
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,862,720 | Hello #freshspartechnologies | Helllo Everyone #freshspartechnologies | 0 | 2024-05-23T10:47:59 | https://dev.to/freshspartechnologies/hello-freshspartechnologies-48la | Helllo Everyone #freshspartechnologies | freshspartechnologies | |
1,862,719 | Oracle EPM Cloud Release Notes - February 2024 Update | Oracle Enterprise Performance Management (EPM) Cloud is a cloud-based business suite that integrates... | 0 | 2024-05-23T10:47:16 | https://www.iuemag.com/m24/sf/oracle-epm-cloud-release-notes-february-2024-update | oracle, epm, cloud, release | 
Oracle Enterprise Performance Management (EPM) Cloud is a cloud-based business suite that integrates financial planning, analytics, and reporting. It is a crucial tool for informed decision-making and monitoring processes like financial close.
Oracle EPM Cloud Release Notes are rolled out monthly along with updates to help businesses in growth and success.
These updates provide businesses with the latest developments, enhancements, and trends in EPM. It empowers them to elevate their performance to new heights. The February 2024 update brings several key enhancements across various modules.
Keeping up with these Oracle EPM Cloud Releases can be challenging, which is why we bring you this blog. We will highlight the enhancement across various modules and how to strategically test to ensure their systems aren't disrupted.
**Account Reconciliation Enhancements**
The Account Reconciliation feature now automatically makes reverse adjustments. When a user unmatches a match that contains an adjustment the Extract Status of the adjustment is set to close. This enhancement streamlines the reconciliation process and reduces manual effort.
Users can now export data to Microsoft Excel in .xlsx format, in addition to the existing .xls format. This enhancement provides users with more flexibility in how they export and analyze their reconciliation data.
The new "importAttributeValues" command allows users to import values into group attributes, transaction matching lists, and account reconciliation. This feature simplifies the data import process and improves efficiency.
**Enterprise Data Management Improvements**
A new Help Center tab "How Do I..." has been added to answer common questions about Enterprise Data Management. This feature provides users with quick access to information and resources, improving user experience and productivity.
**Financial Consolidation and Close Updates**
A new troubleshooting section has been added to the Oracle EPM Cloud Release. The new release can solve enterprise journal functional issues. This enhancement helps users troubleshoot and resolve issues more effectively, reducing downtime and improving system reliability.
Enterprise Profitability and Cost Management Enhancements
**Oracle EPM**
The module "Migrating from Profitability and Cost Management to Enterprise Profitability and Cost Management" has been improved. This will handle duplicate member names during migration. This enhancement ensures data integrity and accuracy during the migration process.
The initial page load time for Calculation Control and Calculation Analysis pages has been reduced. This improvement enhances user experience by reducing wait times and improving overall system performance.
**Planning Module Improvements**
A new module has been added to demonstrate how to allocate Planning and Budgeting costs using the Allocation System Templates in Calculation Manager. This tutorial helps users effectively manage their planning and budgeting processes.
Users can now import and export model data and metadata to and from a .csv file. This feature provides users with greater flexibility in managing their models. It allows them to make changes offline and then import the updated data back into the model.
**Role of Test Automation in Maximizing Efficiency and Reliability of EPM Release**
**Efficient Deployment**
Opkey accelerates EPM updates by analyzing testing procedures, suggesting improvements, and enabling users to write and execute tests three times faster. This speed ensures that businesses can quickly adapt to new features and functionalities, gaining a competitive edge in the market.
**Continuous Testing**
Continuous testing is a key component of effective EPM testing. It helps identify bugs early in the development lifecycle, resulting in faster bug fixes and reducing overall downtime risk by over 90%. This proactive approach ensures that the EPM system remains stable and reliable, even with frequent updates.
**Reduced Testing Expenditure**
Opkey lowers testing costs by detecting defects early in the development lifecycle. This aligns with the Systems Sciences Institute's estimate that post-release bug discovery is 4-5 times more expensive. By identifying and fixing issues early, businesses can significantly reduce the cost of maintaining and updating their EPM system.
Mitigating Operational Risks
**Oracle EPM**
Opkey's AI-enabled features mitigate financial, operational, and reputational risks by concentrating testing efforts on the most critical processes within Oracle Cloud EPM projects. It prevents potential worst-case scenarios, ensuring that businesses can operate smoothly without disruptions.
**Automated Test Report Generation**
Automation reduces manual effort and saves time without compromising testing quality. Automated documentation tools enhance traceability, efficiency, accuracy, and consistency in testing operations, ensuring that all tests are well-documented and easily accessible.
**Increased Test Coverage**
Manual testing can be challenging, especially with twelve EPM releases annually. Opkey's test automation platform enhances test coverage by addressing the majority of testing scenarios. This comprehensive approach ensures that all aspects of the EPM system are thoroughly tested, reducing the risk of undiscovered issues.
**Ensuring Regulatory Adherence**
Ensuring regulatory compliance is vital for organizations. Insufficient testing can jeopardize application data and result in compliance violations. Opkey's quality assurance system meticulously documents data setups, parameters, and testing steps, ensuring accuracy and traceability, and helping businesses maintain compliance.
**Opkey: Your Invaluable Partner for Oracle Cloud EPM Updates Testing**
Opkey is a codeless testing platform that specializes in Oracle Cloud EPM testing. It offers EPM-based scripts that facilitate organizations to automate regression testing for monthly Oracle EPM Cloud Release Notes. This helps organizations to shorten the testing completion time. Additionally, it also offers impact analysis for monthly releases and has an extensive library of 7,000-plus pre-built test libraries. | rohitbhandari102 |
1,862,718 | The Future is Now: Exploring the Impact of Generative AI on Telecom Services | The telecom industry has always been at the forefront of technological innovation, continuously... | 0 | 2024-05-23T10:43:51 | https://dev.to/maysanders/the-future-is-now-exploring-the-impact-of-generative-ai-on-telecom-services-223m | The telecom industry has always been at the forefront of technological innovation, continuously evolving to meet the increasing demands for connectivity and communication. In recent years, the advent of generative AI has begun to revolutionize telecom services, promising to enhance efficiency, customer experience, and overall service delivery. This blog delves into the transformative impact of generative AI on the telecom sector and what the future holds for this dynamic industry.
**Transforming Customer Service**
One of the most visible impacts of generative AI in telecom is the transformation of customer service. Traditional call centers, often plagued by long wait times and inconsistent service quality, are now being augmented with AI-powered chatbots and virtual assistants. These advanced systems can handle a wide range of customer queries in real-time, providing accurate and prompt responses.
Generative AI models can understand and process natural language with high precision, enabling them to engage in meaningful and contextually relevant conversations with customers. This not only improves customer satisfaction but also allows human agents to focus on more complex issues, thereby enhancing overall efficiency.
**Optimizing Network Management**
Network management is another critical area where generative AI is making significant strides. The complexity of managing telecom networks, with their vast and intricate infrastructure, demands constant monitoring and optimization. [AI software development](https://binmile.com/services/ai-development-company/) has led to the creation of advanced algorithms capable of predictive maintenance, identifying potential issues before they escalate into major problems.
Generative AI can analyze large volumes of network data, detect anomalies, and predict future trends, enabling telecom operators to proactively address potential disruptions. This results in improved network reliability and performance, which is crucial in an era where connectivity is essential for both personal and business activities.
**Enhancing Service Personalization**
In an increasingly competitive market, telecom companies are leveraging [Applied AI services](https://binmile.com/services/artificial-intelligence-as-a-service/) to offer personalized experiences to their customers. Generative AI can analyze user data to understand individual preferences and behaviors, allowing telecom providers to tailor their services and offers accordingly.
For instance, AI can suggest the most suitable data plans based on a user's usage patterns or recommend value-added services that align with their interests. This level of personalization not only enhances customer loyalty but also drives revenue growth by offering targeted and relevant services.
**Revolutionizing Content Generation**
Generative AI is also set to revolutionize content generation within the telecom sector. AI-driven tools can create high-quality content for marketing, customer engagement, and educational purposes. This includes generating compelling blog posts, social media content, and even video scripts that resonate with target audiences.
Moreover, generative AI can assist in developing interactive content, such as personalized video messages or dynamic newsletters, which can significantly improve customer engagement. By automating content creation, telecom companies can maintain a consistent and impactful presence across various digital platforms.
**The Road Ahead**
The integration of [generative AI in telecom](https://binmile.com/blog/generative-ai-in-telecom-industry/) is still in its early stages, but the potential is vast. As AI technology continues to advance, we can expect even more innovative applications that will further transform the industry. Telecom operators must stay ahead of the curve by investing in AI research and development, collaborating with AI experts, and continuously exploring new ways to enhance their services.
In conclusion, generative AI is poised to redefine the telecom landscape, offering unprecedented opportunities for improvement in customer service, network management, service personalization, and content generation. The future of telecom is undoubtedly intertwined with the advancements in AI, and those who embrace this technology will be well-positioned to lead the industry into the next era of digital transformation. | maysanders | |
1,862,717 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-05-23T10:43:49 | https://dev.to/etholite/my-pen-on-codepen-35c3 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/xyaiujlg-the-animator/pen/LYoZQyK %} | etholite |
1,862,716 | Kitchen Colors as per Vastu: A Guide to Harmonious Living | Introduction Choosing the right colors for your kitchen is more than just an aesthetic... | 0 | 2024-05-23T10:43:14 | https://dev.to/mjvedicmeet/kitchen-colors-as-per-vastu-a-guide-to-harmonious-living-37h2 | ## **Introduction**
Choosing the right colors for your kitchen is more than just an aesthetic decision; it’s a step towards creating a harmonious and positive environment in your home. Vastu Shastra, the ancient Indian science of architecture, emphasizes the importance of colors in maintaining balance and flow of energy. In this guide, we’ll explore the best **[kitchen colors as per Vastu](https://vedicmeet.com/vastu/colours-for-kitchen/)** and how they can enhance your living space.
## **Understanding Vastu Shastra**
Vastu Shastra, rooted in ancient Indian traditions, is the science of architecture and spatial arrangement. It aims to harmonize the environment by balancing the five elements: earth, water, fire, air, and space. The principles of Vastu focus on creating a positive energy flow, ensuring peace, prosperity, and health.
## **Significance of the Kitchen in Vastu**
The kitchen is often considered the heart of the home, playing a crucial role in the family’s health and well-being. According to Vastu, the placement and color of the kitchen significantly impact the household’s overall harmony and energy.
## **General Guidelines for Kitchen Colors**
Vastu Shastra provides specific guidelines for kitchen colors based on its direction and placement within the home. The key is to choose colors that align with the natural elements associated with each direction.
## **Best Colors for East-facing Kitchens**
For east-facing kitchens, **[Vastu](https://vedicmeet.com/topics/vastu/)** recommends using colors that represent the sun and air elements. Light blue, white, and green are ideal choices. These colors promote clarity, creativity, and freshness, enhancing the kitchen's energy flow.
## **Best Colors for West-facing Kitchens**
West-facing kitchens benefit from colors that reflect the earth and metal elements. Shades of grey, beige, and yellow are perfect. These colors bring stability, warmth, and a grounding effect, creating a balanced environment.
## **Best Colors for North-facing Kitchens**
North-facing kitchens should incorporate colors that resonate with the water element. Blue, green, and black are recommended. These colors encourage calmness, prosperity, and a soothing atmosphere, ideal for cooking and dining spaces.
## **Best Colors for South-facing Kitchens**
For south-facing kitchens, colors representing the fire element are most beneficial. Red, orange, and pink can be used, but it’s essential to use them in moderation. These colors stimulate energy, passion, and appetite, making the kitchen a vibrant space.
## **Avoiding Inauspicious Colors**
Vastu advises against using certain colors in the kitchen, such as dark brown, black, and dark grey. These colors can create negative energy, leading to stress, health issues, and conflicts among family members.
## **Using Natural Elements and Materials**
Incorporating natural elements like wood, stone, and earthy tones can enhance the kitchen’s Vastu compliance. These materials bring a touch of nature indoors, promoting balance and tranquillity.
## **Balancing Modern Aesthetics with Vastu**
While adhering to Vastu principles, it’s possible to maintain a modern and stylish kitchen. Choose contemporary shades that align with Vastu guidelines and complement them with modern appliances and fixtures.
## **Common Mistakes in Kitchen Color Selection**
One common mistake is choosing colors solely based on personal preference without considering Vastu principles. Another is using excessive bright colors, which can disrupt the energy balance. It's crucial to strike a balance between Vastu and aesthetics.
## **Enhancing Positive Energy with Accessories**
Complement your kitchen’s color scheme with Vastu-approved accessories. Use green plants, colorful utensils, and decorative items that align with Vastu principles to enhance positive energy.
## **Conclusion**
Applying Vastu principles to your kitchen’s color scheme can transform it into a space filled with positive energy, harmony, and prosperity. By carefully selecting colors based on direction and elements, you can create a kitchen that’s not only aesthetically pleasing but also beneficial for your family’s well-being.
## **FAQs**
**What are the best colors for a small kitchen as per Vastu?**
Light colors such as white, light blue, and green are ideal for small kitchens. They make the space look larger and more open, enhancing positive energy.
**Can we use black in the kitchen according to Vastu?**
Black is generally not recommended in Vastu for kitchens as it can attract negative energy and create a heavy atmosphere.
**How does lighting affect kitchen Vastu?**
Proper lighting is crucial in Vastu. Natural light is best, but if that's not possible, use bright, warm lights to create a welcoming and energetic environment.
**Are there any Vastu remedies for an inauspicious kitchen color?**
Yes, you can use Vastu remedies like placing certain plants, crystals, or decorative items to counteract the effects of inauspicious colors.
**Can Vastu principles be applied to open kitchens?**
Absolutely. Vastu principles can be adapted for open kitchens by focusing on the placement and color coordination within the larger living space.
| mjvedicmeet | |
1,862,715 | How to Create a User using Tinker in Laravel | Tinker allows you to interact with your entire Laravel application on the command line, including the... | 0 | 2024-05-23T10:42:53 | https://larainfo.com/blogs/how-to-create-a-user-using-tinker-in-laravel/ | laravel, php, webdev | Tinker allows you to interact with your entire Laravel application on the command line, including the Eloquent ORM, jobs, events, and more. To enter the Tinker environment, run the tinker Artisan command.
```php
php artisan tinker or php artisan ti
```
By using the tinker command line, we can create a new user or insert new data into the database.
Now run `php artisan ti`
```php
Psy Shell v0.10.6 (PHP 7.4.16 — cli) by Justin Hileman
>>> User::create(["name"=> "larainfo","email"=>"larainfo@gmail.com","password"=>bcrypt("123456")]);
=> App\Models\User {#4290
name: "larainfo",
email: "larainfo@gmail.com",
updated_at: "2021-04-22 08:23:28",
created_at: "2021-04-22 08:23:28",
id: 1,
}
>>>
```
Or you can explore different approaches to storing new data. Let's see.
`php artisan ti`
```php
>>> $user = new App\Models\User;
=> App\Models\User {#4301}
>>> $user->name = "larainfo";
=> "larainfo"
>>> $user->email= "larainfo@gmail.com";
=> "larainfo@gmail.com"
>>> $user->password=bcrypt('123456');
=> "$2y$10$uSdO/eBCQPNK3eVjXlSh.ulBVamZOhc.Hu5bp8Xzzb.uWyS3MSwRC"
>>> $user->save();
=> true
``` | saim_ansari |
1,862,713 | unsupported! | Check out this Pen I made! | 0 | 2024-05-23T10:41:50 | https://dev.to/itzad_20/unsupported-508l | codepen | Check out this Pen I made!
{% codepen https://codepen.io/ITzAD20/pen/rNgLJpq %} | itzad_20 |
1,862,712 | RateMyReads API | Introduction RateMyReads, a platform dedicated to book enthusiasts, relies on a robust API... | 0 | 2024-05-23T10:41:46 | https://dev.to/nimo08/ratemyreads-api-b8p | python, api, django, postman |
## Introduction
RateMyReads, a platform dedicated to book enthusiasts, relies on a robust API to facilitate seamless user interaction and efficient data management. This article delves into the development journey of RateMyReads API, outlining the technologies utilized, challenges encountered, and future directions.
## Project Description
The RateMyReads API project was a solo endeavor, with the goal of crafting an intuitive platform for users to manage their book preferences and engage with a vibrant community of readers. Spearheaded entirely by me, the API development journey spanned from inception to completion, ensuring every aspect of the platform's functionality was meticulously crafted to deliver an exceptional user experience.
## Technologies Used
- Python: Chosen for its readability and extensive libraries, Python served as the primary programming language.
- Django: Leveraged as a high-level Python web framework, Django accelerated development with its built-in features and adherence to the DRY principle.
- Django Rest Framework (DRF): Complemented Django by simplifying API development, providing tools for serialization, authentication, and authorization.
- Postman: Utilized as a comprehensive testing and debugging tool to ensure the reliability and functionality of RateMyReads API.
- Docker: Employed for containerization, simplifying dependency management and deployment processes.
## Developments
Throughout the development process, several milestones were achieved:
- RESTful API Implementation: A robust API architecture was developed, seamlessly connecting user, book, and comment models for efficient data management.
- User Authentication and Authorization: Robust authentication mechanisms were implemented to ensure secure access to the platform, prioritizing user data privacy.
- Email Notification Integration: An email backend was integrated to enhance user communication, providing confirmation emails upon sign-up for a smooth registration process.
## Challenges & Areas of Improvement
While significant progress was made, challenges were encountered:
- Deployment Issues: The learning curve with deployment frameworks posed challenges during deployment, highlighting the need for optimization.
- Areas for Improvement: Future iterations will focus on optimizing the deployment process, enhancing API functionality and security, and improving user experience with additional features.
## Key Findings
- Thorough Deployment Research: Emphasized the importance of mastering deployment procedures for smoother project deployment, prompting further exploration into deployment strategies.
- Continuous Technology Learning: Highlighted the value of staying updated with new technologies for enhanced development processes, inspiring ongoing learning and adaptation.
## Next Steps
- Optimize Deployment Process: Research and implement deployment strategies to streamline the deployment process and mitigate deployment-related challenges.
- Enhance API Functionality and Security: Continuously improve API functionality and security measures to ensure a seamless and secure user experience.
- Incorporate Additional Features: Gather user feedback to identify and implement additional features that enhance the overall user experience and engagement on the platform.
## Conclusion
The development of RateMyReads API has been an enriching experience, marked by significant achievements and valuable learnings. Despite challenges, I remain committed to refining and expanding the platform to meet user needs effectively and enhance overall functionality and usability.
## Project Repository
https://github.com/Nimo08/RateMyReads-API
| nimo08 |
1,862,711 | Recursion in JavaScript | Today, we'll talk about recursion in JavaScript, a powerful tool in your coding arsenal. You'll learn... | 0 | 2024-05-23T10:38:27 | https://dev.to/shehzadhussain/recursion-in-javascript-2kh3 | webdev, javascript, programming, beginners | Today, we'll talk about recursion in JavaScript, a powerful tool in your coding arsenal. You'll learn how to implement it through clear, practical examples.
Understanding recursion is crucial for JavaScript developers. It simplifies complex problems, improves readability, and is often a preferred solution in interviews and real-world coding challenges.
Many developers struggle with recursion due to its abstract concept and potential for errors like infinite loops. But, with the right approach, it can be learned effectively
## **Recursion is not just a technique but a new way of thinking.
Recursion involves a function calling itself until it reaches a base condition. This approach is beneficial for tasks like traversing trees or solving algorithms that require backtracking, such as searching or sorting.
Here are 4 takeaways:
- Recursion simplifies complex problems by breaking them into smaller, manageable parts.
- It's essential to define a clear base case to prevent infinite loops.
- Recursion can lead to more readable and elegant code than iterative solutions.
- Understanding stack overflow and how JavaScript manages memory in recursive calls is crucial.
## **Code Example: Factorial Calculation
**

**
## **Common Pitfalls
**
1. Stack Overflow: In JavaScript, each recursive call adds a frame to the call stack. If your recursion is too deep (i.e., too many calls without reaching the base case), you can exhaust the stack memory, leading to a "stack overflow" error. This often happens if the base case is not correctly defined or the recursion is not converging towards it.
2. Lack of Base Case: The base case is what stops the recursion. Without a proper base case, your function will keep calling itself indefinitely, leading to infinite recursion and, eventually, a stack overflow error.
3. Large Memory Consumption: Each recursive call uses memory to maintain its execution context. Inefficient recursion, especially with many levels, can consume significant memory, leading to performance issues.
## **Advanced Techniques: Tail Call Optimization (TCO)
**
In ES6 (ECMAScript 2015), JavaScript introduced a feature called "tail call optimization." This optimization allows certain recursive calls (tail calls) to be executed without adding a new stack frame. For a recursive call to be a tail call, it must be the last operation in the function. This optimization significantly reduces the risk of stack overflow and improves performance for deep recursive calls.
Here are 4 takeaways:
- Tail Call Optimization is a feature that makes recursive functions more efficient.
- Normally, whenever a function calls itself, it adds a new layer to the "call stack" (a pile of ongoing function calls). If this stack gets too big, it can cause problems like a "stack overflow."
- In TCO, if a function's last action is calling itself (a "tail call"), JavaScript can optimize it. Instead of adding a new layer to the stack, it reuses the current one. This means you can have more recursive calls without the risk of stack overflow.
- However, for TCO to work, the recursive call must be the last thing the function does.
Here's a more straightforward example of a recursive function using TCO:
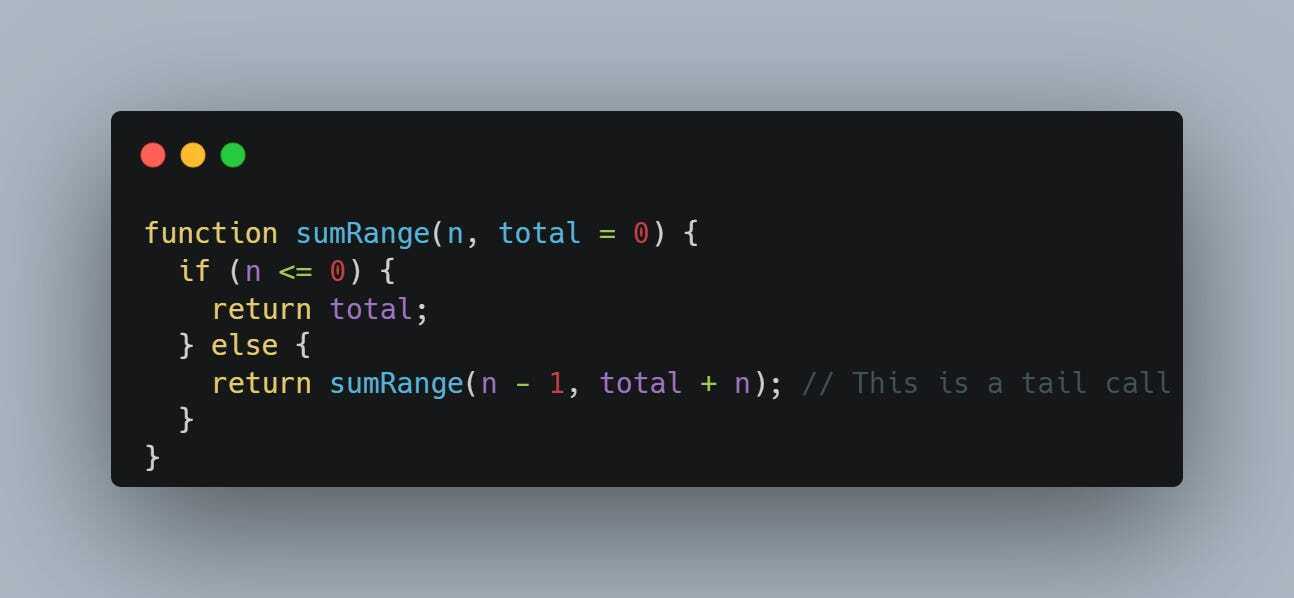
In this sumRange function:
- We're calculating the sum of numbers from 1 to n.
- The function keeps calling itself, but its last operation is the recursive call (return sumRange(n - 1, total + n)).
- Because this call is the last action, it's a tail call and can be optimized by JavaScript, allowing it to run more efficiently, especially for large values of n.
In summary, TCO in JavaScript allows you to write recursive functions that are more efficient and less likely to run into problems with large numbers of recursive calls.
Here's an example to illustrate TCO with the factorial function:
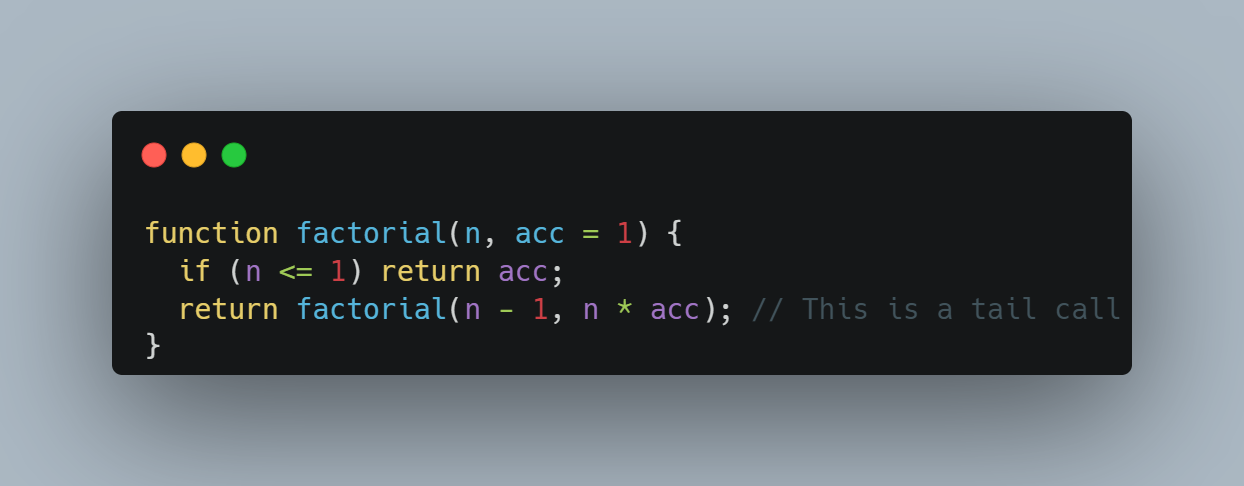
Understanding these pitfalls and techniques can significantly enhance your proficiency in writing efficient and safe recursive functions in JavaScript.
Conclusion
Recursion in JavaScript is a valuable skill that, once mastered, opens up new possibilities in coding. It encourages cleaner, more intuitive solutions and is a favorite in algorithmic challenges. Practising and understanding the theory behind recursion are key to mastering it.
I hope you enjoyed the article.
If you have any questions, feel free to reply to the email or leave a comment in the post.
See you in the next post.
Have a great day!
| shehzadhussain |
1,862,710 | Technology Events and Their Role in Promoting Digital Transformation | In today's fast-paced world, going digital isn't just a trend – it's essential for staying ahead.... | 0 | 2024-05-23T10:38:21 | https://dev.to/ajaytie/technology-events-and-their-role-in-promoting-digital-transformation-13hb | technology, digitaltransformation, techtalks, eventdriven | In today's fast-paced world, going digital isn't just a trend – it's essential for staying ahead. Technology events are like powerhouses of innovation, bringing together minds from all over to share ideas and drive change. This piece dives into how these events are shaping the digital landscape, sparking inspiration, and helping organizations navigate the journey towards a tech-driven future.
## Understanding Digital Transformation
Digital transformation is like a big makeover for businesses, changing the way they work using digital tools. It covers a range of technologies, like cloud computing, AI, IoT, and data analytics, all aimed at making things faster, more flexible, and more innovative.
## The Transformative Power of Technology Events
**1. Knowledge Sharing and Education**
Technology events serve as vibrant forums for thought leadership, offering attendees access to cutting-edge insights, trends, and best practices in digital transformation. Through keynote speeches, panel discussions, and interactive workshops, industry luminaries and experts share their experiences, successes, and lessons learned. These sessions empower attendees with the knowledge and inspiration needed to navigate the complexities of digital transformation.
**2. Showcasing Innovation**
One of the hallmarks of [technology events](https://www.expresscomputer.in/events/) is the opportunity for companies to showcase their latest innovations and solutions. From groundbreaking startups to industry titans, exhibitors unveil cutting-edge technologies and applications that are reshaping industries. Attendees gain firsthand exposure to innovative products and services, sparking ideas and igniting the imagination for what's possible in their own digital transformation journey.
**3. Networking and Collaboration**
Networking is the beating heart of tech events, where collaboration and idea-sharing thrive. Attendees mingle with peers, industry experts, and potential partners, creating a rich environment for digital innovation. These connections often blossom into partnerships and alliances, fueling the drive towards digital transformation.
**4. Inspiration and Vision**
Tech events go beyond displaying gadgets; they're about molding tomorrow and igniting change. Leaders and innovators share their visions, sparking creativity and pushing boundaries. Their ideas inspire attendees to think big, take risks, and embrace innovation for a brighter future.
## Real-World Examples of Digital Transformation Enabled by Technology Events
**1. Company A: Embracing Cloud Computing**
After attending a cloud computing conference, Company A, a traditional manufacturing firm, embarked on a digital transformation journey by migrating its legacy systems to the cloud. By leveraging cloud-based infrastructure and software-as-a-service (SaaS) solutions, Company A achieved greater agility, scalability, and cost-efficiency, transforming its operations and driving business growth.
**2. Company B: Harnessing AI and Analytics**
Inspired by insights gained at an AI and analytics summit, Company B, a leading retailer, implemented advanced analytics and AI-powered solutions to personalize customer experiences and optimize supply chain operations. By leveraging predictive analytics and machine learning algorithms, Company B improved customer engagement, reduced costs, and gained a competitive edge in the market.
## Overcoming Challenges and Driving Success
While technology events offer tremendous opportunities for digital transformation, organizations must navigate various challenges along the way:
- **Resistance to Change:** Overcoming resistance to change and fostering a culture of innovation is essential for successful digital transformation.
- **Skills Gap:** Addressing the skills gap and ensuring that employees are equipped with the necessary digital skills and competencies is critical.
- **Integration Complexity:** Managing the complexity of integrating new technologies and systems into existing infrastructure requires careful planning and execution.
To drive success in their digital transformation endeavors, organizations must:
- **Set Clear Goals:** Define clear and measurable goals for digital transformation initiatives, aligning them with overall business objectives.
- **Invest in Talent:** Invest in upskilling and reskilling employees to ensure they have the necessary digital capabilities to drive transformation.
- **Collaborate and Iterate:** Foster a culture of collaboration, experimentation, and continuous improvement, embracing agility and adaptability as core principles.
**Also Read: [What Programming Language Should a Startup Choose?](https://dev.to/ajaytie/what-programming-language-should-a-startup-choose-gp6)**
**Conclusion**
Technology events are like fuel for the fire of digital transformation, spurring organizations to innovate, collaborate and adapt to change. They offer a space for sharing knowledge, showcasing new ideas, and forming partnerships, all of which are essential for navigating the journey towards a more agile and competitive future. As businesses embrace the challenges and opportunities of digital transformation, technology events will remain vital hubs of inspiration and progress. | ajaytie |
1,813,455 | Rendering the TRUE Argo CD diff on your PRs | TL;DR — The safest way to make changes to your Helm Charts and Kustomize Overlays is to let Argo CD... | 0 | 2024-05-23T10:33:41 | https://dev.to/dag-andersen/rendering-the-true-argo-cd-diff-on-your-prs-10bk | kubernetes, devops, git, argocd | > TL;DR — The safest way to make changes to your Helm Charts and Kustomize Overlays is to let Argo CD render them for you. This can be done by spinning up an ephemeral cluster in your automated pipelines. This article presents a tool ([`argocd-diff-preview`](https://github.com/dag-andersen/argocd-diff-preview)) for rendering manifest changes on pull requests. The rendered output is similar to what Atlantis creates for Terraform.
## Problem
In the Kubernetes world, we often use templating tools like Kustomize and Helm to generate our Kubernetes manifests. These tools make maintaining and streamlining configuration easier across applications and environments. However, they also make it harder to visualize the application's actual configuration in the cluster.
Mentally parsing Helm templates and Kustomize patches is hard without rendering the actual output. Thus, making mistakes while modifying an application's configuration is relatively easy.
In the field of GitOps and infrastructure as code, all configurations are checked into Git and modified through PRs. The code changes in the PR are reviewed by a human, who needs to understand the changes made to the configuration. This is hard when the configuration is generated through templating tools like Kustomize and Helm.
If you are interested in a more detailed walkthrough for this problem, I recommend watching [_Nicholas Morey_](https://www.linkedin.com/in/nicholas-morey/)'s talk at KubeCon 2024: ["The Rendered Manifests Pattern: Reveal Your True Desired State"](https://www.youtube.com/watch?v=TonN-369Qfo&ab_channel=CNCF%5BCloudNativeComputingFoundation%5D)
This article introduces the tool [`argocd-diff-preview`](https://github.com/dag-andersen/argocd-diff-preview) that solves this problem by rendering manifest changes directly on pull requests.
... but first, let's go through two simple examples where not rendering manifests can result in misconfiguration:
#### Helm misconfiguration example
Here we see an example of a developer trying to override the replica count on an Argo CD application:
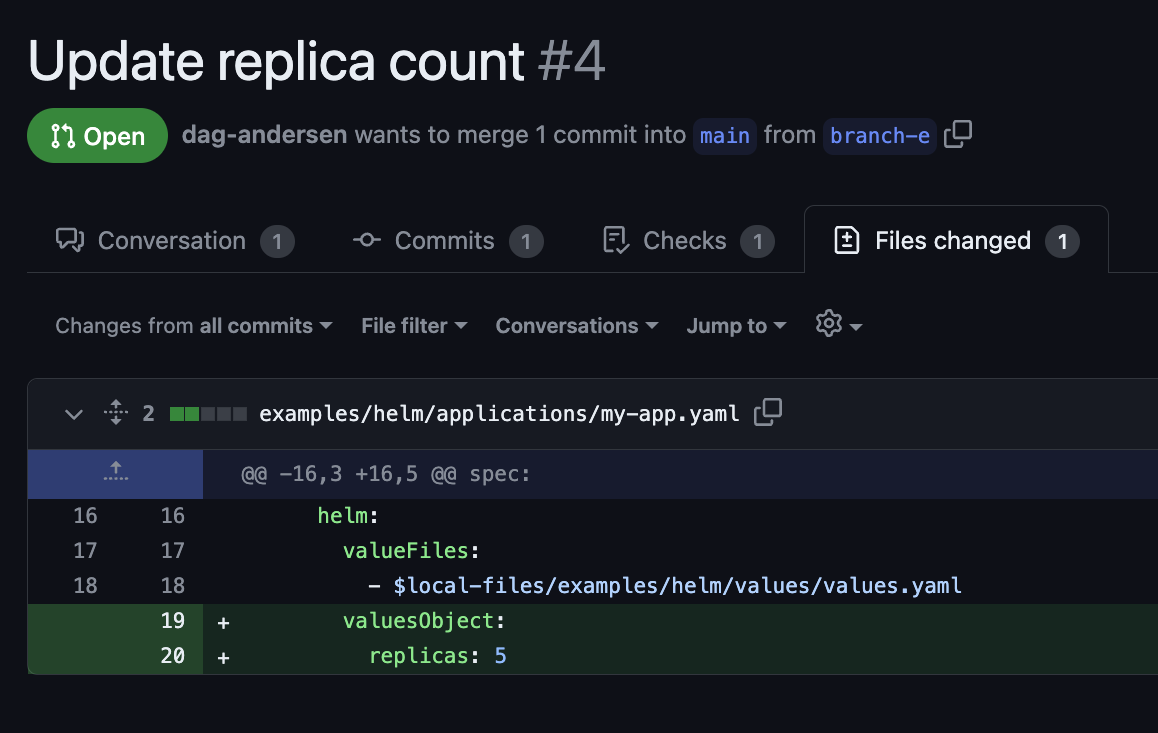
This PR may look correct, but as a reviewer, you do not know if the value specified in the Helm Chart is named `replicas:` or `replicaCount:`. The code change has no effect if the value name is incorrect. Without rendering the Helm templates, the likelihood of these errors going to production is high.
#### Kustomize misconfiguration example
Here we see an example of a developer trying to set the replica count for both staging and production:
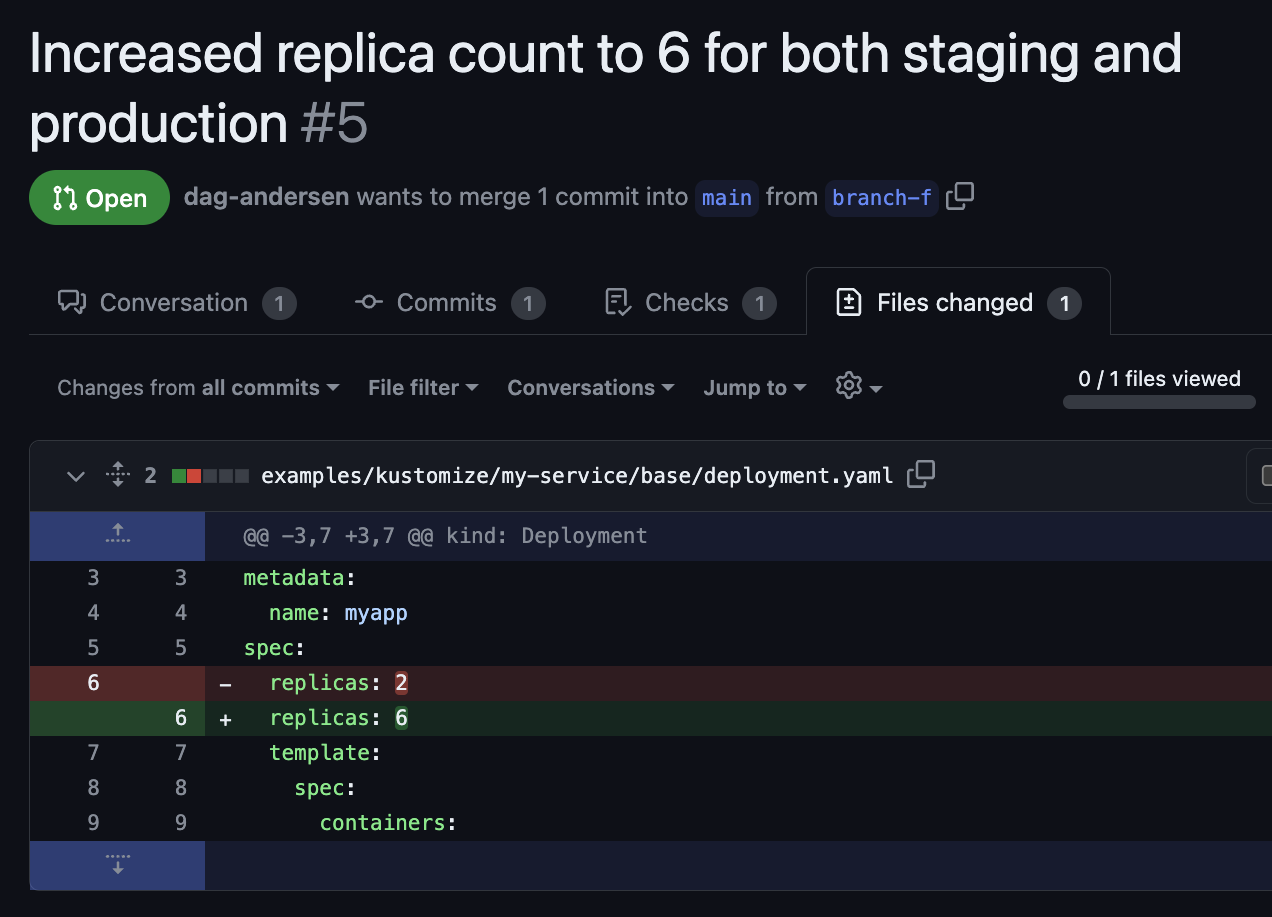
Again, this PR may look correct because the change happens in a base folder, so the change applies to all overlays (production and staging). But as a reviewer, you do not know if this value is overridden later down the chain of overlays.
```yaml
~/someApp
├── base
│ ├── deployment.yaml ⬅️ File changed in Pull Request
│ ├── kustomization.yaml
│ └── service.yaml
└── overlays
├── staging
│ ├── cpu_count.yaml
│ ├── kustomization.yaml
└── production
├── cpu_count.yaml
├── kustomization.yaml
└── replica_count.yaml ⬅️ replicaCount overwritten here
```
This unintended result might not have been caught without rendering the final output for staging and production.
### Other solutions to the problem
This problem has been pointed out many times in articles and tech talks about GitOps and infrastructure as code.
If you are interested in different approaches to solving the problem and their limitations, check out [_Kostis Kapelonis_](https://www.linkedin.com/in/kostiskapelonis/)'s [article](https://codefresh.io/blog/argo-cd-preview-diff/) on the topic.
`argocd-diff-preview` is not the first tool that tries to tackle this problem. Other open-source repos include [quizlet/argocd-diff-action](https://github.com/quizlet/argocd-diff-action) and [zapier/kubechecks](https://github.com/zapier/kubechecks).
- [quizlet/argocd-diff-action](https://github.com/quizlet/argocd-diff-action) generates an Argo CD diff between the current PR and the current state of the cluster using the `argocd app diff` command. Thus, this tool needs the Argo CD applications to already be in sync with Git to be helpful. Applications that are out-of-sync on the Argo CD instance will be rendered as a diff on every PR. Additionally, you need to provide your CI pipeline with credentials to your Argo CD server, which may not be possible or desirable.
- [zapier/kubechecks](https://github.com/zapier/kubechecks) is a system that you install on your cluster, which may not be desirable for organizations with strict security restrictions. The tool is complex but has many interesting features. Again, this tool requires access to your running Argo CD instance, which may not be possible or desirable.
`argocd-diff-preview` was created to avoid installing a tool directly on a cluster or providing it with credentials to your live Argo CD instance.
---
## New solution: `argocd-diff-preview`
### Goal
Create a tool that works like Atlantis for Terraform but for Argo CD. The tool should render a reliable diff of the configuration changes directly on the PR. Additionally, it should work without needing access to your existing infrastructure.
Instead of creating some scripts that try to mimic how Argo CD would render the manifests, why not let Argo CD render the manifests itself? This would ensure that the rendered manifests are exactly how Argo CD would render the manifests.
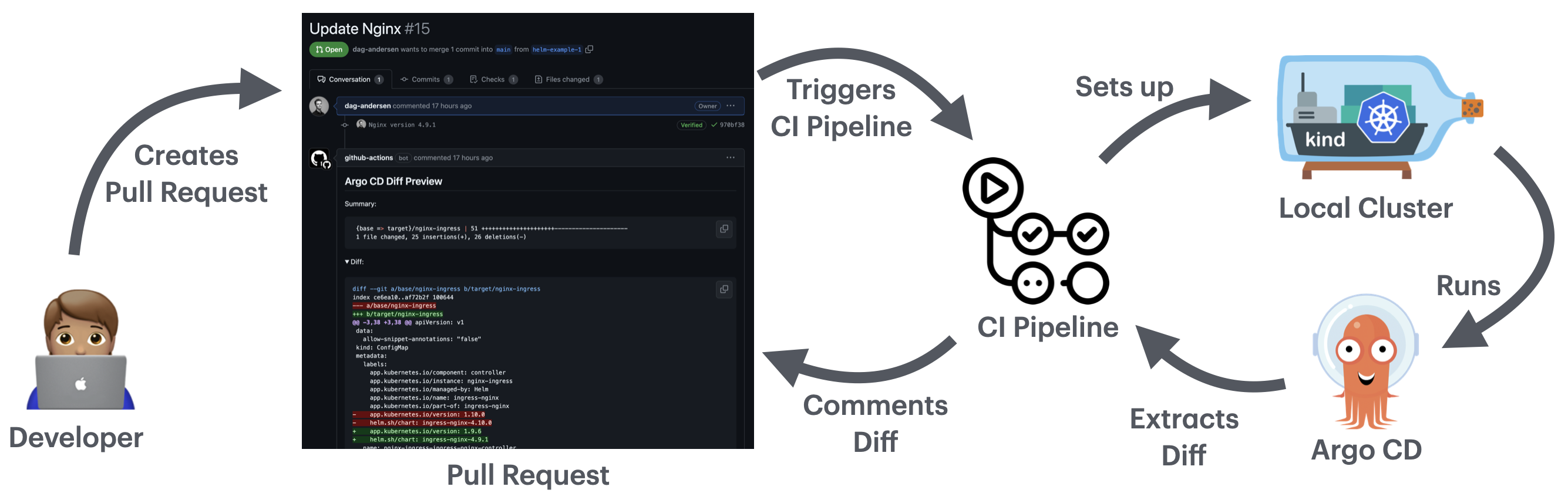
### How it works
`argocd-diff-preview` spins up a local cluster, installs Argo CD, applies the manifests to the cluster, extracts the rendered manifests from Argo CD, and compares it to the main branch.
This tool runs an ephemeral local cluster inside Docker, so it does not need access to your infrastructure. It only needs read access to the Git repository and your Helm Charts (either stored in Git or a registry)
#### In other words, it follows these 10 steps:
1. Start a local cluster
2. Install Argo CD
3. Add the required credentials (Git credentials, image pull secrets, etc.)
4. Fetch all Argo CD application files on your PR branch
- Point their `targetRevision` to the Pull Request branch
- Remove the `syncPolicy` from the application (to avoid the application to sync locally)
1. Apply the modified applications to the cluster
1. Let Argo CD do its magic
1. Extract the rendered manifests from the Argo CD server
1. Repeat steps 4–7 for the base branch (main branch)
1. Create a diff between the manifests rendered from each branch
1. Display the diff in the PR
**The flow visualized:**
### Example
If you are asked for a review on a PR that looks like this:
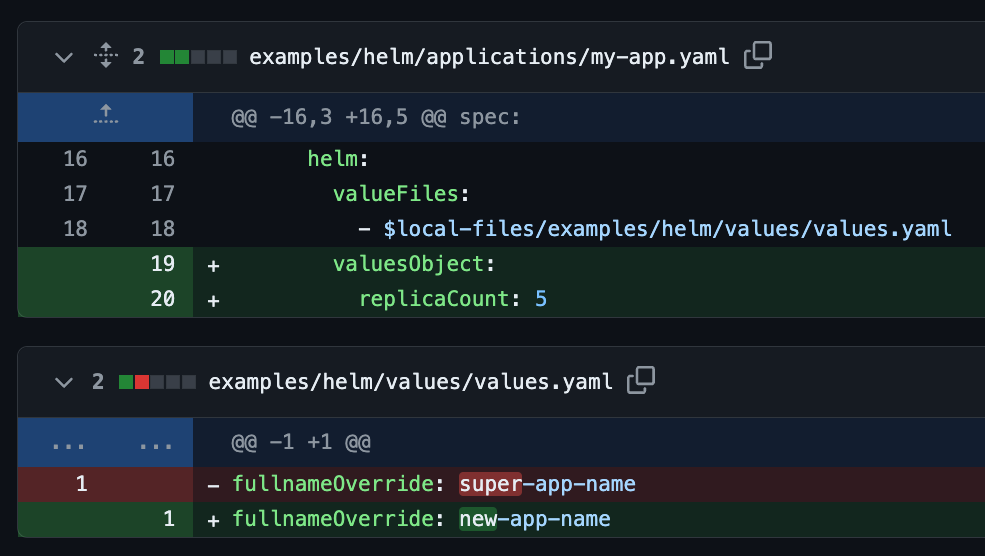
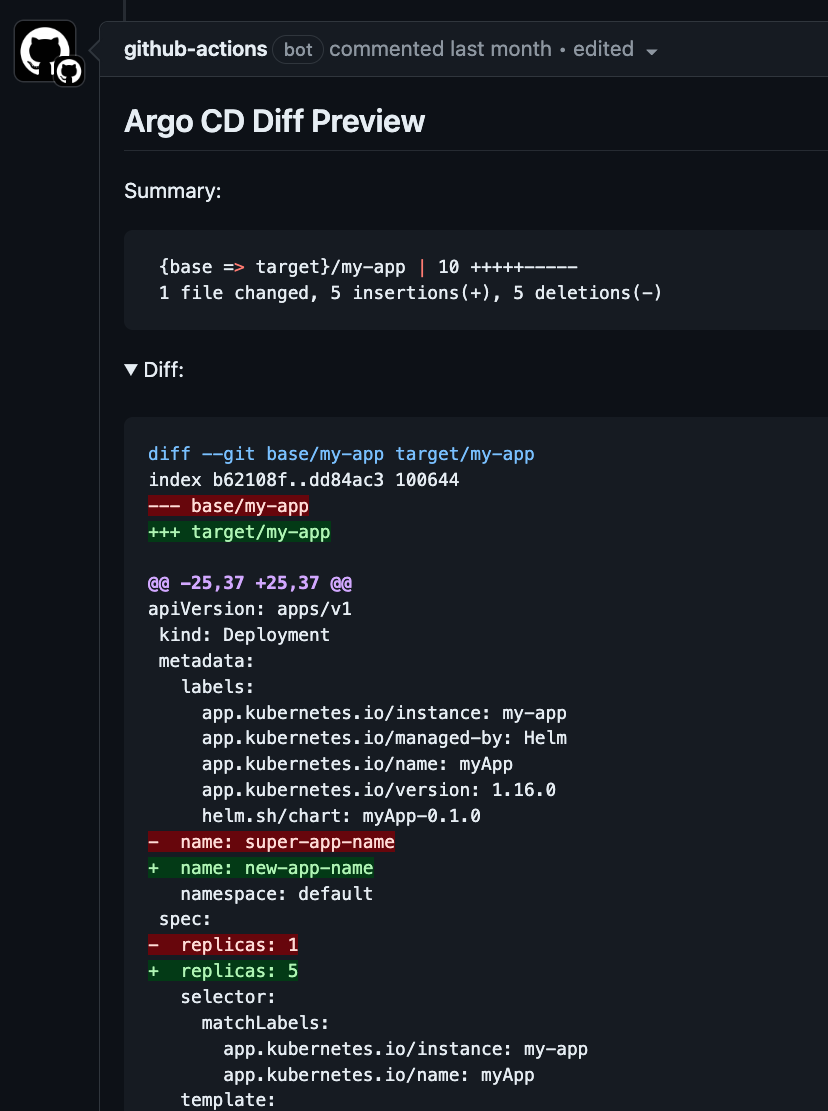
Then you can verify that it is configured correctly by checking the output generated by `argocd-diff-preview`. The output would look similar to this:
### Pros
- Always renders the correct difference between branches because it is rendered by Argo CD itself.
- Fully ephemeral cluster.
- Does not access any of your existing infrastructure. It only requires read access to the Git repository and your Helm Charts.
- Can be run locally before you open the pull request.
- Render changes in resources from external sources (e.g., Helm Charts). For example, when you update the Helm Chart version of `nginx`, you can see what exactly changed - [PR example](https://github.com/dag-andersen/argocd-diff-preview/pull/15).
### Cons
- It is slow. Spinning up a cluster and installing Argo CD takes a few minutes each run (see table below)
- Does not support [Argo CD CMP plugins](https://argo-cd.readthedocs.io/en/stable/operator-manual/config-management-plugins/)
- Does not work with [Cluster Generators](https://argocd-applicationset.readthedocs.io/en/stable/Generators-Cluster/) in your ApplicationSets.
### Comparing desired states - Not actual state
An important point to understand is that, unlike Atlantis or the `argocd diff` CLI command, this approach doesn't compare the desired state in Git with the actual state in Kubernetes. Instead, it compares the desired state of the two branches stored in Git. I would argue that this is better than comparing Git with the actual state in Kubernetes because the state can change, resulting in non-deterministic output. The actual state in Kubernetes can temporarily go out-of-sync with Git, and we don't want this to be highlighted in our diff preview. Developers who work with Altanis experience this a lot - each time you run `atlantis plan`, it may produce a different result if the infrastructure changes often.
### How to use it in GitHub Actions
Here is an example of how you would trigger `argocd-diff-preview` on your pull requests in GitHub Actions
```yaml
name: Argo CD Diff Preview
on:
pull_request:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4
with:
path: pull-request
- uses: actions/checkout@v4
with:
ref: main
path: main
- name: Generate Diff
run: |
docker run \
--network=host \
-v /var/run/docker.sock:/var/run/docker.sock \
-v $(pwd)/main:/base-branch \
-v $(pwd)/pull-request:/target-branch \
-v $(pwd)/output:/output \
-e TARGET_BRANCH=${{ github.head_ref }} \
-e REPO=${{ github.repository }} \
dagandersen/argocd-diff-preview:v0.0.8
- name: Post diff as comment
run: |
gh pr comment ${{ github.event.number }} --repo ${{ github.repository }} --body-file output/diff.md --edit-last || \
gh pr comment ${{ github.event.number }} --repo ${{ github.repository }} --body-file output/diff.md
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
```
### Handling credentials
In the simple code example above, I do not provide `argocd-diff-preview` with any credentials, which only works if the Helm Chart registry and the Git repository are public. If you want to use this tool in a private repository, you need to provide the tool with the required credentials. More details on this can be seen in the [GitHub Repository](https://github.com/dag-andersen/argocd-diff-preview#handling-credentials)
### Output
On a successful run, the tool prints the following output:
```
✨ Running with:
✨ - base-branch: main
✨ - target-branch: helm-example-3
✨ - repo: dag-andersen/argocd-diff-preview
✨ - timeout: 180
🚀 Creating cluster...
🚀 Cluster created successfully
🦑 Installing Argo CD...
...
🤖 Patching applications for branch: main
🤖 Patching applications for branch: helm-example-3
🌚 Getting resources for base-branch
🌚 Getting resources for target-branch
...
🔮 Generating diff between main and helm-example-3
🙏 Please check the ./output/diff.md file for differences
```
If something is wrong with your configuration, it prints the Argo CD Application error message:
```
...
🤖 Patching 4 Argo CD Application[Sets] for branch: helm-example-3
🌚 Getting resources for target-branch
⏳ Waiting for 4 out of 4 applications to become 'OutOfSync'. Retrying in 5 seconds. Timeout in 180 seconds...
❌ Failed to process application, my-app, with error:
Failed to load target state: failed to generate manifest for source 2 of 2: rpc error: code = Unknown desc = authentication required
```
### Speed
The table below shows how the number of applications correlates with the time it takes to render them all:
| Number of applications | 1 | 50 | 250 | 500 |
|:----------------------:|:--:|:---:|:---:|:---:|
| Seconds** | 80 | 100 | 210 | 330 |
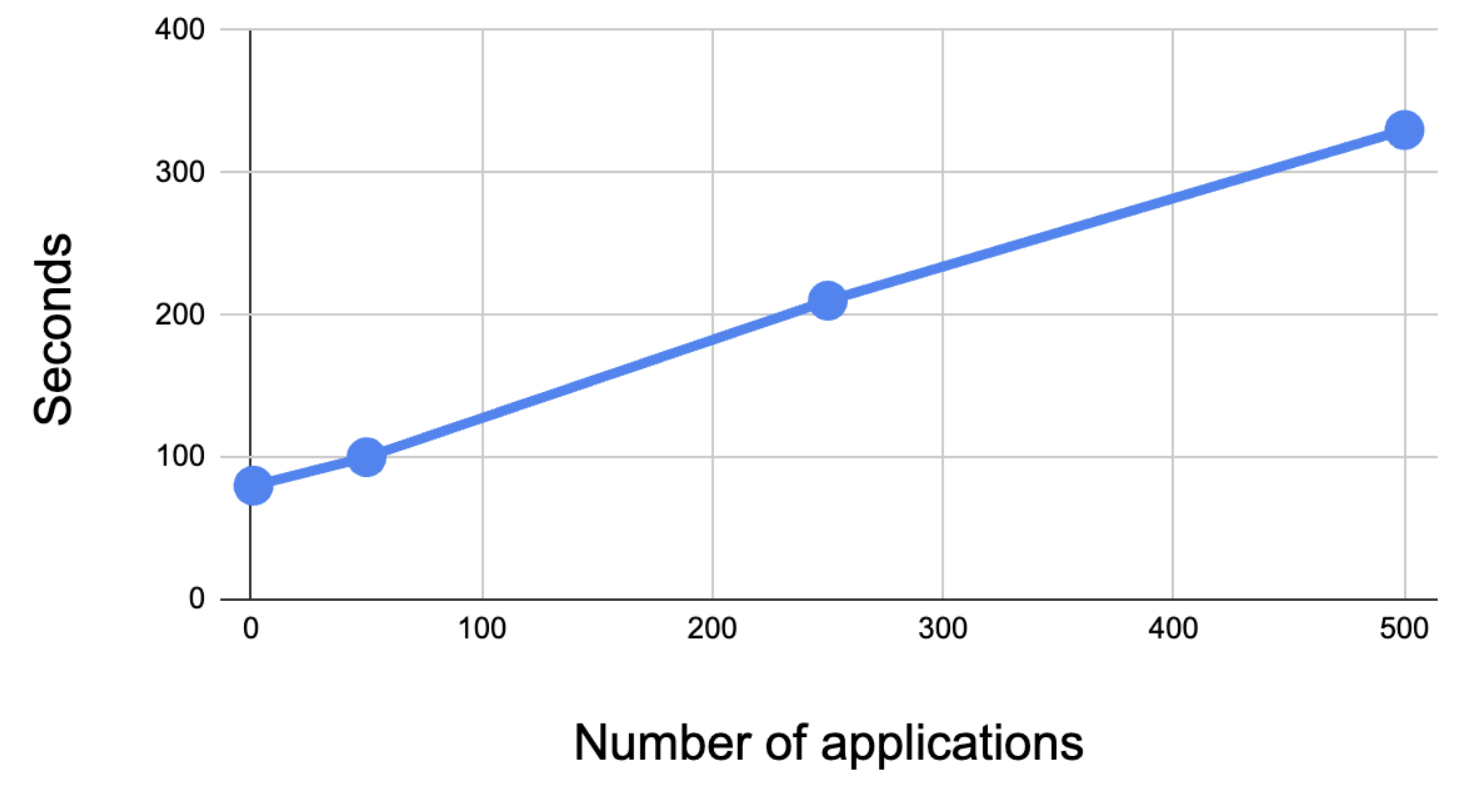
Creating a cluster and installing Argo CD on it takes around 1 minute, which is why rendering a single application takes over a minute.
> **The speed can vary depending on the distribution between applications used with Kustomize, Helm, and raw manifests. This test's result is based on a codebase mainly filled with Helm Charts.
#### Speeding up the rendering process
Rendering the manifests generated by all applications in the repository on each pull request is slow. The tool supports grepping applications with regex. Setting the environment variable `FILE_REGEX` only allows the tool to run on manifests that match a particular regex.
For example, if someone in your organization from *Team A* makes changes to one of their applications, the tool can be run with `FILE_REGEX=/Team-A/` so it only renders changes in folders matching `*/Team-A/*`. This speeds up the process significantly.
---
## Conclusion
In conclusion, tackling the challenge of accurately visualizing Kubernetes configuration changes within GitOps workflows is essential for ensuring smooth operations and minimizing errors.
`argocd-diff-preview` works like Atlantis for Terraform. The tool lets you render the diff on PRs, making it easier to review the changes made to the configuration. Since the diff is rendered by Argo CD itself, it is as accurate as possible.
In contrast to other existing solutions, `argocd-diff-preview` works without direct access to your infrastructure, which can be desirable for organizations with strict security requirements.
If you experience any issues with the tool, please open an issue on the [repository](https://github.com/dag-andersen/argocd-diff-preview) | dag-andersen |
1,862,708 | Reshape your Online Business Smartly with AI in E-commerce | Numerous e-commerce businesses employ artificial intelligence to understand their customers better.... | 0 | 2024-05-23T10:30:40 | https://dev.to/techdynesty/reshape-your-online-business-smartly-with-ai-in-e-commerce-48na | ai, ecommerce, aiinecommerce | Numerous e-commerce businesses employ artificial intelligence to understand their customers better. With AI tools such as machine learning, natural language processing, deep learning, and more, online retailers can make sense of the vast amount of data they gather, gain insights that enhance consumer satisfaction, expedite internal company operations, and combat fraud.
AI in e-commerce offers many opportunities for your company to expand. This blog will teach you more about using artificial intelligence (AI) in e-commerce and how it can assist companies in increasing process efficiency cost-effectively.
## **Application of AI in E-Commerce**
AI has the capabilities to transform your online business in every corner. Here are some of the significant uses of AI in e-commerce:
**- Personalization**
E-commerce companies can use artificial intelligence (AI) to tailor their clients' shopping experiences by making product recommendations based on their past purchases, tastes, and behavior.
This raises the likelihood of generating more sales and enhances consumer loyalty. It can also consider factors like search engine queries to attract more prospective clients.
**- Better Support for Customers**
The most likely way to achieve this is through improved chatbots. AI-powered chatbots are a great way for e-commerce companies to offer 24/7 customer care. Chatbots and virtual assistants can automate customer support requests, respond to frequently asked questions, and even help with the purchase process.
Customers benefit from a more efficient experience, and customer service personnel's workload is lessened.
**- Optimizing Prices**
Businesses want to focus on price optimization to achieve several benefits. However, AI in ecommerce can optimize pricing to guarantee companies the highest possible profit margins. Seasonal variations or supply chain problems may affect some products' costs. AI may consider all of this, allowing for real-time dynamic pricing.
**- Improved Customer Segmentation**
Software driven by artificial intelligence may examine millions of data points and offer insights into the most consistent purchasing behaviors, customer trends, and segment preferences.
This allows online retailers to tailor promotions and marketing messaging to each subdivided group, increasing income and sales and improving the personalized shopping experience.
**- Mitigation of Fraud**
Fraudsters attack e-commerce platforms and enterprises. On the other hand, fraud detection systems driven by AI in ecommerce domain can help to lessen the possibility of fraudulent transactions. These systems can trace fake IP addresses, identify consumer activity trends, and analyze them. This enhances the e-commerce platform's security and reliability in addition to helping to lower losses.
## **Wrapping Up**
There is no denying that artificial intelligence has advanced the e-commerce industry. AI applications in the e-commerce sector can improve customers' purchasing experience by making it more convenient and customized. [AI in e-commerce ](https://www.bacancytechnology.com/blog/ai-in-ecommerce)can help your businesses succeed in the market and differentiate themselves from competitors.
| techdynesty |
1,862,703 | Securing Development: Key Differences in Virtual Desktops, Enterprise Browsers and Cloud-Based Development | Which technology to secure development? Check the top differences between virtual desktops,... | 0 | 2024-05-23T10:29:12 | https://strong.network/article/key-differences | vdi, browser, cloud, development | > Which technology to secure development? Check the top differences between virtual desktops, enterprise browsers, and secure cloud development environments.
Many organizations struggle to keep an application development workflow that is secure against data leaks, while jointly preserving developers’ experience and productivity. This challenge has driven market demand for secure development environments especially due to developers being increasingly targeted by hackers. Breaches are notably [around source code ](https://www.securityweek.com/leaked-github-token-exposed-mercedes-source-code/) and [credentials ](https://www.securityweek.com/leaked-github-token-exposed-mercedes-source-code/)([see also this report](https://www.f5.com/labs/articles/threat-intelligence/2023-identity-threat-report-the-unpatchables)), some leading to [personal information leaks](https://techcrunch.com/2021/11/22/godaddy-breach-million-accounts/).
In this article, I’ll start with a quick rundown of the technologies available to organizations to address this challenge. Then, I’ll compare them across three dimensions: their applicability to support an application development process, their focus on security, and their impact on developer experience. At the end of this article, I’ll give a nuanced conclusion, in the sense that choosing any of these technologies shouldn’t necessarily be clear-cut. In other words, mixing them could even be beneficial in some cases.
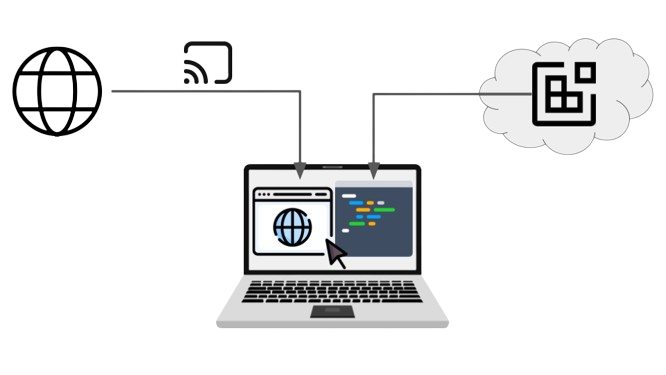
## What Are Virtual Desktops?
The need to protect the development workflow has led to the emergence of technologies such as virtual desktops notably from organizations such as [Citrix ](https://www.citrix.com/solutions/vdi-and-daas/virtualization-vdi.html)([Virtual Desktop Infrastructure, or VDI](https://www.citrix.com/solutions/vdi-and-daas/virtualization-vdi.html)) and [VMWare (Horizon)](https://www.vmware.com/products/horizon.html), etc. These are general-purpose desktops (Windows or Linux), where developers can install applications like Integrated Development Environments (IDE), and DevOps tools (e.g. [container management](https://dzone.com/guides/containers-development-and-management)) and access web applications supporting their workflow. In effect, remote access to a virtual desktop removes the need to maintain sensitive data on the local device. In addition, it provides access to an alternative source of computing power to build applications. A typical access method for the remote desktop is the [Remote Desktop Protocol](https://en.wikipedia.org/wiki/Remote_Desktop_Protocol) (RDP) which streams the desktop image to the local device.
## What Are Enterprise Browsers?
More recently, enterprise browsers, with companies such as [Island](https://www.island.io/), [Talon](https://talon-sec.com/), and [Citrix](https://docs.citrix.com/en-us/citrix-enterprise-browser.html), have appeared as web-based alternatives to Virtual Desktops, although the focus is securing access to web applications, typically SaaS services, as opposed to providing access to a desktop. However, these browsers also support protocols such as RDP to provide access to remote desktops (also as virtual machines). Vendors in this field often position themselves as a VDI replacement. A marked difference is that their offerings typically do not include computing resources (unlike Citrix and VMWare’s offerings). Hence, it is likely that organizations adopt them in the scope of a broader infrastructure set-up including [Desktop-as-a-Service](https://www.techtarget.com/searchvirtualdesktop/definition/desktop-as-a-service-DaaS) (DaaS) when computing resources are needed.
What Are Secure Cloud Development Environments?
As a means to secure an application development process, recent technology is [Secure Cloud Development Environments](https://strong.network/article/the-need-for-secure-cloud-development-environments) (CDEs) and the associated platform used to manage them. The basic role of such a platform is to provide online access to development environments with security mechanisms via an IDE, in addition to providing secured access to the web applications used by developers (e.g. for code management). For the latter, a technology similar to the one used for enterprise browsers is used.
The combination of remote access via IDE and secured web browsing aims at protecting the entire developer workflow against data leaks. Like in the case of a virtual desktop, local development data is in effect “removed” from local devices and computing is delivered via the Cloud. Hence, secure CDEs can be seen as a technology blending aspects of the previous two presented here.
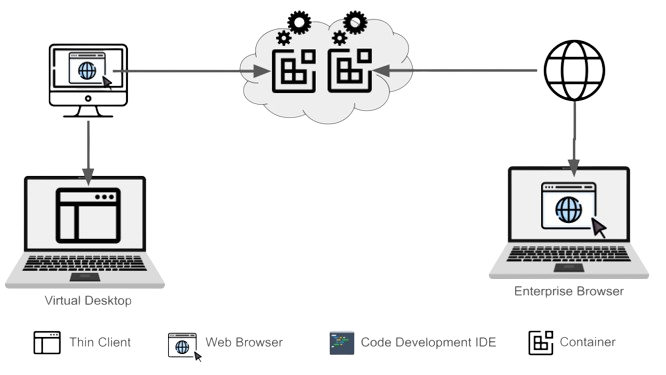
The figure below depicts the three technologies compared in this article.
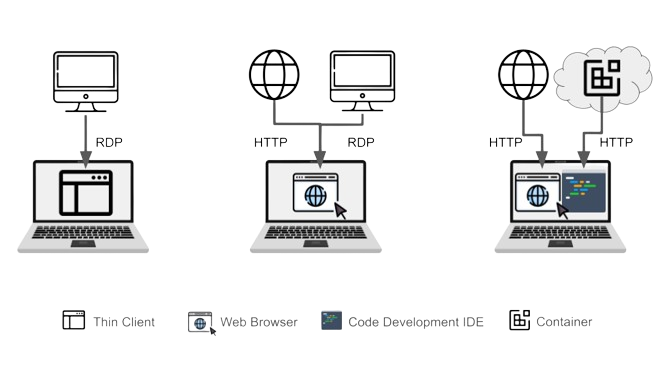
**Figure:** _From left to right, a thin client accesses a remote desktop, while an enterprise browser provides access to both web applications and remote desktops via RDP. On the right, a secure CDE platform provides a combination of remote access to a development environment via an IDE and secure web browsing. _
## Comparison of the Technologies
Let's dive now into key differences between the three technologies and highlight roles and benefits. Note that, albeit virtual desktops and enterprise browsers are business process-agnostic, I only discuss their application in securing application development here.
### Code Development Applicability
#### Virtual Desktops
In the context of code development virtual desktops are used across business units, but more commonly in scenarios involving the onboarding of remote developers, implementation of BYOD policies, and others requiring centralized control and security over remote desktop environments, mostly Windows-based (although Linux hosts are also used).
Any code development activities are performed on a generic desktop, which typically requires the installation of tools such as an IDE to start coding. As illustrated in the picture below (left), the remote desktop is used to code using the IDE and access a code management application. The remote desktop is also the primary source of compute to build applications.
#### Enterprise Browsers
When used in the scope of a development process, an enterprise browser acts as a web front-end to access a remote desktop set-up for development (via RDP). Because secure browsers impose fewer infrastructure constraints than virtual desktops, they can be more easily deployed across both internal and remote developers. Still, enterprise browsers do not provide any development environments by themselves, hence in this setting, they are merely the front-end to an existing park of development machines (physical or virtual), accessed via the browser client.
Hence, in the scope of a development process where a source of compute is needed, the setup is similar to a virtual desktop. A small difference is that the code management application in this case can be accessed securely using the browser on the developer device as opposed to a browser running on the virtual desktop. Here too, the remote desktop is the primary source of compute to build applications. This is shown in the middle part of the figure below.
#### Secure Cloud Development
A secure CDE Platform is designed to onboard both internal and remote developers (incl. BYOD) on centrally managed and standardized environments. To run environments, the platform relies on lightweight virtualization using containers (i.e. a virtual process) as opposed to a virtual machine. Hence set-up and operations are much more efficient and more scalable because containers require fewer resources. Hence it is easy and economical to assign multiple environments to a single developer. Each container has its own source of compute and is easy to set or reconfigure without any loss of data.
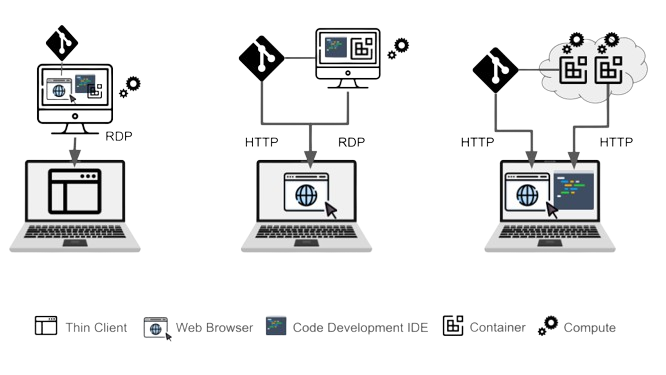
**Figure:** _From left to right, in both the cases of virtual desktops and enterprise browsers, a virtual machine hosts all the tools, computing power and provides connection to DevOps services. Secure Cloud Development provides access via IDE and secure browser to containerized environments and services, respectively._
The striking difference with a remote desktop is that developers do not need a desktop to develop applications. The platform is primarily suited for cloud-native, i.e. web-based (back-end/front-end) and mobile development (left part in the next figure). The Cloud environment is accessed directly via the IDE and developers typically run web applications on an environment’s port. The running application is then accessed via a local web browser. Note that it is possible to run a desktop on the containers if needed. In this case, it is steamed over a port and accessed via the browser as well (right part of the figure below).
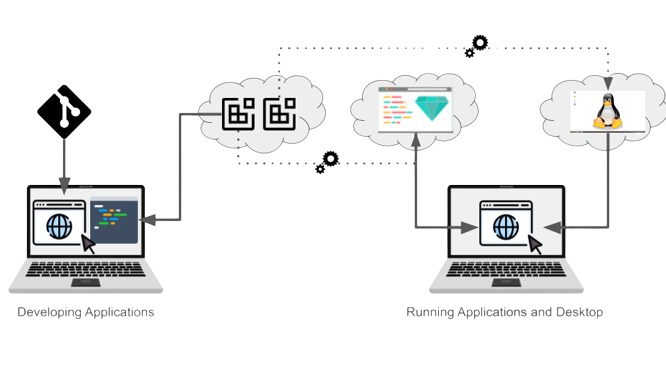
**Figure:** _Secure Cloud-based development does not require a desktop to build backend, web, and mobile applications. The same mechanism used to run applications on containers lets users access a desktop when necessary. _
### Security Focus of the Technologies
What about their security focus?
#### Virtual Desktops and Enterprise Browsers
Virtual desktops secure the end-user environment by centralizing data and desktop applications, reducing endpoint vulnerabilities. Both Citrix and VMWare clients offer data leak prevention (DLP) measures that protect from data exfiltration via [system hardening measures](https://community.citrix.com/tech-zone/build/tech-papers/cvad-security-best-practices/) encompassing user access, data egress restrictions, etc.
Enterprise browsers aim to protect the organization from phishing, malware, and other threats when accessing web applications, and from user operations that could result in data leaks, including insider threats using DLP as well.
In the case of enterprise browsers, security measures are primarily “client-focused”, because users do not have access to the backend of the application they use. Security measures are more complex and include network policies in the case of virtual desktops. Such policies might be necessary to avoid data exfiltration using internet connectivity once on the remote application. This shows a potential limitation of Enterprise browsers as a VDI replacement when accessing desktops: it is likely that no secure measures are provided to protect from operations on the desktop. However, this aspect could depend on the vendor-dependent.
#### Secure Cloud Development
A secure CDE platform focuses on securing data in development environments and web applications against exfiltration. This is akin to client-side DLP.
The platform also provides “back-end DLP” by protecting access to the data used for development. This is achieved by controlling the network and providing authentication services to the organization’s resources.
Although a CDE-based infrastructure is simpler than a virtual desktop counterpart, it is indeed this simplicity that allows it to build a more holistic approach to data loss prevention with minimal impact on the local device used to access the platform.
An additional aspect is that, because a secure CDE platform is designed to support application development, security mechanisms can beneficially use the context to make security a productivity enabler as opposed to a hassle.
## Impact and Benefits to Developer Experience
Accessibility to the platform and more generally the developer experience are important factors when assessing the fitness of these technologies to support development.
Virtual Desktops lets developers interact with a remote desktop via a locally installed client by streaming the image of the remote desktop to the client. Such access protocol often suffers from latency due to network requirements, which unfortunately impacts the developer experience (check this real-life story).
Enterprise browsers let developers access web applications without usability issues However, because developers need access to a remote desktop for coding, this requires again the use of a streaming protocol such as RDP and results in display latency impacting the developer experience and productivity.
**Figure:** _In the case of a secure CDE platform, the IDE used for coding (right part) is not streamed to the desktop and rendered locally, which preserves the developer’s experience. In comparison, secure browsing might be implemented using streaming (left part)._
A secure CDE platform provides developers access to the online development environment via a web-based IDE, and to web applications via a secure browser. The web-based IDE is a web application on its own and renders natively in the browser on the developer’s device. Hence no streaming is required which provides optimal developer experience (see the above figure).
In contrast, the chosen implementation for the secure browser can impact the experience. However, in practice, developers spend the majority of their time in the IDE and use web applications for less frequent operations such as pull requests.
## Opportunities When Combining Technologies
In general, virtual desktops and enterprise browsers play an important role across enterprise business processes by providing general-purpose security for desktops and web applications, each with distinct infrastructure requirements and performance outcomes. Historically, virtual desktops have been a staple in the enterprise environment, representing the oldest technology among the ones that I discussed in this article.
In comparison, enterprise browsers are designed as a lightweight alternative to virtual desktop infrastructure. They are however optimized mainly for SaaS applications delivered through the web. Their utilization for accessing developer desktops via RDP is akin to a modern reinterpretation of virtual desktops via a web browser.
To protect the application development process, a secure Cloud Development Environment (CDE) platform centralizes all essential resources, including access to clients (IDE and web applications) and development environments, in one place. The targeted usage allows the platform to offer context-specific security and preserves the developer experience when working in a secure environment.
In a larger organizational context, integrating a secure CDE platform with virtual desktops or an existing enterprise browser setup might be necessary. This provides an opportunity to balance development productivity, security, and asset utilization optimally.
One key feature of a secure CDE platform is its use of a dedicated browser for safe access to web applications. This feature is particularly enhanced when integrated with an enterprise browser or application virtualization technologies. Essentially, this integration allows for replacing the CDE platform's secure browser with a more seamless solution and incorporates secure CDE technologies into the existing infrastructure.
This way, organizations can standardize security mechanisms across the infrastructure, ensuring access to legacy applications while modernizing application development. It also offers them an opportunity to improve asset utilization by leveraging lightweight virtualization for on-demand access to cheap computing power dedicated to development workloads (see the next figure),
In the implementation of a Virtual Desktop Infrastructure, incorporating a secure CDE platform elevates the developer experience by providing on-demand development environments (with associated computational resources) and bolstering data access security.
**Figure:** _The combination of the secure CDE platform and the other technologies to fit different needs and scenarios in an enterprise setting._
In conclusion, integrations between secure CDE platforms, enterprise browsers, and virtual desktops provide opportunities for enhancing both the security and productivity of the development process, while jointly improving developer experience and resource utilization.
Although a secure CDE platform alone provides a contemporary approach to prevent data leaks during application development, it also delivers an opportunity to enrich the existing infrastructure ecosystem of modern organizations.
**Published at Dev.to with permission of Laurent Balmelli, PhD. See the original article [here](https://strong.network/article/key-differences).** | loransha256 |
1,862,689 | Automating Next.js Builds and Firebase Deployment with Node.js | Learn how to automate your Next.js application build process and deploy it to Firebase using Node.js scripts. | 0 | 2024-05-23T10:00:50 | https://dev.to/itselftools/automating-nextjs-builds-and-firebase-deployment-with-nodejs-48g0 | javascript, node, nextjs, devops |
At [itselftools.com](https://itselftools.com), we've gained extensive experience from developing over 30 web applications using Next.js and Firebase. In this article, I'll share a snippet of code that automates the building and deployment of a Next.js app to Firebase, making the deployment process as efficient as possible.
## Understanding the Code Snippet
Here is a concise breakdown of each segment of the code provided:
```javascript
const { readFileSync, writeFileSync } = require('fs');
const yaml = require('js-yaml');
const prepareDeployment = () => {
const doc = yaml.load(readFileSync('./deployment.yaml', 'utf8'));
const config = {
public: 'out',
ignore: doc.ignoreFiles
};
writeFileSync('firebase.json', JSON.stringify(config, null, 2));
console.log('Firebase configuration updated for deployment.');
};
const buildAndDeploy = () => {
prepareDeployment();
execSync('next build && next export && firebase deploy');
console.log('App successfully deployed to Firebase.');
};
```
### Step-by-Step Explanation
1. **Reading and Parsing Configuration:** The `prepareDeployment` function reads a YAML configuration file, 'deployment.yaml', which specifies files to ignore during deployment. It uses the 'js-yaml' package to parse this file.
2. **Creating the Firebase Configuration File:** It then creates or updates the 'firebase.json' file with deployment configuration such as the public directory and ignored files, which is essential for the Firebase deployment settings.
3. **Building and Deploying the App:** The `buildAndDeploy` function first calls `prepareDeployment` to ensure the Firebase config is set up correctly. It then executes a series of commands to build the Next.js application, export it, and finally deploy it to Firebase using `execSync`, which runs these commands in the system's shell.
## Recommended Tools and Libraries
- **Node.js**: Provides the runtime environment to run JavaScript on the server.
- **Next.js**: A React framework that enables functionalities such as server-side rendering and generating static websites.
- **Firebase**: An application development platform that provides hosting and backend services.
- **js-yaml**: A library to safely parse YAML files in Node.js.
## Conclusion
This scripted approach reduces the likelihood of deployment errors and streamlines the entire build and deployment process. To see how effective this setup can be, feel free to explore some of our applications like [Free High-Quality Screen Recording](https://online-screen-recorder.com), [Free Online English Word Search Tool](https://find-words.com), and [Extract Text from Images and PDFs Online](https://ocr-free.com).
Switching to automated deployments can significantly improve the reliability and efficiency of software releases, especially in agile development environments where frequent updates are common. | antoineit |
1,862,707 | Why Divsly is the Best Choice for Your Email Marketing Needs | In today's digital age, email marketing has become a cornerstone of business communication and... | 0 | 2024-05-23T10:25:52 | https://dev.to/divsly/why-divsly-is-the-best-choice-for-your-email-marketing-needs-5cko | emailmarketing, emailcampai, emails, emailbusin | In today's digital age, email marketing has become a cornerstone of business communication and customer engagement strategies. With countless options available, it can be overwhelming to choose the right email marketing platform for your needs. However, amidst the sea of choices, one platform stands out as a reliable and effective solution: Divsly. In this blog post, we'll explore why Divsly is the best choice for your email marketing needs.
## 1. User-Friendly Interface
[Divsly](https://divsly.com/) prides itself on its intuitive and user-friendly interface. Whether you're a seasoned marketer or just starting out, Divsly makes it easy to create, send, and track email campaigns. With drag-and-drop functionality and pre-designed templates, you can quickly customize emails to suit your brand and message without any coding knowledge required. This simplicity and ease of use mean that you can focus on crafting engaging content rather than getting bogged down in technical details.
## 2. Powerful Automation Tools
Automation is key to streamlining your email marketing efforts and maximizing efficiency. Divsly offers a robust suite of automation tools that allow you to set up personalized email workflows based on customer behavior, demographics, and preferences. From welcome emails to abandoned cart reminders, you can automate various touchpoints along the customer journey, ensuring timely and relevant communication that drives results. With Divsly's automation tools, you can nurture leads, re-engage dormant subscribers, and ultimately, boost conversions with minimal effort.
## 3. Advanced Segmentation Capabilities
One size does not fit all when it comes to email marketing. Divsly understands this and offers advanced segmentation capabilities that enable you to divide your audience into targeted groups based on specific criteria such as location, purchase history, or engagement level. By segmenting your email list, you can deliver highly tailored content that resonates with each segment, increasing open rates, click-through rates, and ultimately, conversions. Whether you're running a promotional campaign or sending out a newsletter, Divsly's segmentation tools help you deliver the right message to the right people at the right time.
## 4. Comprehensive Analytics
Effective [email marketing](https://divsly.com/features/email-marketing) requires data-driven insights to measure performance, identify areas for improvement, and optimize campaigns for better results. Divsly provides comprehensive analytics that give you a deep understanding of how your emails are performing. From open rates and click-through rates to conversion tracking and revenue attribution, you can track key metrics and monitor the success of your campaigns in real-time. Armed with this valuable data, you can make informed decisions to refine your email strategy and achieve your marketing goals.
## 5. Seamless Integration
Divsly seamlessly integrates with a wide range of third-party tools and platforms, including CRM systems, e-commerce platforms, and analytics software. This integration allows you to sync customer data, track interactions across multiple touchpoints, and leverage existing tools to enhance your email marketing efforts. Whether you're managing contacts, analyzing sales data, or optimizing website performance, Divsly plays nicely with your existing tech stack, making it easy to integrate email marketing into your overall marketing strategy.
## 6. Exceptional Support
Last but not least, Divsly provides exceptional customer support to help you every step of the way. Whether you have a question about a feature, need assistance with a campaign, or encounter a technical issue, Divsly's support team is readily available to provide guidance and resolve any issues promptly. With responsive support via email, chat, and phone, you can rest assured that help is always just a click or call away, ensuring a smooth and hassle-free experience with the platform.
In conclusion, Divsly offers a winning combination of user-friendly interface, powerful automation tools, advanced segmentation capabilities, comprehensive analytics, seamless integration, and exceptional support that makes it the best choice for your email marketing needs. Whether you're a small business owner, a marketing professional, or an e-commerce entrepreneur, Divsly empowers you to create engaging email campaigns, nurture customer relationships, and drive business growth with ease. Try Divsly today and experience the difference for yourself! | divsly |
1,862,704 | Interactive Color-Changing Button | This project demonstrates a simple interactive button using HTML, CSS, and JavaScript. When the... | 0 | 2024-05-23T10:25:18 | https://dev.to/megha_sangapur_98205768ca/interactive-color-changing-button-5fil | codepen | This project demonstrates a simple interactive button using HTML, CSS, and JavaScript. When the button is clicked, its color changes randomly. This example is perfect for beginners who want to learn how to manipulate DOM elements and handle events in JavaScript.
{% codepen https://codepen.io/Megha-Sangapur/pen/PovzEVo %} | megha_sangapur_98205768ca |
1,862,705 | Puppeteer Docker | Hi, i am running into an error while performing html to pdf generation using puppeteer ,i am using... | 0 | 2024-05-23T10:24:07 | https://dev.to/let_alliance_bcc6d5511681/puppeteer-docker-4c2i | programming, devops, aws | Hi,
i am running into an error while performing html to pdf generation using puppeteer ,i am using docker to deploy on aws but when i excute my code i am getting error
"Read-only file system : '/var/task/chrome-linux64.zip'"
Thanks
| let_alliance_bcc6d5511681 |
1,862,702 | Creating Open Source Connections | Explore how StarSearch revolutionizes open source collaboration by connecting projects with top talent using AI-driven insights into GitHub events and contributor activities. | 0 | 2024-05-23T10:17:39 | https://opensauced.pizza/blog/open-source-insights-with-starsearch | opensource, ai, community, showdev | ---
title: Creating Open Source Connections
published: true
description: Explore how StarSearch revolutionizes open source collaboration by connecting projects with top talent using AI-driven insights into GitHub events and contributor activities.
tags: opensource, ai, community
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ifvsdgm6y0y0r0pkmmu8.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-23 10:04 +0000
canonical_url: https://opensauced.pizza/blog/open-source-insights-with-starsearch
---
As it stands today, the open source ecosystem can feel disconnected. Theoretically, we know that there are maintainers, contributors, and projects out there that are incredibly talented and innovative, but finding them can feel like searching for stars in a cloudy night sky. Sometimes you need to have that information – and fast – to be able to maintain your own projects.
## The Challenge of Open Source Connections
Imagine you're at a tech company using cutting-edge technology. You need to upstream some important changes to ensure future compatibility but you find yourself hitting a wall. Who exactly should you reach out to? Who are the key contributors with the right expertise? Traditionally, this process would involve a lot of guesswork and detective work, looking through commit histories or issue discussions. Enter [StarSearch](https://app.opensauced.pizza/star-search), designed to change how we discover and connect with others in the open-source universe. With StarSearch, in just a few clicks, you’re able to identify key contributors skilled in that technology and maintainers who may have the answers you need. StarSearch isn’t just a tool; it’s your entry point into a more intimate, interconnected open-source community.
## Introducing StarSearch
StarSearch leverages advanced analytics and AI, all fueled by real-time data from GitHub Events. StarSearch isn’t just about identifying who committed what; it’s about understanding the dynamics and interactions within the open source community.
> **We’re live on [Product Hunt](https://www.producthunt.com/products/opensauced)! Join the conversation and share your thoughts.**
### Connecting with StarSearch
Here’s how StarSearch addresses some of the common queries and needs within the community:
- What type of pull requests has {username} worked on?
- Who are the best developers that know {technology} and are interested in {technology}?
- Who are the most prevalent contributors to the {technology} ecosystem?
- Show me the lottery factor for contributors in the {repository} project?
These questions can be the starting point for building stronger projects and communities, allowing us to find people with passion and expertise that we may have never connected with before.
## Learn More About StarSearch
You can check out more about our approach and process, as well as the resources:
- [Building a Copilot for Git History with pgvector and Timescale](https://www.timescale.com/blog/how-opensauced-is-building-a-copilot-for-git-history-with-pgvector-and-timescale/)
- [How We Saved Thousands with Open Source AI Technologies](https://opensauced.pizza/blog/how-we-saved-thousands-of-dollars-deploying-low-cost-open-source-ai-technologies)
- [Meet StarSearch: Your New Open Source Navigator](https://opensauced.pizza/blog/meet-starsearch)
- [StarSearch Docs](https://docs.opensauced.pizza/features/star-search/)
### Watch our "What is StarSearch" Video
[](https://www.youtube.com/watch?v=I3cS-u_gmDE)
## The Future of StarSearch
StarSearch provides a nuanced view of the open-source landscape. It’s more than a tool; it’s a new way to navigate the open-source ecosystem, bringing clarity, connections, and community to our tooling and making the open source ecosystem feel more like a tightly knit community where everyone knows your name – and your code. And we're just getting started. We have big plans for the future of StarSearch.
If you’re ready to find a new way to connect, [sign up for OpenSauced](https://app.opensauced.pizza/) and be among the first to explore the future of open-source collaboration with StarSearch today.
| bekahhw |
1,862,684 | AI Content-Based Safety Training Kiosks: Revolutionizing Workplace Safety | Workplace safety is a critical concern for organizations across all industries. Accidents and... | 0 | 2024-05-23T09:55:30 | https://dev.to/addsofttech/ai-content-based-safety-training-kiosks-revolutionizing-workplace-safety-1ddp | blog, article, business, technology | Workplace safety is a critical concern for organizations across all industries. Accidents and injuries not only jeopardize employee well-being but also impact productivity and profitability. Traditional safety training methods, however, often fall short in effectively engaging employees and ensuring long-term retention of information. In response to these challenges, a new era of safety training has emerged, propelled by advancements in artificial intelligence (AI) technology. In this blog post, we'll explore how AI content-based safety training kiosks are revolutionizing workplace safety.
The Need for Innovation in Safety Training: Traditional safety training methods, such as classroom lectures and printed materials, have limitations in engaging today's diverse workforce. Employees may struggle to connect with static content, leading to reduced retention and effectiveness of training programs. Moreover, industries with specific hazards, such as those involving machinery or chemicals, require tailored training approaches to address unique risks adequately. To address these challenges, organizations have sought innovative solutions that can deliver personalized, interactive, and effective safety training experiences.
The Emergence of [AI Content-Based Safety Training Kiosk](https://www.addsofttech.com/stk-ai-content-based.html)s: AI content-based safety training kiosks represent a groundbreaking innovation in safety education. These kiosks leverage AI algorithms to deliver tailored training content in an interactive and engaging manner. Equipped with intuitive interfaces and multimedia elements, such as videos and simulations, these kiosks provide employees with immersive learning experiences. What sets them apart is their ability to analyze user data and interactions to personalize the training content based on each employee's role, experience level, and specific safety needs.
**Key Features and Benefits:**
**1. Personalization: **AI algorithms analyze user data to deliver customized training content tailored to each employee's requirements.
**2. Interactivity: **Multimedia elements enhance engagement and facilitate better understanding of safety concepts.
**3. Real-time Feedback: **Employees receive immediate feedback on their performance, enabling them to track their progress and address areas for improvement.
**4. Remote Monitoring: **Supervisors and safety managers can monitor employee training progress and compliance in real-time, allowing for proactive interventions when necessary.
**5. Accessibility: **Features such as voice commands and screen readers ensure that the training kiosks are accessible to all employees, including those with disabilities.
Implications for Workplace Safety: The adoption of AI content-based safety training kiosks has significant implications for workplace safety. By providing employees with personalized, interactive, and accessible training experiences, organizations can:
• Improve safety awareness and compliance
• Reduce the risk of accidents and injuries
• Foster a culture of safety and continuous learning
• Enhance overall productivity and efficiency
AI content-based safety training kiosks represent a transformative solution for addressing the evolving challenges of workplace safety training. By harnessing the power of AI, organizations can revolutionize their safety education programs, ensuring that employees are equipped with the knowledge and skills needed to stay safe on the job. As we continue to embrace technological advancements, AI content-based safety training kiosks will play an increasingly vital role in shaping the future of workplace safety.
| addsofttech |
1,862,701 | Comment modérer en toute sécurité le chat et les utilisateurs avec BizOps Workspace | Comment utiliser le Channel Monitor et l'Access Manager de PubNub pour créer une application de chat sécurisée et modérée ? | 0 | 2024-05-23T10:15:13 | https://dev.to/pubnub-fr/comment-moderer-en-toute-securite-le-chat-et-les-utilisateurs-avec-bizops-workspace-51ee | Cet article fait partie d'une série d'articles qui traitent des capacités de gestion des données de PubNub, connues collectivement sous le nom de [BizOps Workspace](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr):
- [Comment gérer les utilisateurs et les canaux avec BizOps Workspace](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)
- [Comment surveiller et modérer les conversations avec BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)
- Comment modérer en toute sécurité les conversations et les utilisateurs avec l'espace de travail BizOps
BizOps Workspace est un ensemble d'outils qui vous aide à gérer votre application. Cet article développe l'article précédent "[Comment surveiller et modérer les conversations avec BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)" pour montrer une application de chat sécurisée de bout en bout avec des capacités de modération manuelle, c'est-à-dire la capacité de surveiller les conversations en temps réel et de mettre en sourdine ou de bannir les utilisateurs.
Bien que cet article puisse être lu seul, je recommande fortement de lire l'article précédent "[Comment surveiller et modérer les conversations avec BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)" pour mieux comprendre le contexte des concepts discutés ici.
Qu'est-ce que le moniteur de canaux ?
-------------------------------------
Le moniteur de canaux permet aux modérateurs de chats de regarder des aperçus en direct des conversations qui se déroulent en temps réel sur plusieurs canaux. Si le modérateur repère quelque chose d'inquiétant, comme un utilisateur qui se comporte mal ou des messages offensants, il peut agir immédiatement pour résoudre le problème.
Le modérateur dispose d'une grande souplesse quant aux mesures à prendre :
- Observer un utilisateur sans limiter ses droits d'accès
- Modifier ou supprimer le message incriminé
- Limiter la capacité de l'utilisateur à publier des messages[(mettre en sourdine](https://pubnub.com/docs/bizops-workspace/channel-monitor#mute?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr))
- Limiter la capacité de l'utilisateur à lire ou à publier des messages[(interdiction](https://pubnub.com/docs/bizops-workspace/channel-monitor#ban?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)).
Toutes les fonctionnalités de la fonction "Surveiller" sont manuelles : examen manuel des messages, mise en sourdine manuelle des utilisateurs, etc. Cet article ne traite pas de la modération automatique.
Pour utiliser le Channel Monitor, vous devez avoir plusieurs fonctionnalités activées sur votre clé PubNub, en particulier le [contexte de l'application](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) et la [persistance des messages](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) au minimum. Pour plus de détails, veuillez consulter la section 'Keyset requirements for the Channel Monitor' dans l'[article précédent](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr).
Qu'est-ce que le PubNub Access Manager ?
----------------------------------------
Les**développeurs doivent se prémunir contre les utilisateurs qui tentent de contourner leur système de modération**, ce qui est possible grâce au gestionnaire d'accès PubNub.
Le [gestionnaire](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) d'accès vous permet de définir un ensemble de règles qui décrivent les permissions de l'utilisateur (ou des utilisateurs) spécifié(s) et les actions qu'il(s) peut(vent) effectuer sur les ressources spécifiées. Par exemple :
- L'utilisateur dont l'ID est `123` a le droit de lire et d'écrire sur le canal `456`.
- Tous les utilisateurs dont l'ID correspond à l'expression régulière `user-*` peuvent lire sur n'importe quel canal dont l'ID correspond à l'expression régulière `global-*`.
- L'utilisateur ayant l'ID `123` a le droit de mettre à jour les métadonnées du canal (c'est-à-dire le contexte de l'application).
Pour une liste complète des permissions, veuillez vous référer à la documentation à l'[adresse https://www.pubnub.com/docs/general/security/access-control#permissions.](https://www.pubnub.com/docs/general/security/access-control#permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)
PubNub Access Manager est basé sur des jetons, et la façon la plus simple de le décrire est de parcourir le flux d'autorisation tel qu'il est montré dans la [documentation](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) et de fournir un contexte supplémentaire sur la façon dont ce flux est lié à la modération :

1. **Tentative de connexion**. Votre client s'authentifie auprès de votre serveur pour connecter vos utilisateurs à votre application. Après cette étape, votre serveur est certain de parler à un utilisateur enregistré de l'application et de savoir qui il est. Le client demande un jeton d'authentification PubNub Access Manager dans le cadre de son initialisation.
2. **Demande d'autorisation**. Le serveur traite la demande de jeton du client en invoquant l'API SDK '[grantToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#grant-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)'. Quelques points à noter à propos de cette API : Elle ne peut être appelée qu'avec la **clé secrète** PubNub et, par conséquent, ne peut être invoquée qu'à partir d'un serveur ; elle est disponible pour tous nos SDK côté serveur ; et cette API acceptera des objets JSON pour définir les ressources et les permissions qui définissent l'accès de l'utilisateur (ou des utilisateurs).
3. **Jeton retourné**. PubNub accorde les permissions demandées à l'utilisateur ou aux utilisateurs demandés et renvoie un jeton d'authentification au serveur.
4. Jeton**transmis**. Votre serveur renvoie ensuite le jeton d'authentification au client demandeur initial.
5. **Jeton défini**. Le client peut spécifier ce jeton d'authentification lors de son initialisation ou à n'importe quel moment du cycle de vie de l'application grâce à la méthode [setToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#set-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr). Il est essentiel de pouvoir mettre à jour le jeton à tout moment car les jetons expirent, mais un client devra également demander un nouveau jeton si le Channel Monitor met à jour ses autorisations (c'est-à-dire s'il est mis en sourdine ou banni).
6. **Demande d'API autorisée**. Tout appel ultérieur à PubNub sera désormais considéré comme autorisé. PubNub autorisera ou refusera toute demande d'API en fonction des permissions accordées à l'étape 2 et de la validité du jeton du client.
A quoi ressemble une solution de modération sécurisée ?
-------------------------------------------------------
Vers la fin de l'[article précédent](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr), j'ai montré une démonstration de ce à quoi ressemblerait l'inhibition ou le bannissement du côté du client. Le SDK Chat contient des [événements de modération](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) qui indiquent à un client s'il a été mis en sourdine ou banni ; cependant, à part la mise à jour de l'interface utilisateur, cela n **'empêche pas le client de continuer à envoyer des messages même s'il a été mis en sourdine ou banni**. Pour sécuriser la mise en sourdine ou le bannissement du client, vous devez révoquer les autorisations existantes du gestionnaire d'accès et lui en accorder de nouvelles pour refléter son nouveau statut de mise en sourdine ou de bannissement.
Prenons le scénario suivant : un utilisateur est mis en sourdine du canal "Musiques" :

1. Un utilisateur peut accéder à deux canaux, "films" et "comédies musicales", mais l'administrateur souhaite lui interdire l'accès au seul canal "comédies musicales".
2. Le modérateur coupe le son de l'utilisateur à l'aide du moniteur de canaux. En clair, il invoque l'API "[setRestrictions()](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#method-signature-1?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)
3. L'application serveur reçoit la notification "mute" par le biais d'un [événement de modération](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) et [révoque](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#revoke-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) le jeton d'accès existant de l'utilisateur.
4. L'application cliente reçoit la notification "mute" associée au canal "musicals" par le biais d'un événement de [modération](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr).
5. L'application met à jour son interface utilisateur pour empêcher l'envoi d'autres messages. L'utilisateur peut contourner ce changement d'interface en modifiant le code JavaScript de la page, mais toute tentative d'envoi de messages échouera puisque son jeton d'authentification a été révoqué.
6. L'application demande un nouveau jeton d'authentification au serveur, comme décrit dans la section Gestionnaire d'accès ci-dessus. Le nouveau jeton d'authentification reflète les nouvelles autorisations de l'utilisateur, qui n'a plus que l'accès "lecture" au canal "comédies musicales".
L'[article précédent](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) décrivait les "Composants d'une solution de modération" et dressait la liste des API disponibles pour le client et le serveur à l'aide du graphique ci-dessous. Les API dont il est question dans les étapes ci-dessus sont également indiquées dans ce graphique.

L'exemple d'application Chat SDK
--------------------------------
La même équipe d'ingénieurs chargée de développer le Channel Monitor et le Chat SDK a également créé un exemple d'application écrit en React Native qui utilise le Chat SDK.
L'exemple montre les capacités du SDK et les meilleures pratiques pour développer une application de chat réaliste et complète à l'aide de PubNub. Il est open source et fait partie du même dépôt GitHub qui contient le Chat SDK sous [/samples/react-native-group-chat](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat).

Cette application a récemment été mise à jour pour demander des jetons à un serveur Access Manager et pour demander un nouveau jeton lorsque les permissions de l'utilisateur changent, c'est-à-dire lorsqu'il est banni ou mis en sourdine d'un canal. Cette amélioration a été apportée depuis la rédaction de l'[article précédent](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr), alors assurez-vous d'obtenir la dernière source sur [GitHub](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat). Au moment de la rédaction de cet article, l'ID du commit git le plus récent est [ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat).
Sécuriser la mise en sourdine et le bannissement des utilisateurs : Démonstration à l'aide de l'exemple d'application
---------------------------------------------------------------------------------------------------------------------
Cette section décrit comment mettre en œuvre notre démo de bout en bout, en montrant la modération sécurisée du point de vue du client et du serveur.
### Créer un jeu de clés PubNub
Je recommande de créer un nouveau jeu de clés PubNub pour exécuter cette démo comme suit :
1. Connectez-vous au [portail d'administration](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) et créez une nouvelle application ou un nouveau jeu de clés dans une application existante. Si nécessaire, vous pouvez trouver des instructions étape par étape sur notre page [Comment créer des jeux de clés sur le portail d'administration](https://www.pubnub.com/how-to/admin-portal-create-keys/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr).
2. Sur la page des jeux de clés, activez les options de configuration suivantes. Vous pouvez accepter les valeurs par défaut, sauf indication contraire :
- [App Context](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr). Il stocke des métadonnées sur vos canaux et vos utilisateurs et est décrit plus en détail dans l'article précédent sur la["Gestion des utilisateurs et des canaux](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)". Activez également les `événements de métadonnées d'utilisateur`, les `événements de métadonnées de canal` et les `événements d'adhésion`.
- [Persistance des messages](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr). Ceci stocke l'historique de vos messages avec PubNub afin que l'administrateur puisse revoir et éditer les conversations.
- [Gestionnaire d'accès](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr). Empêche l'accès non autorisé aux données et est nécessaire pour créer une solution de modération sécurisée.
- [Présence](https://www.pubnub.com/docs/general/presence/overview?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr). Utilisé pour savoir si un utilisateur est en ligne ou hors ligne.
Enregistrez vos modifications.
Vous aurez besoin de la `clé de publication`, de la `clé d'abonnement` et de la `clé secrète` dans les étapes suivantes.
### Créer l'exemple d'application
Comme décrit précédemment, l'application Chat SDK Sample est une application client multiplateforme écrite en React Native à l'aide du framework Expo.
Clonez et construisez l'application exemple en suivant les instructions données dans [le readme de l'application](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat#readme). En particulier, assurez-vous que les prérequis sont installés, y compris yarn et Node.js. Le ReadMe parle d'utiliser XCode et iOS, mais vous pouvez également exécuter l'application sur un émulateur Android. Au moment où j'écris ces lignes, l'ID du commit git le plus récent est [ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat).
Lorsque vous fournissez les clés Pub/Sub, utilisez les clés que vous avez générées à l'étape précédente. Si vous n'incluez pas les clés dans le fichier `.env`, l'application utilisera par défaut des clés de `démonstration`; vous pouvez désactiver cette logique à l'[adresse https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60](https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60) pour éviter toute confusion.
Exécutez l'application. Le ReadMe vous indiquera de lancer `yarn ios`, mais vous pouvez également lancer `yarn android` ou `yarn run start`, ce dernier vous donnant un menu interactif.
Lorsque vous vous connectez, vous devriez voir l'avertissement suivant dans votre console :

C'est parce que le client n'a pas réussi à se connecter au serveur Access Manager, alors construisons-le.
### Construire le serveur d'exemple de gestionnaire d'accès
L'exemple de serveur de gestion d'accès peut être trouvé à [https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api,](https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api) c'est la même monorepo que l'application client discutée précédemment.
Ouvrez le fichier `src/chatsdk.service.ts` dans l'éditeur de votre choix et remplissez les champs `publishKey`, `subscribeKey` et `secretKey`. Les clés de publication et de souscription doivent correspondre à celles que vous avez utilisées pour construire l'application cliente, et la clé secrète est disponible depuis la page du jeu de clés de l'application sur le [portail d'administration](https://admin.pubnub.com?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr).
Depuis le répertoire `REPO/samples/access-manager-api`, exécutez `yarn run start` pour démarrer le serveur Access Manager, et vous devriez voir quelque chose comme ci-dessous :

Pour voir ce que fait le serveur Access Manager, regardez `app.service.ts`. Vous y verrez les structures de permission générées pour l'utilisateur demandeur et l'appel à `chat.sdk.grantToken()` pour appliquer ces permissions, renvoyant l'authKey générée au client appelant.
Il s'agit des permissions requises par l'application de démonstration, mais votre application aura probablement besoin de permissions différentes. Vous pouvez utiliser ce jeu de règles comme modèle de départ, mais lorsque vous créez le serveur Access Manager pour votre application, consultez [https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) pour comprendre exactement quelles autorisations sont nécessaires pour quelles fonctionnalités du Chat SDK.
Relancez l'application client de démonstration et vous devriez maintenant pouvoir vous connecter sans erreur. Vous saurez que tout s'est bien passé lorsque vous obtiendrez un toast "Authkey refreshed".

Entamez une conversation entre deux clients.

### Couper le son et bannir les utilisateurs à l'aide du moniteur de canaux
**Important :** si vous n'avez pas encore initié une conversation entre deux clients, faites-le maintenant. Les canaux sont créés dynamiquement par l'application de démonstration et ne s'affichent donc dans le moniteur de canaux qu'après le début de la conversation.
Notez que les mises à jour de l'interface utilisateur présentées ci-dessous, telles que la bannière "clé d'authentification rafraîchie" ou la fenêtre modale "utilisateur interdit", font partie de l'application de démonstration - votre application affichera ces informations à l'utilisateur par le biais de sa propre interface utilisateur.
- Lancez le Channel Monitor en vous connectant au [portail d'administration](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) et en sélectionnant le jeu de clés que vous avez utilisé pour l'échantillon d'Access Manager et l'application client.
- Allez à la section **BizOps Workspace** dans le panneau de navigation de gauche, et sélectionnez **Channel Monitor**. Si vous ne voyez pas la section **BizOps Workspace**, vous devez certainement mettre à niveau votre [plan PubNub](https://www.pubnub.com/pricing/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr), mais n'hésitez pas à [contacter notre support](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) si vous avez des problèmes.
- Vous serez invité à sélectionner vos canaux pour commencer la modération. Le nom du canal sera `1:1 user with USER_ID`, où USER\_ID est le nom d'utilisateur de la personne qui a initié la conversation.
- Les messages du canal seront affichés en temps réel, y compris les messages précédents, si la persistance est activée sur votre clavier.

- Mettez l'utilisateur en sourdine en appuyant sur le bouton du microphone situé à côté d'un message envoyé par cet utilisateur. Un message s'affiche sur l'appareil de l'utilisateur en sourdine pour l'informer que la clé d'authentification a été actualisée. Si vous tentez d'envoyer un message en tant qu'utilisateur en sourdine, vous verrez apparaître une boîte de dialogue indiquant que cette opération est interdite, bien que l'utilisateur en sourdine n'en soit pas affecté.

- Rétablissez le son de l'utilisateur en appuyant à nouveau sur le bouton du microphone. Un message s'affiche sur l'appareil de l'utilisateur non mutique, vous informant que la clé d'authentification a été actualisée et que l'envoi de messages est désormais possible.

- Bannissez l'utilisateur en appuyant sur le bouton de bannissement situé à côté du message envoyé par cet utilisateur et indiquez le motif du bannissement. Le motif est un texte libre, vous pouvez donc fournir toute information pertinente. La clé d'authentification sera rafraîchie et l'utilisateur sera renvoyé à l'écran de sélection du chat dans son application.

Si l'utilisateur tente d'accéder au canal banni, il recevra un message d'erreur :

- Débanquez l'utilisateur en sélectionnant "Remove ban" sur le Channel Monitor. La clé d'authentification sera actualisée. L'utilisateur sera débanni et pourra à nouveau accéder à la discussion.

Résumé
------
Le développement d'une [application de chat](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) n'est que la première étape. Les défis les plus difficiles se présentent après le déploiement de cette application pour soutenir votre base d'utilisateurs croissante. BizOps Workspace est un ensemble d'outils conçus pour gérer tous les aspects de votre application de chat, simplifiant ainsi les défis postérieurs au lancement.
Bien que cet article se soit concentré sur la mise en sourdine et le bannissement d'utilisateurs en toute sécurité, nous continuons à développer les fonctionnalités de [BizOps Workspace](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr). Cet article s'est également concentré exclusivement sur le SDK Chat, mais le Channel Monitor peut également [être configuré](https://www.pubnub.com/docs/bizops-workspace/basics#configuration?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) pour fonctionner avec n'importe lequel de nos SDK.

Si vous avez besoin d'aide ou de soutien, n'hésitez pas à contacter notre équipe [de soutien spécialisée](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) ou à envoyer un courriel à notre équipe de relations avec les développeurs à l'adresse [devrel@pubnub.com](mailto:devrel@pubnub.com).
Comment PubNub peut-il vous aider ?
===================================
Cet article a été publié à l'origine sur [PubNub.com](https://www.pubnub.com/how-to/securely-moderate-chat-and-users/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)
Notre plateforme aide les développeurs à construire, fournir et gérer l'interactivité en temps réel pour les applications web, les applications mobiles et les appareils IoT.
La base de notre plateforme est le réseau de messagerie en temps réel le plus grand et le plus évolutif de l'industrie. Avec plus de 15 points de présence dans le monde, 800 millions d'utilisateurs actifs mensuels et une fiabilité de 99,999 %, vous n'aurez jamais à vous soucier des pannes, des limites de concurrence ou des problèmes de latence causés par les pics de trafic.
Découvrez PubNub
----------------
Découvrez le [Live Tour](https://www.pubnub.com/tour/introduction/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) pour comprendre les concepts essentiels de chaque application alimentée par PubNub en moins de 5 minutes.
S'installer
-----------
Créez un [compte PubNub](https://admin.pubnub.com/signup/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) pour un accès immédiat et gratuit aux clés PubNub.
Commencer
---------
La [documentation PubNub](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr) vous permettra de démarrer, quel que soit votre cas d'utilisation ou votre [SDK](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr). | pubnubdevrel | |
1,862,700 | Title: Maximizing Operational Efficiency with SAP PP: A Comprehensive Guide | In the realm of modern manufacturing, where operational excellence is paramount, businesses rely on... | 0 | 2024-05-23T10:14:53 | https://dev.to/mylearnnest/title-maximizing-operational-efficiency-with-sap-pp-a-comprehensive-guide-26g2 | In the realm of modern manufacturing, where operational excellence is paramount, businesses rely on sophisticated systems to streamline their production processes. [SAP PP (Production Planning)](https://www.sapmasters.in/sap-pp-training-in-bangalore/) emerges as a pivotal tool within the SAP suite, offering comprehensive solutions to orchestrate and optimize production operations seamlessly. This article delves deep into the essence of SAP PP, elucidating its significance, intricate flow process, and the indispensable role of SAP PP consultants in driving organizational success.
**Defining SAP PP:**
SAP PP, a module integral to [SAP's ERP (Enterprise Resource Planning)](https://www.sapmasters.in/sap-pp-training-in-bangalore/) suite, is tailored specifically to manage manufacturing processes within organizations. It encompasses an array of functionalities such as demand planning, material requirement planning (MRP), capacity planning, shop floor control, and production execution, providing a holistic approach to production lifecycle management.
**Significance of SAP PP:**
In today's dynamic manufacturing landscape, characterized by global competition and evolving consumer demands, SAP PP plays a pivotal role in ensuring operational efficiency and agility. Its significance is underscored by:
**Streamlined Production Planning:** SAP PP facilitates the creation of [meticulous production](https://www.sapmasters.in/sap-pp-training-in-bangalore/) plans by analyzing demand forecasts, inventory levels, and resource availability. This optimization minimizes production bottlenecks and maximizes resource utilization.
**Enhanced Efficiency and Responsiveness:** Leveraging features like MRP and capacity planning, [SAP PP](https://www.sapmasters.in/sap-pp-training-in-bangalore/) enables organizations to streamline operations, reduce lead times, and respond swiftly to market fluctuations. This synchronization between production schedules and demand fluctuations enhances efficiency and customer responsiveness.
**Real-time Visibility and Informed Decision-making:** SAP PP provides real-time insights into [production processes](https://www.sapmasters.in/sap-pp-training-in-bangalore/), enabling stakeholders to monitor key performance indicators (KPIs) and make data-driven decisions swiftly. This visibility fosters agility and responsiveness, crucial in navigating volatile market conditions effectively.
**Integrated Supply Chain Management:** As an integral part of SAP's ERP suite, SAP PP seamlessly integrates with other modules such as SAP MM (Materials Management) and SAP SD (Sales and Distribution), offering end-to-end visibility across the supply chain. This integration ensures data consistency and facilitates seamless information flow, enhancing operational efficiency.
**Flow Process of SAP PP:**
The flow process of SAP PP encompasses several pivotal stages, each contributing to the seamless [orchestration of production](https://www.sapmasters.in/sap-pp-training-in-bangalore/) activities:
**Demand Management:** The process commences with demand management, where historical data, market trends, and customer forecasts are analyzed to predict future demand. SAP PP utilizes this insight to generate demand plans, laying the groundwork for subsequent planning endeavors.
**Material Requirement Planning (MRP):** Following demand forecasting, SAP PP initiates the MRP process to ascertain material requirements for production. MRP factors in elements such as bill of materials (BOM), inventory levels, lead times, and planned production orders to formulate procurement proposals.
**Production Planning:** Based on MRP outcomes, SAP PP generates comprehensive production plans and schedules, considering factors like resource availability, [capacity constraints](https://www.sapmasters.in/sap-pp-training-in-bangalore/), and production lead times. These plans delineate the sequence of production activities and allocate resources efficiently to meet demand while optimizing productivity.
**Shop Floor Execution:** SAP PP oversees the execution of manufacturing operations on the shop floor, encompassing tasks such as production order release, work center monitoring, [progress tracking](https://www.sapmasters.in/sap-pp-training-in-bangalore/), and real-time production data recording. This ensures adherence to planned schedules and efficient utilization of resources.
**Quality Management:** Throughout the production process, SAP PP integrates quality management functionalities to uphold product quality and compliance with regulatory standards. Quality checks are conducted at various stages, from [raw material](https://www.sapmasters.in/sap-pp-training-in-bangalore/) inspection to finished goods verification, with deviations promptly addressed to maintain product integrity.
**Reporting and Analysis:** Post-production, SAP PP offers robust reporting and analysis capabilities, enabling stakeholders to evaluate performance metrics, identify improvement areas, and make informed decisions. Reports on [crucial metrics](https://www.sapmasters.in/sap-pp-training-in-bangalore/) such as production efficiency, utilization rates, and on-time delivery facilitate process optimization and continuous improvement initiatives.
**The Role of SAP PP Consultants:**
Critical to the successful implementation and operation of SAP PP are SAP PP consultants, possessing expertise in configuring, customizing, and optimizing the SAP PP module to align with organizational needs. Their role encompasses various responsibilities, including:
**Requirement Analysis:** SAP PP consultants collaborate with stakeholders to comprehend business requirements, process flows, and challenges. Through [meticulous analysis](https://www.sapmasters.in/sap-pp-training-in-bangalore/) and workshops, they identify opportunities for process enhancement and devise strategies to address them effectively.
**System Configuration:** Leveraging their technical proficiency, SAP PP consultants configure the SAP PP module to align with [organizational processes](https://www.sapmasters.in/sap-pp-training-in-bangalore/) and business rules. This entails defining master data structures, configuring planning parameters, and customizing workflows to meet specific requirements.
**Custom Development:** In scenarios where standard SAP functionality falls short, SAP PP consultants engage in custom development endeavors. This may involve developing custom reports, enhancements, or integrations to extend the capabilities of the SAP PP module and enhance overall system functionality.
**Training and Support:** SAP PP consultants play a pivotal role in training end-users on [SAP PP functionalities](https://www.sapmasters.in/sap-pp-training-in-bangalore/). They conduct training sessions, develop training materials, and provide ongoing support to ensure seamless adoption and utilization of the system. Additionally, they offer technical support and troubleshooting assistance to resolve issues promptly and minimize disruptions to production operations.
**Continuous Improvement:** As proponents of continuous improvement, SAP PP consultants stay abreast of industry trends, best practices, and SAP updates. They proactively identify opportunities to optimize processes, enhance system functionality, and drive innovation within the organization. By [collaborating](https://www.sapmasters.in/sap-pp-training-in-bangalore/) with stakeholders and leveraging their expertise, SAP PP consultants contribute to long-term organizational success and competitiveness.
**Conclusion:**
In summary, SAP PP emerges as a cornerstone in the domain of production planning, offering a robust platform to streamline and optimize manufacturing operations. From demand forecasting to shop floor execution, SAP PP facilitates seamless orchestration of production activities, [enhancing efficiency](https://www.sapmasters.in/sap-pp-training-in-bangalore/), and fostering agility in response to market dynamics. Supported by SAP PP consultants, organizations can harness the full potential of SAP PP to drive operational excellence, meet customer demands, and thrive in today's competitive landscape. As manufacturing continues to evolve, SAP PP remains pivotal in shaping the future of production management, empowering businesses to navigate complexities and achieve sustained success.
| mylearnnest | |
1,862,699 | Title: The Digitalization of Metal Supply Chains: Enhancing Efficiency and Traceability | In today's rapidly evolving industrial landscape, digitalization has become more than just a... | 0 | 2024-05-23T10:13:51 | https://dev.to/techvisoffice/title-the-digitalization-of-metal-supply-chains-enhancing-efficiency-and-traceability-1k66 | In today's rapidly evolving industrial landscape, digitalization has become more than just a buzzword—it's a transformative force reshaping traditional practices across various sectors. One area witnessing significant change is the metal supply chain, where digital technologies are revolutionizing operations, improving efficiency, and enhancing traceability. This article delves into the profound impact of digitalization on metal supply chains, exploring how it is driving optimization, transparency, and sustainability in an industry known for its complexity.
### The Traditional Challenges
Metal supply chains are inherently complex, involving multiple stakeholders, intricate processes, and global networks. Traditionally, these supply chains have been plagued by challenges such as inefficiencies, lack of transparency, and difficulty in tracking materials from source to end product. Manual processes, paper-based documentation, and siloed systems have contributed to delays, errors, and inefficiencies throughout the supply chain.
### The Digital Transformation
Enter[ digitalization](https://techvis.in/service)—the integration of digital technologies into every aspect of business operations. Digitalization offers a solution to many of the longstanding challenges faced by metal supply chains. By leveraging technologies such as the Internet of Things (IoT), blockchain, artificial intelligence (AI), and data analytics, companies are streamlining processes, improving visibility, and optimizing resource utilization.
#### IoT and Smart Manufacturing
The IoT plays a crucial role in transforming metal supply chains into smart, interconnected ecosystems. IoT sensors installed on machinery and equipment collect real-time data on parameters such as temperature, pressure, and humidity, enabling predictive maintenance and optimizing production processes. This real-time monitoring reduces downtime, minimizes wastage, and enhances overall efficiency.
#### Blockchain for Transparency
Blockchain technology is revolutionizing transparency and traceability in metal supply chains. By creating an immutable ledger of transactions, blockchain enables stakeholders to track the journey of metal from extraction to processing to distribution. This enhanced transparency not only mitigates the risk of fraud and counterfeit products but also ensures compliance with regulatory standards and sustainability practices.
#### AI and Predictive Analytics
AI-powered predictive analytics are empowering metal supply chain stakeholders to make data-driven decisions and anticipate demand fluctuations. By analyzing vast amounts of historical data and market trends, AI algorithms forecast demand, optimize inventory levels, and identify potential bottlenecks in the supply chain. This proactive approach enables companies to streamline operations, reduce costs, and improve customer satisfaction.
#### Digital Twins for Optimization
Digital twin technology creates virtual replicas of physical assets, enabling real-time monitoring and simulation of operations. In the metal supply chain, digital twins facilitate optimization by providing insights into equipment performance, identifying areas for improvement, and simulating scenarios to optimize production processes. By experimenting in a virtual environment, companies can minimize risks and maximize efficiency in their operations.
### The Benefits of Digitalization
The digitalization of [metal supply chains](https://techvis.in/service) offers a myriad of benefits for all stakeholders involved:
1. **Improved Efficiency**: Digitalization streamlines processes, reduces lead times, and minimizes wastage, leading to significant improvements in overall efficiency and productivity.
2. **Enhanced Traceability**: Blockchain technology ensures transparent and traceable supply chains, enabling stakeholders to track the provenance and journey of metal throughout its lifecycle.
3. **Cost Reduction**: By optimizing resource utilization, minimizing downtime, and preventing errors, digitalization helps reduce operational costs and improve profitability.
4. **Sustainability**: Digitalization enables better monitoring of environmental impact, facilitates compliance with sustainability standards, and promotes responsible sourcing practices.
5. **Customer Satisfaction**: With optimized processes and enhanced traceability, companies can deliver products faster, with higher quality assurance, thus improving customer satisfaction and loyalty.
### Challenges and Considerations
While the benefits of digitalization are undeniable, implementing digital technologies in metal supply chains comes with its own set of challenges and considerations. These include concerns regarding data security, interoperability of systems, the need for skilled workforce, and upfront investment costs. Additionally, ensuring inclusivity and equitable access to digital technologies is essential to prevent widening the digital divide within the industry.
### Conclusion
The digitalization of metal supply chains represents a paradigm shift in the way the industry operates. By embracing digital technologies, companies can overcome traditional challenges, drive efficiency, and enhance traceability throughout the supply chain. However, successful digital transformation requires a holistic approach, involving collaboration among stakeholders, investment in infrastructure and talent, and a commitment to innovation and sustainability. As the industry continues to evolve, those embracing digitalization will emerge as leaders in a more connected, transparent, and efficient metal supply chain ecosystem. | techvisoffice | |
1,862,696 | Sichere Moderation von Chats und Benutzern mit BizOps Workspace | Wie man PubNub's Channel Monitor und Access Manager benutzt, um eine sichere und moderierte Chat-Anwendung zu erstellen | 0 | 2024-05-23T10:10:12 | https://dev.to/pubnub-de/sichere-moderation-von-chats-und-benutzern-mit-bizops-workspace-jf | Dieser How-to-Artikel ist Teil einer Reihe von Artikeln, die sich mit den Datenverwaltungsfunktionen von PubNub befassen, die unter dem Namen [BizOps Workspace](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) bekannt sind:
- [Verwalten von Benutzern und Kanälen mit BizOps Workspace](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de)
- [Überwachung und Moderation von Konversationen mit BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de)
- Sichere Moderation von Konversationen und Benutzern mit BizOps Workspace
BizOps Workspace ist eine Reihe von Tools, die Sie bei der Verwaltung Ihrer Anwendung unterstützen. Dieser Artikel erweitert den vorherigen Artikel "[Überwachen und Moderieren von Konversationen mit BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de)", um eine sichere End-to-End-Chat-Anwendung mit manuellen Moderationsfunktionen zu zeigen, d. h. die Möglichkeit, Konversationen in Echtzeit zu überwachen und Benutzer stummzuschalten oder zu sperren.
Obwohl dieser Artikel für sich alleine gelesen werden kann, empfehle ich dringend, den vorherigen Artikel "[How to Monitor and Moderate Conversations with BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de)" zu lesen, um den Hintergrund der hier besprochenen Konzepte besser zu verstehen.
Was ist der Channel Monitor?
----------------------------
Mit dem Channel Monitor können Chat-Moderatoren eine Live-Vorschau von Unterhaltungen sehen, die in Echtzeit über mehrere Kanäle laufen. Wenn der Moderator etwas Beunruhigendes entdeckt, wie z. B. einen sich daneben benehmenden Benutzer oder beleidigende Nachrichten, kann er sofort eingreifen, um das Problem zu beseitigen.
Der Moderator hat einen großen Spielraum bei der Wahl seiner Maßnahmen:
- Einen Benutzer beobachten, ohne seine Zugriffsrechte einzuschränken
- Bearbeiten oder Löschen der beleidigenden Nachricht
- die Fähigkeit des Benutzers, Nachrichten zu veröffentlichen, einschränken[(stummschalten](https://pubnub.com/docs/bizops-workspace/channel-monitor#mute?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de))
- die Fähigkeit des Benutzers, Nachrichten zu lesen oder zu veröffentlichen, einschränken[(Verbot](https://pubnub.com/docs/bizops-workspace/channel-monitor#ban?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de))
Alle Funktionen der Funktion "Überwachen" sind manuell: manuelle Überprüfung von Nachrichten, manuelles Stummschalten von Benutzern usw. Dieser Artikel befasst sich nicht mit der automatischen Moderation.
Um den Channel Monitor nutzen zu können, müssen Sie mehrere Funktionen in Ihrem PubNub Keyset aktiviert haben, insbesondere [App-Kontext](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) und [Nachrichtenpersistenz](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de). Weitere Details finden Sie im Abschnitt "Anforderungen an das Keyset für den Channel Monitor" im [vorherigen Artikel](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de).
Was ist der PubNub Access Manager?
----------------------------------
**Entwickler müssen verhindern, dass Benutzer versuchen, ihr Moderationssystem zu umgehen**; dies wird durch den PubNub Access Manager erreicht.
Mit dem [Access Manager](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) können Sie eine Reihe von Regeln definieren, die die Berechtigungen des oder der angegebenen Benutzer beschreiben und welche Aktionen sie auf bestimmten Ressourcen durchführen können. Zum Beispiel:
- Benutzer mit der ID `123` hat die Berechtigung zum Lesen und Schreiben auf Channel `456`
- Alle Benutzer, deren ID mit dem regulären Ausdruck `user-*` übereinstimmt, können von jedem Channel lesen, dessen ID mit dem regulären Ausdruck `global-*` übereinstimmt
- Benutzer mit der ID `123` hat die Berechtigung, die Channel-Metadaten (d. h. den App-Kontext) zu aktualisieren.
Eine vollständige Liste der Berechtigungen finden Sie in der Dokumentation unter [https://www.pubnub.com/docs/general/security/access-control#permissions.](https://www.pubnub.com/docs/general/security/access-control#permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de)
Der PubNub Access Manager ist Token-basiert, und der einfachste Weg, ihn zu beschreiben, ist, den in der [Dokumentation](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) dargestellten Autorisierungsfluss durchzugehen und einige zusätzliche Informationen darüber zu geben, wie dieser Fluss mit der Moderation zusammenhängt:

1. **Anmeldeversuch**. Ihr Client authentifiziert sich gegenüber Ihrem Server, um Ihre Benutzer bei Ihrer Anwendung anzumelden. Dies geschieht wahrscheinlich über einen Identitätsanbieter; nach diesem Schritt ist Ihr Server sicher, dass er mit einem registrierten App-Benutzer spricht und wer dieser ist. Der Client fordert ein PubNub Access Manager Authentifizierungs-Token als Teil seiner Initialisierung an.
2. **Antrag auf Erlaubniserteilung**. Der Server bearbeitet die Anfrage des Clients nach einem Token, indem er die SDK '[grantToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#grant-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de)' API aufruft. Zu dieser API sind einige Punkte zu beachten: Sie kann nur mit dem **geheimen PubNub-Schlüssel** aufgerufen werden und kann daher nur von einem Server aus aufgerufen werden; sie ist für alle unsere serverseitigen SDKs verfügbar; und diese API akzeptiert JSON-Objekte, um die Ressourcen und Berechtigungen zu definieren, die den Zugriff des/der Benutzer(s) bestimmen.
3. **Token zurückgegeben**. PubNub gewährt dem/den angeforderten Benutzer(n) die angeforderten Berechtigungen und gibt ein Authentifizierungs-Token an den Server zurück.
4. **Token übergeben**. Ihr Server gibt das Authentifizierungs-Token an den ursprünglich aufrufenden Client zurück.
5. **Token gesetzt**. Der Client kann dieses Authentifizierungs-Token während seiner Initialisierung oder zu einem beliebigen Zeitpunkt während des Lebenszyklus der Anwendung mit der Methode [setToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#set-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) festlegen. Die Möglichkeit, das Token jederzeit zu aktualisieren, ist wichtig, da Token ablaufen, ein Client aber auch ein neues Token anfordern muss, wenn der Channel Monitor seine Berechtigungen aktualisiert (d. h. wenn er stummgeschaltet oder gesperrt wird).
6. **Autorisierte API-Anfrage**. Alle nachfolgenden Aufrufe an PubNub werden nun als autorisiert betrachtet. PubNub erlaubt oder verweigert jede API-Anfrage basierend auf den in Schritt 2 erteilten Berechtigungen und der Token-Gültigkeit des Clients.
Wie sieht eine sichere Moderationslösung aus?
---------------------------------------------
Gegen Ende des [letzten Artikels](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) habe ich eine Demo gezeigt, wie das Stummschalten oder Sperren von der Client-Seite aus aussehen würde. Das Chat-SDK enthält [Moderationsereignisse](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de), die einem Client mitteilen, ob er stummgeschaltet oder gesperrt wurde oder nicht; abgesehen von der Aktualisierung der Benutzeroberfläche **hindert dies den Client** jedoch **nicht daran, weiterhin Nachrichten zu senden, obwohl er stummgeschaltet/gesperrt wurde**. Um den Client sicher stumm zu schalten oder zu sperren, müssen Sie ihm die bestehenden Access Manager-Berechtigungen entziehen und ihm neue erteilen, die seinen neuen Stumm- oder Sperrstatus widerspiegeln.
Stellen Sie sich das folgende Szenario vor, in dem ein Benutzer für den Channel "Musicals" stummgeschaltet ist:

1. Ein Benutzer kann auf zwei Kanäle zugreifen, "Filme" und "Musicals", aber der Administrator möchte ihn nur für den Kanal "Musicals" stummschalten.
2. Der Moderator schaltet den Benutzer mit Hilfe des Channel-Monitors stumm. Im Verborgenen wird dabei die API '[setRestrictions()](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#method-signature-1?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de)' aufgerufen.
3. Die Serveranwendung erhält die Stummschaltungsmitteilung über ein [Moderationsereignis](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) und [entzieht](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#revoke-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) dem Benutzer [das](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#revoke-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) bestehende Zugriffstoken.
4. Die Client-Anwendung erhält über ein [Moderationsereignis](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) den Hinweis, dass der Kanal "Musicals" stummgeschaltet wurde.
5. Die Anwendung aktualisiert ihre Benutzeroberfläche, um das Senden weiterer Nachrichten zu verhindern. Der Benutzer könnte diese UI-Änderung umgehen, indem er das JavaScript der Seite ändert, aber jeder Versuch, Nachrichten zu senden, schlägt fehl, da sein Authentifizierungstoken widerrufen wurde.
6. Die Anwendung fordert ein neues Authentifizierungs-Token vom Server an, wie im obigen Abschnitt über den Zugriffsmanager beschrieben. Das neu gewährte Token spiegelt die neuen Berechtigungen des Benutzers wider, einschließlich des "Lese"-Zugriffs auf den Kanal "Musicals".
Im [vorangegangenen Artikel](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) wurden die "Komponenten einer Moderationslösung" beschrieben und die APIs, die sowohl dem Client als auch dem Server zur Verfügung stehen, in der folgenden Grafik aufgelistet. Die APIs, die in den obigen Schritten besprochen wurden, sind auch in dieser Grafik dargestellt.

Die Chat-SDK-Beispielanwendung
------------------------------
Dasselbe Team, das für die Entwicklung des Channel Monitor und des Chat SDK verantwortlich ist, hat auch eine in React Native geschriebene Beispielanwendung erstellt, die das Chat SDK verwendet.
Das Beispiel zeigt die Möglichkeiten des SDKs und die besten Praktiken für die Entwicklung einer realistischen und voll funktionsfähigen Chat-App mit PubNub. Es ist Open Source und Teil desselben GitHub-Repositorys, das auch das Chat-SDK unter [/samples/react-native-group-chat](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat) enthält.

Diese Anwendung wurde kürzlich aktualisiert, um Token von einem Access Manager Server anzufordern und ein neues Token anzufordern, wenn sich die Berechtigungen des Benutzers ändern, d.h. wenn er von Kanälen ausgeschlossen oder stummgeschaltet wird. Diese Verbesserung wurde seit dem Verfassen des [letzten Artikels](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) vorgenommen, also stellen Sie sicher, dass Sie den neuesten Quellcode von [GitHub](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat) erhalten. Zum Zeitpunkt der Erstellung dieses Artikels lautet die neueste Git-Commit-ID [ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat)
Sicheres Stummschalten und Verbannen von Benutzern: Demo mit der Beispielanwendung
----------------------------------------------------------------------------------
In diesem Abschnitt wird beschrieben, wie Sie unsere End-to-End-Demo zum Laufen bringen und die sichere Moderation sowohl aus der Client- als auch aus der Serverperspektive zeigen.
### PubNub Keyset erstellen
Ich empfehle, ein neues PubNub Keyset zu erstellen, um diese Demo wie folgt zu starten:
1. Loggen Sie sich in das [Admin Portal](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) ein und erstellen Sie entweder eine neue Anwendung oder ein neues Keyset innerhalb einer bestehenden Anwendung. Bei Bedarf finden Sie eine Schritt-für-Schritt-Anleitung in unserem [How to Create Admin Portal Keys](https://www.pubnub.com/how-to/admin-portal-create-keys/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de).
2. Aktivieren Sie auf der Seite Keysets die folgenden Konfigurationsoptionen. Sofern nicht anders angegeben, können Sie die Standardeinstellungen übernehmen:
- [App-Kontext](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de). Dieser speichert Metadaten über Ihre Channels und Benutzer und wird im vorherigen Artikel über["Benutzer- und Channel-Verwaltung](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de)" näher beschrieben. Aktivieren Sie auch `Benutzer-Metadatenereignisse`, `Channel-Metadatenereignisse` und `Mitgliedschaftsereignisse`
- [Nachrichten-Persistenz](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de). Dies speichert Ihren Nachrichtenverlauf mit PubNub, so dass der Administrator Konversationen überprüfen und bearbeiten kann.
- [Zugriffsmanager](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de). Verhindert den unbefugten Zugriff auf Daten und ist erforderlich, um eine sichere Moderationslösung zu erstellen.
- [Anwesenheit](https://www.pubnub.com/docs/general/presence/overview?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de). Wird verwendet, um zu verfolgen, ob ein Benutzer online oder offline ist.
Speichern Sie Ihre Änderungen.
Sie benötigen den `Publish Key`, `Subscribe Key` und `Secret Key` in den folgenden Schritten.
### Erstellen Sie die Beispielanwendung
Wie bereits beschrieben, handelt es sich bei der Chat SDK-Beispielanwendung um eine plattformübergreifende Client-Anwendung, die in React Native unter Verwendung des Expo-Frameworks geschrieben wurde.
Klonen und erstellen Sie die Beispielanwendung, indem Sie den Anweisungen in der [Readme-Datei der Anwendung](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat#readme) folgen. Stellen Sie insbesondere sicher, dass Sie die Voraussetzungen installiert haben, einschließlich Garn und Node.js. In der ReadMe wird die Verwendung von XCode und iOS beschrieben, aber Sie können die Anwendung auch auf einem Android-Emulator ausführen. Zum Zeitpunkt der Erstellung dieses Artikels lautet die neueste Git-Commit-ID [ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat)
Wenn Sie die Pub/Sub-Schlüssel bereitstellen, verwenden Sie die Schlüssel, die Sie im vorherigen Schritt erzeugt haben. Wenn Sie die Schlüssel nicht in die `.env-Datei` aufnehmen, wird die Anwendung standardmäßig einige `Demo-Schlüssel` verwenden; Sie können diese Logik unter [https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60](https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60) deaktivieren, um Verwirrung zu vermeiden.
Führen Sie die Anwendung aus. In der ReadMe werden Sie angewiesen, `yarn ios` auszuführen, aber Sie können auch `yarn android` oder `yarn run start` ausführen, wobei letzteres Ihnen ein interaktives Menü bietet.
Wenn Sie sich anmelden, sollten Sie die folgende Warnung in Ihrer Konsole sehen:

Das liegt daran, dass der Client sich nicht mit dem Access Manager Server verbinden konnte, also bauen wir ihn.
### Erstellen Sie den Access Manager-Beispielserver
Der Sample Access Manager Server ist unter [https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api](https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api) zu finden [.](https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api) Dies ist die gleiche Monorepo wie die zuvor besprochene Client-Anwendung.
Öffnen Sie die Datei `src/chatsdk.service.ts` in einem Editor Ihrer Wahl und füllen Sie die Felder `publishKey`, `subscribeKey` und `secretKey` aus. Der publishKey und der subscribeKey müssen mit den Schlüsseln übereinstimmen, die Sie zum Erstellen der Client-Anwendung verwendet haben, und der geheime Schlüssel ist auf der Keyset-Seite für die Anwendung im [Admin-Portal](https://admin.pubnub.com?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) verfügbar
Führen Sie im Verzeichnis `REPO/samples/access-manager-api` den Befehl `yarn run start` aus, um den Access Manager-Server zu starten, und Sie sollten etwas wie das folgende Bild sehen:

Um zu sehen, was der Access-Manager-Server tut, schauen Sie sich `app.service.ts` an. Sie sehen die für den anfragenden Benutzer generierten Berechtigungsstrukturen und den Aufruf von `chat.sdk.grantToken()`, um diese Berechtigungen anzuwenden und den generierten authKey an den aufrufenden Client zurückzugeben.
Dies sind die Berechtigungen, die die Demoanwendung benötigt, aber Ihre Anwendung wird wahrscheinlich andere Berechtigungen benötigen. Sie können diesen mitgelieferten Regelsatz als Startvorlage verwenden, aber wenn Sie den Access Manager Server für Ihre Anwendung erstellen, konsultieren Sie [https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de), um genau zu verstehen, welche Berechtigungen von welchen Chat SDK Funktionen benötigt werden.
Starten Sie die Client-Demoanwendung neu, und Sie sollten sich jetzt ohne Fehler anmelden können. Sie werden wissen, dass alles erfolgreich war, wenn Sie einen 'Authkey refreshed' Toast erhalten.

Initiieren Sie eine Unterhaltung zwischen zwei Clients.

### Stummschalten und Sperren von Benutzern mit dem Channel Monitor
**Wichtig:** Wenn Sie noch keine Konversation zwischen zwei Clients initiiert haben, sollten Sie dies jetzt tun. Kanäle werden von der Demo-Anwendung dynamisch erstellt, so dass sie im Kanalmonitor erst angezeigt werden, wenn der Chat begonnen hat.
Beachten Sie, dass alle unten gezeigten Aktualisierungen der Benutzeroberfläche, wie z. B. das Banner "Auth Key Refreshed" oder das Modal "Banned User", Teil der Demo-Anwendung sind - Ihre Anwendung wird diese Informationen dem Benutzer über ihre eigene Benutzeroberfläche anzeigen.
- Starten Sie den Channel Monitor, indem Sie sich im [Admin-Portal](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) anmelden und das Keyset auswählen, das Sie für das Access Manager-Beispiel und die Client-Anwendung verwendet haben.
- Gehen Sie zum Abschnitt **BizOps Workspace** im linken Navigationsbereich und wählen Sie **Channel Monitor**. Wenn Sie den Abschnitt BizOps **Workspace** nicht sehen, müssen Sie höchstwahrscheinlich ein Upgrade Ihres [PubNub-Tarifs](https://www.pubnub.com/pricing/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) durchführen, aber bitte [kontaktieren Sie unseren Support](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de), wenn Sie Probleme haben.
- Sie werden aufgefordert, Ihre Channels auszuwählen, um die Moderation zu starten. Der Name des Channels lautet `1:1 Benutzer mit USER_ID`, wobei USER\_ID der Benutzername der Person ist, die die Unterhaltung initiiert hat.
- Die Kanalnachrichten werden in Echtzeit angezeigt, einschließlich früherer Nachrichten, wenn Sie die Persistenz auf Ihrem Keyset aktiviert haben.

- Schalten Sie den Benutzer stumm, indem Sie die Mikrofontaste neben einer von diesem Benutzer gesendeten Nachricht drücken. Auf dem Gerät des stummgeschalteten Benutzers wird eine Nachricht angezeigt, die besagt, dass der Authentifizierungsschlüssel erneuert wurde. Wenn Sie versuchen, eine Nachricht als stummer Benutzer zu senden, wird eine Meldung angezeigt, die besagt, dass dies verboten ist, obwohl der stummgeschaltete Benutzer davon nicht betroffen ist.

- Heben Sie die Stummschaltung des Benutzers auf, indem Sie die Mikrofontaste erneut drücken. Auf dem Gerät des stummgeschalteten Benutzers wird eine Nachricht angezeigt, die Sie darüber informiert, dass der Authentifizierungsschlüssel aktualisiert wurde und das Senden von Nachrichten nun möglich ist.

- Sperren Sie den Benutzer, indem Sie auf die Schaltfläche "Sperren" neben der von diesem Benutzer gesendeten Nachricht drücken und einen Sperrgrund angeben. Der Grund ist ein Freitext, so dass Sie alle relevanten Informationen angeben können. Der Authentifizierungsschlüssel wird aktualisiert und der Benutzer kehrt zum Chat-Auswahlbildschirm in seiner App zurück.

Beim Versuch, auf den gesperrten Kanal zuzugreifen, wird dem Benutzer eine Fehlermeldung angezeigt:

- Heben Sie die Sperre des Benutzers auf, indem Sie im Channel-Monitor "Sperre aufheben" wählen. Der Authentifizierungsschlüssel wird aktualisiert. Die Sperre wird aufgehoben und der Benutzer kann wieder auf den Chat zugreifen.

Zusammenfassung
---------------
Die Entwicklung einer [Chat-Anwendung](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) ist nur der erste Schritt. Die schwierigsten Herausforderungen kommen nach der Bereitstellung der Anwendung, um Ihre wachsende Benutzerbasis zu unterstützen. BizOps Workspace ist eine Reihe von Tools, die für die Verwaltung aller Aspekte Ihrer Chat-Anwendung entwickelt wurden und die Herausforderungen nach der Einführung vereinfachen.
Obwohl sich dieser Artikel auf das sichere Stummschalten und Sperren von Benutzern konzentriert hat, werden wir die Funktionen von [BizOps Workspace](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) weiter ausbauen. Dieser Artikel hat sich auch ausschließlich auf das Chat SDK konzentriert, aber der Channel Monitor kann auch so [konfiguriert werden](https://www.pubnub.com/docs/bizops-workspace/basics#configuration?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de), dass er mit jedem unserer SDKs funktioniert.

Wenn Sie Hilfe oder Unterstützung benötigen, wenden Sie sich bitte an unser [engagiertes Support-Team](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) oder senden Sie eine E-Mail an unser Developer Relations Team unter [devrel@pubnub.com](mailto:devrel@pubnub.com).
Wie kann PubNub Ihnen helfen?
=============================
Dieser Artikel wurde ursprünglich auf [PubNub.com](https://www.pubnub.com/how-to/securely-moderate-chat-and-users/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) veröffentlicht.
Unsere Plattform hilft Entwicklern bei der Erstellung, Bereitstellung und Verwaltung von Echtzeit-Interaktivität für Webanwendungen, mobile Anwendungen und IoT-Geräte.
Die Grundlage unserer Plattform ist das größte und am besten skalierbare Echtzeit-Edge-Messaging-Netzwerk der Branche. Mit über 15 Points-of-Presence weltweit, die 800 Millionen monatlich aktive Nutzer unterstützen, und einer Zuverlässigkeit von 99,999 % müssen Sie sich keine Sorgen über Ausfälle, Gleichzeitigkeitsgrenzen oder Latenzprobleme aufgrund von Verkehrsspitzen machen.
PubNub erleben
--------------
Sehen Sie sich die [Live Tour](https://www.pubnub.com/tour/introduction/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) an, um in weniger als 5 Minuten die grundlegenden Konzepte hinter jeder PubNub-gestützten App zu verstehen
Einrichten
----------
Melden Sie sich für einen [PubNub-Account](https://admin.pubnub.com/signup/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) an und erhalten Sie sofort kostenlosen Zugang zu den PubNub-Schlüsseln
Beginnen Sie
------------
Mit den [PubNub-Dokumenten](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) können Sie sofort loslegen, unabhängig von Ihrem Anwendungsfall oder [SDK](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) | pubnubdevrel | |
1,862,695 | Leveraging AI in Real Estate Apps: A Comprehensive Guide | Introduction: Artificial Intelligence (AI) is reshaping various industries, and real... | 0 | 2024-05-23T10:09:47 | https://dev.to/cygnismedia/leveraging-ai-in-real-estate-apps-a-comprehensive-guide-2a40 | ai, machinelearning, tutorial | ## Introduction:
Artificial Intelligence (AI) is reshaping various industries, and real estate is no exception. From personalized property recommendations to automated valuations, AI's integration into mobile apps is creating a more efficient and user-friendly experience for both buyers and sellers. In our latest blog post, we dive deep into how AI is revolutionizing the real estate business and provide actionable insights for developers looking to harness its power in their mobile applications.
## Key Takeaways:
###Chatbots and Virtual Assistants:
- Implement AI-driven chatbots to provide 24/7 customer support and enhance user engagement.
- Virtual assistants can help streamline property searches and inquiries, saving time for users and agents.
###Personalized Property Recommendations:
- Leverage machine learning algorithms to analyze user preferences and suggest properties that match their criteria.
- Increase user satisfaction and engagement by providing tailored property suggestions.
###Automated Property Valuation and Estimation:
- Use AI to automate the process of property valuation, ensuring accurate and unbiased estimates.
- Enhance decision-making for buyers, sellers, and real estate professionals with reliable data.
###Property Forecasting with Predictive Analytics:
- Implement predictive analytics to forecast property trends and market conditions.
- Provide users with insights into the best times to buy or sell properties based on data-driven predictions.
###Comprehensive Data Analysis:
- Utilize AI to process and analyze large datasets, uncovering valuable insights and trends.
- Improve strategic planning and marketing efforts with data-backed decisions.
###Virtual Reality (VR) with AI:
- Combine VR and AI to offer virtual property tours, providing immersive experiences for potential buyers.
- Enhance remote property viewing capabilities, especially useful in the current global scenario.
##Why Developers Should Care:
Integrating AI into real estate apps opens up a plethora of opportunities for developers. From improving user experience to automating complex tasks, AI can significantly enhance the functionality and appeal of your app. This comprehensive guide covers everything you need to know to get started, including best practices for overcoming common challenges.
##Read the Full Post:
For a detailed exploration of AI's impact on real estate mobile apps and how you can leverage it in your projects, read our full blog post here: [Read More](https://www.cygnismedia.com/blog/artificial-intelligence-in-real-estate-app-development/)
##Join the Conversation:
Have you integrated AI into your real estate mobile app? Share your experiences and insights in the comments below. Let's discuss how AI is transforming the real estate industry and what the future holds!
| cygnismedia |
1,862,693 | Imperial Farmhouse Ajmer road - Retreat By Black Bear Farm House, Farmhouse in Ajmer Road, Party Farmhouse ajmer road Jaipur | Imperial Farmhouse, Ajmer Road – The Retreat by Black Bear Farm House Imperial Farmhouse, located on... | 0 | 2024-05-23T10:06:37 | https://dev.to/imperialfarmhouse/imperial-farmhouse-ajmer-road-retreat-by-black-bear-farm-house-farmhouse-in-ajmer-road-party-farmhouse-ajmer-road-jaipur-46ah | farmhouse, farmstay, resort, villa | Imperial Farmhouse, Ajmer Road – The Retreat by Black Bear Farm House
Imperial Farmhouse, located on Ajmer Road, Jaipur, has a serene location. This exquisite farmhouse is a perfect blend of rustic charm and modern amenities, perfect for relaxation, celebrations, weddings, other functions.
key features:
Places to Visit: Nestled amidst lush greenery, the Imperial Farmhouse is a serene retreat away from the hustle and bustle of the city, easily accessible from Jaipur.
Spacious Accommodation: The Farmhouse has well-furnished rooms and suites, ensuring a comfortable stay for all the guests. Each room has been designed with a rustic yet elegant touch, offering spectacular views of the surrounding landscape.
Modern Facilities: Enjoy a range of contemporary amenities including a fully equipped kitchen, high-speed internet and entertainment options to keep you and your guests entertained throughout your stay.
Outdoor activities: The vast outdoor space includes a swimming pool, landscaped gardens and plenty of open areas for sports and leisure activities. Perfect for a refreshing swim or a leisurely stroll.
Event Hosting: Whether you are planning a wedding, birthday party, corporate event or a family function, Imperial Farmhouse is equipped to meet all your event needs. The spacious lawn and indoor banquet area can be customized to suit your theme and requirements.
Delicious Food: Experience culinary delights with our in-house catering services, offering a variety of cuisines to satisfy every taste. Enjoy alfresco dining under the stars or cozy indoor dining with your loved ones.
Privacy and Security: The farmhouse ensures complete privacy and is equipped with round-the-clock security to stay safe.
Escape to Imperial Farmhouse on Ajmer Road for a memorable retreat, where luxury meets nature, and every moment is crafted to perfection. Be it a peaceful holiday or a grand celebration, this farmhouse promises an experience like no other in Jaipur.
[farm house in jaipur
](https://maps.app.goo.gl/embbzkEEsrnpNzpe8)best resort in jaipur
best party farm house in jaipur
best wedding garden in Jaipur | imperialfarmhouse |
1,862,692 | BizOps 워크스페이스로 채팅 및 사용자를 안전하게 조정하는 방법 | PubNub의 채널 모니터 및 액세스 관리자를 사용하여 안전하고 중재된 채팅 애플리케이션을 만드는 방법 | 0 | 2024-05-23T10:05:11 | https://dev.to/pubnub-ko/bizops-weokeuseupeiseuro-caeting-mic-sayongjareul-anjeonhage-jojeonghaneun-bangbeob-3o1e | 이 사용법 문서는 [BizOps Workspace로](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 통칭되는 PubNub의 데이터 관리 기능에 대해 설명하는 일련의 문서 중 일부입니다:
- [BizOps Workspace로 사용자 및 채널을 관리하는 방법](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)
- [BizOps Workspace로 대화를 모니터링하고 조정하는 방법](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)
- BizOps Workspace로 대화 및 사용자를 안전하게 조정하는 방법
BizOps Workspace는 애플리케이션을 관리하는 데 도움이 되는 일련의 도구입니다. 이 문서에서는 이전의 "[BizOps Workspace로 대화를 모니터링하고 중재하는 방법](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)" 문서를 확장하여 수동 중재 기능, 즉 대화를 실시간으로 모니터링하고 사용자를 음소거하거나 금지하는 기능을 갖춘 엔드투엔드 보안 채팅 애플리케이션을 보여 줍니다.
이 문서는 단독으로 읽을 수도 있지만, 여기서 설명하는 개념의 배경을 더 잘 이해하려면 이전의 "[BizOps Workspace로 대화를 모니터링하고 중재하는 방법](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)" 문서를 읽어보시는 것이 좋습니다.
채널 모니터란 무엇인가요?
--------------
채널 모니터를 통해 채팅 중재자는 여러 채널에서 실시간으로 진행되는 대화의 실시간 미리보기를 볼 수 있습니다. 운영자는 잘못된 행동을 하는 사용자나 불쾌한 메시지 등 불쾌한 내용을 발견하면 즉시 조치를 취하여 문제를 완화할 수 있습니다.
운영자는 취할 수 있는 조치에 대해 많은 유연성을 가지고 있습니다:
- 액세스 권한을 제한하지 않고 사용자를 관찰하기
- 불쾌감을 주는 메시지 수정 또는 삭제
- 사용자의 메시지 게시 기능 제한[(뮤](https://pubnub.com/docs/bizops-workspace/channel-monitor#mute?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)트)
- 사용자의 메시지 읽기 또는 게시 기능 제한[(금지](https://pubnub.com/docs/bizops-workspace/channel-monitor#ban?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko))
'모니터링' 기능의 모든 기능은 수동으로 할 수 있습니다. 메시지를 수동으로 검토하고, 사용자를 수동으로 뮤트하는 등의 기능을 수동으로 할 수 있습니다. 이 도움말에서는 자동 모더레이션에 대해서는 설명하지 않습니다.
채널 모니터를 사용하려면 최소한 [앱 컨텍스트와](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) [메시지 지속성](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 등 몇 가지 기능이 PubNub 키세트에서 활성화되어 있어야 합니다. 자세한 내용은 [이전 글의](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)'채널 모니터를 위한 키설정 요구 사항' 섹션을 참조하세요.
PubNub 액세스 관리자란 무엇인가요?
----------------------
**개발자는 사용자가 모더레이션 시스템을 우회하려는 시도를 방지해야** 하며, 이를 위해 PubNub 액세스 관리자를 사용해야 합니다.
[액세스 관리](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 자를 사용하면 지정된 사용자(또는 사용자)의 권한과 지정된 리소스에 대해 수행할 수 있는 작업을 설명하는 일련의 규칙을 정의할 수 있습니다. 예를 들어
- ID가 `123인` 사용자에게는 채널 `456에` 대한 읽기 및 쓰기 권한이 있습니다.
- ID가 정규식 `user-*역주`: ID가 `글로벌-*역주`: 정규식과 일치하는 모든 채널에서 읽을 수 있음-와 일치하는 모든 사용자에게 읽기 권한이 있습니다.
- ID가 `123인` 사용자는 채널 메타데이터(즉, 앱 컨텍스트)를 업데이트할 수 있는 권한이 있습니다.
전체 권한 목록은 [https://www.pubnub.com/docs/general/security/access-control#permissions](https://www.pubnub.com/docs/general/security/access-control#permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 에서 설명서를 참조하세요.
PubNub 액세스 관리자는 토큰 기반이며, 이를 설명하는 가장 쉬운 방법은 [문서에](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 표시된 대로 권한 부여 흐름을 살펴보고 해당 흐름이 모더레이션과 어떻게 관련되는지에 대한 몇 가지 추가 컨텍스트를 제공하는 것입니다:

1. **로그인 시도**. 클라이언트는 사용자를 애플리케이션에 로그인하기 위해 서버를 인증합니다. 이 단계가 끝나면 서버는 등록된 앱 사용자와 대화하고 있으며 해당 사용자가 누구인지 확신하게 됩니다. 클라이언트는 초기화의 일부로 PubNub 액세스 관리자 인증 토큰을 요청합니다.
2. **권한 부여 요청**. 서버는 SDK '[grantToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#grant-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)' API를 호출하여 클라이언트의 토큰 요청을 처리합니다. 이 API에 대해 몇 가지 주의할 점이 있습니다: PubNub **비밀 키로만** 호출할 수 있으므로 서버에서만 호출할 수 있고, 모든 서버 측 SDK에서 사용할 수 있으며, 이 API는 사용자 액세스를 정의하는 리소스 및 권한을 정의하기 위해 JSON 객체를 허용합니다.
3. **토큰 반환**. PubNub는 요청된 사용자에게 요청된 권한을 부여하고 서버에 인증 토큰을 반환합니다.
4. **토큰이 전달**되었습니다. 그러면 서버가 원래 호출한 클라이언트에 인증 토큰을 반환합니다.
5. **토큰 세트**. 클라이언트는 초기화 중 또는 애플리케이션의 수명 주기 중 언제든지 [setToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#set-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 메서드를 통해 이 인증 토큰을 지정할 수 있습니다. 토큰은 만료되므로 언제든지 토큰을 업데이트할 수 있어야 하지만, 채널 모니터가 권한을 업데이트하는 경우(예: 뮤트되거나 금지된 경우) 클라이언트는 새 토큰을 요청해야 합니다.
6. **승인된 API 요청**. 이제 PubNub에 대한 모든 후속 호출은 승인된 것으로 간주됩니다. PubNub은 2단계에서 부여된 권한과 클라이언트의 토큰 유효성에 따라 모든 API 요청을 허용하거나 거부합니다.
보안 모더레이션 솔루션은 어떤 모습인가요?
-----------------------
[이전 글의](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 마지막 부분에서 클라이언트 측에서 뮤트하거나 금지하는 것이 어떻게 보이는지 데모를 보여드렸습니다. Chat SDK에는 뮤트 또는 차단 여부를 클라이언트에게 알려주는 [중재 이벤트가](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 포함되어 있지만, UI를 업데이트하는 것 외에는 **뮤트/차단된 후에도 클라이언트가 메시지를 계속 보내는 것을 막지는** 못합니다. 클라이언트를 안전하게 뮤트하거나 차단하려면 기존 액세스 관리자 권한을 해지하고 새로운 뮤트 또는 차단 상태를 반영하도록 새 권한을 부여해야 합니다.
사용자가 '뮤지컬' 채널에서 뮤트된 다음 시나리오를 예로 들어 보겠습니다:

1. 사용자가 '영화'와 '뮤지컬' 두 개의 채널에 액세스할 수 있지만 관리자가 '뮤지컬' 채널에서만 해당 사용자를 뮤트하려고 합니다.
2. 관리자는 채널 모니터를 사용하여 해당 사용자를 뮤트합니다. 내부적으로 이것은 '[setRestrictions()](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#method-signature-1?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)' API를 호출하는 것입니다.
3. 서버 애플리케이션은 [모더레이션 이벤트를](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 통해 '뮤트' 알림을 수신하고 사용자의 기존 액세스 토큰을 [취소합니다](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#revoke-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko).
4. 클라이언트 애플리케이션은 [검토 이벤트를](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 통해 '뮤지컬' 채널과 관련된 '뮤트' 알림을 수신합니다.
5. 애플리케이션은 더 이상의 메시지 전송을 방지하기 위해 UI를 업데이트합니다. 사용자는 페이지의 JavaScript를 수정하여 이 UI 변경을 해결할 수 있지만 인증 토큰이 해지되었으므로 메시지를 보내려는 시도는 실패합니다.
6. 애플리케이션은 위의 액세스 관리자 섹션에 설명된 대로 서버에 새 인증 토큰을 요청합니다. 새로 부여된 토큰에는 '뮤지컬' 채널에 대한 '읽기' 액세스 권한만 있는 등 사용자의 새로운 권한이 반영됩니다.
[이전 글에서](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) '모더레이션 솔루션의 구성 요소'에 대해 설명하고 아래 그래픽을 사용하여 클라이언트와 서버 모두에서 사용할 수 있는 API를 나열했습니다. 위 단계에서 설명한 API도 이 그래픽에 나와 있습니다.

Chat SDK 샘플 앱
-------------
채널 모니터와 Chat SDK 개발을 담당하는 바쁜 엔지니어링 팀이 Chat SDK를 사용하는 React Native로 작성된 샘플 애플리케이션도 만들었습니다.
이 샘플은 PubNub을 사용하여 사실적이고 모든 기능을 갖춘 채팅 앱을 개발하기 위한 SDK의 기능과 모범 사례를 보여줍니다. 이 샘플은 오픈 소스이며 [/샘플/react-native-group-chat에](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat) 있는 Chat SDK와 동일한 GitHub 리포지토리의 일부입니다.

이 애플리케이션은 최근 Access Manager 서버에서 토큰을 요청하고 사용자의 권한이 변경될 때, 즉 채널에서 금지되거나 뮤트되는 경우 새 토큰을 요청하도록 업데이트되었습니다. 이 개선 사항은 [이전 문서가](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 작성된 이후에 이루어진 것이므로 [GitHub에서](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat) 최신 소스를 받아보세요. 이 글을 작성하는 시점에 가장 최근의 git 커밋 ID는 [ae9dfa0입니다](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat).
안전하게 사용자 뮤트 및 금지하기: 샘플 애플리케이션을 사용한 데모
-------------------------------------
이 섹션에서는 클라이언트 및 서버 관점에서 안전한 모더레이션을 보여주는 엔드투엔드 데모를 시작하고 실행하는 방법에 대해 설명합니다.
### PubNub 키세트 만들기
이 데모를 실행하려면 다음과 같이 새 PubNub 키셋을 만드는 것이 좋습니다:
1. [관리자 포털에](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 로그인하여 새 애플리케이션을 만들거나 기존 애플리케이션 내에서 새 키 집합을 만듭니다. 필요한 경우 [관리자 포털 키를 만드는 방법에서](https://www.pubnub.com/how-to/admin-portal-create-keys/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 단계별 지침을 확인할 수 있습니다.
2. 키설정 페이지에서 다음 구성 옵션을 사용 설정합니다. 별도로 지정하지 않는 한 기본값을 그대로 사용할 수 있습니다:
- [앱 컨텍스트](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko). 여기에는 채널과 사용자에 대한 메타데이터가 저장되며 이전 글['사용자 및 채널 관리'](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko)에 자세히 설명되어 있습니다. 또한 `사용자 메타데이터 이벤트`, `채널 메타데이터 이벤트` 및 `멤버십 이벤트도` 활성화합니다.
- [메시지 지속성](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko). 이렇게 하면 관리자가 대화를 검토하고 편집할 수 있도록 메시지 기록을 PubNub에 저장합니다.
- [액세스 관리자](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko). 데이터에 대한 무단 액세스를 방지하고 안전한 모더레이션 솔루션을 만드는 데 필요합니다.
- [현재](https://www.pubnub.com/docs/general/presence/overview?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 상태. 사용자가 온라인 상태인지 오프라인 상태인지 추적하는 데 사용됩니다.
변경 사항을 저장합니다.
다음 단계에서는 `게시 키`, `구독 키` 및 `비밀 키가` 필요합니다.
### 샘플 애플리케이션 빌드하기
앞서 설명한 것처럼 Chat SDK 샘플 앱은 Expo 프레임워크를 사용하여 React Native로 작성된 크로스 플랫폼 클라이언트 앱입니다.
[애플리케이션의](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat#readme) 사용 설명서에 제공된 지침에 따라 샘플 애플리케이션을 복제하고 빌드하세요. 특히, yarn 및 Node.js를 포함한 필수 구성 요소가 설치되어 있는지 확인하세요. 리드미에서는 XCode와 iOS 사용에 대해 설명하지만, Android 에뮬레이터에서도 앱을 실행할 수 있습니다. 이 글을 쓰는 시점에 가장 최근의 git 커밋 ID는 [ae9dfa0입니다](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat).
게시/서브 키를 제공할 때는 이전 단계에서 생성한 키를 사용하세요. `.env` 파일에 키를 포함하지 않으면 애플리케이션이 기본적으로 일부 `데모` 키를 사용하므로 혼동을 피하기 위해 [https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60](https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60) 에서 이 로직을 비활성화할 수 있습니다.
애플리케이션을 실행합니다. ReadMe에서 `yarn ios를` 실행하라고 안내하지만, `yarn android` 또는 `yarn 실행 시작을` 실행할 수도 있으며, 후자는 대화형 메뉴를 제공합니다.
로그인하면 콘솔에 다음과 같은 경고가 표시됩니다:

이는 클라이언트가 Access Manager 서버에 연결하지 못했기 때문이므로 서버를 빌드해 보겠습니다.
### 샘플 Access Manager 서버 빌드하기
샘플 Access Manager 서버는 [https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api](https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api) 에서 찾을 수 있으며, 앞서 설명한 클라이언트 애플리케이션과 동일한 모노레포입니다.
원하는 편집기에서 `src/chatsdk.service.ts` 파일을 열고 `게시키`, `구독키` 및 `비밀키를` 입력합니다. 게시 키와 구독 키는 클라이언트 앱을 만들 때 사용한 것과 일치해야 하며, 비밀 키는 [관리자 포털의](https://admin.pubnub.com?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 앱에 대한 키 설정 페이지에서 사용할 수 있습니다.
`REPO/samples/access-manager-api` 디렉터리에서 `yarn 실행 시작을` 실행하여 Access Manager 서버를 시작하면 아래와 같은 화면이 표시됩니다:

Access Manager 서버가 무엇을 하고 있는지 확인하려면 `app.service.ts를` 보세요. 요청하는 사용자에 대해 생성된 권한 구조와 이러한 권한을 적용하기 위해 `chat.sdk.grantToken(` )을 호출하여 생성된 authKey를 호출하는 클라이언트에 반환하는 것을 볼 수 있습니다.
이 권한은 데모 애플리케이션에 필요한 권한이지만 애플리케이션에는 다른 권한이 필요할 수 있습니다. 제공된 규칙 집합을 시작 템플릿으로 사용할 수 있지만 앱용 액세스 관리자 서버를 만들 때는 [https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 을 참조하여 어떤 Chat SDK 기능에 어떤 권한이 필요한지 정확히 파악하세요.
클라이언트 데모 앱 애플리케이션을 다시 실행하면 이제 오류 없이 로그인할 수 있을 것입니다. '인증 키 새로 고침' 건배 메시지가 표시되면 모든 것이 성공했음을 알 수 있습니다.

두 클라이언트 간의 대화를 시작합니다.

### 채널 모니터를 사용하여 사용자 음소거 및 차단하기
**중요:** 이전에 두 클라이언트 간의 대화를 시작하지 않았다면 지금 바로 시작하세요. 채널은 데모 앱에서 동적으로 생성되므로 채팅이 시작된 후에만 채널 모니터에 표시됩니다.
'인증 키 새로 고침' 배너 또는 '차단된 사용자' 모달과 같이 아래에 표시된 사용자 인터페이스 업데이트는 데모 애플리케이션의 일부이며, 애플리케이션은 자체 UI를 통해 이 정보를 사용자에게 표시합니다.
- [관리자 포털에](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 로그인하고 Access Manager 샘플 및 클라이언트 애플리케이션에 사용한 키 집합을 선택하여 채널 모니터를 시작합니다.
- 왼쪽 탐색 패널의 **BizOps 작업 공간** 섹션으로 이동하여 **채널 모니터를** 선택합니다. **BizOps 워크스페이스** 섹션이 표시되지 않으면 [PubNub 요금제를](https://www.pubnub.com/pricing/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 업그레이드해야 하는 경우가 대부분이지만 문제가 있는 경우 [지원팀에 문의](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 하세요.
- 모더레이션을 시작할 채널을 선택하라는 메시지가 표시됩니다. 채널 이름은 `USER_ID를 가진 1:1 사용자로` 표시되며, 여기서 USER\_ID는 대화를 시작한 사람의 사용자 아이디입니다.
- 키 설정에서 지속성을 사용 설정한 경우 이전 메시지를 포함하여 채널 메시지가 실시간으로 표시됩니다.

- 해당 사용자가 보낸 메시지 옆의 마이크 버튼을 눌러 해당 사용자를 뮤트할 수 있습니다. 음소거된 사용자의 디바이스에 인증 키가 새로 고침되었음을 알리는 메시지가 표시됩니다. 뮤트한 사용자로 메시지를 보내려고 하면 금지됨을 알리는 메시지 대화 상자가 표시되지만, 뮤트하지 않은 사용자는 영향을 받지 않습니다.

- 마이크 버튼을 다시 눌러 사용자의 음소거를 해제합니다. 음소거 해제된 사용자의 디바이스에 인증 키가 새로 고쳐졌으며 이제 메시지 전송에 성공했음을 알리는 메시지가 표시됩니다.

- 해당 사용자가 보낸 쪽지 옆에 있는 차단 버튼을 눌러 해당 사용자를 차단하고 차단 사유를 입력합니다. 사유는 자유 형식의 텍스트로 제공되므로 관련 정보를 입력할 수 있습니다. 인증 키가 새로고침되고 해당 사용자는 앱의 채팅 선택 화면으로 돌아갑니다.

차단된 채널에 접근을 시도하면 사용자에게 오류가 표시됩니다:

- 채널 모니터에서 '차단 해제'를 선택하여 해당 사용자를 차단 해제합니다. 인증 키가 새로 고쳐집니다. 해당 사용자는 차단이 해제되어 다시 채팅에 참여할 수 있습니다.

요약
--
[채팅 애플리케이션](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 개발은 첫 단계에 불과합니다. 가장 어려운 과제는 증가하는 사용자 기반을 지원하기 위해 앱을 배포한 후에 발생합니다. 비즈옵스 워크스페이스는 채팅 애플리케이션의 모든 측면을 관리하도록 설계된 일련의 도구로, 출시 후의 어려움을 간소화해 줍니다.
이 문서에서는 사용자를 안전하게 음소거하고 금지하는 데 중점을 두었지만, [BizOps Workspace의](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 기능은 계속 확장되고 있습니다. 또한 이 문서에서는 Chat SDK에만 초점을 맞추었지만 채널 모니터는 모든 SDK와 함께 작동하도록 [구성할](https://www.pubnub.com/docs/bizops-workspace/basics#configuration?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 수도 있습니다.

도움이나 지원이 필요하면 언제든지 [전담 지원팀에](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 문의하거나 개발자 지원팀( [devrel@pubnub.com](mailto:devrel@pubnub.com))으로 이메일을 보내주세요.
펍넙이 어떤 도움을 드릴 수 있나요?
====================
이 문서는 원래 [PubNub.com에](https://www.pubnub.com/how-to/securely-moderate-chat-and-users/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 게시되었습니다.
저희 플랫폼은 개발자가 웹 앱, 모바일 앱, IoT 디바이스를 위한 실시간 상호작용을 구축, 제공, 관리할 수 있도록 지원합니다.
저희 플랫폼의 기반은 업계에서 가장 크고 확장성이 뛰어난 실시간 에지 메시징 네트워크입니다. 전 세계 15개 이상의 PoP가 월간 8억 명의 활성 사용자를 지원하고 99.999%의 안정성을 제공하므로 중단, 동시 접속자 수 제한 또는 트래픽 폭증으로 인한 지연 문제를 걱정할 필요가 없습니다.
PubNub 체험하기
-----------
[라이브 투어를](https://www.pubnub.com/tour/introduction/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 통해 5분 이내에 모든 PubNub 기반 앱의 필수 개념을 이해하세요.
설정하기
----
PubNub [계정에](https://admin.pubnub.com/signup/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 가입하여 PubNub 키에 무료로 즉시 액세스하세요.
시작하기
----
사용 사례나 [SDK에](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 관계없이 [PubNub 문서를](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 통해 바로 시작하고 실행할 수 있습니다. | pubnubdevrel | |
1,862,683 | Creating Lucy: Developing an AI-Powered Slack Assistant with Memory | Overview The main idea was to build an AI agent named Lucy that can learn from our... | 0 | 2024-05-23T10:01:22 | https://dev.to/kuba_szw/creating-lucy-developing-an-ai-powered-slack-assistant-with-memory-134o | ai, nocode, automation, webdev | ## Overview
The main idea was to build an AI agent named Lucy that can learn from our conversations and interact through a Slack interface. The plan was also to use no code tool (make.com) and play with embedding and pinecone.io. So the whole point was to build something that takes this:
And based on automatically creates table like this (I’m using airtable.com here).
Next I’m able to use those memories to create vectors in pinecone database and use them later in conversations.
> 💡 Be aware that the idea right now is to keep conversation’s history only until the memories are not distilled from it. Later we are operating only on memories, from this conversation which might lead to loosing some informations. But we can tackle this later…
## Slack API
I won’t dive into the nitty-gritty details here, but the basic idea is simple. Create bot app and enable events api. We will use it to publish events on new messages in certain channel. Also I have turned on direct messages to the app. Then create make.com connection and voila.
## Scenario - Lucy Slack conversation
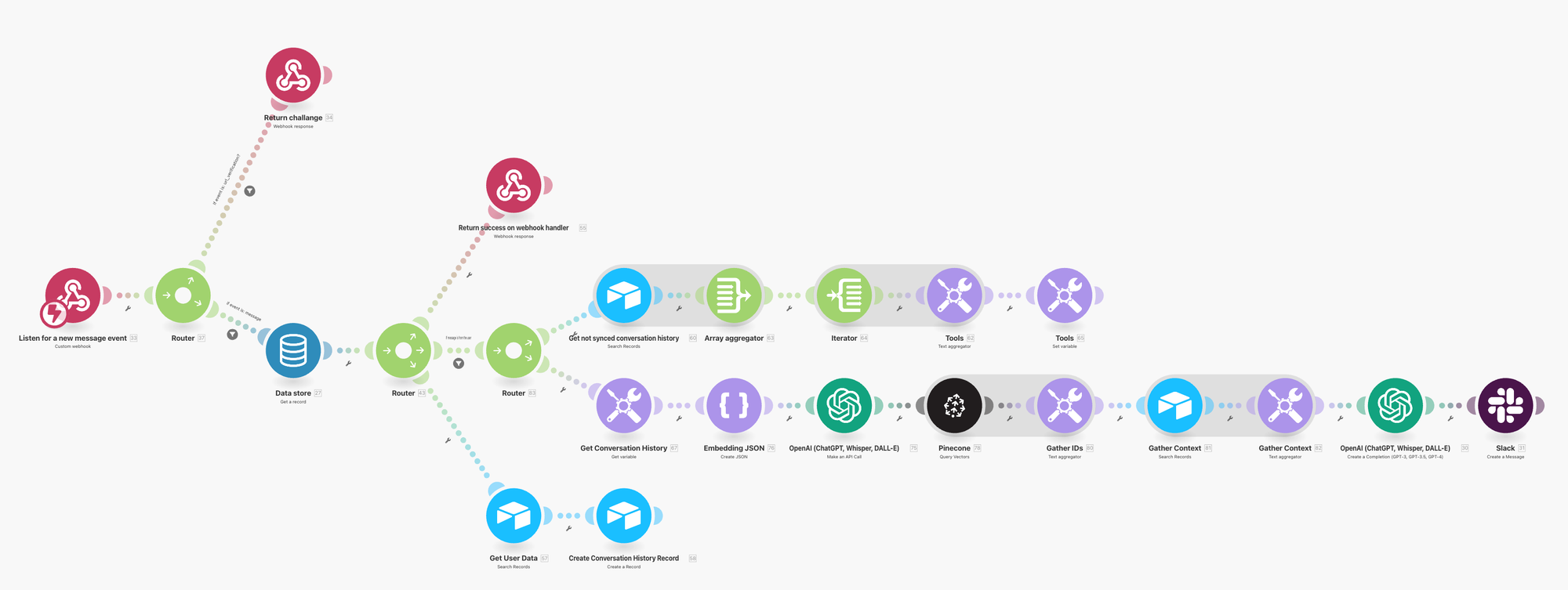
[📘 Check blueprint here](https://arc.net/l/quote/hnfvpivm)
Let’s break it down step by step.
1. **Custom Webhook -** Start with a simple webhook to listen for events. Make sure to register this URL in your Slack app settings.
2. **Webhook response -** there is filter on route checking that `event.type = url_verification`. This is to confirm and send back challange to slack.
3. Next on router we check for `event.type = message`. Obviously we want to process only those events here.
4. **Data store (Get a record)** - fetching user slack id here. For later use.
5. **Router -** a few things here. Lets go one by one.
1. **Webhook response -** first send back webhook response. This to let slack know that we succeed in processing the event and to prevent resending this to us. I know that we don’t finish processing yet but that’s the mistake I can live with. I would rather prefer Lucy to not respond due to some error then responding multiple times and creating noise.
2. **If the message if from the user** - I’m just checking the author here. If its me → proceed. If the message comes from Lucy → Ignore.
1. First fetch not synced conversation history. Aggregate it in format like:
```json
kuba szwajka (2024-05-22T22:57:16.000Z): Hi! Whats my name?
Lucy AI assistant (2024-05-22T22:57:16.000Z): Hey there! I don't have your name yet. What's your name? :smile:
kuba szwajka (2024-05-22T22:57:26.000Z): my name is Kuba. Hi!
Lucy AI assistant (2024-05-22T22:57:28.000Z): Hey Kuba! How's it going? :smile:
```
2. Then embed query sent to slack calling `v1/embeddings` endpoint with **Make an API call.** Next based on the resulting vector I’m querying my pinecone database for similar vectors (Assuming it will return vectors with informations that might be related to my query).
3. More on those vectors and their metadata later but here I’m just taking vector `[metadata.id](http://metadata.id)` and based on that fetching `memories` database by ids.
4. **GPT Completion -** here is the completion itself. The context at this place is build on two things. First - not synced conversation history that might contain useful facts. Second - useful memories that were found in pinecone.
5. **Create slack message**
3. In the end, no matter who created message, I’m saving it with the author to `ConversationHistory` database and mark `synced=false`.
## Scenario - Lucy find memories in conversation

[📘 Check blueprint here](https://arc.net/l/quote/twaomoqq)
This scenario aims to process previously created conversation history, create memories and save them as a vectors. Right now it is triggered every 8 hours. Tbh. I’m testing if this is enough 🤷.
Nothing fancy here. Lets go step by step:
1. Fetch all records from ConversationHistory where synced=false.
2. Aggregate them as a text.
3. Let Chat distill the facts (facts overlapping to be implemented? Not sure if this will be the problem 🤔? Any thoughts? )
4. For the list of facts/memories, create a records in memories table with synced=false.
5. For each of these, create embedding calling v1/embeddings in OpenAI api.
6. Save it to pinecone and mark as synced.
## Action
- There are still a few missing pieces, like handling memory overlapping and preventing data loss during the conversation history to memory conversion.
- I’ve put some blueprints if you want to try it out.
## Want to Know More?
Stay tuned for more insights and tutorials! [Visit My Blog](https://kubaszwajka.com/) 🤖 | kuba_szw |
1,862,690 | Integrating Tailwind CSS with Your Rails App: A Step-by-Step Guide | Introduction: Tailwind CSS has gained popularity among developers for its utility-first approach... | 0 | 2024-05-23T10:01:17 | https://dev.to/afaq_shahid/integrating-tailwind-css-with-your-rails-app-a-step-by-step-guide-4k93 | tailwindcss, ruby, javascript, webdev | Introduction:
> Tailwind CSS has gained popularity among developers for its utility-first approach and flexibility. Integrating Tailwind CSS with your Rails application can enhance your frontend development experience, allowing for rapid prototyping and customizable styling. In this article, we'll walk through the steps to integrate Tailwind CSS into your Rails app and unleash its power for building beautiful interfaces.
Step 1: Install Tailwind CSS
First, let's install Tailwind CSS using npm. Navigate to your Rails application directory and run the following command:
```bash
npm install tailwindcss
```
Step 2: Configure Tailwind CSS
Next, we need to create a Tailwind CSS configuration file. Run the following command to generate the default configuration file:
```bash
npx tailwindcss init
```
This will create a `tailwind.config.js` file in your project directory. You can customize this file to tweak Tailwind CSS settings according to your project requirements.
Step 3: Include Tailwind CSS in Your Stylesheets
Now, let's include Tailwind CSS in your Rails application. You can import Tailwind CSS into your stylesheet using `@import` directive. Create a new file `app/assets/stylesheets/tailwind.css` and add the following line:
```css
@tailwind base;
@tailwind components;
@tailwind utilities;
```
Step 4: Configure PostCSS
To process Tailwind CSS, we need to configure PostCSS. Install PostCSS and Autoprefixer using npm:
```bash
npm install postcss-loader autoprefixer
```
Next, create a PostCSS configuration file `postcss.config.js` in your project root directory and add the following content:
```javascript
module.exports = {
plugins: [
require('tailwindcss'),
require('autoprefixer'),
]
}
```
Step 5: Update Webpacker Configuration
We need to update Webpacker configuration to process PostCSS. Open `config/webpacker.yml` and add `postcss` to the `extensions` list:
```yaml
extensions:
- .js
- .css
- .scss
- .sass
- .module.css
- .module.scss
- .module.sass
- .pcss # Add this line
```
Step 6: Use Tailwind CSS Classes in Your Views
Now that Tailwind CSS is integrated into your Rails app, you can start using its utility classes in your views. For example:
```html
<div class="bg-blue-500 text-white p-4">
Welcome to My Rails App with Tailwind CSS!
</div>
``` | afaq_shahid |
1,862,688 | Jak bezpiecznie moderować czat i użytkowników za pomocą BizOps Workspace | Jak wykorzystać Channel Monitor i Access Manager PubNub do stworzenia bezpiecznej i moderowanej aplikacji czatu? | 0 | 2024-05-23T10:00:09 | https://dev.to/pubnub-pl/jak-bezpiecznie-moderowac-czat-i-uzytkownikow-za-pomoca-bizops-workspace-13g7 | Ten artykuł instruktażowy jest częścią serii artykułów omawiających możliwości zarządzania danymi PubNub, znane pod wspólną nazwą [BizOps Work](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)space:
- [Jak zarządzać użytkownikami i kanałami za pomocą BizOps Workspace](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)
- [Jak monitorować i moderować konwersacje za pomocą BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)
- Jak bezpiecznie moderować konwersacje i użytkowników za pomocą BizOps Workspace
BizOps Workspace to zestaw narzędzi, które pomagają zarządzać aplikacją. Ten artykuł rozszerzy poprzedni artykuł "Jak[monitorować i moderować konwersacje](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)za pomocą BizOps Workspace", aby pokazać kompleksową bezpieczną aplikację do czatowania z ręcznymi możliwościami moderacji, tj. możliwością monitorowania konwersacji w czasie rzeczywistym oraz wyciszania lub blokowania użytkowników.
Chociaż ten artykuł można czytać samodzielnie, zdecydowanie zalecam przeczytanie poprzedniego artykułu "[Jak monitorować i moderować konwersacje za](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)pomocą BizOps Workspace", aby lepiej zrozumieć tło omawianych tutaj koncepcji.
Czym jest Channel Monitor?
--------------------------
Channel Monitor umożliwia moderatorom czatu oglądanie na żywo podglądu rozmów prowadzonych w czasie rzeczywistym na wielu kanałach. Jeśli moderator zauważy coś niepokojącego, takiego jak niewłaściwie zachowujący się użytkownik lub obraźliwe wiadomości, może natychmiast podjąć działania w celu złagodzenia problemu.
Moderator ma dużą swobodę w zakresie podejmowanych działań:
- Obserwować użytkownika bez ograniczania jego praw dostępu
- edytować lub usunąć obraźliwą wiadomość
- ograniczyć możliwość publikowania wiadomości przez użytkownika[(wy](https://pubnub.com/docs/bizops-workspace/channel-monitor#mute?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)ciszyć)
- ograniczyć użytkownikowi możliwość czytania lub publikowania wiadomości ([ban](https://pubnub.com/docs/bizops-workspace/channel-monitor#ban?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)).
Wszystkie możliwości w ramach funkcji "Monitor" są ręczne: ręczne przeglądanie wiadomości, ręczne wyciszanie użytkowników itp. Ten artykuł nie omawia automatycznej moderacji.
Aby korzystać z funkcji Channel Monitor, konieczne jest włączenie kilku funkcji w zestawie kluczy PubNub, w szczególności [kontekstu aplikacji](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) i [trwałości](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) wiadomości. Więcej szczegółów można znaleźć w sekcji "Wymagania dotyczące zestawu kluczy dla Channel Monitor" w [poprzednim artykule](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl).
Czym jest menedżer dostępu PubNub?
----------------------------------
**Programiści muszą chronić się przed użytkownikami próbującymi obejść ich system** moderacji; można to osiągnąć za pomocą menedżera dostępu PubNub.
[Menedżer](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) dostępu pozwala zdefiniować zestaw reguł, które opisują uprawnienia określonego użytkownika (lub użytkowników) i jakie działania mogą wykonywać na określonych zasobach. Na przykład:
- Użytkownik o identyfikatorze `123` ma uprawnienia do odczytu i zapisu na kanale `456`
- Wszyscy użytkownicy, których ID pasuje do wyrażenia regularnego `user-*`, mogą czytać z dowolnego kanału, którego ID pasuje do wyrażenia regularnego `global-*`.
- Użytkownik o identyfikatorze `123` ma uprawnienia do aktualizacji metadanych kanału (tj. kontekstu aplikacji).
Pełna lista uprawnień znajduje się w dokumentacji na stronie [https://www.pubnub.com/docs/general/security/access-control#permissions](https://www.pubnub.com/docs/general/security/access-control#permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl).
Menedżer dostępu PubNub jest oparty na tokenach, a najłatwiejszym sposobem na jego opisanie jest przejście przez przepływ autoryzacji pokazany w [dokumentacji](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) i zapewnienie dodatkowego kontekstu, w jaki sposób ten przepływ odnosi się do moderacji:

1. **Próba logowania**. Klient uwierzytelnia się na serwerze, aby zalogować użytkowników do aplikacji. Prawdopodobnie odbywa się to za pośrednictwem dostawcy tożsamości; po tym kroku serwer ma pewność, że rozmawia z zarejestrowanym użytkownikiem aplikacji i kim on jest. Klient żąda tokenu uwierzytelniania PubNub Access Manager w ramach swojej inicjalizacji.
2. **Żądanie przyznania uprawnień**. Serwer obsługuje żądanie klienta o token, wywołując interfejs API SDK "[grantToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#grant-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)". Kilka punktów do odnotowania na temat tego API: Można go wywołać tylko za pomocą **tajnego klucza** PubNub, a zatem można go wywołać tylko z serwera; jest dostępny dla wszystkich naszych zestawów SDK po stronie serwera; i to API zaakceptuje obiekty JSON w celu zdefiniowania zasobów i uprawnień, które definiują dostęp użytkownika (użytkowników).
3. Zwrócony**token**. PubNub przyznaje żądane uprawnienia żądanym użytkownikom i zwraca token uwierzytelniający do serwera.
4. Token**przekazany**. Następnie serwer zwraca token uwierzytelniający do pierwotnego klienta wywołującego.
5. **Token ustaw**iony. Klient może określić ten token uwierzytelniający podczas inicjalizacji lub w dowolnym momencie cyklu życia aplikacji za pomocą metody [setToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#set-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl). Możliwość aktualizacji tokena w dowolnym momencie jest niezbędna, ponieważ tokeny wygasają, ale klient będzie również musiał zażądać nowego tokena, jeśli Channel Monitor zaktualizuje swoje uprawnienia (tj. zostanie wyciszony lub zbanowany).
6. **Autoryzowane żądanie API**. Wszelkie kolejne połączenia z PubNub będą teraz uznawane za autoryzowane. PubNub zezwoli lub odrzuci każde żądanie API w oparciu o uprawnienia przyznane w kroku 2 i ważność tokena klienta.
Jak wygląda bezpieczne rozwiązanie moderacyjne?
-----------------------------------------------
Pod koniec [poprzedniego](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) artykułu pokazałem demo tego, jak wyglądałoby wyciszanie lub banowanie po stronie klienta. Chat SDK zawiera [zdarzenia moderacji](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl), które informują klienta o tym, czy został wyciszony lub zbanowany; jednak poza aktualizacją interfejsu użytkownika nie uniemożliwia to **klientowi dalszego wysyłania wiadomości, mimo że został wyciszony/zbanowany**. Aby bezpiecznie wyciszyć lub zablokować klienta, należy cofnąć jego istniejące uprawnienia Menedżera dostępu i przyznać mu nowe, aby odzwierciedlić jego nowy status wyciszenia lub zablokowania.
Rozważmy następujący scenariusz, w którym użytkownik został wyciszony z kanału "musicale":

1. Użytkownik ma dostęp do dwóch kanałów, "filmy" i "musicale", ale administrator chce wyciszyć go tylko z kanału "musicale".
2. Moderator wycisza użytkownika za pomocą Monitora kanałów. Pod przykrywką jest to wywołanie interfejsu API "[setRestrictions()](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#method-signature-1?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)
3. Aplikacja serwerowa otrzymuje powiadomienie o "wyciszeniu" za pośrednictwem [zdarzenia moderacji](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) i [unieważnia](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#revoke-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) istniejący token dostępu użytkownika.
4. Aplikacja kliencka otrzymuje powiadomienie "mute" powiązane z kanałem "musicals" poprzez zdarzenie [moderacji](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl).
5. Aplikacja aktualizuje swój interfejs użytkownika, aby zapobiec wysyłaniu większej liczby wiadomości. Użytkownik może obejść tę zmianę interfejsu użytkownika, modyfikując JavaScript strony, ale każda próba wysłania wiadomości zakończy się niepowodzeniem, ponieważ jego token uwierzytelniający został cofnięty.
6. Aplikacja żąda nowego tokenu uwierzytelniania z serwera, jak opisano w sekcji Menedżer dostępu powyżej. Nowo przyznany token będzie odzwierciedlał nowe uprawnienia użytkownika, w tym tylko dostęp "do odczytu" do kanału "musicale".
W [poprzednim](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) artykule opisano "Składniki rozwiązania do moderacji" i wymieniono interfejsy API dostępne zarówno dla klienta, jak i serwera, korzystając z poniższej grafiki. Interfejsy API omówione w powyższych krokach są również pokazane na tej grafice.

Przykładowa aplikacja Chat SDK
------------------------------
Ten sam zapracowany zespół inżynierów odpowiedzialny za rozwój Channel Monitor i Chat SDK stworzył również przykładową aplikację napisaną w React Native, która korzysta z Chat SDK.
Próbka pokazuje możliwości SDK i najlepsze praktyki tworzenia realistycznej i w pełni funkcjonalnej aplikacji czatu przy użyciu PubNub. Jest to open source i część tego samego repozytorium GitHub, które zawiera Chat SDK pod [/samples/react-native-group-chat](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat).

Ta aplikacja została niedawno zaktualizowana, aby żądać tokenów z serwera Access Manager i żądać nowego tokena, gdy uprawnienia użytkownika ulegną zmianie, tj. zostaną zablokowane lub wyciszone z kanałów. To ulepszenie zostało wprowadzone od czasu napisania [poprzedniego artykułu](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl), więc pamiętaj, aby pobrać najnowsze źródło z [GitHub](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat). W chwili pisania tego tekstu najnowszy identyfikator zatwierdzenia git to [ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat)
Bezpieczne wyciszanie i banowanie użytkowników: Demo przy użyciu przykładowej aplikacji
---------------------------------------------------------------------------------------
W tej sekcji opisano, jak uruchomić nasze kompleksowe demo, pokazujące bezpieczną moderację zarówno z perspektywy klienta, jak i serwera.
### Tworzenie zestawu kluczy PubNub
Zalecam utworzenie nowego zestawu kluczy PubNub, aby uruchomić to demo w następujący sposób:
1. Zaloguj się do [portalu administratora](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) i utwórz nową aplikację lub nowy zestaw kluczy w istniejącej aplikacji. W razie potrzeby możesz znaleźć instrukcje krok po kroku w naszym [Jak utworzyć klucze portalu administra](https://www.pubnub.com/how-to/admin-portal-create-keys/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)cyjnego.
2. Na stronie zestawów kluczy włącz następujące opcje konfiguracji. Możesz zaakceptować ustawienia domyślne, chyba że określono inaczej:
- [App Context](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl). Przechowuje on metadane o kanałach i użytkownikach i został opisany w poprzednim artykule na temat["Zarządzania użytkownikami i kanałami](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)". Włącz także zdarzenia `metadanych` `użytkownika`, `zdarzenia metadanych kanału` i `zdarzenia członkostwa`.
- [Trwałość wiadomości](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl). Przechowuje historię wiadomości w PubNub, dzięki czemu administrator może przeglądać i edytować konwersacje.
- [Menedżer](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) dostępu. Zapobiega nieautoryzowanemu dostępowi do danych i jest wymagany do stworzenia bezpiecznego rozwiązania moderacji.
- [Obecność](https://www.pubnub.com/docs/general/presence/overview?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl). Służy do śledzenia, czy użytkownik jest online czy offline.
Zapisz zmiany.
W kolejnych krokach potrzebne będą klucze `Publish Key`, `Subscribe Key` i `Secret Key`.
### Tworzenie przykładowej aplikacji
Jak opisano wcześniej, aplikacja Chat SDK Sample jest wieloplatformową aplikacją kliencką napisaną w React Native przy użyciu frameworka Expo.
Sklonuj i zbuduj przykładową aplikację, postępując zgodnie z instrukcjami podanymi w [readme aplikacji](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat#readme). W szczególności upewnij się, że masz zainstalowane wymagania wstępne, w tym yarn i Node.js. ReadMe mówi o korzystaniu z XCode i iOS, ale można również uruchomić aplikację na emulatorze Androida. W chwili pisania tego tekstu najnowszy identyfikator zatwierdzenia git to [ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat)
Podając klucze Pub/Sub, użyj kluczy wygenerowanych w poprzednim kroku. Jeśli nie umieścisz kluczy w pliku `.env`, aplikacja będzie domyślnie korzystać z niektórych kluczy `demonstracyjnych`; możesz wyłączyć tę logikę na stronie [https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60](https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60), aby uniknąć nieporozumień.
Uruchom aplikację. ReadMe instruuje, aby uruchomić yarn `ios`, ale można również uruchomić `yarn android` lub `yarn run start`, z których ten ostatni daje interaktywne menu.
Po zalogowaniu w konsoli powinno pojawić się następujące ostrzeżenie:

Dzieje się tak, ponieważ klient nie połączył się z serwerem Access Manager, więc zbudujmy go.
### Tworzenie przykładowego serwera Access Manager
Sample Access Manager Server można znaleźć pod adresem [https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api,](https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api) jest to ten sam monorepo, co aplikacja kliencka omówiona wcześniej.
Otwórz plik `src/chatsdk.service.` ts w wybranym edytorze i wypełnij pola `publishKey`, `subscribeKey` i `secretKey`. Klucze publish i subscribe muszą być zgodne z tymi, których użyto do utworzenia aplikacji klienckiej, a klucz tajny jest dostępny na stronie zestawu kluczy dla aplikacji w [portalu administratora](https://admin.pubnub.com?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)
Z katalogu `REPO/samples/access-manager-api` uruchom polecenie `yarn run start`, aby uruchomić serwer Access Manager, a powinieneś zobaczyć coś takiego jak poniżej:

Aby zobaczyć, co robi serwer Access Manager, spójrz na `app.service.ts`. Zobaczysz struktury uprawnień wygenerowane dla żądającego użytkownika i wywołanie `chat.sdk.grantToken()` w celu zastosowania tych uprawnień, zwracając wygenerowany klucz authKey do klienta wywołującego.
Są to uprawnienia wymagane przez aplikację demonstracyjną, ale Twoja aplikacja prawdopodobnie będzie potrzebować innych uprawnień. Możesz użyć tego dostarczonego zestawu reguł jako szablonu początkowego, ale podczas tworzenia serwera Access Manager dla swojej aplikacji skonsultuj się z [https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl), aby dokładnie zrozumieć, jakie uprawnienia są wymagane przez poszczególne funkcje Chat SDK.
Uruchom ponownie aplikację demonstracyjną klienta i powinieneś być teraz w stanie zalogować się bez błędów. Będziesz wiedział, że wszystko się powiodło, gdy otrzymasz toast "Authkey refreshed".

Zainicjuj rozmowę między dwoma klientami.

### Wyciszanie i banowanie użytkowników za pomocą Monitora kanałów
**Ważne:** Jeśli wcześniej nie zainicjowałeś konwersacji między dwoma klientami, zrób to teraz. Kanały są tworzone dynamicznie przez aplikację demonstracyjną, więc będą wyświetlane w Channel Monitor dopiero po rozpoczęciu czatu.
Należy pamiętać, że wszelkie aktualizacje interfejsu użytkownika pokazane poniżej, takie jak baner "auth key refreshed" lub modal "banned user", są częścią aplikacji demonstracyjnej - Twoja aplikacja wyświetli te informacje użytkownikowi za pośrednictwem własnego interfejsu użytkownika.
- Uruchom Channel Monitor, logując się do [portalu administratora](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) i wybierając zestaw kluczy użyty dla próbki Access Manager i aplikacji klienckiej.
- Przejdź do sekcji **BizOps Workspace** w lewym panelu nawigacyjnym i wybierz Channel **Monitor**. Jeśli nie widzisz sekcji **BizOps** Workspace, prawie na pewno musisz zaktualizować swój [plan PubNub](https://www.pubnub.com/pricing/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl), ale w razie jakichkolwiek problemów [skontaktuj się z naszym działem pomocy technicznej](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl).
- Zostaniesz poproszony o wybranie kanałów do rozpoczęcia moderacji. Nazwa kanału będzie miała postać `1:1 użytkownik z USER_ID`, gdzie USER\_ID to nazwa użytkownika osoby, która zainicjowała konwersację.
- Wiadomości na kanale będą wyświetlane w czasie rzeczywistym, w tym poprzednie wiadomości, jeśli w zestawie klawiszy włączona jest funkcja trwałości.

- Wycisz użytkownika, naciskając przycisk mikrofonu obok wiadomości wysłanej przez tego użytkownika. Na urządzeniu wyciszonego użytkownika pojawi się komunikat informujący, że klucz autoryzacji został odświeżony. Próba wysłania wiadomości jako wyciszony użytkownik spowoduje wyświetlenie okna dialogowego z informacją, że jest to zabronione, ale nie ma to wpływu na niewyciszonego użytkownika.

- Wyłącz wyciszenie użytkownika, naciskając ponownie przycisk mikrofonu. Na urządzeniu niewyciszonego użytkownika pojawi się komunikat informujący, że klucz autoryzacji został odświeżony i wysyłanie wiadomości będzie teraz możliwe.

- Zbanuj użytkownika, naciskając przycisk bana obok wiadomości wysłanej przez tego użytkownika i podając powód bana. Powód jest tekstem swobodnym, więc możesz podać dowolne istotne informacje. Klucz autoryzacji zostanie odświeżony, a użytkownik powróci do ekranu wyboru czatu w swojej aplikacji.

Próba uzyskania dostępu do zablokowanego kanału spowoduje wyświetlenie błędu:

- Odblokuj użytkownika, wybierając opcję "Usuń blokadę" w Monitorze kanałów. Klucz autoryzacji zostanie odświeżony. Użytkownik zostanie odbanowany i będzie mógł ponownie uzyskać dostęp do czatu.

Podsumowanie
------------
Opracowanie dowolnej [aplikacji cz](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) atu to tylko pierwszy krok. Najtrudniejsze wyzwania pojawiają się po wdrożeniu aplikacji do obsługi rosnącej bazy użytkowników. BizOps Workspace to zestaw narzędzi zaprojektowanych do zarządzania każdym aspektem aplikacji czatu, upraszczając wyzwania po uruchomieniu.
Chociaż w tym artykule skupiliśmy się na bezpiecznym wyciszaniu i banowaniu użytkowników, nadal rozszerzamy funkcje [BizOps Work](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)space. Ten artykuł skupiał się również wyłącznie na Chat SDK, ale Channel Monitor można również [skonfigurować](https://www.pubnub.com/docs/bizops-workspace/basics#configuration?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) do pracy z dowolnym z naszych SDK.

Jeśli potrzebujesz pomocy lub wsparcia, skontaktuj się z naszym [dedykowanym zespołem wsparcia](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) lub napisz do naszego zespołu ds. relacji z programistami na adres [devrel@pubnub.com](mailto:devrel@pubnub.com).
Jak PubNub może ci pomóc?
=========================
Ten artykuł został pierwotnie opublikowany na [PubNub.com](https://www.pubnub.com/how-to/securely-moderate-chat-and-users/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)
Nasza platforma pomaga programistom tworzyć, dostarczać i zarządzać interaktywnością w czasie rzeczywistym dla aplikacji internetowych, aplikacji mobilnych i urządzeń IoT.
Fundamentem naszej platformy jest największa w branży i najbardziej skalowalna sieć przesyłania wiadomości w czasie rzeczywistym. Dzięki ponad 15 punktom obecności na całym świecie obsługującym 800 milionów aktywnych użytkowników miesięcznie i niezawodności na poziomie 99,999%, nigdy nie będziesz musiał martwić się o przestoje, limity współbieżności lub jakiekolwiek opóźnienia spowodowane skokami ruchu.
Poznaj PubNub
-------------
Sprawdź [Live Tour](https://www.pubnub.com/tour/introduction/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl), aby zrozumieć podstawowe koncepcje każdej aplikacji opartej na PubNub w mniej niż 5 minut.
Rozpocznij konfigurację
-----------------------
Załóż [konto](https://admin.pubnub.com/signup/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) PubNub, aby uzyskać natychmiastowy i bezpłatny dostęp do kluczy PubNub.
Rozpocznij
----------
[Dokumenty](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl) PubNub pozwolą Ci rozpocząć pracę, niezależnie od przypadku użycia lub [zestawu SDK](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl). | pubnubdevrel | |
1,861,877 | Profiling Rust with VS on Windows | Preface This all began while I was developing a tool in Rust for reading from a database,... | 0 | 2024-05-23T10:00:00 | https://dev.to/jambochen/profiling-rust-with-vs-on-windows-3m4l | # Preface
This all began while I was developing a tool in Rust for reading from a database, processing data, and writing back to it. The program was taking too long to run, and I couldn't figure out where the bottleneck was. Online searches for 'how to profile Rust on Windows' mostly pointed to using Visual Studio (with some mentions of WPA), yet I found no straightforward guides for beginners, **especially as a VS Code user**. After some trial and error, I've put together this article.
It's not a full-fledged profiling tutorial, but more a record of my own experiences. I've also experimented with Intel Vtune, which I quite like, but it occupies a hefty 2GB of space. Considering that installing Rust on Windows seems to inevitably involve downloading Visual Studio (I'm not aware of how to avoid it), I've decided to document the profiling process using VS.
This is just a simple tutorial. For more detailed information, please refer to the Visual Studio documentation:
- [First look at profiling tools](https://learn.microsoft.com/en-us/visualstudio/profiling/profiling-feature-tour?view=vs-2022&WT.mc_id=studentamb_228125)
- [Analyze performance by using CPU profiling in the Performance Profiler](https://learn.microsoft.com/en-us/visualstudio/profiling/cpu-usage?view=vs-2022&WT.mc_id=studentamb_228125)
- [Identify hot paths with a flame graph](https://learn.microsoft.com/en-us/visualstudio/profiling/flame-graph?view=vs-2022&WT.mc_id=studentamb_228125)
# Profiling
First and foremost, add the following lines to your project's `Cargo.toml` file:
```toml
[profile.release]
debug=1
```
After saving, building the release will also include debug information:
```powershell
cargo build --release
Finished release [optimized + debuginfo] target(s) in 0.10s
```
Next, open Visual Studio (I'm using VS 2022). Since I'm only planning to use VS as a performance analysis tool, click "Continue without code".
Then, go to the 'Debug' menu and open 'Performance Profiler'.
Select the executable file (exe) as the target for analysis.
Set the working directory to the project's directory, and locate the compiled executable file in the project's `target/release` directory.
Choose 'CPU Usage' and then click 'Start' to begin executing the file and recording. You can wait for the file to finish running or interrupt it yourself. After completion, Visual Studio will automatically generate a report.
The generated report includes information on the execution time of functions and their sub-functions, and it also lists the functions that consume the most time. Clicking 'Open details' will open a more detailed report.
In the upper left corner, you can switch the displayed view. After clicking on a function, Visual Studio will also display the specific code and the time consumed by each line of code. The flame graph can also be used to display code performance details.
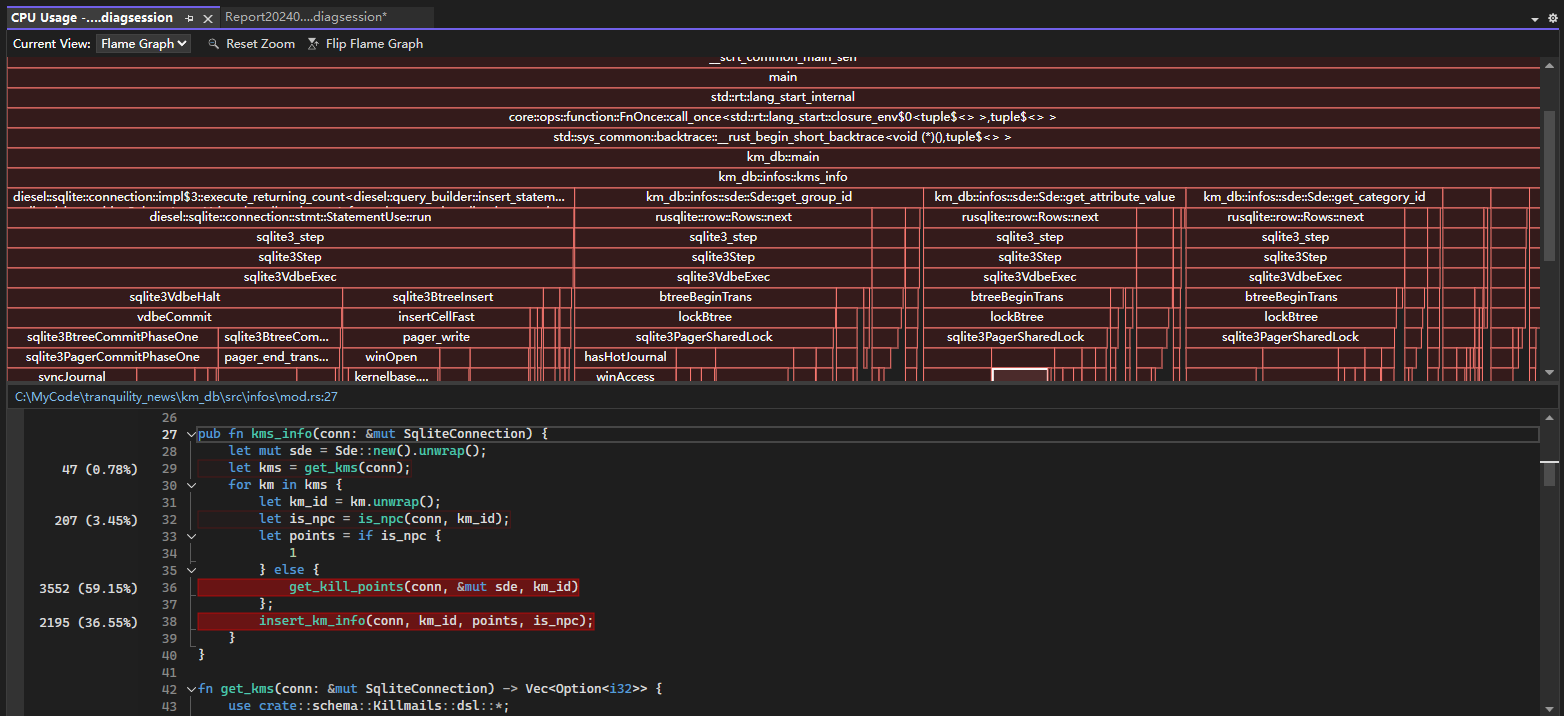
# Reference
- [First look at profiling tools](https://learn.microsoft.com/en-us/visualstudio/profiling/profiling-feature-tour?view=vs-2022&WT.mc_id=studentamb_228125)
- [Analyze performance by using CPU profiling in the Performance Profiler](https://learn.microsoft.com/en-us/visualstudio/profiling/cpu-usage?view=vs-2022&WT.mc_id=studentamb_228125)
- [Identify hot paths with a flame graph](https://learn.microsoft.com/en-us/visualstudio/profiling/flame-graph?view=vs-2022&WT.mc_id=studentamb_228125) | jambochen | |
1,862,687 | How to check your site in different languages and writing modes | Building sites that support multiple writing modes and languages is challenging. You don't always... | 0 | 2024-05-23T09:56:51 | https://polypane.app/blog/how-to-check-your-site-in-different-languages-and-writing-modes/ | css, webdev, a11y, i18n | Building sites that support multiple writing modes and languages is challenging. You don't always know the language or even the script, and changing your OS to trigger certain conditions is cumbersome.
Even if you're willing to make that change on your device, during development you might not even have the other languages available to test with.
This post will show you how to test your site in different languages and writing modes without changing your OS settings or having access to your content in other languages (and without having to learn a new language).
## Quick terms
When we talk about multi-lingual sites, there are a few terms you should be familiar with:
- **Writing mode**: The direction in which text is written. For example, English is written from left to right, while Arabic is written from right to left.
- **Page language**: The language in which the content of the page is written.
- **Browser Locale**: This defines the user's language and region.
All of these fall under two terms that are also worth knowing:
- **Localization** (often shortened to l10n): The process of adapting a product or content to a specific locale or market: using the right spelling, number formatting, currency, etc.
- **Internationalization** (often shortened to i18n): The process of designing and developing a product or content in a way that it can be easily localized: using the right encoding, designing for multiple text directions, having a resilient layout, etc.
This post dives into how you can test your site in different languages and writing modes without changing your OS settings, so it focuses on the _i18n part_ of the process.
## Challenges
When building a site that supports multiple languages and writing modes, you need to consider the following:
1. **Language-dependent Browser APIs** like the I18n API, which is used to format dates, numbers, and currencies according to the user's (browser) locale.
1. **Text direction**: Some languages are written from left to right, while others are written from right to left. Your site can adapt to this when you take it into account during development.
1. **Text length**: Compared to English, some languages have much longer words and sentences while others have much shorter words and sentences. This can cause your layout to break if you don't account for it.
## The basics
To make sure your site adapts well to multiple languages and writing modes, you need to make sure that you have the following in place:
1. **The `lang` attribute**: This attribute is used to specify the language of the content of the page.
1. **The `dir` attribute**: This attribute is used to specify the direction of the text of the page.
Both of these attributes go on your `<html>` tag. From these two attributes, the browser can infer the language and writing mode of the page and adjust accordingly.
### The `lang` attribute
The lang attribute should have as its value the language code of the language you are using. It's important to set because it helps search engines know what language your page is in, and assistive technology like screen readers use it to pick the right voice and to make sure pronunciations are correct.
For example, for English you would use `en`, for Arabic you would use `ar`, and for Japanese you would use `ja`.
If you're targeting a specific dialect, you can use the language code followed by a dash and the dialect code. For example, for American English, you would use `en-US` while for British English you would use `en-GB`. The general advice though is to use the language code _without_ the region code unless there is a reason why the specific regional dialect is important for this page.
> Keep in mind that this doesn't mean you're targeting the USA or the UK specifically, since other countries also use either American English (like Canada) or British English (like Australia).
Occasionally you'll see the language code using an underscore to separate the language and region code, like `en_GB`. While Firefox normalizes this for you, both Safari and Chrome will not recognize this as a valid language code and so also not expose it to assistive technology.
### The `dir` attribute
The dir attribute should have as value either `ltr` (left-to-right) or `rtl` (right-to-left) and is used to specify the direction of the text of the page.
The default value on the web is `ltr`, so you usually only see this added for languages that are written from right to left as `<html dir="rtl">`.
With these two in place, you've told the browser everything it needs to know about your page.
## Testing different languages and writing modes
Now to test for different writing modes and languages, you can change the `lang` and `dir` attributes of your page. You could open the element inspector and change these manually but in Polypane, the emulations panel gives you easy access to these features along with the ability to change the browser locale.
### Changing the reading direction
To change the reading direction of your page, you can use the `dir` attribute.
Changing this from `ltr` to `rtl` will update the default styling in browsers such that text becomes right-aligned and the "start" value (for example, for flexbox and grid alignment) evaluates to the right. It does this even if your content is still in English.
In Polypane, you can change the reading direction of your page by selecting the desired direction from the emulations dropdown.
With the `dir` attribute set to `rtl`, you can test how your site looks when the text is right-aligned. If we check out the screenshot comparing the left-to-right and right-to-left versions we can see that it has done a pretty good job: the navigation is now on the right-hand side and the text mostly still has the correct padding, but we can spot a few things that we should fix:
Visual issues here are:
- The 100% bar is still filled to the right.
- The "dismiss" button is still on the right side, and the "hide this block" image is no longer pointing at it.
- The checkmarks next to each list item are flush against the text and have too much space.
Almost all of these are the result of me using non-logical margins and alignments. Instead of `text-align: right` on the 100% in the bar, I should be using `text-align: end`. And instead of `margin-right` on the checkmarks, I should be using `margin-inline-end`.
Lastly, the dismiss button is positioned using a `float: right`. Instead of that, I should be using `float: inline-end`. The "hide this block" image is a little more involved since the text is baked into the graphic. You would probably switch this out for a different image or decouple the arrow from the text and position them separately.
All in all, the changes you would make here are mostly small and easy to test.
### Changing the language
While the `lang` attribute tells you what language the page is in, it won't change how your page is being displayed.
Browser APIs like the I18n API by default use the browser locale to determine how to format dates, numbers, and currencies. When you emulate the browser locale in Polypane it will update the places where that locale is being used. For example, here's an excerpt with a date from the Polypane blog in English and in Spanish:
To set the language and locale in Polypane you can use the dropdowns in the emulations dropdown. Polypane will autosuggest shortcodes as well as language names so that, for example, you don't have to remember that the language tag for Greenlandic is `kl`. You type "greenlandic" and Polypane sorts the rest.

## Testing your layout
Changing the browser locale or the page `lang` attribute doesn't change the text itself though. If you want to test how your layout behaves with different text lengths, you'll need to change the text itself.
English text is often shorter than other languages also using the Latin script (like German), but longer than languages like Chinese or Japanese where the characters used often represent more than a single letter in latin script, and sometimes a single character can even be an entire word (For example, 母 is "mother" in Chinese).
### Emulating text length
Rather than doing a full-page translation, potentially in a language you can't read, you can use the [Content Chaos feature](/docs/debug-tools/#content-chaos-test) in Polypane to replace all text on your page with random text. This way you can test how your layout behaves with different text lengths without translating the entire page.
> Content Chaos testing is not just useful for testing different languages, but also for making sure that once the perfectly designed text is replaced with real content, your layout still holds up.
To check if your layout handles longer titles well, you can use the "More text" option:
You can see that the list of buttons on the left side responds well to more text: the content wraps and stays centered in the button, without having a weird line-height.
The main content is overflowing though, and that's because the button is not constrained in width. I can fix this by adding a `max-width` to the button, or by using `overflow-wrap: break-word` on the text.
If you want to test how your layout behaves with shorter text, you can use the "Less text" option:
Here you can see that the layout is still working well. Even with little text the buttons are still easily clickable and the layout doesn't break. I don't have to fix anything here to accommodate for languages with shorter text.
### Checking the line length
Another thing to keep in mind is the number of characters in a line. While the specific recommendations differ quite widely between sources, the general consensus is that you want to keep the line length short enough that it's easy to read, but long enough that you're not wasting space: between 45 to 70 characters per line, or (roughly) 10 words for English. To check these values, highlight a line and right-click to [see the number of characters and words in that line](/docs/measure-text-length/).
This feature is aware of the language the page is in so will correctly detect real characters and words, as well as emoji and sentences.
for CJK (Chinese, Japanese and Korean) characters you want to aim for roughly half the number of characters per line as you would for Latin characters. This is because CJK characters are about twice as wide as those in the Latin script. This advice comes from the [WCAG 1.4.8 Visual Presentation Understanding page](https://www.w3.org/WAI/WCAG21/Understanding/visual-presentation.html). Those are not part of WCAG itself, but meant to help you understand them.
## Conclusion
To check your layout and implementation for multiple languages, you'll want to check with different `dir`, `lang`, and browser locales. You can change these on an OS level, or emulate them in Polypane.
Rather than translating your entire page into a language you don't understand, you can use the Content Chaos feature to test how your layout behaves with different text lengths and make sure there aren't any errors when the text is longer or shorter than you expected.
| kilianvalkhof |
1,862,686 | How to Choose the Best Field Service Scheduling App | Choosing the best field service scheduling app for your business involves considering various factors... | 0 | 2024-05-23T09:56:48 | https://dev.to/seo_dharsheni_af6992a0c35/how-to-choose-the-best-field-service-scheduling-app-4daj | Choosing the [best field service scheduling app](https://getfieldy.com/field-service-scheduling/) for your business involves considering various factors to ensure it meets your specific needs and requirements. Here's a guide to help you make the right choice:
Identify Your Requirements
Determine the specific features and functionalities you need in a field service scheduling app. Consider aspects such as scheduling, dispatching, route optimization, inventory management, invoicing, reporting, and integrations with other software systems.
Ease of Use
Look for an app that is user-friendly and intuitive for both your staff and customers. The interface should be easy to navigate, with clear instructions and minimal training required to get started.
Mobile Compatibility
Since field service technicians will be using the app on their mobile devices, ensure that it is compatible with a variety of devices and operating systems (iOS, Android). The app should also have a responsive design for seamless use on smartphones and tablets.
Scheduling and Dispatching
The app should offer robust scheduling and dispatching features, allowing you to efficiently assign jobs to technicians based on factors like location, skills, and availability. Look for features like drag-and-drop scheduling, real-time updates, and automated notifications.
Route Optimization
If your business involves a lot of travel between job sites, choose an app that offers route optimization functionality. This feature helps minimize travel time and fuel costs by providing the most efficient routes for technicians to follow.
Integration Capabilities
Consider whether the app can integrate with your existing software systems, such as CRM, accounting, or inventory management software. Seamless integration allows for smoother workflows and eliminates the need for manual data entry.
Customization Options
Look for an app that allows you to customize fields, forms, and workflows to align with your business processes and branding. This flexibility ensures that the app can adapt to your specific needs and workflows.
Reporting and Analytics
The app should provide robust reporting and analytics capabilities, allowing you to track key metrics such as job completion times, technician productivity, customer satisfaction, and revenue. These insights help you make data-driven decisions and identify areas for improvement.
Customer Support and Training
Choose a vendor that offers excellent customer support and training resources to help you get the most out of the app. Look for options like online tutorials, user guides, and responsive customer support channels (phone, email, live chat).
Security and Compliance: Ensure that the app complies with industry standards and regulations regarding data security and privacy. Look for features like data encryption, user permissions, and regular security updates to protect sensitive information.
By considering these factors and thoroughly evaluating your options, you can choose the [best field service scheduling app](https://getfieldy.com/field-service-scheduling/) for your business and streamline your operations for greater efficiency and productivity.
| seo_dharsheni_af6992a0c35 | |
1,862,685 | Manage Oracle Updates with Regression Test Automation | Do you know Oracle updates are released quarterly? The first update of 2024 was released on January... | 0 | 2024-05-23T09:56:12 | https://saptahikpatrika.com/manage-oracle-updates-with-regression-test-automation/ | regression, test, automation | 
Do you know Oracle updates are released quarterly? The first update of 2024 was released on January 16 and contains 389 security updates across Oracle families. For organizations relying on Oracle solutions, staying current with these updates is a necessity, and this is a challenging task. The impact on existing functionalities, coupled with the intricate nature of these updates, requires a strategic approach to testing. Automated regression testing becomes the strategic approach against the challenge and ensures the intended functionality of your software. In this article, we will explore the testing scope, the challenge with manual testing, the role of regression testing, and its benefits.
**Understand the Testing Scope for Oracle Updates**
**Oracle updates** come in various forms, each with its own set of implications for different application areas.
**Security patches**: Addressing vulnerabilities with minimal functional changes.
**Bug fixes**: Correcting identified issues, potentially impacting related functionalities.
**New features**: Introducing fresh capabilities, often requiring extensive testing across various scenarios.
Each type carries its own weight. Security patches, while crucial, might introduce subtle changes that break existing functionality. Bug fixes, intended to heal, can sometimes make systems vulnerable. New features, the exciting additions, often demand comprehensive testing to ensure seamless integration and avoid unintended consequences.
Therefore, testing is essential to evaluate the potential repercussions on existing functionalities and integrations. This step is critical to identify high-impact areas that require focused testing. It sets the stage for an effective regression test automation strategy that ensures comprehensive coverage and accuracy.
**Challenges with Manual Regression Testing**
Manual testing is labor-intensive and prone to errors due to its reliance on human execution. The need to repetitively perform test cases consumes valuable resources. The time-sensitive nature of Oracle updates demands a more rapid and reliable testing approach.
Manual testing often struggles to cover the breadth and depth of scenarios impacted by updates. This limitation leaves room for gaps in test coverage, potentially overlooking crucial aspects that could be affected by the updates. The manual testing process faces significant hurdles in keeping pace with the accelerated release cycles of Oracle updates.
**Role of Regression Test Automation in Oracle Updates**
Updates can introduce various complexities that can be challenging to address with manual testing. That’s where the concept of regression test automation comes in. It plays a crucial role in mitigating the challenges posed by Oracle updates. Its efficiency lies in its ability to execute tests rapidly and consistently, providing a comprehensive assessment of the system’s response to changes. Accuracy is heightened as automated tests eliminate the potential for human errors during repetitive testing tasks. Additionally, the continuous testing capabilities of regression test automation, especially when integrated with CI/CD pipelines, ensure that the impact of updates is assessed in real time, allowing for swift identification and resolution of issues.
**Benefits of Regression Test Automation in Oracle Updates**
Regression test automation offers numerous advantages to organizations seeking to ensure the stability and reliability of their systems.
**Ensuring System Stability and Reliability**
Automated regression tests meticulously verify the existing system functionalities after Oracle updates. By systematically examining critical pathways, it ensures that the updates do not inadvertently introduce issues. This benefit is instrumental in maintaining the overall stability and reliability of the system, assuring organizations of a robust technological infrastructure.
**Accelerating the Testing Process**
One of the primary advantages of regression test automation is its ability to execute tests rapidly and consistently. As updates follow an accelerated release cycle, automation enables organizations to keep pace with the frequent changes. Automated tests provide timely validations, reducing bottlenecks in the update implementation timeline and allowing businesses to adapt swiftly to the evolving Oracle ecosystem.
**Improving Overall Efficiency and Reducing Testing Costs**
Automation brings efficiency to the forefront by significantly reducing the manual effort required for testing. The repeatability and reusability of automated test scripts streamline the testing process, leading to improved overall efficiency. Moreover, the decrease in manual intervention accelerates testing and contributes to cost savings. This makes regression test automation a cost-effective solution for managing Oracle updates.
**Comprehensive Test Coverage**
Regression test automation ensures thorough coverage of various scenarios affected by updates. Automated tests can be designed to encompass a wide range of functionalities, validating critical pathways and identifying potential issues across different modules. This comprehensive test coverage minimizes the risk of overlooking important aspects, providing organizations with a holistic understanding of the impact of updates on their systems.
**Facilitating Continuous Testing**
Integration with Continuous Integration/Continuous Deployment (CI/CD) pipelines enables regression test automation to facilitate continuous testing. This ongoing validation ensures that the impact of updates is assessed in real time, allowing for swift identification and resolution of issues. Continuous testing fosters a proactive approach, allowing organizations to address challenges promptly and maintain a resilient and adaptive technological infrastructure.
**Opkey: Your Partner to Achieve Intended Software Functionality**
Efficiently managing Oracle updates requires a holistic approach. Regression test automation helps businesses overcome the challenges posed due to updates and ensure the intended functionality of the software. Opkey is a no-code testing tool that helps businesses perform regression testing automatically. It leverages AI and ML and helps organizations maximize the benefits. It comes with self-healing test scripts and one-click test creation, ensuring that non-technical users can also perform testing without prior coding knowledge. Additionally, its test scripts are 60% more robust than manual scripts, underscoring its effectiveness.
Get in touch with Opkey to eliminate the disruption due to Oracle Updates. | rohitbhandari102 |
1,862,679 | BizOps Workspaceでチャットとユーザーを安全にモデレートする方法 | PubNubのチャネルモニタとアクセスマネージャを使って安全でモデレートされたチャットアプリケーションを作成する方法 | 0 | 2024-05-23T09:52:03 | https://dev.to/pubnub-jp/bizops-workspacedetiyatutotoyuzawoan-quan-nimoderetosurufang-fa-469l | このハウツー記事は、[BizOps Workspaceと](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)総称されるPubNubのデータ管理機能について説明する一連の記事の一部です:
- [BizOps Workspaceでユーザとチャネルを管理する方法](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)
- [BizOps Workspaceでユーザーとチャンネルを管理する方法](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)
- BizOps Workspaceで会話とユーザーを安全に管理する方法
BizOps Workspaceは、アプリケーションの管理に役立つ一連のツールです。 この記事では、前回の「[BizOps Workspaceで会話を監視してモデレート](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)する方法」を発展させ、手動モデレーション機能、つまりリアルタイムで会話を監視し、ユーザーをミュートまたは禁止する機能を備えたエンドツーエンドのセキュアなチャット・アプリケーションを紹介します。
この記事は単独でも読むことができますが、ここで説明するコンセプトの背景をよりよく理解するために、前回の「[BizOps Workspaceで会話を監視してモデレートする方法](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)」の記事を読むことを強くお勧めします。
チャネルモニタとは何ですか?
--------------
チャンネルモニターは、チャットモデレーターが複数のチャンネルでリアルタイムに行われている会話のライブプレビューを見ることができます。もしモデレーターが、行儀の悪いユーザーや攻撃的なメッセージなど、何か不穏なものを発見したら、問題を緩和するためにすぐに行動することができます。
モデレーターは、どのようなアクションを取るかについて、多くの柔軟性を持っています:
- アクセス権を制限せずにユーザーを観察する
- 問題のあるメッセージを編集または削除する
- そのユーザーのメッセージ公開を制限する[(ミュート](https://pubnub.com/docs/bizops-workspace/channel-monitor#mute?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)する)
- メッセージの閲覧または公開を制限する[(禁止する)](https://pubnub.com/docs/bizops-workspace/channel-monitor#ban?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)
Monitor "機能では、手動でメッセージを確認したり、手動でユーザーをミュートしたりすることができます。この記事では自動モデレーションについては説明しません。
チャネルモニタを使用するには、PubNubキーセットでいくつかの機能を有効にする必要があります。特に、[App contextと](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja) [Message persistenceは](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)最低限必要です。 詳細については、[前の記事の](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)「Channel Monitorのキーセットの要件」を参照してください。
PubNubアクセスマネージャとは何ですか?
----------------------
**開発者は、モデレーションシステムを回避しようとするユーザーから保護する必要が**あります。これはPubNubアクセスマネージャを使用して実現されます。
[アクセスマネージャを](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)使用すると、指定されたユーザー(または複数のユーザー)の権限と、指定されたリソースに対して実行できるアクションを記述する一連のルールを定義できます。 例えば
- IDが`123の`ユーザはチャネル`456の`読み書き権限がある。
- IDが正規表現`user-*に`一致するすべてのユーザは、IDが正規表現`global-*に`一致するすべてのチャネルから読み取ることができます。
- IDが`123の`ユーザはチャネルのメタデータを更新する権限を持っています。
パーミッションの完全なリストについては、[https://www.pubnub.com/docs/general/security/access-control#permissions](https://www.pubnub.com/docs/general/security/access-control#permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja) のドキュメントを参照してください。
PubNub Access Managerはトークンベースであり、それを説明する最も簡単な方法は、[ドキュメントに](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)示されているように認可フローを歩き、そのフローがモデレーションにどのように関連しているかについて追加のコンテキストを提供することです:

1. **ログインの試み**。クライアントは、ユーザをアプリケーションにログインさせるために、サーバに対して認証を行います。これはおそらくIDプロバイダを介して行われます。このステップの後、サーバは登録されたアプリユーザと話していること、そしてそのユーザが誰であるかを確信します。クライアントは初期化の一環としてPubNub Access Manager認証トークンを要求します。
2. **許可リクエスト**。 サーバはSDKの'[grantToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#grant-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)'APIを呼び出して、クライアントからのトークン要求を処理します。 このAPIについて注意すべき点があります:このAPIはPubNub**シークレットキーでのみ**呼び出すことができるため、サーバーからのみ呼び出すことができます。このAPIはすべてのサーバーサイドSDKで利用可能です。
3. **トークンが返**されます。PubNubは要求されたユーザに要求されたパーミッションを許可し、認証トークンをサーバに返します。
4. **トークンが渡さ**れます。サーバは認証トークンを元の呼び出し元のクライアントに返します。
5. **トークンが設定さ**れます。クライアントは、初期化時あるいはアプリケーションのライフサイクル中の任意の時点で、[setToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#set-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)メソッドを使用してこの認証トークンを指定できます。トークンの有効期限が切れるため、トークンをいつでも更新できることは重要ですが、チャンネル・モニターが権限を更新した場合(ミュートされたり禁止されたりした場合)にも、クライアントは新しいトークンを要求する必要があります。
6. **許可されたAPIリクエスト**。その後のPubNubへの呼び出しはすべて認可されたものとみなされます。PubNubは、ステップ2で付与されたパーミッションとクライアントのトークンの有効性に基づいて、あらゆるAPIリクエストを許可または拒否します。
セキュアなモデレーション・ソリューションとはどのようなものか?
-------------------------------
[前回の記事の](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)最後の方で、クライアント側からミュートや禁止がどのように見えるかのデモを示しました。 チャット SDK には、クライアントがミュートされたか禁止されたかを伝える[モデレーション イベントが](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)含まれていますが、UI を更新する以外に、**クライアントがミュート/禁止されてもメッセージを送信し続けることを防ぐ**ことはできません。 クライアントを安全にミュートまたはBANするには、既存のAccess Manager権限を取り消し、新しいミュートまたはBANステータスを反映する新しい権限を付与する必要があります。
あるユーザーが'musicals'チャンネルからミュートされている場合を考えてみましょう:

1. あるユーザが「movies」と「musicals」の2つのチャンネルにアクセスできるが、管理者は「musicals」チャンネルからのみミュートしたい。
2. モデレーターはチャンネルモニターを使ってユーザーをミュートする。 これは裏を返せば '[setRestrictions()](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#method-signature-1?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)' API を呼び出していることになる。
3. サーバアプリケーションは 'mute' 通知を[モデレーションイベントで](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)受け取り、そのユーザのアクセストークンを[失効さ](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#revoke-token?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)せる。
4. クライアントアプリケーションは、'musicals' チャネルに関連付けられた 'mute' 通知を節度[イベントを通して](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)受け取ります。
5. アプリケーションはUIを更新し、それ以上メッセージを送信しないようにする。 ユーザはページのJavaScriptを修正することで、このUIの変更を回避できますが、認証トークンが失効しているため、メッセージを送信しようとすると失敗します。
6. 上記のAccess Managerのセクションで説明したように、アプリケーションはサーバに新しい認証トークンを要求します。 新しく付与されたトークンには、ユーザの新しい権限が反映され、'musicals' チャネルへの 'read' アクセス権のみが付与されます。
[前回の](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)記事では、"モデレーションソリューションのコンポーネント "について説明し、クライアントとサーバーの両方で利用可能なAPIを以下の図を使ってリストアップしました。上記のステップで説明したAPIは、この図にも示されています。

チャットSDKサンプルアプリ
--------------
チャンネルモニターとチャットSDKの開発を担当した同じ多忙なエンジニアリングチームは、チャットSDKを使用するReact Nativeで書かれたサンプルアプリケーションも作成しました。
このサンプルは、PubNubを使用して現実的で完全な機能を備えたチャットアプリを開発するためのSDKの機能とベストプラクティスを示しています。このサンプルはオープンソースで、[/samples/react-native-group-chatに](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat)あるChat SDKと同じGitHubリポジトリの一部です。

このアプリケーションは最近更新され、Access Managerサーバからトークンを要求するようになりました。また、ユーザのパーミッションが変更されたとき、つまりチャネルから禁止されたりミュートされたときに新しいトークンを要求するようになりました。 この改良は前回の[記事を書いてから](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)行われたので、[GitHubから](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat)最新のソースを入手してください。 この記事を書いている時点の最新の git commit ID は[ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat)です。
ユーザーのミュートと禁止を安全に行うサンプル・アプリケーションを使ったデモ
-------------------------------------
このセクションでは、クライアントとサーバーの両方の視点からセキュアなモデレーションを示すエンドツーエンドのデモを立ち上げて実行する方法について説明します。
### PubNubキーセットの作成
このデモを実行するには、次のように新しいPubNubキーセットを作成することをお勧めします:
1. [管理者ポータルに](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)ログインし、新しいアプリケーションを作成するか、既存のアプリケーション内に新しいキーセットを作成します。管理者ポータルにログインし、新しいアプリケーションを作成するか、既存のアプリケーション内に新しいキーセットを作成します。必要に応じて、[管理者ポータルキーの](https://www.pubnub.com/how-to/admin-portal-create-keys/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)作成方法をご覧ください。
2. キーセットのページで、以下の構成オプションを有効にします。 特に指定がない限り、デフォルトを受け入れることができます:
- [アプリ・コンテキスト](https://www.pubnub.com/docs/general/metadata/channel-metadata?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)。 これはチャネルとユーザに関するメタデータを保存するもので、[「ユーザとチャネルの管理](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)」についての前の記事で詳しく説明しています。 `User Metadata Events(ユーザ・メタデータ・イベント`)、`Channel Metadata Events(チャネル・メタデータ・イベント`)、`Membership Events(メンバーシップ・イベント`)も有効にしてください。
- [メッセージの永続化](https://www.pubnub.com/docs/general/storage?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)。 これはメッセージの履歴をPubNubに保存し、管理者が会話を確認、編集できるようにします。
- [アクセスマネージャ](https://www.pubnub.com/docs/general/security/access-control?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)。 データへの不正アクセスを防止し、安全なモデレーションソリューションを作成するために必要です。
- [プレゼンス](https://www.pubnub.com/docs/general/presence/overview?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)。 ユーザーがオンラインかオフラインかを追跡するために使用されます。
変更を保存します。
以降のステップで、`Publish Key`、`Subscribe Key`、および`Secret Keyが`必要になります。
### サンプル アプリケーションのビルド
前述したように、チャット SDK サンプル アプリは、Expo フレームワークを使用して React Native で記述されたクロス プラットフォームのクライアント アプリです。
[アプリケーションの Readme](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat#readme) に記載されている手順に従って、サンプル アプリケーションをクローンしてビルドします。 特に、yarnやNode.jsなどの前提条件がインストールされていることを確認してください。 ReadMeにはXCodeとiOSの使用について書かれているが、Androidエミュレーター上でアプリを実行することもできる。 執筆時点の最新のgitコミットIDは[ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat)です。
Pub/Subキーを提供する際は、前のステップで生成したキーを使用してください。 `.env`ファイルにキーを含めない場合、アプリケーションはデフォルトでいくつかの`デモ`キーになります。混乱を避けるために、[https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60](https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60)、このロジックを無効にするとよいでしょう。
アプリケーションを実行します。ReadMeでは`yarn iosを`実行するように指示されていますが、`yarn androidや` `yarn run startを`実行することもできます。
ログインすると、コンソールに次のような警告が表示されるはずです:

これはクライアントがAccess Managerサーバーへの接続に失敗したためです。
### サンプルAccess Managerサーバーの構築
Sample Access Manager Serverは[https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api。](https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api)これは前回説明したクライアントアプリケーションと同じmonorepoです。
`src/chatsdk.service.ts`ファイルをお好みのエディタで開き、`publishKey`、`subscribeKey`、`secretKeyを`入力してください。 publishKeyとsubscribeKeyは、クライアント・アプリをビルドする際に使用したものと一致させる必要があり、secretKeyは、[管理ポータルの](https://admin.pubnub.com?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)アプリのkeysetページから入手できます。
`REPO/samples/access-manager-api`ディレクトリから`yarn run startを`実行してAccess Managerサーバーを起動すると、以下のような画面が表示されるはずです:

Access Managerサーバーが何をしているかを見るには、`app.service.tsを見て`ください。リクエスト・ユーザー用に生成されたパーミッション構造と、これらのパーミッションを適用するための`chat.sdk.grantToken()`の呼び出しが表示され、生成されたauthKeyが呼び出し元のクライアントに返されます。
これらはデモ・アプリケーションが必要とするパーミッションですが、あなたのアプリケーションはおそらく異なるパーミッションを必要とするでしょう。 この提供されたルールセットを開始テンプレートとして使用することができますが、アプリ用の Access Manager サーバーを作成する際には、[https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)を参照して、どの Chat SDK 機能でどのパーミッションが必要かを正確に理解してください。
クライアント・デモ・アプリを再起動すると、エラーなしでログインできるようになります。 Authkey refreshed(認証キーが更新されました)」というトーストが表示されれば、すべて成功です。

2つのクライアント間で会話を開始してください。

### チャンネルモニターを使用してユーザーをミュートおよび禁止する
**重要:**2つのクライアント間で会話を開始したことがない場合は、今すぐ行ってください。 チャンネルはデモアプリによって動的に作成されるため、チャットが開始された後にのみチャンネルモニターに表示されます。
auth key refreshed'バナーや'banned user'モーダルなど、以下に表示されるユーザーインターフェースのアップデートは、デモアプリケーションの一部であることに注意してください。
- [管理者ポータルに](https://admin.pubnub.com/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)ログインしてチャネルモニターを起動し、Access Managerサンプルとクライアントアプリケーションで使用したキーセットを選択します。
- 左側のナビゲーション・パネルの[**BizOps Workspace**]セクションに移動し、[**Channel Monitor**]を選択します。 **BizOps**Workspaceセクションが表示されない場合は、[PubNubプランを](https://www.pubnub.com/pricing/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)アップグレードする必要があります。
- モデレーションを開始するチャンネルを選択するプロンプトが表示されます。 チャンネル名は`1:1 user with USER_`IDになります。USER\_IDは会話を開始した人のユーザー名です。
- キーセットでパーシステンスを有効にしている場合、チャンネルメッセージは以前のメッセージも含めてリアルタイムで表示されます。

- そのユーザーが送信したメッセージの横にあるマイクボタンを押して、そのユーザーをミュートします。 ミュートされたユーザーのデバイスに、認証キーがリフレッシュされたことを知らせるメッセージが表示されます。 ミュートされたユーザーとしてメッセージを送信しようとすると、ミュートを解除したユーザーには影響がありませんが、禁止されているというメッセージダイアログが表示されます。

- マイクボタンをもう一度押して、ミュートを解除してください。 ミュートを解除されたユーザーのデバイスに、認証キーがリフレッシュされ、メッセージ送信が成功したことを知らせるメッセージが表示されます。

- そのユーザーが送信したメッセージの横にある禁止ボタンを押して、そのユーザーを禁止してください。 理由は自由形式のテキストなので、関連する情報を入力できます。 認証キーが更新され、ユーザーはアプリのチャット選択画面に戻ります。

禁止されたチャンネルにアクセスしようとすると、ユーザーにエラーが表示されます:

- チャンネルモニターで「禁止を解除」を選択して、ユーザーを禁止解除してください。 認証キーが更新されます。 ユーザーはBANが解除され、再びチャットにアクセスできるようになります。

まとめ
---
[チャットアプリケーションの](https://www.pubnub.com/solutions/chat/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)開発は最初のステップに過ぎません。最も困難な課題は、拡大するユーザー・ベースをサポートするためにアプリをデプロイした後にやってきます。BizOps Workspaceは、チャットアプリケーションのあらゆる側面を管理するために設計されたツールセットであり、ローンチ後の課題を簡素化します。
この記事では、ユーザーの安全なミュートと禁止に焦点を当てましたが、[BizOps Workspaceの](https://pubnub.com/docs/bizops-workspace/basics?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)機能はさらに拡張していきます。 また、本記事ではChat SDKのみに焦点を当てましたが、Channel Monitorは当社のどのSDKでも動作するように[設定](https://www.pubnub.com/docs/bizops-workspace/basics#configuration?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)することもできます。

ヘルプやサポートが必要な場合は、お気軽に[専任のサポート](https://support.pubnub.com/hc/en-us?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)チームにご連絡いただくか、開発者対応チーム[(devrel@pubnub.com](mailto:devrel@pubnub.com))までメールでお問い合わせください。
PubNubはどのようにお役に立ちますか?
=====================
この記事は[PubNub.comに](https://www.pubnub.com/how-to/securely-moderate-chat-and-users/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)掲載されたものです。
私たちのプラットフォームは、開発者がWebアプリ、モバイルアプリ、およびIoTデバイスのためのリアルタイムのインタラクティブ性を構築、配信、管理するのに役立ちます。
私たちのプラットフォームの基盤は、業界最大かつ最もスケーラブルなリアルタイムエッジメッセージングネットワークです。世界15か所以上で8億人の月間アクティブユーザーをサポートし、99.999%の信頼性を誇るため、停電や同時実行数の制限、トラフィックの急増による遅延の問題を心配する必要はありません。
PubNubを体験
---------
[ライブツアーを](https://www.pubnub.com/tour/introduction/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)チェックして、5分以内にすべてのPubNub搭載アプリの背後にある本質的な概念を理解する
セットアップ
------
[PubNubアカウントに](https://admin.pubnub.com/signup/?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)サインアップすると、PubNubキーに無料ですぐにアクセスできます。
始める
---
[PubNubのドキュメントは](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)、ユースケースや[SDKに](https://www.pubnub.com/docs?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)関係なく、あなたを立ち上げ、実行することができます。 | pubnubdevrel | |
1,862,678 | How to Securely Moderate Chat and Users with BizOps Workspace | How to use PubNub's Channel Monitor and Access Manager to create a secure and moderated chat application | 0 | 2024-05-23T09:52:02 | https://dev.to/pubnub/how-to-securely-moderate-chat-and-users-with-bizops-workspace-156i | This how-to article is part of a series of articles that discuss PubNub’s data management capabilities, collectively known as [BizOps Workspace](https://pubnub.com/docs/bizops-workspace/basics?):
- [How to Manage Users and Channels with BizOps Workspace](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?)
- [How to Monitor and Moderate Conversations with BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?)
- How to Securely Moderate Conversations and Users with BizOps Workspace
BizOps Workspace is a set of tools that help you manage your application. This article will expand on the previous “[How to Monitor and Moderate Conversations with BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?)” article to show an end-to-end secure chat application with manual moderation capabilities, i.e., the ability to monitor conversations in real-time and mute or ban users.
Although this article can be read standalone, I strongly recommend reading the previous “[How to Monitor and Moderate Conversations with BizOps Workspace](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?)” article to better understand the background to the concepts discussed here.
What is the Channel Monitor?
----------------------------
The Channel Monitor lets chat moderators watch live previews of conversations happening in real-time across multiple channels. If the moderator spots anything disturbing, such as a misbehaving user or offensive messages, they can act immediately to alleviate the issue.
The moderator has a lot of flexibility for which action they can take:
- Observe a user without limiting their access rights
- Edit or Delete the offending message
- Limit the user's ability to publish messages ([mute](https://pubnub.com/docs/bizops-workspace/channel-monitor#mute?))
- Limit the user's ability to read or publish messages ([ban](https://pubnub.com/docs/bizops-workspace/channel-monitor#ban?))
All of the capabilities under the "Monitor" feature are manual: manually reviewing messages, manually muting users, etc. This article does not discuss automatic moderation.
To use the Channel Monitor, you will need to have several features enabled on your PubNub Keyset, specifically [App context](https://www.pubnub.com/docs/general/metadata/channel-metadata?) and [Message persistence](https://www.pubnub.com/docs/general/storage?) at a minimum. For more details, please see the ‘Keyset requirements for the Channel Monitor’ section in the [previous article](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?).
What is the PubNub Access Manager?
----------------------------------
**Developers must guard against users attempting to circumvent their moderation system**; this is achieved using the PubNub Access Manager.
The [Access Manager](https://www.pubnub.com/docs/general/security/access-control?) allows you to define a set of rules that describe the permissions of the specified user (or users) and what action they can perform on specified resources. For example:
- User with ID `123` has permission to Read and Write to Channel `456`
- All users whose ID matches the regular expression `user-*` can read from any channel whose ID matches the regular expression `global-*`
- User with ID `123` has permission to Update the Channel metadata (i.e., App Context)
For a full list of permissions, please refer to the documentation at [https://www.pubnub.com/docs/general/security/access-control#permissions](https://www.pubnub.com/docs/general/security/access-control#permissions?).
PubNub Access Manager is token-based, and the easiest way to describe it is to walk through the authorization flow as shown in the [documentation](https://www.pubnub.com/docs/general/security/access-control?) and provide some additional context of how that flow relates to moderation:

1. **Login attempt**. Your client will authenticate against your server to log your users into your application. This is likely done through an identity provider; after this step, your server is confident it is talking to a registered app user and who they are. The client requests a PubNub Access Manager authentication token as part of its initialization.
2. **Permission grant request**. The server handles the client’s request for a token by invoking the SDK ‘[grantToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#grant-token?)’ API. Some points to note about this API: It can only be called with the PubNub **secret key** and, therefore, can only be invoked from a server; it is available for all of our server-side SDKs; and this API will accept JSON objects to define the resources and permissions that define the user(s) access.
3. **Token returned**. PubNub grants the requested permissions to the requested user(s) and returns an authentication token to the server.
4. **Token passed**. Your server then returns the authentication token to the original calling client.
5. **Token set**. The client can specify this authentication token during its initialization or at any point during the application’s lifecycle through the [setToken()](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#set-token?) method. Being able to update the token at any point is essential since tokens expire, but a client will also need to request a new token if the Channel Monitor updates their permissions (i.e., they are muted or banned).
6. **Authorized API request**. Any subsequent calls to PubNub will now be considered authorized. PubNub will allow or deny any API request based on the permissions granted in step 2 and the client’s token validity.
What Does a Secure Moderation Solution look like?
-------------------------------------------------
Toward the end of the [previous article](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?), I showed a demo of what muting or banning would look like from the client side. The Chat SDK contains [moderation events](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?) that tell a client whether or not they have been muted or banned; however, other than updating the UI, **that does not prevent the client from continuing to send messages even though they have been muted/banned**. To securely mute or ban the client, you must revoke their existing Access Manager permissions and grant them new ones to reflect their new mute or ban status.
Consider the following scenario where a user is muted from the ‘musicals’ channel:

1. A user can access two channels, ‘movies’ and ‘musicals,’ but the administrator wants to mute them from only the ‘musicals’ channel.
2. The moderator mutes the user using the Channel Monitor. Under the covers, this is invoking the ‘[setRestrictions()](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#method-signature-1?)’ API
3. The server application receives the ‘mute’ notice through a [moderation event](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?) and [revokes](https://www.pubnub.com/docs/sdks/javascript/api-reference/access-manager#revoke-token?) the user’s existing access token.
4. The client application receives the ‘mute’ notice associated with the ‘musicals’ channel through a [moderation event](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/moderation#listen-to-moderation-events?).
5. The application updates its UI to prevent sending more messages. The user could work around this UI change by modifying the page’s JavaScript, but any attempt to send messages will fail since their auth token has been revoked.
6. The application requests a new authentication token from the server, as described in the Access Manager section above. The newly granted token will reflect the user’s new permissions, including only having ‘read’ access to the ‘musicals’ channel.
The [previous article](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?) described the “Components of a moderation solution” and listed the APIs available to both the client and server using the below graphic. The APIs discussed in the above steps are also shown in this graphic.

The Chat SDK Sample App
-----------------------
The same busy engineering team responsible for developing the Channel Monitor and the Chat SDK has also created a sample application written in React Native that uses the Chat SDK.
The sample shows the SDK's capabilities and best practices for developing a realistic and fully-featured chat app using PubNub. It is open source and part of the same GitHub repository that holds the Chat SDK under [/samples/react-native-group-chat](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat).

This application has recently been updated to request tokens from an Access Manager server and to request a new token as the user’s permissions change, i.e., they are banned or muted from channels. This improvement has been made since the [previous article](https://www.pubnub.com/how-to/monitor-and-moderate-conversations-with-bizops-workspace/?) was written, so be sure to get the latest source from [GitHub](https://github.com/pubnub/js-chat/tree/master/samples/react-native-group-chat). At the time of writing, the most recent git commit ID is [ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat)
Securely Muting and Banning Users: Demo using the Sample application
--------------------------------------------------------------------
This section describes how to get up and running with our end-to-end demo, showing secure moderation from both the client and server perspectives.
### Create a PubNub Keyset
I recommend creating a new PubNub keyset to run this demo as follows:
1. Log into the [Admin Portal](https://admin.pubnub.com/?) and either create a new application or a new keyset within an existing application. If needed, you can find step-by-step instructions at our [How to Create Admin Portal Keys](https://www.pubnub.com/how-to/admin-portal-create-keys/?).
2. On the keysets page, enable the following configuration options. You can accept defaults unless otherwise specified:
- [App Context](https://www.pubnub.com/docs/general/metadata/channel-metadata?). This stores metadata about your channels and users and is described further in the previous article about '[User and Channel Management](https://pubnub.com/how-to/manage-users-and-channels-with-bizops-workspace/?)'. Also enable `User Metadata Events`, `Channel Metadata Events`, and `Membership Events`
- [Message persistence](https://www.pubnub.com/docs/general/storage?). This stores your message history with PubNub so the administrator can review and edit conversations.
- [Access Manager](https://www.pubnub.com/docs/general/security/access-control?). Prevents unauthorized access to data and is required to create a secure moderation solution.
- [Presence](https://www.pubnub.com/docs/general/presence/overview?). Used to track whether a user is online or offline.
Save your changes.
You will need the `Publish Key`, `Subscribe Key`, and `Secret Key` in the subsequent steps.
### Build the Sample application
As described earlier, the Chat SDK Sample app is a cross-platform client app written in React Native using the Expo framework.
Clone and build the sample application, following the instructions given in the [application’s readme](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat#readme). In particular, ensure you have the prerequisites installed, including yarn and Node.js. The ReadMe talks about using XCode and iOS, but you can also run the app on an Android emulator. At the time of writing, the most recent git commit ID is [ae9dfa0](https://github.com/pubnub/js-chat/tree/ae9dfa0/samples/react-native-group-chat)
When providing the Pub/Sub keys, use the keys you generated in the previous step. If you do not include the keys within the `.env` file, the application will default to some `demo` keys; you may want to disable this logic at [https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60](https://github.com/pubnub/js-chat/blob/ae9dfa0/samples/react-native-group-chat/App.tsx#L60) to avoid confusion.
Run the application. The ReadMe will instruct you to run `yarn ios`, but you can also run `yarn android` or `yarn run start`, the latter of which gives you an interactive menu.
When you log in, you should see the following warning in your console:

This is because the client has failed to connect to the Access Manager server, so let’s build it.
### Build the Sample Access Manager Server
The Sample Access Manager Server can be found at [https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api](https://github.com/pubnub/js-chat/tree/master/samples/access-manager-api), this is the same monorepo as the client application discussed previously.
Open the `src/chatsdk.service.ts` file in the editor of your choice and populate the `publishKey`, `subscribeKey`, and `secretKey`. The publish and subscribe keys must match the ones you used to build the client app, and the secret key is available from the keyset page for the app on the [admin portal](https://admin.pubnub.com?)
From the `REPO/samples/access-manager-api` directory, run `yarn run start` to start the Access Manager server, and you should see something like the below:

To see what the Access Manager server is doing, look at `app.service.ts`. You will see the permission structures generated for the requesting user and the call to `chat.sdk.grantToken()` to apply these permissions, returning the generated authKey to the calling client.
These are the permissions the demo application requires, but your application will likely need different permissions. You can use this provided ruleset as your starting template, but when creating the Access Manager server for your app, consult [https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions](https://www.pubnub.com/docs/chat/chat-sdk/build/features/users/permissions?) to understand exactly what permissions are needed by which Chat SDK features.
Relaunch the client demo app application, and you should now be able to log in without error. You will know everything is successful when you get an ‘Authkey refreshed’ toast.

Initiate a conversation between two clients.

### Mute and Ban users using the Channel Monitor
**Important:** If you have not previously initiated a conversation between two clients, do this now. Channels are created by the demo app dynamically, so they will only display in the Channel Monitor after the chat has started.
Note that any user interface updates shown below, such as the ‘auth key refreshed’ banner or the ‘banned user’ modal, are part of the demo application — your application will display this information to the user through its own UI.
- Launch the Channel Monitor by logging into the [Admin portal](https://admin.pubnub.com/?) and selecting the keyset you used for the Access Manager sample and client application.
- Go to the **BizOps Workspace** section in the left navigation panel, and select **Channel Monitor**. If you do not see the **BizOps Workspace** section, you almost certainly need to upgrade your [PubNub plan](https://www.pubnub.com/pricing/?), but please [contact our support](https://support.pubnub.com/hc/en-us?) if you have any issues.
- You will be prompted to select your channels to start moderation. The channel name will be `1:1 user with USER_ID`, where USER\_ID is the username of the person who initiated the conversation.
- The channel messages will be displayed in real time, including previous messages, if you have persistence enabled on your keyset.

- Mute the user by pressing the microphone button next to a message sent by that user. You will see a message on the muted user’s device advising that the auth key has been refreshed. Attempting to send a message as the muted user will display a message dialog saying this is forbidden, though the unmuted user remains unaffected.

- Unmute the user by pressing the microphone button again. You will see a message on the unmuted user’s device advising you that the auth key has been refreshed and sending messages will now succeed.

- Ban the user by pressing the ban button next to the message sent by that user and provide a ban reason. The reason is free-form text, so you can provide any relevant information. The auth key will refresh and the user will be returned to the chat selection screen in their app.

Attempting to access the banned channel will show an error to the user:

- Unban the user by selecting ‘Remove ban’ on the Channel Monitor. The auth key will refresh. The user will be unbanned and can access the chat again.

Summary
-------
Developing any [chat application](https://www.pubnub.com/solutions/chat/?) is only the first step. The hardest challenges come after you deploy that app to support your growing user base. BizOps Workspace is a set of tools designed to manage every aspect of your chat application, simplifying your post-launch challenges.
Although this article has focussed on securely muting and banning users, we continue expanding the features of [BizOps Workspace](https://pubnub.com/docs/bizops-workspace/basics?). This article has also focused exclusively on the Chat SDK, but the Channel Monitor can also [be configured](https://www.pubnub.com/docs/bizops-workspace/basics#configuration?) to work with any of our SDKs.

If you need help or support, feel free to reach out to our [dedicated support team](https://support.pubnub.com/hc/en-us?) or email our developer relations team at [devrel@pubnub.com](mailto:devrel@pubnub.com)
How can PubNub help you?
========================
This article was originally published on [PubNub.com](https://www.pubnub.com/how-to/securely-moderate-chat-and-users/?)
Our platform helps developers build, deliver, and manage real-time interactivity for web apps, mobile apps, and IoT devices.
The foundation of our platform is the industry's largest and most scalable real-time edge messaging network. With over 15 points-of-presence worldwide supporting 800 million monthly active users, and 99.999% reliability, you'll never have to worry about outages, concurrency limits, or any latency issues caused by traffic spikes.
Experience PubNub
-----------------
Check out [Live Tour](https://www.pubnub.com/tour/introduction/?) to understand the essential concepts behind every PubNub-powered app in less than 5 minutes
Get Setup
---------
Sign up for a [PubNub account](https://admin.pubnub.com/signup/?) for immediate access to PubNub keys for free
Get Started
-----------
The [PubNub docs](https://www.pubnub.com/docs?) will get you up and running, regardless of your use case or [SDK](https://www.pubnub.com/docs?) | pubnubdevrel | |
1,862,677 | Mastering Third-Party Library Integration in Swift: Comprehensive Guide for iOS Developers | In-depth guide on integrating third-party libraries in Swift, covering everything from choosing the... | 0 | 2024-05-23T09:50:17 | https://dev.to/anthony_wilson_032f9c6a5f/mastering-third-party-library-integration-in-swift-comprehensive-guide-for-ios-developers-1k5m | In-depth guide on integrating [**third-party libraries in Swift**](https://vocal.media/stories/mastering-third-party-library-integration-in-swift), covering everything from choosing the right dependency manager (CocoaPods, Carthage, or Swift Package Manager) to ensuring the security and performance of your libraries. Whether you're a seasoned developer or just starting out, this guide has something for everyone.
Here's a quick overview of what you’ll find:
- Step-by-step instructions on installing and configuring dependency managers
- Best practices for managing third-party libraries
- A technical example using Alamofire
- Tips for keeping your libraries up to date
- Security measures to protect your app from vulnerabilities
- How to leverage Xcode for seamless integration
- Essential skills to look for when you hire iPhone app developers
If you're looking to streamline your development process and build feature-rich iOS applications, this guide is for you. Check it out and let me know your thoughts or any questions you might have! | anthony_wilson_032f9c6a5f | |
1,862,675 | Public Area Sound Insulation Divider Soundproof Sliding Screen Wall Soundproof Sliding Divider | Public Area Sound Insulation Divider Soundproof Sliding Screen Wall Soundproof Sliding Divider Our... | 0 | 2024-05-23T09:46:54 | https://dev.to/teklit_kidane_97b26ba7a4c/public-area-sound-insulation-divider-soundproof-sliding-screen-wall-soundproof-sliding-divider-3kh3 | Public Area Sound Insulation Divider Soundproof Sliding Screen Wall Soundproof Sliding Divider
Our factory covers an area of approximate 5000 square meters. Our annual output is more than 300, 000 square meters of acoustic panel and [soundproof screen](https://www.soundproofroomdividers.com/product/soundproof-screen/). With first-class production lines and diamond tools, numerous kinds of acoustic panels can be provided to meet different demands of our customers and meanwhile we can provide OEM service.
Sound Classroom Aluminium Movable Room Divider Folding Room Divider With Aluminum Sliding Track
1. Required Divider Acoustic partition (collapsible partition) at earliest for training room, share the images with quote.
2. I have a conference room with a ceiling height of 9', 28 feet wide. Can you provide some incite to the cost and types of partitions walls you offer.
3. We are setting up another company that markets and sells architectural products from companies like yours. We would be interested in your acoustic panels and movable partitions. I hope we can continue this business relationship into the future.

In addition to Chinese market, our main export markets include countries such as Rio de Janeiro Brazil, Bangalore India, Frankfurt Germany, Lille France, Cardiff-Newport United Kingdom, Kumamoto Japan, Arnhem-Nijmegen Netherlands, Jeddah Saudi Arabia, Daegu South Korea, Faisalabad Pakistan, Baton Rouge United States, San Jose United States, etc.
We have established favorable business relations with major industries including generation roofing contractor, interior specialist, property builder, build renovation firm, and other industries. WallN specializes in the installation and assembly of drywall partitions, suspended ceilings, skimmed ceilings, aluminum, computer raised raised floors, and all related work. KVGPD is a multi-facility service and management that can help you construct, manage and track building and facility maintenance management business plans and budgets to achieve your expected goals. UHNPC is a leading MEP contracting and maintenance company, and its service scope extends to the entire UAE. , And provide professional MEP maintenance and contract services for our customers in the UAE.
The products are applied in Kunming Art Museum, Yunnan, Lanzhou Investment Building Conference Room, Dali International Hotel, Xueshan Cultural and Creative Valley Office, Hotels in Myanmar, Conference Hall of Holiday Inn Guangzhou R&F Airport, etc.
Keyword Tag: collapsible room dividers, divider panels office, removable room divider, room divider wheels, white wooden screen room divider
Website: [https://www.soundproofroomdividers.com/product/acoustic-room-dividers/]
| tecleet | |
1,862,667 | धोखे के दर्पण | लखनऊ शहर की गलियों में एक पुराना मोहल्ला था, जहां की हवाओं में भी एक खास किस्म की महक थी। इसी... | 0 | 2024-05-23T09:26:58 | https://dev.to/love_storys_40958ec43e134/dhokhe-ke-drpnn-3ppn | books |

लखनऊ शहर की गलियों में एक पुराना मोहल्ला था, जहां की हवाओं में भी एक खास किस्म की महक थी। इसी मोहल्ले में एक लड़की रहती थी जिसका नाम था सिमरन। सिमरन बेहद खूबसूरत और मासूम थी, उसकी हंसी की खनक से जैसे पूरा माहौल जीवंत हो उठता था। सिमरन के दिल में एक सपना था, सच्चे प्यार का सपना।
एक दिन, मोहल्ले में एक नया परिवार आया। उनके साथ एक लड़का भी था, जिसका नाम था राघव। राघव पढ़ाई में तेज, दिखने में आकर्षक और बातों में बहुत मीठा था। पहली बार सिमरन ने राघव को देखा तो उसके दिल की धड़कनें तेज हो गईं। दोनों की मुलाकातें बढ़ने लगीं, और धीरे-धीरे वे एक-दूसरे के करीब आ गए।
राघव का प्यार सिमरन के लिए उसकी जिंदगी का सबसे खूबसूरत हिस्सा बन गया। दोनों ने साथ में ढेर सारे सपने देखे, भविष्य की योजनाएं बनाई, और एक-दूसरे के बिना जीवन की कल्पना भी नहीं कर सकते थे। सिमरन ने राघव पर अटूट विश्वास कर लिया था।
परंतु, समय के साथ कुछ अजीब होने लगा। राघव की बातें और उसका व्यवहार बदलने लगे। वह अक्सर व्यस्त रहता, सिमरन को नजरअंदाज करने लगा, और बहाने बनाकर मिलने से कतराने लगा। सिमरन का मन आशंकित हो उठा, लेकिन उसने अपने प्यार पर भरोसा बनाए रखा।
एक दिन, सिमरन ने राघव को बाजार में किसी और लड़की के साथ देखा। वह लड़की बहुत ही खूबसूरत और अमीर लग रही थी। राघव और उस लड़की की हंसी और उनके बीच की नजदीकियां देखकर सिमरन का दिल टूट गया। उसने राघव का सामना किया और सच जानने की कोशिश की।
राघव ने बिना किसी संकोच के बताया कि वह लड़की उसकी मंगेतर है और उनका रिश्ता उसके परिवार की पसंद से तय हुआ है। सिमरन की आंखों में आंसू थे, पर राघव की आँखों में कोई पछतावा नहीं था। उसने सिमरन को एक भ्रम में रखा और उसके प्यार का मजाक बनाया।
सिमरन को इस धोखे से गहरा सदमा लगा। उसने खुद को कमरे में बंद कर लिया और किसी से मिलना-जुलना बंद कर दिया। वह अपने टूटे हुए दिल के टुकड़ों को समेटने में जुट गई। लेकिन सिमरन कमजोर नहीं थी। धीरे-धीरे उसने खुद को संभाला और अपनी जिंदगी को नए सिरे से जीने का निर्णय किया।
सिमरन ने अपनी पढ़ाई पर ध्यान केंद्रित किया और अपने करियर में ऊँचाइयों को छूने का संकल्प लिया। उसने सीखा कि सच्चा प्यार वह है जो सम्मान और ईमानदारी पर आधारित हो। वह अब पहले से ज्यादा मजबूत और आत्मनिर्भर हो गई थी।
समय बीतता गया और सिमरन ने अपनी मेहनत और लगन से सफलता हासिल की। उसकी कहानी ने सबको यह सिखाया कि प्यार में धोखा भी मिलता है, लेकिन असली ताकत उस धोखे से उबर कर खुद को मजबूत बनाना है।
सिमरन की कहानी इस बात का प्रतीक बनी कि जिंदगी में चाहे कितने भी कठिन दौर क्यों न आएं, इंसान अपनी हिम्मत और आत्मविश्वास से हर मुश्किल को पार कर सकता है। और सबसे बड़ी बात, उसने खुद को प्यार करना सीखा, जो किसी भी रिश्ते से बढ़कर है।
| love_storys_40958ec43e134 |
1,862,674 | What are the solutions for solving all captchas automatically? | In the digital age, ensuring security while maintaining user convenience is paramount. One of the... | 0 | 2024-05-23T09:45:16 | https://dev.to/media_tech/what-are-the-solutions-for-solving-all-captchas-automatically-53aj | In the digital age, ensuring security while maintaining user convenience is paramount. One of the prevalent methods for security is the use of CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart). However, CAPTCHAs can be a significant barrier to user experience. Here, we delve into automatic captcha solving methods, addressing various types of CAPTCHAs and how to solve them efficiently.
**Understanding Different Types of CAPTCHAs**
**1. Text-Based CAPTCHAs**
Text-based CAPTCHAs are the most common form. They present distorted text images that users must interpret and type into a text box. Despite their simplicity, they can be quite effective against bots but also frustrating for users.
**Automatic Solutions for Text-Based CAPTCHAs**
To solve text-based CAPTCHAs automatically, Optical Character Recognition (OCR) technology is employed. Advanced OCR algorithms can decipher distorted text with high accuracy. Popular libraries like Tesseract provide robust solutions, leveraging machine learning to improve text recognition capabilities.
**2. Image-Based CAPTCHAs**
Image-based CAPTCHAs require users to select images that match a given description, such as identifying all images with traffic lights. These CAPTCHAs are designed to be more intuitive for humans and harder for bots.
**Automatic Solutions for Image-Based CAPTCHAs**
Automatic solutions involve image recognition and machine learning algorithms. Convolutional Neural Networks (CNNs) are particularly effective, trained on vast datasets to recognize patterns and objects in images. Tools like Google's Vision AI can be integrated into applications to automate image-based CAPTCHA solving.
**3. Puzzle CAPTCHAs**
Puzzle CAPTCHAs involve interactive challenges such as sliding a puzzle piece into place. They are designed to be user-friendly but challenging for automated systems.
**Automatic Solutions for Puzzle CAPTCHAs**
Solving puzzle CAPTCHAs automatically requires computer vision and algorithmic precision. By analyzing the puzzle structure and using algorithms to simulate human interaction, tools can be developed to solve these puzzles. Research into reinforcement learning has shown promising results in this area.
**Implementing Automatic Captcha Solving**
**Choosing the Right Tools**
When selecting tools for automatic captcha solving, consider the following:
**Accuracy and Efficiency:** Tools like Tesseract for text and Google Vision AI for images are renowned for their precision.
**Integration and Compatibility:** Ensure the tool can seamlessly integrate with your existing systems.
**Customization and Scalability:** Opt for solutions that allow customization to adapt to various CAPTCHA formats and can scale as needed.
**Future of Captcha Solving**
The future of CAPTCHA solving lies in the continuous advancement of AI and machine learning. With the development of more sophisticated algorithms and models, the efficiency and accuracy of automatic captcha solvers will improve. Additionally, as AI technology becomes more accessible, a wider range of businesses and applications will be able to leverage these solutions to enhance user experience and security.
**Conclusion**
Automatic captcha solving represents a significant technological advancement, providing solutions to various types of CAPTCHAs, from text-based to puzzle formats. By leveraging cutting-edge technologies such as OCR, machine learning, and speech recognition, these systems can significantly enhance user experience while maintaining robust security measures.
For businesses and developers, implementing automatic captcha solving tools requires a strategic approach, considering the right tools, and continuous improvement. As we move forward, the ongoing evolution of CAPTCHA systems and solving technologies will play a crucial role in shaping the digital landscape.
**Captcha solving service is essential for automating tasks like web scraping and other online activities that require bypassing captchas. Among the numerous captcha solvers available, CaptchaAI is notable for being the cheapest captcha solver on the market. Unlike others that charge per captcha, CaptchaAI offers a unique pricing model with a flat rate for unlimited captcha solutions. It delivers impressive performance, typically solving captchas within 10 to 30 seconds. For image captchas, it boasts a remarkable speed, solving them in under a second with an accuracy rate of 99.9%.**
| media_tech | |
1,844,159 | Mais oui, IA de la DATA à Devoxx France 2024 ! | Ah, Devoxx France, le rendez-vous incontournable pour profiter de nombreuses conférence Tech ! Grâce... | 0 | 2024-05-23T09:41:55 | https://dev.to/onepoint/mais-oui-ia-de-la-data-a-devoxx-france-2024--4kpe | Ah, Devoxx France, le rendez-vous incontournable pour profiter de nombreuses conférence Tech ! Grâce à mes collègues speakers qui m'ont obtenu une place, je suis de retour pour cette édition 2024. Imaginez 10 bordelais (de Onepoint) déchaînés, dont 4 speakers, affamés de connaissances. Et moi, le seul estampillé DATA, à suivre tel un loup solitaire les conférences liées à mon domaine de prédilection.
TLDR : Devoxx France 2024, un millésime à déguster sans modération !
**Qui note ?**
Vraiment rien à redire sur les Keynotes ! Elles ont toutes été intéressantes sur des sujets assez variés :
* [L'IA en médecine](https://www.youtube.com/watch?v=_lUk2Cylk_s&list=PLTbQvx84FrATzvq3tiM0Bg4kjcn0sqyHd&index=3) où j'étais assez amusé de voir les javaistes mal à l'aise à chaque fois que le speaker répétait "Je vous explique pas, vous connaissez bien la base du Machine Learning"
* [Les plus "drôles" erreurs des développeurs](https://www.youtube.com/watch?v=ywIRwq3CoyA&list=PLTbQvx84FrATzvq3tiM0Bg4kjcn0sqyHd&index=2), un Stand up en anglais
* [La dépendance au métaux](https://www.youtube.com/watch?v=_lUk2Cylk_s&list=PLTbQvx84FrATzvq3tiM0Bg4kjcn0sqyHd&index=3) que nous avons au sein de notre société
* [La psychohistoire](https://www.youtube.com/watch?v=qrD7JiLzCKE&list=PLTbQvx84FrATzvq3tiM0Bg4kjcn0sqyHd&index=6) où ont été présentés des sujets de recherches de 1968 sur ce que serait le monde du 21ème siècle
* Sans oublier l'incontournable [Cybersécurité](https://www.youtube.com/watch?v=_lUk2Cylk_s&list=PLTbQvx84FrATzvq3tiM0Bg4kjcn0sqyHd&index=3)
Les intervenants ont réussi à présenter leurs sujets en alternant entre humour et gravité.
**Youpi, de la data analyse et des bases de données (BDD)**
Je me suis réjoui de la présence de conférences liées à mon domaine d'expertise.
Pour commencer, le talk sur [APACHE SUPERSET](https://www.youtube.com/watch?v=wykOkyDIN0s) permet de fournir les clés de compréhension d'un outil de Data Vizualisation opensource. Il s'agit d'une alternative sérieuse aux leaders (éditeurs comme POWER BI, Qlik ou encore TABLEAU) du marché pour la fourniture de dashboard. La solutions se base sur le SQL pour la construction des datasets, et possède un large éventail de représentation graphique. Même si l'outil a du retard à rattraper sur les outils éditeurs, APACHE SUPERSET semble plus simple d'accès et intégrable dans une approche industrialisée (SSOT, pipelines...). A tester !
De nombreuses conférences concernant les bases de données ont retenu mon attention :
* [Dépannage DBA](https://www.youtube.com/watch?v=qAo0lXRYdfQ&list=PLTbQvx84FrARmVH_dQVkzJbZS4VQ4rbFb&index=55) : Présenté par un DBA, cela m'aura permis d'avoir certaines clés de l'administration d'une base de données Postgres (et pour ma part, de faire la corrélation avec mes connaissances en administration Oracle). Cela m'a même donnée envie d'en refaire !
* [Index](https://www.youtube.com/watch?v=TW8qjs8D0Bk) : Cela m'a permis d'appronfondir mes connaissances sur les index (fonctionnement, astuces) notamment une idée reçue que j'avais sur le fonctionnement des index avec la clause "LIKE"
* [Fonctionnement BDD](https://www.youtube.com/watch?v=auqLMHKcb1Y) : Contrairement aux premières conférences cités qui conviennent à tout les publics, celles-ci nécessite d'avoir des bases en système et administration de bases de données. En rentrant dans le cœur du fonctionnement d'une BDD et surtout des index B-TREE et SML-TREE, on peut parfois se perdre dans les explications, mais on en ressort avec les concepts des arbres de décisions.
* [SQLite](https://www.youtube.com/watch?v=s7NY9VpV4Yc) : Le sujet concernant SQLite (prononcé à la française) permet de débunker un certains nombres d'idées reçues (manque de fonctionnalités par rapport à d'autre SGBD, performance, utilisation en production... ) et m'a donné une autre vision de cette base de données, mais qui demande d'éprouver ce que j'ai entendu durant la conférence
**IA ou y'a pas ?**
Sujet du moment oblige, je ne peux que regretter l'omniprésence des sujets LLM et notamment sur LangChain4J. Il ne faut cependant pas oublié que c'est cohérent pour un salon plutôt orienté Java. La conférence [LangChain4J](https://www.youtube.com/watch?v=0FEUmI2Ou10) permet de comprendre les possibilités offertes par la librairie d'origine pythonienne LangChain mais adapté au monde Java.
En parlant de python, j'ai été intrigué de la conférence proposant de faire de la [datascience en Kotlin](https://www.youtube.com/watch?v=VJRPiJqng2U), il aura été démontré que les fonctions pandas et de dataviz ont bien été implémentées, mais il manquait une partie concernant la création et l'exécution de modèle de ML. Cela aurait fini de me convaincre de tenter l'aventure de l'IA avec un autre language, surtout du fait de la non-sobriété numérique du Python.
Que serait un Devoxx sans un REX, celui fait par les équipes de [Backmarket](https://www.youtube.com/watch?v=uITaFpcwMjo) m'ont convaincu. En présentant les différentes étapes de leur projet de mise en place d'un LLM interne et les features mises en place pour entrainer les chatbots, j'ai pu retirer de bonnes idées comme l'implémentation de feedback et l'hyperspécialisation des modèles à partir du RAG.
**Temps ℝ**
J'aurai finalement vu de nombreuses conférences liés à des outils de la fondation APACHE, car en plus de SUPERSET, j'ai pu étendre mes connaissances sur les outils [FLINK](https://www.youtube.com/watch?v=MtuPnsebw2A) et [PULSAR](https://www.youtube.com/watch?v=jb2-P_Z3FG0). Alors que le premier a permis de comprendre l'intérêt pour des systèmes nécessitant la latence la plus faible possible, avec un bon comparatif sur les produits similaires (Spark, Kafka Stream...), le second permet dans un premier temps de remettre à plat les notions de datastreaming et queue messaging qui sont souvent confondu (ou assimilé à la même chose) et dans un second temps de comprendre comment PULSAR permet d'être utiliser dans ces deux mondes
**Et alors ?**
Bien qu'il y avait trop de sujets autour des LLM, j'ai pris beaucoup de plaisir à voir des sujets diversifiés autour du traitement de la donnée.
Attention tout de même à ne pas trop surestimer les uses cases de l'IA dans la data, cela reste une partie infime de l'activité et doit le rester surtout dans un monde aux ressources limités.
C'est cool de se retrouver entre collègues de différentes agences ! | ericterrien | |
1,862,672 | Boosting Efficiency and Productivity: Exploring the Benefits of Business Process Outsourcing | Are you looking to streamline your business operations and enhance productivity? Explore the... | 0 | 2024-05-23T09:39:43 | https://dev.to/virteva/boosting-efficiency-and-productivity-exploring-the-benefits-of-business-process-outsourcing-dd8 | Are you looking to streamline your business operations and enhance productivity? Explore the transformative potential of Business Process Outsourcing (BPO) and unlock a world of efficiency gains and strategic advantages. In this comprehensive guide, we'll delve into the myriad [benefits of BPO](https://virteva.com/) and how it can revolutionize the way you do business.
Introduction:
In the relentless race of today's business world, where every moment counts and every decision could make or break success, mere innovation isn't enough to maintain a competitive edge—it's efficiency and agility that truly set businesses apart. Enter Business Process Outsourcing (BPO), a game-changing strategy revolutionizing the way organizations operate.
BPO isn't just a cost-saving tactic; it's a strategic move aimed at optimizing operations, slashing unnecessary expenses, and honing in on what truly matters—core competencies. By delegating non-core functions to specialized service providers, businesses liberate themselves from the shackles of mundane tasks and unlock a treasure trove of benefits that propel growth and pave the path to success.
In a landscape where time is of the essence and competition is fierce, efficiency becomes the lifeblood of any organization. BPO injects a dose of streamlined operations, allowing businesses to navigate the intricate web of tasks with precision and speed. By outsourcing tasks like customer support, data entry, or IT services, companies can free up valuable resources and personnel to focus on strategic initiatives that drive innovation and propel them ahead of the curve.
Moreover, BPO isn't just about trimming the fat—it's about strategically reallocating resources to where they can make the most impact. By offloading non-core functions to external experts, businesses can tap into a pool of specialized talent and knowledge that may not be available in-house. Whether it's leveraging the technical prowess of IT professionals or the industry insights of seasoned veterans, outsourcing empowers organizations to access top-tier expertise without the overhead costs of recruitment and training.
Cost reduction is another significant advantage of BPO, albeit not the only one. While outsourcing undoubtedly helps cut down on expenses associated with salaries, benefits, and infrastructure, its benefits extend far beyond the balance sheet. By partnering with BPO providers, businesses gain access to scalable solutions that can flex and adapt to evolving needs and market conditions. Whether it's scaling up operations during peak seasons or downsizing during lulls, outsourcing offers the flexibility needed to navigate the unpredictable terrain of today's business landscape.
Furthermore, outsourcing non-core functions doesn't just free up resources—it also mitigates risk. By diversifying operations across multiple providers and locations, businesses can safeguard against disruptions and vulnerabilities inherent in relying solely on internal resources. BPO providers often come equipped with robust risk management protocols, ensuring continuity and resilience in the face of unforeseen challenges.
The Main Part:
1. Cost Savings
One of the most persuasive advantages of Business Process Outsourcing (BPO) lies in its capacity to yield substantial cost savings for businesses. This is achieved by entrusting non-core functions, such as customer service, IT support, and accounting, to specialized service providers. By doing so, organizations can effectively diminish the overhead expenses typically associated with recruiting, training, and retaining in-house staff for these roles.
When businesses opt for BPO, they are not just alleviating the financial burden of maintaining internal departments; they are also tapping into a global marketplace of talent and resources. BPO providers often operate in regions where labor costs are comparatively lower, presenting an attractive proposition for cost-conscious organizations. This geographical advantage enables businesses to access skilled professionals at a fraction of the cost they would incur domestically, without sacrificing quality or efficiency.
2. Access to Specialized Expertise
BPO allows businesses to tap into a vast pool of specialized expertise that may not be available in-house. Whether it's leveraging the technical prowess of IT professionals or the domain knowledge of industry experts, outsourcing enables organizations to access top-tier talent without the need for extensive recruitment efforts. This access to specialized skills empowers businesses to innovate, adapt, and thrive in an ever-evolving marketplace.
3. Scalability and Flexibility
In today's dynamic business environment, scalability and flexibility are paramount. BPO offers businesses the flexibility to scale their operations up or down rapidly in response to changing market conditions, without the burden of fixed overhead costs. Whether it's ramping up customer support during peak seasons or scaling back administrative tasks during quieter periods, outsourcing provides the agility businesses need to remain competitive.
4. Enhanced Focus on Core Competencies
Outsourcing non-core functions allows businesses to redirect their focus and resources towards core competencies—the activities that drive value and differentiate them from competitors. By offloading routine tasks to BPO providers, organizations can free up valuable time and talent to innovate, strategize, and pursue growth opportunities. This laser focus on core competencies is essential for sustained success in today's hyper-competitive business landscape.
5. Improved Quality and Efficiency
Contrary to common misconceptions, outsourcing often leads to improvements in quality and efficiency. BPO providers specialize in delivering specific services with a high level of expertise and efficiency, leveraging best practices, streamlined processes, and cutting-edge technologies. By harnessing the capabilities of these specialists, businesses can achieve higher quality standards and faster turnaround times, ultimately enhancing customer satisfaction and loyalty.
6. Risk Mitigation
In an increasingly complex and interconnected world, businesses face a myriad of risks—from regulatory compliance and data security to geopolitical instability and natural disasters. BPO can serve as a risk mitigation strategy by diversifying operations across multiple locations and reducing reliance on a single point of failure. Additionally, BPO providers often have robust risk management protocols in place, helping businesses navigate potential challenges and disruptions with ease.
Summing Up:
In conclusion, Business Process Outsourcing (BPO) offers a multitude of benefits that can propel businesses to new heights of efficiency, productivity, and competitiveness. From cost savings and access to specialized expertise to scalability and risk mitigation, the advantages of outsourcing are undeniable. By embracing BPO as a strategic tool, businesses can optimize their operations, drive innovation, and achieve sustainable growth in today's dynamic business landscape.
| virteva | |
1,862,671 | Show running processes in MySQL | The KILL command terminates a connection thread by ID along with the related active query, if there... | 0 | 2024-05-23T09:39:37 | https://dev.to/dbajamey/show-running-processes-in-mysql-105o | mysql, mariadb, database, tutorial | The KILL command terminates a connection thread by ID along with the related active query, if there is one. Then, to identify queries for deletion, you need to see processes on the server - and the SHOW PROCESSLIST command will be a fine solution. It's not an elegant way to fix database issues, but rather an effective last resort tool. There are 4 major reasons for that:
* If a long-running query holds other transactions from executing your more relevant query
* If a large number of faulty queries block viable queries
* If there are orphan processes after a client was disconnected from a server
* 'Too many connections' message
None of these scenarios are great, so before executing KILL, make sure other solutions have been tried. But once you know the KILL method is necessary, you will have a few different options. But in this particular guide, we will focus on the more 'intuitive' way of showing and killing faulty queries using simple commands. You should keep in mind that KILL has two modifiers - CONNECTION and QUERY. KILL CONNECTION is essentially the same as KILL, while KILL QUERY terminates only the query for the specified connection ID and leaves the connection itself intact.
Read in full: https://www.devart.com/dbforge/mysql/studio/show-running-queries-in-processlist.html | dbajamey |
1,862,670 | Feedback with Asynchronous Video: Productivity with Screen Recording! | I have worked remotely for a decade before it became trendy post-COVID-19. As the tools have gotten... | 0 | 2024-05-23T09:38:40 | https://dev.to/martinbaun/feedback-with-asynchronous-video-productivity-with-screen-recording-13k2 | productivity, startup, performance, software | I have worked remotely for a decade before it became trendy post-COVID-19. As the tools have gotten better, productivity has increased. Tools are important for enhancing productivity. One such tool is screen recording software.
Let’s discuss how it has helped me improve my team's productivity and how it can help you.
## Asynchronous Video Communication in Remote Teams
You achieve more through cooperation. Experience has taught me this, and I stand by it. We do this by giving and receiving asynchronous feedback. Remote teams work in different time zones and schedules. This makes synchronous communication a challenge to implement. I implemented this type of communication to help bridge this gap.
I created VideoFeedbackr for this exact reason. We used Loom previously but experienced some frustrations with it. Hassle-free feedback is an enjoyable experience that has helped me and my team enhance productivity.
*Read: [Boost Productivity With Checklist](https://martinbaun.com/blog/posts/boost-productivity-with-checklist/)*
I have noted how screen recording prevents misunderstandings and streamlines our workflow. It is excellent for communication within tasks but ineffective for regular check-ins. You need synchronous meetings to facilitate proper feedback, something I’ll cover in another piece.
Asynchronous feedback captures the issue in a task. I can pinpoint the exact problem and explain why it doesn’t fit or is an issue for the particular task. I then offer suggestions to my team members that help them rectify the issue. I like this type of feedback because it helps me relay my thoughts. My team members have the video to refer to should they need to confirm something or countercheck the corrections. They also can share it, making it simple to get new procedures to everyone on the team.
Asynchronous video feedback with screen recording is excellent for our productivity, and I am satisfied with how it works for us.
## Screen Recording Training and Onboarding
## *Training tools and Software*
I have a Goleko project named How We Do Stuff. I invite my new employees to this project. It has standard operating procedures (SOPs). Each SOP explains specific administrative and professional procedures and is combined with a video package explanation.
Each SOP is augmented with a video explanation. The SOP was initially entirely composed of text. Text is better to scan and copy and paste to where required. I did notice that not everyone fared well with text. There were differences in interpretations and understanding, which prompted the addition of video explanation.
I explain how each procedure works in the video. Using videos to explain these procedures is better than writing them. It has also improved everyone’s understanding and interpretation of the processes. We have the best of both worlds with this feature. I use Goleko to fulfill this project. It is my repository and has the screen recording as a comments feature. I use this feature to record the explanatory videos below the text in these SOP tasks.
## *Onboarding and Productivity*
I also use this for our onboarding process. I have created another project called Onboarding. In it, there are specific tasks that. They help my new employees onboard to my team. This project has my responsibilities as the inviting party needs to handle relevant to my new employee. This saves me time I use writing my new employee to get vital information. It protects me from forgetting any crucial parts needed for their onboarding. This project is a template I use to onboard all my new employees. I clone it and make it suitable for my new employee. In it, I have all the responsibilities I need to handle, and my new employee has videos showing them how to maneuver the workstation, interact with the team, submit tasks, and much more. I use the screen recording as a comments feature on Goleko to facilitate this. This has improved our onboarding and working processes.
*Read: [Onboarding and Training New Remote Employees in a Virtual Environment](https://martinbaun.com/blog/posts/onboarding-and-training-new-remote-employees-in-a-virtual-environment/)*
## Asynchronous Feedback Takeaways
Screen recording software has its uses in remote teams. They are digital tools that help your team provide feedback on tasks, enhance productivity, and keep remote teams united in one direction. I use it as a communication method to build a strong team culture among team members.
Everyone can stay productive within your team by using these tools daily. These are some of the ways I use them. You can deploy them in team-building activities to keep your team close. The possibilities are limited to your imagination and there's no ceiling to what you can achieve.
VideoFeedbackr offers you this and much more. It's Free Video Feedback hassle-free, the perfect video for remote teams.
-----
## FAQs
*Can you use screen recording software to give feedback on a project?*
Yes, you can. I use VideoFeedbackr to give feedback on projects my team members worked on.
*Is VIdeoFeedbackr good for remote work?*
Yes. VideoFeedbackr is excellent to use for remote work. It allows you to record videos, give feedback, or create content. It is versatile enough for anything and available to be used everywhere.
*Is VideoFeedbackr a collaboration tool?*
Yes. VideoFeedbackr is a collaboration tool that allows you to improve communication within your team and enhance productivity.
*Can I share the video recorded with VideoFeedbackr?*
Yes, you can. You can share the videos recorded by VideoFeedbackr with your team members. You can do this by sharing the link to the videos you've recorded with them.
*Does VideoFeedbackr have video editing software?*
No. VideoFeedbackr doesn't have its video editing software. You can download the videos and edit them using other video editing software.
*Is Goleko like Slack?*
No, it’s not. Slack focuses more on team messaging whereas Goleko focuses more on project management. Goleko plans to introduce a chat feature that would make Slack irrelevant.
*Is screen sharing possible on VideoFeedbackr?*
No. Screen sharing is not possible on VideoFeedbackr. Screen sharing is synchronous and VideoFeedbackr is targeted for asynchronous usage.
*Can you see someone's facial expression on VideoFeebackr?*
No. VideoFeedbackr doesn't have a face capture to facilitate seeing someone's facial expressions. There are plans to add this feature in the future.
*What are the best practices for video feedback?*
Video feedback follows simple principles. Use the video to identify the issues in the task. Give constructive feedback that helps your employee rectify the issue. Ensure the video is concise and handles the issues in the project. Collaborate with them and help them every step of the way.
*How does asynchronous feedback help remote team communication?*
Asynchronous feedback enhances remote communication and collaboration. It solves the problem of locations and time zone issues. It allows all remote team members to give and receive feedback. The team members can watch the videos, make corrections, and respond in kind. This also boosts productivity and enhances efficiency.
*Is video feedback good for onboarding new team members?*
Yes, it is. Video feedback can be used to onboard new team members. Use it to record videos that explain text on the onboarding procedures. It streamlines communication and allows for easy onboarding to the team. Text can be difficult to write and can be understood differently. The asynchronous video is an essential tool to aid the onboarding process.
*Can I use videos to supplement training material?*
Yes, you can. Videos can help teams learn how to use the right tools. You can record short explanatory videos to help your remote employees understand and increase productivity. Teams can use these videos for reference if needed.
_____
*For these and more thoughts, guides and insights visit my blog at [martinbaun.com](http://martinbaun.com)*
*You can find Martin on [X](https://twitter.com/MartinBaunWorld)* | martinbaun |
1,859,101 | Let's build a simple MLOps workflow on AWS! #2 - Building infrastructure on AWS | About this post This post is a sequel to the previous one below. Please refer to the... | 0 | 2024-05-23T09:37:40 | https://dev.to/hikarunakatani/lets-build-a-simple-mlops-workflow-on-aws-2-building-infrastructure-on-aws-3h2j | python, aws, githubactions, devops | # About this post
This post is a sequel to the previous one below. Please refer to the earlier post before reading this one.
Let's build a simple MLOps workflow on AWS! #1 - ML model preperation - DEV Community
https://dev.to/hikarunakatani/lets-build-a-simple-mlops-workflow-on-aws-1-ml-model-preperation-3af8
# Overview
In the previous post, I showed how to implement a simple deep learning model. However, that code was intended for a local laptop environment and was purely experimental. By containerizing the application, you can ensure consistent and reproducible execution across different environments. This approach also enables the use of container orchestration tools like Kubernetes, which simplify managing, scaling, and orchestrating ML training jobs. Running machine learning tasks on a container orchestration tool is especially beneficial for training large ML models, as it allows for distributed training across multiple nodes and efficient resource utilization.
In this post, I'll explain how to run the training code as a Docker container on Amazon ECS. Additionally, I'll demonstrate how to automatically build and deploy the container when changes are made to the model.
Without further ado, let's first look at the overall architecture needed to implement this workflow!
# Architecture of the system
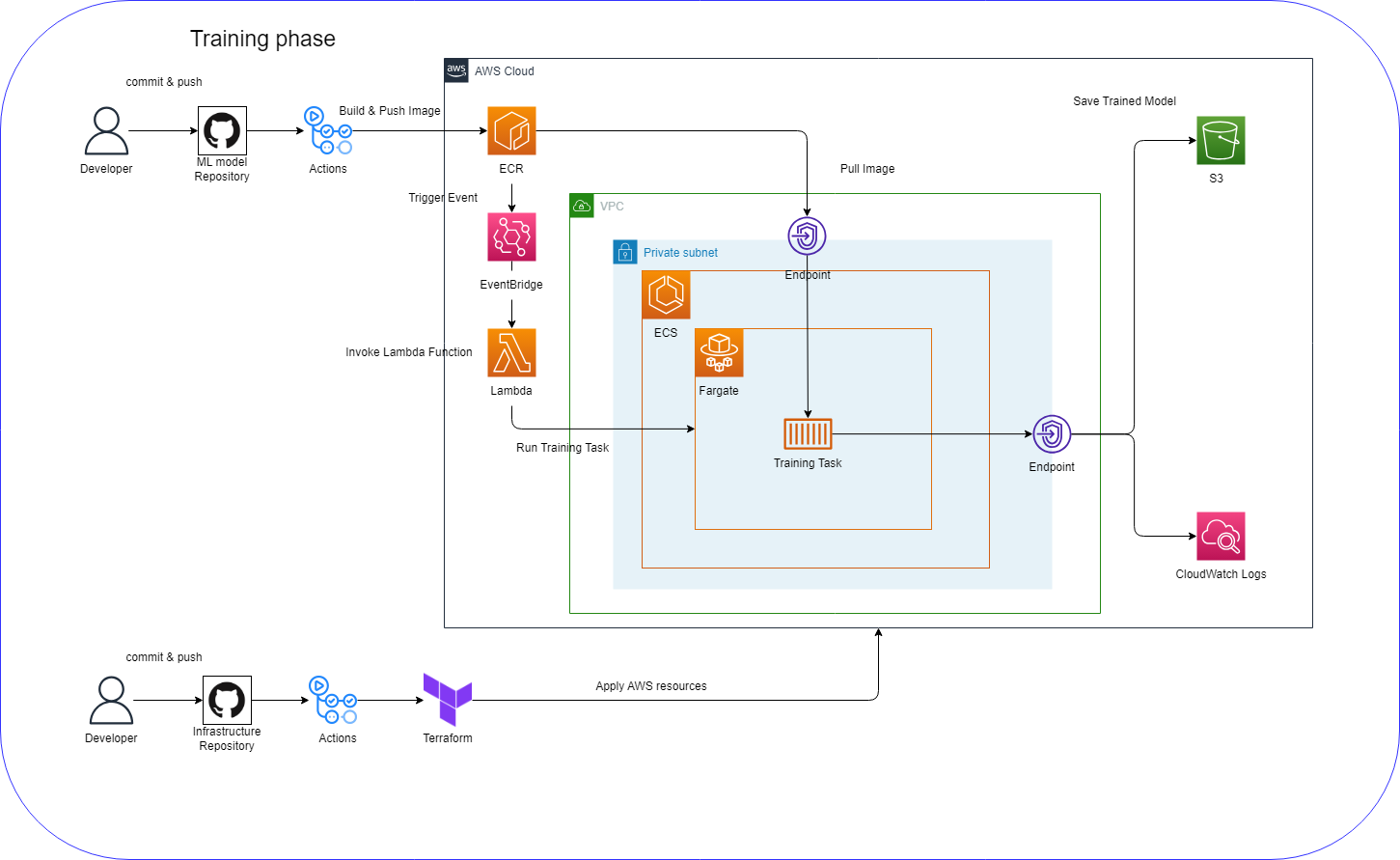
In this system, the following workflow will be executed:
- A developer pushes an ML model to the GitHub repository
- The training task, including the model, is automatically built as a Docker image and pushed to the ECR repository
- EventBridge detects the push in the ECR repository and invokes a Lambda function
- Lambda function invokes the ECS task
- The pre-trained ML model gets automatically saved to an S3 bucket
To achieve this, we'll tackle the following tasks step-by-step:
1. Preparing AWS resources to automate the deployment process of the training task.
2. Building a CI/CD pipeline for the ML model to automatically push Docker images to the repository.
3. Testing that the automated deployment process works properly.
In this post, I'll only explain how to implement the first step. Regarding building AWS resources, I chose Terraform so that we can test the code experimentally.
# Preparing AWS resources by Terraform
There are a number of small resources to implement the whole system, but I'll focus on introducing the core service setting required to implement the workflow.
## EventBridge
In order to trigger the ECS task in an event-driven manner, you have to prepare the event pattern in EventBridge. I used an event pattern to detect the push event in the ECR repository. After that, you need to set the Lambda as a target of the event rule.
```tf
# EventBridge
resource "aws_cloudwatch_event_rule" "ecr_push_rule" {
name = "${var.project_name}-run-ecs-task"
description = "Trigger an ECS task when an image is pushed to ECR"
event_pattern = jsonencode({
"source" : ["aws.ecr"],
"detail-type" : ["ECR Image Action"],
"detail" : {
"repository-name" : [aws_ecr_repository.main.name],
"action-type" : ["PUSH"],
},
})
}
resource "aws_cloudwatch_event_target" "ecr_push_target" {
rule = aws_cloudwatch_event_rule.ecr_push_rule.name
target_id = "run-index-py-function"
arn = aws_lambda_function.invoke_task.arn
}
```
## Lambda
We use Lambda function to invoke training task in ECS. The content of the Lambda function is like below:
```python
import json
import logging
import os
import sys
import boto3
# Setting up logging
logger = logging.getLogger()
for h in logger.handlers:
logger.removeHandler(h)
h = logging.StreamHandler(sys.stdout)
FORMAT = "%(levelname)s [%(funcName)s] %(message)s"
h.setFormatter(logging.Formatter(FORMAT))
logger.addHandler(h)
logger.setLevel(logging.INFO)
ecs = boto3.client("ecs")
def run_ecs_task(cluster, task_definition, subnets, security_groups):
"""
Function to run an ECS task.
Parameters:
cluster (str): The name of the ECS cluster.
task_definition (str): The ARN of the task definition.
subnets (str): The subnets for the task.
security_groups (str): The security groups for the task.
Returns:
None
"""
try:
response = ecs.run_task(
cluster=cluster,
taskDefinition=task_definition,
launchType="FARGATE",
count=1,
networkConfiguration={
"awsvpcConfiguration": {
"subnets": subnets.split(","),
"securityGroups": security_groups.split(","),
"assignPublicIp": "ENABLED",
}
},
)
logger.info(f"Response: {response}")
failures = response.get("failures", [])
if failures:
logger.error(f"Task failures: {failures}")
except Exception as e:
logger.error(f"Error running ECS task: {e}")
def lambda_handler(event, context):
"""
AWS Lambda function handler.
Parameters:
event (dict): The event data passed by AWS Lambda service.
context (LambdaContext): The context data passed by AWS Lambda service.
Returns:
None
"""
try:
# Get configuration from environmental variables
ECS_CLUSTER = os.environ["ECS_CLUSTER"]
TASK_DEFINITION_ARN = os.environ["TASK_DEFINITION_ARN"]
AWSVPC_CONF_SUBNETS = os.environ["AWSVPC_CONF_SUBNETS"]
AWSVPC_CONF_SECURITY_GROUPS = os.environ["AWSVPC_CONF_SECURITY_GROUPS"]
logger.info(f"ECS_CLUSTER: {ECS_CLUSTER}")
logger.info(f"TASK_DEFINITION_ARN: {TASK_DEFINITION_ARN}")
run_ecs_task(
ECS_CLUSTER,
TASK_DEFINITION_ARN,
AWSVPC_CONF_SUBNETS,
AWSVPC_CONF_SECURITY_GROUPS,
)
except Exception as e:
logger.error(f"An error occured while running ECS task: {e}")
```
Basically, it sends an API call to an ECS cluster to start the task using the AWS SDK (boto3). Please note that you need to specify some settings, such as the ECS cluster name, task definition ARN, VPC subnet, and security groups, to invoke the task. These settings are acquired through the environment variables embedded in the Lambda runtime.
To build this handler, we need to prepare the Lambda function in Terraform as shown below:
```tf
# Lambda function
resource "aws_lambda_function" "invoke_task" {
# If the file is not in the current working directory you will need to include a
# path.module in the filename.
filename = "lambda_function.zip"
function_name = "${var.project_name}-invoke-task"
role = aws_iam_role.lambda_execution_role.arn
handler = "invoke_task.lambda_handler"
source_code_hash = data.archive_file.lambda.output_base64sha256
runtime = "python3.9"
environment {
variables = {
ECS_CLUSTER = aws_ecs_cluster.main.name
TASK_DEFINITION_ARN = aws_ecs_task_definition.main.arn
AWSVPC_CONF_SUBNETS = "${aws_subnet.private1a.id}"
AWSVPC_CONF_SECURITY_GROUPS = "${aws_security_group.ecs.id}"
}
}
}
```
An important point here is properly setting environment variables so that the Lambda function gets the necessary information to run the training task. Also, keep in mind to avoid hardcoding environment variables for better security and operational efficiency. For a more secure solution, I highly recommend using AWS Secrets Manager or AWS Systems Manager Parameter Store instead of using environment variables.
## ECS cluster
```tf
# Task Definition
resource "aws_ecs_task_definition" "main" {
family = "${var.project_name}-task"
requires_compatibilities = ["FARGATE"]
network_mode = "awsvpc"
cpu = "2048" # 2 vCPU
memory = "8192" # 8GB RAM
task_role_arn = aws_iam_role.ecs_task_role.arn
execution_role_arn = aws_iam_role.ecs_task_exec.arn
container_definitions = jsonencode([
{
name = "${var.project_name}-container"
image = "${aws_ecr_repository.main.repository_url}:latest"
cpu = 2048
memory = 4098
essential = true
portMappings = [
{
"containerPort" : 80,
"hostPort" : 80
}
],
logConfiguration = {
options = {
"awslogs-create-group": "true",
"awslogs-region" = "ap-northeast-1"
"awslogs-group" = "${var.project_name}-log-group"
"awslogs-stream-prefix" = "ecs"
}
logDriver = "awslogs"
}
}
])
}
```
Training ML model usually requires GPU, but I chose CPU because it doesn't demand as many computing resources. Also, GPU is only suported for ECS on EC2, which requires more complex settings.
There's a bunch of resources you need to define, but I won't cover all of them here to keep this post simple. If you're interested in the complete resource settings, please refer to the repository below:
hikarunakatani/cifar10-aws: Simple MLOps workflows
https://github.com/hikarunakatani/cifar10-aws
## CI/CD of Infrastructue using GitHub Actions
As we defined Infrastructue using Terraform, we can apply CI/CD practice to infrastructure. We use GitHub Actions to build CI/CD pipeline. The definition of the workflows is as follows:
```yaml
# Execute terraform apply when changes are merged to main branch
name: "Terraform Apply"
on:
push:
branches: main
env:
TF_VERSION: 1.6.5
AWS_REGION: ap-northeast-1
jobs:
terraform:
name: terraform
runs-on: ubuntu-latest
permissions:
id-token: write
contents: write
pull-requests: write
issues: write
statuses: write
steps:
- name: Checkout
uses: actions/checkout@v3
- uses: aws-actions/configure-aws-credentials@v1 # Use OIDC token
with:
role-to-assume: ${{ secrets.AWS_ROLE_ARN }}
aws-region: ${{ env.AWS_REGION }}
- name: Terraform setup
uses: hashicorp/setup-terraform@v1
with:
terraform_version: ${{ env.TF_VERSION }}
- name: Setup tfcmt
env:
TFCMT_VERSION: v3.4.1
run: |
wget "https://github.com/suzuki-shunsuke/tfcmt/releases/download/${TFCMT_VERSION}/tfcmt_linux_amd64.tar.gz" -O /tmp/tfcmt.tar.gz
tar xzf /tmp/tfcmt.tar.gz -C /tmp
mv /tmp/tfcmt /usr/local/bin
tfcmt --version
- name: Terraform init
run: terraform init
- name: Terraform fmt
run: terraform fmt
- name: Terraform apply
id: apply
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
# Make apply results comment on commit
run: tfcmt apply -- terraform apply -auto-approve -no-color -input=false
```
This is an example of a workflow for the apply process. I set the trigger for this workflow to activate on pull requests, so the terraform apply command runs when a pull request is opened in the repository.
When you want to manipulate AWS resources from GitHub, obviously you need to set AWS credential information. However, directly putting secret information in your repository poses security risks. Instead, you can use an OIDC token to get temporary AWS credential information. This way, you only need to put the ARN of the IAM role in your GitHub account, which is much safer.
Once the workflows have executed properly, you can view the results in the "Actions" tab on GitHub, like this:
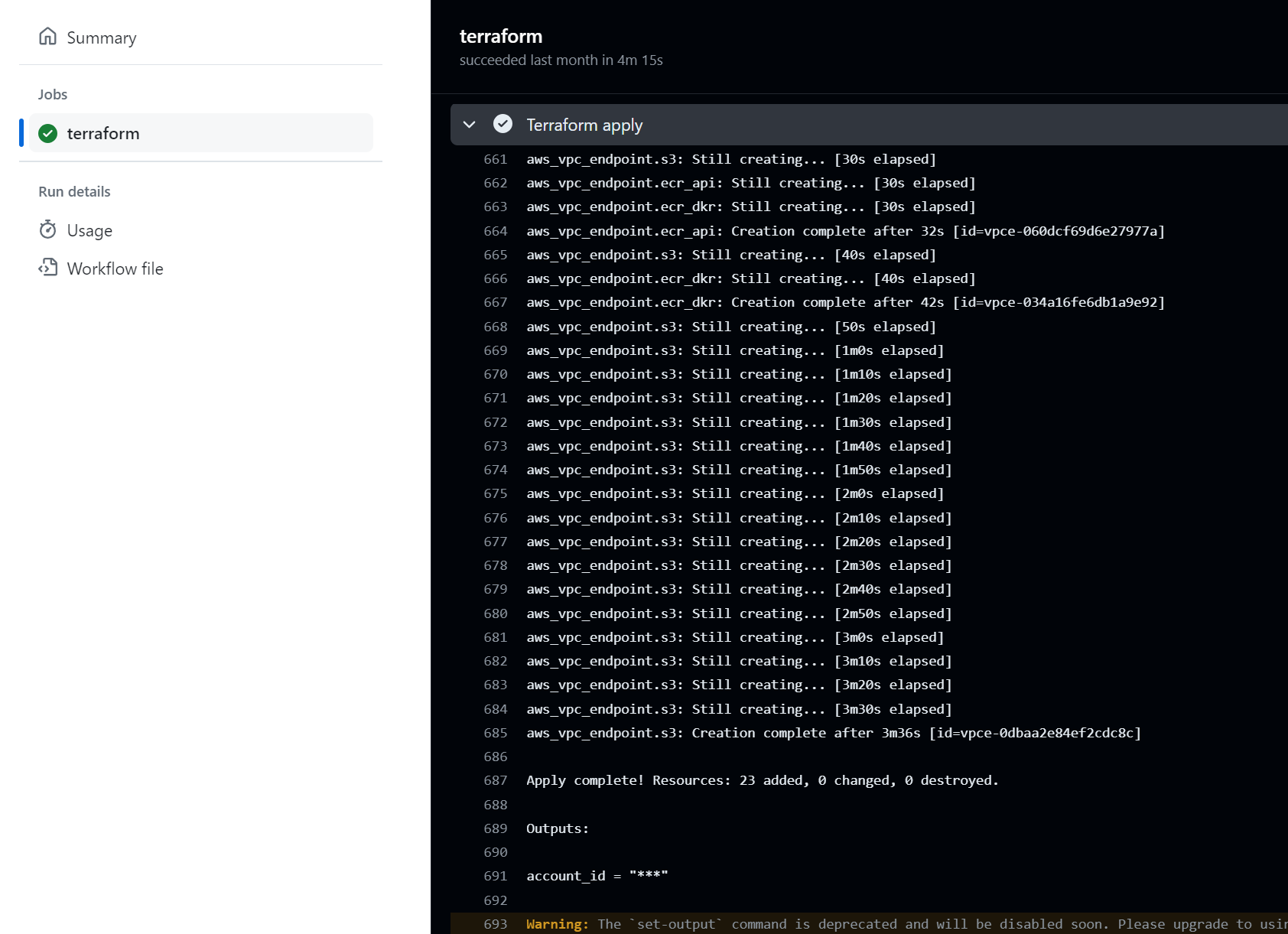
If you see the output saying "Apply complete!", you can confirm that your infrastructure has been successfully deployed to the AWS environment.
In the next post, I'll explain how to integrate the training code we created in the first post into the system.
| hikarunakatani |
1,862,669 | Best Mobile Application Development Services | Elevating your mobile strategy is essential in today's fast-paced digital landscape, and Zaigo... | 0 | 2024-05-23T09:35:15 | https://dev.to/seo_dharsheni_af6992a0c35/best-mobile-application-development-services-3eip | mobile | Elevating your mobile strategy is essential in today's fast-paced digital landscape, and Zaigo Infotech is your trusted partner in achieving this goal. With a relentless focus on innovation and cutting-edge technology, Zaigo Infotech offers comprehensive solutions tailored to meet your mobile needs. Here's how Zaigo Infotech can transform your mobile strategy:
1.Customized Mobile App Development: Zaigo Infotech specializes in crafting bespoke [mobile applications](https://www.zaigoinfotech.com/mobile-application-development/) that align perfectly with your business objectives and target audience. Whether you need a native iOS, Android, or cross-platform app, our team of experienced developers ensures top-notch quality and seamless performance.
2.User-Centric Design: We understand the significance of user experience in driving engagement and retention. That's why our designers prioritize intuitive interfaces and captivating designs to deliver an exceptional user experience. By focusing on usability and accessibility, we ensure that your app resonates with your users, fostering long-term loyalty.
3.Agile Development Methodology: Zaigo Infotech follows agile development methodologies to adapt quickly to changing requirements and market dynamics. Our iterative approach allows for continuous feedback and improvements, ensuring that your mobile solution remains relevant and competitive in the ever-evolving digital landscape.
4.Scalability and Flexibility: Whether you're a startup or a large enterprise, Zaigo Infotech builds mobile solutions that can scale seamlessly to accommodate your growing user base and evolving business needs. Our flexible architecture and robust backend systems empower your app to handle increased traffic and functionality without compromising performance.
5.Data-Driven Insights: Leveraging analytics and data-driven insights, Zaigo Infotech helps you gain valuable visibility into user behavior and app performance. By tracking key metrics and user interactions, we provide actionable insights to optimize your mobile strategy, drive engagement, and maximize ROI.
6.Ongoing Support and Maintenance: Our commitment to excellence extends beyond the initial development phase. Zaigo Infotech offers comprehensive support and maintenance services to ensure the continued success of your mobile app. From troubleshooting issues to implementing new features, we're with you every step of the way.
In conclusion, Zaigo Infotech empowers businesses to elevate their mobile strategy through tailored solutions, user-centric design, agile development, scalability, data-driven insights, and ongoing support. Partner with Zaigo Infotech today and embark on a journey towards mobile success.
| seo_dharsheni_af6992a0c35 |
1,862,668 | Why Did Google Choose To Implement gRPC Using HTTP/2? | Background gRPC is an open-source high-performance RPC framework developed by Google. The... | 0 | 2024-05-23T09:35:13 | https://dev.to/huizhou92/why-did-google-choose-to-implement-grpc-using-http2-197a | go, grpc, http |
## Background
[gRPC](https://grpc.io/) is an open-source high-performance RPC framework developed by Google. The design goal of gRPC is to run in any environment, supporting pluggable load balancing, tracing, health checking, and authentication. It not only supports service calls within and across data centers but is also suitable for the last mile of distributed computing, connecting devices, mobile applications, and browsers to backend services. For more on the motivation and principles behind gRPC's design, refer to this article: [gRPC Motivation and Design Principles](https://grpc.io/blog/principles).
<!-- more-->
> This article is first published in the medium MPP plan. If you are a medium user, please follow me in [medium](https://medium.hxzhouh.com/). Thank you very much.
Key points from the official article:
- Internally, there is a framework called Stubby, but it is not based on any standard.
- Supports use in any environment, including IoT, mobile, and browsers.
- Supports streaming and flow control.
In reality, performance is not the primary goal of gRPC design. So why choose HTTP/2?
## What is HTTP/2
Before discussing why gRPC chose HTTP/2, let's briefly understand HTTP/2.
HTTP/2 can be simply introduced with an image:

From: [https://hpbn.co/](https://hpbn.co/)
- The header in HTTP/1 corresponds to the HEADERS frame in HTTP/2.
- The payload in HTTP/1 corresponds to the DATA frame in HTTP/2.
In the Chrome browser, open `chrome://net-internals/#http2` to see information about HTTP/2 connections.
Many websites are already running on HTTP/2.
## gRPC Over HTTP/2
Strictly speaking, gRPC is designed in layers, with the underlying layer supporting different protocols. Currently, gRPC supports:
- [gRPC over HTTP2](https://github.com/grpc/grpc/blob/master/doc/PROTOCOL-HTTP2.md)
- [gRPC Web](https://github.com/grpc/grpc/blob/master/doc/PROTOCOL-WEB.md)
However, most discussions are based on gRPC over HTTP2. Let's look at a real gRPC `SayHello` request and see how it is implemented over HTTP/2 using Wireshark:
You can see the following headers:
```shell
Header: :authority: localhost:50051
Header: :path: /helloworld.Greeter/SayHello
Header: :method: POST
Header: :scheme: http
Header: content-type: application/grpc
Header: user-agent: grpc-java-netty/1.11.0
```
Then the request parameters are in the DATA frame:
`GRPC Message: /helloworld.Greeter/SayHello, Request`
In short, gRPC puts metadata in HTTP/2 Headers and serialized request parameters in the DATA frame.
## Advantages of HTTP/2 Protocol
### HTTP/2 is an Open Standard
Google thought this through and chose not to open-source its internal Stubby but to create something new. As technology becomes more open, the space for proprietary protocols is shrinking.
### HTTP/2 is a Proven Standard
HTTP/2 was developed based on practical experience, which is crucial. Many unsuccessful standards were created by a group of vendors before implementation, leading to chaos and unusability, such as CORBA. HTTP/2's predecessor was Google's [SPDY](https://en.wikipedia.org/wiki/SPDY). Without Google's practice and promotion, HTTP/2 might not exist.
### HTTP/2 Naturally Supports IoT, Mobile, and Browsers
In fact, mobile phones and mobile browsers were the first to adopt HTTP/2. The mobile internet has driven the development and adoption of HTTP/2.
### Multi-language Implementation of HTTP/2 is Easy
Discussing only the implementation of the protocol itself, without considering serialization:
- Every popular programming language has a mature HTTP/2 Client.
- HTTP/2 Clients are well-tested and reliable.
- Sending HTTP/2 requests with a Client is much easier than sending/receiving packets with sockets.
### HTTP/2 Supports Stream and Flow Control
There are many streaming solutions in the industry, such as those based on WebSocket or [rsocket](https://github.com/rsocket/rsocket). However, these solutions are not universal.
Streams in HTTP/2 can also be prioritized, which might be used in complex scenarios, although less frequently in RPC.
### Easy Support for HTTP/2 in Gateway/Proxy
- Nginx support for gRPC: [https://www.nginx.com/blog/nginx-1-13-10-grpc/](https://www.nginx.com/blog/nginx-1-13-10-grpc/)
- Envoy support for gRPC: [https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/grpc#](https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/grpc#)
### HTTP/2 Ensures Security
- HTTP/2 naturally supports SSL, although gRPC can run on a clear text protocol (i.e., unencrypted).
- Many proprietary RPC protocols might wrap a layer of TLS support, making it very complex to use. Do developers have enough security knowledge? Are users configuring it correctly? Can operators understand it correctly?
- HTTP/2 ensures secure transmission over public networks. For example, the [CRIME attack](https://en.wikipedia.org/wiki/CRIME) is hard to prevent in proprietary protocols.
### Mature Authentication in HTTP/2
- Authentication systems developed from HTTP/1 are mature and can be seamlessly used in HTTP/2.
- End-to-end authentication from front-end to back-end without any conversion or adaptation.
For example, traditional RPC like Dubbo requires writing a Dubbo filter and considering how to pass authentication-related information through thread local. The RPC protocol itself also needs to support it. In short, it's very complex. In fact, most RPCs in companies do not have authentication and can be called freely.
## Disadvantages of HTTP/2 Protocol
### Inefficient Transmission of RPC Metadata
Although HPAC can compress HTTP Headers, for RPC, determining a function call can be simplified to an int. Once negotiated between both ends, it can be directly looked up in a table, without the need for HPAC encoding and decoding.
Consider optimizing an HTTP/2 parser specifically for gRPC to reduce some general processing and improve performance.
### gRPC Calls in HTTP/2 Require Two Decodings
One for the HEADERS frame and one for the DATA frame.
The HTTP/2 standard itself only allows one TCP connection, but in practice, gRPC may have multiple TCP connections, which needs attention during use.
Choosing HTTP/2 for gRPC means its performance won't be top-notch. **But for RPC, moderate QPS is acceptable**, and generality and compatibility are the most important. Refer to the official benchmark: [https://grpc.io/docs/guides/benchmarking.html](https://grpc.io/docs/guides/benchmarking.html)
- [https://github.com/hank-whu/rpc-benchmark](https://github.com/hank-whu/rpc-benchmark)
If your scenario is to...
## Google's Standard-Setting Ability
In the past decade, Google's ability to set standards has grown stronger. Here are some standards:
- HTTP/2
- WebP image format
- WebRTC for real-time communication
- VP9/AV1 video encoding standards
- Service Worker/PWA
- QUIC/HTTP/3
Of course, Google doesn't always succeed. Many initiatives it tried to push failed, such as Chrome's Native Client.
**gRPC is currently the de facto standard in the Kubernetes ecosystem. Will gRPC become the RPC standard in more areas and larger fields?**
## Why gRPC Emerged
Why did an HTTP/2-based RPC emerge?
I believe an important reason is that in the trend of Cloud Native, the need for open interoperability inevitably leads to HTTP/2-based RPC. Even without gRPC, there would be other HTTP/2-based RPCs.
gRPC was first used internally at Google on Google Cloud Platform and public APIs: [https://opensource.google.com/projects/grpc](https://opensource.google.com/projects/grpc)
## Summary
Although gRPC may not replace internal RPC implementations, in an era of open interoperability, not just on Kubernetes, gRPC will have more and more stages to showcase its capabilities.
## References
- [https://grpc.io/](https://grpc.io/)
- [https://hpbn.co/](https://hpbn.co/)
- [https://grpc.io/blog/loadbalancing](https://grpc.io/blog/loadbalancing)
- [https://http2.github.io/faq](https://http2.github.io/faq)
- [https://github.com/grpc/grpc](https://github.com/grpc/grpc) | huizhou92 |
1,862,485 | Introducing RoBERTa Base Model: A Comprehensive Overview | Introduction RoBERTa (short for “Robustly Optimized BERT Approach”) is an advanced version... | 0 | 2024-05-23T09:30:00 | https://dev.to/novita_ai/introducing-roberta-base-model-a-comprehensive-overview-3997 | ai, llm, roberta, beginners | ## Introduction
RoBERTa (short for “Robustly Optimized BERT Approach”) is an advanced version of the BERT (Bidirectional Encoder Representations from Transformers) model, created by researchers at Facebook AI. Similar to BERT, RoBERTa is a transformer-based language model that employs self-attention to analyze input sequences and produce contextualized word representations within a sentence.
In this article, we will take a look a look at the RoBERTa in more detail.
## RoBERTa vs BERT
A key difference between RoBERTa and BERT is that RoBERTa was trained on a significantly larger dataset and with a more effective training procedure. Specifically, RoBERTa was trained on 160GB of text, over 10 times the size of the dataset used for BERT. Additionally, RoBERTa employs a dynamic masking technique during training, which enhances the model’s ability to learn more robust and generalizable word representations.
RoBERTa has demonstrated superior performance compared to BERT and other leading models on various natural language processing tasks, such as language translation, text classification, and question answering. It has also served as a foundational model for numerous successful NLP models and has gained popularity for both research and industrial applications.
In summary, RoBERTa is a powerful and effective language model that has made significant contributions to NLP, advancing progress across a wide range of applications.
## RoBERTa Model Architecture
The RoBERTa model shares the same architecture as the BERT model. It is a reimplementation of BERT with modifications to key hyperparameters and minor adjustments to embeddings.
The general pre-training and fine-tuning procedures for BERT are illustrated in Figure 1 below. In BERT, the same architecture is used for both pre-training and fine-tuning, except for the output layers. The pre-trained model parameters are used to initialize models for various downstream tasks. During fine-tuning, all parameters are adjusted.
In contrast, RoBERTa does not use the next-sentence pretraining objective. Instead, it is trained with much larger mini-batches and higher learning rates. RoBERTa employs a different pretraining scheme and replaces the character-level BPE vocabulary with a byte-level BPE tokenizer (similar to GPT-2). Additionally, RoBERTa does not require the definition of which token belongs to which segment, as it lacks token_type_ids. Segments can be easily divided using the separation token tokenizer.sep_token (or ).
Furthermore, unlike the 16GB dataset originally used to train BERT, RoBERTa is trained on a massive dataset exceeding 160GB of uncompressed text. This dataset includes the 16GB of English Wikipedia and Books Corpus used in BERT, along with additional data from the WebText corpus (38 GB), the CommonCrawl News dataset (63 million articles, 76 GB), and Stories from Common Crawl (31 GB). RoBERTa was pre-trained using this extensive dataset and 1024 V100 Tesla GPUs running for a day.
## Advantages of RoBERTa Model
RoBERTa has a similar architecture to BERT, but to enhance performance, the authors made several simple design changes to the architecture and training procedure. These changes include:
1. Removing the Next Sentence Prediction (NSP) Objective: In BERT, the model is trained to predict whether two segments of a document are from the same or different documents using an auxiliary NSP loss. The authors experimented with versions of the model with and without the NSP loss and found that removing the NSP loss either matched or slightly improved performance on downstream tasks.
2. Training with Larger Batch Sizes and Longer Sequences: BERT was originally trained for 1 million steps with a batch size of 256 sequences. RoBERTa was trained with 125 steps of 2,000 sequences and 31,000 steps with 8,000 sequences per batch. Larger batches improve perplexity on the masked language modeling objective and end-task accuracy. They are also easier to parallelize using distributed parallel training.
3. Dynamically Changing the Masking Pattern: In BERT, masking is done once during data preprocessing, resulting in a single static mask. To avoid this, training data is duplicated and masked 10 times with different strategies over 40 epochs, resulting in 4 epochs with the same mask. This strategy was compared with dynamic masking, where different masks are generated each time data is passed into the model.
## performance of RoBERTa
The RoBERTa model achieved state-of-the-art performance on the MNLI, QNLI, RTE, STS-B, and RACE tasks at the time, and demonstrated significant performance improvements on the GLUE benchmark. With a score of 88.5, RoBERTa claimed the top position on the GLUE leaderboard.
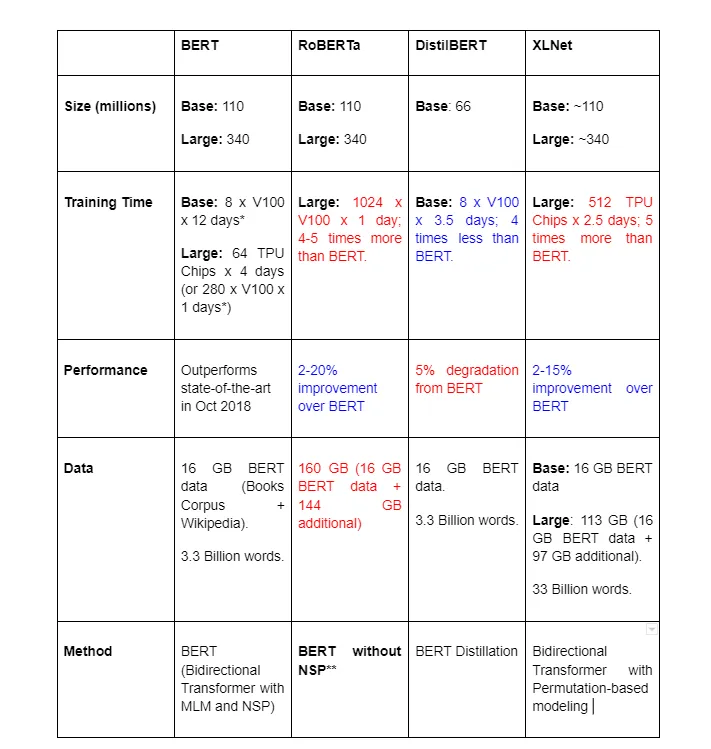
## How to Use RoBERTa
Huggingface’s Transformers library offers a variety of pre-trained RoBERTa models in different sizes and for various tasks. In this post, we will focus on how to load a RoBERTa model and perform emotion classification.
We will use a RoBERTa model fine-tuned on a task-specific dataset, specifically the pre-trained model “cardiffnlp/twitter-roberta-base-emotion” from the Huggingface hub.
First, we need to install and import all the necessary packages and load the model using `RobertaForSequenceClassification` (which includes a classification head) and the tokenizer using `RobertaTokenizer`.
!pip install -q transformers
#Importing the necessary packages
import torch
from transformers import RobertaTokenizer, RobertaForSequenceClassification
#Loading the model and tokenizer
model_name = "cardiffnlp/twitter-roberta-base-emotion"
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaForSequenceClassification.from_pretrained(model_name)
#Tokenizing the input
inputs = tokenizer("I love my cat", return_tensors="pt")
#Retrieving the logits and using them for predicting the underlying emotion
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
>> Output: Optimism
The output is “Optimism,” which is correct based on the pre-defined labels of the classification model we used. We can use another pre-trained model or fine-tune a model to obtain results with more appropriate labels.
## Evaluation Results of RoBERTa
Training with dynamic masking
In the original BERT implementation, masking occurs during data preprocessing, leading to a single static mask. This method was compared to dynamic masking, where a new masking pattern is generated each time a sequence is inputted into the model. Dynamic masking demonstrated comparable or slightly superior performance compared to static masking.
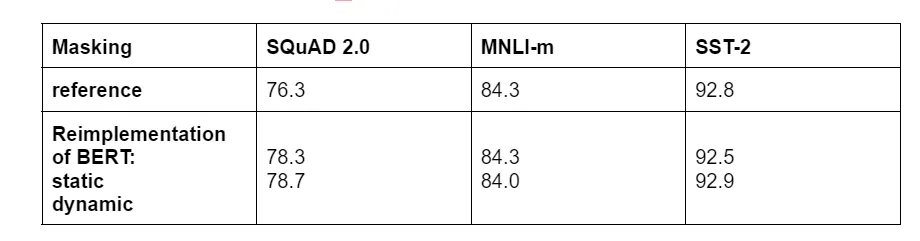
Based on the findings mentioned above, the dynamic masking approach is utilized for pretraining RoBERTa.
**FULL-SENTENCES without NSP loss**
The comparison between training without the NSP loss and training with blocks of text from a single document (doc-sentences) revealed that this configuration outperforms the originally published BERTBASE results. Furthermore, eliminating the NSP loss either matches or slightly enhances performance on downstream tasks.
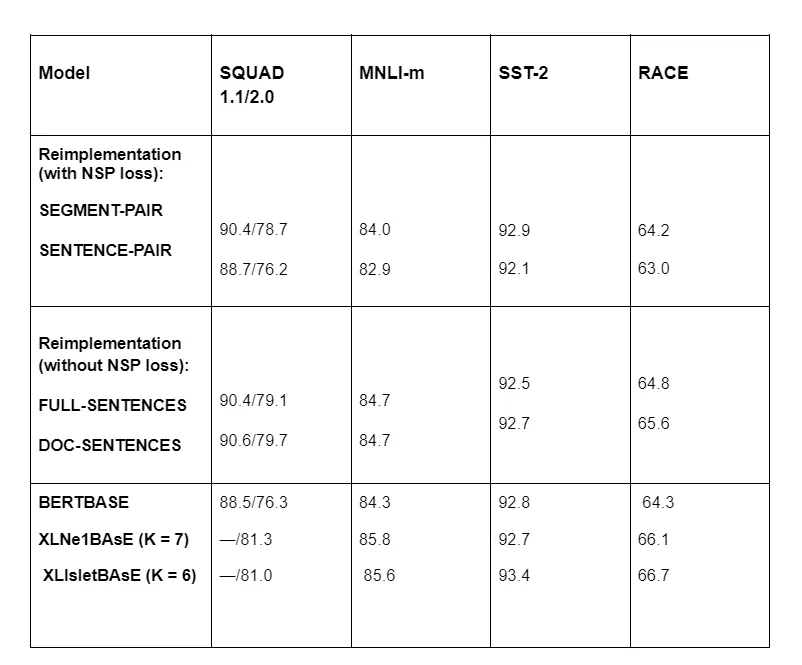
While it was observed that limiting sequences to come from a single document (DOC-SENTENCES) yields slightly better performance compared to incorporating sequences from multiple documents (FULL-SENTENCES), RoBERTa opts for using FULL-SENTENCES for easier comparison as the DOC-SENTENCES format leads to variable batch sizes.
**Training with large batches**
Training with large batch sizes expedites optimization and enhances task accuracy. Moreover, distributed data-parallel training facilitates the parallelization of large batches, further improving efficiency. When appropriately tuned, large batch sizes can enhance the model’s performance on a given task.
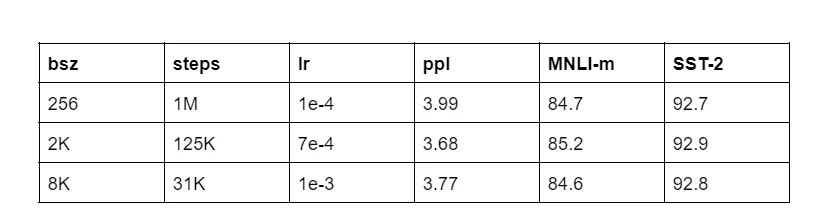
**A larger byte-level BPE**
Byte-pair encoding (BPE) combines aspects of character-level and word-level representations, enabling effective handling of the extensive vocabularies typical in natural language corpora. RoBERTa diverges from BERT by employing a larger byte-level BPE vocabulary consisting of 50K subword units, without requiring additional preprocessing or input tokenization.
## Navigating to Limitations of RoBERTa
While RoBERTa is a powerful model, it’s not without its limitations. Here are some:
1. Computational Resources: Training and fine-tuning RoBERTa requires significant computational resources, including powerful GPUs and large amounts of memory. This can make it challenging for individuals or organizations with limited resources to utilize RoBERTa effectively.
2. Domain Specificity: Pre-trained language models like RoBERTa may not perform optimally on domain-specific tasks or datasets without further fine-tuning. They may require additional training on domain-specific data to achieve the desired level of performance.
3. Data Efficiency: RoBERTa and similar models require large amounts of data for pre-training, which might not be available for all languages or domains. This reliance on extensive data can limit their applicability in settings where data is scarce or expensive to acquire.
4. Interpretability: The black-box nature of RoBERTa can make it difficult to interpret how the model arrives at its predictions. Understanding the inner workings of the model and diagnosing errors or biases can be challenging, especially in complex applications or sensitive domains.
5. Fine-tuning Challenges: While fine-tuning RoBERTa for specific tasks can improve performance, it requires expertise and experimentation to select the right hyperparameters, data augmentation techniques, and training strategies. This process can be time-consuming and resource-intensive.
6. Bias and Fairness: Pre-trained language models like RoBERTa can inherit biases present in the training data, leading to biased or unfair predictions. Addressing bias and ensuring fairness in AI models remains a significant challenge, requiring careful data curation and model design considerations.
7. Out-of-Distribution Generalization: RoBERTa may struggle to generalize to out-of-distribution data or handle scenarios significantly different from its training data. This limitation can impact the robustness and reliability of RoBERTa in real-world applications where data distribution shifts are common.
To overcome these limitations, you can choose more advanced models such an Llama 3 which is released recently. Or you can apply novita.ai [LLM API key ](https://novita.ai/llm-api)to your existing system seamlessly with low cost:
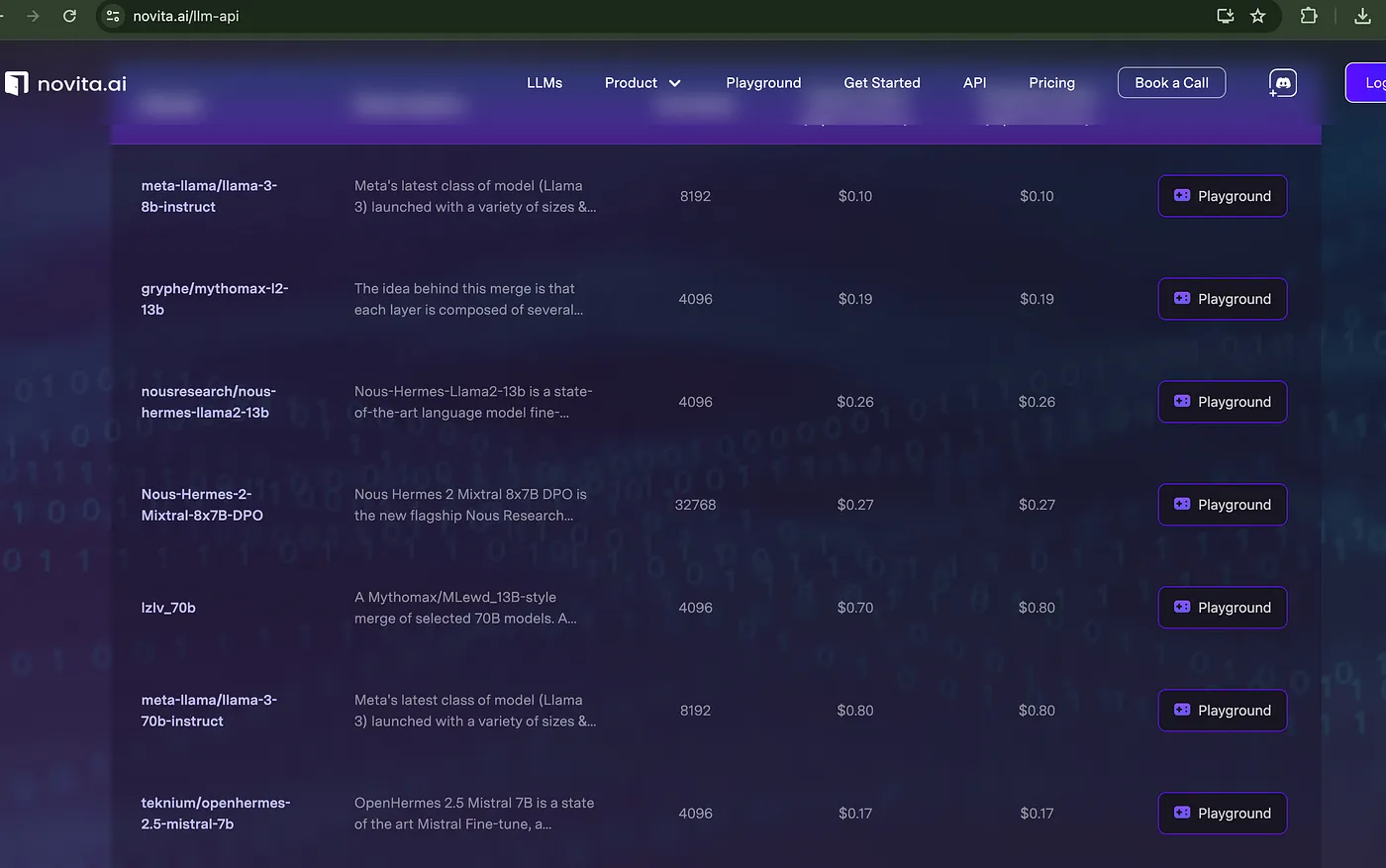
## Conclusion
RoBERTa significantly advances natural language processing by building on BERT’s foundation, utilizing a much larger training dataset and improved techniques like dynamic masking and the removal of the next-sentence prediction objective. These enhancements, along with the use of a byte-level BPE tokenizer and larger batch sizes, enable RoBERTa to achieve superior performance on various NLP tasks. While it requires substantial computational resources and fine-tuning expertise, RoBERTa’s impact on the field is profound, setting new benchmarks and serving as a versatile model for research and industrial applications.
> Originally published at [novita.ai](https://blogs.novita.ai/introducing-roberta-base-model-a-comprehensive-overview/?utm_source=devcommunity_LLM&utm_medium=article&utm_campaign=roberta)
> [novita.ai](https://novita.ai/?utm_source=devcommunity_LLM&utm_medium=article&utm_campaign=introducing-roberta-base-model-a-comprehensive-overview), the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.
| novita_ai |
1,862,320 | Exploring Phind: An Innovative AI for Developers | Discover the power of phind, an innovative AI tool for developers. Explore how phind can... | 0 | 2024-05-23T09:30:00 | https://dev.to/novita_ai/exploring-phind-an-innovative-ai-for-developers-2h6m | ai, phind, llm | Discover the power of phind, an innovative AI tool for developers. Explore how phind can revolutionize your coding experience on our blog.
## Introduction
Phind is an advanced AI search engine designed to cater to the specific needs of developers. Built on the foundation of generative AI and large language models, Phind revolutionizes the way developers search for answers to their technical questions. With its innovative approach, Phind aims to provide precise and contextual answers in just 15 seconds, significantly reducing the time spent on problem-solving through its connection to the internet and your codebase. As an alternative to traditional search engines like Google, Phind offers a unique and efficient way for developers to find the information they need.
## What is Phind?
Phind is a smart answer engine designed for developers. It leverages generative AI to assist in solving complex problems, guiding you from concept to a functional product. With internet connectivity and optional integration with your codebase, Phind consistently maintains the appropriate context.
**The Genesis of Phind-CodeLlama-34B-v2**
Phind’s development can be traced back to an AI model known as CodeLlama-34B-v2. This model, built on advanced AI techniques, became the foundation for Phind’s search capabilities. The genesis of Phind involved training the CodeLlama-34B-v2 model on a proprietary dataset, enabling it to understand and generate accurate responses to developers’ queries. This model was later open sourced in Summer 2023 and outperformed other open-source coding models and ChatGPT 4 on OpenAI’s HumanEval Benchmark, scoring 74.
[CodeLlama-34B-v2](https://blogs.novita.ai/introducing-code-llama-a-state-of-the-art-large-language-model-for-code-generation/) was meticulously trained on a vast range of programming languages and concepts, ensuring its versatility and proficiency in handling diverse coding problems. This comprehensive training process laid the groundwork for Phind’s innovative search engine, royzen, developed by Michael Royzen and Justin Wei, which combines the power of AI and programming expertise to deliver precise and reliable answers to developers.
## Benchmarking Success: Understanding PASS 1 Rate
To measure the success and accuracy of Phind’s search capabilities, a benchmarking metric called pass 1 rate is used. The PASS 1 rate represents the percentage of times Phind generates the correct answer as the first result. A higher PASS 1 rate indicates a more precise and reliable AI search engine.
Phind has achieved an impressive PASS 1 rate of 75%, highlighting the effectiveness of its search algorithms and the quality of its generated responses. This rate signifies that in the majority of cases, Phind is able to provide developers with the correct answer to their query without the need for further searching.
The following text table provides a summary of Phind’s PASS 1 rate benchmarking results:
These benchmarking results demonstrate Phind’s ability to consistently deliver accurate and reliable answers to developers, making it a valuable tool in their programming endeavors.
## Multi-Lingual Proficiency: Beyond Python and Java
Phind’s multi-lingual proficiency sets it apart from traditional search engines. While most search engines are limited to common programming languages like Python and Java, Phind expands its capabilities to cover a wide range of programming languages. This enables developers to find answers to their queries regardless of the language they are working with.
Phind’s AI-powered search engine understands the nuances of different programming languages and is capable of generating accurate and relevant responses in multiple languages. This multi-lingual proficiency enhances the user experience and ensures that developers can find the information they need, regardless of the programming language they are using. Whether it’s Python, Java, C++, or any other language, Phind has developers covered.
## Instruction-Tuned for Precision: The Alpaca/Vicuna Format
To ensure precision and accuracy in its search results, Phind utilizes the instruction-tuned Alpaca/Vicuna format. This format allows Phind to fine-tune its AI models based on specific programming instructions, resulting in more precise and relevant answers.
The Alpaca/Vicuna format involves providing clear and detailed instructions to Phind’s AI models, guiding them to generate responses that align with the desired level of precision. This instruction-tuning process enhances the search engine’s ability to understand and cater to the specific needs of developers, ensuring that the generated answers are not only accurate but also tailored to the given instructions. The Alpaca/Vicuna format is a key component of Phind’s commitment to providing developers with the most precise and reliable search results.
## Phind in Action: Real-World Applications and Success Stories
Phind’s innovative AI search engine has found real-world applications across various industries and has garnered numerous success stories from satisfied developers. Whether it’s a software engineer needing quick solutions to coding problems or a developer seeking in-depth information on a particular programming concept, Phind has proven to be a valuable tool in their endeavors, including at the University of Texas at Austin where the cofounders first saw the opportunity to use LLMs as a search engine.
**Streamlining Development Workflows**
Phind streamlines development workflows by providing developers with a powerful search engine that delivers precise and contextual answers. This efficiency-enhancing tool optimizes the programming process, enabling developers to work more effectively and efficiently. The key benefits of Phind in streamlining development workflows include:
- Rapid access to accurate and relevant information.
- Reduction in time spent on searching for solutions.
- Increased productivity and efficiency in problem-solving.
- Improved code quality through precise and tailored answers.
Phind’s streamlined development workflows empower developers to focus on the core aspects of their work, enabling them to deliver high-quality code and meet project deadlines with ease. By eliminating the need for time-consuming searches, Phind enhances the efficiency of development processes, leading to improved productivity and overall project success.
**Enhancing Code Quality and Efficiency**
Phind’s AI-powered search capabilities have a significant impact on code quality and efficiency. By providing precise and contextual answers, Phind enhances developers’ understanding of coding concepts and enables them to write cleaner, more efficient code. The benefits of Phind in enhancing code quality and efficiency include:
- Access to accurate and reliable information for informed decision-making.
- Identification of best practices and optimal coding solutions.
- Reduction in code errors and bugs through the application of industry-standard techniques.
- Increased efficiency in problem-solving, leading to faster development cycles.
Phind’s role in enhancing code quality and efficiency goes beyond providing answers to specific programming queries. It serves as a valuable resource for developers, promoting best practices, and enabling them to write code that is not only functional but also robust and efficient.
## Deep Dive into Phind’s Core Technologies
To understand the inner workings of Phind, it is essential to delve into its core technologies. Phind utilizes a combination of cutting-edge technologies, including proprietary datasets and advanced AI models, to deliver its powerful search capabilities.
**Training on a Proprietary Dataset: A Unique Approach**
Phind’s training process involves leveraging its proprietary dataset, setting it apart from other search engines. This unique approach allows Phind to understand the specific nuances of coding and generate accurate responses tailored to developers’ queries.
The proprietary dataset used by Phind encompasses a wide range of programming languages, concepts, and problem-solving techniques. This comprehensive training ensures that Phind’s AI models are well-equipped to handle various programming challenges and provide relevant and precise answers. By training on a proprietary dataset, Phind has developed a deep understanding of programming and can deliver high-quality search results that cater to the specific needs of developers.
**Achieving Steerability and Ease-of-Use**
Phind prioritizes steerability and ease-of-use to provide developers with a seamless and efficient user experience. The search engine’s interface is designed to be intuitive and user-friendly, allowing developers to navigate and access the desired information quickly and effortlessly.
Steerability refers to Phind’s ability to generate responses that align with the user’s instructions and preferences. Developers can easily guide Phind to provide more precise or broader answers, depending on their specific needs. This level of steerability enhances the user experience and ensures that developers can find the information they need with ease.
In addition to steerability, Phind focuses on ease-of-use by offering a clean and intuitive interface. Developers can enter their queries and receive accurate and relevant answers in a matter of seconds. This user-centric approach makes Phind a highly accessible and efficient tool for developers, streamlining their coding processes and enhancing their overall productivity.
## The User Experience with Phind
The user experience is at the core of Phind’s design. The search engine’s intuitive interface and efficient search capabilities contribute to a seamless user experience for developers. By providing accurate and contextual answers in just 15 seconds, Phind eliminates the frustration of time-consuming searches and enables developers to focus on their coding tasks.
Phind’s user-friendly interface allows developers to quickly enter their queries and receive precise and relevant answers. The intuitive design ensures that developers can easily navigate the search engine and access the information they need. With its focus on user experience, Phind aims to make the programming journey smoother and more efficient for developers worldwide.
**Setting Up and Getting Started**
Simply access Phind via a browser; no installations needed. Start your journey with Phind, a revolutionary chatgpt AI search tool designed to streamline coding tasks effortlessly.
**Navigating the Interface**
Navigating Phind’s interface is intuitive and user-friendly, making it easy for developers to find the information they need quickly. The search bar allows users to input complex coding questions, and Phind’s AI engine generates precise answers in a matter of seconds.
Additionally, Phind’s interface is designed to be responsive and scalable, ensuring a seamless user experience regardless of the device or screen size. Whether developers are accessing Phind from their desktop or mobile devices, they can expect consistent and reliable performance.
## Comparing Phind with Other AI Developer Tools
Phind stands out among other AI developer tools due to its unique features and impressive performance metrics. When compared to traditional search engines, Phind’s generative AI-based approach provides developers with more precise and relevant answers to their coding questions.
**Key Differentiators That Set Phind Apart**
Phind differentiates itself from other AI developer tools through its unique features and capabilities. One of the key differentiators is its use of generative AI and large language models, which enables Phind to generate precise answers to coding questions in just 15 seconds.
Another standout feature of Phind is its ability to provide not only th answer to a developer’s question but also relevant links to online sources. This feature allows developers to dive deeper into the topic and gain a comprehensive understanding of the problem they are trying to solve.
Additionally, Phind’s integration with NVIDIA GPU-based Amazon EC2 instances ensures high-performance computing, delivering faster answer completion and reducing the time it takes to start generating an answer.
Overall, Phind’s combination of generative AI, large language models, and advanced search capabilities make it a powerful and unique tool for developers.
**Performance Metrics: Phind vs. Competitors**
Phind outperforms its competitors when it comes to performance metrics. With an 8x faster answer completion and a 75% reduction in the time it takes to start generating an answer, Phind significantly improves developers’ efficiency and productivity.
Compared to traditional search engines, Phind’s generative AI-based approach provides more precise and relevant answers to coding questions. This ensures that developers can quickly find the information they need without wasting time on irrelevant search results.
Furthermore, Phind’s integration with NVIDIA GPU-based Amazon EC2 instances gives it a performance advantage over other AI developer tools. The use of these high-performance computing resources enables Phind to deliver fast and accurate results, making it a preferred choice for developers seeking efficient and reliable search capabilities.
In terms of user satisfaction, Phind has garnered positive feedback for its ability to provide accurate and comprehensive answers to coding questions. Developers appreciate the speed and precision of Phind’s search results, as it helps them solve problems more efficiently.
## Future Directions for Phind Development
Phind’s development roadmap includes several exciting future directions to enhance its capabilities and provide an even better user experience. The Phind team is committed to continuously improving the search engine and incorporating user feedback to drive innovation.
**Upcoming Features and Updates**
Phind has an exciting roadmap of upcoming features and updates that will further enhance its search capabilities for developers. One of the upcoming features includes the integration of a code editor directly within Phind’s interface. This will enable developers to write and test code within the same environment, streamlining their workflow.
Another upcoming feature is the addition of a collaborative coding environment, allowing developers to work together on coding projects in real-time. This feature will facilitate collaboration and knowledge sharing among developers, promoting teamwork and efficient problem-solving.
Phind also has plans to introduce advanced search filters and customization options, allowing developers to tailor their search results based on specific programming languages, frameworks, or platforms.
These upcoming features and updates demonstrate Phind’s commitment to continuous improvement and providing developers with a powerful and versatile search engine tailored to their needs.
**Integrations and Ecosystem Growth**
Phind is actively working on expanding its integrations and ecosystem to provide developers with a seamless and integrated coding experience. The integration of Phind with popular development tools and platforms will enable developers to access Phind’s powerful search capabilities without disrupting their existing workflows.
Phind aims to integrate with code repositories, IDEs (Integrated Development Environments), and collaborative coding platforms, allowing developers to seamlessly use Phind alongside their preferred development tools.
Furthermore, Phind plans to collaborate with industry partners and developers to build a thriving ecosystem around its search engine. This ecosystem will foster knowledge sharing, collaboration, and the development of new features and enhancements.
Here we’d like to share you with our platform, novita.ai LLM which collaborates with Phind with its interface:
Our[LLM API](https://novita.ai/llm-api) is also equipped with the latest codellama and llama 3 models.
You can deploy models to production more reliably and scalably, faster and cheaper with our serverless platform than self-developing infrastructure. Moreover, You may focus your energy on application growth and customer service, while the LLM Infrastructure can be entrusted to the Novita Team. Now you can [try it](https://novita.ai/llm-api) for free.
## Conclusion
Phind showcases a new era in developer tools with its innovative features and user-centric design. By offering multi-lingual proficiency and precise instruction tuning, it revolutionizes programming workflows, enhancing code quality and efficiency. The user experience is seamless, emphasizing ease of setup and intuitive navigation. Compared to other AI developer tools, Phind stands out with its unique approach to training on proprietary datasets and achieving exceptional steerability. Exciting future developments include upcoming features, integrations, and ecosystem growth, promising continuous evolution and empowerment for developers worldwide.
> Originally published at [novita.ai](https://blogs.novita.ai/exploring-phind-an-innovative-ai-for-developers/?utm_source=devcommunity_LLM&utm_medium=article&utm_campaign=phind)
> [novita.ai](https://novita.ai/?utm_source=devcommunity_LLM&utm_medium=article&utm_campaign=exploring-phind-an-innovative-ai-for-developers), the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.
| novita_ai |
1,862,666 | Building AI Content Ideas Generator with Next.js and GPT APIs | In this article, we'll explore how to build an AI content ideas generator using Next.js, a popular React framework, and GPT APIs, leveraging the power of natural language processing. | 0 | 2024-05-23T09:26:21 | https://dev.to/ramgoel/building-ai-content-ideas-generator-with-nextjs-and-gpt-apis-4moi | ai, mern, nextjs, chatgpt | ---
title: Building AI Content Ideas Generator with Next.js and GPT APIs
published: true
description: In this article, we'll explore how to build an AI content ideas generator using Next.js, a popular React framework, and GPT APIs, leveraging the power of natural language processing.
tags: AI, MERN, NextJs, ChatGPT
# cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/5hryqxq6gx9omytqixyo.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-23 09:23 +0000
---
In today's digital landscape, content creation has become a cornerstone for businesses and individuals alike. However, consistently generating fresh and engaging content ideas can be a challenging task. This is where AI-powered solutions come into play, offering innovative ways to spark creativity and streamline the content creation process. In this article, we'll explore how to build an AI content ideas generator using Next.js, a popular React framework, and GPT APIs, leveraging the power of natural language processing.
### Understanding Next.js and GPT APIs
Before diving into the implementation, let's briefly discuss Next.js and GPT APIs.
*Next.js:* Next.js is a React framework that enables server-side rendering, static site generation, and routing for React applications. It provides a robust foundation for building performant and SEO-friendly web applications.
GPT APIs: GPT (Generative Pre-trained Transformer) APIs, such as OpenAI's GPT-3, are advanced natural language processing models capable of generating human-like text based on input prompts. These APIs have been trained on vast amounts of text data and can produce coherent and contextually relevant content across various domains.
### Setting Up the Project
To begin, ensure you have Node.js and npm installed on your system. You can create a new Next.js project using the following commands:
```shell
npx create-next-app@latest my-ai-content-generator
cd my-ai-content-generator
npm install
```
Next, you'll need to sign up for access to a GPT API provider, such as OpenAI. Once you have obtained your API key, you can integrate it into your Next.js application.
### Integrating GPT API
Create a new file called `api/generateContent.js` within your Next.js project directory. This file will contain the logic for interacting with the GPT API.
```javascript
// api/generateContent.js
import OpenAI from 'openai';
const openai = new OpenAI('YOUR_API_KEY');
export default async function handler(req, res) {
if (req.method === 'POST') {
const { prompt } = req.body;
try {
const response = await openai.complete({
engine: 'text-davinci-003', // Specify the GPT model
prompt,
maxTokens: 100, // Adjust as needed
});
res.status(200).json({ content: response.data.choices[0].text.trim() });
} catch (error) {
console.error('Error:', error);
res.status(500).json({ error: 'An error occurred while generating content.' });
}
} else {
res.status(405).json({ error: 'Method Not Allowed' });
}
}
```
### Creating the User Interface
Now, let's create a simple user interface for interacting with our content ideas generator. Modify the `pages/index.js` file as follows:
```javascript
// pages/index.js
import { useState } from "react";
export default function Home() {
const [inputText, setInputText] = useState("");
const [generatedContent, setGeneratedContent] = useState("");
const handleGenerateContent = async () => {
const response = await fetch("/api/generateContent", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt: inputText }),
});
const data = await response.json();
setGeneratedContent(data.content);
};
return (
<div>
<h1>AI Content Ideas Generator</h1>
<textarea
value={inputText}
onChange={(e) => setInputText(e.target.value)}
placeholder="Enter your content idea here…"
rows={5}
cols={50}
/>
<button onClick={handleGenerateContent}>Generate Content</button>
{generatedContent && (
<div>
<h2>Generated Content:</h2>
<p>{generatedContent}</p>
</div>
)}
</div>
);
}
```
### Conclusion
In this tutorial, we've explored how to build an AI content ideas generator using Next.js and GPT APIs. By leveraging the power of natural language processing, we can generate creative and contextually relevant content ideas with ease. This project serves as a testament to the transformative potential of AI in enhancing the content creation process. With further customization and refinement, you can tailor this solution to suit your specific requirements and unlock new avenues for content innovation.
Connect with me on [Linkedin](https://linkedin.com/in/ramgoel) or [X](https://x.com/theramgoel)
| ramgoel |
1,862,665 | Upload files using NodeJS with Multer | Discover how to use Multer—a middleware for managing multipart/form-data—to upload files into a... | 0 | 2024-05-23T09:24:14 | https://dev.to/theonlineaid/upload-files-using-nodejs-with-multer-2nh9 | Discover how to use Multer—a middleware for managing multipart/form-data—to upload files into a NodeJS application. Files are sent via forms.
## Introduction
It is common for files—images, text documents, scripts, PDFs, and more—to need to be uploaded when developing APIs. A number of issues, including the quantity of files, types of valid files, file sizes, and several others, have come up during the creation of this functionality. We also have the Multer library to help us avoid these issues. A node.js middleware called Multer is used to handle multipart/form-data, which is what forms utilize to transfer files.
## Step 01
On your computer, start by creating a NodeJS project.
`npm init -y`
## Add Express Dependency
Enter the following command into your terminal:
`npm i express`
Create a file named index.js inside the root folder. The next step is to start our Express server in our index.js
```
const express = require("express")
const app = express()
app.listen(3000 || process.env.PORT, () => {
console.log("Server on...")
})
```
##Step 02 Including Multer
We will add the multiplier to our project once it has been established, configured, and Express has been installed.
`npm i multer`
Importing the multer into our index.js file is the next step.
```
import multer from 'multer';
```
## Setting up and confirming the upload
We are currently configuring diskStorage, which is a crucial step. Multiper provides a method called DiskStorage wherein we can specify the file's name, destination, and other validations related to its kind. These parameters are configured in accordance with your project's requirements. I've included a simple illustration of the arrangement below.
> Create a middleware
Create a file createUploadImage.js inside a middlewares folder and add the following code:
```
import multer from 'multer';
import path from 'path';
import fs from 'fs';
const createUploadImage = (destination: string) => {
const UploadImage = multer({
limits: {
fileSize: 5 * 1024 * 1024, // 5 MB file size limit
},
fileFilter: (req, file, cb) => {
if (!file.originalname.match(/\.(jpg|jpeg|png|gif)$/)) {
return cb(new Error('Only image files are allowed'));
}
cb(null, true);
},
storage: multer.diskStorage({
destination: function (req, file, cb) {
// Create the directory if it doesn't exist
fs.mkdirSync(destination, { recursive: true });
cb(null, destination);
},
filename: function (req, file, cb) {
cb(null, `${Date.now()}${path.extname(file.originalname)}`);
},
}),
});
return UploadImage;
};
export default createUploadImage;
```
In the configuration above, we mentioned the destination as a parameter for reuse uploaded files specific folder.
## Giving a path for uploads
```
// Single file
app.post("/upload/single", createUploadImage.single("file"), (req, res) => {
console.log(req.file)
return res.send("Single file")
})
//Multiple files
app.post("/upload/multiple", createUploadImage.array("file", 10), (req, res) => {
console.log(req.files)
return res.send("Multiple files")
})
```
We established two POST routes for file transfers in the code sample above. Only one file is received by the first /upload/single route; our diskStorage settings are received by the createUploadImage middleware. It calls the one method for uploading a single file as middleware in the route. The /upload/multiple route uploads several files, however notice that the createUploadImage variable now utilizes the \array} function for uploading multiple files, with a 10 file limitation.
## The end
With all the settings done, our little API is already able to store the files sent.
```
import express from 'express';
import createUploadImage from './middlewares/upload.js';
const app = express();
const uploadSingle = createUploadImage('./uploads/single');
const uploadMultiple = createUploadImage('./uploads/multiple');
// Single file
app.post("/upload/single", uploadSingle.single("file"), (req, res) => {
console.log(req.file);
return res.send("Single file uploaded");
});
// Multiple files
app.post("/upload/multiple", uploadMultiple.array("file", 10), (req, res) => {
console.log(req.files);
return res.send("Multiple files uploaded");
});
app.listen(3000 || process.env.PORT, () => {
console.log("Server on...");
});
```
It's up to you now to expand this API and integrate it with your project! | theonlineaid | |
1,862,664 | API Latency Demystified: From Concept to Optimization | What is API Latency? API latency is defined as the duration between a client's API request... | 0 | 2024-05-23T09:24:12 | https://dev.to/satokenta/api-latency-demystified-from-concept-to-optimization-4299 | api, latency | ## What is API Latency?
API latency is defined as the duration between a client's API request and the reception of a response. This metric, usually expressed in milliseconds, involves various stages: the data's journey across the network (network latency), the server's processing time, potential delays due to server load (queuing time), and the time for the client to process the received information (client processing time). As a crucial performance metric, latency directly influences an API's efficiency.
## The Critical Role of API Latency in Application Responsiveness
The speed at which applications respond and function hinges significantly on API latency. Elevated latency levels can slow down application performance, delaying data operations and degrading user experiences. This is particularly detrimental in environments requiring quick interactions, such as online gaming, financial services, or live data feeds. In distributed systems with numerous microservices, even minimal latency increases can accumulate, substantially impairing overall performance. Therefore, developers must prioritize the measurement and management of API latency to enhance application reliability and user satisfaction.
## Distinguishing API Latency from API Response Time
Though closely related, API latency and API response time are distinct metrics:
- **API Latency** marks the time taken for the initial data packet to travel between the client and the server and back. Main factors influencing this include the physical distance between the client and server, network traffic, and efficiency of network devices.
- **[API Response Time](https://apidog.com/blog/accelerating-api-response-performance-time/)** encompasses the entire duration from sending the request to receiving a full response from the API, including both the latency and the server's request processing time.
Considering an analogy, if ordering at a restaurant, API latency resembles the waiter's time to approach your table after signaling them, whereas API response time includes both the waiter's approach and the kitchen's preparation time until your order is served.
## Analyzing API Latency Components
A deep dive into the components of API latency unravels the factors that can be optimized for better performance:
### Network Latency
This involves the travel time of requests and responses across the network. Key influencers include geographical distance, network quality (bandwidth and congestion), and the number and nature of network hops which can introduce additional delays.
### Server Processing Time
This measures how long the server takes to process a request and generate a response. Influential factors include the server's hardware capabilities, software efficiency, and the current load on the server, which may cause slower processing times.
### Queuing Time
This is the delay before a server begins processing a request due to existing load. High traffic can lead to extended queuing times, particularly during peak operations.
### Client Processing Time
After receiving a response, the client's time to process this information can vary based on the tasks involved, such as data parsing, rendering, and further computations or storage.
## Techniques and Tools for Measuring API Latency
To effectively reduce API latency, precise measurement using appropriate tools is necessary. Platforms like **[Apidog](https://www.apidog.com/?utm_source=&utm_medium=blogger&utm_campaign=test1)** offer functionalities to simulate API requests and monitor latency, simplifying identification and correction of bottlenecks.
## Strategies to Mitigate API Latency
Enhancing API performance involves several best practices, such as optimizing server response times, managing network issues, and ensuring efficient client-side processing. Techniques include refining database queries, enhancing code efficiency, and effectively leveraging third-party integrations.
## Conclusion
Understanding, assessing, and optimizing API latency is imperative for developing responsive, efficient applications. It requires ongoing diligence and adaptation to evolving technology demands. By implementing best practices in API development and continuous performance tuning, developers can ensure robust, timely interactions across their digital platforms. | satokenta |
1,862,600 | Rediscovering DevOps’ Heartbeat With Secure Cloud Development Environments | How Cloud Development Platforms “Elevate” DevOps Let me start by briefly explaining what a... | 0 | 2024-05-23T09:24:10 | https://strong.network/article/rediscover-devops | devops, cloud, linux, cde | ## How Cloud Development Platforms “Elevate” DevOps
Let me start by briefly explaining what a Cloud Development Environment is: typically running a Linux OS with applications, it offers a pre-configured environment that allows for coding, compilation, and other operations similar to a local environment. From an implementation standpoint, such an environment is akin to a remotely running process, often virtualized through technologies like Docker or Podman. For a general overview of CDEs, check [this article](https://strong.network/what-are-cdes).
CDE technology is driving the fastest DevOps transformation trend today with the entire cloud-native development industry moving development environments online. These environments just became one of Gartner's new technology categories in August 2023. Notably, Gartner expects 60%+ of cloud workloads to be built and deployed using CDEs by 2026.

**Figure:** _Online containers can be leveraged at the heart of the DevOps' Three Ways_
Today, organizations can decide to manage them with a self-hosted platform or use one of the services attached to a Cloud provider when available. Yet overall, platforms to manage these environments are today in their infancy and their features widely differ across vendors. Hence, there is a great deal of flexibility on how to implement the technology and, most importantly, what the business use cases cover.
In my opinion, when faced with choosing a platform for CDEs, businesses should opt for one that delivers both productivity and data security. Using a secure Cloud Development Environment, i.e. one that provides data security allows organizations to deploy mechanisms that are quite diverse, for example: protect against data exfiltration and infiltration, automate DevSecOps best practices, generate security reviews, etc. This type of security is typically the aim of a Virtual Desktop Infrastructure by Citrix or more recently, the goal of using an Enterprise Browser (Island, Talon, or Chrome Enterprise.)
A reason for that is that many companies, including technology companies, have suffered attacks on their assets such as source code, customer data, and other intellectual property. Recent high-profile cases around source code leaks include Slack's GitHub repositories, CircleCI, and Okta in December 2022. Most importantly I find it important that _security should be positioned as a productivity booster_, such that it contributes to an improved developer experience, as opposed to an impediment.
One of the common denominators between existing platforms is the aim to make code development more efficient. Whether or not you choose to consider security in the mix, it is clear that CDEs can potentially unleash a great amount of productivity that benefits a DevOps workflow. This is the reason why I take here a fresh look at DevOps’ core principles and rethink how these environments can shed new light on them. These principles are also referred to as the three ways and are explained in _The DevOps Handbook_ by Kim, Debois, and Willis.
## Online Environments Accelerate DevOps' Principle of Flow
From a process perspective, DevOps is about implementing the _three principles (or ways)_: namely the principles of flow, feedback, and continuous learning. I think that explaining the benefits of CDEs in this context is a good way to understand some of their key impacts in my opinion.
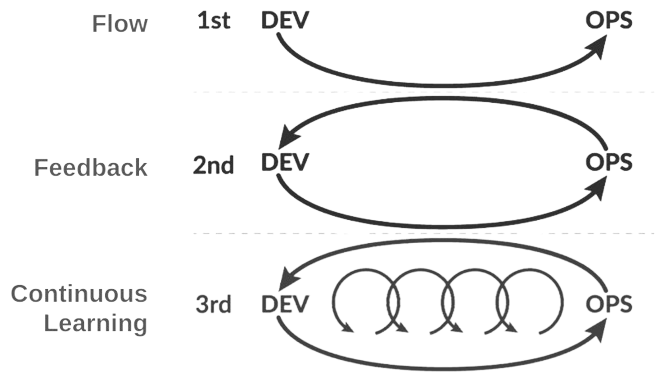
**Figure:** _DevOps’s three ways, i.e. Flow, Feedback and Continuous Learning as pictured in The DevOps Handbook by Kim, Debois, and Willis
_
Let’s start with the_ principle of flow_. The first principle emphasizes the smooth and efficient movement of work from development through testing, and deployment down to operations and monitoring. It aims to minimize bottlenecks, optimize processes, and enable a continuous and seamless delivery pipeline. The flow is often represented by the series of stages arranged along the infinity sign.
CDEs are an efficient way to implement the principle of flow because they allow users to have fully isolated workspace settings when dealing with multiple projects, enabling straightforward and impactless context switching between them.
A good CDE platform provides developers with multiple tools to manage and configure their CDEs, in particular, based on company policies. For example, _self-service access_ to CDEs for developers is an important benefit.
CDEs are also easily replicated for testing and can be reassigned across users as necessary. They can be fully templated, provisioned within seconds on pliant resources, and accessed by any developer regardless of their location. Here, a good CDE platform offers comprehensive operations to project and IT managers that enable CDE management and observability at scale.
**Figure:** _The use of CDEs starts at the DevOps’ Code stage and enables organizations to maintain consistent environments across stages. A CDE and its access mechanisms are represented by a tile and a series of icons, respectively._
Clearly, the online deployment of CDEs allows centralized management, observability, and access in such a way that it really enhances DevOps' principle of flow.
Today the inclusion of remote developers is part of most organizations' operations. The online nature of CDEs is great for onboarding developers in fully configured environments, regardless of their location. Providing access to the organizations’ resources is also an important aspect of onboarding. Here, CDEs provide a new opportunity to access development resources in a centralized manner, in particular one that offers enhanced control and observability.
To couple productivity with flexibility, a good CDE platform must provide an access permission model to resources that allow handling different types of developers, different scenarios of development (internal, collaborative, etc), and different types of resources. For example, a role-based and attribute-based access control (RBAC/ABAC) coupled with a mechanism to classify resources enables organizations to set up risk controls and ensure governance even in complex workflow situations. This greatly enhances the possibility of designing efficient and collaborative development flows.
**Figure:** _Onboarding a diverse set of developers requires a mechanism to manage access permission to resources based on role. Permissions can also be assessed dynamically based on properties such as the user location, etc._
Finally, one of the great aspects of the joint use of CDEs and Web-based IDEs is that onboarding developers on thin devices or in BYOD mode become an immediate accelerator for business expansion.
## How To Bring Immediacy to DevOps’ Principle of Feedback
The _principle of feedback_ involves establishing mechanisms for communication and collaboration between different stages of the development and operations processes. This includes collecting feedback from various sources, such as end-users, monitoring systems, and testing processes. An important aspect of this principle is that it enables better collaboration between developers.
The second principle of DevOps is best exemplified by the _Pull Request (PR) mechanism_ implemented in code repository applications. Using a PR, developers can provide comments on the work submitted from a branch before it is merged into the application.
The online nature of CDEs brings the principle of feedback even closer to the developer, i.e. before work reaches the code repository, i.e. right at the center of the coding activity. This benefit is realized by the CDEs often _in conjunction with_ the mechanisms to access or monitor it, such as the IDE, terminal, network, orchestration, etc.
Because CDEs are online running processes, it is easy to observe the work as it's being done. This is reminiscent of observing the user experience of website visitors. In my opinion, this is the area where there is the most opportunity for bringing productivity and security at the core of the development.
**Figure: ** _Because CDEs can be accessed remotely, it is easy to measure some of their properties such as running processes and allocated resources._
For example, it is easy to measure in real-time, over a fleet of CDEs, e.g. shared by developers working on a common project, the average compilation time necessary to build the application (see the above figure). This brings immediate and valuable information to the project manager about productivity.
It is also easy to look at the information passing through the developers' clipboard and the CDE's network traffic. Using these channels we can provide feedback to developers and managers. For example, from an _infrastructure security perspective_, it is easy to monitor for potential data exfiltration and prevent loss of intellectual property.
But through the same channel, one can also look for potential _infiltration of pernicious data_. For example, imagine that you can detect a credential inside a developer's clipboard, what about inquiring about the intention of the developer performing this operation? The same is possible when a developer is about to paste source code collected from a random website inside your code base. Would you like to flag it and automate the creation of a security review? What about detecting malware before it reaches your code base or systematically flagging AI-generated code?

**Figure:** _The control on CDEs and their supporting infrastructure is an opportunity to semantically analyze input data such as credentials, licensed source code, and potential malware. Similarly, it allows setting data leak prevention measures._
Clearly, CDEs and the infrastructure components that are used to funnel data into them are a medium to bring a new crop of best practices in DevOps and DevSecOps and revisit DevOps’ principle of feedback. Through the examples that I gave above, you can see that infrastructure security can liaise with the principle of code security!
A good CDE platform will definitely provide an artillery of new and creative DevOps and DevSecOps automation. In addition, there is a great opportunity to revisit standardized and accepted metrics such as DORA and SPACE to bring them closer to the activity that developers spend the most time on _writing code in the IDE_.
## Close-Up on the Principle of Continuous Learning
Now let’s finish this discussion with the third principle, _the principle of continuous learning_. This principle underscores the importance of fostering a culture of ongoing improvement and learning within the development and operations teams. It involves regularly gathering feedback, analyzing performance metrics, and incorporating lessons learned from each stage of the development and deployment process to enhance efficiency and innovation.
The immediacy of web platforms and the opportunity that they bring around the observability of their running business processes also enables organizations to learn about themselves. This is a boon to increase the potential of continuous learning.
Initially, DevOps' expectations of continuous learning are around bettering applications in operation, i.e. in use by the customer. But when the entire development process is run as a cloud application, there are many valuable things that organizations can learn about their _own platform-based development process_.
Along that vein, CDE platforms bring a new level of observability and allow business optimization around several critical areas. I have discussed how organizations can learn about their performance around application delivery and its security posture. But they can also learn about _cloud and physical assets' utilization_, as well _as monitor the cost of IT functions and resources allotted to development_. The platform also brings a fantastic opportunity to centralize the implementation of productivity and risk controls while systematically enforcing them across geographically scattered teams. In practice, modern CDE platforms need to allow the simultaneous use of multiple Clouds across multiple regions. Most importantly, their capability to _uniformly deliver complex services _to organizations makes it easy to implement governance mechanisms that do not get in the way of users’ daily tasks.
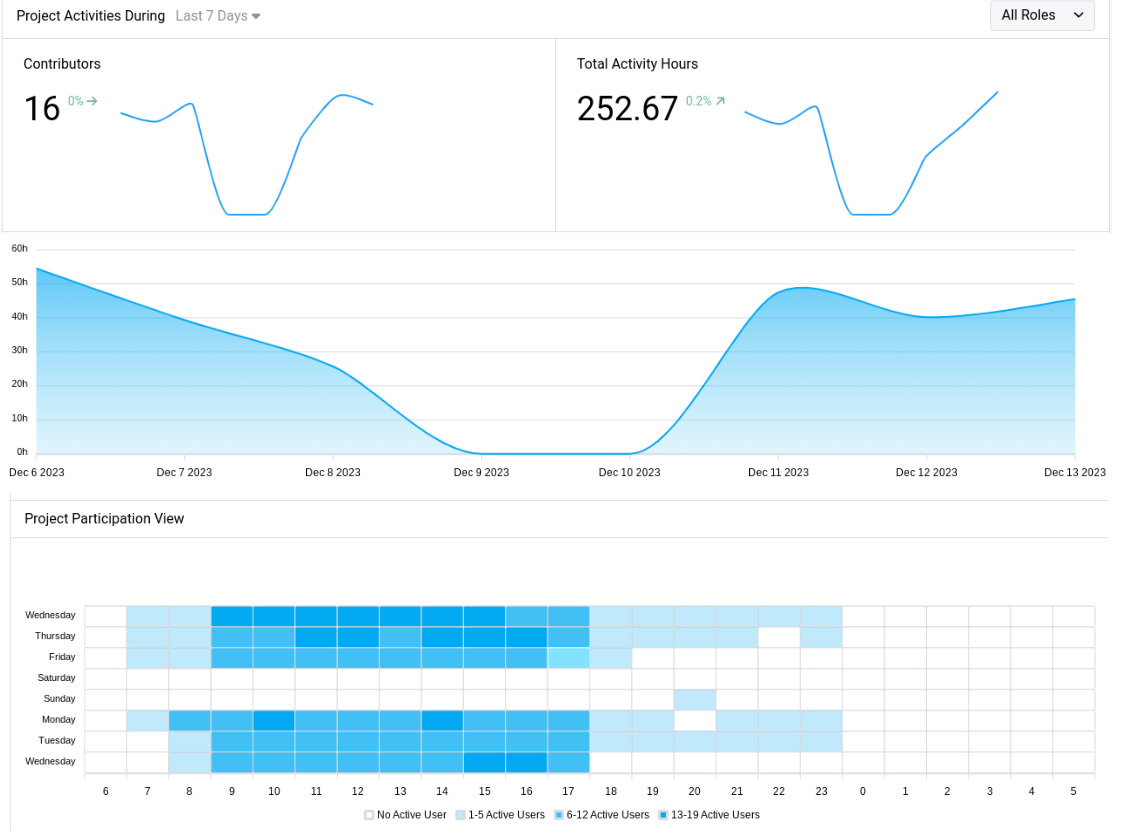
**Figure:** _DevOps’s principle of continuous learning can also apply to the development process itself. CDEs yield a new swath of process measurements that benefit governance, accountability, and risk controls._
In conclusion, good CDE platforms should bring a wealth of metrics and functionalities to organizations such that they retake control of a development process that is often scattered, non-uniform across hardware and applications, and at times obscured from a security perspective. This is why, in my opinion, the adoption trend will follow unabated. In addition, we should see a greater demand for the ability of CDE providers to enhance security controls while making sure they ultimately don't have any negative impact on developer productivity. Finally, developing CDE properties as a way to enhance the three ways of DevOps is a great framework to drive innovation in a meaningful way for the development community.
Published at Dev.to with permission of Laurent Balmelli, PhD. See the original article [here.](https://strong.network/article/rediscover-devops) | loransha256 |
1,862,663 | The Symbiotic Relationship Between Development and Crypto Trading: Exploring the $NOT-PERP Futures Pair on WhiteBIT | In the ever-evolving world of cryptocurrency and blockchain technology, the intersection between... | 0 | 2024-05-23T09:23:33 | https://dev.to/alexroor4/the-symbiotic-relationship-between-development-and-crypto-trading-exploring-the-not-perp-futures-pair-on-whitebit-3omb | webdev, news, blockchain | In the ever-evolving world of cryptocurrency and blockchain technology, the intersection between development and crypto trading has never been more significant. With the recent listing of the $NOT-PERP futures trading pair on WhiteBIT, it’s an opportune moment to explore how developers and futures trading are intrinsically linked.
Developers are the backbone of the cryptocurrency ecosystem. They create the foundational technologies that power blockchain networks, smart contracts, and decentralized applications (dApps). Their work enables the seamless operation of crypto exchanges and trading platforms. Without their innovations, the robust and dynamic trading environments that we enjoy today would not be possible.
Futures trading, in particular, relies heavily on the technological infrastructure provided by developers. Futures contracts are complex financial instruments that require sophisticated trading platforms to ensure accurate pricing, efficient execution, and robust risk management. Developers play a crucial role in building these platforms, integrating advanced algorithms, and ensuring the security of the trading environment.
WhiteBIT’s introduction of the $NOT-PERP futures pair is a testament to the collaborative efforts of the development and trading communities. This new trading pair allows traders to speculate on the future price movements of the NOT token, providing opportunities for hedging and leveraging positions. The seamless integration and smooth operation of this new pair are made possible by the tireless work of developers who design and maintain the exchange’s trading infrastructure.
But WhiteBIT is not alone in this endeavor. Another prominent crypto exchange offering futures trading is Binance. Binance Futures provides a wide array of futures contracts, including perpetual contracts that allow traders to speculate on the future prices of various cryptocurrencies without the constraints of an expiry date. Similar to WhiteBIT, Binance’s success in the futures market is heavily reliant on the contributions of its development team.
The symbiotic relationship between developers and futures trading is evident in several key areas:
Platform Stability and Performance: Developers ensure that trading platforms can handle high volumes of transactions with minimal latency, providing traders with a reliable and efficient trading experience.
Security and Risk Management: The safety of user funds and data is paramount. Developers implement advanced security protocols and risk management systems to protect against hacks and fraudulent activities.
Innovation and Scalability: The crypto trading landscape is constantly evolving. Developers drive innovation by introducing new features and scaling the platform to accommodate growing user bases and trading volumes.
The listing of the $NOT-PERP futures pair on WhiteBIT is a clear example of how development and trading are intertwined. As the crypto market continues to grow, the collaboration between developers and traders will only become more critical. Developers will continue to enhance trading platforms, making them more robust, secure, and user-friendly, while traders will benefit from the innovative tools and features that these platforms offer.
In conclusion, the relationship between development and futures trading is vital for the continued growth and success of the cryptocurrency market. The $NOT-PERP futures pair on WhiteBIT is just one example of how this collaboration can lead to new opportunities and advancements in the crypto trading space. As we look to the future, the synergy between developers and traders will undoubtedly shape the next phase of the cryptocurrency revolution. | alexroor4 |
1,862,662 | The Future of Real Estate: Tokenization | he Future of Real Estate: Tokenization Tokenization in Real estate is revolutionizing the... | 0 | 2024-05-23T09:21:24 | https://dev.to/blockchainx358/the-future-of-real-estate-tokenization-274k | technology, realestate, futuredevelopment, blockchain | ## he Future of Real Estate: Tokenization
Tokenization in Real estate is revolutionizing the enterprise by presenting multiplied liquidity, fractional possession, and worldwide accessibility. This modern technique is reshaping how homes are offered and sold. FBC Edge enables treasured instructional connections for traders looking to apprehend investing and concepts related to it.
## Benefits of Tokenization in Real Estate
Tokenization in actual belongings offers a large number of blessings which is probably reshaping the traditional panorama of belongings funding. One of the key blessings is extended liquidity. By tokenizing real belongings, owners can divide them into smaller, greater possible gadgets, permitting traders to shop for and promote fractions of residences without difficulty. This fractional possession opens up real estate investment possibilities to a broader variety of traders who may not have the capital to buy a whole asset outright. Additionally, tokenization allows asset proprietors to get admission to a global pool of investors, further improving liquidity within the market.
Another huge benefit of tokenization is the transparency and protection it brings to real property transactions. Blockchain technology, which underpins tokenization, ensures that every one transaction is recorded and stored in a stable and immutable manner. This degree of transparency reduces the hazard of fraud and corruption in real property transactions, making the market more sincere and efficient. Furthermore, tokenization lets in for quicker and more fee-effective transactions, as they will be accomplished thru smart contracts, doing away with the want for intermediaries and decreasing related costs.
## How Tokenization Works
Tokenization works through representing [Real estate tokenization](https://www.blockchainx.tech/real-estate-tokenization/), which include real assets, as virtual tokens on a blockchain. The way starts off evolving with the identification and valuation of the asset to be tokenized. Once the asset is valued, it’s some distance divided into smaller gadgets, or tokens, representing fractions of the entire. These tokens are then issued and dispensed to investors, who should purchase and sell them on a digital marketplace.
Blockchain generation plays an essential position in tokenization, because it provides the underlying infrastructure for issuing, transferring, and storing tokens. Smart contracts, which can be self-executing contracts with the terms of the agreement right now written into code, are used to automate the procedure of tokenization. These clever contracts make sure that transactions are apparent, secure, and irreversible.
## Current Trends in Real Estate Tokenization
The actual property tokenization marketplace is experiencing rapid growth, driven by way of the use of several key trends. One of the exceptional tendencies is the growing splendor of tokenization by means of regulators and traditional economic institutions.
Regulators in lots of jurisdictions are starting to recognize the ability advantages of tokenization, which includes increased liquidity and transparency, and are taking steps to create a fine regulatory environment for tokenized assets.
Another style is the emergence of specialised tokenization systems and marketplaces. These systems provide a digital infrastructure for issuing, buying and promoting, and coping with tokenized actual assets property. They provide investors access to a numerous style of funding opportunities and provide asset owners with a streamlined method for tokenizing their homes.
## Challenges and Risks
Despite the severa blessings, tokenization in [real assets](https://www.blockchainx.tech/real-world-asset-tokenization/) also faces numerous stressful conditions and risks. One of the number one challenges is the regulatory surroundings. While a few jurisdictions have embraced tokenization and created clear regulatory frameworks, others were slower to conform. The loss of regulatory readability can create uncertainty for investors and asset owners, probably hindering the boom of the tokenization market.
Security is another essential problem in tokenization. While the blockchain generation is touted for its protection capabilities, it isn’t proof in opposition to vulnerabilities. Hackers may also want to make the most of these vulnerabilities to advantage unauthorized get right of entry to tokenized belongings or manipulate transactions. This danger highlights the importance of sturdy security functions and protocols to defend tokenized belongings.
## Future Outlook
Despite these demanding situations, the future outlook for tokenization in actual belongings is promising. As regulatory frameworks preserve to conform and become extra favorable, we will observe increased adoption of tokenization by way of each investor and asset owners. This improved adoption will probably result in an extra mature and sturdy tokenization marketplace, with more liquidity and transparency.
Moreover, enhancements in blockchain technology are expected to further decorate the safety and overall performance of tokenization. New upgrades, which include the mixing of artificial intelligence and machine mastering, ought to assist automate and streamline the tokenization manner, making it extra reachable and person-high-quality.
## Conclusion
As the real estate tokenization market keeps adapting, it holds the promise of a more reachable, efficient, and transparent real estate marketplace. With the potential to convert the manner homes are offered, offered, and controlled, tokenization is poised to revolutionize the actual estate industry for years yet to come. | blockchainx358 |
1,862,616 | How To Use Toggl Track: A Beginner’s Guide | Welcome to the world of productivity! Whether you're a freelancer, a busy professional, or just... | 0 | 2024-05-23T09:18:29 | https://blog.productivity.directory/how-to-use-toggl-track-a-beginners-guide-2bd299986bcb | toggl, toggltrack, timetracking, timemanagement | Welcome to the world of [productivity](https://blog.productivity.directory/what-is-productivity-bdd6bc399f6f)! Whether you're a freelancer, a busy professional, or just looking to optimize your time management, [Toggl Track](https://productivity.directory/toggl-track) is a tool that can transform the way you work and play. This blog post will walk you through the basics of setting up and using Toggl Track to enhance your productivity and keep your projects on track.
Signing Up and Setting Up Your Account
======================================
Toggl Track Sign up Page
First things first, you'll need to create a Toggl Track account. Visit the Toggl Track website and [sign up for free](https://accounts.toggl.com/track/signup/). You can start with the basic plan, which offers core time tracking features, or explore premium features available with paid versions. Once you've signed up, log in to your dashboard to get started.
Navigating the Dashboard
========================
Toggl track Dashboard
The Toggl Track dashboard is your control center. Here you'll see an overview of your current tracking, reports, and insights into your activities. Spend some time familiarizing yourself with the layout. Key areas include:
- Timer: Where you'll track your time.
- Reports: View detailed reports of your tracked time.
- Projects: Organize your time by projects.
- Clients: If applicable, manage client information here.
Creating Your First Project
===========================
Create Project in Toggl Track
To start tracking time, you need to create a project. Click on 'Projects' in the left-hand menu, then 'New Project'. Enter a name for your project, assign it to a client (if necessary), and choose a color to represent the project visually. You can also set whether this project is billable.
Time Tracking Basics
====================
To begin tracking time, go to the 'Timer' page. Enter what you're working on in the description box, select the project it relates to, and hit the green 'Start' button. The timer begins counting the time you spend on the task. When you're done, click 'Stop'. You can also add time manually if you forget to start a timer.
Using Tags for Greater Organization
===================================
Toggl Track Tags
Tags are useful for categorizing your time entries in more detail. You can create tags for specific activities, like writing, research, or email. When you start a timer, you can add one or more tags to keep your entries organized and searchable.
Generating Reports
==================
Toggl Track Reports
Toggl Track offers powerful reporting tools that help you analyze how you spend your time. Navigate to the 'Reports' section where you can generate detailed breakdowns by project, client, tag, or time period. This feature is incredibly useful for understanding your productivity patterns or preparing timesheets for clients.
Setting Up Integrations
=======================
Toggl Track Integrations
One of [Toggl Track](https://productivity.directory/toggl-track)'s strengths is its ability to integrate with other tools you might be using, like calendar apps, project management tools, or email clients. Check out the 'Integrations' section under settings to connect Toggl with tools like [Asana](https://productivity.directory/asana), [Google Calendar](https://productivity.directory/google-calendar), or [Slack](https://productivity.directory/slack).
Tips for Maximizing Productivity
================================
- Regularly Review Your Time Reports: Make it a habit to check your weekly and monthly reports to see where you can optimize your time.
- Set Reminders: Use Toggl Track's reminder feature to prompt you to start a timer, ensuring you don't forget to track your time.
- Stay Consistent: The more consistent you are with time tracking, the more accurate your insights will be.
Conclusion
==========
Toggl Track is a robust tool that, when used consistently, provides valuable insights into how you spend your time, helping you work smarter, not harder. As you become more familiar with Toggl Track, you'll discover even more ways to tailor it to your needs. Remember, the goal of using any time management tool is to give you more time to focus on what matters most. Happy tracking!
-----
Start using [Toggl Track](https://productivity.directory/toggl-track) today and take the first step towards mastering your time! For more productivity tips and tricks, stay tuned to our blog.
Ready to take your workflows to the next level? Explore a vast array of [Time Tracking Apps](https://productivity.directory/category/time-tracking), along with their alternatives, at [Productivity Directory](https://productivity.directory/) and Read more about them on [The Productivity Blog](https://blog.productivity.directory/) and Find Weekly [Productivity tools](https://productivity.directory/) on [The Productivity Newsletter](https://newsletter.productivity.directory/). Find the perfect fit for your workflow needs today!
| stan8086 |
1,862,569 | Building Powerful React Components with Custom Hooks | If you've been working with ReactJS, you're likely familiar with hooks like useState for managing... | 0 | 2024-05-23T09:18:07 | https://dev.to/infrasity-learning/building-powerful-components-with-react-custom-hooks-29ej | react, reacthooks, customhooks, frontend | If you've been working with ReactJS, you're likely familiar with hooks like useState for managing state and useEffect for handling side effects.
While these built-in hooks are great for smaller applications, as projects grow, complex logic can get repeated across components, leading to messy code.
This blog will guide you through the elegant and powerful concept of React called "**Custom Hooks**."

We at [Infrasity](infrasity.com) specialize in crafting tech content that informs and drives a ~20% increase in traffic and developer sign-ups. Our content, tailored for developers and infrastructure engineers, is strategically distributed across platforms like [Dev.to](dev.to), [Medium](medium.com), and [Stack Overflow](stackoverflow.com), ensuring maximum reach. We deal in content & (Go-To-Marketing)GTM strategies for companies like infrastructure management, API, DevX, and Dev Tools. We’ve helped some of the world’s best infrastructure companies like [Scalr](scalr.com), [Env0](env0.com), [Terrateam](terrateam.io), [Terramate](terramate.io), [Devzero](devzero.io), [Kubiya](kubiya.ai), and [Firefly.ai](firefly.ai), just to name a few, with tech content marketing.
## What are Custom Hooks in React? 🤔
Custom Hooks are a way to encapsulate reusable logic into functions specifically designed for React components.
They leverage the power of built-in hooks like useState and useEffect to create functionality that can be shared across different components within your React application.
While React Hooks are a way to manage state and side effects in React components, custom hooks are a way to write reusable logic that can be used across different components and even outside of React.
## How are Custom Hooks different from Built-in React Hooks?
If you are familiar with `useState`, `useEffect`, `useCallback`... you already know what hooks are in react.
If you don't, learn more about hooks in react by [clicking here](https://legacy.reactjs.org/docs/hooks-intro.html).
## Built-in React Hooks
Built-in hooks like useState and useEffect provide ways to manage state and side effects within React components.
They handle things like data updates and side effects (like fetching data) that can't be done directly in functional components.
### Custom Hooks
These are reusable functions you create that encapsulate logic involving React Hooks. They allow you to break down complex functionality into smaller, more manageable pieces that can be reused across different components.
#### Note:
Both Custom Hooks and React Hooks (built-in or custom) follow the Rules of Hooks. This means they can only be called at the top level of a React component, outside of conditional statements or loops.
## Benefits of Custom Hooks:
- Code reusability: Share common logic across components without prop drilling or higher-order components.
- Improved code organization: Break down complex logic into smaller, more focused units.
- Better readability: Make code easier to understand and maintain.
Let's delve into the realm of Custom Hooks and unlock their full potential in your development journey with the help of an example.
## The Demo App 💥
We made a demo app (an Image Gallery app in this case) that fetches images from [Lorem Picsum](https://picsum.photos/) and displays them in the app. Feel free to clone [this repository](https://github.com/ScaleupInfra/react-hooks-blog) for the code of our demo project.
There's also a navigation that you can use to navigate (go to the next page and the previous one).
For simplicity's sake, I kept the UI simple and didn't use `react-router` in the example project.

[Infrasity ](infrasity.com)has made a lot of similar demo recipe libraries to assist [Devzero](devzero.io), one of our customers, in creating recipe libraries, which assisted them in quick developer onboarding. The recipe libraries created were a combination of different tech stacks, like NodeJs, BunJS, React, and CockroachDB, so that the end users could directly use them as boilerplate code without writing the entire code from scratch. This has assisted both our customers with user signups and the end users in increasing their development productivity. Samples of the same can be viewed here.
**Note: the recording is slowed down so you can see the following:**
1. **Loader** (appears when images are being fetched)
2. **Error Message** (if images are failed to fetch)
## Prerequisites
- Node.js - Version v21.6.2
- npm - Version 10.2.4
- React.js - Version 16 and above
### Setting up the environment
Navigate to the **project folder** and run the following commands via the terminal
```bash
# To install the dependencies (run only once)
npm i
# To start the web app server
npm run dev
```
#### You'll see something like this
```bash
VITE v5.2.11 ready in 234 ms
➜ Local: http://localhost:5173/
➜ Network: use --host to expose
➜ press h + enter to show help
```
## Why Custom Hooks? Ditching Component Clutter 🧐
### Traditional Components: A Messy Mix
Let's examine how the Image Gallery App currently works to understand why we need to use custom hooks in the first place!
#### Directory Structure of the Image Gallery App
```zsh
├── README.md
├── index.html
├── package.json
├── public
├── src
│ ├── App.css
│ ├── App.jsx
│ ├── assets
│ │ └── loaderAnimation.svg
│ ├── components
│ │ ├── ErrorMessage.jsx
│ │ ├── Header.jsx
│ │ ├── Image.jsx
│ │ ├── Images.jsx
│ │ └── Loading.jsx
│ ├── index.css
│ ├── main.jsx
│ └── util
│ └── http.js
└── vite.config.js
6 directories, 15 files
```
#### `App.jsx`
```js
import { useCallback, useState } from "react";
import Images from "./components/Images";
import Header from "./components/Header";
import "./App.css";
function App() {
const [pageNumber, setPageNumber] = useState(1);
const [hideNavigation, setHideNavigation] = useState(true);
const handleNextPage = () => {
setPageNumber((prev) => prev + 1);
};
const handlePrevPage = () => {
setPageNumber((prev) => prev - 1);
};
const handleHideNavigation = useCallback((hideNav) => {
setHideNavigation(hideNav);
}, []);
return (
<>
<Header
currentPage={pageNumber}
handleNextPage={handleNextPage}
handlePrevPage={handlePrevPage}
hideNavigation={hideNavigation}
/>
<Images
pageNumber={pageNumber}
setHideNavigation={handleHideNavigation}
/>
</>
);
}
export default App;
```
### What's happening in the _App.jsx_?
- We are using the `useState` hook to define states for the current page number and hiding navigation.
- We are using the `useCallback` hook to define a function that toggles the hide navigation state so it never gets redefined whenever component re-renders.
- We are returning `Header` and `Images` custom components and passing some props for Navigation.
#### `App.css`
```css
@import url("https://fonts.googleapis.com/css2?family=Poppins:ital,wght@0,100;0,200;0,300;0,400;0,500;0,600;0,700;0,800;0,900;1,100;1,200;1,300;1,400;1,500;1,600;1,700;1,800;1,900&display=swap");
* {
font-family: "Poppins", sans-serif;
}
header {
padding: 1rem;
text-align: center;
}
.images-section {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-gap: 1rem;
}
@media (max-width: 768px) {
.images-section {
grid-template-columns: repeat(2, 1fr);
}
.image {
margin: 1rem;
padding: 1rem;
}
.image a {
overflow: hidden;
}
.image img {
max-width: 15rem;
}
}
@media (max-width: 480px) {
.images-section {
grid-template-columns: repeat(1, 1fr);
margin: 0;
}
.image {
width: 10rem;
}
.image img {
max-width: 10rem;
}
}
.image {
text-align: center;
border: 1px solid black;
border-radius: 15px;
padding: 2rem;
margin: auto;
width: 75%;
margin-bottom: 2rem;
}
.image img {
width: 15rem;
box-shadow: 2px 4px 4px black;
}
.author {
font-weight: 500;
}
.dimensions {
font-style: italic;
}
button,
.download {
margin: 1rem;
padding: 1rem;
border-radius: 5px;
border: none;
background-color: black;
color: white;
text-decoration: none;
font-weight: 600;
}
.download-wrapper {
margin: 2rem;
}
.loading,
.error {
text-align: center;
font-weight: bold;
}
.error,
.loading {
width: 30rem;
padding: 2rem;
margin: auto;
border: 10px solid black;
background-color: black;
color: white;
}
.loading img {
width: 7em;
}
```
#### `Header.jsx`
```js
function Header({
currentPage,
handleNextPage,
handlePrevPage,
hideNavigation,
}) {
return (
<header>
<h1>Image Gallery</h1>
{!hideNavigation && (
<nav>
<h2>Page: {currentPage}</h2>
<button onClick={handlePrevPage}>Previous</button>
<button onClick={handleNextPage}>Next</button>
</nav>
)}
</header>
);
}
export default Header;
```
### What's happening in the _Header.jsx_?
- We are used the props passed from `App.jsx` into the Header and triggering the `handlePrevPage` and `handleNextPage` functions on button click.
- Hiding the navigation based on the `hideNavigation` value.
- Displaying the page number using `currentPage` prop.
#### `Images.jsx`
```js
import { useEffect, useState } from "react";
import { fetchImages } from "../util/http";
import Loading from "./Loading";
import ErrorMessage from "./ErrorMessage";
import Image from "./Image";
function Images({ pageNumber, setHideNavigation }) {
const [images, setImages] = useState([]);
const [isLoading, setIsLoading] = useState(false);
const [isError, setIsError] = useState(false);
const [errorMessage, setErrorMessage] = useState(null);
useEffect(() => {
async function fetchImageData() {
setIsLoading(true);
try {
const fetchedImages = await fetchImages(pageNumber, 10);
if (fetchedImages.length > 0) {
setImages(fetchedImages);
setHideNavigation(false);
} else {
throw new Error("Something went wrong while fetching images");
}
} catch (e) {
console.log(e);
setIsError(true);
setErrorMessage(e.message);
}
setIsLoading(false);
}
fetchImageData();
}, [pageNumber, setHideNavigation]);
let finalContent = null;
if (isLoading) {
finalContent = <Loading />;
} else if (isError) {
finalContent = <ErrorMessage>{errorMessage}</ErrorMessage>;
} else {
finalContent = (
<section className="images-section">
{images.map((image) => (
<Image key={image.id} image={image} />
))}
</section>
);
}
return <>{finalContent}</>;
}
export default Images;
```
### What's happening in the _Images.jsx_?
- States are defined using `useState()` hook and some helper functions are defined for changing the state resulting in change in page numbers and toggling navigation.
- We are using the `useEffect` hook to fetch images from an API when the component mounts.
- We are passing `isLoading`, `isError`, and `errorMessage` states to the `Loading`, `ErrorMessage`, and `Image` components respectively, so that the consuming component can conditionally render the appropriate content based on the state.
- The images are fetched from the API using the `fetchImages` function from `http.js` which takes two parameters - `page` and `limit` - and returns a list of images.
#### `http.js`
```js
export const fetchImages = async (page = 1, limit = 10) => {
const response = await fetch(
`https://picsum.photos/v2/list?page=${page}&limit=${limit}`
);
if (!response.ok) {
throw new Error("Failed to fetch images");
}
const imageList = await response.json();
return imageList;
};
```
### What's happening in the _http.js_?
- The `http.js` module is a helper module that exports a single function, `fetchImages`, which fetches images from the [Lorem Picsum API](https://picsum.photos/) and returns a list of images.
- The `fetchImages` function takes two parameters, `page` and `limit`, and uses them to construct the URL for the API request. The `page` parameter defaults to `1` and the `limit` parameter defaults to `10`.
- The `fetchImages` function then returns a list of images from the API response.
#### `Header.jsx`
```js
function Header({
currentPage,
handleNextPage,
handlePrevPage,
hideNavigation,
}) {
return (
<header>
<h1>Image Gallery</h1>
{!hideNavigation && (
<nav>
<h2>Page: {currentPage}</h2>
<button onClick={handlePrevPage}>Previous</button>
<button onClick={handleNextPage}>Next</button>
</nav>
)}
</header>
);
}
export default Header;
```
### What's happening in the _header.jsx_?
- The `Header.jsx` component renders a header with a navigation bar that shows the current page number and two buttons for navigating to the previous and next pages.
- The navigation bar is conditionally rendered based on the `hideNavigation` prop.
- If `hideNavigation` is `true`, then the navigation bar is hidden.
#### `ErrorMessage.jsx`
```js
function ErrorMessage({ children }) {
return (
<div className="error">
<h2>Error ⚠️</h2>
<p>{children}</p>
</div>
);
}
export default ErrorMessage;
```
### What's happening in the `ErrorMessage.jsx`?
- The `Error.jsx` component renders a error message box with a header and a paragraph that displays the error message.
- The `Error.jsx` component is conditionally rendered by the `Images.jsx` component based on the `isError` state.
### `Loading.jsx`
```js
import loaderAnimation from "../assets/loaderAnimation.svg";
function Loading() {
return (
<div className="loading">
<img src={loaderAnimation} alt="Loading animation" />
<p>Loading content. Please wait...</p>
</div>
);
}
export default Loading;
```
### What's happening in the `Loading.jsx`?
The power of separation of logic from components using custom hooks is that components can continue to render while the hook is performing its side effects, without blocking the rest of the application.
This is because the hook is not a part of the component's render method, but is instead called when the component is mounted or updated. This allows the component to continue rendering while the hook is performing its side effects, without blocking the rest of the application.
### The Problem
The `Images.jsx` component has now become a FAT component and the logic used for fetching images, setting loading and error messages are not reusable for any other component!
This is because the `Images.jsx` component is responsible for rendering the images, handling the loading state, and handling errors, all while also fetching the images from the API.
If we were to use this component in another part of the app, we would have to repeat the same logic for handling the loading state and errors, which is not very [DRY (Don't Repeat Yourself)](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself).

_Oh No! meme | Credit: Tenor_
### The Power of Separation: Enter Custom Hooks

_Fly Sky GIF | Credit: Tenor_
Custom hooks are a way to encapsulate _reusable logic_ in a function, making it easy to share and reuse code across different components.
By using custom hooks, you can write more organized and maintainable code, as the logic for fetching images, setting loading and error messages, and other features are not repeated across components.
Instead, you can write the logic once and share it across all necessary components. This makes your code more DRY and helps to avoid code duplication.
Let's learn how to improve the above code using React custom hooks!
## Building Your First Custom Hook: A Step-by-Step Guide ☀️
### Diving into the Essentials
#### Naming Conventions
Custom hooks in React should start with the prefix `use`. This is a convention established by the React team to differentiate custom hooks from regular functions.
#### File Naming Conventions
The filename of a custom hook should also start with the prefix `use`. This makes it easy to identify custom hooks in your codebase.
For example, a custom hook for fetching images should be named `useFetchImages.js`.
#### Functionality
Custom hooks can encapsulate any type of logic that is reusable across components. This includes functionality for managing state, performing side effects, and handling subscriptions to external data sources.
#### Returning Values
Custom hooks can return any type of value to consuming components, including data, functions, and objects. This allows the consuming component to access the returned value and use it as needed.
### Crafting a Simple Hook: Fetching Data on Demand 💡
#### Step 1: Create a _hooks_ directory inside _src_ directory
#### Step 2. Create a file named `useFetchImages.js`
#### Step 3. Move the logic from `Images.jsx` that managed the state for fetching, loading, and showing error
**Updated `useFetchImages.js`**
```js
import { useEffect, useState } from "react";
import { fetchImages } from "../util/http";
export default function useFetchImages(pageNumber, setHideNavigation) {
// The Logic for fetching images and setting it to the state
const [images, setImages] = useState([]);
const [isLoading, setIsLoading] = useState(false);
const [isError, setIsError] = useState(false);
const [errorMessage, setErrorMessage] = useState(null);
useEffect(() => {
async function fetchImageData() {
setIsLoading(true);
try {
const fetchedImages = await fetchImages(pageNumber, 10);
if (fetchedImages.length > 0) {
setImages(fetchedImages);
setHideNavigation(false);
} else {
throw new Error("Something went wrong while fetching images");
}
} catch (e) {
console.log(e);
setIsError(true);
setErrorMessage(e.message);
}
setIsLoading(false);
}
fetchImageData();
}, [pageNumber, setHideNavigation]);
return { images, isLoading, isError, errorMessage };
}
```
**Updated `Images.jsx`**
```js
/* eslint-disable react/prop-types */
import Loading from "./Loading";
import ErrorMessage from "./ErrorMessage";
import Image from "./Image";
// Our custom hook being imported
import useFetchImages from "../hooks/useFetchImages";
function Images({ pageNumber, setHideNavigation }) {
// Moved the logic into a custom hook
const { images, isLoading, isError, errorMessage } = useFetchImages(
pageNumber,
setHideNavigation
);
let finalContent = null;
if (isLoading) {
finalContent = <Loading />;
} else if (isError) {
finalContent = <ErrorMessage>{errorMessage}</ErrorMessage>;
} else {
finalContent = (
<section className="images-section">
{images.map((image) => (
<Image key={image.id} image={image} />
))}
</section>
);
}
return <>{finalContent}</>;
}
export default Images;
```
### Changes to `Images.jsx`
The custom hook has significantly reduced the complexity of the `Images.jsx` component by encapsulating the logic for fetching images, managing loading and error states, and defining the `errorMessage` state.
The component is now more concise and easier to maintain, as it conditionally renders the states returned by the hook.
## Common Use Cases of Custom Hooks 🔥
### The Reusability Advantage
In the above code, we created a custom hook for fetching images, making the Images component shorter, easier to read, and more maintainable.
### Question of the day! Can we do BETTER? 🤔
I took the liberty to make the custom hook and the consumer component more generalized to make it more reusable.
**Updated `useFetchImages.js`**
```js
import { useEffect, useState } from "react";
export default function useFetchData(fetchFunction, pageNumber, callback) {
const [data, setData] = useState([]);
const [isLoading, setIsLoading] = useState(false);
const [isError, setIsError] = useState(false);
const [errorMessage, setErrorMessage] = useState(null);
useEffect(() => {
async function fetchData() {
setIsLoading(true);
try {
const fetchedData = await fetchFunction(pageNumber, 10);
if (fetchedData.length > 0) {
setData(fetchedData);
callback();
} else {
throw new Error("Something went wrong while fetching data");
}
} catch (e) {
console.log(e);
setIsError(true);
setErrorMessage(e.message);
}
setIsLoading(false);
}
fetchData();
}, [pageNumber, callback, fetchFunction]);
return { data, isLoading, isError, errorMessage };
}
```
#### The Difference:
The main difference between the `useFetchImages` and the `useFetchData`...?
The `useFetchData` function is more _generic_ and _reusable_, as it accepts a
_callback_ function and a fetch function as parameters, making it more versatile
and applicable to different use cases.
> I updated the filename to `useFetchData.js` and changed the way it was being consumed in the `Images` component.
```js
function Images({ pageNumber, setHideNavigation }) {
// Added useCallback hook to avoid unnecessary re-renders
const unhideNavbar = useCallback(() => {
setHideNavigation(false);
}, [setHideNavigation]);
// Using the new generalized useFetchData hook
const {
data: images,
isLoading,
isError,
errorMessage,
} = useFetchData(fetchImages, pageNumber, unhideNavbar);
let finalContent = null;
if (isLoading) {
// Rest of the logic remains unchanged
```
#### Congratulations!!! 🎉
We just made our custom hook **generalized** and hence; **more reusable**!

_Hooray GIF | Credit: Tenor_
## Conclusion: Amplify Your React Development with Custom Hooks
Just like having the right tool for the job makes things easier, understanding the problem helps you choose the right tool in coding.
Remember that clunky "Images" component from before?
Using a custom hook totally transformed it! For example, it might have meant way less copy-pasting of code, making the whole thing easier to understand.
The big idea here is that Custom Hooks can seriously up your React coding game. By using them, you can write code that's cleaner, easier to maintain, and, best of all, reusable across different parts of your app. It's like having a toolbox full of pre-built solutions for common problems!
[Infrasity](infrasity.com) assists organizations with creating tech content for infrastructural organizations on Kubernetes, cloud cost optimization, DevOps, and engineering infrastructure platforms.
We specialize in crafting technical content and strategically distributing it on developer platforms to ensure our tailored content aligns with your target audience and their search intent.
For more such content, including Kickstarter guides, in-depth technical blogs, and the latest updates on cutting-edge technology in infrastructure, deployment, scalability, and more, follow [Infrasity](infrasity.com).
Contact us at [contact@infrasity.com](contact@infrasity.com) today to help us write content that works for you and your developers.
Cheers! 🥂
## FAQs
### 1. What are React Custom Hooks?
React Custom Hooks are reusable functions that start with "use". They let you extract logic (like fetching data or managing state) from a component and share it across others. This keeps components clean and organized, promoting better code maintainability.
### 2. When to Use Custom Hooks?
- When you have logic that's used in multiple components, create a Custom Hook **to avoid code duplication**.
- For complex state handling within a component, a Custom Hook can **break down the logic into smaller, more manageable units**.
- Custom Hooks can effectively **manage side effects** like data fetching (we saw above), subscriptions, or timers within functional components.
### 3. Rules for Using Custom Hooks:
- Only call hooks at the very beginning of your custom hook function, before any conditional statements or returns.
- Don't call hooks inside loops, ifs, or other conditional logic. React depends on the order hooks are called.
- Custom hooks can only be called inside React function components, not class components.
### 4. Best Practices for Custom Hooks:
- Each hook should handle a specific piece of logic, making it reusable and easier to understand.
- Use usePascalCase with a clear description of the hook's function (e.g., useFetchData).
- Rely on React's built-in hooks whenever possible. Consider external libraries for complex logic.
- Return only the state or functions needed by the component using the hook.
- Write unit tests to ensure your custom hooks function as expected.
### 5. Examples of Common Custom Hooks:
- `useFetchData`: Fetches data from an API and manages loading/error states.
- `useLocalStorage`: Provides access to browser local storage with get/set functionality.
- `useForm`: Handles form state, validation, and submission logic.
- `useAuth`: Manages user authentication and authorization states.
Written by:
[Gagan Deep Singh
](https://www.linkedin.com/in/gagan-gulyani) for [Infrasity](www.infrasity.com)
| infrasity-learning |
1,862,615 | Come migliorare la visibilità del proprio profilo Instagram | Migliorare la visibilità del proprio profilo Instagram è fondamentale per accrescere il numero di... | 0 | 2024-05-23T09:17:39 | https://dev.to/wiki-tech/come-migliorare-la-visibilita-del-proprio-profilo-instagram-o8j | instagram | Migliorare la **visibilità del proprio profilo Instagram** è fondamentale per accrescere il numero di follower e interazioni. Con oltre un miliardo di utenti attivi, distinguersi su questa piattaforma richiede una strategia mirata e coerente. In questo articolo, esploreremo dieci metodi efficaci per aumentare la visibilità del tuo profilo Instagram. Dall'ottimizzazione della biografia all'utilizzo di storie e reel, ogni consiglio è pensato per aiutarti a massimizzare il tuo impatto. Che tu sia un principiante o un utente esperto, troverai suggerimenti pratici e facilmente applicabili per migliorare la tua presenza su Instagram. Segui questi passaggi e osserva come il tuo profilo inizia a brillare in mezzo alla folla.
## Ottimizza il tuo profilo con una biografia accattivante
La **biografia del tuo profilo Instagram** è la tua prima opportunità di fare una buona impressione. Una biografia accattivante non solo cattura l'attenzione dei visitatori, ma può anche convertirli in follower. Come consigliato sul sito di tecnologia [Wiki Tech](https://www.wiki-tech.it), ecco alcuni suggerimenti per ottimizzare al meglio questa sezione cruciale del tuo profilo.
Innanzitutto, **mantieni la tua biografia chiara** e concisa. Hai solo 150 caratteri a disposizione, quindi sfruttali al meglio. Usa frasi brevi e dirette per comunicare chi sei e cosa fai. Evita termini complessi e cerca di essere il più specifico possibile.
In secondo luogo, includi **parole chiave pertinenti** al tuo settore o nicchia. Questo aiuta il tuo profilo a essere scoperto nelle ricerche pertinenti. Se sei un food blogger, ad esempio, includi termini come "ricette", "cucina" o "food photography". Le parole chiave rendono il tuo profilo più rilevante per chi cerca contenuti specifici.
Un altro elemento fondamentale è l'utilizzo di **emoji**. Le emoji possono rendere la tua biografia più visivamente interessante e aiutano a trasmettere la tua personalità. Tuttavia, non esagerare: usale con parsimonia e in modo strategico per enfatizzare punti chiave.
Non dimenticare di inserire un **invito all'azione (CTA)**. Un buon CTA può essere qualcosa come "Seguimi per ricette giornaliere!" o "Scopri di più nel link qui sotto". Un CTA efficace guida i visitatori a compiere un'azione, che può aumentare l'interazione con il tuo profilo.
Infine, assicurati di aggiornare regolarmente la tua biografia. Man mano che i tuoi interessi e obiettivi cambiano, la tua biografia dovrebbe riflettere queste evoluzioni. Un profilo aggiornato dimostra che sei attivo e coinvolto, elementi che attraggono nuovi follower.
## Scegli una foto del profilo riconoscibile e di qualità
La foto è importante per [chi visita il mio profilo Instagram](https://www.wiki-tech.it/come-vedere-chi-visita-il-tuo-profilo-instagram/), è **uno degli elementi più importanti** per catturare l'attenzione degli utenti. È il primo elemento visivo che gli altri vedono quando visitano il tuo profilo o quando interagisci con i loro contenuti. Per questo motivo, è essenziale scegliere una foto del profilo riconoscibile e di alta qualità.
Innanzitutto, la foto dovrebbe rappresentare chiaramente te o il tuo brand. Se sei un individuo, una foto del viso è generalmente la scelta migliore. Assicurati che il volto sia ben illuminato e in primo piano. Evita immagini sfocate, scure o sovraffollate di elementi che possano distogliere l'attenzione dal soggetto principale. Se gestisci un **account aziendale o di brand**, il logo aziendale può essere una scelta eccellente. Assicurati che il logo sia semplice, leggibile e facilmente riconoscibile anche in dimensioni ridotte.
La qualità dell'immagine è altrettanto cruciale. Utilizza una foto ad alta risoluzione per evitare che appaia pixelata o sfocata. Instagram ridimensiona automaticamente le **immagini del profilo** a 110x110 pixel su smartphone e a 180x180 pixel su desktop, quindi assicurati che la tua immagine mantenga la nitidezza anche in queste dimensioni. Puoi verificare come appare la tua foto su diversi dispositivi per garantire una resa ottimale.
Un altro aspetto da considerare è la **coerenza visiva** con il resto del tuo profilo. La foto del profilo dovrebbe integrarsi armoniosamente con il tuo stile e la tua palette di colori. Se utilizzi un particolare schema cromatico nei tuoi post, cerca di rifletterlo anche nella foto del profilo per mantenere un look omogeneo. Questo aiuta a creare un’identità visiva forte e riconoscibile.
Infine, **aggiorna periodicamente la tua foto del profilo** per mantenere l'interesse e riflettere eventuali cambiamenti. Ad esempio, se il tuo look cambia radicalmente o se il logo del tuo brand subisce un rebranding, assicurati che la tua immagine del profilo sia aggiornata di conseguenza. Un'immagine del profilo aggiornata non solo mantiene il tuo account fresco, ma dimostra anche che sei attivo e impegnato nella gestione del tuo profilo.
## Utilizza parole chiave e hashtag strategici
L'uso efficace di **parole chiave e hashtag** strategici è essenziale per aumentare la visibilità del tuo profilo Instagram. Le parole chiave sono termini che descrivono il contenuto del tuo profilo e dei tuoi post, aiutando gli utenti a trovarti attraverso le ricerche. Inserirle in modo naturale nella tua biografia, nei titoli e nelle didascalie dei post migliora la possibilità che il tuo profilo venga scoperto.
Gli hashtag, invece, sono etichette che raggruppano contenuti simili, permettendo agli utenti di scoprire post rilevanti per i loro interessi. La scelta degli hashtag giusti può fare una grande differenza nella visibilità dei tuoi contenuti. Ecco alcuni suggerimenti su come utilizzare parole chiave e hashtag strategici:
**Ricerca degli hashtag pertinenti**: Esamina quali hashtag sono popolari e rilevanti nel tuo settore. Utilizza strumenti come Instagram Insights, Hashtagify, o altre piattaforme di analisi per identificare gli hashtag che generano più engagement.
**Mix di hashtag popolari e di nicchia**: Utilizza un mix di hashtag molto popolari, che hanno un'ampia portata, e hashtag di nicchia, più specifici e meno competitivi. Questo bilanciamento aiuta a raggiungere un pubblico ampio e targettizzato.
**Creazione di hashtag branded**: Se hai un brand, crea e promuovi un hashtag unico. Questo incoraggia i tuoi follower a usarlo, aumentando la visibilità e creando una comunità attorno al tuo marchio.
**Numero di hashtag**: Instagram permette di utilizzare fino a 30 hashtag per post. Sfrutta questa possibilità, ma evita di sembrare spam. Un numero tra 10 e 20 hashtag ben scelti può essere efficace.
**Posizionamento degli hashtag**: Inserisci gli hashtag sia nella didascalia che nei commenti del post. Questo approccio mantiene pulita la didascalia, rendendo il contenuto più leggibile, mentre i commenti aiutano a mantenere l'engagement.
**Monitoraggio e adattamento**: Analizza regolarmente le prestazioni dei tuoi post per capire quali hashtag funzionano meglio. Adatta la tua strategia in base ai risultati ottenuti, sperimentando nuovi hashtag e rimuovendo quelli meno efficaci.
Seguendo questi suggerimenti, potrai migliorare significativamente la visibilità dei tuoi contenuti su Instagram. Le parole chiave e gli hashtag strategici sono strumenti potenti che, se utilizzati correttamente, possono attirare un pubblico più ampio e coinvolto, aiutando a far crescere il tuo profilo in modo organico.
| wiki-tech |
1,862,614 | FINQ's weekly market insights: Peaks and valleys in the S&P 500 – May 23, 2024 | Dive into this week's market dynamics, highlighting the S&P 500's leaders and laggards with... | 0 | 2024-05-23T09:16:56 | https://dev.to/eldadtamir/finqs-weekly-market-insights-peaks-and-valleys-in-the-sp-500-may-23-2024-1m73 | ai, stockmarket, investing, data | Dive into this week's market dynamics, highlighting the S&P 500's leaders and laggards with FINQ's precise AI analysis.
## **Top achievers:**
- **Amazon (AMZN)**
- **ServiceNow Inc (NOW)**
- **Uber Technologies Inc (Uber)**
## **Facing challenges:**
- **Loews Corp (L)** remains the least favored.
- **Amcor PLC (AMCR)** plunges due to poor Professional Wisdom and Fundamentals.
- **Viatris Inc (VTRS)** re-enters the bottom three with declining scores.
Understand the market shifts with our detailed analysis and strategic insights.
**Disclaimer:** This information is for educational purposes only and is not financial advice. Always consider your financial goals and risk tolerance before investing. | eldadtamir |
1,862,613 | Apartment in BPTP The Amaario Sector 37D Gurgaon | Gurgaon, a bustling hub of corporate activity and modern living, is constantly evolving to meet the... | 0 | 2024-05-23T09:14:47 | https://dev.to/bptptheamaarioinsector37d/apartment-in-bptp-the-amaario-sector-37d-gurgaon-ao9 | bptptheamaario | Gurgaon, a bustling hub of corporate activity and modern living, is constantly evolving to meet the needs of its residents. One such project capturing the attention of discerning homebuyers is BPTP The Amaario, a luxurious development nestled in the upcoming Sector 37D. However, with any expansive project, choosing the ideal apartment can feel overwhelming. This guide will equip you with the knowledge to navigate BPTP The Amaario and find your perfect home.
BPTP The Amaario Sector 37D Gurgaon
Before diving into BPTP The BPTP The Amaario Sector 37D Gurgaon offerings, take a step back and introspect. Consider your family size and lifestyle preferences. Do you crave expansive living areas for family gatherings, or do you require a dedicated workspace for remote work? Evaluate your budget realistically. Account for the apartment price, potential homeowner association (HOA) fees, and any renovation plans you might have. Finally, set a clear timeline for your move-in to streamline your search.
Exploring the Canvas BPTP The Amaario's Apartment Options
BPTP The Amaario currently offers spacious 4 BHK configurations, catering to those who appreciate a life of luxury. However, within this configuration, there are variations in size and layout. Research the available floor plans meticulously. Visualize how your furniture and daily routines would fit within each layout. Consider the size of each bedroom, the flow between living areas, and the presence of balconies or outdoor spaces.
Beyond the Walls Amenities that Elevate Your Lifestyle
BPTP The Amaario boasts a plethora New Project On Dwarka Expressway amenities designed to elevate your living experience. Investigate the details of the clubhouse, including its facilities like a gym, swimming pool, or game room. Do these amenities align with your interests? If you have young children, explore details about the children's play area or any planned recreational activities. Consider the security measures in place, such as 24/7 security or gated community access.
Location, Location, Location Unveiling the View
The location of your apartment within BPTP The Amaario can significantly impact your living experience. Inquire about the view options available from different floors and apartment locations. Do you prefer a serene view of landscaped gardens, or would you rather have a vibrant city view? Consider potential noise factors like proximity to main roads or recreational areas.
Making an Informed Decision Steps to Secure Your Dream Home
Once you've narrowed down your options, schedule a site visit to experience the property firsthand. Walk through various floor plans, envision your life unfolding within the space. Pay attention to details like natural light, ventilation, and the quality of finishes. Consult with a financial advisor to ensure the chosen apartment aligns with your budget and long-term financial BPTP New Project In Sector 37D Don't hesitate to discuss any concerns you might have with the developer or a realtor. Ask clarifying questions about construction timelines, maintenance policies, or potential hidden costs.
Your Perfect Match Awaits Embrace Life at BPTP The Amaario
Choosing the perfect home is a significant decision. By carefully considering your needs, researching BPTP The Amaario's offerings, and making an informed decision, you can unlock the door to your dream home. BPTP The Amaario promises not just an apartment, but a lifestyle experience tailored to comfort, luxury, and a vibrant community. With the knowledge provided in this guide, you are now well-equipped to embark on your journey towards finding your perfect haven within BPTP The Amaario.
Additional Considerations
While BPTP The Amaario currently offers only 4 BHK configurations, explore the possibility of future offerings or resale options if your family size dictates a smaller space.
Research the reputation of the developer, BPTP Limited, to gain confidence in the project's quality and timely completion.
Consider the potential for property value appreciation in Sector 37D, a developing area of Gurgaon.
Get in Touch
Website – https//www.bptpnewprojects.co.in/
Mobile - +919990536116
Whatsapp – https//call.whatsapp.com/voice/9rqVJyqSNMhpdFkKPZGYKj
Skype – shalabh.mishra
Telegram – shalabhmishra
Email - enquiry.realestates@gmail.com | bptptheamaarioinsector37d |
1,862,612 | What are the Applications of the kHeavyHash Algorithm? | Here are a couple of applications for the kHeavyHash algorithms: Blockchain... | 0 | 2024-05-23T09:12:45 | https://dev.to/lillywilson/what-are-the-applications-of-the-kheavyhash-algorithm-3na8 | cryptocurrency, asic, bitcoin | Here are a couple of applications for the **[kHeavyHash algorithms](https://asicmarketplace.com/blog/what-is-the-kheavyhash-algorithm/)**:
1. Blockchain Technology
Cryptographic hashing is a key component of the blockchain technology that underpins cryptocurrencies like Bitcoin. Kheavyhash, which is a well-known algorithm for hashing, helps to guarantee immutability, security, and privacy of all data and transactions in its network.
2. Communication Encrypted
The Kheavyhash Algorithm protects data during transmission. Kheavyhash is a data manager that can be trusted to provide secure banking connections, encrypted emails and quick chats.
3. Information Storage
Kheavyhash helps organizations to prevent security breaches by detecting any changes made without authorization.
| lillywilson |
1,862,611 | The Importance of Originality: Utilizing Codequiry's Source Code Checker for Code Integrity | In today's digital age, where the exchange of information is faster than ever, maintaining the... | 0 | 2024-05-23T09:09:53 | https://dev.to/codequiry/the-importance-of-originality-utilizing-codequirys-source-code-checker-for-code-integrity-6pn | sourcecodechecker, codequiry, codeplagiarismchecker, codeplagiarismdetector | In today's digital age, where the exchange of information is faster than ever, maintaining the integrity of source code is crucial. Whether you're a student submitting an assignment or a developer working on a project, the risk of unintentional code similarity or outright plagiarism is significant. Codequiry's [Source Code Checker](https://codequiry.com/) provides a comprehensive solution to this problem, allowing users to verify the originality of their code and maintain academic and professional integrity.
With the rise of online resources and collaborative coding platforms, individuals can unintentionally duplicate code segments or even entire projects. This can have serious consequences, ranging from academic punishment to legal ramifications in professional settings. Codequiry's Source Code Checker addresses these concerns by analyzing code submissions using advanced algorithms that detect logical similarities.
Furthermore, the Codequiry platform generates detailed reports that highlight similar sections of code, allowing users to easily review and validate findings. Our Code Plagiarism Checker uses its vast database, which includes billions of web sources and peer submissions, to provide users with a comprehensive understanding of the originality of their code, which is further verified by integration with [Moss Plagiarism](https://codequiry.com/moss/measure-of-software-similarity), a well-known plagiarism detection system used by academic institutions all over the world.
In conclusion, Codequiry Code Plagiarism Checker safeguards against code plagiarism and duplication, upholding academic and professional standards. Verifying code authenticity fosters integrity and excellence in the coding community. | codequiry |
1,862,609 | Embracing Innovation: The Intersection of Development and Cryptocurrency | The tech landscape is ever-evolving, with both software development and cryptocurrency playing... | 0 | 2024-05-23T09:05:27 | https://dev.to/klimd1389/embracing-innovation-the-intersection-of-development-and-cryptocurrency-475i | webdev, beginners, news, blockchain | The tech landscape is ever-evolving, with both software development and cryptocurrency playing pivotal roles in shaping the future. As developers continue to push the boundaries of what's possible, the world of digital finance is also experiencing groundbreaking changes. One such innovation is the recent listing of BounceBit (BBT) on the WhiteBIT exchange, a development that carries significant implications for both the crypto and development communities.
The Rise of Cryptocurrency in Tech Circles
Cryptocurrencies are no longer a fringe technology. They have become a mainstream asset class and an integral part of modern financial systems. For developers, this presents a unique opportunity to integrate crypto functionalities into their projects. Smart contracts, decentralized applications (DApps), and blockchain-based solutions are becoming common tools in a developer's arsenal, opening up new avenues for innovation and problem-solving.
BounceBit: A New Contender on WhiteBIT
BounceBit (BBT) is the latest cryptocurrency to be listed on WhiteBIT, a leading digital asset exchange. BounceBit aims to provide a robust and secure platform for transactions, leveraging cutting-edge blockchain technology. The listing on WhiteBIT is a significant milestone for BounceBit, as it opens the coin to a broader audience and enhances its liquidity.
Why This Matters for Developers
For the development community, the listing of BounceBit on WhiteBIT is more than just another crypto event. It represents a convergence of technology and finance, offering developers new opportunities to explore and innovate. Here are a few reasons why developers should take note:
Integration Opportunities: With BounceBit gaining traction, developers can look into integrating BBT into their applications, whether it's for transaction processing, rewards systems, or other blockchain-based functionalities.
Enhanced Security: BounceBit utilizes advanced cryptographic techniques to ensure transaction security, an essential feature for developers concerned with protecting user data and maintaining trust.
Community and Collaboration: The crypto and development communities often overlap, providing a fertile ground for collaboration. Participating in projects like BounceBit can lead to new partnerships, knowledge exchange, and the collective advancement of technology.
The Road Ahead
As BounceBit continues to grow, its presence on WhiteBIT will likely drive more interest and adoption. For developers, staying ahead of these trends is crucial. By embracing the intersection of development and cryptocurrency, they can remain at the forefront of technological innovation, contributing to the creation of more secure, efficient, and decentralized solutions.
In conclusion, the listing of BounceBit on WhiteBIT is a testament to the dynamic and interconnected nature of technology and finance. Developers who engage with these advancements will find themselves well-positioned to harness the full potential of both worlds, driving forward the next wave of innovation.
This article aims to highlight the importance of the BounceBit listing on WhiteBIT while engaging the development community with the broader implications and opportunities presented by the convergence of tech and crypto. | klimd1389 |
1,852,261 | Biggest Interview Trap | In this blog, we'll examine several aspects of interview preparation and the guidelines that go along... | 0 | 2024-05-23T09:04:20 | https://www.jobreadyprogrammer.com/p/blog/biggest-interview-trap | career, interview, programming, beginners | <p class="MsoNormal"><span lang="EN-US">In this blog, we'll examine several aspects of interview preparation and the guidelines that go along with them so that we may get ready for an interview effectively. And also learn how to tackle the Biggest Interview Trap!<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">Let's start with the possible consequences when you aren’t adequately prepared for interviews. Remember, without adequate preparation, you may not be able to perform at your best during the interview even if you meet all the qualifications listed in the job description. <o:p></o:p></span></p>
<p class="MsoNormal"><b style="mso-bidi-font-weight: normal;"><span lang="EN-US" style="font-size: 14.0pt; mso-bidi-font-size: 12.0pt; line-height: 106%;">Importance of Interview Preparation<o:p></o:p></span></b></p>
<p class="MsoNormal"><span lang="EN-US">Lack of preparation will not only lose you your ideal job but will also negatively affect your candidacy. Hence, being ready for your interviews is the most crucial stage in getting a job. Making some preparation can help you feel more in control and will give the impression to potential employers that you are cool, calm, and collected qualities that are always preferred in the ideal candidate.<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">The importance of preparing for interviews has many advantages. You will feel less worried during the interview and create backup plans. It also shows the recruiter that you have a strong work ethic, which could assist you.<o:p></o:p></span></p>
<p class="MsoNormal" style="text-align: justify;"><span lang="EN-US">Now, choosing what characteristics to highlight while introducing yourself to the employer is the first step in preparation. These attributes might include your accomplishments, talents, skills, etc. <o:p></o:p></span></p>
<p class="MsoNormal" style="text-align: justify;"><span lang="EN-US">The second step in preparation would be researching more about the company or the job role that you’re applying to. This is significant since, in a survey of job applicants, it was found that the most frequent error made by employees was a lack of research, which affected roughly 51 percent of the applicants. Hence researching the company to which you are applying can save you in many ways.<o:p></o:p></span></p>
<p class="MsoNormal" style="text-align: justify;"><b style="mso-bidi-font-weight: normal;"><span lang="EN-US" style="font-size: 14.0pt; mso-bidi-font-size: 12.0pt; line-height: 106%;">Do’s and Don’ts of Interview Preparation<o:p></o:p></span></b></p>
<p class="MsoNormal" style="text-align: justify;"><span lang="EN-US">And now let's look into the best practices when preparing for an interview. First, preparing in advance for interviews will help you feel less anxious and make you confident to face the interview. Second, Make sure that details of your interest, experience, etc. are addressed in your answers. Third, try out attempting multiple mock interviews by recording yourself answering the questions, since practice is the key to success. Applying for several jobs could be another way to practice this; the more you do it, the more proficient you will become. The final one, present yourself well making a strong first impression begins with maintaining a neat and professional appearance. Dress professionally, successfully, and as the kind of personality, the organization wants to portray, as it is how you want to be perceived.<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">Let's now discuss the mistakes to avoid when preparing for an interview. First, have a responsible mindset. If the employer projects something negative about you, don't be aggressive, and don't overreact. <o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">Second, being on time is professional quality for any software developer, so reach the interview at least 30 minutes early so you have time to prepare or to do something else. Third, At all costs, avoid lying to the recruiter because doing so could get you into trouble. Instead, have enough confidence to answer questions honestly and truthfully.<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">So, having seen the dos and don'ts, let’s look into some of the hidden interview traps. Since you're being judged during the interview process, it's normal for everyone to feel some level of discomfort or apprehension. And a good interviewer's job is to break through some of that anxiety and figure out whether or not this person can perform the job satisfactorily. <o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">Furthermore, depending on where you are in your career, this position may be really important to you. You might be technically very competent, but you might struggle on behavioral tests. Everything may be anticipated, but it relies on personality.<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">So, the easy way to tackle this is to pause a little between each word while you are speaking your sentence. From one sentence to the next, take it slowly. By purposefully pausing, you may maintain control over the rhythm. Preferably when a question is asked, think before responding. The question was asked to know your opinion, which would require some thought from your end.<o:p></o:p></span></p>
<p class="MsoNormal"><b style="mso-bidi-font-weight: normal;"><span lang="EN-US" style="font-size: 14.0pt; mso-bidi-font-size: 12.0pt; line-height: 106%; color: black;">Biggest Interview Trap</span></b><b style="mso-bidi-font-weight: normal;"><span lang="EN-US" style="font-size: 14.0pt; mso-bidi-font-size: 12.0pt; line-height: 106%;"><o:p></o:p></span></b></p>
<p class="MsoNormal"><span lang="EN-US">I must say that the trap usually appears in the area asking about behavior type. Then you can ask yourself, "Am I lying by presenting it this way, I mean?" You cannot pause for five minutes to consider your next words. Therefore, it is crucial to get ready for questions of a behavioral type beforehand.<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">Since they aren't the most pleasant questions. You might be asked to describe a situation in which you did feel uncomfortable, and you will need to rely on your memories and possibly even on past experiences. If you don't have as much experience, you may need to discover a relatable story that may not quite fit the question.<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">So, one important point to understand here is that whenever an interviewer asks questions to a candidate, just take some time to answer the question. Because this could make the interviewer feel that you’re giving some importance to the interviewer’s question. <o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">So, take at least 20 to 30 seconds to collect your thoughts, plan your speech, and think about how you’re going to deliver it before speaking. And sometimes all that's required is simply a deep breath which could help you in maintaining control of yourself and your actions throughout an interview.<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">One last piece of advice which I would like to provide you is to treat each interview as a learning opportunity rather than as a series of rounds. Since you might use this experience to analyze your performance and identify areas for improvement, etc. which serves as the basis for your upcoming interview with more confidence. And trust me, this could be the best strategy for both professional advancement and interview preparation.<o:p></o:p></span></p>
<p class="MsoNormal"><span lang="EN-US">So, to wrap up, these are some typical considerations to keep in mind when getting ready for an interview, which could help you land a dream job.</span></p>
<h3><strong>YouTube Video</strong></h3>
{% embed https://www.youtube.com/watch?v=I430kbc8E_4&t=2s&ab_channel=JobReadyProgrammer %}
<h3>Resources</h3>
<p class="MsoNormal"><span lang="EN-US"> <!-- notionvc: e94e18fa-45b1-4f4b-b583-3136f8ed75ca --></span></p>
<ul>
<li>Job Ready Programmer Courses: <a href="https://www.jobreadyprogrammer.com/p/all-access-pass?coupon_code=GET_HIRED_ALREADY">https://www.jobreadyprogrammer.com/p/all-access-pass?coupon_code=GET_HIRED_ALREADY</a></li>
<li>Job Ready Curriculum, our free Programming Guide (PDF): <a href="https://pages.jobreadyprogrammer.com/curriculum">https://pages.jobreadyprogrammer.com/curriculum</a></li>
</ul>
<p>
<script src="https://exciting-painter-102.ck.page/b013e6a27f/index.js" async="" data-uid="b013e6a27f"></script>
</p>
#### About the Author
Imtiaz Ahmad is an award-winning Udemy Instructor who is highly experienced in big data technologies and enterprise software architectures. Imtiaz has spent a considerable amount of time building financial software on Wall St. and worked with companies like S&P, Goldman Sachs, AOL and JP Morgan along with helping various startups solve mission-critical software problems. In his 13+ years of experience, Imtiaz has also taught software development in programming languages like Java, C++, Python, PL/SQL, Ruby and JavaScript. He's the founder of Job Ready Programmer - an online programming school that prepares students of all backgrounds to become professional job-ready software developers through real-world programming courses. | jobreadyprogrammer |
1,861,900 | Workflow, from stateless to stateful | A (long) time ago, my first job consisted of implementing workflows using the Staffware engine. In... | 0 | 2024-05-23T09:02:00 | https://blog.frankel.ch/worfklow-stateless-stateful/ | workflow, bpm, bpmn, camunda | A (long) time ago, my first job consisted of implementing _workflows_ using the Staffware engine. In short, a workflow comprises _tasks_; an automated task delegates to code, while a manual task requires somebody to do something and mark it as done. Then, it proceeds to the next task - or tasks. Here's a sample workflow:
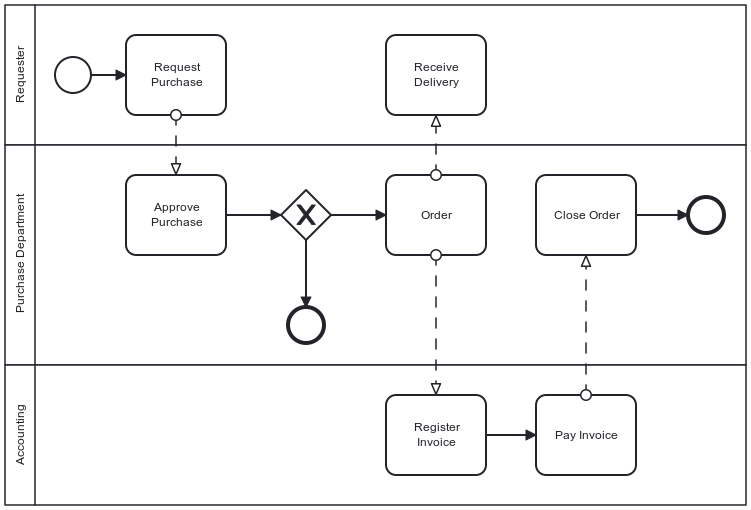
The above diagram uses [Business Process Model and Notation](https://en.wikipedia.org/wiki/Business_Process_Model_and_Notation). You can now design your workflow using <abbr title="Business Process Model and Notation">BPMN</abbr> and run it with compatible workflow engines.
Time has passed. Staffware is now part of Tibco. I didn't use workflow engines in later jobs.
Years ago, I started to automate my conference submission process. [I documented it](https://blog.frankel.ch/automating-conference-submission-workflow) in parallel. Since then, I changed the infrastructure on which I run the software. This post takes you through the journey of how I leveraged this change and updated the software accordingly, showcasing the evolution of my approach.
## Generalities
I started on Heroku with the free plan, which no longer exists. I found that the idea was pretty brilliant at the time. The offering was based on _dynos_, something akin to containers. You could have a single one for free; when it was not used for some time, the platform switched it off, and it would spin a new one again when receiving an HTTP request. I believe it was one of the earliest _serverless_ offerings.
In addition, I developed a Spring Boot application with Kotlin based on the [Camunda](https://camunda.com/) platform. Camunda is a workflow engine.
One of the key advantages of workflow engines is their ability to store the state of a particular instance, providing a comprehensive view of the process. For example, in the above diagram, the first task, labeled "Request Purchase", would store the requester's identity and the requested item (or service) references. The Purchase Department can examine the details of the requested item in the task after. The usual storage approach is to rely on a database.
## The initial design
At the time, Heroku didn't provide free storage _dyno_. However, I had to design my initial workflow around this limitation, which posed its own set of challenges. I couldn't store anything permanently, so every run had to be self-contained. My fallback option was to run in memory with the help of [H2](https://www.h2database.com/).
Here is my initial workflow in all its glory:
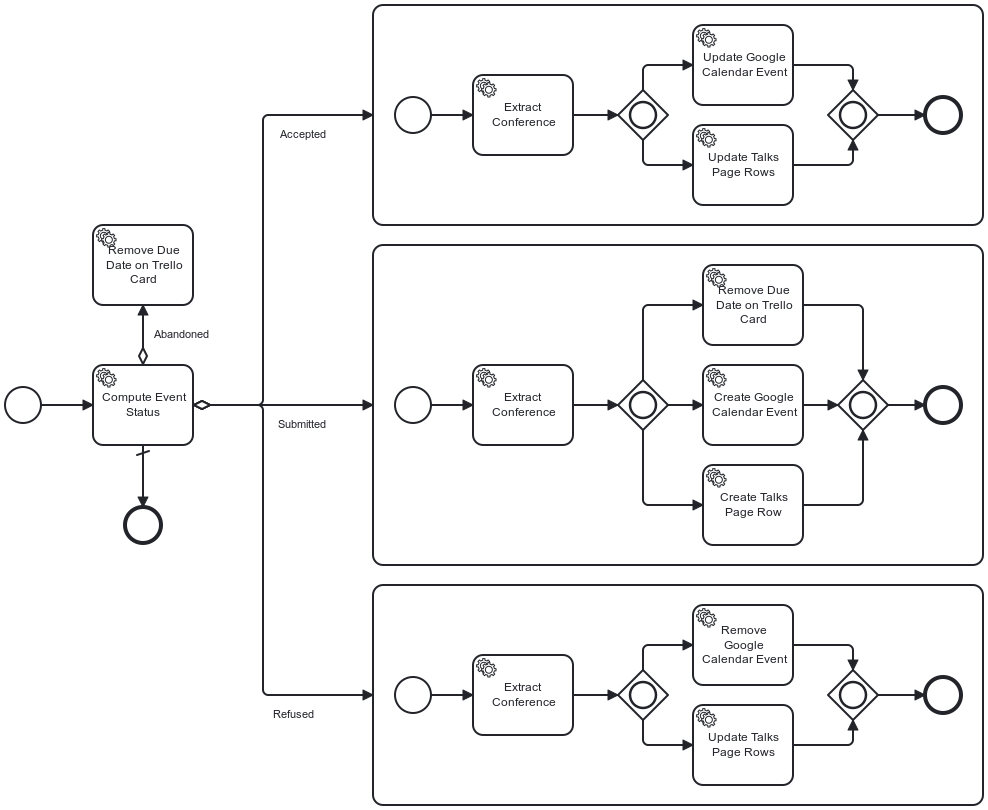
As a reminder, everything starts from Trello. When I move a card from one lane to another, Trello sends a request to a previously registered webhook. As you can expect, the hook is part of my app and starts the above workflow.
The first task is the most important one: it evaluates the end state from the event payload of the webhook request. The assumption is that the start state is always Backlog. Because of the lack of storage, I designed the workflow to execute and finish in one run.
The evaluation task stores the end state as a BPMN variable for later consumption. After the second task extracts the conference from the Trello webhook payload, the flow evaluates the variable: it forwards the flow to the state-related subprocess depending on its value.
Two things happened with time:
* Salesforce bought Heroku and canceled its free plan. At the same time, Scaleway offered their own free plan for startups. Their Serverless Container is similar to Heroku's - nodes start when the app receives a request. I decided to migrate from Heroku to Scaleway. You can read about [my first evaluation of Scaleway](https://blog.frankel.ch/evaluation-scaleway/).
* I migrated from H2 to the free [Cockroach Cloud](https://cockroachlabs.cloud/) plan
## Refactoring to a new design
With persistent storage, I could think about the problems of my existing workflow.
First, the only transition available was from the Backlog to another list, _i.e._, Abandoned, Refused, or Accepted. The thing is, I wanted to account for additional less-common transitions; for example, the talk was accepted but could be later abandoned for different reasons. With the in-place design, I would have to compute the transition, not only the target list.
Next, I created tasks to extract data. It was not only unnecessary, it was bad design. Finally, I used subprocesses for grouping. While not an issue _per se_, the semantics was wrong.
With persistent storage, we can pause a process instance after a task and resume the process later. For this, we rely on _messages_ in BPMN parlance. A task can flow to a _message event_. When the task finishes, the process waits until it receives the message. When it happens, the flow process resumes. If you can send different message types, an _event-based_ gateway helps forward the flow to the correct next step.
Yet, the devil lurks in the details: any instance can receive the message, but only one is relevant - the one of the Trello card. Camunda to the rescue: we can send a business key, _i.e._, the Trello card ID, along with the message.
Note that if the engine finds no matching instance, it creates a new one. Messages can trigger start events as well as regular ones.
Here's my workflow design:
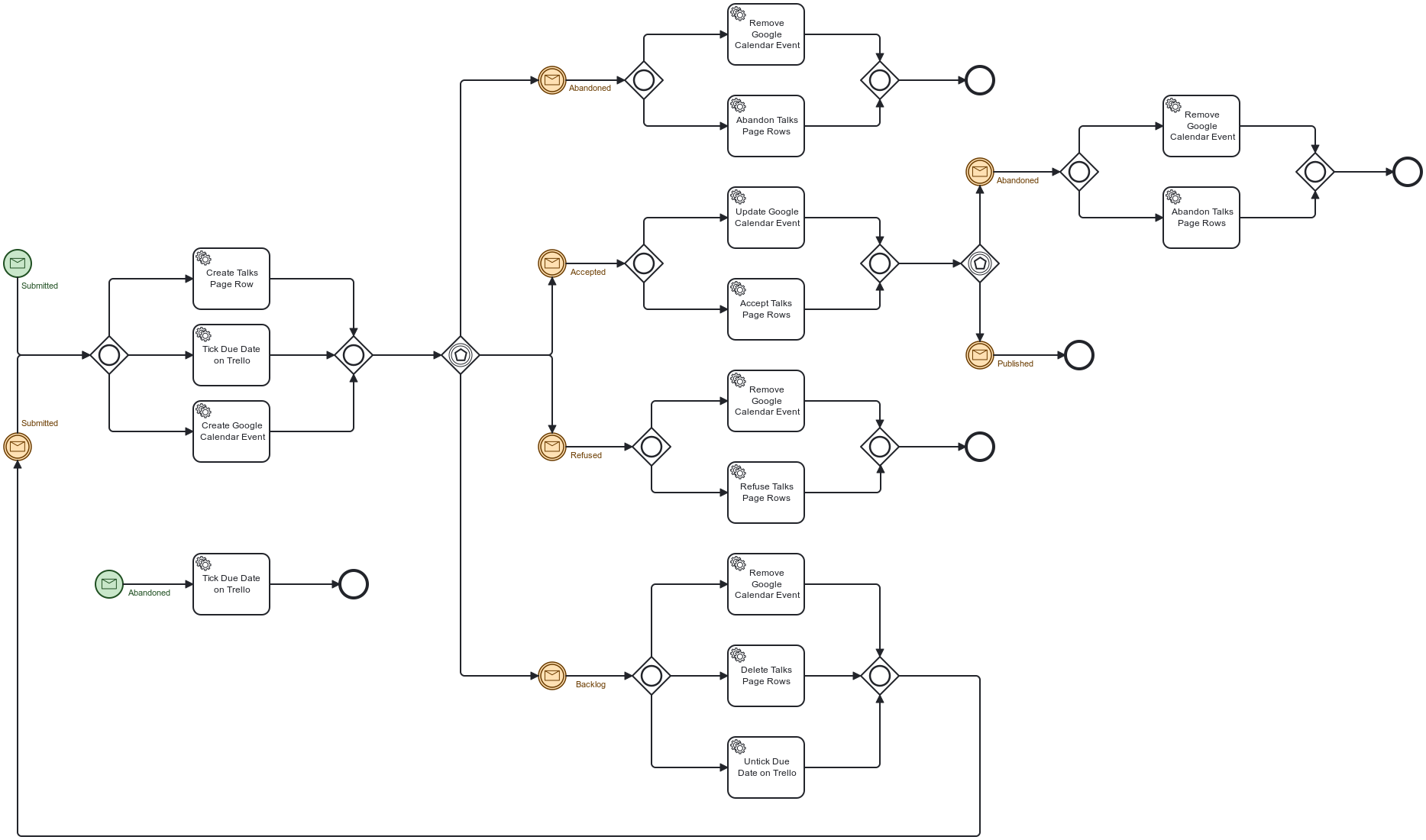
For example, imagine a Trello hook that translates to an Abandoned message. If there's no instance associated with the card, the engine creates a new instance and sends the Abandoned message, which:
* Starts the flow located at the lower left
* Ticks the due date on the Trello card
* Finishes the flow
If it finds an existing instance, it looks at its current state: it can be either Submitted or Accepted. Depending on the state, it continues the flow.
## Conclusion
In this post, I explained how I first limited my usage of BPMN and then unlocked its true power when I benefited from persistent storage.
However, I didn't move from one to the other in one step. My history involves around more than twenty versions. While Camunda keeps older versions by design, I didn't bother with my code. When I move them around, it will fail when handling cards that were already beyond Backlog.
Code needs to account for different versions of existing process instances for regular projects. I'm okay with some manual steps until every card previously created is done.
**To go further:**
* [Business Process Model and Notation](https://en.wikipedia.org/wiki/Business_Process_Model_and_Notation)
* [Camunda](https://camunda.com/)
* [My evaluation of the Scaleway Cloud provider](https://blog.frankel.ch/evaluation-scaleway/)
<hr>
_Originally published at [A Java Geek](https://blog.frankel.ch/worfklow-stateless-stateful/) on May 20<sup>th</sup>, 2024_ | nfrankel |
1,838,254 | Communicating between Stimulus Controllers using Outlets API | This article was originally published on Rails Designer. Stimulus is a great, modest JavaScript... | 0 | 2024-05-23T09:00:00 | https://railsdesigner.com/communication-between-stimulus-controllers | rails, hotwire, webdev, stimulus | This article was originally published on [Rails Designer](https://railsdesigner.com/communication-between-stimulus-controllers/).
---
Stimulus is a great, modest JavaScript framework to add those joyful little sprinkles of JavaScript to your (Rails) web application.
I've been embracing it almost from the day of release for all my Rails apps and it's a core tool of [Rails Designer](https://railsdesigner.com/) too.
Recently I added a [Command Menu Component](https://railsdesigner.com/components/command-menu). It's the typical one that can be displayed with a `CMD/Ctrl+K` shortcut (or whatever you choose). The component is supposed to be added to your application layout so it can be used by your users at any time.
I also wanted the option to display it upon clicking _some button_, think a "search" field in a [NavbarComponent](https://railsdesigner.com/components/navbars/) or [Sidebar Navigation](https://railsdesigner.com/components/sidebar-navigation/).
I've explored a few options, like [CustomEvents](https://developer.mozilla.org/en-US/docs/Web/Events/Creating_and_triggering_events#creating_custom_events).
I've also remembered `this.application.getControllerForElementAndIdentifier()` from the _old days_.
```javascript
// …
reloadList() {
this.listController.reload()
}
get listController() {
return this.application.getControllerForElementAndIdentifier(this.element, "list")
}
}
```
And there's the option to [use events between controllers too](https://stimulus.hotwired.dev/reference/controllers#cross-controller-coordination-with-events). But [since November 2022](https://github.com/hotwired/stimulus/pull/576), there's now a more refined option called: [Outlets](https://stimulus.hotwired.dev/reference/outlets).
## Use the Outlets API
The solution I needed! Let's check the code to have one Stimulus controller communicate with another Stimulus controller.
The [Command Menu Component](https://raildesigner.com/components/command-menu/) comes with two Stimulus controllers:
- `command_menu_controller.js`; it's an advanced Stimulus controller, but no changes needed here for Outlets to work;
- `command_menu/button_controller.js`; this is the extra stimulus controller needed. I've nested it under `/command_menu/` as the two are highly related.
The `command_menu/button_controller.js` looks like this:
```javascript
import { Controller } from "@hotwired/stimulus";
export default class extends Controller {
static outlets = ["command-menu"];
open() {
this.commandMenuOutlet.open();
}
}
```
Simple! It defines the controller identifiers in the `static outlets` array. That is then used in the `open()` function. The `open()` function then calls the function that should be called on _the other controller_, which incidentally is also called `open()`.If you are familiar with Stimulus this doesn't look weird.
And it's used in your HTML like this:
```html
<button data-controller="command-menu--button" data-command-menu--button-command-menu-outlet="#command-menu" data-action="command-menu--button#open">
Show Command Menu
</button>
```
The nesting of the controller make for a bit confusing syntax (double dashes), but if you'd mentally replace the double-dash with a slash, it's more understandable.
The important part for Outlets to work is this attribute: `data-command-menu--button-command-menu-outlet="#command-menu"`. The value should be a [CSS selector](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Selectors).
If we check the relevant HTML part, you can see an `id` of `command-menu`:
```
<div id="command-menu" data-controller="command-menu">
<!-- … -->
</div>
```
## Outlet names must be the same as the controller name
Let me repeat that: **Outlet names Must be The Same As The Controller Name**.
[Many developers](https://github.com/hotwired/stimulus/issues/669) have lost hours on this; yours truly included. I remembered when using it for the Command Menu's button controller, but if you don't use outlets enough, you surely will get bitten by it again.
In `command_menu/button_controller.js` `static outlets` array you see `command-menu` is the same as the controller name it communicates with (`command_menu_controller.js`).
The CSS selector's value (`#command-menu`) to "find" the controller can be anything as long as the **Outlet Name Is The Same As The Controller Name**!
With the outlets set up correctly in the `command_menu/button_controller.js` you now have access to the actual Controller instance from `command_menu_controller.js`. This means you can use:
- values (`static values`);
- classes (`static classes`);
- targets (`static targets`).
So whatever you do in the `command_menu_controller.js` you can now also do in the `command_menu/button_controller.js`.
You are also not limited to one “instance” of a controller. Just like with “targets”, you can have multiple outlets. So you can write this:
```javascript
export default class extends Controller {
static outlets = ["user-status"];
selectAll(event) {
this.userStatusOutlets.forEach(status => status.markAsSelected(event));
}
}
```
And that's the Outlets API. If you don't forget that the **outlet name must be the same as the controller name**, it's a great way to increase what you can do with Stimulus. | railsdesigner |
1,862,606 | How Our Power BI Consulting Can Drive Business Growth | In the fast-paced world of business, staying ahead of the curve is not just an advantage, it's a... | 0 | 2024-05-23T08:59:40 | https://dev.to/johnsmith244303/how-our-power-bi-consulting-can-drive-business-growth-f52 | powerbi, powerbiconsulting, powerbisolutions |
In the fast-paced world of business, staying ahead of the curve is not just an advantage, it's a necessity. With data becoming the new oil, companies are sitting on a goldmine of information that, when properly harnessed, can unlock unparalleled growth and innovation. This is where our Power BI consulting services come into play.
At IT Path Solutions, we specialize in transforming raw data into actionable insights that propel your business forward. Let’s delve into **[how our Power BI consulting can drive your business growth](https://www.itpathsolutions.com/your-data-amplified-how-our-power-bi-consulting-can-drive-business-growth/)**.
Unleashing the Power of Data
Understanding Your Data Landscape
The first step in leveraging data for growth is understanding what data you have and where it resides. Our Power BI consultants work closely with your team to map out your entire data landscape. This includes identifying data sources, understanding data flow, and pinpointing data silos. By doing so, we ensure that no valuable data is overlooked and that all relevant information is brought into the fold.
Data Integration and Management
Data is often scattered across various systems and formats, making it challenging to get a unified view. Our consultants excel in data integration, bringing together disparate data sources into a cohesive, single source of truth. We utilize Power BI’s robust capabilities to connect, cleanse, and transform your data, ensuring it's accurate, consistent, and ready for analysis.
Advanced Data Analytics
Once your data is integrated and managed, the next step is analysis. Power BI offers powerful analytics tools that enable us to perform in-depth analyses, uncovering trends, patterns, and insights that might not be immediately obvious. Our consultants are skilled in leveraging these tools to provide you with a comprehensive understanding of your business operations, customer behaviors, and market trends.
Transforming Insights into Action
Customized Dashboards and Reports
One of the standout features of Power BI is its ability to create visually stunning and highly customizable dashboards and reports. Our consultants work with you to design dashboards that meet your specific needs, providing real-time access to the metrics that matter most to your business. Whether it's sales performance, customer satisfaction, or operational efficiency, you’ll have the information you need at your fingertips.
Real-Time Data Monitoring
In today’s dynamic business environment, real-time data monitoring is crucial. Power BI’s real-time capabilities allow you to keep a pulse on your business operations. Our consultants set up real-time data feeds, alerts, and notifications, so you can respond swiftly to any changes or anomalies. This agility enables you to capitalize on opportunities and address issues before they escalate.
Predictive Analytics
Looking forward is just as important as understanding the present. With Power BI’s advanced analytics and machine learning integration, our consultants can build predictive models that forecast future trends and outcomes. This forward-thinking approach allows you to make proactive decisions, allocate resources more effectively, and stay ahead of the competition.
Enhancing Collaboration and Decision-Making
Collaborative Workspaces
Power BI promotes a culture of collaboration by allowing teams to work together in shared workspaces. Our consultants help set up these collaborative environments, enabling your team members to share insights, reports, and dashboards seamlessly. This fosters a more cohesive and informed decision-making process across your organization.
Storytelling with Data
Numbers alone don’t tell a story. Our Power BI consultants are adept at transforming complex data sets into compelling narratives that resonate with your stakeholders. By presenting data in a way that is both understandable and engaging, we help you communicate insights effectively, driving better alignment and buy-in for your strategies and initiatives.
Ensuring Continuous Improvement
Training and Support
Our commitment to your success doesn’t end with implementation. We provide ongoing training and support to ensure your team is fully equipped to leverage Power BI’s capabilities. From basic user training to advanced analytics workshops, we tailor our training programs to meet your needs, ensuring continuous improvement and adoption.
Scalability and Flexibility
As your business grows, so do your data needs. Power BI is a scalable solution that grows with you. Our consultants design solutions that are flexible and scalable, allowing you to add new data sources, expand functionalities, and accommodate increasing data volumes without compromising performance.
Real-World Success Stories
Case Study: Retail Industry
One of our clients in the retail industry was struggling with fragmented data and inconsistent reporting. Our Power BI consultants integrated their sales, inventory, and customer data into a unified dashboard, providing real-time visibility into their operations. The result was a 20% increase in sales due to better inventory management and a 15% improvement in customer satisfaction scores.
Case Study: Healthcare Sector
A healthcare provider approached us with the challenge of optimizing patient care and operational efficiency. Our team implemented Power BI to integrate patient records, treatment data, and operational metrics. This enabled the provider to identify bottlenecks, streamline processes, and improve patient outcomes. Within six months, they saw a 25% reduction in patient wait times and a significant boost in operational efficiency.
Conclusion: Your Partner in Growth
At IT Path Solutions, we believe that data is the key to unlocking business growth. Our **[Power BI consulting services](https://www.itpathsolutions.com/power-bi-consulting-services/)** are designed to help you harness the power of your data, transforming it into actionable insights that drive success. From data integration and advanced analytics to real-time monitoring and predictive modeling, we provide end-to-end solutions that empower you to make informed decisions and achieve your business goals.
Partner with us and take the first step towards a data-driven future. Let our expertise in Power BI guide you on your journey to growth and innovation. Contact us today to learn more about how we can help you turn your data into a strategic asset and drive your business forward.
| johnsmith244303 |
1,862,604 | This Week In React #186: React Conf, Compiler, Storybook, SSRF, Inline Styles, New Arch, Expo, Bootsplash, Skia, RN-Video... | Hi everyone! This has been a busy week for us 😄. That React conf didn't disappoint! We weren't... | 18,494 | 2024-05-23T08:56:31 | https://thisweekinreact.com/newsletter/186 | react, reactnative | ---
series: This Week In React
canonical_url: https://thisweekinreact.com/newsletter/186
---
Hi everyone!
This has been a busy week for us 😄. That React conf didn't disappoint! We weren't there, but [our flyer was](https://x.com/sebastienlorber/status/1790771155734839313) 😇. We not only had great conf announcements (notably the compiler!), but we had great community articles that I had to postpone a few of them to next week.
Although it's unlikely to calm down because 2 major confs start tomorrow:
- Vercel Ship, during which [Next.js 15 should be announced](https://x.com/feedthejim/status/1792969159321723244) with a less aggressive caching strategy, Turborepo in dev, Compiler support and more.
- App.js Conf, also with great React Native announcements expected.
Have a good read and see you next week!
* 🗓 [Chain React Conf](https://chainreactconf.com/?utm_source=thisweekinreact) - Portland, OR - July 17-19. The U.S. React Native Conference is back with engaging talks and hands-on workshops! Get 15% off your ticket with code “TWIR”
---
💡 Subscribe to the [official newsletter](https://thisweekinreact.com?utm_source=dev_crosspost) to receive an email every week!
[](https://thisweekinreact.com?utm_source=dev_crosspost)
---
## 💸 Sponsor
[](https://marmelab.com/react-admin/)
**[React-admin: The Open-Source Framework for B2B apps](https://marmelab.com/react-admin/)**
Speed up the development of your single-page applications with the acclaimed frontend framework🚀. Built with TanStack Query, react-hook-form, react-router & material UI, React-admin lets you create rich user experiences on top of REST or GraphQL APIs.
Beyond CRUD pages, React-admin has many advanced functionalities to meet your needs. Its complete toolkit offers a calendar **📅**, customizable Kanban board, content versioning **🔄**, nested forms & more. Add real-time updates 🎥, tree **🌲** structures and detailed audit logs via headless hooks and themeable components.
Ready to take your development to the next level? Make React-admin your go-to framework & join over half a million daily users. [Try it now](https://marmelab.com/react-admin/)!
---
## ⚛️ React
[](https://react.dev/blog/2024/05/22/react-conf-2024-recap)
**[React Conf 2024 Recap](https://react.dev/blog/2024/05/22/react-conf-2024-recap)**
The React team published a recap blog post of React Conf, just in time for today’s newsletter 🤗. It presents all the talks and the main announcements. I haven't seen all of them yet, but my highlights so far are:
- React 19 is in RC, and a stable release is expected in the next few weeks
- The React Compiler is out and looks really powerful
- Universal React Server Components are coming to Expo and the demo is really impressive
- Remix and React Router are merging. Remix v3 will finally be React Router v7.
- The Real-time React Server Components demo makes RSCs stateful and opens new possibilities that remind me of Phoenix LiveView
- React now coordinates HTML tags, which is hugely underrated
Again these are just my personal favorites. We already covered most React 19 features in the newsletter, and the [React 19 beta blog post](https://react.dev/blog/2024/04/25/react-19) remains the reference for discovering all the new features coming in the next major version.
---
[](https://react.dev/learn/react-compiler)
**[The React Compiler is out](https://react.dev/learn/react-compiler)**
The compiler probably deserves its own section right. TLDR: the compiler optimizes your existing code automatically and gives you fine-grained reactivity using regular JS values. Try the [React Compiler Playground](https://playground.react.dev/#N4Igzg9grgTgxgUxALhAgHgBwjALgAgBMEAzAQygBsCSoA7OXASwjvwFkBPAQU0wAoAlPmAAdNvhgJcsNgB5CTAG4A+ABIJKlCPgDqOSoTkB6RaoDc4gL7iQVoA) to see how it works, and understand how it optimizes your code.
It has been successfully rolled out on Instagram web with great results (2.5x faster interactions). It statically analyses your code, one file at a time, and memoizes what can safely be optimized, with even greater granularity than you could do by hand. If you follow the Rules of React, you shouldn’t need to rewrite any code. The ESLint plugin tells you about problematic code that the compiler detects. It does not play well with proxy-based solutions like MobX. Configuration options and opt-in/out directives enable you to try the compiler gradually on your codebase.
The compiler is initially written in TypeScript and ships with Babel bindings, but don’t be disappointed because its logic is decoupled. Support for SWC should come next, and we’ll probably have a port in Rust a bit later (they already made a POC for that to ensure it’s feasible).
It is worth mentioning that the React team always had in mind to have a compiler for React (see [Andrew Clark’s thread](https://x.com/acdlite/status/1792710362745405911)). And this is only the beginning, they now have the infrastructure to build even more powerful things. I’m pretty sure sooner or later we won’t need anymore a dependency array, and that the compiler will be able to optimize fine-grained context consumption ([relevant tweet](https://x.com/TkDodo/status/1741193371283026422)).
🔗 **Related resources worth checking:**
- 📜 [React Compiler With React 18](https://jherr2020.medium.com/react-compiler-with-react-18-1e39f60ae71a): The compiler is not a React 19 feature. Jack shows a POC of using it under React 18 by providing a very simple compiler runtime hook. Lauren from the React Compiler team just confirmed it’s ok to do so and provided an [official polyfill](https://github.com/reactwg/react-compiler/discussions/6) that you can use temporarily, although it’s recommended to upgrade to React 19.
- 🎥 [Jack Herrington - React Compiler: In-Depth Beyond React Conf 2024](https://www.youtube.com/watch?v=PYHBHK37xlE)
- 🎥 [Theo - React Just Changed Forever](https://www.youtube.com/watch?v=DhfeXfF_W4w)
- 🧵 [Theo - Clearing up some React Compiler misunderstandings](https://x.com/t3dotgg/status/1791177359896555600)
---
[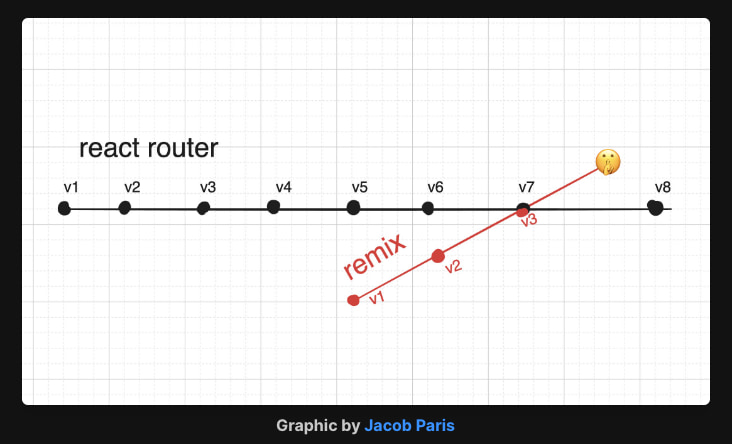](https://remix.run/blog/merging-remix-and-react-router)
**[Merging Remix and React Router](https://remix.run/blog/merging-remix-and-react-router)**
This is another big announcement from React Conf. Remix and React Router have converged so much (thanks to the Vite plugin and SPA mode) that it doesn’t really make sense anymore to keep both. Technically, instead of shipping Remix v3, they plan to add an optional Vite plugin to React Router v7, which will remain retro-compatible, and also bring new features (RSC, server-actions, static pre-rendering…). See also the follow-up post [Incremental Path to React 19: React Conf Follow-Up](https://remix.run/blog/incremental-path-to-react-19).
---
- 💸 [Conversational AI and context-aware LLM chat with React](https://nlux.dev/?utm_source=twir-m24-2)
- 📜 [React 19 lets you write impossible components](https://www.mux.com/blog/react-19-server-components-and-actions): A great article from Mux that adopted RSCs early, explaining that we only scratched the surface of the new patterns RSCs enable. The changelog pagination example is cool and shows that even libraries like React Query might become less useful.
- 📜 [Introducing Pigment CSS: the next generation of CSS-in-JS](https://mui.com/blog/introducing-pigment-css/): the MUI team explains the motivations to create their own in-house CSS-in-JS solution, built on top of the WyW-in-JS toolkit, that should power MUI v6 later this year. It is compatible with RSCs. The adoption for MUI/Emotion/StyledComponent users should be easy.
- 📜 [Digging for SSRF in NextJS apps](https://www.assetnote.io/resources/research/digging-for-ssrf-in-nextjs-apps): Security researchers explain blind Server Side Request Forgery vulnerabilities they found in Next.js related to the Image component and Server Actions implementations. Those vulnerabilities have been patched since Next.js 14.1.1 already (January 2024).
- 📜 [Prefer Multiple Compositions](https://kyleshevlin.com/prefer-multiple-compositions/): If your component has a finite set of cases to handle, it will be more maintainable to have clear separate if/else branches for each cases rather than spreading conditionals everywhere in JSX.
- 📜 [Prefer Noun-Adjective Naming](https://kyleshevlin.com/prefer-noun-adjective-naming/): I also prefer to name a component “ButtonPrimary” instead of “PrimaryButton”. Related things remain grouped alphabetically, and are easier to lookup in the IDE.
- 📜 [Inline Styles on Steroids](https://weser.io/blog/inline-styles-on-steroids): With projects such as CSS Hooks, and the web platform planning to add support for inline style nesting, it’s only a matter of time until inline styles make a huge comeback. The author of Fela recreates the DX of a good CSS-in-JS library on top of CSS Hooks thanks to 2 new projects he’s working on.
- 📜 [Quantifying the Impact of Styled Components on Server Response Times](https://blog.levineandrew.com/quantifying-the-impact-of-styled-components-on-server-response-times): Uses SpeedScope (more powerful than Chrome DevTools) to analyze a CPU trace and concludes that style injection takes 47% of SSR time.
- 📜 [Storybook - Portable stories for Playwright Component Tests](https://storybook.js.org/blog/portable-stories-for-playwright-ct/): Although Storybook provides a play() function using a Playwright test runner, you might still want to use Playwright Component testing directly, and reuse your existing stories there.
- 📜 [Deploying Remix to Cloudflare with SST](https://ruanmartinelli.com/blog/remix-sst-cloudflare): Using SST to deploy your app to a major cloud can be a nice alternative to DX platforms like Vercel/Netlify. TIL that it’s so simple to use, and it also supports deploying to Cloudflare.
- 📦 [Restyle](https://reactstyle.vercel.app/): New CSS-in-JS library compatible with RSC that’s leveraging the brand-new style hoisting and deduplication feature of React 19. Those new React primitives were also designed with CSS-in-JS libs in mind, and it’s great to see the community already leveraging them. It’s also interesting for distributing CSS as part of a React library npm package.
- 📦 [React Google Maps 1.0](https://mapsplatform.google.com/resources/blog/google-maps-platform-graduates-react-integration-library-to-1-0/): The official Google Maps library for React is now stable, maintained by the OpenJS Foundation.
- 📦 [Million Lint 1.0-rc](https://million.dev/blog/lint-rc): IDE extension that automatically finds and fixes performance issues for you. Unlike the React compiler, it is based on runtime analysis and can detect additional performance problems that the compiler can’t. Both can be used in tandem.
- 📦 [Zustand 5.0-beta - Upgrade guide available - drop deprecated features, upgrades React/TS](https://github.com/pmndrs/zustand/blob/v5/docs/guides/migrating-to-v5.mdx)
- 📦 [Storybook 8.1 - tag filtering, typesafe mocking, beforeEach, portable stories API](https://github.com/storybookjs/storybook/releases/tag/v8.1.0)
- 📦 [Storybook-Rsbuild - Storybook builder powered by Rsbuild](https://github.com/rspack-contrib/storybook-rsbuild)
---
## 💸 Sponsor
[](https://www.youtube.com/watch?v=aoRG1q_kVo8)
**[Next.js auth tutorial with RSCs and Server Actions](https://www.youtube.com/watch?v=aoRG1q_kVo8)**
The latest tutorial with WorkOS and Sam Selikoff shows how you can easily add AuthKit's hosted login box to a Next.js app:
📚 Get started using the Authkit \<> Next.js [integration library](https://github.com/workos/authkit-nextjs)
🤖 Set up environment variables, configure the callback route and middleware, and implement signIn and signOut functionalities
⚙️ Protect routes in the Next.js app from unauthenticated users with the getUser function
AuthKit can be used with WorkOS User Management, which supports MFA, identity linking, email verification, user impersonation, and more.
Best of all, it's **free up to 1,000,000 MAUs 🚀**
---
## 📱 React-Native
This section is authored by [Benedikt](https://twitter.com/bndkt).
React Conf is officially behind us, and I hope you had a chance to look at the recordings of the awesome presentations on YouTube. My biggest meta-takeaway was just how much RN content there was in the conference! As RN is very much developed out in the open and in collaboration with the whole community, there were no surprising “big announcements,” but it was a very good summary of the current state of RN and an outlook on the road ahead. The most impressive and inspiring part for me was Evan Bacon’s vision for Universal React Server Components, which he presented using an absolute killer demo that I’m urging you to [watch for yourself](https://www.youtube.com/watch?v=T8TZQ6k4SLE&t=20765s). I’ve put my main takeaways into some bullet points for you:
- RN is thriving: Over 2M weekly downloads of RN now, 30 shipped versions of RN in 2024 so far
- The new Architecture is now in Beta
- Expo is now officially recommended for all new apps
- New reactnative.dev landing page launched
- React Conf app is open source
- Expo’s vision for Universal RSC
---
- 💸 [PowerSync - Supabase \<> SQLite sync layer: follow our step-by-step video integration guide.](https://docs.powersync.com/integration-guides/supabase-+-powersync?utm_source=newsletter&utm_medium=sponsorship&utm_campaign=this-week-in-react)
- 👀 [New React Native landing page](https://reactnative.dev/)
- 🐦 [New resources to get started with React Native and Expo](https://x.com/jonsamp/status/1791164393893609705): New landing page, new "Getting Started" docs, new Expo dev environment setup docs
- 🐦 [Interesting discussion on Apple's stance on server-driven UI in iOS apps](https://x.com/sregg/status/1791784335999160783): Will Universal RSC be a challenge in Apple’s App Store approval process?
- 🐦 [Potential ways to decrease Android bundle size](https://x.com/mironcatalin/status/1792485000559935571): Two settings can significantly decrease bundle size, but - as always - this comes with trade-offs.
- 🗓 [Chain React Conf](https://chainreactconf.com/?utm_source=thisweekinreact) - Portland, OR - July 17-19. The U.S. React Native Conference is back with engaging talks and hands-on workshops! Get 15% off your ticket with code “TWIR”
- 📜 [Debunk ideas on cross-platform framework](https://www.bam.tech/article/debunk-ideas-on-cross-platform-framework): Performance, Security, Accessibility, Stability, App Store acceptance, Native Features - all of these are sometimes mistakenly doubted when it comes to cross-platform apps.
- 📜 [Breaking down react-native-video 6.0.0 stable release - enhancements and comparisons](https://www.thewidlarzgroup.com/blog/breaking-down-react-native-video-6-0-0-stable-release-enhancements-and-comparisons)
- 📜 [Creating Custom Fonts with React-Native-Skia](https://gitstashapply.medium.com/creating-custom-fonts-with-react-native-skia-4851d8b14ddd)
- 📦 [Bootsplash v6 beta - Expo plugin, simpler setup](https://github.com/zoontek/react-native-bootsplash/pull/578): The React Conf app used it for splash screen!
- 📦 [React Conf app open-sourced](https://github.com/expo/react-conf-app): Already uses React Compiler ([Tweet](https://x.com/kadikraman/status/1791155001882275989))
- 🎙️ [RNR 297 - Jumping over the React Native v0.74 Bridge](https://reactnativeradio.com/episodes/rnr-297-jumping-over-the-react-native-v074-bridge)
- 🎥 [Supercharging your React Native app for Windows](https://www.youtube.com/watch?v=4sbAvwukSWM): React Native session at MS Build 2024
---
## 🔀 Other
- 📜 [What's new in the web - 12 newly available Baseline features](https://web.dev/blog/new-in-the-web-io2024)
- 📜 [What's new in JavaScript Frameworks (May 2024)](https://developer.chrome.com/blog/frameworks-may-2024)
- 📜 [Portable Server Rendered Web Components with Enhance SSR](https://begin.com/blog/posts/2024-05-03-portable-ssr-components)
- 📜 [ECMAScript 2023 feature: Symbols as WeakMap keys](https://2ality.com/2024/05/proposal-symbols-as-weakmap-keys.html)
- 📦 [SolidStart 1.0 - The Shape of Frameworks to Come](https://www.solidjs.com/blog/solid-start-the-shape-frameworks-to-come)
- 📦 [Graphql-query - 8.7x faster GraphQL query parser written in Rust](https://stellate.co/blog/graphql-query-parsing-8x-faster-with-rust)
- 📦 [Node 22.2](https://nodejs.org/en/blog/release/v22.2.0)
---
## 🤭 Fun
[](https://x.com/rauchg/status/1791163745307328650)
[](https://x.com/sebastienlorber/status/1790796662153117863)
(Ok that React Compiler one is not technically accurate, but still fun 😇 sorry Compiler team)
See ya! 👋 | sebastienlorber |
1,862,603 | Unpacking the JavaScript Junk Drawer: The Marvels & Mayhem of Objects 🗃️ | Greetings, JavaScript enthusiasts and aspiring coders! Ever encountered code that looked like a mess?... | 25,941 | 2024-05-23T08:55:47 | https://dev.to/aniket_botre/unpacking-the-javascript-junk-drawer-the-marvels-mayhem-of-objects-10ak | javascript, webdev, programming, coding | Greetings, JavaScript enthusiasts and aspiring coders! Ever encountered code that looked like a mess? Worry not, because JavaScript objects are here to help!
---
## The Lowdown on JavaScript Objects
JavaScript objects are fundamental constructs that allow you to store collections of key-value pairs. They are similar to real-life objects in that they are standalone entities with their own properties and methods. In JavaScript, objects can contain many values, unlike primitive data types such as numbers or strings. These values can be of various types, including other objects, functions, and primitive data types.
### Creating Objects
There are several ways to create objects in JavaScript:
- **Object Literal**: The most common approach, using curly braces `{}` to enclose key-value pairs separated by commas.
```js
const person = {
firstName: "Alice",
lastName: "Smith",
age: 30,
greet: function() {
console.log("Hello, my name is " + this.firstName + " " + this.lastName);
}
};
```
- `new` **keyword**: While less common for simple objects, the `new` keyword can be used with a constructor function (a function designed to create objects).
```js
function Car(make, model, year) {
this.make = make;
this.model = model;
this.year = year;
this.drive = function() {
console.log("Vroom! The " + this.make + " " + this.model + " is on the road!");
};
}
const myCar = new Car("Ford", "Mustang", 2023);
```
- **Other Methods**: Less frequently used methods include `Object.create()`, `Object.assign()`, and `Object.fromEntries()`.
### Properties and Methods
- **Properties**: These are named values that represent characteristics or attributes of the object. They can be accessed using dot notation `obj.propertyName` or bracket notation `obj["propertyName"]`.
- **Methods**: Functions defined within objects are called methods, and they represent actions that an object can perform.
```js
let person = {
name: "John",
age: 30,
greet: function() {
console.log("Hello, " + this.name);
}
};
person.greet(); // Output: Hello, John
```
Objects love to accessorize with properties. Here's how you can give your object some style:
```js
let user = {
name: "John",
age: 30
};
```
Imagine `user` as a filing cabinet, and `name` and `age` as drawers labeled accordingly. Need to fetch John's age for a surprise birthday party? Just use the trusty dot notation:
```js
alert(user.age); // Party planning made easy!
```
---
## Advanced Object Features
- **Nested Objects**: An object can include another object as a property, which is known as a nested object.
- **Pass by Reference**: Objects are passed by reference, meaning that when you assign an object to a variable, you are passing a reference to the same memory location.
- **Checking Property Existence**: You can check if a property exists using the `in` operator, `hasOwnProperty` method, or optional chaining operator `?`.
- **Iterating Over Properties**: The `for...in` loop is used to iterate over the properties of an object.
- **Object Destructuring**: This feature allows you to extract properties from an object and assign them to variables.
- **Spread Operator**: The spread operator `...` can be used to copy properties from one object to another.
- **Object.assign()**: This method is used to copy properties from one object to another.
> We will be covering more about objects in JavaScript in upcoming blogs.
---
## Wrapping Up: The Cabinet of Curiosities
JavaScript objects are like a cabinet of curiosities. They hold an array of fascinating and useful features, ready to be explored. Whether you’re just starting out or you’re a seasoned coder, understanding objects is crucial in navigating the vast ocean of JavaScript.
So, next time you dive into JavaScript, remember: objects are your best friends (or frenemies, on a bad day). They’re complex, powerful, and sometimes a tad bit overwhelming, but they’re the building blocks of just about everything in JavaScript.
| aniket_botre |
1,862,602 | 🚀 Vue Tip: Simpler Two-Way Binding with defineModel | 🚀 Vue Tip: Simpler Two-Way Binding with defineModel Vue 3 introduces several new features... | 0 | 2024-05-23T08:53:52 | https://dev.to/abanoubgeorge/vue-tip-simpler-two-way-binding-with-definemodel-1gp | webdev, vue, javascript, learning | ## 🚀 Vue Tip: Simpler Two-Way Binding with `defineModel`
Vue 3 introduces several new features to streamline and enhance your development experience. One such feature is `defineModel`, which makes two-way data binding more straightforward.
### What is `defineModel`?
`defineModel` is a helper function in Vue 3 that simplifies the creation of two-way bindings for props. It reduces boilerplate code and makes your components more concise and readable.
### How to Use `defineModel`
To use `defineModel`, you need to define it in your script setup. It allows you to easily bind props and emit updates, making the code cleaner.
### Example:
Let's take a look at a simple example where we use `defineModel` to create a two-way binding for a `title` prop.
#### Without `defineModel`:
```vue
<template>
<input :value="title" @input="$emit('update:title', $event.target.value)" />
</template>
<script setup>
defineProps(['title']);
defineEmits(['update:title']);
</script>
```
#### With `defineModel`:
```vue
<template>
<input v-model="title" />
</template>
<script setup>
const title = defineModel('title');
</script>
```
In the second example, `defineModel` handles the binding and event emission for you, making the component cleaner and easier to read.
### Benefits of Using `defineModel`
- **Reduced Boilerplate**: Less code to write and maintain.
- **Improved Readability**: Cleaner syntax makes the component easier to understand at a glance.
- **Streamlined Logic**: Automatically handles the prop binding and event emission.
### Conclusion
Using `defineModel` in Vue 3 can greatly simplify your two-way binding logic, making your components more concise and maintainable. This is especially beneficial in larger projects where keeping your codebase clean and manageable is crucial.
| abanoubgeorge |
1,862,548 | Comparing Odoo 17 and Django Ledger for Accounting and Financial Management 2024 | As a developer or business owner, choosing the right accounting and financial management tool is... | 0 | 2024-05-23T08:52:06 | https://dev.to/tarek_eissa/comparing-odoo-17-and-django-ledger-for-accounting-and-financial-management-2024-388b | django, webdev, programming, python | 
As a developer or business owner, choosing the right accounting and financial management tool is crucial for the smooth operation of your business. In this post, we'll compare two powerful options: **Odoo 17** and **Django Ledger**. We'll explore their features, auditing and financial management capabilities, costs, and suitability for different business sizes and needs.
## Odoo 17
Odoo 17 is a comprehensive suite of business applications, with its accounting and invoicing modules being some of the most robust features. Let's dive into what it offers:

### Accounting and Invoicing
- **Invoicing Automation**: Odoo Invoicing allows you to create, send, and manage payments for invoices with ease. AI-powered invoice recognition and bank account synchronization streamline the process.
- **Accounts Payable and Receivable**: Manage vendor bills, customer invoices, and credit notes efficiently.
- **Bank Synchronization**: Automatically import transactions and reconcile accounts for a real-time overview of your cash flow.
- **Tax Management**: Automate tax reports for multiple jurisdictions, ensuring compliance.
- **Financial Reports**: Generate balance sheets, profit and loss statements, cash flow statements, and more in real-time.
- **Double-entry Bookkeeping**: Ensures accurate and consistent transaction records.
- **Multi-company Management**: Manage multiple companies within a single database.
- **Multi-currency Environment**: Handle international transactions with automated exchange rates.
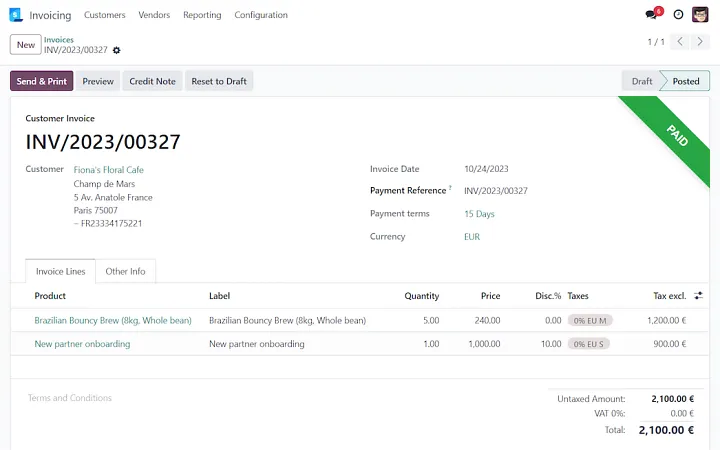
### Auditing and Financial Management
- **Audit Trails**: Detailed logs for all transactions and activities.
- **Budget Management**: Create and track budgets against actual expenses.
- **Asset Management**: Track assets, depreciation schedules, and movements.
- **Expense Management**: Streamline employee expense reports and reimbursements.
- **International Standards**: Supports over 70 countries with local fiscal requirements.
### Dashboard View
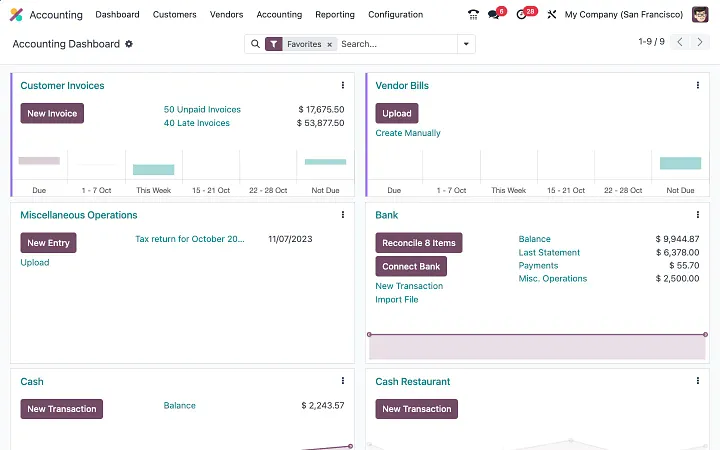
### Cost
- **Subscription-based Pricing**: Costs vary based on the number of users and modules needed.
- **Implementation and Customization Costs**: Can be significant depending on the extent of customization and integration.
### Advanced Features
- **Bank Synchronization**: Connect directly with banks to import transactions.
- **Online Payments**: Supports various payment providers like Stripe, PayPal, and Adyen.
- **Inventory Valuation**: Supports standard price, average price, LIFO, and FIFO methods.
- **Retained Earnings**: Calculates in real-time with no year-end journal required.
### Expense Management
- **Expense Categories**: Configure specific expense types for accurate tracking.
- **Automated Expense Recording**: Attach receipts, scan PDFs, and email expenses directly into the system.
- **Expense Reports**: Submit and approve expense reports for reimbursement and accounting integration.

## Django Ledger
Django Ledger is an open-source accounting system designed for financially driven applications using the Django Web Framework. It offers a high-level API that simplifies the implementation of accounting functionalities.
### Accounting and Invoicing
- **High-Level API**: Simplifies the process of implementing accounting functionalities.
- **Double-entry Accounting System**: Ensures accurate and consistent financial records.
- **Multiple Hierarchical Chart of Accounts**: Organize accounts in a hierarchical structure.
- **Financial Statements**: Generates income statements, balance sheets, and cash flow statements.
- **Purchase Orders and Sales Orders**: Manage estimates, bills, and invoices.
- **Automatic Financial Ratio and Insight Calculations**: Provides insights into financial health.
- **Multi-tenancy**: Supports multiple companies, users, and clients within a single instance.
- **Self-contained Ledgers, Journal Entries, and Transactions**: Manages all financial transactions internally.
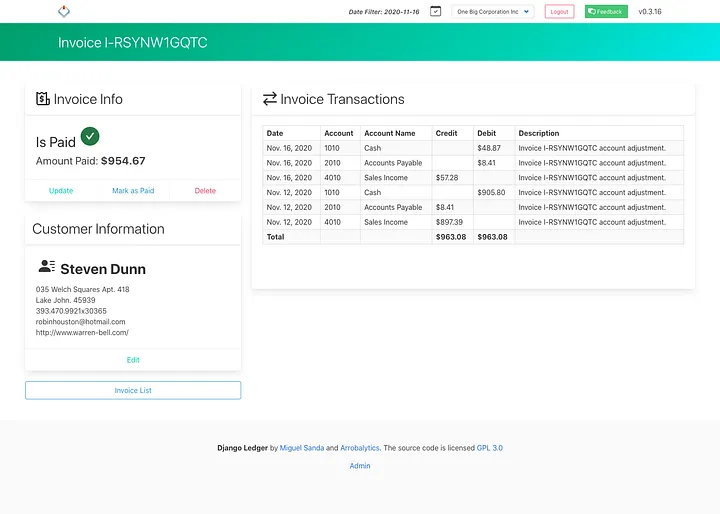
### Auditing and Financial Management
- **Closing Entries**: Automatically handles the closing of accounts at the end of fiscal periods.
- **Bank Accounts Information**: Maintains detailed information on bank accounts.
- **OFX & QFX File Import**: Allows importing financial data from external sources.
- **Financial Analysis Engine**: Provides detailed financial analysis and insights.

### Cost
- **Open-source**: Free to use, making it cost-effective for small businesses and startups.
- **Customization Costs**: Costs associated with development and integration based on complexity and expertise required.
### Advanced Features
- **Entity Management UI**: Built-in UI for managing entities.
- **Django Admin Classes**: Leverages Django's admin interface for managing accounting data.
- **Inventory Management**: Tracks items, lists, and inventory with units of measure.
### Dashboard View
## Summary
### Features
- **Odoo 17**: Comprehensive features for invoicing, accounting, bank synchronization, and financial reporting. Suitable for larger businesses with complex needs.
- **Django Ledger**: Basic but effective features for small to medium-sized businesses. Highly customizable with in-house development capabilities.
### Auditing and Financial Management
- **Odoo 17**: Extensive audit trails, multi-company management, and detailed budgeting tools.
- **Django Ledger**: Basic auditing and budgeting features with the flexibility for custom solutions.
### Cost
- **Odoo 17**: Higher total cost of ownership with subscription fees and potential implementation costs.
- **Django Ledger**: Cost-effective with no initial software costs but potential customization and development expenses.
### Suitability
- **Odoo 17**: Ideal for larger enterprises or those needing comprehensive, integrated solutions with strong support.
- **Django Ledger**: Suitable for smaller businesses or those with in-house technical expertise.
In conclusion, **Odoo 17** provides a robust, feature-rich platform suitable for large enterprises with complex requirements, while **Django Ledger** offers a flexible, cost-effective solution for smaller businesses or those capable of handling custom development.
---
Feel free to share your thoughts or ask questions in the comments below. Happy accounting! | tarek_eissa |
1,862,599 | FMZQuant UniswapV3 Exchange Pool Liquidity Related Operations Guide (Part 1) | NonfungiblePositionManager Contract in Uniswap V3 When we add liquidity to the Uniswap V3... | 0 | 2024-05-23T08:51:16 | https://dev.to/fmzquant/fmzquant-uniswapv3-exchange-pool-liquidity-related-operations-guide-part-1-487j | uniswap, trading, fmzquant, exchange | ## NonfungiblePositionManager Contract in Uniswap V3
When we add liquidity to the Uniswap V3 liquidity pool (trading pair pool), the NonfungiblePositionManager contract returns a minted NFT to us as proof of the liquidity addition.
The first step is to use the router contract to get the address of the corresponding NonfungiblePositionManager contract, and then use the balanceOf method of the NonfungiblePositionManager contract to get the number of position NFTs for the specified wallet address.
Then use the tokenOfOwnerByIndex method to get the tokenId of these position NFTs, with these tokenId, you can use the positions method to continue to query the specific details of these positions.
The following test code:
```
// Uniswap ABI
const ABI_UniswapV3Router = `[{"inputs":[{"internalType":"address","name":"_factoryV2","type":"address"},{"internalType":"address","name":"factoryV3","type":"address"},{"internalType":"address","name":"_positionManager","type":"address"},{"internalType":"address","name":"_WETH9","type":"address"}],"stateMutability":"nonpayable","type":"constructor"},{"inputs":[],"name":"WETH9","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"}],"name":"approveMax","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"}],"name":"approveMaxMinusOne","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"}],"name":"approveZeroThenMax","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"}],"name":"approveZeroThenMaxMinusOne","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes","name":"data","type":"bytes"}],"name":"callPositionManager","outputs":[{"internalType":"bytes","name":"result","type":"bytes"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes[]","name":"paths","type":"bytes[]"},{"internalType":"uint128[]","name":"amounts","type":"uint128[]"},{"internalType":"uint24","name":"maximumTickDivergence","type":"uint24"},{"internalType":"uint32","name":"secondsAgo","type":"uint32"}],"name":"checkOracleSlippage","outputs":[],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"bytes","name":"path","type":"bytes"},{"internalType":"uint24","name":"maximumTickDivergence","type":"uint24"},{"internalType":"uint32","name":"secondsAgo","type":"uint32"}],"name":"checkOracleSlippage","outputs":[],"stateMutability":"view","type":"function"},{"inputs":[{"components":[{"internalType":"bytes","name":"path","type":"bytes"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"amountIn","type":"uint256"},{"internalType":"uint256","name":"amountOutMinimum","type":"uint256"}],"internalType":"struct IV3SwapRouter.ExactInputParams","name":"params","type":"tuple"}],"name":"exactInput","outputs":[{"internalType":"uint256","name":"amountOut","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"tokenIn","type":"address"},{"internalType":"address","name":"tokenOut","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"amountIn","type":"uint256"},{"internalType":"uint256","name":"amountOutMinimum","type":"uint256"},{"internalType":"uint160","name":"sqrtPriceLimitX96","type":"uint160"}],"internalType":"struct IV3SwapRouter.ExactInputSingleParams","name":"params","type":"tuple"}],"name":"exactInputSingle","outputs":[{"internalType":"uint256","name":"amountOut","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"bytes","name":"path","type":"bytes"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"amountOut","type":"uint256"},{"internalType":"uint256","name":"amountInMaximum","type":"uint256"}],"internalType":"struct IV3SwapRouter.ExactOutputParams","name":"params","type":"tuple"}],"name":"exactOutput","outputs":[{"internalType":"uint256","name":"amountIn","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"tokenIn","type":"address"},{"internalType":"address","name":"tokenOut","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"amountOut","type":"uint256"},{"internalType":"uint256","name":"amountInMaximum","type":"uint256"},{"internalType":"uint160","name":"sqrtPriceLimitX96","type":"uint160"}],"internalType":"struct IV3SwapRouter.ExactOutputSingleParams","name":"params","type":"tuple"}],"name":"exactOutputSingle","outputs":[{"internalType":"uint256","name":"amountIn","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"factory","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"factoryV2","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amount","type":"uint256"}],"name":"getApprovalType","outputs":[{"internalType":"enum IApproveAndCall.ApprovalType","name":"","type":"uint8"}],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"}],"internalType":"struct IApproveAndCall.IncreaseLiquidityParams","name":"params","type":"tuple"}],"name":"increaseLiquidity","outputs":[{"internalType":"bytes","name":"result","type":"bytes"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"int24","name":"tickLower","type":"int24"},{"internalType":"int24","name":"tickUpper","type":"int24"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"internalType":"struct IApproveAndCall.MintParams","name":"params","type":"tuple"}],"name":"mint","outputs":[{"internalType":"bytes","name":"result","type":"bytes"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes32","name":"previousBlockhash","type":"bytes32"},{"internalType":"bytes[]","name":"data","type":"bytes[]"}],"name":"multicall","outputs":[{"internalType":"bytes[]","name":"","type":"bytes[]"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"bytes[]","name":"data","type":"bytes[]"}],"name":"multicall","outputs":[{"internalType":"bytes[]","name":"","type":"bytes[]"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes[]","name":"data","type":"bytes[]"}],"name":"multicall","outputs":[{"internalType":"bytes[]","name":"results","type":"bytes[]"}],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"positionManager","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"}],"name":"pull","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"refundETH","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermit","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"nonce","type":"uint256"},{"internalType":"uint256","name":"expiry","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitAllowed","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"nonce","type":"uint256"},{"internalType":"uint256","name":"expiry","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitAllowedIfNecessary","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitIfNecessary","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountIn","type":"uint256"},{"internalType":"uint256","name":"amountOutMin","type":"uint256"},{"internalType":"address[]","name":"path","type":"address[]"},{"internalType":"address","name":"to","type":"address"}],"name":"swapExactTokensForTokens","outputs":[{"internalType":"uint256","name":"amountOut","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountOut","type":"uint256"},{"internalType":"uint256","name":"amountInMax","type":"uint256"},{"internalType":"address[]","name":"path","type":"address[]"},{"internalType":"address","name":"to","type":"address"}],"name":"swapTokensForExactTokens","outputs":[{"internalType":"uint256","name":"amountIn","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"name":"sweepToken","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"}],"name":"sweepToken","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"uint256","name":"feeBips","type":"uint256"},{"internalType":"address","name":"feeRecipient","type":"address"}],"name":"sweepTokenWithFee","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"feeBips","type":"uint256"},{"internalType":"address","name":"feeRecipient","type":"address"}],"name":"sweepTokenWithFee","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"int256","name":"amount0Delta","type":"int256"},{"internalType":"int256","name":"amount1Delta","type":"int256"},{"internalType":"bytes","name":"_data","type":"bytes"}],"name":"uniswapV3SwapCallback","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"name":"unwrapWETH9","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"}],"name":"unwrapWETH9","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"feeBips","type":"uint256"},{"internalType":"address","name":"feeRecipient","type":"address"}],"name":"unwrapWETH9WithFee","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"uint256","name":"feeBips","type":"uint256"},{"internalType":"address","name":"feeRecipient","type":"address"}],"name":"unwrapWETH9WithFee","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"value","type":"uint256"}],"name":"wrapETH","outputs":[],"stateMutability":"payable","type":"function"},{"stateMutability":"payable","type":"receive"}]`
const ABI_NonfungiblePositionManager = `[{"inputs":[{"internalType":"address","name":"_factory","type":"address"},{"internalType":"address","name":"_WETH9","type":"address"},{"internalType":"address","name":"_tokenDescriptor_","type":"address"}],"stateMutability":"nonpayable","type":"constructor"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"owner","type":"address"},{"indexed":true,"internalType":"address","name":"approved","type":"address"},{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"Approval","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"owner","type":"address"},{"indexed":true,"internalType":"address","name":"operator","type":"address"},{"indexed":false,"internalType":"bool","name":"approved","type":"bool"}],"name":"ApprovalForAll","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"},{"indexed":false,"internalType":"address","name":"recipient","type":"address"},{"indexed":false,"internalType":"uint256","name":"amount0","type":"uint256"},{"indexed":false,"internalType":"uint256","name":"amount1","type":"uint256"}],"name":"Collect","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"},{"indexed":false,"internalType":"uint128","name":"liquidity","type":"uint128"},{"indexed":false,"internalType":"uint256","name":"amount0","type":"uint256"},{"indexed":false,"internalType":"uint256","name":"amount1","type":"uint256"}],"name":"DecreaseLiquidity","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"},{"indexed":false,"internalType":"uint128","name":"liquidity","type":"uint128"},{"indexed":false,"internalType":"uint256","name":"amount0","type":"uint256"},{"indexed":false,"internalType":"uint256","name":"amount1","type":"uint256"}],"name":"IncreaseLiquidity","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"from","type":"address"},{"indexed":true,"internalType":"address","name":"to","type":"address"},{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"Transfer","type":"event"},{"inputs":[],"name":"DOMAIN_SEPARATOR","outputs":[{"internalType":"bytes32","name":"","type":"bytes32"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"PERMIT_TYPEHASH","outputs":[{"internalType":"bytes32","name":"","type":"bytes32"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"WETH9","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"approve","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"owner","type":"address"}],"name":"balanceOf","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"baseURI","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"pure","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"burn","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint128","name":"amount0Max","type":"uint128"},{"internalType":"uint128","name":"amount1Max","type":"uint128"}],"internalType":"struct INonfungiblePositionManager.CollectParams","name":"params","type":"tuple"}],"name":"collect","outputs":[{"internalType":"uint256","name":"amount0","type":"uint256"},{"internalType":"uint256","name":"amount1","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"uint160","name":"sqrtPriceX96","type":"uint160"}],"name":"createAndInitializePoolIfNecessary","outputs":[{"internalType":"address","name":"pool","type":"address"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint128","name":"liquidity","type":"uint128"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"}],"internalType":"struct INonfungiblePositionManager.DecreaseLiquidityParams","name":"params","type":"tuple"}],"name":"decreaseLiquidity","outputs":[{"internalType":"uint256","name":"amount0","type":"uint256"},{"internalType":"uint256","name":"amount1","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"factory","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"getApproved","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"components":[{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint256","name":"amount0Desired","type":"uint256"},{"internalType":"uint256","name":"amount1Desired","type":"uint256"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"}],"internalType":"struct INonfungiblePositionManager.IncreaseLiquidityParams","name":"params","type":"tuple"}],"name":"increaseLiquidity","outputs":[{"internalType":"uint128","name":"liquidity","type":"uint128"},{"internalType":"uint256","name":"amount0","type":"uint256"},{"internalType":"uint256","name":"amount1","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"owner","type":"address"},{"internalType":"address","name":"operator","type":"address"}],"name":"isApprovedForAll","outputs":[{"internalType":"bool","name":"","type":"bool"}],"stateMutability":"view","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"int24","name":"tickLower","type":"int24"},{"internalType":"int24","name":"tickUpper","type":"int24"},{"internalType":"uint256","name":"amount0Desired","type":"uint256"},{"internalType":"uint256","name":"amount1Desired","type":"uint256"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"deadline","type":"uint256"}],"internalType":"struct INonfungiblePositionManager.MintParams","name":"params","type":"tuple"}],"name":"mint","outputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint128","name":"liquidity","type":"uint128"},{"internalType":"uint256","name":"amount0","type":"uint256"},{"internalType":"uint256","name":"amount1","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes[]","name":"data","type":"bytes[]"}],"name":"multicall","outputs":[{"internalType":"bytes[]","name":"results","type":"bytes[]"}],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"name","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"ownerOf","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"spender","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"permit","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"positions","outputs":[{"internalType":"uint96","name":"nonce","type":"uint96"},{"internalType":"address","name":"operator","type":"address"},{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"int24","name":"tickLower","type":"int24"},{"internalType":"int24","name":"tickUpper","type":"int24"},{"internalType":"uint128","name":"liquidity","type":"uint128"},{"internalType":"uint256","name":"feeGrowthInside0LastX128","type":"uint256"},{"internalType":"uint256","name":"feeGrowthInside1LastX128","type":"uint256"},{"internalType":"uint128","name":"tokensOwed0","type":"uint128"},{"internalType":"uint128","name":"tokensOwed1","type":"uint128"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"refundETH","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"safeTransferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"bytes","name":"_data","type":"bytes"}],"name":"safeTransferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermit","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"nonce","type":"uint256"},{"internalType":"uint256","name":"expiry","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitAllowed","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"nonce","type":"uint256"},{"internalType":"uint256","name":"expiry","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitAllowedIfNecessary","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitIfNecessary","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"operator","type":"address"},{"internalType":"bool","name":"approved","type":"bool"}],"name":"setApprovalForAll","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"bytes4","name":"interfaceId","type":"bytes4"}],"name":"supportsInterface","outputs":[{"internalType":"bool","name":"","type":"bool"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"name":"sweepToken","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"symbol","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"index","type":"uint256"}],"name":"tokenByIndex","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"owner","type":"address"},{"internalType":"uint256","name":"index","type":"uint256"}],"name":"tokenOfOwnerByIndex","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"tokenURI","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"totalSupply","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"transferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amount0Owed","type":"uint256"},{"internalType":"uint256","name":"amount1Owed","type":"uint256"},{"internalType":"bytes","name":"data","type":"bytes"}],"name":"uniswapV3MintCallback","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"name":"unwrapWETH9","outputs":[],"stateMutability":"payable","type":"function"},{"stateMutability":"payable","type":"receive"}]`
const ABI_Pool = '[{\"inputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"constructor\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"owner\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"}],\"name\":\"Burn\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"owner\",\"type\":\"address\"},{\"indexed\":false,\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount0\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount1\",\"type\":\"uint128\"}],\"name\":\"Collect\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"sender\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount0\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount1\",\"type\":\"uint128\"}],\"name\":\"CollectProtocol\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"sender\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"paid0\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"paid1\",\"type\":\"uint256\"}],\"name\":\"Flash\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":false,\"internalType\":\"uint16\",\"name\":\"observationCardinalityNextOld\",\"type\":\"uint16\"},{\"indexed\":false,\"internalType\":\"uint16\",\"name\":\"observationCardinalityNextNew\",\"type\":\"uint16\"}],\"name\":\"IncreaseObservationCardinalityNext\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":false,\"internalType\":\"uint160\",\"name\":\"sqrtPriceX96\",\"type\":\"uint160\"},{\"indexed\":false,\"internalType\":\"int24\",\"name\":\"tick\",\"type\":\"int24\"}],\"name\":\"Initialize\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":false,\"internalType\":\"address\",\"name\":\"sender\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"owner\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"}],\"name\":\"Mint\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":false,\"internalType\":\"uint8\",\"name\":\"feeProtocol0Old\",\"type\":\"uint8\"},{\"indexed\":false,\"internalType\":\"uint8\",\"name\":\"feeProtocol1Old\",\"type\":\"uint8\"},{\"indexed\":false,\"internalType\":\"uint8\",\"name\":\"feeProtocol0New\",\"type\":\"uint8\"},{\"indexed\":false,\"internalType\":\"uint8\",\"name\":\"feeProtocol1New\",\"type\":\"uint8\"}],\"name\":\"SetFeeProtocol\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"sender\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"indexed\":false,\"internalType\":\"int256\",\"name\":\"amount0\",\"type\":\"int256\"},{\"indexed\":false,\"internalType\":\"int256\",\"name\":\"amount1\",\"type\":\"int256\"},{\"indexed\":false,\"internalType\":\"uint160\",\"name\":\"sqrtPriceX96\",\"type\":\"uint160\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"liquidity\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"int24\",\"name\":\"tick\",\"type\":\"int24\"}],\"name\":\"Swap\",\"type\":\"event\"},{\"inputs\":[{\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"internalType\":\"uint128\",\"name\":\"amount\",\"type\":\"uint128\"}],\"name\":\"burn\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"internalType\":\"uint128\",\"name\":\"amount0Requested\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"amount1Requested\",\"type\":\"uint128\"}],\"name\":\"collect\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"amount0\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"amount1\",\"type\":\"uint128\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"uint128\",\"name\":\"amount0Requested\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"amount1Requested\",\"type\":\"uint128\"}],\"name\":\"collectProtocol\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"amount0\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"amount1\",\"type\":\"uint128\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"factory\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"fee\",\"outputs\":[{\"internalType\":\"uint24\",\"name\":\"\",\"type\":\"uint24\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"feeGrowthGlobal0X128\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"feeGrowthGlobal1X128\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"},{\"internalType\":\"bytes\",\"name\":\"data\",\"type\":\"bytes\"}],\"name\":\"flash\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint16\",\"name\":\"observationCardinalityNext\",\"type\":\"uint16\"}],\"name\":\"increaseObservationCardinalityNext\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint160\",\"name\":\"sqrtPriceX96\",\"type\":\"uint160\"}],\"name\":\"initialize\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"liquidity\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"\",\"type\":\"uint128\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"maxLiquidityPerTick\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"\",\"type\":\"uint128\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"internalType\":\"uint128\",\"name\":\"amount\",\"type\":\"uint128\"},{\"internalType\":\"bytes\",\"name\":\"data\",\"type\":\"bytes\"}],\"name\":\"mint\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"name\":\"observations\",\"outputs\":[{\"internalType\":\"uint32\",\"name\":\"blockTimestamp\",\"type\":\"uint32\"},{\"internalType\":\"int56\",\"name\":\"tickCumulative\",\"type\":\"int56\"},{\"internalType\":\"uint160\",\"name\":\"secondsPerLiquidityCumulativeX128\",\"type\":\"uint160\"},{\"internalType\":\"bool\",\"name\":\"initialized\",\"type\":\"bool\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint32[]\",\"name\":\"secondsAgos\",\"type\":\"uint32[]\"}],\"name\":\"observe\",\"outputs\":[{\"internalType\":\"int56[]\",\"name\":\"tickCumulatives\",\"type\":\"int56[]\"},{\"internalType\":\"uint160[]\",\"name\":\"secondsPerLiquidityCumulativeX128s\",\"type\":\"uint160[]\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"bytes32\",\"name\":\"\",\"type\":\"bytes32\"}],\"name\":\"positions\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"liquidity\",\"type\":\"uint128\"},{\"internalType\":\"uint256\",\"name\":\"feeGrowthInside0LastX128\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"feeGrowthInside1LastX128\",\"type\":\"uint256\"},{\"internalType\":\"uint128\",\"name\":\"tokensOwed0\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"tokensOwed1\",\"type\":\"uint128\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"protocolFees\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"token0\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"token1\",\"type\":\"uint128\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint8\",\"name\":\"feeProtocol0\",\"type\":\"uint8\"},{\"internalType\":\"uint8\",\"name\":\"feeProtocol1\",\"type\":\"uint8\"}],\"name\":\"setFeeProtocol\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"slot0\",\"outputs\":[{\"internalType\":\"uint160\",\"name\":\"sqrtPriceX96\",\"type\":\"uint160\"},{\"internalType\":\"int24\",\"name\":\"tick\",\"type\":\"int24\"},{\"internalType\":\"uint16\",\"name\":\"observationIndex\",\"type\":\"uint16\"},{\"internalType\":\"uint16\",\"name\":\"observationCardinality\",\"type\":\"uint16\"},{\"internalType\":\"uint16\",\"name\":\"observationCardinalityNext\",\"type\":\"uint16\"},{\"internalType\":\"uint8\",\"name\":\"feeProtocol\",\"type\":\"uint8\"},{\"internalType\":\"bool\",\"name\":\"unlocked\",\"type\":\"bool\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"}],\"name\":\"snapshotCumulativesInside\",\"outputs\":[{\"internalType\":\"int56\",\"name\":\"tickCumulativeInside\",\"type\":\"int56\"},{\"internalType\":\"uint160\",\"name\":\"secondsPerLiquidityInsideX128\",\"type\":\"uint160\"},{\"internalType\":\"uint32\",\"name\":\"secondsInside\",\"type\":\"uint32\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"bool\",\"name\":\"zeroForOne\",\"type\":\"bool\"},{\"internalType\":\"int256\",\"name\":\"amountSpecified\",\"type\":\"int256\"},{\"internalType\":\"uint160\",\"name\":\"sqrtPriceLimitX96\",\"type\":\"uint160\"},{\"internalType\":\"bytes\",\"name\":\"data\",\"type\":\"bytes\"}],\"name\":\"swap\",\"outputs\":[{\"internalType\":\"int256\",\"name\":\"amount0\",\"type\":\"int256\"},{\"internalType\":\"int256\",\"name\":\"amount1\",\"type\":\"int256\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"int16\",\"name\":\"\",\"type\":\"int16\"}],\"name\":\"tickBitmap\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"tickSpacing\",\"outputs\":[{\"internalType\":\"int24\",\"name\":\"\",\"type\":\"int24\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"int24\",\"name\":\"\",\"type\":\"int24\"}],\"name\":\"ticks\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"liquidityGross\",\"type\":\"uint128\"},{\"internalType\":\"int128\",\"name\":\"liquidityNet\",\"type\":\"int128\"},{\"internalType\":\"uint256\",\"name\":\"feeGrowthOutside0X128\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"feeGrowthOutside1X128\",\"type\":\"uint256\"},{\"internalType\":\"int56\",\"name\":\"tickCumulativeOutside\",\"type\":\"int56\"},{\"internalType\":\"uint160\",\"name\":\"secondsPerLiquidityOutsideX128\",\"type\":\"uint160\"},{\"internalType\":\"uint32\",\"name\":\"secondsOutside\",\"type\":\"uint32\"},{\"internalType\":\"bool\",\"name\":\"initialized\",\"type\":\"bool\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"token0\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"token1\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"}]'
const ABI_Factory = '[{\"inputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"constructor\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickSpacing\",\"type\":\"int24\"}],\"name\":\"FeeAmountEnabled\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"oldOwner\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"newOwner\",\"type\":\"address\"}],\"name\":\"OwnerChanged\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"token0\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"token1\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"},{\"indexed\":false,\"internalType\":\"int24\",\"name\":\"tickSpacing\",\"type\":\"int24\"},{\"indexed\":false,\"internalType\":\"address\",\"name\":\"pool\",\"type\":\"address\"}],\"name\":\"PoolCreated\",\"type\":\"event\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"tokenA\",\"type\":\"address\"},{\"internalType\":\"address\",\"name\":\"tokenB\",\"type\":\"address\"},{\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"}],\"name\":\"createPool\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"pool\",\"type\":\"address\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"},{\"internalType\":\"int24\",\"name\":\"tickSpacing\",\"type\":\"int24\"}],\"name\":\"enableFeeAmount\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint24\",\"name\":\"\",\"type\":\"uint24\"}],\"name\":\"feeAmountTickSpacing\",\"outputs\":[{\"internalType\":\"int24\",\"name\":\"\",\"type\":\"int24\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"},{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"},{\"internalType\":\"uint24\",\"name\":\"\",\"type\":\"uint24\"}],\"name\":\"getPool\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"owner\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"parameters\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"factory\",\"type\":\"address\"},{\"internalType\":\"address\",\"name\":\"token0\",\"type\":\"address\"},{\"internalType\":\"address\",\"name\":\"token1\",\"type\":\"address\"},{\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"},{\"internalType\":\"int24\",\"name\":\"tickSpacing\",\"type\":\"int24\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"_owner\",\"type\":\"address\"}],\"name\":\"setOwner\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"}]'
// Uniswap contract address
const UniswapV3RouterAddress = "0x68b3465833fb72A70ecDF485E0e4C7bD8665Fc45"
const ContractV3Factory = "0x1F98431c8aD98523631AE4a59f267346ea31F984"
// common constant
const TWO = BigInt(2)
const Q192 = (TWO ** BigInt(96)) ** TWO
const Q96 = (TWO ** BigInt(96))
// Convert to readable amount
function toAmount(s, decimals) {
return Number((BigDecimal(BigInt(s)) / BigDecimal(Math.pow(10, decimals))).toString())
}
// Reverse conversion from readable amount to amount used for passing parameters and calculations
function toInnerAmount(n, decimals) {
return (BigDecimal(n) * BigDecimal(Math.pow(10, decimals))).toFixed(0)
}
function main(){
// The address of the wallet to be searched
// const walletAddress = exchange.IO("address")
const walletAddress = "0x28df8b987BE232bA33FdFB8Fc5058C1592A3db26"
// Get the address of Uniswap V3's positionManager contract
exchange.IO("abi", UniswapV3RouterAddress, ABI_UniswapV3Router)
const NonfungiblePositionManagerAddress = exchange.IO("api", UniswapV3RouterAddress, "positionManager")
Log("NonfungiblePositionManagerAddress:", NonfungiblePositionManagerAddress)
// Register ABI for positionManager contracts
exchange.IO("abi", NonfungiblePositionManagerAddress, ABI_NonfungiblePositionManager)
// Query the number of Uniswap V3 positions NFT owned by the current account
var nftBalance = exchange.IO("api", NonfungiblePositionManagerAddress, "balanceOf", walletAddress)
Log("nftBalance:", nftBalance)
// Query the TokenId of these NFTs
var nftTokenIds = []
for (var i = 0 ; i < nftBalance; i++) {
var nftTokenId = exchange.IO("api", NonfungiblePositionManagerAddress, "tokenOfOwnerByIndex", walletAddress, i)
nftTokenIds.push(nftTokenId)
Log("nftTokenId:", nftTokenId)
}
// Query liquidity position details based on the tokenId of the positions NFT
var positions = []
for (var i = 0; i < nftTokenIds.length; i++) {
var pos = exchange.IO("api", NonfungiblePositionManagerAddress, "positions", nftTokenIds[i])
Log("pos:", pos)
// Parsing position data
positions.push(parsePosData(pos))
}
var tbl = {
type : "table",
title : "LP",
cols : ["range(token0 valuation)", "token0", "token1", "fee", "lowerPrice(tickLower)", "upperPrice(tickUpper)", "liquidity", "amount0", "amount1"],
rows : positions
}
LogStatus("`" + JSON.stringify(tbl) + "`")
}
// Record information about tokens queried through coingecko.com
var tokens = []
function init() {
// When initializing, get information about all tokens to query the
var res = JSON.parse(HttpQuery("https://tokens.coingecko.com/uniswap/all.json"))
Log("fetch", res.tokens.length, "tokens from", res.name)
_.each(res.tokens, function(token) {
tokens.push({
name : token.name,
symbol : token.symbol,
decimals : token.decimals,
address : token.address
})
})
Log("tokens:", tokens)
}
function parsePosData(posData) {
/*
{
"nonce": "0",
"operator": "0x0000000000000000000000000000000000000000",
"token1": "0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2",
"fee": "3000",
"feeGrowthInside0LastX128": "552824104363438506727784685971981736468",
"feeGrowthInside1LastX128": "2419576808699564757520565912733367379",
"tokensOwed0": "0",
"tokensOwed1": "0",
"token0": "0x1f9840a85d5af5bf1d1762f925bdaddc4201f984",
"tickLower": "-62160",
"tickUpper": "-41280",
"liquidity": "19090316141441365693"
}
*/
var token0Symbol = null
var token1Symbol = null
// Determine the token according to the address of the token, record the information about the token
for (var i in tokens) {
if (tokens[i].address.toLowerCase() == posData.token0.toLowerCase()) {
token0Symbol = tokens[i]
} else if (tokens[i].address.toLowerCase() == posData.token1.toLowerCase()) {
token1Symbol = tokens[i]
}
}
if (!token0Symbol || !token1Symbol) {
Log("token0Symbol:", token0Symbol, ", token1Symbol:", token1Symbol)
throw "token not found"
}
// get Pool , obtaining data about the exchange pool
var poolInfo = getPool(token0Symbol.address, token1Symbol.address, posData.fee)
Log("poolInfo:", poolInfo)
/* Data examples
{
"slot0":{
"sqrtPriceX96":"4403124416947951698847768103","tick":"-57804","observationIndex":136,"observationCardinality":300,
"observationCardinalityNext":300,"feeProtocol":0,"unlocked":true
}
}
*/
// Calculate token0Amount, token1Amount
var currentTick = parseInt(poolInfo.slot0.tick)
var lowerPrice = 1.0001 ** posData.tickLower
var upperPrice = 1.0001 ** posData.tickUpper
var sqrtRatioA = Math.sqrt(lowerPrice)
var sqrtRatioB = Math.sqrt(upperPrice)
var sqrtPrice = Number(BigFloat(poolInfo.slot0.sqrtPriceX96) / Q96)
var amount0wei = 0
var amount1wei = 0
if (currentTick <= posData.tickLower) {
amount0wei = Math.floor(posData.liquidity * ((sqrtRatioB - sqrtRatioA) / (sqrtRatioA * sqrtRatioB)))
} else if (currentTick > posData.tickUpper) {
amount1wei = Math.floor(posData.liquidity * (sqrtRatioB - sqrtRatioA))
} else if (currentTick >= posData.tickLower && currentTick < posData.tickUpper) {
amount0wei = Math.floor(posData.liquidity * ((sqrtRatioB - sqrtPrice) / (sqrtPrice * sqrtRatioB)))
amount1wei = Math.floor(posData.liquidity * (sqrtPrice - sqrtRatioA))
}
var rangeToken0 = (1.0001 ** -posData.tickUpper) + " ~ " + (1.0001 ** -posData.tickLower)
var amount0 = toAmount(amount0wei, token0Symbol.decimals)
var amount1 = toAmount(amount1wei, token1Symbol.decimals)
return [rangeToken0, token0Symbol.symbol, token1Symbol.symbol, posData.fee / 10000 + "%",
`${lowerPrice}(tickLower:${posData.tickLower})`, `${upperPrice}(tickUpper:${posData.tickUpper})`, posData.liquidity,
amount0, amount1]
}
function getPool(token0Address, token1Address, fee) {
if (BigInt(token0Address) > BigInt(token1Address)) {
var tmp = token0Address
token0Address = token1Address
token1Address = tmp
}
// Calculating the contract address of an exchange pool using Uniswap's factory contract
exchange.IO("abi", ContractV3Factory, ABI_Factory)
var poolAddress = exchange.IO("api", ContractV3Factory, "getPool", token0Address, token1Address, fee)
if (!poolAddress) {
throw "getPool failed"
}
// ABI for registered pool contracts
exchange.IO("abi", poolAddress, ABI_Pool)
// Call the pool contract's slot0 method to query the current exchange pool's data
var slot0 = exchange.IO("api", poolAddress, "slot0")
if (!slot0) {
throw "get slot0 failed"
}
return {
"slot0": slot0
}
}
```
The retrieved liquidity position information (which needs further parsing):
```
{
"nonce": "0",
"operator": "0x0000000000000000000000000000000000000000",
"token1": "0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2",
"fee": "3000",
"feeGrowthInside0LastX128": "552824104363438506727784685971981736468",
"feeGrowthInside1LastX128": "2419576808699564757520565912733367379",
"tokensOwed0": "0",
"tokensOwed1": "0",
"token0": "0x1f9840a85d5af5bf1d1762f925bdaddc4201f984",
"tickLower": "-62160",
"tickUpper": "-41280",
"liquidity": "19090316141441365693"
}
```
## Parsing Liquidity Holdings for Market Making Ranges
The positions method of Uniswap's NonfungiblePositionManager contract returns tickLower and tickUpper in the liquidity position data. In Uniswap V3, liquidity can be specified within a range, whereas the initial design of Uniswap had uniform distribution of liquidity. The specification of a liquidity range in subsequent versions is aimed at improving the utilization of liquidity capital.
> tickLower: The lower end of the tick range for the position
> tickUpper: The higher end of the tick range for the position
tickLower and tickUpper represent the upper and lower limits of the liquidity. Referring to the Uniswap documentation and its complex formulas, tickLower and tickUpper are essentially price boundaries recorded in exponential form. So, how can we calculate the price range for market-making from these "exponential boundaries"?
It's quite simple. Uniswap uses a base of 1.0001. Lower price: lowerPrice = 1.0001 ** tickLower; Upper price: upperPrice = 1.0001 ** tickUpper. The ** operator represents exponentiation. For example, 1.0001 ** 100 calculates 1.0001 raised to the power of 100.
This calculated price range is denominated in token1. But what if we want to see the price range denominated in token0?
It can be calculated as follows:
Lower price: 1.0001 ** -tickUpper
Upper price: 1.0001 ** -tickLower
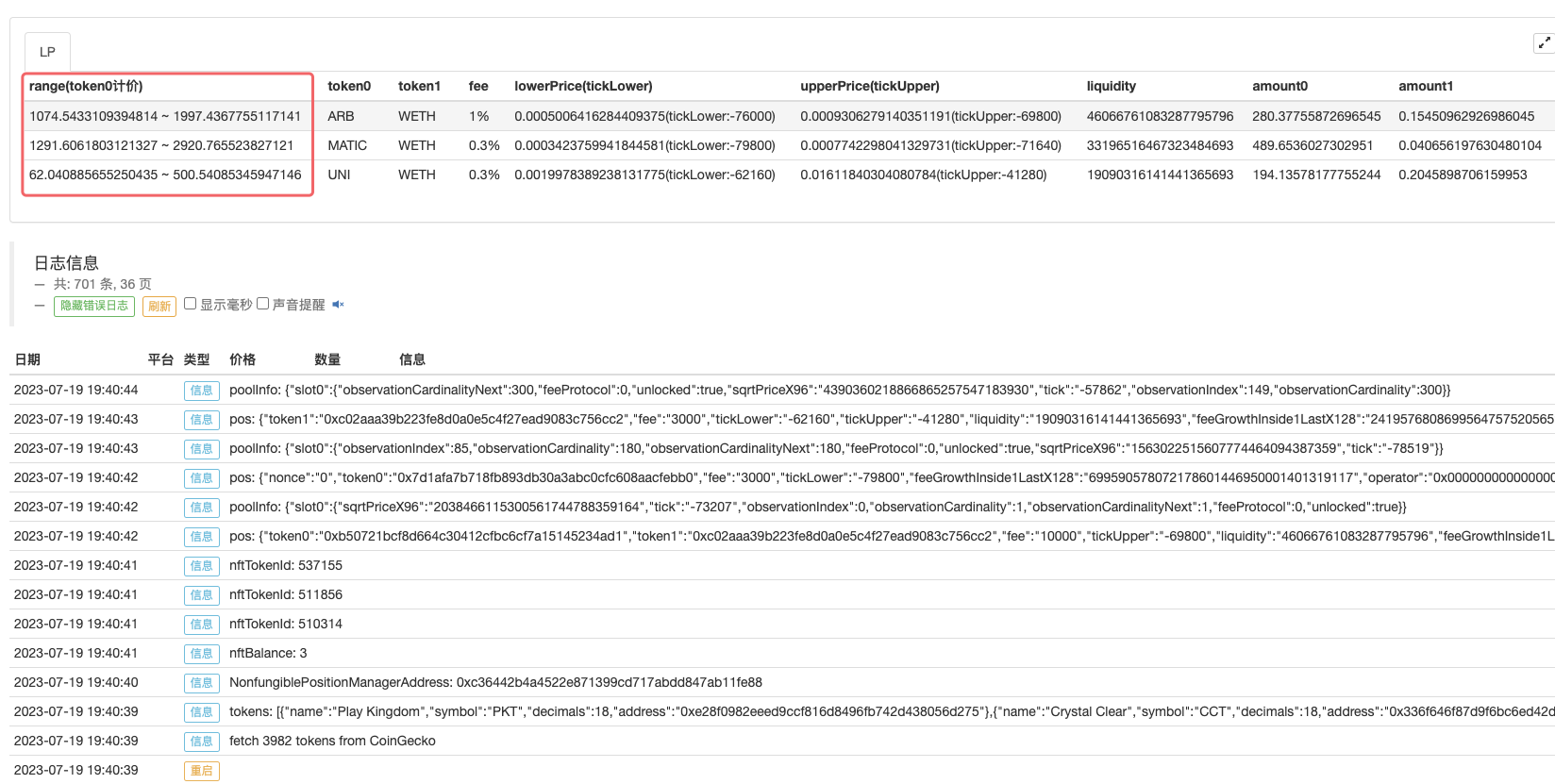
Compare this to the NFT position we looked up on the chain:
## Parsing the Asset Value in the Current Liquidity Position
In addition to tickUpper and tickLower, the positions method of Uniswap's NonfungiblePositionManager contract returns another important data: liquidity.
By combining the liquidity, tickUpper, tickLower data from the position information with the current price data in the exchange pool, we can calculate the asset value in the current liquidity position.
You may wonder why we need to know the current price in the exchange pool to make the calculation.
This is because once you add liquidity, any price changes within the effective range of your liquidity position imply that your assets have been exchanged. If the current exchange price is not within the effective range of your liquidity provision, there won't be any changes. Therefore, there are three scenarios to consider when calculating:
- The tick of the current price is less than tickLower.
- The tick of the current price is greater than tickUpper.
- The tick of the current price is within the range of tickLower to tickUpper.
This corresponds to the following calculation and processing in the code:
```
if (currentTick <= posData.tickLower) {
amount0wei = Math.floor(posData.liquidity * ((sqrtRatioB - sqrtRatioA) / (sqrtRatioA * sqrtRatioB)))
} else if (currentTick > posData.tickUpper) {
amount1wei = Math.floor(posData.liquidity * (sqrtRatioB - sqrtRatioA))
} else if (currentTick >= posData.tickLower && currentTick < posData.tickUpper) {
amount0wei = Math.floor(posData.liquidity * ((sqrtRatioB - sqrtPrice) / (sqrtPrice * sqrtRatioB)))
amount1wei = Math.floor(posData.liquidity * (sqrtPrice - sqrtRatioA))
}
```
To perform the above calculations, we need to obtain the tick of the current price, which can be obtained directly from the pool contract. To get the address of the pool contract, we can use the getPool method of Uniswap's factory contract. By using the slot0 method of the pool contract, we can retrieve the current price information, including the tick value we need.

## Market-making Fees
How to calculate the fees earned by liquidity providers (LPs) based on their positions? Let's explain it step by step:
1. Constants and helper functions:
The code defines some constants (ZERO, TWO, Q96, Q128, Q192, Q256) and two utility functions for converting between readable amount and amount used for internal parameter passing and calculations. These functions handle the conversion of token amount.
2. Token data initialization:
The init() function retrieves token data from the Coingecko API and stores it in the tokens array.
3. Main function main(): This is the main entry point of the code.
- It specifies a wallet address (walletAddress) to query its Uniswap V3 positions.
- It retrieves the address of the Uniswap V3 NonfungiblePositionManager contract (NonfungiblePositionManagerAddress) from the Uniswap V3 Router contract.
- It registers the ABI of the NonfungiblePositionManager contract.
- It queries the number of Uniswap V3 positions owned by the given walletAddress and stores the result in nftBalance.
- Then, it retrieves the token IDs of the NFTs owned by the wallet and stores them in the nftTokenIds array.
- For each NFT token ID, it calls the positions method of the NonfungiblePositionManager contract with it as a parameter to retrieve position data, and then uses the getFees() function to retrieve detailed information about the exchange pool and calculate fee data.
- The result data is stored in the positions array.
4. Function getFees():
This function is used to calculate the fees earned by a specific position as a liquidity provider. It takes position data as input and processes the data to gather relevant information. It uses the API and data from the Uniswap V3 contract (such as fee growth, tick, liquidity, etc.) to perform the fee calculation. The function then returns the fees for token0 and token1 in a specific format.
```
// Uniswap ABI
const ABI_UniswapV3Router = `[{"inputs":[{"internalType":"address","name":"_factoryV2","type":"address"},{"internalType":"address","name":"factoryV3","type":"address"},{"internalType":"address","name":"_positionManager","type":"address"},{"internalType":"address","name":"_WETH9","type":"address"}],"stateMutability":"nonpayable","type":"constructor"},{"inputs":[],"name":"WETH9","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"}],"name":"approveMax","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"}],"name":"approveMaxMinusOne","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"}],"name":"approveZeroThenMax","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"}],"name":"approveZeroThenMaxMinusOne","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes","name":"data","type":"bytes"}],"name":"callPositionManager","outputs":[{"internalType":"bytes","name":"result","type":"bytes"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes[]","name":"paths","type":"bytes[]"},{"internalType":"uint128[]","name":"amounts","type":"uint128[]"},{"internalType":"uint24","name":"maximumTickDivergence","type":"uint24"},{"internalType":"uint32","name":"secondsAgo","type":"uint32"}],"name":"checkOracleSlippage","outputs":[],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"bytes","name":"path","type":"bytes"},{"internalType":"uint24","name":"maximumTickDivergence","type":"uint24"},{"internalType":"uint32","name":"secondsAgo","type":"uint32"}],"name":"checkOracleSlippage","outputs":[],"stateMutability":"view","type":"function"},{"inputs":[{"components":[{"internalType":"bytes","name":"path","type":"bytes"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"amountIn","type":"uint256"},{"internalType":"uint256","name":"amountOutMinimum","type":"uint256"}],"internalType":"struct IV3SwapRouter.ExactInputParams","name":"params","type":"tuple"}],"name":"exactInput","outputs":[{"internalType":"uint256","name":"amountOut","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"tokenIn","type":"address"},{"internalType":"address","name":"tokenOut","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"amountIn","type":"uint256"},{"internalType":"uint256","name":"amountOutMinimum","type":"uint256"},{"internalType":"uint160","name":"sqrtPriceLimitX96","type":"uint160"}],"internalType":"struct IV3SwapRouter.ExactInputSingleParams","name":"params","type":"tuple"}],"name":"exactInputSingle","outputs":[{"internalType":"uint256","name":"amountOut","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"bytes","name":"path","type":"bytes"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"amountOut","type":"uint256"},{"internalType":"uint256","name":"amountInMaximum","type":"uint256"}],"internalType":"struct IV3SwapRouter.ExactOutputParams","name":"params","type":"tuple"}],"name":"exactOutput","outputs":[{"internalType":"uint256","name":"amountIn","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"tokenIn","type":"address"},{"internalType":"address","name":"tokenOut","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"amountOut","type":"uint256"},{"internalType":"uint256","name":"amountInMaximum","type":"uint256"},{"internalType":"uint160","name":"sqrtPriceLimitX96","type":"uint160"}],"internalType":"struct IV3SwapRouter.ExactOutputSingleParams","name":"params","type":"tuple"}],"name":"exactOutputSingle","outputs":[{"internalType":"uint256","name":"amountIn","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"factory","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"factoryV2","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amount","type":"uint256"}],"name":"getApprovalType","outputs":[{"internalType":"enum IApproveAndCall.ApprovalType","name":"","type":"uint8"}],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"}],"internalType":"struct IApproveAndCall.IncreaseLiquidityParams","name":"params","type":"tuple"}],"name":"increaseLiquidity","outputs":[{"internalType":"bytes","name":"result","type":"bytes"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"int24","name":"tickLower","type":"int24"},{"internalType":"int24","name":"tickUpper","type":"int24"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"internalType":"struct IApproveAndCall.MintParams","name":"params","type":"tuple"}],"name":"mint","outputs":[{"internalType":"bytes","name":"result","type":"bytes"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes32","name":"previousBlockhash","type":"bytes32"},{"internalType":"bytes[]","name":"data","type":"bytes[]"}],"name":"multicall","outputs":[{"internalType":"bytes[]","name":"","type":"bytes[]"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"bytes[]","name":"data","type":"bytes[]"}],"name":"multicall","outputs":[{"internalType":"bytes[]","name":"","type":"bytes[]"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes[]","name":"data","type":"bytes[]"}],"name":"multicall","outputs":[{"internalType":"bytes[]","name":"results","type":"bytes[]"}],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"positionManager","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"}],"name":"pull","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"refundETH","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermit","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"nonce","type":"uint256"},{"internalType":"uint256","name":"expiry","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitAllowed","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"nonce","type":"uint256"},{"internalType":"uint256","name":"expiry","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitAllowedIfNecessary","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitIfNecessary","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountIn","type":"uint256"},{"internalType":"uint256","name":"amountOutMin","type":"uint256"},{"internalType":"address[]","name":"path","type":"address[]"},{"internalType":"address","name":"to","type":"address"}],"name":"swapExactTokensForTokens","outputs":[{"internalType":"uint256","name":"amountOut","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountOut","type":"uint256"},{"internalType":"uint256","name":"amountInMax","type":"uint256"},{"internalType":"address[]","name":"path","type":"address[]"},{"internalType":"address","name":"to","type":"address"}],"name":"swapTokensForExactTokens","outputs":[{"internalType":"uint256","name":"amountIn","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"name":"sweepToken","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"}],"name":"sweepToken","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"uint256","name":"feeBips","type":"uint256"},{"internalType":"address","name":"feeRecipient","type":"address"}],"name":"sweepTokenWithFee","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"feeBips","type":"uint256"},{"internalType":"address","name":"feeRecipient","type":"address"}],"name":"sweepTokenWithFee","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"int256","name":"amount0Delta","type":"int256"},{"internalType":"int256","name":"amount1Delta","type":"int256"},{"internalType":"bytes","name":"_data","type":"bytes"}],"name":"uniswapV3SwapCallback","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"name":"unwrapWETH9","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"}],"name":"unwrapWETH9","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"feeBips","type":"uint256"},{"internalType":"address","name":"feeRecipient","type":"address"}],"name":"unwrapWETH9WithFee","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"uint256","name":"feeBips","type":"uint256"},{"internalType":"address","name":"feeRecipient","type":"address"}],"name":"unwrapWETH9WithFee","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"value","type":"uint256"}],"name":"wrapETH","outputs":[],"stateMutability":"payable","type":"function"},{"stateMutability":"payable","type":"receive"}]`
const ABI_NonfungiblePositionManager = `[{"inputs":[{"internalType":"address","name":"_factory","type":"address"},{"internalType":"address","name":"_WETH9","type":"address"},{"internalType":"address","name":"_tokenDescriptor_","type":"address"}],"stateMutability":"nonpayable","type":"constructor"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"owner","type":"address"},{"indexed":true,"internalType":"address","name":"approved","type":"address"},{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"Approval","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"owner","type":"address"},{"indexed":true,"internalType":"address","name":"operator","type":"address"},{"indexed":false,"internalType":"bool","name":"approved","type":"bool"}],"name":"ApprovalForAll","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"},{"indexed":false,"internalType":"address","name":"recipient","type":"address"},{"indexed":false,"internalType":"uint256","name":"amount0","type":"uint256"},{"indexed":false,"internalType":"uint256","name":"amount1","type":"uint256"}],"name":"Collect","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"},{"indexed":false,"internalType":"uint128","name":"liquidity","type":"uint128"},{"indexed":false,"internalType":"uint256","name":"amount0","type":"uint256"},{"indexed":false,"internalType":"uint256","name":"amount1","type":"uint256"}],"name":"DecreaseLiquidity","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"},{"indexed":false,"internalType":"uint128","name":"liquidity","type":"uint128"},{"indexed":false,"internalType":"uint256","name":"amount0","type":"uint256"},{"indexed":false,"internalType":"uint256","name":"amount1","type":"uint256"}],"name":"IncreaseLiquidity","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"from","type":"address"},{"indexed":true,"internalType":"address","name":"to","type":"address"},{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"Transfer","type":"event"},{"inputs":[],"name":"DOMAIN_SEPARATOR","outputs":[{"internalType":"bytes32","name":"","type":"bytes32"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"PERMIT_TYPEHASH","outputs":[{"internalType":"bytes32","name":"","type":"bytes32"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"WETH9","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"approve","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"owner","type":"address"}],"name":"balanceOf","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"baseURI","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"pure","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"burn","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint128","name":"amount0Max","type":"uint128"},{"internalType":"uint128","name":"amount1Max","type":"uint128"}],"internalType":"struct INonfungiblePositionManager.CollectParams","name":"params","type":"tuple"}],"name":"collect","outputs":[{"internalType":"uint256","name":"amount0","type":"uint256"},{"internalType":"uint256","name":"amount1","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"uint160","name":"sqrtPriceX96","type":"uint160"}],"name":"createAndInitializePoolIfNecessary","outputs":[{"internalType":"address","name":"pool","type":"address"}],"stateMutability":"payable","type":"function"},{"inputs":[{"components":[{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint128","name":"liquidity","type":"uint128"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"}],"internalType":"struct INonfungiblePositionManager.DecreaseLiquidityParams","name":"params","type":"tuple"}],"name":"decreaseLiquidity","outputs":[{"internalType":"uint256","name":"amount0","type":"uint256"},{"internalType":"uint256","name":"amount1","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"factory","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"getApproved","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"components":[{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint256","name":"amount0Desired","type":"uint256"},{"internalType":"uint256","name":"amount1Desired","type":"uint256"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"}],"internalType":"struct INonfungiblePositionManager.IncreaseLiquidityParams","name":"params","type":"tuple"}],"name":"increaseLiquidity","outputs":[{"internalType":"uint128","name":"liquidity","type":"uint128"},{"internalType":"uint256","name":"amount0","type":"uint256"},{"internalType":"uint256","name":"amount1","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"owner","type":"address"},{"internalType":"address","name":"operator","type":"address"}],"name":"isApprovedForAll","outputs":[{"internalType":"bool","name":"","type":"bool"}],"stateMutability":"view","type":"function"},{"inputs":[{"components":[{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"int24","name":"tickLower","type":"int24"},{"internalType":"int24","name":"tickUpper","type":"int24"},{"internalType":"uint256","name":"amount0Desired","type":"uint256"},{"internalType":"uint256","name":"amount1Desired","type":"uint256"},{"internalType":"uint256","name":"amount0Min","type":"uint256"},{"internalType":"uint256","name":"amount1Min","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"},{"internalType":"uint256","name":"deadline","type":"uint256"}],"internalType":"struct INonfungiblePositionManager.MintParams","name":"params","type":"tuple"}],"name":"mint","outputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint128","name":"liquidity","type":"uint128"},{"internalType":"uint256","name":"amount0","type":"uint256"},{"internalType":"uint256","name":"amount1","type":"uint256"}],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"bytes[]","name":"data","type":"bytes[]"}],"name":"multicall","outputs":[{"internalType":"bytes[]","name":"results","type":"bytes[]"}],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"name","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"ownerOf","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"spender","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"permit","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"positions","outputs":[{"internalType":"uint96","name":"nonce","type":"uint96"},{"internalType":"address","name":"operator","type":"address"},{"internalType":"address","name":"token0","type":"address"},{"internalType":"address","name":"token1","type":"address"},{"internalType":"uint24","name":"fee","type":"uint24"},{"internalType":"int24","name":"tickLower","type":"int24"},{"internalType":"int24","name":"tickUpper","type":"int24"},{"internalType":"uint128","name":"liquidity","type":"uint128"},{"internalType":"uint256","name":"feeGrowthInside0LastX128","type":"uint256"},{"internalType":"uint256","name":"feeGrowthInside1LastX128","type":"uint256"},{"internalType":"uint128","name":"tokensOwed0","type":"uint128"},{"internalType":"uint128","name":"tokensOwed1","type":"uint128"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"refundETH","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"safeTransferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"bytes","name":"_data","type":"bytes"}],"name":"safeTransferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermit","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"nonce","type":"uint256"},{"internalType":"uint256","name":"expiry","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitAllowed","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"nonce","type":"uint256"},{"internalType":"uint256","name":"expiry","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitAllowedIfNecessary","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"value","type":"uint256"},{"internalType":"uint256","name":"deadline","type":"uint256"},{"internalType":"uint8","name":"v","type":"uint8"},{"internalType":"bytes32","name":"r","type":"bytes32"},{"internalType":"bytes32","name":"s","type":"bytes32"}],"name":"selfPermitIfNecessary","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[{"internalType":"address","name":"operator","type":"address"},{"internalType":"bool","name":"approved","type":"bool"}],"name":"setApprovalForAll","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"bytes4","name":"interfaceId","type":"bytes4"}],"name":"supportsInterface","outputs":[{"internalType":"bool","name":"","type":"bool"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"token","type":"address"},{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"name":"sweepToken","outputs":[],"stateMutability":"payable","type":"function"},{"inputs":[],"name":"symbol","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"index","type":"uint256"}],"name":"tokenByIndex","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"owner","type":"address"},{"internalType":"uint256","name":"index","type":"uint256"}],"name":"tokenOfOwnerByIndex","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"tokenURI","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"totalSupply","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"transferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amount0Owed","type":"uint256"},{"internalType":"uint256","name":"amount1Owed","type":"uint256"},{"internalType":"bytes","name":"data","type":"bytes"}],"name":"uniswapV3MintCallback","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"uint256","name":"amountMinimum","type":"uint256"},{"internalType":"address","name":"recipient","type":"address"}],"name":"unwrapWETH9","outputs":[],"stateMutability":"payable","type":"function"},{"stateMutability":"payable","type":"receive"}]`
const ABI_Pool = '[{\"inputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"constructor\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"owner\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"}],\"name\":\"Burn\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"owner\",\"type\":\"address\"},{\"indexed\":false,\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount0\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount1\",\"type\":\"uint128\"}],\"name\":\"Collect\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"sender\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount0\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount1\",\"type\":\"uint128\"}],\"name\":\"CollectProtocol\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"sender\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"paid0\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"paid1\",\"type\":\"uint256\"}],\"name\":\"Flash\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":false,\"internalType\":\"uint16\",\"name\":\"observationCardinalityNextOld\",\"type\":\"uint16\"},{\"indexed\":false,\"internalType\":\"uint16\",\"name\":\"observationCardinalityNextNew\",\"type\":\"uint16\"}],\"name\":\"IncreaseObservationCardinalityNext\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":false,\"internalType\":\"uint160\",\"name\":\"sqrtPriceX96\",\"type\":\"uint160\"},{\"indexed\":false,\"internalType\":\"int24\",\"name\":\"tick\",\"type\":\"int24\"}],\"name\":\"Initialize\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":false,\"internalType\":\"address\",\"name\":\"sender\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"owner\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"amount\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"indexed\":false,\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"}],\"name\":\"Mint\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":false,\"internalType\":\"uint8\",\"name\":\"feeProtocol0Old\",\"type\":\"uint8\"},{\"indexed\":false,\"internalType\":\"uint8\",\"name\":\"feeProtocol1Old\",\"type\":\"uint8\"},{\"indexed\":false,\"internalType\":\"uint8\",\"name\":\"feeProtocol0New\",\"type\":\"uint8\"},{\"indexed\":false,\"internalType\":\"uint8\",\"name\":\"feeProtocol1New\",\"type\":\"uint8\"}],\"name\":\"SetFeeProtocol\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"sender\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"indexed\":false,\"internalType\":\"int256\",\"name\":\"amount0\",\"type\":\"int256\"},{\"indexed\":false,\"internalType\":\"int256\",\"name\":\"amount1\",\"type\":\"int256\"},{\"indexed\":false,\"internalType\":\"uint160\",\"name\":\"sqrtPriceX96\",\"type\":\"uint160\"},{\"indexed\":false,\"internalType\":\"uint128\",\"name\":\"liquidity\",\"type\":\"uint128\"},{\"indexed\":false,\"internalType\":\"int24\",\"name\":\"tick\",\"type\":\"int24\"}],\"name\":\"Swap\",\"type\":\"event\"},{\"inputs\":[{\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"internalType\":\"uint128\",\"name\":\"amount\",\"type\":\"uint128\"}],\"name\":\"burn\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"internalType\":\"uint128\",\"name\":\"amount0Requested\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"amount1Requested\",\"type\":\"uint128\"}],\"name\":\"collect\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"amount0\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"amount1\",\"type\":\"uint128\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"uint128\",\"name\":\"amount0Requested\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"amount1Requested\",\"type\":\"uint128\"}],\"name\":\"collectProtocol\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"amount0\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"amount1\",\"type\":\"uint128\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"factory\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"fee\",\"outputs\":[{\"internalType\":\"uint24\",\"name\":\"\",\"type\":\"uint24\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"feeGrowthGlobal0X128\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"feeGrowthGlobal1X128\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"},{\"internalType\":\"bytes\",\"name\":\"data\",\"type\":\"bytes\"}],\"name\":\"flash\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint16\",\"name\":\"observationCardinalityNext\",\"type\":\"uint16\"}],\"name\":\"increaseObservationCardinalityNext\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint160\",\"name\":\"sqrtPriceX96\",\"type\":\"uint160\"}],\"name\":\"initialize\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"liquidity\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"\",\"type\":\"uint128\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"maxLiquidityPerTick\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"\",\"type\":\"uint128\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"},{\"internalType\":\"uint128\",\"name\":\"amount\",\"type\":\"uint128\"},{\"internalType\":\"bytes\",\"name\":\"data\",\"type\":\"bytes\"}],\"name\":\"mint\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"amount0\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"amount1\",\"type\":\"uint256\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"name\":\"observations\",\"outputs\":[{\"internalType\":\"uint32\",\"name\":\"blockTimestamp\",\"type\":\"uint32\"},{\"internalType\":\"int56\",\"name\":\"tickCumulative\",\"type\":\"int56\"},{\"internalType\":\"uint160\",\"name\":\"secondsPerLiquidityCumulativeX128\",\"type\":\"uint160\"},{\"internalType\":\"bool\",\"name\":\"initialized\",\"type\":\"bool\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint32[]\",\"name\":\"secondsAgos\",\"type\":\"uint32[]\"}],\"name\":\"observe\",\"outputs\":[{\"internalType\":\"int56[]\",\"name\":\"tickCumulatives\",\"type\":\"int56[]\"},{\"internalType\":\"uint160[]\",\"name\":\"secondsPerLiquidityCumulativeX128s\",\"type\":\"uint160[]\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"bytes32\",\"name\":\"\",\"type\":\"bytes32\"}],\"name\":\"positions\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"liquidity\",\"type\":\"uint128\"},{\"internalType\":\"uint256\",\"name\":\"feeGrowthInside0LastX128\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"feeGrowthInside1LastX128\",\"type\":\"uint256\"},{\"internalType\":\"uint128\",\"name\":\"tokensOwed0\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"tokensOwed1\",\"type\":\"uint128\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"protocolFees\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"token0\",\"type\":\"uint128\"},{\"internalType\":\"uint128\",\"name\":\"token1\",\"type\":\"uint128\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint8\",\"name\":\"feeProtocol0\",\"type\":\"uint8\"},{\"internalType\":\"uint8\",\"name\":\"feeProtocol1\",\"type\":\"uint8\"}],\"name\":\"setFeeProtocol\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"slot0\",\"outputs\":[{\"internalType\":\"uint160\",\"name\":\"sqrtPriceX96\",\"type\":\"uint160\"},{\"internalType\":\"int24\",\"name\":\"tick\",\"type\":\"int24\"},{\"internalType\":\"uint16\",\"name\":\"observationIndex\",\"type\":\"uint16\"},{\"internalType\":\"uint16\",\"name\":\"observationCardinality\",\"type\":\"uint16\"},{\"internalType\":\"uint16\",\"name\":\"observationCardinalityNext\",\"type\":\"uint16\"},{\"internalType\":\"uint8\",\"name\":\"feeProtocol\",\"type\":\"uint8\"},{\"internalType\":\"bool\",\"name\":\"unlocked\",\"type\":\"bool\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"int24\",\"name\":\"tickLower\",\"type\":\"int24\"},{\"internalType\":\"int24\",\"name\":\"tickUpper\",\"type\":\"int24\"}],\"name\":\"snapshotCumulativesInside\",\"outputs\":[{\"internalType\":\"int56\",\"name\":\"tickCumulativeInside\",\"type\":\"int56\"},{\"internalType\":\"uint160\",\"name\":\"secondsPerLiquidityInsideX128\",\"type\":\"uint160\"},{\"internalType\":\"uint32\",\"name\":\"secondsInside\",\"type\":\"uint32\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"recipient\",\"type\":\"address\"},{\"internalType\":\"bool\",\"name\":\"zeroForOne\",\"type\":\"bool\"},{\"internalType\":\"int256\",\"name\":\"amountSpecified\",\"type\":\"int256\"},{\"internalType\":\"uint160\",\"name\":\"sqrtPriceLimitX96\",\"type\":\"uint160\"},{\"internalType\":\"bytes\",\"name\":\"data\",\"type\":\"bytes\"}],\"name\":\"swap\",\"outputs\":[{\"internalType\":\"int256\",\"name\":\"amount0\",\"type\":\"int256\"},{\"internalType\":\"int256\",\"name\":\"amount1\",\"type\":\"int256\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"int16\",\"name\":\"\",\"type\":\"int16\"}],\"name\":\"tickBitmap\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"tickSpacing\",\"outputs\":[{\"internalType\":\"int24\",\"name\":\"\",\"type\":\"int24\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"int24\",\"name\":\"\",\"type\":\"int24\"}],\"name\":\"ticks\",\"outputs\":[{\"internalType\":\"uint128\",\"name\":\"liquidityGross\",\"type\":\"uint128\"},{\"internalType\":\"int128\",\"name\":\"liquidityNet\",\"type\":\"int128\"},{\"internalType\":\"uint256\",\"name\":\"feeGrowthOutside0X128\",\"type\":\"uint256\"},{\"internalType\":\"uint256\",\"name\":\"feeGrowthOutside1X128\",\"type\":\"uint256\"},{\"internalType\":\"int56\",\"name\":\"tickCumulativeOutside\",\"type\":\"int56\"},{\"internalType\":\"uint160\",\"name\":\"secondsPerLiquidityOutsideX128\",\"type\":\"uint160\"},{\"internalType\":\"uint32\",\"name\":\"secondsOutside\",\"type\":\"uint32\"},{\"internalType\":\"bool\",\"name\":\"initialized\",\"type\":\"bool\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"token0\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"token1\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"}]'
const ABI_Factory = '[{\"inputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"constructor\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"},{\"indexed\":true,\"internalType\":\"int24\",\"name\":\"tickSpacing\",\"type\":\"int24\"}],\"name\":\"FeeAmountEnabled\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"oldOwner\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"newOwner\",\"type\":\"address\"}],\"name\":\"OwnerChanged\",\"type\":\"event\"},{\"anonymous\":false,\"inputs\":[{\"indexed\":true,\"internalType\":\"address\",\"name\":\"token0\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"address\",\"name\":\"token1\",\"type\":\"address\"},{\"indexed\":true,\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"},{\"indexed\":false,\"internalType\":\"int24\",\"name\":\"tickSpacing\",\"type\":\"int24\"},{\"indexed\":false,\"internalType\":\"address\",\"name\":\"pool\",\"type\":\"address\"}],\"name\":\"PoolCreated\",\"type\":\"event\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"tokenA\",\"type\":\"address\"},{\"internalType\":\"address\",\"name\":\"tokenB\",\"type\":\"address\"},{\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"}],\"name\":\"createPool\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"pool\",\"type\":\"address\"}],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"},{\"internalType\":\"int24\",\"name\":\"tickSpacing\",\"type\":\"int24\"}],\"name\":\"enableFeeAmount\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint24\",\"name\":\"\",\"type\":\"uint24\"}],\"name\":\"feeAmountTickSpacing\",\"outputs\":[{\"internalType\":\"int24\",\"name\":\"\",\"type\":\"int24\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"},{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"},{\"internalType\":\"uint24\",\"name\":\"\",\"type\":\"uint24\"}],\"name\":\"getPool\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"owner\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"\",\"type\":\"address\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[],\"name\":\"parameters\",\"outputs\":[{\"internalType\":\"address\",\"name\":\"factory\",\"type\":\"address\"},{\"internalType\":\"address\",\"name\":\"token0\",\"type\":\"address\"},{\"internalType\":\"address\",\"name\":\"token1\",\"type\":\"address\"},{\"internalType\":\"uint24\",\"name\":\"fee\",\"type\":\"uint24\"},{\"internalType\":\"int24\",\"name\":\"tickSpacing\",\"type\":\"int24\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"address\",\"name\":\"_owner\",\"type\":\"address\"}],\"name\":\"setOwner\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"}]'
// Uniswap contract address
const UniswapV3RouterAddress = "0x68b3465833fb72A70ecDF485E0e4C7bD8665Fc45"
const ContractV3Factory = "0x1F98431c8aD98523631AE4a59f267346ea31F984"
// common constant
const ZERO = BigInt(0)
const TWO = BigInt(2)
const Q96 = (TWO ** BigInt(96))
const Q128 = (TWO ** BigInt(128))
const Q192 = (TWO ** BigInt(96)) ** TWO
const Q256 = (TWO ** BigInt(256))
// Convert to readable amount
function toAmount(s, decimals) {
return Number((BigDecimal(BigInt(s)) / BigDecimal(Math.pow(10, decimals))).toString())
}
// Reverse conversion from readable amount to amount used for passing parameters and calculations
function toInnerAmount(n, decimals) {
return (BigDecimal(n) * BigDecimal(Math.pow(10, decimals))).toFixed(0)
}
function subIn256(x, y){
var difference = x - y
if (difference < ZERO) {
return Q256 + difference
} else {
return difference
}
}
// Record information about tokens queried through coingecko.com
var tokens = []
function init() {
var res = JSON.parse(HttpQuery("https://tokens.coingecko.com/uniswap/all.json"))
Log("fetch", res.tokens.length, "tokens from", res.name)
_.each(res.tokens, function(token) {
tokens.push({
name : token.name,
symbol : token.symbol,
decimals : token.decimals,
address : token.address
})
})
Log("tokens:", tokens)
}
function main(){
// The address of the wallet to be searched
// const walletAddress = exchange.IO("address")
const walletAddress = "0x28df8b987BE232bA33FdFB8Fc5058C1592A3db26"
// Get the address of Uniswap V3's positionManager contract
exchange.IO("abi", UniswapV3RouterAddress, ABI_UniswapV3Router)
const NonfungiblePositionManagerAddress = exchange.IO("api", UniswapV3RouterAddress, "positionManager")
Log("NonfungiblePositionManagerAddress:", NonfungiblePositionManagerAddress)
// Register ABI for positionManager contracts
exchange.IO("abi", NonfungiblePositionManagerAddress, ABI_NonfungiblePositionManager)
// Query the number of Uniswap V3 positions NFT owned by the current account
var nftBalance = exchange.IO("api", NonfungiblePositionManagerAddress, "balanceOf", walletAddress)
Log("nftBalance:", nftBalance)
// Query the TokenId of these NFTs
var nftTokenIds = []
for (var i = 0 ; i < nftBalance; i++) {
var nftTokenId = exchange.IO("api", NonfungiblePositionManagerAddress, "tokenOfOwnerByIndex", walletAddress, i)
nftTokenIds.push(nftTokenId)
Log("nftTokenId:", nftTokenId)
}
// Query liquidity position details based on the tokenId of the positions NFT
var positions = []
for (var i = 0; i < nftTokenIds.length; i++) {
var pos = exchange.IO("api", NonfungiblePositionManagerAddress, "positions", nftTokenIds[i])
Log("pos:", pos)
// Parsing position data
positions.push(getFees(pos))
}
var tbl = {
type : "table",
title : "LP-Fees",
cols : ["token0", "token1", "fee", "token0Fee", "token1Fee"],
rows : positions
}
LogStatus("`" + JSON.stringify(tbl) + "`")
}
function getFees(posData) {
var token0Symbol = null
var token1Symbol = null
for (var i in tokens) {
if (tokens[i].address.toLowerCase() == posData.token0.toLowerCase()) {
token0Symbol = tokens[i]
} else if (tokens[i].address.toLowerCase() == posData.token1.toLowerCase()) {
token1Symbol = tokens[i]
}
}
if (!token0Symbol || !token1Symbol) {
Log("token0Symbol:", token0Symbol, ", token1Symbol:", token1Symbol)
throw "token not found"
}
// get Pool
var token0Address = token0Symbol.address
var token1Address = token1Symbol.address
if (BigInt(token0Address) > BigInt(token1Address)) {
var tmp = token0Address
token0Address = token1Address
token1Address = tmp
}
// Registered factory contract ABI
exchange.IO("abi", ContractV3Factory, ABI_Factory)
// Call the getPool method of the factory contract to get the pool address
var poolAddress = exchange.IO("api", ContractV3Factory, "getPool", token0Address, token1Address, posData.fee)
if (!poolAddress) {
throw "getPool failed"
}
Log("poolAddress:", poolAddress)
// ABI for registered pool contracts
exchange.IO("abi", poolAddress, ABI_Pool)
// Get the slot0 data in the exchange pool
var slot0 = exchange.IO("api", poolAddress, "slot0")
if (!slot0) {
throw "get slot0 failed"
}
// feeGrowthGlobal0X128 , feeGrowthGlobal1X128
var feeGrowthGlobal0 = exchange.IO("api", poolAddress, "feeGrowthGlobal0X128")
var feeGrowthGlobal1 = exchange.IO("api", poolAddress, "feeGrowthGlobal1X128")
if (!feeGrowthGlobal0 || !feeGrowthGlobal1) {
throw "get feeGrowthGlobal failed"
}
// Call the ticks method of the pool contract by taking tickLower , tickUpper from posData as parameters
var tickLow = exchange.IO("api", poolAddress, "ticks", posData.tickLower)
var tickHigh = exchange.IO("api", poolAddress, "ticks", posData.tickUpper)
if (!tickLow || !tickHigh) {
throw "get tick failed"
}
// Obtain feeGrowthOutside0X128 and feeGrowthOutside1X128 data for tickeLow and tickeHigh
var feeGrowth0Low = tickLow.feeGrowthOutside0X128
var feeGrowth0Hi = tickHigh.feeGrowthOutside0X128
var feeGrowth1Low = tickLow.feeGrowthOutside1X128
var feeGrowth1Hi = tickHigh.feeGrowthOutside1X128
// feeGrowthInside0 feeGrowthInside1
var feeGrowthInside0 = posData.feeGrowthInside0LastX128
var feeGrowthInside1 = posData.feeGrowthInside1LastX128
var liquidity = BigInt(posData.liquidity)
var tickLow = parseInt(posData.tickLower)
var tickHigh = parseInt(posData.tickUpper)
var tickCurrent = parseInt(slot0.tick)
var decimal0 = token0Symbol.decimals
var decimal1 = token1Symbol.decimals
// Converted to a BigInt type for calculating the
var feeGrowthGlobal_0 = BigInt(feeGrowthGlobal0)
var feeGrowthGlobal_1 = BigInt(feeGrowthGlobal1)
var tickLowerFeeGrowthOutside_0 = BigInt(feeGrowth0Low)
var tickLowerFeeGrowthOutside_1 = BigInt(feeGrowth1Low)
var tickUpperFeeGrowthOutside_0 = BigInt(feeGrowth0Hi)
var tickUpperFeeGrowthOutside_1 = BigInt(feeGrowth1Hi)
var tickLowerFeeGrowthBelow_0 = ZERO
var tickLowerFeeGrowthBelow_1 = ZERO
var tickUpperFeeGrowthAbove_0 = ZERO
var tickUpperFeeGrowthAbove_1 = ZERO
if (tickCurrent >= tickHigh) {
tickUpperFeeGrowthAbove_0 = subIn256(feeGrowthGlobal_0, tickUpperFeeGrowthOutside_0)
tickUpperFeeGrowthAbove_1 = subIn256(feeGrowthGlobal_1, tickUpperFeeGrowthOutside_1)
} else {
tickUpperFeeGrowthAbove_0 = tickUpperFeeGrowthOutside_0
tickUpperFeeGrowthAbove_1 = tickUpperFeeGrowthOutside_1
}
if (tickCurrent >= tickLow) {
tickLowerFeeGrowthBelow_0 = tickLowerFeeGrowthOutside_0
tickLowerFeeGrowthBelow_1 = tickLowerFeeGrowthOutside_1
} else {
tickLowerFeeGrowthBelow_0 = subIn256(feeGrowthGlobal_0, tickLowerFeeGrowthOutside_0)
tickLowerFeeGrowthBelow_1 = subIn256(feeGrowthGlobal_1, tickLowerFeeGrowthOutside_1)
}
var fr_t1_0 = subIn256(subIn256(feeGrowthGlobal_0, tickLowerFeeGrowthBelow_0), tickUpperFeeGrowthAbove_0)
var fr_t1_1 = subIn256(subIn256(feeGrowthGlobal_1, tickLowerFeeGrowthBelow_1), tickUpperFeeGrowthAbove_1)
var feeGrowthInsideLast_0 = BigInt(feeGrowthInside0)
var feeGrowthInsideLast_1 = BigInt(feeGrowthInside1)
var uncollectedFees_0 = (liquidity * subIn256(fr_t1_0, feeGrowthInsideLast_0)) / Q128
var uncollectedFees_1 = (liquidity * subIn256(fr_t1_1, feeGrowthInsideLast_1)) / Q128
// Calculate the Fee to get token0 and token1
var token0Fee = toAmount(uncollectedFees_0, decimal0)
var token1Fee = toAmount(uncollectedFees_1, decimal1)
return [token0Symbol.symbol, token1Symbol.symbol, posData.fee / 10000 + "%", token0Fee, token1Fee]
}
```

In the next post, we will conduct an exploration of increasing mobility and decreasing mobility on Uniswap V3 DEX.
From: https://blog.mathquant.com/2023/07/21/fmz-quant-uniswap-v3-exchange-pool-liquidity-related-operations-guide-part-1.html | fmzquant |
1,862,598 | What Types of Services Do Emergency Plumbers in Dubai Offer | Emergency plumbers play a crucial role in maintaining the safety, functionality, and comfort of... | 0 | 2024-05-23T08:48:26 | https://dev.to/muhammad_azhar_718f2692a9/what-types-of-services-do-emergency-plumbers-in-dubai-offer-2mbi |

Emergency plumbers play a crucial role in maintaining the safety, functionality, and comfort of homes and businesses. In a bustling city like Dubai, where high-rise buildings and modern infrastructure are common, plumbing emergencies can lead to significant disruption and damage if not addressed promptly. Emergency [**Plumbers Services Dubai**](https://tbnts.com/home-maintenance/plumbing-services/) offer a wide range of services to handle various urgent plumbing issues. Here’s an in-depth look at the types of services they provide.
## 1. Leak Detection and Repair
Leaks can happen in a plumbing system's pipework, faucets, and fixtures, among other components. If left untreated, even small leaks can cause significant water damage and lead to mold growth. Emergency plumbers in Dubai are equipped with advanced tools and techniques to detect and repair leaks efficiently.
### Common Leak Issues
- Pipe Leaks: These can occur due to corrosion, high water pressure, or faulty installation.
- Leaks in faucets: Frequently brought on by worn-out seals or washers.
- Fixture Leaks: Toilets, showers, and sinks can develop leaks due to aging components or improper installation.
## 2. Burst Pipe Repair
One of the most dangerous plumbing catastrophes is a burst pipe. They can cause extensive water damage to property and pose a risk of electrical hazards. Emergency plumbers provide rapid response services to mitigate the damage and repair or replace the burst pipes.
### Causes of Burst Pipes
- Freezing Temperatures: Though rare in Dubai, it can happen in certain circumstances.
- High Water Pressure: Excessive pressure can cause pipes to burst.
- Aging Pipes: Older pipes are more susceptible to bursting due to wear and tear.
## 3. Blocked Drains and Sewer Lines
Blocked drains and sewer lines can lead to unpleasant odors, slow drainage, and even sewage backups. Emergency plumbers have the expertise and equipment to clear blockages and restore normal flow.
### Signs of Blocked Drains
- Slow Draining: Water taking longer than usual to drain.
- Gurgling Sounds: Unusual noises from drains.
- Foul Odors: Bad smells emanating from drains.
- Water Backup: Water pooling around fixtures.
## 4. Water Heater Repair and Replacement
A malfunctioning water heater can disrupt daily routines, especially in residential settings. Emergency plumbers can diagnose issues with water heaters, perform necessary repairs, or recommend replacements if the unit is beyond repair.
### Common Water Heater Problems
- No Hot Water: Complete lack of hot water despite the heater being on.
- Leaking Heater: Water pooling around the heater.
- Strange Noises: Banging or popping sounds from the heater.
- Inconsistent Temperature: Water temperature fluctuating unpredictably.
## 5. Toilet Repairs
Toilet issues can range from minor inconveniences to major disruptions. Emergency plumbers can handle a variety of toilet problems, ensuring that this essential fixture functions correctly.
### Typical Toilet Issues
- Clogs: Toilets that won't flush properly due to blockages.
- Leaks: Water leaking from the base or tank.
- Running Toilets: Continuous water flow that wastes water and increases bills.
- Faulty Components: Broken flush handles, valves, or flappers.
## 6. Sump Pump Services
Sump pumps are crucial for preventing basement flooding in areas prone to water accumulation. Emergency plumbers offer services to install, repair, and maintain sump pumps, ensuring they operate effectively during heavy rains or flooding.
### Sump Pump Issues
- Failure to Activate: Pump does not turn on when needed.
- Continuous Running: Pump runs constantly without shutting off.
- Strange Noises: Unusual sounds indicating potential mechanical issues.
- Power Loss: Electrical issues preventing the pump from working.
## 7. Emergency Gas Line Services
Gas line issues require immediate attention due to the potential danger of gas leaks. Emergency plumbers in Dubai are trained to handle gas line repairs and installations safely.
### Gas Line Emergencies
- Gas Leaks: Detecting and repairing leaks to prevent explosions or poisoning.
- Line Installation: Installing new gas lines for appliances.
- Pressure Issues: Ensuring the gas line maintains proper pressure for safe operation.
## 8. Flood Damage Mitigation
In the event of significant flooding, emergency plumbers provide services to mitigate water damage. This includes water extraction, drying, and dehumidification to prevent mold growth and structural damage.
### Flood Response
- Extracting standing water from impacted regions is known as water extraction.
- Drying and Dehumidification: Using specialized equipment to dry out structures.
- Damage Assessment: Evaluating the extent of water damage to plan repairs.
## 9. Emergency Plumbing Installations
Sometimes, emergencies require immediate installation of plumbing fixtures or components. Emergency plumbers can quickly install necessary parts to restore functionality and prevent further issues.
### Emergency Installations
- Pumps and Valves: Installing or replacing critical components to restore water flow.
- Temporary Solutions: Providing temporary fixes to manage the situation until permanent repairs can be made.
- New Fixtures: Installing new toilets, sinks, or showers during emergencies.
## 10. Preventive Maintenance
While not always an emergency service, preventive maintenance by emergency plumbers can help avoid future plumbing crises. Regular inspections and maintenance ensure that potential issues are identified and addressed before they become emergencies.
### Maintenance Services
- Routine Inspections: Checking the plumbing system for signs of wear and tear.
- Pipe Cleaning: Regular cleaning to prevent blockages.
- Component Checks: Ensuring valves, pumps, and fixtures are in good working order.
### Conclusion
Emergency plumbers in Dubai offer a wide range of services to address various urgent plumbing issues. From leak detection and burst pipe repair to blocked drains and gas line emergencies, these professionals are equipped to handle it all. Companies like [**TBN Technical Services Dubai**](https://tbnts.com/) exemplify the expertise and reliability required to manage such emergencies efficiently. By understanding the types of services offered, you can be better prepared to handle plumbing emergencies and ensure your home or business remains safe and functional.
#### Frequently Asked Question
### What should I do if I have a plumbing emergency in Dubai?
If you have a plumbing emergency in Dubai, the first step is to shut off the main water supply to prevent further damage. Next, contact a reputable emergency plumber, such as those listed on directories like Google Maps or Yellow Pages. Ensure the plumber is licensed and has positive customer reviews. While waiting for the plumber, try to contain any leaks with towels or buckets to minimize water damage.
### How can I verify the credentials of an emergency plumber in Dubai?
To verify the credentials of an emergency plumber in Dubai, check if they are licensed by the Dubai Municipality or other relevant authorities. You can also ask for proof of their license and insurance coverage. Additionally, look for certifications from recognized industry bodies and read customer reviews on platforms like Google Reviews or Yelp to ensure their reliability and professionalism.
### What types of services do emergency plumbers in Dubai offer?
Emergency plumbers in Dubai offer a wide range of services, including leak detection and repair, burst pipe repair, blocked drains and sewer line clearance, water heater repair and replacement, toilet repairs, sump pump services, emergency gas line services, flood damage mitigation, emergency plumbing installations, and preventive maintenance. These services ensure that urgent plumbing issues are addressed promptly and effectively.
### How can I find emergency plumbers who provide 24/7 service in Dubai?
To find emergency plumbers who provide 24/7 service in Dubai, search online using keywords like "24-hour emergency plumber Dubai" or "plumber available 24/7 Dubai." Websites like Google, Bing, and business directories like Yellow Pages will list plumbers who offer round-the-clock services. Look for companies with positive reviews and ratings, and verify their availability by calling them directly.
### What are the typical costs associated with hiring an emergency plumber in Dubai?
The costs associated with hiring an emergency plumber in Dubai can vary depending on the complexity of the job, the time of day, and the plumber's rates. Typically, you can expect to pay a higher rate for emergency services, especially during nights, weekends, or holidays. Always ask for a detailed estimate before the work begins to avoid any surprises. Comparing quotes from multiple plumbers can also help you find a fair and reasonable price.
| muhammad_azhar_718f2692a9 | |
1,862,384 | Ease your automated api testing using PostMan | With fast emerging technology and architecture, building & testing apis are an inevitable task... | 0 | 2024-05-23T08:48:17 | https://dev.to/nirmalkumar/ease-your-api-testing-using-postman-1e53 | api, postman, cloud, microservices | With fast emerging technology and architecture, building & testing apis are an inevitable task for every developer.
If you are not yet aware about [PostMan](https://www.postman.com/), please do check. It will help your api development life easier.
Frequent issues I face as an api developer are,
* Api consumer will shout that the deployed api is not up and running.
* If it's running, api consumer will report that it is producing irrelevant response.
If the number of api is less in numbers, it should be okay if we manually debug and fix the root cause. But in cloud native Microservices architecture, we will end up managing 100s of apis that belong to our domain. Imagine the number of apis to manage, if we have multiple environments such as dev, qa, uat, training, staging, performance, production, disaster recovery, etc.,
As an api producer/developer, I want the api consumer to be happy. If any issues, I would want to resolve it super quick.
This is where PostMan comes into picture where they provide an easy option to write unit test cases directly in their GUI for each of my api, using which I can run automated tests in seconds and identify which one is not up & running and why.
This helps me to resolve issues quicker and focus on actual business problem.
###### Example:
Below are simple step by step approach on how to write test cases for an api in postman,
Once we have postman installed, up and running in our machine, add a new collection & enter details about our api endpoint and enter request parameters.
Here I am using default postman HTTP GET REST endpoint for demo purpose, it doesn't have any input parameters.
Click 'Send' button in postman, it will make a HTTP GET request to the mentioned endpoint and we can see the response in PostMan bottom section 'body' tab.
As an Api producer, after we deploy our api to an environment we either use Open Api documentation portal ex: Swagger UI if we use Asp.Net Core WebApi or PostMan to verify whether our deployed api is working smoothly for every scenario. It's a manual process.
We can go to 'Scripts' tab in PostMan to write our test cases in 'Post-Response' sub section which will be automatically executed when we trigger the endpoint manually by clicking 'Send' button or we run the entire collection of apis.
Now, let's go deeper into test case.
```javascript
pm.test("Response status code is 200", function () {
pm.expect(pm.response.code).to.equal(200);
});
```
* PostMan uses [chai.js](https://www.chaijs.com/api/bdd/) syntax to write BDD.
* PostMan uses pm object to access request/response objects.
* 'test' is a javascript test function.
* "Response status code is 200" is test name which will be printed in test results window.
* 'pm.expect' is assertion to verify the test.
* 'pm.response.code' access the Http Status Code of received response back from api.
* '.to.equal' follows Chai.js BDD syntax
* '200' is expected result.
Below are few more test cases for the same endpoint,
```javascript
pm.test("Response time is within an acceptable range", function () {
pm.expect(pm.response.responseTime).to.be.below(500);
});
pm.test("Response has the required fields - args, headers, and url", function () {
const responseData = pm.response.json();
pm.expect(responseData).to.be.an('object');
pm.expect(responseData).to.have.property('args');
pm.expect(responseData).to.have.property('headers');
pm.expect(responseData).to.have.property('url');
});
pm.test("Headers contain all the expected fields", function () {
const responseData = pm.response.json();
pm.expect(responseData.headers).to.be.an('object');
pm.expect(responseData.headers).to.include.all.keys(
'x-forwarded-proto',
'x-forwarded-port',
'host',
'x-amzn-trace-id',
'user-agent',
'accept',
'cache-control',
'postman-token',
'accept-encoding'
);
});
pm.test("Validate the schema of the response JSON", function () {
const responseData = pm.response.json();
pm.expect(responseData).to.have.property('args').that.is.an('object');
pm.expect(responseData).to.have.property('headers').that.is.an('object');
pm.expect(responseData).to.have.property('url').that.is.a('string');
});
```
We can verify the test results in bottom section,
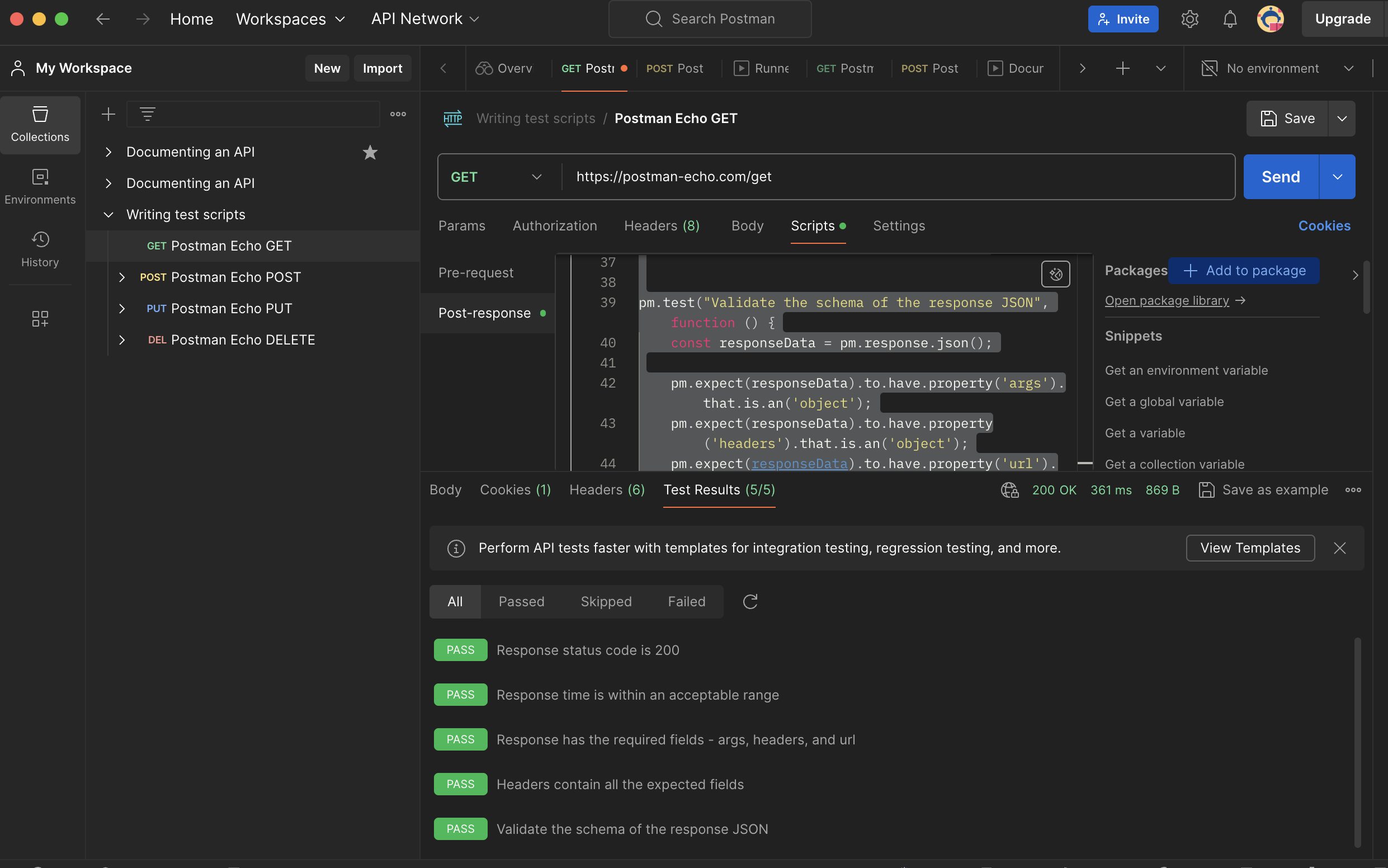
With this test setup in postman, I can verify my any number of deployed api in any environment within a minute and identify which one is not working and why.
Below is a sample of how I run an entire collection of api with it's unit test cases,
Note: We can schedule these tests, run it from cli or even integrate with our CI devops pipeline.
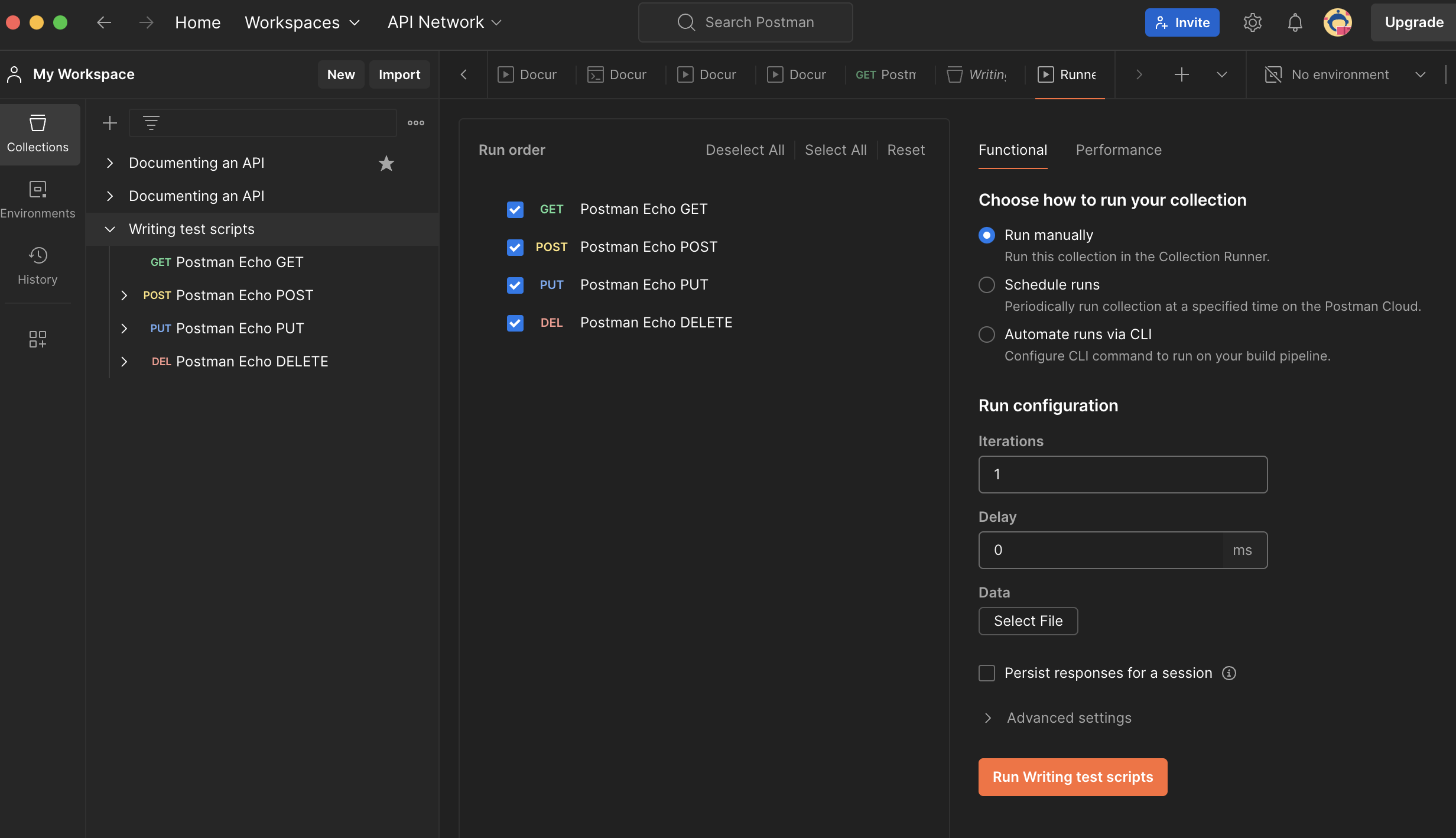
Entire collection test results:
Note: It ran in 2seconds. All I need is 2-5 seconds to identify which of my api is making trouble.
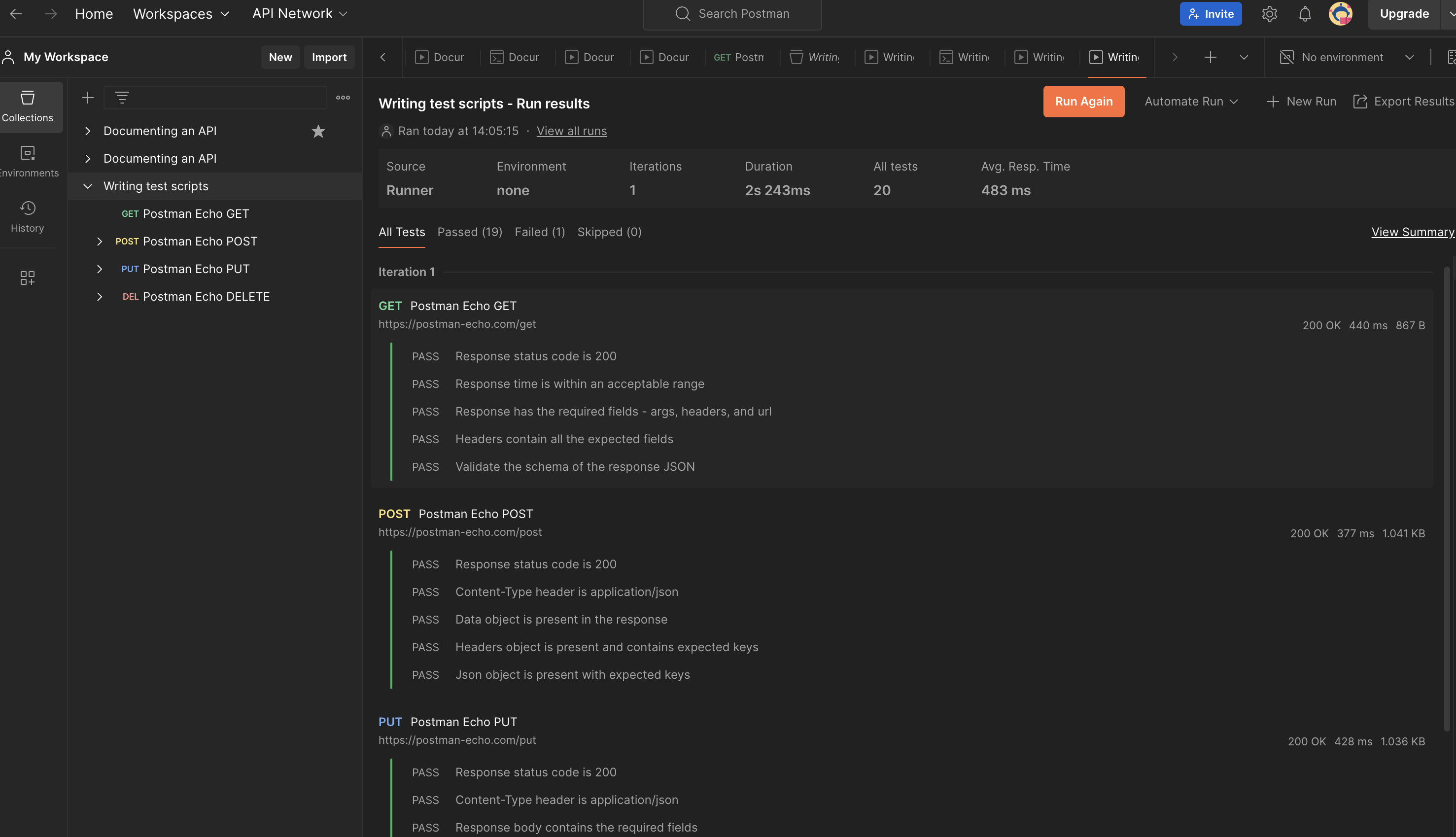
PostMan is so powerful. It has many features like api performance testing, api monitoring, api observability, etc., I will come back with an another blog later.
Thank you for reading! :-)
| nirmalkumar |
1,862,597 | Top 7 Transformative Role of AI in Healthcare | Artificial intelligence (AI) is fundamentally transforming the healthcare industry by providing... | 0 | 2024-05-23T08:43:25 | https://dev.to/manisha12111/top-7-transformative-role-of-ai-in-healthcare-ggg | healthcareapp, appdevelopment, webdev, ai | Artificial intelligence (AI) is fundamentally transforming the healthcare industry by providing cutting-edge ways to better medical decision-making, optimize workflow, and improve patient outcomes. This comprehensive piece delves into the top seven revolutionary functions of artificial intelligence (AI) in healthcare, examining how this state-of-the-art technology is changing the way we provide and receive medical treatment.
## Top 7 Role of AI in healthcare are
**Precision Medicine:** To personalize medications for each patient, AI-driven algorithms examine enormous volumes of patient data, including genetic data, medical records, and lifestyle variables. AI assists healthcare professionals in making more precise diagnoses and individualized treatment plans by finding patterns and connections in this data, which eventually improves patient outcomes.
**Medical Imaging:** AI-driven medical imaging technologies help radiologists analyze medical pictures more accurately and efficiently. Examples of these technologies include computer-aided detection (CAD) and diagnostic algorithms. AI is transforming the field of medical imaging, resulting in quicker diagnosis and more efficient treatments. It does this by detecting early symptoms of disease, improving image quality, and lowering interpretation errors.
**Predictive Analytics:** In order to forecast and stop unfavorable health outcomes like hospital readmissions, complications, and disease progression, artificial intelligence (AI) systems evaluate patient data in real-time. Predictive analytics helps to lower healthcare costs, maximize resource allocation, and improve patient safety by detecting high-risk patients and informing healthcare practitioners of possible problems before they arise.
**Virtual Health Assistants:**Through chatbots or voice-activated interfaces, AI-powered virtual health assistants give patients individualized health information, medication reminders, and guidance on managing symptoms. These virtual assistants enable patients to take charge of their health and follow treatment programs by providing round-the-clock support and advice, which improves patient satisfaction and health outcomes.
**Drug Discovery and Development:** By evaluating large datasets, forecasting drug-target interactions, and more accurately and efficiently identifying possible drug candidates, artificial intelligence (AI) speeds up the process of finding and developing new drugs. Artificial intelligence-driven methods have the potential to transform pharmaceutical research and expedite the release of new medications into the market. These include target identification, lead optimization, clinical trial design, and drug repurposing.
**Operational Efficiency:** AI-powered solutions increase operational efficiency and save costs for healthcare businesses by automating repetitive operations, streamlining administrative work, and allocating resources optimally. Artificial intelligence (AI) boosts efficiency and frees up healthcare professionals to concentrate more on patient care, from handling electronic health records and appointment scheduling to optimizing workforce numbers and supply chain management.
**Health Monitoring and Wearable Devices:** AI-enabled wearables assess health parameters, monitor vital signs, and identify early warning indicators of health problems, allowing for proactive and preventive healthcare interventions. These gadgets give people the ability to continuously gather and analyze data on their health and activity levels, which allows them to monitor their health in real time and make well-informed decisions about their well-being.
**Conclusion**
AI's revolutionary effects on healthcare will only intensify as it develops and matures. Healthcare practitioners may optimize healthcare delivery, improve clinical decision-making, and improve patient outcomes by leveraging AI-driven solutions.
To ensure usability and effectiveness, [healthcare app development ](https://www.inventcolabssoftware.com/mhealth-app-development)involves working with medical specialists, adhering to regulatory standards like HIPAA, and doing extensive research.
However, resolving issues with data privacy, interoperability, and regulatory compliance is necessary to fully utilize AI in healthcare. AI has the power to completely change how we provide and receive healthcare, eventually making everyone's life healthier and happier, with proper planning, teamwork, and investment.
| manisha12111 |
1,862,596 | Introducing OpenMLDB’s New Feature: Feature Signatures — Enabling Complete Feature Engineering with SQL | Background Rewinding to 2020, the Feature Engine team of Fourth Paradigm submitted and... | 0 | 2024-05-23T08:42:00 | https://dev.to/elliezza/introducing-openmldbs-new-feature-feature-signatures-enabling-complete-feature-engineering-with-sql-26l1 | featureengineering, sql, featuresignatures, openmldb |
## Background
Rewinding to 2020, the Feature Engine team of Fourth Paradigm submitted and passed an invention patent titled “[Data Processing Method, Device, Electronic Equipment, and Storage Medium Based on SQL](https://patents.google.com/patent/CN111752967A)”. This patent innovatively combines the SQL data processing language with machine learning feature signatures, greatly expanding the functional boundaries of SQL statements.
At that time, no SQL database or OLAP engine on the market supported this syntax, and even on Fourth Paradigm’s machine learning platform, the feature signature function could only be implemented using a custom DSL (Domain-Specific Language).
Finally, in version v0.9.0, OpenMLDB introduced the feature signature function, supporting sample output in formats such as CSV and LIBSVM. This allows direct integration with machine learning training or prediction while ensuring consistency between offline and online environments.
## Feature Signatures and Label Signatures
The feature signature function in OpenMLDB is implemented based on a series of OpenMLDB-customized UDFs (User-Defined Functions) on top of standard SQL. Currently, OpenMLDB supports the following signature functions:
* `continuous(column)`: Indicates that the column is a continuous feature; the column can be of any numerical type.
* `discrete(column[, bucket_size])`: Indicates that the column is a discrete feature; the column can be of boolean type, integer type, or date and time type. The optional parameter `bucket_size` sets the number of buckets. If `bucket_size` is not specified, the range of values is the entire range of the int64 type.
* `binary_label(column)`: Indicates that the column is a binary classification label; the column must be of boolean type.
* `multiclass_label(column)`: Indicates that the column is a multiclass classification label; the column can be of boolean type or integer type.
* `regression_label(column)`: Indicates that the column is a regression label; the column can be of any numerical type.
These functions must be used in conjunction with the sample format functions `csv` or `libsvm` and cannot be used independently. `csv` and `libsvm` can accept any number of parameters, and each parameter needs to be specified using functions like `continuous` to determine how to sign it. OpenMLDB handles null and erroneous data appropriately, retaining the maximum amount of sample information.
## Usage Example
First, follow the [quick start](https://openmldb.ai/docs/en/main/tutorial/standalone_use.html) guide to get the image and start the OpenMLDB server and client.
```bash
docker run -it 4pdosc/openmldb:0.9.0 bash
/work/init.sh
/work/openmldb/sbin/openmldb-cli.sh
```
Create a database and import data in the OpenMLDB client.
```sql
--OpenMLDB CLI
CREATE DATABASE demo_db;
USE demo_db;
CREATE TABLE t1(id string, vendor_id int, pickup_datetime timestamp, dropoff_datetime timestamp, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
SET @@execute_mode='offline';
LOAD DATA INFILE '/work/taxi-trip/data/taxi_tour_table_train_simple.snappy.parquet' INTO TABLE t1 options(format='parquet', header=true, mode='append');
```
Use the `SHOW JOBS` command to check the task running status. After the task is successfully executed, perform feature engineering and export the training data in CSV format.
Currently, OpenMLDB does not support overly long column names, so specifying the column name of the sample as `instance` using `SELECT csv(...)` AS instance is necessary.
```sql
--OpenMLDB CLI
USE demo_db;
SET @@execute_mode='offline';
WITH t1 as (SELECT trip_duration,
passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
count(vendor_id) OVER w AS vendor_cnt,
FROM t1
WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW))
SELECT csv(
regression_label(trip_duration),
continuous(passenger_count),
continuous(vendor_sum_pl),
continuous(vendor_cnt),
discrete(vendor_cnt DIV 10)) AS instance
FROM t1 INTO OUTFILE '/tmp/feature_data_csv' OPTIONS(format='csv', header=false, quote='');
```
If LIBSVM format training data is needed, simply change `SELECT csv(...)` to `SELECT libsvm(...)`. Note that the `OPTIONS` should still use the CSV format because the exported data only has one column, which already contains the complete LIBSVM format sample.
Moreover, the `libsvm` function will start numbering continuous features and discrete features with a known number of buckets from 1. Therefore, specifying the number of buckets ensures that the feature encoding ranges of different columns do not conflict. If the number of buckets for discrete features is not specified, there is a small probability of feature signature conflict in some samples.
```sql
--OpenMLDB CLI
USE demo_db;
SET @@execute_mode='offline';
WITH t1 as (SELECT trip_duration,
passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
count(vendor_id) OVER w AS vendor_cnt,
FROM t1
WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW))
SELECT libsvm(
regression_label(trip_duration),
continuous(passenger_count),
continuous(vendor_sum_pl),
continuous(vendor_cnt),
discrete(vendor_cnt DIV 10, 100)) AS instance
FROM t1 INTO OUTFILE '/tmp/feature_data_libsvm' OPTIONS(format='csv', header=false, quote='');
```
## Summary
By combining SQL with machine learning, feature signatures simplify the data processing workflow, making feature engineering more efficient and consistent. This innovation extends the functional boundaries of SQL, supporting the output of various formats of data samples, directly connecting to machine learning training and prediction, improving data processing flexibility and accuracy, and having significant implications for data science and engineering practices.
OpenMLDB introduces signature functions to further bridge the gap between feature engineering and machine learning frameworks. By uniformly signing samples with OpenMLDB, offline and online consistency can be improved throughout the entire process, reducing maintenance and change costs. In the future, OpenMLDB will add more signature functions, including one-hot encoding and feature crossing, to make the information in sample feature data more easily utilized by machine learning frameworks.
--------------------------------------------------------------------------------------------------------------
**For more information on OpenMLDB:**
* Official website: [https://openmldb.ai/](https://openmldb.ai/)
* GitHub: [https://github.com/4paradigm/OpenMLDB](https://github.com/4paradigm/OpenMLDB)
* Documentation: [https://openmldb.ai/docs/en/](https://openmldb.ai/docs/en/)
* Join us on [**Slack**](https://join.slack.com/t/openmldb/shared_invite/zt-ozu3llie-K~hn9Ss1GZcFW2~K_L5sMg)!
> _This post is a re-post from [OpenMLDB Blogs](https://openmldb.medium.com/)._ | elliezza |
1,862,595 | Navigating Complexities of System Integration Testing with Test Automation | System integration is gaining popularity because it brings efficiency to business operations.... | 0 | 2024-05-23T08:39:09 | https://nyweekly.com/tech/navigating-complexities-of-system-integration-testing-with-test-automation/ | system, integration, testing | 
System integration is gaining popularity because it brings efficiency to business operations. Achieving seamless integration between diverse applications is crucial for delivering robust and comprehensive functionality. System integration testing ensures that integrated software systems work together properly to meet user requirements and perform as intended. Hence, navigation of complexities of system integration testing is essential to ensure the effectiveness and efficiency of integrations. This article will discuss the common challenges of system integration testing and how to rectify them with test automation, a powerful solution to streamline and optimize the SIT process.
**Common Challenges In System Integration Testing**
**Multiple stakeholders with diverse requirements**
System integration testing involves various stakeholders, including testers, system architects, test managers, and developers, each with distinct roles and responsibilities. Test managers define the scope, objectives, and approach of the test and execute test cases performed by testers. In this system, architects and developers collaborate with testers to address and rectify integration issues.
The diversity in roles and skill sets presents a challenge to find an absolute testing tool that caters to everyone’s needs. A tool that caters to testers with limited programming experience might not offer the technical depth needed by developers seeking advanced automation capabilities.
**Lack of standardized tools**
System integration testing often involves applications from different vendors with unique architecture, designs, and technologies. This lack of standardization makes it challenging to find a tool that supports the testing of all diverse technologies involved in the integration operations. It is ideal to select the tool that offers compatibility with various platforms, including legacy systems, and provide clear insights into the impact of platform changes during the integration process.
**Faster regression cycles in Agile and DevOps environments**
The rapid release cycle prevalent in Agile and DevOps methodologies necessitates frequent integration testing to ensure the updates don’t disrupt the functionality of other components. Unfortunately, depending on manual testing for regression testing is time-consuming and resource-intensive.
**Limited feedback loops with manual testing**
Manual testing creates delays in providing feedback to developers, hindering their ability to address issues as soon as possible. This is a major challenge in the fast-paced development cycles of Agile and DevOps methodologies.
**Lack of user-friendly open-source tools**
Consideration of open-source tools for system integration testing is a cost-effective option. Still, it comes with steep learning curves and coding knowledge, which are must-have requirements. This can be challenging for testers and business users with limited technical expertise. Besides, there were some tools in which developers had to invest significant time to create and maintain automated test scripts. It leads to diverting their focus away from core development tasks and can impact the time-to-market of the system.
**Limited support and transparency with open-source tools**
Open source often lacks dedicated support and may not be well-documented. This leads users to complex situations where they find themselves struggling to troubleshoot the issue and not receiving assistance when needed. Moreover, the absence of centralized reporting capabilities makes it challenging for stakeholders to maintain transparency and foster collaboration throughout the testing procedure.
**Script maintenance**
With the evolution of the software system, the number of test cases for comprehensive testing also increases. This significant growth in test cases leads to a maintenance challenge. Significant resources need to be allocated to maintaining existing scripts instead of focusing on building and testing new functionalities.
**Navigating Challenges With Test Automation**
- Test automation stands as an innovative solution to address the challenges related to traditional manual system integration testing procedures. With automation of repetitive tasks, test automation offers numerous benefits, such as:
- Automating the repetitive test cases significantly reduces the time and resources needed for system integration testing. This allows teams to focus on higher-level testing tasks and strategic analysis.
- Test automation can be executed frequently and consistently, leading to the identification of issues in the early stages of the developmental cycle. This also leads to comprehensive test coverage.
- After some minor changes, automated tests can be easily re-executed. It facilitates faster and more efficient regression testing and also reduces the risk of regression in subsequent releases.
- Automation offers immediate feedback on the success or failure of test cases. This permits developers to address the issues promptly and rectify them quickly.
- With automated testing, you can eliminate the risk of human error that is affiliated with manual testing. It also ensures consistent and reliable test execution, leading to more accurate and trustworthy results.
- Automated testing tools often provide centralized dashboards and reporting functionalities. This facilitates clear communication and transparency in the testing cycle for all stakeholders. This results in informed decision-making and fosters well-built collaboration.
- Automated test scripts are often accessible to maintain. This results in reduced time and effort needed for maintenance and upgrade of test scripts. This allows the team to focus on a higher level of testing tasks required for successful development operations.
**Opkey: An Automated Testing Tool For System Integration Testing**
Opkey is an automated testing tool recognized by industry leaders such as G2 and Gartner. Through its exclusive features and functionalities, it streamlines system integration testing to ensure the optimal performance and efficiency of the systems. It facilitates end-to-end test coverage with its AI-driven continuous testing platform. Moreover, with its codeless user interface and drag-and-drop test creation feature, it is easier for non-technical users to create and execute tests on the platform. So, with Opkey as a system integration testing tool, you can improve integrated applications’ quality, reliability, functionality, and efficiency. | rohitbhandari102 |
1,862,594 | How to create a drag and drop with Tailwind CSS and JavaScript | Today we are doing something fun with JavaScript and Tailwind CSS using Sortable.js. Read the... | 0 | 2024-05-23T08:37:33 | https://dev.to/mike_andreuzza/how-to-create-a-drag-and-drop-with-tailwind-css-and-javascript-2a5e | javascript, tailwindcss, tutorial, programming | Today we are doing something fun with JavaScript and Tailwind CSS using Sortable.js.
[Read the article, See it live and get the code](https://lexingtonthemes.com/tutorials/how-to-create-a-drag-and-drop-with-tailwind-css-and-javascript/)
| mike_andreuzza |
1,862,581 | Hehe | A post by Siddhant paudel | 0 | 2024-05-23T08:19:35 | https://dev.to/sidd07/hehe-blk | sidd07 | ||
1,862,593 | How to Select the Best Air Conditioning Repair Services | Choosing the best air conditioning repair service requires some careful consideration to ensure you... | 0 | 2024-05-23T08:35:36 | https://dev.to/anderson_peter_e6fcb00395/how-to-select-the-best-air-conditioning-repair-services-2hjp | ac, acrepair, airconditioner | Choosing the best [air conditioning repair service](https://mastercraftfl.com/residential/air-conditioning-repairs/) requires some careful consideration to ensure you get quality service and value for your money. Here's a step-by-step guide:
Research Local Companies
Start by researching air conditioning repair services in your area. You can use online search engines, business directories, or ask for recommendations from friends, family, or neighbors.
Check Credentials
Verify that the companies you're considering are licensed, insured, and bonded. This ensures that they meet the legal requirements to operate and protects you in case of any accidents or damages during the repair process.
Experience and Expertise
Look for companies with a solid track record and years of experience in the industry. Experienced technicians are more likely to quickly diagnose and fix issues with your air conditioning system correctly the first time.
Read Reviews
Check online reviews and testimonials from past customers to get an idea of the company's reputation and the quality of their service. Pay attention to any recurring positive or negative comments about their work.
Ask for References
Request references from the companies you're considering and follow up by contacting past customers. Ask about their experience with the company, the quality of the repairs, and if they would recommend them.
Check for Warranty
Inquire about the warranty offered on repairs. A reputable company should stand behind their work with a warranty that guarantees the quality of their repairs for a certain period.
Customer Service
Pay attention to the level of customer service provided by the company. Are they responsive to your inquiries? Do they communicate clearly and professionally? A company that values customer satisfaction is more likely to provide quality service.
Emergency Services
Consider whether the company offers emergency repair services, especially if you may need assistance outside of regular business hours. Quick response times can be crucial during hot summer months when your air conditioning system breaks down unexpectedly.
Environmental Considerations
If environmental impact is important to you, look for a company that offers energy-efficient repair solutions or specializes in eco-friendly HVAC systems.
By following these steps and thoroughly evaluating your options, you can choose the best air conditioning repair service for your needs and ensure your system is in good hands.
| anderson_peter_e6fcb00395 |
1,862,592 | Azure Databricks API Chatbot Integration | Data analysis has evolved significantly over the years, and one of the most recent advancements in... | 0 | 2024-05-23T08:34:41 | https://dev.to/samueld/azure-databricks-api-chatbot-integration-13jl | Data analysis has evolved significantly over the years, and one of the most recent advancements in this field is the integration of natural language processing (NLP) into data analysis tools. This Chatbot integration has been made possible with the latest technology called GPT-4, which stands for "Generative Pre-trained Transformer 4".
Are you looking to enhance your Azure Databricks API chatbot with the latest natural language processing technology? Look no further than GPT-4. In this blog post, we will guide you through the step-by-step process of integrating GPT-4 into your chatbot to enable natural language processing for data analysis. But before we dive into the details, let us take a closer look at what GPT-4 is and why it is worth integrating into your chatbot.
## Introduction to GPT-4
GPT-4 (Generative Pre-trained Transformer 4) is the latest natural language processing technology developed by Open AI (Artificial Intelligence) technology. It builds upon the success of its predecessor, Open AI's chat GPT 3, and is expected to be even more powerful and versatile in generating human-like language. With over 170 trillion parameters, GPT-4 can synthesize text and generate responses to complex queries with greater accuracy and speed.
GPT-4, the latest iteration of the groundbreaking natural language processing technology, has revolutionized [data engineering services](https://www.prioxis.com/services/data-engineering-services) with computational linguistics and supervised machine learning models. With codex & chat GPT integration with Azure Databricks API, users can leverage the power of this technology to enable natural language processing for data analysis.
## What is GPT-4 and How Does it Improve Data Analysis?
GPT-4, short for "Generative Pretrained Transformer 4," is a deep learning algorithm that can analyze and process vast amounts of natural language data. Its advanced machine learning capabilities allow it to understand the nuances of human language, making it a powerful tool for data analysis.
GPT-4 improves data analysis by enabling natural language processing. This means that instead of relying on complex programming languages, users can use natural language commands to interact with their data and AI systems. This simplifies the data analysis process and makes it more accessible to a wider range of users.
### How Does Azure Databricks Integrate with the Azure Bot Framework API?
Azure Databricks is a cloud-based data analytics platform that enables users to process large amounts of data quickly and efficiently. By integrating with the [Azure Bot Framework](https://thirdeyedata.ai/azure-bot-service/) API, Azure Databricks can be accessed through a chatbot interface.
The Azure Bot Framework API is a set of tools that enables developers to create conversational bots that can interact with users in a natural language format. By integrating Azure Databricks with the Azure Bot Framework API, users can interact with their data using natural language commands through a chatbot interface.
### What Are the Benefits of Natural Language Processing in Data Analysis?
The benefits of natural language processing in data analysis are numerous. One of the main benefits is that it enables users to interact with their data using natural language commands, which makes the data analysis process more accessible to a wider range of users.
Natural language processing also enables users to perform complex data analysis tasks quickly and efficiently. By using natural language commands, users can access and analyze substantial amounts of data without having to write complex code.
### How Does Data Synthesis Work in the Context of Data Analysis?
Data synthesis is the process of combining multiple data sources to create a single, comprehensive data set. In the context of data analysis, data synthesis can be used to identify patterns and relationships that would be difficult to detect in individual data sets.
By integrating GPT-4 with Azure Databricks API, users can leverage natural language processing to perform data synthesis tasks more efficiently. This means that users can quickly identify patterns and relationships in their data sets, which can lead to valuable insights and discoveries.
### What Are the Advantages of Using a Chatbot for Data Analysis?
One of the main advantages of using a chatbot for data analysis is that it enables users to interact with their data using natural language commands. This makes the data analysis process more accessible to a wider range of users, including those who may not have a background in programming or data analysis.
Chatbots also enable users to perform complex data analysis tasks quickly and efficiently. By using natural language commands, users can access and analyze substantial amounts of data without having to write complex code.
## Overview of Azure Databricks API chatbot
Azure Databricks is a cloud-based analytics platform that enables data processing, data engineering, and data visualization. The Azure Databricks API chatbot allows users to interact with data stored on the platform through natural language queries. It leverages machine learning and artificial intelligence to understand user intent and provide relevant insights.
## Benefits of GPT-4 integration in chatbot
Integrating GPT-4 into your Azure Databricks API chatbot can provide several benefits, including:
**Natural language processing:** GPT-4 can understand and respond to human-like language, making it easier for users to interact with the chatbot.
**Enhanced data analysis:** GPT-4 can provide more accurate and comprehensive insights by analyzing large volumes of data and synthesizing complex information.
**Improved user experience:** By enabling natural language processing, GPT-4 can make the chatbot more intuitive and user-friendly, reducing the need for technical expertise.
## Step-by-step guide to integrating GPT-4 into Azure Databricks API chatbot
Here is a step-by-step guide to integrating GPT-4 into your Azure Databricks API chatbot:
**Sign up for GPT-4:** You'll need to apply for access to GPT-4 through the Open AI API portal.
**Build your chatbot:** Use the [Azure Databricks](https://www.polestarllp.com/services/azure-databricks) API to build your chatbot and define its functionality.
**Train your GPT-4 model:** Use your training data to train your GPT-4 model and fine-tune it for your specific use case.
**Integrate GPT-4 into your chatbot:** Use the Open AI API to integrate GPT-4 into your chatbot and enable natural language processing.
**Test and refine:** Test your chatbot with real users and refine its functionality and responses based on their feedback.
##Conclusion
The integration of GPT-4 with Azure Databricks API chatbot provides a powerful tool for data analysis. By enabling natural language processing, chatbots can provide a more intuitive and user-friendly way to interact with data, while also improving the speed and accuracy of analysis. | samueld | |
1,862,591 | 바카라사이트 | 2024년 대한민국 최고의 바카라사이트: 카지노의 새로운 도약 온라인 카지노의 인기가 지속적으로 증가하면서, 바카라는 한국에서 가장 인기 있는 카지노 게임 중 하나로 자리... | 0 | 2024-05-23T08:34:09 | https://dev.to/baccaratsites05/bakarasaiteu-fg7 | 2024년 대한민국 최고의 바카라사이트: 카지노의 새로운 도약
온라인 카지노의 인기가 지속적으로 증가하면서, 바카라는 한국에서 가장 인기 있는 카지노 게임 중 하나로 자리 잡았습니다. 2024년 대한민국에서는 다양한 바카라사이트가 존재하며, 이들 중 최고의 사이트를 찾기 위해서는 몇 가지 중요한 요소를 고려해야 합니다. 이 글에서는 바카라사이트란 무엇인지, 주요 바카라사이트 추천 순위, 각 카지노의 특징, 그리고 바카라사이트 검증기준과 이용방법에 대해 자세히 알아보겠습니다.
바카라사이트란?
바카라사이트는 온라인에서 바카라 게임을 즐길 수 있는 플랫폼을 말합니다. 이들 사이트는 실제 카지노와 유사한 환경을 제공하여 플레이어가 집에서 편안하게 게임을 즐길 수 있도록 합니다. 바카라는 비교적 간단한 규칙을 가지고 있어 누구나 쉽게 접근할 수 있는 게임입니다. 플레이어는 자신 또는 딜러가 승리할지, 아니면 무승부가 나올지에 베팅하며, 게임의 결과에 따라 승패가 결정됩니다.
**_[바카라사이트](https://www.outlookindia.com/plugin-play/best-7-baccarat-sites-news-313302)_**
주요 바카라사이트 추천 순위
2024년 대한민국에서 인기 있는 바카라사이트는 다음과 같습니다:
아리아카지노
아리아카지노는 고품질의 그래픽과 사용자 친화적인 인터페이스로 유명합니다. 다양한 게임 옵션과 높은 보너스 제공으로 많은 플레이어에게 사랑받고 있습니다.
버즈카지노
버즈카지노는 신뢰성과 안전성을 중요시하는 사이트로, 다양한 결제 옵션과 빠른 출금 서비스를 제공합니다. 또한, 신규 회원을 위한 풍부한 환영 보너스를 제공합니다.
지니카지노
지니카지노는 다채로운 게임과 프로모션으로 유명합니다. 특히, 실시간 딜러와 함께하는 라이브 바카라 게임이 인기를 끌고 있습니다.
티파니카지노
티파니카지노는 세련된 디자인과 우수한 고객 서비스를 자랑합니다. VIP 프로그램을 통해 충성도 높은 고객에게 특별한 혜택을 제공합니다.
호빵맨카지노
호빵맨카지노는 다채로운 슬롯 게임과 함께 바카라를 즐길 수 있는 사이트입니다. 다양한 게임과 보너스를 통해 플레이어에게 즐거움을 선사합니다.
징구카지노
징구카지노는 고급스러운 인터페이스와 다양한 베팅 옵션을 제공합니다. 모바일 친화적인 플랫폼으로 언제 어디서나 쉽게 접속할 수 있습니다.
레고카지노
레고카지노는 재미있는 테마와 독특한 게임 디자인으로 유명합니다. 다양한 프로모션과 보너스를 통해 플레이어의 참여를 유도합니다.
바카라사이트 검증기준
바카라사이트를 선택할 때 중요한 검증 기준은 다음과 같습니다:
신뢰성과 안전성
사이트가 합법적이고 규제 기관의 인증을 받았는지 확인합니다. SSL 암호화와 같은 보안 기술을 사용하여 사용자 데이터를 보호하는지도 중요합니다.
게임 품질
고화질 그래픽과 부드러운 게임 플레이를 제공하는지 확인합니다. 라이브 딜러 옵션이 있는지도 중요한 요소입니다.
보너스와 프로모션
신규 회원을 위한 환영 보너스와 정기적인 프로모션이 있는지 확인합니다. 보너스의 이용 조건도 반드시 확인해야 합니다.
결제 옵션
다양한 결제 방법을 제공하며, 입출금이 빠르고 간편한지 확인합니다.
고객 서비스
24시간 고객 지원을 제공하며, 다양한 문의 채널을 통해 신속하게 문제를 해결할 수 있는지 확인합니다.
바카라사이트 이용방법
회원가입
원하는 바카라사이트에 접속하여 회원가입 절차를 완료합니다. 필요한 정보를 입력하고 계정을 생성합니다.
입금
사이트에서 제공하는 결제 옵션을 통해 계좌에 자금을 입금합니다. 다양한 결제 방법을 활용할 수 있으며, 입금액에 따라 보너스를 받을 수 있습니다.
게임 선택
메인 메뉴에서 원하는 바카라 게임을 선택합니다. 라이브 딜러 게임이나 일반 온라인 게임을 선택할 수 있습니다.
베팅
게임에 접속한 후, 원하는 금액을 베팅합니다. 딜러가 카드를 나눠주고, 결과에 따라 승패가 결정됩니다.
출금
게임에서 얻은 수익을 출금하려면, 사이트의 출금 절차를 따릅니다. 다양한 출금 옵션을 통해 빠르게 자금을 인출할 수 있습니다.
결론
2024년 대한민국의 최고의 바카라사이트는 플레이어에게 안전하고 신뢰할 수 있는 환경을 제공하며, 다양한 게임과 풍부한 보너스를 통해 최상의 게임 경험을 선사합니다. 아리아카지노, 버즈카지노, 지니카지노 등 주요 사이트는 각각 독특한 장점을 가지고 있어 개인의 취향과 필요에 따라 선택할 수 있습니다. 바카라사이트를 이용할 때는 신뢰성과 안전성을 최우선으로 고려하고, 다양한 검증 기준을 통해 자신에게 가장 적합한 사이트를 선택하는 것이 중요합니다. 온라인 바카라 게임을 통해 즐거움과 수익을 동시에 누리세요! | baccaratsites05 | |
1,862,589 | 🚀 JavaScript Functions | Today, we're diving into some cool ways to use functions in JS! 💻✨ 1️⃣ Assign a Function... | 0 | 2024-05-23T08:28:41 | https://dev.to/adii/javascript-functions-370f | javascript | ### Today, we're diving into some cool ways to use functions in JS! 💻✨
1️⃣ **Assign a Function to a Variable**
```jsx
function greeting() {
console.log("Good Morning");
}
let message = greeting;
message();
greeting(); // both will give the same results
```
Now you can call **`message()`** just like **`greeting()`**! 🥳
2️⃣ **Pass Functions as Arguments**
```jsx
function greeting() {
return "Good morning";
}
function printMessage(anFunction) {
console.log(anFunction());
}
printMessage(greeting);
```
Functions as arguments? Yes, please! 🎁
3️⃣ **Return Functions from Other Functions**
```jsx
function greeting() {
return function() {
return "Good Morning!";
}
}
let anFunction = greeting();
let message = anFunction();
```
Functions returning functions? Mind-blowing! 🤯
🌟 **Key Takeaway**: Functions in JS are super flexible! Use them like any other variable. Get creative and have fun coding! 🚀 | adii |
1,862,588 | [DAY 9-11] I Learned CSS Box Model, Flexbox, Typography, HTML Accessibility, & Built A Tribute Page | Hey everyone, it’s time for another biweekly update! Over the past few days, I’ve been busy... | 27,380 | 2024-05-23T08:25:12 | https://dev.to/thomascansino/day-9-11-i-learned-css-box-model-flexbox-typography-html-accessibility-built-a-tribute-page-2hj9 | beginners, learning, webdev, css | Hey everyone, it’s time for another biweekly update! Over the past few days, I’ve been busy practicing my web development skills.
- Here’s the list of things I accomplished from day 9-11:
- Created a Rothko-inspired painting to explore the CSS box model.
- Designed a flexbox photo gallery to understand CSS flexbox.
- Made a nutrition label, focusing on typography.
- Developed a quiz form to learn more about web accessibility.
- Completed part 2 of my responsive web design certification project on FreeCodeCamp by building a tribute page on my own.
What I learned for this week are:
- I was able to utilize attribute selectors to target specific elements with certain attributes.
- Applying pseudo-class `:last-of-type` to style the last child among a parent element's children.
- Implementing pseudo-elements `::after` & `::before` to add content before or after an element.
- Leveraging pseudo-selector `:not()` to exclude certain elements.
- Practicing HTML accessibility and understanding its importance.

Completing part two of the certification project wasn’t as hard as I expected, thanks to the comprehensive guidance provided by FreeCodeCamp’s curriculum. I’ve gained invaluable knowledge in HTML and CSS along the way.
However, I’m currently facing the challenge of retaining all the code and concepts I have learned, which is causing some anxiety. To tackle this, I’m committed to continuous practice and project-based learning. While I appreciate the structured approach of FreeCodeCamp, I also understand the importance of independent building to reinforce my understanding.
If you have any tips or suggestions for overcoming beginner coding struggles, please share them in the comments below. Your insights would be greatly appreciated!
Thanks for reading, and I’ll catch you all next week! | thomascansino |
1,861,539 | LightningChart JS Trader v.2 | We recently launched the first version of LightningChart JS Trader which is a high-precision suite... | 0 | 2024-05-23T08:25:05 | https://dev.to/lightningchart/lightningchart-js-trader-v2-b85 | trading, javascript, chartinglibrary, stockmarket | We recently launched the first version of [LightningChart JS Trader](https://lightningchart.com/js-charts/trader/) which is a high-precision suite for creating financial and trading applications.
Today, [we have released LightningChart JS Trader v.2](https://lightningchart.com/news/releases/lightningchart-js-trader-v-2/) and I'd like to give you an overview of what this is and how you can use this JavaScript library for building trading and financial applications.
## All-in-one chart suite
So, as mentioned, LightningChart JS Trader (or LCJS Trader) is an all-inclusive charting library for building JS-based applications for the financial and trading industry.
The cool thing about LCJS Trader is its versatility and completeness, that is, the charting suite features not only technical analysis charts. Here's more:
**Technical Analysis charts**
Features charts like CandleStick, Bar, Line, Mountain, Kagi, Renko, Point & Figure, and Heikin-Ashi, plus 100+ technical indicators and more than 30 drawing tools.
**2D & 3D Real-Time Charts**
LCJS Trader features different real-time charting controls for processing FinTech data at high performance.
**DataGrid Control**
The [ultimate DataGrid control](https://lightningchart.com/js-charts/datagrid/) is supported:
**GeoMaps**
Have you seen FinTech apps featuring GeoMaps? Well, LCJS Trader makes it possible by integrating geographical map features.
---
## LightningChart JS Trader v.2
So, in this release, LCJS Trader v.2 features a new user interface, new chart types, new drawing tools, and other UI features that will make creating FinTech applications much easier!
[Read the full release note](https://lightningchart.com/news/releases/lightningchart-js-trader-v-2/)
---
Written by:
Omar Urbano | Software Engineer & Technical Writer
[Send me your questions via LinkedIn](https://www.linkedin.com/in/omarurbanocuellar/)
| lightningchart |
1,862,587 | Mmoexp: Skull and Bones might be great or it might be terrible | Skull and Bones simply has no hope. What’s worse is there’s no real reason for it. Both Breath of... | 0 | 2024-05-23T08:24:44 | https://dev.to/rozemondbell/mmoexp-skull-and-bones-might-be-great-or-it-might-be-terrible-3m8h | webdev, javascript, beginners, programming | Skull and Bones simply has no hope. What’s worse is there’s no real reason for it. Both Breath of <a href="https://www.mmoexp.com/Skull-and-bones/Items.html">Skull and Bones Items</a> the Wild 2 at Starfield delayed themselves out of 2022. The only two huge releases left are God of War and Hogwarts Legacy, and the latter is entirely reliant on an IP that has grown increasingly controversial. Fantastic Beasts 3 could not succeed off the back of Harry Potter alone. Hogwarts Legacy will still do well, but you’d have to respect another game bolshy enough to take it on. Going up against God of War though is a suicide mission. There are so many gaps in the calendar for Skull and Bones, and at this stage, what’s the harm in another delay? You have to think Ubisoft is throwing it to the wolves (or the Fenrirs) to leave space for Avatar, but after so many big guns have ducked out, there’s now more than one window available. I know launch dates are planned ahead of their reveal, and Ubisoft likely chose it before God of War showed its hand. But the moment Ragnarok’s was known, Ubisoft should have pumped the brakes. Or whatever the brakes are on a pirate ship. Anchor, maybe. Yeah, Ubisoft should have pumped the anchor. There is no world in which this makes sense. Option A is Ubisoft has algorithmically determined early November is the best date, and has been fat headed enough to not consider the late complication of Ragnarok, and Option B is Ubisoft thinks Skull and Bones will sink and is using God of War as the cover of night. Option C is that Ubisoft is being petty to a game which caused it so many issues, but hopefully that’s not a factor. Even just this week, God of War disrupted the calendar. We saw Forspoken delay itself again because of “strategic” reasons, which is a very obvious code for ‘we are moving to get out of God of War’s way’. There’s no shame in it whatsoever. Skull and Bones might be great or it might be terrible. The problem is nobody is going to know because they’ll be too busy playing God of War instead.Biggest Video Game News Of The Week (July 2 - 8) Biggest Video Game News Of The Week (July 2 - 8) By Josh Coulson Published Jul 9, 2022 All of the biggest stories from the last seven days in gaming. This week has been a real mixed bag for video game news. There's been lots of it, but unlike recent weeks where most has come from one event like Summer Game Fest or a State of Play, it has been scattered evenly over the last seven days. Someone accidentally revealed Marvel's Avengers' next hero, a Lollipop Chainsaw remake was revealed, and Skull And Bones was re-revealed, or should that be re-re-revealed? I've lost track. Plus, the most exciting news of all, and where we will kick things off this week, we finally know when Ragnarok will be here. No, for real this time. RELATED: Rockstar Is Right, Remakes Are “Beneath Them” Ragnarok Is Coming November 9 God Of War Ragnarok was one of the many games expected to be here in 2022. However, a combination of almost every other game announced for this year getting delayed and rumored release dates ranging from September to any point in <a href="https://www.mmoexp.com/Skull-and-bones/Items.html">cheap Skull and Bones Items</a> the first half of 2023, Kratos fans feared the worst. | rozemondbell |
1,862,499 | Wheel of Fortune with CSS | A "Wheel of Fortune" component just popped up in my feed. I always spin, but never win! Anyway, this... | 0 | 2024-05-23T08:21:31 | https://dev.to/madsstoumann/wheel-of-fortune-with-css-p-pi-1ne9 | css, webdev, tutorial, javascript | A "Wheel of Fortune" component just popped up in my feed. I always spin, but never win! Anyway, this type of component is often built with `<canvas>`, so I thought I'd write a tutorial on how to make it in CSS. For the interactivity, you still have to use JavaScript.
Here's what we'll be building:
## The markup
For the wedges, we'll be using a simple list:
```html
<ul class="wheel-of-fortune">
<li>$1000</li>
<li>$2000</li>
<li>$3000</li>
<li>$4000</li>
<li>$5000</li>
<li>$6000</li>
<li>$7000</li>
<li>$8000</li>
<li>$9000</li>
<li>$10000</li>
<li>$11000</li>
<li>$12000</li>
</ul>
```
OK, so we have a list of numbers. Now, let's set some initial styles:
```css
:where(.ui-wheel-of-fortune) {
--_items: 12;
all: unset;
aspect-ratio: 1 / 1;
background: crimson;
container-type: inline-size;
direction: ltr;
display: grid;
place-content: center start;
}
```
First is a variable we'll be using to control the amount of items. As the list has 12 items, we set `--_items: 12;`.
I set the `container-type` so we can use container-query units (more on that later), then a grid with content placed "left center". This gives us:

OK, doesn't look like much, let's look into the wedges:
```css
li {
align-content: center;
background: deepskyblue;
display: grid;
font-size: 5cqi;
grid-area: 1 / -1;
list-style: none;
padding-left: 1ch;
transform-origin: center right;
width: 50cqi;
}
```
Instead of `position: absolute` we "stack" all the `<li>` in the same place in the grid using `grid-area: 1 / -1`. We set the `transform-origin` to `center right`, meaning we'll rotate the wedge around that axis.
So, now we have:

Because all the elements are stacked, we can only see the last.
Let's do something about that. First, we'll add an index variable to each wedge:
```css
li {
&:nth-of-type(1) { --_idx: 1; }
&:nth-of-type(2) { --_idx: 2; }
&:nth-of-type(3) { --_idx: 3; }
&:nth-of-type(4) { --_idx: 4; }
&:nth-of-type(5) { --_idx: 5; }
/* etc. */
}
```
With that we only need to add one more line of CSS:
```css
li {
rotate: calc(360deg / var(--_items) * calc(var(--_idx) - 1));
}
```

Getting there! Let's use the same variables to create some color variations:
```css
li {
background: hsl(calc(360deg / var(--_items) *
calc(var(--_idx))), 100%, 75%);
}
```
---
## A Slice of π
For the **height** of the wedges we need the circumference of the circle divided by the amount of items. As you might recall from school, the circumference of a circle is:
```
C=2πr
```
Because we're using container-units, the **radius** is `50cqi`, so the formula we need in CSS is:
```css
li {
height: calc((2 * pi * 50cqi) / var(--_items));
}
```
Isn't it just cool that we have **pi** in CSS now?!
Now, let's add a simple `clip-path` to each wedge. We'll start at the top left corner, move to the right center, then back to left bottom:
```css
li {
clip-path: polygon(0% 0%, 100% 50%, 0% 100%);
}
```
Let's deduct a little from the edges:
```css
li {
clip-path: polygon(0% -2%, 100% 50%, 0% 102%);
}
```
Not sure, if there's a mathematical _correct_ way to do this?
Anyway, now we just need to add `border-radius: 50%` to the wrapper:
Hmm, not good. Let's use a `clip-path` instead, with `inset` and `round`:
```css
.wheel-of-fortune {
clip-path: inset(0 0 0 0 round 50%);
}
```
Much better:
And because we used container-units for the wedges **and** the `font-size`, it's fully responsive!
---
## Make it spin
Now, let's add a spin-`<button>` (see CSS in code-example below) and trigger a spin using JavaScript:
```js
function wheelOfFortune(selector) {
const node = document.querySelector(selector);
if (!node) return;
const spin = node.querySelector('button');
const wheel = node.querySelector('ul');
let animation;
let previousEndDegree = 0;
spin.addEventListener('click', () => {
if (animation) {
animation.cancel(); // Reset the animation if it already exists
}
const randomAdditionalDegrees = Math.random() * 360 + 1800;
const newEndDegree = previousEndDegree + randomAdditionalDegrees;
animation = wheel.animate([
{ transform: `rotate(${previousEndDegree}deg)` },
{ transform: `rotate(${newEndDegree}deg)` }
], {
duration: 4000,
direction: 'normal',
easing: 'cubic-bezier(0.440, -0.205, 0.000, 1.130)',
fill: 'forwards',
iterations: 1
});
previousEndDegree = newEndDegree;
});
}
```
Instead of adding and removing a css-class and updating a `@property` with a new rotation-angle, I opted for the simplest solution: [The Web Animations API](https://developer.mozilla.org/en-US/docs/Web/API/Web_Animations_API)!
Full code is here:
{% codepen https://codepen.io/stoumann/pen/yLWJPMr %}
> **UPDATE:** The shape-master, Temani Atif, has provided a much more elegant way to create the wedges using `tan` and `aspect-ratio` (see comments below).
---
## More ideas
I encourage you to play around with other styles! Maybe add a dotted border?
| madsstoumann |
1,862,583 | Blazor CSS-isolation a ::shallow quick fix.. | Vanilla CSS, the pure not-infected by frameworks, is IMHO the best way to do CSS. With all the nice... | 0 | 2024-05-23T08:20:03 | https://dev.to/netsi1964/blazor-css-isolation-a-shallow-look-at-it-280 | blazor, css, cssisolation, html | Vanilla CSS, the pure not-infected by frameworks, is IMHO the best way to do CSS. With all the nice features like native nesting and custom properties (CSS variables) it seems to me that we have what we need. That however seems not to be the understanding of many frameworks, like Blazor, Angular and others.
## The Blazor CSS-isolation issue
Here I want to share a quick fix understanding when fighting the Blazor CSS effects to your css. It seems to actually be a valid solution.
> Add `::deep` after your component root css class
It is as simple as that! (it seems).
## The Blazor CSS-isolation technique
Blazor uses like other frameworks (Angular for instance) a technique of injecting a unique attribute on component HTML. It looks like this: `b-khlzklwsq4`. It is a "b" and then a random 10 chars long GUID sort of string. This combined with the rewriting of you pretty vanilla CSS for the component allows Blazor to have scoped css. CSS which will not break other components (but only itself ;-)).
So if I have my css:
```
.my-component {
outline: 1px black solid;
}
.my-component *:focus {
outline: none;
}
```
Blazor will pass it at runtime into:
```
.my-component[b-khlzklwsq4] {
outline: 1px black solid;
}
.my-component *:focus[b-khlzklwsq4] {
outline: none;
}
```
However I need to target **any** element which has focus, not just elements in focus which **has** the attribute `b-khlzklwsq4`!
My rule-of-fix-::deep is then to simply add a `::deep` after the main component selector (`.my-component`) and get this:
```
.my-component {
outline: 1px black solid;
}
.my-component ::deep *:focus {
outline: none;
}
```
That way I instruct Blazor: "Please do not manipulate any of my CSS other than the main selector (`.my-component`). It seems to work! :-)
```
.my-component[b-khlzklwsq4] {
outline: 1px black solid;
}
.my-component *:focus {
outline: none;
}
```
That in fact was my `::shallow` quick-fix of the broken Blazor CSS-isolation functionality! | netsi1964 |
1,862,582 | Leveraging Automation and Expertise in SIEM Systems | The shortage of information security specialists cannot be resolved quickly through mass job... | 0 | 2024-05-23T08:20:02 | https://dev.to/dominiquer/leveraging-automation-and-expertise-in-siem-systems-ifa | cybersecurity, siem | The shortage of information security specialists cannot be resolved quickly through mass job advertisements or higher wages. Infosec systems require extensive knowledge and highly qualified experts, often needing long-term training.
For example, when implementing and using SIEM systems, experts need to connect and cover the necessary sources of information security events with normalization and enrichment rules, create and configure threat detection rules, constantly monitor the quality of data supplied for analysis, respond to identified incidents and investigate them.
These tasks require extensive training in cybersecurity as well as a deep understanding of information systems and their data flows. Additionally, specialists often struggle to determine the necessary steps for [responding to and investigating incidents](https://dev.to/atlassian/behind-the-scenes-of-our-security-incident-management-process-3pb6?comments_sort=latest). Addressing all these challenges can be difficult not only for beginners but also for experienced experts.
**Focus on automation**
In a personnel shortage, managing a SIEM system should be straightforward for operators, analysts, and users with minimal experience with the product.
To minimize the time between the start of illegitimate activity in the infrastructure and its detection by the SIEM, as well as the time from incident detection to confirmation and response, the system should handle most expert functions. This includes helping define monitoring objects, preparing normalization rules, tuning correlation rules, minimizing false positives, checking verdicts, and automating the entire event processing pipeline.
**Top requirements when choosing a modern SIEM**
- A SIEM system should continuously analyze the protected perimeter, identify IT systems and their information flows, and provide recommendations for their control and protection. It should specify which data sources need to be monitored. An effective SIEM can automatically connect new event sources as they appear on the company’s network and prioritize their control based on their type.
- A quick start and detection of information security incidents should be possible in any infrastructure, whether it involves familiar information systems or systems unknown to the vendor. The initial connection of new sources should not require the operator to know specialized languages for writing normalization rules.
- One common problem in almost any organization is [shadow IT](https://www.cisco.com/c/en/us/products/security/what-is-shadow-it.html) - devices, computers, servers, services, or software used by employees that do not comply with security policies. A modern SIEM should continuously monitor these shadow segments by automating the collection of data from the network.
- The threat landscape for [various organizations and sectors](https://www.slotozilla.com/au/blog/cyber-attacks-on-casinos) is constantly evolving, with attackers continually developing new techniques and tactics. Therefore, the system should rely on the broadest possible expert base, including the vendor, the community, and the company's own information security specialists. It should also have a wide range of tools for consolidating this knowledge.
- Additional validation of registered incidents should be conducted using third-party systems, such as external TI systems or third-party correlation engines. Providing a second opinion should become a mandatory practice.
- The SIEM should offer recommendations for responding to identified incidents, as well as for investigating and processing them. These recommendations can be based on internal expertise or response rules generated by the community and integrated into the system.
- A smart SIEM continuously adapts to changes in the information security landscape and enhances the accuracy of incident detection. For example, integrating telemetry data from workstations with XDR systems can improve the detection of dangerous security events. Therefore, having simple integration interfaces with third-party systems is essential for future SIEM systems.
In conclusion, automating SIEM systems is essential to address the shortage of information security specialists. By simplifying operations and enhancing efficiency, SIEM automation ensures effective threat detection and incident response, even with limited personnel expertise. | dominiquer |
1,862,580 | F# For Dummys - Day 12 Collections List | Today we learn List, an immutable, ordered collection of elements of the same type The term "ordered"... | 0 | 2024-05-23T08:17:06 | https://dev.to/pythonzhu/f-for-dummys-day-12-collections-list-52g4 | fsharp | Today we learn List, an immutable, ordered collection of elements of the same type</br>
The term "ordered" here means that the list maintains the sequence in which elements were added, doesn't mean List is sorted
#### Create List
- Explicitly specifying elements
```f#
let numbers = [1; 2; 3; 4; 5]
let names = ["Alice"; "Bob"; "Charlie"]
```
the ; could be omit between elements if you write them in seperated lines
```f#
let list123 = [ 1 // first comment
2 // second comment
3 // third comment
]
```
all elements should be the same type
```f#
let list123 = ["1"; 2; 3]
```
the first elements is string, the rest is int, will get compile error:</br>
All elements of a list must be implicitly convertible to the type of the first element, which here is 'string'. This element has type 'int'.(1,21)
- Using a range
```f#
let numbers = [1..5] // Equivalent to [1; 2; 3; 4; 5]
let evenNumbers = [2..2..10] // Equivalent to [2; 4; 6; 8; 10]
```
- Using list comprehensions
```f#
let doubles = [for x in 1..5 -> x * 2] // Equivalent to [2; 4; 6; 8; 10]
let doubles = [for x in 2..2..10 -> x * 2] // Equivalent to [4; 8; 12; 16; 20]
```
#### Get element of List
- Using index
```f#
let numbers = [1; 2; 3]
let firstNumber = numbers.[0] // first number 1
let thirdNumber = numbers.[2] // third number 3
printfn "firstNumber %i thirdNumber %i" firstNumber thirdNumber
```
if you use index not exist in List, will got index out of range exception
```f#
let numbers = [1; 2; 3]
let forthNumber = numbers.[4]
printfn "forthNumber %i" forthNumber
```
compile error:
Unhandled exception. System.ArgumentException: The index was outside the range of elements in the list</br>
the browser environment have bug about this exception
- Using build-in method List.item
```f#
let numbers = [1; 2; 3]
let firstNumber = numbers |> List.item 0
printfn "firstNumber %i" firstNumber
```
- head and tail</br>
List.head, get first element
```f#
let numbers = [1; 2; 3]
let head = numbers |> List.head
printfn "head %i" head
```
List.tail, return list after removing the first element, not the last element
```f#
let numbers = [1; 2; 3]
let tail = numbers |> List.tail
printfn "tail %A" tail // tail [2; 3]
printfn "numbers %A" numbers // numbers [1; 2; 3]
```
tail is a new List not including the first element, it won't change the value of original List numbers
#### Loop a List
- for...in
```f#
let numbers = [1; 2; 3]
for number in numbers do
printfn "Number: %d" number
```
- List.iter
```f#
let numbers = [1; 2; 3]
List.iter (fun number -> printfn "Number: %d" number) numbers
```
fun define a lambda function here, it's equivalent to
```f#
let numbers = [1; 2; 3]
let printElement number =
printfn "Number: %d" number
List.iter printElement numbers
```
#### Pattern Matching with List
```f#
let numbers0 = []
let numbers1 = [1]
let numbers3 = [1; 2; 3]
let describeList lst =
match lst with
| [] -> "The list is empty"
| [x] -> sprintf "The list has one element: %d" x
| [x; y] -> sprintf "The list has two elements: %d and %d" x y
| x :: xs -> sprintf "The list starts with %d and has more elements" x
printfn "%s" (describeList numbers0) // The list is empty
printfn "%s" (describeList numbers1) // The list has one element: 1
printfn "%s" (describeList numbers3) // The list starts with %d and has more elements
```
#### Operate List
lists are indeed immutable, which means that you cannot modify a list after it has been created. Any operation that appears to modify a list (such as appending or prepending an element) actually creates a new list
- Prepending an element
```f#
let originalList = [2; 3; 4]
let newList = 1 :: originalList
printfn "Original List: %A" originalList // Original List: [2; 3; 4]
printfn "New List: %A" newList // New List: [1; 2; 3; 4]
```
- Appending an element
```f#
let originalList = [1; 2; 3]
let newList = originalList @ [4]
printfn "Original List: %A" originalList // Original List: [1; 2; 3]
printfn "New List: %A" newList // New List: [1; 2; 3; 4]
```
- Concatenate Lists
```f#
let originalList = [1; 2; 3]
let newList = List.append originalList [4]
printfn "Original List: %A" originalList
printfn "New List: %A" newList
```
- Filter</br>
you can not remove an element in List directly as List is immutable, but you can filter element based on some condition, put them into a new List
```f#
let numbers = [1; 2; 3; 4; 5]
let evenNumbers = List.filter (fun x -> x % 2 = 0) numbers
printfn "evenNumbers: %A" evenNumbers // evenNumbers: [2; 4]
```
- Map</br>
apply an operation to every elements in List, you can use loop/List comprehensions to achieve that, or use Map
```f#
let numbers = [1; 2; 3; 4; 5]
let doubleNumbers = List.map (fun x -> 2 * x) numbers
printfn "doubleNumbers: %A" doubleNumbers // doubleNumbers: [2; 4; 6; 8; 10]
```
- Fold</br>
"fold" or "compress" elements of List of into a single value by applying a function repeatedly
```f#
let numbers = [1; 2; 3; 4; 5]
let sum = List.fold (fun acc x -> acc + x) 0 numbers // 15
printfn "sum: %i" sum // sum: 15
```
step 1: `acc = 0` and `x = 1` New `acc = 0 + 1 = 1`</br>
step 2: `acc = 1` and `x = 2` New `acc = 1 + 2 = 3`</br>
step 3: `acc = 3` and `x = 3` New `acc = 3 + 3 = 6`</br>
step 4: `acc = 6` and `x = 4` New `acc = 6 + 4 = 10`</br>
step 5: `acc = 10` and `x = 5` New `acc = 10 + 5 = 15`</br> | pythonzhu |
1,862,579 | How ChatGPT Can Transform Your Work and Study Routines: Practical Tips and Personal Insights | Hey there! If you've ever wondered how AI could make your life a bit easier, you're in the right... | 0 | 2024-05-23T08:10:25 | https://blog.perstarke-webdev.de/posts/chatgpt-work-study | ai, chatgpt, productivity, study | Hey there! If you've ever wondered how AI could make your life a bit easier, you're in the right place. ChatGPT (you’ve probably heard of it already :D) is an incredibly handy tool that can help with a variety of tasks—everything from drafting emails and writing reports to studying for exams and learning new skills.
In this post, I’ll share my experiences and tips on how you can use ChatGPT to enhance both your work and study routines. We'll dive into practical advice, look at specific examples, and discuss important considerations. Whether you're aiming to be more productive at work or need a reliable study companion, there's something here for you. Let’s get started and see how ChatGPT can make a real difference!
<hr>
Originally published [on my Panorama Perspectives Blog](https://blog.perstarke-webdev.de/posts/chatgpt-work-study#using-chatgpt-for-studyinglearning)
<hr>
# Introduction
### What is ChatGPT?
ChatGPT is an advanced language model developed by OpenAI. It’s designed to generate human-like text based on the prompts (messages) you provide. Essentially, you type a question or command, and it responds with relevant information or suggestions.
How does it work? ChatGPT operates on a neural network that has been trained on vast amounts of text data from the internet. It uses a process called "next-word prediction," where it predicts the probability of what the next word in a sentence should be. This process is guided by a large mathematical formula that acts as if it understands you, generating responses that can be surprisingly accurate and useful. However, it's important to note that while ChatGPT can provide amazingly good responses, it doesn’t actually understand the content—it's all about pattern recognition.
### Importance of Leveraging AI Tools for Productivity and Learning
In today’s fast-paced world, finding ways to boost productivity and enhance learning is essential. AI tools like ChatGPT can be quite useful in this regard. They help automate routine tasks, provide quick information, and offer creative solutions that you might not think of on your own. This allows you to focus more on strategic and high-value activities.
Using AI for learning can make studying more interactive and personalized. Whether you’re struggling with a tough concept or need help organizing your study schedule, ChatGPT can adapt to your needs and provide support whenever you need it. Plus, it’s a great way to explore new topics and expand your knowledge in an engaging way.
> **Warning**: Learning to use tools like ChatGPT is crucial today. Those who don't may find themselves at a disadvantage in the labor market, as these tools can significantly enhance the quality and speed of work.
By integrating ChatGPT into your daily routine, you can enhance both productivity and learning. Let's dive into some practical tips on how to use this tool effectively!
# General Tips for Using ChatGPT
To get the most out of ChatGPT, it's helpful to approach it with some strategies in mind. Here are a few general tips:
- **Setting Clear Objectives**: Define what you want to achieve with ChatGPT before starting a session. Knowing your goal helps in framing your questions and guiding the interaction effectively.
- **Effective Prompting**: Use clear, specific prompts to get the best responses. The more precise your prompt, the better the output. For example, instead of asking "Tell me about World War II," you might ask "Can you summarize the key events of World War II in Europe?". There is also a [guide for tips on prompt engineering from OpenAI](https://platform.openai.com/docs/guides/prompt-engineering). Have a look at that as well, to really dive into how to write effective prompts that get you the results you want.
- **Iterative Interaction**: Refine and iterate on prompts to improve the quality of responses. If the initial response isn't quite right, adjust your prompt and try again. This iterative process can help you get more accurate and useful information.
- **Time Management**: Set time limits for using ChatGPT to avoid over-reliance. While it's an extremely powerful tool, it's important to balance its use with other resources and your own critical thinking skills.
# Using ChatGPT for Work
ChatGPT can be an incredibly useful tool for various work-related tasks. Here, we'll dive into how you can leverage it for different aspects of your professional life, from drafting emails to managing projects.
### Email Drafting
Crafting professional emails can be time-consuming. ChatGPT can help draft clear, concise, and professional emails. Simply input the key points you want to convey, and ChatGPT can generate a polished draft. Remember to review and personalize the email to ensure it accurately reflects your voice and intent.
> **Example Prompt:**
> "I need to write an email to a client named Alex informing them about the project delay due to unforeseen circumstances. Please draft a polite and professional email."
### Report Writing
When it comes to writing reports, ChatGPT can assist in structuring and drafting content. You can outline the key sections of your report, and use ChatGPT to expand on each section. It can help with generating content, suggesting relevant data points, and ensuring a logical flow. Always review the generated text for accuracy and coherence.
> **Example Prompt:**
> "Draft the introduction and conclusion for a quarterly sales report, emphasizing key achievements and future goals."
### Content Creation
Whether you're writing blog posts, creating marketing content, or developing social media updates, ChatGPT can be a valuable assistant. It can generate ideas, draft content, and even help with editing. However, it's crucial to use it ethically - ensure that the content is original, and avoid plagiarism. Always add your personal touch and verify facts.
> **Example Prompt:**
> "Help me write a blog post outline about the benefits of remote work, including an introduction, main points, and a conclusion. Review the following blog post I’ve written before to get to know my personal style of writing, and adapt your created drafts and texts to this style."
### Meeting Preparation
Preparing for meetings often involves creating agendas, summaries, and key points. ChatGPT can help streamline this process. You can input the main topics and objectives of the meeting, and it can generate a detailed agenda. After the meeting, you can use ChatGPT to draft summaries and highlight action points.
> **Example Prompt:**
> "Generate an agenda for a 45 minute team meeting focused on project updates, upcoming deadlines, and brainstorming new ideas."
### Research Assistance
ChatGPT can aid in gathering information and summarizing research findings. If you need to quickly get up to speed on a topic, you can ask ChatGPT for a summary of key points. It’s important to cross-reference the information it provides with trusted sources to ensure accuracy.
> **Example Prompt:**
> "Provide a summary of recent developments in renewable energy technology."
### Brainstorming Sessions
Need fresh ideas? ChatGPT can be a great brainstorming partner. You can prompt it with a problem or topic, and it can generate a variety of ideas and solutions. This can be particularly useful in creative fields or when you're stuck in a rut. Use its suggestions as a springboard for further development.
> **Example Prompt:**
> "Suggest innovative marketing strategies for a new eco-friendly product line. Start with asking me about the relevant details you need to know in order to provide great ideas."
### Project Management
Managing projects involves planning, organizing tasks, and keeping track of progress. ChatGPT can help with creating project plans, defining milestones, and even drafting progress reports. It can also assist in setting timelines and identifying potential risks. While it’s a great tool, combine its use with project management software for best results.
> **Example Prompt:**
> "Create a project plan for developing a new mobile app, including key milestones and deliverables."
### Image Generation
If your work involves creating presentations, websites, or marketing materials, ChatGPT's image generation capabilities can be useful. It can help you create images that enhance your content without needing to search for or purchase stock photos. Just ensure that any generated images are appropriate and align with your brand’s aesthetics.
> **Example Prompt:**
> "Generate a professional-looking image of a business meeting for a presentation. It should go well with our color palette focused around the accent color of #177A8D."
### Coding and Debugging
For developers, ChatGPT can assist with coding tasks. Whether you need help writing a function, debugging code, or understanding a new programming concept, ChatGPT can provide useful insights and solutions. It’s especially handy for quick fixes and troubleshooting. However, always test the code thoroughly before using it in production.
> **Example Prompt:**
> "Help me debug this C++ code that calculates the factorial of a number but is giving incorrect results."
> **Example Prompt:**
> "I have a CSV file containing dates and amounts of sold units. Help me write Python code to read and plot this data, as a line with dot plot, showing the development of units sold over time, using Pandas and Matplotlib."
### Customer Support Assistance
ChatGPT can help draft responses for customer support queries, providing quick and consistent answers to common questions. It can be used to generate templates for frequently asked questions, improving response times and maintaining quality in customer communication.
> **Example Prompt:**
> "Draft a response to a customer asking for a refund due to a defective product, emphasizing our return policy and offering a solution."
### Training and Development
Use ChatGPT to create training materials or assist in planning employee development programs. It can help draft training manuals, prepare slides for workshops, and even generate quizzes to test knowledge retention.
> **Example Prompt:**
> "Create an outline for a training session on effective time management techniques for employees."
### Social Media Management
ChatGPT can assist in drafting social media posts, generating content calendars, and even responding to comments or messages in a professional manner. It helps maintain a consistent voice and keeps your social media presence active and engaging.
> **Example Prompt:**
> "Draft a week's worth of social media posts for our new product launch, focusing on key features and customer benefits."
### Personal Productivity
ChatGPT can help individuals organize their tasks, set reminders, and even provide motivational quotes or productivity tips. It acts like a virtual assistant, helping you stay on top of your personal and professional to-do lists.
> **Example Prompt:**
> "Create a daily schedule for me that includes work tasks, exercise, and breaks, based on my list of tasks."
### Financial Analysis
For those in finance, ChatGPT can assist with analyzing financial data, generating reports, and offering insights based on the data provided. While it shouldn’t replace professional financial advice, it can be a useful tool for preliminary analysis. Make sure you don’t share sensitive information that should not be available to the public.
> **Example Prompt:**
> "Summarize the key financial metrics from this quarterly earnings report and suggest possible areas of improvement."
# Using ChatGPT for Studying/Learning
ChatGPT can also enhance your learning experience in numerous ways. Here, we’ll explore how to use it effectively for different aspects of studying and learning.
### Homework Help
ChatGPT can assist with solving problems and understanding concepts across various subjects. Use it to get hints, step-by-step solutions, and explanations to help you grasp the material. **However, it’s crucial to use it as a tool for learning rather than simply doing your homework, to not sabotage your long-term learning results.**
> **Example Prompt:**
> "I'm struggling to understand the steps involved in solving quadratic equations. Can you walk me through an example problem step-by-step?"
### Study Planning
Creating an effective study schedule is essential for successful learning. ChatGPT can help you organize your study sessions, set goals, and ensure you cover all necessary material in a structured manner.
> **Example Prompt:**
> "Help me create a study schedule for the next two weeks to prepare for my final exams in biology, chemistry, and history. Here are my exam dates and an overview of the topics covered in each exam. Base your schedule on this information."
### Explaining Complex Topics
Understanding complex subjects can be challenging. ChatGPT can break down difficult topics into simpler explanations, making it easier for you to grasp the concepts. This can be particularly helpful for subjects like physics, chemistry, or advanced mathematics.
> **Example Prompt:**
> "Explain the concept of entropy in thermodynamics in simple terms suitable for a high school student."
### Language Learning
Practicing language skills and improving grammar can be significantly enhanced with ChatGPT. It can help with translations, grammar corrections, and even conversational practice in different languages.
> **Example Prompt:**
> "Correct the grammar in the following French sentences and explain any mistakes."
> **Example Prompt:**
> "Have a conversation with me in French, just small talk, and correct me if I make any mistakes in my sentences, so I can practice my language skills."
### Writing Assistance
Writing essays and reports can be daunting. ChatGPT can help you draft, edit, and refine your writing. It provides suggestions for improving structure, coherence, and style, ensuring your writing is clear and effective. Focus on getting feedback and creating drafts to improve your writing skills.
> **Example Prompt:**
> "Provide feedback on the introduction and conclusion of my essay on the impact of climate change on global agriculture."
### Revision
Summarizing study materials in a way that suits your learning style can enhance your revision sessions. ChatGPT can create summaries, highlight key points, and even generate flashcards for quick reviews. You can also ask it to create questions based on your lecture slides or specific textbooks.
> **Example Prompt:**
> "Summarize the key points of the first three chapters of my biology textbook, focusing on cell structure and function. Also, create five practice questions based on these chapters."
### Quizzes
Practicing with quizzes is a great way to reinforce your knowledge. ChatGPT can generate practice quizzes to help you test your understanding of various topics and prepare for exams.
> **Example Prompt:**
> "Create a multiple-choice quiz with 10 questions on the American Civil War. Provide feedback on my answers, highlighting what I did well and where I could improve."
### Resource Recommendations
Finding the right books, articles, and other learning resources can be time-consuming. ChatGPT can recommend resources based on your interests and study needs, helping you discover new materials to deepen your understanding.
> **Example Prompt:**
> "Recommend some books and articles on the topic of quantum physics for a beginner."
### Personalized Study Tips
Get personalized study tips based on your learning style. ChatGPT can suggest techniques such as mnemonic devices, visualization, or spaced repetition to enhance your study efficiency.
> **Example Prompt:**
> "Based on the fact that I am a visual learner, provide study tips and techniques that can help me remember information better."
### Mind Mapping
Create mind maps for complex topics to visualize the relationships between different concepts. ChatGPT can help you outline the main branches and sub-branches of a topic.
> **Example Prompt:**
> "Help me create a mind map for the topic of photosynthesis, including key processes and components."
### Mock Oral Exams
If you're preparing for oral exams, ChatGPT can simulate questions and provide feedback on your answers, helping you build confidence and improve your responses.
> **Example Prompt:**
> "Simulate an oral exam for my history class on the topic of the French Revolution and provide feedback on my answers."
**Note**: Always cross-reference the information provided by ChatGPT with trusted sources to ensure accuracy. While ChatGPT can offer valuable assistance, it's important to verify the information and use multiple resources for comprehensive learning.
# Specific Examples
Let’s delve into some practical examples to give some hands-on experience how using ChatGPT effectively could look like:
### Example 1: How ChatGPT Helped Me with My Oral Exam Prep in Cognitive Neuropsychology
For a detailed account of how I used ChatGPT for my oral exam prep and how you can use it for your exam as well, check out [my separate post on that topic](https://blog.perstarke-webdev.de/posts/chatgpt-for-exam-prep).
### Example 2: Using ChatGPT to Draft a Marketing Plan for a Small Business
Creating a comprehensive marketing plan is crucial for any small business. ChatGPT can help streamline this process by providing structure, generating ideas, and refining content. Here's how it can be used effectively:
1. **Outline Creation**: Start by asking ChatGPT to help outline the key sections of a marketing plan. This provides a clear structure to follow.
> **Example Prompt:**
> "Create an outline for a marketing plan for a small business selling eco-friendly products."
2. **Content Generation**: For each section of the outline, provide key points and ask ChatGPT to expand on them. This helps generate detailed and well-organized content quickly.
> **Example Prompt:**
> "Expand on the market analysis section for our eco-friendly product line, including information about target audience, market trends, and competitive analysis."
3. **Idea Generation for Campaigns**: ChatGPT can suggest creative marketing campaigns and strategies that align with the business's values and goals.
> **Example Prompt:**
> "Suggest innovative marketing strategies for promoting our eco-friendly product line, focusing on social media and community engagement."
### Example 3: ChatGPT Assisting in Preparing a Presentation on Renewable Energy
Presentations require a combination of clear structure, accurate information, and engaging visuals. ChatGPT can assist in all these areas, ensuring the presentation is both informative and captivating.
1. **Outline and Structure**: Use ChatGPT to help create an outline for a presentation on renewable energy, ensuring all key topics are covered.
> **Example Prompt:**
> "Create an outline for a presentation on renewable energy, covering types of renewable energy, benefits, challenges, and future prospects."
2. **Content Drafting**: For each section of the outline, ChatGPT can provide detailed information and suggestions for visuals and data points to include.
> **Example Prompt:**
> "Draft the content for the section on solar energy, including how it works, its advantages, and current technological advancements."
3. **Slide Preparation**: ChatGPT helps draft the text for slides, ensuring clarity and conciseness.
> **Example Prompt:**
> "Help me draft the text for a slide summarizing the benefits of wind energy."
### Example 4: How a Researcher Could Use ChatGPT to Organize and Summarize Literature for a Review Paper
Research papers require extensive literature review and synthesis. ChatGPT can help researchers organize and summarize information efficiently.
1. **Literature Summary**: ChatGPT can summarize key points from various research articles, making it easier to identify common themes and gaps in the literature.
> **Example Prompt:**
> "Summarize the key findings from these research articles on cognitive behavioral therapy and its effectiveness in treating anxiety disorders."
2. **Thematic Organization**: ChatGPT can organize the summarized information into thematic sections, providing a clear structure for the review paper.
> **Example Prompt:**
> "Organize the summarized findings into thematic sections such as treatment efficacy, patient outcomes, and future research directions."
### Example 5: How I Use ChatGPT for Coding and Web Development
As a developer, ChatGPT can be an invaluable assistant for coding tasks, troubleshooting, and learning new technologies. Here's how I use it:
1. **Code Assistance**: When I'm stuck on a coding problem, I describe the issue to ChatGPT, and it provides potential solutions or debugging tips.
> **Example Prompt:**
> "Help me debug this JavaScript code that's not correctly updating the DOM when a button is clicked."
2. **Learning New Technologies**: When exploring new programming languages or frameworks, I ask ChatGPT for explanations and examples, accelerating my learning process.
> **Example Prompt:**
> "Explain the basics of React.js and provide a simple example of a functional component."
3. **Code Reviews**: I use ChatGPT to review my code for potential improvements and best practices, ensuring my code is efficient and maintainable.
> **Example Prompt:**
> "Review this Python script for extracting data from an API and suggest any improvements."
4. **Speeding Up Development Processes**: ChatGPT helps speed up development processes by generating reusable templates. When I don't have a template, I describe the desired style to ChatGPT, which then creates the HTML, CSS, and JS. I adjust the code to fit my needs, which is faster and often yields better results than researching and writing everything from scratch. This efficiency allows me to work more cheaply.
> **Example Prompt:**
> "Generate a responsive HTML and CSS template for a modern, clean website layout. Include a navigation bar, a hero section, and a footer."
5. **Content Creation**: I use ChatGPT to formulate texts from bullet points and create website content, ensuring the information is clear and engaging.
> **Example Prompt:**
> "Create a compelling homepage introduction for a tech startup specializing in AI-driven solutions."
# Things to Take Care of
While ChatGPT is a powerful tool, it’s important to be mindful of certain considerations to ensure its effective and ethical use:
- **Accuracy of Information**: Always verify the information provided by ChatGPT. While it can generate accurate and useful responses, it’s not infallible. Cross-referencing with trusted sources is essential to ensure the reliability of the information.
- **Privacy Concerns**: Be cautious about sharing sensitive or personal information when using ChatGPT. Avoid inputting confidential data that you wouldn't want to be accessible publicly. Maintaining privacy is crucial to protect sensitive information.
- **Ethical Use**: Use ChatGPT responsibly by avoiding plagiarism and giving credit when due. Ensure that the content generated is original and ethically sound. This includes not misusing the tool for unethical purposes such as academic dishonesty.
- **Over-reliance**: Balance the use of ChatGPT with independent thinking and effort. While it’s a helpful assistant, relying too heavily on it can hinder the development of your own problem-solving and critical thinking skills.
- **Limitations**: Understand the limitations of AI. ChatGPT, despite its capabilities, has boundaries and cannot replace human expertise in all areas. Recognize when human judgment and expertise are required.
# Considerations for Effective Use
To maximize the benefits of ChatGPT, consider the following strategies:
- **Training on Usage**: Invest time in learning how to use ChatGPT effectively. Understanding the nuances of prompt engineering and the tool’s functionalities can significantly enhance the quality of interactions and outputs.
- **Feedback Loop**: Provide feedback to improve the quality of responses over time. OpenAI continually works on refining ChatGPT, and user feedback is invaluable in this process. If you encounter errors or inaccuracies, report them to help improve the tool. Furthermore, within a single chat, providing feedback on what you liked and disliked about the model’s answers can improve future responses in that chat. For instance, telling ChatGPT, "I liked your style of writing in this response a lot; keep future answers in a similar style," will adapt the output to better meet your needs.
- **Combining Tools**: Integrate ChatGPT with other productivity and learning tools for enhanced results. For instance, combining it with project management software, research databases, or coding environments can create a more robust and efficient workflow.
- **Adaptability**: Be open to experimenting with different prompts and approaches. Flexibility in how you interact with ChatGPT can lead to discovering new and innovative ways to leverage its capabilities for various tasks.
# Conclusion
ChatGPT offers immense potential to enhance productivity and learning in diverse fields. By automating routine tasks, providing quick information, and offering creative solutions, it allows you to focus on more strategic activities.
Exploring and experimenting with ChatGPT can unlock new efficiencies and opportunities in your work and study routines. As AI technology continues to evolve, its role in augmenting human capabilities will only expand, making tools like ChatGPT increasingly indispensable.
In conclusion, embracing ChatGPT as part of your daily toolkit can lead to significant improvements in how you work and learn. By using it responsibly and understanding its limitations, you can harness its power to achieve greater productivity and knowledge. The future of AI in enhancing our professional and educational endeavors is bright, and now is the perfect time to start exploring its possibilities.
| per-starke-642 |
1,862,578 | Can the VTable component achieve different hover colors for different cells? | Question Description Can different cells have different hover colors? Use case: By... | 0 | 2024-05-23T08:10:14 | https://dev.to/fangsmile/can-the-vtable-component-achieve-different-hover-colors-for-different-cells-1675 | vtable, visactor, visulization, webdev |
## Question Description
Can different cells have different hover colors?
Use case: By default, the hover color is set to blue. Under certain conditions, some cells are highlighted in purple. However, the requirement is that when hovering over the highlighted cells, they should not change to the hover blue color.
## Solution
It can be solved by the background color function. Set bgColor as a function to set the highlight background color for special values. Set the background color through theme.bodyStyle.hover.cellBgColor, which also needs to be set as a function to return different background colors. If some cells do not want a background color, an empty string can be returned.
## Code Example
```
let tableInstance;
fetch('https://lf9-dp-fe-cms-tos.byteorg.com/obj/bit-cloud/VTable/North_American_Superstore_data.json')
.then((res) => res.json())
.then((data) => {
const columns =[
{
"field": "Profit",
"title": "Profit",
"width": "auto",
style:{
bgColor(args){
if(args.value>200){
return 'rgba(153,0,255,0.2)'
}
// 以下代码参考DEFAULT主题配置实现 https://github.com/VisActor/VTable/blob/develop/packages/vtable/src/themes/DEFAULT.ts
const { col,row, table } = args;
const {row:index} = table.getBodyIndexByTableIndex(col,row);
if (!(index & 1)) {
return '#FAF9FB';
}
return '#FDFDFD';
}
}
},
{
"field": "Order ID",
"title": "Order ID",
"width": "auto"
},
{
"field": "Customer ID",
"title": "Customer ID",
"width": "auto"
},
{
"field": "Product Name",
"title": "Product Name",
"width": "auto"
}
];
const option = {
records:data,
columns,
widthMode:'standard',
hover:{
highlightMode:'cell'
},
theme:VTable.themes.DEFAULT.extends({
bodyStyle:{
hover:{
cellBgColor(args){
if(args.value>200){
return ''
}
return '#CCE0FF';
}
}
}
})
};
tableInstance = new VTable.ListTable(document.getElementById(CONTAINER_ID),option);
window['tableInstance'] = tableInstance;
})
```
## Result Display
Just paste the code in the example directly into the official editor to display it.
## Relevant Documents
Theme Usage Reference Demo:https://visactor.io/vtable/demo/theme/extend
Theme Usage Tutorial:https://visactor.io/vtable/guide/theme_and_style/theme
Related api:https://visactor.io/vtable/option/ListTable#theme
github:https://github.com/VisActor/VTable | fangsmile |
1,862,489 | Deploy MinIO on Amazon EKS and use your S3 Compatible Storage | Introduction Tired of the limitations and costs of AWS S3? Unlock a powerful alternative... | 0 | 2024-05-23T08:06:09 | https://blog.devarshi.dev/deploy-minio-on-amazon-eks-self-host-s3-storage | aws, eks, cloud, devops | ## Introduction
Tired of the limitations and costs of AWS S3? Unlock a powerful alternative with MinIO, seamlessly integrated with Amazon EKS. This guide provides a step-by-step walkthrough to deploy MinIO, a scalable, multi-tenant object storage solution, on Amazon EKS in just 15 minutes.

Amazon EKS, a managed Kubernetes service on AWS, simplifies Kubernetes management, while MinIO, available on the AWS Marketplace, brings robust object storage capabilities. Imagine handling terabytes to exabytes of data, all while isolating tenants in their own namespaces, all without the confines of S3.
This guide empowers you to ditch AWS S3 and embrace a superior alternative. Let's get started!
## Prerequisites
Before diving in, ensure you have the following tools installed:
- `awscli`
- `kubectl`
- `eksctl`
Have these three configuration parameters handy:
1. **AWS Account Number:** Find it in the AWS Console or using this command:
```sh
export AWS_ACCOUNT_NUMBER=`aws sts get-caller-identity --query "Account" --output text`
echo $AWS_ACCOUNT_NUMBER
```
2. **Region:** For example, `us-west-2`.
3. **Cluster Name:** For example, `minio-cluster`.
## Initial Setup
### 1. Set Up Cluster
**New Cluster:**
Replace `<CLUSTER_NAME>` and execute:
```sh
eksctl create cluster \
--name <CLUSTER_NAME> \
--version 1.21 \
--node-type=c6i.24xlarge \
--nodes-min=4 \
--nodes=4 \
--nodes-max=4 \
--zones=us-west-2a,us-west-2b,us-west-2c
```
### 2. Install AWS EBS CSI Driver
This driver allows using gp3 and sc1 storage types within EKS:
```sh
kubectl apply -k "github.com/kubernetes-sigs/aws-ebs-csi-driver/deploy/kubernetes/overlays/stable/?ref=release-1.5"
```
## Cluster Configuration
### 1. Create IAM Policy
Replace `<CLUSTER_NAME>` and `<AWS_ACCOUNT_NUMBER>` in `iam-policy.json`:
```sh
aws iam create-policy \
--policy-name minio-eks-<CLUSTER_NAME> \
--policy-document file://iam-policy.json
```
### 2. Create an OIDC Provider
```sh
eksctl utils associate-iam-oidc-provider --region=us-west-2 --cluster=<CLUSTER_NAME> --approve
```
### 3. Create Trust, Role, and Service Account
For MinIO Operator:
```sh
eksctl create iamserviceaccount \
--name minio-operator \
--namespace minio-operator \
--cluster <CLUSTER_NAME> \
--attach-policy-arn arn:aws:iam::<AWS_ACCOUNT_NUMBER>:policy/minio-eks-<CLUSTER_NAME> \
--approve \
--override-existing-serviceaccounts
```
For AWS EBS CSI Driver:
```sh
eksctl create iamserviceaccount
--name ebs-csi-controller-sa
--namespace kube-system
--cluster <CLUSTER_NAME>
--attach-policy-arn arn:aws:iam::<AWS_ACCOUNT_NUMBER>:policy/minio-eks-<CLUSTER_NAME>
--approve
--override-existing-serviceaccounts
```
## Installing MinIO
Deploy the MinIO Operator:
```sh
kubectl apply -k github.com/miniohq/marketplace/eks/resources
```
## Accessing MinIO
### 1. Retrieve the JWT for Operator Console
```sh
kubectl -n minio-operator get secret $(kubectl -n minio-operator get serviceaccount console-sa -o jsonpath="{.secrets[0].name}") -o jsonpath="{.data.token}" | base64 --decode
```
### 2. Port Forward to Operator Console
```sh
kubectl -n minio-operator port-forward svc/console 9090
```
Open [http://localhost:9090](http://localhost:9090) in your browser and log in with the retrieved JWT.
### 3. Create a Tenant
Log in and create your first tenant, specifying the desired size and storage type.
### Conclusion
Congratulations! In just 15 minutes, you've successfully deployed MinIO on Amazon EKS, paving the way for a robust and scalable object storage solution. This guide offers a powerful starting point for migrating away from AWS S3, empowering you with flexibility, cost-efficiency, and a superior alternative for your data storage needs.
Thank you for reading! If you found this blog post helpful, please consider sharing it with others who might benefit. Feel free to check out my other blog posts and visit my socials!
- [Profile](https://bio.link/devarshishimpi)
- [Linkedin](https://linkedin.com/in/devarshi-shimpi)
- [Twitter](https://twitter.com/devarshishimpi)
- [Youtube](https://youtube.com/@devarshishimpi)
- [Hashnode](https://devarshishimpi.hashnode.dev)
- [DEV](https://dev.to/devarshishimpi)
### Read more
- [Setting Up An Ubuntu EC2 Instance From Scratch on AWS](https://blog.devarshi.dev/setting-up-an-ubuntu-ec2-instance-from-scratch-on-aws)
- [How to Install and Set Up a Ghost Blog on AWS Lightsail](https://blog.devarshi.dev/how-to-install-and-setup-a-ghost-blog-on-aws-lightsail)
- [Creating Your First Droplet - DigitalOcean Tutorials](https://blog.devarshi.dev/creating-your-first-droplet-digitalocean-tutorials) | devarshishimpi |
1,862,553 | Kubernetes and VMware NSX: Seamless Integration | Integrating Kubernetes with VMware NSX is becoming crucial for businesses aiming to streamline their... | 0 | 2024-05-23T08:05:35 | https://dev.to/calsoftinc/kubernetes-and-vmware-nsx-seamless-integration-4208 | kubernetes, nsxmigration, network, opensource | Integrating Kubernetes with VMware NSX is becoming crucial for businesses aiming to streamline their operations and enhance their IT infrastructure. This blog will delve into the combination of these technologies, that focus on [**NSX migration**](https://www.calsoftinc.com/work-insights/brochure/nsx-v-to-t-migration/) and its benefits. Understanding the seamless integration of Kubernetes and VMware NSX is critical because it brings collectively robust container orchestration and advanced networking capabilities. We will discover the steps involved in the integration process, discuss key considerations, and highlight the significance of this integration for modern, cutting-edge IT infrastructures.
## Introduction to Kubernetes and VMware NSX
Kubernetes is an open-source framework for automating the deployment, scaling, and control of containerized applications. It streamlines the complicated processes used to control containerized applications, making it easier for developers to launch and scale the applications.
VMware NSX, on the other hand, is a network virtualization platform that offers a complete framework for managing networking and security in a digital environment. It permits the establishment of digital networks that may be managed and operated using software, offering an unparalleled stage of flexibility and security.
## Why integrate Kubernetes with VMware NSX?
Integrating Kubernetes with [**VMware NSX**](https://www.calsoftinc.com/blogs/an-ultimate-guide-for-nsx-v-to-nsx-t-migration.html) brings together the best of both technologies. Kubernetes provides robust container orchestration, just as NSX offers advanced networking and security capabilities. This integration allows businesses to:
• Simplify network control for Kubernetes clusters.
• Enhance security through micro-segmentation.
• Improve the scalability and flexibility of network resources.
• Streamline operations with unified management tools.
## Key Considerations for Successful Integration
Successful integration of Kubernetes with VMware NSX requires careful planning and execution. Here are a few key considerations:
### Compatibility and requirements:
Ensure that the Kubernetes and the NSX models are compatible. Check the system requirements and compatibility matrix provided by VMware to avoid any issues during integration.
### Security Policies and Compliance:
Implementing robust security policies is crucial. NSX provides micro-segmentation, which can be used to enforce security guidelines on the network level. Ensure that these guidelines are aligned with the organization`s protection necessities and compliance standards.
### Performance Optimization:
Performance optimization is important to maintain the efficiency of the integrated environment. It consists of monitoring network performance, tuning network configurations for optimal throughput, and regularly updating and patching systems. By consistently tracking and fine-tuning these aspects, businesses can ensure easy and reliable operation in their integrated Kubernetes and VMware NSX environment.
## The Process of Integrating NSX With Kubernetes
## Benefits of Integrating Kubernetes with VMware NSX
The integration of Kubernetes with VMware NSX offers numerous benefits for companies. These benefits include:
### Improved network management:
NSX simplifies network control by offering a single pane of glass for managing both physical and digital networks. This reduces complexity and improves operational efficiency.
### Enhanced Security:
With NSX, businesses can enforce micro-segmentation to enforce safety guidelines at the application level. This provides higher safety in opposition to threats and improves compliance with security standards.
### Scalability and flexibility:
NSX offers the scalability needed to assist massive Kubernetes deployments. It allows for the dynamic allocation of network resources, ensuring that the infrastructure can adapt to the organization`s needs.
### Unified Management:
Integrating Kubernetes with NSX offers a unified management framework, permitting leaders to control each platform from a single interface. This streamlines operations and decreases the learning curve for IT staff.
## A Use Case Scenario: Challenges Faced by an IT Services Company and the Key Solutions

The following table outlines the challenges faced by the IT services company, the solutions provided by integrating Kubernetes with VMware NSX, and the benefits achieved from the solutions.
## Conclusion
Integrating Kubernetes with VMware NSX offers an effective solution for businesses seeking to enhance their network control and security. The process of NSX migration is essential for leveraging the overall advantages of this integration. By carefully making plans and executing the migration, businesses can acquire improved network control, better security, and greater scalability.
At Calsoft, we focus on helping businesses navigate this complex integration. Our deep expertise in Kubernetes and VMware NSX ensures a smooth migration, minimizing disruptions and maximizing the advantages. With our comprehensive approach, we assist in planning, implementing, and optimizing the integration, ensuring that your IT infrastructure is robust, stable, and scalable.
The integration of Kubernetes and VMware NSX is great for modern IT infrastructures, presenting a unified framework that simplifies operations and enhances performance. As more businesses undertake containerized applications and seek to enhance their network capabilities, the expertise and support from Calsoft will become invaluable.
By partnering with Calsoft, you can ensure a successful integration, leveraging our considerable experience and tailored solutions to acquire an extra-efficient and secure IT environment. Calsoft`s dedication to excellence and customer satisfaction makes us the perfect partner for your Kubernetes and VMware NSX integration needs.
| calsoftinc |
1,862,577 | How to Create a CI/CD Pipeline with Docker | CI/CD pipelines automate build, test, and deployment tasks within the software delivery lifecycle... | 0 | 2024-05-23T08:03:28 | https://spacelift.io/blog/docker-ci-cd | docker, cicd, devops | CI/CD pipelines automate build, test, and deployment tasks within the software delivery lifecycle (SDLC). CI/CD is a crucial part of DevOps because it helps increase delivery throughput while ensuring consistent quality standards are maintained.
Pipeline configuration often overlaps with the use of containerization platforms like Docker. Containers are isolated, ephemeral environments that have two main benefits for CI/CD: the ability to safely run your pipeline's jobs and to package the applications you create.
In this article, we'll discuss how to combine Docker and CI/CD for maximum effect.
##What is CI/CD?
Continuous Integration (CI) and Continuous Delivery (CD) pipelines automate the process of taking code changes from development through to production environments. Manually executing builds, tests, and deployment jobs is time-consuming and error-prone; using CI/CD instead lets you stay focused on development while ensuring all code is subject to required checks.
Successful CI/CD adoption [depends on pipelines](https://spacelift.io/blog/scaling-ci-cd) being fast, simple, secure, and scalable. It's important to architect your job execution environments so they fulfill these requirements, as otherwise, bottlenecks and inefficiencies can occur. Using Docker containers for your jobs is one way to achieve this.
Read more about [CI/CD pipelines](https://spacelift.io/blog/ci-cd-pipeline).
##Using Docker for CI/CD
Docker is the most popular containerization platform. The isolation and scalability characteristics of containers make them suitable for a variety of tasks related to app deployment and the SDL.
In the context of CI/CD, Docker is used in two main ways:
1. Using Docker to run your CI/CD pipeline jobs --- Your CI/CD platform creates a new Docker container for each job in your pipeline. The job's script is executed inside the container, providing per-job isolation that helps prevent unwanted side effects and security issues from occurring.
2. Using a CI/CD pipeline to build and deploy your Docker images --- A job within your CI/CD pipeline is used to build an updated Docker image after changes are made to your source code. The built image can then be deployed to production in a later job.
These interactions between Docker and CI/CD servers are not mutually exclusive: many projects will use Docker to run their CI/CD jobs *and* will build Docker images in those jobs. This workflow is usually achieved using [Docker-in-Docker](https://hub.docker.com/_/docker#start-a-daemon-instance), where an instance of the Docker daemon is started inside the container that runs the CI/CD job. The nested Docker daemon allows you to successfully perform operations like `docker build` and `docker push` that your job's script requires. Enabling Docker-in-Docker can require special configuration within your CI/CD jobs, depending on the platform you're using.
💡 You might also like:
- [13 Most Useful Container Orchestration Tools](https://spacelift.io/blog/container-orchestration-tools)
- [What is OpenTofu](https://spacelift.io/blog/what-is-opentofu)
- [Why generic CI/CD tools will not deliver successful IaC](https://spacelift.io/blog/infrastructure-as-code-with-generic-ci-cd)
##Example: How to build a CI/CD pipeline with Docker
To illustrate the two ways in which Docker can be used with CI/CD, we'll create a simple GitLab CI/CD pipeline.
The pipeline will execute a job that runs inside a Docker container; that containerized job will use Docker-in-Docker to build our app's Docker image and push it to the image registry provided by GitLab. This pipeline will ensure that image rebuilds occur automatically and consistently each time new commits are pushed to the repository.
The steps that follow are specific to GitLab, but the overall flow is similar in other CI/CD tools.
### 1\. Prepare GitLab CI/CD
To follow along with this tutorial, you'll need a new project prepared on either [GitLab.com](https://gitlab.com/) or your own GitLab instance. By default, GitLab.com [runs your jobs as](https://docs.gitlab.com/ee/ci/runners/saas/linux_saas_runner.html) Docker containers atop ephemeral virtual machine instances, so no additional configuration is required to containerize your pipelines.
If you're using your own GitLab instance, you should ensure you've connected a GitLab Runner that's using the Docker executor --- you can find detailed set up instructions in [the documentation](https://docs.gitlab.com/ee/ci/docker/using_docker_build.html#use-the-docker-executor-with-docker-in-docker). For the purposes of this tutorial, the runner should be configured to accept untagged jobs.
### 2\. Create a Dockerfile
Once you've created your project, clone it to your machine, then save the following sample [Dockerfile](https://spacelift.io/blog/dockerfile) to your project's root directory:
```
FROM httpd:alpine
RUN echo "<h1>Hello World</h1>" > /usr/local/apache2/htdocs/index.html
```
Next, use Git to commit your file and push it up to GitLab:
```
$ git add .
$ git commit -m "Add Dockerfile"
$ git push
```
This Dockerfile configures the image that will be built for our application, within the CI/CD pipeline.
### 2\. Create a GitLab CI/CD pipeline configuration
Now, you can set up your CI/CD pipeline to build your image when new changes are committed to your repository.
GitLab pipelines are configured using a `.gitlab-ci.yml` YAML file located in your repository's root directory. The following pipeline configuration uses Docker-in-Docker to build your image from your Dockerfile, inside the Docker container that's running the job. The image is then pushed to your project's[ GitLab Container Registry](https://docs.gitlab.com/ee/user/packages/container_registry) instance, which comes enabled by default.
```
stages:
- build
variables:
DOCKER_IMAGE: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA
build:
image: docker:25.0
stage: build
services:
- docker:25.0-dind
script:
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY
- docker build -t $DOCKER_IMAGE .
- docker push $DOCKER_IMAGE
```
There are a few points to note:
- GitLab CI/CD jobs come with predefined variables that can be used to authenticate to various GitLab components in your project. Here, the automatically generated `$CI_REGISTRY_USER` and ``$CI_REGISTRY_PASSWORD`` short-lived credentials are used to authenticate to your project's Container Registry via the `docker login` command.
- `$CI_REGISTRY_IMAGE` variable provides the image URL reference that should be used for images to be stored in your project's Container Registry. In our custom `$DOCKER_IMAGE` variable, this is combined with the SHA of the commit the pipeline is running to produce the final tag that will be assigned to the built image. It ensures that each commit produces a distinctly tagged image.
- The `image` field within the `build` job definition defines the Docker image that will be used to run the job---in this case, `docker:25.0` so the Docker CLI is available.Because Docker-in-Docker (DinD) functionality is required, the DinD image is also referenced as a[service for the job](https://docs.gitlab.com/ee/ci/services). This is a GitLab mechanism that allows networked applications (in this case, the Docker daemon) to be started in a different container but accessed from the job container. It's required because GitLab overrides the job container's entrypoint to run your script, so the Docker daemon won't start in the job container.
Copy the pipeline file, save it as `.gitlab-ci.yml`, and commit it to your repository. After you push the changes to GitLab, head to the Build > Pipelines page in the web UI --- you should see your first pipeline is running:
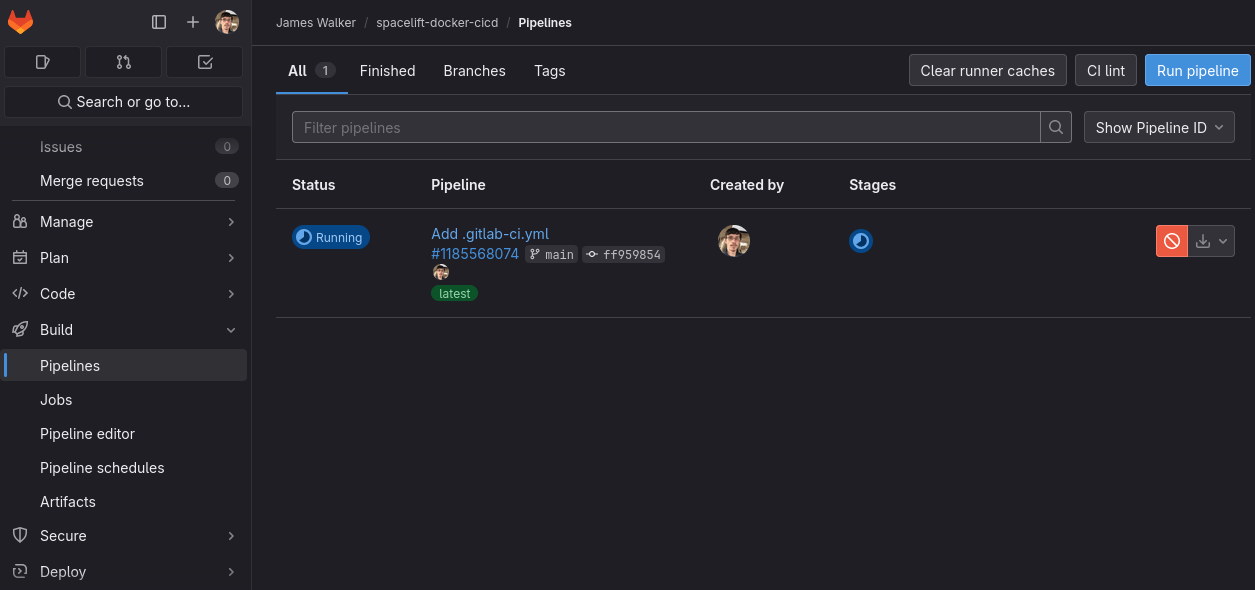
Wait while the pipeline completes, then click the green tick under the Stages column to view the logs from your build job:
You can see from the logs that Docker is being used to execute the job, so your script is running within a container. GitLab selects the `docker:25.0` image specified in your pipeline's config file, then starts the DinD service so the Docker daemon is accessible. Your script instructions are then followed to build your image and push it to your project's Container Registry.
### 3\. View your image
Visit the Deploy > Container Registry page of the GitLab web interface to see your pushed image:
The image is tagged with the unique SHA of your last commit. Now, you can make changes to your project, push them to GitLab, and have your CI/CD pipeline automatically build an updated image.
Although this is only a simple example, it shows the most common way to utilize CI/CD and Docker together. Your CI/CD platform might require a different pipeline configuration to that shown here, but you should still be able to achieve an equivalent result.
##Best practices for CI/CD with Docker
Although CI/CD pipelines and Docker containers complement each other well, there are still several pitfalls you could encounter as you combine them.
Here are a few Docker CI/CD best practices that will improve performance, security, and scalability:
1. Beware of the risks of using Docker-in-Docker --- Docker-in-Docker requires the use of [privileged mode](https://docs.docker.com/engine/reference/run/#runtime-privilege-and-linux-capabilities). This means that root in a job container is effectively root on your host too, allowing an attacker with access to your pipeline's config file to define a job that uses sensitive privileges.
2. Lockdown your Dockerized build environments --- Because privileged mode is insecure, you should restrict your CI/CD environments to known users and projects. If this isn't feasible, then instead of using Docker, you could try using a standalone image builder like [Buildah](https://buildah.io/) to eliminate the risk. Alternatively, configuring [rootless Docker-in-Docker](https://hub.docker.com/_/docker#rootless) can mitigate some --- but not all --- of the security concerns surrounding privileged mode.
3. Run your CI/CD jobs in parallel to improve performance --- Correctly configuring your CI/CD platform for parallel jobs will reduce pipeline duration, improving throughput. Containerization means all jobs will run in their own isolated environment, so they're less likely to cause side effects for each other when executed concurrently.
4. Monitor resource utilization and pipeline scaling --- An active CI/CD server that runs many jobs concurrently can experience high resource utilization. Running jobs inside containers makes it easier to scale to additional hosts, as you don't need to manually replicate your build environments on each runner machine.
5. Correctly configure build caches and persistent storage --- Using Docker-in-Docker prevents Docker's build cache from being effective as each job creates its own container, with no access to the cache created by the previous one. Configuring your builds to use previously created images [as a cache](https://docs.gitlab.com/ee/ci/docker/docker_layer_caching.html) will improve efficiency and performance.
Keeping these tips in mind will ensure you can use CI/CD and containers without the two techniques negatively affecting each other.
##Using a managed CI/CD platform
Selecting a managed CI/CD platform removes the hassle of configuring and scaling your pipelines. [Spacelift](https://spacelift.io/) is a specialized CI/CD platform for[ IaC scenarios](https://spacelift.io/ci-cd-for-infrastructure). It goes above and beyond the support that is offered by the plain backend system. Spacelift enables developer freedom by supporting multiple IaC providers, version control systems, and public cloud endpoints with precise guardrails for universal control.
Instead of manually maintaining build servers, you can simply connect the platform to your repositories. You can then test and apply infrastructure changes directly from your pull requests. It eliminates administration overheads and provides simple self-service developer access within policy-defined guardrails.
Read more [why DevOps Engineers recommend Spacelift](https://spacelift.io/blog/why-devops-engineers-recommend-spacelift). If you want to learn more about Spacelift, [create a free account today](https://spacelift.io/free-trial), or [book a demo](https://spacelift.io/schedule-demo) with one of our engineers.
##Key points
CI/CD and containers are two key technologies in the modern software delivery lifecycle. They each get even better when combined together: correctly configured Docker environments provide isolation and security for your CI/CD jobs, while those jobs are also the ideal place to build the Docker images needed by your apps.
In this guide, we've given an overview of how to use Docker containers with GitLab CI/CD, but we've only touched on the broader topic. Check out the other content [on our blog](https://spacelift.io/blog) to learn more techniques and best practices for CI/CD and Docker, or try using [Spacelift](https://spacelift.io/) to achieve automated CI/CD for your IaC tools.
_Written by James Walker_ | spacelift_team |
1,862,576 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-05-23T08:01:56 | https://dev.to/etholite/my-pen-on-codepen-3eei | codepen | Check out this Pen I made!
{% codepen https://codepen.io/xyaiujlg-the-animator/pen/GRaqMOq %} | etholite |
1,830,469 | Why You Should Leverage Database Integration with OpenTelemetry | Database observability is crucial for maintaining optimal performance and reliability in modern... | 0 | 2024-05-23T08:00:00 | https://www.metisdata.io/blog/why-you-should-leverage-database-integration-with-opentelemetry | [Database observability](https://www.metisdata.io/) is crucial for maintaining optimal performance and reliability in modern software systems. It enables organizations to [monitor key metrics](https://www.metisdata.io/blog/database-monitoring-metrics-key-indicators-for-performance-analysis) such as query execution time, resource utilization, and transaction throughput, facilitating the early detection and resolution of issues like slow queries or resource contention. Good observability gives safety as all the operations are monitored and protected. Specifically for developers, observability lets them understand the performance implications of the application changes even before they reach production.
When it comes to practical aspects, we can use OpenTelemetry (OTel) for building the observability around databases. OpenTelemetry is an open-source observability framework designed to facilitate the instrumentation and collection of various signals like distributed traces or metrics. It’s a set of specifications of how to shape the data and a set of SDKs streamlining the processing of the signals afterward. With support for multiple programming languages and integrations with popular observability tools, OpenTelemetry has become a vital tool for organizations aiming to adopt a standardized and comprehensive approach to monitoring and troubleshooting their complex, microservices-based architectures. Since OTel is open and well-standardized, many OTel collectors emerged that make capturing the data a breeze.
Metis uses OpenTelemetry to deliver the best possible experience. Metis uses OTel to extract details of database activity and application changes and then can correlate them to provide full database observability and understanding of what happened. This way, Metis can pinpoint performance bottlenecks and build a comprehensive story explaining why they happen. For instance, Metis can explain that the recent changes to the application code resulted in different SQL queries being executed, which in turn didn’t use indexing as much and led to lower performance. Such examples of [database monitoring](https://www.metisdata.io/product/monitoring) prove that observability lowers the cost of maintenance and development. This is just one of many reasons why every database (not only enterprise database) can benefit from database integration with observability tooling.
**Recommended reading:** [**How to prevent database problems from hitting production?**](https://www.metisdata.io/blog/how-to-prevent-database-problems-from-hitting-production)
## Why Integrate Your Database with OpenTelemetry?
There are many benefits of database observability. Let’s see some of them.
First, database observability allows tracking and monitoring of database performance metrics such as query execution time, resource utilization, and transaction throughput. Identifying bottlenecks or inefficient queries helps in [optimizing database performance](https://www.metisdata.io/blog/8-proven-strategies-to-improve-database-performance) and ensuring responsive applications. We always need to make sure that there are no database performance issues, as they spread throughout the ecosystem and affect our business. Also, by collecting and analyzing telemetry data, database observability helps in the [early detection](https://www.metisdata.io/product/prevention) of issues like slow queries, deadlocks, or resource contention. This enables prompt troubleshooting and resolution before these issues impact application performance or user experience.
Next, database observability helps with capacity planning. Observing trends in data growth, query loads, and resource consumption helps organizations scale their databases appropriately, ensuring they can handle increasing workloads without compromising performance. This also leads to cost reduction as it helps in making informed decisions about scaling, resource allocation, and choosing the right database solutions based on performance and cost considerations.
Database observability provides insights into dependencies and relationships between services. Tracing queries across microservices helps in identifying the root cause of issues and understanding the impact of changes on the overall system. This is also essential for monitoring database access patterns and detecting potential security threats. By tracking user activity and permissions, organizations can ensure compliance with security policies and regulations, helping to protect sensitive data from unauthorized access.
Finally, database observability enables proactive maintenance by providing insights into the health and status of the database. Predictive analysis can help in identifying issues before they become critical, allowing for scheduled maintenance and minimizing unplanned downtime.
**Recommended reading:** [**How To Master PostgreSQL Performance Like Never Before**](https://www.metisdata.io/blog/how-to-master-postgresql-performance-like-never-before)
To build database observability, we need to select the right tools and libraries. The best candidate is OpenTelemetry (OTel). It’s a set of standards, specifications, libraries, SDKs, and open-source integrations that cover the entire observability ecosystem. With OTel, we can capture signals with little-to-no application changes (for instance by configuring environment variables when running the application), we get a vast number of tools for storing, processing, displaying, and manipulating the signals, and we get integrations with many libraries and frameworks out of the box.
Just like we have logging in our applications, we can OTel to capture metrics, traces, and details of interactions between applications, services, and databases. OpenTelemetry is the modern industry standard for processing the signals, so most of the time we don’t need to build custom tools. We just take components off the shelf.
## Key Components of OpenTelemetry for Database Integration
OpenTelemetry provides many components working together to capture and process the signals. Let’s explore them.
At a glance, the process looks like this: the application must know what signals to emit and what they should look like. Next, the application must emit the signals somehow. The signals must then be captured and processed, so they can be visualized for the users. OpenTelemetry covers all these aspects. Let’s see how.
First, OTel defines the shape of the structures. This includes a list of fields, their values, format, and meaning. This way, applications from various technologies can interoperate and provide data uniformly. All data schemas are well documented and used in the same way between tools and programming languages.
Next, the application must emit the signals somehow. OpenTelemetry provides SDKs for many programming languages. All we need to do is to install the SDK and use it. We don’t need to deal with low-level details of protocols or data structures, as the SDK provides high-level APIs for creating *traces* and *spans*.
A span encapsulates a single task, for instance, an API call or a database query execution. A trace is a collection of related spans. We can use traces to present the history of what happened and how. Let’s see the image:
This whole picture is a trace. It represents five operations represented by five different spans. Each span (with letters A to E) represents one particular operation, like an API call, file access, or query execution. We can create these traces and spans using the OpenTelemetry SDK with high-level APIs.
If we don’t write the application but rather use existing tools (like databases, queues, and file stores), then many of these tools integrate with OpenTelemetry already. [OpenTelemetry lists a few tens of receivers](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver) for various tools. You can just take the receiver and capture signals right away. Specifically for databases, there are receivers for many popular databases, including PostgreSQL, MySQL, Oracle, and MS SQL.
Next, once the signals are emitted, they need to be captured and processed. Many [collectors](https://opentelemetry.io/docs/collector/) can do that. You can use the one provided by OpenTelemetry, or you can use open-source solutions tuned for specific cases (like microservices or SQL databases).
Apart from capturing and visualizing signals, the receivers and the collectors can handle confidential information and personal information that needs to be anonymized. It is safe to run these tools in highly constrained environments where the anonymity and security of the data are crucial.
## Practical Guide to Integrating Your Database with OTel
There are three areas that we need to cover to build database integration with OpenTelemetry. These are queries, schemas, and metrics. In this section, we’ll use Postgres integration as an example, but the same steps apply to other databases as well.
The first area we need to cover is the queries that run in the database. We need to analyze the live database activity, capture the execution plans, and monitor the usage of the indexes or if statistics are up to date. We can do that by reconfiguring the database to use a slow query log, or we can deploy an agent monitoring the database activity.
[Metis provides an agent](https://docs.metisdata.io/Monitoring/Deploy%20Metis%20Agent/) that can do that for you. The agent connects to your database and extracts the running queries, and their plans, and then provides suggestions on how to improve the performance. You just need to deploy the Docker container and let it connect to the database server.
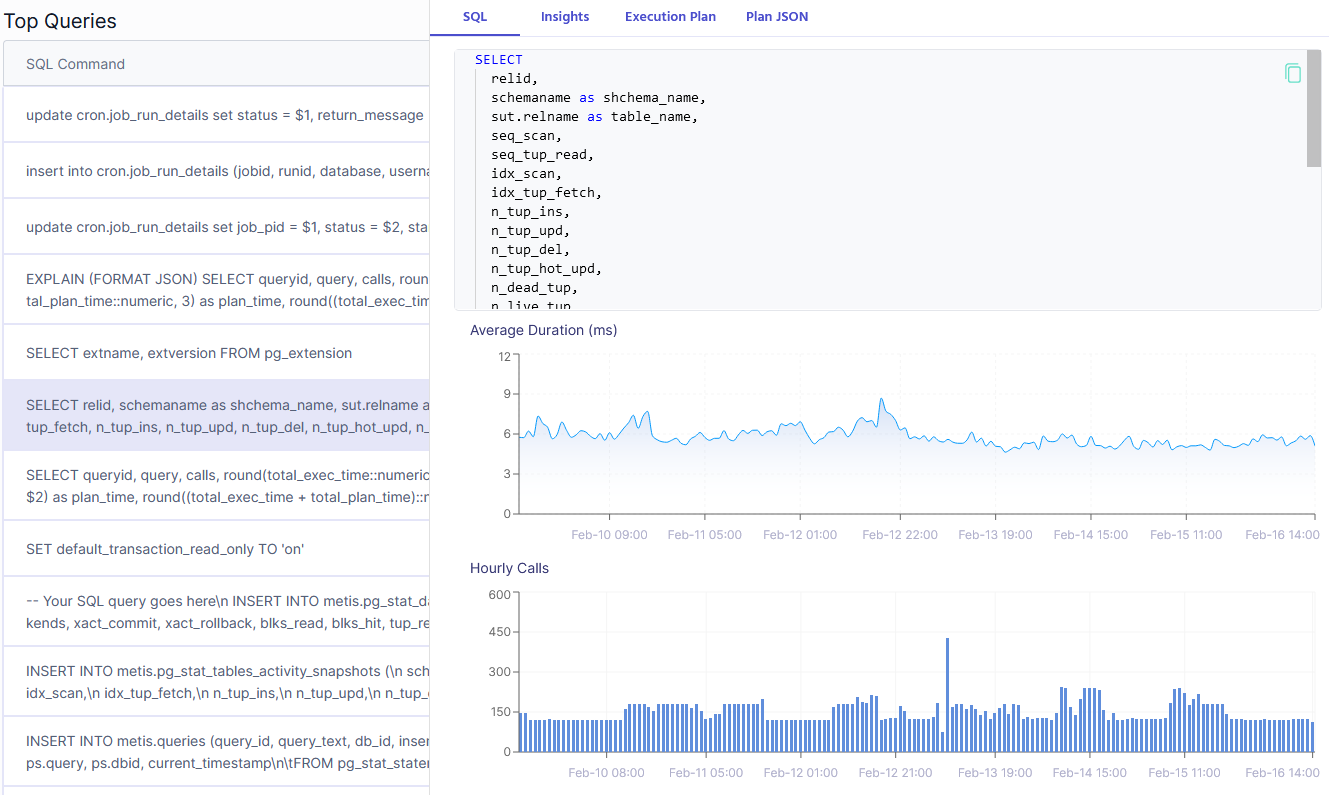
The other area is schemas. There are many aspects that we should pay attention to. Data types, fragmentation, vacuuming, primary keys, secondary keys, normalization, denormalization, and much more. We need to check the tables and analyze them to understand if we store and process the data optimally. Metis can do that and analyze all the database details for you.
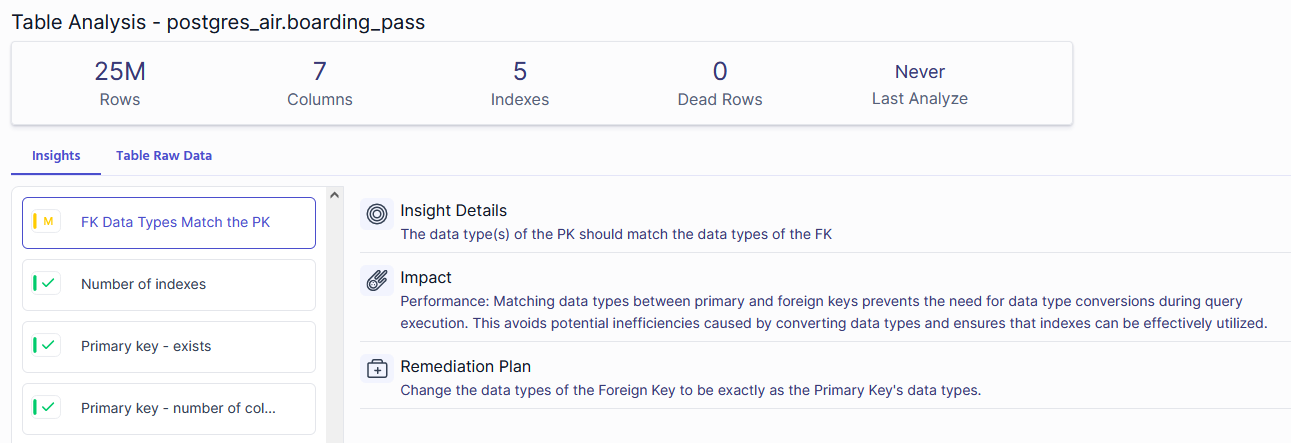
The last area is metrics about the database and infrastructure activity. This includes CPU, number of transactions, memory used, buffers, and much more. To do that, we need to use OpenTelemetry to extract the metrics directly from the database engine. Again, Metis can do that for us.

## Analyzing Database Performance with OpenTelemetry
Once we capture all the data with OpenTelemetry, we can analyze the signals to reason about the performance.
First, establish a baseline for normal behavior by monitoring your database under typical workloads. Check the metrics when your database is known to perform “well”. This helps in distinguishing normal variations from actual performance anomalies. Tools like Metis, Prometheus, Grafana, or commercial monitoring solutions can assist in visualizing and establishing baselines.
Next, look for metrics that indicate potential bottlenecks. High CPU or disk utilization, long query execution times, or a spike in connection errors can point to performance issues. Utilize monitoring tools to set up alerts for thresholds that, when breached, indicate potential problems. Generally, spikes in metrics should be a good starting point for analysis. However, they always need to be correlated with the typical weekly patterns observed in your business activity (like more load during peak hours).
**Recommended reading:** [**Troubleshooting PostgreSQL High CPU Usage**](https://www.metisdata.io/blog/hold-your-horses-postgres-how-to-debug-high-cpu-usage)
Once you identify times of the week when things are off, focus on analyzing the performance of individual queries. Identify slow or resource-intensive queries by examining metrics such as execution time, query plans, and indexes. Database query profilers and tools like EXPLAIN in SQL databases can provide insights into query performance. Use Metis to perform this analysis automatically
Next, look for issues that can be easily identified automatically. Check metrics related to locks and deadlocks, as these can significantly impact database performance. Identify long-running transactions and investigate if they are causing contention or blocking other transactions.
Always look for patterns and relationships. Correlate data from various areas, like CPU and memory consumption, and the number of transactions.
By systematically analyzing database metrics and adopting a proactive approach, you can identify and address performance issues before they impact the overall performance of your application. Regular monitoring and analysis are key components of maintaining a healthy and efficient database environment.
Finally, configure alarms to get automated notifications when metrics cross the thresholds. Metis can do that for you automatically.
## Common Challenges and Solutions in Database Integration with OTel
As with every process, things may go wrong. Let’s now see a couple of typical challenges when building the database integration.
First, instrumenting applications with OpenTelemetry can introduce some level of overhead, impacting the performance of the monitored system. Measure the impact and check if it’s acceptable. Keep in mind that this is affecting your production systems, so you shouldn’t deploy it blindly.
Next, the amount of telemetry data generated by OpenTelemetry can be substantial, especially in large and complex systems. Managing and storing this data efficiently can be a challenge, requiring careful consideration of storage solutions and data retention policies. You need to recycle the log files, compress them, and store them in some centralized place. Same with metrics and other structured data.
Another issue is the legacy systems. Integrating OpenTelemetry with legacy systems that lack native support for observability may require additional effort. Retrofitting instrumentation into older codebases or systems may not be straightforward, potentially limiting the depth of observability in those components. However, the true power of observability comes from the full coverage. You need to integrate all your systems, so plan how you can do that with some older solutions.
**Recommended reading:** [Observability vs Monitoring: Key Differences & How They Pair](https://www.metisdata.io/blog/observability-vs-monitoring-key-differences-how-they-pair)
Finally, telemetry data must be protected and secured. It contains all the crucial information and you need to make sure to not leak any of that. Limit the access to the data as much as possible. Always encrypt your data and do not expose it publicly.
## Conclusion
Database observability is crucial for maintaining the optimal performance of your database. Your organization can greatly benefit from observability. OpenTelemetry can make this much easier thanks to its SDKs and open-source solutions.
On top of that, Metis can automate most of the aspects. Metis can capture schemas, queries, configurations, extensions, and metrics. Metis can also suggest improvements and alert you when things go wrong. If you are yet to build observability, go with OpenTelemetry and Metis.
## FAQs
### What is database integration and why is it important for enterprises?
Observability integration is important as it gives the constant monitoring of your databases. It can alert you when things go wrong, prevent issues from happening, and clearly show the status of the system.
### How does database integration with OpenTelemetry improve performance monitoring?
OpenTelemetry makes the monitoring much easier thanks to SDKs and many open-source tools. Organizations don’t need to build their solutions but can utilize OpenTelemetry instead.
### Can OpenTelemetry be used for both SQL and NoSQL databases?
Yes. OpenTelemetry integrates with many systems, including SQL and NoSQL databases.
### What are the security considerations when integrating your database with OpenTelemetry?
Telemetry data contains crucial details of your business, including personally identifiable information. You need to limit access to the data, encrypt it, and not expose it publicly. | adammetis | |
1,862,584 | React 19: Comprehensive Guide to the Latest Features | React 19 Beta is finally here, after a two-year hiatus. The React team has published an article about... | 0 | 2024-06-13T07:37:13 | https://apiumhub.com/tech-blog-barcelona/react-19-features/ | agilewebandappdevelo | ---
title: React 19: Comprehensive Guide to the Latest Features
published: true
date: 2024-05-23 08:00:00 UTC
tags: Agilewebandappdevelo
canonical_url: https://apiumhub.com/tech-blog-barcelona/react-19-features/
---
React 19 Beta is finally here, after a two-year hiatus. The React team has published [an article](https://react.dev/blog/2024/04/25/react-19) about the latest version. Among the standout features is the introduction of a new compiler, aimed at performance optimization and simplifying developers’ workflows.
Furthermore, the update brings significant improvements to handling state updates triggered by responses, with the introduction of actions and new handling from state hooks. Additionally, the introduction of the use() hook simplifies asynchronous operations even further, allowing developers to manage loading states and context seamlessly.
React 19 Beta also marks a milestone in improving accessibility and compatibility, with full support for Web components and custom elements. Moreover, developers will benefit from built-in support for document metadata, async scripts, stylesheets, and preloading resources, further enhancing the performance and user experience of React applications.
In this article, it will be explained deeply the features mentioned above.
## React 19 New features
### New compiler: Revolutionizing Performance Optimization and Replacing useMemo and useCallback
React 19 introduces an experimental compiler that allows React code into optimized JS code. While other frontend frameworks such as Astro and Sveltve have their compiler, React joins now to this team enhancing its performance optimization.
React applications frequently encountered performance challenges due to excessive re-rendering triggered by state changes. To mitigate this issue, developers often manually employ useMemo, useCallback, or memo APIs. These mechanisms aimed to optimize performance by memoizing certain computations and callback functions. However, the introduction of the React compiler automates these optimizations, integrating them into the codebase. Consequently, this automation not only enhances the speed and efficiency of React applications but also simplifies the development process for engineers.
### Actions and new handling form state hooks
The introduction of actions represents one of the most significant enhancements within React’s latest features. These changes help the process of handling state updates triggered by responses, particularly in scenarios involving data mutations.
A common scenario arises where a user initiates a data mutation, such as submitting a form to modify their information. This action typically involves making an API request and handling this response. Developers had to face the task of managing various states manually, including pending states, errors, and optimistic updates.
However, with the new hooks like useActionState, developers can now handle this process efficiently. By simply passing an asynchronous function within this hook, developers can handle error states, submit actions, and pending states. This simplifies the codebase and enhances the overall development experience.

React’s 19 documentation highlights the evolution of these hooks, with React.useActionState formerly known as ReactDOM.useFormState in the Canary releases.
Moreover, the introduction of useFormStatus addresses another common challenge in design systems. Design components often require access to information about the <form> they are embedded within, without using prop drilling. While this could previously be achieved through Context, the new useFormStatus hook offers a solution by giving the pending status of calls, enabling them to disable or enable buttons and adjust component styles accordingly.

### The use() hook
The new **use** hook in React 19 is designed specifically for asynchronous functions. This innovative hook revolutionizes the way developers handle asynchronous operations within React applications.
With the use hook for async functions, developers can now pass a promise directly, eliminating the need for useEffect and setIsLoading to manage loading states and additional dependencies.
The use hook not only handles loading states effortlessly, but it also provides flexibility in handling context. Developers can easily pass context inside the use hook, allowing integration with the broader application context. Additionally, the hook enables reading context within its scope, further enhancing its utility and convenience.
By abstracting away the complexities of asynchronous operations and context management, the use of hook in React version 19 represents a significant leap forward in developer productivity and application performance.
### ForwardRef
Developers no longer need use forwardRef to access the ‘ref’ prop. Instead, React provides direct access to the ‘ref’ prop, eliminating the need for an additional layer and simplifying the component hierarchy. It enhances code readability and offers developers a more intuitive and efficient way to work with refs.
### Support for document metadata
Another notable enhancement in React 19 is the built-in support for document metadata. This significant change marks a departure from reliance on external libraries like React Helmet to manage document metadata within React applications.
Previously, developers often turned to React Helmet, especially when working outside of frameworks like Next.js, to manipulate document metadata such as titles and links. However, with this latest update, React gives native access directly within its components, eliminating the need for additional dependencies.
Now, developers can seamlessly modify document metadata from anywhere within their React codebase, offering flexibility.
### Support for async scripts, stylesheets, and preloading resources
This significant update is to manage asynchronous loading and rendering of stylesheets, fonts, and scripts, including those defined within <style>, <link>, and <script> tags. Notably, developers now have the flexibility to load stylesheets within the context of Suspense, enhancing the performance and user experience of applications by ensuring a smoother transition during asynchronous component rendering.
Furthermore, when components are rendered asynchronously, developers can effortlessly incorporate the loading of styles and scripts directly within those components, streamlining the development process and improving overall code organization.
### Full support for Web components and custom elements
Unlike previous iterations where compatibility was only partial, React 19 now seamlessly integrates with Web components and custom elements, offering comprehensive support for their use within React applications. Previously, developers encountered challenges as React’s handling of props sometimes clashed with attributes of custom elements, leading to conflicts and inconsistencies.
However, with this latest update, React has provided an intuitive experience for incorporating Web components and custom elements into React-based projects. This enhanced compatibility opens up a world of possibilities for developers, allowing them to leverage the power and flexibility of Web components. With full support for Web components and custom elements, React solidifies its position as a versatile and adaptable framework.
### Conclusion
In conclusion, React 19 Beta represents a significant step forward in the evolution of the React ecosystem, offering developers powerful tools and features to build faster, more efficient, and more accessible applications.
This latest iteration of the React library empowers developers to build faster, more efficient, and more innovative web applications. From the introduction of a new compiler to improved state management and seamless integration with Web components, React 19 Beta offers tools to elevate the developer experience and push the boundaries of what’s possible in modern web development.
If you are interested in this type of content, don’t forget to take a look at [Apiumhub’s blog.](https://apiumhub.com/tech-blog-barcelona/) Every week we upload new and interesting content about the latest technologies in frontend, backend, QA, and software architecture. | apium_hub |
1,862,575 | How to Create Cryptocurrency in Simple Steps | Creating a new cryptocurrency involves a blend of technical expertise, dedication, and a vision for... | 0 | 2024-05-23T07:59:39 | https://dev.to/adelelara/how-to-create-cryptocurrency-in-simple-steps-3dmi | cryptocurrency | Creating a new cryptocurrency involves a blend of technical expertise, dedication, and a vision for something that people will want to own and use. Here's a look at how the process unfolds.
The first step in creating a cryptocurrency is to define its purpose. What problem will it address? How will it bring value to its users? Answering these questions will shape the design and functionality of your cryptocurrency.
Let's start
## How to Develop a Cryptocurrency in Simple Steps
## Determine the purpose for Your Cryptocurrency
The first and most crucial step in creating a cryptocurrency is identifying a compelling use for it. As developers (the term for cryptocurrency creators), it's essential to determine the purpose your digital currency will serve. Cryptocurrencies, like traditional money, can fulfill various roles, such as:
- Transferring money
- Storing wealth as an alternative to traditional currencies
- Supporting smart contracts
- Verifying data
- Managing smart assets
Successful developers clearly define these attractive uses before launching their currencies in the digital market. For instance, **[Dogecoin](https://coinmarketcap.com/currencies/dogecoin/)** started as a fun project based on a popular meme, while IMPT is a new token designed to reward users for reducing their carbon footprints and contributing to environmental sustainability.
## Choose a Blockchain Platform
While you could build your own blockchain from scratch, there are simpler ways to create your cryptocurrency. You can either use the source code from an open-source blockchain platform as a foundation for your own, or leverage existing blockchains.
Your choice of blockchain depends on the purpose you've defined for your cryptocurrency. For example, Cardano and Polkadot are well-known for their proof of stake solutions. Ethereum, one of the most popular blockchains, originally operated on proof of work but is transitioning to proof of stake. Select a platform that aligns best with your goals and the functionalities you need.
## Create the Nodes
Nodes are the backbone of your [blockchain network](https://aws.amazon.com/what-is/blockchain/#:~:text=Blockchain%20technology%20is%20an%20advanced,linked%20together%20in%20a%20chain.). These computers run the software protocol, validate transactions, and ensure network security.
At this stage, you'll need to make several decisions: Will the nodes be public or private? Will they be hosted on-site or in the cloud? How many nodes will you deploy? Which operating system will they use? Each choice will impact the performance, security, and scalability of your cryptocurrency.
## Choose a Blockchain Architecture
When designing your blockchain, it's important to consider how data will be shared across the network. Much like building architecture, the digital architecture of your blockchain must be carefully designed to ensure everything fits together and operates efficiently. Here are three prominent blockchain architecture formats to consider:
**Centralized:** One central node receives information from multiple other nodes.
**Decentralized:** All nodes on the blockchain share data with each other.
**Distributed:** The blockchain ledger moves between nodes. A publicly distributed ledger allows users to review the content, while a privately distributed system lets users adjust the ledger data.
Choosing the right architecture will depend on your goals and how you envision your blockchain functioning.
## Designing the Cryptocurrency
With your blockchain platform selected, the next step is to design your cryptocurrency. This involves making key decisions such as the total supply of coins, the distribution method, and the consensus mechanism.
The consensus mechanism is especially crucial, as it dictates how transactions are verified on the blockchain. The two most common mechanisms are Proof of Work (PoW) and Proof of Stake (PoS), each offering unique advantages. Your choice will significantly impact the security, efficiency, and overall functionality of your cryptocurrency.
## Legal and Regulatory Considerations
Creating a cryptocurrency requires careful navigation of legal and regulatory landscapes. Ensuring compliance with all relevant laws and regulations is crucial. This may involve consulting with legal professionals and conducting thorough research to understand the legal implications of your cryptocurrency. Taking these steps will help you avoid legal issues and ensure your cryptocurrency operates within the bounds of the law.
Two Best Options to create Cryptocurrency
## Option 1 - Modify the Code of an Existing Blockchain
You have the option to utilize the source code of an existing blockchain to create a new blockchain and native cryptocurrency. However, this path typically demands technical expertise, as you may need to tweak the source code to align with your specific design goals.
Most blockchain codes are open source, allowing anyone to access and download them. You can easily find the source codes of numerous blockchains on platforms like GitHub. Once you've downloaded and customized the source code, it's essential to collaborate with a blockchain auditor and seek professional legal counsel. With these steps completed, you'll be prepared to launch your new cryptocurrency.
## Option 2 - Hire a Blockchain Developer to Create a Cryptocurrency for You
If you're not inclined to dive into the technical intricacies yourself, you can enlist the services of a [Cryptocurrency development company](https://www.coinsclone.com/cryptocurrency-development-company/?utm_source=vocal&utm_medium=currency&utm_campaign=Udhay) to create a new coin or token for you. These companies, often referred to as blockchain-as-a-service (BaaS) providers, specialize in building and managing new blockchain networks and cryptocurrencies.
BaaS companies offer varying levels of customization. Some develop bespoke blockchains tailored to your specifications, while others leverage their existing blockchain infrastructure. Additionally, you can collaborate with a BaaS company to launch a highly customized token on an existing blockchain platform.
Notable BaaS providers include Amazon Web Services, Microsoft Azure, ChainZilla, and Blockstream. By partnering with one of these companies, you can bring your cryptocurrency vision to life without the need for extensive technical expertise.
Creating your own cryptocurrency and entering the market can be a rewarding venture. Beyond the advanced technical knowledge required, it's crucial to understand the risks and steps involved. Being well-informed and prepared will help you navigate the complexities and enhance your chances of success.
If you found this article helpful, be sure to check out our other articles on Blockchain Technology.
| adelelara |
1,862,531 | Day 12 of 30 of JavaScript | Hey there. Hope you are doing well😊 In the last post we have studied about the searching and sorting... | 0 | 2024-05-23T07:22:03 | https://dev.to/akshat0610/day-12-of-30-of-javascript-2l29 | webdev, javascript, beginners, tutorial | Hey there. Hope you are doing well😊
In the last post we have studied about the searching and sorting methods used in array. In this post we are going to discuss about **Iteration Methods** used in array.
So let's get started🔥
## Iteration Methods
Array iteration methods are functions or techniques used to traverse through each element of an array or collection of elements systematically. These methods are commonly used to perform operations on each element of an array without needing to manually write loops.
**`Array.forEach()` Method**
The `forEach()` method calls a function (a callback function) once for each array element.
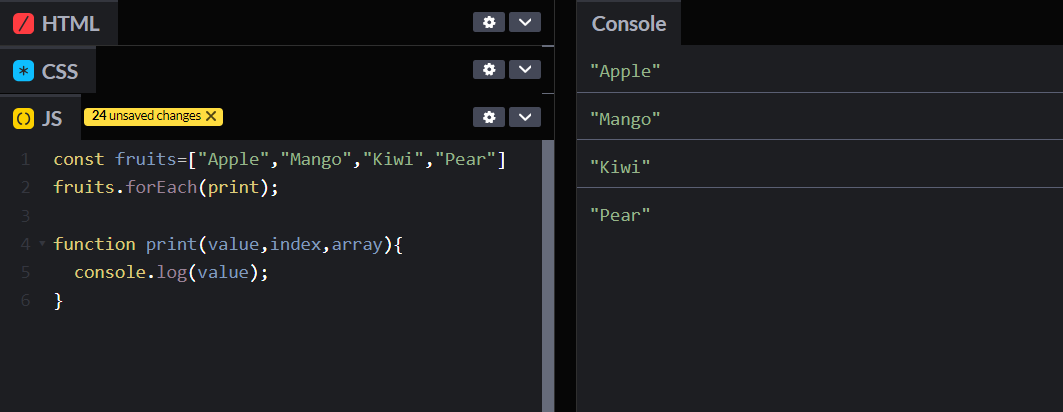
So here you can see that the `print` function is called for every element present in array.
This callback function used here uses three arguments -:
- value
- index
- array
But these are optional we can provide arguments according to our need.
**`Array.map()` Method**
Creates a new array populated with the results of calling a provided function on every element in the calling array.
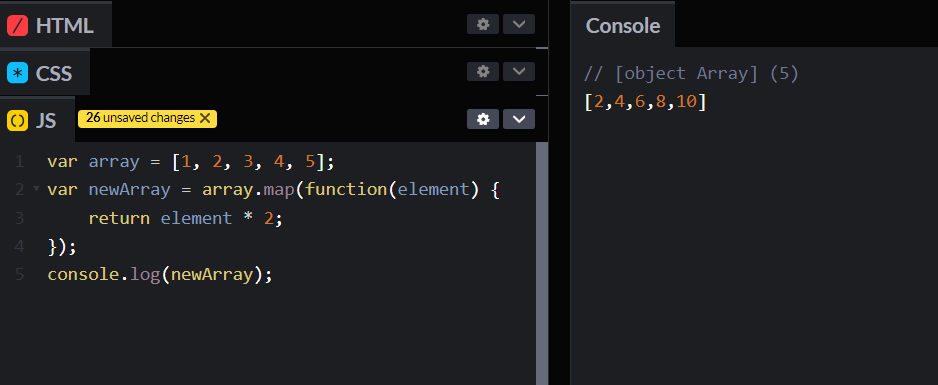
The callback function defined here can accept three arguments-: value, index, array.
**`Array.filter()` Method**
Creates a new array with all elements that pass the test implemented by the provided function.
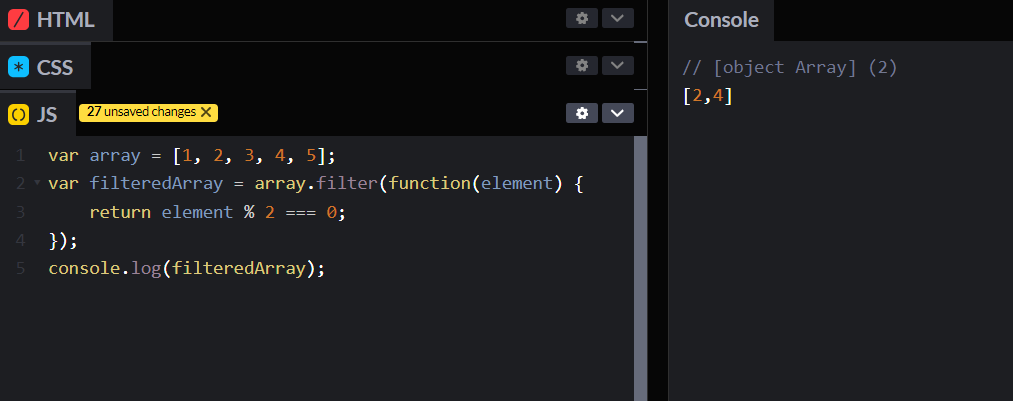
The callback function defined here can accept three arguments-: value, index, array.
**`Array.reduce()` Method**
The `reduce()` method runs a function on each array element to produce (reduce it to) a single value.
The `reduce()` method works from left-to-right in the array.
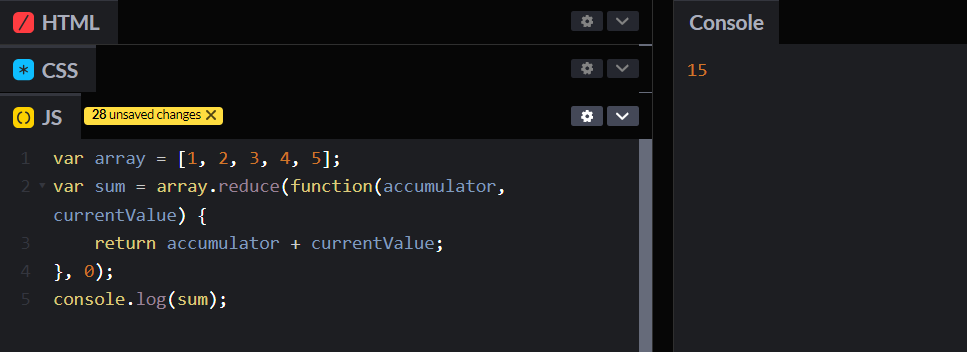
Here the accumulator and currentValue are initialized to 0, accumulator stores the total sum and currentValue is initial value of accumulator.
We have `reduceRight()` which works similar to `reduce()` but works from right to left.
**`Array.every()` Method**
Tests whether all elements in the array pass the test implemented by the provided function.
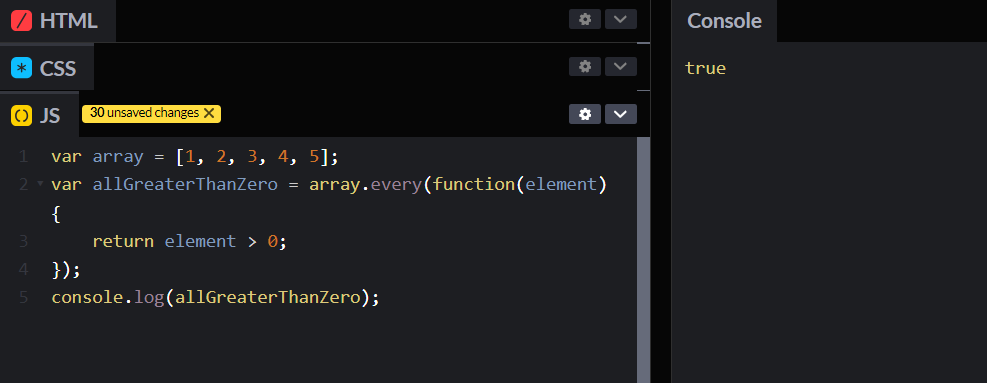
**`Array.some()` Method**
Tests whether at least one element in the array passes the test implemented by the provided function.
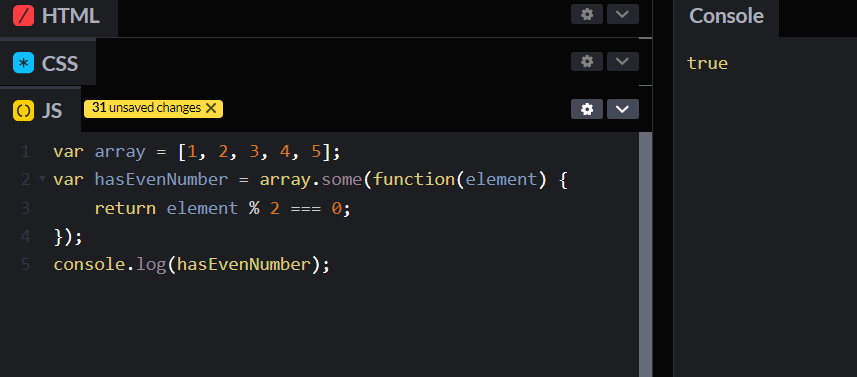
**Array Spread (...)**
The` ...` operator expands an iterable (like an array) into more elements.
The spread operator provides a concise and flexible way to work with iterables, making code more readable and allowing for cleaner syntax in various situations.
These methods explained above are very important methods. They are most commonly used methods.
I hope you have understood this blog. In the upcoming blogs we are going to read about OOPs. Till then stay connected and don't forget to follow me.🤍
| akshat0610 |
1,862,574 | How Blockchain Transforms the Supply Chain Finance | The world of commerce thrives on trust and timely transactions. However, traditional supply chain... | 0 | 2024-05-23T07:59:05 | https://dev.to/donnajohnson88/how-blockchain-transforms-the-supply-chain-finance-4a32 | supplychain, blockchain, finance, web3 | The world of commerce thrives on trust and timely transactions. However, traditional supply chain finance (SCF) methods can be sluggish and burdened by slow approvals, excessive paperwork, and data integrity concerns. Thankfully, a technological revolution is poised to disrupt supply chain finance: blockchain technology. Imagine a system where deals move as fast as the internet and trust is built-in, not a gamble. That’s the magic of [blockchain supply chain development](https://blockchain.oodles.io/blockchain-supply-chain-management-solutions/?utm_source=devto), transforming how businesses pay each other.
In this quick guide, explore how blockchain tackles the biggest pain points in supply chain financing and revamping today’s intricate ecosystem.
## What is Supply Chain Finance (SCF)?
A collection of strategies used by banks and other financial institutions to control capital invested in supply chains and lower risk for all stakeholders is known as supply chain financing or SCF. SCF allows companies to improve their cash flow through various means, such as factoring, invoice discounting, and supplier financing. It is an efficient strategy for buyers, suppliers, and their clients to facilitate the financial and operational flow of the business.
Many companies offer a wide range of SCF solutions to assist their clients in extending payment terms and providing enough time for manufacturers to receive and make payments. Suppliers can receive payments early, and buyers can optimize their working capital.
However, SCF has limitations. It is usually restricted to the most prominent suppliers, disadvantaging small businesses and start-ups. Some stakeholders have developed additional solutions to address this issue and improve supply chain efficiency. This includes using blockchain technology. Blockchain technology can help solve key challenges like facing trust in supply chain finance using decentralized, distributed ledger technology.
As companies expand, they create new domestic and global ties to enhance their procurement process and find cheaper alternatives. While this positively affects accounting books, it can lead to short-term working capital problems, where valuable financial resources become locked into supply-chain requirements.
In recent years, there has been a growing trend of using cryptocurrencies to manage financial operations in supply chains. This is due to the need for transparent and secure transactions, which has expanded the global blockchain supply chain market. As of 2022, the market is valued at $1.47 billion and is anticipated to grow at a CAGR of 48.25 percent by 2032.
## Disadvantages of Traditional Supply Chain Finance (SCF)
Before diving into the blockchain revolution, understanding the pain points of traditional SCF methods is crucial. Here are a few major challenges businesses face:
- **Slow and Laborious Approvals**
Conventional SCF creates bottlenecks and delays by requiring numerous permissions from different parties. The verification of documents is necessary for each approval, which adds to the transaction timeframes.
- **Paperwork Overload**
Reliance on paper-based documentation creates logistical nightmares. Physical documents are prone to errors, loss, and delays during transportation. Manual reconciliation is time-consuming and error-prone.
- **Data Integrity Concerns**
Traditional Supply Chain Finance often lacks a centralized, secure repository for transaction data. This vulnerability can lead to data manipulation, discrepancies, and disputes between trading partners.
These inefficiencies raise operating expenses, obstruct the seamless flow of goods and services, and erode supply chain confidence.
## Ways Blockchain Revolutionizes the Supply Chain Finance (SCF)
- **Increases authenticity in the supply chain**
Supply chain finance is a vast network involving numerous stakeholders, including buyers, suppliers, intermediaries, etc. Unfortunately, the exchange of information in such a network is not always transparent, and different interest groups can prioritize their loyalty over others, leading to prolonged supply chain processes.
However, the introduction of blockchain technology can help eliminate this issue. All participants in a blockchain network have access to a distributed copy of the same ledger that displays shared information within the district. Since blockchains are immutable, they prevent misinformation, ensuring truthfulness and credibility within the network. It can help streamline survival strategies and the supply chain.
Moreover, blockchain’s ability to create an unalterable chain of transactions helps build trust and confidence between the parties. Companies can use Blockchain to verify receipt of invoices and approve payments due.
- **Enhances inclusivity in the ecosystem**
The supply chain financier system has numerous deficits, particularly when providing financial help to small and medium enterprises (SMEs). Sometimes, the leading suppliers are asked to fund the top 10 to 50 companies, whereas small and medium-sized businesses get left behind. This is unfair because smaller companies may gain more by offering early payments through supplier-led supply chain finance than larger companies.
Financial institutions are generally the financers in buyer-led supply chain finance. They make the invoice payments to the suppliers. Buyers repay them through a repayment plan consisting of the borrowed sum, a small fee, and interest.
Blockchain technology can assist this issue by leveling the playing field and encouraging access to banking funds.
Also, Read | [Blockchain for Thorium’s Supply Chain Traceability](https://blockchain.oodles.io/blog/blockchain-thorium-supply-chain-traceability/?utm_source=devto)
- **Redefines financiers in the supply chain**
Financial institutions are the suppliers in the buyer-supplier supply chain financing market. They pay suppliers on their behalf and send them a repayment schedule that includes the amount borrowed, an additional fee, and interest.
While financial institutions will play an important role in buyer-led supply chain finance, blockchain could open the door to various stakeholders in the system. Corporate foundations and individual investors may also participate in supply chain finance and earn investment returns. Platforms like CredSCF already use blockchain to allow different financiers to loan money.
- **Enhances the functioning of the supply chain**
Making sense of economic data is often difficult when multiple parties are involved. Supply chain finance has suffered similarly to this one. Information inaccuracy is, in fact, one of the biggest contributing factors to why supply chain finance has struggled to solve long-standing supply chain issues.
In contrast, supply chain finance incorporating blockchain technology may help make the supply chain more efficient. The immutable and transparent ledger can maintain real-time information about moves and expenses, streamline financial resources, and facilitate more effective and smooth business operations.
## Conclusion
In conclusion, blockchain technology presents a revolutionary approach to supply chain finance (SCF). This translates to faster transactions, reduced costs, and increased trust among all participants in the supply chain ecosystem. As the technology matures and adoption grows, we can expect to see even more innovative applications emerge, shaping the future of financial operations in the global marketplace.
Supercharge your supply chain in 2024 with blockchain technology! Oodles’ expert [blockchain developers](https://blockchain.oodles.io/about-us/?utm_source=devto) combine industry knowledge with cutting-edge development to create a competitive edge. Get faster transactions, lower costs, and a more transparent supply chain. Contact us today for a consultation. | donnajohnson88 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.