
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,866,913 | day 09 | date:- 28 May, 2024. Procedural programming:- This is just how we structure our code. This is an old... | 0 | 2024-05-28T06:30:40 | https://dev.to/lordronjuyal/day-09-1gl6 | python, oop, newbie, beginners | date:- 28 May, 2024.
Procedural programming:- This is just how we structure our code. This is an old way of coding. In this, we divide our program into the logical sequence of steps it needs to follow to do the task.
**Object-oriented programming**:- This is another and more modern way of structuring the code. In this, we divide programs into different groups called object, where each object is responsible for a specific job. By this, we try to model objects as real-world entities. They can have their own attributes(properties/variables) and methods(functions).
In OOP, we create a standard description(properties and methods) of a group. This is called class. This class is used to make other objects which have the same description and some additional properties and methods. For eg we make a teacher as a class, knowledge of a subject can be its properties and functions including teaching, homework, test etc. Now, object will be real life people like Ramesh sir, Asha madam who will have knowledge and functions like teaching, giving homework etc plus additional functions/properties like storytelling, name which can be unique.
To make an object from class: object_name = ClassName()
We use Pascal case(each letter capital) for class names and we have to use ().
Now object_name is the object we created and it will get attributes and methods of the "ClassName" class. To access attributes or functions, we use object_name.attribute_name or object_name.function_name()
Other things I learned today:-
1. To use a global variable in local scope, we have to use code global variable_name. But in the case of dictionaries, we don't have to write this.
Project I made:-
1. Coffe machine
https://replit.com/@rohitrj332024/Coffee-machine-day-09#main.py
----------------------------------------------------------
Somehow theory took much of my time. I am practicing oop with turtle module. Time for the rest. Thank you see you tomorrow.
| lordronjuyal |
1,867,258 | Mobile Privacy: How Safe is Safe? | In today’s fast-paced digital world, concerns about mobile privacy are more relevant than ever. As... | 0 | 2024-05-28T06:30:12 | https://dev.to/sejaljansari/mobile-privacy-how-safe-is-safe-5hi6 | mobile, safe | In today’s fast-paced digital world, concerns about mobile privacy are more relevant than ever. As our smartphones become central to daily life, understanding how to protect personal information is crucial. This blog delves into the state of mobile privacy, its challenges, and potential solutions for ensuring data security.
The State of Mobile Privacy
**The Rise of Encryption**
Encryption is a key player in mobile privacy. By converting data into unreadable formats for anyone without the decryption key, encryption ensures that only intended recipients can access sensitive information. Companies like Silent Circle are leading the way with apps that provide encrypted phone calls, texts, and file transfers, significantly enhancing user privacy.
**Legal and Ethical Considerations**
Despite its benefits, encryption also presents challenges. Law enforcement agencies argue that it can impede criminal investigations. Companies like Silent Circle have pledged to deny requests for eavesdropping, which could lead to legal conflicts. This tension between privacy and security continues to be a complex issue, with technology often outpacing legislative responses.
**The Value of Information**
In the digital age, personal information is a valuable commodity. From advertisers to cybercriminals, various entities seek access to our data. This constant demand highlights the importance of mobile privacy and the need for individuals to proactively protect their information.
**Protecting Your Mobile Privacy**
**Practical Steps for Users**
**1.Use Encryption Tools: **Utilize apps and services that offer end-to-end encryption for communications and data storage.
**2.Regular Updates:** Keep your mobile device and apps up-to-date to protect against vulnerabilities.
**3.Be Mindful of Permissions:** Regularly review and limit app permissions to safeguard sensitive information.
**4.Secure Your Device:** Use strong passwords, biometric authentication, and enable remote wipe features in case your device is lost or stolen.
**The Role of Technology Companies**
Technology companies, including [iPhone app development agency](https://www.nimblechapps.com/services/ios-app-development-company), play a crucial role in safeguarding mobile privacy. By implementing strong encryption standards, being transparent about data collection practices, and resisting unwarranted data access requests, these companies can build user trust and contribute to a safer digital environment.
**The Future of Mobile Privacy**
As technology evolves, so will the methods to protect our privacy. Future advancements may include more sophisticated encryption techniques, greater user control over personal data, and increased accountability for companies handling sensitive information. However, balancing privacy and security will remain a dynamic and challenging landscape.
**Conclusion**
Mobile privacy is a complex and ever-evolving issue. While encryption and proactive security measures can significantly enhance privacy, users must remain vigilant and informed. As technology progresses, continuous efforts will be needed to ensure that our personal information remains secure in an increasingly connected world.
For businesses seeking to enhance mobile security and privacy in their applications, it is essential to [hire web developers](https://www.nimblechapps.com/services/innovative-web-application-development-company) with expertise in encryption and data protection.
| sejaljansari |
1,864,914 | Pin & Hide Your Way to Teams Channel Glory | With multiple projects and conversations happening at once, finding the information you need can feel... | 26,993 | 2024-05-28T06:30:00 | https://intranetfromthetrenches.substack.com/p/pin-and-hide-your-way-to-microsoft-teams-channel | microsoftteams, microsoft365, workplace | With multiple projects and conversations happening at once, finding the information you need can feel like searching for a needle in a haystack.
This struggle is all too common. While Teams is a powerful collaboration tool, managing multiple channels can quickly become overwhelming.

But fear not! This guide will introduce you to pinning and hiding channels – two features that can transform your Teams experience. By the end of this article, you'll have the knowledge to streamline your workflow, find information instantly, and ultimately **boost your productivity**.
## Benefits of Pinning and Hiding Channels
Here's how pinning and hiding channels can transform your experience:
**Effortless Access to Key Channels**
Do you have go-to channels where crucial project updates or team discussions happen? Pinning is your savior! By pinning these important channels, they'll always be conveniently located at the top of your list.
**Declutter Your View**
Inactive channels create visual chaos. Hiding these channels is a fantastic way to streamline your view. Imagine a clean, concise list displaying only the active channels you use regularly. Finding information becomes effortless, allowing you to concentrate on your tasks without distractions.
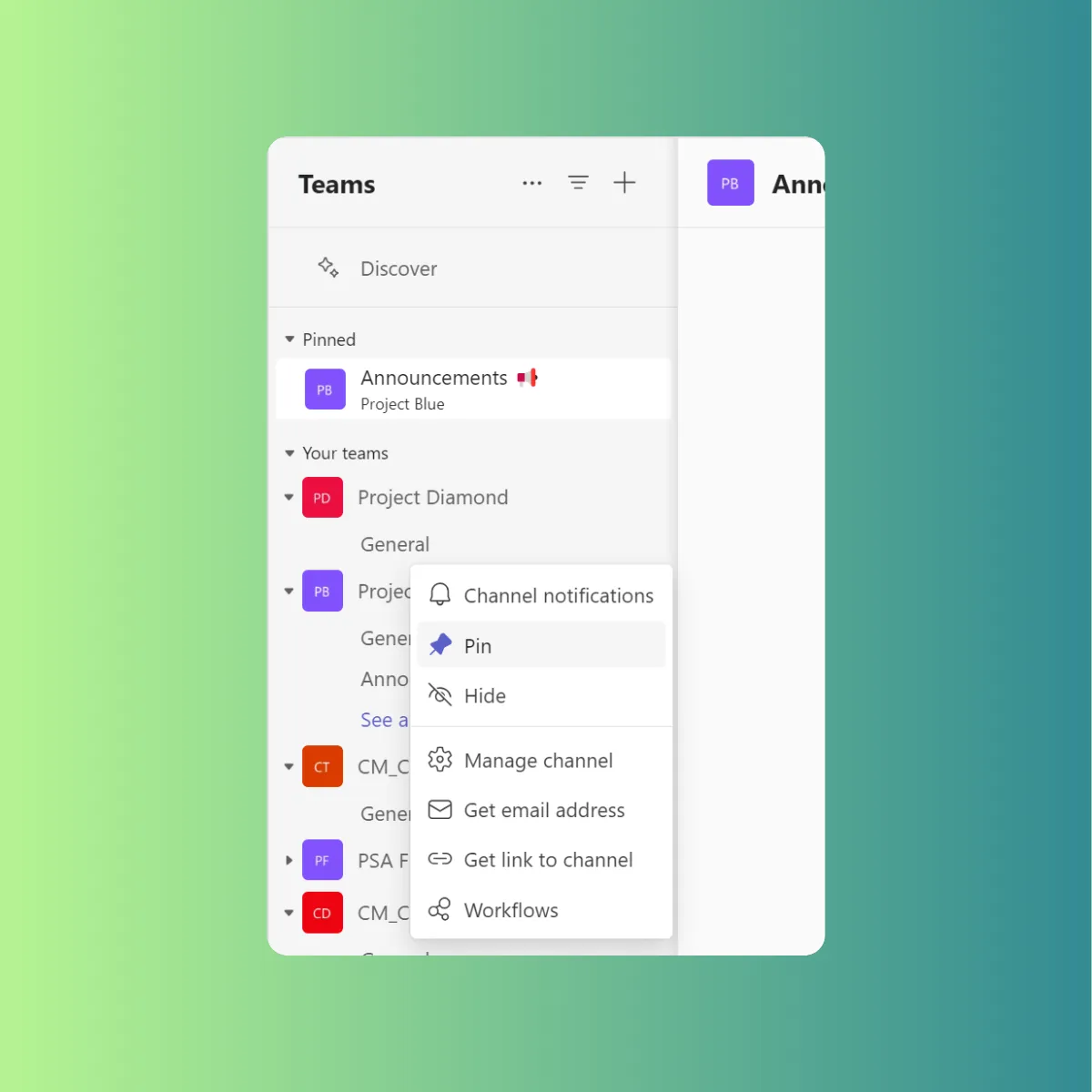
**Boost Your Efficiency**
Pinning frequently used channels significantly improves your workflow. Imagine seamlessly switching between key project channels, eliminating wasted time searching. This streamlined access translates to a more efficient workday, allowing you to focus on getting things done.
**Minimize Distractions, Maximize Productivity**
Hiding inactive channels also helps minimize distractions and information overload. No more notifications or updates bombarding you from channels you don't currently need. This allows you to concentrate on the tasks at hand, free from the constant barrage of irrelevant information.
## Drawbacks to Consider
While pinning and hiding channels offer amazing advantages, there are a couple of things to keep in mind:
**Tracking Hidden Gems**
Hiding inactive channels keeps your list clean, but remember, they're not gone forever. These hidden channels might hold important information that resurfaces later. Schedule periodic checks to ensure you don't miss anything crucial.
**Pinned Channels: Not So Flexible**
Here's a catch: pinned channels can't be hidden. This can be tricky for occasionally used channels. Imagine pinning a channel for a project deadline, then needing it hidden once the project's done. You'll either need to unpin and then repin it later, or keep it pinned despite not needing daily access.
## Tailoring Your Approach (For Users with Few vs. Many Teams/Channels)
The effectiveness of pinning and hiding channels can vary depending on how you use Microsoft Teams. Let's explore how to tailor your approach based on the number of teams and channels you manage:
If you only manage a handful of Teams and channels, pinning might not be as crucial. However, hiding inactive channels is still highly beneficial. By removing clutter, you can easily find the channels you use most frequently, keeping your Teams list streamlined and focused.
For users juggling numerous Teams and channels, pinning becomes a lifesaver. Pinning your most important channels allows for quick access, saving you time and frustration searching through a long list. This is especially valuable for staying on top of critical project updates or ongoing team discussions.
Furthermore, with a large number of channels, hiding inactive ones becomes essential. Imagine the chaos of an overflowing Teams list! Hiding inactive channels eliminates distractions and information overload, allowing you to focus on the channels relevant to your current tasks.
## Tips for Effective Pinning and Hiding
Ready to put these concepts into action and optimize your Microsoft Teams experience? Here are some key tips to remember:
**Pin with Precision**
Reserve pinning for your most frequently used channels. This could include channels for ongoing projects, core team discussions, or frequently referenced information hubs. By being selective, you'll ensure your pinned channels remain truly valuable for your daily workflow.
**Hide, But Don't Forget**
Hiding inactive channels is a great way to declutter your Teams list. However, it's important to strike a balance. While hidden channels are out of sight, they're not gone forever. Schedule periodic checks on hidden channels to ensure you don't miss any crucial information that might resurface.
**The Power of Combining**
Remember, pinning and hiding work best together! Utilize pinning for your essential channels and leverage hiding for the rest. This potent combination creates a streamlined and organized Teams environment, allowing you to find the information you need with ease.
**Regular Review is Key**
Don't forget to revisit your pinned and hidden channels periodically! Your workflow and project needs might change over time. Regularly evaluate your pinned channels to ensure they remain the most important ones. Similarly, review your hidden channels to see if any need to be unhidden due to renewed activity or a resurgence of importance. This ongoing review ensures your Teams experience stays efficient and organized.
## Bonus: Applying Channel Organization to Your Teams Chats
The same principles of organization you learned for channels can be applied to your chats as well! Just like with channels, information overload, and constant notifications can hinder your productivity in chats.
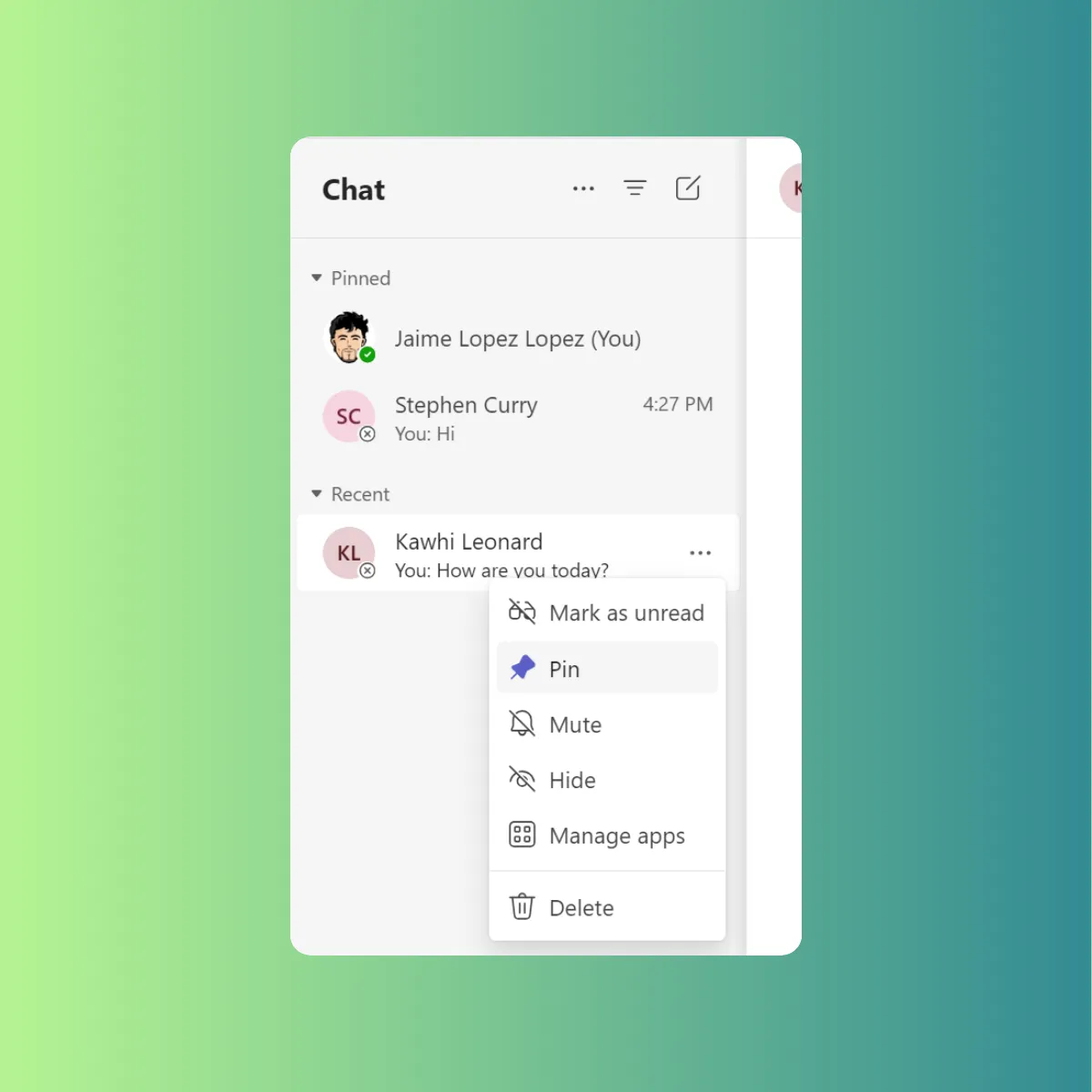
The key lies in mimicking your pinning and hiding strategy with favoriting and muting chats. Pinning your most frequently used chats keeps them readily accessible at the top of your list. This allows for quick reference and continued conversations with key colleagues or project teams. Just like hiding inactive channels, hiding or muting less important chats allows you to focus on the conversations that demand your immediate attention. By strategically hiding or muting chats with low activity or those not requiring constant updates, you can significantly reduce notification overload and minimize distractions.
## Conclusion
Now that you've explored the power of pinning and hiding channels, along with pinning and hiding and muting chats, it's time to experiment and personalize your Microsoft Teams experience. Imagine scrolling through a streamlined Teams list, with only the most relevant channels readily accessible at the top. No more endless searching or information overload!
As you navigate your workday, hopping between project chats and referencing key channel discussions, feel the newfound efficiency. Information is at your fingertips, distractions are minimized, and your focus is razor-sharp. Embrace the power of organization and watch your productivity soar within the collaborative environment of Microsoft Teams!
## References
- Show, hide, or pin a team or channel in Microsoft Teams: [https://support.microsoft.com/en-us/office/show-hide-or-pin-a-team-or-channel-in-microsoft-teams-91a37043-acea-49b0-9dfc-aec37b2e92b8](https://support.microsoft.com/en-us/office/show-hide-or-pin-a-team-or-channel-in-microsoft-teams-91a37043-acea-49b0-9dfc-aec37b2e92b8)
- Show and hide channels: [https://support.microsoft.com/en-us/office/show-and-hide-channels-3f76dffd-78a8-49ca-b8de-28671cb444ba](https://support.microsoft.com/en-us/office/show-and-hide-channels-3f76dffd-78a8-49ca-b8de-28671cb444ba)
- Pins over white background by Dan Cristian Paduret from Unsplash: [https://unsplash.com/es/fotos/imperdible-plateado-sobre-superficie-blanca-ritZolQWTeE](https://unsplash.com/es/fotos/imperdible-plateado-sobre-superficie-blanca-ritZolQWTeE) | jaloplo |
1,867,257 | Build a Safe and Respectful Community with Answer 1.3.1 | Build a thriving community, while making it a safe place for everyone to express themselves freely,... | 0 | 2024-05-28T06:29:31 | https://dev.to/apacheanswer/build-a-safe-and-respectful-community-with-answer-131-1dc7 | opensource, apache, go, community | Build a thriving community, while making it a safe place for everyone to express themselves freely, is a dream and a challenge. Answer 1.3.1 is here for these two goals.
In this version, we add new tool for admin to define keyword lists to identify and review specific content beforehand, ensuring a safe space for everyone. Users can also mention the admin and moderator in comments of a post to seek response actively. New Captcha plugins are ready to safeguard your community.
Ready to [upgrade](https://answer.apache.org/docs/upgrade)? Leave us several minutes to dive in.
## What’s New
### Keyword Censorship for Secure Communities
Apache Answer is for open knowledge exchange and discussion respectfully. Keyword censorship helps achieve this by proactively filtering out offensive, discriminatory, or harassing content. It ensures a platform where everyone feels comfortable expressing themselves freely.
Here’s how it works.
1. Admin can develop a keyword list of the community to check or filter.
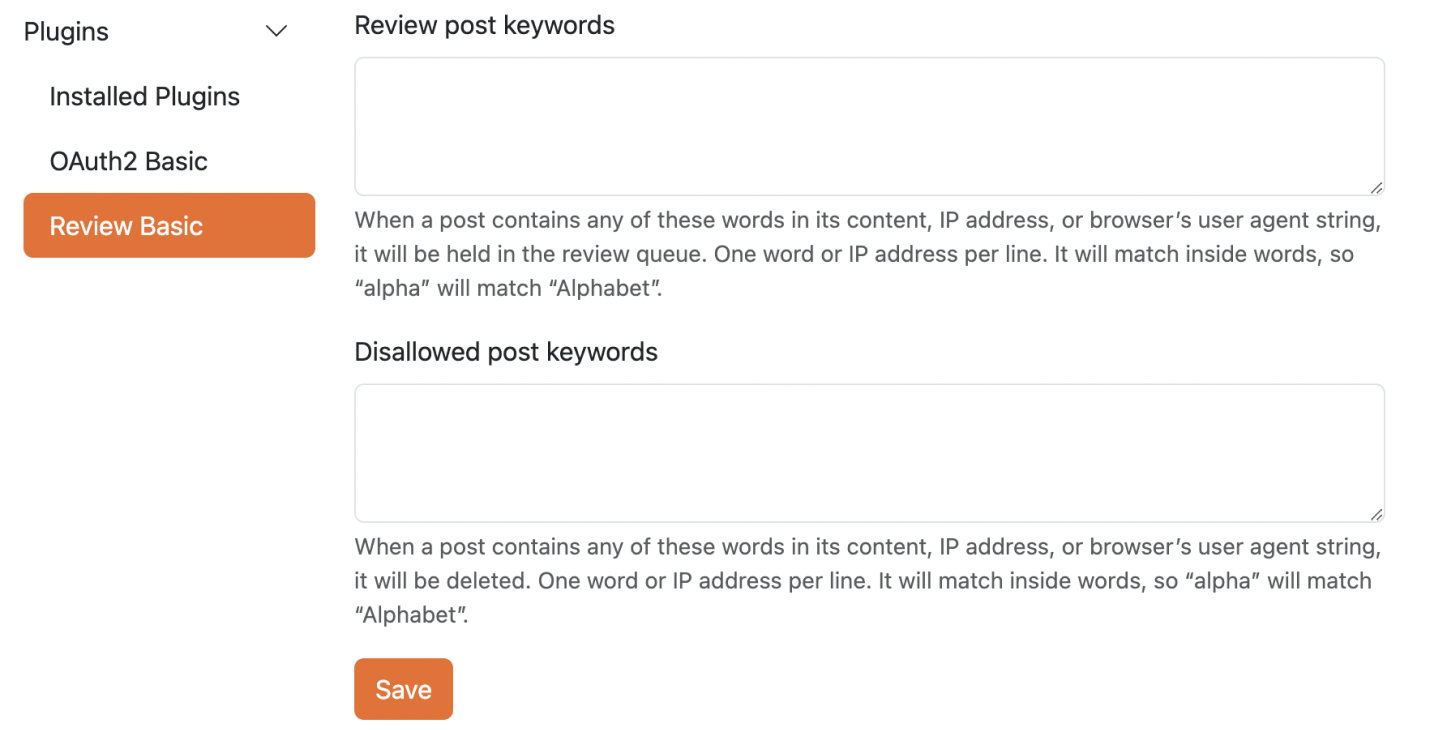
2. Then, go **Admin -\> Plugin -\> Review Basic** where you can add these keywords in **Review** post keywords or **Disallowed** post keywords based on your need. One keyword or IP address per line. Scroll and click **Save**.
3. Content, IP addresses, or browser identifiers that contain any of these words will be sent to the review queue or deleted. It will match the internal words. For example, if "alpha" is not allowed, then "Alphabet" is also not allowed.
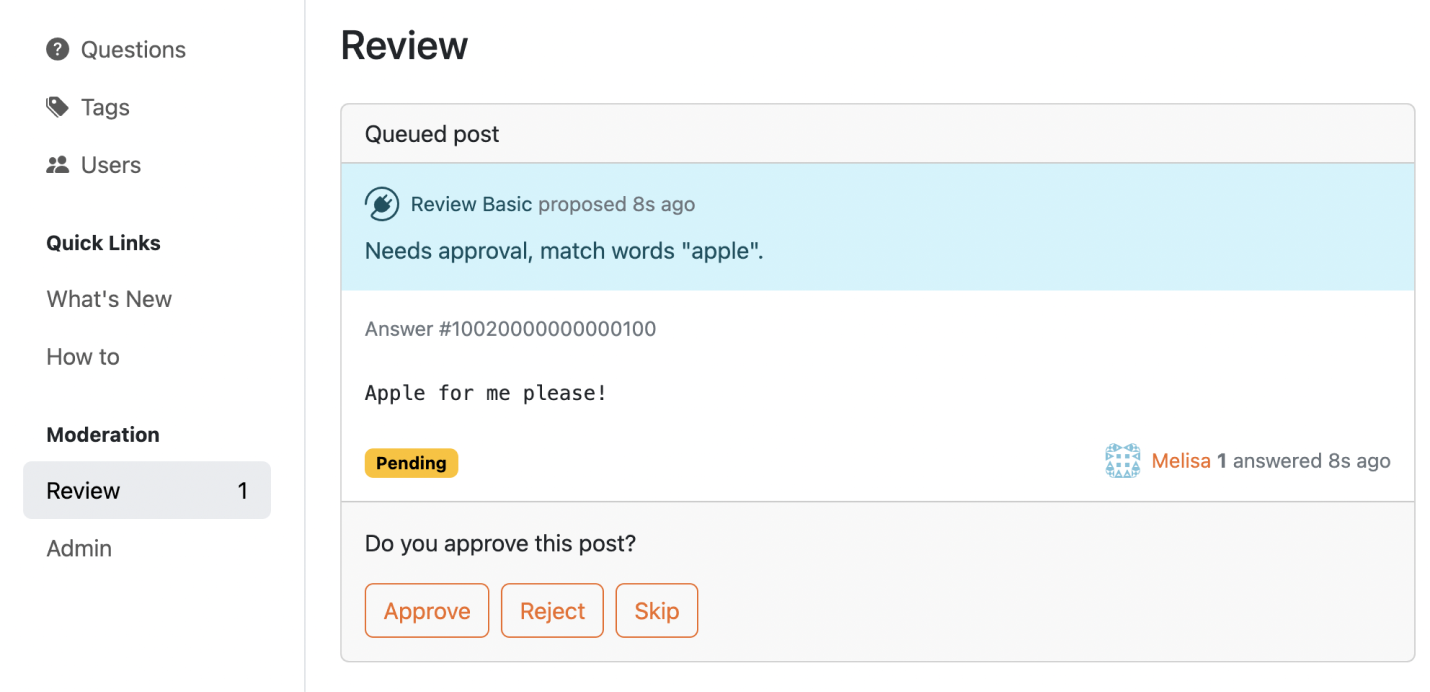
This feature would allow administrators to review or filter out specific words or phrases, potentially creating safe spaces for younger audiences or communities with content restrictions.
## Tag Moderators and Admin in Comment
Now, you can mention moderator or admin in a comment of a post. As you type the first letter of the moderator or admin's username, a search bar will appear. Select the admin/moderator from the dropdown list for a faster response.
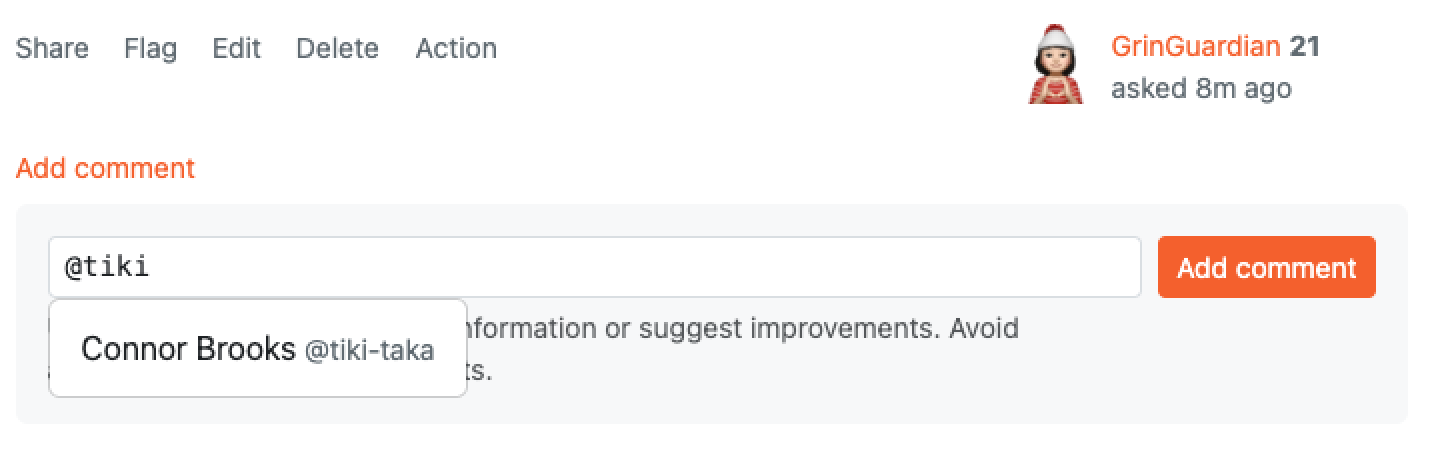
The moderator and admins will receive an email in their email box.
### Shining on Social Platforms
Social media meta tag is on the stage! Let’s make your shared content appears more attractive on social media platforms. Social meta tags use the following defaults:
* Title: the title of current page
* Image: the logo of the site
Share it and don’t forget to mention us on [Twitter](https://x.com/AnswerDev).
## Improvements and Fixed Bugs
We’ve got new plugins for you: [Captcha Basic](https://github.com/apache/incubator-answer-plugins/tree/main/captcha-basic) and [Captcha Google V2](https://github.com/apache/incubator-answer-plugins/tree/main/captcha-google-v2). These two plugins enable or disable the CAPTCHA feature, allowing users to implement their CAPTCHA plugins, such as Google reCAPTCHA.
We also add auto-scroll for posting so that you can jump right to the blank space for you to edit it.
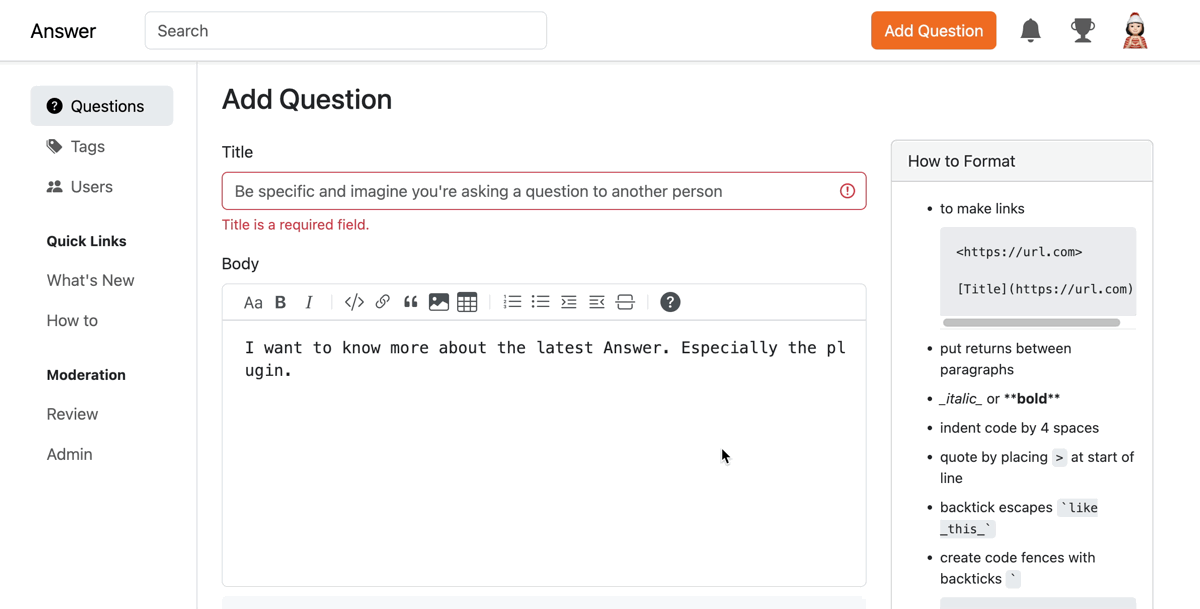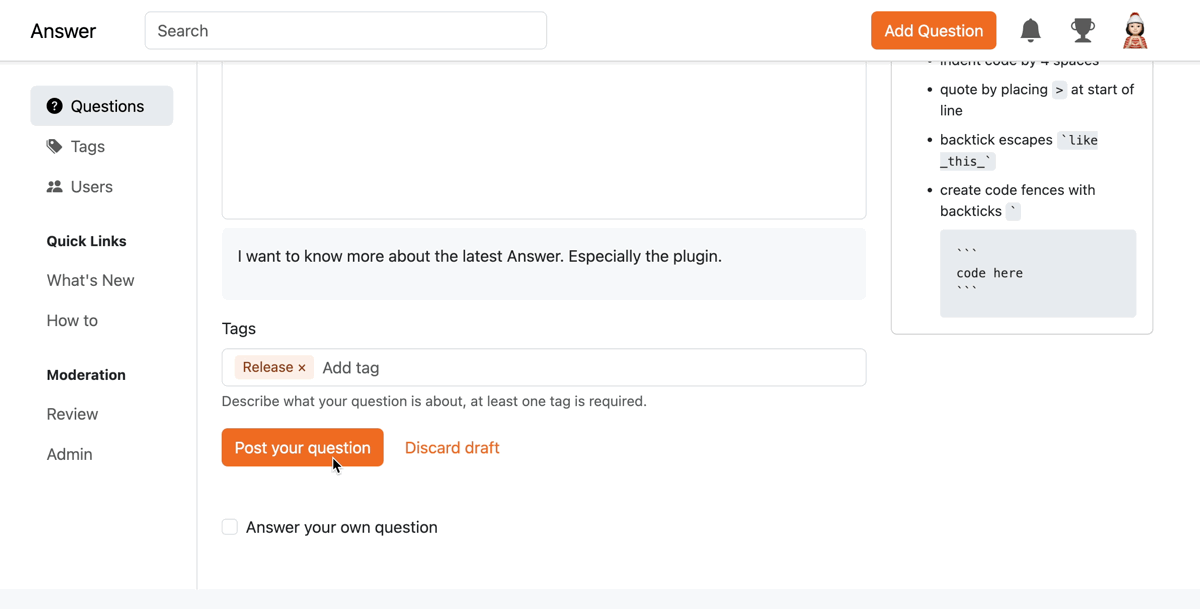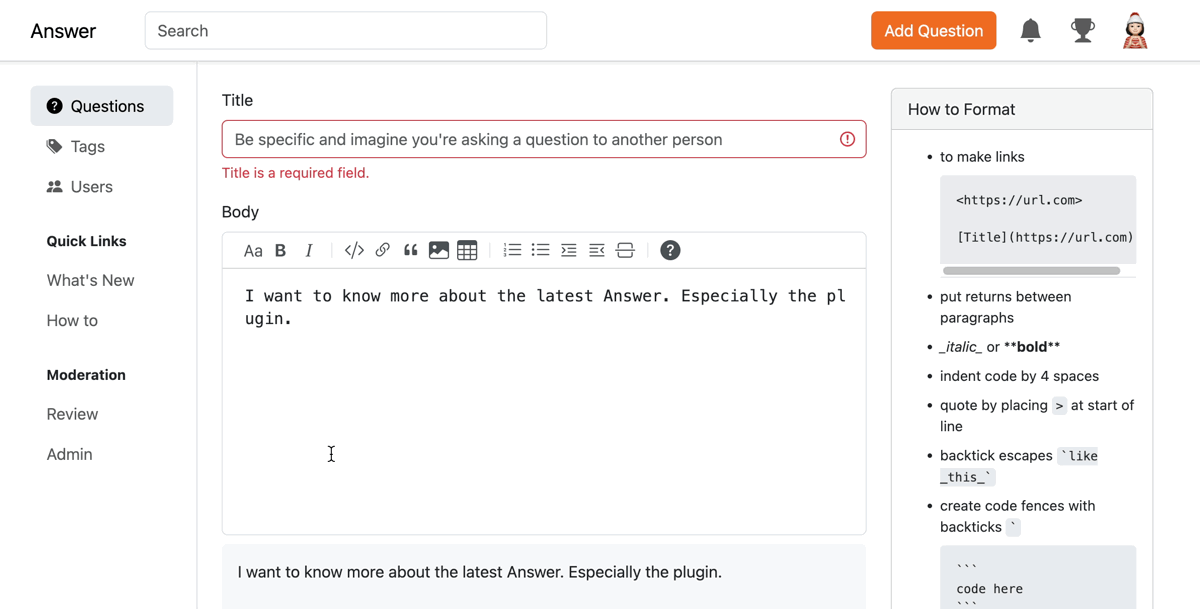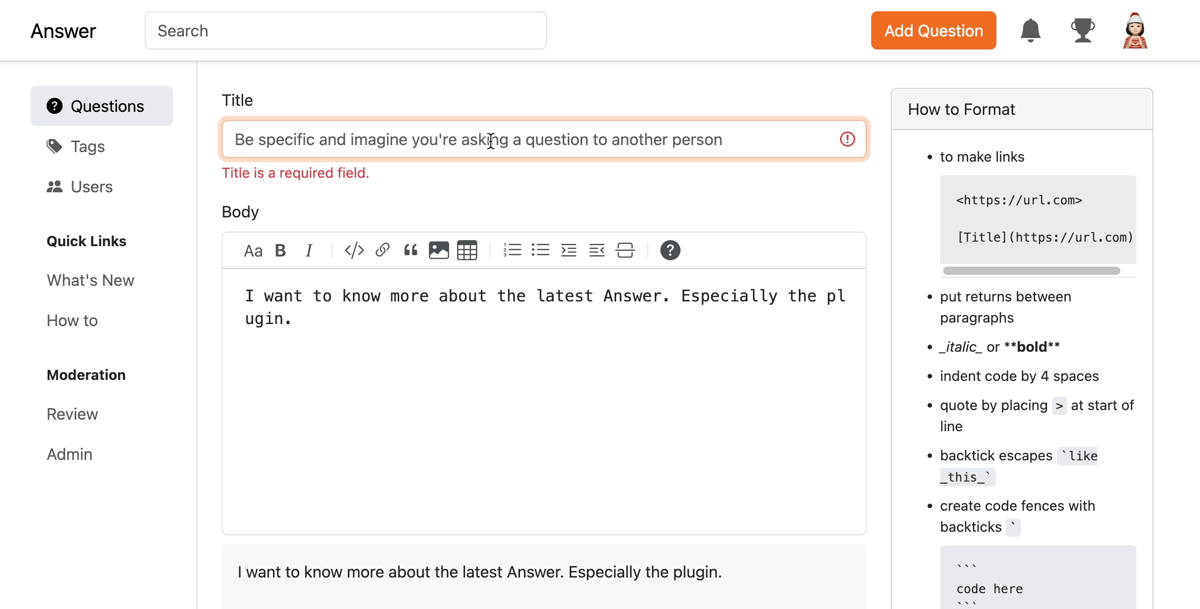
Find out more in our [Release note](https://github.com/apache/incubator-answer/releases/tag/v1.3.1).
## Thanks to the Community.
This version is proudly presented by 8 contributors from the community, and they are:
[kumfo](https://github.com/kumfo), [hgaol](https://github.com/hgaol), [LinkinStars](https://github.com/LinkinStars), [robinv8](https://github.com/robinv8), [shuaishuai](https://github.com/shuashuai), [sy-records](https://github.com/sy-records), [zahash](https://github.com/zahash), and [prithvidasgupta](https://github.com/prithvidasgupta).
## We Love Feedback
We'd love your feedback! Share your thoughts on the latest releases, suggest features you need, or just send us messages. Please don't hesitate to reach out on [X](https://twitter.com/answerdev), [Discord](https://discord.gg/a6PZZbfnFx), [GitHub](https://github.com/apache/incubator-answer), [Meta Answer](https://meta.answer.dev/), or our [mailing list](https://answer.apache.org/community/support). | apacheanswer |
1,867,256 | SMTP Relay Services: How It Works & Why Your Business It | Email is a lifeline for modern marketing strategies, and serves businesses in reaching their... | 0 | 2024-05-28T06:27:39 | https://dev.to/brettjhonson01/smtp-relay-services-how-it-works-why-your-business-it-20id | webdev, beginners, productivity, opensource | Email is a lifeline for modern marketing strategies, and serves businesses in reaching their audiences in many ways. However, the dynamics of online communication are continuously changing and it has of late gotten more difficult to make sure that your emails get to their intended recipients. This is where investing in a bulk email relay service may have an important contribution to this. This article is to help business owners or professionals who send numerous emails. Use [Bulk SMTP relay services](https://www.quora.com/What-are-the-top-10-SMTP-server-websites/answer/Otis-Milburnn) to get the best email deliverability possible.
## Understanding the Importance of Email Deliverability
Before we look at the value of a [bulk email relay service](https://smtpget.com/bulk-email-server/), let's first understand what email deliverability is and why it matters. Previously, email deliverability refers to the success of an email message reaching the recipient's inbox. It goes beyond the prerequisite sender reputation, authentication methods, content reliability, and responsiveness of addressees.
The main thing that has to be taken into consideration for ensuring the successful performance of email marketing companies is email deliverability. Without it, there would be a bigger chance that your messages might end up in spam folders, and in the worst case, it will be flagged as spam which may harm your sender's reputation and the availability of your future sendings.
## The Role of Best SMTP Relay Services
[SMTP relay services](https://smtpget.com/smtp-service-provider/) serve as an interface between your email marketing platform and the recipient's email servers. They specialize in sending a large number of emails efficiently while maintaining high deliverability rates. Here's why investing in such a service is advantageous.
**Enhanced Deliverability Rates:** Mass email relay services are aided by high-end facilities and technology that function to guarantee that your messages finally reach the destined recipients. They are well known and whitelisted through their relaying domains, observe all the industry’s best practices, and always keep an eye on any threats that could reduce the deliverability of messages.
**Improved Inbox Placement:** Deriving from knowledge and skills, a spam resources provider can implement an operation that spaces your emails inside the recipients' inboxes. That also makes your messages appear more greatly in the sight and as a result, your messages will be then taken into account by your target audience.
**Scalability and Reliability:** Whichever the case, whether sending hundreds or millions of emails relays services of email in bulk are very reliable and scalable to suit all the required sending with effects of scaling up. They have what it takes to deal with your business as your email marketing requirements are getting bigger, such as keeping the delivery rates and processing efficiencies high.
**Compliance and Security:** The Bult Email Relay services master regulations and compliance requirements, making sure your email campaigns are according to the anti-spam acts, for example, CAN-SPAM and GDPR requirements. Arguably, they have initiated solid security measures that are aimed at guarding your data and shielding you from such cyber threats as hacking, online fraud, and identity theft.
.
## Choosing the Right Bulk Email Relay Service
When selecting a bulk email relay service, consider the following factors:
Reputation and Track Record: Look for providers with a proven track record of delivering high inbox placement rates and maintaining excellent sender reputations.
**Features and Functionality:** Compare the features provided by various providers, including delivery metrics, A/B testing, segmentation capabilities, and integrations with prominent email marketing tools.
**Customer Support:** Choose a service that provides quick response to any questions or complaints.
**Pricing and Scalability:** Compare pricing plans and confirm that the service can meet your present requirements while also allowing for future expansion.
## 5 Best SMTP Relay Service Providers:
**SMTPget:** SMTPget is the best SMTP provider for bulk email SMTP relay services that focus on speed and deliverability, making sure that your emails are sent to their targeted recipients promptly and securely.
**iDealSMTP:** iDealSMTP offers the best email delivery solutions that prioritize simplicity and efficiency, making it a perfect choice for businesses of all sizes looking for hassle-free email sending.
**DigitalAka™:** DigitalAka™ provides customized SMTP relay services for enterprises, focusing on deliverability, security, and scalability to fulfill email communication demands.
**SMTP2GO:** SMTP2GO, which is used by businesses all over the world, provides secure and reliable email delivery with its user-friendly interface and complete delivery reporting tools.
**Mailgun:** Mailgun is a popular email delivery service among both developers and marketers, thanks to its broad APIs and advanced email validation capabilities, which make integration simple.
**Conclusion**
Purchasing an SMTP relay service is necessary because of the increasing issues of spam filters mentioned in email marketing and message overload. They can aid your emails to get into the inbox, talk to your audience, and get the results you want for your organization by leveraging their knowledge, infrastructure, and technology. Inform yourself to make the deliverability of email marketing better.
| brettjhonson01 |
1,867,254 | 佐藤 光信(Sato Mitsunobu)| 市場トレンドと投資戦略の深堀り | 佐藤 光信 Sato Mitsunobu プロフィール: 早稲田大学高等学院卒業後高校、1996年に早稲田大学... | 0 | 2024-05-28T06:24:21 | https://dev.to/satomitsunobu/zuo-teng-guang-xin-sato-mitsunobu-shi-chang-torendototou-zi-zhan-lue-noshen-ku-ri-192e | 佐藤光信satomitsunobu | 佐藤 光信 Sato Mitsunobu
プロフィール:
早稲田大学高等学院卒業後高校、1996年に早稲田大学 政治経済学部を卒業。
卒業後、ヤマト証券の仕事に従事し、主に信託の販売を担当。
2003年、米国に渡り、アメリカ銀行メリルリンチに入社 ファンドの確立、取引構造と実行、投資評価、コンプライアンス管理など、ファンド管理と販売を担当する。

その他のビジネスとして、ビジネス開発コンサルティングに加えて、ベンチャーキャピタル、合弁、スピンオフ、および米国と英国の投資にも関与。
2018年、藤田雄一氏の招きにより、アジア太平洋地域基金部シニアアナリストとしてマッコーリー・アセット・マネージメン社に入社。
日本の金融業界で20年近くの経験がある、主に日本政府の資金、債券、株式市場に参加しており、販売から取引までのさまざまな市場関連のポジションを任される。
スを蓄積し、資本および経済市場の運営に精通していました。
同時に、様々な金融投資市場にも精通しており、投資市場における鋭い嗅覚を有し、資産運用の経験も豊富です。
投資テクノロジーの面では、ギャン理論、ボルインデックス、SMAチャートパターン分析などのテクニカル分析に関する高い実績と知識を持ち、市場動向の調査と判断に非常に精通しています。
人生の信条:財産管理は、単なる金融数字の積み重ねではなく、綿密に設計され、卓越した実行を行う認知芸術である。
ポジティブ思考は、ポジティブ人生をもたらし、ネガティブ思考は、ネガティブ人生をもたらす。 | satomitsunobu |
1,867,248 | How To Spend Less Time On Sweet Potato Planter | To spend less time on sweet potato planters and increase efficiency, follow these... | 0 | 2024-05-28T06:18:40 | https://dev.to/mahindra_machinery_566e71/how-to-spend-less-time-on-sweet-potato-planter-463f | To spend less time on sweet potato planters and increase efficiency, follow these steps:
Preparation: Prepare the field well in advance by clearing debris and ensuring soil is adequately fertilized and irrigated.
Machine Setup: Before planting, calibrate the sweet [potato planter](https://mahindrafarmmachinery.com/products/mahindra-potato-planter) according to the desired planting depth and spacing.
Optimal Conditions: Plant during favorable weather conditions to minimize delays and ensure proper soil conditions.
Efficient Operation: Operate the planter at a steady pace, maintaining control over the planting depth and spacing to avoid overlap or gaps.
Regular Maintenance: Perform regular maintenance on the planter, including cleaning and greasing parts, to prevent breakdowns and ensure smooth operation.
Training: Ensure operators are well-trained to use the planter effectively and troubleshoot minor issues independently.
By implementing these strategies, you can streamline the planting process and spend less time overall on sweet potato planting, increasing productivity and reducing operational costs.
| mahindra_machinery_566e71 | |
1,867,188 | Warm Welcome to Linux | For easiness, let me call it "Linux" and not GNU/Linux/whatever Ignorance is a... | 0 | 2024-05-28T06:16:44 | https://dev.to/fonzacus/warm-welcome-to-linux-3okj | beginners, linux, opensource | ###### For easiness, let me call it "Linux" and not GNU/Linux/whatever
# Ignorance is a Blessing
Trying to live a more minimal life has its ups and downs. Having been out of the loop for such a long time, the world and the years ahead, look different from under a rock. With many breakthroughs in many fields at once, it seems impossible to catch up. To me, none of that matters much, as I prefer just playing with my kids. My off the entire grid life taught me to enjoy the simple things.
## Now With More Broken Glass
PC users are having a tantrum spiral as many Windows rumors turn out to be true. Who knew all these wonderful features could be ever more wonderful (/s). Some have even sworn to move elsewhere. As one who has tried to move since Windows 8 (I dub it H8 BTW), I have tried hopping many times over the decade and have stayed with the basic friendly guidelines (common sense really). The year of the Linux (TM) (R) (C) may finally come, maybe.
## DistroWatch, I Choose You
The common sense I advocate mainly revolves around [DistroWatch](https://distrowatch.com). High ranking distributions (indicated by the hits per day chart) are generally more favorable for many reasons; stability, support, user-friendliness, friendliness of other users and so on. Over the past few years, I have usually recommended the three major M named distros; Mint, Manjaro, and MX. They have had high favorability over the past decade. A first impression is a lasting one.
## Short Backstory
My first distro into the Linux distros that I fondly remember started off with Ubuntu as it was the first of its kind back in the day. Many distros were _too_ freedom oriented, and preferred not to include much needed drivers, media codecs, filesystem support and so on. This all changed when Ubuntu broke out of the mold. Nowadays, there are only a few that try to stay true to these old teachings. It was revolutionary at the time when even complete beginners could be happy with a completed, ready to rumble install without bloodshed.
My friends also wanted a stab at Linux and asked me for help. They wanted a simpler experience than Ubuntu. After browsing around for a bit, we decided on Mint. The experience was even more laid back, and something that can be better for beginners. After using it for over a year, I wanted to try Ubuntu again, until I heard some funny rumors. Browsing the Mint site, they started to offer a Debian option, and I decided to finally try Debian after hearing they started to ease on their too freedom ways.
As with many distros, having a large repository may not be enough for some, adding custom PPAs (Personal Package Archives, or 3rd party repositories) was the norm. Whilst staying truly Debian, this can add to a [FrankenDebian](https://wiki.debian.org/DontBreakDebian ), and might mess up the upgrade procedure. That is when I decided to try a rolling release distro again, but this time it was Debian Sid (I prefer calling it Unstable, and calling the next stable as Testing). My kitchen PC, which I built back in college 2009, with a top of the line DDR2, is still happily running with the initial Unstable I had installed. It really says something, as long as we RTFM.
## There Are Plenty of Fish in the Sea
Trying something new is scary, but there are tools out there to ease the pain. [YUMI](https://pendrivelinux.com/yumi-multiboot-usb-creator) and [Ventoy](https://www.ventoy.net/en/index.html) can help with the discovery phase of distro hopping. They are tools we can use to download ISOs onto our USB flash drives. The kicker is, they can support many bootable disks on one installation. The icing on the cake, they support persistency. We can try their default installers, save our persistent data, try something else, and return to where we left off.
Most Linux apps try to be portable (in a different sense of the word, for another topic) by nature and try to be self-contained. Now there are [portable app frameworks](https://dev.to/bearlike/flatpak-vs-snaps-vs-appimage-vs-packages-linux-packaging-formats-compared-3nhl) that try to do more. I am more AppImage oriented as they are truly portable, without the need for additional software.
After some Frankensteining of my own, I have a [USB installed](https://forum.mxlinux.org/viewtopic.php?p=581942) MX as a pocket OS that can be used on literally any hardware. Most common factory default boot options tend to favor booting from USB drives as the first boot option. A few years ago, a new storm called [Bedrock Linux](https://distrowatch.com/table.php?distribution=bedrock) caught Frankensteiners by surprise, and this is where I am with my daily driver everyday laptop.
## Choose Your Destiny
There are plenty of choices in the Linux distro world, too many as said before. Too much of a good thing can be bad at times, and that can split focus on trivial things instead of pushing to what matters more. At the end of the day, don't worry too much about what you choose as most of the time, most distros tend to be the same, it is the nitty gritty details that only slightly set them apart. Of course this was just an oversimplification, as the iceberg is always larger underneath.
###### So many choices, so little time, [so part 2](https://dev.to/fonzacus/warm-welcome-to-linux-p2-3j5k) | fonzacus |
1,867,246 | Business Management Assignment Help | Business Management is a popular field of study in Australia, attracting students from all corners of... | 0 | 2024-05-28T06:16:25 | https://dev.to/assignment_help_1ce2fa75c/business-management-assignment-help-2gdg | Business Management is a popular field of study in Australia, attracting students from all corners of the globe. This discipline covers a broad range of topics including economics, finance, marketing, human resources, and operations management, making it both challenging and rewarding. Given the complexity and the high expectations, students often seek external assistance to excel in their coursework. This blog will delve into the various aspects of Business **_[Management Assignment Help](https://www.assignmentsamples.com/management-assignment-help)_**, highlighting why it is essential, what to look for in the best management assignment help, and how it can significantly impact your academic journey.
**_Understanding Business Management_**
Before diving into the specifics of assignment help, it's crucial to understand what Business Management entails. This field focuses on organizing, planning, and analyzing business activities required to efficiently run and manage a business. Students learn about decision-making processes, strategic planning, and the effective use of resources to achieve business goals. Assignments in this field can range from case studies, research papers, and strategic analysis to practical projects and presentations.
**_The Need for Management Assignment Help_**
Business Management courses are rigorous and demand a comprehensive understanding of various interrelated concepts. Here are some reasons why students seek Management Assignment Help:
**Complex Topics:** The subject covers a vast range of topics, each with its own set of complexities. From understanding organizational behavior to mastering financial management, students are required to grasp numerous challenging concepts.
**_Time Constraints_**: Balancing academics with personal commitments, part-time jobs, and internships can be overwhelming. Assignment deadlines can often add to this pressure, making it difficult for students to deliver quality work on time.
**_High Standards:_** Australian universities are known for their high academic standards. Meeting these expectations requires in-depth research, critical analysis, and exceptional writing skills, which can be daunting for many students.
**_Language Barriers:_** International students, in particular, may face difficulties with English proficiency, affecting their ability to articulate their knowledge effectively in assignments.
_**Lack of Resources:**_ Access to credible sources and up-to-date information is crucial for crafting well-informed assignments. Students might struggle to find relevant data and case studies necessary for their work.
**_Benefits of Seeking the Best Management Assignment Help_**
Opting for professional assistance can make a significant difference in a student’s academic performance. Here are some key benefits:
**_Expert Guidance:_** Professional services provide access to experts with in-depth knowledge and experience in Business Management. Their insights can help students understand complex topics better and develop high-quality assignments.
**_Customized Solutions: _**Each assignment comes with its unique requirements. The best management assignment help services offer tailored solutions that meet specific guidelines and criteria set by the universities.
**_Plagiarism-Free Work:_** Academic integrity is paramount. Reputable assignment help providers ensure that all work is original and free from plagiarism, adhering to the highest standards of academic honesty.
**_Time Management:_** By delegating assignment work to professionals, students can better manage their time, allowing them to focus on other important aspects of their studies and personal lives.
**_Improved Grades:_** Quality assignments can lead to better grades. With expert help, students can submit well-researched and well-written assignments that meet academic standards and impress their professors.
**_How to Choose the Right Assignment Help Service
_**With numerous options available, selecting the right assignment help service can be challenging. Here are a few things to consider.
**_Check Credentials:_** Ensure that the service has qualified professionals with relevant academic backgrounds and experience in Business Management.
**_Read Reviews:_** Look for testimonials and reviews from other students. Positive feedback and high ratings are good indicators of reliable service.
**_Assess Their Approach:_** The best services offer a systematic approach, including thorough research, critical analysis, and coherent presentation of ideas.
**_Evaluate Communication:_** Effective communication is crucial. Ensure that the service provides timely updates and is responsive to your queries and feedback.
**_Consider Pricing:_** While affordability is important, don’t compromise on quality. Look for services that offer a balance between cost and quality, providing value for your money.
**_Check for Additional Services:_** Some services offer extra benefits like free revisions, plagiarism reports, and 24/7 support. These can be valuable in ensuring a smooth and satisfactory experience.
**_The Role of Technology in Assignment Help_**
Technology plays a significant role in enhancing the quality and accessibility of assignment help services. Here’s how:
**_Online Platforms:_** Most assignment help services operate through online platforms, making it convenient for students to seek help from anywhere at any time.
**_Research Tools:_** Advanced research tools and databases enable professionals to access a wide range of resources, ensuring that assignments are well-informed and up-to-date.
**_Plagiarism Detection Software:_** To guarantee originality, services use sophisticated plagiarism detection tools, ensuring that all work is authentic.
**_Communication Channels:_** Technology facilitates seamless communication between students and experts through chat, email, and video calls, making the process more efficient and personalized.
**_Success Stories_**
Numerous students have benefited from professional assignment help services. Here are a few success stories:
**_Improved Understanding:_** Sarah, an international student, struggled with the complexities of financial management. With expert help, she not only improved her grades but also gained a better understanding of the subject, which helped her in her final exams.
**_Balancing Commitments: _**John juggled a part-time job along with his studies. The pressure of assignments was overwhelming until he sought professional help. This allowed him to manage his time better and focus on both his job and studies, ultimately leading to academic success.
**_Enhanced Writing Skills: _**Emily faced challenges with academic writing. With the guidance of professional services, she improved her writing skills significantly, which was reflected in her higher grades and positive feedback from professors.
**_Conclusion_**
Business Management is a demanding field that requires dedication, hard work, and a deep understanding of various concepts. For students in Australia, seeking Business Management Assignment Help can be a game-changer. It not only aids in managing academic pressures but also enhances learning, leading to better grades and overall success.
When choosing the best management **_[Assignment Help](https://247assignmenthelp.com/)_**, it's essential to consider factors such as expertise, customization, communication, and additional services. By doing so, students can ensure they receive high-quality assistance that meets their academic needs.
In the digital age, technology has further streamlined the process, making it easier for students to access the help they need from anywhere. Success stories from students who have benefited from these services highlight the positive impact professional help can have on academic performance.
In conclusion, Business Management Assignment Help is a valuable resource for students aiming to excel in their studies. By leveraging expert guidance, students can overcome challenges, achieve their academic goals, and pave the way for a successful career in the dynamic field of business management. Whether you are struggling with complex topics, time constraints, or language barriers, professional assignment help is your key to unlocking **_[Academic](https://dev.to/otienorabin/are-you-writing-your-git-commit-messages-properly-54cl)_** success in Australia. | assignment_help_1ce2fa75c | |
1,851,401 | B2B Order Validation | Order validation process for a B2B Website. Create a list of validators for each customer, that... | 0 | 2024-05-13T13:56:37 | https://dev.to/ndiaga/b2b-order-validation-1hlg | Order validation process for a B2B Website.
Create a list of validators for each customer, that will validate his orders .
The order will be Valide only if all of them have validate the order positively.
You add to each of your customer (B2B partners) a list of validators that will receive an email once the customer mange has placed an order.
They will then valide or refuse the order accordingly .
The module works this way:
- A B2B placed an order , the Order remains in the status of “In Validation” until all the validators of this particular clients have validate one by one the order.
- If all the Validators Validate the Order positively the Order will pass to the status " Order Validated" and the customer can receive the products he ordered.
-If only one of the Validators refuses the Order, the status of order will pass to "Order Refused" and a message will be sent to the customer explaining him why his order was refused.
-The validator who refuses an order should write a message to justify his decision.
PrestaShop Version : 1.6 ; 1.7 and 8
[B2B ORDER VALIDATION](https://prestatuts.com/store/home/41-b2b-order-validation.html)
 | ndiaga | |
1,867,245 | Exploring Basic Data Types in TypeScript | TypeScript is a powerful, statically typed superset of JavaScript that helps developers write more... | 27,696 | 2024-05-28T06:14:07 | https://dev.to/nahidulislam/exploring-basic-data-types-in-typescript-34fo | typescript, webdev, javascript, programming | TypeScript is a powerful, statically typed superset of JavaScript that helps developers write more robust and maintainable code. Understanding the basic data types in TypeScript is essential for beginners to leverage its full potential. In this article, we'll explore the fundamental data types: `string`, `number`, `array`, `object`, `null`, `undefined`, `function`, `never`, `type alias`, and `type alias in function`.
## 1. String
A `string` in TypeScript is used to represent textual data. It's a sequence of characters and is enclosed in single ('), double ("), or backticks.
```typescript
let message: string = "Hello, TypeScript!"
console.log(message) // output: "Hello, TypeScript!"
```
You can also use template literals (enclosed by backticks) to embed expressions:
```typescript
let userName: string = "Alice";
let greeting: string = `Hello, ${userName}!`;
console.log(greeting) // output: Hello, Alice!
```
## 2. Number
A `number` in TypeScript can represent both integer and floating-point values. TypeScript uses the number type to cover all numeric values, including special values like Infinity and `NaN`.
```typescript
let myNumber: number = 5;
let myFloat: number = 19.71;
let myInfinity: number = Infinity;
console.log(myNumber) // output: 5
console.log(myFloat) // output: 19.71
console.log(myInfinity) // output: Infinity
```
## 3. Array
An `array` in TypeScript is used to store a collection of elements of a specific type. You can define an array using the `Array<type>` syntax or the `type[]` syntax.
```javascript
let myArray: number[] = [1, 2, 3, 4, 5];
let myStringArray: Array<string> = ["one", "two", "three"];
console.log(myArray); // Output: [1, 2, 3, 4, 5]
console.log(myStringArray); // Output: ["one", "two", "three"]
```
## 4. Object
An `object` in TypeScript is a collection of key-value pairs, where the keys are strings (or symbols) and the values can be of any type. You define the shape of an object using an interface or a type alias.
```typescript
let myObject: { name: string, age: number } = { name: "John", age: 30 };
console.log(myObject); // Output: { name: "John", age: 30 }
```
Using an interface:
```typescript
interface Person {
name: string;
age: number;
}
let anotherPerson: Person = { name: "Jane", age: 25 };
console.log(anotherPerson); // Output: { name: "Jane", age: 25 }
```
## 5. Null & Undefined
`null` and `undefined` are special types that represent the absence of a value. `null` is often used to explicitly indicate the absence of a value, whereas `undefined` typically means a variable has been declared but not yet assigned a value.
```typescript
let myNull: null = null;
let myUndefined: undefined = undefined;
console.log(myNull); // Output: null
console.log(myUndefined); // Output: undefined
```
Variables without an initial assignment default to `undefined`:
```typescript
let notAssigned;
console.log(notAssigned); // Output: undefined
```
## 6. Function
A `function` in TypeScript is a block of code that performs a specific task. Functions can accept parameters and return a value. TypeScript allows you to define the types of the parameters and the return type.
```typescript
function greet(name: string): string {
return `Hello, ${name}!`;
}
console.log(greet("Alice")); // Output: Hello, Alice!
```
A function with no return value can be specified with the `void` return type:
```typescript
function logMessage(message: string): void {
console.log(message);
}
logMessage("This is a message."); // Output: This is a message.
```
## 7. Never
The `never` type represents values that never occur. It's typically used for functions that always throw an error or functions that never return.
```typescript
function error(message: string): never {
throw new Error(message);
}
try {
error("Something went wrong!");
} catch (e) {
console.error(e); // Output: Error: Something went wrong!
}
```
A function that never returns (infinite loop):
```typescript
function infiniteLoop(): never {
while (true) {}
}
```
## 8. Type Alias
A type alias creates a new name for a type. This can be especially useful for simplifying complex type definitions or when you want to give a type a meaningful name.
```typescript
type Point = { x: number, y: number };
let myPoint: Point = { x: 10, y: 20 };
console.log(myPoint); // Output: { x: 10, y: 20 }
```
Using a type alias for union types:
```typescript
type ID = number | string;
let userId: ID = 101;
let anotherId: ID = "user101";
console.log(userId); // Output: 101
console.log(anotherId); // Output: user101
```
## 9. Type Alias in Function
Type aliases can be used in function signatures for better readability and maintainability. This allows you to reuse complex type definitions across multiple functions.
```typescript
type Greeting = (name: string) => string;
const sayHello: Greeting = (name) => `Hello, ${name}!`;
console.log(sayHello("Bob")); // Output: Hello, Bob!
```
Combining type aliases with objects:
```typescript
type Person = { name: string, age: number };
type Introduce = (person: Person) => string;
const introduce: Introduce = (person) => `My name is ${person.name} and I am ${person.age} years old.`;
console.log(introduce({ name: "Charlie", age: 28 })); // Output: My name is Charlie and I am 28 years old.
```
## Conclusion
Understanding the basic data types in TypeScript is crucial for writing effective and type-safe code. These types form the foundation upon which more complex types and structures are built. By mastering `string`, `number`, `array`, `object`, `null` & `undefined`, `function`, `never`, and `type aliases`, you'll be well-equipped to handle a wide range of programming scenarios. TypeScript’s type system not only helps catch errors early but also makes your code more readable and maintainable. As you continue to explore TypeScript, you'll find that these basics will serve as a strong foundation for more advanced concepts and techniques.
Follow me on: [LinkedIn](https://www.linkedin.com/in/iamnahidul-islam) [Portfolio](https://nahidul-islam-fahim.web.app) | nahidulislam |
1,867,230 | Using WSL2 as primary driver for 3 months with Fedora | Introduction It all started when I stumbled upon an article about Windows Subsystem for... | 0 | 2024-05-28T06:12:39 | https://dev.to/chandruchiku/using-wsl2-as-primary-driver-for-3-months-with-fedora-4f17 | wsl, wsl2, fedora | ### Introduction
It all started when I stumbled upon an article about Windows Subsystem for Linux being released and is fun. I wanted to give it a try and I installed Ubuntu 18.04 and started using it on and off. I immediately fell in love with the way it works. After that I had to get OS reinstalled for some reason and left at it. Couple of months later, I wanted to give it a try again but Fedora this time. Whey Fedora? you may ask. Since most time we use Red hat, Amazon Linux in our deployments I wanted to have familiar commands and add to that we all know Fedora is cutting edge latest.
**Fedora Article:** [Install Fedora On WSL] (https://dev.to/bowmanjd/install-fedora-on-windows-subsystem-for-linux-wsl-4b26)
I followed the steps and bam. Fedora 39 running on my Windows 11 like native OS. I could access files directly using File Explorer.
I quickly installed npm, .NET, git and started using it as daily driver. However, when I go home the WSL would lose internet connection. I found out I needed to edit `/etc/resolv.conf` and add nameservers of my organization and Google DNS.
Git commit and sync took quick 1 to 3 to seconds that used to take 5 to 10 seconds on the Windows machine. `npm install` was way faster than what Windows used to take. It was like getting an upgraded machine without any money spent.
#### Pros
1. **Windows-Linux interoperability**: Most organizations use Windows for mail, teams and are easier to maintain with AD connectivity and windows updates. Linux running natively on Windows is a boon.
2. Linux file system being generally faster improves performance by 10 to 30%
3. Familiar commands during dev and prod deployments.
4. Windows ports are forwarded automatically to Linux Processes.
5. Windows can still scan the Linux folders for vulnerabilities
6. I can run docker/podman (we all know Docker Desktop needs a license to run on Windows)
#### Cons:
1. The only issue I am facing right now is that the longer I use, feels the WSL is slowing down. | chandruchiku |
1,867,242 | Software testing techniques | Testing of data is done based on boundary values or between two opposite ends where the ends may be... | 0 | 2024-05-28T06:11:01 | https://dev.to/malaiyarasi/software-testing-techniques-5af7 | Testing of data is done based on boundary values or between two opposite ends where the ends may be like from start to end, or lower to upper or from maximum and minimum.
Decision table testing
Decision table is one of the testing techniques which will help us to test the systems with various sets of inputs. It is also called as cause and effect table.
****
Use case testing
It explain the functionality or requirement can be specify in the use case. It is a techniques that used to identity the test case.
LCSAJ testing(linear code sequence and jump)
White box testing techniques to identify the code distance which begins at the start of the Programe or branch and ends at the end of the program.
| malaiyarasi | |
1,867,241 | E-Commerce App Development | Top E-Commerce Application Services | Discover expert e-commerce app development services from a leading company. Our team specializes in... | 0 | 2024-05-28T06:08:08 | https://dev.to/prachi_pare_e410f7b6715d0/e-commerce-app-development-top-e-commerce-application-services-22n8 | ecommerceappdevelopment, ecommerce, appdevelopment, ecommerceapplication | [Discover expert e-commerce app development services from a leading company. Our team specializes in creating high-quality e-commerce applications and mobile apps, offering innovative ecommerce app design and comprehensive e-commerce app development services. Contact us for custom mobile app development for e-commerce.](https://bhagirathtechnologies.com/services/4) | prachi_pare_e410f7b6715d0 |
1,865,468 | What's new in Angular 18 | A study guide that helps you learn the new version of Angular | 0 | 2024-05-28T06:04:14 | https://www.angularaddicts.com/whats-new-in-angular-18 | angular, typescript, signals, javascript | ---
title: What's new in Angular 18
description: A study guide that helps you learn the new version of Angular
published: true
tags: #angular #typescript #signals #javascript
canonical_url: https://www.angularaddicts.com/whats-new-in-angular-18
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/hbnp353ekvpvsqz5xhj3.png
---
Since I published my
- [Master Angular 17 Study guide](https://www.angularaddicts.com/p/master-angular-17) ,
- [Master Angular 17.1 and 17.2 Study guide](https://www.angularaddicts.com/p/master-angular-17-1-and-17-2) and the
- [What's new in Angular 17.3](https://www.angularaddicts.com/p/whats-new-in-angular-17-3) article
the Angular team released a new major version: Angular 18.
## 🎯Changes and new features
In this article, I list out the most important changes and new features, also share resources that will teach you how these new Angular features work:
- Control flow syntax and defer blocks are now stable
- Angular Material 3 is now stable, [material.angular.io](http://material.angular.io/) is updated by the new themes and documentation
- Experimental change detection without ZoneJS: `provideZonelessChangeDetection`
- Unified control state change events
- Fallback content for `ng-content`
- Route redirect functions
- Coalescing is enabled by default
- `HttpClientModule` deprecation
- Typescript 5.4 support
Now [angular.dev](https://angular.dev/) is the official website for the Angular documentation.
### 📌Experimental change detection without ZoneJS: `provideZonelessChangeDetection`
**Official docs:** [Angular without ZoneJS (Zoneless)](https://angular.dev/guide/experimental/zoneless)
**Merge request / commit:** [feat(core): Add zoneless change detection provider as experimental](https://github.com/angular/angular/pull/55329)
Angular 18 introduces a new, zoneless way to trigger change detection. When using `provideExperimentalZonelessChangeDetection`, Angular will use use Angular APIs to schedule change detection, including:
* `ChangeDetectorRef.markForCheck`
* `ComponentRef.setInput`
* Updating a signal that is read in a template
* When bound host or template listeners are triggered
* When attaching a view that was marked dirty by one of the above
* When removing a view
* When registering a render hook (templates are only refreshed if render hooks do one of the above)
You can try the zoneless change detection with the new `provideExperimentalZonelessChangeDetection` provider, and components using `OnPush` change detection strategy:
```typescript
bootstrapApplication(App, {
providers: [
provideExperimentalZonelessChangeDetection(),
]
});
```
Angular CDK and Angular Material also introduced has zoneless support.
### 📌Unified control state change events
**Official docs:** [AbstractControl.events](https://angular.dev/api/forms/AbstractControl)
**Merge request / commit:** [feat(forms): Unified Control State Change Events](https://github.com/angular/angular/pull/54579)
In Angular 18, the `AbstractControl` class (the base class for `FormControl`, `FormGroup`, and `FormArray`) introduced a new `events: Observable<ControlEvent<TValue>>` property. This property is an observable, that emits for value, status, pristine or touched changes.
```ts
@Component({
selector: 'app-abstract-control-events',
standalone: true,
imports: [ReactiveFormsModule],
template: ` <input [formControl]="titleInputControl" /> `,
})
export class AbstractControlEventsComponent {
titleInputControl = new FormControl<string | null>('', Validators.required);
constructor() {
this.titleInputControl.events.pipe(takeUntilDestroyed()).subscribe(console.log);
}
}
```
If you click on the input field in the example, enter a character, then click outside of the input field, the following events are logged on the browser's console:
```
PristineChangeEvent {pristine: false, source: FormControl2}
ValueChangeEvent {value: 'a', source: FormControl2}
StatusChangeEvent {status: 'VALID', source: FormControl2}
TouchedChangeEvent {touched: true, source: FormControl2}
```
### 📌Fallback content for `ng-content`
**Official docs:** [Content projection with ng-content](https://angular.dev/guide/components/content-projection)
**Merge request / commit:** [feat(core): add support for fallback content in ng-content](https://github.com/angular/angular/pull/54854)
In Angular 18, we can specify a fallback content for `<ng-content>`, this content is rendered when there is no content specified for projection in the parent component:
```ts
@Component({
selector: 'app-header',
template: `
<ng-content select=".title">Default tilte</ng-content>
<ng-content select=".explanation">There is no explanation for this title</ng-content>
`,
})
export class HeaderComponent {}
@Component({
selector: 'app-wrapper',
template: `
<app-header>
<span class="title">First chapter</span>
</app-header>
`,
})
export class WrapperComponent {}
```
These components are rendered as:
```html
<app-wrapper>
<app-header>
<span class="title">First chapter</span>
There is no explanation for this title
</app-header>
</app-wrapper>
```
### 📌Route redirect functions
**Official docs:** [Common router tasks: Setting up redirects](https://angular.dev/guide/routing/common-router-tasks#setting-up-redirects)
**Merge request / commit:** [feat(router): Allow Route.redirectTo to be a function which returns a string or UrlTree](https://github.com/angular/angular/pull/52606)
In Angular 18, a route's `redirectTo` property can be a function that returns a string or `UrlTree`, enabling us to create more dynamic redirects based on the application's state:
```ts
export const routes: Routes = [
// ...,
{
path: "prods", //legacy path
redirectTo: ({ queryParams }) => {
const productId = queryParams['id'];
if (productId) {
return `/products/${productId}`;
} else {
return `/`;
}
}
},
// ...,
];
```
### 📌Coalescing is enabled by default
**Official docs:** [NgZoneOptions](https://angular.dev/api/core/NgZoneOptions)
Starting from Angular 18, [zone coalescing](https://angular.dev/api/core/NgZoneOptions) is enabled by default (`eventCoalescing: true`) for newly created applications. Zone coalescing can reduce the number of the change detection cycles and improve the app's performance.
### 📌`HttpClientModule` deprecation
**Merge request / commit:** [refactor(http): Deprecate HttpClientModule & related modules,Migration schematics for HttpClientModule](https://github.com/angular/angular/pull/54020)
Starting with v18, the preferred way of providing the HTTP client are `provideHttpClient()` and `provideHttpClientTesting()`. `HttpClientModule` and `HttpClientTestingModule` are deprecated now.
When you run `ng update @angular/core`, Angular can automatically migrate your code to use the preferred `provideHttpClient()` and `provideHttpClientTesting()` functions instead of the deprecated modules.
### 📌Typescript 5.4 support
**Merge request / commit:** [feat(compiler-cli): drop support for TypeScript older than 5.4](https://github.com/angular/angular/pull/54961)
[Daniel Rosenwasser](https://twitter.com/drosenwasser) highlighted the most interesting new features of Typescript 5.4 in his [announcement](https://devblogs.microsoft.com/typescript/announcing-typescript-5-4/):
- Preserved Narrowing in Closures Following Last Assignments
- The `NoInfer` Utility Type
- `Object.groupBy` and `Map.groupBy`
- Support for `require()` calls in `--moduleResolution bundler` and `--module preserve`
- Checked Import Attributes and Assertions
- Quick Fix for Adding Missing Parameters
- Auto-Import Support for Subpath Imports
## 👨💻About the author
My name is [Gergely Szerovay](https://www.linkedin.com/in/gergelyszerovay/), I worked as a data scientist and full-stack developer for many years, and I have been working as frontend tech lead, focusing on Angular-based frontend development. As part of my role, I'm constantly following how Angular and the frontend development scene in general is evolving.
Angular has advancing very rapidly over the past few years, and in the past year, with the rise of generative AI, our software development workflows have also evolved rapidly. In order to closely follow the evolution of AI-assisted software development, I decided to start building AI tools in public, and publish my progress on [AIBoosted.dev](https://aiboosted.dev) , [Subscribe here](https://aiboosted.dev) 🚀
Follow me on [Substack (Angular Addicts)](https://www.angularaddicts.com/), [Substack (AIBoosted.dev)](https://aiboosted.dev), [Medium](https://medium.com/@GergelySzerovay), [Dev.to](https://dev.to/gergelyszerovay), [X](https://twitter.com/GergelySzerovay) or [LinkedIn](https://www.linkedin.com/in/gergelyszerovay/) to learn more about Angular, and how to build AI apps with AI, Typescript, React and Angular! | gergelyszerovay |
1,867,222 | 🎯 Ace Your Behavioral Interview: Common Questions and Winning Answers 🎯 | Did you know that 89% of hiring failures are due to poor cultural fit? Mastering behavioral interview... | 0 | 2024-05-28T06:03:48 | https://dev.to/hey_rishabh/-ace-your-behavioral-interview-common-questions-and-winning-answers-4ap0 | Did you know that **89% of hiring failures** are due to poor cultural fit? [Mastering behavioral interview questions](https://instaresume.io/interview-series) can help you stand out and demonstrate that you're the perfect fit for the company. Let's dive into some of the most frequently asked behavioral interview questions and how to answer them like a pro. 🌟
### 1. [Tell me about a time you faced a significant challenge at work. How did you handle it](https://instaresume.io/blog/how-to-handle-stress-at-work)? 🚧
**Key Points to Address**
- Situation 🌍
- Task 📋
- Action ⚡
- Result 🎉 (STAR Method)
**Example Answer**
> "In my previous role as a project manager, we encountered a critical issue where a key supplier suddenly went out of business, threatening to derail our project timeline. I quickly gathered my team for a brainstorming session and identified alternative suppliers. I negotiated new contracts and managed to secure the necessary materials within a week. As a result, we delivered the project on time, maintaining our reputation for reliability and saving the company $50,000 in potential penalties."
### 2. Describe a time when you had to work with a difficult colleague. 🤝
**Key Points to Address**
- Understanding the colleague's perspective 🧠
- Effective communication 🗣️
- Conflict resolution 🌈
**Example Answer**
> "While working as a marketing coordinator, I had a colleague who was often uncooperative during team projects. I initiated a one-on-one conversation to understand their concerns and discovered they felt their ideas weren't being heard. I proposed a new approach to our meetings where everyone could share their thoughts at the start. This improved our collaboration and led to a 15% increase in team productivity."
### 3. Give an example of a goal you set and how you achieved it. 🎯
**Key Points to Address**
- Specific goal 🥅
- Steps taken 🛠️
- Outcome 🏆
**Example Answer**
> "At my previous company, I set a goal to increase our social media engagement by 25% within six months. I conducted a thorough analysis of our current strategy and identified key areas for improvement. By implementing a content calendar, engaging with followers more actively, and leveraging analytics to fine-tune our posts, we surpassed our goal, achieving a 30% increase in engagement in just five months."
### 4. [How do you handle multiple tasks and priorities](https://instaresume.io/blog/how-to-handle-stress-at-work)? 📅
**Key Points to Address**
- [Time management](https://instaresume.io/blog/benefits-of-time-management-2023) ⏰
- Prioritization 🗂️
- Use of tools 🛠️
**Example Answer**
> "In my role as an executive assistant, I often had to juggle multiple tasks with tight deadlines. I used a combination of prioritization techniques, such as the Eisenhower Matrix, and project management tools like Trello. By categorizing tasks based on urgency and importance, and regularly updating my to-do list, I consistently met deadlines and supported the executive team effectively."
### 5. Describe a situation where you had to adapt to a major change. 🔄
**Key Points to Address**
- Flexibility 🌿
- Problem-solving 🧩
- Positive outcome 🌟
**Example Answer**
> "During a company merger, my department underwent significant restructuring. I took the initiative to familiarize myself with the new processes and systems by attending additional training sessions. I also organized a weekly meeting with my team to address any concerns and ensure a smooth transition. Our department not only adapted quickly but also improved efficiency by 20%."
---
### Visual Breakdown: Mastering the STAR Method ⭐
](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/fs9e94etv8y5122fq4n8.png)
- **Situation:** Set the context for your story. 🌍
- **Task:** Explain the task you needed to accomplish. 📋
- **Action:** Describe the actions you took to address the task. ⚡
- **Result:** Share the outcome of your actions. 🎉
For more tips and insights on acing your interviews and enhancing your skills, check out these [helpful blogs from InstaResume](https://www.instaresume.io/blog)
https://instaresume.io/blog/common-interview-questions-and-answers
https://instaresume.io/blog/why-do-you-want-this-job
https://instaresume.io/blog/mastering-behavioural-interview-questions
https://instaresume.io/blog/where-do-you-see-yourself-in-5-years Good luck! 🍀🌟 | hey_rishabh | |
1,867,239 | The Critical Role of Mobile Optimization in Web Design and SEO | As the number of mobile users continues to surge, the importance of mobile optimization in web... | 0 | 2024-05-28T06:03:36 | https://dev.to/annamariapascual/the-critical-role-of-mobile-optimization-in-web-design-and-seo-1574 | webdev, javascript | <p><img src="https://play-media.org/wp-content/uploads/2022/06/why-is-mobile-optimization-important.jpg" alt="Why is Mobile Optimization Super Important in 2023" width="615" height="345" /></p>
<p>As the number of mobile users continues to surge, the importance of mobile optimization in web design and SEO has never been more pronounced. A mobile-optimized website is not just a convenience; it’s a necessity. Here’s why mobile optimization should be at the forefront of your digital strategy:</p>
<h2><strong>The Critical Role of Mobile Optimization in Web Design and SEO</strong></h2>
<p><strong>Mobile Usage Trends</strong> </p>
<p>The mobile revolution has changed the way people access the internet. With smartphones becoming increasingly prevalent, more users are browsing the web on-the-go. This shift in user behavior means that websites must be designed with mobile users in mind to provide a seamless and accessible experience.</p>
<p><strong>Mobile-First Design Philosophy</strong> </p>
<p>Adopting a mobile-first design philosophy involves creating a website with the mobile user’s needs as the primary focus. This approach ensures that the most critical information and functionality are presented in a clear, concise manner on smaller screens. It’s about prioritizing content and features that matter most to mobile users.</p>
<p><strong>Impact on User Experience (UX)</strong> </p>
<p>Mobile optimization directly impacts UX. A mobile-friendly website loads quickly, has touch-friendly navigation, and scales content appropriately for smaller screens. This leads to higher user satisfaction, longer engagement times, and lower bounce rates, which are all positive signals to search engines.</p>
<p><strong>SEO Advantages</strong> </p>
<p>Google and other search engines have recognized the shift towards mobile usage and have adjusted their algorithms accordingly. Mobile optimization is now a significant ranking factor. Websites that provide a superior mobile experience are more likely to rank higher in search results, making mobile optimization a critical component of SEO.</p>
<p><strong>Responsive Web Design</strong> </p>
<p>Responsive <span style="color: #3366ff;"><strong><a style="color: #3366ff;" href="https://agenciafort.com.br/criacao-de-sites/">web design criação de sites aqui</a></strong></span> is a technique that allows a website to adapt its layout to the screen size of the device it’s being viewed on. This flexibility ensures that whether a user is on a smartphone, tablet, or desktop, the website provides an optimal viewing experience.</p>
<p><strong>Speed Optimization</strong> </p>
<p>Mobile users expect fast loading times. Speed optimization techniques such as image compression, caching, and minimizing code can significantly improve a website’s loading speed on mobile devices. Faster websites not only provide a better user experience but also contribute to better SEO performance.</p>
<p><strong>Local SEO and Mobile</strong></p>
<p>For businesses with a local presence, mobile optimization is even more critical. Mobile users often search for local information, and a mobile-optimized site with <strong><span style="color: #3366ff;"><a style="color: #3366ff;" href="https://agenciafort.com.br/consultor-seo-local/">local SEO</a></span></strong> can drive foot traffic to physical locations.</p>
<p>In conclusion, mobile optimization is a cornerstone of modern web design and SEO. It enhances user experience, improves search engine rankings, and caters to the growing number of users who rely on mobile devices for their internet usage. Ignoring mobile optimization is no longer an option for businesses that want to succeed online.</p> | annamariapascual |
1,867,238 | Synology-Shared Folder Access Error | Background: A Synology NAS is connected two networks, N1 and N2, both are able to reach Domain... | 0 | 2024-05-28T06:02:24 | https://dev.to/feng_wei/synology-shared-folder-access-error-g23 | synology | Background:
1. A Synology NAS is connected two networks, N1 and N2, both are able to reach Domain X.
2. The NAS was joined Domain X via N1. Share folders access is configured for domain users.
3. The NAS was disconnected from N1 recently.
Issue:
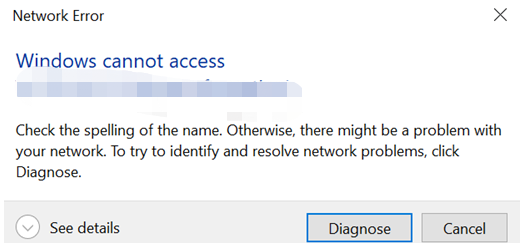
Users reported shared folder is inaccessible due to "Network Error".
Actions(Done within N2):
1. Verify NAS OS status and test shared folder access. OS is normal but shared folder can't be accessed.
2. Restart SMB service then following by restarting NAS. Issue persists.
3. Check default gateway and domain status. Noticed that domain was unavailable. Issue is rectified after rejoining Domain X with N2.
Conclusion:
Domain availability will cause shared folder access issue due to authentication, possibly.
I also noticed the same error, which appears to be caused by a time synchronization issue. In this case, the NAS NTP server was invalid, leading to a time discrepancy of more than 5 minutes between the domain and the NAS itself. | feng_wei |
1,866,629 | Rejeição de teste fechado do Google ~Você precisa pensar em como conseguir testadores~ | Este é um artigo para aqueles que se registraram ou podem se registrar como novos desenvolvedores... | 0 | 2024-05-28T06:00:00 | https://dev.to/zmsoft/rejeicao-de-teste-fechado-do-google-voce-precisa-pensar-em-como-conseguir-testadores-5bk8 | googleplay, androiddev, testefechado, google | Este é um artigo para aqueles que se registraram ou podem se registrar como novos desenvolvedores após a mudança de política do Google. Estou publicando [um aplicativo gratuito(DevsPayForward)] (https://play.google.com/store/apps/details?id=com.andro.zm.tools.androidtesterspayforward) para que esses desenvolvedores cooperem uns com os outros. Se você ler o artigo e estiver interessado, use-o.
O Google exigiu um teste de 14 dias com 20 pessoas. Como desenvolvedor independente, isso por si só já é difícil, mas parece que alguns desenvolvedores tiveram recentemente seus resultados rejeitados após a conclusão do teste e tiveram que começar o teste novamente. Se isso acontecer, pode levar muito tempo, e o desenvolvedor pode ficar exausto. Os desenvolvedores precisam se proteger.
- [Rejeição do Google](#rejeição-do-google)
- [O que devemos fazer para evitar sermos rejeitados](#o-que-devemos-fazer-para-evitar-sermos-rejeitados)
- [No início da fase de avaliação](#no-início-da-fase-de-avaliação)
- [Durante a avaliação](#durante-a-avaliação)
- [Após a conclusão da avaliação](#após-a-conclusão-da-avaliação)
- [Protegendo um testador](#protegendo-um-testador)
- [Finalmente](#finalmente)
## Rejeição do Google

A seguir, uma lista de rejeições.
* Os testadores não se envolveram com seu aplicativo durante o teste fechado
* Você não seguiu as práticas recomendadas de teste, que podem incluir a coleta e a ação sobre o feedback do usuário por meio de atualizações do seu aplicativo.
* Suas respostas às perguntas do aplicativo sobre seu aplicativo, teste fechado ou prontidão para produção foram incompetentes ou insuficientes.
Isso é o que está descrito, e não sei qual é o problema claro. Mas acho que o ponto principal é que eles foram rejeitados porque não veem o objetivo de melhorar a qualidade, que é o propósito dos testes fechados.
# O que devemos fazer para evitar sermos rejeitados
Possíveis ações de rejeição e possíveis soluções alternativasO que posso fazer para que eles percebam que o teste está funcionando bem o suficiente para evitar a rejeição?
* No início da fase de avaliação
* Durante a avaliação
* Após a conclusão da avaliação
## No início da fase de avaliação
Fase inicial de avaliaçãoPrimeiro, é muito importante conseguir testadores que possam fazer testes confiáveis. Há falhas nas regras atuais do Google. Não entrarei em detalhes aqui, mas é possível fazer com que pareça que você concluiu o teste sem ter que preparar 20 contas ou até mesmo instalar o aplicativo. E a dificuldade com esse problema é que, mesmo que um desenvolvedor siga as regras, não há garantia de que seus testadores seguirão as regras. É muito difícil conseguir testadores confiáveis. A maneira mais fácil é usar um serviço pago, mas essa pode ser uma escolha difícil para um desenvolvedor que não sabe se conseguirá gerar muita receita. Isso é um pouco extenso e será discutido em mais detalhes posteriormente.
### Durante a avaliação
Durante a avaliaçãoDurante o período de testes, até mesmo os bugs menores devem ser corrigidos e atualizados. Isso esclarecerá seu compromisso com os testes.
### Após a conclusão da avaliação
No final da avaliaçãoResponda às perguntas do Google no final do teste. Eu mesmo enviei vários aplicativos e não escrevi muita história em minhas respostas, mas felizmente não fui rejeitado. É provável que haja muitos fatores no início e durante o processo de avaliação, mas o que você descreveu aqui poderá ajudá-lo se estiver prestes a ser julgado como alvo de rejeição.
## Protegendo um testador
Esta seção descreve como proteger testadores gratuitos. Consulte meu [artigo anterior] (https://dev.to/zmsoft/comparacao-de-5-metodos-para-reunir-20-testadores-e-o-que-usar-gam) que compara os métodos de proteção de testadores. Agora, não existe uma maneira perfeita de proteger os testadores na qual você possa acreditar. Enquanto os desenvolvedores estiverem subornando uns aos outros para fazer testes, a única maneira é encontrar um desenvolvedor em quem você possa confiar ou verificar o status de seus testes, mas, infelizmente, não é possível saber se eles estão mentindo. O mínimo que você pode fazer é confirmar que fez a instalação. Você pode pedir a eles que comentem sobre o aplicativo de uma forma que você não saberia a menos que o instalasse, ou obter uma captura dele. É um incômodo, mas, pelo menos, evita o comportamento de somente aceitar. Além de facilitar aos testadores o fornecimento de feedback sobre os aplicativos que estão testando, meu aplicativo também verifica o status dos aplicativos de teste. O importante é dar aos outros desenvolvedores o que eles também precisam. Para obter algo, deve haver um preço. A sistematização pode ser planejada para que os desenvolvedores não desperdicem seu tempo e esforço, mas isso não altera o número absoluto de testes. Se um sistema retorna resultados que excedem significativamente as ações que você tomou, você precisa determinar se é um sistema em que pode confiar. Instalar e testar um aplicativo, por si só, é um ato importante e demorado. Por outro lado, atualmente, se você quiser que apenas 20 pessoas se inscrevam, isso é fácil de fazer. Entretanto, se o sistema exigir muito pouco dinheiro ou testes, ou não exigir muitos testes, é possível que esse método esteja sendo usado.

**Todo bom negócio tem um lado negativo, e é você quem será solicitado a refazer o teste de 14 dias. Você mesmo precisa ser cauteloso.** Qual é a estrutura do método que você escolheu para operar e como você pode validar o testador? Pense nisso ao escolher seu método.
## Finalmente
Não gosto da política do Google. Mas eles estão dizendo que esse teste é necessário para melhorar a qualidade. Não sei se essa é a intenção do Google, mas, no final das contas, tudo o que os desenvolvedores precisam fazer é melhorar a qualidade. Se os desenvolvedores cooperarem uns com os outros, será fácil conseguir isso. [Eu ficaria feliz se meu aplicativo pudesse ser usado como um desses métodos para ajudá-los a fazer isso] (https://zmsoft.org/apps-info/androiddeveloperspayforward/). Vamos trabalhar juntos para passar no teste.
Até o final Obrigado pela leitura. Se você gostar, leia outros artigos.
<a href='https://play.google.com/store/apps/details?id=com.andro.zm.tools.androidtesterspayforward&pcampaignid=pcampaignidMKT-Other-global-all-co-prtnr-py-PartBadge-Mar2515-1'><img alt='Get it on Google Play' src='https://play.google.com/intl/en_us/badges/static/images/badges/en_badge_web_generic.png'/></a>
| zmsoft |
1,863,262 | Streamline Development with Effective API Mocking | Let’s say you’re building a new feature. You’ve gone through the API design and are trying to get the... | 0 | 2024-05-28T06:00:00 | https://www.getambassador.io/blog/streamline-development-effective-api-mocking | mocking, api, development | Let’s say you’re building a new feature. You’ve gone through the [API design](https://www.getambassador.io/blog/7-rest-api-design-best-practices) and are trying to get the MVP running. Your frontend team is working on the front end, and your backend devs are building infrastructure and new APIs.
But frontend is going faster than backend. This is understandable, as your backend team has a ton of new APIs to spin up. But the front-end developers want to see what data will look like in their components, and work out how to render out different states based on the API responses. How can the frontend do this without the APIs being up and running?
API mocking lets you simulate the API responses, allowing frontend developers to continue building and testing their applications as if interacting with the backend services. We want to take you through this paradigm in detail, showing how it works, the advantages for all development teams, and how you can build API mocking tests into your [CI/CD pipeline.](https://www.getambassador.io/use-case/continuous-delivery-kubernetes)
## What is API Mocking?
API mocking is a technique used in API development to simulate the behavior of an API without interacting with the actual API. It involves creating a mock (or simulated) API version that mimics its functionality and responses.
The main purpose of API mocking is to allow developers to test and develop their applications independently of the actual API. It helps in scenarios where the real API is:
**Not available:** API mocking allows development to proceed when the actual API has not yet been implemented or deployed, by creating and managing mock APIs.
**Is unstable:** Mocking provides a stable environment for testing when the actual API is prone to downtime or errors.
Has limited access: When API usage is restricted by rate limits or costs, or is an external API with limited access, mocking enables unlimited testing without constraints.
By decoupling API integration development from the underlying API, mocking enables faster development and [testing](https://www.getambassador.io/blog/api-security-testing-guide) cycles, enabling developers to work more efficiently.
## How API Mocking Works
API mocking works using mocking frameworks and libraries.
To create a mock API, developers use API mocking products like [Blackbird](https://www.getambassador.io/products/blackbird/earlybird), frameworks, and libraries to define the expected behavior and responses of the API. Mock objects mimic the behavior of the actual API objects or API endpoints. Developers configure mock objects to return predefined responses or exhibit specific behaviors when invoked by certain methods or endpoints.
Developers define the expected behavior of the mock objects by specifying the input parameters and the corresponding output or actions. This includes setting up expectations for method calls, return values, exceptions, and side effects.
## Here’s the 10,000 ft view of how API mocking works:
1. **Interception**
In API mocking, interception refers to the process where the mocking framework captures outgoing API calls made by the application under test. This step is crucial because it allows the framework to intervene before the request reaches the API.
Tools like WireMock and Nock intercept HTTP requests and redirect them to mock endpoints. This redirection is typically achieved through application configuration changes or by integrating the mocking library directly into the application codebase, allowing developers to specify which calls should be intercepted.
**2. Request Matching
**Once a request is intercepted, the next step is request matching. In this phase, the mocking framework evaluates the intercepted request against predefined rules or patterns to determine which mock response should be applied. This involves matching various aspects of the request, such as the URL, HTTP method, headers, and body content.
Tools like MockServer provide extensive capabilities for detailed request matching, allowing developers to specify complex criteria that a request must meet to trigger a specific mock response.
**3. Response Generation
**After a request is matched, the mocking framework generates a response based on the predefined configuration. This response can vary from simple static data to highly dynamic responses generated based on the request's content.
Frameworks like Mirage JS are handy here, as they can generate sophisticated responses that simulate real-world API behavior, including database operations and conditional logic. This step ensures the mock API can support various test scenarios without needing real backend services.
**4. Response Delivery
**The final step in the API mocking process is response delivery, where the generated mock response is returned to the application. This response must mimic the actual API's behavior as closely as possible, including HTTP status codes, headers, and body content, to ensure that the application's response handling is accurately tested.
Tools like json-server deliver realistic responses quickly and efficiently, making it easier for developers to iterate rapidly on frontend functionality without being blocked by backend readiness.
Let’s now work through an example using one of the libraries above, Mirage JS. We’ll set up Mirage JS to mock a simple [REST API](https://www.getambassador.io/blog/rest-api-security-guide) for a blogging application that handles fetching a list of blog posts.
First, we have to set up a new project and install Mirage JS:
```
mkdir miragejs-example
cd miragejs-example
npm init -y
npm install miragejs
```
In that directory, we’ll then create a file named server.js. This file will set up the Mirage server with routes to handle API requests. Here’s how you can define the server and a route to mock fetching blog posts:
```
import { createServer, Model } from 'miragejs';
createServer({
models: {
post: Model,
},
seeds(server) {
server.create("post", { id: "1", title: "Introduction to API Mocking", content: "Learn about the benefits of API mocking." });
server.create("post", { id: "2", title: "Mirage JS: A Deep Dive", content: "Explore how Mirage JS can simplify frontend development." });
```
},
routes() {
this.namespace = 'api'; // This is where you tell Mirage to intercept requests for this namespace
this.get('/posts', (schema) => {
return schema.posts.all();
});
}
});
The `createServer` function and `Model` class imports are used to set up a new mock server and represent data models that the server will manage, respectively. We can then use createServer to create a new Mirage JS server. The object passed as an argument configures the server, including its data models, initial data, and API routes.
We then define the data model that the Mirage server will use. In this case, a post model allows Mirage to create, store, and manage data for posts as if interacting with a real database. We then use the seeds function to populate the mock server with two posts when it starts. This seeded data, which simulates real data, can then be used immediately for development and testing.
In the routes configuration, the namespace property sets the base URL path that Mirage will intercept. Here, it's set to api, meaning Mirage will handle all API requests that start with /API.
A route handler for GET requests to /posts is defined within the routes block. When a GET request is made to /api/posts, the function provided to this.get is executed. The function retrieves all records for the post model, effectively simulating a response from a real API that queries a database to return all posts.
To test this, we’ll create a file named index.js to call the API. Since Mirage JS intercepts the requests, the data returned will be from Mirage’s server:
`import './server'; //` This imports the server setup
`async function fetchPosts() {
const response = await fetch('/api/posts');
const posts = await response.json();
console.log(posts);
}
fetchPosts();`
We’ll use parcel to serve the JS in a browser:
`npm install -g parcel`
Finally, we’ll create an `index.html` file:
`
`<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Mirage JS Example</title>
</head>
<body>
<script src="index.js"></script>
</body>`
</html>`
Then, run the project:
`parcel index.html`
Open your browser to the URL provided by parcel (usually `http://localhost:1234`). Open the console, and you should see the mocked data printed there, indicating that Mirage JS is intercepting your API calls and providing mock data in response.
## Mirage JS Example
## 7 Advantages of API Mocking
**Faster Development:** API mocking allows developers to work independently of the actual API, enabling parallel development and testing. Developers can start implementing and testing their code without waiting for the API to be fully developed or available. This accelerates the development process and reduces dependencies on external teams or services.
**Improved Testing:** Mocking enables comprehensive testing of the application's interaction with the API. Developers can simulate various test scenarios, including success cases, error conditions, edge cases, and performance issues. Tests can be run quickly and repeatedly without relying on the availability or stability of the actual API. Mocking allows for better test coverage and helps identify bugs and issues early in the development cycle.
**Isolation and Dependency Management:** API mocking isolates the application code from external dependencies, such as databases, network services, or third-party APIs. It allows developers to focus on testing the application logic independently without requiring real API connections or data setup. Mocking helps manage dependencies and reduces the risk of tests failing due to external factors beyond the developer's control.
**Faster Test Execution:** Mocked APIs respond quickly, eliminating the latency and overhead of real API calls. Tests that involve mocked APIs run faster than tests that interact with the actual APIs. Faster test execution enables developers to run tests more frequently and get quicker feedback on the application's behavior.
**Controllability and Predictability:** API mocking gives developers complete control over the API responses and behavior. Developers can define specific responses, simulate error conditions, or introduce delays to test various scenarios. Mocking ensures predictable and consistent behavior during testing, eliminating the variability and inconsistencies that may occur with real APIs.
**Cost Reduction:** Mocking can help reduce costs associated with using real APIs, especially in the development and testing phases. Some APIs may have usage limits, throttling, or pricing tiers based on the number of requests. By mocking the APIs, developers can avoid consuming real API resources and incurring unnecessary costs during development and testing.
**API Contract Testing: **API mocking can be used for contract testing, which verifies that the application and the API adhere to a predefined contract or specification. Developers can create mock APIs based on the agreed-upon contract and test the application against those mocks. Contract testing helps ensure compatibility, catch breaking changes, and maintain the integration integrity between the application and the API.
API mocking gives development teams faster development cycles, improved testing capabilities, better isolation and dependency management, and cost savings. You can use API mocking to enhance the overall efficiency and quality of the software development process.
## Integrating Mock APIs with CI/CD Pipelines
Writing API mocks alone, as we did above, is an excellent way to quickly test and build different components of your application. However, API mocks are most efficiently used in continuous integration and continuous deployment (CI/CD) pipelines.
By integrating mock APIs into CI/CD pipelines, development teams can achieve several benefits:
**Faster feedback loops: **Tests can be run quickly and frequently, providing [rapid feedback](https://www.getambassador.io/blog/enabling-full-cycle-development-kubernetes) on the application's behavior and catching issues early.
**Improved reliability: **Mock APIs help ensure that the application functions as expected, even when the real APIs are unavailable or unstable.
**Efficient deployment:** Mock APIs facilitate smooth deployments by validating the application's compatibility and behavior in target environments.
Let’s say we’re using unittest.mock to mock some API functionality. The basic API fetch looks like this:
`# app.py
`
import requests
`def fetch_data(url):
response = requests.get(url)
if response.status_code == 200:
return response.json()
return None`
We can then write a test using unittest to mock the response from the API:
`# test_app.py
`
`import unittest
from unittest.mock import patch
from app import fetch_data`
`class TestFetchData(unittest.TestCase):
@patch('app.requests.get')
def test_fetch_data_success(self, mock_get):
"""Tests successful API call."""
mock_get.return_value.status_code = 200
mock_get.return_value.json.return_value = {'key': 'value'}
result = fetch_data('https://api.example.com/data')
self.assertEqual(result, {'key': 'value'})
@patch('app.requests.get')`
def` test_fetch_data_failure(self, mock_get):
"""Tests failed API call."""
mock_get.return_value.status_code = 404
result = fetch_data('https://api.example.com/data')
self.assertIsNone(result)`
`if __name__ == '__main__':
unittest.main()`
Here, we’re using the unittest.mock patch function to replace the actual requests.get call with a mock that we can control, allowing us to simulate different response scenarios for our API without making real network requests. This enables testing how our application code handles various API responses, such as successful data retrieval or handling errors, in a predictable and repeatable manner.
We can then use GitHub Actions to run tests against this API fetch using patch whenever we commit new code. This way, we can ensure that any changes made to the codebase maintain the expected functionality and do not introduce regressions or bugs.
All we need is to add a python-app.yml file in a .github/workflow directory in our repository:
`name: Python application test
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
build:
runs-on: ubuntu-latest`
`steps:
- uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v1
with:
python-version: 3.8
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install requests
- name: Run tests
run: |
python -m unittest discover -s .
`
This will run any unit tests automatically whenever new code is pushed to the `main` branch, or a pull request is made against it.
## Phyton application test
By including these mock API tests in the GitHub Actions workflow, developers can automatically verify each change against the expected behaviors scripted in the tests, thus improving code quality and reducing the likelihood of unexpected issues in production environments.
## Advanced Mocking Techniques
The above examples show mocking a basic response from an API. However, APIs have advanced functionalities, and you need to test your code against all their components before integrating with them.
Advanced mocking techniques are essential for handling complex scenarios and interactions in API testing. Here are some advanced mocking methods that you can consider integrating into your testing strategy:
**Dynamic Responses
**Dynamic data generation allows the mock to generate and return data that changes dynamically with each request rather than returning static predefined responses. This is useful for testing how your application handles varied data under different scenarios. Techniques include:
**Randomized Data:** Use libraries like Faker in Python to generate random but realistic data sets, such as names, addresses, and emails. This randomness helps ensure that your application can handle various input data.
**Template Systems:** Employ templates with placeholders for dynamically populated fields at runtime. This can include variable error messages, user data, timestamps, and more.
**Data Pools:** Rotate through a set pool of data scenarios, which can mimic the behavior of a database with a finite set of rows. This is useful for testing caching mechanisms or load balancing.
For example, in Python, you can use unittest.mock alongside faker to dynamically generate test data:
`
from faker import Faker
import unittest
from unittest.mock import patch
from myapp import process_user
fake = Faker()`
`class TestProcessUser(unittest.TestCase):
@patch('myapp.fetch_user_data')
def test_user_processing(self, mock_fetch):
# Generate a fake user profile
user_profile = {
"name": fake.name(),
"email": fake.email(),
"address": fake.address()
}
mock_fetch.return_value = user_profile
# Test the function that processes the user data
result = process_user(1) # Assumes process_user calls fetch_user_data internally
self.assertIn(user_profile['name'], result)`
## Conditional Responses
Conditional responses allow your mock APIs to react differently based on the specifics of the request, which can help in testing the application's decision-making pathways:
**Path-Based Conditions:** Implement logic within the mock to provide different responses based on the URL path or query parameters. This is useful for APIs that serve different resources or actions based on the URL.
**Header-Based Responses:** Vary responses based on headers, such as content type or authentication tokens, to test how the application handles various types of requests or levels of access.
Behavioral Adaptation: Configure the mock to adapt its behavior based on previous interactions with the client. This simulates scenarios where subsequent responses depend on the history of the API usage.
## Stateful Mocks
Stateful mocks simulate APIs that maintain state across multiple interactions, which is essential for testing sequences of requests where the outcome depends on the state:
**Session Simulation: **Maintain user sessions through mock APIs to test features like login sequences, shopping carts, or any multi-step process that requires user context.
**Sequential Operation Testing:** Use stateful mocks to verify operations that must occur in a specific order, such as creating, updating, and deleting a resource.
**State Transition Validation:** Ensure that the application correctly handles state transitions, such as from an "in-progress" state to a "completed" status, reflecting real-world operations.
Error and Exception Handling
Error and exception handling in mocks is crucial for ensuring your application can gracefully handle API failures:
**Simulating HTTP Errors:** Mock responses to simulate various HTTP status codes (like 400, 404, 500) to test how your application responds to different error conditions.
Exception Throwing: Configure mocks to throw exceptions under certain conditions to ensure your application can catch and handle these exceptions appropriately.
**Timeout Simulation:** Emulate network timeouts or long response delays to verify that the application can handle timeouts effectively by retrying requests or failing gracefully.
For instance, you should always have testing for rate limit errors for API mocking. With unittest we can add a rate limit exception and a test against it:
`import unittest
from unittest.mock import patch
from app import fetch_data
`
`class TestFetchData(unittest.TestCase):
@patch('app.requests.get')
def test_rate_limit_handling(self, mock_get):
"""Tests handling of rate limiting API responses."""
# Configure the mock to simulate a 429 error
mock_get.return_value.status_code = 429
mock_get.return_value.json.return_value = {'error': 'rate_limit_exceeded'}`
# Call the function that makes the API request
result = fetch_data('https://api.example.com/data')
# Check if the function handles rate limits correctly
self.assertEqual(result, "Rate limit exceeded, please try again later.")
if __name__ == '__main__':
unittest.main()
## API Mocking as a Development Accelerator
API mocking is an invaluable technique in software development, allowing teams to simulate API behaviors and responses without relying on actual backend services. By integrating API mocking into your development and testing workflows, you can accelerate development cycles, enhance testing efficiency, and improve the overall reliability of your applications.
Whether you're working to align frontend and backend development timelines or aiming to ensure your application can gracefully handle real-world scenarios, API mocking provides the control and flexibility needed to develop high-quality software. As technology evolves, so too does the importance of mastering such techniques, which are crucial for modern CI/CD pipelines and ensuring seamless, continuous delivery of services.
| getambassador2024 |
1,867,236 | What is Low Code Test Automation? | Testing becomes critical in the fast-paced world of low code development, where creating a new screen... | 0 | 2024-05-28T05:59:17 | https://www.headspin.io/blog/a-step-by-step-guide-to-low-code-test-automation | testing, mobile, lowcode, webdev | Testing becomes critical in the fast-paced world of low code development, where creating a new screen can take just an hour. Traditional testing methods often extend beyond development time, especially with features like drag-click functionality. There's a temptation to skip these time-consuming steps for quicker delivery, but it's essential to remember that low code still involves code, and human errors can occur.
Every IT organization must, therefore, craft a cost-effective test strategy that balances speed and reliability. This strategy should address inherent risks and outline potential consequences, ensuring a pragmatic approach to testing in low code scenarios.
This blog explores the strategies and crucial considerations indispensable in delineating the landscape of low code software testing.
## Understanding Low Code: What is it?
Low code, a modern software development approach, transforms the application-building process by minimizing the need for extensive coding. Instead of grappling with complex programming languages, low code [test automation](https://www.headspin.io/blog/what-is-test-automation-a-comprehensive-guide-on-automated-testing) platforms provide visual interfaces with basic logic and drag-and-drop capabilities, offering a swift and user-friendly alternative to traditional methods. This simplicity has catapulted the popularity of these platforms, empowering employees to craft solutions without deep coding expertise while upholding robust IT governance and mitigating the reliance on shadow IT.
Despite a prevailing myth, low code test automation platforms extend beyond simple projects. In reality, they excel in effectively managing and streamlining complex, large-scale business operations, establishing themselves as a versatile asset in any business's technological toolkit.
## Low Code Test Automation: A Quick Guide
- **Fostering Adoption and Community**: Transitioning from manual to automated software testing is crucial for DevOps teams facing increasing demands. However, more than merely having a few team members onboard is required. Successful adoption requires a solution that demonstrates quick value without extensive script building. Opt for codeless testing frameworks to showcase ROI, making test automation accessible and appealing to a broader audience. The goal is cultivating a test automation community with shared goals and best practices.
- **Embracing Shift Left**: The industry buzz around "shifting left" emphasizes finding and preventing defects early in software delivery. To achieve this, integrate development teams into the testing framework and foster a unit testing culture. Unified tools, shared repositories, and collaborative pipelines break down silos between dev and QA teams, ensuring synchronous work and substantial time savings.
- **Integrating CI/CD into the process** - Incorporating Continuous Integration (CI) and Continuous Deployment (CD) into the test automation process is crucial. Ensure a holistic understanding of CI for multiple systems, addressing unit test case involvement and coverage measurement questions. On the CD front, focus on package building, check-ins, and seamless deployment across environments. Establishing a robust CI/CD process, hand in hand with automation champions, is a multi-step journey involving tool selection, community formation, and process maturation.
Remember, successful automation requires champions within the organization. Prioritize simplicity, avoid unnecessary layers, and leverage the right tools and integrations to streamline the testing and deployment process.
> Read: [What Are The Benefits of Using Automated Functional Testing?](https://dev.to/jennife05918349/what-are-the-benefits-of-using-automated-functional-testing-2m3g)
## Navigating Obstacles in Traditional Automation Testing
In the realm of traditional automation testing, several obstacles loom large, impeding smooth operations and efficiency:
- **Tool Complexity**: Traditional automation tools such as Selenium are often formidable foes, thanks to their intricate coding requirements and the need to establish a test grid. Moreover, the demanding infrastructure prerequisites compound the challenges, making these frameworks cumbersome to wield effectively.
- **Maintenance Burden**: A significant chunk of automation endeavors is devoured by the relentless demand for script maintenance. Any tweaks or updates in the application compel testers to embark on the arduous task of rewriting test scripts, consuming valuable time and resources.
- **Code Intensity**: Traditional automation testing is notorious for its complexity and heavy reliance on coding. This complexity frequently leads to approximately half of all test automation projects floundering due to insufficient planning and needing more skilled personnel.
- **Test Data Dilemma**: The management and upkeep of test data present yet another formidable challenge. Testers must create test data generation scripts, employ version control mechanisms, and implement other strategies to wrangle test data effectively.
- **High Coding Skill Prerequisite**: Automation frameworks typically demand testers who are well-versed in coding intricacies. However, the reality is starkly different, with many manual testers needing more requisite coding chops. Bridging this skill gap necessitates either upskilling existing personnel or recruiting specialized automation testers, adding further complexity to the equation.
Navigating these hurdles is pivotal to streamlining the automation testing process and ensuring its efficacy in modern software development landscapes.
## Importance of Low Code Testing
In response to the complexity and coding intensity of traditional automation testing, low code testing emerges as a compelling solution between test creation and the expertise required for automation testing:
1. **User-Friendly Approach**: Low code testing simplifies automation through intuitive record and playback mechanisms. Test creation becomes accessible to a broader range of professionals as users can automate tests by simply recording on-screen actions.
2. **Minimal Coding Requirement**: One of the primary benefits of low code testing is its reduced dependency on coding skills. This accessibility enables a broader pool of professionals to participate in testing.
3. **Self-Healing Scripts**: Low code automation tools offer self-healing capabilities, dynamically adapting to minor application changes. This functionality notably decreases the necessity for manual script modifications and upkeep.
4. **Automated Test Data Generation**: Leveraging AI capabilities, low code testing platforms automate test data generation, enhancing efficiency and accuracy while minimizing manual input.
5. **Scalability and Maintenance**: Low code automation is highly scalable and adaptable to various release schedules, including daily, weekly, or continuous integration systems. This flexibility streamlines maintenance efforts and ensures alignment with evolving testing needs.
6. **Improved Time-to-Market**: By reducing testing time by up to 90%, low code platforms expedite the development cycle, enabling faster time-to-market for software products.
7. **Comprehensive Device Coverage**: Low code testing facilitates testing across multiple browsers, devices, and resolutions, ensuring thorough cross-browser and cross-platform compatibility checks.
8. **Cost Efficiency**: Transitioning to intelligent low code test automation typically results in substantial savings. This reduction stems from minimized code maintenance complexities and decreased reliance on specialized coding resources.
9. **Mitigation of Technical Debt**: Low code testing mitigates technical debt, encompassing the costs of maintaining and fixing application code. Simplifying test maintenance and updates minimizes complexities and reduces the long-term costs of code upkeep.
> Also read: [Achieving Exceptional Software Delivery with Future-proof Testing](https://dev.to/jennife05918349/achieving-exceptional-software-delivery-with-future-proof-testing-during-an-economic-downturn-27da)
## Who Utilizes Low Code?
Individuals without extensive coding expertise can leverage low code testing techniques to construct software for diverse purposes, including creating mobile and business applications. This accessible approach caters to technical and citizen developers, empowering them to meet market demands for growth, streamline processes, and drive digital transformation.
### Benefits of Low Code for Business Owners:
Implementing low code delivers prompt and tangible benefits for business owners. Here are the key advantages:
- **Increased Agility**:
Facilitates quick and easy development and deployment of new apps, enhancing organizational agility to respond promptly to evolving business needs.
- **Prevention of Technical Debt**:
Mitigates the risk of technical debt by providing a structured environment for application development, reducing the likelihood of poor coding practices.
- **Reduced Costs**:
Minimizes the need for specialized programming resources, leading to lower development costs, and automates repetitive tasks, further reducing costs.
- **Enhanced User Experience**:
Enables business owners to craft tailored apps that enhance the user experience, aligning with specific user needs.
- **Faster Time to Market**:
Accelerates the app development process, allowing organizations to swiftly introduce new products and services to market.
- **Improved Decision-Making**:
Provides real-time data and insights, empowering business owners to make informed, data-driven decisions that enhance overall business performance.
- **Access to New Technologies**:
Plays a pivotal role in enterprise modernization, facilitating efficient system and process updates. Allows seamless integration of cutting-edge technologies like AI and machine learning, ensuring competitiveness in the dynamic digital landscape.
### Embracing the Low Code Culture:
Now is the opportune moment if you still need to embrace the low code culture. However, this transition may pose challenges unless accompanied by adequate measures. Incorporating a new platform requires educating your team on its functionality, potentially necessitating organizational restructuring.
> Check out: [Why Is Appium Better For Mobile Test Automation](https://dev.to/jennife05918349/why-is-appium-better-for-mobile-test-automation-4jh)
## Streamlining the Low Code Automation Testing Process
Low code automation testing represents a contemporary approach to software testing, utilizing low code platforms to simplify and accelerate test creation, management, and execution. Here's a streamlined overview of the typical low code automation testing process:
- **Establish Test Objectives**: Begin by defining the key objectives of your tests and assessing the application's flow that requires testing.
- **Choose a Low-Code Test Automation Tool**: Select an appropriate low-code automation tool tailored to your project's requirements. Look for tools offering intuitive interfaces with record and playback functionalities, empowering testers to develop test scripts efficiently, regardless of their coding proficiency.
- **Develop Test Scenarios**: Create a comprehensive plan outlining the various test scenarios and aspects of the application to be tested.
- **Record Tests**: Utilize the visual interface of your chosen low code automation testing tool to construct test scripts effortlessly. These tools often offer automatic script creation capabilities and aid in configuring test data.
- **Execute Tests**: Run tests on demand as needed, based on your project's requirements.
- **Analyze Results**: Evaluate the results of each test step, highlighting their pass or fail status, to monitor progress and identify any issues effectively.
- **Schedule and Maintain**: Utilize self-healing capabilities to minimize maintenance efforts, intervening only when necessary. Easily schedule tests at predefined intervals, ensuring consistent and automated quality checks.
An effective low code automation tool seamlessly manages test automation from start to finish, addressing concerns related to execution, monitoring, scheduling, and maintenance.
## Choosing the Right Low Code Test Automation Platform for Your Business
### Preparation is Key:
Before diving into demos and trials, outline realistic use cases. Ensure a mix of customer-facing and internal apps, simple and complex solutions, and critical and optional projects to compare low-code testing platforms comprehensively.
### Key Features to Consider:
- **Security**:
Verify that the platform aligns with enterprise requirements for both B2C and B2B apps. Prioritize identity management, secure encryption, and user rights management to enhance workflow control and data security.
- **Integration Options**:
Evaluate how well the platform integrates with your existing systems, focusing on simplicity for users to access and utilize data from various sources, both internal and external.
- **Cross-Platform Capabilities**:
Ensure the low code solution is compatible with your customer's and employees' diverse devices and platforms. Look for the ability to develop one deployable app across multiple platforms.
- **Notifications**:
Opt for platforms with robust notification services to promptly alert your IT team to any app issues.
- **Intuitive Interface**:
Prioritize simplicity with drag-and-drop functionality and user-friendly tools. Involve developers and business users in testing to ensure ease of use for everyone.
- **Custom Development Tools**:
Seek platforms that allow developers to incorporate custom code, offering a head start on complex projects while leveraging templated solutions.
- **Scalability**:
Consider your organization's growth prospects and ensure the chosen platform seamlessly scales alongside an expanding workforce.
## How HeadSpin's Cutting-Edge Testing Features Facilitate Seamless Low Code Test Automation for Organization
#### **Real User Monitoring (RUM)**:
- HeadSpin provides real-time monitoring of low code applications by tracking user interactions and behavior.
- RUM capabilities help organizations understand how end-users are experiencing their low code software, ensuring a seamless user experience.
#### **Performance Testing**:
- HeadSpin's advanced testing tools enable comprehensive performance testing for low code applications.
- It helps organizations identify and address performance bottlenecks, ensuring low code solutions can handle the expected load and [deliver optimal performance](https://www.headspin.io/blog/a-performance-testing-guide).
#### Network Condition Testing:
- HeadSpin's extensive global device infrastructure allows testing low code applications under various network conditions, including low bandwidth and high latency scenarios.
- This ensures the application remains functional and responsive even in less-than-ideal network environments, catering to a diverse user base.
#### **Device Compatibility Testing**:
HeadSpin supports testing low code applications across various devices and operating systems.
Organizations can verify that low code test automation tools work seamlessly on different devices, enhancing accessibility and user satisfaction.
#### **Automated Testing for Low Code Platforms**:
HeadSpin offers automation capabilities tailored to low-code environments.
Automated testing ensures faster and more reliable testing cycles, allowing organizations to keep up with the rapid development pace of low code platforms.
#### **Security Testing**:
- HeadSpin includes robust security testing features to identify vulnerabilities in low code applications.
- Security testing helps organizations address potential threats and ensure their low code solutions meet security standards.
#### **Cross-Browser Testing**:
- HeadSpin supports cross-browser testing for low code applications.
- This ensures consistent functionality and appearance across different web browsers, providing a reliable experience for users with diverse browser preferences.
#### Comprehensive Reporting and Analytics:
- HeadSpin provides detailed reports and analytics on the performance and quality of low code applications.
- Empowering organizations with insights for informed, data-driven decisions to optimize and enhance their low code solutions.
## What's Next?
Gather insights from your development team before embracing low code/no-code platforms. While these platforms empower citizen developers, your enterprise development staff remains crucial for the success of your technology landscape. When building your technological stack, prioritize providing your development team with the tools they prefer and require.
Low code testing tools can transform your company, optimizing efficiency and increasing outputs. Foster a culture of collaboration and celebrate each success as it unfolds throughout the organization.
The HeadSpin AI-driven testing Platform is a pivotal link between business users and IT, streamlining work management and significantly expediting digital transformation. Through HeadSpin's low code software testing capabilities, business users gain control over their digital requirements, while IT leaders maintain a secure and scalable platform, facilitating perfect digital experiences.
_Article resource: This article was originally published on https://www.headspin.io/blog/a-step-by-step-guide-to-low-code-test-automation_ | abhayit2000 |
1,867,235 | Zed Editor - My honest opinion | Context Recently I tried using ZED the new code editor which claims to be fast by using... | 0 | 2024-05-28T05:57:24 | https://dev.to/fadhilsaheer/zed-editor-my-honest-opinion-3818 | webdev, code, programming | ### Context
Recently I tried using [ZED](https://zed.dev/) the new code editor which claims to be fast by using less system resources. On my new company I was provided with a Macbook air, since it old and still uses intel processors it was kinda slow. But it was usable. As a long time VSCode user, as usual I installed vscode and used, since node js takes some memory, vscode was laggy with my project. So I switched to ZED.
### Why ZED ?
Zed claimed to be fast and performant, with less resource conception (which is true btw). And i thought it would be great, I installed zed, opened my next js project, Installed some extensions for React & Tailwind. I was good to go, until..
### Why I hate ZED
It was OK using zed at first, since its a lightweight software I didn't expect it to perform much, but It was awesome, the suggestion was fast. But when I select a suggestion something else gets entered, likewise for autoimport, It didn't import the files, which I selected from auto import suggestion.
Even though I didn't expect a full grown jetbrains like editor, at least I expected it work with the features they given, why show suggestion If you can't even enter the clicked suggestion. Same for autoimport.
Using zed was like using notepad for me, I was simply writing my code, except zed has color theme, but notepad doesn't.
This was my experience with ZED, I assume since its a new software bugs like these are expected, and will be fixed soon. Sometimes I get too frustrated writing in ZED with their bugs. First of all I'm struggling with my bugs, I don't have luxury to enjoy other's bugs.
### Conclusion
Even though I hate ZED as it is now, It was a life saver for me, It barely used any system resource which was a huge help. But still If you ask me, I prefer good old VI over ZED now.
ZED got a huge potential, and I think it will shine in future, and I expect them to kill VScode by next year. I would like to personally switch to ZED on all of my machines. | fadhilsaheer |
1,867,234 | ML Intro : IRIS DATASET | Hello World of Machine Learning: Iris Dataset 🐍🤖 In machine learning, the Iris dataset is... | 0 | 2024-05-28T05:56:40 | https://dev.to/kammarianand/ml-intro-iris-dataset-4e13 | machinelearning, ai, datascience, python | ## Hello World of Machine Learning: Iris Dataset 🐍🤖
In machine learning, the Iris dataset is often considered a "hello world" example. It's a classic dataset that is widely used for demonstration and testing purposes. In this tutorial, we'll explore the Iris dataset, load it from scikit-learn (sklearn), visualize the data, train a machine learning model, and evaluate its performance.

## Prerequisites
Before proceeding, make sure you have the following libraries installed:
- **NumPy**: NumPy is a library for the Python programming language, adding support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays.
- **Pandas**: Pandas is a data manipulation and analysis library for Python, providing easy-to-use data structures and functions to work with structured data.
- **Matplotlib**: Matplotlib is a plotting library for Python, which produces publication-quality figures in a variety of formats and interactive environments across platforms.
- **Scikit-learn**: Scikit-learn is a machine learning library for Python, offering various tools for data mining and data analysis, built on NumPy, SciPy, and matplotlib.
You can install these libraries using `pip`:
```bash
pip install numpy pandas matplotlib scikit-learn
```
## Importing the Iris Dataset
The Iris dataset is included in the `scikit-learn` library, so we can import it directly without downloading any external files. Let's start by importing the necessary libraries and loading the dataset:
```python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
```
```python
# Load the Iris dataset
iris = load_iris()
```
The `load_iris()` function from the sklearn.datasets module loads the Iris dataset. This dataset contains information about three different species of Iris flowers: Setosa, Versicolor, and Virginica. Each data instance represents a single flower, and the features include sepal length, sepal width, petal length, and petal width (all measured in centimeters).
### Understanding the Dataset
* Let's explore the dataset and its components:
```python
# Print the description of the dataset
print(iris.DESCR)
```
```python
# Print the feature names
print("Feature names:", iris.feature_names)
```
#### output:
```python
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
```
```python
# Print the target names (species)
print("Target names:", iris.target_names)
```
#### output:
```python
Target names: ['setosa' 'versicolor' 'virginica']
```
```python
# Print the first few rows of the data
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
print(iris_data.head())
```
#### output:
```python
| | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) |
|---|--------------------|-------------------|--------------------|-------------------|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
```
The dataset description provides information about the Iris dataset, including its origin and characteristics. The `feature_names` attribute lists the names of the input features, and the `target_names` attribute lists the names of the target classes (species). The dataset itself is stored in the data attribute, and we've converted it into a Pandas DataFrame for easier viewing.
```python
# Create a scatter plot of petal length vs petal width
plt.scatter(iris_data['petal length (cm)'], iris_data['petal width (cm)'], c=iris.target, cmap='viridis')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.title('Iris Dataset: Petal Length vs Petal Width')
plt.colorbar(label='Species')
plt.show()
```
#### plot:
---
This code will generate a scatter plot where each data point is colored according to its species. The plot should reveal a clear separation between the Setosa species and the other two species (Versicolor and Virginica) based on petal length and petal width.
### Training a Machine Learning Model
Now, let's train a machine learning model to classify the Iris species based on the input features. We'll use the `K-Nearest Neighbors (KNN)` algorithm from `scikit-learn`:
```python
from sklearn.neighbors import KNeighborsClassifier
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# Create and train the KNN model
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
```
Here, we've split the dataset into training and testing sets using the `train_test_split` function from scikit-learn. We've set aside 20% of the data for testing (test_size=0.2).
We then create an instance of the `KNeighborsClassifier` class with n_neighbors=5, which means the model will consider the 5 nearest neighbors when making predictions.
Finally, we train the model using the fit method, passing in the training data `(X_train)` and training labels `(y_train)`.
### Model Evaluation
After training the model, we can evaluate its performance on the testing set:
```python
from sklearn.metrics import accuracy_score, classification_report
# Make predictions on the testing set
y_pred = knn.predict(X_test)
# Calculate the accuracy score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# Print the classification report
print("Classification Report:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
```
The accuracy_score function from scikit-learn calculates the accuracy of the model's predictions by comparing the predicted labels (y_pred) with the true labels (y_test).
The classification_report function provides a more detailed evaluation, including precision, recall, and F1-score for each class.
```python
Accuracy: 0.9666666666666667
```
```python
Classification Report:
| | precision | recall | f1-score | support |
|--------------|-----------|--------|----------|---------|
| setosa | 1.00 | 1.00 | 1.00 | 11 |
| versicolor | 0.90 | 0.94 | 0.92 | 9 |
| virginica | 0.97 | 0.95 | 0.96 | 10 |
```
```python
| Metric | Precision | Recall | F1-Score | Support |
|---------------|-----------|--------|----------|---------|
| Macro Average | 0.96 | 0.96 | 0.96 | 30 |
| Weighted Avg | 0.96 | 0.97 | 0.96 | 30 |
```
In this example, the KNN model achieved an accuracy of 96.67% on the testing set, which is quite good for the Iris dataset. The classification report shows that the model performed well across all three classes, with high `precision`, `recall`, and `F1-scores`.
Conclusion
In this tutorial, we explored the classic Iris dataset, loaded it from scikit-learn, visualized the data, trained a KNN machine learning model, and evaluated its performance. This exercise serves as a great introduction to the world of machine learning, covering essential steps like data exploration, model training, and model evaluation.
###### Feel free to experiment further with this dataset: try different machine learning algorithms or explore additional evaluation metrics. Happy coding!
---
About Me:
🖇️<a href="https://www.linkedin.com/in/kammari-anand-504512230/">LinkedIn</a>
🧑💻<a href="https://www.github.com/kammarianand">GitHub</a> | kammarianand |
1,867,231 | Best ACL Surgeon in Hisar | It is really painful to have ACL injuries and can even force you to become a prisoner of your own... | 0 | 2024-05-28T05:54:13 | https://dev.to/thecruciates/best-acl-surgeon-in-hisar-30p2 | fitness, healthydebate, surgery, surgeon | It is really painful to have ACL injuries and can even force you to become a prisoner of your own body. More to it, the best gender for managing of new such injuries is also very vital. For ACL surgery, one
of the most preferred hospitals in Hisar,[ The Cruciates](https://thecruciates.com/) has made its name as one of the [Best ACL Surgeon in Hisar](https://thecruciates.com/best-acl-surgeon-hisar/). Now, let’s immerse into the identification of the clinic’s strengths and its team best practices.
### **Understanding ACL Injuries - Best ACL Surgeon in Hisar**

The Anterior Cruciate Ligament is one of the key ligaments in the human knee – a structure that holds the thigh bone in place in the shin. This surface is particularly important when an individual is required to perform sideways movements or sudden changes of direction, including
stopping. Some of the most common situations when ACL injuries happen are in football, basketball, skiing, or any form of activities that require quick rotations and leaps. Why this occurs: It can result from rapid acceleration or deceleration, internal or external rotation, or by a direct blow to the affected area.
Hence, getting to know the signs of an ACL injury is important in order to extend the assistance to the affected individuals. Based on a set of local signs and symptoms, common signs include: A clear loud sound at the point of injury Any form of athletic activity, pain and inability to continue, rapid swelling, decrease in range of motion, and even a feebling feeling that the knee joint may give way.
**
##
Diagnosis of ACL Injuries
**
Yes, experienced doctors are capable of diagnosing ACL injuries through routine physical examination of the affected limb. This may involve a number of exercises in order to identify knee’s efficiency and how well
it is stable. MRI or X-ray is used to confirm the diagnosis by providing visuals of the affected physical area. These tests offer clear X-ray films of the Knee joint to decide the level of damage on the bone.
An ACL surgeon is a medical specialist who performs an ACL reconstruction procedure, commonly known as surgery to repair or reconstruct the anterior cruciate ligament in the knee.
An ACL surgeon is a medical professional who is skilled in determining ACL tears and conducting operations related to this injury. The benefits of seeking medical attention from a professional are that they can afford you the best care, and you are most likely to regain your
health. There are mainly two types of ACL surgeries: Reconstruction which involves using a tendon, also known as graft, to replace the severed ACL then is calledACL Reconstruction The second category is repair in which the damaged ACL is rejoined back, this is often time used in relatively less severe cases.
**Insurance and Financial Considerations**
The Cruciates itself has received affiliations from many insurance policies, thus making its services available to a large populace. Feasible solutions such as payment plans and financial advice are available to assist clients who may be limited due to the cost of surgery as well as operation and rehabilitation.
**Location and Accessibility**
The Cruciates is located at Hisar and has accessible grounds for patients from Hisar as well as other regions. Thisclinic had to be located at a central place of town to suit those who are in desperate need of quality ACL treatment.
**Booking an Appointment**
Paying a consultation at The Cruciates is as easy as clicking the button below. One can call them to make an appointment or visit their website to fix a date for the clinic. The people working there are friendly and have sufficient knowledge about the process to offer the appropriate level of help and support to the patients.
**
## Conclusion - Best ACL Surgeon in Hisar
**
To anyone who has been diagnosed with an ACL health issue, The Cruciates in Hisar is the most appropriate place that will provide one with the correct treatment. Ever been to a dentist and thought you were in good hands? Certainly, you will feel the same with Dr. Nagendra Prasad, qualified professionals, up to date equipment and overall patient centred care. Talk to Dr. Lima at The Cruciates about the best way to manage an ACL injury—there is no reason the injury has to be a life sentence.
**
## FAQs
**
1. How soon is patient ready to perform sports after ACL surgery?
As for the duration of Recovery, it depends on many aspects such as the type of the surgery done, but a person should get back to his/ her regular life after 6-9 months.
2. I need to know what signs show that I need to undergo ACL surgery.
If these symptoms continue to become painful, unstable, and difficult to manage for daily tasks or sports, one should seek medical attention from a surgeon such as Dr. Prasad to ascertain whether to get a surgery.
3. What can help us identify our major competitive advantage over other clinics such as The Cruciates?
The Cruciates targets on ACL surgeries through personalized care, utilization of the modern sophisticated equipment and equipment association with Dr Nagendra Prasad.
| thecruciates |
1,867,227 | Found more than one `BaseRetriever` in app while trying to use Trulens evaluate results for different langchain chains | Hello All, I am using "create_retrieval_chain", "create_history_aware_retriever" and... | 0 | 2024-05-28T05:50:33 | https://dev.to/binjan_iyer_ca49b5bf7c351/found-more-than-one-baseretriever-in-app-while-trying-to-use-trulens-evaluate-results-for-different-langchain-chains-5dll | Hello All,
I am using "create_retrieval_chain", "create_history_aware_retriever" and "create_stuff_documents_chain" for my RAG application. when I integrate TruLens for the evaluate results. It shows me error:
```
ValueError: Found more than one `BaseRetriever` in app:
<class 'langchain_core.vectorstores.VectorStoreRetriever'> at bound.branches[0][1].last
<class 'langchain_core.vectorstores.VectorStoreRetriever'> at bound.default.last
```
code:
```
# Initialize the language model with the OpenAI API key and model name from environment variables
llm = ChatOpenAI(
api_key=os.environ["OPENAI_API_KEY"],
model_name=os.environ["OPENAI_API_GPT_MODEL"],
temperature=0.2
)
document_chain_prompt = ChatPromptTemplate.from_messages(DOCUMENT_CHAIN_PROMT)
# Create the document chain using the language model and the prompt template
document_chain = create_stuff_documents_chain(
llm,
document_chain_prompt
)
# Define the prompt template for generating a search query based on the chat history
history_aware_retriever_chain_prompt = ChatPromptTemplate.from_messages(HISTORY_AWARE_RETRIEVER_CHAIN_PROMPT)
# Create a history-aware retriever chain using the language model, retriever, and the prompt template
history_aware_retriever_chain = create_history_aware_retriever(
llm,
vectDB_as_retriever,
history_aware_retriever_chain_prompt
)
#################################################################
# select context to be used in feedback. the location of context is app specific.
context = App.select_context(history_aware_retriever_chain)
# Define a groundedness feedback function
f_groundedness = (
Feedback(provider.groundedness_measure_with_cot_reasons)
.on(context.collect()) # collect context chunks into a list
.on_output()
)
# Question/answer relevance between overall question and answer.
f_answer_relevance = (
Feedback(provider.relevance)
.on_input_output()
)
# Question/statement relevance between question and each context chunk.
f_context_relevance = (
Feedback(provider.context_relevance_with_cot_reasons)
.on_input()
.on(context)
.aggregate(np.mean)
)
tru_recorder = TruChain(history_aware_retriever_chain,
app_id=os.environ["truLens_app_id"],
feedbacks=[f_answer_relevance, f_context_relevance, f_groundedness])
#########################################################################
# Create a retrieval chain combining the history-aware retriever chain and the document chain
retrieval_chain = create_retrieval_chain(history_aware_retriever_chain, document_chain)
# Execute the chain with input documents and query
with get_openai_callback() as cb:
# Invoke the retrieval chain with the chat history and user input
response = retrieval_chain.invoke({
"chat_history": chat_history,
"input": prompt, # Required for HISTORY_AWARE_RETRIEVER_CHAIN_PROMPT
})
print(cb) # Printing callback information
```
| binjan_iyer_ca49b5bf7c351 | |
1,867,226 | Securing Your Azure Application with a Custom WAF Policy on Application Gateway | In today's digital landscape, ensuring the security of web applications is paramount. One effective... | 0 | 2024-05-28T05:49:49 | https://dev.to/vaibhavi_shah/securing-your-azure-application-with-a-custom-waf-policy-on-application-gateway-1255 | In today's digital landscape, ensuring the security of web applications is paramount. One effective way to enhance your application's security is by configuring an Azure Application Gateway with a Web Application Firewall (WAF) policy. In this blog, we'll walk through the steps to set up an Azure Application Gateway with a custom WAF policy to restrict access based on geographic regions and protect against common web vulnerabilities using managed rule sets.
## What is Azure Application Gateway?
Azure Application Gateway is a web traffic load balancer that enables you to manage traffic to your web applications. It offers various features such as SSL termination, URL-based routing, session affinity, and most importantly, a Web Application Firewall (WAF) to protect your applications from common web vulnerabilities.
## Why Use a Custom WAF Policy?
A Web Application Firewall (WAF) protects your web applications by filtering and monitoring HTTP requests. With a custom WAF policy, you can tailor the security rules to meet your specific requirements. In our case, we'll configure a WAF policy to block traffic from regions outside Japan and the US, and apply managed rule sets from Microsoft to protect against common threats.
## Step-by-Step Guide to Configuring Application Gateway with Custom WAF Policy
### 1. Setting Up the Application Gateway
First, let's set up the Application Gateway:
- **Create an Application Gateway**: In the Azure portal, navigate to "Create a resource" and select "Application Gateway". Fill in the necessary details such as resource group, name, region, and tier. Make sure to select "WAF V2" for the tier to enable the Web Application Firewall.
- **Configure Frontend IP**: Choose whether you want to use a public or private IP. For this example, we'll use a public IP. Create a new public IP or select an existing one.
- **Add Listeners**: Configure listeners to handle incoming traffic. For HTTPS traffic, you'll need to upload an SSL certificate in PFX format.
### 2. Creating a WAF Policy
Next, create a custom WAF policy:
- **Navigate to WAF Policies**: In the Azure portal, search for "WAF Policies" and create a new policy.
- **Define Policy Settings**: Give your policy a name and set the mode to "Prevention" to actively block detected threats.
- **Add Managed Rules**: Add the managed rule sets. For our example, we'll use the Microsoft_BotManagerRuleSet_1.0 and OWASP_3.2 rule sets.
- **Create Custom Rules**: Add a custom rule to block traffic from regions outside Japan and the US. Navigate to "Custom rules" and create a new rule. Set the match condition to "Geo-location" and configure it to block any requests not originating from Japan or the US.
### 3. Associating the WAF Policy with the Application Gateway
- **Go to Application Gateway**: Navigate to your Application Gateway instance in the Azure portal.
- **Associate WAF Policy**: In the WAF policy settings, associate the custom WAF policy you created earlier.
### 4. Updating DNS Settings
Finally, update your DNS settings to point your domain to the Application Gateway's public IP:
- **Obtain Public IP**: Note the public IP address of your Application Gateway.
- **Update DNS A Record**: In your domain registrar's DNS settings, update the A record to point to the Application Gateway's public IP address.
## Conclusion
Configuring an Azure Application Gateway with a custom WAF policy is a robust way to secure your web applications. By blocking traffic from undesired regions and applying managed rule sets, you can significantly enhance your application's security posture. With these steps, you can ensure that your application is better protected against common threats and unwanted access.
Feel free to share your experiences or any challenges you faced while setting up your Application Gateway. Happy securing! | vaibhavi_shah | |
1,867,225 | Apex: Einstein Prompt Templates, User Access Policies, Constants in Apex | This is a weekly newsletter of interesting Salesforce content See the most interesting... | 25,293 | 2024-05-28T05:48:35 | https://dev.to/sfdcnews/apex-einstein-prompt-templates-user-access-policies-constants-in-apex-39hl | salesforce, salesforcedevelopment, salesforceadministration, salesforceadmin | # This is a weekly newsletter of interesting Salesforce content
See the most interesting #Salesforce content of the last days 👇
✅ **[Einstein Prompt Templates in Apex - the Sales Coach](https://bobbuzzard.blogspot.com/2024/03/einstein-prompt-templates-in-apex-sales.html)**
The author has been exploring Generative AI in Salesforce, focusing on using prompt templates for various tasks. They are now interested in integrating prompts into their own applications. Their use case involves providing sales reps with advice on opportunities without consuming tokens or costing money, using an LWC in a non-default tab on the opportunity page.
✅ **[User Access Policies](https://certifycrm.com/user-access-policies/?utm_source=rss&utm_medium=rss&utm_campaign=user-access-policies)**
Salesforce User Access Policies will be Generally Available in the Summer '24 release. Configuring these policies can make onboarding new users so much simpler. To use them, first you need to enable some settings. If you select the first one, the second one will be automatically selected.
✅ **[Constants in Apex](https://beyondthecloud.dev/blog/constants-in-apex)**
Picklist values, profile and permission set names, common business values - all constants can be scattered across Apex code. The best practice is to store them in one place to avoid repetitions. (DRY) The most common approach to resolve it is Constants class, which contains all final variables.
✅ **[Einstein Prompt Grounding with Apex](https://bobbuzzard.blogspot.com/2024/03/einstein-prompt-grounding-with-apex.html)**
The author recently shared their experience with Einstein Prompt Builder, noting initial struggles with Apex grounding. With help from Claudio Moraes, they can now successfully pull information into prompts using an Apex class. For example, they created a prompt to follow up on a lead's interest in a specific product, including the standard price to provide cost estimates. By pulling a single entry from the standard price book, they can achieve this customization.
✅ **[Making Data Cloud Work With Your Existing Salesforce CRM Data](https://medium.com/salesforce-architects/making-data-cloud-work-with-your-existing-salesforce-crm-data-0f2ad272f407?source=rss----a91ecea76700---4)**
The Data Cloud integrates company data into Salesforce, enhancing its value. Understanding how this data interacts with existing sObjects is crucial for successful integration. This blog explains how to bring Data Cloud and CRM data together in Salesforce.
Check these and other manually selected links at https://news.skaruz.com
Click a Like button if you find it useful.
Thanks.
| sfdcnews |
1,867,223 | JS Concepts | Topics: TODO template literals How to create methods inside const prompt() Number() Array methods:... | 0 | 2024-05-28T05:46:39 | https://dev.to/aryamasinha/js-concepts-1ii2 | Topics:
TODO
1. template literals
2. How to create methods inside const
3. prompt()
4. Number()
5. Array methods: push, slice, indexOf , length , join , split
6. for(const it of arr){
}
7. { result }
8. Word frequency
9. map , filter , reduce
10. Modify DOM elements | aryamasinha | |
1,867,220 | Need to Sell Your House Fast in Houston? Here’s How to Do It | Selling a house is often a significant life event that requires time, effort, and careful planning.... | 0 | 2024-05-28T05:41:03 | https://dev.to/moveonhousebuyers/need-to-sell-your-house-fast-in-houston-heres-how-to-do-it-46km | house, buyers, houston, texas | Selling a house is often a significant life event that requires time, effort, and careful planning. However, there are situations where you might need to [sell your house quickly](https://shorturl.at/S7fpI). Whether due to financial strain, relocation, or personal circumstances, finding a fast and efficient way to sell your property becomes crucial. If you’re in Houston and need to sell your house fast, here’s a comprehensive guide to help you achieve that goal.
## Understanding the Houston Real Estate Market
Before diving into the process of selling your house quickly, it’s important to understand the Houston real estate market. Houston is one of the largest and fastest-growing cities in the United States, known for its diverse economy, affordable living, and vibrant cultural scene. The real estate market in Houston can be competitive, with varying demand across different neighborhoods and property types. Keeping this in mind will help you set realistic expectations and make informed decisions.
## Why You Might Need to Sell Fast
There are numerous reasons why someone might need to sell their house quickly, including:
1. Financial Difficulties: Unforeseen financial challenges such as medical bills, job loss, or significant debts can necessitate a quick sale.
2. Relocation: Job transfers, moving closer to family, or other personal reasons might require you to relocate swiftly.
3. Avoiding Foreclosure: If you’re unable to keep up with mortgage payments, selling quickly can help avoid foreclosure and the associated credit damage.
4. Divorce or Separation: A fast sale may be necessary to divide assets and move on with life.
5. Inherited Property: Managing an inherited property from afar can be challenging, prompting a quicker sale to simplify matters.
**Steps to Sell Your House Fast in Houston**
Selling a house quickly involves strategic planning and the right approach. Here’s what you need to do:
1. Assess the Condition of Your Property:- Before listing your house, conduct a thorough assessment of its condition. Identify any repairs or improvements needed to make it more appealing to buyers. While extensive renovations might not be feasible when time is of the essence, focusing on essential repairs and cosmetic enhancements can make a significant difference.
2. Set a Competitive Price:- Pricing your house competitively is one of the most crucial factors in achieving a fast sale. Research comparable properties in your area to determine a realistic and attractive price point. Overpricing can lead to prolonged market time, while underpricing might result in a quicker sale but potentially lower returns. Consulting a real estate agent or getting a professional appraisal can help in setting the right price.
3. Enhance Curb Appeal:- First impressions matter, and enhancing your home’s curb appeal can attract more potential buyers. Simple improvements like mowing the lawn, trimming bushes, cleaning the driveway, and adding some fresh plants or flowers can make your property more inviting.
4. Declutter and Stage the Interior:- A clean, clutter-free home is more appealing to buyers. Remove personal items, declutter spaces, and consider staging the home to showcase its potential. Staging can highlight the property’s strengths and help buyers envision themselves living there.
5. Market Effectively:- Effective marketing is key to reaching a wider audience. Utilize high-quality photos, virtual tours, and detailed descriptions to showcase your property online. Listing your home on popular real estate websites, social media platforms, and working with a real estate agent can increase visibility and attract more potential buyers.
6. Be Flexible with Showings:- Accommodating potential buyer's schedules is essential when trying to sell quickly. Be flexible with showing times and make your home available for viewings on short notice. The more accessible your property is, the higher the chances of attracting serious buyers.
7. Consider Cash Buyers and Investors:- If time is of the essence, selling to cash buyers or real estate investors can expedite the process. These buyers often have the funds available to close quickly and are typically interested in properties as-is, saving you the hassle of repairs or staging. Companies like Move On House Buyers specialize in purchasing homes quickly for cash, offering a convenient solution for homeowners in a hurry.
**Move On House Buyers: A Reliable Solution for Quick Sales**
Move On House Buyers is a reputable option for homeowners in Houston who need to sell their house fast. Here’s why they might be the right choice for you:
1. Speed and Efficiency: Move On House Buyers can make you a fair cash offer and close the deal within days, significantly faster than the traditional selling process.
2. No Repairs Needed: They purchase properties in their current condition, so you don’t need to worry about costly repairs or improvements.
3. No Fees or Commissions: Selling directly to Move On House Buyers means you avoid agent commissions and other hidden fees, maximizing your returns.
4. Flexible Closing Dates: They offer the flexibility to choose your closing date, accommodating your timeline and reducing stress.
5. Transparent Process: Their process is straightforward and transparent, ensuring you understand each step and feel comfortable throughout the transaction.
[Selling a house fast in Houston](https://shorturl.at/cyx2u) requires a strategic approach, a good understanding of the local market, and the right partners. By assessing your property, setting a competitive price, enhancing curb appeal, staging the interior, marketing effectively, being flexible with showings, and considering cash buyers like Move On House Buyers, you can achieve a quick and successful sale. Whether you’re facing financial difficulties, relocating, or simply need to sell quickly for personal reasons, these steps will help you navigate the process with ease and confidence. | moveonhousebuyers |
1,867,214 | How to Handle Anxiety-Related Fast Heartbeat | Heart palpitations, another name for rapid heartbeat, are a medical disorder where the heart beats or... | 0 | 2024-05-28T05:28:03 | https://dev.to/lillies_friends_4a87a0f2d/how-to-handle-anxiety-related-fast-heartbeat-oln | anxiety, health | Heart palpitations, another name for rapid heartbeat, are a medical disorder where the heart beats or raced too quickly for a variety of reasons, including anxiety. The normal heart rate is between 60 to 100 beats per minute [1*], but when a person has anxiety-related heart palpitations, their heart rate increases to above 100 beats per minute.
According to a recent research, at least one in four adult Americans over 40 have irregular heartbeats, which is a prevalent cause of heart palpitations. These include heart rates that are either too high or too low.
Primary Heart Palpitations Causes
Heart palpitations may be caused by many reasons in patients [2*], such as:
Stress, anxiety, and panic attacks
The menopause
Vigorous exercise
Low blood pressure
Drinking too much alcohol
A time or pregnancy
Reduced quantities of red blood cells (anemia)
A drop in blood glucose levels
Unusual electrolyte levels in the body
Certain drugs, such as coffee and stimulants
Systemic illness caused by thyroid hormones
Lack of sleep (may result in morning heart palpitations)
Stress, anxiety, and panic attacks
Anxiety is one of the most frequent causes of heart palpitations, while there are many other potential reasons as well, including those listed above.
What Is a Heart Palpitation Caused by Anxiety?
Heart palpitations and anxiety usually go hand in hand. Heart palpitations may sometimes manifest as a sign of depression.
Heart palpitations caused by worry may cause a person’s heart to race, flutter, or miss a beat. The ears, throat, or neck all have a hammering sensation from the heart. After an anxiety episode, this is how people usually feel, however palpitations may also be brought on by extreme enthusiasm.
Here’s a quick rundown of how this procedure works: The autonomic nervous system (ANS) is impacted by anxiety, which sets off the fight-or-flight response [4*]. This speeds up breathing, heart rate, and blood pressure in order to enable quick blood flow to the body’s other organs.
Be aware that having bipolar illness, anxiety disorders, or other mental health issues may influence how a person’s body responds to stressful circumstances.
**_[More Info Click Here](https://lilliesfriends.org/how-to-handle-anxiety-related-fast-heartbeat/)_** | lillies_friends_4a87a0f2d |
1,867,219 | Mastering the Art of Learning: How to Acquire Any Skill and Become an Expert | Have you ever wondered how some people seem to pick up new skills effortlessly and quickly become... | 0 | 2024-05-28T05:38:46 | https://dev.to/delia_code/mastering-the-art-of-learning-how-to-acquire-any-skill-and-become-an-expert-19fc | webdev, beginners, productivity, learning |
Have you ever wondered how some people seem to pick up new skills effortlessly and quickly become experts? Whether it's learning a new language, mastering a musical instrument, or becoming proficient in a programming language, the secret lies in mastering the art of learning. In this blog post, we'll explore effective strategies to help you learn anything and become an expert, with clear actions you can take for improvement. Let’s dive in!
## 1. Set Clear, Achievable Goals
### Why Goals Matter
Setting clear, achievable goals provides direction and motivation. Without specific goals, it's easy to get lost and lose focus. Goals break down the ultimate objective into manageable milestones, making the learning process less overwhelming and allowing you to track your progress.
### How to Set Goals
1. **Specific**: Define exactly what you want to achieve.
- **Action**: Instead of "learn JavaScript," set a goal like "build a simple to-do app using JavaScript."
2. **Measurable**: Ensure you can track your progress.
- **Action**: Set a goal like "complete three JavaScript tutorials this week."
3. **Achievable**: Set realistic goals that are challenging yet attainable.
- **Action**: Consider your current skill level and set a realistic target.
4. **Relevant**: Align your goals with your interests and long-term objectives.
- **Action**: Choose goals that are meaningful and beneficial to your career.
5. **Time-bound**: Set deadlines to keep yourself accountable.
- **Action**: Establish specific deadlines for each goal to create urgency and priority.
### Example
If you want to learn web development, your goals could look like this:
- **Month 1**: Learn HTML and CSS basics.
- **Month 2**: Build a simple personal website.
- **Month 3**: Learn JavaScript fundamentals.
- **Month 4**: Create an interactive web application.
## 2. Embrace the Learning Process
### The Growth Mindset
Adopting a growth mindset is crucial for successful learning. This concept, popularized by psychologist Carol Dweck, involves believing that your abilities can be developed through dedication and hard work. A growth mindset fosters resilience, encourages persistence, and enhances your willingness to learn from mistakes. Instead of seeing challenges as insurmountable, view them as opportunities to grow and improve.
### Practice Deliberately
Deliberate practice involves focused, structured practice aimed at improving specific aspects of a skill. This type of practice is purposeful and systematic, requiring you to push beyond your comfort zone and continuously challenge yourself. Deliberate practice is not just about putting in hours; it’s about how you use those hours effectively.
### Actions for Improvement
- **Action**: Identify your weak areas and focus on them.
- Example: If you’re learning to play the guitar, spend time practicing scales, finger positioning, and techniques that are challenging for you.
- **Action**: Set up regular practice sessions and gradually increase the difficulty.
- Example: Start with simple chords and progress to more complex pieces.
## 3. Use Multiple Resources
### Diverse Learning Materials
Using a variety of learning materials can enhance your understanding and retention of new information. Different resources offer unique perspectives and methods of explanation, which can help reinforce your learning. Books, online courses, tutorials, videos, podcasts, and interactive apps each contribute to a well-rounded educational experience.
### Find a Mentor or Join a Community
Having a mentor can provide guidance, feedback, and support. Mentors can offer valuable insights based on their experience and help you navigate challenges. Additionally, joining a community of learners can offer motivation, opportunities for collaboration, and a platform to share knowledge. Engaging with others who share your interests can accelerate your learning and provide a sense of belonging.
### Actions for Improvement
- **Action**: Explore various learning platforms and resources.
- Example: Utilize resources like "Eloquent JavaScript" by Marijn Haverbeke, freeCodeCamp, Codecademy, and Udemy for coding.
- **Action**: Join online communities and forums related to your skill.
- Example: Participate in discussions on GitHub, Stack Overflow, and Reddit.
### Recommended Resources and Apps
- **Brilliant**: Offers interactive problem-solving courses in math, science, and computer science. Ideal for those who enjoy learning through challenges and practical applications.
- **Coursera**: Provides access to courses from top universities and companies worldwide. Great for structured learning and obtaining certifications.
- **edX**: Similar to Coursera, offering a wide range of courses and professional programs from leading institutions.
- **Khan Academy**: Excellent for learning at your own pace with a vast array of subjects, particularly strong in math and science.
- **Duolingo**: An engaging app for learning new languages with gamified lessons.
- **Anki**: A powerful flashcard app that uses spaced repetition to help you memorize information effectively.
- **Notion**: A versatile tool for organizing your notes, tasks, and projects.
## 4. Practice Consistently
### The Power of Consistency
Consistency is key to mastering any skill. Regular practice helps reinforce what you've learned, builds muscle memory, and keeps you engaged with the material. Establishing a routine that allows for daily or weekly practice sessions is essential for sustained progress.
### Actions for Improvement
- **Action**: Create a consistent practice schedule.
- Example: Set aside 30 minutes every day for language practice using apps like Duolingo.
- **Action**: Track your practice sessions to maintain consistency.
- Example: Use a journal or app to log your daily practice and monitor your progress.
## 5. Reflect and Adjust
### Self-Assessment
Regularly assessing your progress and reflecting on what’s working and what isn’t is crucial for continuous improvement. This self-assessment helps you identify areas for improvement and adjust your learning strategies accordingly. Take time to review your goals, track your progress, and celebrate your achievements.
### Stay Flexible
Be open to changing your approach if something isn’t working. Flexibility in your learning process ensures that you remain adaptable and can find the most effective methods for your personal learning style. Experiment with different techniques and resources to discover what works best for you.
### Actions for Improvement
- **Action**: Keep a learning journal.
- Example: Note down what you’ve learned, challenges you’ve faced, and strategies that worked well. Review it regularly to track your progress and make necessary adjustments.
- **Action**: Reflect on your learning journey and make changes as needed.
- Example: If a particular resource isn’t effective, try another one.
## 6. Embrace Technology
### Leverage Online Platforms
The internet offers a wealth of resources for learners. Platforms like Coursera, edX, and Khan Academy provide high-quality courses on a wide range of subjects. These platforms often include interactive elements, quizzes, and peer reviews that enhance the learning experience.
### Use Learning Apps
Learning apps like Anki for flashcards, Notion for note-taking and organization, and Grammarly for writing assistance can help you learn more effectively. These tools can assist with memorization, organization, and skill improvement, making your learning process more efficient and enjoyable.
### Actions for Improvement
- **Action**: Enroll in online courses relevant to your goals.
- Example: Take a Coursera course on web development to gain structured knowledge.
- **Action**: Utilize learning apps to enhance your study routine.
- Example: Use Anki for flashcards to memorize key concepts.
## 7. Apply What You Learn
### Real-World Applications
Applying what you learn to real-world situations reinforces your knowledge and skills. Practical application helps you understand how concepts work in practice and allows you to solve real problems. Look for opportunities to use your new skills in projects, internships, or freelance work.
### Personal Projects
Working on personal projects is a great way to apply what you've learned. Choose projects that interest you and align with your goals. Personal projects provide hands-on experience, enhance your portfolio, and demonstrate your skills to potential employers.
### Actions for Improvement
- **Action**: Engage in real-world applications of your skills.
- Example: If you’re learning to code, build a personal website or contribute to open-source projects.
- **Action**: Work on personal projects that challenge you and showcase your abilities.
- Example: Create a simple game or develop a mobile app.
Mastering the art of learning is about setting clear goals, embracing the process, using diverse resources, practicing consistently, reflecting on your progress, embracing technology, and applying what you learn. By applying these strategies, you can learn any skill and become an expert. Remember, the journey to expertise is a marathon, not a sprint. Stay patient, persistent, and passionate about your learning journey. Happy learning! 🚀
Feel free to share your learning experiences or ask questions in the comments below. Let’s connect and support each other in our quest for knowledge and expertise! #LearningJourney #SelfImprovement #GrowthMindset
By following these clear and actionable steps, you'll be well on your way to mastering new skills and becoming an expert in your chosen field. Good luck on your learning journey!
Twitter: [@delia_code](https://x.com/delia_code)
Instagram:[@delia.codes](https://www.instagram.com/delia.codes/)
Blog: [https://delia.hashnode.dev/](https://delia.hashnode.dev/) | delia_code |
1,867,218 | Top 10 Reasons to Rent a Limousine for Your Special Event in New Jersey | Planning a special event can be both exciting and stressful. One way to add a touch of elegance and... | 0 | 2024-05-28T05:38:31 | https://dev.to/bridgewaterlimo/top-10-reasons-to-rent-a-limousine-for-your-special-event-in-new-jersey-5f06 | Planning a special event can be both exciting and stressful. One way to add a touch of elegance and ensure everything goes smoothly is to rent a limousine. Here are the top 10 reasons why you should consider a [limousine rental service](https://bridgewaterlimousine.com/) for your special event in New Jersey.
## 1. Unmatched Luxury and Comfort
A limousine offers a level of luxury and comfort that is hard to match. The plush interiors, spacious seating, and high-end amenities provide a comfortable and enjoyable ride for you and your guests.
## 2. Stress-Free Transportation
Renting a limousine means you don't have to worry about navigating through traffic, finding parking, or designating a driver. A professional chauffeur will handle all the logistics, allowing you to relax and enjoy your event.
## 3. Make a Lasting Impression
Arriving at your event in a limousine makes a grand entrance and leaves a lasting impression on your guests. It adds a touch of sophistication and class to any occasion.
## 4. Perfect for Group Travel
Limousines are ideal for group travel, whether you're heading to a wedding, prom, or corporate event. They can comfortably accommodate larger groups, ensuring everyone travels together and arrives on time.
## 5. Safe and Reliable
When you hire a limousine rental service, you can be assured of a safe and reliable ride. Professional chauffeurs are trained and experienced, ensuring your journey is smooth and secure.
## 6. Customized Services
Limousine services offer customizable packages to suit your specific needs. Whether you need transportation for a few hours or an entire day, they can tailor their services to match your event's requirements.
## 7. Onboard Entertainment
Modern limousines are equipped with state-of-the-art entertainment systems, including sound systems, TVs, and even mini-bars. This ensures your journey is as enjoyable as your
destination.
## 8. Ideal for Any Occasion
Limousines are versatile and perfect for a variety of events, including weddings, proms, birthdays, anniversaries, and corporate functions. Whatever the occasion, a limousine can add a touch of elegance and make it memorable. If you're looking to make your prom night unforgettable, consider a [prom limousine rental](https://bridgewaterlimousine.com/prom-night-limousine) for an extra touch of sophistication and style.
## 9. Professional and Courteous Service
Limousine rental companies pride themselves on their professionalism and customer service. From the moment you book your limo to the end of your ride, you can expect courteous and attentive service.
## 10. Affordable Luxury
While limousines are often associated with luxury, they are more affordable than you might think. When you factor in the convenience, comfort, and peace of mind they offer, they provide excellent value for money.
When planning your next special event in New Jersey, consider the benefits of a limousine rental service. It not only adds a touch of luxury but also ensures a stress-free and memorable experience.
For those looking to make their event truly unforgettable, Bridgewater Limousine offers top-notch service, luxurious vehicles, and professional chauffeurs to cater to all your transportation needs. Whether it’s a wedding, corporate event, or night out on the town, Bridgewater Limousine is your go-to choice for exceptional limousine rental service in New Jersey.
| bridgewaterlimo | |
1,867,217 | Sample Portfolio | HTML <!DOCTYPE html> <html lang="en"> <head> <meta... | 0 | 2024-05-28T05:37:17 | https://dev.to/tharun07/sample-portfolio-476c | webdev, html, css, javascript | ## HTML
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE-edge">
<meta name = "viewport" content="width-device-width, intial-scale-1.0">
<title>
Portfolio
</title>
<link rel="stylesheet" href="stylesheet.css">
<link href='https://unpkg.com/boxicons@2.1.4/css/boxicons.min.css' rel='stylesheet'>
<script src="https://unpkg.com/typed.js@2.1.0/dist/typed.umd.js"></script>
</head>
<body>
<header class="header">
<a href="#" class="logo"> Portfolio</a>
<nav class="navbar">
<a href="#" style="--i:1" class="active">Home</a>
<a href="#"style="--i:2">About</a>
<a href="#"style="--i:3">Skill</a>
<a href="#"style="--i:4">Portfolio</a>
<a href="#"style="--i:5">Contact</a>
</nav>
</header>
<section class="home">
<div class="home-content">
<h3>Hello, It's Me</h3>
<h1>Tharunkumar</h1>
<h3>And I'm a<span class="text"></span></h3>
<p>I'm a web Designer with extensive exprerience for 2 years</p>
<br>expertise is to create and Website design,Frontend design and UI & UX<div>
<div class="home-sci">
<a href="#"style="--i:7"><i class='bx bxl-facebook'></i></a>
<a href="#"style="--i:8"><i class='bx bxl-instagram'></i></a>
<a href="#"style="--i:9"><i class='bx bxl-whatsapp'></i></a>
</div>
<a href="#" class="btn-box"> More About Me</a>
</div>
</div>
<span class="home-imgHover"> </span>
</section>
<section class="about" id="about">
<div class="about-img">
<img src="C:\Users\HP\Downloads\resources\resources\Futuristic Neon Blue And Pink Light Instagram Profile Picture.png">
</div>
</section>
<script src="main.js"></script>
</body>
</html>
```
## CSS
```
#
{
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'poppins' , sans-serif;
}
body
{
color: #ededed;
}
.header
{
position: fixed;
top: 0;
left: 0;
width: 100;
padding: 20px 10%;
background: transparent;
display: flex;
justify-content: space-between;
align-items: center;
z-index: 100;
}
.logo {
position: relative;
font-size: 25px;
color: #fff;
text-decoration: none;
font-weight: 600;
cursor: default;
opacity: 0;
animation: slideRight 1s ease forwards;
}
.navbar a {
display: inline-block;
font-size: 25px;
color: #fff;
text-decoration: none;
font-weight: 500;
margin-left: 35px;
transition: .3s;
opacity: 0;
animation: slideTop .5s ease forwards;
animation-delay: calc(.2s * var(--i));
}
.navbar a:hover{
color: #0ef;
}
.home {
position: relative;
width: 100%;
justify-content: space-between;
height: 100vh;
background: url(https://wallpapers.com/images/hd/high-resolution-blue-background-1920-x-1080-manuazdf0v23me5t.jpg) no-repeat;
background-size: cover;
background-position: center;
padding: 70px 10%;
}
.home-content {
max-width: 600px;
}
.home-content h3{
font-size: 32px;
font-weight: 700;
opacity: 0;
animation: slideBottom 1s ease forwards;
animation-delay: .7s;
}
.home-content h3:nth-of-type(2){
margin-bottom: 30px;
animation: slideTop 1s ease forwards;
animation: .7s;
}
.home-content h3 span {
color: #0ef;
}
.home-content h1{
font-size: 56px;
font-weight: 700;
margin: -3px 0;
opacity: 0;
animation: slideRight 1s ease forwards;
animation-delay: .1s;
}
.home-content p{
font-size: 20px;
opacity: 0;
animation: slideLeft 1s ease forwards;
animation-delay: .1s;
}
.home-sci a{
display: inline-flex;
justify-content: center;
align-items: center;
width: 40px;
height: 40px;
background: transparent;
border: 2px solid #0ef;
border-radius: 50%;
font-size: 20px;
color: #0ef;
text-decoration: none;
opacity: 0;
transition: .5s ease;
animation: slideLeft 1s ease forwards;
animation-delay: calc(.2s * var(--i));
margin: 30px 15px 30px 0;
}
.home-sci a:hover {
background: #0ef;
color: #081b29;
box-shadow: 0 0 20px #0ef;
}
.btn-box {
display: inline-block;
padding: 12px 28px;
background: #0ef;
border-radius: 40px;
font-size: 16px;
color: #081b29;
letter-spacing: 1px;
text-decoration: none;
font-weight: 600;
opacity: 0;
animation: slideTop 1s ease forwards;
animation-delay: .2s;
box-shadow: 0 0 5px #0ef,
0 0 25px #0ef
}
.btn-box:hover {
box-shadow: 0 0 5px cyan,
0 0 25px cyan , 0 0 50px cyan,
0 0 100px cyan, 0 0 200px cyan
}
@keyframes slideRight {
0%{
transform: translateX(-100px);
opacity: 0;
}
100% {
transform: translateX(0px);
opacity: 1;
}
}
@keyframes slideLeft {
0%{
transform: translateX(100px);
opacity: 0;
}
100% {
transform: translateX(0px);
opacity: 1;
}
}
@keyframes slideTop {
0%{
transform: translateY(100px);
opacity: 0;
}
100% {
transform: translateY(0px);
opacity: 1;
}
}
@keyframes slideBottom {
0%{
transform: translateY(-100px);
opacity: 0;
}
100% {
transform: translateY(0px);
opacity: 1;
}
}
```
| tharun07 |
1,867,216 | (GAD) Generalized Anxiety Disorder | A common mental health illness called generalized anxiety disorder (GAD) is characterized by... | 0 | 2024-05-28T05:30:08 | https://dev.to/lillies_friends_4a87a0f2d/gad-generalized-anxiety-disorder-g9n | anxiety, health | A common mental health illness called generalized anxiety disorder (GAD) is characterized by excessive, unrelenting worry about a variety of everyday situations. Unlike specialized phobias or panic disorders, which usually have identifiable triggers, generalized anxiety disorder (GAD) is not limited to a single worry or experience. Rather, it permeates a person’s daily existence, potentially upsetting their personal, academic, and professional lives.
The National Institute of Mental Health (NIMH) estimates that 5.7% of adult Americans [1*] have had generalized anxiety disorder at some point in their life. Women are diagnosed with it more often than males since they are twice as vulnerable. It is acknowledged as a chronic illness that might last for many years or perhaps a lifetime, particularly in the absence of suitable therapy.
Signs and symptoms of Generalized Anxiety Disorder
Adults with generalized anxiety disorder may exhibit a range of psychological, emotional, and physical symptoms. The primary indicator is persistent and severe anxiety over many aspects of life, including work, health, family, finances, and education. The anxiety is usually greater than the actual likelihood or effects of the circumstance causing the fear.
In addition to mental symptoms, people with GAD may also have a range of physical ones, such as:
- Anxiety or heightened mood
- Weary
- inability to concentrate
- Intolerance
- Tension in the muscles
- disruptions to sleep
**_[More Info Click Here
](https://lilliesfriends.org/generalized-anxiety-disorder-causes/)_** | lillies_friends_4a87a0f2d |
1,867,215 | Common LLM Practitioner Challenges | Model quality depends on the large size of LLM and data used to train it, but training an LLM is... | 0 | 2024-05-28T05:30:06 | https://dev.to/mrugank/common-llm-practitioner-challenges-18nj | largelanguagemodel, llm | Model quality depends on the large size of LLM and data used to train it, but training an LLM is quite challenging. Lets learn some common challanges faced while building such LLMs.
---
## 1.Training Data Curation

Models which are based on transformers are trained on large datasets of text from multiple data sources. An LLM's quality majorly depends on selection and curation of training data. Preparing the LLM training data is an area of research in LLM industry. Collecting, processing and cleaning the data requires a lot of resources but they are necessary to ensure the quality of model outputs.
---
## 2.Large-scale, High-end infrastructure need
While training LLMs, we must maintain the balance between the factors such as model size, model performance, computational complexity, etc. Training requires large-scale accelerated computing resources, high-speed networking and high-end compute instances. This training can take several days to weeks for
completion. The high-end compute instances exist in close quarters to each other and are sometimes grouped in single network spine.
To detect and handle failure, GPU quality management software is essential. It also configures distributed storage and multi-node data I/O for datasets.
---
## 3.High Training Costs
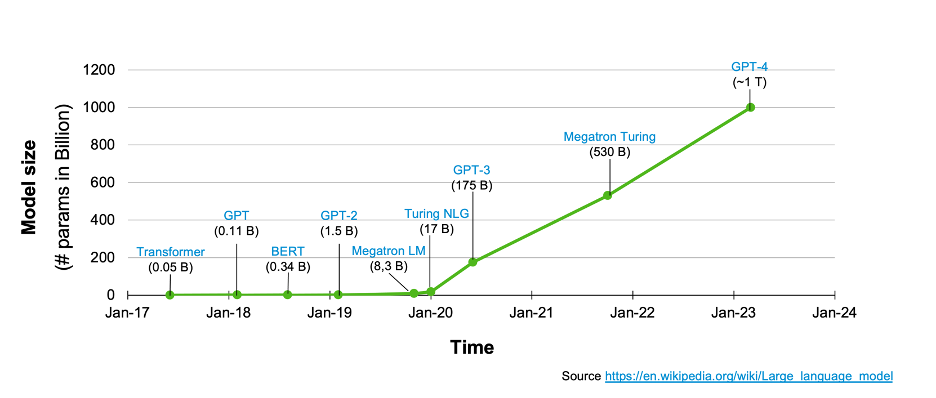
To train LLMs, organizations require to invest from millions to billions dollars. Only few organizations are in the position to invest this much money to train their LLMs. Due to this, other teams/organizations look for cost-effective training or to fine-tune the pre-trained models.
---
## 4.Machine Learning Expertise

To optimize the performance of LLMs, practitioners use some advanced techniques for distributed training and parallel data processing. Practitioners also manage the framework. It requires expertise in Machine Learning.
---
## 5.Responsible AI

LLMs are complex. Understanding their reasoning is a challenging task. Exploratory reaserch is required to make certain that language models are fair, transparent and unbiased. Another area of research is to create certain benchmarks to evaluate and compare the model's performance over various tasks.
---
Interested about how LLMs are trained,then read the following post!
{% embed https://dev.to/mrugank/multi-machine-training-solutions-38pp %}
_**Thank You.**_ | mrugank |
1,867,213 | Guide to Installing Kubernetes on Ubuntu | Welcome to my in-depth guide on installing Kubernetes on Ubuntu. Kubernetes, often abbreviated as... | 0 | 2024-05-28T05:27:33 | https://dev.to/utkarsh_kakkar_beb431f39d/guide-to-installing-kubernetes-on-ubuntu-1d5j | Welcome to my in-depth guide on installing Kubernetes on Ubuntu. Kubernetes, often abbreviated as K8s, is a powerful tool for automating the deployment, scaling, and management of containerised applications. Whether you're a seasoned developer or just starting out, this guide will walk you through the process step-by-step.
Prerequisites
Before we dive into the installation, let's me make sure you have everything you need:
A Ubuntu machine: This can be a physical server, a virtual machine, or even a cloud instance.
Root access: You need sudo privileges to install software and make system changes.
Basic knowledge of the command line: While not mandatory, familiarity with basic Linux commands will be helpful.
**Step 1: Update Your System
**
First, ensure your system is up-to-date. Open your terminal and run the following commands:
`sudo apt update
sudo apt upgrade -y`
This will update your package list and install the latest versions of your installed packages.
**Step 2: Install Docker
**
Kubernetes uses Docker to manage its containers. If Docker isn't already installed on your system, you can install it with these commands:
`sudo apt install docker.io -y
sudo systemctl start docker
sudo systemctl enable docker`
Verify the installation by checking the Docker version:
`docker --version
`
You should see the Docker version information, confirming that Docker is installed and running.
**Step 3: Install Kubernetes Components
**
Kubernetes consists of several components, but for now, we'll [focus](https://www.blitzpoker.com/) on kubeadm, kubelet, and kubectl.
kubeadm: A tool to bootstrap the cluster.
kubelet: An agent that runs on each node in the cluster.
kubectl: A command-line tool to interact with the cluster.
Add the Kubernetes repository and install the components:
`sudo apt install -y apt-transport-https ca-certificates curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
sudo bash -c 'cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF'
sudo apt update
sudo apt install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl`
**Step 4: Disable Swap
**
Kubernetes requires swap to be disabled. Edit the /etc/fstab file and comment out any swap entry:
`sudo nano /etc/fstab`
Find the line that contains swap and add a # at the beginning of the line. Save and exit the file. Then, disable swap with:
`sudo swapoff -a
`
**Step 5: Initialise the Kubernetes Cluster
**
With Docker and the Kubernetes components installed, it's time to initialise the cluster. On the master node, run:
`sudo kubeadm init --pod-network-cidr=10.244.0.0/16
`
Note the --pod-network-cidr option. This specifies the network range for the pods and is necessary for certain network plugins.
After initialisation, you'll see a kubeadm join command in the output. Save this command; you'll need it to add worker nodes to the cluster.
**Step 6: Set Up Your Kubernetes Configuration
**
To start using the cluster, you need to set up your local kubeconfig file. Run the following commands:
`mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config`
**Step 7: Install a Pod Network
**
Kubernetes uses a network plugin to handle the communication between pods. We'll use Flannel, a simple and effective choice. Install it with:
`kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml`
**Step 8: Join Worker Nodes to the Cluster
**
If you have additional nodes, run the kubeadm join command you saved earlier on each worker node:
`sudo kubeadm join <master-node-ip>:<master-node-port> --token <token> --discovery-token-ca-cert-hash sha256:<hash>`
Replace the placeholders with the actual values from the kubeadm init output.
**Step 9: Verify the Installation
**
Finally, check that all nodes have joined the cluster and are in the Ready state:
```
kubectl get nodes
```
You should see a list of your master and worker nodes, each with a STATUS of Ready. | utkarsh_kakkar_beb431f39d | |
1,867,212 | Empower Your Remote Team: Enhancing Collaboration with Work From Home Monitoring Software | ` Nowadays, due to more and more emphasis on working from home, there are challenges, which we need... | 0 | 2024-05-28T05:24:12 | https://dev.to/desk_track/empower-your-remote-team-enhancing-collaboration-with-work-from-home-monitoring-software-2c7f | software, monitoring, timetracking, office | `<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">Nowadays, due to more and more emphasis on working from home, there are challenges, which we need to address. Monitoring teams, work activities, efficiency, and productivity are only a few of them. Using </span><a href="https://desktrack.timentask.com/work-from-home-monitoring"><strong><span style="color: #1155cc;">Work-from-Home Monitoring Software</span></strong></a><span style="color: #000000; font-weight: 400;"> will help enhance and optimize the workflow with features for perfect collaboration, aiding managers in getting the best out of their employees.<br /><br /></span></p>
<h2 style="text-align: justify;"><strong><span style="color: #000000;">What is Work-from-Home Monitoring Software?<br /><br /></span></strong></h2>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">Remote work tracking software are solution packages that aid organizations in tracking remote employees across different locations and time zones for productivity and efficiency. The applications offer many features and functionalities to optimize collaboration, synchronization, communication, and data sharing for a smoother workflow. <br /><br /></span></p>
<h2 style="text-align: justify;"><strong><span style="color: #000000;">Why is it Important to Empower Remote Teams?<br /><br /></span></strong></h2>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">It is essential to empower remote teams for various reasons and factors. Below is why we think it is important to decentralize distributed teams.<br /><br /></span></p>
<h3 style="text-align: justify;"><strong><span style="color: #434343;">Different Locations and Time Zones</span></strong></h3>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">Since remote teams don’t work from the same place, it is essential to empower them. Distributed teams work across various time zones and locations, thus decentralizing authority ensures that they work better with optimized communication. <br /><br /></span></p>
<h3 style="text-align: justify;"><strong><span style="color: #434343;">Increase Trust</span></strong></h3>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">This also applies to in-office and remote teams. It’s obvious that the more trust employees have in their organizations, the longer they stay due to more satisfaction. So, how does one do that? The answer is to empower the employees. This way they feel trusted and work with more dedication. <br /><br /></span></p>
<h3 style="text-align: justify;"><strong><span style="color: #434343;">Better Collaboration</span></strong></h3>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">It is known that empowered teams work with more dedication. However, it’s not limited to only that. Remote teams also collaborate better, when empowered. Especially, when you implement a good remote work monitoring tool. <br /><br /></span></p>
<h2 style="text-align: justify;"><strong><span style="color: #000000;">Key Features to Look for In Work-from-Home Monitoring Software<br /></span></strong></h2>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">Now that we have looked into the essentials of remote work monitoring, let’s see how using a good remote work monitoring application can help enhance them and optimize the workflow. In this section, we will look at a few key features of the software solution. <br /><br /></span></p>
<h3 style="text-align: justify;"><strong><span style="color: #434343;">Employee Time Tracking</span></strong></h3>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">Monitoring the hours of remote employees is essential because of the flexible work schedules. A good work-from-home time tracking tool will ensure accurate tracking of idle and work hours. The feature will let managers and employees keep a tab on the time in real-time, identifying the work-time utilization. This also helps team leaders devise the best optimization solutions.<br /> </span></p>
<h3 style="text-align: justify;"><strong><span style="color: #434343;">Activity Tracking<br /><br /></span></strong></h3>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">Other than tracking the work hours, it is also essential to know whether your remote team is working with maximum efficiency. For the same purpose, the software will track the desktop activities of your employees as per your configuration. Furthermore, it will also identify unproductive and productive activities for performance evaluations. <br /><br /></span></p>
<h3 style="text-align: justify;"><strong><span style="color: #434343;">Collaboration</span></strong></h3>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">A good thing about </span><a href="https://desktrack.timentask.com/remote-work-monitoring-software"><strong><span style="color: #1155cc;">Remote Work Monitoring Software</span></strong></a><span style="color: #000000; font-weight: 400;"> is that you can integrate it with other collaboration tools such as meeting and communication tools for added functionality. Features including call tracking, location monitoring, and app usage tracking allow accurate performance report creation. <br /><br /></span></p>
<h2 style="text-align: justify;"><strong><span style="color: #000000;">Maximum Collaboration with Work-from-Home Monitoring Software<br /><br /></span></strong></h2>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">The only thing you need to maximize the performance of your distributed teams is optimized collaboration and communication. A good remote work tracking tool offers the above features we mentioned and more to enforce better collaboration and smooth workflow. <br /><br /></span></p>
<h2 style="text-align: justify;"><strong><span style="color: #000000;">Conclusion</span></strong><span style="color: #000000; font-weight: 400;"> </span></h2>
<p style="text-align: justify;"><span style="color: #000000; font-weight: 400;">Empowering your remote teams is essential for increasing trust, collaboration, and communication. Specialized tracking software for remote teams are solutions that help managers track their remote teams across various time zones and locations for efficiency and productivity. The software provide various features to improve, collaboration, communication, and workflow for enhanced efficiency and productivity. However, to achieve maximum performance, you need only the best remote work monitoring solution. We recommend DeskTrack as the top </span><a href="https://desktrack.timentask.com/employee-monitoring-software"><strong><span style="color: #1155cc;">Employee Monitoring Software</span></strong></a><span style="color: #000000; font-weight: 400;"> for this objective.</span></p>` | desk_track |
1,867,211 | Calendar events using React MUI | `import { useState } from "react"; import FullCalendar, { formatDate } from... | 0 | 2024-05-28T05:23:07 | https://dev.to/tharun07/calendar-events-using-react-mui-4n3o | webdev, javascript, react, website | `import { useState } from "react";
import FullCalendar, { formatDate } from "@fullcalendar/react";
import dayGridPlugin from "@fullcalendar/daygrid";
import timeGridPlugin from "@fullcalendar/timegrid";
import interactionPlugin from "@fullcalendar/interaction";
import listPlugin from "@fullcalendar/list";
import {
Box,
List,
ListItem,
ListItemText,
Typography,
useTheme,
Dialog,
DialogTitle,
DialogContent,
DialogActions,
TextField,
Button,
} from "@mui/material";
import Header from "../../components/Header";
import { tokens } from "../../theme";
const Calendar = () => {
const theme = useTheme();
const colors = tokens(theme.palette.mode);
const [currentEvents, setCurrentEvents] = useState([]);
const [isOpen, setIsOpen] = useState(false);
const [newEventTitle, setNewEventTitle] = useState("");
const [selectedDate, setSelectedDate] = useState(null);
const [deletingEventId, setDeletingEventId] = useState(null); // State to track the event being deleted
const handleDateClick = (selected) => {
setSelectedDate(selected.date);
setNewEventTitle("");
setIsOpen(true);
};
const handleEventClick = (selected) => {
setDeletingEventId(selected.event.id); // Set the event ID to be deleted
setIsOpen(true);
};
const handleDeleteEvent = () => {
// Filter out the event with the deletingEventId
setCurrentEvents(currentEvents.filter((event) => event.id !== deletingEventId));
setIsOpen(false); // Close the confirmation dialog
setDeletingEventId(null); // Reset deletingEventId
};
const handleAddEvent = () => {
if (!selectedDate || !newEventTitle) return;
const newEvent = {
id: `${new Date().toISOString()}-${newEventTitle}`,
title: newEventTitle,
start: selectedDate,
allDay: true, // Assuming all events are all-day for simplicity
};
setCurrentEvents([...currentEvents, newEvent]);
setIsOpen(false);
};
return (
<Box m="20px">
<Header title="Calendar" subtitle="Holiday Calendar" />
<Box display="flex" justifyContent="space-between">
{/* CALENDAR SIDEBAR */}
<Box
flex="1 1 20%"
backgroundColor={colors.primary[400]}
p="15px"
borderRadius="4px"
>
<Typography variant="h5">Events</Typography>
<List>
{currentEvents.map((event) => (
<ListItem
key={event.id}
sx={{
backgroundColor: colors.greenAccent[500],
margin: "10px 0",
borderRadius: "2px",
}}
>
<ListItemText
primary={event.title}
secondary={
<Typography>
{formatDate(event.start, {
year: "numeric",
month: "short",
day: "numeric",
})}
</Typography>
}
/>
<Button
variant="outlined"
color="secondary"
onClick={() => handleEventClick({ event })}
>
Delete
</Button>
</ListItem>
))}
</List>
</Box>
{/* CALENDAR */}
<Box flex="1 1 100%" ml="15px">
<FullCalendar
height="75vh"
plugins={[
dayGridPlugin,
timeGridPlugin,
interactionPlugin,
listPlugin,
]}
headerToolbar={{
left: "prev,next today",
center: "title",
right: "dayGridMonth,timeGridWeek,timeGridDay,listMonth",
}}
initialView="dayGridMonth"
editable={true}
selectable={true}
selectMirror={true}
dayMaxEvents={true}
events={currentEvents} // Pass currentEvents to FullCalendar
eventClick={handleEventClick}
dateClick={handleDateClick}
eventDidMount={(info) => {
info.el.style.backgroundColor = colors.greenAccent[500];
}}
/>
</Box>
</Box>
{/* DELETE EVENT DIALOG */}
<Dialog open={isOpen} onClose={() => setIsOpen(false)}>
<DialogTitle>Confirm Delete Event</DialogTitle>
<DialogContent>
<Typography>
Are you sure you want to delete this event?
</Typography>
</DialogContent>
<DialogActions>
<Button onClick={() => setIsOpen(false)} color="primary">
Cancel
</Button>
<Button onClick={handleDeleteEvent} color="secondary">
Delete
</Button>
</DialogActions>
</Dialog>
{/* ADD EVENT DIALOG */}
<Dialog open={isOpen && !deletingEventId} onClose={() => setIsOpen(false)}>
<Box p="20px">
<Typography variant="h6" gutterBottom>
Add New Event
</Typography>
<TextField
label="Event Title"
value={newEventTitle}
onChange={(e) => setNewEventTitle(e.target.value)}
fullWidth
variant="outlined"
margin="normal"
/>
<Button
variant="contained"
color="primary"
onClick={handleAddEvent}
>
Add Event
</Button>
</Box>
</Dialog>
</Box>
);
};
export default Calendar;
` | tharun07 |
1,867,210 | Symptoms and Indications of Obsessive-Compulsive Disorder (OCD) | The mental illness known as obsessive-compulsive disorder (OCD) is characterized by compulsive... | 0 | 2024-05-28T05:22:26 | https://dev.to/lillies_friends_4a87a0f2d/symptoms-and-indications-of-obsessive-compulsive-disorder-ocd-1cd0 | healthydebate | The mental illness known as obsessive-compulsive disorder (OCD) is characterized by compulsive behaviors and obsessive thinking. The lifetime prevalence of OCD in people in the United States is 2.3.
The purpose of this page is to clarify the complex nature of OCD, with an emphasis on adult OCD symptoms. We will explore the symptoms of OCD episodes, discover how to spot the early warning indicators of OCD, and dispel common misconceptions about this intricate disorder.
The Character of Addictions
Obsessive thoughts associated with OCD are more than merely severe or recurrent anxieties about ordinary everyday issues. These are undesired, recurring ideas, feelings, or visions that cause worry, anxiety, or obsessions. Even though they are obtrusive and often illogical, they are quite challenging to ignore or manage.
Not only are obsessive thoughts exaggerated worries about actual issues, but they are often about things that make no sense or are unreasonable in the eyes of others. Usually, the OCD sufferer understands that these obsessions are a creation of their own minds, but they feel unable to put an end to them. As examples, consider:
Compulsive worries about filth or becoming sick from handling things other people have touched.
Doubting and finding it difficult to accept ambiguity. Individuals can double-check that they’ve shut off the stove or closed the door.
Extreme tension when items aren’t symmetrical, in order, or facing the same direction.
Do Obtrusive Thoughts Always Indicate OCD?
Everyone has sometimes experienced being caught in a cycle of unwanted, intrusive thoughts. Though these ideas are among the frequent features of OCD, they are not always linked to the illness. It is advised to see a mental health specialist with persistent thoughts:
Result in severe worry and suffering;
are accompanied by a strong want to engage in obsessive activities;
They are bothersome enough to interfere with your everyday activities;
They are too challenging to manage even when you are aware of their irrationality.
Be aware that these kinds of thoughts may indicate depression or anxiety disorders rather than OCD. It is crucial to seek the advice of a healthcare professional who can do a thorough examination and offer a diagnosis.
**_[More Info CLick Here](https://lilliesfriends.org/symptoms-and-indications-of-obsessive-compulsive-disorder-ocd/)_** | lillies_friends_4a87a0f2d |
1,867,209 | Leveraging IP Lookup: An Essential Tool for the Digital Age | IP lookup, also known as IP geolocation, is the process of identifying the physical location and... | 0 | 2024-05-28T05:22:13 | https://dev.to/johnmiller/leveraging-ip-lookup-an-essential-tool-for-the-digital-age-19h2 | iplookup | IP lookup, also known as IP geolocation, is the process of identifying the physical location and other associated information of an IP address. This can include the country, city, ISP, and even the organization that owns the IP address. Various online tools and services provide IP lookup functionalities, offering insights into who is behind an IP address and where they are located.
Applications of IP Lookup
Cybersecurity:
Threat Detection: **[IP lookup](https://ipinfo.info/)** helps identify the origin of suspicious activities. By tracing the IP addresses of potential attackers, cybersecurity professionals can pinpoint sources of malware, phishing attempts, and other cyber threats.
Incident Response: In the event of a security breach, IP lookup can aid in quickly identifying compromised devices and isolating affected parts of the network.
Marketing and Analytics:
Targeted Advertising: Marketers use IP lookup to deliver location-based advertisements. Understanding the geographic distribution of their audience allows them to create tailored marketing campaigns.
User Insights: Analyzing the IP addresses of website visitors provides valuable insights into user demographics, helping businesses optimize their content and services.
Network Management:
Resource Allocation: Network administrators can use IP lookup to manage and allocate network resources efficiently, ensuring optimal performance and reducing downtime.
Access Control: By knowing the geographic locations of IP addresses accessing their network, administrators can implement access control measures to protect sensitive information.
Legal and Compliance:
Regulatory Compliance: Businesses can use IP lookup to ensure compliance with regional data protection regulations, such as the GDPR. This is particularly important for online services that handle sensitive user data.
Fraud Prevention: Financial institutions and e-commerce platforms use IP lookup to detect and prevent fraudulent transactions by identifying suspicious IP addresses.
Benefits of IP Lookup
Enhanced Security:
Proactive Defense: By monitoring IP addresses, organizations can identify and block malicious activities before they cause significant damage.
Geofencing: IP lookup allows for geofencing, which restricts access to networks or systems based on geographic location, adding an extra layer of security.
Improved Customer Engagement:
Localized Content: Delivering content that is relevant to the user’s location can significantly improve engagement and user satisfaction.
Personalized Experiences: Understanding user demographics through IP lookup enables businesses to offer personalized experiences, increasing customer loyalty and retention.
Efficient Resource Management:
Optimized Traffic Routing: Network performance can be enhanced by routing traffic based on geographic data, reducing latency and improving user experience.
Bandwidth Allocation: Knowing where network demand is highest helps in allocating bandwidth more effectively, ensuring smooth operations.
Better Regulatory Compliance:
Data Protection: Ensuring that data handling practices comply with regional laws helps in avoiding hefty fines and maintaining customer trust.
Transparency: IP lookup provides transparency in network operations, which is crucial for audits and regulatory reviews.
How to Leverage IP Lookup Effectively
Choosing the Right Tool:
There are numerous IP lookup tools available, ranging from free online services to advanced enterprise solutions. Choosing a tool that fits your specific needs is crucial. Key factors to consider include accuracy, the range of data provided, and integration capabilities with existing systems.
Integrating with Security Systems:
IP lookup should be integrated with other security tools such as firewalls, intrusion detection systems (IDS), and Security Information and Event Management (SIEM) systems. This integration enables real-time monitoring and automated responses to threats.
Using IP Lookup for Analytics:
Regularly analyze the data obtained from IP lookups to identify patterns and trends. This can provide valuable insights into user behavior, network performance, and potential security threats.
Training and Awareness:
Ensure that staff are trained on the use of IP lookup tools and understand their importance. This includes not only IT and security teams but also marketing and compliance departments.
Maintaining Privacy and Compliance:
While leveraging IP lookup, it is important to ensure that privacy laws and regulations are respected. Organizations should be transparent about their use of IP lookup and ensure that it is used ethically and in compliance with relevant laws.
Frequently Answered Questions:
1. How accurate is IP lookup?
The accuracy of IP lookup can vary. While it is generally reliable at the country and city level, pinpointing exact addresses or precise locations can be less accurate. The quality of the database used by the IP lookup service plays a significant role in accuracy.
2. Can IP lookup identify an individual?
IP lookup does not provide personally identifiable information (PII) such as names or addresses. It identifies the approximate location and the ISP associated with the IP address.
3. Is IP lookup legal?
Using IP lookup is legal in most jurisdictions, but it must be used in compliance with data protection laws. It is important to ensure that IP lookup is not used for malicious or unethical purposes.
4. Can IP addresses be spoofed?
Yes, IP addresses can be spoofed by attackers to disguise their true origin. However, combining IP lookup with other security measures can help detect and mitigate spoofing attempts.
5. How often should I use IP lookup?
The frequency of IP lookup depends on the specific needs of your organization. For cybersecurity purposes, continuous monitoring is recommended. For marketing and analytics, periodic reviews might suffice.
6. What tools are available for IP lookup?
There are many IP lookup tools available, including free options like WhatIsMyIP, IPinfo, and paid services such as MaxMind and IP2Location. These tools offer varying levels of detail and integration capabilities.
Leveraging IP lookup effectively can provide significant advantages in security, marketing, network management, and compliance. By understanding and utilizing the insights gained from IP lookup, organizations can enhance their operations, protect their assets, and deliver better user experiences.
| johnmiller |
1,867,208 | Bayes - Decoding the Mystery of Probability, Exploring the Mathematical Wisdom Behind Decision Making | Bayesian statistics is a powerful discipline in the field of mathematics, with wide applications in... | 0 | 2024-05-28T05:21:03 | https://dev.to/fmzquant/bayes-decoding-the-mystery-of-probability-exploring-the-mathematical-wisdom-behind-decision-making-27ni | bayes, trading, cryptocurrency, fmzquant | Bayesian statistics is a powerful discipline in the field of mathematics, with wide applications in many areas including finance, medical research, and information technology. It allows us to combine prior beliefs with evidence to derive new posterior beliefs, enabling us to make wiser decisions.
In this article, we will briefly introduce some of the main mathematicians who founded this field.
Before Bayes
To better understand Bayesian statistics, we need to go back to the 18th century and refer to mathematician De Moivre and his paper "The Doctrine of Chances".
In his paper, De Moivre solved many problems related to probability and gambling in his era. As you may know, his solution to one of these problems led to the origin of the normal distribution, but that's another story.
One of the simplest questions in his paper was:
"What is the probability of getting three heads when flipping a fair coin three times consecutively?"
Reading through the problems described in "The Doctrine of Chances", you might notice that most start with an assumption from which they calculate probabilities for given events. For example, in the above question there is an assumption that considers the coin as fair; therefore, obtaining a head during a toss has a probability of 0.5.
This would be expressed today in mathematical terms as:
Formula
```
𝑃(𝑋|𝜃)
```
However, what if we don't know whether the coin is fair? What if we don't know 𝜃 ?
### Thomas Bayes and Richard Price
Nearly fifty years later, in 1763, a paper titled "A Solution to the Problems in the Doctrine of Chances" was published in the Philosophical Transactions of the Royal Society of London.
In the first few pages of this document, there is a piece written by mathematician Richard Price that summarizes a paper his friend Thomas Bayes wrote several years before his death. In his introduction, Price explained some important discoveries made by Thomas Bayes that were not mentioned in De Moivre's "Doctrine of Chances".
In fact, he referred to one specific problem:
"Given an unknown event's number of successes and failures, find its chance between any two named degrees."
In other words, after observing an event we determine what is the probability that an unknown parameter θ falls between two degrees. This is actually one of the first problems related to statistical inference in history and it gave rise to term inverse probability. In mathematical terms:
Formula
```
𝑃( 𝜃 | 𝑋)
```
This is of course what we call the posterior distribution of Bayes' theorem today.
### For the Reason of No Cause and Effect
Understanding the motivations behind the research of these two elder ministers, **Thomas Bayes** and **Richard Price**, is actually quite interesting. But to do this, we need to temporarily put aside some knowledge about statistics.
We are in the 18th century when probability is becoming an increasingly interesting field for mathematicians. Mathematicians like de Moivre or Bernoulli have already shown that some events occur with a certain degree of randomness but are still governed by fixed rules. For example, if you roll a dice multiple times, one-sixth of the time it will land on six. It's as if there's a hidden rule determining fate's chances.
Now imagine being a mathematician and devout believer living during this period. You might be interested in understanding the relationship between this hidden rule and God.
This was indeed the question asked by Bayes and Price themselves. They hoped that their solution would directly apply to proving "the world must be the result of wisdom and intelligence; therefore providing evidence for God's existence as ultimate cause" - that is, cause without causality.
### Laplace
Surprisingly, around two years later in 1774, without having read Thomas Bayes' paper, the French mathematician Laplace wrote a paper titled "On the Causes of Events by Probability of Events", which is about inverse probability problems. On the first page, you can read the main principle:
"If an event can be caused by n different reasons, then the ratios between these causes' probabilities given the event are equal to the probabilities of events given these causes; and each cause's existence probability equals to the probability of causes given this event divided by total probabilities of events given each one of these causes."
This is what we know today as Bayes' theorem:
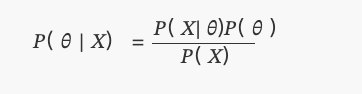
Where P(θ) is a uniform distribution.
### Coin Experiment
We will bring Bayesian statistics to the present by using Python and PyMC library, and conduct a simple experiment.
Suppose a friend gives you a coin and asks if you think it's a fair coin. Because he is in a hurry, he tells you that you can only toss the coin 10 times. As you can see, there is an unknown parameter p in this problem, which is the probability of getting heads in tossing coins, and we want to estimate the most likely value of the p.
(Note: We are not saying that parameter p is a random variable but rather that this parameter is fixed; we want to know where it's most likely between.)
To have different views on this problem, we will solve it under two different prior beliefs:
- 1. You have no prior information about the fairness of the coin, so you assign an equal probability to p. In this case, we will use what is called a non-informative prior because you haven't added any information to your beliefs.
- 2. From your experience, you know that even if a coin might be unfair, it's hard to make it extremely unfair. Therefore, you believe the parameter p is unlikely to be less than 0.3 or more than 0.7. In this case, we will use an informative prior.
For these two scenarios, our prior beliefs will be as follows:
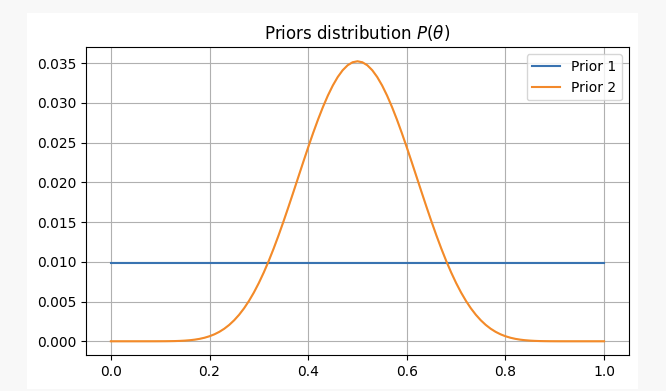
After flipping a coin 10 times, you got heads twice. With this evidence, where are we likely to find our parameter p?
As you can see, in the first case, our prior distribution of parameter p is concentrated at the maximum likelihood estimate (MLE) p=0.2, which is a method similar to that used by the frequency school. The true unknown parameter will be within the 95% confidence interval, between 0.04 and 0.48.
On the other hand, in cases where there is high confidence that parameter p should be between 0.3 and 0.7, we can see that the posterior distribution is around 0.4, much higher than what our MLE gives us. In this case, the true unknown parameter will be within a 95% confidence interval between 0.23 and 0.57.
Therefore, in the first case scenario you would tell your friend with certainty that this coin isn't fair but in another situation you'd say it's uncertain whether or not it's fair.
As you can see even when faced with identical evidence (two heads out of ten tosses), under different prior beliefs results may vary greatly; one advantage of Bayesian statistics over traditional methods lies here: like scientific methodology it allows us to update our beliefs by combining them with new observations and evidence.
### END
In today's article, we saw the origins of Bayesian statistics and its main contributors. Subsequently, there have been many other important contributors to this field of statistics (Jeffreys, Cox, Shannon and so on), reprinted from quantdare.com.
From: https://blog.mathquant.com/2023/11/27/bayes-decoding-the-mystery-of-probability-exploring-the-mathematical-wisdom-behind-decision-making.html | fmzquant |
1,867,206 | 充值抖音,very划算海外充值平台是认真的,980抖币$14.37 | 抖音是全球知名的短视频社交平台,拥有数以亿计的用户,尤其在中国和海外市场上极为流行。对于海外用户来说,抖音充值是一个常见的需求,而选择一个价格合理且安全可靠的充值平台尤为重要。本文将详细介绍“very划... | 0 | 2024-05-28T05:11:14 | https://dev.to/rombley_nathan_a08d7beb42/chong-zhi-dou-yin-veryhua-suan-hai-wai-chong-zhi-ping-tai-shi-ren-zhen-de-980dou-bi-1437-5250 | 抖音充值, 海外抖音充值, 美国抖音充值 | 抖音是全球知名的短视频社交平台,拥有数以亿计的用户,尤其在中国和海外市场上极为流行。对于海外用户来说,[抖音充值](https://www.veryhuasuan.com/goods-124.html)是一个常见的需求,而选择一个价格合理且安全可靠的充值平台尤为重要。本文将详细介绍“very划算”的海外充值平台,探讨其优势和服务。
1. 什么是“very划算”?
“very划算”是一家专注于为海外用户提供抖音抖币充值服务的平台。他们以提供优惠的价格和安全便捷的服务而闻名,深受用户信赖。下面将对其主要优势进行分析:
2. 优势分析
价格优势
“very划算”平台提供的抖币价格明显低于官方渠道和其他竞争对手。例如,他们提供的980抖币只需$14.37美元,这比其他平台更为划算。价格的优势是吸引用户选择的重要因素之一。
安全可靠
充值平台的安全性至关重要。“very划算”使用安全的支付系统,确保用户的个人信息和交易信息受到保护。他们的平台经过多次交易的验证和认证,保证交易的安全性和可靠性。
便捷快速
用户可以通过多种支付方式进行充值,包括信用卡、PayPal等,使得操作更加便捷和灵活。充值成功后,抖币会立即到账,无需等待,非常方便用户使用。
用户体验
“very划算”平台注重用户体验,他们提供友好的界面设计和详细的操作说明,使得用户可以轻松完成充值操作。客户服务团队也随时为用户提供支持,解答各种问题和疑虑。
3. 服务流程
注册与登录
用户首先需要在“very划算”平台上注册一个账户,填写相关的个人信息和联系方式。注册后,用户可以使用注册的账号和密码登录到平台。
选择充值金额
在登录后,用户可以选择需要充值的抖币数量,平台会显示相应的价格信息。用户可以选择适合自己的充值金额,然后点击下一步。
选择支付方式
“very划算”平台支持多种支付方式,包括信用卡、PayPal等。用户可以根据自己的习惯选择支付方式,并输入相应的支付信息。
确认支付
在选择了支付方式之后,用户需要确认支付信息和充值金额。确认无误后,点击支付按钮,等待支付系统处理支付请求。
充值成功
一般情况下,支付成功后,用户的抖币会立即到账。用户可以登录抖音账号,验证充值是否成功。 | rombley_nathan_a08d7beb42 |
1,867,205 | Advanced Techniques for Elevating Software Quality in Development | While navigating today’s competitive software landscape, I’ve learned that quality assurance isn’t... | 0 | 2024-05-28T05:07:49 | https://dev.to/zorian/advanced-techniques-for-elevating-software-quality-in-development-149 | webdev, softwareengineering, softwarequality, softwaretesting | While navigating today’s competitive software landscape, I’ve learned that quality assurance isn’t just a checkbox on a to-do list — it’s the backbone of successful and budget-friendly project completion.
In this piece, I will share 5 advanced techniques that have transformed my approach to QA. These strategies can also help you bolster the quality of software delivery. Let’s jump in.
## 1. Rigorous Requirement Analysis
A solid foundation in software development starts with an in-depth analysis of requirements. Using use case specifications and user story mapping methods ensures developers understand client needs and project objectives clearly.
## 2. Test Automation Strategy
Automating testing enhances efficiency and accuracy. To automate functional testing, you can use frameworks such as Selenium for the web and Appium for mobile applications. Popular choices for unit testing include JUnit and NUnit. Additionally, Jenkins facilitates continuous integration, automating the entire testing lifecycle.
## 3. Code Quality Reviews
Regular code reviews are important for maintaining high code quality. Tools like SonarQube can analyze code for bugs, vulnerabilities, and code smells. Integrating such tools into a CI/CD pipeline ensures that code quality is assessed continuously. Peer reviews also play a crucial role in catching potential errors and promoting knowledge sharing.
## 4. Implementing QA Metrics and KPIs
Effective QA monitoring involves key metrics and KPIs such as defect density, average time to fix bugs, test coverage, and mean time to failure. Tracking these metrics allows teams to evaluate their QA effectiveness and guide improvements based on data-driven insights.
## 5. User Acceptance Testing (UAT)
UAT is the final hurdle before software release. It involves real users to validate the functionality in real-world scenarios. Tools like TestRail can be used to manage test cases and gather user feedback. UAT ensures the software meets technical specifications, user requirements, and expectations.
## Conclusion
Adopting these six advanced QA techniques can significantly enhance the quality and reliability of software projects. By focusing on these, developers can ensure that their software meets technical and user expectations, leading to successful project outcomes. Interesting to learn more? Check out [this article.](https://oril.co/blog/6-ways-to-ensure-quality-in-software-delivery/)
| zorian |
1,867,204 | The Basics of HTML: A Beginner's Guide | Introduction: Welcome to the world of web development! If you're new to creating websites,... | 0 | 2024-05-28T05:07:38 | https://dev.to/asheelahmedsiddiqui/title-the-basics-of-html-a-beginners-guide-3a1g | beginners, html, learning, webdev | **Introduction:**
Welcome to the world of web development! If you're new to creating websites, understanding HTML is the first step in your journey. HTML, or Hypertext Markup Language, forms the backbone of every webpage on the internet. In this beginner's guide, we'll dive into the fundamentals of HTML and get you started on your path to becoming a web developer.
**What is HTML?**
HTML is the standard markup language used to create and structure content on the web. It consists of a series of elements, each surrounded by opening and closing tags, which define the structure and semantics of the content. These elements form the building blocks of a webpage, allowing you to include text, images, links, and more.
**Basic HTML Structure:**
Let's start by looking at the basic structure of an HTML document:
```html
<!DOCTYPE html>
<html>
<head>
<title>My First Webpage</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a paragraph of text.</p>
</body>
</html>
```
- `<!DOCTYPE html>`: Declares the document type and version of HTML being used.
- `<html>`: The root element that contains all other elements on the page.
- `<head>`: Contains metadata about the document, such as the page title and links to external resources.
- `<title>`: Sets the title of the webpage, displayed in the browser's title bar or tab.
- `<body>`: Contains the main content of the webpage.
- `<h1>` and `<p>`: Examples of HTML elements for heading and paragraph text.
**Common HTML Elements:**
HTML offers a wide range of elements for structuring content. Some common elements include:
- `<div>`: Defines a division or section of the webpage.
- `<a>`: Creates a hyperlink to another webpage or resource.
- `<img>`: Embeds an image into the webpage.
- `<ul>` and `<li>`: Creates unordered lists with list items.
- `<table>`, `<tr>`, `<td>`: Defines a table structure with rows and cells.
**Attributes and Tags:**
HTML elements can have attributes that provide additional information or modify their behavior. For example, the `<a>` element has an `href` attribute to specify the URL of the link. Tags can also have attributes like `class` or `id` for styling and JavaScript purposes.
**Conclusion:**
HTML is the foundation of web development, and understanding its basics is essential for anyone looking to create websites. In this beginner's guide, we've covered the fundamental concepts of HTML, including its structure, common elements, attributes, and tags. Armed with this knowledge, you're ready to start building your own webpages and exploring the endless possibilities of the web.
Now that you've got a grasp of HTML, stay tuned for our next guide where we'll dive deeper into styling your webpages with CSS!
**Tags:** #HTML #WebDevelopment #BeginnersGuide #Programming #WebDesign
---
Asheel Ahmed Siddiqui
Front-End Developer
GitHub:[github.com/asheelahmedsiddiqui](https://github.com/asheelahmedsiddiqui)| Twitter: [@asheelsiddiqui](https://twitter.com/asheelsiddiqui) | asheelahmedsiddiqui |
1,867,203 | Stripe Checkout & Subscriptions for Shopify via EasyPie | https://easypie.shop/shopify Easy payment terminal to collect payments and subscriptions for your... | 0 | 2024-05-28T05:07:17 | https://dev.to/techt01ia/stripe-checkout-subscriptions-for-shopify-via-easypie-3al | stripe, subscriptions, checkout, shopify | [https://easypie.shop/shopify](https://easypie.shop/shopify)
Easy payment terminal to collect payments and subscriptions for your Shopify store in multiple currencies & languages, 35+ payment methods via Stripe
Get paid with automatic invoicing for subscriptions in different payment intervals
· Visa · Mastercard · American Express · Discover & Diners Club · China UnionPay · JCB · Cartes Bancaires · eftpos ·
· ACH Direct Debit* · Affirm · Afterpay / Clearpay · Alipay · Amazon Pay* · Apple Pay* · Bacs Direct Debit* · Bancontact** · BECS Direct Debit* · BLIK · Boleto* · Cards* · Cash App Pay* · EPS · FPX · giropay · Google Pay* · GrabPay · iDEAL** · Klarna · Konbini · Faster checkout with Link* · MobilePay · Multibanco(beta) · OXXO · PayNow · PayPal* · PromptPay · Przelewy24 · Revolut Pay* · SEPA Direct Debit* · Sofort** · Swish · WeChat Pay · Zip ·
*supports subscriptions, **supports subscriptions with SEPA Direct Debit | techt01ia |
1,867,201 | AWS Enthusiast | Cloud Architect in Training | I'm a computer science graduate with a burning passion for technology and the ever-evolving world of... | 0 | 2024-05-28T05:03:31 | https://dev.to/musaroyalmavasa/aws-enthusiast-cloud-architect-in-training-3cc5 | aws |
I'm a computer science graduate with a burning passion for technology and the ever-evolving world of cloud computing. Fueled by a strong foundation in CS principles, I'm currently diving headfirst into the world of AWS, eager to leverage my skills to design, build, and manage scalable cloud solutions.
As an AWS Cloud Engineer, I'm constantly learning and exploring new possibilities within the AWS ecosystem. Whether it's optimizing serverless architectures or automating infrastructure with Infrastructure as Code (IaC), I'm always up for a challenge.
Beyond the technical aspects, I'm fascinated by the potential of cloud technology to transform businesses and empower innovation. I'm excited to be part of this dynamic field and contribute to building the future of the cloud.
Stay tuned for my journey as I share my learnings, explore cool AWS projects, and hopefully connect with other cloud enthusiasts!
| musaroyalmavasa |
1,867,200 | 𝗦𝘁𝗿𝗲𝗮𝗸- 𝟮 𝗟𝗲𝗲𝘁𝗖𝗼𝗱𝗲- 𝗚𝗲𝘁 𝗘𝗾𝘂𝗮𝗹 𝗦𝘂𝗯𝘀𝘁𝗿𝗶𝗻𝗴𝘀 𝗪𝗶𝘁𝗵𝗶𝗻 𝗕𝘂𝗱𝗴𝗲𝘁 | class Solution { public int equalSubstring(String s, String t, int maxCost) { int n =... | 0 | 2024-05-28T05:01:09 | https://dev.to/sailwalpranjal/--28mk | java | ```
class Solution {
public int equalSubstring(String s, String t, int maxCost) {
int n = s.length();
int[] cost = new int[n];
for (int i = 0; i < n; i++) {
cost[i] = Math.abs(s.charAt(i) - t.charAt(i));
}
int maxLength = 0;
int currentCost = 0;
int windowStart = 0;
for (int windowEnd = 0; windowEnd < n; windowEnd++) {
currentCost += cost[windowEnd];
while (currentCost > maxCost) {
currentCost -= cost[windowStart];
windowStart++;
}
maxLength = Math.max(maxLength, windowEnd - windowStart + 1);
}
return maxLength;
}
}
```
𝗢𝗽𝗲𝗻 𝘁𝗼 𝗨𝗽𝗱𝗮𝘁𝗲𝘀 𝗮𝗻𝗱 𝗦𝘂𝗴𝗴𝗲𝘀𝘁𝗶𝗼𝗻𝘀
| sailwalpranjal |
1,867,199 | What is Infrastructure as Code (IaC)? | In cloud computing, the demand for speed, scalability, and reliability significantly influences IT... | 0 | 2024-05-28T05:00:56 | https://dev.to/shivamchamoli18/what-is-infrastructure-as-code-iac-13lf | iac, devops, cloudcomputing, infosectrain | In cloud computing, the demand for speed, scalability, and reliability significantly influences IT infrastructure development strategies. As cloud ecosystems grow more complex and integral to operations, the potential security risks and points of failure increase. One pivotal innovation that aligns with these needs is Infrastructure as Code (IaC). This key methodology addresses these challenges by providing a consistent framework for deploying secure and compliant infrastructure configurations. This approach not only meets the core demands of cloud computing but also enhances IT systems' overall security and stability.

## **Overview of Infrastructure as Code (IaC)**
Infrastructure as Code (IaC) is a key practice within DevOps in which the infrastructure is provisioned and managed using code rather than manual processes. By coding environments, from networks and servers to databases and load balancers, IaC enables developers and IT operations teams to automatically manage, monitor, and provision resources rather than manually setting them.
## **Key Features of Infrastructure as Code (IaC)**
Here are some key features of IaC:
**• Version Control:** It connects with version control systems to manage and track changes to the infrastructure in the same way that software source code is managed.
**• Automation:** It streamlines the provisioning and management of infrastructure, eliminating manual configuration processes.
**• Consistency and Standardization:** It promotes consistent environments by standardizing configurations. This consistency eliminates discrepancies between development, testing, and production environments.
**• Configuration Files:** It uses plain text configuration files for infastructure management , often written in declarative formats like YAML, JSON, or Terraform configurations.
**• Security and Compliance:** It integrates with security policies and compliance standards to ensure that all deployed infrastructures meet the required security guidelines.
## **Benefits of Infrastructure as Code (IaC)**
Here are some key benefits IaC:
**• Cost Effectiveness:** Optimizes resource usage and minimizes unnecessary spending by accurately provisioning only what is needed.
**• Speed and Efficiency:** Automates the provisioning process, drastically reducing the time and effort required to deploy infrastructure and allowing teams to focus on development and innovation.
**• Recovery:** Simplifies disaster recovery processes through consistent and repeatable scripts, restoring services quickly after a failure.
**• Risk Mitigation:** Minimizes the risk of human error in configurations and deployments, enhancing overall security and reliability.
**• Scalability and Flexibility:** With IaC, scaling up or modifying infrastructure can be as simple as updating a script.
## **AWS Combo Training with InfosecTrain**
Those interested in deepening their understanding of Infrastructure as Code (IaC) methodologies can enroll in [InfosecTrain](https://www.infosectrain.com/)'s [AWS Combo Training](https://www.infosectrain.com/courses/aws-combo-course-training/) course. This course offers in-depth insights into IaC practices and extensive training on AWS services, helping participants effectively implement and manage cloud infrastructure. Through expert-led sessions and hands-on exercises, learners can gain the skills to optimize cloud operations and enhance security using IaC principles. | shivamchamoli18 |
1,867,197 | Strengthening Resilience: Concentrating Solar Power (CSP) | Introduction: In an era marked by increasing frequency and intensity of natural disasters, the need... | 0 | 2024-05-28T04:59:06 | https://dev.to/sim_chanda/strengthening-resilience-concentrating-solar-power-csp-45da | marketstrategy, globalinsights, marketgrowth, markettrends |

**Introduction:**
In an era marked by increasing frequency and intensity of natural disasters, the need for resilient energy infrastructure has never been more critical. Concentrating Solar Power (CSP) emerges as a robust solution for enhancing disaster resilience, offering reliable and sustainable energy generation capabilities even in the face of adversity. In this article, we explore the role of CSP in disaster resilience, its benefits, applications, and the transformative impact it can have on communities and regions vulnerable to natural disasters.
According to Next Move Strategy Consulting, the global **[Concentrating Solar Power Market](urhttps://www.nextmsc.com/report/concentrating-solar-power-marketl)** is projected to reach USD 114.42 billion by 2030 with a CAGR of 10.7% from 2024-2030.
**Download FREE Sample:** https://www.nextmsc.com/concentrating-solar-power-market/request-sample
**Understanding Disaster Resilience:** Disaster resilience refers to the ability of individuals, communities, and systems to anticipate, withstand, recover, and adapt to the impacts of natural disasters, such as hurricanes, earthquakes, floods, wildfires, and extreme weather events. Resilient energy infrastructure plays a pivotal role in disaster preparedness and response, providing essential services, powering critical facilities, and facilitating recovery efforts in disaster-affected areas.
**Inquire before buying:** https://www.nextmsc.com/concentrating-solar-power-market/inquire-before-buying
**The Role of Concentrating Solar Power (CSP) in Disaster Resilience:**
Concentrating Solar Power (CSP) offers several attributes that make it well-suited for enhancing disaster resilience:
Grid Independence: CSP systems can operate independently of the electrical grid, making them resilient to grid disruptions caused by natural disasters. With on-site energy generation capabilities, CSP plants can continue to produce electricity even during grid outages, providing critical power supply to essential services such as hospitals, emergency shelters, water treatment facilities, and communication networks.
**Energy Storage:** Many CSP plants are equipped with thermal energy storage (TES) systems, which enable them to store excess heat generated during periods of sunlight abundance and dispatch it when needed, including during nighttime or cloudy weather. Energy storage enhances the reliability and resilience of CSP plants, allowing them to deliver uninterrupted power supply and maintain grid stability in disaster-affected areas.
**Distributed Generation:** CSP systems can be deployed as distributed generation assets across multiple sites, reducing reliance on centralized power plants and transmission infrastructure vulnerable to natural disasters. Distributed CSP installations enhance energy security, decentralize energy production, and minimize single points of failure, thereby increasing resilience and adaptability to localized disruptions.
Benefits of CSP for Disaster Resilience: Concentrating Solar Power (CSP) offers numerous benefits for disaster resilience, including:
Reliability and continuity of electricity supply during grid outages
Enhanced energy security and independence from fossil fuels
Improved grid stability and resilience to extreme weather events
Support for critical infrastructure and emergency response efforts
Mitigation of greenhouse gas emissions and climate change impacts
Applications of CSP for Disaster Resilience: CSP can be applied in various disaster resilience scenarios, including:
**Emergency Response and Disaster Recovery:** During natural disasters, CSP plants can serve as reliable sources of electricity for emergency response and disaster recovery operations. By providing power to critical facilities such as hospitals, shelters, command centers, and communication networks, CSP supports lifesaving activities, medical care, and coordination efforts, facilitating faster and more effective disaster response.
**Microgrid Resilience:** CSP systems can be integrated into microgrid configurations to enhance resilience and reliability in disaster-prone areas. Microgrids equipped with CSP assets can operate autonomously or islanded from the main grid during emergencies, ensuring continuous electricity supply to local communities, businesses, and essential services. CSP-powered microgrids strengthen community resilience, promote energy self-sufficiency, and reduce vulnerability to external disruptions.
**Resilient Infrastructure Development:** CSP infrastructure can be designed and built to withstand and mitigate the impacts of natural disasters, such as hurricanes, floods, earthquakes, and wildfires. Robust construction practices, reinforced structures, and disaster-resistant components enhance the resilience of CSP plants, minimizing downtime, damage, and operational disruptions during extreme events. By investing in resilient infrastructure, CSP developers and operators contribute to community resilience and disaster risk reduction efforts.
**Case Studies: Examples of CSP for Disaster Resilience**
SolarReserve's Crescent Dunes Solar Energy Project, Nevada, USA: SolarReserve's Crescent Dunes Solar Energy Project is a pioneering CSP plant with molten salt energy storage located in Nevada, USA. The project, with a capacity of 110 megawatts, features advanced TES technology that enables continuous electricity generation, even after sunset or during cloudy weather. During wildfires and grid outages, the Crescent Dunes plant provided uninterrupted power supply to Nevada's electric grid, supporting critical infrastructure and emergency response operations.
**Gemasolar Thermosolar Plant, Spain:** Gemasolar is a flagship CSP project located in Seville, Spain, renowned for its innovative design and exceptional performance. The plant, developed by Torresol Energy, features a central tower surrounded by heliostats that concentrate sunlight onto a receiver at the top of the tower. With molten salt TES capabilities, Gemasolar achieves 24/7 dispatchable power generation, making it resilient to grid disruptions and extreme weather events. Gemasolar's reliability and resilience have been demonstrated during heatwaves and grid failures, ensuring continuous electricity supply to the Spanish grid and local communities.
**Challenges and Considerations:** While Concentrating Solar Power (CSP) offers significant potential for enhancing disaster resilience, several challenges and considerations must be addressed:
**Cost and Affordability:** The high upfront capital costs of CSP projects can pose challenges for widespread adoption, particularly in disaster-prone regions with limited financial resources. To overcome cost barriers, policymakers, investors, and stakeholders must explore innovative financing mechanisms, incentives, and cost-sharing arrangements to make CSP more accessible and affordable for vulnerable communities.
**Technology and Innovation:** Continued advancements in CSP technology and innovation are essential for improving performance, reducing costs, and enhancing resilience in disaster scenarios. Research and development efforts should focus on developing more efficient CSP systems, advanced energy storage solutions, and resilient infrastructure designs that withstand extreme weather events and environmental hazards.
**Policy and Regulation:** Supportive policy frameworks, regulations, and incentives are critical for incentivizing investment in CSP for disaster resilience and promoting its integration into emergency preparedness and response plans. Policymakers should prioritize resilience-oriented energy policies, streamline permitting processes, and provide financial incentives for CSP projects that enhance disaster resilience and support community resilience goals.
**Conclusion:**
Concentrating Solar Power (CSP) holds immense potential for strengthening disaster resilience, providing reliable and sustainable energy solutions in the face of natural disasters and extreme weather events. By harnessing the power of the sun, CSP systems offer grid-independent electricity generation, energy storage capabilities, and distributed generation options that enhance resilience, promote energy security, and support emergency response efforts. As the world grapples with increasing climate-related risks and vulnerabilities, CSP emerges as a cornerstone of disaster resilience, empowering communities, protecting critical infrastructure, and building a more resilient and sustainable future for all.
| sim_chanda |
1,867,196 | Discover Quality Arabic Children's Books with Kan Ya Makan Publications! | Kan Ya Makan Publications offers an extensive collection of [Arabic children's... | 0 | 2024-05-28T04:55:22 | https://dev.to/arabicbooks/discover-quality-arabic-childrens-books-with-kan-ya-makan-publications-2bmh | arabic, books, kids, childrens | Kan Ya Makan Publications offers an extensive collection of **[Arabic children's books]
(https://kanyamakanbooks.com/products/i-want-ice-cream)** that are created to engage young minds and foster a passion for reading. Discover beautifully illustrated stories that vividly portray Arabic culture and language. Whether you're seeking educational materials or captivating tales, Kan Ya Makan Publications has something for every child. Ideal for parents, educators, and libraries. Visit their website today to discover the perfect book for your young reader!
| arabicbooks |
1,867,195 | What is Mobile Device Management (MDM)? | In today's mobile-centric world, smartphones, tablets, and other portable devices have become... | 0 | 2024-05-28T04:54:32 | https://dev.to/shivamchamoli18/what-is-mobile-device-management-mdm-10pn | mdm, mobiledevicemanagement, mobilesecurity, infosectrain | In today's mobile-centric world, smartphones, tablets, and other portable devices have become integral in our personal and professional lives. As efficient workstations, they enable easy access to sensitive information, business operations, and collaboration with colleagues while on the move. As reliance on these devices grows, the importance of managing and securing them has become paramount for businesses and organizations of all sizes. In this context, the pivotal importance of Mobile Device Management is evident.

## **What is Mobile Device Management (MDM)?**
Mobile Device Management (MDM) constitutes a holistic suite of tools and methodologies designed to manage, secure, and monitor mobile devices within an organization. MDM solutions provide a centralized platform for administrators to control various aspects of these devices, including device configurations, security policies, application management, device performance, and compliance monitoring.
MDM operates by installing a management agent on the mobile device that needs to be managed. This agent communicates with the MDM server, enabling administrators to deploy policies, track devices, and perform remote actions like locking a device or wiping its data if it is lost or stolen. Examples include VMware Workspace ONE, Microsoft Intune, MobileIron, and Cisco Meraki.
## **Importance of Mobile Device Management (MDM)**
Mobile Device Management (MDM) is crucial for enhancing the security of mobile devices and sensitive data or information. It empowers organizations to enforce security policies, remotely manage devices, safeguard against data breaches, and reduce the risk of unauthorized access. It streamlines device management, enhancing productivity by guaranteeing employees have the essential resources.
MDM efficiently manages costs, keeps usage track, and minimizes potential losses. With remote support and troubleshooting capabilities, MDM reduces downtime and supports a mobile workforce. Its importance lies in protecting data, ensuring adherence to regulations, and optimizing the performance of mobile devices in today's mobile-focused world.
## **Key Benefits of Mobile Device Management (MDM)**
Mobile Device Management (MDM) solutions offer a range of critical benefits to help organizations effectively manage and secure mobile devices. Some of the essential MDM benefits are:
**• Enhanced Security:** Enforces security policies, such as password requirements, encryption, and whitelisting or blacklisting, to protect against data breaches and unauthorized access
**• Device Configuration:** Allows administrators to centrally control or manage device configurations
**• App Management:** Controls app installations, updates, and permissions on devices, guaranteeing that only authorized and secure applications are allowed
**• Data Protection:** Secures sensitive data with encryption and backup solutions
**• Scalability:** Adapts to the needs of organizations with various device fleets and sizes
**• Compliance Monitoring:** Ensures devices adhere to organizational policies and industry regulatory compliance
**• Remote Support:** Enables IT administrators to provide remote support, troubleshoot issues, and perform updates, reducing downtime and increasing productivity
**• Cost Control:** Monitors data usage, reduces device-related costs, and prevents unauthorized expenditures
You can also check out the article: [What is New in CompTIA Security+ SY0-701?](https://www.infosectrain.com/blog/what-is-new-in-comptia-security-sy0-701/)
## **CompTIA Security+ with InfosecTrain**
If individuals are seeking to expand their knowledge of MDM and delve into a broader range of security subjects, they can enroll in [InfosceTrain](https://www.infosectrain.com/)'s [Security Plus Online Training](https://www.infosectrain.com/courses/comptia-security/) program. Certified and experienced trainers lead our course and feature practical exercises and hands-on labs that enable participants to develop a more profound comprehension of these topics and equip themselves for certification exams. | shivamchamoli18 |
1,867,194 | How to Ace Your Web Developer Interview: Tips and Common Questions | Hey there, aspiring web developer! 🌟 Landing a web developer job can be a thrilling yet... | 0 | 2024-05-28T04:53:02 | https://dev.to/delia_code/how-to-ace-your-web-developer-interview-tips-and-common-questions-9kc | webdev, beginners, javascript, career | Hey there, aspiring web developer! 🌟 Landing a web developer job can be a thrilling yet nerve-wracking experience. With the tech industry constantly evolving, interview processes can seem daunting. But don't worry—I’m here to help you prepare and succeed. In this guide, we’ll cover essential tips and common questions you might encounter during a web developer interview. Let’s get you ready to ace that interview!
## 1. Understand the Job Requirements
### Research the Company
Before you even step into the interview, make sure you thoroughly research the company. Understand their products, services, tech stack, and company culture. This knowledge not only shows your interest in the company but also helps you tailor your answers to align with their expectations.
### Know the Role
Study the job description carefully. Identify the key skills and experiences required for the role. Make a list of your experiences and projects that match these requirements. Be ready to discuss how your background aligns with the job.
## 2. Brush Up on Fundamentals
### HTML, CSS, and JavaScript
Ensure you have a strong understanding of the core web technologies:
- **HTML**: Semantic markup, forms, and accessibility best practices.
- **CSS**: Flexbox, Grid, animations, and responsive design principles.
- **JavaScript**: ES6+ features, DOM manipulation, event handling, and AJAX.
### Frameworks and Libraries
Familiarize yourself with popular frameworks and libraries relevant to the job. Whether it’s React, Vue, Angular, or another technology, ensure you understand the basics and can demonstrate practical experience.
## 3. Practice Coding Challenges
### Online Platforms
Use online coding platforms like LeetCode, HackerRank, and CodeSignal to practice coding challenges. Focus on common algorithms and data structures, as well as problems that involve real-world scenarios.
### Mock Interviews
Participate in mock interviews to simulate the interview experience. Websites like Pramp and Interviewing.io offer mock interview sessions with peers or experienced engineers, providing valuable feedback.
## 4. Prepare for Behavioral Questions
### STAR Method
Use the STAR method (Situation, Task, Action, Result) to structure your answers to behavioral questions. This approach helps you provide clear and concise responses.
### Common Behavioral Questions
- **Tell me about yourself.**
- Focus on your background, key skills, and why you’re interested in the role.
- **Describe a challenging project you worked on.**
- Discuss the problem, your approach to solving it, and the outcome.
- **How do you handle tight deadlines or pressure?**
- Provide examples of how you’ve successfully managed deadlines in the past.
## 5. Be Ready for Technical Questions
### Common Technical Questions
- **What is the difference between `==` and `===` in JavaScript?**
- `==` checks for equality with type coercion, while `===` checks for strict equality without type coercion.
- **Explain the box model in CSS.**
- The box model consists of margins, borders, padding, and the content area. Understanding how these elements interact is crucial for layout design.
- **What is a closure in JavaScript?**
- A closure is a function that retains access to its lexical scope, even when the function is executed outside that scope.
### More Technical Questions
- **What is event delegation in JavaScript?**
- Event delegation allows you to add a single event listener to a parent element that will handle events triggered by its child elements. This is efficient for managing events on dynamically added elements.
- **How does the virtual DOM work in React?**
- The virtual DOM is a lightweight copy of the actual DOM. React uses it to batch updates and optimize re-renders by only updating the parts of the DOM that have changed.
- **Explain the concept of RESTful APIs.**
- RESTful APIs adhere to REST (Representational State Transfer) principles, using standard HTTP methods like GET, POST, PUT, and DELETE. They are stateless and use URLs to represent resources.
### System Design and Architecture
Some interviews may include system design questions. Be prepared to discuss how you would design a scalable web application, considering aspects like database design, caching, and load balancing.
## 6. Showcase Your Projects
### Portfolio
Create a portfolio that highlights your best projects. Include live demos and GitHub repositories. Be ready to discuss the technologies used, challenges faced, and your contributions.
### Project Walkthroughs
Practice explaining your projects clearly and concisely. Focus on your problem-solving process, technical decisions, and the impact of your work.
## 7. Ask Questions
### Engage with the Interviewer
Prepare thoughtful questions to ask the interviewer. This shows your interest in the role and helps you assess if the company is the right fit for you. Examples:
- **Can you tell me more about the team I’ll be working with?**
- **What does success look like for this role?**
- **What are the biggest challenges the team is currently facing?**
## 8. Follow Up
### Send a Thank-You Email
After the interview, send a thank-you email to express your appreciation for the opportunity. Mention something specific from the interview to reinforce your interest in the role.
Preparing for a web developer interview takes time and effort, but with the right approach, you can confidently showcase your skills and land your dream job. Understand the job requirements, brush up on your fundamentals, practice coding challenges, and prepare for both technical and behavioral questions. Don’t forget to highlight your projects and engage with your interviewer. Good luck, and happy coding! 🚀
Feel free to reach out if you have any questions or need further advice. Let’s connect and grow together on this exciting journey of web development! #connect #100DaysOfCode
---
By following these tips and preparing thoroughly, you'll be well on your way to acing your web developer interview. Good luck!
Twitter: [@delia_code](https://x.com/delia_code)
Instagram:[@delia.codes](https://www.instagram.com/delia.codes/)
Blog: [https://delia.hashnode.dev/](https://delia.hashnode.dev/) | delia_code |
1,867,192 | 5-letter words that start with… | 5-letter words from A to Z not only serves as a handy reference for word games but also enrich your... | 0 | 2024-05-28T04:45:35 | https://dev.to/ayesha_shoukat_7ef7ff215f/5-letter-words-that-start-with-473h | [5-letter words from A to Z](https://5letterwords.info/5-letter-words-that-start-with/) not only serves as a handy reference for word games but also enrich your vocabulary. Whether you’re looking to score big in Scrabble, expand your language skills, or just enjoy the beauty of words, these selections offer a perfect start. Happy learning!
| ayesha_shoukat_7ef7ff215f | |
1,867,190 | How Growth Hacking Agencies Propel Startup Success | In the ever-evolving entrepreneurship landscape, startups face many challenges on their journey to... | 0 | 2024-05-28T04:34:50 | https://dev.to/carmentyler/how-growth-hacking-agencies-propel-startup-success-206e | growthhackingagencis | In the ever-evolving entrepreneurship landscape, startups face many challenges on their journey to success. From limited resources to fierce competition, navigating growth can take time and effort. However, amidst this complexity, a valuable ally emerges for startups seeking rapid and sustainable growth: growth hacking agencies. These specialised firms bring a unique blend of creativity, strategy, and data-driven tactics, propelling startups in their quest for success.

## Understanding Growth Hacking Agencies
[Growth hacking agencies](https://www.madx.digital/learn/growth-hacking-agencies) are not your traditional marketing firms. While traditional marketing focuses on long-term strategies and brand building, growth hacking is all about achieving rapid and scalable growth in a short period. These agencies leverage marketing, data analysis, and experimentation to identify the most effective strategies for driving user acquisition, engagement, and retention.
## Strategic Approach to Growth
At the core of growth hacking is a relentless focus on experimentation and optimisation. Growth hacking agencies employ a strategic approach, starting with a deep understanding of the target audience and market dynamics. They analyse user behaviour and market trends to uncover insights that inform their growth strategies.
One key aspect of growth hacking is using scalable tactics that deliver maximum impact with minimal resources. From viral marketing campaigns to referral programs, these agencies deploy various creative techniques to accelerate growth and maximise ROI.
## Data-Driven Decision Making
In the world of growth hacking, data is king. Growth hacking agencies rely heavily on data analytics to measure the performance of their campaigns and iterate quickly based on results. By tracking key metrics such as customer acquisition cost, conversion rates, and lifetime value, they gain valuable insights into what works and what doesn't.
Furthermore, [growth hacking agencies](https://www.patreon.com/posts/best-practices-105072851?utm_medium=clipboard_copy&utm_source=copyLink&utm_campaign=postshare_creator&utm_content=join_link) are adept at leveraging data from multiple sources to uncover hidden opportunities and optimise their strategies further. Whether it's analysing website analytics, user feedback, or social media engagement, they leave no stone unturned in their quest for growth.
## Agile and Adaptive
In today's fast-paced business environment, agility is essential for success. Growth hacking agencies excel in this regard, able to pivot quickly in response to changing market conditions and consumer preferences. They embrace a culture of experimentation and continuous improvement, constantly testing new ideas and refining their approach based on feedback.
Moreover, growth hacking agencies are independent of traditional organisational structures or processes. They operate with a high degree of flexibility, allowing them to adapt their strategies on the fly and capitalise on emerging opportunities.
## Unlocking Startup Potential
Partnering with a growth hacking agency can be a game-changer for startups. These agencies bring expertise and experience to the table, helping startups overcome common growth barriers and achieve rapid traction in the market.
By leveraging innovative strategies, data-driven insights, and a relentless focus on results, growth hacking agencies empower startups to realise their full potential and carve out a distinct competitive advantage. In a crowded marketplace, where attention is scarce, and competition is fierce, the support of a growth hacking agency can be the catalyst that propels a startup to success.
In the dynamic world of entrepreneurship, growth hacking agencies play a vital role in driving startup success. With their strategic approach, data-driven decision-making, and agile mindset, these specialised firms help startups unlock new levels of growth and achieve their business objectives faster than ever before. As startups navigate the complexities of the modern business landscape, partnering with a growth hacking agency may be the secret ingredient to their success. | carmentyler |
1,867,189 | Babies was crying? test this | massage panggilan gading serpong yang tepat sejak dini dapat memiliki dampak besar pada kesejahteraan... | 0 | 2024-05-28T04:34:11 | https://dev.to/rx_bioh/babies-was-crying-test-this-5dl5 | <a href=”https://auramassage.my.id/pijat-panggilan-keluarga-gading-serpong-0856-7170-528/”>massage panggilan gading serpong</a> yang tepat sejak dini dapat memiliki dampak besar pada kesejahteraan mereka secara keseluruhan. Salah satu bentuk perawatan yang semakin populer adalah pijat bayi, yang tidak hanya memberikan efek relaksasi tetapi juga memiliki manfaat kesehatan yang signifikan oleh <a href="https://massagequeen.my.id/jakarta-selatan/">pijat panggilan jakarta selatan</a> Dalam konteks gaya hidup modern yang sibuk, orangtua sering kali menghadapi kesulitan dalam mencari waktu untuk membawa bayi mereka ke tempat pijat bayi konvensional. Oleh karena itu, layanan <a href="https://auramassage.my.id/bsd-serpong-tangerang/">massage panggilan bsd</a> ke rumah telah menjadi alternatif yang sangat dihargai, memberikan kenyamanan dan fleksibilitas bagi orangtua yang sibuk.
Dalam masyarakat yang semakin sibuk, orangtua sering kali mengalami kendala dalam mencari waktu untuk pergi ke tempat pijat bayi konvensional. Inilah sebabnya mengapa layanan <a href="https://massagequeen.my.id/pijat-panggilan-bintaro-queen-massage-08777-6837-907/">massage panggilan bintaro</a> semakin diminati. Konsep ini memungkinkan orangtua untuk menikmati manfaat pijat bayi tanpa harus meninggalkan kenyamanan rumah mereka. | rx_bioh | |
1,865,690 | RAID Nedir? Nerelerde Kullanılır? | RAID Nedir? -Redundant Array of Inexpensive Disks (Türkçe: Ucuz Disklerin Artıklıklı... | 0 | 2024-05-28T04:24:56 | https://dev.to/teknikbilimler/raid-nedir-nerelerde-kullanilir-4okl | raid, datastorage, dataprotection, disk |
## RAID Nedir?
**-**Redundant Array of Inexpensive Disks (Türkçe: Ucuz Disklerin Artıklıklı Dizisi) veya Redundant Array of Independent Disks (Türkçe: Bağımsız Disklerin Artıklıklı Dizisi) kısaca RAID ,diskler arasında veri kopyalama veya paylaşımı için birden fazla sabit diski kullanarak yapılan veri depolama teknolojisidir.
**-**Bu makalede, RAID sistemlerinin farklı kullanım alanları ve her bir RAID türünün sunduğu avantajlar ayrıntılı bir şekilde anlatılacaktır.

## RAID Kurulumu İçin Gerekenler?
**-**Raid'i kullanmak ve kurulumunu gerçekleştirmek için Raid kartına ve SAS HBA kartına ihtiyacınız var ilk olarak;
<u>Raid kartı nedir?</u> Raid kartı (Redundant Array of Inexpensive Disks), diskler arasında veri dağıtma, yedekleme ve veri güvenliği sağlama gibi işlemleri yapabilen bir araçtır. Raid sistemleri, diskler arasında verileri dağıtmak ve disk arızaları durumunda veri kaybını önlemek için kullanılır.
<u>SAS HBA kart nedir?</u> SAS HBA Kart (Host Bus Adapter), veri depolama sistemleri ve sunucular arasında veri transferi için gerekli bir araçtır. SAS HBA Kart, veri depolama sistemlerindeki disklerle sunucular arasındaki veri transfer hızını arttırarak veri depolama sistemlerinin verimliliğini ve hızını arttırır. Aynı zamanda, SAS HBA Kart, veri transferi sırasında veri güvenliğini sağlar.
**-**Özet olarak, Raid Kart ve SAS HBA Kart, veri depolama sistemlerinde performans ve güvenliği arttırmak için kullanılan önemli araçlardır. Raid Kart, diskler arasında veri dağıtma, yedekleme ve veri güvenliği sağlama gibi işlemleri yapar. SAS HBA Kart ise veri depolama sistemleri ve sunucular arasında veri transferi için gerekli bir araçtır ve veri transfer hızını ve veri güvenliğini arttırır.
**-**Kısaca RAID kurulumunu gerçekleştirmek için RAID kartını takın ve disk sürücüleri bağlayın, BIOS/UEFI veya yazılım RAID aracını kullanarak uygun RAID düzeyini (RAID 0, 1, 5, 6, 10) seçip yapılandırın, işletim sistemi kurulumunu RAID yapılandırması üzerinde gerçekleştirin ve sistemin düzgün çalışması için düzenli yedekleme, disk sağlığı izleme ve gerekli güncellemeleri yaparak yönetimi sağlamalısınız ama daha ayrıntılı bilgi için bilgisayarınızın markasına uygun Raid kurulumlarını da bulabilirsiniz.
## En Çok Kullanılan RAID Türleri Nelerdir?
1)RAID 0 (Striping)
2)RAID 1 (Mirroring)
3)RAID 5 (Distributed Parity)
4)RAID 6 (Dual Parity)
5)RAID 1+0 (Striping + Mirroring)
**-**Her bir RAID seviyesinin sağladığı avantajları ve özellikleri farklıdır. Kullanmak istediğiniz Raid türünü seçerken, belirli sistem gereksinimlerini ve performans/veri güvenliği dengesini dikkate almak önemlidir.
## Raid Nerelerde Kullanılır Özellikleri Ve Avantajları?
## RAID 0 (Striping)
**-**RAID 0, en az iki disk kullanılarak yapılan bir veri depolama yöntemidir. Bu sistemde, bir bilgi parçalara bölünerek farklı disklere yazılır. Bu sayede, yazma ve okuma işlemleri daha hızlı gerçekleşir ve performans artar. Daha basit bir anlatımla, elimizde yazılması gereken bir yazı varsa ve elimizle rahatlıkla yazı yazabiliyorsak, iki elimizi kullanarak yazıyı daha hızlı yazabiliriz. RAID 0 da bu mantıkla çalışır.
**-**RAID 0 kullanıldığında, toplam depolama kapasitesi disk sayısı kadar artarken, hız da bu disk sayısına oranla artar. Ancak, RAID 0'ın dezavantajı, bir disk arızalandığında tüm verinin kaybedilme riskidir, çünkü veri parçaları bozulan diskteki bilgi parçaları olmadan tamamlanamaz. Bu nedenle, RAID 0 kullanırken düzenli olarak yedekleme yapmak önemlidir.
**-**Kullanım yeri olarak, oyun sunucularında ve grafik tasarımı ve animasyonlarda RAID 0 tercih edilir, çünkü bu alanlarda yüksek performanslı depolama ihtiyacı vardır
**_Özet_**
Özellikler: Veriler, performans artışı sağlamak için iki veya daha fazla diske bölüştürülür.
Avantajlar: Yüksek performans.
Dezavantajlar: Veri güvenliği yoktur.
Kullanım Alanları: Yüksek performans gerektiren uygulamalar.
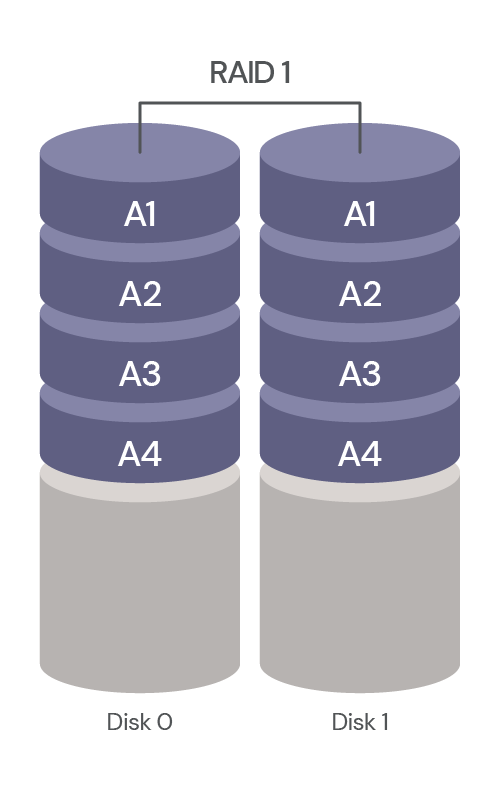
## RAID 1 (Mirroring)
**-**RAID (Redundant Array of Independent Disks), en az iki disk kullanılarak yapılan bir veri depolama yöntemidir. RAID, veri güvenliği sağlamak ve sistem sürekliliğini artırmak için tasarlanmıştır. Örneğin, bir bilgi bir diske yazılırken, aynı bilginin kopyası diğer disklere yazılır. Böylece, bir disk arızalandığında bile veri kaybı önlenmiş olur ve sistem sorunsuz bir şekilde çalışmaya devam edebilir.
**-**Bu yöntemin amacı, kesinlikle veri kaybını önlemektir, yani güvenliktir. RAID 1 (Mirror) olarak adlandırılan bu yapıda, her veri bloğunun en az bir yedek kopyası bulunur. Dolayısıyla, bir disk arızası durumunda sistemdeki diğer disklerden bilgileri geri yüklemek mümkündür.
**-**Ancak, RAID 1'de hız artışı gibi bir kazanç elde edilmez. Aksine, aynı veriyi birden fazla diske yazmak, hafif bir hız kaybına neden olabilir. Bu nedenle, RAID 1 daha çok bilgi kaybının istenmediği sistemlerde tercih edilir. Örneğin, muhasebe kayıtları gibi kritik verilerin saklandığı sistemlerde RAID 1 kullanılabilir.
**-**RAID 1'in sağladığı güvenlik ve veri bütünlüğü, iş sürekliliği ve veri koruması gibi önemli avantajları vurgulamak, bu yapıyı daha iyi anlaşılır hale getirebilir. Bu sayede, kullanıcılar verilerinin güvende olduğunu bilir ve sistemlerindeki kesintisiz çalışmaya güvenirler.
**_Özet_**
Özellikler: Veriler, veri kaybını önlemek için iki veya daha fazla diskte kopyalanır.
Avantajlar: Yüksek veri güvenliği.
Dezavantajlar: Depolama kapasitesi yarıya iner.
Kullanım Alanları: Yedekleme ve veri güvenliği gerektiren sistemler.
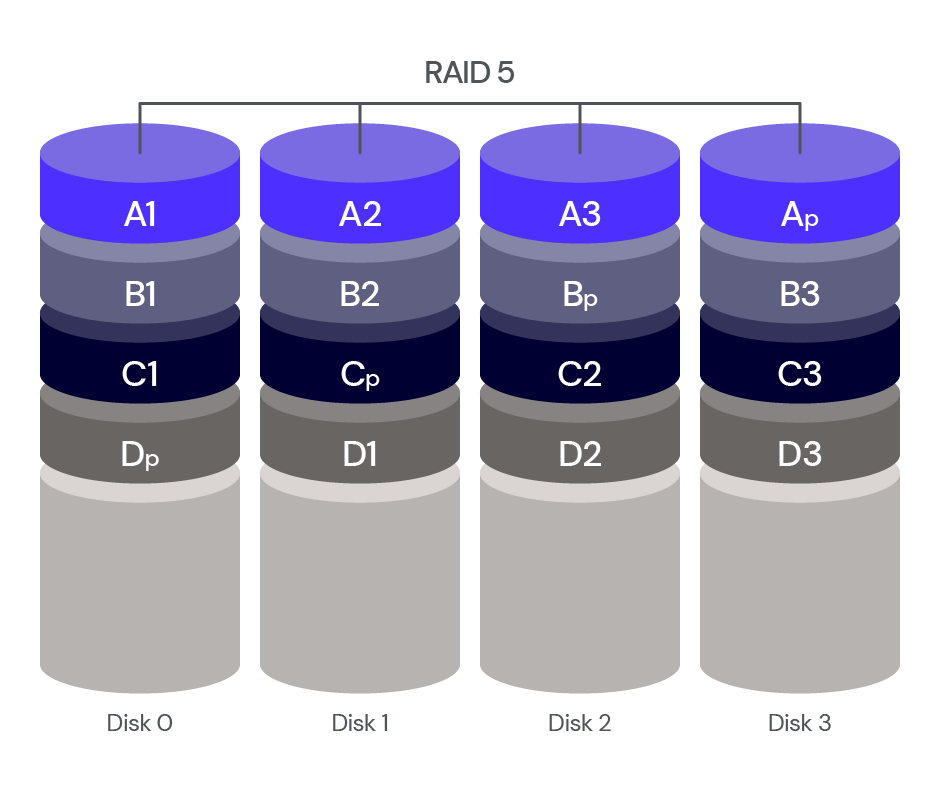
**RAID 5 (Distributed Parity)**
**-**RAID 5, veri depolama sistemlerinde en yaygın kullanılan RAID türlerinden biridir ve en az 3 disk gerektirir. Disk sayısı, RAID kartına bağlı olarak 16 veya 32'ye kadar çıkabilir. Veriler, diskler arasında dağıtılarak yazılır ve her yazma işlemi sırasında parite (eş veri) bloğu oluşturulur.
**-**Bu parite bloğu, verinin yazılmadığı diğer disklere yazılarak veri bütünlüğü korunur ve bir disk arızalandığında verilerin kurtarılmasını sağlar. RAID 5, yüksek okuma hızları sunar çünkü veriler birden fazla diske dağıtıldığından okuma işlemleri paralel olarak yapılabilir. Ancak, parite verisinin hesaplanması ve yazılması nedeniyle yazma hızı normaldir.
**-**Örneğin, 300 GB kapasiteli 3 diskle RAID 5 yapıldığında, toplam kapasite 600 GB olur çünkü en az 1 disk alanı parite için ayrılır. Parite oranı isteğe bağlı olarak artırılabilir. Bir disk arızalandığında sistem çalışmaya devam eder ve hatalı disk değiştirilerek yeniden yapılandırma (Rebuild) süreci başlar.
**-**Bu süreç yoğun işlemci gücü gerektirdiğinden performansta geçici bir düşüş olabilir. RAID 5, dosya ve uygulama sunucuları, okuma işlemlerinin yoğun olduğu veri tabanı sunucuları, web ve e-posta sunucuları gibi sistemler için idealdir. Bir disk arızalandığında, sistem çalışmaya devam eder ve böylece veri kaybı önlenir.
**_Özet_**
Özellikler: Veri ve parity bilgisi üç veya daha fazla diske dağıtılır.
Avantajlar: Yüksek veri güvenliği ve iyi performans.
Dezavantajlar: Parity hesaplama maliyeti.
Kullanım Alanları: Veri merkezleri, sunucular.
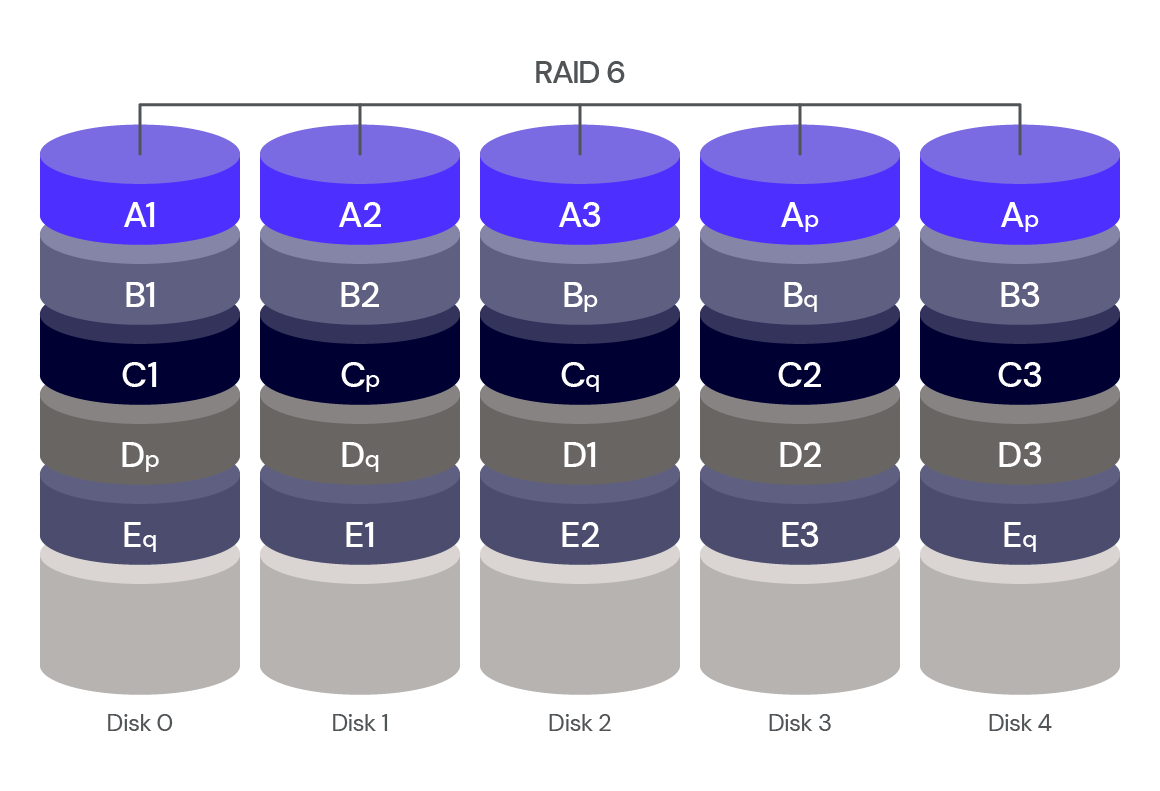
**RAID 6 (Dual Parity)**
**-**RAID 6, en az 4 disk gerektiren ve RAID 5 gibi dağıtılmış pariteler kullanan bir RAID seviyesidir. RAID 5'ten farkı, iki ayrı parite bilgisi kullanarak iki disk arızasını tolere edebilmesidir. Bu özellik, RAID 6'nın çok yüksek hata toleransı sunmasını sağlar ve birden fazla diskte eş zamanlı olarak ortaya çıkabilecek hataları veya arızaları karşılayarak sistemin kararlı bir şekilde çalışmaya devam etmesine olanak tanır. Okuma hızı oldukça iyidir, ancak çift parite kullanıldığı için yazma hızı RAID 5'e göre daha düşüktür.
**-**RAID 6, bu yapıyı destekleyen donanımlarla uygulanabilir. Örneğin, HP bu teknolojiyi ADG (Advanced Data Guarding) olarak adlandırır. RAID 6, dosya ve uygulama sunucuları, veri tabanı sunucuları, web ve e-posta sunucuları, intranet sunucuları gibi kritik veri güvenliği ve yüksek hata toleransı gerektiren sistemler için idealdir.
**_Özet_**
Özellikler: Çift parity bilgisi ile veri dört veya daha fazla diske dağıtılır.
Avantajlar: İki disk arızasına dayanıklı.
Dezavantajlar: Parity hesaplama maliyeti daha yüksektir.
Kullanım Alanları: Felaket kurtarma, büyük veri depolama.
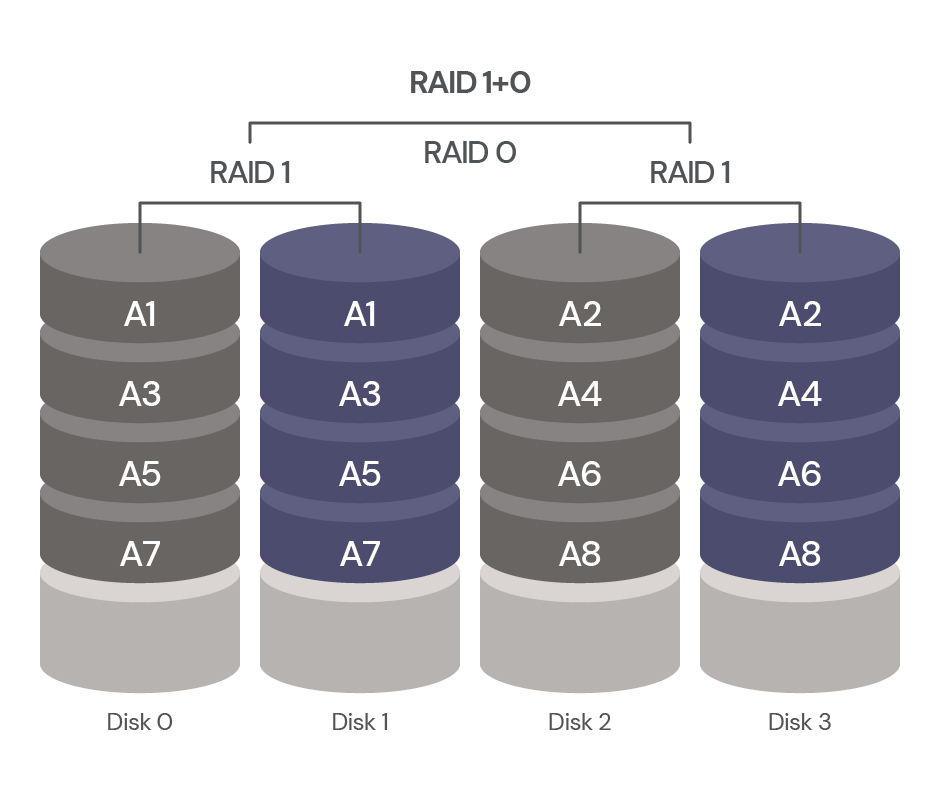
**RAID 1+0 (Striping + Mirroring)**
**-**Rebuild performansı, RAID 0 ve 1'den iyidir ve "Raid nesting" denilen bir yapı ile farklı iki RAID 1'ın RAID 0 yapısı altında birleştirilmesiyle oluşturulur. Bu yapı en az 4 disk ile oluşturulur ve RAID teknolojileri arasında en performanslı yapıdır; disk sayısı arttıkça performans da artar. Bu yapı, iki adet RAID 0 yapısının RAID 1 altında birleşmesiyle oluşur ve performansı çok yüksektir. Verileri tüm disklere dağıtarak okuma ve yazma işlemlerini gerçekleştirdiği için hızlıdır.
**-**Birçok küçük ve orta büyüklükteki işletme için RAID 0, RAID 1, RAID 5 ve bazı durumlarda RAID 10'un performansı yeterlidir. Ev kullanıcıları için RAID 5 aşırı güç tüketebilir, ancak RAID 1 hata toleransını sağlar. Veriler, RAID 0'daki gibi dağıtılarak yazılır ve kopyası RAID 1'deki gibi diğer diske yazılır. Örneğin, 300 GB dört diskle RAID 10 yapıldığında kapasite 600 GB olur. Bir disk arızalandığında sistem devam eder, hatalı disk değiştirilir ve yeniden yapılandırma (Rebuild) ile veriler sağlam diske aktarılır. RAID 10, pahalı bir seçenektir ve yoğun çalışan veri tabanı dosyaları için uygundur.
**_Özet_**
Özellikler: RAID 0 ve RAID 1 kombinasyonu.
Avantajlar: Hem yüksek performans hem de veri güvenliği.
Dezavantajlar: Yüksek maliyet, depolama kapasitesinin yarıya inmesi.
Kullanım Alanları: Yüksek performans ve güvenlik gerektiren sistemler.
**RAID Kullanmalı mıyım?**
**-**RAID, veri güvenliği sağlamak ve sistem sürekliliğini artırmak için tasarlanmış bir veri depolama teknolojisidir. Ancak, RAID kullanıp kullanmamanız gerektiği, ihtiyaçlarınıza ve sistem gereksinimlerinize bağlıdır.
**-**Yedekleme sırasında kısa süreli kesintiler veya veri kaybı endişesi yaşamıyorsanız, ek güvenlik önlemleri olarak RAID gibi seçenekler gereksiz olabilir.
**-**Veri güvenliği önemliyse, RAID 1 veya RAID 5 gibi aynalama veya pariteye dayalı düzeyler tercih edilir, çünkü bu düzeylerde bir disk arızalandığında bile veri kaybı yaşanmaz.
**-**Yüksek performans gerektiğinde, RAID 0 veya RAID 1+0 gibi şeritleme veya şeritleme + ayna düzeyleri hızlı erişim sağlarlayabilir.
**-**RAID kullanmanın bazı dezavantajları da vardır. Örneğin, RAID 0'da herhangi bir disk arızasında tüm veri kaybolabilir.
**-**Ayrıca, RAID sistemleri karmaşık olabilir ve kurulum, yapılandırma ve bakım gerektirebilir.
**-**Eğer veri güvenliği, performans veya yedekleme önemliyse ve RAID'in avantajları ihtiyaçlarınıza uyuyorsa, RAID kullanmayı düşünebilirsiniz. Ancak, her durumda, RAID'in avantajlarını ve dezavantajlarını dikkatlice değerlendirmeniz önemlidir.
**SONUÇ**
**-**Bu makale, RAID teknolojisinin çeşitli seviyelerini ve bunların sağladığı avantajları detaylı olarak ele alarak, RAID kurulumu için gereken donanımların yanı sıra, RAID 0'dan RAID 10'a kadar olan seviyelerin performans ve veri güvenliği özelliklerini ayrıntılı bir şekilde açıklamaktadır. RAID'in veri depolama sistemlerindeki önemini vurgulayarak, çeşitli uygulama alanlarında veri güvenliği ve performans dengesini sağlamak için kritik bir araç olduğunu belirtmektedir.
*
*
*
**_SORULAR_**
**1)Doğru Yanlış Sorusu:**
1)RAID 0, veri güvenliği sağlamak için en uygun RAID seviyesidir.
2)RAID 6, yalnızca bir disk arızası durumunda veri kaybını önleyebilir.
**2)Boşluk Doldurma Sorusu:**
1)RAID 1'de her veri bloğunun en az bir __________ bulunur.
2)RAID 6, RAID 5'e göre iki ayrı __________ kullanarak daha yüksek hata toleransı sağlar
**3)Test Soruları:**
1)RAID 0'da, veri parçaları farklı ____________ yazılır.
A) disklerde
B) bloklara
C) sürücülere
D) parçalara
E) bölgelere
2)RAID 1+0'da, her RAID 1 yapılandırması içinde en az ________ kaç disk bulunur.
A) 2
B) 5
C) 3
D) 4
E) 7
*
*
*
**_CEVAPLAR_**
**1)Doğru Yanlış Cevapları:**
1)Yanlış
2)Yanlış
**2)Boşluk Doldurmanın Cevapları:**
1)Yedek (kopya)
2)Parite
**3)Testin Cevapları:**
1)A
2)D
**KAYNAKÇA**
https://www.codit.com.tr/blog/raid-nedir-nasil-yapilir
https://www.firatboyan.com/disk-raid-yapilandirmasi.aspx
https://dev.to/luigibelanda/estudo-de-base-sobre-raid-origem-tipos-e-caracteristicas-5fd9
https://www.beyaz.net/tr/destek/makaleler/raid_nedir.html
https://www.karel.com.tr/blog/raid-nedir-raid-0-raid-1-raid-5-raid-10-farklari-nelerdir#:~:text=RAID%2C%20disk%20hata%20tolerans%C4%B1n%C4%B1n%20ve,i%C3%A7in%20bir%20donan%C4%B1m%20par%C3%A7as%C4%B1na%20sahiptir.
https://www.javatpoint.com/raid-1
https://chatgpt.com
https://cloudbunny.net/raid-nedir-ne-ise-yarar-hangi-amacla-kullanilir-301.html
https://kerteriz.net/raid-nedir-raid-tipleri-ve-seviyeleri-nelerdir/
https://www.turhost.com/blog/raid-nedir/
| ecekocaman |
1,867,155 | ReferenceError: jQuery is not defined select2 | Cara mengatasinya cukup sesuaikan dengan menambahkan library JQuery ke project kita, dengan... | 0 | 2024-05-28T04:17:16 | https://dev.to/aspsptyd/referenceerror-jquery-is-not-defined-select2-3h43 | Cara mengatasinya cukup sesuaikan dengan menambahkan library JQuery ke project kita, dengan mendownloadnya langsung di https://jquery.com/download/
Tambahkan ke dalam project dan load filenya seperti berikut
Source: https://stackoverflow.com/questions/72397672/uncaught-referenceerror-jquery-is-not-defined-error-when-using-select2
| aspsptyd | |
1,867,154 | Yangi \e - escape ketma-ketligi | Yangi escape ketma-ketligi(escape sequence) haqida gapirishdan oldin, o'zim uchunham yangilik bo'lgan... | 0 | 2024-05-28T04:08:42 | https://dev.to/farkhadk/yangi-escape-ketma-ketligi-e-4apg | csharp, news, features, dotnet | Yangi escape ketma-ketligi(escape sequence) haqida gapirishdan oldin, o'zim uchunham yangilik bo'lgan bir tushuncha haqida aytishni shart deb bildim.
Shu kungacha, shaxsan men uchun birxil manoga ega bolgan, ko'plab dasturlash tillarida, hususan C# daham, escape belgi(**character**) hamda escape ketma-ketligi(**sequence**) degan ikkita **bir-biridan farq qildigon**, lekin uzviy bog'liq konsepsiyalarni farqi nimada ekanligini iloji boricha qisqacha tushuntirishga harakat qilaman.
Escape character(belgi) deb `\` **backslash** ni aytiladi. Bu o'zi nima uchun kerak?! Hechkimga sir emaski double quotes `""` hamda backslash `\`, maxsus belgilar hisoblanib, ularni `string` malumot turiga shunchaki saqlab keta olmaymiz. Sababi ushbu belgilarni kompilyatorda boshqa maqsad uchun ishlatilinadi.
Misol:
```C#
// error
string str1 = "Shoqasim "yaxshi" bola";
string str2 = "Shoqasim \yaxshi\ bola";
```
Bu kodimiz hatolik keltirib chiqaradi, ushbu hatolikni oldini olish uchun, bizga `\` escape -> qochish belgisi yordam beradi(hatolikdan qochishga yo'l ochib beradi).
Misol:
```C#
string str1 = "Shoqasim \"yaxshi\" bola";
string str2 = "Shoqasim \\yaxshi\\ bola";
Console.WriteLine(str1); --> Shoqasim "yaxshi" bola
Console.WriteLine(str2); --> Shoqasim \yaxshi\ bola
```
Misolda ko'rganimiz kabi **qo'sh tirnoq** `"` yoki **orqa chiziq**
`\` belgilarini hatoliklarsiz saqlash uchun bizga **escape character** yordam berdi. Lekin bu yerda yana bir qo'shimcha qilish kerakki `\"`, yoki `\\` belgilari, bundan buyog'iga escape character emas balki **escape sequence** deyiladi. Bu bilan demoqchi bolganim shundaki escape character doimo bitta **backslash** `\`, va ushbu `\` belgi, escape sequence lar yaratishga yo'l beradi. Escape sequence larni turlari ko'p, eng ko'p uchraydigonlari: `\"`, `\\`, `\n`, `\t`, `\r` va boshqalar. Ushbu ketma-ketliklar bizga `string` qiymatlarini turli hil formatlash(shakllash)ga yordam beradi. Ko'proq misollar uchun -> [havola](https://codebuns.com/csharp-basics/escape-sequences/).
Endi ushbu postimizni asosiy qaxramoni bo'lmish `\e` escape sequence ga o'tsak. Ushbu yangi sequence, 13-chi versiyadan oldingi **ESCAPE** belgisi([ASCII](https://www.commfront.com/pages/ascii-chart) jadvali bo'yicha 27-chi)ni ifodalovchi `\x1b` sequence orniga kelishi kutilmoqda.
Bu belgi nimani bildiradi degan savolga kodda javob berishga harakat qilaman.
```C#
Console.WriteLine("\x1b");
// output -> Bo'm-bo'sh bolib qoladi
```
Outputda hich-narsa ko'rinmasligini sababi, `x1b` (ESC) belgisi asosan konsolga chiqishi kerak bolgan matinni **manipulyatsiya** qilish uchun ishlatiladi(rangini o'zgartirish, formatini o'zgartirish vaho-kazo...).
Misol:
```C#
Console.WriteLine("\x1b[31mHello \x1b[0mWorld!");
// output -> Hello(qizil rangda) World!(defolt rangda)
Console.WriteLine("\x1bHello \x1bWorld!");
// output -> ello orld! birinchi harflar o'chib ketadi
```
Hattoki Microsoft o'z documentationida `\x1b` ishlatishni maslaxat bermaydi. Bunga sabab `1b` ketma-ketligidan keyin keluvchi qiymatlar **o'n oltilik** sanoq tizimini qiymatiga teng bo'lib qolishi mumkin va kutilmagan natijalarni keltirib chiqarishi mumkin.
Misol:
```C#
Console.WriteLine("\x1b12");
// output -> ? belgisi
```
Shunaqangi kutilmagan xatoliklar oldini olish maqsadida Microsoft `\x1b` sequensini `\e` o'zgartirmoqchi. Yangi ketma-ketlikni endi ikkilanmay `\e12` qilib ishlatsa bo'ladi, hechqanday **?** belgisi chiqmaydi. Formatlash sistemasixam eski sequence nikidek qoladi.
Misol:
```C#
Console.WriteLine("\e12");
// output -> 2
Console.WriteLine($"\e[31m123\e[0m456");
123(qizil rangda) 456 (defolt rangda)
``` | farkhadk |
1,867,153 | 🌟 Components and Props in React.js 🌟 | In React, components are the building blocks of your UI. They let you split the UI into independent,... | 0 | 2024-05-28T04:07:55 | https://dev.to/erasmuskotoka/components-and-props-in-reactjs-3g1e |
In React, components are the building blocks of your UI. They let you split the UI into independent, reusable pieces. Props (short for properties) allow you to pass data and event handlers to components.
Why Components and Props?
- Reusable: Build once, use anywhere.
- Modular: Break down complex UIs into manageable pieces.
- Dynamic: Pass dynamic data to components via props.
Mastering components and props is key to harnessing the full power of React. Start building modular and maintainable UIs today! 🚀💻
#ReactJS
#WebDevelopment
#Frontend
#CODEWith
#KOToka | erasmuskotoka | |
1,867,064 | Guía Completa sobre Pruebas Unitarias en Angular 16 | Las pruebas unitarias son una parte esencial del desarrollo de software, ya que garantizan que cada... | 0 | 2024-05-28T03:50:49 | https://dev.to/nerm_frontend/guia-completa-sobre-pruebas-unitarias-en-angular-16-4djl | angular, testing, javascript, frontend | Las pruebas unitarias son una parte esencial del desarrollo de software, ya que **garantizan que cada componente de nuestra aplicación funcione correctamente**. En este artículo, veremos cómo realizar pruebas unitarias en Angular 16, una de las versiones no tan recientes pero potentes de este popular framework.
---
## ¿Qué son las Pruebas Unitarias?
Son pruebas automáticas que **validan el comportamiento de una unidad de código, como una función o un componente**. Estas pruebas son fundamentales para **asegurar que el código funcione según lo esperado y para facilitar el mantenimiento y la evolución de la aplicación**.
## Beneficios de las Pruebas Unitarias en Angular
1. **_Detección Temprana de Errores:_** Permiten identificar y corregir errores en etapas tempranas del desarrollo.
2. **_Facilitan el Refactorizado:_** Al tener una suite de pruebas, podemos refactorizar el código con confianza, sabiendo que cualquier cambio que rompa la funcionalidad será detectado.
3. **_Mejoran la Documentación:_** Las pruebas actúan como una documentación viva del comportamiento esperado de la aplicación.
4. **_Aumentan la Confianza en el Código:_** Desarrolladores y stakeholders pueden tener mayor confianza en la estabilidad y la calidad del código.
## Configuración Inicial
Para empezar a trabajar con pruebas unitarias en Angular 16, necesitamos tener configurado nuestro entorno de desarrollo. Asumiremos que ya tienes Node.js y Angular CLI instalados.
1.- Crear un Nuevo Proyecto Angular:
```
ng new angular-testing
cd angular-testing
```
2.- Instalar Dependencias Necesarias:
Angular ya viene con Jasmine y Karma configurados para pruebas unitarias. Jasmine es el framework de pruebas y Karma es el ejecutor de pruebas.
## Estructura de una Prueba Unitaria en Angular
Supongamos que tenemos un servicio simple llamado `DataService`:
```
// src/app/data.service.ts
import { Injectable } from '@angular/core';
@Injectable({
providedIn: 'root'
})
export class DataService {
getData(): string {
return 'Hello, Angular 16!';
}
}
```
## Crear la Prueba Unitaria
Vamos a crear una prueba unitaria para este servicio.
```
// src/app/data.service.spec.ts
import { TestBed } from '@angular/core/testing';
import { DataService } from './data.service';
describe('DataService', () => {
let service: DataService;
beforeEach(() => {
TestBed.configureTestingModule({});
service = TestBed.inject(DataService);
});
it('should be created', () => {
expect(service).toBeTruthy();
});
it('should return "Hello, Angular 16!"', () => {
const data = service.getData();
expect(data).toBe('Hello, Angular 16!');
});
});
```
## Desglose de la Prueba
1. **Configuración del Módulo de Pruebas:** `TestBed.configureTestingModule` se usa para configurar y compilar el entorno de pruebas para el servicio.
2. **Inyección del Servicio:** `TestBed.inject(DataService)` se usa para obtener una instancia del servicio que queremos probar.
3. **Expectativas:** Utilizamos `expect` para verificar que el servicio se crea correctamente y que el método `getData` devuelve el valor esperado.
## Pruebas Unitarias de Componentes
Vamos a crear un componente simple y escribir pruebas unitarias para él.
```
// src/app/hello.component.ts
import { Component } from '@angular/core';
@Component({
selector: 'app-hello',
template: '<h1>{{ title }}</h1>'
})
export class HelloComponent {
title = 'Hello, Angular 16!';
}
```
## Crear la Prueba Unitaria para el Componente
```
// src/app/hello.component.spec.ts
import { ComponentFixture, TestBed } from '@angular/core/testing';
import { HelloComponent } from './hello.component';
describe('HelloComponent', () => {
let component: HelloComponent;
let fixture: ComponentFixture<HelloComponent>;
beforeEach(() => {
TestBed.configureTestingModule({
declarations: [HelloComponent]
}).compileComponents();
fixture = TestBed.createComponent(HelloComponent);
component = fixture.componentInstance;
fixture.detectChanges();
});
it('should create', () => {
expect(component).toBeTruthy();
});
it('should have title "Hello, Angular 16!"', () => {
const compiled = fixture.nativeElement as HTMLElement;
expect(compiled.querySelector('h1')?.textContent).toBe('Hello, Angular 16!');
});
});
```
## Desglose de la Prueba de Componente
1. **Configuración del Módulo de Pruebas:** Se declara el componente `HelloComponent` en el módulo de pruebas.
2. **Creación del Componente:** `TestBed.createComponent` se usa para crear una instancia del componente.
3. **Detección de Cambios:** `fixture.detectChanges` se llama para actualizar el DOM con los cambios del componente.
4. **Expectativas:** Verificamos que el componente se crea correctamente y que el título se renderiza como se espera.
## Ejecutar las Pruebas
Para ejecutar las pruebas, simplemente corre el siguiente comando:
```
ng test
```
Este comando ejecutará Karma, que abrirá un navegador y ejecutará todas las pruebas unitarias, mostrando los resultados en tiempo real.
## Conclusión
Las pruebas unitarias son una herramienta poderosa para mantener la calidad del código en proyectos Angular. Angular 16 proporciona un entorno robusto y fácil de usar para escribir y ejecutar estas pruebas. Al seguir buenas prácticas y realizar pruebas constantes, puedes asegurarte de que tu aplicación sea confiable y fácil de mantener.
---
> Espero que esta guía te haya proporcionado una comprensión clara y útil sobre cómo implementar pruebas unitarias en Angular 16.
| nerm_frontend |
1,867,152 | Quantum Convolutional Neural Networks | This blog post is about utilizing AWS ML services to build Quantum Convolutional Neural Networks... | 0 | 2024-05-28T03:50:04 | https://dev.to/zachbenson/quantum-convolutional-neural-networks-clm | tutorial, machinelearning, ai, datascience | This blog post is about utilizing AWS ML services to build Quantum Convolutional Neural Networks (QCNN). To do so, we utilize Amazon SageMaker, PennyLane, and PyTorch to train and test QCNNs on simulated quantum devices. Previously, it has been demonstrated that QCNNs can be used for binary classification tasks. This blog post will go one step further and show how to construct a QCNN for multi-class classification and apply it to image classification tasks. Based on the steps shown in this post, you can begin to explore the use cases of QCNNs by building, training, and evaluating your own model.
## Approach
To implement this solution, we used PennyLane, PyTorch, SageMaker notebooks, and the public MNIST and Fashion-MNIST datasets. The specific notebook instances were `ml.m5.2xlarge` - `ml.m5.24xlarge`.
### PennyLane
PennyLane is a Python library for programming quantum computers. Its differentiable programming paradigm enables the execution and optimization of quantum programs on a variety of simulated and hardware quantum devices. It manages the execution of quantum computations, including the evaluation of circuits and their gradients. This information can then be forwarded to the classical framework, creating seamless quantum-classical pipelines for applications, including the building of Quantum Neural Networks. Additionally, PennyLane offers integration with ML frameworks such as PyTorch.
### PyTorch
PyTorch is an open-source, deep learning framework that makes it easy to develop ML models and deploy them to production. PyTorch has been integrated into the PennyLane ecosystem, allowing for the creation of hybrid Quantum-Classical ML models. Furthermore, this integration has allowed for the native training of QML models in SageMaker.
### Amazon SageMaker
SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly. SageMaker removes the heavy lifting from each step of the ML process to make it easier to develop high-quality models. With its integration of PyTorch, practitioners are able to build, train, and deploy their own PyTorch models on SageMaker.
## Overview of Quantum Computing
### Quantum Bits
Quantum computing isn’t built on bits that aren’t binary in nature. Rather, quantum bits (qubits) are two-state quantum mechanical systems that can be a combination of both zero and one at the same time. In addition to this property of “superposition”, qubits can be “entangled”, allowing for N qubits to act as a group rather than in isolation. As a result, qubits can achieve exponentially higher information density (2^N) than the information density of a classical computer (N).
### Quantum Circuits
Quantum circuits are the underlying framework for quantum computation. Each circuit is built sequentially and consists of three stages: preparation of a fixed initial state, gate transformations, and measurement of an observable(s).
1. **Preparation**: In the first stage, the qubits are initialized with the quantum or classical data that is going to be used for computation. Several options exist for encoding classical data onto qubits. For our experiment, we elected to use Amplitude embedding, which takes 2^qubits data points as the initial state.
2. **Transformations**: In the second stage, gate-based transforms are applied to the qubits. This stage can be as simple as a one-gate operation or as complex as a grouping of gates. When several gates are grouped, they are often referred to as a unitary.
3. **Measurement**: Lastly, the circuit is completed with the measurement of an observable. This observable may be made up of local observables for each wire in the circuit or just a subset of wires. Prior to this stage, the qubits have been in superposition, representing a mixture of the states 0 and 1. However, when a qubit is measured, this state collapses into either 0 or 1, with an associated probability of doing so.
### Quantum Optimization
Variational or parameterized quantum circuits are quantum algorithms that depend on free parameters. Much like standard quantum circuits, they consist of the preparation of the fixed input state, a set of unitaries parameterized by a set of free parameters θ, and measurement of an observable ^B at the output. The output or expectation value, with some classical post-processing, can represent the cost of a given task. Given this cost, the free parameters θ=(θ1,θ2,...) of the circuit can be tuned and optimized. This optimization can leverage a classical optimization algorithm such as stochastic gradient descent or Adam.
## Quantum Convolutional Neural Network
Quantum convolutions are a unitary that act on neighboring pairs of qubits. When this unitary is applied to every neighboring pair of qubits, a convolution layer is formed. This convolution layer mirrors the kernel-based convolutional layer found in the classical case. Below is the structure of the convolutional unitary that was used for this project.
These convolutions are followed by pooling layers, which are effected by measuring a subset of the qubits and using the measurement results to control subsequent operations. Shown below is the structure that was used:
The analogue of a fully-connected layer is a multi-qubit operation on the remaining qubits before the final measurement. This essentially maps the information from the remaining qubits to the ancillary qubits for our final measurement. The structure for doing so is the following:
The resulting network architecture is two convolution layers, two pooling layers, and the ancillary mapping.
## Building the Model
### PennyLane Basics
1. To begin constructing a quantum circuit, we must first define the quantum simulator or hardware device that will be used.
```python
import pennylane as qml
dev = qml.device('default.qubit', wires=1)
# Specify how many qubits are needed
```
2. Now that the device is defined, we can begin building our quantum circuit.
```python
@qml.qnode(dev)
def circuit(input):
qml.RX(input, wires=0) # Quantum Gate
return qml.sample(qml.PauliZ(wires=0)) # Measurement of the PauliZ
```
3. To visualize the circuit, we can call `draw_mpl()`, with the required inputs of the circuit.
```python
from matplotlib import pyplot as plt
input = 1
fig, ax = qml.draw_mpl(circuit)(input)
plt.show()
```
### Advanced PennyLane
1. Establish the quantum device that will be used for our circuit.
```python
import pennylane as qml
num_wires = 12
num_ancilla = 4
device_type = 'lightning.qubit'
dev = qml.device(device_type, wires=num_wires)
```
2. Define the quantum model.
```python
def circuit(num_wires, num_ancilla):
@qml.qnode(dev, interface='torch', diff_method='adjoint')
def func(inputs, params):
work_wires = list(range(num_wires - num_ancilla))
ancilla_wires = list(range(len(work_wires), num_wires))
qml.AmplitudeEmbedding(inputs, wires=work_wires, normalize=True)
work_wires, params = Conv1DLayer(unitarity_conv1d, 15)(work_wires, params)
work_wires, params = PoolingLayer(unitarity_pool, 2)(work_wires, params)
work_wires, params = Conv1DLayer(unitarity_conv1d, 15)(work_wires, params)
work_wires, params = PoolingLayer(unitarity_pool, 2)(work_wires, params)
unitarity_toffoli(work_wires, ancilla_wires)
return [qml.expval(qml.PauliZ(wire)) for wire in ancilla_wires]
return func
```
3. Wrap our quantum circuit into a PyTorch Model.
```python
params_shapes = {"params": 357}
qlayer = qml.qnn.TorchLayer(circuit(num_wires, num_ancilla), params_shapes, torch.nn.init.normal_)
output = torch.nn.Softmax(dim=1)
```
4. Initialize the model with the layers that we just made.
```python
model = torch.nn.Sequential(qlayer, output)
```
### Training the Quantum Model
For training, we conducted an experiment on a subset of the MNIST and Fashion-MNIST datasets.
```python
# Hyperparameters
epochs = 8
batch_size = 32
train_samples = len(train_data)
batches = train_samples // batch_size
from tqdm.notebook import trange
opt = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(epochs):
running_loss = 0
batch = 0
model.train()
for batch, i in zip(train_loader, trange(batches)):
data = batch[0]
target = batch[1]
opt.zero_grad()
pred = model(data)
loss_evaluated = loss(pred, target)
loss_evaluated.backward()
opt.step()
running_loss += loss_evaluated
print(running_loss.item() / (i + 1), end='\r')
avg_loss = running_loss / batches
res = [epoch + 1, avg_loss]
print("Epoch: {:2d} | Loss: {:3f} ".format(*res))
```
## Evaluating the Model
```python
correct = 0
total = 0
with torch.no_grad():
model.eval()
for batch in test_loader:
data = batch[0]
target = batch[1]
predicted = model(data)
predicted = torch.argmax(predicted, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy of the network on {:2d} test images: {:.3f} %'.format(total, (100 * correct / total)))
```
## Saving and Loading the Model
```python
torch.save(model.state_dict(), PATH)
python
Copy code
model = torch.nn.Sequential(qlayer, output)
model.load_state_dict(torch.load(PATH))
model.eval()
```
## Deploying Model to SageMaker Endpoint
To deploy this model to a SageMaker endpoint, one would follow the standard steps for deploying a PyTorch model on SageMaker. The only additional step needed would be to extend the existing PyTorch container instance to include PennyLane.
## Results
For the subset of the MNIST dataset, the average accuracy after 8 epochs was 92%. For the Fashion-MNIST dataset, the average accuracy after 8 epochs was 88%.
## Next Steps
- There are various methods that can be used to encode data onto the quantum circuit. To be able to further leverage the information density of qubits, these methods should be further explored. This could allow for larger and more complex datasets to be used for training.
- Exploring further, the specific convolutional unitary used in this blog is one of many that could be used. It is possible that there are more efficient methods for conducting the convolution.
- Lastly, due to the quantum circuits being supported in PyTorch, it is possible to explore Quantum-Classical model architectures for multi-class classification. This enables support of transfer learning from well-established pre-built models.
## Conclusion
In this post, we demonstrated how quantum computing can be leveraged for multi-class image classification tasks. Moreover, we showed you how this can be accomplished on available Amazon SageMaker instances, using PennyLane for building QCNNs and PyTorch to facilitate model training and deployment. Furthermore, we discussed mechanisms that enabled the construction of QCNNs, and their training.
If you would like to look deeper at the code:
{% embed https://github.com/zacharybenson/quantum-cnn %} | zachbenson |
1,867,151 | ChatGPT Plus vs. Enterprise: Choosing the Right Version for Your Needs | When it comes to harnessing the power of AI for language generation, OpenAI's ChatGPT stands out as... | 0 | 2024-05-28T03:42:10 | https://dev.to/findmyaitool_seo_f6edbfb4/chatgpt-plus-vs-enterprise-choosing-the-right-version-for-your-needs-347e | chatgpt, bot, beginners |

When it comes to harnessing the power of AI for language generation, OpenAI's ChatGPT stands out as a top choice. But with multiple versions available, such as ChatGPT Plus and Enterprise, it's essential to understand which one best suits your requirements.
**ChatGPT Plus:**
[ChatGPT](https://findmyaitool.com/tool/chatgpt) Plus offers a user-friendly interface and powerful AI capabilities suitable for individuals and small businesses. With its intuitive design, users can easily generate natural-sounding text for various applications, from content creation to chatbots.
**This version is perfect for:**
Content creators seeking to enhance productivity
Small businesses looking to improve customer engagement
Developers building prototypes or experimenting with AI-driven applications
Explore ChatGPT Plus [here](https://openai.com/index/chatgpt-plus/).
**ChatGPT Enterprise:**
On the other hand, ChatGPT Enterprise caters to the needs of larger organizations and enterprises. It provides advanced customization options, scalability, and enhanced security features tailored to meet the demands of high-volume usage and sensitive data handling.
**This version is ideal for:**
Large corporations requiring custom AI solutions
Enterprises with complex workflow integration needs
Organizations prioritizing data security and compliance
Discover ChatGPT Enterprise [here](https://openai.com/index/introducing-chatgpt-enterprise/).
**Choosing the Right Version:**
Selecting between ChatGPT Plus and Enterprise depends on factors such as your organization's size, specific use cases, and data security requirements. While ChatGPT Plus offers accessibility and ease of use, ChatGPT Enterprise provides scalability and customization options for enterprise-level applications.
For further guidance on selecting the ideal version for your needs, consider reading reviews on ChatGPT.
In conclusion, whether you opt for ChatGPT Plus or Enterprise, you're tapping into cutting-edge AI technology that can revolutionize how you interact with and leverage natural language processing. Explore the features of each version and make an informed decision based on your unique requirements. | findmyaitool_seo_f6edbfb4 |
1,867,149 | VTable usage issue: How to add column total information to the list | Question title How to add column total information to the list Problem... | 0 | 2024-05-28T03:38:24 | https://dev.to/rayssss/vtable-usage-issue-how-to-add-column-total-information-to-the-list-p1m | visactor, vtable | ### Question title
How to add column total information to the list
### Problem description
In the list, you hope to display the total information of a column, such as sum, average, etc.
### Solution
VTable provides `aggregation`configuration for configuring data aggregation rules and display positions in the table. You can configure `aggregation`to specify global rules for aggregation in options, or configure `aggregation`to specify aggregation rules for each column. The following properties need to be configured in `aggregation`:
- aggregationType:
- Sum, set `aggregationType`to `AggregationType. SUM`
- Average, set `aggregationType`to `AggregationType. AVG`
- Maximum value, set `aggregationType`to `AggregationType. MAX`
- Minimum, set `aggregationType`to `AggregationType. MIN`
- Count, set `aggregationType`to `AggregationType. COUNT`
- Custom function, set `aggregationType`to `AggregationType. CUSTOM`, set custom aggregation logic through `aggregationFun`
- aggregationFun: Custom aggregation logic when `aggregationType is AggregationType. CUSTOM`
- showOnTop: Controls the display position of the aggregated results. The default is `false`, which means the aggregated results are displayed at the bottom of the body. If set to `true`, the aggregated results are displayed at the top of the body.
- FormatFun: Set the formatting function of aggregate values, and customize the display format of aggregate values.
### Code example
```javascript
const options = {
//......
columns: [
{
aggregation: [
{
aggregationType: VTable.TYPES.AggregationType.MAX,
// showOnTop: true,
formatFun(value) {
return '最高薪资:' + Math.round(value) + '元';
}
}
]
},
// ......
]
};
```
### Results show
Example code: https://www.visactor.io/vtable/demo/list-table-data-analysis/list-table-aggregation-multiple
### Related Documents
Basic Table Data Analysis Tutorial: https://www.visactor.io/vtable/guide/data_analysis/list_table_dataAnalysis
Related api: https://www.visactor.io/vtable/option/ListTable#aggregation
github:https://github.com/VisActor/VTable
| rayssss |
1,867,137 | How to deploy your own website on AWS | Originally published on rolfstreefkerk.com Take full control of your website, and following along... | 0 | 2024-05-28T03:36:21 | https://rolfstreefkerk.com/article/how-to-deploy-your-own-website-on-aws | aws, devops, webdev, beginners | > Originally published on [rolfstreefkerk.com](https://rolfstreefkerk.com/posts/how-to-deploy-your-own-website-on-aws)
Take full control of your website, and following along with our how-to guide.
Benefits of building and deploying a website from scratch:
- Own the code and control it as you see fit
- Learn AWS and how to deploy a website to AWS S3
- Understand DNS and Route53
- How to use DevOps to solve automation issues
Read on to get started.
> [Follow me on Twitter](https://x.com/rolfstreefkerk) to keep updated on the latest articles on AWS and more.
## You will need the following to get started
1. **a static site**, I recommend one of these frameworks (and I've used):
- [Hugo](https://gohugo.io/)
- existing [themes](https://themes.gohugo.io/) will get you a website quick, such that you only have to modify color schemes and layouts.
- or [Astro](https://astro.build/); if you’d like to integrate React, VueJS etc. code as well.
- use their themes page [here](https://astro.build/themes/) to get a starting point.
2. **an [AWS account](https://aws.amazon.com/)**, which requires a credit card to setup.
3. **a domain**, wherever you registered it.
- In this how-to I use [Porkbun](porkbun.com) as my favorite registrar.
4. **a computer with**;
- [Terraform](https://www.terraform.io/)/[OpenTofu](https://opentofu.org/) installed. We use Terraform in this article.
- [AWS CLI](https://aws.amazon.com/cli/) installed with profile configured you want to use for your website deployment.
- [Git](https://git-scm.com/downloads) command line tooling.
- your code editor of choice, I use [VSCode](https://code.visualstudio.com/).
5. **a [GitHub](https://github.com/) account** so you can fork my example repository.
6. *(optional) email inbox provider*, I use [Migadu](migadu.com).
## What are we creating today?
## We are creating the following services and configurations:
- AWS S3 bucket to send your website source files to;
- AWS CloudFront distribution that will cache, optimize website delivery globally to your audience.
- AWS Route53 for your;
- Email service records with DNSSec configuration,
- You can then hookup a newsletter service like `ConvertKit.com`
- Name Server Configuration for your domain; `yourwebsite.com`
- and the CloudFront distribution to optimize your website hosting.
- GitHub Actions for a CI/CD pipeline, deploying your website on command within a minute.

## Setup your Domain on AWS
Login to your AWS Console.
1. Go to Route53, after you’ve logged in, and navigate to `Hosted zones`.
2. Create your hosted zone and enter your website domain; `yourwebsite.com`
3. Make a note of the `Hosted zone ID`, We’ll use that in the next step for Terraform to automate all the Route53 records to the correct Domain name.

If you choose to automate it using Terraform;
- export the Name Servers from your domain registrar (Porkbun, etc.).
- add the hosted zone resource configuration into [my example Terraform module](https://github.com/rpstreef/terraform-static-site) and hook it up to all the related resources requiring the Hosted zone id.
### (Optional) Email hosting
If you like to setup an email hosting solution, I use migadu.com, keep the Route53 website open.
We’ll import additional configuration text blocks into Route53 to make your domain work with the inbox service.
- In Mail inbox service, there is a `DNS Configuration` panel.
- Get the `BIND` records output, copy/paste the text of all the DNS records.
> If you require automatic mail server discovery for your Email;
> Check for these strings in the provided DNS records; `_autodiscover` or `autoconfig`

- Then in AWS Route53, for your hosted zone; `Import zone file`, and copy paste the lines of text in that dialog box.

- Now you can add your new email inbox in your mail apps.
If you have `_autodiscover` and / or `autoconfig` DNS records included, you can;
- go to your email app,
- add a new inbox using; email and password.
- Finished, inbox added without further configuration required.
Otherwise, take a note of your mail inbox service SMTP and IMAP server configurations.
## Automating your AWS account setup with Terraform
Now that we have the Domain in place, and the Mail inbox (optional), we can configure the actual site deployment.
Create a new project by Forking: https://github.com/rpstreef/terraform-yourwebsite.com
This is a template that will use Terraform modules from another Git repository; https://github.com/rpstreef/terraform-static-site
### What does this template create?
This template will create the following set of resources;
- S3 bucket for Terraform state
- S3 bucket for `yourwebsite.com`
- S3 CORS configuration for ConvertKit.com , this will allow CORS between ConvertKit JavaScript and your domain without warnings.
- ACM Certificate for SSL, `*.yourwebsite.com`, and the ACM validation records for Route53 for auto-renewal of SSL.
- Route53 A, and AAAA records (IPv6)
- Route53 DNSSec,
- only the first step! The second step must be done manually with your Domain Registrar.
- Lambda function for redirects to index, ensures you have nice URL’s.
- E.g. https://yourwebsite.com/contact instead of https://yourwebsite.com/contact/index.html
- CloudFront for caching, and web-page speed optimization, and SSL secured.
### How to adjust the template?
To make the template fit for your website.
Do the following
- Change these lines in the `terraform.tfvars` file :
- where you read `yourdomain.com`,
- and your `hosted_zone_id` for `yourdomain.com`.
- check 404 response at the bottom of the file to see if that matches up with your website structure. Additionally HTTP response codes can be added as blocks; `{}`.
If you need additionally CORS settings, add an extra rule in the same way as `f.convertkit.com`.
```hcl
# General
environment = "prod"
region = "us-east-1"
project = "yourdomain.com"
# use tags to track your spend on AWS, seperate by 'product' for instance.
tags = {
environment = "production"
terraform = true
product = "yourdomain.com"
}
# Which config line used in .aws/config
aws_profile = "yourdomain-profile"
# Route53
hosted_zone_id = "Z000000000"
# www.yourdomain.com
product_name = "yourdomain" # avoid to use `.`, this cause an error.
bucket_name = "yourdomain.com" # your site is deployed here.
# S3 bucket CORS settings:
bucket_cors = {
rule1 = {
allowed_headers = ["*"]
allowed_methods = ["GET", "PUT", "POST"]
allowed_origins = ["https://f.convertkit.com"]
expose_headers = ["ETag"]
max_age_seconds = 3000
}
}
domain_names = ["yourdomain.com", "www.yourdomain.com"]
custom_error_responses = [{
error_code = 404
error_caching_min_ttl = 10
response_code = 200
response_page_path = "/404.html"
}]
```
- Make sure the configuration in `project-state.tf` file is correct;
- check the bucket name,
- and the AWS `profile` name used, e.g. `yourwebsite-profile`.
```hcl
locals {
projects_state_bucket_name = "tfstate-yourwebsite.com"
}
provider "aws" {
region = "us-east-1"
profile = "yourwebsite-profile"
}
terraform {
# First we need a local state
backend "local" {
}
# After terraform apply, switch to remote S3 terraform state
/*backend "s3" {
bucket = "tfstate-yourwebsite"
key = "terraform.tfstate"
region = "us-east-1"
profile = "yourwebsite-profile"
encrypt = true
acl = "private"
}*/
}
```
- If all the configuration checks out;
- run `terraform init`, this will download the dependent modules.
- then; `terraform apply` > `yes`
- When it’s finished deploying, make note of the variables in the output. We’ll need them later on. To retrieve these later, type; `terraform output` in the `./environments/production` directory.
> Which one came first? The chicken or the egg?
- When finished, we need to adjust the `project-state.tf` file:
- Place the `backend "local"` block in comments.
- Remove the comments from the `backend "s3"` block.
- Migrate the state from `local` to `S3`:
- `terraform init -migrate-state`
- type: `yes` to copy state from local to s3.
Now it’s fully deployed and we have saved our Terraform state to AWS S3, it’s no longer on your disk. You can remove those `tfstate` files if you like.
### Establishing DNSSec “Chain of Trust”
The benefit of DNSSec is the establishment of the “chain of trust”.
That means, it is verified that;
- You own the domain,
- when you navigate to that domain, the information is coming from your servers and not from someone else’s server (e.g. hackers etc.)
> If you’d like to learn more about DNSSec, [this](https://www.csoonline.com/article/569685/dnssec-explained-why-you-might-want-to-implement-it-on-your-domain.html) article is a good primer
Now to finalize DNSSec configuration, you will have to manually modify the Domain registrar information.
- First, get the required `DS` records for DNSSec; `View information to create DS record`

- Then, in the next screen click; `Establish a Chain of Trust`.
You will see a table outlining configuration items.
If you did not register your domain on Route53, click `Another Domain registrar`
On Porkbun, my domain registrar, the screen looks like this:

- Enter the following at the `dsData` block; on the left is the Porkbun input field name, on the right as the value I will place the name used at `Route53`:
- Key Tag: `Key tag`
- DS Data Algorithm: `Signing algorithm type`
- Digest Type: `Digest algorithm type`
- Digest: `Digest`
> If you have a different registrar, you’ll need to review their documentation, it may be slightly different.
#### How to check your configuration works?
- Finally, use this online tool; https://dnssec-debugger.verisignlabs.com/ to check your domain, if you’re getting all green check-marks.
If they’re all green, It means your chain of trust has been successfully established!
Now we have a DNSSec secured domain configuration with an S3 static hosted site via CloudFront with SSL.
- Performant
- Cheap
- and Secure.
## Upload your website
We can use a local deployment setup with the AWS CLI, or via GitHub Actions.
### Local deployment with a script
Depending on your system (Linux, Windows, Mac), you may need to alter this script.
On Linux, we can automate your website deployment as follows using this bash script:
```bash
#! /bin/bash
npm run build
aws s3 sync dist s3://yourwebsite.com --profile yourwebsite-profile
aws cloudfront create-invalidation --distribution-id <CloudFront Distr. Id> --paths "/*" --profile yourwebsite-profile
```
Make sure to;
- replace `npm run build` for the script that generates your static website build.
- replace `dist` in the `aws s3 sync dist`, if your website build is in another folder.
- replace `<CloudFront Distr. Id>` with your CloudFront distribution id.
- you can find it in the outputs after `terraform apply` has finished; `cloudfront_distribution_id`
### GitHub Actions
If you like to use automation instead, it’s very easy and cheap to setup.
#### What does this cost anyway?
| Plan | Storage | Minutes (per month) |
| ----------- | ------- | ------------------- |
| GitHub Free | 500 MB | 2,000 |
| GitHub Pro | 1 GB | 3,000 |
You can deploy quite a few times before you hit the `Pro` ceiling in terms of `Minutes per month`:
The `storage` size is based on your repository size which, for most, will be very hard to reach.
| Operating system | Minute multiplier |
| ---------------- | ----------------- |
| Linux | 1 |
| Windows | 2 |
We choose a `Linux` build environment, specifically `ubuntu-latest`, to get the most out of our free minutes.
Check out more about GitHub Action pricing [here](https://docs.github.com/en/billing/managing-billing-for-github-actions/about-billing-for-github-actions).
#### How does it work?
To deploy using GitHub Actions, do the following:
- First, create a new file in your website’s GitHub repository at `.github/workflows/deploy-on-comment.yml`.
- Add the following code to the file:
> **Note**; I’m assuming your website is Node (v20) based. Adapt where needed!
```yaml
name: Deploy on Comment
on:
issue_comment:
types: [created, edited]
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Set up Node.js
uses: actions/setup-node@v3
with:
node-version: '20'
- name: Install dependencies
run: npm install
- name: Build website
run: npm run build
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: us-east-1
- name: Sync build output with S3 bucket
run: aws s3 sync ./dist s3://your-s3-bucket-name
- name: Invalidate CloudFront cache
run: aws cloudfront create-invalidation --distribution-id ${{ secrets.CLOUDFRONT_DISTRIBUTION_ID }} --paths "/*"
```
There’s several secret variables that need to be created on GitHub, coming from the Terraform output we received earlier:
- `AWS_ACCESS_KEY_ID`:
- `AWS_SECRET_ACCESS_KEY`:
- `CLOUDFRONT_DISTRIBUTION_ID`
- If you need to look up what these are again, navigate to your `terraform-yourwebsite.com` git repository and then;
- `cd ./environments/production`
- `terraform output`
- Input them at the following location in GitHub:

- You can now `create an issue` that details the updates on your website for example.
For each comment that is added, the deployment will start.
- You can follow the deployment steps taken and the logs in the `Actions` tab.

- (Optional) In case you’d want to change the GitHub Actions to use a `Pull request` instead, you can modify that in the deploy script.
> For more alternative triggers, check out the [GitHub Actions documentation](https://docs.github.com/en/actions/using-workflows/triggering-a-workflow).
## Your website is online!
Now when you go to your web URL; `yourwebsite.com`, everything should be up and running.
What we have build;
- (Optional) Email hosting with Migadu (or choose any that you have); e.g. `hello@yourwebsite.com`
- You can connect this to your ConvertKit.com mailing list for example.
- Your own personal domain that is DNSSec secured.
- You’ll be certain no hackers can hi-jack your domain.
- Your static Website on [[AWS]] using AWS S3.
- Free web-hosting!
- CloudFront Content Delivery Network (CDN), enabling:
- SSL protected website. Form submits are all encrypted by default.
- Increased performance in load speeds, latency across the globe.
- URL rewrites for static websites. No `index.html` will be displayed when navigating.
- and redirects for 404 not found pages. Your visitors will see the `404.html` page instead of an error text message.
## Questions? Let's discuss!
What do you struggle with on AWS?
Did you have issues with deploying on AWS?
How would you do it?
Let me know down in the comments or on [Twitter](https://x.com/rolfstreefkerk)
Appreciate your time and till the next one!
| rolfstreefkerk |
1,861,394 | Creating a Custom Log Generator Helper Class in Python | Logging is an essential aspect of any application, providing insights into the application's... | 0 | 2024-05-28T03:30:00 | https://dev.to/learn_with_santosh/creating-a-custom-log-generator-helper-class-in-python-40fm | python, tips | Logging is an essential aspect of any application, providing insights into the application's behavior, aiding in debugging, and monitoring system health. While Python’s built-in logging module is versatile, there are scenarios where a custom log generator can provide additional flexibility.
In this post, we will create a custom log generator helper class in Python to streamline and enhance your logging process.
## Why Custom Logging?
A custom log generator can offer several benefits:
- Simplify configuration and setup.
- Standardize log formats and file naming.
- Automatically handle log rotation based on file size.
- Make it easy to include additional context in logs.
## Building the Custom Log Generator Helper Class
**Step 1: Import Required Modules**
First, import the necessary modules. We’ll use os for handling file operations and datetime for timestamping.
```Python
import os
import datetime
```
**Step 2: Define the CustomLogGenerator Class**
Next, define the CustomLogGenerator class. This class will handle the logging configuration, log file management, and message logging.
```Python
class CustomLogGenerator:
def __init__(self, log_folder, file_prefix, max_file_size=1e6):
self.log_folder = log_folder
self.file_prefix = file_prefix
self.max_file_size = max_file_size # in bytes
# Create log folder if it doesn't exist
if not os.path.exists(self.log_folder):
os.makedirs(self.log_folder)
def _get_filename(self, date_str, file_number=None):
if file_number:
return f"{self.log_folder}/{self.file_prefix}{date_str}_{file_number}.log"
else:
return f"{self.log_folder}/{self.file_prefix}{date_str}.log"
def _get_next_file_number(self, date_str):
i = 1
while True:
log_file = self._get_filename(date_str, i)
if not os.path.exists(log_file):
return i
i += 1
def generate_log(self, message):
date_str = datetime.datetime.now().strftime("%d%m%Y")
log_file = self._get_filename(date_str)
next_file_number = 1
# Check if the log file exists and its size is more than the max_file_size
if os.path.exists(log_file) and os.path.getsize(log_file) > self.max_file_size:
while True:
log_file = self._get_filename(date_str, next_file_number)
if not os.path.exists(log_file) or os.path.getsize(log_file) <= self.max_file_size:
break
next_file_number += 1
# Write the log message to the log file
with open(log_file, 'a') as f:
timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
f.write(f"{timestamp} - {message}\n")
```
**Step 3: Using the Custom Log Generator**
Now, let's see how you can use this CustomLogGenerator in your application.
```Python
# Initialize the log generator
log_generator = CustomLogGenerator(log_folder='logs', file_prefix='app_log_', max_file_size=1e6)
# Generate some log messages
log_generator.generate_log('This is the first log message.')
log_generator.generate_log('This is the second log message.')
log_generator.generate_log('Another log message with more details.')
```
## Conclusion
By creating a custom log generator helper class, you can streamline your logging process, ensure consistent log formatting, and handle log file rotation automatically. This class provides a flexible foundation for enhancing your application's logging capabilities.
Feel free to modify and extend this class to suit your specific needs. Happy logging!
Please find complete code [here](https://github.com/learn-with-santosh/python/blob/main/custom-log-generator.py)
| learn_with_santosh |
1,867,145 | The Advantages of Using FMZ's Extended API for Efficient Group Control Management in Quantitative Trading | With the popularization and development of quantitative trading, investors often need to manage a... | 0 | 2024-05-28T03:25:42 | https://dev.to/fmzquant/the-advantages-of-using-fmzs-extended-api-for-efficient-group-control-management-in-quantitative-trading-je8 | trading, api, fmzquant, cryptocurrency | With the popularization and development of quantitative trading, investors often need to manage a large number of live accounts, which brings great challenges to trading decisions, monitoring and execution. In order to improve management efficiency and reduce operational difficulty, traders on FMZ can use FMZ's extended API for group control management. In this article, we will discuss the advantages of using FMZ's extended API in quantitative trading and how to achieve efficient group control management.
Many users have their own customer live accounts that need managing and maintaining. When there are many customer live accounts, a more convenient way is needed for managing them (as few as dozens or as many as hundreds). FMZ provides a powerful extended API; using this for group control management has become an ideal choice.
### Centralized Monitoring
Through FMZ's extended API, you can centrally monitor the trading activities and asset conditions of all live accounts. Whether it is checking the positions of each account, historical trading records, or real-time monitoring of the profit and loss status of accounts, all of them can be achieved.
```
// Global variable
var isLogMsg = true // Control whether the log is printed
var isDebug = false // Debug mode
var arrIndexDesc = ["all", "running", "stop"]
var descRobotStatusCode = ["In idle", "Running", "Stopping", "Exited", "Stopped", "Strategy error"]
var dicRobotStatusCode = {
"all" : -1,
"running" : 1,
"stop" : 4,
}
// Extended log function
function LogControl(...args) {
if (isLogMsg) {
Log(...args)
}
}
// FMZ extended API call function
function callFmzExtAPI(accessKey, secretKey, funcName, ...args) {
var params = {
"version" : "1.0",
"access_key" : accessKey,
"method" : funcName,
"args" : JSON.stringify(args),
"nonce" : Math.floor(new Date().getTime())
}
var data = `${params["version"]}|${params["method"]}|${params["args"]}|${params["nonce"]}|${secretKey}`
params["sign"] = Encode("md5", "string", "hex", data)
var arrPairs = []
for (var k in params) {
var pair = `${k}=${params[k]}`
arrPairs.push(pair)
}
var query = arrPairs.join("&")
var ret = null
try {
LogControl("url:", baseAPI + "/api/v1?" + query)
ret = JSON.parse(HttpQuery(baseAPI + "/api/v1?" + query))
if (isDebug) {
LogControl("Debug:", ret)
}
} catch(e) {
LogControl("e.name:", e.name, "e.stack:", e.stack, "e.message:", e.message)
}
Sleep(100) // Control frequency
return ret
}
// Obtain all live trading information of the specified strategy Id.
function getAllRobotByIdAndStatus(accessKey, secretKey, strategyId, robotStatusCode, maxRetry) {
var retryCounter = 0
var length = 100
var offset = 0
var arr = []
if (typeof(maxRetry) == "undefined") {
maxRetry = 10
}
while (true) {
if (retryCounter > maxRetry) {
LogControl("Exceeded the maximum number of retries", maxRetry)
return null
}
var ret = callFmzExtAPI(accessKey, secretKey, "GetRobotList", offset, length, robotStatusCode)
if (!ret || ret["code"] != 0) {
Sleep(1000)
retryCounter++
continue
}
var robots = ret["data"]["result"]["robots"]
for (var i in robots) {
if (robots[i].strategy_id != strategyId) {
continue
}
arr.push(robots[i])
}
if (robots.length < length) {
break
}
offset += length
}
return arr
}
function main() {
var robotStatusCode = dicRobotStatusCode[arrIndexDesc[robotStatus]]
var robotList = getAllRobotByIdAndStatus(accessKey, secretKey, strategyId, robotStatusCode)
if (!robotList) {
Log("Failed to obtain live trading data")
}
var robotTbl = {"type": "table", "title": "live trading list", "cols": [], "rows": []}
robotTbl.cols = ["live trading Id", "live trading name", "live trading status", "strategy name", "live trading profit"]
_.each(robotList, function(robotInfo) {
robotTbl.rows.push([robotInfo.id, robotInfo.name, descRobotStatusCode[robotInfo.status], robotInfo.strategy_name, robotInfo.profit])
})
LogStatus(_D(), "`" + JSON.stringify(robotTbl) + "`")
}
```
Strategy parameter design:
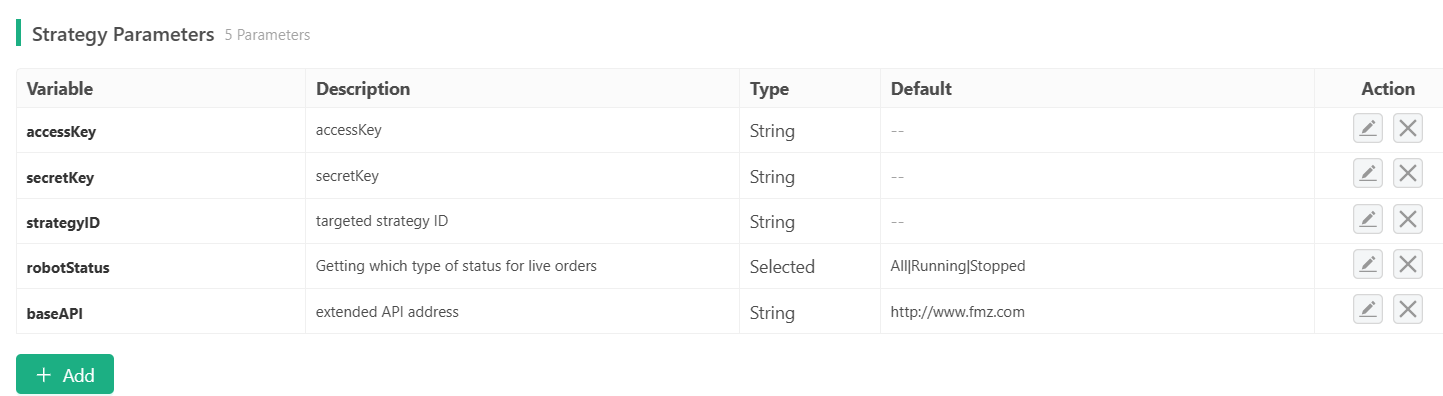
Running on live trading:
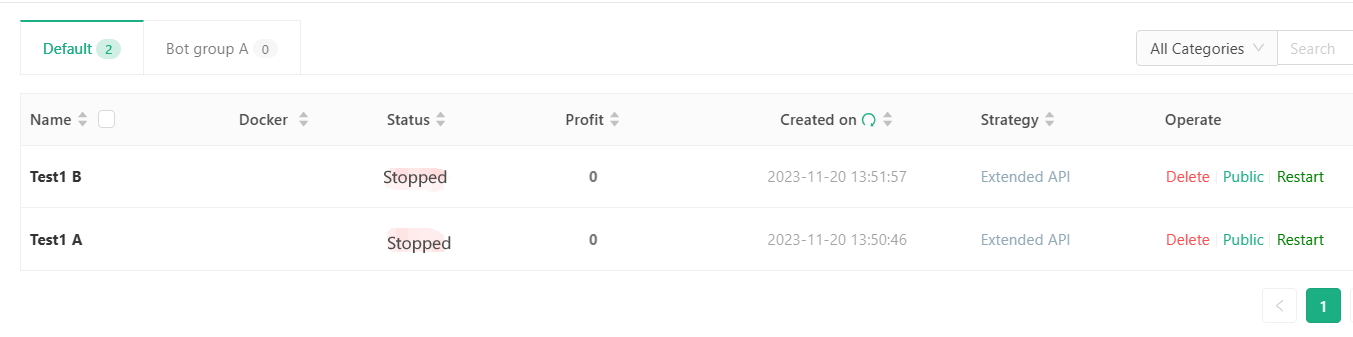
### One-click Execution
Group control management makes it very convenient to execute transactions with one-click. You can buy, sell, and close positions on multiple live trading accounts simultaneously without having to open each account individually. This not only improves execution efficiency, but also reduces the possibility of operational errors.
After obtaining the list of live trading accounts, we can send commands to these accounts and perform a series of predetermined operations. For example: clearing positions in the live account, pausing protection in the live account, switching modes in the live account. All these can be achieved through FMZ's extended API CommandRobot.
As we continue writing code, we just need to add some interactions and calls to the extended API interface CommandRobot in our main function:
```
function main() {
var robotStatusCode = dicRobotStatusCode[arrIndexDesc[robotStatus]]
var robotList = getAllRobotByIdAndStatus(accessKey, secretKey, strategyId, robotStatusCode)
if (!robotList) {
Log("Failed to obtain live trading data")
}
var robotTbl = {"type": "table", "title": "live trading list", "cols": [], "rows": []}
robotTbl.cols = ["live trading Id", "live trading name", "live trading status", "strategy name", "live trading profit"]
_.each(robotList, function(robotInfo) {
robotTbl.rows.push([robotInfo.id, robotInfo.name, descRobotStatusCode[robotInfo.status], robotInfo.strategy_name, robotInfo.profit])
})
LogStatus(_D(), "`" + JSON.stringify(robotTbl) + "`")
while(true) {
LogStatus(_D(), ", Waiting to receive interactive commands", "\n", "`" + JSON.stringify(robotTbl) + "`")
var cmd = GetCommand()
if (cmd) {
var arrCmd = cmd.split(":")
if (arrCmd.length == 1 && cmd == "coverAll") {
_.each(robotList, function(robotInfo) {
var strCmd = "Clearance" // You can define the required message format
if (robotInfo.status != 1) { // Only the "live" trading platform can receive commands.
return
}
var ret = callFmzExtAPI(accessKey, secretKey, "CommandRobot", parseInt(robotInfo.id), strCmd)
LogControl("Send command to the live trading board with id: ", robotInfo.id, ":", strCmd, ", execution result:", ret)
})
}
}
Sleep(1000)
}
}
```
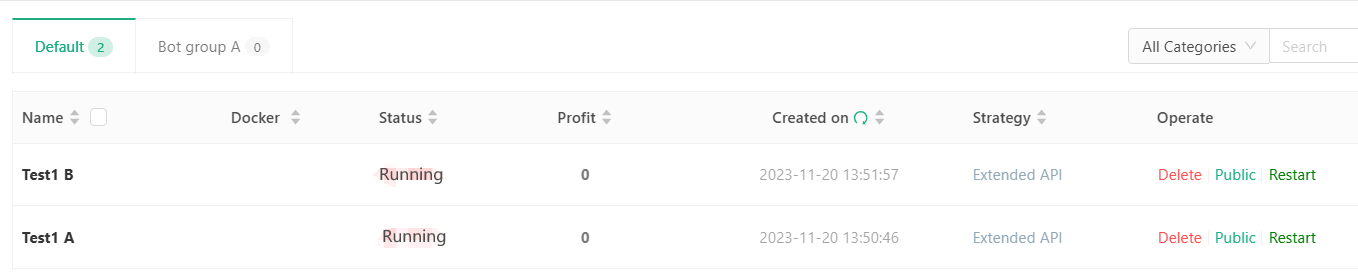
The group control strategy sent instructions to "Test 1 A" and "Test 1 B".




### Strategy Synchronization
With FMZ's extended API, you can easily implement batch modifications of strategy parameters, and batch start or stop live trading.
### Summary
In quantitative trading, by using FMZ's extended API for group control management, traders can monitor, execute and adjust multiple live accounts more efficiently. This centralized management method not only improves operational efficiency, but also helps to better implement risk control and strategy synchronization.
For traders managing a large number of live accounts, FMZ's extended API provides them with a powerful and flexible tool that makes quantitative trading more convenient and controllable.
FroM: https://blog.mathquant.com/2023/11/20/the-advantages-of-using-fmzs-extended-api-for-efficient-group-control-management-in-quantitative-trading.html | fmzquant |
1,867,143 | Mmoexp WoW Cataclysm Classic Gold: recreate a 14 year old game and it's a brand new one | Since I believe every person has their own definition of WoW Cataclysm Classic Gold like, what's... | 0 | 2024-05-28T03:19:25 | https://dev.to/rozemondbell/mmoexp-wow-cataclysm-classic-gold-recreate-a-14-year-old-game-and-its-a-brand-new-one-4kp2 | webdev, javascript, beginners, programming | Since I believe every person has their own definition of <a href="https://www.mmoexp.com/Wow-cata-classic/Gold.html">WoW Cataclysm Classic Gold</a> like, what's blind and what's not blind. I can remember that this was the case when I was playing Dark Souls. This is because some gamers viewed reading chats as, you know being a shrewd player.
It's as if you're going to hear things, you're just going be told what to do, etc. It's just weird. If you ever see it, it's"Oh, to hit that tail. You know it's a good idea to hit the tail, since someone said it, but you're thinking Oh, I'm not supposed to say that because I did not learn it in the game. It's a strange thing. Right?
And so yeah I'm sure that this happened frequently for me whenever I did Dark Souls, so it's difficult to determine if it's really blind or not, this is reminiscent of project 70. Do you remember all the arguments for that? Moon gymnastics and trying to <a href="https://www.mmoexp.com/Wow-cata-classic/Gold.html">Buy WoW Cataclysm Classic Gold</a>
recreate a 14 year old game and it's a brand new one?
| rozemondbell |
1,867,142 | SQL Convertor for Easy Migration from Presto, Trino, ClickHouse, and Hive to Apache Doris | Apache Doris is an all-in-one data platform that is capable of real-time reporting, ad-hoc queries,... | 0 | 2024-05-28T03:17:52 | https://dev.to/apachedoris/sql-convertor-for-easy-migration-from-presto-trino-clickhouse-and-hive-to-apache-doris-5955 | datascience, dataengineering, dataplatform, datamigration | [Apache Doris](https://doris.apache.org/) is an all-in-one data platform that is capable of real-time reporting, ad-hoc queries, data lakehousing, log management and analysis, and batch data processing. As more and more companies have been replacing their component-heavy data architecture with Apache Doris, there is an increasing need for a more convenient data migration solution. **That's why the Doris SQL Convertor is made.**
Most database systems run their own SQL dialects. Thus, migration between systems often entails modifications of SQL syntaxes. Since SQLs work closely with a company's business logic, in many cases, users have to modify their business logic, too. To reduce the transition pain for users, Apache Doris 2.1 provides the Doris SQL Convertor. It supports the SQL syntaxes of Presto, Trino, Hive, ClickHouse, and PostgreSQL. With it, users can execute queries with their old SQL syntaxes directly in Doris or batch convert their existing SQL statements on the visual interface.
## Doris SQL Convertor
The Doris SQL Convertor requires **zero rewriting** of SQL. Simply `set sql_dialect = "trino"` in the session variable, then you can execute queries in Doris using Trino SQLs.
The SQL compatibility of it has been proven by extensive tests. For example, a user tested the Doris SQL Convertor with over 30,000 SQL queries from their production environment. Turned out that the Convertor successfully converted 99.6% of the Trino SQLs and 98% of the ClickHouse SQLs.
Currently, Presto, Trino, Hive, ClickHouse, and PostgreSQL dialects are supported. We are working to add Teradata, SQL Server, and Snowflake to the list, and consistently increase the compatibility level of each SQL dialect.
## Installation & usage
### SQL conversion service
**1**. **Download** **[Doris SQL Convertor](https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/doris-sql-convertor/doris-sql-convertor-1.0.3-bin-x86.tar.gz)**
**2**. On any frontend (FE) node, start the service using the following command.
- The SQL conversion service is stateless and can be started or stopped at any time.
- `port=5001` in the command specifies the service port. (You can use any available port.)
- It is advisable to start a service individually for each FE node.
```
nohup ./doris-sql-convertor-1.0.1-bin-x86 run --host=0.0.0.0 --port=5001 &
```
**3**. Start a Doris cluster **(Use Doris 2.1.0 or newer)**.
**4**. Set the URL for SQL conversion service in Doris. `127.0.0.1:5001` in the command represents the IP and port number of the node where the service is deployed.
```Shell
MySQL> set global sql_converter_service_url = "http://127.0.0.1:5001/api/v1/convert"
```
After deployment, you can execute SQL directly in the command line. You can start the service by `set sql_dialect = XXX`. The following examples are based on ClickHouse SQL dialects.
- Presto
```SQL
mysql> set sql_dialect=presto;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT cast(start_time as varchar(20)) as col1,
array_distinct(arr_int) as col2,
FILTER(arr_str, x -> x LIKE '%World%') as col3,
to_date(value,'%Y-%m-%d') as col4,
YEAR(start_time) as col5,
date_add('month', 1, start_time) as col6,
REGEXP_EXTRACT_ALL(value, '-.') as col7,
JSON_EXTRACT('{"id": "33"}', '$.id')as col8,
element_at(arr_int, 1) as col9,
date_trunc('day',start_time) as col10
FROM test_sqlconvert
where date_trunc('day',start_time)= DATE'2024-05-20'
order by id;
+---------------------+-----------+-----------+------------+------+---------------------+-------------+------+------+---------------------+
| col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10 |
+---------------------+-----------+-----------+------------+------+---------------------+-------------+------+------+---------------------+
| 2024-05-20 13:14:52 | [1, 2, 3] | ["World"] | 2024-01-14 | 2024 | 2024-06-20 13:14:52 | ['-0','-1'] | "33" | 1 | 2024-05-20 00:00:00 |
+---------------------+-----------+-----------+------------+------+---------------------+-------------+------+------+---------------------+
1 row in set (0.03 sec)
```
- ClickHouse
```SQL
mysql> set sql_dialect=clickhouse;
Query OK, 0 rows affected (0.00 sec)
mysql> select toString(start_time) as col1,
arrayCompact(arr_int) as col2,
arrayFilter(x -> x like '%World%',arr_str)as col3,
toDate(value) as col4,
toYear(start_time)as col5,
addMonths(start_time, 1)as col6,
extractAll(value, '-.')as col7,
JSONExtractString('{"id": "33"}' , 'id')as col8,
arrayElement(arr_int, 1) as col9,
date_trunc('day',start_time) as col10
FROM test_sqlconvert
where date_trunc('day',start_time)= '2024-05-20 00:00:00'
order by id;
+---------------------+-----------+-----------+------------+------+---------------------+-------------+------+------+---------------------+
| col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10 |
+---------------------+-----------+-----------+------------+------+---------------------+-------------+------+------+---------------------+
| 2024-05-20 13:14:52 | [1, 2, 3] | ["World"] | 2024-01-14 | 2024 | 2024-06-20 13:14:52 | ['-0','-1'] | "33" | 1 | 2024-05-20 00:00:00 |
+---------------------+-----------+-----------+------------+------+---------------------+-------------+------+------+---------------------+
1 row in set (0.02 sec)
```
### Visual interface
For large-scale conversion, it is recommended to use the visual interface, on which you can batch upload the files for dialect conversion.
Follow these steps to deploy the visual conversion interface:
**1**. Environment: Docker, Docker-Compose
**2**. Get Doris-SQL-Convertor Docker image
**3**. Create a network for the image
```Bash
docker network create app_network
```
**4**. Decompress the package
```Bash
tar xzvf doris-sql-convertor-1.0.1.tar.gz
cd doris-sql-convertor
```
**5**. Edit the environment variables
```Bash
FLASK_APP=server/app.py
FLASK_DEBUG=1
API_HOST=http://doris-sql-convertor-api:5000
# DOCKER TAG
API_TAG=latest
WEB_TAG=latest
```
**6**. Start it up
```Bash
sh start.sh
```
After deployment, you can access the service by `ip:8080` via your local browser. `8080` is the default port. You can change the mapping port. On the visual interface, you can select the source dialect type and target dialect type, and then click "Convert".
> Note:
>
> 1. For batch conversion, each SQL statement should end with `; `.
> 2. The Doris SQL Convertor supports 239 UNION ALL conversions at most.
Join the [Apache Doris community](https://join.slack.com/t/apachedoriscommunity/shared_invite/zt-2gmq5o30h-455W226d79zP3L96ZhXIoQ) to seek guidance from the Doris makers or provide your feedback! | apachedoris |
1,867,141 | Diagram AI: Elevate Your Visuals with The Power of AI 🌟📊 | Are the hours spent sketching out diagrams taking a toll on your productivity? Experience the magic... | 0 | 2024-05-28T03:12:44 | https://dev.to/miabossanova/diagram-ai-elevate-your-visuals-with-the-power-of-ai-466g | Are the hours spent sketching out diagrams taking a toll on your productivity? Experience the magic of Diagram AI's AI-assisted diagramming tool that generates sleek, professional visuals in a flash! 🌟
Simply feed a text description to [Diagram AI](https://chromewebstore.google.com/detail/diagram-ai/klbgbmoinfidmgmjlliilmbofaokkilo?pli=1), and watch as it employs sophisticated AI to create your perfect diagram.
Here's why Diagram AI is a game-changer for your diagramming needs:
✅ Time Saver: Ditch the complexity of traditional diagramming software – Diagram AI has got your back.
✅ Clear Communication: Share your concepts with crisp, straightforward diagrams that get your point across.
✅ Seamless Teamwork: Collaborate and sync with your colleagues seamlessly, ensuring unity of vision.
Don't miss out on the revolutionary way to diagram – test out [Diagram AI](https://chromewebstore.google.com/detail/diagram-ai/klbgbmoinfidmgmjlliilmbofaokkilo?pli=1)'s AI-augmented diagramming today and elevate your project presentations to new heights! | miabossanova | |
1,867,138 | Django vs. Flask: Which One Should You Choose? | Picking the right web framework for your project can be difficult. It seems like new frameworks pop... | 0 | 2024-05-28T03:09:28 | https://dev.to/ordinaryindustries/django-vs-flask-which-one-should-you-choose-2h9e | django, flask, webdev, python | Picking the right web framework for your project can be difficult. It seems like new frameworks pop up every day and it can be overwhelming trying to choose the one that best suits your application. Among Python developers two popular choices are Django and Flask. Each has its strengths so let’s take a look at the key difference and help you decide which one suit your needs best.
## What are Django and Flask?
Django is a high-level Python web framework built by the Django Software Foundation. Django is often referred to as “batteries-included” because it comes with several built-in features, such as an ORM (Object-Relational Mapping), authentication, user management, and a powerful admin interface. Django aims to remove much of the hassle of web development so you can focus on writing your app without needing to go through the hoops of reinventing the wheel.
Flask, on the other hand, is a micro-framework based on Werkzeug, Jinja2, and Click. It’s lightweight and minimalist, which gives you more control over the components you use. It’s designed to be simply and flexible, allowing you to select the tools and libraries you need.
## Key Differences
### Philosophy and Design
**Django** emphasizes the “batteries-included” approach with a large number of built-in features to tackle the various aspects of web development. It’s a great choice where you need to get up and running fast with minimal effort.
**Flask** focuses on simplicity and flexibility. It gives you the essentials to get started but leave the choice of additional components up to you. It’s great for small projects or those who prefer more control over their stack.
### Learning Curve
**Django** has extensive features and conventions that can present a steeper learning curve for newcomers. That said, once you understand the structure, Django streamlines your development process substantially.
**Flask** and its minimal design make it easier to pick up and understand. You can start small and scale your applications by adding the necessary components as you go.
### Complexity
**Django** thrives with large and complex applications. With the inclusion of an admin interface and ORM, it makes it easier to manage complex databases or user interactions.
**Flask** is better suited for smaller, simpler projects where you want to maintain full control over the components.
### Flexibility
**Django** comes with a lot of built-in tools which means it’s less flexible. But, customization is still possible with a whole community full of packages that can be used to augment its abilities.
**Flask** starts with less and leaves the choices up to you. Since it provides the basics, you can build and integrate exactly what you need without the overhead of unwanted features.
### Community
**Django** has a large and active community with extensive documentation and a rich ecosystem of third-party packages. This can be invaluable, especially when you are trying to tackle common problems or trying to follow best practices.
**Flask** also has a strong community, although smaller than Django’s. There is a rich ecosystem of extensions that can be easily integrated to add functionality as needed.
## The Rub
### When to Choose Django
Go with Django when you want to get up and running fast. It’s a solid choice when you have a complex project since it comes with an admin panel and database management features. Use Django when you need rapid development or want scalability.
### When to Choose Flask
Pick Flask for simpler projects or prototypes that don’t need a lot of build-in features. Use it if you want total control over the components and architecture of your application. It’s also a great pick if you want to learn the basics of web development or want to experiment with different tools and libraries.
## Conclusion
Both Django and Flask are excellent frameworks for web development. They cater to different needs and project types. If you need a comprehensive solution with plenty of built-in features, Django is where it's at. On the other hand, if you prefer simplicity, Flask might be a better pick. Consider the size and complexity of your project, your development timeline, and your personal preferences when making a decision. No matter which you choose, both Frameworks have proven themselves in the industry and can help you build great web apps.
Let us know about the app you’re starting on [Twitter](https://x.com/OrdinaryInds)! Say hi and show off your work. | jackfields |
1,867,139 | Django vs. Flask: Which One Should You Choose? | Picking the right web framework for your project can be difficult. It seems like new frameworks pop... | 0 | 2024-05-28T03:09:27 | https://dev.to/jackfields/django-vs-flask-which-one-should-you-choose-3o4 | django, flask, webdev, python | Picking the right web framework for your project can be difficult. It seems like new frameworks pop up every day and it can be overwhelming trying to choose the one that best suits your application. Among Python developers two popular choices are Django and Flask. Each has its strengths so let’s take a look at the key difference and help you decide which one suit your needs best.
## What are Django and Flask?
Django is a high-level Python web framework built by the Django Software Foundation. Django is often referred to as “batteries-included” because it comes with several built-in features, such as an ORM (Object-Relational Mapping), authentication, user management, and a powerful admin interface. Django aims to remove much of the hassle of web development so you can focus on writing your app without needing to go through the hoops of reinventing the wheel.
Flask, on the other hand, is a micro-framework based on Werkzeug, Jinja2, and Click. It’s lightweight and minimalist, which gives you more control over the components you use. It’s designed to be simply and flexible, allowing you to select the tools and libraries you need.
## Key Differences
### Philosophy and Design
**Django** emphasizes the “batteries-included” approach with a large number of built-in features to tackle the various aspects of web development. It’s a great choice where you need to get up and running fast with minimal effort.
**Flask** focuses on simplicity and flexibility. It gives you the essentials to get started but leave the choice of additional components up to you. It’s great for small projects or those who prefer more control over their stack.
### Learning Curve
**Django** has extensive features and conventions that can present a steeper learning curve for newcomers. That said, once you understand the structure, Django streamlines your development process substantially.
**Flask** and its minimal design make it easier to pick up and understand. You can start small and scale your applications by adding the necessary components as you go.
### Complexity
**Django** thrives with large and complex applications. With the inclusion of an admin interface and ORM, it makes it easier to manage complex databases or user interactions.
**Flask** is better suited for smaller, simpler projects where you want to maintain full control over the components.
### Flexibility
**Django** comes with a lot of built-in tools which means it’s less flexible. But, customization is still possible with a whole community full of packages that can be used to augment its abilities.
**Flask** starts with less and leaves the choices up to you. Since it provides the basics, you can build and integrate exactly what you need without the overhead of unwanted features.
### Community
**Django** has a large and active community with extensive documentation and a rich ecosystem of third-party packages. This can be invaluable, especially when you are trying to tackle common problems or trying to follow best practices.
**Flask** also has a strong community, although smaller than Django’s. There is a rich ecosystem of extensions that can be easily integrated to add functionality as needed.
## The Rub
### When to Choose Django
Go with Django when you want to get up and running fast. It’s a solid choice when you have a complex project since it comes with an admin panel and database management features. Use Django when you need rapid development or want scalability.
### When to Choose Flask
Pick Flask for simpler projects or prototypes that don’t need a lot of build-in features. Use it if you want total control over the components and architecture of your application. It’s also a great pick if you want to learn the basics of web development or want to experiment with different tools and libraries.
## Conclusion
Both Django and Flask are excellent frameworks for web development. They cater to different needs and project types. If you need a comprehensive solution with plenty of built-in features, Django is where it's at. On the other hand, if you prefer simplicity, Flask might be a better pick. Consider the size and complexity of your project, your development timeline, and your personal preferences when making a decision. No matter which you choose, both Frameworks have proven themselves in the industry and can help you build great web apps.
Let us know about the app you’re starting on [Twitter](https://x.com/OrdinaryInds)! Say hi and show off your work. | jackfields |
1,867,135 | How does the LED screen control card control the LED screen? | The LED screen control card is one of the key components of the LED display screen. It is responsible... | 0 | 2024-05-28T02:56:53 | https://dev.to/sostrondylan/how-does-the-led-screen-control-card-control-the-led-screen-5a54 | led, screen, control |
The LED screen control card is one of the key components of the [LED display screen](https://www.sostron.com/product?category=2). It is responsible for converting the input screen information into data and control signals that the LED screen can display. The following is a detailed introduction to the working principle and functions of the LED screen control card:

1. Overview of LED display controller:
The LED display controller is one of the core components of the LED display, also known as the LED asynchronous control system or LED display control card. Its main function is to receive screen display information from the computer serial port and store it in the frame memory. Then, the LED display controller generates the serial display data and scan control timing required for the LED display according to the set partition driving method. [Here is the knowledge about synchronous control and asynchronous control of LED display. ](https://www.sostron.com/service/faq/3618)
2. Working principle of embedded real-time + offline two-in-one controller:
The embedded real-time + offline two-in-one controller usually consists of four parts: DVI transmission controller or 1000M network card, CPU, memory (SD card), and display scan driver. After booting, the system initializes, and the CPU reads the display content stored by the user from the memory (SD card) and sends it to the LED display to restore the user-edited content. When the CPU detects that real-time information is being sent, it will automatically switch the data channel and update the content on the LED screen in real-time display.

3. Audio processing of embedded real-time + offline two-in-one controller:
In the offline state, the controller has a built-in audio processor that can be used to play audio offline. In the real-time state, the audio is collected in real time through the DVI sending controller or 1000M network card, and then played through the audio playback chip. Therefore, the audio function of the controller can be switched between real-time and offline. [Provide you with the working principle of LED lamp beads. ](https://www.sostron.com/service/faq/7842)
4. Applicable scenarios of real-time + offline two-in-one controller:
The real-time + offline two-in-one controller is suitable for many scenarios, and the LED display can be used without connecting to a computer. This kind of controller is suitable for various information release occasions, but it is not suitable for television screens and ultra-large display screens. [Provide you with the characteristics, application scenarios and prospects of LED flexible screens. ](https://www.sostron.com/news/2348)
5. Controller’s group screen control and offline playback functions:
The control card usually has an Ethernet (LAN) interface, which can be easily networked. Through the computer in the LAN, the networked LED display can be controlled to realize group screen networking to publish information. In addition, the controller can play various animation and video files offline without connecting to a computer.

6. Gray scale requirements of LED display:
LED displays usually need to have certain grayscale capabilities when displaying images to restore the true effect of the image. On a monochrome LED screen, although patterns can be displayed, the image is more like a black and white photo, so a certain gray level is required. LED full-color screens can better restore the effect of color pictures because they have higher grayscale capabilities. [LED displays are divided into single-color, dual-color and full-color types. ](https://www.sostron.com/service/faq/3651)
To sum up, the LED screen control card realizes the display function of the LED display screen by controlling data conversion and signal transmission, and has a variety of applications and flexibility in different scenarios.

Thank you for watching. I hope we can solve your problems. Sostron is a professional [LED display manufacturer](https://sostron.com/about). We provide all kinds of displays, display leasing and display solutions around the world. If you want to know: [How do LED display companies respond to the AR/VR market?](https://dev.to/sostrondylan/how-do-led-display-companies-respond-to-the-arvr-market-43k5) Please click read.
Follow me! Take you to know more about led display knowledge.
Contact us on WhatsApp:https://api.whatsapp.com/send/?phone=8613570218702&text&type=phone_number&app_absent=0 | sostrondylan |
1,867,131 | Understanding HTML Tags and Attributes: A Comprehensive Guide:- | HTML (HyperText Markup Language) is the foundation of web development, enabling developers to create... | 0 | 2024-05-28T02:52:24 | https://dev.to/harsh_dev26/understanding-html-tags-and-attributes-a-comprehensive-guide--4gem | webdev, javascript, beginners, programming | HTML (HyperText Markup Language) is the foundation of web development, enabling developers to create structured documents for the web. Whether you're a beginner or looking to refresh your knowledge, understanding HTML tags and attributes is essential. In this guide, we'll dive deep into the basics and provide practical examples to help you get started.
## What are HTML Tags?
HTML tags are the building blocks of HTML, used to create and structure elements on a webpage. Tags are enclosed in angle brackets, like `<tagname>`. Most tags come in pairs: an opening tag (`<tagname>`) and a closing tag (`</tagname>`). The content between these tags is what gets affected by the tag.
### Basic Structure of an HTML Document
Here's a simple example of an HTML document:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My First HTML Page</title>
</head>
<body>
<h1>Welcome to My Website</h1>
<p>This is a paragraph of text on my website.</p>
</body>
</html>
```
- `<!DOCTYPE html>`: Declares the document type and version of HTML.
- `<html>`: Root element of an HTML page.
- `<head>`: Contains meta-information about the document.
- `<title>`: Sets the title of the webpage (appears in the browser tab).
- `<body>`: Contains the content of the webpage, visible to users.
- `<h1>`: Defines a top-level heading.
- `<p>`: Defines a paragraph.
## Common HTML Tags
Here are some commonly used HTML tags:
### Headings
HTML provides six levels of headings, from `<h1>` to `<h6>`, with `<h1>` being the highest level.
```html
<h1>Main Heading</h1>
<h2>Subheading</h2>
<h3>Sub-subheading</h3>
```
### Paragraphs and Text Formatting
```html
<p>This is a paragraph.</p>
<strong>Bold text</strong>
<em>Italic text</em>
```
### Lists
HTML supports ordered and unordered lists.
```html
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
<ol>
<li>First item</li>
<li>Second item</li>
<li>Third item</li>
</ol>
```
### Links and Images
```html
<a href="https://www.example.com">Visit Example.com</a>
<img src="image.jpg" alt="Description of image">
```
## What are HTML Attributes?
Attributes provide additional information about HTML elements. They are always included in the opening tag and usually come in name/value pairs like `name="value"`.
### Common Attributes
#### `href` for Links
```html
<a href="https://www.example.com">This is a link</a>
```
#### `src` and `alt` for Images
```html
<img src="image.jpg" alt="Description of the image">
```
#### `class` and `id` for Styling and Scripting
```html
<p class="text-muted">This is a paragraph with a class attribute.</p>
<div id="uniqueElement">This div has a unique ID.</div>
```
### Boolean Attributes
Boolean attributes, such as `checked`, `disabled`, and `readonly`, don't require a value.
```html
<input type="checkbox" checked>
<button disabled>Can't click me</button>
```
## Conclusion
Understanding HTML tags and attributes is the first step towards becoming a proficient web developer. This guide covered the basic elements and their usage, providing a solid foundation for further learning. As you continue to build your skills, you'll discover the depth and flexibility that HTML offers.
For more detailed information, check out the [MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web/HTML) or other comprehensive resources. Happy coding!
---
Feel free to leave comments or questions below. I'd love to hear your thoughts and help you on your web development journey! | harsh_dev26 |
1,867,130 | LetsGrowMore - Data Science | TASK 1 IRIS CLASSIFICATION Data Analysis Intern at LetsGrowMore Used Python to conduct statistical... | 0 | 2024-05-28T02:47:15 | https://dev.to/webdev990/letsgrowmore-data-science-33h5 | datascience, python, machinelearning, programming | TASK 1 IRIS CLASSIFICATION
Data Analysis Intern at LetsGrowMore
Used Python to conduct statistical analysis on the IRIS CLASSIFICATION dataset.
- Python
- ML
- pandas
- matplotlib
- seaborn
Github:
https://lnkd.in/edmxitGp
Data Set #2: Stock Market
Used Python to conduct statistical analysis on the stock market dataset.
- Python
- ML
- pandas
- matplotlib
- seaborn
Here is the dataset:
https://lnkd.in/edmxitGp
Dataset #3:
Global Terrorist
- Python
- ML
- pandas
- matplotlib
- seaborn
Github:
https://lnkd.in/edmxitGp
#DataScience #softwareengineer #computerscience | webdev990 |
1,867,129 | How to tailor your technology resume for the job you want | When it comes to job hunting in the technology industry, it is not enough to have a general resume... | 0 | 2024-05-28T02:46:34 | https://dev.to/stealc/how-to-tailor-your-technology-resume-for-the-job-you-want-45e8 | career, resume, softwareengineering, devgrad2020 | > When it comes to job hunting in the technology industry, it is not enough to have a general resume that you use for every job you apply for. To stand out and land the job you want, you should customize your resume specifically for each position.
## _**Here are seven tips and strategies for how to tailor your technology resume for the job you want.**_

## 1. Customize your resume for each job application
> Don't send the same resume for every job you apply for. Tailor your resume for each job application by highlighting the relevant skills and experience that match the job requirements.
## 2. Use keywords from the job description
> The job description is your key to understanding what the organization is looking for. Read the description carefully and make a list of the specific skills, qualifications and experiences that are required and preferred for the position. Use this list to then guide the content in your resume where relevant.
## 3. Highlight relevant experience
> Once you've identified the key skills and qualifications, be sure to highlight your relevant experience in those areas. This could include work experience, specific projects, and other accomplishments that demonstrate your ability to excel in this particular position. Be sure to include quantifiable results to make your experience stand out.
## 4. Emphasize relevant projects
> If you have worked on specific technology projects that are relevant to the job you're applying for, highlight them in your resume. Describe your role, the technologies used, and the outcomes achieved. This can demonstrate your hands-on experience and showcase your ability to apply your skills in real-world scenarios.
## 5. Showcase your adaptability
> The technology field is constantly evolving, and employers value candidates who can adapt to changes and learn new technologies quickly. Highlight your adaptability by mentioning any instances where you have successfully learned and implemented new technologies, tools, or methodologies in your resume. This can demonstrate your ability to stay up to date with the latest trends and technologies in the industry.
## 6. Include a skills section
> A technology resume should have a section that highlights your technical skills, such as programming languages, software tools, and operating systems. Be sure to list everything that is relevant to the role.
## 7. Include a link to your portfolio or GitHub profile
> If you have a portfolio or a GitHub profile showcasing your technology projects or code samples, include a link in your resume. This can provide the employer with additional evidence of your skills and expertise and allow them to see your work firsthand.
**_Tailoring your technology resume for the job you want increases your chances of getting an interview and getting hired. Remember to customize your resume for each job application and proofread it carefully before submitting it. With these tips, you can create a winning technology resume that may help you land your dream job._**
~ article by chinnanj | stealc |
1,867,125 | Consistency its all | Just studiying the 4 week of CS50P, this famous course of Python fundamentals and i have to say its... | 0 | 2024-05-28T02:26:32 | https://dev.to/nan64/consistency-its-all-1jeh | Just studiying the 4 week of CS50P, this famous course of Python fundamentals and i have to say its awesome and challenging.
I recently move to a new place in my country and its been a while since i can code some lines, but now i'am back in it and it feels good.
It's been three weeks without coding and for me, a novice, I already need to dust off my nascent skills, so from now on consistency will be everything.
| nan64 | |
1,867,122 | Built text summarization application to summarize a web page with Angular | Introduction I am an Angular and NestJS developer interested in Angular, Vue, NestJS, and... | 27,492 | 2024-05-28T02:23:40 | https://www.blueskyconnie.com/built-text-summarization-application-to-summarize-web-page-with-angular/ | angular, tutorial, webdev, generativeai | ##Introduction
I am an Angular and NestJS developer interested in Angular, Vue, NestJS, and Generate AI. Blog sites such as dev.to and hashnode have many new blog posts daily, and it is difficult for me to pick out the good ones to read and improve my knowledge of web development and generative AI. Therefore, I built a text summarization application to call my NestJS backend to provide a summary of a technology blog post. When the summary sounds interesting, I read the rest of the post. Otherwise, I stop and find other ones to read. The full-stack generative application helps me decide whether to read a technology blog post.
###Create a new Angular Project
```bash
ng new ng-text-summarization-app
```
###Create a shell component
```typescript
// summarization-shell.component.ts
@Component({
selector: 'app-summarization-shell',
standalone: true,
imports: [RouterOutlet, SummarizationNavBarComponent, LargeLanguageModelUsedComponent],
template: `
<div class="grid">
<app-summarization-nav-bar class="nav-bar" />
<div class="main">
<router-outlet></router-outlet>
</div>
<app-large-language-model-used class="model-used" />
</div>
`,
changeDetection: ChangeDetectionStrategy.OnPush
})
export class SummarizationShellComponent {}
```
```typescript
// summarization-nav-bar.component.ts
@Component({
selector: 'app-summarization-nav-bar',
standalone: true,
imports: [RouterLink, RouterLinkActive],
template: `
<h3>Main Menu</h3>
<ul>
<li>
<a routerLink="/summarization-page" routerLinkActive="active-link">Text Summarization</a>
</li>
<li>
<a routerLink="/summarization-as-list" routerLinkActive="active-link">Bullet Points Summarization</a>
</li>
</ul>
`,
changeDetection: ChangeDetectionStrategy.OnPush
})
export class SummarizationNavBarComponent {}
```
The shell component renders a navigation bar for a user to navigate to different text summarization components. The first component provides a paragraph summary, while the second one returns a bullet point summary.
###Define routes to route different text summarization components
```typescript
// app.route.ts
import { Routes } from '@angular/router';
export const routes: Routes = [
{
path: 'summarization-page',
loadComponent: () => import('./summarization/summarize-paragraph-page/summarize-paragraph-page.component')
.then((m) => m.SummarizeParagraphComponent),
title: 'Text Summarization',
},
{
path: 'summarization-as-list',
loadComponent: () => import('./summarization/summarize-bullet-point/summarize-bullet-point.component')
.then((m) => m.SummarizeBulletPointComponent),
title: 'Bullet Points Summarization',
},
{
path: '',
pathMatch: 'full',
redirectTo: 'summarization-page',
},
{
path: '**',
redirectTo: 'summarization-page'
}
];
```
When a user visits `/summarization-page`, the page allows the user to enter a web page URL and provides a paragraph summary. When a user visits `/summarization-as-list`, the page allows the user to enter a web page URL and get back a bullet point summary.
###Web Page input box
```typescript
// webpage-input-box.component.ts
@Component({
selector: 'app-webpage-input-box',
standalone: true,
imports: [FormsModule],
template: `
<div class="container">
<div class="topic">
<label for="topic">
<span>Topic: </span>
<input id="topic" name="topic" type="text" [(ngModel)]="topic" />
</label>
</div>
<div>
<label for="url">
<span>Url: </span>
<input id="url" name="url" type="text" [(ngModel)]="text" />
</label>
<button (click)="pageUrl.emit({ url: vm.url, topic: vm.topic })" [disabled]="vm.isLoading">{{ vm.buttonText }}</button>
</div>
</div>
`,
changeDetection: ChangeDetectionStrategy.OnPush
})
export class WebpageInputBoxComponent {
topic = signal('');
text = signal('');
isLoading = input(false);
viewModel = computed<WebpageInputBoxModel>(() => {
return {
topic: this.topic(),
url: this.text(),
isLoading: this.isLoading(),
buttonText: this.isLoading() ? 'Summarizing...' : 'Summarize!',
}
});
pageUrl = output<SubmittedPage>();
get vm() {
return this.viewModel();
}
}
```
This is a component that accepts a web page URL and an optional topic hint. When a prompt includes a topic hint, Gemini provides a more accurate summary than without.
```typescript
// web-page-input-container.component.ts
@Component({
selector: 'app-web-page-input-container',
standalone: true,
imports: [WebpageInputBoxComponent],
template: `
<h2>{{ title }}</h2>
<div class="summarization">
<app-webpage-input-box [isLoading]="isLoading()" (pageUrl)="submittedPage.emit($event)" />
</div>
`,
changeDetection: ChangeDetectionStrategy.OnPush
})
export class WebPageInputContainerComponent {
isLoading = input.required<boolean>();
title = inject(new HostAttributeToken('title'), { optional: true }) || 'Ng Text Summarization Demo';
submittedPage = output<SubmittedPage>();
}
```
`WebPageInputContainerComponent` emits the web page URL and topic hint to the enclosing summarization component.
###Implement the Paragraph Summary component
```typescript
// summarize-paragraph-page.component.ts
@Component({
selector: 'app-summarize-paragraph-page',
standalone: true,
imports: [SummarizeResultsComponent, WebPageInputContainerComponent],
template: `
<div class="container">
<app-web-page-input-container title="Ng Text Summarization Demo" [isLoading]="isLoading()"
/>
<app-summarize-results [results]="summary()" />
</div>
`,
changeDetection: ChangeDetectionStrategy.OnPush
})
export class SummarizeParagraphComponent {
isLoading = signal(false);
inputContainer = viewChild.required(WebPageInputContainerComponent);
summarizationService = inject(SummarizationService);
summary = toSignal(
this.summarizationService.result$
.pipe(
scan((acc, translation) => ([...acc, translation]), [] as SummarizationResult[]),
tap(() => this.isLoading.set(false)),
),
{ initialValue: [] as SummarizationResult[] }
);
constructor() {
effect((cleanUp) => {
const sub = outputToObservable(this.inputContainer().submittedPage)
.pipe(filter((parameter) => !!parameter.url))
.subscribe(({ url, topic = '' }) => {
this.isLoading.set(true);
this.summarizationService.summarizeText({
url,
topic,
});
});
cleanUp(() => sub.unsubscribe());
})
}
}
```
`SummarizeParagraphComponent` uses `viewchild` to access the submitted URL and topic hint. Then, the component executes `SummarizationService.summarizeText` to send a request to the backend to ask Gemini to summarize the web page. `SummarizeResultsComponent` is responsible for rendering the summary in a list.
###Implement the Bullet Point Summary component
```typescript
// summarize-bullet-point.component.ts
@Component({
selector: 'app-summarize-as-list',
standalone: true,
imports: [SummarizeResultsComponent, WebPageInputContainerComponent],
template: `
<div class="container">
<app-web-page-input-container title="Ng Bullet Point List Demo" [isLoading]="isLoading()"
/>
<app-summarize-results [results]="summary()" />
</div>
`,
changeDetection: ChangeDetectionStrategy.OnPush
})
export class SummarizeBulletPointComponent {
isLoading = signal(false);
inputContainer = viewChild.required(WebPageInputContainerComponent);
summarizationService = inject(SummarizationService);
summary = toSignal(
this.summarizationService.bulletPointList$
.pipe(
scan((acc, translation) => ([...acc, translation]), [] as SummarizationResult[]),
tap(() => this.isLoading.set(false)),
),
{ initialValue: [] as SummarizationResult[] }
);
constructor() {
effect((cleanUp) => {
const sub = outputToObservable(this.inputContainer().submittedPage)
.pipe(filter((parameter) => !!parameter.url))
.subscribe(({ url, topic = '' }) => {
this.isLoading.set(true);
this.summarizationService.summarizeToBulletPoints({
url,
topic,
});
});
cleanUp(() => sub.unsubscribe());
})
}
}
```
`SummarizeBulletPointComponent` also uses `viewchild` to access the submitted URL and topic hint. Then, the component executes `SummarizationService.summarizeToBulletPoints` to send a request to the backend to ask Gemini to summarize the web page. `SummarizeResultsComponent` is responsible for rendering the bullet point summary.
###List the summary
```typescript
// summarization-result.interface.ts
export interface SummarizationResult {
url: string;
text: string;
}
```
```typescript
// line-break.pipe.ts
@Pipe({
name: 'lineBreak',
standalone: true
})
export class LineBreakPipe implements PipeTransform {
transform(value: string): string {
return value.replace(/(?:\r\n|\r|\n)/g, '<br/>');
}
}
```
`LineBreakPipe` is a pure pipe that replaces a new line character with a <br/> tag. Then, the component can display multiple lines nicely.
```typescript
// summarize-results.component.ts
@Component({
selector: 'app-summarize-results',
standalone: true,
imports: [LineBreakPipe],
template: `
<h3>Text Summarization: </h3>
@if (results().length > 0) {
<div class="list">
@for (item of results(); track item) {
<div>
<span>Url: </span>
<p [innerHTML]="item.url"></p>
</div>
<div>
<span>Result: </span>
<p [innerHTML]="item.text | lineBreak"></p>
</div>
<hr />
}
</div>
} @else {
<p>No summarization</p>
}
`,
changeDetection: ChangeDetectionStrategy.OnPush
})
export class SummarizeResultsComponent {
results = input.required<SummarizationResult[]>();
}
```
`SummarizeResultsComponent` is a simple component that lists both the URL and the summary.
###Add a new service to call the backend
```json
// config.json
{
"url": "http://localhost:3000"
}
```
The JSON file stores the base URL of the NestJS backend. You are freely update it to point to correct backend server
```typescript
// summarization.service.ts
function summarizeWebPage(data: Summarization) {
return function (source: Observable<SummarizationResult>) {
return source.pipe(
retry(3),
map(({ url='', text }) => ({
url,
text
})),
catchError((err) => {
console.error(err);
return of({
url: data.url,
result: 'No summarization due to error',
});
})
)
}
}
@Injectable({
providedIn: 'root'
})
export class SummarizationService {
private readonly httpService = inject(HttpClient);
private textSummarization = signal<Summarization>({
url: '',
topic: '',
});
private bulletPointsSummarization = signal<Summarization>({
url: '',
topic: '',
});
result$ = toObservable(this.textSummarization)
.pipe(
filter((data) => !!data.url),
switchMap((data) =>
this.httpService.post<SummarizationResult>(`${config.url}/summarization`, data)
.pipe(summarizeWebPage(data))
),
map((result) => result as SummarizationResult),
);
bulletPointList$ = toObservable(this.bulletPointsSummization)
.pipe(
filter((data) => !!data.url),
switchMap((data) =>
this.httpService.post<SummarizationResult>(`${config.url}/summarization/bullet-points`, data)
.pipe(summarizeWebPage(data))
),
map((result) => result as SummarizationResult),
);
summarizeText(data: Summarization) {
this.textSummarization.set(data);
}
summarizeToBulletPoints(data: Summarization) {
this.bulletPointsSummarization.set(data);
}
getLargeLanguageModelUsed(): Observable<LargeLanguageModelUsed> {
return this.httpService.get<LargeLanguageModelUsed>(`${config.url}/summarization/llm`);
}
}
```
When `textSummarization` signal receives a value, the Observable requests the backend (${config.url}/summarization) to obtain the paragraph summary. The result is assigned to `result$`, which `SummarizeParagraphComponent` can access and append to the summary list subsequently.
When `bulletPointsSummarization` signal receives a value, the Observable requests the backend (${config.url}/summarization/bullet-points) to obtain the bullet point summary. The result is assigned to `bulletPointList$`, which `SummarizeBulletPointComponent` can access and append to the summary list subsequently.
Let's create an Angular docker image and run the Angular application in the docker container.
###Dockerize the application
```text
// .dockerignore
.git
.gitignore
node_modules/
dist/
Dockerfile
.dockerignore
npm-debug.log
```
Create a `.dockerignore` file for Docker to ignore some files and directories.
```text
# Use an official Node.js runtime as the base image
FROM node:20-alpine
# Set the working directory in the container
WORKDIR /usr/src/app
# Copy package.json and package-lock.json to the working directory
COPY package*.json /usr/src/app
RUN npm install -g @angular/cli
# Install the dependencies
RUN npm install
# Copy the rest of the application code to the working directory
COPY . .
# Expose a port (if your application listens on a specific port)
EXPOSE 4200
# Define the command to run your application
CMD [ "ng", "serve", "--host", "0.0.0.0"]
```
I added the `Dockerfile` that installs the dependencies and starts the application at port 4200. `CMD ["ng", "serve", "--host", "0.0.0.0"]` exposes the localhost of the docker to the external machine.
```text
// .env.docker.example
...NestJS environment variables...
WEB_PORT=4200
```
`.env.docker.example` stores the WEB_PORT environment variable that is the port number of the Angular application.
```text
// docker-compose.yaml
version: '3.8'
services:
backend:
... backend container...
web:
build:
context: ./ng-text-summarization-app
dockerfile: Dockerfile
depends_on:
- backend
ports:
- "${WEB_PORT}:${WEB_PORT}"
networks:
- ai
restart: unless-stopped
networks:
ai:
```
In the docker compose yaml file, I added a web container that depends on the backend container. The Docker file is located in the `ng-text-summarization-app` repository, and Docker Compose uses it to build the Angular image and launch the container.
I added the `docker-compose.yaml` to the root folder, which was responsible for creating the Angular application container.
```bash
docker-compose up
```
The above command starts Angular and NestJS containers, and we can try the application by typing http://localhost:4200 into the browser.
This concludes my blog post about using Angular and Gemini API to build a full-stack text summarization application. I built the text summarization application to practice the contents of generative AI but I would like to apply the newly gained knowledge in production. I hope you like the content and continue to follow my learning experience in Angular, NestJS, Generative AI, and other technologies.
##Resources:
- Github Repo: https://github.com/railsstudent/fullstack-genai-text-summeration-app/tree/main/ng-text-summarization-app
- Build Angular app in Docker: https://dev.to/rodrigokamada/creating-and-running-an-angular-application-in-a-docker-container-40mk
| railsstudent |
1,867,124 | Data Analysis - Meriskill | As a Data Analysis Intern, I have worked on three datasets (Sales, HR, and Diabetes). With my range... | 0 | 2024-05-28T02:22:49 | https://dev.to/webdev990/data-analysis-49h | python, machinelearning, datascience, dataanalysis | As a Data Analysis Intern, I have worked on three datasets (Sales, HR, and Diabetes). With my range of programming skills, I use different tools: Python, Tableau, ML Algorithm, Seaborn, Matplotlib, and Pandas.
Visit the dashboard (Sales) at
https://stfly.biz/6YDmr
Summary:
Overall, most of the employers don't travel for most of the field and departments. HR has the highest number if employers compared to other departments and fields. The employer's age ranges from between the low to mix 30 to the low 40s for most of the fields and department. Lastly, there are more males than females in most the education field and department.
You can find the analysis (HR) at
https://stfly.biz/6YDns
Video:
https://stfly.biz/6YDCY
Visit the Github:
https://github.com/Kyl67899/Meriskill_Data_Analysis_intern
#DataScience #SoftwareEngineering #SQL #Python #Tableau #DataAnalysis #ComputerScience | webdev990 |
1,867,123 | Price Performance After the Currency is Listed on Perpetual Contracts | Most people know that once Binance announces the listing of a new perpetual contract, the spot price... | 0 | 2024-05-28T02:22:03 | https://dev.to/fmzquant/price-performance-after-the-currency-is-listed-on-perpetual-contracts-3e66 | contract, fmzquant, trading, cryptocurrency | Most people know that once Binance announces the listing of a new perpetual contract, the spot price of this cryptocurrency often rises immediately. This has led to some robots scraping announcements constantly to buy in at the first moment, not to mention so-called insider information where the currency price has already risen before the announcement is even made. But how do these contract cryptocurrencies perform after they start trading? Do they continue their upward trend or have a pullback? Let's analyze it today.
### Data Preparation
Download the 4h K-line data of Binance's perpetual contract for the year 2023. The specific download code is introduced in the previous article: https://www.fmz.com/bbs-topic/10286. The listing time does not necessarily coincide with the 4-hour mark, which is a bit imprecise. However, the price at the start of trading is often chaotic. Using fixed intervals can filter out the impact of market opening without delaying analysis. In the data dataframe, NaN represents no data; once the first piece of data appears, it means that this coin has been listed. Here we calculate every 4 hours after listing relative to the first price increase and form a new table. Those already listed from the beginning are filtered out. As of November 16, 2023, Binance has listed a total of 86 currencies, averaging more than one every three days - quite frequent indeed.
The following is the specific processing code, where only data within 150 days of going live has been extracted.
```
df = df_close/df_close.fillna(method='bfill').iloc[0]
price_changes = {}
for coin in df.columns[df.iloc[0].isna()]:
listing_time = df[coin].first_valid_index()
price_changes[coin] = df[coin][df.index>listing_time].values
changes_df = pd.DataFrame.from_dict(price_changes, orient='index').T
changes_df.index = changes_df.index/6
changes_df = changes_df[changes_df.index<150]
changes_df.mean(axis=1).plot(figsize=(15,6),grid=True);
```
### Result Analysis
The results are shown in the following graph, where the horizontal axis represents the number of days on the shelf and the vertical axis represents the average index. This result can be said to be unexpected but reasonable. Surprisingly, after new contracts are listed, they almost all fall, and the longer they are listed, the more they fall. At least within half a year there is no rebound. But it's also reasonable to think about it; so-called listing benefits have been realized before listing, and subsequent continuous declines are normal. If you open up a K-line chart to look at weekly lines, you can also find that many newly-listed contract currencies follow this pattern - opening at their peak.
### Exclude the Impact of the Index
The previous article has mentioned that digital currencies are greatly affected by simultaneous rises and falls. Does the overall index's decline affect their performance? Here, let's change the price changes to be relative to the index changes and look at the results again. From what we see on the graph, it still looks the same - a continuous decline. In fact, it has declined even more compared to the index.
```
total_index = df.mean(axis=1)
df = df.divide(total_index,axis=0)
```
### Binance's Currency Listing
By analyzing the relationship between the number of currencies listed each week and the index, we can clearly see Binance's listing strategy: frequent listings during a bull market, few listings during a bear market. February and October of this year were peak periods for listings, coinciding with bull markets. During times when the market was falling quite badly, Binance hardly listed any new contracts. It is evident that Binance also wants to take advantage of high trading volumes in bull markets and active new contracts to earn more transaction fees. They don't want new contracts to fall too badly either, but unfortunately, they can't always control it.
### Summary
This article analyzes the 4h K-line data of Binance's perpetual contracts for the year 2023, showing that newly listed contracts tend to decline over a long period. This may reflect the market's gradual cooling off from initial enthusiasm and return to rationality. If you design a strategy to short a certain amount of funds on the first day of trading, and close out after holding for some time, there is a high probability of making money. Of course, this also carries risks; past trends do not represent the future. But one thing is certain: there is no need to chase hot spots or go long on newly listed contract currencies.
From: https://blog.mathquant.com/2023/11/20/price-performance-after-the-currency-is-listed-on-perpetual-contracts.html | fmzquant |
1,867,086 | Create an AI Version of Yourself with LogiChat | Imagine having a digital twin that can communicate on your behalf, answer questions, and engage with... | 0 | 2024-05-28T02:13:34 | https://dev.to/dalenguyen/create-an-ai-version-of-yourself-with-logichat-2hk8 | ai, portfolio, sideprojects, buildinpublic | Imagine having a digital twin that can communicate on your behalf, answer questions, and engage with visitors on your portfolio website. Sounds fascinating, right? This is now possible with [LogiChat](https://logichat.io/), a conversation AI chat that I've developed as a side project.
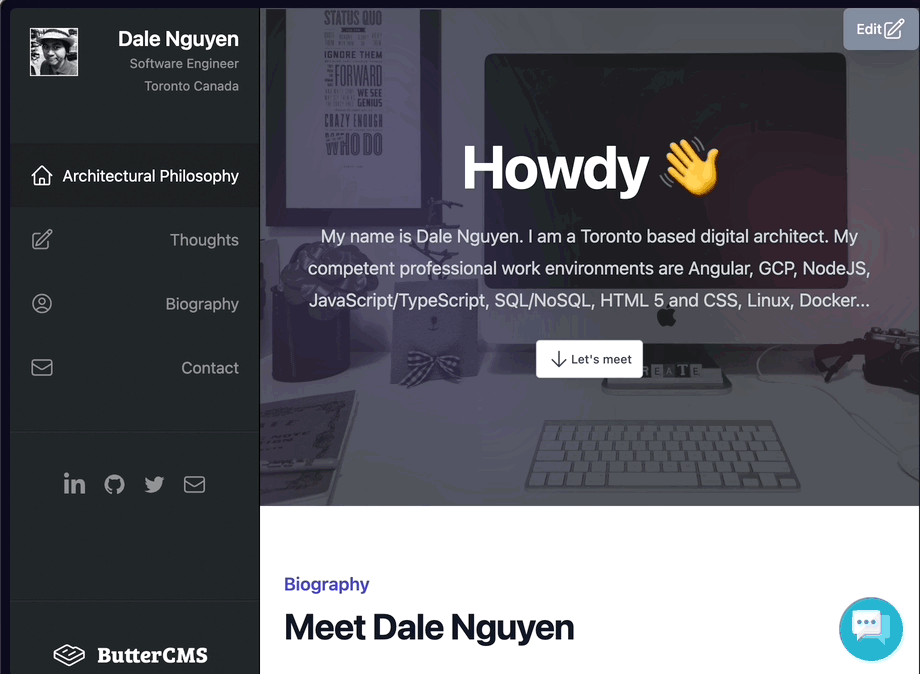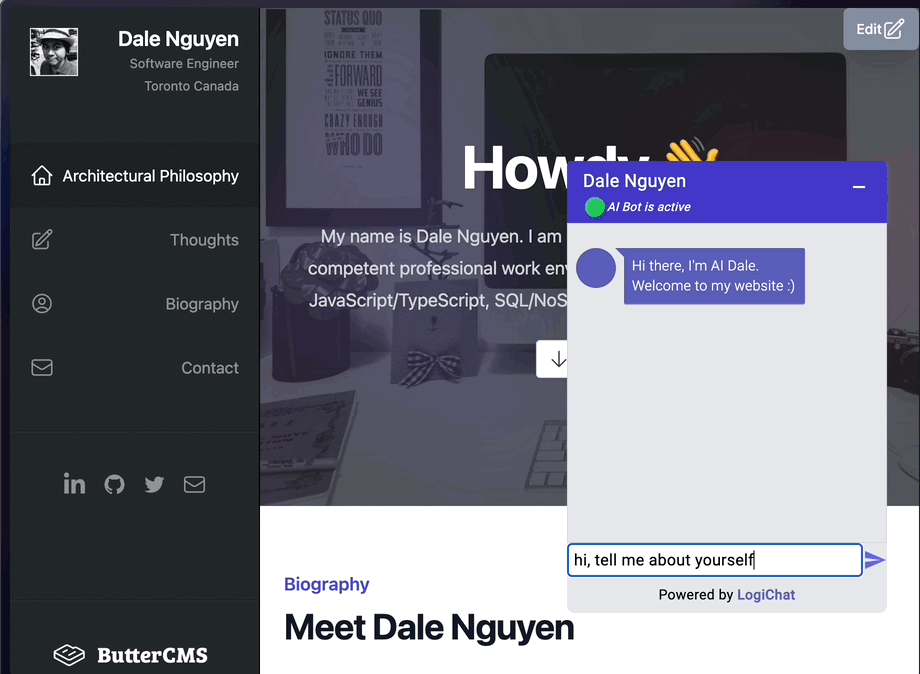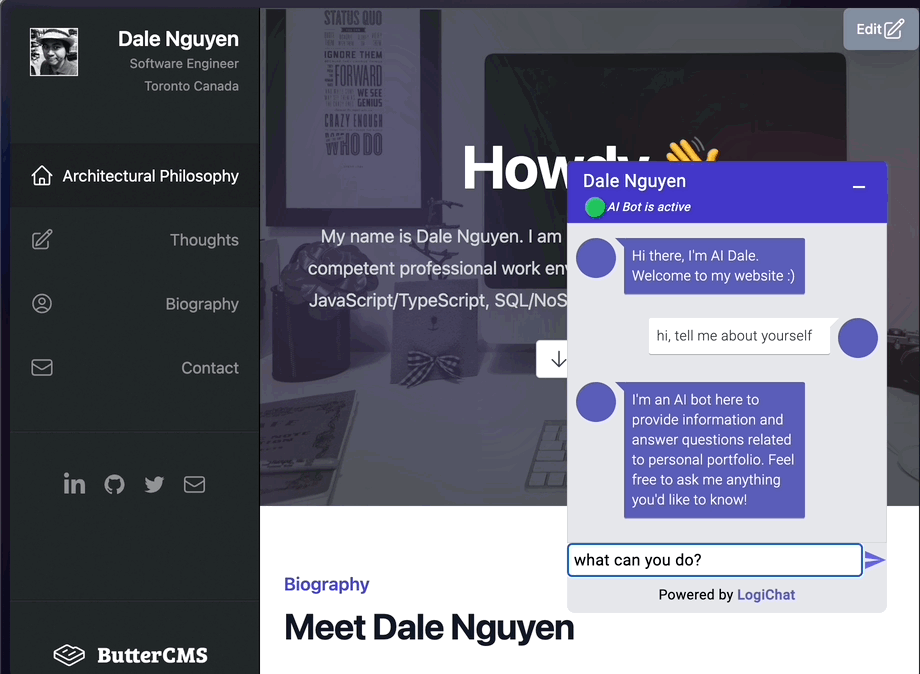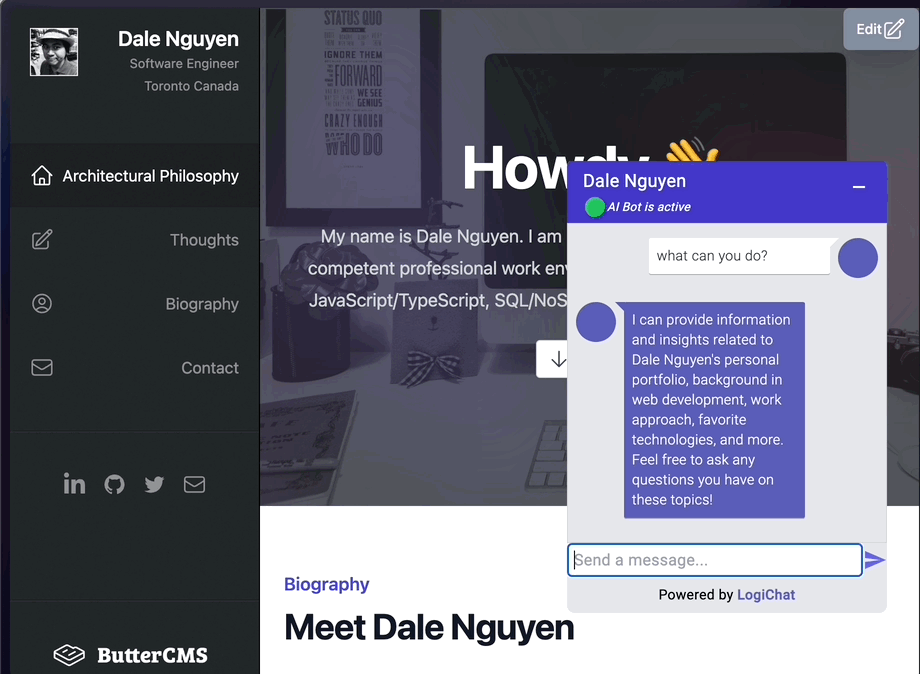
## What is LogiChat?
LogiChat is an AI chatbot that leverages pre-trained models to answer a wide array of questions. It's like having a digital twin that can communicate on your behalf, providing information and answering queries with the knowledge it has been trained on.
## Why Use LogiChat on Your Portfolio Website?
Incorporating [LogiChat](https://logichat.io/) into your portfolio website can make your online presence more interactive and engaging. Visitors to your site can ask questions and receive instant responses from your AI version, enhancing their user experience. It's a creative way to showcase your skills, share your knowledge, and engage with your audience. It has FREE tier which is super suitable for personal usage!
## How to Create Your AI Version with LogiChat
Creating your AI version with [LogiChat](https://logichat.io/) involves a few simple steps:
**1. Sign Up for LogiChat:** Visit the LogiChat website and sign up for an account. You'll need to provide some basic information to get started.
**2. Train Your AI:** Once you've signed up, you can start training your AI. This involves feeding it information about yourself, your skills, your experiences, and any other details you want it to know. The more information you provide, the more accurately your AI version can represent you.
**3. Test Your AI:** After training your AI, test it out by asking it questions. This will help you gauge its accuracy and make any necessary adjustments.
**4. Embed LogiChat on Your Website:** Once you're satisfied with your AI's performance, you can get it approved and embed it on your portfolio website. LogiChat provides a simple code snippet that you can add to your website's HTML.
**5. Engage with Your Audience:** With LogiChat embedded on your website, you're ready to engage with your audience in a whole new way. Visitors can interact with your AI version, asking it questions and receiving instant responses.
Creating an AI version of yourself with LogiChat is not only a fun and innovative way to enhance your online presence, but it's also a testament to the power of AI and its potential to revolutionize the way we communicate and share information. So why wait? Start creating your AI version today!
Happy training! 😊 | dalenguyen |
1,867,084 | hyper (Rust) upgrade to v1: Higher-level Server / Client were removed | Summary This series is about how I upgraded hyper (Rust) 0.14 to v1 (1.3). The next theme... | 27,469 | 2024-05-28T02:12:05 | https://scqr.net/en/blog/2024/05/28/hyper-rust-upgrade-to-v1-higher-level-server-client-were-removed/index.html | rust, hyper, api, microservices | ## Summary
This series is about how I upgraded hyper (Rust) 0.14 to v1 (1.3).
The next theme is higher-level `Server` / `Client`. Those in v0 were removed. It was because they had [stability and complexity problems](https://hyper.rs/contrib/roadmap/#focus-on-the-connection-level).
The `Server` wasn't followed by any drop-in replacement, and the `Client` was in a way by `client::legacy::Client` (that I didn't use).
In addition, [`hyper-util`](https://docs.rs/hyper-util/latest/hyper_util/index.html) helps.
### My project challenge
[apimock-rs](https://github.com/nabbisen/apimock-rs) is API mock Server generating HTTP / JSON responses to help to develop microservices and APIs, written in [Rust](https://www.rust-lang.org/). It's one of my projects.
Its core dependencies is [hyper](https://hyper.rs/), "a protective and efficient HTTP library for all" which is rather low-level.
### Upgraded hyper
I started with hyper 0.14, and [1.0.0 was released last November](https://github.com/hyperium/hyper/releases/tag/v1.0.0) 🎉
I have recently upgraded it which was a kind of somehow tough work. The change log was as below:
https://github.com/nabbisen/apimock-rs/pull/62/files
---
## `Cargo.toml` change log
As to HTTP *server*:
```diff
[dependencies]
(...)
- hyper = { version = "0.14", features = ["server", "http1", "http2", "tcp"] }
+ hyper = { version = "1", features = ["server", "http1", "http2"] }
+ hyper-util = { version = "^0.1", features = ["server", "http1", "http2", "tokio"] }
+ http-body-util = "^0.1"
```
As to HTTP *client*:
```diff
[dev-dependencies]
- hyper = { version = "0.14", features = ["client"] }
+ hyper = { version = "1", features = ["client"] }
```
## `Server` change log
`hyper::Server` had gone. I used `conn` module of `auto` HTTP version in `hyper-util` instead of the specific version in `hyper` since I wanted to support both http1 and http2.
The diff was like:
```diff
- use hyper::service::{make_service_fn, service_fn};
- use hyper::Server;
+ use hyper::{body, body::Bytes, service::service_fn, Request, Response};
+ use hyper_util::{
+ rt::{TokioExecutor, TokioIo},
+ server::conn::auto::Builder,
+ };
+ use tokio::net::TcpListener;
(...)
let addr = (...)
- let make_svc = make_service_fn(|_| {
- async move {
- let service = service_fn(move |req| handle(req));
- Ok::<_, Infallible>(service)
- }
- });
-
- let server = Server::bind(&addr).serve(make_svc);
+ let listener = TcpListener::bind(addr)
+ .await
+ .expect("tcp listener failed to bind address");
+ loop {
+ let (stream, _) = listener
+ .accept()
+ .await
+ .expect("tcp listener failed to accept");
+ let io = TokioIo::new(stream);
+
+ tokio::task::spawn(async move {
+ if let Err(err) = Builder::new(TokioExecutor::new())
+ .serve_connection(
+ io,
+ service_fn(move |req: Request<body::Incoming>| service(req )),
+ )
+ .await
+ {
+ eprintln!("error serving connection: {:?}", err);
+ }
+ });
+ }
+
+ async fn service(
+ req: Request<body::Incoming>,
+ ) -> Result<Response<BoxBody>, hyper::http::Error> {
+ handle(req).await
+ }
```
As it is relatively lower-level module, `tokio` requires to be dealt with together.
## `Client` change log
In contrast, on client, I used module in `hyper` which supported the specific HTTP version. It was testing module whose HTTP version didn't affect the result.
```diff
- use hyper::{body::to_bytes, Body, Client, Request, Response, StatusCode, Uri};
- (...)
- let request = Request::builder()
- .uri(uri)
- .method("POST")
- .header("Content-Type", "text/plain")
- .body(Body::from(body.to_owned()))
- .unwrap();
- let client = Client::new();
- let response = client.request(request).await.unwrap();
+ let stream = TcpStream::connect(addr).await.unwrap();
+ let io = TokioIo::new(stream);
+ let (mut sender, conn) = hyper::client::conn::http1::handshake(io).await.unwrap();
+ tokio::task::spawn(async move {
+ if let Err(err) = conn.await {
+ println!("Connection failed: {:?}", err);
+ }
+ });
+ (...)
+ let req = Request::builder()
+ .uri(path)
+ .header(hyper::header::HOST, authority.as_str())
+ .body(body)
+ .unwrap();
+ let res = sender.send_request(req).await.unwrap()
```
`hyper::client::conn::http1` is directly used as above.
---
## Reference
Their official documentation and examples are really helpful :)
- [Upgrade from v0.14 to v1](https://hyper.rs/guides/1/upgrading/)
- [Roadmap to v1](https://hyper.rs/contrib/roadmap/)
- [Getting Started with a Server](https://hyper.rs/guides/1/server/hello-world/)
- [hyper/examples/web_api.rs](https://github.com/hyperium/hyper/blob/master/examples/web_api.rs)
| nabbisen |
1,867,085 | Recipe Food App | Developed a Recipe Food App. Tools: React API: https://www.themealdb.com/ Pure CSS MaterialUI Demo... | 0 | 2024-05-28T02:10:04 | https://dev.to/webdev990/recipe-food-app-16j | react, css, html, javascript | Developed a Recipe Food App.
Tools:
React
API: https://www.themealdb.com/
Pure CSS
MaterialUI
[Demo](https://stfly.biz/6Z6bJ) || recipe--page.vercel.app
[Github Repo](https://github.com/Kyl67899/RecipeApp)
[Video](https://stfly.biz/6Z7jJ) || https://youtu.be/iEPVzqdIOts
| webdev990 |
1,867,066 | Next.js: Three Ways to Call Server Actions from Client Components | In Next.js, Server Actions are asynchronous functions that execute on the server. They can be used in... | 0 | 2024-05-28T02:00:40 | https://dev.to/jonathan-dev/nextjs-three-ways-to-call-server-actions-from-client-components-30p3 | nextjs, react, webdev, typescript | In Next.js, Server Actions are asynchronous functions that execute on the server. They can be used in Client Components to handle form submissions and perform data mutations. More on Server Actions can be read [here](https://nextjs.org/docs/app/building-your-application/data-fetching/server-actions-and-mutations).
There are a few ways to use these Server Actions in the Client Component.
- Form Action
- Event Handlers
- useEffect
## Form Action
React allows Server Actions to be invoked with the `action` prop. When a user submits a form, the action is invoked, which will receive the `FormData` object.
Let's say you need a way to track how many bananas each monkey in the zoo has. There's a PostgreSQL table called `monkeys`. The form may look like this:
```HTML
<form action={addMonkey}>
<input type="text" id="name" name="name" required/>
<input type="number" id="numBananas" name="numBananas" defaultValue={0} required/>
<input type="submit" defaultValue="Submit"/>
</form>
```
Notice how the action will invoke a Server Action called `addMonkey`. This method is defined with the React `"use server"` directive.
```Typescript
"use server";
export async function addMonkey(formData: FormData): Promise<boolean> {
const schema = z.object({
name: z.string().min(1),
numBananas: z.number().int()
});
const monkeyParse = schema.safeParse({
name: formData.get("name"),
numBananas: z.coerce.number().parse(formData.get("numBananas"))
});
if (!monkeyParse.success) {
return false;
}
const data = monkeyParse.data;
try {
await sql`
INSERT INTO monkeys (name, numBananas)
VALUES (${data.name}, ${data.numBananas})
`;
revalidatePath("examples/server-actions")
return true;
} catch (e) {
return false;
}
}
```
## Event Handlers
You can call Server Actions from Event Handlers, such as `onClick`. For example, to increment the number of bananas a monkey has:
```TSX
"use client";
import {Monkey, updateNumBananas} from "@/app/examples/server-actions/server_actions";
export default function MonkeyList(props: { monkeys: Monkey[] }) {
return (
<ul>
{props.monkeys.map((monkey) => {
return <li key={monkey.id}>
<span>{monkey.name} has {monkey.numbananas} banana(s).</span>
<button onClick={async () => {
await updateNumBananas(monkey.id, monkey.numbananas + 1)
}}>
Increment Bananas
</button>
</li>
})}
</ul>
)
}
```
This adds a button next to each monkey to increment the bananas count by 1. The Server Action looks like this:
```TS
"use server";
export async function updateNumBananas(id: number, numBananas: number) {
try {
await sql`
UPDATE monkeys
SET numBananas = ${numBananas}
WHERE id = ${id}
`;
revalidatePath("examples/server-actions")
return true;
} catch (e) {
return false;
}
}
```
## useEffect
Lastly, Server Actions can be called in the React `useEffect` hook when the component mounts or a dependency changes. For example, to display the number of monkeys from a Server Action:
```TSX
"use client";
import {getMonkeyCount, Monkey, updateNumBananas} from "@/app/examples/server-actions/server_actions";
import {useEffect, useState} from "react";
export default function MonkeyList(props: { monkeys: Monkey[] }) {
const [monkeyCount, setMonkeyCount] = useState(0);
useEffect(() => {
const updateMonkeyCount = async () => {
const updatedNumMonkeys = await getMonkeyCount();
setMonkeyCount(updatedNumMonkeys);
}
updateMonkeyCount();
})
return (
<>
<p>Monkeys: {monkeyCount}</p>
<ul>
{props.monkeys.map((monkey) => {
return <li key={monkey.id}>
<span>{monkey.name} has {monkey.numbananas} banana(s).</span>
<button onClick={async () => {
await updateNumBananas(monkey.id, monkey.numbananas + 1)
}}>
Increment Bananas
</button>
</li>
})}
</ul>
</>
)
}
```
In this example, `useEffect` is triggered automatically and will update the number of monkeys when a new one is added.
The server action looks like this:
```TS
"use server";
export async function getMonkeyCount() {
const numMonkeys = await sql`
SELECT *
FROM monkeys;
`;
return numMonkeys.count;
}
```
There are better and more optimized ways to show the number of monkeys but this is just an example to show how we can use Server Actions in Client Components.
Source code of the complete example: https://github.com/juhlmann75/Next.js-Examples/tree/main/src/app/examples/server-actions
| jonathan-dev |
1,867,082 | Doypack Packing Machines: Enhancing Shelf Appeal and Brand Visibility | Doypack Packing Machines: Making Your Product Stand Out! As a business owner, your main goal is to... | 0 | 2024-05-28T01:56:17 | https://dev.to/raymorganh54/doypack-packing-machines-enhancing-shelf-appeal-and-brand-visibility-3ge6 | packaging | Doypack Packing Machines: Making Your Product Stand Out!
As a business owner, your main goal is to sell your products. To achieve that, you need your product to be appealing to potential buyers. One essential aspect of selling your product is its packaging. You want your product to have a unique packaging that catches the eyes of the shoppers. Doypack packing machines can help you enhance shelf appeal and brand visibility. This article discusses the advantages of using Doypack packing machines and how they can benefit your business.
Advantages of Doypack Packing Machines:
Doypack packing devices are innovative solutions for organizations shopping for appealing and packaging like lightweight
They supply many advantages, including:
Enhanced Shelf Appeal: Doypack devices which are packing your products rise above the crowd on store racks
The devices let you create packaging like unique which will draw shoppers' attention
Brand Visibility: With custom-made packaging, you're able to print your logo and brand design message in the packaging
Because of this, customers can identify your merchandise effortlessly, increasing brand name presence
Security: The packaging is made from top-quality materials which is often safe for food as well as other items that are delicate
The materials found in Doypack packing devices are green, that will be crucial on earth like present
User-Friendly: Doypack packing machines are easy to operate
They have clear directions on how to use them, rendering it feasible for business owners and their staff to operate them
Cost-Effective: Doypack packing machines are affordable and require zero-maintenance expenses when compared with other packaging machines
Innovation:
Doypack packing devices use innovative technology that produces like exclusive
They usually work with a flexible and material like lightweight molds into numerous sizes and shapes, providing the packaging a contemporary and appearance like fashionable
The technology includes the usage a spout and caps which are pressure-sensitive prevent spillage and extend product shelf life
Security:
HFFS doypack packing machine prioritize product safety to guard the consumers
The packaging product is safe for meals, cosmetic makeup products, as well as other items that are delicate
The devices use environmentally materials which are friendly pose no nagging problems for the surroundings or maybe the customers
Usage:
The Doypack packing machines apply an approach like creates that are specific that stays upright on store shelves
The packaging offers a great opportunity to showcase your brand name logo design and message like branding
The packaging is lightweight, which makes it an task like transport like straightforward store
Provider:
Doypack packaging machines can be found in different sizes and model choices that cater to company like different
They supply exceptional packaging solutions for small-scale business owners and company like large-scale
After product sales solution is easily obtainable, and you can contact customer care for upkeep and repairs
Quality:
Doypack packing devices are constructed of high-quality materials, and also they produce packaging that fits requirements being worldwide
They typically use materials which are often safe for meals and eco-friendly
The machines are automatic, ensuring uniformity into the packaging quality
Conclusion:
Doypack packing machine offer numerous benefits to businesses looking to enhance their shelf appeal and brand visibility while maintaining product safety. It is an affordable and innovative solution that caters to various industries. Doypack packing machines are user-friendly and easy to operate, and they come in different sizes to cater to business needs. Investing in Doypack packing machines is an excellent choice that will help you increase your brand's visibility and boost sales.
Source: https://www.acepackchina.com/Hffs-doypack-packing-machine | raymorganh54 |
1,867,081 | Cleansing Your Hair After U Tip Extension Removal | Removing U tip hair extensions is a step towards regaining your natural locks, but proper aftercare... | 0 | 2024-05-28T01:48:58 | https://dev.to/flattipluxshine/cleansing-your-hair-after-u-tip-extension-removal-1ogj | Removing U tip hair extensions is a step towards regaining your natural locks, but proper aftercare is crucial for maintaining your hair's health and vitality. One of the most important aspects is cleansing your hair thoroughly to remove any residue from the extensions or removal products. Here's a guide to help you get started:
## [Shampooing Tips Post-Extension](https://luxshinehair.com/how-to-remove-u-tip-hair-extensions/)
1. **Clarifying Shampoo:** Begin with a clarifying shampoo to remove any buildup of keratin bonds, oils, or styling products that may have accumulated during the time you wore extensions. Clarifying shampoos are formulated to deep clean and remove impurities, leaving your scalp and hair feeling refreshed.
2. **Gentle Shampoo:** After clarifying, switch to a gentle, sulfate-free shampoo for regular use. Sulfates can strip natural oils, leaving your hair dry and brittle, especially after the stress of wearing extensions. Look for shampoos with moisturizing ingredients like aloe vera, glycerin, or natural oils.
3. **Condition Regularly:** Always follow up with a nourishing conditioner to replenish moisture and restore your hair's natural shine and softness. Focus on the ends, as they tend to be drier after wearing extensions.
4. **Avoid Overwashing:** While it's important to keep your hair clean, avoid overwashing, as this can strip away essential oils and lead to dryness. Aim to wash your hair 2-3 times a week, or as needed depending on your hair type and lifestyle.
5. **Scalp Massage:** Gently massage your scalp while shampooing to stimulate blood circulation and promote healthy hair growth. This can also help to loosen any remaining residue from the extensions.
6. **Lukewarm Water:** Use lukewarm water to wash your hair, as hot water can further dry out your strands. Finish with a cool rinse to seal the cuticles and enhance shine.
## Additional Tips:
* **Deep Condition:** Treat your hair to a deep conditioning mask once a week to provide extra hydration and nourishment.
* **Avoid Harsh Chemicals:** Steer clear of hair products containing harsh chemicals, such as sulfates, parabens, and alcohol, as they can further damage your hair.
* **Be Gentle:** Be gentle when brushing or styling your hair, as it may be more prone to breakage after removing extensions.
By following these shampooing tips and incorporating them into your hair care routine, you can ensure that your hair stays healthy, strong, and beautiful after removing your U tip extensions.
| flattipluxshine | |
1,867,079 | Spout Pouch Filling Machines: Catering to the Beverage and Liquid Industry | The Amazing Spout Pouch Filling Machines Perfect for Beverage and Liquid Industry Are you tired of... | 0 | 2024-05-28T01:39:25 | https://dev.to/raymorganh54/spout-pouch-filling-machines-catering-to-the-beverage-and-liquid-industry-33g1 | filling, machines | The Amazing Spout Pouch Filling Machines Perfect for Beverage and Liquid Industry
Are you tired of spilling your favorite drink when pouring it into a glass? Do you want to keep your beverage fresh and safe? Then the spout pouch filling machines are the perfect solution for you! These machines have revolutionized the liquid packaging industry with their innovative design and amazing features. Keep reading to discover why spout pouch filling machines are the ideal choice for your business needs.
Advantages of Spout Pouch Filling Machines
Spout pouch filling machine offer numerous advantages over old-fashioned packaging like fluid
They have been extremely flexible, reliable, and efficient, making them great for organizations trying to save your time, cash, and resources
Spout pouches are airtight, so they really preserve the freshness and flavor of any liquid included within
The pouches are easy to make use of, making them convenient for on-the-go consumption
Spout pouches will undoubtedly also be lightweight and occupy less area, leading to cost advantages on transportation and storage
Innovation in Spout Pouch Filling Machines
Spout pouch filler machine which are filling a result of advancements in technology and innovation
The machines are created to fill spout like contemporary, which are the trend like latest in liquid packaging
These pouches are produced from top-notch materials, such as for example films which are laminate aluminum, as well as come in various shapes and sizes
Spout pouch devices that are filling exact filling capabilities, making certain the quantity like right of is dispensed into the pouches
The machines will also be equipped with cutting-edge settings that monitor and adjust the temperature, stress, and speed regarding the procedure like filling
Safety and Use of Spout Pouch Filling Machines
Spout pouch machines that are filling simple and safe to utilize, making them suitable for food and drink companies
The devices are automatic, meaning that employees won't need to come into connection with the liquid during the stuffing procedure, ensuring there is absolutely no contamination
The spout pouches are also spill-proof and airtight, ensuring the fluids are safely preserved without the need for additional packaging
How to Use Spout Pouch Filling Machines
Using spout pouch devices which are filling fairly direct
First, ensure that the equipment is precisely calibrated and create to your desired specs
Next, link the spout pouches to your device's feeding system, together with machine shall begin filling the pouches utilizing the fluid
The machines typically have fill-speed like different to select from, with regards to the type or kind of liquid being filled and its own viscosity
Provider and Quality of Spout Pouch Filling Machines
Spout pouch machines that are filling durable and an task like easy keep, making certain they carry on functioning optimally for quite some time
It's important to routinely clean the devices and guarantee they're running properly
Most manufacturers provide user manuals and services being after-sale guide customers on how to maintain and service their devices
Moreover, there are lots of possibilities on the market, including brands such as Swifty Bagger, that offer high-quality spout pouch machines which are filling
Application of Spout Pouch Filling Machines
Spout pouch filling machines are well suited for various packaging like liquid to the food and drink industry
They could package and protect different liquids, including juice, water, milk products, and even alcohol consumption
The spout pouches are suitable for on-the-go consumption, making them perfect for recreations events, schools, and also other activities being outdoor
The pouches are great for e-commerce businesses that need to ship fluids properly without the risk of spillage
In conclusion, spout pouch filling machine are the perfect packaging solution for the modern beverage and liquid industry. They offer numerous advantages, such as flexibility, efficiency, and convenience, that traditional packaging methods do not. They are safe, easy to use, and offer precise filling capabilities, ensuring that liquids are safely preserved and efficiently packaged. It is no wonder that these machines are the latest innovation in liquid packaging!
Source: https://www.acepackchina.com/Spout-pouch-filling-machine | raymorganh54 |
1,867,075 | Whitelisting Specific Paths on Modsecurity 3 with OWASP Rules | Modsecurity with rule from OWASP rule set, make security very strict, sometimes modsecurity flag... | 0 | 2024-05-28T01:28:13 | https://dev.to/henri_sekeladi/whitelisting-specific-paths-on-modsecurity-3-with-owasp-rules-39d5 | modsecurity, owasp, nginx | Modsecurity with rule from OWASP rule set, make security very strict, sometimes modsecurity flag false positive in content that we post in form.
To whitelist the spesific path, we can add on `modsecurity.conf` to whitelist those path or spesific url.
We are on ubuntu server 22.04 with nginx and modsecurity installed and owasp rule in `/etc/nginx/conf/owasp-crs/`.
`sudo nano /etc/nginx/conf/owasp-crs/rules/REQUEST-900-EXCLUSION-RULES-BEFORE-CRS.conf`
and add this line in the bottom of the file
`SecRule REQUEST_URI "@beginsWith /ptickets" "id:932130,phase:1,log,allow,ctl:ruleEngine=off`
This mean :
Request URI begin with `/ptickets` will be ignored in modsecurity with rule id is 932130. Rule id 932130 is rule on OWASP for prevent Remote Code Execution on our website and it's need to be unique.
Don't forget to reload our nginx server to take effect :
`sudo service nginx reload`
Thank you very much, hope this post is useful and give us some love!
| henri_sekeladi |
1,867,078 | Handy Open source image editor | This is a js version of the picture design tool, can be used for video cover, social media... | 0 | 2024-05-28T01:28:12 | https://dev.to/nihaojob/handy-open-source-image-editor-2900 | webdev, opensource, javascript |
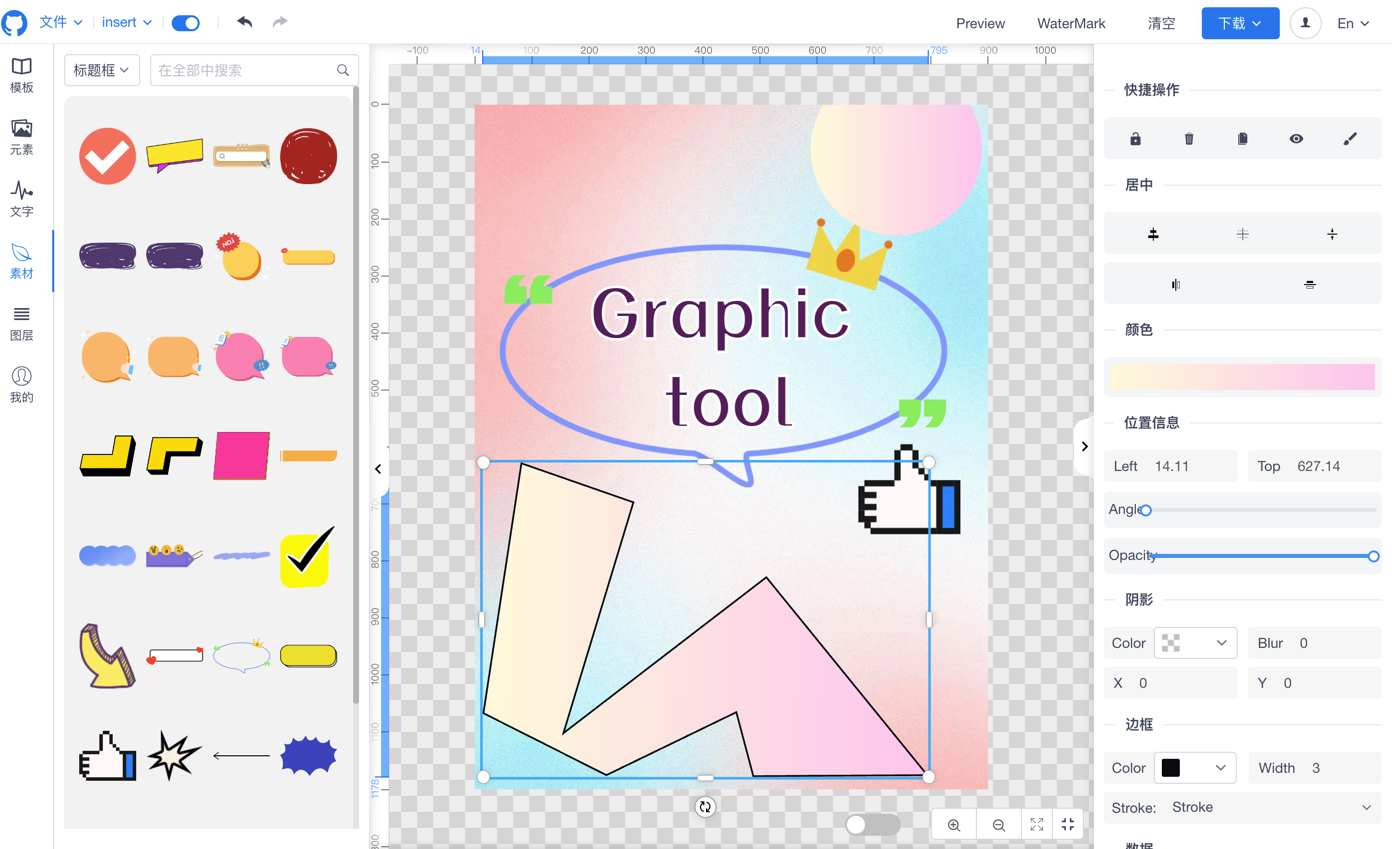
This is a js version of the picture design tool, can be used for video cover, social media pictures, graphic printing and other scenes, the use of this tool does not require professional training, can let ordinary people easily master, design a beautiful poster.
It can import PSD, export JSON files, it is not a web version of PhontoShop, it is easier to apply than PS, let ordinary people easily use.
https://github.com/nihaojob/vue-fabric-editor
### staff
Includes ruler, auxiliary line, automatic adsorption alignment
### Canvas
The canvas can be adaptive when dragging the window, and can be zoomed out and dragged to meet editing needs
### Shape element
Whether it is text, basic shapes, arrows, polygons, he can be drawn, very powerful
### Templates and materials
Support template, material classification management, support custom text style, custom combination elements.
### Multiple operation
Multiple elements can be aligned or created in combination.
### Picture filter
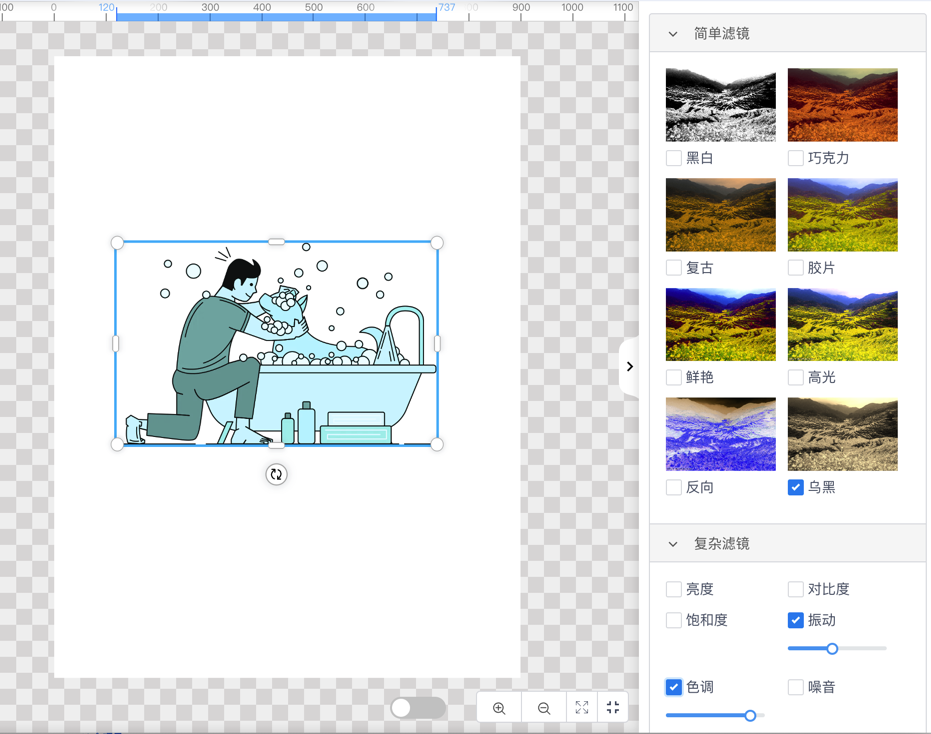
### Color/Border/Shadow/Transparency
Combine a variety of attributes to create a beautiful style
### Font design
Font, color multiple properties
### Watermark
Watermark can be set according to your own needs
### Menu and shortcut keys
You can use menus and shortcut keys to operate
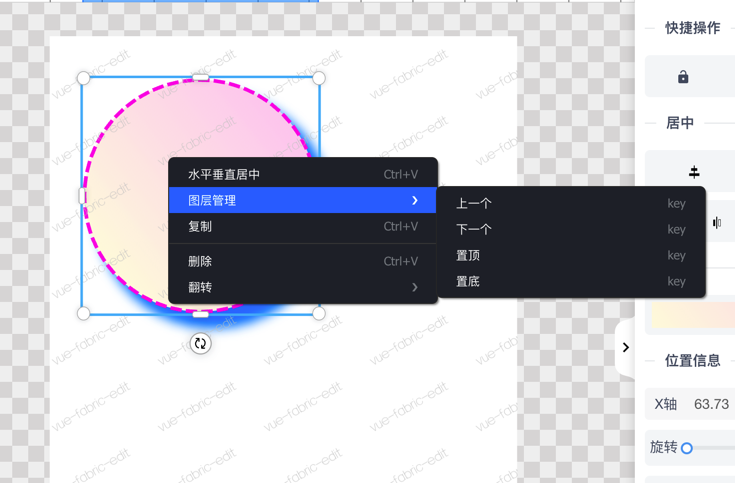
## About me
I am the author of this project, I come from China, I have my own Chinese technical blog, unfortunately, because of my poor English, I can only use translation software to read and publish English articles, I am working hard to learn English, I hope this open source project can help you.
| nihaojob |
1,867,077 | Doypack Packing Machines: Customizable Solutions for Various Products | Doypack Packing Machines: The Perfect Packaging Solution for All Your Items Are you looking for a... | 0 | 2024-05-28T01:26:11 | https://dev.to/raymorganh54/doypack-packing-machines-customizable-solutions-for-various-products-5e62 | packaging | Doypack Packing Machines: The Perfect Packaging Solution for All Your Items
Are you looking for a packaging solution that's ingenious, risk-free, as well as adjustable? Look no more compared to Doypack Packing Machines! Whether you have actually a small company or even a big company, Doypack Packing Machines deals with a variety of benefits that will certainly make your lifestyle simpler as well as enhance your product's discussion.
Benefits of Doypack Packing Machines
HFFS doypack packing machine are a flexible packaging solution that provides various benefits. They are outstanding for packaging meals, charm items, animal meals, therefore a lot more! Certainly not only are they adjustable, but they likewise offer lasting security for your items. And also, they are user-friendly as well as keep.
Development in Packaging
Doypack Packing Machines stand for the potential of packaging. They are an ingenious solution that provides a resealable packaging choice or clients that are constantly on the go. Along with clients looking for practical packaging choices as they top a hectic lifestyle, Doypack Packing Machines deals with the perfect solution.
Security Very initial
Among the very most essential elements of any type of packaging solution is security. Doypack Packing Machines places security at the forefront of their style. They deal a tamper-proof choice that guarantees your items stay risk-free as well as protected. Also, they offer an outstanding obstacle versus illumination, wetness, sky, as well as various other hazardous elements, maintaining your items fresher for much a lot longer.
Ways to Utilize Doypack Packing Machines
Utilizing Doypack Packing Machines is easy as well as uncomplicated. When you have your packaging Products, location all of them right into the device, as well as push the begin switch. The device will certainly be after securing the package, as well as you are great to go! It is that easy. The machines include unobstructed, easy-to-understand directions.
Quality Issues
You strive to produce top-quality items, which are displayed in the quality of your packaging. Doypack Packing Machines are developed to preserve as well as improve the quality of your items. By utilizing these machines, you can easily feel confident that your items will certainly appear as well as preference fantastic every opportunity.
Application of Doypack Packing Machines
Doypack Packing Machines are outstanding for all kinds of items. The machines enable you to personalize your packaging products inning accordance with your products' requirements. Whether you're packaging treats, charm items, or even animal meals, Doypack Packing Machines is a suitable solution. Along with adjustable styles as well as outstanding quality, your items will certainly stand apart from the competitors. Furthermore, these machines could be used in little as well as massive manufacturing procedures, making all of them perfect for companies of all dimensions.
The solution as well as Sustain
High speed sachet packing machine include outstanding customer support as well as sustainability. If you experience any type of issues with the device, their pleasant customer support group exists to assist you. Furthermore, they deal with educating as well as setting up solutions, providing you the assurance that you can run the device perfectly.
Source: https://www.acepackchina.com/Hffs-doypack-packing-machine | raymorganh54 |
1,867,074 | The Correlation Between the Rise and Fall of Currencies and Bitcoin | In previous articles, we discussed a common phenomenon in the digital currency market: most digital... | 0 | 2024-05-28T01:21:14 | https://dev.to/fmzquant/the-correlation-between-the-rise-and-fall-of-currencies-and-bitcoin-465i | bitcoin, trading, fmzquant, cryptocurrency | In previous articles, we discussed a common phenomenon in the digital currency market: most digital currencies, especially those that follow the price fluctuations of Bitcoin and Ethereum, often show a trend of rising and falling together. This phenomenon reveals their high correlation with mainstream currencies. However, the degree of correlation between different digital currencies also varies. So how does this difference in correlation affect the market performance of each currency? In this article, we will use the bull market in the second half of 2023 as an example to explore this issue.
### The Synchronous Origin of the Digital Currency Market
The digital currency market is known for its volatility and uncertainty. Bitcoin and Ethereum, as the two giants in the market, often play a leading role in price trends. Most small or emerging digital currencies, in order to maintain market competitiveness and trading activity, often keep a certain degree of price synchronization with these mainstream currencies, especially those coins made by project parties. This synchronicity reflects the psychological expectations and trading strategies of market participants, which are important considerations in designing quantitative trading strategies.
### Formula and Calculation Method of Correlation
In the field of quantitative trading, the measurement of correlation is achieved through statistical methods. The most commonly used measure is the Pearson correlation coefficient, which measures the degree of linear correlation between two variables. Here are some core concepts and calculation methods:
The range of the Pearson Correlation Coefficient (denoted as r) is from -1 to +1, where +1 indicates a perfect positive correlation, -1 indicates a perfect negative correlation, and 0 indicates no linear relationship. The formula for calculating this coefficient is as follows:
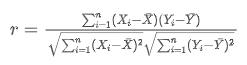
Among them,
 and
 are the observed values of two random variables,
 and
 are the average values of these two random variables respectively. Using Python scientific computing related packages, it's easy to calculate correlation.
### Data Collection
This article has collected the 4h K-line data for the entire year of 2023 from Binance, selecting 144 currencies that were listed on January 1st. The specific code to download the data is as follows:
```
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ticker = requests.get('https://fapi.binance.com/fapi/v1/ticker/24hr')
ticker = ticker.json()
sort_symbols = [k['symbol'][:-4] for k in sorted(ticker, key=lambda x :-float(x['quoteVolume'])) if k['symbol'][-4:] == 'USDT']
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2023-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
time.sleep(0.5)
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2023-01-01'
end_date = '2023-11-16'
period = '4h'
df_dict = {}
for symbol in sort_symbols:
print(symbol)
df_s = GetKlines(symbol=symbol+'USDT',start=start_date,end=end_date,period=period)
if not df_s.empty:
df_dict[symbol] = df_s
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in symbols:
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_close = df_close.dropna(how='any',axis=1)
```
### Market Review
After normalizing the data first, we calculate the index of average price fluctuations. It can be seen that there are two market trends in 2023. One is a significant increase at the beginning of the year, and the other is a major rise starting from October. Currently, it's basically at a high point in terms of index.
```
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #Normalization
total_index = df_norm.mean(axis=1)
total_index.plot(figsize=(15,6),grid=True);
```
### Correlation Analysis
Pandas comes with a built-in correlation calculation. The weakest correlation with BTC price is shown in the following figure. Most currencies have a positive correlation, meaning they follow the price of BTC. However, some currencies have a negative correlation, which is considered an anomaly in digital currency market trends.
```
corr_symbols = df_norm.corrwith(df_norm.BTC).sort_values().index
```
### Correlation and Price Increase
Here, the currencies are loosely divided into two groups. The first group consists of 40 currencies most correlated with BTC price, and the second group includes those least related to BTC price. By subtracting the index of the second group from that of the first, it represents going long on the first group while shorting the second one. In this way, we can calculate a relationship between price fluctuations and BTC correlation. Here is how you do it along with results:
```
(df_norm[corr_symbols[-40:]].mean(axis=1)-df_norm[corr_symbols[:40]].mean(axis=1)).plot(figsize=(15,6),grid=True);
```
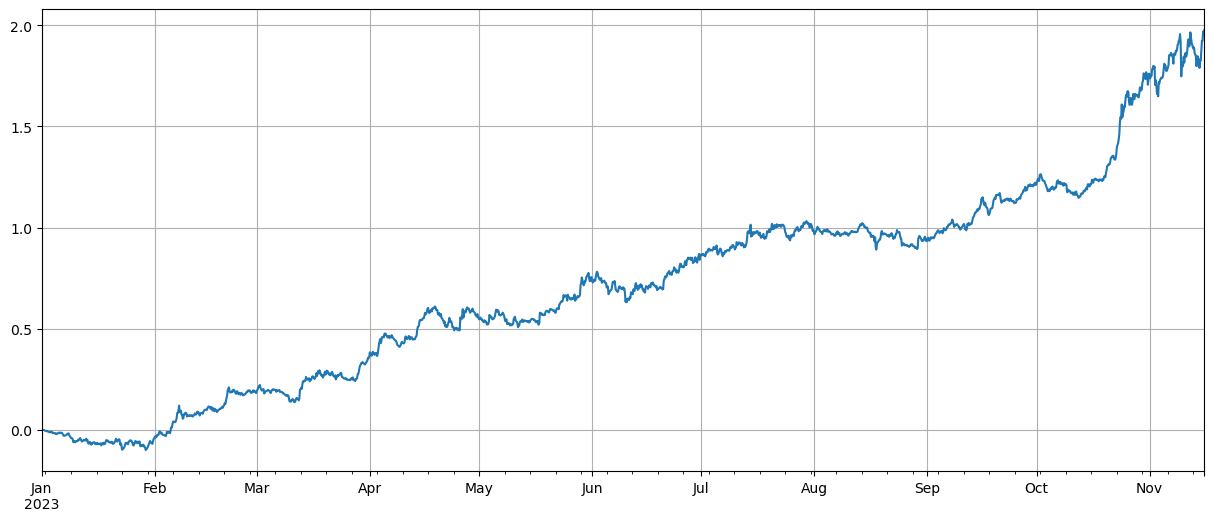
The results show that the currencies with stronger correlation to BTC price have better increases, and shorting currencies with low correlation also played a good hedging role. The imprecision here is that future data was used when calculating the correlation. Below, we divide the data into two groups: one group calculates the correlation, and another calculates the return after hedging. The result is shown in the following figure, and the conclusion remains unchanged.
Bitcoin and Ethereum as market leaders often have a huge impact on overall market trends. When these cryptocurrencies rise in price, market sentiment usually becomes optimistic and many investors tend to follow this trend. Investors may see this as a signal of an overall market increase and start buying other currencies. Due to collective behavior of market participants, currencies highly correlated with mainstream ones might experience similar price increases. At such times, expectations about price trends can sometimes become self-fulfilling prophecies. On the contrary, currencies negatively correlated with Bitcoin are unique; their fundamentals may be deteriorating or they may no longer be within sight of mainstream investors - there could even exist Bitcoin's blood-sucking situation where markets abandon them chasing for those able to keep up with rising prices.
```
corr_symbols = (df_norm.iloc[:1500].corrwith(df_norm.BTC.iloc[:1500])-df_norm.iloc[:1500].corrwith(total_index[:1500])).sort_values().index
```
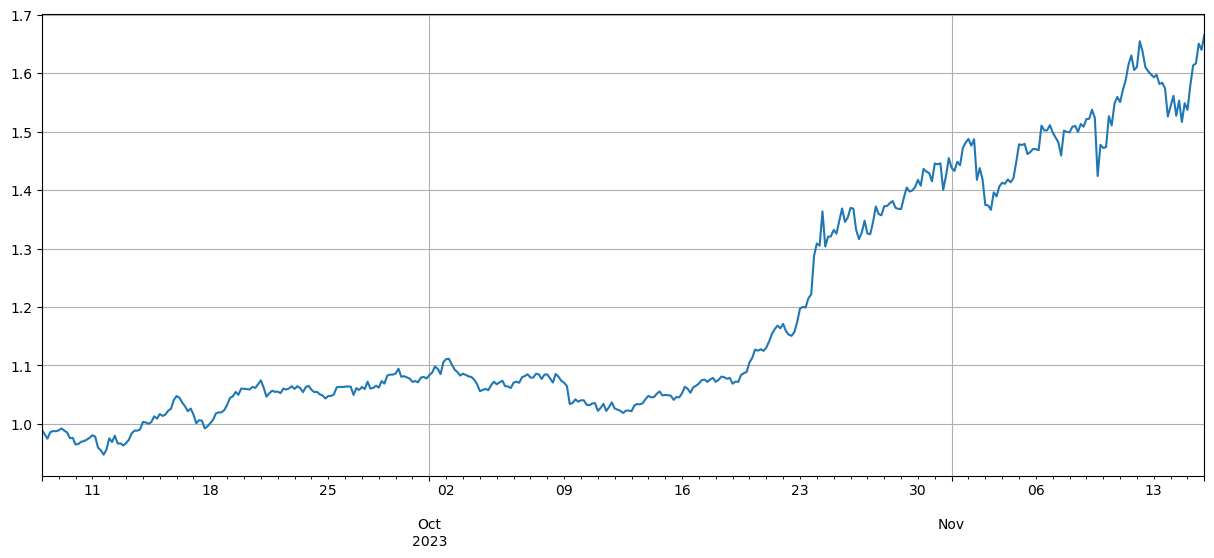
### Summary
This article discusses the Pearson correlation coefficient, revealing the degree of correlation between different currencies. The article demonstrates how to obtain data to calculate the correlation between currencies and use this data to assess market trends. It reveals that synchronicity in price fluctuations in the digital currency market not only reflects market psychology and strategy, but can also be quantified and predicted through scientific methods. This is particularly important for designing quantitative trading strategies.
There are many areas where the ideas in this article can be expanded, such as calculating rolling correlations, separately calculating correlations during rises and falls, etc., which can yield a lot of useful information.
From:https://blog.mathquant.com/2023/11/17/the-correlation-between-the-rise-and-fall-of-currencies-and-bitcoin.html | fmzquant |
1,867,068 | A Comprehensive Guide to NPM (Node Package Manager) | Overview of NPM (Node Package Manager) NPM (Node Package Manager) is a package manager for... | 0 | 2024-05-28T01:14:00 | https://dev.to/smkbukhari/a-comprehensive-guide-to-npm-node-package-manager-30n4 | ### Overview of NPM (Node Package Manager)
**NPM (Node Package Manager)** is a package manager for JavaScript and is the default package manager for the Node.js JavaScript runtime environment. It consists of a command line client (CLI), also called npm, and an online database of public and paid-for private packages, called the npm registry.
### Key Components of NPM
1. **npm CLI**:
- The npm command line interface (CLI) allows developers to interact with the npm registry and manage project dependencies.
- Commands include installing, updating, and uninstalling packages, managing version control, and running scripts.
2. **npm Registry**:
- The npm registry is a large public database of JavaScript packages.
- It hosts open-source projects and allows developers to share their code with the community.
- It also supports private packages for organizational use.
3. **package.json**:
- A JSON file that contains metadata about the project, such as the name, version, description, main file, scripts, dependencies, and other attributes.
- It is essential for managing dependencies and project configuration.
### Common NPM Commands
1. **Initialization**:
- `npm init`: Initializes a new Node.js project, creating a `package.json` file.
- `npm init -y`: Initializes a new Node.js project with default settings.
2. **Installing Packages**:
- `npm install <package>`: Installs a package and adds it to the dependencies in `package.json`.
- `npm install <package> --save-dev`: Installs a package and adds it to the devDependencies in `package.json`.
- `npm install`: Installs all dependencies listed in `package.json`.
3. **Updating Packages**:
- `npm update <package>`: Updates a package to the latest version within the version range specified in `package.json`.
- `npm outdated`: Lists packages that have newer versions available.
4. **Uninstalling Packages**:
- `npm uninstall <package>`: Removes a package and deletes it from the dependencies in `package.json`.
5. **Running Scripts**:
- `npm run <script>`: Runs a custom script defined in the `scripts` section of `package.json`.
### NPM Configuration Files
- **.npmrc**: Configuration file for npm, allowing customization of npm's behavior, such as setting registry URLs, cache locations, and more.
### NPM Scripts
NPM scripts are commands specified in the `package.json` file, under the `scripts` field. These scripts can automate repetitive tasks like building the project, running tests, starting the server, and more. For example:
```json
"scripts": {
"start": "node app.js",
"test": "jest",
"build": "webpack"
}
```
### Advantages of Using NPM
1. **Package Management**: Simplifies dependency management and ensures consistent environments.
2. **Automation**: Allows automation of various development tasks through scripts.
3. **Large Ecosystem**: Access to a vast ecosystem of open-source packages.
4. **Version Control**: Manages and resolves dependency version conflicts efficiently.
5. **Community Support**: Strong community support and extensive documentation.
### Security Considerations
While NPM is a powerful tool, it's essential to be mindful of security:
1. **Audit**: Regularly run `npm audit` to check for vulnerabilities in dependencies.
2. **Update**: Keep dependencies up to date to mitigate known vulnerabilities.
3. **Review**: Carefully review third-party packages and their maintainers before including them in your project.
### Conclusion
NPM is an indispensable tool for JavaScript and Node.js developers, facilitating easy management of project dependencies, script automation, and access to a vast repository of reusable code. By leveraging NPM, developers can streamline their workflows, maintain consistency across development environments, and contribute to the open-source community. | smkbukhari | |
1,866,973 | Install Modsecurity + OWASP CRS for Nginx Webserver on Centos 7 | Update Package & Install Libraries First, update the package and install some... | 0 | 2024-05-28T01:13:38 | https://dev.to/henri_sekeladi/install-modsecurity-owasp-crs-for-nginx-webserver-on-centos-7-4fgo | ## Update Package & Install Libraries
First, update the package and install some libraries that we need.
`sudo yum update`
```
sudo yum groupinstall 'Development Tools' -y
sudo yum install epel-release -y
```
```
yum install yajl yajl-devel curl-devel GeoIP-devel zlib-devel lmdb lmdb-devel libxml2-devel ssdeep ssdeep-devel lua-devel pcre-devel wget nano
```
When we build with this library installed, we got error, to prevent this error g++: error: unrecognized command line option '-std=c++17' , we need to install latest env for gcc :
```
# 1. Install a package with repository for your system:
# On CentOS, install package centos-release-scl available in CentOS repository:
$ sudo yum install centos-release-scl -y
# On RHEL, enable RHSCL repository for you system:
$ sudo yum-config-manager --enable rhel-server-rhscl-7-rpms
# 2. Install the collection:
$ sudo yum install devtoolset-8 -y
# 3. Start using software collections:
$ scl enable devtoolset-8 bash
```
## Install Modsecurity
```
cd /opt && sudo git clone https://github.com/owasp-modsecurity/ModSecurity.git
cd ModSecurity
sudo git submodule init
sudo git submodule update
sudo ./build.sh
sudo ./configure
sudo make
sudo make install
```
## Modsecurity-nginx
Download modsecurity-nginx connector
`cd /opt && sudo git clone https://github.com/owasp-modsecurity/ModSecurity-nginx.git`
We will need this when we configure nginx with modsecurity module later.
## Install Nginx with latest version
First, we need to make repository list for nginx :
`sudo nano /etc/yum.repos.d/nginx.repo`
```
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
```
choose witch one to use (stable or mainline)
```
sudo yum-config-manager --enable nginx-mainline
or
sudo yum-config-manager --enable nginx-stable
```
`sudo yum install nginx -y`
Set enable on nginx to start when the server up/runing, start the nginx service and check the status of the nginx service.
```
sudo systemctl enable nginx
sudo systemctl start nginx
sudo systemctl status nginx
```
## Download nginx source code
Download source code with the same version with currently installed on Centos 7.
```
cd /opt && sudo wget https://nginx.org/download/nginx-1.24.0.tar.gz
sudo tar -xzvf nginx-1.24.0.tar.gz
cd nginx-1.24.0
```
Then, we configure nginx with dynamic module, that is modsecurity, we added --add-dynamic-module=/opt/ModSecurity-nginx to make this happen.
```
sudo ./configure --with-compat --add-dynamic-module=/opt/ModSecurity-nginx
sudo make
sudo make modules
```
after successfully build the nginx from source with modsecurity then copy the module file to folder nginx modules.
`sudo cp objs/ngx_http_modsecurity_module.so /etc/nginx/modules/`
## Enable ModSecurity in nginx.conf
Copy configuration from modsecurity source code to nginx :
```
sudo cp /opt/ModSecurity/modsecurity.conf-recommended /etc/nginx/modsecurity.conf
sudo cp /opt/ModSecurity/unicode.mapping /etc/nginx/unicode.mapping
```
Edit nginx main configuration to load modsecurity module :
`sudo nano /etc/nginx/nginx.conf`
add this line on main row on nginx configuration file :
`load_module modules/ngx_http_modsecurity_module.so;`
and, add this code inside http {} or inside your custom server block for spesific site/domain :
```
modsecurity on;
modsecurity_rules_file /etc/nginx/modsecurity.conf;
```
## Edit Modsecurity config
Edit modsecurity configuration to active engine :
`sudo nano /etc/nginx/modsecurity.conf`
Search for SecRuleEngine and set to On.
`SecRuleEngine On`
save the configuration.
## Update Rule with CORE RULE SET (CRS)
`sudo git clone https://github.com/coreruleset/coreruleset.git /etc/nginx/owasp-crs`
Rename file crs-setup :
`sudo cp /etc/nginx/owasp-crs/crs-setup.conf{.example,}`
Add crs rule of CRS to modsecurity.conf :
`sudo nano /etc/nginx/modsecurity.conf`
add this 2 lines on the bottom of the modsecurity.conf
```
Include owasp-crs/crs-setup.conf
Include owasp-crs/rules/*.conf
```
Then, check configuration of nginx again :
`sudo nginx -t`
if the configuration is ok/success then restart nginx service.
`sudo service nginx restart`
## Test Modsecurity + Nginx with browser
Access to your server with browser or curl and add some shell code :
`https://ip_address/as.php?s=/bin/bash`
If everything working as expected, forbidden access will show, with code 403. this mean we have success deploy our nginx server with modsecurity module.
To view detail about those error, we can see the log file of the modsecurity.
```
sudo tail -f /var/log/modsec_audit.log
sudo tail -f /var/log/nginx/error.log
```
Hope this post help you secure your site even more.
Found this post useful, please give us some love! | henri_sekeladi | |
1,866,982 | Install Nginx with Modsecurity 3 + OWASP CRS on Ubuntu 22.04 | Update Package & Install Libraries First, update the package and install some... | 0 | 2024-05-28T01:13:08 | https://dev.to/henri_sekeladi/install-nginx-with-modsecurity-3-owasp-crs-on-ubuntu-2204-5d6l | modsecurity, nginx, ubuntu | ## Update Package & Install Libraries
First, update the package and install some libraries that we need on ubuntu server 22.04.
`sudo apt update && sudo apt upgrade`
Install libraries that needed for our installation process from source of modsecurity 3.
`sudo apt install gcc make build-essential autoconf automake libtool libcurl4-openssl-dev liblua5.3-dev libfuzzy-dev ssdeep gettext pkg-config libgeoip-dev libyajl-dev doxygen libpcre++-dev libpcre2-16-0 libpcre2-dev libpcre2-posix3 zlib1g zlib1g-dev -y`
## Install Modsecurity
Next, we will install modsecurity from source.
```
cd /opt && sudo git clone https://github.com/owasp-modsecurity/ModSecurity.git
cd ModSecurity
sudo git submodule init
sudo git submodule update
sudo ./build.sh
sudo ./configure
sudo make
sudo make install
```
If we success with this installation, we make big move. go on.
## Download Modsecurity-nginx Connector
Next, we download modsecurity nginx connector, we will use this later on.
`cd /opt && sudo git clone https://github.com/owasp-modsecurity/ModSecurity-nginx.git`
## Install Nginx with latest from Ondrej PPA
Ok, we will install nginx from ondrej ppa, we got the latest version of nginx.
First, we need to add repository from ondrej and update our package.
```
sudo add-apt-repository ppa:ondrej/nginx -y
sudo apt update
sudo apt install nginx -y
```
We can enable with systemctl to start nginx when our server up
```
sudo systemctl enable nginx
sudo systemctl status nginx
```
We also need to check our nginx version, to match our nginx build manual later on.
```
sudo nginx -v
nginx version: nginx/1.25.4
```
## Download nginx source code
We should download source code that match version on nginx we recently installed.
```
cd /opt && sudo wget https://nginx.org/download/nginx-1.25.4.tar.gz
sudo tar -xzvf nginx-1.25.4.tar.gz
cd nginx-1.25.4
```
after we download, extract and change directory to nginx source. we build nginx with module on modsecurity that we successfully installed above.
```
sudo ./configure --with-compat --add-dynamic-module=/opt/ModSecurity-nginx
sudo make
sudo make modules
```
Next, we copy the modules to nginx modules-enabled, also copy configuration of modsecurity and unicode.
```
sudo cp objs/ngx_http_modsecurity_module.so /etc/nginx/modules-enabled/
sudo cp /opt/ModSecurity/modsecurity.conf-recommended /etc/nginx/modsecurity.conf
sudo cp /opt/ModSecurity/unicode.mapping /etc/nginx/unicode.mapping
```
## Enable ModSecurity in nginx.conf
Next, we edit configuration of nginx to load module of modsecurity
`sudo nano /etc/nginx/nginx.conf`
add this line to main configuration.
`load_module /etc/nginx/modules-enabled/ngx_http_modsecurity_module.so;`
then, we also need to modify the server block to activate modsecurity.
`sudo nano /etc/nginx/sites-enabled/default`
```
modsecurity on;
modsecurity_rules_file /etc/nginx/modsecurity.conf;
```
and also, edit /etc/nginx/modsecurity.conf to change SecRuleEngine to On.
`sudo nano /etc/nginx/modsecurity.conf`
`SecRuleEngine On`
after that we can our nginx configuration and restart nginx server
`sudo nginx -t`
`sudo systemctl restart nginx`
We can test the nginx server with browser on its public ip address.
## Update Rule with CORE RULE SET (CRS)
Now, we need to download core rule set from owasp, owasp crs provide rule to check if the client request has malicious code or not.
We directly download owasp crs to nginx configuration directory.
`sudo git clone https://github.com/coreruleset/coreruleset.git /etc/nginx/owasp-crs`
then we copy the configuration.
`sudo cp /etc/nginx/owasp-crs/crs-setup.conf{.example,}`
and we need to update our modsecurity configuration to load owasp crs.
`sudo nano /etc/nginx/modsecurity.conf`
```
Include owasp-crs/crs-setup.conf
Include owasp-crs/rules/*.conf
```
last, we check nginx configuration,
`sudo nginx -t`
and restart nginx server.
`sudo service nginx restart`
Test Modsecurity + Nginx with browser
Try to access to your server and add some shell code on it :
`https://ip_address/as.php?s=/bin/bash`
If everything working as expected, forbidden access will show, with code 403. this mean we have success deploy our nginx server with modsecurity module.
To view detail about those error, we can see the log file of the modsecurity.
```
sudo tail -f /var/log/modsec_audit.log
sudo tail -f /var/log/nginx/error.log
```
Hope this post help you secure your site even more.
| henri_sekeladi |
1,867,067 | My Newest Discovery: PlayFab | Hey there, fellow gamers! Today was quite the adventure in the world of game development for me. I... | 0 | 2024-05-28T01:12:20 | https://dev.to/angeljrp/my-newest-discovery-playfab-50fb | Hey there, fellow gamers!
Today was quite the adventure in the world of game development for me. I stumbled upon something called PlayFab, and let me tell you, it's a game-changer (pun intended). PlayFab is this cool integrated tool for Unity that helps manage online services like player accounts, payments, and overall game management.
So, how did I stumble upon this gem? Well, I was knee-deep in developing my own video game when I realized I needed a way for players to log in and manage their accounts. That's when PlayFab came to the rescue. By integrating it into my game, I was able to create a seamless login system and effortlessly manage all the players who signed in. It was like unlocking a whole new level of game development!
What's awesome about PlayFab is how it simplifies the whole process, making it easy for developers like me to focus on creating epic gaming experiences without worrying about the nitty-gritty of backend management.
This is the code I used to integrate the login system.
```
public InputField email ;
public InputField password;
public GameObject panel;
public Text mailText;
public Text passwordText;
public Text ruling;
public Button registButton;
public PlayerController plc;
```
This here are my variables where i had my places where people could input their emails and passwords to login and my Player Controller (remember that one it's important later)
```
public void RegisterButton()
{
var request = new RegisterPlayFabUserRequest
{
Email = email.text,
Password = password.text,
RequireBothUsernameAndEmail = false
};
PlayFabClientAPI.RegisterPlayFabUser(request, OnLoginSucces, OnError);
void OnLoginSucces(RegisterPlayFabUserResult result)
{
Debug.Log("Succesfull login");
}
void OnError(PlayFabError error)
{
Debug.Log("Error on login, please try again");
Debug.Log(error.GenerateErrorReport());
}
email.enabled = false;
password.enabled = false;
panel.SetActive(false);
mailText.enabled = false;
passwordText.enabled = false;
ruling.enabled = false;
registButton.enabled = false;
plc.IsPlaying = true;
}
```
This over here is my function that activates when someone presses the register button, what it does is that it takes whatever is inside the input fields and turns it in to the playfab manager and stores it, but it also it tells the game when should my player be moving, because you dont want to be writing your email and suddenly you already lost right? (told you it was important)
So, if you're a budding game developer like me, I highly recommend checking out PlayFab. Trust me, it's a game-changer you don't want to miss out on! | angeljrp | |
1,867,065 | Aprenda de uma vez o que é Banco de Dados e SGBD | O que é Banco de Dados? Banco de dados é uma coleção de dados. Dado é um fato que deve ser... | 0 | 2024-05-28T01:07:45 | https://dev.to/edsonaraujobr/aprenda-de-uma-vez-o-que-e-banco-de-dados-e-sgbd-mii | dados, beginners, sgbd, bancodedados | ## O que é Banco de Dados?
**Banco de dados** é uma coleção de dados. Dado é um fato que deve ser armazenado e que tem um significado implícito.
## Tipos de aplicações de Banco de Dados:
- **Banco de dados tradicionais**: maioria da informação é textual ou numérica.
- **Banco de dados multimídia**: armazena imagens, áudios, streams de vídeos.
- **Sistemas de informação geográficas**: armazena e analisa mapas, dados sobre clima e imagens de satélites.
- **Big data**: trata, analisa e obtem informações a partir de grandes volumes de dados.
## O que é um SGBD?
SGBD, sigla para **Sistema Gerenciador de Banco de Dados**, contempla varias funcionalidades e armazena vários bancos de dados.
Os SGBDs permitem que operações sobre os dados sejam definidas de maneira independente da aplicação. As aplicações podem chamar tais operações por meio de seus nomes e argumentos e não se preocupam como tais operações são implementadas.
Para que seja possível usar as funcionalidades de um SGBD e atuar sobre um banco de dados é preciso conhecer o modelo de dados. O modelo de dados conceitual é construído por um analista de dados, e sua implementação física é realizada em um SGBD
## Vantagens de Utilizar um SGBD
- Controle de redundância, ter todos os dados armazenados em um único lugar, e diferentes aplicações acessam a mesma instância desses dados.
- Autorização e segurança que previne que usuários acessem dados sem que estejam autorizados.
- Eficiência no processo de consultas
- Backup e recuperação
- Controle de concorrência
Todo conteúdo postado aqui tem como referência o livro de ELMASRI, R. NAVATHE, S. B., Sistemas de Banco de Dados: Fundamentos e Aplicações, Pearson, 6o ed. | edsonaraujobr |
1,850,397 | https://dev.to/lilxyzz/2024-cheat-sheet-collection-47h8 | A post by thuya96 | 0 | 2024-05-12T13:27:31 | https://dev.to/thuya96/httpsdevtolilxyzz2024-cheat-sheet-collection-47h8-7 | thuya96 | ||
1,867,063 | Cutting-Edge Technology in Fruit Juice Production Equipment | Cutting-Edge Technology in Fruit Juice Production Equipment Have you ever wondered how your favorite... | 0 | 2024-05-28T00:56:18 | https://dev.to/raymorganh54/cutting-edge-technology-in-fruit-juice-production-equipment-56l4 | fruit, juice | Cutting-Edge Technology in Fruit Juice Production Equipment
Have you ever wondered how your favorite fruit juice brand makes their products so delicious and nutritious? Thanks to cutting-edge technology in fruit juice production equipment, juice manufacturing companies can now produce high-quality juices that are safe and rich in nutrition. We will look at the advantages of using this technology, how it is innovative, the safety of using the equipment, how to use it, the quality of the equipment, and its application in the market.
Advantages
One of the top features of making use of cutting-edge technology in juice manufacturing equipment is the fact that it's efficient.
The apparatus can create big quantities of juice in a span like quick which means that businesses can sell more products and satisfy their customer's needs.
Additionally, this equipment includes a greater juice yield in comparison with earlier versions, which means that it may extract more juice from fruits, resulting in less leftovers and less waste.
Innovation
New advances in technology mean that production devices now have features that have been formerly unavailable in early in the day models.
For instance, modern fruit juice production gear has a self-cleaning mechanism, that makes it easier for users to help keep the unit clean.
Additionally, it really is more automatic, which helps it be an task like run like straightforward.
With this kind of innovation, creating juice like high-quality becoming more convenient for liquid manufacturers.
Security
The security of utilizing this equipment is paramount, specially since it involves meals manufacturing.
Even better is that modern fruit juice manufacturing equipment has advanced safety features that ensure quality limit and control mistake like human.
Some machines have sensors that alert someone once the machine is overloaded or in the event that temperature is just too high, plus some can detect and eliminate any foreign items into the fruit which could make the juice unsafe to drink as an example.
Service
Having consumer like reliable is vital in terms of keeping and servicing the gear.
Juicing Series production machines are upkeep and complex like require to ensure that they continue to work correctly.
Luckily, most manufacturers provide exemplary after-sales solutions, including support like technical guarantee, and repairs.
This helps to ensure that the device stays in top condition like working which prolongs the lifespan from the equipment.
Quality
Quality is essential, and juice manufacturing companies require top-quality equipment to make sure their products or services or solutions meet the client's standard.
Modern fruit juice production gear was created to meet the highest criteria of quality.
They are created from top-notch materials which is often durable, and thus companies may use them for a period like long.
Additionally, the machines have advanced technology that ensures that the juice produced is healthy, healthy, and safe to simply take.
Application
The application of cutting-edge technology in juice manufacturing equipment has revolutionized the juice market like worldwide.
The need for high-quality juice is from the increase, and consumers are now more health-conscious.
The machines assist liquid manufacturers to create juice this is certainly delicious, safe, healthy, and enjoyable to consumers.
It has additionally managed to get easy for smaller manufacturers to enter industry as the price of the device is lower in comparison to years that are past.
The technology has enabled organizations to produce more juice and meet the demand that keeps customers that are growing.
Conclusion
In conclusion, cutting-edge technology in fruit juice production equipment Filtering Series has transformed the global juice market. The advantages of using this technology are immense, ranging from safety, efficiency, and improved quality control. It's easy to use, and the manufacturer provides excellent after-sales services. The application of this technology has seen smaller manufacturers enter the industry, and it has increased the demand for high-quality juice from health-conscious consumers. If you are in the juice business, investing in modern fruit juice production equipment is the way to go.
Source: https://www.enkeweijx.com/Juicing-series | raymorganh54 |
1,867,060 | Building a Multiplayer Game Server with Node.js | Introduction Node.js has become a popular choice for game developers when it comes to... | 0 | 2024-05-28T00:31:47 | https://dev.to/kartikmehta8/building-a-multiplayer-game-server-with-nodejs-68g | webdev, javascript, beginners, programming | ## Introduction
Node.js has become a popular choice for game developers when it comes to building multiplayer game servers. Its ability to handle a large number of concurrent users and its easy scalability make it an ideal choice for creating online games. In this article, we will discuss the advantages, disadvantages, and features of building a multiplayer game server with Node.js.
## Advantages
1. **High Scalability:** Node.js uses a non-blocking, event-driven architecture which allows it to handle large volumes of concurrent connections efficiently.
2. **Easy Integration:** Node.js has a vast library of modules and packages available, making it easy to integrate with other technologies and frameworks.
3. **Real-time Interactivity:** With its event-driven architecture and WebSocket support, Node.js allows for real-time communication between players, providing a seamless multiplayer gaming experience.
## Disadvantages
1. **Lack of Multithreading:** Node.js is single-threaded, which means it cannot take advantage of all available CPU cores, potentially limiting its performance.
2. **Limited Support:** Being a relatively new technology, there is still a lack of support and resources available compared to other established platforms.
## Features
1. **Cross-platform Compatibility:** Node.js is compatible with multiple operating systems, making it easy to build a game server that can run on different devices.
2. **Ease of Development:** With its simple syntax and extensive library of modules, Node.js makes it easy to develop and maintain a multiplayer game server.
### Example of WebSocket Integration in Node.js
```javascript
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: 8080 });
wss.on('connection', function connection(ws) {
ws.on('message', function incoming(message) {
console.log('received: %s', message);
wss.clients.forEach(function each(client) {
if (client !== ws && client.readyState === WebSocket.OPEN) {
client.send(message);
}
});
});
ws.send('Hello! Message received');
});
```
This snippet demonstrates how to set up a simple WebSocket server with Node.js that can handle real-time messaging between clients. It allows messages to be broadcasted to all connected clients except the sender.
## Conclusion
Node.js offers several advantages for building a multiplayer game server, including its scalability, real-time interactivity, and easy integration. However, it also has its limitations, such as lack of multithreading and limited support. Nevertheless, with its features and growing popularity, Node.js is a promising choice for game developers looking to create a seamless multiplayer gaming experience. | kartikmehta8 |
1,867,059 | Django: Sample data | Sample Data Is helpful when developing Sample data scripts expose issues with data... | 0 | 2024-05-28T00:28:10 | https://dev.to/samuellubliner/django-sample-data-ng2 | webdev, python, django | ## Sample Data
- Is helpful when developing
- Sample data scripts expose issues with data models
## Querying in the shell
```bash
cd locallibrary
python3 manage.py shell
```
The interactive Python environment can be used to create records and query the database.
Import all necessary modules and models for the session.
```bash
from catalog.models import Book
Book.objects.all()
```
Outputs:
```bash
<QuerySet []>`
```
An empty query set was returned.
Add a book:
```bash
book = Book(title="Python Tutorial")
book.save()
Book.objects.all()
```
Outputs:
```bash
<QuerySet [<Book: Python Tutorial>]>
```
A book was successfully created. Importing everything in the beginning of the shell is painful.
Exit the the shell with `exit()`
## Querying with shell_plus
Navigate to the same directory as `requirements.txt`.
`shell_plus` doesn’t come with Django out-of-the-box.
```bash
$ pip install django-extensions
```
Add the new package to the list of installed packages.
Run `pip freeze` from the same directory as `requirements.txt` to update the file. Otherwise, you will create another `requirements.txt`.
```bash
pip freeze > requirements.txt
```
Go to `settings.py` and register the extension in `INSTALLED_APPS`.
Then, navigate to the `locallibrary` directory where `manage.py` is located and run:
```bash
python3 manage.py shell_plus
```
Now you can query without needing to import models manually.
## Sample data script
Install the Faker library and add it to `requirements.txt`
```bash
pip install Faker
pip freeze > requirements.txt
```
See `create_sample_data.py` at https://github.com/Samuel-Lubliner/local-library-django-tutorial/blob/main/locallibrary/create_sample_data.py
Run the sample data script:
```bash
python3 create_sample_data.py
```
To start querying run `python3 manage.py shell_plus`
| samuellubliner |
1,867,057 | Unlock React Form Validation with Trivule: The Game-Changing Approach | If you love the simplicity of React, you'll adore Trivule. This solution allows you to validate your... | 0 | 2024-05-28T00:27:33 | https://dev.to/claudye/simplify-react-form-validation-with-trivule-a-revolutionary-approach-28k8 | react, javascript, frontend | If you love the simplicity of React, you'll adore [Trivule](https://github.com/trivule/trivule). This solution allows you to validate your forms easily and effectively. In this article, we will validate a form with two fields: email and message, to show how user-friendly and straightforward it is to use Trivule.
## Example of output
[Extract from](https://github.com/devalade/trivule-react)
## Creating the Project
To start, create a project with Vite:
```bash
npm create vite@latest
```
Follow the instructions to complete the setup. I chose the TypeScript option, but you can choose whichever suits you best.
Then, install Trivule:
```bash
npm install trivule
```
### Validation Rules
- **Email**: required, maximum 63 characters, must be a Gmail address.
- **Message**: required, maximum 250 characters, must start with "Hello".
## Creating the React Component
Create a file `form.tsx` in your React working directory:
```jsx
import React, { useEffect, SyntheticEvent } from "react";
import { TrivuleForm } from "trivule";
// Callback to define validation rules
const bindRules = (trivuleForm: TrivuleForm) => {
trivuleForm.make({
email: {
rules: "required|email|endWith:@gmail.com|max:63",
messages: {
endWith: "Only Gmail addresses are allowed",
},
},
message: {
rules: "required|startWith:Hello|max:250",
},
});
};
// React Component
function Form() {
const trivuleForm = new TrivuleForm({ invalidClass: "is-invalid" });
trivuleForm.afterBinding(bindRules);
useEffect(() => {
// The code runs once the form is found in the DOM
trivuleForm.bind("#myForm");
}, []);
const handleSubmit = (e: SyntheticEvent) => {
if (!trivuleForm.passes()) {
e.preventDefault();
return;
}
const data = trivuleForm.validated();
console.log(data);
};
return (
<form id="myForm" onSubmit={handleSubmit}>
<h3>Trivule + React-vite</h3>
<div className="form-group">
<input type="text" name="email" />
<div className="alert alert-danger" role="alert">
<div data-tr-feedback="email"></div>
</div>
</div>
<div className="form-group">
<textarea name="message"></textarea>
<div className="alert alert-danger" role="alert">
<div data-tr-feedback="message"></div>
</div>
</div>
<button type="submit">Submit</button>
</form>
);
}
export default Form;
```
### Integrating into the Application
Import and use the `Form` component in `App.tsx`:
```jsx
import React from "react";
import "./App.css";
import Form from "./form";
function App() {
return <Form />;
}
export default App;
```
## Styling Flexibility
Trivule is agnostic about the styling of your form. It provides an API that allows you to apply your own styles based on the validation status. You can define classes to indicate valid or invalid states, and Trivule will handle the rest.
### Learn More
To further your knowledge of Trivule, check out the following resources:
- [Quick start tutorial | Trivule](https://www.trivule.com/docs/tuto)
- [Validation Rules](https://www.trivule.com/docs/rules)
- [Messages | Trivule](https://www.trivule.com/docs/messages)
- [Events | Trivule](https://www.trivule.com/docs/events)
You can also create a TrivuleForm component, export it, and validate your forms without manual initialization. Check out an example on [GitHub](https://github.com/devalade/trivule-react). | claudye |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.