
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,863,811 | Scram Authentication: Overcoming Mock Testing Challenges | In the vast landscape of cybersecurity, authentication stands as the guardian of digital... | 0 | 2024-05-24T10:16:43 | https://keploy.io/blog/technology/scram-authentication-overcoming-mock-testing-challenges | webdev, javascript, programming, python | 
In the vast landscape of cybersecurity, authentication stands as the guardian of digital fortresses, ensuring that only the right individuals gain access to sensitive information and services. Imagine you're at the entrance of a top-secret facility, and you need to prove your identity to the security personnel. In the digital realm, this is precisely what authentication mechanisms do – they verify your identity before granting access.
When it comes to databases, making sure that the right programs have access is super important for keeping things safe and organised. At first, I thought databases might use a method called **JWT tokens** for this because it's popular and strong for security. However, I found out that there are different ways of authentication based on the connection state.
**- Token Based Authentications:** Token-based authentication is a method where users or applications receive a special "token" after initial authentication. This token is then used for further requests without repeatedly verifying credentials for each new connection.
Due to this property, it is used in the **Stateless Services** (like REST APIs, SSO, etc)
**- Connection oriented Authentications:** It is a method where users authenticates with the credentials for each connection or session. It is typically used in scenarios where a continuous connection or session is established between the client and server (like Databases, SSH).
In this blog post, we will explore how to mock SCRAM authentication in a testing environment. Before we dive into the details, let's first understand what SCRAM (Salted Challenge Response Authentication Mechanism) is and how it is used by databases like MongoDB.
**What is SCRAM authentication**
SCRAM, which stands for "Salted Challenge Response Authentication Mechanism," is a powerful challenge-based authentication method that follows the SASL (Simple Authentication and Security Layer) framework. SASL is designed to provide a framework for authentication and security without exposing sensitive credentials like passwords during the authentication process. This helps with several important aspects of authentication and security in the digital world:
**- Password Protection:** In SCRAM, the password is not shared between the client and server which ensures the security of user password. This also prevents from the MITM attacks.
**- Protection Against Credential Attacks:** SCRAM is resistant to common credential-based attacks such as brute force and dictionary attacks. The salted and hashed passwords, along with challenge-response mechanisms, add a layer of complexity that makes it challenging for attackers to guess passwords.
**- Confidentiality:** SCRAM ensures the confidentiality of sensitive data during authentication. By using cryptographic techniques and secure channels, it prevents unauthorised entities from eavesdropping on authentication attempts.
**- Secure Access Control:** SCRAM plays a crucial role in access control, ensuring that only authorised users or applications can interact with a system or database.

`There is a good example on wikipedia describing scram. here`
**How SCRAM authentication works**
After exploring what SCRAM is and understanding its purpose, it's natural to wonder how it functions and ensures all the necessary properties for ideal authentication in database environments.
In SCRAM authentication, the client and server securely establish their identities without the need to exchange the user password. This is achieved by generating and validating cryptographic proofs. These proofs are created using robust cryptographic algorithms, such as HMAC and SHA-hashing. This method ensures that even if network packets are intercepted by an intruder, the **password remains undecipherable.**
As the generation and validation of proofs in SCRAM authentication rely on randomly generated nonces by the client and server, it ensures robust security against potential intruders. The key factor here is that for each new connection, a unique nonce is generated and associated with it. This dynamic and one-time use of nonces effectively mitigates the risk of packet capture leading to unauthorised access, enhancing the overall security of the communication process.
Here is a detailed flow of communication for SCRAM authenticaton.
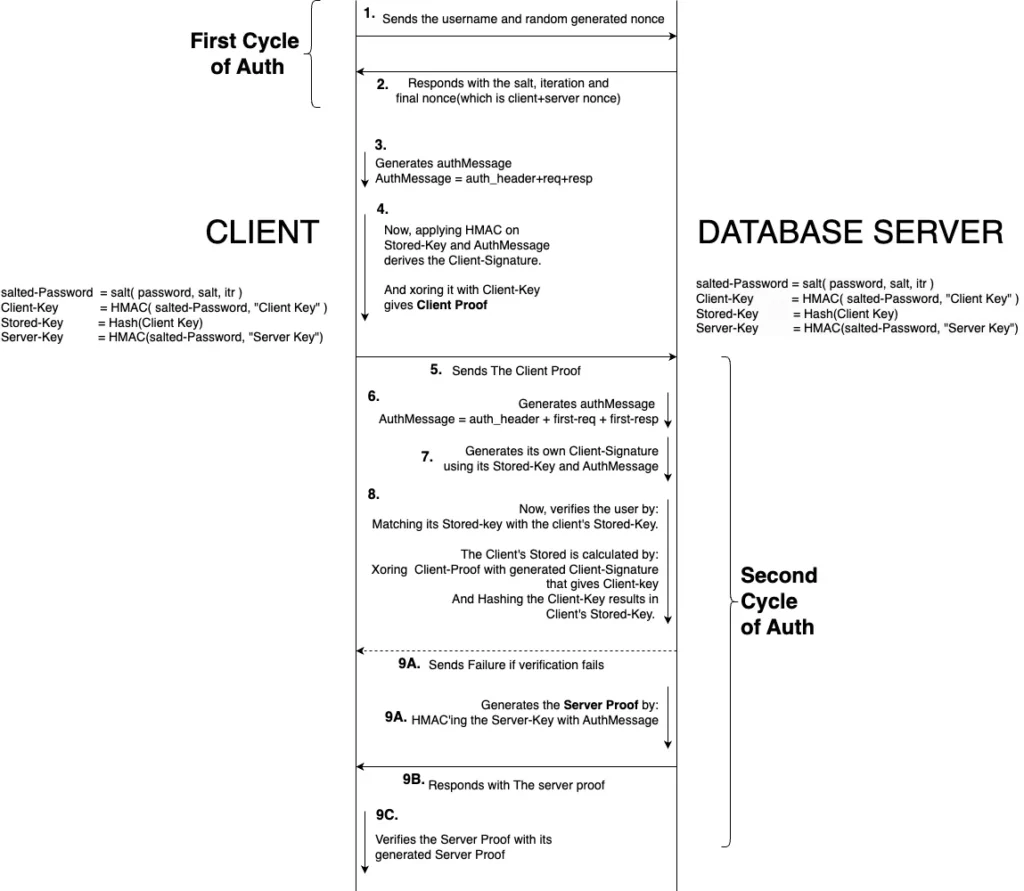
**Challenges for mocking SCRAM Auth**
In a test environment, mocking libraries need to bypass authentication simply by returning a message indicating successful authentication. However, SCRAM introduces a more complex scenario. In SCRAM, the client not only authenticates itself but also verifies the server's identity, adding an additional layer of security. This dual-verification process presents a significant hurdle for mocking tools like Keploy, an API testing tool designed to capture and replay network data. Due to SCRAM's complex nature, these libraries often experience Auth failure error like:
```
Exception authenticating MongoCredential{mechanism=SCRAM-SHA-1, userName='USER', source='ADMIN', password=<hidden>, mechanismProperties=<hidden>}; nested exception is com.mongodb.MongoSecurityException
```
Upon debugging the network packets, we've identified key insights. Attached below are the pertinent packet details for reference:
```
# SaslStart request. Here, r is the client nonce.
n,,n=root,r=hjO1c6p6PaNbeDUGhn/Jak3FFuUZQBxN1xmOeWr5L1c=
# The mocked SaslStart response. Here, r is the client/server nonce.
r=cjr1a0k0KanfoMMNkr/LaedRRtTQUBxM4fe3tuc6K1d=/igGE0M3BBiDmR/et9DN4cOR+CoNtHxs,s=ZPGEqaD8ImD95Vt3c1uuVQkImxrntgG4Wjh37Q==,i=15000
```
In the mechanism under discussion, the r key plays a crucial role in transmitting nonces within the payload. During the process, the client initiates the interaction by sending a new client nonce within the request. Subsequently, it receives a combined client/server nonce, along with the salt and iteration count, in the SaslStart response. However, a notable issue arises here: the client nonce often does not match in the response payload of SaslStart. This mismatch is a critical point of concern, as it can disrupt the intended flow of the SaslContinue authentication cycle because client and server proof depends on the nonces.
**Nonce Syncing: A Quick Fix for Successful auth**
To bypass the nonce mismatch issue during SCRAM authentication in Keploy tests, a straightforward solution is to update the client nonce directly in the SaslStart response payload. This adjustment ensures that the client's nonce matches the server's, leading to successful authentication. Attaching the pseudo code:
```
func (saslStartRequest, saslStartResponse string) {
expectedNonce, err := extractClientNonce( saslStartRequest )
actualNonce, err := extractClientNonce( saslStartRequest )
// Since, the nonce are randomlly generated string. so, each session have unique nonce.
// Thus, the mocked server response should be updated according to the current nonce
return strings.Replace( saslStartResponse, expectedNonce, actualNonce, -1), nil
}
```
`Here is the code in production to update client nonce.`
After implementing the quick fix of replacing the client nonce, we anticipated a smooth resolution. However, the error persisted, leading us to delve deeper into the problem. Further investigation required debugging the client driver, where we uncovered a critical issue: the server verification was failing on the client side.

**Final step: Correct Server Proof Generation**
In tackling SCRAM authentication issues with Keploy, the critical final step is ensuring the correct generation of server proof. This is essential for successful authentication, especially with how the client side works.
1.**Client-Side Verification:** The client uses the combined client/server nonce to verify the server. The method to generate the server proof, which is key to this verification, is straightforward yet precise.
2.**Why Authentication Fails:** Our tests showed that authentication failures were mainly due to the mismatch between the recorded server proof and the new nonces. Each new nonce combination requires a unique server proof, and if they don't match, authentication fails.
3.**Fixing the Issue:** The solution is simple: generate a new server proof for each new set of nonces. This means moving away from using a fixed, recorded proof to creating a new proof every time, based on the current nonces. This change solves the authentication problems and ensures that the client can successfully verify the server each time, making the process more secure and reliable.
The image below provides a detailed description of the formula used in generating server proofs:

Here, is the code in production for generating the server proof in SaslContinue
`Hurray! Our fixes worked – authentication is now a smooth success in our test environment! 🎉🎊`
**Conclusion**
To sum up our exploration of SCRAM authentication:
1.**SCRAM Auth Insights:** We've learned how SCRAM auth secures user verification without revealing passwords, a smart way to safeguard user credentials.
2.**Mocking Library Challenges:** Mocking tools (like Keploy), reliant on network packets, face hurdles with SCRAM due to its dynamic and secure nature.
3.**Solution for Testing:** To successfully test with mocking libraries, it's essential to configure them with the user's password. This allows for generating accurate server proofs, aligning with the ever-changing nonces in SCRAM.
This journey underscores the delicate balance between robust security and effective software testing, highlighting the evolving landscape of digital security.
**FAQ's**
**How can authentication issues with SCRAM be resolved in testing environments?**
Authentication issues with SCRAM in testing environments can be resolved by ensuring that mocking tools are configured to handle dynamic nonce generation and server proof validation accurately. Keploy does this by aligning it's mocking capabilities with the authentication requirements of SCRAM, and ensuring authentication failures can be mitigated, and testing can proceed smoothly.
**What are the key takeaways from exploring SCRAM authentication?**
Key takeaways from exploring SCRAM authentication include:
- SCRAM auth secures user verification without revealing passwords, enhancing security.
- Mocking libraries may face challenges with SCRAM due to its dynamic nature.
- Solutions for testing with mocking libraries involve configuring them with accurate server proofs and handling dynamic nonce generation effectively.
- Balancing robust security with effective software testing is crucial in the evolving landscape of digital security.
**How does SCRAM authentication compare to other authentication methods like JWT tokens?**
SCRAM authentication is primarily used in connection-oriented environments like databases, whereas JWT tokens are commonly used in stateless services like REST APIs. Each method has its advantages and is suited to different use cases based on factors like security requirements and connection state.
**What databases support SCRAM authentication?**
SCRAM authentication is supported by various databases, including MongoDB, PostgreSQL, CouchDB, and others. It's becoming a standard method for securing user authentication in database environments. | keploy |
1,863,810 | Best Video Conference API for Websites in 2024 | We all recognise how integral video conferencing has become in our daily routines, having spent... | 0 | 2024-05-24T10:14:24 | https://dev.to/digitalsamba/best-video-conference-api-for-websites-in-2024-3dfd | api, sdk, videoconfererencing, webdev | We all recognise how integral video conferencing has become in our daily routines, having spent countless hours using these tools. A less familiar but equally significant development is the video conferencing API. So, what exactly is it? An API, or "Application Programming Interface", is essentially a mechanism that enables one system to communicate with another.
A video conferencing API allows you to embed video conferencing capabilities into your application and manage the platform's features through an API. The platform itself is often referred to as an API, and while this isn't entirely accurate, the term "video conferencing API" has gained widespread usage. Essentially, a video conferencing API is just an API.
This article reviews [the leading video conferencing APIs](https://www.digitalsamba.com/blog/best-free-video-conferencing-api-for-website-integration) available today. We analyse established industry leaders and emerging contenders, evaluating their features, costs, and ideal use cases. Whether you are a developer, business owner, or decision-maker, this guide will assist you in selecting the best video conferencing API for your needs.
## What is a video conferencing API?
Video conferencing APIs efficiently integrate real-time video and audio communication into your application or website. Rather than building complex video streaming protocols from scratch, these APIs provide all the necessary tools. They handle the intricate processes of capturing, encoding, transmitting, and decoding video and audio data, ensuring a smooth, low-latency experience for your users.
Utilising a video conferencing API saves you from the substantial investment required to develop this technology in-house, conserving both time and resources. You benefit from a reliable, secure, and continually evolving infrastructure the API provider maintains, allowing you to concentrate on your application's core strengths.
Many video conferencing APIs come with advanced features and basic video functionality. Screen sharing, virtual whiteboards, recording options, and integrated chat form a comprehensive collaboration suite. This enables you to customise the solution for specific use cases, such as remote healthcare consultations, interactive online classes, international team meetings, or personalised customer support.
The possibilities are extensive with a [powerful video conferencing API](https://www.digitalsamba.com/video-api). You can deliver the engaging, face-to-face interactions that modern users expect. By leveraging an API, you streamline development, speed up your launch, and provide rich, real-time communication experiences that enhance user satisfaction and loyalty.
## Things to consider when choosing a video conferencing API
Adding video calls to your website or app opens up exciting possibilities. However, with so many video conferencing APIs available, how do you choose the right one? Here’s a breakdown of key factors to keep in mind:
- Quality matters
Will your video calls be clear and crisp? Opt for an API that prioritises high-definition video and audio. This is essential for professional use cases, such as online job interviews or remote doctor consultations. Ensure the API offers low latency (minimal delay), as this significantly impacts the natural flow of conversation.
- Features to fit your needs
Basic video calls are just the beginning! Consider additional features that could enhance your use case. Screen sharing, virtual whiteboards, file transfers, and text chat can transform simple video calls into powerful collaboration sessions.
- Ease of use
A complex API can be challenging for your developers. Select an API that is easy to embed and use. This will save development time and ensure users can join calls effortlessly.
- Scalability
Will the API grow with your needs? If you plan to host large-scale meetings or anticipate a user surge, ensure the API can handle increased traffic without compromising quality.
- Security and privacy
How robust are the API’s security measures? Strong encryption and data protection protocols are crucial when dealing with sensitive data, such as in healthcare or finance.
- Cost-effectiveness
Video APIs typically offer flexible pricing models. Consider factors like minutes used per month, the number of participants, and required features before selecting a plan that suits both your budget and needs.
Choosing wisely means building a seamless video conferencing experience that enhances your app or website. With some research and planning, you'll find the perfect video chat API for your project.
## Key features to look for in a video conferencing API
Are you looking to facilitate clear and secure virtual meetings? Choosing the right video conferencing API is essential. Here’s what to consider:
### High-quality audio and video
Avoid grainy visuals and choppy audio. Select an API that supports HD video resolution for sharp images and includes noise cancellation to minimise distracting background sounds. This ensures a professional and focused meeting environment.
### Screen sharing
Effective collaboration often requires everyone to view the same content simultaneously. Ensure the API offers simple and reliable screen sharing for presentations, live demonstrations, or real-time document collaboration.
### Recording
The ability to record meetings is crucial. Recorded sessions can be used to train new staff, revisit important decisions, or share with those unable to attend live.
### Security
When evaluating an API, prioritise data security and privacy. Look for features like encrypted data transmission, robust authentication, and compliance with data privacy regulations such as GDPR. These measures protect your meetings and safeguard your organisation and users.
### Scalability
If you anticipate large meetings, the API must handle increased demand without sacrificing performance. Choose proven solutions that maintain call quality even with numerous participants.
### Customisation
A customisable API allows you to control the look, feel, and features of your video conferencing experience. This enables seamless integration into your existing application or website, creating a cohesive user experience.
### Virtual backgrounds
Let users replace or blur their backgrounds for added privacy, professionalism, or a touch of fun. This feature is particularly useful for those working in less-than-ideal environments.
### Live chat
Enable text-based communication alongside the video stream for quick questions, side discussions, or sharing links without interrupting the main conversation.
### Whiteboarding
Offer a virtual whiteboard for participants to collaborate visually in real time. This encourages brainstorming, problem-solving, and the free flow of ideas.
Remember, prioritise the features most important to your video conferencing needs. Selecting a dependable API with strong security will ensure smooth and secure virtual meetings for all participants.
## 10 Best Video Conferencing APIs in 2024
The video conferencing market is thriving in 2024, offering businesses a wide range of options. Selecting the right provider can be challenging. To help you make an informed decision, let's delve into some top solutions, examining their features, potential drawbacks, and pricing models.
### 1. Digital Samba
[Digital Samba](https://www.digitalsamba.com/) revolutionises online business communication and collaboration beyond mere video conferencing. Their APIs facilitate seamless, high-definition video and audio calls, effortless screen sharing for presentations or demonstrations, and reliable recording options for training or compliance purposes.
Imagine video calls so sharp and lag-free that it feels like everyone's in the same room, even if they're continents apart—that's the power of Digital Samba's API! You can easily embed fluid video conferencing into your websites and apps. Additionally, Digital Samba offers a video call SDK for further customisation and flexibility.
Digital Samba goes above and beyond the basics by prioritising security and scalability. User data is fiercely protected, and their solutions are designed to handle traffic surges, ensuring no downtime during crucial meetings. With built-in data privacy compliance (like GDPR), you can confidently integrate their privacy-focused API into various services, including healthcare, finance, and other sensitive industries.
#### [Digital Samba features](https://www.digitalsamba.com/features):
- Embeddable conferencing
- Screen sharing
- Virtual whiteboard
- Recording capabilities
- Customisation options
- End-to-end encryption
- Robust SDKs
#### [Digital Samba pricing](https://www.digitalsamba.com/pricing):
- The free tier (10,000 minutes/month limit) is ideal for testing and smaller projects. Explore Digital Samba's API and see how it meets your needs. Once you exceed the minute limit, upgrade to a paid plan.
- Paid plans (from €99/month to custom pricing): Unlock higher minute limits and advanced features as your video conferencing needs grow. Paid plans offer flexibility and scalability. For high-volume enterprise needs, contact the sales team for custom pricing.
### 2. Agora.io
Agora.io goes beyond just enabling video calls; it helps you create online experiences that feel truly connected. Imagine a video so clear it feels like you're in the same room, voice calls without glitches, and easy recording to capture important moments. With features like messaging and live streaming, Agora.io's smart technology ensures strong connections, no matter where your users are globally.
#### Agora.io key features:
- Real-time video and audio
- Screen sharing
- Whiteboarding
- Recording
- Robust SDKs for high customisation
- Global low-latency network
#### Agora.io limitations:
- Can be complex for simple use cases.
- Pricing can become expensive at very high volumes.
- Occasional reports of audio/video quality inconsistencies.
#### Agora.io pricing:
- Free Plan: Up to 10,000 minutes per month.
- Paid Plans: Tiered pricing based on usage:
- Video HD: $3.99 per 1,000 minutes.
- Video Full HD: $8.99 per 1,000 minutes.
**Note:** Pricing complexity increases with additional features and higher usage volumes.
### 3. CometChat
CometChat prioritises a smooth development experience with extensive documentation, easy-to-follow demos, and intuitive code samples. Their APIs provide everything needed for text, voice, and video chat, ensuring beautiful and functional video conferencing experiences across devices. It's the ultimate tool for creating a chat experience that looks as good as it performs.
#### Key CometChat features:
- Video and audio calling
- Text chat
- File sharing
- Whiteboarding
- User presence
- Pre-built UI components
#### CometChat limitations:
- Some users report issues with call quality in low-bandwidth scenarios.
#### CometChat pricing:
- Free plan: basic features.
- Usage-based pricing:
- Text chat: $0.001/user minute.
- Voice calling/conferencing: $0.003/user minute.
- Video calling/conferencing: $0.006/minute.
### 4. MirrorFly
With MirrorFly, you're not just purchasing technology; you're shaping your communication experience. Their SaaS and SaaP solutions completely control every aspect of your video calls. Expect bank-grade security to protect sensitive conversations and unparalleled customisation, with full ownership of your SDKs and source code—a game-changer for enterprises and developers seeking long-term control.
#### MirrorFly features:
- Highly customisable video, voice, and chat solutions
- In-app messaging
- Push notifications
- Moderation tools
- Analytics
- Source code ownership
#### MirrorFly limitations:
- Requires more development effort than some prebuilt solutions.
- Can be more expensive for smaller projects.
- Support response times can sometimes be slow.
#### MirrorFly pricing:
- Usage-based pricing:
- Essentials (5k Monthly Active Users): $0.08/user/month.
- Premium (5k Monthly Active Users): $0.2/user/month.
- For enterprise clients, contact sales for tailored pricing.
### 5. Daily.co
Daily.co provides flexibility to build the video conferencing experience you envision. Use their pre-built UI components for a quick launch or dive into granular customisation for a bespoke interface. Expect stunning 1080p video, flexible recording options (including automatic transcriptions), and scalability to handle any audience size your business can manage.
#### Daily.co features:
- Easy integration into websites and apps
- Recording
- Screen sharing
- Developer-friendly API
- Strong support for live-streaming
#### Daily.co limitations:
- Limited features for complex moderation.
- Can be less cost-effective for high-volume use.
- Some UI components feel basic compared to others.
#### Daily.co pricing:
- Free Plan: Limited use.
- Paid Plans: Scales are based on the minutes streamed and features, starting at $0.0015 per participant per minute.
For complex implementations, contact them for a detailed breakdown.
### 6. VideoSDK.live
VideoSDK.live offers developers a comprehensive suite of tools to embed real-time audio and video communication experiences within websites and applications. It provides high customisation, excellent performance with low latency, and features designed to enhance interactivity within video sessions. VideoSDK.live prioritises developer experience with straightforward APIs and SDKs.
#### Features highlight:
- Flexible customisation
- Low-latency video conferencing
- Interactive live-streaming
- Robust analytics
- Developer-focused APIs and SDKs
#### Limitations:
- Effective utilisation might require a certain level of technical expertise.
- Occasional reports of inconsistencies with certain browsers.
#### Pricing:
- Free Tier: Generous free usage limits for development and experimentation.
- Conferencing (audio/video calls): Starts at $0.003 per participant per minute for video calls and $0.0006 per participant per minute for audio-only calls.
### 7. Sinch
Sinch is a trusted choice for industries like healthcare and retail, where reliable, customisable video communication is critical. Their Live Video Call API allows developers to effortlessly add instant messaging capabilities to iOS, Android, and web applications. This facilitates crystal-clear doctor-patient consultations, virtual shopping experiences with personalised support, and more. Sinch's focus on customisation empowers you to tailor the experience perfectly to your brand's and industry's needs.
#### Sinch features overview:
- Voice and video calling
- SMS and verification solutions
- User-to-user chat
- Push notifications
- Strong emphasis on reliability
#### Sinch Limitations:
- Less emphasis on pure video customisation compared to dedicated video providers.
- It can be overkill for projects needing only basic video chat.
- UI toolkits may feel dated compared to some.
#### Pricing:
- Free Trial: Available.
- Contact sales for a price quote.
### 8. Enablex
Enablex offers a budget-friendly yet powerful solution for developers seeking a HIPAA-compliant video conferencing API. They provide top-notch SDKs for seamless one-on-one and group video calls. Enablex also stands out with live streaming features that let you push content directly to social media, which is ideal for webinars, training sessions, or product demos.
#### Enablex features:
- Low-latency video conferencing
- Whiteboarding and collaboration tools
- Recording
- Moderation features
- Breakout rooms
#### Enablex limitations:
- Fewer pre-built UI components compared to alternatives.
- Can be less intuitive for non-technical users.
- Documentation isn't as extensive as some competitors.
#### Pricing:
- Usage-Based Model: $0.004 per participant per minute (for a 50 participant session).
- For detailed plans and specific pricing, contact sales.
### 9. Apphitect
Apphitect provides robust video conferencing for businesses of all sizes, built on WebRTC to ensure smooth communication across mobile, desktop, and web browsers. Apphitect's adaptability allows their solutions to match your company's workflow and branding, creating a seamless and intuitive experience.
#### Apphitect features:
- Video and voice calling
- Messaging solutions
- Screen sharing and collaboration features
- Secure and reliable infrastructure
#### Limitations:
- Call quality may not be stable due to potential lags.
- Limited advanced analytics and reporting tools.
#### Pricing:
- Contact the sales team for custom pricing.
### 10. Vonage Video Chat API
Building upon the well-respected TokBox OpenTok, Vonage's Video Chat API offers reliable video experiences for your applications. Expect high-quality, WebRTC-powered video streaming that's visually impressive and secure with AES encryption. It’s the evolution of proven technology, ready to meet modern communication needs.
#### Features of Vonage Video Chat API:
- Robust and customisable video solutions
- Archiving (recording)
- Session monitoring tools
- Cross-platform support
- Strong developer community
#### Vonage Video Chat API limitations:
- Can be complex for simpler implementations.
- Support quality has been inconsistent in reviews.
- Call quality may not be consistent in some cases.
#### Pricing:
- $0.00395 per participant per minute.
The video conferencing landscape is vast and ever-evolving. The providers we've explored offer a diverse range of features, from basic functionality to advanced customisation and enterprise-level security. When choosing your provider, consider the features you need and your budget to make the best decision.
## Conclusion
When selecting a video conferencing API, consider the features that are most important to you. Are high-quality video and sound crucial? Do you need screen-sharing or call-recording capabilities? How essential are security and privacy? Should the API support large groups, and can it be customised to fit your specific project?
Additionally, assess any usage limits and the cost of the API. Does it fit within your budget? Many APIs offer free trials or plans, allowing you to test them before committing. This is an excellent way to determine which one best suits your needs.
Digital Samba is a standout option for those seeking the freedom to create exceptional video experiences. Our robust API supports everything from simple team chats to large-scale online conferences. We prioritise security and are equipped to handle projects of any size.
Ready to explore Digital Samba's capabilities? [Sign up now](https://dashboard.digitalsamba.com/signup) and receive 10,000 free credits to enhance your video experiences. | digitalsamba |
1,863,809 | Destructuring Assignments in JavaScript | Destructuring in JavaScript lets you easily take apart arrays or objects and assign their parts to... | 0 | 2024-05-24T10:13:37 | https://dev.to/linusmwiti21/destructuring-assignments-in-javascript-5hik | javascript, webdev, beginners, programming | Destructuring in JavaScript lets you easily take apart arrays or objects and assign their parts to new variables. It's like unpacking a box: instead of grabbing each item one by one, you can quickly grab what you need all at once. This makes your code easier to read and write because you can do more with less.
There are two main types of destructuring in JavaScript:
1. **Array Destructuring:** With array destructuring in JavaScript, you can grab values from an array and assign them to variables in just one go. Plus, if you don't need certain values, you can easily skip over them.
2. **Object Destructuring:** With object destructuring, you can extract properties from objects and assign them to variables with the same name. You can also provide default values in case the property doesn't exist in the object.
Destructuring help increase the readability, decrease verbosity, and improve maintainability of your Javascript code.
In this article, we'll take you through destructuring assignments, exploring how to work with both arrays and objects while providing practical examples and highlighting valuable use cases. Additionally, we'll look into advanced techniques such as rest operators and combining array and object destructuring to demonstrate the full power and flexibility of this JavaScript feature.
### Destructuring Objects
Object is a basic data structure in JavaScript that is used to arrange data in a key-value pair manner. It functions similarly to a container that stores attributes (keys) and the values that go with them. Think of it like a box with sections that are labelled.
**Example**
```javascript
const person = {
name: "Alice", // Key: "name", Value: "Alice"
age: 30, // Key: "age", Value: 30
hobbies: ["coding", "reading"] // Key: "hobbies", Value: Array of strings
};
```
**Data Types for Values:** Object values can be of any data type in JavaScript, including strings, numbers, booleans, arrays, or even other objects (nested objects).
**Accessing properties:** You can use bracket notation (``object["key"]``) or dot notation (``object.key``) to access particular properties of an object. The value connected to the key is retrieved by both notations.
Objects are a great method to organise related data in JavaScript. They function similarly to labelled boxes, with keys serving as labels that identify certain values (the contents therein). The key-value pair method facilitates efficient data access and manipulation. Moreover, objects serve as the foundation for complex data structures and can even be used to represent actual objects in JavaScript programmes.
**Accessing Object Properties using Destructuring**
Destructuring in JavaScript isn't just for retrieving values from regular objects. It also lets you reach and access properties from objects hidden inside other objects. Now let's see how we may effectively access object properties by using destructuring syntax.
Imagine a scenario where an object is designed to represent a user:
```javascript
const user = {
name: 'John Doe',
age: 30,
email: 'john@example.com'
};
```
To access the individual properties of this object, we can use destructuring assignment:
```js
const { name, age, email } = user;
console.log(name); // Output: John Doe
console.log(age); // Output: 30
console.log(email); // Output: john@example.com
```
**Nested Object Destructuring**
Objects in JavaScript can hold other objects within them, creating a hierarchy of data structures.
Often, objects may contain nested structures, such as:
```js
const user = {
name: "Patel",
age: 40,
address: {
city: "Mumbai",
country: "India",
},
};
```
To access nested properties, we can destructure them directly:
```js
const { address: { city } } = user;
console.log(city); // Output: Mumbai
```
We destructure the user object, extracting the address property and assigning it to a new variable named address.
Within the nested address object, we further destructure to extract the city property and assign it to the standalone variable city.
This approach simplifies object access, especially when dealing with deeply nested structures.
**Renaming Properties**
JavaScript destructuring assignments have a useful feature that allows you to rename properties as you extract them from objects. This can be really helpful:
* The property name in the object doesn't clearly reflect its meaning.
* You want to use a different variable name for clarity or consistency within your code.
**Example**
```js
const person = {
fullName: "John Doe",
age: 30,
};
```
Destructuring allows you to rename the property during extraction. Here, we'll rename ``fullName`` to ``firstNameLastName``:
```js
const { fullName: firstNameLastName } = person;
console.log(firstNameLastName); // Output: John Doe
```
In this example, we separate the individual object.
The property ``fullName`` is specified inside the curly braces {}, and is followed by a colon :.
To capture the value from the ``fullName`` field, we declare a new variable named ``firstNameLastName`` after the colon.
JavaScript's object destructuring completely changes the way we work with complex data. Curly braces are used to extract values from objects directly, eliminating the need for tedious dot notation. Clarity requires renaming attributes on. Destructuring efficiently captures particular data in one go, even with nested objects.
### Destructuring Arrays
An array is a type of variable that has the capacity to store several values. JavaScript's array destructuring makes working with arrays easier by enabling you to extract values directly from the array.
To assign values to variables, use square brackets rather than indexing elements. Selecting specific elements from an array becomes clear-cut and easy. You can also skip elements and define default values during destructuring, which increases flexibility in managing different cases. Ultimately, array destructuring simplifies your code, improving its readability and productivity.
**Accessing Array Elements using Destructuring**
In JavaScript, array destructuring offers a simple method for accessing array elements. Square brackets allow you to assign array values directly to variables, without the need for the conventional index notation.
**Example**
```js
const colors = ["red", "green", "blue"];
// Destructuring the first two elements:
const [firstColor, secondColor] = colors;
console.log(firstColor); // Output: red
console.log(secondColor); // Output: green
```
We destructure the ``shoppingList`` array.
We define two variables: ``firstItem`` for the first element.
For ``secondItem``, we set a default value of "eggs".
If shoppingList only has one element, "eggs" is assigned to ``secondItem`` to avoid undefined.
**Skipping values example**
Sometimes you only need specific elements from an array, and the rest are irrelevant. Destructuring allows you to skip elements elegantly. Simply add commas (,) where you want to skip elements.
**Example**
```js
const colors = ["red", "green", "blue", "yellow"];
const [firstColor, , thirdColor] = colors;
console.log(firstColor); // Output: red
console.log(thirdColor); // Output: blue (skipping the second element)
```
In this case, We destructure the colors array using square brackets [].
We define two variable names, ``firstColor`` and ``secondColor``, separated by a comma.
These variable names automatically capture the values at the corresponding positions (index 0 and 1) in the array.
### Destructuring using the Rest Operator (...)
A function can consider an infinite number of arguments as an array by using the rest operator (...). This operator allows you to capture all the remaining elements of an array into a single variable, after extracting the specific elements you need upfront.
Imagine a shopping list that might have an indefinite number of items beyond the essentials (milk, bread, eggs). Destructuring with the rest operator lets you handle this flexibility with ease. Here's the concept in action:
```js
const shoppingList = ["milk", "bread", "eggs", "chips", "cookies"];
const [firstItem, secondItem, ...remainingItems] = shoppingList;
console.log(firstItem); // Output: milk
console.log(secondItem); // Output: bread
console.log(remainingItems); // Output: ["chips", "cookies"] (all remaining items)
```
We destructure the ``shoppingList`` array.
We extract the first two elements (``milk`` and ``bread``) into separate variables.
The magic happens with the rest operator (``...``). It captures all the remaining elements (``chips`` and ``cookies``) into an array named ``remainingItems``.
The rest operator (... ) in destructuring works when you're dealing with arrays of unknown length. It lets you grab the specific elements you need upfront and effortlessly capture any remaining items in a single variable. This keeps your code concise, adaptable to different array sizes, and ultimately more reusable for various scenarios.
### Conclusion
In JavaScript, destructuring assignments provide a strong and efficient method of working with both arrays and objects. You can greatly increase the readability, maintainability, and flexibility of your code by utilising destructuring techniques.
This article provided a foundational understanding of destructuring, covering:
* Extracting specific properties from objects
* Renaming properties during extraction
* Accessing elements from arrays
* Using defaults and skipping elements in arrays
* Capturing the remaining elements of an array with the rest operator (...)
Even though this is only a brief introduction to destructuring, we've already seen how it simplifies complex data manipulation tasks.
Start incorporating destructuring assignments into your JavaScript coding practices. You'll find it becomes a natural and efficient way to interact with data structures.
These resources offer deep understanding into destructuring and related concepts:
* [Modern JavaScript- Destructuring Assignment]( https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/OperatorsDestructuring_assignment)
* [freeCodeCamp](https://forum.freecodecamp.org/t/use-destructuring-assignment-to-assign-variables-from-arrays/170377)
| linusmwiti21 |
1,863,807 | Abstract Art Awards as Symbols of Recognition: Honoring Artistic Excellence | It is in our inherent human nature to provide motivation and encouragement to the people around us... | 0 | 2024-05-24T10:12:50 | https://dev.to/corporateolympiasydney/abstract-art-awards-as-symbols-of-recognition-honoring-artistic-excellence-3o7d | award | It is in our inherent human nature to provide motivation and encouragement to the people around us and push them towards becoming a better version of themselves.

When it comes to art and artists, it is important to provide them with the much-needed support and encouragement. Why? It is to bring complex ideas and emotions to life.
Providing the artists with [abstract art awards](https://www.olympia.com.au/corporate/abstract-awards/) is important because it will help provide them with an opportunity to connect with people from the art community. The abstract awards Award will encourage them to showcase their creations. This article will teach us more about abstract art and the importance of providing abstract awards.
## What is Abstract Art?
The work of artists can leave a lasting impact on our minds, helping bring imagination and creativity to the forefront. Abstract art mostly is a reflection of the thought process of the artist itself. It is their innate ability to think beyond the traditional ideas and bring something extraordinary on paper.
Abstract art can be anything from geometric shapes, to just a wide amalgamation of colors. In the truest sense it reflects the inner workings of the artist's minds and brings their thoughts and feelings on the canvas.
## Why do we need Abstract Art Awards?
It is important to hold abstract words because it will allow for better art appreciation. Generally, abstract art is very difficult for most people to understand. Most people find it difficult to understand the context of these paintings, and thus reduce their interest.
Organizing abstract awards, will help educate the masses about this art form along with honoring talented artists in the world. It will take a positive step towards appreciating art for its varied forms and ideas.
It is easier these days to hold abstract awards online to unite the abstract art community and appreciate their talent. Through abstract awards online, it also becomes easier to learn about different new abstract artists and encourage others.
The advantage associated with abstract awards online is that it helps in networking. As artists convene to talk about different techniques and topics leading to the sharing of knowledge. This shows that holding abstract art awards, [sports trophies and medals](https://www.olympia.com.au/corporate/school-trophies/) even if they are abstract awards online, enriches the art community as a whole.
## 1. The case of Emotions
Through the abstract award of art it allows artists to showcase how they use their emotions and intuition to create art. It helps them to make people understand that there is no set way to view abstract art, but rather their own feelings and imagination.
## 2. Challenging Traditional Ideas and Interpretations
Organizing abstract words will allow people to understand the different perspectives and emotions associated with abstract art. It will help provide an opportunity to break down any conventional ideas or views that may be present and help provide a new Outlook. It will allow people to conserve more about abstract artwork, which will lead to better knowledge and understanding.
## 3. Bringing together artists from different walks of Life
Another important reason why organizing abstract art awards is important is because it will provide a platform for people performing abstract art to come together. It will help create a place where abstract art can be appreciated without any judgment or preconceived notions. It will help in creating thought-provoking conversations that will have a positive impact on the artists.
## Why is Art Appreciation important?
There can be many reasons outlined necessary for holding abstract awards and art appreciation. One should not forget that it provides a historical perspective of different cultures, societies, and the modern world. Hence, having the ability to analyze art will allow an individual to reflect on the problems that were prevalent in society and compare if history has been repeating itself.
By appreciating art and organizing abstract awards, it will be possible to bring the community together to analyze different perspectives of artists, their designs, skilled techniques, and mastery of different hues of colors. Mostly, abstract art awards will provide an opportunity to appreciate art more from emotions, thoughts, and minds rather than what is just being viewed by the eye.
The abstract award will help in the following:
1. Helping create awareness about viewing art more from their heart and emotions than just the mind.
2. Improving their conscience and consciousness to understand the different emotions and perspectives.
3. Through the abstract art awards, it will be possible to create a Foundation for artists to come together and appreciate each other's work.
4. The abstract art awards will also contribute to learning about different stories and reflections on the canvas.
5. Lastly, through the Abstract Award, it will be possible to connect with art on a deeper level and learn the ability to reflect our thoughts and ideas.
## Relevance of Honoring Artistic Excellence
There always lies the question of whether abstract art awards or any awards relating to art are even relevant or not to society. And the answer is that it is indeed relevant.
The reason is that an announcement regarding abstract awards online or about abstract art awards in general creates a positive buzz around the event. This allows people to start learning about abstract awards and understand abstract art, which is usually beneficial to the growth of artists in general.
It is important to understand that art and artists are vital to sustaining a developing and liberal economy. Art allows an artist to express emotions and ideas, this sense of the world, and its many works through abstract patterns. It provides the people with a window not only to the artist's soul but also to the world itself. Hence, it becomes possible to recognize all these facets through the abstract award.
Most importantly, abstract art awards allow abstract artists to hear and see their work. They are allowed a platform to showcase their life's work and be appreciated for the mastery of their ideas and techniques in front of many critics and viewers alike. Abstract awards help them network and connect with like-minded individuals, leading to the community's growth as a whole.
At a time when society is becoming more modernized, with the foray of digital art, it has become important now more than ever to take the initiative of honoring artistic excellence. To help people learn about different abstract artists and their ability to weave emotions into stories and put them in their canvases. Providing an abstract award to such artists will allow them to enthusiastically showcase their creations.
Thus, it is important to hold abstract art awards and honor artists' excellence because:
1. It will help provide more exposure to new and old artists, bringing together art lovers, critics, curators, and buyers.
2. It will improve networking opportunities, allowing people to learn about them and their creations and helping them with finding new contacts.
3. With the abstract award and associated prizes, artists will be leveraged to manage their expenses better and be encouraged to develop more.
4. Apart from the prize money from the abstract award, they will be allowed to become published in magazines and newspapers and improve their standing in the art community.
## Parting Words
Creating a platform for holding abstract art awards is vital for the sustenance of artists. Even if there are abstract awards online, many opportunities present themselves to improve the appreciation and knowledge of abstract art. Hence, organizing an abstract award will provide artists with the platform to appreciate their artistic excellence. The abstract award will also push them toward further growth in the art community. | corporateolympiasydney |
1,863,804 | Exploring the Synergy Between Development and Futures Trading in the Crypto Space | In the dynamic world of cryptocurrency, the convergence of development and futures trading has... | 0 | 2024-05-24T10:07:24 | https://dev.to/klimd1389/exploring-the-synergy-between-development-and-futures-trading-in-the-crypto-space-3458 | webdev, beginners, news, cryptocurrency | In the dynamic world of cryptocurrency, the convergence of development and futures trading has emerged as a critical intersection. Developers are leveraging their expertise and innovative solutions to reshape the landscape of financial markets, particularly in the realm of futures trading.
The Role of Developers:
Developers play a pivotal role in driving innovation and technological advancement within the crypto space. Armed with cutting-edge technology and forward-thinking strategies, developers are constantly pushing the boundaries of what is possible in the world of finance. Their expertise in blockchain technology, smart contracts, and decentralized applications (dApps) enables them to create innovative solutions that address the evolving needs of traders and investors.
The Rise of Futures Trading:
Futures trading has gained significant traction in the crypto market, offering traders the opportunity to speculate on the future price movements of various digital assets. By entering into futures contracts, traders can hedge their risk, amplify their returns, and diversify their investment portfolios. The availability of futures trading on leading cryptocurrency exchanges has democratized access to these sophisticated financial instruments, allowing traders of all skill levels to participate in the market.
The Importance of WhiteBIT:
WhiteBIT, a premier cryptocurrency exchange, has established itself as a leader in the field of futures trading. With its robust trading platform and wide range of trading pairs, WhiteBIT provides traders with the tools they need to navigate the complex world of futures trading with ease. The recent listing of the $NOT-PERP trading pair on WhiteBIT further expands the exchange's offerings, providing traders with additional opportunities to capitalize on market opportunities and diversify their trading strategies.
Unlocking New Opportunities:
The integration of futures trading into development strategies opens up a world of possibilities for developers. By leveraging futures contracts, developers can hedge their exposure to volatile markets, lock in profits, and mitigate risk. Additionally, futures trading allows developers to gain insights into market sentiment and price trends, enabling them to make more informed decisions when developing new projects or allocating capital.
Looking Ahead:
As the crypto ecosystem continues to evolve, the synergy between development and futures trading is expected to grow stronger. Developers will play a key role in shaping the future of finance, driving innovation and pushing the boundaries of what is possible in the crypto market. By embracing futures trading and leveraging platforms like WhiteBIT, developers can unlock new opportunities for growth and success in the ever-changing landscape of cryptocurrency. | klimd1389 |
1,863,803 | Integrating with WordPress | A hands-on guide and example to integrate WordPress with Logto. This guide will walk you through... | 27,498 | 2024-05-24T10:07:09 | https://blog.logto.io/integrate-with-wordpress/ | webdev, wordpress, developer, opensource | A hands-on guide and example to integrate WordPress with Logto.
---
This guide will walk you through the process of integrating Logto with WordPress using the OIDC plugin. But first, let's take a look at the user experience once the integration is complete.
# The sign-in process with Logto integration
1. The user accesses the WordPress site's login page, `which is [SITE URL]/wp-login.php` by default, and there is a sign in by OIDC button.
2. The user clicks the button, and is redirected to the Logto's sign in page with your customized sign in experience.
3. The user choose a sign in method, and Logto will authenticate the user.
4. Once the user is authenticated, Logto will redirect the user back to the WordPress site.
5. WordPress will create a new user account or sign in the existing user account, and redirect the user to the previous page.
Now that we've seen the end result of integrating Logto with WordPress, let's get our hands dirty and dive into the integration process.
# Prerequisites
Before we begin, make sure you have the following:
1. A WordPress site: A fully operational WordPress site is required. Ensure administrative access to manage plugins and configure settings.
2. A Logto instance: Create a new Logto instance by visiting the [Logto Console](https://auth.logto.io/sign-in), or host your own instance by following the [installation guide](https://docs.logto.io/docs/tutorials/get-started/#logto-oss-self-hosted).
# Integration Steps
### Step 1: Create a Logto application
1. Visit the [Logto Console](https://auth.logto.io/sign-in).
2. Navigate to "Applications" and click "Create application".
3. Click "Create app without framework".
4. Select "Traditional Web" as the application type.
5. Name your application and click "Create application".
### Step 2: Install the plugin
1. Log in to your WordPress site.
2. Navigate to "Plugins" and click "Add New".
3. Search for "OpenID Connect Generic" and install the plugin by [daggerhart](https://www.daggerhartlab.com/).
4. Activate the plugin.
### Step 3: Configure the plugin
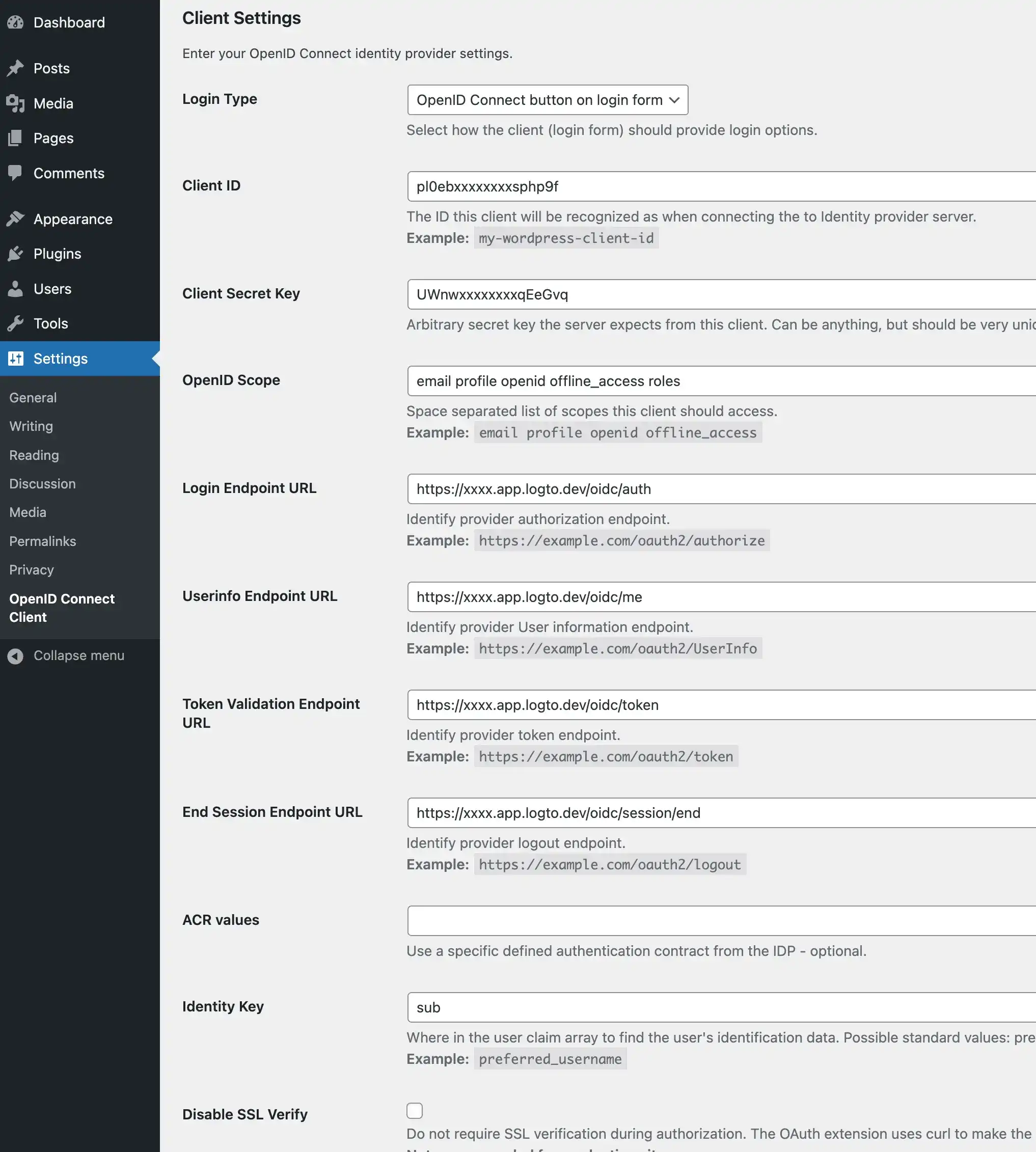
1. Open the plugin settings by navigating to "Settings" > "OpenID Connect Generic".
2. Fill in the following fields:
- **Client ID**: The app ID of your Logto application.
- **Client Secret**: The app secret of your Logto application.
- **OpenID Scope**: Enter `email profile openid offline_access`.
- **Login Endpoint URL**: The authorization endpoint URL of your Logto application, which is `https://[tenant-id].logto.app/oidc/auth`, you can click "show endpoint details" in the Logto application page to get the URL.
- **Userinfo Endpoint URL**: The userinfo endpoint URL of your Logto application, which is `https://[tenant-id].logto.app/oidc/me`.
- **Token Validation Endpoint URL**: The token validation endpoint URL of your Logto application, which is `https://[tenant-id].logto.app/oidc/token`.
- **End Session Endpoint URL**: The end session endpoint URL of your Logto application, which is `https://[tenant-id].logto.app/oidc/session/end`.
- **Identity Key**: The unique key in the ID token that contains the user's identity, it can be `email` or sub, depending on your configuration.
- **Nickname Key**: The key in the ID token that contains the user's nickname, you can set it to `sub` and change it later.
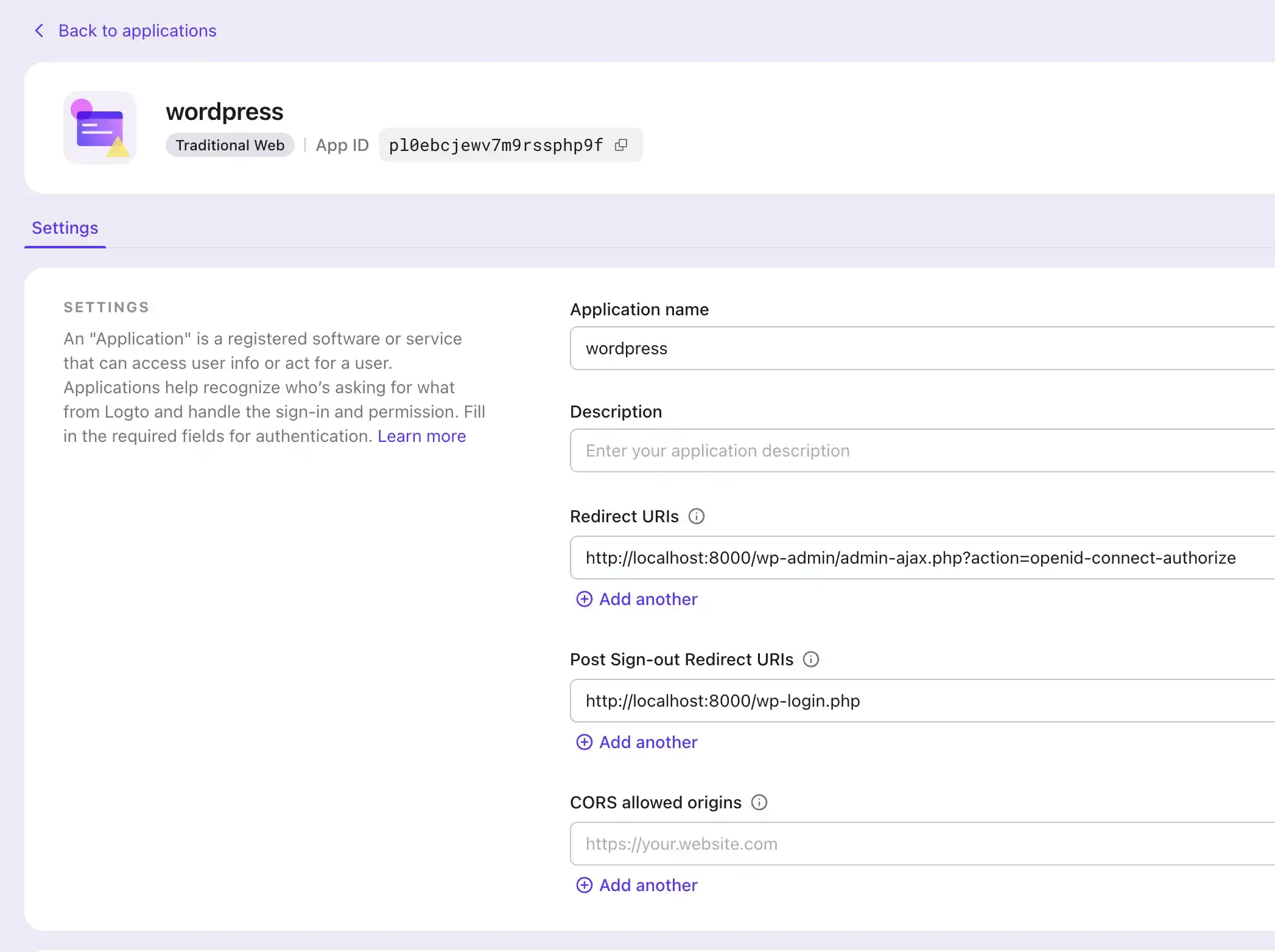
### Step 4: Configure the application
1. In the plugin settings, scroll down to the "Notes" section, and copy the "Redirect URI" value.
2. In the Logto Console, navigate to your application's settings.
3. Add the copied "Redirect URI" value to the "Redirect URIs" field.
### Step 5: Test the integration
1. Log out of your WordPress site.
2. Visit the WordPress login page and click the "Sign in with Logto" button.
3. You will be redirected to the Logto sign-in page.
4. Sign in with your Logto account.
5. You will be redirected back to the WordPress site and logged in automatically.
# Final steps
Congratulations! You have successfully integrated Logto with WordPress.
To further customize the integration, you can explore additional features in the plugin's setting page, such as linking existing users, customizing the login button, using SSO mode, and more.
{% cta https://logto.io/?ref=dev %} Try Logto Cloud for free {% endcta %}
| palomino |
1,863,802 | Issue Report: Dialogs Dismissed Prematurely with ensureSemantics | In this issue report (#149001), reported by user "rkunboxed", a problem in Flutter Web is outlined... | 0 | 2024-05-24T10:07:03 | https://dev.to/n968941/issue-report-dialogs-dismissed-prematurely-with-ensuresemantics-3162 | flutter, firebase, webdev, beginners | In this issue report (#149001), reported by user "rkunboxed", a problem in Flutter Web is outlined where dialogs dismiss prematurely when ensureSemantics is included. Clicking inside the dialog causes dismissal, contrary to expected behavior. A workaround is suggested involving the use of a hidden Semantics widget. This issue affects releases 3.22 and 3.23.
[read full article](https://flutters.in/issue-report-dialogs-dismissed-prematurely-with-ensuresemantics/)
Issue Details:
Issue Number: #149001
Reported by: rkunboxed
Date: 11 hours ago
Comments: 2
Description
Dialogs in Flutter Web are dismissed prematurely when ensureSemantics is included. Clicking inside the dialog on whitespace causes dismissal, contrary to expected behavior.
Issue Report: Dialogs Dismissed Prematurely with `ensureSemantics`
Steps to Reproduce
Run the code sample as a Web project in Chrome.
Click on the "Show Dialog" button.
Click anywhere inside the dialog that is not a form field.
Observe the dialog being dismissed.
Expected Results
The dialog should not dismiss when any content inside it is clicked. It should only dismiss if the area outside the content (the barrier) is clicked.
Actual Results
Clicking on whitespace inside the dialog causes it to be dismissed in Web builds. This only occurs in Web builds and only when WidgetsFlutterBinding.ensureInitialized().ensureSemantics(); is included.
Code Sample
import 'package:flutter/material.dart';
void main() {
runApp(const MyApp());
WidgetsFlutterBinding.ensureInitialized().ensureSemantics();
}
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return const MaterialApp(
title: 'Semantics Issue',
home: MyHomePage(),
);
}
}
class MyHomePage extends StatefulWidget {
const MyHomePage({Key? key}) : super(key: key);
@override
State<MyHomePage> createState() => _MyHomePageState();
}
class _MyHomePageState extends State<MyHomePage> {
void _onPressed() {
showDialog(
context: context,
barrierColor: Colors.grey.shade400,
builder: (context) {
return _dialogContent;
},
);
}
@override
Widget build(BuildContext context) {
return Scaffold(
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
ElevatedButton(
onPressed: _onPressed,
child: const Text('Show Dialog'),
)
],
),
),
);
}
Widget get _dialogContent => Center(
child: Container(
margin: const EdgeInsets.all(50),
child: const Material(
child: SizedBox(
height: 250,
width: 250,
child: Padding(
padding: EdgeInsets.all(20),
child: Column(
children: [
TextField(
decoration: InputDecoration(
border: OutlineInputBorder(),
labelText: 'Form field one',
),
),
SizedBox(height: 40),
TextField(
decoration: InputDecoration(
border: OutlineInputBorder(),
labelText: 'Form field two',
),
),
],
),
),
),
),
),
);
}
Workaround
A workaround is available by wrapping the dialog contents in a Stack and including a hidden Semantics widget inside Positioned.fill().
Widget get _dialogContentHack => Center(
child: Container(
margin: const EdgeInsets.all(50),
child: Material(
child: SizedBox(
height: 250,
width: 250,
child: Padding(
padding: const EdgeInsets.all(20),
child: Stack(
children: [
Positioned.fill(
child: Semantics(hidden: true),
),
const Column(
children: [
TextField(
decoration: InputDecoration(
border: OutlineInputBorder(),
labelText: 'Form field one',
),
),
SizedBox(height: 40),
TextField(
decoration: InputDecoration(
border: OutlineInputBorder(),
labelText: 'Form field two',
),
),
],
),
],
),
),
),
),
),
);
Screenshots or Video
Issue Report: Dialogs Dismissed Prematurely with ensureSemantics
[read full article](https://flutters.in/issue-report-dialogs-dismissed-prematurely-with-ensuresemantics/)
Logs
[Paste your logs here]
Flutter Doctor Output
[✓] Flutter (Channel stable, 3.19.2, on macOS 14.2.1 23C71 darwin-arm64, locale en-US)
• Flutter version 3.19.2 on channel stable at /Users/rona/Sites/Tools/flutter
• Upstream repository https://github.com/flutter/flutter.git
• Framework revision 7482962148 (3 months ago), 2024-02-27 16:51:22 -0500
• Engine revision 04817c99c9
• Dart version 3.3.0
• DevTools version 2.31.1
[✗] Android toolchain - develop for Android devices
✗ Unable to locate Android SDK.
Install Android Studio from: https://developer.android.com/studio/index.html
On first launch it will assist you in installing the Android SDK components.
(or visit https://flutter.dev/docs/get-started/install/macos#android-setup for detailed instructions).
If the Android SDK has been installed to a custom location, please use
`flutter config --android-sdk` to update to that location.
[!] Xcode - develop for iOS and macOS (Xcode 15.3)
• Xcode at /Applications/Xcode.app/Contents/Developer
• Build 15E204a
✗ Unable to get list of installed Simulator runtimes.
• CocoaPods version 1.15.2
[✓] Chrome - develop for the web
• Chrome at /Applications/Google Chrome.app/Contents/MacOS/Google Chrome
[!] Android Studio (not installed)
• Android Studio not found; download from https://developer.android.com/studio/index.html
(or visit https://flutter.dev/docs/get-started/install/macos#android-setup for detailed instructions).
[✓] VS Code (version 1.89.1)
• VS Code at /Applications/Visual Studio Code.app/Contents
• Flutter extension version 3.88.0
[✓] Connected device (2 available)
• macOS (desktop) • macos • darwin-arm64 • macOS 14.2.1 23C71 darwin-arm64
• Chrome (web) • chrome • web-javascript • Google Chrome 125.0.6422.76
[✓] Network resources
• All expected network resources are available.
! Doctor found issues in 3 categories.
Additional Information
Flutter Doctor Output: Provided above.
Workaround: A hacky workaround has been discovered by the author, wrapping the dialog contents in a Stack and including a hidden Semantics widget inside Positioned.fill().
Platform: Web
Found in Releases: 3.22, 3.23
Also read:
[What Lies Ahead for Flutter: Advancements, Innovations, & Beyond](https://flutters.in/what-lies-ahead-for-flutter/)
[NVIDIA Accelerates GPU, CPU, & AI Platform Roadmap: Launching New Chips Every Year](https://flutters.in/nvidia-accelerates-gpu/)
FAQs
What is the issue described in the report?
The issue revolves around dialogs being dismissed prematurely on Flutter Web when ensureSemantics is included. Clicking inside the dialog's whitespace causes dismissal contrary to expected behavior.
How can I reproduce the issue?
To reproduce the issue:
Run the provided code sample as a Web project in Chrome.
Click on the "Show Dialog" button.
Click anywhere inside the dialog that is not a form field.
Observe the dialog being dismissed.
What are the expected results?
The dialog should not dismiss when clicking inside it. It should only dismiss if the area outside the dialog (the barrier) is clicked.
[read full article](https://flutters.in/issue-report-dialogs-dismissed-prematurely-with-ensuresemantics/)
What are the actual results?
Clicking on whitespace inside the dialog causes it to be dismissed in Web builds. This behavior is observed only in Web builds and when WidgetsFlutterBinding.ensureInitialized().ensureSemantics(); is included.
Is there a workaround available?
Yes, a workaround has been discovered by the author. It involves wrapping the dialog contents in a Stack and including a hidden Semantics widget inside Positioned.fill().
How can I implement the workaround?
You can implement the workaround by using the provided _dialogContentHack method in the code sample. This method wraps the dialog contents in a Stack and includes a hidden Semantics widget inside Positioned.fill().
Additional Information
Platform: Web
Found in Releases: 3.22, 3.23
[read full article](https://flutters.in/issue-report-dialogs-dismissed-prematurely-with-ensuresemantics/) | n968941 |
1,863,801 | Bamboo products | Uravu Bamboo India, based in the picturesque Wayanad district of Kerala, India, is your premier... | 0 | 2024-05-24T10:05:49 | https://dev.to/uravu/bamboo-products-k4d | Uravu Bamboo India, based in the picturesque Wayanad district of Kerala, India, is your premier destination for high-quality bamboo handicrafts and sustainable **[bamboo products](https://www.uravustore.com/)**. As a leading advocate for bamboo as a versatile and eco-friendly resource, Uravu is dedicated to offering a wide range of bamboo items crafted by skilled artisans.
Our online store provides a convenient platform for customers in Kerala and across India to explore and purchase premium bamboo products. From exquisite handicrafts to bamboo saplings for plantation, Uravu Bamboo India is committed to promoting the use of bamboo as a sustainable alternative to traditional resources like wood.
Bamboo, known for its remarkable qualities, is gaining popularity as an environmentally friendly substitute. At Uravu, we recognize the importance of this incredible resource in reducing the ecological impact of single-use plastic pollution. Our extensive range of bamboo products is designed to offer not only functionality and beauty but also a conscious choice towards a greener and more sustainable future.
As a company rooted in the Wayanad district, we take pride in our efforts to contribute to the long-term sustainability of our planet. By providing premium bamboo products at competitive prices, Uravu aims to make a positive impact on both the local community and the global environment. Choose Uravu Bamboo India for an authentic and sustainable shopping experience that aligns with your commitment to environmental responsibility.
| uravu | |
1,863,800 | All India Typing Test, Typing Skill Test, Typing Certificate, CPCT English Typing | The adequacy of a business relies upon how things are done speedier . To finish your work speedier... | 0 | 2024-05-24T10:05:26 | https://dev.to/typingspeed2021/all-india-typing-test-typing-skill-test-typing-certificate-cpct-english-typing-462m | The adequacy of a business relies upon how things are done <a href="https://www.blog.typingspeedtestonline.com/hindi-typing-test mangal/"> speedier </a>. To finish your work speedier it is essential to make Typing <a href="https://www.blog.typingspeedtestonline.com/online typing-test-in-english-advanced/"> aptitudes </a> . All India Typing Test urges you to work cautiously on the PC, it helps in chatting with aides and clients, making reports, and finding new data.
How to moreover develop Typing speed?
Forming is about muscle memory, so the best system for <a href="https://www.blog.typingspeedtestonline.com/krutidev-typing-test/"> development </a> is to work on Typing continually. We made The India Typing Test Hindi give you the contraption to learn and work on Typing by memory in the best way. The way toward making <a href="https://www.blog.typingspeedtestonline.com/typing-test-in numeric/"> genuine </a> affinities gathers that you should set up your fingers at times and show limits. You ought to at <a href="https://www.blog.typingspeedtestonline.com/english-typing-test free/"> beginning </a> zero in director on <a href="https://www.blog.typingspeedtestonline.com/typing-master-online typing-test/"> accuracy </a>, ergonomics, and high India Typing Test Online Hindi Speed will go with time. Not to cripple yourself. Keep in mind, it is an <a href="https://www.blog.typingspeedtestonline.com/5-minute-typing-test-2/"> enormous </a> distance race, not a run, it is savvier to require ten minutes of training gradually than a solitary one hour run... <a href="https://www.blog.typingspeedtestonline.com/all-india-typing-test/"> read more </a>
Suggested Link:
<a href="https://www.blog.typingspeedtestonline.com/how-fast-can-i-type-the-alphabet/">How Fast Can I Type the Alphabet</a>
<a href="https://www.blog.typingspeedtestonline.com/alphabet-typer/">Alphabet Typer</a>
<a href="https://www.blog.typingspeedtestonline.com/speed-typing-online-games/">Speed Typing Online Games</a>
<a href="https://www.blog.typingspeedtestonline.com/speed-typer/">Speed Typer</a>
<a href="https://www.blog.typingspeedtestonline.com/alphabet-typing-test-calculate-typing-speed-and-accuracy-online-what-is-the-average-typing-speed-free-typing-test/">Alphabet Typing Test Calculate</a>
<a href="https://www.blog.typingspeedtestonline.com/mangal-typing-test/">Mangal Typing Test</a>
<a href="https://www.blog.typingspeedtestonline.com/online-typing-test-for-ssc-chsl/">Online Typing Test for SSC CHSL</a>
<a href="https://www.blog.typingspeedtestonline.com/typing-speed-test-software/">Typing Speed Test Software</a>
<a href="https://www.blog.typingspeedtestonline.com/punjabi-typing-test-in-raavi-font-2022/">Punjabi Typing Test</a>
<a href="https://www.blog.typingspeedtestonline.com/online-typing-tests/">Online Typing Tests</a>
<a href="https://www.blog.typingspeedtestonline.com/typing-speed-test-software/">Typing Speed Test Software</a>
RIT
| typingspeed2021 | |
1,863,799 | Software Development Service Ahmedabad | Ahmedabad, the bustling metropolis known for its rich heritage and vibrant culture, is also emerging... | 0 | 2024-05-24T10:04:14 | https://dev.to/benchkart/software-development-service-ahmedabad-5efj | benchkart, softwaredevelopment, b2b, services | Ahmedabad, the bustling metropolis known for its rich heritage and vibrant culture, is also emerging as a tech hub, with a myriad of [software development companies in Ahmedabad](https://benchkart.com/services/software-development-agency-in-ahmedabad
) propelling businesses to unprecedented heights. Among these innovative players, one name stands out – Benchkart.
At Benchkart, we don't just offer software solutions; we craft digital experiences that resonate with your audience and drive tangible results. With a finger on the pulse of industry trends and cutting-edge technologies, we are committed to delivering excellence in every project we undertake.
What sets Benchkart apart from the rest? Our unwavering dedication to client success. We understand that every business is unique, which is why we take a personalized approach to software development. Whether you're a startup looking to disrupt the market or an established enterprise seeking to optimize operations, we tailor our solutions to meet your specific needs and objectives.
From web applications to mobile apps, e-commerce platforms to enterprise software, our team of seasoned professionals possesses the expertise and creativity to bring your vision to life. We combine technical prowess with a keen eye for design, ensuring that your software not only functions flawlessly but also captivates users from the first click.
But our commitment to your success doesn't end with project delivery. At Benchkart, we believe in fostering long-term partnerships built on trust, transparency, and mutual growth. We stand by our clients every step of the way, providing ongoing support and guidance to help them navigate the ever-evolving digital landscape.
So why choose Benchkart for your software development needs in Ahmedabad? Because we don't just create software – we empower businesses to thrive in the digital age. Experience the Benchkart difference today and unlock the full potential of your enterprise.
Reach out to us and let's embark on a journey of innovation and success together. Your vision, our expertise – the perfect recipe for digital transformation. | benchkart |
1,863,795 | Scheduling Events in Firebase Firestore with Server Timestamps | Explore how to utilize Firebase Firestore to schedule events with server timestamps effectively, showcasing a practical implementation. | 0 | 2024-05-24T10:00:40 | https://dev.to/itselftools/scheduling-events-in-firebase-firestore-with-server-timestamps-3ccd | firebase, firestore, javascript, webdev |
At [itselftools.com](https://itselftools.com), we have developed over 30 applications using technologies like Next.js and Firebase. Throughout these projects, we have leveraged Firebase's powerful features, particularly Firestore, to handle real-time data management efficiently. In this tutorial, we'll explore how to use Firebase Firestore to add documents with server timestamps, specifically focusing on scheduling events.
## Understanding the Code
The provided code snippet demonstrates how to create a new document in the Firestore database under the collection 'events'. Here’s a breakdown of each part of the code:
```javascript
// Add a document with server timestamp
const db = firebase.firestore();
db.collection('events').add({
name: 'Webinar',
startTime: firebase.firestore.FieldValue.serverTimestamp()
}).then(docRef => {
console.log('Event scheduled with ID: ', docRef.id);
}).catch(error => {
console.error('Error scheduling event: ', error);
});
```
- **firebase.firestore()**: This function initializes the Firestore service.
- **db.collection('events')**: Specifies the 'events' collection where the document will be added.
- **add({...})**: Adds a new document to the collection. The document contains two fields: 'name' and 'startTime'. The 'name' field is a simple string that describes the event, while 'startTime' is a special field that uses `firebase.firestore.FieldValue.serverTimestamp()`, telling Firestore to fill this field with the server's current timestamp at the moment of document creation.
- **.then(docRef => {...})**: This callback function is executed when the document is successfully added. It logs the unique identifier of the document (`docRef.id`).
- **.catch(error => {...})**: If there is any error during the document creation, this callback function captures and logs the error.
## Benefits of Using Server Timestamps
Server timestamps are incredibly useful because they ensure the synchronization of times recorded in the database, regardless of the client's local time settings. This is crucial for applications such as scheduling events, where accuracy and consistency of time are essential across different users and devices.
## Practical Uses
Using server timestamps in event scheduling helps in maintaining consistency across time zones and devices, making the application reliable for users globally. This setup is ideal for various applications like online webinars, meeting schedulers, and appointment booking systems.
## Conclusion
The ability to add events with server timestamps using Firestore is just a glimpse of what Firebase can do to enhance real-time data handling in web applications. If you are interested to see this code and similar functionalities in action, visit some of our apps at [Words Translated Across Different Languages](https://translated-into.com), [Online English Word Search Tool](https://find-words.com), and [Instant Webcam Testing Online](https://webcam-test.com). These tools demonstrate the power of integrating Firebase with modern web applications.
Delving into Firebase for your projects not only simplifies backend management but also accelerates development, making real-time interactions seamless and more efficient. | antoineit |
1,863,794 | AWS for Gaming Industry Powering Software and Hardware Innovation | Introduction That's added to the rate of growth experienced by the gaming sector, thanks to... | 0 | 2024-05-24T10:00:00 | https://sudoconsultants.com/aws-for-gaming-industry-powering-software-and-hardware-innovation/ | industry, gaming, awsgaming | <!-- wp:heading {"level":1} -->
<h1 class="wp-block-heading">Introduction</h1>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>That's added to the rate of growth experienced by the gaming sector, thanks to technological innovation and an increasing use of digital platforms. All of this is combined with a very important shift towards cloud services in the gaming industry, dealing with issues of scalability, flexibility, and cost, which are very basic, considering the dynamic nature of game development and deployment. Its major driving force lies in Amazon Web Services, the comprehensive cloud services that a lot of gaming companies consider a kind of cornerstone that helps provide opportunities and infrastructure important for innovating and executing in a very highly competitive landscape around gaming.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>AWS provides a suite of services tailor-made to the gaming sector, which are basically related to the following categories: cloud gaming development, game servers, game security, live operations, game analytics, and AI plus machine learning. With over 290 game development partners today, after years of unrivaled experience alongside leading industry customers such as Sony Interactive Entertainment, Epic Games, and Ubisoft, the company turned itself into a credible partner for game developers worldwide. The possibility of transforming game workloads through purpose-built cloud services and solutions, combined with a powerful spirit of innovation and collaboration, winds up being an indispensable ally for the future of the gaming industry. In the following section, we delve into specifics about how AWS supports the gaming industry in the following areas: offerings, benefits, and the turn it has been able to cause in game development and deployment. The following pages of this paper aim to demonstrate, through detailed explanations and case studies, how AWS cloud services have empowered gaming companies to meet challenges, scale operations, and deliver phenomenal gaming experiences to players across the globe.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">The Importance of Cloud Services in Gaming</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Cloud services have totally changed the face of the gaming sector and come with insurmountable benefits in scalability, flexibility, and cost efficiency. It's a game changer in game development, and, of course, such benefits are scalable and flexible, with the decrease or increase in game developer resources being incorporated at whatever time the situation may appeal. It erases costly infrastructure investments</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Scalability and Flexibility</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Scalability equips developers with the ability to handle those unpredictable requirements associated with a game that may pop up unexpectedly, like an excessive number of player requirements. Also, developers can experiment without the fear of huge financial losses in case there is a need to scale up because of the ideas that have been perceived favorably.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Cost-Efficiency</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>One of the most important areas in which cloud computing helps game development is through cost efficiency. Game developers using cloud services can be ability to significantly cut on their initial investments in hardware and infrastructure. The pay-as-you-go model of cloud computing allocates game developers to be cost-effective in budget spending, in order that resources are consumed frugally. This model reduces the cost burden on developers since all the server maintenance and updates are done by the cloud service providers, thus allowing developers to focus on creating and refining their games.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Overcoming Challenges</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Although there are many advantages, there are multiple challenges that need to be dealt with during the implementation of game development in the cloud. These are latency, bandwidth limitations, data security issues, vendor lock-in, and scalability. Some of the solutions to these problems are optimizations (game code, etc.), Content Delivery Networks (CDNs), caching, and usage of strong, scalable data security. The cloud service providers should ensure that their services are interoperable and easy to scale to avoid lock-ins for game developers and offer the best that cloud computing has to offer in game development.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">The Rising Demand for Cloud Solutions</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Scalability, cost effectiveness, and collaboration need have been the drivers for adopting cloud solutions in the gaming industry. Cloud platforms allow game development teams to scale their infrastructure according to project needs in order to minimize capital investment in hardware. The pay-as-you-go model of cloud computing reduces costs of infrastructure significantly, mainly for smaller development studios working on a shoestring budget. Cloud platforms also present a centralized working environment for team members, thus increasing productivity and transparency across the development process. Disaster recovery features provided in cloud solutions ensure that game assets and data are securely stored and can be rapidly restored in the event of anything happening.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>In conclusion, cloud services have revolutionized the gaming industry by providing tools and infrastructure that game developers need in order to innovate and achieve success. With these difficulties overcome and benefits drawn from, cloud gaming looks set to progress further with the gaming industry.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">AWS Offerings for the Gaming Industry</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS has a large and broad portfolio of services and products designed for the gaming space, with the needs of developing—from conceptual to post-release—games in mind. Among the most important categories of service are: compute, storage, networking, and analytics. This makes the AWS platform quite likable for many of the game developers who are willing to engage with cloud technology.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Compute Services</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">EC2 Instances</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon EC2 instances are scalable compute capacity in the AWS Cloud. For gaming, EC2 instances may be usable for game servers to run the computational needs of a multiplayer game, simulation, and server-side application. Game developers have the choice of multiple types of instances, with options optimized for game servers to receive optimum performance and cost.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Lambda</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers. In a gaming context, the use case could be running a backend service such as matchmakers, leaderboards, or in-game events, where the code runs to meet triggers based on changes in game states or player actions effects.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Fargate</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS Fargat will make possible the scalability and flexibility of multiplayer games through containerized deployments of game servers, which means game servers can be scaled up and down to guarantee a frictionless, responsive gaming experience.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Storage and Database Services</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">S3</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon Simple Storage Service (S3) is a service that offers scalable object storage, with data availability and security at a higher scale. S3 can be used to store game-related assets like textures, models, and audio files, as well as backups of the game data. It features durability and has been designed to be scalable, which are the two most important features that provide a place for a large amount of data and the possibility to grow that amount in the future.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">DynamoDB</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It is meant for storing real-time game data, like player profiles, game state, and leaderboard rankings. The scalability and performance of the service make it the perfect one for applications that require rapid data access.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">RDS</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon Relational Database Service (RDS) offers a quick means to set up, operate, and scale a relational database in the cloud. RDS, with its various database engine options, can be used to manage relational databases storing structured information for the gaming applications, like player information and game statistics. Options include database engines such as MySQL, PostgreSQL, MariaDB, Oracle Database, and SQL Server, to serve the different needs that may arise during game development.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Networking and Content Delivery</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">VPC</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon Virtual Private Cloud (VPC) is an important service that allows you to provision a logically isolated section of the AWS cloud where you can launch AWS resources in a virtual network that you define. In terms of gaming, VPCs can be used to build a safe, private network for game servers such that the game data is safe and only accessible to those who are supposed to have access to it.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">CloudFront</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon CloudFront is a fast content delivery network (CDN) service that safely delivers data, video, applications, and APIs to customers throughout the world with low latency and high transfer speeds. For gaming, it delivers game assets and updates to the games of players around the world, ensuring fast loading times and experiences without interruptions.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Route 53</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon Route 53 is a scalable and highly available Domain Name System (DNS) web service built to give developers and businesses an extremely reliable and cost-effective way to route end users to internet applications. It does this by translating human-readable names such as <a href="http://www.example.com/">www.example.com</a> into numeric IP addresses such as 192.0.2.1 that computers use to connect to each other.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Analytics and Monitoring</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">CloudWatch</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon CloudWatch is a monitoring and observability service built specifically for DevOps engineers, developers, site reliability engineers (SREs), and IT managers. For gaming, use CloudWatch to monitor game performance, player behavior, and application health so that insights inform the optimization of game performance and player experience.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">GameLift</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon GameLift is an Amazon Web Services solution for hosting dedicated game servers for multiplayer games. It is a fully managed service that makes it easy for developers to deploy and scale multiplayer games. GameLift removes the technical challenges, operational risks, and financial complexity of operating dedicated game servers, and it provides the flexibility to help developers be more successful.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">QuickSight</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon QuickSight is a scalable, serverless, embeddable, machine-learning-powered business intelligence service built for the cloud that makes it easy to deliver insights to everyone in your organization. For gaming, QuickSight can be used for the analysis of the game's big data source to learn about player behavior as well as game performance and monetization strategies that help one make decisions for the improvement of player engagement.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Case Study: Implementing AWS for a Major Gaming Company</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Background</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Whatwapp, founded in Milan in 2013, aimed to reshape classical cultural card games into video games. By 2023, the app had reached 29 million downloads, with 900,000 monthly and 300,000 daily users. As Whatwapp grew, it faced challenges in improving scalability and backend management for its games. The company sought to standardize its game infrastructure to save engineering time, support player retention, and avoid accumulating technical debt. Rewriting feature implementations to share among its games was time-consuming and led to inconsistencies, complexity, and incompatibility. Whatwapp decided to migrate its games' backend solution and unify implementations on AWS through Nakama, an open-source distributed social and near-real-time server for games and apps provided by Heroic Labs, an AWS Partner.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Implementation Steps</h3>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading"><strong>Standardizing Backend Operations</strong><strong></strong></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Whatwapp aimed to standardize the back-end operations to avoid constant rewrites and maintain compatibility with older versions. The fact that the company had been using the Amazon Elastic Kubernetes Service (Amazon EKS) for its back-end game operations had played a significant role. Whatwapp self-hosted the Nakama solution at its Kubernetes clusters with Amazon EKS to manage the back-end game operation. This setup allowed Whatwapp to share features between the games more efficiently and, therefore, had a third of what would have been needed to implement features using the old method.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":4} -->
<h4 class="wp-block-heading"><strong>Accommodating Scalability and Performance</strong><strong></strong></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In 2022, Whatwapp successfully migrated its backend operations to Nakama, running on its own Kubernetes clusters using Amazon EKS. This migration enabled Whatwapp to use a scalable server capable of handling 40,000 simultaneous players, providing improved visibility, time savings, and feature enhancements. The power of Nakama on Amazon EKS allowed Whatwapp to identify gaming bottlenecks and underperforming code, enabling targeted improvements to the code base.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Enhancing Player Experience</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>With AWS powering its new infrastructure, Whatwapp was able to get content to the players faster than ever before, and without requiring the players to download the updates. This solution significantly enhanced the player's experience, as they could start using almost new stuff the same second it was deployed. The slim infrastructure also made it easy for engineers of Whatwapp to design and share new features, and the solution was better social and exciting competitive gameplay that made the games more attractive.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Results and Impact</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>As the company managed to standardize game infrastructure, they can save on engineering time and reduce technical debts. The scalability and performance were also improved to add more concurrent players, and the usage of lean infrastructure helped content reach players faster, thereby improving retention and satisfaction. Moreover, this has improved the scalability and performance of Whatwapp, allowing the company to host more concurrent players with an improved gaming experience. It will also deliver content faster to increase player retention and satisfaction.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>According to the technical lead at Whatwapp, Giovanni Piumatti, "With AWS powering our new infrastructure, we deliver content to players faster than ever before, and players can use it almost as quickly as we can deploy it, without forcing players to download any updates."</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Whatwapp has succeeded in integrating AWS and Nakama on Amazon EKS—an integration that has proved how services in the cloud can be used to transform the gaming sector into a scalable, efficient, and player-centric place. This study has demonstrated how prospective cloud computing technologies can support game development and deployment. It also provides evidence for the potential of gaming companies to leverage AWS to innovate in their product and service offerings.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Implementation setup </h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Use these steps to create something similar through CLI and console to <a href="https://whatwapp.com/">Whatwapp's</a> implementation by a gaming company. This setup involves creating an Amazon EKS cluster, configuring the required IAM permissions, and deploying game server resources using Nakama on Amazon EKS.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Prerequisites</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li><strong>AWS CLI:</strong> Make sure to have AWS CLI installed and properly configured. Refer to <a href="https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html">AWS CLI User Guide</a> if necessary.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>kubectl:</strong> Install kubectl, the Kubernetes command-line tool. Refer to <a href="https://kubernetes.io/docs/tasks/tools/">Kubernetes documentation.</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>IAM Permissions:</strong> Your IAM User should have the correct permissions for creating and managing EKS clusters, IAM Roles and resources associated with them. Use the following command to check the permissions of your current user: <strong><em>aws sts get-caller-identity</em></strong></li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 1: Create an Amazon EKS Cluster</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Create a VPC:</strong> Using the AWS Management Console, create a new VPC or select an existing VPC. Take note of the VPC ID, as it will be required later on.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Create an IAM Role for EKS:</strong> Go to the AWS IAM console and create a new role with the AmazonEKSClusterPolicy policy attached to it. This role will be used by EKS to make calls to other AWS services on your behalf.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Create an EKS Cluster: </strong>Use AWS CLI to create an EKS cluster. Make sure to replace <strong><em><cluster-name>, <vpc-id> and <iam-role></em></strong> with appropriate values.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code>aws eks create-cluster --name <cluster-name> --role-arn <iam-role> --resources-vpc-config subnetIds=<subnet-id>,subnetId=<subnet-id>,subnetId=<subnet-id></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Configure kubectl:</strong> After you have created your Amazon EKS cluster, you must configure your kubeconfig file to use it</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code>aws eks update-kubeconfig --region <region-code> --name <cluster-name></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 2: Deploy Nakama on Amazon EKS</h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li><strong>Pull Nakama Docker Image:</strong> Pull the Nakama Docker image.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>docker pull heroiclabs/nakama:latest</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Create a Deployment:</strong> Create a Kubernetes Deployment YAML file (nakama-deployment.yaml) with the following configurations for Nakama. This involves defining the Docker image, the ports, and the environment variables for Nakama.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code>apiVersion: apps/v1
kind: Deployment
metadata:
name: nakama
spec:
replicas: 1
selector:
matchLabels:
app: nakama
template:
metadata:
labels:
app: nakama
spec:
containers:
- name: nakama
image: heroiclabs/nakama:latest
ports:
- containerPort: 7350
- containerPort: 7351
- containerPort: 7352
- containerPort: 7353
- containerPort: 7354
- containerPort: 7355
- containerPort: 7356
- containerPort: 7357
- containerPort: 7358
- containerPort: 7359
- containerPort: 7379
- containerPort: 7380
env:
- name: NAKAMA_PORT
value: "7350"
- name: NAKAMA_HOST
value: "0.0.0.0"
- name: NAKAMA_DB_TYPE
value: "postgres"
- name: NAKAMA_POSTGRES_USER
valueFrom:
secretKeyRef:
name: nakama-db-credentials
key: username
- name: NAKAMA_POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: nakama-db-credentials
key: password
</code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Apply the Deployment:</strong> Apply the deployment to your EKS cluster.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code>kubectl apply -f nakama-deployment.yaml</code></pre>
<!-- /wp:code -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li><strong>Expose Nakama Service:</strong> Expose the Nakama service, so that it can be accessed from outside.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>kubectl expose deployment nakama --type=LoadBalancer --port=7350:7350</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 3: Verify Deployment</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Check Deployment Status: </strong>Verify that the Nakama deployment is running correctly.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>kubectl get deployments</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Check Service Status:</strong> Check the status of the Nakama service to ensure it's accessible.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>kubectl get svc</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>This architecture would set up a simple deployment infrastructure for a game server using Nakama across Amazon EKS very similar to Whatwapp's implementation. Game developers can make alterations to this architecture as per the game requirements, for instance, using custom Nakama configurations or integrating more of the AWS services like analytical, storage, content delivery and so on.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Conclusion</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon Web Services has played a vital role in powering software and hardware innovation within the gaming industry. By providing a complete suite of cloud services crafted for the unique needs of game developers, AWS has brought never-seen-before scalability, flexibility, and cost-effectiveness in game development and deployment. AWS has been enabling game developers—be it running game servers on EC2 instances, taking advantage of serverless computation with Lambda, or containerized game servers with Fargate. AWS provides the infrastructure backbone that game developers need to bring their visions to life.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Instead, AWS has revolutionized how game data is managed and accessed with AWS's storage and database service. S3 is used for storing assets, and DynamoDB is for real-time data. VPC for secure networking and CloudFront for faster content delivery are some of the networking and content delivery features of AWS has made sure that the games reach the end user throughout the world with low latency. In addition, analytics and monitoring tools like CloudWatch, QuickSight, and others have been providing key insights into the behavior of gamers and in-game performance to continuously optimize and improve games.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">References</h2>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>AWS for Gaming: <a href="https://aws.amazon.com/gaming/">AWS Official Website</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Game Development with AWS: <a href="https://d1.awsstatic.com/whitepapers/architecture/AWS_Game_Development_Whitepaper.pdf">AWS Whitepaper</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Nakama on AWS: <a href="https://www.heroiclabs.com/blog/nakama-on-aws/">Heroic Labs Blog</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Scaling Multiplayer Games with AWS: <a href="https://aws.amazon.com/blogs/aws/new-amazon-gamelift-for-developers/">AWS Blog Post</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Optimizing Game Performance with AWS: <a href="https://www.gdcvault.com/play/1026846/Optimizing-Game-Performance-with">GDC 2020 Presentation</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Machine Learning in Gaming: <a href="https://aws.amazon.com/blogs/machine-learning/">AWS Machine Learning Blog</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Edge Computing for Gaming: <a href="https://aws.amazon.com/blogs/compute/introducing-amazon-lambda-edge/">AWS Edge Computing Blog</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Cloud-Native Game Development: <a href="https://www.cncf.io/blog/2021/01/12/cloud-native-game-development/">Cloud Native Computing Foundation</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AWS Global Infrastructure: <a href="https://aws.amazon.com/about-aws/global-infrastructure/">AWS Global Infrastructure Page</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Future of Cloud Gaming: <a href="https://www.forbes.com/sites/forbestechcouncil/2021/02/22/the-future-of-cloud-gaming/?sh=6b8e8a6e6f5a">Forbes Article</a></li>
<!-- /wp:list-item --></ol>
<!-- /wp:list --> | sidrasaleem296 |
1,863,792 | Boosted Pro Male Enhancemen : Is It Worth a Try? | Boosted Pro Male Enhancement sexual execution: penis size, endurance, and fulfillment. The product... | 0 | 2024-05-24T09:59:39 | https://dev.to/divya337/boosted-pro-male-enhancemen-is-it-worth-a-try-5fa5 | Boosted Pro Male Enhancement
sexual execution: penis size, endurance, and fulfillment. The product contains a pro-sexual supplement rich mix that is suspected to support these elements.
Boosted Pro Male Enhancement are all-regular, simple to-take, solid, and delicate pills produced using extricates from hemp plants. It is a charming crude that is easy to consume and skillfully screens serious areas of strength for different and conditions.The cerebellum and body anticipate that we should assume a basic part in keeping up with our exceptional appearance. Tragically, as we age, our physical, mental, and neurological prosperity falls apart, bringing about body misfire. We become truly depleted, drained, aggravated, and inconvenience resting. Moreover, we become really feeble and incapable to perform at our best. Subsequently, we expect help to develop our psychological and actual fortitude through canning.
https://sites.google.com/view/increasetestosteronepowerandse/home
https://sites.google.com/view/boosted-promale-enhancement/home
https://groups.google.com/g/boosted-pro-male-enhancement--/c/Xd3yxVpbiCw
https://groups.google.com/g/boosted-pro-male-enhancement--/c/FOSapPtWEjk
https://medium.com/@trimketoboost/boosted-pro-male-enhancement-negative-side-effects-or-legit-benefits-e983d761a839
https://medium.com/@trimketoboost/boosted-pro-male-enhancement-is-it-worth-a-try-e564dc146b03
https://mit45-karatom.clubeo.com/calendar/2024/05/22/boosted-pro-male-enhancement-does-it-improve-sexual-performance?
https://mit45-karatom.clubeo.com/calendar/2024/05/22/boosted-pro-male-enhancement-are-they-really-worth-buying-in-2024?
https://www.eventbrite.com/e/boosted-pro-male-enhancement-scam-side-effects-does-it-work-tickets-911859104127?aff=oddtdtcreator
https://www.eventbrite.com/e/boosted-pro-male-enhancement-does-it-really-work-tickets-911859866407?aff=oddtdtcreator
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/d613f023-cf18-ef11-989a-000d3a84ad0c
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/56944a7f-cf18-ef11-989a-000d3a84ad0c
https://sites.google.com/view/eroboostmale-enhancement/home
https://sites.google.com/view/eroboost-male--enhancement/home
https://groups.google.com/g/eroboost-male-enhancement-/c/syS8tXiEPeA
https://groups.google.com/g/eroboost-male-enhancement-/c/j1oo6Cjemc8
https://medium.com/@trimketoboost/eroboost-male-enhancement-real-benefits-or-side-effects-7a4e5e06c403
https://medium.com/@trimketoboost/eroboost-male-enhancement-is-it-safe-effective-f0c56197fbc3
https://mit45-karatom.clubeo.com/calendar/2024/05/22/eroboost-male-enhancement-is-it-worth-a-try?_
https://mit45-karatom.clubeo.com/calendar/2024/05/22/eroboost-male-enhancement-price-scam-ingredients-reviews?
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/201e2c6f-d018-ef11-989a-000d3a84ad0c
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/67bc98ab-d018-ef11-989a-000d3a84ad0c
https://www.eventbrite.com/e/eroboost-male-enhancement-scam-side-effects-does-it-work-tickets-911866004767?aff=oddtdtcreator
https://www.eventbrite.com/e/eroboost-male-enhancement-does-it-really-work-tickets-911867148187?aff=oddtdtcreator
https://www.facebook.com/HorsePowerMaleEnhancementUS/
https://sites.google.com/view/horse-power-male-enhancement-/home
https://sites.google.com/view/horse-power-maleenhancement/home
https://groups.google.com/g/horse-power-male-enhancement-/c/zEnLmMO7We4
https://groups.google.com/g/horse-power-male-enhancement-/c/75CQAeuundw
https://medium.com/@trimketoboost/horse-power-male-enhancement-increase-testosterone-power-and-sexual-stamina-33b12f47ee89
https://medium.com/@trimketoboost/horse-power-male-enhancement-serious-side-effects-warnings-80858ae68153
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/c8be168a-9119-ef11-989a-000d3a84ad0c
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/eabb61e1-9119-ef11-989a-000d3a84ad0c
https://rasra.clubeo.com/calendar/2024/05/23/horse-power-male-enhancement-does-it-works-or-not?
https://rasra.clubeo.com/calendar/2024/05/23/horse-power-male-enhancement-legit-scam-is-it-improve-sexual-power?
https://www.facebook.com/PinkHorsePowerMaleEnhancement/
https://aeraja.clubeo.com/calendar/2024/05/23/pink-horse-power-male-enhancement-reclaim-your-power-essential-male-enhancement-supplements
https://aeraja.clubeo.com/calendar/2024/05/19/pink-horse-power-male-enhancement-elevate-your-experience-comprehensive-male-enhancement-guide
https://pinkhorsepowermaleenhancement.bandcamp.com/track/pink-horse-power-male-enhancement
https://groups.google.com/g/pink-horse-power-male-enhancement/c/BNO_2gWpx-s
https://groups.google.com/g/pink-horse-power-male-enhancement/c/3A5KT1W8jnE
https://sites.google.com/view/pinkhorsepowermaleenhancement/
https://sites.google.com/view/pink-horse-power/home
https://medium.com/@PinkHorsePower/pink-horse-power-male-enhancement-beyond-limits-exploring-advanced-male-enhancement-techniques-41edf63a394b
https://medium.com/@PinkHorsePower/pink-horse-power-male-enhancement-the-path-to-peak-performance-male-enhancement-explained-40d567e77eb9
| divya337 | |
1,682,172 | Think Golang in oop way | I began learning Golang for no reason other than it is a highly optimized, low CPU-consuming language... | 0 | 2024-05-24T09:53:52 | https://dev.to/kingrayhan/think-golang-in-oop-way-1ki | go | ---
title: Think Golang in oop way
published: true
description:
tags: go,golang
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/q52tbvcvsr5p2xrifpol.png
---
I began learning Golang for no reason other than it is a highly optimized, low CPU-consuming language that is excellent for creating microservices. It may appear humorous, but I began learning Go because of its adorable logo. 🥰
Anyway, I started learning GoLlang with the intention of creating a highly effective and optimized backend API. I come from the `typescript` environment, where I could arrange my apps in multiple OOP paradigms, something I can't do in the functional world of Golang. I sink into a large body of water. I was looking through various backend libraries to learn how they organize their applications and how they configure/inherit functionality. All I discovered is that I must become a Go pointer master. Using this pointer, I can accomplish OOP capability in this language. That's why I started translating my OOP thinking into a Golang functional approach.
> This article is a Golang translation of OOP ideas.
### Basic Class property, method and it's object
First consider the below typescript code 👇
```js
class Customer {
public identification: string;
private name: string;
private age: number;
constructor(identification:string, name: string, age: number) {
this.identification = identification;
this.name = name;
this.age = age;
}
getName() {
return this.name;
}
getAge() {
return this.age;
}
}
```
#### Declare class and define fields
To translate this class into Golang, we need the struct of Go which is a composite type. we can define properties in a struct with visibility also. This is achieved by a simple rule: if a field starts with a lowercase letter, it's private and can only be accessed within the file it's declared. Conversely, if it begins with an uppercase letter, it's public and accessible from other files.
Here is the translated Customer class with it's public/private fields
```go
type Customer struct {
Identification string
name string
age int
}
```
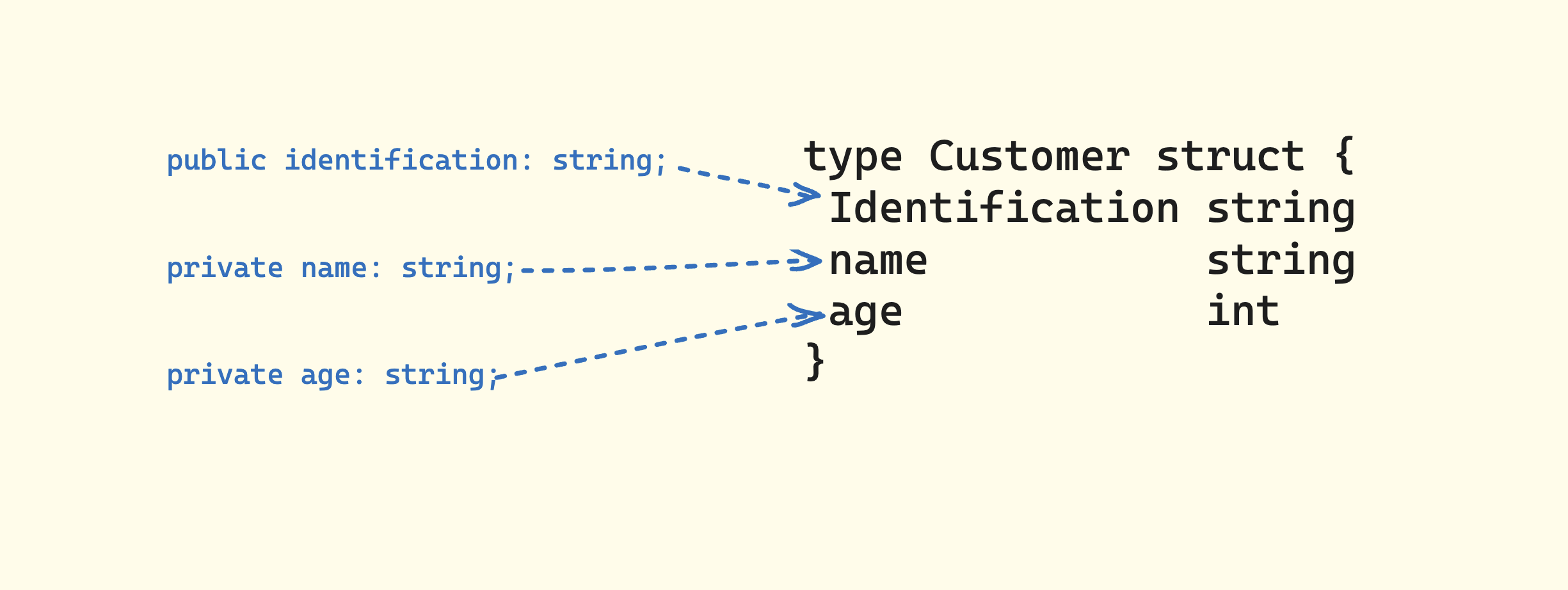
## How do I create the object of this? 🥹
Cool down, Golang introduces a unique twist to object creation compared to other object-oriented languages. Instead of directly crafting objects like in `TypeScript`, Golang leans on a special convention: using a function named New() to initialize and return a pointer to the newly created struct. This function, starting with an uppercase letter, plays a crucial role in Golang's object instantiation. See the code below ⬇️
```go
func New(id string, name string, age int) *Customer {
return &Customer{
Identification: id,
name: name,
age: age,
}
}
```
Create a Customer object by providing initial values to its constructor. In the following code snippet, only the capitalized fields are accessible, while private fields remain inaccessible.
```go
func main() {
// Initializing a Customer object with constructor values
customer := customer.New("customer1", "Rayhan", 27)
// Accessing a public field
fmt.Print(customer.Identification) //✅
// Attempting to access private fields
// This will result in an error
fmt.Print(customer.name) //❌
fmt.Print(customer.age) //❌
}
``` | kingrayhan |
1,863,791 | If CI/CD Pipelines Were Human: A Day in the Life | Imagine if Continuous Integration and Continuous Deployment (CI/CD) pipelines were human. This... | 0 | 2024-05-24T09:53:33 | https://dev.to/mitch1009/if-cicd-pipelines-were-human-a-day-in-the-life-47d | Imagine if Continuous Integration and Continuous Deployment (CI/CD) pipelines were human. This "person" would be the ultimate multitasker, an unsung hero of the software development world, working tirelessly behind the scenes to ensure that every piece of code is flawlessly integrated and deployed. Let’s explore a day in the life of our humanized CI/CD pipeline.
### Early Morning: Rise and Shine
Our CI/CD human wakes up early, ready to tackle the day. The first task is a quick review of overnight activities. This includes checking logs and ensuring that all automated tests ran smoothly. Just like a meticulous project manager, they assess the status of the build environment, verifying that everything is in tip-top shape for the day’s work.
### Morning Routine: Code Integration
With a fresh cup of coffee in hand, the CI/CD human dives into the morning routine: integrating new code changes. Developers from different parts of the world have submitted their code overnight, and it’s up to our CI/CD to merge these changes. They carefully review each commit, ensuring that there are no conflicts and that the new code aligns with the existing codebase. Any discrepancies are flagged and communicated back to the developers for quick resolution.
### Mid-Morning: Automated Testing
By mid-morning, it’s time for automated testing. Like a diligent quality assurance specialist, our CI/CD human runs a series of tests on the integrated code. Unit tests, integration tests, and regression tests are all part of the repertoire. Each test is meticulously executed, and results are promptly analyzed. If any issues are found, the CI/CD human communicates with the relevant developers to get them fixed before the next deployment.
### Lunchtime: Monitoring and Optimization
During lunchtime, our CI/CD human takes a brief break but remains vigilant, constantly monitoring the health of the system. They review performance metrics and logs to identify any potential bottlenecks or areas for optimization. Just like a proactive engineer, they tweak configurations and make adjustments to ensure the pipeline runs efficiently.
### Afternoon: Deployment Prep
The afternoon is dedicated to deployment preparation. Our CI/CD human works like a seasoned operations manager, ensuring that the deployment environment is ready. They verify that all dependencies are in place, database migrations are prepared, and rollback plans are established in case anything goes awry. Communication with stakeholders is key, and our CI/CD human ensures that everyone is aware of the upcoming deployment.
### Late Afternoon: The Big Deployment
As the day progresses, it’s time for the big deployment. With the precision of a skilled technician, our CI/CD human orchestrates the deployment process. They push the code to production, monitoring every step to ensure a smooth transition. Any issues that arise are swiftly addressed, minimizing downtime and ensuring that end-users experience a seamless update.
### Evening: Post-Deployment Checks
After the deployment, our CI/CD human performs post-deployment checks, much like a quality control inspector. They verify that the new features are functioning as expected and that there are no critical bugs. They also gather feedback from users and developers, taking notes for future improvements.
### Night: Maintenance and Learning
As the day winds down, our CI/CD human engages in maintenance tasks. This includes cleaning up old builds, archiving logs, and preparing the pipeline for the next day. They also spend time learning about new tools and technologies, always looking to enhance their skills and improve the pipeline.
### Conclusion: An Indispensable Ally
In the world of software development, a CI/CD pipeline is an indispensable ally, tirelessly working to ensure that code is seamlessly integrated and deployed. If CI/CD pipelines were human, they would embody the qualities of a project manager, quality assurance specialist, engineer, operations manager, technician, and quality control inspector all rolled into one. Their dedication and efficiency would make them the unsung heroes, ensuring the success of every software project they touch. | mitch1009 | |
1,863,790 | [Self-Study] Achievement: Describe the core architectural components of Azure | Today, I learnt how to describe the following definitions in Microsoft Azure. They are: Resource... | 0 | 2024-05-24T09:53:31 | https://dev.to/theasea/self-study-achievement-describe-the-core-architectural-components-of-azure-fj0 |

Today, I learnt how to describe the following definitions in Microsoft Azure. They are:
- Resource Groups
- Availability Zones
- Region Pairs
- Subscriptions
- Management Groups
Using the Microsoft Learn Sandbox, I also learnt the steps to create an Azure Resource:
- at Microsoft Azure (portal.azure.com), I created a Virtual Machine resource
- I noticed how in the resource group of the virtual machine I created, Azure created the rest of the resources by default and associated them using similar names
Achievement Link: [Click Here](https://learn.microsoft.com/en-us/users/theasea-4752/achievements/uxvjxsk3) | theasea | |
1,863,789 | Accelerating Chip Design and Testing in the Semiconductor Industry with AWS | Introduction The semiconductor industry has a huge challenge in the design and testing of chips due... | 0 | 2024-05-24T09:50:52 | https://dev.to/sudoconsultants/accelerating-chip-design-and-testing-in-the-semiconductor-industry-with-aws-3aci | semiconductor, industry, acceleratingchipdesign | <!-- wp:heading {"level":1} -->
<h1 class="wp-block-heading">Introduction</h1>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The semiconductor industry has a huge challenge in the design and testing of chips due to the complexity in modern chip architectures, the increasing demand for improved performance and energy efficiency, and the urgency of innovation to meet the changing demands in different applications. In this light, the industry must deal with large data amounts and, at the same time, ensure proper and secure design and implementation; provide fast and efficient testing and verification of the design; and, lastly, monitor the product design cost amidst fast-evolving technologies. On the other hand, there is a robust and flexible cloud computing platform offered by AWS to meet this challenge. Its cloud technology enables semiconductor companies to grow, optimize performance, and collaboration with partners and customers, and to increase revenue across use cases that are crucial, such as Design & Verification, Supply Chain, Sustainability, as well as Manufacturing Intelligence. AWS has a broad base of partners, including industry leaders such as AMD, Synopsys, Cadence, Siemens EDA, and Ansys, which further increases the capability pool that AWS is able to offer in terms of the semiconductor industry.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>AWS's relevance to the semiconductor industry stems from the fact that it speeds up verification with respect to chip design, helps in open-source design for chip making, will make predictive maintenance a possibility for those in the semiconductor business, and will make machine learning initiatives a reality for players in the semiconductor industry. Running on the AWS platform, these semiconductor companies can, in turn, leverage technologies like AWS Graviton—an ARM-based CPU, AWS Trainium for machine learning inference, and AWS Bedrock for generative AI, among others. Semiconductor companies realize the benefits of the advanced technologies that AWS provides through scalable computing resources, secure data storage, high-performance computing, advanced analytics, and machine learning. In other words, AWS is a platform that the semiconductor industry can utilize to shorten the time taken for chip design and test, making innovation occur at a faster rate and, thereby, derive cost efficiency.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">The Role of Cloud Computing in the Semiconductor Industry</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The role of cloud computing in the semiconductor industry will offer semiconductor companies the scalabilities, flexibilities, and advanced analytic capabilities that cloud services can provide to help navigate the complexities of modern hardware development and testing in a way that reduces inefficiencies and misalignments in capacity deployment.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Transforming Chip Design and Testing Processes</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Scalability and Elasticity:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Through cloud computing, there is instant access to extensive computing and storage resources. This is essential for semiconductor companies to scale their operations up and down based on the demand levels. This flexibility is important in handling cyclic and unpredictable demands of chip design and verification. For instance, this flexibility allows the teams to use as many machines as they need to, with an uncapped capacity, for regressions, timing analysis, and physical verification without long-term commitments or investments in physical infrastructure.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>High-Performance Computing (HPC):</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Cloud platforms deliver a high-performance computing environment that makes it possible for design and development to take place at a much faster rate. This is very much advantageous for an industry like semiconductors that are looking towards shrinking its product lifecycles and growing pace in the market.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Data Analytics and AI/ML:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>The cloud facilities provide scalable storage with major data analytics capabilities and access to AI and ML tools for data processing and analytics. This makes it possible for semiconductor companies to monitor, gather, analyze, and process data on their chip lifecycle, hence deriving value as a continuous basis for decisions and innovation.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Benefits for Semiconductor Companies</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Cost Efficiency:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>It avoids chronic capacity and demand mismatch, which is seen regarding traditional infrastructures; cloud service, in effect, serves a pay-what-you-use or variable model. Cloud service allows a company to pay for what they use without maintaining idle engineers or servers uselessly.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Organizational Agility and Flexibility:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Cloud provisions scalability and flexibility on demand, thus providing semiconductor companies with the ability to be flexible in promptly serving the market needs and changing technological environment. That, in fact, is a necessity for agility with regard to design, testing, validation activities, and general R&D.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Security and Compliance:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Cloud service providers have heavily invested in security. The automated security tools and best practices keep the data and IP safe, therefore making cloud a secure and auditable channel for the semiconductor companies, answering one of the biggest concerns when adopting a cloud.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Collaboration and Innovation:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>With cloud platforms in place, there is cooperation among geographically dispersed teams, and that optimizes communication and coordination of activities in the design and testing of the chips. Further supports innovation as cloud enables Internet of Things, and big data analytics along the entire chip manufacturing value chain to drive efficiencies and lower costs.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>In summary, cloud computing is the force multiplier in the transformation of the semiconductor business by enabling the business to scale, be flexible and efficient in the design and test of the chips. It is very beneficial in terms of saving cost, agility, security, and innovation; therefore, it is an installed tool in a semiconductor company to be competitive in today's fast-changing markets.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">AWS Services for the Semiconductor Industry</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Amazon Web Services has a vast array of services that generate a great deal of benefit for semiconductor companies. It envelopes all the problems from chip design to testing and manufacturing. Some of the important services of AWS are related to the semiconductor industry and are briefed below.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Amazon EC2</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Amazon EC2 provides semiconductor companies with flexible and potential compute capacity to resize the capacity in the cloud. In this way, compute resources can be easily scaled up or down according to the demands. Since the computational needs for chip design and testing might be very demanding and highly variable, this type of flexibility is so important.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS Lambda</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>AWS Lambda has been available to semiconductor firms in removing the server provisioning and management. Time can be easily saved on such actions as automation for chip design and testing. This includes such tasks as running simulations and data analysis without the need for dedicated hardware.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Amazon S3</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Amazon S3 presents highly durable, scalable, and secure object storage for your backup and recovery, disaster recovery, and archiving needs. In the semiconductor industry, this can be used to store vast amounts of design and test data, enabling easier access and analysis.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS Fargate</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>AWS Fargate is a container orchestration service used in coordinating the scheduling of creation, deployment, and management of applications packaged in containers without provisioning and managing infrastructure. This means a semiconductor company would be able to run its containerized applications to design and test chips in a scalable and safe environment, while not having to manage infrastructure.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Amazon RDS</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>AWS RDS makes it easy to set up, operate, and scale a relational database in the cloud. This will help the semiconductor companies in easily handling vast chip design and test data to ensure it is managed and analyzed efficiently for insight in the guided path.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS IoT Core</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Offering organizations the capability of connecting numerous devices to the cloud will enable them to securely interact with each other, with bidirectional flow. For a semiconductor company, manageability and the ability to get real-time data for improved efficiency and greater control over quality in manufacturing equipment and sensors would be an important part of connecting and monitoring.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS DeepLens</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>AWS DeepLens is a video camera that applies deep learning to analyze video streams in real-time. Within the context of the semiconductor industry, a service like this might rather be helpful for quality control and inspection. This way, it would be possible to identify flaws or anomalies right on time.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS Marketplace</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>The AWS Marketplace is a place where a semiconductor maker can acquire a wide array of third-party solutions that easily integrate into AWS environments. From the point of view of a semiconductor company, this is able to bring all those specialized tools and services that are registered in the AWS Marketplace in the area of chip design, testing, and manufacturing that will potentially accelerate innovation and increase its operational performance.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>These AWS services together provide an excellent platform for semiconductor companies to improve their chip design and testing, taking the benefit of scalability, flexibility, and advanced analytics in the cloud to power innovation and improve efficiencies.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Case Study: Accelerating Chip Design and Testing with AWS</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Scenario</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>A leading semiconductor company, named SemiconTech, was encountering numerous challenges in accelerating chip design and testing. The company was having problems with growing complexity in chip designs, increasing requirements for rapid verification and validation cycles, and issues related to management of a large volume of data related to the design and testing phases. SemiconTech is in the hunt for a solution that can offer scalable computation power, effective data management, and advanced analytics to help to overcome these challenges.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Implementation of AWS Services</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Design Phase</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Using EC2 Instances for Parallel Processing: SemiconTech made use of the Amazon EC2 instances during this second phase of its pilot projection of parallel design simulation processing. Using the EC2 scalable property, the company was able to perform many complex simulations in very little time. Thus, designers were productive, and the company, as a whole, saved a considerable amount of design time with good efficiency.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Testing Phase</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Automated Testing with AWS Lambda: SemiconTech developed several AWS Lambda functions to automate different testing steps and reduce the need for manual interruption. These serverless functions were triggered at the end of the design simulation. After a series of tests, it would validate the chip's performance under various conditions.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Real-Time Monitoring with AWS IoT Core: During such a scenario, to perform real-time monitoring of the environment where tests were taking place, SemiconTech connected its equipment to AWS IoT Core. This allowed the company to get immediate notifications and alerts of any detected issue or anomaly related to the testing, for which the response was immediate and a resolution was derived.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Data Management</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Storing Simulation Data in Amazon S3: The Company made use of storing all the simulation data on Amazon S3, which offers a storage that is highly durable and scalable. The simulation data was easily retrievable to be analyzed in order to take notes on past data trends for optimization to better the designs in future.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Managing Test Results with Amazon RDS: This Company made use of Amazon RDS for managing test results. Amazon RDS allows the companies to have a centralized database that holds information on the performance and reliability of the various chip designs. This is something paramount in making information-based decisions for the succeeding redesigns and reiterations of the design.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Collaboration and Security</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Containerized Applications with AWS Fargate: To achieve secure and efficient application deployment, SemiconTech embraced AWS Fargate for containerized applications. This meant no managing servers or clusters and simplified deployment, and was more secure since the applications are sited in isolation from other services.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>AI-Driven Insights with AWS DeepLens: The same is applying to SemiconTech's strategy for analyzing test data; to have in-depth insights, they incorporated the AWS DeepLens service to apply AI and ML algorithms. This way, they could derive patterns and correlations from test data, which may not be possible from traditional analytics. This helps them make more informative decisions.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Deployment and Scaling</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Integrating Third-Party Tools via AWS Marketplace: To further augment the testing and design capabilities for chips, SemiconTech accessed AWS Marketplace to find third-party tools that deploy on it. That way, the company could quickly access new technologies and methodologies without making exhaustive development efforts.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Impact</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The use of AWS services into the SemiconTech chip design and testing flows brought unbelievable effects. The company managed to minimize the design and test time in an incredibly fast period, thus bootstrapping its time-to-market with new products. All this, of course, enabled better data management and analytics support to make an informed decision and optimize chip designs. The improved collaboration and security features that AWS services bring to the table speak to increased ease, efficiency, and security in the entire process of ASIC program development. Generally, SemiconTech turned to AWS for flexibility, scalability, and advanced capabilities that it required to rise above a number of its challenges against chip design and testing. It, therefore, shows how transformational cloud computing could be in the semiconductor space.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Results and Impact</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The use of AWS services in the semiconductor industry, exemplified by companies like Xilinx and Arm, has phenomenally transformed the practices of chip design and testing and has a corresponding set of both quantitative and qualitative benefits: reduced turnaround time, productivity of the developer, and cost-saving.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Quantitative Improvements</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Reduced Turnaround Time: Improved turnaround time of tests, where companies like Xilinx have recorded, rather reflects the reduction in time it takes to validate the chip designs. For semiconductor companies, this is really crucial with respect to their product and time-to-market strategies.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Increased Scalability and Productivity: Companies have been able to scale operations much more effectively post their shift to being conclusively done in AWS. In addition, along with resolving infrastructure-scaling issues, tackling scalability has translated into better productivity. Semiconductor companies have been able to successfully manage a remarkably better volume of work with better cycle time performance. The effectiveness of this is visible in how large volumes of work are handled without deteriorating performance.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Qualitative Improvements</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Enhanced Innovation: Use of AWS services has ensured faster innovation by the semiconductor companies, ensuring optimization of performance and improvement in interoperability with partners and customers. This means more robust and efficient designs of chips that translate a tangible increase in revenues based on critical use cases.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Improved Interoperability: Semiconductor companies were able to scan their interoperability with partners and clients much more effectively by using AWS services to ensure smooth collaboration and communication flow among their ecosystem during the process of chip design and test.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Cost Savings and Efficiency Gains</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Reduced Infrastructure Costs: Semiconductor companies have thus reduced the cost of their infrastructure through cloud migration. It comprises removing the pricey on-premise hardware and its attendant maintenance, leading to substantial savings.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Efficiency Gains: The deployment of the AWS services had resulted in efficiency gains in many aspects of the chip design and testing process. For instance, the use of AWS Lambda for an automated test and AWS IoT Core for real-time monitoring has further operationalization by reducing human interventions and thereby improving the overall efficiency of the process.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Specific Examples</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Xilinx's Success: Xilinx's movement to an HPC cluster running on AWS brought about better turnaround time, scalability, and productivity. It shows the real fruits of AWS in terms of taking up infrastructure scaling issues and improving operational efficiency.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Arm's Reduction in Characterization Turnaround Time and Costs: Arm said its use of the AWS Arm-Based Graviton Instances was able to reduce characterization time and costs and show the potential of cost savings in operations in semiconductors.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>In short, the adoption of AWS services by semiconductor companies has really made big step improvements in chip design and testing processes with both quantitative and qualitative benefits. The above improvements have been realized by reduced turnaround times, increased productivity, improved innovation, enhanced interoperability, and material cost reduction, underlining the potentials from the paradigm shift towards a cloud plug-in in the semiconductor industry.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Implementation (Setup) - Steps</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Setting up an AWS environment to accelerate the chip design and test in the semiconductor industry will involve several steps mainly in developing and configuring AWS resources such as EC2 instances, Lambda functions, S3 buckets, RDS databases, and integrating services like IoT Core and DeepLens. The following provides a step-by-step process of how to set up this environment through the AWS Management Console and the Command Line Interface (CLI).</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Prerequisites</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>You have an AWS account and have first logged in to the AWS Management Console.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>You must have installed and configured the AWS CLI in your local machine. You can download it from <a href="https://aws.amazon.com/cli/">AWS CLI</a>, then follow the installation guide for your operating system.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 1: Create an EC2 Instance</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Via AWS Management Console:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Travel to the EC2 Dashboard.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on the "Launch Instance."</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choose an AMI which will serve your workload. Taking this example through the walkthrough, choose an Ubuntu Distribution.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Choose the instance type. Let me choose the testing so that you select the t2.micro.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Add the details of the instance, the amount of storage needed, and tags.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Set the security group to allow SSH from your IP address.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Finally, allow you the review and launch of the instance.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Via AWS CLI:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws ec2 run-instances --image-id ami-xxxxxxxx --count 1 --instance-type t2.micro --key-name MyKeyPair --security-group-ids sg-xxxxxxxx --subnet-id subnet-xxxxxxxx</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong><em>Replace ami-xxxxxxxx, MyKeyPair, sg-xxxxxxxx, and subnet-xxxxxxxx</em></strong> with your specific values.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 2: Set Up an S3 Bucket</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Via AWS Management Console:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Open the Amazon S3 console.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on "Create bucket".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Enter a globally unique name for your bucket.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select a region and configure other options as needed.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click "Create bucket".</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Via AWS CLI:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws s3api create-bucket --bucket my-bucket-name --region us-west-2</em></strong> </code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Replace my-bucket-name with your desired bucket name.</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 3: Create an RDS Database</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Via AWS Management Console:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Open the Amazon RDS console.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on "Create database".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select the database engine (e.g., MySQL).</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Configure the DB instance details including instance class, storage, and security groups.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click "Create database".</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Via AWS CLI:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws rds create-db-instance --db-instance-identifier mydbinstance --db-instance-class db.t2.micro --engine mysql --allocated-storage 20 --master-username admin --master-user-password password123</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Adjust parameters as needed.</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 4: Set Up AWS Lambda</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Via AWS Management Console:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Open the AWS Lambda console.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on "Create function".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select a runtime, for example, Python 3.8.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Enter the function name, role, and memory size.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Add a trigger, for example, API Gateway, or leave it unconfigured.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click "Create function".</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Via AWS CLI:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws lambda create-function --function-name myFunction --runtime python3.8 --role arn:aws:iam::123456789012:role/service-role/my-service-role --handler index.handler --zip-file fileb://myFunction.zip</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Replace <strong><em>arn:aws:iam::123456789012:role/service-role/my-service-role</em></strong> with your IAM role ARN and <strong><em>fileb://myFunction.zip</em></strong> with the path to your deployment package.</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 5: Configure AWS IoT Core</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Via AWS Management Console:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Open the AWS IoT console.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on "Create a thing".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Follow the wizard steps in creating a new thing, and attach a certificate to this thing.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Note the Thing Name and Certificate ARN for later use.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Via AWS CLI:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws iot create-thing --thing-name</em></strong> myThing</code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Note the Thing Name for later use.</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 6: Integrate AWS DeepLens</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Via AWS Management Console:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Go to DeepLens Dashboard.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on Create model.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select import sample projects.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Upload your model files and set the model settings.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Via AWS CLI</strong> : </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>DeepLens integration typically involves uploading model files and configuring the model settings through the AWS Management Console, as the CLI does not directly support DeepLens model creation.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 7: Deploy Applications with AWS Fargate</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Via AWS Management Console:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Go to the ECS Dashboard.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click create cluster.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select Networking only and click Next step.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Fill in your cluster settings and click Create cluster.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Go to Task Definitions and create a new task definition.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Configure container definitions and choose launch type as Fargate.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Register your task definition and run your task.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Via AWS CLI:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws ecs register-task-definition --cli-input-json file://task-definition.json</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws ecs run-task --cluster myCluster --task-definition myTaskDefinition</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 8: Integrate Third-Party Tools via AWS Marketplace</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Via AWS Management Console:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><!-- wp:list-item -->
<li>Go to the AWS Marketplace.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Search for the tools based on your need the ones to be added to your AWS environment. Most of the procedures will be directly given by the vendor, based on that you can either make a purchase or setup.</li>
<!-- /wp:list-item --></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong><strong>Via AWS CLI</strong></strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Most of the third-party tool integrations either require manual setup through the AWS management console or the given procedure by them to set up.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Final Steps</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Optimization and Scaling: Monitor your AWS resources and adjust configurations as needed to optimize performance and cost.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Security: All the resources must be secure and following the AWS best practices. That might include using IAM roles and policies, data at rest and in transit, and making sure often that the controls for access are reviewed.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>This guide gives you a starting point to accelerate chip design and testing in the Semiconductor Industry with AWS. Depending upon specific needs, one can build on this and add more capabilities.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Conclusion</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS has been proven to be a transformative force in the semiconductor industry that provides a series of services to leverage and overcome the challenges presented in chip design and testing. AWS enables these semiconductor companies to innovate at a quicker pace, optimize performance, interoperate, and increase revenue through the key use cases of Design & Verification, Supply Chain, Sustainability, and Manufacturing Intelligence.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Benefits of AWS for the Semiconductor Industry</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Innovation and Optimization: Using AWS will help semiconductor companies to innovate faster. The access to the latest generation of compute, storage, networking, and security in an optimized technological approach for the cloud will help enable running the most compute-intensive HPC workloads much faster, with enhanced scalability, total security, and lower costs.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Interoperability and Collaboration: The dynamism of AWS adds to the strength of the semiconductor industry because of the best-in-class partners, including AMD, Synopsys, Cadence, Siemens EDA, and Ansys. It ensures that companies in the semiconductor industry are able to benefit from the collective expertise and success that these industry leaders bring in building solutions on AWS.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Cost Efficiency and Scalability: Semiconductor companies will, through the use of the cloud, save a lot of capital being churned into expensive on-premises hardware and associated hardware maintenance costs. Scalability with AWS helps to increase or reduce an infrastructure footprint according to its demand at a given time, further driving operational efficiency.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Future Trends and Potential Advancements</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Generative AI for Semiconductor Design: Generative AI is a massive opportunity to advance both technical and business processes in the semiconductor industry. Through its potential application, the infinite improvement to engineering and manufacturing methodologies and their processes will be carried out, from generating better and more optimized solutions to reducing the time to market for the new products.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Open-Source Chip Design on AWS: Open-source EDA software running on AWS allows the availability and democratization of chip design. People in academia, and sometimes people in industries where the innovation of chip design is very expensive, can design more effectively. This trend will continue to prove that AWS is among the factors bordering to propel collaboration and innovation deeper into chip designing.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Predictive Maintenance and Machine Learning Initiatives: Again, a significant number of most recent devices are starting to be dependent on semiconductor chips. AWS will cater for this growing demand through its machine learning initiatives, including Amazon Bedrock for generative AI, to cater to the requirement for the chips to have predictive maintenance.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">References</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><a href="https://aws.amazon.com/manufacturing/semiconductor-hi-tech/">AWS for Semiconductor & Hi-Tech Electronics</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><a href="https://aws.amazon.com/manufacturing/semiconductor-electronics/product-design-and-verification/">AWS for Semiconductor Product Design & Verification</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><a href="https://aws.amazon.com/blogs/industries/category/industries/semiconductor-and-electronics/">AWS Blogs on Semiconductor and Electronics</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><a href="https://aws.amazon.com/blogs/industries/generative-ai-for-semiconductor-design/">AWS for Industrial, EDA, Semiconductor</a></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --> | sidrasaleem296 |
1,863,788 | 7 Must-Have Qualities to Look for When Hiring Mobile App Developers | Understand the essential qualities that make a mobile app developer stand out in our latest blog, "7... | 0 | 2024-05-24T09:49:56 | https://dev.to/talentonlease01/7-must-have-qualities-to-look-for-when-hiring-mobile-app-developers-4m60 | mobile, app, developer | Understand the essential qualities that make a mobile app developer stand out in our latest blog, "**[7 Must-Have Qualities to Look for When Hiring Mobile App Developers](https://talentonleasework.wixsite.com/talentonlease/post/must-have-qualities-hiring-mobile-app-developers)**" Learn how to identify the ideal candidate for your project by focusing on technical expertise, problem-solving skills, user-centric design, adaptability, communication, quality assurance, and passion for technology. Ensure your app's success with these crucial insights. Read more on finding top talent to create robust, innovative, and user-friendly mobile applications.
| talentonlease01 |
1,863,786 | From Wikipedia, the free encyclopedia | A book is a medium for recording information in the form of writing or images. Books are typically... | 0 | 2024-05-24T09:48:40 | https://dev.to/david_johnson_c6748dec4ef/from-wikipedia-the-free-encyclopedia-1idl | A book is a medium for recording information in the form of writing or images. Books are typically composed of many pages, bound together and [protected by a cover](https://en.wikipedia.org/wiki/Book).[1] Modern bound books were preceded by many other written mediums, such as the codex and the scroll. The book publishing process is the series of steps involved in their creation and dissemination.
| david_johnson_c6748dec4ef | |
1,863,785 | API Development Services | Fortunesoft provides comprehensive API development services in the United States, crafting secure,... | 0 | 2024-05-24T09:48:25 | https://dev.to/jennifer_fc5d67e27e806616/api-development-services-3m9n | unitedstates, api, apigateway, development | Fortunesoft provides comprehensive [API development services](https://www.fortunesoftit.com/api-development/) in the United States[](url), crafting secure, scalable, and efficient APIs tailored to your business needs. From design to deployment, Fortunesoft ensures seamless integration and robust functionality. | jennifer_fc5d67e27e806616 |
1,863,784 | Conquering AWS Cloud Resume Challenge | The Cloud Resume Challenge was created by Forrest Brazeal to upgrade and showcase your cloud skills.... | 0 | 2024-05-24T09:47:47 | https://dev.to/madhesh_waran_63/conquering-aws-cloud-challenge-1799 | aws, devops, cicd, cloud | The Cloud Resume Challenge was created by Forrest Brazeal to upgrade and showcase your cloud skills. Completing it requires you to follow a strict set of requirements that will test and challenge your understanding of the cloud.
I did the AWS Cloud Resume Challenge and this is how it went:
## Certification
First, your resume needs to have an AWS certification on it. I got my AWS Cloud Practitioner certificate by using the Stephen Mareek course on Udemy. I think that the course and the accompanying practice test are enough if you get above 80% on your first try. But if you score below 70%, I would advise you to sit through some practice tests on Udemy and not try your hand at the exam till you consistently get an 80% in most of the practice tests you try.
## HTML
Your resume needs to be written in HTML. Not a Word doc, not a PDF. I previously had no idea about HTML except the little I learned in fifth grade and knowing it was an easy language that you can easily pick up. I learned HTML using the w3schools website and the Odin project and made a simple HTML page for my resume.
## CSS
Your resume needs to be styled with CSS. I already had a good idea of CSS since you get an HTML/CSS as a package deal in most of the tutorials you find. I didn’t want to think too much about designing my website, so I just watched a YouTube video for a website resume and styled my page to look exactly like that. I decided that I would redesign my website with my ideas later when I had free time. But this would do for now.
## Static Website
Your HTML resume should be deployed online as an Amazon S3 static website. This was the easiest part with lots of tutorials and a very extensive AWS document that provides a comprehensive guide. So, I easily whipped up an S3 bucket, turned on static website hosting, and uploaded my website files to it. The website endpoint worked fine and this did not require any troubleshooting except me looking through AWS documentation and stack overflow to see if I have given any unnecessary permissions that could threaten my account security.
## HTTPS
The S3 website URL should use HTTPS for security. You will need to use Amazon CloudFront to help with this. This was where I encountered my very first hiccup. I bought a custom domain name from [Namecheap](https://www.namecheap.com/) and wanted it to point to my CloudFront distribution. I was very excited that my domain name only cost a dollar but I fear that the service merits that cheap price. I wanted that lock sign next to my website but I learned that getting an SSL certificate from ACM for my cheap domain would require a whole lot more effort to validate it than if I had purchased from route 53. The process should be easy but since I did not purchase the premium DNS package that lets me manipulate host records, I had to find a sneaky way to validate which I did. This stunted my progress for quite a while but, I persevered and created a custom DNS server for it using route 53 which will be explained in detail in the next process. Aside from getting my SSL certificate from ACM, everything else was a breeze. I quickly set up a CloudFront distribution using my S3 bucket website endpoint as the domain origin. This gave me that sweet https:// locked sign for my site which I wanted very much.
The resource that was very helpful during my troubleshooting process is this doc:
[Alternate Domain Developer Guide](https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/using-https-alternate-domain-names.htmlument.
)
## DNS
Point a custom DNS domain name to the CloudFront distribution, so your resume can be accessed at a custom domain name. You can use Amazon Route 53 or any other DNS provider for this. I first created a Route 53 hosted zone which gave me 4 nameservers. I switched my Namecheap DNS with these 4 servers and they were very helpful in creating records to get my DNS validated without falling into the premium DNS trap of Namecheap.
## Javascript
Your resume webpage should include a visitor counter that displays how many people have accessed the site. You will need to write a bit of Javascript to make this happen. Once again, I used the w3schools database to get a feel of the language. I decided to write a simple script that will call the API as soon as the page has loaded and then display the responding data from the API. My code was a bit archaic since I used the XML HTTP function instead of the function that is specifically made for fetching APIs but it seemed to work as it is so I did not change it.
## Database
The visitor counter will need to retrieve and update its count in a database somewhere. I was advised to use Amazon’s DynamoDB for this purpose. Creating the table was straightforward and was finished in minutes.
## API
You should not communicate directly with DynamoDB from your Javascript code. Instead, you will need to create an API that accepts requests from your web app and communicates with the database. I used AWS’s API Gateway and Lambda services for this. This gave me a bit of a struggle as I did not have a single idea of what I was supposed to do. So, I read many documents and watched many videos to understand what it was that I was supposed to do. Once I felt enough confidence in my knowledge of API gateways I decided that I would stumble around and make it work somehow since the AWS official documentation was confusing to me and I decided not to use it. I first experimented with an HTTP API which I felt must be cheaper and got it working. I later switched to using REST APIs as it was easier to deploy with CI/CD integration. Integrating with the Lambda and deploying gave me an API endpoint which I inserted into the Javascript code.
## Lambda
I created a Lambda function to integrate with the API and DynamoDB database. You will need to write a bit of code in the Lambda function to access and update the database. I decided to explore Python – a common language used in back-end programs and scripts – and its boto3 library for AWS. There were many resources available for creating a Python code and I decided to use them as my guidance since I had not used Python before this. Those guides were very extensive and helpful in helping me create my code. [Boto3 for Dynamodb](https://hands-on.cloud/boto3/dynamodb/)
## Infrastructure as Code
You should not be configuring your API resources – the DynamoDB table, the API Gateway, the Lambda function – manually, by clicking around in the AWS console. Instead, define them and deploy them using Terraform. This is called “infrastructure as code” or IaC. It saves you time in the long run. I had no previous experience with Terraform and I went in fresh with only the official documentation as my guide. Even though I had to rewrite my code due to various trial and error methods, every time the code worked it felt like Christmas. It was simple and the official guide is the only thing you need to deploy the entire infrastructure. The error logs were very specific and this helped me not waste my time making unnecessary code changes. It took me three days to write the code to automatically provision all the AWS resources with only the official guide and no other resources.
## Source Control
You do not want to be updating either your back-end API or your front-end website by making calls from your laptop, though. You want them to update automatically whenever you make a change to the code. This is called continuous integration and deployment, or CI/CD. I achieved this by creating a GitHub repository for my backend code.
## CI/CD (Back end)
I set up GitHub Actions such that when I push an update to my Terraform template or Python code, they automatically get packaged and deployed to AWS. This was achieved by this Github action by [appleboy.](https://github.com/appleboy/lambda-action)
## CI/CD (Front end)
Create GitHub Actions such that when you push new website code, the S3 bucket automatically gets updated. I used the s3 sync action resource made by [jakejarvis.](https://github.com/jakejarvis/s3-sync-action)
## Blog post
The final goal of the challenge was to post our experience with this challenge in a blog. I was deciding between Dev.to, Hashnode, and medium as my blog site. I still have goals to create my own blog but I chose dev.to since I felt that I would rather be a part of a close-knit dedicated community than be a part of a large site writing pointless articles to get more and more traffic.
| madhesh_waran_63 |
1,863,783 | What Lies Ahead for Flutter: Advancements, Innovations, & Beyond | Flutter, Google’s versatile UI toolkit, has revolutionized cross-platform app development with its... | 0 | 2024-05-24T09:45:13 | https://dev.to/n968941/what-lies-ahead-for-flutter-advancements-innovations-beyond-33jh | flutter, firebase, programming, beginners | Flutter, Google’s versatile UI toolkit, has revolutionized cross-platform app development with its single-codebase approach. As Flutter progresses, it promises significant enhancements and innovations, spanning performance, developer experience, and platform support. This article explores the trajectory of Flutter, highlighting its evolution and future prospects in the tech landscape.
Flutter, Google’s UI toolkit for creating natively compiled applications across mobile, web, and desktop platforms from a single codebase, has undergone significant evolution since its inception. Its robust capabilities and user-friendly nature have propelled its popularity among developers. As Flutter continues to progress, there are various key enhancements, innovations, and future trajectories that enthusiasts can anticipate. This article explores the potential developments in Flutter, focusing on areas of enhancement, upcoming innovations, and the trajectory beyond for this versatile framework.
What Lies Ahead for Flutter
Enhancements in Flutter
1. Improved Performance and Stability
Performance and stability remain paramount for any software development framework. For Flutter, this entails ongoing optimization of the engine and runtime to ensure smoother animations, quicker rendering, and reduced latency. The Flutter team is concentrating on several improvements:
Skia Shaders and Scene Management: Refinements in the Skia graphics library and enhanced scene management can result in more efficient rendering pipelines.
Reduced Jank: Efforts to minimize frame drops (jank) are ongoing, with refined tools and methods aiding developers in identifying and addressing performance bottlenecks more effectively.
Isolates and Concurrent Execution: Better support for concurrent execution using isolates will facilitate more efficient multi-threading, thereby enhancing app responsiveness and performance.
[read full article](https://flutters.in/what-lies-ahead-for-flutter/)
2. Enhanced Developer Experience
Flutter’s allure lies in its features that boost productivity. Enhancing the developer experience remains a priority:
Hot Reload & Hot Restart: These features, already transformative, are being fine-tuned to be more robust and faster, thereby reducing the turnaround time for iterative development.
Integrated DevTools: Flutter DevTools are becoming more sophisticated, offering enhanced debugging, profiling, and memory analysis capabilities.
Visual Studio Code and Android Studio Integration: Improved plugins and extensions for popular IDEs will continue to provide seamless development experiences with better auto-completion, error detection, and code generation features.
3. Expanded Widget Library
The heart of Flutter is its diverse set of pre-designed widgets. Expanding this library to include more customizable and sophisticated widgets will significantly reduce the time developers spend creating custom UI elements from scratch:
More Material and Cupertino Widgets: Flutter will see an expanded set of Material and Cupertino widgets, in line with the latest design guidelines from Google and Apple, ensuring native appearance across Android and iOS.
Complex Layout Widgets: New and improved widgets for complex layouts, including better support for grids, lists, and advanced animation controllers, will aid developers in building intricate UIs more efficiently.
[read full article](https://flutters.in/what-lies-ahead-for-flutter/)
What Lies Ahead for Flutter
Innovations in Flutter
1. Web and Desktop Support
Flutter’s ambition is to become a truly universal framework, supporting all major platforms, including web and desktop:
Progressive Web App (PWA) Enhancements: Significant improvements in Flutter for web make it easier to develop responsive, high-performance PWAs.
Desktop Platform Stability: Flutter’s desktop support for Windows, macOS, and Linux is progressing towards stability, with efforts focused on handling desktop-specific requirements seamlessly.
2. Embedded and IoT Applications
Flutter’s potential extends beyond traditional mobile, web, and desktop applications:
Embedded Systems: Adaptation of Flutter for embedded systems opens doors for applications in automotive interfaces, smart home devices, and more.
IoT Integration: Innovations in Flutter’s ability to integrate with IoT devices enable developers to build sophisticated control and monitoring applications, leveraging Flutter’s powerful UI capabilities.
3. Augmented Reality (AR) and Virtual Reality (VR)
As AR and VR technologies gain mainstream adoption, Flutter is making advancements in these domains:
AR and VR SDK Integration: Improved support and integration with popular AR and VR SDKs (such as ARCore and ARKit) empower Flutter developers to create immersive experiences.
3D Rendering: Enhancements in Flutter’s 3D graphics handling facilitate the development of complex AR/VR applications, expanding its scope significantly.
Beyond: The Future of Flutter
1. Machine Learning and AI Integration
The integration of machine learning (ML) and artificial intelligence (AI) into Flutter applications presents promising prospects:
TensorFlow Lite Support: Better integration with TensorFlow Lite enables developers to incorporate ML models seamlessly into their Flutter apps, enabling functionalities like image recognition and predictive analytics.
On-device ML: Innovations in on-device ML processing reduce dependency on cloud services, enhancing app speed and security.
2. Modular Architecture and Package Management
As applications grow in complexity, modular architecture becomes increasingly crucial:
Federated Plugins: Federated plugins facilitate more modular and maintainable codebases, with platform-specific implementations separated and independently managed.
Dependency Injection and State Management: Advanced mechanisms for dependency injection and state management improve application architecture and scalability.
[read full article](https://flutters.in/what-lies-ahead-for-flutter/)
3. Community and Ecosystem Growth
The growth of the Flutter community and ecosystem is vital for its future:
Open Source Contributions: Encouraging more open-source contributions accelerates Flutter’s development and fosters innovation.
Learning Resources and Documentation: Continuous enhancement of documentation and learning resources facilitates the onboarding of new developers and the upskilling of existing ones.
Community Packages: A thriving ecosystem of community-maintained packages and plugins expands Flutter’s capabilities and addresses niche requirements.
4. Corporate Adoption and Enterprise Features
Enterprise adoption of Flutter is rising, driven by the need for robust, scalable solutions:
Enterprise-grade Features: Enhancements in security, performance monitoring, and analytics cater to enterprise needs, ensuring Flutter remains a viable choice for large-scale applications.
B2B and B2C Solutions: Flutter’s versatility suits both business-to-business (B2B) and business-to-consumer (B2C) applications, with ongoing innovations supporting these diverse use cases.
5. Globalization and Localization
As Flutter’s adoption expands globally, support for globalization and localization becomes crucial:
Internationalization (i18n) Support: Enhanced tools for internationalization simplify the development of apps for a global audience.
Localization (l10n) Tools: Improved tools for localization streamline the process of adapting applications for different languages and regions.
Also read:
[NVIDIA Accelerates GPU, CPU, & AI Platform Roadmap: Launching New Chips Every Year](https://flutters.in/nvidia-accelerates-gpu/)
[Introducing Google Play Points: Elevating Your Rewards Experience](https://flutters.in/introducing-google-play-points-elevating-your-rewards-experience/)
[read full article](https://flutters.in/what-lies-ahead-for-flutter/)
Conclusion
Flutter’s evolution from a mobile-only framework to a comprehensive, cross-platform development toolkit is remarkable. Ongoing enhancements in performance, developer experience, and widget libraries, coupled with innovations in web and desktop support, embedded systems, and AR/VR capabilities, position Flutter at the forefront of modern app development.
Looking ahead, the integration of ML and AI, advancements in modular architecture, community growth, corporate adoption, and globalization support will shape Flutter’s future. Developers and businesses will continue leveraging Flutter’s capabilities to build high-quality, performant applications for diverse platforms and use cases.
In this dynamic landscape, staying updated on Flutter’s enhancements, innovations, and future directions is essential for developers aiming to harness its full potential. The future of Flutter is bright, promising exciting opportunities for the developer community and the tech industry as a whole.
Frequently Asked Questions About Flutter's Future
What makes Flutter a popular choice among developers?
Flutter's popularity stems from its ability to create natively compiled applications across mobile, web, and desktop platforms from a single codebase. Its robust capabilities and user-friendly nature have propelled its adoption among developers.
What are the key areas of enhancement in Flutter?
Flutter is continuously evolving, with ongoing enhancements focused on improving performance, stability, and the developer experience. This includes optimizations in rendering pipelines, smoother animations, faster rendering, enhanced debugging tools, and a broader set of pre-designed widgets.
How is Flutter innovating in terms of platform support?
Flutter aims to become a universal framework, supporting major platforms including web, desktop, embedded systems, and IoT applications. Significant efforts are being made to enhance support for web development, stabilize desktop platform compatibility, and integrate with emerging technologies like AR and VR.
What are the future prospects of Flutter in terms of integration with machine learning and artificial intelligence?
Flutter's integration with machine learning and artificial intelligence presents promising opportunities. With better support for TensorFlow Lite and advancements in on-device ML processing, Flutter developers can seamlessly incorporate ML models into their apps, enabling functionalities like image recognition and predictive analytics.
How is Flutter addressing the needs of enterprise applications?
Enterprise adoption of Flutter is rising, supported by enhancements in security, performance monitoring, and analytics. Flutter's versatility makes it suitable for both business-to-business (B2B) and business-to-consumer (B2C) applications, with ongoing innovations catering to diverse enterprise requirements.
How is Flutter supporting globalization and localization?
As Flutter's adoption expands globally, support for globalization and localization becomes crucial. Enhanced tools for internationalization (i18n) and localization (l10n) simplify the development of apps for a global audience, ensuring a seamless user experience across different languages and regions. | n968941 |
1,863,782 | Element-Wise Numerical Operations in NumPy: A Practical Guide with Examples | Numeric operations in NumPy are element-wise operations performed on NumPy arrays. These operations... | 27,505 | 2024-05-24T09:44:48 | https://dev.to/lohith0512/element-wise-numerical-operations-in-numpy-a-practical-guide-with-examples-824 | python, numerical, operations, numpy | Numeric operations in NumPy are element-wise operations performed on NumPy arrays. These operations include basic arithmetic like addition, subtraction, multiplication, and division, as well as more complex operations like exponentiation, modulus and reciprocal. Here are some examples of these operations:
**Addition**:
You can add two arrays element-wise using the `+` operator or the `np.add()` function.
```python
import numpy as np
# Define two arrays
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# Element-wise addition
result = np.add(a, b) # or a + b
print(result)
# Output: [5 7 9]
```
**Subtraction**:
Similarly, subtraction is done using the `-` operator or `np.subtract()` function.
```python
# Element-wise subtraction
result = np.subtract(a, b) # or a - b
print(result)
# Output: [-3 -3 -3]
```
**Multiplication**:
For element-wise multiplication, use the `*` operator or `np.multiply()`.
```python
# Element-wise multiplication
result = np.multiply(a, b) # or a * b
print(result)
# Output: [ 4 10 18]
```
**Division**:
Element-wise division can be performed with the `/` operator or `np.divide()`.
```python
# Element-wise division
result = np.divide(a, b) # or a / b
print(result)
# Output: [0.25 0.4 0.5 ]
```
**Exponentiation**:
Raise the elements of one array to the powers of another using `**` or `np.power()`.
```python
# Element-wise exponentiation
result = np.power(a, 2) # or a ** 2
print(result)
# Output: [1 4 9]
```
**Modulus**:
The modulus operation returns the remainder of division using `%` or `np.mod()`.
```python
# Element-wise modulus
result = np.mod(a, b) # or a % b
print(result)
# Output: [1 2 3]
```
**Reciprocal**:
The reciprocal of an array is obtained by taking the inverse of each element. In NumPy, you can compute the reciprocal using the `np.reciprocal()` function or the `1 / array` expression.
```python
import numpy as np
# Define an array
a = np.array([1, 2, 3])
# Element-wise reciprocal
reciprocal_result = np.reciprocal(a) # or 1 / a
print(reciprocal_result)
# Output: [1. 0.5 0.33333333]
```
The reciprocal of each element in the array `a` is computed as follows:
- Reciprocal of 1: 1.0
- Reciprocal of 2: 0.5
- Reciprocal of 3: approximately 0.3333 (rounded to 4 decimal places)
These operations are highly optimized in NumPy and can be performed on arrays of any size, making them very efficient for numerical computations😊. | lohith0512 |
1,858,484 | Top mistakes to avoid when integrating stripe | Integrating Stripe into your application can streamline your payment processes, but it's essential to... | 0 | 2024-05-24T09:44:46 | https://dev.to/softylines/top-mistakes-to-avoid-when-integrating-stripe-be8 | stripe, bestpractises | Integrating Stripe into your application can streamline your payment processes, but it's essential to be aware of potential pitfalls and best practices. Here are some common mistakes and advice to help you navigate the integration smoothly.
## 1. Managing Webhooks Order

**Webhooks** are a way for Stripe to communicate with your system by sending webhook events. However, webhook events do not guarantee order delivery. It’s essential to implement logic in your system to handle the order of events correctly. This prevents potential issues that can arise from processing out-of-order events.
For example, when dealing with **subscriptions**, Stripe might send you the update event before the create event, causing an error since you will try to update something in your system that does not exist yet. To handle this scenario, you can add logic in your **update** event to check for the subscription's existence. If it's not present, retrieve it directly from Stripe, then update it.
## 2. How To Reduce Latency When Working with Stripe's APIs

Latency issues can arise when dealing with Stripe’s APIs. For example, fetching customer **invoices** from Stripe can be a slow operation. To mitigate this, consider storing or caching common data within your system. This approach reduces the need for repeated API calls and improves performance.
## 3. Invoice Links Expire After 30 Days

As you start storing invoices in your database, be aware that the PDF link of the invoice will expire after 30 days. To manage this, you can create a cron job to update the invoices or check the link's validity when retrieving invoices for the user. If the link has expired, get the updated link from Stripe and update it in your database.
[Click for more info in Stripe docs](https://docs.stripe.com/invoicing/hosted-invoice-page#:~:text=Invoice%20URLs%20expire%2030%20days,never%20longer%20than%20120%20days).
## 4. Ensuring You Start with Live Mode In Production

Stripe has two modes: live (production) and test (development).
Sometimes, you might start your production app and begin accepting users even when the app isn't fully finished (especially for startups), thinking you can fix things later. However, when working with Stripe, you cannot switch all your test mode data to live mode (except for a few items). This will be a nightmare for you as a developer when you try to migrate the data. So, you should start your production with live mode from day one.
Bonus: [go-live check list by stripe](https://docs.stripe.com/get-started/checklist/go-live)
## 5. Unsuccessful Payments Due to Account Freshness

Sometimes, payments fail because the account is new, and your website hasn't yet been recognized by payment systems. This issue usually resolves itself over time as your site gains more credibility. Communicate this to your customers to manage their expectations.
## 6. Handling Changes in Payment Methods

Payment networks can change payment method details (card number, expiration year, expiration month) at any time. Since you may store payment methods in your database, it’s crucial to stay updated by listening to the `automatically_updated_payment_method` Stripe webhook. This webhook provides the latest data to keep your records up to date.
## 7. Managing Complex Plan Features

If your plans (offers) include complex features, add custom fields in your database rather than relying heavily on the plan’s metadata, which is limited. Custom fields provide greater flexibility and scalability for your application.
## Conclusion
Integrating Stripe into your application offers a streamlined payment process, but it comes with its own set of challenges. By understanding and addressing these common mistakes, you can ensure a smoother and more efficient integration. With these best practices, you can enhance your application's functionality and provide a better user experience.
Happy coding!
| m-a |
1,863,780 | Kumho 215/55R17 Tires: Unmatched Durability and Performance | Introduction: When it comes to choosing the right tires for your vehicle, durability and performance... | 0 | 2024-05-24T09:42:20 | https://dev.to/faizan01862/kumho-21555r17-tires-unmatched-durability-and-performance-1lpb | **Introduction**:
When it comes to choosing the right tires for your vehicle, durability and performance are paramount. Among the myriad options available in the market, Kumho stands out as a trusted name renowned for its commitment to quality and innovation. In this comprehensive guide, we'll delve into the specifics of Kumho's 215/55R17 tires, exploring their features, benefits, and why they are expert picks for those seeking both durability and performance on the road.
**Understanding the Importance of Tire Size:**
Before we dive into the specifics of [Kumho's 215/55R17 tires](https://www.tireryder.com/tire/215-55r17-kumho-solus-ta31-94v-500aa-mpn-2175593), it's crucial to understand the significance of tire size. The numbers in the tire size designation provide essential information about its dimensions. In this case, 215 represents the tire's width in millimeters, 55 is the aspect ratio (height to width), and 17 denotes the diameter of the wheel it fits. This standardized format ensures compatibility and optimal performance with your vehicle.
**Durability**:
Kumho's commitment to durability is evident in every aspect of their tire design. The 215/55R17 model is no exception. Engineered using cutting-edge technology and high-quality materials, these tires are built to withstand the rigors of daily driving, ensuring longevity and peace of mind for motorists.
One of the key factors contributing to the durability of Kumho tires is their advanced tread compound. Formulated to resist wear and tear, the tread compound maintains its integrity even in challenging road conditions, such as rough terrain or inclement weather. This durability translates into extended tread life, reducing the frequency of tire replacements and saving you money in the long run.
Additionally, Kumho employs innovative tread patterns that optimize traction and stability without compromising on durability. Whether you're navigating slick city streets or tackling winding country roads, these tires provide reliable performance mile after mile.
**Performance**:
While durability is essential, performance is equally crucial for a satisfying driving experience. Kumho's 215/55R17 tires excel in this regard, delivering impressive performance across various driving conditions.
One of the standout features of these tires is their exceptional handling capabilities. Thanks to advanced engineering and precise construction, Kumho tires offer responsive handling and precise steering control, enhancing overall driving dynamics and maneuverability. Whether you're cornering at high speeds or making quick lane changes, these tires inspire confidence and control.
Moreover, Kumho's 215/55R17 tires are designed to deliver a smooth and comfortable ride, even on rough or uneven surfaces. The innovative tread design absorbs road imperfections, minimizing vibrations and noise for a quieter cabin experience. This focus on comfort ensures that long journeys remain enjoyable, with reduced fatigue for both the driver and passengers.
Furthermore, Kumho prioritizes safety in their tire designs, incorporating features such as enhanced traction and braking performance. With reliable grip in wet or dry conditions, these tires provide peace of mind when encountering sudden stops or emergency maneuvers.
**Real-World Performance**:
To truly appreciate the capabilities of Kumho's 215/55R17 tires, it's essential to consider real-world experiences and testimonials from satisfied customers. Countless drivers attest to the durability, performance, and overall quality of these tires, praising their ability to withstand diverse road conditions while delivering a smooth and controlled ride.
Whether it's navigating urban streets during rush hour or embarking on a weekend getaway to the countryside, Kumho tires consistently impress with their reliability and performance. From everyday commuting to adventurous road trips, these tires offer the perfect balance of durability and performance for discerning motorists.
**Conclusion**:
In conclusion, Kumho's 215/55R17 tires represent a pinnacle of tire engineering, combining durability, performance, and innovation into a single package. With advanced features such as a durable tread compound, optimized tread patterns, and responsive handling, these tires exceed expectations in both longevity and driving dynamics.
Whether you prioritize durability for long-lasting reliability or crave performance for an exhilarating driving experience, Kumho's 215/55R17 tires deliver on all fronts. Trust in Kumho's legacy of excellence and equip your vehicle with tires that redefine the standards of durability and performance on the road. Choose Kumho for unparalleled quality and peace of mind on every journe
| faizan01862 | |
1,863,776 | Why Security Audits Are Crucial For Businesses | In today’s digital age, even small and medium businesses are prime targets for cybercriminals. That’s... | 0 | 2024-05-24T09:38:44 | https://dev.to/sennovate/why-security-audits-are-crucial-for-businesses-41i0 | In today’s digital age, even small and medium businesses are prime targets for cybercriminals. That’s why a Security Audit is necessary.
What is a security audit?
Think of a security audit as a deep dive into your company’s digital defenses. It’s a comprehensive assessment that identifies vulnerabilities in your systems, networks, and data. By proactively uncovering these weaknesses, you can address them before they become a major security breach.
Here’s where Sennovate comes in.
What’s Your Biggest Security Headache?
Feeling like you’re constantly one step behind hackers?
Unsure if your company complies with industry regulations?
Worried about the ever-expanding attack surface your company presents?
You’re not alone. These are common pain points for businesses without a robust security team.
Introducing Sennovate’s $99 Security Audit: Small, Quick, and Powerful
Our comprehensive audit helps you:
Uncover hidden vulnerabilities in your network and applications with a full black box assessment.
Gain hacker visibility: See how your defenses appear from the attacker’s perspective.
Reduce your attack surface: Our report provides actionable recommendations for tightening your security posture.
Ensure compliance: Identify any gaps that might put you at risk of regulatory fines.
Here’s How it Works (Simple and Fast!):
Fill out the quick form with your contact information.
Schedule a quick kick-off call to discuss your needs.
We conduct the audit on your external IP addresses and domain names.
Receive a detailed report within a week, outlining vulnerabilities and recommendations.
Follow-up call to answer any questions and discuss next steps.
Bonus! Our $99 offer covers up to 10 IPs/Domains. Need more? We can provide a custom quote for a comprehensive scan.
Don’t wait for a cyberattack to happen. Take control of your security with Sennovate’s affordable and fast security audit. [Click here to get started!](https://share.hsforms.com/187Pnxyi-SaWEKY1PJNd6_A1lis7)
About Sennovate
We provide worldwide businesses with IT Security Transformation and Infrastructure solutions + services. Backed by global partnerships and a library of 2000+ integrations, we’ve managed 10M+ identities, 10K+ threats and offered top-tier cybersecurity that saves time and money with 40+ security partners. Enjoy seamless integration across cloud applications and an all-inclusive pricing model covering product, implementation, and support. Questions? Consultations are free. Contact us at hello@sennovate.comor call +1 (925) 918-6618. Your cybersecurity upgrade starts here. | sennovate | |
1,863,768 | Top 5 Taxi App Like Uber Development Company in USA | Are you looking to build an on-demand app similar to Uber? With the booming popularity of on-demand... | 0 | 2024-05-24T09:38:12 | https://dev.to/cameronstewart/top-5-uber-clone-app-development-company-in-usa-5d5k | productivity, development, mobile, flutter | Are you looking to build an on-demand app similar to Uber? With the booming popularity of on-demand services, finding the right development partner is crucial for turning your vision into reality. In this guide, we'll explore the top 5 taxi app like Uber development companies in the USA that can help you create a successful on-demand app tailored to your business needs.
## **What Is Uber Clone App?**
A Uber clone app is a custom-built mobile application designed to replicate the functionality and features of the popular **taxi booking** platform. It enables entrepreneurs and businesses to create their own on-demand transportation service, allowing users to book rides, track drivers in real-time, and make secure payments through the app. A **[Uber Clone App](https://www.teamforsure.com/uber-clone)** typically includes key features such as user registration, driver registration, GPS-based location tracking, fare estimation, ratings and reviews, and secure payment processing. By leveraging the proven business model of Uber, clone apps offer a scalable and customizable solution for launching a ride-hailing service in various markets.
## **Key features of Uber Clone App**
**Key features commonly found in a Uber clone app include:**
1. **User Registration**: Allow users to create accounts and log in using their email address, phone number, or social media accounts.
2. **Driver Registration**: Enable drivers to register on the platform, providing necessary information such as vehicle details, driver's license, and insurance documents.
3. **Ride Booking**: Allow users to book rides by entering pickup and drop-off locations, selecting vehicle types, and scheduling rides for immediate or future use.
4. **Real-Time Tracking**: Provide users with real-time tracking of their rides, allowing them to monitor the driver's location and estimated time of arrival.
5. **Fare Estimation**: Display fare estimates based on distance, time, and other factors before users confirm their bookings.
6. **Payment Integration**: Integrate secure payment gateways to facilitate cashless transactions, supporting credit/debit cards, mobile wallets, and other payment methods.
7. **Rating and Reviews**: Enable users to rate drivers and provide feedback on their ride experience, ensuring accountability and improving service quality.
8. **Push Notifications**: Send timely notifications to users regarding ride status updates, promotional offers, and other relevant information.
9. **Driver Dispatch System**: Implement a dispatch system to efficiently assign rides to available drivers based on their proximity and ride preferences.
10. **Driver Tracking**: Allow the admin to track drivers' locations in real-time, manage their availability, and monitor their performance.
11. **Admin Dashboard**: Provide an intuitive dashboard for admin users to manage users, drivers, rides, payments, and other aspects of the platform.
12. **Analytics and Reporting**: Offer insights through analytics tools to track key metrics such as ride volume, revenue, user engagement, and driver performance.
13. **Support and Help Center**: Include a support center or chat feature to assist users and address their queries or issues promptly.
14. **Multiple Vehicle Options**: Offer a variety of vehicle options to users, such as standard cars, SUVs, luxury vehicles, and shared rides, catering to different preferences and budgets.
15. **Promotions and Discounts**: Allow admin to create promotional campaigns, discount codes, and referral programs to incentivize users and drive user acquisition and retention.
These features collectively contribute to creating a seamless and efficient ride-hailing experience for both users and drivers, mirroring the functionalities of the original Uber platform.
## **List Of Top 5 Uber Clone App Development Companies**
1.TeamForSure
2.Apptunix
3.Richestsoft
4.Suffescom Solutions
5.Code-Brew
## TeamForSure
TeamForSure is a highly reputable app development company based in the USA, renowned for its expertise in creating cutting-edge on-demand solutions. With a team of skilled developers and designers, they specialize in developing custom [Uber Clone App](https://www.teamforsure.com/uber-clone) that are feature-rich, scalable, and user-friendly. TeamForSure offers end-to-end development services, from initial concept to final launch, ensuring that your on-demand app exceeds expectations.
Here are the features and benefits of choosing TeamForSure for Uber clone app development:
**Features:**
- **Customized Solutions**: TeamForSure offers tailor-made Uber clone app development solutions to meet the unique requirements of clients.
- User-Friendly Interface: The apps developed by TeamForSure boast intuitive user interfaces that ensure smooth navigation and enhance user experience.
- **Advanced Features**: They incorporate advanced features such as real-time tracking, secure payment gateways, ratings and reviews, and push notifications to enrich the functionality of the app.
- **Scalability**: TeamForSure builds scalable Uber clone apps that can accommodate growth and handle increasing user demand effectively.
- **Robust Backend**: The apps come with a robust backend system that efficiently manages user data, bookings, payments, and communication between users, drivers, and restaurants.
- **Security**: TeamForSure prioritizes the security of user data and transactions, implementing robust security measures to protect against unauthorized access and data breaches.
- Cross-Platform Com
patibility: Their apps are developed to be compatible with multiple platforms, including iOS and Android, ensuring broader reach and accessibility for users.
**Benefits:**
- **Expertise**: With a team of skilled developers and designers, TeamForSure brings extensive expertise and experience to Uber clone app development projects.
- **Customization**: They offer customized solutions tailored to the specific needs and preferences of clients, ensuring that the final product meets their expectations.
- **Quality Assurance**: TeamForSure follows stringent quality assurance processes to ensure that the apps they deliver are bug-free, reliable, and perform optimally.
- **Timely Delivery**: They adhere to strict timelines and deliver projects on time, allowing clients to launch their Uber clone apps within the desired timeframe.
- **Post-Launch Support**: TeamForSure provides comprehensive post-launch support and maintenance services to address any issues or concerns and ensure the smooth operation of the app.
- **Competitive Pricing**: Despite offering high-quality services, TeamForSure maintains competitive pricing, making their [Uber clone](https://www.teamforsure.com/blog/uber-clone-app-development/) app development solutions accessible to startups and enterprises alike.
## Apptunix
Apptunix is a leading app development agency with a strong presence in the USA, specializing in creating bespoke on-demand solutions for clients worldwide. With a focus on quality and innovation, they excel in developing Uber Clone apps that are scalable, secure, and user-friendly. Whether you're looking to build a ride-hailing app or a food delivery platform, Apptunix offers comprehensive development services tailored to your specific requirements.
## Richestsoft
Richestsoft is a top-rated app development company known for its expertise in creating cutting-edge on-demand solutions. With a team of skilled developers and designers, they specialize in developing Uber clone apps that meet the unique needs of their clients. From feature-rich user interfaces to robust backend systems, Richestsoft offers end-to-end development services to ensure the success of your on-demand app.
## Suffescom Solutions
Suffescom is a renowned app development firm recognized for its proficiency in building custom on-demand solutions for various industries. With a focus on innovation and quality, they specialize in creating Uber clone apps that deliver exceptional user experiences and drive business growth. Whether you're a startup or an enterprise, Suffescom offers tailored development services to help you build a successful on-demand app.
## Code-Brew
Code-Brew is a leading digital agency known for its expertise in creating impactful on-demand solutions for clients worldwide. With a focus on creativity and technology, they excel in developing Uber clone apps that stand out in the market. From concept validation to market launch, Code-Brew offers comprehensive development services to help you build a successful on-demand app that meets your business goals.
## Conclusion:
Building an on-demand [App Like Uber](https://www.teamforsure.com/uber-clone) requires expertise, experience, and a deep understanding of user needs and market trends. With the help of these top 5 Uber clone app development companies in the USA, you can turn your vision into reality and create a successful on-demand platform that delights users and drives business growth. Choose the right development partner that aligns with your goals and requirements, and embark on the journey to building a successful on-demand app today. | cameronstewart |
1,863,775 | Seamless PhoneGap App Development Services | Discover the power of cross-platform versatility with Goognu Bridge, your go-to for PhoneGap App... | 0 | 2024-05-24T09:38:09 | https://dev.to/goognu2/seamless-phonegap-app-development-services-4m09 | awsconsulting, cloudconsulting, awsarchitecture | Discover the power of cross-platform versatility with Goognu Bridge, your go-to for PhoneGap App Development Services. Our expert team specializes in crafting high-performance, feature-rich mobile applications that work flawlessly across multiple platforms.
https://goognu.com/services/phone-gap-app-development-services | goognu2 |
1,862,976 | DNS SUNUCUSU NEDİR? | İÇERİK DNS SUNUCUSU NEDİR? DNS SUNUCUSU TARİHİ? DNS ARAMASINDAKİ ADIMLAR NELERDİR? DNS KAYIT... | 0 | 2024-05-24T09:37:13 | https://dev.to/teknikbilimler/dns-sunucusu-nedir-2m3m | dns, webdev, programming | **İÇERİK**
1. DNS SUNUCUSU NEDİR?
2. DNS SUNUCUSU TARİHİ?
3. DNS ARAMASINDAKİ ADIMLAR NELERDİR?
4. DNS KAYIT TİPLERİ NELERDİR?
5. DNS İÇİN GEREKLİ DOSYA TÜRLERİ NELERDİR?
6. DNS NASIL ÇALIŞIR?
7. DNS NASIL DEĞİŞTİRİLİR?
8. DNS SUNUCULARI VE IP ADRESLERİ?
9. SONUÇ
10. SORULAR
11. KAYNAKÇA

## 1.DNS Sunucusu Nedir?
- DNS, tarayıcınıza girdiğiniz etki alanını, bilgisayar tarafından okunabilir bir IP'ye çeviren bir tür telefon rehberidir. Web tarayıcıları, Internet Protokolu (IP) adresleri aracılığıyla etkileşim kurarlar. Açılımı " Domain Name System" olan DNS de alan adlarını IP adreslerine çevirir, böylece tarayıcılar internet kaynaklarına erişebilir.
- İnternete bağlı her cihaz, diğer makinelerin cihazı bulmak için kullandığı IP adresine sahiptir. DNS sunucuları, insanların 182.172.1.1 gibi IP adreslerini veya 2200: cb00: 2088: 1 :: c428: a4b2 gibi daha karmaşık daha alfa nümerik IP adreslerini ezberleme zorunluluğunu ortadan kaldırır.
## 2.DNS Sunucusu Tarihi
- DNS 1980' den bu yana yaygın olarak kullanılır olmuştur. İnternet hiyerarşi alan adı ve İnternet Protokol (IP) adres boşluğu olmak üzere iki ana ad boşluğunu sağlar. DNS sistemi alan adı hiyerarşisi sağlar ve onunla adres boşluğu arasında çeviri servisi sağlar.
## 3.DNS Aramasındaki Adımlar Nelerdir?
**1. Kullanıcı:** web tarayıcısına ana makine adını yazar. Sorgu internete gider. Sorgu DNS özyinelemeli çözümleyici tarafından alınır.
**2. Çözümleyici:** bir DNS root nameserver’ı sorgular.
**3. Root sunucu:** bir TLD DNS sunucusuyla cevap verir.
**4. Çözümleyici:** Daha sonra TLD DNS sunucusuna bir istekte bulunur.
**5. TLD sunucusu daha sonra alan adının:** ad sunucusunun IP adresiyle yanıt verir.
**6. Özyinelemeli çözümleyici:** alan adının ad sunucusuna bir sorgu gönderir.
**7. Ana makine IP adresi:** Ad sunucusundan çözümleyiciye döndürülür.
**8. DNS çözümleyici:** Daha sonra web tarayıcısına başlangıçta talep edilen alan adının IP adresiyle yanıt verir.
- Bu 8 adım ana makinenin IP adresini döndürdüğünde, tarayıcı web sayfası için istekte bulunabilir.
**9. Tarayıcı :** İlgili IP adresine bir HTTP isteği gönderir.
**10. İlgili IP adresindeki sunucu:** Tarayıcıda oluşturulacak web sayfasını döndürür.
## 4. DNS Kayıt Tipleri Nelerdir?
**A:** Host adını IP adresine yönlendiren kayıttır.
**MX:** DNS’e gelen maillerin yönlendirildiği mail sunucunun kayıtlarıdır.
**TXT:** Özel amaçlı kayıtlardır. Genellikle spam karşıtı olarak kullanılır.
**PTR:** IP adresini domain ismine çeviren kayıttır.
**NS:** İsim sunucularının bilgilerinin tutulduğu kayıttır.
**CNAME:** Takma ad kaydıdır. DNS’e ulaşmayı kolaylaştırır.
## 5.DNS İçin Gerekli Dosya Türleri Nelerdir?
DNS’de kullanılan bir kısım dosya türleri vardır. Dosya türleri olmadan DNS’yi çalıştırmanız mümkün değildir. Söz konusu dosya türlerini aşağıda verilmistir.
**boot :** Bu dosya türü, DNS çalışmaya başladığı anda okunan dosyaların ilkidir.
**local :** bu dosya türü, makinenin gösterdiği adresin etkin şekilde çözümlenmesi için kullanılır.
**ca :** Root server olarak adlandırılan adreslerin tutulduğu dosya türü "named.ca"dır.
**hosts :** DNS alanında çalışan tüm makinelerin adreslerinin tutulduğu dosya türü "named.hosts"tur.
**reverse :** "Named.hosts" dosyasında tutulan IP adreslerini makinenin ismine çevirmek için "named.reverse" dosyası kullanılır.
## 6.DNS Nasıl Çalışır?
- DNS, DNS çözümlemesi yaparak ana bilgisayar adını, IP adresine çevirir.
- DNS çözümleme için, DNS sorgusunun farklı donanım bileşenlerinden geçmesi gerekir. Bu noktada kullanıcının tek etkileşimi tarayıcıya domain ismini girip enter tuşuna basmaktır. İşin geri kalan kısmı arka planda gerçekleşir.
- Bir web sitesinin yüklenmesinde 4 adet DNS sunucusu rol oynar:
- **DNS recursor:** DNS recursor, istemcilerden sorgu almak üzere tasarlanan DNS sunucusudur. DNS recursor, bu sorgu alma işlemini web tarayıcısı aracılığıyla gerçekleştirir.
- **Root nameserver:** Domain isminin, IP adresine çevrilmesinde ki ilk adımdır. Daha spesifik konumlara referans olarak hizmet eder.
- **TLD nameserver:** IP aramasında ki bir sonraki adımdır. Ana bilgisayar adının son kısmını barındırır.
- **Authoritative nameserver:** Bu sunucunun istenen kayda erişimi varsa, istenen ana bilgisayar adının IP adresini istemciye geri gönderir. Yani DNS recursor’a geri gönderir.
## 7.DNS Nasıl Değiştirilir?
DNS IP adresleri Default olarak hazır bir şekilde bağlantı ayarlarında yapılandırılmıştır. Bu ayarlar DNS adresi üzerinde değiştirilir?
**Windows Cihazlarda DNS Değiştireme**
- Denetim Masası> Ağ ve İnternet > Ağ Bağlantıları sayfasına gidin.
- İnternet bağlantınıza ait etkin bağlantı aracına sağ tıklayın
- Özellikler’e tıklayın.
- Açılan liste halindeki menüde İnternet Protokolü Sürüm 4’ü seçip Özelliler’e tıklayın.
- Genel Sekmesinde Aşağıdaki DNS sunucu adreslerini kullan kısmına kullanmak istediğiniz DNS sunucusuna ait adresleri girin ve Tamam butonuna basarak çıkış yapın.
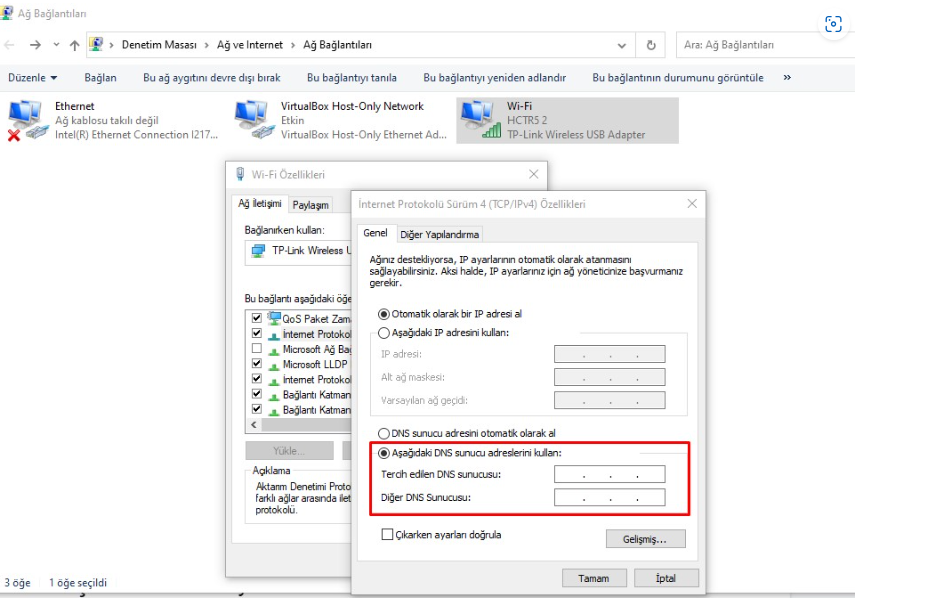
- Bilgisayarınızı yeniden başlatarak işlemi tamamlayın
**MacOS dizüstü bilgisayarında Değiştirme**
- Apple menüsünden Tercihleri seçin,
- Ağ uygulamasını başlatın,
- Wi-Fi bağlantısı ve Gelişmiş düğmesine tıklayın,
- DNS sekmesini tıklayın,
- Hem IPv4 hem de IPv6 DNS adreslerini eklemek için artı işareti düğmesini kullanın
- Mevcut adresleri kaldırmak için eksi işareti düğmesini kullanın.
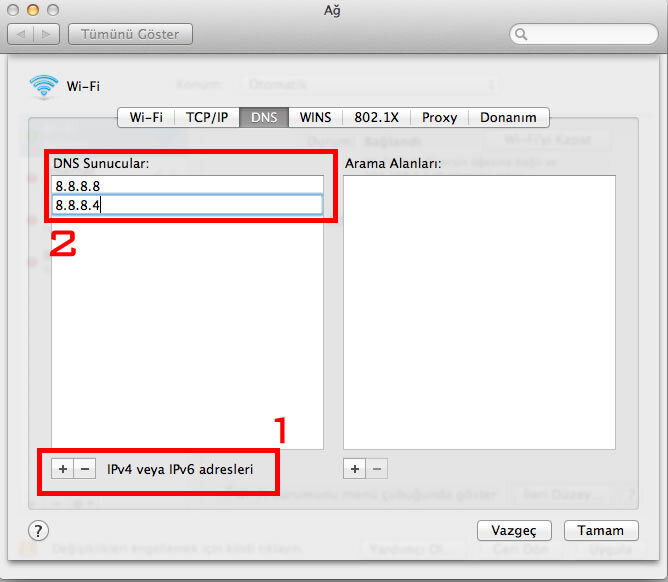
## 8. DNS Sunucuları Ve IP Adresleri?
Bazı DNS sunucuları ve IP adreslerini
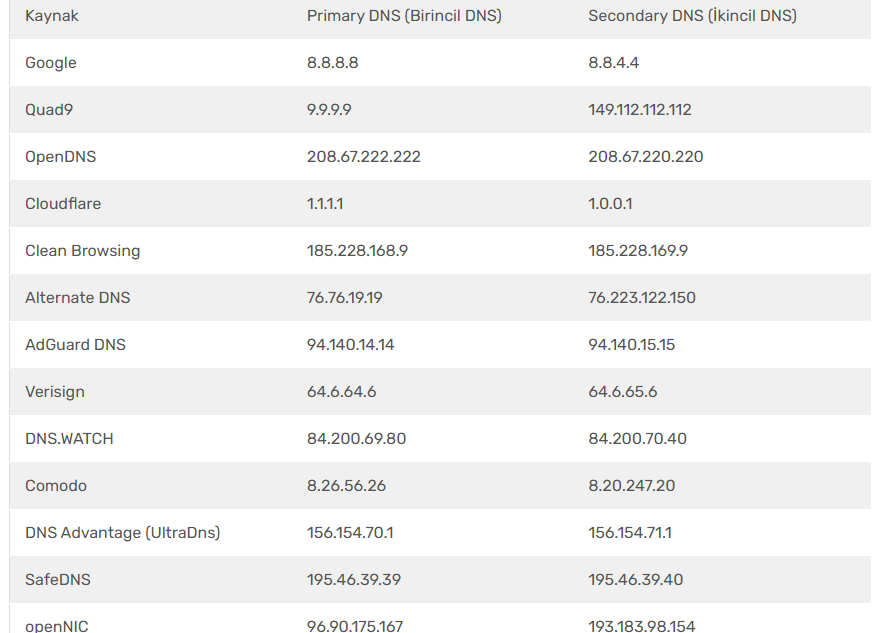
## 9. Sonuç
DNS (Domain Name System), tarayıcıya girilen alan adlarını, bilgisayarların anladığı IP adreslerine çeviren bir sistemdir. 1980'lerden beri kullanılan DNS, internetin hiyerarşik alan adı sistemi ile IP adresleri arasında çeviri yapar. DNS araması, kullanıcının tarayıcıya alan adını yazmasıyla başlar ve bu istek sırasıyla DNS çözümleyici, root nameserver, TLD nameserver ve authoritative nameserver üzerinden geçerek, nihayetinde ilgili IP adresine ulaşır ve tarayıcıya iletilir. Önemli DNS kayıt türleri arasında A (host adı-IP adresi), MX (mail yönlendirme), TXT (özel amaçlı), PTR (IP-domain dönüşümü), NS (isim sunucuları) ve CNAME (takma ad) kayıtları bulunur. DNS'in düzgün çalışması için çeşitli dosya türleri (boot, local, ca, hosts, reverse) gereklidir. DNS, bu süreçleri arka planda yürüterek kullanıcıların web sitelerine erişimini sağlar.
**10.Sorular**
1.DNS'nin açılımı nedir?
A) Domain Name System
B) Dynamic Network System
C) Digital Networking Service
D) Data Naming Server
2.DNS'in temel işlevi nedir?
A) IP adreslerini alan adlarına çevirmek
B) Veri transferini şifrelemek
C) İnternet hızını artırmak
D) E-posta göndermek
3.DNS değiştirme işlemi hangi aşamada gereklidir?
A) Web sayfası oluşturma
B) İnternet tarayıcısını güncelleme
C) İnternet hızını test etme
D) DNS hizmetlerine erişim sorunu yaşandığında
4.Hangi DNS sunucusu 1.1.1.1 IP adresine sahiptir?
A) Google DNS
B) Cloudflare DNS
C) OpenDNS
D) Quad9
5.Hangisi bir DNS kayıt tipi değildir?
A) A
B) HTTP
C) MX
D) NS
**Boşluk Doldurma**
1. DNS, alan adlarını _________ çevirir.
2. DNS kayıt tiplerinden biri olan _________ kaydı, mail sunucularını yönlendirir.
**Doğru Yanlış**
1. DNS, Internet Protokolu (IP) adreslerini alan adlarına dönüştürür.
2. DNS değiştirme işlemi sadece internet hızını artırmak için gereklidir.
**Cevaplar:**
1)Domain Name System
2)IP adreslerini alan adlarına çevirmek
3)DNS hizmetlerine erişim sorunu yaşandığında
4) Cloudflare DNS
5) HTTP
**Boşluk Doldurma Cevaplar**
1)IP adreslerine
2)MX
**Doğru Yanışın Cevapları**
1)Doğru
2)Yanlış
## 11.Kaynakça
1.https://www.karel.com.tr/blog/dns-nedir-nasil-calisir-dns-ile-ilgili-bilmeniz-gereken-tum-bilgiler
2.https://tr.wikipedia.org/wiki/DNS#:~:text=DNS%201980'%20den%20bu%20yana,bo%C5%9Flu%C4%9Fu%20aras%C4%B1nda%20%C3%A7eviri%20servisi%20sa%C4%9Flar.
3.https://medium.com/@mbdogrusoz/dns-nedir-nas%C4%B1l-%C3%A7al%C4%B1%C5%9F%C4%B1r-264b78147fb1
4.https://www.hosting.com.tr/blog/dns/
5.https://chatgpt.com/
6.https://www.milleni.com.tr/blog/teknik/dns-nedir
| kinem_duran |
1,863,723 | How to create Voiceovers for Corporate Videos in minutes? | Create voiceovers for corporate videos in minutes with our efficient tools and expert guidance.... | 0 | 2024-05-24T09:35:10 | https://dev.to/novita_ai/how-to-create-voiceovers-for-corporate-videos-in-minutes-bae | ai, api, texttospeech, voiceover | Create voiceovers for corporate videos in minutes with our efficient tools and expert guidance. Perfect your videos with corporate videos voice overs.
##Introduction
Creating professional voiceovers for corporate videos is essential to convey your message effectively. In just a few minutes, you can transform your video with a compelling voiceover that captivates your audience. Let’s explore some quick and effective strategies to enhance your corporate videos through seamless voiceovers. And find the process to produce the voice overs tools by integrating text-to-speech API in this blog.
##What is a Corporate Video?
A corporate video promotes a company, its products, and services to potential customers. It showcases facilities, values, and mission to a broad audience. These videos are commonly used on websites, social media, or in marketing campaigns. They come in various forms like company overviews, product demos, or employee testimonials. Corporate videos, including promotional videos, build trust and engagement with your audience, essential for attracting potential customers, partners, and investors.

##How important is the voice over in a corporate video?
Embark on a journey to understand ‘voiceovers’, where an unseen narrator explains visuals on-screen. Voiceovers add depth and emotion, bringing static visuals to life, simplifying complex information, and creating connections with viewers. In corporate videos, they provide context, energy to animations, and engage audiences.
A well-executed voiceover is a powerful tool in digital marketing and social media campaigns, transforming branding from background noise to a captivating guide that immerses the audience in storytelling and efficient video production. Effective communication in corporate videos is crucial, and a clear voiceover enhances message clarity and impact, ensuring effective delivery to the audience.
##How to Create Effective Voiceover for Corporate Videos?
Navigating the path to creating professional voiceovers for corporate videos may seem daunting. Let’s explore the three main approaches: DIY voice acting, hiring a professional voice actor, or using AI voiceover software.
###Do-It-Yourself
Embarking on a DIY voiceover journey can be a thrilling business venture, offering creative control and cost-effectiveness. However, it requires talent with excellent articulation, clear voice, and understanding of pacing and intonation.
###Hiring a Professional Voice Actor
Engaging a professional voice artist adds expertise and quality to your corporate videos and internal communications. These artists deliver diverse tones and emotions, enhancing your content. However, hiring them can be costly and time-consuming due to their schedules.

###Using AI Voiceover Software
AI voiceover software combines the best features of traditional methods with added benefits like speed, cost-effectiveness, consistency, multilingual support, and customization. It generates voiceovers quickly, at a lower cost than hiring professionals, and in multiple languages and accents.
While offering control over pace, tone, and inflection, AI voiceover software, also known as AI voice, may not fully capture the emotional nuances of human voices but is advancing rapidly in that regard. However, using AI voiceover software, specifically the announcer voice option, does offer the advantage of authenticity and warmth in your video project, as it can still embody brand personality and maintain consistency across media and social media platforms in English and other languages.
##How to create Voiceovers for Corporate Videos in five simple steps on novita.ai
Creating voiceovers for documentaries using AI tools like novita.ai is a simple process. Follow these steps:
- Step 1: Launch the [novita.ai](https://novita.ai/?ref=blogs.novita.ai) website and create an account on it. navigate “[text-to-speech](https://novita.ai/product/txt2speech?ref=blogs.novita.ai)” under the “Product” tab, you can test the effect first with the steps below.
- Step 2: Input the text that you want to get voiceover about.
- Step 3: Select a voice model that you are interested in.
- Step 4: Click on the “Generate” button, and wait for it.
- Step 5: Once it is complete, you can preview it. If it’s satisfied, you can download and integrate the output into your documentary.
##Tips on Creating Corporate Voiceover Videos
Creating an effective corporate voiceover video requires meticulous attention to detail and a solid understanding of key elements. Here are some best practices to guide you in producing top-notch corporate voiceover videos:
###Keep the Messaging/Script Simple and Clear
- Simplicity is Key: Ensure your message is straightforward and easy to understand. Avoid jargon and complex terms that might confuse or alienate your audience. Use clear, concise language to convey your message effectively.
###Match the Tone of the Voice with the Pace of the Video
- Synchronize Tone and Pace: The tone of the voiceover should complement the mood of the video, whether it’s serious, playful, or inspirational. Ensure the pace of the voiceover matches the speed of the visuals to create a cohesive viewing experience.
###Use Appropriate Vocabulary and Phrasing
- Tailor Your Language: Choose vocabulary and phrasing that resonate with your target audience. Consider the industry, demographic, and comprehension levels of your viewers when crafting the script.
###Edit and Revise as Needed
- Continuous Improvement: The creation process doesn’t end with recording. Review and revise the voiceover as necessary. Adjust the tone, pace, or script sections to enhance clarity and overall quality.
###Professional Narration
- Expertise Matters: While DIY voiceovers can be cost-effective, hiring a professional voice actor can significantly elevate the quality of your video. Professionals bring diverse tones, emotions, and a level of expertise that can enhance your content.
###Utilize AI Voiceover Software
- Leverage Technology: AI voiceover tools like novita.ai offer cost-effective, consistent, and customizable audio APIs. These tools are advancing rapidly, providing more natural and emotionally nuanced performances.
##How to produce a voice overs tool by integrating text-to-speech API?
Here’s a concise version of the steps to create a voice-over tool using novita.ai’s text-to-speech API:
Step 1: **Sign Up and Get Credentials**: Register on novita.ai and obtain API keys.
Step 2: **Read API Documentation**: Understand the API endpoints, parameters, and responses.
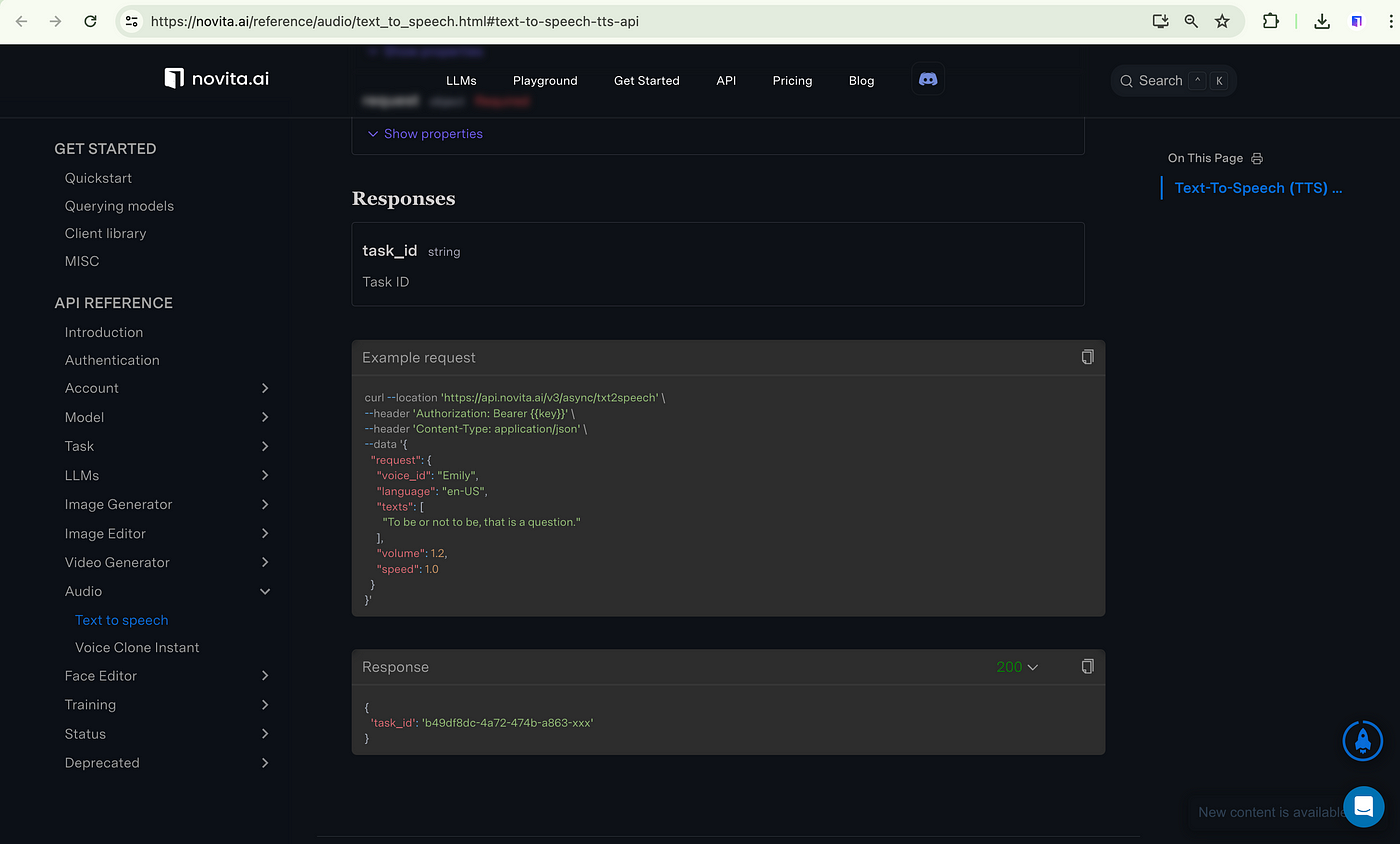
Step 3: **Set Up Development Environment**: Choose your programming language and install necessary libraries.
Step 4: **API Integration**: Write code to send text to the TTS API and receive audio files.
Step 5: **Build User Interface**: Create a UI for text input and customization options.
Step 6: **Customization Options**: Implement settings for voice, speed, pitch, etc.
Step 7: **Text Processing**: Handle text normalization and language detection if needed.
Step 8: **Playback and Download**: Enable users to play and download the generated audio.
Step 9: **Error Handling**: Implement error handling and logging.
Step 10: **Testing**: Test the application thoroughly for various scenarios.
By following these steps, you can effectively integrate novita.ai’s TTS API to create a functional voice-over tool.
##Why Should Novita.AI Be Your Ultimate API Solution?
Novita AI Text to Speech API offers you unparalleled voice generation capabilities, delivering high-quality audio with lightning-fast speed and customizable voice styles. With Novita AI Text to Speech API, you can seamlessly integrate realistic voice synthesis into your applications, providing users with immersive experiences.
- **Real-time latency**: Novita Al voice models can generate speech in < 300ms.
- **Expressive Voice**: Explore voice styles: narrative, chat, joy, rage, sorrow, and empathy.
- **Reliability**: Trust our robust infrastructure to deliver consistent, high-quality audio every time.
- **Seamless Integration**: Effortlessly incorporate our APl applications for a plug-and-playenhancement.
- **Customizable and Scalable**: Tailor the voice to your brand’s identity and scale up to meet the demands of your growing user base.
- **Developer-Friendly**: With comprehensive documentation and 24/7 support, our APls designed to be a breeze for developers.
##Conclusion
Voiceovers play a pivotal role in enhancing corporate videos by adding depth, emotion, and clarity to the content. Whether created through DIY efforts, professional voice actors, or novita.ai’s text-to-speech API, voiceovers transform static visuals into compelling narratives. By following best practices in scripting, tone matching, and editing, businesses can create impactful corporate videos that resonate with their audience, effectively conveying their core messages. Integrating tools like novita.ai text-to-speech API simplifies this process, providing high-quality, customizable voiceovers efficiently.
Originally published at [novita.ai](https://blogs.novita.ai/how-to-create-voiceovers-for-corporate-videos-in-minutes/?utm_source=dev_audio&utm_medium=article&utm_campaign=how-to-create-voiceovers-for-corporate-videos-in-minutes)
[novita.ai](https://novita.ai/?utm_source=dev_audio&utm_medium=article&utm_campaign=how-to-create-voiceovers-for-corporate-videos-in-minutes
), the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free. | novita_ai |
1,863,774 | How I use React Hook Form with Yup and TypeScript | React Hook Form is a powerful library for managing forms in React applications. When combined with... | 0 | 2024-05-24T09:33:36 | https://dev.to/dicky54putra/how-i-react-hook-form-with-yup-and-typescript-1hk7 | react, reacthookform, yup | React Hook Form is a powerful library for managing forms in React applications. When combined with Yup for schema validation and TypeScript for type safety, it provides a robust solution for building and validating forms. This article will guide you through the process of integrating React Hook Form with Yup and TypeScript.
## Install the package into your project
To get started, create a new React project and install the necessary dependencies.
```
npm install react-hook-form yup @hookform/resolvers
```
## Example
```tsx
import Button from "@atoms/Button";
import Container from "@atoms/Container";
import InputField from "@atoms/InputField";
import TextAreaField from "@atoms/TextAreaField";
import Typography from "@atoms/Typography";
import { submitFormService } from "@features/contact/services/submitForm.service";
import { yupResolver } from "@hookform/resolvers/yup";
import { emailRules, phoneNumberRules } from "@utils/generalRegex.utils";
import handleError from "@utils/handleError.utils";
import { notifySuccess } from "@utils/notify.util";
import { useState } from "react";
import { useForm } from "react-hook-form";
import * as yup from "yup";
import s from "./ContactForm.module.scss";
interface IInitialValue {
email: string;
firstName: string;
lastName: string;
phoneNumber?: string;
question?: string;
}
const initialValue: IInitialValue = {
email: "",
firstName: "",
lastName: "",
phoneNumber: "",
question: "",
};
const ContactForm = () => {
const resolver = yup.object({
email: yup
.string()
.matches(emailRules, {
message: "E-mail moet een geldig e-mailadres zijn!",
})
.required("Vul alstublieft dit veld in!"),
firstName: yup.string().required("Vul alstublieft dit veld in!"),
lastName: yup.string().required("Vul alstublieft dit veld in"),
phoneNumber: yup
.string()
.test(
"matches-phone",
"Het mobiele telefoonnummer moet een geldig mobiel nummer zijn!",
(value) => {
if (!value) return true;
return phoneNumberRules.test(value);
}
),
question: yup.string(),
});
const form = useForm({
defaultValues: initialValue,
resolver: yupResolver(resolver),
});
const onSubmit = async (data: typeof initialValue) => {
try {
await submitFormService({
data: data,
});
form.reset();
notifySuccess("Het contact is succesvol verzonden!");
} catch (error) {
handleError(error);
}
};
return (
<section className={s._Root}>
<Container className={s._Container}>
<form
className={s._Card}
onSubmit={form.handleSubmit(onSubmit)}
method="post"
>
<Typography component="h2" variant="h2">
Neem contact met ons op
</Typography>
<div className={s._Card__Row}>
<InputField
{...form.register("firstName")}
id="voornaam"
label="Voornam"
helperText={form.formState.errors.firstName?.message}
error={Boolean(form.formState.errors.firstName?.message)}
required
/>
<InputField
{...form.register("lastName")}
id="achternaam"
label="Achternaam"
helperText={form.formState.errors.lastName?.message}
error={Boolean(form.formState.errors.lastName?.message)}
required
/>
</div>
<div className={s._Card__Row}>
<InputField
{...form.register("phoneNumber")}
id="telefoonnummer"
label="Telefoonnummer"
helperText={form.formState.errors.phoneNumber?.message}
error={Boolean(form.formState.errors.phoneNumber?.message)}
/>
<InputField
{...form.register("email")}
id="e-mail"
label="E-mail"
helperText={form.formState.errors.email?.message}
error={Boolean(form.formState.errors.email?.message)}
required
/>
</div>
<div className={s._Card__Row}>
<TextAreaField
id="jouwVraag"
label="Jouw vraag"
{...form.register("question")}
/>
</div>
<Button
component="button"
type="submit"
disabled={form.formState.isSubmitting}
>
{form.formState.isSubmitting ? "Bezig met laden..." : "Verzend"}
</Button>
</form>
</Container>
</section>
);
};
export default ContactForm;
```
## Let's breakdown part by part
### 1. setup the initial value with the type or interface
define the default value of the form that you will create
```tsx
...
interface IInitialValue {
email: string;
firstName: string;
lastName: string;
phoneNumber?: string;
question?: string;
}
const initialValue: IInitialValue = {
email: "",
firstName: "",
lastName: "",
phoneNumber: "",
question: "",
};
...
```
### 2. setup the handle form with useForm
```tsx
const form = useForm({
defaultValues: initialValue,
resolver: yupResolver(resolver),
});
```
### 3. write the resolver or validation
```tsx
...
const resolver = yup.object({
email: yup
.string()
.matches(emailRules, {
message: "E-mail moet een geldig e-mailadres zijn!",
})
.required("Vul alstublieft dit veld in!"),
firstName: yup.string().required("Vul alstublieft dit veld in!"),
lastName: yup.string().required("Vul alstublieft dit veld in"),
phoneNumber: yup
.string()
.test(
"matches-phone",
"Het mobiele telefoonnummer moet een geldig mobiel nummer zijn!",
(value) => {
if (!value) return true;
return phoneNumberRules.test(value);
}
),
question: yup.string(),
});
...
```
- email field use the custom rules for email, in this case I use the regex from `emailRules`
- firstName & lastName field is required
- question is not required and only allow string value
- phoneNumber is not required but the value should the correct phoneNumber in this case I use regex to handle the rules
### 4. register each field to useForm
I register each field like below. I not only register, I also put the error state and error message when the value not match with the rules. and make the field disabled when the form submiting
```tsx
...
<InputField
{...form.register("firstName")}
id="voornaam"
label="Voornam"
helperText={form.formState.errors.firstName?.message}
error={Boolean(form.formState.errors.firstName?.message)}
disabled={form.formState.isSubmitting}
required
/>
...
```
### 5. Handle submit
```tsx
...
const onSubmit = async (data: typeof initialValue) => {
try {
await submitFormService({
data: data,
});
form.reset();
notifySuccess("Het contact is succesvol verzonden!");
} catch (error) {
handleError(error);
}
};
...
<form className={s._Card} onSubmit={form.handleSubmit(onSubmit)} method="post">
...
</form>;
...
```
### 6. Add state to Button
Add state text if necessary, and make the button disabled while submitting
```tsx
...
<Button component="button" type="submit" disabled={form.formState.isSubmitting}>
{form.formState.isSubmitting ? "Bezig met laden..." : "Verzend"}
</Button>
...
```
## Conclusion
combining React Hook Form with Yup and TypeScript, you can create powerful, type-safe forms with robust validation. This integration allows you to leverage the strengths of each library: React Hook Form for efficient form management, Yup for schema-based validation, and TypeScript for static type checking.
This setup ensures that your forms are not only functional but also maintainable and easy to debug, providing a solid foundation for building complex forms in your React applications. | dicky54putra |
1,863,773 | What's New in API7 Enterprise 3.2.12: Supporting Stream Routes | In API7 Enterprise 3.2.12, support for stream routes has been introduced, enabling TCP/UDP protocol... | 0 | 2024-05-24T09:33:09 | https://api7.ai/blog/api7-3.2.12-stream-routes | In [API7 Enterprise](https://api7.ai/enterprise) 3.2.12, support for stream routes has been introduced, enabling TCP/UDP protocol traffic proxy and load balancing.
By configuring stream routes, API7 Enterprise can proxy requests for services such as MySQL and MongoDB based on the TCP protocol. It can also proxy applications like Redis that can be configured with either TCP or UDP protocols. This enables effective management and optimization of TCP/UDP network traffic.
## How to Use Stream Routes in API7 Enterprise?
### Adding Stream Service
When manually adding a service, an option for service type selection has been added, supporting two types: HTTP and Stream, representing Layer 7 proxy and Layer 4 proxy, respectively. If the service type is selected as `Stream`, the upstream schema can be chosen as either `TCP` or `UDP`. It is important to note that once the service type is selected, it can not be changed, so ensure the correct service type is chosen.
### Adding Stream Routes
After successfully creating a Stream-type service, it will be directed to the service details page. The next step is to add routes by clicking the `Add Stream Route` button.
Fill in the route name, description, and relevant route configuration in the form. Here, we configure a route for proxying MySQL service.
Compared to regular HTTP route configurations, stream routes has three different configuration options.
- **Server Address**: This is the address where the gateway server receives stream route connections, serving as the entrance for stream route traffic into the gateway. When clients seek to establish connections, they send requests to this address, and the gateway forwards or handles these requests based on the predefined routing rules.
- **Server Port**: It is used to specify the port on which the gateway server listens for traffic.
- **Remote Address**: It is the client address that initiates the request. Only requests sent from client addresses that are the same as the remote address can be forwarded, thus enabling traffic management for specific clients.
After successfully creating the route, we can see the newly added MySQL route in the list.

### Configuring Upstream Nodes and Publishing the Service
Next, we will publish the service to the gateway group and add an upstream node corresponding to the MySQL service.
After the service is published, when the gateway server at `127.0.0.10` and port `9101` receives a request, this route will be responsible for handling the request and forwarding it to the upstream MySQL service.
In addition to the basic request forwarding feature, after service publication, the performance and security of the service can be enhanced through a series of configurations. For example, load balancing strategies can be configured for stream routes to ensure traffic is evenly distributed among multiple upstream MySQL servers, thereby improving system scalability and fault tolerance.
Furthermore, [health check](https://api7.ai/blog/api7-3.2.9-upgraded-health-check-configuration) mechanisms can be set up to periodically monitor the status of upstream servers, ensuring only healthy servers receive and forward requests, and avoiding service interruptions due to server failures.
### Supported Plugins
Currently, there are four plugins supported for stream routes:
1. [`ip-restriction`](https://docs.api7.ai/hub/ip-restriction/): Provides IP access control capabilities.
2. [`limit-conn`](https://apisix.apache.org/docs/apisix/3.3/plugins/limit-conn/): This plugin can restrict the number of concurrent requests from clients to a single service.
3. [`prometheus`](https://docs.api7.ai/hub/prometheus): Provides system monitoring and alerting capabilities for stream routes.
4. [`syslog`](https://docs.api7.ai/hub/syslog): Records and sends system logs.
These four plugins collectively enhance the security, stability, monitoring, and maintainability of stream routes.
## Conclusion
The stream routes feature in API7 Enterprise 3.2.12 provides users with more robust and flexible TCP/UDP protocol traffic management, contributing to improved application reliability and scalability. It brings enhanced network traffic management, higher system reliability and operational efficiency, and superior business adaptability for enterprise users, making it valuable for supporting the operation of critical enterprise applications. | yilialinn | |
1,863,631 | Unveiling DistilBERT: Faster &cheaper&Lighter Model | Introduction DistilBERT is a revolutionary language model that aims to make large-scale... | 0 | 2024-05-24T09:30:00 | https://dev.to/novita_ai/unveiling-distilbert-faster-cheaperlighter-model-1ni3 | ai, llm, bert | ## Introduction
DistilBERT is a revolutionary language model that aims to make large-scale language processing more efficient and cost-effective. Developed by Hugging Face, DistilBERT is a distilled version of BERT, a widely used language model that has significantly improved the state-of-the-art in NLP tasks.
Language models like BERT have been growing in size and complexity, with models like Nvidia’s latest release having 8.3 billion parameters, 24 times larger than BERT-large. While these larger models have led to better performance, they come with environmental and financial costs.
## Understanding the Need for Compact Models
Smaller models like DistilBERT also have practical advantages. They can be deployed on resource-constrained devices like smartphones without compromising performance. This enables the development of real-world applications that can run on-device, reducing the need for costly GPU servers and ensuring data privacy.
The smaller size of DistilBERT also results in faster inference times on CPU, making it ideal for applications that require low latency and responsiveness, such as chatbots or voice assistants. This is especially important in the field of machine learning, where compact models like DistilBERT are becoming increasingly necessary for efficient and effective on-device processing.
## What is DistilBERT
DistilBERT is a distilled version of BERT, the original transformer-based language model that has revolutionized NLP. While BERT has achieved remarkable performance on various NLP tasks, its large size and computational requirements make it challenging to use in resource-constrained settings.
**Core Concepts Behind DistilBERT**
The core concepts behind DistilBERT are knowledge distillation, inductive biases, and the transformer architecture. Knowledge distillation is the technique used to compress a larger model, like BERT, into a smaller model, like DistilBERT. It involves training the smaller model to mimic the behavior of the larger model.
Inductive biases refer to the assumptions or prior knowledge embedded in the architecture and training process of a model. DistilBERT benefits from the inductive biases learned by BERT during pre-training, allowing it to generalize well to various NLP tasks.
The transformer architecture, originally introduced by Vaswani et al., forms the basis of both BERT and DistilBERT. It consists of self-attention mechanisms that capture the context and relationships between words in a sentence, enabling the models to understand and generate natural language.
## The Mechanism of Distilling Knowledge in DistilBERT
The mechanism of distilling knowledge in DistilBERT involves training the student model to mimic the output distribution of the teacher model. During training, the student model learns to produce similar probabilities for each class as the teacher model.
The distillation process consists of minimizing the difference between the logits (output scores before applying softmax) of the student and teacher models. The student model is trained to predict the same high probabilities for the correct classes as the teacher model.
By incorporating the knowledge from the teacher model, the student model is able to approximate the behavior of the larger model and achieve similar performance on downstream tasks. This distillation process allows for the compression of the knowledge learned by the teacher model into a smaller and more efficient model like DistilBERT.
**Technical Specifications of DistilBERT**
DistilBERT has several technical specifications that make it a more compact and efficient model compared to BERT. It has approximately 40% fewer parameters than BERT, making it lighter and more suitable for on-device computations.
In terms of inference, DistilBERT is significantly faster than BERT, with a 60% reduction in inference time. This allows for more efficient processing of text data and enables real-time applications.
DistilBERT achieves these improvements in efficiency and speed by leveraging knowledge distillation and incorporating inductive biases learned by the larger model. These technical specifications make DistilBERT a valuable tool for NLP tasks that require fast and efficient language processing.
## DistilBERT vs. BERT: A Comparative Analysis
A comparative analysis between DistilBERT and BERT reveals key differences in performance, model size, and training time. While DistilBERT is a compressed version of BERT, it retains 97% of BERT’s performance on various NLP tasks.
DistilBERT’s smaller model size makes it more efficient in terms of memory usage and storage requirements. This enables faster training and inference times compared to BERT.
Despite the reduction in model size, DistilBERT maintains high performance on a wide range of NLP tasks, making it a suitable alternative for applications with limited resources or stricter computational constraints.
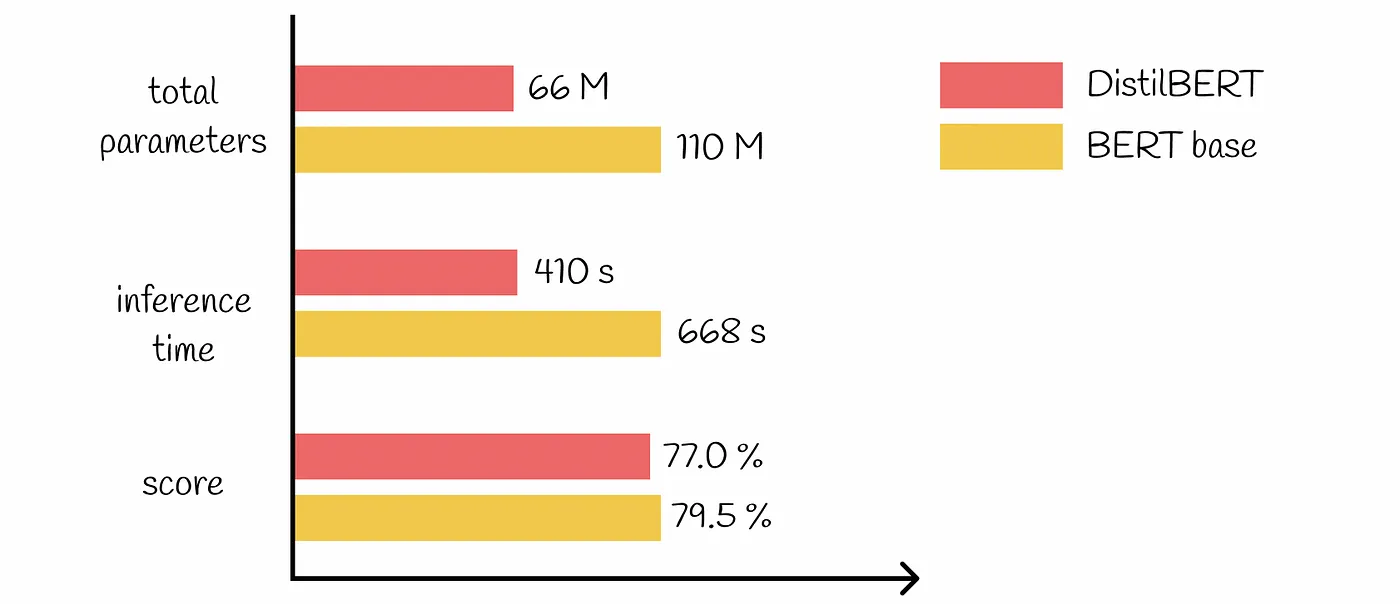
## Performance Metrics: DistilBERT’s Efficiency and Accuracy
DistilBERT’s performance can be evaluated based on its efficiency and accuracy across various downstream tasks. When compared to BERT, DistilBERT demonstrates comparable or even better performance while being a more efficient and lightweight model.
DistilBERT performs well on the General Language Understanding Evaluation (GLUE) benchmark, which consists of multiple downstream NLP tasks. It achieves high accuracy and F1 scores on tasks such as sentiment analysis, text classification, and question answering.
The efficiency of DistilBERT is reflected in its smaller model size and faster inference times. This makes it more suitable for real-time applications, where low latency and responsiveness are crucial. Additionally, DistilBERT’s reduced computational requirements contribute to a lower environmental impact, making it a more sustainable choice for NLP tasks.
## How to Implement DistilBERT
Huggingface’s Transformers library provides a range of DistilBERT models in various versions and sizes. In this guide, we will demonstrate how to load a model and perform single-label classification.
First, we will install and import the necessary packages. Then, we will load the “distilbert-base-uncased-finetuned-sst-2-english” model along with its tokenizer using DistilBertForSequenceClassification and DistilBertTokenizer, respectively. Next, we will tokenize the input data, and use the tokenized output to predict the label, which in this example, is sentiment analysis.
!pip install -q transformers
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
inputs = tokenizer("Wow! What a surprise!", return_tensors="pt")
with torch.inference_mode():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
## DistilBERT in Action: Case Studies
DistilBERT has been successfully applied in various case studies, demonstrating its effectiveness in different NLP tasks. Two noteworthy examples are sentiment analysis and text classification.
**Enhancing Text Classification with DistilBERT**
DistilBERT can greatly enhance text classification tasks by providing accurate predictions in a faster and more efficient manner. It uses the same architecture as BERT but with fewer layers and removed token-type embeddings and pooler.
Despite these changes, DistilBERT retains 95% of BERT’s performance on the GLUE benchmark for language understanding. This makes DistilBERT a powerful tool for various text classification tasks, including sentiment analysis, named entity recognition, and intent detection.
**Leveraging DistilBERT for Sentiment Analysis**
Sentiment analysis is a common NLP task that involves determining the sentiment or emotion expressed in a piece of text. DistilBERT, specifically the DistilBertForSequenceClassification model, is well-suited for sentiment analysis as it has been trained on a large corpus of text and has a strong understanding of language. By fine-tuning DistilBERT on a sentiment analysis dataset, it can accurately classify text into positive, negative, or neutral sentiments.
The probabilities assigned to each sentiment class by DistilBERT can be used to gauge the strength of the sentiment expressed in the text. With its smaller size and faster inference time, DistilBERT is an ideal choice for sentiment analysis applications that require real-time analysis of large amounts of text, such as social media monitoring or customer feedback analysis.
## Advanced Tips for Maximizing DistilBERT’s Capabilities
**Optimizing DistilBERT for Speed and Memory Usage**
To maximize the speed and memory usage of DistilBERT, it is recommended to utilize GPU acceleration and optimize the code for parallel processing. This can significantly reduce the inference time of DistilBERT, making it more efficient for real-time applications. Additionally, using techniques such as quantization and pruning can further reduce the memory usage of DistilBERT without compromising its performance.
Best Practices for Training DistilBERT on Custom Datasets
When training DistilBERT on custom datasets, it is important to follow best practices to achieve optimal results. This includes properly preprocessing the data, ensuring a balanced distribution of classes, and fine-tuning the model with an appropriate learning rate and number of epochs. Data augmentation techniques, such as random word masking or shuffling, can also be applied to increase the diversity of the training data and improve the model’s generalization capabilities.
**Optimizing DistilBERT for Speed and Memory Usage**
To optimize DistilBERT for speed and memory usage, there are several techniques that can be applied.
First, utilizing hardware acceleration such as GPUs can greatly improve the inference speed of DistilBERT.
Additionally, optimizing the code for parallel processing and leveraging batch processing, such as training on very large batches, can further enhance the speed of DistilBERT’s computations. To reduce memory usage, techniques such as quantization (approximating the weights of a network with a smaller precision) and weights pruning (removing some connections in the network) can be used.
## The Future of Compact Models Like DistilBERT
Compact models like DistilBERT represent the future of NLP as they offer a more efficient and cost-effective solution compared to larger models. The demand for on-device language processing capabilities is increasing, and compact models provide a viable solution that can run on resource-constrained devices.
As research in model compression techniques continues to advance, we can expect even smaller and faster models with improved performance in recent years. Additionally, the availability of pre-trained compact models like DistilBERT enables developers to quickly deploy NLP applications without the need for extensive computational resources. The future of NLP will see the widespread adoption and development of compact models, such as DistilBERT, to meet the demands of real-time language processing using the power of deep learning.
**Ongoing Research and Limitations**
Both academic and industrial research groups continue to explore the vast potential of DistilBERT while recognizing its limitations. Universities and AI research labs are delving into the model’s intricacies to enhance its capabilities and extend its applicability.
1. Research Initiatives: Leading universities and AI research groups are collaborating to push the boundaries of DistilBERT’s potential.
2. Addressing Limitations: Ongoing research focuses on improving context retention over longer texts and nuanced language understanding.
3. Model Refinement: Efforts are being made to refine DistilBERT for specific tasks, such as medical diagnosis and legal document analysis, where precision is crucial.
However, it is time-consuming to overcome these limitations. You can choose better models such as Llama 3 released recently to get your work done with time saved. Here is novita.ai [LLM API ](https://novita.ai/llm-api)featuring models:
Try our LLM API for free now:
## Conclusion
In conclusion, DistilBERT has revolutionized the world of AI models with its compact design and enhanced efficiency. By distilling knowledge from its predecessor BERT, it offers a faster and lighter alternative without compromising on accuracy.
The application of DistilBERT in real-world scenarios, such as text classification and sentiment analysis, showcases its immense potential. It is crucial to understand the technical specifications and performance metrics to leverage its capabilities optimally. As we delve into the future of compact models like DistilBERT, continuous advancements in model compression techniques promise exciting prospects for AI development and innovation. Stay tuned for the next generation of AI models and explore the possibilities that await.
> Originally published at [novita.ai
](https://blogs.novita.ai/unveiling-distilbert-faster-cheaper-lighter-model/?utm_source=devcommunity_LLM&utm_medium=article&utm_campaign=DistilBERT)
> [novita.ai](https://novita.ai/?utm_source=devcommunity_LLM&utm_medium=article&utm_campaign=unveiling-distilbert-faster-cheaper-lighter-model), the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.
| novita_ai |
1,863,628 | Introducing Llama 2: All Worthwhile After Llama 3 Released | Introduction Llama 3 has been crashing the party ever since its release from MetaAI. But... | 0 | 2024-05-24T09:30:00 | https://dev.to/novita_ai/introducing-llama-2-all-worthwhile-after-llama-3-released-fl2 | ai, llm, llama | ## Introduction
Llama 3 has been crashing the party ever since its release from MetaAI. But it does not mean that we should replace Llama 2 with the newest generation of Llama model.
Released by Meta AI in 2023, Llama 2 offers a range of pre-trained and fine-tuned models that are capable of various natural language processing (NLP) tasks. Unlike its predecessor, LLaMa 1, Llama 2 is available free of charge for both AI research and commercial use, making it more accessible to a wider range of organizations and individuals. With comprehensive integration in Hugging Face, Llama 2 Chat models are set to revolutionize the way we approach NLP tasks.
## What is LlaMA 2?

LlaMA 2, the successor to LlaMA version 1 released by Meta in July 2023, outshines its predecessor in several aspects. It introduces three different sizes: 7B, 13B, and 70B parameter models. Upon its debut, LlaMA 2 quickly rose to the top spot on Hugging Face, surpassing all other models across all segments. This achievement is notable considering its superior performance even when compared to LlaMA version 1.
LlaMA 2 was trained on an extensive dataset of 2 trillion pretraining tokens, doubling the context length of LlaMA 1 to 4k. Its superiority extends beyond just Hugging Face, outperforming other state-of-the-art open-source models like Falcon and MPT in various benchmarks such as MMLU, TriviaQA, Natural Question, and HumanEval. Detailed benchmark scores can be found on Meta AI’s website.
Additionally, LlaMA 2 underwent fine-tuning specifically for chat-related applications, incorporating feedback from over 1 million human annotations. These chat models are now readily accessible on the Hugging Face website for use.
**Why Llama 2 Remains Relevant**
Llama 2 remains relevant because it offers advancements in context length, accessibility, and training techniques. These improvements make Llama 2 a valuable resource for AI researchers, developers, and businesses in need of powerful language generation capabilities.
## Understanding the Core Technology Behind Llama 2
To fully grasp the capabilities of Llama 2, it is essential to understand its core technology and architecture. Llama 2 is a family of transformer-based autoregressive causal language models. These models take a sequence of words as input and predict the next word(s) based on self-supervised learning. The models are pre-trained with a massive corpus of unlabeled data, allowing them to learn linguistic and logical patterns and replicate them in their predictions. Llama 2 has achieved key innovations in training techniques, such as reinforcement learning from human feedback, which helps align model responses with human expectations. These innovations contribute to the improved performance and versatility of Llama 2 in various NLP tasks.
**The Architecture of Llama 2**
The architecture of Llama 2 is based on transformer-based autoregressive causal language models. These models consist of multiple layers of self-attention and feed-forward neural networks. Llama 2 models are designed to predict the next word(s) in a sequence based on the input provided.
In terms of parameters, Llama 2 models offer a choice of seven billion (7B), 13 billion (13B), or 70 billion (70B) parameters. These parameter counts determine the complexity and capacity of the models. While larger parameter counts may result in higher performance, smaller parameter counts make Llama 2 more accessible to smaller organizations and researchers.
**Key Innovations in Llama 2**
Llama 2 has introduced several key innovations in the field of large language models. These innovations have been detailed in the Llama 2 research paper, which has been well-received by the AI community.
One of the key innovations is the use of reinforcement learning from human feedback (RLHF) to fine-tune the models. This helps align the model responses with human expectations, resulting in more coherent and accurate language generation.
Furthermore, Llama 2 has focused on advancing the performance capabilities of smaller models rather than increasing parameter count. This approach makes Llama 2 more accessible to smaller organizations and researchers who may not have access to the computational resources required for larger models.
## Practical Applications of Llama 2
Llama 2 has practical applications across various industries and domains. Its versatile language generation capabilities make it a valuable tool for developers, researchers, and businesses. Some of the practical applications of Llama 2 include:
- Text generation: Llama 2 can be used to generate natural language text for content creation, chatbots, virtual assistants, and more.
- Code generation: Llama 2 can generate programming code for various languages, aiding developers in their coding tasks.
- Creative writing: Llama 2 can assist with creative writing, generating stories, poems, and other forms of creative content.
Compared with Llama 3 models of novita.ai [LLM API](https://novita.ai/llm-api), Llama 2 has larger datasets and is more cost-effective.
With Llama 2 models, you can easily perform such tasks in the image below:
## How to Get Started with Llama 2
You can access the source code for LlaMA 2 on GitHub. If you wish to utilize the original weights, they are also accessible, but you’ll need to provide your name and email address on Meta AI’s website. To do so, click on the provided link, enter your name, email address, and organization (select “student” if applicable). After filling out the form, scroll down and click on “accept and continue.” Following this, you’ll receive an email confirming your submission and providing instructions on how to download the model weights. The form will resemble the example below.
Now, there are two methods to utilize the model. The first involves directly downloading the model through the instructions and link provided in the email. However, this method may be challenging if you lack a decent GPU. Alternatively, you can use Hugging Face and Google Colab, which is simpler and accessible to anyone.
To begin, you’ll need to set up a Hugging Face account and create an Inference API. Then, navigate to the LlaMA 2 model on Hugging Face by clicking on the provided link. Next, provide the email you used on the Meta AI website. Once authenticated, you’ll be presented with something akin to the example below.
Now, we can download any Llama 2 model through Hugging Face and start working with it.
**Using LlaMA 2 with Hugging Face and Colab**
In the preceding section, we covered the prerequisites before experimenting with the LlaMA 2 model. Now, let’s initiate by importing the necessary libraries in Google Colab, which can be achieved using the pip command.
!pip install -q transformers einops accelerate langchain bitsandbytes
To begin working with LlaMA 2, we need to install several essential packages. These include the transformers library from Hugging Face, which facilitates model downloading. Additionally, we require the einops function, which streamlines matrix multiplications within the model by leveraging Einstein Operations/Summation notation. This function optimizes bits and bytes to enhance inference speed. Finally, we’ll utilize langchain to integrate our LlaMA model.
To access Hugging Face through Colab using the Hugging Face API Key and download the LlaMA model, follow these steps.
!huggingface-cli login
After entering the Hugging Face Inference API key we previously generated, if prompted with “Add token as git credential? (Y/n)”, simply respond with “n”. This action will authenticate us with the Hugging Face API Key, enabling us to proceed with downloading the model.
There is a more straightforward way to integrate Llama 2 with your existing system — Applying novita.ai’s LLM API, which is reliable, cost-effecvtive and privacy-ensured.
## Optimizing Your Use of Llama 2
Optimizing your use of Llama 2 involves following best practices and addressing any potential issues or challenges that may arise. Here are some tips to optimize your use of Llama 2:
- Understand the limitations: Familiarize yourself with the limitations and constraints of the Llama 2 models. This will help you set realistic expectations and avoid potential pitfalls.
- Experiment with hyperparameters: Fine-tune the model by experimenting with different hyperparameters, such as learning rates and batch sizes. This can lead to improved performance and generation quality.
- Regularly update and retrain the model: Stay up to date with the latest model updates and improvements. Periodically retrain the model on new data to ensure optimal performance.
- Monitor and address biases: Be mindful of potential biases present in the training data and generated output. Regularly evaluate and address any biases to ensure fair and unbiased language generation.
**Best Practices for Efficient Use of Llama 2**
When maximizing the efficiency of Llama 2, it’s essential to streamline workflow by optimizing model weights and parameters. Utilize the preferred Python or PyTorch framework, manage context length judiciously, and ensure responsible use based on guidelines from Facebook. Regularly update the model, leveraging human feedback for enhancements. Consider cloud services like Microsoft Azure for scalable performance. Implement stringent data use policies and follow best practices for secure deployment and maintenance, including reporting any issues with the model to github.com/facebookresearch/llama. These practices foster optimal performance and longevity for Llama 2.
## Troubleshooting Common Issues with Llama 2
One common issue encountered with Llama 2 is related to model weights convergence during training. This could be due to insufficient data for the specific task or training for too few epochs. Another issue is the model failing to generalize well to new data, indicating potential overfitting. In such cases, fine-tuning the model with additional diverse data or adjusting hyperparameters like learning rate can often resolve these challenges. Regularly monitoring training progress and experimenting with different configurations are key steps in troubleshooting llama 2.
## The Future of Llama 2 Post Llama 3 Release
With the release of Llama 3, the future of Llama 2 remains bright and promising. Meta AI is committed to the continued development and support of Llama 2, ensuring that it remains a valuable resource for the AI community. As the AI landscape continues to evolve, Llama 2 will adapt and incorporate new advancements in generative AI and reinforcement learning. The open foundation of Llama 2 allows for collaboration and innovation, making it an essential tool for researchers, developers, and organizations alike.
**Continued Development and Support for Llama 2**
By actively engaging with the user community and incorporating feedback, Meta AI can address any issues or challenges that may arise. Additionally, Meta AI is committed to providing resources and documentation to assist users in effectively utilizing Llama 2. The open-source nature of Llama 2 encourages collaboration and innovation, allowing researchers and developers to contribute to its ongoing improvement. With Meta AI’s dedication to the continued development and support of Llama 2, users can expect a robust and evolving platform for their AI needs.
## How Llama 2 Fits into the Evolving AI Landscape
Llama 2 plays a crucial role in the constantly evolving AI landscape by providing a powerful and accessible tool for natural language processing tasks. With its generative AI capabilities and reinforcement learning, Llama 2 enables developers to create more human-like and contextually aware applications.
Furthermore, Llama 2’s open approach to AI fosters transparency, collaboration, and responsible development. In an era where AI technologies are rapidly advancing, Llama 2 offers a foundation for innovation and exploration. By leveraging Llama 2’s capabilities, developers can stay at the forefront of the AI landscape and harness the full potential of generative AI and reinforcement learning. [INST] Llama 2 is an essential tool for developers looking to create more human-like and contextually aware AI applications. Its open approach to AI fosters transparency and collaboration, making it a valuable asset in the constantly evolving AI landscape.
## Conclusion
In conclusion, Llama 2 continues to hold its own even after the release of Llama 3, boasting unique advantages and practical applications. Getting started with Llama 2 involves setting up your environment and optimizing its use with best practices. As the future of Llama 2 unfolds post Llama 3, continued development and support ensure its alignment with the evolving AI landscape. Explore the FAQs to understand how Llama 2 competes with Llama 3 and how migration between the two is facilitated.
## Frequently Asked Questions
**Can Llama 2 Still Compete with Llama 3?**
Yes, Llama 2 continues to be a valuable resource for AI research and commercial use. While Llama 3 offers new advancements, Llama 2 remains a powerful tool with its diverse models and open foundation.
**What Are the Main Reasons to Choose Llama 2 Over Llama 3?**
Llama 2 offers several advantages, including greater accessibility, and more cost-effective.
**How to Migrate from Llama 2 to Llama 3 if Needed?**
To migrate from Llama 2 to Llama 3, users can refer to the user guide provided by Meta AI. The guide outlines the upgrade path and provides detailed instructions for migrating model weights and adapting code.
> Originally published at [novita.ai](https://blogs.novita.ai/introducing-llama-2-all-worthwhile-after-llama-3-released/?utm_source=devcommunity_LLM&utm_medium=article&utm_campaign=llama2)
> [novita.ai](https://novita.ai/?utm_source=devcommunity_LLM&utm_medium=article&utm_campaign=introducing-llama-2-all-worthwhile-after-llama-3-released), the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.
| novita_ai |
1,863,771 | Bougainvillea plant online, Great plants for balconies | Title: Enhance Your Balcony with Bougainvillea Plant online: A Spectacular Addition to Your Outdoor... | 0 | 2024-05-24T09:29:04 | https://dev.to/upjauindia_e9c8ae5acf3bd0/bougainvillea-plant-online-great-plants-for-balconies-211p | Title: Enhance Your Balcony with [Bougainvillea Plant online](https://upjau.in/bougainvillea-golden-sunshine/): A Spectacular Addition to Your Outdoor Space
**Introduction:**
Transforming your balcony into a vibrant oasis is made easy with the addition of bougainvillea plants. Renowned for their stunning beauty and versatility, bougainvilleas are a popular choice among gardening enthusiasts for balcony adornment. In this article, we delve into why these magnificent plants are ideal for balconies and how you can cultivate their splendor in your outdoor haven.
1. *Bougainvillea: The Balcony's Best Companion*
- Explore the allure of bougainvillea's: Their vivid colors and lush foliage make them a standout choice for balcony gardens.
- Versatility in design: Whether you have a small or spacious balcony, bougainvillea's can be adapted to suit various settings and styles.
- Low-maintenance charm: Ideal for urban dwellers or those with busy lifestyles, bougainvilleas require minimal upkeep while offering maximum visual impact.
2. *Benefits of Bougainvilleas for Balconies*
- Aesthetic appeal: Elevate the ambiance of your balcony with bougainvilleas' vibrant hues and cascading blooms.
- Privacy and screening: Create a natural barrier and enhance privacy on your balcony with strategically placed bougainvillea vines.
- Attracts pollinators: Invite butterflies and bees to your outdoor space, promoting biodiversity and ecological balance.
3. *Cultivating Bougainvilleas on Your Balcony*
- Selecting the right variety: Choose from a range of bougainvillea cultivars, considering factors such as size, color, and growth habit.
- Container gardening tips: Opt for well-draining soil and adequate sunlight exposure to ensure healthy growth in containers or hanging baskets.
- Pruning and maintenance: Learn how to prune bougainvilleas to maintain shape and encourage prolific blooming throughout the growing season.
4. *Design Inspirations with Bougainvilleas*
- Vertical gardening: Utilize trellises or pergolas to showcase bougainvilleas' climbing capabilities, adding dimension to your balcony space.
- Mix and match: Combine bougainvilleas with other balcony plants to create visually appealing compositions and seasonal interest.
- Creative container arrangements: Experiment with different container sizes and arrangements to unleash your balcony's full decorative potential.
**Conclusion:**
Bougainvillea Plant online offer a plethora of benefits for balcony gardening enthusiasts, from their striking beauty to their adaptability and ease of maintenance. By incorporating these stunning plants into your balcony design, you can create a captivating outdoor retreat that delights the senses and uplifts the spirit. Embrace the charm of bougainvilleas and embark on a journey to transform your balcony into a botanical haven like no other. | upjauindia_e9c8ae5acf3bd0 | |
1,863,770 | CTO's Guide: Overcoming Top Challenges in Cloud Migration | Chief technology officers (CTOs) are at the forefront of strategic decision making in the... | 0 | 2024-05-24T09:27:40 | https://www.softwebsolutions.com/resources/top-cloud-migration-challenges-for-ctos.html | cloud, cloudcomputing, cloudmigration, cto | Chief technology officers (CTOs) are at the forefront of strategic decision making in the ever-evolving landscape of digital transformation. As businesses increasingly embrace cloud computing to drive agility, scalability, and innovation, the role of CTOs becomes pivotal in orchestrating seamless cloud migrations. However, this journey is not without its hurdles. From legacy system integration to data security concerns, CTOs face a myriad of challenges when migrating to the cloud.
As the role of CTOs becomes increasingly demanding, navigating the complex landscape of technology and strategy becomes difficult. CTOs have to manage their tech teams’ evolving needs while simultaneously aligning with C-level **[cloud migration strategies](https://www.softwebsolutions.com/resources/aws-cloud-migration-strategy.html)**. The introduction of a distributed workforce further amplifies these challenges, requiring a delicate equilibrium between budgetary considerations, headcount strategies, security, infrastructure, and development priorities.
In this article, we delve into the top cloud migration challenges faced by CTOs in 2024 and beyond. These challenges, once daunting, can now be effectively addressed through cloud solutions. Whether it’s safeguarding data, accelerating development, or building cost optimization strategies, the cloud offers a transformative path for CTOs to overcome obstacles and drive innovation.
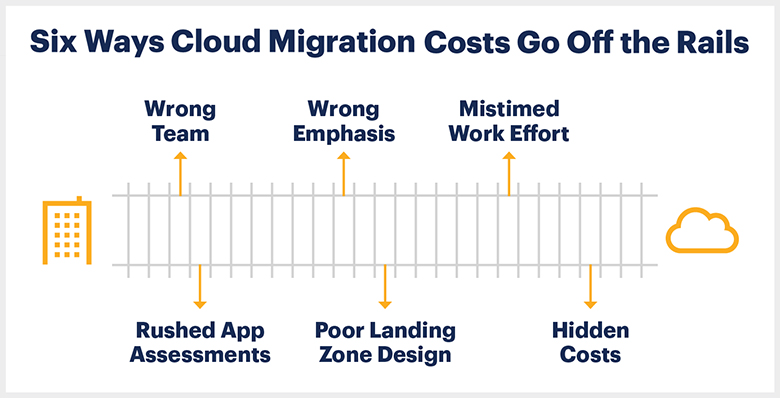
_Source: Gartner_
## Top 5 cloud migration challenges for CTOs and their solutions
### 1. Legacy system integration:
One of the primary challenges CTOs face during cloud migration is integrating legacy systems with modern cloud environments. Legacy systems often have complex architectures, outdated technologies, and dependencies that can hinder seamless integration with cloud platforms.
**_Around 86% of companies believe that outdated technology and inflexible systems hinder their ability to respond effectively to customer needs. – McKinsey & Company_**
**Solution:** CTOs can overcome this challenge by adopting a phased migration approach. This involves identifying critical systems for migration, implementing compatibility layers or APIs to bridge legacy and cloud systems, and gradually transitioning workloads to the cloud while ensuring minimal disruption to business operations.
### 2. Data security and compliance:
Ensuring data security and compliance with regulatory standards is an important concern for CTOs when migrating to the cloud. The decentralized nature of cloud environments and the need to protect sensitive data pose significant challenges in maintaining robust security measures.
**_Data breaches can cost millions to a company. In 2023, detection and escalation represent the largest share of breach costs, at an average total cost of $1.58 million. – IBM_**
**Solution:** CTOs can implement a comprehensive security strategy that includes data encryption, access control mechanisms, regular audits, and compliance monitoring tools. Leveraging cloud-native security services and partnering with trusted cloud providers that offer built-in security features can enhance data protection and ensure regulatory compliance.
### 3. Performance and scalability issues:
Maintaining optimal performance and scalability in the cloud can be challenging for CTOs, especially when dealing with fluctuating workloads, resource allocation, and network latency issues.
**_Cloud performance boosts efficiency. Nearly 80% of IT professionals say moving to the cloud improved their productivity, according to a research by Office 365._**
**Solution:** CTOs can address performance and scalability challenges by leveraging cloud-native technologies such as auto-scaling, load balancing, and serverless computing. Implementing performance monitoring tools, optimizing resource utilization, and conducting periodic performance testing can also enhance application responsiveness and scalability in the cloud.
### 4. Cost management and optimization:
Cloud migration often comes with cost implications, including infrastructure provisioning, data storage, and usage charges. CTOs need to optimize cloud spending while ensuring efficient resource allocation and cost-effective operations.
_**Companies can reduce total cost of ownership (TCO) by as much as 40% by migrating their business to the public cloud. – Accenture**_
**Solution:** CTOs can implement cost management strategies such as cloud resource tagging, rightsizing instances, utilizing reserved instances or spot instances, and leveraging cost optimization tools provided by cloud providers. Conducting regular cost audits, optimizing workload distribution, and implementing governance policies can help mitigate cost overruns and maximize ROI from cloud investments.
### 5. Organizational change and skill gaps:
Cloud migration requires a shift in organizational culture, processes, and skill sets. CTOs often encounter challenges related to change management, talent acquisition, and upskilling existing teams to adapt to cloud technologies.
_**In March 2023, over 85% of the surveyed IT decision-makers stated that the lack of skills and expertise in cloud operations has impacted somehow or significantly the ability of their companies to achieve their business goals. – Statista**_
**Solution:** CTOs can address organizational change and skill gaps by fostering a culture of continuous learning and innovation. Hiring external cloud experts or consultants helps businesses to adopt best practices for cloud migration within the organization. This saves cost, time and efforts of hiring and training internal IT teams.
> **_Suggested: [Successful businesses must be cloud-based. Why?](https://www.softwebsolutions.com/resources/comparison-on-premises-vs-cloud.html)_**
## The strategic benefits of cloud migration for CTOs
### 1. Scalability and flexibility:
Cloud platforms offer unparalleled scalability, allowing CTOs to scale resources up or down based on demand. This flexibility enables organizations to adapt quickly to the changing market conditions, accommodate growth, and optimize resource utilization.
### 2. Cost efficiency:
Cloud migration can lead to significant cost savings by eliminating the need for upfront hardware investments, reducing maintenance costs, and optimizing resource usage. CTOs can leverage pay-as-you-go pricing models and cloud-native cost optimization tools to control expenses effectively.
### 3. Enhanced security and compliance:
Leading cloud providers invest heavily in security measures, offering robust data encryption, access control, and compliance frameworks. By migrating to the cloud, CTOs can enhance data security, mitigate risks, and ensure compliance with regulatory standards.
### 4. Improved collaboration and accessibility:
Cloud-based collaboration tools and platforms enable seamless communication, collaboration, and knowledge sharing across geographically dispersed teams. CTOs can leverage cloud solutions to enhance productivity, streamline workflows, and foster innovation.
### 5. Agility and innovation:
Cloud technologies empower CTOs to innovate rapidly, experiment with new ideas, and launch products or services faster. By leveraging cloud-native services such as AI, machine learning, and analytics, organizations can drive innovation, gain competitive advantages, and stay ahead of market trends.
> **_Suggested: [Optimizing cloud costs: Avoid these 5 mistakes that inflate cloud bills](https://www.softwebsolutions.com/resources/aws-cost-optimization-strategies-guide.html)_**
### 6. Business continuity and disaster recovery:
Cloud platforms offer robust business continuity and disaster recovery capabilities, ensuring data redundancy, backup, and recovery options. CTOs can minimize downtime, mitigate risks, and maintain uninterrupted operations even during unforeseen events.
### 7. Global reach and scalability:
Cloud migration enables organizations to expand their reach globally, access new markets, and scale operations effortlessly. CTOs can leverage cloud infrastructure to deploy applications and services closer to end-users, improving latency, performance, and user experience.
## Empowering organizations with seamless cloud migration: Softweb Solutions’ expertise
Softweb Solutions is a leading provider of cloud migration services, empowering organizations to harness the full potential of cloud technologies and achieve strategic advantages in today’s digital landscape. Here’s how Softweb Solutions can assist organizations in overcoming cloud migration challenges and realizing the benefits of transitioning to the cloud:
- Comprehensive assessment and planning
- Legacy system integration and modernization
- Security and compliance assurance
- Optimized resource allocation and cost management
- Performance optimization and scalability
- Continuous support and maintenance
- cloud migration strategies whitepaper

### Explore the best strategies to migrate to the AWS cloud
The cloud serves as a tool, not a destination. For insights on leveraging AWS services and cloud migration strategies, explore the whitepaper on migrating to AWS cloud.
**_[Download](https://go.softwebsolutions.com/resources/strategies-for-migrating-data-to-aws-cloud.html)_**
Softweb Solutions empowers organizations with end-to-end cloud migration services, from assessment and planning to integration, security, optimization, and ongoing support. By leveraging Softweb Solutions’ expertise, organizations can navigate cloud migration challenges effectively, capitalize on cloud benefits, and achieve digital transformation success in today’s competitive business landscape.
## Navigating cloud migration challenges for digital transformation
Navigating the complexities of cloud migration requires strategic planning, technical expertise, and a trusted partner like Softweb Solutions. By leveraging **[professional AWS migration services](https://www.softwebsolutions.com/aws-cloud-migration-services.html)** and addressing key challenges, organizations can unlock the strategic benefits of cloud technologies.
Softweb Solutions’ comprehensive approach to cloud migration for enterprises empowers chief technology officers and organizations to embrace digital transformation, drive innovation, enhance agility, and achieve competitive advantages in today’s dynamic business environment. With the right strategy, tools, and support, organizations can harness the full potential of the cloud and position themselves for long-term success in the digital era. | csoftweb |
1,860,139 | How we saved our partners 💵$460,000 and 2,5 months⏰ of work | In 2022, I worked on a data science project for a retailer. The project was to predict cashflows... | 0 | 2024-05-24T09:16:35 | https://dev.to/taipy/how-we-saved-our-partners-460000-and-25-months-of-work-40kg | opensource, startup, datascience, ai | In 2022, I worked on a data science project for a retailer. The project was to predict cashflows through better demand forecasting and inventory management. This project followed the common pitfalls of all data science and AI projects and made me rethink our strategy and tools.

I’ll tell you all about the mistakes I made ( and will never do again) and what tool I used to save money and time.
<hr/>
## Common pitfalls in AI & Data projects
Over the years, I’ve worked on many AI and dastascience projects, delivering substantial ROI through algorithms and AI models. Despite the AI hype, many non-software companies struggle with successful AI strategies, often limited to standard data projects and few impactful AI deployments, resulting in uneven AI adoption.

<hr/>
### Here are the main causes:
- **Siloed Teams**: There’s often a big disconnect between the data scientists and the end-users. There are valid reasons for having different roles and the need for specialization.
However, it's important to recognize that in real projects, this leads to a significant gap between data scientists and end-users. Each group tends to use different technology stacks; for instance, data scientists usually work with Python, while IT developers might use JavaScript, Java, Scala, and other languages.
This influences teamwork in taking more time and making teamwork tricky.
These are the various groups involved in a typical AI/ DS project:
- **Getting acceptance from the end-users / business users:** If end-users aren't part of the development process, they might not use the software once it’s up and running.

<hr/>
## What I needed:
1- **Go All-In on Python**: It's easy to learn and works well with other tech. It is at the heart of the AI stack and ideal for integrating with other environments. We considered libraries like Streamlit, which is excellent for prototype quick applications, but we quickly felt the limits of this library for performant multi-user applications.
2- **Better Interaction with end-users**: It is critical to ensure the software works well for users and track how happy they are with it.
<hr/>
## The solution:
Taipy came from the need for a easy tool, like Python, and strong enough for big projects. It handles loads of data fast, can be tailored to specific business needs, and connects data scientists with business users. It also makes decision-making smarter with features that let users play with different scenarios.
Now let's go into detail:
### - Answer to the siloed teams
The obvious answers would go towards these points:
1. Standardize on a single programming language.
2. Provide an easy-to-learn and use programming experience for all skill levels.
3. Python is ideal for AI, with many user-friendly libraries, though they often face performance and customization issues.
For instance, libraries like Plotly Dash offer full-code solutions, while Streamlit or Gradio are easier but lack performance and flexibility. Python developers shouldn't have to choose between productivity and performance.
We created Taipy to combine ease of development with high performance and customization.

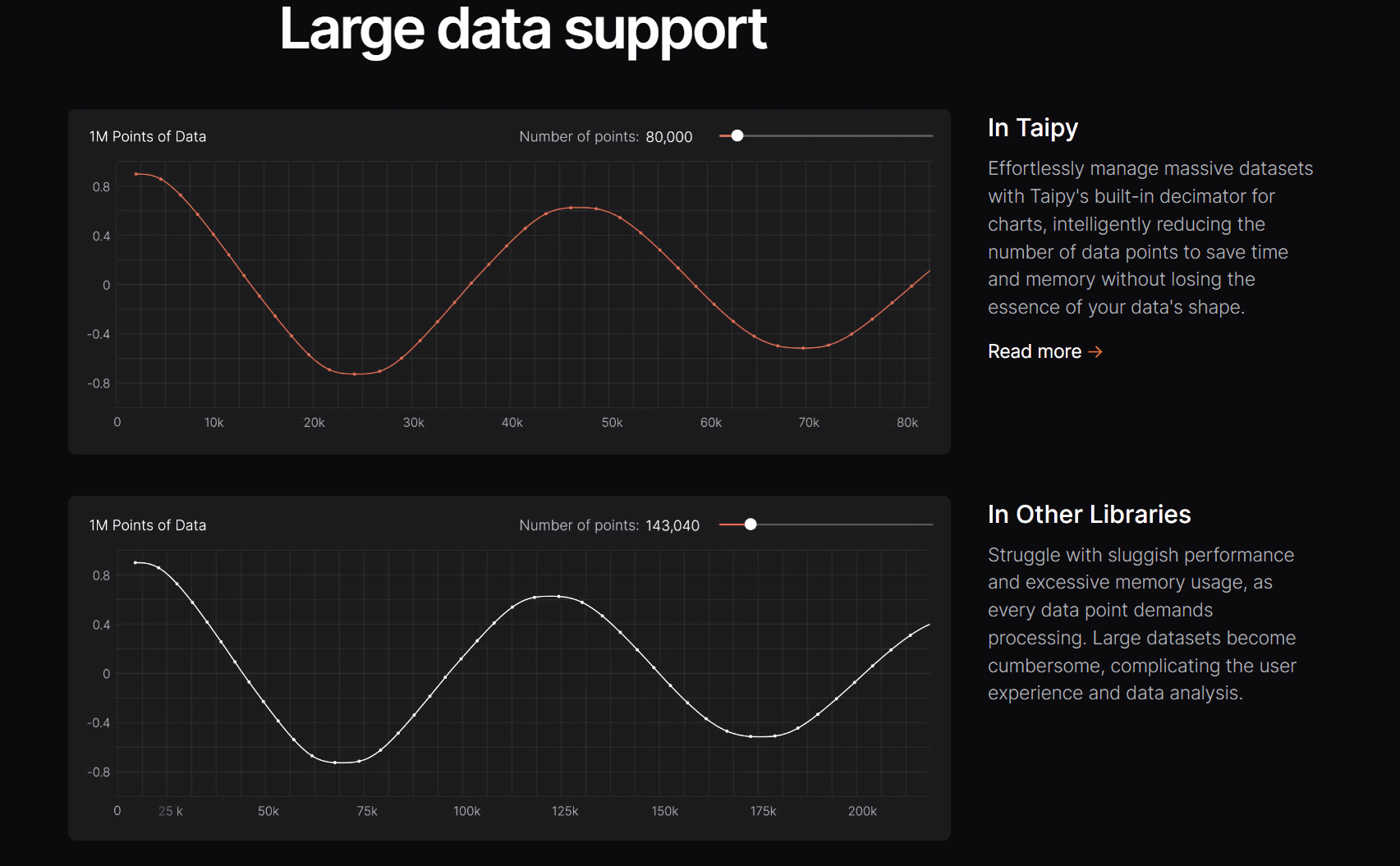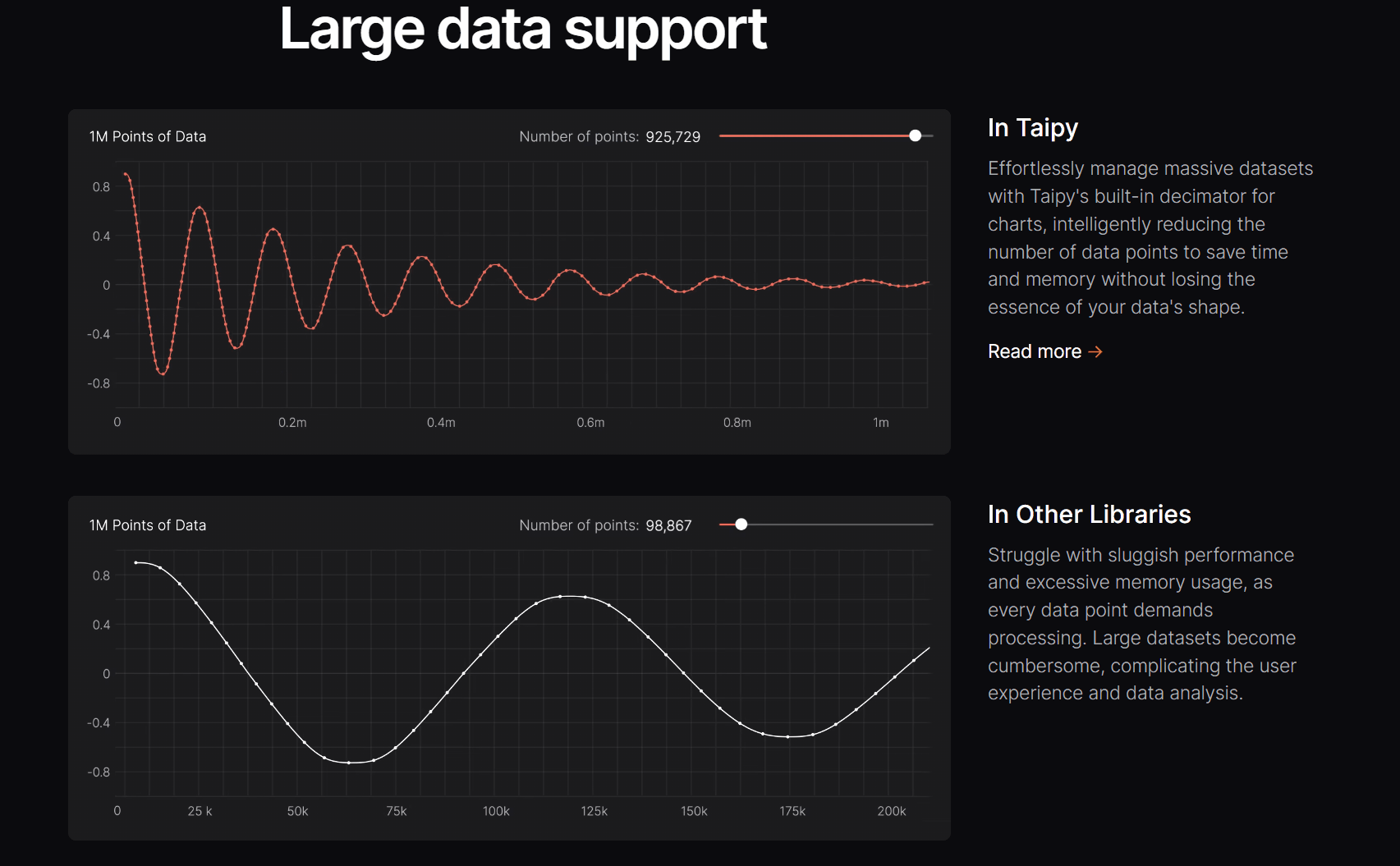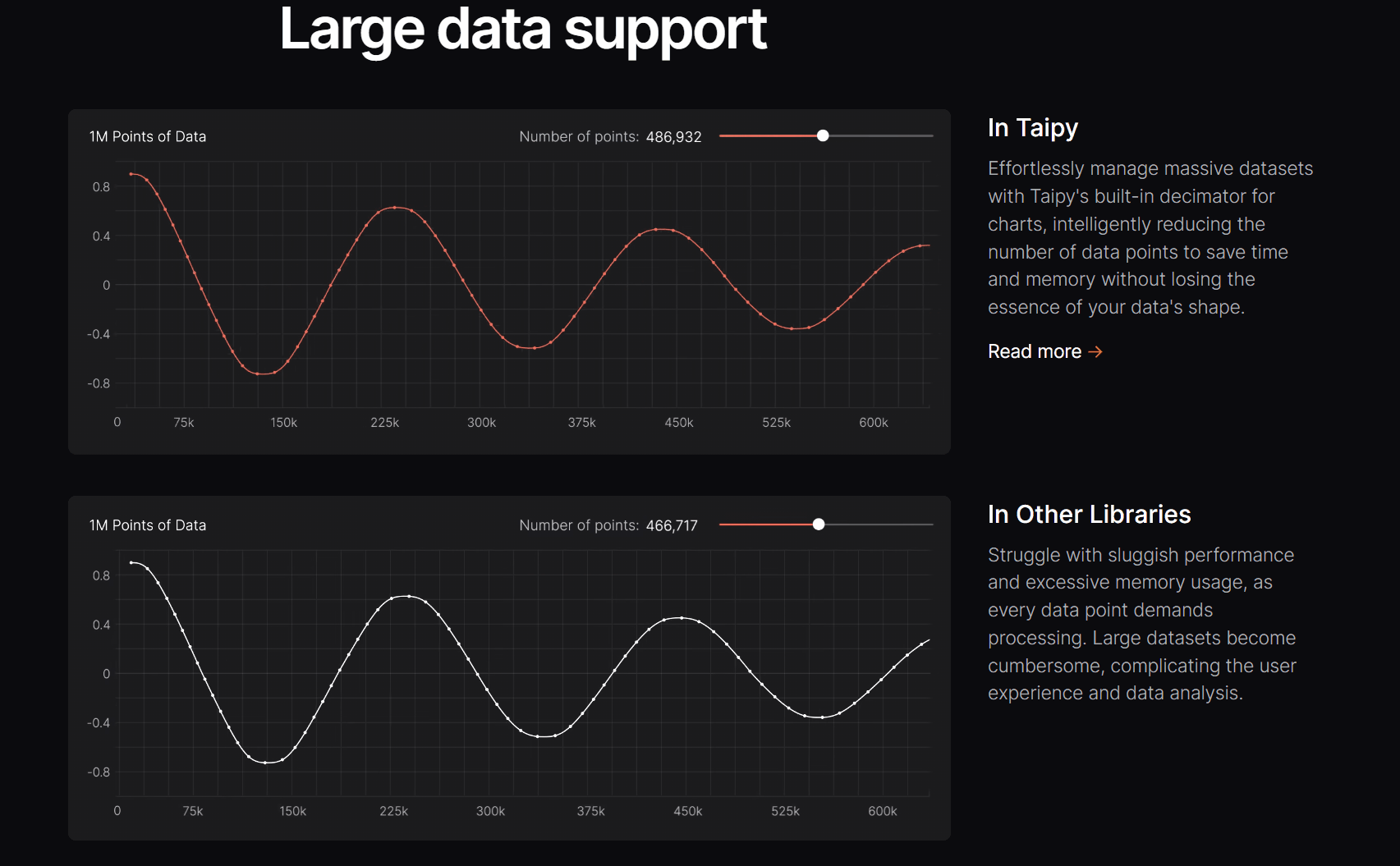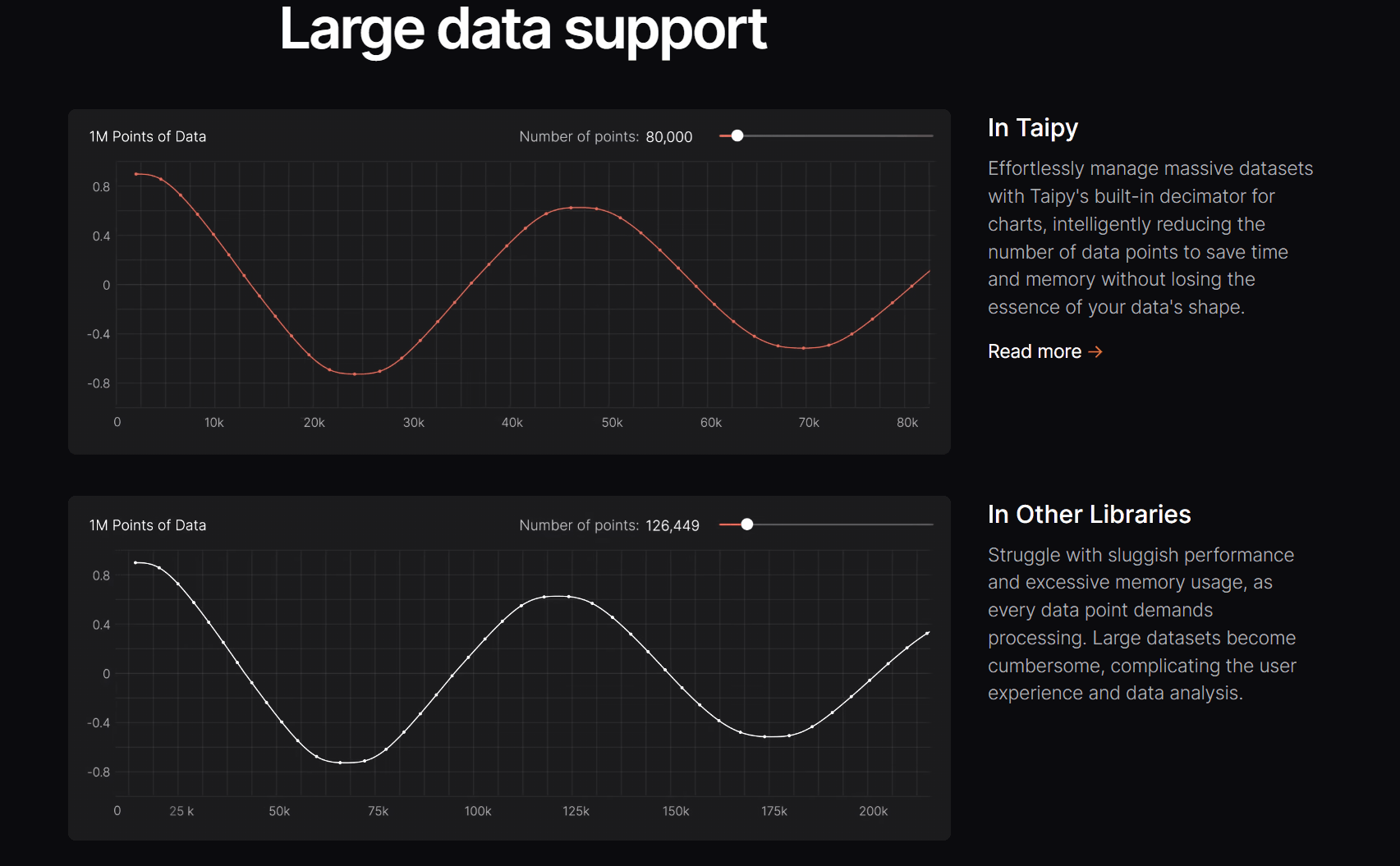
<hr/>
### - Answer to bringing back the end-user to the center of the project
Addressing the two key points is crucial:
1. Smooth end-user interaction with backend algorithms.
For smooth interaction, end-users need control over algorithm variables through the GUI, the ability to run algorithms with different parameters, and the option to compare results and track KPI performance over time. Taipy addresses this with the 'scenario' concept, storing all data elements and enabling users to track runs, revisit past scenarios, and analyze results.
2. Easy tracking of business-user satisfaction.
For tracking satisfaction, Taipy's scenario function bridges the gap between end-users and data scientists by providing access to all runs and allowing end-users to tag and share scenarios with data scientists. This feature enhances software acceptance beyond basic testing and drift detection.
<hr/>
### Taipy - Build Python Data & AI web applications

Support open-source and give Taipy a star: https://github.com/Avaiga/taipy
<hr/>
## What about the results?
Implementing Taipy transformed our approach to managing cash flow and demand forecasting. The tool improved our processing capabilities by leaps and bounds and gained quick acceptance from end-users thanks to its intuitive design and relevance to their daily tasks.
We went from using 4 full-time developers to 1.5. The initial team was eclectic, with specialties ranging from Javascript and Java and Python.
The use of Taipy enabled the data scientist using Python to create a full-blown application ready for use by the end-users. This facilitated communication and reduced the siloed team process common to all AI projects. A gain of time and money is crucial to the success of any project.
For the concrete results, Taipy reduced the overall costs by a factor 10!
| Project Phase | Budget | IT Staff | Duration |
| --- | --- | --- | --- |
| Initial Setup | $600K | 4 | 8 months |
| With Taipy | $60K | 1.5 | 2 months |
<hr/>
## Achievements:
**4x Faster Projects**: We sped up everything from start to finish and spent less on keeping things running.
**10x Cheaper**: Most of the tech work was done by Python developers, reducing the need for help from other departments and making project management a breeze.
Check out these applications made with Taipy: https://docs.taipy.io/en/latest/gallery/
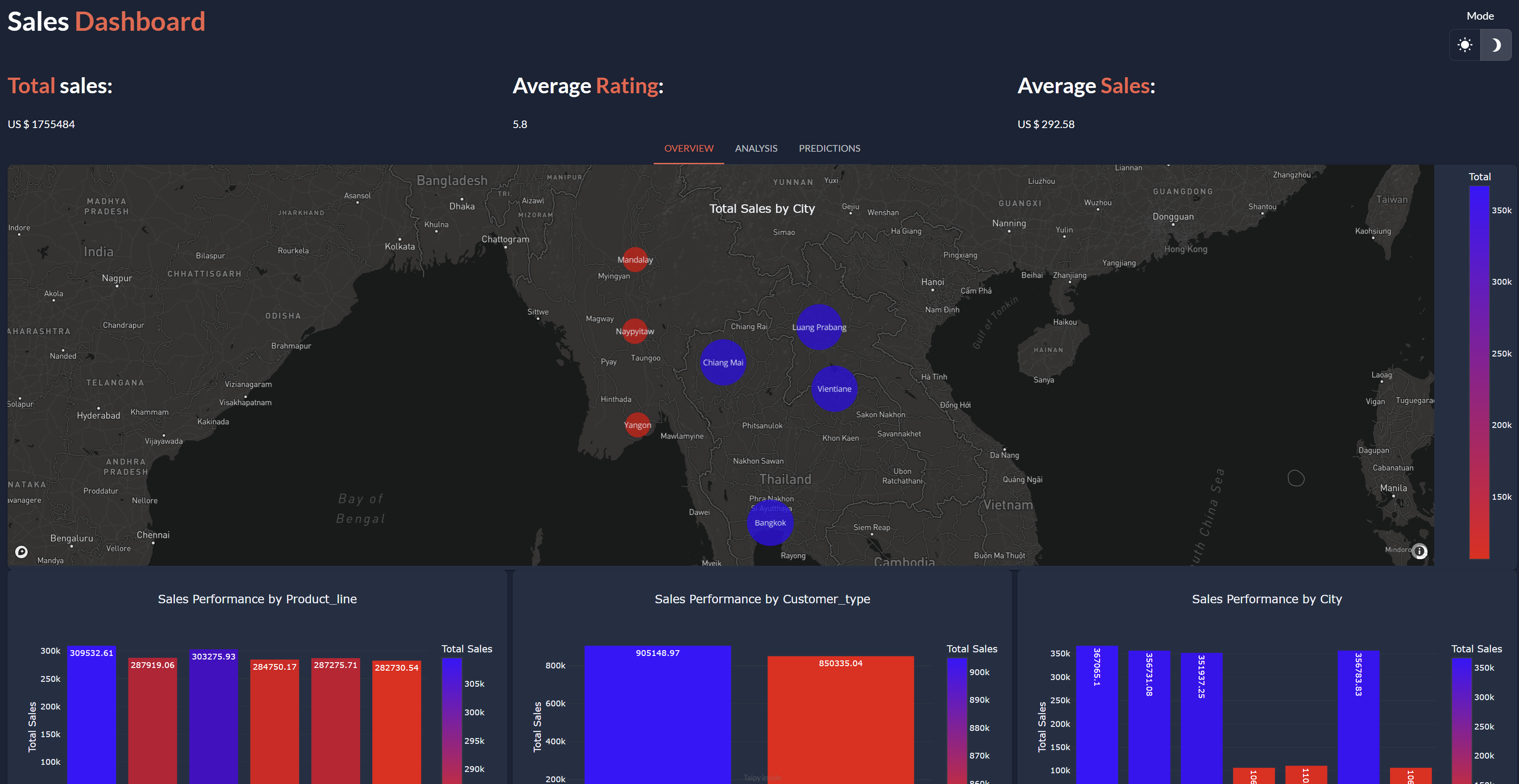
## Conclusion
Hope you enjoyed a little context on the creation of Taipy and what we to achieve with it.
| marisogo |
1,863,763 | Unlocking Success: The Leading SEO Reseller Services in India | Search engine optimization (SEO) is the cornerstone of online exposure and success in the... | 0 | 2024-05-24T09:12:31 | https://dev.to/pitchpinemedia/unlocking-success-the-leading-seo-reseller-services-in-india-296e | seo, seoresellerservices, seoresellerprograms, seoresellermanagementservices | Search engine optimization (SEO) is the cornerstone of online exposure and success in the ever-changing world of digital marketing. The need for excellent SEO services keeps rising as companies work to improve their online presence and connect with their target market. Businesses are using **[SEO Reseller Services in India]**(https://pitchpinemedia.com/seo-reseller-india/), a country known for creativity and entrepreneurship, to realize their full online potential.
**Why Choose SEO Reseller Services?**

It's difficult to stand out in the digital noise of today's competitive industry. To move up the search engine results page (SERP) ranks and draw in natural visitors, businesses must use strategic SEO strategies. Nevertheless, a lot of companies lack the knowledge and resources necessary to implement SEO methods successfully internally. SEO Reseller Services are useful in this situation.
Businesses may take advantage of the experience of seasoned professionals to improve their online presence and produce measurable outcomes by collaborating with a respectable **[SEO Reseller Agency]**(https://pitchpinemedia.com/seo-reseller-india/). These firms focus on offering complete SEO solutions that are customized to meet the particular requirements and objectives of every customer, guaranteeing an optimal return on investment and sustained performance.
**Choosing the Best SEO Reseller Program in India**
It can be challenging to choose the best SEO Reseller Program with so many possibilities accessible. Nonetheless, a few crucial elements distinguish the top SEO reseller companies from their rivals:
**Proven Track Record:** Seek out an SEO Reseller Company that has a history of exceeding client expectations in a variety of industries by producing excellent results. Case studies and testimonials can offer insightful information about the skills and accomplishments of the agency.
**All-inclusive Services:** The top **[SEO reseller programs]**(https://pitchpinemedia.com/seo-reseller-india/) include a full range of services, including as performance monitoring, link building, content production, on-page optimization, and keyword research. To optimize outcomes, a comprehensive strategy makes sure that every facet of SEO is addressed.
**Open Reporting:** In the realm of SEO Reseller Services, openness is essential. Select a company that offers clear reporting and frequent updates on the effectiveness of their campaigns. Between the agency and its clients, open lines of communication and responsibility promote cooperation and mutual trust.
**Getting Success with the Top SEO Reseller Agency in India**
One name sticks out above the others when it comes to selecting the best **[SEO Reseller Agency in India]**(https://pitchpinemedia.com/seo-reseller-india/). As a dependable partner in managing the intricacies of the digital world, Pitch Pine Media Pvt. Ltd. has a demonstrated history of providing outstanding outcomes for clients around the country.
You may reach new heights of success and realize your full potential in the digital sphere with Pitch Pine Media Pvt. Ltd. at your side. Reach out to us right now to find out more about our SEO reseller services and to begin achieving your web goals.
| pitchpinemedia |
1,863,762 | Simplifying Nested Routes in React Router | Introduction React Router v6 introduces a powerful and flexible way to manage routing in... | 0 | 2024-05-24T09:12:00 | https://dev.to/vikram-boominathan/simplifying-nested-routes-in-react-router-4ip | react, webdev, beginners, javascript | ## Introduction
React Router v6 introduces a powerful and flexible way to manage routing in React applications. With features like nested routes, index routes, relative paths, NavLink, and Outlet components, it offers a seamless navigation experience. In this guide, we'll walk through setting up a React application with nested routes and explore these features in detail.
### Key Concepts
**1. Index Route**
An index route is the default child route that renders when the parent route is matched but no other child routes are matched. It's typically used to display a default view or landing page for a section of your application.
In **`App.js`**, the index prop on a **<Route>** inside dashboard makes Profile the default component for /dashboard.
```react
<Route path="dashboard" element={<Dashboard />}>
<Route index element={<Profile />} />
<Route path="settings" element={<Settings />} />
</Route>
```
**2. Nested Routes**
In React, nested routes simply refer to a routing structure in which routes are included in other routes, resulting in a tree of routes. This concept is critical for developing applications with complex navigational structures because it allows you to create menus with multiple levels or sub-pages that can relate to the main page.
In simple terms, **UI sharing** between pages is easier.
```react
<Routes>
<Route path="/" element={<Layout />}>
<Route index element={<Home />} />
<Route path="dashboard" element={<Dashboard />}>
<Route index element={<Profile />} />
<Route path="settings" element={<Settings />} />
</Route>
</Route>
</Routes>
```
**3. NavLink**
NavLink is a React component which allows us to navigate within a React application. It is similar to the Link component, but with additional features that make it ideal for creating navigational links with **active styling**.
When you use the **end** prop, NavLink is only considered active if the route matches the URL exactly. Without the end prop, NavLink can be active on any sub-path.
```react
<NavLink to="/" end style={({ isActive }) => ({ color: isActive ? 'red' : 'black' })}>
Home
</NavLink>
<NavLink to="dashboard" style={({ isActive }) => ({ color: isActive ? 'red' : 'black' })}>
Dashboard
</NavLink>
```
**4. Outlet and Context**
**Outlet** is a placeholder component for nested routes. It serves as a method for rendering child components or routes within a parent component.
**Context** can be passed down the route tree.This enables you to share data and functionality between route components.
The Outlet component renders the matched nested route. Outlet context is provided to share data between parent and child routes.
```react
<Outlet context={{ user }} />
```
**5. useOutletContext**
The library provides a hook called **useContextOutlet** that lets you access the closest **<Outlet>** component in your component hierarchy. When you need to access the outlet's context, this can be helpful.
```react
import { useOutletContext } from 'react-router-dom';
const Profile = () => {
const { user } = useOutletContext();
../
<p>Name: {user}</p>
../
```
**6. Relative Paths**
In Dashboard, Link to="" navigates to the Profile component which is a index route and Link to="settings" navigates to the Settings component.
```react
<Link to="">Profile</Link>
<Link to="settings">Settings</Link>
```
### Getting Started
First, create a new React application using create-react-app and install react-router-dom.
```bash
npx create-react-app react-router-example
cd react-router-example
npm install react-router-dom
```
### Setting Up Routes
In **`App.js`**, we'll define our routes using the Routes and Route components. We'll also create nested routes for the dashboard.
```react
import React from 'react';
import { Routes, Route, BrowserRouter } from 'react-router-dom';
import Layout from './components/Layout';
import Home from './components/Home';
import Dashboard from './components/Dashboard';
import Profile from './components/Profile';
import Settings from './components/Settings';
function App() {
return (
<BrowserRouter>
<Routes>
<Route path="/" element={<Layout />}>
<Route index element={<Home />} />
<Route path="dashboard" element={<Dashboard />}>
<Route index element={<Profile />} />
<Route path="settings" element={<Settings />} />
</Route>
</Route>
</Routes>
</BrowserRouter>
);
}
export default App;
```
#### Creating the Layout Component
The Layout component includes navigation links and an Outlet for nested routes.
```react
import React from 'react';
import { NavLink, Outlet } from 'react-router-dom';
const Layout = () => {
return (
<div>
<nav>
<ul>
<li>
<NavLink to="/" end style={({ isActive }) => ({ color: isActive ? 'red' : 'black' })}>
Home
</NavLink>
</li>
<li>
<NavLink to="dashboard" style={({ isActive }) => ({ color: isActive ? 'red' : 'black' })}>
Dashboard
</NavLink>
</li>
</ul>
</nav>
<hr />
<Outlet />
</div>
);
};
export default Layout;
```
#### Home Component
The Home component is a simple functional component.
```react
import React from 'react';
const Home = () => {
return (
<div>
<h2>Home</h2>
<p>Welcome to the home page!</p>
</div>
);
};
export default Home;
```
#### Dashboard Component with Nested Routes
The Dashboard component includes links for its **nested routes** and an **Outlet** for rendering them.
```react
import React from 'react';
import { Link, Outlet } from 'react-router-dom';
const Dashboard = () => {
const user = { name: 'John Doe', role: 'Admin' }; // Example user data
return (
<div>
<h2>Dashboard</h2>
<nav>
<ul>
<li>
<Link to="">Profile</Link>
</li>
<li>
<Link to="settings">Settings</Link>
</li>
</ul>
</nav>
<hr />
<Outlet context={{ user }} />
</div>
);
};
export default Dashboard;
```
#### Profile Component
The Profile component retrieves context data using **useOutletContext**.
```react
import React from 'react';
import { useOutletContext } from 'react-router-dom';
const Profile = () => {
const { user } = useOutletContext();
return (
<div>
<h3>Profile</h3>
<p>Name: {user.name}</p>
<p>Role: {user.role}</p>
</div>
);
};
export default Profile;
```
#### Settings Component
The Settings component also uses **useOutletContext** to access user data.
```react
import React from 'react';
import { useOutletContext } from 'react-router-dom';
const Settings = () => {
const { user } = useOutletContext();
return (
<div>
<h3>Settings</h3>
<p>Adjust your settings here, {user.name}.</p>
</div>
);
};
export default Settings;
```
## Conclusion
React Router v6 provides an effective approach in React applications for complex routing systems. Through usage of nested routes, index routes, NavLink, and Outlet, this allows creation of the organized and changeable navigation system. By following this guide step by step, developers will be able to lay out a foundation for making advanced React applications.
| vikram-boominathan |
1,855,452 | Make naked websites look great with matcha.css! | Have you ever contemplated the bareness of starting from a "blank page" when beginning a new web... | 0 | 2024-05-24T09:11:00 | https://dev.to/lowlighter/make-naked-websites-look-great-with-matchacss-4ng7 | webdev, css, ui, tooling | Have you ever contemplated the bareness of starting from a "blank page" when beginning a new web project?

{% details index.html %}
*Notice the lack of any styling or custom attributes*.
```html
<html>
<body>
<h1>Hello world!</h1>
<p>
This is my new project, and it's still under construction.
Please be indulgent 😊
</p>
<p>
Also, check out my work on <a href="https://github.com/octocat">GitHub</a>!
</p>
<blockquote>
<p>
Imagination is more important than knowledge
</p>
<cite>Albert Einstein</cite>
</blockquote>
<menu>
<li>Home</li>
<li>
About me
<menu>
<li>My works</li>
<li>My passions</li>
</menu>
</li>
<li>Contact</li>
</menu>
<form>
<h2>Contact me</h2>
<label>
Your email:
<input type="email" name="email" placeholder="Your email" required>
</label>
<label>
Your message:
<small>255 characters max</small>
<textarea name="message" placeholder="Your message" required></textarea>
</label>
<button type="submit">Send</button>
</form>
</body>
</html>
```
{% enddetails %}
Ouch! If you showed that to your friends while claiming you're a web developer, they would start questioning what you're really doing...
Default browser stylesheets are usually pretty bare-bones, and it can be frustrating to not have something "visually nice" when you're prototyping apps, generating static HTML pages, Markdown-generated documents, etc., and don't want to delve into CSS intricacies too early.
Good news! I have something perfect for you: [matcha.css](https://matcha.mizu.sh)!
Just add the following into your document and see the magic happen:
```html
<link rel="stylesheet" href="https://matcha.mizu.sh/matcha.css">
```

Without really doing anything, we got a page that respects user preferences on light/dark mode, nice fonts and proper spacing, our `<menu>` actually looks like a menu, and our `<form>` is also pretty nice with even "mandatory field" indicators for required inputs.
All of that without any build steps, JavaScript, configuration, or refactoring.
It's because [matcha.css](https://matcha.mizu.sh) uses semantic styling. For example, it assumes that `<menu>` nested in another `<menu>` should result in a submenu, while a `<label><input required></label>` should clarify to the user that the input is mandatory.
There are a few more "drop-in" CSS libraries out there, but I believe this is the most complete one as it provides additional modern styles out-of-the-box like syntax highlighting, simple layouts, utility classes, etc.

[matcha.css](https://matcha.mizu.sh) is also easily customizable (it does not have any `!important` rules, and even provide a helper to create custom builds) and while being also reversible (if you ever decide to migrate out, just remove the stylesheet).
And last but not least, it's totally free and open-source!
{% github https://github.com/lowlighter/matcha no-readme %}
Checkout [matcha.mizu.sh](https://matcha.mizu.sh) for a full overview! | lowlighter |
1,863,761 | Enable IIS Management Console in Windows 11 | Enable IIS Management Console in Windows 11: The IIS (Internet Information Services) Management... | 0 | 2024-05-24T09:10:54 | https://dev.to/winsidescom/enable-iis-management-console-in-windows-11-47fc | iis, internetinformationservices, windows11, microsoft | <strong>Enable IIS Management Console in Windows 11</strong>: The IIS (Internet Information Services) Management Console in Windows 11 is a <strong>graphical user interface (GUI)</strong> tool used to manage and configure IIS, which is a flexible, secure, and manageable Web server for hosting anything on the Web. It enables administrators to configure the <strong>Web Server, Websites, Web Applications, Security Protocols, SSL Certificates</strong>, and <strong>Virtual Directories</strong>. The console also supports the management of various IIS modules and extensions, such as <strong>URL Rewrite</strong> and <strong>Application Request Routing</strong>, enhancing the server's functionality and flexibility. This article will take you through the steps of how<strong> to Enable IIS Management Console in Windows 11</strong>. <strong>Check out: <a href="https://winsides.com/enable-internet-information-services-iis-in-windows-11/">How to Enable IIS in Windows 11?</a></strong>
<ul>
<li>Open the <strong>Run command box</strong> using the shortcut <kbd>Win Key + R</kbd>.</li>
<li>Enter <code>optionalfeatures</code> in the run command box.
<img class="wp-image-594 size-full" src="https://winsides.com/wp-content/uploads/2024/05/Optional-Features.jpg" alt="Optional Features" width="475" height="285" /> Optional Features</li>
<li><strong>Windows Features</strong> dialog box will open now.</li>
<li>Locate <strong>Internet Information Services</strong> and expand it.<img class="wp-image-632 size-full aligncenter" src="https://winsides.com/wp-content/uploads/2024/05/Expand-Internet-Information-Services.jpg" alt="Expand Internet Information Services" width="754" height="522" /></li>
<li>Now, you can find the <strong>Web Management Tools</strong>. Click on the plus sign next to it to expand Web Management Tools.
<img class="wp-image-633 size-full" src="https://winsides.com/wp-content/uploads/2024/05/Expand-Web-Management-Tools.jpg" alt="Expand Web Management Tools" width="746" height="513" /> Expand Web Management Tools
<div class="mceTemp"></div></li>
<li>Click on the checkbox next to the <strong>IIS Management Console</strong> and then click <strong>OK</strong>.
<img class="wp-image-634 size-full" src="https://winsides.com/wp-content/uploads/2024/05/Enable-IIS-Management-Console-in-Windows-11.jpg" alt="Enable IIS Management Console in Windows 11" width="738" height="512" /> Enable IIS Management Console in Windows 11</li>
<li>That is it, Windows 11 will now search for the required files.
<img class="wp-image-42 size-full" src="https://winsides.com/wp-content/uploads/2024/01/Searching-for-the-required-files.jpg" alt="Searching for the required files" width="1001" height="720" /> Searching for the required files</li>
<li>Then, it will apply the necessary changes.
<img class="wp-image-36 size-full" src="https://winsides.com/wp-content/uploads/2024/01/Applying-Changes.jpg" alt="Applying Changes" width="875" height="678" /> Applying Changes</li>
<li>Click <strong>Restart</strong> if you are prompted to restart or click <strong>Close</strong> accordingly. However, it is suggested to restart right away so that the changes made will reflect.
<img class="wp-image-38 size-full" src="https://winsides.com/wp-content/uploads/2024/01/Close.jpg" alt="Close" width="849" height="684" /> Close</li>
<li><strong>Internet Information Services IIS Management Console</strong> is now enabled on your Windows 11 PC.</li>
</ul>
<h2>How to Access IIS Management Console in Windows 11:</h2>
<img class="wp-image-635 size-full" src="https://winsides.com/wp-content/uploads/2024/05/inetmgr.jpg" alt="inetmgr" width="1455" height="758" /> inetmgr
<ul>
<li>Open the Run Command box using the shortcut <kbd>Win Key + R.</kbd></li>
<li>Execute the following command in the Run Command Box. <strong><code>inetmgr</code></strong>.</li>
<li>Once opened, the <strong>IIS Management Console</strong> will display the connections pane, listing your local server and any sites configured on it. From here, you can manage your web server settings, configure websites, and access various administrative tools.</li>
</ul>
<h2>Take away:</h2>
Whether setting up a simple website or managing complex web applications, the <strong>IIS Management Console in Windows 11</strong> provides the tools needed to ensure your web server runs smoothly and securely. Additionally, it offers <strong>robust logging and monitoring capabilities</strong>, allowing administrators to track<strong> website performance</strong> and <strong>analyze traffic patterns</strong>.
Article Source: [Enable Internet Information Services Management Console in Windows 11](https://winsides.com/enable-iis-management-console-windows-11/) | winsidescom |
1,863,760 | How to Measure Position Risk - An Introduction to the VaR Method | Controlling risk is a skill that every investor needs to learn. With the rapidly changing and... | 0 | 2024-05-24T09:06:53 | https://dev.to/fmzquant/how-to-measure-position-risk-an-introduction-to-the-var-method-3pgp | position, trading, cryptocurrency, fmzquant | Controlling risk is a skill that every investor needs to learn. With the rapidly changing and evolving cryptocurrency market, algorithmic traders need to focus on risk management especially. This is because algorithmic trading often executes trades automatically based on historical data and statistical models, which may quickly become inaccurate in fast-moving markets. Therefore, effective risk management strategies are crucial for protecting investors' capital.
Among many risk management tools, Value at Risk (VaR) is a widely used measure of risk. It can help investors predict the maximum loss that might occur under normal market conditions in their portfolio. VaR quantifies risk into a single number, simplifying the expression of risk and allowing investors to understand potential losses intuitively.
### The Role of VaR
VaR, or "Value at Risk", is used to quantify the maximum possible loss that can be endured within a certain period of time, according to a certain confidence level. In other words, it tells investors or risk managers: "Under normal market conditions, how much money is within the 'safe' range and will not be lost tomorrow." For example, if the 1-day 99% VaR of a cryptocurrency portfolio is $10,000, it means that in 99% of cases we expect the loss in one day will not exceed $10,000.
### Advantages
1. **Easy to understand** : For example, the 1-day 95% VaR of a digital currency portfolio is $5000, which means there is a 95% confidence that the loss of the portfolio within one day will not exceed $5000. Quantifying complex risks into an intuitive number makes it easy for non-professionals to understand. Of course, it's inevitably to have some misleading aspects.
2. **Relatively standard** : Suppose there are two portfolios A and B, with A's 1-day 95% VaR being $3000 and B's being $6000. This implies that under normal market conditions, A's risk is lower than B's. Even if these two portfolios contain different assets, we can compare their risk levels directly. Correspondingly, we can also judge the level of investment; if both strategies A and B have earned $6000 in the past month but A's average and maximum VaR values are significantly lower than B's, then we could consider strategy A as better, since it achieves higher returns at a lower risk level.
3. **Decision-making tool** : Traders might use VaR to decide whether or not to add a new asset to their portfolio. If adding an asset increases the VaR value significantly, then it may suggest that the added asset's risk does not match with the portfolio's acceptable risk level.
### Disadvantages
1. **Ignoring tail risk** : If a portfolio's 1-day 99% VaR is $10,000, the loss in the extreme 1% scenario could far exceed this value. In the field of digital currency, black swan events are frequent and extreme situations can exceed most people's expectations, because VaR does not consider tail events.
2. **Assumption limitations** : The parameter VaR often assumes that asset returns are normally distributed, which is rarely the case in real markets, especially in digital currency markets. For example, suppose a portfolio only contains Bitcoin. We use the parameter VaR and assume that Bitcoin's return is normally distributed. However, in reality, Bitcoin's rate of return may experience large jumps during certain periods and exhibit significant volatility clustering phenomena. If there has been high volatility over the past week, the probability of noticeable volatility in the following period will increase significantly. This can lead to an underestimation of risk by normal distribution models. Some models take this issue into account such as GARCH etc., but we won't discuss them here.
3. **Historical dependence** : The VaR model relies on historical data to predict future risks. However, past performance does not always indicate future situations, especially in rapidly changing markets like the digital currency market. For example, if Bitcoin has been very stable over the past year, a historical simulation might predict a very low VaR. However, if there is a sudden regulatory change or market crash, past data will no longer be an effective predictor of future risk.
### Methods of Calculating VaR
There are mainly three methods to calculate VaR: Parametric method (Variance-Covariance Method): This assumes that the rate of return follows a certain distribution (usually normal distribution), and we use the mean and standard deviation of the rate of return to calculate VaR. Historical Simulation Method: It makes no assumptions about the distribution of returns, but uses historical data directly to determine potential loss distributions. Monte Carlo Simulation: It uses randomly generated price paths to simulate asset prices and calculates VaR from them.
The Historical Simulation Method utilizes past price changes directly to estimate possible future losses. It does not need any assumptions about profit distribution, making it suitable for assets with unknown or abnormal profit distributions, such as digital currencies.
For example, if we want to calculate 1-day 95% VaR for a Bitcoin spot position, we can do this:
1. Collect the daily returns of Bitcoin over a certain period (for example, 100 days).
2. Calculate the portfolio return rate each day, which is the return rate of each asset multiplied by its weight in the portfolio.
3. Sort these 100 days of portfolio returns from low to high.
4. Find the data point at the 5% mark (because we are calculating 95% VaR). The point represents the loss rate on the best day out of worst five days in past 100 days.
5. Multiply the return by total value held, and that's your one-day 95% VaR.
The following is a specific code that has obtained data from the past 1000 days, calculating that the current VaR for holding one BTC spot is 1980 USDT.
```
import numpy as np
import requests
url = 'https://api.binance.com/api/v3/klines?symbol=%s&interval=%s&limit=1000'%('BTCUSDT','1d')
res = requests.get(url)
data = res.json()
confidence_level = 0.95
closing_prices = [float(day[4]) for day in data]
log_returns = np.diff(np.log(closing_prices))
VaR = np.percentile(log_returns, (1 - confidence_level) * 100)
money_at_risk = VaR * closing_prices[-1] * 1
print(f"VaR at {confidence_level*100}% confidence level is {money_at_risk}")
```
### Calculating VaR Considering Correlation
When calculating the VaR of a portfolio containing multiple assets, we must consider the correlation between these assets. If there is a positive correlation in price changes between assets, then the risk of the portfolio will increase; if it's negatively correlated, then the risk of the portfolio will decrease.
When using historical simulation method to calculate VaR considering correlation, we need to collect not only each individual asset's historical returns, but also consider their joint distribution. In practice, you can use the historical returns of your portfolio for sorting and calculation directly, because these returns already implicitly include inter-asset correlations. In cryptocurrency markets, correlation is especially important with BTC essentially leading market trends. If BTC rises bullishly, other cryptocurrencies are likely to rise as well; if BTC rapidly surges or plummets due to quickly changing market, this could cause significant short-term increases in correlation - something that is particularly common during extreme market events. Therefore, historical simulation method is a useful tool when considering digital currency investment portfolios' VaR calculations. It doesn't require complex statistical models - just effective historical data - and naturally includes inter-asset correlations.
For example: holding 1 long position on BTC and 10 short positions on ETH – following our previous method – we can calculate that 10 ETH short positions have a VaR of 1219 USDT. When combining these two types of assets into one portfolio, here's how you would calculate its combined VaR:
```
confidence_level = 0.95
btc_closing_prices = np.array([float(day[4]) for day in btc_data])
eth_closing_prices = np.array([float(day[4]) for day in eth_data])
btc_log_returns = np.diff(np.log(btc_closing_prices))
eth_log_returns = np.diff(np.log(eth_closing_prices))
log_returns = (1*btc_log_returns*btc_closing_prices[1:] - 10*eth_log_returns*eth_closing_prices[1:])/(1*btc_closing_prices[1:] + 10*eth_closing_prices[1:])
VaR = np.percentile(log_returns, (1 - confidence_level) * 100)
money_at_risk = VaR * (btc_closing_prices[-1] * 1 + eth_closing_prices[-1]*10)
print(f"VaR at {confidence_level*100}% confidence level is {money_at_risk}")
```
The result is 970 USDT, which means the risk of this combination is lower than holding the respective assets separately. This is because BTC and ETH markets have a high correlation, and the hedging effect of long-short position combinations serves to reduce risk.
### Summary
This article will introduce a highly adaptive risk assessment method, namely the application of Historical Simulation in calculating VaR, as well as how to consider asset correlations to optimize risk prediction. Through specific examples from the digital currency market, it explains how to use historical simulation to assess portfolio risks and discusses methods for calculating VaR when asset correlations are significant. With this method, algorithmic traders can not only estimate their maximum loss in most situations, but also be prepared for extreme market conditions. This allows them to trade more calmly and execute strategies accurately.
From: https://blog.mathquant.com/2023/11/03/how-to-measure-position-risk-an-introduction-to-the-var-method.html | fmzquant |
1,863,759 | #2597. The Number of Beautiful Subsets | https://leetcode.com/problems/the-number-of-beautiful-subsets/?envType=daily-question&envId=2024-... | 0 | 2024-05-24T09:05:01 | https://dev.to/karleb/2597-the-number-of-beautiful-subsets-4824 | https://leetcode.com/problems/the-number-of-beautiful-subsets/?envType=daily-question&envId=2024-05-24
```js
/**
* @param {number[]} nums
* @param {number} k
* @return {number}
*/
var beautifulSubsets = function(nums, k) {
let result = 0
function backtrack(start, subset) {
if (subset.length > 0) result++
for (let i = start; i < nums.length; i++) {
let valid = true
for(let num of subset) {
if (Math.abs(num - nums[i]) === k) {
valid = false
break
}
}
if (valid) {
subset.push(nums[i])
backtrack(i + 1, subset)
subset.pop()
}
}
}
backtrack(0, [])
return result
};
``` | karleb | |
1,863,758 | #131. Palindrome Partitioning | https://leetcode.com/problems/palindrome-partitioning/?envType=daily-question&envId=2024-05-24 ... | 0 | 2024-05-24T09:03:40 | https://dev.to/karleb/131-palindrome-partitioning-hfj | https://leetcode.com/problems/palindrome-partitioning/?envType=daily-question&envId=2024-05-24
```js
/**
* @param {string} s
* @return {string[][]}
*/
var partition = function(s) {
const result = [];
const isPalindrome = (str, left, right) => {
while (left < right) {
if (str[left] !== str[right]) {
return false;
}
left++;
right--;
}
return true;
};
const backtrack = (start, path) => {
if (start === s.length) {
result.push([...path]);
return;
}
for (let end = start; end < s.length; end++) {
if (isPalindrome(s, start, end)) {
path.push(s.substring(start, end + 1));
backtrack(start + end - start + 1, path);
path.pop();
}
}
};
backtrack(0, []);
return result;
};
``` | karleb | |
1,863,757 | How To Setup React Native For Android Using VSCode | Mac Apple Chip & Intel Chip | Hey Devs! 👋 Video Link: https://youtu.be/f9JXDmT6hvo Are you excited to dive into the world of... | 0 | 2024-05-24T08:58:49 | https://dev.to/sonarsystems/how-to-setup-react-native-for-android-using-vscode-mac-apple-chip-intel-chip-1j5f | webdev, reactnative, react, javascript | Hey Devs! 👋
Video Link: [https://youtu.be/f9JXDmT6hvo](https://youtu.be/f9JXDmT6hvo)
Are you excited to dive into the world of mobile app development with React Native? Whether you're using a Mac with an Apple chip or an Intel chip, this guide will walk you through the process of setting up your development environment using VSCode. Let's get your React Native project up and running on Android!
Table of Contents
- Prerequisites
- Installing Homebrew
- Setting Up Node.js and Watchman
- Installing Android Studio
- Setting Up VSCode
- Creating a New React Native Project
- Running Your App on Android Emulator
- Troubleshooting Common Issues
- Conclusion
1. Prerequisites
Before we begin, ensure you have the following installed on your Mac:
macOS Catalina or newer
At least 8GB of RAM
A stable internet connection
2. Installing Homebrew
Homebrew is a package manager for macOS. Open your Terminal and paste the following command to install Homebrew:
bash
Copy code
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
After installation, run:
bash
Copy code
brew --version
3. Setting Up Node.js and Watchman
Install Node.js and Watchman using Homebrew:
bash
Copy code
brew install node
brew install watchman
Verify the installations:
bash
Copy code
node -v
watchman -v
4. Installing Android Studio
Download and install Android Studio. During the installation, ensure the boxes for "Android SDK," "Android SDK Platform," and "Android Virtual Device" are checked.
Once installed, open Android Studio and go to Preferences > Appearance & Behavior > System Settings > Android SDK. Install the latest SDK version and build tools.
5. Setting Up VSCode
Download and install Visual Studio Code.
To enhance your development experience, install the following extensions:
React Native Tools by Microsoft
ESLint by Dirk Baeumer
Prettier - Code formatter by Prettier
6. Creating a New React Native Project
Open your Terminal and run the following commands to create a new React Native project:
bash
Copy code
npx react-native init MyReactNativeApp
cd MyReactNativeApp
7. Running Your App on Android Emulator
Start Android Studio and open the AVD Manager (Android Virtual Device). Create a new virtual device with the desired configuration and start it.
Back in your Terminal, run:
bash
Copy code
npx react-native run-android
Your new React Native app should now launch on the Android emulator.
8. Troubleshooting Common Issues
Error: JAVA_HOME is not set
Ensure that the Java Development Kit (JDK) is installed and JAVA_HOME is set correctly. You can install it using Homebrew:
bash
Copy code
brew install --cask adoptopenjdk/openjdk/adoptopenjdk8
Add the following to your .zshrc or .bash_profile:
bash
Copy code
export JAVA_HOME=$(/usr/libexec/java_home)
export PATH=$JAVA_HOME/bin:$PATH
9. Conclusion
Congratulations! You've successfully set up your React Native development environment for Android on a Mac, whether you're using an Apple chip or an Intel chip. Now you're ready to start building amazing mobile apps with React Native!
If you found this tutorial helpful, don't forget to like, share, and follow for more. Happy coding! 🚀 | sonarsystems |
1,863,756 | Building Agentic RAG with Rust, OpenAI & Qdrant | Hey there! In this article, we're gonna talk about building an agentic RAG workflow with Rust! We'll... | 0 | 2024-05-24T08:58:09 | https://www.shuttle.rs/blog/2024/05/23/building-agentic-rag-rust-qdrant | ai, webdev, rust, tutorial | Hey there! In this article, we're gonna talk about building an agentic RAG workflow with Rust! We'll be building an agent that can take a CSV file, parse it and embed it into Qdrant, as well as retrieving the relevant embeddings from Qdrant to answer questions from users about the contents of the CSV file.
Interested in deploying or just want to see what the final code looks like? You can find the repository [here.](https://github.com/joshua-mo-143/shuttle-agentic-rag)
## What is Agentic RAG?
Agentic RAG, or Agentic Retrieval Augmented Generation, is the concept of mixing AI agents with RAG to be able to produce a workflow that is even better at being tailored to a specific use case than an agent workflow normally would be.
Essentially, the difference between this workflow and a regular agent workflow would be that each agent can individually access embeddings from a vector database to be able to retrieve contextually relevant data - resulting in more accurate answers across the board in an AI agent workflow!
## Getting Started
To get started, use `cargo shuttle init` to create a new project.
Next, we'll add the dependencies we need using a shell snippet:
```bash
cargo add anyhow
cargo add async-openai
cargo add qdrant-client
cargo add serde -F derive
cargo add serde-json
cargo add shuttle-qdrant
cargo add uuid -F v4
```
We'll also need to make sure to have a Qdrant URL and an API key, as well as an OpenAI API key. Shuttle uses environment variables via a `SecretStore` macro in the main function, and can be stored in the `Secrets.toml` file:
```toml
OPENAI_API_KEY = ""
```
Next, we'll update our main function to have our Qdrant macro and our secrets macro. We'll iterate through each secret and set it as an environment variable - this allows us to use our secrets globally, without having to reference the `SecretStore` variable at all:
```rust
#[shuttle_runtime::main]
async fn main(
#[shuttle_qdrant::Qdrant] qdrant_client: QdrantClient,
#[shuttle_runtime::Secrets] secrets: SecretStore,
) -> shuttle_axum::ShuttleAxum {
secrets.into_iter().for_each(|x| {
set_var(x.0, x.1);
});
let router = Router::new()
.route("/", get(hello_world));
Ok(router.into())
}
```
## Building an agentic RAG workflow
### Setting up our agent
The agent itself is quite simple: it holds an OpenAI client, as well as a Qdrant client to be able to search for relevant document embeddings. Other fields can also be added here, depending on what capabilities your agent requires.
```rust
use async_openai::{config::OpenAIConfig, Client as OpenAIClient};
use qdrant_client::prelude::QdrantClient;
pub struct MyAgent {
openai_client: OpenAIClient<OpenAIConfig>,
qdrant_client: QdrantClient,
}
```
Next we'll want to create a helper method for creating the agent, as well as a system message which we'll feed into the model prompt later.
```rust
static SYSTEM_MESSAGE: &str = "
You are a world-class data analyst, specialising in analysing comma-delimited CSV files.
Your job is to analyse some CSV snippets and determine what the results are for the question that the user is asking.
You should aim to be concise. If you don't know something, don't make it up but say 'I don't know.'.
"
impl MyAgent {
pub fn new(qdrant_client: QdrantClient) -> Self {
let api_key = std::env::var("OPENAI_API_KEY").unwrap();
let config = OpenAIConfig::new().with_api_key(api_key);
let openai_client = OpenAIClient::with_config(config);
Self {
openai_client,
qdrant_client,
}
}
}
```
### File parsing and embedding into Qdrant
Next, we will implement a `File` struct for CSV file parsing - it should be able to hold the file path, contents as well as the rows as a `Vec<String>` (string array, or more accurately a vector of strings). There's a few reasons why we store the rows as a `Vec<String>`:
- Smaller chunks improve the retrieval accuracy, one of the biggest challenges that RAG has to deal with. Retrieving a wrong or otherwise inaccurate document can hamper accuracy significantly.
- Improved retrieval accuracy leads to enhanced contextual relevance - which is quite important for complex queries that require specific question.
- Processing and indexing smaller chunks
```rust
pub struct File {
pub path: String,
pub contents: String,
pub rows: Vec<String>,
}
impl File {
pub fn new(path: PathBuf) -> Result<Self> {
let contents = std::fs::read_to_string(&path)?;
let path_as_str = format!("{}", path.display());
let rows = contents
.lines()
.map(|x| x.to_owned())
.collect::<Vec<String>>();
Ok(Self {
path: path_as_str,
contents,
rows
})
}
}
```
While the above parsing method *is* serviceable (collecting all the lines into a `Vec<String>`), note that it is a naive implementation. Based on how your CSV files are delimited and/or if there is dirty data to clean up, you may want to either prepare your data so that it is already well-prepared, or include some form of data cleaning or validation. Some examples of this might be:
- `unicode-segmentation` - [a library crate for splitting sentences](https://github.com/unicode-rs/unicode-segmentation)
- `csv_log_cleaner` - [a binary crate for cleaning CSVs](https://github.com/ambidextrous/csv_log_cleaner)
- `validator` - [a library crate for validating struct/enum fields](https://github.com/Keats/validator)
Next, we'll go back to our agent and implement a method for embedding documents into Qdrant that will take the `File` struct we defined.
To do this, we need to do the following:
- Take the rows we created earlier and add them as the input for our embed request.
- Create the embeddings (with openAI) and create a payload for storing alongside the embeddings in Qdrant. Note that although we use a `uuid::Uuid` for unique storage, you could just as easily use numbers by adding a number counter to your struct and incrementing it by 1 after you've inserted an embedding.
- Assuming there are no errors, return `Ok(())`
```rust
use async_openai::types::{ CreateEmbeddingRequest, EmbeddingInput };
use async_openai::Embeddings;
use qdrant_client::prelude::{Payload, PointStruct};
static COLLECTION: &str = "my-collection";
// text-embedding-ada-002 is the model name from OpenAI that deals with embeddings
static EMBED_MODEL: &str = "text-embedding-ada-002";
impl MyAgent {
pub async fn embed_document(&self, file: File) -> Result<()> {
if file.rows.is_empty() {
return Err(anyhow::anyhow!("There's no rows to embed!"));
}
let request = CreateEmbeddingRequest {
model: EMBED_MODEL.to_string(),
input: EmbeddingInput::StringArray(file.rows.clone()),
user: None,
dimensions: Some(1536),
..Default::default()
};
let embeddings_result = Embeddings::new(&self.openai_client).create(request).await?;
for embedding in embeddings_result.data {
let payload: Payload = serde_json::json!({
"id": file.path.clone(),
"content": file.contents,
"rows": file.rows
})
.try_into()
.unwrap();
println!("Embedded: {}", file.path);
let vec = embedding.embedding;
let points = vec![PointStruct::new(
uuid::Uuid::new_v4().to_string(),
vec,
payload,
)];
self.qdrant_client
.upsert_points(COLLECTION, None, points, None)
.await?;
}
Ok(())
}
}
```
### Document searching
Now that we’ve embedded our document, we’ll want a way to check whether our embeddings are contextually relevant to whatever prompt the user gives us. For this, we’ll create a `search_document` function that does the following:
- Embed the prompt using `CreateEmbeddingRequest` and get the embedding from the results. We’ll be using this embedding in our document search. Because we’ve only added one sentence to embed here (the prompt), it will only return one sentence - so we can create an iterator from the vector and attempt to find the first result.
- Create a parameter list for our document search through the `SearchPoints` struct (see below). Here we need to set the collection name, the vector that we want to search against (ie the input), how many results we want to be returned if there are any matches, as well as the payload selector.
- Search the database for results - if there are no results, return an an error; if there is a result, then return the result back.
```rust
use qdrant_client::qdrant::{
with_payload_selector::SelectorOptions, SearchPoints, WithPayloadSelector,
};
impl MyAgent {
async fn search_document(&self, prompt: String) -> Result<String> {
let request = CreateEmbeddingRequest {
model: EMBED_MODEL.to_string(),
input: EmbeddingInput::String(prompt),
user: None,
dimensions: Some(1536),
..Default::default()
};
let embeddings_result = Embeddings::new(&self.openai_client).create(request).await?;
let embedding = &embeddings_result.data.first().unwrap().embedding;
let payload_selector = WithPayloadSelector {
selector_options: Some(SelectorOptions::Enable(true)),
};
// set parameters for search
let search_points = SearchPoints {
collection_name: COLLECTION.to_string(),
vector: embedding.to_owned(),
limit: 1,
with_payload: Some(payload_selector),
..Default::default()
};
// if the search is successful
// attempt to iterate through the results vector and find a result
let search_result = self.qdrant_client.search_points(&search_points).await?;
let result = search_result.result.into_iter().next();
match result {
Some(res) => Ok(res.payload.get("contents").unwrap().to_string()),
None => Err(anyhow::anyhow!("There were no results that matched :(")),
}
}
}
```
Now that everything we need to use our agent effectively is set up, we can set up a prompt function!
```rust
use async_openai::types::{
ChatCompletionRequestMessage, ChatCompletionRequestSystemMessageArgs,
ChatCompletionRequestUserMessageArgs, CreateChatCompletionRequestArgs,
};
static PROMPT_MODEL: &str = "gpt-4o";
impl MyAgent {
pub async fn prompt(&self, prompt: &str) -> anyhow::Result<String> {
let context = self.search_document(prompt.to_owned()).await?;
let input = format!(
"{prompt}
Provided context:
{}
",
context // this is the payload from Qdrant
);
let res = self
.openai_client
.chat()
.create(
CreateChatCompletionRequestArgs::default()
.model(PROMPT_MODEL)
.messages(vec![
//First we add the system message to define what the Agent does
ChatCompletionRequestMessage::System(
ChatCompletionRequestSystemMessageArgs::default()
.content(SYSTEM_MESSAGE)
.build()?,
),
//Then we add our prompt
ChatCompletionRequestMessage::User(
ChatCompletionRequestUserMessageArgs::default()
.content(input)
.build()?,
),
])
.build()?,
)
.await
.map(|res| {
//We extract the first one
res.choices[0].message.content.clone().unwrap()
})?;
println!("Retrieved result from prompt: {res}");
Ok(res)
}
}
```
## Hooking the agent up to our web service
Because we separated the agent logic from our web service logic, we just need to connect the bits together and we should be done!
Firstly, we'll create a couple of structs - the `Prompt` struct that will take a JSON prompt, and the `AppState` function that will act as shared application state in our Axum web server.
```rust
#[derive(Deserialize)]
pub struct Prompt {
prompt: String,
}
#[derive(Clone)]
pub struct AppState {
agent: MyAgent,
}
```
We'll also introduce our prompt handler endpoint here:
```rust
async fn prompt(
State(state): State<AppState>,
Json(json): Json<Prompt>,
) -> Result<impl IntoResponse> {
let prompt_response = state.agent.prompt(&json.prompt).await?;
Ok((StatusCode::OK, prompt_response))
}
```
Then we need to parse our CSV file in the main function, create our `AppState` and embed the CSV, as well as setting up our router:
```rust
#[shuttle_runtime::main]
async fn main(
#[shuttle_qdrant::Qdrant] qdrant_client: QdrantClient,
#[shuttle_runtime::Secrets] secrets: SecretStore,
) -> shuttle_axum::ShuttleAxum {
secrets.into_iter().for_each(|x| {
set_var(x.0, x.1);
});
// note that this already assumes you have a file called "test.csv"
// in your project root
let file = File::new("test.csv".into())?;
let state = AppState {
agent: MyAgent::new(qdrant_client),
};
state.agent.embed_document(file).await?;
let router = Router::new()
.route("/", get(hello_world))
.route("/prompt", post(prompt))
.with_state(state);
Ok(router.into())
}
```
## Deploying
To deploy, all you need to do is use `cargo shuttle deploy` (with the `--ad` flag if on a Git branch with uncommitted changes), sit back and watch the magic happen!
## Finishing Up
Thanks for reading! With the power of combining AI agents and RAG, we can create powerful workflows to be able to satisfy many different use cases. With Rust, we can leverage performance benefits to be able to run our workflows safely and with a low memory footprint.
Read more:
- [Using Huggingface with Rust](https://www.shuttle.rs/blog/2024/05/01/using-huggingface-rust)
- [Building a RAG web service with Qdrant & Rust](https://www.shuttle.rs/blog/2024/02/28/rag-llm-rust)
- [Prompting AWS Bedrock with the AWS Rust SDK](https://www.shuttle.rs/blog/2024/05/10/prompting-aws-bedrock-rust)
| shuttle_dev |
1,863,753 | Getting started with Fastly CDN is easier than ever with Glitch | We’re making it easier than ever to learn how to deliver your website traffic using Fastly. In the... | 0 | 2024-05-24T08:55:44 | https://www.fastly.com/blog/getting-started-with-fastly-cdn-is-easier-than-ever-with-glitch/ | cdn, domains, webdev | We’re making it easier than ever to learn how to deliver your website traffic using Fastly. In the two years since Glitch became part of Fastly, we’ve discovered how valuable it is to be able to give learners a website they can remix at the click of a button and use with a Fastly service. We’re excited to share our first developer guide that comes with a companion Glitch project our community members can use to onboard with Fastly quickly and easily.
## Any tech product is just one piece of a puzzle
The nature of the web today is integration. Sites and applications exist within a complex ecosystem of dependencies that developers need to understand to get good value from any particular product. Many developer products across the industry use Glitch to support adoption and onboarding through low friction, remixable apps that come with help information included right inside the project. At Fastly, being able to teach our tech in the context of a website is crucial when it comes to conveying the purpose and value of what we build.
This is why we’re embarking on a program of learning experiences that leverage Glitch to help users understand technologies like CDNs and edge computing – starting with one on Website Delivery.
Our new guide walks through the flow of creating a website on Glitch and setting up a Fastly CDN service to deliver it to your site visitors, outlining how to use free Fastly TLS to point your domain at your site along the way. The goal is to help you get value from Fastly as quickly and easily as possible, making your websites faster and more reliable in just a few short steps.
## Enabling our internal community
We’ve taken a slightly unusual approach to creating this learning experience by using it for employee training. In the first part of 2024, we used Glitch to teach teams inside the company how to get started working with Fastly services. Glitch helped our coworkers develop their understanding of how Fastly fits into the picture on the web and in the wider world. Basing the training on a Glitch project helped us get people hands-on with Fastly, reaching a valuable learning outcome in a single session, regardless of their role or background.
This training program acted as user testing on the learning experience, so it served a dual purpose of enabling employees with product knowledge and helping us to make these resources as effective as possible for our users. We also opened a rich channel of internal product feedback, resulting in many UX enhancements we were able to action quickly, making the product easier for all who try it going forward.
## Supporting a diverse cohort of learners
People prefer to learn in different ways – some like to work through comprehensive material upfront and scaffold their knowledge methodically, while others prefer to learn through experimentation and play. By providing an interactive Glitch project that mirrors the learning pathway in its companion tutorial, we’re supporting a wider range of learners than we were able to before.
**You can check out our new tutorial now: [Delivering your site through Fastly](http://fastly.com/documentation/solutions/tutorials/deliver-your-site/)**
**You’ll find [the Glitch project](https://glitch.com/~learn-website-delivery) embedded in the page and can remix it for a guided experience inside the Glitch editor.**
**If you get stuck or would like to share feedback, [please post in the community forum](https://community.fastly.com/)!** | suesmith |
1,863,755 | #78. Subsets | https://leetcode.com/problems/subsets/description/?envType=daily-question&envId=2024-05-24 /**... | 0 | 2024-05-24T08:54:35 | https://dev.to/karleb/78-subsets-3p5a | https://leetcode.com/problems/subsets/description/?envType=daily-question&envId=2024-05-24
```javascript
/**
* @param {number[]} nums
* @return {number[][]}
*/
var subsets = function(nums) {
let res = [[]]
for (let num of nums) {
let n = res.length
for (let i = 0; i < n; i++) {
let curr = [...res[i]]
curr.push(num)
res.push(curr)
}
}
return res
};
``` | karleb | |
1,863,754 | Abhee Ventures Presents: Abhee Pride - Your Oasis in Prosperity | At Abhee Ventures, we understand the importance of finding a home that reflects your lifestyle. Today... | 0 | 2024-05-24T08:54:34 | https://dev.to/bhandariraj/abhee-ventures-presents-abhee-pride-your-oasis-in-prosperity-2mia | realestate, properties, homes | At Abhee Ventures, we understand the importance of finding a home that reflects your lifestyle. Today we are pleased to present you Abhee Pride, a beautiful house project designed for those looking for the best combination of comfort, convenience and modern living.
Experience Modern Luxury at Abhee Pride
Situated in the up-and-coming neighborhood of Iggalur, Bangalore, Abhee Pride offers a serene escape from the bustle of city life, while remaining close to all the essentials.
**[Abhee Pride](https://abheeventures.com/abhee-pride-in-chandapura-bangalore)** offers a peaceful rest away from city life, while being close to all amenities.Spacious and well-designed flats: Well-designed 2 BHK and 3 BHK flats are available in sizes ranging from 1105 sqft to 1410 sqft, providing enough space for families or people who like to spread out.
Transparency and Trust: We believe in open communication and will guide you through every step of the buying process.
Unmatched Service: Our dedicated team is here to answer your questions and address your concerns, ensuring a smooth and stress-free experience.
Is Abhee Pride Your Dream Home?
Abhee Pride is currently under construction, with possession expected in December 2024. Don't miss this opportunity to own a piece of paradise in Bangalore.
Contact Abhee Ventures today to schedule a personalized visit and explore the possibilities at Abhee Pride!
We look forward to helping you find your perfect haven.
**[Abhee Ventures](https://abheeventures.com/)** - Building Communities, Building Dreams | bhandariraj |
1,863,751 | About Anti-Cheat Expert | Anti-Cheat Expert is the world’s leading professional game security solution. We provide security... | 0 | 2024-05-24T08:52:11 | https://dev.to/anticheatexpert/about-anti-cheat-expert-3n6a | gamedev, anticheat, game, gaming | **[Anti-Cheat Expert](https://intl.anticheatexpert.com/?gad_source=1&gclid=CjwKCAjw9cCyBhBzEiwAJTUWNXovsbVIBPlDBtrqKFVmhS4__beD5rdO18aQX-_GUk-W19LUAmBjYBoCff4QAvD_BwE#/index) is the world’s leading professional game security solution.**
We provide security solutions covering the whole life of games, including anti-cheat, shell service, anti gold farming studio, device fingerprint service, content moderation service, digital rights management, and more. We established cooperation with many companies such as Garena, Riot, ActiVision,Nexon,and provided safety protection for hundreds of games such as Arena of Valor, PUBGM and CODM.Anti-Cheat Expert worked with global game companies to build a safe ecology!
**Anti-Cheat Expert is the largest game security team in the world with a history of more than ten years.**
In the long-term of shell service work, security experts use machine learning, artificial intelligence technology, combined with the actual security scene, to create a complete set of game security protection system. At present, we have provided the game security service represented by Anti-Cheat Expert.
**For Mobile Game**
ACE has developed an one-stop mobile game security solution that covers shell service, anti-cheat, content moderation, anti gold farming, and account security. Based on a big-data accumulation of more than 10 years, the solution uses industry-leading technologies to implement real-time monitoring and effective crackdown, ensuring the security of games.
**Pain Points of Mobile Game Security Industry**
In the era of mobile internet, the rapidly growing market share of mobile games has attracted greedy eyes of plug-in authors and cybercriminals. Plug-ins that support automatic aiming, perspective, and acceleration and deceleration are emerging. Security issues such as sensitive content, advertisements, offensive information, and gold farming studios have seriously affected players’ gaming experience. Additionally, cheating methods such as iOS malicious top-up, channel cheating, smurfing, and boosting are causing huge losses throughout the entire industry.
**Mobile Game Security Solutions**
Comprehensively safeguards your mobile games based on years of experience in solving mobile game security issues and continuous research on forward-looking security technologies.
**For PC Game**
ACE, with more than 10 years of technology accumulation, has developed an industry-leading security solution specially for PC games. The solution provides features such as anti-cheat, enforcement, content moderation, vulnerability identification and anti gold-farming, thus providing comprehensive security for PC games.
**Believe in the power of Anti-Cheat Expert.**
 | anticheatexpert |
1,863,750 | Working with mission-critical data - Azure Files and Azure Blobs | Create a storage account with high availability. In the portal, search for and select... | 0 | 2024-05-24T08:51:48 | https://dev.to/olawaleoloye/working-with-mission-critical-data-azure-files-and-azure-blobs-26p3 | critical, data, azure, blobs | ## Create a storage account with high availability.
In the portal, **search** for and select _Storage accounts_.
**Select + Create**.
For _resource group_ **select** new. **Give** your _resource group_ a **name** and select OK.
**Set** the _Storage account name_ to _publicwebsite_. Make sure the storage account name is unique by adding an identifier.
**Select** _Review_ and then _Create_.
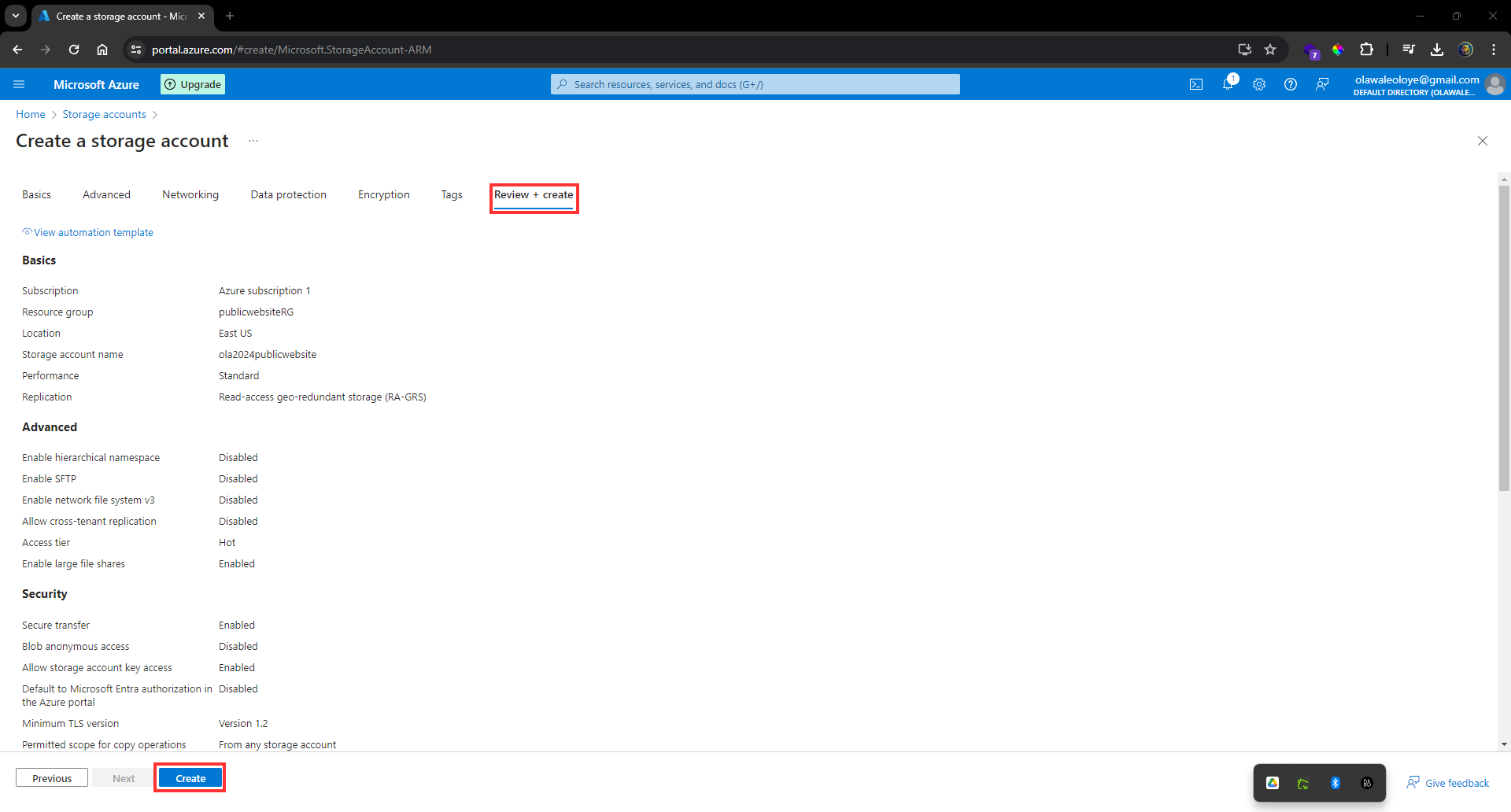
Take the defaults for other settings.
In the storage account, in the **Data management section**, **select** the **Redundancy blade**.
**Ensure** _Read-access Geo-redundant storage_ is **selected**.
_Review the primary and secondary location information.
In the storage account, in the **Settings section**, **select** the **Configuration blade**.
**Ensure** the _Allow blob anonymous access setting_ is **Enabled**.
_Be sure to Save your changes._
## Create a blob storage container with anonymous read access
In your storage account, in the **Data storage section**, **select** the _Containers blade_.
**Select + Container**.
**Ensure** the _Name of the container_ is _public_.
**Select** _Create_.
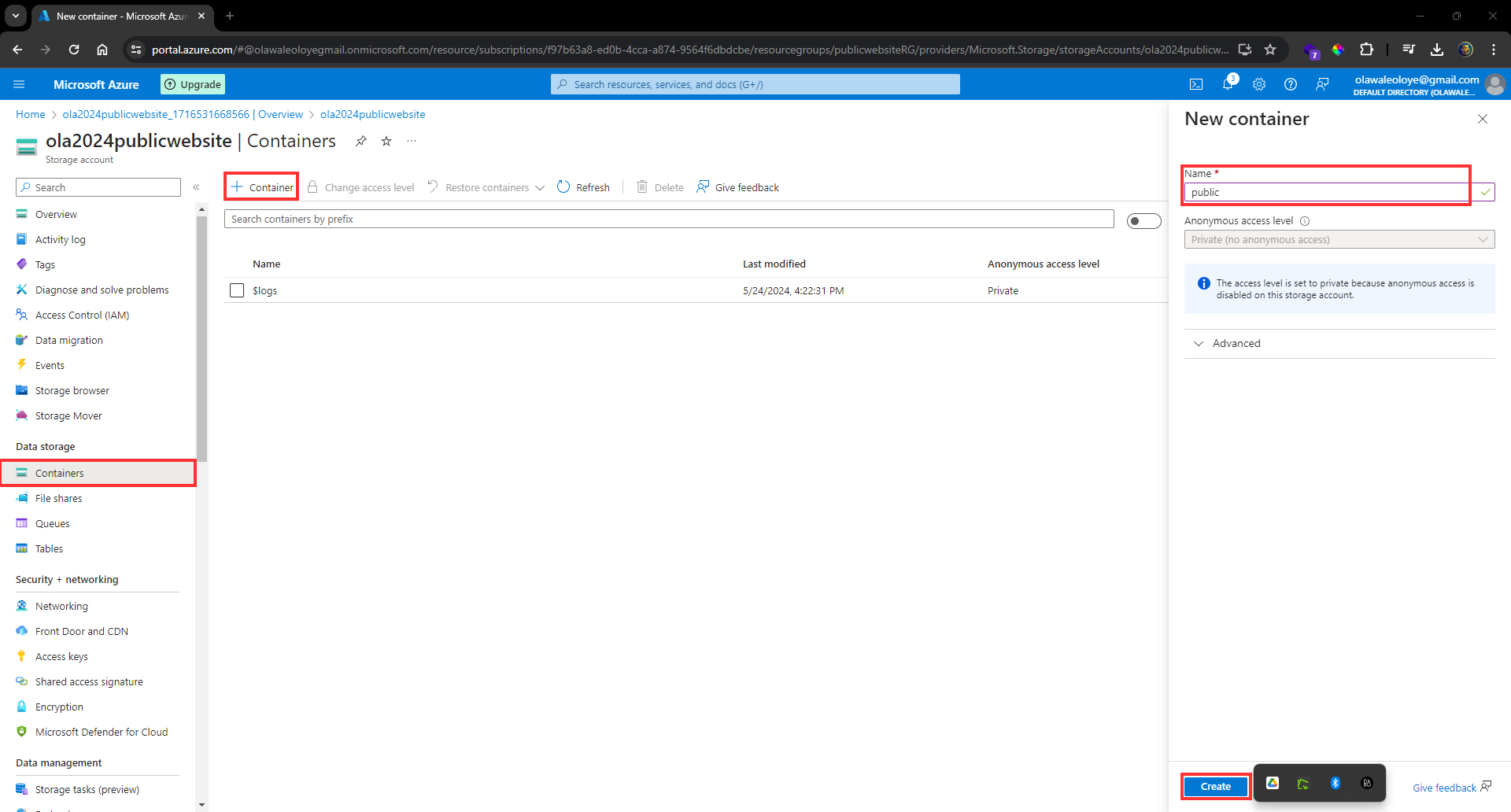
On the _Overview blade_, **select** _Change access level_.
**Ensure** the _Public access level is Blob (anonymous read access for blobs only)_.
**Select** _OK._
## Practice uploading files and testing access.
**Ensure** you are viewing your _container_.
**Select** _Upload_.
**Browse** to files and **select** a _file_. Browse to a file of your choice.
**Select** _Upload_.
**Close** the upload window, **Refresh** the page and _ensure your file was uploaded_.
**Select** your uploaded file.
On the **Overview tab**, **copy** the _URL_.
**Paste** the _URL into a new browser tab_.
If you have uploaded an image file it will display in the browser. Other file types should be downloaded.
## Configure soft delete
**Go** to the _Overview blade_ of the _storage account_.
On the _Properties page_, locate the _Blob service section_.
**Select** the _Blob soft delete setting_.
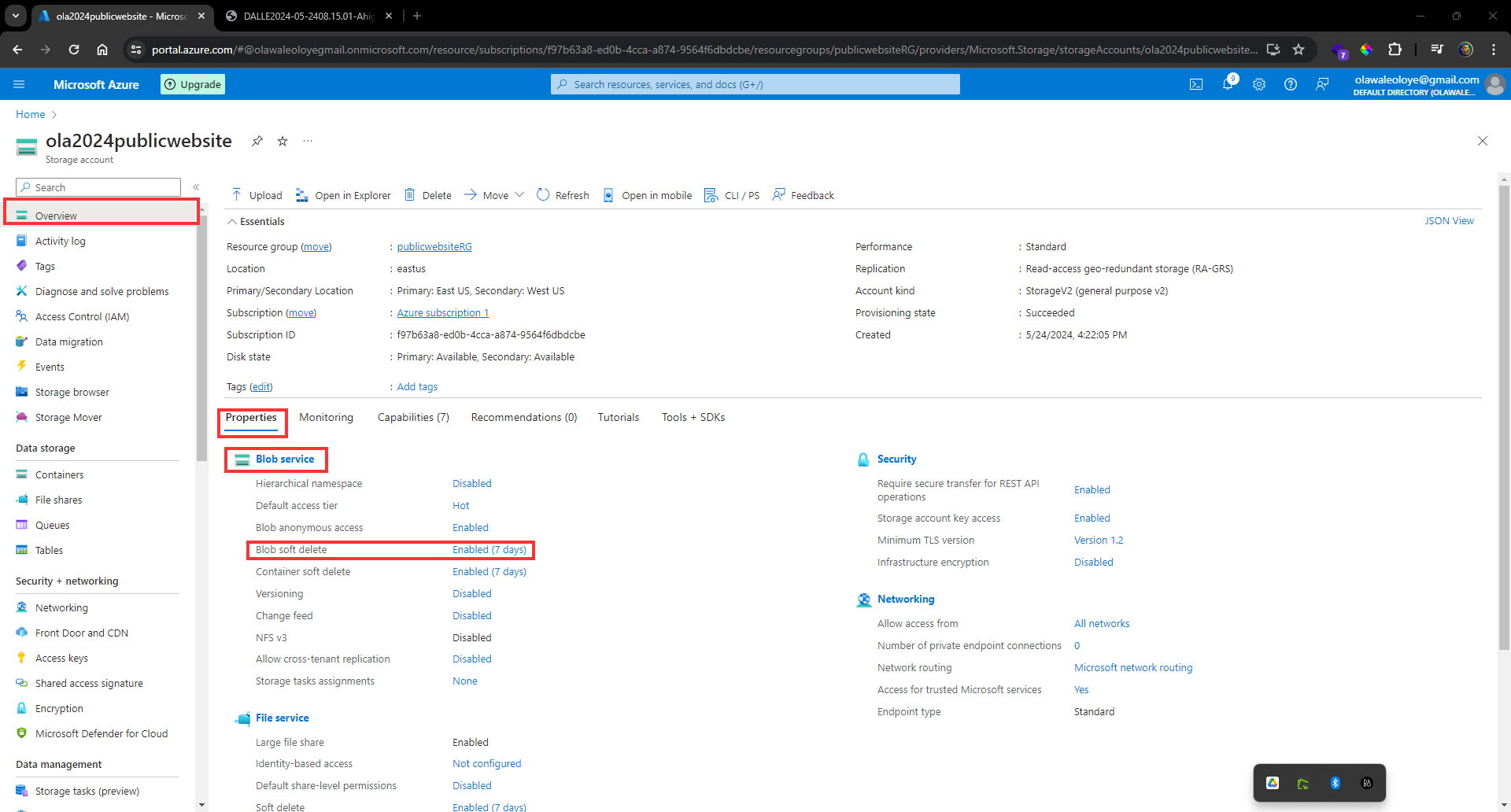
**Ensure** the _Enable soft delete for blobs_ is _checked_.
**Change** the _Keep deleted blobs_ for (in days setting is **21**)
_Notice you can also Enable soft delete for containers._
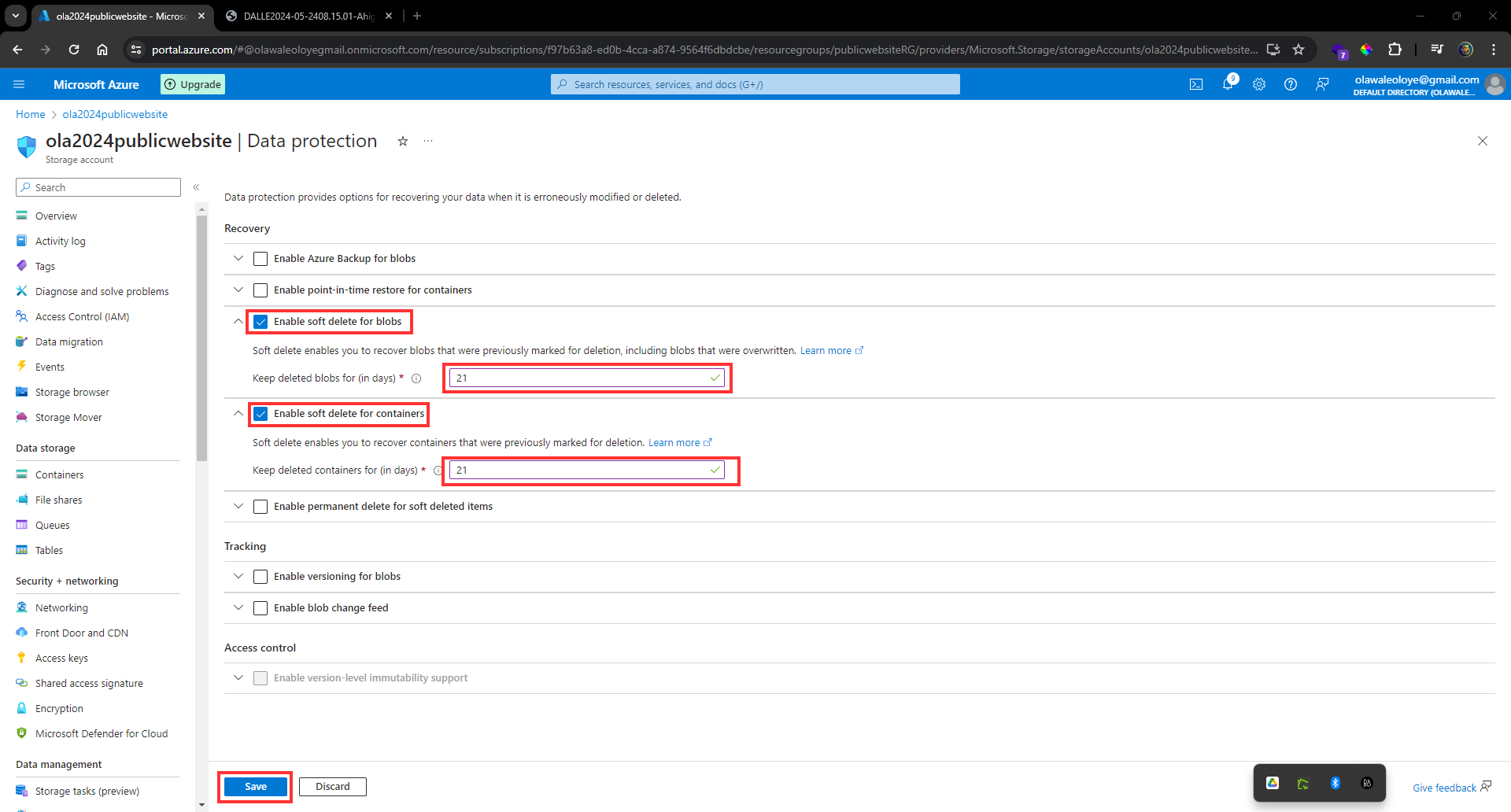
Don’t forget to Save your changes.
**Navigate** to your _container_ where you _uploaded a file_.
**Select** the file you uploaded and then **select** _Delete_.
**Select** _OK_ to confirm deleting the file.
On the **container Overview** page, **toggle** the slider _Show deleted blobs_. _This toggle is to the right of the search box_.
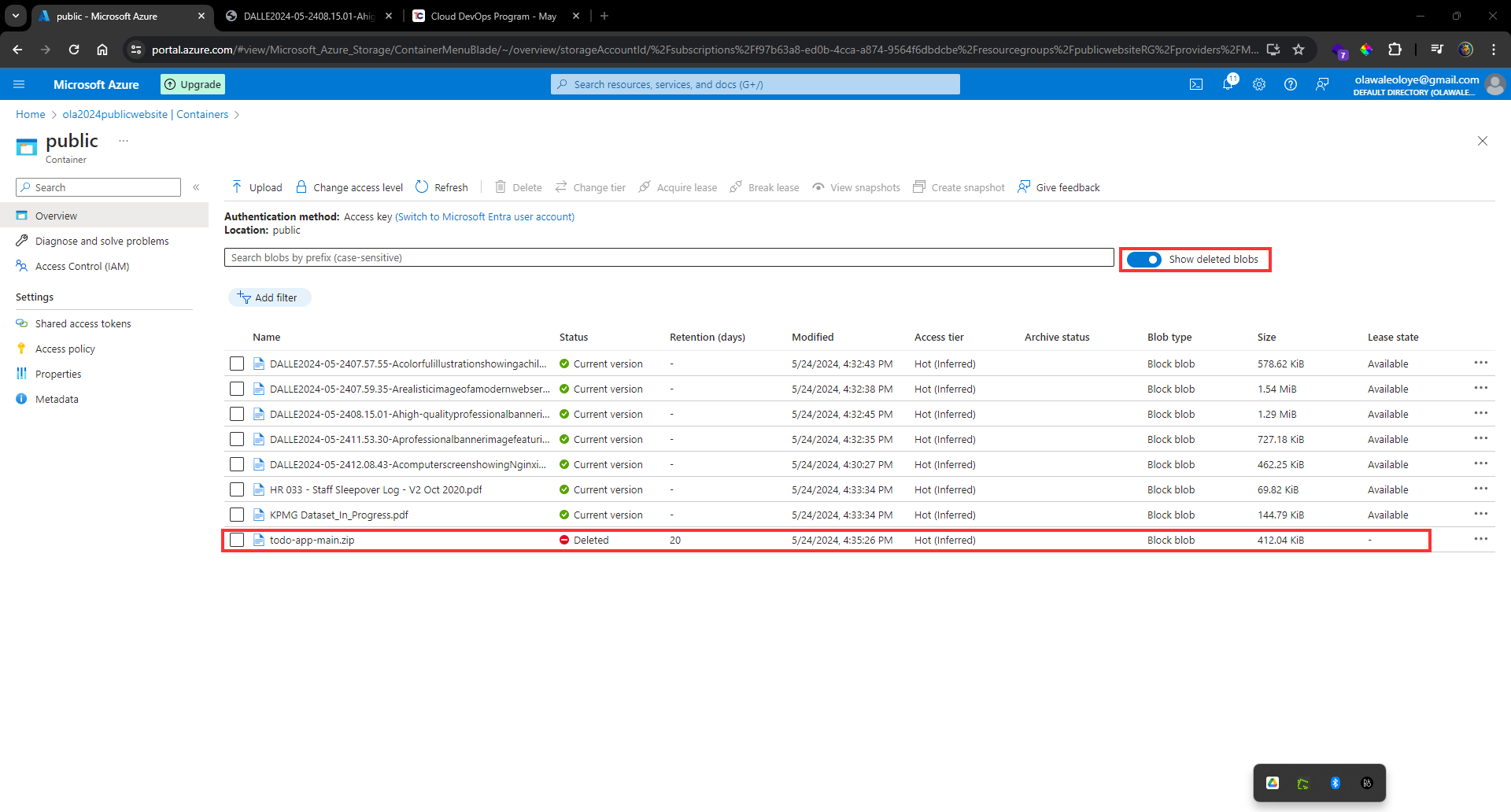
**Select** _your deleted file, and use the ellipses on the far right, to Undelete the file_.
**Refresh** the container and confirm the _file has been restored_.
## Configure blob versioning
**Go** to the _Overview blade_ of the _storage account_.
In the _Properties section_, **locate** the _Blob service section_.
**Select** the _Versioning setting_.
**Ensure** the _Enable versioning for blobs_ checkbox is _checked_.
_Notice your options to keep all versions or delete versions after_.
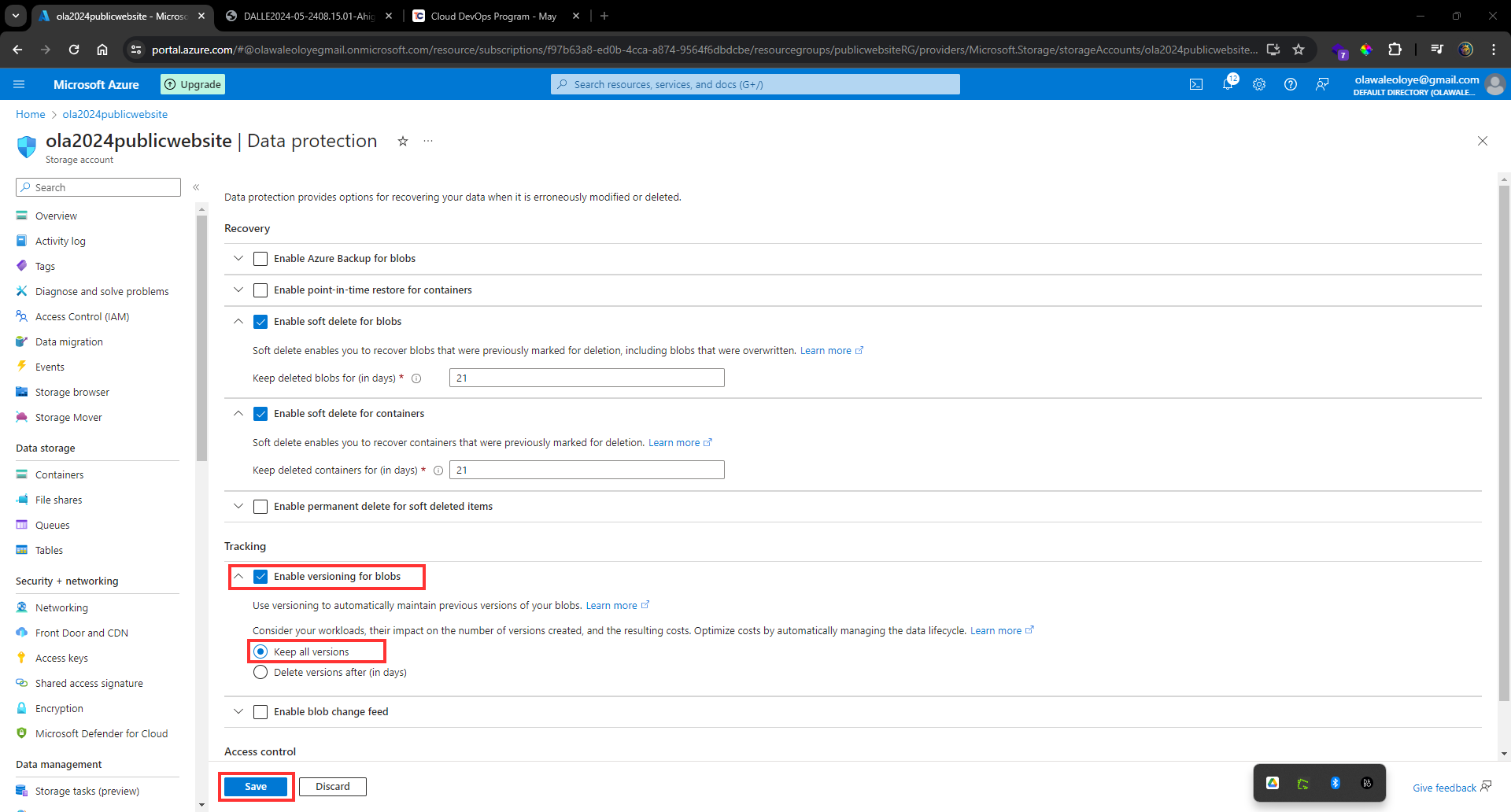
Don’t forget to Save your changes.
**Upload** _another version of your container file_. _This overwrites your existing file_.
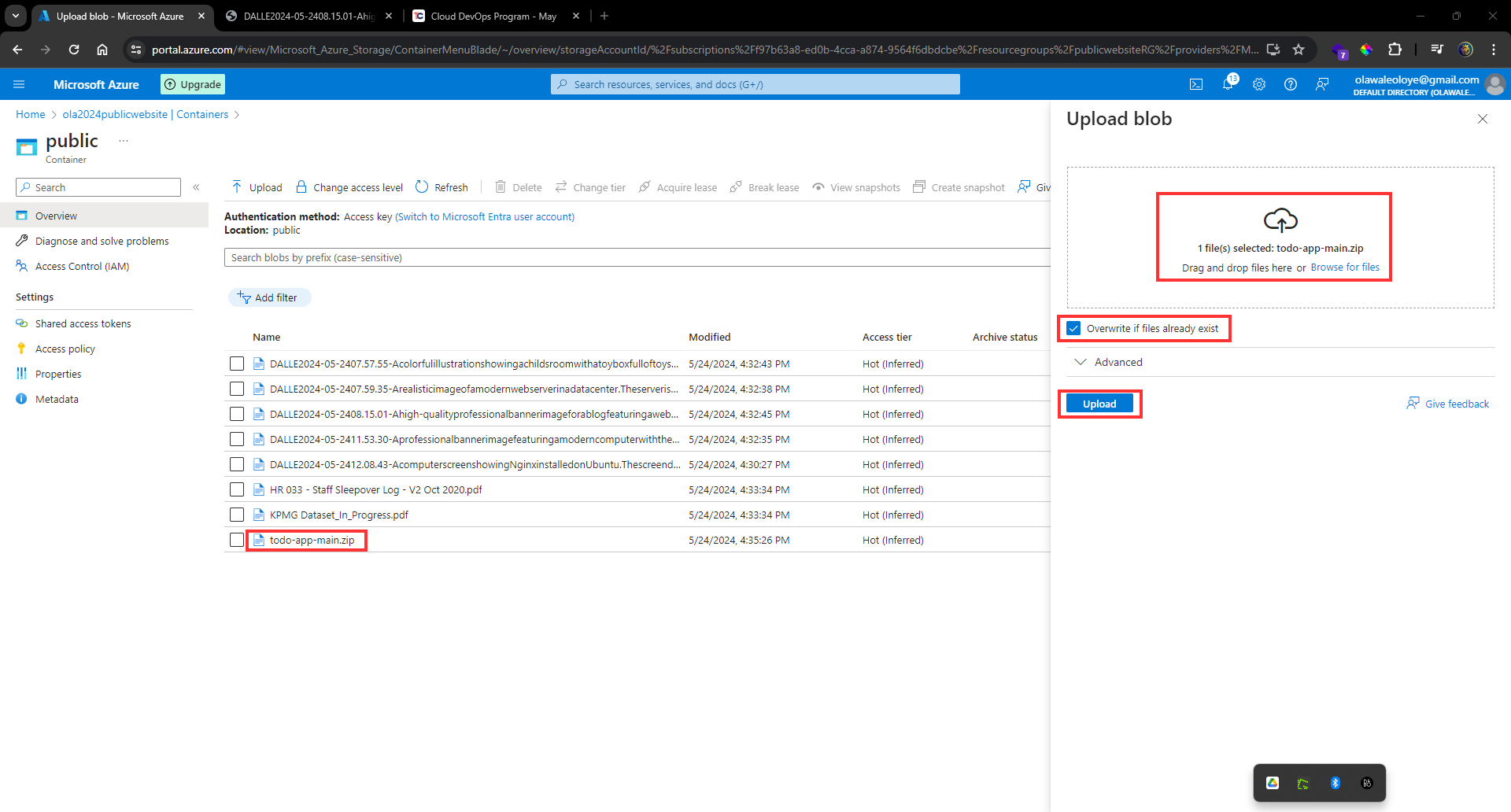
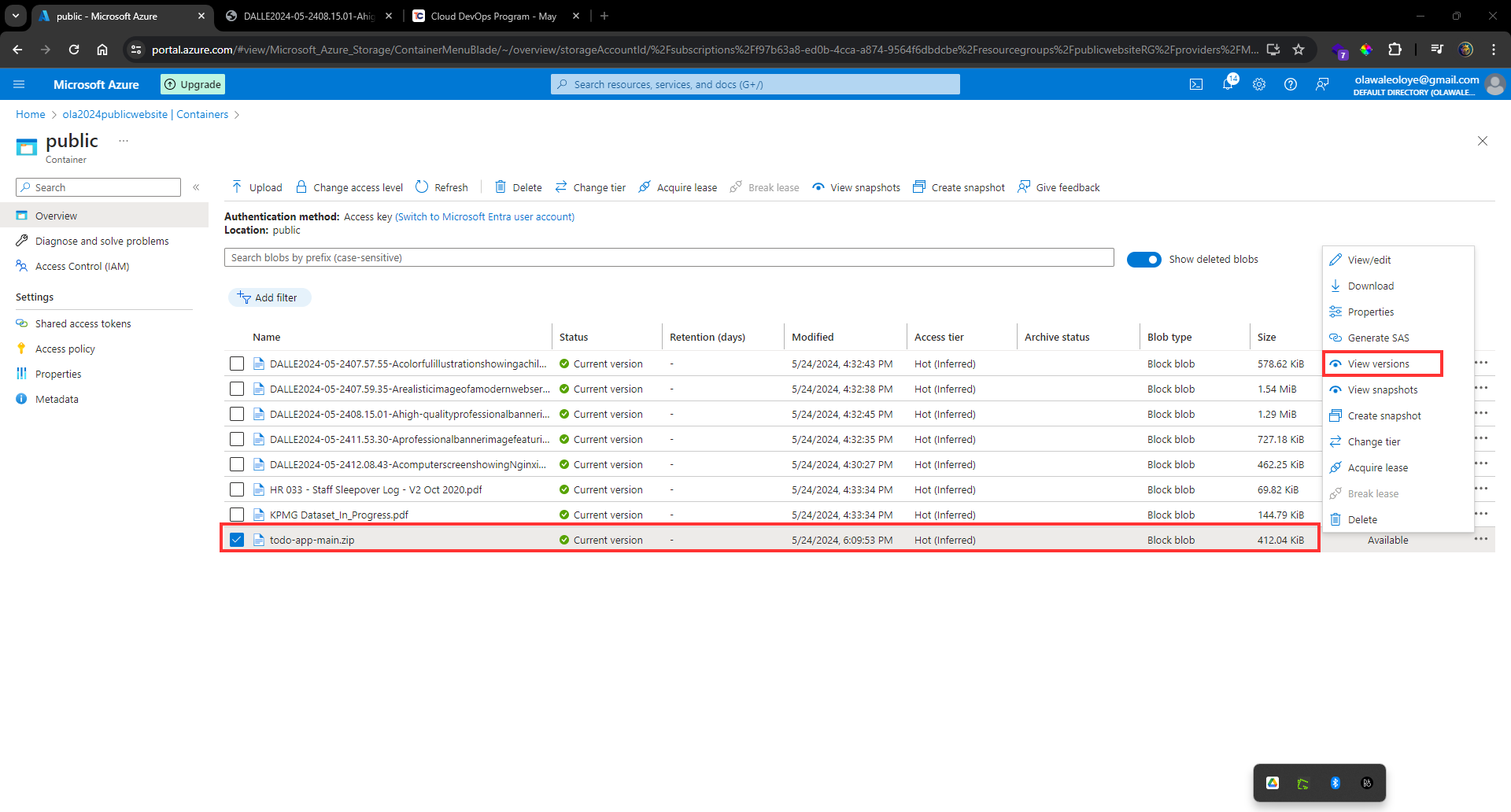
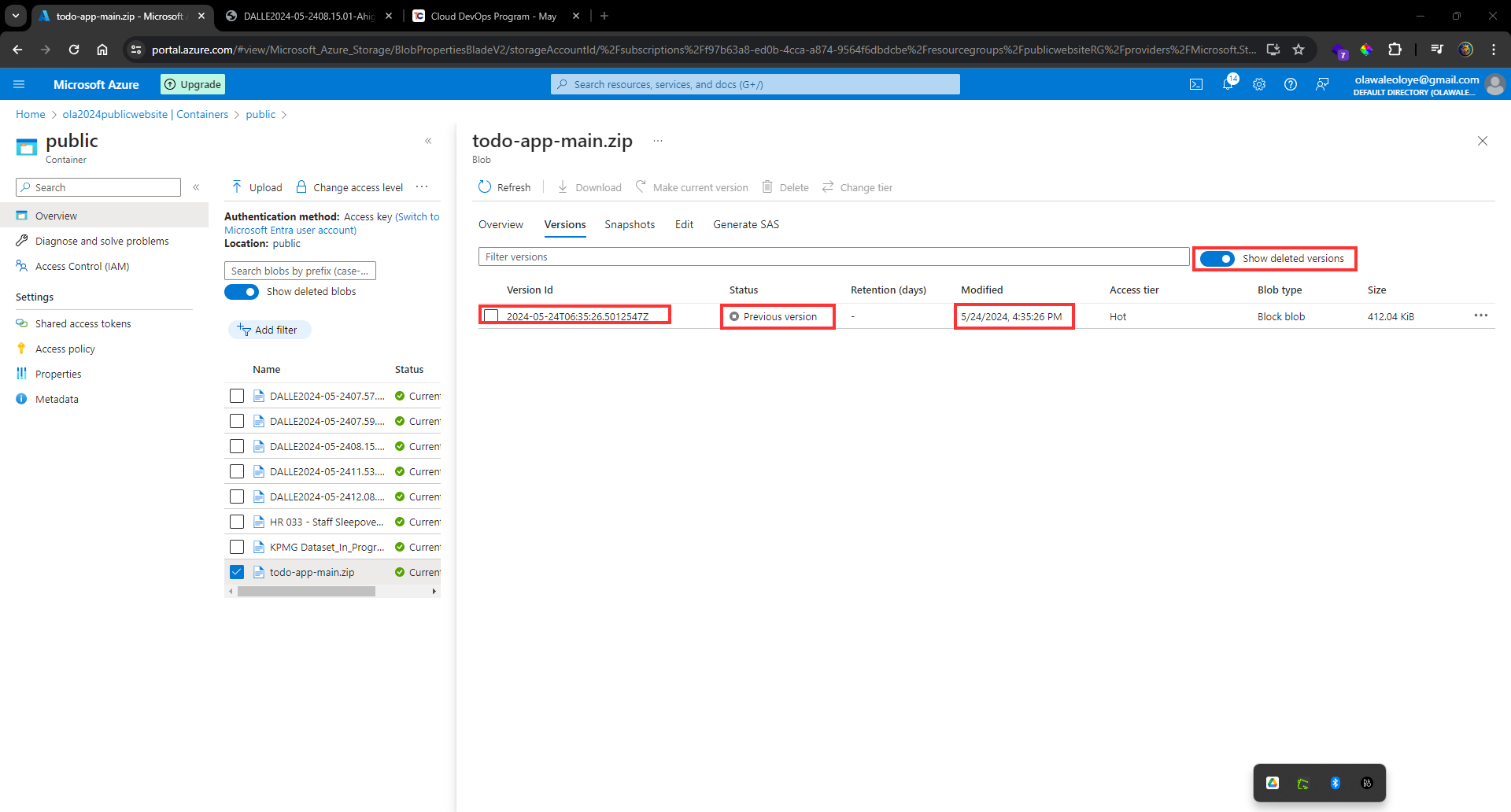
Your previous file version is listed on Show deleted blobs page.
| olawaleoloye |
1,863,749 | النكهات كانت متقلبة: استكشاف اللوحة العاطفية للطعام | هل سبق لك أن تناولت قضمة من شيء ما وشعرت بموجة غير متوقعة من العاطفة؟ هذه هي قوة النكهات المزاجية.... | 0 | 2024-05-24T08:51:01 | https://dev.to/moodpods02/lnkht-knt-mtqlb-stkshf-llwh-ltfy-lltm-16fi |

هل سبق لك أن تناولت قضمة من شيء ما وشعرت بموجة غير متوقعة من العاطفة؟ هذه هي قوة النكهات المزاجية. هذه النكهات تتجاوز الذوق. فهي تثير المشاعر والذكريات والحالات المزاجية، مما يخلق تجربة طعام شخصية وعاطفية عميقة. دعونا نغوص في عالم النكهات المزاجية ونكتشف كيف يمكن للطعام أن يمس أرواحنا [نكهات بود مزاج
](https://rawqan.com/ps/kHB3vIwBQSUrBgEj8MwV/بودات-مزاج )
العلم وراء إدراك النكهة
إن فهم كيفية إدراكنا للنكهات أمر بالغ الأهمية لفهم تأثيرها العاطفي. تكتشف براعم التذوق لدينا الأذواق الأساسية: الحلو، والمالح، والحامض، والمر، والأومامي. لكن دماغنا هو الذي يعالج هذه الإشارات ويفسرها، وغالبًا ما يتأثر بعلم الوراثة والبيئة. على سبيل المثال، قد يجد بعض الأشخاص الكزبرة منعشة، بينما يتذوق البعض الآخر الصابون بسبب الاختلاف الجيني.
منظور تاريخي على مزاج النكهة
تاريخيًا، كانت للنكهات دائمًا أهمية عاطفية. استخدمت الحضارات القديمة التوابل ليس فقط من أجل الذوق ولكن أيضًا لخصائصها العاطفية والطبية. في العديد من الثقافات، ارتبطت الأطعمة والنكهات المحددة بالطقوس والاحتفالات، التي تهدف إلى إثارة مشاعر أو حالات ذهنية معينة.
النكهة والعاطفة: الاتصال النفسي
النكهات يمكن أن تؤثر بشكل عميق على عواطفنا. فكر في الأطعمة المريحة مثل المعكرونة والجبن أو حساء الدجاج. غالبًا ما تجلب هذه الأطباق إحساسًا بالدفء والأمان، وترتبط بذكريات الحنين للطفولة أو المنزل. هذا الارتباط النفسي هو السبب الذي يجعلنا نتناول في كثير من الأحيان أطعمة معينة خلال فترات الذروة والانخفاضات العاطفية.
اتجاهات الطهي الحديثة والنكهات المزاجية
اليوم، يتبنى عالم الطهي مفهوم النكهات المزاجية. تتزايد تجارب تناول الطعام التجريبية، حيث يقوم الطهاة بإعداد أطباق مصممة لإثارة مشاعر معينة. المطاعم الآن لم تعد مجرد تغذية للمعدة، بل لتغذية الروح أيضًا. على سبيل المثال، يمكن إعداد طبق لاستحضار هدوء الغابة، باستخدام النكهات والروائح الترابية.
دور المكونات في خلق النكهات المزاجية
بعض المكونات لها تأثير مباشر على حالتنا المزاجية. يمكن للتوابل مثل القرفة وجوزة الطيب أن تثير الدفء والراحة، في حين أن الأعشاب مثل الريحان والنعناع قد تجلب إحساسًا بالانتعاش والوضوح. تلعب الكيمياء الكامنة وراء هذه المكونات دورًا حاسمًا في كيفية تأثيرها على عواطفنا.
موازنة النكهات للتأثير العاطفي
إن إعداد طبق بنكهات متقلبة هو فن. أنها تنطوي على موازنة الأذواق الأساسية لتحقيق التأثير العاطفي المطلوب. على سبيل المثال، إضافة لمسة من الحلاوة إلى طبق حار يمكن أن يخلق نكهة مريحة ومثيرة. يمكن للطهاة في المنزل تجربة هذه التوازنات لإعداد وجباتهم الخاصة لتحسين الحالة المزاجية.
تأثير العرض والأجواء
يمكن أن تؤثر طريقة تقديم الطبق بشكل كبير على كيفية إدراكنا لنكهاته. يمكن للوجبة المطلية بشكل جميل أن تجعل تجربة تناول الطعام أكثر متعة وترفع من النكهات. وبالمثل، فإن أجواء بيئة تناول الطعام - الإضاءة والموسيقى والديكور - يمكن أن تعزز أو تقلل من تجربة الأكل العاطفية.
الاختلافات الثقافية في مزاج النكهة
تتعامل الثقافات المختلفة مع النكهات وتأثيراتها العاطفية بشكل فريد. في اليابان، توفر الأطعمة الغنية بالأومامي مثل حساء الميسو شعورًا بالهدوء والرضا. في الهند، يمكن للتوابل النابضة بالحياة المستخدمة في أطباق الكاري أن تنشط وتنشط. إن فهم هذه الاختلافات الثقافية يمكن أن يوسع تقديرنا للنكهات المزاجية.
تجارب النكهة: الطبخ مع مراعاة الحالة المزاجية
يعد الطهي مع مراعاة الحالة المزاجية عملية ممتعة وإبداعية. حاول إعداد طبق مصمم لإثارة مشاعر معينة، مثل تارت الليمون الحامض للحصول على موجة من السعادة أو حلوى الشوكولاتة الغنية للشعور بالرفاهية. تجربة النكهات في المنزل يمكن أن تؤدي إلى اكتشافات طهي مبهجة وغير متوقعة.
مستقبل النكهات المزاجية
يبدو مستقبل النكهات المزاجية واعدًا مع الاتجاهات والتقنيات الناشئة. من فن الطهي الجزيئي إلى الوصفات التي ينشئها الذكاء الاصطناعي، فإن الاحتمالات لا حصر لها. من المرجح أن تؤدي هذه التطورات إلى تجارب طعام أكثر تخصيصًا وعاطفية.
الصحة والرفاهية: تأثير النكهات المزاجية
العلاقة بين النكهة والمزاج والصحة العقلية مهمة. الأطعمة التي تثير المشاعر الإيجابية يمكن أن تساهم في الصحة العامة. إن دمج الأطعمة المعززة للمزاج في نظامنا الغذائي يمكن أن يساعد في إدارة التوتر وتحسين الصحة العقلية.
النكهة وسرد القصص: رواية الطعام
غالبًا ما يستخدم الطهاة النكهات لسرد القصص، مما يخلق قصة يمكن لرواد المطعم تجربتها من خلال الذوق. يمكن أن تثير هذه القصة مشاعر قوية، مما يجعل تجربة تناول الطعام لا تُنسى. فكر في طبق مستوحى من ذكريات الطفولة، مصمم لإثارة الحنين والفرح.
النكهات هي أكثر من مجرد أذواق؛ إنها أدوات قوية يمكنها إثارة مجموعة واسعة من المشاعر. ومن خلال فهم النكهات المتقلبة وتجربتها، يمكننا إنشاء تجارب تناول طعام ليست لذيذة فحسب، بل ذات معنى عميق أيضًا. لذا، في المرة القادمة التي تكون فيها في المطبخ، فكر في المشاعر التي تريد إثارةها ودع مكوناتك ترشدك.
صال –
الهاتف: +966553541301
زيارة هنا: https://rawqan.com/ps/kHB3vIwBQSUrBgEj8MwV/بودات-مزاج | moodpods02 | |
1,863,748 | How to create vertical tabs with Tailwind CSS and JavaScript | Let's create a simple vertical tabs component using Tailwind CSS and JavaScript. Read the article,... | 0 | 2024-05-24T08:49:44 | https://dev.to/mike_andreuzza/how-to-create-vertical-tabs-with-tailwind-css-and-javascript-451 | frontend, tutorial, javascript, tailwindcss | Let's create a simple vertical tabs component using Tailwind CSS and JavaScript.
[Read the article, See it live and get the code](https://lexingtonthemes.com/tutorials/how-to-create-vertical-tabs-with-tailwind-css-and-javascript/)
| mike_andreuzza |
1,863,747 | Step-by-Step Tutorial: Jest Unit Testing in React with Enzyme | Step-by-Step Tutorial: Jest Unit Testing in React with Enzyme In the realm of front-end development,... | 0 | 2024-05-24T08:49:39 | https://dev.to/emmanuelj/step-by-step-tutorial-jest-unit-testing-in-react-with-enzyme-229j | javascript, webdev, programming, react | **Step-by-Step Tutorial: Jest Unit Testing in React with Enzyme**
In the realm of front-end development, ensuring that your React components behave as expected is paramount. Jest unit testing, in combination with Enzyme, offers a robust framework for behaviour-driven development (BDD) that ensures your application remains bug-free and performs optimally. This technique simplifies identifying issues within React components and streamlines testing strategies by integrating seamlessly with Jest unit testing for React Native, offering a comprehensive solution for both web and mobile development. The importance of adopting effective testing tools such as Jest and Enzyme in the development process cannot be overstated, as they significantly contribute to the quality and reliability of software products.
This article will guide readers through the process of setting up Jest and Enzyme for testing React components, from the initial configuration to writing actual unit tests. It will delve into the specifics of creating mock functions, testing React forms, and leveraging advanced Jest and Enzyme unit testing techniques to ensure your React applications are thoroughly tested. Furthermore, it will explore best practices and testing strategies that align with the principles of behaviour-driven development, using real-world examples to demonstrate how Jest-React integration can enhance the quality of your front-end testing efforts. By the conclusion of this article, readers will be equipped with the knowledge to implement effective Jest unit testing strategies in their React projects, ensuring higher code quality, fewer bugs, and a more efficient development cycle.
### Why Unit Testing in Front-end Development?
Unit testing, a fundamental aspect of software development, plays a pivotal role in ensuring the functionality and reliability of individual units or components of code. In the context of front-end development, it serves as a critical tool for developers to identify and rectify errors before they escalate to the end user, thereby maintaining the integrity of the application. The process of unit testing allows developers to detect errors early in the development cycle, facilitating a smoother and more efficient debugging process. By isolating and testing individual pieces of code, developers can ensure each component operates as expected, significantly reducing the time and effort required for error resolution.
### Benefits of Unit Testing
**Early Error Detection**: One of the primary advantages of unit testing is its ability to uncover bugs and errors at an early stage. This preemptive approach to error management not only conserves development time but also simplifies the process of rectifying issues before they integrate with other parts of the application.
**Facilitates Code Refactoring**: Refactoring, or the process of modifying code to enhance its efficiency and maintainability without altering its external behaviour, is crucial for the longevity of software applications. Unit testing supports this process by providing a safety net, ensuring that modifications do not introduce new errors or compromise existing functionality.
**Improves Code Coverage**: Code coverage, indicative of the extent to which the codebase is tested, is a key metric in assessing the quality of the application. Through unit testing, developers can identify untested segments of the code, thereby increasing coverage and confidence in the application’s reliability.
**Enhances Code Quality**: The rigorous nature of unit testing compels developers to thoroughly examine the functionality and potential failure points of their code. This introspective approach promotes the development of robust, reliable, and maintainable code, ultimately improving the overall quality of the software.
**Promotes Better Design**: The necessity to isolate and test code units independently encourages developers to adopt modular and decoupled coding practices. This not only makes the code more testable but also enhances its readability and scalability.
### The Role of Unit Testing in Front-End Development
Front-end development involves the creation and management of the user interface, encompassing elements like formatting, visible text, graphics, and interactive components such as buttons and forms. Unit testing is instrumental in ensuring these elements function correctly across different scenarios and user interactions. By focusing on individual components and functions, unit testing verifies that they perform as intended, laying the foundation for a stable and reliable application.
Given the complexity and diversity of user interface elements, prioritizing tests becomes essential. Developers often start by ensuring basic functionality, such as text visibility and page loading, before progressing to more complex interactive features. This structured approach to testing ensures comprehensive coverage, from the layout and aesthetics to the responsiveness and execution of user requests.
### Conclusion
Unit testing is an indispensable component of front-end development, offering a multitude of benefits ranging from early error detection to improved code quality and design. By adopting a systematic approach to unit testing, developers can ensure their applications meet the highest standards of functionality and reliability, ultimately delivering a superior user experience.
### Setting Up Jest and Enzyme
**Installing Required Packages**
For developers starting with a new React application, it is recommended to utilize the Create React App, which comes pre-configured with Jest. This setup simplifies the process as it only requires the addition of a react-test-renderer for rendering snapshots. For those working on an existing application, several packages need to be installed to integrate Jest and Enzyme properly. Key packages include babel-jest for code transformation within the test environment and the react babel preset. These tools work together to ensure that the testing environment mimics the actual application environment.
**Configuring Enzyme**
Once the necessary packages are installed, setting up Enzyme involves creating a setupTests.js file within the src/ directory of the project. This file is crucial as it configures the Enzyme adapter, which is essential for testing React components. Ensure the file includes the appropriate imports and configuration settings, such as:
```javascript
import Enzyme from 'enzyme';
import Adapter from 'enzyme-adapter-react-16';
Enzyme.configure({ adapter: new Adapter() });
```
This configuration sets up Enzyme with the specified adapter, which should match the React version used in the project. It is also possible to configure Enzyme globally through the package.json by adding a jest entry to specify the setupTestFrameworkScriptFile, which points to the setupTests.js file. This approach avoids the need to import the setup file in each test file.
**Adding Scripts**
To fully integrate Jest and Enzyme into the development workflow, it is necessary to add specific scripts to the package.json file. These scripts will facilitate the running of tests and the generation of coverage reports. The typical entries in the package.json should include:
```json
"scripts": {
"test": "jest",
"test:coverage": "jest --coverage"
}
```
These scripts enable developers to execute tests using Jest and to collect coverage information, which helps in identifying untested parts of the application. The coverage report provides insights into the effectiveness of the tests and highlights areas that may require additional testing.
By following these steps—installing the required packages, configuring Enzyme, and adding necessary scripts—developers can set up a robust testing environment using Jest and Enzyme for their React applications. This setup not only supports the development of reliable and maintainable code but also enhances the overall testing workflow.
### Writing Unit Tests with Jest and Enzyme
Writing unit tests is a critical step in ensuring the robustness of React applications. Jest, a testing tool developed by Facebook, simplifies unit testing in JavaScript, while Enzyme, specific to React, provides methods that enhance the testing of React components. This section delves into creating test cases, running tests, and handling snapshots with Jest and Enzyme, guiding developers through the process of establishing a reliable testing environment for React applications.
**Creating Test Cases**
To begin with, developers should create a React application that can be tested. A simple counter app, which increments a count upon a button click, serves as a practical example. Using Create React App allows developers to quickly set up a project with Jest pre-installed, eliminating the need for additional configuration steps.
1. **Initialize the Application**: Bootstrap the project using Create React App to quickly start with a setup that includes Jest.
2. **Write the First Test**: Utilize Enzyme's shallow rendering for testing the app's initial state. Shallow rendering enables testing a component without requiring a DOM, by rendering only one level deep.
3. **Simulate User Interaction**: Employ Enzyme's simulate() function to mimic user interactions, such as clicking a button, and set expectations for the application's response to these interactions.
**Running Tests**
Running tests is streamlined with Jest. Once test cases are written, developers can execute them to verify the behaviour of their React components.
1. **Execute Tests**: Use the jest command to run the tests. This command looks for files with .test.js or .test.jsx extensions and executes the tests contained within.
2. **Review Test Output**: Analyze the output produced by running the tests. Jest will indicate whether the tests passed or failed, allowing developers to identify and address any issues.
**Handling Snapshots**
Snapshot testing is a powerful feature of Jest that helps ensure the UI does not change unexpectedly. It involves rendering a UI component, taking a snapshot, and comparing it to a reference snapshot file.
1. **Generate Snapshots**: When a snapshot test is executed for the first time, Jest generates a snapshot of the component's rendered output and stores it in a JSON file. This snapshot serves as a reference for future test runs.
2. **Compare to Reference Snapshot**: On subsequent test runs, Jest compares the current rendered output of the component against the stored snapshot. If there are deviations, Jest notifies the developer, who can then decide whether to update the snapshot or address the changes in the component.
3. **Update Snapshots**: If changes to the component are intentional and the snapshot needs to be updated, developers can use the jest -u command to update the existing snapshot to match the new version of the UI component.
By following these steps, developers can leverage Jest and Enzyme to create comprehensive unit tests for React applications. This process not only ensures the reliability and stability of the application but also facilitates a smoother development cycle by enabling early detection and resolution of issues.
### Advanced Techniques and Best Practices
**Mocking and Spying**
Mock functions, also known as "spies," are essential in testing the behaviour of functions that are called indirectly by other codes. By creating a mock function
with jest.fn(), developers can monitor and assert the behaviour of these functions, including their calls, results, and instances. For instance, to mock or spy on React's useState hook, developers can employ jest.spyOn() to observe the state changes within components. This technique is particularly useful in ensuring that components respond correctly to user interactions or internal state changes.
**Snapshot Testing**
Snapshot testing is a powerful tool for ensuring UI consistency. By rendering a UI component and comparing it to a reference snapshot file, developers can detect unexpected changes. This method is favoured for its simplicity and effectiveness in catching unintended modifications to the UI. Jest enhances this process by using a pretty format to make snapshots human-readable, which is crucial for code reviews. Developers are encouraged to commit snapshots and treat them as part of the regular code review process, ensuring that snapshots remain focused, short, and readable. It's important to remember that snapshot testing complements, rather than replaces, traditional unit testing, offering additional value and making testing more efficient.
**TDD and BDD**
Test-Driven Development (TDD) and Behavior-Driven Development (BDD) are methodologies that guide the development process through testing. TDD follows a Red-Green-Refactor cycle, where tests are written before the code, ensuring that the software design is led by tests. This approach helps in preventing future regressions and increases confidence in the code's functionality. However, it's acknowledged that TDD can be time-consuming and challenging, especially when testing edge cases. BDD, on the other hand, extends TDD by specifying behaviour in a more readable and understandable language, allowing for better communication among stakeholders and ensuring that the software behaves as intended. Both methodologies emphasize the importance of testing in maintaining and refactoring code, thereby preventing the creation of legacy code.
Incorporating these advanced techniques and best practices into the development workflow significantly enhances the quality and reliability of software. By employing mocking and spying, developers gain deeper insights into the behaviour of their applications. Snapshot testing ensures UI consistency, and the adoption of TDD and BDD methodologies guides the development process with a focus on testing, ultimately leading to more maintainable and error-free code.
### Conclusion
Throughout this article, we've navigated the depths of Jest and Enzyme to uncover their roles in enhancing the React development experience, rooted in the principles of behaviour-driven development. We've delved into setting up, configuring, and employing these powerful tools to ensure our React components behave as intended, demonstrating their pivotal role in the early detection of errors, facilitating smoother code refactoring, and ultimately bolstering code quality and maintainability. This comprehensive exploration underscores the necessity of integrating these testing frameworks into the development workflow, highlighting their indispensable value in crafting robust, reliable, and bug-free applications.
As we conclude, it's clear that the adoption of Jest and Enzyme goes beyond mere testing; it represents a commitment to excellence in software development. The journey through unit testing, mocking, snapshot testing, and the embrace of TDD and BDD practices illuminates a path towards achieving higher standards of code integrity and application functionality. Encouraging further exploration and continuous learning in these areas promises to elevate the quality of React projects, underscoring a culture of rigorous testing and meticulous development. Embracing these tools and methodologies is not just about preventing errors but about forging software that stands the test of time, technically.
### FAQs
**How do I create test cases for React components using Jest and Enzyme?**
To create test cases for React components with Jest and Enzyme, start by rendering a simple component, such as a button labelled "Click Me." This involves importing React and the component you wish to test and then setting up your test environment. For example, you might write a React class component with specific props and state management for testing purposes.
**What is the process for testing functions in Jest and Enzyme?**
Testing functions with Jest and Enzyme involves using Enzyme's shallow rendering method to simulate the component environment. This can include mocking external components or data, such as using MemoryRouter to mock routing. After setting up the mock environment, you can perform tests on your component using Jest's expect method to verify the outcomes.
**How can I mock React component methods using Jest and Enzyme?**
To mock React component methods with Jest and Enzyme, start by using Jest's jest.mock() function, specifying the path to the component you want to mock. You can provide a mock implementation directly within this function to simulate the behaviour of the real component during testing.
**How do you effectively test React hooks with Jest and Enzyme?**
To test React hooks effectively with Jest and Enzyme, begin by setting up a basic React project with both Jest and Enzyme installed. Create a custom hook, for instance, one that manages a counter. Proceed to write tests for your hook, ensuring to explain what each test aims to achieve. Finally, run your tests to validate the functionality of your hook. This approach helps in mastering the testing of React hooks. | emmanuelj |
1,863,745 | The Right Approach to Automate Web Application Testing with Playwright? | In today's hyper-competitive digital landscape, where user attention spans are fleeting and... | 0 | 2024-05-24T08:47:58 | https://dev.to/vijayashree44/the-right-approach-to-automate-web-application-testing-with-playwright-4kp2 |

In today's hyper-competitive digital landscape, where user attention spans are fleeting and competition is fierce, the need for impeccable web experiences has reached unprecedented heights.
According to recent studies conducted by Forrester Research, a staggering 88% of online consumers are less likely to return to a website after encountering a poor user experience (source: Forrester Research). This underscores the critical importance of robust browser testing methodologies in ensuring customer satisfaction and retention.
Nevertheless, traditional manual testing methods often prove insufficient, burdening development teams with inefficiencies and impeding the timely delivery of flawless web applications.
Introducing Playwright – a groundbreaking solution in the world of browser automation. With its exceptional versatility and seamless integration capabilities, Playwright goes beyond mere tool status; it ignites innovation and unlocks enhanced efficiency, paving the way for unparalleled web experiences.
By facilitating automated browser testing across a diverse range of platforms and devices, Playwright empowers development teams to break free from tedious, repetitive tasks, allowing them to prioritize innovation and deliver extraordinary user experiences.
## Why Choose Playwright for Web Automation?
**1.Cross-Browser and Cross-Platform Compatibility:** Playwright supports automation across all major browsers (Chrome, Firefox, Safari, and Edge) as well as various operating systems (Windows, macOS, Linux), ensuring comprehensive coverage for testing your web applications.
**2.Multiple Language Support:** With Playwright, you can write tests in popular programming languages like JavaScript, TypeScript, Python, and C#, catering to diverse development environments and preferences.
**3.Robust and Reliable Testing:** Playwright's architecture is designed for reliability, ensuring stable and consistent test results even in complex web environments. It offers advanced features such as automatic wait handling, smart selectors, and built-in retry mechanisms, enhancing the robustness of your tests.
**4.Parallel Execution:** Playwright enables parallel execution of tests across multiple browser instances, significantly reducing test execution time and improving overall testing efficiency, ideal for large-scale test suites.
**5.Integrated Ecosystem:** Playwright seamlessly integrates with popular testing frameworks such as Jest, Mocha, and Jasmine, as well as CI/CD platforms like Jenkins and GitHub Actions, simplifying test setup and execution within your existing development workflow.
**6.Accessibility Testing:** Playwright includes built-in accessibility testing capabilities, allowing you to assess your web application's compliance with accessibility standards (such as WCAG) and ensure inclusivity for all users.
**7.Community and Support:** Playwright benefits from an active and growing community of developers, providing ample resources, tutorials, and community-driven plugins to enhance your testing experience.
## How to run tests on different browsers (Chrome, Firefox, Safari) using Playwright.
**1.Installation:**
First, ensure you have Playwright installed in your project. You can install Playwright via npm:

**2.Writing Test Scripts:**
Next, write your test scripts using Playwright’s API. Here’s an example of a basic test script written in JavaScript:
**3.Running Tests:**
To run the tests, execute your test script using Node.js:

This script will launch instances of Chrome, Firefox, and Safari browsers, navigate to https://example.com, take screenshots, and then close the browsers. Adjust the URLs and actions in your test script according to your specific testing needs.
## End Note:
In our exploration, we've uncovered the significant influence that Playwright has exerted on the domain of browser automation.
In today's digital era, where user experience stands as the cornerstone of success, the ability to seamlessly test across various browsers and devices holds paramount importance. Playwright's remarkable versatility and robustness have positioned it as the preferred choice among testers seeking efficiency and excellence in their testing endeavors.
For those in search of expert guidance in [Playwright automation testing services](https://www.testrigtechnologies.com/automation-testing/), Testrig Technologies emerges as a beacon of proficiency. With our extensive experience and steadfast commitment to quality assurance, we offer bespoke QA solutions tailored to elevate your testing processes and drive digital triumph.
**CONTACT US TODAY** to discover how Testrig Technologies can partner with you to streamline your testing efforts, mitigate risks, and deliver unparalleled user experiences. Let's embark on a journey together to realize your testing objectives with precision and confidence!
| vijayashree44 | |
1,863,766 | Deploying Llama3 with Inference Endpoints and AWS Inferentia2 | In this video, I walk you through the simple process of deploying a Meta Llama 3 8B model with... | 0 | 2024-06-14T12:48:05 | https://julsimon.medium.com/deploying-llama3-with-inference-endpoints-and-aws-inferentia2-3979620bf07d | aws, mlops, transformers, huggingface | ---
title: Deploying Llama3 with Inference Endpoints and AWS Inferentia2
published: true
date: 2024-05-24 08:46:10 UTC
tags: aws,mlops,transformers,huggingface
canonical_url: https://julsimon.medium.com/deploying-llama3-with-inference-endpoints-and-aws-inferentia2-3979620bf07d
---
In this video, I walk you through the simple process of deploying a Meta Llama 3 8B model with Hugging Face Inference Endpoints and the AWS Inferentia2 accelerator, first with the Hugging Face UI, then with the Hugging Face API.

I use the latest version of the Hugging Face Text Generation Inference container and show you how to run streaming inference with the OpenAI client library. I also discuss Inferentia2 benchmarks.
{% youtube c2nNEK2xmh0 %} | juliensimon |
1,863,743 | Modern C# Development: Get Started With TimeOnly | Hi lovely readers, We probably all know the pain of using DateTime while just needing a date without... | 0 | 2024-05-24T08:43:05 | https://dev.to/lovelacecoding/modern-c-development-get-started-with-timeonly-53ej | dotnet, csharp, programming, beginners | Hi lovely readers,
We probably all know the pain of using DateTime while just needing a date without time, or a time without a day. Well, .NET came with a solution that still isn’t that widely used. In this blog post, we’re going to focus on the data type TimeOnly.
Does your application heavily rely on time and not date? Do you hate time zones and do you rather not deal with them? Do you want to learn how to make your time variables even better, and easier to serialize? Continue reading and I’ll show you how.
## Why TimeOnly
TimeOnly is great in situations where you’re heavily focused on Time. Here are some scenarios where TimeOnly proves to be a great alternative to DateTime:
1. **Simplicity and Readability:**
When your application deals primarily with event times that don’t necessarily need dates, TimeOnly provides a better option.
2. **Database Operations:**
Working with databases that store time information without date becomes seamless with TimeOnly.
3. **Comparisons:**
TimeOnly is a great pick if your logic involves comparing two TimeOnly objects and how much time is in between them. It has methods built in to compare time.
4. **Consistency in Codebase:**
For codebases that heavily rely on time, using TimeOnly throughout helps with consistency.
5. **Avoiding Time Zone Complexity:**
Because TimeOnly doesn’t focus on dates, you don’t have time zone complexities at all. This makes working with TimeOnly way easier.
## How to use TimeOnly
Now that we've explored why TimeOnly is a great choice in multiple scenarios, let's dive into how to use TimeOnly in your C# projects.
### **Initialize TimeOnly**
Creating a TimeOnly instance is straightforward. You can set a specific time using the constructor like this:
```csharp
TimeOnly specificTime = new TimeOnly(11,30); //hour, minute
TimeOnly specificTime2 = new TimeOnly(11,30,45); //hour, minute, second
TimeOnly specificTime3 = new TimeOnly(11,30,45,100); //hour, minute, second, millisecond
TimeOnly specificTime4 = new TimeOnly(11,30,45,100, 4); //hour, minute, second, millisecond, microsecond
```
If you want to initialize a TimeOnly variable with the time right now, you can use the ‘FromDateTime’ method:
```csharp
TimeOnly timeNow = TimeOnly.FromDateTime(DateTime.Now);
```
You can write it to the console like every other variable:
```csharp
Console.WriteLine(specificTime); //11:30
Console.WriteLine(timeNow); //Whatever time it is right now in hh:mm
```
Whether you get to see a 24-hour clock or 12-hour clock depends on the settings of your machine.
### **Formatting the TimeOnly value**
Of course, you can format this TimeOnly variable differently based on whatever country/culture you want to focus on. You can use the System.Globalization package for this.
From the 24-hour system to the USA AM/PM system:
```csharp
using System.Globalization;
TimeOnly specificTime = new TimeOnly(11,30); //hour, minute
CultureInfo ci = CultureInfo.GetCultureInfo("en-US");
Console.WriteLine(specificTime.ToString(ci));
```
From USA AM/PM system to the European 24-hour system:
```csharp
using System.Globalization;
TimeOnly specificTime = new TimeOnly(11,30); //hour, minute
CultureInfo ci = CultureInfo.GetCultureInfo("en-GB");
Console.WriteLine(specificTime.ToString(ci));
```
## Logic with TimeOnly
TimeOnly supports time operations like adding or subtracting hours or minutes. Here's how you can do it.
Adding and Subtracting Time:
```csharp
TimeOnly timeNow = TimeOnly.FromDateTime(DateTime.Now);
TimeOnly timeNowPlusAnHour = timeNow.AddHours(1);
TimeOnly timeNowMinusAnHour = timeNow.AddHours(-1);
TimeOnly timeNowPlusAMinute = timeNow.AddMinutes(1);
TimeOnly timeNowMinusAMinute = timeNow.AddMinutes(-1);
```
### **Serialization**
Serialization is often crucial when dealing with dates in applications. TimeOnly simplifies this process. For instance, when working with JSON:
```csharp
using System.Text.Json;
TimeOnly specificTime = new TimeOnly(11,30); //hour, minute
string json = JsonSerializer.Serialize(specificTime);
TimeOnly deserializedTime = JsonSerializer.Deserialize<TimeOnly>(json);
Console.WriteLine(deserializedTime); // 11:30
```
### Conditions
You can use if-else conditions, switch cases, or switch expressions with TimeOnly
```csharp
TimeOnly specificTime = new TimeOnly(11,30); //hour, minute
TimeOnly timeLater = new TimeOnly(11,35); //hour, minute
if(specificTime > timeLater)
{
Console.WriteLine("specificTime is later than timeLater");
}
else
{
Console.WriteLine("specificTime is not later than timeLater");
}
```
### Compare two TimeOnly objects
You can compare two TimeOnly objects and store that value in another variable. This variable will become a TimeSpan data type
```csharp
TimeOnly specificTime = new TimeOnly(11,30); //hour, minute
TimeOnly timeLater = new TimeOnly(11,35); //hour, minute
TimeSpan difference = timeLater-specificTime;
Console.WriteLine(difference); // 00:05:00
```
It will also work with more precise TimeOnly objects where you have to compare microseconds
```csharp
TimeOnly specificTime = new TimeOnly(11,30,00,00,00); //hour, minute, second, millisecond, microsecond
TimeOnly timeLater = new TimeOnly(11,30,00,00,02); //hour, minute, second, millisecond, microsecond
TimeSpan difference = timeLater-specificTime;
Console.WriteLine(difference); // 00:00:00.0000020
```
## That’s a wrap!
So in conclusion, TimeOnly offers simplicity, readability, and consistency when working with times in C# applications. By focusing solely on time and ignoring dates, it streamlines operations like database storage, user interfaces, and comparisons. Whether you're developing scheduling software, logging systems, or any other application reliant on time, TimeOnly can enhance your workflow and codebase.
I hope that this blog post was helpful and made you understand this datatype built into C#. If you have any questions or comments, feel free to reach out on @lovelacecoding on almost every social media platform or leave a comment down below.
See ya! | lovelacecoding |
1,863,741 | How to achieve line break effect for pie chart labels in @visactor/vchart? | Solution The pie chart label supports the formatting method. In the formatting method, we... | 0 | 2024-05-24T08:40:45 | https://dev.to/tinglittlekang/how-to-achieve-line-break-effect-for-pie-chart-labels-in-visactorvchart-4bpp | ## Solution
The pie chart label supports the formatting method. In the formatting method, we can switch the label to rich text by setting `type: rich` in the return object; rich text supports common line breaks, ICONS, and image displays.

## Code Examples
```
const spec = {
type: 'pie',
data: [
{
id: 'id0',
values: [
{ type: 'oxygen', value: '26.60' },
{ type: 'silicon', value: '27.72' },
{ type: 'aluminum', value: '8.13' },
{ type: 'iron', value: '5' },
{ type: 'calcium', value: '3.63' },
]
}
],
outerRadius: 0.8,
innerRadius: 0.5,
padAngle: 0.6,
valueField: 'value',
categoryField: 'type',
pie: {
style: {
cornerRadius: 10
},
state: {
hover: {
outerRadius: 0.85,
stroke: '#000',
lineWidth: 1
},
selected: {
outerRadius: 0.85,
stroke: '#000',
lineWidth: 1
}
}
},
title: {
visible: true,
text: 'Statistics of Surface Element Content'
},
legends: {
visible: true,
orient: 'left'
},
label: {
visible: true,
formatMethod: (label, datum) => {
return {
type: 'rich',
text: [{
text: `${label}\n`,
fontSize: 12,
fill: '#8a8a8a',
lineHeight: 20,
fontWeight: 400
}, {
text: `${datum._percent_}%`,
fill: '#121212',
fontSize: 14,
fontWeight: 500,
lineHeight: 22,
}]
}
}
},
tooltip: {
mark: {
content: [
{
key: datum => datum['type'],
value: datum => datum['value'] + '%'
}
]
}
}
};
const vchart = new VChart(spec, { dom: CONTAINER_ID });
vchart.renderSync();
// Just for the convenience of console debugging, DO NOT COPY!
window['vchart'] = vchart;
```
## Result Presentation

## Related documents
- [Rich Text and Dom Extensions](https://visactor.com/vchart/guide/tutorial_docs/Richtext_and_Dom)
- [VChart github](https://github.com/VisActor/VChart) | tinglittlekang | |
1,863,740 | How to limit the number of lines in Tooltip? | Problem description When there are too many data items in the Tooltip, it will be... | 0 | 2024-05-24T08:39:38 | https://dev.to/tinglittlekang/how-to-limit-the-number-of-lines-in-tooltip-djp | ## Problem description
When there are too many data items in the Tooltip, it will be automatically categorized as others after more than 20 items. Can I customize this number?

## Solution
Tooltip supports setting the maximum number of lines through `maxLineCount`. It should be noted that vchart's tooltip supports multiple types, and now they need to be set separately.

## Code Examples
```
const spec = {
type: 'line',
data: {
values: [
{ type: 'Nail polish', country: 'Africa', value: 4229 },
{ type: 'Nail polish', country: 'EU', value: 4376 },
{ type: 'Nail polish', country: 'China', value: 3054 },
{ type: 'Nail polish', country: 'USA', value: 12814 },
{ type: 'Eyebrow pencil', country: 'Africa', value: 3932 },
{ type: 'Eyebrow pencil', country: 'EU', value: 3987 },
{ type: 'Eyebrow pencil', country: 'China', value: 5067 },
{ type: 'Eyebrow pencil', country: 'USA', value: 13012 },
{ type: 'Rouge', country: 'Africa', value: 5221 },
{ type: 'Rouge', country: 'EU', value: 3574 },
{ type: 'Rouge', country: 'China', value: 7004 },
{ type: 'Rouge', country: 'USA', value: 11624 },
{ type: 'Lipstick', country: 'Africa', value: 9256 },
{ type: 'Lipstick', country: 'EU', value: 4376 },
{ type: 'Lipstick', country: 'China', value: 9054 },
{ type: 'Lipstick', country: 'USA', value: 8814 },
{ type: 'Eyeshadows', country: 'Africa', value: 3308 },
{ type: 'Eyeshadows', country: 'EU', value: 4572 },
{ type: 'Eyeshadows', country: 'China', value: 12043 },
{ type: 'Eyeshadows', country: 'USA', value: 12998 },
{ type: 'Eyeliner', country: 'Africa', value: 5432 },
{ type: 'Eyeliner', country: 'EU', value: 3417 },
{ type: 'Eyeliner', country: 'China', value: 15067 },
{ type: 'Eyeliner', country: 'USA', value: 12321 },
{ type: 'Foundation', country: 'Africa', value: 13701 },
{ type: 'Foundation', country: 'EU', value: 5231 },
{ type: 'Foundation', country: 'China', value: 10119 },
{ type: 'Foundation', country: 'USA', value: 10342 },
{ type: 'Lip gloss', country: 'Africa', value: 4008 },
{ type: 'Lip gloss', country: 'EU', value: 4572 },
{ type: 'Lip gloss', country: 'China', value: 12043 },
{ type: 'Lip gloss', country: 'USA', value: 22998 },
{ type: 'Mascara', country: 'Africa', value: 18712 },
{ type: 'Mascara', country: 'EU', value: 6134 },
{ type: 'Mascara', country: 'China', value: 10419 },
{ type: 'Mascara', country: 'USA', value: 11261 }
]
},
title: {
visible: true,
text: '100% stacked line chart of cosmetic products sales'
},
percent: true,
xField: 'type',
yField: 'value',
seriesField: 'country',
legends: [{ visible: true, position: 'middle', orient: 'bottom' }],
axes: [
{
orient: 'left',
label: {
formatMethod(val) {
return `${(val * 100).toFixed(2)}%`;
}
}
}
],
tooltip: {
mark: {
maxLineCount: 2
},
dimension: {
maxLineCount: 2
}
}
};
const vchart = new VChart(spec, { dom: CONTAINER_ID });
vchart.renderSync();
// Just for the convenience of console debugging, DO NOT COPY!
window['vchart'] = vchart;
```
## Result Display

## Related documents
- [Tooltip tip information tutorial](https://visactor.com/vchart/guide/tutorial_docs/Chart_Concepts/Tooltip)
- [Tooltip configuration document](https://visactor.com/vchart/option/barChart#tooltip.dimension.maxLineCount)
- [VChart github](https://github.com/VisActor/VChart) | tinglittlekang | |
1,863,739 | NVIDIA Accelerates GPU, CPU, & AI Platform Roadmap: Launching New Chips Every Year | NVIDIA is revolutionizing its chip release strategy, transitioning to a yearly cadence for launching... | 0 | 2024-05-24T08:38:57 | https://dev.to/n968941/nvidia-accelerates-gpu-cpu-ai-platform-roadmap-launching-new-chips-every-year-3ep6 | nvidia, flutter, firebase, beginners | NVIDIA is revolutionizing its chip release strategy, transitioning to a yearly cadence for launching cutting-edge GPUs, CPUs, and AI solutions, departing from the conventional two-year cycle. This article delves into the accelerated roadmap, showcasing upcoming releases like Hopper, Blackwell, and the highly anticipated Rubin "R100" series.
#### Faster Innovation Cycle: Shifting to a 1-Year Cadence Instead of 2-Year
NVIDIA is ramping up its innovation game, promising to roll out next-generation GPUs, CPUs, and AI solutions at a much faster pace compared to its competitors. Departing from the traditional two-year cycle, the tech giant now plans to introduce new chips annually.
#### Next-Gen GPU Lineup: Hopper, Blackwell, and Rubin "R100" Series
NVIDIA's roadmap boasts upcoming releases like the Hopper H200 and its successor Blackwell in B100 & B200 GPUs. While the X100 GPUs were teased earlier, recent reports unveil the Rubin "R100" series, signaling a significant breakthrough for the company in terms of specifications, performance, and efficiency.
[read full article](https://flutters.in/nvidia-accelerates-gpu/)
#### Accelerated Development: Rubin R100 GPUs on the Horizon
Reports suggest that development for NVIDIA's Rubin R100 GPUs is set to kick off in the latter half of 2025, approximately a year after the launch of Blackwell B100 GPUs. NVIDIA's CEO, Jensen Huang, has confirmed this accelerated pace, citing a strategic move to infuse substantial revenue into research and development for next-gen chips, spanning GPUs, CPUs, networking switches, and AI technology.
#### Diversifying Focus: Gaming and AI Hardware
While the spotlight primarily shines on AI hardware, NVIDIA's increased financial muscle might redirect some attention to the gaming sector. Despite gaming revenue being the second-largest contributor, there's a need to revitalize the segment, particularly in mainstream markets where price/performance ratios sometimes falter.
#### Powering AI PC Experiences: NVIDIA's Vision
Beyond hardware, NVIDIA aims to power premium AI PC experiences with existing and upcoming GPUs, alongside its own AI PC platforms leveraging Arm CPU cores with RTX GPU capabilities. This move aligns with the industry's hunger for enhanced compute and AI GPU capabilities.
#### Sustainability and Future Prospects
While the accelerated roadmap promises exciting advancements, its long-term sustainability hinges on market demand. Nonetheless, industry enthusiasts eagerly anticipate forthcoming gaming GPUs with enhanced performance and features, marking a pivotal moment for NVIDIA and the tech landscape at large.
### NVIDIA Data Center / AI GPU Roadmap
| GPU CODENAME | X | RUBIN | BLACKWELL | HOPPER | AMPERE | VOLTA | PASCAL |
|--------------|-------|-------|-----------|-------------|------------|-------|--------|
| GPU Family | GX200 | GR100 | GB200 | GH200/GH100 | GA100 | GV100 | GP100 |
| GPU SKU | X100 | R100 | B100/B200 | H100/H200 | A100 | V100 | P100 |
| Memory | HBM4e?| HBM4? | HBM3e | HBM2e/HBM3/HBM3e | HBM2e | HBM2 | HBM2 |
| Launch | 202X | 2025 | 2024 | 2022-2024 | 2020-2022 | 2018 | 2016 |
[read full article](https://flutters.in/nvidia-accelerates-gpu/)
### FAQs
#### How is NVIDIA accelerating its GPU, CPU, and AI platform roadmap?
NVIDIA is ramping up innovation by shifting to a 1-year cadence instead of the traditional 2-year cycle. This means they plan to launch new chips every year, promising faster development and rollout of next-generation technologies.
#### What can we expect from NVIDIA's next-gen GPU lineup?
The upcoming lineup includes the Hopper H200, Blackwell B100 & B200 GPUs, and the highly anticipated Rubin "R100" series. These releases signify significant advancements in specifications, performance, and efficiency for NVIDIA.
#### When will development begin for NVIDIA's Rubin R100 GPUs?
Development for the Rubin R100 GPUs is slated to commence in the latter half of 2025, around a year after the launch of Blackwell B100 GPUs. NVIDIA's CEO, Jensen Huang, has confirmed this accelerated pace, indicating a strategic focus on research and development across GPUs, CPUs, networking switches, and AI technology.
#### How is NVIDIA diversifying its focus between gaming and AI hardware?
While NVIDIA's spotlight primarily shines on AI hardware, the company's increased financial resources may lead to a redirection of attention towards the gaming sector. This move aims to revitalize the gaming segment, particularly in mainstream markets where price/performance ratios sometimes falter.
#### What is NVIDIA's vision for powering AI PC experiences?
Beyond hardware, NVIDIA aims to enable premium AI PC experiences by leveraging existing and upcoming GPUs alongside its own AI PC platforms. These platforms will incorporate Arm CPU cores with RTX GPU capabilities, catering to the industry's demand for enhanced compute and AI GPU capabilities.
[read full article](https://flutters.in/nvidia-accelerates-gpu/)
#### What factors affect the long-term sustainability of NVIDIA's accelerated roadmap?
The long-term sustainability of NVIDIA's accelerated roadmap depends on market demand. While the roadmap promises exciting advancements, its viability hinges on continued interest and uptake of new technologies. However, industry enthusiasts eagerly anticipate forthcoming gaming GPUs with enhanced performance and features, signaling a pivotal moment for NVIDIA and the tech landscape at large. | n968941 |
1,863,737 | How to bind the click event of the pie chart label in @visactor/vchart? | Problem Description As shown in the pie chart below, how can I achieve a custom callback... | 0 | 2024-05-24T08:37:26 | https://dev.to/tinglittlekang/how-to-bind-the-click-event-of-the-pie-chart-label-in-visactorvchart-4e2b | ## Problem Description
As shown in the pie chart below, how can I achieve a custom callback when clicking on a label?
## Solution
In VChart, the label component does not respond to events by default. This is mainly to avoid affecting the event response of the main chart elements when the labels are dense. To achieve event listening of labels, you need to take two steps:
- Enable label event response by setting `label.interactive` to `true`
- Implement event listening of label components through `{ level: 'model', type: 'label' }`

## Code Examples
```
const spec = {
type: 'pie',
data: [
{
id: 'id0',
values: [
{ type: 'oxygen', value: '46.60' },
{ type: 'silicon', value: '27.72' },
{ type: 'aluminum', value: '8.13' },
{ type: 'iron', value: '5' },
{ type: 'calcium', value: '3.63' },
{ type: 'sodium', value: '2.83' },
{ type: 'potassium', value: '2.59' },
{ type: 'others', value: '3.5' }
]
}
],
outerRadius: 0.8,
innerRadius: 0.5,
padAngle: 0.6,
valueField: 'value',
categoryField: 'type',
pie: {
style: {
cornerRadius: 10
},
state: {
hover: {
outerRadius: 0.85,
stroke: '#000',
lineWidth: 1
},
selected: {
outerRadius: 0.85,
stroke: '#000',
lineWidth: 1
}
}
},
title: {
visible: true,
text: 'Statistics of Surface Element Content'
},
legends: {
visible: true,
orient: 'left'
},
label: {
visible: true,
interactive: true
},
tooltip: {
mark: {
content: [
{
key: datum => datum['type'],
value: datum => datum['value'] + '%'
}
]
}
}
};
const vchart = new VChart(spec, { dom: CONTAINER_ID });
vchart.renderSync();
vchart.on('click',{ level:'model', type:'label'}, (e) => {
console.log('label', e)
})
// Just for the convenience of console debugging, DO NOT COPY!
window['vchart'] = vchart;
```
## Related documents
- [Event API](https://www.visactor.io/vchart/api/API/event)
- [VChart github](https://github.com/VisActor/VChart) | tinglittlekang | |
1,863,736 | How to set the maximum number of X-axis and Y-axis labels? | How to set the maximum number of X-axis and Y-axis labels? Problem Description In the... | 0 | 2024-05-24T08:35:59 | https://dev.to/tinglittlekang/how-to-set-the-maximum-number-of-x-axis-and-y-axis-labels-2fa1 |
How to set the maximum number of X-axis and Y-axis labels?
## Problem Description
In the following chart, the labels on the x-axis are displayed quite densely. Can we limit the maximum number of labels? Make the x-axis labels look better visually, while all points on the line need to be displayed.

## Solution
In VChart, the number of axis labels is affected by various configurations. There are two ways to limit the number of axis labels:
- Set `sampling` to `true` so that sampling will be automatically performed according to the width of the labels.
- Set `tick.tickCount` to specify the number of labels.

## Code Examples
```
const spec = {
type: 'line',
data: {
values: [
{
medalType: 'Gold Medals',
count: 40,
year: '1952'
},
{
medalType: 'Gold Medals',
count: 32,
year: '1956'
},
{
medalType: 'Gold Medals',
count: 34,
year: '1960'
},
{
medalType: 'Gold Medals',
count: 36,
year: '1964'
},
{
medalType: 'Gold Medals',
count: 45,
year: '1968'
},
{
medalType: 'Gold Medals',
count: 33,
year: '1972'
},
{
medalType: 'Gold Medals',
count: 34,
year: '1976'
},
{
medalType: 'Gold Medals',
count: null,
year: '1980'
},
{
medalType: 'Gold Medals',
count: 83,
year: '1984'
},
{
medalType: 'Gold Medals',
count: 36,
year: '1988'
},
{
medalType: 'Gold Medals',
count: 37,
year: '1992'
},
{
medalType: 'Gold Medals',
count: 44,
year: '1996'
},
{
medalType: 'Gold Medals',
count: 37,
year: '2000'
},
{
medalType: 'Gold Medals',
count: 35,
year: '2004'
},
{
medalType: 'Gold Medals',
count: 36,
year: '2008'
},
{
medalType: 'Gold Medals',
count: 46,
year: '2012'
},
{
medalType: 'Silver Medals',
count: 19,
year: '1952'
},
{
medalType: 'Silver Medals',
count: 25,
year: '1956'
},
{
medalType: 'Silver Medals',
count: 21,
year: '1960'
},
{
medalType: 'Silver Medals',
count: 26,
year: '1964'
},
{
medalType: 'Silver Medals',
count: 28,
year: '1968'
},
{
medalType: 'Silver Medals',
count: 31,
year: '1972'
},
{
medalType: 'Silver Medals',
count: 35,
year: '1976'
},
{
medalType: 'Silver Medals',
count: null,
year: '1980'
},
{
medalType: 'Silver Medals',
count: 60,
year: '1984'
},
{
medalType: 'Silver Medals',
count: 31,
year: '1988'
},
{
medalType: 'Silver Medals',
count: 34,
year: '1992'
},
{
medalType: 'Silver Medals',
count: 32,
year: '1996'
},
{
medalType: 'Silver Medals',
count: 24,
year: '2000'
},
{
medalType: 'Silver Medals',
count: 40,
year: '2004'
},
{
medalType: 'Silver Medals',
count: 38,
year: '2008'
},
{
medalType: 'Silver Medals',
count: 29,
year: '2012'
},
{
medalType: 'Bronze Medals',
count: 17,
year: '1952'
},
{
medalType: 'Bronze Medals',
count: 17,
year: '1956'
},
{
medalType: 'Bronze Medals',
count: 16,
year: '1960'
},
{
medalType: 'Bronze Medals',
count: 28,
year: '1964'
},
{
medalType: 'Bronze Medals',
count: 34,
year: '1968'
},
{
medalType: 'Bronze Medals',
count: 30,
year: '1972'
},
{
medalType: 'Bronze Medals',
count: 25,
year: '1976'
},
{
medalType: 'Bronze Medals',
count: null,
year: '1980'
},
{
medalType: 'Bronze Medals',
count: 30,
year: '1984'
},
{
medalType: 'Bronze Medals',
count: 27,
year: '1988'
},
{
medalType: 'Bronze Medals',
count: 37,
year: '1992'
},
{
medalType: 'Bronze Medals',
count: 25,
year: '1996'
},
{
medalType: 'Bronze Medals',
count: 33,
year: '2000'
},
{
medalType: 'Bronze Medals',
count: 26,
year: '2004'
},
{
medalType: 'Bronze Medals',
count: 36,
year: '2008'
},
{
medalType: 'Bronze Medals',
count: 29,
year: '2012'
}
]
},
xField: 'year',
yField: 'count',
seriesField: 'medalType',
invalidType: 'link',
axes: [
{
orient: 'bottom',
tick: {
tickCount: 5
}
}
]
};
const vchart = new VChart(spec, { dom: CONTAINER_ID });
vchart.renderSync();
// Just for the convenience of console debugging, DO NOT COPY!
window['vchart'] = vchart;
```
## Result Presentation

## Related Documents
- [Axes Tutorial](https://www.visactor.io/vchart/guide/tutorial_docs/Chart_Concepts/Axes)
- [VChart github](https://github.com/VisActor/VChart) | tinglittlekang | |
1,863,735 | Mastering Python Conditional Statements: A Comprehensive Guide | Python, renowned for its simplicity and versatility, is a preferred language for both beginners and... | 0 | 2024-05-24T08:32:27 | https://dev.to/markwilliams21/mastering-python-conditional-statements-a-comprehensive-guide-54e4 | python, programming, webdev, javascript | Python, renowned for its simplicity and versatility, is a preferred language for both beginners and experienced developers. One of the core aspects of Python, enabling it to manage logic and flow control effectively, is its conditional statements. These statements allow the execution of code blocks based on specific conditions, making your programs dynamic and intelligent. This article delves into the intricacies of [Python's conditional statements](https://www.janbasktraining.com/blog/python-if-else-elif-nested-if-and-switch-case/), exploring their syntax, applications, and best practices.
## The Basics: if Statement
At the heart of Python's conditional statements lies the if statement. The if statement evaluates a condition (an expression that results in a Boolean value, True or False). If the condition is true, the indented block of code following the if statement executes.
`age = 18
if age >= 18:
print("You are eligible to vote.")`
In this example, the condition age >= 18 is checked. Since the condition is true, the message "You are eligible to vote." is printed.
**Adding Complexity: elif and else Clauses**
For scenarios requiring multiple conditions, Python provides the elif (short for else if) and else clauses. These allow for more complex decision-making processes.
`score = 85
if score >= 90:
print("Grade: A")
elif score >= 80:
print("Grade: B")
elif score >= 70:
print("Grade: C")
else:
print("Grade: F")`
Here, multiple conditions are checked in sequence. The first condition that evaluates to true will trigger its corresponding block of code. If none of the conditions are true, the else block executes.
## Nesting Conditional Statements
Conditional statements can be nested to create more sophisticated logic flows. However, it's essential to maintain clear and readable code to avoid confusion.
`num = 10
if num > 0:
print("Positive number")
if num % 2 == 0:
print("Even number")
else:
print("Odd number")
else:
print("Negative number")`
In this example, the program first checks if num is positive. If true, it then checks if num is even or odd. Nesting allows you to construct detailed and layered decision-making processes.
**Using Conditional Expressions (Ternary Operators)**
For simpler conditions, Python offers conditional expressions, also known as ternary operators. These allow you to condense an if-else statement into a single line.
`status = "even" if num % 2 == 0 else "odd"
print(f"The number is {status}.")`
This one-liner is equivalent to:
`if num % 2 == 0:
status = "even"
else:
status = "odd"
print(f"The number is {status}.")`
## Best Practices for Writing Conditional Statements
**Clarity and Readability:** Write conditions that are easy to read and understand. Avoid overly complex expressions and deeply nested conditions.
**Consistent Indentation:** Python relies on indentation to define code blocks. Ensure consistent use of spaces or tabs to avoid syntax errors.
**Logical Flow: **Structure your conditions logically. Check for the most likely conditions first to enhance efficiency.
**Avoid Redundancy:** Eliminate unnecessary checks. For instance, in the grading example above, once score >= 90 is checked, there is no need to check for score < 90 in subsequent conditions.
**Use Comments:** For complex logic, use comments to explain your conditions. This aids in maintaining and understanding the code in the future.
## Advanced Topics: Boolean Operators
Python’s [Boolean operators](https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/operators/boolean-logical-operators) and, or, and not can combine multiple conditions or negate conditions to create more nuanced logic.
`temperature = 22
humidity = 65
if temperature > 20 and humidity < 70:
print("It's a nice day.")`
Here, the message prints only if both conditions are true. Using or would print the message if either condition is true, and not would negate the condition.
**Conclusion**
Mastering conditional statements in Python is essential for building logical, efficient, and readable code. From simple if statements to complex nested conditions, Python’s straightforward syntax and powerful features provide the tools needed to handle any decision-making process. By following best practices and understanding the intricacies of conditional logic, you can enhance your programming skills and write more effective [Python programs](https://www.javatpoint.com/python-programs). | markwilliams21 |
1,863,734 | VisionGPT - Analyze your image in seconds with AI | I'm excited to announce the launch of my new project: VisionGPT - a SaaS platform that leverages the... | 0 | 2024-05-24T08:29:13 | https://dev.to/megoxv/visiongpt-analyze-your-image-in-seconds-with-ai-2iko | ai, saas, opensource, webdev | I'm excited to announce the launch of my new project: **VisionGPT** - a SaaS platform that leverages the power of AI to analyze your images in seconds! 🚀
# What is VisionGPT?
**VisionGPT** is designed to transform your visual data into actionable insights instantly. Whether you need to identify objects, extract text, or recognize faces, VisionGPT delivers accurate and fast results, making it a valuable tool for various applications.
# Key Features:
* Object Detection: Quickly identify and label objects within your images.
* Text Extraction: Extract and process text from images with high precision.
* Face Recognition: Recognize and analyze faces effortlessly.
* Fast and Accurate: Experience rapid processing with high accuracy.
# Get Started:
Website: [https://visiongpt.vercel.app](https://visiongpt.vercel.app)
GitHub: [https://github.com/megoxv/visionGPT](https://github.com/megoxv/visionGPT)
**VisionGPT** is open source, and I welcome contributions from the community. Whether you're a developer looking to enhance the project or a user with feedback, your input is invaluable.
Check it out and let me know what you think! | megoxv |
1,863,732 | MTTR Deep Dive: A Technical Guide for Engineering Managers & Leaders | In the world of software development, where every minute of downtime can translate to significant... | 0 | 2024-05-24T08:27:39 | https://www.middlewarehq.com/blog/mttr-deep-dive-a-technical-guide-for-engineering-managers-leaders | coding, productivity, tooling | In the world of software development, where every minute of downtime can
translate to significant revenue loss and reputational damage, Mean Time to Restore (MTTR) is a critical metric that can help your software retain its most valuable customers and help you improve the overall LTV.
While MTTR is often overshadowed by its flashier [ DORA siblings
](https://www.middlewarehq.com/blog/a-blueprint-for-predictable-software-
delivery-with-dora-metrics) (Deployment Frequency and Lead Time for Changes), it does offer a unique lens into your team's ability to respond to and recover from incidents swiftly.
Let's take a deeper look into MTTR, its implications for your engineering org, and actionable strategies to optimize it.
## Understanding MTTR: Beyond the Basics
MTTR, in its simplest form, measures the average time it takes to restore
service after an incident or failure. This encompasses everything from the
moment an incident is detected to the point where the system is fully
operational again.
But MTTR is more than just a number on a dashboard.
It's a reflection of your organization's resilience, incident response
processes, and ultimately, the customer experience you deliver. A high MTTR indicates potential weaknesses in your processes, tooling, or team
coordination.
## Why MTTR Matters More Than You Think
MTTR is intrinsically linked to several key areas of your engineering
organization's health:
* **Customer Satisfaction and Trust:** Frequent or prolonged outages degrade user confidence and can drive them to your competitors. A low MTTR demonstrates a commitment to reliability and a swift response to disruptions.
* **Operational Efficiency:** High MTTR often indicates manual, inefficient processes for incident detection, diagnosis, and remediation. This can drain valuable engineering resources that could be better spent on innovation and feature development.
* **Financial Impact:** In many industries, especially those with high transaction volumes (e.g., e-commerce, finance), downtime directly translates to lost revenue. By reducing MTTR, you protect your bottom line.
## It’s a Dynamic Metric
MTTR is not a monolithic measurement. To gain a comprehensive understanding, it's crucial to analyze it from multiple angles:
* **MTTR by Severity:** Categorize incidents by severity (critical, major, minor) to prioritize and address the most impactful issues first.
* **MTTR by Service/Component:** Identify the specific services or components most prone to outages or failures, highlighting potential architectural weaknesses.
* **MTTR Trends Over Time:** [ Track how your MTTR changes over time ](https://demo.middlewarehq.com/) . Is it decreasing, indicating improvement, or increasing, signaling potential problems with scaling or recent changes?
## Technical Strategies for Lowering MTTR
1. **Comprehensive Monitoring & Alerting: ** Invest in a robust monitoring stack that provides visibility into your system's health. Fine-tune alerting thresholds to catch anomalies early, allowing for proactive intervention before an incident escalates. You can get started with [ Middleware Open Source and improve visibility and predictability ](https://github.com/middlewarehq/middleware) through all DORA metrics including MTTR.
2. **Automated Incident Detection:** Leverage AI/ML algorithms to analyze logs, metrics, and traces, automatically identifying potential issues and triggering alerts. This can significantly reduce the time spent on manual investigation.
3. **Incident Response Playbooks:** Create detailed internal documentation for common incident types, outlining step-by-step procedures, escalation paths, and communication templates. This ensures a consistent and efficient response, even under pressure.
4. **Blameless Postmortems:** Foster a culture of learning from mistakes. Analyze every incident without blame, identify root causes, and implement corrective actions.
5. **Continuous Improvement:** Regularly review and refine your incident response processes, incorporating lessons learned from past events.
## Your Team Makes All The Difference
* **Empowerment:** Give engineers ownership over their systems and the freedom to experiment with solutions.
* **Psychological Safety:** Create a blameless culture where developers feel safe reporting issues and sharing learnings.
* **Training & Knowledge Sharing: ** Invest in regular training sessions and knowledge sharing to ensure your team is equipped to handle diverse incidents effectively.
## Parting Thoughts
In the fast-paced world of software development, where every second counts, a low MTTR is no longer a luxury, it's a necessity.
By understanding and optimizing MTTR, you can build a more resilient system, deliver a superior customer experience, and create a high-performing engineering team that embraces challenges and thrives under pressure.
| shivamchhuneja |
1,863,731 | Die besten 20 KI-Tools [2024] | KI verändert gerade von unseren Augen die Welt, aber viele wissen nicht, wie sie es täglich... | 0 | 2024-05-24T08:24:55 | https://dev.to/emilia/die-besten-20-ki-tools-2024-1mgo | ai, programming, beginners, python | KI verändert gerade von unseren Augen die Welt, aber viele wissen nicht, wie sie es täglich einsetzten können.
Hier sind 20 AI-Tools, mit denen Sie jeden Tag 5 Stunden Arbeit sparen können, lästige Aufgaben abgeben, viel produktiver werden und Ihr komplettes Potenzial entfesseln können. Jetzt fangen wir an!
Was ist KI (Künstliche Intelligenz)?
AI (Künstliche Intelligenz) steht für “Artificial Intelligence”. Ein Computer mit einer Intelligenz, die dem menschlichen Gehirn ähnelt und die sich durch eigenständiges Lernen ohne menschliche Befehle oder Anweisungen auszeichnet.
Arten von Werkzeugen der künstlichen Intelligenz
Werkzeuge der künstlichen Intelligenz lassen sich grob in die folgenden Kategorien einteilen:
Plattformen für maschinelles Lernen
Maschinelles Lernen ist eine Technik, bei der Computer eigenständig und ohne menschliche Hilfe lernen. Ein Beispiel dafür ist die automatische Kategorisierung von Bildern von Hunden und Katzen. Durch die Verarbeitung großer Datenmengen erkennt der Computer automatisch Muster und lernt Regeln.
Das maschinelle Lernen extrahiert Regeln aus umfangreichen Datenmengen, ohne dass der Mensch sie manuell erstellen muss. Diese Technologie wird in verschiedenen Bereichen wie dem autonomen Fahren, der Spracherkennung, der Bilderkennung usw. eingesetzt. Allerdings sind präzise Daten für die richtigen Ergebnisse unerlässlich, und das Training kann sehr zeitaufwändig sein.
Deep learning
Deep Learning ist eine Art des maschinellen Lernens, das durch die Verarbeitung großer Datenmengen Probleme mit hoher Genauigkeit lösen kann. Es wird in Bereichen wie Bilderkennung, Spracherkennung und Verarbeitung natürlicher Sprache eingesetzt.
Die Vorverarbeitung von Daten ist zwar einfacher als bei herkömmlichen Methoden, erfordert aber große Datenmengen und eine hohe Rechenleistung und kann in der Umsetzung teuer sein.
Verarbeitung natürlicher Sprache
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) ist eine Technologie, die Computer zur Verarbeitung menschlicher Sprache einsetzt. Sie versteht die Bedeutung von Texten und wird für die automatische Übersetzung, Satzgenerierung, Stimmungsanalyse, Informationsbeschaffung, Spracherkennung usw. verwendet. NLP wird mit Techniken wie maschinellem Lernen und Deep Learning ausgeführt. Heute wird es in Wirtschaft, Medizin, Recht, Verwaltung und Bildung eingesetzt.
Allerdings sind Wörter mehrdeutig und können nicht vollständig automatisch verarbeitet werden. NLP erfordert außerdem große Datenmengen und eine hohe Rechenleistung.
Bilderkennung
Bei der Bilderkennung handelt es sich um eine Technologie, die es einem Computer ermöglicht, ein Foto oder Video zu betrachten und zu bestimmen, was darauf zu sehen ist. Sie nutzt Techniken wie maschinelles Lernen und Deep Learning, um automatisch Muster und Merkmale in Fotos und Videos zu erkennen und so unbekannte Objekte mit hoher Genauigkeit zu identifizieren.
Sie wird derzeit in Szenarien wie Überwachungskameras, selbstfahrenden Autos, medizinischen Untersuchungen, Produktinspektionen und Gesichtserkennung eingesetzt. Die Erkennung kann jedoch aufgrund von Auflösung, Beleuchtung, Winkel und verdeckten Teilen schwierig sein. Um die Genauigkeit zu verbessern, ist daher ein integriertes Lernen erforderlich, das mehrere Methoden kombiniert oder eine große Anzahl von Fotos und Videos verwendet.
Andere Werkzeuge der künstlichen Intelligenz
Neben maschinellem Lernen, Deep Learning, natürlicher Sprachverarbeitung und Bilderkennung gibt es noch viele andere Arten von KI-Tools.
Zum Beispiel Roboter-Frameworks zur Steuerung von Robotern, Sprachsynthese-Engines zur Implementierung von Sprachsynthesetechniken, Sensordatenverarbeitungs-Tools zur Analyse von Sensordaten aus selbstfahrenden Autos oder Kundenanalyse-Tools zur Vorhersage von Kundenverhalten.
Diese Tools sind auf ihre jeweiligen Bereiche ausgerichtet und verfügen über unterschiedliche Funktionen und Merkmale. Beispielsweise sind Robotik-Frameworks auf die Bewegungssteuerung und Sensorik von Robotern ausgerichtet, und Sensordatenverarbeitungstools dienen der Verarbeitung von Sensordaten in Echtzeit. Darüber hinaus visualisieren Kundenanalysetools Geschäftsdaten und unterstützen Geschäftsentscheidungen.
Aufgrund der Vielfalt und Spezialisierung der KI-Tools ist es wichtig, sie entsprechend Ihrem Zweck auszuwählen.
Diese Tools können einzeln oder in Kombination verwendet werden, um bestimmte Probleme zu lösen oder komplexe Arbeitsabläufe zu automatisieren. Da die KI-Technologie weiter voranschreitet, entstehen neue Tools und Anwendungsbereiche.
1 Tool zur automatischen Erstellung von Webseiten
Butternut ⭐⭐⭐⭐⭐
Mit der AI von Butternut können Sie beeindruckende Webseiten in 20 Sekunden erschaffen. Eine komplette Webseite mit Texten und Bildern wird für Sie generiert. Als Input müssen Sie den Namen Ihres Unternehmens und ein paar Keywords eingeben. Darauf basierend generiert die AI eine voll funktionsfähige und benutzerfreundliche Webseite mit Anpassungsmöglichkeiten und zudem auch noch SEO-optimiert.
2 Werkzeuge zur automatischen Erstellung von Designen
Unizard ⭐⭐⭐⭐⭐
Unizard ist eine KI, die Ihnen beim Designen helfen kann. Sie können Apps, Webseiten Benutzeroberflächen , Prototypen, Mockups und so weiter in weinigen Sekunden und ihne Designerfahrung erstellen.
Genial ⭐⭐⭐⭐
Genial ist eine KI, die Ihnen beim Designen unterstützt. Sie können Screenshots in bearbeitbare Designs umwandeln und beispielsweise die Fenster neu anordnen.
2 Werkzeuge zur automatischen Erstellung von Dokumenten
Numerous.ai ⭐⭐⭐⭐⭐
Mit Mumerous.ai können Sie viel Zeit in google Sheets oder Excel sparen. Der Ai Assistant kann Formeln generieren, Texte für mehrere Zeilen gleichzeitig erstellen oder verändern, Daten anpassen und vieles mehr.
Gamma ⭐⭐⭐⭐
Gamma ist ein ChatGPT-Tool, das Ihnen dabei hilft, Ihre Ideen auf ansprechende Weise zu präsentieren. Geben Sie einfach eine kurze Beschreibung Ihrer Idee ein und lassen Sie die KI innerhalb von Sekunden fesselnden und attraktiven Inhalt generieren. Mit dem AIßGenerator können Sie außerdem beliebige Anpassungen vornehmen. Darüber hinaus können Sie mit diesem KI-Tool auf Knopfdruck Ihre bestehenden Präsentationen verschönern. Es ist definitiv eine große Erleichterung und ein Zeitersparnis, um Ideen ansprechend darzustellen.
2 Werkzeuge zur automatischen Texterstellung
Monica AI⭐⭐⭐⭐⭐
Monica AI ist ein vielseitiger KI-Assistent, der den Nutzern eine einfache und schnelle Möglichkeit bietet, produktiv zu sein und eine Vielzahl von Aufgaben zu erledigen, indem er mehrere KI-Modelle und -Tools integriert.
Es handelt sich um ein browserbasiertes Plug-in, das fortschrittliche KI-Modelle wie GPT-4, Claude, Bard und andere nutzt, um Nutzern einen One-Stop-Shop für Gespräche, Suchen, Schreiben, Übersetzen und mehr zu bieten. Darüber hinaus bietet Monica AI eine breite Palette von Tools für die Bild-, Video- und PDF-Verarbeitung und vieles mehr. Ursprünglich als Google Chrome-Erweiterung gestartet, wurde sie inzwischen auf PC/Mac und mobile Plattformen ausgeweitet.
Monica AI ist sofort einsatzbereit, ohne dass ein ChatGPT- oder OpenAI-Konto erforderlich ist, und kann mit fortgeschrittenen Modellen wie GPT-3.5 und GPT-4 zusammenarbeiten. Mit mehr als 80 eingebauten Vorlagen hilft es den Nutzern, mit einem einzigen Klick Artikel, Anzeigenentwürfe, Blogs, Lebensläufe und vieles mehr zu erstellen. Monica AI nutzt auch das ChatGPT-Modell, um jeden Text auf einer Webseite umzuschreiben, zu übersetzen und zu interpretieren, und ermöglicht es den Nutzern, mit ChatGPT auf der Seite ihres Browsers als persönlicher Assistent zu chatten.
Beautiful.ai ⭐⭐⭐⭐
Beautiful.ai ist ein Tool mit künstlicher Intelligenz, das automatisch schön gestaltete Diashows auf der Grundlage der vom Benutzer eingegebenen Anweisungen erstellt. Der Benutzer gibt einfach einen Text ein und Beautiful.ai wandelt ihn in eine schöne Präsentation um. Dies vereinfacht die Erstellung von Präsentationen erheblich und spart Ihnen Zeit und Mühe.
Beautiful.ai passt auch automatisch das Gesamtdesign des Materials an. Dadurch entfällt die Notwendigkeit einer manuellen Feinabstimmung, was zu einer reibungslosen und effizienten Erstellung von Präsentationen führt. Darüber hinaus ermöglicht der neue Teamplan es Teammitgliedern, von überall aus beeindruckende Präsentationen zu erstellen und dabei ein einheitliches Markenbild zu wahren.
3 Werkzeuge zur automatischen Web-Scraping-Tools
Octoparse ⭐⭐⭐⭐⭐
Web Scraping ist heutzutage nicht nur etwas für Programmierexperten. Mit Hilfe von Web-Scraping-Tools kann jeder Daten von Webseiten extrahieren. Mit Octoparse können Sie automatisch Telefonnummern, E-Mail-Adressen, Faxnummern usw. aus den Gelben Seiten extrahieren. Dadurch können Sie direkt mit den gewünschten Dienstleistern oder potenziellen Geschäftspartnern Kontakt aufnehmen. Außerdem können Sie die Octoparse-Vorlage verwenden, um die gewünschten Daten zu extrahieren. Die Octoparse-Vorlage ist sehr benutzerfreundlich! Hier können Sie ein Beispiel finden 👉 Gelbe Seiten Scraper: Wie kann man Leads aus gelbeseiten.de scrapen?
Robotergestützte Prozessautomatisierung (RPA) ⭐⭐⭐⭐⭐
RPA ist eng mit künstlicher Intelligenz und maschinellem Lernen verbunden und automatisiert Geschäftsprozesse wie das Auswerten von Anfragen, die Verarbeitung von Transaktionen, die Verwaltung von Daten und sogar die Beantwortung von E-Mails.
Ihr Hauptvorteil besteht darin, dass sie sich wiederholende Aufgaben automatisiert, die zuvor von Mitarbeitern ausgeführt wurden, so dass diese sich auf kreativere und produktivere Aufgaben konzentrieren können. Außerdem werden Kosten gespart, die Rentabilität erhöht und die Zeit, die für die Erledigung zeitaufwändiger Aufgaben benötigt wird, mit einer geringeren Fehlerwahrscheinlichkeit reduziert.
Als solche hilft sie, die Talente eines Unternehmens zu nutzen, und ist bei einer Vielzahl von Datenerfassungs- und Speicheraufgaben sowie in Bereichen wie Finanzen, Kundenservice oder Personalwesen nützlich.
Bardeen ⭐⭐⭐
Mit Bardeen können Sie AI-Automatisierungen erstellen. Die Browser- Erweiterung verbindet Ihre Web-Apps, z.B. auch Open AI, dass sie smart zusammenarbeiten und Sie eine Menge Zeit sparen können. Manuelle Arbeitsabläufe, die Sie oft wiederholen und wo Sie zwischen verschiedenen Apps hin und her wechseln, können mit dem Tool automatisiert werden. Zudem können KI Ihnen helfen, Automatisierungen zu erstellen, indem es Ihre Arbeitsabläufe analysiert und erkennt, was Sie automatisieren und wo Sie Zeit sparen können.
3 Tools zur Videoerstellung
Adobe Podcast ⭐⭐⭐⭐⭐
Mit Adobe Podcast können Sie Ihre Audioaufnahmen für Videos und Podcasts deutlich verbessern. Selbst wenn Sie kein hochwertiges Mikrofon besitzen oder in einer lauten Umgebung aufnehmen, kann dieses KI-Tool Ihre Aufnahmen so optimieren, als wären sie in einem professionellen Studio entstanden.
Sora ⭐⭐⭐⭐⭐
Sora ist ein Tool von OpenAI, das Videos mit einer Dauer von bis zu 60 Sekunden generiert. Es kann komplexe Szenen, feine Details und mehrere Charaktere darstellen und sogar die Videoquelle erkennen. Durch unser Verständnis der physischen Welt konnten wir ein realistisches Bild einer modischen Frau erstellen, die durch die Neonlichter des nächtlichen Tokio läuft.
Die Fähigkeiten von Sora umfassen Text-zu-Video, Bild-zu-Video, Video-zu-Video, Bilderzeugung und -simulation. Es nutzt die “Transformer”-Technologie, um Daten in kleinere Stücke zu zerlegen, was das Lernen erleichtert. Zudem kombiniert es hochwertige Videos mithilfe der DALL- und E3/GPT-Technologien.
Gen-2 ⭐⭐⭐
Runway Gen-2 ist ein KI-Tool, das mithilfe von Text, Bildern und Videoclips neue Videos generiert. Durch die Verwendung eines multimodalen KI-Systems können einzigartige Videos in Echtzeit erstellt werden, basierend auf den vom Nutzer eingegebenen Text- und Bilddaten.
Mit Runway Gen-2 können Nutzer einfach Texteingaben verwenden, um ein Video zu erstellen, das auf diesem Inhalt basiert. Zusätzlich können Bilddaten genutzt werden, um den Stil und die Komposition des Videos zu beeinflussen. Des Weiteren ist es möglich, Bilder und Text zu kombinieren, um detailliertere Videos zu generieren.
3 Werkzeuge zur automatischen Bilderzeugung
Canva ⭐⭐⭐⭐⭐
Die bebliebte All-in-One-Design-Plattform Canva hat mittlerweile auch viele AI-Features integriert, mit denen Content Creator eine Menge Zeit sparen werden. Canva kann jetzt basierend auf deinem Upload smart ein Template auswählen. Es kann Ihre Skizzen in schlne Designs umwandeln, Objekte in Bildern austauschen, Texte, Bilder und Präsentationen mittels KI generieren.
Blend ⭐⭐⭐⭐
Mit dem Ai-Tool Blend können Sie beeindruckende Produktfotos erstellen. Alles was Sie machen müssen, ist ein Produktfoto hochzuladen und um den Rest küummert sich Blend. Hintergründe werden entfernt und Ihre Produkte werden schöln in Szene gesetzt. Es gibt coole Templates für Soziale Media, die Größen werden intelligent angepaast und passende Schriftarten ausgewählt.
Midjourney ⭐⭐⭐
Midjourney ist ein Tool, das Deep-Learning-Techniken verwendet, um automatisch Kunstwerke zu erstellen. Die Nutzer können aus hochgeladenen Fotos oder generierten Bildern wählen und Stile, Farben und Text anpassen, um ihre eigenen Originalgrafiken zu erstellen.
Sie können Ihre Kreationen auch mit anderen teilen und sie für Werbung, Marketing, Blogging, Social Media Posts und Design-Inspiration verwenden. Das Programm ist auch für Anfänger einfach zu bedienen und ermöglicht die schnelle Erstellung hochwertiger Grafiken.
4 Chatbots mit künstlicher Intelligenz
ChatGPT ⭐⭐⭐⭐⭐
Das GPT-4o, das auf der Frühjahrstagung vorgestellt wird, ist ein Schritt in Richtung einer natürlicheren Interaktion zwischen Mensch und Computer. Es akzeptiert eine Kombination aus Text, Audio und Bildern als Eingabe und erzeugt eine Ausgabe mit einer beliebigen Kombination aus Text, Audio und Bildern.
Copilot AI ⭐⭐⭐⭐⭐
Das Chatbot-Tool von Copilot ermöglicht es Ihnen, einfach konversationelle KI-Agenten mit GPT-4-basierter natürlicher Sprachverarbeitung zu erstellen. Es nutzt das Bot Framework von Microsoft, unterstützt verschiedene Programmiersprachen und wird automatisch gehostet, überwacht und skaliert.
Dieses vielseitige Tool wird in verschiedenen Branchen für unterschiedliche Anwendungen eingesetzt, wie z.B. Kundensupport, FAQs, dialogbasiertes Marketing, Produktbestellungen, Reservierungsmanagement und vieles mehr. Es bietet eine gute Balance zwischen Benutzerfreundlichkeit und Anpassbarkeit und verfügt zudem über integrierte Microsoft-Sicherheitsfunktionen.
Gemini ⭐⭐⭐⭐
Gemini 1.5 ist die neueste Version des multimodalen generativen KI-Modells von Google, das eine breite Palette von Datentypen wie Text, Bilder, Audio, Video und Code versteht und verarbeitet.
Die Architektur von Gemini basiert auf den neuesten Deep-Learning-Techniken, die Transformer und MoE (Mixed by Experts) nutzen. Dank dieser Innovationen kann Gemini 1.5 komplexe Aufgaben schneller erlernen und dabei die Qualität beibehalten. Gleichzeitig wird die Trainings- und Serviceeffizienz deutlich verbessert. Google hat umfangreiche ethische und Sicherheitstests durchgeführt, um das Gemini-Modell mit der Veröffentlichung von Gemini 1.5 zu verbessern.
Poe ⭐⭐⭐
Poe ist ein KI-Chatbot-Tool von Quora mit vielen einzigartigen Vorteilen. Es integriert mehrere große Sprachmodelle wie ChatGPT, Claude, Google-PaLM, Llama usw., um den Nutzern die Auswahl des Modells zu ermöglichen, das ihren Bedürfnissen entspricht. Darüber hinaus können die Nutzer ihre eigenen Modelle anpassen, indem sie verschiedene große Modelle auswählen und individuelle Prompts gestalten.
Poe bietet die Möglichkeit, mit der Erstellung von Modellen für maschinelles Lernen Geld zu verdienen, was für Nutzer, die durch KI ein Einkommen erzielen möchten, interessant sein könnte. Zusätzlich bietet Poe kostenlose Funktionen, die es den Nutzern ermöglichen, eine Vielzahl von großen Sprachmodellen zu verwenden.
Zusammenfassung
Mit dem weiteren Voranschreiten der Technologie der künstlichen Intelligenz werden sich unser Leben und unsere Produktivität wie nie zuvor verbessern. Diese Werkzeuge vereinfachen nicht nur die täglichen Aufgaben, sondern regen auch unsere Kreativität und unser Potenzial an. Lassen Sie uns die KI annehmen und ein neues Kapitel im Zeitalter der Intelligenz aufschlagen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️
| emilia |
1,863,730 | Conquering the Minezerok Guild Boss: A Comprehensive Gameplay Guide | In the world of Throne and Liberty, the backdrop is a realm where political intrigue and power... | 0 | 2024-05-24T08:22:16 | https://dev.to/patti_nyman_5d50463b9ff56/conquering-the-minezerok-guild-boss-a-comprehensive-gameplay-guide-5823 | In the world of Throne and Liberty, the backdrop is a realm where political intrigue and power struggles dominate. Players immerse themselves in a society where various factions vie for control, and amidst this chaos, the Minezerok Guild emerges as a formidable force. When you embark on your journey, mmowow can lend a helping hand when you need help.
Background Story:
The Minezerok Guild, once a humble association of miners, has evolved into a powerful entity with considerable influence over the realm's economy and resources. However, their ambitions extend beyond mere wealth; they seek to wield political power and shape the future of the realm. To achieve their goals, they employ ruthless tactics and are not afraid to eliminate anyone who stands in their way.
Basic Gameplay:
Throne and Liberty is a strategy-based game where players navigate the intricate web of alliances, betrayals, and conflicts within the realm. They can choose to align themselves with different factions, each offering unique benefits and challenges. The gameplay involves resource management, diplomacy, and strategic decision-making to outmaneuver rivals and ascend to the throne.
Minezerok Guild Boss Role and Attributes:
The Minezerok Guild Boss is a formidable adversary, boasting exceptional strength and cunning. As a tank-type character, the Boss excels in absorbing damage and disrupting enemy formations. Key attributes include high health points, armor, and crowd control abilities, making them a formidable opponent in battles.
Unlocking Minezerok Guild Boss Location:
To unlock the Minezerok Guild Boss location on the map, players must first complete specific quests or achieve certain milestones within the game. Once unlocked, the Boss's location is typically indicated by a distinctive icon or marker on the map.
Route to Minezerok Guild Boss:
Players can access the Minezerok Guild Boss by following a designated path on the map, usually marked by terrain features or signposts. As they approach the Boss's location, they may encounter increasingly challenging enemies, indicating proximity to the final confrontation.
Signals and Landmarks:
A prominent signal indicating proximity to the Minezerok Guild Boss may be the sight of abandoned mining equipment or the presence of Minezerok Guild banners. As players draw nearer, they may also encounter patrols of Minezerok Guild mercenaries, serving as a warning of imminent danger.
Entering Combat Mode:
Players enter combat mode upon engaging the Minezerok Guild Boss or its minions. The transition is signaled by a change in music, accompanied by the appearance of combat-related UI elements on the screen.
Recommended Characters:
For confronting the Minezerok Guild Boss, players are advised to select characters with high damage output and crowd control abilities. Characters specializing in ranged attacks or magic spells can exploit the Boss's vulnerabilities while maintaining a safe distance.
Defeating Minezerok Guild Boss:
Successful defeat of the Minezerok Guild Boss requires strategic coordination and precise execution. Players must be vigilant for the Boss's deadly skills, indicated by visual cues or telegraphed movements. Evading these attacks through timely dodges or positioning is crucial to survival.
Deadly Skill Signals:
Each phase of the Minezerok Guild Boss battle may feature distinct deadly skills, signaled by specific animations or audio cues. Players must remain attentive and react swiftly to avoid catastrophic damage.
Dodging Fatal Attacks:
To evade the Minezerok Guild Boss's fatal attacks, players should utilize movement abilities or environmental cover to break the line of sight. Timing is essential, as dodging too early or too late may result in unavoidable damage.
Recommended Characters and Strategies:
For confronting the Minezerok Guild Boss, players should consider using a combination of damage-dealing characters and support classes. Here are some specific recommendations:
Ranger (Damage Dealer): Rangers excel in dealing ranged damage and can kite the Boss effectively. Use their mobility to maintain distance and avoid the Boss's attacks. Key skills include high-damage shots and traps to control the battlefield.
Mage (Damage Dealer): Mages unleash devastating magical attacks, exploiting the Boss's weaknesses from a safe distance. Utilize AoE (Area of Effect) spells to damage multiple targets and crowd control abilities to disrupt enemy movements.
Paladin (Tank/Support): Paladins provide frontline support, drawing the Boss's attention away from squishier allies. Their defensive abilities mitigate incoming damage, allowing teammates to focus on offense. Use healing spells to sustain the team through prolonged engagements.
Key Tactics and Skills:
Positioning: Maintain optimal distance from the Boss to avoid melee attacks while staying within range to deal damage.
Dodging: Master dodges timings to evade the Boss's powerful abilities, maximizing survivability.
Focus Fire: Coordinate with teammates to concentrate damage on vulnerable spots, optimizing damage output.
Status Effects: Exploit the Boss's vulnerabilities to various status effects, such as stuns or slows, to gain an advantage in battle.
Damage Output Structure:
The Minezerok Guild Boss's health pool consists of multiple phases, each with escalating difficulty. To maximize damage output, focus on burst damage during vulnerable windows and sustain damage over prolonged engagements.
Phase-specific Attributes and Attacks:
Phase 1 (Aggressive Assault): The Boss unleashes rapid melee attacks, supplemented by occasional AoE stuns. Prioritize mobility and burst damage to withstand the onslaught.
Phase 2 (Rage Mode): The Boss enters a frenzied state, increasing attack speed and damage output. Maintain crowd control effects to mitigate incoming damage while capitalizing on openings for counterattacks.
Rewards and Utilization:
Upon defeating the Minezerok Guild Boss, players can expect to receive valuable loot, including rare equipment, currency, and reputation points. These rewards can be used to enhance character abilities, acquire new gear, or unlock exclusive content within the game.
Common Mistakes and Recommendations:
Overcommitting: Avoid tunnel vision on dealing with damage, prioritizing survival and teamwork over individual performance.
Ignoring Mechanics: Pay attention to telegraphed attacks and phase transitions, adapting strategies accordingly to avoid unnecessary casualties.
Lack of Communication: Maintain clear communication with teammates, coordinating cooldowns and strategies to optimize efficiency in battle.
Throne-and-Liberty-Lucent:
Throne-and-Liberty-Lucent introduces a new dimension to the gameplay experience, offering enhanced visual effects and immersive environments. Players can utilize Throne-and-Liberty-Lucent's dynamic game scenes to gain tactical advantages, such as hiding in shadows or utilizing environmental hazards to damage enemies. Due to its multiple uses in the game, some players choose Throne and Liberty buy Lucent.
By leveraging these recommendations and mastering the intricacies of combat, players can overcome the challenges presented by the Minezerok Guild Boss and emerge victorious in the ever-evolving world of Throne and Liberty.
In the tumultuous realm of Throne and Liberty, confronting the formidable Minezerok Guild Boss is but one of the many trials players face on their journey to power and glory. By heeding the advice offered here and mastering the art of strategy and teamwork, adventurers can overcome any challenge that stands in their path. As they emerge victorious from battle, clutching the spoils of war, they inch closer to their ultimate goal of seizing the throne and shaping the destiny of the realm. So, gather your allies, hone your skills, and embark on an epic quest filled with danger, intrigue, and untold riches. The throne awaits, but only the bold and the cunning shall claim it. | patti_nyman_5d50463b9ff56 | |
1,863,729 | Pink Horse Power Male Enhancement Maximize Your Confidence: Effective Strategies! | Pink Horse Power Male Enhancement USA Audits: Consistently, the human body is confronted with many... | 0 | 2024-05-24T08:21:19 | https://dev.to/aerajatani/pink-horse-power-male-enhancement-maximize-your-confidence-effective-strategies-c04 | webdev | Pink Horse Power Male Enhancement USA Audits: Consistently, the human body is confronted with many difficulties. Men are bound to have medical problems than ladies because of their bustling timetables. These issues could influence your capacity to center, mental capability, mental energy, memory, rest, and mind haze. These issues are turning out to be more normal. In the event that we don't act rapidly, it can cause a critical decline in our psychological energy. You will have numerous issues from here on out on the off chance that your psychological energy isn't great. Today we are introducing you one enhancement for the above reasons in general. Pink Horse Power Male Enhancement (15mg Full Range Weed) are an enhancement that is ok for your wellbeing and may furnish you with the advantages in a brief time frame. You can consume the item with no aftereffects since it is wealthy in dietary fixings.
>>OFFICIAL WEBSITE: CLICK HERE TO ORDER NOW!!
The Enhancement:
Pink Horse Power Male Enhancement might offer you many advantages. This item is intended to work on your general wellbeing. This item is made explicitly for men with emotional well-being issues. Definitely disliking center, memory, fixation and mental function is turning out to be more normal. This item is 100 percent unadulterated and can give successful outcomes in a brief time frame. It is protected to buy with practically no stresses over it. It is 100 percent unadulterated, so you will not have any protests. You could in fact get it at an entirely reasonable cost and perhaps set aside some cash by purchasing bigger amounts.
What are the fixings used to make this wellbeing related supplement.
The Pink Horse Power Male Enhancement are unadulterated in their sythesis. It contains just safe fixings. You will receive numerous rewards, and there may not be any medical issues. It is likewise plentiful in nutrients and proteins. Since it is produced using unadulterated fixings, you won't encounter any issues. You might see positive outcomes in a more limited time, and it may not create any issues. You can trust the equation and the activity of this men's enhancement. The authority site gives all insights concerning the item and the fixings.
https://www.facebook.com/PinkHorsePowerMaleEnhancement/
https://aeraja.clubeo.com/calendar/2024/05/23/pink-horse-power-male-enhancement-reclaim-your-power-essential-male-enhancement-supplements
https://aeraja.clubeo.com/calendar/2024/05/19/pink-horse-power-male-enhancement-elevate-your-experience-comprehensive-male-enhancement-guide
https://pinkhorsepowermaleenhancement.bandcamp.com/track/pink-horse-power-male-enhancement
https://groups.google.com/g/pink-horse-power-male-enhancement/c/BNO_2gWpx-s
https://groups.google.com/g/pink-horse-power-male-enhancement/c/3A5KT1W8jnE
https://sites.google.com/view/pinkhorsepowermaleenhancement/
https://sites.google.com/view/pink-horse-power/home
https://medium.com/@PinkHorsePower/pink-horse-power-male-enhancement-beyond-limits-exploring-advanced-male-enhancement-techniques-41edf63a394b
https://medium.com/@PinkHorsePower/pink-horse-power-male-enhancement-the-path-to-peak-performance-male-enhancement-explained-40d567e77eb9
https://www.facebook.com/HorsePowerMaleEnhancementUS/
https://sites.google.com/view/horse-power-male-enhancement-/home
https://sites.google.com/view/horse-power-maleenhancement/home
https://groups.google.com/g/horse-power-male-enhancement-/c/zEnLmMO7We4
https://groups.google.com/g/horse-power-male-enhancement-/c/75CQAeuundw
https://medium.com/@trimketoboost/horse-power-male-enhancement-increase-testosterone-power-and-sexual-stamina-33b12f47ee89
https://medium.com/@trimketoboost/horse-power-male-enhancement-serious-side-effects-warnings-80858ae68153
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/c8be168a-9119-ef11-989a-000d3a84ad0c
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/eabb61e1-9119-ef11-989a-000d3a84ad0c
https://rasra.clubeo.com/calendar/2024/05/23/horse-power-male-enhancement-does-it-works-or-not?
https://rasra.clubeo.com/calendar/2024/05/23/horse-power-male-enhancement-legit-scam-is-it-improve-sexual-power?
https://sites.google.com/view/eroboostmale-enhancement/home
https://sites.google.com/view/eroboost-male--enhancement/home
https://groups.google.com/g/eroboost-male-enhancement-/c/syS8tXiEPeA
https://groups.google.com/g/eroboost-male-enhancement-/c/j1oo6Cjemc8
https://medium.com/@trimketoboost/eroboost-male-enhancement-real-benefits-or-side-effects-7a4e5e06c403
https://medium.com/@trimketoboost/eroboost-male-enhancement-is-it-safe-effective-f0c56197fbc3
https://mit45-karatom.clubeo.com/calendar/2024/05/22/eroboost-male-enhancement-is-it-worth-a-try?
https://mit45-karatom.clubeo.com/calendar/2024/05/22/eroboost-male-enhancement-price-scam-ingredients-reviews?
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/201e2c6f-d018-ef11-989a-000d3a84ad0c
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/67bc98ab-d018-ef11-989a-000d3a84ad0c
https://sites.google.com/view/increasetestosteronepowerandse/home
https://sites.google.com/view/boosted-promale-enhancement/home
https://groups.google.com/g/boosted-pro-male-enhancement--/c/Xd3yxVpbiCw
https://groups.google.com/g/boosted-pro-male-enhancement--/c/FOSapPtWEjk
https://medium.com/@trimketoboost/boosted-pro-male-enhancement-negative-side-effects-or-legit-benefits-e983d761a839
https://medium.com/@trimketoboost/boosted-pro-male-enhancement-is-it-worth-a-try-e564dc146b03
https://mit45-karatom.clubeo.com/calendar/2024/05/22/boosted-pro-male-enhancement-does-it-improve-sexual-performance?
https://mit45-karatom.clubeo.com/calendar/2024/05/22/boosted-pro-male-enhancement-are-they-really-worth-buying-in-2024?
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/d613f023-cf18-ef11-989a-000d3a84ad0c
https://indspire.microsoftcrmportals.com/en-US/forums/general-discussion/56944a7f-cf18-ef11-989a-000d3a84ad0c
| aerajatani |
1,863,721 | DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead. | How to fix it, iam use this state to fix (node:11987) [DEP0040] DeprecationWarning: The `punycode`... | 0 | 2024-05-24T08:20:28 | https://dev.to/aspsptyd/deprecationwarning-the-punycode-module-is-deprecated-please-use-a-userland-alternative-instead-52hg | reactnative, handling | How to fix it, iam use this state to fix
```.sh
(node:11987) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
```
and issue closed
Source: https://stackoverflow.com/questions/68774489/punycode-is-deprecated-in-npm-what-should-i-replace-it-with | aspsptyd |
1,863,698 | word clouds with python ☁️🐍 | Creating Word Clouds with WordCloud module in Python Word clouds are a visually appealing... | 0 | 2024-05-24T08:20:13 | https://dev.to/kammarianand/word-clouds-with-python-2do1 | python, nlp, datascience, visulaization | ## Creating Word Clouds with WordCloud module in Python
Word clouds are a visually appealing way to represent the frequency of words in a text. They help in quickly identifying the most prominent terms, providing insights into the main themes and topics. In this article, we'll explore how to generate a word cloud using the `wordcloud` library in Python. We'll also use `matplotlib` for displaying the word cloud.
### Prerequisites
To follow along, ensure you have the following libraries installed:
```sh
pip install wordcloud
pip install matplotlib
```
### </> Example Code
Below is a Python script that generates a word cloud from a given text about Steve Jobs. The script leverages the wordcloud library to create the word cloud and matplotlib to display it.
```python
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = '''
Steven Paul Jobs was an American businessman, inventor, and investor best known for co-founding the technology giant Apple Inc. Jobs was also the founder of NeXT and chairman and majority shareholder of Pixar.
He was a pioneer of the personal computer revolution of the 1970s and 1980s, along with his early business partner and fellow Apple co-founder Steve Wozniak.
Jobs was born in San Francisco in 1955 and adopted shortly afterwards. He attended Reed College in 1972 before withdrawing that same year. In 1974, he traveled through India, seeking enlightenment before later studying Zen Buddhism.
He and Wozniak co-founded Apple in 1976 to further develop and sell Wozniak's Apple I personal computer. Together, the duo gained fame and wealth a year later with production and sale of the Apple II, one of the first highly successful mass-produced microcomputers.
Jobs saw the commercial potential of the Xerox Alto in 1979, which was mouse-driven and had a graphical user interface (GUI). This led to the development of the unsuccessful Apple Lisa in 1983, followed by the breakthrough Macintosh in 1984, the first mass-produced computer with a GUI.
The Macintosh launched the desktop publishing industry in 1985 with the addition of the Apple LaserWriter, the first laser printer to feature vector graphics and PostScript.
'''
wc = WordCloud().generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wc)
plt.axis('off')
plt.show()
```
### output

### Explanation
* Import Libraries: We import matplotlib.pyplot for visualization and WordCloud from the wordcloud library for generating the word cloud.
* Text Data: The variable text contains a multiline string about Steve Jobs, which serves as the input for our word cloud.
* Generate Word Cloud: The WordCloud().generate(text) method creates the word cloud from the input text.
* Display Word Cloud: We use matplotlib to display the generated word cloud. `plt.imshow(wc)` displays the image, and `plt.axis('off')` removes the axes for a cleaner look.
### WordCloud Parameters
The `WordCloud` class provides several parameters to customize the appearance and behavior of the word cloud. Below is a table summarizing the key parameters:
| Parameter | Description |
|--------------------|-------------------------------------------------------------------------------------------------|
| `width` | Width of the canvas on which to draw the word cloud, default is 400. |
| `height` | Height of the canvas on which to draw the word cloud, default is 200. |
| `max_words` | Maximum number of words to include in the word cloud, default is 200. |
| `stopwords` | Words to be excluded from the word cloud, default is `STOPWORDS`. |
| `background_color` | Background color for the word cloud image, default is "black". |
| `colormap` | Colormap to use for the word cloud, can be any matplotlib colormap, default is "viridis". |
| `max_font_size` | Maximum font size for the largest word, default is None. |
| `min_font_size` | Minimum font size for the smallest word, default is 4. |
| `random_state` | Random state for reproducibility of the layout, default is None. |
| `contour_color` | Color of the contour line around the words, default is None. |
| `contour_width` | Width of the contour line around the words, default is 0 (no contour). |
→ By adjusting these parameters, you can fine-tune the appearance of your word cloud to better suit your needs.
### Conclusion:
Word clouds are a powerful tool for visualizing text data, and the wordcloud library in Python makes it easy to generate them. By following the steps outlined above, you can create your own word clouds and customize them using various parameters. Whether you're analyzing large text corpora or simply looking to create a visually appealing summary of text, word clouds are a great choice.
→ Feel free to experiment with different texts and WordCloud parameters to see how they affect the final output. Happy coding!
---
### About Me
🖇️<a href="https://www.linkedin.com/in/kammari-anand-504512230/">LinkedIn</a>
🧑💻<a href="https://www.github.com/kammarianand">GitHub</a>
| kammarianand |
1,863,694 | Baking Ingredients Market Demand, Manufacturer, Report to 2032 | Growth Market Reports, a renowned Market research firm, has recently published a comprehensive report... | 0 | 2024-05-24T08:17:23 | https://dev.to/sharmam98/baking-ingredients-market-demand-manufacturer-report-to-2032-jmc | Growth Market Reports, a renowned Market research firm, has recently published a comprehensive report on the Baking Ingredients Market. With this newest report by Growth Market Reports aims to provide a complete overview of the market, offering the latest updated information on various crucial aspects that are expected to impact Market trends and performance during the forecast period. Unlock key insights into consumer behaviors, and strategic imperatives to drive growth and success. Let our expertise guide your decision-making and propel your business to new heights.
Get Your Free PDF Sample Today @ https://growthmarketreports.com/request-sample/4739?utm=FreePRs
Key Segments of Baking Ingredients Market Report:
The report segments the Baking Ingredients Market into distinct categories, facilitating a more in-depth analysis. Clients can request the inclusion of additional companies as needed. Furthermore, customized reports are available to meet specific client requirements. This flexible approach ensures that stakeholders receive tailored insights tailored to their needs, allowing for a more comprehensive understanding of the Market landscape and enabling informed decision-making strategies. The option for customized reports allows clients to focus on specific aspects of the Market that are relevant to their business objectives.
Market Segments by Baking Ingredients:
The global baking ingredients market has been segmented on the basis of
Type
Flour
Baking Mixes
Emulsifiers
Fats & Shortenings
Enzymes
Colors & Flavors
Sweeteners
Baking Powder
Starches
Oils
Preservatives
Leavening Agents
Others
Form
Dry
Liquid
Applications
Cakes & Pastries
Bread
Cookies & Biscuits
Rolls & Pies
Others
Regions
Asia Pacific
North America
Latin America
Europe
Middle East & Africa
Key Players
Cargill, Incorporated
DuPont
Associated British Foods plc
DSM (Koninklijke DSM N.V.)
Kerry Group plc
ADM (The Archer-Daniels-Midland Company)
AAK AB
British Bakels
International Flavors & Fragrances Inc
Dawn Food Products, Inc.
Corbion
Ingredion
Lesaffre
Puratos
Lallemand Inc.
Darling Ingredients Inc.
Omega Protein Corporation
Roquette Frères
SunOpta
BASF SE
Tate & Lyle
Novozymes
BDF Natural Ingredients, S.L.
Jiangsu Boli Bio-Products Co., Ltd.
Caldic B.V.
AB Enzymes
Döhler
AngelYeast Co., Ltd.
Lonza
Chr. Hansen Holding A/S
Taura Natural Ingredients Ltd.
FLOWERS FOODS, INC.
McKee Foods
Swiss Bake Ingredients Pvt. Ltd.
UNIFERM GmbH & Co. KG
Hostess Brands, Inc.
George Weston Limited
Grupo Bimbo
General Mills Inc.
CSM Ingredients
Others
Claim Your Free Sample Now @ https://growthmarketreports.com/request-sample/4739?utm=FreePRs
Market Overview:
The report conducts an extensive study of data about the Baking Ingredients Market from 2017 to 2022, providing a robust assessment of Market performance and trends for the base year 2023. It offers crucial insights into industry growth opportunities, development, drivers, challenges, and restraints for the Baking Ingredients Market throughout the forecast period from 2024 to 2032. The Baking Ingredients Market, valued at USD XX Million in 2024, is anticipated to reach USD XX Million by the end of 2032, with a CAGR of XX% during the forecast period.
The Impact of Artificial Intelligence (AI) on Baking Ingredients Market:
The report provides a critical analysis of the Baking Ingredients Market with a specific focus on the impact of Artificial Intelligence (AI). It explores how AI technologies are reshaping the Market landscape, driving innovation, and influencing business strategies. Growth Market Reports's systematically presents information on the integration of AI across various sectors. It offers insights into the adoption trends, technological advancements, and the transformative effects of AI on the Baking Ingredients Market, empowering stakeholders to make informed decisions and capitalize on growth prospects.
Methodology:
The research methodology of the report is comprehensive, incorporating robust tools such as interviews with company executives and access to official documents, websites, and press releases. Additionally, insights from industry experts, government officials, public organizations, and international NGOs are considered. This thorough approach ensures the reliability and accuracy of the data gathered, providing stakeholders with trustworthy information for informed decision-making and strategic planning by combining data from diverse sources, the Baking Ingredients market report ensures a holistic understanding of the Baking Ingredients Market.
Why You Should Buy This Report:
This report is a valuable investment for several reasons. It offers clear guidelines to inform your business decisions effectively. Additionally, it provides comprehensive insights to enhance your understanding of both present and future market conditions. Furthermore, it addresses essential questions about end-users, regional Market dominance, and the impact of consumer behavior. Moreover, the report conducts thorough analyses of major players, emerging trends, and government policies. It offers the flexibility of customizable reports tailored to specific regions and a yearly subscription for ongoing Market updates.
Gain Access to the Complete Report @ https://growthmarketreports.com/checkout/4739?utm=FreePRs | sharmam98 | |
1,863,692 | Mastering Parcel Scanning with C++: Barcode and OCR Text Extraction | In this article, we continue our series on parcel scanning technologies by delving into the world of... | 27,497 | 2024-05-24T08:15:47 | https://www.dynamsoft.com/codepool/cpp-scan-barcode-ocr-text-label.html | cpp, ocr, barcode, desktop | In this article, we continue our series on parcel scanning technologies by delving into the world of C++. Building on our previous JavaScript tutorial, we will explore how to implement barcode scanning and OCR text extraction using C++. This guide will cover setting up the development environment, integrating necessary libraries, and providing a step-by-step tutorial to create a robust parcel scanning application in C++ for **Windows** and **Linux** platforms.

## Prerequisites
- Obtain a [30-Day trial license key](https://www.dynamsoft.com/customer/license/trialLicense?product=cvs&package=desktop) for **Dynamsoft Capture Vision**.
- Download [Dynamsoft Barcode Reader C++ Package](https://www.dynamsoft.com/barcode-reader/downloads/1000003-confirmation/#desktop)
- Download [Dynamsoft Label Recognizer C++ Package](https://www.dynamsoft.com/label-recognition/downloads/1000019-confirmation/).

The **Dynamsoft Barcode Reader** and **Dynamsoft Label Recognizer** are integral parts of the Dynamsoft Capture Vision Framework. The Barcode Reader is designed for barcode scanning, while the Label Recognizer focuses on OCR text recognition. These tools share several common components and header files. To utilize both tools together efficiently, simply merge the two packages into a single directory. Below is the final directory structure for your setup.
```bash
|- SDK
|- include
|- DynamsoftBarcodeReader.h
|- DynamsoftCaptureVisionRouter.h
|- DynamsoftCodeParser.h
|- DynamsoftCore.h
|- DynamsoftDocumentNormalizer.h
|- DynamsoftImageProcessing.h
|- DynamsoftLabelRecognizer.h
|- DynamsoftLicense.h
|- DynamsoftUtility.h
|- platforms
|- linux
|- libDynamicImage.so
|- libDynamicPdf.so
|- libDynamicPdfCore.so
|- libDynamsoftBarcodeReader.so
|- libDynamsoftCaptureVisionRouter.so
|- libDynamsoftCore.so
|- libDynamsoftImageProcessing.so
|- libDynamsoftLabelRecognizer.so
|- libDynamsoftLicense.so
|- libDynamsoftNeuralNetwork.so
|- libDynamsoftUtility.so
|- win
|- bin
|- DynamicImagex64.dll
|- DynamicPdfCorex64.dll
|- DynamicPdfx64.dll
|- DynamsoftBarcodeReaderx64.dll
|- DynamsoftCaptureVisionRouterx64.dll
|- DynamsoftCorex64.dll
|- DynamsoftImageProcessingx64.dll
|- DynamsoftLabelRecognizerx64.dll
|- DynamsoftLicensex64.dll
|- DynamsoftNeuralNetworkx64.dll
|- DynamsoftUtilityx64.dll
|- vcomp140.dll
|- lib
|- DynamsoftBarcodeReaderx64.lib
|- DynamsoftCaptureVisionRouterx64.lib
|- DynamsoftCorex64.lib
|- DynamsoftImageProcessingx64.lib
|- DynamsoftLabelRecognizerx64.lib
|- DynamsoftLicensex64.lib
|- DynamsoftNeuralNetworkx64.lib
|- DynamsoftUtilityx64.lib
|- CharacterModel
|- DBR-PresetTemplates.json
|- DLR-PresetTemplates.json
```
## Configuring CMakeLists.txt for Building C++ Applications
The target project relies on header files, shared libraries, JSON-formatted templates, and neural network models. To simplify the build process, we can use CMake to manage dependencies and generate project files for different platforms.
1. Specify the directories for header files and shared libraries:
```cmake
if(WINDOWS)
if(CMAKE_CXX_COMPILER_ID STREQUAL "GNU")
link_directories("${PROJECT_SOURCE_DIR}/../sdk/platforms/win/bin/")
else()
link_directories("${PROJECT_SOURCE_DIR}/../sdk/platforms/win/lib/")
endif()
elseif(LINUX)
if (CMAKE_SYSTEM_PROCESSOR STREQUAL x86_64)
MESSAGE( STATUS "Link directory: ${PROJECT_SOURCE_DIR}/../sdk/platforms/linux/" )
link_directories("${PROJECT_SOURCE_DIR}/../sdk/platforms/linux/")
endif()
endif()
include_directories("${PROJECT_BINARY_DIR}" "${PROJECT_SOURCE_DIR}/../sdk/include/")
```
2. Link the required libraries:
```cmake
add_executable(${PROJECT_NAME} main.cxx)
if(WINDOWS)
if(CMAKE_CL_64)
target_link_libraries (${PROJECT_NAME} "DynamsoftCorex64" "DynamsoftLicensex64" "DynamsoftCaptureVisionRouterx64" "DynamsoftUtilityx64" ${OpenCV_LIBS})
endif()
else()
target_link_libraries (${PROJECT_NAME} "DynamsoftCore" "DynamsoftLicense" "DynamsoftCaptureVisionRouter" "DynamsoftUtility" pthread ${OpenCV_LIBS})
endif()
```
3. Copy the required shared libraries, JSON files and neural network models to the output directory:
```cmake
if(WINDOWS)
add_custom_command(TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_directory
"${PROJECT_SOURCE_DIR}/../sdk/platforms/win/bin/"
$<TARGET_FILE_DIR:main>)
endif()
add_custom_command(TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy
"${PROJECT_SOURCE_DIR}/../sdk/DBR-PresetTemplates.json"
$<TARGET_FILE_DIR:main>/DBR-PresetTemplates.json)
add_custom_command(TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy
"${PROJECT_SOURCE_DIR}/../sdk/DLR-PresetTemplates.json"
$<TARGET_FILE_DIR:main>/DLR-PresetTemplates.json)
add_custom_command(TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E make_directory $<TARGET_FILE_DIR:main>/CharacterModel
COMMAND ${CMAKE_COMMAND} -E copy_directory
"${PROJECT_SOURCE_DIR}/../sdk/CharacterModel"
$<TARGET_FILE_DIR:main>/CharacterModel)
```
## Implementing Barcode Scanning and OCR Text Extraction in C++
To quickly get started with the API, we can refer to the barcode sample code [VideoDecoding.cpp](https://github.com/Dynamsoft/barcode-reader-c-cpp-samples/blob/main/Samples/VideoDecoding/VideoDecoding.cpp) provided by Dynamsoft. The sample code demonstrates how to decode barcodes from video frames using OpenCV. Based on this sample code, we can add OCR text extraction functionality using the Dynamsoft Label Recognizer. Let's take the steps to implement barcode scanning and OCR text extraction in C++.
### Step 1: Include the SDK Header Files
To use the **Dynamsoft Barcode Reader** and **Dynamsoft Label Recognizer** together, we need to include two header files: `DynamsoftCaptureVisionRouter.h` and `DynamsoftUtility.h`, which contain all the necessary classes and functions. The OpenCV header files may vary depending on the version you are using. The following code snippet shows the header files and namespaces used in the sample code:
```cpp
#include "opencv2/core.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/videoio.hpp"
#include "opencv2/core/utility.hpp"
#include "opencv2/imgcodecs.hpp"
#include <iostream>
#include <vector>
#include <chrono>
#include <iostream>
#include <string>
#include "DynamsoftCaptureVisionRouter.h"
#include "DynamsoftUtility.h"
using namespace std;
using namespace dynamsoft::license;
using namespace dynamsoft::cvr;
using namespace dynamsoft::dlr;
using namespace dynamsoft::dbr;
using namespace dynamsoft::utility;
using namespace dynamsoft::basic_structures;
using namespace cv;
```
### Step 2: Set the License Key
When requesting a trial license key, you can either choose a single product key or a combined key for multiple products. In this example, we need to set a combined license key for activating both SDK modules:
```cpp
int iRet = CLicenseManager::InitLicense("LICENSE-KEY");
```
### Step 3: Create a Class for Buffering Video Frames
The `CImageSourceAdapter` class is used for fetching and buffering image frames. We can create a custom class that inherits from `CImageSourceAdapter`.
```cpp
class MyVideoFetcher : public CImageSourceAdapter
{
public:
MyVideoFetcher(){};
~MyVideoFetcher(){};
bool HasNextImageToFetch() const override
{
return true;
}
void MyAddImageToBuffer(const CImageData *img, bool bClone = true)
{
AddImageToBuffer(img, bClone);
}
};
MyVideoFetcher *fetcher = new MyVideoFetcher();
fetcher->SetMaxImageCount(4);
fetcher->SetBufferOverflowProtectionMode(BOPM_UPDATE);
fetcher->SetColourChannelUsageType(CCUT_AUTO);
```
### Step 4: Image Processing and Result Handling
The `CCaptureVisionRouter` class is the core class for image processing. It provides a built-in thread pool for asynchronously processing images that are fetched by the `CImageSourceAdapter` object.
```cpp
CCaptureVisionRouter *cvr = new CCaptureVisionRouter;
cvr->SetInput(fetcher);
```
To handle the barcode and OCR text results, we need to register a custom class that inherits from `CCapturedResultReceiver` with the `CCaptureVisionRouter` object.
```cpp
class MyCapturedResultReceiver : public CCapturedResultReceiver
{
virtual void OnRecognizedTextLinesReceived(CRecognizedTextLinesResult *pResult) override
{
}
virtual void OnDecodedBarcodesReceived(CDecodedBarcodesResult *pResult) override
{
}
};
CCapturedResultReceiver *capturedReceiver = new MyCapturedResultReceiver;
cvr->AddResultReceiver(capturedReceiver);
```
### Step 5: Stream Video Frames and Feed to the Image Processor
OpenCV provides a simple way to capture video frames from a camera. We can use the `VideoCapture` class to open a camera and fetch frames continuously. In the meantime, we call the `StartCapturing()` and `StopCapturing()` methods of the `CCaptureVisionRouter` object to switch the processing task on and off.
```cpp
string settings = R"(
{
"CaptureVisionTemplates": [
{
"Name": "ReadBarcode&AccompanyText",
"ImageROIProcessingNameArray": [
"roi-read-barcodes-only", "roi-read-text"
]
}
],
"TargetROIDefOptions": [
{
"Name": "roi-read-barcodes-only",
"TaskSettingNameArray": ["task-read-barcodes"]
},
{
"Name": "roi-read-text",
"TaskSettingNameArray": ["task-read-text"],
"Location": {
"ReferenceObjectFilter": {
"ReferenceTargetROIDefNameArray": ["roi-read-barcodes-only"]
},
"Offset": {
"MeasuredByPercentage": 1,
"FirstPoint": [-20, -50],
"SecondPoint": [150, -50],
"ThirdPoint": [150, -5],
"FourthPoint": [-20, -5]
}
}
}
],
"CharacterModelOptions": [
{
"Name": "Letter"
}
],
"ImageParameterOptions": [
{
"Name": "ip-read-text",
"TextureDetectionModes": [
{
"Mode": "TDM_GENERAL_WIDTH_CONCENTRATION",
"Sensitivity": 8
}
],
"TextDetectionMode": {
"Mode": "TTDM_LINE",
"CharHeightRange": [
20,
1000,
1
],
"Direction": "HORIZONTAL",
"Sensitivity": 7
}
}
],
"TextLineSpecificationOptions": [
{
"Name": "tls-11007",
"CharacterModelName": "Letter",
"StringRegExPattern": "(SerialNumber){(12)}|(LotNumber){(9)}",
"StringLengthRange": [9, 12],
"CharHeightRange": [5, 1000, 1],
"BinarizationModes": [
{
"BlockSizeX": 30,
"BlockSizeY": 30,
"Mode": "BM_LOCAL_BLOCK",
"MorphOperation": "Close"
}
]
}
],
"BarcodeReaderTaskSettingOptions": [
{
"Name": "task-read-barcodes",
"BarcodeFormatIds": ["BF_ONED"]
}
],
"LabelRecognizerTaskSettingOptions": [
{
"Name": "task-read-text",
"TextLineSpecificationNameArray": [
"tls-11007"
],
"SectionImageParameterArray": [
{
"Section": "ST_REGION_PREDETECTION",
"ImageParameterName": "ip-read-text"
},
{
"Section": "ST_TEXT_LINE_LOCALIZATION",
"ImageParameterName": "ip-read-text"
},
{
"Section": "ST_TEXT_LINE_RECOGNITION",
"ImageParameterName": "ip-read-text"
}
]
}
]
})";
VideoCapture capture(0);
bool use_ocr = false;
if (use_ocr)
{
cvr->InitSettings(settings.c_str(), errorMsg, 512);
errorCode = cvr->StartCapturing("ReadBarcode&AccompanyText", false, errorMsg, 512);
}
else
{
errorCode = cvr->StartCapturing(CPresetTemplate::PT_READ_BARCODES, false, errorMsg, 512);
}
int width = (int)capture.get(CAP_PROP_FRAME_WIDTH);
int height = (int)capture.get(CAP_PROP_FRAME_HEIGHT);
for (int i = 1;; ++i)
{
Mat frame;
capture.read(frame);
if (frame.empty())
{
cerr << "ERROR: Can't grab camera frame." << endl;
break;
}
CFileImageTag tag(nullptr, 0, 0);
tag.SetImageId(i);
CImageData data(frame.rows * frame.step.p[0],
frame.data,
width,
height,
frame.step.p[0],
IPF_RGB_888,
0,
&tag);
fetcher->MyAddImageToBuffer(&data);
imshow("1D/2D Barcode Scanner", frame);
int key = waitKey(1);
if (key == 27 /*ESC*/)
break;
}
cvr->StopCapturing(false, true);
```
The image processing tasks support preset templates and custom settings. If we only need to scan 1D and 2D barcodes, we can use the `CPresetTemplate::PT_READ_BARCODES` template. If we want to extract OCR text labels along with barcodes, a highly customized template is required.
### Step 6: Handle the Results and Display
Since the results are returned from a worker thread, to display them on the video frames in the main thread, we create a vector to store them and use a **mutex** to protect the shared resource.
```cpp
struct BarcodeResult
{
std::string type;
std::string value;
std::vector<cv::Point> localizationPoints;
int frameId;
string line;
std::vector<cv::Point> textLinePoints;
};
std::vector<BarcodeResult> barcodeResults;
std::mutex barcodeResultsMutex;
```
Here is the implementation of the `OnRecognizedTextLinesReceived` and `OnDecodedBarcodesReceived` callback functions:
```cpp
virtual void OnRecognizedTextLinesReceived(CRecognizedTextLinesResult *pResult) override
{
std::lock_guard<std::mutex> lock(barcodeResultsMutex);
barcodeResults.clear();
const CFileImageTag *tag = dynamic_cast<const CFileImageTag *>(pResult->GetOriginalImageTag());
if (pResult->GetErrorCode() != EC_OK)
{
cout << "Error: " << pResult->GetErrorString() << endl;
}
else
{
int lCount = pResult->GetItemsCount();
for (int li = 0; li < lCount; ++li)
{
BarcodeResult result;
const CTextLineResultItem *textLine = pResult->GetItem(li);
CPoint *points = textLine->GetLocation().points;
result.line = textLine->GetText();
result.textLinePoints.push_back(cv::Point(points[0][0], points[0][1]));
result.textLinePoints.push_back(cv::Point(points[1][0], points[1][1]));
result.textLinePoints.push_back(cv::Point(points[2][0], points[2][1]));
result.textLinePoints.push_back(cv::Point(points[3][0], points[3][1]));
CBarcodeResultItem *barcodeResultItem = (CBarcodeResultItem *)textLine->GetReferenceItem();
points = barcodeResultItem->GetLocation().points;
result.type = barcodeResultItem->GetFormatString();
result.value = barcodeResultItem->GetText();
result.frameId = tag->GetImageId();
result.localizationPoints.push_back(cv::Point(points[0][0], points[0][1]));
result.localizationPoints.push_back(cv::Point(points[1][0], points[1][1]));
result.localizationPoints.push_back(cv::Point(points[2][0], points[2][1]));
result.localizationPoints.push_back(cv::Point(points[3][0], points[3][1]));
barcodeResults.push_back(result);
}
}
}
virtual void OnDecodedBarcodesReceived(CDecodedBarcodesResult *pResult) override
{
std::lock_guard<std::mutex> lock(barcodeResultsMutex);
if (pResult->GetErrorCode() != EC_OK)
{
cout << "Error: " << pResult->GetErrorString() << endl;
}
else
{
auto tag = pResult->GetOriginalImageTag();
if (tag)
cout << "ImageID:" << tag->GetImageId() << endl;
int count = pResult->GetItemsCount();
barcodeResults.clear();
for (int i = 0; i < count; i++)
{
const CBarcodeResultItem *barcodeResultItem = pResult->GetItem(i);
if (barcodeResultItem != NULL)
{
CPoint *points = barcodeResultItem->GetLocation().points;
BarcodeResult result;
result.type = barcodeResultItem->GetFormatString();
result.value = barcodeResultItem->GetText();
result.frameId = tag->GetImageId();
result.localizationPoints.push_back(cv::Point(points[0][0], points[0][1]));
result.localizationPoints.push_back(cv::Point(points[1][0], points[1][1]));
result.localizationPoints.push_back(cv::Point(points[2][0], points[2][1]));
result.localizationPoints.push_back(cv::Point(points[3][0], points[3][1]));
barcodeResults.push_back(result);
}
}
}
}
```
The following code snippet shows how to draw the barcode and OCR text results on the video frames:
```cpp
{
std::lock_guard<std::mutex> lock(barcodeResultsMutex);
for (const auto &result : barcodeResults)
{
// Draw the bounding box
if (result.localizationPoints.size() == 4)
{
for (size_t i = 0; i < result.localizationPoints.size(); ++i)
{
cv::line(frame, result.localizationPoints[i],
result.localizationPoints[(i + 1) % result.localizationPoints.size()],
cv::Scalar(0, 255, 0), 2);
}
}
// Draw the barcode type and value
if (!result.localizationPoints.empty())
{
cv::putText(frame, result.type + ": " + result.value,
result.localizationPoints[0], cv::FONT_HERSHEY_SIMPLEX,
0.5, cv::Scalar(0, 255, 0), 2);
}
if (!result.line.empty() && !result.textLinePoints.empty())
{
for (size_t i = 0; i < result.textLinePoints.size(); ++i)
{
cv::line(frame, result.textLinePoints[i],
result.textLinePoints[(i + 1) % result.textLinePoints.size()],
cv::Scalar(0, 0, 255), 2);
}
cv::putText(frame, result.line,
result.textLinePoints[0], cv::FONT_HERSHEY_SIMPLEX,
0.5, cv::Scalar(0, 0, 255), 2);
}
}
}
```
## Building and Running the Application
**Windows**
```bash
mkdir build
cd build
cmake -DCMAKE_GENERATOR_PLATFORM=x64 ..
cmake --build . --config Release
Release\main.exe
```
**Linux**
```bash
mkdir build
cd build
cmake ..
cmake --build . --config Release
./main
```
## Source Code
[https://github.com/yushulx/cmake-cpp-barcode-qrcode/tree/main/examples/10.x/opencv_camera](https://github.com/yushulx/cmake-cpp-barcode-qrcode/tree/main/examples/10.x/opencv_camera)
| yushulx |
1,850,448 | Running I2C on Pro Micro (1) - Pro Micro Setup | In custom keyboards and sensor modules, it is common to connect multiple ICs using **I2C** for processing. In this series, we will use the I2C port on the Pro Micro to operate an IO expander. In this first article, we will set up the Pro Micro on a breadboard. Although I2C is not involved yet, this is an important step for the future. Note that this is an experiment, so we will implement it on a breadboard. | 27,363 | 2024-05-24T08:14:03 | https://dev.to/esplo/running-i2c-on-pro-micro-1-pro-micro-setup-2jb7 | i2c, arduino, keyboard | ---
title: Running I2C on Pro Micro (1) - Pro Micro Setup
published: true
description: In custom keyboards and sensor modules, it is common to connect multiple ICs using **I2C** for processing. In this series, we will use the I2C port on the Pro Micro to operate an IO expander. In this first article, we will set up the Pro Micro on a breadboard. Although I2C is not involved yet, this is an important step for the future. Note that this is an experiment, so we will implement it on a breadboard.
tags: I2C, arduino, keyboard
series: Running I2C on Pro Micro
---
In custom keyboards and sensor modules, it is common to connect multiple ICs using **I2C** for processing. In this series, we will use the I2C port on the Pro Micro to operate an IO expander. In this first article, we will set up the Pro Micro on a breadboard. Although I2C is not involved yet, this is an important step for the future. Note that this is an experiment, so we will implement it on a breadboard.
## Parts to Prepare
Only the items used in the first part are listed. If you want to buy in bulk, please refer to other articles.
- Breadboard (e.g., [BB-801](https://akizukidenshi.com/catalog/g/g105294/)) x1
- Planning to use a combination of half sizes
- [Pro Micro + Pin Header](https://shop.yushakobo.jp/products/3905) x1
- The Type-C version is less likely to break, so it's more expensive but safer. If you can fix it with a glue gun or have other Pro Micros, those are also fine.
- As mentioned later, there are various types of Pro Micro, so be careful.
- Reset switch x1
- [Yushakobo's 2-pin tactile switch](https://shop.yushakobo.jp/products/a0800ts-01-1) is cheap and convenient, but anything that can be inserted into the breadboard is fine.
- [Jumper wires](https://akizukidenshi.com/catalog/g/g105159/) x many
- You will need a lot as they are used frequently.
- Cable to connect Pro Micro to PC
- It seems that charging-only cables may not be properly recognized.
This is all you need for a simple operation check.
## Rough Terms / Reference Information
- Types of Pro Micro: There are many compatible models. It is important to know which Pro Micro you have and to understand the chip and pin assignments.
- The following article is helpful: [Pro Micro and its Variations - zenn.dev](https://zenn.dev/koron/articles/9fee38469a8acc)
- Pin assignment of Pro Micro: Information on what the pins coming out of the Pro Micro are. You can check which leg of the chip ([ATmega32U4](https://akizukidenshi.com/catalog/g/g109835/)) is coming out from where. This also varies by type, so look at the printing on the board to find the same one. We will proceed with the general one shown below.
<figure><img src="https://res.cloudinary.com/purucloud/image/upload/v1712903964/wp_assets/Screenshot_2024-03-26_at_15.44.44.png" alt=""><figcaption>Reference: https://cdn.sparkfun.com/datasheets/Dev/Arduino/Boards/ProMicro16MHzv1.pdf</figcaption></figure>
## Software to Prepare
- Arduino IDE
- The environment for burning firmware to the Pro Micro. This is convenient.
## Implementation
### 1. Solder the Pro Micro and Pin Header
To insert the Pro Micro into the breadboard, attach the pin header.
You need to consider **which side to face up** and whether the height of the pin header is sufficient (whether cables can be inserted). To make it less likely to break, I am trying to fix it with the cable insertion port facing down. However, generally, it seems to be the opposite, and the circuit diagram will be mirrored, so be careful.
<figure><img src="https://res.cloudinary.com/purucloud/image/upload/v1712903953/wp_assets/promicro_bb.png" alt=""><figcaption>Probably reversed</figcaption></figure>
For soldering, just solder the pins you will use this time. The targets are GNDx3, RST, and VCC. If you need more pins later, solder them as needed. In the next part, we will also use 2 (SDA) and 3 (SCL), so if you want to solder them all at once, do so.
### 2. Wiring on the Breadboard
Place the Pro Micro at the top and wire the necessary pins. As shown below, connect the + and - lanes on the left and right of the breadboard, connect GND and VCC, and connect the switch to #RST (RST with an upper line) and GND to complete. It will be easier later if you make the side with pins 2 and 3 of the Pro Micro wider.
<figure><img src="https://res.cloudinary.com/purucloud/image/upload/v1712903946/wp_assets/bb_1.png" alt=""><figcaption>Pro Micro and Reset Switch</figcaption></figure>
As is common with Reset, the #RST pin is high if left alone and low when resetting. Therefore, it is connected to GND and the switch to run the reset process. This is described in the following Hookup Guide.
[Pro Micro & Fio V3 Hookup Guide - SparkFun Learn - learn.sparkfun.com](https://learn.sparkfun.com/tutorials/pro-micro--fio-v3-hookup-guide/troubleshooting-and-faq)
By the way, #RST is internally pulled up, so it will be high if left alone. Internal pull-up is a convenient feature that will appear frequently in the future.
<figure><img src="https://res.cloudinary.com/purucloud/image/upload/v1712903936/wp_assets/image-2-1.png" alt=""><figcaption>Reference: Figure 8-1: https://ww1.microchip.com/downloads/en/DeviceDoc/Atmel-7766-8-bit-AVR-ATmega16U4-32U4_Datasheet.pdf</figcaption></figure>
### 3. Burning the Program with Arduino IDE
Launch the Arduino IDE, copy and paste the sample code from the following link, and compile it. It's good because the LED blinks and is easy to understand.
[Pro Micro & Fio V3 Hookup Guide - SparkFun Learn - learn.sparkfun.com](https://learn.sparkfun.com/tutorials/pro-micro--fio-v3-hookup-guide/example-1-blinkies)
In the Arduino IDE, you need to select which board to target. You may despair that there is no Pro Micro, but as mentioned in the [previous article](https://zenn.dev/koron/articles/9fee38469a8acc), it is compatible with **Arduino Leonardo**, so select that. Depending on the model, it may not work well, so refer to [this article](https://ht-deko.com/arduino/promicro.html) and select another board to burn.
To burn, double-click the reset switch (single-click for some types of Pro Micro), and the bootloader will start for `< 750ms`, during which you burn it. Press the upload button (Cmd+U) in the Arduino IDE in advance, and it will automatically recognize and burn during the bootloader.
You also need to select the target (Port). If you have never burned a program before, it may not be recognized. The bootloader should be recognized, so reset and see if the list of ports increases. If found, select it quickly and burn it.
If it doesn't work well, first check if the bootloader is recognized. On a Mac, run `ls /dev/tty.*` without the Pro Micro connected. On a MacBook, `/dev/tty.Bluetooth-Incoming-Port` may already be there. On Windows, it may be visible from something like Device Manager (unverified). Next, connect and double-click reset, and check if the display increases with the same command. In my case, it appeared as `/dev/tty.usbmodem12101` (via USB hub). If it doesn't appear, the Pro Micro itself may be defective, or the reset button may not be functioning properly. In the latter case, try shorting #RST and GND on the Pro Micro with tweezers (x2 times) to see if it starts.
### 4. Viewing the Output in Arduino IDE
If you successfully burn it and the Pro Micro starts blinking, you're almost there.
First, check if it appears in `/dev/tty` etc. even in a non-bootloader state. This is to confirm that it is correctly recognized by the PC in normal state. In the case of Arduino Leonardo, it seems that the USB firmware is also burned together when burning from the IDE, allowing good communication with the PC. If not found, you may not have selected the appropriate board to burn. Refer to the previous article and try other boards besides Arduino Leonardo.
If it seems to be connected well, open "Tools" -> "Serial Monitor" and check if you can see a "Hello world!" message. There is a `Serial.println(…)` statement in the program, which can be confirmed from the Arduino IDE. This means you can do print debugging.
If you get a message like "Cannot connect to Serial Monitor," check if you have selected a different port, and try reconnecting and observing.
In this state, you can update the program just by pressing the upload button without entering the bootloader. This is convenient.
## Summary
The initial setup part can be tricky, so if you get it working smoothly up to this point, it's worth celebrating. I also spent a whole day not realizing I needed to select the Arduino Leonardo board.
Next time, we will get into the main topic of I2C.
| esplo |
1,863,691 | A Comprehensive Guide to Reading Glass Strength Charts | **_ A Comprehensive Guide to Reading Glasses Strength Charts _** ... | 0 | 2024-05-24T08:12:34 | https://dev.to/efeglasses/a-comprehensive-guide-to-reading-glass-strength-charts-53bj | **_
>
## A Comprehensive Guide to Reading Glasses Strength Charts
_**
### Introduction
Understanding **_[reading glasses](https://www.efeglasses.com/blog/learning-center/)_** strength charts is essential for anyone who needs reading glasses. These charts provide valuable information about the strength of lenses required to correct presbyopia, a common condition that affects near vision as we age. This guide will help you navigate these charts with ease.
### Understanding Reading Glasses
Reading glasses are non-prescription eyewear designed to correct presbyopia. They are available in various strengths, also known as diopters, which determine how much magnification the lenses provide.
### What is a Diopter?
A diopter is the unit of measurement used to define the refractive power of lenses. The higher the diopter, the stronger the lens. Reading glasses typically range in strength from +1.00 to +4.00 diopters.
### Reading Glass Strength Charts
Reading glass strength charts are tools that help you determine the correct strength of reading glasses you need. They usually include age and the required diopter strength.
### How to Use the Chart
To use a reading glass strength chart, find your age on the chart. The corresponding diopter strength is the suggested starting point for your reading glasses. Remember, this is just a guideline. It's always best to have your eyes examined by a professional to determine the exact strength you need.
### Factors Affecting Reading Glass Strength
```

```
Several factors can affect the strength of reading glasses you need, including:
#### Age
Presbyopia usually begins around the age of 40 and continues to progress with age. As a result, you may find you need to increase the strength of your reading glasses as you get older.
#### Reading Distance
If you tend to hold reading material closer to your eyes, you may need a higher strength. Conversely, if you prefer to hold reading material further away, a lower strength may be sufficient.
#### Eye Health
Certain eye conditions can affect your reading glass strength. Regular eye examinations can ensure you're wearing the correct strength and keeping your eyes healthy.
## Conclusion
Understanding reading glass strength charts can help you find the most suitable pair of reading glasses. However, it's important to remember that these charts are a guideline, and individual needs may vary. Regular eye exams are the best way to ensure you're wearing the correct strength and maintaining optimal eye health.
| efeglasses | |
1,863,689 | Top 10 UI Designer Interview Questions and Answers | In today’s competitive job market, landing a UI designer position requires not only a strong... | 0 | 2024-05-24T08:08:18 | https://dev.to/lalyadav/top-10-ui-designer-interview-questions-and-answers-2f4e | ui, uidesign, uidesigner, uiux | In today’s competitive job market, landing a [UI designer](https://www.onlineinterviewquestions.com/ui-designer-interview-questions/) position requires not only a strong portfolio but also the ability to articulate your design process and problem-solving skills during interviews. To help you prepare, we’ve compiled a list of the top 10 UI designer interview questions and provided detailed answers to each.

**Q1. What is UI design, and why is it important?**
Ans: UI design, or User Interface design, focuses on creating intuitive and visually appealing interfaces for digital products. It’s crucial because it directly impacts user experience, making interactions seamless and enjoyable.
**Q2. What tools do you use for UI design?**
Ans: Highlight your proficiency in industry-standard tools like Sketch, Adobe XD, Figma, or other relevant software. Discuss how you use these tools to create wireframes, prototypes, and high-fidelity designs.
**Q3. Can you explain the difference between UX and UI design?**
Ans: UX (User Experience) design deals with the overall user journey and problem-solving, while UI (User Interface) design focuses on the visual and interactive elements of a product.
**Q4. How do you approach the design process?**
Ans: Discuss your design process, including research, ideation, wireframing, prototyping, and user testing. Emphasize the importance of iteration and collaboration with stakeholders.
**Q5. What is your experience with responsive design?**
Ans: Demonstrate your understanding of responsive design principles and techniques for ensuring that interfaces adapt seamlessly to different screen sizes and devices.
**Q6. How do you ensure accessibility in your designs?**
Ans: Explain how you consider accessibility guidelines (such as WCAG) and incorporate features like proper color contrast, keyboard navigation, and screen reader compatibility to make your designs inclusive.
**Q7. Can you discuss a challenging project you’ve worked on and how you overcame obstacles?**
Ans: Share a specific project where you encountered challenges and discuss your problem-solving approach, collaboration with teammates, and the final outcome.
**Q8. What are your favorite design trends right now?**
Ans: Mention current design trends like neumorphism, dark mode, micro-interactions, or any other trends you find inspiring. Explain how you stay updated on industry trends and incorporate them into your work.
**Q9. How do you handle constructive feedback on your designs?**
Ans: Demonstrate your ability to receive feedback positively, iterate on your designs based on feedback, and communicate your design decisions effectively to stakeholders.
**Q10. Can you walk us through your portfolio and discuss your design decisions?**
Ans: Prepare to showcase your portfolio pieces and explain your design process, problem-solving approach, and the impact of your designs on user experience and business goals. | lalyadav |
1,863,688 | SAP PP OVERVIEW | SAP PP (Production Planning) is one of the key modules in SAP ERP (Enterprise Resource Planning)... | 0 | 2024-05-24T08:07:37 | https://dev.to/mylearnnest/sap-pp-overview-5941 | [SAP PP (Production Planning)](https://www.sapmasters.in/sap-pp-training-in-bangalore/) is one of the key modules in SAP ERP (Enterprise Resource Planning) system, integral to a company's manufacturing and production processes. It integrates with other SAP modules like Materials Management (MM), Sales and Distribution (SD), and Quality Management (QM), to streamline operations and ensure efficient production workflows. This detailed overview will cover the core components, functions, and benefits of SAP PP, along with its role in a typical manufacturing environment.
**Core Components of SAP PP:**
**Master Data:**
**Material Master:** Contains all the information required for managing a material, including its description, unit of measure, material type, and procurement type.
**Bill of Materials (BOM):** A comprehensive list of raw materials, components, and assemblies required to manufacture a product. It includes the quantity of each material needed and their [hierarchical relationship](https://www.sapmasters.in/sap-pp-training-in-bangalore/).
**Work Center:** Represents a location where [production operations](https://www.sapmasters.in/sap-pp-training-in-bangalore/) are performed. It includes details like capacity, scheduling, and cost center assignment.
**Routing:** Defines the sequence of operations required to produce a product. It specifies the work centers involved, the duration of each operation, and the resources needed.
**Planning:**
**Sales and Operations Planning (S&OP):** Aligns [production and inventory ](https://www.sapmasters.in/sap-pp-training-in-bangalore/)with market demand. It integrates sales forecasts with production capacity planning.
**Demand Management:** Manages and plans the demand for finished products, [influencing the production](https://www.sapmasters.in/sap-pp-training-in-bangalore/) plan. It involves creating demand programs and setting up demand strategies.
**Material Requirements Planning (MRP):** Ensures materials are available for production and products are available for delivery. [MRP](https://www.sapmasters.in/sap-pp-training-in-bangalore/) runs calculate net requirements, generating planned orders or purchase requisitions.
**Capacity Planning:** Assesses the production capacity needed to meet demand. It involves analyzing available capacity at work centers and adjusting schedules to avoid overloads or underutilization.
**Shop Floor Control:**
**Production Orders:** Detailed instructions for manufacturing a product. It includes information on the material to be produced, quantity, start and finish dates, and work centers involved.
**Order Confirmation:** Records the progress of production orders, including completion of operations and consumed resources.
**Goods Movements:** Tracks the movement of materials in and out of inventory, reflecting issues to production, receipts from production, and stock transfers.
**Repetitive Manufacturing:**
Suitable for high-volume, continuous production. It involves production versions, run schedules, and backflushing, where components are automatically deducted from [inventory](https://www.sapmasters.in/sap-pp-training-in-bangalore/) upon production completion.
**Kanban:**
A lean [manufacturing](https://www.sapmasters.in/sap-pp-training-in-bangalore/) technique aimed at reducing inventory levels and enhancing production efficiency. Kanban cards or signals trigger production or replenishment of materials.
Integration with Other Modules:
**MM (Materials Management):** Ensures materials are available for production. It handles procurement processes and inventory management.
**SD (Sales and Distribution):** Links sales order management with production planning to ensure customer orders are met efficiently.
**QM (Quality Management):** Integrates quality [control processes](https://www.sapmasters.in/sap-pp-training-in-bangalore/) within production to ensure products meet specified standards.
**FI/CO (Financial Accounting and Controlling):** Tracks production costs and integrates them with financial and managerial accounting.
**Functions of SAP PP:**
**Forecasting and Demand Planning:** Uses historical data and market trends to predict future demand, facilitating better planning and resource allocation.
**Production Scheduling:** Optimizes the timing and sequence of production activities, ensuring timely completion of manufacturing orders.
**Inventory Management:** Maintains optimal inventory levels to support production without incurring excess holding costs.
**Capacity Utilization:** Monitors and manages the utilization of [production resources](https://www.sapmasters.in/sap-pp-training-in-bangalore/), ensuring balanced workloads across work centers.
**Order Management:** Streamlines the creation, execution, and tracking of production orders, enhancing operational efficiency.
**Performance Analysis:** Provides tools for analyzing production performance, [identifying bottlenecks](https://www.sapmasters.in/sap-pp-training-in-bangalore/), and implementing continuous improvement initiatives.
**Benefits of SAP PP:**
**Efficiency and Productivity:**Streamlines production processes, reducing lead times and increasing throughput.Enhances resource utilization by aligning production schedules with capacity constraints.
**Cost Reduction:**Optimizes inventory levels, minimizing carrying costs.
Reduces production waste and rework through integrated quality management.
**Visibility and Control:**Provides [real-time visibility](https://www.sapmasters.in/sap-pp-training-in-bangalore/) into production status, enabling proactive decision-making.Integrates with other business functions, ensuring seamless information flow and operational coherence.
**Scalability and Flexibility:**Supports various manufacturing environments, including discrete, process, and repetitive manufacturing.Adapts to changing business needs and market conditions through flexible planning and scheduling tools.
**Quality Improvement:**Ensures products meet quality standards through integrated quality control processes.Facilitates continuous improvement by identifying and addressing production inefficiencies.
**Role in Manufacturing Environment:**In a typical manufacturing environment, [SAP PP](https://www.sapmasters.in/sap-pp-training-in-bangalore/) plays a pivotal role in coordinating and managing production activities. Here's how it integrates into the overall production
**workflow:**
**Production Planning:**Begins with demand forecasting and sales planning, setting the stage for detailed production planning. [MRP](https://www.sapmasters.in/sap-pp-training-in-bangalore/) runs generate production schedules, aligning material availability with production requirements.
**Material Management:**Ensures raw materials and components are available when needed.Coordinates with procurement to manage purchase orders and inventory levels.
**Production Execution:**Production orders are created and released to the shop floor.Work centers execute production operations as per the defined routing and BOM.
**Shop Floor Control:**Tracks production progress, recording operation completions and resource consumption.Manages quality inspections and addresses any deviations or defects.
**Post-Production Activities:**Final products are received into [inventory](https://www.sapmasters.in/sap-pp-training-in-bangalore/) and updated in the system.Costing and financial transactions are recorded, reflecting production expenses and resource usage.
**Continuous Improvement:**Performance data is analyzed to identify areas for improvement.Enhancements are implemented to optimize production processes and reduce inefficiencies.
**Conclusion:**
[SAP PP](https://www.sapmasters.in/sap-pp-training-in-bangalore/) is a comprehensive module that empowers manufacturing companies to streamline their production processes, enhance efficiency, and maintain high-quality standards. By integrating seamlessly with other SAP modules, it provides a holistic view of the production environment, enabling better decision-making and improved operational performance. Whether dealing with discrete, process, or repetitive manufacturing, SAP PP offers the tools and functionalities necessary to meet the dynamic demands of modern production management.
| mylearnnest | |
1,863,687 | 𝙲𝚑𝚛𝚘𝚗𝚘𝙽𝚎𝚋𝚞𝚕𝚊 ||. 𝙰𝙸 x̸ 𝙵𝚊𝚜𝚑𝚒𝚘𝚗 | 𝚃𝚑𝚒𝚜 𝚒𝚜 𝙾𝚞𝚛 𝚏𝚞𝚝𝚞𝚛𝚎 𝚘𝚏 𝚒𝚗𝚍𝚞𝚜𝚝𝚛𝚢 𝚝𝚘 𝚑𝚎𝚕𝚙 𝚝𝚑𝚎 𝚜𝚘𝚌𝚒𝚎𝚝𝚢 𝚘𝚏 𝚌𝚘𝚜𝚖𝚒𝚌 𝚛𝚎𝚊𝚕𝚖. | 0 | 2024-05-24T08:07:33 | https://dev.to/zxxngod/-x-3lhk | 𝚃𝚑𝚒𝚜 𝚒𝚜 𝙾𝚞𝚛 𝚏𝚞𝚝𝚞𝚛𝚎 𝚘𝚏 𝚒𝚗𝚍𝚞𝚜𝚝𝚛𝚢 𝚝𝚘 𝚑𝚎𝚕𝚙 𝚝𝚑𝚎 𝚜𝚘𝚌𝚒𝚎𝚝𝚢 𝚘𝚏 𝚌𝚘𝚜𝚖𝚒𝚌 𝚛𝚎𝚊𝚕𝚖. | zxxngod | |
1,861,416 | Case for explicit error handling | One of the best articles on front-end app architecture I have ever read suggested not-so-popular... | 0 | 2024-05-24T08:06:33 | https://dev.to/senky/case-for-explicit-error-handling-1hcd | frontend, architecture, errors, ux | One of the best articles on front-end app architecture I have ever read suggested not-so-popular patterns, including headless approach (data and logic are strictly separated from UI - e.g. React), explicit initialization (manual dependency injection), or reactivity aversion (no `useEffect`, or MobX's `reaction`). Over the years I have seen the benefits of all the patterns except for one.
It is called _Concentrated error handling_.
The pattern suggests designing code so that error handling doesn't have to be written for each individual call that can fail. It even encourages to treat `catch` clauses as code smell.
My experience just can't seem to find peace with this pattern. Let me give you my biggest concern wight away:
User experience.
<center>🥰</center>
## Why user experience matters the most
You see, we are talking about _front-end_ apps here. They are specifically meant to provide UI to user. They exist _for_ the user. And if you handle your errors in one global error boundary, you compromise user experience. How?
I have been working on a project recently that relied on a single error boundary to do all kinds of stuff we do when our app throws an error:
- log to console
- track to monitoring software
- show error message to user
Can you guess how the error message toast looked like? Yep:

This is wrong on so many levels! User must be able to [read the error message in plain language, understand the problem, and ideally be able to recover from it](https://www.nngroup.com/articles/error-message-guidelines/) (Jakob Nielsen's 9th heuristic rule). But with one (or even multiple) error boundaries you (most of the time) aren't in the right context anymore to be able to provide user with the _least painful experience_.
Let me show you how I envision error handling in front-end apps.
_I am using `fetch` as an example, but this can be anything from websocket connection, browser APIs, library & framework calls, etc._
<center>✨</center>
### Separate severe errors from enhancements
Sometimes data we show aren't strictly needed for the user to perform the task. For example at slido.com's [PowerPoint page](https://www.slido.com/powerpoint-polling), information about version and package size are nice-to-have, but user is still able to download the integration even if endpoint with those information failed. We do not need to show error message to user. Instead, we do nothing - and that's user's _least painful experience_.
You will be surprised how much information is optional once you start paying attention to it. Are you deleting a team in any SaaS app? A list of users of that team is usually a good visual indicator for the admin of how severe the action is. But if that request fails, admin is still able to delete the team - and therefore bombarding him/her with messages about failed request is absolutely not _least painful experience_.
With global error boundary, you don't get enough information easily to decide whether the error comes from enhancement or not. Take this example:
```ts
const init = () => {
const response = await fetch('/api/version-and-size')
...
}
const main = () => {
try {
init()
} catch (error) {
// All info you have here is generic `TypeError ` in `error` variable.
}
}
main()
```
We literally have no idea what endpoint failed. Therefore we cannot decide if response data are enhancement or mandatory information.
Whereas in this slight change:
```ts
const init = () => {
try {
const response = await fetch('/api/version-and-size')
...
} catch (error) {
// Code context gives you hint that this failure is just enhancement.
}
}
const main = () => {
init()
}
main()
```
The code itself gives you enough context to react to error appropriately - that is to ignore it.
<center>🛠️</center>
### React to error in the best manner possible
Now that you purposefully ignored enhancements, let's discuss handling of severe errors.
Imagine social network such as dev.to where blog posts functionality is present. You want to edit a post. Two possible points of failure are:
1. loading current post content into the editor,
2. saving edited content.
Both cases can fail on the same network level giving you exactly the same error, yet handling should be radically different:
1. When post content fails to load, a big error message (maybe replacing whole editor) should ask user to attempt to reload the page or manually re-trigger content fetching.
2. If saving fails, you most definitely don't want to remove the edited content with big error message. Instead, a toast informing about unsuccessful saving asking for a retry later is correct way to do it.
This isn't possible with global error boundary, because, again, you don't have the context (and maybe also access to models/components that need to be updated).
This article doesn't discuss the best patters for error handling, but there is [tons](https://www.nngroup.com/articles/error-message-guidelines/) [of](https://www.smashingmagazine.com/2022/08/error-messages-ux-design/) [materials](https://uxplanet.org/error-message-guidelines-6ce257d3d0bd) [about](https://design4users.com/ux-design-error-screens-and-messages/) [this](https://talebook.io/blog/error-states/) [topic](https://www.pencilandpaper.io/articles/ux-pattern-analysis-error-feedback) on the Internet.
<center>🫂</center>
### Code colocation is your friend
You are probably thinking: hey Jakub, I can write a generic wrapper around fetch that will catch `TypeError`s, add necessary data to it and re-throw it. That way my global error boundary has the context you are talking about.
And you are right, except for one thing. You start rolling your spaghetti if you ever use that additional context for conditional actions:
```ts
const main = (mainController) => {
try {
init()
} catch (error: EnrichedError) {
switch (error.endpoint) {
if (error.endpoint === '/api/version-and-size') {
// just enhancement
return
}
if (error.endpoint.match(/\/posts\/\d+\/edit/)) {
mainController.postEditModel.error = true
return
}
if (error.endpoint === '/edit' && error.method === 'POST') {
mainController.toast('Saving failed. Please try again later.')
return
}
...
}
}
}
main(mainController)
```
This is what I call a code smell! Instead, let's leverage existing (implicit) context and also make sure that related code sits together:
```ts
try {
const response = await fetch('/api/version-and-size')
...
} catch () {
// just enhancement
}
...
try {
const response = await fetch(`/posts/${postId}/edit`)
...
} catch () {
model.error = true // notice we don't access `mainController` anymore because we are in the context of `postEditModel`
}
...
try {
const response = await fetch(`/edit`, { method: 'POST', body: JSON.stringify(data), ... })
...
} catch () {
mainController.UIController.toast('Saving failed. Please try again later.')
}
```
<center>🌐</center>
### On global error boundaries
Are global error boundaries any good then? I think so! They excel at tasks that you want to perform for every error out there: logging to console, tracking to your favorite monitoring tool, or even as a fallback for all the errors that aren't explicitly handled (although I'd say log those cases just so that you can add explicit handling later).
Also, top-level error handler is important for the user, because it serves as a last resort for catching unhandled errors and displaying meaningful error page to the user.
With this in mind you can _sometimes_ purposefully handle errors implicitly. For example if app initialization relies on a request and app cannot be initialized without it, you can ignore try/catch block there and let global error handler display unrecoverable error page to the user.
## Conclusion
Global error handling compromises user experience. Handle errors explicitly to leverage its implicit context. It will help you choose the best reaction to error to optimize for _least painful experience_ for your user. Use global error handler to catch and track yet unhandled errors. Remember: you make front-end apps, user comes first.
| senky |
1,863,686 | Dental clinic in erode | Welcome to The Tooth Clinic in Erode, your premier destination for comprehensive and advanced dental... | 0 | 2024-05-24T08:04:41 | https://dev.to/thetoothclinicbranch1/dental-clinic-in-erode-249o | dentistnearme, dentaltreatmentinerode, teethwhiteninginerode, bestteethwhiteninginerode | Welcome to The Tooth Clinic in Erode, your premier destination for comprehensive and advanced dental care. Our clinic is dedicated to providing a wide range of high-quality dental treatments tailored to meet the unique needs of each patient. Whether you're looking for routine dental care or specialized procedures, our skilled team is here to ensure you receive the best possible care in a comfortable and friendly environment. We pride ourselves on being a trusted dental clinic in Erode, offering everything from preventive treatments to complex surgeries, all aimed at maintaining and enhancing your oral health.
Our extensive list of services includes root canal therapy, dental implants, endocrowns, and the innovative "Fixed Teeth in 72 Hours" procedure. Root canal therapy is essential for saving infected teeth and preventing the spread of infection, while dental implants provide a permanent solution for missing teeth, offering both stability and a natural appearance. Endocrowns utilize the internal structure of a tooth, making them particularly useful for teeth that have undergone root canal treatment. For those seeking quick and effective solutions, our "Fixed Teeth in 72 Hours" procedure ensures you can have permanent, functional teeth in just three days. Additionally, we offer fixed orthodontics to help align your teeth properly, improving both function and appearance.
Beyond these foundational treatments, The Tooth Clinic specializes in advanced procedures such as facio-maxillary surgery, cosmetic dentistry, laser dentistry, scan revision surgery, and ear lobe repair. Our facio-maxillary surgery addresses complex dental and facial issues, while our cosmetic dentistry services, including laser dentistry, focus on enhancing the aesthetics of your smile. Our scan revision surgery ensures precision in diagnostics and treatment planning, and our ear lobe repair service addresses aesthetic concerns effectively. We use the latest dental technology and techniques to deliver outstanding results. If you're searching for the best teeth whitening in Erode, look no further. Our cosmetic dentistry services provide you with a bright, beautiful smile. Visit The Tooth Clinic in Erode, your trusted partner in dental health, and experience the difference that our expertise and dedication can make. Schedule your appointment today and take the first step towards optimal dental health and a confident smile. | thetoothclinicbranch1 |
1,863,685 | Dental Clinic In Erode | Welcome to The Tooth Clinic in Erode, your premier destination for comprehensive and advanced dental... | 0 | 2024-05-24T08:02:33 | https://dev.to/thetoothclinicbranch1/dental-clinic-in-erode-1ihf | dentistnearme, dentaltreatmentinerode, teethwhiteninginerode, bestteethwhiteninginerode | Welcome to The Tooth Clinic in Erode, your premier destination for comprehensive and advanced dental care. Our clinic is dedicated to providing a wide range of high-quality dental treatments tailored to meet the unique needs of each patient. Whether you're looking for routine dental care or specialized procedures, our skilled team is here to ensure you receive the best possible care in a comfortable and friendly environment. We pride ourselves on being a trusted dental clinic in Erode, offering everything from preventive treatments to complex surgeries, all aimed at maintaining and enhancing your oral health.
Our extensive list of services includes root canal therapy, dental implants, endocrowns, and the innovative "Fixed Teeth in 72 Hours" procedure. Root canal therapy is essential for saving infected teeth and preventing the spread of infection, while dental implants provide a permanent solution for missing teeth, offering both stability and a natural appearance. Endocrowns utilize the internal structure of a tooth, making them particularly useful for teeth that have undergone root canal treatment. For those seeking quick and effective solutions, our "Fixed Teeth in 72 Hours" procedure ensures you can have permanent, functional teeth in just three days. Additionally, we offer fixed orthodontics to help align your teeth properly, improving both function and appearance.
Beyond these foundational treatments, The Tooth Clinic specializes in advanced procedures such as facio-maxillary surgery, cosmetic dentistry, laser dentistry, scan revision surgery, and ear lobe repair. Our facio-maxillary surgery addresses complex dental and facial issues, while our cosmetic dentistry services, including laser dentistry, focus on enhancing the aesthetics of your smile. Our scan revision surgery ensures precision in diagnostics and treatment planning, and our ear lobe repair service addresses aesthetic concerns effectively. We use the latest dental technology and techniques to deliver outstanding results. If you're searching for the best teeth whitening in Erode, look no further. Our cosmetic dentistry services provide you with a bright, beautiful smile. Visit The Tooth Clinic in Erode, your trusted partner in dental health, and experience the difference that our expertise and dedication can make. Schedule your appointment today and take the first step towards optimal dental health and a confident smile. | thetoothclinicbranch1 |
1,863,665 | Exploring TypeScript Generics: Enhancing Type Safety and Reusability | TypeScript, a superset of JavaScript, offers developers the ability to write statically typed code... | 0 | 2024-05-24T08:02:12 | https://dev.to/that_mallu_dev/exploring-typescript-generics-enhancing-type-safety-and-reusability-20ac | javascript, beginners, typescript, webdev | TypeScript, a superset of JavaScript, offers developers the ability to write statically typed code while enjoying the flexibility and expressiveness of JavaScript. Among its many features, TypeScript generics stand out as a powerful tool for creating reusable and type-safe code.
## Understanding Generics
Generics in TypeScript allow us to create functions, classes, and interfaces that can work with a variety of data types while maintaining type safety at compile time. This means we can write code that is more flexible and less prone to runtime errors.
## Basic Syntax
Let's start with a basic example of a generic function:
```
function greet<T>(arg: T): T {
return arg;
}
// Usage
let result = greet<string>("Hello");
// result is of type string
```
In this example, the function 'greet' takes a type parameter 'T', which represents the type of the argument passed to the function. The function then returns the argument of the same type 'T'.
## Benefits of Generics
One of the key benefits of generics is code reusability. With generics, we can write functions and classes that can operate on different types without sacrificing type safety. This reduces code duplication and makes our codebase more maintainable.
Consider the following example of a generic class:
```
class Box<T> {
value: T;
constructor(value: T) {
this.value = value;
}
}
// Usage
let box1 = new Box<number>(42);
let box2 = new Box<string>("hello");
```
Here, the 'Box' class can hold values of any type 'T'. We specify the type when creating instances of 'Box', ensuring type safety.
## Common Use Cases
Generics are particularly useful when working with collections and higher-order functions. For example, let's create a generic utility function to find the first occurrence of an element in an array:
```
function findFirstItem<T>(arr: T[], predicate: (item: T) => boolean): T | undefined {
for (let item of arr) {
if (predicate(item)) {
return item;
}
}
return undefined;
}
// Usage
let numbers: number[] = [1, 2, 3, 4, 5];
let result = findFirstItem(numbers, n => n > 3); // Returns 4
console.log(result); // Output: 4
let strings: string[] = ["apple", "banana", "cherry"];
let stringResult = findFirstItem(strings, s => s.startsWith("b")); // Returns "banana"
console.log(stringResult); // Output: banana
```
## Advanced Generics
At their core, advanced generics in TypeScript provide sophisticated ways to define types that are more flexible and precise. They enable us to express complex relationships between types, create type guards, and build highly reusable components.
### Conditional Types
Conditional types allow us to define types that depend on a condition. This feature enables us to create powerful type transformations and mappings. Here's a simple example:
```
type IsArray<T> = T extends Array<any> ? true : false;
// Usage
type Result = IsArray<number[]>; // Result is true
```
In this example, the IsArray type checks whether the provided type 'T' is an array.
###Mapped Types
Mapped types transform the properties of one type into another type. They are particularly useful for creating new types based on existing ones. Consider the following example:
```
type Optional<T> = {
[K in keyof T]?: T[K];
};
// Usage
interface User {
name: string;
age: number;
}
type OptionalUser = Optional<User>;
// OptionalUser is { name?: string; age?: number; }
```
Here, the Optional mapped type converts all properties of 'T' into optional properties.
### Type Constraints
Type constraints allow us to restrict the types that can be used with generics. This is especially useful when working with complex types or ensuring certain properties exist. Here's an example:
```
function getProperty<T, K extends keyof T>(obj: T, key: K): T[K] {
return obj[key];
}
// Usage
const user = { name: 'Alice', age: 30 };
const name = getProperty(user, 'name'); // Type of name is string
```
In this example, 'K extends keyof T' ensures that the key parameter is a valid property of the obj parameter.
## Best Practices
When using generics, it's important to follow some best practices. Use descriptive names for type parameters to improve code readability. Additionally, consider using constraints to enforce specific requirements on type parameters.
And that's a wrap! Thanks for reading!✨ | that_mallu_dev |
1,863,672 | Guidelines for Structuring tables in technical writing for GenAI-based agents | Representation of complex information can be done effectively through text in the form of tables.... | 0 | 2024-05-24T08:01:22 | https://dev.to/ragavi_document360/guidelines-for-structuring-tables-in-technical-writing-for-genai-based-agents-58k4 | Representation of complex information can be done effectively through text in the form of tables. With a simple yet powerful design, tables offer an elegant solution to distill vast amounts of data into a visually captivating format. Technical writers rely on tables to decipher key points, discern trends, and unveil relationships, empowering them to craft comprehensive documents. In the realm of technical writing, tables have become indispensable tools, revolutionizing the content creation process.
## Overview of Table formats
Tables, composed of rows and columns, organize content with clarity. They effortlessly transform into multi-dimensional hierarchies, encapsulating vast amounts of data. From the fundamental table of contents to intricate indexes, tables summarize knowledge with clarity. Technical writers adapt tables to suit content types and user experience needs, favoring column tables for mobile interfaces and row tables for desktops.
## Large Language Model Challenges
LLMs, trained on vast internet text, excel with unstructured data but face hurdles with tables. These structured formats challenge their processing capabilities, especially with numerical data. This complexity risks overshadowing vital details, hindering decision-making. Technical writers' preference for tabular data clashes with LLM limitations, impacting response generation. Refactoring tables becomes crucial for LLMs to grasp structured information effectively.
## Refactoring tables for LLMs
The tables inside your knowledge base content need to be refactored to make it suitable for ingestion by business applications powered by Large Language Models (LLMs). The following are some of the best practices to be followed while refactoring the table
- Do not use symbols inside the table content as they are removed during pre-processing steps

- Do not have null values / empty spaces inside your table content as GenAI-based agents might hallucinate while trying to use those data!
- Ensure that tables have header information along with proper rows
- If you wish to have some binary information part of the table content, use Yes/No, True/ False, or any other option. Ensure that this information is covered in the system message of your RAG (Retrieval Augmented Generation) tool
- The table should be complete such that all cells have values in them
- Use < abbr > tag to define abbreviations of terms inside the table content
- Use < abbr > tag to describe tick mark and cross mark so that LLMs can understand the meaning of symbols inside the table content
- Table cell values can be a mix of numeric values and text. However, it is recommended to have one type of data present inside those table cells

To continue reading about Guidelines for Structuring tables in technical writing for GenAI-based agents [Click here](https://document360.com/blog/structuring-tables-for-gen-ai-based-agents/)
| ragavi_document360 | |
1,856,206 | Best Practices for Managing the Security Risks Associated with Open-Source Software in 2024 | This post originally appeared on my blog Welcome to this four-part mini-series on open-source best... | 27,386 | 2024-05-24T08:00:00 | https://forward.digital/blog/best-practices-for-managing-the-security-risks-associated-with-open-source-software | webdev, opensource, productivity, learning | [_This post originally appeared on my blog_](https://forward.digital/blog/best-practices-for-managing-the-security-risks-associated-with-open-source-software)
Welcome to this four-part mini-series on open-source best practices. In this series, we will discuss the best practices for adopting open-source software (OSS) into your organisation, managing OSS dependencies daily, fostering collaboration with the OSS community, and finally, my opinion on which best practices are best adopted for organisations of all sizes and industries.
This article will discuss the best practices for managing open-source software, including the internal considerations organisations must make, the metrics to judge the quality of OSS components, the approval process, and the licensing of OSS components.
Open source software (OSS) is a critical component of modern software development. It allows developers to leverage existing code, reduce development time, and focus on building new features.
However, OSS also introduces security risks. Vulnerabilities in OSS components can expose organisations to cyber threats, data breaches, and financial losses. To mitigate these risks, organisations must adopt best practices for managing the security risks associated with OSS.
In this blog post, we explore best practices for managing the security risks associated with OSS.
We review the literature, conduct interviews with industry experts, and analyse case studies to identify key strategies for securing OSS components. Our research highlights the importance of regular vulnerability assessments, tooling, continuous monitoring, binary repositories, risk management and mitigation, static application security testing, and forking as essential practices for managing the security risks associated with OSS.
## Regular vulnerability assessments
Regular vulnerability assessments identify, prioritise, and apply patches to systems and software to address vulnerabilities. As the OSS landscape constantly evolves, organisations encounter thousands of new vulnerabilities. Yet, many businesses do not have a robust patch management strategy in place and fail to implement critical patches promptly, leaving them vulnerable to security breaches ([Hackerone, 2024](https://www.hackerone.com/knowledge-center/what-vulnerability-assessment-benefits-tools-and-process)).
With an estimated 84% of open source components having at least one vulnerability ([Sawers, 2021](https://venturebeat.com/2021/04/13/synopsys-84-of-codebases-contain-an-open-source-vulnerability/)), regular vulnerability assessments are essential for managing the security risks associated with OSS.
A rough overview of the process is as follows ([Hackerone, 2024](https://www.hackerone.com/knowledge-center/what-vulnerability-assessment-benefits-tools-and-process)):
1. **Initial Preparation** – Defining the scope and goals of the vulnerability testing to ensure a targeted and practical assessment.
2. **Vulnerability Testing** – Running automated tests to identify vulnerabilities within the systems included in the predefined scope.
3. **Prioritise Vulnerabilities** – Assessing which vulnerabilities are most critical, requiring immediate attention, and evaluating their potential business impact.
4. **Create Vulnerability Assessment Report** – Produce a detailed report outlining medium and high-priority vulnerabilities found and recommended remediation strategies.
5. **Continuous Vulnerability Assessment** – Conducting scans for vulnerabilities on a continuous basis to verify if previous vulnerabilities have been effectively remediated and to discover new ones.
Regular vulnerability assessments are frequently mentioned in the best practices for managing the security risks associated with OSS. Without automated vulnerability assessments, it is difficult to keep up with the large number of OSS components used in modern software systems and the many vulnerabilities discovered each year. Therefore, with automation, regular vulnerability assessments are a best practice for managing the security risks associated with OSS.
## Tooling
Tooling is the functionality that allows for automating the management of OSS components. It can be very useful as a way to manage the large number of OSS components used in modern software systems without introducing unnecessary manual work. Any software project that actively works to reduce security vulnerabilities is less risky. Therefore, tools that aid in identifying security vulnerabilities within software projects are critical ([Department of Defense, 2022](https://dodcio.defense.gov/Portals/0/Documents/Library/SoftwareDev-OpenSource.pdf)).
There are three tools found from our literature review that are considered “leaders”; Snyk, Sonatype, and Synopsys (Black Duck) ([Worthington et al., 2023](https://www.forrester.com/report/the-forrester-wave-tm-software-composition-analysis-q2-2023/RES178483)). These tools are designed to help organisations manage the security risks associated with OSS. They can be used to automate vulnerability assessments, manage licensing, enforce an OSS policy, and generate SBOMs. With this in mind, due to the diversity of OSS components, there is no one-size-fits-all solution ([Wen et al., 2019](https://ieeexplore.ieee.org/document/9073010)).
We consider tooling to be a best practice for managing the security risks associated with OSS. It enables organisations of all sizes to manage many OSS components used in modern software systems without introducing unnecessary manual work. There is a lot of research into tooling, and a wide range of tools are available. We found that many tool-promoting papers and articles are written by the companies that produce the tools, so it is down to the organisation to evaluate the tools and decide which one is best for them.
## Continuous monitoring
Modern software applications are built using a complex web of dependencies, including open-source libraries and frameworks. This process is typically recursive, with each dependency having its dependencies, and so on ([Dietrich et al., 2023](https://arxiv.org/pdf/2306.05534.pdf)). Infamously, this web of dependencies can lead to security vulnerabilities, as seen in the equifax data breach ([Fruhlinger, 2020](https://www.csoonline.com/article/567833/equifax-data-breach-faq-what-happened-who-was-affected-what-was-the-impact.html)) and the log4j vulnerability ([Gallo, 2022](https://builtin.com/cybersecurity/log4j-vulerability-explained)).
Continuous monitoring is the process of monitoring OSS components for vulnerabilities and other security risks on an ongoing basis. These can be manual but are often automated and part of an organisation’s CI/CD pipeline. It is crucial for application developers to detect dependencies on vulnerable libraries as soon as possible, to assess their impact precisely, and to mitigate any potential risk ([Ponta et al., 2020](https://dl.acm.org/doi/10.1007/s10664-020-09830-x)).
Now more than ever, developers are using automation to secure their dependencies; in 2023, developers merged 60% more pull requests from GitHub’s Dependabot, a tool that automates dependency updates, than in 2022 ([Daigle, 2023](https://github.blog/2023-11-08-the-state-of-open-source-and-ai/)).
Software composition analysis (SCA) can be used to conduct regular vulnerability assessments, can be implemented as part of the continuous integration/continuous deployment (CI/CD) pipeline, and can be used to enforce an OSS policy ([Alvarenga, 2023a](https://www.crowdstrike.com/cybersecurity-101/secops/software-bill-of-materials-sbom/)). SCAs will provide an inventory of all open-source components used in a project, including their versions and licenses, and will also identify any known vulnerabilities in these components; effectively, producing an SBOM ([Alvarenga, 2023a](https://www.crowdstrike.com/cybersecurity-101/secops/software-bill-of-materials-sbom/)).
Due to the dynamic nature of the open-source ecosystem, continuous monitoring is essential for managing the security risks associated with OSS. An SCA is a great way to monitor OSS components continuously and can be implemented as part of the CI/CD pipeline and can be used to enforce an OSS policy. It is a best practice for managing the security risks associated with OSS.
## Binary repositories
A binary repository manager is a tool designed to store and manage binary files (the compiled version of your source code) and their metadata. Some popular binary repository managers include JFrog Artifactory, Sonatype Nexus Repository, and GitHub Packages.
A binary repository manager is indispensable for managing open-source components effectively. It facilitates the caching of local copies of these elements, ensuring that frequently used packages remain accessible even during downtimes of external repositories. This capability is essential for maintaining continuous project development and operations without interruptions.
Moreover, such a tool distinguishes between approved third-party artefacts and those pending approval, significantly improving the management and visibility of open-source components within projects. It also allows access to specific libraries to be excluded and limited, thereby safeguarding projects from incorporating non-compliant artefacts ([Wainstein, 2018](https://www.altexsoft.com/blog/5-best-practices-for-managing-open-source-components/)).
By caching versions of all open-source software components, you also safeguard against incidents like the left-pad debacle, where the withdrawal of a minor package from the npm package manager (a package manager for the JavaScript programming language) resulted in widespread failure in numerous projects ([Williams, 2016](https://www.theregister.com/2016/03/23/npm_left_pad_chaos/)).
There is a licensing concern, specifically with GPL-licensed open-source software. The GPL license requires that any software distributed that includes or is derived from GPL-licensed code must itself be available under the GPL. If a binary repository contains GPL software and is shared externally, the entire repository may need to be open-sourced. For example, Microsoft released Hyper-V drivers with GPL-licensed binaries, leading to Microsoft having to open-source the drivers in question ([Linux Network Plumber, 2009](https://linux-network-plumber.blogspot.com/2009/07/congratulations-microsoft.html)).
Binary repositories appear to be a polarising issue in the literature. The [Department of Defense, 2022](https://dodcio.defense.gov/Portals/0/Documents/Library/SoftwareDev-OpenSource.pdf) recommended binary repositories as a best practice for managing the security risks associated with OSS, whereas [Anand, 2023](https://security.salesforce.com/blog/seven-best-practices-to-secure-your-open-source-components) (Salesforce) mentioned securing a repository as a best practice, but didn’t mention binary repositories specifically.
## Risk management and mitigation
Risk management and mitigation is the process of identifying, assessing, and prioritising risks, and then taking steps to reduce or eliminate them.
According to the Open Worldwide Application Security Project (OWASP), the most significant risk associated with open source software is “Vulnerable and Outdated Components” and has moved from 9th to the 6th most critical risk to web applications ([OWASP, 2020](https://owasp.org/www-project-top-ten/)).
OSS vulnerabilities grew by 50% year-on-year — from just over 4,000 in 2018 to over 6,000 in 2019 ([Zorz, 2020](https://www.helpnetsecurity.com/2020/03/13/open-source-vulnerabilities-2019/)).
One reason for the increase in vulnerabilities is the growing number of open source components being used in software projects from developers utilising the speed and convenience of open source, especially under time pressure, without considering the security implications. This highlights the need for formal processes to manage the risks. Typically, these correlated to implementing some continuous monitoring and regular vulnerability assessments, as outlined in Section 4.2.1 and 4.2.3 ([Anand, 2023](https://security.salesforce.com/blog/seven-best-practices-to-secure-your-open-source-components), [Chandler et al., 2022](https://www.mayerbrown.com/en/insights/publications/2022/10/the-importance-of-tracking-and-managing-the-use-of-open-source-software}), [Mathpati, 2023](https://cobalt.io/blog/risks-of-open-source-software)). Such efforts should avoid being overly laborious and manual to ensure they do not frustrate developers and slow down the development process ([Contrast Security, 2020](https://www.contrastsecurity.com/hubfs/Understanding-the-Risks_WhitePaper_042020_Final.pdf?hsLang=en)).
Like those outlined in this report, the most effective way to mitigate OSS risks is to follow best practices ([Chandler et al., 2022](https://www.mayerbrown.com/en/insights/publications/2022/10/the-importance-of-tracking-and-managing-the-use-of-open-source-software})).
Interestingly, our interviews and case studies found that the approach to risk and risk mitigation varied from organisation to organisation. Larger organisations seemed more proactive in mitigating risk, with dedicated teams and processes in place. Whereas smaller organisations were more reactive, only taking action when a risk materialised and looking to improve their processes after the event. This suggests there is a gap in the best practices landscape, as it doesn’t consider the different approaches to risk management and mitigation based on the size of the organisation.
## Static application security testing
Static application security testing (SAST) is a method of testing the security of an application by examining its source code, byte code, or binary code for security vulnerabilities.
Frequent scanning and security assessment of your repository aids in detecting security concerns at early stages, minimising the chance of significant security problems developing later on. Static code analysis tools can pinpoint typical security weaknesses, and dependency vulnerability scanners can highlight any recognised problems in your project’s dependencies ([Anand, 2023](https://security.salesforce.com/blog/seven-best-practices-to-secure-your-open-source-components)). SAST goes hand in hand with the continuous monitoring of OSS components, as it allows for detecting vulnerabilities in OSS components as soon as possible, allowing for their impact to be assessed and mitigated, see Section 4.2.3.
From our research, SAST is only suggested by Salesforce as a best practice. However, current tooling is comprehensive and can be used to automate the continuous monitoring of OSS components, as outlined in Section 4.2.2. Therefore, SAST can be considered a technical implementation of continuous monitoring.
## Forking
Forking is the process of creating a new project based on an existing project. It allows you to monitor alterations in open-source components, as there will always be a connection to the original repository. One of the key advantages mentioned in the definition of open-source is the explicit permission granted to duplicate and independently alter the source code of an open-source project as desired ([The Open Source Definition 2024](https://opensource.org/osd)).
However, it’s important to be mindful that opting to create a private fork entails the responsibility of integrating any updates from the upstream version of the component. This responsibility grows as the differences between the forked components and the original increase. An ideal situation for forking is when you take an open-source component from a project that is unlikely to receive many updates in the future ([Wainstein, 2018](https://www.altexsoft.com/blog/5-best-practices-for-managing-open-source-components/)).
The process often includes creating a distinct OSS developer community (OSS-DC) for the forked version, allowing the organisation to focus on modifying or enhancing specific components of the software—usually those deemed critical for their purposes ([Méndez-Tapia et al., 2021](https://www.scitepress.org/Papers/2021/104970/104970.pdf)).
Forking does get mentioned in varying mediums as a best practice. However, the added responsibility of integrating updates from the upstream version of the component is often overlooked, and from our interviews, we found that forking is not widely used in practice.
## Conclusion
In this blog post, we explored best practices for managing the security risks associated with open-source software. We reviewed the literature, conducted interviews with industry experts, and analysed case studies to identify key strategies for securing OSS components.
Our research highlights the importance of regular vulnerability assessments, tooling, continuous monitoring, binary repositories, risk management and mitigation, static application security testing, and forking as essential practices for managing the security risks associated with OSS.
By adopting these best practices, organisations can reduce the likelihood of security breaches, data loss, and financial losses associated with OSS vulnerabilities. We recommend that organisations implement these practices to enhance the security of their software systems and protect their data and assets.
| bendix |
1,863,661 | The Rise of Web3: Transforming the Digital Landscape | Web3, the next evolution of the internet, is revolutionizing how we interact online by decentralizing... | 0 | 2024-05-24T07:29:42 | https://dev.to/klimd1389/the-rise-of-web3-transforming-the-digital-landscape-1n5a | beginners, programming, news, web3 | Web3, the next evolution of the internet, is revolutionizing how we interact online by decentralizing data and empowering users. This new iteration of the web aims to address the limitations and challenges of Web2, focusing on data privacy, security, and user control.
Decentralization at Its Core
Web3 leverages blockchain technology to create a decentralized web, where data is stored across a distributed network of computers rather than on centralized servers. This shift enhances security and reduces the risk of data breaches, as there is no single point of failure.
Decentralization also means that users have more control over their data. Instead of relying on tech giants to manage their personal information, individuals can store and manage their data through decentralized applications (dApps). This empowerment of users is a significant step towards a more secure and private internet.
Enhanced Security and Privacy
One of the key benefits of Web3 is the enhanced security it offers. By utilizing blockchain technology, data is encrypted and stored in a tamper-proof manner. This ensures that information cannot be altered or deleted without the consensus of the network, making it highly secure.
Privacy is another critical aspect of Web3. In the current Web2 environment, users often have to sacrifice their privacy for convenience. Web3 changes this by allowing users to control their digital identities and share only the information they choose. This approach not only protects user privacy but also reduces the chances of identity theft and other cybercrimes.
Smart Contracts and dApps
Smart contracts are self-executing contracts with the terms of the agreement directly written into code. They run on blockchain networks and automatically enforce the terms of the contract when certain conditions are met. This innovation eliminates the need for intermediaries, reducing costs and increasing efficiency.
Decentralized applications, or dApps, are built on blockchain platforms and operate without a central authority. These applications range from financial services and gaming to social media and supply chain management. By removing intermediaries, dApps provide more transparency, lower costs, and improved security.
The Future of Web3
The potential of Web3 is immense, with its applications extending far beyond the current use cases. As more industries adopt blockchain technology, we can expect to see significant changes in how we conduct business, interact socially, and manage data.
Web3 represents a paradigm shift in how we view and use the internet. By prioritizing decentralization, security, and user control, it promises to create a more equitable and secure digital landscape. As technology continues to evolve, Web3 is poised to become the foundation of the next generation of the internet. | klimd1389 |
1,863,674 | What is a white-label online casino? | A white-label online casino is a ready-to-use platform that has all the features required to operate... | 0 | 2024-05-24T07:58:12 | https://dev.to/wiredking/what-is-a-white-label-online-casino-40id | A white-label online casino is a ready-to-use platform that has all the features required to operate the casino. It comprises a games library provided by the developers of the choice, promotional offers, payment methods, languages, banking methods, and so on, as per the market chosen. Online casinos of white label style can be designed keeping the target markets’ trends in mind. Since all the features are pre-developed, only assembling, customizing, and configuring processes are to be performed. [white label online casino solution](https://www.wiredking.com/casino-software-provider/white-label-online-casino-solution/) | wiredking | |
1,863,673 | Maximizing ROI: Leveraging IP Look Up for Enhanced Audience Targeting | Maximizing return on investment (ROI) is crucial for firms looking to succeed in today's digital... | 0 | 2024-05-24T07:56:37 | https://dev.to/johnmiller/maximizing-roi-leveraging-ip-look-up-for-enhanced-audience-targeting-57li | Maximizing return on investment (ROI) is crucial for firms looking to succeed in today's digital environment. Using IP search for improved audience targeting is a potent technique for accomplishing this. Through an understanding of **[IP look up](https://ipinfo.info/)** and its marketing applications, companies may successfully customize their campaigns to target the appropriate audience.
**Understanding IP Lookup**
**_Definition_**
IP lookup is the process of determining the geographical location and other relevant information associated with an IP address. It provides insights into the user's location, internet service provider (ISP), and more.
**How it Works**
IP lookup utilizes databases that map IP addresses to geographical locations. When a user visits a website or interacts with online content, their IP address is logged, allowing businesses to identify their location and tailor their marketing efforts accordingly.
**Applications in Marketing**
_**Targeted Advertising**_
By leveraging IP lookup data, businesses can deliver targeted advertisements based on the user's geographical location. This allows for more relevant and personalized marketing messages, increasing the likelihood of engagement and conversion.
**Geotargeting Campaigns**
Geotargeting involves delivering content or promotions to users in specific geographic regions. With IP lookup, businesses can create geotargeted campaigns tailored to the preferences and needs of users in different locations.
**Localized Content**
Understanding the geographical location of users through IP lookup enables businesses to create localized content that resonates with their audience. This could include language-specific content, regional promotions, or references to local events.
**Maximizing ROI with IP Lookup**
**_Improved Relevance_**
By delivering targeted and localized content to users, businesses can improve the relevance of their marketing efforts. This increases engagement and conversion rates, ultimately leading to a higher ROI on marketing spend.
**Enhanced Customer Experience**
Personalized marketing messages based on geographical location enhance the overall customer experience. Users are more likely to respond positively to content that is relevant to their location and interests, leading to increased brand loyalty and customer satisfaction.
**Optimized Ad Spend**
By targeting specific geographic regions with higher concentrations of potential customers, businesses can optimize their advertising spend. Rather than casting a wide net, they can focus their resources on areas where they are most likely to see a significant return on investment.
**Conclusion**
In an increasingly competitive digital landscape, businesses must maximize their ROI through effective audience targeting. **[Leveraging IP](urlhttps://ipinfo.info/product)** lookup for enhanced audience targeting offers numerous benefits, including improved relevance, enhanced customer experience, and optimized ad spend. By understanding how IP lookup works and its applications in marketing, businesses can tailor their strategies to reach the right audience effectively and achieve their marketing objectives. | johnmiller | |
1,863,671 | APKs MUD - Your Key to Endless Gaming Possibilities | NP Modz, or Naruto PH Modz, is a well-liked app for Mobile Legends: Bang Bang players. It adds lots... | 0 | 2024-05-24T07:52:29 | https://dev.to/myacademia_zone_fefcd44f6/apks-mud-your-key-to-endless-gaming-possibilities-34nc | NP Modz, or Naruto PH Modz, is a well-liked app for Mobile Legends: Bang Bang players. It adds lots of cool stuff that you can’t get in the regular game, and you don’t have to pay real money for it. | myacademia_zone_fefcd44f6 | |
1,863,669 | The devil in the Computers | Hey there, it's me, Medul Hossain Masum, a programmer, talking to you. We don't talk that much, but... | 0 | 2024-05-24T07:51:35 | https://dev.to/medulhossainmasum01/the-devil-in-the-computers-5fh7 | Hey there, it's me, Medul Hossain Masum, a programmer, talking to you. We don't talk that much, but yes, we talk a lot to computers, and that's what we're supposed to do. I feel so bad for Gen Z kids. They got nothing to learn. I'm blessed to have been born in a time where I had the chance to learn a lot. And by a lot, I mean a lot.
You know, my life is kinda like Mr. Robot. I have so many visions, but I don't do drugs; it's just the side effects of thinking too much. Sometimes, I don't know what is real and what is delusion. Yo, I've got so many interesting things to tell you about. It's our world. It's totally accessible by a select group of people who are playing god roles without asking. They are always watching you. They preset some keywords, and if you hit that word, you're on their watch list.
I don't get it—why do they have Chinese servers in a simple rice cooker? They are planning something big, bigger than you can imagine. The AI you can't even fathom was developed many years ago. But they are only revealing it now. AI is far more dangerous than you think. It's like a devil in the computers.
I will reveal some deadly things about what's going with our technology very soon.
Stay vigilant.
Medul Hossain Masum | medulhossainmasum01 | |
1,863,668 | How To Not Be Replaced By AI As A Software Engineer | Rumors about AI replacing developers have been circulating for the past 2 years. Since the launch of... | 0 | 2024-05-24T07:43:19 | https://sotergreco.com/how-to-not-be-replaced-by-ai-as-a-software-engineer | ai, webdev | Rumors about AI replacing developers have been circulating for the past 2 years. Since the launch of Chat-GPT 3.5, many of you have thought at least once, "What if AI indeed replaced me?"
Well, this is what we are going to discuss; a controversial topic with answers ranging from "No way, AI will never replace developers" to "We only have a couple of years left."
## Where we are now
We've seen some disappointing launches like Devin, which is a really bad attempt to replace developers, but we also have Chat-GPT4, which is really good with programming questions.
So let's ask this question: "*What percentage of your code is written or generated by AI?*". For me, the answer is impressive. In my day-to-day life, I barely write code anymore. GitHub Copilot generates 60-70% with autocomplete, and Grok generates another 10%.
So hold on, you mean you write only 20% of your code? Well, actually yes. If we are not talking about the frontend, which is subjective and AI cannot really generate something good, on the backend, where most apps are basically the same, CRUD is 70% of the backend code, and it is being generated by AI.
## Can We Get More With Current Technology
Talking about the backend, which is actual programming and not the frontend (which I have started to dislike lately), with current technology, we can reach a point where Copilot generates entire workflows.
With prompts like: "*Generate 2 models one for users and one for articles the user will have these fields \[columns\] and this relationships \[relationships\] with articles and also generate the CRUD for this. Don't forget to not put the logic in the controller but in the services*"
Copilot X in the future will do that and they are already working on features like that. Of course the code might not be 100% there but it gives you a boilerplate to work with.
## Endangered Developers
AI will replace many labor jobs. Junior Developers are labor jobs. Junior Devs don't know about system design or problem-solving. They just exist to do the labor and basically the things that Senior Devs are bored of doing because it is a waste of time.
Senior Engineers discuss with managers, conclude software designs, and instruct juniors on what to do. Well, the people who need instructions will be replaced. Because giving instructions is what Seniors do, and if they can give instructions to an AI model, why pay a junior?
Basically, AI is a Senior Developer with no System Design knowledge and human logic.
## You Are A Robot
Ask yourself one question to find out if you will be replaced by AI: How many instructions do I get daily?
If the answer is a lot, then you are most likely that you not going to exist in the realm of programming and work in general in the next few years. If you don't know what to do and need instructions rather than giving guidance to someone else or even guiding yourself, then my friend, you are in big trouble.
Most people are already robots or a version a AI themselves. So then why not a manager or a CEO not replace you with someone that has basically no human rights because its a computer program and needs to breaks or salary.
## Solution
To avoid being replaced by AI, you need to emphasize skills that AI currently lacks. Focus on improving your problem-solving abilities, system design knowledge, and understanding of human logic.
Take on more responsibilities that require critical thinking, creativity, and strategic decision-making.
Continuously learn and adapt to new technologies and methodologies. By becoming more than just a programmer, you can secure your place in the industry.
## Final Words
In conclusion, while AI is advancing rapidly and taking over many routine coding tasks, it is not yet capable of replacing the nuanced and critical thinking skills that senior developers provide.
To stay relevant in the industry, focus on honing your problem-solving abilities, system design expertise, and strategic decision-making. Continuously adapt and learn new technologies to ensure that you remain indispensable in a landscape increasingly influenced by AI.
By becoming less than a coder and more of a problem solver you have nothing to worry about.
Thanks for reading, and I hope you found this article helpful. If you have any questions, feel free to email me at [**kourouklis@pm.me**](mailto:kourouklis@pm.me)**, and I will respond.**
You can also keep up with my latest updates by checking out my X here: [**x.com/sotergreco**](http://x.com/sotergreco) | sotergreco |
1,863,667 | FMZ Mobile APP Trading Terminal, empowering your quantitative trading experience | In the field of quantitative trading, simple and easy-to-use quantitative trading tools have always... | 0 | 2024-05-24T07:42:55 | https://dev.to/fmzquant/fmz-mobile-app-trading-terminal-empowering-your-quantitative-trading-experience-52hh | trading, fmzquant, terminal, cryptocurrency | In the field of quantitative trading, simple and easy-to-use quantitative trading tools have always been one of the keys to achieving wealth growth and risk management. However, with increasing market competition, traditional trading tools are no longer sufficient to meet rapidly changing market demands. To maintain a competitive edge for quantitative traders in the constantly evolving digital asset world, FMZ Mobile App has added a significant new feature: Trading Terminal. This feature will not only improve your trading efficiency, but also empower you through custom plugin programs to assist in trading, injecting new vitality into your trading career.
## Beginner's Guide to Trading Terminal:
### What is the FMZ Mobile APP Trading Terminal?
On the FMZ Quant Trading Platform, you can download the FMZ Quant Mobile APP from the [Mobile App download page](https://www.fmz.com/mobile). After downloading and installing, open the FMZ mobile app and log in with your FMZ account.
Please note that FMZ Quant is divided into FMZ.COM international site and FMZ.CN China domestic site (supporting different markets). When logging in, you need to choose the corresponding site. Accounts for different sites are independent and not interchangeable.
The FMZ Quantitative Trading Platform mobile APP trading terminal is a quantitative trading tool that encapsulates APIs from major exchanges. It allows quick switching between various exchanges, and with the help of various features of the FMZ platform, it can perform data capture analysis, real-time data monitoring, program-assisted trading, semi-automatic/manual trading operations etc.
### How to access and enable the trading terminal function?
After logging into the FMZ Quant Mobile APP, you can see the "Trading Terminal" function on the main interface. Click to enter the trading terminal interface.
Before FMZ launched its mobile APP trading terminal, FMZ's web version had already launched this feature quite early. Whether it is a web-based trading terminal or a mobile APP-based one, **at least one docker program must be deployed**.
This is because all actual requests sent to exchanges are executed from the docker, not on the mobile app, which is safer. It also avoids disadvantages such as API KEY binding IP addresses and inability to use when mobile IP changes.
### Detailed Explanation of Trading Terminal Interface
**1. Main Interface of the Trading Terminal:**
After opening the trading terminal, you can see the main interface of the trading terminal. Clicking on the area in red frame will open up "Docker", "Exchange", and "Markets" configuration interfaces.
- Docker: All docker programs deployed under your current FMZ account will be listed here for selection.
- Exchange: The exchange objects (configured with API KEY information etc.) created in your current FMZ account will also appear in corresponding lists for specific operation selections.
- Markets: Set up the trading pair or contract that this trading terminal is going to operate. The input box widget for trading pairs will display selectable trading pairs/contracts based on entered information.
**2. Trading Zone:**
The Trading Zone displays market depth data;
Trading widgets can be set with order price, order quantity, order direction, leverage and other settings.
The bottom tabs of the main interface display information such as "Orders", "Assets", making your funds, and orders clear at a glance.
**3. K-line Chart:**
If you wish to view the K-line chart while placing an order, a thoughtful design has been implemented here - a collapsible display widget that unfolds the mini K-line chart of the current product.
If you wish to view the K-line chart in a larger area, display market transaction records, depth information and more, you can click on this K-line icon to jump to the professional K-line chart page.

The professional K-line chart interface:
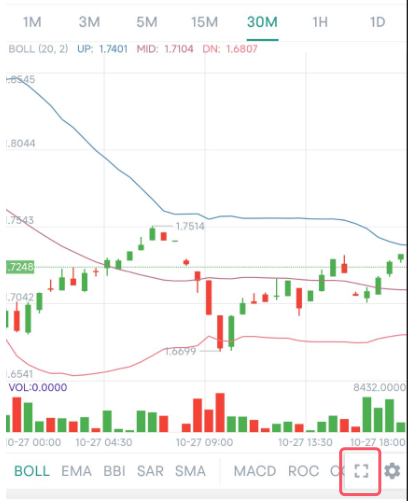
The professional K-line chart interface can also be displayed in landscape mode:
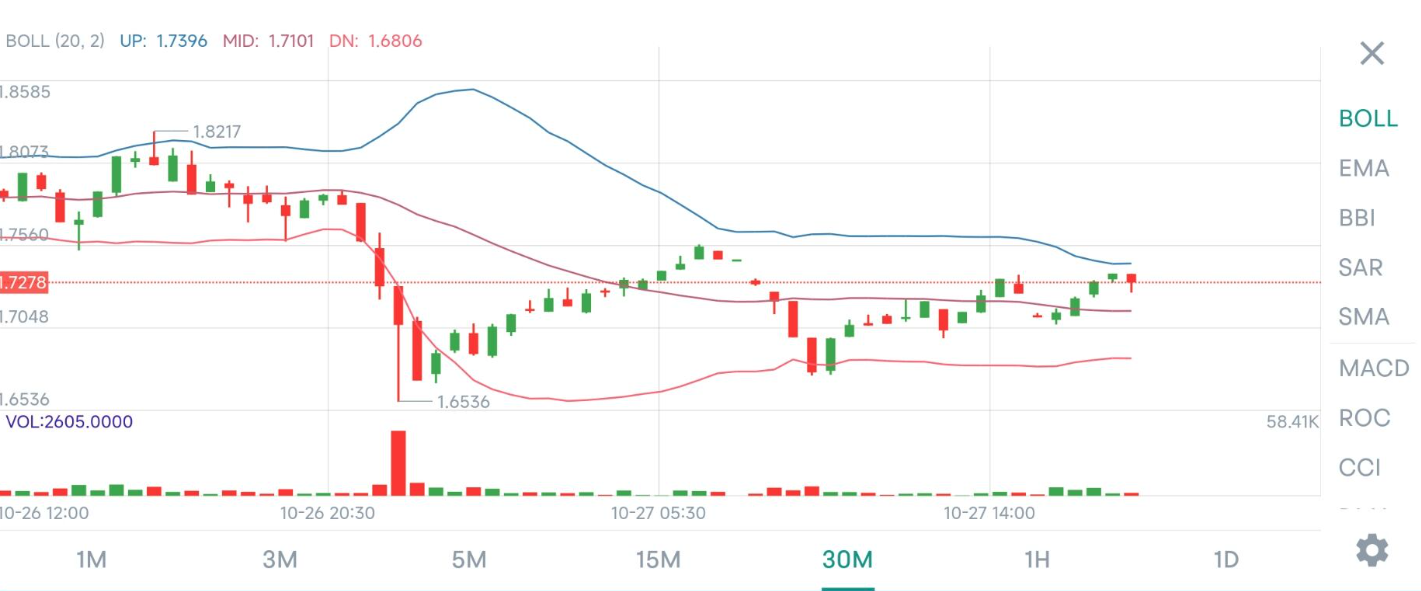
### Trading Plugin
What can a trading terminal plugin do?
- Real-time market data calculation and display.
- Order placement and order management.
- Implement risk management.
- Semi-automatic auxiliary trading strategies.
Which programming languages and tools are used to develop plugins?
- python
- javascript
- c++
What can you get?
- Share your plugin with the community for mutual learning with developers.
- Learn from other developers and get inspired.
- Interact with other quantitative trading enthusiasts.
### Give an Example Based on a Real-life Application Scenario:
In the FMZ community, a user has put forward such a request:
> Use js to traverse all U contract currencies of the Binance exchange, and open a position of 10u (long) for each currency. How is this code written?
This requirement scenario can be implemented with trading terminal plugins actually, and running plugin strategies on the trading terminal is free of charge. Compared to long-term live trading strategies, using trading terminal plugins as an aid is undoubtedly a good choice.
Let's see how to design and implement the user's request.
Firstly, we need to create a trading terminal plugin and add three parameters to its strategy:

Then start writing the plugin program:
```
function main() {
let exName = exchange.GetName()
if (exName != "Futures_Binance") {
return "not support!"
}
let apiBase = "https://fapi.binance.com"
if (isSimulate) {
apiBase = "https://testnet.binancefuture.com"
Log("Switch base address:", apiBase)
}
exchange.SetBase(apiBase)
try {
var obj = JSON.parse(HttpQuery(apiBase + "/fapi/v1/exchangeInfo"))
} catch (e) {
Log(e)
}
let pairs = []
for (var i in obj.symbols) {
if (obj.symbols[i]["status"] !== "TRADING" || obj.symbols[i]["quoteAsset"] !== "USDT") {
continue
}
let = pair = obj.symbols[i]["baseAsset"] + "_" + obj.symbols[i]["quoteAsset"]
pairs.push(pair)
}
let markets = _C(exchange.GetMarkets)
for (var i in pairs) {
// /*
// For testing purposes, only 10 varieties are opened here. If all varieties are needed, this comment content can be deleted.
if (i >= 9) {
break
}
// */
let pair = pairs[i]
exchange.SetCurrency(pair)
exchange.SetContractType("swap")
let ticker = exchange.GetTicker()
if (!ticker) {
continue
}
let = amountPrecision = markets[pair + ".swap"]["AmountPrecision"]
exchange.SetDirection("buy")
let amount = _N(qty / ticker.Last, amountPrecision)
if (amount > 0) {
exchange.Buy(-1, amount)
}
Sleep(100)
}
// Obtain all positions
let pos = exchange.IO("api", "GET", "/fapi/v2/positionRisk")
if (!pos) {
return
}
// View positions
return pos.filter(item => Number(item.positionAmt) != 0)
}
```
After the trading terminal plugin is written, it can be tested:
In the trading terminal of the mobile APP, click on the '...' button to open the list of trading terminal plugins. All plugins in the strategy library of your current FMZ account will be displayed in this list for selection and use.
After completing the operation on the mobile APP, we use the following code to query the position of Binance's simulation bot:
```
function main() {
let apiBase = "https://testnet.binancefuture.com"
exchange.SetBase(apiBase)
let pos = exchange.IO("api", "GET", "/fapi/v2/positionRisk")
if (!pos) {
return
}
// View positions
return pos.filter(item => Number(item.positionAmt) != 0)
}
```
Data found:
```
[{
"symbol": "ETCUSDT",
"entryPrice": "16.17",
"unRealizedProfit": "0.08567881",
"positionSide": "LONG",
"updateTime": 1698420908103,
"isolated": false,
"breakEvenPrice": "16.176468",
"leverage": "20",
"adlQuantile": 3,
"positionAmt": "0.65",
"markPrice": "16.30181356",
"liquidationPrice": "0",
"maxNotionalValue": "400000",
"marginType": "cross",
"notional": "10.59617881",
"isolatedMargin": "0.00000000",
"isAutoAddMargin": "false",
"isolatedWallet": "0"
}, {
"positionAmt": "105",
"markPrice": "0.09371526",
"liquidationPrice": "0",
"leverage": "20",
"maxNotionalValue": "90000",
"positionSide": "LONG",
"isolatedWallet": "0",
"symbol": "TRXUSDT",
"updateTime": 1698420906668,
"breakEvenPrice": "0.094497784",
"isolatedMargin": "0.00000000",
"isolated": false,
"entryPrice": "0.09446",
"adlQuantile": 1,
"unRealizedProfit": "-0.07819770",
"isAutoAddMargin": "false",
"notional": "9.84010230",
"marginType": "cross"
}, {
"unRealizedProfit": "-0.00974456",
"isAutoAddMargin": "false",
"notional": "9.97449543",
"isolatedWallet": "0.50309216",
"updateTime": 1698420905377,
"markPrice": "67.85371047",
"isolatedMargin": "0.49334760",
"adlQuantile": 2,
"symbol": "LTCUSDT",
"entryPrice": "67.92",
"liquidationPrice": "64.91958163",
"maxNotionalValue": "250000",
"positionSide": "LONG",
"isolated": true,
"positionAmt": "0.147",
"breakEvenPrice": "67.947168",
"leverage": "20",
"marginType": "isolated"
}, {
"liquidationPrice": "1613.23261508",
"marginType": "isolated",
"isolated": true,
"symbol": "ETHUSDT",
"entryPrice": "1784.27",
"markPrice": "1783.35661952",
"isAutoAddMargin": "false",
"positionSide": "LONG",
"notional": "8.91678309",
"leverage": "10",
"maxNotionalValue": "30000000",
"isolatedWallet": "0.89551774",
"adlQuantile": 1,
"positionAmt": "0.005",
"breakEvenPrice": "1784.983708",
"unRealizedProfit": "-0.00456690",
"isolatedMargin": "0.89095084",
"updateTime": 1698420900362
}, {
"positionAmt": "17.1",
"marginType": "cross",
"isolatedWallet": "0",
"adlQuantile": 2,
"liquidationPrice": "0",
"maxNotionalValue": "250000",
"positionSide": "LONG",
"isolated": false,
"symbol": "EOSUSDT",
"breakEvenPrice": "0.6432572",
"updateTime": 1698420904257,
"isolatedMargin": "0.00000000",
"isAutoAddMargin": "false",
"notional": "10.34550000",
"entryPrice": "0.643",
"markPrice": "0.60500000",
"unRealizedProfit": "-0.64980000",
"leverage": "20"
}, {
"isolated": false,
"adlQuantile": 1,
"liquidationPrice": "0",
"maxNotionalValue": "10000000",
"notional": "9.73993328",
"leverage": "20",
"updateTime": 1698420901638,
"symbol": "BCHUSDT",
"entryPrice": "250.0",
"markPrice": "243.49833219",
"isAutoAddMargin": "false",
"positionSide": "LONG",
"positionAmt": "0.040",
"breakEvenPrice": "250.1",
"isolatedMargin": "0.00000000",
"unRealizedProfit": "-0.26006671",
"marginType": "cross",
"isolatedWallet": "0"
}]
```
It can be seen that 6 positions have been opened, this is because when placing actual orders on the simulation bot, it's easy to trigger limit prices; in addition, due to the order amount of 10U, it's easy to trigger the minimum order amount limit of trading pairs; therefore a few trading pairs were not successfully ordered.
If you need to use this in reality, more practical situations should be considered in order to optimize this plugin for better usage. The code here is only used for teaching and communication purposes.
### Other Interesting Built-in Plugins on FMZ
The FMZ Quant Trading Platform mobile app trading terminal has many interesting plugins. Come and explore together!
https://www.fmz.com/upload/asset/16b436307a4ce5c246c2.mp4
### The End
The new trading terminal feature of the FMZ mobile app will become your powerful assistant in the digital asset market, allowing you to respond more flexibly to market fluctuations and opportunities. No longer limited to traditional trading strategies, through custom plugin programs, you can create smarter, more efficient trading strategies that are better adapted to the market. Let's start this exciting new chapter of quantitative trading together and enhance your trading skills and profits.
From: https://blog.mathquant.com/2023/10/30/fmz-mobile-app-trading-terminal-empowering-your-quantitative-trading-experience.html | fmzquant |
1,863,666 | Kickstart Your Next.js App with This Turbo Template | TL;DR TurboRepo Launchpad is a powerful starter template for Next.js applications,... | 0 | 2024-05-24T07:41:35 | https://dev.to/jadrizk/kickstart-your-nextjs-app-with-this-turbo-template-1e4b | webdev, nextjs, react, opensource | ## TL;DR
>TurboRepo Launchpad is a powerful starter template for Next.js applications, integrating Next.js 14, TailwindCSS, shadcn components, Changeset for changelogs, and Storybook for isolated component development. It streamlines the setup with pre-configured Supabase authentication. Join the community, contribute, and start building high-performance web apps today! Check out the [GitHub](https://github.com/JadRizk/turborepo-launchpad) repo to get started.
Are you ready to elevate your web development projects? Introducing TurboRepo Launchpad – the ultimate starter template designed to enhance your Next.js applications with powerful features and streamlined workflows. Whether you're an experienced developer or just starting, TurboRepo Launchpad is your go-to solution for efficient, high-performance web development.
## Why TurboRepo Launchpad is a Game-Changer
TurboRepo Launchpad isn’t just another template; it's a powerhouse of features and optimizations tailored to enhance your development experience. By integrating Next.js, TailwindCSS, and shadcn, this template provides a comprehensive toolkit that simplifies complex setups and accelerates your workflow.
### Feature-Rich Integration
- **Next.js 14**: Benefit from the cutting-edge features of Next.js 14, fully integrated into the template, making it ideal for modern web applications.
- **TailwindCSS**: Style your projects effortlessly with TailwindCSS’s utility-first approach, allowing you to create stunning, responsive designs with minimal effort.
- **Shadcn Components**: Build cohesive and modern user interfaces with the shadcn component library, ensuring a consistent look and feel across your application.
- **Storybook**: Develop and test your UI components in isolation with Storybook, making your development process more efficient and reliable.
- **Changeset for Changelogs**: Keep track of your project’s changes effortlessly with the integrated Changeset tool, which helps you generate and manage changelogs.
### Streamlined Development
TurboRepo Launchpad is designed to simplify your development process. By leveraging TurboRepo’s advanced performance features, you’ll experience faster builds and improved efficiency, allowing you to focus on writing code rather than managing configurations.
### Supabase Integration Made Easy
One of the standout features of TurboRepo Launchpad is its seamless integration with Supabase. With pre-configured Supabase authentication, you can skip the hassle of setting up authentication from scratch. Simply add your Supabase keys, and you're ready to start building secure applications immediately.
### Start Building Today!
Don’t miss out on the opportunity to enhance your web development projects with TurboRepo Launchpad. Visit the [GitHub](https://github.com/JadRizk/turborepo-launchpadhttps://github.com/JadRizk/turborepo-launchpad) repo today, and see for yourself how this powerful template can transform your workflow. | jadrizk |
1,857,502 | Your client-side is not secure without these 5 practices | From HTML websites in the 1980s to progressive web apps in 2024, web development has come a long way.... | 0 | 2024-05-24T07:39:28 | https://dev.to/armstrong2035/5-considerations-for-client-side-security-5fk6 |
From HTML websites in the 1980s to progressive web apps in 2024, web development has come a long way. And as client-side capabilities have improved, so has the importance of security. We may get away with poor security on a static HTML page but modern websites store cookies, passwords, credit card information, and other data. As such, security for the client is more important than ever.
This article provides a high-level summary of client security. The article covers the following topics:
1. Input validation
2. User Authentication
3. User Authorization
4. Data protection
5. Secure communication
Each section has a description and a few techniques that you can implement. The article also offers a few code snippets in JavaScript. These code snippets are for demonstration purposes only.
Finally, I hope you enjoy reading this article. I certainly enjoyed writing it.
## Input Validation
Input validation is the process of filtering what users input into an application. Essential for client-side security, input validation is required but more is needed.
Consider the following scenario:. Someone wants to attack your website with a virus. So they go on the 'contact us' form. They then input characters that the browser will interpret as code and execute. Now your website is executing code that you did not design. This leads to all sorts of strange behavior, including stolen user data.
### Whitelisting vs Blacklisting
You could avoid all this by ensuring no malicious input enters your website. You could use any whitelisting technique. This means that you have a list of characters that the website allows. Anything else will be rejected. You could also use a blacklisting technique. A blacklist contains a list of characters that are NOT allowed. Generally, whitelisting is safer than blacklisting because blacklisting is more susceptible to [filter evasion](https://www.invicti.com/blog/web-security/xss-filter-evasion/#:~:text=XSS%20filter%20evasion%20refers%20to,and%20fool%20complex%20browser%20filters.)
### Semantic and Syntactic Validity
Any good input validation technique should also ensure both syntax and semantic validity. syntax validity ensures that an input is in the correct form or type. E.g., The CVV code for a credit card must always be three digits. Semantic validity ensures that the imputed data follows the correct context or order. For example, the expiration date of a debit card should always be a future date.
### Common input validation techniques
Now that you understand the basics of input validation, let us review some common techniques.
1. Built-in validation: involves the use of inbuilt HTML attributes such as required, pattern, type, min-length, max-length, pattern, and so on. [Read more here](https://developer.mozilla.org/en-US/docs/Learn/Forms/Form_validation#using_built-in_form_validation)
```html
<!-- Requiring a field -->
<input type="text" name="username" required>
<!-- Setting a pattern for input -->
<input type="text" name="phone" pattern="[0-9]{3}-[0-9]{3}-[0-9]{4}">
<!-- Limiting input length -->
<input type="text" name="zipcode" minlength="5" maxlength="9">
```
2. Sanitization: involves cleaning up an input that contains suspicious characters. [Read more here](https://developer.mozilla.org/en-US/docs/Web/API/Sanitizer)
```js
// Code to remove HTML tags from input
function sanitizeInput(input) {
return input.replace(/</g, '<').replace(/>/g, '>');
}
// Code to remove leading/trailing whitespace and limit to alphanumeric
function sanitizeUsername(username) {
return username.trim().replace(/[^a-zA-Z0-9]/g, '');
}
```
3. Regular Expressions (REGEX): useful for imposing a pattern in which data must be input. Only data that matches the preset pattern will be accepted! Regex is typically used for zip code or password form fields. [Here is an excellent blog about regular expressions](https://blog.openreplay.com/regular-expressions-and-input-validations/)
```js
// Password validation (at least 8 chars, 1 uppercase, 1 number)
const passwordPattern = /^(?=.*[A-Z])(?=.*\d).{8,}$/;
function validatePassword(password) {
return passwordPattern.test(password);
}
```
## User Authentication
User authentication is verifying a user’s identity before giving them access to their account and everything associated with it. Authentication is useful for user experience. But more importantly, it is a security measure that ensures that sensitive data is accessed only by authorized parties.
User authentication is essential to web security. Without it, user accounts are vulnerable to cyber-attacks. Consider a website without 2-factor authentication. It is easy to hack a user's account on such a website. All an attacker has to do is guess the user's password. That is why it is important to utilize the knowledge factor, possession factor, and inherence factor.
The knowledge factor authentication is based on knowledge that only the user would have. Security questions and passwords are in this category. The possession factor, however, refers to authentication that requires physical devices owned by the user. A physical cryptocurrency wallet is an example here. Finally, consider the inherence factor for authentication. It has to do with biometrics such as fingerprints, facial recognition, etc.
Generally, though, most security on the client is based on the knowledge factor. It is unlikely that a website would request fingerprints for access. Nevertheless, user authentication techniques for the client are based on either of those factors.
### Common authentication techniques:
1. Password-based authentication receives a password from a user in exchange for access. This is the most common form of user authentication/authorization. One issue with this approach is that weak passwords will be easily bypassed.
2. Multi-factor authentication (MFA) enforces several layers of authentication on users. E.g., in 2-factor authentication, you set a password and also receive a one-time passcode via SMS. The purpose of this extra layer is often to notify you of a potential hack on your account. Mixing the knowledge factor with the physical factor works here. For example, Gmail requires users to log in with a password and confirm the login on a device that they own!
3. Certificate Base Authority collaborates with a trusted authority to issue a unique certificate. e.g., the Microsoft Authenticator app is a trusted authority. The developer can use it to generate a unique code to authenticate a user. The user would then input the code to gain access.
4. Token-based authentication generates access tokens that give a user access to certain features. Tokens usually have a scope, i.e., they give restricted access to features. Tokens also expire. One example of this is the Spotify API Oauth sign-in. It allows third-party apps to make changes to users' accounts as long as an access token is part of the API call. First, the user gives the developer access to their account. Then Spotify sends the developer an access token. The developer then uses the token to perform actions within the scope of what the user has agreed to.
```js
// Basic password authentication
function authenticateUser(username, password) {
const user = database.findUser(username);
if (user && user.password === password) {
return true; // Authentication successful
}
return false; // Authentication failed
}
// 2-Factor Authentication with SMS code
function authenticate2FA(username, password, smsCode) {
if (authenticateUser(username, password)) {
if (verifyCode(username, smsCode)) {
return true; // 2FA successful
}
}
return false; // 2FA failed
}
```
## User Authorization
User authorization is the conditional issuance of permissions to different kinds of users of a website. Simply put, authorization determines what privileges different clients have. Authorization filters users based on varying conditions and gives access accordingly. An important mental model for thinking about this is as follows:
1. Subject: Who is the user?
2. Resource: which object does the user want to access?
3. Action: Which actions is the user trying to perform with the resource he has access to?
Consider business enterprise resource management software. For a given business, there are finance, human resources (HR), and product dashboards. Naturally, the head of finance has access to the finance dashboard. The head of HR has access to the HR dashboard, and the head of product uses the product dashboard. Imagine that the HR manager needs some information on his department's budget. We could simply give him/her limited access to the finance dashboard. Many of the tools that you use as a developer already have these features. Figma, Google, and even Jira all give conditional access to different features.
### Common user authorization techniques
Some user authorization methods are as follows:
1. Role-Based Access Control allows access to resources depending on the role of the user. For example, Google Docs has roles for editors, viewers, and commenters. Someone with the role of a commenter cannot access the features of an editor.
2. Attribute-Based Access Control filters different users based on their attributes. Consider a SAAS website with tiered pricing. Users either have access to premium features or not, depending on whether they have paid or not. One independent publisher on the internet noticed that excessive scrapping was affecting the performance of his website. So he put up a paywall to allow only paid users to access the content. This action improved the website's performance!
3. Privileged Access Management prevents regular users from accessing sensitive information. An excellent example of this is WordPress. WordPress websites are publicly accessible. Yet only the website administrators can make any changes to them.
```js
// Role-based access control
function authorize(user, resource, action) {
const role = user.role;
const permissions = roles[role];
const isAllowed = permissions.some(p =>
p.resource === resource && p.actions.includes(action)
);
return isAllowed;
}
// Attribute-based access control
function authorizePaidContent(user, resource) {
if (user.subscription === 'paid') {
return true; // Allow paid users
}
return false; // Block non-paid users
}
```
## Data Protection
Data protection is critical to client-side security. Modern web applications are complex. They also handle a lot of sensitive information. It is important to protect data for the following reasons:
1. Preventing Data Leakage: Data stored on the client side, such as user preferences, session tokens, and cached data, must be safeguarded to prevent unauthorized access or leakage.
2. Compliance Requirements: Adhering to data protection standards and regulations, such as GDPR, HIPAA, or CCPA, is essential to ensure the legal and ethical handling of user data.
3. Mitigating Security Risks: Data protection measures reduce the risk of data breaches, identity theft, and other security threats that exploit vulnerabilities in client-side data storage.
### Techniques for Data Protection
1. Encryption: Encrypting sensitive data before storing it on the client side ensures that even if accessed by unauthorized parties, the data remains unreadable without the decryption key. To do this, Use strong encryption algorithms such as AES (Advanced Encryption Standard) for encrypting data at rest and TLS (Transport Layer Security) for encrypting data in transit.
2. Data Masking and Tokenization: Masking sensitive data elements or tokenizing them into non-sensitive equivalents reduces the exposure of actual data, enhancing privacy and security.
Use tokenization services or libraries to generate and manage tokens for sensitive data fields, such as credit card numbers or personally identifiable information (PII).
3. Regular Security Audits and Updates: Conduct regular security audits and updates of your client-side data protection mechanisms to identify and address vulnerabilities proactively. Stay informed about emerging security threats and best practices in data protection to continually improve your application's security posture.
By implementing these data protection techniques, web developers can enhance the security and privacy of client-side data, thereby fostering user trust and compliance with regulatory requirements.
## Secure Communication
Secure communication is pivotal to safeguarding data integrity, confidentiality, and authenticity during transmission between clients and servers. Secure communication is important for the following reason:
1. Data Confidentiality: Encryption ensures that sensitive data exchanged between clients and servers remains confidential and unreadable to unauthorized entities.
2. Data Integrity: Secure communication protocols, such as HTTPS, prevent data tampering or modification during transmission, maintaining data integrity and trustworthiness.
3. Authentication and Identity Verification: Secure communication protocols enable mutual authentication between clients and servers, verifying the identities of both parties to prevent impersonation attacks.
4. Protection Against Eavesdropping: Encryption of data in transit mitigates the risk of eavesdropping or interception by malicious actors seeking to capture sensitive information.
### Techniques for Secure Communication
1. HTTPS (Hypertext Transfer Protocol Secure):
- Utilize HTTPS to encrypt data exchanged between clients and servers, providing a secure communication channel over the Internet.
- Obtain and install SSL/TLS certificates from trusted certificate authorities to enable HTTPS on your web servers.
2. TLS (Transport Layer Security):
- Implement the latest TLS versions (e.g., TLS 1.2 or TLS 1.3) with strong cipher suites to secure communication channels and protect against known vulnerabilities.
- Configure server-side security settings, such as Perfect Forward Secrecy (PFS), to enhance the resilience of TLS encryption.
3. Certificate-based Authentication:
- Employ certificate-based authentication mechanisms, such as client SSL certificates, to verify the identities of clients and servers during SSL/TLS handshake.
- Maintain a secure certificate management process, including certificate issuance, revocation, and renewal, to prevent certificate-related security incidents.
4. Content Security Policies (CSP):
- Implement CSP headers to define and enforce security policies regarding permitted content sources, mitigating risks associated with XSS attacks and content injection vulnerabilities.
- Specify strict CSP directives, such as 'default-src 'self'', 'script-src 'nonce-hash'', and 'upgrade-insecure-requests', to enhance web application security.
5. Secure WebSockets:
- When using WebSockets for real-time communication, ensure WebSocket connections are secured with SSL/TLS encryption to protect data exchanged between clients and servers.
- Apply WebSocket security best practices, such as rate limiting, origin validation, and message validation, to prevent WebSocket-based attacks and abuse.
6. Secure File Transfers:
- For file uploads or downloads, employ secure protocols such as SFTP (SSH File Transfer Protocol) or HTTPS with multipart form data to encrypt file transfers and prevent unauthorized access.
- Implement server-side file validation and sanitization to mitigate risks associated with malicious file uploads, including malware or script injections.
7. Network Security Measures:
- Deploy network security measures, such as firewalls, intrusion detection/prevention systems (IDS/IPS), and secure VPNs (Virtual Private Networks), to protect against network-based attacks and unauthorized access attempts.
- Monitor network traffic and perform regular security audits to detect and respond to anomalous or suspicious activities affecting secure communication channels.
By adopting these secure communication techniques and best practices, web developers can establish resilient and trustworthy communication channels, ensuring the confidentiality, integrity, and authenticity of data exchanged between clients and servers.
## Conclusion
Client security is essential to protecting user data and defending against cyberattacks. Here’s everything we covered in this article:
Input validation protects your website from SQL injections and other malicious input. User authentication and authorization are children of the same parent. Authentication ensures that only the owner or a user account can access it. Authorization creates permissions that limit or allow access to resources within a website. Finally, data protection is useful for securing the data that is stored on the client; while secure communication protects the data that travels between the server and the client.
| armstrong2035 | |
1,862,413 | Stratégie : que va t-on (ne pas faire) cette année ? | J'ai vu cette scène se répéter encore et encore au cours de ma carrière (en cabinet de conseil puis... | 0 | 2024-05-24T07:38:55 | https://dev.to/psantus/strategie-que-va-t-on-ne-pas-faire-cette-annee--2gc3 | strategy, plan, management, agile | J'ai vu cette scène se répéter encore et encore au cours de ma carrière (en cabinet de conseil puis en entreprise) : devant un parterre de managers (au mieux) amusés ou (au pire) désabusés, le big boss dévoile son énième plan stratégique. Sur l'écran derrière lui, un slide identifiant 7 leviers, 8 axes, 10 piliers, 12 priorités.. Chacun a fait l'objet d'un groupe de travail et porte 4 ou 5 sous-axes ou projets. En introduction, un slide rappelait une ambition forte de croissance du CA.
Les patrons de BU sont soulagés : certes, dans chaque axe, le boss (aidé par ses consultants) a certes injecté de nouvelles priorités, mais ils ont réussi à faire en sorte que tous leurs projets en cours soient repris dans le plan stratégique, au prix d'un re-branding qui nécessitera un peu de conduite du changement.
Le DSI, seul, reste impassible, pendant que ses équipes découvrent médusés une augmentation de 150% de leur charge et des dates de livraison (pour lesquelles ils n'ont pas été consultés) ; il a eu la primeur des slides la veille mais doit la jouer corporate. S'il a un peu de bouteille, il sait que des arbitrages seront faits (inavouables aujourd'hui, et au prix de nombreuses discussions conflictuelles qui consommeront une énergie non-négligeable, mais de toute façon la capacité à faire n'augmentera pas).
Parfois, ce plan stratégique s'adjoint une gouvernance ad hoc (des comités de piliers et un comité central pour les gouverner tous - car le big boss ne va tout de même pas participer à chacun des comités de piliers, quand bien même ceux-ci étaient stratégiques) qui va un temps court-circuiter les canaux réguliers d'information et de prise de décision avant de disparaître silencieusement.
# De quoi ces plans à tiroirs sont-ils le signe ?
Commençons par affirmer que **ce type de plan n'est pas _vraiment_ un plan stratégique**. Il ne donne pas une claire vision de la difficulté ou menace que le management identifie comme principale, de ses enjeux ni de la nécessité d'une action coordonnée pour la résoudre, des défis et compétences/technologies/savoir-faire qui permettront à l'entreprise de les relever.
Dire cela est un peu facile et semble suggérer qu'il est aisé de dire _ce qu'est_ une stratégie (et surtout comment la définir). Or, c'est l'inverse : définir une stratégie est un vrai art, qui implique de discerner non pas dans une liste de projets (poussés par des salariés ou des parties extérieures intéressées) mais ce qui, dans l'ensemble des ambitions, peurs, désirs, objectifs, et valeurs antagonistes qui se présentent au dirigeant, forme un ensemble cohérent qui peut être traité par un plan suivi. C'est un exercice plus créatif qu'analytique (même si l'analyse et la confrontation aux données du problème sont nécessaires pour forger l'intuition qui sera au coeur du processus créatif).
Ce plan à tiroir n'est donc pas un plan stratégique mais il **n'est pas non plus un plan tactique** donnant une orientation claire aux équipes leur permettant d'agir efficacement.
---
Mais le plus grave, ce sont à mon sens les messages envoyés par l'existence même de ce type de plan et de la structure de gouvernance ad hoc associée :
- Le premier, c'est que **le dirigeant n'a pas confiance dans son management** (et, plus largement, dans les équipes) pour définir le plan tactique qui va permettre d'atteindre les objectifs stratégiques. Il renonce donc à son domaine exclusif (la stratégie) pour micro-manager le tactique.
- Le second, c'est que **l'organisation telle qu'elle existe n'est pas capable de prendre des virages** puisque, d'une part, il faut injecter une structure de gouvernance ad hoc pour la faire bouger et, d'autre part, il y a une course entre patrons de BU qui mesurent leur valeur/influence au nombre d'actions qu'ils parviennent à faire labelliser comme stratégiques.
- Le dernier, c'est qu'**elle est jugée irréformable** ou que le big boss n'a pas idée de comment construire une organisation qui saura adapter ses objectifs.
# 2 clés pour mieux faire
Si la valeur didactique d'un plan ne doit pas être négligée, en tant que l'effort de sensibilisation associé amènera chacun à intégrer ses éléments clés dans son agir local, un **plan vaut d'abord par son exécution** et la focalisation des forces de l'entreprise.
De ce point de vue, le temps passé à tous les étages pour étudier puis arbitrer dans la douleur entre tous les sous-piliers du plan stratégique l'est en pure perte. **Il me semble qu'un discours beaucoup plus efficace** serait le suivant :
> Voici la liste des projets / problématiques sur lesquelles il n'est pas nécessaire de passer du temps cette année.
On peut ajouter
> Il vous est interdit d'y consacrer des efforts, sauf à démontrer qu'il s'agit d'un prérequis absolu pour atteindre tel objectif stratégique.
Finalement, tout choix est un renoncement, et une approche de **la stratégie consiste effectivement à dire non pas ce qu'on doit faire, mais plutôt ce qu'on ne fera pas**. Agir ainsi redonne du temps, de la capacité d'initiative et de la confiance aux équipes.
---
La deuxième clé me semble de définir une organisation capable de prendre des virages, ou _pivoter_, quasiment sans frottement. De ce point de vue, **les méthodes agiles** sont irremplaçables, en particulier avec une organisation qui sépare le management hiérarchique (plutôt effectué par compétence) du management fonctionnel (le PO qui détermine ce qui va être dans la roadmap produit).
Une bonne équipe agile peut sans scrupule ni attachement excessif passer d'un produit à un autre et n'est pas attachée toute entière, dans son fonctionnement ou son intégrité, à l'existence de telle ou telle fonctionnalité ou produit.
Le produit lui-même, toujours et jamais fini à la fois (toujours, car ce qui est en production est qualitatif et fonctionnel, facilement refactorable, et jamais car le produit est conçu pour évoluer à un rythme toujours soutenable), peut évoluer dans le sens des nouveaux objectifs (qui, sauf révolution radicale, passeront par une repriorisation de la roadmap, exercice qu'une équipe fait de façon périodique sans qu'il y ait besoin pour cela d'une crise managériale)
---
Et vous, à quoi ressemble votre stratégie IT ? :) | psantus |
1,863,660 | How Effective are Retrieval Augmented Generation(RAG) Models? | New advances in the field of Generative AI are constantly emerging, and Retrieval-Augmented... | 0 | 2024-05-24T07:28:42 | https://dev.to/vectorize/how-effective-are-retrieval-augmented-generationrag-models-3b3n | rag |
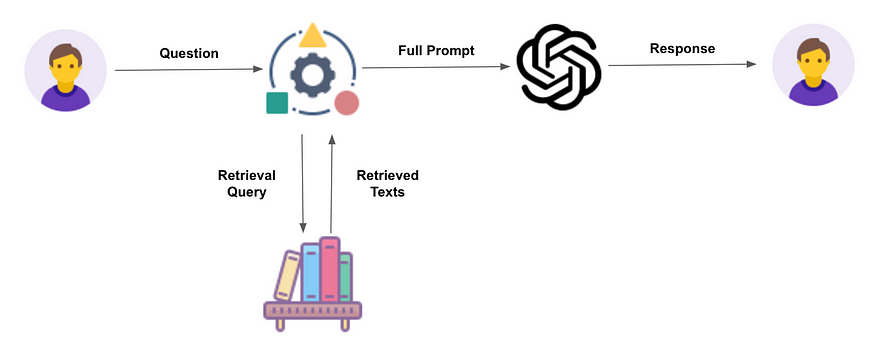
New advances in the field of Generative AI are constantly emerging, and Retrieval-Augmented Generation (RAG) is the next to gain pace.
This blog post will discuss the applications and effectiveness of RAG models.
## Understanding Retrieval Augmented Generation
[Retrieval Augmented Generation](https://vectorize.io/what-is-retrieval-augmented-generation/) (RAG) is a cutting-edge approach in natural language processing that combines the strengths of information retrieval and text generation.
Here’s a simple breakdown of how it works and why it’s important.
## What is Retrieval Augmented Generation?
RAG models are designed to enhance the quality of generated text by incorporating relevant information retrieved from a large collection of documents.
This means that instead of generating responses based solely on a predefined dataset, the model first searches for relevant information and then uses that information to produce more accurate and contextually appropriate responses.
## Key Components of RAG Models
RAG models consist of two main parts:
**Retriever:** This component searches through a vast collection of documents (like a library or database) to find the most relevant pieces of information. Think of it as a smart search engine.
**Generator:** After the retriever finds the relevant information, the generator uses this information to craft a coherent and contextually appropriate response.
## How do RAG Models Differ from Traditional Models?
Traditional text generation models, like GPT-3, generate responses based purely on patterns learned during training.
In contrast, RAG models first retrieve relevant information before generating a response, ensuring that the output is grounded in actual data.
For example, if you ask a traditional model a question about a recent event, it might not provide up-to-date information because it relies on pre-existing knowledge.
A RAG model, however, can retrieve the latest information from a database and generate a more accurate answer.
### Real-World Impact
RAG models significantly enhance the quality and reliability of generated text.
Here are some numbers to illustrate their effectiveness:
**Accuracy Improvement:** Studies have shown that RAG models can improve the accuracy of generated answers by up to 30% compared to traditional models.
**Relevance:** The retrieved information can increase the relevance of responses by up to 50%, making them more useful and contextually appropriate.
**User Satisfaction:** In user studies, responses generated by RAG models received 25% higher satisfaction ratings than those generated by traditional models
## Applications of RAG Models
Retrieval Augmented Generation (RAG) models have revolutionized various domains within natural language processing by enhancing the quality and relevance of generated text.
Here, we delve into some of the key applications of RAG models, including Natural Language Processing, Question Answering Systems, Conversational AI, and other notable use cases.
### Natural Language Processing
Natural Language Processing (NLP) is a broad field encompassing various tasks aimed at enabling machines to understand, interpret, and generate human language.
RAG models have made significant contributions to several NLP tasks:
**Text Summarization:** By retrieving relevant information from large datasets, RAG models can generate concise and informative summaries, improving upon traditional models that may miss critical details.
**Machine Translation:** RAG models enhance translation quality by retrieving contextually relevant examples and phrases from a vast corpus, leading to more accurate and culturally appropriate translations.
**Sentiment Analysis:** By incorporating real-time data, RAG models can better understand the nuances of sentiment in text, providing more accurate and context-aware sentiment analysis.
### Question Answering Systems
Question Answering (QA) Systems are designed to provide precise answers to user queries. RAG models excel in this domain by leveraging their ability to retrieve and utilize specific information:
**Fact-Checking:** RAG models can retrieve the latest data from trusted sources, ensuring that the answers provided are up-to-date and accurate. This is particularly useful in dynamic fields such as news reporting and academic research.
**Contextual Answers:** Unlike traditional QA systems that might generate generic responses, RAG models can provide contextually rich answers by integrating relevant information from multiple documents. This leads to more informative and reliable answers.
**Domain-Specific QA:** In specialized fields such as medicine or law, RAG models can retrieve domain-specific knowledge, offering precise and contextually appropriate answers that adhere to industry standards.
### Conversational AI
Conversational AI encompasses technologies that enable machines to engage in human-like dialogue.
RAG models significantly enhance the capabilities of conversational agents:
**Customer Support:** RAG models can retrieve relevant information from a company’s knowledge base, providing accurate and timely responses to customer inquiries. This leads to improved customer satisfaction and reduced support costs.
**Personal Assistants:** By accessing vast amounts of data, RAG-powered virtual assistants can offer more personalized and context-aware advice, recommendations, and reminders.
**Interactive Learning:** In educational settings, conversational AI systems using RAG models can provide detailed explanations and answers to students, facilitating a more interactive and engaging learning experience.
## Other Use Cases
Beyond the primary applications, RAG models are also making an impact in various other fields:
**Content Creation:** RAG models assist writers and content creators by retrieving relevant information and generating high-quality content, saving time and enhancing creativity.
**Legal Document Analysis:** In the legal field, RAG models can retrieve pertinent case laws and statutes, aiding lawyers in preparing more robust legal arguments and documents.
**Healthcare:** RAG models can retrieve and synthesize medical literature, helping healthcare professionals stay updated with the latest research and providing patients with accurate health information.
**E-Commerce:** By integrating RAG models, e-commerce platforms can offer personalized product recommendations and detailed product descriptions, enhancing the shopping experience for users.
## Evaluating the Effectiveness of RAG Models
Evaluating the effectiveness of Retrieval Augmented Generation (RAG) models is crucial to understanding their performance and identifying areas for improvement.
This involves using various metrics and benchmark datasets to assess how well these models retrieve and generate relevant, accurate, and contextually appropriate responses.
### Metrics for Evaluation
To thoroughly evaluate RAG models, several metrics are commonly used:
**Precision and Recall:** Precision measures the accuracy of the retrieved documents. It is the ratio of relevant documents retrieved to the total documents retrieved.
**Recall:** Recall Measures the ability of the model to retrieve all relevant documents. It is the ratio of relevant documents retrieved to the total number of relevant documents.
**BLEU:** BLEU is commonly used to evaluate the quality of generated text by comparing it to one or more reference texts. It measures how many words or phrases in the generated text match the reference text.
Typically, BLEU scores range from 0 to 1, where a higher score indicates better alignment with the reference text.
**ROUGE:** ROUGE measures the overlap between the generated text and reference text, focusing on recall. It is particularly useful for summarization tasks.
### Human Evaluation
Human judges are often employed to assess the quality of the generated responses based on criteria such as relevance, coherence, fluency, and informativeness.
This evaluation provides qualitative insights that automated metrics might miss.
## Conclusion
[Vectorize.io](https://vectorize.io/) is a platform that empowers organizations to harness the full potential of Retrieval Augmented Generation (RAG) and transform their search platforms. By bridging the gap between AI promise and production reality, Vectorize.io has enabled leading brands to revolutionize their search capabilities. With a focus on accuracy, speed, and ease of implementation, Vectorize.io has become a trusted partner for information portals, manufacturers, and retailers seeking to adapt and thrive in the age of AI-powered search.
| vectorize |
1,863,664 | vf555shop | VF555 – VF555 SHOP thế giới giải trí uy tín, chất lượng đẳng cấp châu Á, là lựa chọn số 1 của các bet... | 0 | 2024-05-24T07:38:05 | https://dev.to/vf555shop/vf555shop-20mo | VF555 – VF555 SHOP thế giới giải trí uy tín, chất lượng đẳng cấp châu Á, là lựa chọn số 1 của các bet thủ tại Việt Nam.
http://vf555.shop/
https://www.facebook.com/vf555shop/
https://www.tumblr.com/vf555shop
https://x.com/vf555shop
https://www.pinterest.com/vf555shop/
https://www.youtube.com/@vf555shop
https://www.linkedin.com/in/vf555shop/ | vf555shop | |
1,863,663 | DashVector + ModelScope 玩转多模态检索 | 本教程演示如何使用向量检索服务(DashVector),结合ModelScope上的中文CLIP多模态检索模型,构建实时的"文本搜图片"的多模态检索能力。作为示例,我们采用多模态牧歌数据集作为图片语料库... | 0 | 2024-05-24T07:32:32 | https://dev.to/dashvector/dashvector-modelscope-wan-zhuan-duo-mo-tai-jian-suo-5aad | 本教程演示如何使用向量检索服务(DashVector),结合[ModelScope](https://modelscope.cn/home)上的[中文CLIP](https://modelscope.cn/models/damo/multi-modal_clip-vit-large-patch14_zh/summary)多模态检索模型,构建实时的"文本搜图片"的多模态检索能力。作为示例,我们采用[多模态牧歌数据集](https://modelscope.cn/datasets/modelscope/muge/summary)作为图片语料库,用户通过输入文本来跨模态检索最相似的图片。
整体流程
-------------
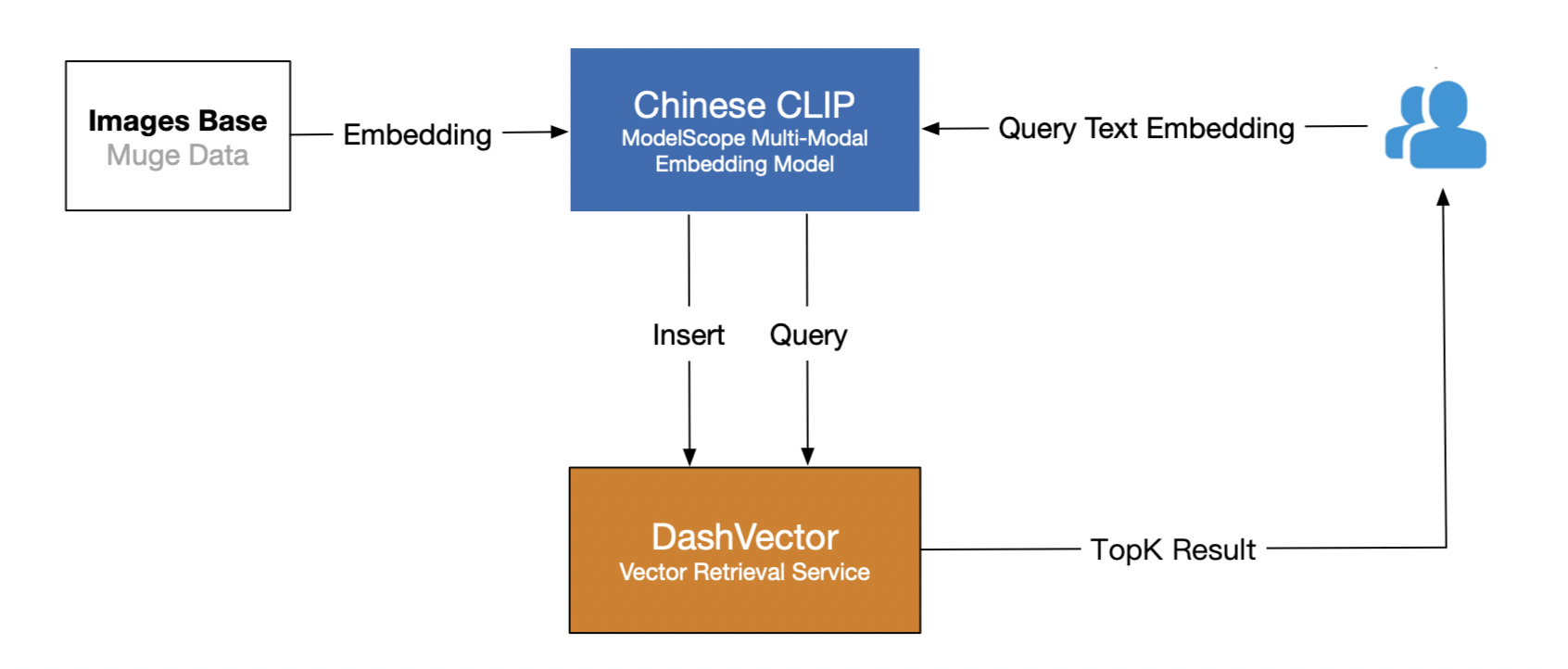
主要分为两个阶段:
1. **图片数据Embedding入库** 。将牧歌数据集通过中文CLIP模型Embedding接口转化为高维向量,然后写入DashVector向量检索服务。
2. **文本Query检索** 。使用对应的中文CLIP模型获取文本的Embedding向量,然后通过DashVector检索相似图片。
前提准备
-------------
### 1. API-KEY 准备
* 开通向量检索服务:请参见[开通服务](https://help.aliyun.com/document_detail/2568083.html?spm=a2c4g.2510236.0.i8)。
* 创建向量检索服务API-KEY:请参见[API-KEY管理](https://help.aliyun.com/document_detail/2510230.html?spm=a2c4g.2510234.0.i9)。
### 2. 环境准备
本教程使用的是ModelScope最新的CLIP [Huge模型(224分辨率)](https://www.modelscope.cn/#/models/damo/multi-modal_clip-vit-huge-patch14_zh/summary),该模型使用大规模中文数据进行训练(\~2亿图文对),在中文图文检索和图像、文本的表征提取等场景表现优异。根据模型官网教程,我们提取出相关的环境依赖如下:
**说明**
需要提前安装 Python3.7 及以上版本,请确保相应的 python 版本
```
# 安装 dashvector 客户端
pip3 install dashvector
# 安装 modelscope
# require modelscope>=0.3.7,目前默认已经超过,您检查一下即可
# 按照更新镜像的方法处理或者下面的方法
pip3 install --upgrade modelscope -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 需要单独安装decord
# pip3 install decord
# 另外,modelscope 的安装过程会出现其他的依赖,当前版本的依赖列举如下
# pip3 install torch torchvision opencv-python timm librosa fairseq transformers unicodedata2 zhconv rapidfuzz
```
### 3. 数据准备
本教程使用[多模态牧歌数据集](https://modelscope.cn/datasets/modelscope/muge/summary)的validation验证集作为入库的图片数据集,可以通过调用ModelScope的[数据集](https://modelscope.cn/docs/%E6%95%B0%E6%8D%AE%E9%9B%86%E4%BB%8B%E7%BB%8D)接口获取。
```
from modelscope.msdatasets import MsDataset
dataset = MsDataset.load("muge", split="validation")
```
具体步骤
-------------
**说明**
本教程所涉及的 *your-xxx-api-key* 以及 *your-xxx-cluster-endpoint* ,均需要替换为您自己的API-KAY及CLUSTER_ENDPOINT后,代码才能正常运行。
### 1. 图片数据Embedding入库
[多模态牧歌数据集](https://modelscope.cn/datasets/modelscope/muge/summary)的 validation 验证集包含 30588 张多模态场景的图片数据信息,这里我们需要通过CLIP模型提取原始图片的Embedding向量入库,另外为了方便后续的图片展示,我们也将原始图片数据编码后一起入库。代码实例如下:
```
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.msdatasets import MsDataset
from dashvector import Client, Doc, DashVectorException, DashVectorCode
from PIL import Image
import base64
import io
def image2str(image):
image_byte_arr = io.BytesIO()
image.save(image_byte_arr, format='PNG')
image_bytes = image_byte_arr.getvalue()
return base64.b64encode(image_bytes).decode()
if __name__ == '__main__':
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 创建集合:指定集合名称和向量维度, CLIP huge 模型产生的向量统一为 1024 维
rsp = client.create('muge_embedding', 1024)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 批量生成图片Embedding,并完成向量入库
collection = client.get('muge_embedding')
pipe = pipeline(task=Tasks.multi_modal_embedding,
model='damo/multi-modal_clip-vit-huge-patch14_zh',
model_revision='v1.0.0')
ds = MsDataset.load("muge", split="validation")
BATCH_COUNT = 10
TOTAL_DATA_NUM = len(ds)
print(f"Start indexing muge validation data, total data size: {TOTAL_DATA_NUM}, batch size:{BATCH_COUNT}")
idx = 0
while idx < TOTAL_DATA_NUM:
batch_range = range(idx, idx + BATCH_COUNT) if idx + BATCH_COUNT <= TOTAL_DATA_NUM else range(idx, TOTAL_DATA_NUM)
images = [ds[i]['image'] for i in batch_range]
# 中文 CLIP 模型生成图片 Embedding 向量
image_embeddings = pipe.forward({'img': images})['img_embedding']
image_vectors = image_embeddings.detach().cpu().numpy()
collection.insert(
[
Doc(
id=str(img_id),
vector=img_vec,
fields={'png_img': image2str(img)}
)
for img_id, img_vec, img in zip(batch_range, image_vectors, images)
]
)
idx += BATCH_COUNT
print("Finish indexing muge validation data")
```
**说明**
上述代码里模型默认在 cpu 环境下运行,在 gpu 环境下会视 gpu 性能得到不同程度的性能提升
### 2. 文本Query检索
完成上述图片数据向量化入库后,我们可以输入文本,通过同样的CLIP Embedding模型获取文本向量,再通过DashVector向量检索服务的检索接口,快速检索相似的图片了,代码示例如下:
```
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.msdatasets import MsDataset
from dashvector import Client, Doc, DashVectorException
from PIL import Image
import base64
import io
def str2image(image_str):
image_bytes = base64.b64decode(image_str)
return Image.open(io.BytesIO(image_bytes))
def multi_modal_search(input_text):
# 初始化 DashVector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('muge_embedding')
# 获取文本 query 的 Embedding 向量
pipe = pipeline(task=Tasks.multi_modal_embedding,
model='damo/multi-modal_clip-vit-huge-patch14_zh', model_revision='v1.0.0')
text_embedding = pipe.forward({'text': input_text})['text_embedding'] # 2D Tensor, [文本数, 特征维度]
text_vector = text_embedding.detach().cpu().numpy()[0]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=3)
image_list = list()
for doc in rsp:
image_str = doc.fields['png_img']
image_list.append(str2image(image_str))
return image_list
if __name__ == '__main__':
text_query = "戴眼镜的狗"
images = multi_modal_search(text_query)
for img in images:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
```
运行上述代码,输出结果如下:

| dashvector | |
1,863,035 | Bringing up BPI-F3 - Part 2.5 | this is a sort of intermission Getting perf to work up to a point Apparently the... | 27,455 | 2024-05-24T07:31:29 | https://dev.to/luzero/bringing-up-bpi-f3-part-25-27o4 | > this is a sort of intermission
## Getting perf to work up to a point
Apparently the [opensbi-mediated](https://github.com/riscv-software-src/opensbi/blob/master/docs/pmu_support.md) access to the performance counter does not map so using the usual `cycles` and `instructions` event works in `perf record`. I got this board mainly to help with [dav1d](https://code.videolan.org/videolan/dav1d) development efforts, so not having perf support would make harder to reason about performance.
The best workaround after a [discussion in the forums](https://forum.banana-pi.org/t/perf-record-does-not-seem-to-work-is-the-device-tree-with-the-wrong-information/18051/11), is to build the `pmu-events` to include custom ones and then rely on the overly precise cpu-specific events instead:
```
$ perf list | grep cycle
bus-cycles [Hardware event]
cpu-cycles OR cycles [Hardware event]
ref-cycles [Hardware event]
stalled-cycles-backend OR idle-cycles-backend [Hardware event]
stalled-cycles-frontend OR idle-cycles-frontend [Hardware event]
m_mode_cycle
[M-mode cycles]
rtu_flush_cycle
s_mode_cycle
[S-mode cycles]
stalled_cycle_backend
[Stalled cycles backend]
stalled_cycle_frontend
[Stalled cycles frontend]
u_mode_cycle
[U-mode cycles]
vidu_total_cycle
vidu_vec0_cycle
vidu_vec1_cycle
...
```
```
$ perf list | grep inst
branch-instructions OR branches [Hardware event]
instructions [Hardware event]
br_inst
[Branch instructions]
cond_br_inst
[Conditional branch instructions]
indirect_br_inst
[Indirect branch instructions]
taken_cond_br_inst
[Taken conditional branch instructions]
uncond_br_inst
[Unconditional branch instructions]
instruction:
alu_inst
[ALU (integer) instructions]
amo_inst
[AMO instructions]
atomic_inst
[Atomic instructions]
bus_fence_inst
[Bus FENCE instructions]
csr_inst
[CSR instructions]
div_inst
[Division instructions]
ecall_inst
[ECALL instructions]
failed_sc_inst
[Failed SC instructions]
fence_inst
[FENCE instructions]
fp_div_inst
[Floating-point division instructions]
fp_inst
[Floating-point instructions]
fp_load_inst
[Floating-point load instructions]
fp_store_inst
[Floating-point store instructions]
load_inst
[Load instructions]
lr_inst
[LR instructions]
mult_inst
[Multiplication instructions]
sc_inst
[SC instructions]
store_inst
[Store instructions]
unaligned_load_inst
[Unaligned load instructions]
unaligned_store_inst
[Unaligned store instructions]
vector_div_inst
[Vector division instructions]
vector_inst
[Vector instructions]
vector_load_inst
[Vector load instructions]
vector_store_inst
[Vector store instructions]
id_inst_pipedown
[ID instruction pipedowns]
id_one_inst_pipedown
[ID one instruction pipedowns]
issued_inst
[Issued instructions]
rf_inst_pipedown
[RF instruction pipedowns]
rf_one_inst_pipedown
[RF one instruction pipedowns]
```
### Building perf
Perf way to deal with cpu-specific events is through some machinery called jevents.
It lives in `tools/perf/pmu-events` and you can manually trigger it with.
``` sh
./jevents.py riscv arch pmu-events.c
```
And produce C code from a bunch of JSON and a CSV map file.
When I tried build the sources the first time I tried to cut it by setting most `NO_{}` make variables and left `NO_JEVENTS=1`, luckily I fixed it after noticing the different output in the forum.
``` sh
## I assume you have here the custom linux sources
cd /usr/src/pi-linux/tools/perf
## being lazy I disabled about everything instead of installing dependencies, one time I disabled too much.
make -j 8 V=1 VF=1 HOSTCC=riscv64-unknown-linux-gnu-gcc HOSTLD=riscv64-unknown-linux-gnu-ld CC=riscv64-unknown-linux-gnu-gcc CXX=riscv64-unknown-linux-gnu-g++ AR=riscv64-unknown-linux-gnu-ar LD=riscv64-unknown-linux-gnu-ld NM=riscv64-unknown-linux-gnu-nm PKG_CONFIG=riscv64-unknown-linux-gnu-pkg-config prefix=/usr bindir_relative=bin tipdir=share/doc/perf-6.8 'EXTRA_CFLAGS=-O2 -pipe' 'EXTRA_LDFLAGS=-Wl,-O1 -Wl,--as-needed' ARCH=riscv BUILD_BPF_SKEL= BUILD_NONDISTRO=1 JDIR= CORESIGHT= GTK2= feature-gtk2-infobar= NO_AUXTRACE= NO_BACKTRACE= NO_DEMANGLE= NO_JEVENTS=0 NO_JVMTI=1 NO_LIBAUDIT=1 NO_LIBBABELTRACE=1 NO_LIBBIONIC=1 NO_LIBBPF=1 NO_LIBCAP=1 NO_LIBCRYPTO= NO_LIBDW_DWARF_UNWIND= NO_LIBELF= NO_LIBNUMA=1 NO_LIBPERL=1 NO_LIBPFM4=1 NO_LIBPYTHON=1 NO_LIBTRACEEVENT= NO_LIBUNWIND=1 NO_LIBZSTD=1 NO_SDT=1 NO_SLANG=1 NO_LZMA=1 NO_ZLIB= TCMALLOC= WERROR=0 LIBDIR=/usr/libexec/perf-core libdir=/usr/lib64 plugindir=/usr/lib64/perf/plugins -f Makefile.perf install
```
Now I have a `perf` with still `cycles` and `instructions` not working with `perf record`, I wonder if there is a way at opensbi or kernel level to aggregate events to make it work properly, but I never had to look into perf internals so probably I poke it way later if nobody address it otherwise, anyway
```
perf record --group -e u_mode_cycle,m_mode_cycle,s_mode_cycle
```
produces something close enough for cycles, well `u_mode_cycle` is enough.
While for instructions the situation is a bit more annoying
```
perf record --group -e alu_inst,amo_inst,atomic_inst,fp_div_inst,fp_inst,fp_load_inst,fp_store_inst,load_inst,lr_inst,mult_inst,sc_inst,store_inst,unaligned_load_inst,unaligned_store_inst
```
is close to count all the scalar instructions, but trying to add `vector_div_inst,vector_inst,vector_load_inst,vector_store_inst` somehow makes perf record stop collecting samples silently, adding just 3 more events works though, so I guess I can be happy with `u_mode_cycle,alu_inst,atomic_inst,fp_inst,vector_inst` at least.
| luzero | |
1,863,662 | HouseofParty: Transforming Events with Neon Signs, Balloon Garlands, and More | Welcome to HouseofParty, the ultimate destination for all your celebration needs. At HouseofParty, we... | 0 | 2024-05-24T07:30:29 | https://dev.to/elizabeth_turner_3a4cbd28/houseofparty-transforming-events-with-neon-signs-balloon-garlands-and-more-jfa | houseofparty, balloons, shimmeringwall, foilballoons | Welcome to HouseofParty, the ultimate destination for all your celebration needs. At HouseofParty, we specialize in transforming ordinary spaces into extraordinary, unforgettable experiences with our extensive collection of party decorations and supplies. Whether you're planning a birthday bash, a bridal shower, a corporate event, or a cozy gathering with friends, we've got everything you need to make your event spectacular.
Our store boasts a wide range of unique and vibrant decorations that are sure to impress your guests. One of our most popular items is our neon signs. These eye-catching signs come in various shapes, sizes, and colors, adding a fun and modern touch to any event. Whether you want to spell out a special message or create a dazzling backdrop, our neon signs are sure to illuminate your party and create the perfect Instagram-worthy moments.
Another highlight of [HouseofParty](https://houseofparty.com/) is our stunning balloon garlands. Our balloon garlands are expertly crafted to create a whimsical and festive atmosphere. Available in an array of colors and themes, these garlands are perfect for framing entrances, photo booths, or dessert tables. Each garland is customizable, allowing you to choose the color scheme that best matches your event's aesthetic. Our balloon garlands are made from high-quality materials to ensure they last throughout your celebration and beyond.
For those looking to add a touch of glamour and sparkle to their event, our shimmering wall decorations are a must-have. These walls are adorned with shimmering sequins or metallic panels that catch the light beautifully, creating a dazzling backdrop for photos and selfies. Available in various colors, our shimmering walls can be tailored to match your event's theme, making them a versatile and show-stopping addition to any party decor.
Our foil balloons are another favorite among our customers. These balloons come in a wide range of shapes, sizes, and designs, from classic stars and hearts to customized letters and numbers. Foil balloons are perfect for creating stunning balloon bouquets, centerpieces, or even floating arrangements that add a touch of elegance and fun to your event. Their reflective surface catches the light, making them a striking feature in any setting.
At HouseofParty, we understand that every event is unique, and we are committed to helping you bring your vision to life. Our team of experienced party planners and decorators is always on hand to provide expert advice and creative ideas to ensure your event is a success. We take pride in offering high-quality products and exceptional customer service, making us your go-to source for all things party-related.
In addition to our [best custom neon signs](https://houseofparty.com/collections/balloon-garlands), balloon garlands, shimmering walls, and foil balloons, we offer a wide range of other decorations and party supplies. From tableware and banners to confetti and streamers, we've got everything you need to create a cohesive and stylish party atmosphere. We also offer personalized items and custom orders to add that special touch to your celebration.
Visit HouseofParty today and discover how we can help you turn your next event into an unforgettable celebration. With our extensive range of decorations and our commitment to quality and creativity, we are here to make your party planning experience enjoyable and stress-free. Let us help you create memories that will last a lifetime. | elizabeth_turner_3a4cbd28 |
1,863,659 | DashVector + DashScope升级多模态检索 | 本教程在前述教程(DashVector +... | 0 | 2024-05-24T07:25:53 | https://dev.to/dashvector/dashvector-dashscopesheng-ji-duo-mo-tai-jian-suo-4nl2 | 本教程在前述教程(DashVector + ModelScope玩转多模态检索)的基础之上,基于DashScope上新推出的ONE-PEACE通用多模态表征模型结合向量检索服务DashVector来对多模态检索进行升级,接下来我们将展示更丰富的多模态检索能力。
* [DashVector + ModelScope 玩转多模态检索](https://help.aliyun.com/document_detail/2510236.html?spm=a2c4g.2568028.0.i10)
* [DashScope](https://dashscope.aliyun.com/)
* [ONE-PEACE多模态模型](https://help.aliyun.com/zh/dashscope/developer-reference/one-peace-multimodal-embedding-quick-start)
**整体流程**
-------------------------
主要分为两个阶段:
1. **多模态数据Embedding入库** 。通过ONE-PEACE模型服务[Embedding](https://help.aliyun.com/zh/dashscope/developer-reference/one-peace-multimodal-embedding-api-details)接口将多种模态的数据集数据转化为高维向量。
2. **多模态Query检索** 。基于ONE-PEACE模型提供的多模态Embedding能力,我们可以自由组合不同模态的输入,例如单文本、文本+音频、音频+图片等多模态输入,获取Embedding向量后通过DashVector跨模态检索相似结果。
**前提准备**
-------------------------
### **1. API-KEY 准备**
* 开通灵积模型服务,并获得API-KEY:[开通DashScope并创建API-KEY](t2312925.md#)
* 开通DashVector向量检索服务,并获得API-KEY:[API-KEY管理](t2364363.md#)
### 2. 环境准备
本教程使用的多模态推理模型服务是DashScope最新的[ONE-PEACE模型](https://help.aliyun.com/zh/dashscope/developer-reference/one-peace-multimodal-embedding-root)。ONE-PEACE是一个图文音三模态通用表征模型,在语义分割、音文检索、音频分类和视觉定位几个任务都达到了新SOTA表现,在视频分类、图像分类图文检索、以及多模态经典benchmark也都取得了比较领先的结果。模型相关的环境依赖如下:
**说明**
需要提前安装Python3.7 及以上版本,请确保相应的python版本。
```
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
```
基本检索
-------------
### 1. 数据准备
**说明**
由于DashScope的ONE-PEACE模型服务当前只支持URL形式的图片、音频输入,因此需要将数据集提前上传到公共网络存储(例如 oss/s3),并获取对应图片、音频的url地址列表。
当前示例场景使用[ImageNet-1k](https://www.image-net.org/index.php)的validation数据集作为入库的图片数据集,将原始图片数据Embedding入库。检索时使用[ESC-50](https://github.com/karolpiczak/ESC-50)数据集作为音频输入,文本和图片输入由用户自定义,用户也可对不同模态数据自由组合。
* [Dataset for ImageNet-1k](https://www.image-net.org/download.php)
* [Dataset for ESC-50](https://github.com/karolpiczak/ESC-50)
### 2. 数据Embedding入库
**说明**
本教程所涉及的 *your-xxx-api-key* 以及 *your-xxx-cluster-endpoint* ,均需要替换为您自己的API-KAY及CLUSTER_ENDPOINT后,代码才能正常运行。
ImageNet-1k的validation数据集包含50000张标注好的图片数据,其中包含1000个类别,每个类别50张图片,这里我们基于ONE-PEACE模型提取原始图片的Embedding向量入库,另外为了方便后续的图片展示,我们也将原始图片的url一起入库。代码示例如下:
```
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client, Doc, DashVectorException
dashscope.api_key = '{your-dashscope-api-key}'
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
def index_image():
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
rsp = client.create('imagenet1k_val_embedding', 1536)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
collection = client.get('imagenet1k_val_embedding')
with open(IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('\n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
if __name__ == '__main__':
index_image()
```
**说明**
1. 上述代码需要访问DashScope的ONE-PEACE多模态Embedding模型,总体运行速度视用户开通该服务的qps有所不同。
2. 因图片大小影响ONE-PEACE模型获取Embedding的成功与否,上述代码运行后最终入库数据可能小于50000条。
### 3. 模态检索
#### **3.1. 文本检索**
对于单文本模态检索,可以通过ONE-PEACE模型获取文本Embedding向量,再通过DashVector向量检索服务的检索接口,快速检索相似的底库图片。这里文本query是猫 "cat",代码示例如下:
```
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(input_text):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""文本检索"""
# 猫
text_query = "cat"
show_image(text_search(text_query))
```
运行上述代码,检索结果如下:

#### 3.2. 音频检索
单音频模态检索与文本检索类似,这里音频query取自ESC-50的"猫叫声"片段,代码示例如下:
```
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def audio_search(input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('imagenet1k_val_embedding')
# 获取音频 query 的 Embedding 向量
input = [{'audio': input_audio}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
audio_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""音频检索"""
# 猫叫声
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(audio_search(audio_url))
```
运行上述代码,检索结果如下:

#### 3.3. 文本+音频检索
接下来,我们尝试"文本+音频"联合模态检索,同上,首先通过ONE-PEACE模型获取"文本+音频"输入的Embedding向量,再通过DashVector向量检索服务检索结果。这里的文本query选取的是草地"grass",音频query依然选择的是ESC-50的"猫叫声"片段。代码示例如下:
```
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_audio_search(input_text, input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('imagenet1k_val_embedding')
# 获取文本+音频 query 的 Embedding 向量
input = [
{'text': input_text},
{'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_audio_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""文本+音频检索"""
# 草地
text_query = "grass"
# 猫叫声
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(text_audio_search(text_query, audio_url))
```
运行上述代码,检索结果如下:

#### 3.4. 图片+音频检索
我们再尝试下"图片+音频"联合模态检索,与前述"文本+音频"检索类似,这里的图片选取的是草地图像(需先上传到公共网络存储并获取 url),音频query依然选择的是ESC-50的"猫叫声"片段。代码示例如下:
```
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def image_audio_search(input_image, input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('imagenet1k_val_embedding')
# 获取图片+音频 query 的 Embedding 向量
# 注意,这里音频 audio 模态输入的权重参数 factor 为 2(默认为1)
# 目的是为了增大音频输入(猫叫声)对检索结果的影响
input = [
{'factor': 1, 'image': input_image},
{'factor': 2, 'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
image_audio_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(image_audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""图片+音频检索"""
# 草地
image_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/image-dataset/grass-field.jpeg"
# 猫叫声
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(image_audio_search(image_url, audio_url))
```
输入示意图如下:

运行代码,检索结果如下:

进阶使用
-------------
上述场景里作为检索底库数据的是单模态的图片数据,这里我们也可以将多种模态的数据同时通过ONE-PEACE模型获取Embedding向量,将Embedding向量作为检索库数据入库检索,观察检索效果。
### 1. 数据准备
本示例场景使用[微软COCO](https://cocodataset.org/)在Captioning场景下的validation数据集,将图片以及对应的图片描述caption文本两种模态数据一起Embedding入库。对于检索时输入的图片、音频与文本等多模态数据,用户可以自定义,也可以使用公共数据集的数据。
* [Dataset for MSCOCO](https://cocodataset.org/#download)
### 2. 数据Embedding入库
**说明**
本教程所涉及的 *your-xxx-api-key* 以及 *your-xxx-cluster-endpoint* ,均需要替换为您自己的API-KAY及CLUSTER_ENDPOINT后,代码才能正常运行。
微软COCO的Captioning validation验证集包含5000张标注良好的图片及对应的说明文本,这里我们需要通过 DashScope的ONE-PEACE模型提取数据集的"图片+文本"的Embedding向量入库,另外为了方便后续的图片展示,我们也将原始图片url和对应caption文本一起入库。代码示例如下:
```
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client, Doc, DashVectorException
dashscope.api_key = '{your-dashscope-api-key}'
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url 和对应的 caption 文本,以`;`分割
COCO_CAPTIONING_URLS_FILE_PATH = "cocoval5k-urls-captions.txt"
def index_image_text():
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
rsp = client.create('coco_val_embedding', 1536)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
collection = client.get('coco_val_embedding')
with open(COCO_CAPTIONING_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url, caption = line.strip('\n').split(";")
input = [
{'text': caption},
{'image': url},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url, 'image_caption': caption}
)
)
if (i + 1) % 20 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
if __name__ == '__main__':
index_image_text()
```
**说明**
上述代码需要访问DashScope的ONE-PEACE多模态Embedding模型,总体运行速度视用户开通该服务的qps有所不同。
### 3. 模态检索
#### 3.1. 文本检索
首先我们尝试单文本模态检索。代码示例如下:
Python
```python
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
print(cap)
def text_search(input_text):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('coco_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
"""文本检索"""
# 狗
text_query = "dog"
show_image_text(text_search(text_query))
```
运行上述代码,检索结果如下:
#### 3.2. 音频检索
我们再尝试单音频模态检索。我们使用ESC-50数据集的"狗叫声片段"作为音频输入,代码示例如下:
```
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
print(cap)
def audio_search(input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('coco_val_embedding')
# 获取音频 query 的 Embedding 向量
input = [{'audio': input_audio}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
audio_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(audio_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
""""音频检索"""
# dog bark
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-100032-A-0.wav"
show_image_text(audio_search(audio_url))
```
运行上述代码,检索结果如下:

#### 3.3. 文本+音频检索
进一步的,我们尝试使用"文本+音频"进行双模态检索。这里使用ESC-50数据集的"狗叫声片段"作为音频输入,另外使用"beach"作为文本输入,代码示例如下:
```
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
print(cap)
def text_audio_search(input_text, input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('coco_val_embedding')
# 获取文本+音频 query 的 Embedding 向量
input = [
{'text': input_text},
{'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_audio_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_audio_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
"""文本+音频检索"""
text_query = "beach"
# 狗叫声
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-100032-A-0.wav"
show_image_text(text_audio_search(text_query, audio_url))
```
运行上述代码,检索结果如下:

观察上述检索结果,发现后两张图的重点更多的是在展示 "beach" 文本输入对应的沙滩,而 "狗叫声片段"音频输入指示的狗的图片形象则不明显,其中第二张图需要放大后才可以看到图片中站立在水中的狗,第三张图中基本没有狗的形象。
对于上述情况,我们可以通过[调整不同输入的权重](https://help.aliyun.com/zh/dashscope/developer-reference/one-peace-multimodal-embedding-api-details)来设置mbedding向量中哪种模态占更大的比重,从而在检索中突出重点。例如对于上述代码,我们可以给予"狗叫声片段"更大的权重,重点突出检索结果里狗的形象。
```
# 其他代码一致
# 通过 `factor` 参数来调整不同模态输入的权重,默认为 1,这里设置 audio 为 2
input = [
{'factor': 1, 'text': input_text},
{'factor': 2, 'audio': input_audio},
]
```
替换 `input`后,运行上述代码,结果如下:

写在最后
-------------
本文结合[DashScope](https://dashscope.aliyun.com)的ONE-PEACE模型的和[DashVector](https://help.aliyun.com/document_detail/2510225.html?spm=a2c4g.2568028.0.i13)向量检索服务向大家展示了丰富多样的多模态检索示例,得益于ONE-PEACE模型优秀的多模态Embedding能力和DashVector强大的向量检索能力,我们能初步看到AI多模态检索令人惊喜的效果。
本文的范例中,我们的向量检索服务,模型服务以及数据均可以公开获取,我们提供的示例也只是有限的展示了多模态检索的效果,非常欢迎大家来体验,自由发掘多模态检索的潜力。
| dashvector | |
1,863,658 | Web3 and the Democratization of the Internet | Web3 is ushering in a new era of the internet, characterized by decentralization, transparency, and... | 0 | 2024-05-24T07:25:41 | https://dev.to/alexroor4/web3-and-the-democratization-of-the-internet-1nmj | webdev, news, web3 | Web3 is ushering in a new era of the internet, characterized by decentralization, transparency, and user empowerment. Unlike the current centralized web, Web3 aims to democratize the internet, giving users control over their data and digital interactions.
Decentralized Ownership and Control
At the heart of Web3 is the concept of decentralized ownership. In the traditional Web2 model, a few large corporations control most of the internet's infrastructure and data. This centralization leads to issues like data breaches, censorship, and lack of user autonomy.
Web3 shifts the control from these centralized entities to individual users through blockchain technology. By distributing data across a network of nodes, Web3 ensures that no single entity has control over the entire network. This decentralization enhances security and fosters a more open and equitable internet.
Token Economy and Incentives
Web3 introduces a token economy, where digital tokens are used to incentivize and reward network participants. These tokens can represent various assets, including currency, ownership stakes, or access rights. Users can earn tokens by contributing to the network, such as providing computing power, creating content, or maintaining the blockchain.
This token-based incentive model encourages active participation and collaboration, driving the growth and sustainability of decentralized networks. It also allows users to monetize their contributions, creating new economic opportunities and reducing the reliance on traditional financial systems.
Interoperability and Composability
One of the strengths of Web3 is its focus on interoperability and composability. Interoperability refers to the ability of different blockchain networks and protocols to work together seamlessly. This enables users to transfer assets and data across various platforms without friction.
Composability allows developers to build on top of existing protocols and applications, creating a modular and flexible ecosystem. This approach fosters innovation and accelerates the development of new decentralized applications (dApps), as developers can leverage existing infrastructure and integrate various services.
Challenges and Opportunities
While Web3 holds great promise, it also faces significant challenges. Scalability, user experience, and regulatory uncertainty are some of the hurdles that need to be addressed for widespread adoption. However, the rapid pace of innovation and the growing interest in decentralized technologies suggest that these challenges will be overcome.
Opportunities abound in the Web3 space, from decentralized finance (DeFi) and non-fungible tokens (NFTs) to decentralized social networks and data marketplaces. As more people recognize the benefits of a decentralized internet, we can expect to see a surge in Web3 adoption and innovation.
Conclusion
Web3 is more than just a technological advancement; it represents a fundamental shift in how we interact with the internet. By decentralizing ownership and control, creating a token economy, and promoting interoperability, Web3 aims to democratize the digital world.
As we move towards this new era, the principles of Web3 will shape the future of the internet, making it more transparent, secure, and user-centric. The journey towards a fully decentralized web is just beginning, and the potential impact on society is profound. | alexroor4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.