machine Learning**
AI and ML technologies are increasingly being integrated into storage solutions to enhance data management and analysis. These technologies can automate data classification, optimize storage utilization, and provide predictive analytics for better decision-making.
**3. Enhanced Security Measures**
As cyber threats continue to evolve, so too must the security measures in enterprise storage solutions. Expect to see more advanced encryption, improved access controls, and enhanced monitoring and response capabilities to protect against data breaches and cyber attacks.
**4. Greater Emphasis on Sustainability**
Sustainability is becoming a critical consideration in enterprise storage, with businesses seeking energy-efficient solutions to reduce their environmental impact. Advances in storage technology, such as more efficient SSDs and innovative cooling methods, will contribute to more sustainable data centers.
## **Conclusion **
Enterprise storage is a critical component of modern business operations, enabling organizations to effectively manage and leverage data for competitive advantage. By understanding the key components and technologies of enterprise storage and implementing robust, scalable, and secure solutions, businesses can ensure their data infrastructure supports their growth and innovation goals. From rack mounting and server maintenance to data recovery services, a comprehensive approach to enterprise storage is essential to address the evolving needs and challenges of today's data-driven world. By staying informed about the latest trends and technologies and adopting best practices, businesses can navigate the complexities of storage infrastructure and unlock the full potential of their data.
| liong |
1,866,716 | Ghe Massage Life Sport | "Các mẫu ghế massage của Lifesport được trang bị nhiều tính năng thông minh và hiện đại, giúp bạn tận... | 0 | 2024-05-27T16:02:55 | https://dev.to/ghemassage/ghe-massage-life-sport-2367 | "Các mẫu ghế massage của Lifesport được trang bị nhiều tính năng thông minh và hiện đại, giúp bạn tận hưởng cảm giác mát-xa thư giãn như ở spa. Ghế mát xa Lifesport có thiết kế đẹp, mẫu mã đã dạng, mức giá cũng khác nhau, đáp ứng mọi nhu cầu sử dụng của khách hàng.
SĐT: 1800 6807
Email: info@lifesport.vn
Địa chỉ: Lầu 3, số 6 Phan Chu Trinh, P.Tân Thành, Q.Tân Phú, TP.Hồ Chí Minh
Map: https://maps.app.goo.gl/3H4sxa77fb7QEvhB7
Website: https://lifesport.vn/ghe-massage
Hastag: #lifesport #lifesportvn #xedaptaplifesport #ghemassagelifesport"
Website: https://lifesport.vn/ghe-massage
Phone: 1800 6807
Address: Lầu 3, số 6 Phan Chu Trinh, P.Tân Thành, Q.Tân Phú, TP.Hồ Chí Minh
https://vnxf.vn/members/fmghemassage.81354/#about
https://www.creativelive.com/student/ghe-massage-life-sport?via=accounts-freeform_2
https://active.popsugar.com/@ooghemassage/profile
https://potofu.me/ghemassage
https://www.ohay.tv/profile/ooghemassage
https://huggingface.co/ghemassage
https://hashnode.com/@abghemassage
https://www.noteflight.com/profile/37e184582788667e3b1b225de9677a99414f325b
https://leetcode.com/u/fighemassage/
https://www.quia.com/profiles/ghemassagel
https://justpaste.it/u/ghemassage2
https://www.hahalolo.com/@6654a58f6df3d00810d37f9d
https://hackerone.com/fsghemassage?type=user
https://www.intensedebate.com/people/azghemassage
https://hypothes.is/users/xhghemassage
https://us.enrollbusiness.com/BusinessProfile/6698560/ghemassage
https://www.cineplayers.com/ghemassage
https://research.openhumans.org/member/rlghemassage
https://dreevoo.com/profile.php?pid=642183
https://www.bark.com/en/gb/company/ghemassage/NOG0e/
https://peatix.com/user/22392706/view
https://www.storeboard.com/Ghe%20MassageLife%20Sport
https://www.equinenow.com/farm/ghemassage.htm
https://www.funddreamer.com/users/ghe-massage-life-sport
https://makersplace.com/gregory49alexander5455/about
https://disqus.com/by/disqus_bKOHUi9Kes/about/
https://sinhhocvietnam.com/forum/members/74537/#about
https://teletype.in/@geghemassage
https://wibki.com/swghemassage?tab=Ghe%20Massage%20Life%20Sport
https://padlet.com/gregory49alexander5455
https://www.fimfiction.net/user/746511/hrghemassage
https://www.facer.io/u/ghemassage
https://glose.com/u/zdghemassage
https://www.huntingnet.com/forum/members/cqghemassage.html
https://www.diggerslist.com/jighemassage/about
https://git.industra.space/ghemassage
https://www.patreon.com/ghemassage901
https://tupalo.com/en/users/6778644
https://www.mountainproject.com/user/201829257/ghe-massage-life-sport
https://expathealthseoul.com/profile/ghe-massage-life-sport/
https://qiita.com/tsghemassage
https://muckrack.com/ghe-massage-life-sport
https://www.pling.com/u/sughemassage/
https://timeswriter.com/members/crghemassage/
https://penzu.com/p/ce2e4874a069f4b4
https://www.artscow.com/user/3196386
https://wperp.com/users/ghemassage/
https://pastelink.net/h24bw3fj
https://readthedocs.org/profiles/vbghemassage/
https://app.talkshoe.com/user/llghemassage
https://chodilinh.com/members/ghemassage.78858/#about
https://www.instapaper.com/p/uyghemassage
https://www.deviantart.com/oighemassage/about
https://myanimelist.net/profile/pgghemassage
https://forum.dmec.vn/index.php?members/ghemassage.60997/
https://fileforum.com/profile/wughemassage
http://buildolution.com/UserProfile/tabid/131/userId/405675/Default.aspx
https://telegra.ph/ghemassage-05-27
https://participez.nouvelle-aquitaine.fr/profiles/ghemassage/activity?locale=en
https://gifyu.com/aighemassage
http://hawkee.com/profile/6958721/
https://dev.to/ghemassage
https://pubhtml5.com/homepage/vbguu/
https://worldcosplay.net/member/1770773
https://confengine.com/user/ghe-massage-life-sport
https://rotorbuilds.com/profile/42351/
https://inkbunny.net/gcghemassage
https://community.fyers.in/member/tx5Y2enyUm
https://linkmix.co/23441472
https://vimeo.com/user220266388
https://www.speedrun.com/users/etghemassage
https://portfolium.com/ghemassage
https://lab.quickbox.io/ndghemassage
https://stocktwits.com/vaghemassage
https://www.penname.me/@ghemassage
http://idea.informer.com/users/wtghemassage/?what=personal
https://www.guilded.gg/profile/mR1Z6OYd
https://bentleysystems.service-now.com/community?id=community_user_profile&user=4df5bfef47dac61488c56642846d4365
https://roomstyler.com/users/kkghemassage
https://play.eslgaming.com/player/20129697/
https://www.pearltrees.com/yfghemassage
https://www.are.na/ghe-massage-life-sport/channels
https://hackmd.io/@ghemassage
https://data.world/rbghemassage
https://8tracks.com/tbghemassage
https://www.divephotoguide.com/user/pyghemassage/
https://answerpail.com/index.php/user/kzghemassage
https://www.5giay.vn/members/doghemassage.101974389/#info
https://socialtrain.stage.lithium.com/t5/user/viewprofilepage/user-id/65154
https://www.ethiovisit.com/myplace/ghemassage
https://os.mbed.com/users/szghemassage/
https://camp-fire.jp/profile/ukghemassage
https://www.mixcloud.com/vkghemassage/
https://linktr.ee/rrghemassage
https://visual.ly/users/gregory49alexander5455
https://hubpages.com/@rzghemassage#about
https://able2know.org/user/qdghemassage/
https://www.silverstripe.org/ForumMemberProfile/show/152496
https://willysforsale.com/profile/ghemassage
https://zzb.bz/gqJiu
https://www.metooo.io/u/6654ab23d22b3c780930de86
http://forum.yealink.com/forum/member.php?action=profile&uid=342280
https://dribbble.com/jgghemassage/about
https://wmart.kz/forum/user/163315/
https://www.gaiaonline.com/profiles/tgghemassage/46697187/
https://collegeprojectboard.com/author/ghemassage/
https://chart-studio.plotly.com/~rtghemassage
https://vnseosem.com/members/ghemassage.31062/#info
https://doodleordie.com/profile/owghemassage
https://edenprairie.bubblelife.com/users/ghemassage
https://crowdin.com/project/ghemassage
https://www.exchangle.com/izghemassage
https://naijamp3s.com/index.php?a=profile&u=ghemassage
https://jsfiddle.net/user/jyghemassage/
https://www.scoop.it/u/ghe-massagelife-sport
https://www.anibookmark.com/user/nlghemassage.html
https://www.credly.com/users/ghe-massage-life-sport/badges
https://myspace.com/qwghemassage
https://www.gta5-mods.com/users/prghemassage
https://www.kniterate.com/community/users/ghemassage/
https://www.cakeresume.com/me/ghemassage
https://guides.co/a/ghe-massage-life-sport
https://rentry.co/ub9bozko
https://community.tableau.com/s/profile/0058b00000IZYTt
https://www.wpgmaps.com/forums/users/ghemassage/
https://slides.com/lqghemassage
https://topsitenet.com/profile/ghemassage/1195596/
https://www.designspiration.com/gregory49alexander5455/
https://www.trepup.com/@ghemassagelifesport
https://connect.garmin.com/modern/profile/cf1382d0-724f-4ac4-8c9c-e1df6d04bf3d
https://wakelet.com/@GheMassageLifeSport68682
https://www.plurk.com/rdghemassage/public
https://www.dermandar.com/user/kvghemassage/
https://devpost.com/gregory49alexander5455
https://diendannhansu.com/members/ghemassage.49775/#about
https://vocal.media/authors/ghe-massage-life-sport
| ghemassage | |
1,866,715 | Understanding Skin Damage and Inflammation | Understanding Skin Damage and Inflammation Skin Damage: The skin is the body's largest organ and... | 0 | 2024-05-27T16:02:11 | https://dev.to/softwareindustrie24334/understanding-skin-damage-and-inflammation-2dd1 | Understanding Skin Damage and Inflammation
Skin Damage: The skin is the body's largest organ and serves as a protective barrier. Damage can manifest as dryness, fine lines, wrinkles, hyperpigmentation, and loss of elasticity. Factors contributing to skin damage include UV radiation, oxidative stress from free radicals, dehydration, and collagen breakdown.
Inflammation: Inflammation is the body's response to injury or irritation, often appearing as redness, swelling, heat, and pain. Chronic inflammation can lead to skin conditions like rosacea, psoriasis, and dermatitis.
Key Strategies for Repairing Skin Damage
Sun Protection: The most crucial step in preventing and repairing skin damage is protecting it from UV rays. Use a broad-spectrum sunscreen with at least SPF 30 daily, even on cloudy days. Reapply every two hours if you are outdoors.
Hydration: Keeping the skin hydrated is essential. Use moisturizers that contain hyaluronic acid, glycerin, or ceramides to lock in moisture. Drinking plenty of water also helps maintain skin hydration from within.
https://www.mayanmagicsoaps.com | softwareindustrie24334 | |
1,866,646 | TW Elements - JavaScript. Free UI/UX design course | JavaScript As the name suggests, Tailwind CSS is a CSS framework. It does not contain... | 25,935 | 2024-05-27T16:00:00 | https://tw-elements.com/learn/te-foundations/tailwind-css/javascript/ | javascript, webdev, beginners, tailwindcss | ## JavaScript
As the name suggests, Tailwind CSS is a CSS framework. It does not contain JavaScript code and does not offer solutions related to it.
However, that doesn't mean we shouldn't use JS in Tailwind. Quite the opposite.
By not providing any JavaScript code by default, Tailwind wants to be agnostic - that is, it has no "preference" when it comes to the technologies it will be used with - be it React, Vue, Angular, Svelte or any other JavaScript code - Tailwind CSS will make friends with everyone.
This approach, of course, has its pros and cons.
The most obvious disadvantage is that when using regular Tailwind, we have a very limited choice when it comes to interactivity or advanced functionalities that we would like to add to our UI.
And here libraries such as TW Elements come to our aid - it offers not only a number of ready-to-use components, built from Tailwind classes, but also provide JavaScript code, thanks to which we can enjoy interactivity and advanced functionalities (such as Navbar collapsing and extending on mobile, what have we seen in the previous lesson).
So let's take a closer look at how this JavaScript and the interactivity and advanced features it provides work.
_Psst! Don't worry if you don't feel too comfortable with JS. We won't be writing JavaScript code here, but we'll just explain useful concepts and usage that will help us in future lessons._
## Data attributes
Have a look at the Navbar code we have in our current project.
Have you noticed elements like data-twe-navbar-ref or data-twe-collapse-init in your HTML code?
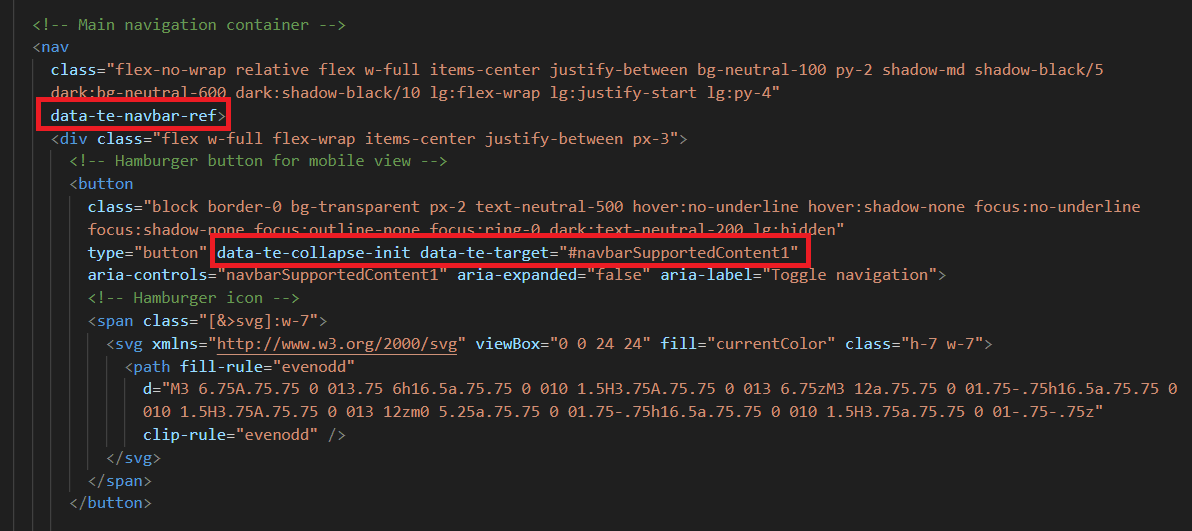
These are so called data attributes. They are used to store additional information in HTML elements.
_"HTML is designed with extensibility in mind for data that should be associated with a particular element but need not have any defined meaning. data-* attributes allow us to store extra information on standard, semantic HTML elements without other hacks such as non-standard attributes, or extra properties on DOM."_ - [MDB Web Docs](https://mdbootstrap.com/docs/standard/)
You don't have to try to remember exactly what each attribute does, let alone memorize them.
That would be pointless because there are so many of them and you always have access to them in the documentation.
**What is important** is that you know that the Tailwind Elements library uses these data attributes to provide interactivity and functionality to components.
Without data attributes, TW Elements cannot function properly, **so never remove them**.
## How does it exactly work?
It may look complicated, but the concept is very simple - data attributes indicate to the TW Elements library where what functionality (what JavaScript code) should be used.
For example, if you look at our navbar's code and look at the item commented <!-- Collapsible navigation container --> you will find the data-twe-collapse-item attribute.
**HTML**
```
<!-- Collapsible navigation container -->
<div
class="!visible hidden flex-grow basis-[100%] items-center lg:!flex lg:basis-auto"
id="navbarSupportedContent1"
data-twe-collapse-item>
[...]
</div>
```
Recall how in the previous lesson we initialized Navbar by pasting the following code into our project:
**JAVASCRIPT**
```
// Initialization for ES Users import { Collapse, Dropdown, initTWE, } from
"tw-elements"; initTWE({ Collapse, Dropdown });
```
Do you see the **collapse** import?
It's a bit oversimplification, but you could say it's the following instructions for the TW Elements library:
1. Import and add collapse functionality to my project
2. Find the element marked with the data-twe-collapse-item attribute in the HTML code
3. Apply the collapse functionality to this element and make the Navbar collapse and expand on the mobile view
I hope it makes sense now and data attributes will no longer look disturbing to you 😉 | keepcoding |
1,843,763 | How To Manage IAM Access Analyzer in AWS Organizations Using Terraform | Introduction Since I began covering the implementation of security controls in AWS, I have... | 27,647 | 2024-05-27T15:59:55 | https://blog.avangards.io/how-to-manage-iam-access-analyzer-in-aws-organizations-using-terraform | aws, terraform, security | ## Introduction
Since I began covering the [implementation of security controls in AWS](https://dev.to/acwwat/series/26815), I have provided walkthroughs on configuring [Amazon GuardDuty](https://dev.to/aws-builders/how-to-manage-amazon-guardduty-in-aws-organizations-using-terraform-3pg6) and [AWS Security Hub](https://dev.to/aws-builders/how-to-manage-aws-security-hub-in-aws-organizations-using-terraform-5gl4) in a centralized setup using Terraform. In this blog post, we will explore another security service: AWS IAM Access Analyzer. This service helps identify unintended external access or unused access within your organization. Setting up IAM Access Analyzer is simpler than the other services, so let's dive right in!
## About the use case
[AWS Identity and Access Management (IAM) Access Analyzer](https://docs.aws.amazon.com/IAM/latest/UserGuide/what-is-access-analyzer.html.) is a feature of AWS IAM that identifies resources shared with external entities and detects unused access, enabling you to mitigate any unintended or obsolete permissions.
IAM Access Analyzer [can be used in AWS Organizations](https://aws.amazon.com/blogs/aws/new-use-aws-iam-access-analyzer-in-aws-organizations/), allowing analyzers that use the organization as the zone of trust to be managed by either the management account or a [delegated administrator account](https://docs.aws.amazon.com/IAM/latest/UserGuide/access-analyzer-settings.html). This enables the consolidation of findings, which can then be ingested by AWS Security Hub in a centralized setup.
Since it is increasingly common to establish an AWS landing zone using [AWS Control Tower](https://docs.aws.amazon.com/controltower/latest/userguide/what-is-control-tower.html), we will use the [standard account structure](https://docs.aws.amazon.com/controltower/latest/userguide/accounts.html) in a Control Tower landing zone to demonstrate how to configure IAM Access Analyzer in Terraform:
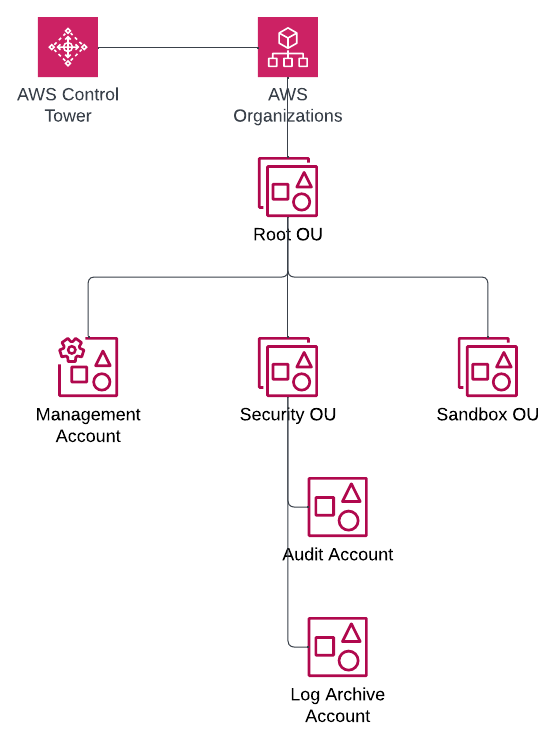
The relevant accounts for our use case in the landing zone are:
1. The **Management** account for the organization where AWS Organizations is configured. For details, refer to [Settings for IAM Access Analyzer](https://docs.aws.amazon.com/IAM/latest/UserGuide/access-analyzer-settings.html).
2. The **Audit** account where security and compliance services are typically centralized in a Control Tower landing zone.
The objective is to delegate IAM Access Analyzer administrative duties from the **Management** account to the **Audit** account, after which all organization configurations are managed in the **Audit** account. With that said, let's see how we can achieve this using Terraform!
## Designating an IAM Access Analyzer administrator account
The IAM Access Analyzer delegated administrator is configured in the **Management** account, so we need a provider associated with it in Terraform. To simplify the setup, we will use a multi-provider approach by defining two providers: one for the **Management** account and another for the **Audit** account. We will use AWS CLI profiles as follows:
```terraform
provider "aws" {
alias = "management"
# Use "aws configure" to create the "management" profile with the Management account credentials
profile = "management"
}
provider "aws" {
alias = "audit"
# Use "aws configure" to create the "audit" profile with the Audit account credentials
profile = "audit"
}
```
Unlike other security services that have specific Terraform resources for designating a delegated administrator, this is done using the more general [`aws_organizations_delegated_administrator` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/organizations_delegated_administrator) as follows:
```terraform
data "aws_caller_identity" "audit" {
provider = aws.audit
}
resource "aws_organizations_delegated_administrator" "this" {
provider = aws.management
account_id = data.aws_caller_identity.audit.account_id
service_principal = "access-analyzer.amazonaws.com"
}
```
With the **Audit** account designated as the IAM Access Analyzer administrator, we can now create the analyzers for the organization.
## Creating analyzers with organizational zone of trust
As mentioned earlier, there are two types of analyzers: external access and unused access. To make the setup more configurable, we will add some variables and keep them in a separate file called `variables.tf`. To create the external access analyzer with the organization as the zone of trust, we can define the Terraform configuration as follows:
```terraform
# Defined in variables.tf
variable "org_external_access_analyzer_name" {
description = "The name of the organization external access analyzer."
type = string
default = "OrgExternalAccessAnalyzer"
}
```
```terraform
# Defined in main.tf
resource "aws_accessanalyzer_analyzer" "org_external_access" {
provider = aws.audit
analyzer_name = var.org_external_access_analyzer_name
type = "ORGANIZATION"
depends_on = [aws_organizations_delegated_administrator.this]
}
```
Since the unused access analyzer is a paid feature, we ought to make it optional. The Terraform configuration can be defined in the following manner:
```terraform
# Defined in variables.tf
variable "org_unused_access_analyzer_name" {
description = "The name of the organization unused access analyzer."
type = string
default = "OrgUnusedAccessAnalyzer"
}
variable "eanble_unused_access" {
description = "Whether organizational unused access analysis should be enabled."
type = bool
default = false
}
variable "unused_access_age" {
description = "The specified access age in days for which to generate findings for unused access."
type = number
default = 90
}
```
```terraform
resource "aws_accessanalyzer_analyzer" "org_unused_access" {
provider = aws.audit
count = var.eanble_unused_access ? 1 : 0
analyzer_name = var.org_unused_access_analyzer_name
type = "ORGANIZATION_UNUSED_ACCESS"
configuration {
unused_access {
unused_access_age = var.unused_access_age
}
}
depends_on = [aws_organizations_delegated_administrator.this]
}
```
>✅ You can find the complete Terraform in the [GitHub repository](https://github.com/acwwat/terraform-aws-accessanalyzer-organization-example) that accompanies this blog post.
With the complete Terraform configuration, you can now apply it with the appropriate variable values to establish the **Audit** account as the delegated administrator and create the analyzers with the organization as the zone of trust.
## Additional considerations
IAM Access Analyzer is a regional service, so you must create an analyzer in each region. However, it primarily applies to external access analysis, which examines the policies of regional resources such as S3 buckets and KMS keys. Since unused access analysis works with IAM users and roles, which are global resources, creating multiple unused access analyzers would only increase costs without adding value. Therefore, it is recommended to create one external access analyzer per region and only one unused access analyzer in the home region.
Another consideration is that there are times when the organizational zone of trust is not desirable. For example, if you wish to have full segregation of member accounts because they represent different tenants, then you would actually want analyzers created in each member account with itself as the zone of trust. This unfortunately would have to be managed at a per-account level.
## Summary
In this blog post, you learned how to manage IAM Access Analyzer in AWS Organizations using Terraform by defining a delegated administrator and using analyzers with the organization as the zone of trust. If you have also [configured AWS Security Hub to operate at the organization level](https://dev.to/aws-builders/how-to-manage-aws-security-hub-in-aws-organizations-using-terraform-5gl4), you can manage IAM Access Analyzer findings across accounts and regions, thereby streamlining your security operations.
I hope you find this blog post helpful. Be sure to keep an eye out for more how-to articles on configuring other AWS security services in Terraform, or learn about other topics like [generative AI](https://dev.to/aws-builders/building-a-basic-forex-rate-assistant-using-agents-for-amazon-bedrock-17fp), on the [Avangards Blog](https://blog.avangards.io). | acwwat |
1,866,709 | 7 Reasons, Why You Should Learn the Power Platform. | Introduction I found a publication that stated that the Power Platform is now a $2 billion... | 0 | 2024-05-27T15:58:36 | https://prince-adimado.hashnode.dev/7-reasons-why-you-should-learn-the-power-platform | microsoft, powerplatform, powerautomate, powerapps | ## Introduction
I found a [publication](https://www.thurrott.com/dev/270412/power-platform-now-has-over-7-million-active-users) that stated that the Power Platform is now a $2 billion business with over 7 million monthly active users (MAUs). It also went further to state that 97 percent of the Fortune 500 use the Power Platform and even 92 percent of the Fortune 500 uses Power Apps in at least one department.
What am I driving at? This shows that learning the Power Platform is a great tool in your arsenal of skills. During the Global Power Platform Bootcamp 2023 in Accra, I had the privilege of hearing [Samuel Adranyi](https://mvp.microsoft.com/en-us/PublicProfile/5003737?fullName=Samuel%20Segbornya%20Kodzo%20Adranyi), a Microsoft MVP, deliver an inspiring demo. He emphasized that when it comes to the usage of the Microsoft Power Platform, our imagination is the only limit to what we can achieve.
[Check out my blog post on how I integrated Power Automate and React.](https://dev.to/primado/power-automate-and-react-integration-automate-business-processes-2oli)
If that didn't even blow your mind even further, it’s said that there are going to be 500 million apps to be built in the next five years. We should not pretend that there are enough code-first developers to do this.
Low code/no-code tools like the Microsoft Power Platform is a game changer that offers many services from data analytics and visualization, and automation, to app development, chatbot development, and recently website development which leverages the organization’s data.
How much more can I say? Than to give you 7 reasons why you should learn the Microsoft Power Platform.
## 7 Reasons, Why You Should Learn the Power Platform.
### 1️⃣ Rapid Application Development
The Power Platform offers a low-code/no-code environment, allowing you to quickly build applications without extensive programming knowledge. Imagine trying to build a flow that sends an email when a new response is submitted and the data must be stored in either an Excel workbook or a SharePoint list.
Wouldn’t it be very productive if there were existing connectors available like what we have in Power Automate rather than going full Ninja 🥷 mode to write all code for the APIs and integrations just to make this happen?
Again, imagine a scenario where your organization receives hundreds of customer inquiries through various channels every day. Manually sorting through inquiries, assigning them to the appropriate team members, and responding individually can be time-consuming and prone to human error.
However, with the Power platform’s Power Automate, you can create a workflow that automatically captures and categorizes incoming inquiries, assigns relevant teams based on predefined rules, and even generates email responses.
This automation not only makes the organization productive but also ensures faster response times improved customer satisfaction and increased operational efficiency.
### 2️⃣ Customizable Solutions
With the Microsoft Power Platform, you can tailor applications to specific business needs. It’s so flexible that it enables you to create custom solutions that fit your organization’s unique requirements.
### 3️⃣ Data Visualization
Looking for ways to analyze and visualize your data. Look no further, Power BI, a tool of the Power Platform, offers robust data visualization and analytics capabilities. You can create interactive dashboards and reports to gain valuable insights from your data, empowering data-driven decision-making.
### 4️⃣ Extensive Connector Library
The second point showed how customizable the Power Platform is. Let’s talk about the extensibility of the Power Platform.
Power Platform won’t be where it is today if it can’t be extended to include 3<sup>rd</sup> party services. Do you know that you can create custom connectors to connect to your own API or third-party APIs?
You can create customer actions that can be used in your workflows. And don’t worry if your data source is on an on-premises database. You can still create custom connectors for on-premise data sources. [Learn more.](https://learn.microsoft.com/en-us/power-automate/gateway-reference)
In Power Apps, you can create custom controls that can be used in your apps. Learn more about how to create custom controls using the [Power Apps Component Framework.](https://docs.microsoft.com/en-us/powerapps/developer/component-framework/overview)
In data analytics and visualization, Power BI developers can extend Power BI’s capability to [create custom data extensions](https://learn.microsoft.com/en-us/power-bi/connect-data/desktop-connector-extensibility).
Power Virtual Agents can also be extended in several ways. Bots can be configured to suit the individual needs of an organization and to provide further extensibility with other services and features. This includes the use of Microsoft Bot Framework skills to augment the bot’s capabilities, integration with Microsoft Teams, Facebook, Telegram, and other channels, and more.
The list can go on and on about how the Power Platform has evolved into what we have today.
### 5️⃣ Integration Capabilities
The Power Platform seamlessly integrates with other Microsoft products and services, such as Microsoft 365, Dynamics 365, and Azure.
This integration allows you to leverage existing data and systems, enhancing overall efficiency and productivity.
Power Platform Integrates with Microsoft 365 to provide you with the tools you need to build custom apps, automate workflows, and analyze data.
You can use Power Automate to create workflows that connect to Microsoft 365 services like Outlook, Excel, and SharePoint. You can also use Power Apps to build custom apps that integrate with Microsoft 365 services like Teams and Dynamics 365.
Moreover, you can use Power BI to analyze data from Microsoft 365 services like Excel and SharePoint.
### 6️⃣ Learning and Career Opportunities
Acquiring skills in the Power Platform can open various career opportunities. The demand for professionals proficient in this awesome tool called the Power Platform is on the rise and organizations are seeking individuals who can leverage its capabilities to drive digital transformation.
### 7️⃣ Community and Support
Power Platform has a vibrant and supportive community of users, developers, and experts. There are Microsoft MVPs I cited in one of my articles on [tips to master the Power Platform](https://prince-adimado.hashnode.dev/mastering-the-power-platform-essential-tips-to-level-up-your-skills). Power Platform has a huge community of users, find out more [here](https://powerusers.microsoft.com?wt.mc_id=studentamb_158955).
Engaging with the community provides opportunities for learning, collaboration, and knowledge sharing, ensuring you.
You can also find user groups on the Power Users page I provided at this point. User groups organize community-led events which bring together can continually enhance your skills and stay up to date with the latest developments tech enthusiasts, students, and developers under one roof to learn and network.
## 🙏 Let's Conclude
Thank you for reading this far. I have shared 7 solid reasons why you should learn the Microsoft Power Platform. From how applications, no matter how small or big, can be built rapidly through the Power Platform. Applications built with the Power Platform are highly customizable to suit the organizational brand.
Writing complex lines of code to visualize your data shouldn't be a limitation to you when you have the data Visualization tool, Power BI which is the leading industry tool in data visualization.
If you haven’t read my article on tips to learn the Power Platform, [check it out here](https://prince-adimado.hashnode.dev/mastering-the-power-platform-essential-tips-to-level-up-your-skills).
Support me by, [BUYING ME A COFFEE](https://buymeacoffee.com/primado). 🙏 | primado |
1,866,712 | Interactive Loading Animation with CSS | This project demonstrates how to create an engaging loading animation using pure CSS. The animation... | 0 | 2024-05-27T15:57:04 | https://dev.to/alikhanzada577/interactive-loading-animation-with-css-26fm | codepen, css, frontend, animation | This project demonstrates how to create an engaging loading animation using pure CSS.
The animation features a rotating background color and a loader composed of** 20 spinning dots **that pulsate sequentially. The background hue shifts continuously, creating a dynamic visual effect. Each dot is positioned using CSS variables and animated with keyframes to scale up and down in a rhythmic pattern.
**Key Features:**
- Rotating Background: Smooth color transitions using hue-rotate.
- Pulsating Dots: Sequential animation delays for a wave effect.
- Pure CSS: No JavaScript required, ensuring lightweight performance.
**Usage**
- Embed the HTML in your webpage.
- Add the CSS to your stylesheet.
- Adjust the number of spans and their styles as needed for different visual effects.
**This loader is perfect for adding a modern, visually appealing touch to your web projects.**
## **HTML**
```
<section>
<div class="loader">
<span style="--i:1;"></span>
<span style="--i:2;"></span>
<span style="--i:3;"></span>
<span style="--i:4;"></span>
<span style="--i:5;"></span>
<span style="--i:6;"></span>
<span style="--i:7;"></span>
<span style="--i:8;"></span>
<span style="--i:9;"></span>
<span style="--i:10;"></span>
<span style="--i:11;"></span>
<span style="--i:12;"></span>
<span style="--i:13;"></span>
<span style="--i:14;"></span>
<span style="--i:15;"></span>
<span style="--i:16;"></span>
<span style="--i:17;"></span>
<span style="--i:18;"></span>
<span style="--i:19;"></span>
<span style="--i:20;"></span>
</div>
</section>
```
## **CSS**
```
body, html {
margin: 0;
padding: 0;
overflow: hidden;
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
width:100%;
background: #042104;
animation: animateBg 10s linear infinite;
}
@keyframes animateBg {
0% {
filter: hue-rotate(0deg);
}
100% {
filter: hue-rotate(360deg);
}
}
section .loader {
position: relative;
width: 120px;
height: 120px;
}
section .loader:hover {
position: relative;
width: 140px;
height: 140px;
}
section .loader span {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
transform: rotate(calc(18deg * var(--i)));
}
section .loader span::before {
content: '';
position: absolute;
top: 0;
left: 50%;
transform: translateX(-50%);
width: 15px;
height: 15px;
background: #00ff0a;
border-radius: 50%;
box-shadow: 0 0 10px #00ff0a,
0 0 20px #00ff0a,
0 0 40px #00ff0a,
0 0 60px #00ff0a,
0 0 80px #00ff0a,
0 0 100px #00ff0a;
animation: animate 2s linear infinite;
animation-delay: calc(0.1s * var(--i));
}
@keyframes animate {
0% {
transform: scale(1);
}
80%, 100% {
transform: scale(0);
}
}
```
{% codepen https://codepen.io/Alikhanzada577/pen/oNRYzME %} | alikhanzada577 |
1,866,710 | How to Use GitHub Actions to Display Dev.to Blog Posts on Your README.md | In this tutorial, you'll learn how to use GitHub Actions to automatically update your GitHub... | 0 | 2024-05-27T15:55:10 | https://dev.to/arafatweb/how-to-use-github-actions-to-display-devto-blog-posts-on-your-readmemd-362f | In this tutorial, you'll learn how to use GitHub Actions to automatically update your GitHub repository's `README.md` file with the latest blog posts from your Dev.to feed. This automation will help showcase your recent writings directly on your GitHub profile or project page, keeping it dynamically updated.
[View Demo](https://github.com/arafat-web/arafat-web)

### Prerequisites
- A GitHub account
- A Dev.to account and an active blog with an RSS feed
- Basic knowledge of Git and GitHub
### Step 1: Identify Your Dev.to Feed URL
Your Dev.to blog's RSS feed URL is typically in the format `https://dev.to/feed/username`. Replace `username` with your own Dev.to username.
### Step 2: Setting Up Your GitHub Repository
If you haven't already, create a new repository or choose an existing one where you want to display your blog posts.
### Step 3: Create a GitHub Actions Workflow
1. **Navigate to your repository** on GitHub.
2. Click on the **Actions** tab, then choose **New workflow**.
3. Start from scratch by selecting **"set up a workflow yourself"**.
Replace the content of the workflow file with the following:
```yaml
name: Update README with Latest Blog Posts
# Controls when the action will run.
on:
schedule:
- cron: '0 * * * *' # Runs every hour, can be adjusted to your preference
push:
branches:
- main # Runs on pushes to the main branch; adjust if your default branch has a different name
jobs:
update-readme:
runs-on: ubuntu-latest # The type of runner that the job will run on
steps:
- name: Checkout Repository
uses: actions/checkout@v3 # Checks out your repository under $GITHUB_WORKSPACE, so your job can access it
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '18' # Sets up a specific version of Node.js
- name: Install dependencies
run: |
npm install rss-parser # Installs the rss-parser package to parse the RSS feed
- name: Run script to update README
run: node .github/scripts/update-readme.js # Executes a Node.js script to update README.md
- name: Commit changes
run: |
git config --local user.email "action@github.com"
git config --local user.name "GitHub Action"
git add README.md
git commit -m "Update README with latest blog posts" -a || echo "No changes to commit"
git push
```
### Step 4: Create the Node.js Script
1. In your repository, create a new directory called `.github/scripts`.
2. Inside this directory, create a file named `update-readme.js`.
3. Add the following Node.js script to this file:
```javascript
const fs = require('fs');
const Parser = require('rss-parser');
const parser = new Parser();
(async () => {
const feed = await parser.parseURL('https://dev.to/feed/yourusername'); // Your Dev.to feed
let readmeContent = fs.readFileSync('README.md', 'utf8');
let newBlogContent = '';
feed.items.slice(0, 5).forEach(item => {
const formattedDate = new Date(item.pubDate).toLocaleDateString('en-US', { year: 'numeric', month: 'long', day: 'numeric' });
newBlogContent += `### [${item.title}](${item.link})\n`;
newBlogContent += `📅 ${formattedDate}\n\n`; // Adds formatted date with a calendar emoji
});
const newReadme = readmeContent.replace(/<!-- BLOG-POST-LIST:START -->.*<!-- BLOG-POST-LIST:END -->/s, `<!-- BLOG-POST-LIST:START -->\n${newBlogContent}<!-- BLOG-POST-LIST:END -->`);
fs.writeFileSync('README.md', newReadme);
})();
```
### Step 5: Update Your README.md to Include Placeholders
In your `README.md`, include the following placeholders where you want the blog posts to appear:
```markdown
<!-- BLOG-POST-LIST:START -->
<!-- BLOG-POST-LIST:END -->
```
### Conclusion
Now, every time the GitHub Action runs, it will fetch the latest blog posts from your Dev.to feed, update your `README.md` accordingly, and commit the changes. This automation enhances your GitHub profile by keeping it fresh and engaging for visitors, showcasing your latest writing without manual updates. | arafatweb | |
1,866,708 | 30 Days of JavaScript - Day 1 | Hey, join me in answering the 30 Days of Javascript from Leetcode. Here is the description of Day... | 0 | 2024-05-27T15:49:47 | https://dev.to/lmscunha/30-days-of-javascript-day-1-2kcm | Hey, join me in answering the [30 Days of Javascript](https://leetcode.com/studyplan/30-days-of-javascript/) from Leetcode.
Here is the description of [Day 1](https://leetcode.com/problems/create-hello-world-function/?envType=study-plan-v2&envId=30-days-of-javascript).
Answer:
This is an easy challenge. To return "Hello World", we could do the following:
```javascript
var createHelloWorld = function() {
return function(...args) {
return "Hello World"
}
}
```
The time complexity is O(1) because it's always returning "Hello World". No matter if we increase the input size.
The space complexity is also O(1) because nothing more will be stored in memory if we increase the input size.
That's it. Simple, right? Let's go to Day 2.
| lmscunha | |
1,866,707 | Interact with AI from your Terminal with Gen-ai-chat | Introduction Are you tired of constantly switching between different applications just to... | 0 | 2024-05-27T15:49:44 | https://arindam1729.hashnode.dev/interact-with-ai-from-your-terminal-with-gen-ai-chat | node, javascript, ai, cli | ## Introduction
Are you tired of constantly switching between different applications just to generate text? Are you looking for a way to utilize the power of AI directly from your Linux command-line interface (CLI) terminal?
If so, then this article has the perfect solution for you.
I've created [Gen-ai-chat](https://www.npmjs.com/package/gen-ai-chat), a powerful npm package that allows you to interact with AI without ever leaving your terminal.
Let's dive deep and explore how this can improve your workflow.
## **What is Gen-ai-chat?**
Gen-ai-chat is a Node.js command-line interface (CLI) tool that interacts with the Google Gemini API to generate content based on user input. With this tool, you can ask questions directly from your terminal, and get instant responses without the need to switch between different applications.
This makes it an incredibly efficient solution for developers and users who prefer working within the terminal environment.
Whether you're looking to generate text, get coding assistance, or seek answers to complex questions, `Gen-ai-chat` streamlines the process, saves you time and enhances your productivity.
## Features:
It has a variety of features designed to make your interactions with AI seamless and efficient:
1. **Direct Questions**: You can ask questions directly from the command line.
2. **File and Directory Context**: Provide additional context from files or entire directories.
3. **Interactive Mode**: Engage in a multi-question session without restarting the CLI.
4. **Model Selection**: Choose your favorite AI model interactively or specify it directly.
5. **Logging**: Write logs to a file for later review.
6. **Environment Variable Configuration**: Easily manage your API keys using a `.env` file.
## How to use it?
### Installation
To get started with Gen-ai-chat, you need to have Node.js and npm installed. You can install the package globally using npx:
```javascript
npx gen-ai-chat@latest
```
> Note: You can also use this without installing the package globally
### Basic Usage
You can start interacting with Gemini from your commandline with this simple command:
```javascript
npx gen-ai-chat "Your Question"
```
> Note: By default You can make 10 Requests/hour. You need to add your API key to use it unlimitedly
It's that simple! Right?
But wait we can do more things with this!
### **Using a File as Context**
While writing code, we often have questions or doubts. To find answers, we usually have to manually copy the code and search on different AI platforms.
However, with gen-ai-chat, you can simply mention the file where the code is located using the `-f` option, and it will do the rest of the work!
Here's an example:
```javascript
npx gen-ai-chat "Explain the code" -f ./index.js
```
This will use the `index.js` file as context and generate response based on that!
### **Using a Directory as Context**
Similar to files, if we need to use multiple files as context, we can simply mention the root directory where all the files are located using the `-d` option, and it will add all the files as context.
Here's an example usage:
```javascript
npx gen-ai-chat "Your Question" -d /path/to/your/directory
```
This will iterate through each files in the directory and add them as a context to that question.
<div data-node-type="callout">
<div data-node-type="callout-emoji">💡</div>
<div data-node-type="callout-text">Note: While adding files within directories, It will skip larger files such as <code>node_modules</code>, <code>package-lock.json</code> .</div>
</div>
### **Interactive Mode**
We can also use this as a chatbot and as multiple questions using the interactive mode. Start the interactive mode using the following command:
```javascript
npx gen-ai-chat -i
```
or
```javascript
npx gen-ai-chat --interactive
```
In interactive mode, the prompt `gen-ai-chat>` will appear, indicating that the tool is ready for your questions.
To exit the iteractive mode, you can just type `quit` or `exit` .
### **Choosing Your Favorite Model**
Another cool feature of gen-ai-chat is multi-model support. You can choose your favorite model interactively by using the `--choose-model` option:
```javascript
npx gen-ai-chat --choose-model
```
This command will prompt you to select a model from the available options:
From these options you can choose a model according to your preference.
Alternatively,You can specify the model directly using the `--model` flag:
```javascript
npx gen-ai-chat "Your question here" --model gemini-1.5-flash-latest
```
## It's Open Source: Contribute now!
Gen-ai-chat is an open-source project, and contributions are always welcome! If you have ideas for new features or improvements, feel free to open an issue on the GitHub repository.
Ready to code? Fork the repository, make your changes, and submit a pull request.
For more details and to contribute, visit the [GitHub repository](https://github.com/Arindam200/gen-ai).
## Conclusion
Overall, Gen-ai-chat provides a seamless and efficient way to integrate AI capabilities into your terminal workflow, enhancing productivity and enabling more sophisticated interactions with AI models.
Install it today and transform your workflow with the ease of AI at your fingertips
If you found this blog post helpful, please consider sharing it with others who might benefit.
For Paid collaboration mail me at : [arindammajumder2020@gmail.com](mailto:arindammajumder2020@gmail.com)
Connect with me on [Twitter](https://twitter.com/intent/follow?screen_name=Arindam_1729), [LinkedIn](https://www.linkedin.com/in/arindam2004/), [Youtube](https://www.youtube.com/channel/@Arindam_1729) and [GitHub](https://github.com/Arindam200).
Thank you for Reading :)
 | arindam_1729 |
1,866,704 | Mastering the Power Platform: Essential Tips to Level Up Your Skills | Introduction Maybe you click to open this article to find out how you can learn Power... | 0 | 2024-05-27T15:45:09 | https://prince-adimado.hashnode.dev/mastering-the-power-platform-essential-tips-to-level-up-your-skills/ | microsoft, powerautomate, powerplatform, powerapps |
## **Introduction**
Maybe you click to open this article to find out how you can learn Power Platform to skill up or you wanted to have a good read just to find out what the article contains. No matter the reason; time they say it’s money, give me a few minutes of your valuable time to share my truth.
The Microsoft Power Platform has evolved over the years with the initial release of Power BI in 2011 which serves as a powerful tool for data visualization and business intelligence capabilities for users. Microsoft went further to release Power Apps a low-code application development in 2016 together with Power Automate which was initially called Flow for creating workflows to streamline business processes.
Microsoft thought it wise to integrate and expand these tools. In 2017, Microsoft Integrated Power BI, Power Apps, and Power Automate under a unified umbrella known as the Microsoft Power Platform.
What if businesses can build and deploy chatbots without writing complex lines of code or even if code should be written it should be low code? Microsoft introduced Power Virtual Agents (PVA) in 2019 to come and demystify chatbot development.
Until recently, the new kid on the block, Power Pages, which provides rich, customizable templates, a fluid user experience through the design studio, and an integrated learning hub to quickly build sites for your unique needs.
Through these years low-code languages like Power Fx were introduced to provide developers superpowers to build applications in Excel-like syntax.
## 🤝 Getting Started
[It was estimated that 500 million apps will be created in the next in next five years](https://powerapps.microsoft.com/en-us/blog/3-low-code-trends-why-low-code-will-be-big-in-your-2021-tech-strategy/#:~:text=In%20the%20next%20five%20years%2C%20500%20million%20more,the%20last%2040%20years%2C%20according%20to%20the%20IDC.).
There simply aren’t enough professional pro code developers to go around the volume of work ahead to modernize businesses. But the good news is that low-code platforms like the Power Platform are here to empower more people regardless of their coding ability to create apps.
As a Power Platform developer, myself, I have devised 4 tips to help us to continue to skill up and stay updated in the tool we have purposed in our hearts to learn.
Here are the four powerful tips to help you learn the Microsoft Power Platform.
## Four Tips to Help You Learn the Microsoft Power Platform
## 💡 Documentation
We have heard the phrase “Read the docs”. How these three words could save us from a lot of frustration and waste of precious pearls of time. I remember the first workflow I built in Power Automate during a Microsoft Student Ambassador event by then-a Gold Student Ambassador, Shadrack Inusah who gave a demo. I re-watched the recording repeatedly just to fully build and run my first flow.
I was a novice who had heard of how amazing the Microsoft Power Platform is. The fact is I didn’t read the documentation of Power Automate and it went on for months, always trying to build workflows but the thought of looking up the docs didn’t come up my mind.
I remember, pausing learning the Power Platform because I didn’t know how to use certain connectors. So, I paused, until the 4<sup>th</sup> quarter of 2022 when I started to explore Power Automate again.
But this time, I started reading the Power Automate documentation, and I realized Microsoft has all the connectors documented. So, I started to explore and learn to build workflows.
How can one learn a tool without reading the documentation of its usage?
Documentation refers to the written information, instructions, and explanations that accompany a software, product, service, or process.
It provides comprehensive details about how to use, configure, troubleshoot, and maintain a particular item or system.
Documentation serves as a valuable resource for users, developers, administrators, and other stakeholders involved in the use or implementation of a product or service.
To us developers, Documentation provides developers with insights into the purpose, features, and functionality of a software, library, or API. It helps us gain a comprehensive understanding of how to effectively use the tool or framework.
To conclude on this point, I say just Read the Docs. It can’t be overemphasized.
Links to the various Documentation of the Power Platform
🔸[Power Platform Documentation](https://learn.microsoft.com/power-platform?wt.mc_id=studentamb_158955)
🔸[Power Automate Documentation](https://learn.microsoft.com/power-automate?wt.mc_id=studentamb_158955)
🔸[Power Apps Documentation](https://learn.microsoft.com/power-apps?wt.mc_id=studentamb_158955)
🔸[Power BI Documentation](https://learn.microsoft.com/power-bi?wt.mc_id=studentamb_158955)
🔸[Power Virtual Agents Documentation](https://learn.microsoft.com/power-virtual-agents?wt.mc_id=studentamb_158955)
🔸[Power Pages Documentation](https://learn.microsoft.com/power-pages?wt.mc_id=studentamb_158955)
## 💡Community
Each one of us comes from a community. A community is a group of individuals who share common interests, goals, or characteristics and come together to interact, support, and collaborate with one another.
To developers, the community holds significant importance and offers several benefits. Here are what community means to developers:
* **Learning and Knowledge Sharing:** community provides an environment for developers to learn from one another, exchange ideas, and share knowledge. It also offers opportunities to expand technical skills, stay updated with the latest industry trends, and explore new technologies. Developers can ask questions, and seek guidance from experienced members of the community.
* **Career Growth and Opportunities:** Engaging in a developer community can present career growth opportunities, such as attending conferences, participating in hackathons, or coding challenges.
When you check the documentation pages of the various Power Platform tools, you will see “Community” on the navigation bar. Microsoft Power Platform has community forums for all the tools. Do you have a question you want to ask, a bug that has been troubling you for days or even weeks? Check the Power Platform community, it could be that your issue has been fixed.
Apart from the Community forums, there are Microsoft Power Platform User groups depending on where you find yourself. Do you even know that all the Microsoft User Groups can be found on the community page of the Power Platform website? [Learn more](https://powerusers.microsoft.com?wt.mc_id=studentamb_158955).
## 💡Resources from Microsoft Cloud Advocates and MVPs
Microsoft MVPs are part of the driving force to help Microsoft to continue fulfill its mission which is “to empower every individual and organization on the planet to achieve more”.
It cannot be overstressed; Microsoft MVPs are doing the most to promote the Microsoft Technologies their MVPs for.
Microsoft MVPs (Most Valuable Professionals) are individuals who are recognized by Microsoft for their exceptional contributions to the technical community.
MVPs demonstrate expertise, community engagement, and willingness to share knowledge and experience with others.
Microsoft has tons of technologies you may not even know, but there are MVPs for all technology categories in Microsoft.
These professionals have YouTube Channels, and blog websites, some even go to the extent to produce tutorials to sell on either their own platforms or paid platforms like Udemy.
They contribute to the body of knowledge and without them, you may even guess the disadvantage.
Overall, Microsoft MVPs are highly respected and influential community leaders who make significant contributions to the technical community by sharing their expertise, promoting Microsoft technologies, and fostering collaboration and knowledge-sharing among developers, IT professionals, and other technology enthusiasts.
On the other side, we have Microsoft employees. Microsoft Cloud advocates are technical evangelists who work closely with developers, IT professionals, and even students and the broader technical community to drive the adoption and provide guidance on Microsoft’s cloud technologies.
Cloud Advocates are passionate about empowering individuals and organizations to leverage the full potential of Microsoft Azure, Power Platform, and other cloud services.
If you’re truly within the Microsoft ecosystem, you may have seen some on LinkedIn and Twitter
I can’t end this point without mentioning Microsoft Learn Student Ambassadors. At this moment you’re reading a blog post written by a Gold Student Ambassador. We also help promote Microsoft Technologies on our various campuses across the globe. We are on-campus student ambassadors helping our peers to leverage the opportunities Microsoft has to offer to students.
<div data-node-type="callout">
<div data-node-type="callout-emoji">💡</div>
<div data-node-type="callout-text">I have an event coming up on July 22, 2023, on the Power Platform. This webinar will help you get started or even if you’re into it already, a Power Platform specialist will be my guest speaker to tell us the skills needed to secure a job as a Power Platform developer. <a target="_blank" rel="noopener noreferrer nofollow" href="https://lu.ma/7d5zdo34" style="pointer-events: none">Learn more.</a></div>
</div>
### 📚 Resources by Microsoft Cloud Advocates
🔸 [April Dunnam](https://www.youtube.com/@AprilDunnam/)
🔸 [Reza Dorrani](https://www.youtube.com/@RezaDorrani)
🔸 [TheOyinbooke](https://www.youtube.com/@TheOyinbooke/)
### 📚 Resources by Microsoft MVPs
🔸 [Samuel Adranyi](https://www.youtube.com/@sadranyi)
🔸 [Shadrack Inusah](https://www.youtube.com/@kojo_shaddy)
🔸 [Shane Young](https://www.youtube.com/@ShanesCows)
🔸 Thomas Festus [(FestMan Learning Hub)](https://festman.io/)
🔸 [Lisa Crosbie](https://www.youtube.com/@LisaCrosbie/)
🔸 [kristine Kolodziejski](https://www.youtube.com/@KristineKolodziejski)
🔸 [DamoBird365](https://www.youtube.com/@DamoBird365)
🔸 [Rachel Irabor](https://www.youtube.com/@Richie4love)
## 💡 Build Projects and Document
From time to time, we are told by Microsoft Cloud Advocates, MVPs, and even student ambassadors to learn in public. You don’t know it all, don’t hide what you’re learning. For this one, we will continue to over-emphasize it. 😂
Some people secured job offers by learning and sharing in public. They utilize LinkedIn and Twitter to share their learning.
We are encouraged to document our journey into Tech, and this is one of the ways to achieve that.
Whenever you build a project no matter how small it is, document it. As you continue to do this you will have good memories to fall back on later in the future.
I can’t make this point lengthy, so I will cut it short.
## 🙏 Let's Conclude
Microsoft Power Platform will continue to evolve and even expand to include more services. You may not know how well-integrated the Microsoft Power Platform is unless you follow the first tip. Which is to read the docs.
Documentation will save you a lot more time and effort which otherwise would have been wasted in over-brainstorming and saying to yourself “why”.
Create an account on the community page of Power Platform there are tons of information over there. How much more can we say about Microsoft MVPs, Cloud Advocates, and Microsoft Learn Student Ambassadors who help in the adoption of Microsoft Technologies?
If you’re a student engage with the Student Ambassadors communities on your campus and if there is none. [Why don’t you become a Microsoft Learn Student Ambassador?](https://prince-adimado.hashnode.dev/all-you-need-to-know-about-microsoft-learn-student-ambassadors-program-mlsa)
Continue to learn and build your skills in the Power Platform by utilizing the resources and tips to help you skill up.
If you have been able to make it this far, thank you.
Support me by, [BUYING ME A COFFEE](https://buymeacoffee.com/primado). 🙏 | primado |
1,866,703 | Retrieval-Augmented Generation (RAG) Technology Guide | 1. Preface Generative Artificial Intelligence (GenAI), such as ChatGPT and Midjourney, has... | 0 | 2024-05-27T15:43:19 | https://dev.to/happyer/retrieval-augmented-generation-rag-technology-guide-2o78 | ai, design, image, development | ## 1. Preface
Generative Artificial Intelligence (GenAI), such as ChatGPT and Midjourney, has demonstrated exceptional performance in tasks like text generation and text-to-image generation. However, these models also have limitations, such as a tendency to produce hallucinations, weak mathematical abilities, and a lack of explainability. Research into Retrieval-Augmented Generation (RAG) technology aims to improve the factualness and reasonableness of generated content by enabling models to interact with the external world and acquire knowledge.
## 2. Introduction to RAG Technology
RAG technology provides large language models (LLMs) with retrieved information as a basis for generating answers. It typically includes two stages: retrieving contextually relevant information and using the retrieved knowledge to guide the generation process. RAG is a popular system architecture based on LLMs, widely used in question-answering services and applications that interact with data.
## 3. Basic RAG Technology
The basic RAG process includes chunking text, embedding chunks using an encoding model, placing vectors into an index, and finally creating prompts for the LLM to guide the model in answering user queries. At runtime, the user query is vectorized using the same encoder model, a search for the query vector is performed to find the most relevant results, and these are input as context into the LLM prompt.
## 4. Advanced RAG Techniques
### 4.1. Chunking and Vectorization
Chunking involves dividing a document into chunks of a certain size to better represent its semantics. Vectorization is the selection of a model to embed our chunks, such as the bge-large or E5 embedding series.
### 4.2. Search Index
The search index is a key part of the RAG process, used to store vectorized content. Approximate nearest neighbor searches can be implemented using Faiss, nmslib, annoy, or managed solutions like OpenSearch or ElasticSearch.
### 4.3. Re-ranking and Filtering
Retrieved results can be optimized through filtering, re-ranking, or transformation. Models such as LLMs, sentence-transformer cross-encoders, Cohere re-ranking endpoints, etc., can be used to re-rank results.
### 4.4. Query Transformation
Query transformation uses LLMs to modify user input to improve retrieval quality, including breaking down complex queries into subqueries, back-off prompts, query rewriting, etc.
### 4.5. Chat Engine
The chat engine takes into account the conversational context, supporting subsequent questions and user commands related to the previous conversation context.
### 4.6. Query Routing
Query routing is a decision step supported by LLMs that decides the next action based on the user query, such as summarizing, performing a search, or trying multiple routes.
### 4.7. Agents in RAG
Agents are LLMs capable of reasoning and providing a set of tools and tasks. Agents can include deterministic functions, external APIs, or other Agents.
### 4.8. Response Synthesizer
The response synthesizer is the final step in the RAG pipeline, generating answers based on all retrieved contexts and the initial user query.
## 5. Architecture of RAG
The RAG model architecture contains two core components: the retriever and the generator.
- Retriever: Typically a BERT-based neural network model that encodes the input query into a vector and compares it with pre-encoded document vectors in the database to retrieve the most relevant document fragments.
- Generator: A pre-trained sequence-to-sequence model that receives document fragments provided by the retriever and the original query, fuses this information through an attention mechanism, and generates coherent and relevant text output.
### 5.1. Retrieval System
#### 5.1.1. Indexed Database
The core of the retrieval system is an indexed database that stores a large number of documents or information fragments. These documents can be text files, web pages, books, or any other form of text data.
#### 5.1.2. Retrieval Algorithm
The retrieval algorithm is responsible for finding the most relevant information from the indexed database based on the user's query. This typically involves techniques such as keyword matching, semantic search, and ranking algorithms.
#### 5.1.3. Retrieval Efficiency
To improve retrieval efficiency, retrieval systems often use techniques such as inverted indexing and vector search to quickly locate the most relevant documents or information fragments.
### 5.2. Generation Model
#### 5.2.1. Pre-trained Language Model
The generation model is usually a pre-trained language model, such as GPT, BERT, or other variants. These models have been trained on a large amount of text data and have the ability to understand and generate natural language.
#### 5.2.2. Context Fusion
In RAG, the generation model must not only process the user's original query but also fuse the relevant context information provided by the retrieval system. This requires the model to understand and integrate information from different sources.
#### 5.2.3. Generation Strategy
The generation model generates answers or text based on the fused context information. This may involve conditional generation, sequence-to-sequence transformation, and other techniques.
### 5.3. RAG Workflow
#### 5.3.1. Receive Query
The user poses a question or query, which is the starting point of the RAG workflow.
#### 5.3.2. Retrieve Information
The retrieval system retrieves the most relevant information from the indexed database based on the user's query.
#### 5.3.3. Information Fusion
The retrieved information is passed to the generation model to be fused with the user's original query.
#### 5.3.4. Generate Output
The generation model combines the retrieved information and the user's query to generate an answer or text.
#### 5.3.5. Output Results
The generated text is returned to the user as the final output.
## 6. Advantages of RAG
### 6.1. Context Understanding
RAG can use retrieved context information to improve understanding of user queries, thereby generating more accurate answers.
### 6.2. Information Richness
By retrieving a large amount of data, RAG can provide richer and more detailed answers, surpassing the limitations of traditional language models.
### 6.3. Flexibility
RAG can be applied to various tasks, including question-answering systems, text summarization, content creation, etc., and is highly flexible.
## 7. Fine-tuning RAG System Models
The RAG system involves multiple models, including encoder models, LLMs, and sorters, all of which can be fine-tuned to improve performance.
## 8. Evaluating RAG Systems
Evaluating the performance of RAG systems can use multiple frameworks, focusing on metrics such as answer relevance, fundamentality, fidelity, and the relevance of retrieved context.
## 9. Codia AI's products
Codia AI has rich experience in multimodal, image processing, and AI.
1.[**Codia AI DesignGen: Prompt to UI for Website, Landing Page, Blog**](https://codia.ai/t/pNFx)

2.[**Codia AI Design: Screenshot to Editable Figma Design**](https://codia.ai/d/5ZFb)

3.[**Codia AI VectorMagic: Image to Full-Color Vector/PNG to SVG**](https://codia.ai/v/bqFJ)

4.[**Codia AI Figma to code:HTML, CSS, React, Vue, iOS, Android, Flutter, Tailwind, Web, Native,...**](https://codia.ai/s/YBF9)

## 10. Conclusion
RAG (Retrieval-Augmented Generation) is a hybrid model that combines retrieval and generation capabilities, capable of providing more accurate and coherent answers. It has a wide range of applications across various fields, demonstrating its powerful potential. As technology continues to evolve, RAG models are expected to achieve even greater breakthroughs and applications in the future. | happyer |
1,866,701 | Football news! | Welcome to the fan site dedicated to Mohammed Al-Owais, the famous goalkeeper who became the... | 0 | 2024-05-27T15:40:58 | https://dev.to/opo_io_54741c3d60830623b6/football-news-1anp | webdev, javascript, beginners, programming | Welcome to the fan site dedicated to Mohammed Al-Owais, the famous goalkeeper who became the cornerstone of both Al-Hilal and the Saudi Arabian national team. This site is your definitive source for all things Al Owais, featuring the latest news, in-depth analysis and comprehensive coverage of the most notable events of his career.
Mohammed Al Owais
Check out our in-depth match recaps highlighting Al Owais' key rebounds and contributions in key matches. Immerse yourself in a selection of videos that showcase his best moments as a member, from acrobatic stunts to the dazzling performances that have earned him awards on both the domestic and international stages.
Keep up to date with the latest news on Al Owais's career, including match results, injury updates and transfer news. Our selected articles provide deeper insight into his technique, training routines and the journey that has made him one of the best goalkeepers in Asian football.
Connect with the fan community on our forums, where you can discuss match strategies, share content and interact with other fans. Whether you're analyzing his recent performance or celebrating his accomplishments, this is the perfect place for fans to gather and share their passion. [Mohammed Al Owais](https://mohammed-alowais-ar.com/) | opo_io_54741c3d60830623b6 |
1,866,700 | Creating Your First Telegram Bot: Step-by-Step Guide with BotFather | Part 1 | In this tutorial, we'll walk you through the initial steps of setting up your own Telegram bot using... | 0 | 2024-05-27T15:39:16 | https://dev.to/eaca89/creating-your-first-telegram-bot-step-by-step-guide-with-botfather-part-1-5do4 | pythonproject, telegrambot, telebot, pythondevelopment | In this tutorial, we'll walk you through the initial steps of setting up your own Telegram bot using BotFather. You'll learn how to create a new bot, interact with BotFather, and obtain your bot's API token, which is essential for further development. Whether you're a complete beginner or looking to refresh your knowledge, this video will provide you with a solid foundation to build on.
Stay tuned for the upcoming videos in this series, where we'll dive deeper into coding and customizing your bot, integrating various functionalities, and making your bot more interactive and useful.
{% embed https://www.youtube.com/watch?v=RIrIXLAj8bE %} | eaca89 |
1,866,699 | Launch and Connect to AWS EC2 Instance | Introduction Launching and connecting to an AWS EC2 instance is a fundamental task for... | 0 | 2024-05-27T15:38:53 | https://dev.to/suravshrestha/launch-and-connect-to-aws-ec2-instance-47bm | aws, cloud, cloudcomputing, iaas | 
### Introduction
Launching and connecting to an AWS EC2 instance is a fundamental task for any cloud-based development or application hosting. This guide will walk you through the steps to create and connect to an EC2 instance on AWS, and then verify the connection by running some basic commands.
### Prerequisites
Before starting, ensure you have an [AWS](https://aws.amazon.com/) account. ☁️
### Step 1: Launch an EC2 Instance
1. **Log in to your AWS Management Console**. 🔑
2. **Navigate to the EC2 Dashboard** and click on "Launch Instance". 🚀
3. **Configure the instance settings as follows** (leave other settings as default):
- **Enter the name of the EC2 Instance** (e.g., "My EC2 Instance"). 🖥️
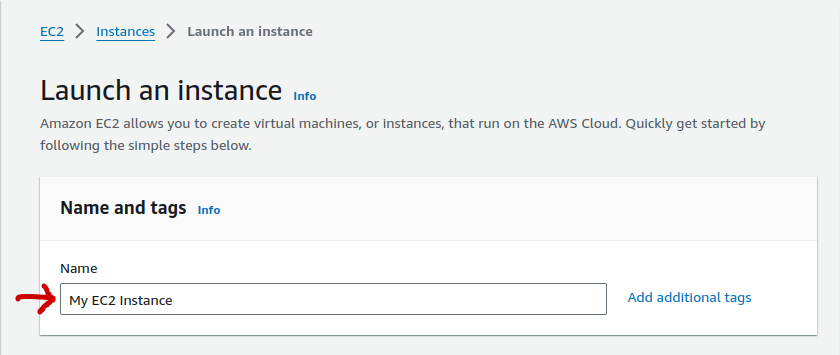
- **Select `Ubuntu` as the Amazon Machine Image (AMI)**. 🐧
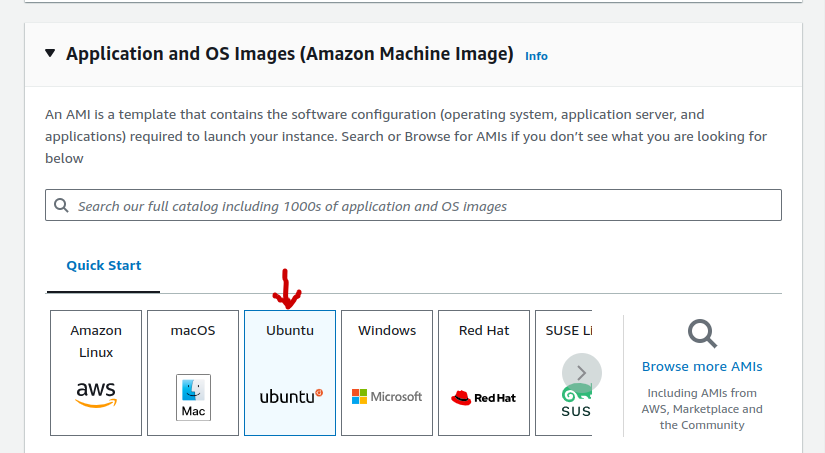
- **Create a key pair to access the instance from the command line**. 🔑
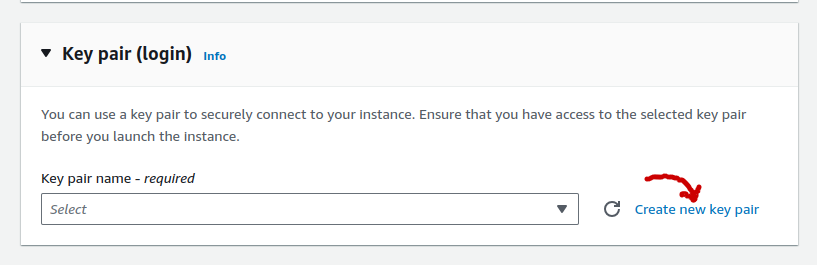
- **Enter an appropriate name for the key pair**. 📝
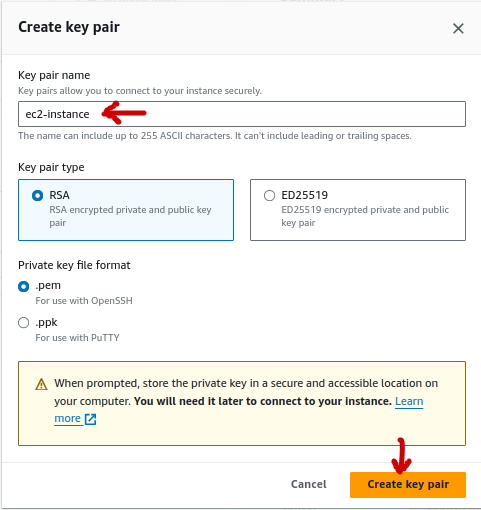
This will save the key pair file (named `ec2-instance.pem` in this case) to your local machine. 💾
- **Configure the Security Group** - add a rule to allow HTTP traffic (port 80). 🔒
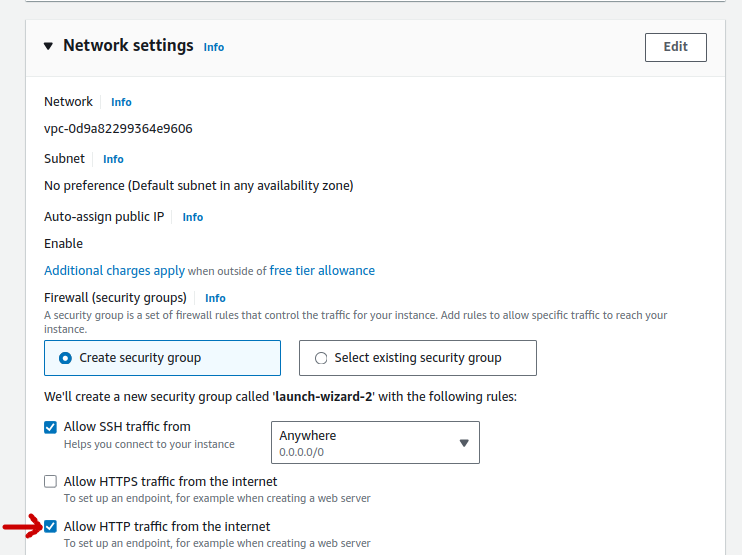
4. **Review your settings and launch the instance**. ✅
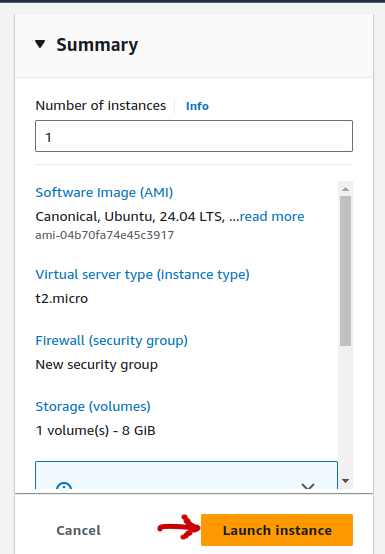
### Step 2: Connect to Your EC2 Instance
After the instance is successfully running:
1. **Click on the `Instance ID` of the EC2 instance you just created**. 🆔
2. **On the Instance summary page, click on the `Connect` button**. 🔌
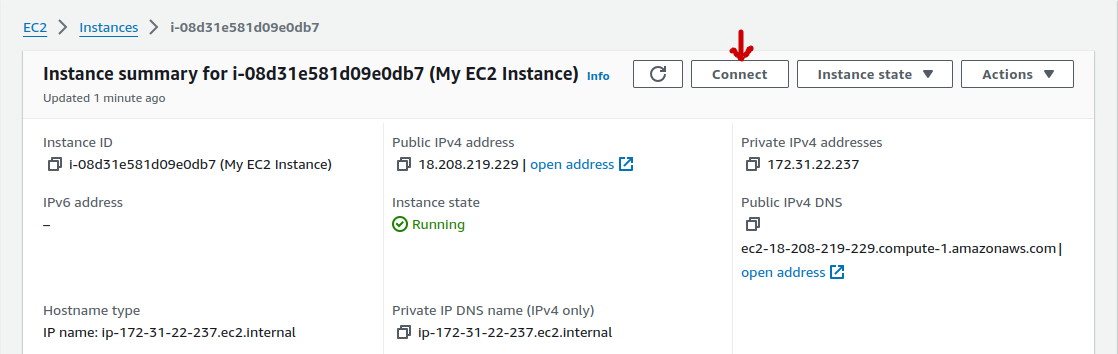
3. **Copy the command to connect to the EC2 instance**. 📋
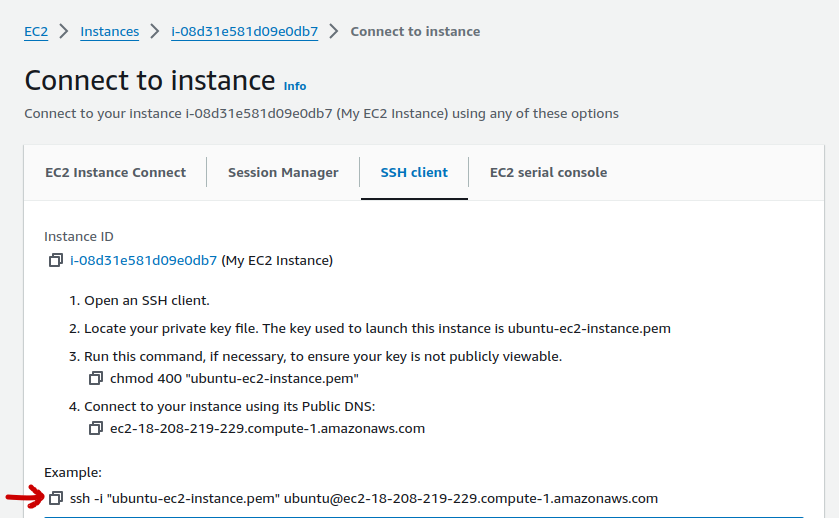
4. **Open a new local terminal from where the private key was saved**. 🖥️
5. **Run this command to ensure your key is not publicly viewable**:
```bash
sudo chmod 400 "ec2-instance.pem"
```
6. **Paste the command copied from Step 3 to connect to your instance**:
```bash
sudo ssh -i "ec2-instance.pem" ubuntu@ec2-18-208-219-229.compute-1.amazonaws.com
```
### Step 3: Verify Your EC2 Instance
After connecting to the EC2 instance, you can use commands as you would on your local machine. Here are some common commands to verify and manage your instance:
1. **Update the package list**:
```bash
sudo apt update
```
1. **Upgrade the installed packages**:
```bash
sudo apt upgrade -y
```
### Conclusion
You've successfully launched, connected to, and verified your AWS EC2 instance. This setup can now serve as the foundation for your web applications or development environment. 🌐
### Additional Resources
- [AWS EC2 Documentation](https://docs.aws.amazon.com/ec2/) 📖
If you have any questions or run into issues, feel free to leave a comment below.
Happy cloud computing! ☁️👩💻👨💻 | suravshrestha |
1,866,680 | Power Automate and React Integration: Automate Business Processes | Introduction Are you curious about the rising trend of citizen developers and their... | 0 | 2024-05-27T15:37:42 | https://prince-adimado.hashnode.dev/power-automate-and-react-integration-automate-business-processes/ | react, excel, outlook, powerplatform |
## Introduction
Are you curious about the rising trend of citizen developers and their collaboration with professional developers to streamline business processes? Discover how the Microsoft Power Platform empowers both developers to work hand in hand as we walk you through building a registration form with React, integrating it with Power Automate, and leveraging Excel as a data storage solution.
Imagine an organization instructing its software engineers to build a registration landing page for an event, the data must be stored in an Excel file. Also, imagine in that same organization there is a low-code developer. How can these two developers work together on this project?
This is where the citizen developer and the pro developer can work together to execute this project.
I first saw a demo of a web app like this in ASP.NET Core during the Global Power Platform Bootcamp 2023, in Accra, Ghana by [Frank Odoom a Microsoft MVP](https://mvp.microsoft.com/en-us/PublicProfile/5003756?fullName=Frank%20Arkhurst%20Odoom). So, I decided to replicate it in a JavaScript library I'm familiar with.
In this article, I will walk you through how to build a registration form with React that sends data through an API to Power Automate and then saves the data in an Excel file. We won't just save the form data in Excel but also send out an email to the user, this is to make sure that the email address is valid else it won't be saved in file Excel which is acting as our data storage.
## Getting Started
To start building this project, we first need our API. How can we get the API to use in our source code in React? Let me first list the steps I went through to fully build this project.
1. Set up the Power Automate workflow to handle API data.
2. Test the API using Postman to ensure successful data transmission.
3. Create a React app and build the registration form.
4. Utilize Axios for making HTTP requests from the React app.
5. Implement React Hook Form for form validation and handling.
6. Use React Router for seamless navigation, including a success page.
7. Create the Success page.
8. Deploy the React app to make it accessible online.
## Build the Power Automate Workflow
If you are new to Power Automate, you will need a Microsoft 365 license to be able to use the Power Platform. Create your Microsoft 365 developer tenant here. If you're unsure how to get started you can see this post with more details on how to set up Microsoft 365 Developer Account.
### Step 1:
To start with, we first need to know which type of Power Automate flow to use. Understanding the flow type will help you know the trigger connector to use. For this flow, we shall use the Instant cloud flow.
From the figure below, give your flow a name, then select the connector ***“When an HTTP request is received”***. Proceed to create your flow, by selecting the Create button.
### Step 2:
After selecting the create button, you will be directed to your flow. You will see the trigger connector when you first create it. In the connector, you will need to generate the JSON payload.
A JSON payload refers to the data that is sent or received in JSON format as part of a request or response in a web application or API. Power Automate has made it very simple for us to just write a sample payload and then use the feature in the connector to generate schema.
Click on the “Use sample payload to generate schema”.
After writing your sample payload, click on **"Done"** to generate the schema.
Click to show the advanced options, in the method dropdown menu, choose POST as the HTTP verb. We are going to make a POST request.
### Step 3:
Search for the connector, ***“Parse JSON”*** and select it.
Select the on the Content input, to add ***“Body”*** as the dynamic content.
At the schema input, just copy the JSON payload generated in the trigger connector.
You should have something like this.
### **Step 4:**
Select the ***“Compose”*** connect and parse the JSON variables generated in the ***“Parse JSON”*** connector above, as dynamic content in the ***“Compose”*** connector.
You should have something like this.
### **Step 5:**
In this step, we have to initialize the data received to a variable. So search for ***“Variable”*** and Select it to show the connectors. Choose the ***“Initialize Variable”*** connector.
Give the variables a name and initialize, select ***“String”*** as the data type for both variables ***“full\_name"*** and ***"email\_address”***. Remember that in the JSON payload schema, the data types are both strings.
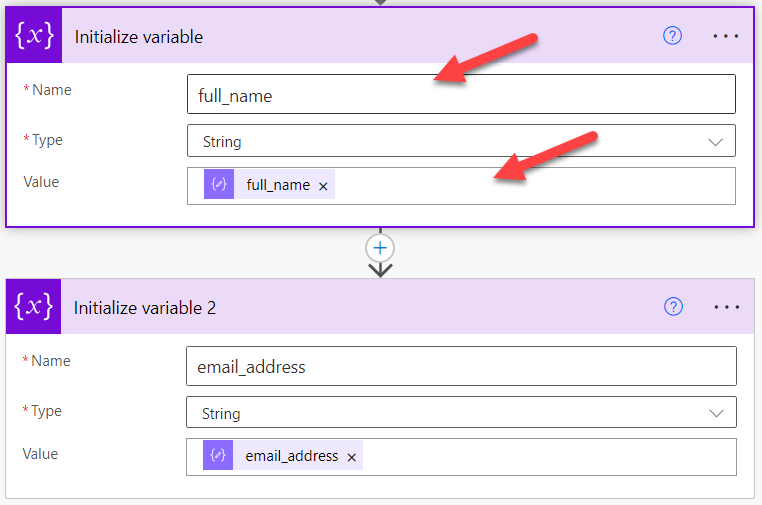
### **Step 6:**
In this step, we proceed to craft our email message. Search for Outlook and choose the ***“Send an email (V2)”*** connector. We will use this connector to send an email once the form is submitted.
Craft your email message, this is how I wrote mine.
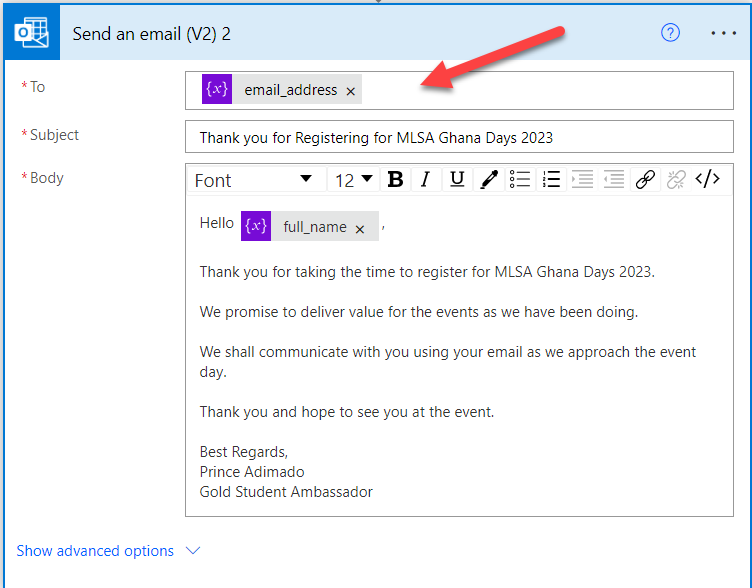
### **Step 7:**
We shall use Excel for data storage when the form is submitted. You first go to your OneDrive and create an Excel online file. It will be ideal to create a folder where you can be able to reference this easily. As I did for Outlook in the previous step, search for Excel and choose ***“Excel Online (Business)”***. From the list of Excel connectors, choose the ***“Add a row into the table”*** connector.
## **Test the API using Postman to ensure successful data transmission.**
Now we are done building our flow, the next step is to test whether our flow works. We don’t need to finish building the UI with React to be able to test our flow.
Create a Postman account if you don’t have one. We will use Postman to make a POST request to the HTTP POST URL or the API.
To get the API URL, go to the trigger connector to copy the URL.
***Note: you will need to save your flow for the HTTP POST URL to be generated.***
Follow this guide to test your flow.
{% embed https://youtu.be/6EsItBfvrsw %}
## **Create a React app and build the registration form.**
This is where we build the UI of the registration form using React.
To follow along, I used Tailwind CSS as the framework for styling, and also we will use Vite as our development server and a build tool that focuses on fast development experiences.
To create a Vite project, run this command:
```powershell
npm create vite@latest my-project -- --template react
cd my-project
```
Install Tailwind CSS, run these commands
```powershell
$ npm install -D tailwindcss postcss autoprefixer
$ npx tailwindcss init -p
```
Finally, run this command:
```powershell
npm install
```
Follow this guide on the [Tailwind CSS website](https://tailwindcss.com/docs/guides/vite) to finish the setup-up of your project.
Now, let’s proceed to build the form. Since this is a guide, I won’t be giving details on how I style the form. But I will show I applied React Hook Form, Axios, and React Router to achieve the functionality of the web app.
```javascript
import { useEffect } from 'react'
import { useForm } from "react-hook-form";
export default function App() {
return (
<div className="App font-serif bg-gray-300 min-h-screen">
<div className="flex justify-center items-center py-[5rem] sm-425:py-0 ">
<div className="max-w-[30rem] ">
<div className="flex flex-col bg-[#fff] w-full rounded-md px-5 py-12 sm-425:pt-16 sm-425:min-h-screen sm-375:min-h-screen sm-375:pt-16 sm-320:min-h-screen sm-320:pt-12">
<div className="description mb-5">
<div>
<img
src={badge}
alt="mlsa logo"
className="w-20 h-20 mx-auto"
/>
</div>
<h1 className="text-black text-2xl font-semibold text-center py-3 sm-320:text-center sm-425:text-center sm-375:text-center">MLSA Ghana Days 2023 </h1>
<p className="font-medium text-sm text-justify ">MLSA Ghana Days is a 3-day event that brings together students,
developers, and tech enthusiasts to learn, network, and share ideas on the latest
technologies from Microsoft.
</p>
<h2 className="mt-3 text-lg font-semibold">Register here</h2>
</div>
<div className="">
<form action="#" onSubmit={handleSubmit(onSubmit)}>
<div className="form__group flex flex-col mb-5">
<label htmlFor="name">Full Name</label>
{watchAllFields && <input
type="text"
id="name"
placeholder="Enter your full name"
className="border-2 outline-none border-gray-400 focus:ring-1 focus:ring-amber-500 rounded-md p-2"
{...register("full_name", { required: true, maxLength: 70 })}
aria-invalid={errors.full_name ? "true" : "false"}
/>}
{ errors.full_name?.type === "required" && ( <span role='alert' className="text-red-500 text-sm">This field is required</span> )}
</div>
<div className="form__group flex flex-col mb-5">
<label htmlFor="email">Email Address</label>
{ watchAllFields && <input
type="email"
id="email"
placeholder="Enter your address"
className="border-2 outline-none border-gray-400 focus:ring-1 focus:ring-amber-500 rounded-md p-2"
{...register("email", { required: true, pattern: /^\S+@\S+$/ })}
aria-invalid={errors.email ? "true" : "false"}
/> }
{ errors.email?.type === "required" && ( <span role='alert' className="text-red-500 text-sm">This field is required</span> )}
</div>
<div className="form__group ">
<input
type="submit"
value="Submit"
className="bg-amber-500 w-full text-white font-semibold py-2 px-4 rounded-md cursor-pointer hover:bg-amber-600 active:bg-amber-700 focus:outline-none focus:ring-1 focus:ring-amber-500"
/>
</div>
</form>
</div>
</div>
</div>
</div>
</div>
)
}
```
In the above code represents a React Component that renders a registration form for an event called MLSA Ghana Days 2023. The form includes 2 fields, and these fields are the same as the JSON payload in the Power Automate flow. The form includes fields for the user’s full name and email address, along with a submit button. It utilizes React Hook form for form validation and handling. When the form is submitted, the `onSubmit` function is called. Finally, the form is styled by Tailwind CSS classes and made responsive.
## Utilize Axios for making HTTP requests from the React app.
```javascript
import { useEffect } from 'react'
import { useForm } from "react-hook-form";
import axios from 'axios';
import { useNavigate } from 'react-router-dom';
export default function App() {
const { register, handleSubmit, watch, getValues, reset, formState: { errors } } = useForm();
const watchAllFields = watch();
const navigate = useNavigate();
const onSubmit = async () => {
try {
const formdata = getValues()
const {full_name, email} = formdata;
const response = await axios.post("/api",
{
"full_name": full_name,
"email": email
});
console.log('Response:', response)
reset();
// Redirect to Success message
navigate('/success')
} catch (error) {
console.log('Error:', error)
}
}
useEffect(() => {
const subscription = watch((value, {name, type}) => console.log(value, name, type));
return () => subscription.unsubscribe();
}, [watch]);
return (
// JSX code for the form below
)
}
```
The provided code snippet showcases the functionality of a registration form implemented in a React application. Here's an overview of its functionality:
1. The `useForm` hook from the React Hook Form library is utilized to handle form registration, submission, and validation. It provides methods like `register`, `handleSubmit`, and `watch`, as well as access to form state and validation errors.
2. The `watch` function is used to monitor changes in form fields and store the values in the `watchAllFields` variable.
3. The `useNavigate` hook from React Router is used to enable programmatic navigation. It allows for redirection to a success page after form submission.
4. The `onSubmit` function is called when the form is submitted. It retrieves the form data using `getValues` a component from React Hook Form and makes a POST request to the `/api` endpoint, sending the `full_name` and `email` values in the request body.
Note: The /`api` is the HTTP POST URL you copied in Power Automate to test the flow. Copy the API URL and paste it, to allow Axios to make the request.
1. If the request is successful, the `reset` function is called to clear the form fields, and the user is redirected to the success page using the `navigate` function.
2. If there is an error during the submission process, the error is logged to the console.
3. The `useEffect` hook is used to subscribe to changes in form field values using `watch`. Whenever a change occurs, a callback function is triggered to log the updated value, field name, and field type. The subscription is unsubscribed when the component is unmounted.
In your `main.jsx`, create a route using `CreateBrowserRouter`. This will handle the navigation between the two pages.
```javascript
import ReactDOM from 'react-dom/client'
import App from './App.jsx'
import Success from "./component/Success.jsx"
import {
createBrowserRouter,
RouterProvider,
} from "react-router-dom";
const router = createBrowserRouter([
{
path: "/",
element: <App />,
},
{
path: "/success",
element: <Success />,
}
])
ReactDOM.createRoot(document.getElementById('root')).render(
<RouterProvider router={router} />
)
```
Well, we are almost done. Let’s proceed to create the success page, this page as mentioned above, after form submission `useNavigate` will route from the home page to this success page.
```javascript
import check from "../assets/check.png";
export default function Success() {
return (
<div className="success font-serif bg-gray-300 min-h-screen">
<div className="flex justify-center items-center py-[10rem] sm-425:py-0 sm-375:py-0 sm-320:py-0">
<div className="max-w-[30rem] bg-white rounded-xl shadow-2xl sm-425:min-h-screen sm-425:rounded-none">
<div className="">
<div className="description px-5 py-5 sm-425:py-[10rem] sm-375:py-[10rem] sm-320:py-[10rem]">
<div className="flex flex-col ">
<img
src={check}
alt=" success check icon"
className="w-20 h-20 mx-auto"
/>
<h1 className="text-black text-2xl text-center font-semibold py-3">
Thank you for registering for MLSA Ghana Days 2023
</h1>
</div>
<h2 className="font-medium text-base text-center mt-2 text-gray-600">Kindly check your email for a confirmational message.</h2>
</div>
</div>
</div>
</div>
</div>
)
}
```
The success page only contains styling for the page and does not include any functionality but just displays the page.
Now we are done, but you must test your application to make sure it works and after form submission, it saves the data to Excel. I will include a demo video here to show you how my version of the web app functions and looks.
{% embed https://youtu.be/5K068gF_ol8 %}
## **Conclusion**
In conclusion, we have embarked on an exciting journey of building a registration form with React, harnessing the power of Power Automate. By leveraging the capabilities of React Hook Form and Axios, we have achieved seamless form validation and submission.
The integration of Power Automate and React has demonstrated how low-code solutions can complement traditional software development, enabling us to create robust applications with ease.
I hope this guide has inspired you to explore the endless possibilities of integrating drag-and-drop tools like the Power Platform into your development projects, we are only limited by our imagination by the extensibility of the Power Platform.
You can find the link to the GitHub repository of the source code [here](https://github.com/primado/registration-form-pa).
Feel free to share your feedback and connect with me on [LinkedIn](https://linkedin.com/in/primado) and [Twitter](https://twitter.com/_primado). Let's continue innovating together!
Support me by, [BUYING ME A COFFEE](https://buymeacoffee.com/primado). 🙏
| primado |
1,866,697 | Unlock the power of neural networks 🚀 | Dive into the fundamentals, understand how they work, explore future trends, and discover top... | 0 | 2024-05-27T15:30:59 | https://dev.to/futuristicgeeks/unlock-the-power-of-neural-networks-mcb | webdev, javascript, python, ai |
Dive into the fundamentals, understand how they work, explore future trends, and discover top resources to enhance your skills. Perfect for AI and machine learning enthusiasts eager to stay ahead in the tech world.
Read more on: https://lnkd.in/gfaNjbry
Don't forget to follow us for more insights and updates! 🔍📈
| futuristicgeeks |
1,866,695 | Como trabalhar com várias contas do git em uma única máquina | Você já se encontrou em uma situação onde precisa ter mais de uma conta Git configurada na mesma... | 0 | 2024-05-27T15:25:28 | https://dev.to/pripoliveira50/como-trabalhar-com-varias-contas-do-git-em-uma-unica-maquina-3k25 | github, git | Você já se encontrou em uma situação onde precisa ter mais de uma conta Git configurada na mesma máquina? Talvez você precise de uma conta pessoal e outra para a empresa.
Nesses casos, não é interessante ter um usuário global configurado na máquina, pois isso poderia acarretar no problema de fazer um commit com a conta errada para um projeto específico.
Antes de mais nada, vamos configurar duas chaves SSH, uma para cada perfil.
### Criando a chave SSH
Abra o seu terminal e digite o seguinte comando:
```
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
```
Isso cria uma nova chave SSH, usando o e-mail fornecido como rótulo.
```
> Generating public/private ALGORITHM key pair.
```
Quando for solicitado a "Inserir um arquivo no qual salvar a chave", você pode pressionar Enter para aceitar o local padrão do arquivo.
Porém recomendo mudar o nome do arquivo pois teremos 2 chaves distintas.
```
> Enter a file in which to save the key (/Users/YOU/.ssh/id_rsa_nome_aqui): [Press enter]
```
Depois de pressionar enter provavelmente aparcerá a frase a seguir:
```
> Enter passphrase (empty for no passphrase): [Type a passphrase]
```
Você pode optar por não usar uma senha para suas chaves SSH. Se preferir adicionar uma senha, digite-a e pressione Enter. Caso contrário, apenas pressione Enter sem digitar nada.
Repita o mesmo procedimento para a segunda chave.
Não se esqueça de adicionar cada chave à sua conta do GitHub ou outro serviço que você esteja utilizando.
### Configurando a Chave para Repositórios Distintos
Vamos criar dois aliases para facilitar a configuração do Git.
O que é um "alias"?
Um alias é uma maneira de definir comandos personalizados para economizar tempo e digitar menos.
Abra seu terminal com o editor de sua preferência. Aqui, usaremos o Vim.
`$ vim ~/.zshrc`
Se você também usa o Vim, pressione "a" para entrar no modo de inserção e cole o seguinte:
```
# ALIAS CONFIG GIT
alias gcg="git config --edit --global"
alias gcl="git config --edit --local"
```
Pressione Esc e digite:
`:wq!`
Agora, recarregue seu arquivo de configuração do seu terminal:
`souce ~/.zshrc`
Vá até o diretório do seu repositório e abra o terminal a partir dele. Digite:
`$ gcl`
Isso abrirá o arquivo .git/config do repositório no qual você está. Configure-o da seguinte forma:
```
[core]
sshCommand = ssh -i ~/.ssh/sua-chave-ssh -F /dev/null
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
[remote "origin"]
url = git@github.com:seu-username/seu-repo
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "main"]
remote = origin
merge = refs/heads/main
[credential]
username = Seu-username
[user]
email = seuemail@teste.com
name = Seu Nome
"~/seu-caminho/seu-repositorio/.git/config" 19L,
```
Dentro [core] coloque:
` sshCommand = ssh -i ~/.ssh/sua-chave-ssh -F /dev/null`
Logo a baixo nas últimas linhas coloque:
```
[credential]
username = Seu-username
[user]
email = seuemail@teste.com
name = Seu Nome
```
Dessa forma, o repositório específico utilizará as credenciais configuradas.
Não se esqueça de recarregar o arquivo de configuração
`source ~/.zshrc`
Para atualizar o terminal.
Lembre-se de repetir esse processo para cada repositório em sua máquina.
Espero que isso tenha ajudado! | pripoliveira50 |
1,864,839 | From Frustration to Fascination: The Truth About Double Booking Problem | In 2019, I remember eagerly awaiting the release of "Avengers: Endgame." Like millions of fans around... | 0 | 2024-05-27T15:20:21 | https://dev.to/varungarg/from-frustration-to-fascination-the-truth-about-double-booking-problem-3apb | database, webdev, programming, learning | In 2019, I remember eagerly awaiting the release of "Avengers: Endgame." Like millions of fans around the world, I wanted to experience the epic conclusion to the Marvel saga on the opening night.
I remember sitting at my computer, the clock ticking down to the exact moment tickets went on sale. As soon as they did, I jumped into action, quickly selecting two perfect seats – center row, not too close, not too far. **Seats H10, H11**! My heart was racing as I clicked "confirm," imagining the triumphant moment when I'd have the tickets in hand.
But instead of a confirmation screen, I was greeted with an error message: **_"Those seats are no longer available."_** My excitement turned to frustration. How could this happen so quickly? 5 years later, after a deep dive into databases, I finally found my 'technical' answer!
<img width="100%" style="width:100%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExc2N4cHVrd245OHpwZTZ6dHN5dWphOHFnY2N4ODNkemNhY3hmdzgweiZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/ioXhRXap3qODZaPsfU/giphy.gif">
---
Well, as frustrating as it might be, the booking websites employ clever technical tricks to prevent double bookings and ensure a smooth user experience. Let me try to explain in with the help of an analogy!
> **Analogy Time** - Imagine booking a movie ticket as a high-stakes race against the other eager viewers. Whoever 'runs' through the process and clicks "confirm" first secures the perfect seat.
> The problem is that with lightning-fast internet and multiple users vying for the same spot, things can get down to the wire. This is where booking websites step in as the race officials, having a powerful tool in the toolkit called **database locks** to ensure a fair and smooth experience.
**How do we they lock down our seats??!!**
Think of your ideal cinema seat – the one with ample legroom and an unobstructed view (H10,H11) in Audi 5.
When you click to select seats H10 and H11, here's what unfolds in the digital realm:
**The MVP (SELECT FOR UPDATE):** When you proceed to checkout, the website initiates a **transaction** with a special database query which goes like-
```
SELECT * FROM audi5 WHERE seat_id IN ('H10', 'H11') FOR UPDATE;
```
This query acts like magic, targeting specific rows (seats H10 and H11) within the audi5 table stored in the database. Notice the _SELECT FOR UPDATE_ clause at the beginning. This is what instructs the database to lock the rows retrieved by the query, but it's important to understand that this locking attempt might not always be successful.
**Verifying the Lock and Retrieving Information:** The SELECT FOR UPDATE not only retrieves information about the seats' availability (H10 and H11) but also attempts to lock those specific rows in the audi5 table. This lock prevents other users from seeing H10 and H11 as available while you finalize your purchase. Imagine it like putting up a temporary "reserved" sign on the digital records of seats H10 and H11.
<img width="100%" style="width:100%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExMmh3bGR0eHcxbHJtYmxqemVpajU5Nm1ic2J5ZTF2OWlxM2o4dHgzYiZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/3ohjUOFS6bU1oyiAM0/giphy.gif">
**Success or Sorry? (Depending on Lock Acquisition):** Crucially, the information retrieved by the SELECT FOR UPDATE also indicates whether the lock acquisition was successful. This is because another user might have grabbed those seats (and successfully acquired the lock) before your query finished executing in the database!
Now let us say that you made it to the checkout page! What happens here? Remember I mentioned that the database initiates a transaction?
Well, Transactions guarantee that everything goes smoothly.They act like mini-programs that ensure data consistency within the database. When you confirm your booking, the website initiates a transaction in a 2 step manner:
1. It leverages the information retrieved by the SELECT FOR UPDATE query. This information includes both the availability of the seats (H10 and H11) and whether the lock acquisition was successful.
2. If the lock acquisition was successful and the seats are still free, the transaction updates the database to mark H10 and H11 as booked, associating them with your ticket purchase.
However, if something goes wrong during checkout (like the lock expiring, or the lock acquisition failing), the entire transaction is rolled back. This releases any lock attempts on H10 and H11, and the database remains unchanged, ready for someone else to try booking those seats.
For the geeks reading this, the final query will look something like this in the database (Although a lot of this is done through the code in the server)
```
START TRANSACTION; -- Begin the transaction
SELECT * FROM audi5 WHERE seat_id IN ('H10', 'H11') FOR UPDATE; -- Lock seats H10 and H11 (may fail due to timeout or other transactions)
-- Check if lock acquisition was successful and seats are available (addresses query 1)
IF @@ROWCOUNT = 2 AND available IN (1, 1) THEN -- Check both rows returned and availability is true (1)
UPDATE audi5
SET available = 0, -- Mark seats as booked
booked_by = USER_ID() -- Assign booked_by to current user
WHERE seat_id IN ('H10', 'H11');
COMMIT; -- Commit the transaction if successful
ELSE
ROLLBACK; -- Rollback if lock acquisition fails or seats unavailable (addresses query 2)
END IF;
-- Additional logic can follow here, like processing payment or finalizing ticket confirmation`
```
> Ever wonder why some websites give you a time limit to complete your ticket purchase? This isn't just about creating a sense of urgency (although it can do that too). It's also a technical safeguard (by **rolling back** the above-mentioned transactions) to prevent seats from being held indefinitely by someone who might not complete their purchase. This time limit ensures that seats become available again quickly for others who are eager to snag them!
<img width="100%" style="width:100%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExeGsxMGRrZWtsZjFhYXFlM2I4cHMyMGJ6ZmwxMmFhY3lmZjgzd2xpbCZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/n8SkNR77udWlG/giphy.gif">
So, the next time you encounter the dreaded "seats no longer available" message, remember, it's not bad luck or slow internet. It's a complex dance between you, other eager moviegoers, and the booking website's sophisticated system, all working behind the scenes to ensure there are no double bookings and it is a smooth and frustration-free experience.
Have you ever been in a similar situation? Let me know your thoughts!
**Bonus:**
You just might be also wondering how different ticketing platforms (Paytm, BookMyShow etc) show the same available seats? It's all thanks to **channel managers**! These act like middlemen, constantly checking seat availability across theaters and using special protocols to ensure all systems are in sync. This eliminates conflicts and guarantees the info you see is up-to-date. More on them later! | varungarg |
1,866,676 | Power Automate and React Integration: Automate Business Processes | A post by Prince Adimado | 0 | 2024-05-27T15:00:50 | https://prince-adimado.hashnode.dev/power-automate-and-react-integration-automate-business-processes | powerplatform, powerautomate | primado | |
1,866,686 | When you try to serve all needs... | This meal perfectly describes the "All in one App" - it ends up like... | 0 | 2024-05-27T15:15:38 | https://dev.to/apiphine/when-you-try-to-serve-all-needs-18bi | webdev, softwaredevelopment, wordpress | This meal perfectly describes the "All in one App" - it ends up like Wordpress.
> Lopadotemachoselachogaleokranioleipsanodrimypotrichomatosilphiokarabomelitokatakechymenokichlepikossyphophattoperisteralektryonoptocephaliokigclopeleiolagōiosiraiobaphētraganopteryx
The word comes from the Greek satirist Aristophanes' who wrote the play Ecclesiazusae that depicts the reforms of Praxagora. Praxagora take over the Athenian assembly and implement a series of radical changes aimed at creating a utopian society. The reforms include communal ownership and equal distribution of resources. As they attempt to satisfy everyone's needs and wants, the resultant policies become increasingly absurd and impractical, which is humorously illustrated by the creation of this comically complex dish.

| apiphine |
1,866,736 | Curso De Java Gratuito Com Certificado Da Cubos Academy | A Cubos Academy apresenta um minicurso gratuito de Programação Java, totalmente online e... | 0 | 2024-06-23T13:52:19 | https://guiadeti.com.br/curso-java-gratuito-certificado-cubos-academy/ | cursogratuito, cursosgratuitos, java, programacao | ---
title: Curso De Java Gratuito Com Certificado Da Cubos Academy
published: true
date: 2024-05-27 15:14:31 UTC
tags: CursoGratuito,cursosgratuitos,java,programacao
canonical_url: https://guiadeti.com.br/curso-java-gratuito-certificado-cubos-academy/
---
A Cubos Academy apresenta um minicurso gratuito de Programação Java, totalmente online e acessível.
O curso oferece uma introdução completa aos fundamentos do Java, uma das linguagens de programação mais populares do mercado.
Os participantes terão a oportunidade de entender a orientação a objetos e aprender a configurar um projeto Spring Boot de maneira descomplicada.
Tendo o total de 2 horas de conteúdo distribuídas em 16 aulas em vídeo, o curso concede certificado de conclusão e acesso vitalício às aulas, permitindo que os alunos alcancem o próximo estágio em sua jornada de aprendizagem.
## Minicruso Programação Java
A Cubos Academy disponibiliza um minicurso gratuito de Programação Java, totalmente online e acessível.
_Imagem da página do curso_
Este curso oferece uma introdução completa aos fundamentos do Java, uma das linguagens de programação mais populares do mercado.
### Fundamentos do Java
Os participantes terão a oportunidade de entender a orientação a objetos e aprender a configurar um projeto Spring Boot de maneira descomplicada.
Possuindo um total de 2 horas de conteúdo distribuídas em 16 aulas em vídeo, o curso dá um certificado de conclusão e acesso vitalício às aulas, permitindo que os alunos alcancem o próximo estágio em sua jornada de aprendizagem. Confira a ementa:
- Variáveis e constantes;
- Tipos de dados primitivos;
- Arrays e Loops;
- Criação de objetos com classes;
- Conceitos de API REST.
### Comece Sua Jornada em Java
Crie a sua conta ou faça login para dar o “play” na sua jornada em Java! No minicurso gratuito, você aprenderá os principais conceitos dessa linguagem.
O objetivo é transmitir os conhecimentos básicos do zero e motivá-lo a ingressar na área da programação.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Minicurso-Java-280x210.png" alt="Minicurso Java" title="Minicurso Java"></span>
</div>
<span>Curso De Java Gratuito Com Certificado Da Cubos Academy</span> <a href="https://guiadeti.com.br/curso-java-gratuito-certificado-cubos-academy/" title="Curso De Java Gratuito Com Certificado Da Cubos Academy"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/12/Santander-Curso-de-Ingles-1-280x210.png" alt="Santander Open Academy" title="Santander Open Academy"></span>
</div>
<span>Santander Oferece 8.000 Bolsas Para Ensino De Inglês</span> <a href="https://guiadeti.com.br/santander-bolsas-ingles/" title="Santander Oferece 8.000 Bolsas Para Ensino De Inglês"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Bootcamp-De-ServiceNow-280x210.png" alt="Bootcamp De ServiceNow" title="Bootcamp De ServiceNow"></span>
</div>
<span>Bootcamp De ServiceNow Gratuito Com Chance De Contratação</span> <a href="https://guiadeti.com.br/bootcamp-servicenow-gratuito-contratacao/" title="Bootcamp De ServiceNow Gratuito Com Chance De Contratação"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Webinar-Carreira-UXUI-280x210.png" alt="Webinar Carreira UX/UI" title="Webinar Carreira UX/UI"></span>
</div>
<span>Webinar Sobre UX/UI Gratuita: Estratégias Para Iniciar Carreira</span> <a href="https://guiadeti.com.br/webinar-ux-ui-gratuita-estrategias-para-carreira/" title="Webinar Sobre UX/UI Gratuita: Estratégias Para Iniciar Carreira"></a>
</div>
</div>
</div>
</aside>
## Java
Java é uma das linguagens de programação mais populares e utilizadas no mundo da tecnologia. Desenvolvida originalmente pela Sun Microsystems, agora parte da Oracle Corporation, Java é conhecida por sua portabilidade, robustez e facilidade de uso.
### História e Evolução
Java foi lançado em 1995 e rapidamente se tornou uma das linguagens de programação mais utilizadas devido à sua filosofia “write once, run anywhere” (escreva uma vez, execute em qualquer lugar).
Desde então, a linguagem evoluiu significativamente, com atualizações e melhorias contínuas que mantêm sua relevância no desenvolvimento de software moderno.
### Princípios Fundamentais
#### Orientação a Objetos
Java é uma linguagem orientada a objetos, o que significa que ela organiza o código em “objetos” que podem conter dados e métodos.
Dessa forma, facilita a modularização do código, tornando-o mais fácil de gerenciar e reutilizar. Conceitos chave da orientação a objetos nessa linguagem incluem classes, objetos, herança, polimorfismo e encapsulamento.
#### Portabilidade
Uma das principais vantagens da linguagem é sua portabilidade. Graças à Máquina Virtual Java (JVM), o mesmo código pode ser executado em diferentes plataformas sem modificação. Esse alcance acontece através da compilação do código fonte em bytecode, que é interpretado pela JVM específica de cada plataforma.
### Componentes Principais
#### JVM (Java Virtual Machine)
A JVM é uma peça central dessa linguagem de programação. Ela permite que os programas sejam executados em qualquer dispositivo ou sistema operacional que tenha uma JVM instalada.
A JVM é responsável por converter o bytecode em instruções específicas da máquina e gerenciar recursos como memória e threads.
#### JDK (Java Development Kit)
O JDK é um kit de desenvolvimento completo para programadores dessa linguagem. Ele inclui a JVM, bibliotecas padrão, ferramentas de desenvolvimento como o compilador (javac), e depuradores. O JDK é essencial para a criação, compilação e execução de programas Java.
#### API (Application Programming Interface)
A linguagem possui uma extensa API que fornece bibliotecas e frameworks para quase todas as necessidades de desenvolvimento, desde manipulação de dados até redes e gráficos.
A API do Java é organizada em pacotes que facilitam a localização e utilização das funcionalidades necessárias.
#### Aplicações do Java
Java é usado em diversas aplicações, desde desenvolvimento web e aplicativos móveis até sistemas embarcados e aplicações empresariais. Algumas áreas de destaque incluem:
- Desenvolvimento Web: Frameworks como Spring e JavaServer Faces (JSF) permitem o desenvolvimento de aplicações web robustas e escaláveis. A linguagem também é amplamente utilizado em servidores de aplicação como Apache Tomcat e JBoss.
- Aplicativos Móveis: Android, o sistema operacional móvel mais popular do mundo, é construído nessa linguagem. O desenvolvimento de aplicativos Android utiliza uma variante da linguagem, proporcionando aos desenvolvedores uma base sólida para criar aplicativos móveis.
- Aplicações Empresariais: Java é uma escolha popular para aplicações empresariais devido à sua escalabilidade e segurança. Frameworks como Hibernate e EJB (Enterprise JavaBeans) facilitam o desenvolvimento de aplicações complexas e de grande escala.
Sendo você um iniciante ou um desenvolvedor experiente, aprender essa linguagem pode abrir muitas portas no mundo do desenvolvimento de software.
## Cubos Academy
A Cubos Academy é uma instituição de ensino dedicada a formar profissionais qualificados no campo da tecnologia.
Tendo uma metodologia voltada para o mercado, a Cubos Academy oferece vários cursos que capacitam os alunos a desenvolverem habilidades essenciais para suas carreiras.
### Missão e Visão
A missão da Cubos Academy é democratizar o acesso à educação de qualidade em tecnologia, preparando indivíduos para os desafios e oportunidades do mercado de trabalho atual.
A visão da instituição é ser reconhecida como líder em formação tecnológica, impulsionando a transformação digital através de programas educativos inovadores e acessíveis.
### Abordagem Educacional
Os cursos são feitos para que os alunos coloquem em prática o que aprendem, através de projetos reais e desafios práticos. A partir disso, os alunos adquiram conhecimento teórico e desenvolvam habilidades práticas que são altamente valorizadas no mercado de trabalho.
### Foco no Mercado
Todos os cursos da Cubos Academy são desenvolvidos com a contribuição de profissionais experientes da indústria. Dessa maneira, garante que o conteúdo esteja sempre atualizado com as últimas tendências e demandas do mercado.
A instituição mantém parcerias com empresas de tecnologia para garantir que seus programas educativos preparem os alunos para carreiras de sucesso.
### Impacto e Resultados
Muitos alunos da Cubos Academy já alcançaram sucesso significativo em suas carreiras após a conclusão dos cursos.
A instituição se orgulha de suas histórias de sucesso, onde ex-alunos conseguiram posições de destaque em empresas de tecnologia ou lançaram suas próprias startups.
## Inscreva-se agora no minicurso gratuito da Cubos Academy e comece a aprender hoje mesmo!
As [inscrições para o Minicruso Programação Java](https://www.cubos.academy/lp/minicurso-java?) devem ser realizadas no site da Cuboa Academy.
## Compartilhe o minicurso gratuito da Cubos Academy com seus amigos e colegas!
Gostou do conteúdo sobre o minicurso gratuito de Java? Então compartilhe com a galera!
O post [Curso De Java Gratuito Com Certificado Da Cubos Academy](https://guiadeti.com.br/curso-java-gratuito-certificado-cubos-academy/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,866,653 | Nuxt Layer issue `Importing directly from module entry-points is not allowed` | Yesterday that I was working on my open source Sass template starter with Nuxt Layers, I encounter a... | 0 | 2024-05-27T15:13:17 | https://dev.to/leamsigc/nuxt-layer-issue-importing-directly-from-module-entry-points-is-not-allowed-2k2 | nuxt, vue, javascript, webdev |
Yesterday that I was working on my open source Sass template starter with Nuxt Layers,
I encounter a problem, when I was trying to use one of my layers in another layer, let me explain a little bit my project set up so you can have a better overview of the problem:
My folder structure is the following:
```tree
-- nux-sass-layer
-- packages
-- ui
-- content
-- auth
-- email
-- dashboard
--site
```
When I implemented my `UI` layer, there was no error at all, and everything compiled like always.
I was importing some `types` from `radix-vue` and everything seems fine, until!!
> I try to import a component from the `ui` Layer for the time was fine, because that first component wasn’t using any `external types`
So the problem start when I imported my `HeaderNavigation` but that component depends on other components that use external types, like `TheMenuItem` component.
I start getting `500` errors and the following message in the terminal:
`Importing directly from module entry-points is not allowed`
And `Pre-transform error: [@vue/compiler-sfc] Failed to resolve import source "radix-vue"`.
The component that was doing the import of the type
```vue
<script setup lang="ts">
import { NavigationMenuRoot } from "radix-vue";
import NavigationMenuViewport from "./NavigationMenuViewport.vue";
import { cn } from "@UI/lib/utils";
import type { NavigationMenuRootProps, NavigationMenuRootEmits } from "radix-vue"; //<- This was the line that was breaking everithing
const props = defineProps<NavigationMenuRootProps & { class?: string }>();
const emits = defineEmits<NavigationMenuRootEmits>();
</script>
```
I spend more than a couple of hours trying to find a solution and looking if anyone has encountered the same issue.
But not luck, I got some feedback from the Discord community of `Nuxt`.
But after a walk with the dog and some coffee, I look deeper at the error details and where the error was coming from, then did a deep dive in the `.nuxt` folder and look at the output and notice that the `tsconfig.json` that was created was target to `moduleResolution:module` and not to "Node”, update my `tsconfig.josn` to make the `moduleResolution` to `Node`.
```json
{
"extends": "./.nuxt/tsconfig.json",
"compilerOptions": {
"paths": { "@UI/*": ["./*"] },
"moduleResolution": "Node"
}
}
```
This solves the problem 🤗
Here is the link to the project if you want to take a look at it or need an example on how to or not to use Nuxt layers for your project.
[nuxt-monorepo-layers](https://github.com/leamsigc/nuxt-monorepo-layers)
> Please if anyone have a better way please comment below and let's learn together
{% gist https://gist.github.com/leamsigc/68d3f891d9298c35de273caa2b21e453 %}
> Working on the audio version
[The Loop VueJs Podcast](https://podcasters.spotify.com/pod/show/the-loop-vuejs)
| leamsigc |
1,866,684 | Working with JSON and XML in Go | Working with JSON and XML in Go JSON (JavaScript Object Notation) and XML (eXtensible... | 0 | 2024-05-27T15:10:04 | https://dev.to/romulogatto/working-with-json-and-xml-in-go-59he | # Working with JSON and XML in Go
JSON (JavaScript Object Notation) and XML (eXtensible Markup Language) are two popular data interchange formats used in various applications. Whether you're working on a web service, developing an API, or building any application that deals with data exchange, Go provides excellent support for both JSON and XML handling.
In this guide, we will explore how to work with JSON and XML in Go. We'll cover encoding and decoding data using these formats, as well as parsing and manipulating the structured data within them.
## Encoding and Decoding JSON
Go makes it simple to encode structs or maps into JSON format by utilizing the built-in `encoding/json` package. To encode a struct/map into JSON, follow these steps:
1. Create a struct or map containing your desired data fields.
2. Import the `encoding/json` package.
3. Use the `json.Marshal()` function to encode your struct/map into a byte slice representing the JSON object.
Here's an example illustrating how to encode a struct to JSON:
```go
import (
"encoding/json"
"fmt"
)
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Emails []string `json:"emails,omitempty"`
}
func main() {
p := Person{Name: "John Doe", Age: 30}
jsonBytes, err := json.Marshal(p)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(string(jsonBytes))
}
```
Decoding is equally straightforward; it involves unmarshaling the encoded bytes back into a variable of type struct/map using `json.Unmarshal()`. Here's an example:
```go
import (
"encoding/json"
"fmt"
)
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Emails []string `json:"emails,omitempty"`
}
func main() {
jsonStr := `{"name":"John Doe","age":30}`
var p Person
err := json.Unmarshal([]byte(jsonStr), &p)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("%+v", p)
}
```
## Parsing and Manipulating XML
Go also provides a robust package called `encoding/xml` for parsing and manipulating XML data. This package allows you to easily navigate through the XML document, access tags, and attributes, and manipulate the underlying data.
To parse and work with an XML document in Go, follow these steps:
1. Import the `encoding/xml` package.
2. Create appropriate struct types that match your desired XML structure.
3. Use the `xml.Unmarshal()` function to unmarshal the XML data into your defined struct variable.
4. Access and manipulate the structured data within your struct variable.
Let's look at an example where we decode an XML string into a custom struct:
```go
import (
"encoding/xml"
"fmt"
)
type City struct {
Name string `xml:"name"`
Country string `xml:"country"`
Population int `xml:"population"`
}
func main() {
xmlStr :=
`<city>
<name>New York</name>
<country>USA</country>
<population>8622698</population>
</city>`
var c City
err := xml.Unmarshal([]byte(xmlStr), &c)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("%+v", c)
}
```
By defining appropriate struct fields with corresponding tags matching XML elements/attributes names, we can easily map our desired values from the parsed XML data.
## Conclusion
Working with JSON and XML in Go is straightforward and efficient, thanks to the `encoding/json` package for JSON handling and the `encoding/xml` package for XML manipulation. With these capabilities, you can confidently encode, decode, parse, and manipulate structured data in your Go applications. So go ahead and leverage these powerful features while developing your next application!
| romulogatto | |
1,866,683 | Git Error | warning: in the working copy of 'JS/bootstrap.bundle.min.js', LF will be replaced by CRLF the next... | 0 | 2024-05-27T15:09:16 | https://dev.to/fahd93/git-error-1moa | git, errors | warning: in the working copy of 'JS/bootstrap.bundle.min.js', LF will be replaced by CRLF the next time Git touches it
how can I
 fix this error in git? | fahd93 |
1,866,681 | Essential data sanitization techniques for robust security at every development stage 🔐 | Being GDPR-compliant across all your projects is a daily challenge—especially if you’re managing... | 0 | 2024-05-27T15:07:46 | https://dev.to/upsun/essential-data-sanitization-techniques-for-robust-security-at-every-development-stage-o15 | webdev, tutorial, devops, programming | Being GDPR-compliant across all your projects is a daily challenge—especially if you’re managing sensitive user data on your projects. Upsun adopts a [GDPR everywhere approach](https://upsun.com/blog/gdpr-compliance-everywhere/) with high levels of built-in security and compliance as standard—but there are ways to secure your data on our PaaS further when it comes to preview environments.
Each time you create a new Git branch on a project on Upsun, the corresponding environment inherits the data (assets and database) from its parent. This means that potentially sensitive data from your production website could be exposed to the preview environment.
So, how do you navigate this and ensure your application remains compliant? ✨ **Two words: data sanitization.** ✨ The deliberate and permanent erasure of sensitive data from a storage device making the data non-recoverable.
Dive into the key methods of data sanitization whcih you can implement for to ensure your data remains safe at every stage of development 👉 **[learn more now](https://upsun.com/blog/how-to-sanitize-preview-environment-data/?utm_source=devto&utm_medium=organic_social&utm_campaign=upsun_blog&utm_id=upsun).**
| celestevanderwatt |
1,866,679 | Introduction to GitHub 🧑💻 : Part 1 | GitHub is an online software development and code hosting platform, a web-based version control and... | 0 | 2024-05-27T15:06:58 | https://dev.to/thoufiqizhar7/introduction-to-github-part-1-3405 | webdev, github, git, learning | **GitHub** is an online software development and code hosting platform, _a web-based version control and collaboration platform for software developers. It’s used for storing, tracking, and collaborating on software projects._
GitHub follows a **Software as a Service (SaaS)** business model and was launched in 2008. It was built on Git, _an open-source code management_ system created by **_Linus Torvalds_** to facilitate faster software development. In 2018, _**Microsoft**_, the biggest single contributor to GitHub, _acquired the platform for $7.5 billion_.

## Why Was GitHub Created?
Here’s why: Assume you are participating in a hackathon or a group project where your teammates are from different countries. In that case, you need a way to collaborate on the project you’re working on, such as tracking changes in code, the features you’re building, and more.
The main problem is how you and your collaborators/contributors will work on the project.
So what’s the solution?
GitHub! It’s a platform with functionalities that every developer needs to maintain their code and collaborate. It maintains everything as a _**central database**_, also known as a _‘Single Source of Truth’_.
## What Is Version Control?
**Version control** helps developers _track and manage changes to software code in a collaborative environment_. Two major concepts are branching and merging, which you’ll learn about in a further series on GitHub.
## What Is Git?
**Git** is _an open-source version control software used for managing and tracking file revisions_. Git is used to manage projects on your local system. Git is the most widely used version control system in software development, and GitHub provides services that complement this technology, hence the name “GitHub”.

Now you’ve grasped the basic overview of GitHub. You’ll learn more about working practically and setting up Git and GitHub in my upcoming blogs.
Feel free to connect with me on other social media platforms 😊🤝 to stay updated on my latest adventures in web development and open for collaboration. Until next time, happy learning! 👨💻🚀
[GitHub](https://github.com/Thoufiq-Uchiha-23)
[Hashnode](https://hashnode.com/@Thoufiq-Izhar-1729)
[Medium](https://medium.com/@thoufiqizhar022)
[Twitter(X)](https://twitter.com/IzharThouf29718) | thoufiqizhar7 |
1,866,677 | May Chay Bo Life Sport | "Các mẫu máy chạy bộ tại Lifesport được trang bị nhiều tính năng thông minh và hiện đại, giúp bạn có... | 0 | 2024-05-27T15:06:11 | https://dev.to/maychaybo/may-chay-bo-life-sport-14io | "Các mẫu máy chạy bộ tại Lifesport được trang bị nhiều tính năng thông minh và hiện đại, giúp bạn có thể nâng cao sức khỏe một cách toàn diện nhất. Máy chạy bộ Lifesport có thiết kế đẹp, mẫu mã đã dạng, mức giá cũng khác nhau, đáp ứng mọi nhu cầu sử dụng của khách hàng.
SĐT: 1800 6807
Email: info@lifesport.vn
Địa chỉ: Lầu 3, số 6 Phan Chu Trinh, P.Tân Thành, Q.Tân Phú, TP.Hồ Chí Minh
Map: https://maps.app.goo.gl/3H4sxa77fb7QEvhB7
Website: https://lifesport.vn/may-chay-bo
Hastag: #lifesport #lifesportvn #xedaptaplifesport #ghemassagelifesport #maychaybo"
Website: https://lifesport.vn/may-chay-bo
Phone: 1800 6807
Address: Lầu 3, số 6 Phan Chu Trinh, P.Tân Thành, Q.Tân Phú, TP.Hồ Chí Minh
https://slides.com/maychaybo
https://www.metooo.io/u/6654970b3687e56dc75e5275
https://doodleordie.com/profile/maychaybo
https://myspace.com/pvmaychaybo
https://pubhtml5.com/homepage/yrhmu/
https://www.wpgmaps.com/forums/users/maychaybo/
https://bandcamp.com/maychaybo
https://allmylinks.com/maychaybo
https://www.kniterate.com/community/users/maychaybo/
https://www.funddreamer.com/users/may-chay-bo-life-sport
https://linktr.ee/maychaybo
https://roomstyler.com/users/maychaybo
https://stocktwits.com/maychaybo
https://rotorbuilds.com/profile/42342/
https://connect.garmin.com/modern/profile/92aca4f2-b2bb-421b-a561-63d47e025b6e
https://rentry.co/smkhst89
https://my.desktopnexus.com/maychaybo/
https://www.reverbnation.com/maychaybo5
https://forum.dmec.vn/index.php?members/maychaybo.60989/
https://camp-fire.jp/profile/maychaybo
www.artistecard.com/maychaybo#!/contact
https://peatix.com/user/22392016/view
https://readthedocs.org/projects/httpslifesportvnmay-chay-bo/
https://hubpages.com/@lzmaychaybo#about
https://telegra.ph/maychaybo-05-27
https://play.eslgaming.com/player/20129603/
https://www.designspiration.com/benjamin13rivera1410/
https://disqus.com/by/maychaybo/about/
https://www.credly.com/users/may-chay-bo-life-sport/badges
https://hackerone.com/maychaybo?type=user
https://collegeprojectboard.com/author/maychaybo/
https://os.mbed.com/users/maychaybo/
https://www.artscow.com/user/3196381
https://8tracks.com/maychaybo
https://naijamp3s.com/index.php?a=profile&u=maychaybo
https://zzb.bz/VfDIY
https://www.dnnsoftware.com/activity-feed/userid/3198814
https://gettr.com/user/xcmaychaybo
https://www.chordie.com/forum/profile.php?id=1964237
https://www.instapaper.com/p/gfmaychaybo
https://vimeo.com/user220263498
https://www.pearltrees.com/ypmaychaybo
https://forum.codeigniter.com/member.php?action=profile&uid=108580
https://linkmix.co/23440028
https://www.divephotoguide.com/user/zmmaychaybo/
https://diendannhansu.com/members/maychaybo.49766/#about
https://www.fimfiction.net/user/746495/mymaychaybo
https://www.storeboard.com/maychaybolifesport2
https://dreevoo.com/profile_info.php?pid=642172
https://visual.ly/users/benjamin13rivera1410
https://inkbunny.net/maychaybo
https://topsitenet.com/profile/maychaybo/1195550/
https://www.diggerslist.com/maychaybo/about
https://active.popsugar.com/@maychaybo/profile
https://edenprairie.bubblelife.com/users/maychaybo
https://www.equinenow.com/farm/maychaybo.htm
https://research.openhumans.org/member/maychaybo
https://lab.quickbox.io/hvmaychaybo
https://able2know.org/user/maychaybo/
https://pastelink.net/qje58gyj
https://www.scoop.it/u/may-chay-bolife-sport
http://idea.informer.com/users/maychaybo/?what=personal
https://glose.com/u/vumaychaybo
https://teletype.in/@maychaybo
https://sinhhocvietnam.com/forum/members/74532/#about
https://500px.com/p/maychaybo?view=photos
https://www.plurk.com/maychaybo/public
https://www.5giay.vn/members/maychaybo.101974385/#info
https://www.deviantart.com/xfmaychaybo/about
https://www.ohay.tv/profile/maychaybo
https://community.fyers.in/member/RHhtdedSal
https://tinhte.vn/members/maychaybo.3022965/
https://huggingface.co/maychaybo
https://turkish.ava360.com/user/maychaybo/#
https://dribbble.com/uumaychaybo/about
https://www.speedrun.com/users/maychaybo
https://potofu.me/maychaybo
https://makersplace.com/benjamin13rivera1410/about
https://leetcode.com/u/maychaybo/
https://motion-gallery.net/users/608600
https://www.patreon.com/maychaybo
https://www.anibookmark.com/user/maychaybo.html
https://www.hahalolo.com/@66549c5d05740e60d09465a5
https://www.noteflight.com/profile/5ad5a5bb00dcebf7c17653cccb42cc44b733a77e
https://vnseosem.com/members/maychaybo.31059/#info
https://www.mountainproject.com/user/201829215/may-chay-bo-life-sport
https://piczel.tv/watch/maychaybo
https://muckrack.com/may-chay-bo-life-sport
https://bentleysystems.service-now.com/community?id=community_user_profile&user=f799e3ab1bde8214dc6db99f034bcbd0
https://chodilinh.com/members/maychaybo.78849/#about
https://vocal.media/authors/may-chay-bo-life-sport
https://www.discogs.com/user/maychaybo
https://guides.co/a/may-chay-bo-life-sport
https://worldcosplay.net/member/1770749
https://newspicks.com/user/10314703
https://qooh.me/maychaybo
https://us.enrollbusiness.com/BusinessProfile/6698540/maychaybo
https://devpost.com/benjamin13rivera1410
https://socialtrain.stage.lithium.com/t5/user/viewprofilepage/user-id/65149
https://wmart.kz/forum/user/163308/
https://hashnode.com/@maychaybo
https://fileforum.com/profile/maychaybo
https://files.fm/maychaybo
https://www.beatstars.com/benjamin13rivera1410/about
https://www.silverstripe.org/ForumMemberProfile/show/152489
https://magic.ly/maychaybo
https://www.intensedebate.com/people/ahmaychaybo
https://www.are.na/may-chay-bo-life-sport/channels
https://www.dermandar.com/user/maychaybo/
https://hackmd.io/@fnmaychaybo
https://chart-studio.plotly.com/~maychaybo
https://qiita.com/maychaybo
http://forum.yealink.com/forum/member.php?action=profile&uid=342267
https://www.creativelive.com/student/may-chay-bo-life-sport?via=accounts-freeform_2
https://www.gaiaonline.com/profiles/femaychaybo/46697142/
http://hawkee.com/profile/6958385/
https://myanimelist.net/profile/uvmaychaybo
https://git.industra.space/maychaybo
https://ficwad.com/a/maychaybo
https://www.codingame.com/profile/e355f5a7b0679c6aa6c71529adcf23685675906
https://www.ethiovisit.com/myplace/maychaybo
https://www.exchangle.com/maychaybo
https://www.facer.io/u/maychaybo
http://buildolution.com/UserProfile/tabid/131/userId/405672/Default.aspx
https://expathealthseoul.com/profile/may-chay-bo-life-sport/
https://tupalo.com/en/users/6778454
https://willysforsale.com/profile/maychaybo
https://www.quia.com/profiles/malifesport
https://sketchfab.com/maychaybo
https://controlc.com/a08b7483
https://www.pling.com/u/maychaybo/
https://app.talkshoe.com/user/maychaybo
| maychaybo | |
1,855,636 | Host a Static Website using Amazon S3 and Serve it Through Amazon CloudFront. | AWS S3 buckets can be used to host static web pages but you would need to make it publicly... | 0 | 2024-05-27T15:03:17 | https://dev.to/chigozieco/host-a-static-website-using-amazon-s3-and-serve-it-through-amazon-cloudfront-3om8 | AWS S3 buckets can be used to host static web pages but you would need to make it publicly accessible. This opens your bucket and assets to vulnerabilities, how then can you serve your site to the public while minimizing the risks of being attacked by bad actors?
We can do this using AWS Cloudfront. You do this by serving your site via cloudfront. In this walkthrough, we will do just that. At no point will we make our bucket public accessible.
### Prereq
- You need to have an AWS account, the services used here are covered by the free tier and so you should not incur any costs.
- If you are just creating your account ensure you create an IAM user that has administrator privilege (it's not recommended to use the root user for regular day to day activities) as well as an active access key.
- You need to have AWS CLI 2 installed and configured for programmatic access to your AWS account.
- You also need to have an HTML page (the static website you want to host), don't fret you don't have to start designing one if you don't have one handy you can get [html templates here](https://www.tooplate.com/). I will be using a template gotten from there as well.
## Amazon S3 Bucket
Amazon S3 (Simple Storage Service) is an object storage built to store and retrieve any amount of data from anywhere. It integrates with many other AWS services, is highly available and durable and also highly cost-effective. Amazon S3 also provides easy management features to organize data for websites, mobile applications, backup and restore, and many other applications.
You can configure a storage bucket to host and serve as a static website, on a static website, individual webpages include static content. They might also contain client-side scripts.
It however cannot be used to host a dynamic website as a dynamic website relies on server-side processing, including server-side scripts, such as PHP, JSP, or ASP.NET. Amazon S3 does not support server-side scripting, but AWS has other resources for hosting dynamic websites.
### Configure AWS CLI
I will be using the AWS CLI to programmatically create my bucket and upload the resources into the bucket as well as to enable static web hosting.
:zap: First you need to download the [aws cli 2](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html). From the provided link follow the instructions for your device and follow along with the rest of the project.
:warning: <span id=aws> **NOTE**
If you want to interact with AWS outside of the AWS Management Console and use the cli as I will be in this walkthrough you need to have programmatic access. You need to create an access key for the IAM user you will be using.
:zap: Simply navigate to the IAM user and scroll down to the `access key` and click on `create key`

For the use case select the first option being `Command Line Interface (CLI)` and click on `next`

You can choose to add a tag or not (tags will make it easier for you to identify your access key) and then go ahead to create the key.
:zap: The next thing you need to do is to setup the cli for use. Use the `aws configure` command and enter your `access key`
```sh
$ aws configure
AWS Access Key ID [****************W0FM]: <your access key ID>
AWS Secret Access Key [****************okxa]: <your secret access key>
Default region name [us-east-1]: <whatever region you want to be your default>
Default output format [None]: <you can leave empty by clicking enter>
```
You can run the `aws sts get-caller-identity` command to verify that you have configured the CLI correctly. The output of this command will display the present user ID, account and ARN.
Verify that this is the correct credentials and continue.
Now you are ready to use the AWS CLI for this walk through. </span>
### Create S3 Bucket
We will be creating a bucket with the default settings. We want our bucket to be private and to block all public access.
Because we are serving the site through the content distribution network cloudfront (more on that later) we can afford to block all public access to our bucket as it won't be required.
To create a bucket via the cli, use the below command:
```sh
aws s3api create-bucket --bucket <your unique bucket name> --region <your preferred aws region>
```
:warning: **NOTE**
Your bucket name must be globally unique, no two buckets in the whole world can ever have the same exact name, there must be a variation.
Also if you set your default AWS region and you're ok with your bucket residing in that region you do not need to specify the region with the `--region` flag. Remember that your bucket is region specific so it will only exist in the region you created it.
I won't be using the region tag as I'm ok using my set default region.
```sh
aws s3api create-bucket --bucket altschool-sem3-site
```
If it was successful you should see something that resembles the below:

You can list your available buckets using `aws s3 ls` command.

### Upload Objects into S3
Now we need to upload our static website assets.
A static webpage is one that is sent to a web browser in its identical stored format. It is sometimes referred to as a flat page or a stationary page.
Until the site is redesigned or the site administrator makes changes directly in the code, the page will not be altered by anything either the user or the site administrator does on the page.
Our static website assets are our html, css etc, those files you downloaded from the [html templates here](https://www.tooplate.com/).
Time to upload our objects in the S3 bucket, we do that using the code below:
```sh
aws s3 cp /local/file/path s3://bucket-name --recursive
aws s3 cp ./2093_flight/ s3://altschool-sem3-site --recursive
```
The recursive flag will help us upload multiple files at the same time, it will ensure that all the files and subdirectories within the specified directory are uploaded.

To verify that you have successfully uploaded the objects we will list the objects available in the bucket.
Use the command below to do that:
```sh
aws s3 ls s3://bucket-name
aws s3 ls s3://altschool-sem3-site
```

You should see a list of the objects you just uploaded into your bucket. From the screenshot above you can see my uploaded objects.
## Amazon CloudFront
Amazon CloudFront is a content delivery network operated by Amazon Web Services. It is a service that helps you distribute your static and dynamic content quickly and reliably with high speed by using a network of proxy servers to cache content, such as web videos or other bulky media, more locally to consumers, to improve access speed for downloading the content.
We will use the management console for this, log in with your IAM user and navigate to cloudfront under the Networking & Content Delivery category.
When you load the cloudfront page click on `create distribution`

### CloudFront configurations
### - Origin
#### :zap: Origin Domain
Origins are where you store the original versions of your web content. CloudFront gets your web content from your origins and serves it to viewers via a worldwide network of edge servers.
The origin domain is the DNS domain name of the Amazon S3 bucket or HTTP server from which you want CloudFront to get objects for this origin.
To that effect select the S3 Bucket we created earlier, from the dropdown, as your `origin domain`
#### :zap: Origin path
Leave this blank, as is.
#### :zap: Name
This will automatically be filled in when you enter your origin domain

#### :zap: Origin Access
In other to further restrict the access to our Amazon S3 bucket origin to only specific CloudFront distributions we will set our `origin access` to the AWS recommended setting which is `Origin access control settings`
Once that is selected, we will create a new Origin access control settings.
Select the `Origin access control settings` radio button and then click on `Create new OAC`

The pop up that appears when you click on create new OAC will be populated with the necessary details, leave it as is and click on `Create`

As soon as this new AOC is created, you will see a warning (same as shown below) telling you that you will need to update your bucket policy with the policy that will be provided after the distribution is created.

### - All Other Config
For the Web Application Firewall, select `do not enable security protections`, You could actually choose to enable it if you want I am just trying to be safe and not incur any unexpected costs.
The last setting you will be changing is the `default root object`, type in `index.html`. This will allow CloudFront to serve your index page to your site visitors.
Leave all other configurations in their default settings, those settings work just fine for what we are trying to do.
Your configuration should look like the screenshots below:






Scroll down to the bottom of the page and click `create distribution`

Copy the provided policy, you can see it highlighted in yellow on your screen, see screenshot above for the item labelled `1` to know where to locate it.
After copying the policy click on the link to take you to the bucket in order to update the permissions with the policy you just copied.
## Update Bucket Policy With Necessary Permission
You could either manually navigate to the S3 bucket we have been using for this project or you could click on the link in the above picture labelled 2 to take you directly to the bucket.
Once the bucket is open, click on the permissions tab.

Scroll down to `Bucket Policy` and click on `edit` to add the permissions we copied at the end of the cloudfront distribution creation.

The copied policy is shown below, ensure you use the one you copied from your cloudfront console as it will carry your unique ARN.
```json
{
"Version": "2008-10-17",
"Id": "PolicyForCloudFrontPrivateContent",
"Statement": [
{
"Sid": "AllowCloudFrontServicePrincipal",
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::altschool-sem3-site/*",
"Condition": {
"StringEquals": {
"AWS:SourceArn": "arn:aws:cloudfront::<redacted>:distribution/EOE3G4O3YYZSA"
}
}
}
]
}
```
Now save your changes.
Your bucket policy should now look like this:

## Access Your Site
Head back to your cloudfront console and retrieve your distribution domain name as shown in the image below.

This is the address you will enter in your browser to be able to see your website.
We can see from the screenshot below that cloudfront is serving the webpage correctly without have to unblock public access of our bucket.

And that's it!! We have successfully served a static webpage using Amazon S3 and Amazon CloudFront.
| chigozieco | |
1,864,085 | Spring Boot 3 application on AWS Lambda - Part 6 Develop application with AWS Lambda Web Adapter | Introduction In the part 5 we introduced AWS Lambda Web Adapter. In this article we'll... | 26,522 | 2024-05-27T15:01:43 | https://dev.to/aws-builders/spring-boot-3-application-on-aws-lambda-part-6-develop-application-with-aws-lambda-web-adapter-h88 | aws, java, serverless, springboot | ## Introduction
In the [part 5](https://dev.to/aws-builders/spring-boot-3-application-on-aws-lambda-part-5-introduction-to-aws-lambda-web-adapter-m21) we introduced AWS Lambda Web Adapter. In this article we'll take a look into how to write AWS Lambda function with Java 21 runtime and AWS Lambda Web Adapter using Spring Boot 3.2 version. To use the newer version of Spring Boot (i.e. 3.3) it should be enough to update the version in pom.xml.
## How to write AWS Lambda with AWS Lambda Web Adapter using Spring Boot 3.2
For the sake of explanation, we'll use our Spring Boot 3.2 [sample application](https://github.com/Vadym79/AWSLambdaJavaWithSpringBoot/tree/master/spring-boot-3.2-with-lambda-web-adapter) and use Java 21 runtime for our Lambda functions.
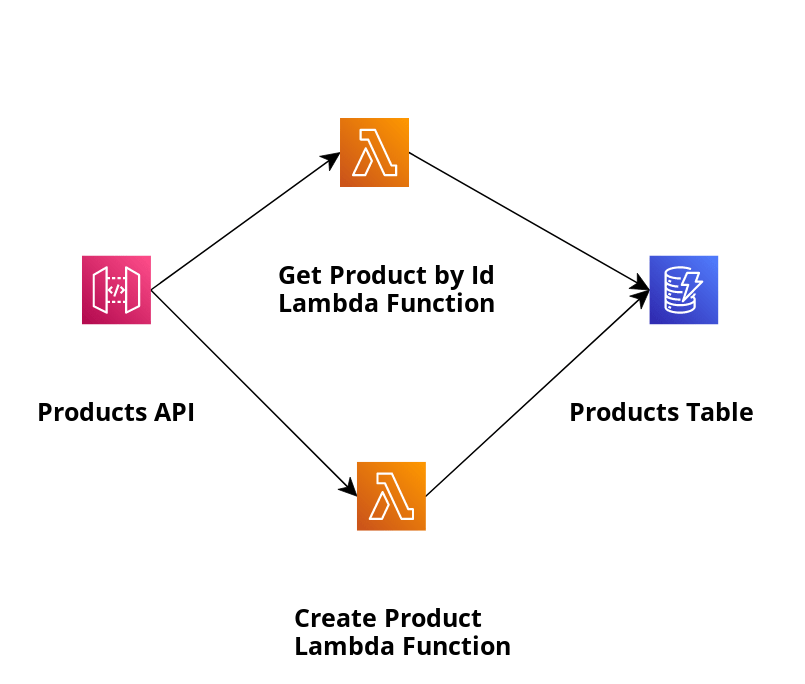
In this application we'll create and retrieve [products](https://github.com/Vadym79/AWSLambdaJavaWithSpringBoot/tree/master/spring-boot-3.2-with-lambda-web-adapter/src/main/java/software/amazonaws/example/product/entity/Product.java) and use DynamoDB as the NoSQL database. You can find the DynamoProductDao.java implementation [here](https://github.com/Vadym79/AWSLambdaJavaWithSpringBoot/tree/master/spring-boot-3.2-with-lambda-web-adapter/src/main/java/software/amazonaws/example/product/dao/DynamoProductDao.java). We also put Amazon API Gateway in front of it as defined in [AWS SAM template](https://github.com/Vadym79/AWSLambdaJavaWithSpringBoot/tree/master/spring-boot-3.2-with-lambda-web-adapter/template.yaml).
Spring Boot [Product Controller](https://github.com/Vadym79/AWSLambdaJavaWithSpringBoot/tree/master/spring-boot-3.2-with-lambda-web-adapter/src/main/java/software/amazonaws/example/product/controller/ProductController.java) annotated with **@RestController** and
**@EnableWebMvc** defines **getProductById** and **createProduct** methods.
```
@RequestMapping(path = "/products/{id}", method = RequestMethod.GET, produces = MediaType.APPLICATION_JSON_VALUE)
public Optional<Product> getProductById(@PathVariable("id") String id) {
return productDao.getProduct(id);
}
@RequestMapping(path = "/products/{id}", method = RequestMethod.PUT, consumes = MediaType.APPLICATION_JSON_VALUE)
public void createProduct(@PathVariable("id") String id, @RequestBody Product product) {
product.setId(id);
productDao.putProduct(product);
}
```
Until this point in time the application based on AWS Lambda Web Adapter looks exactly the same as based on AWS Serverless Java Container as we can re-use our Spring Boot based application.
Now come the differences. They are mainly in the [AWS SAM template](https://github.com/Vadym79/AWSLambdaJavaWithSpringBoot/tree/master/spring-boot-3.2-with-lambda-web-adapter/template.yaml).
1) We need to attach Lambda Web Adapter as a Lambda layer to our Lambda functions. Here is the example for GetProductByIdWithSpringBoot32WithLambdaWebAdapter Lambda function :
```
GetProductByIdFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: GetProductByIdWithSpringBoot32WithLambdaWebAdapter
Layers:
- !Sub arn:aws:lambda:${AWS::Region}:753240598075:layer:LambdaAdapterLayerX86:20
```
For Lambda function running on the arm64 architecture (which currently doesn't support Lambda SnapStart) there is another Lambda Layer to be attached: arn:aws:lambda:${AWS::Region}:753240598075:layer:LambdaAdapterLayerArm64:20
2) In the Globals: Function: section of the SAM template we need to define the following for all Lambda functions:
```
Globals:
Function:
Handler: run.sh
CodeUri: target/aws-spring-boot-3.2-lambda-web-adapter-1.0.0-SNAPSHOT.jar
Runtime: java21
....
Environment:
Variables:
....
RUST_LOG: info
REMOVE_BASE_PATH: /v1
AWS_LAMBDA_EXEC_WRAPPER: /opt/bootstrap
```
What we are doing here is to configure Lambda environment variable AWS_LAMBDA_EXEC_WRAPPER to /opt/bootstrap. When we add a layer to a Lambda function, Lambda extracts the layer contents into the /**opt** directory in our function’s execution environment. All natively supported Lambda runtimes include paths to specific directories within the **/opt** directory. This gives our Lambda function access to our layer content. For more information about these specific paths, see [Packaging your layer content](https://docs.aws.amazon.com/lambda/latest/dg/packaging-layers.html).
We also set function handler to our web application start up script (instead of the Java Lambda Handler class). e.g. run.sh.
In the [run.sh script](https://github.com/Vadym79/AWSLambdaJavaWithSpringBoot/blob/master/spring-boot-3.2-with-lambda-web-adapter/src/main/resources/run.sh) we put everything (jars) in the lib folder into the class path and start our Spring Boot application main class [software.amazonaws.Application](https://github.com/Vadym79/AWSLambdaJavaWithSpringBoot/blob/master/spring-boot-3.2-with-lambda-web-adapter/src/main/java/software/amazonaws/Application.java). In case of Spring Boot this is the class annotated with **@SpringBootApplication**.
```
#!/bin/sh
exec java -cp "./:lib/*" "software.amazonaws.Application"
```
AWS_LWA_REMOVE_BASE_PATH / REMOVE_BASE_PATH - The value of this environment variable tells the adapter whether the application is running under a base path. For the detailed explanation of this parameter please read the documentation on the AWS Lambda Web Adapter [main page](https://github.com/awslabs/aws-lambda-web-adapter).
Because of this definition of the **REMOVE_BASE_PATH: /v1** the Path variable of the API Gateway mapping to each Lambda function also needs to start with **/v1** like **Path: /v1/products/{id}** for the sample for the Lambda function GetProductByIdWithSpringBoot32WithLambdaWebAdapter below
```
GetProductByIdFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: GetProductByIdWithSpringBoot32WithLambdaWebAdapter
....
Events:
GetRequestById:
Type: Api
Properties:
RestApiId: !Ref MyApi
Path: /v1/products/{id}
Method: get
```
Then we need to deploy the application with **sam deploy -g** and to retrieve the existing product we have to invoke the following:
```
curl -H "X-API-Key: a6ZbcDefQW12BN56WED2"
https://{$API_GATEWAY_URL}/prod/v1/products/1
```
## Conclusion
In this article we took a look into how to write AWS Lambda functions with Java 21 runtime with AWS Lambda Web Adapter using Spring 3.2 version. As we explored, we can re-use the Spring Boot Rest Controller as well as it was the case with AWS Serverless Java Container.
In the next article of the series, we'll measure the cold and warm start times for this sample application including enabling SnapStart on the Lambda function but also applying priming for the DynamoDB invocation. | vkazulkin |
1,868,482 | 🚀 Auto-Switch iTerm2 Modes, Day & Night! 🌞🌚 | iTerm2 recently introduced a great feature: separate light and dark mode colors. This feature... | 0 | 2024-05-29T04:47:47 | https://carloschac.in/2024/05/27/iterm2-dark-light-mode/ | iterm2, macos, tipsandtricks, terminal | ---
title: 🚀 Auto-Switch iTerm2 Modes, Day & Night! 🌞🌚
published: true
date: 2024-05-27 15:00:00 UTC
tags: iterm2,macos,tipsandtricks,terminal
canonical_url: https://carloschac.in/2024/05/27/iterm2-dark-light-mode/
---

[iTerm2](https://iterm2.com/) recently introduced a great feature: separate light and dark mode colors. This feature enhances the visual appeal of your terminal and keeps it in sync with your Mac’s mode.
This feature is not just about aesthetics; it’s about comfort. Imagine your terminal always matching your Mac’s light or dark mode, creating a seamless and visually pleasing experience. This enhances the visual appeal and reduces eye strain, making your terminal usage more comfortable.
{% embed https://youtu.be/Lrvdve8JNm0?si=XArIv9VEmhOWbn-8?sub_confirmation=1" %}
## The Problem
In the image below, you can notice that the iTerm2 does not change by default when we switch between light and dark modes.
<!-- more -->
## Ok, let’s discover this game-changer feature!
## Step 1
Go to iTerm2 settings and click the `Profiles` tab.
## Step 2
Click the `Colors` tab under `Profiles.`
## Step 3
Enable the checkbox to `Use different colors for light and dark mode.`
## Step 4
Select the desired dual theme. In this case, I’m selecting `Solarized,` which has light and dark versions.
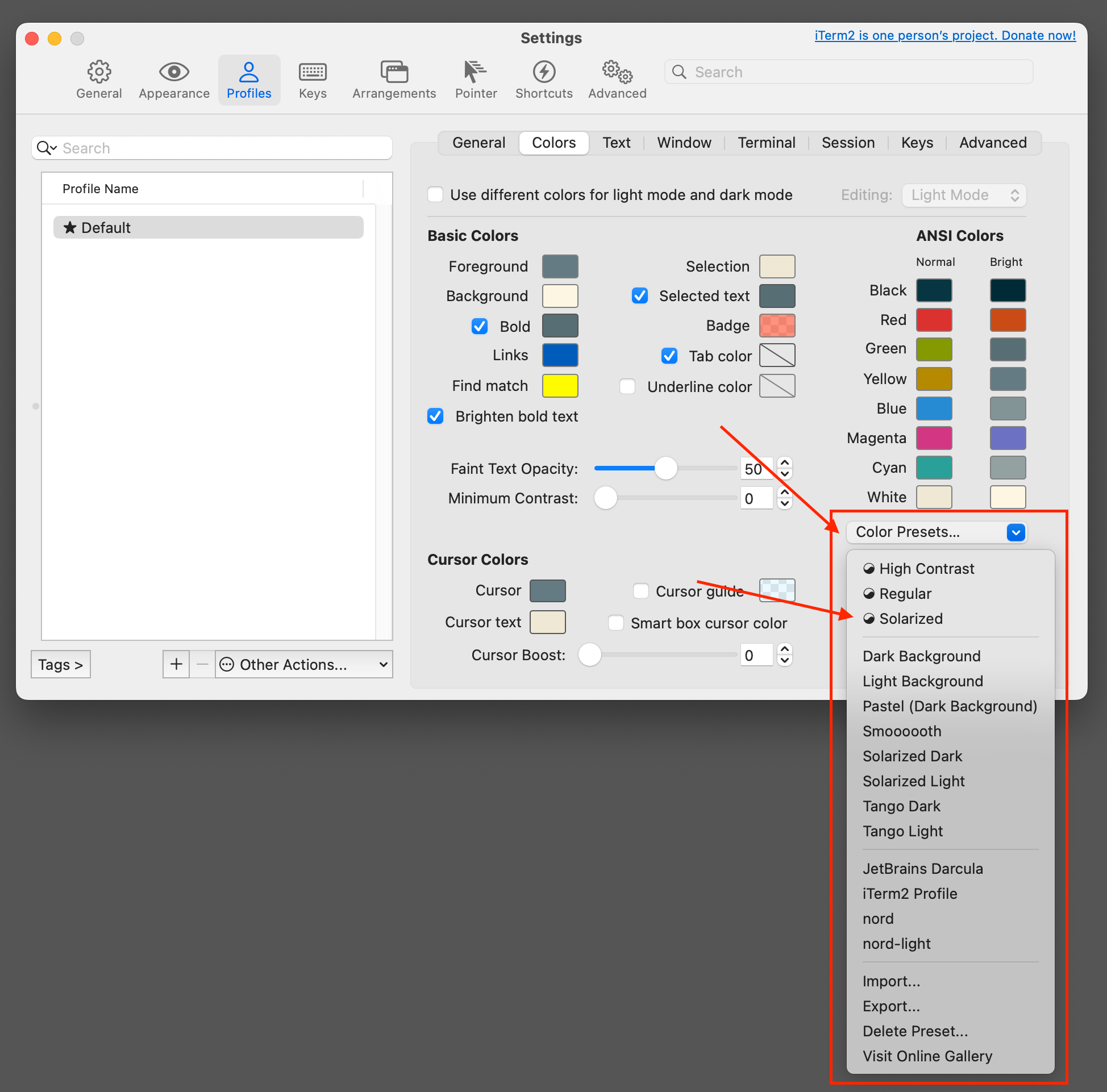
## Step 5
Click on `Update Both Modes`
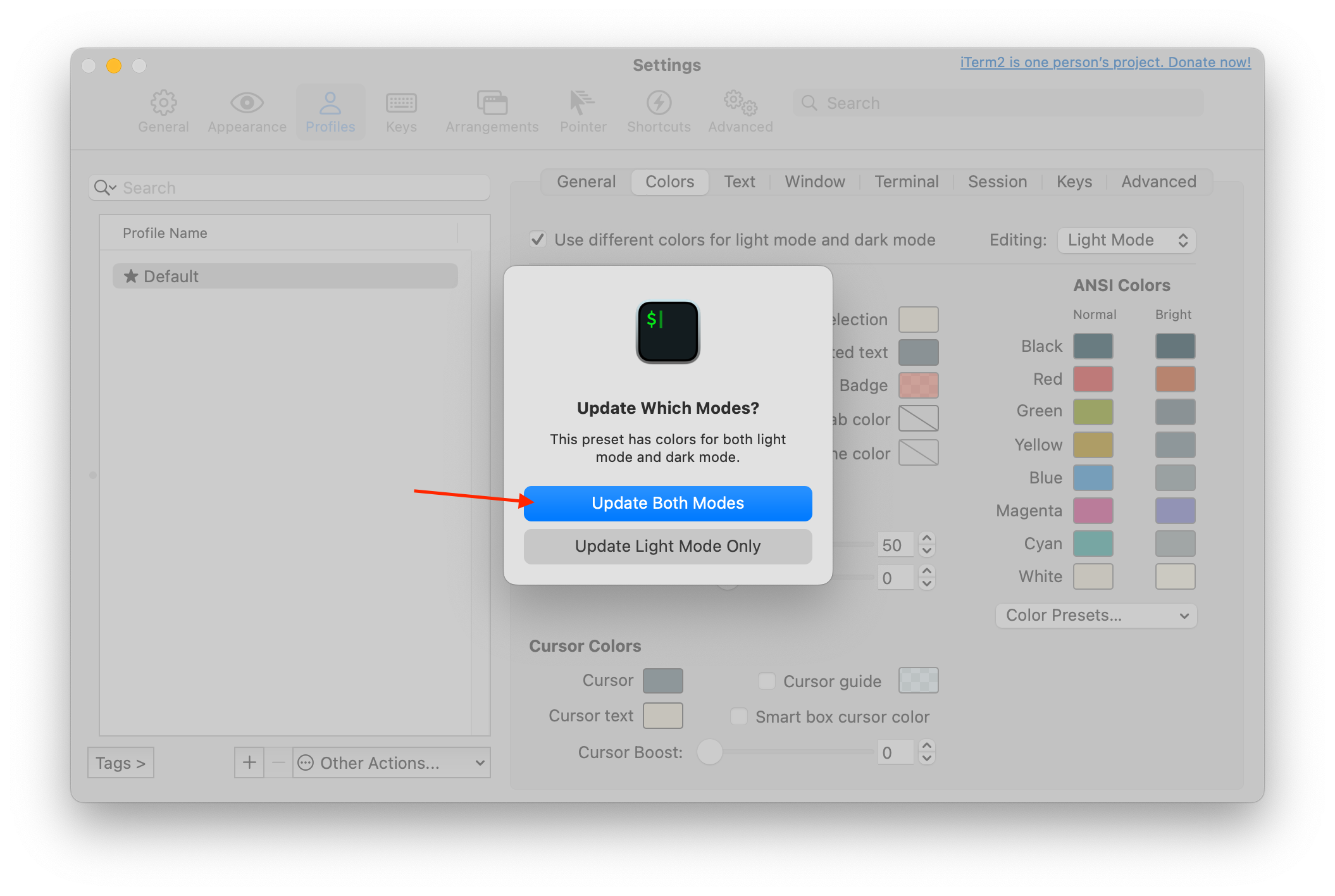
## The Result
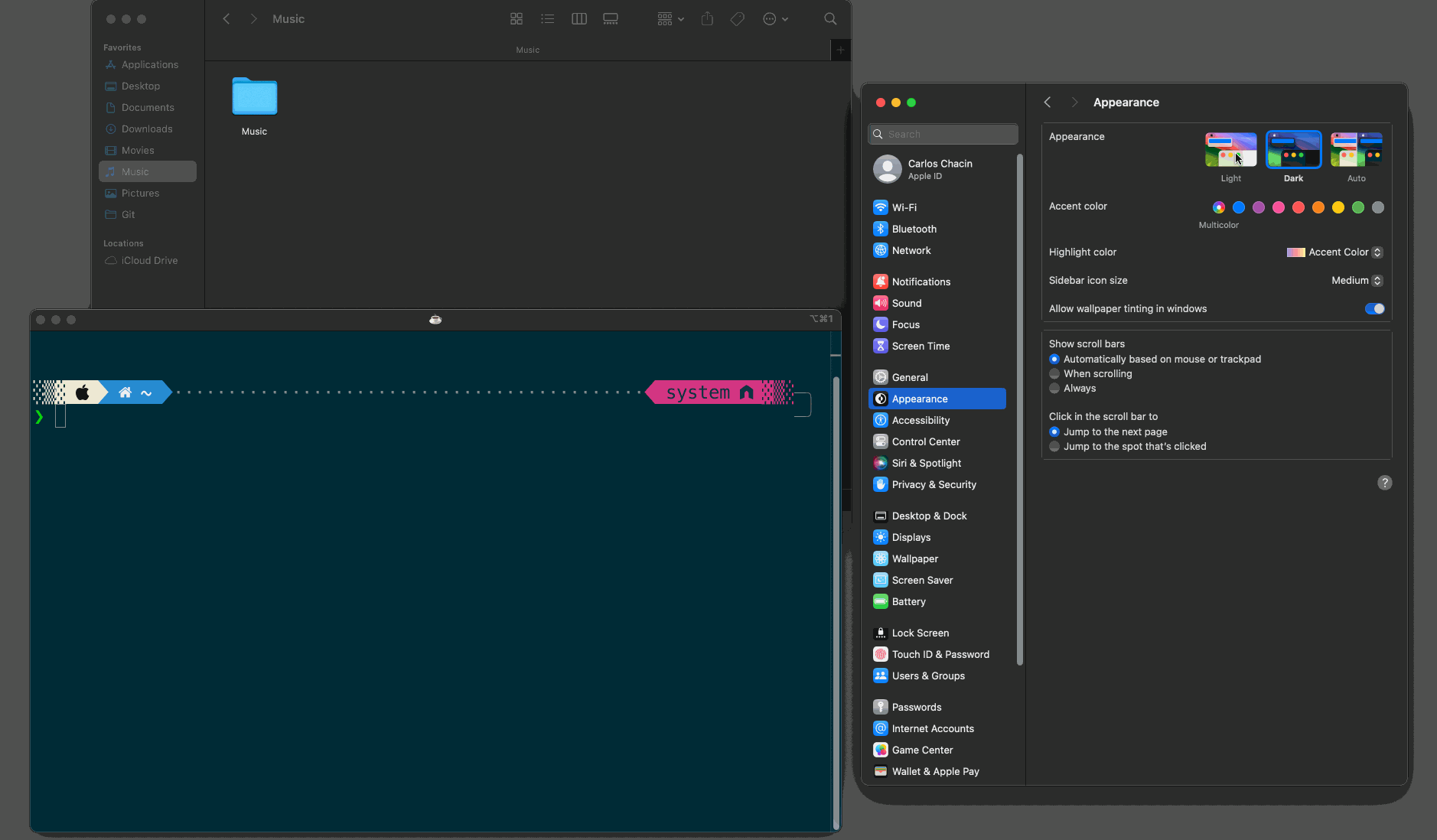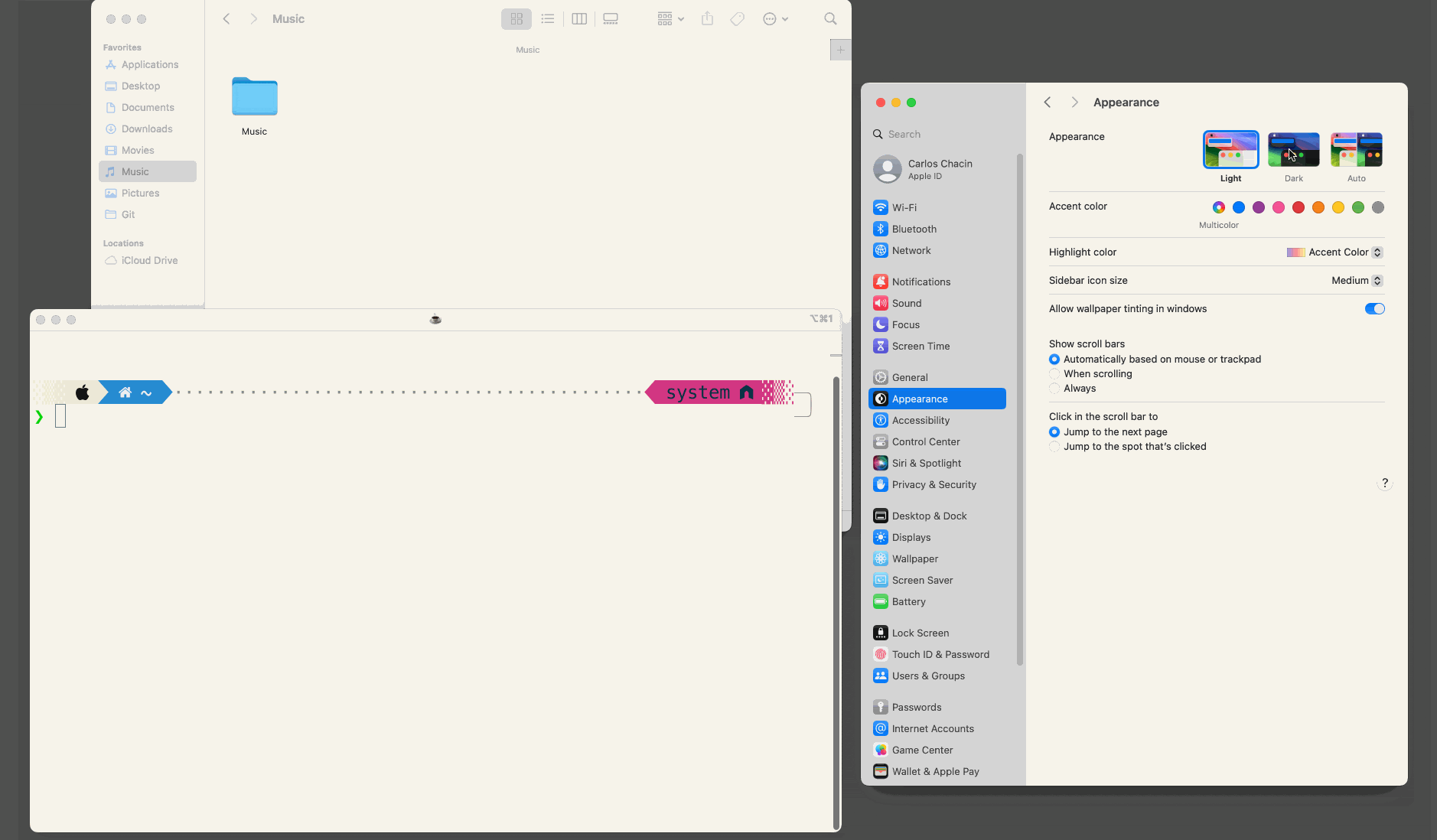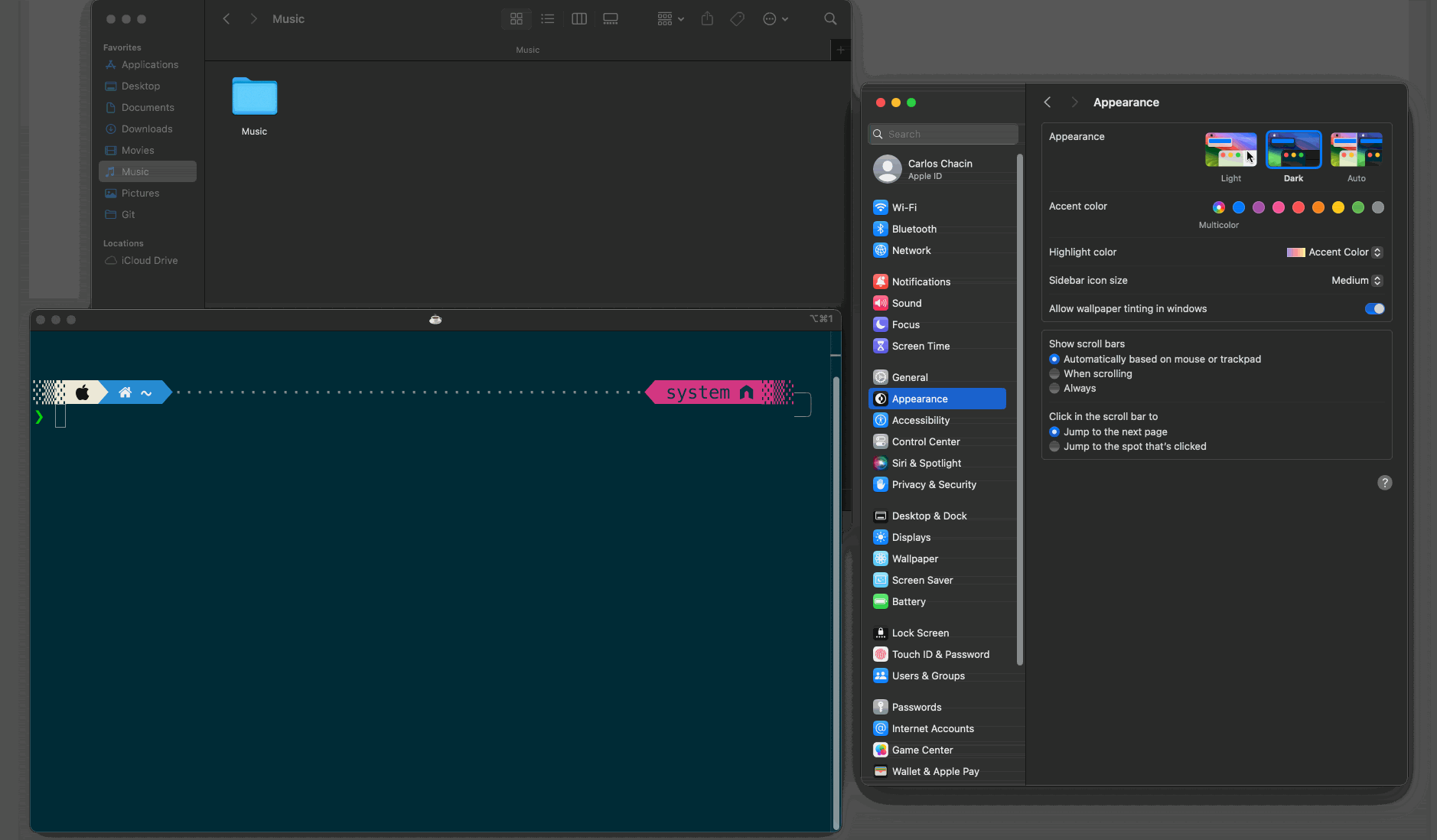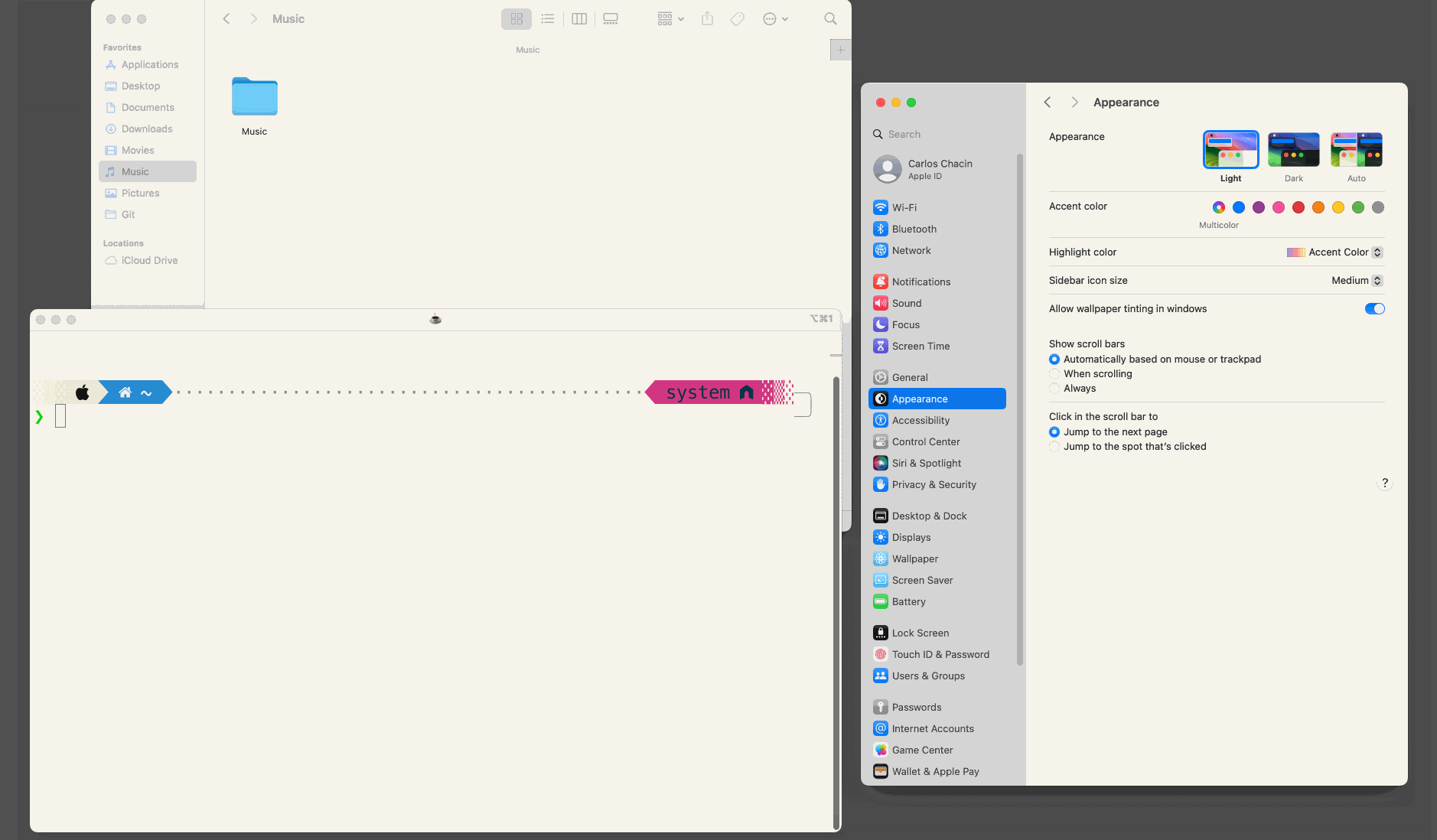 | cchacin |
1,866,675 | My suitable posts | HTTP Caching HTTP CORS Server-side | 0 | 2024-05-27T14:59:22 | https://dev.to/hieupham259/my-suitable-posts-5d1i | webdev, programming, python, web3 | [HTTP Caching](https://developer.mozilla.org/en-US/docs/Web/HTTP/Caching#overview)
[HTTP CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS)
[Server-side](https://developer.mozilla.org/en-US/docs/Learn/Server-side) | hieupham259 |
1,866,674 | angular devkit issue while angular upgrade | while upgrading to angular getting this issue if anyone has solution...? | 0 | 2024-05-27T14:58:05 | https://dev.to/suraj_rajegore_2b927c7233/angular-devkit-issue-while-angular-upgrade-22m3 |
while upgrading to angular getting this issue if anyone has solution...? | suraj_rajegore_2b927c7233 | |
1,866,673 | Mapping Your Rails Journey: A Guide to Leaflet Integration | Using maps in your application is always the best way to showcase your skill and shine at the moment.... | 0 | 2024-05-27T14:57:28 | https://dev.to/asimkhan2019/mapping-your-rails-journey-a-guide-to-leaflet-integration-390l | webdev, beginners, frontend, ruby | Using maps in your application is always the best way to showcase your skill and shine at the moment. Google Maps is one of the best-used maps in any application development, and while it is the best up-to-date map in the market, its only drawback is that it requires a billing payment and an active web URL hosted for it work properly, otherwise, it won't display the map correctly and show a development mode map where there is not much you can do about it.
There are many other alternatives to Google Maps, some of them are:
- OpenStreetMap
- Mapbox
- HERE Technologies
- TomTom Maps
- Bing Maps
- Leaflet
Leaflet with the OpenStreetMap is a good alternative if you know you're way around tweaking it and rooting out some of the issues of implementing it in ROR, then it is quite a feature to use. How did I discover Leaflet? By total accident really. Like all solutions and code blocks discovered by accident, I once googled an alternative to Google Maps and found Leaflet.
Simple to implement, totally compatible with all browsers, and no Javascript compiling or load issues where Javascript is not properly loaded.
**Setting up Leaflet with ROR**
Setting up the Leaflet with ROR was straightforward, you start by opening your application.html.erb file, and add the following to the layout.
```
<!-- Leaflet CSS -->
<link rel="stylesheet" href="https://unpkg.com/leaflet@1.9.4/dist/leaflet.css" integrity="sha256-p4NxAoJBhIIN+hmNHrzRCf9tD/miZyoHS5obTRR9BMY=" crossorigin=""/>
```
We will also be calling the script for the Leaflet right after the yield section, calling the script in the body section is the right place.
```
<%= yield %>
<script src="https://unpkg.com/leaflet@1.9.4/dist/leaflet.js" integrity="sha256-20nQCchB9co0qIjJZRGuk2/Z9VM+kNiyxNV1lvTlZBo=" crossorigin=""></script>
```
**Setting up your Model**
Since I will be using the Properties model, I will first start by setting some validation for the latitude and longitude in the properties model class
```
validates :latitude, :longitude, presence: true
```
Word of advice, I learned it the hard way, and caused me a lot of pain while implementing the maps. Never use this line if you are using validation
```
attr_accessor :latitude, :longitude
```
There will always be a conflict between the validates and attr_accessor. The attr_accessor creates getter and setter methods that override the default behavior provided by Active Record, the Rails ORM library. By commenting attr_accessor we will allow the ActiveRecord to use its default methods for accessing and setting these attributes.
**Setting up the View**
Now let's setup the show.html.erb
```
<p style="color: green"><%= notice %></p>
<%= render @property %>
<div>
<%= link_to "Edit this property", edit_property_path(@property) %> |
<%= link_to "Back to properties", properties_path %>
<%= button_to "Destroy this property", @property, method: :delete %>
</div>
```
After that we will setup a div container to hold the map and call in the script to retrieve and show the map along with the markers of the location based on the latitude and longitude. So we will set this up in property.html.erb
```
<!-- Include a unique identifier for the map container -->
<div class="map-container" id="map-<%= property.id %>" style="width: 800px; height: 400px;"></div>
<script type="text/javascript">
document.addEventListener("DOMContentLoaded", function() {
var mapElement = document.getElementById('map-<%= property.id %>');
var latitude = <%= property.latitude || 37.7749 %>;
var longitude = <%= property.longitude || -122.4194 %>;
if (!isNaN(latitude) && !isNaN(longitude)) {
// Initialize map if it hasn't been initialized yet
if (!mapElement.classList.contains('map-initialized')) {
var map = L.map(mapElement).setView([latitude, longitude], 13);
L.tileLayer('https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', {
maxZoom: 19,
attribution: 'OpenStreetMap'
}).addTo(map);
mapElement.classList.add('map-initialized');
}
// Add marker for this property
L.marker([latitude, longitude]).addTo(map)
.bindPopup('<%= j property.name %>');
} else {
mapElement.innerHTML = 'Location not provided for this property.';
}
});
</script>
```
I know what you are thinking, this code could have been written better. Well I got news for you, You are right!!!. Moving on....
What the above code is doing is
```
var map = L.map(mapElement).setView([latitude, longitude], 13);
```
This initializes the map using Leaflet, setting the view to the provided latitude and longitude coordinates and a zoom level of 13.
```
L.tileLayer('https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', {...}).addTo(map);
```
This adds a tile layer from OpenStreetMap to the map.
```
mapElement.classList.add('map-initialized');
```
This adds a class to the map container to indicate that the map has been initialized. And finally we can add markers to the map with the coordinates and the property name by binding it to the map.
```
L.marker([latitude, longitude]).addTo(map)
.bindPopup('<%= j property.name %>');
```
**Adding a marker to the map with latitude and longitude**
This is the interesting part, we get to add some coordinates on the map and then save it the property data, we will be using _form.html.erb to setup the coordinates.
```
<div>
<%= form.label :latitude %>
<%= form.hidden_field :latitude, id: 'latitude', value: @property.latitude || 37.7749 %>
</div>
<div>
<%= form.label :longitude %>
<%= form.hidden_field :longitude, id: 'longitude', value: @property.longitude || -122.4194 %>
</div>
<div style="width: 800px; height: 400px;" id="map"></div>
<script type="text/javascript">
document.addEventListener("DOMContentLoaded", function() {
var mapElement = document.getElementById('map');
var latitude = parseFloat(mapElement.dataset.latitude) || 37.7749; // Default latitude
var longitude = parseFloat(mapElement.dataset.longitude) || -122.4194; // Default longitude
var map = L.map('map').setView([latitude, longitude], 13);
L.tileLayer('https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', {
maxZoom: 19,
attribution: 'OpenStreetMap'
}).addTo(map);
var marker = L.marker([latitude, longitude], {draggable: true}).addTo(map)
.bindPopup('<%= j @property.name %>')
.openPopup();
marker.on('dragend', function(event) {
var lat = marker.getLatLng().lat;
var lng = marker.getLatLng().lng;
document.getElementById('latitude').value = lat;
document.getElementById('longitude').value = lng;
});
map.on('click', function(event) {
var lat = event.latlng.lat;
var lng = event.latlng.lng;
marker.setLatLng([lat, lng]);
document.getElementById('latitude').value = lat;
document.getElementById('longitude').value = lng;
});
// Submit the form when the user clicks a submit button
var submitButtons = document.querySelectorAll('input[type="submit"], button[type="submit"]');
submitButtons.forEach(function(button) {
button.addEventListener('click', function() {
var form = document.querySelector('form'); // Assuming there's only one form
form.submit();
});
});
});
</script>
```
Ugh, this code is ugly wish I was at another location than this one. Well lucky for us that is exactly what this code block does. If the property is getting updated then it is important to load the current latitude and longitude of the property on the map, or else point out to the default location. The below-mentioned event listener is triggered when the marker is dragged and dropped, updating the latitude and longitude values with the new marker position
```
marker.on('dragend', function(event) {
var lat = marker.getLatLng().lat;
var lng = marker.getLatLng().lng;
document.getElementById('latitude').value = lat;
document.getElementById('longitude').value = lng;
});
```
The below-mentioned event listener is triggered when the map is clicked, moving the marker to the clicked location and updating the latitude and longitude values
```
map.on('click', function(event) {
var lat = event.latlng.lat;
var lng = event.latlng.lng;
marker.setLatLng([lat, lng]);
document.getElementById('latitude').value = lat;
document.getElementById('longitude').value = lng;
});
```
One unusual error I encountered is when submitting the button on the form, where the form would update the property data but not the marker's location on the map or show the new latitude and longitude. To address this issue it is important to add the event listener to the click event on the submit button on the form that would trigger the function to update the coordinates on the map.
```
var submitButtons = document.querySelectorAll('input[type="submit"], button[type="submit"]');
submitButtons.forEach(function(button) {
button.addEventListener('click', function() {
var form = document.querySelector('form'); // Assuming there's only one form
form.submit();
});
});
```
This is a simple approach to attaching and displaying the latitude and longitude on the map and pointing the marker on the map. | asimkhan2019 |
1,866,670 | SaladUI - Implement avatar component for Phoenix LiveView | This post is written after I implement Avatar component for SaladUI component library for Phoenix... | 0 | 2024-05-27T14:55:31 | https://dev.to/bluzky/saladui-avatar-component-for-phoenix-liveview-3j1l | elixir, phoenix, liveview | This post is written after I implement Avatar component for [SaladUI component library](http://localhost:4000/welcome) for Phoenix Liveview.
An avatar component is quite simple, but I want to enhance it with fallback avatar text. The template structure is as following:
```html
<.avatar>
<.avatar_image src="./my-profile-img.jpg"></.avatar_image>
<.avatar_fallback class="bg-primary text-white">CN</.avatar_fallback>
<.avatar>
```
Here is an implementation of avatar component in html
```html
<span class="relative rounded-full overflow-hidden w-10 h-10">
<img class="aspect-square w-full h-full" src="https://github.com/shadcn.png">
<span class="flex rounded-full bg-primary text-white items-center justify-center w-full h-full">CN</span>
</span>
```
It's the happy case, the image exist, and the fallback element is push down and hidden due to class `overflow-hidden`.
But when the image doesn't exist, the broken image is displayed.

Hmm, the image should be hidden if it does not exist or got error while loading. Fortunately, `img` provide `onerror` event.
```html
<span class="relative rounded-full overflow-hidden w-10 h-10">
<img class="aspect-square w-full h-full" src="badimage.png" onerror="this.style.display='none'">
<span class="flex rounded-full bg-primary text-white items-center justify-center w-full h-full">CN</span>
</span>
```
Guest what. Nothing changed, the broken image is still visible.
It took me a while to discover the reason. `onerror="this.style.display='none'"` change attribute on client side, when Phoenix LiveView update, it patch the html and remove the `display` style value. So just add `phx-update="ignore"` and you got the error image hidden.
```html
<span class="relative rounded-full overflow-hidden w-10 h-10">
<img class="aspect-square w-full h-full" src="https://github.com/shadcn.png" onerror="this.style.display='none'" phx-update="ignore">
<span class="flex rounded-full bg-primary text-white items-center justify-center w-full h-full">CN</span>
</span>
```
And it works as expected

**Now wrap up the component**
```elixir
defmodule SaladUI.Avatar do
@moduledoc false
use Phoenix.Component
attr(:class, :string, default: nil)
attr(:rest, :global)
def avatar(assigns) do
~H"""
<span class={classes(["relative h-10 w-10 overflow-hidden rounded-full", @class])} {@rest}>
<%= render_slot(@inner_block) %>
</span>
"""
end
attr(:class, :string, default: nil)
attr(:rest, :global)
def avatar_image(assigns) do
~H"""
<img
class={classes(["aspect-square h-full w-full", @class])}
{@rest}
phx-update="ignore"
style="display:none"
onload="this.style.display=''"
/>
"""
end
attr(:class, :string, default: nil)
attr(:rest, :global)
slot(:inner_block, required: false)
def avatar_fallback(assigns) do
~H"""
<span
class={
classes(["flex h-full w-full items-center justify-center rounded-full bg-muted", @class])
}
{@rest}
>
<%= render_slot(@inner_block) %>
</span>
"""
end
end
```
You may notice that I use `onload` event instead of `onerror`:
```
style="display:none"
onload="this.style.display=''"
```
Using `onerror` browser waits until the image loading complete to decide if there is any error then trigger the event. This cause the white avatar while loading image. Using `onload` event to show image when the loading process complete, so by default if the image loading is slow, the fallback avatar still displays.
If you want to learn more, then visit my github repo [https://github.com/bluzky/salad_ui](https://github.com/bluzky/salad_ui).
Thanks for reading.
| bluzky |
1,866,669 | Memory Management and Concurrency in Go | Go, developed by Google, is known for its efficiency and simplicity in handling memory management and... | 0 | 2024-05-27T14:55:02 | https://victorleungtw.com/2024/05/27/go/ | go, concurrency, goroutines, garbagecollection | Go, developed by Google, is known for its efficiency and simplicity in handling memory management and concurrency. In this blog post, we'll explore how Go manages memory, how its garbage collector (GC) works, and the fundamentals of goroutines that enable Go's powerful concurrency model.

### Memory Management in Go
Effective memory management is crucial for any programming language, and Go handles it with a combination of efficient allocation, dynamic stack management, and garbage collection.
#### Memory Allocation
Go uses a heap for dynamic memory allocation. Here's a closer look at how memory is allocated:
- **Small Objects (≤32KB)**: These are allocated using a technique called **size classes**. Go maintains separate pools for objects of different sizes, which helps in reducing fragmentation and speeding up allocation.
- **Large Objects**: For objects larger than 32KB, Go maintains a free list of large objects. Allocation and deallocation of these objects are handled separately to optimize performance.
In Go, you can allocate memory using the `new` and `make` functions:
- `new`: Allocates zeroed storage and returns a pointer to it. It’s used for value types like integers and structures.
- `make`: Used for slices, maps, and channels. It initializes the internal data structure and returns a ready-to-use instance.
#### Stack Management
Each goroutine in Go has its own stack, starting small (e.g., 2KB) and growing as needed. This dynamic sizing allows Go to handle many goroutines efficiently without consuming too much memory upfront.
When a stack needs to grow, Go creates a new, larger stack and copies the contents of the old stack to the new one. This process is seamless and ensures that goroutines can continue to run efficiently without manual intervention.
### Garbage Collection in Go
Garbage collection is a critical component of Go's memory management system. Go uses a concurrent garbage collector, which minimizes pause times by running alongside your program. Here's a breakdown of how it works:
#### Mark-and-Sweep Algorithm
Go's GC uses a **mark-and-sweep** algorithm, consisting of two main phases:
1. **Mark**: The GC starts by marking all objects that are reachable from the root set (global variables, stack variables, etc.). This process identifies all live objects.
2. **Sweep**: After marking, the GC sweeps through the heap to reclaim memory occupied by unmarked objects, effectively cleaning up unused memory.
#### Tri-Color Marking and Write Barriers
To manage the marking process efficiently, Go employs **tri-color marking**. Objects are classified into three colors:
- **White**: Unreachable objects that can be collected.
- **Grey**: Objects that have been found but whose references have not been processed.
- **Black**: Objects that have been fully processed and are reachable.
**Write barriers** are used to handle new references created during the GC process. They ensure that any changes to the object graph are correctly tracked, maintaining the integrity of the GC process.
#### Triggering the Garbage Collector
The GC in Go is typically triggered automatically based on memory usage and allocation patterns. However, it can also be manually invoked using `runtime.GC()`. The automatic triggering occurs when:
- A certain amount of new memory has been allocated since the last collection.
- The heap size exceeds a specified threshold.
- The runtime's heuristics determine it’s necessary to balance performance and memory usage.
### Goroutines: Lightweight Concurrency
One of Go's standout features is its lightweight concurrency model, built on goroutines.
#### Creating Goroutines
Goroutines are created using the `go` keyword followed by a function call. For example:
```go
go myFunction()
```
Goroutines are much cheaper to create and manage compared to traditional OS threads, enabling the creation of thousands of concurrent tasks without significant overhead.
#### Execution and Scheduling
Goroutines are scheduled by Go's runtime scheduler, which uses **M:N scheduling**. This means multiple goroutines (N) are multiplexed onto a smaller or equal number of OS threads (M). The scheduler efficiently manages goroutine execution, ensuring that system resources are used effectively.
#### Communication via Channels
Goroutines communicate and synchronize using **channels**. Channels provide a way to send and receive values between goroutines, enabling safe and efficient data sharing without explicit locks or shared memory.
#### Dynamic Stack Growth
As mentioned earlier, goroutines start with a small stack and grow as needed. This dynamic growth helps manage memory more efficiently compared to fixed-size stacks, allowing Go to handle large numbers of concurrent goroutines.
### Conclusion
Go's memory management and concurrency model are key factors in its performance and simplicity. The combination of efficient memory allocation, a sophisticated garbage collector, and lightweight goroutines makes Go a powerful choice for building scalable and high-performance applications. Understanding these core concepts will help you leverage Go's full potential in your projects.
| victorleungtw |
1,866,667 | Получите эксклюзивные бонусы на игры в онлайн-казино! | Привет, разработчики! Если вы, как и я, увлечены азартными играми, то я рад поделиться с вами... | 0 | 2024-05-27T14:50:06 | https://dev.to/__efe20b54e3945/poluchitie-ekskliuzivnyie-bonusy-na-ighry-v-onlain-kazino-42ie |
Привет, разработчики!
Если вы, как и я, увлечены азартными играми, то я рад поделиться с вами отличной новостью. На веб-сайте [https://bibicasino.com/bonuses/] вы можете получить доступ к эксклюзивным бонусам на игры в онлайн-казино!
Независимо от того, любите ли вы слоты, покер, рулетку или блэкджек, у нас есть бонусы, которые приятно удивят вас. Мы постоянно обновляем наши предложения, чтобы гарантировать вам самые выгодные условия игры.
Не упустите шанс повысить свой шанс на выигрыш и получить дополнительные вознаграждения. Посетите ссылку прямо сейчас и начните погружение в захватывающий мир азарта!
Давайте сделаем ваше онлайн-казино опытным и выгодным! | __efe20b54e3945 | |
1,866,665 | How to add YouTube Analytics Api to get the channel statistics with React and nextJs? | YouTube has become a cornerstone for creators and businesses alike, providing a platform to share... | 0 | 2024-05-27T14:46:36 | https://dev.to/codegirl0101/how-to-add-youtube-analytics-api-to-get-the-channel-statistics-with-react-and-nextjs-44gk | webdev, tutorial, nextjs, react | YouTube has become a cornerstone for creators and businesses alike, providing a platform to share videos and engage with audiences worldwide. However, managing and analyzing your YouTube channel's performance requires powerful tools. Enter the YouTube Analytics API—that allows developers to access detailed insights and metrics.
[In this blog](https://www.codegirl0101.dev/2024/05/how-to-add-youtube-analytics-api-to.html), I'll demonstrate how to integrate the YouTube Analytics API into a web application built with React and Next.js. We'll set up the API, authenticate your requests, and fetch valuable data such as channel statistics and video details in very easy way.
Read the full blog here: https://www.codegirl0101.dev/2024/05/how-to-add-youtube-analytics-api-to.html | codegirl0101 |
1,866,663 | Mastering ASP.NET Core Middleware | Hi there! I’m Michael and in this video we’re going to talk about ASP.NET Core middleware. What is it? How does it work? How can I create custom middleware? And how to inject services into it. | 0 | 2024-05-27T14:40:02 | https://dev.to/michaeljolley/mastering-aspnet-core-middleware-3f3p | dotnet, csharp | ---
title: Mastering ASP.NET Core Middleware
published: true
description: Hi there! I’m Michael and in this video we’re going to talk about ASP.NET Core middleware. What is it? How does it work? How can I create custom middleware? And how to inject services into it.
tags: dotnet, csharp
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/a8rwpw81ffrgkydf5npy.png
---
{%youtube cu4CUJAcJ-4 %} | michaeljolley |
1,866,477 | Configuring the CodeBehind Framework in the ASP.NET Core Project | This tutorial teaches the basics of building a CodeBehind framework web application under ASP.NET... | 27,500 | 2024-05-27T14:39:14 | https://dev.to/elanatframework/configuring-the-codebehind-framework-in-the-aspnet-core-project-4a0p | tutorial, dotnet, beginners, backend | This tutorial teaches the basics of building a [CodeBehind framework](https://github.com/elanatframework/Code_behind) web application under ASP.NET Core.

## Installation of Visual Studio Code and necessary items
In this training series, we use the Visual Studio Code code editor. To download and install it, refer to the following link:
https://code.visualstudio.com/download
After installing Visual Studio Code, you need to install the latest .NET SDK package. Currently, version 8.0 is the latest version of .NET; you can download and install it from the following link:
https://dotnet.microsoft.com/en-us/download/dotnet/8.0
In the last step, download and install the C# Dev Kit package from the link below:
https://marketplace.visualstudio.com/items?itemName=ms-dotnettools.csdevkit
## Creating a new .NET project
In order to create a .NET 8.0 project, first open the Visual Studio Code editor that you installed earlier.
In the menu section, first select the file option and then Open Folder, and then create a directory named `MyProjects` in the desired path.
Then, enter the following value in the above console to create a new ASP.NET Core project in the `MyProjects` directory.
`>.NET: New Project`
`ASP.NET Core Empty`
Then name the project `MyCodeBehindProjct` and select and confirm the next items in the console (Then select `Default directory` and then `Create project`.).
The image below shows the location of the console section in Visual Studio Code.
## Add CodeBehind Framework package
To install the CodeBehind framework package in the console, enter the following value:
`> NuGet: Add NuGet Package`
Then search for the name `CodeBehind` and after the new box opens, select and install the latest version of the CodeBehind framework.
## Configure the CodeBehind framework in the Program.cs class
To access the files and directories of the project you created, select View and then Explorer from the menu (or you can select the combination keys Ctrl + Shift + E).
According to the image below, Explorer is added in the right part of Visual Studio Code.
Open the `Program.cs` class in the Explorer section and then replace the previous values of this class with the following values.
```csharp
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
SetCodeBehind.CodeBehindCompiler.Initialization();
app.UseCodeBehind();
app.Run();
```
The code in the above section is the configuration of the CodeBehind framework in ASP.NET Core.
> Note: In order to have automatic error management, you can use `app.UseCodeBehind();` Set the value to `true`.
Example: `app.UseCodeBehind(true);`
## Run project
Then select `Run` and then `Start Debugging` or `Start Without Debugging` from the menu. Then the console menu will open and you have to select the `C#` option and then select the project name.
The image below you are viewing is the default template of the CodeBehind framework. If you see this page, it means that you have completed all the steps successfully.
Back to Visual Studio Code; if you configure the CodeBehind framework for the first time and run the project, the default template of the CodeBehind framework will be added to the `wwwroot` path of your project. For the next time, the default template will be added when there is no `wwwroot` directory and in the option file. CodeBehind, `view_path` should be according to `wwwroot`.
Also, a directory called `code_behind` will be added in your project.
In the next tutorials, we will fully teach how to set the options of the options file. We also introduce the files in the `code_behind` directory.
### Related links
CodeBehind on GitHub:
https://github.com/elanatframework/Code_behind
CodeBehind in NuGet:
https://www.nuget.org/packages/CodeBehind/
CodeBehind page:
https://elanat.net/page_content/code_behind | elanatframework |
1,866,662 | Install Apache Web Server in Ubuntu AWS EC2 Instance | Introduction Installing a web server is a foundational step in web development and... | 0 | 2024-05-27T14:35:59 | https://dev.to/suravshrestha/install-apache-web-server-in-ubuntu-aws-ec2-instance-5fgf | cloud, aws, cloudcomputing, iaas | 
### Introduction
Installing a web server is a foundational step in web development and server management. [Apache](https://httpd.apache.org/) is one of the most popular web servers due to its reliability and extensive features. In this guide, we'll walk you through the steps to install and configure the Apache Web Server on an Ubuntu AWS EC2 instance.
### Prerequisites
Before we begin, ensure you have the following:
1. An [AWS](https://aws.amazon.com/) account
2. An EC2 instance running Ubuntu
### Step 1: Launch and Connect to EC2 Instance
For detailed instructions on launching and connecting to an AWS EC2 instance, you can refer to this article: [Launch and Connect to AWS EC2 Instance](https://dev.to/suravshrestha/launch-and-connect-to-aws-ec2-instance-47bm).
### Step 2: Update Your Instance
Once connected to your EC2 instance, update the package lists:
```bash
sudo apt update
```
### Step 3: Install Apache Web Server
Now, install Apache using the package manager:
```bash
sudo apt install apache2 -y
```
### Step 4: Verify Apache Installation
You can verify that Apache is running by accessing your instance’s public IP address in a web browser:
```http
http://ec2-18-208-219-229.compute-1.amazonaws.com
```
You should see the default Apache2 Ubuntu Default Page, indicating that Apache is successfully installed and running. 🎉
**Note**: The webpage is served from the `/var/www/html/index.html` file in the EC2 instance. You can edit this file to customize the content as desired.
### Conclusion
You’ve successfully installed and configured the Apache Web Server on your Ubuntu AWS EC2 instance. This setup can now serve as the foundation for your web applications. 🌐
### Additional Resources
- [Apache HTTP Server Documentation](https://httpd.apache.org/docs/) 📚
- [AWS EC2 Documentation](https://docs.aws.amazon.com/ec2/) 📖
If you have any questions or run into issues, feel free to leave a comment below.
Happy coding! 👩💻👨💻 | suravshrestha |
1,866,661 | Astro 4.9.1 - Upgrade Experience | There is so much more out there that can help you learn and build with Astro! Here is some... | 0 | 2024-05-27T14:33:38 | https://dev.to/kellyewest/astro-491-upgrade-experience-37da | astro, vercel, webdev, programming | There is so much more out there that can help you learn and build with Astro! Here is some educational content produced and maintained by the Astro community.
## Upgrade Astro
This guide covers how to update your version of Astro and related dependencies, how to learn what has changed from one version to the next, and how to understand Astro’s versioning system and corresponding documentation updates.
## What has changed?
The latest release of Astro is v4.9.1.
You can find an exhaustive list of all changes in Astro’s changelog, and important instructions for upgrading to each new major version in our upgrade guides.
## Upgrade to the latest version
Update your project’s version of Astro and all official integrations to the latest versions with one command using your package manager:
```
# Upgrade Astro and official integrations together
npx @astrojs/upgrade
```
## Manual Upgrading
To update Astro and integrations to their current versions manually, use the appropriate command for your package manager.
```
# Example: upgrade Astro with React and Tailwind integrations
npm install astro@latest @astrojs/react@latest @astrojs/tailwind@latest
```
## Install a specific version number
To install a specific version of Astro or integrations, use the appropriate command for your package manager.
```
npm install astro@4.5.3 @astrojs/react@3.0.10
```
## Documentation updates
This documentation is updated for each minor release and major version release. When new features are added, or existing usage changes, the docs will update to reflect the current behavior of Astro. If your project is not updated, then you may notice some behaviors do not match the up-to-date documentation.
New features are added to docs with the specific version number in which they were added. This means that if you have not updated to the latest release of Astro, some documented features may be unavailable. Always check the Added in: version number and make sure your project is updated before attempting to use new features!
If you have not upgraded to the latest major version of Astro, you may encounter significant differences between the Astro documentation and your project’s behavior. We strongly recommend upgrading to the current major version of Astro as soon as you are able. (If you're interested, here's the link to the [Instagram Story Viewer](https://storiesig.cfd/) ). Both the code and the documentation for earlier versions is unsupported.
## Upgrade Guides
After every major version release, you will find an upgrade guide with information about important changes and instructions for upgrading your project code.
The main Astro documentation pages are always accurate for the latest released version of Astro. They do not describe or compare to how things worked in previous versions, nor do they highlight updated or changed behavior.
See the upgrade guides below for an explanation of changes, comparing the new version to the old. The upgrade guides include everything that could require you to change your own code: breaking changes, deprecations, feature removals and replacements as well as updated usage guidance. Each change to Astro includes a “What should I do?” section to help you successfully update your project code.
## Older docs (unmaintained)
Documentation for older versions of Astro is not maintained, but is available as a static snapshot. Use these versions of docs if you are unable to upgrade your project, but still wish to consult guides and reference:
## Semantic versioning
Astro attempts to adhere as much as possible to semantic versioning, which is a set of rules developers use to determine how to assign a version number to a release. Semantic version follows a predictable pattern to inform users of the kind of changes they can expect from one version to the next.
Semantic versioning enforces a pattern of X.Y.Z for software version numbers. These values represent **major (X), minor (Y),** and **patch (Z)** updates.
## Patch changes
Patch changes are the least disruptive changes. They do not change the way you use Astro, and no change to your own code is required when you update.
When Astro issues a “patch” version, the last number increases. (e.g. astro@4.3.14 -> astro@4.3.15)
Patches may be released for reasons such as:
Internal changes that do not change Astro’s functionality:
refactors
performance improvements
increase or change in test coverage
aligning with stated documentation and expected behavior
Improvements to logging and error messages.
Re-releases after a failed release.
Patch changes also include most bug fixes, even in cases where users were taking advantage of existing unintended or undesirable behavior.
## Extended maintenance
The Core team will provide extended maintenance for security fixes only for one previous major version. This means that if the current major is v4.*, the Core team will back port security fixes and issue a new v3.* release.
| kellyewest |
1,866,660 | Steps To Create A Simple Web Driver Script | Below are the steps to create a simple Selenium WebDriver script in Java to automate a basic scenario... | 0 | 2024-05-27T14:30:47 | https://dev.to/akshara_chandran_0f2b21d7/steps-to-create-a-simple-web-driver-script-30k8 | Below are the steps to create a simple Selenium WebDriver script in Java to automate a basic scenario of opening a web page and performing an action. Let's create a script to open the Google homepage, search for a term, and print the page title.
### Step 1: Set Up Your Development Environment
Make sure you have the following set up:
- Java Development Kit (JDK) installed
- Integrated Development Environment (IDE) like IntelliJ IDEA or Eclipse installed
- Selenium WebDriver Java bindings added to your project's dependencies
### Step 2: Create a New Java Class
Create a new Java class in your project with a meaningful name (e.g., `SimpleWebDriverScript`).
### Step 3: Write the Selenium WebDriver Script
Write the Selenium WebDriver script to automate the desired scenario. Here's the code to open Google, search for a term, and print the page title:
```java
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class SimpleWebDriverScript {
public static void main(String[] args) {
// Set the path to the chromedriver executable
System.setProperty("webdriver.chrome.driver", "/path/to/chromedriver");
// Initialize the Chrome driver
WebDriver driver = new ChromeDriver();
// Open Google homepage
driver.get("https://www.google.com");
// Find the search box element
WebElement searchBox = driver.findElement(By.name("q"));
// Enter the search term
searchBox.sendKeys("Selenium WebDriver");
// Submit the search query
searchBox.submit();
// Print the page title
System.out.println("Page title is: " + driver.getTitle());
// Close the browser
driver.quit();
}
}
```
### Step 4: Run the Script
Run the script in your IDE. It will open Google, perform the search, print the page title, and then close the browser.
### Note:
- Make sure to replace `"/path/to/chromedriver"` with the actual path to your ChromeDriver executable.
- You may need to include the Selenium WebDriver Java bindings (`selenium-java.jar`) in your project's dependencies.
- Ensure that the version of ChromeDriver you use is compatible with the version of Google Chrome installed on your machine.
That's it! You've created a simple Selenium WebDriver script to automate a basic web scenario. You can extend this script to automate more complex interactions and scenarios as needed. | akshara_chandran_0f2b21d7 | |
1,859,701 | User Research 101: Basic Methods to Collect Data and Understand Your Users | A post by Anirudh Eyyani | 27,458 | 2024-05-27T14:30:00 | https://dev.to/anirudheyyani/user-research-101-basic-methods-to-collect-data-and-understand-your-users-359o | design, ux | anirudheyyani | |
1,866,658 | Browser driver that is used in Selenium | Selenium WebDriver supports automation across multiple web browsers through browser-specific drivers.... | 0 | 2024-05-27T14:29:28 | https://dev.to/akshara_chandran_0f2b21d7/browser-driver-that-is-used-in-selenium-3lp3 | Selenium WebDriver supports automation across multiple web browsers through browser-specific drivers. Each browser has its own WebDriver implementation that allows Selenium to control and interact with the browser. Here are the browser drivers commonly used with Selenium:
1. **ChromeDriver**: Used for automating Google Chrome browser. ChromeDriver is provided by the Chromium project and is compatible with the latest versions of Google Chrome.
2. **GeckoDriver (Firefox)**: Used for automating Mozilla Firefox browser. GeckoDriver is provided by the Mozilla project and is compatible with the latest versions of Firefox.
3. **Microsoft Edge Driver (Edge)**: Used for automating Microsoft Edge browser. Edge Driver is provided by Microsoft and supports the latest versions of Microsoft Edge.
4. **SafariDriver (Safari)**: Used for automating Safari browser on macOS. SafariDriver is included with Safari browser on macOS and can be enabled through Safari's Developer menu.
5. **OperaDriver (Opera)**: Used for automating Opera browser. OperaDriver is provided by the Opera project and supports the latest versions of Opera browser.
6. **InternetExplorerDriver (IE)**: Used for automating Internet Explorer browser. InternetExplorerDriver is provided by the Selenium project and supports older versions of Internet Explorer.
7. **Edge ChromiumDriver**: Used for automating the Chromium-based Microsoft Edge browser. Edge ChromiumDriver is provided by Microsoft and supports the latest versions of Chromium-based Microsoft Edge.
8. **PhantomJSDriver**: Used for headless testing. PhantomJSDriver allows Selenium to interact with web pages without opening a browser window. Note that PhantomJS is deprecated and not recommended for use in production environments.
These browser drivers are necessary for Selenium WebDriver to communicate with the respective web browsers and control their behavior during test automation. They provide a bridge between Selenium scripts and the browser's native automation APIs, allowing testers to simulate user interactions and validate application behavior across different browsers and platforms. | akshara_chandran_0f2b21d7 | |
1,866,648 | CROSS BROWSER TESTING | Cross-browser testing is a critical aspect of software testing that ensures that a web application... | 0 | 2024-05-27T14:16:19 | https://dev.to/akshara_chandran_0f2b21d7/cross-browser-testing-5d9 | Cross-browser testing is a critical aspect of software testing that ensures that a web application functions correctly and consistently across different web browsers and browser versions. Here's an overview of cross-browser testing:
### What is Cross-Browser Testing?
Cross-browser testing involves testing a web application's functionality, compatibility, and performance across multiple web browsers and browser versions. The goal is to identify and address any inconsistencies or issues that may arise due to differences in browser rendering engines, HTML/CSS standards, JavaScript execution, and other factors.
### Why is Cross-Browser Testing Important?
1. **User Experience**: Ensures a consistent and optimal user experience for all users, regardless of their choice of web browser.
2. **Market Share**: Helps reach a wider audience by supporting popular web browsers used by different segments of users.
3. **Bug Identification**: Helps identify and fix browser-specific bugs and compatibility issues early in the development cycle.
4. **Compliance**: Ensures compliance with web standards and accessibility guidelines across different browsers.
5. **Brand Reputation**: Maintains brand reputation by delivering a seamless experience across all platforms and devices.
### Approaches to Cross-Browser Testing:
1. **Manual Testing**: Manually testing the application across different browsers and platforms.
2. **Automated Testing**: Using automation testing frameworks like Selenium WebDriver to automate cross-browser testing.
3. **Cloud-Based Testing**: Using cloud-based testing platforms like BrowserStack, Sauce Labs, or CrossBrowserTesting for running tests on real browsers and devices.
4. **Emulators and Simulators**: Using browser emulators and simulators to simulate different browser environments.
5. **Browser Compatibility Tools**: Using browser compatibility testing tools to identify and address compatibility issues.
### Best Practices for Cross-Browser Testing:
1. **Define Browser Support**: Define a list of supported browsers and browser versions based on user demographics and market share.
2. **Test Early and Often**: Start cross-browser testing early in the development cycle and continue testing throughout the development process.
3. **Use Real Devices**: Test on real devices whenever possible to simulate real-world usage scenarios accurately.
4. **Test Responsive Design**: Ensure that the application is responsive and adapts correctly to different screen sizes and resolutions.
5. **Validate HTML/CSS**: Validate HTML/CSS code to ensure compliance with web standards and avoid browser rendering issues.
### Tools for Cross-Browser Testing:
1. Selenium WebDriver
2. BrowserStack
3. Sauce Labs
4. CrossBrowserTesting
5. LambdaTest
6. TestingBot
7. Ranorex
8. Applitools
### Conclusion:
Cross-browser testing is essential for delivering a high-quality web application that works seamlessly across different browsers and platforms. By adopting effective cross-browser testing strategies and tools, teams can ensure a consistent and optimal user experience for all users, leading to increased customer satisfaction and retention. | akshara_chandran_0f2b21d7 | |
1,866,657 | What is Selenium? How it is useful in Automation Testing? | Selenium is an open-source automation testing framework primarily used for web applications. It... | 0 | 2024-05-27T14:28:22 | https://dev.to/akshara_chandran_0f2b21d7/what-is-selenium-how-it-is-useful-in-automation-testing-4l1p | Selenium is an open-source automation testing framework primarily used for web applications. It provides a suite of tools that allows testers to automate web browser interactions across different browsers and platforms. Selenium is widely used for automating web testing tasks such as form filling, UI testing, and regression testing. Here's how Selenium is useful in automation testing:
1. **Cross-Browser Compatibility Testing**: Selenium allows testers to automate tests across different web browsers such as Chrome, Firefox, Safari, and Internet Explorer. This helps ensure that web applications function correctly and consistently across various browsers and versions.
2. **Platform Independence**: Selenium supports multiple operating systems (Windows, macOS, Linux) and programming languages (Java, Python, C#, etc.). This makes it highly flexible and suitable for diverse software development environments.
3. **Reusable Test Scripts**: Test scripts written in Selenium can be reused across different projects and environments, saving time and effort in test development and maintenance.
4. **Parallel Test Execution**: Selenium Grid, a component of Selenium, enables parallel execution of tests across multiple browsers, operating systems, and machines. This helps reduce test execution time and increases testing efficiency.
5. **Integration with Testing Frameworks**: Selenium can be integrated with various testing frameworks such as JUnit, TestNG, NUnit, and others. This allows testers to organize and manage their test suites effectively, generate test reports, and perform assertions.
6. **Support for Web Element Interaction**: Selenium provides APIs for interacting with web elements such as text boxes, buttons, dropdowns, etc. Testers can perform actions like clicking, typing, selecting, and verifying the properties and states of these elements.
7. **Continuous Integration and Continuous Testing (CI/CT)**: Selenium can be integrated with CI/CD tools like Jenkins, Bamboo, and Travis CI to automate the execution of tests as part of the software delivery pipeline. This ensures that new code changes are tested automatically, leading to faster feedback loops and better software quality.
8. **Regression Testing**: Selenium is well-suited for regression testing, where tests are rerun to ensure that new code changes have not introduced unintended side effects or regressions in the application.
Overall, Selenium is a powerful and versatile automation testing framework that empowers testers to automate web testing tasks effectively, improve testing efficiency, and deliver high-quality software products. | akshara_chandran_0f2b21d7 | |
1,866,655 | DIFFERENCE BETWEEN SELENIUM IDE, SELENIUM WEBDRIVER AND SELENIUM GRID | Selenium IDE, Selenium WebDriver, and Selenium Grid are three components of the Selenium suite, each... | 0 | 2024-05-27T14:22:49 | https://dev.to/akshara_chandran_0f2b21d7/difference-between-selenium-ide-selenium-webdriver-and-selenium-grid-2nel | Selenium IDE, Selenium WebDriver, and Selenium Grid are three components of the Selenium suite, each serving different purposes in web automation testing. Here's a breakdown of the differences between them:
### Selenium IDE:
1. **Definition**: Selenium IDE (Integrated Development Environment) is a record and playback tool for creating automated tests in the browser.
2. **Features**:
- Record and Playback: Allows testers to record their interactions with the web application and play them back as automated test cases.
- UI-based Test Creation: Provides a simple interface for creating test cases without writing code.
- Export Test Cases: Test cases recorded in Selenium IDE can be exported to various programming languages such as Java, Python, etc., for further customization and execution.
3. **Use Cases**:
- Quick Test Creation: Selenium IDE is useful for creating simple, quick tests or prototypes.
- Learning and Experimentation: It can be used by beginners to learn Selenium and experiment with automated testing.
### Selenium WebDriver:
1. **Definition**: Selenium WebDriver is a programming interface that allows testers to write code to automate web browser interactions.
2. **Features**:
- Programmatically Control Browser: Provides APIs in various programming languages (Java, Python, C#, etc.) for interacting with web browsers programmatically.
- Cross-Browser Testing: Supports automation across different browsers and platforms.
- Dynamic Test Scenarios: Allows testers to create dynamic and complex test scenarios by writing code.
3. **Use Cases**:
- Comprehensive Test Automation: Selenium WebDriver is suitable for automating complex web applications with dynamic content and interactions.
- Integration with Test Frameworks: It is often integrated with testing frameworks such as JUnit, TestNG, NUnit, etc., for structured test automation.
### Selenium Grid:
1. **Definition**: Selenium Grid is a tool for distributing test execution across multiple machines or browsers in parallel.
2. **Features**:
- Parallel Test Execution: Allows tests to be run concurrently across multiple browsers, operating systems, and machines.
- Scalability: Provides scalability by distributing test execution load across a grid of nodes.
- Cross-Browser Testing: Supports running tests on different browsers and versions simultaneously.
3. **Use Cases**:
- Cross-Browser Testing: Selenium Grid is used for testing web applications across multiple browsers and platforms simultaneously.
- Scalable Test Execution: It is suitable for running large test suites in parallel to reduce test execution time.
### Key Differences:
- **Purpose**: Selenium IDE is primarily for record and playback of test cases, Selenium WebDriver is for writing code-based test automation scripts, and Selenium Grid is for distributing tests across multiple environments.
- **Level of Automation**: Selenium IDE offers low-level automation with record and playback, while Selenium WebDriver provides high-level automation with programmatically controlled browser interactions.
- **Scalability**: Selenium Grid is designed for distributed test execution and scalability across multiple machines and browsers, while Selenium WebDriver and IDE focus on single-machine automation.
In summary, Selenium IDE, Selenium WebDriver, and Selenium Grid are complementary tools in the Selenium suite, each serving different purposes in web automation testing. While Selenium IDE is suitable for quick test creation and prototyping, Selenium WebDriver provides more flexibility and control for complex test scenarios, and Selenium Grid enables scalable and distributed test execution across multiple environments. | akshara_chandran_0f2b21d7 | |
1,866,651 | How to Use Searchable in Laravel 10 Filament v3 | In this section, we will see how to implement search functionality in Laravel 10 with filamentphp... | 0 | 2024-05-27T14:17:32 | https://larainfo.com/blogs/how-to-use-searchable-in-laravel-10-filament-v3/ | laravel, php, filament, webdev | In this section, we will see how to implement search functionality in Laravel 10 with filamentphp v3.
You can utilize the searchable feature through the **searchable()** method.
```php
use Filament\Tables\Columns\TextColumn;
TextColumn::make('title')
->searchable()
```
Additionally, we will demonstrate how to integrate the search feature into a Laravel 10 filament v3 CRUD application.
[Laravel 10 Filament v3 CRUD Operation Example](https://larainfo.com/blogs/laravel-10-filament-v3-crud-operation-example)
**Filament/Resources/BlogResource.php**
```php
<?php
namespace App\Filament\Resources;
use App\Filament\Resources\BlogResource\Pages;
use App\Filament\Resources\BlogResource\RelationManagers;
use App\Models\Blog;
use Filament\Forms;
use Filament\Forms\Form;
use Filament\Resources\Resource;
use Filament\Tables;
use Filament\Tables\Table;
use Filament\Forms\Components\TextInput;
use Filament\Forms\Components\Textarea;
use Filament\Tables\Columns\TextColumn;
use Filament\Forms\Components\Section;
use Filament\Forms\Components\RichEditor;
use Filament\Tables\Columns\ImageColumn;
use Illuminate\Database\Eloquent\Builder;
use Illuminate\Database\Eloquent\SoftDeletingScope;
class BlogResource extends Resource
{
protected static ?string $model = Blog::class;
protected static ?string $navigationIcon = 'heroicon-o-rectangle-stack';
public static function form(Form $form): Form
{
return $form
->schema([
Section::make()
->schema([
TextInput::make('title')->required(),
RichEditor::make('content')->required(),
])
]);
}
public static function table(Table $table): Table
{
return $table
->columns([
TextColumn::make('id'),
TextColumn::make('title')->searchable(),
TextColumn::make('content')->limit(20)->markdown()->searchable(),
])
->filters([
//
])
->actions([
Tables\Actions\EditAction::make(),
])
->bulkActions([
Tables\Actions\BulkActionGroup::make([
Tables\Actions\DeleteBulkAction::make(),
]),
])
->emptyStateActions([
Tables\Actions\CreateAction::make(),
]);
}
public static function getRelations(): array
{
return [
//
];
}
public static function getPages(): array
{
return [
'index' => Pages\ListBlogs::route('/'),
'create' => Pages\CreateBlog::route('/create'),
'edit' => Pages\EditBlog::route('/{record}/edit'),
];
}
}
```
### See Also
⭐[Laravel 10 Filament v3 Toggle Switch Example](https://larainfo.com/blogs/laravel-10-filament-v3-toggle-switch-example/)
⭐[Laravel 10 Filament v3 CRUD Operation Example](https://larainfo.com/blogs/laravel-10-filament-v3-crud-operation-example/)
⭐[Laravel 10 Filamentphp v3 Multiple Images Example](https://larainfo.com/blogs/laravel-10-filamentphp-v3-multiple-images-example/)
⭐[How to Use DataTables in Laravel 10 Filament v3](https://larainfo.com/blogs/how-to-use-datatables-in-laravel-10-filament-v3/) | saim_ansari |
1,866,650 | Test-Driven Development (TDD) and Behavior-Driven Development (BDD) | Test-Driven Development (TDD) and Behavior-Driven Development (BDD) are both approaches to software... | 0 | 2024-05-27T14:17:27 | https://dev.to/akshara_chandran_0f2b21d7/test-driven-development-tdd-and-behavior-driven-development-bdd-21f9 | Test-Driven Development (TDD) and Behavior-Driven Development (BDD) are both approaches to software development that emphasize the importance of testing throughout the development process. While they share some similarities, they have distinct focuses and methodologies. Let's explore each approach:
### Test-Driven Development (TDD):
1. **Definition**: TDD is a software development approach where tests are written before the actual code is implemented. The development cycle in TDD typically follows the pattern of writing a failing test, writing the minimal code required to pass the test, and then refactoring the code.
2. **Workflow**:
- **Write Test**: Initially, a developer writes a test case that defines the desired behavior or functionality of the code.
- **Run Test (Fail)**: Since the code does not exist yet, the test will fail.
- **Write Code**: The developer writes the minimum code necessary to pass the test.
- **Run Test (Pass)**: The test is run again, and if the code passes the test, the test is considered successful.
- **Refactor Code**: Once the test passes, the developer refactors the code to improve its design and maintainability without changing its behavior.
3. **Benefits**:
- Encourages a focus on writing clean, modular, and testable code.
- Provides immediate feedback on the correctness of the code.
- Reduces the likelihood of introducing bugs and regressions.
- Helps drive the design of the software based on its requirements.
4. **Tools**: Popular tools for TDD include JUnit (for Java), NUnit (for .NET), and pytest (for Python).
### Behavior-Driven Development (BDD):
1. **Definition**: BDD is a software development approach that extends TDD by emphasizing collaboration between developers, testers, and stakeholders. BDD focuses on defining the behavior of the system from the perspective of its users or stakeholders using natural language specifications.
2. **Workflow**:
- **Define Behavior**: Stakeholders and developers collaborate to define the behavior of the system using user stories or scenarios written in a structured, natural language format (e.g., Given-When-Then).
- **Automate Behavior**: Developers translate these behavior specifications into executable tests using BDD frameworks such as Cucumber or SpecFlow.
- **Write Code**: Developers write code to implement the behavior specified by the tests, following the TDD approach.
- **Run Tests**: The automated tests are run to verify that the code behaves as expected based on the defined behavior.
3. **Benefits**:
- Facilitates communication and collaboration between developers, testers, and stakeholders.
- Ensures that the software meets the requirements and expectations of its users.
- Provides a clear and structured approach to defining and validating the behavior of the system.
- Helps prioritize development efforts based on user needs and business value.
4. **Tools**: Popular tools for BDD include Cucumber, SpecFlow, Behave (for Python), and Jasmine (for JavaScript).
### Key Differences:
- **Focus**: TDD focuses on writing tests that validate the behavior of individual units of code, while BDD focuses on defining and validating the behavior of the system as a whole from the perspective of its users.
- **Language**: TDD tests are typically written using programming languages and testing frameworks, while BDD scenarios are written in a structured natural language format.
- **Collaboration**: BDD emphasizes collaboration between developers, testers, and stakeholders to define and validate the behavior of the system, while TDD is primarily developer-driven.
In summary, both TDD and BDD are valuable approaches to software development that promote the creation of high-quality, well-tested software. TDD focuses on writing tests before writing code to drive development, while BDD emphasizes collaboration and communication to define and validate the behavior of the system from the perspective of its users. | akshara_chandran_0f2b21d7 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.