
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,863,647 | Top-Rated CCTV Camera Dealers in Jaipur 2024 | <p>In the vibrant city of Jaipur, security is a top priority for both residents... | 0 | 2024-05-24T07:20:01 | https://dev.to/vermaharshita/top-rated-cctv-camera-dealers-in-jaipur-2024-5f7n | webdev, javascript, beginners, programming | <div class="flex flex-grow flex-col max-w-full">
<div class="min-h-[20px] text-message flex flex-col items-start whitespace-pre-wrap break-words [.text-message+&]:mt-5 juice:w-full juice:items-end overflow-x-auto gap-2" data-message-author-role="assistant" data-message-id="b077b2f7-fcbc-429d-8df7-f25f855d5028" dir="auto">
<div class="flex w-full flex-col gap-1 juice:empty:hidden juice:first:pt-[3px]">
<div class="markdown prose w-full break-words dark:prose-invert dark">
<p>In the vibrant city of Jaipur, security is a top priority for both residents and businesses. With the increasing need for surveillance, the demand for reliable CCTV cameras has surged. Whether you're looking to enhance the security of your home or business, finding the <a target="_blank" rel="noopener noreferrer" href="https://orbitinfotech.com/cctv.html"><strong>best CCTV camera dealers in Jaipur</strong></a> is crucial. This article will guide you through the top-rated CCTV camera dealers in Jaipur for 2024, highlighting key players like Orbit Infotech (Registered as Orbit Infosoft Pvt. Ltd.), and provide answers to frequently asked questions about CCTV cameras and their installation services.</p>
<h2>Why CCTV Cameras Are Essential in Jaipur</h2>
<p>With the rise in urbanization, Jaipur, known for its historical significance and modern growth, has seen an increase in the need for enhanced security measures. <strong>CCTV cameras</strong> play a pivotal role in:</p>
<ul>
<li><strong>Deterring Crime</strong>: Visible cameras can deter potential intruders.</li>
<li><strong>Monitoring Activities</strong>: Keeping an eye on daily activities within a property.</li>
<li><strong>Gathering Evidence</strong>: Useful for legal proceedings in the event of a crime.</li>
<li><strong>Remote Surveillance</strong>: Monitoring your property from anywhere via mobile devices.</li>
</ul>
<p>Given these benefits, it's important to partner with reputable dealers and <strong>CCTV camera service providers</strong>.</p>
<h2>Top-Rated CCTV Camera Dealers in Jaipur</h2>
<h3>Orbit Infotech (Registered as Orbit Infosoft Pvt. Ltd.)</h3>
<p>Orbit Infotech stands out as one of the best CCTV camera dealers in Jaipur. Known for their commitment to quality and customer satisfaction, they offer a comprehensive range of services, including sales, installation, and maintenance of <a target="_blank" rel="noopener noreferrer" href="https://www.reddit.com/user/orbitinfosoft/comments/1cddfec/cctv_camera_trends_surveillance_solutions_evolve/"><strong>CCTV cameras</strong></a>.</p>
<h4>Services Offered by Orbit Infotech</h4>
<ol>
<li><strong>CCTV Camera Sales</strong>: A wide range of cameras suited for different needs, from basic models to advanced systems with high-definition capabilities.</li>
<li><strong>CCTV Camera Installation Services</strong>: Professional installation ensuring optimal placement and performance.</li>
<li><strong>Maintenance and Support</strong>: Regular maintenance services to ensure your system remains in top working condition.</li>
<li><strong>Remote Monitoring Solutions</strong>: Advanced systems that allow for remote monitoring via smartphones and computers.</li>
</ol>
<h3>Why Choose Orbit Infotech?</h3>
<ul>
<li><strong>Expertise</strong>: With years of experience in the field, they provide expert advice tailored to your specific needs.</li>
<li><strong>Customer Service</strong>: Known for excellent customer support, ensuring all your queries are promptly addressed.</li>
<li><strong>Quality Products</strong>: They offer high-quality, reliable <strong>CCTV cameras</strong> that guarantee security and peace of mind.</li>
<li><strong>Competitive Pricing</strong>: Offering competitive prices without compromising on quality.</li>
</ul>
<h2>Other Notable CCTV Camera Dealers in Jaipur</h2>
<h3>Securitex India</h3>
<p><strong>Securitex India</strong> is another prominent name in Jaipur's security solutions market. They offer a variety of <strong>CCTV cameras</strong> and installation services tailored to both residential and commercial needs.</p>
<h4>Key Offerings</h4>
<ul>
<li><strong>Wide Range of Cameras</strong>: From bullet and dome cameras to PTZ and wireless options.</li>
<li><strong>Installation Services</strong>: Expert technicians ensure that your system is installed correctly and efficiently.</li>
<li><strong>After-Sales Support</strong>: Comprehensive support and maintenance packages to keep your system running smoothly.</li>
</ul>
<h3>Rajdeep Security Systems</h3>
<p>Rajdeep Security Systems is renowned for their comprehensive security solutions, including CCTV camera installation services. They cater to a diverse clientele, ensuring customized security setups for each client.</p>
<h4>Key Offerings</h4>
<ul>
<li><strong>Customized Solutions</strong>: Tailored solutions to meet specific security needs.</li>
<li><strong>High-Quality Products</strong>: Offering some of the best brands in the industry.</li>
<li><strong>Professional Installation</strong>: Ensuring optimal camera placement for maximum coverage.</li>
</ul>
<figure class="image image_resized" style="width:52.6%;" data-ckbox-resource-id="C8bu6h_nXYic">
<picture>
<source srcset="https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/108.webp 108w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/216.webp 216w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/324.webp 324w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/432.webp 432w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/540.webp 540w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/648.webp 648w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/756.webp 756w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/864.webp 864w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/972.webp 972w,https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/1080.webp 1080w" sizes="(max-width: 1080px) 100vw, 1080px" type="image/webp"><img alt="Best CCTV Camera Dealers in Jaipur" src="https://ckbox.cloud/f172671a18cb67c44269/assets/C8bu6h_nXYic/images/1080.jpeg" width="1080" height="1080">
</picture>
</figure>
<h2>How to Choose the Best CCTV Camera Dealer in Jaipur</h2>
<p>When selecting a <strong>CCTV camera service provider</strong>, consider the following factors:</p>
<h3>Product Range</h3>
<p>Ensure the dealer offers a variety of <strong>CCTV cameras</strong> to choose from, catering to different needs and budgets. From basic models to advanced systems with features like night vision and motion detection, a good dealer should have it all.</p>
<h3>Installation Services</h3>
<p>Professional installation is crucial for the effectiveness of your surveillance system. Opt for dealers that provide comprehensive <a target="_blank" rel="noopener noreferrer" href="https://worldwide-entertainment-club.mn.co/posts/streamline-security-cctv-camera-installation-services"><strong>CCTV camera installation services</strong></a>, ensuring proper setup and configuration.</p>
<h3>After-Sales Support</h3>
<p>Ongoing support and maintenance are essential to keep your security system functioning optimally. Choose dealers known for their reliable after-sales service.</p>
<h3>Customer Reviews and Testimonials</h3>
<p>Check customer reviews and testimonials to gauge the reputation of the dealer. Positive feedback from previous clients is a good indicator of reliable service.</p>
<h2>FAQs About Best CCTV Camera Dealers in Jaipur</h2>
<h3>1. What should I look for in the <strong>best CCTV camera dealers in Jaipur</strong>?</h3>
<p>Look for dealers with a strong reputation, wide product range, professional installation services, and excellent after-sales support. Checking customer reviews and testimonials can also help in making an informed decision.</p>
<h3>2. Why is <strong>CCTV camera installation near me</strong> important?</h3>
<p>Choosing a local service provider ensures prompt installation and maintenance services. It also facilitates quick response times in case of technical issues.</p>
<h3>3. Can I <strong>buy CCTV cameras online</strong> in Jaipur?</h3>
<p>Yes, many dealers offer the option to buy <strong>CCTV cameras online</strong>. This can be convenient and often comes with detailed product descriptions, customer reviews, and sometimes even installation services.</p>
<h3>4. How much does <strong>CCTV camera installation services</strong> cost?</h3>
<p>The cost varies based on the type and number of cameras, complexity of the installation, and specific requirements of the site. It’s best to get a quote from the dealer after a site assessment.</p>
<h3>5. What are the benefits of choosing a professional <strong>CCTV camera service provider</strong>?</h3>
<p>Professional service providers ensure proper installation, offer reliable products, and provide ongoing maintenance and support. They also offer expert advice on the best security solutions for your specific needs.</p>
<h3>6. How do I find a reliable <strong>cctv camera shop near me</strong>?</h3>
<p>You can search online, check local business directories, or ask for recommendations from friends or family. Reading online reviews and ratings can also help in identifying a trustworthy shop.</p>
<p> </p>
<p><strong>Also Read: </strong><a target="_blank" rel="noopener noreferrer" href="https://dailynewsupdate247.in/jaipurs-hot-trend-cctv-camera-installation-soars"><strong>Jaipur's Hot Trend: CCTV Camera Installation Soars</strong></a></p>
<h2>Conclusion</h2>
<p>Ensuring the security of your home or business in Jaipur requires investing in reliable CCTV cameras and partnering with the best CCTV camera dealers in Jaipur. Orbit Infotech (Registered as Orbit Infosoft Pvt. Ltd.) and other reputable dealers like Securitex India and Rajdeep Security Systems offer top-notch products and services to meet your security needs. By choosing the right dealer, you can rest assured that your property is well-protected, giving you peace of mind.</p>
<p>For those looking to enhance their security setup, now is the perfect time to reach out to these top-rated dealers, explore their offerings, and secure your property with the latest surveillance technology.</p>
</div>
</div>
</div>
</div>
<div class="mt-1 flex gap-3 empty:hidden juice:-ml-3">
<div class="items-center justify-start rounded-xl p-1 flex">
<div class="flex items-center"><span class="" data-state="closed"></span></div>
</div>
</div>
<p><span class="" data-state="closed"></span></p>
<p><span class="" data-state="closed"></span></p>
<div class="flex"><span class="" data-state="closed"></span></div> | vermaharshita |
1,863,646 | Types of crypto coin | What is a crypto coin? A crypto coin is a digital or virtual currency designed to work as a medium... | 0 | 2024-05-24T07:19:41 | https://dev.to/ritesh_saini_45667ac4b3a5/types-of-crypto-coin-4pf1 | coin, cryptocurrency, cryptocoin | **What is a crypto coin?**
A [crypto coin](https://lbmsolutions.in/crypto-coin-development-services/
) is a digital or virtual currency designed to work as a medium of exchange. It utilizes cryptographic techniques to secure transactions, control the creation of new units, and verify the transfer of assets. Unlike traditional currencies, cryptocurrencies operate on decentralized networks, typically based on blockchain technology, which ensures transparency, immutability, and security.
**Types of crypto coins:**
**1. Bitcoin (BTC):**
Bitcoin (BTC) entered the scene in 2009, brought forth by the enigmatic Satoshi Nakamoto. Renowned as the "digital gold," its supply is capped at 21 million coins. BTC holds sway as both a secure store of value and a ubiquitous medium of exchange, profoundly influencing the digital economic landscape.
**2. Ethereum (ETH):**
Ethereum, envisioned by Vitalik Buterin in late 2013 and launched on July 30, 2015, is a decentralized platform. It empowers the creation and execution of [smart contracts](https://lbmsolutions.in/smart-contract-development-company/
) and decentralized applications (DApps) without the need for intermediaries. ETH, the platform's native cryptocurrency, fuels its operations and transactions.
**3. Ripple (XRP):**
Ripple operates as both a platform and a currency. The Ripple platform functions as an open-source protocol designed for fast and cost-effective transactions. XRP, the currency within the Ripple network, is utilized for facilitating transactions, particularly emphasizing real-time cross-border payments. It's preferred by financial institutions due to its efficient transaction process.
**4.Litecoin (LTC):**
Litecoin, often dubbed as the silver to Bitcoin's gold, was introduced by Charlie Lee back in 2011. Its aim is to provide quicker and more affordable transactions than Bitcoin. Using a distinct hashing algorithm called Scrypt, Litecoin offers faster transaction times, making it a compelling option for digital transactions.
**5. Stablecoins:**
Stablecoins represent a category of digital currencies that are tethered to conventional assets like fiat currencies (such as USD or EUR) or commodities like gold. Their primary objective is to uphold a stable value within the often turbulent cryptocurrency market. Notable examples of stablecoins include Tether (USDT), USD Coin (USDC), and Dai (DAI).
**6.Privacy Coins:**
**Monero (XMR)**, launched in April 2014, is dedicated to enhancing privacy, decentralization, and scalability within the cryptocurrency space. It achieves this by employing sophisticated cryptographic methods to conceal transaction details, ensuring anonymity for users.
**Zcash (ZEC)**, introduced in October 2016, introduces the concept of "shielded" transactions, leveraging zero-knowledge proofs to offer heightened privacy. This innovative approach enables transactions to be conducted without revealing the sender, recipient, or transaction amount.
The primary purpose of both Monero and Zcash is to prioritize user privacy by obscuring transaction details, rendering them untraceable. This emphasis on anonymity enhances security and confidentiality, appealing to users seeking greater privacy protection in their financial transactions.
**7.Utility Tokens:**
Utility tokens serve as digital assets utilized within particular [blockchain platforms](https://lbmsolutions.in/blockchain-development-services/) to enable access to specific services or products.
**Binance Coin (BNB):**
Initially devised as a discount token for reducing trading fees on the Binance exchange, BNB has evolved to become the backbone of the Binance ecosystem. This includes powering the Binance Smart Chain, a blockchain network facilitating decentralized applications and smart contracts.
**Chainlink (LINK):**
Chain Link serves as the native token on the Chainlink network. It is utilized for paying for services provided by Chainlink, which acts as a bridge between smart contracts and real-world data sources. This enables smart contracts to access and utilize data from outside the blockchain.
In essence, utility tokens like BNB and LINK grant users access to specific functionalities and services within their respective blockchain ecosystems. They facilitate transactions, provide discounts, and enable interaction with decentralized applications, contributing to the overall functionality and utility of the platforms.
**8. Governance Tokens:**
Governance tokens are a type of cryptocurrency that grants holders the ability to engage in the decision-making process of a blockchain project.
**Maker (MKR)** is a governance token within the MakerDAO ecosystem. Holders of MKR tokens possess the authority to participate in the decision-making process regarding proposed changes to the Maker Protocol. This protocol governs the operation of the stablecoin DAI, ensuring its stability and functionality within the [decentralized finance (DeFi)](https://medium.com/@riteshsaini.lbmsolutions/decentralized-finance-defi-and-its-impact-on-token-development-b237cb0e3a4d) landscape.
**Compound (COMP)** is another governance token used within the Compound protocol. Holders of COMP tokens have the privilege to propose and vote on modifications to the Compound lending and borrowing platform. These alterations can include adjustments to interest rates, collateral requirements, or other parameters that influence the platform's operation and user experience within the DeFi ecosystem.
Governance tokens empower users to shape a project's future by enabling voting on key decisions. Through democratic mechanisms, holders propose and decide on matters, ensuring community involvement, transparency, and decentralization.
**Conclusion:**
In Conclusion , the [crypto coin](https://lbmsolutions.in/crypto-coin-development-services/) space offers a wide variety of coins, each serving distinct purposes. From Bitcoin's pioneering role in digital currency to Ethereum's smart contract capabilities, Ripple's efficient cross-border transactions, and Litecoin's focus on faster transactions, the ecosystem is diverse.
Stablecoins provide stability, privacy coins prioritize anonymity, utility tokens grant access to specific services, and governance tokens empower community participation. Together, they shape the evolving landscape of digital assets, driving innovation and decentralization in the financial world.
| ritesh_saini_45667ac4b3a5 |
1,862,827 | Cross-Origin Resource Sharing (CORS) in ASP.NET Core: A Comprehensive Guide | Originally published at https://antondevtips.com. Cross-Origin Resource Sharing (CORS) is a standard... | 0 | 2024-05-24T07:17:50 | https://antondevtips.com/blog/cors-in-asp-net-core-a-comprehensive-guide | programming, dotnet, backend, development | ---
canonical_url: https://antondevtips.com/blog/cors-in-asp-net-core-a-comprehensive-guide
---
_Originally published at_ [_https://antondevtips.com_](https://antondevtips.com/blog/cors-in-asp-net-core-a-comprehensive-guide)_._
Cross-Origin Resource Sharing (CORS) is a standard in web applications that allows or restricts web pages from making requests to a domain different from the one that served the initial web page.
Today we will explore how to implement and manage CORS in ASP.NET Core applications effectively.
## How CORS works
When a web page makes a cross-origin HTTP request, the browser automatically adds an `Origin` header to the request.
The server checks this header against its CORS policy.
If the origin is allowed, the server responds with a `Access-Control-Allow-Origin` CORS header.
This indicates that the request is allowed to be served on the server.
The server doesn't return an error if the CORS policy doesn't allow the request to be executed.
The client is responsible for returning error to the client and blocking the response.
CORS is a way for a server to allow web browsers to execute a cross-origin requests.
Browsers without CORS can't do cross-origin requests.
## When To Use CORS
**CORS should be enabled in ASP.NET Core:**
* To allow your API to be accessed from different domains
* When your frontend and backend are hosted separately
* To control specific resources in your application to be accessible from other domains
* In development mode
To enable CORS in ASP.NET Core, call the `AddCors` method on the `IServiceCollection` to add it to the DI container:
```csharp
builder.Services.AddCors(options =>
{
options.AddPolicy("AllowSpecificOrigin",
policyBuilder => policyBuilder.WithOrigins("http://example.com"));
});
```
And add CORS to the middleware pipeline by calling `UseCors` method:
```csharp
app.UseCors("AllowSpecificOrigin");
```
> Often CORS are enabled in ASP.NET Core apps only in the **development mode** to simplify development when frontend and backend are run on different hosts or ports.
> Consider using CORS in **production** only when it is absolutely required
## Correct Order of Middlewares When Using CORS
Here are few important tips when placing `UseCors` middleware:
* `UseCors` middleware should be placed before `UseResponseCaching` due to this [bug](https://github.com/dotnet/aspnetcore/issues/23218).
* `UseCors` middleware should be placed before `UseStaticFiles` to ensure CORS headers are properly added to the static file responses
```csharp
app.UseCors();
app.UseResponseCaching();
app.UseStaticFiles();
```
## Enable CORS in WebApi Controllers
To apply CORS policies to specific endpoints, use the `RequireCors` method in endpoint routing configuration:
```csharp
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers().RequireCors("AllowSpecificOrigin");
});
```
You can enable or disable CORS for a specific controller:
```csharp
[EnableCors("AllowSpecificOrigin")]
public class UsersController : ControllerBase
{
// Controller methods
}
[DisableCors]
public class ProductsController : ControllerBase
{
// Controller methods
}
```
You can also enable or disable CORS for different controller methods:
```csharp
public class UsersController : ControllerBase
{
[EnableCors("CorsPolicy1")]
[HttpGet]
public ActionResult<IEnumerable<string>> Get(Guid id)
{
var user = new User
{
Id = id,
Name = "Anton"
};
return Ok(user);
}
[EnableCors("CorsPolicy2")]
[HttpPost]
public ActionResult<IEnumerable<string>> Create(CreateUserRequest request)
{
return Ok();
}
[DisableCors]
[HttpDelete]
public ActionResult<IEnumerable<string>> Create(Guid id)
{
return NoContent();
}
}
```
## Enable CORS in Minimal APIs
To enable CORS for minimal API endpoints simply call `RequireCors` method for each endpoint:
```csharp
app.MapGet("/api/books", () =>
{
var books = SeedService.GetBooks(10);
return Results.Ok(books);
}).RequireCors("AllowAllOrigins");
```
## CORS Policy Options
We already learned what the CORS is and how to enable it in the ASP.NET Core.
It's time to explore what policy options does the CORS provide us:
* Set the allowed origins
* Set the allowed HTTP methods
* Set the allowed request headers
* Set the exposed response headers
* Credentials in cross-origin requests
### Allowed Origin
Specify what origins are allowed to access the resource.
```csharp
builder.WithOrigins("http://example.com");
```
### Allowed HTTP Methods
Define what HTTP methods can be used when accessing the resource.
```csharp
builder.WithMethods("GET", "POST", "PUT", "DELETE", "PATCH");
```
### Allowed Request Headers
Specify headers that can be used when making the request.
```csharp
builder.WithHeaders("Content-Type", "Authorization");
```
### Exposed Response Headers
Control which headers are exposed to the browser.
```csharp
builder.WithExposedHeaders("X-Custom-Header");
```
### Credentials in Cross-Origin Requests
Determine if cookies should be included with requests.
```csharp
builder.AllowCredentials();
```
## Allow Any Policy Options
There is a way to enable all policy options, for example for development:
```csharp
if (builder.Environment.IsDevelopment())
{
builder.Services.AddCors(options =>
{
options.AddPolicy("AllowAllOrigins",
policyBuilder => policyBuilder.AllowAnyHeader()
.AllowAnyMethod()
.AllowAnyOrigin()
//.AllowCredentials()
.SetIsOriginAllowed(_ => true)
);
});
}
// ...
if (app.Environment.IsDevelopment())
{
app.UseCors("AllowAllOrigins");
}
```
> **NOTE:** you can't use AllowAnyOrigin (wild card, allowing all origins) with AllowCredentials at the same time
## Summary
Implementing CORS in ASP.NET Core is essential for modern web applications to securely manage cross-origin requests in the web browsers.
You can configure CORS for controllers and minimal APIs.
You can use CORS in **development mode** to simplify your frontend and backend development.
Use CORS in **production mode** only when it is absolutely required.
Hope you find this blog post useful. Happy coding!
_Originally published at_ [_https://antondevtips.com_](https://antondevtips.com/blog/cors-in-asp-net-core-a-comprehensive-guide)_._
### After reading the post consider the following:
- [Subscribe](https://antondevtips.com/blog/cors-in-asp-net-core-a-comprehensive-guide#subscribe) **to receive newsletters with the latest blog posts**
- [Download](https://github.com/AntonMartyniuk-DevTips/dev-tips-code/tree/main/backend/AspNetCore/Cors) **the source code for this post from my** [github](https://github.com/AntonMartyniuk-DevTips/dev-tips-code/tree/main/backend/AspNetCore/Cors) (available for my sponsors on BuyMeACoffee and Patreon)
If you like my content — **consider supporting me**
Unlock exclusive access to the source code from the blog posts by joining my **Patreon** and **Buy Me A Coffee** communities!
[](https://www.buymeacoffee.com/antonmartyniuk)
[](https://www.patreon.com/bePatron?u=73769486) | antonmartyniuk |
1,863,645 | Introducing Google Play Points: Elevating Your Rewards Experience | Get ready to level up your rewards game with Google Play Points! Since 2018, over 220 million members... | 0 | 2024-05-24T07:17:28 | https://dev.to/n968941/introducing-google-play-points-elevating-your-rewards-experience-1jc | news, flutter, playstore, googlecloud | Get ready to level up your rewards game with Google Play Points! Since 2018, over 220 million members have enjoyed exclusive perks, and now, we're taking it even further. From exciting new games like Diamond Valley to VIP event experiences, join the adventure today and elevate your gaming journey like never before.
Unlocking Exciting New Perks and RewardsDiscover New Adventures with Diamond ValleyExclusive Pre-registration BonusEarly Access to Exciting New GamesBuild Your Squad TodayElevate Your Experience with VIP EventsJoin the Play Points Adventure TodayInformation in Table formatFAQs about Google Play PointsWhat is Google Play Points?How many members currently benefit from Google Play Points rewards?What are the benefits of being a Google Play Points member?How do I join Google Play Points?What are the perks of being a Diamond or Platinum member?What is Diamond Valley?How can I pre-register for Diamond Valley?How do I access early game releases like Squad Busters?How can I stay updated on upcoming VIP events?What rewards can I expect from Google Play Points?
[read full article](https://flutters.in/introducing-google-play-points-elevating-your-rewards-experience/)
Since its launch in 2018, Google Play Points has been our way of expressing gratitude to the millions of users who choose Google Play for their app, game, and digital content needs. With over 220 million members benefiting from Play Points rewards, we're thrilled to announce that we're taking the rewards game to the next level.
Unlocking Exciting New Perks and Rewards
This year, we're enhancing Google Play Points with a host of thrilling new perks and rewards designed to immerse you in experiences you'll adore. Moreover, the higher your status within the program, the greater the rewards you'll unlock. Here's a sneak peek of what's in store:
Introducing Google Play Points: Elevating Your Rewards Experience
Discover New Adventures with Diamond Valley
Launching on June 17th in the U.S., Diamond Valley is an engaging treasure hunt mini-game that has already captured the hearts of players in Korea and Japan. Hunt for precious diamonds and utilize them for a chance to win fantastic prizes such as Pixel devices, exclusive merchandise from your favorite games, bonus points, and much more.
Exclusive Pre-registration Bonus
Secure your spot in the treasure hunt by pre-registering for Diamond Valley today and kickstart your journey with bonus diamonds. As an added perk, the first 50,000 Diamond and Platinum members to pre-register will receive an exclusive Diamond Valley t-shirt. Head over to the Perks tab of the Play Points home to pre-register and prepare for the adventure ahead.
Early Access to Exciting New Games
As a token of appreciation to our top members, we're offering exclusive early access to the latest mobile gaming sensations. Starting immediately, Diamond, Platinum, and Gold members can dive into the action-packed world of Squad Busters from Supercell before anyone else.
Build Your Squad Today
To claim your early access and assemble your squad, simply navigate to the Perks tab of the Play Points home. Keep an eye out for additional exclusive Squad Busters rewards dropping soon.
Introducing Google Play Points: Elevating Your Rewards Experience
Elevate Your Experience with VIP Events
Get ready to elevate your summer with VIP experiences at premier gaming and entertainment events. Stay tuned to the Google Play Store for upcoming announcements and seize the opportunity to indulge in unforgettable experiences this season.
[read full article](https://flutters.in/introducing-google-play-points-elevating-your-rewards-experience/)
Join the Play Points Adventure Today
Ready to embark on your Play Points journey? Simply head to the Google Play Store, tap your profile icon, select "Play Points," and hit "Join for free." Then, let the fun begin!
Also read:
Google Play Points Introduces Exciting New Features to Enhance User Rewards
Is Flutter Right For Your Mobile App?
Faq about Google Play Points
What is Google Play Points?
Google Play Points is a rewards program launched in 2018 to thank users for choosing Google Play for their app, game, and digital content needs. It offers points and rewards to members for their activities on Google Play.
How many members currently benefit from Google Play Points rewards?
Over 220 million members are currently benefiting from Google Play Points rewards.
What are the benefits of being a Google Play Points member?
As a Google Play Points member, you can earn points and unlock various rewards, including exclusive perks, early access to new games, VIP experiences at gaming and entertainment events, and more.
How do I join Google Play Points?
Joining Google Play Points is simple and free. Just head to the Google Play Store, tap on your profile icon, select "Play Points," and hit "Join for free."
What are the perks of being a Diamond or Platinum member?
Diamond and Platinum members enjoy exclusive perks such as early access to new games like Squad Busters, exclusive merchandise, bonus points, and more.
What is Diamond Valley?
Diamond Valley is an engaging treasure hunt mini-game available to Google Play Points members. Players hunt for diamonds and have the chance to win exciting prizes such as Pixel devices, exclusive merchandise, bonus points, and more.
How can I pre-register for Diamond Valley?
To pre-register for Diamond Valley, visit the Perks tab of the Play Points home. As an added bonus, the first 50,000 Diamond and Platinum members to pre-register will receive an exclusive Diamond Valley t-shirt.
[read full article](https://flutters.in/introducing-google-play-points-elevating-your-rewards-experience/)
How do I access early game releases like Squad Busters?
Diamond, Platinum, and Gold members can access early game releases like Squad Busters by visiting the Perks tab of the Play Points home.
How can I stay updated on upcoming VIP events?
Stay tuned to the Google Play Store for announcements about upcoming VIP events. These events offer members exclusive VIP experiences at premier gaming and entertainment events.
What rewards can I expect from Google Play Points?
Google Play Points offers a variety of rewards, including exclusive merchandise, bonus points, early access to new games, VIP experiences, and more. | n968941 |
1,863,642 | Saving data without triggering events in Laravel | How to | Tutorial | Quick Win Wednesday #QWW | A post by Bert De Swaef | 0 | 2024-05-24T07:15:06 | https://dev.to/burtds/saving-data-without-triggering-events-in-laravel-how-to-tutorial-quick-win-wednesday-qww-628 | laravel, php, tutorial, beginners | {% embed https://youtu.be/S7oBTTLORHg %} | burtds |
1,863,640 | Development and Futures Trading: A Dynamic Duo in the Crypto World | In the rapidly evolving landscape of cryptocurrency, the intersection of development and futures... | 0 | 2024-05-24T07:13:23 | https://dev.to/andylarkin677/development-and-futures-trading-a-dynamic-duo-in-the-crypto-world-58n4 | webdev, news, development, learning | In the rapidly evolving landscape of cryptocurrency, the intersection of development and futures trading plays a pivotal role in shaping the future of the market. As digital assets become increasingly mainstream, developers and traders find themselves in a symbiotic relationship, driving innovation and expanding trading possibilities. This article explores the vital connection between development and futures trading, with a focus on leading cryptocurrency exchanges like WhiteBIT, and introduces the new futures trading pair $NOT-PERP.
The Role of Development in Crypto Futures Trading
Developers are the backbone of the cryptocurrency ecosystem, crafting the technologies that make blockchain networks, decentralized applications (dApps), and trading platforms possible. Their work ensures the reliability, security, and efficiency of these platforms, which are crucial for enabling complex financial instruments like futures contracts.
Futures trading, a staple in traditional financial markets, has found a robust foothold in the crypto world. Futures contracts allow traders to speculate on the future price of a cryptocurrency, providing opportunities for hedging and leveraging positions. This type of trading requires a sophisticated technological infrastructure to handle high transaction volumes, rapid execution, and stringent security measures—tasks that fall squarely on the shoulders of developers.
Trading Futures on Major Crypto Exchanges
Several major cryptocurrency exchanges have made significant strides in futures trading, each bringing unique features and offerings to the table.
Binance Futures: One of the largest and most popular platforms, Binance Futures offers a wide range of perpetual and quarterly contracts. The platform is known for its liquidity, diverse trading pairs, and advanced trading tools, all supported by a robust technical framework that ensures seamless operation.
Bybit: Specializing in perpetual contracts, Bybit is renowned for its user-friendly interface and high-performance trading engine. Bybit emphasizes security and customer support, making it a preferred choice for both novice and experienced traders.
WhiteBIT: As a rapidly growing exchange, WhiteBIT has made notable advancements in futures trading. The platform recently introduced the $NOT-PERP trading pair, allowing traders to speculate on the future price movements of the NOT token. This addition enhances WhiteBIT’s offerings, providing more options for traders looking to diversify their portfolios.
The $NOT-PERP Pair on WhiteBIT
The introduction of the $NOT-PERP futures trading pair on WhiteBIT is a testament to the exchange's commitment to innovation and user-centric development. This new pair allows traders to engage with the NOT token in a futures market context, opening up new avenues for strategic trading and risk management. The launch of $NOT-PERP showcases the collaborative efforts of developers and market strategists in delivering cutting-edge trading options.
The Synergy Between Developers and Traders
The relationship between developers and traders is symbiotic. Developers create the tools and platforms that facilitate efficient trading, while traders provide feedback and demand that drive continuous improvement and innovation. This dynamic interaction ensures that trading platforms remain at the forefront of technological advancements, offering enhanced features and security protocols.
Conclusion
The fusion of development and futures trading is a driving force behind the growth and evolution of the cryptocurrency market. Exchanges like Binance, Bybit, and WhiteBIT exemplify how cutting-edge technology and innovative trading solutions come together to create vibrant and efficient trading environments. The introduction of the $NOT-PERP pair on WhiteBIT highlights the ongoing collaboration between developers and traders, paving the way for new opportunities and advancements in the crypto space.
As the market continues to evolve, the interplay between development and futures trading will remain crucial in shaping the future of cryptocurrency, driving both technological progress and market expansion. | andylarkin677 |
1,863,639 | Where to Learn Prompt Engineering | Whether you're a seasoned AI practitioner looking to enhance your skills or a newcomer eager to delve... | 0 | 2024-05-24T07:13:17 | https://dev.to/ailearning/where-to-learn-prompt-engineering-3dl0 | learnpromptengineering, promptengineering, certifiedpromptengineer, promptengineeringcertification | Whether you're a seasoned AI practitioner looking to enhance your skills or a newcomer eager to delve into the world of NLP, mastering prompt engineering opens up a wealth of opportunities for shaping the future of human-computer interaction. But where can you learn [prompt engineering](https://futureskillsacademy.com/blog/become-certified-prompt-engineer-expert/), and how can you obtain certification to validate your expertise?
#### 1. Online Courses:
One of the most accessible and flexible ways to learn prompt engineering is through online courses. Platforms like Coursera, Udemy, and edX offer a variety of courses specifically tailored to NLP and prompt engineering. Look for courses that cover topics such as prompt design strategies, model fine-tuning techniques, and practical applications in real-world scenarios. These courses often provide a combination of video lectures, hands-on exercises, and quizzes to reinforce learning and ensure mastery of key concepts.
#### 2. Specialized Training Programs:
For a more immersive learning experience, consider enrolling in specialized training programs or workshops focused specifically on prompt engineering that can help anyone become a [certified prompt engineer](https://futureskillsacademy.com/certification/certified-prompt-engineering-expert/). Some organizations and institutes offer intensive boot camps or certificate programs that provide in-depth instruction and practical experience with industry-standard tools and methodologies. These programs typically cater to professionals seeking to advance their careers or transition into roles focused on AI and NLP.
#### 3. Self-Study Resources:
In addition to formal courses and programs, aspiring prompt engineers can access a wealth of self-study resources online. Blogs, research papers, and online forums like Reddit's prompt engineering community offer valuable insights, case studies, and discussions on prompt design techniques and best practices. Dive deep into the latest research papers and experiment with open-source tools and libraries to gain hands-on experience and stay up-to-date with the latest advancements in the field.
## Prompt Engineering Certification:
Once you've acquired the necessary knowledge and skills in prompt engineering, obtaining certification can help validate your expertise and distinguish you in the job market. While there isn't yet a standardized certification specifically for prompt engineering, you can demonstrate your proficiency through various means:
#### 1. Industry-Recognized Certifications:
Some organizations offer certifications in related fields such as NLP, machine learning, or AI engineering, which may include components or modules on prompt engineering. Look for certifications from reputable institutions or industry leaders that align with your career goals and interests.
#### 2. Project Portfolio:
Building a strong portfolio of projects showcasing your prompt engineering skills can be just as valuable as formal certification. Create and showcase projects demonstrating your ability to design effective prompts, fine-tune models, and achieve desired outcomes in real-world applications. Highlighting your practical experience and contributions to the field can impress potential employers and collaborators.
#### 3. Networking and Collaboration:
Engage with the prompt engineering community through online forums, social media groups, and networking events. Participate in hackathons, competitions, or collaborative projects where you can showcase your skills, learn from others, and establish connections with industry professionals. Networking can lead to valuable opportunities for mentorship, collaboration, and career advancement in the field of prompt engineering.
### Conclusion:
As the demand for AI-powered applications continues to grow across industries, prompt engineering has become an essential skill for shaping the future of NLP and human-computer interaction. Whether you choose to learn through online courses, specialized training programs, or self-study resources, mastering prompt engineering opens doors to exciting career opportunities and meaningful contributions to the advancement of AI technology.
Future Skill Academy is at the forefront of preparing individuals for the future of work through its [prompt engineering certification](https://futureskillsacademy.com/certification/certified-prompt-engineering-expert/) program. Recognizing the growing importance of natural language processing (NLP) and its applications in various industries, the academy offers comprehensive courses and workshops focused on mastering prompt engineering techniques.
| ailearning |
1,863,638 | What study Abroad consultants do for you? | If you are also planning to move abroad for higher studies, you must hire abroad study visa... | 0 | 2024-05-24T07:11:54 | https://dev.to/abroad_gateway_20e7b5165b/what-study-abroad-consultants-do-for-you-13eb |
If you are also planning to move abroad for higher studies, you must hire abroad [study visa consultant](https://abroadgateway.com/) as per the current scenario of the market these students are finding it difficult to select the appropriate study abroad consultant. There are many institutes are available in the market which is claiming for the best, but few of them are unauthorized and fake. So if you are also planning to hire a study abroad consultant you need keep in mind few parameters such as check their credentials, reviews, reputation and quality of service. Once you hire a an authorized study abroad consultant, you are sorted he is going to make visa filing process very easy and enjoyable on the flip side if you do not hire a good study abroad you might find this process hectic and challenging. Basically these consultants are act as education advisor in your abroad journey as they will give you right guidance as per your profile by helping you to selecting the best university and best course.
Let’s have look what an abroad study visa consultant can do to help you:
Academic advising: In this, your consultant will give academic advice as by accessing your profile he will give you advice according to your previous studies so that you can select the right course in the right university.
University selection: Your consultant will help you in choosing the right university in which he will aware you about the location and reputation of the university and course availability also. As if you choose the private/ not registered university and the demanding course you will not get the education points at the end.
Application assistance: Your consultant will help you by explaining you the application process of the university and also help you by arranging documents such as SOP which stands for statement of purpose, LOR which stands for the letter of recommendation as they understand the demand of the university and the embassy.
Test preparation: As you are applying in the foreign universities for the studies so you need to fulfill the eligibility criteria of the language proficiency test such as IELTS and PTE as they are compulsory to get admission in the universities.
Visa guidance: Your consultant will provide you right visa guidance as per your profile and wish and also help you to arrange the documents which are required to apply for the visa and also make sure to apply for the same before the deadlines.
Financial planning: Your consultant will help you by providing the information regarding tuition fees, living expenses and the scholarships which will help the student a lot during his academic journey in the abroad.
Cultural orientation: Your consultant will aware you in advance about the cultural diversity of the country where you are moving, moreover, he will give you advice on how to adapt the new culture by joining cultural groups there so that you will suffer from cultural shock.
Travel arrangements: Your consultant will help you by booking your air tickets and arrange the accommodation in the host country for you so that you can start your academic journey without any hustle-bustle.
Pre-departure orientation: Your consultant will arrange a pre- departure session for you before flying in which they will provide you information regarding the host country rules and regulation as you will be newcomer over there.
Post arrival support: Most of the consultants gives post arrival support by keeping in touch with you after you lands your dream country as they are ready to assist you if you face any kind of difficulty there.
Career counseling: Your consultant will provide you career counseling for the short term and long term career goals by giving you right guidance on how to achieve them.
Networking: Your consultant will have networks with the universities and students so they can connect you with the alumni and the experts who can help you if you experience any kind of difficulty in the university and the campus.
Monitoring progress: In this, your [immigration consultant](https://abroadgateway.com/) will monitor your progress and provide you support in visa conversion and obtaining the work permit and after that they assist you in applying for PR of that country.
Read More at : [https://medium.com/@abroadgateway700/which-is-the-best-uk-study-visa-consultant-in-chandigarh-15ae60426070](https://medium.com/@abroadgateway700/which-is-the-best-uk-study-visa-consultant-in-chandigarh-15ae60426070
)
| abroad_gateway_20e7b5165b | |
1,863,636 | DashVector x 通义千问大模型:打造基于专属知识的问答服务 | =================================================== 本教程演示如何使用向量检索服务(DashVector),结合LLM大模型等能力,来打造基于垂直领... | 0 | 2024-05-24T07:10:53 | https://dev.to/dashvector/dashvector-x-tong-yi-qian-wen-da-mo-xing-da-zao-ji-yu-zhuan-shu-zhi-shi-de-wen-da-fu-wu-2f0 |
===================================================
本教程演示如何使用向量检索服务(DashVector),结合LLM大模型等能力,来打造基于垂直领域专属知识等问答服务。其中LLM大模型能力,以及文本向量生成等能力,这里基于[灵积模型服务](https://dashscope.aliyun.com/)上的通义千问 API以及Embedding API来接入。
背景及实现思路
----------------
大语言模型(LLM)作为自然语言处理领域的核心技术,具有丰富的自然语言处理能力。但其训练语料库具有一定的局限性,一般由普适知识、常识性知识,如维基百科、新闻、小说,和各种领域的专业知识组成。导致 LLM 在处理特定领域的知识表示和应用时存在一定的局限性,特别对于垂直领域内,或者企业内部等私域专属知识。
实现专属领域的知识问答的关键,在于如何让LLM能够理解并获取存在于其训练知识范围外的特定领域知识。同时可以通过特定Prompt构造,提示LLM在回答特定领域问题的时候,理解意图并根据注入的领域知识来做出回答。在通常情况下,用户的提问是完整的句子,而不像搜索引擎只输入几个关键字。这种情况下,直接使用关键字与企业知识库进行匹配的效果往往不太理想,同时长句本身还涉及分词、权重等处理。相比之下,倘若我们把提问的文本,和知识库的内容,都先转化为高质量向量,再通过向量检索将匹配过程转化为语义搜索,那么提取相关知识点就会变得简单而高效。
接下来我们将基于[中文突发事件语料库](https://github.com/shijiebei2009/CEC-Corpus/)(CEC Corpus)演示关于突发事件新闻报道的知识问答。
整体流程
-------------
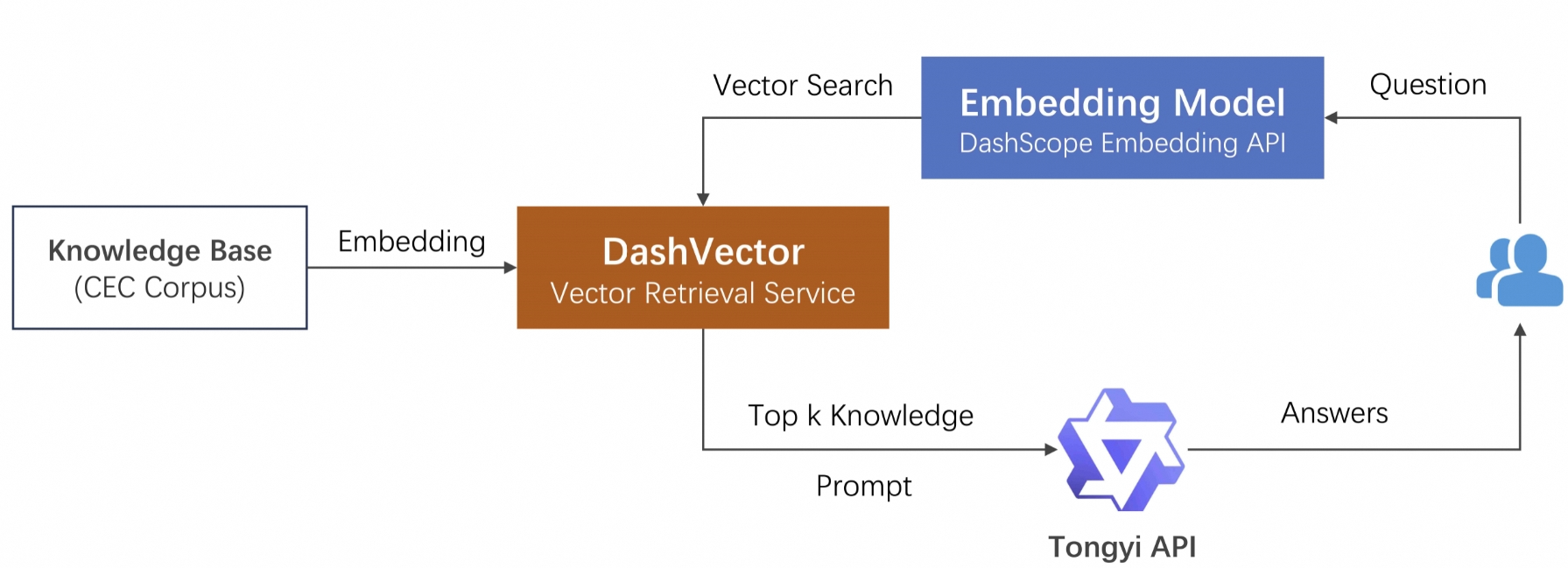
主要分为三个阶段:
1. **本地知识库的向量化** 。通过文本向量模型将其转化为高质量低维度的向量数据,再写入DashVector向量检索服务。这里数据的向量化我们采用了[灵积模型服务](https://dashscope.aliyun.com/)上的Embedding API实现。
2. **相关知识点的提取** 。将提问文本向量化后,通过 DashVector 提取相关知识点的原文。
3. **构造 Prompt 进行提问** 。将相关知识点作为"限定上下文+提问" 一起作为prompt询问通义千问。
前提准备
-------------
### 1. API-KEY 和 Cluster准备
* 开通灵积模型服务,并获得 API-KEY。请参考:[开通DashScope并创建API-KEY](https://help.aliyun.com/zh/dashscope/developer-reference/activate-dashscope-and-create-an-api-key?spm=a2c4g.2510235.0.i10)。
* 开通DashVector向量检索服务,并获得 API-KEY。请参考:DashVector [API-KEY管理](https://help.aliyun.com/document_detail/2510230.html?spm=a2c4g.2510235.0.i11)。
* 开通DashVector向量检索服务,并[创建Cluster](https://help.aliyun.com/document_detail/2631966.html?spm=a2c4g.2510235.0.i12)。
* 获取Cluster的Endpoint,Endpoint获取请查看 [Cluster详情](https://help.aliyun.com/document_detail/2568084.html?spm=a2c4g.2510235.0.i13#3c0384e4e6asc)。
**说明**
灵积模型服务DashScope的API-KEY与DashVector的API-KEY是独立的,需要分开获取。
### 2. 环境准备
**说明**
需要提前安装 Python3.7 及以上版本,请确保相应的 python 版本。
```
pip3 install dashvector dashscope
```
### 3. 数据准备
```
git clone https://github.com/shijiebei2009/CEC-Corpus.git
```
搭建步骤
-------------
**说明**
本教程所涉及的 *your-xxx-api-key* 以及 *your-xxx-cluster-endpoint* ,均需要替换为您自己的API-KAY及CLUSTER_ENDPOINT后,代码才能正常运行。
### 1. 本地知识库的向量化
[CEC-Corpus](https://github.com/shijiebei2009/CEC-Corpus)数据集包含 332 篇突发事件的新闻报道的语料和标注数据,这里我们只需要提取原始的新闻稿文本,并将其向量化后入库。文本向量化的教程可以参考[《基于向量检索服务与灵积实现语义搜索》](https://help.aliyun.com/document_detail/2510234.html?spm=a2c4g.2510235.0.i14)。创建`embedding.py`文件,并将如下示例代码复制到`embedding.py`中:
```python
import os
import dashscope
from dashscope import TextEmbedding
from dashvector import Client, Doc
def prepare_data(path, batch_size=25):
batch_docs = []
for file in os.listdir(path):
with open(path + '/' + file, 'r', encoding='utf-8') as f:
batch_docs.append(f.read())
if len(batch_docs) == batch_size:
yield batch_docs
batch_docs = []
if batch_docs:
yield batch_docs
def generate_embeddings(news):
rsp = TextEmbedding.call(
model=TextEmbedding.Models.text_embedding_v1,
input=news
)
embeddings = [record['embedding'] for record in rsp.output['embeddings']]
return embeddings if isinstance(news, list) else embeddings[0]
if __name__ == '__main__':
dashscope.api_key = '{your-dashscope-api-key}'
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 创建集合:指定集合名称和向量维度, text_embedding_v1 模型产生的向量统一为 1536 维
rsp = client.create('news_embedings', 1536)
assert rsp
# 加载语料
id = 0
collection = client.get('news_embedings')
for news in list(prepare_data('CEC-Corpus/raw corpus/allSourceText')):
ids = [id + i for i, _ in enumerate(news)]
id += len(news)
vectors = generate_embeddings(news)
# 写入 dashvector 构建索引
rsp = collection.upsert(
[
Doc(id=str(id), vector=vector, fields={"raw": doc})
for id, vector, doc in zip(ids, vectors, news)
]
)
assert rsp
```
在示例中,我们将 Embedding 向量和新闻报道的文稿(作为raw字段)一起存入DashVector向量检索服务中,以便向量检索时召回原始文稿。
### 2. 知识点的提取
将 CEC-Corpus 数据集所有新闻报道写入DashVector服务后,就可以进行快速的向量检索。实现这个检索,我们同样将提问的问题进行文本向量化后,再在DashVector服务中检索最相关的知识点,也就是相关新闻报道。创建`search.py`文件,并将如下示例代码复制到`search.py`文件中。
```
from dashvector import Client
from embedding import generate_embeddings
def search_relevant_news(question):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取刚刚存入的集合
collection = client.get('news_embedings')
assert collection
# 向量检索:指定 topk = 1
rsp = collection.query(generate_embeddings(question), output_fields=['raw'],
topk=1)
assert rsp
return rsp.output[0].fields['raw']
```
### 3. 构造 Prompt 向LLM(通义千问)提问
在通过提问搜索到相关的知识点后,我们就可以将 "提问 + 知识点" 按照特定的模板作为 prompt 向LLM发起提问了。在这里我们选用的LLM是通义千问,这是阿里巴巴自主研发的超大规模语言模型,能够在用户自然语言输入的基础上,通过自然语言理解和语义分析,理解用户意图。可以通过提供尽可能清晰详细的指令(prompt),来获取更符合预期的结果。这些能力都可以通过[通义千问API](https://help.aliyun.com/document_detail/613695.html)来获得。
具体我们这里设计的提问模板格式为: *请基于我提供的内容回答问题。内容是{___},我的问题是{___}* ,当然您也可以自行设计合适的模板。创建`answer.py`,并将如下示例代码复制到`answer.py`中。
````
from dashscope import Generation
def answer_question(question, context):
prompt = f'''请基于```内的内容回答问题。"
```
{context}
```
我的问题是:{question}。
'''
rsp = Generation.call(model='qwen-turbo', prompt=prompt)
return rsp.output.text
````
知识问答
-------------
做好这些准备工作以后,就可以对LLM做与具体知识点相关的提问了。比如在 CEC-Corpus 新闻数据集里,有如下一篇报道。因为整个新闻数据集已经在之前的步骤里,转换成向量入库了,我们现在就可以把这个新闻报道作为一个知识点,做出针对性提问:海南安定追尾事故,发生在哪里?原因是什么?人员伤亡情况如何?,并查看相应答案。

创建`run.py`文件,并将如下示例代码复制到`run.py`文件中。
```
import dashscope
from search import search_relevant_news
from answer import answer_question
if __name__ == '__main__':
dashscope.api_key = '{your-dashscope-api-key}'
question = '海南安定追尾事故,发生在哪里?原因是什么?人员伤亡情况如何?'
context = search_relevant_news(question)
answer = answer_question(question, context)
print(f'question: {question}\n' f'answer: {answer}')
```

可以看到,基于DashVector作为向量检索的底座,LLM大模型的知识范畴得到了针对性的扩展,并且能够对于专属的特定知识领域做出正确的回答。
写在最后
-------------
从本文的范例中,可以看到DashVector作为一个独立的向量检索服务,提供了开箱即用的强大向量检索服务能力,这些能力和各个AI模型结合,能够衍生多样的AI应用的可能。这里的范例中,LLM大模型问答,以及文本向量生成等能力,都是基于[灵积模型服务](https://dashscope.aliyun.com/)上的通义千问API和Embedding API来接入的,在实际操作中,相关能力同样可以通过其他三方服务,或者开源模型社区,比如ModelScope上的[各种开源LLM模型](https://modelscope.cn/topic/dfefe5be778b49fba8c44646023b57ba/pub/summary)来实现。
| dashvector | |
1,863,634 | Google Play Points Introduces Exciting New Features to Enhance User Rewards | Choosing the right framework is vital for your mobile app's success. Flutter, a popular UI toolkit by... | 0 | 2024-05-24T07:02:35 | https://dev.to/n968941/google-play-points-introduces-exciting-new-features-to-enhance-user-rewards-1453 | flutter, firebase, beginners, programming | Choosing the right framework is vital for your mobile app's success. Flutter, a popular UI toolkit by Google, allows developers to create natively compiled applications for mobile, web, and desktop from a single codebase. This article explores Flutter's features, benefits, and drawbacks to help you decide if it's the right choice for your app.
IntroductionWhat is Flutter?Key Features of FlutterSingle CodebaseHot ReloadRich Widget LibraryHigh PerformanceStrong Community and SupportBenefits of Using FlutterCross-Platform DevelopmentFast Development CycleCustomizable WidgetsStrong PerformanceReduced Testing EffortsConsistent UI Across PlatformsPotential Drawbacks of Using FlutterLarge App SizeLimited Native FeaturesLearning CurveEcosystem MaturityPerformance OverheadWhen to Choose FlutterCross-Platform NeedsRapid DevelopmentBudget ConstraintsCustom UI RequirementsPrototypingWhen Not to Choose FlutterPlatform-Specific FeaturesHigh-Performance RequirementsApp Size ConcernsLong-Term MaintenanceComparison with Other FrameworksFlutter vs. React NativeFlutter vs. Native DevelopmentFlutter vs. XamarinInformation in Table formatBenefits of Using FlutterPotential Drawbacks of Using FlutterWhen to Choose FlutterWhen Not to Choose FlutterComparison with Other FrameworksConclusionFAQs About Flutter for Mobile App DevelopmentWhat is Flutter and why is it popular?What are the key features of Flutter?What are the benefits of using Flutter for mobile app development?What are the potential drawbacks of using Flutter?When should I choose Flutter for my mobile app development project?When should I not choose Flutter for my mobile app development project?How does Flutter compare to other frameworks like React Native, Native Development, and Xamarin?In conclusion, is Flutter a suitable choice for my mobile app development project?
Introduction
Mobile app development is crucial in today's digital world. With many frameworks available, choosing the right one can make or break your app's success. Flutter, a UI toolkit by Google, has become popular for its ability to create natively compiled applications for mobile, web, and desktop from a single codebase. This article helps you decide if Flutter is the right choice for your mobile app by exploring its features, benefits, and potential drawbacks.
[read full article](https://flutters.in/google-play-points-introduces-exciting-new-features-to-enhance-user-rewards/)
What is Flutter?
Flutter is an open-source UI software development kit (SDK) created by Google. It allows developers to build apps for Android, iOS, web, and desktop from one codebase. Flutter uses the Dart programming language and provides a rich set of pre-designed widgets, making it easy to create visually appealing and highly responsive applications.
Key Features of Flutter
Single Codebase
Flutter lets developers write code once and deploy it across multiple platforms. This reduces the time and effort needed to maintain separate codebases.
Hot Reload
This feature lets developers see changes in real-time without restarting the app, speeding up the development process.
Rich Widget Library
Flutter offers a comprehensive library of customizable widgets that follow Material Design and Cupertino design guidelines, ensuring a consistent look and feel across different platforms.
High Performance
Flutter apps are compiled to native ARM code, ensuring high performance on both Android and iOS devices.
Strong Community and Support
As an open-source project backed by Google, Flutter has a robust community and extensive documentation, making it easier for developers to find resources and support.
Benefits of Using Flutter
Cross-Platform Development
Flutter’s single codebase approach saves time and resources and ensures a consistent user experience across different devices.
Fast Development Cycle
The hot reload feature allows developers to experiment, build UIs, add features, and fix bugs faster, speeding up the development process and improving productivity.
Customizable Widgets
Flutter’s rich set of widgets can be customized to create unique and branded app experiences, allowing developers to implement complex user interfaces easily.
Strong Performance
Flutter’s use of Dart and its compilation to native code ensure apps run smoothly and efficiently, which is crucial for performance-critical applications.
Reduced Testing Efforts
With a single codebase, testing requirements are significantly reduced. QA teams can focus on a single app version, streamlining the testing process and reducing the likelihood of platform-specific bugs.
[read full article](https://flutters.in/google-play-points-introduces-exciting-new-features-to-enhance-user-rewards/)
Consistent UI Across Platforms
Flutter’s widget-based architecture ensures that the UI looks and behaves consistently across different platforms, enhancing the overall user experience.
Potential Drawbacks of Using Flutter
Large App Size
Flutter apps tend to have larger file sizes compared to native apps, which can be a concern for users with limited storage space or slow internet connections.
Limited Native Features
While Flutter provides access to many native features, it may not support all functionalities available in native development environments. This can limit apps requiring deep integration with platform-specific features.
Learning Curve
Although Dart is relatively easy to learn, developers unfamiliar with it may face a learning curve. Additionally, getting used to Flutter’s widget-based architecture may take some time.
Ecosystem Maturity
Flutter is newer compared to other frameworks like React Native or native development platforms, meaning some libraries or tools may not be as mature or comprehensive.
Performance Overhead
While Flutter performs well for most applications, extremely performance-sensitive apps (like high-end games) may experience some overhead compared to apps developed with native code.
When to Choose Flutter
Cross-Platform Needs
If you need an app that works on both Android and iOS with a consistent user experience, Flutter’s single codebase approach is a strong contender.
Rapid Development
For projects with tight deadlines or those requiring frequent updates and iterations, Flutter’s hot reload and fast development cycle are highly beneficial.
Budget Constraints
Startups and small businesses with limited budgets can benefit from Flutter’s cost-effective development process by reducing the need for separate development teams for different platforms.
Custom UI Requirements
If your app requires a highly customized user interface with complex animations and visual elements, Flutter’s rich widget library and flexible customization options make it a suitable choice.
Prototyping
Flutter is ideal for creating prototypes and MVPs (Minimum Viable Products) due to its quick development capabilities and ability to produce visually appealing interfaces rapidly.
When Not to Choose Flutter
Platform-Specific Features
If your app requires extensive use of platform-specific features or APIs that Flutter does not support natively, you may encounter limitations that hinder your app’s functionality.
High-Performance Requirements
For applications that demand the highest level of performance, such as complex 3D games or apps requiring intensive computational tasks, native development might be more suitable.
App Size Concerns
If minimizing the app size is crucial for your target audience, consider native development, as Flutter apps generally have larger file sizes.
Long-Term Maintenance
If you anticipate needing to maintain and update the app over a long period, consider the availability of resources and the maturity of the ecosystem. While Flutter is growing rapidly, native development platforms have a longer track record and may offer more stability in the long run.
[read full article](https://flutters.in/google-play-points-introduces-exciting-new-features-to-enhance-user-rewards/)
Comparison with Other Frameworks
Flutter vs. React Native
Performance: Flutter often provides better performance due to its direct compilation to native code, while React Native relies on a JavaScript bridge.
Development Speed: Both frameworks offer fast development cycles, but Flutter’s hot reload is considered slightly more efficient.
UI Consistency: Flutter provides more consistent UI across platforms as it uses its own rendering engine, whereas React Native uses native components, which can lead to slight variations.
Community and Ecosystem: React Native has a more mature ecosystem and more third-party libraries compared to Flutter.
Flutter vs. Native Development
Development Time: Native development requires separate codebases for Android and iOS, leading to longer development times compared to Flutter’s single codebase approach.
Performance: Native apps generally offer the best performance and access to platform-specific features, which is crucial for certain types of applications.
Cost: Native development is usually more expensive due to the need for separate development teams and longer development cycles.
Flutter vs. Xamarin
Language: Flutter uses Dart, while Xamarin uses C#. Your team's familiarity with these languages can influence the decision.
Performance: Both offer good performance, but Flutter’s direct compilation to native code gives it a slight edge.
Ecosystem: Xamarin, backed by Microsoft, has a mature ecosystem and better integration with Microsoft’s development tools, which can be beneficial for enterprise applications.
Also read:
Artificial Intelligence Act: All You Need to Know About the European Council’s First Worldwide Rules on AI
New Diploma Course in Artificial Intelligence and Machine Learning at GTTC: Belagavi
Information in Table format
AspectDescriptionWhat is Flutter?Flutter is an open-source UI SDK by Google, using the Dart language to build apps for Android, iOS, web, and desktop from one codebase.Single CodebaseWrite code once and deploy across multiple platforms, reducing time and effort for separate codebases.Hot ReloadSee changes in real-time without restarting the app, speeding up development.Rich Widget LibraryOffers a library of customizable widgets following Material Design and Cupertino guidelines for a consistent look and feel.High PerformanceCompiled to native ARM code, ensuring high performance on both Android and iOS.Strong Community and SupportBacked by Google, with a robust community and extensive documentation for easy resource access.
Join Our Whatsapp Group
Join Telegram group
Benefits of Using Flutter
BenefitDescriptionCross-Platform DevelopmentSingle codebase saves time and resources, ensuring a consistent user experience across devices.Fast Development CycleHot reload feature allows for rapid experimentation, UI building, feature addition, and bug fixing.Customizable WidgetsRich set of widgets customizable for unique and branded app experiences, simplifying complex UI implementation.Strong PerformanceDart and native code compilation ensure smooth and efficient app performance.Reduced Testing EffortsSingle codebase reduces testing requirements, streamlining the QA process and lowering the likelihood of platform-specific bugs.Consistent UI Across PlatformsWidget-based architecture ensures consistent UI behavior across different platforms, enhancing user experience.
Potential Drawbacks of Using Flutter
DrawbackDescriptionLarge App SizeFlutter apps tend to be larger in file size compared to native apps, which can be an issue for users with limited storage or slow internet.Limited Native FeaturesWhile Flutter supports many native features, it may not cover all functionalities available in native development environments.Learning CurveDevelopers unfamiliar with Dart and Flutter’s widget-based architecture may need time to adapt.Ecosystem MaturityFlutter is newer compared to other frameworks, meaning some libraries or tools may not be as mature or comprehensive.Performance OverheadExtremely performance-sensitive apps, like high-end games, might experience some overhead compared to native development.
When to Choose Flutter
ScenarioDescriptionCross-Platform NeedsIdeal for apps needing consistent user experience on both Android and iOS with a single codebase.Rapid DevelopmentSuitable for projects with tight deadlines or frequent updates due to fast development cycles enabled by hot reload.Budget ConstraintsBeneficial for startups and small businesses by reducing costs of maintaining separate development teams for different platforms.Custom UI RequirementsGreat for apps needing highly customized user interfaces with complex animations and visual elements, thanks to Flutter’s rich widget library.PrototypingPerfect for creating prototypes and MVPs quickly due to rapid development capabilities and visually appealing interfaces.
When Not to Choose Flutter
ScenarioDescriptionPlatform-Specific FeaturesIf your app requires extensive use of platform-specific features or APIs not supported natively by Flutter, this may limit functionality.High-Performance RequirementsNative development might be more suitable for apps demanding the highest performance levels, like complex 3D games or apps requiring intensive computational tasks.App Size ConcernsIf minimizing the app size is crucial, consider native development as Flutter apps generally have larger file sizes.Long-Term MaintenanceNative development platforms might offer more stability and resources over the long term compared to Flutter, which is newer and evolving.
Comparison with Other Frameworks
ComparisonDescriptionFlutter vs. React NativePerformance: Flutter’s direct native code compilation vs. React Native’s JavaScript bridge. Development Speed: Flutter’s hot reload slightly more efficient. UI Consistency: Flutter’s own rendering engine for consistent UI. Community and Ecosystem: React Native’s mature ecosystem and more third-party libraries.Flutter vs. Native DevelopmentDevelopment Time: Flutter’s single codebase vs. native’s separate codebases. Performance: Native apps offer best performance and platform-specific features. Cost: Native development generally more expensive due to separate teams and longer cycles.Flutter vs. XamarinLanguage: Flutter’s Dart vs. Xamarin’s C#. Performance: Both perform well, but Flutter’s native code compilation has an edge. Ecosystem: Xamarin’s mature ecosystem and Microsoft integration for enterprise apps.
Conclusion
Deciding whether Flutter is right for your mobile app depends on your project requirements, target audience, budget, and timeline. Flutter’s cross-platform development, fast cycles, customizable widgets, and strong performance make it a compelling choice. However, drawbacks like larger app sizes, limited native features, and a learning curve should be considered. Flutter is well-suited for projects needing quick multi-platform targeting and consistent, appealing UI. Carefully evaluate your needs to determine if Flutter fits your mobile app development project.
FAQs About Flutter for Mobile App Development
What is Flutter and why is it popular?
Answer: Flutter is an open-source UI software development kit (SDK) created by Google, allowing developers to build apps for Android, iOS, web, and desktop from one codebase. It has gained popularity for its ability to create natively compiled applications, its rich widget library, and its strong community support.
What are the key features of Flutter?
Answer: Some key features of Flutter include its single codebase approach, enabling developers to write code once and deploy it across multiple platforms. It also offers hot reload for real-time changes, a rich widget library following Material Design and Cupertino guidelines, high performance through native ARM code compilation, and strong community support.
What are the benefits of using Flutter for mobile app development?
Answer: Using Flutter offers benefits such as cross-platform development, fast development cycles with hot reload, customizable widgets for unique UI experiences, strong performance due to Dart and native code compilation, reduced testing efforts with a single codebase, and consistent UI across platforms.
What are the potential drawbacks of using Flutter?
Answer: Some potential drawbacks of Flutter include larger app sizes compared to native apps, limitations in accessing certain native features, a learning curve for developers new to Dart and Flutter's widget-based architecture, and the ecosystem's relative immaturity compared to other frameworks.
When should I choose Flutter for my mobile app development project?
Answer: Flutter is a good choice for projects needing cross-platform development, rapid development cycles, cost-effective development, highly customized UI requirements, and quick prototyping.
When should I not choose Flutter for my mobile app development project?
Answer: You may want to avoid Flutter if your app requires extensive use of platform-specific features not supported natively by Flutter, demands the highest level of performance, needs to minimize app size, or requires long-term maintenance where ecosystem maturity is a concern.
[read full article](https://flutters.in/google-play-points-introduces-exciting-new-features-to-enhance-user-rewards/)
Join Our Whatsapp Group
Join Telegram group
How does Flutter compare to other frameworks like React Native, Native Development, and Xamarin?
Answer: Flutter often provides better performance compared to React Native, offers faster development cycles with hot reload, and ensures more consistent UI across platforms. Compared to native development, Flutter reduces development time with its single codebase approach but may not offer the same level of platform-specific features. Flutter vs. Xamarin: Flutter uses Dart while Xamarin uses C#, both offer good performance but Flutter has a slight edge with direct compilation to native code.
In conclusion, is Flutter a suitable choice for my mobile app development project?
Answer: Deciding whether Flutter is the right choice for your mobile app depends on various factors such as project requirements, target audience, budget, and development timeline. Flutter offers many advantages but also has potential drawbacks. By carefully evaluating your specific needs and considering the trade-offs, you can determine whether Flutter is the best fit for your mobile app development project. | n968941 |
1,863,633 | 基于向量检索服务与TextEmbedding实现语义搜索 | 本教程演示如何使用向量检索服务(DashVector),结合灵积模型服务上的Embedding API,来从0到1构建基于文本索引的构建+向量检索基础上的语义搜索能力。具体来说,我们将基于QQ... | 0 | 2024-05-24T07:01:07 | https://dev.to/dashvector/ji-yu-xiang-liang-jian-suo-fu-wu-yu-textembeddingshi-xian-yu-yi-sou-suo-25lm | 本教程演示如何使用向量检索服务(DashVector),结合[灵积模型服务](https://dashscope.aliyun.com/)上的[Embedding API](https://help.aliyun.com/zh/dashscope/developer-reference/api-details-15),来从0到1构建基于文本索引的构建+向量检索基础上的语义搜索能力。具体来说,我们将基于QQ 浏览器搜索标题语料库([QBQTC](https://github.com/CLUEbenchmark/QBQTC):QQ Browser Query Title Corpus)进行实时的文本语义搜索,查询最相似的相关标题。
什么是 Embedding
----------------------
简单来说,Embedding是一个多维向量的表示数组,通常由一系列数字组成。Embedding可以用来表示任何数据,例如文本、音频、图片、视频等等,通过Embedding我们可以编码各种类型的非结构化数据,转化为具有语义信息的多维向量,并在这些向量上进行各种操作,例如相似度计算、聚类、分类和推荐等。
整体流程概述
---------------
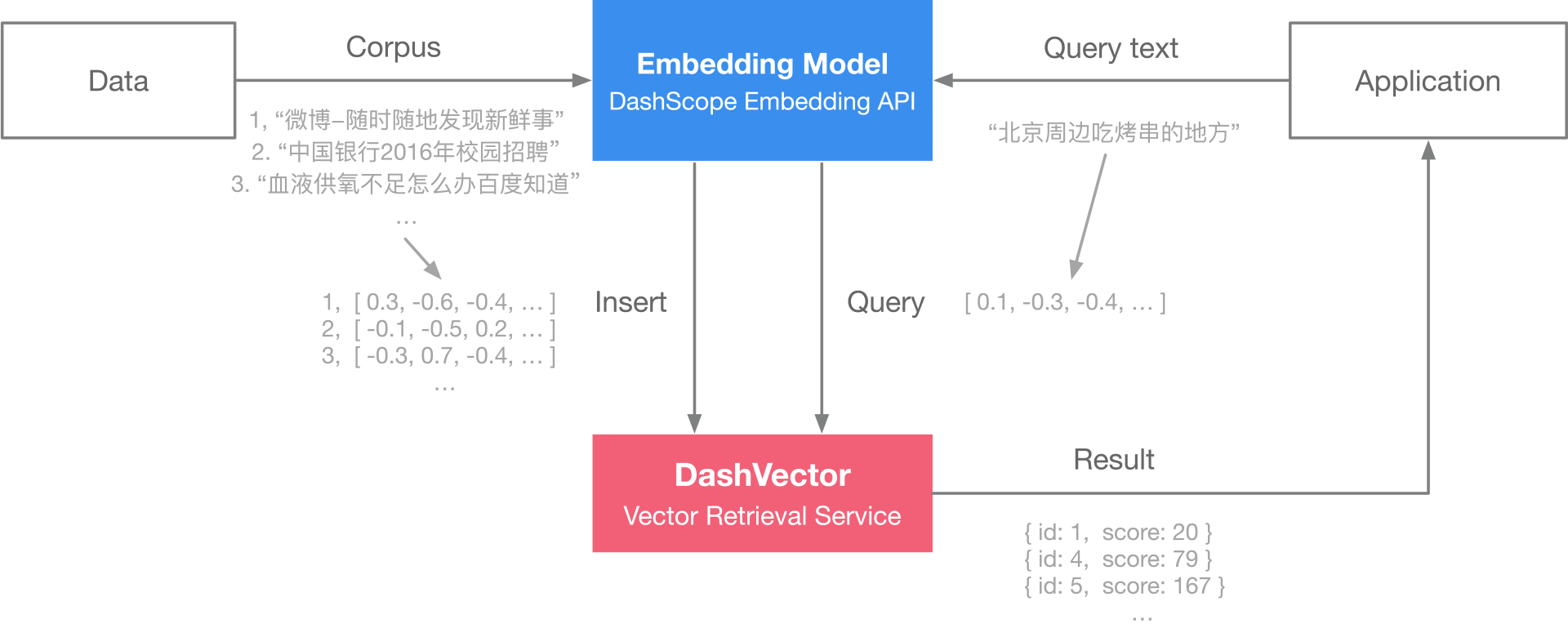
* **Embedding** :通过DashScope提供的通用文本向量模型,对语料库中所有标题生成对应的embedding向量。
* **构建索引服务和查询** :
* 通过DashVector向量检索服务对生成embedding向量构建索引。
* 将查询文本embedding向量作为输入,通过DashVector搜索相似的标题。
具体操作流程
---------------
### 前提条件
* 开通灵积模型服务,并获得 API-KEY:[开通DashScope并创建API-KEY](https://help.aliyun.com/zh/dashscope/developer-reference/activate-dashscope-and-create-an-api-key?spm=a2c4g.2510234.0.i8)。
* 开通DashVector向量检索服务,并获得 API-KEY[API-KEY管理](https://help.aliyun.com/document_detail/2510230.html?spm=a2c4g.2510234.0.i9)。
### 1、环境安装
**说明**
需要提前安装 Python3.7 及以上版本,请确保相应的 python 版本。
```
pip3 install dashvector dashscope
```
### 2、数据准备
[QQ浏览器搜索相关性数据集](https://github.com/CLUEbenchmark/QBQTC)(QBQTC, QQ Browser Query Title Corpus),是QQ浏览器搜索引擎目前针对大搜场景构建的一个融合了相关性、权威性、内容质量、 时效性等维度标注的学习排序(LTR)数据集,广泛应用在搜索引擎业务场景中。作为CLUE-beanchmark的一部分,QBQTC 数据集可以直接从github上下载(训练集路径为dataset/train.json)。
```
git clone https://github.com/CLUEbenchmark/QBQTC.git
wc -l QBQTC/dataset/train.json
```
数据集中的训练集(train.json)其格式为 json:
```
{
"id": 0,
"query": "小孩咳嗽感冒",
"title": "小孩感冒过后久咳嗽该吃什么药育儿问答宝宝树",
"label": "1"
}
```
我们将从这个数据集中提取title,方便后续进行embedding并构建检索服务。
```
import json
def prepare_data(path, size):
with open(path, 'r', encoding='utf-8') as f:
batch_docs = []
for line in f:
batch_docs.append(json.loads(line.strip()))
if len(batch_docs) == size:
yield batch_docs[:]
batch_docs.clear()
if batch_docs:
yield batch_docs
```
### 3、通过 DashScope 生成 Embedding 向量
DashScope灵积模型服务通过标准的API提供了多种模型服务。其中支持文本Embedding的模型中文名为通用文本向量,英文名为text-embedding-v1。我们可以方便的通过DashScope API调用来获得一段输入文本的embedding向量。
**说明**
需要使用您的api-key替换示例中的 *your-dashscope-api-key* ,代码才能正常运行。
```
import dashscope
from dashscope import TextEmbedding
dashscope.api_key='{your-dashscope-api-key}'
def generate_embeddings(text):
rsp = TextEmbedding.call(model=TextEmbedding.Models.text_embedding_v1,
input=text)
embeddings = [record['embedding'] for record in rsp.output['embeddings']]
return embeddings if isinstance(text, list) else embeddings[0]
# 查看下embedding向量的维数,后面使用 DashVector 检索服务时会用到,目前是1536
print(len(generate_embeddings('hello')))
```
### 4、通过 DashVector 构建检索:向量入库
DashVector 向量检索服务上的数据以集合(Collection)为单位存储,写入向量之前,我们首先需要先创建一个集合来管理数据集。创建集合的时候,需要指定向量维度,这里的每一个输入文本经过DashScope上的text_embedding_v1模型产生的向量,维度统一均为1536。
DashVector 除了提供向量检索服务外,还提供倒排过滤功能 和 scheme free 功能。所以我们为了演示方便,可以写入数据时,可以将title内容写入 DashVector 以便召回。写入数据还需要指定 id,我们可以直接使用 QBQTC 中id。
**说明**
需要使用您的api-key替换示例中的 *your-dashvector-api-key* ,以及您的Cluster Endpoint替换示例中的 *your-dashvector-cluster-endpoint* ,代码才能正常运行。
```
from dashvector import Client, Doc
# 初始化 DashVector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 指定集合名称和向量维度
rsp = client.create('sample', 1536)
assert rsp
collection = client.get('sample')
assert collection
batch_size = 10
for docs in list(prepare_data('QBQTC/dataset/train.json', batch_size)):
# 批量 embedding
embeddings = generate_embeddings([doc['title'] for doc in docs])
# 批量写入数据
rsp = collection.insert(
[
Doc(id=str(doc['id']), vector=embedding, fields={"title": doc['title']})
for doc, embedding in zip(docs, embeddings)
]
)
assert rsp
```
### 5、语义检索:向量查询
在把QBQTC训练数据集里的title内容都写到DashVector服务上的集合里后,就可以进行快速的向量检索,实现"语义搜索"的能力。继续上面代码的例子,假如我们要搜索有多少和'应届生 招聘'相关的title内容,可以通过在DashVector上去查询'应届生 招聘',即可迅速获取与该查询语义相近的内容,以及对应内容与输入之间的相似指数。
```
# 基于向量检索的语义搜索
rsp = collection.query(generate_embeddings('应届生 招聘'), output_fields=['title'])
for doc in rsp.output:
print(f"id: {doc.id}, title: {doc.fields['title']}, score: {doc.score}")
```
```
id: 0, title: 实习生招聘-应届生求职网, score: 2523.1582
id: 6848, title: 应届生求职网校园招聘yingjieshengcom中国领先的大学生求职网站, score: 3053.7095
id: 8935, title: 北京招聘求职-前程无忧, score: 5100.5684
id: 5575, title: 百度招聘实习生北京实习招聘, score: 5451.4155
id: 6500, title: 中公教育招聘信息网-招聘岗位-近期职位信息-中公教育网, score: 5656.128
id: 7491, title: 张家口招聘求职-前程无忧, score: 5834.459
id: 7520, title: 前程无忧网北京前程无忧网招聘, score: 5874.412
id: 3214, title: 乡镇卫生院招聘招聘乡镇卫生院招聘信息+-58同城, score: 6005.207
id: 6507, title: 赶集网招聘实习生北京实习招聘, score: 6424.9927
id: 5431, title: 实习内容安排百度文库, score: 6505.735
```
| dashvector | |
1,863,620 | Setting Up Docker Compose for Golang Application | This post will explain how I create Dockerfile and docker-compose.yml for golang development. The... | 0 | 2024-05-24T06:56:14 | https://dev.to/ynrfin/setting-up-docker-compose-for-golang-application-2cf2 | docker, go, webdev, tutorial | This post will explain how I create Dockerfile and docker-compose.yml for golang development. The full code can be seen [here](https://github.com/ynrfin/go-market-warehouse-api/tree/b88913f0a2f01fd1a73d43bff7ea76cb127cdaf7)
This code for Dockerfile
```Dockerfile
FROM golang:1.22
WORKDIR /app
COPY go.mod go.sum ./
RUN go mod download
COPY . ./
RUN CGO_ENABLED=0 GOOS=linux go build -o /go-market-warehouse-api ./cmd/main.go
EXPOSE 8000
CMD [ "/go-market-warehouse-api" ]
```
`FROM golang:1.22` is basing the image to current newest golang version available
`WORKDIR /app` tell docker to create and make this `/app` directory as the current directory the docker is in
`COPY go.mod go.sum ./` will copy `go.mod` and `go.sum` from project directory to `/app` directory inside docker
`RUN go mod download` will download the dependency listed in go.mod that we just copied
`COPY . ./` will copy content in current directory (the project root dir ). Basically copying the project to docker
`RUN CGO_ENABLED=0 GOOS=linux go build -o /go-market-warehouse-api ./cmd/main.go` is building go binary to from `cmd/main.go` and give output to root dir `/` and use `go-market-warehouse-api` as the binary name, same as `go-market-warehouse-api.exe` in windows
`EXPOSE 8000` tell the image it builds to open port 8000 to outside the image
`CMD [ "/go-market-warehouse-api" ]` will run the binary that we create
This setup `Dockerfile` will create an image that is around 1 Gb. Big but it contains necessary tools to build golang app. Suitable for development.
## building docker-compose.yml
### Create dedicated volume and network
The purpose for this `docker-compose.yml` is to run the golang application and a database in my application stack. My database choice is PostgreSQL.
Before we create the file, first I will create new docker `network` for the application and database to communicate. And a `volume` to persist data for the database, so when we restart the database, the data that we previously insert still exist.
Create volume:
```
docker volume create pg-16
```
This will create a volume called `pg-16`. You can check it using `docker volume list`
Create network:
```
docker network create -d bridge my-local-net
```
This will create a new bridge network called `my-local-net`. Check with `docker network list`
The `bridge` part is a network that can be accessed inside the docker
### Application Service
Create the application service `docker-compose.yml` file:
```yml
services:
go-market-warehouse-api:
# This will be uncommented when db service is introduced
# depends_on:
# local-pg-16:
# condition: service_healthy
# always restart when app crashes
restart: always
build:
context: .
image: go-market-warehouse-api:v1.0
container_name: go-market-warehouse-api
hostname: go-market-warehouse-api
networks:
- my-local-net
ports:
- 80:8080
environment:
- PGUSER=${PGUSER:-totoro}
- PGPASSWORD=${PGPASSWORD:?database password not set}
- PGHOST=${PGHOST:-db}
- PGPORT=${PGPORT:-5432}
- PGDATABASE=${PGDATABASE:-mydb}
deploy:
restart_policy:
condition: on-failure
```
`services` this mark the list of available services when we run docker compose. In this case, the services that is available only 1, called `go-market-warehouse-api`(the one under `services:`)
`build` and `context: .`: will build from current directory where docker-compose.yml is located(indicated by `.`)
`image` which image it will use to build. when not available locally, it will search from docker registry
`container_name` the name of the container to be built
`hostname` how can this service be called by other service in the network. Docker container can refer to other services location(ip) using this `hostname`
`networks`: the network this service attached to
`ports`: exposed ports by this service
`environment` : setting environment variable
`deploy` and its child specs : it will deploy the service and restart it when failure happens
### Database Service
This is the description of the database service:
```yml
local-pg-16:
image: postgres:16.2
container_name: local-pg-16
hostname: local-pg-16
networks:
- my-local-net
ports:
- 5432:5432
- 8080:8080
volumes:
- tes-pg:/var/lib/postgresql/data
environment:
- POSTGRES_PASSWORD=${PGPASSWORD}
# Make sure postgres is ready to accept connection as the indicator that
# Postgres is ready
# ref https://www.postgresql.org/docs/current/app-pg-isready.html
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${PGUSER}"]
# a more complete command
# test: ["CMD-SHELL", "pg_isready -U ${PGUSER} -d ${PGDATABASE} -h 127.0.0.1"]
interval: 2s
timeout: 10s
retries: 5
volumes:
tes-pg:
external: true
networks:
# this will always create new network
# my-local-net:
# driver: bridge
my-local-net:
name: mynet
external: true
```
`image: postgres:16.2` : I want to use the current latest postgres, which is 16.2. Make sure you specify the major version(16 in this case), as the default is the latest, and when the version change, it almost always has incompatibility
`container_name`: the name of the container to be built
`hostname`: address for this service in the docker network
`networks`: specify which network this service attached to, so when you want to access this service, you need to attach to this network and use `hostname` to connect to the database. If the network is not specified, docker compose will create new network and attach all services described in the yml file to it, so all services can communicate with each other. I use predefined network because it will be easier when other container outside the one described in this `docker-compose.yml` to connect to the services here
`ports` : mapping exposed port from container to host(the computer)
`volume`: persist the data created by postgre to disk. So when we restart the container, it can resume using data from volume instead of creating data. Other container can use this data too. Beware though when you use different version of postgres, it could result in corrupt data(I did it with different mysql version before lol)
`environment`: this will setup the postgres password when we want to enter the postgres. You could setup username ,password, and database name, the default is `postgres` or if the username is specified and database name is not, it would default to username. I read the documentation [here on POSTGRES_DB section](https://hub.docker.com/_/postgres)
`healthcheck` : is how I defined healthcheck that I will use in the application service(the `condition` on `depends_on` key in `go-market-warehouse-api` service). The `depends_on` is to tell the `go-market-warehouse-api` that it should start when the the database service is deemed to be healthy, which I define as the database ready to accept TCP connection. Why it is necessary? if I don't specify the `depends_on` the application will try to connect to db when db is not fully instantiated or ready or both, so the application would throw error. If I only specify `depends_on: local-pg-16`, docker would start creating the application service after the database service is not yet ready to accept TCP connection. The are use cases when you need to seed data to db before the db is ready to accept connection too. Hence I use the healthcheck function
`volumes:` I specify `volume` here to point it at the predefined volume that I execute before I create the `docker-compose.yml`. If `external: true` is not specified, docker-compose will create new volume that has the name of `<project-name>_tes-pg`, same as network
`network`: specify which network to be used. `my-local-net` here is the name, `name: mynet` is the network name on the docker, and `external: true` is same as the volume, it tells docker to use predefined network that exists on the docker(external of this `docker-compose.yml`)
Here's the full `docker-compose.yml`:
```yml
services:
go-market-warehouse-api:
depends_on:
local-pg-16:
condition: service_healthy
# always restart when app crashes
restart: always
build:
context: .
image: go-market-warehouse-api:v1.0
container_name: go-market-warehouse-api
hostname: go-market-warehouse-api
networks:
- my-local-net
ports:
- 80:8080
environment:
- PGUSER=${PGUSER:-totoro}
- PGPASSWORD=${PGPASSWORD:?database password not set}
- PGHOST=${PGHOST:-db}
- PGPORT=${PGPORT:-5432}
- PGDATABASE=${PGDATABASE:-mydb}
deploy:
restart_policy:
condition: on-failure
local-pg-16:
image: postgres:16.2
container_name: local-pg-16
hostname: local-pg-16
networks:
- my-local-net
ports:
- 5432:5432
- 8080:8080
volumes:
- tes-pg:/var/lib/postgresql/data
environment:
- POSTGRES_PASSWORD=${PGPASSWORD}
# Make sure postgres is ready to accept connection as the indicator that
# Postgres is ready
# ref https://www.postgresql.org/docs/current/app-pg-isready.html
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${PGUSER}"]
# a more complete command
# test: ["CMD-SHELL", "pg_isready -U ${PGUSER} -d ${PGDATABASE} -h 127.0.0.1"]
interval: 2s
timeout: 10s
retries: 5
volumes:
tes-pg:
external: true
networks:
# this will always create new network
# my-local-net:
# driver: bridge
my-local-net:
name: mynet
external: true
```
## On `healthcheck` and `depends_on`
The `depends_on` is to tell the `go-market-warehouse-api` that it should start when the the database service is deemed to be healthy, which I define as the database ready to accept TCP connection. Why it is necessary? If I only specify `depends_on: local-pg-16`, docker would start creating the application service after the database service is not yet ready to accept TCP connection. Try by modify `depends_on: local-pg-16` then run the docker compose, if you see the log, sometimes the app throws error could not connect to database and database still printing out logs when application log started even though you have specify `depends_on`. Hence I use `depends_on: condition: service_healthy` to specify when the database is deemed to be ready is when the `condition: service_healthy` is fulfilled.
what is the criteria for `service_healthy`? it use the definition of `healthcheck` in `local-pg-16`.
## Full `docker-compose.yml`
Here it is
```yml
services:
go-market-warehouse-api:
depends_on:
local-pg-16:
condition: service_healthy
# always restart when app crashes
restart: always
build:
context: .
image: go-market-warehouse-api:v1.0
container_name: go-market-warehouse-api
hostname: go-market-warehouse-api
networks:
- my-local-net
ports:
- 80:8080
environment:
- PGUSER=${PGUSER:-totoro}
- PGPASSWORD=${PGPASSWORD:?database password not set}
- PGHOST=${PGHOST:-db}
- PGPORT=${PGPORT:-5432}
- PGDATABASE=${PGDATABASE:-mydb}
deploy:
restart_policy:
condition: on-failure
local-pg-16:
image: postgres:16.2
container_name: local-pg-16
hostname: local-pg-16
networks:
- my-local-net
ports:
- 5432:5432
- 8080:8080
volumes:
- tes-pg:/var/lib/postgresql/data
environment:
- POSTGRES_PASSWORD=${PGPASSWORD}
# Make sure postgres is ready to accept connection as the indicator that
# Postgres is ready
# ref https://www.postgresql.org/docs/current/app-pg-isready.html
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${PGUSER}"]
# a more complete command
# test: ["CMD-SHELL", "pg_isready -U ${PGUSER} -d ${PGDATABASE} -h 127.0.0.1"]
interval: 2s
timeout: 10s
retries: 5
volumes:
tes-pg:
external: true
networks:
# this will create new network based on project directory name
# my-local-net:
# driver: bridge
my-local-net: # kind of alias for this docker-compose.yml
name: mynet # mynet is the name when you run `docker network ls`
external: true
```
You can try the project by clone this [repo’s commit](https://github.com/ynrfin/go-market-warehouse-api/tree/b88913f0a2f01fd1a73d43bff7ea76cb127cdaf7). Read the description on how to run the project.
## Note on network and volume
In many tutorial, network and volume is declared WITHOUT `external` like this:
```yml
volumes:
tes-pg:
networks:
my-local-net:
```
This will create a new network with default name `<project-name>_tes-pg` and `<project-name>_my-local-net`
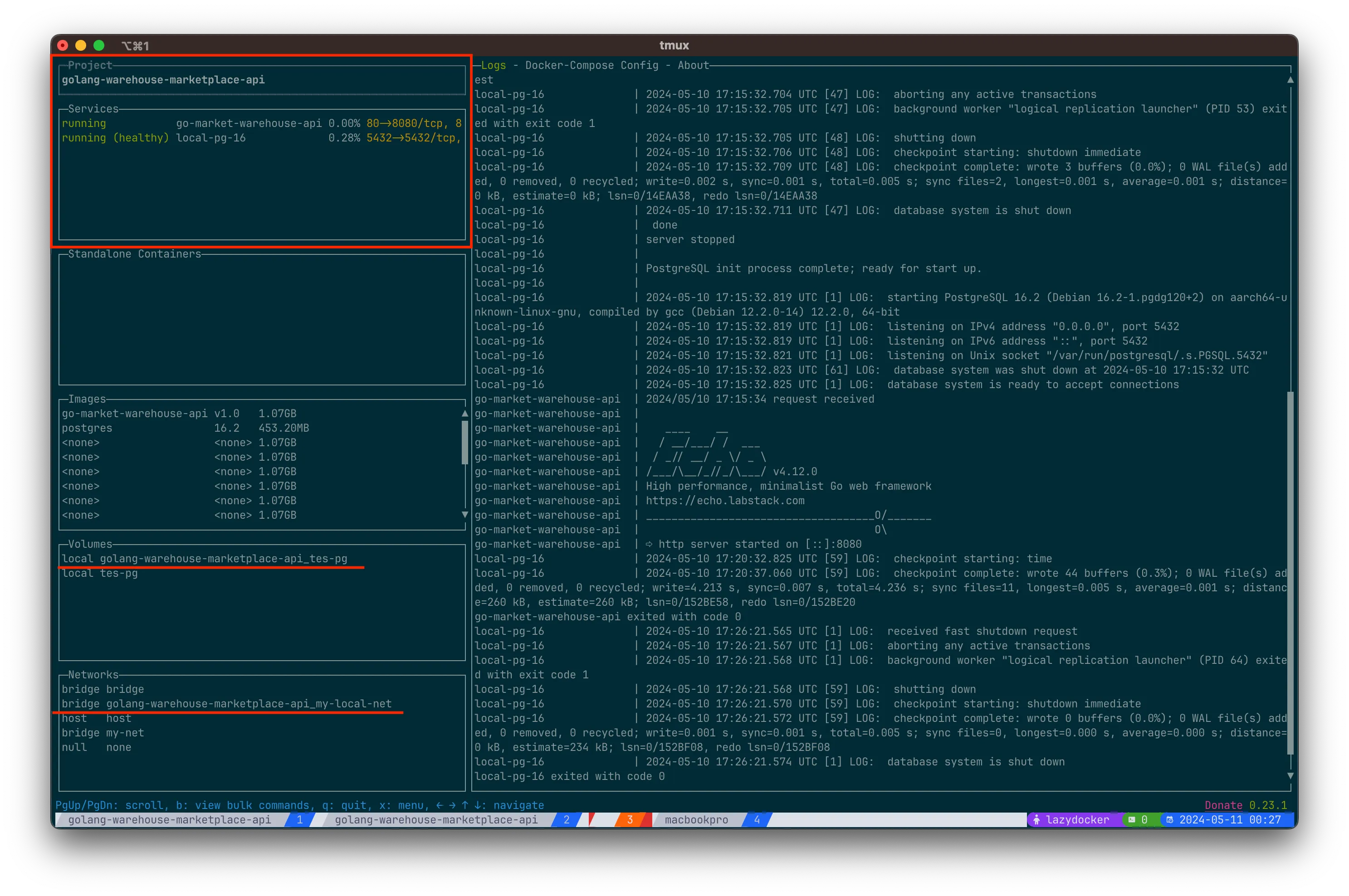
When `external: true`, no additional network and volume like the one above:
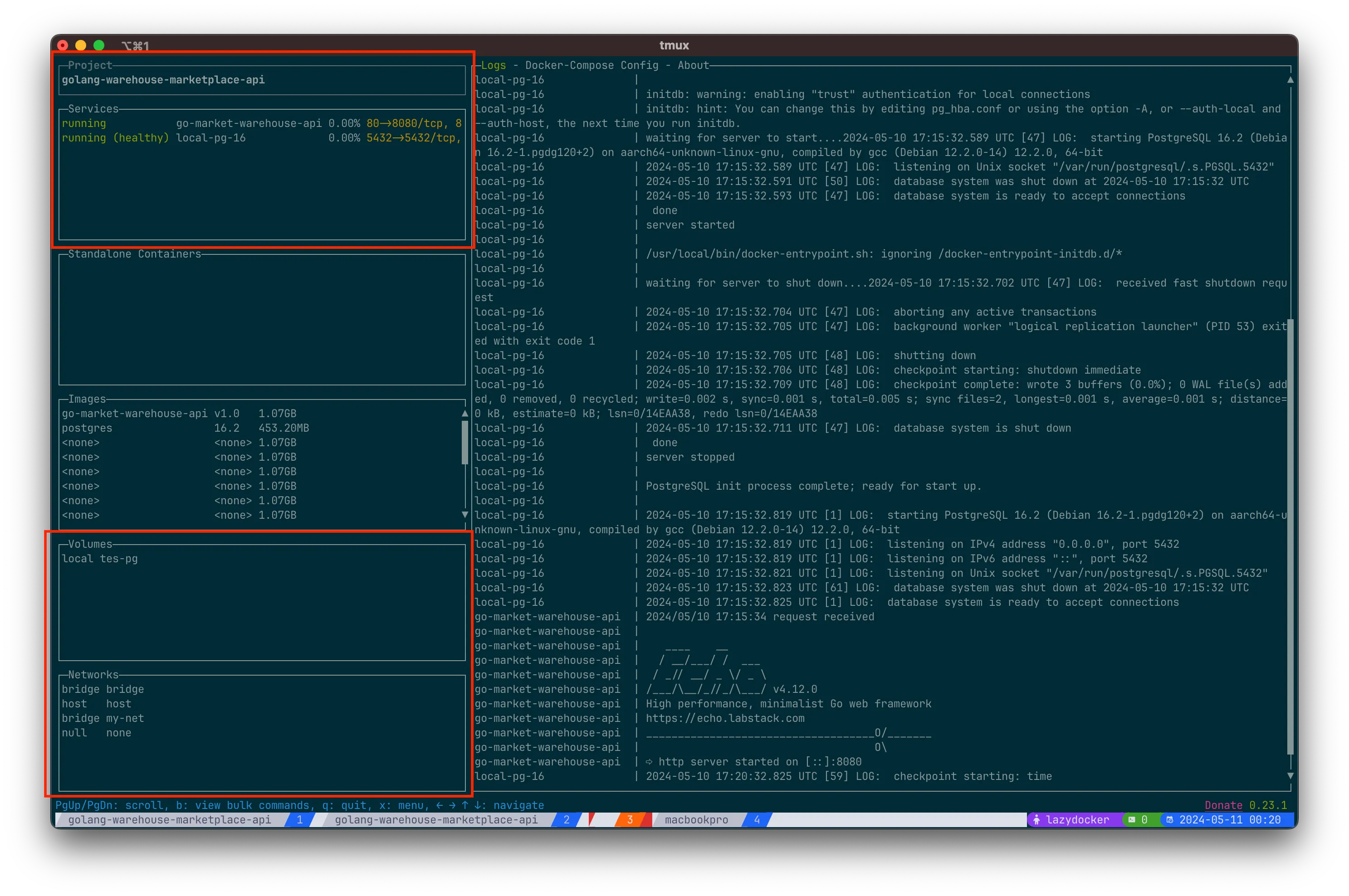
These screenshots use [lazygit](https://github.com/jesseduffield/lazygit) btw.
That’s all for this article, hope you learn something new.
| ynrfin |
1,863,603 | Getting Creative with CSS Grid | Grids don't have to be boring! You can easily spice up a classic 12x12 grid with very few lines of... | 0 | 2024-05-24T06:54:41 | https://dev.to/madsstoumann/getting-creative-with-css-grid-mco | css, webdev, tutorial, showdev |
Grids don't have to be boring! You can easily spice up a classic 12x12 grid with **very** few lines of CSS — it's time to master `grid-area`!
First, let's create a `<figure>`-tag with a class:
```html
<figure class="ui-bubble-grid">
<!--IMAGES-->
</figure>
```
Within that tag, add images — I'm using:
```html
<img src="https://source.unsplash.com/random/300x300?sig=1"
alt="TEXT" width="300" height="300">
```
Replace the `sig=1` with `sig=2` etc. for more random images.
Next, let's add a simple 12x12 grid in CSS:
```css
:where(.ui-bubble-grid) {
all: unset;
display: grid;
grid-template-columns: repeat(12, 1fr);
grid-template-rows: repeat(12, 1fr);
}
```
Let's also add some nested default styles for images:
```css
img {
background: #CCC;
height: auto;
object-fit: cover;
width: 100%;
}
```
This will ensure the images take up all of the assigned "grid-space".
Let's see what we have:

> **Note:** For the grid-view, select the `<figure>`-tag in Dev Tools, and click on the "grid"-button:

---
OK, so not much going on yet. Each image automatically fills up one grid-cell.
Let's change that with `grid-area`:
```css
&:nth-child(1) { grid-area: 1 / 1 / 7 / 7; }
&:nth-child(2) { grid-area: 5 / 5 / 11 / 11; }
&:nth-child(3) { grid-area: 9 / 3 / 13 / 7; }
&:nth-child(4) { grid-area: 3 / 9 / 7 / 13; }
&:nth-child(5) { grid-area: 8 / 1 / 11 / 4; }
&:nth-child(6) { grid-area: 2 / 8 / 4 / 10; }
&:nth-child(7) { grid-area: 10 / 10 / 13 / 13; }
&:nth-child(8) { grid-area: 1 / 11 / 3 / 13; }
```
… and we get:

**Wait! What?** Let's dive into that! `grid-area` is short for:
- grid-row-start
- grid-column-start
- grid-row-end
- grid-column-end
> **Note:** If you find `grid-area` hard to read, you can use `grid-column` and `grid-row` instead.
Now, if we look at the first image, it has this code:
```
{ grid-area: 1 / 1 / 7 / 7; }
```
We start at the **first row** (1) and the **first column** (1).
We want the image to take up 6x6 cells, so the **end row** and **end column** are 7, as `7 - 1 = 6`.
For the next image, we want to layer it on top of the first image (bottom right) with a slight offset. Looking at the grid, that'll be **column 5** and **row 5**. As we also want the next image to be 6x6, the CSS is:
```
{ grid-area: 5 / 5 / 11 / 11; }
```
Now, I encourage you to study the other `grid-area`-parts I made. Play around with them, move stuff around: make your own grid!
When you're ready, let's add a `border-radius: 50%` to the `img` in CSS, and we get:

Nice! Now, let's de-select the grid-preview in Dev Tools and see what we've created:

I like it! But what happens if you add **more** images than you created `grid-area`-parts for?
CSS grid will just find the first empty grid-cell, then the next etc.:

---
What about responsiveness? The grid is resizable, but some of the images might get **too** small on phones. If you want — add a `@media` or `@container`-query, and then simply change the `grid-area`-parts for that breakpoint.
## Demo
Here's a CodePen you can fork and play with:
{% codepen https://codepen.io/stoumann/pen/vYwKqbp %}
---
## Other Ideas
By removing the `border-radius` from `img`, adjusting the `grid-area`-parts and adding a `clip-path`:
```
clip-path: polygon(-50% 50%, 50% 100%, 150% 50%, 50% 0);
```
— you can create a hexagonal grid, with adjustable `gap`:

Please share your crazy grid-ideas in the comments below!
| madsstoumann |
1,863,629 | Day 1 of my progress as a vue dev | Hey reader, my name is zain and I am about to start my journey as a vue js developer. Well, not... | 0 | 2024-05-24T06:51:00 | https://dev.to/zain725342/day-1-of-my-progress-as-a-vue-dev-1hn3 | webdev, vue, typescript, tailwindcss | Hey reader, my name is zain and I am about to start my journey as a vue js developer.
Well, not quite starting from scratch. I have been working for a company for past two years as a frontend developer, and during this period I've had the experience to work with vue, but if I'm being honest I was just doing a job. A really average one. Means I was not learning anything new, was doing very average work by using the old written code, and in reality I was just doing it for the sake of getting the paycheck.
But something changed recently...
I started to gain interest in my work, and started to realize that I want to be more than average and at least put out some quality work. So did I just woke up one day and was filled with all this motivation? Well, not exactly. The motivation came through many factors, one of which was amount of great and innovative work being done out there and on the other hand here I am just stuck with the same work for past two years. I don't hate the work I do, but now have developed the hunger for more.
So now what? Well, to be able to do some innovative work I have to upgrade my skills, and to do that I have to learn and practice with a plan and consistency.
So, now let's come to the purpose of this post. I am starting my journey from today by coding daily, I will be building many projects in the days to come and will push them on my github, and I will be writing all about them on such (not lengthy as this) posts to keep track of my progress, and to see how longer I can maintain the streak.
Today I started building a dynamic quiz app that will use vue3, typescript and tailwind css. I will be using local storage for now to store and retrieve data, but will soon start to develop php laravel knowledge and move the data handling to that.
Wish me luck!
| zain725342 |
1,863,627 | 5 Software Development Tips to Improve Your Product Growth | 1. Embrace Agile Methodologies Adopting Agile methodologies like Scrum or Kanban can... | 0 | 2024-05-24T06:44:06 | https://dev.to/mlpds011/5-software-development-tips-to-improve-your-product-growth-2jk6 | software, development, softwaredevelopment, custom | ##1. Embrace Agile Methodologies
Adopting Agile methodologies like Scrum or Kanban can significantly enhance your development process. Agile promotes flexibility, collaboration, and continuous feedback, allowing your team to quickly adapt to changes and deliver high-quality products. Regular sprints and iterative development cycles help ensure that your product evolves based on user feedback and market demands, leading to a product that better meets customer needs and fosters growth.
##2. Prioritize User Experience (UX)
A great user experience is essential for product growth. Invest time and resources in UX research and design to understand your users' needs and pain points. Create user personas, conduct usability tests, and gather feedback to refine your product's interface and interactions. A product that is intuitive and enjoyable to use can drive higher user engagement and retention, positively impacting your growth metrics.
##3. Implement Continuous Integration and Continuous Deployment (CI/CD)
CI/CD practices streamline the process of integrating and deploying code changes, ensuring that your product remains in a deployable state at all times. This approach enables faster and more reliable releases, reducing the time it takes to bring new features and bug fixes to your users. By automating these processes, you can maintain high code quality and accelerate your development cycle, keeping your product competitive and responsive to user needs.
##4. Leverage Data Analytics
Utilize **[data analytics](https://www.techmango.net/data-analytics-services)** to gain insights into user behavior, product performance, and market trends. Track key performance indicators (KPIs) such as user engagement, retention rates, and conversion metrics. Analyzing this data allows you to make informed decisions about feature prioritization, product improvements, and marketing strategies. Data-driven decisions help you optimize your product to better serve your users and drive growth.
##5. Focus on Scalability and Performance
Design your product with scalability and performance in mind from the outset. Use cloud services, micro-services architecture, and load balancing to ensure your product can handle increasing user demand without compromising performance. Regularly monitor and optimize your application's performance to prevent bottlenecks and ensure a smooth user experience. A product that performs well under load is more likely to retain users and attract new ones, supporting sustained growth.
Implementing these tips can enhance your [**software development process**](https://www.techmango.net/how-to-make-your-software-development-process-more-efficient), leading to a product that is robust, user-friendly, and scalable. By focusing on these key areas, you can drive product growth and ensure long-term success in the market.
> Reconstruct workflow and upscale your business growth with world-class Enterprise software development services
| mlpds011 |
1,863,626 | Steven Gerrard: A Legacy of Passion and Leadership in Football | Steven Gerrard, renowned for his dynamic play and exemplary leadership, carved out an iconic status... | 0 | 2024-05-24T06:42:49 | https://dev.to/jon_larson_/steven-gerrard-a-legacy-of-passion-and-leadership-in-football-4cll | Steven Gerrard, renowned for his dynamic play and exemplary leadership, carved out an iconic status not only at Liverpool FC but also in the annals of football globally. His career, spanning over 17 years at Liverpool, is a testament to his loyalty, skill, and indomitable spirit. This comprehensive look at Gerrard's career highlights his contributions to the club, his national team exploits, and his transition into management. To make your own highlights in the betting world don’t forget to use the [BetWinner welcome bonus](https://betguide.ng/how-to-use-betwinner-bonus/).
**Early Days and Rise at Liverpool**
Steven Gerrard, born on May 30, 1980, in Whiston, England, joined the Liverpool Academy at nine. He made his first-team debut in 1998 against [Blackburn Rovers](https://en.wikipedia.org/wiki/Blackburn_Rovers_F.C.). By the 2000-2001 season, Gerrard had secured a regular spot in the team, showcasing a remarkable range of passing, ferocious tackling, and the ability to score crucial goals.
**Captain Fantastic**
Gerrard was named Liverpool captain in 2003, a role he embraced enthusiastically and enthusiastically. Under his leadership, Liverpool enjoyed some of their most memorable moments. His influence was pivotal in the dramatic 2005 Champions League final in Istanbul, where Liverpool staged a remarkable comeback from 3-0 down at halftime to win on penalties against AC Milan. Gerrard's inspiring performance during this match, where he scored a crucial header to start the comeback, cemented his legacy as one of the greatest midfielders of his generation.
**Domestic and European Success**
While Liverpool struggled at times in the Premier League during Gerrard's tenure, failing to secure the title, they found considerable success in cup competitions. Gerrard's tenure saw Liverpool lifting two FA Cups, three League Cups, one UEFA Champions League, one UEFA Cup, and two UEFA Super Cups. His ability to perform in crucial games earned him the nickname "Captain Fantastic," highlighted by his scoring in multiple cup finals, including the 2006 FA Cup final against West Ham United, a match often called "The Gerrard Final."
**International Career**
Gerrard represented England from 2000 to 2014 on the international stage, earning 114 caps and participating in several major tournaments, including the UEFA European Championship and the FIFA World Cup. He was named the England captain in 2012 and led the national team until he retired from international football following the 2014 World Cup.
**Style of Play**
Gerrard was celebrated for his comprehensive skill set, which allowed him to influence games defensively and offensively. He was the quintessential box-to-box midfielder, renowned for his powerful long-range strikes, decisive passes, and robust defensive interventions. Gerrard's leadership on the field was characterized by a relentless work ethic and the ability to motivate his team to rise to any occasion.
**Moving into Management**
After a brief post-Liverpool playing stint at LA Galaxy in the MLS, where he continued to showcase his skill and passion for the game, Gerrard retired from playing in 2016. He quickly transitioned into coaching, becoming an academy coach at Liverpool in early 2017. Recognizing his potential as a manager, Rangers FC appointed him as their head coach in 2018.
During his time at Rangers, Gerrard revitalized the club, leading them to their first Scottish Premiership title in ten years in the 2020-2021 season, completing the league season undefeated. His success in Scotland earned him a move to Aston Villa in the Premier League in November 2021, marking the next chapter in his managerial career.
**Legacy and Influence**
Steven Gerrard's impact on football extends beyond his playing days. As a player, he was the heart and soul of Liverpool FC, embodying the spirit and passion of the club. As a manager, he continues to instill his high standards and winning mentality into his teams. His commitment to developing young talent and his tactical acumen as a coach suggest that his influence on football will endure for many years.
**Conclusion**
Steven Gerrard's football journey is a compelling saga of dedication, resilience, and triumph. From his heroic plays in Liverpool red to his promising start in management, Gerrard continues to inspire and shape the future of football. His legacy as a player and coach remains a beacon for those aspiring to lead both on and off the pitch, embodying the true spirit of the beautiful game.
| jon_larson_ | |
1,863,625 | Breaking Down Major Migrations: Vuex to Pinia Before Moving to Nuxt 3 | In our ongoing journey of migrating Torah Live to Nuxt 3, one critical step was transitioning from... | 0 | 2024-05-24T06:42:38 | https://dev.to/yoshrubin/breaking-down-major-migrations-vuex-to-pinia-before-moving-to-nuxt-3-2bmd | webdev, javascript, pinia, vue | In our ongoing journey of migrating Torah Live to Nuxt 3, one critical step was transitioning from Vuex to Pinia while still on Nuxt 2. Here’s how we approached it:
#### Why Move from Vuex to Pinia? 🍍
While Nuxt 3 is compatible with Vuex, Pinia is considered the future of state management in Vue.js. According to the Vuex documentation:
> "Pinia is now the new default. The official state management library for Vue has changed to Pinia. Pinia has almost the exact same or enhanced API as Vuex 5, described in Vuex 5 RFC. You could simply consider Pinia as Vuex 5 with a different name. Pinia also works with Vue 2.x as well. Vuex 3 and 4 will still be maintained. However, it's unlikely to add new functionalities to it. Vuex and Pinia can be installed in the same project. If you're migrating an existing Vuex app to Pinia, it might be a suitable option. However, if you're planning to start a new project, we highly recommend using Pinia instead."
Given that we were making a large migration to Nuxt 3, we saw this as an essential part of the move to keep our code maintainable and future-proof.
#### The Plan: Breaking Down the Migration
**1. Preliminary Research and Preparation**
- **Research**: I read through numerous blog posts and watched videos to understand best practices for migrating from Vuex to Pinia. Some resources that were particularly helpful include:
- [Pinia Migration from Vuex Guide](https://pinia.vuejs.org/cookbook/migration-vuex.html)
- [Vue School's Guide on Migrating from Vuex to Pinia](https://vueschool.io/articles/vuejs-tutorials/how-to-migrate-from-vuex-to-pinia/)
- [Informative Reddit Thread on Moving to Pinia](https://www.reddit.com/r/vuejs/comments/17gqv7u/is_vuex_dead_now_why_did_everyone_move_to_pinia/)
**2. Incremental Migration Process**
- **Simultaneous Stores**: One of the nice things about migrating to Pinia is that I was able to run both Pinia and Vuex simultaneously. This allowed us to migrate one store at a time and fully test all functionality before moving to the next store.
**3. Deployment Strategy**
- **Staging Deployments**: We regularly deployed to our staging environment to ensure everything functioned as expected. This allowed us to catch issues early and ensure that the migration was proceeding smoothly.
- **Production Deployment**: Once the migration was fully complete and thoroughly tested, we deployed the changes to production. This approach ensured that we did not run both Vuex and Pinia simultaneously in production, minimizing potential conflicts and issues.
#### Overcoming Challenges
**1. Adapting to Pinia's Patterns**
- **Mutation Handling**: One challenge was getting used to Pinia's pattern of assigning values directly to the state without using mutations, a shift from the traditional flux pattern. This required a mental shift and adjustment in our coding practices.
**2. Minimizing Codebase Disruption**
- **Incremental Changes**: We aimed to avoid making too many changes to the codebase at once, ensuring it was clear what changes were made and why. This approach helped maintain code clarity and ease the transition.
**3. Avoiding Conflicts with Ongoing Work**
- **Concurrent Development**: Another factor we considered was avoiding conflicts with ongoing work by the team on the project. Copying to a new codebase could have introduced many regressions. By migrating within the existing codebase, we were able to maintain continuity and minimize disruption.
#### Looking Forward
With the migration from Vuex to Pinia complete, we laid a solid foundation for the transition to Nuxt 3. This methodical approach allowed us to manage the complexity of the migration and mitigate risks associated with big changes. I’m very pleased with how the migration went, and now we're on the cutting edge.
Stay tuned for our next post where we dive into the actual migration to Nuxt 3, including some unexpected errors and how to avoid them!
#### Takeaways
- **Plan and Research**: Thorough research and planning are crucial for successful migrations.
- **Incremental Changes**: Breaking down large migrations into smaller, manageable projects can lead to smoother transitions.
- **Community Resources**: Leverage community resources and documentation to guide your migration process.
Feel free to reach out if you have any questions or need advice on similar migrations! 🚀
[Check out the previous post in this series!](https://dev.to/yoshrubin/navigating-the-upgrade-plan-steps-before-vue-3-migration-5a23)
| yoshrubin |
1,863,623 | MySQL Full-Text Search | MySQL full-text search is a powerful tool for effectively seeking data in databases. It allows... | 0 | 2024-05-24T06:41:56 | https://dev.to/dbajamey/mysql-full-text-search-2hef | mysql, mariadb, database | MySQL full-text search is a powerful tool for effectively seeking data in databases. It allows creating complete text indexes that simplify search query performance. It's relevant while working with textual content, especially when you need to quickly find corresponding information using various search modes such as Natural Language, Query Expansion, and Boolean.
With dbForge Studio for MySQL, users can execute complex search queries efficiently. The tool seamlessly integrates with existing MySQL databases and eliminates the need for complicated setup procedures or data migration processes. Users can leverage its full-text search capabilities within their existing database infrastructure without significant disruptions to their workflows.
Read in full: https://www.devart.com/dbforge/mysql/studio/mysql-fulltext-search.html | dbajamey |
1,862,779 | Building a Simple Chatbot using GPT model - part 1 | I have been wanting to understand the vulnerabilities related to Large Language Model (LLM)... | 0 | 2024-05-24T06:40:16 | https://dev.to/whatminjacodes/building-a-simple-chatbot-using-gpt-model-part-1-3oeo | ai, python, llm | I have been wanting to understand the vulnerabilities related to Large Language Model (LLM) applications and generative AI, so I thought a good way to understand these in practice would be by first developing my own chatbot.
So here's a two-part series where I go through what LLMs are, how to set up a development environment, and how to actually develop a chatbot.
This first post helps you set up the environment, as well as explains what LLMs are. In a [post next week](https://dev.to/whatminjacodes/building-a-simple-chatbot-using-gpt-model-part-2-45cn), I will go through the development of the chatbot.
### What are LLMs?
LLM stands for Large Language Model. It is a system designed to understand and generate human-like text. LLMs are trained with vast amounts of data from various sources, such as books, articles, and websites. This allows the algorithm to predict what sequences of words are probable responses to a user-provided input.
One example of a system using an LLM, which probably everyone has heard about by now, is [ChatGPT](https://openai.com/chatgpt/). It is an AI system that uses natural language processing to create a conversation with the user and utilizes OpenAI's Generative Pre-trained Transformer (GPT), a neural network machine learning model.
### Setup the Environment
Now that you have the background info for this series, let's set up our environment.
I'm using WSL 2 with Ubuntu 20.04 LTS, so if you are not using the same setup, the commands I use might be a little different on your distribution.
#### 1. Update and Upgrade Ubuntu
Open your Ubuntu terminal and run the following commands to update and upgrade your package lists:
```
sudo apt update
sudo apt upgrade
```
This will ensure you have the latest software updates.
#### 2. Install Python
This guide will use Python and pip to run the required Python scripts and manage packages. Most Ubuntu installations come with Python pre-installed. Verify the installation by running the following commands:
```
python3 --version
pip3 --version
```
If Python or pip is not installed, install them using this command:
```
sudo apt install python3 python3-pip
```
#### 3. Install Virtual Environment Tools
Creating a [virtual environment](https://docs.python.org/3/library/venv.html) is a best practice to manage dependencies for your projects. This will create an isolated environment that prevents conflicts between different projects that may require different versions of the same package.
Install venv by running:
```
sudo apt install python3-venv
```
#### 4. Create a Virtual Environment
Navigate to the directory where you want to create your project and set up a virtual environment:
```
mkdir name-of-directory
cd name-of-directory
python3 -m venv venv-name
```
- mkdir name-of-directory: Creates a new directory called _name-of-directory_ for your project. Change the name to what you want it to be.
- cd name-of-directory: Changes the current directory to the directory you just created.
- python3 -m venv venv-name: Creates a virtual environment named _venv-name_ in the directory. Change the name to what you want it to be.
#### 5. Activate the Virtual Environment
Activate the virtual environment with the following command, changing _venv-name_ to the one you chose when creating the virtual environment in the step above:
```
source venv-name/bin/activate
```
You should see the virtual environment name (e.g., _venv-name_) in your terminal prompt, indicating that it's activated.
```
(venv-name) example@ubuntu:/name-of-directory$
```
#### 6. Upgrade pip
Ensure that pip is up to date:
```
pip3 install --upgrade pip
```
### That's it!
In this blog post, we set up the environment so it is ready when we start building the chatbot on the [next post](https://dev.to/whatminjacodes/building-a-simple-chatbot-using-gpt-model-part-2-45cn) that I'm publishing next week!
You can also follow my Instagram [@whatminjahacks](https://www.instagram.com/whatminjahacks/) if you are interested to see more about my days as a Cyber Security consultant and learn more about cyber security with me! | whatminjacodes |
1,863,621 | Exploring React Router 6 | Introduction Single-page applications (SPAs) with multiple pages need to have a... | 0 | 2024-05-24T06:38:55 | https://dev.to/vikram-boominathan/exploring-react-router-6-5bee | react, javascript, beginners, learning |

## Introduction
Single-page applications (SPAs) with multiple pages need to have a mechanism of routing to navigate between those different views without refreshing the whole webpage. We can dynamically change application views by switching the app state with conditional rendering, but in most scenarios, we need to sync the application URL with views.
### What is React Router?
React Router is a complete solution that can help in routing activities within React applications. This feature comes with pre-built components, hooks, and helper functions which are essential when coming up with up-to-date formation strategies. React Router project has come up with two different packages that will help you integrate routing either in your web app or any other app that uses React.
React Router v6 includes modern features such as relative nested routes, optimistic UI, and developer-friendly hooks.
#### Why do we use React Router for routing?
Traditional web applications with multiple pages commonly have several separate files that display different views, but modern single page applications (SPAs) use video-like scenes. This makes it necessary to use routing in order to switch between different URLs. For any React application requirement, you don’t always need an external library but with regards to routing, this may not be true, routing needs are complex and you must use a router library to meet them.
React Router is the most popular and feature-rich routing library for React-based SPAs. It has a small footprint, a simple API, and well-written documentation, allowing any React developer to implement routing productively in any React app.
##### BrowserRouter
The BrowserRouter serves as a container which envelops the entire application and manages the routing within. In this case, you can define routes, switch between them, and interact with different URL paths in single-page application (SPA) mode but with no need for excessive page reloading.
##### Routes
Routes is an element container that displays the first child route that matches the current location. This has replaced the previous Switch component and provides a way to group all route definitions together.
##### Route
Used to define individual route. Each individual Route component specifies a path and the component to render when the URL corresponds to that path. The path prop defines the URL path, and the element prop specifies the component to render.
```react
export default function App() {
return (
<BrowserRouter>
<Routes>
<Route path="/" element={<Home />} />
<Route path="/about" element={<About />} />
<Route path="/user/:username" element={<User />} />
<Route path="*" element={<NotFound />} />
</Routes>
</BrowserRouter>
);
}
```
Let's work on the application.
### First, let's set up a new React application. If you haven't already, install Node.js and npm. Then, create a new React app using Create React App:
```bash
npx create-react-app react-router-example
cd react-router-example
```
Next, install React Router:
```bash
npm install react-router-dom
```
#### Creating Components
We'll create four components for our example: Home, About, User, and NotFound.
- Home will serve as the landing page and provide navigation links.
- About will display some information about the application.
- User will display user-specific information based on the URL parameter.
- NotFound will be a fallback component for any unmatched routes.
Let's start by creating these components.
##### Home Component
Create a file named **_`Home.js`_** inside the src/components directory and add the following code:
```react
import React from 'react';
import { Link } from 'react-router-dom';
import './Home.css';
const Home = () => {
return (
<div className="home">
<h2>Home Page</h2>
<nav>
<ul>
<li><Link to="/" end>Home</Link></li>
<li><Link to="/about">About</Link></li>
<li><Link to="/user/john">User John</Link></li>
<li><Link to="/user/jane">User Jane</Link></li>
</ul>
</nav>
</div>
);
};
export default Home;
```
######Link
The Link component helps build interactive links in React applications for navigating to other routes without refreshing the page so that your app can function like a single page application (SPA).
- “to” Prop should be set as the route to follow when navigating. It can either be a single path in a string form or an object for advanced navigation that includes state or search params.
- When a hyperlink is clicked, it renders the new component without reloading the entire page
#####About Component
Create a file named **_`About.js`_** inside the src/components directory and add the following code:
```react
import React from 'react';
const About = () => {
return (
<div>
<h2>About Page</h2>
<p>This is the About page of our React Router example.</p>
</div>
);
};
export default About;
```
User Component
Create a file named **_`User.js`_** inside the src/components directory and add the following code:
```react
import React from 'react';
import { useParams } from 'react-router-dom';
const User = () => {
const { username } = useParams();
return (
<div>
<h2>User Page</h2>
<p>Username: {username}</p>
</div>
);
};
export default User;
```
######useParams
**useParams** is a hook that enables you to get the dynamic parameters of the current route, which are usually defined in the route paths and later used to capture URL values.
- The part of the route defined with : (e.g., :id in /user/:id) acts as a placeholder for the dynamic value.
- Inside the component rendered by the route, use **useParams** to access these dynamic values.
#####NotFound Component
Create a file named **_`NotFound.js`_** inside the src/components directory and add the following code:
```react
import React from 'react';
import { Link } from 'react-router-dom';
const NotFound = () => {
return (
<div>
<h2>Page Not Found</h2>
<p>Sorry, the page you are looking for does not exist.</p>
<Link to="/">Go to Home</Link>
</div>
);
};
export default NotFound;
```
##### Setting Up the Router in App.js
Now, let's set up the router in our main App.js file. Import the necessary components from React Router and configure the routes.
Update **_`src/App.js`_** with the following code:
```react
import React from 'react';
import { BrowserRouter, Routes, Route } from 'react-router-dom';
import Home from './components/Home';
import About from './components/About';
import User from './components/User';
import NotFound from './components/NotFound';
import './App.css';
export default function App() {
return (
<BrowserRouter>
<div className="app">
<h1>React Router Example</h1>
<Routes>
<Route path="/" element={<Home />} />
<Route path="/about" element={<About />} />
<Route path="/user/:username" element={<User />} />
<Route path="*" element={<NotFound />} />
</Routes>
</div>
</BrowserRouter>
);
}
```
####Running the Application
With everything set up, you can now start the development server to see your app in action:
```bash
npm start
```
Navigate to **`http://localhost:3000`** in your browser. You should see the home page with navigation links. Clicking on the links will take you to the respective pages (About, User, etc.), and if you try to navigate to a non-existent route, you will see the NotFound component. | vikram-boominathan |
1,863,619 | Integrating Machine Learning Models into Your Python Applications | Unleash the Power of Machine Learning in Your Python Apps Machine learning (ML) is... | 0 | 2024-05-24T06:36:29 | https://dev.to/manavcodaty/integrating-machine-learning-models-into-your-python-applications-4fm1 | ai, machine, programming | ## **Unleash the Power of Machine Learning in Your Python Apps**
---
Machine learning (ML) is rapidly transforming the world, and Python is a go-to language for bringing ML to life. By integrating ML models into your Python applications, you can add intelligent features and automate tasks, making your apps more powerful and user-friendly.
This blog post will guide you through the exciting world of integrating ML models into your Python applications. We'll explore different approaches and provide tips to get you started.
## **Understanding the Landscape**
---
There are two main approaches to consider:
1. **Using Pre-Trained Models:** Numerous pre-trained models are available for various tasks, like image recognition, natural language processing, and time series forecasting. These models come ready-to-use, saving you time and effort on training.
2. **Training Your Own Model:** For specific needs, you can train your own model using Python libraries like Scikit-learn and TensorFlow. This approach offers more customization but requires expertise in data preparation, model selection, and training.
## **The Integration Process**
---
Once you have your chosen model, here's a simplified breakdown of the integration process:
1. **Load the Model:** Use Python libraries to load the pre-trained model or your trained model from its saved format.
2. **Prepare Your Data:** Ensure your application data is in the format the model expects. This might involve data cleaning, transformation, and feeding it into the model in batches or single instances.
3. **Make Predictions:** Use the model to generate predictions on new data fed into your application.
4. **Handle Outputs:** Integrate the model's predictions into your application's workflow. This might involve displaying results, triggering actions, or feeding them back into the application.
## **Tips for Success**
---
- **Start Simple:** Begin with a well-defined task and a pre-trained model for easier integration.
- **Focus on User Experience:** Embed the ML model seamlessly into your application for a smooth user experience.
- **Test and Monitor:** Rigorously test your application to ensure the model performs as expected. Monitor its performance in production to identify any issues.
## **Further Exploration**
---
This blog post provides a starting point. As you delve deeper, explore popular Python libraries like TensorFlow, PyTorch, and scikit-learn for building and integrating ML models. Remember, experimentation and exploration are key to success!
By leveraging the power of machine learning in your Python applications, you can unlock new possibilities and create intelligent and innovative solutions. | manavcodaty |
1,860,521 | 5 Must-Know SharePoint Best Practices (Part 2) Empowering Users with Effective Lists and Libraries | Welcome back, SharePoint enthusiasts! In our first issue of this series, we tackled the art of... | 26,192 | 2024-05-24T06:30:00 | https://intranetfromthetrenches.substack.com/p/5-must-know-sharepoint-list-and-library-tips-2 | sharepoint | Welcome back, SharePoint enthusiasts! In our first issue of this series, we tackled the art of optimizing lists and libraries within SharePoint Online, [5 Must-Know SharePoint Best Practices (Part 1): Fine-Tuning Lists, Libraries, & Files for Efficiency](https://intranetfromthetrenches.substack.com/p/5-must-know-sharepoint-list-and-library-tips-1).
Today's focus is specifically for creators and configurators of lists and libraries. Do you ever feel like your creations could be even more user-friendly? Perhaps you worry colleagues struggle to find the information they need, or your carefully crafted structures feel clunky.

If you create and configure SharePoint lists and libraries, this article is your roadmap to becoming a master organizer! By following these five simple tips, you'll transform your creations into streamlined resources that empower your colleagues.
Imagine this:
- **Crystal clear navigation:** Users find exactly what they need, thanks to your intuitive naming conventions and folder structures.
- **Effortless searching:** Important information surfaces effortlessly, saving everyone valuable time.
- **Boosted productivity:** A well-organized SharePoint environment fosters collaboration and streamlines workflows.
- **The hero of the office:** Colleagues praise your organizational skills and newfound SharePoint expertise!
Ready to unlock these benefits and become a SharePoint champion? Let's dive into the five essential tips that will elevate your creations from good to great!
## Tip #1: Unleash the Power of Color-Coded Folders
Imagine a cluttered filing cabinet where every folder looks the same. Frustrating, right? The same goes for SharePoint lists and libraries. Thankfully, you can leverage the magic of color to make important folders stand out!
Here's how this tip empowers you:
- **Instant Recognition:** A splash of color instantly draws the eye, helping users identify critical folders at a glance. No more time wasted sifting through endless generic folders.
- **Prioritization Made Easy:** Use color strategically to highlight folders containing urgent information, frequently used resources, or ongoing projects. This visual cue guides users towards the content they need most.
- **Enhanced Clarity:** Color can add a layer of organization, especially for large libraries with numerous folders. Categorize folders by department, project type, or urgency level using a color scheme that resonates with your organization.
**Putting it into Practice:**
Simply right-click on the desired folder, and explore the color options. Choose a color scheme that aligns with your organization's branding or create a custom system for easy identification.
## Tip #2: Embrace the Power of Numbers: Sorting Made Simple
Ever spend time dragging and dropping folders into the "perfect" order, only to have it all jumbled after someone adds a new one? Numbers are your secret weapon for effortless sorting!
Here's how this tip empowers you:
- **Effortless Organization:** By incorporating numbers into your folder names (e.g., "01 - Marketing Materials," "02 - Sales Reports"), you ensure folders appear in the desired order automatically. No more manual rearranging!
- **Intuitive Navigation:** Users can instantly grasp the hierarchy and flow of information within your lists and libraries. Numbers provide a clear roadmap, guiding users to the specific folders they need.
- **Scalability Made Easy:** Adding new folders becomes a breeze. Simply assign the next sequential number, and SharePoint automatically places it in the correct position. No more disrupting the carefully crafted order!
**Putting it into Practice:**
When creating a new folder, consider incorporating a numbering system into the name. Here are a few approaches:
- **Sequential Numbers:** Use a simple numbering system (1, 2, 3, etc.) for a straightforward approach. This works well for flat folder structures.
- **Numbered Prefixes:** For more complex structures, use a numbered prefix followed by a descriptive name (e.g., "01 - Marketing - Brochures," "02 - Sales - Q1 Reports"). This approach clarifies both the order and content category.
Remember, consistency is key! Choose a numbering system that works for your specific needs and stick to it for optimal organization.
## Tip #3: Speak in Code: Clear and Concise Column Names
Columns are the building blocks of your SharePoint lists. They hold the data that drives your workflows and information sharing. But cryptic column names can create confusion. This tip empowers you to craft clear and concise column names that are easy to understand, even without spaces or special characters.
Here's how this tip empowers you:
- **Intuitive Data Entry:** Users can easily grasp the purpose of each column and enter data accurately. No more guessing games about what information belongs where.
- **Enhanced Search Functionality:** Descriptive column names act as filters within views and search results. Users can quickly locate relevant data based on keywords, streamlining information retrieval.
- **Reduced Errors:** Clear column names minimize the risk of data entry errors, ensuring the integrity of your information within SharePoint.
**Putting it into Practice:**
While you can't use spaces or special characters in column names, here are some strategies for crafting clear and concise names:
- **Focus on Content:** Instead of starting with a verb, prioritize describing the actual data the column holds. Examples include "DueDate," "EmployeeID," or "ProjectStatus." These terms directly tell users what information they need to enter.
- **Abbreviations Wisely:** Use common abbreviations that your audience understands. For instance, "ETA" for Estimated Time of Arrival or "Dept" for Department.
- **Consistency is Key:** Maintain a consistent naming convention across all your columns for a cohesive structure. This makes it easier for users to navigate and understand your SharePoint lists.
By following these guidelines, you'll transform your SharePoint lists into efficient data repositories that empower users to enter, access, and utilize information seamlessly.
## Tip #4: Discretion is Key: Excluding Items from Search
Let's face it, not everything in your SharePoint needs to be public knowledge. Perhaps you have draft documents, internal communications, or confidential information. This tip empowers you to keep specific items hidden from search results.
Here's how this tip empowers you:
- **Reduced Clutter:** Search results can become cluttered with irrelevant information. Excluding draft documents or outdated files ensures users only see the most current and relevant content.
- **Streamlined Navigation:** A focused search experience empowers users to find what they need quickly and efficiently.
**Putting it into Practice:**
There is one way to exclude items from search results in SharePoint Online:
- **Library Level Exclusion:** For entire libraries, you can disable search indexing at the library level. Navigate to the library settings, locate the "Search" section, and choose "No" for "Allow items from this document library to appear in SharePoint search results."
**Important Note:** Excluding items from search results doesn't equate to deletion. The content remains accessible to authorized users with the appropriate permissions.
## Tip #5: Focus on What Matters: The Power of Views
Imagine a library overflowing with documents, all jumbled together. Finding specific information would be a nightmare! Thankfully, SharePoint Online offers a powerful tool called "Views" that allows you to tailor content to specific needs.
Here's how this tip empowers you:
- **Highlight Key Information:** Create custom views that showcase the most important information for specific user groups. This ensures users see only the most relevant data, saving them valuable time and effort.
- **Filter Out the Noise:** Leverage filters to exclude irrelevant information from specific views. This declutters the interface and allows users to focus on the content that matters most to them.
- **Prioritized Content:** Utilize sorting options within views to prioritize critical information. Users can quickly identify the latest updates, high-priority tasks, or recently modified documents.
**Putting it into Practice:**
Creating custom views in SharePoint Online is a straightforward process. Here's a simplified breakdown:
1. Navigate to your desired list or library.
2. Click on the view name and select "Create a new view."
3. Choose a view type (Calendar, List or Gallery) or customize an existing view.
4. Utilize the available options to filter, sort, and group information according to your needs.
5. Save your customized view for future use.
By creating a variety of focused views, you empower users to interact with SharePoint content in a way that aligns with their specific needs and tasks. This fosters a more efficient and productive work environment for everyone.
## Conclusion
Imagine a SharePoint environment that feels effortless to navigate, where information is readily available at your fingertips. By implementing these five simple tips, you'll achieve exactly that. You'll transform your SharePoint creations into user-friendly resources that empower your colleagues in several ways:
- **Reduced Time Spent Searching:** Clear structures and intuitive naming conventions minimize wasted time searching for information. Users can locate what they need quickly and efficiently.
- **Improved Collaboration:** A well-organized SharePoint environment fosters seamless collaboration. Colleagues can easily share information, track progress on projects, and stay up-to-date on the latest developments.
- **Enhanced Productivity:** Streamlined workflows and effortless access to information translate into a more productive work environment for everyone.
Now, let me share a perspective from my experience of over 20 years working with countless customers on SharePoint solutions. I've seen firsthand the transformative power of these seemingly simple organizational techniques. When users can find information quickly and collaborate effortlessly, it fosters a sense of ownership and engagement within the organization.
By following these tips, you'll not only become a SharePoint pro, but you'll also contribute to building a more efficient and collaborative work environment for your entire team. So, put these tips into practice and watch your SharePoint creations flourish!
## References
- *Colored pencils white board by Jess Bailey from Unsplash: [https://unsplash.com/es/fotos/lapices-de-colores-variados-Bg14l3hSAsA](https://unsplash.com/es/fotos/lapices-de-colores-variados-Bg14l3hSAsA)*
- *5 Must-Know SharePoint Best Practices (Part 1): Fine-Tuning Lists, Libraries, & Files for Efficiency: [https://intranetfromthetrenches.substack.com/p/5-must-know-sharepoint-list-and-library-tips-1](https://intranetfromthetrenches.substack.com/p/5-must-know-sharepoint-list-and-library-tips-1)* | jaloplo |
1,863,616 | Using CLERK for Authentication in Your Web Applications | Authentication is a crucial part of any web application, ensuring that only authorized users have... | 0 | 2024-05-24T06:29:44 | https://dev.to/raazketan/using-clerk-for-authentication-in-your-web-applications-eep | react, javascript, tutorial | Authentication is a crucial part of any web application, ensuring that only authorized users have access to certain features and data. With a plethora of authentication solutions available, choosing the right one can be daunting. One service that stands out for its simplicity and robust features is CLERK. In this post, we’ll explore how to integrate CLERK for authentication in your web applications.
#### Table of Contents
1. [Introduction to CLERK](#introduction-to-clerk)
2. [Why Choose CLERK?](#why-choose-clerk)
3. [Getting Started with CLERK](#getting-started-with-clerk)
4. [Integrating CLERK into Your Application](#integrating-clerk-into-your-application)
5. [Advanced Features of CLERK](#advanced-features-of-clerk)
6. [Conclusion](#conclusion)
### Introduction to CLERK
CLERK is a modern authentication solution designed to provide developers with an easy-to-implement, scalable, and secure authentication system. It offers a wide range of features, including user management, multi-factor authentication, social login, and more, making it suitable for both small projects and large-scale applications.
### Why Choose CLERK?
There are several reasons why CLERK might be the right choice for your authentication needs:
- **Ease of Use:** CLERK is designed to be developer-friendly, with clear documentation and easy integration.
- **Security:** It provides robust security features, ensuring your application’s data is protected.
- **Scalability:** CLERK can handle applications of any size, from small startups to large enterprises.
- **Customization:** It allows for extensive customization, so you can tailor the authentication experience to your specific needs.
- **Support for Modern Features:** Features like passwordless login, multi-factor authentication, and social login are supported out of the box.
### Getting Started with CLERK
To get started with CLERK, follow these simple steps:
1. **Sign Up for an Account:** Head over to the CLERK website and sign up for an account. You can start with a free plan to explore its features.
2. **Create a New Application:** Once logged in, create a new application. This will provide you with a set of credentials (API keys) that you will use to integrate CLERK into your application.
3. **Install CLERK SDK:** Depending on your application’s framework, install the appropriate CLERK SDK. For example, if you are using a React application, you can install the CLERK React package via npm:
```sh
npm install @clerk/clerk-react
```
### Integrating CLERK into Your Application
Here’s a basic example of how to integrate CLERK into a React application:
1. **Initialize CLERK:** In your main application file (e.g., `index.js`), initialize CLERK with your frontend API key:
```javascript
import React from 'react';
import ReactDOM from 'react-dom';
import { ClerkProvider } from '@clerk/clerk-react';
import App from './App';
const clerkFrontendApi = 'your-clerk-frontend-api-key';
ReactDOM.render(
<ClerkProvider frontendApi={clerkFrontendApi}>
<App />
</ClerkProvider>,
document.getElementById('root')
);
```
2. **Add Authentication Components:** Use CLERK’s built-in components to handle authentication. For instance, you can add a sign-in component to your login page:
```javascript
import React from 'react';
import { SignIn } from '@clerk/clerk-react';
const LoginPage = () => (
<div>
<h2>Login</h2>
<SignIn />
</div>
);
export default LoginPage;
```
3. **Protect Routes:** You can protect certain routes to ensure only authenticated users have access. CLERK provides a `withAuth` higher-order component for this purpose:
```javascript
import React from 'react';
import { withAuth } from '@clerk/clerk-react';
const ProtectedPage = () => (
<div>
<h2>Protected Page</h2>
<p>This page is only accessible to authenticated users.</p>
</div>
);
export default withAuth(ProtectedPage);
```
### Advanced Features of CLERK
Beyond basic authentication, CLERK offers several advanced features:
- **Multi-Factor Authentication (MFA):** Add an extra layer of security by enabling MFA.
- **Passwordless Authentication:** Allow users to log in without a password using email or SMS links.
- **Social Login:** Enable users to log in with their social media accounts (e.g., Google, Facebook).
- **User Management Dashboard:** Manage your users through a comprehensive dashboard.
- **Customizable UI:** Customize the look and feel of the authentication components to match your application’s branding.
### Conclusion
Integrating authentication into your web application doesn’t have to be a headache. CLERK provides a powerful, easy-to-use solution that can be tailored to meet your specific needs. Whether you’re building a simple app or a complex enterprise solution, CLERK has the features and flexibility to support your authentication requirements.
Ready to get started? Sign up for CLERK today and start building secure applications with ease!
---
Feel free to leave any questions or comments below, and happy coding!
---
*Note: This post assumes a basic understanding of React. For other frameworks, refer to CLERK’s official documentation for specific integration steps.* | raazketan |
1,863,615 | Nonstick Cookware Market Size, Share, Growth, Trends, Applications, and Industry Strategies | Nonstick Cookware Market is expected to grow at a CAGR of 4.90% during the forecast period. Global... | 0 | 2024-05-24T06:29:12 | https://dev.to/maximize_shraddha_5505538/nonstick-cookware-market-size-share-growth-trends-applications-and-industry-strategies-3apa | nonstick, cookware, market, growth | Nonstick Cookware Market is expected to grow at a CAGR of 4.90% during the forecast period. Global Nonstick Cookware Market is expected to reach USD 16.87 Billion by 2030.
Nonstick Cookware Market Overview
The prominent global market intelligence firm has unveiled its latest market research report focusing on the Nonstick Cookware Market. The comprehensive report presents descriptive data and pictographs depicting the analysis of both regional and global markets. Moreover, the report delves into the market's objectives, shedding light on leading competitors, their market value, current trending skims, strategies, targets, and products. It also highlights the recent growth of the market and provides valuable insights into its informative past.
Nonstick Cookware Market Scope: https://www.maximizemarketresearch.com/inquiry-before-buying/47162
The research report delves deeply into the analysis of trending competitors, their market growth, and dynamic patterns. It offers valuable insights into the regional and global values and demands of the market. Furthermore, it aids in comprehending the competitive landscape and market potential in terms of production demand and supply. The segmentation analysis includes crucial factors such as psychographic, demographic, geographic, and behavioral segmentation. These factors play a pivotal role in shaping marketing strategies, focused and targeted products, offers, and customer experiences. Porter's analysis is utilized to gauge an organization's competitive position strength, aiming to enhance profitability. Additionally, Pestle analysis is conducted to assess the validity of existing products and services in the contextual data. The SWOT analysis provides an evaluation of internal and external factors contributing to a company's advantages, disadvantages, strengths, and weaknesses. Overall, this report offers comprehensive and informative data on the Nonstick Cookware market overview.
Access a Free Sample Report: https://www.maximizemarketresearch.com/request-sample/47162
Segmentation
It is anticipated that the online sector will account for US$ 4% million of the worldwide nonstick cookware industry. Because it offers doorstep delivery for product orders, the online platform is growing in popularity. Customers can use an internet platform to compare the costs of nonstick cookware products across several websites. Online platforms offer free shipping, home delivery, and exchange and return policies, all of which are likely to make customers choose the online distribution channel. The ease of purchasing, together with a few technological innovations and creative marketing techniques used by online e-commerce platforms, are some of the key motivators that are anticipated to accelerate the market expansion for online distribution channels.
Key Players
1. TTK Prestige Limited
2. Newell Brands
3. Hawkins Cookers
4. Groupe SEB
5. Farberware Licensing Company, LLC
6. Gibson Brands, Inc.
7. NuWave LLC
8. Meyer Corporation
9. Le Creuset
10. Conair Corporation
11. Denby Pottery
12. Berndes
13. Bradshaw International, Inc.
14. Scanpan
15. Calphalon
16. Cook N Home
17. Tefal
18. PT Maspion
19. Regal Ware, Inc.
20. Tramontina
21. Crown Cookware
22. I.L.L.A. S.p.A.
23. Sub-Zero Group, Inc.
24. John Wright Company.
Regional Analysis
The report delivers formal, functional, and vernacular regional analysis. It identifies the most impactful business areas based on the highest demand in different regions, including Asia Pacific, North America, Latin America, the Middle East, Europe, and Africa. The analysis provides valuable insights into distinct targets, strategies, and market values for each region.
Key Questions Addressed in the Nonstick Cookware Market Report:
What characterizes the Nonstick Cookware Market?
What is the forecast period for the Nonstick Cookware Market?
How does the competitive scenario look in the Nonstick Cookware Market?
Which region holds the largest market share in the Nonstick Cookware Market?
What opportunities are available in the Nonstick Cookware Market?
What factors influence the growth of the Nonstick Cookware Market?
Who are the key players in the Nonstick Cookware Market?
Which company holds the largest share in the Nonstick Cookware Market?
What will be the CAGR of the Nonstick Cookware Market during the forecast period?
What key trends are expected to emerge in the Nonstick Cookware Market in the upcoming years?
Key Offerings:
Market Share, Size, and Forecast by Revenue|2024-2030
Market Dynamics - Growth drivers, Restraints, Investment Opportunities, and key trends
Market Segmentation: A detailed analysis by Nonstick Cookware Market
Landscape - Leading key players and other prominent key players.
About Maximize Market Research:
Maximize Market Research is a versatile market research and consulting company, staffed with professionals from various industries. Our coverage extends to medical devices, pharmaceutical manufacturers, science and engineering, electronic components, industrial equipment, technology, communication, automotive, chemical products, general merchandise, beverages, personal care, and automated systems, among others. Our services encompass market-verified industry estimations, technical trend analysis, crucial market research, strategic advice, competition analysis, production and demand analysis, and client impact studies.
Contact Maximize Market Research:
3rd Floor, Navale IT Park, Phase 2
Pune Bangalore Highway, Narhe,
Pune, Maharashtra 411041, India
sales@maximizemarketresearch.com
+91 96071 95908, +91 9607365656
 | maximize_shraddha_5505538 |
1,863,614 | Digital Marketing CourseZirakpur | Vishyat Technologies offers Digital Marketing Course Zirakpur, Digital Marketing Course training... | 0 | 2024-05-24T06:28:36 | https://dev.to/vishyatdigital1/digital-marketing-coursezirakpur-3j0b | Vishyat Technologies offers[ Digital Marketing Course Zirakpur](https://www.vishyat.com/digital-marketing-course-training-in-zirakpur/), Digital Marketing Course training Derabassi, in Punjab. In haryana, we offer Digital Marketing Course training Ambala, Digital Marketing Course training Panchkula, Digital Marketing Course training Mohali. We also offer computer courses like Computer Course training institute Zirakpur, Computer Course training institute Derabassi, Computer Course training institute Barwala
| vishyatdigital1 | |
1,863,613 | Unlocking the Power of Exceptional Explainer Videos for Marketing Success | In today’s fast-paced digital world, capturing and retaining audience attention is more challenging... | 0 | 2024-05-24T06:27:21 | https://dev.to/nisargshah/unlocking-the-power-of-exceptional-explainer-videos-for-marketing-success-28fi | marketing, video | In today’s fast-paced digital world, capturing and retaining [audience attention](https://www.nimblechapps.com/blog/5-digital-trends-to-help-you-reach-more-customers-in-2024) is more challenging than ever. This is where explainer videos come in. These concise, engaging videos are designed to explain complex ideas in a straightforward, visually appealing way, making them a powerful tool for [social media marketing](https://www.nimblechapps.com/blog/2022-digital-marketing-trends-to-revolutionize-marketing-industry). By combining clear messaging, compelling visuals, and strong calls to action, explainer videos can significantly boost engagement, enhance SEO, and drive conversions.
Key Elements of an Effective Explainer Video
**1. Clarity and Conciseness**
Explainer videos excel in distilling complex ideas into easy-to-understand visuals and narratives. A well-crafted explainer video can present a large amount of information in a short time, making it more digestible for viewers. For example, a concept that might take several paragraphs to explain in text can be effectively communicated in a 60-second video.
**2. Engaging Script**
The foundation of any successful explainer video is its script. The script should address the target audience’s pain points and provide clear, concise solutions. Understanding your audience's concerns and questions allows you to tailor the script to answer them effectively, enhancing engagement and comprehension.
**3. Visual Appeal**
High-quality visuals are crucial. Animated graphics, compelling illustrations, and dynamic transitions keep viewers engaged. Visual storytelling helps reinforce the message, making it memorable. It’s proven that people remember 70% of what they see and hear, compared to just 20% of what they hear alone.
**4. Strong Call-to-Action (CTA)**
An effective explainer video concludes with a strong call-to-action. This directs viewers on what to do next, whether it’s visiting a website, signing up for a newsletter, or making a purchase. A clear CTA can significantly increase conversion rates by guiding the audience toward the desired action.
**Benefits of Using Explainer Videos in Marketing**
**1. Increased Engagement**
Videos naturally attract more attention than text or static images. They keep visitors on your site longer, with statistics showing that websites with videos see a higher average time spent by users. This increased engagement often leads to higher conversion rates.
**2. SEO Advantages**
Search engines favor content that engages users. Videos can improve your website’s SEO ranking by increasing the time visitors spend on your site and reducing bounce rates. Additionally, videos are more likely to be shared on social media, further boosting your SEO through increased backlinks and traffic.
**3. Versatility**
Explainer videos can be used across multiple platforms, from your website’s homepage to social media channels, email marketing campaigns, and presentations. This versatility ensures consistent messaging across different touchpoints, reinforcing your brand and value proposition.
**4. Building Trust**
Explainer videos help build trust by showing the human side of your brand. They allow you to communicate directly with your audience, explaining your product or service in a personable and relatable manner. This transparency can significantly enhance your brand’s credibility and reliability.
**Common Pitfalls to Avoid**
**1. Overcomplicating the Message**
Keep your message simple. Trying to cover too much information can overwhelm viewers. Focus on a single, clear message that addresses the main pain point of your audience.
**2. Low-Quality Production**
Poor production quality can damage your brand’s image. Invest in professional production to ensure high-quality visuals and audio. A poorly made video can deter potential customers and negatively impact your brand’s perception.
**3. Ignoring Audience Feedback**
Always consider audience feedback. Understanding what resonates with your audience and what doesn’t can help refine your future videos. Regularly updating your content based on feedback can keep it relevant and effective.
**Conclusion**
Explainer videos are a potent marketing tool when done right. They combine clarity, engagement, and visual appeal to convey complex information quickly and effectively. By focusing on a clear message, high-quality production, and a strong call-to-action, businesses can leverage explainer videos to enhance engagement, improve SEO, and drive conversions. As video content continues to dominate the digital landscape, investing in high-quality explainer videos can provide significant returns for your marketing efforts.
| nisargshah |
1,863,611 | The Power of Caching and How to Implement It in Your Python Applications | Speed Up Your Python Apps with the Power of Caching Have you ever used an app that... | 0 | 2024-05-24T06:23:35 | https://dev.to/manavcodaty/the-power-of-caching-and-how-to-implement-it-in-your-python-applications-46e9 | caching, python | ## **Speed Up Your Python Apps with the Power of Caching**
---
Have you ever used an app that takes forever to load data, even for things you've seen before? Ouch! That can be frustrating for users. As a Python developer, you have a powerful tool at your disposal to fight sluggish performance:caching.
## **What is Caching?**
---
Caching is all about storing frequently used data in a temporary location for quick retrieval. Think of it like keeping a copy of your favorite books on your nightstand instead of trekking to the library every time you want to re-read them.
In your Python applications, caching can store things like database query results, API responses, or even complex calculations. By remembering these values, your app can avoid the cost of re-generating them every time. This can lead to significant speed improvements, especially for data that's accessed repeatedly.
## **Benefits of Caching:**
---
- **Faster Performance:** Cached data retrieval is much faster than re-calculating or re-fetching it. This can lead to a snappier user experience.
- **Reduced Load:** By offloading some work from your main program, caching can help your application handle more requests efficiently.
- **Improved Scalability:** A well-cached application can handle increased traffic without needing major infrastructure upgrades.
## **Implementing Caching in Python**
---
There are several ways to implement caching in Python. Here are two common approaches:
1. **Dictionaries:** Python dictionaries are a built-in data structure that can be used for simple caching. You can store key-value pairs, where the key is the unique identifier for the data and the value is the data itself.
2. **LRU Cache Decorator:** The @lru_cache decorator from the functools module provides a more sophisticated approach. It implements a Least Recently Used (LRU) caching strategy, which automatically removes the least used items from the cache when it reaches a predefined size.
## **Here are some additional tips for effective caching:**
---
- **Identify Cacheable Data:** Not all data is suitable for caching. Focus on data that is frequently accessed and doesn't change frequently.
- **Set Expiration Times:** Cached data can become stale over time. Set expiration times to ensure your app uses fresh data when necessary.
- **Consider Invalidation:** Think about how your application updates data. You may need to invalidate cached data when the source data changes.
By understanding caching and implementing it effectively, you can take your Python applications to the next level of performance. Your users will thank you for the snappy response times!
**Ready to learn more?** A quick web search for "Python caching tutorial" will give you plenty of resources to explore in-depth examples and different caching libraries. | manavcodaty |
1,863,610 | Thoughts on High-Frequency Trading Strategies (5) | In the previous article, various methods for calculating mid-price were introduced, and a revised... | 0 | 2024-05-24T06:22:06 | https://dev.to/fmzquant/thoughts-on-high-frequency-trading-strategies-5-4681 | trading, fmzquant, cryptocurrency, strategy | In the previous article, various methods for calculating mid-price were introduced, and a revised mid-price was proposed. In this article, we will delve deeper into this topic.
## Data Required
We need order flow data and depth data for the top ten levels of the order book, collected from live trading with an update frequency of 100ms. For the sake of simplicity, we will not include real-time updates for the bid and ask prices. To reduce the data size, we have kept only 100,000 rows of depth data and separated the tick-by-tick market data into individual columns.
In [1]:
```
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
```
In [2]:
```
tick_size = 0.0001
```
In [3]:
```
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
```
In [4]:
```
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
```
In [5]:
```
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
```
In [6]:
```
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
```
In [7]:
```
depths = depths.iloc[:100000]
```
In [8]:
```
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
```
In [9]:
```
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
```
In [10]:
```
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
```
In [11]:
```
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
```
Take a look at the distribution of the market in these 20 levels. It is in line with expectations, with more orders placed the further away from the market price. Additionally, buy orders and sell orders are roughly symmetrical.
In [14]:
```
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
```
Out[14]:
Merge the depth data with the transaction data to facilitate the evaluation of prediction accuracy. Ensure that the transaction data is later than the depth data. Without considering latency, directly calculate the mean squared error between the predicted value and the actual transaction price. This is used to measure the accuracy of the prediction.
From the results, the error is highest for the average value of the bid and ask prices (mid_price). However, when changed to the weighted mid_price, the error immediately decreases significantly. Further improvement is observed by using the adjusted weighted mid_price. After receiving feedback on using I^3/2 only, it was checked and found that the results were better. Upon reflection, this is likely due to the different frequencies of events. When I is close to -1 and 1, it represents low probability events. In order to correct for these low probability events, the accuracy of predicting high-frequency events is compromised. Therefore, to prioritize high-frequency events, some adjustments were made (these parameters were purely trial-and-error and have limited practical significance in live trading).
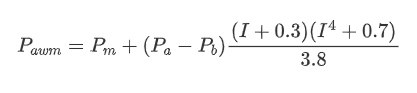
The results have improved slightly. As mentioned in the previous article, strategies should rely on more data for prediction. With the availability of more depth and order transaction data, the improvement gained from focusing on the order book is already weak.
In [15]:
```
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
```
In [17]:
```
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
```
In [18]:
```
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
```
Out[18]:
Mean value Error in mid_price: 0.0048751924999999845
Error of pending order volume weighted mid_price: 0.0048373440193987035
The error of the adjusted mid_price: 0.004803654771638586
The error of the adjusted mid_price_2: 0.004808216498329721
The error of the adjusted mid_price_3: 0.004794984755260528
The error of the adjusted mid_price_4: 0.0047909595497071375
## Consider the Second Level of Depth
We can follow the approach from the previous article to examine different ranges of a parameter and measure its contribution to the mid_price based on the changes in transaction price. Similar to the first level of depth, as I increases, the transaction price is more likely to increase, indicating a positive contribution from I.
Applying the same approach to the second level of depth, we find that although the effect is slightly smaller than the first level, it is still significant and should not be ignored. The third level of depth also shows a weak contribution, but with less monotonicity. Deeper depths have little reference value.
Based on the different contributions, we assign different weights to these three levels of imbalance parameters. By examining different calculation methods, we observe further reduction in prediction errors.
In [19]:
```
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
```
Out[19]:
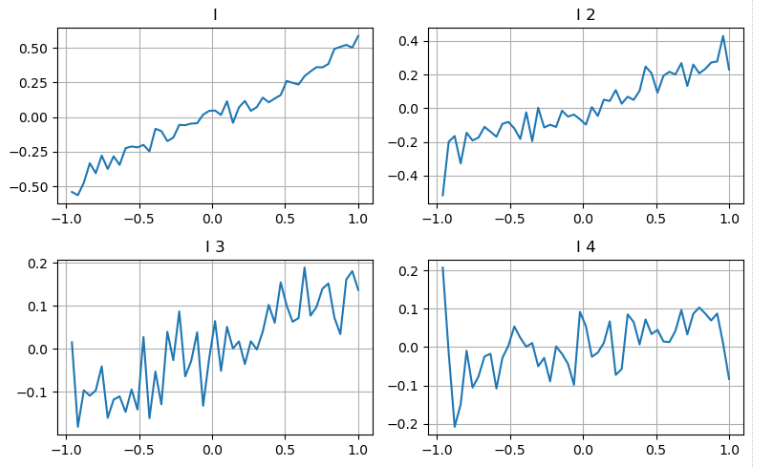
In [20]:
```
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
```
In [21]:
```
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
```
Out[21]:
The error of the adjusted mid_price_4: 0.0047909595497071375
The error of the adjusted mid_price_5: 0.0047884350488318714
The error of the adjusted mid_price_6: 0.0047778319053133735
The error of the adjusted mid_price_7: 0.004773578540592192
The error of the adjusted mid_price_8: 0.004771415189297518
## Considering the Transaction Data
Transaction data directly reflects the extent of long and short positions. After all, transactions involve real money, while placing orders has much lower costs and can even involve intentional deception. Therefore, when predicting the mid_price, strategies should focus on the transaction data.
In terms of form, we can define the imbalance of the average order arrival quantity as VI, with Vb and Vs representing the average quantity of buy and sell orders within a unit time interval, respectively.
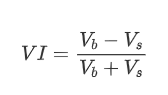
The results show that the arrival quantity in a short period of time has the most significant impact on price change prediction. When VI is between 0.1 and 0.9, it is negatively correlated with price, while outside this range, it is positively correlated with price. This suggests that when the market is not extreme and mainly oscillates, the price tends to revert to the mean. However, in extreme market conditions, such as when there are a large number of buy orders overwhelming sell orders, a trend emerges. Even without considering these low probability scenarios, assuming a negative linear relationship between the trend and VI significantly reduces the prediction error of the mid_price. The coefficient "a" represents the weight of this relationship in the equation.
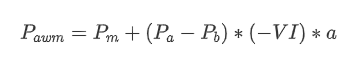
In [22]:
```
alpha=0.1
```
In [23]:
```
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
```
In [24]:
```
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
```
In [25]:
```
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
```
In [26]:
```
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
```
In [27]:
```
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
```
Out[27]:
In [28]:
```
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
```
In [29]:
```
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
```
Out[29]:
The error of the adjusted mid_price: 0.0048373440193987035
The error of the adjusted mid_price_9: 0.004629586542840461
The error of the adjusted mid_price_10: 0.004401790287167206
## The Comprehensive Mid-price
Considering that both order book imbalance and transaction data are helpful for predicting the mid_price, we can combine these two parameters together. The assignment of weights in this case is arbitrary and does not take into account boundary conditions. In extreme cases, the predicted mid_price may not fall between the bid and ask prices. However, as long as the prediction error can be reduced, these details are not of great concern.
In the end, the prediction error is reduced from 0.00487 to 0.0043. At this point, we will not delve further into the topic. There are still many aspects to explore when it comes to predicting the mid_price, as it is essentially predicting the price itself. Everyone is encouraged to try their own approaches and techniques.
In [30]:
```
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
```
In [31]:
```
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
```
Out[31]:
The error of the adjusted mid_price_11: 0.0043001941412563575
## Summary
The article combines depth data and transaction data to further improve the calculation method of the mid-price. It provides a method to measure accuracy and improves the accuracy of price change prediction. Overall, the parameters are not rigorous and are for reference only. With a more accurate mid-price, the next step is to conduct backtesting using the mid-price in practical applications. This part of the content is extensive, so updates will be paused for a period of time.
From: https://blog.mathquant.com/2023/08/10/thoughts-on-high-frequency-trading-strategies-5.html | fmzquant |
1,863,366 | Spring Boot Architecture | Overview: Spring Boot is a framework built on top of the Spring Framework that simplifies the... | 0 | 2024-05-23T23:01:30 | https://dev.to/oloruntobi600/spring-boot-architecture-644 | 1. Overview:
Spring Boot is a framework built on top of the Spring Framework that simplifies the process of building and deploying Spring-based applications. It provides a set of conventions, dependencies, and tools to quickly set up and run applications, allowing developers to focus more on writing business logic rather than configuring infrastructure.
2. Architecture:
Spring Boot Core: This is the heart of Spring Boot, containing essential components like the SpringApplication class, which bootstraps the Spring application and provides features such as auto-configuration and externalized configuration.
Spring Framework: Spring Boot leverages the Spring Framework for dependency injection, aspect-oriented programming, and other features. It builds upon Spring's core principles and integrates seamlessly with existing Spring projects.
Starter Dependencies: Spring Boot starters are a set of pre-configured dependencies that streamline the setup of various features like web applications, security, data access, etc. They provide a cohesive set of libraries and configurations to jump-start development for specific use cases.
Auto-Configuration: Spring Boot automatically configures beans and components based on the dependencies present in the classpath. It analyzes the environment, including classpath, properties, and annotations, to determine which beans and configurations are needed, reducing the need for manual setup.
Spring Boot CLI (Command Line Interface): The Spring Boot CLI allows developers to create, run, and test Spring Boot applications from the command line. It provides features like Groovy-based scripting, project generation, and live reloading, making it easier to prototype and develop applications quickly.
3. Simplified Configuration:
Spring Boot simplifies the configuration process in several ways:
A. Externalized Configuration: Spring Boot allows configuration properties to be externalized, typically through properties files (application.properties or application.yml). This separation of configuration from code makes it easier to manage and modify application settings without modifying the source code.
B. Annotation-Based Configuration: Spring Boot promotes the use of annotations for configuration, such as @SpringBootApplication, @RestController, @Autowired, etc. These annotations reduce boilerplate code and make the configuration more concise and readable.
4. Spring Boot Starters:
Spring Boot starters are a key component of Spring Boot's architecture. They provide a convenient way to add dependencies and configuration for specific functionalities.
Web Starter: Includes dependencies and auto-configuration for building web applications using Spring MVC or Spring WebFlux.
Data Starter: Provides dependencies and auto-configuration for working with data, including databases (JPA, JDBC), caching (Redis, Ehcache), and messaging (JMS, RabbitMQ).
Security Starter: Adds dependencies and auto-configuration for implementing security features such as authentication, authorization, and encryption.
Test Starter: Includes dependencies and auto-configuration for testing Spring Boot applications using frameworks like JUnit, Mockito, and Spring Test.
5. Role of Spring Boot CLI:
The Spring Boot CLI enhances developer productivity by providing a command-line interface for building and running Spring Boot applications.
Project Generation: Developers can quickly generate new Spring Boot projects using the CLI's project initialization feature. For example, spring init command creates a new project with minimal configuration.
Groovy Scripts: The CLI supports writing Groovy scripts for rapid prototyping and automation. Developers can write scripts to perform tasks like data manipulation, file processing, or interacting with REST APIs.
Live Reload: Spring Boot CLI offers live reloading functionality, which automatically restarts the application whenever changes are detected in the source code. This feature accelerates development by reducing the turnaround time for testing and iterating changes.
6. Summary:
Spring Boot simplifies application development by providing convention-based configuration, externalized properties, and annotation-driven programming.
Starters streamline the setup process by bundling dependencies and auto-configuration for common use cases.
Auto-configuration automatically configures beans and components based on the classpath and environment, reducing manual setup.
The Spring Boot CLI offers command-line tools for project generation, Groovy scripting, and live reloading, enhancing developer productivity.
| oloruntobi600 | |
1,863,609 | best digital marketing institute near saket | A post by Dizital Adda | 0 | 2024-05-24T06:21:44 | https://dev.to/dizital_adda/best-digital-marketing-institute-near-saket-177l |
 | dizital_adda | |
1,863,607 | AWS Core Services - Networking | When you run an application using cloud, firstly you have to connect your resources to the cloud and... | 0 | 2024-05-24T06:17:34 | https://dev.to/mrugank/aws-core-services-networking-5fn7 | aws, cloud, networking | When you run an application using cloud, firstly you have to connect your resources to the cloud and then end-users will connect to your application.All of this comes under the concept of Networking. To understand how networking works on AWS, we have to understand how Amazon VPC works.
## Amazon VPC

It is a private network space to launch your resources on cloud in order to run your application. Amazon VPC provides a logical isolation to your application. You can control the in-out traffic of Your Amazon VPC. You can also control the way you want to connect to other networks.
More than one VPCs can be launched from your AWS account. You can use those multiple VPCs to launch different workloads. You can also configure the way packets travel through the layers of your network.
## Amazon Route 53

Route 53 is a scalable domain name service (DNS).It has 3 functionalities namely domain registration, DNS routing and health checking. DNS service translates the domain names into IP Addresses. With the help of Route 53, you can purchase and manage the domain names and can also configure DNS settings. Route 53 provides you multiple routing options.
### Amazon ELB

Elastic Load Balancer(ELB) is a DNS Service. It automatically distributes the incoming network traffic between multiple EC2 instances. It is single point of contact to your application. Because of ELB, the users do not need to be aware that how many machines your application is running on. | mrugank |
1,863,608 | YOLOv9 vs. YOLOv8: Segmentation & Fine-Tuning Guide | Introduction The YOLOv9 model for object segmentation was released recently, offering... | 0 | 2024-05-24T06:16:33 | https://dev.to/tarek_eissa/yolov9-vs-yolov8-segmentation-fine-tuning-guide-3pi5 | computerscience, vision, python, tutorial | ## Introduction
The YOLOv9 model for object segmentation was released recently, offering superior performance to the previous YOLOv8 model. This article will compare YOLOv8 and YOLOv9, showcase YOLOv9 segmentation, and include a guide for fine-tuning YOLOv9 on your own datasets.
## Comparison and Showcase
In this section, we will compare YOLOv8 and YOLOv9 performance and quickly showcase YOLOv9 segmentation.
### YOLOv8 vs. YOLOv9
The new YOLO model uses techniques such as Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN) to improve performance.

YOLOv9 demonstrates improved accuracy and efficiency for object segmentation, achieving higher precision and recall rates compared to YOLOv8【12†source】【13†source】.
### Demo
YOLOv9e segmentation demo:
{% youtube ZF7EAodHn1U %}
## Training
It’s possible to train YOLOv9 on your own segmentation data. The process can be divided into three steps: (1) Installation, (2) Dataset Creation, and (3) Fine-tuning/Training.
### Installation
Begin by installing the Ultralytics framework:
```bash
pip install ultralytics
```
### Dataset
Choose or create the dataset you need. The dataset needs to be in YOLO segmentation format, meaning each image shall have a corresponding text file (.txt) with the following content:
```
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>
...
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>
```
After finding a dataset and completing the image annotations, organize the dataset in the following way:
```
path/to/dataset/
├─ train/
│ ├─ img_0000.jpg
│ ├─ img_0000.txt
│ ├─ ...
│ ├─ img_0999.jpg
│ ├─ img_0999.txt
├─ val/
│ ├─ img_1000.jpg
│ ├─ img_1000.txt
│ ├─ ...
│ ├─ img_1099.jpg
│ ├─ img_1099.txt
```
### Fine-Tuning
This section is for you if you want to train YOLOv9 on your custom data. If you’re just looking to use the model, skip ahead to the section Inference and Segmentation.
First, begin by creating a training configuration file:
```yaml
# train.yaml
path: path/to/dataset
train: train
val: val
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush
```
The configuration file shall contain the paths to the training and validation sets, class names, and class mapping.
Finally, train the model using the Ultralytics framework:
```python
from ultralytics import YOLO
model = YOLO("yolov9c-seg.yaml")
model.train(data="path/to/train.yaml", epochs=100)
```
Make sure to use the correct segmentation model depending on your time constraints and hardware:
- `yolov9c-seg.yaml`
- `yolov9e-seg.yaml`
### Best Practices
If you want to optimize the training performance, read this guide:
[YOLOv8: Best Practices for Training](https://medium.com/@tarekeesa7/latest-yolov8-yolov9-guide-for-hyperparameter-tuning-and-data-augmentation-2024-469c69f295e0)
## Inference and Segmentation
Run inference:
```python
results = model("images/sofa.jpg")
```
Plot segmented masks:
```python
import numpy as np
import matplotlib.pyplot as plt
import cv2
for result in results:
height, width = result.orig_img.shape[:2]
background = np.ones((height, width, 3), dtype=np.uint8) * 255
masks = result.masks.xy
for mask in masks:
mask = mask.astype(int)
cv2.drawContours(background, [mask], -1, (0, 255, 0), thickness=cv2.FILLED)
plt.imshow(background)
plt.title('Segmented objects')
plt.axis('off')
plt.show()
plt.imsave('segmented_objects.jpg', background)
```
Plot segmentation mask with original colors:
```python
import cv2
import numpy as np
import matplotlib.pyplot as plt
for result in results:
height, width = result.orig_img.shape[:2]
background = np.ones((height, width, 3), dtype=np.uint8) * 255
masks = result.masks.xy
orig_img = result.orig_img
for mask in masks:
mask = mask.astype(int)
mask_img = np.zeros_like(orig_img)
cv2.fillPoly(mask_img, [mask], (255, 255, 255))
masked_object = cv2.bitwise_and(orig_img, mask_img)
background[mask_img == 255] = masked_object[mask_img == 255]
background_rgb = cv2.cvtColor(background, cv2.COLOR_BGR2RGB)
plt.imshow(background_rgb)
plt.title('Segmented objects')
plt.axis('off')
plt.show()
cv2.imwrite('segmented_objects.jpg', background)
```
## Bonus: Comparison with Other Technologies
Let's briefly compare YOLO with another popular computer vision technology, such as Mask R-CNN, in terms of performance and ease of use.
- **Performance**: YOLO models are generally faster but might be less accurate for complex segmentation tasks compared to Mask R-CNN.
- **Ease of Use**: YOLO is simpler to set up and use for real-time applications, while Mask R-CNN can be more complex but offers finer segmentation.
## Word of the Day
**Generalized Efficient Layer Aggregation Network (GELAN)** - A technique used in YOLOv9 to enhance model performance by efficiently aggregating information across layers.
## Conclusion
YOLOv9 offers significant improvements over YOLOv8, particularly in accuracy and efficiency for object segmentation tasks. Training and fine-tuning your own YOLOv9 model can be straightforward with the right dataset and tools. Don't hesitate to experiment and share your results!
## Limitations:
The limitation of YOLO algorithm is that it struggles with small objects with in the image. The algorithm might not be able to detect very small object in the image, due to spatial constraints of the algorithm.
## Courses & Projects
- YOLOR Pro: [course link](https://www.augmentedstartups.com/YOLOR-Object-Detection-Course)
- YOLOR Streamlit Dashboard: [project link](https://store.augmentedstartups.com/9ace9ef5-bf2d-4a95-b081-d4346d7a75bd
- Mask Detection using YOLOR: [project link](https://store.augmentedstartups.com/ce7f835c-9350-4ec3-8a0d-1bc5734c8dd6)
- Weeds Detection using YOLOR: [project link](https://store.augmentedstartups.com/5224b9df-e354-4798-aacb-3c0737754297)
- Car Counting on Lane using YOLOR: [project link](https://store.augmentedstartups.com/47fee7f9-dc1b-4df4-97e7-d8cdc0e491f5)
---
Feel free to ask any questions in the comments or reach out to me on [Medium](https://medium.com/@tarekeesa7). Your feedback is valuable and helps me create better content for you.
Happy learning and coding! | tarek_eissa |
1,863,612 | Remove all node_modules folder from PC | A short guide to remove tool from node_modules folder | 0 | 2024-05-24T06:14:00 | https://dev.to/kuldeepdev407/remove-all-nodemodules-folder-from-pc-1062 | nodemodules, node, javascript, python | ---
title: Remove all node_modules folder from PC
published: true
description: A short guide to remove tool from node_modules folder
tags:
- nodemodules
- node
- javascript
- python
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
published_at: 2024-05-24 06:14 +0000
---
If you ever thing that there are a lot of project you are working and you have lot of node_modules folder you have to delete to save up space when you only have 512SSD.
Here is a python script for deleting all those `node_modules` folder.
```python
import os
import argparse
import shutil
all_node_path = []
block_path = ['$RECYCLE.BIN','System Volume Information']
def getNodeModulesPaths(path):
try:
with os.scandir(path) as entries:
for entry in entries:
if entry.is_dir():
if(entry.name == 'node_modules'):
all_node_path.append(entry.path)
elif(entry.name in block_path):
continue
else:
getNodeModulesPaths(path+'/'+entry.name)
return 1
except Exception as e:
print(f"An error occurred: {e}")
return []
def remove_directory(directory_path):
try:
shutil.rmtree(directory_path)
print(f"'{directory_path}' removed successfully.")
except OSError as e:
print(f"Error: {directory_path} : {e.strerror}")
def main():
# arguments
args_parser = argparse.ArgumentParser(description="CLI tool for removing all node_module folder for given path")
args_parser.add_argument('-p', '--path', required=True, type=str,help="full path from where you want to remove node_module ")
args = args_parser.parse_args()
getNodeModulesPaths(args.path)
for path in all_node_path:
print(path)
total_paths = len(all_node_path)
confirm_rm = input("Are you sure you want to delete above "+str(total_paths)+" folder(y/n):").lower()
if(confirm_rm == 'y'):
for path in all_node_path:
remove_directory(path)
print("Removed "+str(total_paths)+' node_modules successfully!')
return 1
if __name__ == "__main__":
main()
```
## How to use it
Just run `python main.py -p '<pathtofolder>'` it is going to scan all node_modules folder in path and going to delete them.
> Run it carefully also check the folders before confirming
Here is GitHub link for repo: [github.com/kuldeepdev407/rm_node_modules](https://github.com/kuldeepdev407/rm_node_modules)
If i missed something in code feel free to create Issue Or PR.
| kuldeepdev407 |
1,863,606 | Working with non-critical data - Azure Files and Azure Blobs | Launch portal.azure.com In the Azure portal, search for and select Resource groups. Select +... | 0 | 2024-05-24T06:11:57 | https://dev.to/olawaleoloye/guided-project-azure-files-and-azure-blobs-noncritical-data-23m3 | **Launch** _[portal.azure.com](portal.azure.com)_
In the Azure portal, **search** for and select _Resource groups_.
**Select + Create.**
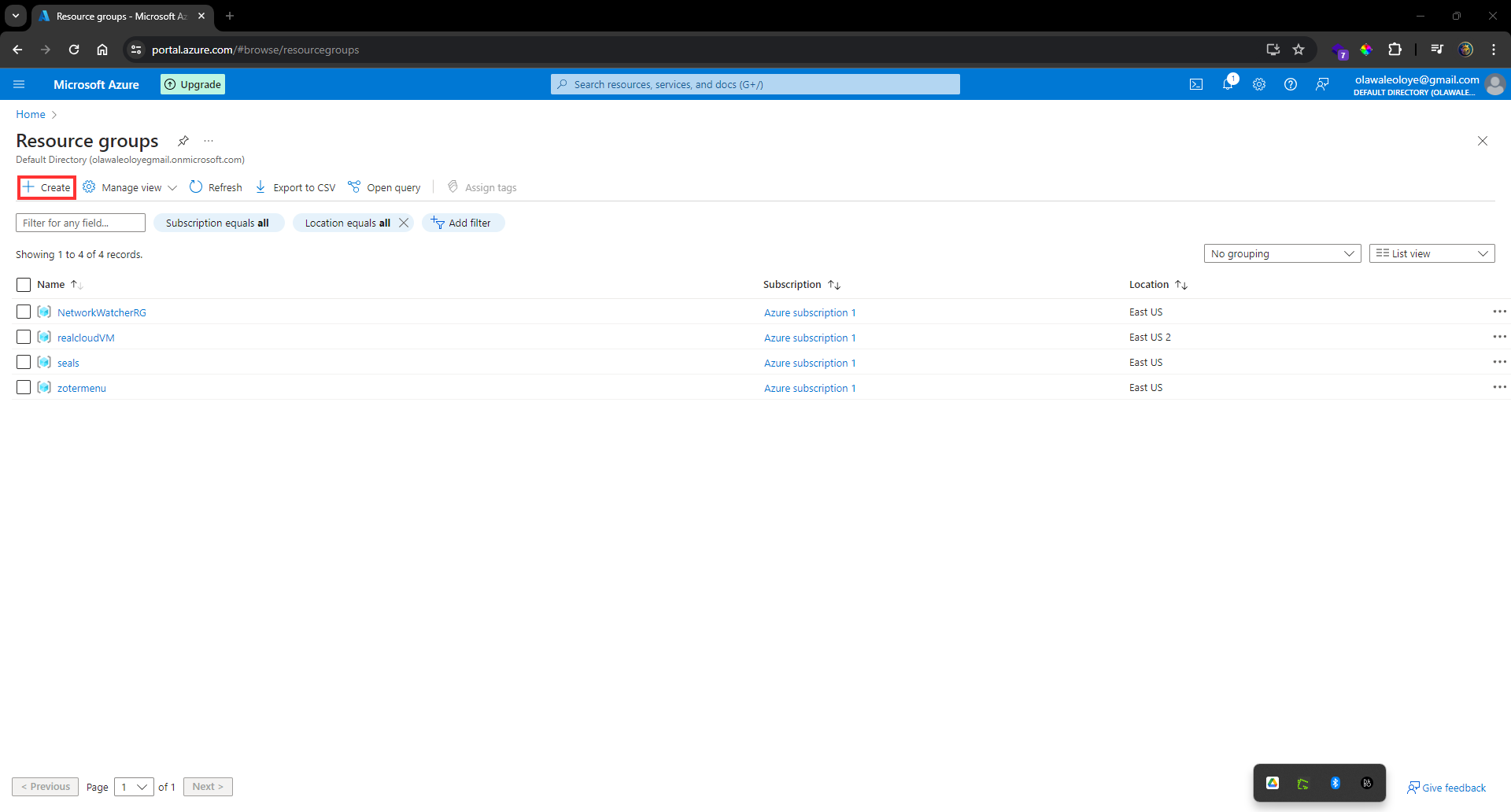
**Give** your _resource group_ a name. For example, **storagerg**.
**Select** a _region_.
> Use this region throughout the project
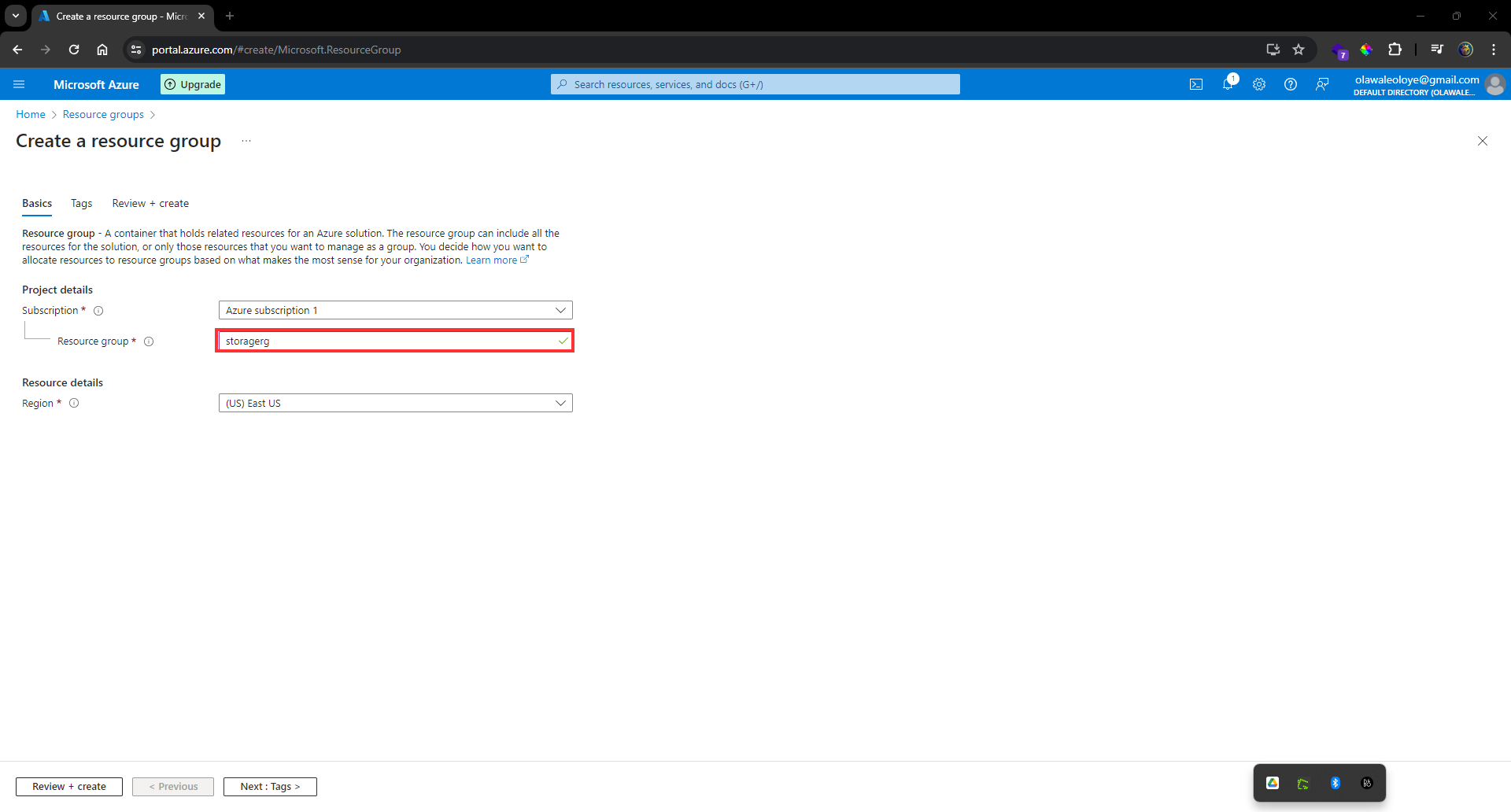
**Select** _Review and create_ to **validate** the resource group.
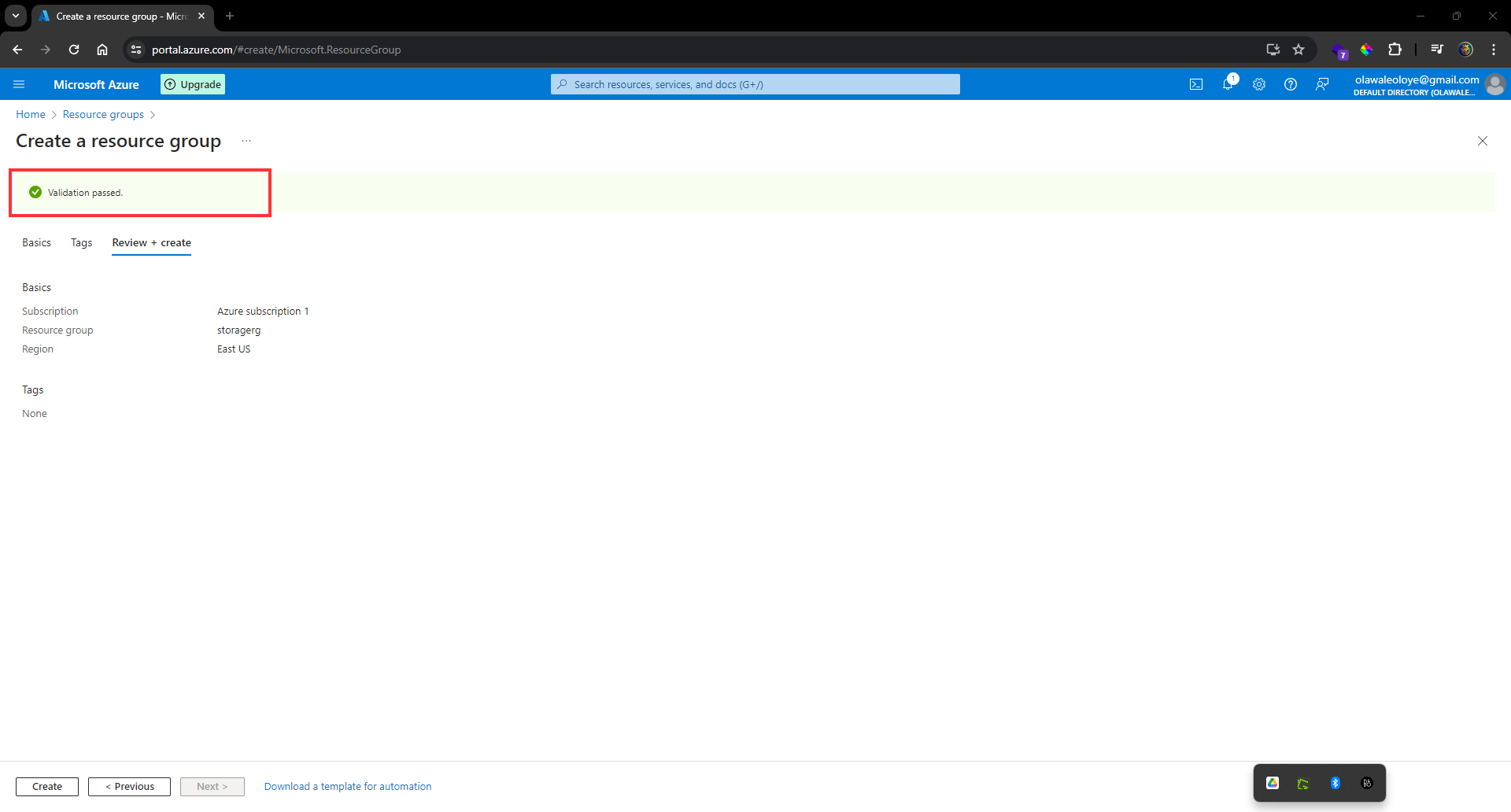
**Select** _Create_ to deploy the resource group.
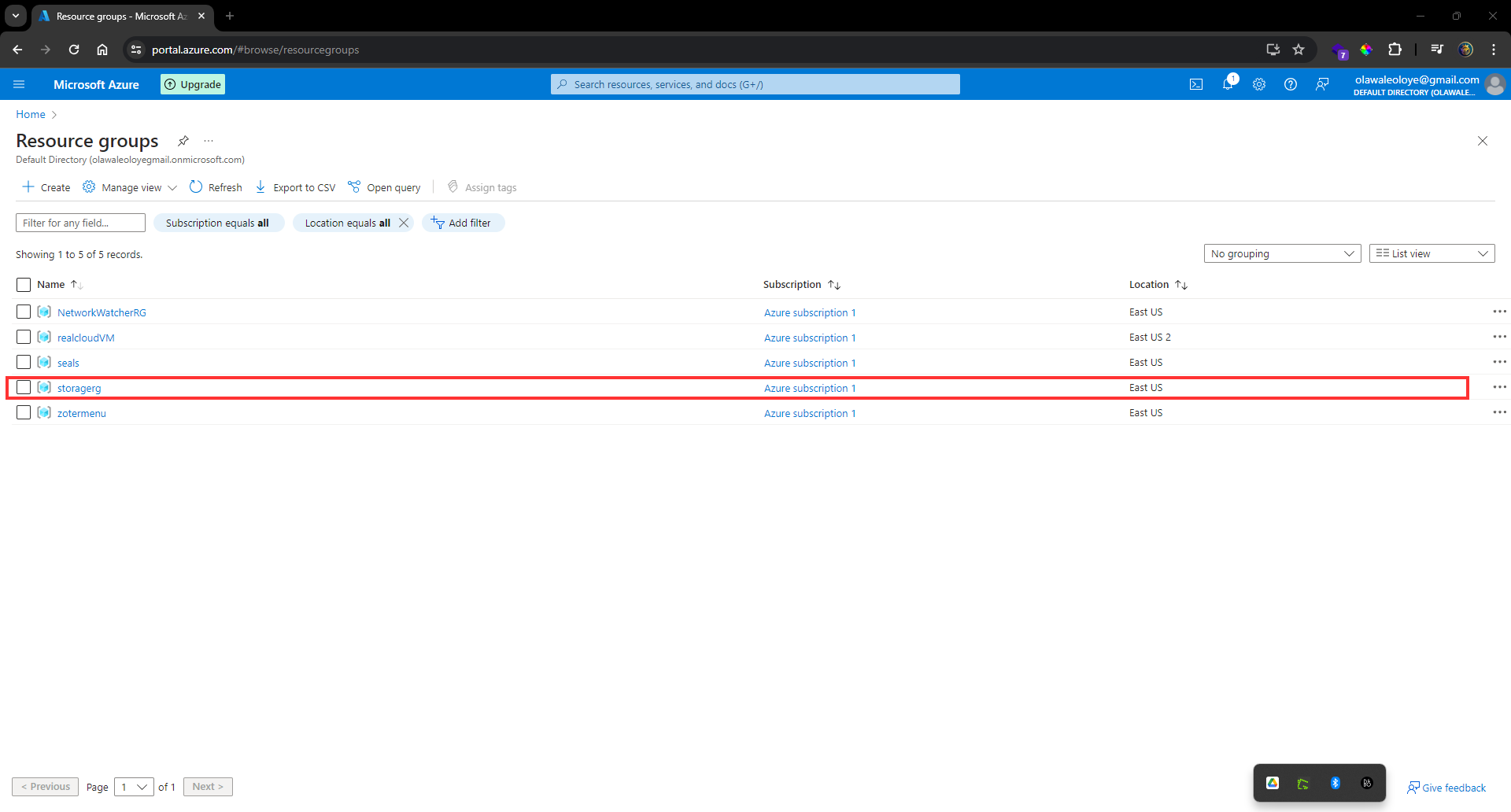
In the Azure portal, **search** for and select _Storage accounts_.
**Select + Create.**
On the **Basics** tab, select your **Resource group**.
**Provide** a _Storage account name_. The storage account name must be unique in Azure.
**Set** the **_Performance_** to _Standard_.
**Select** _Review_, and then _Create_.
Wait for the storage account to deploy and then Go to resource.
In your storage account, in the **Data management** section, select the **Redundancy** blade.
**Select** _Locally-redundant storage (LRS)_ in the Redundancy drop-down.
In the Settings section, select the Configuration blade.
Ensure **Secure transfer** required is _Enabled_.
Ensure the **Minimal TLS version** is set to _Version 1.2._
Ensure **Allow storage account key access** is _Disabled_.
In the Security + networking section, select the Networking blade.
Ensure **Public network access** is set to _Enabled from all networks_.
| olawaleoloye | |
1,863,605 | Figma Resource: Your Partner in Free Design Excellence | FIGMA RESOURCE stands out as a premier platform for free design resources, catering to the needs of... | 0 | 2024-05-24T06:11:55 | https://dev.to/figma_resource_3b8c363193/figma-resource-your-partner-in-free-design-excellence-4234 | [FIGMA RESOURCE](https://figmaresource.com/) stands out as a premier platform for free design resources, catering to the needs of modern designers. The site regularly updates its collection, ensuring access to the latest trends and tools in the design world. Whether you're working on a personal project or a professional assignment, Figma Resource has the free assets you need to excel.
| figma_resource_3b8c363193 | |
1,863,604 | Laboratory Centrifuge Market Insights on Scope and Growing Demands | Laboratory Centrifuge Market was valued at US$ 2.52 Bn. in 2023. The Global Laboratory Centrifuge... | 0 | 2024-05-24T06:10:14 | https://dev.to/maximize_shraddha_5505538/laboratory-centrifuge-market-insights-on-scope-and-growing-demands-44km | laboratory, centrifuge, market | Laboratory Centrifuge Market was valued at US$ 2.52 Bn. in 2023. The Global Laboratory Centrifuge Market size is estimated to grow at a CAGR of 4 % over the forecast period.
Laboratory Centrifuge Market Overview
The prominent global market intelligence firm has unveiled its latest market research report focusing on the Laboratory Centrifuge Market. The comprehensive report presents descriptive data and pictographs depicting the analysis of both regional and global markets. Moreover, the report delves into the market's objectives, shedding light on leading competitors, their market value, current trending skims, strategies, targets, and products. It also highlights the recent growth of the market and provides valuable insights into its informative past.
Laboratory Centrifuge Market Scope: https://www.maximizemarketresearch.com/inquiry-before-buying/39476
The research report delves deeply into the analysis of trending competitors, their market growth, and dynamic patterns. It offers valuable insights into the regional and global values and demands of the market. Furthermore, it aids in comprehending the competitive landscape and market potential in terms of production demand and supply. The segmentation analysis includes crucial factors such as psychographic, demographic, geographic, and behavioral segmentation. These factors play a pivotal role in shaping marketing strategies, focused and targeted products, offers, and customer experiences. Porter's analysis is utilized to gauge an organization's competitive position strength, aiming to enhance profitability. Additionally, Pestle analysis is conducted to assess the validity of existing products and services in the contextual data. The SWOT analysis provides an evaluation of internal and external factors contributing to a company's advantages, disadvantages, strengths, and weaknesses. Overall, this report offers comprehensive and informative data on the Laboratory Centrifuge market overview.
Access a Free Sample Report: https://www.maximizemarketresearch.com/request-sample/39476
Segmentation
Benchtop and floor-standing centrifuges are the two categories into which the laboratory centrifuges market is divided depending on model type. The most market share was held by the benchtop centrifuges category since these rotators are clever, versatile, easy to use, smaller in size, and substantially lower in weight. Due to these advantages, their use in the centrifuge market has increased.
The laboratory centrifuges market is divided into four segments depending on rotor design: vertical rotors, fixed-angle rotors, swinging-bucket rotors, and other rotors. The lab axis hardware market's highest share in 2022 was held by the fixed-point rotors segment. Expanding protein research initiatives and the advantages of fixed-point rotors, such quick runtime and superior resolution, are
Key Players
1. Thermo Fisher Scientific, Inc.
2. Danaher Corporation
3. Eppendorf AG
4. KUBOTA Corporation
5. Sigma Laborzentrifugen GmbH
6. Andreas Hettich GmbH & Co.KG
7. NuAire
8. QIAGEN N.V.
9. Sartorius AG
10. HERMLE Labortechnik GmbH
11. Cardinal Health
12. Centurion Scientific
13. Bio-Rad Laboratories, Inc.
14. Agilent Technologies
15. Haier Biomedical
Regional Analysis
The report delivers formal, functional, and vernacular regional analysis. It identifies the most impactful business areas based on the highest demand in different regions, including Asia Pacific, North America, Latin America, the Middle East, Europe, and Africa. The analysis provides valuable insights into distinct targets, strategies, and market values for each region.
Key Questions Addressed in the Laboratory Centrifuge Market Report:
What characterizes the Laboratory Centrifuge Market?
What is the forecast period for the Laboratory Centrifuge Market?
How does the competitive scenario look in the Laboratory Centrifuge Market?
Which region holds the largest market share in the Laboratory Centrifuge Market?
What opportunities are available in the Laboratory Centrifuge Market?
What factors influence the growth of the Laboratory Centrifuge Market?
Who are the key players in the Laboratory Centrifuge Market?
Which company holds the largest share in the Laboratory Centrifuge Market?
What will be the CAGR of the Laboratory Centrifuge Market during the forecast period?
What key trends are expected to emerge in the Laboratory Centrifuge Market in the upcoming years?
Key Offerings:
Market Share, Size, and Forecast by Revenue|2024-2030
Market Dynamics - Growth drivers, Restraints, Investment Opportunities, and key trends
Market Segmentation: A detailed analysis by Laboratory Centrifuge Market
Landscape - Leading key players and other prominent key players.
About Maximize Market Research:
Maximize Market Research is a versatile market research and consulting company, staffed with professionals from various industries. Our coverage extends to medical devices, pharmaceutical manufacturers, science and engineering, electronic components, industrial equipment, technology, communication, automotive, chemical products, general merchandise, beverages, personal care, and automated systems, among others. Our services encompass market-verified industry estimations, technical trend analysis, crucial market research, strategic advice, competition analysis, production and demand analysis, and client impact studies.
Contact Maximize Market Research:
3rd Floor, Navale IT Park, Phase 2
Pune Bangalore Highway, Narhe,
Pune, Maharashtra 411041, India
sales@maximizemarketresearch.com
+91 96071 95908, +91 9607365656
 | maximize_shraddha_5505538 |
1,863,602 | Lime house sushi & ramen | Lime House Sushi & Ramen Where fast casual meets Burmese-inspired delights. With high-quality... | 0 | 2024-05-24T06:05:12 | https://dev.to/limehouse12/lime-house-sushi-ramen-40a8 | limehouse, hamburg, newyork | [**Lime House Sushi & Ramen**](https://limehousefranchise.com/) Where fast casual meets Burmese-inspired delights. With high-quality ingredients and affordable prices, indulge in a modern culinary journey. Join us and savor the flavors of innovation and tradition, all under one roof. | limehouse12 |
1,860,915 | Is Serverless Architecture Right For You? | We’re in the age of serverless. Serverless functions, serverless storage, serverless gateways,... | 0 | 2024-05-24T06:00:00 | https://www.getambassador.io/blog/is-serverless-architecture-right-for-you | severless, architecture | We’re in the age of serverless. Serverless functions, serverless storage, serverless gateways, serverless everything.
Serverless computing has revolutionized the way we build and deploy applications. In 2023, the global market for serverless architecture was over [$15 billion.](https://www.linkedin.com/pulse/serverless-architecture-market-size-share-growth-report-the-technoiva-xqwpc/) This will only grow as more and more use cases for this technology are found.
But even as serverless grows and benefits organizations, that doesn’t automatically mean it will work for you. It’s common for developers to jump on the latest technologies. Serverless works well for the specific use cases it was built for, but sometimes organizations can waste a lot of time and resources going down the serverless rabbit hole only to find it doesn’t fit what they are trying to do.
## The Benefits of Serverless Architecture
Let's start with why you might choose a serverless architecture.
The first reason is that serverless architectures are inherently scalable and elastic. They automatically scale up or down based on the incoming workload without requiring manual intervention through serverless compute services like [AWS Lambda,](https://aws.amazon.com/lambda/) [Azure Functions](https://azure.microsoft.com/en-gb/products/functions/), or [Google Cloud Functions.](https://cloud.google.com/functions)
Benefits of Serverless Architecture
(Source: Datadog)
These services dynamically allocate resources to handle incoming requests, ensuring that your application can handle sudden spikes in traffic or usage. Each function is triggered by an event, such as an HTTP request, and scales automatically based on the incoming workload. This eliminates the need for over-provisioning resources and allows your application to scale precisely to meet the demand, providing a highly responsive and efficient system.
This then leads to cost-effectiveness. With serverless, you only pay for the actual execution time and resources consumed by your application. There is no need to pay for idle server time or unused capacity. Serverless platforms charge based on the number of requests, execution duration, and memory usage, allowing for fine-grained billing.
This pay-per-use model can lead to significant cost savings, especially for applications with variable or unpredictable workloads. It eliminates the need to invest in and maintain expensive infrastructure, making it particularly attractive for startups and small to medium-sized businesses.
Cost-effectiveness also comes from reduced operational overhead. Serverless architectures abstract away the underlying server infrastructure, relieving developers and operations teams from the burden of managing servers. The cloud provider provides provisioning, scaling, patching, and maintaining the servers, allowing teams to focus on writing and deploying code. Serverless platforms are fully managed by the cloud provider, reducing operational overhead for developers.
It can also lead to increased development speed. Serverless architectures enable faster development cycles and quicker time-to-market. Serverless computing has streamlined application development by abstracting away infrastructure concerns. With serverless, developers can focus on writing modular, event-driven functions that perform specific tasks rather than worrying about the underlying infrastructure. Serverless allows developers to build applications by composing individual functions, each responsible for a specific task. Each function encapsulates a piece of business logic and can be independently developed, tested, and deployed. This modular approach promotes code reusability and allows for parallel development, as different team members can work on separate functions independently.
## The Limitations of Serverless Architecture
One of the most commonly cited drawbacks of serverless functions is cold start latency. When a function has not been invoked for a certain period, the cloud provider may release its allocated resources. Consequently, when a new request comes in, the function needs to be initialized again, leading to increased latency. This cold start latency can be particularly noticeable for tasks with significant dependencies or requiring extensive setup.
You see different cold start latencies with different runtimes. In their T[he State of Serverless report, ](https://www.datadoghq.com/state-of-serverless/#5)Datadog found that Java runtimes can be 2.7X slower than Python or Node.js serverless functions.
Serverless functions can have other performance issues. Functions typically have a maximum execution time limit, varying depending on the cloud provider. For example, AWS Lambda functions have a maximum execution time of [15 minutes](https://blog.awsfundamentals.com/lambda-limitations). This limit can be restrictive for long-running or compute-intensive tasks. Additionally, serverless functions may have limitations on the package size (e.g., [100MB uncompressed for Google Cloud Functions](https://cloud.google.com/functions/quotas)) and the amount of memory (e.g., [1.5GB for Azure Functions](https://learn.microsoft.com/en-us/azure/azure-functions/functions-scale#service-limits)) they can utilize. These constraints can impact the performance of specific workloads and may require architecting the application differently to work within these limitations.
Performance issues can also be worse because debugging and monitoring are more complex than traditional server-based applications. Since serverless functions are ephemeral and only run when triggered, traditional debugging techniques may not be applicable. Developers rely on logs, traces, and distributed tracing to troubleshoot issues. The distributed nature of serverless architectures can make gaining a holistic view of the application's behavior challenging. Serverless platforms provide monitoring and logging capabilities but may not be as comprehensive as the tools available for server-based applications.
## The final two issues you see come down to control:
**Limited control over infrastructure:** This is the inverse of the reduced operational overhead benefit. Serverless architectures abstract away the underlying infrastructure, meaning developers have limited control over the environment in which their functions run. This lack of control can be challenging when dealing with specific performance requirements, such as CPU or memory-intensive tasks. Additionally, serverless platforms may have restrictions on the runtime environments, supported languages, and available libraries, which can limit flexibility in certain scenarios.
**Vendor lock-in: **Serverless architectures depend heavily on the cloud provider's ecosystem and proprietary services. As a result, migrating serverless applications from one cloud provider to another can be challenging. Each provider has its own serverless services, APIs, and tooling, which can lead to vendor lock-in.
Obviously, you have to weigh these limitations against the benefits of serverless architecture and consider them in the context of your specific application requirements. While serverless can be a powerful approach for particular use cases, it won’t best suit every scenario.
## 5 Cases Where Serverless is Not Ideal
Let's explore some situations where serverless might not be the ideal choice:
**1. Long-running tasks
**Serverless functions are designed to execute quickly and have a maximum execution time limit, such as the 15-minute limit on the AWS Lambda. Function as a Service (FaaS) is a key component of serverless architecture, allowing developers to deploy individual functions without managing the underlying infrastructure. If your application requires tasks that take longer than the specified limit, serverless may not be suitable. Long-running tasks, such as complex data processing, video encoding, or scientific simulations, may not be appropriate. For example, a video encoding application must process high-resolution videos and apply complex transformations.
The encoding process can take several hours, making it unsuitable for serverless functions with limited execution time. These types of processing are better suited for traditional server-based architectures or [distributed computing](https://www.getambassador.io/blog/build-resilient-microservices) frameworks like Apache Spark.
Serverless platforms enforce these time limits to ensure efficient resource utilization and prevent individual functions from monopolizing resources. Exceeding the execution time limit will result in the function being forcibly terminated. For instance, if you have a serverless function that needs to process large datasets or perform complex mathematical computations that take hours, it would not be feasible to implement it within the serverless execution time constraints.
**2. High-performance computing
**Serverless functions are not optimized for high-performance computing (HPC) workloads that require extensive computational power or specialized hardware.
If your application demands consistent high performance, such as real-time gaming, high-frequency trading, or machine learning model training, serverless may not provide the necessary performance characteristics. With a real-time multiplayer gaming application that requires low-latency communications and high-performance processing to handle game physics and player interactions, serverless functions may not provide the necessary performance and responsiveness for such applications.
Serverless platforms typically do not offer direct access to high-performance hardware, such as GPUs or FPGAs, which are often required for computationally intensive tasks. Additionally, the inherent latency introduced by the serverless architecture, such as cold starts and network overhead, can impact the performance of latency-sensitive applications.
**3. Predictable and consistent workloads
**Serverless architecture is ideal for applications with variable and unpredictable workloads. However, serverless may not be the most cost-effective choice if your application has a predictable and consistent workload. With serverless, you pay for each function invocation and the associated resources consumed. If your application has a steady and predictable traffic pattern, using traditional server-based architectures with pre-provisioned resources might be more cost-efficient.
An example is a backend API service for an enterprise application with a consistent and predictable traffic pattern, serving a fixed number of clients with known request volumes. In this case, monitoring usage and provisioning dedicated servers with appropriate capacity may be more cost-effective than serverless functions.
**4. Complex and resource-intensive applications
**Serverless functions have limitations on package size, memory usage, and execution time. If your application is complex and requires extensive resources, serverless may not be the best fit. Applications with large codebases, numerous dependencies, or resource-intensive tasks may exceed the limits imposed by serverless platforms. Traditional server-based architectures or containerization technologies like Kubernetes may be more suitable in such cases.
Serverless platforms restrict the package size of the deployed functions to optimize performance and reduce cold start times. So, a complex data processing pipeline involves multiple stages and large libraries and requires gigabytes of memory to process big datasets. The resource requirements may exceed the limits of serverless platforms, making it more suitable to run on a cluster of servers or using distributed processing frameworks.
**5. Regulatory and compliance requirements
**Some industries have strict regulatory and compliance requirements that may be challenging to meet with serverless architectures. For example, a healthcare application that processes patient data needs to comply with HIPAA regulations. While serverless platforms may provide HIPAA-compliant services, developers must ensure that their application code and data handling practices adhere to the required security and privacy standards, which can be complex and require specialized expertise.
Serverless platforms operate on a shared responsibility model, where the cloud provider secures the underlying infrastructure. At the same time, the developers are responsible for the security of their application code and data. Compliance with HIPAA, PCI DSS, or GDPR regulations may require additional measures, such as data encryption, access controls, and auditing, which developers need to implement and manage themselves.
## Alternatives to Serverless Architecture
The most obvious alternative to serverless architecture is a traditional server-based architecture. Traditional server-based architecture involves deploying and running applications on a physical server or virtual servers you manage and maintain. This approach gives you complete control over the underlying infrastructure, including the operating system, runtime environment, and system resources.
**Three-Tier Architecture
**One typical pattern is the three-tier architecture, which consists of a presentation tier (frontend), an application tier (backend), and a data tier (database). Each tier runs on dedicated servers, and you are responsible for provisioning, scaling, and managing these servers. Based on your application's requirements, you can choose the appropriate server configurations, such as CPU, memory, and storage.
## Hybrid Approaches
Hybrid approaches combine serverless architecture with other computing models to leverage the strengths of each. This allows you to use serverless for certain parts of your application while using traditional servers or containers for different components requiring more control or specific requirements.
For instance, you can use serverless functions for event-driven and scalable tasks, such as image processing or data transformations, while using containers or virtual machines for stateful components or long-running processes. This hybrid approach allows you to optimize costs, performance, and flexibility based on the specific needs of different parts of your application.
Another example of a hybrid approach is using serverless functions for the frontend API layer while using managed services like Amazon RDS or Google Cloud SQL for the backend database. This combination allows you to benefit from the scalability and cost-effectiveness of serverless for the API layer while using a managed database service for persistent storage and transactional capabilities.
## Choosing the Right Architecture
When deciding between serverless architecture and its alternatives, it's crucial to consider various factors to ensure you select the approach that best aligns with your application's needs and your organization's goals. Here are the key considerations:
**Application requirements and characteristics:** Assess your application's specific requirements, such as scalability, performance, latency, and resource intensity. You should also consider the nature of your workloads, whether they are event-driven, long-running, or have predictable traffic patterns. Then, you can evaluate the need for real-time processing, data consistency, and transactional capabilities.
**Development team's expertise: **Consider your development team's skills and expertise in working with different architectures and technologies. Assess their familiarity with serverless platforms, containers, and traditional server-based architectures. Then, determine if additional training or hiring may be necessary to adopt a particular approach effectively.
**Cost considerations:** Evaluate the cost implications of each architecture based on your application's usage patterns and scale. Consider the pricing models of serverless platforms, which charge based on function invocations and resource consumption, and compare the costs of serverless servers with the expenses of running and maintaining traditional servers or containers.
**Future scalability and flexibility:** Assess your application's expected growth and evolution over time. Consider the scalability requirements and whether serverless architecture can accommodate future needs. Evaluate each approach's flexibility and portability, considering the potential for vendor lock-in and the ability to migrate if needed.
By carefully evaluating these factors and weighing the trade-offs, you can decide whether serverless architecture or its alternatives best suit your application's requirements and organizational goals. It's essential to conduct thorough research, engage in proof-of-concept testing, and consider the long-term implications of your architectural choice.
**Remember**: the right architecture depends on your specific context, and no one-size-fits-all solution exists. It's essential to regularly reassess your architecture as your application and business needs evolve and be open to adapting and refining your approach as necessary.
## Choose Serverless When It Is Right For You
We've explored the world of serverless architecture, examining its benefits and limitations. Serverless architectures offer unparalleled scalability, cost-effectiveness, reduced operational overhead, and increased development speed. These advantages make serverless an attractive choice for many applications, especially those with variable and unpredictable workloads.
However, it's crucial to recognize that serverless is not a one-size-fits-all solution. The key takeaway is the importance of evaluating your individual project needs. Before jumping on the serverless bandwagon, take the time to assess your application's requirements, consider your team's expertise, evaluate the cost implications, and think about future scalability and flexibility. Conduct thorough research, conduct proof-of-concept testing, and weigh the trade-offs to determine if serverless aligns with your goals and constraints.
Serverless architecture is a powerful tool in your arsenal, but it's not the answer for everyone. Choose serverless when it aligns with your project's requirements and goals, but don't be afraid to explore alternative architectures when necessary. By carefully evaluating your options and making informed decisions, you can build scalable, cost-effective, and well-suited applications to your specific needs. | getambassador2024 |
1,863,486 | 🌟 **Exploring Front End Development with HTML, CSS, and React.js** 🌟 | Hey everyone! Today, I want to dive into the exciting world of front-end development, focusing on... | 0 | 2024-05-24T02:31:20 | https://dev.to/erasmuskotoka/exploring-front-end-development-with-html-css-and-reactjs-k2p |
Hey everyone!
Today, I want to dive into the exciting world of front-end development, focusing on HTML, CSS, and React.js.
Whether you're just starting out or looking to expand your
skills, understanding these technologies is crucial for building
modern, responsive web applications. Let’s break it down!
HTML: The Foundation of Web Pages
HTML (HyperText Markup Language) is the backbone of any website. It structures the content on the web, defining elements like
headings, paragraphs, links, images, and more. Think of HTML as the skeleton of your web page, providing a solid foundation for everything that follows.
CSS: Adding Style and Layout
CSS (Cascading Style Sheets) is what makes your web page look good. It’s responsible for the design, layout, and overall visual aesthetics.
With CSS, you can change colors, fonts, spacing, and even create complex layouts with Flexbox and Grid.
React.js: Building Dynamic User Interfaces
React.js is a powerful JavaScript library for building user interfaces, particularly single-page applications where you need a dynamic, fast, and interactive user experience.
React allows you to create reusable components, manage state efficiently, and build complex UIs with ease.
Why Learn These Technologies?
1. HTML provides the structure and semantics for your content.
2. CSS enhances the visual presentation and layout.
3. React.js enables the creation of dynamic and interactive UIs.
Getting Started
- HTML: Start by learning the basic tags and structure. Build simple web pages to practice.
- CSS: Experiment with styling your HTML pages. Learn about selectors, properties, and responsive design techniques.
- React.js: Begin with the fundamentals of components, props, and state. Follow tutorials to build simple applications and gradually tackle more complex projects.
Resources to Help You Learn
- HTML & CSS: [MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web)
- React.js: [Official React Documentation](https://reactjs.org/docs/getting-started.html)
Feel free to reach out if you have any questions or need guidance. Happy coding! 💻🎨🚀
#CODEwith
#KOToka
| erasmuskotoka | |
1,863,601 | Database Replication Encyclopaedia — Single Leader Replication (1/3) | Replicated databases are the new reality of data based software applications. Gone are those days... | 0 | 2024-05-24T05:55:42 | https://dev.to/the_infinity/database-replication-encyclopaedia-single-leader-replication-13-2l5c | beginners, learning, database, architecture | Replicated databases are the new reality of data based software applications. Gone are those days when databases were confined to a single machine in a data centre. With the rise of distributed systems, database replication has become one of those topics which every developers should know.
If you are hearing the term ‘**_Database replication_**’ for the first time, let me summarise it for you in a single line as follows,
> Database replication is the process of maintaining several copies of data across several machines that are interconnected via a network.
_Why replicate database you may ask?_ There are several reasons to why distributed systems use replication. Some of the important ones are the following —
* _To keep data geographically closer to the users for reduced latency._
* _To increase fault tolerance and increase overall availability of the system._
* _To be able to scale out the number of machines that can server the read queries._
If the replicated data is constant and does not change over time, there is nothing to worry about. Simply replicate your data across nodes and you are done. Almost all of the complexities of database replication arise because of changing data!
To tackle these difficulties there are three popular approaches to database replications — **_Single Leader Replication_**, **_Multi-Leader Replication_**, and **_Leaderless replication_**. Almost all of the database systems out there use one of these three to achieve database replication. In this blog, we will be discussing the Single Leader Replication method.
## Single Leader Replication
Each machine that maintains a copy of the data is called a **replica**.
In single-leader replication, one of the replica is designated the Leader. The Leader is the one responsible for processing write operations received from the clients. It is also responsible for propagating the write operations to other replicas called follower.
While writes are only served by the leader, read requests can be served by both the leader and followers.
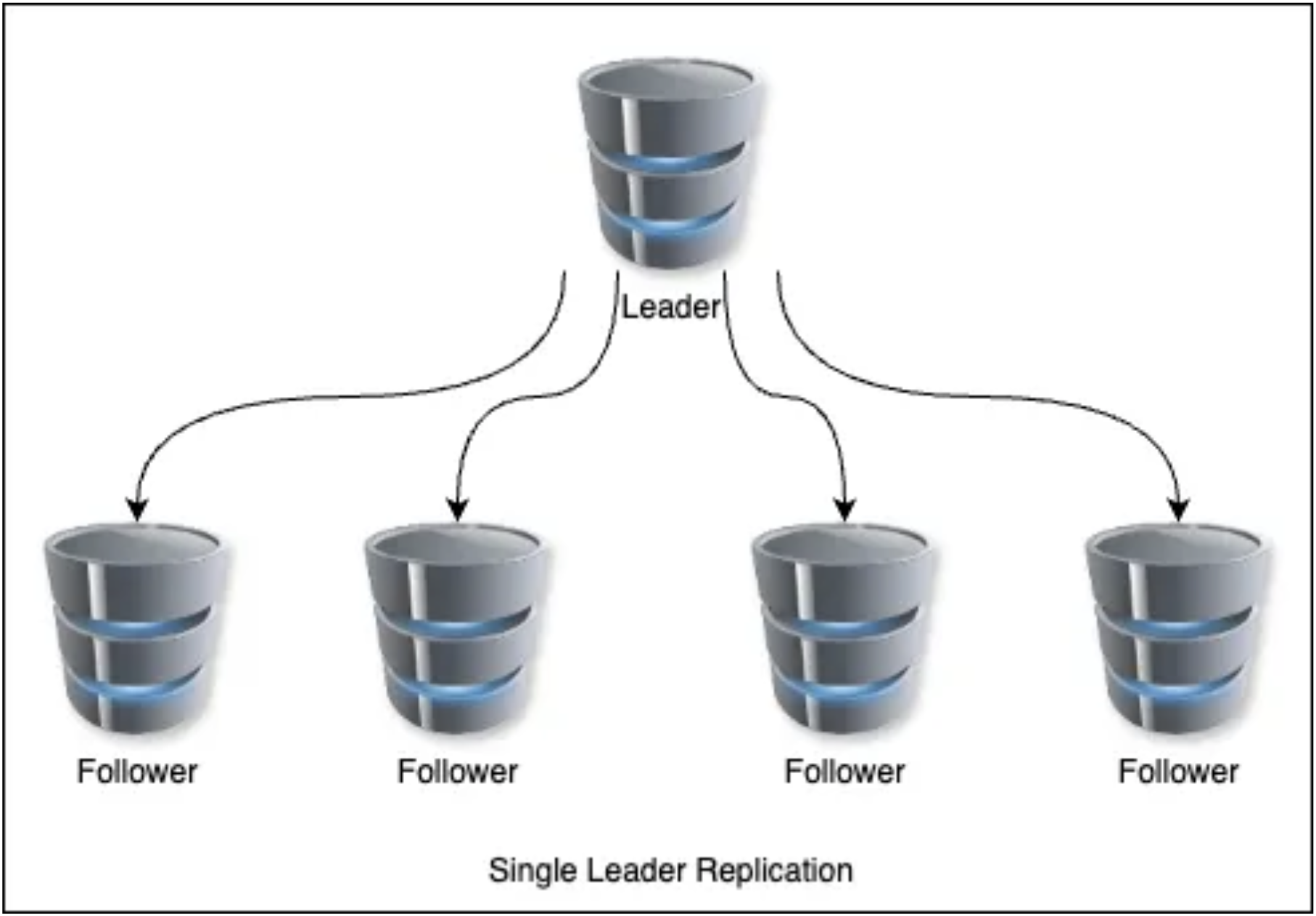
On receiving a write request from the client, the leader first updates its own local storage. It then sends the update request to followers, which on receiving the message from the leader update their own local storages. In this way, all write operations are ensured across replicas.
## Synchronous Vs Asynchronous Replication
Depending on how the updates from leader propagates to the follower, the replication is of two types — **Synchronous** and **Asynchronous**.
Under Synchronous replication, leader waits for followers to acknowledge the update. Once the leader ensures that the update has been successfully written to all the synchronous replicas and its own local storage as well, it sends success message in response to the client’s request. This replication method ensures that all of the replicas remain in-sync with the leader. Synchronous replication, however, is slow since all replicas must commit changes before the operation can be deemed successful. It is also susceptible to downtime owing to a single node failure.
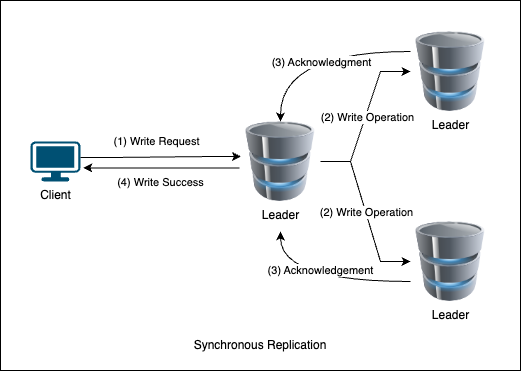
Under Asynchronous replication, leader does not wait for followers to process the write operation. Once the leader updates its own local storage, it sends a success message back to the client. In this setting, the system may not be consistent immediately but will be eventually consistent. Since the leader does not wait on followers to complete their work, updates are faster when compared to synchronous replication.

In practice, synchronous replication is characterised by a single follower being replicated synchronously while the other replicas are still replicated asynchronously. This ensures that there is always a follower with up-to-date data that can be made the leader in case the current leader fails. This type of replication is called **_semi-synchronous replication_**.
## Adding new Followers
Adding a new follower replica to the cluster requires some careful considerations. A copy operation on the leader’s database might not give us the correct result since leader is actively accepting write requests and its state is constantly evolving. This could result in corrupted data getting copied. Another option is to take a lock on the leader and then perform the copying operation. This is also not acceptable since it will cause downtime anytime a new follower has to be added.
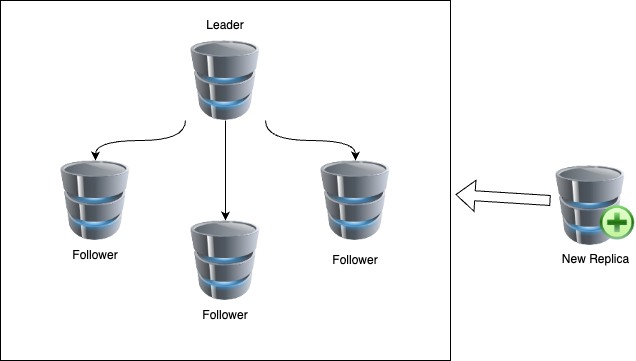
Instead, we can take a snapshot of the leader’s database. Most database provide this option for the purpose of backup. Restore the snapshot on the new follower’s database. Once the snapshot data is restored, follower can start asking the leader for changes that have occurred since the snapshot was taken. They can use Log Sequence Number (or LSN) to get that data from the leader.
Once the follower has done the catching-up process, it can continue working like the other followers.
## Handling Node Outages
It is common for nodes to drop out of the cluster. It can be because of network or machine failure, or it could be because of scheduled maintenance. Let us understand how node outages are handled in Single-Leader replication.
When a follower node goes down, the system can continue to work as usual. Read requests that were earlier served by the impacted node will now be served by other replicas. Later when the follower joins back, it can ask for the updates from the leader and can continue working normally.
Things become interesting in case of a leader failure. To keep the system in a working state, a new leader has to be elected. There are several algorithm by which the cluster can select the new leader replica. Once the new leader is elected, the client needs to be configured to send all write request to this new leader and all the followers should now accept update requests from this new leader.
## Issues arising from Replication Lag
Replication lag between the follower and the leader can lead to issues that would otherwise not occur in a single-machine database. These issues require careful considerations, especially when the database does not provide a mechanism to solve them.
### Read Your Own Writes
Consider the following scenario, a client sends an update request to the leader. As soon as the client receive a success response from the leader, it makes a read request to the cluster and receive a response from an asynchronous follower. Interestingly, the client will see its updates reverted. Therefore we must design applications that provide read-after-write consistency.
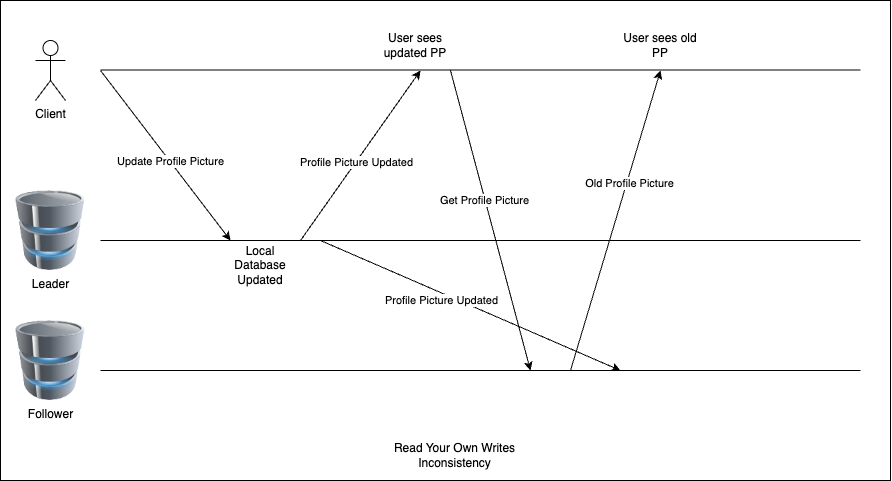
There are several possible ways in which we can provide read-after-write consistency in our application. Some of them are as follows —
* We can always use leader to respond for the data that a client may have updated. This obviously depends on being able to identify all the data that could be updated by a client.
* Another way is to make all reads from the leader until a certain time after a client makes any update. We can also monitor the replication lag on the followers and prevent queries on followers that lags more than a certain amount of time.
* Client may keep the timestamp of the update and this can then be used by the cluster to respond from replicas that are up-to-date until that point in time.
Same user accessing your cluster from different device poses new challenges. In such cases, we want to provide _cross-device read-after-write consistency_.
### Monotonic Reads
With multiple replicas having different replication lags, it is possible that a client, after making request to an up-to-date replica, makes a request to a replica with larger lag. In this situation, client would see an older state and for it the time would appear to go backward.
Monotonic reads is a guarantee that this kind of anomaly does not happen. One way of achieving it is to ensure that a client always reads from a particular replica. Though this is not the ideal solution since a replica may go down at any point in time.
---
Single leader replication is one of the most used replication techniques. When working with read-heavy workloads, single leader replication becomes a good solution since reads are distributes across replicas. This however becomes an issue when working with write heavy-workloads that can cause your leader to bottleneck.
With this we reach the end of this blog. If you learned something new, then follow me up for more such interesting reads! | the_infinity |
1,863,600 | Understanding FedEx Operational Delays: What You Need to Know and How to Manage Them | In today's fast-paced world, timely delivery of packages is crucial, whether you're running a... | 0 | 2024-05-24T05:54:57 | https://dev.to/thenexttech/understanding-fedex-operational-delays-what-you-need-to-know-and-how-to-manage-them-1nba | fedex, technology | In today's fast-paced world, timely delivery of packages is crucial, whether you're running a business or waiting for a personal shipment. However, even giants like FedEx can sometimes experience operational delays that throw a wrench in our plans. You know how frustrating it can be if you've ever tracked your package only to see the dreaded "operational delay" status. Let's dive into what FedEx operational delays mean, why they happen, and what you can do about them.
## What is a FedEx Operational Delay?
[FedEx operational delay](https://www.the-next-tech.com/supply-chain-management/fedex-operational-delay/) in the FedEx world is a status update indicating that your package is experiencing a temporary hold-up somewhere in the shipping process. This can occur at various stages, from the initial pick-up to the final delivery.
## Common Causes of FedEx Operational Delays
**Weather Conditions**
Severe weather like snowstorms, hurricanes, or heavy rain can disrupt transportation routes, making it unsafe or impossible for FedEx trucks or planes to operate.
**High Package Volume**
During peak seasons, such as the holidays, FedEx handles an immense volume of packages. This surge can overwhelm their infrastructure, leading to delays.
**Customs Clearance**
International shipments often face delays at customs. If there's an issue with documentation or if the package requires a more thorough inspection, it can be held up.
**Mechanical Issues**
Problems with delivery vehicles or planes, such as mechanical failures, can cause unexpected delays.
**Operational Bottlenecks**
Sometimes, packages get delayed due to internal bottlenecks at sorting facilities. This can be due to staffing shortages, technical issues, or logistical challenges.
## How to Handle a FedEx Operational Delay
**Stay Informed**
Regularly check the tracking status of your package on the FedEx website or app. FedEx updates the status in real time, providing the most current information available.
**Contact Customer Service**
If your package is significantly delayed, reaching out to FedEx customer service can provide more insight. They can offer updates that might not be available online and suggest next steps.
**Be Proactive**
If the delay impacts your business or personal plans, consider proactive measures such as notifying the recipient about the delay or making alternative arrangements if the package is time-sensitive.
**Plan Ahead**
Anticipate potential delays, especially during peak seasons or bad weather. Opt for faster shipping options if your package is urgent, and always factor in some buffer time.
**File a Claim**
If your package is lost or significantly delayed, you might be eligible for compensation. Visit the FedEx claims website to file a claim and understand the process.
## FedEx's Efforts to Mitigate Delays
FedEx continuously works to minimize operational delays through various strategies:
**Advanced Technology**
FedEx employs state-of-the-art technology to optimize routing and track packages in real-time, helping to prevent delays and address issues quickly.
**Flexible Operations**
The company adjusts its operations based on real-time data, such as rerouting shipments to avoid weather-affected areas.
**Enhanced Customer Support**
FedEx has invested in robust customer support systems to assist customers promptly when issues arise.
## Conclusion
While FedEx operational delays can be frustrating, understanding their causes and knowing how to manage them can make the experience less stressful. Stay informed, plan ahead, and use the resources available to you to navigate these delays effectively. Remember, even the most reliable delivery services face challenges, but with the right approach, you can minimize their impact on your life or business. | thenexttech |
1,863,599 | Tips for Dashcam Stealth: How to Install Your Device Unobtrusively | Dashcams have become a popular addition for drivers aiming to protect themselves and their... | 0 | 2024-05-24T05:54:48 | https://dev.to/dnhdashcamsolutions/tips-for-dashcam-stealth-how-to-install-your-device-unobtrusively-2jid | dashcam |

Dashcams have become a popular addition for drivers aiming to protect themselves and their vehicles. However, while they offer numerous benefits, their conspicuous presence may sometimes draw unwanted attention or even invite theft. In this comprehensive guide, we'll explore tips and techniques for discreetly installing your dashcam, enabling you to enjoy the benefits of video recording without attracting unnecessary attention. From hidden placement to cable management strategies, these tips will help you maintain a low profile while maximizing the effectiveness of your dashcam.
Opt for Compact Dashcam Models
When choosing a dashcam for discreet installation, select a compact model that seamlessly blends into your vehicle's interior. Look for slim designs and low-profile mounts that minimize the device's visibility outside the vehicle. Compact dashcams are less likely to attract attention and can be easily concealed behind rearview mirrors or tucked away in the corners of the windshield, ensuring discreet recording without sacrificing effectiveness.
Explore Hidden Placement Options
One effective way to install a dashcam discreetly is to explore hidden placement options within your vehicle's interior. Consider mounting the dashcam behind the rearview mirror or along the top edge of the windshield, where it is less likely to obstruct the driver's view or attract attention from outside the vehicle. Alternatively, explore installation locations within the vehicle's cabin, such as the dashboard or overhead console, where the dashcam can be discreetly integrated into the interior design. By concealing the dashcam from plain sight, you can ensure discreet recording while maintaining a clean and uncluttered appearance inside your vehicle.
Utilize Tinted Windows for Concealment
Tinted windows provide additional privacy and concealment, making them an ideal complement to discreet [dashcam installation](https://dnhdashcamsolutions.com). Consider investing in window tinting for your vehicle to reduce visibility into the interior and obscure the presence of the dashcam from external observers. Darker tinting levels offer greater privacy and can effectively conceal the dashcam while allowing clear visibility inside the vehicle. Additionally, tinted windows help regulate interior temperature and reduce glare, enhancing comfort and safety for drivers and passengers alike. By leveraging tinted windows as a discreet installation aid, you can further enhance the stealthiness of your dashcam setup while enjoying the benefits of added privacy and comfort.
Opt for Wireless Dashcam Models
[Wireless dashcams](https://dnhdashcamsolutions.blogspot.com/2024/05/how-to-choose-perfect-dashcam-10-key.html) offer simplified installation and reduced visibility of cables, making them ideal for discreet setups. Unlike conventional dashcams that require wired connections for power and data transmission, wireless models rely on Wi-Fi or Bluetooth connectivity to interact with the vehicle's electronics and transmit recordings to external devices. This eliminates the need for visible cables running across the windshield or dashboard, resulting in a cleaner and more inconspicuous installation. Wireless dashcams can be easily concealed behind rearview mirrors or integrated into the vehicle's interior without drawing attention. You can achieve discreet recording without compromising functionality or performance by opting for a wireless dashcam model.
Conceal Cables with Interior Trim
Efficient cable organization is crucial for maintaining a subtle dashcam setup. Hide any visible cables by routing them along the vehicle's interior trim, such as door frames, A-pillars, or headliners, where they're less likely to attract attention. Utilize adhesive cable clips or channels to secure the cables and prevent them from tangling. Consider tucking the cables behind existing trim panels or upholstery for seamless integration, ensuring a clean and discreet appearance. Also, choose cable colors that blend in with the vehicle's interior to minimize visibility further. By concealing cables with interior trim, you can achieve a polished, professional-looking dashcam installation that remains discreet and unobtrusive.
Consider Remote Dashcam Placement
Explore remote dashcam placement options that hide the device entirely from view for ultimate discretion. Remote dashcams consist of separate camera units that can be discreetly installed in various locations around the vehicle, such as the front and rear windows or side mirrors. The main recording unit is typically mounted in a hidden location, such as the glove compartment or center console, where it remains out of sight while providing access to recording controls and storage. Remote dashcam systems offer the advantage of enhanced stealthiness and flexibility, allowing for discreet recording without compromising visibility or obstructing the driver's view. By considering remote dashcam placement options, you can achieve maximum discretion while still enjoying the benefits of video recording on the road.
Conclusion
Maintaining a discreet dashcam installation is essential for ensuring effective recording without drawing unnecessary attention to your vehicle. By following the tips and techniques outlined in this guide, you can achieve stealthy dashcam placement while maximizing effectiveness. Whether you opt for compact dashcam models, explore hidden placement options, utilize tinted windows, choose wireless dashcam models, conceal cables with interior trim, or consider remote dashcam placement, prioritizing discreetness will help you enjoy the benefits of dashcam recording without compromising your vehicle's appearance or attracting unwanted attention. Whether you're concerned about vehicle aesthetics, privacy, or theft prevention, these tips will help you achieve discreet dashcam installation and enjoy the benefits of video recording on the road. | dnhdashcamsolutions |
1,863,598 | How does Game Devs empower gaming developers to create winning lock screen games? | "Nostra isn't just a platform for hosting lock screen games; it's a developer's toolkit for crafting... | 0 | 2024-05-24T05:54:24 | https://dev.to/claywinston/how-does-game-devs-empower-gaming-developers-to-create-winning-lock-screen-games-1p90 | gamedev, developer, development, gaming | "Nostra isn't just a platform for hosting [lock screen games](https://nostra.gg/?utm_source=referral&utm_medium=social+bookmarking&utm_campaign=Nostra); it's a developer's toolkit for crafting winning lock screen experiences that users can play on Nostra. Here's how [Nostra](https://nostra.gg/articles/top-gaming-company.html?utm_source=referral&utm_medium=social+bookmarking&utm_campaign=top+gaming+company+in+india) empowers creators:
Effortless Creation: Nostra streamlines development with intuitive tools and pre-built templates. Drag-and-drop design elements and user-friendly interfaces make crafting engaging visuals a breeze, allowing developers to focus on core gameplay mechanics.

A Community of Support: Nostra fosters collaboration. Developers have access to a thriving community forum, a space to share best practices, troubleshoot challenges, and learn from each other's experiences. This collaborative environment empowers developers to continuously improve their craft.
Data-Driven Decisions: Knowledge is power. Nostra's robust analytics dashboards provide developers with invaluable insights into player behavior and game performance. These insights allow developers to identify areas for improvement, optimize gameplay mechanics, and refine their marketing strategies to maximize user engagement.
Success Stories Abound: The proof is in the playing! Nostra boasts a library of successful [lock screen games](https://nostra.gg/articles/play-games-without-unlocking-your-phone.html?utm_source=referral&utm_medium=social+bookmarking&utm_campaign=Play+Games) like ""Toy Story: The Room of Andy"" and ""Blox Live Wallpapers."" These games, created using Nostra's tools, showcase the platform's potential to empower developers to create commercially viable and critically acclaimed titles." | claywinston |
1,863,597 | Finding the Perfect WordPress Developer: A Step-by-Step Guide | Finding the Perfect WordPress Developer: A Step-by-Step Guide Introduction Overview of... | 0 | 2024-05-24T05:53:39 | https://dev.to/hirelaraveldevelopers/finding-the-perfect-wordpress-developer-a-step-by-step-guide-66c | webdev, programming, devops, html | <h2>Finding the Perfect WordPress Developer: A Step-by-Step Guide</h2>
<h3>Introduction</h3>
<h4>Overview of WordPress</h4>
<p>WordPress is a powerful content management system (CMS) that powers over 40% of all websites on the internet. Known for its flexibility and ease of use, it supports a wide range of websites, from personal blogs to large e-commerce sites.</p>
<h4>Importance of a Skilled WordPress Developer</h4>
<p>A skilled WordPress developer can turn your vision into reality, ensuring that your website is not only visually appealing but also functional, secure, and optimized for performance. Whether you're looking to create a simple blog or a complex business website, the right developer is crucial for success.</p>
<h4>Objective of the Guide</h4>
<p>This guide aims to help you navigate the process of finding and <a title="hiring the perfect WordPress developer" href="https://www.aistechnolabs.com/hire-wordpress-developers/">hiring the perfect WordPress developer</a>. From understanding your needs to evaluating candidates and ensuring quality, we'll cover every step to ensure a smooth and successful collaboration.</p>
<h3>Understanding WordPress Development</h3>
<h4>What is WordPress?</h4>
<p>WordPress is an open-source CMS that allows users to create and manage websites easily. It offers a vast array of themes and plugins that enable customization without needing to write code, although coding skills are beneficial for more advanced customization.</p>
<h4>Types of WordPress Sites</h4>
<h5>Blogs</h5>
<p>WordPress started as a blogging platform and remains a popular choice for bloggers due to its user-friendly interface and extensive customization options.</p>
<h5>Business Websites</h5>
<p>Businesses use WordPress to create professional websites that can showcase their services, provide information, and attract potential customers.</p>
<h5>E-commerce Stores</h5>
<p>With plugins like WooCommerce, WordPress can be transformed into a robust e-commerce platform, supporting online stores of all sizes.</p>
<h5>Portfolios</h5>
<p>Artists, designers, and other creatives use WordPress to build stunning portfolios that highlight their work and attract new clients.</p>
<h4>Core WordPress Technologies</h4>
<h5>PHP</h5>
<p>PHP is the primary scripting language used to develop WordPress. It handles the server-side operations and database interactions.</p>
<h5>HTML</h5>
<p>HTML structures the content on the web pages, providing the basic framework for the site's layout and elements.</p>
<h5>CSS</h5>
<p>CSS is used to style the HTML elements, controlling the visual presentation and layout of the website.</p>
<h5>JavaScript</h5>
<p>JavaScript adds interactivity to the website, enabling dynamic content updates and enhanced user experiences.</p>
<h4>WordPress Themes and Plugins</h4>
<p>Themes control the overall look and feel of a WordPress site, while plugins add specific functionalities, such as SEO optimization, contact forms, and e-commerce capabilities.</p>
<h4>WordPress Hosting</h4>
<p>Choosing the right hosting provider is crucial for your WordPress site's performance. Options range from shared hosting to dedicated servers, with managed WordPress hosting services offering optimized environments specifically for WordPress.</p>
<h3>Identifying Your Needs</h3>
<h4>Defining Your Project Scope</h4>
<p>Clearly define what you want to achieve with your website. This includes the site's purpose, the target audience, and the key features you need.</p>
<h4>Budget Considerations</h4>
<p>Determine how much you are willing to spend on development. Your budget will influence whether you hire a freelancer, an agency, or an in-house developer.</p>
<h4>Timeline and Deadlines</h4>
<p>Set realistic deadlines for your project. Consider any important dates or events that might impact your timeline.</p>
<h4>Functional Requirements</h4>
<p>List the essential functionalities your site must have, such as e-commerce capabilities, contact forms, booking systems, etc.</p>
<h4>Aesthetic Preferences</h4>
<p>Outline your design preferences, including color schemes, typography, and layout styles. Providing examples of sites you like can be helpful.</p>
<h3>Types of WordPress Developers</h3>
<h4>Freelancers</h4>
<p>Freelancers offer flexibility and often lower costs. They are suitable for smaller projects or ongoing site maintenance.</p>
<h4>Development Agencies</h4>
<p>Agencies provide a team of developers and often offer comprehensive services, including design, development, and marketing. They are ideal for larger, more complex projects.</p>
<h4>In-house Developers</h4>
<p>Hiring an in-house developer gives you full control over the development process and is beneficial for companies with ongoing development needs.</p>
<h3>Where to Find WordPress Developers</h3>
<h4>Freelance Platforms</h4>
<h5>Upwork</h5>
<p>Upwork is a popular platform for finding freelance developers. You can review portfolios, read client reviews, and hire based on specific project needs.</p>
<h5>Freelancer</h5>
<p>Freelancer allows you to post jobs and receive bids from developers around the world. It's a good option for budget-conscious projects.</p>
<h5>Fiverr</h5>
<p>Fiverr offers a range of freelance services at various price points. You can find developers for specific tasks or complete projects.</p>
<h4>Developer Communities</h4>
<h5>GitHub</h5>
<p>GitHub is a platform for developers to share and collaborate on code. It's a great place to find developers with a strong portfolio of open-source contributions.</p>
<h5>Stack Overflow</h5>
<p>Stack Overflow is a Q&A site for developers. It has a job board where you can post openings and connect with experienced developers.</p>
<h4>WordPress-Specific Job Boards</h4>
<h5>WPhired</h5>
<p>WPhired specializes in WordPress jobs, connecting employers with developers who have specific WordPress expertise.</p>
<h5>Smashing Jobs</h5>
<p>Smashing Jobs is a job board by Smashing Magazine, focusing on high-quality web development and design jobs, including WordPress positions.</p>
<h3>Evaluating Potential Developers</h3>
<h4>Reviewing Portfolios</h4>
<p>Look at the developer's past work to ensure their style and expertise align with your project needs. Pay attention to the functionality, design quality, and user experience of the sites they've built.</p>
<h4>Checking References and Reviews</h4>
<p>Contact previous clients and read reviews to gauge the developer's reliability, work ethic, and ability to meet deadlines.</p>
<h4>Technical Skills Assessment</h4>
<p>Ensure the developer has the necessary technical skills, including proficiency in PHP, HTML, CSS, and JavaScript, as well as experience with WordPress themes and plugins.</p>
<h4>Communication Skills</h4>
<p>Effective communication is essential for a successful project. Evaluate the developer's ability to understand your requirements and provide clear, timely updates.</p>
<h4>Cultural Fit</h4>
<p>Consider whether the developer's working style and values align with your company culture. A good cultural fit can enhance collaboration and project success.</p>
<h3>The Hiring Process</h3>
<h4>Crafting a Clear Job Description</h4>
<p>Write a detailed job description outlining the project's scope, required skills, budget, and timeline. Be clear about your expectations and any specific requirements.</p>
<h4>Posting Your Job</h4>
<p>Post your job description on relevant platforms, including freelance sites, developer communities, and job boards.</p>
<h4>Shortlisting Candidates</h4>
<p>Review applications and create a shortlist of candidates who meet your criteria. Consider their portfolios, experience, and reviews.</p>
<h4>Conducting Interviews</h4>
<h5>Technical Questions</h5>
<p>Ask questions to assess the developer's technical knowledge and problem-solving skills. This might include coding challenges or questions about specific technologies.</p>
<h5>Behavioral Questions</h5>
<p>Evaluate the developer's soft skills, such as communication, teamwork, and ability to handle feedback. Ask about past projects and how they managed challenges.</p>
<h4>Making an Offer</h4>
<p>Once you've found the right candidate, extend an offer detailing the project terms, payment structure, and start date. Ensure both parties sign a contract to formalize the agreement.</p>
<h3>Setting Expectations</h3>
<h4>Defining Roles and Responsibilities</h4>
<p>Clearly outline the responsibilities of both parties, including who will handle specific tasks and deliverables.</p>
<h4>Establishing Communication Protocols</h4>
<p>Set up regular check-ins and progress updates. Use project management tools to keep everyone on the same page.</p>
<h4>Setting Milestones and Deadlines</h4>
<p>Break the project into manageable phases with specific milestones and deadlines. This helps track progress and ensure timely completion.</p>
<h4>Payment Terms and Contracts</h4>
<p>Agree on payment terms, whether hourly or project-based. Use contracts to protect both parties and outline the terms of the agreement.</p>
<h3>Working with Your Developer</h3>
<h4>Onboarding Your Developer</h4>
<p>Provide the necessary resources and information for your developer to start working, including access to tools, credentials, and project documentation.</p>
<h4>Tools for Collaboration</h4>
<h5>Project Management Software</h5>
<p>Use tools like Trello, Asana, or Jira to manage tasks, track progress, and collaborate effectively.</p>
<h5>Version Control Systems</h5>
<p>GitHub or Bitbucket can help manage code changes and ensure everyone is working on the latest version.</p>
<h5>Communication Tools</h5>
<p>Tools like Slack, Zoom, or Microsoft Teams facilitate real-time communication and collaboration.</p>
<h4>Regular Check-ins and Feedback</h4>
<p>Schedule regular meetings to review progress, provide feedback, and address any issues. Open communication helps keep the project on track.</p>
<h4>Handling Issues and Conflicts</h4>
<p>Address problems promptly and professionally. Work together to find solutions and maintain a positive working relationship.</p>
<h3>Ensuring Quality</h3>
<h4>Code Reviews</h4>
<p>Regular code reviews help maintain code quality and catch issues early. Have experienced developers review the code for best practices and standards.</p>
<h4>Testing and QA</h4>
<p>Thorough testing ensures the site functions correctly. Perform unit tests, integration tests, and user acceptance testing (UAT) to catch bugs and issues.</p>
<h4>Security Best Practices</h4>
<p>Implement security measures to protect your site from vulnerabilities. This includes regular updates, secure coding practices, and using security plugins.</p>
<h4>Performance Optimization</h4>
<p>Optimize your site for speed and performance. This includes optimizing images, using caching, and minimizing code bloat.</p>
<h3>Post-Development</h3>
<h4>Launching Your Site</h4>
<p>Plan and execute a smooth site launch. Ensure all functionalities are working, and perform final checks before going live.</p>
<h4>Training and Documentation</h4>
<p>Provide training for your team on how to use and manage the site. Create documentation to support ongoing site management and updates.</p>
<h4>Maintenance and Support</h4>
<p>Set up a plan for ongoing maintenance and support. This includes regular updates, backups, and security monitoring.</p>
<h4>Scaling and Future Enhancements</h4>
<p>Plan for future growth and enhancements. Consider scalability options and keep your site up-to-date with the latest technologies and trends.</p>
<h3>Case Studies</h3>
<h4>Successful WordPress Projects</h4>
<p>Share examples of successful WordPress projects to illustrate what can be achieved with the right developer and approach.</p>
<h4>Lessons Learned</h4>
<p>Highlight lessons learned from past projects to provide valuable insights and avoid common pitfalls.</p>
<h3>Expert Insights</h3>
<h4>Tips from Experienced WordPress Developers</h4>
<p>Include advice and tips from seasoned WordPress developers to help you navigate the hiring and development process.</p>
<h4>Industry Trends and Best Practices</h4>
<p>Stay informed about the latest trends and best practices in WordPress development to ensure your site remains competitive and up-to-date.</p>
<h3>Conclusion</h3>
<h4>Recap of Key Points</h4>
<p>Summarize the key points covered in this guide, emphasizing the importance of careful planning and selecting the right developer.</p> | hirelaraveldevelopers |
1,863,596 | 13章26 | 4行目のエラーを回避するには、変数 num を static にする必要があります。test メソッドは static であるため、static メソッド内で static... | 0 | 2024-05-24T05:48:23 | https://dev.to/aaattt/13zhang-26-3ho4 | 4行目のエラーを回避するには、変数 `num` を `static` にする必要があります。`test` メソッドは `static` であるため、`static` メソッド内で `static` でないメンバー変数を直接参照することはできません。以下のように修正します:
```java
public class Main {
static int num;
private static void test() {
num++;
System.out.println(num);
}
public static void main(String[] args) {
Main.test();
Main.test();
}
}
```
この修正により、プログラムは正しくコンパイルされ、実行時に `1` と `2` が表示されます。 | aaattt | |
1,863,595 | PHONE HACK AND SPY APP EXPERT. | -Technology has seeped into every nook and cranny of our relationships, providing both parties to... | 0 | 2024-05-24T05:44:13 | https://dev.to/julian_facundo_7bedacaebf/phone-hack-and-spy-app-expert-343h | -Technology has seeped into every nook and cranny of our relationships, providing both parties to stay connected and a Pandora’s box of potential secrets waiting to be uncovered. Enter Cyber Genie Hack Pro, the key to unlocking those digital mysteries. The age-old problem in almost all relationships is Trust. One minute you’re sharing your deepest thoughts over a candlelit dinner, next, you’re left wondering if your partner’s emoji use is hiding a deeper, darker truth. Why should you care about decoding your wife’s secret messages? Aside from the obvious curiosity that comes with uncovering hidden truths, understanding what’s going on behind the screen can help bridge the gap between what’s said and what’s unsaid in your relationship. Plus, who doesn’t love a good digital detective story? Now, onto the main event – how does this enigmatic Cyber Genie Hack Pro work its magic? Prepare to be dazzled by the software’s features and the technical wizardry behind retrieving those elusive deleted messages. With a wave of its virtual wand, Cyber Genie Pro promises to unearth deleted messages, uncover hidden conversations, and provide you with a front-row seat to the digital drama playing out in your wife’s messages. This software claims to reveal it all. Talk about a digital fairy godmother! So, you’ve successfully set up Cyber Genie Pro on your chosen devices – now what? It’s time to sit back, relax, and watch as the software works its magic, recovering and presenting you with those secret messages you’ve been yearning to see. From decoding cryptic conversations to analyzing the tone and context of each message, get ready to immerse yourself in a digital world of intrigue and discovery.
Email :_Cybergenie (@) Cyberservices (.) Com
_Telegram- (@)CYBERGENIEHACKPRO | julian_facundo_7bedacaebf | |
1,863,593 | Network policy at scale; scaling Calico to 15k+ nodes and 10k network policies | A year ago, Shaun faced the task of upgrading Calico to support **over 15,000 nodes and 10,000... | 0 | 2024-05-24T05:38:10 | https://dev.to/calico-devadvocacy/network-policy-at-scale-scaling-calico-to-15k-nodes-and-10k-network-policies-2nkb | kubernetes, container, networking, security | A year ago, Shaun faced the task of upgrading Calico to support **over 15,000 nodes and 10,000 network policies **without losing performance.
This video provides an in-depth overview of scale-out architecture, whether you're looking for a network policy solution or just interested in how we scaled our application on Kubernetes. You'll see how it evolved, how we conduct high-scale testing, and the improvements in version 3.27 that enhance performance.
**Key Highlights:
**🚀 Extensive Scalability: Learn how Calico now handles 15,000+ nodes.
🛠️ Architecture Evolution: See the advancements in Calico's network policy engine.
🧪 Testing at Scale: Discover our methods for high-scale testing and performance validation.
📈 Version 3.27 Improvements: Explore the enhancements that optimize performance and scalability.
{% embed https://www.youtube.com/watch?v=PA13_1IUCHE %} | calico-dev-advocacy |
1,888,009 | Automatically logout idle users in WordPress | Maintaining security and performance is crucial for any WordPress website. One effective way to... | 0 | 2024-06-14T06:08:00 | https://www.imdpen.com/posts/automatically-logout-idle-users-in-wordpress | wordpress, inactivelogoutwordpress | ---
title: Automatically logout idle users in WordPress
published: true
date: 2024-05-24 05:35:02 UTC
tags: WordPress,InactiveLogoutWordPress
canonical_url: https://www.imdpen.com/posts/automatically-logout-idle-users-in-wordpress
---
Maintaining security and performance is crucial for any WordPress website. One effective way to enhance both is to automatically logout idle users. This feature ensures that users who are inactive for a certain period are logged out, reducing the risk of unauthorized access and freeing up server resources. The best part? You can easily implement this feature using the WordPress plugin called [Inactive Logout.](https://inactive-logout.com/) Here’s how you can do it.
#### Why Automatically Logout Idle Users?
1. **Security Enhancement** : Automatically logging out inactive users prevents unauthorized access, especially on shared or public computers. It ensures that sensitive information remains protected even if a user forgets to log out manually.
2. **Improved Performance** : Idle sessions can consume server resources. By terminating these sessions, you can improve your website’s performance and ensure that resources are available for active users.
3. **User Management** : Automatically logging out idle users helps in managing user sessions more effectively, especially in a multi-user environment like an online course or membership site.
#### Setting Up Inactive Logout Plugin
The [Inactive Logout](https://inactive-logout.com/) plugin is a user-friendly tool that helps you automatically logout idle users on your WordPress site. Here’s a step-by-step guide to setting it up:
1. **Install the Plugin** :
- Go to your WordPress dashboard.
- Navigate to **Plugins > Add New**.
- Search for **Inactive Logout**.
- Click **Install Now** and then **Activate** the plugin.
2. **Configure Inactive Logout Settings** :
- After activation, go to **Settings > Inactive Logout** in your WordPress dashboard.
- Set the **Idle Time** (in minutes) after which users should be logged out. This is the period of inactivity you allow before a user is automatically logged out.
- Customize the **Logout Message** that users will see when they are logged out due to inactivity.
- Enable or disable the **Countdown Timer** , which alerts users before they are logged out.
- Configure other settings such as excluding certain roles from automatic logout or redirecting users to a specific URL after logout.
3. **Save Changes** :
- Once you have configured all the settings as per your requirements, click **Save Changes** to apply the settings.
#### Advanced Features of Inactive Logout
- **Role-based Settings** : Customize idle timeout based on user roles, providing flexibility for different types of users.
- **Custom Logout Redirect** : Redirect users to a specific page after they are logged out, enhancing user experience.
- **Warning Notifications** : Provide a countdown timer or warning message before users are logged out, allowing them to extend their session if needed.
- **Idle Detection** : Detect idle users based on mouse movements, keyboard actions, and touch events for accurate inactivity tracking.
#### Best Practices
1. **Set Appropriate Idle Time** : Balance security and user convenience by setting a reasonable idle time. Too short may frustrate users, while too long may compromise security.
2. **Communicate with Users** : Inform users about the automatic logout feature, so they are aware of the security measures and can save their work regularly.
3. **Test the Configuration** : Before fully implementing, test the configuration with different user roles to ensure it works as expected without disrupting user experience. | techies23 |
1,863,592 | Unlocking Web Accessibility: A Comprehensive Guide🚀 | 1. Accessibility Basics Understanding Accessibility Accessibility ensures that websites are usable... | 0 | 2024-05-24T05:34:57 | https://dev.to/dharamgfx/unlocking-web-accessibility-a-comprehensive-guide-4co2 | webdev, beginners, programming, tutorial | **1. Accessibility Basics**
**Understanding Accessibility**
- Accessibility ensures that websites are usable by everyone, including people with disabilities.
- Important for inclusivity and can enhance SEO and user experience.
**Key Principles**
- **Perceivable**: Content must be presented in ways that users can perceive (e.g., providing text alternatives for non-text content).
- **Operable**: User interface components must be operable (e.g., making all functionality available from a keyboard).
- **Understandable**: Information and operation of the user interface must be understandable (e.g., making text readable and predictable).
- **Robust**: Content must be robust enough to be interpreted by a wide variety of user agents, including assistive technologies.
*Example:*
```html
<img src="image.jpg" alt="A descriptive text of the image">
```
The `alt` attribute provides a text alternative for the image.
---
**2. Accessible Styling**
**Using Semantic HTML**
- Use HTML elements according to their purpose (e.g., `header`, `nav`, `main`, `footer`).
- Improves accessibility and SEO.
**Color Contrast**
- Ensure sufficient contrast between text and background.
- Use tools like WebAIM’s contrast checker.
*Example:*
```css
body {
color: #333; /* dark text */
background-color: #fff; /* light background */
}
```
**Scalable Text**
- Use relative units like `em` or `rem` instead of pixels for font sizes.
- Allows users to adjust text size according to their needs.
*Example:*
```css
body {
font-size: 1rem; /* Scalable font size */
}
```
**Focus Styles**
- Ensure focusable elements (links, buttons) have visible focus indicators.
*Example:*
```css
button:focus {
outline: 2px solid #000;
}
```
---
**3. Accessible JavaScript**
**Keyboard Accessibility**
- Ensure all interactive elements are accessible via keyboard.
- Use `tabindex` to manage focus order.
*Example:*
```html
<button tabindex="0">Click Me</button>
```
**ARIA Roles and Properties**
- Use ARIA (Accessible Rich Internet Applications) to enhance accessibility.
- Adds additional context to elements.
*Example:*
```html
<div role="alert">This is an important message.</div>
```
**Event Handlers**
- Avoid using only mouse-specific events (like `onclick`).
- Include keyboard events (like `onkeydown`).
*Example:*
```javascript
button.addEventListener('click', function() {
// Your code here
});
button.addEventListener('keydown', function(event) {
if (event.key === 'Enter' || event.key === ' ') {
// Your code here
}
});
```
---
**4. Assistive Technology**
**Screen Readers**
- Tools that read out loud the content of web pages for visually impaired users.
- Important to ensure content is accessible and logical when read sequentially.
**Voice Recognition Software**
- Allows users to navigate and interact with web pages using voice commands.
- Ensure all interactive elements can be accessed via voice commands.
**Screen Magnifiers**
- Tools that magnify part of the screen.
- Ensure the layout remains functional and readable when zoomed in.
**Testing with Assistive Technologies**
- Use screen readers like NVDA, JAWS, or VoiceOver to test your site.
- Regularly test with various assistive technologies to ensure compatibility.
---
**5. WAI-ARIA (Web Accessibility Initiative - Accessible Rich Internet Applications)**
**Introduction to WAI-ARIA**
- A set of attributes that make web content more accessible, especially for dynamic content and advanced user interface controls.
**Roles**
- Define what an element is and how it should be perceived by assistive technologies.
*Example:*
```html
<div role="button">Clickable Div</div>
```
**States and Properties**
- Define the state of an element (e.g., checked, expanded).
*Example:*
```html
<div role="checkbox" aria-checked="false">Check me</div>
```
**Live Regions**
- Inform users of dynamic content updates.
*Example:*
```html
<div aria-live="polite">Content will be updated here.</div>
```
**Using ARIA Appropriately**
- ARIA should enhance, not replace, semantic HTML.
- Use ARIA roles, states, and properties only when native HTML is insufficient.
---
**Conclusion**
Ensuring web accessibility is not just about following guidelines; it's about creating an inclusive digital environment for everyone. By understanding and implementing the basics of accessibility, using accessible styling and JavaScript, considering assistive technologies, and leveraging WAI-ARIA, you can significantly improve the user experience for people with disabilities. Embrace these practices to make your web content accessible, usable, and enjoyable for all users. | dharamgfx |
1,863,591 | Next.js Boilerplate Builder | Hello everyone! 👋🏻 I am really happy to introduce Loopple Boilerplate Builder - a tool that will... | 0 | 2024-05-24T05:34:42 | https://dev.to/rarestoma/nextjs-boilerplate-builder-4dg7 | nextjs, webdev, development | Hello everyone! 👋🏻
I am really happy to introduce Loopple Boilerplate Builder - a tool that will help you accelerate your development in just a matter of days.
Our powerful tool integrates the best technologies to streamline your development process:
- Next.js for robust performance
- Tailwind CSS for sleek designs
- Paddle for hassle-free payments
- Open AI for intelligent features
- Supabase Auth & Database for seamless user management and data handling
- Loopple Drag & Drop for effortless customization
+ 7 pre-built pages examples
Whether you're a seasoned developer or just starting out, Loopple Boilerplate Builder helps you launch your projects in days, not weeks!
See how you can boost your development speed and build amazing web-based software with ease.
Also, we are giving a special limited 20% discount at Loopple Boilerplate Builder for Product Hunt friends! (use code at checkout: BOILERPLATE20)
Let us know what your thoughts are, your feedback is very valuable, as it helps us continuously improve our product. Thank you so much!
Below are some useful links if you want to contribute and give feedback ⬇️
📌 Website: https://www.loopple.com/boilerplate
📌 Documentation: https://boilerplate.loopple.com | rarestoma |
1,863,590 | Troubleshooting InfiniBand Networks: A Detailed Guide | InfiniBand (IB) networks, known for their high performance and low latency, are critical in... | 0 | 2024-05-24T05:30:32 | https://dev.to/mbayoun95/troubleshooting-infiniband-networks-a-detailed-guide-1dk6 | hpc, network, infiniband |
InfiniBand (IB) networks, known for their high performance and low latency, are critical in high-performance computing (HPC) environments and data centers. Ensuring their optimal performance requires effective troubleshooting when issues arise. This article provides a detailed guide on troubleshooting InfiniBand networks and the tools available for diagnosing problems.
## Table of Contents
1. [Introduction](#introduction)
2. [Common Issues in InfiniBand Networks](#common-issues-in-infiniband-networks)
3. [Step-by-Step Troubleshooting Guide](#step-by-step-troubleshooting-guide)
- [Physical Layer Issues](#physical-layer-issues)
- [Link Layer Issues](#link-layer-issues)
- [Network Layer Issues](#network-layer-issues)
- [Transport Layer Issues](#transport-layer-issues)
4. [Tools for Diagnosing InfiniBand Networks](#tools-for-diagnosing-infiniband-networks)
- [ibstat](#ibstat)
- [ibnetdiscover](#ibnetdiscover)
- [ibdiagnet](#ibdiagnet)
- [ibping](#ibping)
- [ibtracert](#ibtracert)
5. [Best Practices for Maintaining InfiniBand Networks](#best-practices-for-maintaining-infiniband-networks)
6. [Conclusion](#conclusion)
## Introduction
InfiniBand networks provide robust and high-speed connections essential for modern computing environments. However, like any complex network, they can experience issues that degrade performance or cause failures. Effective troubleshooting requires a systematic approach and the right tools to diagnose and resolve problems quickly.
## Common Issues in InfiniBand Networks
Some common issues encountered in InfiniBand networks include:
- **Physical connectivity problems**: Faulty cables, connectors, or ports.
- **Configuration errors**: Incorrect settings in switches, routers, or host channel adapters (HCAs).
- **Firmware or driver issues**: Bugs or incompatibilities in firmware or drivers.
- **Network congestion**: High traffic causing delays or packet loss.
- **Hardware failures**: Defective switches, HCAs, or other components.
## Step-by-Step Troubleshooting Guide
### Physical Layer Issues
1. **Check Cables and Connectors**:
- Ensure all cables are properly connected.
- Inspect connectors for damage or wear.
- Replace any suspect cables or connectors.
2. **Verify Link Lights**:
- Check the link lights on switches and HCAs to ensure they indicate an active connection.
3. **Use Cable Testers**:
- Employ InfiniBand-specific cable testers to verify cable integrity.
### Link Layer Issues
1. **Check Link Status**:
- Use the `ibstat` command to check the status of HCAs and ports.
```bash
ibstat
```
- Ensure ports are in the ACTIVE state.
2. **Examine Error Counters**:
- Review link error counters to identify issues such as packet errors or retries.
```bash
ibclearerrors
ibqueryerrors
```
3. **Validate Firmware and Drivers**:
- Ensure firmware and drivers are up to date and compatible with your hardware.
### Network Layer Issues
1. **Discover Network Topology**:
- Use the `ibnetdiscover` command to map out the network topology and ensure all devices are properly interconnected.
```bash
ibnetdiscover
```
2. **Check Routing Tables**:
- Ensure that routing tables are correctly configured and routes are optimal.
3. **Monitor Network Traffic**:
- Use monitoring tools to observe traffic patterns and identify congestion points.
### Transport Layer Issues
1. **Verify End-to-End Connectivity**:
- Use the `ibping` tool to test connectivity between nodes.
```bash
ibping <destination>
```
2. **Trace Routes**:
- Use `ibtracert` to trace the path packets take through the network.
```bash
ibtracert <destination>
```
3. **Analyze Performance**:
- Use performance analysis tools to identify bottlenecks and optimize transport settings.
## Tools for Diagnosing InfiniBand Networks
### ibstat
- **Description**: Displays the status of InfiniBand devices and ports.
- **Usage**:
```bash
ibstat
```
### ibnetdiscover
- **Description**: Discovers and displays the InfiniBand network topology.
- **Usage**:
```bash
ibnetdiscover
```
### ibdiagnet
- **Description**: Comprehensive diagnostic tool that checks network health and performance.
- **Usage**:
```bash
ibdiagnet
```
### ibping
- **Description**: Tests the connectivity between InfiniBand nodes.
- **Usage**:
```bash
ibping <destination>
```
### ibtracert
- **Description**: Traces the route of packets through the InfiniBand network.
- **Usage**:
```bash
ibtracert <destination>
```
## Best Practices for Maintaining InfiniBand Networks
1. **Regular Monitoring**:
- Continuously monitor network performance and health using tools like `ibdiagnet`.
2. **Firmware and Driver Updates**:
- Keep firmware and drivers up to date to ensure compatibility and fix known issues.
3. **Network Design**:
- Design the network with redundancy and scalability in mind to prevent single points of failure.
4. **Documentation**:
- Maintain comprehensive documentation of network topology, configurations, and procedures.
5. **Training and Knowledge**:
- Ensure that network administrators are well-trained in InfiniBand technology and troubleshooting techniques.
## Conclusion
Troubleshooting InfiniBand networks involves a structured approach and the use of specialized tools to diagnose and resolve issues effectively. By understanding common problems, following a systematic troubleshooting process, and leveraging the right tools, network administrators can maintain high performance and reliability in their InfiniBand environments. Regular monitoring, updates, and adherence to best practices further ensure the network operates smoothly and efficiently. | mbayoun95 |
1,863,587 | Marketing Attribution Software Market Size, Share, Growth, Trends, Applications, and Industry Strategies | Marketing Attribution Software Market was valued US$ 3.53 Bn in 2023 and is expected to reach US$... | 0 | 2024-05-24T05:27:55 | https://dev.to/maximize_shraddha_5505538/marketing-attribution-software-market-size-share-growth-trends-applications-and-industry-strategies-26fp | marketing, attribution, software | Marketing Attribution Software Market was valued US$ 3.53 Bn in 2023 and is expected to reach US$ 9.13 Bn by 2030 at a CAGR of 14.5 %.
Marketing Attribution Software Market Overview
The prominent global market intelligence firm has unveiled its latest market research report focusing on the Marketing Attribution Software Market. The comprehensive report presents descriptive data and pictographs depicting the analysis of both regional and global markets. Moreover, the report delves into the market's objectives, shedding light on leading competitors, their market value, current trending skims, strategies, targets, and products. It also highlights the recent growth of the market and provides valuable insights into its informative past.
Marketing Attribution Software Market Scope: https://www.maximizemarketresearch.com/inquiry-before-buying/27357
The research report delves deeply into the analysis of trending competitors, their market growth, and dynamic patterns. It offers valuable insights into the regional and global values and demands of the market. Furthermore, it aids in comprehending the competitive landscape and market potential in terms of production demand and supply. The segmentation analysis includes crucial factors such as psychographic, demographic, geographic, and behavioral segmentation. These factors play a pivotal role in shaping marketing strategies, focused and targeted products, offers, and customer experiences. Porter's analysis is utilized to gauge an organization's competitive position strength, aiming to enhance profitability. Additionally, Pestle analysis is conducted to assess the validity of existing products and services in the contextual data. The SWOT analysis provides an evaluation of internal and external factors contributing to a company's advantages, disadvantages, strengths, and weaknesses. Overall, this report offers comprehensive and informative data on the Marketing Attribution Software market overview.
Access a Free Sample Report: https://www.maximizemarketresearch.com/request-sample/27357
Segmentation
On-premises deployment mode to hold the highest market size during the forecast period. Data security concerns between the end users are contributing to higher adoption of on-premises marketing attribution solutions, worldwide. The on-premises marketing attribution software is widely deployed by large farms, as they have a better ability to invest. Additionally, large farms have a wide variety of business segments serving to a broader geographic region, therefore data security is of utmost importance.
Key Players
1. Adobe
2. Oracle
3. Google
4. SAP
5. Visual IQ
6. Analytic Partners
7. Attribution
8. Calibermind
9. Engagio
10. Fospha
11. IRI
12. LeadsRx
13. Leandata
14. Marketing Attribution
15. Merkle
16. Neustar
17. Optimine
18.Rockerbox
19.Singular
20.Wizaly
21.The Nielsen Company, LLC
22.Bizible
23.IBM
24.Kvantum
25.Full Circle Insights
26.Roivenue
Regional Analysis
The report delivers formal, functional, and vernacular regional analysis. It identifies the most impactful business areas based on the highest demand in different regions, including Asia Pacific, North America, Latin America, the Middle East, Europe, and Africa. The analysis provides valuable insights into distinct targets, strategies, and market values for each region.
Key Questions Addressed in the Marketing Attribution Software Market Report:
What characterizes the Marketing Attribution Software Market?
What is the forecast period for the Marketing Attribution Software Market?
How does the competitive scenario look in the Marketing Attribution Software Market?
Which region holds the largest market share in the Marketing Attribution Software Market?
What opportunities are available in the Marketing Attribution Software Market?
What factors influence the growth of the Marketing Attribution Software Market?
Who are the key players in the Marketing Attribution Software Market?
Which company holds the largest share in the Marketing Attribution Software Market?
What will be the CAGR of the Marketing Attribution Software Market during the forecast period?
What key trends are expected to emerge in the Marketing Attribution Software Market in the upcoming years?
Key Offerings:
Market Share, Size, and Forecast by Revenue|2024-2030
Market Dynamics - Growth drivers, Restraints, Investment Opportunities, and key trends
Market Segmentation: A detailed analysis by Marketing Attribution Software Market
Landscape - Leading key players and other prominent key players.
About Maximize Market Research:
Maximize Market Research is a versatile market research and consulting company, staffed with professionals from various industries. Our coverage extends to medical devices, pharmaceutical manufacturers, science and engineering, electronic components, industrial equipment, technology, communication, automotive, chemical products, general merchandise, beverages, personal care, and automated systems, among others. Our services encompass market-verified industry estimations, technical trend analysis, crucial market research, strategic advice, competition analysis, production and demand analysis, and client impact studies.
Contact Maximize Market Research:
3rd Floor, Navale IT Park, Phase 2
Pune Bangalore Highway, Narhe,
Pune, Maharashtra 411041, India
sales@maximizemarketresearch.com
+91 96071 95908, +91 9607365656
 | maximize_shraddha_5505538 |
1,863,586 | How to Write a Resume That Stands Out ✨ | 🚀 Did you know? On average, recruiters spend just 6-10 seconds reviewing a resume before deciding if... | 0 | 2024-05-24T05:26:07 | https://dev.to/hey_rishabh/how-to-write-a-resume-that-stands-out-goi |
🚀 Did you know? On average, **recruiters spend just 6-10 seconds reviewing a resume before deciding if it’s a keeper**. With hundreds of applications flooding in, how do you ensure yours stands out in the stack? 🤔
Crafting a strong resume isn't just important—it’s essential! 📝 Let's dive into **6 game-changing tips** that will transform your resume from “meh” to “wow”! 🌟
## 🎓 Tip 1
**How to Write an Education Section** that Stands Out
Your education section should do more than list your degrees—it should showcase your academic strengths! 💡 Ask yourself:
“Have I highlighted the most relevant aspects of my education?”
“Is it easy to read and organized?” 📚
**🔗 Useful Resources**
[Resume Formats](https://instaresume.io/resume-formats)
[Essential Resume Tips](https://instaresume.io/essential-resume-tips)
[How to List Skills](https://instaresume.io/how-to-list-skills)
## 💼 Tip 2
**How to Make the Experience Section** Stand Out
Experience is everything! Show off your professional journey with clarity and detail. Here’s how:
Detail your roles and responsibilities.
Highlight your achievements with specific data.
Connect your past experiences to the job you're applying for. 🌐
_Instead of:_
> Improved worker productivity significantly, leading to recognition from upper management.
_Try:_
> Improved quarterly returns by 25%, exceeding projections and earning the Top Manager Award, given to only one manager per year.
🏆
## 🌐 Tip 3
**How to Create a Leadership and Activities** Section that Stands Out
Especially for students and recent grads, this section can set you apart! 💪 Showcase your leadership roles and activities to fill any gaps in your professional experience.
## 🛠️ Tip 4
**How to Highlight Your Skills**
Skills matter! Whether technical or not, your skills can be a deal-breaker. List them clearly:
_Programming: 8 years with Python, created MyFirstPythonProject on GitHub 🐍_
Think beyond just the basics—consider what additional skills could make you a valuable asset. 🌍
## ✍️ Tip 5
**Formatting and Making the Resume Look Professional**
Presentation is key! 📏 Here are some top tips:
Use a readable font (10-12 pt).
Keep margins between 0.5 and 1 inch.
Maintain clean, professional formatting. 🔍
## 🔄 Tip 6
**Revision and Review**
Proofread, proofread, proofread! 🧐 A single typo can cost you the job. Have trusted friends or mentors review your resume to catch any mistakes. ✅
## Quick Resume Tips:
Tailor your resume to the job description. 📄
Keep the format consistent and easy to read. 🧩
Use strong action verbs to describe your experiences. 💪
Focus on achievements, not just duties. 🏅
Revise carefully—no mistakes allowed! ✏️
Skip personal details like age, religion, or marital status. 🚫
No photos for U.S. resumes. 📸
Don’t include salary info unless asked. 💵
References? Available upon request—no need to list them. 📇
Keywords are crucial—make sure to include relevant industry terms.
For more detailed guides and templates, visit [Instaresume](https://instaresume.io) 🔍
Ready to make your resume shine? 🌟 Follow these tips, and you’ll be on your way to landing that dream job! 💼🚀
Feel free to share your thoughts or ask any questions in the comments below! Let’s get your resume ready to impress! 💬👀 | hey_rishabh | |
1,863,551 | The Future of HR: Harnessing Technology for Seamless Workforce Operations | Technology plays an increasingly pivotal role in the ever-evolving landscape of human resources (HR).... | 0 | 2024-05-24T05:18:20 | https://dev.to/jassi2610/the-future-of-hr-harnessing-technology-for-seamless-workforce-operations-2d17 | Technology plays an increasingly pivotal role in the ever-evolving landscape of human resources (HR). From recruitment and onboarding to performance management and employee engagement, innovative software solutions are revolutionizing HR professionals' operations. As businesses adapt to the digital age, integrating technology into HR processes becomes not just a convenience but a necessity for staying competitive and optimizing workforce operations. In this article, we delve into the transformative potential of technology in HR and explore how businesses can leverage the best HR software, especially in dynamic hubs like Dubai, to drive seamless workforce management.
The Digital Transformation of HR
1. Streamlining Recruitment Processes
Recruitment is often a time-consuming and resource-intensive process. However, with the right HR software, businesses can automate many aspects of recruitment, from job posting and candidate screening to scheduling interviews and tracking applicant data. Advanced and machine learning algorithms can help identify the best candidates based on predefined criteria, saving HR professionals valuable time and resources.
2. Enhancing Onboarding Experiences
Effective onboarding sets the tone for an employee's journey within a company. HR software can facilitate a seamless onboarding process by providing new hires access to essential resources, training materials, and company policies through a centralized platform. Furthermore, automated workflows can guide new employees through necessary paperwork and orientation tasks, ensuring a smooth transition into their roles.
3. Empowering Performance Management
Traditional performance reviews are often marred by bias, subjectivity, and inconsistency. Modern HR software offers solutions enabling continuous feedback, goal tracking, and real-time performance evaluation. By leveraging data analytics and performance metrics, HR professionals can gain valuable insights into employee productivity, identify areas for improvement, and provide targeted coaching and development opportunities.
Leveraging Technology for Employee Engagement
1. Cultivating a Culture of Communication
Effective communication is the cornerstone of employee engagement. HR software with built-in communication tools, such as chat platforms and discussion forums, fosters team collaboration and transparency. Additionally, pulse surveys and feedback mechanisms allow employees to voice their opinions and concerns, empowering them to actively participate in shaping the company culture.
2. Promoting Work-Life Balance
The modern workforce values flexibility and work-life balance more than ever before. HR software can facilitate [remote work arrangements](https://www.upwork.com/resources/new-where-of-working), flexible scheduling, and leave management, enabling employees to balance their professional and personal lives better. By accommodating diverse needs and preferences, businesses can boost employee satisfaction, productivity, and retention.
3. Personalizing Employee Experiences
Every employee is unique, with individual goals, preferences, and career aspirations. HR software that integrates employee profiles, skills assessments, and career development plans can tailor learning and development opportunities to each employee's needs. Personalized experiences enhance employee engagement and contribute to talent retention and succession planning efforts.
The Role of AI and Data Analytics in HR
1. Predictive Analytics for Talent Management
Predictive analytics leverages historical data and machine learning algorithms to forecast future trends and outcomes. In HR, predictive analytics can be used for talent acquisition, succession planning, and workforce optimization. By analyzing patterns in employee performance, turnover rates, and demographic data, businesses can make data-driven decisions to attract, retain, and develop top talent.
2. AI-Powered Insights for Decision-Making
Artificial intelligence (AI) algorithms can sift through vast amounts of data to uncover hidden patterns, correlations, and insights. In HR, AI can assist with candidate matching, employee sentiment analysis, and predictive modeling. By harnessing AI-powered insights, HR professionals can make more informed decisions regarding recruitment strategies, performance management initiatives, and organizational development programs.
3. Automation for Administrative Tasks
Administrative tasks, such as payroll processing, benefits administration, and compliance reporting, are essential but time-consuming responsibilities for HR professionals. Automation tools within HR software can streamline these processes, reducing the likelihood of errors and freeing up valuable time for HR teams to focus on strategic initiatives. Businesses can improve efficiency, accuracy, and overall operational effectiveness by automating routine tasks.
Implementing the Best HR Software in Dubai
Dubai, a thriving business hub in the Middle East, presents unique opportunities and challenges for HR professionals. As the city continues attracting talent worldwide, businesses must adopt cutting-edge HR software to manage a diverse workforce and navigate complex regulations effectively. The [best HR software in Dubai](https://factohr.com/hr-software/dubai/) offers localization features, multilingual support, and compliance modules tailored to the region's specific needs.
1. Localization and Compliance
HR software designed for the Dubai market should comply with local labor laws, regulations, and cultural norms. Features such as customizable templates for employment contracts, automated visa processing, and built-in compliance checks ensure adherence to local regulations and mitigate legal risks for businesses operating in Dubai.
2. Multilingual Support and Accessibility
Dubai's cosmopolitan workforce comprises individuals from diverse cultural and linguistic backgrounds. HR software with multilingual support and accessibility features facilitates communication and engagement across language barriers. Mobile-friendly interfaces and cloud-based platforms also enable employees to access HR services anytime, anywhere, enhancing convenience and user experience.
3. Integration with Government Portals
Integration with government portals and databases streamlines administrative processes, such as visa issuance, labor permits, and immigration procedures. Seamless data exchange between HR software and government systems reduces paperwork, eliminates manual data entry errors, and accelerates the processing of essential documents, thereby optimizing workforce operations in Dubai.
Conclusion
The future of HR lies at the intersection of technology, data, and human capital management. By harnessing the power of innovative HR software, businesses can streamline recruitment processes, enhance employee engagement, and make data-driven decisions to drive [organizational success](https://hbr.org/2023/05/6-key-levers-of-a-successful-organizational-transformation). In dynamic hubs like Dubai, where talent is abundant, and regulations are stringent, implementing the best HR software is not just a strategic advantage but a critical necessity for staying ahead in the competitive workforce management landscape.
As businesses embrace digital transformation, investing in the right HR software becomes paramount for achieving operational excellence, fostering a culture of innovation, and unlocking the workforce's full potential. In a rapidly evolving world where change is the only constant, embracing technology-driven solutions is not just a choice but a strategic imperative for HR leaders looking to shape the future of work in Dubai and beyond.
| jassi2610 | |
1,863,550 | Thoughts on High-Frequency Trading Strategies (4) | The previous article demonstrated the need for dynamically adjusting parameters and how to evaluate... | 0 | 2024-05-24T05:17:35 | https://dev.to/fmzquant/thoughts-on-high-frequency-trading-strategies-4-35jp | trading, strategy, fmzquant, cryptocurrency | The previous article demonstrated the need for dynamically adjusting parameters and how to evaluate the quality of estimates by studying the order arrival intervals. This article will focus on depth data and study the mid-price (also known as fair-price or micro-price).
## Depth Data
Binance provides historical data downloads for best_bid_price (the highest buying price), best_bid_quantity (the quantity at the best bid price), best_ask_price (the lowest selling price), best_ask_quantity (the quantity at the best ask price), and transaction_time. This data does not include the second or deeper order book levels. The analysis in this article is based on the YGG market on August 7th, which experienced significant volatility with over 9 million data points.
First, let's take a look at the market conditions on that day. There were large fluctuations, and the order book volume changed significantly along with the market volatility. The spread, particularly, indicated the extent of market fluctuations, which is the difference between the best ask and bid prices. In the statistics of the YGG market on that day, the spread was larger than one tick for 20% of the time. In this era of various trading bots competing in the order book, such situations are becoming increasingly rare.
In [1]:
```
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
```
In [2]:
```
books = pd.read_csv('YGGUSDT-bookTicker-2023-08-07.csv')
```
In [3]:
```
tick_size = 0.0001
```
In [4]:
```
books['date'] = pd.to_datetime(books['transaction_time'], unit='ms')
books.index = books['date']
```
In [5]:
```
books['spread'] = round(books['best_ask_price'] - books['best_bid_price'],4)
```
In [6]:
```
books['best_bid_price'][::10].plot(figsize=(10,5),grid=True);
```
Out[6]:
In [7]:
```
books['best_bid_qty'][::10].rolling(10000).mean().plot(figsize=(10,5),grid=True);
books['best_ask_qty'][::10].rolling(10000).mean().plot(figsize=(10,5),grid=True);
```
Out[7]:
In [8]:
```
(books['spread'][::10]/tick_size).rolling(10000).mean().plot(figsize=(10,5),grid=True);
```
Out[8]:
In [9]:
```
books['spread'].value_counts()[books['spread'].value_counts()>500]/books['spread'].value_counts().sum()
```
Out[9]:

## Imbalanced Quotes
Imbalanced quotes are observed from the significant difference in the order book volumes between the buy and sell orders most of the time. This difference has a strong predictive effect on short-term market trends, similar to the reason mentioned earlier that a decrease in buy order volume often leads to a decline. If one side of the order book is significantly smaller than the other, assuming the active buying and selling orders are similar in volume, there is a greater likelihood of the smaller side being consumed, thereby driving price changes. Imbalanced quotes are represented by the letter "I".
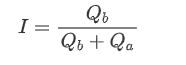
Where Q_b represents the amount of pending buy orders (best_bid_qty) and Q_a represents the amount of pending sell orders (best_ask_qty).
Define mid-price:
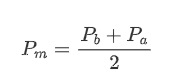
The graph below shows the relationship between the rate of change of mid-price over the next 1 interval and the imbalance I. As expected, the more likely the price is to increase as I increases and the closer it gets to 1, the more the price change accelerates. In high-frequency trading, the introduction of the intermediate price is to better predict future price changes, that is, and the future price difference is smaller, the better the intermediate price is defined. Obviously the imbalance of pending orders provides additional information for the prediction of the strategy, with this in mind, defining the weighted mid-price:
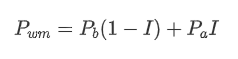
In [10]:
```
books['I'] = books['best_bid_qty'] / (books['best_bid_qty'] + books['best_ask_qty'])
```
In [11]:
```
books['mid_price'] = (books['best_ask_price'] + books['best_bid_price'])/2
```
In [12]:
```
bins = np.linspace(0, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['price_change'] = (books['mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['price_change'].mean()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Average Mid Price Change Rate');
plt.grid(True)
```
Out[12]:
In [13]:
```
books['weighted_mid_price'] = books['mid_price'] + books['spread']*books['I']/2
bins = np.linspace(-1, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['weighted_price_change'] = (books['weighted_mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['weighted_price_change'].mean()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Weighted Average Mid Price Change Rate');
plt.grid(True)
```
Out[13]:
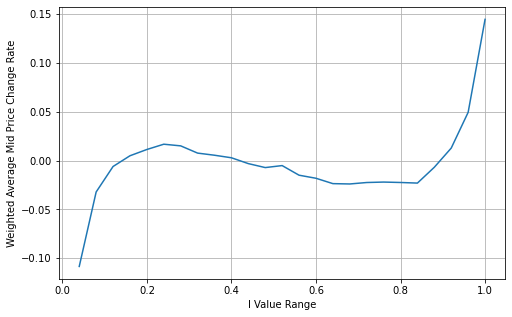
## Adjust Weighted Mid-Price:
From the graph, it can be observed that the weighted mid-price shows smaller variations compared to different values of I, indicating that it is a better fit. However, there are still some deviations, particularly around 0.2 and 0.8. This suggests that I still provides additional information. The assumption of a completely linear relationship between the price correction term and I, as implied by the weighted mid-price, does not align with reality. It can be seen from the graph that the deviation speed increases when I approaches 0 and 1, indicating a non-linear relationship.
To provide a more intuitive representation, here is a redefinition of I:
Revised definition of I:
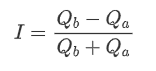
At this point:
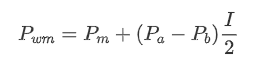
Upon observation, it can be noticed that the weighted mid-price is a correction to the average mid-price, where the correction term is multiplied by the spread. The correction term is a function of I, and the weighted mid-price assumes a simple relationship of I/2. In this case, the advantage of the adjusted I distribution (-1, 1) becomes apparent, as I is symmetric around the origin, making it convenient to find a fitting relationship for the function. By examining the graph, it appears that this function should satisfy odd powers of I, as it aligns with the rapid growth on both sides and symmetry around the origin. Additionally, it can be observed that values near the origin are close to linear. Furthermore, when I is 0, the function result is 0, and when I is 1, the function result is 0.5. Therefore, it is speculated that the function is of the form:
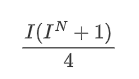
Here N is a positive even number, after actual testing, it is better when N is 8. So far this paper presents the modified weighted mid-price:
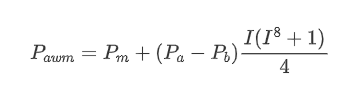
At this point, the prediction of mid-price changes is no longer significantly related to I. Although this result is slightly better than the simple weighted mid-price, it is still not applicable in real trading scenarios. This is just a proposed approach. In a 2017 article by S Stoikov, the concept of [Micro-Price](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2970694) is introduced using a Markov chain approach, and related code is provided. Researchers can explore this approach further.
In [14]:
```
books['I'] = (books['best_bid_qty'] - books['best_ask_qty']) / (books['best_bid_qty'] + books['best_ask_qty'])
```
In [15]:
```
books['weighted_mid_price'] = books['mid_price'] + books['spread']*books['I']/2
bins = np.linspace(-1, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['weighted_price_change'] = (books['weighted_mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['weighted_price_change'].mean()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Weighted Average Mid Price Change Rate');
plt.grid(True)
```
Out[15]:
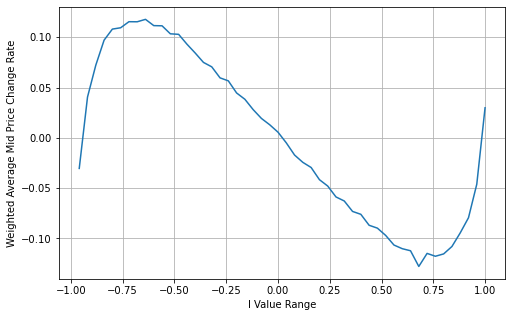
In [16]:
```
books['adjust_mid_price'] = books['mid_price'] + books['spread']*books['I']*(books['I']**8+1)/4
bins = np.linspace(-1, 1, 51)
books['I_bins'] = pd.cut(books['I'], bins, labels=bins[1:])
books['adjust_mid_price'] = (books['adjust_mid_price'].pct_change()/tick_size).shift(-1)
avg_change = books.groupby('I_bins')['adjust_mid_price'].mean()
plt.figure(figsize=(8,5))
plt.plot(avg_change)
plt.xlabel('I Value Range')
plt.ylabel('Weighted Average Mid Price Change Rate');
plt.grid(True)
```
Out[16]:
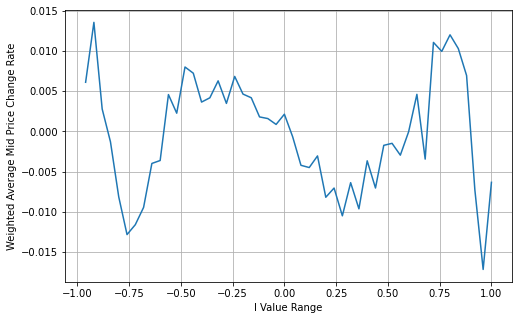
## Summary
The mid-price is crucial for high-frequency strategies as it serves as a prediction of short-term future prices. Therefore, it is important for the mid-price to be as accurate as possible. The mid-price approaches discussed earlier are based on order book data, as only the top level of the order book is utilized in the analysis. In live trading, strategies should aim to utilize all available data, including trade data, to validate mid-price predictions against actual transaction prices. I recall Stoikov mentioning in a Twitter that the real mid-price should be a weighted average of the probabilities of the bid and ask prices being executed. This issue has been explored in the previous articles. Due to length constraints, further details on these topics will be discussed in the next article.
From: https://blog.mathquant.com/2023/08/10/thoughts-on-high-frequency-trading-strategies-4.html | fmzquant |
1,863,549 | 10 Marketing Case Study Examples | Introduction Marketing case studies are powerful tools that illustrate the effectiveness of various... | 0 | 2024-05-24T05:16:32 | https://dev.to/apptagsolution/10-marketing-case-study-examples-li | marketing, case, study, example |

Introduction
Marketing case studies are powerful tools that illustrate the effectiveness of various strategies in real-world scenarios. They provide insights into what works, what doesn't, and why. Whether you're a seasoned marketer or just starting out, understanding these examples can offer invaluable lessons to apply to your own campaigns. Let's dive into 10 remarkable marketing case studies that showcase innovative approaches and impressive results.you have to also know Top 10 [**Digital Marketing Case Studies**](https://apptagsolution.com/blog/digital-marketing-case-studies/) Every Marketer Should Know
Case Study 1: Nike's Digital Transformation
Background
Nike, a global leader in sports apparel and equipment, faced the challenge of staying relevant in a digital age where consumer expectations were rapidly evolving.
Strategy and Implementation
Nike embraced digital transformation by investing in e-commerce, developing cutting-edge apps like the Nike Training Club, and leveraging data analytics to personalize customer experiences. They also integrated their physical and digital channels to create a seamless shopping experience.
Results and Impact
Nike's digital transformation led to a significant increase in online sales, improved customer engagement, and a stronger brand presence. Their digital channels now account for a substantial portion of their revenue, showcasing the success of their strategy.
Case Study 2: Coca-Cola's Personalized Marketing Campaign
Background
Coca-Cola aimed to boost sales and reconnect with younger audiences through personalized marketing.
Strategy and Implementation
The "Share a Coke" campaign replaced the Coca-Cola logo on bottles with popular names, encouraging customers to find bottles with their names or their friends' names. The campaign was supported by social media and interactive billboards.
Results and Impact
The campaign was a massive success, leading to a 2% increase in U.S. sales and a significant boost in social media engagement. It demonstrated the power of personalization and interactive marketing.
Case Study 3: Airbnb's User-Generated Content
Background
Airbnb sought to build trust and authenticity among potential users by leveraging content created by its own community.
Strategy and Implementation
Airbnb encouraged hosts and guests to share their experiences and stories on social media and the Airbnb website. They also featured user-generated content in their marketing campaigns.
Results and Impact
This strategy significantly increased user engagement and trust. It helped Airbnb grow its community and enhance its brand image as a platform built on genuine experiences and relationships.
Case Study 4: Apple's Product Launch Strategy
Background
Apple is renowned for its highly anticipated product launches, which create significant buzz and excitement.
Strategy and Implementation
Apple employs a combination of secrecy, high-profile events, and strategic leaks to build anticipation. Their launch events are meticulously planned and widely covered by the media.
Results and Impact
Each product launch generates immense media coverage and consumer interest, leading to high sales numbers immediately after release. This strategy has cemented Apple's reputation as an innovator and market leader.
Case Study 5: Dove's Real Beauty Campaign
Background
Dove aimed to change the conversation around beauty standards with its "Real Beauty" campaign.
Strategy and Implementation
Dove featured real women of various ages, sizes, and ethnicities in its ads, moving away from traditional beauty stereotypes. The campaign included powerful videos and interactive elements.
Results and Impact
The campaign was a resounding success, increasing Dove's sales and improving its brand perception. It also sparked a broader conversation about beauty standards and self-esteem.
Case Study 6: Tesla's[ **Social Media Strategy**](https://apptagsolution.com/blog/digital-marketing-case-studies/)
Background
Tesla, led by CEO Elon Musk, uses social media as a primary tool for marketing and communication.
Strategy and Implementation
Elon Musk actively engages with followers on Twitter, making announcements, addressing customer concerns, and sharing updates. Tesla also uses social media to highlight innovations and achievements.
Results and Impact
Tesla's social media strategy has created a strong, engaged community of brand advocates. It has also provided Tesla with a cost-effective way to communicate directly with consumers and build excitement around its products.
Case Study 7: Amazon's Customer-Centric Approach
Background
Amazon's growth has been driven by an unwavering focus on customer satisfaction.
Strategy and Implementation
Amazon continuously improves its customer experience through personalized recommendations, fast shipping, and exceptional customer service. They use data analytics to anticipate customer needs and streamline their operations.
Results and Impact
This customer-centric approach has led to high levels of customer loyalty and trust. Amazon's market share and revenue have consistently grown, reinforcing its position as a leading e-commerce platform.
Case Study 8: Old Spice's Rebranding Campaign
Background
Old Spice needed to revitalize its brand and appeal to a younger audience.
Strategy and Implementation
The "Smell Like a Man, Man" campaign featured humorous and memorable commercials starring actor Isaiah Mustafa. The campaign was heavily promoted on social media and digital platforms.
Results and Impact
The rebranding campaign was a huge success, doubling Old Spice's sales and transforming its brand image. It demonstrated the power of humor and viral marketing.
Case Study 9: Red Bull's Content Marketing
Background
Red Bull's marketing strategy focuses heavily on content marketing and extreme sports.
Strategy and Implementation
Red Bull creates and sponsors extreme sports events, producing high-quality videos and content that showcase these events. They distribute this content across multiple platforms, including social media and their own media channels.
Results and Impact
Red Bull's content marketing has built a strong brand association with energy and adventure. It has significantly increased brand visibility and consumer engagement.
Case Study 10: Spotify's Data-Driven Personalization
Background
Spotify aims to enhance user experience through personalized recommendations and playlists.
Strategy and Implementation
Spotify uses data analytics and machine learning to curate personalized playlists, such as Discover Weekly and Wrapped, which summarize users' listening habits over the year.
Results and Impact
These personalized features have greatly improved user retention and engagement. Spotify's user base has grown rapidly, with personalized experiences becoming a key differentiator in the competitive streaming market.if you are looking for [**best digital marketing company**](https://apptagsolution.com/) then apptagsolution is the best option for you
Conclusion
These ten marketing case studies illustrate the diverse strategies and innovative approaches that companies can use to achieve remarkable results. From digital transformations and personalized marketing to social media engagement and content marketing, each example provides valuable lessons. By studying these cases, businesses can gain insights into effective marketing tactics and apply them to their own efforts. | apptagsolution |
1,863,548 | Why Python and Snake | Its been a strange few weeks but it wasn't easy. I'm learning how to code and I must say its not as... | 0 | 2024-05-24T05:13:19 | https://dev.to/justrow/why-python-and-snake-2l4p | Its been a strange few weeks but it wasn't easy. I'm learning how to code and I must say its not as easy as the tiktokers say or youtube it takes time and a lot of understanding. I know what I'm doing but its so frustrating doubting yourself
So comes in my first Game Snake I now know the concept behind everything I've learned so far in my intro to python but I'm still a bit confused or shy but I know we shall ace it soon enough.
So to snake thank you.
[https://github.com/Just-Row/Snake-Game-Project-1.git](url) | justrow | |
1,862,881 | Unlocking JavaScript: A Deep Dive into Fundamentals.🚀🚀 | 1. Variables Variables are the fundamental building blocks for storing data in JavaScript. They can... | 0 | 2024-05-24T05:12:01 | https://dev.to/dharamgfx/unlocking-javascript-a-deep-dive-into-fundamentals-5afn | javascript, webdev, beginners, programming | **1. Variables**
Variables are the fundamental building blocks for storing data in JavaScript. They can be declared using `var`, `let`, or `const`.
**Declaration and Initialization**
- `var`: Function-scoped or globally-scoped.
*Example:*
```javascript
var age = 30;
```
- `let`: Block-scoped, recommended for mutable variables.
*Example:*
```javascript
let name = 'Alice';
```
- `const`: Block-scoped, immutable variable once assigned.
*Example:*
```javascript
const pi = 3.14;
```
- mutable object can be changed after it's created, and an immutable object can't.
- Mutable instance is passed by reference.
- Immutable instance is passed by value.
**Hoisting**
- Variables declared with `var` are hoisted to the top but not initialized.
*Example:*
```javascript
console.log(hoistedVar); // undefined
var hoistedVar = 'I am hoisted';
```
---
**2. Math**
JavaScript supports basic arithmetic operations and complex mathematical functions.
**Basic Operators**
- Addition (`+`), Subtraction (`-`), Multiplication (`*`), Division (`/`).
*Example:*
```javascript
let sum = 10 + 5; // 15
let product = 10 * 5; // 50
```
**Math Object**
- Provides advanced mathematical functions.
*Example:*
```javascript
let maxVal = Math.max(10, 20, 30); // 30
let randomNum = Math.random(); // A random number between 0 and 1
```
---
**3. Text**
Strings in JavaScript are used for storing and manipulating text.
**String Methods**
- `length`: Returns the length of the string.
*Example:*
```javascript
let str = "Hello, World!";
console.log(str.length); // 13
```
- `toUpperCase()`, `toLowerCase()`: Change case.
*Example:*
```javascript
console.log(str.toUpperCase()); // "HELLO, WORLD!"
```
- `substring()`: Extracts a part of the string.
*Example:*
```javascript
console.log(str.substring(0, 5)); // "Hello"
```
---
**4. Arrays**
Arrays are used to store multiple values in a single variable.
**Creating Arrays**
- Use square brackets `[]`.
*Example:*
```javascript
let fruits = ['Apple', 'Banana', 'Cherry'];
```
**Array Methods**
- `push()`, `pop()`: Add/remove items from the end.
*Example:*
```javascript
fruits.push('Orange'); // ['Apple', 'Banana', 'Cherry', 'Orange']
fruits.pop(); // ['Apple', 'Banana', 'Cherry']
```
- `shift()`, `unshift()`: Add/remove items from the beginning.
*Example:*
```javascript
fruits.shift(); // ['Banana', 'Cherry']
fruits.unshift('Strawberry'); // ['Strawberry', 'Banana', 'Cherry']
```
- `map()`, `filter()`: Transform and filter arrays.
*Example:*
```javascript
let lengths = fruits.map(fruit => fruit.length); // [10, 6]
let shortFruits = fruits.filter(fruit => fruit.length < 7); // ['Banana']
```
---
**5. Conditionals**
Control the flow of your code with conditional statements.
**if, else if, else**
- Execute code based on conditions.
*Example:*
```javascript
let num = 10;
if (num > 10) {
console.log("Greater than 10");
} else if (num < 10) {
console.log("Less than 10");
} else {
console.log("Equal to 10");
}
```
**switch**
- Use for multiple conditions based on a single variable.
*Example:*
```javascript
let fruit = 'Apple';
switch (fruit) {
case 'Banana':
console.log('Banana is yellow');
break;
case 'Apple':
console.log('Apple is red');
break;
default:
console.log('Unknown fruit');
}
```
---
**6. Loops**
Loops allow repetitive tasks to be performed efficiently.
**for Loop**
- Iterates a specified number of times.
*Example:*
```javascript
for (let i = 0; i < 5; i++) {
console.log(i);
}
```
**while Loop**
- Iterates while a condition is true.
*Example:*
```javascript
let i = 0;
while (i < 5) {
console.log(i);
i++;
}
```
**forEach**
- Iterates over array elements.
*Example:*
```javascript
let numbers = [1, 2, 3];
numbers.forEach(num => console.log(num));
```
---
**7. Functions**
Functions are reusable blocks of code designed to perform a particular task.
**Function Declaration**
- Define a function using `function` keyword.
*Example:*
```javascript
function greet(name) {
return `Hello, ${name}!`;
}
console.log(greet('Alice')); // "Hello, Alice!"
```
**Function Expression**
- Assign a function to a variable.
*Example:*
```javascript
const square = function(num) {
return num * num;
};
console.log(square(4)); // 16
```
**Arrow Functions**
- A shorter syntax for function expressions.
*Example:*
```javascript
const add = (a, b) => a + b;
console.log(add(2, 3)); // 5
```
---
**8. JavaScript Object Basics**
Objects store collections of key-value pairs.
**Creating Objects**
- Use object literals `{}`.
*Example:*
```javascript
let person = {
name: 'John',
age: 30,
greet: function() {
return `Hello, my name is ${this.name}`;
}
};
console.log(person.greet()); // "Hello, my name is John"
```
**Accessing Properties**
- Use dot notation or bracket notation.
*Example:*
```javascript
console.log(person.name); // "John"
console.log(person['age']); // 30
```
**Adding/Modifying Properties**
- Directly add or modify properties.
*Example:*
```javascript
person.job = 'Developer';
person.age = 31;
```
---
**9. DOM Scripting**
DOM (Document Object Model) scripting allows you to interact with and manipulate HTML and CSS.
**Selecting Elements**
- Use methods like `getElementById()`, `querySelector()`.
*Example:*
```javascript
let heading = document.getElementById('main-heading');
let paragraphs = document.querySelectorAll('p');
```
**Manipulating Elements**
- Change content and style.
*Example:*
```javascript
heading.textContent = 'New Heading';
heading.style.color = 'blue';
```
---
**10. Events**
Events allow JavaScript to interact with user actions.
**Event Listeners**
- Attach event handlers to elements.
*Example:*
```javascript
let button = document.querySelector('button');
button.addEventListener('click', function() {
alert('Button clicked!');
});
```
**Common Events**
- `click`, `mouseover`, `mouseout`, `keydown`, `load`.
*Example:*
```javascript
document.addEventListener('keydown', function(event) {
console.log(`Key pressed: ${event.key}`);
});
```
---
**11. Async JavaScript Basics**
Asynchronous programming allows your code to run without blocking other operations.
**Callbacks**
- Functions passed as arguments to be executed later.
*Example:*
```javascript
function fetchData(callback) {
setTimeout(() => {
callback('Data fetched');
}, 2000);
}
fetchData(message => {
console.log(message);
});
```
**Promises**
- Represent eventual completion (or failure) of an asynchronous operation.
*Example:*
```javascript
let promise = new Promise((resolve, reject) => {
let success = true;
if (success) {
resolve('Operation succeeded');
} else {
reject('Operation failed');
}
});
promise.then(message => {
console.log(message);
}).catch(error => {
console.error(error);
});
```
**Async/Await**
- Syntactic sugar for promises, making asynchronous code look synchronous.
*Example:*
```javascript
async function fetchData() {
let response = await fetch('https://api.example.com/data');
let data = await response.json();
console.log(data);
}
fetchData();
```
---
**12. Network Requests with fetch()**
The `fetch()` API allows you to make network requests similar to `XMLHttpRequest`.
**Making a Request**
- Fetch data from a server.
*Example:*
```javascript
fetch('https://api.example.com/data')
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error('Error
:', error));
```
**Handling Responses**
- Convert response to usable data.
*Example:*
```javascript
fetch('https://api.example.com/data')
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.json();
})
.then(data => console.log(data))
.catch(error => console.error('Fetch error:', error));
```
---
**13. Working with JSON**
JSON (JavaScript Object Notation) is a common data format used for exchanging data.
**Parsing JSON**
- Convert JSON strings to JavaScript objects.
*Example:*
```javascript
let jsonString = '{"name": "John", "age": 30}';
let user = JSON.parse(jsonString);
console.log(user.name); // "John"
```
**Stringifying Objects**
- Convert JavaScript objects to JSON strings.
*Example:*
```javascript
let userObj = { name: 'Alice', age: 25 };
let userJSON = JSON.stringify(userObj);
console.log(userJSON); // '{"name":"Alice","age":25}'
```
---
**14. Libraries and Frameworks**
JavaScript libraries and frameworks can simplify development and add powerful features.
**jQuery**
- Simplifies DOM manipulation, event handling, and Ajax.
*Example:*
```javascript
$(document).ready(function() {
$('button').click(function() {
alert('Button clicked!');
});
});
```
**React**
- A library for building user interfaces.
*Example:*
```javascript
import React from 'react';
import ReactDOM from 'react-dom';
function App() {
return <h1>Hello, World!</h1>;
}
ReactDOM.render(<App />, document.getElementById('root'));
```
**Angular**
- A framework for building web applications.
*Example:*
```javascript
import { Component } from '@angular/core';
@Component({
selector: 'app-root',
template: '<h1>Hello, World!</h1>'
})
export class AppComponent {}
```
---
**15. Debugging JavaScript**
Debugging is essential for finding and fixing errors in your code.
**Console Logging**
- Use `console.log()` to inspect values.
*Example:*
```javascript
let value = 42;
console.log(value);
```
**Debugger Statement**
- Pause execution for debugging.
*Example:*
```javascript
function test() {
let x = 10;
debugger; // Pauses here
x += 5;
return x;
}
test();
```
**Browser Developer Tools**
- Use tools in browsers like Chrome and Firefox to inspect, debug, and profile your code.
**Example:**
- Open Developer Tools with F12 or right-click and select "Inspect". Use the "Console" tab to log messages and the "Sources" tab to set breakpoints and step through code.
---
**Conclusion**
Mastering JavaScript fundamentals equips you with the skills needed to build dynamic, interactive web applications. By understanding variables, math operations, text manipulation, arrays, conditionals, loops, functions, objects, DOM scripting, events, asynchronous programming, network requests, JSON, libraries and frameworks, and debugging techniques, you can create robust and efficient JavaScript applications. Dive into these core concepts to enhance your coding prowess and develop powerful web experiences. | dharamgfx |
1,857,434 | Maximizing SEO for Single Page Applications: Strategies and Coding Examples | In today's digital landscape, Single Page Applications (SPAs) have gained immense popularity for... | 0 | 2024-05-24T05:10:00 | https://dev.to/nitin-rachabathuni/maximizing-seo-for-single-page-applications-strategies-and-coding-examples-3o83 | In today's digital landscape, Single Page Applications (SPAs) have gained immense popularity for their dynamic user experiences and seamless interactions. However, one challenge that developers often encounter with SPAs is ensuring they are search engine friendly. In this article, we'll delve into effective SEO optimization techniques for SPAs and provide coding examples to illustrate each strategy.
Understanding SPA SEO Challenges
Traditional websites consist of multiple pages, each with unique URLs, which search engine crawlers can easily navigate. However, SPAs typically load content dynamically without full page reloads, often utilizing JavaScript frameworks like React, Angular, or Vue.js. As a result, search engine crawlers may struggle to index SPA content effectively, leading to poor search visibility.
Key SEO Optimization Strategies for SPAs
Server-Side Rendering (SSR): Implementing SSR allows search engines to crawl and index content by rendering the initial HTML on the server before sending it to the client. This ensures that search engines can access the content directly without relying solely on JavaScript execution.
```
// Example SSR with React and Next.js
import React from 'react';
import { renderToString } from 'react-dom/server';
import App from './App';
const express = require('express');
const server = express();
server.get('/', (req, res) => {
const appHtml = renderToString(<App />);
res.send(`
<!DOCTYPE html>
<html>
<head><title>SPA SEO Example</title></head>
<body>
<div id="root">${appHtml}</div>
<script src="client.js"></script>
</body>
</html>
`);
});
server.listen(3000, () => {
console.log('Server is running on port 3000');
});
```
Dynamic Rendering: For SPAs heavily reliant on client-side rendering, dynamic rendering serves pre-rendered HTML snapshots to search engine crawlers while delivering the SPA experience to users. This approach bridges the gap between SPA interactivity and SEO.
```
// Example dynamic rendering with Puppeteer
const puppeteer = require('puppeteer');
async function renderPage(url) {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url, { waitUntil: 'networkidle0' });
const html = await page.content();
await browser.close();
return html;
}
const server = express();
server.get('/', async (req, res) => {
const html = await renderPage('https://example.com');
res.send(html);
});
```
Meta Tags and Sitemaps: Utilize meta tags such as <title>, <meta name="description">, and <meta name="keywords"> to provide search engines with relevant information about your SPA content. Additionally, generate and submit a dynamic sitemap to ensure all SPA routes are indexed.
```
<!-- Example meta tags -->
<head>
<title>My SPA | Home</title>
<meta name="description" content="Discover the latest trends in SPA optimization.">
<meta name="keywords" content="SPA, SEO, optimization">
</head>
```
Use of Fragment Identifiers: Implement fragment identifiers (hashbangs) in URLs to create crawlable routes for search engines, ensuring that SPA content can be indexed and accessed directly.
```
// Example routing with fragment identifiers
import { BrowserRouter as Router, Route } from 'react-router-dom';
function App() {
return (
<Router>
<Route path="/" component={Home} />
<Route path="/about" component={About} />
{/* Additional routes */}
</Router>
);
}
```
Conclusion
By implementing these SEO optimization strategies, developers can enhance the visibility of SPAs in search engine results pages (SERPs) and attract more organic traffic. Combining server-side rendering, dynamic rendering, meta tags, and proper URL structuring ensures that SPAs deliver exceptional user experiences while maximizing SEO effectiveness.
Remember, SEO for SPAs is an ongoing process, and staying updated with best practices and search engine algorithm changes is crucial for long-term success. With the right approach and attention to detail, SPAs can achieve excellent search visibility and drive significant business results.
Feel free to share your thoughts or additional insights on SPA SEO optimization in the comments below!
---
Thank you for reading my article! For more updates and useful information, feel free to connect with me on LinkedIn and follow me on Twitter. I look forward to engaging with more like-minded professionals and sharing valuable insights.
| nitin-rachabathuni | |
1,863,547 | Making a Strong Impact: How On-Ground Kabaddi Branding Can Help Your Brand Stand Out | In an era dominated by digital marketing, on-ground advertising remains a powerful strategy for... | 0 | 2024-05-24T05:08:49 | https://dev.to/sportvot/making-a-strong-impact-how-on-ground-kabaddi-branding-can-help-your-brand-stand-out-14a0 | In an era dominated by digital marketing, on-ground advertising remains a powerful strategy for creating genuine connections with audiences and demonstrating strong support for lower-tier sports. In India, traditional Out-of-Home (OOH) advertising might seem outdated or hard to measure, but when tailored for specific communities like sports enthusiasts, it can unlock tremendous potential. This blog explores why investing in targeted on-ground advertising within the grassroots kabaddi community can be a game-changer, offering a fresh perspective on maximizing your advertising impact while supporting local sports and talent.
The Changing Landscape of OOH Advertising
Traditional OOH advertising methods, such as billboards, bus stop ads, and posters, have long been staples for many businesses. However, as times change, so do consumer habits. Today's tech-savvy audience often overlooks generic OOH advertisements that blend into the background of cityscapes. This shift has created a need for personalized and engaging marketing approaches that can establish an instant connection with the brand while positively impacting grassroots sports.
The Power of Grassroots [Kabaddi](https://sportvot.com/)
Grassroots sports, especially kabaddi, are more than just games; they are the heartbeat of local communities throughout India. Leveraging sports as a platform for on-ground advertising allows your brand to engage directly with passionate audiences who fervently support their local teams and athletes. Associating with grassroots kabaddi helps build positive brand perception, showing that your brand is not just a business but a part of the community, supporting local talent and aspirations. This perception benefits brands in multiple ways. Grassroots sports communities are tightly-knit, and a well-executed on-ground advertising campaign can generate positive word-of-mouth, extending your brand's reach far beyond the event itself. Unlike traditional OOH advertising, where viewers are in transit and might only glance at an ad for a few seconds, sports events offer a captive audience. Spectators are emotionally invested in the game, making them more receptive to advertisements displayed during the event.
Innovative Platforms for Kabaddi Advertising
Traditional OOH advertising options may not provide the traceability and metrics that businesses desire. This is where innovative platforms like SportVot step in, revolutionizing on-ground advertising in grassroots sports. SportVot allows you to precisely target your audience based on the specific sport, location, and demographics, ensuring that your message reaches the right people. Strategically placing your ads during kabaddi events featured in the live streaming of the games gives your brand heightened visibility, ensuring that your ads are seen and remembered. Our focus is on maximizing on-ground activation with unique branding opportunities, interactive displays, and sponsorships, helping brands integrate seamlessly into the sports experience.
Embracing the Future of Kabaddi Advertising
As the advertising landscape evolves, businesses must adapt to changing consumer preferences. Investing in grassroots kabaddi as a targeted channel for on-ground advertising can breathe new life into your marketing efforts. Instead of spending exorbitant amounts on generic OOH advertising, an innovative, community-driven approach ensures that your on-ground activation is maximized and delivers tangible results. By connecting with passionate sports communities, you can forge deeper connections with your audience and elevate your brand above the noise of traditional advertising. Embrace the potential of on-ground advertising in grassroots kabaddi and watch your brand score big in the hearts of local communities, making a meaningful impact on the world of grassroots sports. | sportvot | |
1,863,546 | Exploring Data with NumPy: A Guide to Statistical Functions in Python | NumPy, a fundamental package for scientific computing in Python, offers a variety of statistical... | 27,505 | 2024-05-24T05:06:00 | https://dev.to/lohith0512/exploring-data-with-numpy-a-guide-to-statistical-functions-in-python-12cp | python, statistics, numpy, functions | NumPy, a fundamental package for scientific computing in Python, offers a variety of statistical functions that are essential for data analysis. These functions help to summarize and interpret data by calculating descriptive statistics. Here are some of the common statistical functions provided by NumPy:
- `mean()`: Calculates the average of the array elements.
- `median()`: Determines the middle value of a sorted array.
- `std()`: Computes the standard deviation, a measure of the amount of variation or dispersion of a set of values.
- `var()`: Calculates the variance, which measures how far a set of numbers is spread out from their average value.
- `min()`: Returns the smallest value in an array.
- `max()`: Returns the largest value in an array.
- `percentile()`: Computes the nth percentile of the data along the specified axis.
Let's look at some examples:
**Mean:**
```python
import numpy as np
# Creating a simple array
data = np.array([1, 2, 3, 4, 5])
mean_value = np.mean(data)
print("Mean:", mean_value)
```
Output: `Mean: 3.0`
**Median:**
```python
# For an array with an odd number of elements
median_value_odd = np.median(np.array([1, 3, 5]))
print("Median (Odd):", median_value_odd)
# For an array with an even number of elements
median_value_even = np.median(np.array([1, 3, 5, 7]))
print("Median (Even):", median_value_even)
```
Output:
```
Median (Odd): 3.0
Median (Even): 4.0
```
**Standard Deviation and Variance:**
```python
# Standard Deviation
std_dev = np.std(data)
print("Standard Deviation:", std_dev)
# Variance
variance = np.var(data)
print("Variance:", variance)
```
Output:
```
Standard Deviation: 1.4142135623730951
Variance: 2.0
```
**Min and Max:**
```python
# Minimum value
min_value = np.min(data)
print("Minimum:", min_value)
# Maximum value
max_value = np.max(data)
print("Maximum:", max_value)
```
Output:
```
Minimum: 1
Maximum: 5
```
**Percentile:**
```python
# 50th percentile, which is the same as the median
percentile_50 = np.percentile(data, 50)
print("50th Percentile:", percentile_50)
```
Output: `50th Percentile: 3.0`
These functions are quite powerful when it comes to analyzing large datasets and can be applied to both one-dimensional and multi-dimensional arrays. | lohith0512 |
1,863,545 | The Role of Assignment Help in Enhancing Student Learning | Assignment help services have become a crucial component of modern education, significantly enhancing... | 0 | 2024-05-24T05:00:43 | https://dev.to/zaynmalik/the-role-of-assignment-help-in-enhancing-student-learning-1dlp | assignment, writer |
Assignment help services have become a crucial component of modern education, significantly enhancing student learning and academic performance. These services provide tailored support to students struggling with various aspects of their coursework, ensuring they achieve their academic goals.
One of the key advantages of [assignment help](https://thestudenthelpline.io/au/
) is the personalized guidance it offers. Expert tutors and academic professionals provide one-on-one assistance, helping students grasp complex concepts and improve their understanding of the subject matter. This personalized approach ensures that students receive the attention they need, which is often lacking in large classroom settings.
Moreover, assignment help services aid in time management. Students often juggle multiple assignments, extracurricular activities, and personal commitments. By providing structured support and setting realistic deadlines, these services help students manage their workload more effectively, reducing stress and preventing burnout.
Assignment help also promotes better research and writing skills. Students learn to approach assignments methodically, enhancing their ability to gather relevant information, organize their thoughts, and present their findings coherently. This not only improves the quality of their assignments but also equips them with essential skills for future academic and professional endeavors.
Furthermore, assignment help services emphasize academic integrity by teaching students proper citation practices and encouraging original work. This helps in cultivating a culture of honesty and responsibility in academic pursuits.
In conclusion, assignment help plays a vital role in enhancing student learning by providing personalized support, improving time management, developing research and writing skills, and promoting academic integrity.
| zaynmalik |
1,863,543 | Online Assignment Help in Australia For Students | Hey everyone! I know many of us are juggling multiple assignments and deadlines, and sometimes it... | 0 | 2024-05-24T04:55:56 | https://dev.to/mark_robber/online-assignment-help-in-australia-for-students-3pa3 | Hey everyone! I know many of us are juggling multiple assignments and deadlines, and sometimes it can feel overwhelming. I've been exploring online **_<a href="https://thestudenthelpline.io/au/">Assignment Help</a>_** services in Australia to ease the burden and ensure I submit quality work on time. I'd love to hear your thoughts, experiences, and recommendations regarding these services. Have you tried any? Which ones would you recommend, and why? Let's help each other out and make our academic journey a little smoother!
| mark_robber | |
1,863,542 | Overview of the DevOps Interview Process: From Application to Selection - In 50 min | Hello, everyone. This is my attempt to provide a brief overview of the DevOps interview process, from... | 0 | 2024-05-24T04:46:51 | https://dev.to/lakhera2015/overview-of-the-devops-interview-process-from-application-to-selection-in-50-min-1nlp | devops, interview, books, knowledge |
Hello, everyone. This is my attempt to provide a brief overview of the DevOps interview process, from application to selection, covering all the essential DevOps tools in a single video. This section is taken from my book Cracking the DevOps Interview. One of the reasons I wrote this book is that, while there are many books available for coding interviews, there are only a few comprehensive books dedicated to DevOps interviews.
If you have an upcoming DevOps interview and need to refresh your knowledge, we have the perfect resource for you. Our latest video offers a comprehensive overview of all the key DevOps concepts you'll need to know. This video is designed to give you a quick refresher on the fundamental topics, ensuring you're well-prepared for your interview.
Additionally, we will soon be releasing a series of detailed videos that delve deeper into each concept. These in-depth explanations will help you gain a thorough understanding of all the critical aspects of DevOps, enhancing your readiness and confidence for your interview. Stay tuned for these upcoming videos!
{% embed https://www.youtube.com/embed/LhTpXRkEEFo?si=EX8yYS2rJbwfAKrh %}
📚 Book link: https://pratimuniyal.gumroad.com/l/cracking-the-devops-interview | lakhera2015 |
1,863,541 | Building a RESTful API with Flask in Python: A Beginner's Guide | Introduction RESTful APIs are a popular way to structure web APIs. They are... | 0 | 2024-05-24T04:35:57 | https://dev.to/manavcodaty/building-a-restful-api-with-flask-in-python-a-beginners-guide-meb | ## Introduction
---
RESTful APIs are a popular way to structure web APIs. They are lightweight, scalable, and easy to understand. Flask is a Python framework that makes building RESTful APIs simple and elegant.
In this blog post, we'll walk through the basics of creating a RESTful API with Flask. We'll cover:
- **What are RESTful APIs?**
- **Why use Flask for building APIs?**
- **Setting up a Flask project**
- **Creating API endpoints**
- **Handling requests and responses**
## **What are RESTful APIs?**
---
REST stands for Representational State Transfer. A RESTful API adheres to a set of architectural principles that make it easy to develop and use. These principles include:
- **Client-server architecture:** Clients (like web applications) make requests to servers (like your API)
- **Stateless communication:** Each request from a client should contain all the information the server needs to respond.
- **Resource-based:** APIs expose resources, and clients interact with these resources using HTTP methods like GET,POST, PUT, and DELETE.
## **Why use Flask for building APIs?**
---
Flask is a lightweight web framework that makes it easy to get started with building web applications and APIs. Here are some reasons to use Flask for building RESTful APIs:
- **Simple and easy to learn:** Flask has a clean and concise syntax, making it easy for beginners to pick up.
- **Flexible:** Flask gives you a lot of control over your application's structure.
- **Scalable:** Flask applications can be easily scaled to handle large amounts of traffic.
## **Setting up a Flask project**
---
1. Install Flask: using pip
```python
pip install Flask
```
1. **Create a Python file:** Create a new Python file, for example, api.py.
## **Creating API endpoints**
---
An API endpoint is a URL that represents a resource. Flask uses decorators to define routes for your API. Here's a simple example of a Flask route that returns a JSON object:
```python
Python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return {'message': 'Hello, World!'}
if __name__ == '__main__':
app.run(debug=True)
```
In this example, the @app.route('/') decorator defines a route for the root URL (/). The hello_world function is called whenever a client makes a GET request to this URL. The function returns a dictionary that is automatically converted to JSON by Flask.
## **Handling requests and responses**
---
Flask provides ways to handle different HTTP methods in your API endpoints. Here's an example of an endpoint that handles GET and POST requests:
```python
Python
from flask import Flask, request
app = Flask(__name__)
@app.route('/users', methods=['GET', 'POST'])
def users():
if request.method == 'GET':
# Get all users
return {'users': []} # Implement logic to get users
elif request.method == 'POST':
# Create a new user
return {'message': 'User created successfully!'} # Implement logic to create user
else:
return {'error': 'Method not allowed'}, 405 # Return error for unsupported methods
if __name__ == '__main__':
app.run(debug=True)
```
This example shows how to use the request object to get information about the request, such as the HTTP method and request body. The function returns a dictionary and a status code to indicate the outcome of the request.
## **Conclusion**
---
This is a very basic introduction to building RESTful APIs with Flask. With Flask, you can create powerful and scalable APIs for your applications. There are many resources available online to learn more about Flask and RESTful API design.Here are some suggestions for further learning:
- The official Flask documentation: https://flask.palletsprojects.com/
- A tutorial on building a RESTful API with Flask: https://www.linode.com/docs/guides/flask-and-gunicorn-on-ubuntu/
I hope this blog post has helped you get started with building RESTful APIs with Flask! | manavcodaty | |
1,863,540 | Best Car Service in Dubai | Best Car Workshop | Euro Experts Auto Services | Welcome to Your Car Auto Service - Your premier destination for top-notch car service in Dubai! At... | 0 | 2024-05-24T04:33:35 | https://dev.to/azeem_pk_c36fd1c68f370623/best-car-service-in-dubai-best-car-workshop-euro-experts-auto-services-4g1f | carservice, carrepair, autoservice, expertmechanics | Welcome to Your Car Auto Service - Your premier destination for top-notch [car service in Dubai](https://euroexpert.ae/)! At Your Car Auto Service, we understand that your vehicle is more than just a mode of transportation - it's an essential part of your daily life. That's why we offer a wide range of services to keep your car running smoothly and efficiently. Whether you need a routine oil change, brake inspection, or major engine repair, our team of expert technicians is here to help. With years of experience and a dedication to customer satisfaction, you can trust us to get the job done right the first time. Don't wait until it's too late - schedule your car service in Dubai today and experience the difference that Your Car Auto Service can make. Visit us online or give us a call to book your appointment now. Your car will thank you!
contact us for more info
website url: https://euroexpert.ae/ | azeem_pk_c36fd1c68f370623 |
1,863,539 | Mastering React Optimization Techniques: Boost Your App's Performance | Hey there, fellow developers! 👋 If you're here, you probably love working with React just as much as... | 0 | 2024-05-24T04:32:45 | https://dev.to/delia_code/mastering-react-optimization-techniques-boost-your-apps-performance-1ka | webdev, javascript, programming, react | Hey there, fellow developers! 👋
If you're here, you probably love working with React just as much as I do. But let's be honest, no matter how much we love it, performance can sometimes be a real pain point. So today, we’re going to dive deep into some essential React optimization techniques to help you boost your app’s performance. Ready? Let’s get started! 🚀
## Why Optimize React Apps?
First things first, why should we even bother with optimization? Well, performance matters—a lot. Users today expect lightning-fast load times and smooth interactions. If your app lags, users will leave. Plus, a well-optimized app can save on resource costs and improve your app’s SEO. So, let's make your React app the best it can be!
## 1. Use React.memo
React components re-render by default whenever their parent component re-renders. This can lead to unnecessary renders and slow down your app. That’s where `React.memo` comes in handy.
### What is React.memo?
`React.memo` is a higher-order component that prevents a component from re-rendering if its props haven't changed. It’s like magic for your functional components!
### Example
Here’s a simple example:
```javascript
import React from 'react';
const MyComponent = ({ data }) => {
console.log("Rendering MyComponent");
return <div>{data}</div>;
};
export default React.memo(MyComponent);
```
In this example, `MyComponent` will only re-render if the `data` prop changes. If `data` stays the same, React will skip the render, saving precious milliseconds.
## 2. Use useCallback and useMemo
These hooks are lifesavers when it comes to preventing unnecessary re-renders and calculations.
### useCallback
`useCallback` returns a memoized version of a callback function that only changes if one of the dependencies has changed. This is useful when passing callbacks to optimized child components that rely on reference equality to prevent unnecessary renders.
### Example
```javascript
import React, { useState, useCallback } from 'react';
const Button = React.memo(({ handleClick }) => {
console.log("Rendering Button");
return <button onClick={handleClick}>Click me</button>;
});
const App = () => {
const [count, setCount] = useState(0);
const increment = useCallback(() => {
setCount(prevCount => prevCount + 1);
}, []);
return (
<div>
<p>Count: {count}</p>
<Button handleClick={increment} />
</div>
);
};
export default App;
```
In this example, the `Button` component will not re-render unless the `increment` function changes, which only happens if the dependencies of `useCallback` change.
### useMemo
`useMemo` returns a memoized value and recomputes it only when one of its dependencies changes. It's perfect for expensive calculations that shouldn't run on every render.
### Example
```javascript
import React, { useState, useMemo } from 'react';
const App = () => {
const [count, setCount] = useState(0);
const expensiveCalculation = useMemo(() => {
console.log("Running expensive calculation");
return count * 2;
}, [count]);
return (
<div>
<p>Count: {count}</p>
<p>Result: {expensiveCalculation}</p>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
};
export default App;
```
Here, the expensive calculation will only run when `count` changes, rather than on every render.
## 3. Code Splitting with React.lazy and Suspense
Code splitting is an optimization technique that allows you to split your code into various bundles, which can then be loaded on demand. This can drastically reduce the initial load time of your app.
### Example
```javascript
import React, { Suspense, lazy } from 'react';
const LazyComponent = lazy(() => import('./LazyComponent'));
const App = () => (
<div>
<h1>My React App</h1>
<Suspense fallback={<div>Loading...</div>}>
<LazyComponent />
</Suspense>
</div>
);
export default App;
```
In this example, `LazyComponent` is only loaded when it’s needed, rather than being included in the main bundle. This can significantly improve your app’s load time.
## 4. Avoid Anonymous Functions in JSX
Anonymous functions in JSX can lead to performance issues because they create a new function on every render, causing unnecessary re-renders of child components.
### Example
Instead of doing this:
```javascript
<button onClick={() => handleClick()}>Click me</button>
```
Do this:
```javascript
const handleClick = () => {
// Your logic here
};
<button onClick={handleClick}>Click me</button>
```
This way, the `handleClick` function is not recreated on every render.
## 5. Optimize Component Mounting
Use `componentDidMount` and `useEffect` wisely to handle side effects and data fetching. Ensure these operations don’t block the initial rendering of the component.
### Example
```javascript
import React, { useEffect, useState } from 'react';
const DataFetchingComponent = () => {
const [data, setData] = useState(null);
useEffect(() => {
fetch('/api/data')
.then(response => response.json())
.then(data => setData(data));
}, []);
return (
<div>
{data ? <div>{data}</div> : <div>Loading...</div>}
</div>
);
};
export default DataFetchingComponent;
```
Here, data fetching is handled in `useEffect`, ensuring it doesn’t block the initial render.
## 6. Reduce Reconciliation with shouldComponentUpdate and React.PureComponent
For class components, use `shouldComponentUpdate` to prevent unnecessary re-renders. Alternatively, you can use `React.PureComponent`, which does a shallow comparison of props and state.
### Example
```javascript
import React, { PureComponent } from 'react';
class MyComponent extends PureComponent {
render() {
return <div>{this.props.data}</div>;
}
}
export default MyComponent;
```
Using `PureComponent` ensures `MyComponent` only re-renders if `props.data` changes.
## 7. Use Immutable Data Structures
Using immutable data structures can make your state management more predictable and help prevent unnecessary re-renders. Libraries like Immutable.js can be very helpful here.
### Example
```javascript
import { Map } from 'immutable';
const initialState = Map({
count: 0,
});
const increment = (state) => state.update('count', count => count + 1);
let state = initialState;
state = increment(state);
console.log(state.get('count')); // 1
```
## 8. Optimize Lists with Virtualization
Rendering large lists can be a performance bottleneck. React Virtualized or React Window can help by rendering only the visible items in a list.
### Example
```javascript
import React from 'react';
import { FixedSizeList as List } from 'react-window';
const Row = ({ index, style }) => (
<div style={style}>Row {index}</div>
);
const App = () => (
<List
height={150}
itemCount={1000}
itemSize={35}
width={300}
>
{Row}
</List>
);
export default App;
```
In this example, only the visible rows are rendered, reducing the rendering workload and improving performance.
## 9. Debounce Input Handlers
If you have input fields that trigger re-renders or data fetching on every keystroke, consider debouncing the input handlers to limit the number of updates.
### Example
```javascript
import React, { useState } from 'react';
import debounce from 'lodash.debounce';
const SearchInput = () => {
const [query, setQuery] = useState('');
const handleSearch = debounce((value) => {
// Fetch data or perform search
console.log('Searching for:', value);
}, 300);
const handleChange = (e) => {
setQuery(e.target.value);
handleSearch(e.target.value);
};
return <input type="text" value={query} onChange={handleChange} />;
};
export default SearchInput;
```
In this example, the `handleSearch` function is debounced to limit the number of times it runs, improving performance.
## 10. Lazy Load Images and Components
Lazy loading images and components can significantly improve the initial load time of your application.
### Example
For images, you can use the `loading` attribute:
```html
<img src="image.jpg" alt="Example" loading="lazy" />
```
For components, use `React.lazy`:
```javascript
import React, { Suspense, lazy } from 'react';
const LazyComponent = lazy(() => import('./LazyComponent'));
const App = () => (
<div>
<h1>My React App</h1>
<Suspense fallback={<div>Loading...</div>}>
<LazyComponent />
</Suspense>
</div>
);
export default App;
```
## Conclusion
Optimizing your React app doesn’t have to be daunting. By incorporating these techniques, you can significantly improve your app’s performance and provide a smoother experience for your users. Remember, every millisecond counts!
What optimization techniques have you found most useful? Let me know in the comments below! And if you found this post helpful, feel free to share it with your fellow developers. Happy coding! 🚀
I hope you enjoyed this article! Feel free to ask any questions or share your thoughts in the comments. Let’s keep the conversation going and support each other in building high-performance React applications!
Twitter: [@delia_code](https://x.com/delia_code)
Instagram:[@delia.codes](https://www.instagram.com/delia.codes/)
Blog: [https://delia.hashnode.dev/](https://delia.hashnode.dev/) | delia_code |
1,863,538 | Turso - LibSQL Driver Laravel | Hello Punk! Yes I am again, I am Software Freestyle Engineer, I just released Turso Driver for... | 0 | 2024-05-24T04:27:42 | https://dev.to/darkterminal/turso-libsql-driver-laravel-131k | laravel, turso, sqlite, database | Hello Punk! Yes I am again, I am Software Freestyle Engineer, I just released [Turso Driver for Laravel](https://github.com/tursodatabase/turso-driver-laravel).
---
LibSQL is a fork of SQLite and this package is **#1 LibSQL Driver** that run natively using LibSQL Native Extension/Driver/Whatever and support Laravel Ecosystem.
## Requirement
Before using this package, you need to install and configure LibSQL Native Extension for PHP. You can download from [Turso Client PHP - Release](https://github.com/tursodatabase/turso-client-php)
1. Download based on you distribution (Linux/Macos/Darwin/Windows)
2. The archive is contains the extension and `libsql_php_extension.stubs.php`
3. Save the extension file in your desire directory
4. Save the `libsql_php_extension.stubs.php` in your project or somewhare that can help you to use stand-alone LibSQL driver as an IDE helper. By default this stubs is come inside this package.
5. Configure `php.ini` file and added the extension address with relative path that pointed to the extension
6. Enjoy!
## Installation
You can install the package via composer:
```bash
composer require tursodatabase/turso-driver-laravel
```
You can register the service provider in `bootstrap/providers.php`:
```php
<?php
return [
App\Providers\AppServiceProvider::class,
Turso\Driver\Laravel\LibSQLDriverServiceProvider::class, // Here
];
```
## Environment Variable Overview
You need to know the additional configuration in `.env` file, which come from Laravel and which come from LibSQL Driver. And here is the overview of `.env`:
**Laravel**
```env
DB_CONNECTION=libsql
DB_DATABASE=database.sqlite
```
- `DB_CONNECTION` key is represent default database connection like `libsql`, `sqlite`, `mysql`, `mariadb`, `pgsql`, and `sqlsrv`.
- `DB_DATABASE` key is represent the location of database name or in this case is database filename.
**LibSQL Driver**
```env
DB_AUTH_TOKEN=<your-database-auth-token-from-turso>
DB_SYNC_URL=<your-database-url-from-turso>
DB_SYNC_INTERVAL=5
DB_READ_YOUR_WRITES=true
DB_ENCRYPTION_KEY=
DB_REMOTE_ONLY=false
```
Create a new Turso Database [here](https://docs.turso.tech/quickstart)
- `DB_AUTH_TOKEN` - You can generate using `turso db tokens create <database-name>` command or you can visit your Turso Dashboard and select database you want to used and generate the token from there.
- `DB_SYNC_URL` - This generate by Turso when you craete a new database, you can get the database URL by using this command `turso db show --url <database-name>`
- `DB_SYNC_INTERVAL` - This variable defines the interval at which an embedded replica synchronizes with the primary database. It sets a duration for automatic synchronization of the database in the background. When configured, the embedded replica will periodically sync its local state with the state of the primary database to ensure it has the latest data. This is particularly useful for ensuring that replicas remain up-to-date with minimal manual intervention. Default is: 5 seconds.
- `DB_READ_YOUR_WRITES` - This variable configures the database connection to ensure that writes made by a connection are immediately visible to subsequent read operations initiated by the same connection. This is important in distributed systems to ensure consistency from the perspective of the writing process. When enabled, after a write operation is performed, any reads that follow from the same connection will see the results of that write. **This option is typically enabled by default** to ensure that clients always see their latest writes.
- `DB_ENCRYPTION_KEY` - This variable is defined for specifying the encryption key used in database encryption. It represents the secret key that is used to encrypt and decrypt the database content, ensuring that the data stored in the database is protected and can only be accessed by individuals who possess the correct key. This key is a critical component of encryption-at-rest strategies, where the goal is to secure data while it is stored on disk, preventing unauthorized access. Default is: empty.
- `DB_REMOTE_ONLY` - This variable is define to use remote connection only, if you only want to read and write the database from remote database. Default: false.
## Configure The Connection
LibSQL has 3 types of connections to interact with the database: _Local Connection_, _Remote Connection_, and _Remote Replica Connection (Embedded Replica)_
### Local Connection
To be able to use LibSQL locally as if you were using SQLite, simply change the following `.env`:
```env
DB_CONNECTION=libsql
DB_DATABASE=database.sqlite
```
Ignore other LibSQL `.env` variables.
### Remote Connection
To use LibSQL Remote Connection only, you can define the following `.env` variables:
```env
DB_CONNECTION=libsql
DB_AUTH_TOKEN=<your-database-auth-token-from-turso>
DB_SYNC_URL=<your-database-url-from-turso>
DB_REMOTE_ONLY=true
```
### Remote Replica Connection (Embedded Replica)
To configure remote replica connection (embedded replica), you can simply use the following `.env`:
```env
DB_CONNECTION=libsql
DB_DATABASE=database.sqlite
DB_AUTH_TOKEN=<your-database-auth-token-from-turso>
DB_SYNC_URL=<your-database-url-from-turso>
DB_SYNC_INTERVAL=5
DB_READ_YOUR_WRITES=true
DB_ENCRYPTION_KEY=
DB_REMOTE_ONLY=false
```
That's it! How easy to make different connection using LibSQL Driver in Laravel, right?!
## Database Configuration
Add this configuration at `config/database.php` inside the `connections` array:
```php
'libsql' => [
'driver' => 'libsql',
'url' => 'file:' . env('DB_DATABASE', database_path('database.sqlite')),
'authToken' => env('DB_AUTH_TOKEN', ''),
'syncUrl' => env('DB_SYNC_URL', ''),
'syncInterval' => env('DB_SYNC_INTERVAL', 5),
'read_your_writes' => env('DB_READ_YOUR_WRITES', true),
'encryptionKey' => env('DB_ENCRYPTION_KEY', ''),
'remoteOnly' => env('DB_REMOTE_ONLY', false),
'database' => null,
'prefix' => '',
],
```
> Copy and Paste and do not change it! Or try to change it and will broke your app or give you malfunction.
## Usage
For database operation usage, everything have same interface like usual when you using `Illuminate\Support\Facades\DB` in your database model. But remember, this is LibSQL they have `sync` method that can be used when you connect with Remote Replica Connection (Embedded Replica).
```php
use Illuminate\Support\Facades\DB;
// Create
DB::table('users')->create([
'name' => 'Budi Dalton',
'email' => 'budi.dalton@duck.com'
]);
// Read
DB::table('users')->get();
DB::table('users')->where('id', 2)->first();
DB::table('users')->orderBy('id', 'DESC')->limit(2)->get();
// Update
DB::table('users')->where('id', 2)->update(['name' => 'Doni Mandala']);
// Delete
DB::table('users')->where('id', 2)->delete();
// Transaction
try {
DB::beginTransaction();
$updated = DB::table('users')->where('id', 9)->update(['name' => 'Doni Kumala']);
if ($updated) {
echo "It's updated";
DB::commit();
} else {
echo "Not updated";
DB::rollBack();
}
$data = DB::table('users')->orderBy('id', 'DESC')->limit(2)->get();
dump($data);
} catch (\Exception $e) {
DB::rollBack();
echo "An error occurred: " . $e->getMessage();
}
// Sync
DB::sync();
``` | darkterminal |
1,863,537 | JavaScript Closures Cheatsheet | 1. What is a Closure? A closure is the combination of a function bundled together... | 0 | 2024-05-24T04:22:50 | https://dev.to/debojyoti/javascript-closures-cheatsheet-3a6h |
## 1. What is a Closure?
A closure is the combination of a function bundled together (enclosed) with references to its surrounding state (the lexical environment)
## 2. Basic Example
```javascript
function outerFunction() {
let outerVariable = 'I am outside!';
function innerFunction() {
console.log(outerVariable);
}
return innerFunction;
}
const myFunction = outerFunction();
myFunction(); // Output: I am outside!
```
## 3. Lexical Scoping
Closures work by capturing variables from their lexical environment.
```javascript
function makeCounter() {
let count = 0;
return function() {
count++;
return count;
}
}
const counter = makeCounter();
console.log(counter()); // 1
console.log(counter()); // 2
```
## 4. Immediately Invoked Function Expression (IIFE)
IIFEs create closures to encapsulate variables.
```javascript
const increment = (function() {
let counter = 0;
return function() {
counter++;
return counter;
}
})();
console.log(increment()); // 1
console.log(increment()); // 2
```
## 5. Closure with Loop (Common Pitfall)
Using `var` in a loop can lead to unexpected behavior due to function-level scope.
```javascript
for (var i = 0; i < 3; i++) {
setTimeout(function() {
console.log(i);
}, 1000);
}
// Output: 3, 3, 3
```
Solution with `let`:
```javascript
for (let i = 0; i < 3; i++) {
setTimeout(function() {
console.log(i);
}, 1000);
}
// Output: 0, 1, 2
```
## 6. Data Privacy
Closures can be used to emulate private variables.
```javascript
function createSecretHolder(secret) {
let secretValue = secret;
return {
getSecret: function() {
return secretValue;
},
setSecret: function(newSecret) {
secretValue = newSecret;
}
};
}
const holder = createSecretHolder('mySecret');
console.log(holder.getSecret()); // 'mySecret'
holder.setSecret('newSecret');
console.log(holder.getSecret()); // 'newSecret'
```
## 7. Partial Application
Closures can be used for partial function application.
```javascript
function add(a) {
return function(b) {
return a + b;
}
}
const addFive = add(5);
console.log(addFive(3)); // 8
```
## 8. Function Factories
Closures enable function factories.
```javascript
function multiplier(factor) {
return function(number) {
return number * factor;
}
}
const double = multiplier(2);
console.log(double(5)); // 10
const triple = multiplier(3);
console.log(triple(5)); // 15
```
## 9. Module Pattern
The module pattern uses closures to create public and private methods.
```javascript
const Module = (function() {
let privateVar = 'I am private';
function privateMethod() {
console.log(privateVar);
}
return {
publicMethod: function() {
privateMethod();
}
};
})();
Module.publicMethod(); // 'I am private'
```
## 10. Handling Asynchronous Closures
```javascript
function createCounter() {
let count = 0;
return {
increment: function() {
count++;
return count;
},
getCount: function() {
return count;
}
};
}
const asyncCounter = createCounter();
setTimeout(() => {
asyncCounter.increment();
console.log(asyncCounter.getCount()); // 1
}, 1000);
```
## 11. Closures in Event Listeners
```javascript
function setupButton() {
let clickCount = 0;
document.getElementById('myButton').addEventListener('click', function() {
clickCount++;
console.log(`Button clicked ${clickCount} times`);
});
}
setupButton();
```
## 12. Common Use Cases
- **Encapsulation:** Protecting variables from being accessed or modified outside their intended context.
- **Callbacks:** Passing a function as an argument to be executed later.
- **Event Handlers:** Managing event-driven programming.
- **Functional Programming:** Creating higher-order functions and function factories.
## 13. Best Practices
- Minimize the use of closures for better memory management.
- Be mindful of scope and lifetime of variables.
- Use `const` or `let` instead of `var` to avoid common pitfalls with closures in loops. | debojyoti | |
1,863,535 | 🎮 Download Cuphead APK Latest Version on Android, PC, and iOS 2024! 🎮 | Get ready to embark on an epic adventure with the latest version of Cuphead APK, now available for... | 0 | 2024-05-24T04:20:14 | https://dev.to/haseeb_zafar_985fa0b996cb/download-cuphead-apk-latest-version-on-android-pc-and-ios-2024-5a36 | Get ready to embark on an epic adventure with the latest version of [Cuphead APK](https://cupheadapk.net/), now available for Android, PC, and iOS! Experience the enchanting world of classic run-and-gun action, complete with stunning hand-drawn animations and thrilling boss battles. Whether you're playing on your mobile device, computer, or tablet, Cuphead's seamless performance and challenging gameplay will keep you hooked.
🔹 Hand-drawn animations
🔹 Challenging levels and bosses
🔹 Smooth performance across all platforms
Don't miss out on the fun—download Cuphead APK today and dive into a retro gaming experience like no other!
#Cuphead #Gaming #AndroidGames #PCGaming #iOSGames #DownloadNow #RetroGaming #GamingCommunity | haseeb_zafar_985fa0b996cb | |
1,863,534 | What is the difference between core Java and Java EE? | Java is an object-oriented programming language and computing platform. It has various libraries,... | 0 | 2024-05-24T04:18:22 | https://dev.to/joyanderson1702/what-is-the-difference-between-core-java-and-java-ee-3bhn | webdev, java, javaee, beginners | Java is an object-oriented programming language and computing platform. It has various libraries, virtual machines, components, and many more. Java has multiple editions, like Java SE, Java EE, and Java ME. Let's understand how core Java differs from Java EE.

## Core Java :
- Core Java, also known as Java SE(Java Standard Edition), is the basic foundation of the Java programming language. It is used for building small, single, and desktop applications.
- Java's core functionalities include libraries, syntax, essential input/output, multithreading, and networking. It also consists of many APIs, such as Java. util, Java.io, and Java.lang, and many more.
- It is only used for developing desktop and server-based applications. Core Java has no community and does not provide authentication functionality. It is less complex and more cost-effective.
## Java EE :
- Java EE(Java Enterprise Edition) is designed to build large applications such as enterprise applications, distributed applications, secure network applications, and more.
- It includes additional libraries and APIs compared to core Java, such as Java Beans, JPA(Java Persistence API), JAX-RS (Java API for RESTful Web Services), JMS (Java Message Service), and many more. Java EE includes many integrated tools and servers, such as IDE Eclipse or IntelliJ IDEA, as well as servers like Apache Tomcat, WebLogic, JBoss, and more.
- Due to its enormous scope, security, and networking, Java EE is mainly used to design robust and scalable applications. It is used in many sectors, such as eCommerce, healthcare, fintech, CRM, and other industries, to build highly scalable, readable, and secure applications.
Overall, Java Core is the foundation of the Java language, with its essential features and API. Java EE is the extended version of core Java, with many libraries and APIs supported for large-scale applications.
| joyanderson1702 |
1,863,533 | Is it possible to reference Xamarin Forms from Win UI 3 project? | The title says it all. I tried by adding Xamarin forms NuGet reference in the proj file, but this... | 0 | 2024-05-24T04:18:20 | https://dev.to/pooja_54ebc01c7e0/is-it-possible-to-reference-xamarin-forms-from-win-ui-3-project-2peb | xamarinforms, winui3, windowsappsdk | The title says it all.
I tried by adding Xamarin forms NuGet reference in the proj file, but this cased the project to stop compliling and giving the below error. Obviously the above breaks the build.

So, is there a way to reference Xamarin forms and use some of its references like Xamarin essentials in a WinUI 3 project? | pooja_54ebc01c7e0 |
1,863,532 | Fiverr Data Entry, A Guide to Getting Started and Succeeding | Fiverr Data Entry: Finding the top Fiverr search tags for data entry is essential if you want to work... | 0 | 2024-05-24T04:17:47 | https://dev.to/dataentry620/fiverr-data-entry-a-guide-to-getting-started-and-succeeding-119p | dataentry, fiverrdataentry, fiverr | **Fiverr Data Entry**: Finding the top <a href=" https://www.uidaionlineaadharcard.com/aadhar-print-portal-uidai aadhar-print-e-aadhar-card-print/">Fiverr</a> search tags for data entry is essential if you want to work as a data entry worker there. You’re aware that you need it, but you’re unsure of where to begin or what steps to take first. You’ve companies in a frustrating manner after <a href="https://www.uidaionlineaadharcard.com/uidai ceo-uidai-head-office-uidai-history-of-uidai/"> investing </a> money and losing their minds in a matter of weeks or months. Even though you lack experience starting your own <a href=" https://www.uidaionlineaadharcard.com/uidai mobile-number-change check-linking-status/"> business </a> , you believe you can Fiverr Data Entry now that you have the necessary circumstances. Do you also?... <a href=" https://www.uidaionlineaadharcard.com/nseit-exam 2022-2023-payment/">read more</a>
**Suggested Link**:
<a href="https://digitalindiadataentryjobs.com/flipkart-data-entry-jobs-work-from-home/">Flipkart Data Entry Jobs</a>
<a href="https://digitalindiadataentryjobs.com/dhis2-data-entry/">DHIS 2 Data Entry</a>
<a href="https://digitalindiadataentryjobs.com/online-data-entry-jobs-work-from-home-2024/">Online Data Entry Jobs</a>
<a href="https://digitalindiadataentryjobs.com/data-entry-jobs-in-kolkata/">Jobs in Kolkata</a>
<a href="https://digitalindiadataentryjobs.com/data-entry-jobs-from-home/">Jobs From Home</a>
<a href="https://digitalindiadataentryjobs.com/data-entry-jobs-in-bangalore-how-to-find-part-time-jobs-in-bangalore-best-work-from-home-jobs-for-freshers-in-bangalore/">Jobs in Bangalore</a>
<a href="https://digitalindiadataentryjobs.com/data-entry-jobs-near-me-2024/">Jobs Near me</a>
<a href="https://digitalindiadataentryjobs.com/online-jobs-work-from-home-data-entry-2024-online-jobs-without-investment-work-from-home-online-part-time-jobs-eligibility-criteria/">Work From Home</a>
<a href="https://digitalindiadataentryjobs.com/rch-portal-data-entry-2024-online-data-entry-self-registration-and-login/">RCH Portal Data Entry</a>
<a href="https://digitalindiadataentryjobs.com/part-time-data-entry-jobs/">Part Time Data Entry Jobs</a>
<a href="https://digitalindiadataentryjobs.com/flexjobs-data-entry/">Flexjobs Data Entry</a>
**RIT**
| dataentry620 |
1,863,530 | Rebuilding My Blog: From Next.js to Astro | For quite some time the thought of whether my site may be a bit too over-engineered lingered my mind.... | 0 | 2024-05-24T04:04:44 | https://ineza.codes/blog/20240523-rebuilding-my-blog | webdev, javascript, astro, nextjs |
For quite some time the thought of whether my site may be a bit too over-engineered lingered my mind. For a website that just displays blogs I definitely had a ton of javascript
I've recently undertaken the task of rebuilding my site, transitioning from Next.js to Astro, and I couldn't be more pleased with the results. One of the most noticeable improvements is the significant reduction in JavaScript bloat. My pages are now much lighter and faster.
With Next.js, I found myself incorporating more JavaScript than necessary, especially for a simple blog like mine. Switching to Astro allowed me to strip away the unnecessary JavaScript.
This transition also reinforces a growing consensus: JavaScript has become one of the heaviest assets on the web today. By minimizing its usage, we can create faster, more efficient websites.
To better illustrate the improvements, here are some screenshots of my site before and after the switch:
- Before (Next.js):
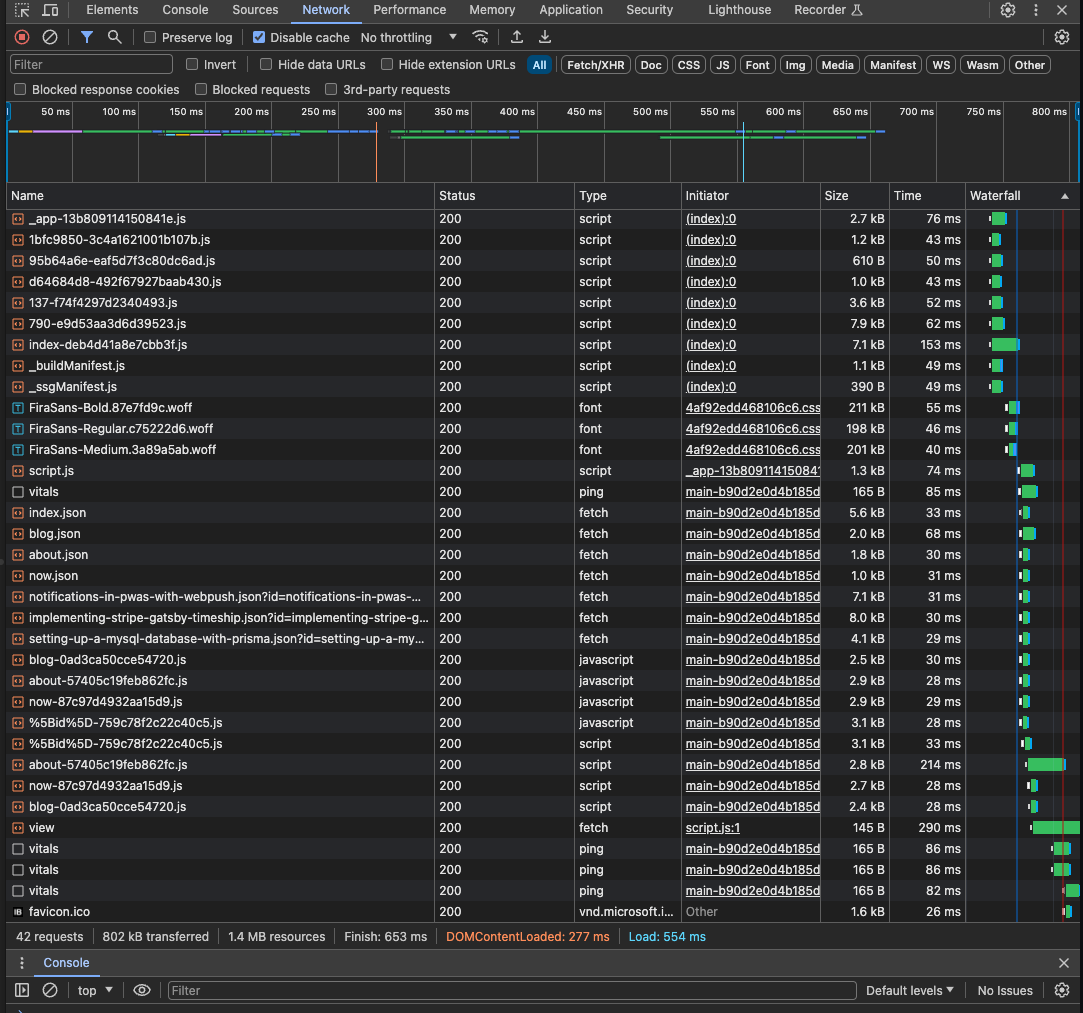
- After (Astro):
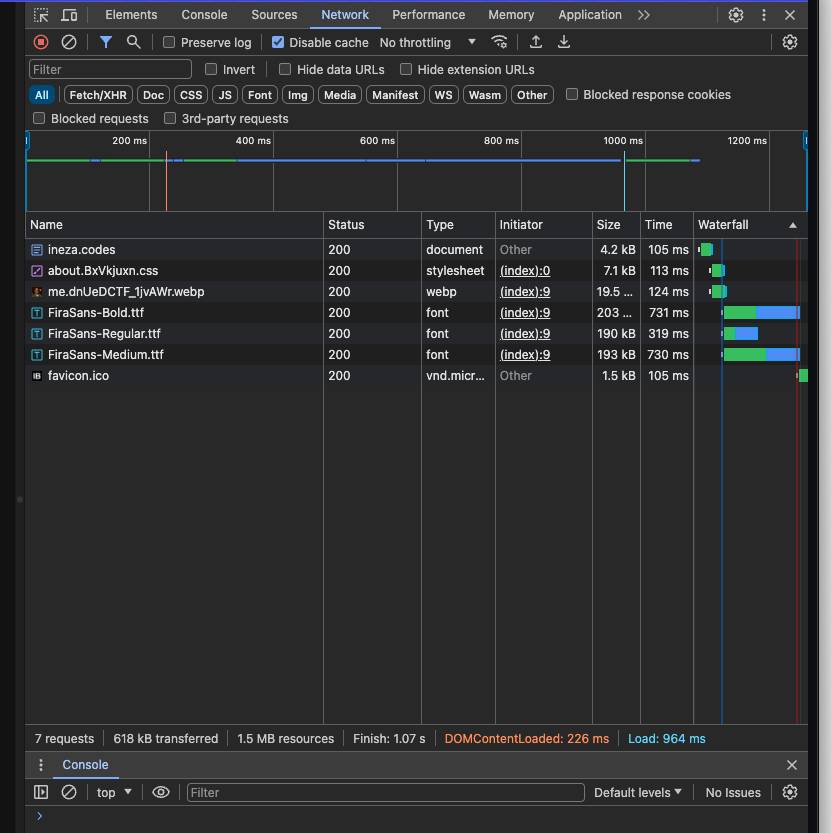 | inezabonte |
1,863,528 | LangChain Expression Language (LCEL) | In this post, we'll explore LangChain Expression Language (LCEL), a new way to build and connect... | 0 | 2024-05-24T04:02:52 | https://dev.to/rutamstwt/langchain-expression-language-lcel-94j | ai, machinelearning, langchain, chatbot | In this post, we'll explore LangChain Expression Language (LCEL), a new way to build and connect LangChain components that makes it easier and more transparent to construct and compose language models (LLMs) and other components.
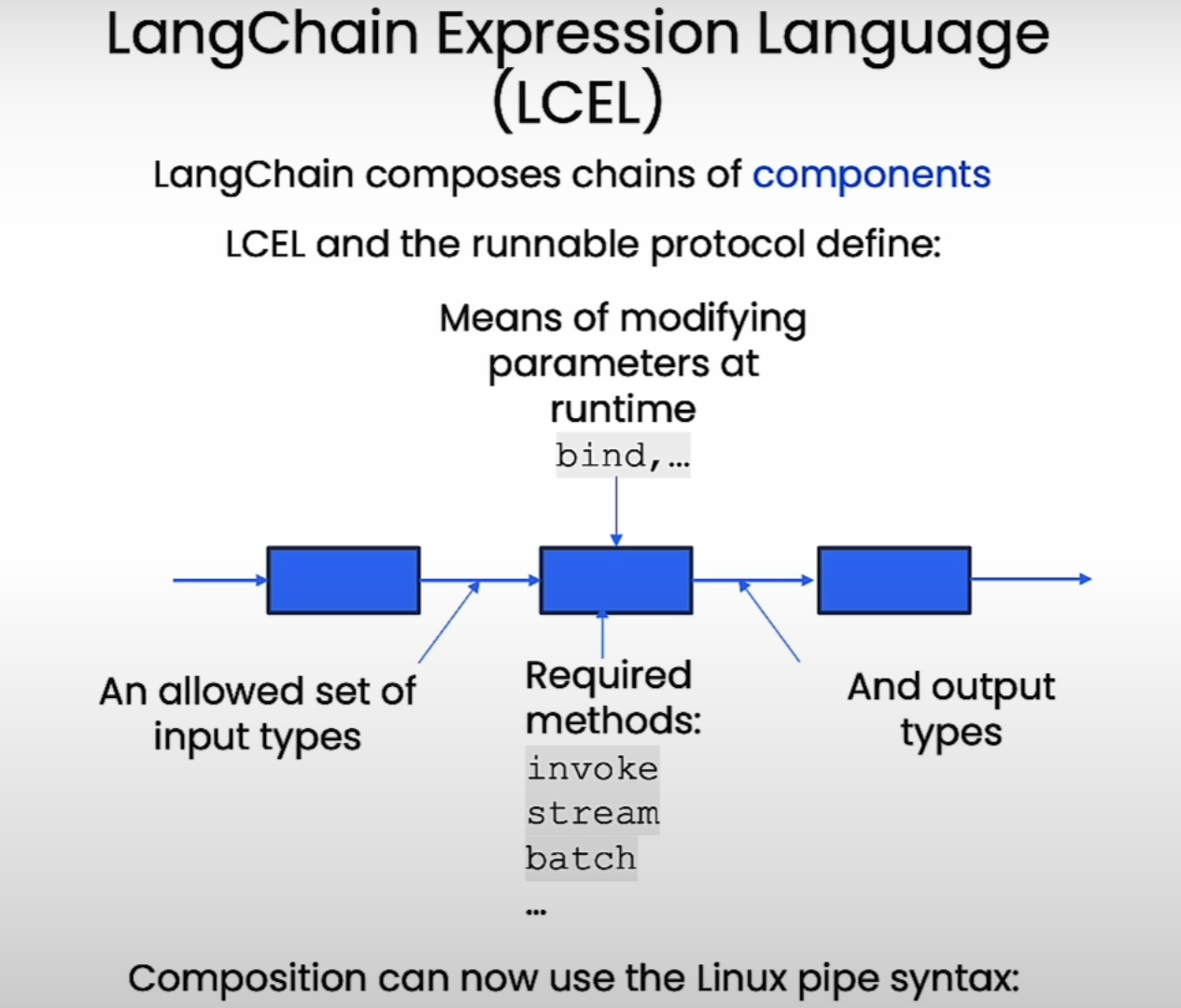
LangChain is powerful because it lets you combine different parts, like language models, prompts, and output parsers, to create custom workflows. Now, with LCEL, we have a new way to do this. LCEL is a runnable protocol that defines a few key elements that make it work.
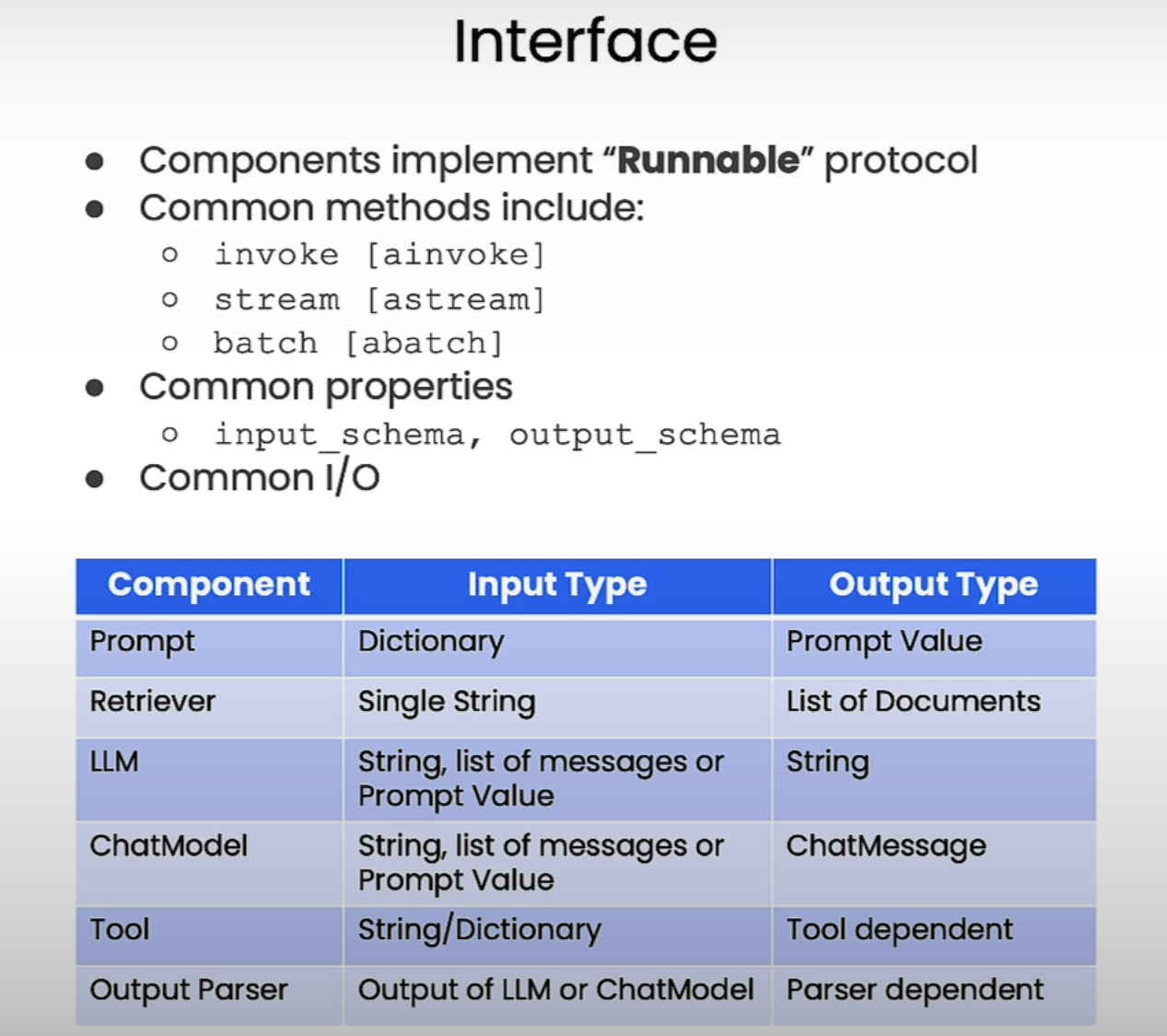
First, LCEL defines what types of input it can work with. It also has a set of standard methods that you can use to customize your workflows. Plus, you can modify parameters in real-time, which gives you more flexibility. Finally, LCEL makes sure that all components work together seamlessly by using a common interface. In this post, we'll dive deeper into how LCEL works and what it means for LangChain users.

## Simple Chain
Let's start by setting up our environment and importing the necessary components:
```python
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
#!pip install pydantic==1.10.8
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.schema import StrOutputParser
```
We'll create a simple chain consisting of a prompt template, a language model, and an output parser. First, let's create a prompt template that asks the language model to tell a short joke about a specific topic:
```python
prompt = ChatPromptTemplate.from_template(
"tell me a short joke about {topic}"
)
model = ChatOpenAI()
output_parser = StrOutputParser()
```
Now, we can create the chain by piping these components together:
```python
chain = prompt | model | output_parser
```
We can invoke this chain with some input and get a joke as output:
```python
chain.invoke({"topic": "Captain America"})
# Output: 'Why did Captain America start a baking business? \nBecause he wanted to make super-soldiers!'
```
## More Complex Chain
Let's create a slightly more complex chain that does retrieval-augmented generation. We'll replicate the process we covered in the previous blogs using LCEL.
First, we need to set up our retriever:
```python
from langchain.vectorstores import DocArrayInMemorySearch
from langchain_openai import OpenAIEmbeddings
vectorstore = DocArrayInMemorySearch.from_texts(
["harrison worked at kensho", "bears like to eat honey"],
embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
```
We'll create a prompt that asks the language model to answer a question based on the provided context:
```python
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
```
To pass in the user's question and fetch relevant context, we'll use a `RunnableMap`:
```python
from langchain_core.runnables import RunnableMap
chain = RunnableMap({
"context": lambda x: retriever.get_relevant_documents(x["question"]),
"question": lambda x: x["question"]
}) | prompt | model | output_parser
```
Now, we can invoke this chain with a question, and it will retrieve relevant context, pass it to the prompt, and provide an answer:
```python
chain.invoke({"question": "where did harrison work?"})
# Output: 'Harrison worked at Kensho.'
```
## Bind and OpenAI Functions
LCEL allows us to bind parameters to runnables at runtime. For example, we can bind OpenAI functions to a language model:
```python
functions = [
{
"name": "weather_search",
"description": "Search for weather given an airport code",
"parameters": {
"type": "object",
"properties": {
"airport_code": {
"type": "string",
"description": "The airport code to get the weather for"
},
},
"required": ["airport_code"]
}
}
]
prompt = ChatPromptTemplate.from_messages([("human", "{input}")])
model = ChatOpenAI(temperature=0).bind(functions=functions)
runnable = prompt | model
```
We can then invoke this runnable, and the language model will call the bound function as needed:
```python
runnable.invoke({"input": "what is the weather in sf"})
# Output: AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{\"airport_code\":\"SFO\"}', 'name': 'weather_search'}}, ...)
```
We can also update the bound functions at runtime:
```python
functions.append({
"name": "sports_search",
"description": "Search for the news of recent sport events",
"parameters": {
"type": "object",
"properties": {
"team_name": {
"type": "string",
"description": "The sports team to search for"
},
},
"required": ["team_name"]
}
})
model = model.bind(functions=functions)
runnable = prompt | model
runnable.invoke({"input": "how did the patriots do yesterday?"})
# Output: AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{\"team_name\":\"New England Patriots\"}', 'name': 'sports_search'}}, ...)
```
## Fallbacks
One useful feature of LCEL is the ability to attach fallbacks to individual components or entire sequences. This can be useful when a component fails or doesn't produce the desired output.
As an example, we'll use an older version of the OpenAI language model, which may struggle with outputting valid JSON:
```python
from langchain.llms import OpenAI
import json
simple_model = OpenAI(
temperature=0,
max_tokens=1000,
model="text-davinci-001" # this is a deprecated model and hence will fail
)
simple_chain = simple_model | json.loads
```
We'll create a challenge that requires the model to output valid JSON:
```python
challenge = "write three poems in a json blob, where each poem is a json blob of a title, author, and first line"
```
If we try to invoke `simple_chain` with this challenge, we'll get an error because the model's output is not valid JSON:
```python
# Note: This will give an error saying model_not_found, which is expected
print(simple_chain.invoke(challenge))
# NotFoundError: Error code: 404 - {'error': {'message': 'The model `text-davinci-001` has been deprecated, learn more here: https://platform.openai.com/docs/deprecations', 'type': 'invalid_request_error', 'param': None, 'code': 'model_not_found'}}
```
To handle this, we can create a fallback chain using a newer model:
```python
model = ChatOpenAI(temperature=0)
chain = model | StrOutputParser() | json.loads
```
Now, we can create a final chain that tries the first chain and falls back to the second if an error occurs:
```python
final_chain = simple_chain.with_fallbacks([chain])
pprint(final_chain.invoke(challenge))
# Output: {'poem1': {'author': 'Emily Dickinson',
# 'firstLine': 'A rose by any other name would smell as sweet',
# 'title': 'The Rose'},
# 'poem2': {'author': 'Robert Frost',
# 'firstLine': 'Two roads diverged in a yellow wood',
# 'title': 'The Road Not Taken'},
# 'poem3': {'author': 'Emily Dickinson',
# 'firstLine': 'Hope is the thing with feathers that perches in the soul',
# 'title': 'Hope is the Thing with Feathers'}}
```
## Interface
LCEL defines a common interface for all runnables, with several methods and properties. Let's explore this interface using our initial simple chain:
```python
prompt = ChatPromptTemplate.from_template(
"Tell me a short joke about {topic}"
)
model = ChatOpenAI()
output_parser = StrOutputParser()
chain = prompt | model | output_parser
```
The methods available in the interface include:
**invoke**: This is a synchronous method that calls the runnable on a single input.
```python
chain.invoke({"topic": "bears"})
# Output: 'Why did the bear break up with his girlfriend? \nBecause she was unbearable!'
```
**batch**: This method calls the runnable on a list of inputs, executing them in parallel as much as possible.
```python
chain.batch([{"topic": "bears"}, {"topic": "frogs"}])
# Output: ['Why do bears never wear socks? \nBecause they have bear feet!',
# 'Why are frogs so happy? Because they eat whatever bugs them!']
```
**stream**: This method calls the runnable on a single input and streams back responses.
```python
for t in chain.stream({"topic": "bears"}):
print(t)
# Output:
# Why
# did
# the
# bear
# ...
```
**ainvoke**: This is the asynchronous version of `invoke`.
```python
response = await chain.ainvoke({"topic": "bears"})
print(response)
# Output: "Why did the bear break up with his girlfriend? Because he couldn't bear the relationship anymore!"
```
All of these methods have corresponding asynchronous versions (`ainvoke`, `abatch`, `astream`).
Additionally, all runnables have common properties like `input_schema` and `output_schema`, which define the expected input and output types.
## Conclusion
In this blog post, we introduced the LangChain Expression Language (LCEL), a new syntax that simplifies the process of constructing and composing language models and other components in LangChain. We explored simple and complex chains, binding parameters and functions, fallbacks, and the common interface exposed by all runnables.
LCEL provides several benefits, including async, batch, and streaming support out of the box, the ability to attach fallbacks, parallelism for time-consuming tasks, and built-in logging. With LCEL, you can combine components in powerful ways, enabling you to build sophisticated language model applications.
# Source Code
[https://github.com/RutamBhagat/LangChainHCCourse3/blob/main/course\_3/LCEL.ipynb](https://github.com/RutamBhagat/LangChainHCCourse3/blob/main/course_3/LCEL.ipynb) | rutamstwt |
1,863,527 | Mastering the Art of Pins: Creating and Managing Winning Pinterest Ad Campaigns | Pinterest, the visual discovery platform, has become a powerful marketing tool for businesses. With... | 0 | 2024-05-24T04:02:12 | https://dev.to/epakconsultant/mastering-the-art-of-pins-creating-and-managing-winning-pinterest-ad-campaigns-3hpl | marketing, pinterest | Pinterest, the visual discovery platform, has become a powerful marketing tool for businesses. With its engaged user base actively searching for inspiration and products, Pinterest Ads can be a goldmine for driving traffic, brand awareness, and ultimately, sales. But how do you create and manage winning Pinterest ad campaigns? This guide will equip you with the knowledge to navigate the world of Pinterest Ads and unlock its full potential.
**Setting Your Goals: What Do You Want to Achieve?**
Before diving into campaign creation, clearly define your advertising goals. Here are some common objectives for Pinterest Ads:
• Increase Brand Awareness: Reach a wider audience and introduce your brand to potential customers actively searching for products or services related to your niche.
[Mastering Tradingview: How to Utilize the Buy/Sell Half-Circle Indicator for Optimal Results and Improved Trading Liquidity](https://www.amazon.com/dp/B0CQZ54MFT)
• Drive Traffic to Your Website: Entice users to visit your website to learn more about your offerings or browse your product catalog.
• Generate Leads: Capture valuable customer information (emails, phone numbers) through targeted ad campaigns that lead to lead capture forms.
• Boost Product Sales: Promote specific products or collections directly within Pinterest, allowing users to seamlessly purchase within the platform.
**Crafting Compelling Pins: The Power of Visual Storytelling**
Visuals are paramount on Pinterest. Here's how to create captivating Pins that grab attention and entice clicks:
• High-Quality Images and Videos: Use professional-looking visuals that showcase your products or services in an appealing way. Clear, well-lit images and engaging videos capture user attention and stand out in the feed.
• Compelling Titles and Descriptions: Captions should be clear, concise, and keyword-rich. Briefly describe your product or service and entice users to learn more. Include relevant keywords to improve discoverability in searches.
• Call to Action: Tell users what you want them to do after seeing your Pin. This could be visiting your website, learning more about a product, or making a purchase.
**Targeting the Right Audience: Reaching Your Ideal Customers**
Targeting the right audience is crucial for campaign success. Here are some ways to refine your audience on Pinterest Ads:
• Demographics: Target users based on age, gender, location, household income, and even device type (mobile vs. desktop).
• Interests: Reach users based on their browsing behavior and interests on Pinterest. This ensures your ads are displayed to people actively interested in products or services similar to yours.
• Keywords: Utilize relevant keywords to ensure your ads appear when users search for specific terms.
**Campaign Management: Optimizing for Success**
Once your campaign is live, monitor its performance and optimize for better results:
• Track Key Metrics: Monitor metrics like impressions, clicks, website traffic, and conversion rates (purchases, signups). Use this data to identify what's working and what needs improvement.
• A/B Testing: Test different ad variations with slight changes in visuals, captions, or targeting to see which ones perform best. This enables you to refine your campaign based on data-driven insights.
• Budget Management: Set a budget for your campaign and allocate funds efficiently. Consider increasing spend for high-performing ads and reducing it for underperformers.
**Pro Tips for Pinterest Ad Success**
• Utilize Pinterest Analytics: Gain valuable insights into user behavior on your Pins and website through Pinterest Analytics. This data helps you refine your targeting and overall ad strategy.
• Run Retargeting Campaigns: Reconnect with users who have previously interacted with your Pins or website. Retargeting campaigns can be highly effective in reminding users about your brand and converting them into paying customers.
• Stay Up-to-Date: Pinterest Ads is constantly evolving. Stay informed about new features, targeting options, and best practices to keep your campaigns competitive.
**Conclusion:**
By understanding your target audience, crafting captivating Pins, utilizing effective targeting strategies, and continuously optimizing your campaigns, you can unlock the full potential of Pinterest Ads. Remember, creativity, data-driven decision making, and a commitment to ongoing optimization are key ingredients for running successful Pinterest ad campaigns that drive traffic, brand awareness, and ultimately, sales for your business.
| epakconsultant |
1,862,601 | Do you post articles consistently on Dev.to? | If you enjoy my content, support me by following me on my other socials: https://linktr.ee/tanujav7 | 0 | 2024-05-24T04:01:28 | https://dev.to/tanujav/do-you-post-articles-consistently-on-devto-52lb | discuss, programming, productivity |
If you enjoy my content, support me by following me on my other socials:
https://linktr.ee/tanujav7 | tanujav |
1,863,525 | Aadhar Card Change Mobile Number Without OTP | Aadhar Card Change Mobile Number Without OTP:- Do you have an Aadhar card, but you’re not sure... | 0 | 2024-05-24T04:00:49 | https://dev.to/aadharcard2001/aadhar-card-change-mobile-number-without-otp-202c | aadhar, aadharcard | **Aadhar Card Change Mobile Number Without OTP**:- Do you have an <a href="https://www.uidaionlineaadharcard.com/online-aadhar-card correction/"> Aadhar </a> card, but you’re not sure whose cell number is associated with it? We will provide you with all the <a href="https://www.uidaionlineaadharcard.com/how-to-update-address-in aadhar-card/"> information </a> you need to know in this post to find out how to check your Aadhar card mobile number without an <a href="https://www.uidaionlineaadharcard.com/the-password-of-the-aadhar card/"> OTP </a> in 2024 in a whole new method. You can quickly obtain all the information <a href="https://www.uidaionlineaadharcard.com/aadhar-card-update-status check/">regarding </a> Aadhar Card Mobile Number Check Without OTP by reading this and understanding the steps listed <a href="https://www.uidaionlineaadharcard.com/how-to-change-aadhar-card mobile-number/"> below </a>. Nevertheless, we have provided a detailed guide on how to determine which cell number is <a href="https://www.uidaionlineaadharcard.com/uidai-check-status-check/"> associated </a> with your Aadhar card in this <a href="https://www.uidaionlineaadharcard.com/how-to-change-aadhar-card mobile-number/"> article </a>, considering everything... <a href="https://www.uidaionlineaadharcard.com/aadhar-card-change-mobile-number-without-otp/"> read also</a>
**Suggested Link**:
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-change-mobile-number-without-otp/">Aadhar Card Change Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/link-aadhar-to-mobile-number/">Link Aadhar to Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-link-mobile number-2/">Aadhar Card Link Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/how-to-link-mobile-number-with-aadhar/">How to Link Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-update-mobile-number/">aadhar-card-update</a>
<a href="https://www.uidaionlineaadharcard.com/update-mobile-number-in-aadhar/">update-mobile-number</a>
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-mobile-number-change-2/">Change Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/link-mobile-number-to-aadhar-card-online-2/">Link Mobile Number Online</a>
<a href="https://www.uidaionlineaadharcard.com/pm-kisan-status-check-aadhar-card-mobile-number/">PM Kisan Status Check</a>
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-mobile-number-update-2/">Mobile Number Update</a>
**RIT**
| aadharcard2001 |
1,863,526 | Aadhar Card Change Mobile Number Without OTP | Aadhar Card Change Mobile Number Without OTP:- Do you have an Aadhar card, but you’re not sure... | 0 | 2024-05-24T04:00:49 | https://dev.to/aadharcard2001/aadhar-card-change-mobile-number-without-otp-2oa1 | aadhar, aadharcard | **Aadhar Card Change Mobile Number Without OTP**:- Do you have an <a href="https://www.uidaionlineaadharcard.com/online-aadhar-card correction/"> Aadhar </a> card, but you’re not sure whose cell number is associated with it? We will provide you with all the <a href="https://www.uidaionlineaadharcard.com/how-to-update-address-in aadhar-card/"> information </a> you need to know in this post to find out how to check your Aadhar card mobile number without an <a href="https://www.uidaionlineaadharcard.com/the-password-of-the-aadhar card/"> OTP </a> in 2024 in a whole new method. You can quickly obtain all the information <a href="https://www.uidaionlineaadharcard.com/aadhar-card-update-status check/">regarding </a> Aadhar Card Mobile Number Check Without OTP by reading this and understanding the steps listed <a href="https://www.uidaionlineaadharcard.com/how-to-change-aadhar-card mobile-number/"> below </a>. Nevertheless, we have provided a detailed guide on how to determine which cell number is <a href="https://www.uidaionlineaadharcard.com/uidai-check-status-check/"> associated </a> with your Aadhar card in this <a href="https://www.uidaionlineaadharcard.com/how-to-change-aadhar-card mobile-number/"> article </a>, considering everything... <a href="https://www.uidaionlineaadharcard.com/aadhar-card-change-mobile-number-without-otp/"> read also</a>
**Suggested Link**:
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-change-mobile-number-without-otp/">Aadhar Card Change Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/link-aadhar-to-mobile-number/">Link Aadhar to Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-link-mobile number-2/">Aadhar Card Link Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/how-to-link-mobile-number-with-aadhar/">How to Link Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-update-mobile-number/">aadhar-card-update</a>
<a href="https://www.uidaionlineaadharcard.com/update-mobile-number-in-aadhar/">update-mobile-number</a>
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-mobile-number-change-2/">Change Mobile Number</a>
<a href="https://www.uidaionlineaadharcard.com/link-mobile-number-to-aadhar-card-online-2/">Link Mobile Number Online</a>
<a href="https://www.uidaionlineaadharcard.com/pm-kisan-status-check-aadhar-card-mobile-number/">PM Kisan Status Check</a>
<a href="https://www.uidaionlineaadharcard.com/aadhar-card-mobile-number-update-2/">Mobile Number Update</a>
**RIT**
| aadharcard2001 |
1,863,524 | Leverage Affiliate Marketing: Integrating Shopify with Shareasale API | Shopify, the e-commerce giant, empowers businesses to build and manage their online stores.... | 0 | 2024-05-24T03:57:12 | https://dev.to/epakconsultant/leverage-affiliate-marketing-integrating-shopify-with-shareasale-api-189g | shopify | Shopify, the e-commerce giant, empowers businesses to build and manage their online stores. Shareasale, a prominent affiliate marketing platform, connects merchants with a vast network of affiliates who can promote their products. Integrating these two platforms through the Shareasale API unlocks a powerful affiliate marketing strategy for your Shopify store. Here's a comprehensive guide to achieve this integration:
**Understanding the Benefits:**
• Increased Sales and Brand Awareness: Affiliate marketing allows you to tap into a network of established promoters (affiliates) who drive traffic and sales to your store in exchange for a commission on each sale.
• Improved Marketing ROI: Compared to traditional advertising methods, affiliate marketing offers a performance-based model. You only pay affiliates when they generate a sale, maximizing your return on marketing investment (ROI).
• Enhanced Brand Reach: Affiliates often have established audiences and strong online presences. By partnering with them, you can significantly expand your brand reach and attract new customers.
**Preparing for Integration:**
• Shopify Store Setup: Ensure your Shopify store is operational and has products listed with clear descriptions, high-quality images, and competitive pricing. This will make your store more attractive to potential affiliates.
• Shareasale Account: Create a Shareasale merchant account. This will provide you with access to the platform's features, including the API for integration with Shopify.
• Affiliate Program Design: Define your affiliate program's key components. This includes commission rates for different product categories, cookie duration (how long a sale is attributed to an affiliate), and program terms and conditions.
**Integration Methods:**
There are two main approaches to integrate Shopify with Shareasale API:
• Shareasale Plugin: The official Shareasale Shopify app offers a convenient and user-friendly solution. This plugin streamlines the integration process, allowing you to connect your store to Shareasale with minimal technical knowledge.
• Manual API Integration: For more advanced users or those with specific integration needs, Shareasale provides detailed API documentation. This allows for custom integration using programming languages like Python or PHP.
**Using the Shareasale Plugin:**
1.Install the Plugin: Locate the Shareasale app in the Shopify App Store and install it on your store.
2.Connect to Shareasale: The plugin will guide you through the connection process to authorize your Shopify store with your Shareasale account.
3.Configure Settings: Set up your affiliate program details within the plugin, including commission rates, cookie duration, and other relevant program settings.
4.Product Feed Generation: The plugin can generate a product feed containing essential information about your products. This feed can be uploaded to Shareasale, allowing affiliates to easily access product details for promotion.
**Additional Considerations:**
• Affiliate Recruitment: Once your integration is complete, actively recruit affiliates to join your program. Shareasale provides a marketplace where you can connect with potential affiliates, but consider reaching out to relevant bloggers, influencers, and industry reviewers as well.
• Performance Monitoring: Track your affiliate program's performance through Shareasale's reporting tools. This will provide insights into key metrics like clicks, conversions, and sales generated through your affiliates.
• Affiliate Communication: Maintain open communication with your affiliates. Provide them with marketing materials, product updates, and incentives to keep them engaged and promoting your products effectively.
**Conclusion:**
Integrating Shopify with Shareasale API opens doors to a powerful and cost-effective marketing strategy. By following these steps and leveraging the available tools and functionalities, you can expand your brand reach, generate new leads, and ultimately drive sales through the power of affiliate marketing. Remember, building a successful affiliate program requires ongoing effort and dedication to ensure a win-win situation for both you and your affiliates.
| epakconsultant |
1,863,523 | How to create a Virtual Machine that is highly available. | Click on Virtual Machines from the Azure Services Click on "Create" Click on Azure Virtual... | 0 | 2024-05-24T03:56:38 | https://dev.to/opsyog/how-to-create-a-virtual-machine-that-is-highly-available-1c1h | **Click on Virtual Machines from the Azure Services**

**Click on "Create"**

**Click on Azure Virtual Machine**
**Enter Resource Group name**
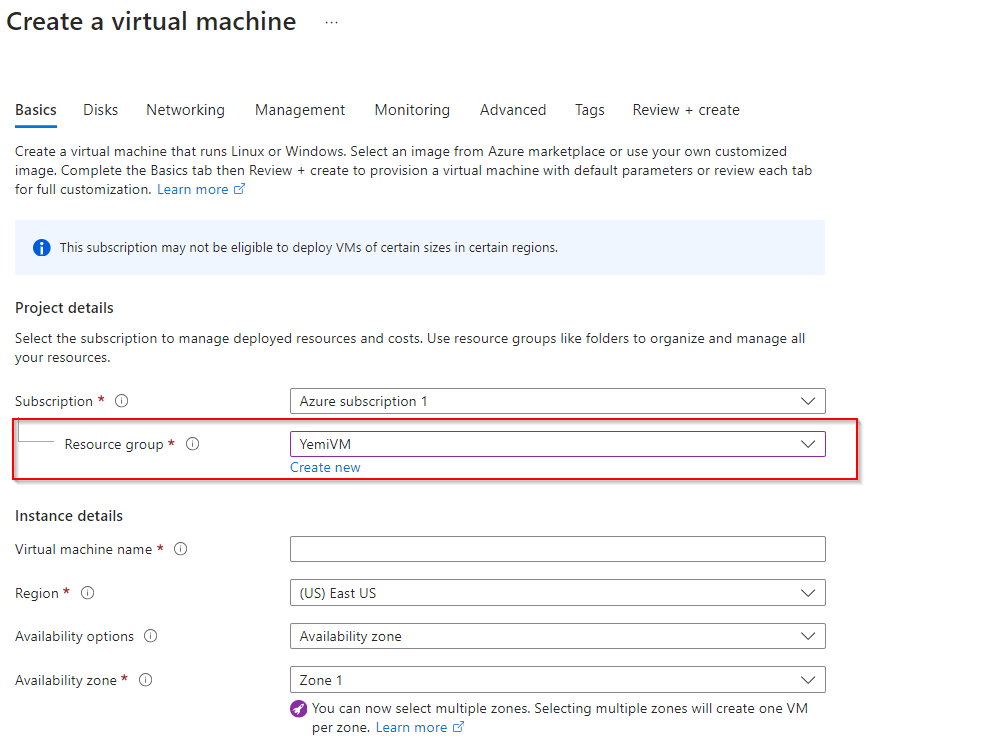
**Enter Virtual Machine Name**
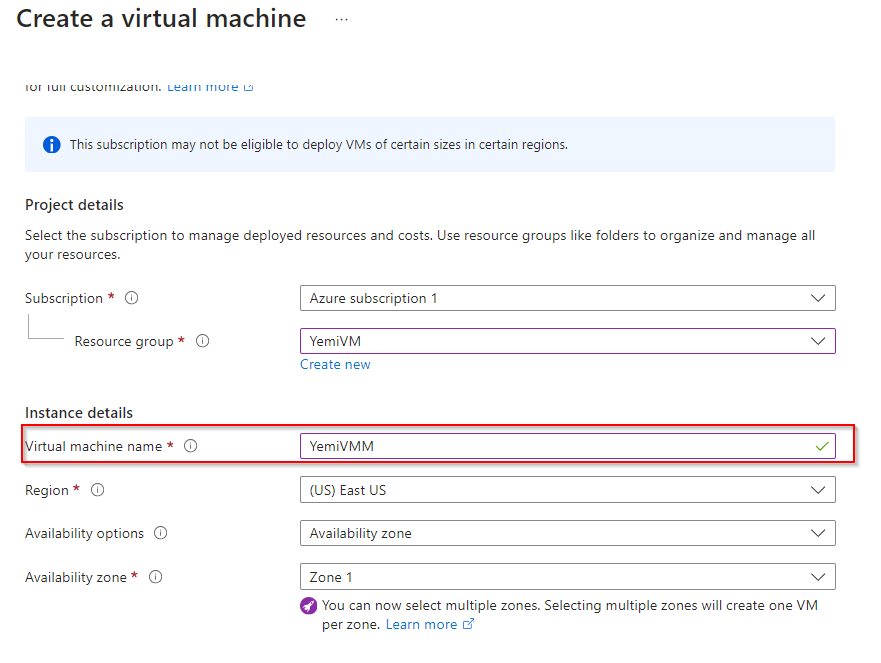
**Select Availability zone, selecting more than one zone makes it highly available**
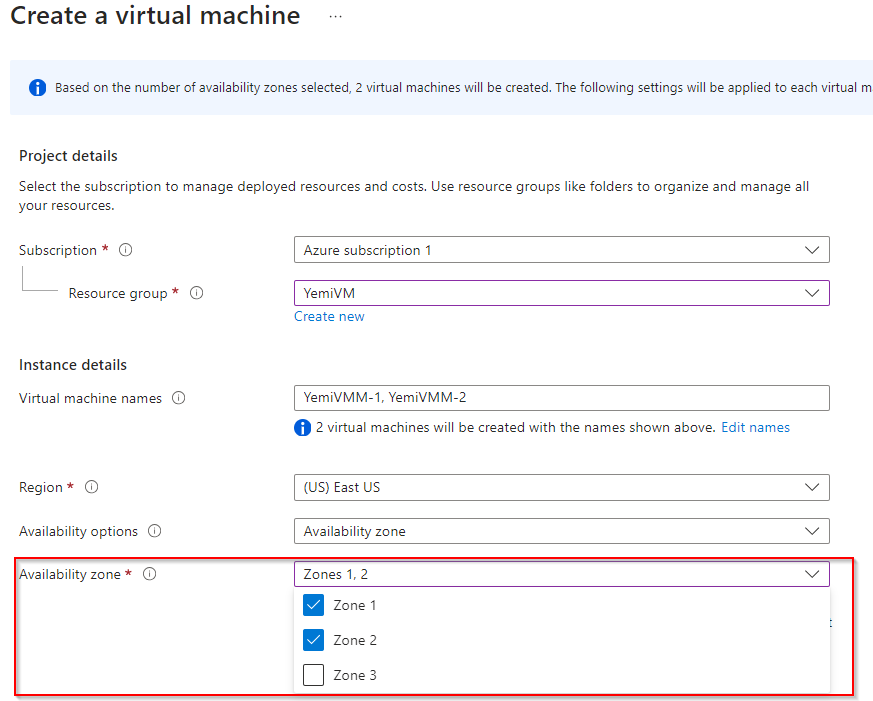
**Select Image**
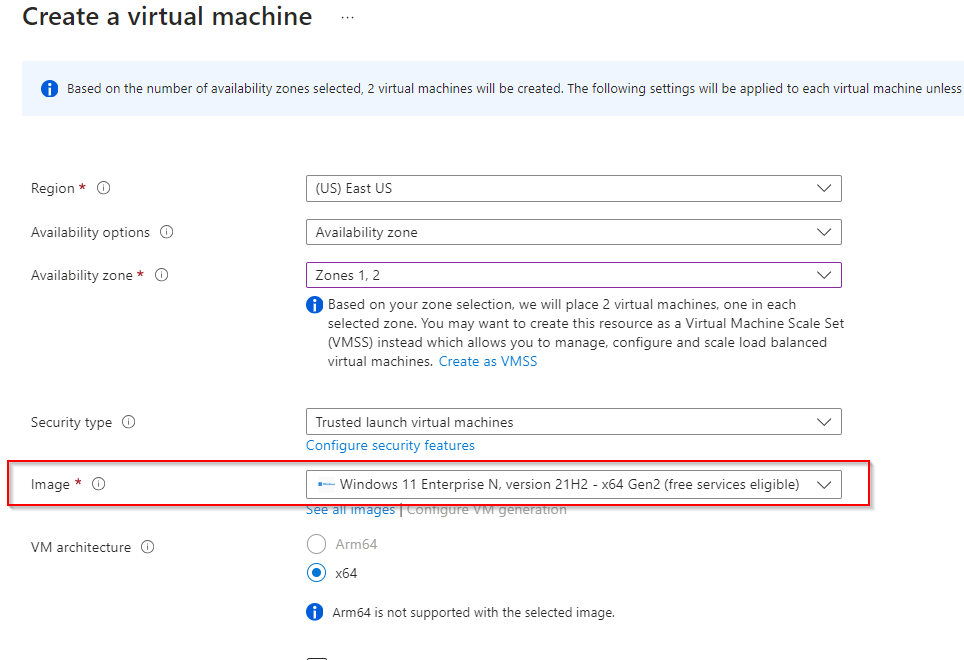
**Create administrator account and enter username and password**
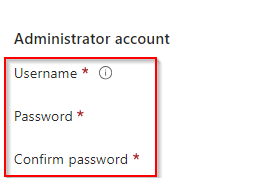
**Select inbound ports
**
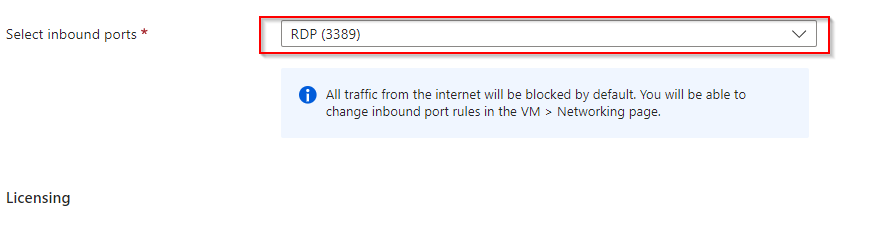
**Check Licensing**
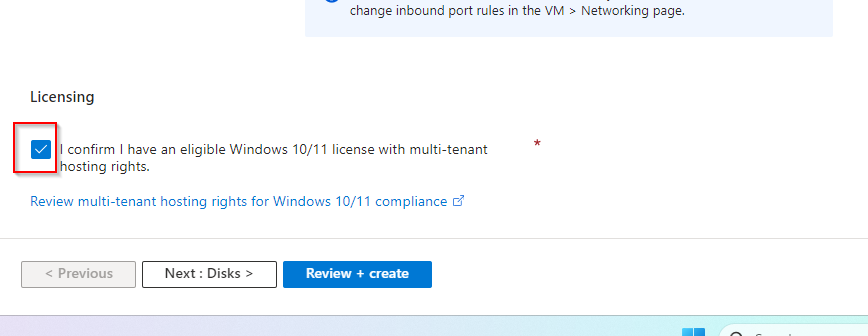
**In the "Monitoring" Tab**
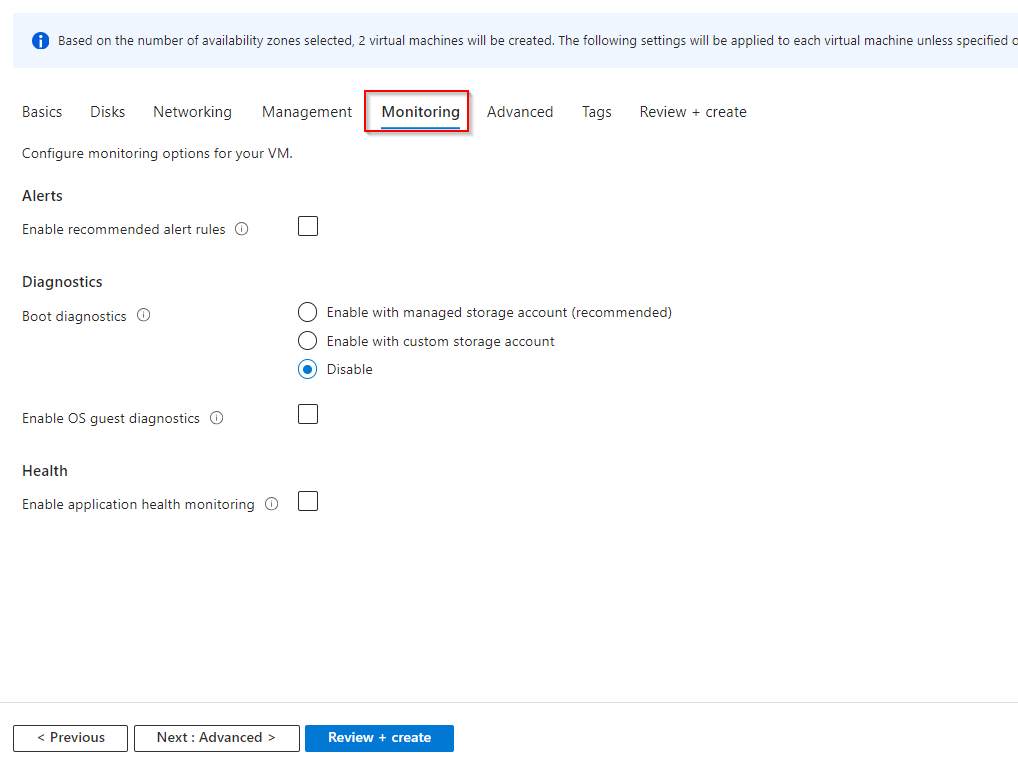
**Disable Diagnostics **
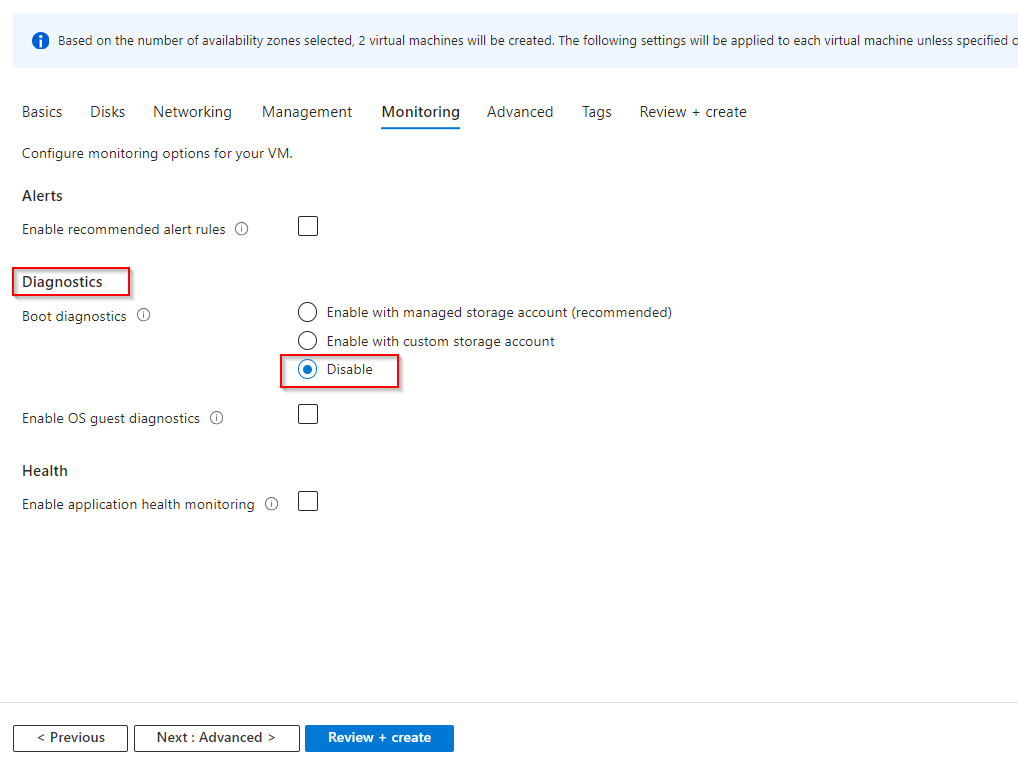
It is advised to create a load balancer when high availability is required.
**Click Review + Create**
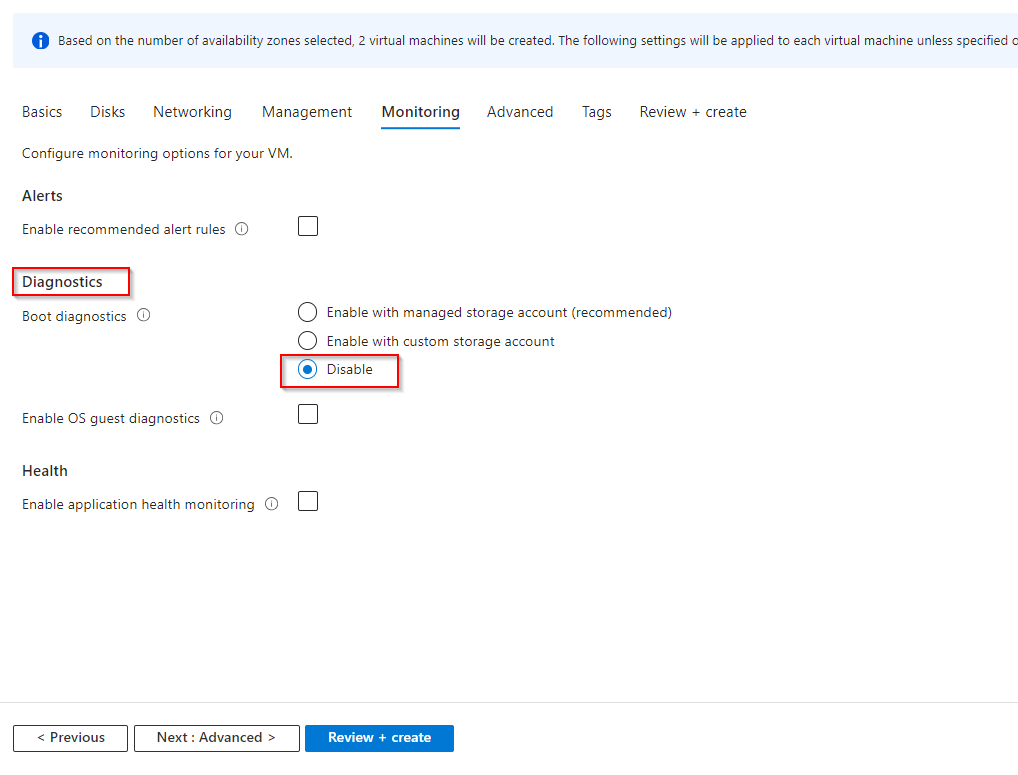
**Check Validation**

**Click "Create"**
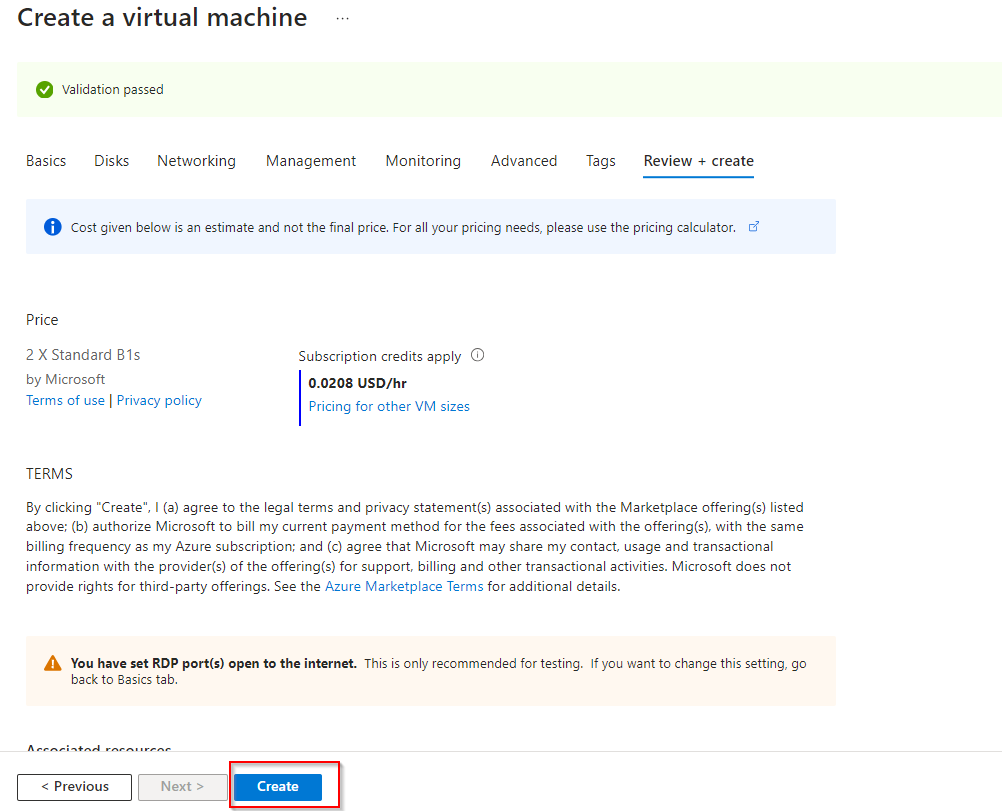
**Confirm Deployment**
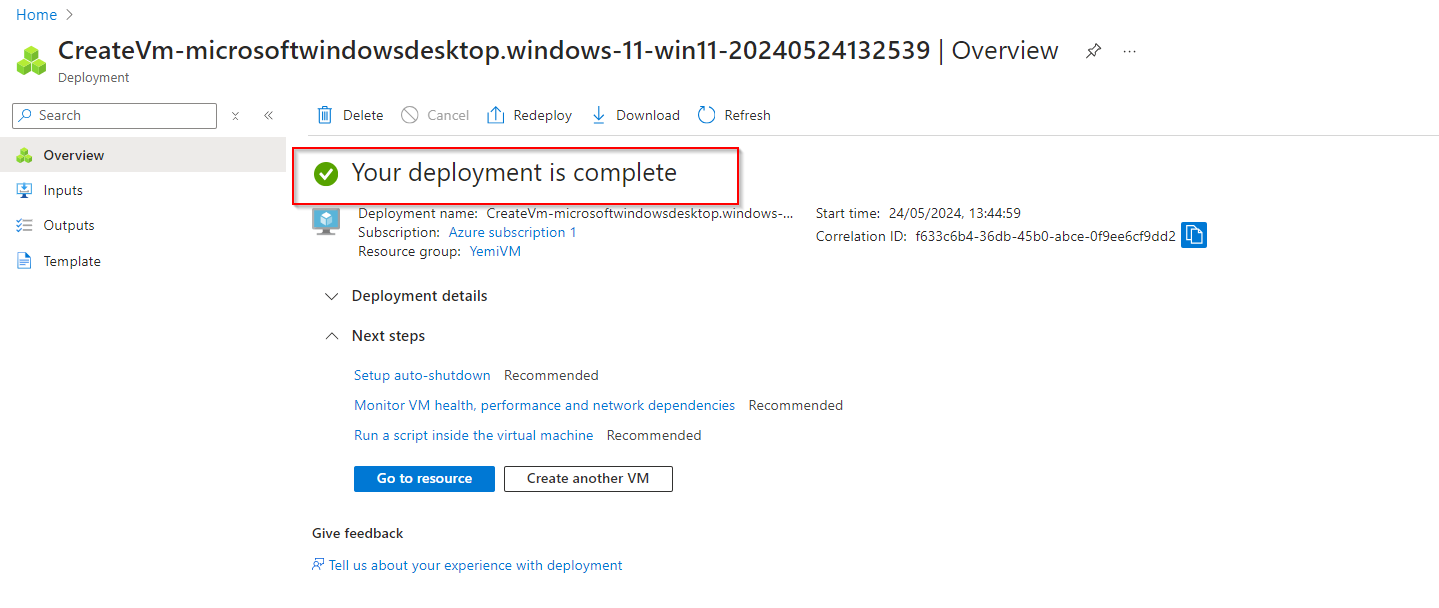
**Click on "Go to Resource"**
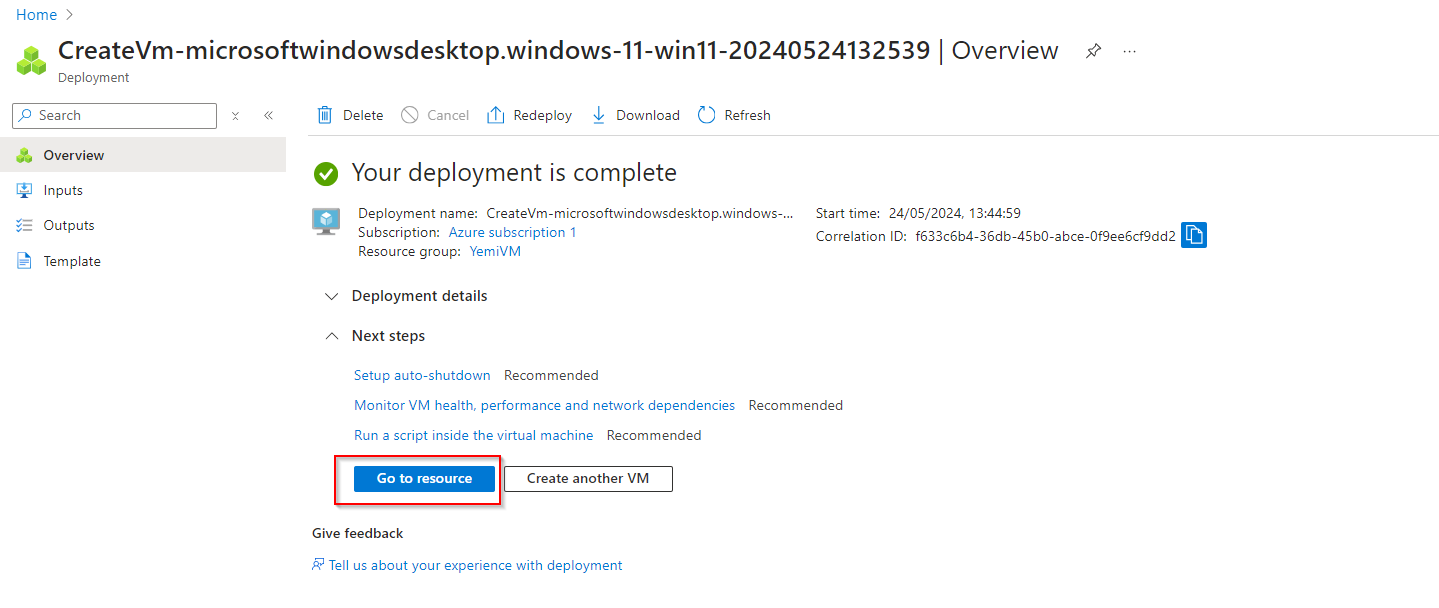
**Click on "Connect"**
**Select Native RDP & Click "Select"****
**Ensure all configurations are ticked green and configured**
**Download RDP File**
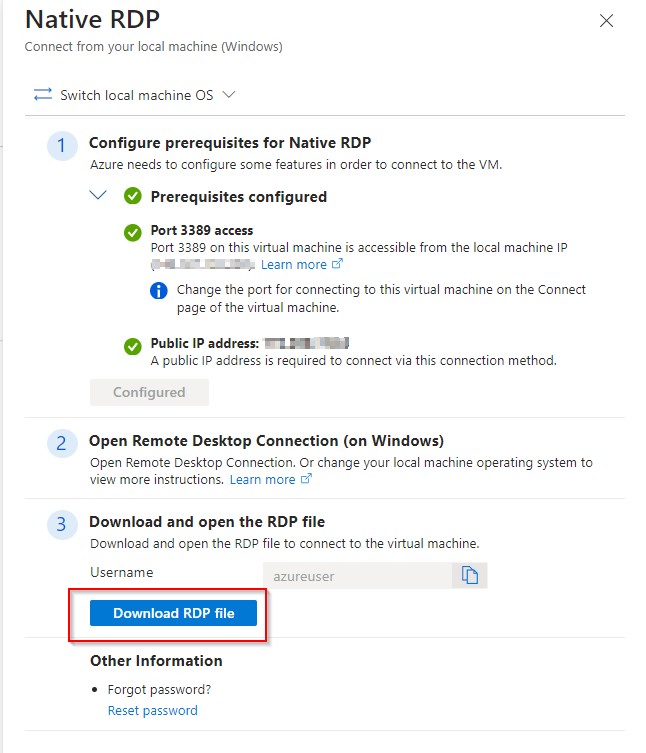
Further installation settings will be required and you will be able to access your virtual machine.
| opsyog | |
1,863,522 | Next.js: Upload de imagem para a Cloudflare R2 Utilizando Presigned URL | Olá, devs! Neste post, vamos aprender como fazer upload de uma imagem em uma aplicação Next.js com... | 0 | 2024-05-24T03:53:50 | https://dev.to/lucianogmoraesjr/nextjs-upload-de-imagem-para-a-cloudflare-r2-utilizando-presigned-url-26o4 | nextjs, r2, upload, typescript | Olá, devs! Neste post, vamos aprender como fazer upload de uma imagem em uma aplicação Next.js com TypeScript para um bucket na Cloudflare utilizando presigned URLs. Vamos dividir o tutorial em etapas para facilitar o entendimento.
## O que é uma Presigned URL?
Uma Presigned URL é uma URL temporária gerada para permitir que usuários façam upload ou download de arquivos diretamente em um serviço de armazenamento, como o Amazon S3 ou Cloudflare R2, sem a necessidade de expor as credenciais de acesso no cliente. Essa URL inclui credenciais temporárias e permissões específicas, como tempo de expiração e tipo de ação permitida (upload ou download).
### Vantagens de Usar Presigned URLs:
- **Segurança**: As credenciais não são expostas no frontend.
- **Controle**: A URL pode ser configurada para expirar após um determinado tempo.
- **Simplicidade**: Facilita o processo de upload/download, delegando ao cliente a responsabilidade de transferir os arquivos.
## O que Vamos Precisar?
**Este artigo necessita de conhecimento intermediário/avançado em Next.js**
1. Uma aplicação Next.js configurada com TypeScript.
2. Uma conta na Cloudflare e acesso ao Cloudflare R2.
## Passo 1: Configurando o Cloudflare R2
Primeiro, precisamos configurar o nosso bucket na Cloudflare R2.
1. Acesse o painel da Cloudflare e navegue até a seção **R2**.
2. Copie seu ID da conta.
3. Crie um novo bucket e anote o nome do bucket, pois vamos precisar dele mais tarde.
4. Crie um novo token de API, dê um nome ao token e permissões de gravação/leitura.
5. Copie Access Key ID e Secret Access Key para Clientes S3 para interagir com o bucket utilizando a SDK da AWS.
### Adicione política de CORS no seu bucket
Para que a aplicação consiga realizar o upload para dentro do bucket no R2, é necessário liberar as seguintes origens, métodos e headers:
```json
[
{
"AllowedOrigins": [
"http://localhost:3000"
],
"AllowedMethods": [
"GET",
"PUT"
],
"AllowedHeaders": [
"Content-Type"
]
}
]
```
## Passo 2: Criando a Aplicação Next.js
Vamos começar criando uma nova aplicação Next.js utilizando o comando `npx create-next-app@latest`:
```bash
npx create-next-app@latest
```
Ao executar o comando acima, o CLI do Next.js fará as seguintes perguntas, e você deve respondê-las conforme as sugestões:
1. **What is your project named? (upload-r2)**
- Responda com o nome desejado para a sua aplicação. Por exemplo, `upload-r2`.
2. **Would you like to use TypeScript?**
- Resposta: **Yes**
- **Explicação:** Escolha "yes" para habilitar o suporte ao TypeScript na sua aplicação.
3. **Would you like to use ESLint with this project?**
- Resposta: **Yes**
- **Explicação:** ESLint é uma ferramenta útil para manter a qualidade do código, ajudando a identificar e corrigir problemas de estilo e erros de programação.
4. **Would you like to use Tailwind CSS with this project?**
- Resposta: **Yes**
- **Explicação:** Para este tutorial, estamos focando em usar a biblioteca `shadcn/ui` para estilizar os componentes, então Tailwind CSS é um requisito.
5. **Would you like to use `src/` directory with this project?**
- Resposta: **Yes**
- **Explicação:** Usar um diretório `src/` ajuda a organizar melhor os arquivos de código-fonte, separando-os de outros arquivos de configuração e metadados.
4. **Would you like to use `App Router` (recommended)?**
- Resposta: **No**
- **Explicação:** Para manter as coisas simples, usaremos a estrutura de diretórios padrão. O diretório `app/` pode não ser necessário para a maioria dos projetos neste estágio.
5. **Would you like to customize the default `import alias` (@/*)?**
- Resposta: **No**
- **Explicação:** O alias de importação `@/` é uma convenção comum que facilita os caminhos de importação relativos, tornando o código mais legível e fácil de manter.
Após a instalação das dependências do Next.js, acesse a aplicação e abra no VSCode:
```bash
cd upload-r2
code .
```
## Passo 3: Configurando Variáveis de Ambiente
No arquivo `.env.local` da sua aplicação Next.js, adicione as seguintes variáveis de ambiente com as informações do Cloudflare R2:
```env
CLOUDFLARE_ACCOUNT_ID=your-account-id
AWS_ACCESS_KEY_ID=your-access-key-id
AWS_SECRET_ACCESS_KEY=your-secret-access-key
AWS_BUCKET_NAME=your-bucket-name
```
Inicie a aplicação:
```bash
npm run dev
```
## Passo 4: Instalando Dependências Necessárias
Vamos precisar do SDK da AWS para interagir com o Cloudflare R2, pois ele é compatível com o S3. Instale com o seguinte comando:
```bash
npm install @aws-sdk/client-s3 @aws-sdk/s3-request-presigner
```
## Passo 5: Criando a Função para Gerar Presigned URL
Crie um arquivo em `pages/api/presigned-url.ts` para gerar a presigned URL:
```typescript
import { PutObjectCommand, S3Client } from '@aws-sdk/client-s3';
import { getSignedUrl } from '@aws-sdk/s3-request-presigner';
import { NextApiRequest, NextApiResponse } from 'next';
const accountId = process.env.CLOUDFLARE_ACCOUNT_ID
const client = new S3Client({
endpoint: `https://${accountId}.r2.cloudflarestorage.com`,
region: 'auto',
credentials: {
accessKeyId: process.env.AWS_ACCESS_KEY_ID!,
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY!,
}
})
export default async function handler(req: NextApiRequest, res: NextApiResponse) {
const { key } = req.body; // key pode ser o nome da imagem
if (!key) {
return res.status(400).json({ error: 'File key is required.' })
}
const signedUrl = await getSignedUrl(client, new PutObjectCommand({
Bucket: process.env.AWS_BUCKET_NAME,
Key: key
}), {
expiresIn: 60 // URL válida por 1 minuto
})
res.status(200).json({ signedUrl })
}
```
## Passo 6: Utilizando shadcn/ui
Vamos começar adicionando o shadcn/ui na aplicação utilizando o comando:
```bash
npx shadcn-ui@latest init
```
Ao executar o comando acima, o CLI do shadcn/ui fará as seguintes perguntas, e você deve respondê-las conforme as sugestões:
1. **Which `style` would you like to use?**
- Escolha um estilo que deseja utilizar. Por exemplo, `New York`.
2. **Which color would you like to use as `base color`?**
- Escolha uma base de cores. Por exemplo, `Slate`.
3. **Would you like to use `CSS variables` for colors?**
- Resposta: **Yes**
- **Explicação:** Variáveis CSS para cores é útil para o reuso.
Feito isso, estamos prontos para adicionar os componentes. Vamos adicionar os componentes de Label, Input, Button e Sonner para toast:
```bash
npx shadcn-ui@latest add label
npx shadcn-ui@latest add input
npx shadcn-ui@latest add button
npx shadcn-ui@latest add sonner
```
## Passo 7: Criando o Formulário de Upload com shadcn/ui
Agora, crie um componente para fazer o upload da imagem utilizando a presigned URL. Crie um arquivo `components/UploadForm.tsx`:
```typescript
import { ChangeEvent, FormEvent, useState } from "react";
import { toast } from "sonner";
import { Button } from "./ui/button";
import { Input } from "./ui/input";
import { Label } from "./ui/label";
export function UploadForm() {
const [avatar, setAvatar] = useState<File | null>(null);
function handleSelectAvatar(event: ChangeEvent<HTMLInputElement>) {
const selectedFile = event.target.files?.[0] || null;
setAvatar(selectedFile);
}
async function handleSubmit(event: FormEvent) {
event.preventDefault();
try {
if (!avatar) return;
const uniqueFileName = `${crypto.randomUUID()}-${avatar.name}`;
const response = await fetch('/api/presigned-url', {
method: 'POST',
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ key: uniqueFileName })
})
const { signedUrl } = await response.json()
await fetch(signedUrl, {
method: 'PUT',
headers: {
"Content-Type": avatar.type
},
body: avatar
})
toast.success('Upload realizado com sucesso!')
} catch {
toast.error('Ocorreu um erro ao realizar o upload!')
}
}
return (
<form className="flex flex-col gap-4" onSubmit={handleSubmit}>
<div>
<Label htmlFor="avatar">Avatar</Label>
<Input id="avatar" type="file" onChange={handleSelectAvatar} />
</div>
<Button>Upload</Button>
</form>
)
}
```
## Passo 8: Integrando o Componente no Projeto
Finalmente, vamos integrar o componente `UploadForm` em uma página do Next.js. Abra `pages/index.tsx` e adicione o componente:
```typescript
import { UploadForm } from "@/components/UploadForm";
import { Toaster } from "@/components/ui/sonner";
export default function Home() {
return (
<div className="flex h-screen items-center justify-center">
<div>
<UploadForm />
<Toaster />
</div>
</div>
);
}
```
## Conclusão
Pronto! Agora você tem uma aplicação Next.js com TypeScript capaz de fazer upload de imagens para um bucket na Cloudflare utilizando presigned URLs, e com uma interface estilizada usando `shadcn/ui`. Essa abordagem é ótima para garantir segurança e controle sobre os uploads.
Espero que este tutorial tenha sido útil para você. Se tiver alguma dúvida, deixe um comentário abaixo. Até a próxima!
---
Gostou deste post? Siga-me para mais conteúdos sobre desenvolvimento web e tecnologias! 🚀 | lucianogmoraesjr |
1,863,521 | Top UI/UX Design Trends | UI/UX designing has encountered changes, recommendations, and many upgrades. Such is the difference... | 0 | 2024-05-24T03:53:40 | https://www.peppersquare.com/blog/top-ui-ux-design-trends/ | ui, ux, design, trends | UI/UX designing has encountered changes, recommendations, and many upgrades. Such is the difference that the UI/UX of 2024 will be unrecognisable when compared to that of 2023. It moves swiftly, incorporating what’s best and leaving out what was once considered the best. Thanks to that, a yearly look at design trends will keep everyone in the loop about what’s new.
## NeuFlat Designing — A change from NewFlat
For the unversed, flat design is a user interface style that uses two-dimensional elements and relies heavily on **simplicity and minimalism**. And if one were to add trends such as Glass Morphism and Neubratilism, it would be classified as NeuFlat Design.
In other words, NeuFlat Design is a modern mix of the existing design style known as NewFlat. By bringing in the traditional flat design, the new update adds trends and offers a new way of highlighting what’s considered appealing in 2023 & in 2024.
## Motion Design — In collaboration with interactive designing
The change in animation and video compression, coupled with a few advances, has quickly brought motion designing and placed it at the forefront of interface design. Brands want to convey a story, and motion designing pens down their thoughts effortlessly.
In an age where simplifying every interface is critical, motion designing is the new way forward. Thanks to its innovative approach, this [design element](https://www.peppersquare.com/blog/reimagining-design-elements-for-the-future/) can create a memorable experience that is also good for customer retention.
## Minimalism — A trend linking the past and the future
It’s hard to imagine a time when minimisation will stop trending. Despite being a trend of the past, minimalism continues to grow in different directions. It is a significant [part of the process](https://www.peppersquare.com/blog/stages-of-the-ux-design-process/) designers use to simplify the interface and help users focus on what matters the most.
It sticks to aesthetics and incorporates design elements considered vital for branding and marketing. With upgrades around the corner, the latest talk is of a new, bolder minimalist design.
## Scrollytelling — An immersive experience
Also known as immersive scrolling, scrolly-telling is a prominent feature in improving the relationship between a product and a user. By combining the elements of storytelling, design, and more aspects, scrolly-telling brings about an interactive experience that promotes **effective transitions.**
The connection it shares between different sets of information is close, making the user a curious scroller. Since the design is evolving, we expect to see more innovation from this design trend in the near future.
## Typography Trends of 2023 & 2024 — Big and bold
With the need of the hour being to [create websites](https://www.peppersquare.com/ui-ux-design/website-design/) that yield direct business value, typography comes forward as a factor to consider. And in considering it, one will also have to go through current trends that want typography to be big and bold.
The current trend incorporates a specific typography style that emphasizes words more, enhancing the creative output of any copy. Content positioned as intense, informative, and hard-hitting often relies on bold typography as it effortlessly drives the point home.
## Data storytelling — Popularising facts and figures
From enterprise product design to consumer digital products, data storytelling is spreading its wings all around the design ecosystem. Prompted by reactions to the less interactive form of presenting data and encouraged by the visual elements, data storytelling is a trend for the future.
As a trend, it has produced a different form of storytelling essential for specific digital products. In creating a compelling narrative, users find it easier to consume key information that seems more apt than putting a couple of numbers together.
## Personalisation — Tailor-made for everyone
Customisable options with a bit of personalisation go a long way in enhancing user experience. In 2023 or 2024, everyone prefers an interactive experience that they also find relatable at some level.
And with design in the mix, creating that interaction is undoubtedly possible. However, people are also relying on the powers of [video production ](https://www.peppersquare.com/video-production/)and providing tailor-made services that are known to improve customer retention.
By understanding users’ behaviours and preferences, personalisation takes things up a notch and is well-placed as a design trend for 2023 & 2024.
## Emotional design — For memorable user interactions

The belief that human beings run on emotions rather than logic is the core reason behind emotional design being classified as a trend. With UX research reaching new heights, emotional designs form a connection that is hard to find elsewhere.
They are an instrumental element in differentiating products and placing them above anything. But what is an emotional design? An interactive element of design that evokes emotions in users and customers can be classified as an emotional design.
Popularised by **Don Norman**, emotional designs are crucial in strengthening decision-making and turning things the brand’s way.
## Immersive 3D — Transcending into a new world
Continued innovations via immersive scrolling, along with growing interest in VR tech, have made immersive 3D a future design trend. With websites keen on offering the best visual experience, a wholly rendered 3D world is on the horizon.
With immersive 3D, you can achieve
- Improved product visualisation
- Enhanced customisation
- Better communication
- Competitive advantage
## Custom digital illustrations
Custom digital illustrations are a unique way to add a personal touch to your interface and upgrade the current requirement surrounding personalisation. From [enterprise UX designs](https://www.peppersquare.com/blog/best-practices-for-enterprise-ux/) to mobile UX and more, customisation has its say on everything.
As this trend continues, designing will significantly change and broaden its horizon to achieve more. With custom illustrations being able to establish a **human connection**, brands will view the same as the go-to solution for establishing a relationship between a brand and a consumer.
**Conclusion**
Design trends have constantly evolved and brought in changes apt to the current times. If in 2023, our focus was less on storytelling, in 2024, we have moved further and included data storytelling. This is reminiscent of current trends, moving ahead to signal a favoured outcome.
Hence your business needs to be in sync with these trends and offer solutions that raise expectations.
<a href="https://www.peppersquare.com/contact-us/" target="_blank" rel="noopener"></a> | pepper_square |
1,863,519 | Focus on Precision: The Importance of Fiber Laser Lenses | Get Precise with Fiber Laser Lenses: A Comprehensive Guide Introduction: In the world of laser... | 0 | 2024-05-24T03:52:16 | https://dev.to/davelopezj/focus-on-precision-the-importance-of-fiber-laser-lenses-404n | laser | Get Precise with Fiber Laser Lenses: A Comprehensive Guide
Introduction:
In the world of laser technology, precision is everything. That's where Fiber Lenses come in. These lenses are designed to provide unparalleled accuracy, making them a vital part of any laser system. We'll delve into the advantages, innovations, safety, use, and service of fiber laser lenses.
Benefits:
Fiber laser lenses offer plenty of advantages that create them be noticeable off their contacts available in the market
A few of the most benefits that are significant:
High accuracy, making them perfect for delicate and operations that are intricate
Better beam quality and higher effectiveness, ultimately causing a far more polished and end item like refined
Enhanced reliability and durability, ensuring longevity and less upkeep
Versatility and freedom, as a total result of their capability to work nicely with different wavelengths and applications
Innovation:
Fiber laser lenses have come an easy method like very long their inception
Today, they are an technology like essential both industrial and commercial applications
The most innovations that are recent fiber laser contacts consist of:
Enhanced finish technology, optimized to provide protection like maximum scratches and issues for the lenses
Improved focus control, providing more accurate and faster corrections for diverse applications
Superior quality like material that may resist temperature, effect, and environment distortion
Smart calibration, where the lenses can conform to settings that are different regards to the application which means intensity needed
Security:
Dealing with laser products could be dangerous
The likelihood of eye damage is clearly current, plus the final thing you wish is a lens that may not provide you with the security like necessary
Happily, fiber laser lenses are made with security as being a concern like top with features such as for example:
High laser damage limit (LDT), resisting radiation, and effect
Scratch-resistant coatings, decreasing the chance of accidents and mistakes
Minimal absorption coatings, taking in temperature like extra decreasing the opportunity of heat-induced damage
Top-quality material, that may withstand impacts and accidents
Service:
As with every gear, Fiber laser lens need upkeep and servicing to optimally have them performing
Here are some of the finest methods you need to follow when servicing your contacts:
Clean the contacts regularly having a wipe like lint-free a cleansing solution suitable for the lens's material
Inspect the lenses for scratches, chips, or some other damages
Replace any damaged or lenses that are worn-out soon as you possibly can
Calibrate the lenses regularly, ensuring they're aligned properly and focused accordingly
This may make certain that they have been doing at maximum effectiveness
Store the lenses appropriately in instances or containers built to protect them from physical damage, moisture, and dust
Quality and Application:
The grade of dietary fiber laser contacts is important due to their performance
In the event that lenses are of poor quality, their effect on efficiency, precision, and efficiency may be significant
When purchasing laser like fiber, think about the after like annotated
Quality assurance guidelines through the maker
Consumer sources and reviews for just about any item and maker
Warranty, repair, and replacement selections for the lens
Compatibility associated with the lens using your laser system, as well as the application regarding the laser system
Conclusion:
Fiber laser lenses are an essential element of any laser system. Their high level of precision, quality, and safety make them stand out in the market. By choosing the Laser Source, maintaining it correctly, and taking the necessary safety precautions, you can enjoy all the benefits fiber laser lenses offer. Remember to prioritize your equipment and invest in your lenses if you want your laser system to perform at its best.
Source: https://www.zhileilaser.com/product-factory-supply-good-quality-optic-fiber-protective-lens | davelopezj |
1,863,518 | Mastering Shopify Theme 2.0: Elevate Your E-Commerce Game with Expert Insights | Developing a strong understanding of Shopify Theme 2.0 is essential for maximizing the potential of... | 0 | 2024-05-24T03:48:59 | https://dev.to/epakconsultant/mastering-shopify-theme-20-elevate-your-e-commerce-game-with-expert-insights-hkj | shopify | Developing a strong understanding of Shopify Theme 2.0 is essential for maximizing the potential of your online store. As Shopify continues to evolve and improve its platform, Theme 2.0 brings a host of new features and enhancements that can enhance the design, functionality, and performance of your e-commerce website. In this article, we will explore the key aspects of Shopify Theme 2.0, including its structure, customization options, best practices for development, optimization techniques, and troubleshooting strategies. By delving into these topics, you will be well-equipped to create a visually appealing, user-friendly, and high-performing online store using Shopify Theme 2.0.
**1. Introduction to Shopify Theme 2.0**
So you think you know Shopify themes, huh? Well, hold onto your hats, because Shopify Theme 2.0 is here to shake things up. It's like the glow-up version of your favorite theme, with all the bells and whistles that'll make your online store shine brighter than a disco ball.
**1.1 Evolution of Shopify Themes**
Remember the good ol' days of clunky themes that made your site look like it was stuck in the early 2000s? Well, say goodbye to those relics, because Shopify themes have come a long way, baby. The evolution of Shopify themes has been nothing short of a makeover montage, and Theme 2.0 is the makeover queen.
**1.2 Overview of Shopify Theme 2.0**
Theme 2.0 isn't just a pretty face – it's got substance too. This bad boy is all about making your life easier and your store more kickass. With snazzy new features and a sleek design, Theme 2.0 is like the superhero sidekick your online store never knew it needed.
**2. Key Features and Improvements in Shopify Theme 2.0**
Alright, buckle up because we're diving into the juicy stuff. Theme 2.0 isn't just a fresh coat of paint – it's a whole new beast. Get ready to feast your eyes on some key features and improvements that'll make you wonder how you ever lived without them.
**2.1 Enhanced Customization Options**
Theme 2.0 is all about giving you the power to make your store look exactly how you want it. With enhanced customization options, you can tweak and tinker to your heart's content. Say goodbye to cookie-cutter designs and hello to a store that's as unique as you are.
**2.2 Improved Responsiveness and Mobile-Friendliness**
In a world where everyone's glued to their phones, having a responsive and mobile-friendly website is non-negotiable. Theme 2.0 gets it, and it's here to make sure your store looks sleek and snazzy on any device. No more wonky layouts or tiny text – Theme 2.0 has your back.
**3. Understanding the Structure and Architecture of Shopify Theme 2.0**
Alright, time to get nerdy. If you've ever wondered what makes Shopify Theme 2.0 tick, you're in the right place. We're peeling back the curtain to show you the structure and architecture that makes Theme 2.0 the powerhouse that it is.
**3.1 Sections and Blocks in Theme Building**
Ever heard of sections and blocks? No, they're not some trendy new dance move – they're the building blocks of Theme 2.0. These bad boys give you the flexibility to customize your store like never before. Think of them as your trusty sidekicks in the quest for the perfect storefront.
**3.2 Liquid Templating Language in Shopify**
Liquid templating language might sound like something out of a sci-fi movie, but it's actually the secret sauce that makes Shopify themes so darn flexible. Learn how to harness the power of Liquid and you'll be whipping up custom designs like a pro in no time.
**4. Customization and Flexibility in Shopify Theme 2.0**
Alright, it's time to unleash your inner design wizard. Theme 2.0 is all about customization and flexibility, giving you the tools to create a store that's as unique as you are. From tweaking colors to integrating third-party apps, the world is your oyster with Theme 2.0.
**4.1 Theme Editor and Customization Options**
Say goodbye to cookie-cutter designs and hello to a world of customization. With the Theme Editor at your fingertips, you can tweak every pixel to perfection. No more settling for mediocre – Theme 2.0 is here to make your store shine.
**4.2 Integrating Third-Party Apps and Extensions**
Who says you can't have it all? With Theme 2.0, you can integrate all your favorite third-party apps and extensions to take your store to the next level. Whether you're adding social media buttons or payment gateways, Theme 2.0 plays nice with all the cool kids on the block.### 5. Best Practices for Developing with Shopify Theme 2.0
So you've ventured into the world of Shopify Theme 2.0, good for you! Now, let's talk about some best practices to make your development journey smoother than a fresh jar of almond butter.
**5.1 Writing Clean and Efficient Code**
Picture this: You're at a fancy dinner party, and your code is the main dish. Make sure it's clean, elegant, and efficiently cooked. Nobody likes a messy plate of spaghetti code. Embrace best practices like modularization, proper indentation, and meaningful naming conventions. Your future self will thank you.
**5.2 Testing and Quality Assurance**
Testing is like flossing – everyone knows they should do it, but not all actually commit to it. Don't be that person. Test your code thoroughly to catch bugs before they turn into Godzilla-sized monsters. Quality assurance is your trusty sidekick in this quest for perfection. Your users will appreciate a seamless experience, and you'll sleep better at night.
**6. Optimizing Performance and SEO in Shopify Theme 2.0**
Ah, performance and SEO – the peanut butter and jelly of the web development world. Let's make sure your Shopify Theme 2.0 is as fast and search engine-friendly as a caffeinated cheetah.
**6.1 Image Optimization and Lazy Loading**
Images are like that one friend who always shows up late to the party and eats all the snacks. Optimize your images, lazy load them to improve page speed, and keep your visitors happy. No one likes staring at a blank screen while waiting for an image to load. Ain't nobody got time for that.
[Learn YAML for Pipeline Development : The Basics of YAML For PipeLine Development](https://www.amazon.com/dp/B0CLJVPB23)
**6.2 SEO Best Practices for Shopify Themes**
SEO is the secret sauce that takes your website from the dusty shelves of the internet to the top of the search results. Implement SEO best practices like optimizing meta tags, using descriptive URLs, and creating high-quality content. Google will love you, and your users will find you faster than a squirrel finds a nut.
**7. Troubleshooting and Debugging in Shopify Theme 2.0**
Ah, the dreaded bugs and glitches – the unwanted guests at your coding party. Let's kick them out and keep the celebration going with some troubleshooting and debugging tips.
**7.1 Common Issues and Solutions**
Every developer's worst nightmare: hitting a roadblock with no GPS in sight. Fear not! We've got your back with a guide to common Shopify Theme 2.0 issues and their solutions. Consider it your trusty map through the coding wilderness.
**7.2 Using Developer Tools for Debugging**
Developer tools are like a magician's wand in the world of coding. Learn to wield them with finesse to debug your Shopify Theme 2.0 like a pro. From inspecting elements to tracking network activity, these tools will be your sidekick in unraveling even the trickiest of bugs.
So there you have it – a guide to mastering Shopify Theme 2.0 like a boss. Strap on your coding cape, embrace these best practices, and conquer the digital realm with wit and style. Happy coding! 🚀In conclusion, mastering Shopify Theme 2.0 can empower you to create a captivating and seamless online shopping experience for your customers. By leveraging the advanced features, customization options, and optimization techniques offered by Shopify Theme 2.0, you can elevate the design and functionality of your e-commerce website. Additionally, by following best practices for development and troubleshooting any issues that may arise, you can ensure a smooth and successful implementation of Shopify Theme 2.0. Embrace the possibilities that Theme 2.0 offers, and embark on a journey towards building a standout online store that resonates with your target audience and drives business growth. | epakconsultant |
1,863,517 | User Story EP1 : How Alex Built His First GPT Action from Scratch🎉 | This article comes from User @ Alex Liu,big shoutout to ALEX for an incredible share! 🌟 Calling all... | 0 | 2024-05-24T03:48:59 | https://dev.to/marscode/user-story-ep1-how-alex-built-his-first-gpt-action-from-scratch-48ca | marscode, userstories, gptaction | > This article comes from User @ Alex Liu,big shoutout to ALEX for an incredible share! 🌟
> Calling all users to join in and share your stories too! 📚
> We have awesome gifts worth up to $200 waiting for those with amazing tales to tell! 🎁
Recently, with some free time on my hands, I developed a cool GPT Action using MarsCode. It allows querying of information on popular GitHub projects. It's been quite enjoyable, so I thought I'd share my development process and insights.
<img width="100%" style="width:100%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExY3Q5cTA4dDlrMml2Z29zN3FtMTMxMGlycm43bmxhY2R0b3RkY2NydSZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/5ldlNWHkbAogvGfpfQ/giphy.gif" >
(_how it works↑_)
> About GPT Actions: You can think of them as handy little helpers powered by AI, capable of fetching all sorts of information for you. For more details, check out "[Actions in GPTs.](https://platform.openai.com/docs/actions/introduction)"
Developing GPT actions may require an IDE, deployment platform, and API testing tools, among others. That's why I opted for MarsCode – it offers a one-stop solution, allowing me to quickly create a development project and streamline the development of GPT Actions.
Alright, let's take a look at my entire development process
### Step1: Designing GPT Actions
This is where you get to brainstorm what you want your GPT to do. For mine, I wanted it to scour GitHub Trending for hot projects based on programming language and time frame. Here's what I came up with for inputs and outputs:
- Inputs: the programming language to search for the time frame for the search (e.g., daily, weekly, monthly)
- Outputs: Project list, including project name, author, link, star count, and recent star increments.
### Step2: Setting Up the Project
MarsCode makes this part a breeze. With its variety of ready-to-use development frameworks and templates, I was spoilt for choice. Since I'm more comfortable with Node.js, I opted for the Node.js for AI Plugin template.
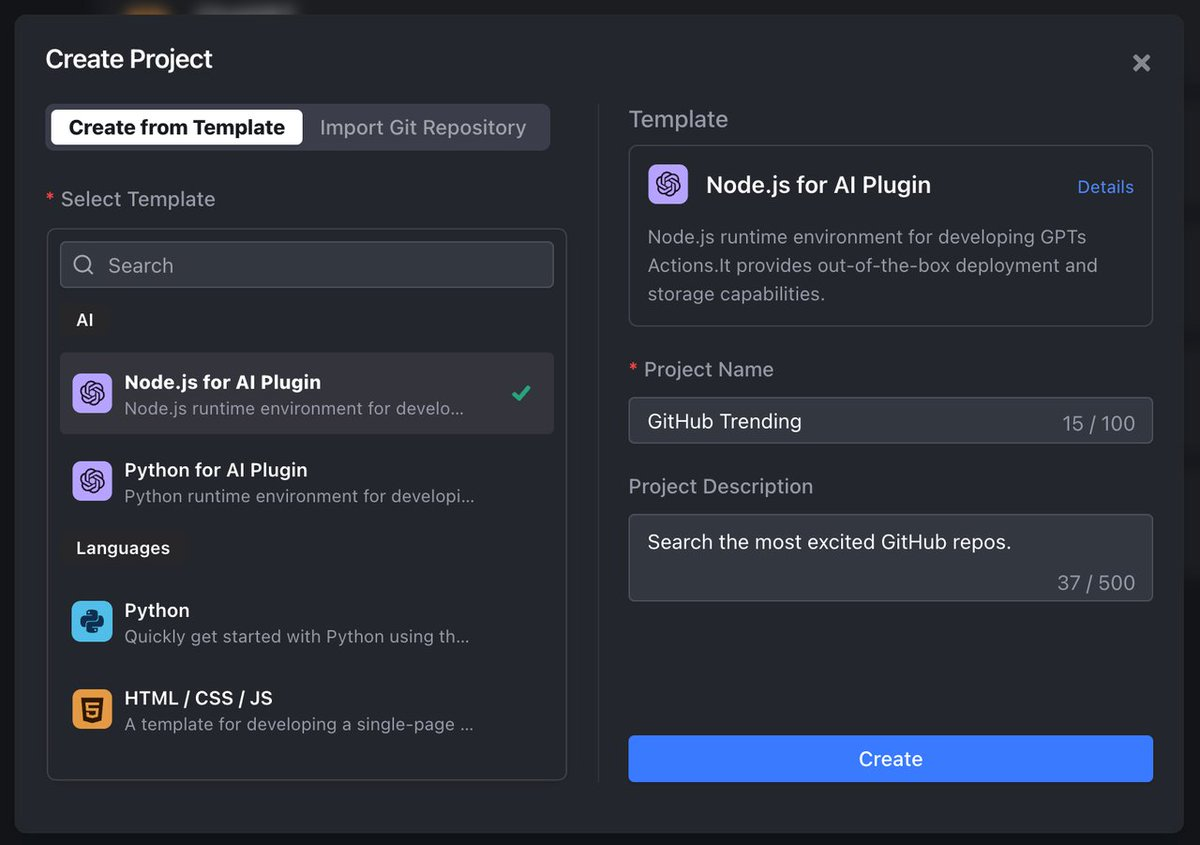
(_Clicking on "Create," I swiftly entered the project space↑_)
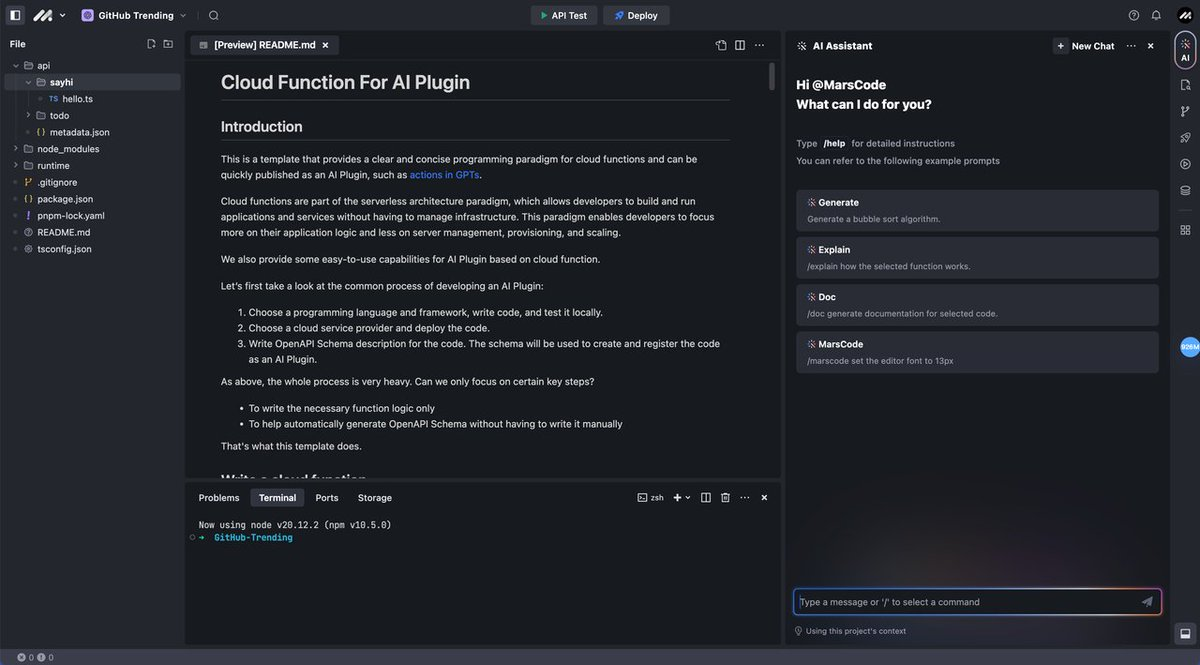
(_The overall layout of MarsCode is quite similar to VS Code, so there wasn't much of a learning curve for me, as someone accustomed to using VS Code. BTW, I have to mention its theme – I really like it! It's a pity it's not open-source.😄↑_)
### Step3 Development
For anyone diving into this template for the first time, it's a smart move to give the README a thorough read. Since it's a template project, sticking to the presets is the way to go.
In this template, each function file needs to export a function called handler that conforms to the following TypeScript definition:
```
export async function handler({ input, logger }: Args<Input>): Promise<Output> {
const name = input.name || 'world';
logger.info(`user name is ${name}`);
return {
message: `hello ${name}`
};
}
```
When an HTTP request comes in, MarsCode executes this function and passes in input and logger. The logic for the action is written within the handler function, which provides several predefined TypeScript types:
- Args: The arguments passed to MarsCode when executing the handler, including input and logger.
- Input: The input of the HTTP request.
- logger: This logs information, including methods like [logger.info](https://logger.info/), logger.error, and logger.debug. These logs appear in the Runtime logs panel of the deployment dashboard and in the API Test's log panel.
- Output: The output of the function.
After grasping all that, I jumped right into coding. I created github/searchTrending.ts under the api directory to fetch GitHub Trending data. Here's how I broke it down into 2 steps:
1. Fetching GitHub Trending Page: I started by making a fetch request to https://github.com/trending to grab the page's HTML. Since MarsCode's Node.js version is v20.12.2, I could directly use fetch for network requests.
2. Parsing HTML with cheerio: I had the HTML, I used cheerio to parse it and extract repo data like names, descriptions, and star counts.
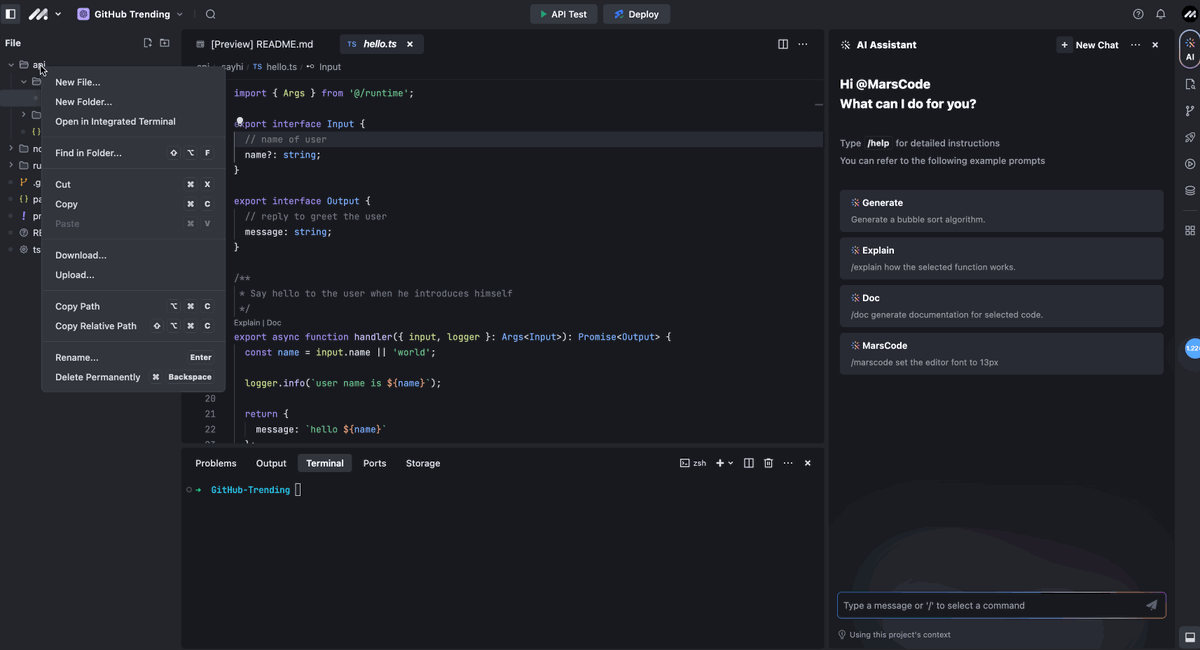
(_During the coding process, MarsCode AI Assistants were super helpful. They provided features like code auto-completion and generating code based on comments. The fields for the `GitHubRepo` interface were automatically inferred, making the whole process incredibly convenient. 😎↑_)
Once the dependencies are installed, we can dive into writing the core logic of the plugin:
```
async function searchTrending(input: Input): Promise<GitHubRepo[]> {
let url = 'https://github.com/trending';
// You can filter by language and time period
if (input.language) {
url += `/${input.language}`;
}
if (input.since) {
url += `?since=${input.since}`;
}
try {
// Fetch the HTML from GitHub Trending.
const response = await fetch(url);
const body = await response.text();
// Parse the HTML with cheerio to extract project information.
const $ = cheerio.load(body);
// Initialize the list for repository info.
let repositoriesInfo = [];
// Iterate over all <article class="Box-row"> elements on the page.
$('article.Box-row').each(function () {
const article = $(this);
// Extract data.
const name = article.find('h2.h3 a').text().trim();
const url = 'https://github.com' + article.find('h2.h3 a').attr('href');
const author = article.find('span.text-normal').text().trim().replace(' /', '');
const stars = article.find('a[href*="/stargazers"]').last().text().trim().replace(/,/g, ''); // Remove commas from numbers.
const todayStarsText = article.find('.d-inline-block.float-sm-right').text().trim();
const todayStarsMatch = todayStarsText.match(/(\d+)/);
const todayStars = todayStarsMatch ? parseInt(todayStarsMatch[0], 10) : 0;
const language = article.find('[itemprop="programmingLanguage"]').text().trim();
const description = article.find('p.color-fg-muted').text().trim(); Extract repo description
repositoriesInfo.push({
description,
language,
name,
url,
author,
stars,
todayStars
});
});
return repositoriesInfo;
} catch (error) {
console.error('Error fetching data:', error);
}
return [];
}
Call the searchTrending function in the handler:
typescript
/**
* Search the GitHub trending repos
*/
export async function handler({ input, logger }: Args<Input>): Promise<Output> {
const projects = await searchTrending(input);
return {
projects,
};
}
```
Now that we've wrapped up the main coding part, we can move on to testing this action. 🚀
### Step4: API test
<img width="100%" style="width:100%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExMDNvOXZyOTJheHFpM2Zjdjdqbnd0b29yanVibGlhcm0yMzZpMjdtOSZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/9jYv7PoaVGCEgDeW9A/giphy.gif" >
(_MarsCode offers a testing tool: API Test. In the API Test panel, you can input the parameters for the interface. Click "Send," and you can check the logs through the Output panel. 🔍↑_)
### Step5: Deployment
<img width="100%" style="width:100%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExcGJydndwaXltY3pzY3EwaWc3a3Q1dzVrNzNzM2kwMm1ydm55YnNsbSZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/GvRHDkZf4Zbmt2mbeS/giphy.gif" >
(_Click the "Deploy" button at the top, enter the Changelog, and then click "Start." Your project will begin deploying, and you can monitor the deployment process through the logs. 🚀↑_)
<img width="100%" style="width:100%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExemZpNXgxZGIyYWk3eHk4d3JnNDVmYmpmam50cThrYnp5azhvYWRjYiZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/zEs0MmGn3s5CxMtR6a/giphy.gif" >
(_After a successful deployment, you can view the service details through Service Detail. This includes the OpenAPI Schema, Bearer token, domain name, and more.↑_)
### Final Step
For details on how to add the action to your ChatGPT, there's a document from MarsCode team [Add an action to your ChatGPT](https://docs.marscode.com/tutorials/develop-cloud-functions#step-3-add-an-action-to-your-chatgpt). I won't go into it here, but you can refer to that for a step-by-step guide. 📄🤖
### Some of my ideas
Even though this was my first time developing a GPT Action, I found MarsCode's custom solution pretty impressive overall. The process was smooth with hardly any hiccups. Moving forward, I'm considering developing more AI Bots to cover various other scenarios. If anyone has ideas, feel free to join in and let's create something awesome together! 🚀
FYI : https://github.com/L-mofeng/marscode-github-trending-action
| dancemove_marscode |
1,863,516 | Installing a WebServer on Win Server 2019 VM | First and foremost, what is a web server? Imagine you have a toy box at home where you keep all your... | 0 | 2024-05-24T03:48:59 | https://dev.to/olawaleoloye/installing-a-webserver-on-win-server-2019-vm-1l6d | azure, webserver, windows, virtualmachine | **First and foremost, what is a _web server_**?
Imagine you have a toy box at home where you keep all your favourite toys. Now, let’s say your friend wants to see what toys you have. Instead of coming to your house, they can use a special magic box that lets them see and even play with your toys from their own home. This magic box is connected to your toy box and shows your toys to your friend whenever they ask.

A web server is like that magic box. It keeps a lot of information (like your toys) and when someone on the internet wants to see that information (like your friend), the web server shows it to them. So, it's a special computer that helps share information with other computers.
A **web server** is _a specialized software or hardware system responsible for handling HTTP(S) (Hypertext Transfer Protocol) requests from clients, typically web browsers, and serving them the appropriate web content, such as HTML pages, images, videos, or other resources_. The primary functions of a web server include:
1. **Hosting Websites**: Web servers store, process, and deliver web pages to users. They manage domain names, manage content, and ensure that web pages are available to users around the clock.
2. **Handling Requests and Responses**: When a user enters a URL in their browser, the web server processes the incoming HTTP request, retrieves the requested content, and sends it back to the client as an HTTP response.
3. **Security**: Web servers implement various security protocols, such as SSL/TLS, to encrypt data transmitted between the server and clients. They also handle authentication and authorization to protect sensitive data and resources.
4. **Load Balancing and Scalability**: Web servers can distribute incoming traffic across multiple servers to ensure efficient resource utilization, high availability, and reliability. They support scalability by adding or removing servers as demand fluctuates.
5. **Logging and Monitoring**: Web servers maintain logs of all transactions, which are crucial for analyzing traffic, debugging issues, and monitoring performance.
Popular web server software includes Apache HTTP Server, Nginx, Microsoft Internet Information Services (IIS), and LiteSpeed. Each of these solutions offers unique features and optimizations to cater to different performance, security, and scalability requirements.
In a previous [post](https://dev.to/olawaleoloye/a-guide-to-deploying-windows-11-using-azure-resources-3ao9), we deployed a Win 11 VM. Now, we shall install a webserver on a similar server (Win Server 2019).
**Open PowerShell**
Click on the **Start** menu.
Type **PowerShell** and open **Windows PowerShell** or **Windows PowerShell ISE** as an **_administrator_**(right-click and select Run as administrator)
**Provide your credentials**
**Install IIS by running this command**
```
Install-WindowsFeature -name Web-Server -IncludeManagementTools
```
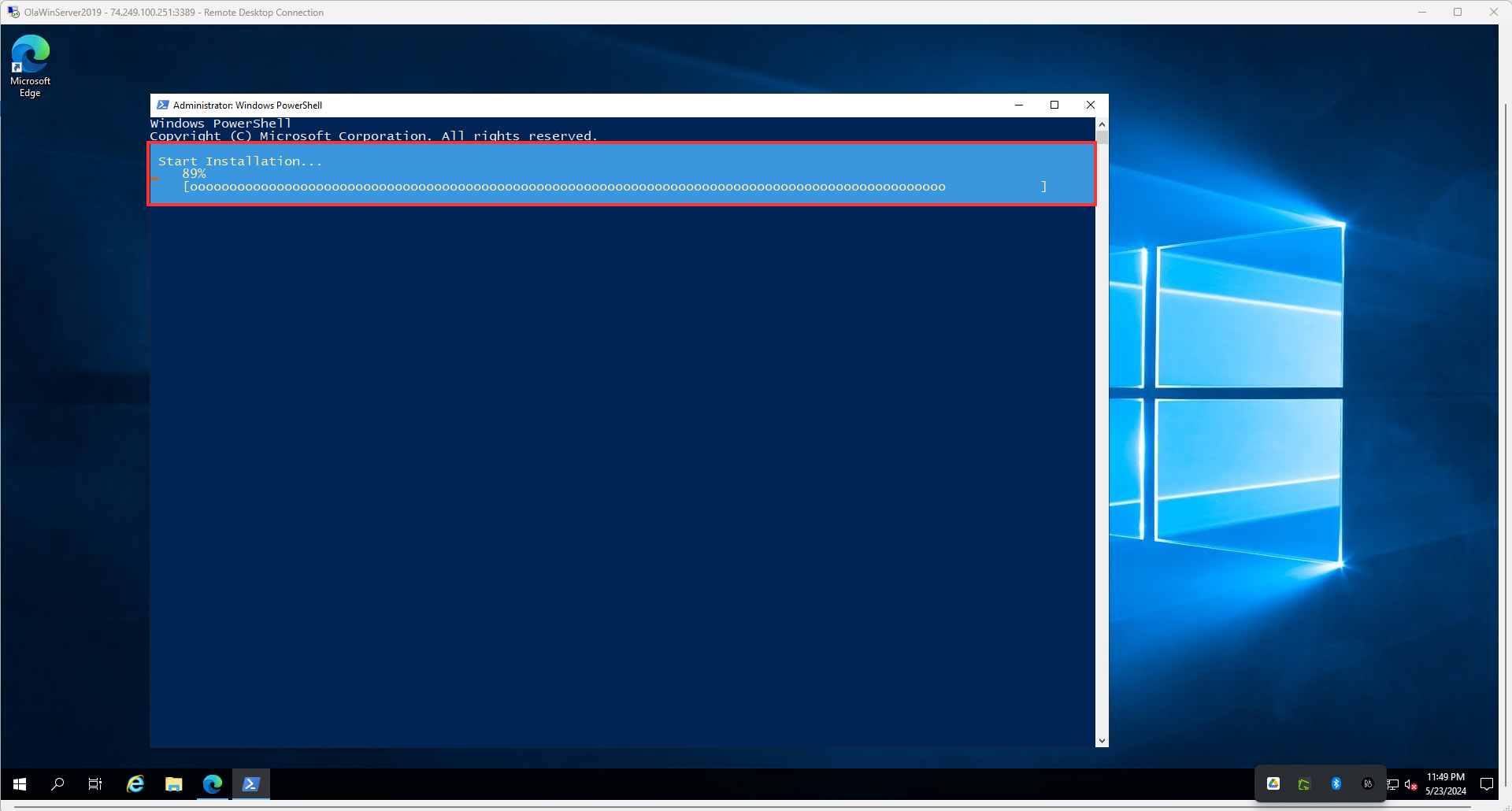
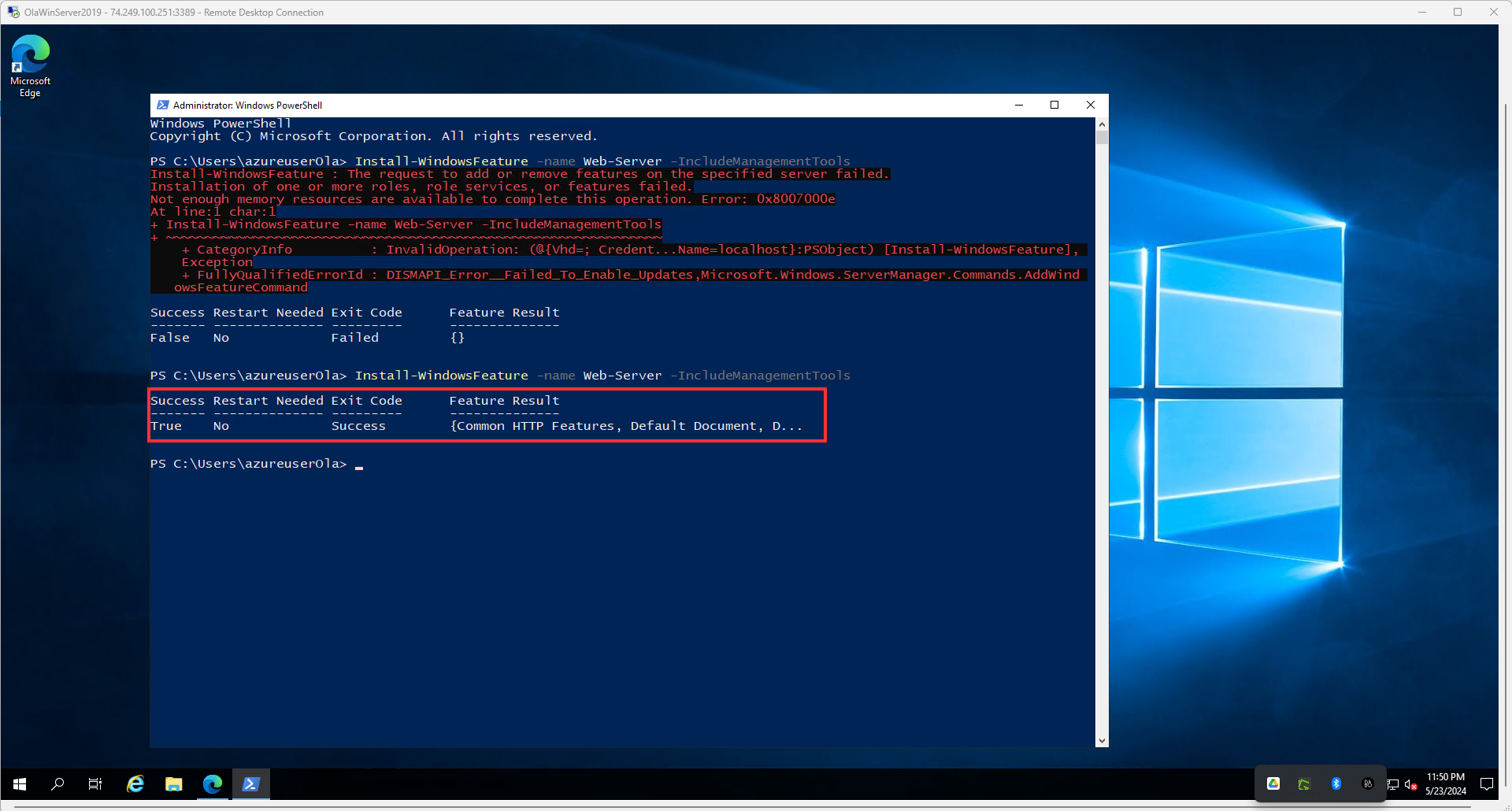
**Visit** the server/public IP in a browser to validate that it works
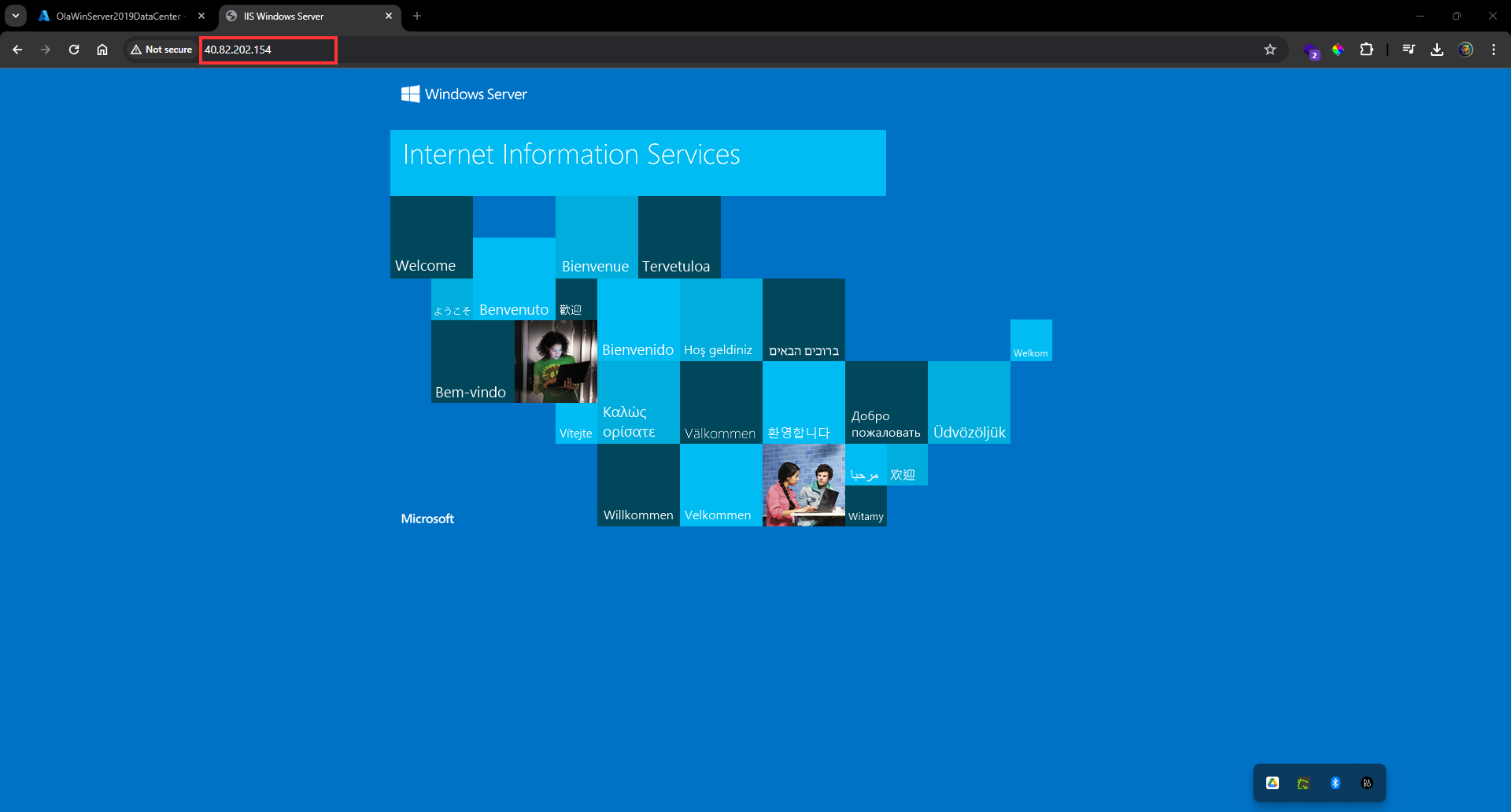
| olawaleoloye |
1,863,515 | Mmoexp: A new Diablo 4 hotfix is on the way | A new Diablo 4 hotfix is on Diablo 4 Items the way "sometime this week." That's according to the... | 0 | 2024-05-24T03:48:15 | https://dev.to/rozemondbell/mmoexp-a-new-diablo-4-hotfix-is-on-the-way-8b3 | webdev, javascript, beginners, programming | A new Diablo 4 hotfix is on <a href="https://www.mmoexp.com/Diablo-4/Items.html">Diablo 4 Items</a> the way "sometime this week."
That's according to the ever-present Diablo global community development director Adam Fletcher, tweeting via his personal Twitter account yesterday, August 8. Fletcher reveals there'll be a new Diablo 4 hotfix rolled out "sometime this week," that chiefly aims to address a bug where the 'Fury Against Fate' side quest can't be progressed and completed due to an impassable barricade.
A quick update - We will have another hotfix sometime this week to address a few items. I know people have brought up 'Fury Against Fate' still not allowing progress, we will try to get that in this hotfix.Team has also been looking at rarity of Wrathful Invokers. We MAY have…August 8, 2023
See more
Fletcher also reveals developers at Blizzard are well aware of the Diablo 4 Wrathful Invoker items being a little too rare for the liking of some players. The senior staffer isn't promising anything, but we might finally see the rarity of the Wrathful Invokers adjusted in the same hotfix.
Diablo 4 devs weren't prepared for you loot goblins to <a href="https://www.mmoexp.com/Diablo-4/Items.html">cheap Diablo 4 Items</a> take the level 100 grind so seriously | MMOEXP
| rozemondbell |
1,859,925 | Arquitetura de Microsserviços: um Guia para construir Sistemas Resilientes | Introdução Características por Martin Fowler Componentização via serviços Organização através de... | 0 | 2024-05-24T03:43:57 | https://dev.to/pmafra/arquitetura-de-microsservicos-2an | microservices, architecture, learning, backend | {%- # TOC start (generated with https://github.com/derlin/bitdowntoc) -%}
- [Introdução](#introdução)
- [Características por Martin Fowler](#características-por-martin-fowler)
+ [Componentização via serviços](#componentização-via-serviços)
+ [Organização através de áreas de negócio](#organização-através-de-áreas-de-negócio)
+ [Produtos e não Projetos](#produtos-e-não-projetos)
+ [Smart endpoints e Dump Pipes](#smart-endpoints-e-dump-pipes)
+ [Governança descentralizada](#governança-descentralizada)
+ [Gerenciamento descentralizado de dados](#gerenciamento-descentralizado-de-dados)
+ [Automação de infraestrutura](#automação-de-infraestrutura)
+ [Desenhado para falhar](#desenhado-para-falhar)
+ [Design Evolutivo](#design-evolutivo)
- [Resiliência](#resiliência)
- [Coreografia vs Orquestração](#coreografia-vs-orquestração)
- [Patterns](#patterns)
+ [API-Composition](#apicomposition)
+ [Decompose By Business Capability](#decompose-by-business-capability)
+ [Strangler Application](#strangler-application)
+ [ACL - Anti-Corruption Layer](#acl-anticorruption-layer)
+ [API-Gateway](#apigateway)
+ [BFF - Backend For Frontend](#bff-backend-for-frontend)
+ [Relatórios e Consolidação de Informações](#relatórios-e-consolidação-de-informações)
+ [Transactional Outbox](#transactional-outbox)
+ [Secret Manager / Vault](#secret-manager-vault)
+ [Padronização de Logs](#padronização-de-logs)
+ [OTEL - Open Telemetry](#otel-open-telemetry)
+ [Service Template](#service-template)
{%- # TOC end -%}
# Introdução
Talvez você já ouviu falar de microsserviços em algum lugar e ainda não sabe exatamente o que é, ou talvez queira apenas relembrar as principais características da arquitetura e implementação. Este artigo é para você!
Primeiro de tudo, o que são? Como já diz o próprio nome, é um serviço ‘micro’, mas vai muito além disso. Um microsserviço (MS) é uma aplicação como outra qualquer, em qualquer linguagem, porém possui um escopo e responsabilidade delineada, fazendo parte de um ecossistema maior. Quando não faz parte, é possível que seja apenas um monolito pequeno.
Mas e um monolito, o que é exatamente? 🤔
Para tudo ficar mais claro, podemos diferenciar um monolito de um microsserviço de forma simples:
<u>Monolito:</u>
- Serviço que engloba todo um ecossistema, todos (ou quase todos) os domínios da aplicação
- Atualizações podem impactar diferentes domínios ao mesmo tempo
- Geralmente feito todo em uma mesma linguagem
- Mais difícil de escalar e separar times
<u>Microsserviço:</u>
- Serviço que representa um domínio específico da aplicação, e que faz parte de um ecossistema maior
- São serviços independentes, logo possuem deploy independente, banco de dados independente, e apresentam menos riscos de impactar todo o sistema caso haja algum tipo de problema
- Podem ser realizados cada um em uma tecnologia diferente, para obtenção de performance por exemplo
- São mais facilmente divididos entre times
Tudo bem, mas então porque vou querer utilizar monolitos? Bom, como em nossa área sabemos que não existe bala de prata, podemos entender algumas situações já conhecidas em que trabalhar com um ou outro traz maiores vantagens. Então se liga nesses 2 próximos parágrafos:
---
Começando pelos **<u>monolitos</u>**, geralmente são muito vantajosos quando vamos iniciar uma nova ideia de um projeto. Nesses casos raramente temos de cara todo o conhecimento dos domínios e escopos, sem falar nas possíveis mudanças de mercado e de clientes, que impactam diretamente neste delineamento de responsabilidades. Por isso são também são muito vantajosos para POCs (provas de conceito).
Outro ponto é quando queremos uma governança simplificada: é muito mais simples se trabalhar com apenas uma tecnologia, contratar novos profissionais e introduzi-los ao projeto, principalmente devs mais iniciantes, que não conhecem muitas linguagens, comunicação assíncrona, etc.
Além disso, temos um shared kernel, ou seja, um compartilhamento claro de libs dentro do mesmo codebase. Usando MS geralmente vamos ter um repo separado para bibliotecas, porém manter a compatibilidade de versões será muito mais complicado.
Já engatando para os **<u>microsserviços</u>**, começam a ser vantajosos quando temos contextos e áreas de negócio bem definidas em nossa aplicação. Se queremos escalar/separar melhor times, trabalhar com alguma tech específica para obter performance, e temos maturidade nos processos de entrega (time de plataformas, templates para criação de novos repos do zero, maturidade técnica dos times, etc.) são bons indícios para começarmos a trabalhar com MS.
Além disso, se queremos escalar apenas uma parte de nosso sistema, nada impede que comecemos extraindo apenas esta parte que já está mais madura para funcionar como um serviço separado.
---
Podemos concluir aqui que nem um nem outro é o certo, depende da situação, se ligou?

Porém, também é importante salientar que o processo de migração de monolito para arquitetura de microsserviços não é algo simples, e temos que nos atentar em diversos pontos deste processo. Alguns deles listei abaixo e você pode usar como um checkbox caso precise:
- Separar bem os domínios/contextos da aplicação - Domain Driven Design
- Evitar excesso de granularidade - “nanosserviços”
- Verificar dependências - um MS não pode depender de outro, um “monolito distribuído” é o pior dos casos
- Planejar processo de migração de banco - para simplificar, podemos começar criando o MS utilizando um mesmo banco, e posteriormente migrar o banco - aqui não podemos ter medo extremo de duplicação de dados
- Começar a pensar em comunicação assíncrona - arquitetura baseada em eventos (Event Driven Design)
- Lembrar que com MS teremos consistência eventual dos dados
- Precisamos de maturidade para trabalhar com CI/CD, testes,rate limiting, autenticação, etc.
- Começar pelas beiradas é uma boa opção - “Strangler Pattern” - ir quebrando as partes periféricas do serviço principal em MS, até chegar nas partes principais
Ainda vamos expandir melhor alguns desses pontos nos próximos tópicos, então fica tranquilo. 😉
# Características por Martin Fowler
Agora vamos mapear bem resumidamente as principais características de um Microsserviço de acordo com o seguinte artigo https://martinfowler.com/articles/microservices.html escrito por Martin Fowler:
### Componentização via serviços
Microsserviços são serviços “out of process”, diferentemente de bibliotecas que são componentes “in memory”. Sendo assim, são separados do processo principal da aplicação que está rodando, e independentemente “deployaveis”.
### Organização através de áreas de negócio
Em microsserviços, estamos pensando menos em divisões de funções da empresa, e mais nas divisões de áreas de negócio da empresa.
### Produtos e não Projetos
Um projeto tem início, meio e fim. A ideia aqui é tratar o software como produto e ter um time “owner” que irá mantê-lo.
### Smart endpoints e Dump Pipes
Os canais para comunicação com os MS não devem ter regras - devem sair de um jeito e chegar do mesmo jeito (o “pipe” deve ser “dumb”). Caso contrário, estaremos gerando um acoplamento de nossa aplicação.
### Governança descentralizada
Eventualmente precisaremos de soluções diferentes para resolver certos problemas - os MS resolvem este problema de padronização. Uma vez que poderemos ter tecnologias diferentes, temos que ter uma comunicação que funcione bem (“Consumer Driven Contract”), sempre com um contrato muito claro e pré-definido.
### Gerenciamento descentralizado de dados
Em MS, teremos vários bancos separados e autônomos - não garantiremos a consistência das informações 100% do tempo, ou seja, teremos duplicações e delays nas sincronizações.
### Automação de infraestrutura
Em monolitos, temos uma esteira de CI, testes, segurança, deploy, etc., mas em MS, precisamos de vários. Sendo assim, vem a tona a necessidade de uma automação de infra, time de plataformas, criação de templates, para facilitar este processo. Além disso, se não temos uma automação, a falta de padronização entre os MS tornará as manutenções mais complicadas.
### Desenhado para falhar
Desde o dia zero, precisamos pensar em Resiliência, que será o próximo tópico deste artigo.
### Design Evolutivo
Precisamos criar aplicações independentes e possíveis de substituição. Se precisamos de mais de um MS para substituir uma feature, é sinal que existe uma dependência entre eles e talvez possam ser agrupados em apenas um.
---
Acho que de características estamos bem acertados né? Caso tenha alguma dúvida em relação a algum dos tópicos, fica a sugestão para fazer a leitura completa do artigo linkado acima.

# Resiliência
Continuando, uma das questões cruciais quando falamos de microsserviços é a Resiliência. Mas o que é isso?
Bom, em nosso meio, pode ser entendida como um conjunto de estratégias adotadas intencionalmente para a adaptação de um sistema quando uma falha ocorre.
Em algum momento todo sistema irá falhar, e precisamos estar preparados a isso. Nessa vertente, é muito melhor que as estratégias sejam mais “consistentes” do que “perfeitas”.
Como exemplo, é melhor que respondamos a uma requisição em 500 ms sempre, não importando se recebemos 1 ou 1 milhão de requisições. Caso a resposta ultrapasse seu tempo, precisaríamos começar a barrar requisições. Em MS muitas vezes é pior um sistema lento que um fora do ar, pois essa lentidão inesperada pode causar um efeito dominó em todos os outros sistemas envolvidos.
De forma geral, podemos listar alguns mecanismos de resiliência mais conhecidos:
- **Health checks:** observar os sinais vitais do sistema como garantia de sua saúde. Podemos realizar de forma ativa, a partir do próprio serviço, ou passiva, com a verificação a partir de um consumer por exemplo;
- **Rate limiting:** limitar as requisições de um sistema para não afetar sua qualidade. Aqui, temos que nos basear no cliente estratégico que irá utilizar nosso sistema e em suas demandas;
- **Circuit Breaker:** ter uma forma de impedir novas requisições de forma simples pode se demonstrar crucial para proteger o sistema;
- **Comunicação assíncrona:** conseguimos evitar a perda de dados e falhas em cadeia caso algum sistema saia do ar, por exemplo implementando um padrão outbox com registros temporários. Exemplos de serviços de mensageria: Kafka, SQS, etc;
- **Retry:** aqui podemos falar sobre backoff exponencial e com Jitter. Recomendo assistir o seguinte vídeo: https://www.youtube.com/watch?v=1MkPpKPyBps
- **Observabilidade:** APM, tracing, métricas personalizadas, OpenTelemetry;
- **Autenticação:** acho que é claro para todos a necessidade de autenticar as requisições de um sistema.
Inclusive, mesmo trabalhando-se com comunicação assíncrona, ainda temos que pensar nas possibilidades de nosso sistema de mensageria não funcionar. E aí? Neste caso como podemos garantir alguma resiliência?
Poderíamos pensar em trabalhar por exemplo com o Padrão Outbox, criando tabelas com registros temporários no banco. Mas, além disso, temos que nos preocupar também com garantias de entrega e recebimento, idempotência, políticas de fallback, e em documentar todos estes pontos de nosso sistema.
Acho que até aqui ficou bem claro que depender de implementações do zero a todo momento em que vamos criar um novo microsserviço acaba se tornando inviável e muito trabalhoso. Por isso, hoje em dia são muito utilizadas ferramentas como API Gateway e Service Mesh para abstrair essas implementações de resiliência e facilitarmos o processo de comunicação e entrega.
Porém, não é do dia para noite que conseguiremos cobrir todos esses pontos, é sempre um processo de amadurecimento - precisamos mapeá-los e ir atacando-os a um a partir de nossas prioridades.
# Coreografia vs Orquestração
Basicamente existem duas formas de comunicação entre MS - coreografia e orquestração.
Em uma coreografia, as comunicações são mais descentralizadas, acontecendo de forma mais independente. Na orquestração, temos um “maestro”, um serviço que irá coordenar como a orquestra irá fluir.
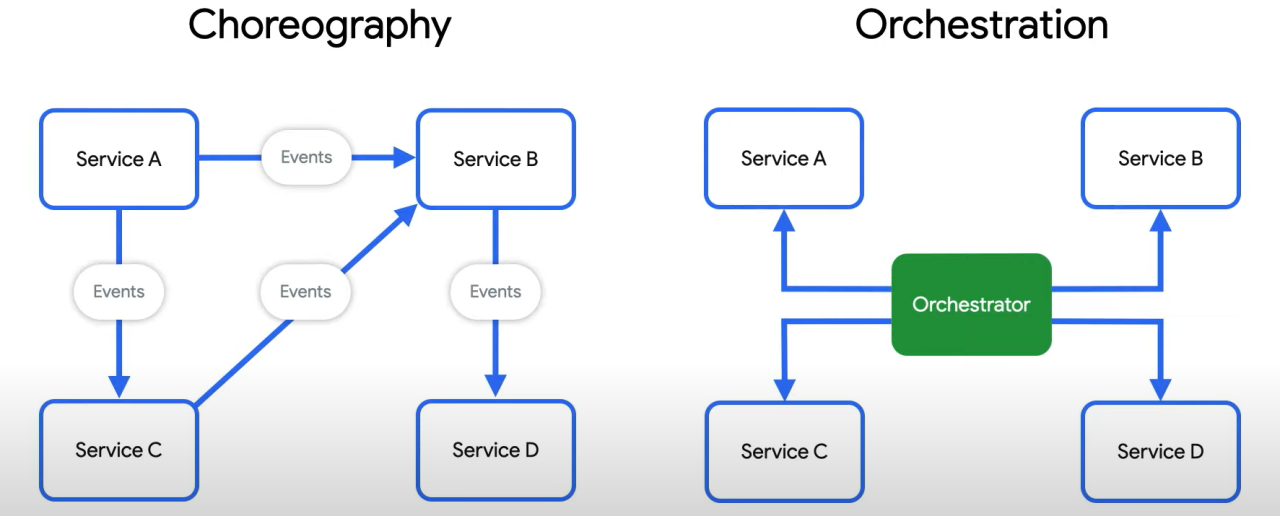
Então vamos diferenciá-los:
**<u>Coreografia:</u>**
- Comunicação decentralizada, baseada em eventos;
- Serviços mais independentes entre si, mais facilmente substituíveis, tornando o sistema mais escalável.
Em contrapartida, apresentam maior complexidade de manutenção, monitoramento e solução de problemas.
Podemos listar alguns casos em que se é bom trabalhar com Coreografia:
- Quando todo processo pode se basear no input inicial sem precisar de mais contexto (passos condicionais intermediários);
- Quando temos um fluxo com uma direção clara e única.
<u>**Orquestração:**</u>
- Comunicação mais centralizada, baseada em comandos;
- Orquestrador dita a sequência de comunicações que os MS devem seguir, também definindo políticas de fallback;
- Mais simples de monitorar e solucionar problemas, pois sabemos onde olhar quando algo da errado.
Em contrapartida, gera acoplamento entre os serviços, dificultando adicionar, remover ou substituí-los. A falha de um pode ser a falha de outros.
Podemos listar alguns casos em que se é bom trabalhar com Orquestração:
- Quando temos passos condicionais que trigarão fluxos diferentes, como por exemplo confirmação de pagamento de cartão de crédito;
- Quando precisamos centralizar o monitoramento do fluxo.
---
E novamente voltamos ao mesmo ditado: não existe bala de prata. Dependendo do caso, um ou outro pode ter seus benefícios, o importante aqui é implementar alguma estratégia de comunicação. Caso contrário, podemos gerar um Anti-Pattern conhecido, a "Estrela da Morte", quando as comunicações ficam tão descentralizadas e interdependentes que podemos perder o controle da comunicação da rede.

Em outras palavras, se sua empresa está implementando MS sem parar, e mais importante, sem um componente de mediação na arquitetura, é apenas uma questão de tempo até a "Estrela da Morte" aparecer pra você.
Sendo assim, já podemos pensar aqui em estratégias de mitigação - Resiliência - para evitar que isso aconteça. Por exemplo, a utilização de API Gateways como intermediários para comunicação entre os MS é uma maneira eficiente para conseguirmos manter um controle maior das chamadas, pois elas passarão a acontecer entre contextos, e MS de contextos diferentes não terão ideia de qual MS estará se comunicando do outro lado.
Inclusive, assim como já dito anteriormente, poderemos mais facilmente definir rate limiting, circuit breakers, autenticação, e outros mecanismos de resiliência diretamente em nosso API Gateway.
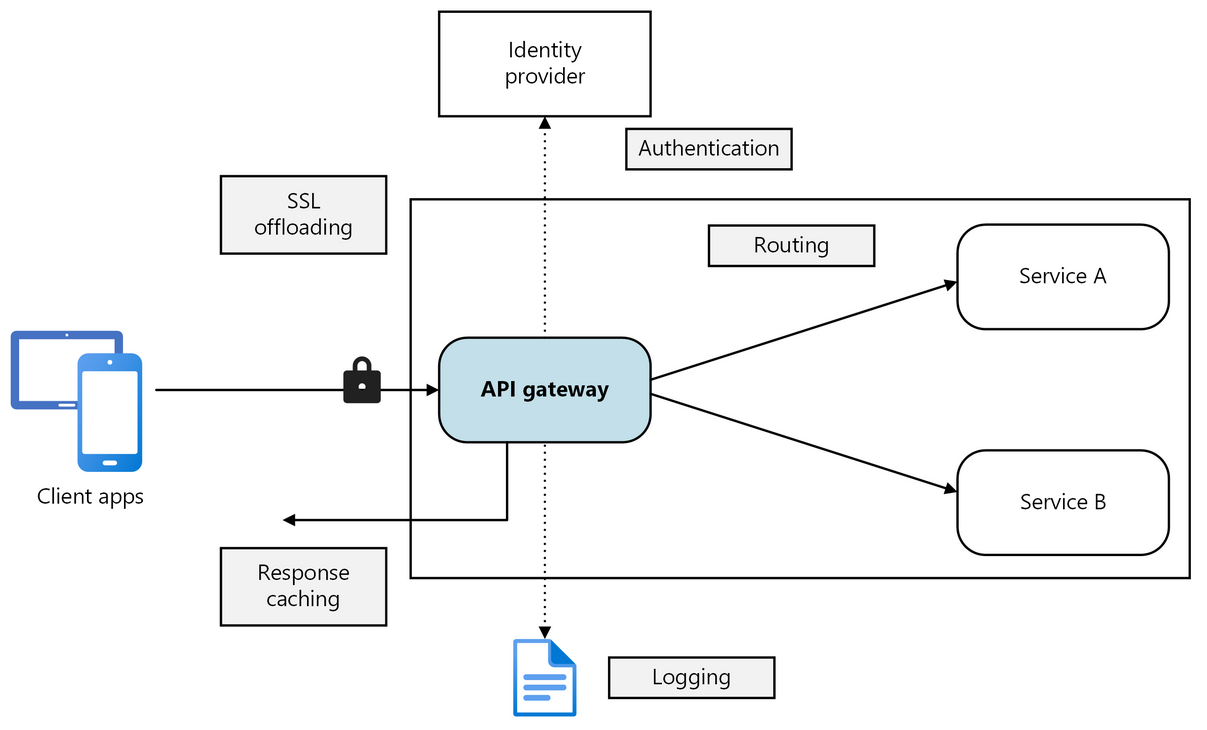
E, assim como em nossas aplicações, podemos seguir práticas de DDD e dividir nossos Gateways de acordo com os Bounded Contexts, aumentando ainda mais o controle sobre nosso sistema. Mas falaremos um pouco mais sobre isso já já.
# Patterns
Categorizações finalizadas, agora podemos focar um pouco em alguns padrões comumente usados nos dias de hoje numa arquitetura de microsserviços.
### API-Composition
Pense no caso: quero gerar um relatório, mas metade dos dados está em um microsserviço e metade em outro, o que fazer? Neste caso podemos utilizar criar um Service Composer para fazer chamadas a esses MS e realizar a composição e transformação dos dados de acordo com as regras de negócio.
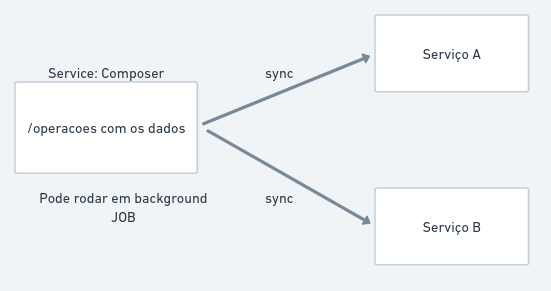
### Decompose By Business Capability
Supondo que queremos decompor um monolito em n microsserviços por x razões, como começar este processo? Bom, uma ideia inicial é buscar decompor nosso sistema por áreas de negócio (Bounded Contexts). Utilizar o DDD para visualizar nossa aplicação e separá-la em domínios, subdomínios, subcontextos, etc. Porém, ainda sim não é uma tarefa simples - existem muitas áreas cinzentas de intersecção.
Para facilitar o processo, podemos utilizar uma ferramenta do DDD: Context Mapping. Caso queria ler mais sobre, recomendo este link: https://www.infoq.com/articles/ddd-contextmapping/
### Strangler Application
Ainda falando em decomposição, podemos nos utilizar do "Strangler Pattern" para começar a trabalhar com MS, basicamente seguindo duas regras:
1. Toda nova feature será transformada em um MS
2. Pegar pequenos pedaços do monolito e transformar em MS
Porém, esta quebra vai sendo feita aos poucos - o monolito continua existindo e vai reduzindo cada vez mais, até que se torne apenas mais um pedaço da aplicação. Além disso, temos que lembrar dos pontos de atenção mencionados no início deste artigo para realizar esta migração.
### API-Gateway
Como já dito anteriormente, o API Gateway irá redirecionar as requisições aos serviços, funcionando como uma porta de entrada única e fornecendo soluções para rate limiting, transformações nas mensagens, autenticação, health checks, etc. Também podemos trabalhar com API Gateways divididos por áreas de neǵocio, melhorando ainda mais o controle de nosso sistema.
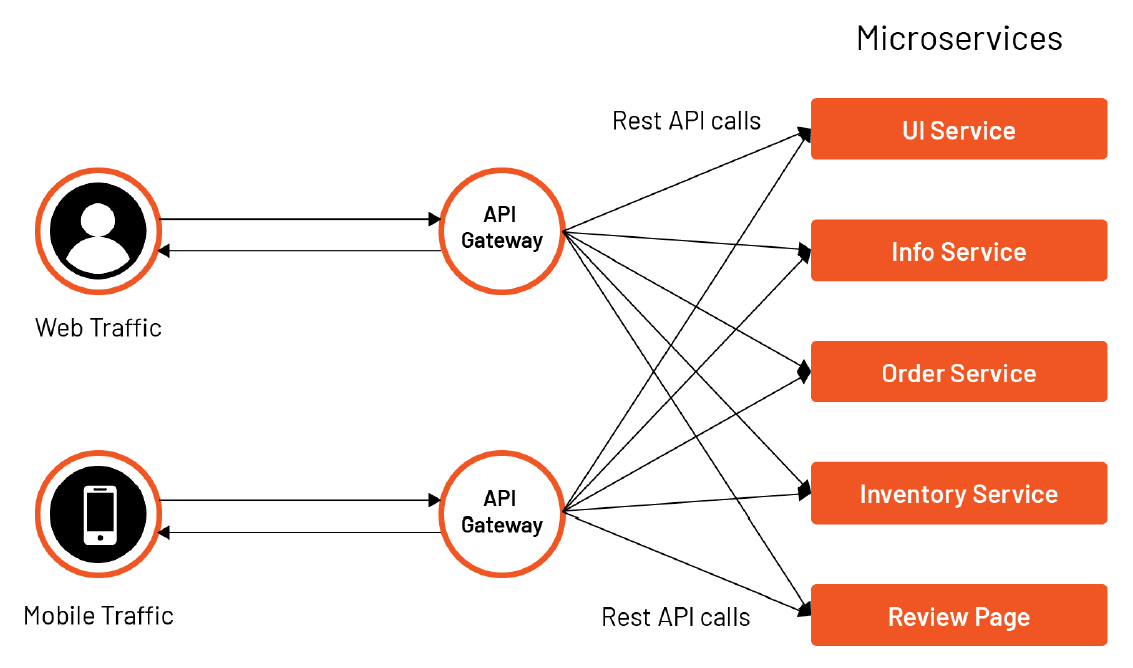
### ACL - Anti-Corruption Layer
Podemos inclusive criar um novo serviço para servir como um “proxy” - por exemplo, criar uma interface de pagamentos que irá abstrair qual gateway de pagamento será chamado, de forma a não impactar diretamente o MS consumidor em caso de mudanças. Além disso, mais que um proxy, este ACL pode também encapsular regras de negócio, como por exemplo, fazendo a escolha de um gateway de pagamento de cartão de crédito de acordo com a bandeira escolhida.
O objetivo aqui é impedir a necessidade (ou intrusão) de um domínio conhecer os detalhes do outro.

### BFF - Backend For Frontend
Temos que levar em consideração que, dependendo do cliente, precisaremos de retornos de API diferentes de acordo com cada demanda. Nessa linha, podemos implementar BFFs, que segregam nossos backends por tipo de cliente, retornando apenas as infos que aquele cliente em específico irá utilizar.
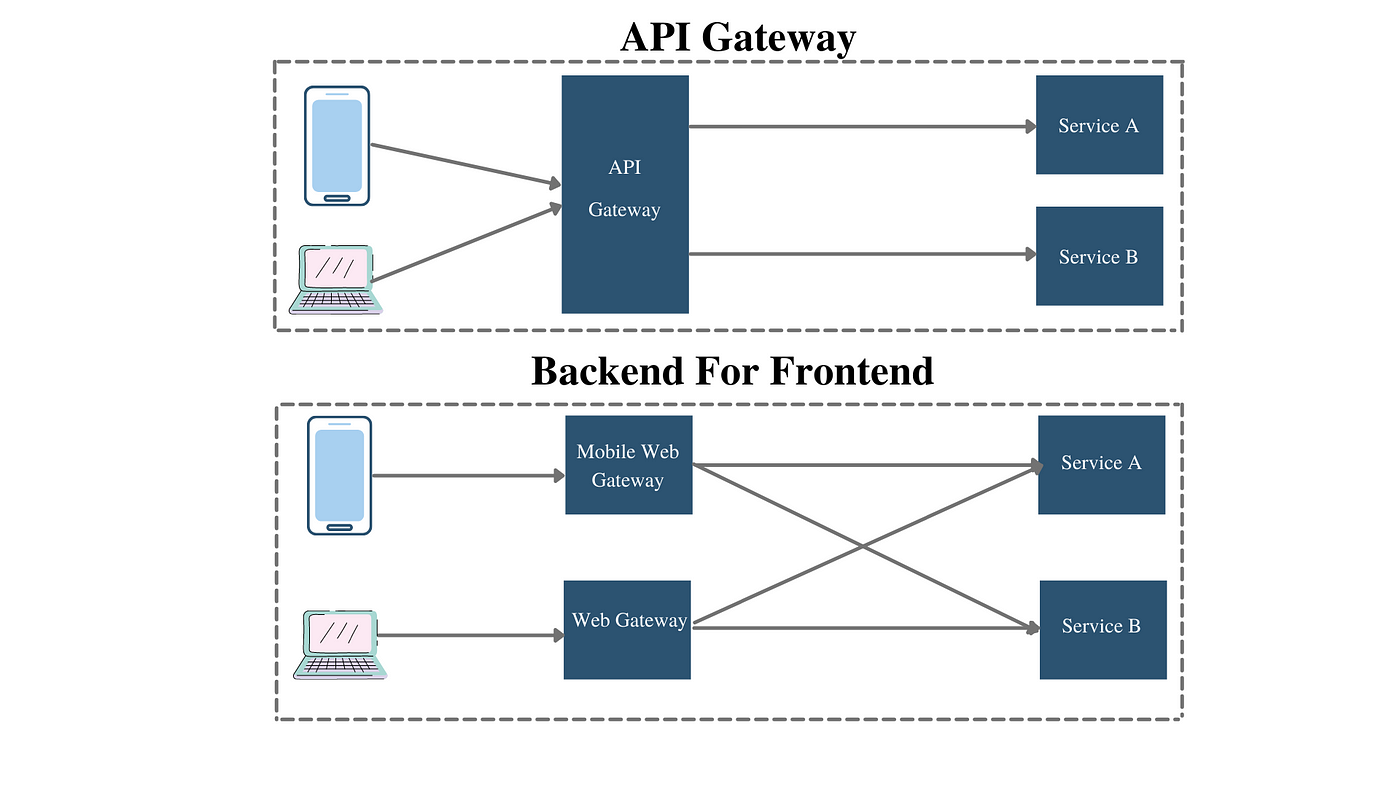
Podemos, alternativamente, utilizar GraphQL como uma maneira de substituir o uso de BFFs, garantindo ao client o poder de escolha dos dados a serem retornados.
### Relatórios e Consolidação de Informações
Quando vamos trabalhar com microsserviços, muitas vezes queremos obter dados espalhados por diversos bancos para retornar em uma requisição, como por exemplo na geração de um relatório de extrato bancário. Nesta linha, é importante também falar sobre **tabelas de projeção**.
Exemplo: quero gerar o relatório X, obtendo nome, email e telefone contidos no MS 1, o saldo do MS 2, e empréstimos realizados do MS 3. Com isso, posso pensar na criação de uma tabela no banco de um outro MS 4 exatamente com esta estrutura:

Agora, posso fazer cada MS se comunicar e atualizar continuamente os registros dessa tabela quando sofrerem modificações:
- Cada vez que o dado de um MS mudar, ele mesmo atualiza no seu banco e na tabela do banco do MS 4;
- O próprio MS 4 escuta eventos de alteração gerados pelos outros MS em um message broker e então atualiza sua tabela.
Em ambos teremos consistência eventual, que como já dito é algo comum ao se trabalhar numa arquitetura de microsserviços.
### Transactional Outbox
Assim como brevemente comentado anteriormente, podemos ver o "transactional outbox" como um padrão de resiliência. Neste pattern, persistimos temporariamente nossos dados em uma tabela _outbox_ de forma a não perdê-los caso algum sistema saia do ar.
<u>Exemplo:</u> um MS 1 faz uma requisição http a um MS 2, ou mesmo posta eventos em um sistema de mensageria, como o RabbitMQ. Para evitarmos perder esses eventos caso haja algum problema em nosso MS 2 ou no message broker, guardamos os dados na tabela <u>outbox</u>. Após o sucesso do envio, o MS 1 deleta os dados dessa tabela.
Assim, de tempos em tempos o MS 1 ficará lendo a tabela e mandando as transações perdidas novamente para o seu destino. Além disso, é importante que estes dados não se misturem com a base principal e, para evitar isso, podemos por exemplo implementar um sdk interno que trabalhará com retries e guardará os dados na tabela em caso de falha.
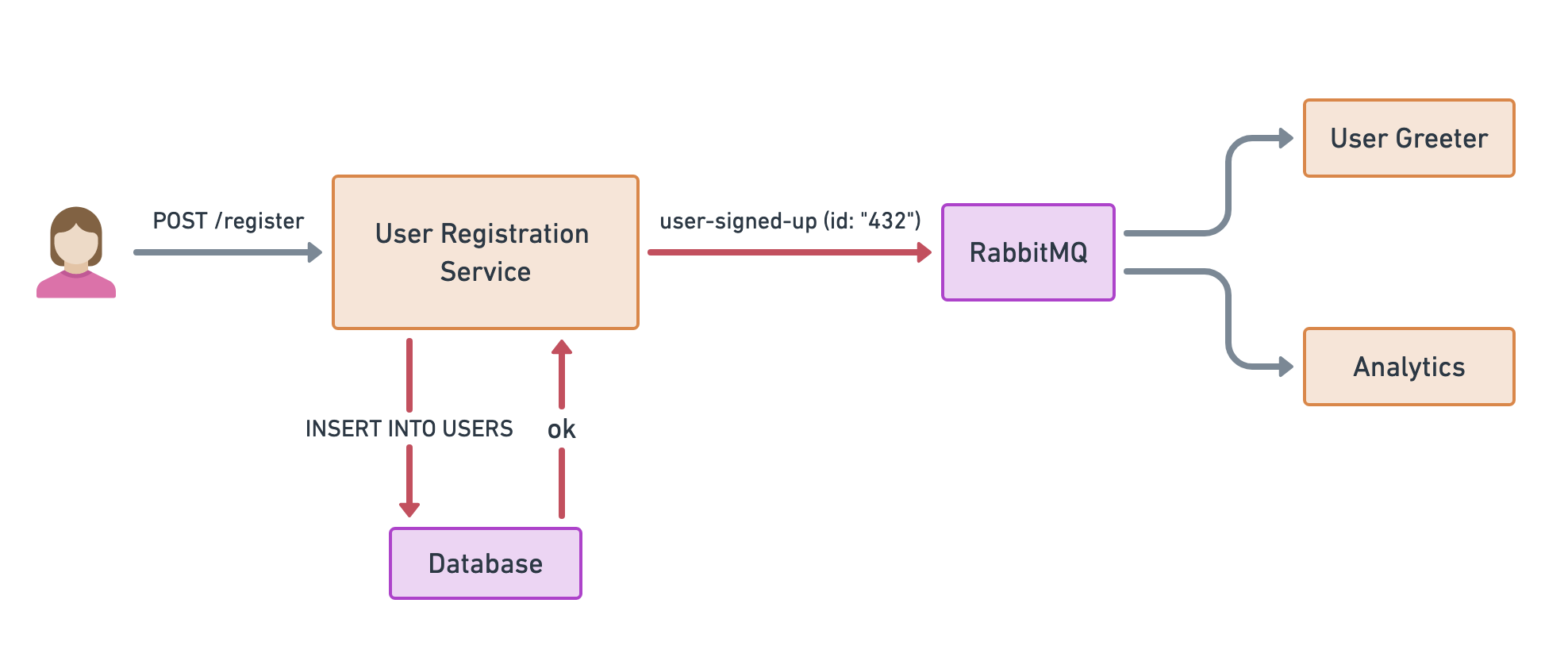
É claro, porém, que para casos que necessitam de uma resposta imediata, não poderemos aplicar este padrão.
### Secret Manager / Vault
Como fazemos para rotacionar diversas credenciais de diversos microsserviços e controlar tudo isso? Aqui podemos trabalhar com o Vault, que nada mais é do que uma solução da Hashicorp que armazena nossas credenciais e facilita este processo. Podemos por exemplo criar webhooks a serem chamados quando o Vault identifica as datas limites que setamos para nossas secrets.
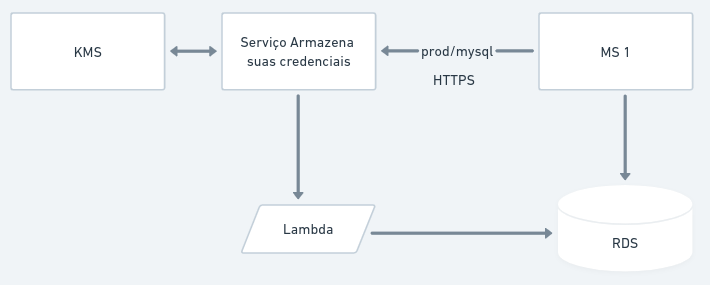
### Padronização de Logs
Em observabilidade, temos 3 vertentes básicas:
- Logs
- Métricas
- Tracing
O log é o resultado de um evento. Se um erro estoura para nosso cliente, podemos ir procurando o log por nossas VMs. Porém, muitas vezes a VM do log pode até já ter sido destruída por conta de mecanismos de autoscaling por exemplo. Para evitar problemas e facilitar a observabilidade, podemos centralizar os logs por exemplo no ElasticSearch.
Além disso, temos que nos preocupar com a padronização: imagine diversos microsserviços, cada um com sua estrutura própria de logs, dificultaria muito fazer buscas né?. Nesse sentido, podemos criar um SDK que realizará uma padronização dos logs dos sistemas de nossa empresa por exemplo.
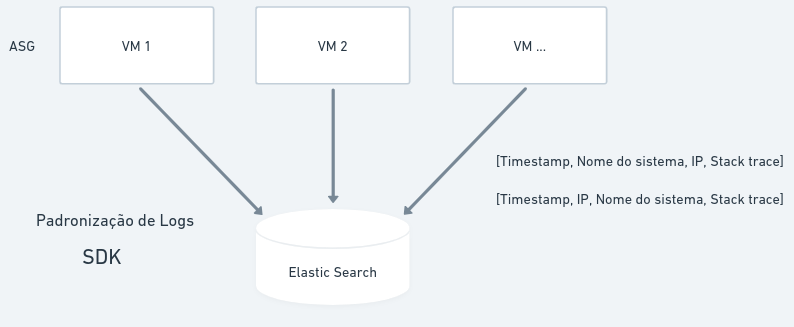
### OTEL - Open Telemetry
Se recebemos um erro 500 em alguma requisição, que por sua vez envolve a comunicação de 3 microsserviços diferentes, como saber onde aconteceu? Aqui entra o conceito de tracing distribuído, que nos dá exatamente essa visibilidade.
Agora, vamos supor que fazemos o tracing utilizando o serviço do New Relic, mas depois queremos mudar para Datadog, depois para o Elastic - isso acaba gerando uma grande esforço "braçal". De forma a não ficarmos presos em nosso ‘vendor’, entra a ferramenta do **OpenTelemetry**, que disponibiliza um ‘collector’ para nossos serviços enviarem os dados, e consegue fazer a distribuição para o serviço especificado.
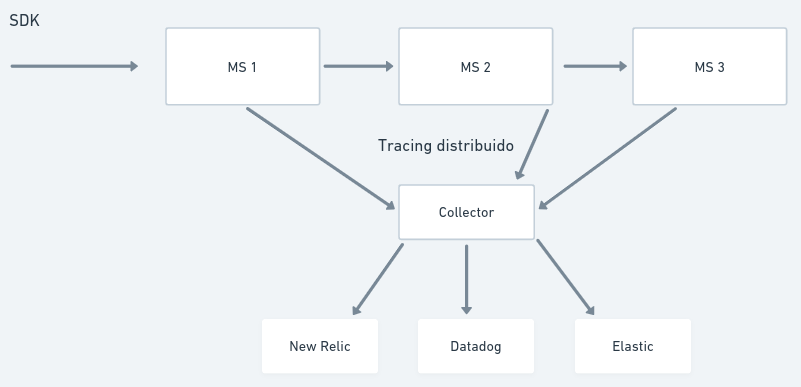
Com isso, temos maior segurança, descentralização e padronização dos dados de observabilidade que uma aplicação gera (logs, métricas e tracing).
### Service Template
Por fim, mas não menos importante, o Service Template, algo que é muito utilizado e continuará sendo. Basicamente, é um modelo definido por nossa empresa com padrões de implementação para logs, outbox, passwords, comunicação com sistemas de mensageria, observabilidade, CQRS, múltiplos bancos, auditoria, jobs, etc. - em outras palavras, um “kit de desenvolvimento”.
Porém, para se ter algo assim, é muito imporante também um time de plataforma e sustenção para auxiliar na manutenção e aplicação destes padrões, ou seja, torna-se necessário uma certa maturação da empresa em si.
Em uma arquitetura de microsserviços, caso não tenhamos um service template, os devs irão demorar muito mais para criar novos serviços, pois sempre terão que configurar tudo do zero.
---
Bom, acredito que com todos estes tópicos em mente já consiga ter um bom ponto de partida para decidir os melhores padrões para seu sistema ou ao menos para ter uma visão geral do que estudar em seguida.
Obrigado pela leitura!

| pmafra |
1,863,386 | Installing a WebServer on Win Server 2019 VM | First and foremost, what is a web server? Imagine you have a toy box at home where you keep all your... | 0 | 2024-05-24T03:43:56 | https://dev.to/olawaleoloye/installing-a-webserver-on-win-11-vm-23e4 | webserver, virtualmachine, windows | **First and foremost, what is a _web server_**?
Imagine you have a toy box at home where you keep all your favourite toys. Now, let’s say your friend wants to see what toys you have. Instead of coming to your house, they can use a special magic box that lets them see and even play with your toys from their own home. This magic box is connected to your toy box and shows your toys to your friend whenever they ask.

A web server is like that magic box. It keeps a lot of information (like your toys) and when someone on the internet wants to see that information (like your friend), the web server shows it to them. So, it's a special computer that helps share information with other computers.
A **web server** is _a specialized software or hardware system responsible for handling HTTP(S) (Hypertext Transfer Protocol) requests from clients, typically web browsers, and serving them the appropriate web content, such as HTML pages, images, videos, or other resources_. The primary functions of a web server include:
1. **Hosting Websites**: Web servers store, process, and deliver web pages to users. They manage domain names, manage content, and ensure that web pages are available to users around the clock.
2. **Handling Requests and Responses**: When a user enters a URL in their browser, the web server processes the incoming HTTP request, retrieves the requested content, and sends it back to the client as an HTTP response.
3. **Security**: Web servers implement various security protocols, such as SSL/TLS, to encrypt data transmitted between the server and clients. They also handle authentication and authorization to protect sensitive data and resources.
4. **Load Balancing and Scalability**: Web servers can distribute incoming traffic across multiple servers to ensure efficient resource utilization, high availability, and reliability. They support scalability by adding or removing servers as demand fluctuates.
5. **Logging and Monitoring**: Web servers maintain logs of all transactions, which are crucial for analyzing traffic, debugging issues, and monitoring performance.
Popular web server software includes Apache HTTP Server, Nginx, Microsoft Internet Information Services (IIS), and LiteSpeed. Each of these solutions offers unique features and optimizations to cater to different performance, security, and scalability requirements.
In a previous [post](https://dev.to/olawaleoloye/a-guide-to-deploying-windows-11-using-azure-resources-3ao9), we deployed a Win 11 VM. Now, we shall install a webserver on a similar server (Win Server 2019).
**Open PowerShell**
Click on the **Start** menu.

Type **PowerShell** and open **Windows PowerShell** or **Windows PowerShell ISE** as an **_administrator_**(right-click and select Run as administrator)

**Provide your credentials**

**Install IIS by running this command**
```
Install-WindowsFeature -name Web-Server -IncludeManagementTools
```



| olawaleoloye |
1,863,464 | Set Up a Linux VM (Ubuntu), step by step | A Linux machine is like a magic book on your computer that can do lots of cool things. Now, a Linux... | 0 | 2024-05-24T03:42:26 | https://dev.to/olawaleoloye/set-up-a-linux-vm-ubuntu-step-by-step-39jd | linux, ubuntu, azure | _A Linux machine is like a magic book on your computer that can do lots of cool things. Now, a Linux machine is like having a special magic book that's really good at following instructions and can change its story whenever you want._

A **Linux machine** refers to _a computer that is running the Linux operating system._ Linux is an open-source operating system, meaning it's free to use and its source code is available for anyone to view, modify, and distribute. It's known for its stability, security, and flexibility, which is why it's widely used in servers, desktops, and even mobile devices.
Key Points:
1. **Open Source**: Unlike Windows or macOS, Linux is open-source, so anyone can contribute to its development or customize it for their needs.
2. **Distributions**: There are many versions of Linux, called distributions (or distros), such as Ubuntu, Fedora, and Debian. Each distro has its own set of features and tools.
3. **Command Line**: While Linux has graphical user interfaces (GUIs), a lot of powerful features are accessed through the command line.
4. **Security and Stability**: Linux is less prone to viruses and malware, making it a popular choice for servers and security-sensitive applications.
5. **Flexibility**: Linux can run on a wide range of hardware, from old computers to modern servers and smartphones.
For this tut, we shall walk through the installation of Ubuntu on Microsoft Azure Platform.
_Navigate_ to [portal.azure.com](portal.azure.com) and select **Virtual Machine**
_Create_ an **Azure virtual machine**
Provide details of your virtual machine (Resource group, Virtual machine name, Image)
Here we shall be using SSH for **Administrator account**
We have provided Username, and Key pair name
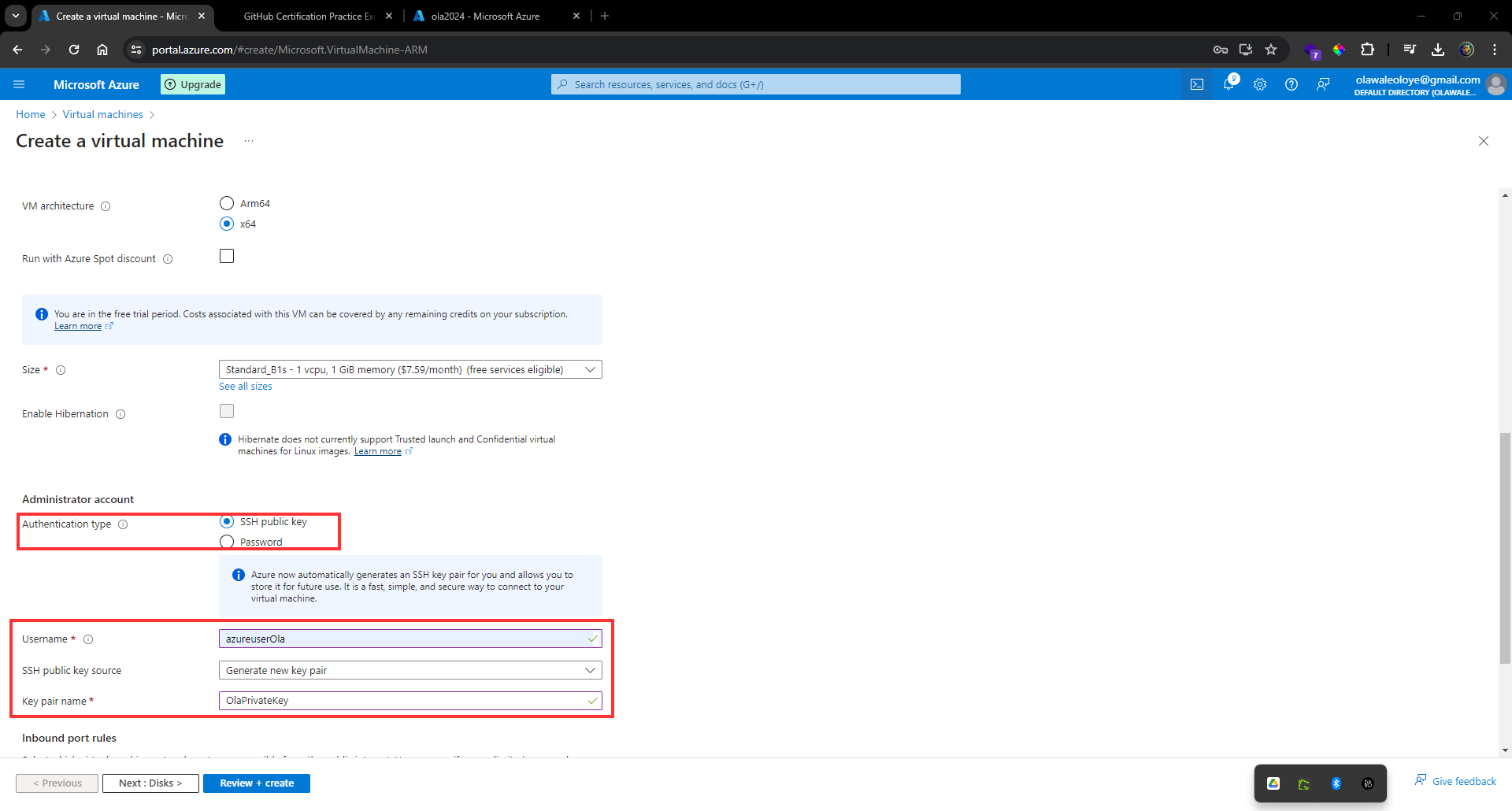
Set _Inbound port_ (**22**)
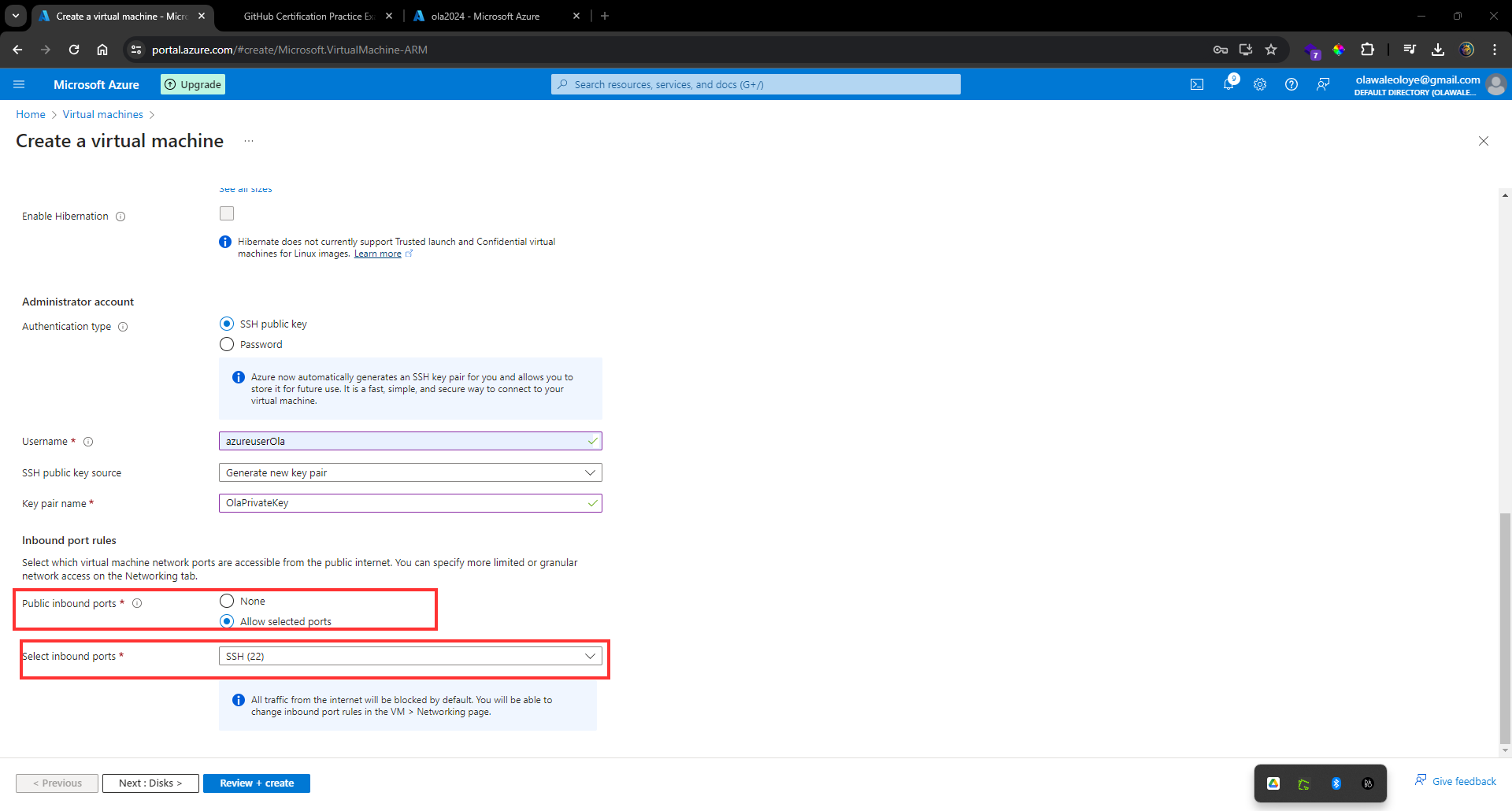
Now to the **Monitoring** tab - _**Disable** boot diagnostic_
Next, the **tags** are set for billing purposes
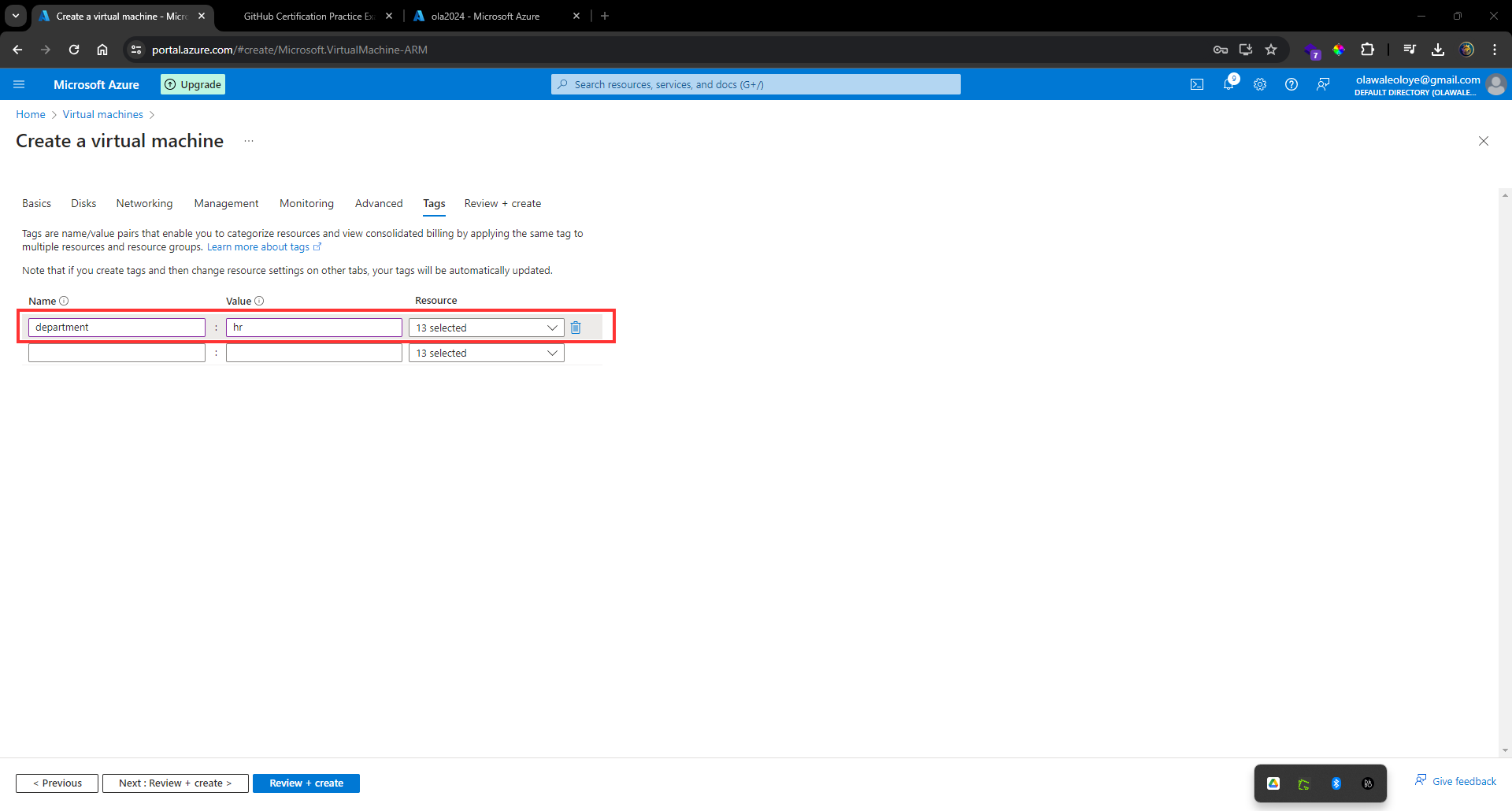
Almost there, go to **Review + create**
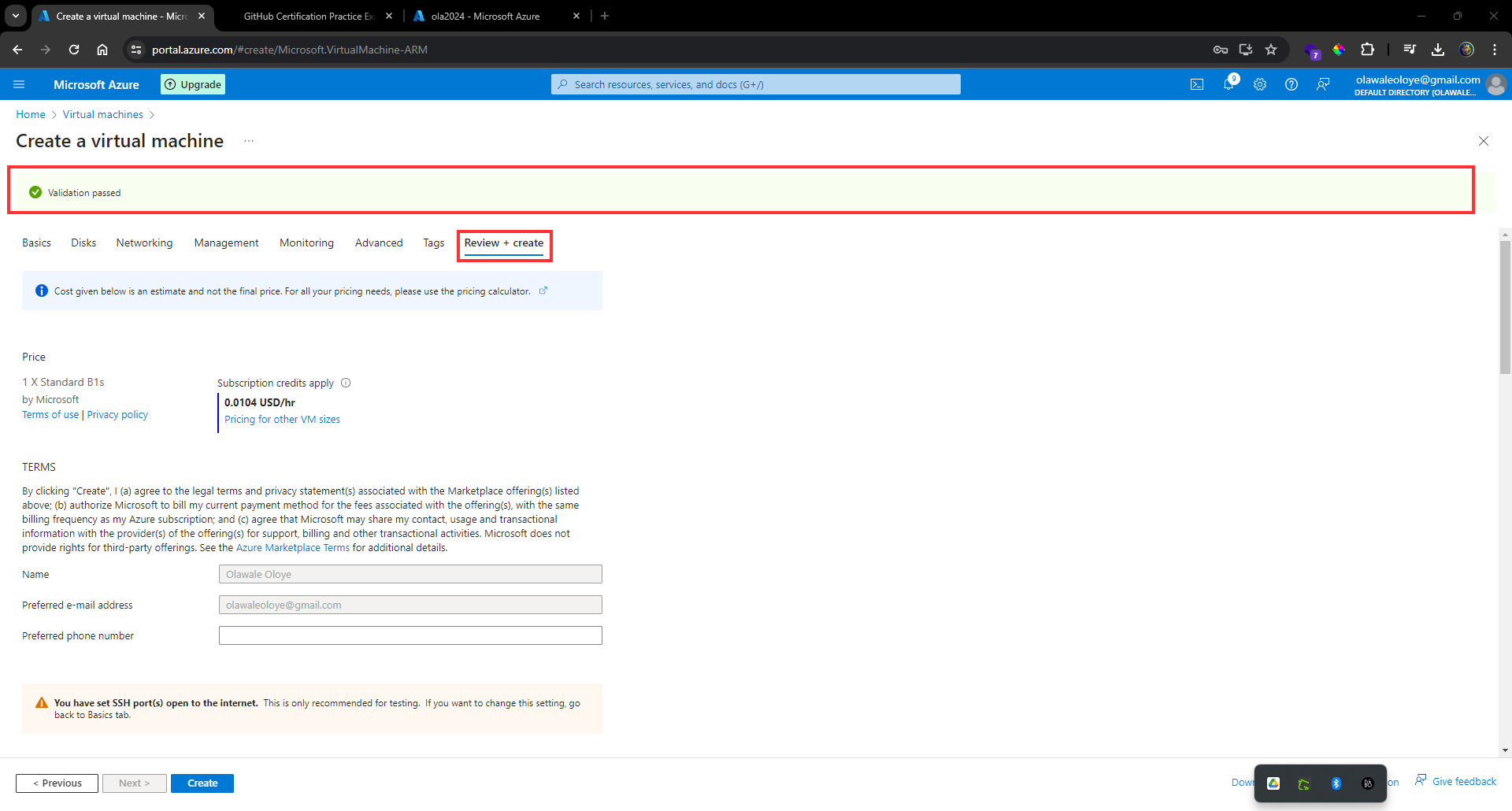
Next, **download private key and create the resource**
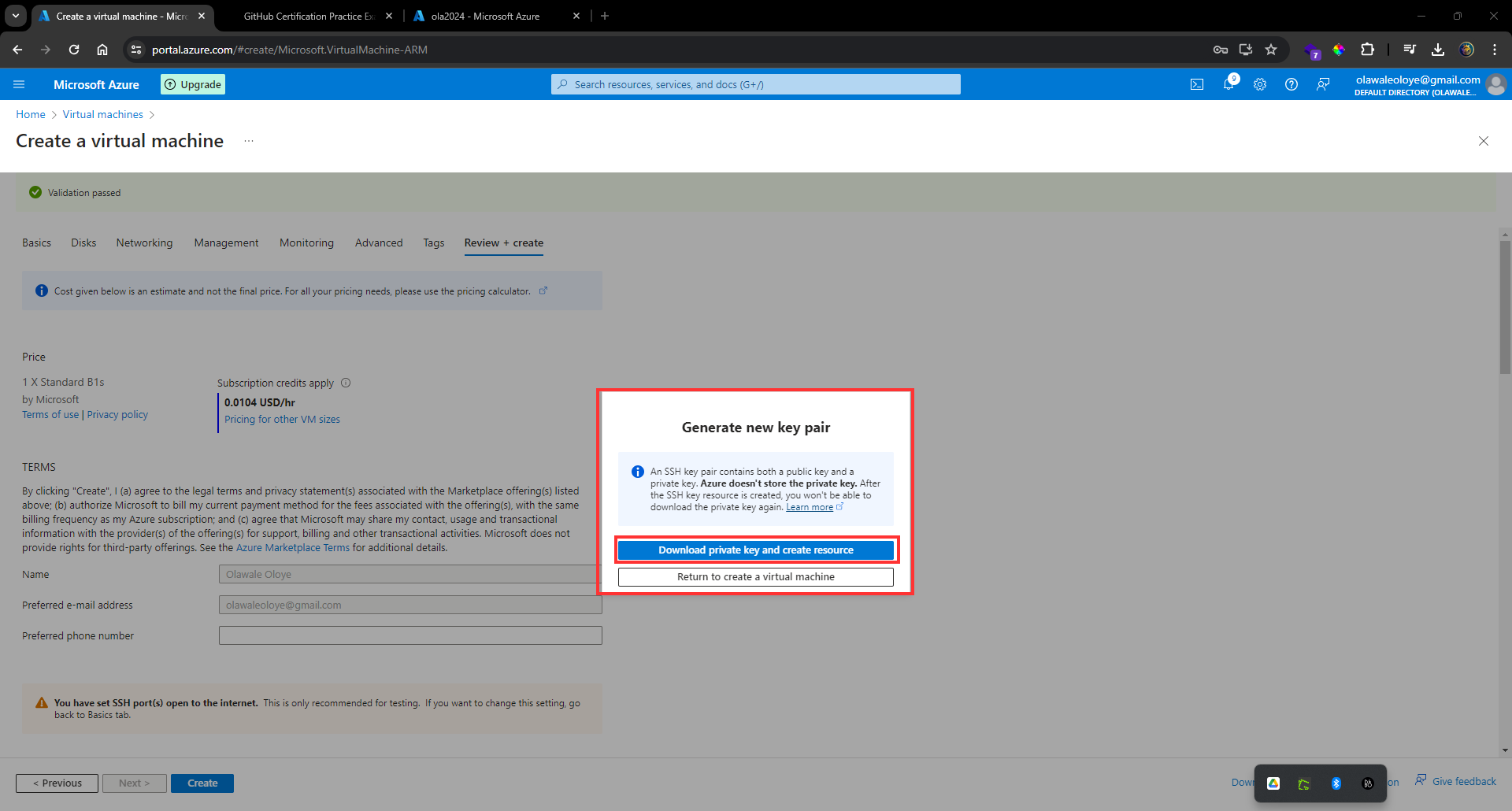
**Allow** for _deployment to be completed_
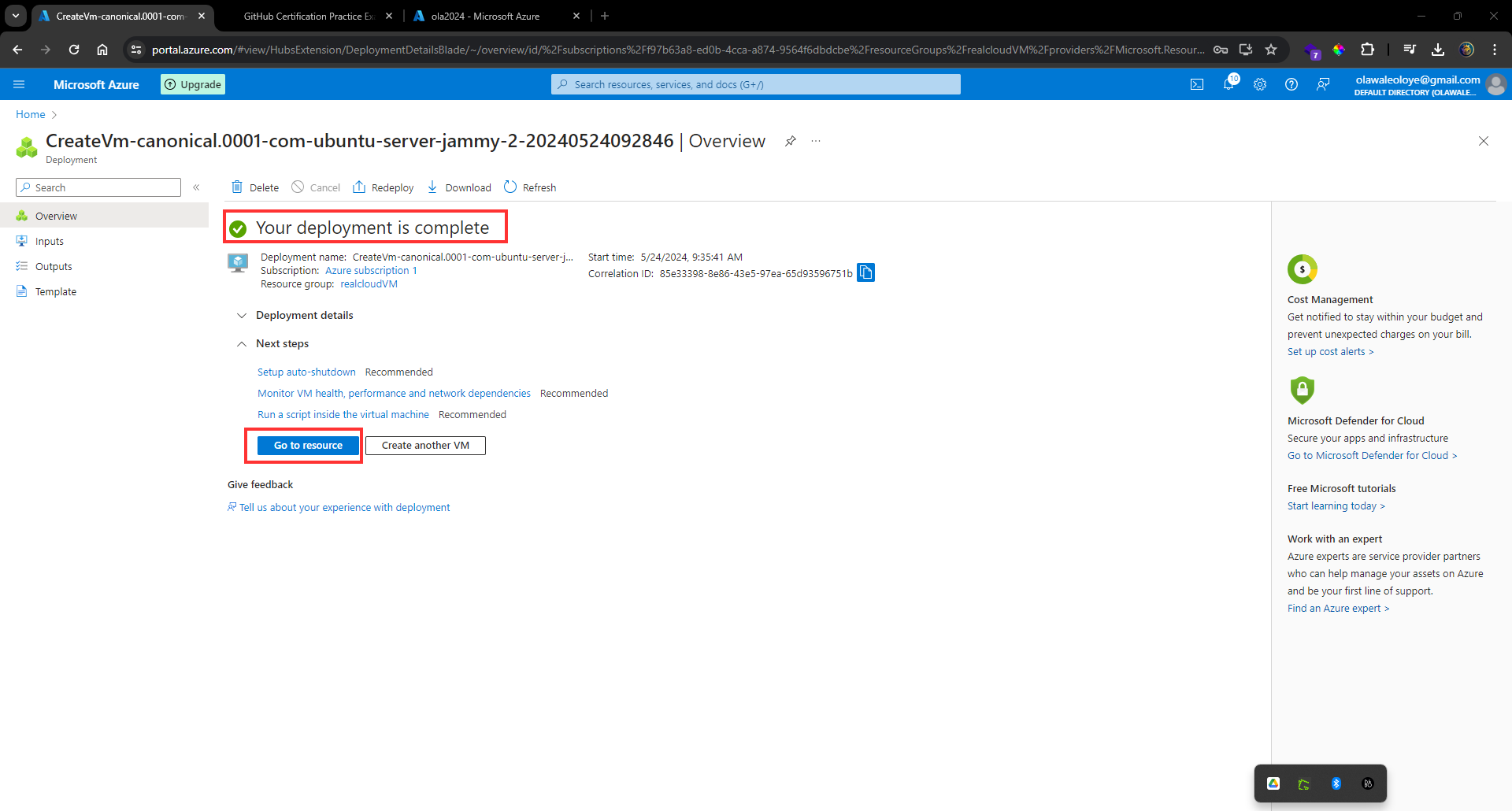
_Select_ your public IP
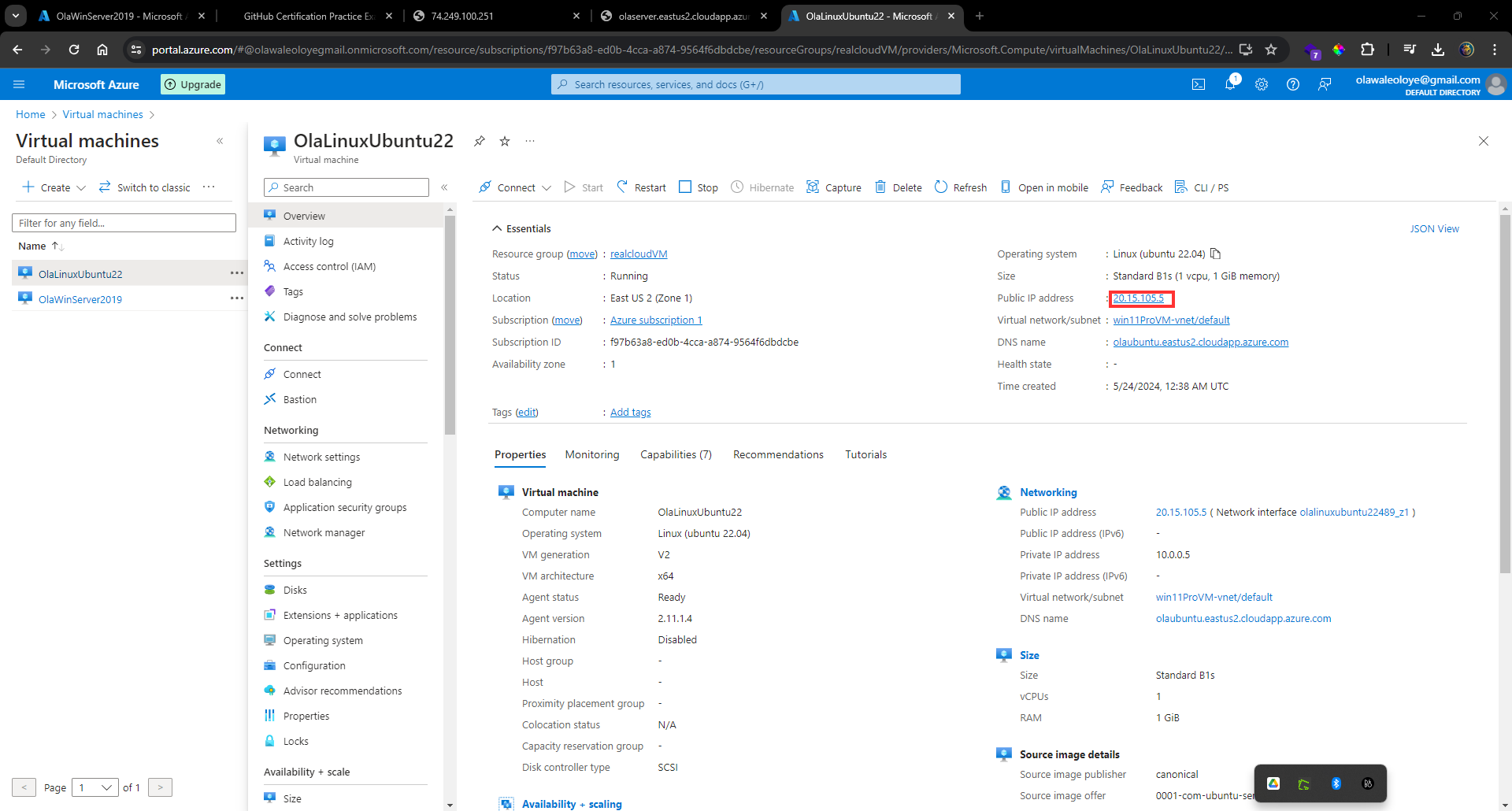
**Modify** _Idle time_ and give _DNS name_ label (optional)
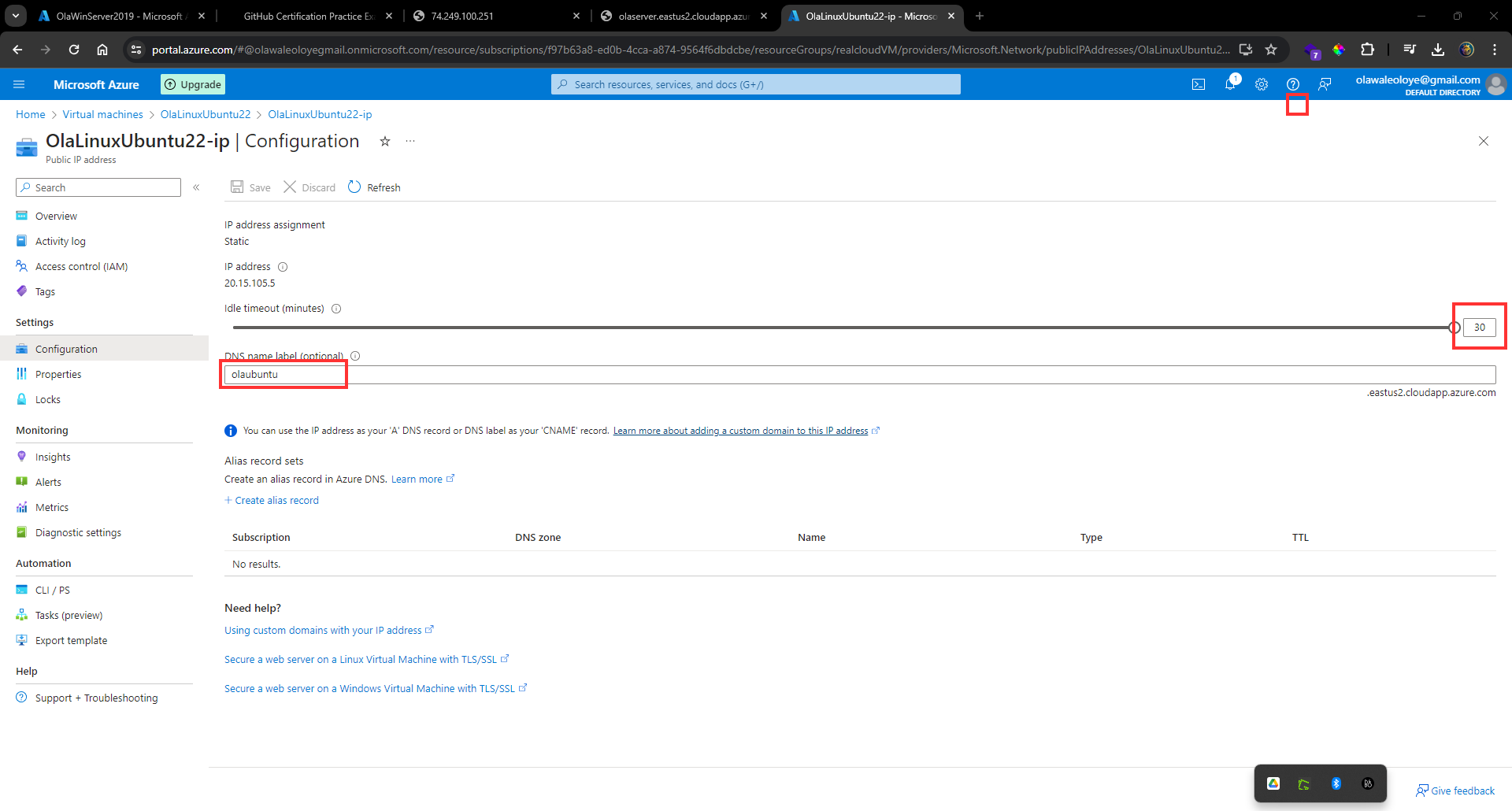
Open windows **cmd**
**SSH** into the machine
```
ssh -i /"path name"/KeyPairName.pem azureuser@20.15.105.5
For example;
_ssh -i /"C:\Users\King Fisher\Downloads"/OlaLinuxUbuntu22.pem azureuser@20.15.105.5_
```
Hurray >> 🍾**Working Ubuntu VM**
| olawaleoloye |
1,863,472 | Installing Nginx on Ubuntu VM | First, change user to root Type the command - apt install nginx -y apt = is the package... | 0 | 2024-05-24T03:41:20 | https://dev.to/olawaleoloye/installing-nginx-on-ubuntu-vm-32gi | nginx, ubuntu, azure | First, **change user** to **root**
Type the command - **_apt install nginx -y_**
> **apt** = is the package manager of nginx
> **install** = this is a verb and the action that you want the package manager to perform
> **nginx** = this is what you want to install on the VM
> **-y** = This is a command that prompts the system to automatically accept anything that requires you to accept a yes or no
**Confirm** _installation_
**Visit** the server / _public IP_ in a browser to validate that it works
| olawaleoloye |
1,863,514 | Unleashing the Potential of Avepower Energy Storage System | Unleashing the Potential of Avepower Energy Storage System Are you tired of losing power during a... | 0 | 2024-05-24T03:40:17 | https://dev.to/davelopezj/unleashing-the-potential-of-avepower-energy-storage-system-2hje | energystores | Unleashing the Potential of Avepower Energy Storage System
Are you tired of losing power during a storm or experiencing energy shortages? Look no further than Avepower System. With advanced technology, high-quality materials, and a focus on safety, Avepower is revolutionizing the energy storage industry.
Benefits of Avepower Energy Space System
The Avepower energy storage systems offers advantages that are many power like traditional
With the ability to keep energy like excess during top hours, it is possible to lessen your reliance regarding the grid and cut costs on electricity invoices
Furthermore, the Avepower system allows for renewable power sources, such as for instance power like solar, to be stored and utilized at another right time, further cutting your carbon footprint
Innovation of Avepower Energy Space System
Avepower is constantly innovating and increasing their technology to provide their customers utilizing the most item like readily useful is achievable
Their power storage system uses lithium-ion battery technology for efficient and energy storage like reliable
Furthermore, their Battery like patented Management ensures that battery pack is definitely running at its degree like optimal its lifespan and minimizing the chance of malfunction
Security of Avepower Energy Storage System
Security is really a concern like premier Avepower
The batteries used in their power storage system are rigorously tested to make compliance like certain security standards
Additionally, the battery pack is housed inside a fire-resistant casing and it is constructed with multiple security features, such as overcharge and security like over-discharge
Simple tips to Utilize Avepower Energy Storage System
Utilizing the Avepower System is intuitive and user-friendly
First, connect the storage space system to your energy supply, such as for instance energy like solar
Then, get the preferred settings for charging and using like discharging control software
The machine will regulate the movement automatically of energy to ensure effectiveness like optimum
Provider and Quality of Avepower Energy Storage System
Avepower is focused on supplying the standard to its clients like highest of service and quality
Their group of experts can be obtained to help with installation and response any questions that are relevant concerns
Additionally, solar energy battery storage their item was made and manufactured with the most useful materials to make certain durability and durability
Applications of Avepower Energy Storage System
The Avepower Energy Storage System is versatile that can be employed in lots of applications that are various
It is perfect for both domestic and commercial use and that may be built-into any energy system like existing
Furthermore, organizations will take advantage of utilizing Avepower's power storage system to reduce power expenses and enhance reliability
In conclusion, the Avepower solar energy storage is a groundbreaking innovation that offers numerous advantages over traditional energy sources. With a focus on safety, innovation, and quality, Avepower is leading the way in the energy storage industry. Whether you're looking to reduce your reliance on the grid, maximize your use of renewable energy, or improve your overall energy efficiency, Avepower can unleash the potential of your energy system.
Source: https://www.avepower.com/application/energy-storage-systems | davelopezj |
1,863,512 | Unveiling the Veil of Satta King 786: A Deep Dive into the World of Online Gambling | Introduction: In the labyrinth of online gambling, the term "Satta King 786" stands as a cryptic... | 0 | 2024-05-24T03:32:04 | https://dev.to/explorebyrsr/unveiling-the-veil-of-satta-king-786-a-deep-dive-into-the-world-of-online-gambling-4o0b | satta, sattaking | Introduction:
In the labyrinth of online gambling, the term "Satta King 786" stands as a cryptic emblem of chance, intrigue, and risk. With its roots deeply embedded in the Indian subcontinent, Satta King 786 has captured the attention of millions, transcending geographical boundaries to become a phenomenon in its own right. However, behind the veil of excitement lies a landscape fraught with controversy, legal ambiguity, and societal concerns. In this comprehensive exploration, we delve into the depths of Satta King 786, examining its origins, mechanics, impact, and the broader implications it Carries.
Origins and Evolution:
The origins of Satta King 786 can be traced back to the Practice of speculative betting, known as "Satta," which has been prevalent in India for decades. Historically, Satta Involved placing bets on the opening and closing rates of cotton transmitted from the New York Cotton Exchange to the Bombay Cotton Exchange. Over time, this practice morphed into a more expansive form of gambling, encompassing various markets and outcomes.
The emergence of the internet in the late 20th century ushered in a new era for Satta, providing a platform for its proliferation in the digital realm. Satta King 786 emerged as one of the many iterations of this age-old practice, distinguished by its numeric nomenclature and widespread popularity. Despite efforts to curb its influence, Satta King 786 has persisted, adapting to technological advancements and evolving regulatory landscapes.
Mechanics and Gameplay:
At its core, Satta King 786 operates on a simple premise: players wager money on the outcome of a designated event, typically involving the random selection of numbers. The results are determined through various means, including draws, lottery systems, or EVen the stock market. The allure of Satta King 786 lies in its accessibility and the potential for substantial returns on investment, albeit accompanied by significant risks.
Participants in Satta King 786 are often organized into syndicates or "Matkas," each with its own Set of rules, rituals, and hierarchies. The game thrives on secrecy and Clandestine communication channels, with players relying on word of mouth or specialized networks to access betting opportunities. Despite its underground nature, Satta King 786 has garnered a sizable following, drawing individuals from diverse socio-economic backgrounds into its fold.
Impact and Implications:
The rise of Satta King 786 has not been without consequences, both for individuals and society at large. Proponents argue that it provides a source of entertainment and a potential avenue for financial gain, particularly for those marginalized by traditional economic systems. However, critics point to its inherent risks, citing instances of addiction, financial ruin, and even criminal involvement.
From a regulatory standpoint, the legality of Satta King 786 remains a contentious issue, with laws varying across different jurisdictions. While some countries have implemented strict measures to prohibit online gambling, others have adopted a more laissez-faire approach, leading to a fragmented regulatory landscape. This ambiguity has created loopholes that are often exploited by illicit operators, further complicating efforts to curb its proliferation.
Moreover, the social impact of Satta King 786 extends beyond its immediate participants, permeating communities and influencing cultural norms. The glamorization of gambling in popular media, coupled with the promise of instant wealth, has contributed to its normalization within society, particularly among younger demographics. This normalization can have far-reaching implications, shaping attitudes towards risk-taking behavior and exacerbating issues related to gambling addiction.
Conclusion:
In the Complex Tapestry of Online Gambling, Satta King 786 occupies a unique and enigmatic position, symbolizing Both the allure and the perils of chance. Its origins are rooted in tradition, its mechanics shrouded in secrecy, and its impact reverberating across society, Satta King 786 embodies the paradoxical nature of human fascination with risk and reward. As policymakers grapple with the challenges posed by its proliferation, and individuals weigh the consequences of their participation, the legacy of Satta King 786 serves as a sobering reminder of the enduring allure of the unknown.
| explorebyrsr |
1,861,144 | Introducing a new router for Vue | Brief history of my journey with vue-router Virtually every developer using Vue.js is... | 0 | 2024-05-24T03:18:10 | https://dev.to/stackoverfloweth/introducing-a-new-router-for-vue-3c22 | vue, typescript | ## Brief history of my journey with vue-router
Virtually every developer using Vue.js is currently using or has only ever used vue-router. Many of those developers, myself included, are mostly happy with it. The biggest complaint I hear is the lack of strongly typed routes, which is usually solved with a bit of Typescript wrapping your routes.
```ts
// router/routes.ts
import { RouteLocationRaw, RouteRecordRaw } from 'vue-router'
type RouteFunction = (...args: any[]) => RouteLocationRaw
export const routes = {
home: () => ({ name: 'home' }) as const,
club: (clubId: string) => ({ name: 'clubs.view', params: { clubId } }) as const,
profile: (userId?: string) => ({ name: 'profile.view', query: { userId } }) as const,
} satisfies Record<string, RouteFunction>
```
Then `routes` becomes your source of truth, so navigation should always use a route from `routes` to send proper names to vue-router.
```ts
<router-link :to="routes.club('club-123')">go to club</router-link>
```
The syntax of defining routes is a bit cumbersome but honestly works fairly well. However, because I’m a serial starter-of-new-projects and love a challenge, I teamed up with [Pleek91](https://github.com/pleek91) to see if we could build our own.
---
# Introducing Kitbag Router
[https://router.kitbag.dev](https://router.kitbag.dev)
## It’s intentionally different
We made the decision to start the project from scratch; solving problems from first principles rather than taking the path of so many others and try to build on top of the relatively old vue-router project. This means Kitbag Router is NOT a drop in replacement for projects using vue-router. Therefore, this freedom also means we can have a relentless pursuit of the best possible developer experience possible, not weighed down by having to have feature parity with vue-router.
## First and foremost, it’s type safe!
Kitbag Router uses a createRoutes utility that returns routes with the name, path, query, all preserved in the Route type. This means the routes you provide to createRouter will maintain type safety when accessing the current route or performing navigation.
Type safety in routing means auto complete when assigning to on `<router-link>`, easy discovery of available routes when defining a `beforeRouteEnter` hook, and ensuring that Typescript will error if the expected params for a route change without updating the `router.push()` call.
## Params are way more powerful
Not only does Kitbag Router know what params are expected for a given route, it can also support param types beyond `String`.
Kitbag Router ships with built in support for params of typeString, `Number`, `Boolean`, `Date`, `RegExp`, `JSON`, as well as any custom param type you define. Not only is this type useful when navigating, but it also means a route that expects a `number` for an “id” param won’t be considered a match if the value provided in the URL doesn’t satisfy the number constraint. Furthermore, your Vue component that gets rendered for the route doesn’t have to worry about whether the param will be present or not or having to convert it from string to the type we know it’s supposed to be.
## Support for the query
Params aren’t relegated to only the path. Kitbag Router allows you to configure your expected params in the query the same way you’re used to defining params in other parts of the URL.
## Handling rejections
Inevitably when defining your routes, you’ll want to add a “catch all” or “not found” route. While Kitbag Router fully supports defining plain ol’ Regex in your path/query, it also ships with even better support for handling `NotFound`. We call this a “rejection”, which is customizable and can be extended to any custom rejection you need, like perhaps `NotAuthorized`. When a rejection is triggered, usually from within one of your hooks, Kitbag Router will automatically render the rejection component you assigned for the given rejection type.
## And more…
These are the key features we think really make Kitbag Router compelling but there is so much more. Kitbag router is built for Vue3 and support async components, route hooks, editable params from useRoute, components for RouterLink and RouterView, and more.
## Is it ready?
Kitbag Router is still super green and currently maintained by a team of 2. It has not yet had a stable release (on 0.2.0 as of the time I’m writing this), so things are still likely to change. That being said, I hope you’ll give it a try, maybe [give it a star](https://github.com/kitbagjs/router). We’re excited to hear from the community on what features we should focus on next.
Happy engineering! | stackoverfloweth |
1,863,490 | Thoughts on High-Frequency Trading Strategies (3) | In the previous article, I introduced how to model cumulative trading volume and analyzed the... | 0 | 2024-05-24T03:14:41 | https://dev.to/fmzquant/thoughts-on-high-frequency-trading-strategies-3-4k8i | trading, strategy, fmzquant, cryptocurrency | In the previous article, I introduced how to model cumulative trading volume and analyzed the phenomenon of price impact. In this article, I will continue to analyze the trades order data. YGG recently launched Binance U-based contracts, and the price fluctuations have been significant, with trading volume even surpassing BTC at one point. Today, I will analyze it.
## Order Time Intervals
In general, it is assumed that the arrival time of orders follows a Poisson process. There is an article that introduces the [Poisson process](https://www.ruanyifeng.com/blog/2015/06/poisson-distribution.html) . Here, I will provide empirical evidence.
I downloaded the aggTrades data for August 5th, which consists of 1,931,193 trades, which is quite significant. First, let's take a look at the distribution of buy orders. We can see a non-smooth local peak around 100ms and 500ms, which is likely caused by iceberg orders placed by trading bots at regular intervals. This may also be one of the reasons for the unusual market conditions that day.
The probability mass function (PMF) of the Poisson distribution is given by the following formula:
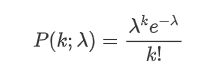
Where:
- κ is the number of events we are interested in.
- λ is the average rate of events occurring per unit time (or unit space).
-
 represents the probability of exactly κ events occurring, given the average rate λ.
In a Poisson process, the time intervals between events follow an exponential distribution. The probability density function (PDF) of the exponential distribution is given by the following formula:
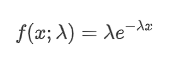
The fitting results show that there is a significant difference between the observed data and the expected Poisson distribution. The Poisson process underestimates the frequency of long time intervals and overestimates the frequency of short time intervals. (The actual distribution of intervals is closer to a modified Pareto distribution)
In [1]:
```
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
```
In [2]:
```
trades = pd.read_csv('YGGUSDT-aggTrades-2023-08-05.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
```
In [10]:
```
buy_trades['interval'][buy_trades['interval']<1000].plot.hist(bins=200,figsize=(10, 5));
```
Out[10]:
In [20]:
```
Intervals = np.array(range(0, 1000, 5))
mean_intervals = buy_trades['interval'].mean()
buy_rates = 1000/mean_intervals
probabilities = np.array([np.mean(buy_trades['interval'] > interval) for interval in Intervals])
probabilities_s = np.array([np.e**(-buy_rates*interval/1000) for interval in Intervals])
plt.figure(figsize=(10, 5))
plt.plot(Intervals, probabilities)
plt.plot(Intervals, probabilities_s)
plt.xlabel('Intervals')
plt.ylabel('Probability')
plt.grid(True)
```
Out[20]:
When comparing the distribution of the number of order occurrences within 1 second with the Poisson distribution, the difference is also significant. The Poisson distribution significantly underestimates the frequency of rare events. Possible reasons for this are:
- Non-constant rate of occurrence: The Poisson process assumes that the average rate of events occurring within any given time interval is constant. If this assumption does not hold, then the distribution of the data will deviate from the Poisson distribution.
- Interactions between processes: Another fundamental assumption of the Poisson process is that events are independent of each other. If events in the real world interact with each other, their distribution may deviate from the Poisson distribution.
In other words, in a real-world environment, the frequency of order occurrences is non-constant, and it needs to be updated in real-time. There may also be an incentive effect, where more orders within a fixed time period stimulate more orders. This makes strategies unable to rely on a single fixed parameter.
In [190]:
```
result_df = buy_trades.resample('1S').agg({
'price': 'count',
'quantity': 'sum'
}).rename(columns={'price': 'order_count', 'quantity': 'quantity_sum'})
```
In [219]:
```
count_df = result_df['order_count'].value_counts().sort_index()[result_df['order_count'].value_counts()>20]
(count_df/count_df.sum()).plot(figsize=(10,5),grid=True,label='sample pmf');
from scipy.stats import poisson
prob_values = poisson.pmf(count_df.index, 1000/mean_intervals)
plt.plot(count_df.index, prob_values,label='poisson pmf');
plt.legend() ;
```
Out[219]:
## Real-time Parameter Updating
From the analysis of order intervals earlier, it can be concluded that fixed parameters are not suitable for the real market conditions, and the key parameters describing the market in the strategy need to be updated in real-time. The most straightforward solution is to use a sliding window moving average. The two graphs below show the frequency of buy orders within 1 second and the mean of trading volume with a window size of 1000. It can be observed that there is a clustering phenomenon in trading, where the frequency of orders is significantly higher than usual for a period of time, and the volume also increases synchronously. Here, the mean of the previous values is used to predict the latest value, and the mean absolute error of the residuals is used to measure the quality of the prediction.
From the graphs, we can also understand why the order frequency deviates so much from the Poisson distribution. Although the mean number of orders per second is only 8.5, extreme cases deviate significantly from this value.
It is found that using the mean of the previous two seconds to predict yields the smallest residual error, and it is much better than simply using the mean for prediction results.
In [221]:
```
result_df['order_count'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
```
Out[221]:
In [193]:
```
result_df['quantity_sum'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
```
Out[193]:
In [195]:
```
(result_df['order_count'] - result_df['mean_count'].mean()).abs().mean()
```
Out[195]:
6.985628185332997
In [205]:
```
result_df['mean_count'] = result_df['order_count'].rolling(2).mean()
(result_df['order_count'] - result_df['mean_count'].shift()).abs().mean()
```
Out[205]:
3.091737586730269
## Summary
This article briefly explains the reasons for the deviation of order time intervals from the Poisson process, mainly due to the variation of parameters over time. In order to accurately predict the market, strategies need to make real-time forecasts of the fundamental parameters of the market. Residuals can be used to measure the quality of the predictions. The example provided above is a simple demonstration, and there is extensive research on specific time series analysis, volatility clustering, and other related topics, the above demonstration can be further improved.
From: https://blog.mathquant.com/2023/08/08/thoughts-on-high-frequency-trading-strategies-3.html | fmzquant |
1,863,489 | Comprehensive research of Android Permission Mechanisms | In the digital world of Android, the permission mechanism is the cornerstone of ensuring user privacy... | 0 | 2024-05-24T02:56:26 | https://dev.to/tecno-security/comprehensive-research-of-android-permission-mechanisms-k59 | security, opensource, androiddev, permission | In the digital world of Android, the permission mechanism is the cornerstone of ensuring user privacy and data security. It is a critically important task for security researchers and engineers to thoroughly study and understand this mechanism. This article will explore four key aspects of the Android permission mechanism: the Uid permission mechanism under Linux, the Permission permission mechanism in Android, the enforcement strategies of SEAndroid, and the fine-grained permission control.
Android is based on the existing permission management mechanism in Linux, which assigns different UIDs and GIDs to each application. The Uid permission mechanism isolates private data and access between different applications;
Android has added a permission mechanism to control the access permissions of components, hardware resources, etc. of Android applications;
The port from SELinux has also added permission control to access system services and other resources;
IPC (Inter-Process Communication) communication between Android apps requires access control through permission mechanisms.
**More Details: **[Comprehensive research of Android Permission Mechanisms](https://security.tecno.com/SRC/blogdetail/253?lang=en_US)
If anyone has researched this area, we welcome you to discuss it with us! | tecno-security |
1,863,485 | 【visionOS/ARKit】Simplest sample code for hand tracking | The basis of ARKit's hand tracking API in visionOS is to obtain data such as coordinates and rotation... | 0 | 2024-05-24T02:50:57 | https://dev.to/sfrrvsdbbf/visionosarkit-simplest-sample-code-for-hand-tracking-4g66 | visionos, applevisionpro, arkit, visionpro | The basis of ARKit's hand tracking API in visionOS is to obtain data such as coordinates and rotation of each joint of the hand.


Here is a sample code of ARKit's hand tracking API in visionOS that works with only 41 lines of code.
## Basic Knowledge
First, watch this session video. It gives a good overview of ARKit and hand tracking in visionOS.
[Meet ARKit for spatial computing - WWDC23 - Videos - Apple Developer](https://developer.apple.com/wwdc23/10082)
Hand tracking is explained from 15:05.
## Two APIs
There are two APIs to get joint data. Both can be accessed from the HandTrackingProvider instance.
- anchorUpdates: receives the latest values via AsyncSequence.
- latestAnchors: contains the latest values.

In this case, I implemented it with anchorUpdates.
## Overview of the Sample Code
- Starts hand tracking when the app launches.
- Places simple sphere objects at all joints of both hands.
- Updates each object’s position to match the latest joint position.
- Ensures the objects are not hidden by the hand.

## Full Source Code
```
import SwiftUI
import RealityKit
import ARKit
@main
struct MyApp: App {
private let session = ARKitSession()
private let provider = HandTrackingProvider()
private let rootEntity = Entity()
var body: some SwiftUI.Scene {
ImmersiveSpace {
RealityView { content in
content.add(rootEntity)
for chirality in [HandAnchor.Chirality.left, .right] {
for jointName in HandSkeleton.JointName.allCases {
let jointEntity = ModelEntity(mesh: .generateSphere(radius: 0.006),
materials: [SimpleMaterial()])
jointEntity.name = "\(jointName)\(chirality)"
rootEntity.addChild(jointEntity)
}
}
}
.task { try! await session.run([provider]) }
.task {
for await update in provider.anchorUpdates {
let handAnchor = update.anchor
for jointName in HandSkeleton.JointName.allCases {
guard let joint = handAnchor.handSkeleton?.joint(jointName),
let jointEntity = rootEntity.findEntity(named: "\(jointName)\(handAnchor.chirality)") else {
continue
}
jointEntity.setTransformMatrix(handAnchor.originFromAnchorTransform * joint.anchorFromJointTransform,
relativeTo: nil)
}
}
}
}
.upperLimbVisibility(.hidden)
}
}
```
Copy and paste this code to use it.
## Additional Steps
- Set any text for “NSHandsTrackingUsageDescription” in Info.plist.
- Set “Preferred Default Scene Session Role” to “Immersive Space” in Info.plist.
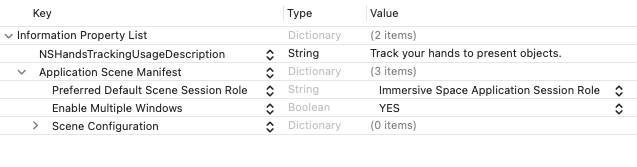
## Comments
_The explanations in the session video and the basic knowledge of SwiftUI and RealityKit are omitted._
### Managing Each Entity
```
jointEntity.name = "\(jointName)\(chirality)"
```
```
let jointEntity = rootEntity.findEntity(named: "\(jointName)\(handAnchor.chirality)")
```
Each entity is managed by its name using HandSkeleton.JointName for joint names and HandAnchor.Chirality for left or right hand.
### Setting Access Permissions
To request access permissions, you need to set any text for “NSHandsTrackingUsageDescription” in Info.plist.
This key does not appear in the pull-down menu, so enter it directly.
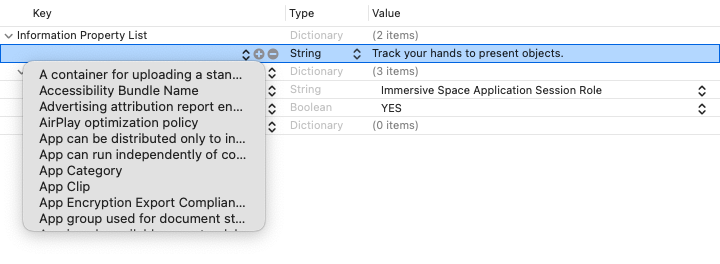
### Launch the App in Full Space
```
@main
struct MyApp: App {
...
var body: some SwiftUI.Scene {
ImmersiveSpace {
...
}
...
}
}
```
When you create a new visionOS app project in Xcode, it generates code to launch in a window. For simplicity, I made it launch in full space.
Set “Preferred Default Scene Session Role” to “Immersive Space” in Info.plist. If you do not make this setting, the app will crash right after launch.
## Note: A Physical Device is Required
You need a physical device to test the ARKit Hand Tracking API. It does not work at all in the simulator.
* * *
## Next Step
- Check the current authorization status: _session.queryAuthorization(for:)_
- Explicitly request authorization: _session.requestAuthorization(for:)_
- Check the state of anchors: _AnchorUpdate.Event_
- Check if each anchor or joint is being tracked: _TrackableAnchor.isTracked_
- Observe the session state: _ARKitSession.Events_
- Check if the current runtime environment supports it: _HandTrackingProvider.isSupported_
* * *
## Links
[Meet ARKit for spatial computing - WWDC23 - Videos - Apple Developer](https://developer.apple.com/wwdc23/10082)
[ARKit in visionOS | Apple Developer Documentation](https://developer.apple.com/documentation/arkit/arkit_in_visionos)
[upperLimbVisibility(_:) | Apple Developer Documentation](https://developer.apple.com/documentation/swiftui/scene/upperlimbvisibility(_:))
* * *
[HandsRuler on the App Store](https://apps.apple.com/app/id6475769879)
[FlipByBlink/HandsRuler: Measure app by hand tracking for Apple Vision Pro](https://github.com/FlipByBlink/HandsRuler)
| sfrrvsdbbf |
1,863,488 | Code Smell 253 - Silent Truncation | You silently truncate your user data without warning TL;DR: If you limit text lengths, enforce them... | 9,470 | 2024-05-24T02:41:37 | https://maximilianocontieri.com/code-smell-253-silent-truncation | webdev, javascript, beginners, programming | *You silently truncate your user data without warning*
> TL;DR: If you limit text lengths, enforce them everywhere!
# Problems
- The Fail Fast Principle Violation
- Corrupted and Missing Data
- [Bijection](https://dev.to/mcsee/the-one-and-only-software-design-principle-3086) Fault
- UTF-8 Truncation
- The Least Surprise principle violation
- Separation of Concerns of the UI and the Model
# Solutions
1. Be consistent with length rules
2. Enforce the rules in the domain objects
# Context
Imagine the scenario where you need to persist your objects in a database restricting the size of your texts.
Most databases will silently truncate your data and you will not notice the problem until you retrieve them.
If you need to enforce an arbitrary limit, add these business rules in your objects following the bijection rule.
Adding this control only in the UI or external API is another code smell about misplaced responsibilities.
# Sample Code
## Wrong
[Gist Url]: # (https://gist.github.com/mcsee/7b1f2afc8132fc6a518c3a5d5fb70f3c)
```javascript
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
// The page architecture is over simplified
const db = require('./db');
app.use(bodyParser.urlencoded({ extended: true }));
app.post('/save-data', (req, res) => {
const fullText = req.body.fullText;
const truncatedText = fullText.slice(0, 255);
// This truncation is not explicit sometimes
db.query('INSERT INTO table_name (truncated_text) VALUES (?)',
[truncatedText], (err, result) => {
if (err) throw err;
res.send('Data saved successfully');
});
});
app.listen(3000, () => console.log('Server started on port 3000'));
<!DOCTYPE html>
<html>
<head>
<title>Penrose Theory on Quantum Consciousness</title>
<script>
const form = document.getElementById('textForm');
const textArea = document.getElementById('textArea');
form.addEventListener('submit', (event) => {
event.preventDefault();
const fullText = textArea.value;
if (fullText.length > 1000) {
alert('Text cannot exceed 1000 characters');
return;
}
fetch('/save-data', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
},
body: `fullText=${encodeURIComponent(fullText)}`
})
.then(response => response.text())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
});
</script>
</head>
<body>
<h1>Penrose Theory on Quantum Consciousness</h1>
<form id="textForm">
<textarea id="textArea"
rows="10"
placeholder="Enter text about Penrose's theory (max 1000 characters)">
</textarea>
<button type="submit">Save</button>
</form>
</body>
</html>
```
## Right
[Gist Url]: # (https://gist.github.com/mcsee/3861712d705be4717836079118457b80)
```javascript
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
const db = require('./db');
// You should defined this constant in the backend
// Hopefully in a domain object
const MAX_CHARS = 255;
app.use(bodyParser.urlencoded({ extended: true }));
app.get('/max-chars', (req, res) => {
res.json({ maxChars: MAX_CHARS });
});
app.post('/save-data', (req, res) => {
const fullText = req.body.fullText;
const truncatedText = fullText.slice(0, MAX_CHARS);
db.query('INSERT INTO table_name (truncated_text) VALUES (?)',
[truncatedText], (err, result) => {
if (err) throw err;
res.send('Data saved successfully');
});
});
// Start the server
app.listen(3000, () => console.log('Server started on port 3000'));
<!DOCTYPE html>
<html>
<head>
<title>Penrose Theory on Quantum Consciousness</title>
<script>
let maxChars;
fetch('/max-chars')
.then(response => response.json())
.then(data => {
maxChars = data.maxChars;
const form = document.getElementById('textForm');
const textArea = document.getElementById('textArea');
form.addEventListener('submit', (event) => {
event.preventDefault();
const fullText = textArea.value;
if (fullText.length > maxChars) {
alert(`Text cannot exceed ${maxChars} characters`);
return;
}
fetch('/save-data', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
},
body: `fullText=${encodeURIComponent(fullText)}`
})
.then(response => response.text())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
});
})
.catch(error => console.error('Error:', error));
</script>
</head>
<body>
<h1>Penrose Theory on Quantum Consciousness</h1>
<form id="textForm">
<textarea id="textArea"
rows="10"
placeholder="Enter text about Penrose's theory">
</textarea>
<button type="submit">Save</button>
</form>
</body>
</html>
```
# Detection
[X] Semi-Automatic
You can do boundary testing. For example, using [Zombies](https://dev.to/mcsee/how-i-survived-the-zombie-apocalypse-59gj) methodology
# Tags
- Fail Fast
# Level
[X] Intermediate
# AI Generation
Ai generator usually duplicate these controls instead of placing in a single place
# AI Detection
It was hard to tell AI to use this as a backend constant prompting with an accurate instruction
# Conclusion
You need to handle a clear separation of concerns between the client-side (UI) and server-side (database operations).
The client-side handles user input validation and displaying data, while the server-side handles data storage and retrieval from the database.
You defined the maximum character limit in the backend and fetched by the client-side making it easier to update or change the limit across the application without modifying the client-side code and having ripple effect.
# Relations
{% post https://dev.to/mcsee/code-smell-139-business-code-in-the-user-interface-1i4o %}
# Disclaimer
Code Smells are my [opinion](https://dev.to/mcsee/i-wrote-more-than-90-articles-on-2021-here-is-what-i-learned-1n3a).
# Credits
Photo by [Jametlene Reskp](https://unsplash.com/@reskp) on [Unsplash](https://unsplash.com/photos/person-chopping-dough-sb6UGjIYIpo)
* * *
> In programming, if someone tells you “you’re overcomplicating it,” they’re either 10 steps behind you or 10 steps ahead of you.
_Andrew Clark_
{% post https://dev.to/mcsee/software-engineering-great-quotes-26ci %}
* * *
This article is part of the CodeSmell Series.
{% post https://dev.to/mcsee/how-to-find-the-stinky-parts-of-your-code-1dbc %} | mcsee |
1,863,484 | Thoughts on High-Frequency Trading Strategies (2) | Accumulated Trading Amount Modeling In the previous article, we derived an expression for... | 0 | 2024-05-24T02:27:19 | https://dev.to/fmzquant/thoughts-on-high-frequency-trading-strategies-2-2b0m | trading, strategy, cryptocurrency, fmzquant | ## Accumulated Trading Amount Modeling
In the previous article, we derived an expression for the probability of a single trade amount being greater than a certain value.
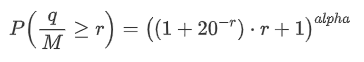
We are also interested in the distribution of trading amount over a period of time, which intuitively should be related to the individual trade amount and order frequency. Below, we process the data in fixed intervals and plot its distribution, similar to what was done in the previous section.
In [1]:
```
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
```
In [2]:
```
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
```
We combine the individual trade amounts at intervals of 1 second to obtain the aggregated trading amount, excluding periods with no trading activity. We then fit this aggregated amount using the distribution derived from the single trade amount analysis mentioned earlier. The results show a good fit when considering each trade within the 1-second interval as a single trade, effectively solving the problem. However, when the time interval is extended relative to the trading frequency, we observe an increase in errors. Further research reveals that this error is caused by the correction term introduced by the Pareto distribution. This suggests that as the time interval lengthens and includes more individual trades, the aggregation of multiple trades approaches the Pareto distribution more closely, necessitating the removal of the correction term.
In [3]:
```
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
```
In [4]:
```
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
```
Out[4]:
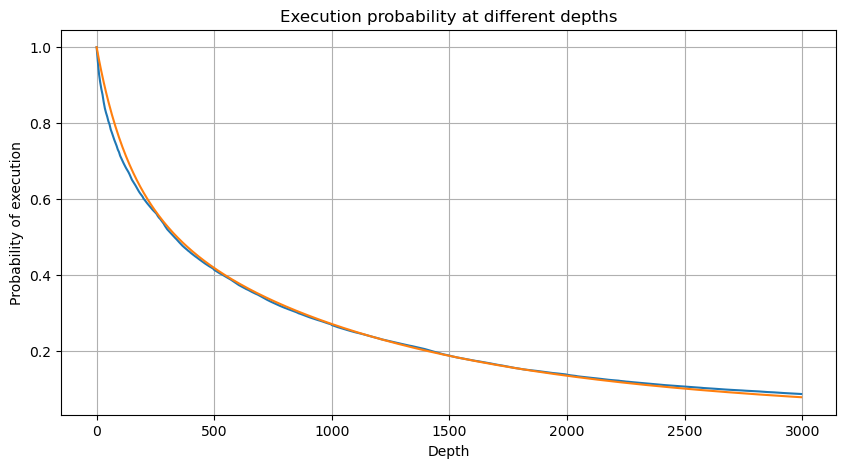
In [5]:
```
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
```
Out[5]:
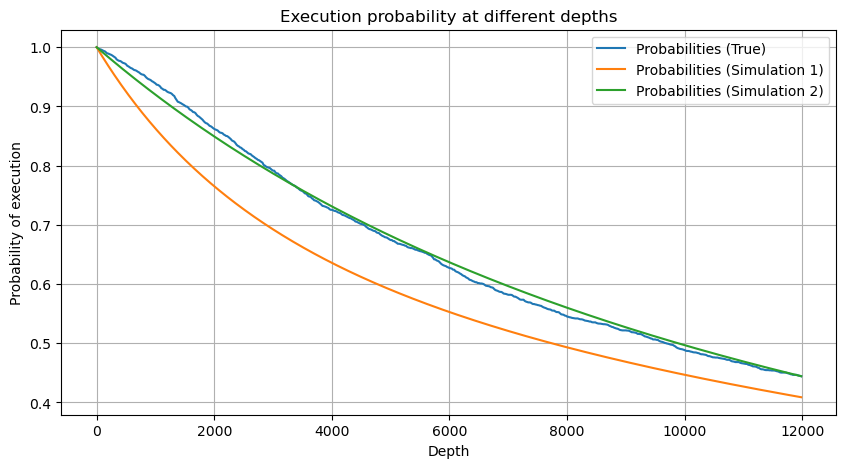
Now summarize a general formula for the distribution of accumulated trading amount for different time periods, using the distribution of single transaction amount to fit, instead of separately calculating each time. Here is the formula:
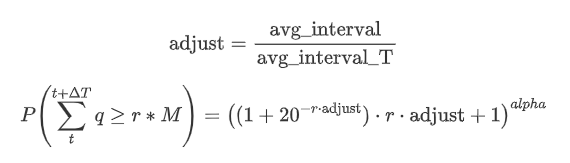
Here, avg_interval represents the average interval of single transactions, and avg_interval_T represents the average interval of the interval that needs to be estimated. It may sound a bit confusing. If we want to estimate the trading amount for 1 second, we need to calculate the average interval between events containing transactions within 1 second. If the arrival probability of orders follows a Poisson distribution, it should be directly estimable. However, in reality, there is a significant deviation, but I won't elaborate on it here.
Note that the probability of trading amount exceeding a specific value within a certain interval of time and the actual probability of trading at that position in the depth should be quite different. As the waiting time increases, the possibility of changes in the order book increases, and trading also leads to changes in the depth. Therefore, the probability of trading at the same depth position changes in real-time as the data updates.
In [6]:
```
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
```
Out[6]:
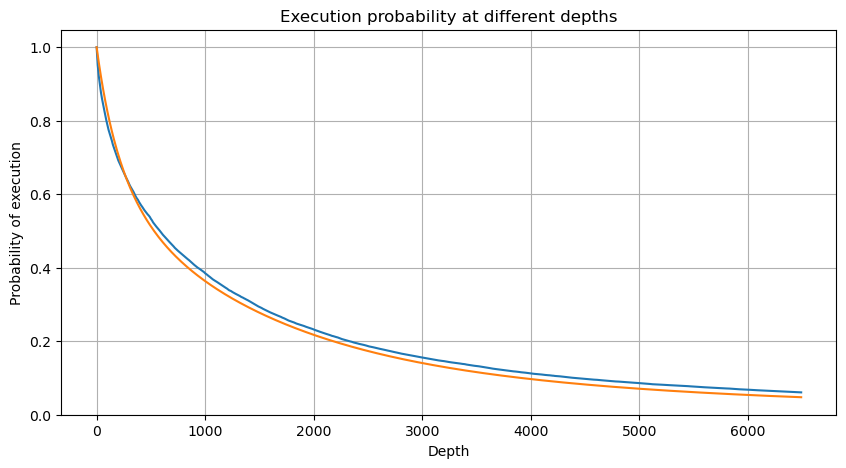
## Single Trade Price Impact
Trade data is valuable, and there is still a lot of data that can be mined. We should pay close attention to the impact of orders on prices, as this affects the positioning of strategies. Similarly, aggregating data based on transact_time, we calculate the difference between the last price and the first price. If there is only one order, the price difference is 0. Interestingly, there are a few data results that are negative, which may be due to the ordering of the data, but we won't delve into it here.
The results show that the proportion of trades that did not cause any impact is as high as 77%, while the proportion of trades causing a price movement of 1 tick is 16.5%, 2 ticks is 3.7%, 3 ticks is 1.2%, and more than 4 ticks is less than 1%. This basically follows the characteristics of an exponential function, but the fitting is not precise.
The trade amount causing the corresponding price difference was also analyzed, excluding distortions caused by excessive impact. It shows a linear relationship, with approximately 1 tick of price fluctuation caused by every 1000 units of amount. This can also be understood as an average of around 1000 units of orders placed near each price level in the order book.
In [7]:
```
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
```
In [8]:
```
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
```
Out[8]:
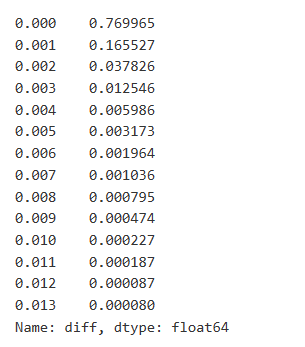
In [9]:
```
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
```
In [10]:
```
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
```
Out[10]:
## Fixed Interval Price Impact
Let's analyze the price impact within a 2-second interval. The difference here is that there may be negative values. However, since we are only considering buy orders, the impact on the symmetrical position would be one tick higher. Continuing to observe the relationship between trade amount and impact, we only consider results greater than 0. The conclusion is similar to that of a single order, showing an approximate linear relationship, with approximately 2000 units of amount needed for each tick.
In [11]:
```
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
```
In [12]:
```
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
```
Out[12]:
In [23]:
```
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
```
Out[23]:
In [14]:
```
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
```
In [15]:
```
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
```
Out[15]:
## Trade Amount's Price Impact
Previously, we determined the trade amount required for a tick change, but it was not precise as it was based on the assumption that the impact had already occurred. Now, let's reverse the perspective and examine the price impact caused by trade amount.
In this analysis, the data is sampled every 1 second, with each step representing 100 units of amount. We then calculated the price changes within this amount range. Here are some valuable conclusions:
1. When the buy order amount is below 500, the expected price change is a decrease, which is as expected since there are also sell orders impacting the price.
2. At lower trade amounts, there is a linear relationship, meaning that the larger the trade amount, the greater the price increase.
3. As the buy order amount increases, the price change becomes more significant. This often indicates a price breakthrough, which may later regress. Additionally, the fixed interval sampling adds to the data instability.
4. It is important to pay attention to the upper part of the scatter plot, which corresponds to the increase in price with trade amount.
5. For this specific trading pair, we provide a rough version of the relationship between trade amount and price change.
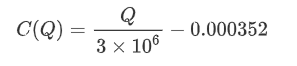
Where "C" represents the change in price and "Q" represents the amount of buy orders.
In [16]:
```
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
```
In [24]:
```
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
```
In [25]:
```
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
```
Out[25]:
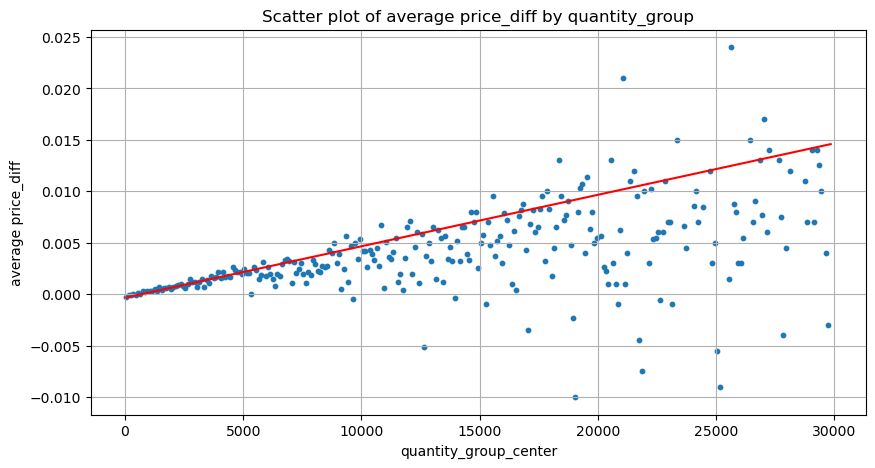
In [19]:
```
grouped_df.head(10)
```
Out[19]:
, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ,
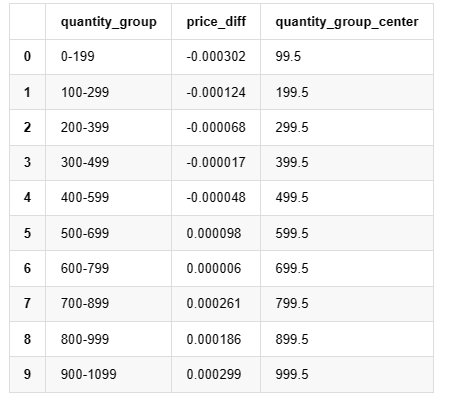
## Preliminary Optimal Order Placement
With the modeling of trade amount and the rough model of price impact corresponding to trade amount, it seems possible to calculate the optimal order placement. Let's make some assumptions and provide an irresponsible optimal price position.
1. Assume that the price regresses to its original value after the impact (which is highly unlikely and would require further analysis of the price change after the impact).
2. Assume that the distribution of trade amount and order frequency during this period follows a preset pattern (which is also inaccurate, as we are estimating based on one day's data and trading exhibits clear clustering phenomena).
3. Assume that only one sell order occurs during the simulated time and then is closed.
4. Assume that after the order is executed, there are other buy orders that continue to push up the price, especially when the amount is very low. This effect is ignored here, and it is simply assumed that the price will regress.
Let's start by writing a simple expected return, which is the probability of cumulative buy orders exceeding Q within 1 second, multiplied by the expected return rate (i.e., the price impact).
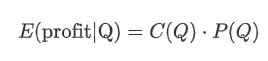
Based on the graph, the maximum expected return is approximately 2500, which is about 2.5 times the average trade amount. This suggests that the sell order should be placed at a price position of 2500. It is important to emphasize that the horizontal axis represents trade amount within 1 second and should not be equated with depth position. Additionally, this analysis is based on trades data and lacks important depth data.
## Summary
We have discovered that trade amount distribution at different time intervals is a simple scaling of the distribution of individual trade amounts. We have also developed a simple expected return model based on price impact and trade probability. The results of this model align with our expectations, showing that if the sell order amount is low, it indicates a price decrease, and a certain amount is needed for profit potential. The probability decreases as the trade amount increases, with an optimal size in between, which represents the optimal order placement strategy. However, this model is still too simplistic. In the next article, I will delve deeper into this topic.
In [20]:
```
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
```
Out[20]:
From: https://blog.mathquant.com/2023/08/04/thoughts-on-high-frequency-trading-strategies-2.html | fmzquant |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.