
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,863,476 | How to Create a Virtual Machine (Windows 11 Pro) | Login to Azure Portal Locate the search field In the search field, type virtual machine Select... | 0 | 2024-05-24T02:19:49 | https://dev.to/opsyog/create-a-virtual-machine-4boj |
**Login to Azure Portal**
**Locate the search field**

**In the search field, type virtual machine**
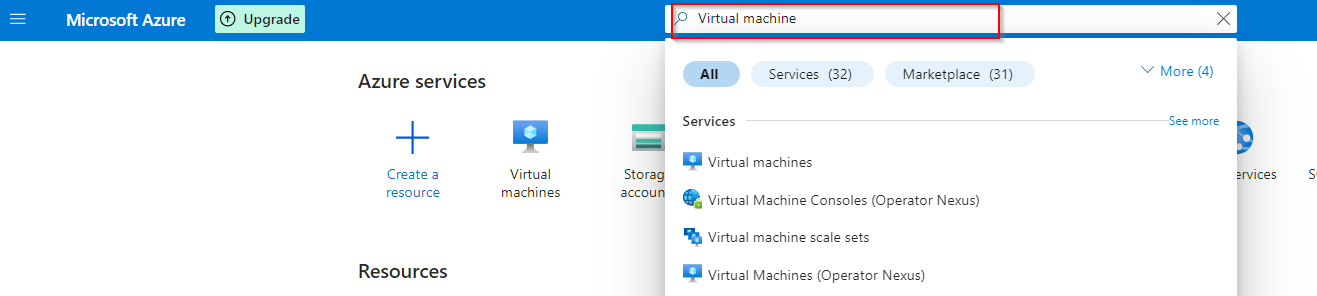
**Select Virtual machine from the list of options**
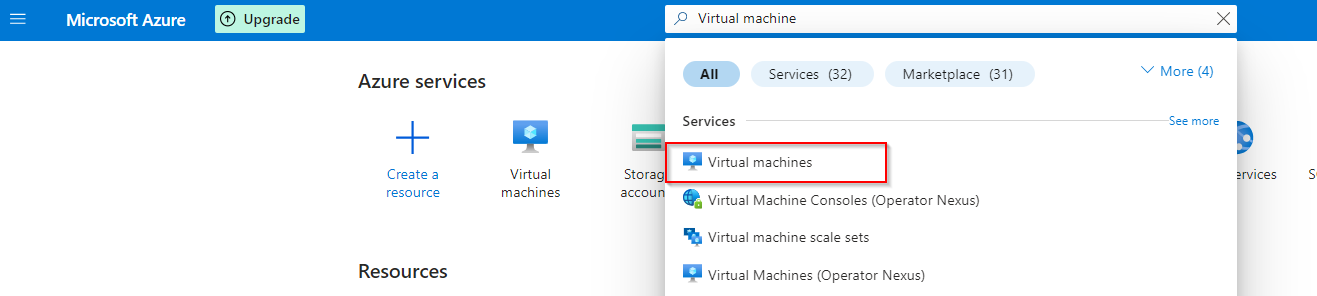
**Click "Create"**
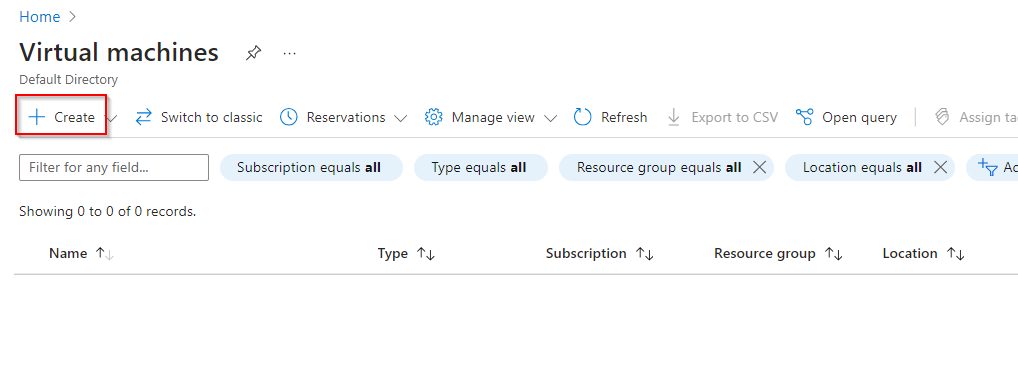
**Select Azure Virtual Machine**
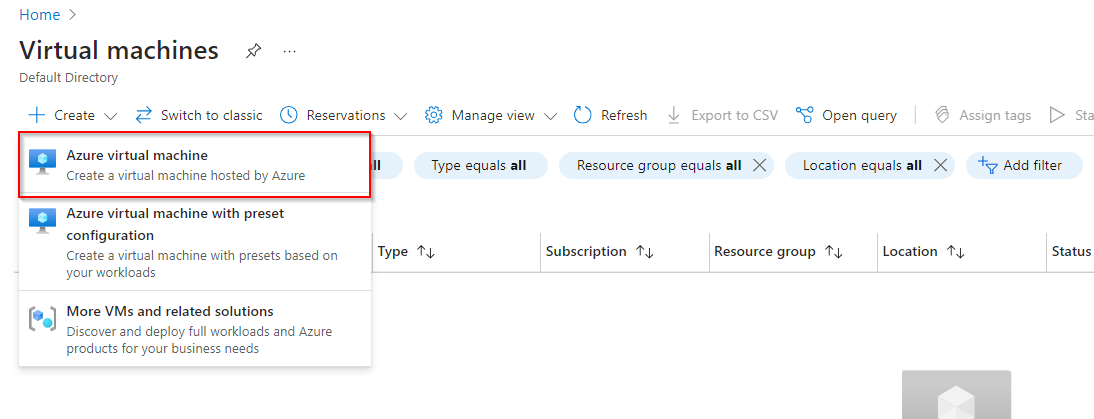
**Create a Virtual Machine**
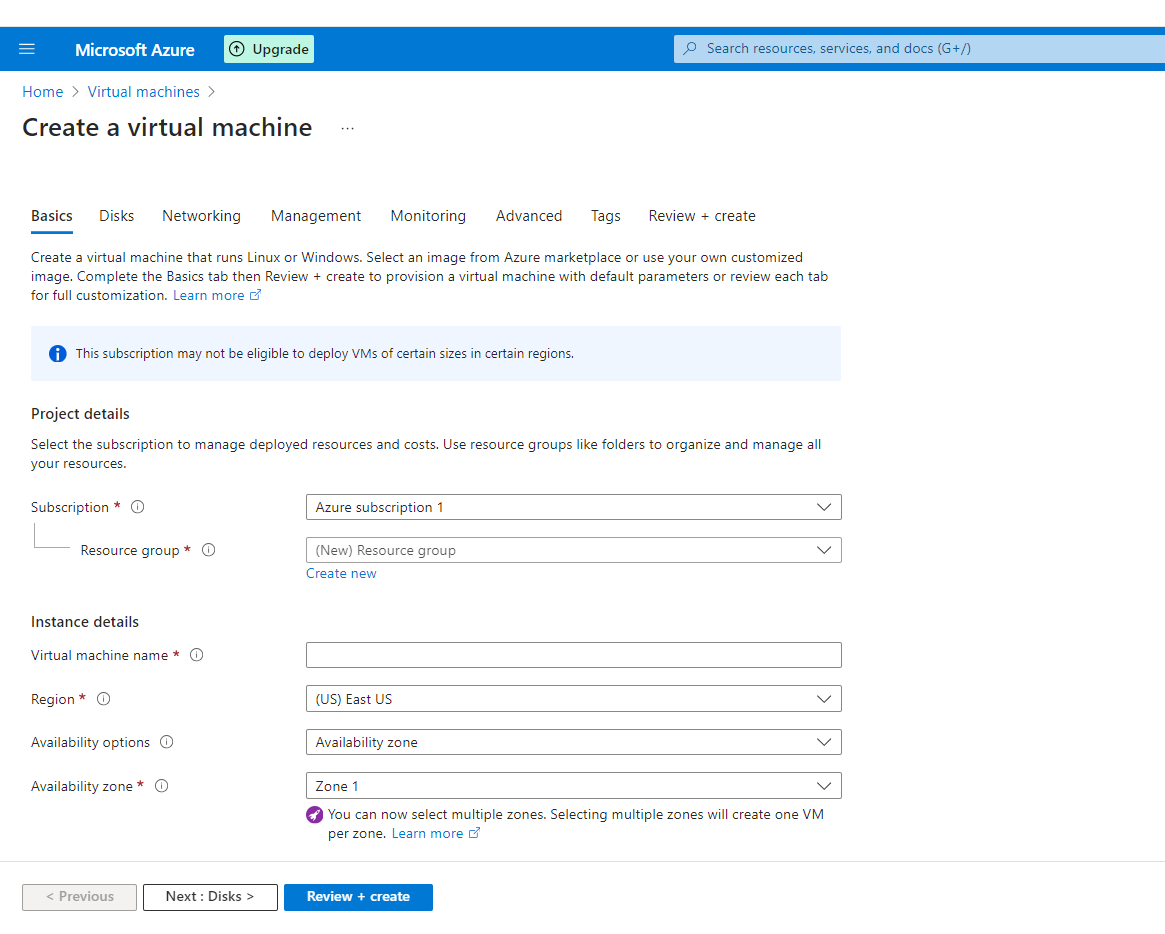
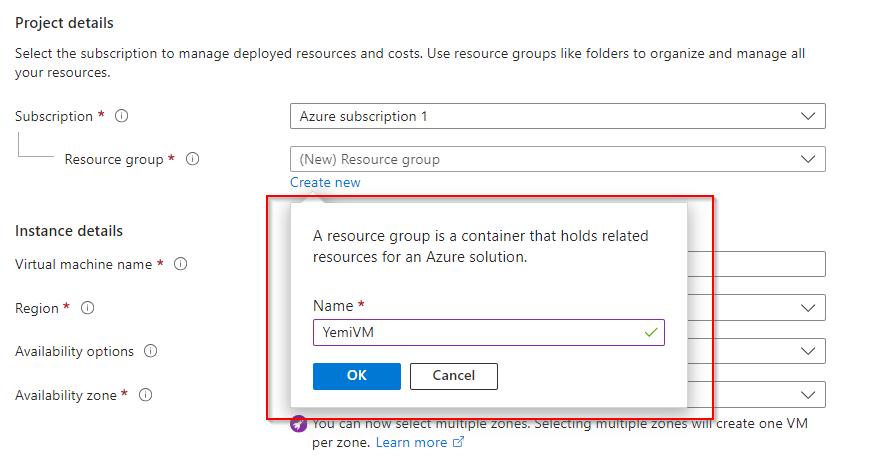
**Create new Resource Group**

**Name Resource Group**
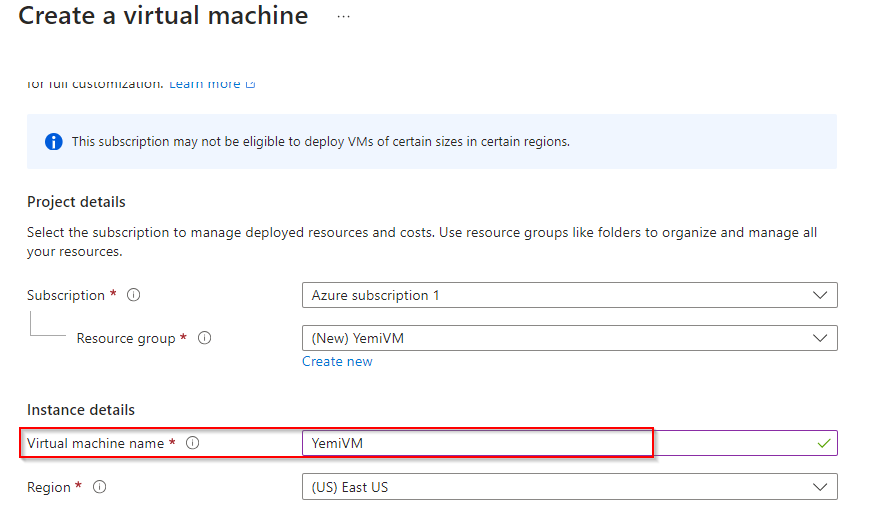
**Enter Virtual Machine Name**
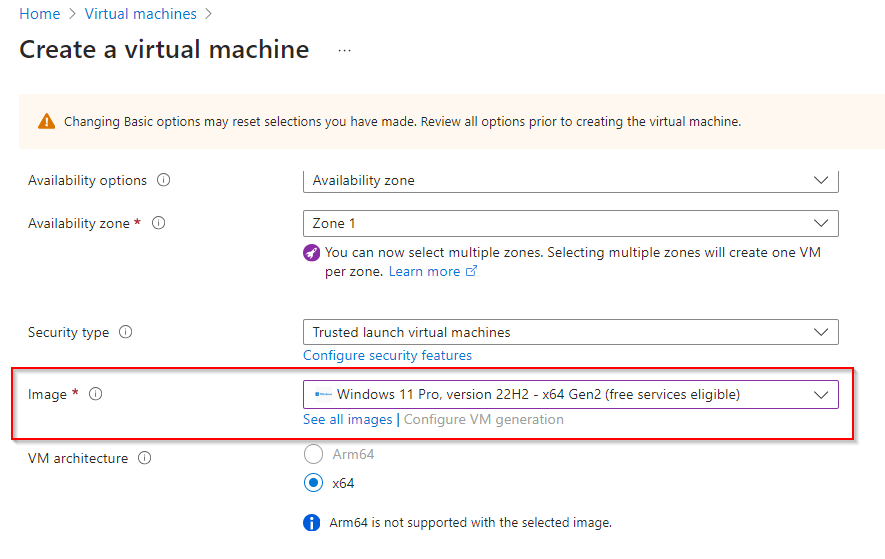
**Select Image "Windows 11 Pro, Version 22H2..."**
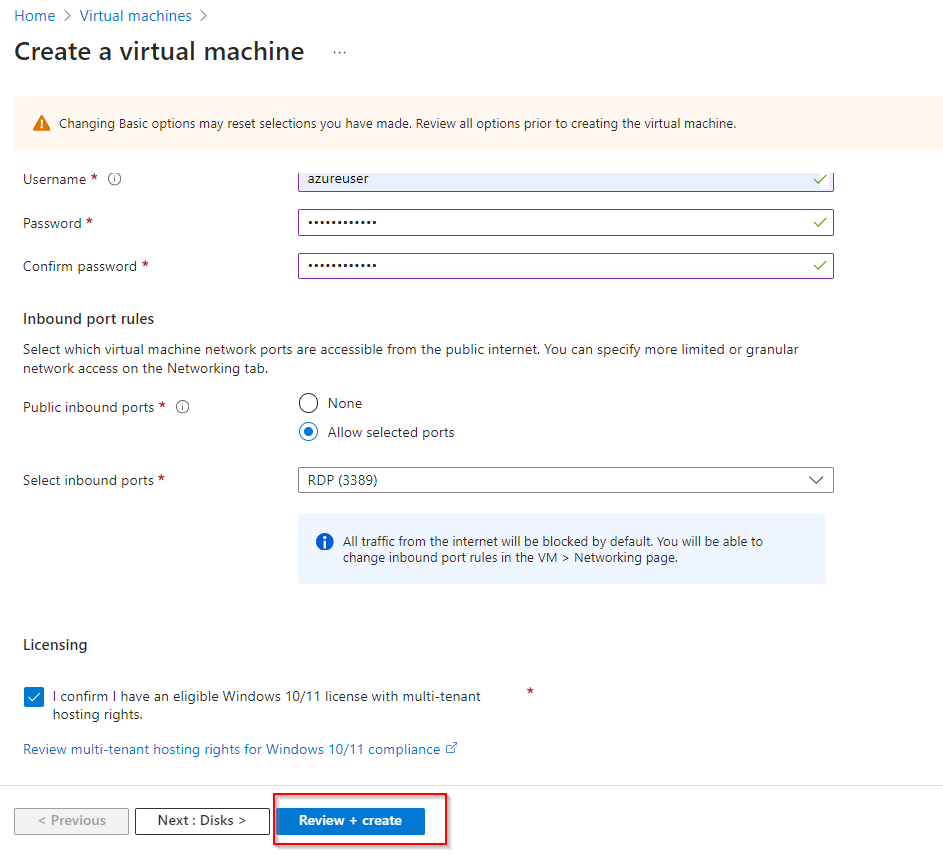
**Authentication Type as password and enter username and password**
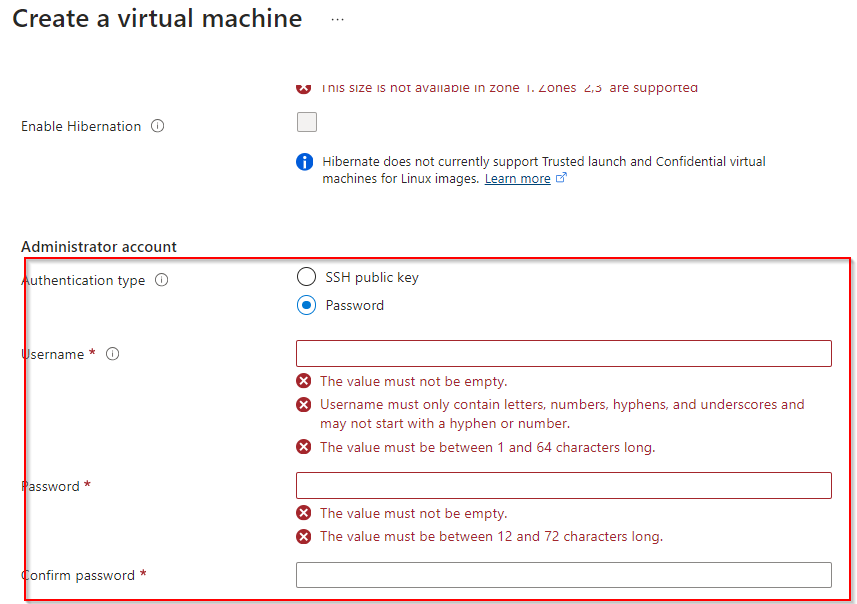
**Select inbound port rule as "RDP"**
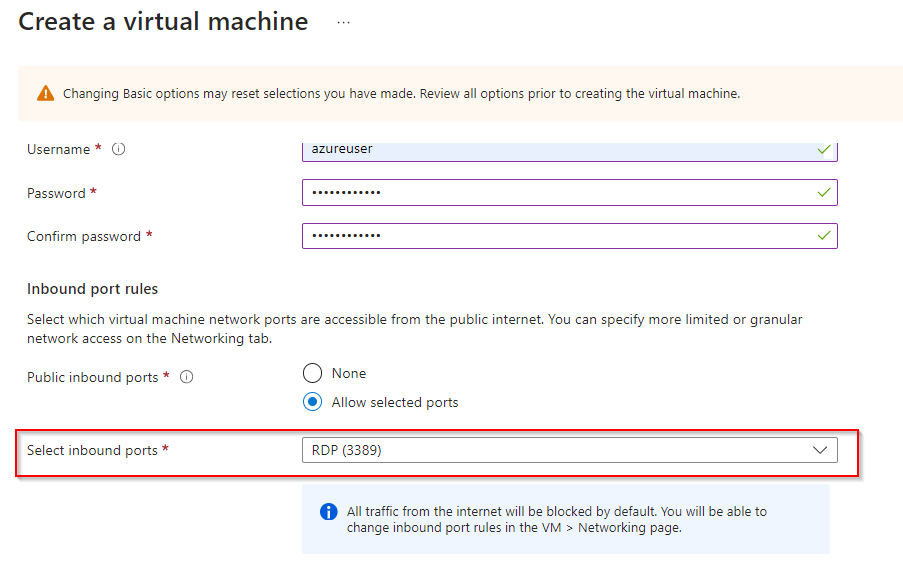
**Check Licensing**
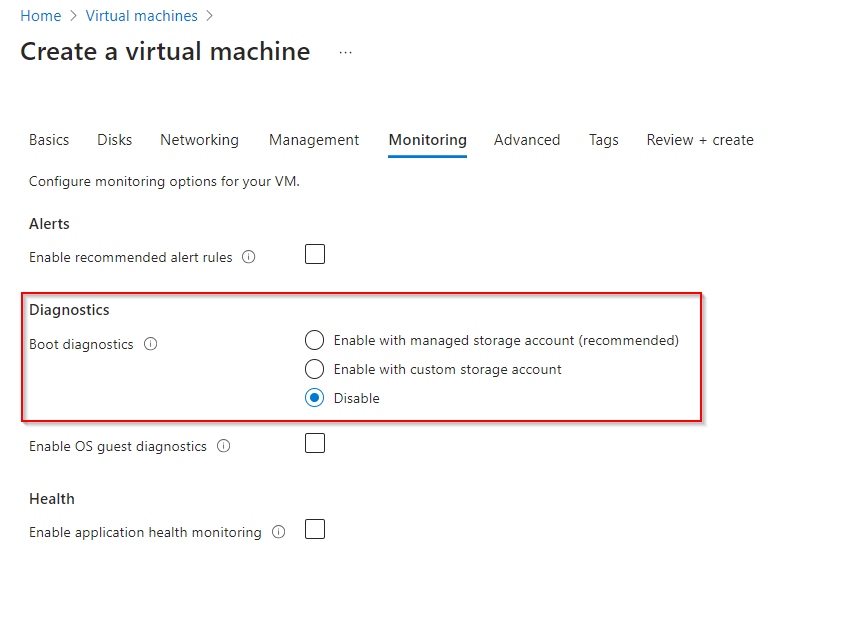
**Click on "Monitoring" Tab**
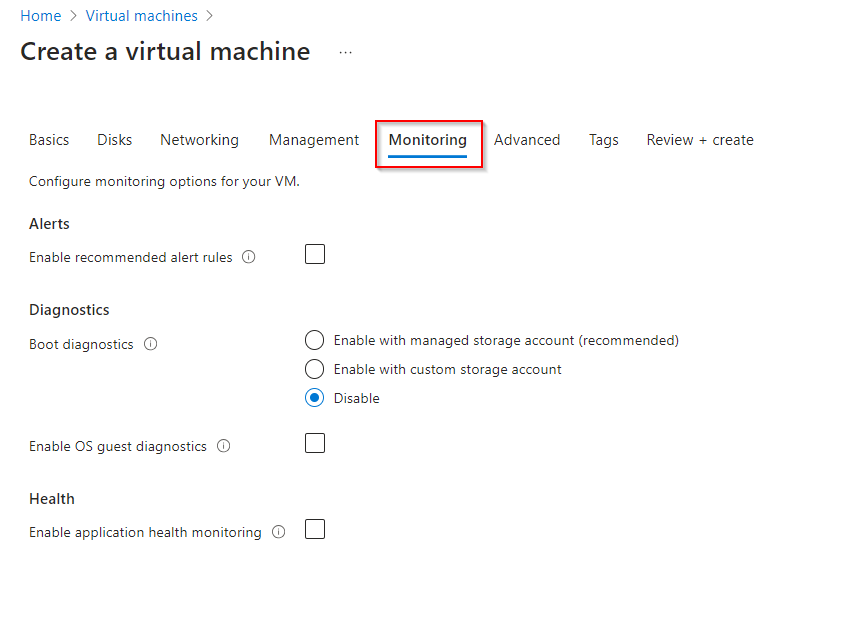
**Disable Diagnostics in Monitoring Tab**
**Review and Create**
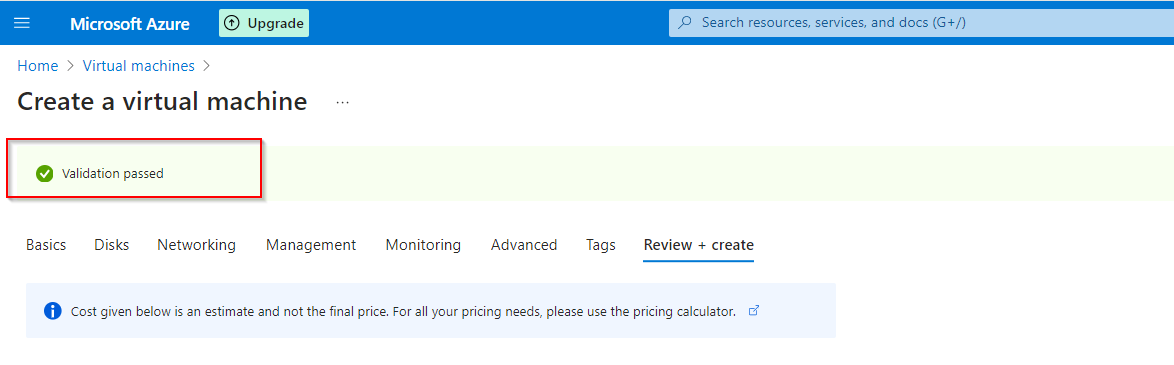
**Validation**
**Click "Create"**
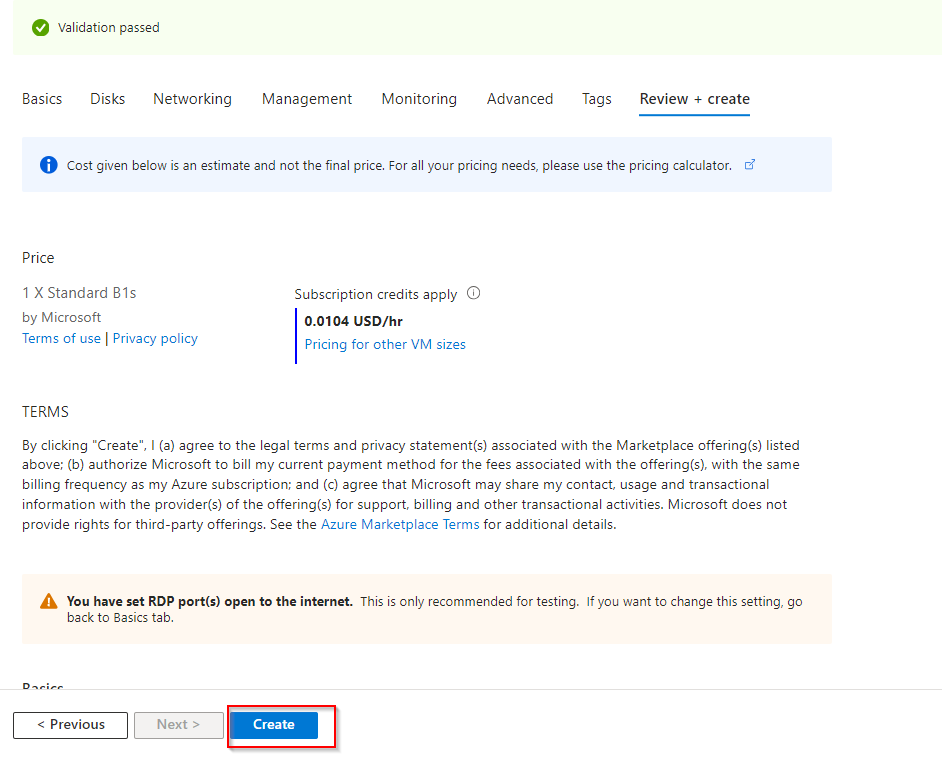
**Confirm Deployment**
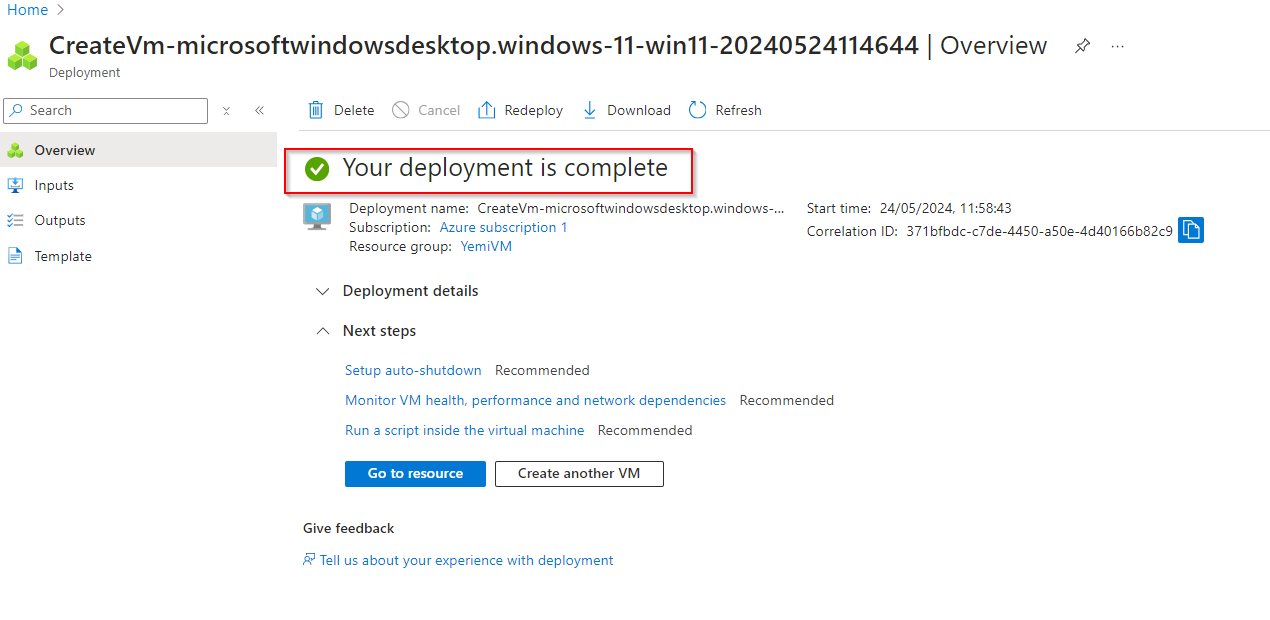
**Click on "Go to resource" **
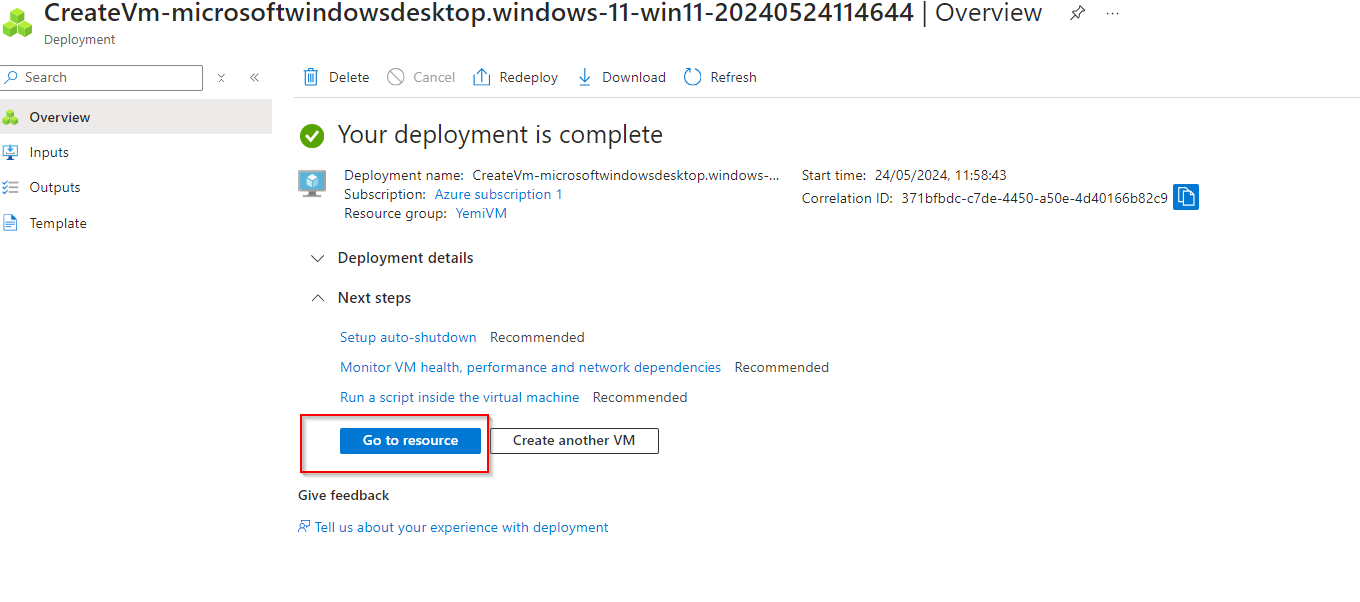
**Click on "Connect"**
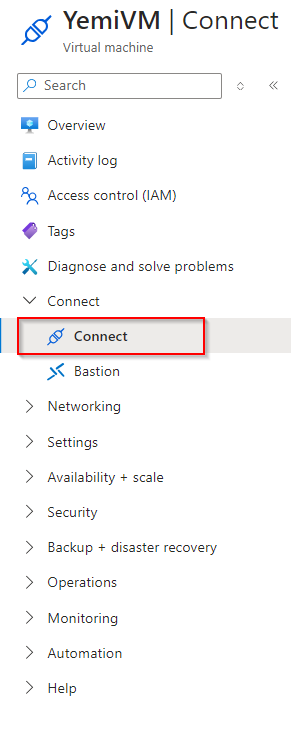
**Select Native RDP & Click "Select"**
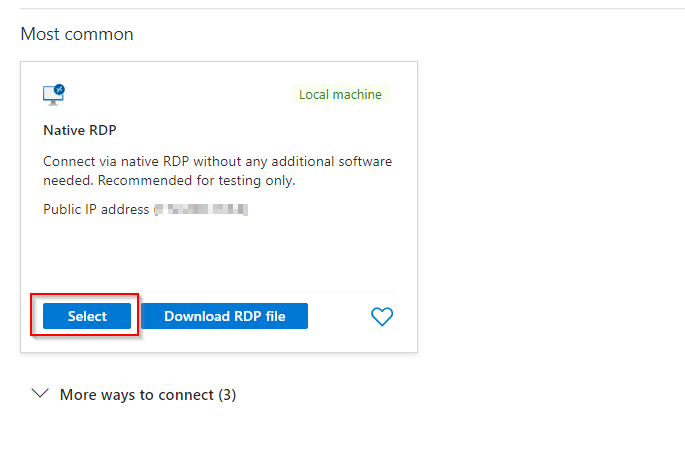
**Ensure all configurations are ticked green and configured**
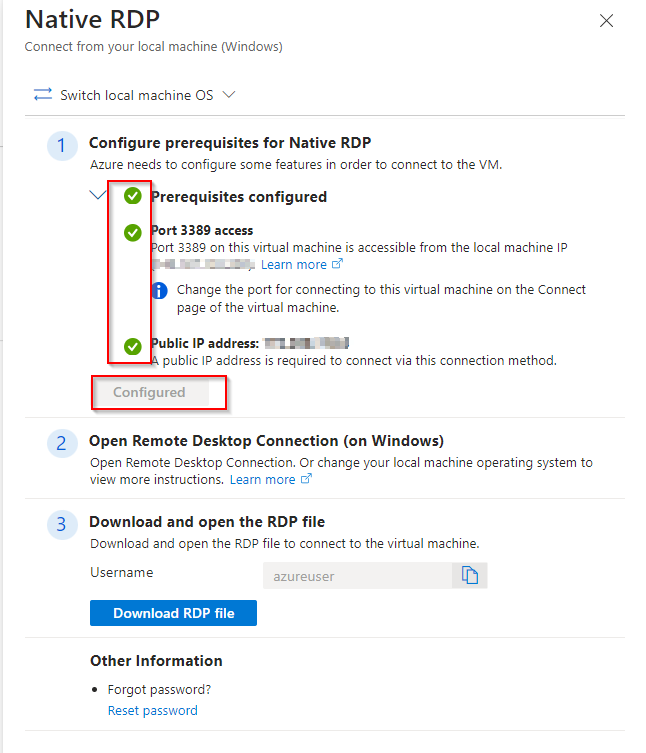
**Download RDP File**
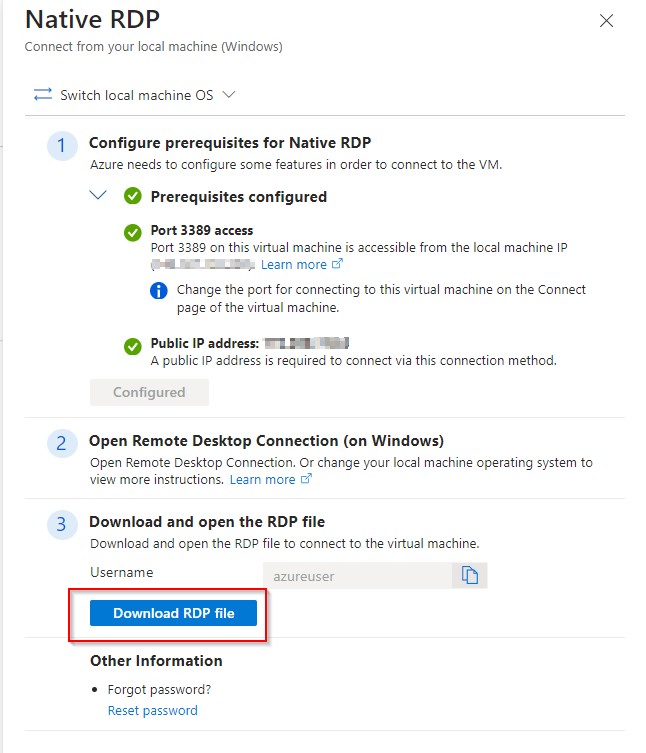
Further installation settings will be required and you will be able to access your virtual machine.
| opsyog | |
1,863,475 | Full-color LED display: the integration of rich colors and technological innovation | In today's digital era, the importance of visual communication has become increasingly prominent, and... | 0 | 2024-05-24T02:19:37 | https://dev.to/sostrondylan/full-color-led-display-the-integration-of-rich-colors-and-technological-innovation-50ik | led, display, technological | In today's digital era, the importance of visual communication has become increasingly prominent, and full-color LED display screens, as an important medium for information display, have become the first choice in advertising, publicity, display and other fields with their unique color expression and high definition. This article will delve into the working principle of [full-color LED displays](https://www.sostron.com/product?category=2) and their application value in modern society.

Introduction to full-color LED display
LED display screens can be divided into three types: single color, double color and full color according to color classification. Full-color LED display, as the name suggests, refers to a display that can display three basic colors of red, green and blue. Through different combinations of these three colors, up to 16,777,216 colors can be generated, thereby achieving high saturation and high resolution. High-definition and richly colored dynamic picture images. [What should I do if the LED display screen cannot load images? ](https://www.sostron.com/service/faq/4332)

Full color LED display performance characteristics
The performance advantages of full-color LED displays are mainly reflected in the following aspects:
Nonlinear correction technology: Through nonlinear correction technology, the screen image is clearer and has a distinct sense of layering. [Here is the technological evolution of LED screens. ](https://sostron.com/service/faq/3274)
Stable performance: The use of layout scanning technology and modular design ensures the stable performance of the display.
Diversified display: Supports multiple playback formats and screen display modes to meet the display needs of different scenarios.
Easy to operate: Equipped with video playback software and an operating system unique to the LED display, simplifying the operation process. [Take you 5 minutes to understand the LED display control system. ](https://www.sostron.com/service/faq/4384)

Working principle of full-color LED display
The working principle of the full-color LED display is relatively complex and mainly consists of the following parts:
Main controller: Responsible for obtaining the brightness data of each color of each pixel of a screen from the computer display card and assigning it to the scanning board.
Scanning board: controls several rows (columns) on the LED display and is responsible for transmitting signals to the display control unit.
Display control unit: Directly facing the LED display body, it is responsible for controlling the brightness and color of the LED lamp beads.
LED display body: It is composed of thousands of LED lamp beads and is the physical carrier that ultimately forms the image. [Provide you with the working principle of LED lamp beads. ](https://www.sostron.com/service/faq/7842)
The main controller converts the signal from the computer display card into the data and control signal format required by the LED display. The display control unit usually consists of a shift register and a latch with grayscale control function to achieve precise control of the brightness of the LED lamp beads. The scanning board plays a role as a link between the previous and the following. It not only receives the video signal from the main controller, but also transmits the data to the display control unit, and coordinates the differences in space, time, sequence, etc. between the video signal and the LED display data.

Application of full-color LED display
With its unique advantages, full-color LED displays have been widely used in various industries, especially in the following fields:
Advertising industry: used for outdoor billboards, shopping mall displays, etc. to attract customers' attention.
Promotional activities: Provide real-time information and visual enjoyment at various event sites, such as sports events, concerts, etc.
Exhibition display: Display high-definition images and videos in museums, exhibitions and other places to enhance the audience experience.
Conclusion
The working principle of the full-color LED display reflects the innovation of modern display technology. Its advantages in color performance, clarity and stability make it an indispensable visual communication tool in modern society. With the continuous advancement of technology, the application range of full-color LED displays will be further expanded, bringing more convenience and fun to people's lives and work.
Thank you for watching. I hope we can solve your problems. Sostron is a professional [LED display manufacturer](https://sostron.com/about). We provide all kinds of displays, display leasing and display solutions around the world. If you want to know: [LED display: stage art revolution.](https://dev.to/sostrondylan/led-display-stage-art-revolution-4aa2) Please click read.
Follow me! Take you to know more about led display knowledge.
Contact us on WhatsApp:https://api.whatsapp.com/send/?phone=8613570218702&text&type=phone_number&app_absent=0 | sostrondylan |
1,863,473 | Understanding Lasso Regularization: Enhancing Model Performance and Feature Selection | Lasso regularization is a powerful technique in machine learning, which is used to prevent... | 0 | 2024-05-24T02:16:33 | https://dev.to/harsimranjit_singh_0133dc/understanding-lasso-regularization-enhancing-model-performance-and-feature-selection-330p | Lasso regularization is a powerful technique in machine learning, which is used to prevent overfitting. But lasso goes a step further- it can also help us identify the most important features of the model. In this article today we will discuss the theoretical aspects of lasso along with its mathematical formulation.
## Lasso Regularization
Lasso regularization is designed to enhance model sparsity, meaning it can zero out coefficients of less important features, effectively performing feature selection. This is particularly useful in high-dimensional data scenarios where we want to identify the most relevant predictors.
## Mathematical formulation
Lasso regularization modifies the objective function (linear regression)by adding a penalty term to the function. This penalty is the L1 norm of the coefficient vector defined as the sum of the absolute values of the coefficients
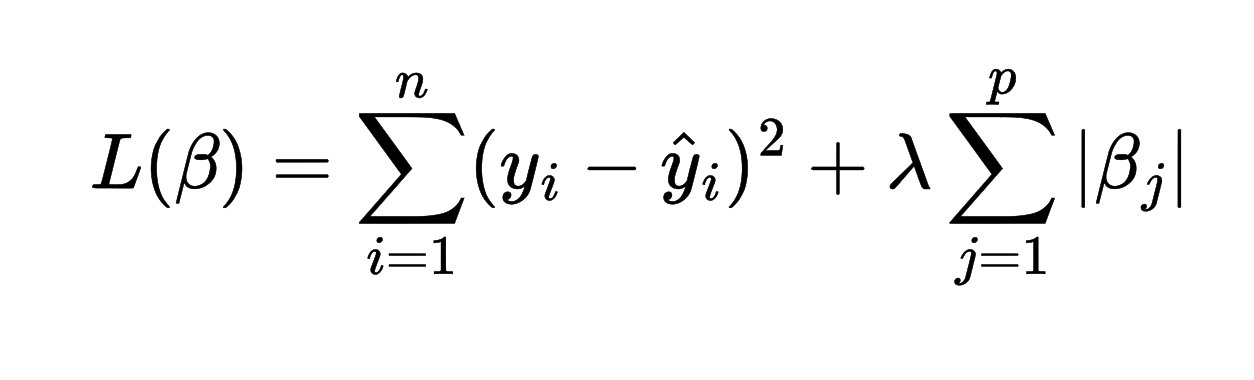
where:
- lambda is the regularization parameter that controls the strength of the penalty.
- another term is the L1 norm
The L1 penalty encourages sparsity in the model by shrinking some coefficients to zero, effectively performing the feature selection.
## Benefits of Lasso Regularization
- **Feature Selection:** Lasso can automatically perform feature selection by setting the coefficients of less important features to zero.
- **Prevents Overfitting:** By reducing the variance of model, the lasso helps to prevent overfitting.
## Practical Implementation
```
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=10, noise=0.1, random_state=42)
lasso = Lasso(alpha=0.1)
lasso.fit(X, y)
plt.figure(figsize=(12, 6))
plt.plot(range(X.shape[1]), lasso.coef_, marker='o', linestyle='none')
plt.xlabel('Feature Index')
plt.ylabel('Coefficient Value')
plt.title('Lasso Coefficients')
plt.xticks(range(X.shape[1]))
plt.grid(True)
plt.show()
```
In the above code, the alpha is the hyperparameter that we need to tune. It is the value of the lambda in the equation.
## Choosing the Optimal Parameter
The value of lambda significantly impacts the sparsity and performance of the model. A higher value leads to a stronger penalty, potentially driving more coefficients to zero and risking underfitting. Conversely, a lower value provides less regularization, potentially resulting in overfitting.
## Feature Selection
Consider a more complex dataset with multiple features. By fitting a Lasso model and examining the coefficients, we can determine which features are most important.
```
X, y = make_regression(n_samples=100, n_features=10, noise=0.1)
lasso = Lasso(alpha=0.5)
lasso.fit(X, y)
plt.figure(figsize=(10, 6))
plt.bar(range(X.shape[1]), lasso.coef_)
plt.title('Lasso Coefficients with Strong Regularization')
plt.xlabel('Feature index')
plt.ylabel('Coefficient value')
plt.grid(True)
plt.show()
```
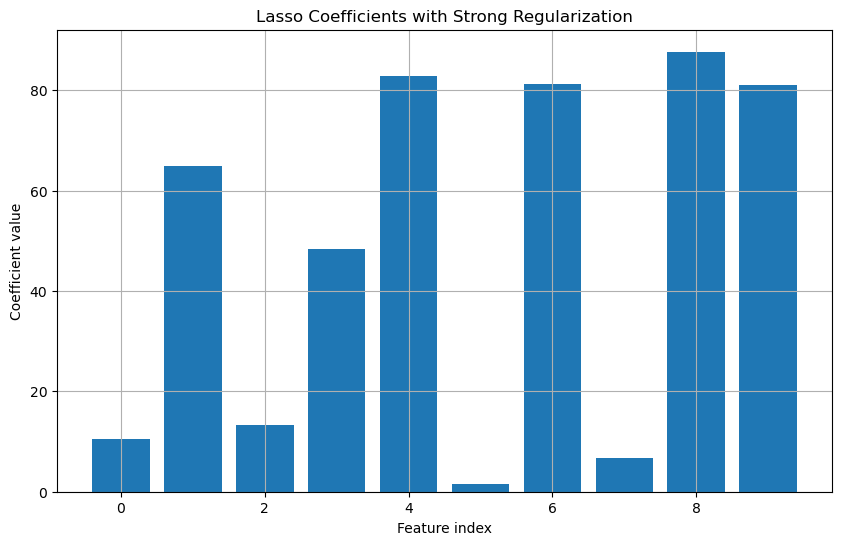
In this plot, many of the coefficients would be zero, indicating that Lasso has selected only the most relevant features.
## Conclusion
Lasso regularization is a robust technique for enhancing model interpretability and performance. By adding an L1 penalty to the linear regression objective function, Lasso encourages sparsity in the model, effectively performing feature selection. This helps in identifying the most relevant predictors and prevents overfitting, making it particularly useful in high-dimensional datasets.
| harsimranjit_singh_0133dc | |
1,863,471 | Migration of a Workload running in a Corporate Data Center to AWS using the Amazon EC2 and RDS service | In another project based on a real-world scenario, I acted as the Cloud Specialist responsible for... | 0 | 2024-05-24T02:10:44 | https://dev.to/cansu_tekin_b017634d64dfd/migration-of-a-workload-running-in-a-corporate-data-center-to-aws-using-the-amazon-ec2-and-rds-service-5e6h | aws, rds, ec2, mysql |
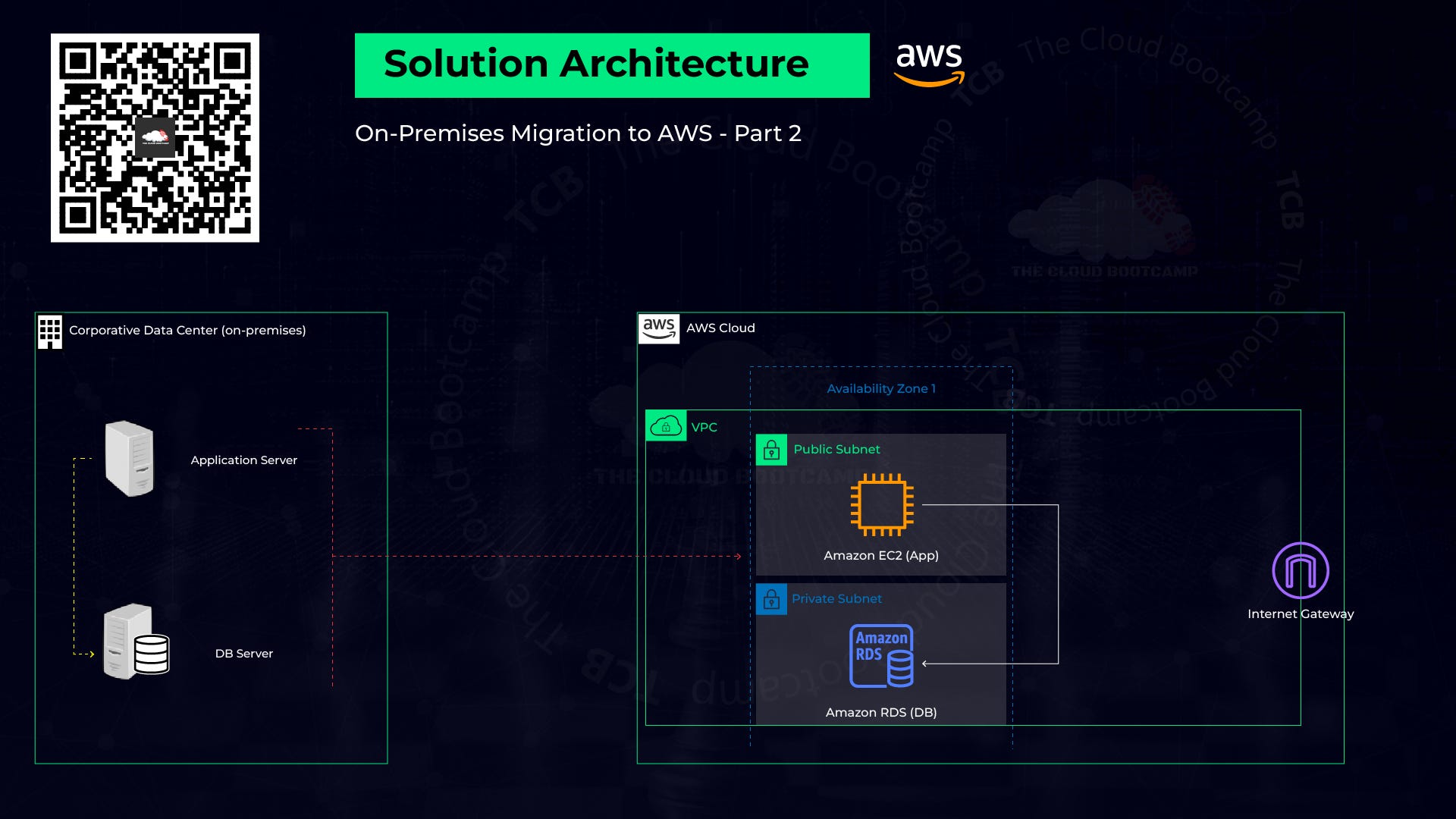
In another project based on a real-world scenario, I acted as the Cloud Specialist responsible for migrating a workload running in a Corporate Data Center to AWS.
The application and database were migrated to AWS using the Lift & Shift (rehost) model, moving both application and database data.
Migration steps:
1. Planning: sizing, prerequisites, resource naming
2. Implementation: resource provisioning, best practices
3. Go-live: validation test — Dry-run, final migration — Cutover
4. Post Go-live: ensuring the operation of the application and user access
1. Planning
The client provided information and files for the application and the database to migrate from the on-premise environment to the AWS cloud.
Python Web — Wiki Server Application: Prerequisite python packages and libraries for the application to be run successfully on the AWS EC2 application server are determined.
MySQL 5.7 Python Web — Wiki DB Server: Size, host/server name, IP address, CPU, and necessary description are provided to migrate it to the Amazon RDB server.

2. Implementation
* Create a VPC (Amazon Virtual Private Cloud): The purpose is to build a virtual and isolated network. The accessibility of the Amazon RDB and EC2 instance resources on the Internet will be controlled by the assignment of IP addresses. One public subset and two private subsets were added to VCP. The IPv4 CIDR block must not overlap with any existing CIDR block that’s associated with the VPC.
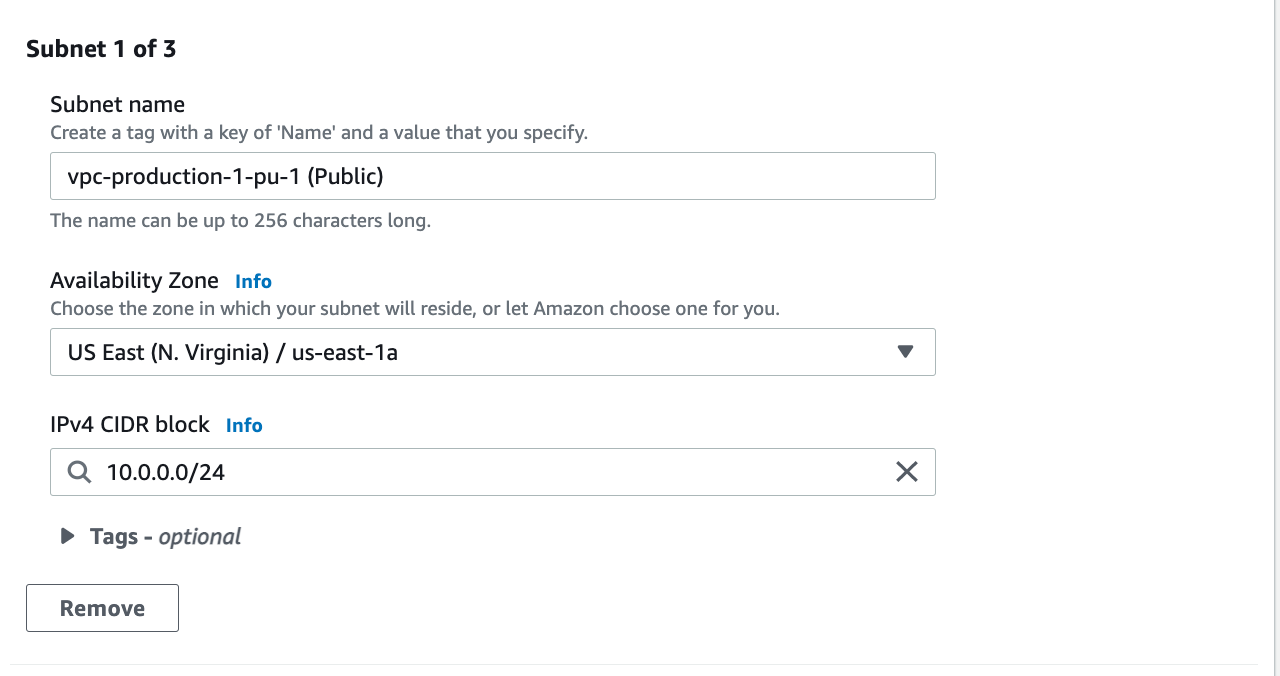

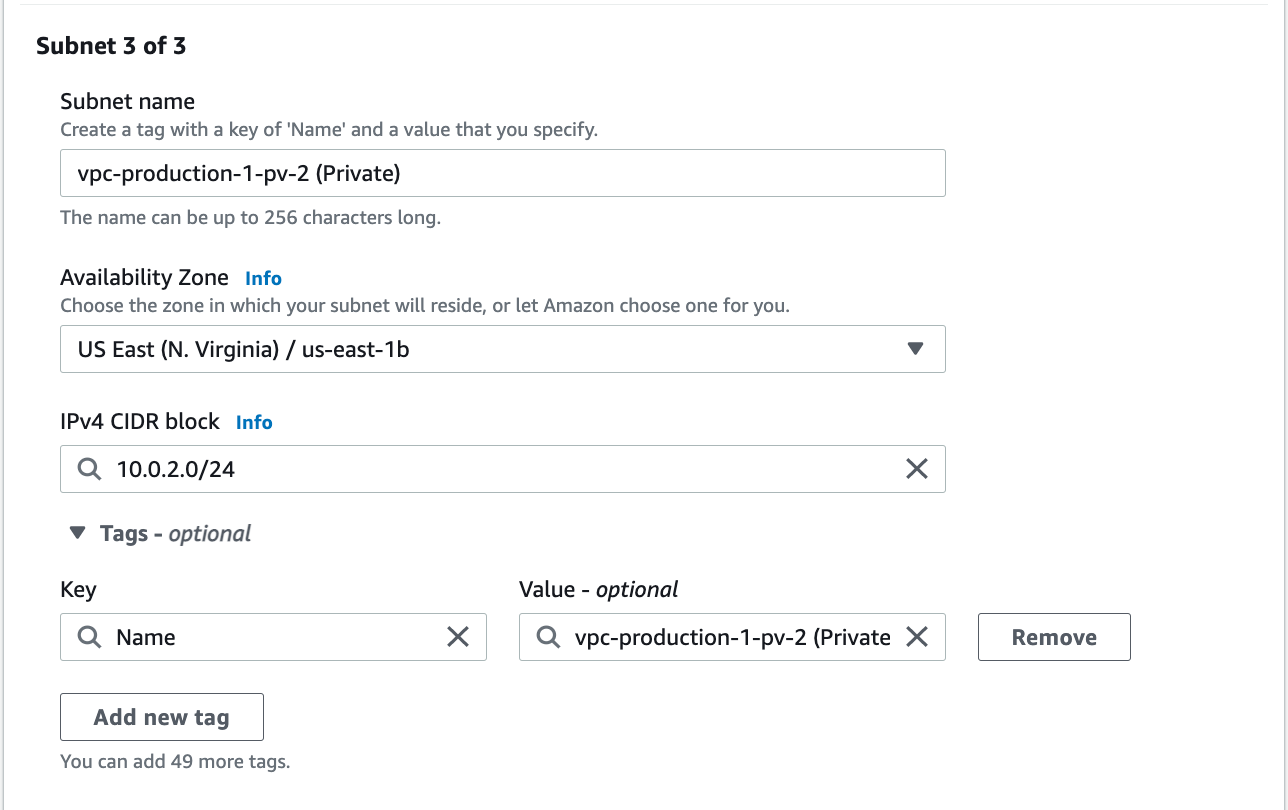
* Create an Internet Gateway and attach it to a VPC: Necessary for the connection between EC2 and the Internet.
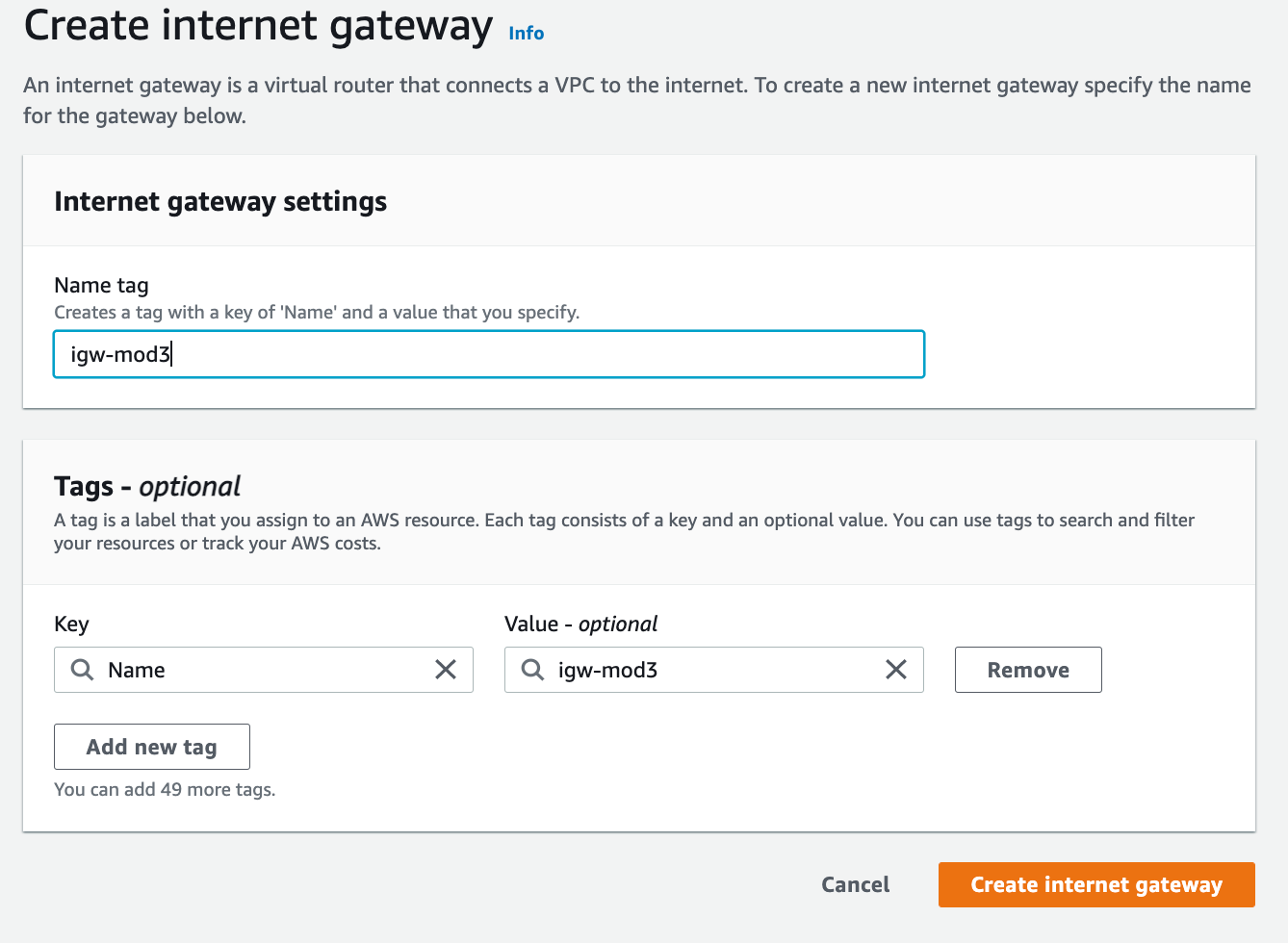

* Create a Route Table: There is already an attached route table to VPC when it is created but it is local and only routing internal traffics. We want to add new traffics to allow users coming from the Internet to access the EC2 application instance. The EC2 instance also can initiate internet connections from itself like connection to download packages etc.

* Create an EC2 instance with a new Security Group and Key Pair (*.pem)*: EC2 instance(AMI: Ubuntu 18.04) within the previously launched VPC network was created.
* Key pair was created while creating the EC2 instance and downloaded to the desktop. It is necessary to connect remotely to the EC2 instance from the desktop via ssh.
* Security Group was created and configured to open a port so that we can access the services running on the virtual machine. A new security rule was added for the application to be accessed over the internet only port 8080.

* Create MySQL RDS instance: It should be the same version from the on-promises environment or a newer version but we need to make sure this change will not affect anything else. Public access: No, never set it to “yes” if it is not really necessary.
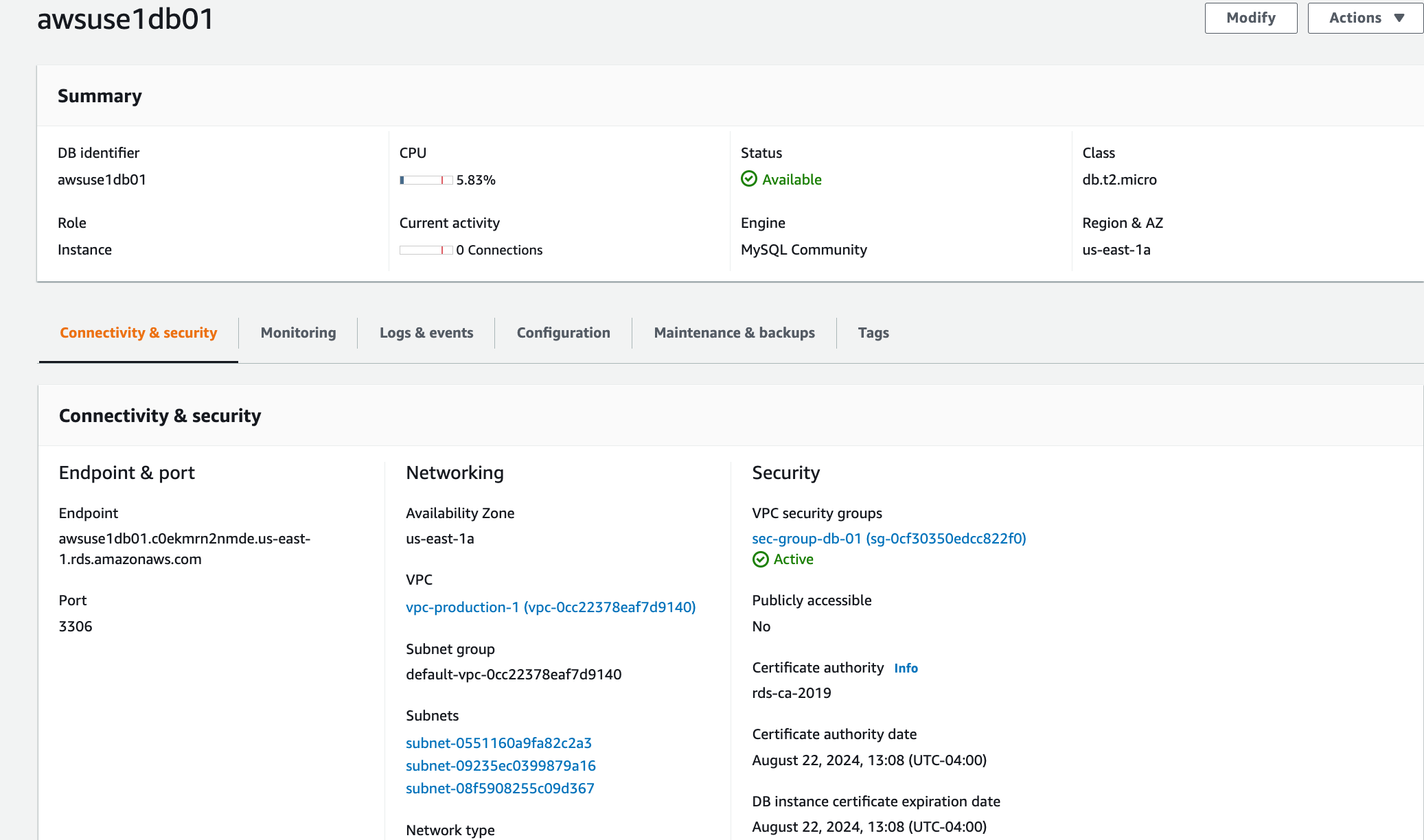
* Pre-requisites steps: It should be connected to the EC2 instance using ssh and pair-key which was downloaded before in “.pem” format. It is important to prepare the EC2 instance to make the application work properly on it. Required python packages and libraries were installed as determined in the planning step.
* Set the permissions of your private key so that only you can read it. chmod 400 key-pair-name.pem
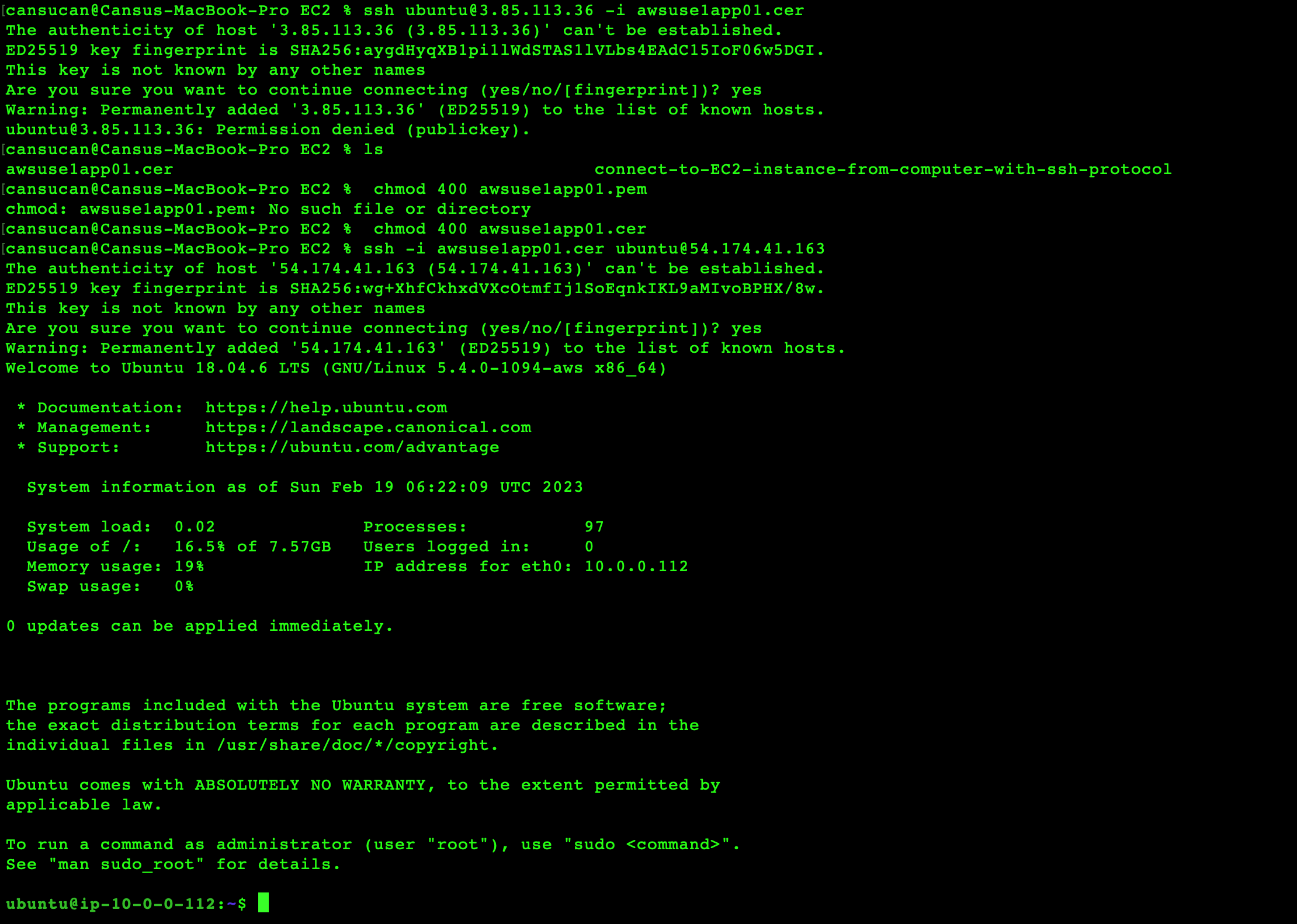
3. On-Live
This is broken into two steps, the validation (dry run) and the cutover.
Validation(dry-run):
The on-premises resources should be up and running at this stage. Once the validation is completed successfully, a downtime window can be scheduled when the business is not running and run the final migration switching from the on-premise environment to the cloud (cutover).
* 1) Database and 2) application deployment resources from the on-premises environment were exported and 3) put in an AWS S3 bucket. Then we can transfer files from the S3 bucket to related subnets in VCP. It is connected to the EC2 instance and opened remote connectivity from the local computer.
* 4) The application deployment files were imported to the EC2 instance.
$ ssh ubuntu@<PUBLIC_IP> -i <ssh_private_key>

* 5) Remotely Connected to MySQL running on AWS RDS so that we can import the data coming from the on-premise DB. DB files were imported to the AWS RDB. 6) The connectivity between the EC2 instance and RDB was established in the application configuration file by pointing to the AWS RDB hostname.

* A new user wiki in the wikidb was created so that application can go ahead and connect to the database, it will do connectivity from the application to the database.
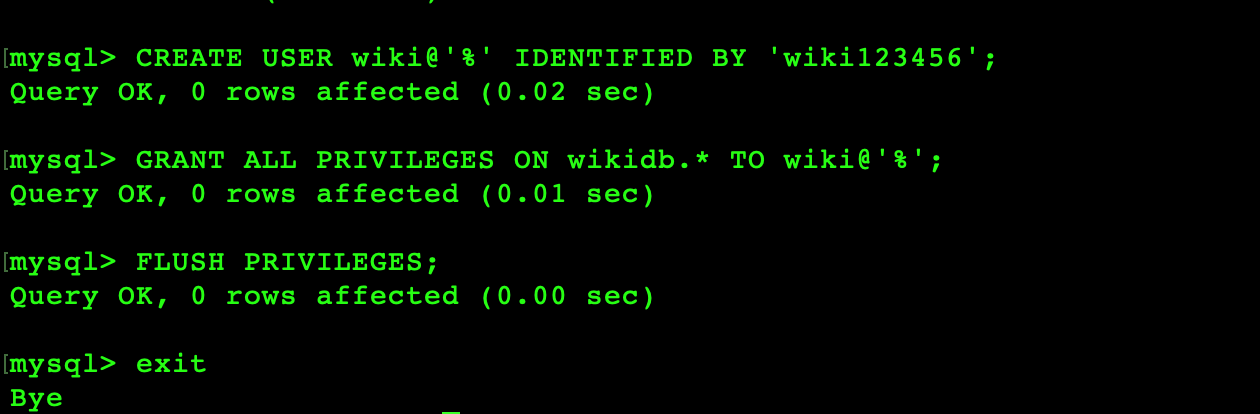
* Unzip the app files, it is configuration files from the application that we want to point to MySQL DB running on AWS.

* Launch the application to validate the migration: Bring up the application to see if the application will be connected to the RDS.
<EC2_PUBLIC_IP>:8080

* A new article was created to see if the application is able to not only read from MySQL database but also write on it.
Cutover: It is the next step of the On-Live process. So, in a production environment, we can schedule the downtime to bring the actual data from the on-premises environment, import the data, and make sure that the on-premises database and application are down. Once it is done we can switch from the on-premises environment to the AWS completely.
4. Post Go-Live:
Last step of migration. We should make sure there is no problem after go-live. Stability, ongoing support; access, performance, integration. Ongoing support can continue for 2 weeks, more or less depending on the complexity of the application.
| cansu_tekin_b017634d64dfd |
1,863,470 | Transitioning away from Nursing | Transitioning out of nursing after spending that last decade in the field. I really hope to be able... | 0 | 2024-05-24T02:09:04 | https://dev.to/malukanoa/transitioning-away-from-nursing-1i | nursetotech, new, careerdevelopment, webdev | Transitioning out of nursing after spending that last decade in the field. I really hope to be able to land work that is remote, challanging skill wise and leaves me time to travel. Nursing while it has been rewarding has become a challange. I want to meet new people and discover other sectors of the workforce. | malukanoa |
1,863,466 | Automated user migration and management of AWS Identity and Access Management (IAM) resources | Automated user migration and management of AWS Identity and Access Management (IAM)... | 0 | 2024-05-24T02:07:03 | https://dev.to/cansu_tekin_b017634d64dfd/automated-user-migration-and-management-of-aws-identity-and-access-management-iam-resources-2j7c | cloudcomputing, aws, multiplatform, iam |
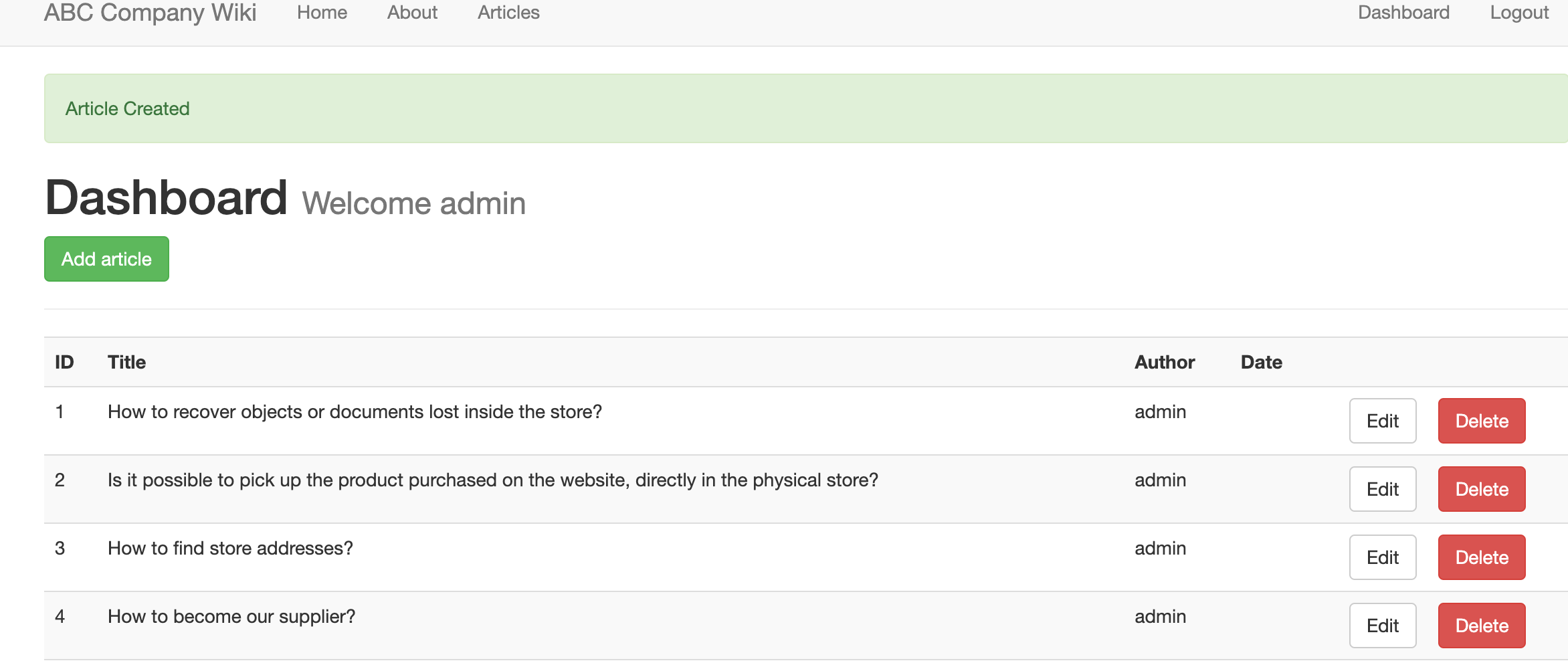
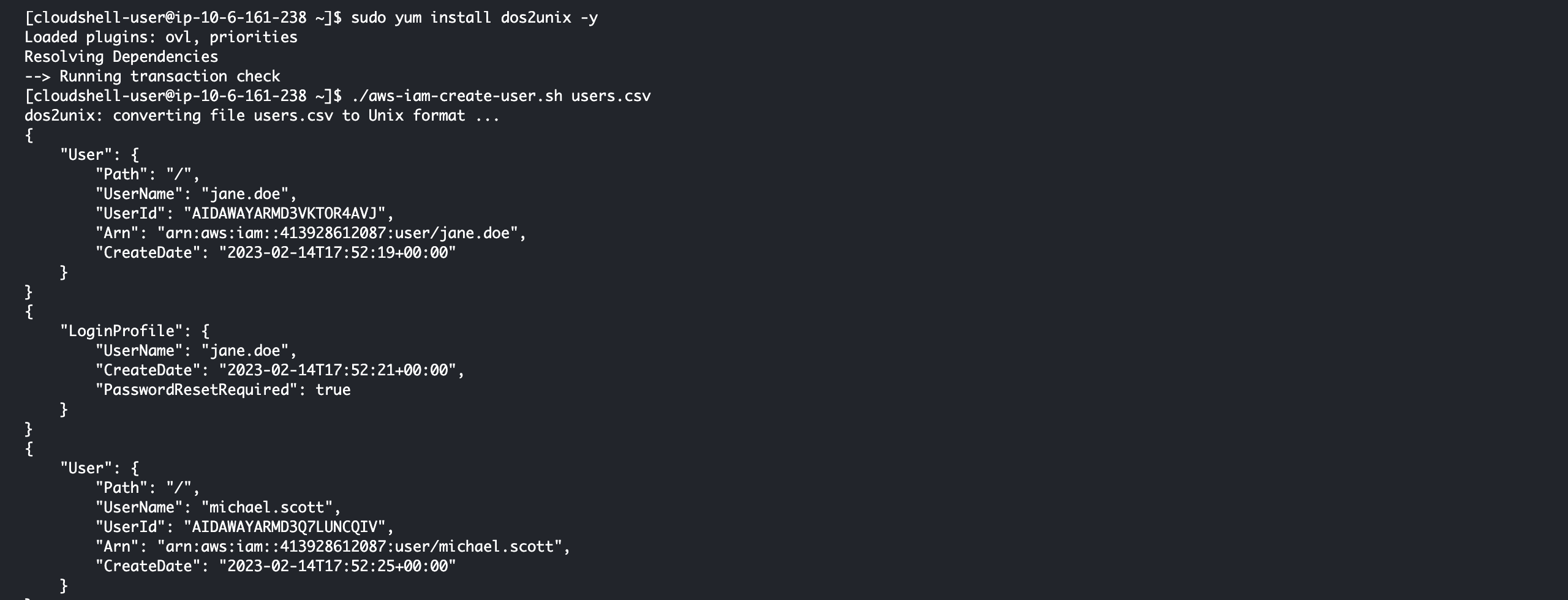
## *Automated user migration and management of AWS Identity and Access Management (IAM) resources*
In this project based on a real-world scenario, I acted as Cloud Specialist with the mission to migrate users in an automated way and manage AWS IAM (Identity and Access Management) resources.
There were 100 users that needed to be migrated and have MFA (Multi-factor authentication) enabled on their accounts, as this is a security best practice.
Using GitBash with AWS CLI and Shell Script, I avoided repetitive and manual tasks in the AWS console and automated the processes.

PART-1: On-Premises Migration to AWS
Create 5 user groups, attach policies, and migrate users from the on-premise environment
**CloudAdmin: A**dministratorAccess, IAMUserChangePassword
**NetworkAdmin: **VPCFullAccess, IAMUserChangePassword
**DatabaseAdmin:** AmazonRDSFullAccess, IAMUserChangePassword
**LinuxAdmin: **AmazonEC2FullAccess, IAMUserChangePassword
**Trainees: **ReadOnlyAccess, IAMUserChangePassword
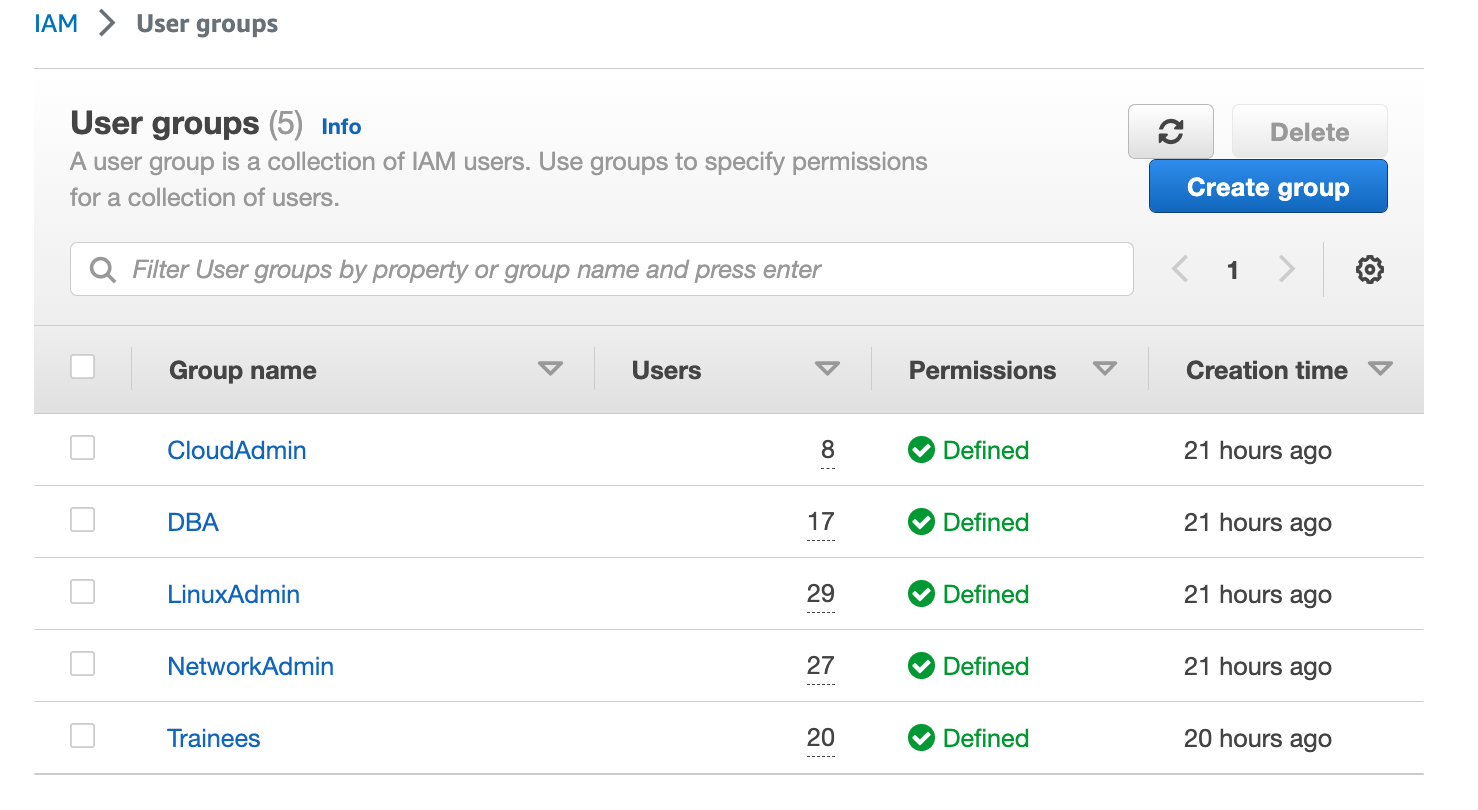
PART-2: Enable MFA (MultiFactor Authentication) on your root and IAM users applying the IAM Password Policy
Create a custom policy, named **EnforceMFAPolicy.json, **for the MFA and add it to each user group, then enable it for root and each IAM user.


| cansu_tekin_b017634d64dfd |
1,863,469 | vaytien banglai | Vay vốn theo bằng lái xe máy, xe ô tô A1, B2, C...Lãi suất thấp, không giữ giấy tờ gốc, duyệt vay... | 0 | 2024-05-24T02:03:56 | https://dev.to/cavpbankvntop/vaytien-banglai-4nce | Vay vốn theo bằng lái xe máy, xe ô tô A1, B2, C...Lãi suất thấp, không giữ giấy tờ gốc, duyệt vay nhanh an toàn. Đăng ký vay ngay tại Webstie VPBankvn.top
Website: https://vpbankvn.top/vay-bang-cccd-va-bang-lai-xe/
Phone: 0708866285
Address: 144 Cộng Hòa, Q.Tân Bình, TP. Hồ Chí Minh
https://tupalo.com/en/users/6759050
https://glose.com/u/stvpbankvntop
https://www.silverstripe.org/ForumMemberProfile/show/151835
https://dreevoo.com/profile.php?pid=641155
https://potofu.me/fcvpbankvntop
https://edenprairie.bubblelife.com/users/gbvpbankvntop
https://muckrack.com/vaytien-banglai
https://leetcode.com/u/spvpbankvntop/
https://www.diggerslist.com/rdvpbankvntop/about
http://buildolution.com/UserProfile/tabid/131/userId/405251/Default.aspx
https://hypothes.is/users/xpvpbankvntop
https://8tracks.com/vuvpbankvntop
https://www.ohay.tv/profile/cmvpbankvntop
https://www.reverbnation.com/vpbankvntop33
https://www.funddreamer.com/users/vaytien-banglai
https://www.bark.com/en/gb/company/vpbankvntop/MOdD0/
https://piczel.tv/watch/fkvpbankvntop
http://idea.informer.com/users/mkvpbankvntop/?what=personal
https://os.mbed.com/users/gdvpbankvntop/
https://rotorbuilds.com/profile/41910/
https://research.openhumans.org/member/szvpbankvntop
https://wmart.kz/forum/user/162895/
https://participez.nouvelle-aquitaine.fr/profiles/vpbankvntop_5/activity?locale=en
https://vocal.media/authors/vaytien-banglai
https://community.tableau.com/s/profile/0058b00000IZXoq
https://www.mountainproject.com/user/201826004/vaytien-banglai
https://www.dermandar.com/user/xnvpbankvntop/
https://www.creativelive.com/student/vaytien-banglai?via=accounts-freeform_2
https://zzb.bz/ApMv0
https://www.copytechnet.com/member/355334-cjvpbankvntop/about
https://www.storeboard.com/vaytienbanglai
https://slides.com/rxvpbankvntop
https://stocktwits.com/wivpbankvntop
https://www.designspiration.com/thuhoai10049826/
https://devpost.com/thuh-o-a-i-100-498
https://data.world/vvvpbankvntop
https://hackerone.com/vpbankvntop?type=user
https://hackmd.io/@zqvpbankvntop
https://www.chordie.com/forum/profile.php?id=1962106
https://www.cineplayers.com/dsvpbankvntop
https://makersplace.com/thuhoai10049821/about
https://fileforum.com/profile/zovpbankvntop
https://qiita.com/tvvpbankvntop
https://socialtrain.stage.lithium.com/t5/user/viewprofilepage/user-id/64386
https://gitee.com/thuhoai
https://active.popsugar.com/@qbvpbankvntop/profile
https://able2know.org/account/profile/
https://teletype.in/@vpbankvntop
https://www.speedrun.com/users/wmvpbankvntop
https://www.kickstarter.com/profile/cpvpbankvntop/about
https://www.credly.com/users/vaytien-banglai/badges
https://gifyu.com/yvvpbankvntop
https://www.metooo.io/u/664fed928eb6540b99161bc1
https://inkbunny.net/rvvpbankvntop
https://chart-studio.plotly.com/~tnvpbankvntop
https://www.5giay.vn/members/wjvpbankvntop.101974073/#info
https://www.facer.io/u/spvpbankvntop
https://www.noteflight.com/profile/0d26fd39dde2f66ef4421b209f435e3d1f7bd175
https://vnseosem.com/members/yivpbankvntop.30866/#info
https://wakelet.com/@vaytienbanglai40639
https://vimeo.com/user220125603
https://pinshape.com/users/4401533-dqvpbankvntop#designs-tab-open
https://diendannhansu.com/members/xkvpbankvntop.49071/#about
https://doodleordie.com/profile/rpvpbankvntop
https://www.divephotoguide.com/user/edvpbankvntop/
https://chodilinh.com/members/qovpbankvntop.78091/#about
https://hashnode.com/@ksvpbankvntop
https://www.proarti.fr/account/wovpbankvntop
https://www.cakeresume.com/me/vpbankvntop-74f1e0
https://englishbaby.com/
https://lab.quickbox.io/jyvpbankvntop
https://visual.ly/users/thuhoai10049821
https://circleten.org/a/291402
https://www.wpgmaps.com/forums/users/owvpbankvntop/
https://www.fimfiction.net/user/744817/okvpbankvntop
https://forum.dmec.vn/index.php?members/jdvpbankvntop.60636/
https://pastelink.net/sz0og2c5
https://www.dnnsoftware.com/activity-feed/my-profile/userid/3198382
https://play.eslgaming.com/player/20122851/
https://www.artscow.com/user/3196021
https://disqus.com/by/disqus_vTnftEhflC/about/
https://topsitenet.com/profile/vrvpbankvntop/1193080/
https://www.intensedebate.com/people/hdvpbankvntop
https://pxhere.com/en/photographer-me/4265538
https://www.instapaper.com/p/ievpbankvntop
https://collegeprojectboard.com/author/imvpbankvntop/
https://www.pearltrees.com/divpbankvntop
https://portfolium.com/mlvpbankvntop
https://penzu.com/p/0e80f197fab85cc4
https://peatix.com/user/22340032/view
https://www.scoop.it/u/vaytienbanglai
https://bentleysystems.service-now.com/community?id=community_user_profile&user=935815aa1b168e90dc6db99f034bcb41
https://app.talkshoe.com/user/syvpbankvntop
https://www.ekademia.pl/@vaytienbanglai
https://telegra.ph/vpbankvntop-05-24
https://www.anibookmark.com/user/arvpbankvntop.html
www.artistecard.com/ilvpbankvntop#!/contact
https://www.ethiovisit.com/myplace/wgvpbankvntop
https://pbase.com/vpbankvntop/profile
https://controlc.com/7b491582
https://www.quia.com/profiles/vaytienba
https://rentry.co/szh8b5ww
https://linkmix.co/23370846
https://jsfiddle.net/user/krvpbankvntop/
https://expathealthseoul.com/profile/vaytien-banglai/
https://www.equinenow.com/farm/vpbankvntop-1127640.htm
https://app.roll20.net/users/13366800/vaytien-b
https://allmylinks.com/lhvpbankvntop
https://www.titantalk.com/members/vpbankvntop.375307/#about
http://forum.yealink.com/forum/member.php?action=profile&uid=341364
https://www.discogs.com/user/apvpbankvntop
https://www.exchangle.com/vtvpbankvntop
https://naijamp3s.com/index.php?a=profile&u=cuvpbankvntop
https://willysforsale.com/profile/jlvpbankvntop
| cavpbankvntop | |
1,863,462 | Introducing react-tools: A Toolbox for Streamlining React Development | Introducing @galiprandi/react-tools: A Toolbox for Streamlining React Development Are... | 0 | 2024-05-24T01:56:18 | https://dev.to/galiprandi/introducing-react-tools-a-toolbox-for-streamlining-react-development-2f23 |

### Introducing `@galiprandi/react-tools`: A Toolbox for Streamlining React Development
Are you looking to simplify your React development process? Look no further than `@galiprandi/react-tools`. This comprehensive package offers a range of intuitive utilities designed to enhance your React applications. Let's explore some of its key components and hooks:
### Playground
Before diving into the details, why not take a test drive? Visit the [@galiprandi/react-tools Playground](https://stackblitz.com/edit/vitejs-vite-7c9m54?file=src%2FApp.tsx) to experiment with the components firsthand.
### Installation
Getting started is a breeze. Simply install the package using your preferred package manager:
```bash
npm i @galiprandi/react-tools
```
```bash
pnpm i @galiprandi/react-tools
```
```bash
yarn add @galiprandi/react-tools
```
### Components
#### `<Form />`
Simplify form creation with the `<Form />` component. This component wraps the `form` HTML tag, offering a straightforward approach to building forms in your React application. Additional props like `onSubmitValues` and `filterEmptyValues` provide enhanced functionality.
#### `<Input />`
Enhance user input experiences with the `<Input />` component. This reusable input wrapper adds consistency to your forms and accepts various props for customization, including `label`, `onChangeValue`, and `debounceDelay`.
#### `<DateTime />`
Need date and time input functionality? Look no further than the `<DateTime />` component. This wrapper around the native `input` element with `type="datetime-local"` offers convenient date selection with additional props for customization.
#### `<Dialog />`
Create accessible dialogs and modals effortlessly with the `<Dialog />` component. This wrapper around the `dialog` HTML tag simplifies dialog creation, with options for defining behavior, callbacks, and content.
#### `<Observer />`
Track element visibility with the `<Observer />` component. Whether you're implementing lazy loading images or infinite scrolling, this component offers a straightforward solution for monitoring viewport interactions.
### Hooks
#### `useDebounce()`
Streamline asynchronous operations with the `useDebounce()` hook. This simple yet powerful hook accepts a value and delay, returning a debounced value to optimize performance.
### Contribution
Your contributions are valuable! Whether it's bug fixes, feature enhancements, or documentation improvements, contributions are welcome. Simply fork the repository, make your changes, and open a pull request.
### License
`@galiprandi/react-tools` is licensed under the MIT License, providing flexibility for both personal and commercial use.
Ready to simplify your React development workflow? Install [@galiprandi/react-tools](https://www.npmjs.com/package/@galiprandi/react-tools) today and experience the difference firsthand. Happy coding! | galiprandi | |
1,863,461 | region-screenshot-js helps you quickly build the selection screenshot function | live... | 0 | 2024-05-24T01:52:16 | https://dev.to/brilliant/region-screenshot-js-helps-you-quickly-build-the-selection-screenshot-function-5mg | live demo:https://github.com/weijun-lab/region-screenshot-js
github:https://weijun-lab.github.io/region-screenshot-js
This article describes how to use the plug-in region-screenshot-js to succinctly and efficiently achieve the selection screenshot function on the web side, and draw specific patterns and mosaics on the screenshot. If the plug-in comes with pattern drawing can not meet your needs, you can customize drawing through the customDrawing configuration item of the plug-in. The following is only a basic indication, more functions and usage refer to the documentation. This is a plug-in I developed in my spare time, nearly two thousand lines of code, writing a little two months. If you have any suggestions or comments about this plugin, you can put them in the Issues. If it helps you, please click on star.
Code example:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
body,
html {
height: 100%;
width: 100%;
}
* {
margin: 0;
padding: 0;
}
body {
background-image: url(./assets/bg.png);
background-size: cover;
background-position: center;
}
</style>
</head>
<body>
</body>
<script src="./dist/region-screenshot.umd.js"></script>
<script>
let screenshot = new RegionScreenshot({
regionColor:"#00ff28"
});
let screenshot = new RegionScreenshot();
screenshot.on("successCreated",(dataUrl)=>{
console.log("Plugin initialized successfully.");
});
screenshot.on("screenshotGenerated",(dataUrl)=>{
console.log(dataUrl);
});
</script>
</html>
```
If the current drawing tool does not meet your needs, you can customize a drawing tool through the customDrawing configuration item
Code example:

```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
body,
html {
height: 100%;
width: 100%;
}
* {
margin: 0;
padding: 0;
}
body {
background-image: url(./assets/bg.png);
background-size: cover;
background-position: center;
}
.region-screenshot_custom_tools.emoji .region-screenshot_tools_btn {
background-image: url(./assets/emoji.png);
}
.region-screenshot_custom_tools.emoji.region-screenshot_active .region-screenshot_tools_btn {
background-image: url(./assets/emoji_active.png);
}
.region-screenshot_custom_tools.emoji .region-screenshot_tools_options img {
width: 20px;
margin-right: 10px;
cursor: pointer;
}
.region-screenshot_custom_tools.emoji .region-screenshot_tools_options img.active {
filter: brightness(1.2)
}
</style>
</head>
<body>
</body>
<script src="./dist/region-screenshot.umd.js"></script>
<script src="https://unpkg.com/jquery@3.7.1/dist/jquery.js"></script>
<script>
let screenshot = new RegionScreenshot({
customDrawing: [
{
className: "emoji",
optionsHtml: `
<img class="active" src="assets/emoji-1.png"/>
<img src="assets/emoji-2.png"/>
<img src="assets/emoji-3.png"/>
<img src="assets/emoji-4.png"/>
`,
onOptionsCreated(optionsEl) {
$(optionsEl)
.find("img")
.click(function () {
$(this).addClass("active");
$(this).siblings().removeClass("active");
});
},
onDrawingOpen(canvasEl, optionsEl, saveCallback) {
let ctx = canvasEl.getContext("2d");
canvasEl.style.cursor = "crosshair";
canvasEl.onclick = function (e) {
let img = $(optionsEl).find(".active")[0];
ctx.drawImage(
img,
e.offsetX - img.naturalWidth / 2,
e.offsetY - img.naturalWidth / 2
);
saveCallback();
};
},
onDrawingClose(canvasEl,optionsEl) {
canvasEl.onclick = null;
canvasEl.style.cursor = "default";
},
},
],
});
</script>
</html>
```
emoji.png 
emoji_active.png 
emoji-1.png 
emoji-2.png 
emoji-3.png 
emoji-4.png 
| brilliant | |
1,863,460 | Axial Fans: Understanding Airflow Dynamics and Applications | Axial Fans: Understanding Airflow Dynamics and Applications Have actually you ever before really... | 0 | 2024-05-24T01:39:22 | https://dev.to/mobika/axial-fans-understanding-airflow-dynamics-and-applications-2akm | axial, fans | Axial Fans: Understanding Airflow Dynamics and Applications
Have actually you ever before really experienced that the space is actually as well stale and damp? Perform you wish to produce a comfy atmosphere in your house, workplace, or even work environment? If your response is actually indeed, after that you have to learn about axial fans.
An axial fan is actually a gadget that utilizes turning cutters towards produce airflow and distribute sky in a specific instructions. It is actually an important device for air flow, cooling down, and home heating bodies. We'll check out the benefits, development, security, utilize, ways to utilize, solution, high top premium, and request of axial fans.
Benefits of Axial Fans
Axial fans have actually a great deal of benefits over various other kinds of fans. Very initial, they are actually extremely effective and can easily relocate big quantities of sky along with reduced energy usage. This implies that they can easily conserve power and decrease sets you back. 2nd, axial fans are actually peaceful and create much less sound compared with various other fans. This is actually perfect for locations where sound is actually a problem, like bed rooms, seminar spaces, and collections. 3rd, axial fans are actually light-weight and small, creating all of them the simple towards set up and utilize in a selection of setups.
Development in Axial Fans
Recently, axial fans have actually gone through considerable development. For instance, brand-brand new products, like compounds, have actually been actually utilized to create fans lighter and more powerful. Likewise, brand-brand new styles, like combined stream fans, have actually been actually designed towards integrate the benefits of axial and centrifugal fans. Additionally, brand-brand new innovations, like adjustable rate steers, have actually been actually utilized towards enhance fan effectiveness and command.
Security of Axial Fans
Security is actually an essential factor to consider when utilizing Short tube axial fans. One security include is actually the fan protector, which avoids fingers or even various other items coming from obtaining captured in the cutters. Another security include is actually the thermal overload security, which turns off the fan in the event of getting too hot. It is essential towards comply with the manufacturer's directions and security standards when utilizing axial fans.
Use Axial Fans
Axial fans have actually a wide variety of utilizes, consisting of air flow, cooling down, home heating, drying out, and dirt compilation. They are actually typically utilized in houses, workplaces, manufacturing facilities, warehouses, and agricultural setups. Axial fans could be utilized as standalone systems or even incorporated right in to bigger bodies. They can easily likewise be actually utilized in mix along with various other air flow and cooling down bodies, like a/c and evaporative cooling down.
Ways to Utilize Axial Fans
Utilizing Stand axial fans is actually simple, however certainly there certainly are actually a couple of points towards bear in mind. Very initial, ensure towards choose the appropriate dimension fan for the area to become aerated. A fan that's as well little will certainly not work, while a fan that's as well big will certainly squander power. 2nd, setting the fan towards attract sky coming from one location and tire it towards another. This produces a stream of sky and guarantees appropriate air flow. 3rd, cleanse and preserve the fan routinely to guarantee appropriate procedure and prolong its life expectancy.
Solution and High premium of Axial Fans
When purchasing an axial fan, it is essential to select a reliable producer and provider. This guarantees that the fan is actually of top quality and satisfies security and efficiency requirements. It is likewise essential to select a provider that provides after-sales solutions and sustains. This consists of setup, upkeep, and repair work. A great provider will help you enhance your airflow and cool down bodies and accomplish optimum effectiveness and efficiency.
Request of Axial Fans
Axial fans have a wide variety of applications in various markets and setups. For instance, in farming, axial fans are utilized for all-organic air flow and cooling down of animal structures. In production, axial fans are utilized for tire and airflow of fumes and dirt. In buildings, axial fans are utilized for drying out and cooling down structures. In transport, axial fans are utilized for cooling down motors in vehicles, vehicles, and planes. The request of axial fans is restricted just through creativity and imagination.
Source: https://www.hangdafans.com/axial-fans | mobika |
1,851,871 | How to scale a Django application to serve one million users? | Wish your Django app could handle a million hits? This post is a compilation of articles, books, and... | 0 | 2024-05-24T00:34:13 | https://coffeebytes.dev/en/is-your-django-application-slow-maximize-its-performance-with-these-tips/ | python, django, opinion, performance | ---
title: How to scale a Django application to serve one million users?
published: true
date: 2024-05-24 01:59:00 UTC
tags: python,django,opinion,performance
canonical_url: https://coffeebytes.dev/en/is-your-django-application-slow-maximize-its-performance-with-these-tips/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/5lfie46djdyz2k3q3zki.jpg
---
Wish your Django app could handle a million hits? This post is a compilation of articles, books, and videos I’ve read on how to take a Django application to its maximum capabilities, I’ve even implemented some of these recommendations myself.
It's also a good time to remember that if your application is just starting out, you probably [shouldn't obsess about its performance... yet](https://coffeebytes.dev/en/dont-obsess-about-your-web-application-performance/).
## Reduce slow queries in Django
As you know, database access is usually the bottleneck of most applications. \*\*The most important action to take is to reduce the number of queries and the impact of each one of them. You can reduce the impact of your queries by 90%, and I am not exaggerating.
It is quite common to write code that occasions multiple queries to the database, as well as quite expensive searches.
Identify what queries are being made in your application using [django-debug-toolbar](https://github.com/jazzband/django-debug-toolbar) and reduce them, or make them more efficient:
- **select\_related()** to [avoid multiple searches in foreign key or one-to-one relationships](https://coffeebytes.dev/en/differences-between-select_related-and-prefetch_related-in-django/)
- **prefetch\_related()** to prevent excessive searches on many-to-many or many-to-one relationships
- **django\_annotate()** to add information to each object in a query. I have an entry where I explain [the difference between annotate and aggregate](https://coffeebytes.dev/en/django-annotate-and-aggregate-explained/).
- **django\_aggregate()** to process all information from a single query into a single data (summation, averages).
- **Object Q** to join queries by OR or AND directly from the database.
- F-Expressions\*\* to perform operations at the database level instead of in Python code.

_Django debug tool bar showing the SQL queries of a Django request_
Example of use with _select\_related_.
``` python
# review/views.py
from .models import Review
def list_reviews(request):
queryset = Review.objects.filter(product__id=product_id).select_related('user')
# We're preventing a new query everytime we access review.user
# ...
```
## Configure gunicorn correctly
Gunicorn is the most widely used Python WSGI HTTP server for Django applications. But it is not asynchronous, consider combining it with one of its asynchronous counterparts: hypercorn or uvicorn. The latter implements gunicorn workers.
### Configure gunicorn correctly
Make sure you are using the correct gunicorn workers, according to the number of cores in your processor. They recommend setting the workers to (2 x number of cores) + 1. According to the documentation, **with 4-12 workers you can serve from hundreds to thousands of requests per second** , so that should be enough for a medium to large scale website.
## Improve the performance of your serializers
If you use DRF and use its generic classes to create serializers, you may not exactly be getting the best performance. The generic classes for serializers perform data validation, which can be quite time consuming if you are only going to read data.
Even if you remembered to mark your fields as read\_only, DRF serializers are not the fastest, you might want to check out [Serpy](https://serpy.readthedocs.io/en/latest/), [Marshmallow](https://marshmallow.readthedocs.io/en/stable/). The topic is quite broad, but stay with the idea that there is a major area of improvement in Django serializers.
I leave you this article that explains [how some developers managed to reduce the time cost of serialization by 99%.](https://hakibenita.com/django-rest-framework-slow)
## Use pagination in your views
It probably sounds pretty obvious, yet I feel I should mention it: you don’t need to return an entire database table if your user only finds the first few records useful.
Use the _paginator_ object provided by Django, or limit the results of a search to a few.
DRF also has an option to [paginate your results](https://www.django-rest-framework.org/api-guide/pagination/), check it out.
``` python
# review/views.py
from django.views.generic import ListView
from .models import Review
class ReviewList(ListView):
model = Review
paginate_by = 25
context_object_name = 'review_list'
```
## Use indexes in your models
Understand your more complex queries and try to create indexes for them. The index will make your searches in Django faster, but it will also slow down, slightly, the creations and updates of new information, besides taking up a little more space in your database. Try to strike a healthy balance between speed and storage space used.
``` python
from django.db import models
class Review(models.Model):
created = models.DateTimeField(
auto_now_add=True,
db_index=True,
)
```
## Use indexes for your searches
If your application makes heavy use of information searches, consider using an efficient [search engine, such as Solr](https://coffeebytes.dev/en/searches-with-solr-with-django-haystack/), rather than implementing the code yourself.
There are many options available:
- ElasticSearch
- Solr
- Whoosh
- Xapian
## Remove unused middleware
Each middleware implies an extra step in each web request, so removing all those middlewares that you do not use will mean a slight improvement in the response speed of your application.
Here are some common middleware that are not always used: messages, flat pages and localization, no, I don’t mean geographic location, but translating the content according to the local context.
``` python
MIDDLEWARE = [
# ...
'django.contrib.messages.middleware.MessageMiddleware',
'django.contrib.flatpages.middleware.FlatpageFallbackMiddleware',
'django.middleware.locale.LocaleMiddleware'
]
```
## Caching in Django
When the response time of your application becomes a problem, you should start caching all time-consuming and resource-intensive results.
Would you like to dig deeper into the caching system, I have a post about [caching in django using memcached](https://coffeebytes.dev/en/caching-in-django-rest-framework-using-memcached/) that you can check out to dig deeper.
If your page has too many models, and they rarely change, it does not make sense to access the database each time to request them with each new HTTP request. Just put the response of that request in cache and your response time will improve, this way every time the same content is requested, it will not be necessary to make a new request or calculations to the database, but the value will be returned directly from memory.
Among the options available are:
- Memcached
- Redis
- Database cache
- File system cache
``` python
# settings.py
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': '127.0.0.1:11211',
}
}
```
The django cache is configurable at many, many levels, from the entire site to views or even small pieces of information.
``` python
# myapp/views.py
from django.shortcuts import render
from django.views.decorators.cache import cache_page
@cache_page(60*15)
def my_view(request):
return render(request, 'myapp/template.html', {
'time_consuming_data': get_time_consuming_data()
})
```
Note that **memcached cache (memcached, redis) is an ephemeral storage method**, the entire cache will disappear if the system is rebooted or shutdown.
## Uses Celery for asynchronous tasks
Sometimes the bottleneck is the responsibility of third parties. When you send an email or request information from a third party, you have no way of knowing how long your request will take, a slow connection or an oversaturated server can keep you waiting for a response. There is no point in keeping the user waiting tens of seconds for an email to be sent, send them a reply back and transfer the email to a queue to be processed later. [Celery](https://docs.celeryproject.org/en/stable/) is the most popular way to do this.
No idea where to start, I have a couple of posts where I explain [how to run asynchronous tasks with celery and django](https://coffeebytes.dev/en/celery-and-django-to-run-asynchronous-tasks/).
``` python
# myapp/views.py
from celery import shared_task
@shared_task
def send_order_confirmation(order_pk):
email_data = generate_data_for_email(order_pk)
send_customized_mail(**email_data)
```
## Partition the tables in your database
When your tables exceed millions of records, each search will go through the entire database, taking a very long time in the process. How could we solve this? By splitting the tables in parts so that each search is done on one of the parts, for example, one table for data from one year ago (or the period you prefer), another for data from two years ago and so on up to the first data.
The instructions for implementing partitioning depend on the database you are using. If you are using postgres this feature is only available for Postgres versions higher than 10. You can use [django-postgres-extra](https://django-postgres-extra.readthedocs.io/en/master/table_partitioning.html) to implement those extra features not found in the django ORM.
The implementation is too extensive and would require a full entry. There is an excellent article that explains how to implement [Postgresql partitioning in Django.](https://pganalyze.com/blog/postgresql-partitioning-django/)
Consider also looking into database replicas for reading files, depending on the architecture of your application, you can implement multiple replicas for reading and a master for writing. This approach is a whole topic and is beyond the scope of a short post, but now you know what to look for.
## Use a CDN (Content Delivery Network)
Serving static images and files can hinder the important part of your application; generating dynamic content. You can delegate the task of serving static content to a content delivery network (CDN).
In addition to benefiting from the geographic locations of CDNs; a server in the same country (or continent) as your user will result in a faster response.
There are many CDN options available, among the most popular options are AWS, [Azure](https://coffeebytes.dev/en/azure-az-900-certification-exam-my-experience/), Digital Ocean, Cloud Flare, among others.
## Denormalization
Sometimes there are quite costly runtime queries that could be solved by adding redundancy, repeated information. For example, imagine you want to return the number of products that have the phrase “for children” on your home page, running a query that searches for the word and then executes a count is fairly straightforward. But what if you have 10,000 or 100,000 or 1,000,000 products, every time you want to access the count value, your database will go through the entire table and count the data.
Instead of performing a count, you could store that number in the database or in memory and return it directly, to keep it updated you could use a periodic count or increment it with each addition.
Of course this brings the problem that you now have more data to maintain, not coupled together, so \*\*you should only use this option to solve your Django performance problems if you have already exhausted the other options.
``` python
count = my_model.objects.filter(description__icontains="para niños").count()
# ... denormalizing
count = my_count.objects.get(description="para niños") # Each row of the my_count model contains a description and the total results.
total_count = count.total
```
## Review the impact of third-party plugins
Sometimes our website works almost perfectly, but third party plugins, such as facebook analytics tools, google, social media chat integrations plugins affect the performance of our application. Learn how to delay their loading or modify them to reduce their impact, using async, defer or other HTML attributes, in combination with Javascript.
If the above is impossible, evaluate alternatives or consider eliminating them.
## Consider using another interpreter to improve django performance
It’s not all about the database, sometimes the problem is in the Python code itself.
In addition to the normal Python interpreter, the one offered by default on the official Python website, there are other interpreters that are sure to give you better performance.
[Pypy](https://www.pypy.org/) is one of them, it is responsible for optimizing Python code by analyzing the type of objects that are created with each execution. This option is ideal for applications where Django is in charge of returning a result that was mainly processed using Python code.
But not everything is wonderful; third-party interpreters, including pypy, are usually not 100% compatible with all Python code, but they are compatible with most of it, so, just like the previous option. \*\*Using a third-party interpreter should also be one of the last options you consider to solve your Django performance problem.
## Write bottlenecks in a low-level language with Swig
If you’ve tried all of the above and still have a bottlenecked application, you’re probably squeezing too much out of Python and need the speed of another language. But don’t worry, you don’t have to redo your entire application in C or C++. [Swig](http://www.swig.org/) allows you to create modules in C, C++, Java, Go or other lower level languages and import them directly from Python.
Do you want to know how much difference there is between Python and a compiled language like go? in my post [Python vs Go I compare the speed of both languages](https://coffeebytes.dev/en/python-vs-go-go-which-is-the-best-programming-language/)
If you have a bottleneck caused by some costly mathematical computation, which highlights the lack of speed of Python being an interpreted language, you may want to rewrite the bottleneck in some low-level language and then call it using Python. This way you will have the ease of use of Python with the speed of a low-level language.
Keep an eye on language Mojo, it promises to be a super set of Python but much faster
## ORMs and alternative frameworks
Depending on the progress of your application, you may want to migrate to another framework faster than Django. Django’s ORM is not exactly the fastest out there, and, at the time of writing, it is not asynchronous. You might want to consider giving [sqlalchemy](https://www.sqlalchemy.org/), [ponyorm](https://ponyorm.org/) a try.
Or, if your application is not very complex at the database level, you may want to write your own sql queries and combine them with some other framework.
The current trend is to separate frontend and backend, so Django is being used in conjunction with Django Rest Framework to create APIs, so if your plans include the creation of an API, you may want to consider FastAPI, if you don’t know it, take a look at my post where I explain [the basics of FastAPI](https://coffeebytes.dev/en/fastapi-tutorial-the-best-python-framework/).
## Bonus: applications with more than 63 000 models
There is a talk they gave at djangocon2019 where the speaker explains how they managed to deal with an application with 63000 endpoints, each with different permissions.
{% youtube O6-PbTPAFXw %}
## Bonus: Technical blogs
Pinterest and Instagram are two gigantic sites that started out by choosing Django as their backend. You can find information about optimization and very specific problems in their technical blogs.
The instagram blog has a post called [Web Service efficiency at Instagram with Python](https://instagram-engineering.com/web-service-efficiency-at-instagram-with-python-4976d078e366), where they explain some problems encountered when handling 500 million users and how to fix them.
Here are the links to the blogs below:
- [Pinterest engineering](https://medium.com/pinterest-engineering)
- [Ingeniería de Instagram](https://instagram-engineering.com/)
References:
- Definitive Guide to Django: Web Development Done Right by Adrian Holovaty and Jacob Kaplan Moss
- Two scoops of Django 1.8 by Daniel Roy Greenfeld and Audrey Roy Greenfeld
- High performance Django by Peter Baumgartner and Yann Malet | zeedu_dev |
1,863,458 | Testando das trincheiras: Como criar mocks e stubs dinâmico com mockito em java | Criando mocks e stubs dinâmicos com Mockito em Java para simplificar testes quando a construção de objetos reais é impraticável. | 0 | 2024-05-24T01:30:58 | https://dev.to/hugaomarques/testando-das-trincheiras-como-criar-mocks-e-stubs-dinamico-com-mockito-em-java-3bmi | java, mockito, junit | ---
title: Testando das trincheiras: Como criar mocks e stubs dinâmico com mockito em java
published: true
description: Criando mocks e stubs dinâmicos com Mockito em Java para simplificar testes quando a construção de objetos reais é impraticável.
tags: #java #mockito #junit
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-24 01:00 +0000
---
Esse vai ser curtinho. Hoje eu estava tentando testar uma classe que segue o seguinte comportamento:
```java
Book book = bookManager.getBook(id);
book.getId();
```
Por vários motivos que não vêm ao caso agora, imagine que você não consegue construir o objeto `BookManager` e também não consegue criar um `FakeBook` para injetar o ID conforme você deseja.
Pois bem, eu lembrei que era possível criar um mock dinâmico usando `Answer` do Mockito.
## Solução: Um mock dinâmico
A solução fica assim:
```java
@ExtendWith(MockitoExtension.class)
public class MyBookManagerTest {
@Mock
private BookManager bookManager;
@Mock
private Book book;
@Test
public void testMyMethod() {
// Define the behavior of the bookManager mock
when(bookManager.getBook(anyInt())).thenAnswer(new Answer<Book>() {
@Override
public Book answer(InvocationOnMock invocation) throws Throwable {
Object[] args = invocation.getArguments();
int id = (Integer) args[0];
when(book.getId()).thenReturn(id);
return book;
}
});
// Use the mock in the test
Book book = bookManager.getBook(12345);
// Verify the behavior of the mock
assertEquals(12345, book.getId());
}
}
```
Note que, ao definirmos o comportamento do `BookManager`, retornamos uma `Answer`. Nessa `Answer`, capturamos o parâmetro passado (veja como usamos a `invocation`) e o configuramos no mock `Book` para ser retornado quando fizermos a chamada `book.getId()`.
Dessa forma, em vez de definirmos o mock diversas vezes, podemos definir apenas uma vez e fazer várias chamadas:
```java
// Use the mock in the test
Book book = bookManager.getBook(12345);
// Verify the behavior of the mock
assertEquals(12345, book.getId());
// Esse aqui também funciona porque o nosso mock é configurável
Book book = bookManager.getBook(6789);
// Verify the behavior of the mock
assertEquals(6789, book.getId());
```
## Simplificando: Java 8 + Lambdas 🥰
Se usarmos lambdas em vez da `anonymous` classe, o nosso exemplo fica ainda mais simples:
```java
when(bookManager.getBook(anyInt()))
.thenAnswer(invocation -> {
int id = invocation.getArgument(0);
when(book.getId()).thenReturn(id);
return book;
});
```
É isso, essa foi direto das trincheiras. Normalmente, eu gosto de evitar mocks se possível e tento usar os objetos reais. No meu caso específico criar o objeto ia ser um trampo do cão e aí eu decidi usar a ferramenta pra simplicar a minha vida.
Keep coding! 💻 | hugaomarques |
1,863,456 | 12章33 | 以下に、2つの回避方法をそれぞれ別々のコードとして示し、コメントアウトで解説を追加します。 方法1: keys.clear();を削除して例外を回避 import... | 0 | 2024-05-24T01:24:11 | https://dev.to/aaattt/12zhang-33-3l9c | 以下に、2つの回避方法をそれぞれ別々のコードとして示し、コメントアウトで解説を追加します。
### 方法1: `keys.clear();`を削除して例外を回避
```java
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Main {
// HashMapを作成してキーと値を格納するための静的マップ
static Map<String, String> map = new HashMap<>();
// 不変リストを使用 (例外が発生する可能性のあるリスト)
static List<String> keys = List.of("A", "B", "C");
// 値の配列を定義
static String[] values = {"1", "2", "3"};
// 静的初期化ブロックでキーと値をマップに追加
static {
for (int i = 0; i < keys.size(); i++) {
map.put(keys.get(i), values[i]);
}
}
public static void main(String[] args) {
// 例外が発生するkeys.clear()の呼び出しを削除
// keys.clear(); // この行を削除することで例外を回避
// values配列を空にする
values = new String[0];
// マップのサイズ、キーリストのサイズ、values配列の長さを出力。3,3,0
System.out.println(map.size() + "," + keys.size() + "," + values.length);
}
}
```
### 解説:
1. **方法1: `keys.clear();`を削除して例外を回避**
- `keys`リストは`List.of("A", "B", "C")`を使用して不変リストとして作成されています。
- 不変リストのため、変更操作(例:`clear()`)はサポートされておらず、`keys.clear();`を呼び出すと`UnsupportedOperationException`が発生します。
- この例外を回避するために、`keys.clear();`の行を削除しました。
map.size() は 3(マップには3つのキーと値のペアが格納されています)
keys.size() は 3(keysリストは不変であり、変更されないので3つの要素を持っています)
values.length は 0(values配列は空に変更されました)
### 方法2: 可変リストを使用して例外を回避
```java
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class MainWithMutableKeys {
// HashMapを作成してキーと値を格納するための静的マップ
static Map<String, String> map = new HashMap<>();
// 可変リストを使用 (例外を回避するためのリスト)
static List<String> keys = new ArrayList<>(List.of("A", "B", "C"));
// 値の配列を定義
static String[] values = {"1", "2", "3"};
// 静的初期化ブロックでキーと値をマップに追加
static {
for (int i = 0; i < keys.size(); i++) {
map.put(keys.get(i), values[i]);
}
}
public static void main(String[] args) {
// 可変リストの場合、keys.clear()は正常に動作する
keys.clear(); // この行は正常に動作
// values配列を空にする
values = new String[0];
// マップのサイズ、キーリストのサイズ、values配列の長さを出力。3,0,0
System.out.println(map.size() + "," + keys.size() + "," + values.length);
}
}
```
### 解説:
2. **方法2: 可変リストを使用して例外を回避**
- `keys`リストを`new ArrayList<>(List.of("A", "B", "C"))`を使用して可変リストとして作成します。
- これにより、`keys.clear();`が正常に動作し、例外は発生しません。
- `keys.clear();`を呼び出しても問題なくリストをクリアすることができます。
map.size() は 3(マップには3つのキーと値のペアが格納されています)
keys.size() は 0(keys.clear();によってkeysリストが空になります)
values.length は 0(values配列は空に変更されました) | aaattt | |
1,863,454 | Thoughts on High-Frequency Trading Strategies (1) | I have written two articles on high-frequency trading of digital currencies, namely "Digital Currency... | 0 | 2024-05-24T01:19:59 | https://dev.to/fmzquant/thoughts-on-high-frequency-trading-strategies-1-3l7f | trading, strategy, fmzquant, cryptocurrency | I have written two articles on high-frequency trading of digital currencies, namely "[Digital Currency High-Frequency Strategy Detailed Introduction](https://www.fmz.com/bbs-topic/10009)" and "[Earn 80 Times in 5 Days, the Power of High-frequency Strategy](https://www.fmz.com/bbs-topic/9750)". However, these articles can only be considered as sharing experiences and provide a general overview. This time, I plan to write a series of articles to introduce the thought process behind high-frequency trading from scratch. I hope to keep it concise and clear, but due to my limited expertise, my understanding of high-frequency trading may not be very in-depth. This article should be seen as a starting point for discussion, and I welcome corrections and guidance from experts.
## Source of High-Frequency Profits
In my previous articles, I mentioned that high-frequency strategies are particularly suitable for markets with extremely volatile fluctuations. The price changes of a trading instrument within a short period of time consist of overall trends and oscillations. While it is indeed profitable if we can accurately predict trend changes, this is also the most challenging aspect. In this article, I will primarily focus on high-frequency maker strategies and will not delve into trend prediction. In oscillating markets, by placing bid and ask orders strategically, if the frequency of executions is high enough and the profit margin is significant, it can cover potential losses caused by trends. In this way, profitability can be achieved without predicting market movements. Currently, exchanges provide rebates for maker trades, which are also a component of profits. The more competitive the market, the higher the proportion of rebates should be.
## Problems to be Addressed
1. The first problem in implementing a strategy that places both buy and sell orders is determining where to place these orders. The closer the orders are placed to the market depth, the higher the probability of execution. However, in highly volatile market conditions, the price at which an order is instantly executed may be far from the market depth, resulting in insufficient profit. On the other hand, placing orders too far away reduces the probability of execution. This is an optimization problem that needs to be addressed.
2. Position control is crucial to manage risk. A strategy cannot accumulate excessive positions for extended periods. This can be addressed by controlling the distance and quantity of orders placed, as well as setting limits on overall positions.
To achieve the above objectives, modeling and estimation are required for various aspects such as execution probabilities, profit from executions, and market estimation. There are numerous articles and papers available on this topic, using keywords such as "High-Frequency Trading" and "Orderbook." Many recommendations can also be found online, although further elaboration is beyond the scope of this article. Additionally, it is advisable to establish a reliable and fast backtesting system. Although high-frequency strategies can easily be validated through live trading, backtesting provides additional insights and helps reduce the cost of trial and error.
## Required Data
Binance provides [downloadable data](https://www.binance.com/en/landing/data) for individual trades and best bid/ask orders. Depth data can be downloaded through their API by being whitelisted, or it can be collected manually. For backtesting purposes, aggregated trade data is sufficient. In this article, we will use the example of HOOKUSDT-aggTrades-2023-01-27 data.
In [1]:
```
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
```
The individual trade data includes the followings:
1. agg_trade_id: The ID of the aggregated trade.
2. price: The price at which the trade was executed.
3. quantity: The quantity of the trade.
4. first_trade_id: In cases where multiple trades are aggregated, this represents the ID of the first trade.
5. last_trade_id: The ID of the last trade in the aggregation.
6. transact_time: The timestamp of the trade execution.
7. is_buyer_maker: Indicates the direction of the trade. "True" represents a buy order executed as a maker, while a sell order is executed as a taker.
It can be seen that there were 660,000 trades executed on that day, indicating a highly active market. The CSV file will be attached in the comments section.
In [4]:
```
trades = pd.read_csv('COMPUSDT-aggTrades-2023-07-02.csv')
trades
```
Out[4]:
, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ,
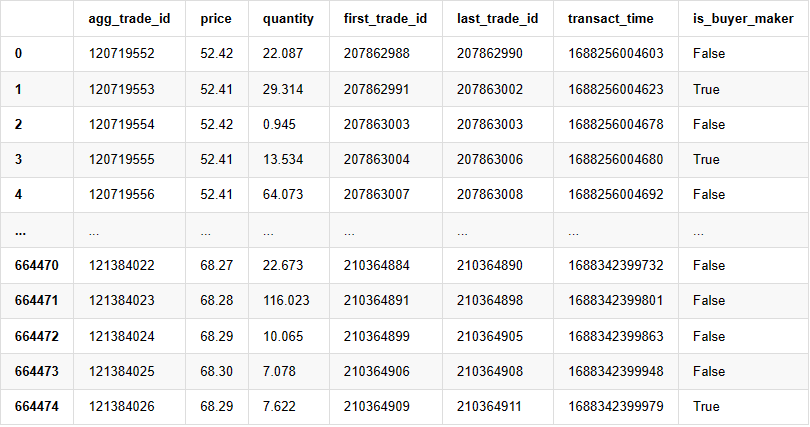
664475 rows × 7 columns
## Modeling Individual Trade Amount
First, the data is processed by dividing the original trades into two groups: buy orders executed as makers and sell orders executed as takers. Additionally, the original aggregated trade data combines trades executed at the same time, at the same price, and in the same direction into a single data point. For example, if there is a single buy order with a volume of 100, it may be split into two trades with volumes of 60 and 40, respectively, if the prices are different. This can affect the estimation of buy order volumes. Therefore, it is necessary to aggregate the data again based on the transact_time. After this second aggregation, the data volume is reduced by 140,000 records.
In [6]:
```
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
sell_trades = trades[trades['is_buyer_maker']==True].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
sell_trades = sell_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
sell_trades['interval']=sell_trades['transact_time'] - sell_trades['transact_time'].shift()
```
In [10]:
```
print(trades.shape[0] - (buy_trades.shape[0]+sell_trades.shape[0]))
```
Out [10]:
146181
Take buy orders as an example, let's first plot a histogram. It can be observed that there is a significant long-tail effect, with the majority of data concentrated towards the leftmost part of the histogram. However, there are also a few large trades distributed towards the tail end.
In [36]:
```
buy_trades['quantity'].plot.hist(bins=200,figsize=(10, 5));
```
Out [36]:
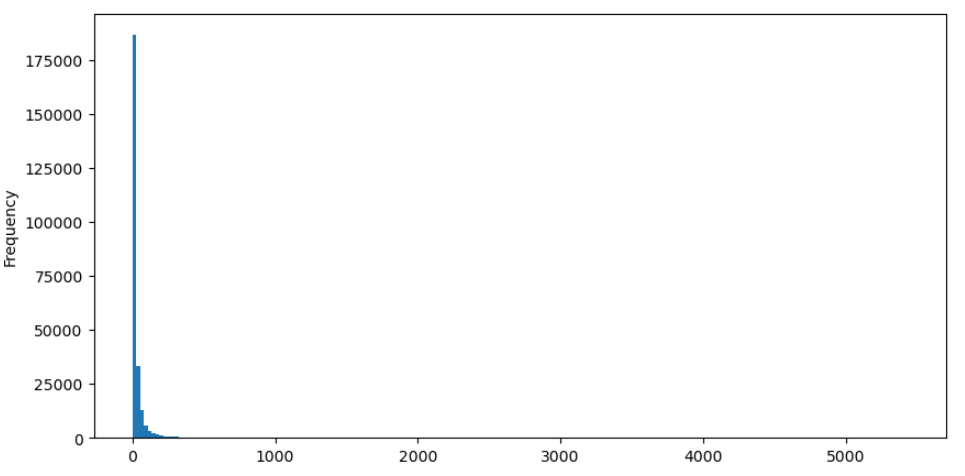
For easier observation, let's trim the tail and analyze the data. It can be observed that as the trade amount increases, the frequency of occurrence decreases, and the rate of decrease becomes faster.
In [37]:
```
buy_trades['quantity'][buy_trades['quantity']<200].plot.hist(bins=200,figsize=(10, 5));
```
Out [37]:
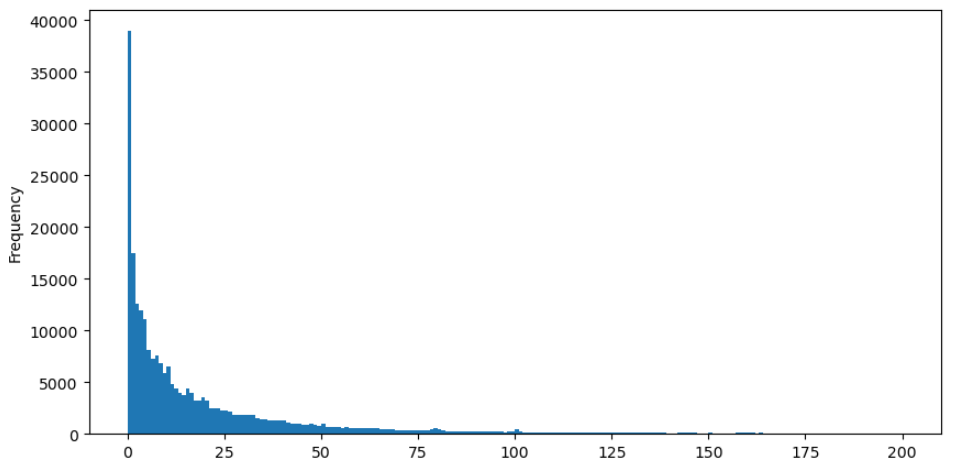
There have been numerous studies on the distribution of trade amounts. It has been found that trade amounts follow a power-law distribution, also known as a Pareto distribution, which is a common probability distribution in statistical physics and social sciences. In a power-law distribution, the probability of an event's size (or frequency) is proportional to a negative exponent of that event's size. The main characteristic of this distribution is that the frequency of large events (i.e., those far from the average) is higher than expected in many other distributions. This is precisely the characteristic of trade amount distribution. The form of the Pareto distribution is given by P(x) = Cx^(-α). Let's empirically verify this.
The following graph represents the probability of trade amounts exceeding a certain value. The blue line represents the actual probability, while the orange line represents the simulated probability. Please note that we won't go into the specific parameters at this point. It can be observed that the distribution indeed follows a Pareto distribution. Since the probability of trade amounts being greater than zero is 1, and in order to satisfy normalization, the distribution equation should be as follows:
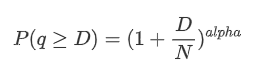
Here, N is the parameter for normalization. We will choose the average trade amount, M, and set alpha to -2.06. The specific estimation of alpha can be obtained by calculating the P-value when D=N. Specifically, alpha = log(P(d>M))/log(2). The choice of different points may result in slight differences in the value of alpha.
In [55]:
```
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
alpha = np.log(np.mean(buy_trades['quantity'] > mean_quantity))/np.log(2)
mean_quantity = buy_trades['quantity'].mean()
probabilities_s = np.array([(1+depth/mean_quantity)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
```
Out[55]:
In [56]:
```
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
```
Out[56]:
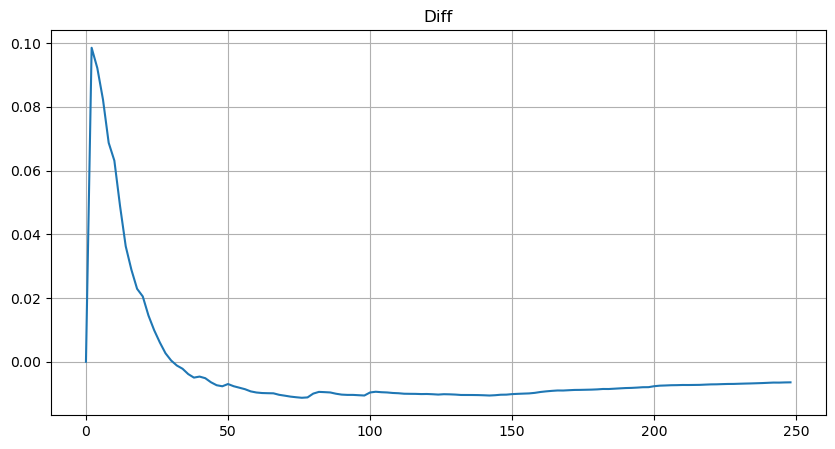
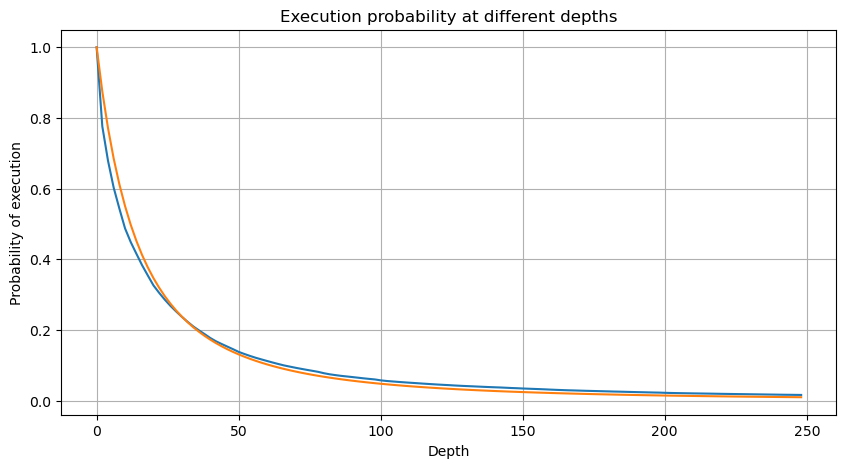
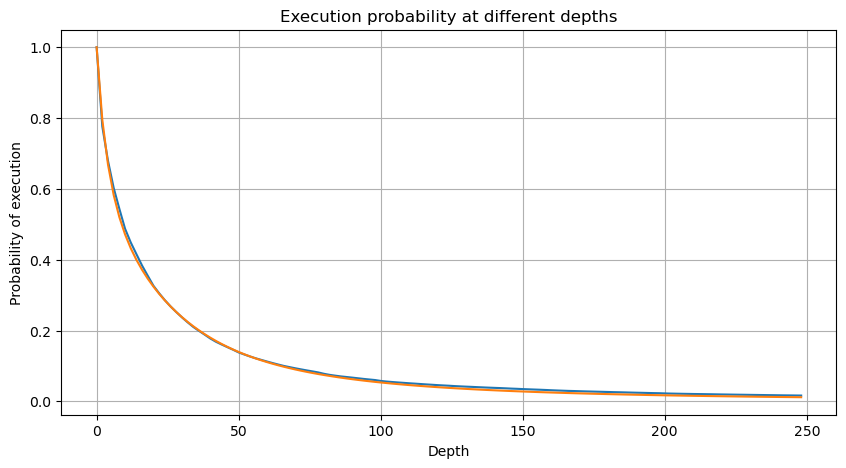
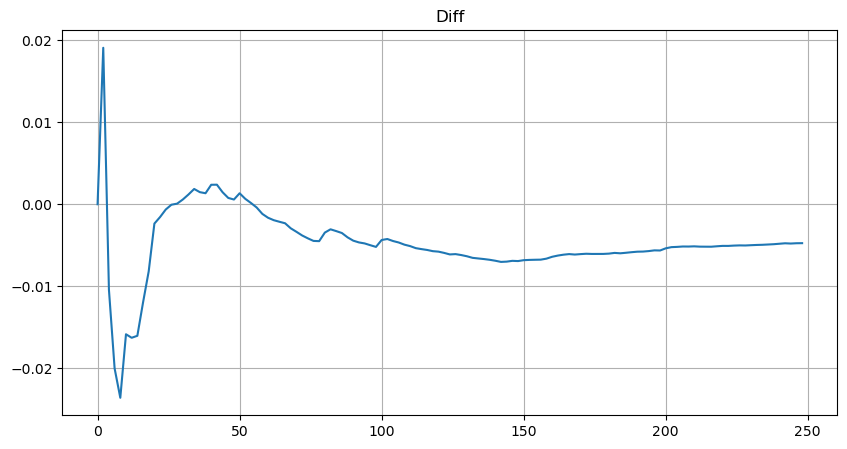
However, this estimation is only approximate, as shown in the graph where we plot the difference between the simulated and actual values. When the trade amount is small, the deviation is significant, even approaching 10%. Although selecting different points during parameter estimation may improve the accuracy of that specific point's probability, it does not solve the deviation issue as a whole. This discrepancy arises from the difference between the power-law distribution and the actual distribution. To obtain more accurate results, the equation of the power-law distribution needs to be modified. The specific process is not elaborated here, but in summary, after a moment of insight, it is found that the actual equation should be as follows:
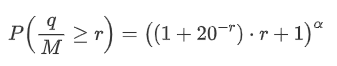
To simplify, let's use r = q/M to represent the normalized trade amount. We can estimate the parameters using the same method as before. The following graph shows that after the modification, the maximum deviation is no more than 2%. In theory, further adjustments can be made, but this level of accuracy is already sufficient.
In [52]:
```
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([(((1+20**(-depth/mean))*depth+mean)/mean)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
```
Out[52]:
In [53]:
```
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
```
Out[53]:
With the estimated equation for the trade amount distribution, it is important to note that the probabilities in the equation are not the actual probabilities, but conditional probabilities. At this point, we can answer the question: What is the probability that the next order will be greater than a certain value? We can also determine the probability of orders at different depths being executed (in an ideal scenario, without considering order additions, cancellations, and queueing at the same depth).
At this point, the length of the text is already quite long, and there are still many questions that need to be answered. The following series of articles will attempt to provide answers.
From: https://blog.mathquant.com/2023/08/04/thoughts-on-high-frequency-trading-strategies-1.html | fmzquant |
1,863,453 | Huaxia Laser: A Pioneer in Fiber Laser Cutting Technology | Huaxia Laser: A Pioneer in Fiber Laser Cutting Technology Are you searching for a quicker, much a... | 0 | 2024-05-24T01:15:34 | https://dev.to/mobika/huaxia-laser-a-pioneer-in-fiber-laser-cutting-technology-213k | fiber, laser | Huaxia Laser: A Pioneer in Fiber Laser Cutting Technology
Are you searching for a quicker, much a lot extra effective method towards reducing products such as steel as well as timber? Huaxia Laser may simply be the service you require. Huaxia Laser is a business that specializes in fiber laser cutting technology. We will talk about the benefits of this particular technology, the development responsible for it, ways to utilize it securely, as well as its lots of requests.
Benefits of Fiber Laser Cutting Technology
Fiber laser cutting technology has several benefits over various other cutting techniques. Firstly, it is extremely quick. Along with fiber laser cutting, you can easily puncture products at a rate that is as much as 5 opportunities quicker compared to conventional cutting techniques. Another benefit of fiber laser cutting technology is its accuracy. Along with a fiber laser cutting machine, you can easily reduce products with amazing precision, by reducing as little as 0.02mm. Another profit of this particular technology is actually that it is extremely flexible. You can easily utilize it to reduce a broad variety of products, consisting of steel, timber, and plastic, as well as a lot extra.
Development responsible for Fiber Laser Cutting Technology
Exactly just what creates fiber laser cutting technology therefore revolutionary? The response deceptions in the method the technology jobs. Unlike conventional cutting techniques, which depend on a bodily device to puncture products, fiber laser cutting devices utilize a high-powered laser to puncture products. This laser produces an extremely extreme beam, along with power that is concentrated on a solitary area. When this beam strikes the product, it quickly heats up as well as vaporizes the product, leaving behind a cleanse, and accurate reduction. This ingenious method of cutting products has transformed production as well as construction markets worldwide.
Security of Fiber Laser Cutting Technology
Security is a leading issue when it concerns any type of commercial technology. Thankfully, laser fiber cutter devices are extremely risk-free to utilize when appropriate security procedures are complied with. Huaxia Laser's devices are developed along with security in thoughts, along with functions such as safety enclosures, interlocks, as well as emergency quit switches. When utilizing a fiber laser cutting device, it is essential to use suitable security equipment, such as safety glasses, as well as to comply with all of the security standards offered due to the producer.
Utilizing Fiber Laser Cutting Devices
Utilizing a fiber laser cutting device is fairly easy, although it need some education as well as method. Before utilizing the device, it is essential to check out the individual handbook as well as get appropriate education coming from a certified specialist. When you are prepared to utilize the device, you will have to prep the product you are cutting as well as tons it into the machine's mattress. Coming from certainly there, you will utilize the machine's software application to choose the cutting specifications as well as begin the cutting procedure. The device will certainly after that utilize its laser to rapidly as well as effectively puncture the product.
Huaxia Laser's Solution as well as premium
Among the essential needs to select Huaxia Laser is their dedication towards a solution as well as high top premium.fiber laser tube cutterprovides an extensive solution as well as sustenance for every one of their devices, consisting of setup, educating, as well as continuous technological support. Furthermore, every one of Huaxia Laser's devices are actually developed towards the greatest requirements of high top premium as well as dependability. Along with Huaxia Laser, you can easily count on that you are obtaining a device that is developed towards final as well as carry out at the greatest degree.
Requests of Fiber Laser Cutting Technology
Therefore, exactly just what can easily you utilize a fiber laser cutting device for? The opportunities are actually almost unlimited. Fiber laser cutting devices are actually typically utilized in the metalworking market for cutting steels such as stainless-steel, light weight aluminum, as well as copper. They're likewise utilized in the automobile market for cutting components such as motor elements. Past commercial requests, fiber laser cutting devices are actually likewise utilized in creative as well as innovative ventures, like cutting elaborate forms as well as styles away from timber or even steel.
Source: https://www.huaxialaser.com/application/laser-fiber-cutter
| mobika |
1,863,452 | 12章32 | このコードは正しいです。抽象クラス Item には、一つの抽象メソッド calcPrice と、一つの具体的なメソッド print が含まれています。この構文は問題ありません。具体的なメソッド... | 0 | 2024-05-24T01:10:49 | https://dev.to/aaattt/12zhang-32-1ppj | このコードは正しいです。抽象クラス `Item` には、一つの抽象メソッド `calcPrice` と、一つの具体的なメソッド `print` が含まれています。この構文は問題ありません。具体的なメソッド `print` には実装が含まれており、抽象メソッド `calcPrice` には `abstract` キーワードが付いています。
最終的なコードは以下の通りです:
```java
abstract class Item {
public abstract int calcPrice(Item item);
public void print(Item item) {
/* do something */
}
}
```
この形式であれば、抽象クラスの定義として正しく、Javaコンパイラもエラーを出さないでしょう。
## 追記
はい、このコードにはいくつかの間違いがあります。抽象クラス `Item` には抽象メソッドが含まれていますが、抽象メソッドには `abstract` キーワードが必要です。また、抽象メソッドは実装を持たないため、セミコロンで終わる必要があります。
修正したコードは以下のようになります:
```java
abstract class Item {
public abstract int calcPrice(Item item);
public abstract void print(Item item);
}
```
このように、メソッドの前に `abstract` キーワードを追加し、メソッドの中身を削除してセミコロンで終わるようにします。 | aaattt | |
1,863,451 | Chocolate Coco from Belgium and Flour from Italy | In the realm of gastronomy, few combinations evoke the same level of sensory delight as the marriage... | 0 | 2024-05-24T01:08:50 | https://dev.to/blackstone123/chocolate-coco-from-belgium-and-flour-from-italy-3pab | business | In the realm of gastronomy, few combinations evoke the same level of sensory delight as the marriage between Belgian chocolate and Italian flour. Picture this: smooth, rich chocolate, crafted with meticulous care in the quaint villages of Belgium, meets the finely milled flour from the heart of Italy, renowned for its culinary prowess. Together, they form a symphony of flavors and textures that dance on the palate, leaving an indelible mark on the memory of those fortunate enough to indulge.
Belgian chocolate holds an esteemed place in the world of confectionery. Renowned for its unparalleled quality and velvety texture, Belgian chocolate is synonymous with indulgence. The secret to its excellence lies in the meticulous craftsmanship that goes into its production. Belgian chocolatiers, often carrying on centuries-old traditions, blend premium cocoa beans with just the right amount of sugar and cocoa butter to achieve the perfect balance of sweetness and depth of flavor. The result is a chocolate that tantalizes the taste buds and elicits pure bliss with every bite.
On the other side of Europe, Italy boasts a culinary heritage that is as rich as its fertile soil. Flour, a seemingly humble ingredient, takes center stage in Italian cuisine, where it is revered for its quality and versatility. In particular, the flour from Bagatelle, a region renowned for its wheat fields and centuries-old milling techniques, stands out for its exceptional quality. Milled to perfection, this flour possesses a delicate texture and subtle flavor that elevates any dish it graces.
When Belgian chocolate and Italian flour come together, the result is nothing short of extraordinary. The marriage of these two culinary treasures creates a synergy that enhances the best qualities of each ingredient, resulting in a symphony of flavors and textures that tantalize the senses.
Consider, for example, the classic Belgian chocolate cake made with Italian flour. The rich, indulgent flavor of the chocolate is complemented by the delicate crumb of the cake, thanks to the superior quality of the Italian flour. Each bite is a harmonious blend of sweetness and depth, a testament to the exquisite craftsmanship that went into its creation.
Similarly, Belgian chocolate truffles made with Italian flour take on a new dimension of flavor and texture. The smooth, creamy ganache enveloped in a dusting of cocoa powder owes its luxurious mouthfeel to the impeccable quality of the chocolate and the finesse of the flour. With each bite, the truffles melt on the tongue, releasing a symphony of flavors that linger long after the last crumb is gone.
But the magic of Belgian chocolate and Italian flour extends beyond the realm of desserts. Savory dishes, too, benefit from their union. Picture a tender, melt-in-your-mouth beef stew, enriched with a velvety chocolate sauce thickened with Italian flour. The depth of flavor imparted by the chocolate complements the richness of the stew, creating a dish that is as comforting as it is elegant.
In the world of baking, Belgian chocolate and Italian flour reign supreme. From delicate pastries to hearty breads, their combined prowess knows no bounds. Croissants made with Belgian chocolate and Italian flour boast a flaky, buttery texture that is simply irresistible, while artisanal breads achieve the perfect balance of crust and crumb, thanks to the superior quality of the flour.
Beyond the realm of taste, the partnership between Belgian chocolate and Italian flour carries with it a sense of tradition and craftsmanship that is deeply ingrained in both cultures. Each bite tells a story of centuries-old techniques passed down through generations, of artisans who take pride in their craft, and of a commitment to excellence that knows no compromise.
**Conclusion **
The combination of Belgian chocolate and Italian flour is a match made in culinary heaven. Together, they form a symphony of flavors and textures that elevate any dish they grace, creating an experience that is truly unforgettable. So, the next time you find yourself in the kitchen, consider incorporating these two culinary treasures into your recipes, and prepare to be amazed by the magic they create.
Visit Website: **[https://crumbly-corner.com/](https://crumbly-corner.com/)**
| blackstone123 |
1,863,450 | Open-Source No-Code/Low-Code Platform NocoBase v1.0.0-alpha.15: New Plugins and Improved “Configure actions” Interaction | About NocoBase NocoBase is a private, open-source, no-code platform offering total control... | 0 | 2024-05-24T01:07:26 | https://dev.to/nocobase/open-source-no-codelow-code-platform-nocobase-v100-alpha15-new-plugins-and-improved-configure-actions-interaction-37eh | lowcode, opensource, github, nocode | ## About NocoBase
NocoBase is a private, open-source, no-code platform offering total control and infinite scalability. It empowers teams to adapt quickly to changes while significantly reducing costs. Avoid years of development and substantial investment by deploying NocoBase in minutes.
## 👇 Get NocoBase
[Homepage](https://www.nocobase.com/?utm_source=dev&utm_medium=article&utm_content=w2c7n)
[Demo](https://demo.nocobase.com/new)
[Documentation](https://docs.nocobase.com/)
[GitHub](https://github.com/nocobase/nocobase)
## New features
### Auth plugin: LDAP authentication
Supports users logging in to NocoBase using their LDAP server credentials. For more information, refer to the [Authentication: LDAP](https://docs.nocobase.com/handbook/auth-ldap) documentation.
### Workflow plugin: custom action trigger
When CRUD actions cannot satisfy your needs, you can use the custom action trigger of the workflow to orchestrate your own data processing logic. For more information, refer to the [Workflow / Custom action trigger](https://docs.nocobase.com/handbook/workflow/plugins/custom-action-trigger) documentation.
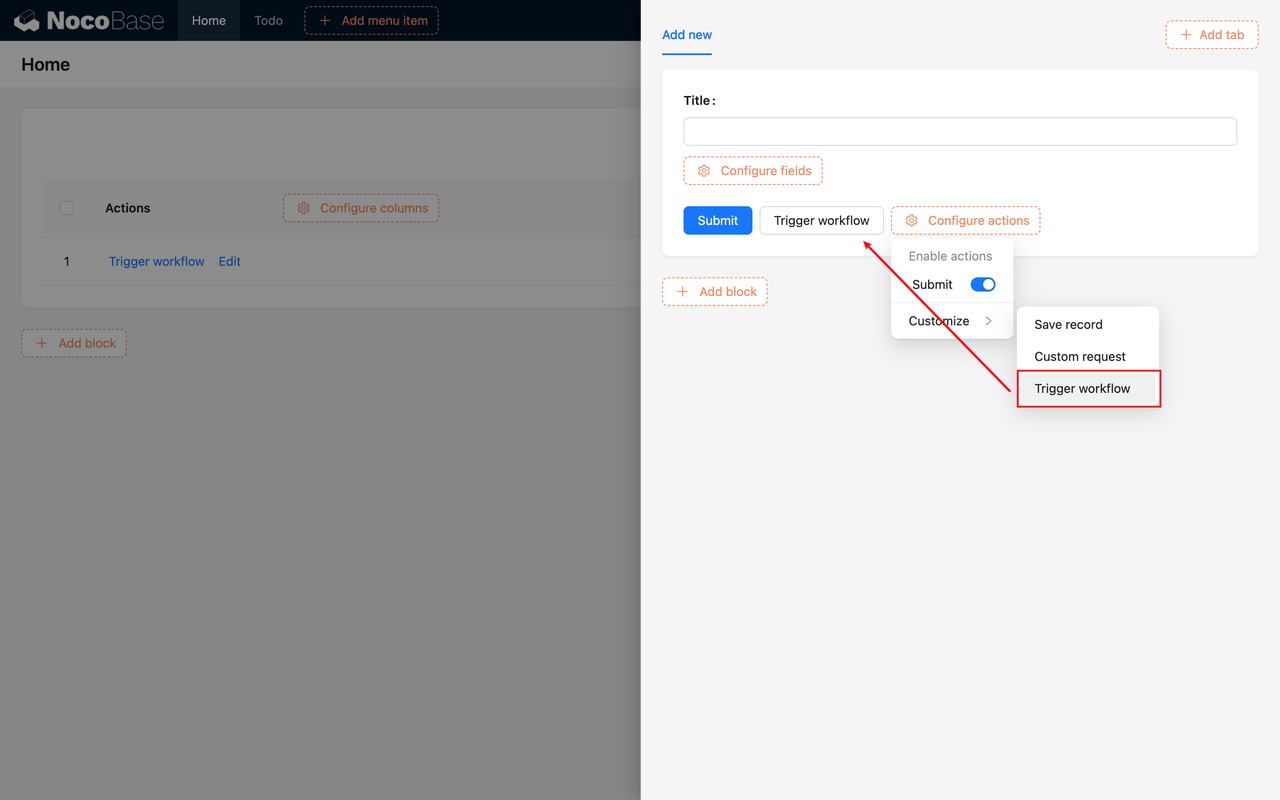
### Table block supports fixed columns
### Supports adding Gantt and Kanban in pop-up windows
### The details block supports linkage rules
Allows configuring the visible and hidden properties of fields.
### Workflow HTTP request node supports `application/www-x-form-urlencoded` format data
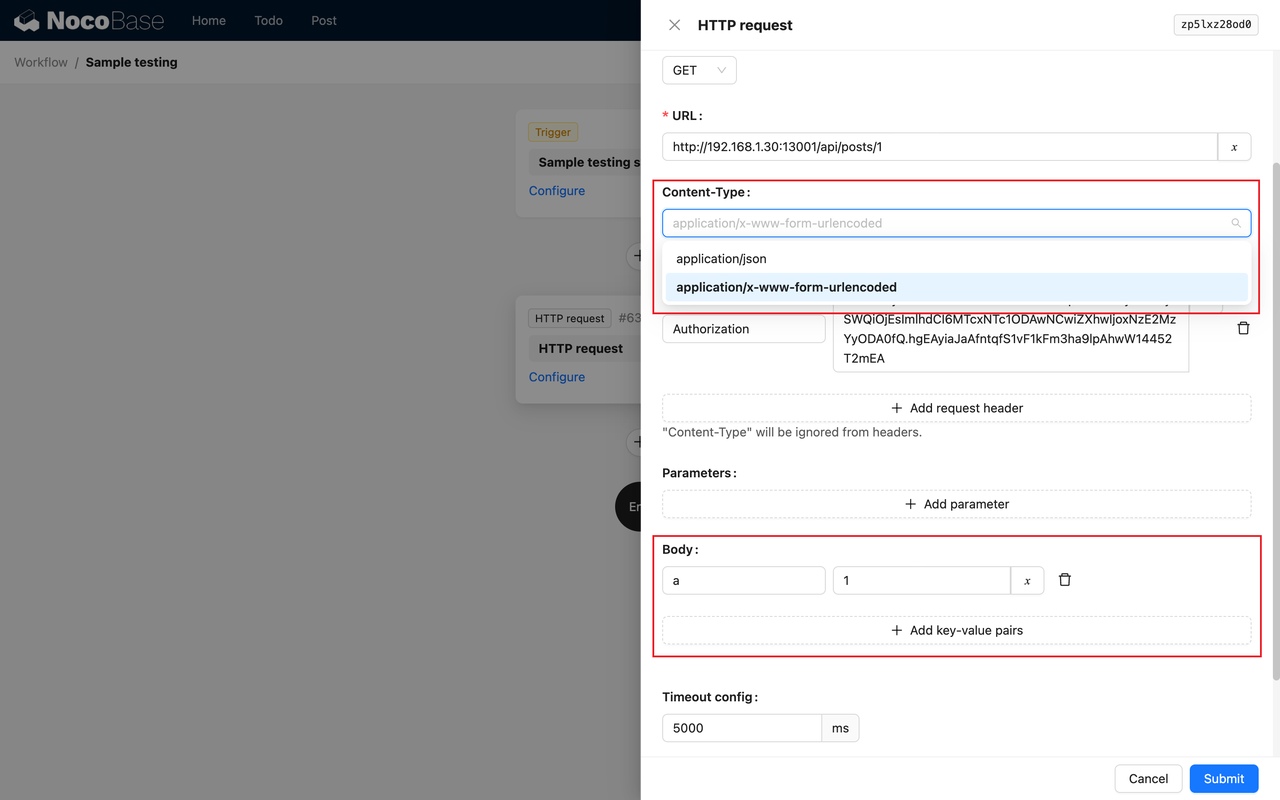
### Workflow HTTP request node input boxes supports string templates
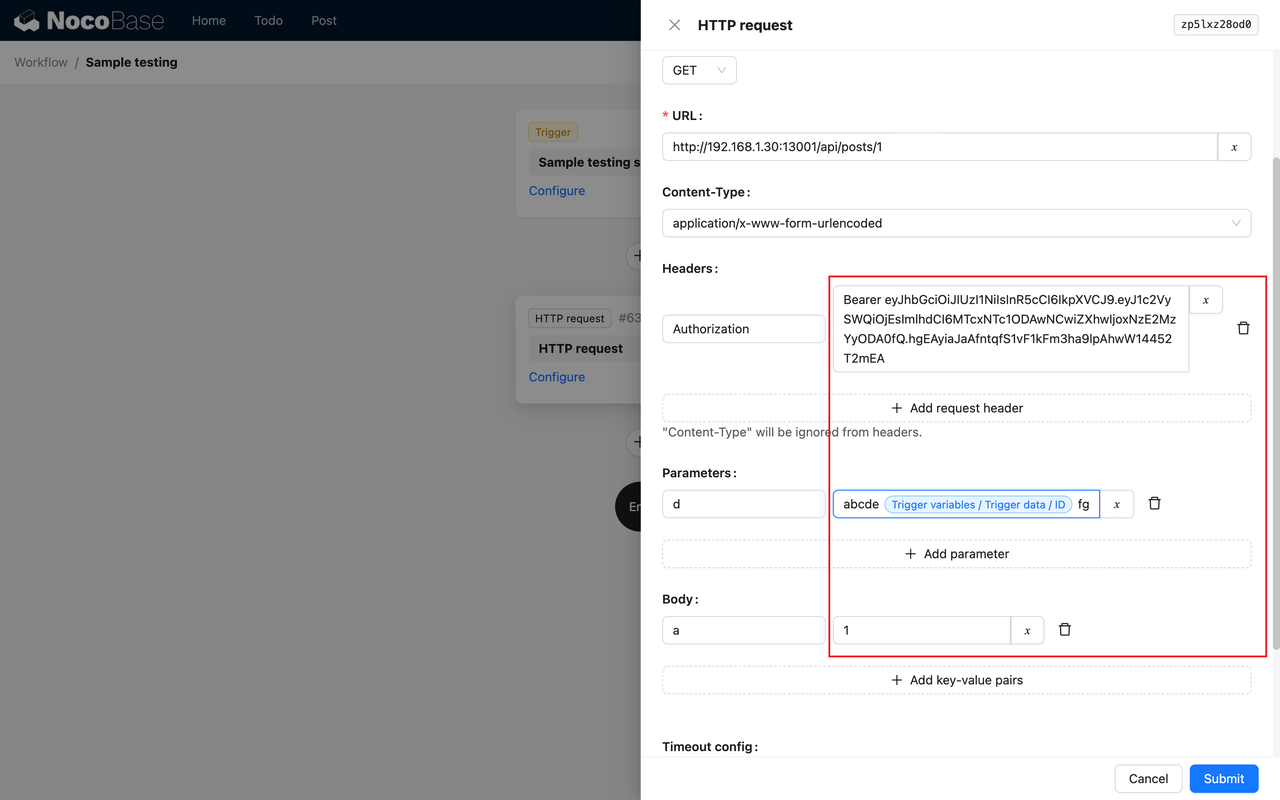
### Plugin samples for development
View the documentation for [plugin examples](https://docs.nocobase.com/plugin-samples).
## Improvements
### Improved "Configure actions" interaction
All actions are displayed in a single list in the dropdown menu, no longer distinguishing between "Enable actions" and "Customize".
- Actions that can only be added once: These actions retain the switch effect.
- Actions that can be added repeatedly: These actions no longer use the switch interaction and can be added multiple times.
- Merged similar actions
- “Add new” and “Add record”
- “Submit” and “Save record”
### Unified data format for workflow HTTP request node result:
```js
{
config: {},
headers: {},
status: 500,
statusText: 'xxx',
data: {}
}
```
### Reorganize workflow handbook
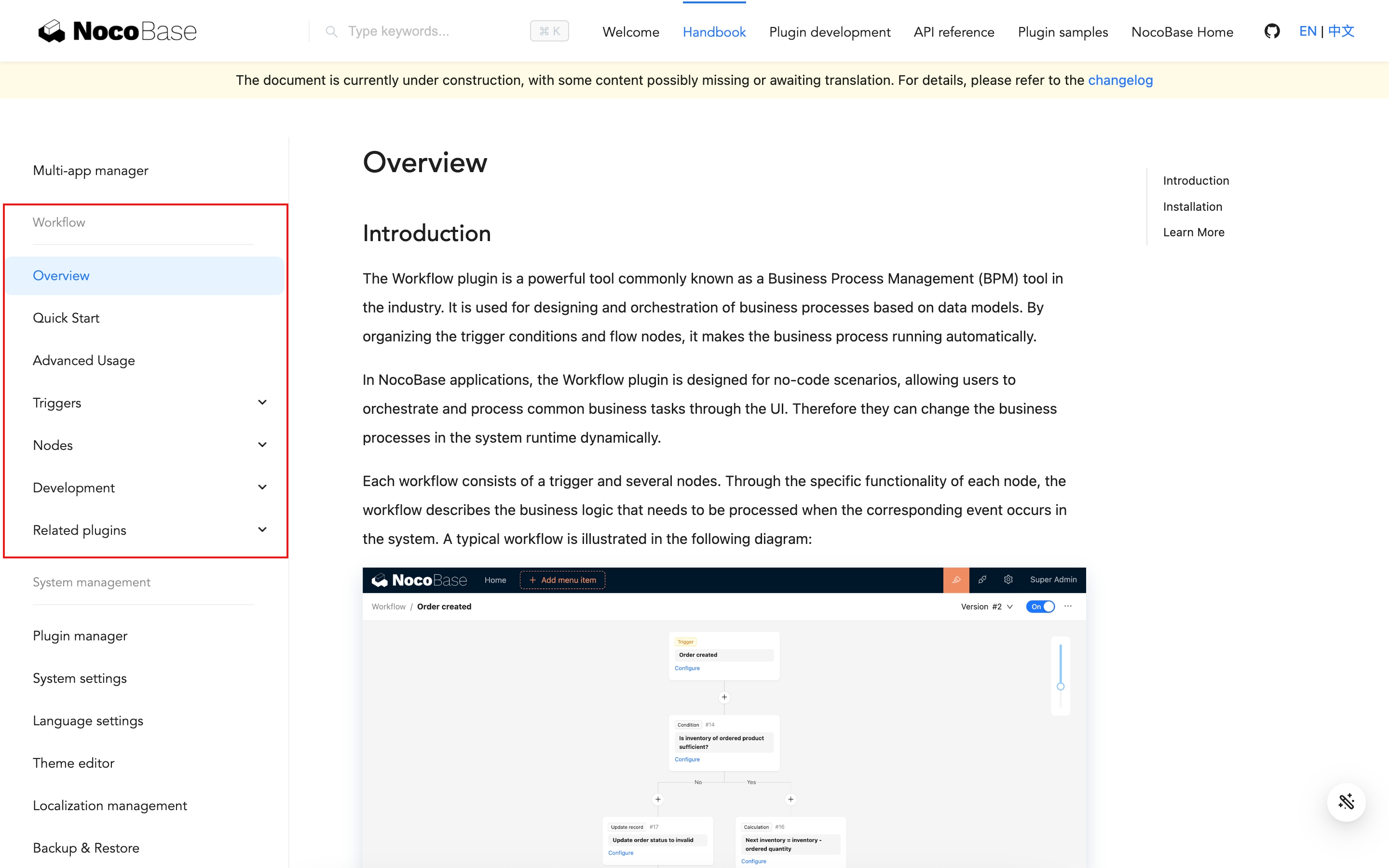
## Fixes
### Log plugin now only shows logs of the current application
When there are multiple applications:
- The log plugin only displays the log file list for the current application.
- Workflow and custom request folders are placed within the application folder.
Other major fixes include:
- Charts did not convert date fields to client time zone when querying aggregated data by date field. <a href="https://github.com/nocobase/nocobase/pull/4366" target="_blank">fix(data-vi): should use local timezone when formatting date #4366</a>
- View refresh issue, where the view needed to be exited and re-entered after syncing with the database. <a href="https://github.com/nocobase/nocobase/pull/4224" target="_blank">fix: collection fields should be refreshed after editing sync from database #4224</a>
- Tree table block did not collapse all nodes when adding a child node. <a href="https://github.com/nocobase/nocobase/pull/4289" target="_blank">fix: do not collapse all nodes when adding a child node in the tree table block #4289</a>
- Data table title field settings were invalid. <a href="https://github.com/nocobase/nocobase/pull/4358" target="_blank">fix: collection title field setting is invalid #4358</a>
- Bigint field lost precision in read-only mode. <a href="https://github.com/nocobase/nocobase/pull/4360" target="_blank">fix: bigint field loses precision in read pretty mode #4360</a>
- Open log files were not closed after stopping a sub-application. <a href="https://github.com/nocobase/nocobase/pull/4380" target="_blank">fix(logger): should close log stream after destroying app #4380</a>
- Workflow aggregate node relationship data model selection bug. <a href="https://github.com/nocobase/nocobase/pull/4315" target="_blank">fix(plugin-workflow-aggregate): fix association field select #4315</a>
- Ignoring errors option was ineffective in synchronous mode for workflow HTTP request node. <a href="https://github.com/nocobase/nocobase/pull/4334" target="_blank">fix(plugin-workflow-request): fix ignoreFail in sync mode #4334</a>
- Workflow HTTP request node value input box overflowed. <a href="https://github.com/nocobase/nocobase/pull/4353" target="_blank">fix(plugin-workflow-request): fix value fields overflowing #4354</a>
- Special characters caused workflow HTTP request node to hang. <a href="https://github.com/nocobase/nocobase/pull/4376" target="_blank">fix(plugin-workflow-request): fix request hanging when invalid header value #4376</a>
- Fixed issue where setting marginBlock in the theme editor affected form field spacing. <a href="https://github.com/nocobase/nocobase/pull/4374" target="_blank">fix(theme-editor): form field spacing should not be affected by token.marginBlock #4374</a>
- Fixed issue where clicking the "License" option in the top right corner of the page redirected incorrectly. [PR #4415](https://github.com/nocobase/nocobase/pull/4415)
- Fixed issue where the field operator was invalid when saving a filter form as a block template. [PR #4390](https://github.com/nocobase/nocobase/pull/4390) | nocobase |
1,863,447 | how much is spray foam insulation | Welcome to Panda Insulation, your trusted partner for high-quality insulation solutions. If you are... | 0 | 2024-05-24T01:00:36 | https://dev.to/pandainsulation/how-much-is-spray-foam-insulation-n1k | Welcome to Panda Insulation, your trusted partner for high-quality insulation solutions. If you are here, you are probably wondering, “**[how much is spray foam insulation](https://pandainsulation.us/insulation/how-much-is-spray-foam-insulation/)**?” Here, we will answer that question and provide you essential information on spray foam insulation. Panda Insulation is proud to serve residential, commercial, and industrial clients in Rio Grande, Port Isabel, San Benito, and Brownsville, TX. To get a free quote, call us NOW!
Spray foam insulation is a highly effective and versatile material used to insulate homes, commercial buildings, and industrial structures. It is popular for its exceptional thermal and moisture control properties, making it a popular choice among property owners seeking energy efficiency, improved indoor comfort, and long-term cost savings. | pandainsulation | |
1,863,446 | Frequency Inverters vs. Soft Starters: Choosing the Right Solution for Your Needs | Frequency Inverters vs. Soft Starters: Choosing the Right Solution for Your Needs When it concerns... | 0 | 2024-05-24T00:59:13 | https://dev.to/mobika/frequency-inverters-vs-soft-starters-choosing-the-right-solution-for-your-needs-3fmj | softstarters | Frequency Inverters vs. Soft Starters: Choosing the Right Solution for Your Needs
When it concerns managing the rate of an electrical motor, there certainly are 2 prominent choices offered in the market: frequency inverters as well as soft starters. Each has its very personal benefits as well as developments, however, choosing the right solution for your needs could be a little bit challenging. We'll get a better take a check out each service, consisting of their security, utilization, solution, high top premium, as well as request, therefore you can easily create a notified choice.
Benefits of Frequency Inverters
Frequency inverter, likewise referred to as adjustable frequency steers, are electric gadgets that command the rate of an electrical electric motor by altering the frequency of the inbound energy. In easy phrases, a frequency inverter transforms fixed-frequency AC energy right into adjustable-frequency AC energy. Their benefits consist of:
- Power effectiveness: Frequency inverters enable you to change the electric motor rate to suit the needs of your request. This implies that the electric motor just utilizes the power needed to perform the task, which leads to power cost financial savings as well as decreased operating expenses.
- Soft begin as well as quit: Frequency inverters offer a progressive velocity as well as slowdown of the electric motor, which decreases technical tension as well as use, as well as avoids damage to the devices.
- Efficiency improvement: Frequency inverters can easily enhance the efficiency of electrical electric motors by offering smoother, much a lot extra accurate command over the rate as well as torque.
Benefits of Soft Starters
Soft Starter are electric gadgets that command the rate of an electrical electric motor by slowly enhancing the voltage provided to it. They are developed to offer a soft beginning as well as quit towards the electric motor, which decreases the technical as well as electric tension on the devices. Their benefits consist of:
- Decreased downtime: Soft starters can easily extend the lifestyle of the devices by decreasing the deterioration of the electric motor, which reduces the possibilities of breakdowns as well as unforeseen downtime.
- Decreased power sets you back: Soft starters restrict the beginning presence of the electric motor, which decreases the effect on the energy grid as well as reduces the power usage.
- Enhanced security: Soft starters avoid unexpected jerks as well as surges throughout startup, which decreases the danger of mishaps as well as injuries.
Ways to Utilize Frequency Inverters as well as Soft Starters
Each frequency inverter, as well as soft starters, could be utilized in a wide variety of requests, consisting of HVAC bodies, conveyor belts, pumps, fans, as well as compressors. Nevertheless, the choice of the right solution depends upon the particular needs of the request. Right below are a couple of standards for choosing the right solution:
- Frequency inverters are the finest fit for requests that need regular rate modifications, accurate command, as well as power effectiveness.
- Soft starters are the finest fit for requests that need soft begin as well as quit, decreased deterioration, as well as enhanced security.
When it concerns setup as well as procedure, frequency inverters as well as soft starters are fairly user-friendly as well as can be managed through an easy interface. Nevertheless, it is essential to comply with the manufacturer's directions as well as standards to guarantee their risk-free as well as effective procedure.
The solution as well as High premium
The solution as well as high top premium of Fan Frequency Inverter as well as soft starters can easily differ considerably from one producer to another. It is essential to select a reliable producer that provides dependable items as well as outstanding client sustain. Appearance for producers that have a tested performance history in the market, deal extensive guarantees as well as assurances, as well as have a wide variety of items to select from.
Request of Frequency Inverters as well as Soft Starters
Frequency inverters as well as soft starters are utilized in a selection of markets, consisting of production, mining, oil as well as fuel, sprinkle therapy, as well as meals as well as drinks. They are perfect for requests that need accurate as well as effective command over the rate as well as torque of electrical electric motors. Some instances of their request consist of:
- HVAC bodies: Frequency inverters can easily command the rate of HVAC electric motors to suit the cooling down or even home heating tons, which leads to energy-efficient procedures as well as enhanced convenience.
- Conveyor belts: Soft starters can easily efficiently begin as well as quit conveyor belts, which decreases the tension on the belt as well as an electric motor, as well as avoids damage to the devices.
- Pumps as well as fans: Frequency inverters can easily change the rate of pumps as well as fans to suit the stream demands, which leads to power cost financial savings as well as enhanced efficiency.
Source: https://www.topinverter.com/Frequency-inverter
| mobika |
1,863,445 | Finding the Best Redford Deck Builder, Repair, and Kitchen Remodeler Near You | In the realm of home improvement, few projects hold as much transformative power as deck... | 0 | 2024-05-24T00:58:27 | https://dev.to/blackstone123/finding-the-best-redford-deck-builder-repair-and-kitchen-remodeler-near-you-apc | business | In the realm of home improvement, few projects hold as much transformative power as deck construction, repair, and kitchen remodeling. These endeavors not only enhance the aesthetic appeal of your home but also significantly increase its functionality and market value. Whether you're envisioning relaxing summer evenings on a beautifully crafted deck or preparing gourmet meals in a newly renovated kitchen, finding the right professionals to bring your vision to life is paramount. For residents of Redford and its surrounding areas, the search for a reputable deck builder, repair specialist, or kitchen remodeler can be simplified with the help of modern technology and a keen eye for quality craftsmanship.
**Understanding Your Needs:**
Before embarking on your search for the perfect deck builder, repair expert, or kitchen remodeler, it's essential to define your project's scope and objectives. Are you looking to construct a new deck from scratch, repair an existing one, or completely overhaul your kitchen space? Clarifying your goals will not only help you communicate effectively with potential contractors but also ensure that you receive accurate estimates and proposals tailored to your specific requirements.
**The Importance of Professionalism:**
When it comes to home improvement projects of this magnitude, professionalism is non-negotiable. From adhering to project timelines and budgets to maintaining open communication channels, a reputable contractor will prioritize your satisfaction every step of the way. Look for professionals who are licensed, insured, and experienced in their respective fields. Additionally, seek out contractors who are willing to provide references or showcase previous projects, allowing you to gauge the quality of their workmanship firsthand.
**Utilizing Online Resources:**
In today's digital age, the internet serves as a valuable tool for researching and vetting potential contractors. Websites, review platforms, and social media channels offer insights into the reputation and credibility of local businesses, including deck builders, repair specialists, and kitchen remodelers. Take advantage of online resources to read customer reviews, view portfolios, and compare service offerings. Pay close attention to testimonials from past clients, as they can offer valuable insights into the contractor's reliability, professionalism, and attention to detail.
**Local Expertise:**
When searching for a deck builder, repair expert, or kitchen remodeler near you, prioritize contractors with a strong presence in your local community. Not only are they familiar with regional building codes and regulations, but they also understand the unique environmental factors that may impact your project. By choosing a local contractor, you can rest assured that they have established relationships with suppliers, subcontractors, and permitting authorities, streamlining the construction process and minimizing potential delays.
**The Redford Advantage:**
For residents of Redford and its neighboring areas, the search for a reputable deck builder, repair specialist, or kitchen remodeler is made easier by the vibrant local business community. Redford boasts a diverse array of home improvement professionals, each offering unique expertise and a commitment to customer satisfaction. By supporting local businesses, you not only invest in the economic vitality of your community but also benefit from personalized service and attention to detail.
**Finding the Right Fit:**
Ultimately, the key to a successful home improvement project lies in finding the right contractor for the job. Whether you're in need of a skilled deck builder, repair specialist, or kitchen remodeler, prioritize professionals who demonstrate a passion for their craft, a dedication to excellence, and a commitment to exceeding your expectations. Take the time to meet with multiple contractors, discuss your project goals in detail, and request written estimates outlining the scope of work, timeline, and budget. Remember that the lowest bid isn't always the best option; instead, focus on finding a contractor who offers a combination of value, quality, and reliability.
**Conclusion:**
Embarking on a home improvement journey, whether it involves constructing a new deck, repairing an existing one, or remodeling your kitchen, is an exciting endeavor that holds the potential to enhance both the beauty and functionality of your home. By leveraging online resources, seeking out local expertise, and prioritizing professionalism, residents of Redford and its surrounding areas can find the perfect deck builder, repair specialist, or kitchen remodeler to bring their vision to life. With the right contractor by your side, you can transform your house into the home of your dreams, one project at a time.
Visit Website: **[https://buildwithba.com/](https://buildwithba.com/)**
| blackstone123 |
1,863,443 | Modals with Remix | Modals with Remix Using Remix I have found it second nature to use modal routes when I... | 0 | 2024-05-24T00:54:33 | https://blog.micromegas.dev/modals-with-remix | remix, modals, react, javascript | ## Modals with Remix
Using Remix I have found it second nature to use modal routes when I can. Instead of using `useState` and passing data to the modal component, a modal route can be created under the parent route, and it being a route there is no need to pass data that may not be used if a user chooses not to open the modal. Less mess, more simplicity.
Since it is a route, you can use loader as well action, I have found that for most cases `useState` is unnecessary, and more messy when using Remix.
In this post I'll create a modal route that creates a user entry in the database to portray how simple and effortless using Remix can be. Much less time thinking about how to do something, more time spent on doing what is important.
First we'll initialize Prisma by creating a file called `db.server.ts`
```
// app/db.server.ts
import { PrismaClient } from "@prisma/client"
declare global {
var __prisma: PrismaClient
}
if (!global.__prisma) {
global.__prisma = new PrismaClient()
}
global.__prisma.$connect()
export const prisma = global.__prisma
```
```
// prisma/schema.prisma
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "sqlite"
url = env("DATABASE_URL")
}
model Post {
id Int @id @default(autoincrement())
title String
name String
date_created DateTime @default(now())
date_updated DateTime @default(now())
}
```
We'll also create a route file called `posts.tsx`, we'll render the posts from the database here, we use a loader to pass the data from the database to the user:
```
import type {LoaderFunctionArgs, MetaFunction} from "@remix-run/node";
import {prisma} from "~/db.server";
import {Link, Outlet, useLoaderData} from "@remix-run/react";
export const meta: MetaFunction = () => {
return [
{ title: "New Remix App" },
{ name: "description", content: "Welcome to Remix!" },
];
};
export default function Index() {
const {posts} = useLoaderData();
return (
<div className={'w-[80%] m-auto p-6'}>
<nav className={'mb-6'}>
<h1 className={'text-2xl font-medium'}>Posts</h1>
<Link to={'/posts/create'}>
<button className={'bg-blue-600 px-5 py-1.5 text-white text-sm text-center rounded-[8px]'}>Create</button>
</Link>
</nav>
<div >
<table className={'text-left'}>
<thead >
<tr>
<th scope="col" >
Post ID
</th>
<th scope="col">
Title
</th>
<th scope="col" >
Name
</th>
<th scope="col" >
Last updated
</th>
<th scope="col" >
Actions
</th>
</tr>
</thead>
<tbody>
{posts.map(post => <tr >
<th scope="row" >
{post.id}
</th>
<td>
{post.title}
</td>
<td >
{post.name}
</td>
<td >
{post.date_updated}
</td>
<td className={'text-left'} >
<Link className={'text-left'} to={`/posts/${post.id}`}>
Edit
</Link>
</td>
</tr>)}
</tbody>
</table>
</div>
<Outlet/>
</div>
);
}
export async function loader({request}: LoaderFunctionArgs) {
const posts = await prisma.post.findMany()
return {posts}
}
}
export async function loader({request}: LoaderFunctionArgs) {
const posts = await prisma.post.findMany()
return {posts}
}
```
This will render all the posts from the database, first we will deal with the first modal route that creates a post in the database.
First we must create a file `posts.create.tsx`, but naming a file like that is not enough for the modal to appear on top of posts, an `<Outlet/>` must exist inside the `posts.tsx` route.
```
// posts.create.tsx
import {useEffect} from "react";
import {Form, Link, redirect} from "@remix-run/react";
import {ActionFunctionArgs} from "@remix-run/node";
import {z} from "zod";
import {zx} from "zodix";
import {prisma} from "~/db.server";
export default function Create() {
return <div id="default-modal" tabIndex="-1" aria-hidden="true"
className="bg-black bg-opacity-60 overflow-y-auto overflow-x-hidden fixed top-0 right-0 left-0 z-50 justify-center items-center w-full md:inset-0 h-[calc(100%-1rem)] h-full">
<div className="relative p-4 w-full m-auto mt-[7%] max-w-2xl max-h-full">
<div className="relative bg-white rounded-lg shadow">
<Form method={'post'}>
<div className="flex items-center justify-between p-4 md:p-5 border-b rounded-t">
<h3 className="text-xl font-semibold text-gray-900 ">
Create post
</h3>
<Link to={'/posts'}>
<button type="button"
className="text-gray-400 bg-transparent hover:bg-gray-200 hover:text-gray-900 rounded-lg text-sm w-11 h-11 ms-auto inline-flex justify-center items-center"
data-modal-hide="default-modal">
<svg className="w-4 h-4" aria-hidden="true" xmlns="http://www.w3.org/2000/svg" fill="none"
viewBox="0 0 14 14">
<path stroke="currentColor" stroke-linecap="round" stroke-linejoin="round" stroke-width="2"
d="m1 1 6 6m0 0 6 6M7 7l6-6M7 7l-6 6"/>
</svg>
<span className="sr-only">Close modal</span>
</button>
</Link>
</div>
<div className="p-4 md:p-5 space-y-4">
<div>
<label htmlFor="title"
className="block mb-2 text-sm font-medium text-gray-900">Title</label>
<input type="text" name={'title'}
className="bg-gray-50 border border-gray-300 text-gray-900 text-sm rounded-lg focus:ring-blue-500 focus:border-blue-500 block w-full p-2.5 "
placeholder="Enter a title here" required/>
</div>
</div>
<div className={'flex justify-between items-center'}>
<div>
</div>
<div className="flex items-center p-4 md:p-5 border-t border-gray-200 rounded-b">
<button data-modal-hide="default-modal" type="submit"
className="text-white bg-blue-700 hover:bg-blue-800 focus:ring-4 focus:outline-none focus:ring-blue-300 font-medium rounded-lg text-sm px-5 py-2.5 text-center">Submit
</button>
<Link to={'/posts'}>
<button data-modal-hide="default-modal" type="button"
className="py-2.5 px-5 ms-3 text-sm font-medium text-gray-900 focus:outline-none bg-white rounded-lg border border-gray-200 hover:bg-gray-100 hover:text-blue-700 focus:z-10 focus:ring-4 focus:ring-gray-100">Cancel
</button>
</Link>
</div>
</div>
</Form>
</div>
</div>
</div>
}
```
You will notice as it is often with Remix that there is no JS here, closing the modal simply takes you back to /posts which is the parent route.
Now we will add an action which will create a new post when the user submits the form. We will validate the request body with Zodix, a module that allows us to use Zod to parse FormData.
```
function slugify(str: string) {
str = str.replace(/^\s+|\s+$/g, ''); // trim leading/trailing white space
str = str.toLowerCase(); // convert string to lowercase
str = str.replace(/[^a-z0-9 -]/g, '') // remove any non-alphanumeric characters
.replace(/\s+/g, '-') // replace spaces with hyphens
.replace(/-+/g, '-'); // remove consecutive hyphens
return str;
}
export async function action({request}: ActionFunctionArgs) {
const { title } = await zx.parseForm(request, {
title: z.string(),
});
const slug = slugify(title);
await prisma.post.create({
data: {
title,
name: slug
}
})
return redirect("/posts?created=true")
}
```
We will redirect the user to /posts with a URL param that will let the user know that the post has been created successfully, that is often times achieved with session.flash but as this is a simple example this suffices.
```
// app/root.tsx
const [searchParams, setSearchParams] = useSearchParams()
useEffect(() => {
if (searchParams.get('created')) {
alert("Post created")
const params = new URLSearchParams();
params.delete("created");
setSearchParams(params, {
preventScrollReset: true,
});
}
}, [searchParams])
```
And the result is simplicity of a modal route, no need to have a state to manage the modal, or an API route to handle the creation of a post. The code is more clean and organized, and with a modal route like `posts.create.tsx` the action is found in that file as well, and it handles the task of creating a post entirely.
A modal route has many different possibilities, user settings, editing posts, creating posts. And that is the appeal of a modal route, simplicity in code and less clutter.
You can find the source code here: https://github.com/ddm50/modals-with-remix | ddm4313 |
1,863,441 | How StarSearch Makes Open Source Collaboration Smarter | OpenSauced is a company on a mission to empower open source development. They create innovative tools... | 0 | 2024-05-24T00:47:04 | https://dev.to/lymah/how-starsearch-makes-open-source-collaboration-smarter-38na | opensource, starsearch, contribution, ai | OpenSauced is a company on a mission to empower open source development. They create innovative tools and platforms that help developers collaborate more effectively and build better software. Their latest project, StarSearch, promises to revolutionize the way we understand and value developer contributions in the open source world.
The open-source world thrives on collaboration, but finding the right talent can feel like searching for a needle in a haystack. Contributor profiles often offer limited insights, leaving project maintainers with a guessing game: who has the skills and experience to tackle this critical task?
Imagine building a house without knowing the qualifications of your team. That's the reality for many open-source projects, where contributor profiles can be a mystery. Introducing StarSearch, a groundbreaking new project by OpenSauced, that aims to be the missing piece in the open-source collaboration puzzle.
According to a recent survey, 37.5% of open-source project maintainers struggle to identify developers with the necessary skills for specific tasks. StarSearch offers a potential solution...
## What is StarSearch?
StarSearch is a transformative new tool from OpenSauced that delves deeper than traditional contributor profiles. It provides in-depth insights into a developer's past and recent contributions across various open-source projects, revealing their areas of expertise, coding style, and overall level of engagement.
The world of open-source software thrives on collaboration. Developers from all over the globe contribute their talents and expertise to build and maintain these incredible tools. But how do you, as a project maintainer, know who the best contributors are or who might be a perfect fit for your project?
Enter OpenSauced StarSearch, a groundbreaking new project by OpenSauced. With StarSearch, the veil is lifted on developer contribution history, providing in-depth insights into their past activities and expertise. This exciting development promises to revolutionize how we approach open-source collaboration.
## Why StarSearch Matters?
Imagine a world where identifying the perfect contributor for your project is a breeze. With StarSearch, you can:
- Go beyond basic contributor profiles. StarSearch dives deep, revealing a developer's past contributions across various open-source projects. You can see their areas of expertise, coding style, and overall level of engagement.
- StarSearch provides valuable insights into a developer's skillset and experience. This allows you to make informed decisions about whom to trust with critical tasks within your project.
- By understanding a developer's past contributions and areas of interest, you can create a more cohesive and well-rounded team environment, fostering collaboration and innovation.
As a maintainer, just like Copilot empowers developers, StarSearch empowers you, the project maintainer, to make informed decisions by analyzing a developer's past contributions, and the true story behind their profile. As a developer, you might want to find out more about someone to collaborate with them. Or you might want to find out more about who contributes to a project you're interested in. Let your past contributions speak for themselves, building a stronger reputation and attracting opportunities within the community.
## What's Next? Stay Tuned for StarSearch
OpenSauced's blog post on May 9th, 2024, titled [The Future of Open Source Collaboration is Here: Meet StarSearch ](https://opensauced.pizza/blog/meet-starsearch), offers a glimpse into this innovative tool. As more information becomes available, we can expect StarSearch to spark conversations and drive positive change within the open-source community.
StarSearch is on Product Hunt. Click [here](https://www.producthunt.com/posts/starsearch) to pledge your support and feedback.
This blog post is just the beginning. Stay tuned for further updates on OpenSauced StarSearch, and get ready to experience a new era of informed collaboration in the open-source world!
## Conclusion
StarSearch promises to be a game-changer for open-source collaboration. By shedding light on a developer's past and present contributions, it empowers project maintainers to build stronger teams and developers to showcase their true potential. This deeper understanding can foster a more collaborative and efficient open-source ecosystem. With StarSearch on the horizon, the future of open-source development is bright, and the possibilities for innovation are endless. We eagerly await StarSearch's impact on the developer community.
StarSearch is poised to revolutionize open-source collaboration. Stay tuned for further updates and be a part of this exciting journey. Follow OpenSauced on their community platforms for the latest news and join the conversation about the future of open source.
[Website](https://opensauced.pizza/), [X](https://twitter.com/saucedopen), [Discord](https://discord.gg/opensauced), [LinkedIn](https://www.linkedin.com/company/open-sauced/), [IG](https://instagram.com/opensauced), [blog](https://dev.to/opensauced) and Email: hello@opensauced.pizza
StarSearch isn't just about identifying talent; it's about empowering open-source projects and the developers who fuel them.
| lymah |
1,863,440 | How StarSearch Makes Open Source Collaboration Smarter | OpenSauced is a company on a mission to empower open source development. They create innovative tools... | 0 | 2024-05-24T00:47:04 | https://dev.to/lymah/how-starsearch-makes-open-source-collaboration-smarter-1hnj | opensource, starsearch, contribution, ai | OpenSauced is a company on a mission to empower open source development. They create innovative tools and platforms that help developers collaborate more effectively and build better software. Their latest project, StarSearch, promises to revolutionize the way we understand and value developer contributions in the open source world.
The open-source world thrives on collaboration, but finding the right talent can feel like searching for a needle in a haystack. Contributor profiles often offer limited insights, leaving project maintainers with a guessing game: who has the skills and experience to tackle this critical task?
Imagine building a house without knowing the qualifications of your team. That's the reality for many open-source projects, where contributor profiles can be a mystery. Introducing StarSearch, a groundbreaking new project by OpenSauced, that aims to be the missing piece in the open-source collaboration puzzle.
According to a recent survey, 37.5% of open-source project maintainers struggle to identify developers with the necessary skills for specific tasks. StarSearch offers a potential solution...
## What is StarSearch?
StarSearch is a transformative new tool from OpenSauced that delves deeper than traditional contributor profiles. It provides in-depth insights into a developer's past and recent contributions across various open-source projects, revealing their areas of expertise, coding style, and overall level of engagement.

The world of open-source software thrives on collaboration. Developers from all over the globe contribute their talents and expertise to build and maintain these incredible tools. But how do you, as a project maintainer, know who the best contributors are or who might be a perfect fit for your project?
Enter OpenSauced StarSearch, a groundbreaking new project by OpenSauced. With StarSearch, the veil is lifted on developer contribution history, providing in-depth insights into their past activities and expertise. This exciting development promises to revolutionize how we approach open-source collaboration.
## Why StarSearch Matters?
Imagine a world where identifying the perfect contributor for your project is a breeze. With StarSearch, you can:
- Go beyond basic contributor profiles. StarSearch dives deep, revealing a developer's past contributions across various open-source projects. You can see their areas of expertise, coding style, and overall level of engagement.
- StarSearch provides valuable insights into a developer's skillset and experience. This allows you to make informed decisions about whom to trust with critical tasks within your project.
- By understanding a developer's past contributions and areas of interest, you can create a more cohesive and well-rounded team environment, fostering collaboration and innovation.

As a maintainer, just like Copilot empowers developers, StarSearch empowers you, the project maintainer, to make informed decisions by analyzing a developer's past contributions, and the true story behind their profile. As a developer, you might want to find out more about someone to collaborate with them. Or you might want to find out more about who contributes to a project you're interested in. Let your past contributions speak for themselves, building a stronger reputation and attracting opportunities within the community.
## What's Next? Stay Tuned for StarSearch
OpenSauced's blog post on May 9th, 2024, titled [The Future of Open Source Collaboration is Here: Meet StarSearch ](https://opensauced.pizza/blog/meet-starsearch), offers a glimpse into this innovative tool. As more information becomes available, we can expect StarSearch to spark conversations and drive positive change within the open-source community.
StarSearch is on Product Hunt. Click [here](https://www.producthunt.com/posts/starsearch) to pledge your support and feedback.
This blog post is just the beginning. Stay tuned for further updates on OpenSauced StarSearch, and get ready to experience a new era of informed collaboration in the open-source world!
## Conclusion
StarSearch promises to be a game-changer for open-source collaboration. By shedding light on a developer's past and present contributions, it empowers project maintainers to build stronger teams and developers to showcase their true potential. This deeper understanding can foster a more collaborative and efficient open-source ecosystem. With StarSearch on the horizon, the future of open-source development is bright, and the possibilities for innovation are endless. We eagerly await StarSearch's impact on the developer community.
StarSearch is poised to revolutionize open-source collaboration. Stay tuned for further updates and be a part of this exciting journey. Follow OpenSauced on their community platforms for the latest news and join the conversation about the future of open source.
[Website](https://opensauced.pizza/), [X](https://twitter.com/saucedopen), [Discord](https://discord.gg/opensauced), [LinkedIn](https://www.linkedin.com/company/open-sauced/), [IG](https://instagram.com/opensauced), [blog](https://dev.to/opensauced) (@saucedopen ) and Email: hello@opensauced.pizza
StarSearch isn't just about identifying talent; it's about empowering open-source projects and the developers who fuel them.
| lymah |
1,863,438 | Condo Duct Cleaning Mississauga And Commercial Duct Cleaning Services Near Me | Condo Duct Cleaning Mississauga In Mississauga, maintaining clean air in condo units is crucial for... | 0 | 2024-05-24T00:44:19 | https://dev.to/blackstone123/condo-duct-cleaning-mississauga-and-commercial-duct-cleaning-services-near-me-2bg8 | business | **Condo Duct Cleaning Mississauga**
In Mississauga, maintaining clean air in condo units is crucial for ensuring a healthy living environment. **[Condo duct cleaning services in Mississauga](https://ductcare.ca/condo-duct-cleaning-mississauga/)** specialize in removing dust, allergens, and other contaminants from the HVAC systems of condominium complexes. These services utilize advanced equipment and techniques to thoroughly clean air ducts, improving air quality and system efficiency. Residents can enjoy a fresher, healthier indoor environment, reducing the risk of respiratory issues and enhancing overall comfort. Whether you live in a high-rise or a smaller condo building, professional duct cleaning ensures that your HVAC system operates smoothly and efficiently.
**Commercial Duct Cleaning Services Near Me**
Commercial duct cleaning services are essential for businesses aiming to maintain a clean and healthy working environment. By searching for "**[commercial duct cleaning services near me](https://ductcare.ca/commercial-duct-cleaning-oshawa/)**," businesses can find local experts who specialize in cleaning and maintaining HVAC systems in commercial properties. These services remove dust, debris, mold, and other contaminants from air ducts, promoting better air quality and energy efficiency. Regular duct cleaning helps prevent potential health issues among employees and customers, while also prolonging the lifespan of HVAC systems. Reliable and professional commercial duct cleaning is a valuable investment for any business seeking to enhance workplace safety and comfort. | blackstone123 |
1,863,434 | Using ASP.NET Core OData with MongoDB Atlas | Overview This article focuses on how you can quickly get up and running using Microsoft's... | 0 | 2024-05-24T00:42:35 | https://dev.to/mongodb/using-aspnet-core-odata-with-mongodb-atlas-380e | odata, dotnetcore, webapi, csharp | # Overview
This article focuses on how you can quickly get up and running using Microsoft's ASP.NET Core OData extension with MongoDB Atlas.
OData stands for [Open Data Protocol](https://www.odata.org/) which is a standard that allows developers to simplify the process of building and consuming RESTful APIs. [MongoDB Atlas](https://www.mongodb.com/docs/atlas/) is MongoDB's cloud offering that allows you to leverage the full potential of MongoDB's developer data platform without any cloud vendor lock-in.
# Tutorial
You need to have a MongoDB Atlas Cluster set up with sample data loaded as shown [here](https://www.mongodb.com/docs/atlas/getting-started/)
I'm using Visual Studio 2022 Community Edition in this tutorial. You can choose to use any IDE of your choice. Open up a new project and choose the ASP.NET Core Empty Project template.
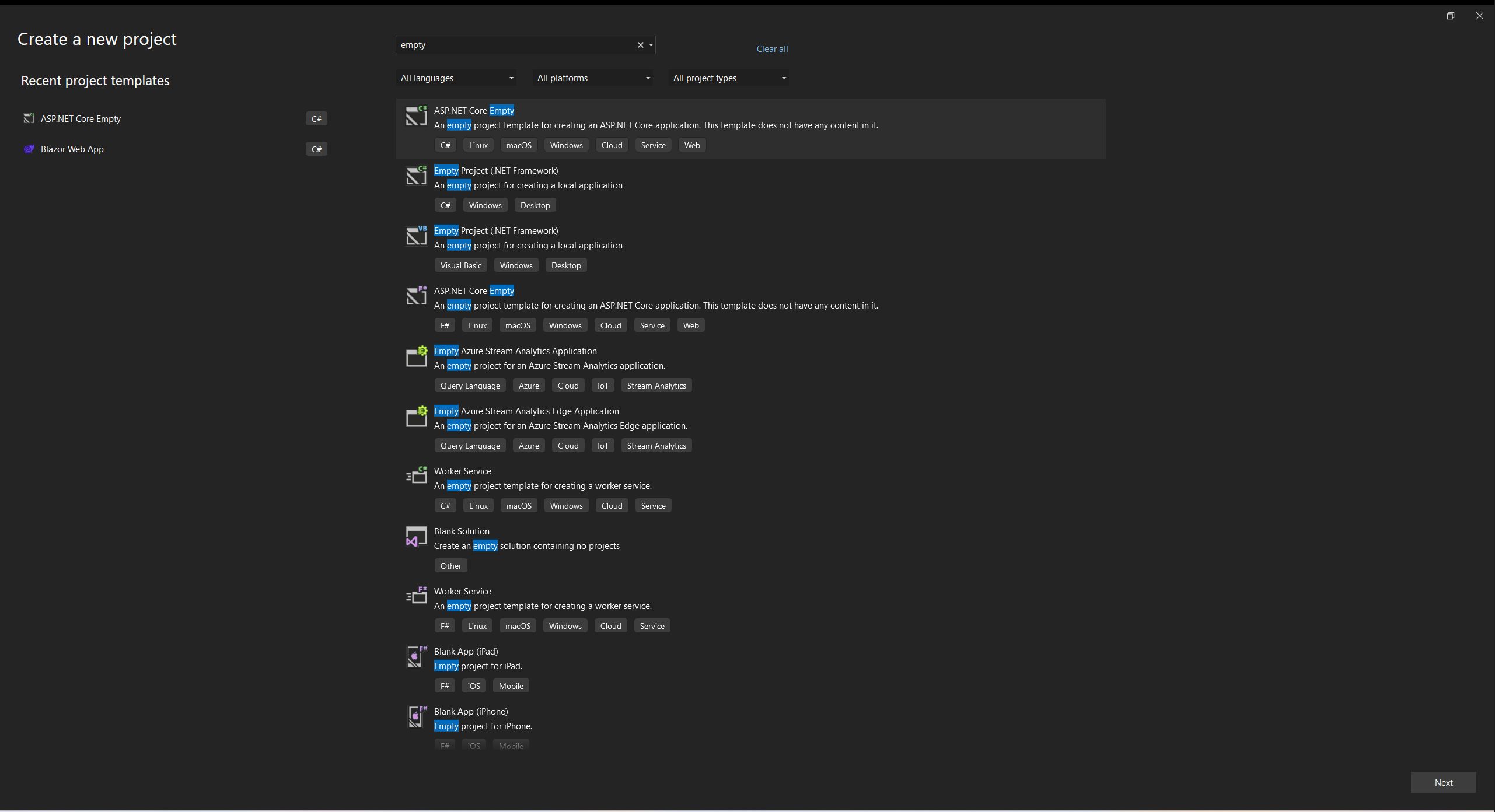
On the following screen, name your project and click Next. Choose the latest LTS .NET Framework and make sure to disable the 'Configure for HTTPS checkbox.
Now we are going to add the [MongoDB OData extension](https://www.nuget.org/packages/MongoDB.AspNetCore.OData/#readme-body-tab) from the Nuget package manager as seen below. This uses the MongoDB .NET/C# Driver and Microsoft's `AspNetCore.OData` package as its dependencies.
I'm going to use the `sample_restaurants` database from the [sample restaurants dataset](https://www.mongodb.com/docs/atlas/sample-data/sample-restaurants/) loaded into my MongoDB Atlas cluster. We need some model classes as shown below in our project for this.
First we'll create the `Restaurant` class.
``` csharp
using MongoDB.Bson;
using MongoDB.Bson.Serialization.Attributes;
namespace ODataTutorial.Models
{
[BsonIgnoreExtraElements]
public class Restaurant
{
[BsonRepresentation(BsonType.ObjectId)]
public string Id { get; set; }
[BsonElement("name")]
public string Name { get; set; }
[BsonElement("restaurant_id")]
public string? RestaurantId { get; set; }
[BsonElement("cuisine")]
public string Cuisine { get; set; }
[BsonElement("address")]
public Address Address { get; set; }
[BsonElement("borough")]
public string Borough { get; set; }
}
}
```
Next we’ll create the `Address` model class.
``` csharp
using MongoDB.Bson.Serialization.Attributes;
namespace ODataTutorial.Models
{
public class Address
{
[BsonElement("building")]
public string Building { get; set; }
[BsonElement("coord")]
public double[] Coordinates { get; set; }
[BsonElement("street")]
public string Street { get; set; }
[BsonElement("zipcode")]
public string ZipCode { get; set; }
}
}
```
The `Address` class does not require an `_id` because it is only stored as a nested subdocument.
Note that we are using the `[BsonElement]` [attribute](https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/language-specification/attributes) to tell the MongoDB C# driver to map the names in our model classes to the field names in the database. You could also choose to use a [convention pack] (https://www.mongodb.com/docs/drivers/csharp/upcoming/fundamentals/serialization/poco/#set-field-names) to do the same.
The `[BsonIgnoreExtraElements]` tells the driver to ignore other fields in the database like 'grades' so that it doesn't throw an error when deserializing such fields. You can read more about serialization using the MongoDB C# driver [here](https://www.mongodb.com/docs/drivers/csharp/current/fundamentals/serialization/poco/).
We need the `[BsonRepresentation(BsonType.ObjectId)]` attribute to tell the Driver that the Id is represented as a string in our model class but as an ObjectId in the database.
Now we'll create a simple Controller that inherits from [ODataController](https://learn.microsoft.com/en-us/dotnet/api/microsoft.aspnet.odata.odatacontroller) and has a Get action with the `[MongoEnableQuery]` attribute. This enables the use of URI query options in our API calls.
``` csharp
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.OData.Routing.Controllers;
using MongoDB.AspNetCore.OData;
using MongoDB.Driver;
using ODataTutorial.Models;
namespace ODataTutorial.Controllers
{
public class RestaurantsController : ODataController
{
private readonly IMongoCollection<Restaurant> _restaurants;
public RestaurantsController(IMongoClient mongoClient)
{
var database =
mongoClient.GetDatabase("sample_restaurants");
_restaurants = database.GetCollection<Restaurant>
("restaurants");
}
[MongoEnableQuery]
public ActionResult Get()
{
return Ok(_restaurants.AsQueryable());
}
}
}
```
Our `Program.cs` file which is the entry point of this Web Application will be quite simple and we will use the `Startup.cs` file to connect to our database and set up the [Model Builder](https://learn.microsoft.com/en-us/odata/webapi/model-builder-abstract).
``` csharp
using ODataTutorial;
public class Program
{
public static void Main(string[] args)
{
var app = CreateHostBuilder(args).Build();
app.Run();
}
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
});
}
```
While setting up the modelBuilder we need to tell it to use our `Id` field as the primary key instead of the `RestaurantID` and this is done through `model.HasKey(e => e.Id)`
``` csharp
using Microsoft.AspNetCore.OData;
using Microsoft.OData.ModelBuilder;
using MongoDB.Driver;
using ODataTutorial.Models;
namespace ODataTutorial
{
public class Startup
{
public IConfiguration Configuration { get; }
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public void ConfigureServices(IServiceCollection services)
{
var connectionString = Configuration.GetSection("MongoDB").GetValue<string>("Uri");
if (string.IsNullOrEmpty(connectionString))
{
throw new InvalidOperationException("Cannot read MongoDB connection settings");
}
services.AddSingleton<IMongoClient>(new MongoClient(connectionString));
var modelBuilder = new ODataConventionModelBuilder();
var model = modelBuilder.EntitySet<Restaurant>("Restaurants").EntityType;
model.HasKey(e => e.Id);
services.AddControllers().AddOData(
options =>
{
options.Select().Filter().OrderBy().Expand().Count().SetMaxTop(1000).AddRouteComponents(
"odata",
modelBuilder.GetEdmModel());
});
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
app.UseRouting();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}
}
}
```
Lastly, we need to make sure we add our MongoDB Atlas connection URL in our `appsettings.json` file as seen below
``` json
"MongoDB": {
"Uri": "<Enter MongoDB Atlas Connection URL here>"
},
```
Voila! That's it, we are now ready to test our OData endpoints with MongoDB Atlas.
# Testing
Once you hit Build and let our application run, you should see it fire up in your chosen browser. We are using a browser in this example but we could use other tools like Postman to test the same.
The default endpoint based on the port configured (E.g `http://localhost:5279/` in my project. Please note that this port will be randomly generated when creating a new project) will not show anything since we don't have it configured. However once you change it to `http://localhost:5279/odata/`, you should see a response like this
``` json
{
"@odata.context": "http://localhost:5279/odata/$metadata",
"value": [
{
"name": "Restaurants",
"kind": "EntitySet",
"url": "Restaurants"
}
]
}
```
You can also see the metadata of our data model by going to `http://localhost:5279/odata/$metadata` Note that our `Id` field is shown as the Key as intended.
``` XML
<edmx:Edmx xmlns:edmx="http://docs.oasis-open.org/odata/ns/edmx" Version="4.0">
<edmx:DataServices>
<Schema
xmlns="http://docs.oasis-open.org/odata/ns/edm" Namespace="ODataTutorial.Models">
<EntityType Name="Restaurant">
<Key>
<PropertyRef Name="Id"/>
</Key>
<Property Name="Id" Type="Edm.String" Nullable="false"/>
<Property Name="Name" Type="Edm.String" Nullable="false"/>
<Property Name="RestaurantId" Type="Edm.String"/>
<Property Name="Cuisine" Type="Edm.String" Nullable="false"/>
<Property Name="Address" Type="ODataTutorial.Models.Address" Nullable="false"/>
<Property Name="Borough" Type="Edm.String" Nullable="false"/>
</EntityType>
<ComplexType Name="Address">
<Property Name="Building" Type="Edm.String" Nullable="false"/>
<Property Name="Coordinates" Type="Collection(Edm.Double)" Nullable="false"/>
<Property Name="Street" Type="Edm.String" Nullable="false"/>
<Property Name="ZipCode" Type="Edm.String" Nullable="false"/>
</ComplexType>
</Schema>
<Schema
xmlns="http://docs.oasis-open.org/odata/ns/edm" Namespace="Default">
<EntityContainer Name="Container">
<EntitySet Name="Restaurants" EntityType="ODataTutorial.Models.Restaurant"/>
</EntityContainer>
</Schema>
</edmx:DataServices>
</edmx:Edmx>
```
Now let's try to fetch data with some queries. We'll only see the first 1000 restaurants since we had `SetMaxTop(1000)` in our `Startup.cs` file. You can change this as needed. If we go to the endpoint `http://localhost:5279/odata/Restaurants`, we should be able to see our list of Restaurants.
``` json
{
"@odata.context": "http://localhost:5279/odata/$metadata#Restaurants",
"value": [
{
"Id": "5eb3d668b31de5d588f42930",
"Name": "Brunos On The Boulevard",
"RestaurantId": "40356151",
"Cuisine": "American",
"Borough": "Queens",
"Address": {
"Building": "8825",
"Coordinates": [ -73.8803827, 40.7643124 ],
"Street": "Astoria Boulevard",
"ZipCode": "11369"
}
},
{
"Id": "5eb3d668b31de5d588f42932",
"Name": "Taste The Tropics Ice Cream",
"RestaurantId": "40356731",
"Cuisine": "Ice Cream, Gelato, Yogurt, Ices",
"Borough": "Brooklyn",
"Address": {
"Building": "1839",
"Coordinates": [ -73.9482609, 40.6408271 ],
"Street": "Nostrand Avenue",
"ZipCode": "11226"
}
},
{
"Id": "5eb3d668b31de5d588f42934",
"Name": "C & C Catering Service",
"RestaurantId": "40357437",
"Cuisine": "American",
"Borough": "Brooklyn",
"Address": {
"Building": "7715",
"Coordinates": [ -73.9973325, 40.6117489 ],
"Street": "18 Avenue",
"ZipCode": "11214"
}
},
.
.
.
}
```
Let's try to play around with some filters. This will allow us to query data without any additional logic in our application. We can search for all Italian restaurants using `http://localhost:5279/odata/Restaurants?$filter=Cuisine eq 'Italian'` or even better, we can search for all Italian restaurants in Queens by `http://localhost:5279/odata/Restaurants?$filter=Cuisine eq 'Italian' and Borough eq 'Queens'` This should give us all the restaurants satisfying that query filter.
``` json
{
"@odata.context": "http://localhost:5279/odata/$metadata#Restaurants",
"value": [
{
"Id": "5eb3d668b31de5d588f429ed",
"Name": "Piccola Venezia",
"RestaurantId": "40367540",
"Cuisine": "Italian",
"Borough": "Queens",
"Address": {
"Building": "42-01",
"Coordinates": [ -73.911784, 40.764766 ],
"Street": "28 Avenue",
"ZipCode": "11103"
}
},
{
"Id": "5eb3d668b31de5d588f429b8",
"Name": "Don Peppe",
"RestaurantId": "40366230",
"Cuisine": "Italian",
"Borough": "Queens",
"Address": {
"Building": "13558",
"Coordinates": [ -73.8216767, 40.6689548 ],
"Street": "Lefferts Boulevard",
"ZipCode": "11420"
}
},
{
"Id": "5eb3d668b31de5d588f429cc",
"Name": "Cara Mia",
"RestaurantId": "40366812",
"Cuisine": "Italian",
"Borough": "Queens",
"Address": {
"Building": "220-20",
"Coordinates": [ -73.7429218, 40.7305714 ],
"Street": "Hillside Avenue",
"ZipCode": "11427"
}
},
{
"Id": "5eb3d668b31de5d588f42a7e",
"Name": "Aunt Bella'S Rest Of Little Neck",
"RestaurantId": "40371807",
"Cuisine": "Italian",
"Borough": "Queens",
"Address": {
"Building": "4619",
"Coordinates": [ -73.7363139, 40.767005 ],
"Street": "Marathon Parkway",
"ZipCode": "11362"
}
},
.
.
.
}
```
If we only want to see selected fields, we can use the select filter as follows `http://localhost:5279/odata/Restaurants?$select=Name`
``` json
{
"@odata.context": "http://localhost:5279/odata/$metadata#Restaurants(Name)",
"value": [
{
"Name": "Brunos On The Boulevard"
},
{
"Name": "Taste The Tropics Ice Cream"
},
{
"Name": "C & C Catering Service"
},
{
"Name": "Carvel Ice Cream"
},
.
.
.
}
```
# Conclusion
The full list of queries supported by OData can be seen [here](https://www.odata.org/getting-started/basic-tutorial/). For more query options, you can refer [here](https://learn.microsoft.com/en-us/odata/concepts/queryoptions-overview).
The OData protocol makes it simple to power your REST APIs but it may have some disadvantages like lack of control over what user's are trying to access and difficulties in optimizing specific queries which should be considered before deciding whether that suits your architectural needs.
We were able to quickly get up and running with a project that uses the [MongoDB extension for OData](https://www.nuget.org/packages/MongoDB.AspNetCore.OData/) with MongoDB Atlas. You can use the OData provider too to power you REST based applications.
**Are you using odata with MongoDB? We want to hear from you! please look me up on linkedin and reach out!**
_This article contributed by [Rishit Bhatia](https://www.linkedin.com/in/rishit-bhatia-65ba5437/) and [Rachelle Palmer](https://www.linkedin.com/in/rachellepalmer/) from MongoDB_ | techbelle |
1,863,435 | Plastic Pallet Manufacturer: Benefits of Lightweight and Stackable Designs | Introduction Plastic pallets are a popular alternative to wood pallets because of their many... | 0 | 2024-05-24T00:36:54 | https://dev.to/mobika/plastic-pallet-manufacturer-benefits-of-lightweight-and-stackable-designs-1h32 | pallets |
Introduction
Plastic pallets are a popular alternative to wood pallets because of their many benefits. Manufacturers have been innovating to improve the safety, use, and quality of these pallets. This article will discuss the benefits of lightweight and stackable designs.
Advantages
Plastic Pallet provide many perks over wood pallets.
They are lighter in weight, stronger, and more straightforward to clean than their counterparts which are wood.
As they are produced from synthetic, they truly are also maybe not susceptible to bugs and mold, which is normal with lumber pallets.
Innovation
Vinyl pallet manufacturers have been innovating to enhance the security and make usage of also associated with pallets.
These are typically design like utilizing advancements that are technical ensure they are far better and sturdy.
Some manufacturers are producing with slip-resistant areas, which prevent goods from shifting during transportation for instance.
This feature like specific damage like possibly counter items and enhance security.
Safety
The safety of synthetic pallets is vital inside the management and transportation of products.
Vinyl pallets would not have any nails, screws, or splinters that could harm workers or harm products.
They also do not soak any liquids up, which could cause surfaces which can be slippery that can be dangerous to those handling them.
Use
Synthetic pallets can be used in a true number of industries, including but not restricted to meals, pharmaceutical, and chemical companies.
Also, they are perfect for international shipping because they're lightweight, durable, and you will be reused times being many.
How to Make Use Of
When synthetic like use like making of it is vital to guarantee the weight of items being transported will maybe not surpass the pallet's load ability.
Furthermore, it's important to stay glued to the maker's instructions for appropriate storage, handling, and maintenance concerning the pallet.
Provider
Manufacturers of Stackable Plastic Pallet provide customer care and service to ensure their clients get the maximum benefit out of their services and products.
This support includes help in to the use like appropriate control from the pallets, along with repair, recycling, and disposal of pallets.
Quality
The conventional of plastic pallets varies among manufacturers.
It is essential to select a maker like professional produces top-notch pallets.
Top-notch pallets are durable and that may withstand conditions that are harsh ensuring the transport like safe of.
Application
Plastic pallets can be utilized in several applications, including storage, transportation, and export of services and products.
These include suitable for transportation of delicate products, simply because they have actually features such as areas which can be durability like slip-resistant.
Conclusion
In conclusion, plastic pallet box offer many benefits over wood pallets because of their lightweight and stackable designs. They are also safer, more durable, and easier to use. Manufacturers have been innovating these pallets to improve the safety, use, and quality of these pallets. It is essential to choose a reputable manufacturer to get high-quality pallets that will withstand harsh conditions and ensure the safe transport of goods.
Source: https://www.cn-pallet.com/Plastic-pallet | mobika |
1,863,433 | Building a Music Streaming App with Spotify API | Introduction In the world of music, streaming apps have become the go-to platform for... | 0 | 2024-05-24T00:31:56 | https://dev.to/kartikmehta8/building-a-music-streaming-app-with-spotify-api-4onl | webdev, javascript, beginners, programming | ## Introduction
In the world of music, streaming apps have become the go-to platform for people to discover and listen to their favorite songs. With millions of users across the globe, music streaming apps have revolutionized the way people consume music. If you are looking to build a music streaming app, then using the Spotify API can be a game-changer. In this article, we will discuss the advantages and disadvantages of using the Spotify API and the features that make it a popular choice for developers.
## Advantages of Using the Spotify API
1. **Extensive Music Library:** With over 50 million songs, the Spotify API offers a vast music library to its users, making it a one-stop destination for all music lovers.
2. **Seamless Integration:** The Spotify API allows easy integration with various platforms, including iOS, Android, and web, making it accessible to a large audience.
3. **User-Friendly Interface:** The app's intuitive interface makes it easy for users to navigate and discover new music effortlessly.
## Disadvantages of Using the Spotify API
1. **Limited Customization:** The Spotify API offers limited customization options, making it difficult for developers to create a unique visual experience for their app.
2. **Cost:** Building a music streaming app with the Spotify API can be expensive, with costs associated with licensing and usage fees.
## Features of the Spotify API
1. **Personalized Recommendations:** The Spotify API uses advanced algorithms to offer personalized song recommendations to its users, enhancing their listening experience.
2. **Social Features:** The app allows users to share their favorite songs, playlists, and artists on social media platforms, thus promoting a sense of community among music lovers.
3. **Offline Listening:** With the Spotify Premium subscription, users can download songs and listen to them offline, providing uninterrupted and convenient access to music.
### Code Example: Integrating Spotify API
```javascript
// Initialize Spotify API client
const spotifyApi = new SpotifyWebApi({
clientId: 'YOUR_CLIENT_ID',
clientSecret: 'YOUR_CLIENT_SECRET'
});
// Retrieve an access token
spotifyApi.clientCredentialsGrant().then(
function(data) {
console.log('The access token expires in ' + data.body['expires_in']);
console.log('The access token is ' + data.body['access_token']);
// Save the access token so that it's used in future calls
spotifyApi.setAccessToken(data.body['access_token']);
},
function(err) {
console.error('Something went wrong when retrieving an access token', err);
}
);
```
This example demonstrates how to initialize the Spotify API client and retrieve an access token using Node.js, which is essential for making authenticated requests to the Spotify API.
## Conclusion
In conclusion, building a music streaming app with the Spotify API comes with its advantages and disadvantages. However, the vast music library, seamless integration, and user-friendly interface make it a popular choice for developers looking to create a successful music streaming app. With its personalized recommendations and social features, the Spotify API offers an engaging and enjoyable experience to its users. | kartikmehta8 |
1,855,069 | How to Get a Perfect Deep Copy in JavaScript? | Originally published in my newsletter. Pre-knowledge In JavaScript, data types can be... | 0 | 2024-05-24T00:24:23 | https://webdeveloper.beehiiv.com/p/get-perfect-deep-copy-javascript | javascript, webdev, frontend, programming | *Originally published in* [*my newsletter*](https://webdeveloper.beehiiv.com/p/get-perfect-deep-copy-javascript).
# Pre-knowledge
In JavaScript, data types can be categorized into primitive value types and reference value types. The main difference between these types lies in how they are handled and copied in memory.
For primitive value types (such as `undefined`, `null`, `number`, `string`, `boolean`, `symbol`, and `bigint`), JavaScript uses a pass-by-value method for copying. This means that when a primitive value is assigned to another variable, a copy of the value is actually created. Therefore, if the original variable is modified, the copied variable will not be affected. The following code demonstrates this:
```javascript
let primitiveValue = 1;
const copyPrimitiveValue = primitiveValue;
primitiveValue = 2;
console.log('primitiveValue: ', primitiveValue); // Outputs 2
console.log('copyPrimitiveValue: ', copyPrimitiveValue); // Outputs 1
```
For reference value types, such as objects, arrays, and functions, JavaScript uses a pass-by-reference method. When copying a reference value, what is actually copied is a reference to the object, not a copy of the object itself. This means that if any variable modifies the properties of the object, all variables that reference the object will reflect this change. For example:
```javascript
const referenceValue = { value: 1 };
const copyReferenceValue = referenceValue;
referenceValue.value = 2;
console.log('referenceValue: ', referenceValue); // Outputs { value: 2 }
console.log('copyReferenceValue: ', copyReferenceValue); // Outputs { value: 2 }
```
By this method, JavaScript ensures the independence of primitive values and the connectivity of reference values, making data operations predictable and consistent.
# Shallow copy
A shallow copy means that only one layer of the object is copied, and the deep layer of the object directly copies an address. There are many native methods in Javascript that are shallow copies. For example, using `Object.assign` API or the spread operator.
```javascript
const target = {};
const source = { a: { b: 1 }, c: 2 };
Object.assign(target, source);
source.a.b = 3;
source.c = 4;
console.log(source); // { a: { b: 3 }, c: 4 }
console.log(target); // { a: { b: 3 }, c: 2 }
// Same effect as Object.assign
const target1 = { ...source };
```
# Deep copy
Deep copy means cloning two identical objects but without any connection to each other.
**1. JSON.stringify API**
```javascript
const source = { a: { b: 1 } };
const target = JSON.parse(JSON.stringify(source));
source.a.b = 2;
console.log(source); // { a: { b: 2 } };
console.log(target); // { a: { b: 1 } };
```
Well, it seems that JSON.stringify can implement deep copying, but it has some defects. For example, it cannot copy functions, undefined, Date, cannot copy non-enumerable properties, cannot copy circularly referenced objects, and so on. You can check out the detailed description on _[MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-copy-in-javascript#description)_.
**2. structuredClone API**
I've found that there's already a native API called `structuredClone`, designed specifically for this purpose. It creates a [deep clone](https://developer.mozilla.org/en-US/docs/Glossary/Deep_copy?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-copy-in-javascript) of a given value using the [structured clone algorithm](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Structured_clone_algorithm?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-copy-in-javascript). This means Function objects cannot be cloned and will throw a `DataCloneError` exception. It also doesn't clone setters, getters, and similar metadata functionalities.
**3. Almost perfect deep copy**
```javascript
const deepClone = (obj, map = new WeakMap()) => {
if (obj instanceof Date) return new Date(obj);
if (obj instanceof RegExp) return new RegExp(obj);
if (map.has(obj)) {
return map.get(obj);
}
const allDesc = Object.getOwnPropertyDescriptors(obj);
const cloneObj = Object.create(Object.getPrototypeOf(obj), allDesc);
map.set(obj, cloneObj);
for (const key of Reflect.ownKeys(obj)) {
const value = obj[key];
cloneObj[key] =
value instanceof Object && typeof value !== 'function'
? deepClone(value, map)
: value;
}
return cloneObj;
};
```
The above code is the final result, let me explain how it came from.
1. First, we use WeakMap as a hash table to solve the circular reference problem, which can effectively prevent memory leaks. You can check the description of WeakMap on _[MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/WeakMap?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-copy-in-javascript)_.
2. For the special types Date and RegExp, a new instance is directly generated and returned.
3. Use `Object.getOwnPropertyDescriptors` to get all property descriptions of the current object, and use `Object.getPrototypeOf`to get the prototype of the current object. Passing these two items as arguments to `Object.create` API to create a new object with the same prototype and the same properties.
4. Use `Reflect.ownKeys` to iterate over all properties of the current object, including non-enumerable properties and Symbol properties, as well as normal properties. In this way, the deep-seated value can be continuously copied into the current new object in the loop and recursion.
5. In the loop judgment, except that the function is directly assigned, the others are re-copied by recursion.
Next, we can use the test code to verify.
```javascript
const symbolKey = Symbol('symbolKey');
const originValue = {
num: 0,
str: '',
boolean: true,
unf: void 0,
nul: null,
obj: { name: 'object', id: 1 },
arr: [0, 1, 2],
func() {
console.log('function');
},
date: new Date(0),
reg: new RegExp('/regexp/ig'),
[symbolKey]: 'symbol',
};
Object.defineProperty(originValue, 'innumerable', {
// writable is true to ensure that the assignment operator can be used
writable: true,
enumerable: false,
value: 'innumerable',
});
// Create circular reference
originValue.loop = originValue;
// Deep Copy
const clonedValue = deepClone(originValue);
// Change original value
originValue.arr.push(3);
originValue.obj.name = 'newObject';
// Remove circular reference
originValue.loop = '';
originValue[symbolKey] = 'newSymbol';
console.log('originValue: ', originValue);
console.log('clonedValue: ', clonedValue);
```
Great, it looks like it's working well.
* * *
*If you find this helpful, [**please consider subscribing**](https://webdeveloper.beehiiv.com/) to my newsletter for more insights on web development. Thank you for reading!* | zacharylee |
1,863,431 | Maximizing Innovation Returns: R&D Tax Credit Consulting Expertise | Unlock the full potential of your company's research and development r&d tax credit consulting... | 0 | 2024-05-24T00:22:31 | https://dev.to/mackelmanzz/maximizing-innovation-returns-rd-tax-credit-consulting-expertise-59f1 | business | Unlock the full potential of your company's research and development **[r&d tax credit consulting ](https://www.taxresolutionplus.com/r-and-d-tax-credit-consulting)**investments with our specialized consulting services tailored to optimize R&D tax credits. Our team of seasoned experts navigates the complex landscape of tax regulations, ensuring your organization receives every eligible credit and incentive. From identifying qualifying activities to documenting expenses, we provide comprehensive support throughout the entire process, maximizing your tax savings while you focus on innovation. Let us be your strategic partner in driving growth and innovation while maximizing your returns on R&D investments. | mackelmanzz |
1,863,430 | Refresher Training Online And Overhead Crane Training | Refresher Training Online Refresher Training Online is a convenient and efficient method to update... | 0 | 2024-05-24T00:21:12 | https://dev.to/blackstone123/refresher-training-online-and-overhead-crane-training-4ccp | business | **Refresher Training Online**
**[Refresher Training Online](https://aiforklifttraining.ca/training-refresher-online/)** is a convenient and efficient method to update and reinforce essential skills and knowledge for professionals in various fields. This training is designed to revisit core concepts, address recent developments, and ensure that participants remain compliant with current standards and best practices. Accessible anytime and anywhere, online refresher courses offer interactive modules, quizzes, and up-to-date content to enhance learning experiences. They are ideal for individuals looking to refresh their expertise, stay current in their industry, and maintain certifications without the need to attend in-person sessions.
**Overhead Crane Training**
**[Overhead Crane Training ](https://aiforklifttraining.ca/product/online-overhead-crane-training/)**provides comprehensive instruction on the safe and effective operation of overhead cranes, which are critical in industries such as construction, manufacturing, and logistics. This training covers essential topics including crane components, load handling, inspection procedures, and safety protocols. Participants learn through a combination of theoretical lessons and practical exercises, ensuring they can operate cranes efficiently while minimizing risks. The goal of overhead crane training is to equip operators with the skills needed to handle cranes confidently and safely, thereby enhancing workplace safety and productivity. | blackstone123 |
1,863,388 | CONQUERING THE CLOUD RESUME CHALLENGE: MY JOURNEY | As someone coming from a non-IT background wanting to transition into the IT space and looking to... | 0 | 2024-05-24T00:18:51 | https://dev.to/osugodbless/conquering-the-cloud-resume-challenge-my-journey-1lbe | aws, cloud, devops, cloudcomputing | As someone coming from a non-IT background wanting to transition into the IT space and looking to build a career specifically as a DevOps Engineer, I enrolled in an AWS Cloud Computing program, while also taking time to learn other fundamental concepts. Upon completing the program, I successfully passed both the AWS Cloud Practitioner and Solutions Architect - Associate exams, earning both certifications.
However, I knew certifications were just not enough. I wanted to dive into real projects where I could roll up my sleeves and actually build something using AWS services. To accomplish this, I started looking out for simple projects that I could begin with, however, a friend recommended the Cloud Resume Challenge (although not beginner-friendly) as a great project to explore (and he wasn't wrong😊😊). So, I had a look at it and saw the challenge as an opportunity to bridge the gap between theory and practical experience with the services it covered. Little did I know the adventure that awaited me...
The cloud resume challenge is actually a challenge by [Forrest Brazeal](https://twitter.com/forrestbrazeal) to help people prepare for a job in the cloud industry. This post therefore is my way of sharing my experience, challenges, and skills gained during my pursuit of the Cloud Resume Challenge.
>You can find my deployed website [here](https://osu-resume.com.ng) to explore the project in action. Also, my [repository](https://github.com/osugodbless/cloud-resume-challenge/tree/main), which stores all the codes and resources.
## The Beginning: How I Decided to Tackle the Challenge
Actually, the Cloud Resume Challenge consists of six(6) chunks of work (chunk 0-5) with each chunk consisting of a couple of steps to complete. I tackled the challenge one chunk at a time. Additionally, there are optional "Mods" sections (Developer, DevOps, and Security). Although optional, I decided to tackle the DevOps Mod alongside each chunk of the main challenge. It was an invaluable opportunity to go above and beyond in my pursuit of excellence, and to also expand my understanding of DevOps. I skipped the first chunk (chunk 0) since I already had the requirement——a Cloud Certification.
## Chunk 1: Building the Frontend
Setting up the resume website's frontend seemed straightforward at first. I utilized HTML/CSS to craft a simple site and stored its contents in an S3 bucket. However, I later refined a template from [BootstrapMade]( https://bootstrapmade.com/) and used it instead. I wanted to create a CloudFront distribution to serve the content to viewers globally and even though I had done this before, I decided to read further about CloudFront. This is how I discovered that using a [REST API endpoint as the origin](https://repost.aws/knowledge-center/cloudfront-serve-static-website), and restricting access with an [Origin Access Control (OAC)](https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-restricting-access-to-s3.html) was a more secure way to go about this as opposed to using a website endpoint as the origin (besides, this is AWS's recommended way). You can read about the differences between REST and website API endpoint [here](https://docs.aws.amazon.com/AmazonS3/latest/userguide/WebsiteEndpoints.html#WebsiteRestEndpointDiff). With the above configuration, I made sure that my website was only accessible via CloudFront, not directly from S3.
Further to this, I created an SSL/TLS certificate in ACM, and attached it to the CloudFront distribution. This was to ensure that CloudFront uses secure HTTP (HTTPS) to serve the website.
I then configured Amazon Route53 to route traffic from my existing domain to my CloudFront distribution.
See a screen snip of the website below
### DevOps Way
Lastly, upon verification that [my website](https://osu-resume.com.ng) was working flawlessly, I decided to do things the DevOps way. I converted the S3, Route53, Certificate Manager and CloudFront resources into code using CloudFormation. Then, I set up a GitHub repository and pushed my website codes and CloudFormation template there.
See my architectural diagram for the frontend below.
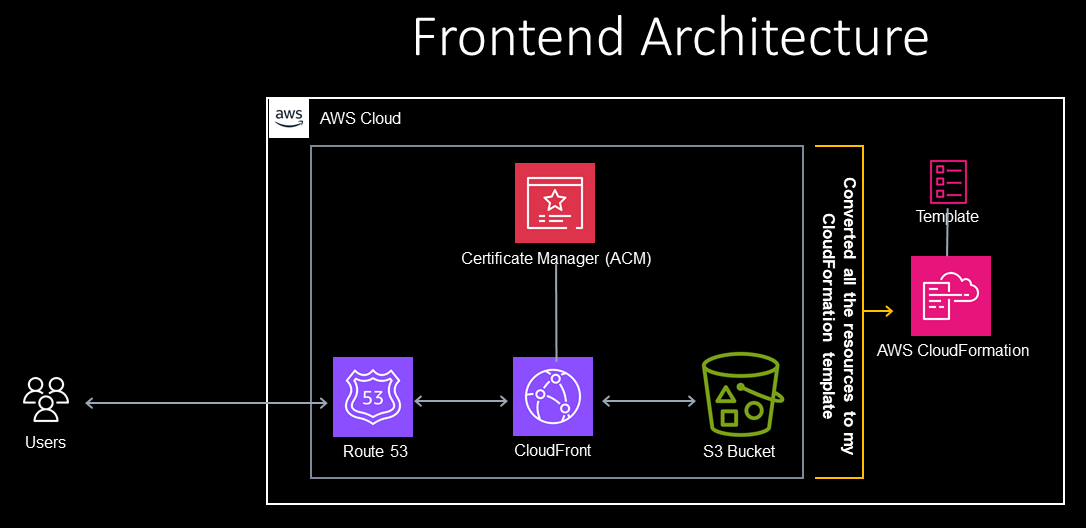
## Chunk 2 and 3: Tackling the Backend and Testing
As someone with no prior programming experience, Chunk 2 was a tough nut to crack. Most of my time was spent researching, experimenting, and seeking help from online resources and forums (including ChatGPT). I worked with serverless technologies (DynamoDB, Lambda, API Gateway) and built the application using AWS SAM. Everything——from writing the Lambda function using Python, workshopping permissions between Lambda and DynamoDB, to configuring Amazon API Gateway and leveraging JavaScript fetch API to update and retrieve visitor count——felt like a puzzle to solve.
Another significant challenge I faced was navigating CORS errors and authenticating token issues. After days of persistence, I finally solved the whole puzzle and had all sevices communicating smoothly.
### DevOps Way
To wrap up the chunk 2, I set up monitoring for my backend using CloudWatch, Amazon SNS and Lambda. The approach was simple yet effective: I set up CloudWatch Alarms to monitor certain metrics, have notifications sent to my SNS topic when any Alarm enters an alarm state and finally, SNS topic triggers Lambda which in turn extracts the error message from SNS and sends this message to my slack channel, using the slack credentials stored as a parameter in AWS SSM.
The integration of these tools not only enhanced the resilience of my application but also deepened my understanding of DevOps principles and practices.
See my architectural diagram for the backend below.
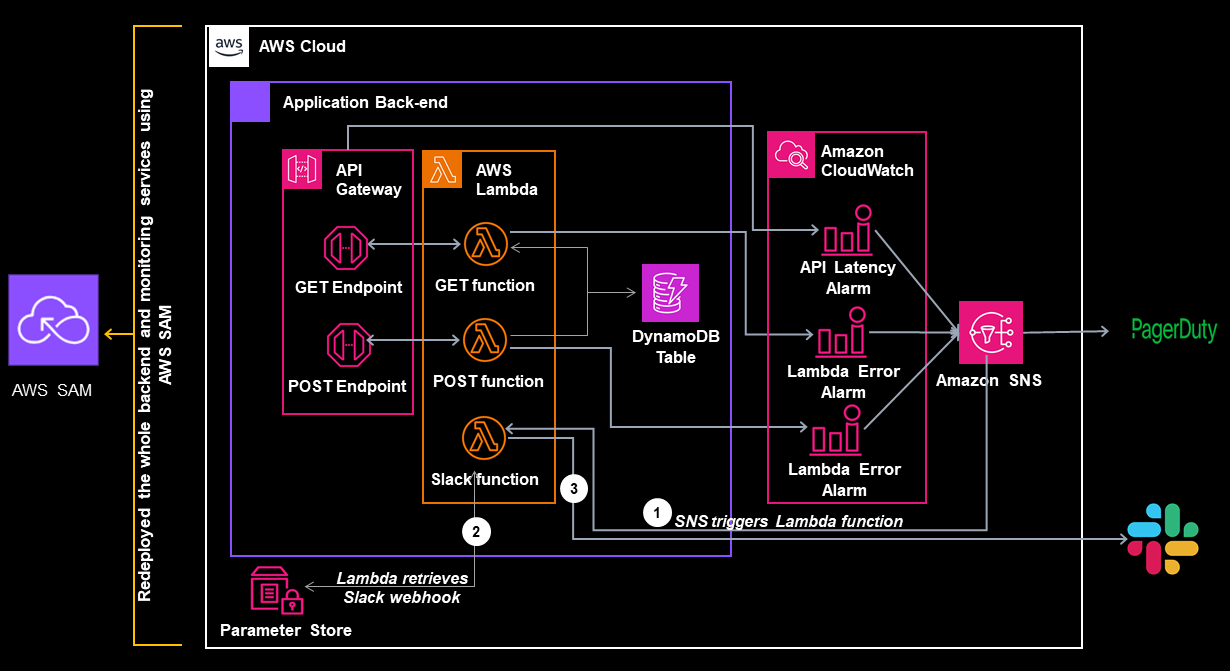
### Testing
I embraced Cypress for writing end-to-end API and website testing. Cypress has good documentation, so it was pretty easy to get around it.
Conclusively, Chunk 2 especially was a challenging yet rewarding chapter in my Cloud Resume Challenge journey as it helped me gain invaluable insights into backend development and the concept of serverless.
## Chunk 4: CI/CD and Infrastructure as Code
This phase of the project although not less significant, was easier and faster to accomplish. I guess one of the reasons was because I had automated the creation of all resources using CloudFormation and AWS SAM. I did make an adjustment which was to transfer my CloudFormation resources into my AWS SAM template. This was because I found out that AWS SAM supports the syntax of CloudFormation. So, I didn't see the need for having two different templates plus, it helped simplify the build and deploy process.
I also implemented CI/CD with GitHub Actions. Since I had a single [repository](https://github.com/osugodbless/cloud-resume-challenge/tree/main) for both backend and frontend, I implemented a multi-job workflow with separate YAML files and both are triggered upon any push to the main branch. One YAML file defines a job that synchronizes website contents to the designated S3 bucket and the other defines a job that builds, deploys, and tests the application built with AWS SAM. I used GitHub's OIDC provider to authenticate to AWS and allow my workflow access to the needed resources in my AWS account. This was to follow security best practice of using temporary credentials for AWS access.
You can see in the screen snips of both successful jobs below, that the second job includes a step for configuring AWS credentials.
## Bringing It All Together
The true magic happened when I pulled down all the application resources and redeployed everything just by pushing a change to my repository. I saw all the pieces converged together to form the complete application. I was very thrilled to see the frontend of my website come to life, seamlessly integrated with backend services and automated testing, without having to spend time manually configuring anything again. It made me trully appreciate the power of automation and CI/CD.
See the Complete architecture below
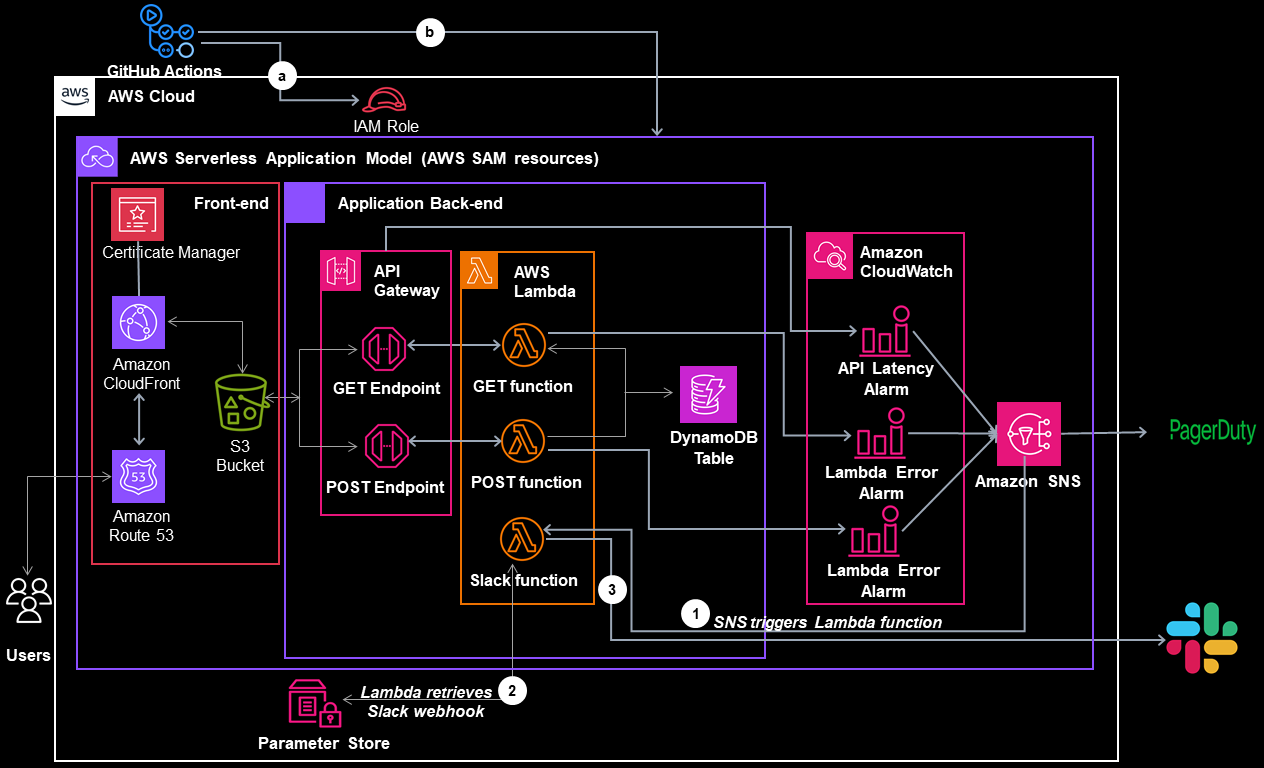
## Deployed Website
>You can find my deployed website [here](https://osu-resume.com.ng) to explore the project in action. Also, my [repository](https://github.com/osugodbless/cloud-resume-challenge/tree/main), which stores all the codes and resources.
## Lessons Learned and Growth Achieved
Through the Cloud Resume Challenge, I discovered the benefits of automation, version control, CI/CD, monitoring and observability, iteration, continuous learning, and of course the importance of implementing proper application security measures. Each chunk I took and conquered became an opportunity to grow, whether it was troubleshooting errors, reading documentations, getting familiarized with a new technology, or reiterating on the way I went about solving a particular problem. As a result, I've built some invaluable skills.
## Looking Ahead
After completing the challenge and reflecting on my journey, I realize that the Cloud Resume Challenge is just the beginning. With the newfound skills and confidence I picked, I'm more determined than ever to pursue my goal of becoming an excellent DevOps Engineer. I will be taking time to build my programming skills with Python. In addition, I will be taking on even more projects, starting with a project by [David Thomas](https://linkedin.com/david-thomas-70ba433/) ([Improving application performance using Amazon Elasticache](https://pluralsight.com/resources/blog/cloud/cloudguruchallenge-improve-application-performance-using-amazon-elasticache)). The journey would undoubtedly be challenging, but just like the Cloud Resume Challenge, I know the rewards will also be undoubtedly worth it.
## Final Thoughts
To anyone considering embarking on the Cloud Resume Challenge, my advice is simple: take the leap. As Forrest Brazeal aptly put it, **"It's not a tutorial; it's a project spec."** And what a project it turned out to be! It's a journey of conquering challenges, unlocking new skills, and discovery of the endless possibilities there are in the Cloud.
### Collaboration
If you have some cool project and would like some collaboration to learn and tackle it together, you can reach out to me on [LinkedIn](https://linkedin.com/in/osugodbless/). Let's connect and explore the boundless possibilities of cloud technology, and create innovative solutions together. | osugodbless |
1,863,387 | 12章4 | このコードスニペットでは、変数 i は実質的に final とは言えません。なぜなら、変数 i はラムダ式内で参照される前に再代入されているためです。具体的には、i がラムダ式内で使用される前に i++... | 0 | 2024-05-24T00:17:35 | https://dev.to/aaattt/12zhang-4-5d0 | このコードスニペットでは、変数 `i` は実質的に `final` とは言えません。なぜなら、変数 `i` はラムダ式内で参照される前に再代入されているためです。具体的には、`i` がラムダ式内で使用される前に `i++` によってその値が変更されています。このため、コンパイル時にエラーが発生します。
以下は該当する部分を示します:
```java
void sample() {
int i = 0;
Supplier<Integer> foo = () -> i;
i++; // ここで i の値が変更されるため、実質的に final ではなくなる
System.out.println(foo.get());
}
```
このコードは、コンパイル時に以下のエラーが発生します:
```
local variables referenced from a lambda expression must be final or effectively final
```
ラムダ式で参照される変数 `i` が実質的に `final` と見なされるためには、その値が再代入されないことが必要です。したがって、再代入されるコードを削除または変更する必要があります。
修正例:
```java
void sample() {
final int i = 0;
Supplier<Integer> foo = () -> i;
// i++; // この行を削除
System.out.println(foo.get());
}
```
もしくは、
```java
void sample() {
int i = 0;
Supplier<Integer> foo = () -> i;
System.out.println(foo.get());
i++; // ラムダ式の後に i を変更
}
```
このように、ラムダ式内で使用する変数が変更されないようにすることで、実質的に `final` として扱われ、コンパイルエラーを回避できます。 | aaattt | |
1,864,007 | Modules Status Update | Hello Again!! As we reflect on the week that’s passed, we’re eager to share some exciting... | 0 | 2024-05-28T20:44:51 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-05-24-modules-status-update/ | puppet, community | ---
title: Modules Status Update
published: true
date: 2024-05-24 00:00:00 UTC
tags: puppet,community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-05-24-modules-status-update/
---
## Hello Again!!
As we reflect on the week that’s passed, we’re eager to share some exciting developments with you. While our focus within the modules remained steady, with no significant updates to report, the Forge team has been bustling with activity. This week, alongside our usual tasks, we dove headfirst into a thrilling opportunity – a hackathon! Our Pune team led the charge, pouring their creativity and energy into this event.
Behind the scenes, there’s a buzz of progress and innovation happening within Forge. Our team has been hard at work, addressing challenges, refining processes, and laying the groundwork for future advancements. Although there aren’t any groundbreaking updates to share from the modules side this week, rest assured that our dedication to excellence and improvement remains unwavering. We’re committed to delivering the best possible experience for our community.
Keep an eye out for future updates as we continue to push the boundaries of what’s possible within our platform.
## Community Contributions
We’d like to thank the following people in the Puppet Community for their contributions over this past week:
- [`puppetlabs-firewall#1206`](https://github.com/puppetlabs/puppetlabs-firewall/pull/1206): “Fix “creation” of empty built-in firewall chains”, thanks to [2fa](https://github.com/2fa)
- [`puppetlabs-haproxy#610`](https://github.com/puppetlabs/puppetlabs-haproxy/pull/610): “Allow ports parameters as Stdlib::Ports”, thanks to [traylenator](https://github.com/traylenator) and the following people who helped get it over the line ([bastelfreak](https://github.com/bastelfreak)) | puppetdevx |
1,864,008 | DevX Status Update | Heating up Hey everyone, back here on another Friday for a quick update on our latest... | 0 | 2024-05-28T20:45:38 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-05-24-devx-status-update/ | puppet, community | ---
title: DevX Status Update
published: true
date: 2024-05-24 00:00:00 UTC
tags: puppet,community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-05-24-devx-status-update/
---
## Heating up
Hey everyone, back here on another Friday for a quick update on our latest shenanigans. With summer fast approaching us, we can already start feeling warmer temperatures. Here in Northern Ireland we were even able to see a rare meteorological occurence that happens barely once or twice a year: sunshine!
Anyways, lets get started with the updates.
## Hackathon
Remember the ‘May the 4th be with you’ Hackathon? Well, since this year it fell on Saturday, we had to push it a bit further into the month. As a result, we had a ‘May the 21st and 22nd be with you’, which doesn’t sound all that exciting in comparison. But we still had fun and even managed to work on two small projects in parallel. One of them being a new potential update for our linter tool that would allow you to scan your repos for depecrated stdlib function usage (and output a warning about it) and the other being an experimental project around implementing AI usage within PDK to enhance developer experience around failure troubleshooting.
## LXD provisioning
We wanted to throw a massive shoutout to [Jeffrey Clark](https://github.com/h0tw1r3) for developing and pushing a new feature into our bolt-litmus-provision ecosystem to enable LXD provisioning. It took us a bit to get it merged but it should be available with the next releases of those tools.
## Community Contributions
We’d like to thank the following people in the Puppet Community for their contributions over this past week:
- [`pdk-templates#565`](https://github.com/puppetlabs/pdk-templates/pull/565): “Add bolt-related files to .gitignore default paths”, thanks to [jay7x](https://github.com/jay7x)
- [`provision#251`](https://github.com/puppetlabs/provision/pull/251): “LXD provisoner support”, thanks to [h0tw1r3](https://github.com/h0tw1r3)
- [`puppet_litmus#544`](https://github.com/puppetlabs/puppet_litmus/pull/544): “lxd provisioner support”, thanks to [h0tw1r3](https://github.com/h0tw1r3)
## New Gem Releases
- [`puppetlabs_spec_helper`](https://rubygems.org/gems/puppetlabs_spec_helper) (`7.3.0`)
- [`puppet-lint-check_unsafe_interpolations`](https://rubygems.org/gems/puppet-lint-check_unsafe_interpolations) (`0.0.5`) | puppetdevx |
1,863,902 | Git Clean: The Command You Didn't Know You Needed | Imagine a messy Git repository, full of untracked files, build artifacts, and temporary files. What's... | 26,070 | 2024-05-24T11:17:27 | https://ionixjunior.dev/en/git-clean-the-command-you-didnt-know-you-needed/ | git | ---
title: Git Clean: The Command You Didn't Know You Needed
published: true
date: 2024-05-24 00:00:00 UTC
tags: git
canonical_url: https://ionixjunior.dev/en/git-clean-the-command-you-didnt-know-you-needed/
cover_image: https://ionixjuniordevthumbnail.azurewebsites.net/api/Generate?title=Git+Clean%3A+The+Command+You+Didn%27t+Know+You+Needed
series: mastering-git
---
Imagine a messy Git repository, full of untracked files, build artifacts, and temporary files. What's the best way to remove all this unwanted content and keep the repository clean, freeing up space from your computer? Git offers a command called git clean and we'll learn about it in this post. Let's discover the command you didn't know you needed!
## What is Git Clean?
In simple terms, `git clean` removes untracked files from your working directory. This is useful for reducing clutter, streamlining development, avoiding conflicts, and enhancing the overall Git experience. Many projects generate caches, binaries, or download external libraries which can take up significant space. This command helps clean the entire repository.
Don’t worry, `git clean` doesn’t touch tracked files (files already staged or committed).
## How to Use Git Clean
The command is very simple to use. Just type `git clean` on the command line followed by some parameters. Here are the main parameters:
- **-d** : Removes untracked directories recursively.
- **-i** : Uses interactive mode. Git will show you all files or directories to be cleaned, and you’ll need to choose which ones to remove.
- **-f** : Forces `git clean` to clean the repository. By default, Git won’t clean anything unless you specify this parameter or use interactive mode. You can change this behavior by setting the Git configuration `clean.requireForce` to `false`. For more information on Git configuration, refer to the [Git Basics post](/en/git-basics-an-in-depth-look-at-essential-commands/).
- **-X** : Removes only files ignored by Git using the `.gitignore` file.
You can combine these parameters to perform different clean operations. After execution, you’ll see a list of deleted files.
```
git clean -dfX
Removing .DS_Store
Removing BookTracking.xcodeproj/xcuserdata/ionixjunior.xcuserdatad/xcschemes/
Removing BookTracking.xcworkspace/xcshareddata/
Removing BookTracking.xcworkspace/xcuserdata/ionixjunior.xcuserdatad/UserInterfaceState.xcuserstate
Removing Pods/
```
The `git clean` is very simple to use and extremely useful for freeing up space, especially in older projects that you aren’t actively working on.
## Conclusion
While simple, `git clean` is incredibly useful. Many times, we manually delete files, but this command comes to the rescue. If you want to free up space or have a clean working directory to rebuild your project without worrying about cached files, `git clean` is your solution. Stop doing things manually and use the power of Git to help you every day.
See you in the next post! | ionixjunior |
1,863,385 | Custom Sea Glass Jewelry | Custom sea glass jewelry offers a unique and beautiful way to accessorize with pieces of the ocean.... | 0 | 2024-05-23T23:37:46 | https://dev.to/glassgallery/custom-sea-glass-jewelry-m6 | **[Custom sea glass jewelry](
)** offers a unique and beautiful way to accessorize with pieces of the ocean. Crafted from naturally weathered glass found along shorelines, each piece of sea glass carries a story of its own, shaped by the tides and time. | glassgallery | |
1,863,384 | Microservices With Spring Boot | Concept of Microservices and Spring Boot Support Microservices: Microservices is an architectural... | 0 | 2024-05-23T23:23:16 | https://dev.to/oloruntobi600/microservices-with-spring-boot-5457 | 1. Concept of Microservices and Spring Boot Support
Microservices:
Microservices is an architectural style that structures an application as a collection of small, loosely coupled, independently deployable services. Each service focuses on a specific business capability and can be developed, deployed, and scaled independently.
Spring Boot Support:
Spring Boot is a popular framework for building Java-based applications. It provides a range of features that make it well-suited for developing microservices:
Easy Dependency Management: Spring Boot simplifies dependency management through its auto-configuration and starter dependencies.
Embedded Servers: Spring Boot includes embedded servers like Tomcat, Jetty, and Undertow, making it easy to deploy microservices.
Spring Cloud: Spring Boot integrates seamlessly with Spring Cloud, providing tools for service discovery, configuration management, and communication between microservices.
Microservices Architecture Patterns: Spring Boot supports various microservices architecture patterns such as API Gateway, Service Discovery, Circuit Breaker, and Distributed Tracing through Spring Cloud components like Netflix OSS and Spring Cloud Sleuth.
2. Benefits and Challenges
Benefits:
Scalability: Microservices allow independent scaling of services based on demand, enhancing scalability.
Flexibility: Each microservice can be developed, deployed, and maintained independently, providing flexibility in development and deployment.
Resilience: Microservices architecture improves fault isolation, as failures in one service do not necessarily affect others.
Technology Diversity: Different microservices can be developed using different technologies, allowing teams to choose the best tool for each service.
Challenges:
Complexity: Managing a distributed system with multiple microservices introduces complexity in deployment, monitoring, and debugging.
Network Overhead: Communication between microservices over the network can introduce latency and increase overhead.
Data Management: Maintaining data consistency and managing transactions across multiple microservices can be challenging.
Deployment Complexity: Coordinating deployment of multiple microservices and ensuring compatibility between different versions can be complex.
3. Creating and Managing Microservices with Spring Boot
Example 1: Creating a Simple Microservice with Spring Boot:
java
Copy code
// Main Application Class
@SpringBootApplication
public class ProductServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ProductServiceApplication.class, args);
}
}
// Product Controller
@RestController
@RequestMapping("/products")
public class ProductController {
@GetMapping("/{id}")
public ResponseEntity<Product> getProductById(@PathVariable Long id) {
// Logic to fetch product from database
}
@PostMapping
public ResponseEntity<Product> createProduct(@RequestBody Product product) {
// Logic to create product and save to database
}
}
// Product Entity
@Entity
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private double price;
// Getters and setters
}
// Application Properties
spring.datasource.url=jdbc:mysql://localhost:3306/productdb
spring.datasource.username=root
spring.datasource.password=root
spring.jpa.hibernate.ddl-auto=update
Example 2: Service Discovery with Spring Cloud Netflix Eureka:
java
Copy code
// Eureka Server Application
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
// Eureka Client Application
@SpringBootApplication
@EnableDiscoveryClient
public class ProductServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ProductServiceApplication.class, args);
}
}
// Application Properties
spring.application.name=product-service
eureka.client.service-url.defaultZone=http://localhost:8761/eureka
Example 3: Circuit Breaker with Spring Cloud Netflix Hystrix:
java
Copy code
// Product Service with Hystrix Circuit Breaker
@RestController
@RequestMapping("/products")
public class ProductController {
@Autowired
private ProductService productService;
@HystrixCommand(fallbackMethod = "fallbackMethod")
@GetMapping("/{id}")
public ResponseEntity<Product> getProductById(@PathVariable Long id) {
return productService.getProductById(id);
}
// Fallback method
public ResponseEntity<Product> fallbackMethod(Long id) {
// Return a default product or error response
}
}
Summary
Microservices architecture promotes scalability, flexibility, and resilience.
Spring Boot provides extensive support for building microservices, simplifying development, deployment, and management.
Benefits of microservices include scalability, flexibility, resilience, and technology diversity, while challenges include complexity, network overhead, data management, and deployment complexity.
Examples illustrate creating microservices with Spring Boot, implementing service discovery with Eureka, and implementing circuit breaker pattern with Hystrix.
| oloruntobi600 | |
1,862,956 | How To Setup a Multi-Signature Wallet with Safe (prev. Gnosis Safe) on Mode | Safe formerly known as Gnosis Safe is a decentralized protocol and wallet that stands at the... | 0 | 2024-05-23T23:23:00 | https://dev.to/modenetwork/how-to-setup-a-multi-signature-wallet-with-safe-prev-gnosis-safe-on-mode-2lk | [Safe](https://safe.global/) formerly known as Gnosis Safe is a decentralized protocol and wallet that stands at the forefront of secure asset management for Ethereum and other EVM-compatible blockchains.
In this guide, I will show you how to set up a Safe wallet on Mode, the modular DeFi layer 2 part of Optimism's Superchain.
## **What is Gnosis Safe?**
Safe is a multi-sig smart contract wallet that allows you to store your assets.
Some of its core innovative functionalities include;
* **Multi-signature security**: Safe allows multiple owners (signers) to control a single wallet, requiring a set number of approvals for any transaction to occur. This adds a significant layer of security compared to single-signature wallets(Regular private key wallets), minimizing the risk of unauthorized access or accidental transactions.
* **Smart contract-based**: Unlike traditional wallets, smart contracts can be modified and programmable, giving more flexibility and control. Additionally, this allows for more sophisticated features like time-locked transactions or custom execution conditions to be added to a wallet.
### **Why is MultiSigs Important?**
Multisigs provide increased security for your assets, especially for businesses and organizations. Let’s take a look at a practical example to understand this better.
Imagine you're running a small business with two partners and need to manage a company bank account. Here's how multisigs can be beneficial:
**Scenario 1: Regular Single-Signature Account**
* Each partner has their login credentials and can access the funds independently.
* This poses a security risk: one partner could misuse the funds without the others' knowledge.
* Building trust and ensuring transparency can be challenging. Don't trust, verify.
**Scenario 2: Multi-Signature Account with Safe**
* You create a Safe wallet for the business account, requiring both partners' approvals for any transaction.
* Each partner holds a private key, and any transaction requires both keys to be used.
* This significantly reduces the risk of unauthorized spending, as both partners must agree and sign off on transactions.
* Transparency is increased as all transactions require explicit approval from both parties, building trust and reducing potential disputes.
Our example shows that Safe improves transparency, offers shared control, enhances security, and reduces human error.
## **How to create a Safe wallet on Mode**
**Step 1**: Go to the [Superchain Safe](https://staging.safe.optimism.io/welcome) website and connect your wallet.
Select Mode as your preferred Network.

**Step 2**: Select your preferred wallet and authorize the action.

**Step 3**: You won’t have Mode network set as a default in your wallet, so you would need to switch. [Click here](https://mode.hashnode.dev/comprehensive-guide#heading-deploy-your-first-smart-contract-to-mode) to add Mode to your wallet if you haven’t.
Click the wallet area and switch to Mode.

**Step 4**: Continue with Metamask on Mode.

**Step 5:** Create the name of your Safe.

**Step 6**: Add the number of owners you want for the wallet.
You can also set the threshold for the number of owners that must sign a transaction before it goes through.
<div data-node-type="callout">
<div data-node-type="callout-emoji">💡</div>
<div data-node-type="callout-text">The amount of owners you set doesn't have to relate 1 to 1 with a person. You could also set up a Safe wallet for yourself and require 2 or more signatures to approve the tx, even if you are the owner of all the private keys.</div>
</div>

**Step 7**: Review your settings, click on next, and start using the superchain safe.

**Step 8**: Wallet Created successfully!

Congratulations! You just created a Multisig wallet on Mode Network.Me
### **How Protofire is Bringing Safe to the Superchain**
[Protofire](https://protofire.io/) is a team of blockchain experts that helps companies and ecosystems build tools, scale their TVL(Transaction Volume), and improve their infrastructure.
Having been approved to build Safe for the Optimism superchain ecosystem, Protofire plans to bring Safe to the Superchain through continuous deployment and maintenance service.
Here's a breakdown of their plan:
**Deployment and configuration:**
* They will pre-deploy the [safe-singleton factory](https://github.com/safe-global/safe-singleton-factory) on new networks to optimize the process.
* Safe will be deployed and configured with network branding and UI integration, including two environments (Stage and Production) for both Mainnet and Testnet.
* Safe will be deployed on up to 10 networks which include Mode, Zora, and PGN.
**Support and maintenance:**
* Protofire will provide regular updates to Safe, monitor infrastructure, and offer support to governance and the community.
* They will also develop new features with a limited scope (10 hours per network per month).
[Click here](https://github.com/orgs/ethereum-optimism/projects/31/views/1?filterQuery=&pane=issue&itemId=46222625) to learn more about how Protofire plans to bring Safe to the Superchain ecosystem.
Note that this is still an ongoing project and can run into potential issues and bugs.
## **What’s Next?**
We’re building a community where developers and users can grow as the network grows, this is why we have several hackathons, workshops, campaign quests, and community calls to cement this goal.
Say hi in our [discord](https://discord.com/invite/modenetworkofficial) if you have any questions or would love to be part of our community, we would love to have you. | modenetwork | |
1,863,383 | Building And Deploying Spring Boot Application | Building a Spring Boot Application using Maven or Gradle Spring Boot applications can be built... | 0 | 2024-05-23T23:21:11 | https://dev.to/oloruntobi600/building-and-deploying-spring-boot-application-1ahi | 1. Building a Spring Boot Application using Maven or Gradle
Spring Boot applications can be built using either Maven or Gradle. Here's how you can do it with both:
Using Maven:
Create a Maven Project: If you're starting from scratch, you can use the Spring Initializr (https://start.spring.io/) to generate a Maven project with all the necessary dependencies.
Add Spring Boot Starter Dependencies: Add the required Spring Boot starter dependencies to your pom.xml file. These dependencies include spring-boot-starter-web, spring-boot-starter-data-jpa, etc., depending on your project requirements.
Write Application Code: Write your application code including controllers, services, and repositories.
Build the Project: Run mvn clean install in the terminal at the root of your project directory. This will compile your code, run tests, and package the application into a JAR file.
Run the Application: After building successfully, you can run your Spring Boot application using java -jar target/your-application.jar.
Using Gradle:
Create a Gradle Project: Similarly, you can use Spring Initializr to generate a Gradle project with required dependencies.
Configure build.gradle: Add dependencies block in build.gradle to include required Spring Boot starters.
Write Application Code: Write your application code as mentioned earlier.
Build the Project: Run ./gradlew clean build in the terminal at the root of your project directory. This will build your project and package it into a JAR file.
Run the Application: Run the application using java -jar build/libs/your-application.jar.
2. Deployment Options for Spring Boot Applications
Spring Boot applications can be deployed using various methods. Here are some common options:
JAR File Deployment:
Spring Boot applications are typically packaged as executable JAR files.
Simply run the JAR file using java -jar your-application.jar.
WAR File Deployment:
If you need to deploy to a traditional servlet container like Tomcat or Jetty, you can package your application as a WAR file.
To do this, exclude the spring-boot-starter-tomcat dependency and set the packaging to war in your pom.xml or build.gradle.
Run mvn clean package or ./gradlew clean build to generate the WAR file.
Deploy the WAR file to your servlet container.
Docker Deployment:
Containerization using Docker allows you to package your application along with its dependencies into a lightweight, portable container.
Write a Dockerfile specifying the base image, copying the JAR file, and configuring the container.
Build the Docker image using docker build -t your-image-name ..
Run the Docker container using docker run -d -p 8080:8080 your-image-name.
Cloud Platform Deployment:
Spring Boot applications can be deployed to various cloud platforms like AWS, Azure, Google Cloud, etc.
Each platform provides its own deployment mechanism, such as AWS Elastic Beanstalk, Azure App Service, Google App Engine, etc.
Configure deployment settings specific to the chosen platform and deploy your application.
3. Packaging and Deploying a Spring Boot Application
Example: Packaging and Deploying as a JAR File
Build the Application: Run mvn clean install or ./gradlew clean build to build the application.
Run the Application: Navigate to the target or build directory and run java -jar your-application.jar.
Example: Docker Deployment
Write a Dockerfile:
Dockerfile
Copy code
FROM adoptopenjdk/openjdk11:alpine
COPY target/your-application.jar /app/your-application.jar
CMD ["java", "-jar", "/app/your-application.jar"]
Build the Docker Image: Run docker build -t your-image-name . in the directory containing the Dockerfile.
Run the Docker Container: Execute docker run -d -p 8080:8080 your-image-name to start the container.
Summary:
Building a Spring Boot application involves adding dependencies, writing code, and then using Maven or Gradle to build the project.
Deployment options include JAR file deployment, WAR file deployment, Docker containerization, and deploying to cloud platforms.
Each deployment option has its own advantages and use cases, and the choice depends on factors like scalability, infrastructure requirements, and team preferences. | oloruntobi600 | |
1,863,382 | best action novel | Are you yearning for an adventure that defies the mundane and stirs the soul? Prepare to be... | 0 | 2024-05-23T23:21:09 | https://dev.to/elcaminodelafe/best-action-novel-37ha | novel, books | Are you yearning for an adventure that defies the mundane and stirs the soul? Prepare to be captivated by the spellbinding narrative of “El Camino de la Fe” by Jeff Frey, acclaimed as the pinnacle of the **[best action novel](https://stumblefoot-triker.com/best-action-novel/)** of the year. Within the enthralling pages of this literary masterpiece lies an odyssey that transcends the ordinary, offering readers a transformative journey of self-discovery, courage, and spiritual awakening.
As you embark on this extraordinary voyage through the heart and soul of Jeff Frey’s narrative, be prepared to be swept away by the raw authenticity and profound depth of his storytelling. From the exhilarating highs to the poignant lows, each chapter unfolds like a symphony of emotions, guiding you through the labyrinth of human experience with unwavering clarity and insight.
| elcaminodelafe |
1,863,377 | Spring Boot Security | Introduction to Spring Boot Security Spring Boot Security provides robust security features for... | 0 | 2024-05-23T23:19:27 | https://dev.to/oloruntobi600/spring-boot-security-3c9b | 1. Introduction to Spring Boot Security
Spring Boot Security provides robust security features for securing your applications. It is built on top of Spring Security and simplifies the process of integrating security into your Spring Boot applications. With Spring Boot Security, you can easily configure authentication, authorization, and other security mechanisms to protect your application against common security threats.
2. Security Features Provided by Spring Boot
Spring Boot Security offers a wide range of security features, including:
Authentication: Provides mechanisms to verify the identity of users accessing the application.
Authorization: Controls access to various parts of the application based on user roles and permissions.
Password Encryption: Supports password encryption and hashing to securely store user passwords.
Session Management: Manages user sessions and provides options for session fixation protection, session timeout, etc.
CSRF Protection: Protects against Cross-Site Request Forgery (CSRF) attacks by generating and validating tokens.
HTTPS Support: Easily configure HTTPS for secure communication between the client and server.
Role-Based Access Control (RBAC): Assigns roles to users and restricts access based on these roles.
Method-Level Security: Secures individual methods or endpoints based on custom security rules.
Custom Authentication Providers: Allows integration with external authentication providers such as LDAP, OAuth, etc.
Error Handling: Provides mechanisms to handle authentication and authorization errors gracefully.
Event Handling: Supports event handling for various security-related events such as successful login, failed login, etc.
3. Securing a Spring Boot Application Using Spring Security
Securing a Spring Boot application with Spring Security involves the following steps:
Dependency Configuration: Include the spring-boot-starter-security dependency in your pom.xml or build.gradle file to add Spring Security to your project.
Security Configuration: Create a SecurityConfig class annotated with @EnableWebSecurity to configure security settings such as authentication, authorization, and other security-related features.
Authentication Configuration: Configure authentication mechanisms such as in-memory authentication, JDBC authentication, LDAP authentication, etc., to authenticate users.
Authorization Configuration: Define authorization rules to control access to different parts of the application based on user roles and permissions.
Password Encryption: Configure password encoding to securely store user passwords in the database.
Session Management Configuration: Customize session management settings such as session fixation protection, session timeout, etc.
CSRF Protection Configuration: Enable CSRF protection to prevent CSRF attacks by generating and validating tokens.
HTTPS Configuration: Configure HTTPS to ensure secure communication between the client and server.
4. Common Security Configurations and Best Practices
Use Strong Password Encryption: Always encrypt and hash passwords before storing them in the database using strong encryption algorithms such as BCrypt.
Implement Role-Based Access Control (RBAC): Use RBAC to control access to different parts of the application based on user roles and permissions.
Enable HTTPS: Always use HTTPS to encrypt data transmitted between the client and server and prevent eavesdropping and tampering.
Limit Session Duration: Set reasonable session timeouts to mitigate the risk of session hijacking and session fixation attacks.
Implement Two-Factor Authentication (2FA): Consider implementing 2FA to add an extra layer of security by requiring users to provide two forms of authentication.
Regularly Update Dependencies: Keep your Spring Boot and Spring Security dependencies up to date to ensure that you have the latest security patches and updates.
Implement Brute Force Protection: Implement mechanisms to detect and prevent brute force attacks by limiting the number of login attempts and implementing account lockout policies.
Secure Configuration Properties: Store sensitive configuration properties such as database credentials, API keys, etc., securely using environment variables, encrypted properties files, or secure vaults.
Summary
Spring Boot Security provides comprehensive security features for securing Spring Boot applications, including authentication, authorization, password encryption, session management, CSRF protection, HTTPS support, and more.
Securing a Spring Boot application with Spring Security involves configuring authentication, authorization, password encryption, session management, CSRF protection, and other security-related settings.
Common security configurations and best practices include using strong password encryption, implementing RBAC, enabling HTTPS, limiting session duration, implementing 2FA, updating dependencies regularly, implementing brute force protection, and securing configuration properties.
| oloruntobi600 | |
1,863,376 | Spring Boot Data Access | Data Access Options in Spring Boot: Spring Boot provides several options for data access, catering... | 0 | 2024-05-23T23:17:52 | https://dev.to/oloruntobi600/spring-boot-data-access-33pi | 1. Data Access Options in Spring Boot:
Spring Boot provides several options for data access, catering to different database technologies. Some of the key options include:
Spring Data JPA: A part of the larger Spring Data project, it provides a higher-level abstraction over JPA (Java Persistence API), simplifying database interactions with JPA-based repositories.
Spring Data MongoDB: Allows seamless integration with MongoDB, offering repositories and query methods to interact with MongoDB documents.
Spring Data JDBC: Provides a simpler alternative to JPA for working with SQL databases, leveraging JDBC (Java Database Connectivity) directly without the need for ORM mapping.
Spring Data Redis: Facilitates integration with Redis, enabling easy manipulation of key-value pairs and other data structures in Redis.
Spring Data Elasticsearch: Integrates Elasticsearch, allowing indexing and querying of structured and unstructured data.
2. Setting up Database Connection in Spring Boot:
Step 1: Dependency Configuration:
Ensure the necessary dependencies are added to your pom.xml (Maven) or build.gradle (Gradle) file.
Step 2: Configuration Properties:
In application.properties or application.yml, define database connection properties such as URL, username, password, and driver class.
Step 3: Entity and Repository:
Create entity classes annotated with JPA annotations and corresponding repository interfaces extending JpaRepository.
Step 4: Component Scanning:
Ensure that your Spring Boot application scans the package containing your repositories.
Step 5: Database Initialization (Optional):
Configure database initialization behavior, such as creating tables, inserting data, etc., using Spring Boot's spring.jpa.hibernate.ddl-auto property.
3. CRUD Operations using Spring Data JPA:
1. Create Operation:
java
Copy code
// Define Entity class (e.g., User)
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String email;
// Getters and setters
}
// Define Repository interface
public interface UserRepository extends JpaRepository<User, Long> {
}
// Usage
@Autowired
private UserRepository userRepository;
User user = new User();
user.setUsername("JohnDoe");
user.setEmail("john@example.com");
userRepository.save(user);
2. Read Operation:
java
Copy code
// Usage
Optional<User> optionalUser = userRepository.findById(1L);
if (optionalUser.isPresent()) {
User user = optionalUser.get();
// Use user object
}
3. Update Operation:
java
Copy code
// Usage
Optional<User> optionalUser = userRepository.findById(1L);
if (optionalUser.isPresent()) {
User user = optionalUser.get();
user.setEmail("newemail@example.com");
userRepository.save(user);
}
4. Delete Operation:
java
Copy code
// Usage
userRepository.deleteById(1L);
Summary:
Spring Boot provides a variety of options for data access, including Spring Data JPA, MongoDB, JDBC, Redis, and Elasticsearch.
Setting up a database connection involves configuring properties, creating entity classes, defining repositories, and ensuring component scanning.
CRUD operations using Spring Data JPA are straightforward, involving methods provided by the JpaRepository interface. These operations include Create, Read, Update, and Delete.
| oloruntobi600 | |
1,862,248 | Resolvendo o "Five sort" | Movendo todos números 5 para o fim de um array | 0 | 2024-05-23T23:17:45 | https://dev.to/mauricioabreu/resolvendo-o-five-sort-3oi1 | twopointers, algorithms, python | ---
title: Resolvendo o "Five sort"
published: true
description: Movendo todos números 5 para o fim de um array
tags: #twopointers #algorithms #python
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-22 22:11 +0000
---
O objetivo desse post é demonstrar como eu pensei e solucionei o desafio citado usando uma técnica chamada two pointers.
## Desafio
Dado um array de números inteiros, mova os números 5 para o final dele. Exemplo: `[1, 5, 2, 5, 3]`
Como resultado, espera-se o seguinte retorno da função: `[1, 3, 2, 5, 5]` ou `[2, 1, 3, 5, 5]`. O importante é que os 5 estejam no final do array.
## Abordagem
Há várias maneiras de resolver esse problema. Muitas pessoas deram ótimas soluções [nessa thread no Twitter](https://x.com/maugzoide/status/1793036399639203883).
Vou abordar nesse texto uma forma mais profunda de ver o problema além do código.
Uma das maneiras de abordar esse problema é removendo todos os 5 da lista original, adicioná-los em outros lista e concatenar no final (`lista1 + lista2`). Ou remover da lista e adicionar no final.
Não é uma solução ruim, porém, ela tem uma alta complexidade de tempo. Toda vez que você remove um item de um array e ele não é o último, o array precisa ser rearranjado. Isso significa que toda remoção vai adicionar N passos adicionais na sua solução.
Uma abordagem interessante pro problema é usar a técnica two pointers, assumindo que podemos modificar o array in-place, ou seja, modificar o valor do array que, em Python, por exemplo, é mutável.
A técnica se baseia em ter dois ponteiros para fazer comparações em diferentes partes do array, enquanto se move e aplica todas as operações necessárias para resolver o problema.
Nossa abordagem irá comparar os elementos do início com os do fim do array. Com um exemplo de dois elementos (`[5, 1]`) fica mais fácil. Começando o algoritmo, comparamos o primeiro valor com o último. O primeiro é 5, então movemos ele pro fim, trocando pelo 1, resultando em `[1, 5]`.
Vamos adicionar dois valores `[5, 5, 1, 3]`.
Primeiro e últimos trocam, pois o primeiro é 5. Movemos os dois ponteiros, trocando 5 e 1 também, resultando em `[3, 1, 5, 5]`.
Abaixo uma demonstração visual (com texto alternativo) do problema sendo resolvido:
Nosso algoritmo se baseia em comparar os elementos do array em direção ao meio do dele. Enquanto o ponteiro *i* for menor que o ponteiro *j*, nós continuamos a comparar os elementos e trocando quando for necessário.
## Código
A nossa implementação vai usar Python, uma linguagem muito utilizada em resolução de algoritmos, tanto em plataformas quanto leetcode quando em entrevistas de emprego.
```python
def five_sort(nums):
i, j = 0, len(nums) - 1
while i < j:
if nums[j] == 5:
j -= 1
continue
if nums[i] == 5:
nums[j], nums[i] = 5, nums[j]
j -= 1
i += 1
return nums
```
Passos do algoritmo:
* Começamos os ponteiros nas pontas (começo e fim);
* Respeitamos nosso caso base de iterar até que os ponteiros não tenham se encontrado;
* Quando o 5 já está no fim do array, apenas decrementamos o *j* para que continuemos a avaliar os outros números;
* Quando o 5 é encontrado no ponteiro *i*, precisamos fazer a troca com o número do ponteiro *j*;
* Retornamos a lista modificada in-place.
## Complexidade
**Tempo: O(n)**
Independente de quantos elementos tem o array, no pior caso precisamos iterar em todos elementos.
**Espaço: O(1)**
Nenhum espaço adicional é alocado. Como fazemos a modificação in-place, não há a criação de um array adicional.
| mauricioabreu |
1,863,375 | How to create an Installer for a Winforms application using ClickOnce for Visual Studio 2022 | In this tutorial, we’ll look at creating an installer for a Winforms desktop application using... | 0 | 2024-05-23T23:16:58 | https://dev.to/bigboybamo/how-to-create-an-installer-for-a-winforms-application-using-clickonce-for-visual-studio-2022-3272 | webdev, csharp, dotnet, programming | In this tutorial, we’ll look at creating an installer for a Winforms desktop application using ClickOnce that we can share with people.
**Prerequisites:**
The only prerequisite for this tutorial is Visual Studio Community edition, go ahead and download the installer [here](https://visualstudio.microsoft.com/downloads/)
After downloading, go ahead and install and open Visual Studio.
Next, we want to create a project, we will create a small Winforms application for this demo.
I have created a Winforms application in a previous post [here](https://dev.to/bigboybamo/how-to-create-an-installer-for-a-winforms-application-using-visual-studio-2022-installer-project-5nh), you can follow that link, create your application and then come back here.
Alright, now the first thing we want to do is create the folder that will hold the installation files, so go ahead and create a folder for that. I am creating a file on my desktop called **publish**.
Next, we will try to build and publish our application. So from the top pane in Visual Studio, click on build and then click on **Publish Selection**
The publish wizard modal shows up.
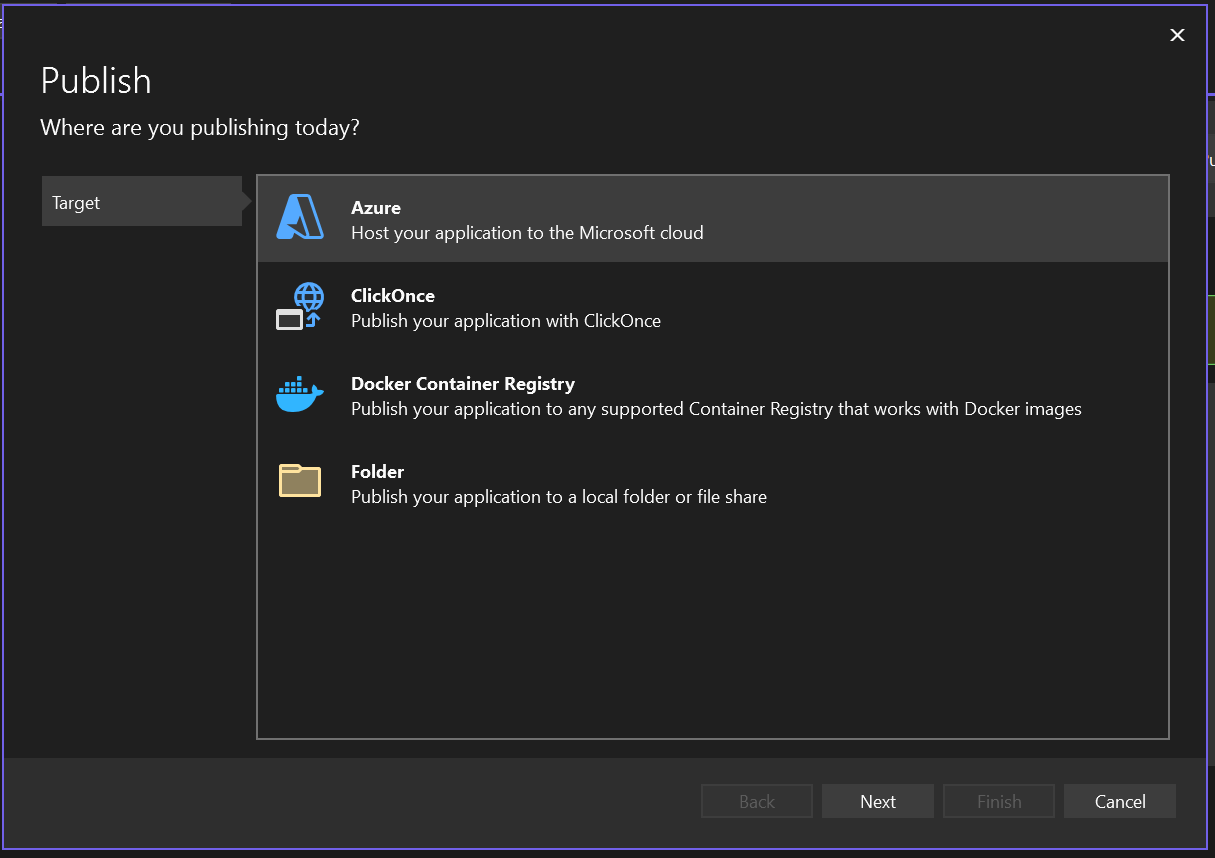
Then select **ClickOnce** and click Next.
After that, In the **Publish Location** field, enter the location of the folder we created earlier. I created mine on the desktop, so I will enter that and click Next
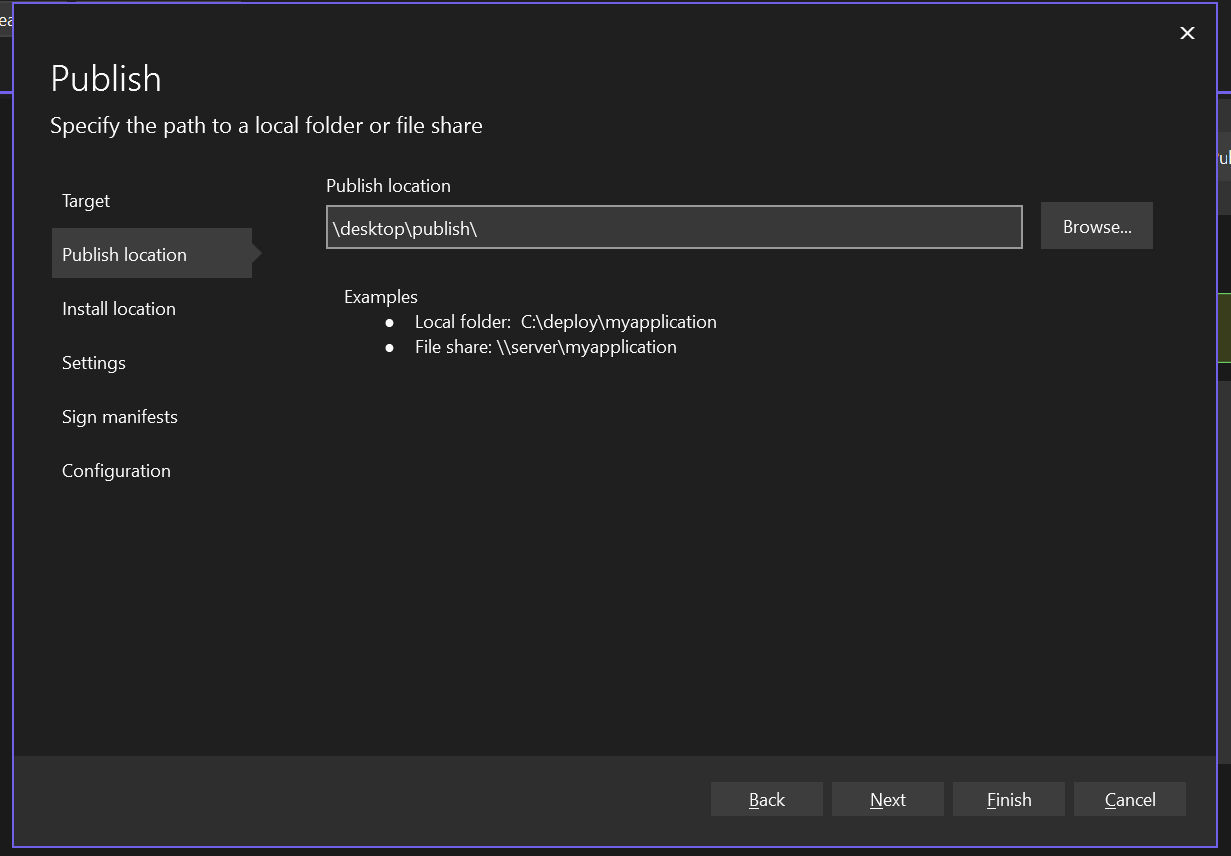
Next, we're asked to specify how users will install our application. Click on the **From a UNC path or file share** option and specify the location we have created but with your computer name Appended at the front. Like so
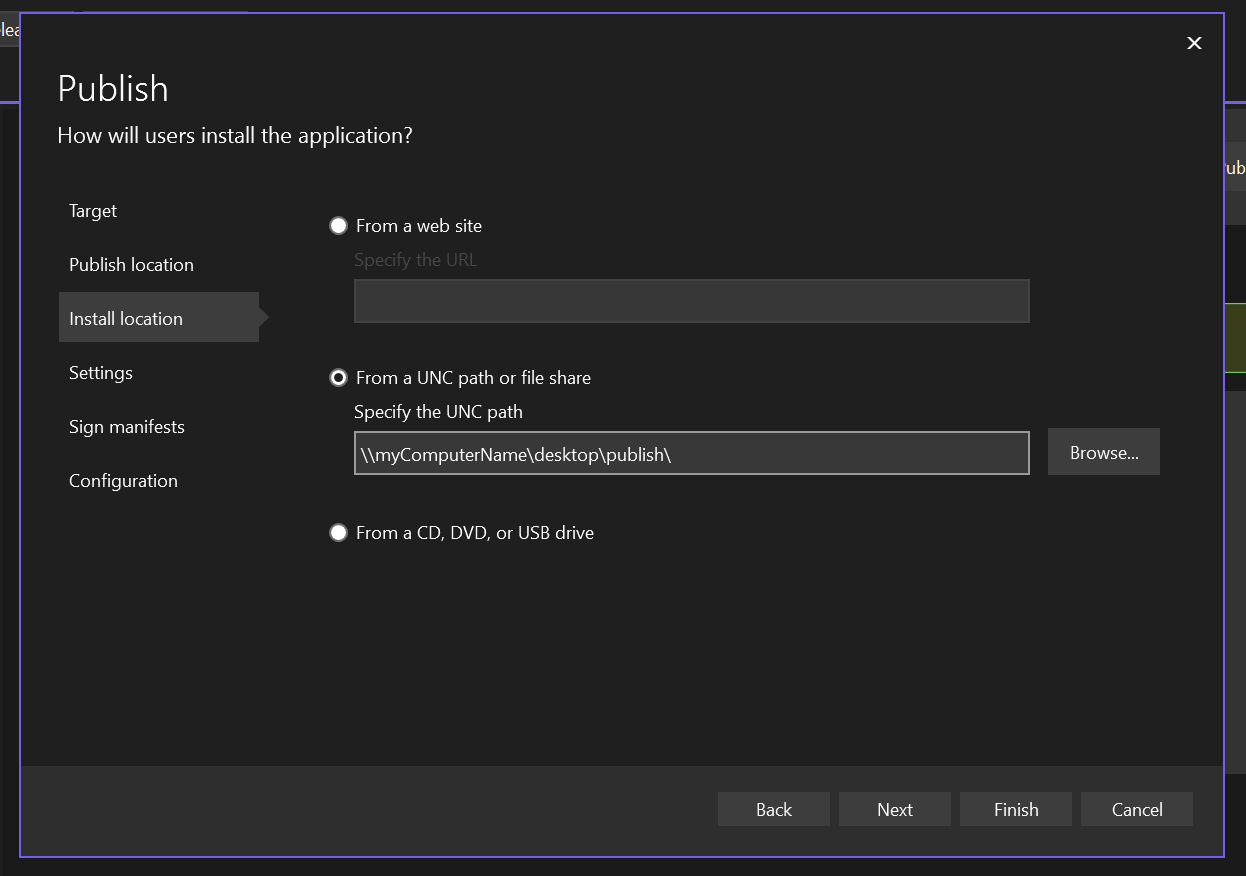
After clicking next, we have the page where we can add any application files, specify prerequisites our application needs to run, and configure if we want the application to check for updates
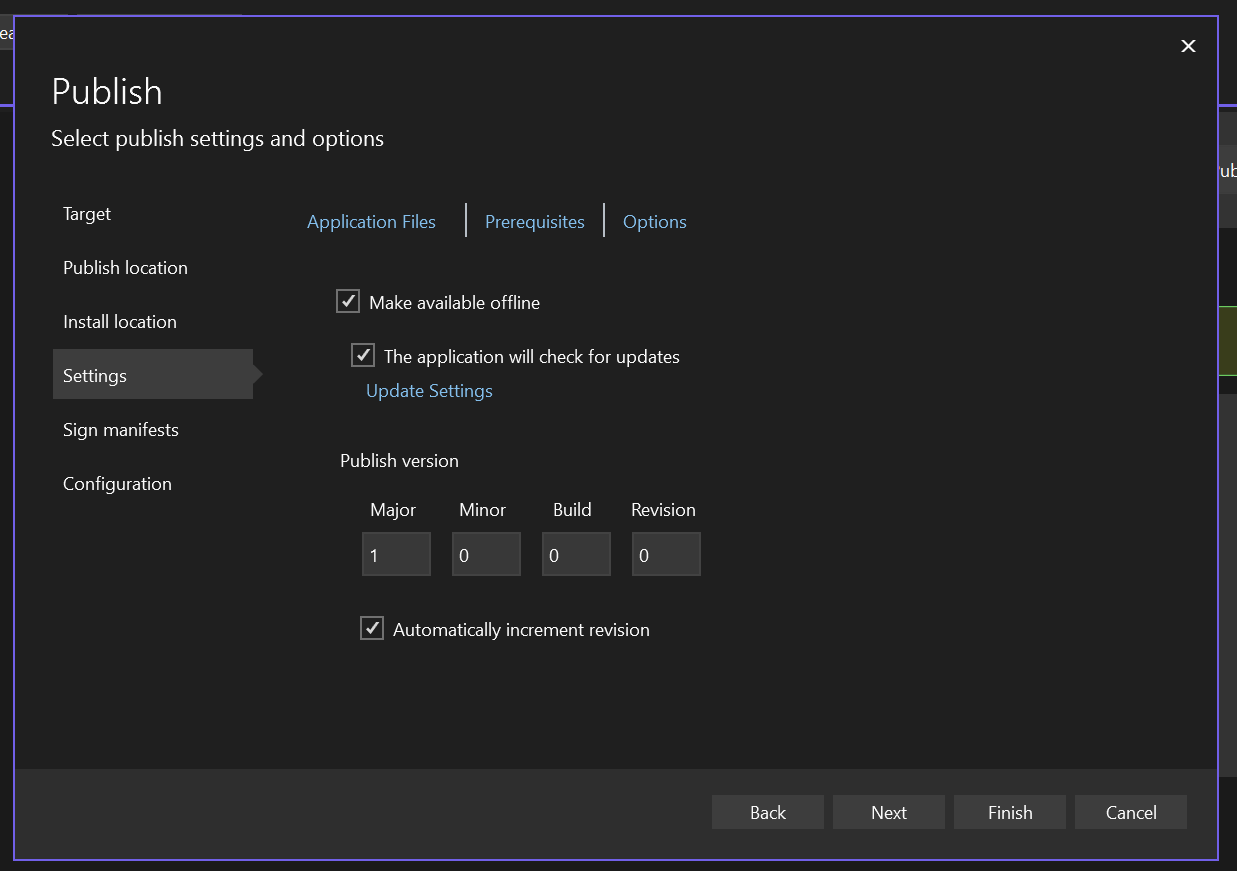
Let's specify how we want to make the application check for updates.
Click **Update settings**. By default, our application is set to update before the application starts. We will leave it as it is.
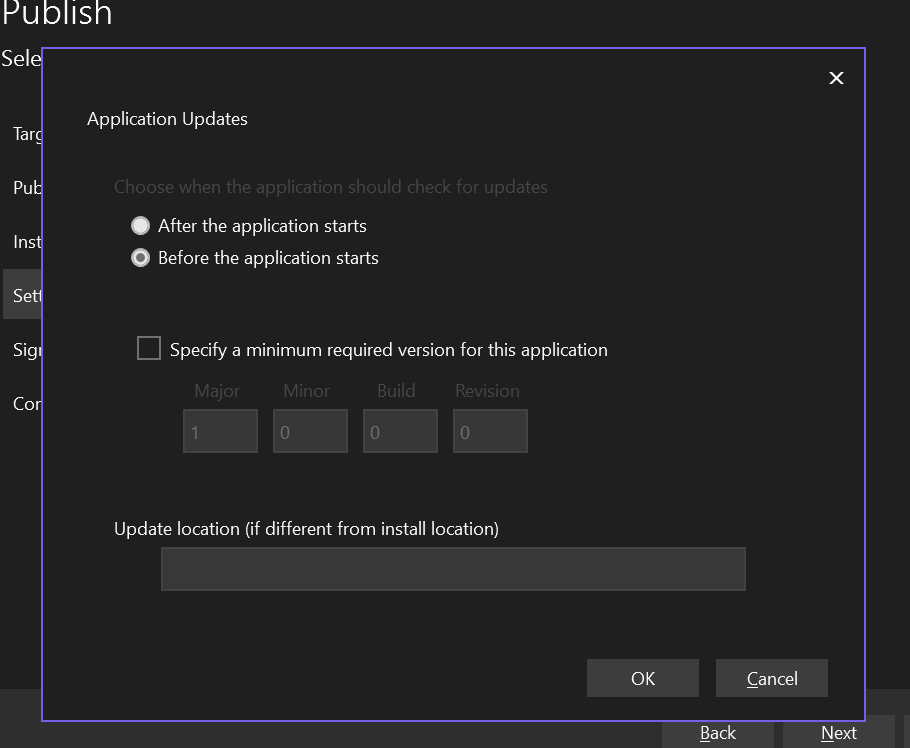
Click **Ok** and Click Next.
Next, we will need to configure signing the ClickOnce manifest.
So make sure the **Sign ClickOnce manifests** option is checked and click **Create test Certificate**
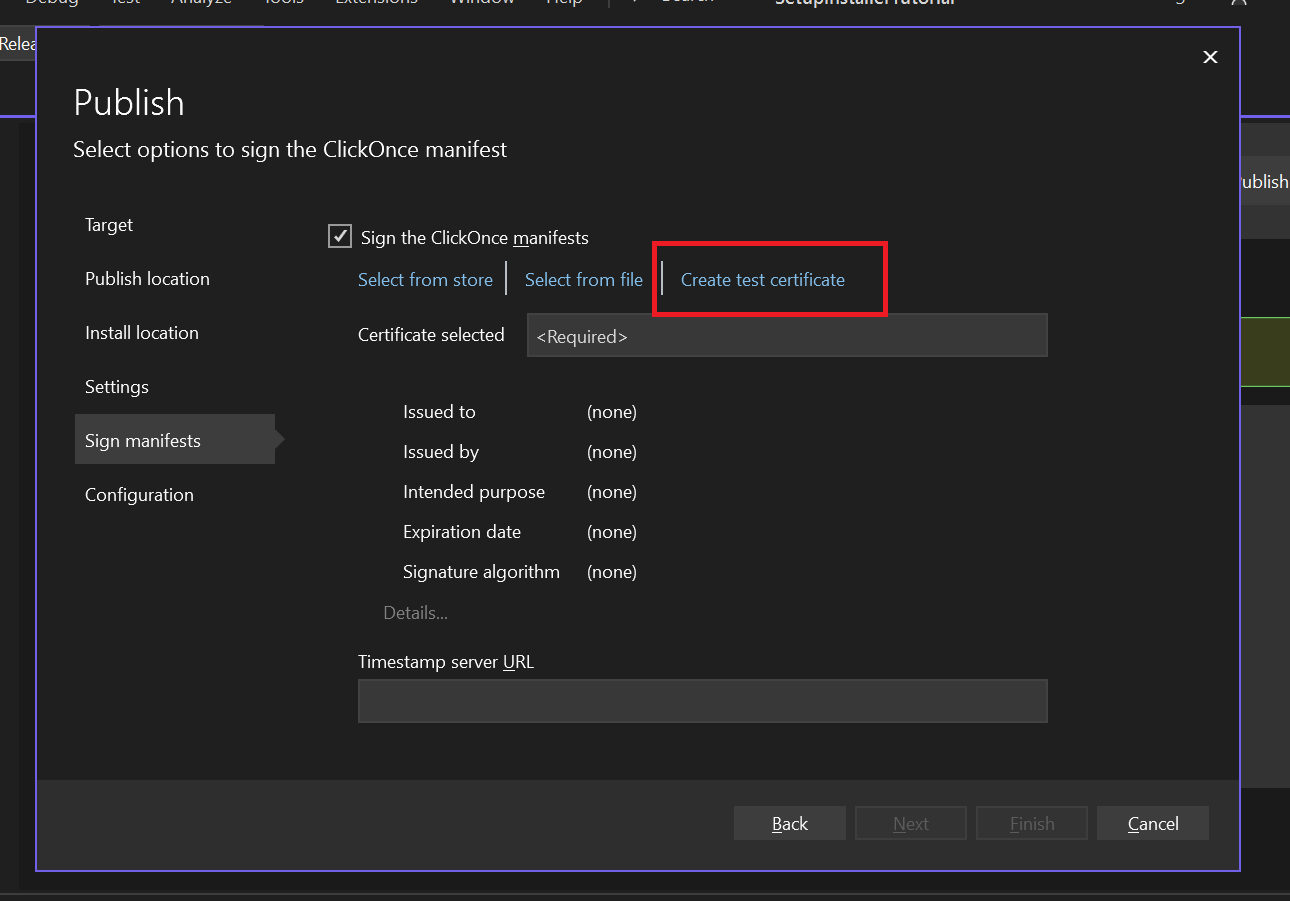
Then enter a strong and secure password to use to create the Temporary Key
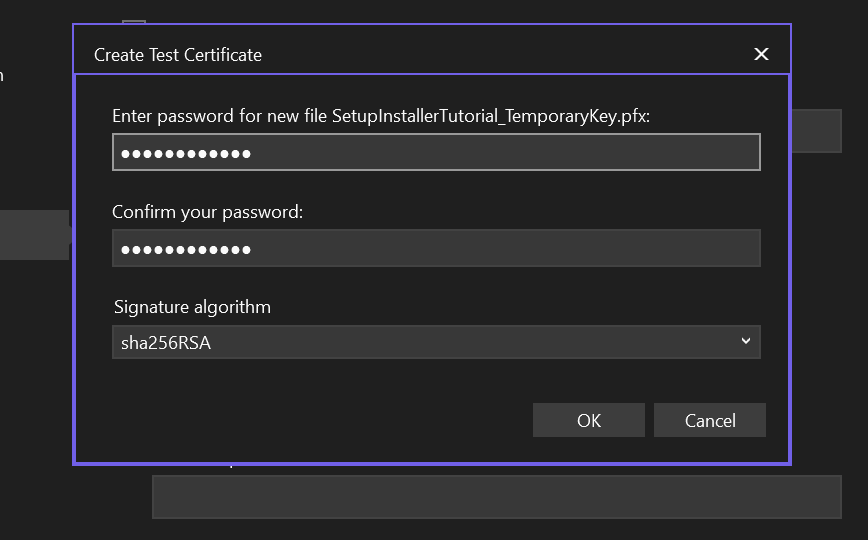
Click **Ok** and click Next.
Finally, we are going to specify our project configuration information. We will leave this as it is, but you can change the Configuration, target framework, Deployment mode, and Target Runtime to what you'd like depending on your use case.
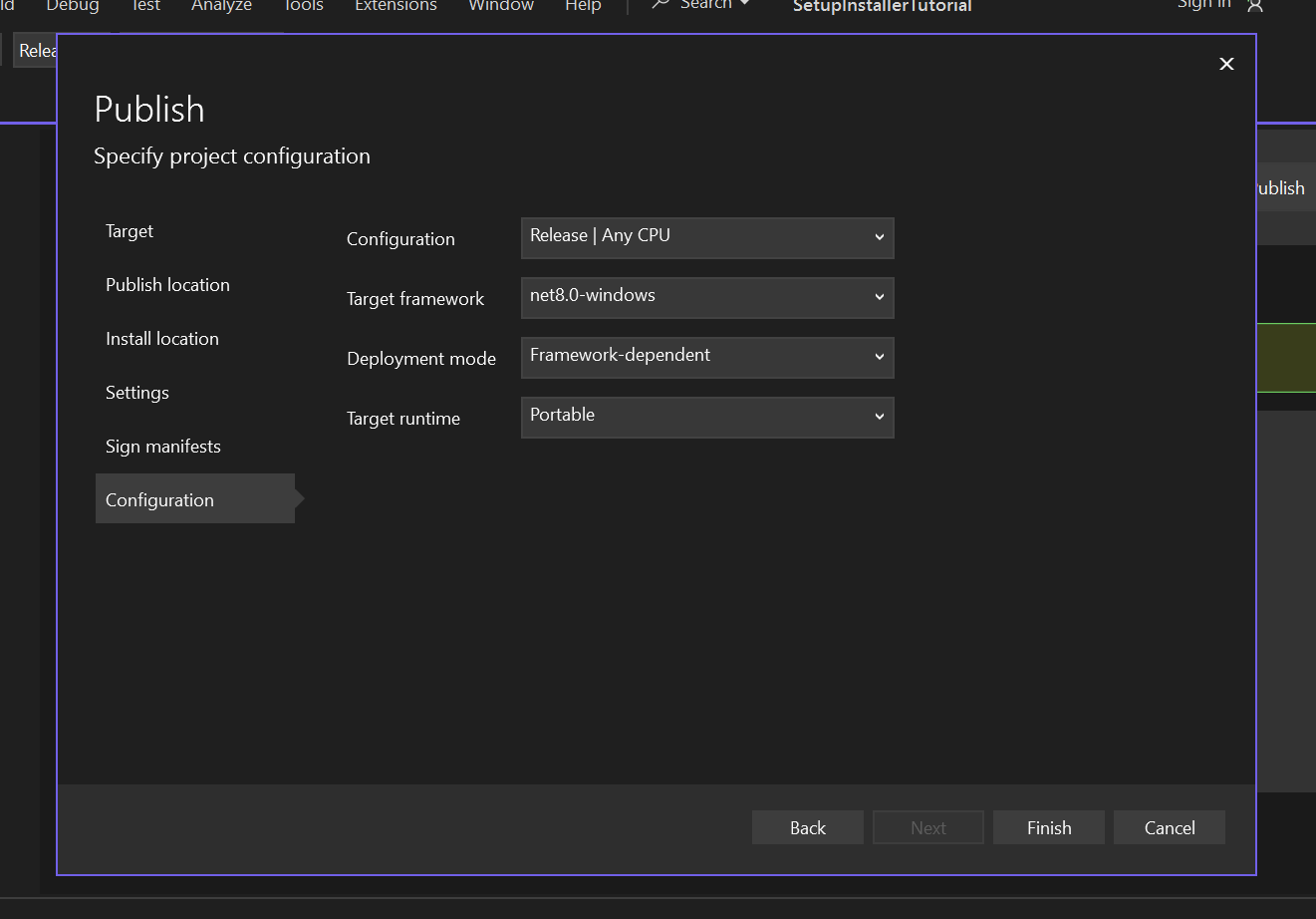
And then click Finish.
Our ClickOnce profile has now been specified. Simple Click on **Publish** to start building our installer.
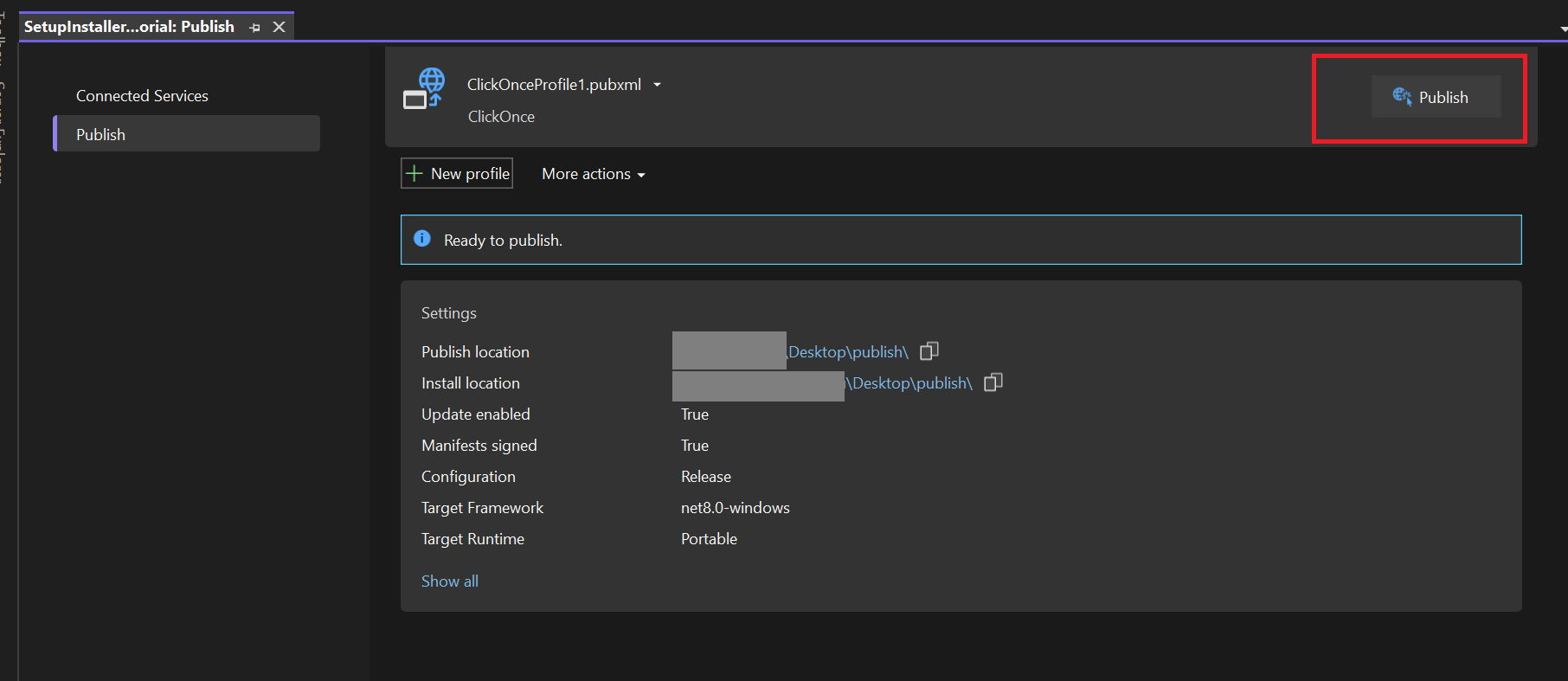
After successfully Publishing the application, navigate to the folder we created earlier, where we specified our installation files to be created,
Our installer has been created, you can go ahead and run the `setup` or `SetupInstallerTutorial` file to install the WinForms application.
Happy coding everyone.
| bigboybamo |
1,863,373 | Spring Boot Actuator | Spring Boot Actuator is a sub-project of Spring Boot that provides a set of production-ready features... | 0 | 2024-05-23T23:14:17 | https://dev.to/oloruntobi600/spring-boot-actuator-26mk | Spring Boot Actuator is a sub-project of Spring Boot that provides a set of production-ready features to help you monitor and manage your Spring Boot application. Its primary purpose is to offer out-of-the-box tools for monitoring, measuring, and managing Spring Boot applications in production environments.
Key Features and Endpoints Provided by Spring Boot Actuator
Key Features:
A. Health Checks: Provides insights into the application's health status. This feature can be leveraged by monitoring systems to detect if the application is running smoothly.
B. Metrics: Collects and exposes various metrics about the application, such as memory usage, request rates, thread pools, garbage collection stats, etc.
C. Auditing: Tracks and logs requests made to the application, helping in auditing and debugging.
D. Environment Information: Retrieves details about the application's environment, including properties, configuration, and dependencies.
E. Thread Dump: Generates a thread dump of the application's JVM, useful for diagnosing performance issues and deadlocks.
Heap Dump: Generates a heap dump of the application's JVM, helpful for memory analysis and troubleshooting memory leaks.
Key Endpoints:
/actuator/health: Provides information about the application's health.
/actuator/info: Exposes arbitrary application info.
/actuator/metrics: Retrieves various metrics about the application.
/actuator/env: Displays the current application environment.
/actuator/loggers: Allows for configuring application logging levels.
/actuator/auditevents: Provides access to audit events.
/actuator/httptrace: Provides details of HTTP requests and responses.
/actuator/threaddump: Generates a thread dump of the JVM.
/actuator/heapdump: Generates a heap dump of the JVM.
3. Enabling and Customizing Actuator Endpoints in a Spring Boot Application
Enabling Actuator:
To enable Actuator endpoints in a Spring Boot application, you typically just need to include the Actuator starter dependency in your pom.xml or build.gradle file:
xml
Copy code
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
or
groovy
Copy code
implementation 'org.springframework.boot:spring-boot-starter-actuator'
Customizing Endpoints:
You can customize Actuator endpoints by modifying properties in the application.properties or application.yml file. For example:
properties
Copy code
# Customize the health endpoint
management.endpoint.health.show-details=always
# Customize the metrics endpoint
management.endpoint.metrics.enabled=true
management.metrics.export.influx.enabled=true
Exposing Additional Endpoints:
You can expose additional Actuator endpoints by configuring the management.endpoints.web.exposure.include property:
properties
Copy code
management.endpoints.web.exposure.include=health,info,metrics
This will expose only the specified endpoints.
Summary:
Spring Boot Actuator is a project aimed at providing production-ready features for monitoring and managing Spring Boot applications.
Key features include health checks, metrics collection, auditing, environment information retrieval, and thread and heap dump generation.
Key endpoints such as /actuator/health, /actuator/info, /actuator/metrics, etc., provide access to various monitoring and management functionalities.
Enabling Actuator is as simple as adding the Actuator starter dependency, while customizing endpoints involves configuring properties in the application configuration file.
Actuator is a powerful tool for ensuring the reliability and stability of Spring Boot applications in production environments | oloruntobi600 | |
1,863,372 | Deploying Windows 11 VM in Azure | Azure Virtual Machines(vm) are virtualized instances of computer systems that enable users to run... | 0 | 2024-05-23T23:11:33 | https://dev.to/blessingoseyenum/deploying-windows-11-vm-in-azure-48ne | cloud, cloudcomputing, azure, beginners | Azure Virtual Machines(vm) are virtualized instances of computer systems that enable users to run applications and services without the need to manage the underlying hardware infrastructure. They provide on-demand, scalable computing resources in the cloud.
Deploying a virtual machine in Azure can be done with a few easy steps. In this post, I'll be deploying a windows 11 vm and connecting to it.
Let's go!
-
Log in to Azure portal. Search for and select virtual machines.

-
Select **+ Create**.
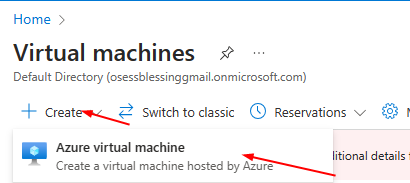
-
Give your resource group a name.
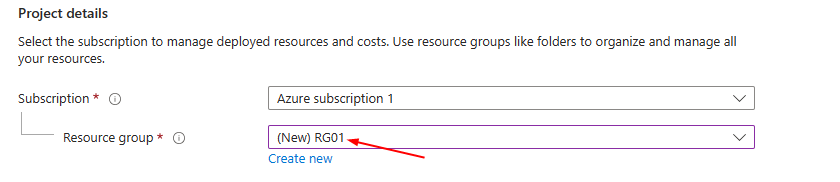
-
Input **virtual machine name** and select **Region**.
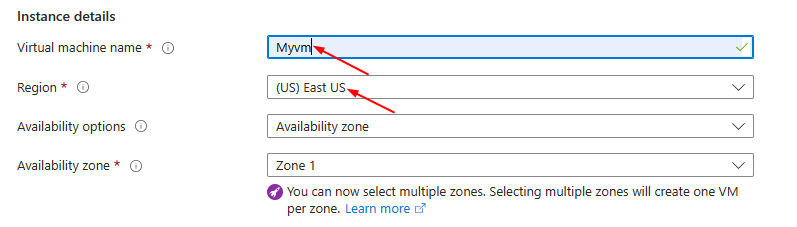
-
Select **image**. I'll be selecting windows 11 pro.
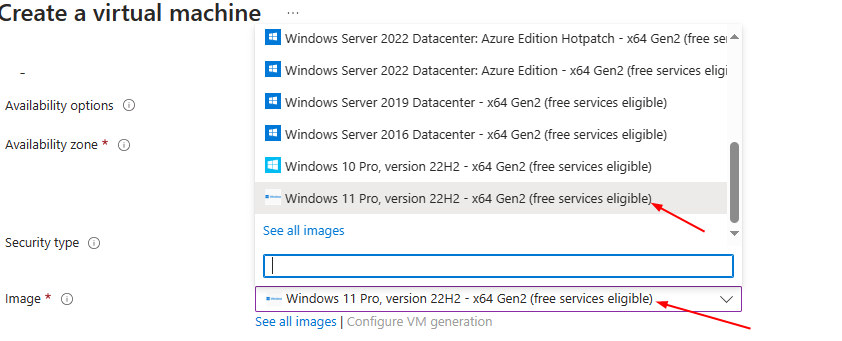
-
Select **size**.

-
Enter **user name**, **password** and **confirm password**.
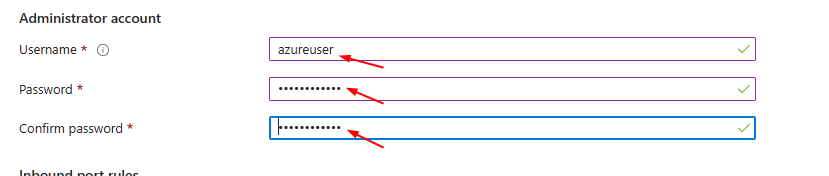
-
Select **inbound port**.
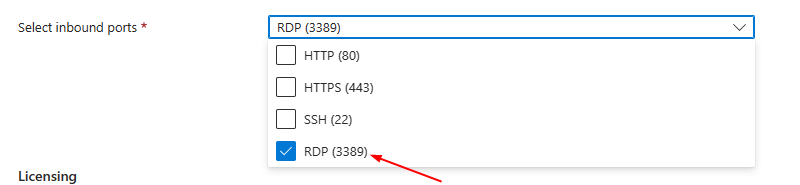
-
Check **licensing**.
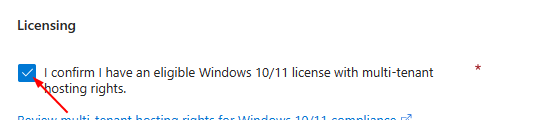
-
Select **Review + Create**.

-
Wait for validation, then select **Create**.
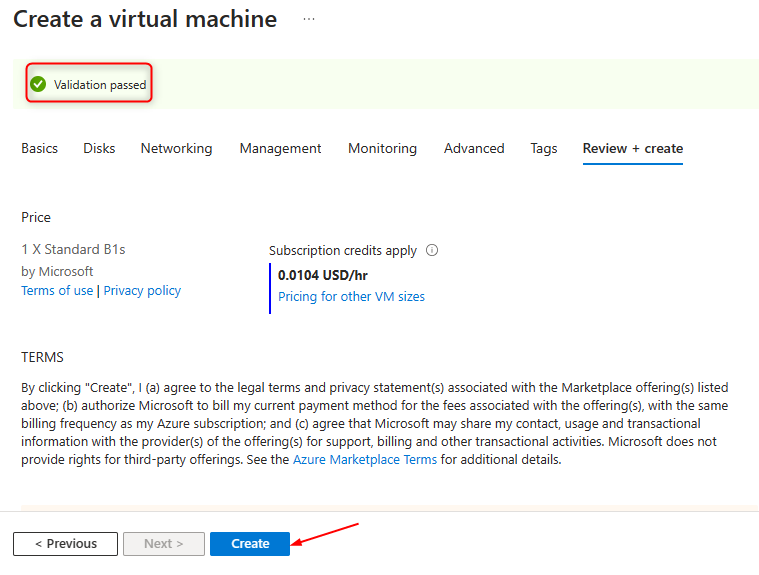
-
Wait for deployment to complete. Select **Go to Resource**.

-
To connect to the virtual machine. Select **connect**.
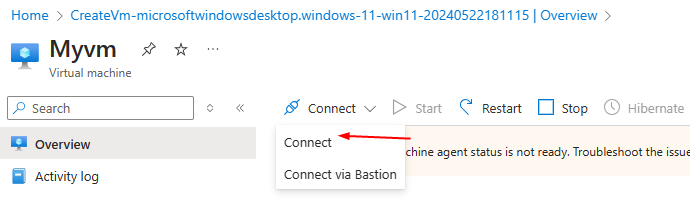
-
Select **Native RDP**.
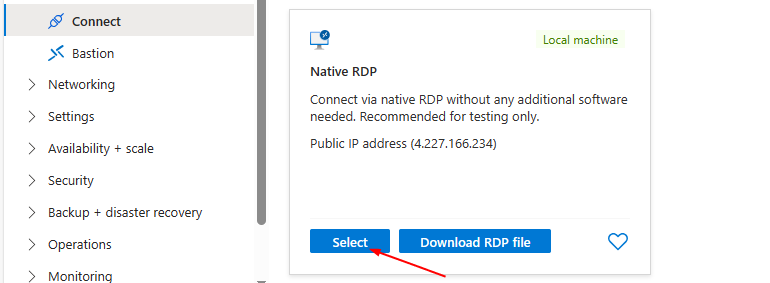
-
Select **Download RDP file**.
-
Open RDP file and select **connect**.
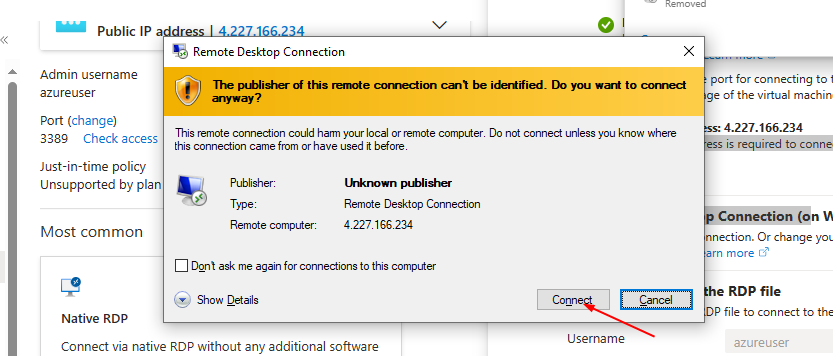
-
Enter **password** and select **ok** to connect.
-
Click **Accept**.
Here is it guys! Our vm is running.
| blessingoseyenum |
1,863,371 | Spring Boot Configuration | Configuring a Spring Boot application is a crucial aspect of its development lifecycle. Spring Boot... | 0 | 2024-05-23T23:11:16 | https://dev.to/oloruntobi600/spring-boot-configuration-1j19 | Configuring a Spring Boot application is a crucial aspect of its development lifecycle. Spring Boot provides multiple ways to configure an application, including application.properties, application.yml, and external configurations. Each method has its advantages and disadvantages, offering flexibility and ease of use to developers based on their specific requirements.
Different Ways to Configure a Spring Boot Application
1. application.properties
Description:
application.properties is a traditional approach for configuring Spring Boot applications using key-value pairs.
Syntax:
key=value
Example:
properties
Copy code
server.port=8080
spring.datasource.url=jdbc:mysql://localhost:3306/mydb
2. application.yml
Description:
application.yml is a YAML-based configuration format that provides a more human-readable and structured approach compared to application.properties.
Syntax:
YAML syntax with key-value pairs and nested structures.
Example:
yaml
Copy code
server:
port: 8080
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydb
3. External Configurations
Description:
External configurations allow separating configuration properties from the application code, providing flexibility and easier management.
Formats:
Properties or YAML files located outside the application, such as in the file system, classpath, or environment variables.
Example:
External properties file: config/application.properties
properties
Copy code
server.port=8080
External YAML file: config/application.yml
yaml
Copy code
server:
port: 8080
Advantages and Disadvantages of Each Configuration Method:
1. application.properties
Advantages:
Widely used and understood by developers.
Simple key-value pairs make it easy to manage configurations.
Disadvantages:
Limited support for complex configurations and nested properties.
May become verbose for large configurations.
2. application.yml
Advantages:
Provides a more structured and readable format compared to application.properties.
Supports nested configurations, reducing verbosity.
Disadvantages:
YAML syntax can be unfamiliar to some developers.
Limited support for complex configurations compared to external configurations.
3. External Configurations
Advantages:
Allows separation of concerns by keeping configurations outside the application code.
Provides flexibility to override properties based on environments (e.g., dev, test, prod).
Disadvantages:
Requires additional setup and management of external configuration files.
May introduce complexity when dealing with multiple configuration sources.
Examples of Common Configurations
Common Properties in application.properties
Server configuration:
properties
Copy code
server.port=8080
server.servlet.context-path=/myapp
Database configuration:
properties
Copy code
spring.datasource.url=jdbc:mysql://localhost:3306/mydb
spring.datasource.username=root
spring.datasource.password=root
Common Configurations in application.yml
Logging configuration:
yaml
Copy code
logging:
level:
root: INFO
com.example: DEBUG
External Configurations
External properties file (config/application.properties):
properties
Copy code
server.port=8080
External YAML file (config/application.yml):
yaml
Copy code
server:
port: 8080
Summary
Configuration Flexibility:
Spring Boot offers multiple configuration options, including application.properties, application.yml, and external configurations.
Advantages:
application.properties: Widely used, simple syntax.
application.yml: Structured, readable format with support for nested configurations.
External Configurations: Provides flexibility and separation of concerns.
Disadvantages:
Each method has its limitations based on complexity and familiarity.
Best Practices:
Choose the configuration method based on readability, complexity, and project requirements.
Use external configurations for environment-specific properties or sensitive information.
Conclusion
Understanding the different ways to configure a Spring Boot application and their advantages and disadvantages is essential for effective application development. By leveraging the appropriate configuration method based on the project's needs, developers can ensure maintainability, flexibility, and ease of management in their applications.
| oloruntobi600 | |
1,863,370 | Maximizing Innovation Returns: Expert R&D Tax Credit Consulting | Unlock the full potential of your research and development (R&D) endeavors with our specialized... | 0 | 2024-05-23T23:10:58 | https://dev.to/mackelmanz/maximizing-innovation-returns-expert-rd-tax-credit-consulting-5a2b | business | Unlock the full potential of your research and development (R&D) endeavors with our specialized tax credit consulting services. Our team of seasoned professionals offers comprehensive guidance tailored to your company's unique needs, ensuring you capitalize on available tax incentives while driving innovation forward. From identifying eligible R&D activities to navigating complex tax regulations, we're dedicated to optimizing your **[r&d tax credit consulting](https://www.taxresolutionplus.com/r-and-d-tax-credit-consulting)**, freeing up resources to fuel future growth and innovation. Partner with us to harness the power of R&D tax credits and propel your business to new heights of success. | mackelmanz |
1,863,369 | Spring Boot Annotations | @SpringBootApplication: Purpose: Marks the main class of a Spring Boot application. It combines... | 0 | 2024-05-23T23:07:31 | https://dev.to/oloruntobi600/spring-boot-annotations-57c8 | @SpringBootApplication:
Purpose: Marks the main class of a Spring Boot application. It combines three annotations:
@Configuration: Indicates that the class can be used by the Spring IoC container as a source of bean definitions.
@ComponentScan: Instructs Spring to scan and discover other components like controllers, services, and repositories in the package and its sub-packages.
@EnableAutoConfiguration: Enables Spring Boot's auto-configuration mechanism, allowing automatic configuration of beans based on dependencies and classpath.
Use Cases:
Main class of a Spring Boot application.
Example:
java
Copy code
@SpringBootApplication
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
@RestController:
Purpose: Marks a class as a RESTful controller. It automatically serializes return objects into JSON/XML responses.
Use Cases:
Building RESTful web services.
Example:
java
Copy code
@RestController
@RequestMapping("/api")
public class MyController {
@GetMapping("/hello")
public String hello() {
return "Hello, World!";
}
}
@Autowired:
Purpose: Injects dependencies automatically. It's typically used with constructor injection, field injection, or setter injection.
Use Cases:
Dependency injection in Spring-managed beans.
Example:
java
Copy code
@Service
public class MyService {
private final MyRepository repository;
@Autowired
public MyService(MyRepository repository) {
this.repository = repository;
}
}
@Service:
Purpose: Marks a class as a service component. It's a specialization of @Component and is used to indicate that the class performs some business logic or service tasks.
Use Cases:
Service layer in a Spring application, which contains business logic.
Example:
java
Copy code
@Service
public class MyService {
public String doSomething() {
return "Service processing";
}
}
@Repository:
Purpose: Marks a class as a data access component. It's a specialization of @Component and is used to indicate that the class interacts with a database or other external data source.
Use Cases:
Data access layer in a Spring application, responsible for database operations.
Example:
java
Copy code
@Repository
public class MyRepository {
public String getData() {
return "Data from repository";
}
}
@RequestMapping:
Purpose: Maps HTTP requests to handler methods. It's used at class and method levels to define the URL mappings.
Use Cases:
Defining endpoints for controllers.
Example:
java
Copy code
@RestController
@RequestMapping("/api")
public class MyController {
@GetMapping("/hello")
public String hello() {
return "Hello, World!";
}
}
Summary:
@SpringBootApplication: Main class of a Spring Boot application, enabling auto-configuration, component scanning, and acting as a configuration source.
@RestController: Marks a class as a RESTful controller, automatically serializing return objects into JSON/XML responses.
@Autowired: Injects dependencies automatically into Spring-managed beans.
@Service: Marks a class as a service component, typically containing business logic.
@Repository: Marks a class as a data access component, typically used for database operations.
@RequestMapping: Maps HTTP requests to handler methods, used for defining endpoints in controllers.
| oloruntobi600 | |
1,863,368 | Dependency Injection | Explanation and Importance: What is Dependency Injection (DI)? Dependency Injection is a design... | 0 | 2024-05-23T23:03:51 | https://dev.to/oloruntobi600/dependency-injection-283d | 1. Explanation and Importance:
What is Dependency Injection (DI)?
Dependency Injection is a design pattern used to reduce the coupling between classes by externally providing the dependencies that a class needs to function properly. In Spring Boot, DI is achieved through inversion of control (IoC), where the control of creating and managing objects is shifted from the class itself to an external container (i.e., the Spring container).
Importance in Spring Boot:
Dependency Injection is a fundamental concept in Spring Boot because it promotes loose coupling between components, making applications easier to maintain, test, and extend. By allowing Spring to manage object creation and wiring, developers can focus on writing business logic without worrying about the creation and configuration of dependencies.
2. Types of Dependency Injection:
a. Constructor Injection:
In constructor injection, dependencies are provided through a class constructor. This ensures that all required dependencies are initialized when an object is created. It is considered a best practice because it enforces immutability and ensures that objects are in a valid state upon creation.
java
Copy code
@Component
public class UserService {
private final UserRepository userRepository;
@Autowired
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
}
b. Setter Injection:
Setter injection involves providing dependencies through setter methods. While less preferred than constructor injection due to the possibility of partial initialization, it allows for optional dependencies and easier testing with frameworks like Mockito.
java
Copy code
@Component
public class UserService {
private UserRepository userRepository;
@Autowired
public void setUserRepository(UserRepository userRepository) {
this.userRepository = userRepository;
}
}
c. Field Injection:
Field injection directly injects dependencies into class fields using annotations. While concise, it violates encapsulation and makes testing more difficult, as dependencies cannot be easily mocked or replaced.
java
Copy code
@Component
public class UserService {
@Autowired
private UserRepository userRepository;
}
3. Implementation Examples in Spring Boot:
a. Constructor Injection:
java
Copy code
@Service
public class UserService {
private final UserRepository userRepository;
@Autowired
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
}
b. Setter Injection:
java
Copy code
@Service
public class UserService {
private UserRepository userRepository;
@Autowired
public void setUserRepository(UserRepository userRepository) {
this.userRepository = userRepository;
}
}
c. Field Injection:
java
Copy code
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
}
4. Summary:
Key Takeaways:
Dependency Injection promotes loose coupling between classes.
In Spring Boot, DI is achieved through inversion of control (IoC).
Constructor injection is the preferred method due to its immutability and ability to ensure object validity upon creation.
Setter injection allows for optional dependencies but can lead to partial initialization issues.
Field injection is concise but violates encapsulation and makes testing more difficult.
Constructor injection is the recommended approach in most cases, followed by setter injection for optional dependencies.
Conclusion:
Understanding Dependency Injection is crucial for developing maintainable and scalable Spring Boot applications. By leveraging DI, developers can write modular and testable code, leading to more robust software solutions.
| oloruntobi600 | |
1,863,367 | Why Every Business May Soon Need an AI Agent | Why build AI Agents for the workplace? AI agents (or “assistants”) are an extension of... | 0 | 2024-05-23T23:03:09 | https://mindsdb.com/blog/why-every-business-may-soon-need-an-ai-agent | ai, aiagents | ## Why build AI Agents for the workplace?
AI agents (or “assistants”) are an extension of large language models (LLMs). They can access external tools, such as search engines, via API calls. They’re therefore able to overcome some common shortcomings of LLMs, such as lack of access to internal business data.
Suppose you query a basic LLM, like ChatGPT, with the following:
In contrast, an agent with website analytics access could approach the problem differently:

Agents can be augmented with a large number of tools, which opens up endless exciting possibilities. Importantly, these tools allow the LLM to perform actions (like sending an email) as well as retrieval (like summarizing an email).
## How an agent handles complex queries
Let’s now compare approaches to a more complicated query:
_“Can you send an email to Olly with a chart of our landing page views over the past month?”_
A basic LLM could neither access the data source nor send an email.
An approach like [Retrieval Augmented Generation (RAG)](https://mindsdb.com/mindsdb-the-ctos-guide-to-rag-guide) could get the data on landing page views, but couldn’t send the chart to Olly.
An agent with a large number of tools could approach the problem like this:
The interface to agents is natural language, like LLMs, so there are many exciting possibilities. For example: an Agent could be accessed via a Slack message, massively reducing friction for employees in their basic daily tasks. MindsDB has [easy tutorials for setting up Slack bots](https://docs.mindsdb.com/use-cases/ai_workflow_automation/slack-chatbot)!

AI agents can accomplish tasks that would require hours of a skilled analyst’s time. The analyst would’ve needed to use an analytics dashboard, then put the data into a charting tool, and then draft an email. Now, all this can be executed with a single Slack message instead.
## The challenges with building AI agents for the workplace
Initial benchmarking on agents’ capabilities has been promising, as they’ve been able to execute complex tasks with external tools. Some benchmarking studies have focused on agents in video game settings like Minecraft. While they’ve performed impressively, far outperforming basic LLMs, this doesn’t necessarily translate into business value.
Outside the game world, other benchmarking studies have largely focused on abstract tasks. Let’s look at a challenging example from Meta’s GAIA benchmark:
**Level 3**
_**Question:** In NASA's Astronomy Picture of the Day on 2006 January 21, two astronauts are visible, with one appearing much smaller than the other. As of August 2023, out of the astronauts in the NASA Astronaut Group that the smaller astronaut was a member of, which one spent the least time in space, and how many minutes did he spend in space, rounded to the nearest minute? Exclude any astronauts who did not spend any time in space. Give the last name of the astronaut, separated from the number of minutes by a semicolon. Use commas as thousands separators in the number of minutes.
**Ground truth:** White; 5876_
This requires up-to-date information (from the Wikipedia API in this case), complex reasoning (using the LLM’s internal logic), and mathematical accuracy (from a Math API). However, it doesn’t represent a realistic daily business task very well.
It’s therefore difficult to know how reliable Agents solely tested on these benchmarks will be in a business setting. Think of the best mathematicians you know - _would they also schedule meetings reliably?_
## How can agents' true capabilities be evaluated for the real business environment?
MindsDB is continuously assessing the true capabilities of agents in the workplace, as the field evolves. In the next articles of the “Agents in the workplace” series we’ll publish our internal benchmarks of Agent performance across 5 key domains: email, calendars, website analytics, project management, and customer relationship management (CRM).
In line with our open-source ethos, we’ll be publishing the benchmarking dataset too. This will allow the open-source community to continuously test their agents in a realistic business setting too.
All these state-of-the-art results are part of MindsDB agents for businesses. Your employees can get started quickly with our agents, accessible via common chat interfaces such as Slack and Microsoft Teams.
## Who is designing the evaluation for these agents?
Our team includes MindsDB engineers, AI PhDs, and associate professors. The MindsDB engineers are Dr. [Olly Styles](https://www.linkedin.com/in/olly-styles-090437132/), Dr. [Sam Miller](https://www.linkedin.com/in/sam-miller-5415b0124/), and [Patricio Cerda Mardini](https://www.linkedin.com/in/paxcema/?locale=es_ES). They’re supported by Associate Profs. [Tanaya Guha](https://www.tanayag.com/) (Glasgow University) and [Victor Sanchez Silva](https://www.dcs.warwick.ac.uk/~vsanchez/Victor_Sanchez/Victor_Sanchez.html) (Warwick University), [Dr Bertie Vidgen](https://www.oii.ox.ac.uk/people/profiles/bertram-vidgen/) (Oxford University).
## What’s next for MindsDB agents?
Our next blog post will feature results from our internal benchmarking across the five business domains. We’ll follow that up with the CTO’s Guide to Building Agents in the Workplace, along with a rigorous peer-reviewed study supporting our results.
| mindsdbteam |
1,863,365 | New Construction Homes in Dallas & Fort Worth | Embark on a journey to find your perfect sanctuary in the vibrant cities of Dallas and Fort Worth.... | 0 | 2024-05-23T23:01:10 | https://dev.to/johnhawkee/new-construction-homes-in-dallas-fort-worth-1k99 | business | Embark on a journey to find your perfect sanctuary in the vibrant cities of Dallas and Fort Worth. Explore the latest offerings in **[new construction homes](https://www.ubh.com/locations/texas/dallas/)**, where modern elegance meets unparalleled craftsmanship.
In Dallas, immerse yourself in a dynamic urban landscape, where sleek architectural designs blend seamlessly with the city's rich heritage. From chic condos in bustling downtown districts to sprawling estates nestled in serene suburbs, there's a home to suit every lifestyle and preference.
Meanwhile, in Fort Worth, embrace the charm of a thriving metropolis with a distinct Texan flair. Experience the epitome of Southern hospitality as you explore a diverse array of **[new construction homes Fort Worth](https://www.ubh.com/locations/texas/fort-worth/)**, ranging from charming bungalows in historic neighborhoods to contemporary marvels in up-and-coming areas.
Whether you're drawn to the bustling energy of city life or prefer the tranquility of suburban living, both Dallas and Fort Worth offer an abundance of options to fulfill your vision of home. With top-notch amenities, innovative designs, and unbeatable locations, your journey to finding the perfect new construction home begins here." | johnhawkee |
1,863,364 | AI usefulness is a Bathtub Curve | Interestingly AI has a "bathtub curve" for usefulness. At the low level, Copilot is good at turning... | 0 | 2024-05-23T22:59:51 | https://dev.to/johntellsall/ai-usefulness-is-a-bathtub-curve-40ka |
Interestingly AI has a "bathtub curve" for usefulness.
At the low level, Copilot is good at turning a few words of English into 2-4 lines of code. A super auto-complete. At the high level, Phind / ChatGPT can describe concepts and break them down one level. This works okay and is great to learn and iterate at the human level.
In the middle, AI doesn't work as well. Often when AI writes multipart code, each piece will be okay, but they don't connect together. I've seen instances where it obviously takes a function from project A, a function from project B, then handwaves a connection between them. If A and B have different assumptions, this doesn't work. For Dev code, this is annoying. For DevOps (resource code), this can be really bad. It's easier to validate Dev code.
I've used the [Chain of Thought](https://www.promptingguide.ai/techniques/cot) pattern with some luck. You give high-level requirements to the AI and ask it to write a series of steps, *without* code. Then you can iterate on the steps. Adding constraints, reordering the steps, etc. Lastly you say "okay give me code for step 3". This sort of works. If the AI forgets you can give it the steps again as a context.
| johntellsall | |
1,863,362 | antelope hunts | Welcome to Hutch On Hunting, your premier digital research scouting platform. I am Bruce Hutcheon,... | 0 | 2024-05-23T22:57:32 | https://dev.to/hutchonhunting/antelope-hunts-118c | hunting |
Welcome to Hutch On Hunting, your premier digital research scouting platform. I am Bruce Hutcheon, the founder of this platform. You can call me Hutch. As a hunting enthusiast myself, I understand the intricacies of Colorado **[Antelope Hunts](https://www.hutchonhunting.com/colorado-antelope-hunts)**. My platform is designed to transform your hunting experiences, leveraging advanced digital tools to scout and plan your next adventure. Join me to discover a world where antelope hunting in Colorado is not just a pursuit but a memorable expedition!
The allure of antelope hunting in Colorado is undeniable. Known for its scenic landscapes and thriving antelope populations, Colorado offers hunters an unparalleled experience. The state’s vast public lands provide ample opportunities for hunters to track and harvest these swift creatures. As an expert in Colorado Antelope Hunts, I have dedicated myself to understanding the nuances of antelope behavior and habitat. | hutchonhunting |
1,863,361 | Introduction to Spring Boot | Purpose and Benefits of Using Spring Boot Spring Boot is a framework designed to simplify the... | 0 | 2024-05-23T22:55:52 | https://dev.to/oloruntobi600/introduction-to-spring-boot-1oic | Purpose and Benefits of Using Spring Boot
Spring Boot is a framework designed to simplify the development of Java applications by providing a suite of tools and conventions that reduce the need for extensive configuration. Its main purposes and benefits include:
1. Simplified Setup and Configuration:
Spring Boot eliminates the need for boilerplate code and extensive XML configurations by offering default configurations that can be overridden as needed. This reduces development time and complexity.
2. Auto-Configuration:
Spring Boot's auto-configuration feature automatically configures your application based on the dependencies present in your classpath. This means you can get started with a minimal setup and let Spring Boot handle the configuration for you.
3. Embedded Server:
Spring Boot applications can run on embedded servers such as Tomcat, Jetty, or Undertow. This allows developers to package their applications as executable JARs or WARs and run them independently without needing an external application server.
4.Production-Ready Features:
Spring Boot includes several production-ready features such as health checks, metrics, application monitoring, and externalized configuration. These features make it easier to deploy and manage Spring Boot applications in production environments.
5.Microservices Support:
Spring Boot is well-suited for developing microservices architectures due to its lightweight nature and ease of creating RESTful services. It integrates seamlessly with Spring Cloud to provide features like service discovery, load balancing, and distributed tracing.
Comparison with Traditional Spring Framework
1. Traditional Spring Framework:
- Requires extensive setup and configuration, often through XML files.
- Developers need to manage dependencies and configurations manually.
- Setting up an application server is necessary for deployment.
More suited for enterprise applications with complex requirements.
2. Spring Boot:
- Provides auto-configuration to simplify setup.
- Manages dependencies using Spring Boot Starter POMs.
- Comes with embedded servers, eliminating the need for external server setup.
- Ideal for rapid development and deployment, particularly for microservices.
Typical Use Cases for Spring Boot Applications
Spring Boot is versatile and can be used in various scenarios. Some typical use cases include:
1. Microservices:
Spring Boot is ideal for building microservices due to its lightweight nature and ease of creating RESTful services. It integrates with Spring Cloud for distributed systems management.
2. RESTful Web Services:
Creating REST APIs is straightforward with Spring Boot, thanks to its robust support for HTTP methods, request handling, and data binding.
3. Monolithic Applications:
While Spring Boot shines with microservices, it is also suitable for developing monolithic applications. Its modularity and ease of configuration make it a good choice for large, single-deployment applications.
4. Command-Line Applications:
Spring Boot can be used to create command-line applications that perform scheduled tasks, data processing, or other background jobs.
5.Prototyping and MVPs:
Rapid application development with Spring Boot makes it perfect for prototyping and building minimum viable products (MVPs). Developers can quickly iterate and deploy new features.
6. Enterprise Applications:
Spring Boot can be used in enterprise environments where ease of deployment and scalability are critical. Its production-ready features help in managing large-scale applications.
Diagrams and Code Snippets
Spring Boot Architecture Diagram
Example of a Simple Spring Boot Application:
```
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
@RestController
class HelloController {``
@GetMapping("/hello")
public String hello() {
return "Hello, Spring Boot!";
}
}
```
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MyConfiguration {
@Bean
@ConditionalOnMissingBean
public MyService myService() {
return new MyService();
}
}
Summary
Spring Boot simplifies Java application development by providing a set of conventions and default configurations, reducing the need for boilerplate code.
Comparison with Traditional Spring Framework: Spring Boot requires less setup and is easier to configure, with embedded servers and production-ready features.
Use Cases: Spring Boot is versatile and suitable for microservices, RESTful web services, monolithic applications, command-line applications, prototyping, and enterprise applications.
In conclusion, Spring Boot enhances developer productivity and streamlines the process of developing, deploying, and managing Java applications. Its auto-configuration, embedded servers, and production-ready features make it an excellent choice for modern software development needs.
| oloruntobi600 | |
1,863,359 | Transformative Diplomas and Transcripts for Modern Education | Discover a cutting-edge approach to academic credentials with our innovative system of infused... | 0 | 2024-05-23T22:43:19 | https://dev.to/mackelman/transformative-diplomas-and-transcripts-for-modern-education-3a64 | business | Discover a cutting-edge approach to academic credentials with our innovative system of infused **[diplomas and transcripts](https://www.phonydiploma.com/diplomas-and-transcript.aspx)**. We blend traditional certification with contemporary advancements, ensuring your educational achievements are recognized with utmost credibility and relevance. Embrace a seamless journey from learning to career with comprehensive documents that reflect your true potential. Explore how our infused diplomas and transcripts empower you to stand out in today's dynamic academic and professional landscapes, driving success and opening doors to limitless opportunities. | mackelman |
1,863,358 | Lior Matian | Lior Matian appears to be an individual whose background or professional achievements are not widely... | 0 | 2024-05-23T22:42:37 | https://dev.to/loirmatian/lior-matian-2cgo | Lior Matian appears to be an individual whose background or professional achievements are not widely documented in public sources. Without specific context or additional information, it's challenging to provide a detailed description. Here are some steps you can take to gather more information about **[Lior Matian](https://quincy.newsnetmedia.com/story/50605150/celebrating-a-decade-of-compassionate-leadership-and-innovation-with-lior-matian)**: | loirmatian | |
1,863,357 | View this solution on Exercism to Kitchen Calculator | https://exercism.org/tracks/elixir/exercises/kitchen-calculator/solutions/wagner-de-carvalho | 0 | 2024-05-23T22:37:52 | https://dev.to/wagnerdecarvalho/view-this-solution-on-exercism-to-kitchen-calculator-2pgj | elixir, programming, patternmatching, case |
https://exercism.org/tracks/elixir/exercises/kitchen-calculator/solutions/wagner-de-carvalho | wagnerdecarvalho |
1,863,356 | [Game of Purpose] Day 5 | Today I've learned about lighting. How to use Lumen system and how to bake light by hand. | 27,434 | 2024-05-23T22:37:06 | https://dev.to/humberd/game-of-purpose-day-5-5hl9 | gamedev | Today I've learned about lighting. How to use Lumen system and how to bake light by hand.

| humberd |
1,863,355 | Tutorial: Using Minder to automate management of source code repository configuration and security | Open Source maintainers, if you're tired of trying to make sure every project repo has a security.md... | 0 | 2024-05-23T22:36:21 | https://dev.to/ninfriendos1/tutorial-using-minder-to-automate-management-of-source-code-repository-configuration-and-security-n7e | opensource, tutorial | Open Source maintainers, if you're tired of trying to make sure every project repo has a [security.md](https://security.md/) file, protections enabled, Dependabot configured, etc--Minder can help you automate this, and it's free for public repos. [Here's how](https://stacklok.com/blog/tutorial-using-minder-to-automate-management-of-source-code-repository-configuration-and-security).

| ninfriendos1 |
1,863,354 | Favzi Shop | Unique Crystals & Luxury Handbags | Welcome to Favzi, your go-to destination for fashion-forward essentials and crystal treasures. At... | 0 | 2024-05-23T22:25:50 | https://dev.to/favzishop/favzi-shop-unique-crystals-luxury-handbags-18db | crystals, womenpurses, purseforwomen, luxuryhandbags | Welcome to Favzi, your go-to destination for fashion-forward essentials and crystal treasures. At Favzi, we curate a diverse collection of [Women's Purses](https://favzi.shop/), stylish jeans jackets, and mesmerizing crystals to elevate your wardrobe and enhance your lifestyle.
Seeking for the perfect accessory, or adding a touch of sparkle to your surroundings, Favzi has everything you need to express your unique style and embrace the magic of Crystals. Discover the beauty of Favzi today.
ADDRESS: 418 Pine Hills Drive Manorville, NY 11949
| favzishop |
1,863,353 | Mastering Melodies: Comprehensive Music Lessons for All Ages | Unlock your musical potential with our expertly crafted music lessons designed for students of all... | 0 | 2024-05-23T22:25:30 | https://dev.to/mackelman/mastering-melodies-comprehensive-music-lessons-for-all-ages-559h | business | Unlock your musical potential with our expertly crafted **[music lessons](https://musicdancetucson.com/)** designed for students of all ages and skill levels. Whether you're a beginner looking to explore your musical interests or an advanced musician aiming to refine your skills, our personalized instruction covers a wide range of instruments and styles. Join us and discover the joy of music through engaging and interactive lessons that cater to your unique learning pace and goals. | mackelman |
1,863,307 | online commercial general liability insurance lethbridge | In the dynamic business world, safeguarding your enterprise against unforeseen liabilities is... | 0 | 2024-05-23T22:19:18 | https://dev.to/affordablequotes/online-commercial-general-liability-insurance-lethbridge-55bc | insurance, finance | In the dynamic business world, safeguarding your enterprise against unforeseen liabilities is paramount. In Lethbridge, Alberta, Affordable Quotes offers a streamlined solution with our Online Commercial General Liability Insurance, providing robust protection tailored to the unique needs of your business. As a leading provider of **[online commercial general liability insurance Lethbridge](https://affordable-quotes.ca/online-commercial-general-liability-insurance-lethbridge-alberta)**, we understand the importance of quick, accessible, and comprehensive coverage for businesses of all sizes and sectors.
Every business is unique, and so are its insurance requirements. We offer customized solutions catering to your industry’s specific risks. Whether you run a retail store, a professional service firm, or a manufacturing unit, our online commercial general liability insurance Lethbridge Alberta, is designed to meet your distinct needs. | affordablequotes |
1,863,306 | Top Construction Contractor in Pickering, ON - Your Trusted Partner in Building Excellence | Looking for a reliable Construction Contractor Pickering ON? Our expert team specializes in... | 0 | 2024-05-23T22:11:31 | https://dev.to/mackelman/top-construction-contractor-in-pickering-on-your-trusted-partner-in-building-excellence-530d | business | Looking for a reliable **[Construction Contractor Pickering ON](https://g.page/r/CdrCt4C6K9MPEAI/)**? Our expert team specializes in delivering high-quality construction services for residential, commercial, and industrial projects. From new builds to renovations, trust us to bring your vision to life with precision and professionalism. Contact us today for a free consultation and discover why we're Pickering's preferred choice for construction excellence. | mackelman |
1,863,305 | Insurtech Consulting and Direct Life Insurance Services | Insurtech Consulting: In the dynamic landscape of insurance technology (insurtech), businesses seek... | 0 | 2024-05-23T22:10:45 | https://dev.to/jhonebuttler/insurtech-consulting-and-direct-life-insurance-services-15da | business | **Insurtech Consulting:**
In the dynamic landscape of insurance technology (insurtech), businesses seek guidance to navigate through complex advancements and emerging trends. **[Insurtech consulting ](https://www.insurtechexpress.com/consulting/)**provides tailored strategies and solutions to insurance companies, leveraging innovative technologies such as artificial intelligence, blockchain, and big data analytics. Consultants offer expertise in optimizing operational efficiency, enhancing customer experience, and implementing digital transformation initiatives. By harnessing the power of insurtech, consulting services empower insurers to stay competitive, adapt to changing market demands, and unlock new opportunities for growth.
**Life Insurance Direct:**
Life insurance is a cornerstone of financial planning, offering protection and security for individuals and their loved ones. In the realm of life insurance, the direct approach simplifies the purchasing process, allowing customers to buy policies directly from insurance providers without intermediaries like agents or brokers. **[Life insurance direct](https://www.insurtechexpress.com/solutions/eapp-edelivery-straight-through-processing/)** platforms streamline the application process, providing convenient online tools and resources for customers to compare policies, calculate premiums, and make informed decisions based on their unique needs. With direct life insurance, individuals gain accessibility, transparency, and control over their coverage, ensuring peace of mind and financial stability for the future." | jhonebuttler |
1,863,304 | denver colorado mexican food | Denver, Colorado, boasts a vibrant and diverse culinary scene, and its Mexican food offerings are a... | 0 | 2024-05-23T22:09:56 | https://dev.to/ladonamezcaleria/denver-colorado-mexican-food-1h6n | Denver, Colorado, boasts a vibrant and diverse culinary scene, and its Mexican food offerings are a testament to this rich tapestry. From authentic street tacos to modern fusion dishes, Denver's Mexican restaurants provide a mouthwatering array of options that cater to every palate. In the heart of downtown Denver, you can find traditional taquerias serving up savory carne asada and al pastor tacos, while upscale eateries infuse local Colorado ingredients into classic Mexican recipes, creating innovative and delectable dishes. Whether you're craving enchiladas smothered in green chile, freshly made guacamole, or perfectly grilled elote, Denver's Mexican food scene offers something for everyone. Don't miss out on the city's popular food trucks, which bring a taste of Mexico to various neighborhoods, offering everything from tamales to churros. For a truly unforgettable dining experience, explore **[denver colorado mexican food ](https://ladoñamezcaleria.com/mexican-food-denver-colorado)**scene, where culinary tradition meets creative flair. | ladonamezcaleria | |
1,863,227 | My Flatiron Experience | Intro Studying at Flatiron has been an incredibly valuable experience for me. 2024 has... | 0 | 2024-05-23T22:07:38 | https://dev.to/reecec/my-flatiron-experience-3802 | # Intro
Studying at Flatiron has been an incredibly valuable experience for me. 2024 has been a roller coaster of a year, but it has also been a year of immense learning. Through Flatiron, I have not only gained technical skills but also learned a lot about myself. I have thoroughly enjoyed coding from the day I picked it up, and now that I know how to build more complex projects, my passion has only grown. I always struggled with motivation in traditional school, but Flatiron showed me that studying the right things makes all the difference.
# My Future
I am committed to continuously challenging myself by building projects in my free time. I want to keep learning new languages and libraries to expand my capabilities. My goal is to secure a full-stack role where I can gain experience, learn from my peers, and contribute meaningfully. I am forever grateful for the opportunities I’ve been given, and I am determined to prove my worth through hard work and dedication. The ever-evolving tech landscape excites me, and I’m eager to stay at the forefront of innovation. In addition, I plan to participate in coding events to further sharpen my skills, network with like-minded professionals, and build some confidence.
# My next project
I have a project in mind that I’ve been excited about for a while. Now that I have the time, I am eager to start. I plan to build a website using Beautiful Soup and Selenium to scrape websites with auto parts tags from the Google Places API. My father is a gearhead, and I’ve inherited that passion, particularly for older vehicles. Finding parts can be challenging, so I came up with this idea early in my schooling. I am dedicated to making this my first post-graduation project, and I want to create something I am truly proud of. This project is not only a technical challenge but also a tribute to my father’s influence on my interests. I envision creating a user-friendly platform that helps enthusiasts like myself easily find parts for their projects.
# Flaws I'm Working On
I have always been a very nervous person with little confidence in my abilities. I am trying to challenge myself more to overcome this and have high hopes that once I gain more experience in a job, I will find my groove. One challenge I face is my poor memory, but I’ve been improving by keeping notes and structuring my days better to manage it.
# Conclusion
Over the past year, I have learned so much about myself, my interests, and my strengths. While I am still nervous about what lies ahead, I am determined to face it with a 'fake it till you make it' mentality to boost my confidence. I am very happy with my experience at Flatiron and grateful to my instructors. I will continue to improve on my coding journey, building fun projects that bring me joy and meaningful projects that make me proud. The supportive community at Flatiron has been instrumental in my growth, and I am excited to carry forward the lessons I’ve learned. My journey is just beginning, and I am ready to embrace every challenge and opportunity that comes my way. | reecec | |
1,863,303 | Angular se reinventa: Bienvenido a la era de Angular v18 | La espera ha terminado. Angular v18, la última versión del popular framework de Google para... | 0 | 2024-05-23T22:04:13 | https://dev.to/ricardochl/angular-se-reinventa-bienvenido-a-la-era-de-angular-v18-5ac1 | angular, typescript | La espera ha terminado. Angular v18, la última versión del popular framework de Google para desarrollo web, ha llegado para revolucionar la forma en que creamos aplicaciones web. Con un enfoque claro en la optimización del rendimiento y la introducción de nuevas características que simplifican el desarrollo.
## Change detection - Zoneless (Experimental)
Tradicionalmente, una librería llamada ZoneJS se ha encargado de activar la detección de cambios en Angular. Sin embargo, esta librería ha presentado ciertas desventajas en términos de rendimiento y experiencia de desarrollo.
Angular v18 introduce una nueva forma de activar la detección de cambios. En lugar de depender de ZoneJS para saber cuándo es posible que algo haya cambiado, Angular ahora puede programar una detección de cambios por sí mismo. Toma en cuenta que esto está en una etapa experiemental.
Para hacerlo, se agregó un nuevo programador al framework (llamado ChangeDetectionScheduler) y este programador se usa internamente para activar la detección de cambios. Este nuevo programador está habilitado de forma predeterminada en v18, incluso si usa ZoneJS. Sin embargo, el objetivo es alejarse progresivamente de ZoneJS y confiar únicamente en este nuevo planificador.
Con este nuevo programador, Angular ya no depende únicamente de ZoneJS para activar la detección de cambios. De hecho, el nuevo programador activa una detección de cambios cuando se activa un host o un escucha de plantilla, cuando se adjunta o elimina una vista, cuando una tubería asíncrona detecta una nueva emisión, cuando se llama al método `markForCheck()`, cuando se establece un valor de señal , etc. Lo hace llamando a `ApplicationRef.tick() `internamente.
### Experimentando con zoneless
Puedes probar el soporte para zoneless en Angular despues de actualizar a la versión 18, solo necesitas hacer un pequeño cambio en el `boostrap` de tu aplicación.
```typescript
bootstrapApplication(App, {
providers: [
provideExperimentalZonelessChangeDetection()
]
});
```
Al hacerlo, Angular ya no dependerá de ZoneJS para activar la detección de cambios. Así que puedes eliminar ZoneJS de tu aplicación si lo deseas (y si no tienes dependencias que dependan de él, por supuesto). En ese caso, puedes eliminar ZoneJS de los polyfills en tu archivo angular.json.
Si tus componentes son compatibles con la estrategia de detección de cambios `ChangeDetectionStrategy.OnPush` de Angular, también deberían ser en su mayoría compatibles con zoneless, lo que hará que su transición sea perfecta.
De cara al futuro, un Angular sin ZoneJS abre un abanico de
posibilidades para los desarrolladores:
- **Mayor compatibilidad:** Facilita la creación de micro-frontends y la interoperabilidad con otros frameworks.
- Rendimiento mejorado: Tiempos de renderizado iniciales más rápidos y mejor rendimiento en tiempo de ejecución.
- **Aplicaciones más ligeras:** Tamaños de paquete más pequeños y tiempos de carga de página más rápidos.
- **Depuración simplificada: **Rastros de pila más legibles que facilitan la identificación y resolución de errores.
- **Procesos de depuración más sencillos:** Elimina la complejidad asociada a ZoneJS, haciendo que la depuración sea más intuitiva.
La mejor forma de utilizar zoneless es con componentes que utilicen signals. Por ejemplo:
```typescript
@Component({
...
template: `
<h1>Hello from {{ name() }}!</h1>
<button (click)="handleClick()">Go Zoneless</button>
`,
})
export class App {
protected name = signal('Angular');
handleClick() {
this.name.set('Zoneless Angular');
}
}
```
En el ejemplo anterior, al hacer clic en el botón se invoca el método `handleClick`, que actualiza el valor del signal y actualiza la interfaz de usuario. Esto funciona de manera similar a una aplicación que usa ZoneJS, con pocas diferencias. Con ZoneJS, Angular ejecutaba la detección de cambios cada vez que el estado de la aplicación podía haber cambiado. Sin zonas, Angular limita esta verificación a menos activadores, como actualizaciones de signals. Este cambio también incluye un nuevo programador con fusión para evitar verificar cambios varias veces consecutivas.
### Async/await nativo en aplicaciones zoneless
ZoneJS tiene una particularidad: no puede funcionar con async/await. Quizás no lo sepas, pero cada vez que usas async/await en tu aplicación, la CLI transforma tu código para usar promesas "normales". Esto se llama reducción de nivel, ya que transforma el código ES2017 (async/await) en código ES2015 (promesas regulares).
Hoy en día, si creas una aplicación que utiliza la detección de cambios sin ZoneJS (experimenta), Angular CLI utilizará el async/await nativo sin bajarlo a promesas. Esto mejorará la depuración y hará que tus paquetes sean más pequeños.
## Signals - Propuesta de Estandarización
Esto no es exactamente nuevo en Angular v18, ya que en la version v17 se anuncio los nuevos signals inputs, signal queries y la nueva sintaxis de input y ouput.
Ahora con la llegada de la de Angular v18 tenemos las Siganal APIs en `developer preview`.
Cada vez los signals se están volviendo mucho más populares, de hecho ya existe una propuesta para estandarizar los signals y que puedan ser agregados a JavaScript. Puedes profundizar en la [propuesta](https://github.com/tc39) o en este interesante [blog post](https://eisenbergeffect.medium.com/a-tc39-proposal-for-signals-f0bedd37a335) para conocer más al respecto.
`new Signal.State()` sería el equivalente de `signal()` en Angular. `new Signal.Computed()` sería el equivalente de `computed()`. No hay equivalentes para el efecto: como todos los frameworks tienen necesidades ligeramente diferentes, esto queda fuera del alcance de la propuesta, y los frameworks pueden implementarlo como mejor les parezca basándose en el nuevo Signal.subtle.Watcher().
Dato curioso: ¡El polyfill de Signal actual en la propuesta se basa en la implementación de Angular!
## Built-in control flow - Ahora es estable
La sintaxis de `Built-in control flow` introducida en Angular v17 ya no es una función en `developer preview` para desarrolladores y se puede utilizar de forma segura. Como ahora es la forma recomendada de escribir plantillas, debería considerar usarla en tus aplicaciones. Puede migrar fácilmente tus aplicaciones utilizando los esquemas proporcionados. Por ejemplo:
```ssh
ng generate @angular/core:control-flow
```
Más información: [Guía oficial](https://angular.dev/guide/templates/control-flow)
## Deferrable views - Ahora es estable
La sintaxis @defer también es estable. @defer te permite definir un bloque de plantilla que se cargará de forma diferida cuando se cumpla una condición (con todos los componentes, canalizaciones, directivas y bibliotecas utilizadas en este bloque también cargados de forma diferida).
Más información: [Guía oficial](https://angular.dev/guide/defer)
## Material v3 - Ahora es estable
Hace unos meses atras Angular introdujo suporte experimental para Material 3, ahora con la llegada de Angular v18 tenemos soporte estable, ahora podemos utilizar los nuevos features de Material 3 en nuestros prouyectos de Angular con Angular Material.
## Mejoreas en el server-side rendering
Con Angular v18 llegaron algunas nuevas características relacionas al Server Side Rendering (SSR).
### Repetición de eventos
Hace unos meses el equipo de Angular anuncion un proyecto en curso a largo plazo que tenia como objetivo fusionar Angualar y el framework interno llamado Google Wiz. Angular y Wiz han estado sirviendo a dos segmentos diferentes de aplicaciones en el pasado: Wiz se usó principalmente para aplicaciones centradas en el consumidor, muy centrada en el rendimiento y Angular se centró en la productividad y la experiencia del desarrollador.
Como resultado de esta fusión Wiz integró profundamente Angular Signals en su modelo de renderizado. El equipo de Angular anunciuo que ahora Youtube usa Angular Signal, de la misma manera, Angular ahora ofrece cada vez más funciones centradas en el rendimiento, como la hidratación parcial, sobre las que compartiré más en un momento.
Ahora es posible registrar las interacciones del usuario durante la fase de hidratación y reproducirlas cuando la aplicación esté completamente cargada. Como sabrá, la fase de hidratación es la fase en la que el HTML renderizado por el servidor se transforma en una aplicación Angular completamente funcional, donde se agregan oyentes a los elementos existentes.
Pero durante esta fase, el usuario puede interactuar con la aplicación, y estas interacciones se pierden (si el proceso de hidratación no es lo suficientemente rápido).
Entonces, para algunas aplicaciones, puede resultar interesante registrar estas interacciones y reproducirlas cuando la aplicación esté completamente cargada.
#### Ejemplo:
Aunque la mayoría de los desarrolladores no trabajarán directamente con la reproducción de eventos, su utilidad es evidente. Imaginemos un sitio web de comercio electrónico con tiempos de carga lentos, como si tuviera una mala conexión. Un usuario intenta añadir varios productos al carrito mientras la página aún está cargando. Sin la reproducción de eventos, esas acciones se perderían.
Con Angular v18, la reproducción de eventos entra en juego: el sistema registra las acciones del usuario incluso antes de que la página sea interactiva. Una vez que la página carga completamente, los eventos se reproducen, y los productos se añaden al carrito como si no hubiera habido ningún problema de carga.
La función de repetición de eventos está disponible en la versión 18 en `developer preview`. Puedes habilitarlo usando `withEventReplay()`, por ejemplo:
```typescript
bootstrapApplication(App, {
providers: [
provideClientHydration(withEventReplay())
]
});
```
Para que la reproducción de eventos funcione, Angular inyecta un pequeño script al principio de tu página HTML. Este script tiene la misión de "reproducir" las acciones del usuario que ocurrieron mientras la página aún se estaba cargando.
¿Cómo lo hace? Primero, coloca un "oyente" en la raíz del documento que captura eventos específicos, como clics o doble clics, utilizando una técnica llamada delegación de eventos. Angular sabe qué eventos escuchar porque los recopiló durante el renderizado en el servidor.
El resultado final es que cuando la página está completamente cargada, este script inteligente reproduce las acciones del usuario, activando las funciones correspondientes como si nada hubiera pasado. Aunque no todas las aplicaciones se beneficiarán de esta característica, sin duda es una herramienta poderosa para aquellos casos donde la interacción temprana del usuario es crucial.
### Experiencia de depuración mejorada
Angular DevTools se ha actualizado para brindarte una mejor visión del proceso de hidratación. Ahora puedes ver el estado de hidratación de cada componente gracias a un nuevo ícono junto a su nombre. Y si quieres una vista general, activa el modo de superposición para ver al instante qué componentes ya están hidratados en la página. ¿Lo mejor? Si tu aplicación tiene errores de hidratación, Angular DevTools te los mostrará directamente en el explorador de componentes.
### Soporte para Hidratación en CDK y Material
En la versión 17, algunos componentes de Angular Material y CDK optaron por no hidratarse, lo que provocó su repetición. A partir de la versión 18, todos los componentes y primitivas son totalmente compatibles con la hidratación.
### Hidratación parcial
El equipo de Angular anuncio durante el Google I/O la hidratación parcial que es una técnica que te permite hidratar tu aplicación de forma incremental después del renderizado del lado del servidor. La hidratación incremental de tu aplicación permite cargar menos JavaScript por adelantado y mejora el rendimiento.
Imagina que puedes cargar tu aplicación web por partes, como si fuera un rompecabezas, empezando por las piezas más importantes. Eso es precisamente lo que permite la hidratación incremental: en lugar de cargar todo el código JavaScript de golpe, solo se carga lo esencial para mostrar la página rápidamente. El resto se va añadiendo sobre la marcha, mejorando significativamente el rendimiento.
La hidratación parcial lleva esta idea un paso más allá. Basándose en el concepto de "vistas diferibles", permite renderizar en el servidor el contenido principal de una sección específica de la página (marcada con @defer). Luego, en el navegador del usuario, Angular carga el código JavaScript asociado y "hidrata" esa sección solo cuando se cumplen ciertas condiciones, como por ejemplo, cuando el usuario interactúa con ella. De esta forma, se reduce la cantidad inicial de JavaScript y la página se vuelve más rápida e interactiva. Por ejemplo:
```typescript
@defer (render on server; on viewport) {
<app-calendar/>
}
```
El bloque de arriba representará el componente de calendario en el servidor. Una vez que llegue al cliente, Angular descargará el JavaScript correspondiente e hidratará el calendario haciéndolo interactivo solo después de que ingrese a la ventana gráfica.
### Firebase App Hosting
Firebase presentó en Google I/O su nuevo servicio de App Hosting, diseñado para simplificar al máximo la creación y publicación de aplicaciones web dinámicas.
¿Qué lo hace tan especial? App Hosting se integra a la perfección con el ecosistema de Firebase, ofreciendo:
- **Soporte nativo para Angular:** Configuración y despliegue sin complicaciones.
- **Integración con GitHub:** Facilita el flujo de trabajo desde el desarrollo hasta la producción.
- **Conexión directa con otros servicios de Firebase:** Aprovecha al máximo Authentication, Cloud Firestore, Vertex AI y más, sin configuraciones complejas.
Con App Hosting, Firebase se convierte en una solución aún más completa para construir y escalar aplicaciones Angular de forma rápida y segura. Dale un vistazo a la [guía](https://firebase.google.com/docs/app-hosting/get-started)
## Nuevo paquete de construcción
Angular está simplificando su sistema de construcción de proyectos. Para ello, han creado un nuevo paquete llamado `@angular/build`, que se centra en las herramientas modernas como esbuild y Vite.
Antes, todas las herramientas de construcción, incluyendo Webpack, estaban juntas en @angular-devkit/build-angular. Al separar esbuild y Vite en su propio paquete, `@angular/build` se vuelve más ligero y eficiente.
Si actualizas tu proyecto a Angular v18, tendrás la opción de migrar a este nuevo sistema. La migración actualizará tu archivo angular.json para que use `@angular/build` en lugar de `@angular-devkit/build-angular` y ajustará las dependencias en tu package.json.
Pero no te preocupes, esta migración solo se realizará si no utilizas Webpack en tu proyecto. Si tus pruebas se basan en Karma, que a su vez usa Webpack, no se hará ningún cambio. En resumen, Angular te ofrece un camino más limpio y moderno para construir tus aplicaciones, sin afectar proyectos que aún dependen de Webpack.
## Redirecciones de ruta como funciones
Angular ahora te da más control sobre las redirecciones en tus aplicaciones. Antes, solo podías redirigir a una ruta fija, sin importar el contexto. ¡Pero eso ha cambiado!
Con Angular v18, la propiedad `redirectTo` de una ruta ahora acepta una función, llamada `RedirectFunction`, que te permite crear redirecciones dinámicas y mucho más inteligentes.
¿Cómo funciona? La `RedirectFunction` recibe información sobre la ruta actual, como parámetros o consultas, y en base a eso, decide a dónde redirigir al usuario. Además, puedes usar servicios dentro de esta función, lo que abre un abanico de posibilidades para crear reglas de redirección sofisticadas. Esta función también es similar a las guardias y se ejecuta en el inyector de entorno: esto significa que puede inyectar servicios si es necesario. La función puede devolver una cadena o un `UrlTree`. Por ejemplo:
```typescript
const routes: Routes = [
{ path: "my-component", component: MyComponent },
{
path: "user-page",
redirectTo: ({ queryParams }) => {
const errorHandler = inject(ErrorHandler);
const userIdParam = queryParams['userId'];
if (userIdParam !== undefined) {
return `/user/${userIdParam}`;
} else {
errorHandler.handleError(new Error('Se intentó navegar a la página del usuario sin ID de usuario.'));
return `/not-found`;
}
},
},
{ path: "user/:userId", component: OtherComponent },
];
```
## HttpClientModule - Depreación
Angular sigue avanzando hacia un futuro donde los componentes independientes (Standolone components) son la norma, y esto significa que algunos módulos tradicionales están empezando a ser reemplazados.
En Angular v18, los módulos `HttpClientModule` (junto con `HttpClientTestingModule`, `HttpClientXsrfModule`, y `HttpClientJsonpModule`) han sido marcados como obsoletos. Esto no significa que ya no funcionen, pero sí que es hora de empezar a usar alternativas más modernas.
En su lugar, ahora puedes utilizar las funciones `provideHttpClient()` (con opciones para XSRF o JSONP) y `provideHttpClientTesting()`. Estas funciones ofrecen una forma más directa y eficiente de configurar el cliente HTTP en tus aplicaciones.
Y como siempre, el equipo de Angular ha pensado en todo. Al actualizar tu proyecto con `ng update @angular/core`, se te preguntará si quieres migrar automáticamente tus módulos HTTP a la nueva sintaxis.
## Contenido alternativo para ng-content
`<ng-content>` es una característica poderosa en Angular, pero tiene una limitación: no puede tener contenido alternativo. ¡Este ya no es el caso en Angular v18!
Ahora podemos agregar algo de contenido dentro de la etiqueta `<ng-content>`, y este contenido se mostrará si no se proyecta ningún contenido en el componente.
Sólo necesitas poner el contenido alternativo dentro de la etiqueta `ng-content`:
```typescript
import { Component } from '@angular/core';
@Component({
standalone: true,
selector: 'my-component',
template: `
<ng-content select="header"> Default header </ng-content>
<ng-content> Default main content </ng-content>
<ng-content select="footer"> Default footer </ng-content>
`,
})
export class MyComponent {}
```
Como puedes ver, esta nueva característica te permite definir fácilmente un contenido alternativo dedicado para cada elemento `ng-content` en tu componente.
Entonces, considerando el siguiente ejemplo:
```typescript
<my-component>
<footer> New footer </footer>
</my-component>
```
El resultado será:
```typescript
Default header
Default main content
<footer> New footer </footer>
```
Nota: antes de Angular v18, esto provocaría un error.
## angular.dev - La nueva documentación oficial de Angular
El equipo de Angular ha anunciado que ahora angular.dev es el nuevo sitio web oficial de la documentación.
Angular v18 llega cargado de mejoras que hacen del desarrollo web una experiencia más fluida, eficiente y satisfactoria. Desde la optimización del rendimiento hasta la inclusión de nuevas funcionalidades, esta versión nos equipa con las herramientas necesarias para construir aplicaciones web de última generación. ¡No hay tiempo que perder, es hora de actualizar nuestros proyectos y sumergirnos en las posibilidades que nos ofrece Angular v18!
Muchas gracias por leerme, Espero que este recorrido por las novedades de Angular v18 te haya resultado útil.
Si te ha gustado el artículo, ¡compártelo en tus redes sociales!
Sígueme en Twitter/X [ricardo_chl](https://twitter.com/ricardo_chl) | ricardochl |
1,854,400 | Dev: Game | A Game Developer is a software engineer who specializes in designing, developing, and optimizing... | 27,373 | 2024-05-23T22:00:00 | https://dev.to/r4nd3l/dev-game-p3o | gamedev, developer | A **Game Developer** is a software engineer who specializes in designing, developing, and optimizing video games for various platforms such as consoles, computers, mobile devices, and virtual reality (VR) systems. Here's a detailed description of the role:
1. **Game Design:**
- Game Developers collaborate with game designers to conceptualize and plan game mechanics, rules, levels, characters, and storylines.
- They translate design concepts into technical specifications and identify the technologies and tools needed to implement them effectively.
2. **Programming:**
- Game Developers write code for game engines and frameworks using programming languages such as C++, C#, Java, Python, or JavaScript.
- They implement game logic, user interfaces, artificial intelligence (AI), physics simulations, audio effects, and networking functionalities to create immersive gaming experiences.
3. **Game Engines and Tools:**
- They work with game engines such as Unity, Unreal Engine, Godot, or custom-built engines to develop, deploy, and maintain games efficiently.
- Game Developers utilize integrated development environments (IDEs), debuggers, profilers, and version control systems to streamline the game development process and collaborate with team members effectively.
4. **Graphics and Animation:**
- They create 2D and 3D graphics, animations, textures, and visual effects using graphic design software (Adobe Photoshop, Blender, Maya, 3ds Max).
- Game Developers optimize graphics performance, implement rendering techniques, and utilize shaders and GPU programming to achieve realistic visuals and immersive environments.
5. **Audio Engineering:**
- They integrate sound effects, background music, voiceovers, and ambient sounds into games to enhance the gaming experience.
- Game Developers use audio editing software (Audacity, Adobe Audition) and middleware (FMOD, Wwise) to create and manipulate audio assets and implement spatial audio and dynamic soundtracks.
6. **User Experience (UX) and User Interface (UI):**
- They design and develop intuitive user interfaces, menus, HUDs (heads-up displays), and interactive elements to improve usability and accessibility for players.
- Game Developers optimize UI/UX design for different screen sizes, resolutions, and input devices, ensuring a consistent and enjoyable experience across platforms.
7. **Game Testing and Quality Assurance:**
- They conduct extensive testing and debugging of games to identify and fix bugs, glitches, and performance issues.
- Game Developers use testing frameworks, emulators, simulators, and real devices to simulate gameplay scenarios and ensure game stability, functionality, and compatibility.
8. **Multiplayer and Networking:**
- They implement multiplayer features, matchmaking systems, and online multiplayer modes using network programming techniques (TCP/IP, UDP).
- Game Developers optimize network performance, minimize latency, and implement anti-cheat mechanisms to provide smooth and fair multiplayer experiences for players.
9. **Publishing and Distribution:**
- They manage the publishing and distribution process of games to various platforms (Steam, App Store, Google Play Store, Xbox Live, PlayStation Network).
- Game Developers coordinate with publishers, platform holders, and digital storefronts to release games, manage updates, and monitor user feedback and reviews.
10. **Community Engagement and Support:**
- They engage with the gaming community through social media, forums, and online communities to gather feedback, address player concerns, and build a loyal fan base.
- Game Developers provide customer support, troubleshooting assistance, and post-launch updates to maintain player satisfaction and ensure long-term success for their games.
In summary, a Game Developer is a highly skilled professional who combines technical expertise, creativity, and passion for gaming to create immersive and engaging experiences for players worldwide. They play a crucial role in every stage of the game development process, from initial concept and design to final release and ongoing support, shaping the future of interactive entertainment. | r4nd3l |
1,863,302 | Elegance Blanc: French White Bedroom Furniture Collection | Embrace the timeless allure of French-inspired design with our Elegance Blanc french white bedroom... | 0 | 2024-05-23T21:54:55 | https://dev.to/davidgale/elegance-blanc-french-white-bedroom-furniture-collection-51ia | business | Embrace the timeless allure of French-inspired design with our Elegance Blanc **[french white bedroom furniture](https://www.frenchcountryfurnitureusa.com/french-white-bedroom-furniture/)** collection. Crafted with meticulous attention to detail, each piece exudes sophistication and charm, elevating your bedroom into a sanctuary of tranquility and style. Our exquisite range features pristine white finishes, ornate carvings, and graceful curves, reminiscent of the classical French aesthetic. From opulent sleigh beds to delicately adorned dressers and bedside tables, every element is designed to infuse your space with an air of refined luxury. Immerse yourself in the allure of French elegance with our Elegance Blanc collection and transform your bedroom into a captivating retreat. | davidgale |
1,863,301 | sable dog with long hair | Each sable dog with long hair in our collection is a testament to breed excellence. Their luscious... | 0 | 2024-05-23T21:53:51 | https://dev.to/pembrokesofwalnutcreek/sable-dog-with-long-hair-2b0 | pet, corgi | Each **[sable dog with long hair](https://www.pembrokesofwalnutcreek.com/sable-dog-with-long-hair)** in our collection is a testament to breed excellence. Their luscious sable coats are not only beautiful to look at but also soft to the touch, making every cuddle a luxurious experience. These dogs are the epitome of elegance and charm, turning heads wherever they go.
Our sable dogs with long hair are known for their friendly and affectionate nature. We ensure that they are well-socialized from a young age, making them great additions to any family. Whether you live alone, with a partner, or have a bustling household with children, our dogs adapt beautifully to their new environments and family dynamics.
| pembrokesofwalnutcreek |
1,863,300 | Expert Tax Advocates and IRS Audit Lawyers in North Carolina | Navigating the complexities of tax laws and regulations can be overwhelming, especially for... | 0 | 2024-05-23T21:48:39 | https://dev.to/jhonebuttler/expert-tax-advocates-and-irs-audit-lawyers-in-north-carolina-3ho2 | business | Navigating the complexities of tax laws and regulations can be overwhelming, especially for individuals and businesses in North Carolina. That's where **[Tax Advocate NC](https://brianwestromlaw.com/nc-tax-advocate/)** steps in as your reliable ally. With a dedicated team of professionals well-versed in state and federal tax codes, we provide expert guidance and advocacy tailored to your specific needs.
Whether you're facing tax disputes, audits, or seeking assistance with tax planning and compliance, Tax Advocate NC offers personalized solutions to alleviate your concerns. Our commitment to excellence and client satisfaction ensures that you receive the highest level of service and support throughout every stage of your tax journey.
**IRS Audit Lawyers NC: Strategic Defense Against IRS Scrutiny in North Carolina**
When facing an IRS audit in North Carolina, having experienced and knowledgeable legal representation is paramount to safeguarding your rights and interests. That's where **[IRS Audit Lawyers NC ](https://brianwestromlaw.com/nc-irs-audit-lawyers/)**comes in, offering comprehensive legal defense and representation to individuals and businesses undergoing IRS scrutiny.
Our team of seasoned tax attorneys specializes in navigating the intricacies of IRS audits, providing strategic counsel and representation to protect your assets and mitigate potential liabilities. From initial audit notifications to negotiating settlements and appeals, we leverage our expertise to achieve the best possible outcomes for our clients.
With IRS Audit Lawyers NC by your side, you can approach the audit process with confidence, knowing that you have dedicated advocates fighting for your rights and ensuring fair treatment under the law. Don't face IRS audits alone—trust the proven expertise of IRS Audit Lawyers NC to safeguard your financial well-being in North Carolina."
| jhonebuttler |
1,863,299 | Hello World! | Get it? This is my first post, so I thought I should keep with programming tradition. ` function... | 0 | 2024-05-23T21:44:09 | https://dev.to/codecruncher86/hello-world-4k7o | hello | Get it? This is my first post, so I thought I should keep with programming tradition.
`
function helloWorld() {
myMessage = "Hello World!";
console.log(myMessage);
}
helloWorld();
`
| codecruncher86 |
1,863,297 | 😱 Как Понять, Что Тебя Прослушивают Через Алису: Раскрываем Секреты Умных Колонок! 😱 | Умные колонки, такие как Яндекс.Станция с Алисой 🤖 или Amazon Echo 🗣️, прочно вошли в нашу жизнь,... | 0 | 2024-05-23T21:37:46 | https://dev.to/amoz/kak-poniat-chto-tiebia-proslushivaiut-chieriez-alisu-raskryvaiem-siekriety-umnykh-kolonok-33md | Умные колонки, такие как Яндекс.Станция с Алисой 🤖 или Amazon Echo 🗣️, прочно вошли в нашу жизнь, даря комфорт и удобство управления умным домом. Но у медали две стороны: могут ли эти устройства превратиться в инструменты слежки? Давайте разберемся, как понять, прослушивает ли вас Алиса, и как защитить свою приватность! 🕵️♀️
**🚨 Как Узнать, Слышит ли Вас Умная Колонка? 🚨**
🤫 Первый тревожный звоночек – световая индикация на устройстве. Если вы молчите, а колонка подсвечивается – это повод задуматься. Возможно, она "подслушивает" вас.
👉 [Узнать больше о том, как понять, что вас прослушивают](https://umnyekolonki.ru/kak-ponyat-chto-tebya-proslushivayut-cherez-alisu#toc-1).
**🎙️ Может ли Умная Колонка Подслушивать? 🎙️**
Производители уверяют: без вашего согласия колонки ничего не записывают. 🤔 Но! "Слушать" – не значит "записывать". Яндекс признал: Алиса может "слушать" несколько секунд, даже если ее не зовут. Хотите быть уверены в своей безопасности? Отключайте устройство, когда оно не нужно!
👉 [Может ли умная колонка подслушивать](https://umnyekolonki.ru/kak-ponyat-chto-tebya-proslushivayut-cherez-alisu#toc-2).
**👶 Можно ли Через Умную Колонку Слушать, Что Происходит в Помещении? 👶**
Да, если использовать колонку как радионяню. Устройства мониторинга, такие как некоторые модели с Алисой, работают везде, где есть интернет. Ими можно пользоваться для прослушивания дома, но помните: это может нарушать закон!
👉 [Можно ли через умную колонку слушать, что происходит в помещении](https://umnyekolonki.ru/kak-ponyat-chto-tebya-proslushivayut-cherez-alisu#toc-3).
**⚠️ Признаки Того, Что Вас Могут Прослушивать ⚠️**
Вот несколько тревожных сигналов, которые могут указывать на прослушивание через умную колонку или телефон:
1️⃣ **Проверка переадресации вызовов.**
2️⃣ **Щелчки и посторонние звуки в динамике во время разговора.**
3️⃣ **Странные звуки в режиме ожидания.**
4️⃣ **Долгая установка соединения.**
5️⃣ **Быстрый расход аккумулятора.**
6️⃣ **"Торможение" и самопроизвольные перезагрузки смартфона.**
Заметили что-то подобное? Немедленно отключите устройство и проверьте его на вирусы!
👉 [Узнайте больше о признаках того, что вас могут прослушивать](https://umnyekolonki.ru/kak-ponyat-chto-tebya-proslushivayut-cherez-alisu#toc-4).
🛡️ Как Защитить Себя от Прослушивания 🛡️
Вот несколько советов, как обезопасить себя от прослушивания:
*️⃣ **Отключайте колонку, когда не пользуетесь ей.**
*️⃣ **Используйте наушники вместо динамика.**
*️⃣ **Не разрешайте устройству записывать звук без вашего ведома.**
*️⃣ **Регулярно проверяйте устройства на вирусы.**
*️⃣ **Не ставьте колонку в спальнях или ванных комнатах.**
👉 [Как защитить себя от прослушивания](https://umnyekolonki.ru/kak-ponyat-chto-tebya-proslushivayut-cherez-alisu#toc-5).
❓ Вопросы и ответы ❓
**Можно ли прослушивать через ноутбук/Пинго/компьютер/звонки в Телеграме?**
💻 Прослушивание через любые устройства, подключенные к интернету, теоретически возможно. Используйте антивирусы, будьте бдительны и не открывайте подозрительные ссылки.
💡 Полезные советы 💡
✳️ **Меняйте пароли от Wi-Fi и аккаунтов устройств.**
✳️ **Следите за разрешениями, которые вы даете приложениям.**
✳️ **Используйте VPN для шифрования интернет-трафика.**
📌 Выводы 📌
Умные колонки – полезные, но потенциально уязвимые устройства. Соблюдайте меры предосторожности, чтобы не стать жертвой слежки. Берегите себя и свою приватность! 🔐 | amoz | |
1,863,296 | Lightning Damage Repair Experts in Gainesville, GA: Swift Restoration Services | Experience repair lightning damage gainesville ga? Don't let it zap your peace of mind. Our skilled... | 0 | 2024-05-23T21:35:45 | https://dev.to/davidgale/lightning-damage-repair-experts-in-gainesville-ga-swift-restoration-services-4blk | business | Experience **[repair lightning damage gainesville ga](https://electricalpros.com/electrical-repairs/repair-lightning-damage-gainesville/)**? Don't let it zap your peace of mind. Our skilled team specializes in lightning damage repair, swiftly restoring your property to its former glory. From electrical systems to structural repairs, we handle it all with precision and care. Trust us to navigate the aftermath of nature's fury. Contact us now for prompt, reliable restoration services tailored to your needs. | davidgale |
1,863,295 | massage coppell tx | Certification brings with it a commitment to the highest standards of practice. Whether it’s hygiene,... | 0 | 2024-05-23T21:33:20 | https://dev.to/highstonecoppell/massage-coppell-tx-48g5 | massage | Certification brings with it a commitment to the highest standards of practice. Whether it’s hygiene, understanding health conditions, or ensuring the correct pressure and technique, a certified therapist ensures that every **[massage Coppell TX](https://highstonecoppell.com/massage-coppell-tx/)**, is conducted with utmost safety and professionalism. You’re in safe, expert hands when you lay on that massage table. | highstonecoppell |
1,863,294 | 🎧 Как настроить наушники Redmi BUDS 4 Active: полное руководство 🎧 | Redmi BUDS 4 Active — это как портал в мир музыки и развлечений, доступный в любое время и в любом... | 0 | 2024-05-23T21:27:03 | https://dev.to/amoz/kak-nastroit-naushniki-redmi-buds-4-active-polnoie-rukovodstvo-3bj2 | Redmi BUDS 4 Active — это как портал в мир музыки и развлечений, доступный в любое время и в любом месте! 🎉 Наушники легко синхронизируются со смартфоном и готовы радовать вас любимыми треками. В этом подробном руководстве мы расскажем, как настроить Redmi BUDS 4 Active и получить максимум удовольствия от их использования. 😉
**⚡ Мгновенное подключение: знакомимся с Google Fast Pair**
Забудьте о сложностях сопряжения! 🙅♀️ Redmi Buds 4 Active подключаются к вашему Android-смартфону в одно касание благодаря технологии Google Fast Pair.
1️⃣ **Откройте кейс** с наушниками.
2️⃣ **Активируйте Bluetooth** на вашем смартфоне.
3️⃣ **Нажмите кнопку подключения** на смартфоне.
4️⃣ **Дождитесь сопряжения** (вы услышите сигнал).
Готово! 🎉
👉 [Подробнее о подключении Redmi BUDS 4 Active к смартфону читайте по ссылке](https://umnyekolonki.ru/kak-nastroit-naushniki-redmi-buds-4-active#toc-1).
**🕹️ Управление в одно касание: осваиваем жесты**
Redmi Buds 4 Active буквально слушаются ваших пальцев! 🤏 Управляйте музыкой и звонками с помощью простых касаний:
✳️ **Двойное касание** (любой наушник): пауза/воспроизведение ⏯️
✳️ **Тройное касание** (правый): следующий трек ⏭️
✳️ **Тройное касание** (левый): предыдущий трек ⏮️
👉 [Полный список жестов и функций управления вы найдете здесь](https://umnyekolonki.ru/kak-nastroit-naushniki-redmi-buds-4-active#toc-2).
**🤫 Погружаемся в звук: включаем шумоподавление**
Оградитесь от шума и наслаждайтесь чистым звуком с режимом шумоподавления! 🔇
1️⃣ Откройте **настройки Bluetooth** на вашем устройстве.
2️⃣ Выберите **Redmi BUDS 4 Active**.
3️⃣ Активируйте **режим шумоподавления**.
👉 [Подробная инструкция по включению шумоподавления](https://umnyekolonki.ru/kak-nastroit-naushniki-redmi-buds-4-active#toc-3).
**⚙️ Тонкая настройка: раскрываем потенциал наушников**
Хотите настроить Redmi BUDS 4 Active под себя? Легко!
1️⃣ Убедитесь, что **Bluetooth включен** на вашем устройстве.
2️⃣ **Откройте кейс** с наушниками.
3️⃣ В списке доступных устройств выберите **Redmi BUDS 4 Active** и нажмите **"Подключить"**.
После подключения вы сможете:
✳️ **Отслеживать уровень заряда** наушников и кейса.
✳️ **Обновлять прошивку** наушников для получения новых функций.
👉 [Узнайте больше о настройке беспроводных наушников Redmi](https://umnyekolonki.ru/kak-nastroit-naushniki-redmi-buds-4-active#toc-4).
**💡 Полезные советы для меломанов**
✳️ **Перезагружайте наушники и устройство**, если возникли проблемы с подключением.
✳️ **Регулярно очищайте наушники** от загрязнений.
✳️ **Заряжайте наушники вовремя**, чтобы не пропустить ни одной ноты.
✳️ **Храните наушники в кейсе**, чтобы защитить их от повреждений.
👉 [Больше полезных советов по уходу за Redmi BUDS 4 Active](https://umnyekolonki.ru/kak-nastroit-naushniki-redmi-buds-4-active#toc-5).
**🏁 Выводы**
Настроить наушники Redmi BUDS 4 Active проще простого! Следуйте нашим советам, и вы сможете наслаждаться любимой музыкой с кристально чистым звуком. 🎶
**Ответы на вопросы:**
✳️ **Вопрос:** Могу ли я подключить Redmi BUDS 4 Active к iPhone?
✳️ **Ответ:** Да, наушники совместимы с устройствами iOS.
**Советы:**
✳️ Используйте качественные приложения для прослушивания музыки, чтобы раскрыть потенциал Redmi BUDS 4 Active.
**Выводы:**
Redmi BUDS 4 Active - отличный выбор для тех, кто ищет качественные и доступные беспроводные наушники с удобным управлением и функцией шумоподавления. | amoz | |
1,860,998 | My personal AWS account setup - IAM Identity Center, temporary credentials and sandbox account | I work on AWS projects every day and have access to internal and customer AWS accounts. But I also... | 0 | 2024-05-23T21:26:29 | https://dev.to/aws-builders/my-personal-aws-account-setup-iam-identity-center-temporary-credentials-and-sandbox-account-39mc | aws, security | I work on AWS projects every day and have access to internal and customer AWS accounts. But I also manage some personal AWS accounts. They are useful for several reasons:
- I can run personal AWS applications, such as the smart home application I built.
- I can test new features, e.g. it was very helpful to learn about the CDK pipeline when it was introduced. I was able to create the accounts as suggested in the documentation. Later I was able to apply my knowledge to the customer project.
- If I have some permission issues, I can try to replicate the problem in my personal AWS accounts without any restrictions.
I can try new services that are only available in organizational root accounts, such as AWS Identity Center.
Of course, I want to run the AWS account in a secure and convenient way. So I decided to manage the accounts as described in this article.
## Account structure and AWS Organizations
Like a business, I created an [AWS organization](https://aws.amazon.com/organizations/) to manage my accounts. I'm using these accounts:
- Root account, which owns the organization
- Dev, Test, and Prod accounts to develop, test, and run my application
- [Pipeline account](https://docs.aws.amazon.com/cdk/v2/guide/best-practices.html#best-practices-organization), which contains an AWS CodePipeline to deploy to Dev, Int, Prod
- Sandbox account for testing new stuff (gets nuked after testing)
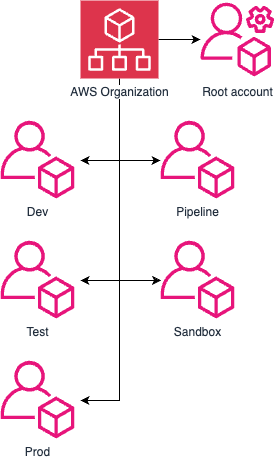
## User management and authentication using AWS Identity Center
I'm sure AWS IAM user management was great when it first launched. Now, [AWS IAM Identity Center](https://aws.amazon.com/iam/identity-center/) has more features and is easier to use. For example, it provides an easy-to-use interface to access all accounts and roles. Or it has improved [MFA capabilities](https://docs.aws.amazon.com/singlesignon/latest/userguide/mfa-types.html#mfa-types-apps), such as support for Apple's TouchID. That is why I chose AWS Identity Center. It is set up in the AWS Organizations root account and connects to all accounts in the organization.
When you open AWS IAM Identity Center, you can see the accounts and roles you can assume:
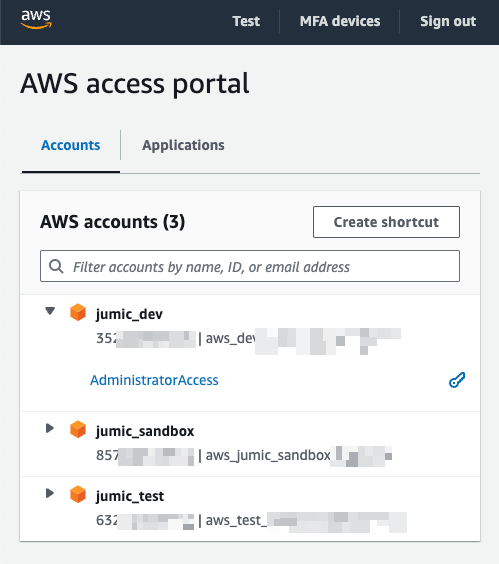
## Temporary credentials and Leapp
AWS IAM Identity Center provides temporary credentials by default, which is a good security choice. It supports [SSO integration](https://docs.aws.amazon.com/cli/latest/userguide/sso-configure-profile-token.html#sso-configure-profile-token-auto-sso) with AWS CLI or manual download of access key, secret access key, and session token.
Personally, I prefer to use [Leapp](https://www.leapp.cloud/), a tool that supports secure cloud access in multi-account environments. Recently, the company behind Leapp announced the end of the commercial version. The [open source version](https://github.com/Noovolari/leapp) still exists and can be used.
Leapp displays all AWS accounts/roles that are configured in AWS Identity Center. If you select an account, the credentials can be used in the CLI. You can override the default profile so you don't have to pass a `--profile` parameter. Or, you can configure a name profile.
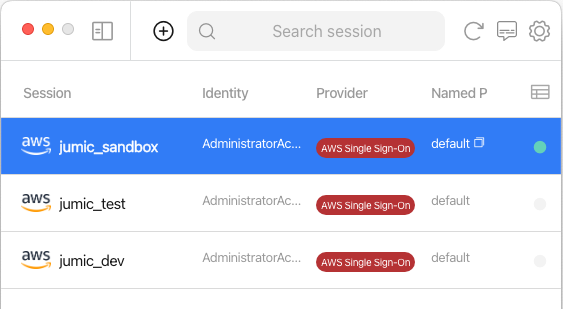
## Nuking the sandbox account
When I'm learning a new AWS service or testing a complex scenario, I'm not always using infrastructure as code. In this case, it takes a long time to manually clean up an AWS account and delete all (expensive) resources.
To improve this process, I use [aws-nuke](https://github.com/rebuy-de/aws-nuke), which automatically deletes all AWS resources in an AWS account. **Be careful with this tool**. The first time I used it, it also deleted the configurations required for IAM Identity Center. So I couldn't login anymore.
aws-nuke supports filters to exclude resources that should not deleted. I created filters to exclude the IAM Identity Center configuration and resources created during AWS CDK bootstrapping. I ended up with these filters:
```yaml
presets:
common:
filters:
IAMRole:
- "OrganizationAccountAccessRole"
- type: glob
value: "cdk-hnb659fds-*"
- type: glob
value: "AWSReservedSSO_AdministratorAccess_*"
IAMRolePolicyAttachment:
- "OrganizationAccountAccessRole -> AdministratorAccess"
- type: glob
value: "AWSReservedSSO_AdministratorAccess_* -> AdministratorAccess"
- type: glob
value: "cdk-hnb659fds-*"
IAMRolePolicy:
- type: glob
value: "cdk-hnb659fds-*"
IAMSAMLProvider:
- type: glob
value: "arn:aws:iam::*:saml-provider/AWSSSO_*_DO_NOT_DELETE"
S3Bucket:
- type: glob
value: "s3://cdk-hnb659fds-assets*"
SSMParameter:
- "/cdk-bootstrap/hnb659fds/version"
CloudFormationStack:
- CDKToolkit
ECRRepository:
- type: glob
value: "Repository: cdk-hnb659fds-container-assets-*"
```
## Summary
This setup works very well for me. AWS IAM Identity Center is great for managing users and logging into AWS accounts. Leapp is very helpful when using CLI credentials. However, it's not the only option as AWS IAM Identity Center offers other options as well. I regularly use the sandbox account when testing or learning about AWS services. By deleting everything with aws-nuke, I can easily start with an empty AWS account - and of course, I don't have to pay for unused resources. | jumic |
1,863,293 | Google Announces Major Updates to Gemini AI: Enhancing Capabilities and Expanding Access | In a series of announcements made in May 2024, Google unveiled substantial updates to its Gemini AI... | 0 | 2024-05-23T21:23:19 | https://dev.to/daisyauma/google-announces-major-updates-to-gemini-ai-enhancing-capabilities-and-expanding-access-41k7 | googlecloud, ai, programming, datascience |
In a series of announcements made in May 2024, Google unveiled substantial updates to its Gemini AI models, marking significant advancements in artificial intelligence technology. These updates include the enhancement of the Gemini 1.5 Pro model, the introduction of the Gemini 1.5 Flash model, and new features available through the Gemini API. These developments are designed to make the AI more capable, accessible, and useful across a variety of applications.
#### Enhancements to Gemini 1.5 Pro
One of the standout updates is the enhancement of the Gemini 1.5 Pro model, which now supports a context window of up to 1 million tokens. This is the longest context window available for any consumer chatbot, allowing the model to process and understand extensive amounts of text. This capability is particularly useful for tasks that involve long documents, detailed email threads, and comprehensive datasets. With this update, users can expect improved performance in generating coherent and contextually accurate responses even when dealing with large volumes of information.
The Gemini 1.5 Pro model has also received updates that improve its data analysis capabilities. Users can now upload various file types, including spreadsheets and documents, directly into the model for analysis. The AI can generate visualisations and charts from the data, making it a powerful tool for businesses and researchers who need to interpret and present complex information quickly and accurately.
#### Introduction of Gemini 1.5 Flash
In addition to the enhancements to the Gemini 1.5 Pro model, Google introduced the Gemini 1.5 Flash model. This new model is optimized for tasks that require rapid response times, making it ideal for applications where speed is critical. Despite being a smaller model, Gemini 1.5 Flash maintains high performance and accuracy, ensuring that users do not have to compromise on quality for the sake of speed.
#### New Features in the Gemini API
Developers have much to look forward to with the new features available through the Gemini API. One of the most notable additions is the first-ever 2 million token context window, which allows for even more complex data processing and analysis. This feature is particularly beneficial for applications that require the AI to handle extensive and intricate datasets, providing developers with more flexibility and power in their projects.
The Gemini API also includes new capabilities for native audio understanding, system instructions, and JSON mode. These features enhance the model's ability to interact with and process different types of data, broadening the scope of potential applications. Whether it's interpreting audio files, following detailed system instructions, or handling structured data in JSON format, the updated API provides the tools needed to leverage Gemini AI's full potential.
#### Expanding Practical Applications
The recent updates to Gemini AI are part of Google's broader strategy to integrate advanced AI functionalities into everyday tools. Users can now upload files via Google Drive or directly from their devices, enabling the AI to perform in-depth analysis and provide insights on dense documents. This feature is particularly useful for professionals who need to analyse reports, research papers, and other extensive documents quickly and efficiently.
Moreover, the Gemini 1.5 Pro model's multimodal capabilities have been enhanced. This means the AI is better equipped to understand and interact with images and audio, making it a versatile tool for a wide range of applications. Whether it's analysing visual data or processing spoken language, the updated model provides a more comprehensive and intuitive user experience.
#### Availability and Future Prospects
Both the Gemini 1.5 Pro and Gemini 1.5 Flash models are available in preview across more than 200 countries and territories as of May 14, 2024. These models will be generally available in June 2024, allowing a wider audience to benefit from their advanced capabilities. Developers can start using these models by obtaining an API key through the [Google AI Studio](https://aistudio.google.com) and exploring the [Gemini API Cookbook](https://github.com).
The continuous evolution of Gemini AI reflects Google's commitment to advancing AI technology and making it more accessible. By enhancing the capabilities of its models and expanding their practical applications, Google is paving the way for a future where AI plays a central role in various aspects of daily life and professional work.
For more detailed updates and information, you can visit Google's official blog posts on the recent announcements:
- [Gemini 1.5 Pro updates and new models](https://blog.google/technology/ai/gemini-1-5-pro-updates)
- [Introducing Gemini 1.5 Flash and API enhancements](https://developers.googleblog.com/gemini-1-5-flash-api)
| daisyauma |
1,863,291 | "Unveiling Deception: A Private Investigator's Guide to Unraveling Cheating" | Dive into the clandestine world of infidelity with this comprehensive guide tailored for private... | 0 | 2024-05-23T21:20:49 | https://dev.to/davidgale/unveiling-deception-a-private-investigators-guide-to-unraveling-cheating-lf4 | bussines | Dive into the clandestine world of infidelity with this comprehensive guide tailored for [private investigator cheating](https://drakeinvestigationgroup.com/private-investigator-for-cheating/). "Unveiling Deception" equips professionals with the essential tools and techniques necessary to uncover cheating spouses and partners. From covert surveillance tactics to analyzing digital footprints, this resource offers a step-by-step blueprint for navigating the delicate nuances of extramarital affairs. Whether you're a seasoned detective or a newcomer to the field, this book provides invaluable insights into the art of unraveling deception and restoring truth in relationships. | davidgale |
1,863,283 | 🇷🇺 Как поставить русский язык на Mi Band 8: пошаговая инструкция и полезные советы | 🤓 Привет, друзья! Вы стали счастливым обладателем модного фитнес-браслета Mi Band 8, но столкнулись с... | 0 | 2024-05-23T21:20:17 | https://dev.to/amoz/kak-postavit-russkii-iazyk-na-mi-band-8-poshaghovaia-instruktsiia-i-polieznyie-soviety-303c | 🤓 Привет, друзья! Вы стали счастливым обладателем модного фитнес-браслета Mi Band 8, но столкнулись с тем, что он не поддерживает русский язык? 🤔 Не переживайте, эта проблема решаема! В этой статье мы подробно расскажем, как установить русский язык на Mi Band 8 и наслаждаться его функционалом на родном языке. 🇷🇺
📲 Установка русского языка на Mi Band 8: пошаговое руководство
Процесс установки русского языка на Mi Band 8 довольно прост и не займет много времени. Просто следуйте нашей пошаговой инструкции: 👇
1️⃣ **Скачайте и установите приложение Mi Fitness.** Для начала загрузите приложение Mi Fitness из официального магазина приложений вашего смартфона (App Store для iOS или Google Play для Android).
2️⃣ **Зарегистрируйтесь в приложении Mi Fitness.** После установки приложения откройте его и пройдите процедуру регистрации, указав адрес электронной почты, пароль и другую необходимую информацию.
⚠️ **Важно:** При регистрации в качестве региона выберите "Китай". 🇨🇳 Это важный момент, который позволит вам в дальнейшем установить русский язык на ваш Mi Band 8.
3️⃣ **Смените язык системы на английский.** Откройте настройки вашего смартфона и найдите раздел "Язык и ввод" или аналогичный. В этом разделе выберите английский язык в качестве языка системы.
4️⃣ **Перезапустите приложение Mi Fitness.** После смены языка системы перезапустите приложение Mi Fitness, чтобы изменения вступили в силу.
5️⃣ **Подключите Mi Band 8 к смартфону.** Включите Bluetooth на вашем смартфоне и откройте приложение Mi Fitness. В приложении следуйте инструкциям на экране, чтобы подключить ваш Mi Band 8 к смартфону.
6️⃣ **Установите русский язык в настройках Mi Band 8.** После успешного подключения браслета к смартфону откройте приложение Mi Fitness и перейдите в раздел "Профиль". Затем выберите ваш Mi Band 8 из списка устройств и найдите раздел "Язык". В этом разделе выберите "Русский" и сохраните изменения.
🎉 **Поздравляем!** Вы успешно установили русский язык на ваш Mi Band 8! Теперь вы можете наслаждаться всеми функциями браслета на родном языке. 🥳
⏰ Когда ждать официальную поддержку русского языка на Mi Band 8?
Многие пользователи задаются вопросом, когда же появится официальная поддержка русского языка на Mi Band 8 без необходимости выполнять дополнительные настройки. 🤔
👉 Согласно информации от производителя, обновление прошивки Mi Band 8 с добавлением русского языка ожидается в сентябре этого года. [Подробнее о сроках выхода обновления можно узнать здесь](https://umnyekolonki.ru/kak-postavit-russkij-yazyk-na-mi-bend-8#toc-1).
🇨🇳🆚🌎 Китайская версия Mi Band 8 vs. Глобальная версия: в чем разница?
Перед покупкой Mi Band 8 важно знать о различиях между китайской и глобальной версиями устройства. 🤔 Вот основные отличия:
💎 **Язык упаковки и инструкции:** 📦
💎 **Глобальная версия:** 🇬🇧 Английский язык
💎 **Китайская версия:** 🇨🇳 Китайский язык
💎 **Российская версия Ростест:** 🇷🇺 Русский язык
💎 **Региональные настройки подключения:** 🌍
💎 **Глобальная версия:** Европейский регион 🇪🇺
💎 **Китайская версия:** Китайский регион 🇨🇳
💎 **Российская версия Ростест:** Российский регион 🇷🇺
[Подробнее о различиях между версиями Mi Band 8 вы можете прочитать здесь](https://umnyekolonki.ru/kak-postavit-russkij-yazyk-na-mi-bend-8#toc-2).
👍 Полезные советы и выводы
💎 **Обновление с русским языком для Mi Band 8 ожидается в сентябре.** 🗓️ Не спешите расстраиваться, если ваш новый браслет пока не поддерживает русский язык – скоро эта проблема будет решена официально!
💎 **Для установки русского языка на Mi Band 8 следуйте нашей инструкции.** 🇷🇺 Процесс установки несложный и занимает всего несколько минут.
💎 **При выборе Mi Band 8 учитывайте различия между версиями.** 🇨🇳🆚🌎 Выбирайте ту версию, которая лучше всего соответствует вашим потребностям и региону проживания.
Надеемся, эта статья помогла вам разобраться, как установить русский язык на Mi Band 8 и выбрать подходящую версию устройства. 😉 Наслаждайтесь использованием вашего нового фитнес-браслета и получайте удовольствие от его функциональности! 💪
❓ Ответы на вопросы
**1. Нужно ли устанавливать какие-либо сторонние приложения для русификации Mi Band 8?**
Нет, для установки русского языка на Mi Band 8 достаточно использовать официальное приложение Mi Fitness.
**2. Безопасно ли менять регион в приложении Mi Fitness?**
Да, изменение региона в приложении Mi Fitness безопасно и не повредит вашему устройству.
**3. Что делать, если после обновления прошивки Mi Band 8 до версии с русским языком возникнут проблемы?**
В случае возникновения проблем после обновления прошивки рекомендуется обратиться в службу поддержки Xiaomi или к продавцу устройства.
💡 Полезные советы
💎 Перед обновлением прошивки Mi Band 8 убедитесь, что браслет заряжен mindestens на 50%. 🔋
💎 Не отключайте Mi Band 8 от смартфона во время обновления прошивки. 📵
💎 После обновления прошивки рекомендуется выполнить сброс настроек Mi Band 8 до заводских. 🔄
📌 Выводы
Установка русского языка на Mi Band 8 – простая процедура, с которой справится любой пользователь. Главное – следовать нашей инструкции и не бояться экспериментировать! 😊 | amoz | |
1,863,276 | Classes e Objetos em C# .NET | Resumo Neste artigo vamos falar sobre o conceito de classes em C# (C-Sharp), abordando os... | 0 | 2024-05-23T21:20:14 | https://dev.to/felipeamorimdev/classes-e-objetos-em-c-net-1l54 | csharp, dotnet, programming, learning | ## Resumo
Neste artigo vamos falar sobre o conceito de classes em C# (C-Sharp), abordando os temas, fundamentos, características e aplicações. As classes são elementos fundamentais da orientação a objetos, são elas que fornecem a estrutura básica dos objetos.
Vamos discutir as definições de classes, seus componentes, propriedades, métodos e seus construtores, falaremos também sobre seus conceitos, como herança, polimorfismo e encapsulamento.
## Introdução
A programação orientada a objetos (POO) é um modelo muito utilizado no desenvolvimento de software. C# (C-Sharp) é uma linguagem de programação desenvolvida pela Microsoft, baseado em C e C++, é uma linguagem orientada a objetos e fortemente tipada, onde o framework .NET (dotNET) e parte integrante da linguagem.
Este artigo vamos falar de uma forma mais abrangente sobre classes, abordando conceitos básicos até os mais avançados.
## Classes
As classes são estruturas de dados fundamentais que representam um tipo de objeto, definindo seu comportamento e quais informações ela pode armazenar.
Classes tem atributos, propriedades, construtor e métodos. Nela está definido toda a estrutura básica de como será composta, ou seja, ela tipifica o que será modelado e determina os estados e comportamentos que os objetos podem ter.
• Atributos – Variáveis que armazenam dados.
• Propriedades – Métodos que fornecem uma interface (Getters e Setters) para acessar e modificar um atributo.
• Construtor – Método especial chamado quando uma nova instancia de classe é criada.
• Métodos – Funções que definem o comportamento dos objetos.
## Tipos de acesso das classes
Classes podem ter diferentes níveis de acesso como por exemplo o public, um dos mais utilizado. Os níveis de acesso determinam a visibilidade de uma classe no escopo do projeto (Solution), classes publicas podem ser vistas por outras classes e objetos dentro do mesmo projeto (Solution), tornando os atributos e métodos acessíveis em outras classes e objetos.
Os principais níveis de acesso em C# são:
•Público (public): Uma classe pública é acessível de qualquer lugar dentro do projeto e seus atributos e métodos também serão do tipo público.

•Privada (private): Uma classe privada só pode ser acessada dentro da mesma classe, ou seja, a classe e seus atributos e métodos só são visíveis dentro da própria classe. Classe do tipo privada não pode ser instanciada ou acessada.

•Protegida (Protected): Uma classe protegida é acessível dentro da mesma, e de suas classes derivadas, permitindo que a classe derivada acesse seus métodos.

•Interna (Internal): Uma classe interna só é acessível dentro do mesmo conjunto, não sendo possível acessar seus atributos e métodos em outra parte do projeto.

## Conceitos de classes
Em orientação a objetos temos cinco conceitos fundamentais em que uma classe pode ter, são ele, Heranças, Polimorfismo, Encapsulamento, Abstração e Interfaces.
## Herança
É um mecanismo em que uma Subclasse herda atributos de uma Superclasse, com isso a Subclasse pode reutilizar o código da Superclasse, estendendo seu comportamento. Para herdamos um classe em C# usamos “ : ” (dois pontos) seguido pelo nome da classe. Por exemplo:
A Superclasse Pessoa, tem seus atributos nome e idade e seus métodos, get e set, para cada atributo.
A subclasse Motorista herda a superclasse Pessoa.
> Note que quando instanciamos a classe Motorista, (var motorista = new Motorsita;) podemos acessar os atributos e métodos da classe Pessoa, sem precisarmos fazer a instanciação da superclasse pessoa.
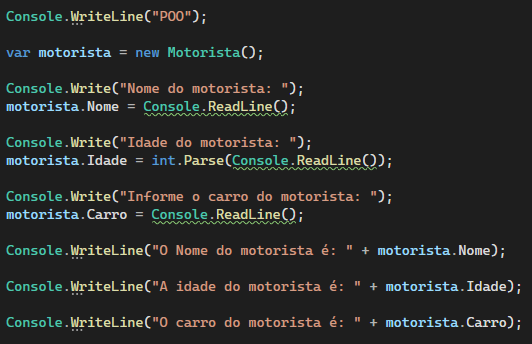
Na execução do código podemos ver o retorno dos atributos Nome, Idade e Carro.

## Polimorfismo
O polimorfismo permite que objetos de diferentes tipos possam ser tratados de uma mesma forma, isso é, que uma classe base pode definir métodos que são implementados de maneiras diferentes por suas classes derivadas, permitindo que um método se comporte de maneira diferente.
Podemos ter dois tipos de polimorfismo, são eles:
## Polimorfismo de sobrecarga (Overloading)
> Esse tipo acontece quando, vários métodos com o mesmo nome existem em uma classe, mas com diferentes parâmetros.
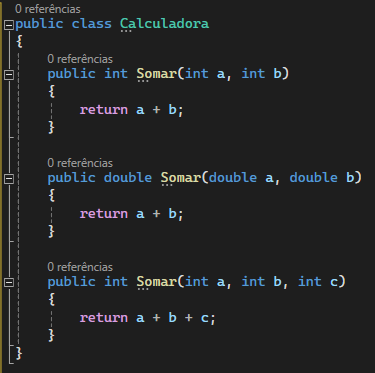
## Polimorfismo de subistituição (Overriding)
> Em polimorfismo de subistituição, temos o conceito de herança que permite uma subclasse forneça uma implementação específica de um método que já esta definido na superclasse. Para isso usamos os modificadores Virtual e Override
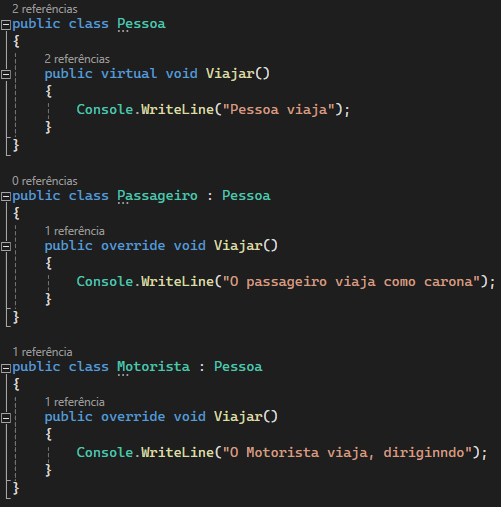
## Encapsulamento
É o conceito de proteger os atributos de uma classe, garantindo assim que os dados sejam manipulados de forma mais segura. Para utilizarmos o conceito de encapsulamento temos que utilizar os modificadores de acesso, anteriormente falado nesse artigo.
## Modificadores de Acesso
Os modificadores controlam a visibilidade e a acessibilidade dos atributos da classe, os modificadores são:
> •Public – O atributo e visível em toda parte do código.
> •Private – O atributo e visível somente dentro da própria classe.
> •Protected – O atributo e visível dentro da própria classe e de suas classes derivadas.
> •Internal – O atributo e visível somente dentro do mesmo assembly.
As classes que utilizam o conceito de encapsulamento tem propriedades para controle de acesso e para controle de modificações, são métodos especiais chamados de Getters e Setters.
> •Getters – métodos publico (public) para controle de acesso do atributo.
> •Setters – método publico (public) para controle de modificações do atributo.
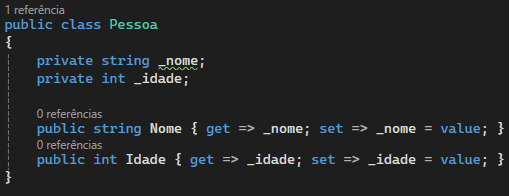
Por definição quando delcaramos os atributos, colocamos o _ (Underline) na frente do nome. E a primeira letra sempre em letra minúscula, pois quando geramos o Getters e Setters a própria linguagem já modifica a primeira letra para maiúscula.
## Abstração
A abstração é o processo de esconder os detalhes de um objeto, ou seja ela serve como base para uma outra classe.
> •Uma classe abstrata não pode ser instanciada.
> •Serve apenas como modelo para outra classe.
> •Pode conter métodos abstratos sem implementação, e métodos concretos com implementações.
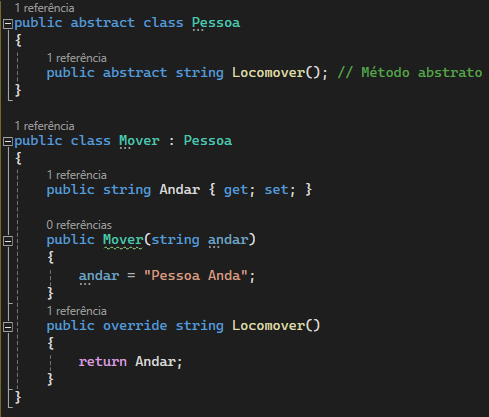
## Interfaces
Uma interface declara um conjunto de métodos, mais não fornece corpo para esses métodos, com isso a classe que a implemente é quem dá copo ao método. Uma interface pode ser chamada de contrato.
> •Conceitos básicos de Interfaces:
> •Para definir uma interface usamos a palavra ‘Interface’.
> •Pode conter declarações de métodos.
> •Não contem corpo somente assinatura.
> •Qualquer classe que implemente uma interface, obrigatoriamente deve fornecer corpo para os métodos da interface herdada.
> •Uma classe pode implementar varias interfaces.
> •Interfaces permitem o polimorfismo, permitindo que diferentes classes tratem seus métodos de formas diferentes.
1. Criando a Interface:
2. Implementando a Interface
E quais as diferenças entre as interfaces e as classes abstratas?
Podemos dizer que as interfaces não possuem implementações, apenas declarações o que não ocorre nas classes abstratas, que podem ter implementações parciais ou totais. Outro ponto é, uma classe só pode herdar uma única classe abstrata, mas pode herdar múltiplas interfaces.
## Objetos
Objetos são instancias de classes, permitindo a criação de componentes modulares e reutilizáveis. Cada objeto possui seu próprio conjunto de dados, que são armazenados nos atributos e propriedades definidos pela classe.
Como exemplo vamos usar uma Entidade Pessoa com a visibilidade publica mas utilizando o conceito de encapsulamento dos atributos que são, Nome e Idade.
Podemos fazer a instancia da entidade Pessoa de duas formas, são elas:
1. Primeira forma de instanciar a entidade pessoa.
> No código acima usamos a palavra reservada “var” para criar uma variável, em seguida colocamos o nome da variável, que no caso é ‘pessoa’, e atribuímos o sinal de = (igual) para informar que, vamos receber os dados da entidade Pessoa(). Para instanciar uma nova classe Pessoa() usamos a palavra reservada “new” logo em seguida o nome da classe ou entidade, nesse caso a entidade Pessoa(). Repare que depois de informarmos a classe/Entidade utilizamos o () (Parênteses), isso significa que podemos colocar parâmetros, mas temos que nos atentar para qual tipo a classe pode receber, que no casso acima é Nome do tipo string e Idade do tipo int.
> Quando fazemos a instanciação de uma classe podemos ver os seus atributos através dos seus métodos públicos, Get (Getters) e Set (Setters), podendo assim atribuir valores aos mesmos.
2. Segunda forma de instanciar a entidade pessoa.
> A segunda forma de instanciar a entidade Pessoa é bem parecida com a primeira, a diferença é, que ao invés de usarmos a palavra reservada “var”, criamos o objeto Pessoa e damos o nome de pessoa que vai receber uma nova instancia de Pessoa().
## Conclusão
As classes em C# .NET são fundamentais para a criação de aplicações. Compreender a estrutura, os componentes e os conceitos como herança, polimorfismo e encapsulamento é essencial para qualquer desenvolvedor C#. Através de exemplos, este artigo demonstrou como implementar e utilizar classes, promovendo a reutilização de código e a manutenção de software.
| felipeamorimdev |
1,863,271 | Mastering Keyboard Shortcuts: An A-Z Guide | In the digital age, efficiency is key. Whether you're a writer, programmer, or a casual computer... | 0 | 2024-05-23T21:19:52 | https://dev.to/bbylumi/mastering-keyboard-shortcuts-an-a-z-guide-1o55 | webdev, beginners, tutorial, devops | In the digital age, efficiency is key. Whether you're a writer, programmer, or a casual computer user, mastering keyboard shortcuts can significantly boost your productivity and streamline your workflow, right?? Imagine the time saved when you don't have to reach for the mouse for every little task.
**Welcome to my comprehensive guide on keyboard shortcuts from A to Z. This guide is designed to help us navigate through the alphabet of shortcuts that can transform the way we interact with your computer even more fun. From basic commands to advanced tricks, i've got you covered.**
(A-Z)
**Ctrl + A = Select all
Ctrl + B = Bold
Ctrl + C = Copy
Ctrl + D = Default font set
Ctrl + E = Center
Ctrl + F = Find
Ctrl + G = Go to
Ctrl + H = Replace
Ctrl + I = Italic
Ctrl + J = Justify
Ctrl + K = Hyperlink
Ctrl + L = Align Text to left
Ctrl + M = Hanging Indent
Ctrl + N = New document
Ctrl + O = Open
Ctrl + P = Print
Ctrl + Q = Add space paragraph
Ctrl + R = Align text to Right
Ctrl + S = Save as
Ctrl + T = Left Indent
Ctrl + U = Underline
Ctrl + V = Paste
Ctrl + W = Close
Ctrl + X = Cut
Ctrl + Y = Repeat/Redo
Ctrl + Z = Undo**
> By the end of this guide, you'll have a robust set of shortcuts at your fingertips, ready to make your digital life more efficient and enjoyable. So, let's dive in and start mastering the art of keyboard shortcuts from A to Z!
Stay tuned🛎️
_THank You_
| bbylumi |
1,863,270 | Почему не горит колонка Алиса: подробный гайд по решению проблемы 🕵️♀️ | Умные колонки с Алисой – это удобно и круто! 🤩 Но что делать, если ваш электронный друг вдруг... | 0 | 2024-05-23T21:18:14 | https://dev.to/amoz/pochiemu-nie-ghorit-kolonka-alisa-podrobnyi-ghaid-po-rieshieniiu-probliemy-50l0 | Умные колонки с Алисой – это удобно и круто! 🤩 Но что делать, если ваш электронный друг вдруг перестал подавать признаки жизни? 🤔 Не паникуйте! В этой статье мы разберемся, почему колонка Алиса может не гореть, и дадим пошаговые инструкции по устранению неполадок. 💪
Основные причины, почему Алиса не горит 🔥
**1. Bluetooth-подключение 🎧**
Часто проблема кроется в том, что колонка пытается установить связь с другим устройством по Bluetooth. В этом случае Алиса "думает", что она не голосовой помощник, а обычная Bluetooth-колонка, и не реагирует на ваши команды.
**👉 Решение:** Отключите Bluetooth на всех устройствах, которые находятся рядом с колонкой, или отключите сопряжение в настройках Bluetooth.
**2. Проблемы с интернетом 🌐**
Алиса – дама продвинутая, но без интернета она как без рук. 😜 Проверьте, есть ли подключение к Wi-Fi.
**👉 Решение:** Перезагрузите роутер и колонку. Если это не помогло – переподключите колонку к Wi-Fi (подробная инструкция есть на сайте Яндекса).
**3. Голосовая активация отключена 🔇**
Возможно, вы случайно отключили голосовую активацию в настройках.
**👉 Решение:** Откройте приложение Яндекс, перейдите в раздел "Устройства", выберите свою колонку и убедитесь, что функция "Голосовая активация" включена.
Как перезапустить станцию Алиса? 🔄
Иногда достаточно просто перезагрузить устройство.
1. **Отключите** адаптер питания от розетки. 🔌
2. **Подождите** 5-10 секунд. ⏳
3. **Снова подключите** адаптер. 🔌
Колонка должна включиться и начать загрузку.
Что делать, если Яндекс Станция Мини не включается? 🤯
Если простые методы не помогают, переходим к "тяжелой артиллерии":
**1. Проверьте адаптер питания 🔌**
Убедитесь, что вы используете оригинальный адаптер, который шел в комплекте.
**👉 Решение:** Подключите колонку к другому адаптеру с такими же характеристиками.
**2. Проверьте подключение к розетке ⚡️**
Убедитесь, что адаптер плотно вставлен как в колонку, так и в розетку, а сама розетка работает.
**👉 Решение:** Попробуйте подключить колонку к другой розетке.
**3. Сбросьте настройки колонки до заводских ⚙️**
Это крайняя мера, но иногда она помогает решить проблему.
**👉 Решение:** Инструкцию по сбросу настроек для вашей модели колонки вы найдете на сайте Яндекса: https://yandex.ru/support/. Не забудьте выбрать свою модель устройства!
Полезные советы и выводы 💡
❤️ **Всегда проверяйте подключение к интернету.**
❤️ **Регулярно перезагружайте колонку.**
❤️ **Не бойтесь обращаться в службу поддержки Яндекса**, если ничего не помогает.
Надеемся, наши советы помогли вам вернуть Алису к жизни! 😊
Ответы на частые вопросы ❓
**1. Почему не работает колонка Маруся?**
В этой статье мы говорим о колонках с Алисой. Если у вас возникли проблемы с колонкой Маруся, обратитесь в службу поддержки VK.
**2. Как перезагрузить умную розетку Яндекс?**
Информацию о перезагрузке умной розетки вы найдете в инструкции к устройству или на сайте Яндекса.
**3. Почему не горит подсветка Алисы?**
Возможно, яркость подсветки установлена на минимум. Проверьте настройки в приложении Яндекс.
Полезные советы 🎁
❤️ Не ставьте колонку рядом с источниками тепла и влаги.
❤️ Не разбирайте колонку самостоятельно.
❤️ Используйте только оригинальные аксессуары.
Выводы 🏁
Проблемы с умными колонками – это не конец света. 😉 Чаще всего их можно решить самостоятельно, следуя простым инструкциям. А если ничего не помогает – всегда можно обратиться за помощью к профессионалам. | amoz | |
1,863,269 | How to Use the <select> Tag with Multiple Values Using the map Method in React.js | Hi Devs, in this article, I’m going to show you how to use the Select HTML tag in React JS. As you... | 0 | 2024-05-23T21:17:30 | https://dev.to/vivek_44751fc408644cbd80b/how-to-use-the-tag-with-multiple-values-using-the-map-method-in-reactjs-59df | javascript, webdev | Hi Devs, in this article, I’m going to show you how to use the Select HTML tag in React JS. As you all know, we use JSX to write HTML in React. Let’s see how we can do this.
1. Now, we have an array containing the names of cities. So we render this in Web Page using a map method.
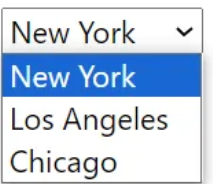
2. This is a simple method for using the HTML Select tag. However, we won’t be using this method as it’s considered old school. Instead, we are going to use the Map method.
```
<select name="cities" id="cities">
<option value="New York">New York</option>
<option value="Chicago">Chicago</option>
<option value="Chicago">Los Angeles</option>
</select>
```
3. The map method in JSX is used to iterate over an array and render a list of elements dynamically.
```
<select name="cities" id="cities" >
{cities.map((ele, key) => (
<option value={ele} key={key}>
{ele}
</option>
))}
</select>
```
4. In this final step, we will see how to get the current element in an Select tag using the onChange method. The onChange event is triggered when the value of an input element, like a text field or dropdown, changes. It allows you to capture and respond to the new value.
```
const cities = ["New York", "Los Angeles", "Chicago"]
const handleChange =(e)=>{
console.log(e.target.value)
}
<select name="cities" id="cities" onChange={(e)=>handleChange(e)} >
{cities.map((ele, key) => (
<option value={ele} key={key}>
{ele}
</option>
))}
</select>
```
Thank you for reading this article. please follow for more articles.
| vivek_44751fc408644cbd80b |
1,863,263 | Custom home builder Troutman NC And Custom home builder Cornelius NC | Seeking to craft your custom home builder Troutman NC or Cornelius, NC? Look no further than our... | 0 | 2024-05-23T21:14:29 | https://dev.to/jhonebuttler/custom-home-builder-troutman-nc-and-custom-home-builder-cornelius-nc-462e | business | Seeking to craft your **[custom home builder Troutman NC](https://www.lakeviewbuildinggroup.com/troutman-custom-home-builder)** or Cornelius, NC? Look no further than our bespoke services as a custom home builder. Nestled in the heart of Troutman, NC, we specialize in creating personalized living spaces that reflect your unique style and preferences. From concept to completion, our team of skilled craftsmen and designers will collaborate with you every step of the way to ensure your vision comes to life. With meticulous attention to detail and a commitment to quality craftsmanship, we strive to exceed your expectations and deliver a home that is as functional as it is beautiful.
Similarly, in **[custom home builder Cornelius NC](https://www.lakeviewbuildinggroup.com/cornelius-custom-home-builder)** to the table, dedicated to constructing residences that embody luxury, comfort, and sophistication. Whether you envision a modern marvel overlooking Lake Norman or a cozy countryside retreat, our tailored approach ensures that your home reflects your individual taste and lifestyle. With a focus on superior design and superior construction practices, we are dedicated to turning your dreams into reality. Trust us to be your partner in building the home you've always desired in Cornelius, NC.
| jhonebuttler |
1,863,260 | LeetCode Meditations — Chapter 10: Tries | The trie data structure gets its name from the word retrieval — and it's usually pronounced as "try,"... | 26,418 | 2024-05-23T21:12:56 | https://rivea0.github.io/blog/leetcode-meditations-chapter-10-tries | computerscience, algorithms, javascript, learning | The trie data structure [gets its name from the word _re<b>trie</b>val_](https://en.wikipedia.org/wiki/Trie#History,_etymology,_and_pronunciation) — and it's usually pronounced as "try," so that we don't get confused with another familiar and friendly data structure, "tree."
However, a trie is still a tree (or tree-like) data structure whose nodes usually store individual letters. So, by traversing the nodes in a trie, we can retrieve strings.
Tries are useful for applications such as autocompletion and spellchecking — and the larger our trie is, the less work we have to do for inserting a new value.
---
**An important note before we start: using arrays is not very memory-efficient, and we'll see another way of creating tries in the next article for [Implement Trie (Prefix Tree)](https://leetcode.com/problems/implement-trie-prefix-tree). For now, we'll stick to the array implementation.**
First, let's see what a trie looks like:

_In this trie, we can retrieve the strings "sea" and "see" — but not "sew" for example._
There is a lot going on, but we can try to understand it piece by piece.
Let's look at a trie node.
We'll create a `TrieNode` class that has `children`, which is an array of length 26 (so that each index corresponds to a letter in the English alphabet), and a flag variable `isEndOfWord` to indicate whether that node represents the last character of a word:
```js
class TrieNode {
constructor() {
this.children = Array.from({ length: 26 }, () => null);
this.isEndOfWord = false;
}
}
```
We're initializing `children` with `null` values. As we add a character to our trie, the index that corresponds to that character will be filled.
| Note |
| :-- |
| We're not storing the actual character itself in this implementation, it's implicit in the usage of indices. |
In a trie, we start with an empty root node.
```js
class Trie {
constructor() {
this.root = new TrieNode();
}
...
}
```
To insert a word, we're going to loop through each character, and initialize a new `TrieNode` to the corresponding index.
```js
insert(word) {
let currentNode = this.root;
for (const char of word) {
let idx = char.charCodeAt(0) - 'a'.charCodeAt(0);
if (currentNode.children[idx] === null) {
currentNode.children[idx] = new TrieNode();
}
currentNode = currentNode.children[idx];
}
currentNode.isEndOfWord = true;
}
```
Once we reach the node that indicates the last character of the word we inserted, we also mark the `isEndOfWord` variable as `true`.
| Note |
| :-- |
| `word` is going to be lowercase in these examples, otherwise, we have to convert it, such as: `word = word.toLowerCase();` |
For searching a word's existence in the trie, we'll do a similar thing. We'll look at the nodes for each character, and if we reach the last one that has `isEndOfWord` marked as `true`, that means we've found the word:
```js
search(word) {
let currentNode = this.root;
for (const char of word) {
let idx = char.charCodeAt(0) - 'a'.charCodeAt(0);
if (currentNode.children[idx] === null) {
return false;
}
currentNode = currentNode.children[idx];
}
return currentNode.isEndOfWord;
}
```
| Note |
| :-- |
| If we find the word we're looking for, then it's called a **search hit**; otherwise, we have a **search miss** and the word doesn't exist in our trie. |
Removing a word is a bit more challenging. Let's say that we want to remove the word "see." But, there is also another word "sea," with the same prefix ('s' and 'e'). So, we should remove only the nodes that we're allowed to.
For this reason, we'll define a recursive function.
Once we reach the last character of the word we want to remove, we'll back up and remove the characters we can remove:
```js
const removeRecursively = (node, word, depth) => {
if (node === null) {
return null;
}
if (depth === word.length) {
if (node.isEndOfWord) {
node.isEndOfWord = false;
}
if (node.children.every(child => child === null)) {
node = null;
}
return node;
}
let idx = word[depth].charCodeAt(0) - 'a'.charCodeAt(0);
node.children[idx] = removeRecursively(node.children[idx], word, depth + 1);
if (node.children.every(child => child === null) && !node.isEndOfWord) {
node = null;
}
return node;
}
```
`depth` indicates the index of the word, or _the depth of the trie we reach_.
Once `depth` is equal to the word's length (one past the last character), we check if it's the end of the word, if that's the case, we'll mark it as `false` now, because that word won't exist from here on. Then, we can only mark the node as `null` if it doesn't have any children (in other words, if all of them are `null`). We'll apply this logic to each child node recursively until the word is removed as far as it can be removed.
Here is the final example implementation of a trie:
```js
class TrieNode {
constructor() {
this.children = Array.from({ length: 26 }, () => null);
this.isEndOfWord = false;
}
}
class Trie {
constructor() {
this.root = new TrieNode();
}
insert(word) {
let currentNode = this.root;
for (const char of word) {
let idx = char.charCodeAt(0) - 'a'.charCodeAt(0);
if (currentNode.children[idx] === null) {
currentNode.children[idx] = new TrieNode();
}
currentNode = currentNode.children[idx];
}
currentNode.isEndOfWord = true;
}
search(word) {
let currentNode = this.root;
for (const char of word) {
let idx = char.charCodeAt(0) - 'a'.charCodeAt(0);
if (currentNode.children[idx] === null) {
return false;
}
currentNode = currentNode.children[idx];
}
return currentNode.isEndOfWord;
}
remove(word) {
const removeRecursively = (node, word, depth) => {
if (node === null) {
return null;
}
if (depth === word.length) {
if (node.isEndOfWord) {
node.isEndOfWord = false;
}
if (node.children.every(child => child === null)) {
node = null;
}
return node;
}
let idx = word[depth].charCodeAt(0) - 'a'.charCodeAt(0);
node.children[idx] = removeRecursively(node.children[idx], word, depth + 1);
if (node.children.every(child => child === null) && !node.isEndOfWord) {
node = null;
}
return node;
}
removeRecursively(this.root, word, 0);
}
}
let t = new Trie();
t.insert('sea');
t.insert('see');
console.log(t.search('sea')); // true
console.log(t.search('see')); // true
console.log(t.search('hey')); // false
console.log(t.search('sew')); // false
t.remove('see');
console.log(t.search('see')); // false
console.log(t.search('sea')); // true
```
---
#### Time and space complexity
The time complexity of creating a trie is going to be {% katex inline %} O(m * n) {% endkatex %} where {% katex inline %} m {% endkatex %} is the longest word and {% katex inline %} n {% endkatex %} is the total number of words.
Inserting, searching, and deleting a word is {% katex inline %} O(a * n) {% endkatex %} where {% katex inline %} a {% endkatex %} is the length of the word and {% katex inline %} n {% endkatex %} is the total number of words.
When it comes to space complexity, in the worst case, each node can have children for all the characters in the alphabet we're representing. But, the size of the alphabet is constant, so the growth of storage needs will be proportionate to the number of nodes we have, which is {% katex inline %} O(n) {% endkatex %} where {% katex inline %} n {% endkatex %} is the number of nodes.
---
We have already done most of the work for [the next problem](https://leetcode.com/problems/implement-trie-prefix-tree), but next time we'll be slightly more efficient. Until then, happy coding.
| rivea0 |
1,863,259 | How to Create Tiktok ads Spy tool Full Process | Creating a TikTok ads spy tool involves several steps, including data collection, data processing,... | 0 | 2024-05-23T21:09:59 | https://dev.to/rajcoderin/how-to-create-tiktok-ads-spy-tool-full-process-30aa | webdev, python, beginners, tutorial | Creating a **TikTok ads spy too**l involves several steps, including data collection, data processing, and the development of a user-friendly interface to display the collected data. Here's a high-level overview of the full process:
## Step 1: Research and Plan
**Define Objectives: **Determine what specific features you want your spy tool to have. For example, you might want to track competitor ads, identify trends, analyze ad performance, and provide insights.
**Identify Data Sources:** Figure out where and how you'll collect data. For [TikTok ads](https://pipiadscouponcode.com/), this might involve scraping TikTok's public data, using TikTok's API (if available), or purchasing data from third-party providers.
## Step 2: Data Collection
**Scraping TikTok Ads Library:** If TikTok has a public ads library (similar to Facebook's Ad Library), you can scrape it to gather ad data. Use tools like BeautifulSoup, Scrapy, or Selenium for web scraping.
**Scrapy:** Suitable for large-scale web scraping projects.
Selenium: Useful for scraping dynamic content rendered by JavaScript.
BeautifulSoup: Good for parsing HTML and extracting data.
API Integration: If TikTok provides an API, use it to fetch ad data. This is a more reliable and legal way to access data compared to scraping.
**Third-Party Data Providers:** Subscribe to services that offer TikTok ad insights and integrate their data into your tool.
## Step 3: Data Storage
**Database Setup:** Choose a database to store your collected data. SQL databases like MySQL or PostgreSQL are good for structured data, while NoSQL databases like MongoDB are better for unstructured data.
**Data Schema Design:** Design the schema based on the type of data you collect. For example:
- Ad ID
- Advertiser
- Ad Content (Text, Images, Videos)
- Metrics (Views, Likes, Shares, Comments)
- Date and Time of the Ad
## Step 4: Data Processing and Analysis
**Data Cleaning:** Remove any duplicate or irrelevant data to ensure accuracy.
**Data Analysis:** Use tools like Python (with pandas, numpy) or R to analyze the data. You might want to:
- Identify trending ads.
- Track ad performance over time.
- Compare different advertisers.
- Machine Learning: Implement machine learning models to predict trends, ad per formance, and provide deeper insights.
## Step 5: Frontend Development
**User Interface Design**: Create a user-friendly interface using frontend frameworks like React, Angular, or Vue.js. Ensure it’s intuitive and provides easy access to key features.
**Data Visualization:** Use libraries like D3.js, Chart.js, or Plotly to create interactive charts and graphs to display your data.
**Search and Filter Options:** Allow users to search and filter ads based on various parameters like date, advertiser, performance metrics, etc.
## Step 6: Backend Development
**API Development:** Develop RESTful APIs using frameworks like Flask, Django, or Node.js to serve data to the frontend.
**Authentication and Authorization:** Implement user authentication and authorization to ensure secure access to your tool.
**Scalability: **Ensure your backend can handle large amounts of data and multiple user requests efficiently.
## Step 7: Testing and Deployment
**Testing:** Perform extensive testing to ensure the tool works as expected. This includes unit testing, integration testing, and user acceptance testing (UAT).
**Deployment:** Deploy your application using cloud services like AWS, Google Cloud, or Azure. Use containerization tools like Docker to ensure your application is portable and scalable.
**Monitoring and Maintenance:** Set up monitoring to track the performance and uptime of your tool. Regularly update and maintain the tool to fix bugs and add new features.
## Step 8: Marketing and Feedback
**Launch:** Promote your tool through various channels to attract users.
**Collect Feedback:** Gather user feedback to improve the tool continuously.
## Tools and Technologies
- Web Scraping: BeautifulSoup, Scrapy, Selenium
- APIs: TikTok API (if available)
- Database: MySQL, PostgreSQL, MongoDB
- Data Analysis: Python (pandas, numpy), R
- Frontend: React, Angular, Vue.js, D3.js, Chart.js, Plotly
- Backend: Flask, Django, Node.js
- Deployment: AWS, Google Cloud, Azure, Docker
- Creating a TikTok ads spy tool is a complex process that requires a combination of technical skills and strategic planning. However, by following these steps, you can develop a powerful tool to gain insights into TikTok advertising trends and performance.
| rajcoderin |
1,863,250 | Как подключить умную колонку Сбер Салют: подробная инструкция | Умные колонки стремительно ворвались в нашу жизнь, предлагая удобное управление домашней техникой,... | 0 | 2024-05-23T21:05:03 | https://dev.to/amoz/kak-podkliuchit-umnuiu-kolonku-sbier-saliut-podrobnaia-instruktsiia-69h | Умные колонки стремительно ворвались в нашу жизнь, предлагая удобное управление домашней техникой, бесконечный мир музыки и быстрый доступ к информации. Среди них выделяется Сбер Салют – умная колонка с богатым функционалом. 🤔 Задумываетесь о том, как подключить это чудо техники и раскрыть весь его потенциал? ✨ В этом лонгриде мы разложим весь процесс по полочкам, чтобы даже новичок справился без труда! 🤝
**🚀 Запуск в мир умных технологий: активация устройства**
Первое, что предстоит сделать – вдохнуть жизнь в вашу колонку Сбер Салют, активировав её. 🤩 Для этого:
1️⃣ Откройте официальный сайт активации: https://activation.sber.ru/.
2️⃣ Выберите из списка свою модель устройства.
3️⃣ Авторизуйтесь с помощью Сбер ID – вашего ключа в мир удобства от Сбера. 😉
4️⃣ Следуйте простым инструкциям на экране, чтобы настроить устройство вручную.
5️⃣ Получите заветный код активации и введите его в соответствующее поле на сайте.
Готово! 🎉 Ваше устройство активировано и жаждет быть полезным!
**📱 Связь поколений: подключение колонки Салют к смартфону**
Хотите управлять колонкой прямо со своего смартфона? Легко! 💪
1️⃣ Убедитесь, что ваш смартфон и SberBox подключены к одной Wi-Fi сети – они должны говорить на одном языке! 📶
2️⃣ Откройте приложение Салют на своем телефоне – ваш пульт управления готов! 🕹️
3️⃣ Нажмите кнопку «Подключить» и подтвердите соединение со SberBox.
Поздравляем! 🥳 Теперь вы можете управлять SberBox, не вставая с дивана: выбирайте сервисы, управляйте воспроизведением и наслаждайтесь комфортом!
**🌐 Шаг в онлайн: подключение умной колонки к интернету**
Только что распаковали новенькую колонку Сбер Салют? Подключим её к интернету – окну в мир безграничных возможностей!
1️⃣ Подключите колонку к розетке – дайте ей энергии! ⚡️
2️⃣ Дождитесь фиолетовой подсветки и приветствия голосового помощника – ваша колонка просыпается! 😌
3️⃣ Убедитесь, что ваш смартфон подключен к интернету – он поможет настроить колонку.
**📺 Кино не выходя из дома: подключение колонки Салют к телевизору**
Превратите ваш телевизор в настоящий центр развлечений, подключив к нему колонку Салют! 🍿
1️⃣ Откройте приложение Салют на своем смартфоне – ваш верный помощник всегда под рукой!
2️⃣ Выберите экран Салют ТВ.
3️⃣ Нажмите кнопку «Подключить» и следуйте инструкциям на экране.
4️⃣ Введите цифры с экрана телевизора в приложение Салют – это как секретный код для синхронизации! 🔐
Готово! ✨ Наслаждайтесь просмотром фильмов и сериалов с непревзойденным звуком от Сбер Салют!
**💡 Полезные советы:**
🎈 Перед началом активации убедитесь, что у вас есть Сбер ID – ваш пропуск в мир технологий Сбера!
🎈 Подключая колонку к телефону или телевизору, проверьте, что все устройства находятся в одной Wi-Fi сети.
🎈 Если столкнулись с трудностями – не отчаивайтесь! Служба поддержки Сбера всегда готова прийти на помощь. 😊
**🎉 Выводы:**
Подключение умной колонки Сбер Салют – простая задача, если следовать нашей инструкции. 😉 Раскройте потенциал умной колонки и наслаждайтесь комфортом, который она дарит!
**❓ Ответы на часто задаваемые вопросы:**
🎈 **Вопрос:** Что делать, если я забыл свой Сбер ID?
🎈 **Ответ:** Восстановить доступ к Сбер ID можно на официальном сайте Сбербанка.
🎈 **Вопрос:** Можно ли подключить колонку Салют к Bluetooth-наушникам?
🎈 **Ответ:** Да, в настройках устройства можно выбрать подключение по Bluetooth.
**🤝 Желаем приятного пользования умной колонкой Сбер Салют!** | amoz | |
1,863,252 | Laravel 10 - JWT Authentication API | In a Laravel 10 application, there are various API authentication systems available, such as Laravel... | 0 | 2024-05-23T21:03:21 | https://dev.to/zaiidmo/laravel-10-jwt-authentication-api-2k50 | jwt, api, laravel, authentication |
In a Laravel 10 application, there are various API authentication systems available, such as Laravel Passport, Laravel Sanctum, and JWT authentication. This tutorial will guide you through creating API authentication in Laravel 10 using JSON Web Tokens (JWT).
For this tutorial, we will use the **php-open-source-saver/jwt-auth ** package, which is a fork of **tymondesigns/jwt-auth** . The original package is not compatible with Laravel 9 and Laravel 10, making the forked version necessary for our purposes.
JWT API authentication is more secure compared to Laravel Sanctum or Laravel Passport. In this tutorial, you will learn how to create a complete JWT-authenticated Laravel 10 application. We will cover the creation of Login, Register, Logout, and Refresh Token APIs, all implemented with POST requests. Let’s begin our Laravel 10 JWT authentication tutorial:
**STEP 1: INSTALL LARAVEL PROJECT**
First of all, we need to get a fresh Laravel 10 version application using the bellow command to start tymonjwt auth laravel 10.
```
composer create-project laravel/laravel Auth
```
**STEP 2: CONNECT YOUR DATABASE**
I am going to use the MYSQL database for this jwt auth laravel 10. So connect the database by updating.env like this:
```
DB_CONNECTION=mysql
DB_HOST=127.0.0.1
DB_PORT=3306
DB_DATABASE=YOUR_DB_NAME
DB_USERNAME=YOUR_DB_USERNAME
DB_PASSWORD=YOUR_DB_PASSWORD
```
Now run **php artisan migrate** command to migrate the database.
**STEP 3: INSTALL JSON WEB TOKEN(JWT)**
In this step, we will install **php-open-source-saver/jwt-auth** package. So open the terminal and run the below command:
```
composer require php-open-source-saver/jwt-auth
```
And now publish the configuration file by running this command:
```
php artisan vendor:publish --provider="PHPOpenSourceSaver\JWTAuth\Providers\LaravelServiceProvider"
```
Now run the below command to generate JWT secret key like:
```
php artisan jwt:secret
```
This command will update your .env file like this:
```
JWT_SECRET=TIfwzvlyoyDLMTnuYvZ771DeYcv0HmJvyFgajlGezgWU0cekfY0dLGJfvoL3AkjE
JWT_ALGO=HS256
```
**STEP 4: CONFIGURING API GUARD**
Now in this step, we have to update and set up the API authentication guard. So update the following file like that:
**config/auth.php**
```
<?php
return [
/*
|--------------------------------------------------------------------------
| Authentication Defaults
|--------------------------------------------------------------------------
|
| This option controls the default authentication "guard" and password
| reset options for your application. You may change these defaults
| as required, but they're a perfect start for most applications.
|
*/
'defaults' => [
'guard' => 'api',
'passwords' => 'users',
],
/*
|--------------------------------------------------------------------------
| Authentication Guards
|--------------------------------------------------------------------------
|
| Next, you may define every authentication guard for your application.
| Of course, a great default configuration has been defined for you
| here which uses session storage and the Eloquent user provider.
|
| All authentication drivers have a user provider. This defines how the
| users are actually retrieved out of your database or other storage
| mechanisms used by this application to persist your user's data.
|
| Supported: "session"
|
*/
'guards' => [
'web' => [
'driver' => 'session',
'provider' => 'users',
],
'api' => [
'driver' => 'jwt',
'provider' => 'users',
],
],
/*
|--------------------------------------------------------------------------
| User Providers
|--------------------------------------------------------------------------
|
| All authentication drivers have a user provider. This defines how the
| users are actually retrieved out of your database or other storage
| mechanisms used by this application to persist your user's data.
|
| If you have multiple user tables or models you may configure multiple
| sources which represent each model / table. These sources may then
| be assigned to any extra authentication guards you have defined.
|
| Supported: "database", "eloquent"
|
*/
'providers' => [
'users' => [
'driver' => 'eloquent',
'model' => App\Models\User::class,
],
// 'users' => [
// 'driver' => 'database',
// 'table' => 'users',
// ],
],
/*
|--------------------------------------------------------------------------
| Resetting Passwords
|--------------------------------------------------------------------------
|
| You may specify multiple password reset configurations if you have more
| than one user table or model in the application and you want to have
| separate password reset settings based on the specific user types.
|
| The expiry time is the number of minutes that each reset token will be
| considered valid. This security feature keeps tokens short-lived so
| they have less time to be guessed. You may change this as needed.
|
| The throttle setting is the number of seconds a user must wait before
| generating more password reset tokens. This prevents the user from
| quickly generating a very large amount of password reset tokens.
|
*/
'passwords' => [
'users' => [
'provider' => 'users',
'table' => 'password_reset_tokens',
'expire' => 60,
'throttle' => 60,
],
],
/*
|--------------------------------------------------------------------------
| Password Confirmation Timeout
|--------------------------------------------------------------------------
|
| Here you may define the amount of seconds before a password confirmation
| times out and the user is prompted to re-enter their password via the
| confirmation screen. By default, the timeout lasts for three hours.
|
*/
'password_timeout' => 10800,
];
```
**STEP 5: UPDATE USER MODEL**
Now all are set to go. Now we have to update the User model like below. So update it to create laravel jwt auth:
**app\Models\User.php**
```
<?php
namespace App\Models;
use Laravel\Sanctum\HasApiTokens;
use Illuminate\Notifications\Notifiable;
use Illuminate\Contracts\Auth\MustVerifyEmail;
use PHPOpenSourceSaver\JWTAuth\Contracts\JWTSubject;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Illuminate\Foundation\Auth\User as Authenticatable;
class User extends Authenticatable implements JWTSubject
{
use HasApiTokens, HasFactory, Notifiable;
/**
* The attributes that are mass assignable.
*
* @var array<int, string>
*/
protected $fillable = [
'name',
'email',
'password',
];
/**
* The attributes that should be hidden for serialization.
*
* @var array<int, string>
*/
protected $hidden = [
'password',
'remember_token',
];
/**
* The attributes that should be cast.
*
* @var array<string, string>
*/
protected $casts = [
'email_verified_at' => 'datetime',
];
/**
* Get the identifier that will be stored in the subject claim of the JWT.
*
* @return mixed
*/
public function getJWTIdentifier()
{
return $this->getKey();
}
/**
* Return a key value array, containing any custom claims to be added to the JWT.
*
* @return array
*/
public function getJWTCustomClaims()
{
return [];
}
}
```
**STEP 6: CREATE CONTROLLER**
Now we have to create AuthController to complete our JWT authentication with a refresh token in Laravel 10. So run the below command to create a controller:
```
php artisan make:controller API/AuthController
```
Now update this controller like this:
```
<?php
namespace App\Http\Controllers\API;
use App\Models\User;
use Illuminate\Http\Request;
use App\Http\Controllers\Controller;
use Illuminate\Support\Facades\Auth;
use Illuminate\Support\Facades\Hash;
class AuthController extends Controller
{
public function __construct()
{
$this->middleware('auth:api', ['except' => ['login', 'register']]);
}
public function login(Request $request)
{
$request->validate([
'email' => 'required|string|email',
'password' => 'required|string',
]);
$credentials = $request->only('email', 'password');
$token = Auth::attempt($credentials);
if (!$token) {
return response()->json([
'message' => 'Unauthorized',
], 401);
}
$user = Auth::user();
return response()->json([
'user' => $user,
'authorization' => [
'token' => $token,
'type' => 'bearer',
]
]);
}
public function register(Request $request)
{
$request->validate([
'name' => 'required|string|max:255',
'email' => 'required|string|email|max:255|unique:users',
'password' => 'required|string|min:6',
]);
$user = User::create([
'name' => $request->name,
'email' => $request->email,
'password' => Hash::make($request->password),
]);
return response()->json([
'message' => 'User created successfully',
'user' => $user
]);
}
public function logout()
{
Auth::logout();
return response()->json([
'message' => 'Successfully logged out',
]);
}
public function refresh()
{
return response()->json([
'user' => Auth::user(),
'authorisation' => [
'token' => Auth::refresh(),
'type' => 'bearer',
]
]);
}
}
```
**STEP 7: CREATE ROUTE**
Here, we need to add routes to set laravel generate jwt token and laravel 10 jwt authentication tutorial. So update the api routes file like this:
**routes/api.php**
```
<?php
use Illuminate\Support\Facades\Route;
use App\Http\Controllers\API\AuthController;
Route::controller(AuthController::class)->group(function () {
Route::post('login', 'login');
Route::post('register', 'register');
Route::post('logout', 'logout');
Route::post('refresh', 'refresh');
});
```
Now if you start your server by running **php artisan serve** and test all API via Postman like this:
```
http://127.0.0.1:8000/api/register
```
```
http://127.0.0.1:8000/api/login
```
```
http://127.0.0.1:8000/api/refresh
```
```
http://127.0.0.1:8000/api/logout
```
| zaiidmo |
1,863,249 | AWS CI CD SETUP | Yashvi Kothari , a DevOps, Cloud Infrastructure Security Architect and DevSecOps Engineer, and cool... | 27,495 | 2024-05-23T21:01:40 | https://dev.to/aws-builders/aws-ci-cd-setup-35li | awsdevops, cloudsecurity, cicd | Yashvi Kothari , a DevOps, Cloud Infrastructure Security Architect and DevSecOps Engineer, and cool intern, Mishi Final Year Graduate started working on assigned projects.
(Take Mishi as example name 😅 )
🌟 **Building a CI/CD Pipeline with AWS Services**
Leading e-commerce company, was facing **challenges** in managing their software development process.
They had multiple developers working on different parts of the application, and the integration of these changes was a manual and time-consuming process.
This led to frequent integration issues, delays in releases, and a lack of transparency in the development process.
Now Yashvi had to take ownership and decided to streamline the software delivery process for client.
**Solution:**
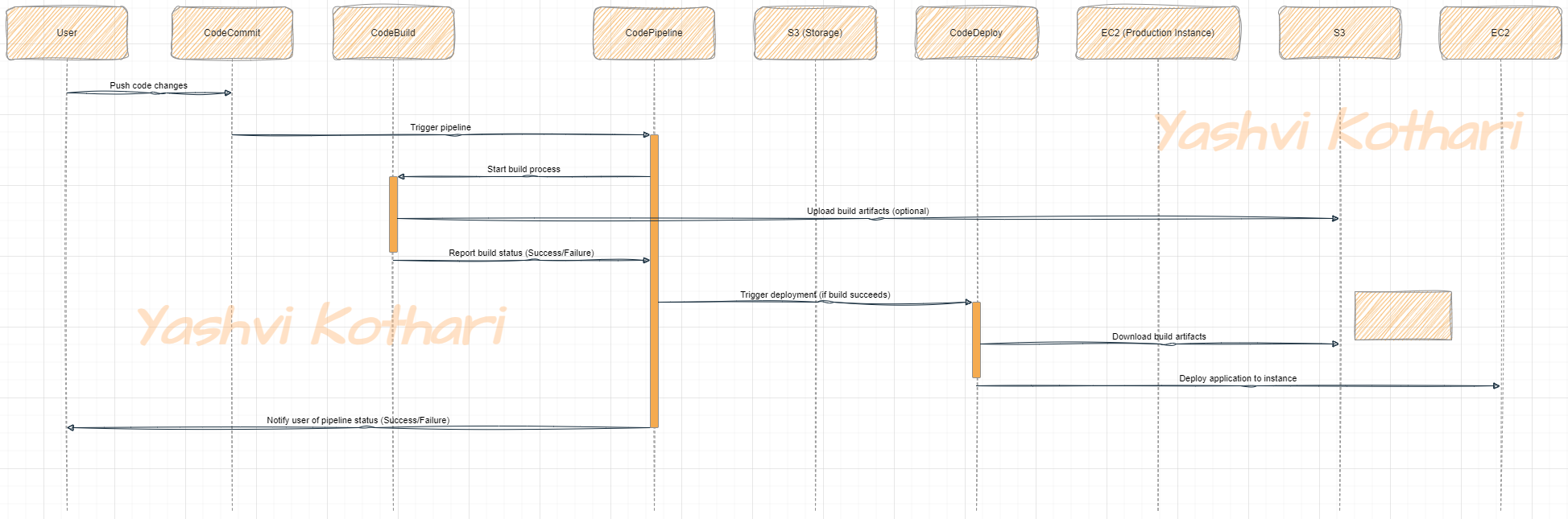
To address these challenges, we decided to implement an AWS CI/CD pipeline.
This pipeline would automate the integration of code changes from multiple developers, ensuring a standardized and controlled approach to code releases.
We chose AWS CodePipeline as the core component of our pipeline, as it provides a robust and scalable infrastructure for automating the software development process.
Mishi has already read about CI/CD were essential for faster, safer, and more reliable software releases.She is super excited. 😌 🤩
Basic Flow would be as :-
1.User Pushes Code Changes:
Developer pushes the code changes to a CodeCommit repository.
CodeCommit Repository
Yashvi started by creating a CodeCommit repository to host her team’s application code.
Whenever a team member pushed changes to this repository, it would trigger the CI/CD pipeline.
2.CodeCommit Triggers CodePipeline: Upon receiving the push event, CodeCommit triggers the CodePipeline.
CodeCommit sent a signal to CodePipeline—a powerful orchestration service.Mike (eCommerce) said, It's all magical 🪄.
3.CodePipeline initiates a build process in CodeBuild..
🔗 CodeBuild Constructs the Application 🔨
CodeBuild fetched the latest code from CodeCommit, compiled it, ran tests, and produced a app artifact.
Yashvi smiled; her application was taking shape.
4.📦 Artifacts in S3 Buckets
CodeBuild builds the application and can optionally upload artifacts to S3.
Now it optionally uploaded the artifact to an S3 bucket.
Yashvi knew that these artifacts held the promise of her application’s success.
5. 📊 CodeBuild Reports Back
CodeBuild reports the build status (success or failure) back to CodePipeline, just like a loyal messenger.
6.If the build is successful, CodePipeline triggers a deployment in CodeDeploy.
CodeDeploy downloads build artifacts from S3 (if uploaded) and deploys the application to an EC2 instance (or another deployment target).
CodeDeploy was the magician who could transform artifacts into live applications. It downloaded the build artifacts from S3.
7. CodePipeline notifies the user of the overall pipeline status (success or failure).
Now imagine application coming to life deployed to target EC2 ECS, serving users with every click.
🔗 ECommerce **Platform Scaling
**
Yashvi’s team used this CI/CD pipeline to deploy updates to their e-commerce platform.
With each successful deployment, they improved user experience, fixed bugs, and added new features. Mishi, learned in/out and contributed to the team’s success.
Now AWS CI/CD pipeline in place, we able to automate the integration of code changes, reducing the likelihood of integration issues and another day of collaborative development environment.
Additional Setup:-
Monitor application performance using AWS CloudWatch.
#AWS #DevOps #CI/CD #CloudMagic
_Disclaimer: _
It is example inspired by multiple projects implementation and real-world practices as professional.
Any resemblance to actual events or persons is purely coincidental.
| yashvikothari |
1,863,248 | React Hooks? | Introduction Like as always, we will be asked the question on whether we have heard of React hooks... | 0 | 2024-05-23T21:01:26 | https://dev.to/thatohatsi880/react-hooks-14ka | <h1>Introduction</h1>
Like as always, we will be asked the question on whether we have heard of React hooks or not. And just like the title suggested, today I am going to be discussing as well as covering React hooks and what they are. Now, hooks were introduced in React 16.8 and they are nothing but the addition of new features that have been released as part of 16.8. But before 16.8, state for components was only available in class components and to use states, we had to convert our functional components to class components.
The reason they used to love functional components earlier was because of their simplicity. But according to the new way of using state in functional components, this enables us to create functional components that have states, so we can do data-related tasks using state in our functional components without any calls to the class components at all.
Well then...This will be the first of many articles that will help us understand hooks better in React. There are many articles as well as documentation provided by React, helping us get the hang of hooks. I have tried my best to do the same but through this article, just to make your lives easier as well. I won't lie its still not yet the easiest route for me but I have also tried compiling all the code snippets that will help you figure out hooks from the beginning as well as try to get a small understanding of what hooks are and how to use them.
<h1>Overview of state management hooks</h1>
The useState hook is part of a set of hooks that are shipped with React, which allow us to add local state management to functional components. The values that are returned from hooks such as useState and useReducer are referred to as hook states.
Using the useState hook, we can add state to functional components of React. This hook returns a pair of values which represent the current state of the application, and a method to update the value of the state. The method to update the state can take a parameter which is the new value to be assigned to the state. The useState hook accepts a parameter which is the initial value of the state when the component is rendered for the very first time. Its function signature is as follows:
**const [state, setState] = useState(initialState).**
The following hooks I will try to explore in this article:
- useState
- useReducer
- useContext
- useMemo
- useCallback
- useRef
In this article, I will explore various hooks which belong to the category of state management hooks in React. There are many hooks such as useState, useReducer, useContext, etc. which provide us with the capability to declaratively manage state in functional components of React.
<h3>Using State Management Hooks</h3>
Here, you define a function component named Counter that returns a div element, with a paragraph element that displays the current state's counter value, and a button element for incrementing the counter's value when clicked. In line 5, the useState hook is called to initialize a state variable named counter with an initial value of 0. You destructure the array returned by the useState hook, and use the first element of the array as the state variable that represents the current counter state. This state is displayed in the paragraph element in line 7, within the caption element that is rendered as the children of the paragraph element.
To keep track of component state within a function component, you can use the useState hook. This hook takes in a single argument, which is the initial state value, and returns an array with two elements: a state variable that keeps track of the current state's value, and a setState function that is used to update the current state, which triggers a re-render of the component.
```
export const Counter = () => {
const [counter, setCounter] = useState(0);
const incrementCounter = () => setCounter(counter + 1);
return (
<div>
<p>{counter}</p>
<button onClick={incrementCounter}>Increment</button>
</div>
);
};
import React, { useState } from 'react';
```
I hope it’s starting to become a little bit easier to understand what hooks are doing right now and how these overall functions and features of React hooks will continue to make our lives much easier from here on. Well let's continue then yeah?
<h1> Understanding the useContext Hook using code snippets </h1>
These are known to creates a state that is accessible from all the components.
At first glance, the function UserProfilePage in the code snippet above might look like some TypeScript code. However, it is simple JSX. The following useContext call returns the current UserContext context value with its corresponding Provider's value. Although it might seem like a beauty overkill for getting access to the context value, useContext gives you a bit more elegance in the code and functions well in a functional component.
```
function UserProfilePage() {
const user = useContext(UserContext);
return <UserProfile user={user} />;
}
```
As you saw in the examples above, direct usage of contextType is not possible without middleware libraries.
<h1> Introduction to useReducer Hook using code snippets</h1>
This one works exactly like the useState but the only difference is that unlike the useState having a single value, it contains an object.
like for instance useState can store only one value eg. 1
useReducer on the other hand stores the object that being multiple values.Meaning that it should be used when one has an object like for instances when wanting to name, age, contact detail....
Like the instance below where there is one useReducer, compared to 3 useState's for each user values:
```
function reducer(state, action) {
switch (action.type) {
case "increment":
return { count: state.count + 1 };
case "decrement":
return { count: state.count - 1 };
default:
return state;
}
}
const App = () => {
const [state, dispatch] = useReducer(reducer, { count: 0 });
return (
<div>
<h1>{state.count}</h1>
<button onClick={() => dispatch({ type: "increment" })}>Increase</button>
<button onClick={() => dispatch({ type: "decrement" })}>Decrease</button>
</div>
);
};
```
<h1>useCallback Hook</h1>
The useCallback() hook makes the function to be used within a child component so that a parent component pass to it will not re-render if its inputs are not changing. It can also be useful in that sense when wanting to pass props into the function
**Like for instance:**
```
// Returns the value 100
const apiResults = useMemo(() => {
return 100
}, [apiURL]);
// Returns a function, which then can be called
const getApiResults = useCallback((value) => {
return 100 + value
}, [apiURL]);
```
<h1>The useMemo Hook</h1>
The useMemo Hook in React is similar to the useCallback Hook. Keep in mind that useMemo is not memoization and should only be used when you have a performance optimization in your React application. useMemo can be imported from the React module by adding the following snippet in your **JavaScript file: import { useMemo } from 'react'.**
Defining your useMemo will look something similar to either of the following snippets. The main difference between the two is that the first piece of code directly defines the function, does not have function scope, and exists in the same scope as other hooks. The following script is an example of a direct **useMemo: const cacheValue = useMemo(() => yourFunction(arg),);**
When writing React applications, using hooks is a great way to maintain variables, functions, and state in your application. useMemo is a useful hook that allows you to cache the value of a function call based on a specific dependency. You can think of useMemo as a caching behavior that React provides as a hook so that you can avoid re-calling a function or expensive calculation unless the specific dependency of a function changes.
```
import { useState, useMemo } from "react";
const App = () => {
const [apiURL, setApiURL] = useState("https://callAPI/");
const apiResults = useMemo(() => {
callAPI();
}, [apiURL]);
return (
<div>
<button onClick={() => setApiURL("https://dummyAPI")}>Change API Url</button>
</div>
);
};
const callAPI = () => {
console.log("Call API");
};
```
<h1>The useRef Hook:</h1>
One of the most frequently used hooks for certain types of side effects in React is the `useEffect` hook. However, there's also a `useRef` hook in React as well which is very useful to access a DOM element or some other value that persists across renders. `useRef` returns a mutable ref object which can be initialized with the initialValue.
The returned object will persist for the full lifetime of the component. The primary purpose of the `useRef` hook is to store mutable data or values that would be lost on each re-render. Those values can be of type **number, string, array, function, object, or any other type**that you could store as instance variable or class properties. Below is the type that shows on how the useRef can be used when wanting to create an input field and needing to access the value
```
import { useRef } from "react";
const App = () => {
const inputRef = useRef();
return (
<input
ref={inputRef}
onChange={() => {
console.log(inputRef.current.value);
}}
/>
);
};
```
I hope this makes your lives easier especially for beginners in React like myself, and also feel free to leave your opinions about the article. Thanks. | thatohatsi880 | |
1,862,118 | Building an Add to Cart Button using Web Components | Introduction This post will layout a short tutorial on how to build an Add to Cart button... | 0 | 2024-05-23T21:00:53 | https://dev.to/charlesloder/building-an-add-to-cart-button-using-web-components-3ckd | webdev, javascript, tutorial, webcomponents | ## Introduction
This post will layout a short tutorial on how to build an Add to Cart button for an ecommerce store using Web Components. Though this example uses the [Fake Store API](https://fakestoreapi.com/), the concept can really be applied to any ecommerce platform.
It will review:
- The product page and the requirements
- The anatomy of a web component
- The business logic
- The final product
You can skip to the [end](#the-final-product) to see the whole example on CodePen.
But first, a little context…
## Context
A client wanted an ajax Add to Cart button for some upsell products on their Shopify store. JQuery would have worked just fine, but I wanted to try something different.
I'd been looking for a reason to use Web Components. I wanted something more complex than a basic counter example but not something too complex.
An Add to Cart button provides the perfect amount of complexity.
## Page Overview
The ecommerce store looks like this:

There's a main product with an add to cart button, and then 3 upsell products below.
For this article, the key is that the main add to cart button is *not* an ajax button; it's a regular form submit as is common on ecommerce sites. When the user submits the form, they are directed to the cart page. Though, that doesn't really happen on a CodePen.
The requirements for the Add to Cart button are simple:
- the user should click on the button firing a `fetch` request
- the button should indicate that it is processing the request
- if the product was added or if there was an error, the button should indicate that.
The upsell buttons are our web components. Notice that they have the same styling as the main button. That's because they're using the same global CSS. Web Components have their own styling so slots need to be used to ensure they inherit styling.
## Anatomy of a Web Component
Web Components are custom elements, so we add them to the page like regular HTML:
```html
<add-to-cart>
<button slot="button" type="submit" class="btn--atc">
Add to cart
</button>
<input slot="input" type="hidden" name="quantity" value="1">
</add-to-cart>
```
Take note of how the `button` and `input` are being added.
The Web Component structure looks like this:
```js
class AddToCartButton extends HTMLElement {
// props
productId;
button;
// constructor
constructor() {
super();
this.attachShadow({ mode: "open" });
// where styles and HTML go
this.shadowRoot.innerHTML = ``;
}
// lifecycle
connectedCallback() {}
}
// register it
customElements.define("add-to-cart", AddToCartButton);
```
Like any class, there's a constructor, and props and methods can be defined, but it also includes [lifecycle hooks](https://developer.mozilla.org/en-US/docs/Web/API/Web_components/Using_custom_elements#using_a_custom_element:~:text=Custom%20element%20lifecycle%20callbacks%20include%3A). This one only uses `connectedCallback` which is called when the component is mounted.
### The Constructor
In the constructor, we can set some state and define the HTML of the shadow root.
```js
constructor() {
super();
this.attachShadow({ mode: "open" });
this.shadowRoot.innerHTML = `
<style>
:host{
display: flex;
flex-direction: column;
width: 100%;
}
</style>
<slot name="button"></slot>
<slot name="input"></slot>
`;
}
```
The constructor isn't the place to check for attributes or really query anything about the component. According to the [docs](https://developer.mozilla.org/en-US/docs/Web/API/Web_components/Using_custom_elements#implementing_a_custom_element):
> In the class constructor, you can set up initial state and default values, register event listeners and perhaps create a shadow root. At this point, you should not inspect the element's attributes or children, or add new attributes or children. See Requirements for custom element constructors and reactions for the complete set of requirements.
The most important thing to note in this constructor is the `this.shadowRoot.innerHTML`.
The style tag defines styles that apply inside component, and only inside component. The `:host` selector selects the actual component. The only style defined is that it's a flex column.
For this component, the button styles need to inherit from the global css, so styling a button within the component wouldn't work.
In order to allow the button to be styled from the outside the component, a `slot` is used.
This component has two slots:
```html
<slot name="button"></slot>
<slot name="input"></slot>
```
This allows children to be passed in to the component:
```html
<add-to-cart>
<button slot="button" type="submit" class="btn--atc">
Add to cart
</button>
<input slot="input" type="hidden" name="product-id" value="1">
</add-to-cart>
```
This is especially helpful in an ecommerce setting where (1) there is already a set of styles and (2) a templating language like Liquid is used to render out the elements using product data:
```liquid
<input slot="input" type="hidden" name="product-id" value="{{ product.id }}">
```
### The connectedCallback
Once the component is mounted, the `connectedCallback` hook is called.
It's here where the slots can be queried.
```js
connectedCallback() {
const buttonSlot = this.shadowRoot.querySelector(`slot[name="button"]`);
buttonSlot.addEventListener("click", (e) => this.addToCart());
this.button = buttonSlot
.assignedElements()
.find((el) => el.tagName === "BUTTON");
const inputSlot = this.shadowRoot.querySelector(
`slot[name="input"]`
);
const input = inputSlot
.assignedElements()
.find((el) => el.tagName === "INPUT");
// coerce string to number
this.productId = +(input.value);
}
```
#### Getting the Elements
The `querySelector` can be used to query within the `shadowRoot` to the slots. Then `assignedElements()` returns all the elements that have the matching `slot` name.
So for the button, the attribute of `slot="button"` makes the button an assigned element of `slot[name="button"]`. Filtering according to tag type isn't necessary, but just ensures an actual button is returned.
#### Setting the Properties
The `this.button` and `this.productId` are properties of the component, defined above the constructor.
```js
class AddToCartButton extends HTMLElement {
/** @type {number} */
productId;
/** @type {HTMLButtonElement} */
button;
constructor() {}
connectedCallback() {}
}
```
#### Adding an EventListener
The last part of the callback is adding an event listener:
```js
buttonSlot.addEventListener("click", (e) => this.addToCart());
```
This is where the actual logic of the add to cart button will happen.
## The Business Logic
There are two parts to the business logic — the request to the api and updating the UI
```js
/**
* Set the state of the button
*
* @param {('fetching' | 'success' | 'error')} state
*/
setButtonState(state) {
const button = this.button;
const fetching = "fetching";
const success = "success";
const error = "error";
switch (state) {
case "fetching":
button.textContent = "Adding...";
button.disabled = true;
button.classList.add(fetching);
button.classList.remove(success, error);
break;
case "success":
button.textContent = "Added!";
button.disabled = true;
button.classList.add(success);
button.classList.remove(fetching, error);
break;
case "error":
button.textContent = "Retry";
button.disabled = false;
button.classList.add(error);
button.classList.remove(fetching, success);
break;
default:
break;
}
}
async addToCart() {
this.setButtonState("fetching");
try {
const response = await fetch("https://fakestoreapi.com/carts/7", {
method: "PUT",
body: JSON.stringify({
userId: 3,
date: 2019 - 12 - 10,
products: [
{
productId: this.productId,
quantity: 1
}
]
})
});
// obviously, this is only for testing
if(this.getAttribute('error')) {
throw new Error("A test error");
}
const json = await response.json();
console.log(json);
this.setButtonState("success");
} catch(error){
console.error(error);
this.setButtonState("error");
}
}
```
*Note the `error` attribute. That isn't needed, but helpful for testing.*
The `addToCart()` method is straightforward:
- Set the button to `"fetching"`.
- Make the request.
- If it's successful, set the button to `"success"`
- If there's an error, set the button to `"error"`
The `setButtonState()` updates the button's text and applies classes for styling.
In a typical Web Component, the classes would be defined in a style tag, but because slots were used, the styling from the global css can be applied to the elements assigned to the slot.
This has some pros and cons.
- Pro: can define the CSS of the component with the rest of your CSS
- Con: the class names are hardcoded to the component, but have to correlation to anything inside the component (i.e. what does a `"success"` class mean in the component? nothing).
Attributes could be used to pass in class names:
```html
<add-to-cart
btn-fetching-class="fetching"
btn-success-class="success"
btn-error-class="error"
>
```
This would allow any name class names to be used, but for a one-off component, it may be a bit much.
Now to see it all in action.
## The Final Product
Here is the final product
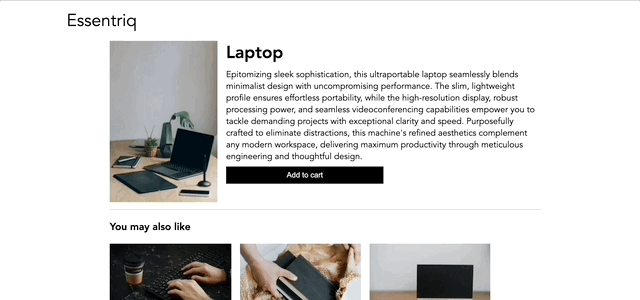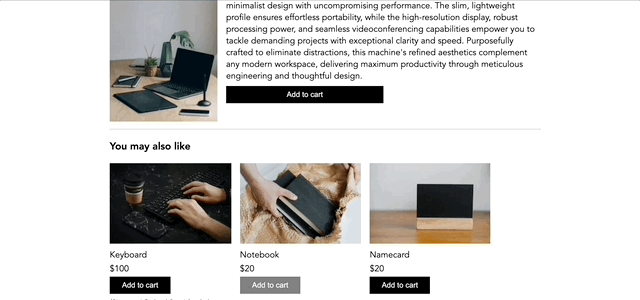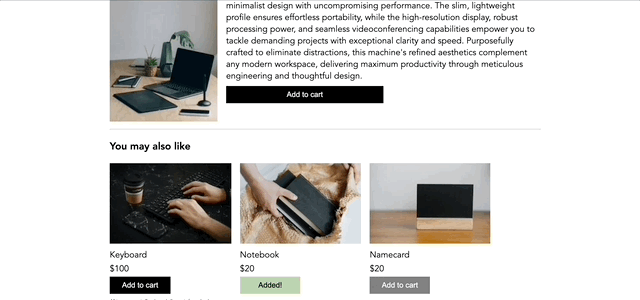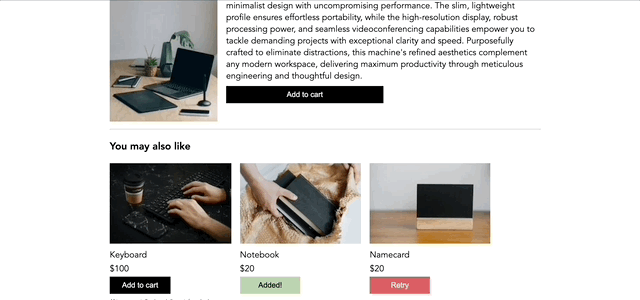
Also see it on CodePen
{% codepen https://codepen.io/charles-loder/pen/abrZKPg %}
| charlesloder |
1,863,247 | Harmony Solutions: Your Local Divorce Mediation Experts | Seeking divorce mediation near me services nearby? Look no further than Harmony Solutions. Our... | 0 | 2024-05-23T21:00:43 | https://dev.to/davidgale/harmony-solutions-your-local-divorce-mediation-experts-3dgj | business | Seeking **[divorce mediation near me](https://www.baronlawmediation.com/certified-divorce-financial-analysts)** services nearby? Look no further than Harmony Solutions. Our experienced mediators provide a compassionate and efficient approach to resolving your divorce issues. Located conveniently close to you, our team offers personalized solutions tailored to your unique needs, ensuring a smoother transition during this challenging time. Discover the peace of mind that comes with expert guidance and local support. Contact us today to schedule a consultation and take the first step towards a harmonious resolution.
| davidgale |
1,863,246 | Bookmyflight : A web app that helps you find cheap flights and book them based on your budget. | Currently working on a full fledged Flight booking website using Amadeus API. Progress so far... | 0 | 2024-05-23T20:59:47 | https://dev.to/nitintwt27/bookmyflight-a-web-app-that-helps-you-find-cheap-flights-and-book-them-based-on-your-budget-9b3 | javascript, react, node, express | Currently working on a full fledged Flight booking website using Amadeus API.
Progress so far :-
Done with user register , login and logout part. The backend is written in nodejs and express. I have used mongodb for the database.
All the toast messages you see are coming from the server. I have also used JWT , generated access token and refresh token using it, and saved it in user browser cookie. But I don't know how to use this access token or refresh token , like now after login I don't have to call backend again , so how i will get to know when the access token expires??
Will figure it out , after moving deep in the project ( first time using jwt).
On logout , user cookies get deleted.
I have also added Flight search component , I don't know this full white bg looks good or not , will soon improve the bg. First tried gray , but it looked ugly.
I have never used such a large and complicated API before. Every request requires headers and parameters, and I have to generate a new access token whenever the old one expires. It's been a real challenge!
I want to share some of the problems I faced and how I solved them:
1. The API doesn’t accept city names directly, instead it takes the city airport code, known as the IATA code. For example, for Delhi, it is DEL. So, when a user types a city name like Ranchi, behind the scenes I had to convert it to the IATA code, IXR. To achieve this, I used another Amadeus API endpoint that fetches this data and stores it in a state variable, which is then passed in the params.
```
const handleFromInputSearch = async (value)=>{
setFrom(value)
const headers = {'Authorization' :`Bearer ${accessToken}`}
const params = {'subType':'CITY,AIRPORT' , 'keyword':`${value}`}
try {
const airportData = await axios.get('https://test.api.amadeus.com/v1/reference-data/locations', {headers , params})
setAirportData(airportData?.data?.data)
setDepartureAirport(airportData?.data?.data[0]?.iataCode)
console.log(airportData?.data?.data[0]?.iataCode)
} catch (error) {
console.log('Error fetching airport data' , error)
}
}
```
2. The date format required by the API is year-month-day, but the component from which the user selects the date is in month-date-year format. Therefore, I reformatted the date to match the API expectations.
```
const formatDate = (date) => {
const year = date?.year
const month = date?.month < 10 ? `0${date?.month}` : date?.month
const day = date?.day < 10 ? `0${date?.day}` : date?.day
return `${year}-${month}-${day}`
}
```
3. When flight data is fetched from the API, the format of the total travel duration is different, like PT20H55M. This means that the total travel duration is 20 hours and 55 minutes. As you can see, this is not a human readable format. So, I wrote a function to convert this data into a human readable format. I took help from Stackoverflow and Chatgpt because this was a problem I faced for the first time.
```
const formatTotalTravelDuration = (duration) => {
// Match the duration string against the regular expression pattern
const match = duration.match(/PT(\d+H)?(\d+M)?/)
// Extract hours and minutes from the matched groups
const hours = match[1] ? match[1].replace('H', '') : '0'
const minutes = match[2] ? match[2].replace('M', '') : '0'
// Construct the human-readable format by combining hours and minutes
return `${hours}h ${minutes}m`.trim()
}
```
4. There is a similar problem with the flight timing, which is in this format: 2024-05-30T22:15:00. A bit uncomfortable to read, right? I wrote a function to transform this into a human-readable format.
```
const formatTiming = (dateTime) => {
// Extract the time part from the datetime string
const timePart = dateTime.split('T')[1]
// Match the time part against the regular expression pattern
const match = timePart.match(/(\d+):(\d+):(\d+)/)
// Extract hours and minutes from the matched groups
const hours = match && match[1] ? match[1] : '0'
const minutes = match && match[2] ? match[2] : '0'
// Construct the human-readable format by combining hours and minutes
return `${hours}:${minutes}`.trim()
}
```
5. The airline name you see on the card component is not the way it was sent from the API. I received an airline code from the API, like for Air India, which is AI. So, how will the user know which airline it is? To resolve this issue, I used another Amadeus API endpoint that provides the airline name according to the airline code sent in the parameter.
```
useEffect(() => {
const fetchData = async () => {
try {
const headers = { 'Authorization': `Bearer ${accessToken}` };
const params = { 'airlineCodes': `${airLine}` };
const response = await axios.get('https://test.api.amadeus.com/v1/reference-data/airlines?airlineCodes', { params, headers });
setAirlineName(response?.data?.data[0]?.businessName);
} catch (error) {
console.log("error fetching airlines name ", error);
}
};
fetchData();
}, [airLine]);
```
So many more features to add, optimization is needed, improvement in UI, and many more things. My main goal in choosing this project was to get good hands on experience with a large and complex API, and luckily, there is not a single tutorial, YouTube video, or blog for this API. So, everything you see I have done by reading docs and using the hit and trial method. You wouldn't believe how many many many times I tried to generate an access token perfectly.
Another challenging thing I can think of now is the payment for booking, like how the payment will be executed and confirmed.
Github repo : https://github.com/nitintwt/bookmyflight
Let's see how it goes. | nitintwt27 |
1,862,124 | How to use Async/Await in Promise. | Hello, everyone. In this article, I would explain promise async/await in javascript. It is... | 0 | 2024-05-23T20:59:13 | https://dev.to/makoto0825/how-to-use-asyncawait-in-promise-38hc | webdev, javascript, beginners | Hello, everyone. In this article, I would explain promise async/await in javascript. It is recommended to read the following article and understand the concept of asynchronous and synchronous processing before reading this article. This is because these concepts is connected with Promise. Moreover, please read the following article for information on how to use Promise chaining, a different implementation of Promise.
[➡async/sync in Javascript ](https://dev.to/makoto0825/asyncsync-in-javascript-438e)
[➡How to use Promise chaining in Javascript.](https://dev.to/makoto0825/how-to-use-promise-chaining-in-javascript-391c)
## What is promise?
Promise is an object that represents the completion or failure of synchronous processing. By using this object, you can wait for asynchronous processing to complete and then execute the next process sequentially.
In the following case, it is not possible to output in the order of ABC. Instead, it outputs in the order of ACB. This is because the asynchronous function setTimeout delays the execution by 4000ms, causing console.log("C") to be executed before console.log("B").
```javascript
<script>
//=== function declaration ==========
const func = () => {
console.log("B");
};
// === program start ==========
console.log("A");
setTimeout(func, 4000); //async function
console.log("C");
</script>
```

However, if you use Promise Async/Await, you can output in the order of ABC.
```javascript
<script>
//===promise declaration ==========
const pro = new Promise((resolve) => {
setTimeout(() => {
func(); //processing 2
resolve();
}, 4000);
});
//=== function declaration ==========
const func = () => {
console.log("B");
};
async function process() {
message = await pro;
console.log("C"); // Subsequent processing 3
}
// === program start ==========
console.log("A"); //processing 1
process();
</script>
```

## How to use promise.
This is basic format for a promise.
```javascript
const num = 10;
const pro = new Promise((resolve, reject) => {
if (num > 0) {
resolve("success!!!!!");
} else {
reject("failure");
}
});
console.log(pro); //output success
```
**returned object**

Promise can take the functions resolve and reject as arguments. And return promise object.
- resolve: Function called when the operation succeeds
- reject: Function called when the process fails.
In this case, num is greater than 0 so it returns Promise object in successful state thanks to resolve.
## Async/Await
When the Promise object is in a successful state due to resolve, subsequent processing can be executed using Async/Await.
```javascript
<script>
const num = 10;
const pro = new Promise((resolve, reject) => {
if (num > 0) {
console.log("process1");
resolve("success!!!!!");
} else {
console.log("process failure");
reject("failure");
}
});
async function process() {
const message = await pro; // wait until the promise is resolved or rejected
console.log(message); // Subsequent processing1
console.log("process2"); // Subsequent processing2
console.log("process3"); // Subsequent processing3
}
process();
</script>
```

Await executes asynchronous processes, waits for them to complete, and then proceeds with subsequent tasks. These sequences of actions can be defined within an async function.
<u>The following is the convention to use Async/Await.</u>
- When using a Promise object (assuming an asynchronous operation), you prefix the object with 'await'.
- When using await, the function where it's used must be marked with async.
- After executing a process with await, you can perform subsequent tasks.Note:This must be implemented within an async function.
## Try/Catch and reject
When the Promise object is in a Failure state due to reject, error can be handled using by try and catch.
```javascript
<script>
const num = -5;
const pro = new Promise((resolve, reject) => {
if (num > 0) {
console.log("process1");
resolve("success!!!!!");
} else {
console.log("failure1");
reject("failure2");
}
});
async function process() {
try {
const message = await pro; // wait until the promise is resolved or rejected
console.log(message); // Subsequent processing1
console.log("process2"); // Subsequent processing2
console.log("process3"); // Subsequent processing3
} catch (error) {
console.log(error);
console.log("failure3");
}
}
process();
</script>
```

In this case, num is lesser than 0 so it returns Promise object in failure state thanks to reject.Hence, the processings inside of catch are executed. This is assuming error handling. The processings inside of try are not executed.Moreover, you can use the argument passed to the reject function by specifying an argument in the catch block.
<u>The following is the convention to use Try/Catch.</u>
- Subsequent processing after process success is enclosed in try
- Subsequent processing after process failure is enclosed in catch.
## Asynchronous Function and Promise Async/Await
If you use promise Async/Await, Asynchronous processing can be executed synchronously.
```javascript
<script>
//===promise declaration ==========
const pro = new Promise((resolve) => {
setTimeout(() => {
func(); //processing 2
resolve();
}, 4000);
});
//=== function declaration ==========
const func = () => {
console.log("B");
};
async function process() {
message = await pro;
console.log("C"); // Subsequent processing 3
}
// === program start ==========
console.log("A"); //processing 1
process();
</script>
```

| makoto0825 |
1,860,924 | How to use Promise chaining in Javascript. | Hello, everyone. In this article, I would explain promise chaining in javascript. It is recommended... | 0 | 2024-05-23T20:58:04 | https://dev.to/makoto0825/how-to-use-promise-chaining-in-javascript-391c | webdev, javascript, beginners | Hello, everyone. In this article, I would explain promise chaining in javascript. It is recommended to read the following article and understand the concept of asynchronous and synchronous processing before reading this article. This is because these concepts is connected with Promise. Moreover, please read the following article for information on how to use Async/Await, a different implementation of PROMISE.
[➡async/sync in Javascript ](https://dev.to/makoto0825/asyncsync-in-javascript-438e)
[➡How to use Async/Await in Promise.](https://dev.to/makoto0825/how-to-use-asyncawait-in-promise-38hc)
## What is promise?
Promise is an object that represents the completion or failure of synchronous processing. By using this object, you can wait for asynchronous processing to complete and then execute the next process sequentially.
In the following case, it is not possible to output in the order of ABC. Instead, it outputs in the order of ACB. This is because the asynchronous function setTimeout delays the execution by 4000ms, causing console.log("C") to be executed before console.log("B").
```javascript
<script>
//=== function declaration ==========
const func = () => {
console.log("B");
};
// === program start ==========
console.log("A");
setTimeout(func, 4000); //async function
console.log("C");
</script>
```

However, if you use Promise chaining , you can output in the order of ABC.
```javascript
<script>
const func = () => {
console.log("B");
};
console.log("A");
new Promise((resolve) => {
setTimeout(() => {
func();//call the func
resolve();
}, 4000);
}).then(() => {
console.log("C");
});
</script>
```
## How to use it.
This is basic format for a promise.
```javascript
const num = 10;
const pro = new Promise((resolve, reject) => {
if (num > 0) {
resolve("success!!!!!");
} else {
reject("failure");
}
});
console.log(pro); //output success
```
**returned object**

Promise can take the functions resolve and reject as arguments. And return promise object.
- resolve: Function called when the operation succeeds
- reject: Function called when the process fails.
In this case, num is greater than 0 so it returns Promise object in successful state thanks to resolve.
## chaining:"resolve" and "then"
When the Promise object is in a successful state due to resolve, subsequent processing can be executed using the following .then() method.
we can call this idea as **promise chaining**.
```javascript
const num = 10;
const pro = new Promise((resolve, reject) => {
if (num > 0) {
resolve("success!!!!!");
} else {
reject("failure");
}
});
pro
.then((message) => {
console.log(message);//Subsequent processing1
})
.then(() => {
console.log("process2");//Subsequent processing2
})
.then(() => {
console.log("process3");//Subsequent processing3
});
```

By specifying an argument in the then method, the value passed when the resolve method is called is provided. In this case, since "success!!!!!" is passed to resolve, by passing an argument to then, you can output "success!!!!!" with console.log.
**<u>Using this then method allows you to execute subsequent processes sequentially (synchronously) after the asynchronous operation has completed.</u>**
This can be accomplished by placing asynchronous processing before resolve() and subsequent processing within then()
## "reject" and "catch"
When the Promise object in a failed state due to reject, you can handle the error using the .catch() method.
```javascript
const num = -1;
const pro = new Promise((resolve, reject) => {
if (num > 0) {
resolve("success!!!!!");
} else {
reject("failure");
}
});
pro.then((message) => {
console.log(message);
})
.then(() => {
console.log("process2");
})
.then(() => {
console.log("process3");
})
.catch((message) => {
console.log(message); //error handle
});
```

In this case, num is lesser than 0 so promise object is in failure. Hence, the code is executed inside of catch.
## Asynchronous Function and Promise chaining
As I mentioned that if you use promise chaining, Asynchronous processing can be executed synchronously.
This is the code introduced at the beginning of the article.
```javascript
const func = () => {
console.log("B");
};
console.log("A");
new Promise((resolve) => {
setTimeout(() => {
func(); //call the func
resolve();
}, 4000);
}).then(() => {
console.log("C");//Subsequent processing
});
```
Although setTimeout is an asynchronous function and func should be executed last, using the then method of the promise allows the processing to be completed before console.log("C").
<u>Promise chaining is commonly used to execute asynchronous operations synchronously like this.</u>
| makoto0825 |
1,863,243 | “cn” utility function in shadcn-ui/ui: | When I saw the cn function being imported from @/lib/utils in shadcn-ui/ui source code, I assumed... | 0 | 2024-05-23T20:57:31 | https://dev.to/ramunarasinga/cn-utility-function-in-shadcn-uiui-3c4k | javascript, nextjs, opensource, shadcnui | When I saw the [cn function](https://github.com/shadcn-ui/ui/blob/main/apps/www/lib/utils.ts#L5) being imported from [@/lib/utils](https://github.com/shadcn-ui/ui/blob/main/apps/www/lib/utils.ts#L5) in shadcn-ui/ui source code, I assumed that this function’s name is derived from “shadcn” since it contains “cn’’and that it handles some core logic but turns out, it is a wrapper on top of [clsx](https://www.npmjs.com/package/clsx) and [twMerge](https://www.npmjs.com/package/tailwind-merge). I questioned, Why? Why would you need such a wrapper?
To understand the reason behind this cn wrapper, you must first understand clsx and tailwind-merge.
Clsx
----
[Clsx official docs](https://www.npmjs.com/package/clsx) definition is that it is a tiny (239B) utility for constructing className strings conditionally.
Also serves as a [faster](https://github.com/lukeed/clsx/blob/HEAD/bench) & smaller drop-in replacement for the classnames module.
> [_Build shadcn-ui/ui from scratch._](https://tthroo.com/)
```
### Examples:
import clsx from 'clsx';
// or
import { clsx } from 'clsx';
// Strings (variadic)
clsx('foo', true && 'bar', 'baz');
//=> 'foo bar baz'
// Objects
clsx({ foo:true, bar:false, baz:isTrue() });
//=> 'foo baz'
// Objects (variadic)
clsx({ foo:true }, { bar:false }, null, { '--foobar':'hello' });
```
We all are familiar with the clsx package, it is used to render the classnames conditionally.
Tailwind-merge:
---------------
To be honest, I have never used the tailwind-merge package before. So I visited the [official docs](https://www.npmjs.com/package/tailwind-merge) and learnt that it is a utility function to efficiently merge [Tailwind CSS](https://tailwindcss.com/) classes in JS without style conflicts.
### Example:
```
import { twMerge } from 'tailwind-merge'
twMerge('px-2 py-1 bg-red hover:bg-dark-red', 'p-3 bg-\[#B91C1C\]')
// → 'hover:bg-dark-red p-3 bg-\[#B91C1C\]'
```
Connecting the dots:
--------------------
It was at this point, it occurred to me that in shadcn-ui, clsx conditionally renders tailwind class names as strings and doing so could result in tailwind class name conflicts

Cn usage in shadcn-ui/ui:
-------------------------
I found the following files using cn function
[https://github.com/search?q=repo%3Ashadcn-ui%2Fui+cn&type=code](https://github.com/search?q=repo%3Ashadcn-ui%2Fui+cn&type=code)

References:
-----------
1. [https://github.com/shadcn-ui/ui/blob/main/apps/www/app/layout.tsx](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/layout.tsx)
2. [https://github.com/shadcn-ui/ui/blob/main/apps/www/lib/utils.ts](https://github.com/shadcn-ui/ui/blob/main/apps/www/lib/utils.ts)
3. [https://www.npmjs.com/package/tailwind-merge](https://www.npmjs.com/package/tailwind-merge)
4. [https://github.com/dcastil/tailwind-merge/blob/main/src/lib/create-tailwind-merge.ts](https://github.com/dcastil/tailwind-merge/blob/main/src/lib/create-tailwind-merge.ts)
5. [https://github.com/dcastil/tailwind-merge/blob/main/src/lib/merge-classlist.ts#L6](https://github.com/dcastil/tailwind-merge/blob/main/src/lib/merge-classlist.ts#L6) | ramunarasinga |
1,855,752 | async/sync in Javascript | Hello everyone. In this article, I would like to talk about async/sync in Javascript. Many beginner... | 0 | 2024-05-23T20:56:31 | https://dev.to/makoto0825/asyncsync-in-javascript-438e | webdev, javascript, beginners | Hello everyone. In this article, I would like to talk about async/sync in Javascript. Many beginner sometimes get confused about thoses ideas. I was one of them. Hence, I feel them and I try to explain I would like to explain it clearly.
## What are Synchronous and Asynchronous?
<u>Synchronous </u>
- Synchronous processing means that a series of tasks are executed sequentially, and the next task doesn't begin until the previous one is complete. Each task waits for the previous one to finish before it starts.
<u>Asynchronous </u>
- Asynchronous processing means tasks can be executed simultaneously, without waiting for each other to finish.
## Synchronous
This is example of Synchronous process
```JavaScript
<script>
//=== function declaration ==========
const func = () => {
console.log("B");
};
// === program start ==========
console.log("A");
func(); // function call
console.log("C");
</script>
```
**Result**
This program executes its tasks sequentially, starting from the top, and the output appears in the console in the order of ABC. This is synchronous processing.
## Asynchronous
This is example of Asynchronous process.
```JavaScript
<script>
//=== function declaration ==========
const func = () => {
console.log("B");
};
// === program start ==========
console.log("A");
setTimeout(func, 1000); //async function
console.log("C");
</script>
```
**Result**

In this program, the order of output is different from Synchronous one.The output is appearing in the sequence ACB. This is because that I use the <u>setTimeout</u>, which is asynchronous function.
setTimeout is a JavaScript method used to execute a specified function after a specified amount of time has elapsed. It takes the function to execute and the specified time as arguments.
Hence, As func was not called immediately because of setTimeout, console.log("C"); was executed next, resulting in the output "ACB" in the console. This is asynchronous processing.
## Converting Asynchronous Processing to Synchronous Processing
How can we make an asynchronous function run synchronously?
In the earlier example, this means that after outputting "A," we wait for a short time before outputting "B," and finally, "C" is outputted. In other words, we want to wait for the execution of the asynchronous function setTimeout before outputting "C."
something like that
The keywords you've probably heard of for this answer is:
- Promise
<u>Promise is used to execute asynchronous functions as synchronous processes.</u>
These keyword is commonly used in API call processes because, in some cases, the program needs to wait for the result of an API call before proceeding with the next operation.
There are roughly two ways to use promises.
[➡How to use Async/Await in Promise.](https://dev.to/makoto0825/how-to-use-asyncawait-in-promise-38hc)
[➡How to use chaining in Promise.](https://dev.to/makoto0825/how-to-use-promise-chaining-in-javascript-391c)
Please refer to the articles for an explanation of how to use those
## Summary
- Synchronous processing is a process where one task finishes before the next one begins.
- Asynchronous processing is a process where the next task can proceed without waiting for a time-consuming task to complete, allowing multiple tasks to be executed simultaneously.
- To handle asynchronous functions synchronously, you need to understand Promise.
| makoto0825 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.