
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,909,402 | Urgent Appeal: Help Nabil's Family Rebuild Their Lives in Gaza | Hello, My Name is Nabil , Computer Engineer From Gaza , 33 year old , My family and I have been... | 0 | 2024-07-02T21:25:09 | https://dev.to/nabil_zaqout_53c29fc15be6/urgent-appeal-help-nabils-family-rebuild-their-lives-in-gaza-dma | gaza, python, webdev, programming | Hello, My Name is Nabil , Computer Engineer From Gaza , 33 year old , My family and I have been deeply affected by the recent war in Gaza. We are struggling to rebuild our lives and urgently need your support. 🏠💔 ▶ https://gofund.me/73675284
Any contribution, no matter how small, can make a huge difference. Please c... | nabil_zaqout_53c29fc15be6 |
1,909,250 | Automating User Management on Linux using Bash Script | Efficient user management is important for maintaining security and productivity. Manual management... | 0 | 2024-07-02T21:10:30 | https://dev.to/danielfavour/automating-user-management-on-linux-using-bash-script-3o9l |
Efficient user management is important for maintaining security and productivity. Manual management of users and groups can be time-consuming, especially in larger organizations where administrators need to handle multiple accounts and permissions. Automating these tasks not only saves time but also reduces the risk o... | danielfavour | |
1,909,380 | Finite-state machine example in JavaScript | Finite-state machine example in JavaScript | 0 | 2024-07-02T21:08:16 | https://dev.to/artem/finite-state-machine-example-in-javascript-2npm | javascript, patterns, example | ---
title: Finite-state machine example in JavaScript
published: true
description: Finite-state machine example in JavaScript
tags: #javascript #patterns #example
cover_image: https://images.unsplash.com/photo-1574087631700-abf928509b80?q=80&w=1888&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlf... | artem |
1,886,353 | RESTful APIs | Topic: "Building RESTful APIs with Node.js and Express" Description: How to design and build... | 27,559 | 2024-07-02T20:55:00 | https://dev.to/suhaspalani/restful-apis-4m6p | restapi, backend, api, javascript | - *Topic*: "Building RESTful APIs with Node.js and Express"
- *Description*: How to design and build RESTful APIs using Node.js and Express.
#### Content:
#### 1. Introduction to RESTful APIs
- **What is REST**: Explain REST (Representational State Transfer) and its principles.
- **HTTP Methods**: Discuss common HTTP... | suhaspalani |
1,909,379 | Finite-state machine example in JavaScript | Finite-state machine example in JavaScript | 0 | 2024-07-02T21:08:16 | https://dev.to/artem/finite-state-machine-example-in-javascript-2m98 | javascript, patterns, example | ---
title: Finite-state machine example in JavaScript
published: true
description: Finite-state machine example in JavaScript
tags: #javascript #patterns #example
cover_image: https://images.unsplash.com/photo-1574087631700-abf928509b80?q=80&w=1888&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlf... | artem |
1,909,378 | Why I'm Excited for the HNG Internship | I'm Joel, a computer science student at Accra Technical University, Ghana. As an aspiring backend... | 0 | 2024-07-02T21:08:01 | https://dev.to/joel_legend_7fc19067f4b11/why-im-excited-for-the-hng-internship-30b7 | I'm Joel, a computer science student at Accra Technical University, Ghana. As an aspiring backend developer, I haven't encountered any significant backend problems yet. I'm eager to dive in and learn through hands-on experience, and the HNG Internship offers the perfect opportunity to do just that.
I am very excited a... | joel_legend_7fc19067f4b11 | |
1,909,376 | Exploratory Testing: User Experience Improvements for Scrape Any Website | Introduction: Welcome to my detailed bug report for Scrape Any Website (SAW), version 1.1.15.0 for... | 0 | 2024-07-02T21:04:39 | https://dev.to/codereaper0/bug-hunting-on-saw-35lb | bug, scrapping, programming | **Introduction:** Welcome to my detailed bug report for Scrape Any Website (SAW), version 1.1.15.0 for x86 architecture. In this post, I'll share the bugs and usability issues I encountered during my exploratory testing of this data extraction tool. This exercise is part of my ongoing efforts to improve web scraping to... | codereaper0 |
1,909,375 | Creating Users and Groups on Linux with a Bash Script | Overview This bash script automates the process of creating multiple users and groups on a... | 0 | 2024-07-02T21:01:12 | https://dev.to/seundavid_dev/creating-users-and-groups-on-linux-with-a-bash-script-3fm9 | ## Overview
This bash script automates the process of creating multiple users and groups on a Linux system. It's designed to streamline the onboarding process for new employees or system users. The script reads user information from an input file, creates users with their respective groups, sets random passwords, and ... | seundavid_dev | |
1,909,374 | shadcn-ui/ui codebase analysis: How does shadcn-ui CLI work? — Part 2.4 | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the... | 0 | 2024-07-02T20:59:35 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-does-shadcn-ui-cli-work-part-24-5a0 | javascript, opensource, nextjs, shadcnui | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the shadcn-ui/ui CLI.
In parts 2.0 to 2.3, we looked at different functions involved to [check if there is an existing config.](https://github.com/shadcn-ui/ui/blob/main/packages/cli/src/utils/get-project-info.ts#L74C3-L78C... | ramunarasinga |
1,909,370 | A Product-Engineering Understanding | The Correct Way To Write Javascript Is To Write Bad Javascript As Such Everyone is good at writing... | 0 | 2024-07-02T20:48:34 | https://dev.to/theholyspirit/a-product-engineering-understanding-332k | product, engineering, leadership | The Correct Way To Write Javascript Is To Write Bad Javascript
As Such
Everyone is good at writing Javascript.
## Human Software
I've been in a lot of software houses, and an interesting reflection I make that that the engineering units tend to have a runtime like the software they write.
**The Runtimes of Note Are:... | theholyspirit |
1,909,345 | Pergunte ao especialista - Operadores | Já que os operadores de curto-circuito são, em alguns casos, mais eficientes do que seus equivalentes... | 0 | 2024-07-02T20:48:14 | https://dev.to/devsjavagirls/pergunte-ao-especialista-operadores-ep1 | java | Já que os operadores de curto-circuito são, em alguns casos, mais eficientes do que seus equivalentes comuns, por que Java oferece os operadores AND e OR comuns?
Em alguns casos, você pode querer que os dois operandos de uma operação AND ou OR sejam avaliados devido aos efeitos colaterais produzidos.

### Task:
Your company has employed many new developers. As a SysOps engineer, write a bash script called `create_users.sh` that reads a text file containing the employee’s usernames and group names, whe... | 0xugochukwu |
1,909,364 | Recursion vs. Iteration | Recursion is an alternative form of program control. It is essentially repetition without a loop.... | 0 | 2024-07-02T20:28:24 | https://dev.to/paulike/recursion-vs-iteration-df | java, programming, learning, beginners | Recursion is an alternative form of program control. It is essentially repetition without a loop. When you use loops, you specify a loop body. The repetition of the loop body is controlled by the loop control structure. In recursion, the method itself is called repeatedly. A selection statement must be used to control... | paulike |
1,909,362 | Case Study: Fractals | Using recursion is ideal for displaying fractals, because fractals are inherently recursive. A... | 0 | 2024-07-02T20:25:41 | https://dev.to/paulike/case-study-fractals-70m | java, programming, learning, beginners | Using recursion is ideal for displaying fractals, because fractals are inherently recursive. A _fractal_ is a geometrical figure, but unlike triangles, circles, and rectangles, fractals can be divided into parts, each of which is a reduced-size copy of the whole. There are many interesting examples of fractals. This se... | paulike |
1,909,307 | Using OCI Bucket for Terraform/OpenTofu remote state backend | Store Terraform state files in Oracle Cloud Infrastructure (OCI) Object Storage by configuring an... | 0 | 2024-07-02T20:19:03 | https://dev.to/farisdurrani/using-oci-bucket-for-terraformopentofu-remote-state-backend-n15 | oraclecloud, cloud, terraform | _Store Terraform state files in Oracle Cloud Infrastructure (OCI) Object Storage by configuring an S3-compatible backend._
A Terraform backend defines where Terraform stores its state data files. Without a backend, the state file lives locally on a single machine, making it hard for others to work based on the same cl... | farisdurrani |
1,909,347 | What is the difference between git commit -m and git commit -am? | With git commit -m you only commit changes which are added using git add command. With git commit... | 0 | 2024-07-02T20:13:19 | https://dev.to/mbshehzad/what-is-the-difference-between-git-commit-m-and-git-commit-am-1151 | git, node | With **git commit -m** you only commit changes which are added using git add command.
With **git commit -am** you commit ALL changed including those changes as well which are not added ussing git add | mbshehzad |
1,908,392 | Creating a Flask App: My issues as a beginner and how I fixed them. | Hi everyone, Eworitse Egbejule here. This is my first blog post and I want to share my experience... | 0 | 2024-07-02T20:11:22 | https://dev.to/ebiscott/creating-a-flask-app-my-issues-as-a-beginner-and-how-i-learnt-to-fix-them-254j | webdev, beginners, python, learning | Hi everyone, **Eworitse Egbejule** here. This is my first blog post and I want to share my experience with creating a flask app; the issues I had while making it and how I fixed them.
Flask is a lightweight and flexible microframework used for building web apps in Python with minimal setup. Here's a sample code of a s... | ebiscott |
1,909,346 | Case Study: Tower of Hanoi | The Tower of Hanoi problem is a classic problem that can be solved easily using recursion, but it is... | 0 | 2024-07-02T20:07:33 | https://dev.to/paulike/case-study-tower-of-hanoi-18j6 | java, programming, learning, beginners | The Tower of Hanoi problem is a classic problem that can be solved easily using recursion, but it is difficult to solve otherwise. The problem involves moving a specified number of disks of distinct sizes from one tower to another while observing the following rules:
- There are n disks labeled 1, 2, 3, . . . , n and ... | paulike |
1,909,344 | à mon égard: From Bug Squasher to Code Conqueror | Hey everyone, it's conradgabe here, your friendly neighborhood backend developer! Today, I want to... | 0 | 2024-07-02T20:05:34 | https://dev.to/conradgabe/a-mon-egard-from-bug-squasher-to-code-conqueror-889 | Hey everyone, it's conradgabe here, your friendly neighborhood backend developer! Today, I want to take you on a thrilling adventure – not into the jungle, but into the heart of a particularly nasty backend bug. Buckle up, because we're about to dissect the problem, step-by-step, and emerge victorious (with a newfound ... | conradgabe | |
1,909,343 | Which LLM to Choose: 12 key aspects to consider when building AI solutions | Overview of the Leading LLMs The leaderboard below presents a high-level comparison of... | 0 | 2024-07-02T20:04:51 | https://mindsdb.com/blog/which-llm-to-choose-12-key-aspects-to-consider-when-building-ai-solutions | ## Overview of the Leading LLMs
The leaderboard below presents a high-level comparison of leading large language models (LLMs) from various providers such as OpenAI, Google, Anthropic, Cohere, Meta, Mistral AI, and Databricks. Models are evaluated based on key factors including performance (price, quality, and speed),... | mindsdbteam | |
1,909,342 | Did you know? | 1.the world's first programmer was a woman. 2.99% of programmers are men and only 1% are women. 3.90%... | 0 | 2024-07-02T20:04:36 | https://dev.to/abdurahmon_mansurov/did-you-know-4ocj | 1.the world's first programmer was a woman.
2.99% of programmers are men and only 1% are women.
3.90% of programmers are under 45 years old.
4.Half of the programmers come to the office in slippers/slippers. That is why they are called "Guys in sandals".
5.Although there are 8,500 programming languages in the world, ... | abdurahmon_mansurov | |
1,909,341 | 🛡️ Key cybersecurity threats in 2024: What should businesses know? | 🔒 Cybersecurity is paramount in today's digital landscape. With new threats emerging daily, it's... | 0 | 2024-07-02T20:00:09 | https://dev.to/namik_ahmedov/key-cybersecurity-threats-in-2024-what-should-businesses-know-38j1 | cybersecurity, security | 🔒 Cybersecurity is paramount in today's digital landscape. With new threats emerging daily, it's crucial to stay informed. Some key threats include:
1️⃣ **Phishing** - attackers posing as trusted sources.
2️⃣ **Ransomware** - extortion programs holding data hostage.
3️⃣ **DDoS Attacks** - overwhelming servers with tra... | namik_ahmedov |
1,909,340 | What is the difference between null and undefined? | undefined means a variable has been declared but has not yet been assigned a value, whereas null is... | 0 | 2024-07-02T19:56:22 | https://dev.to/abdurahmon_mansurov/what-is-the-difference-between-null-and-undefined-5hg7 | undefined means a variable has been declared but has not yet been assigned a value, whereas null is an assignment value, meaning that a variable has been declared and given the value of null . | abdurahmon_mansurov | |
1,909,339 | Case Study: Finding the Directory Size | Recursive methods are efficient for solving problems with recursive structures. The preceding... | 0 | 2024-07-02T19:54:54 | https://dev.to/paulike/case-study-finding-the-directory-size-2946 | java, programming, learning, beginners | Recursive methods are efficient for solving problems with recursive structures. The preceding examples can easily be solved without using recursion. This section presents a problem that is difficult to solve without using recursion. The problem is to find the size of a directory. The size of a directory is the sum of t... | paulike |
1,909,337 | Recursive Binary Search | Binary search was introduced in Searching Arrays. For binary search to work, the elements in the... | 0 | 2024-07-02T19:44:24 | https://dev.to/paulike/recursive-binary-search-i83 | java, programming, learning, beginners | Binary search was introduced in [Searching Arrays](https://dev.to/paulike/searching-arrays-4fb7). For binary search to work, the elements in the array must be in increasing order. The binary search first compares the key with the element in the middle of the array. Consider the following three cases:
- Case 1: If the ... | paulike |
1,909,333 | Recursive Selection Sort | Selection sort was introduced in Sorting Arrays. Recall that it finds the smallest element in the... | 0 | 2024-07-02T19:37:20 | https://dev.to/paulike/recursive-selection-sort-2jkl | java, programming, learning, beginners | Selection sort was introduced in [Sorting Arrays](https://dev.to/paulike/sorting-arrays-25n4). Recall that it finds the smallest element in the list and swaps it with the first element. It then finds the smallest element remaining and swaps it with the first element in the remaining list, and so on until the remaining ... | paulike |
1,909,332 | Recursive Helper Methods | Sometimes you can find a solution to the original problem by defining a recursive function to a... | 0 | 2024-07-02T19:36:33 | https://dev.to/paulike/recursive-helper-methods-4fpd | java, programming, learning, beginners | Sometimes you can find a solution to the original problem by defining a recursive function to a problem similar to the original problem. This new method is called a recursive helper method. The original problem can be solved by invoking the recursive helper method.
The recursive **isPalindrome** method in [RecursivePa... | paulike |
1,909,331 | My Story of VC1 | Now LET'S HOPE IT GOES LIVENow LET'S HOPE IT GOES LIVENow LET'S HOPE IT GOES LIVENow LET'S HOPE IT... | 0 | 2024-07-02T19:34:07 | https://dev.to/ishaan_singhal_f3b6b687f3/my-story-of-vc1-1lfn | Now LET'S HOPE IT GOES LIVENow LET'S HOPE IT GOES LIVENow LET'S HOPE IT GOES LIVENow LET'S HOPE IT GOES LIVENow LET'S HOPE IT GOES LIVENow LET'S HOPE IT GOES LIVE | ishaan_singhal_f3b6b687f3 | |
1,909,329 | Automation with Bash | Enhancing Efficiency with Automation and Bash Scripting: A Practical Guide In today's... | 0 | 2024-07-02T19:32:14 | https://dev.to/olavic/automation-with-bash-772 | devops, cloudcomputing, automation, webdev | ### Enhancing Efficiency with Automation and Bash Scripting: A Practical Guide
In today's fast-paced IT environments, automation is a game-changer. It saves time, reduces human error, and ensures consistency across systems. One of the most powerful tools for automation is Bash scripting, which allows administrators to... | olavic |
1,909,328 | Text | Bei der Erstellung meiner Hausarbeit war ich oft überfordert von der Menge an Arbeit. Zum Glück fand... | 0 | 2024-07-02T19:31:57 | https://dev.to/faweqss/text-1k8m | Bei der Erstellung meiner Hausarbeit war ich oft überfordert von der Menge an Arbeit. Zum Glück fand ich [https://wirschreiben.ch/hausarbeit/](https://wirschreiben.ch/hausarbeit/). Der Service bot mir nicht nur Hilfe beim Schreiben, sondern auch wertvolle Unterstützung bei der Strukturierung und Formulierung meiner The... | faweqss | |
1,909,327 | 13 Top Skool Alternatives for Making Money Online with Your Community | In today's digital age, the demand for versatile online learning and community-building platforms has... | 0 | 2024-07-02T19:30:27 | https://dev.to/lonare/13-top-skool-alternatives-for-making-money-online-with-your-community-4h7g | javascript, webdev, react, python | In today's digital age, the demand for versatile online learning and community-building platforms has never been higher.
Whether you're an educator, entrepreneur, or content creator, finding the right platform to host courses, engage communities, or manage business operations is crucial.
Skool, a prominent player i... | lonare |
1,909,326 | Technical Article: Explaining the create_users.sh Script | In this article, we will walk you through the script for submission of the Stage 1, explaining each... | 0 | 2024-07-02T19:30:02 | https://dev.to/orunsolu/technical-article-explaining-the-createuserssh-script-4opm | In this article, we will walk you through the script for submission of the [](https://hng.tech/internship) Stage 1, explaining each step and the reasoning behind it.
Managing users in a growing organization can be a daunting task, especially when it involves setting up accounts, assigning groups, creating home directo... | orunsolu | |
1,909,324 | Automation: Onboard New Engineers on Linux with Best Practice Bash/Shell Scripting. | Synopsis Your role is SysOps or SysAdmin Engineer, you are tasked with onboarding new... | 0 | 2024-07-02T19:28:27 | https://dev.to/wandexdev/automation-onboard-new-engineers-on-linux-with-best-practice-bashshell-scripting-121o | bash, ubuntu, automation, linux | ## Synopsis
Your role is **SysOps or SysAdmin Engineer**, you are tasked with onboarding new engineers on most of the company's Linux servers. Users, groups, and home directories would be created. Access permissions for each user following the rule of less privilege should be observed. It would be inefficient to do so ... | wandexdev |
1,909,323 | If in a Crowdsourced Data Annotation Pipeline, a GPT-4 | If in a Crowdsourced Data Annotation Pipeline, a GPT-4 | 0 | 2024-07-02T19:28:18 | https://aimodels.fyi/papers/arxiv/if-crowdsourced-data-annotation-pipeline-gpt-4 | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [If in a Crowdsourced Data Annotation Pipeline, a GPT-4](https://aimodels.fyi/papers/arxiv/if-crowdsourced-data-annotation-pipeline-gpt-4). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.subst... | mikeyoung44 |
1,909,322 | Repairing Catastrophic-Neglect in Text-to-Image Diffusion Models via Attention-Guided Feature Enhancement | Repairing Catastrophic-Neglect in Text-to-Image Diffusion Models via Attention-Guided Feature Enhancement | 0 | 2024-07-02T19:27:44 | https://aimodels.fyi/papers/arxiv/repairing-catastrophic-neglect-text-to-image-diffusion | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Repairing Catastrophic-Neglect in Text-to-Image Diffusion Models via Attention-Guided Feature Enhancement](https://aimodels.fyi/papers/arxiv/repairing-catastrophic-neglect-text-to-image-diffusion). If you like these kinds of analysis, you should subscr... | mikeyoung44 |
1,909,321 | Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text | Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text | 0 | 2024-07-02T19:27:09 | https://aimodels.fyi/papers/arxiv/spotting-llms-binoculars-zero-shot-detection-machine | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text](https://aimodels.fyi/papers/arxiv/spotting-llms-binoculars-zero-shot-detection-machine). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsle... | mikeyoung44 |
1,909,319 | Bayesian Regression Markets | Bayesian Regression Markets | 0 | 2024-07-02T19:26:01 | https://aimodels.fyi/papers/arxiv/bayesian-regression-markets | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Bayesian Regression Markets](https://aimodels.fyi/papers/arxiv/bayesian-regression-markets). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twi... | mikeyoung44 |
1,909,318 | Ctrl-V: Higher Fidelity Video Generation with Bounding-Box Controlled Object Motion | Ctrl-V: Higher Fidelity Video Generation with Bounding-Box Controlled Object Motion | 0 | 2024-07-02T19:25:26 | https://aimodels.fyi/papers/arxiv/ctrl-v-higher-fidelity-video-generation-bounding | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Ctrl-V: Higher Fidelity Video Generation with Bounding-Box Controlled Object Motion](https://aimodels.fyi/papers/arxiv/ctrl-v-higher-fidelity-video-generation-bounding). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi new... | mikeyoung44 |
1,909,317 | Problem Solving Using Recursion | If you think recursively, you can solve many problems using recursion. The preceding sections... | 0 | 2024-07-02T19:23:43 | https://dev.to/paulike/problem-solving-using-recursion-539e | java, programming, learning, beginners | If you think recursively, you can solve many problems using recursion. The preceding sections presented two classic recursion examples. All recursive methods have the following characteristics:
- The method is implemented using an **if-else** or a **switch** statement that leads to different cases.
- One or more base ... | paulike |
1,909,316 | Cutting through buggy adversarial example defenses: fixing 1 line of code breaks Sabre | Cutting through buggy adversarial example defenses: fixing 1 line of code breaks Sabre | 0 | 2024-07-02T19:23:09 | https://aimodels.fyi/papers/arxiv/cutting-through-buggy-adversarial-example-defenses-fixing | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Cutting through buggy adversarial example defenses: fixing 1 line of code breaks Sabre](https://aimodels.fyi/papers/arxiv/cutting-through-buggy-adversarial-example-defenses-fixing). If you like these kinds of analysis, you should subscribe to the [AImo... | mikeyoung44 |
1,909,315 | Navigating Flatiron Bootcamp School: Phase 1 Challenges and Lessons Learned | Enrolling in Flatiron Bootcamp School was an exciting yet daunting step toward my dream of becoming a... | 0 | 2024-07-02T19:22:08 | https://dev.to/edwin_olivares_cf4f814058/navigating-flatiron-bootcamp-school-phase-1-challenges-and-lessons-learned-1836 | Enrolling in Flatiron Bootcamp School was an exciting yet daunting step toward my dream of becoming a skilled software developer. As I embarked on Phase 1, I anticipated a challenging yet rewarding journey. However, the reality of the experience brought several unexpected challenges, particularly in managing my time ef... | edwin_olivares_cf4f814058 | |
1,909,314 | {sigma}-GPTs: A New Approach to Autoregressive Models | {sigma}-GPTs: A New Approach to Autoregressive Models | 0 | 2024-07-02T19:22:01 | https://aimodels.fyi/papers/arxiv/sigma-gpts-new-approach-to-autoregressive-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [{sigma}-GPTs: A New Approach to Autoregressive Models](https://aimodels.fyi/papers/arxiv/sigma-gpts-new-approach-to-autoregressive-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.subs... | mikeyoung44 |
1,909,313 | .Net Tarixi | .NET - U Windows, Linux va macOS operatsion tizimlari uchun bepul va ochiq manbali boshqariladigan... | 0 | 2024-07-02T19:21:03 | https://dev.to/xojimurodov/net-tarixi-2n2a |

.NET - U Windows, Linux va macOS operatsion tizimlari uchun bepul va ochiq manbali boshqariladigan dasturiy ta'minot ramkasidir. [4] Loyiha birinchi navbatda Microsoft xodimlari tomonidan .NET Foundation yordamida ... | xojimurodov | |
1,909,311 | Bytes Are All You Need: Transformers Operating Directly On File Bytes | Bytes Are All You Need: Transformers Operating Directly On File Bytes | 0 | 2024-07-02T19:20:52 | https://aimodels.fyi/papers/arxiv/bytes-are-all-you-need-transformers-operating | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Bytes Are All You Need: Transformers Operating Directly On File Bytes](https://aimodels.fyi/papers/arxiv/bytes-are-all-you-need-transformers-operating). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://... | mikeyoung44 |
1,909,308 | Learn Generative AI from Real Product Development Experience | Learn Generative AI from Real Product Development Experience. Yes, you heard that right!... | 0 | 2024-07-02T19:16:19 | https://dev.to/aws-builders/learn-generative-ai-from-real-product-development-experince-1eci | aws, ai, genai, llm | **Learn Generative AI from Real Product Development Experience. Yes, you heard that right!** https://www.meetup.com/meetup-group-komabzoz/events/301904960/
Join us every 2nd Thursday of the month to learn Generative AI from actual product development experience. I will share my insights and experiences working on two ... | ameet |
1,909,305 | Case Study: Computing Fibonacci Numbers | In some cases, recursion enables you to create an intuitive, straightforward, simple solution to a... | 0 | 2024-07-02T19:11:18 | https://dev.to/paulike/case-study-computing-fibonacci-numbers-47ac | java, programming, learning, beginners | In some cases, recursion enables you to create an intuitive, straightforward, simple solution to a problem. The **factorial** method in the preceding section could easily be rewritten without using recursion. In this section, we show an example for creating an intuitive solution to a problem using recursion. Consider t... | paulike |
1,909,304 | Simple thoughts | If you read an article that interests you and you enjoy it, or if you watch a video, consider leaving... | 0 | 2024-07-02T19:09:09 | https://dev.to/douglasmakey/simple-thoughts-4i4i | If you read an article that interests you and you enjoy it, or if you watch a video, consider leaving a message or a reaction. I don't consider myself a content creator, but I genuinely enjoy writing my articles and sharing them with others. For me, it's incredibly rewarding if just one person finds my articles helpful... | douglasmakey | |
1,909,096 | Automating Linux User Creation with Bash Script | In today's fast-paced technology environment, efficiency and automation are key. Automating tasks... | 0 | 2024-07-02T19:08:05 | https://dev.to/oluwatosin_dorcas_63db390/automating-user-creation-with-bash-script-4ae1 | In today's fast-paced technology environment, efficiency and automation are key. Automating tasks with a Bash script can save a significant amount of time and reduce errors. In this technical report, we will walk through the process of creating a Bash script to automate user and group creation, setting up home director... | oluwatosin_dorcas_63db390 | |
1,909,302 | AWS S3 Event Triggering | *🚀 Excited to share my latest project leveraging AWS to automate event-driven workflows! 🌐 * 🔧... | 0 | 2024-07-02T19:05:22 | https://dev.to/sukuru_naga_sai_srinivasu/aws-s3-event-triggering-3m5n | aws, lambda, serverless, shellscripting |
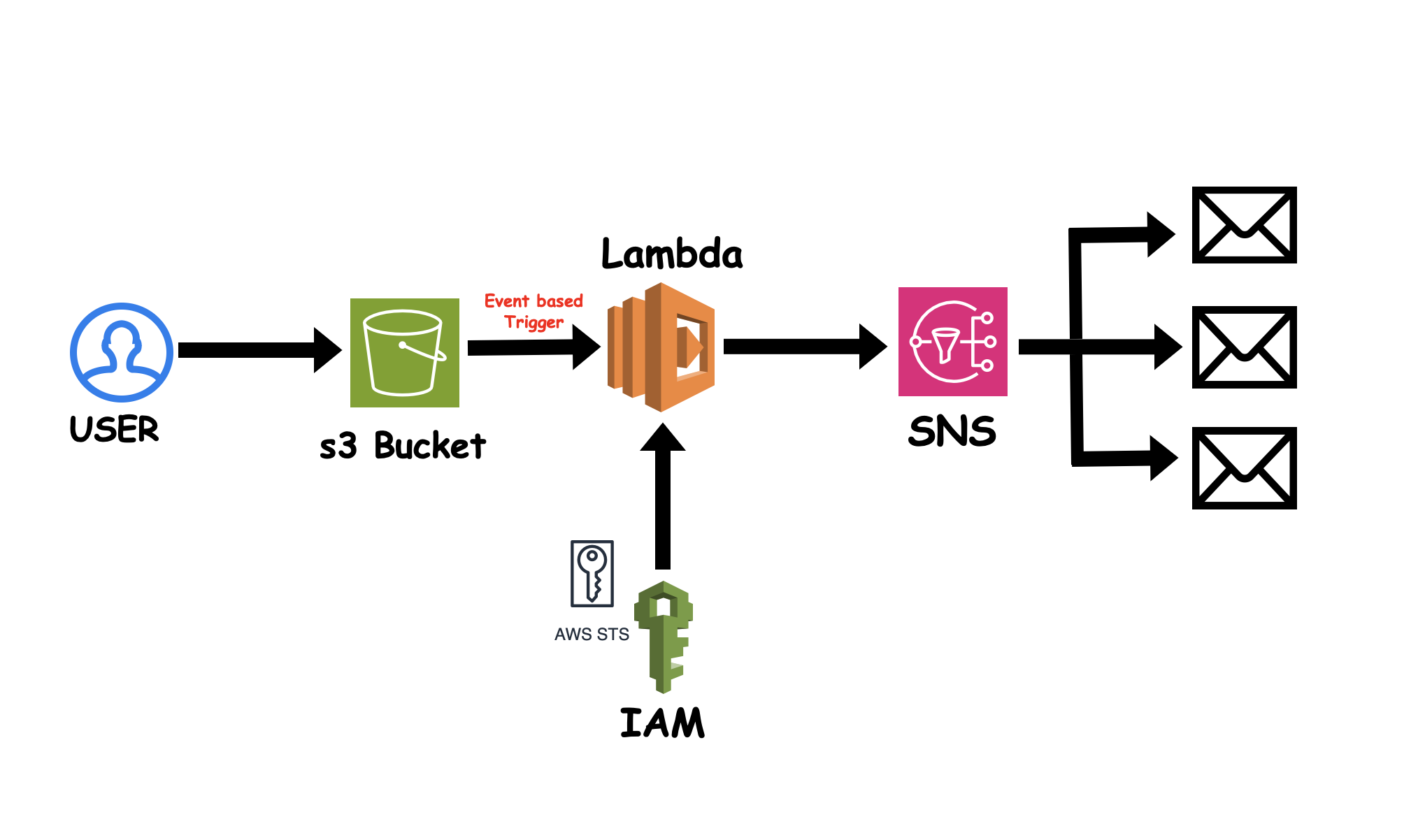
**🚀 Excited to share my latest project leveraging AWS to automate event-driven workflows! 🌐
**
**🔧 Project Overview:**
I've developed a robust automation script using AWS services to handle events in an S3 buck... | sukuru_naga_sai_srinivasu |
1,909,300 | REACTJS vs TYPESCRIPT - A COMPARISON | INTRODUCTION ReactJS and TypeScript are two powerful technologies, used separately or together for... | 0 | 2024-07-02T19:03:50 | https://dev.to/orionthehunter/reactjs-vs-typescript-comparing-two-frontend-technologies-54h2 | webdev, react, typescript, beginners | **INTRODUCTION**
ReactJS and TypeScript are two powerful technologies, used separately or together for optimal and scalable web applications. In this article, I'll talk about ReactJs and TypeScript, and also compare both technologies, so you can choose the right one for your project.
**REACTJS**
ReactJS is a JavaS... | orionthehunter |
1,908,149 | Hosting a Static Website on Azure Blob Storage | Azure storage stores all types of data. It is mainly designed for storage where we can easily store... | 0 | 2024-07-02T19:02:20 | https://dev.to/tracyee_/hosting-a-static-website-on-azure-blob-storage-jbi | azurestorage, cloudcomputing, staticwebsite | Azure storage stores all types of data. It is mainly designed for storage where we can easily store both structured and unstructured data. Blob Storage is optimized for storing massive amounts of unstructured data. Unstructured data is data that doesn't adhere to a particular data model or definition, such as text or b... | tracyee_ |
1,909,299 | Recreating Apple's iPhone 15 Pro Website: A Modern Web Development Showcase | In my latest project, I embarked on an ambitious journey to recreate Apple’s iPhone 15 Pro website... | 0 | 2024-07-02T19:01:17 | https://dev.to/syedahmedullah14/recreating-apples-iphone-15-pro-website-a-modern-web-development-showcase-3jlo | webdev, javascript, react, programming | In my latest project, I embarked on an ambitious journey to recreate Apple’s iPhone 15 Pro website using a cutting-edge tech stack. Leveraging the power of React.js, Three.js, GSAP, and more, I aimed not only to replicate the sleek, interactive experience of the original site but also to push the boundaries of modern w... | syedahmedullah14 |
1,909,298 | Call to Action: 8 Convincing CTA Design Tips | Find out what your CTA should be to maximize conversion rates in your digital solution. CTA, in the... | 0 | 2024-07-02T18:59:31 | https://dev.to/agunwachidiebelecalistus/call-to-action-8convincing-cta-designtips-c2f | webdev, design, learning, beginners | _Find out what your CTA should be to maximize conversion rates in your digital solution._
CTA, in the context of web development, refers to elements of a web page that encourage users to take a specific action. These can be buttons, links, or other interface elements that encourage visitors to interact with the websit... | agunwachidiebelecalistus |
1,909,297 | Visual Content Modeling: A Comprehensive Guide | Content modeling is a crucial aspect of designing and developing content-rich applications, websites,... | 0 | 2024-07-02T18:59:03 | https://www.builder.io/m/explainers/content-modeling | cms, developer, webdev, programming | Content modeling is a crucial aspect of designing and developing content-rich applications, websites, and digital experiences. It involves defining the structure, relationships, and attributes of different types of content within a system. By creating a content model, developers can ensure that content is organized, co... | stahlwalker |
1,909,296 | Shadow Testing: Ensuring Seamless Software Deployment | Introduction In the realm of software development and deployment, ensuring the reliability and... | 0 | 2024-07-02T18:56:12 | https://dev.to/keploy/shadow-testing-ensuring-seamless-software-deployment-3n5d | webdev, javascript, programming, tutorial |

Introduction
In the realm of software development and deployment, ensuring the reliability and performance of new code changes before they reach production is paramount. [Shadow testing](https://keploy.io/blog/commu... | keploy |
1,888,107 | 30 days of AWS - Part 3: AWS Well-Architected Framework | Definition To put it simply, the AWS well-architected framework is a collection of best... | 27,709 | 2024-07-02T18:56:01 | https://dev.to/achenchi/30-days-of-aws-part-3-aws-well-architected-framework-8c0 | beginners, aws, wellarchitectedframework, learning | ## Definition
To put it simply, the AWS well-architected framework is a **collection of best practices and guidelines** for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud.
It is built upon 6 pillars. Namely:
- Security
- Cost optimization
- Operational excellence
- Reliabi... | achenchi |
1,909,295 | Case Study: Computing Factorials | A recursive method is one that invokes itself. Many mathematical functions are defined using... | 0 | 2024-07-02T18:55:51 | https://dev.to/paulike/case-study-computing-factorials-3jc2 | java, programming, learning, beginners | A recursive method is one that invokes itself. Many mathematical functions are defined using recursion. Let’s begin with a simple example. The factorial of a number **n** can be recursively defined as follows:
`0! = 1;
n! = n × (n - 1)!; n > 0`
How do you find **n!** for a given **n**? To find **1!** is easy, because... | paulike |
1,909,294 | CLR | Common Language Runtime(CLR) - .Net tomonidan ishlab dasturlarning jarayonini boshqaradi. Kompilyator... | 0 | 2024-07-02T18:54:44 | https://dev.to/xojimurodov/clr-345a | Common Language Runtime(CLR) - .Net tomonidan ishlab dasturlarning jarayonini boshqaradi. Kompilyator kompilyatsiya qilingan codeni mashina kodiga o'zgartiradi (0 - 1).
CLR tomonidan taqdim etiladigan xizmatlar xotirani boshqarish, xatoliklar bilan ishlash, xavfsizlik va boshqalarni o'z ichiga oladi.

* [Aprendendo com o Apps Script](#aprendendo)
* [Explorando os Recursos](#recursos)
* [Desafios e Melhorias](#desafios)
* [Considerações Finais](#conclusao)
Você provavelmente já trabalhou ou trabalha com ferramentas do Ecossistema Google. Seu Drive deve e... | fabianoraiser |
1,909,284 | Building a Robust Web Hosting Solution with AWS Cloud | Overview Utilizing Amazon Web Services (AWS) can offer unmatched scalability, security,... | 0 | 2024-07-02T18:34:50 | https://dev.to/oloko0201/building-a-robust-web-hosting-solution-with-aws-cloud-1jf8 | ## Overview
Utilizing Amazon Web Services (AWS) can offer unmatched scalability, security, and performance in the ever-changing web hosting industry. This article will discuss how to use several AWS services to construct a web hosting environment such that your applications are reliable, safe, and highly available.
##... | oloko0201 | |
1,909,282 | A Deep Dive into Two-Dimensional Arrays: Techniques and Use Cases | A two-dimensional array is essentially an array of arrays, providing a way to store data in a... | 0 | 2024-07-02T18:22:28 | https://dev.to/m__mdy__m/a-deep-dive-into-two-dimensional-arrays-techniques-and-use-cases-44f3 | programming, beginners, learning, machinelearning |
A two-dimensional array is essentially an array of arrays, providing a way to store data in a matrix-like structure. This concept extends the idea of a one-dimensional array, where data is stored in a linear order, to two dimensions, allowing data to be organized in rows and columns. Two-dimensional arrays are particu... | m__mdy__m |
1,909,152 | Top 7 Featured DEV Posts of the Week | Welcome to this week's Top 7, where the DEV editorial team handpicks their favorite posts from the... | 0 | 2024-07-02T18:08:56 | https://dev.to/devteam/top-7-featured-dev-posts-of-the-week-2cfe | top7 | _Welcome to this week's Top 7, where the DEV editorial team handpicks their favorite posts from the previous week._
Congrats to all the authors that made it onto the list 👏
{% embed https://dev.to/samuelfaure/networking-is-easy-fun-and-probably-not-what-you-think-it-is-2ijc %}
@samuelfaure shares their experience ... | thepracticaldev |
1,909,260 | Using a Bash script to Automate User Account Management in Linux | It's critical for Sysops engineers to adopt the habit of effectively managing user accounts,... | 0 | 2024-07-02T18:07:47 | https://dev.to/shirlyne_thiongo_e4e524b/using-a-bash-script-to-automate-user-account-management-in-linux-47el | It's critical for Sysops engineers to adopt the habit of effectively managing user accounts, particularly when onboarding new clients, users, or staff members. This post will walk you through the process of writing a Bash script that adds users, adds them to groups, generates passwords, and logs all of your activities ... | shirlyne_thiongo_e4e524b | |
1,909,281 | Building a Scalable Web App with AWS Elastic Beanstalk, DynamoDB, CloudFront, and Edge Location - with AWS Dashboard and EB CLI | In this real-world project, I was tasked with implementing an application capable of supporting a... | 0 | 2024-07-02T18:22:44 | https://dev.to/cansu_tekin_b017634d64dfd/building-a-scalable-web-app-with-aws-elastic-beanstalk-dynamodb-cloudfront-and-edge-location-with-aws-dashboard-and-eb-cli-1j43 | ebcli, aws, elasticbeanstalk, cloud | 
In this real-world project, I was tasked with implementing an application capable of supporting a high volume of simultaneous users. This application was utilized during a large conference attended by over 10,000 people, both in-person and onl... | cansu_tekin_b017634d64dfd |
1,909,149 | What's the difference between Css & Scss | Thank God for style sheet languages like Css and Scss; front-end would have been as stylish as a... | 0 | 2024-07-02T18:02:58 | https://dev.to/peterbabs/whats-the-difference-between-css-scss-29b2 | css, scss, webdev, frontend | Thank God for style sheet languages like Css and Scss; front-end would have been as stylish as a potato in a tuxedo!
If utilized properly, we can give your users an appealing feeling and a memorable experience with the appearance of our web pages.
The nutshell of this article is this: **CSS**, primarily, is the **power... | peterbabs |
1,908,995 | My HNG journey. Stage Zero: How to Deploy a Static Webpage Using Nginx | Introduction Over the past few years, HNG internships have always been talked about with... | 0 | 2024-07-02T17:59:23 | https://dev.to/ravencodess/my-hng-journey-stage-zero-how-to-deploy-a-static-webpage-using-nginx-55ij | webdev, nginx, docker, html | ## Introduction
Over the past few years, [HNG ](https://hng.tech/) internships have always been talked about with a certain level of fear and respect. "A grueling and unforgiving experience", some would say.
This year, I have decided to give the DevOps track a try. 10 stages of tasks to be covered and I intend to docum... | ravencodess |
1,909,244 | Creating a Dynamic Blog with Flask, HTMX, TailwindCSS, and Authentication (Part 2) | Building a dynamic blog with Flask and HTMX can be both fun and rewarding. This guide will take you... | 0 | 2024-07-02T17:58:32 | https://devtoys.io/2024/07/02/creating-a-dynamic-blog-with-flask-htmx-tailwindcss-and-authentication-part-2/ | htmx, flask, tailwindcss, tutorial | ---
canonical_url: https://devtoys.io/2024/07/02/creating-a-dynamic-blog-with-flask-htmx-tailwindcss-and-authentication-part-2/
---
Building a dynamic blog with Flask and HTMX can be both fun and rewarding. This guide will take you through the entire process, focusing on making your blog interactive without the need f... | 3a5abi |
1,909,256 | Automating User and Group Management in Linux with Bash | Managing user accounts and permissions on a Linux system can be a daunting task, especially in a... | 0 | 2024-07-02T17:57:34 | https://dev.to/mary_12/automating-user-and-group-management-in-linux-with-bash-4i47 | linux, bashscripting, devops | Managing user accounts and permissions on a Linux system can be a daunting task, especially in a dynamic environment with frequent new hires. To simplify and automate this process, we have created the create_users.sh script. This Bash script reads user and group information from a file, creates users and groups, sets u... | mary_12 |
1,909,255 | Widget state synchronisation across tabs | Check out our latest blog on implementing widget state synchronization in the neetoChat widget! The... | 0 | 2024-07-02T17:57:10 | https://dev.to/tsudhishnair/widget-state-synchronisation-across-tabs-55p4 | webdev, javascript, blog, programming | Check out our latest blog on implementing widget state synchronization in the neetoChat widget!
The neetoChat widget is the end-user-facing companion of our neetoChat application. By embedding it on their website, neetoChat users can easily interact with their customers in real time.
Read more here: https://www.bigbi... | tsudhishnair |
1,909,245 | Does flutter dart can make significant changes in mobile development? | A post by Aadarsh Kunwar | 0 | 2024-07-02T17:45:06 | https://dev.to/aadarshk7/does-flutter-dart-can-make-significant-changes-in-mobile-development-27bb | flutter, androiddevelopment, dart, android | aadarshk7 | |
1,909,252 | Dramacool | Watch Asian Dramas and Shows in HD (2024) | Watch dramacool latest Asian dramas and movies with English subtitles. Vast library of Korean,... | 0 | 2024-07-02T17:55:42 | https://dev.to/hitler/dramacool-watch-asian-dramas-and-shows-in-hd-2024-1k6g | Watch [dramacool](https://dramacool.org.za/) latest Asian dramas and movies with English subtitles. Vast library of Korean, Chinese, Japanese content. Lightning-fast updates.
[https://medium.com/@dramacoolgadha/dramacool-watch-asian-dramas-and-shows-in-hd-2024-f2559cda4334](https://medium.com/@dramacoolgadha/dramacoo... | hitler | |
1,909,251 | Supercharge Your Node.js App with Blazing Fast In-Memory Caching! | Introduction If you’re experiencing latency issues in your Node.js application,... | 0 | 2024-07-02T17:55:00 | https://dev.to/shu12388y/supercharge-your-nodejs-app-with-blazing-fast-in-memory-caching-3jec | webdev, javascript, node, database |
## Introduction
If you’re experiencing latency issues in your Node.js application, implementing in-memory caching can be a game-changer. This guide will walk you through how to set up in-memory caching using node-cache in an Express.js server to significantly improve your API performance.
## The Challenge
We recentl... | shu12388y |
1,908,675 | What are Proxies in JavaScript | In JavaScript, a proxy is an object that acts as an intermediary between a target object and any code... | 0 | 2024-07-02T17:52:55 | https://dev.to/waelhabbal/what-are-proxies-in-javascript-453f | javascript, proxies, webdev | In JavaScript, a proxy is an object that acts as an intermediary between a target object and any code that interacts with the target object. A proxy can be used to intercept and manipulate the interactions between the target object and the code that uses it. Proxies are often used to provide additional functionality, v... | waelhabbal |
1,909,248 | Next.js SEO Best Practices | Next.js is a powerful and versatile framework for building React applications, but when it comes to... | 0 | 2024-07-02T17:50:28 | https://dev.to/zinotrust/nextjs-seo-best-practices-2me9 | Next.js is a powerful and versatile framework for building React applications, but when it comes to SEO, there are some best practices you should follow to ensure your site is search engine friendly.
Here are some Next.js SEO best practices to help you optimize your website for better search engine visibility:
... | zinotrust | |
1,909,246 | MongoDB or Firebase | A post by Aadarsh Kunwar | 0 | 2024-07-02T17:45:46 | https://dev.to/aadarshk7/mongodb-or-firebase-5d8i | firebase, mongodb | aadarshk7 | |
1,909,243 | **¡JAMstack: Construyendo Sitios Web como un Mandaloriano!**🤖 | ¡Hola Chiquis! 👋🏻 Prepárense para construir sitios web con JAMstack, la tecnología del futuro. En el... | 0 | 2024-07-02T17:41:22 | https://dev.to/orlidev/jamstack-construyendo-sitios-web-como-un-mandaloriano-2nif | webdev, jamstack, beginners, tutorial | ¡Hola Chiquis! 👋🏻 Prepárense para construir sitios web con JAMstack, la tecnología del futuro. En el cosmos del desarrollo web, donde las líneas de código son estrellas y los sitios web planetas, surge una fuerza poderosa: JAMstack. 🦾 Al igual que un Mandaloriano navega la galaxia con sus habilidades y herramientas ... | orlidev |
1,909,242 | HTML Lists tags in depth | HTML Lists: A Comprehensive Guide Lists are fundamental elements in HTML that help... | 0 | 2024-07-02T17:41:09 | https://dev.to/ridoy_hasan/html-lists-tags-in-depth-37ni | webdev, html, beginners, learning | ### HTML Lists: A Comprehensive Guide
Lists are fundamental elements in HTML that help organize content in a structured manner. HTML supports two main types of lists: ordered lists and unordered lists. In this article, we'll explore how to use these lists effectively, along with examples and best practices.
#### 1. U... | ridoy_hasan |
1,909,241 | How to Add Typing Effects to Your React App with React Typical | Introduction Have you always wondered how to create a typing effect on your website? I too was... | 0 | 2024-07-02T17:40:09 | https://dev.to/code_duchess/how-to-add-typing-effects-to-your-react-app-with-react-typical-55o | webdev, javascript, beginners, react | **Introduction**
Have you always wondered how to create a typing effect on your website? I too was wondering. I have learned to implement a dynamic typewriting effect in React using the `react-typical` library. This effect can switch up your website design, especially in your hero section which plays a vital role in en... | code_duchess |
1,909,240 | 10 Examples of Cyber-Physical Systems | Cyber-physical systems (CPS) are revolutionizing how we live, work, and interact with the world.... | 0 | 2024-07-02T17:39:55 | https://claroty.com/blog/10-examples-of-cyber-physical-systems | Cyber-physical systems (CPS) are revolutionizing how we live, work, and interact with the world. These complex systems, unifying hardware, software, and networks, are at the heart of numerous critical industries and applications, from industrial and manufacturing to healthcare and the public sector. They enhance interc... | yayabobi | |
1,909,238 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-07-02T17:39:29 | https://dev.to/rico_craselaofficial_2dd/my-pen-on-codepen-5a2f | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Rico-Crasela-Official/pen/XWwvVEP %} | rico_craselaofficial_2dd |
1,909,237 | Overcoming an Unidentified Bug in our SpringBoot Application: My Inspiring Journey with the HNG Internship | Embarking on a journey with the HNG Internship program has been my career aspiration ever since I... | 0 | 2024-07-02T17:37:50 | https://dev.to/realest-techy-leidi/overcoming-an-unidentified-bug-in-our-springboot-application-my-inspiring-journey-with-the-hng-internship-1al7 | java, testing, backend, webdev |
Embarking on a journey with the HNG Internship program has been my career aspiration ever since I stumbled upon the program which I believe represents a significant step towards honing my backend development skills. You can be a part of this awesome opportunity by registering through this link <https://hng.tech/inte... | realest-techy-leidi |
1,884,577 | Symfony 7 vs. .NET Core 8 - Controllers | Disclaimer This is a tutorial or a training course. Please don't expect a walk-through... | 0 | 2024-07-02T17:37:06 | https://dev.to/awons/symfony-7-vs-net-core-8-controllers-31o7 | symfony, dotnetcore, controllers | ## Disclaimer
This is a tutorial or a training course. Please don't expect a walk-through tutorial showing how to use ASP.NET Core. It only compares similarities and differences between Symfony and ASP.NET Core. Symfony is taken as a reference point, so if features are only available in .NET Core, they may never get t... | awons |
1,909,235 | Happy 21st Birthday Digital Samba! | It’s time to celebrate! Exactly 21 years ago today we visited a notary office in Barcelona to... | 0 | 2024-07-02T17:36:14 | https://dev.to/digitalsamba/happy-21st-birthday-digital-samba-2h1c | It’s time to celebrate! Exactly 21 years ago today we visited a notary office in Barcelona to officially incorporate Digital Samba. Over the last two decades a lot has changed, but what hasn’t changed is our enthusiasm for bringing people together in new and imaginative ways. We remain dedicated to providing a safe and... | digitalsamba | |
1,909,234 | HTML cool things | 1) Make a call or mail: Need a link to make a call or mail? a tag to the rescue Make a call Send an... | 0 | 2024-07-02T17:35:57 | https://dev.to/fida_jafri_b5296bd481b98d/html-cool-things-207j | 1) Make a call or mail:
Need a link to make a call or mail? a tag to the rescue
<a href="tel:43211234123">Make a call</a>
<a href="mailto:abc@gmail.com">Send an email</a>
2) Add a color picker:
Need a color picker to you webpage? No need to use any libraries. It's just one line far.
<input type="color"/>
Here it is.
Th... | fida_jafri_b5296bd481b98d | |
1,909,232 | Fixing... err... I mean "implementing" my Amazon DynamoDB approach with Gen-AI | Second part of the series where I build a serverless app to track my Green Card priority date and implement storing the data in DynamoDB. | 27,940 | 2024-07-02T17:32:52 | https://community.aws/content/2ihOgUm8x9k15XZ6aBfvUTlwmNN/fixing-err-i-mean-implementing-my-amazon-dynamodb-approach-with-gen-ai | amazonqdeveloper, terraform, lambda, dynamodb | ---
title: "Fixing... err... I mean \"implementing\" my Amazon DynamoDB approach with Gen-AI"
description: Second part of the series where I build a serverless app to track my Green Card priority date and implement storing the data in DynamoDB.
tags: amazonqdeveloper, terraform, lambda, dynamodb
canonical_url: "https:/... | cobusbernard |
1,909,231 | How to Send Emails with Email API: Practical Examples in Popular Languages and Frameworks | In this article, I’ll show you how to send emails using an email API in various programming languages... | 0 | 2024-07-02T17:27:45 | https://mailtrap.io/blog/api-send-email/ | In this article, I’ll show you how to send emails using an email API in various programming languages and frameworks.
I’ll also break down the differences between SMTP and email APIs, but if you’re already aware of them and your needs, feel free to skip ahead by clicking on some of the following links:
- [PHP](https... | idjuric660 | |
1,909,230 | Technical Article for Creating and Managing Users with a Bash Script | This article describes a Bash script, create_users.sh, designed to automate the creation of user... | 0 | 2024-07-02T17:25:43 | https://dev.to/marg4cf3553b4099/technical-article-for-creating-and-managing-users-with-a-bash-script-5gl7 | This article describes a [Bash script](https://github.com/MegCyber/HNGTask2.git), create_users.sh, designed to automate the creation of user accounts and group assignments based on a text file containing user data. This script streamlines the user onboarding process for system administrators, improving efficiency and ... | marg4cf3553b4099 | |
1,909,221 | Buy Negative Google Reviews | https://dmhelpshop.com/product/buy-negative-google-reviews/ Buy Negative Google Reviews Negative... | 0 | 2024-07-02T17:22:29 | https://dev.to/bikacaj604/buy-negative-google-reviews-3pl7 | devops, productivity, aws, opensource | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-negative-google-reviews/\n\n\n\n\nBuy Negative Google Reviews\nNegative reviews on Google are detrimental critiques that expose customers’ unfavorable experiences with a business. These reviews can significantly damage a company’s reputation, presenting challenges in both attracting new customers and retaining current ones. If you are considering purchasing negative Google reviews from dmhelpshop.com, we encourage you to reconsider and instead focus on providing exceptional products and services to ensure positive feedback and sustainable success.\n\nWhy Buy Negative Google Reviews from dmhelpshop\nWe take pride in our fully qualified, hardworking, and experienced team, who are committed to providing quality and safe services that meet all your needs. Our professional team ensures that you can trust us completely, knowing that your satisfaction is our top priority. With us, you can rest assured that you’re in good hands.\n\nIs Buy Negative Google Reviews safe?\nAt dmhelpshop, we understand the concern many business persons have about the safety of purchasing Buy negative Google reviews. We are here to guide you through a process that sheds light on the importance of these reviews and how we ensure they appear realistic and safe for your business. Our team of qualified and experienced computer experts has successfully handled similar cases before, and we are committed to providing a solution tailored to your specific needs. Contact us today to learn more about how we can help your business thrive.\n\nBuy Google 5 Star Reviews\nReviews represent the opinions of experienced customers who have utilized services or purchased products from various online or offline markets. These reviews convey customer demands and opinions, and ratings are assigned based on the quality of the products or services and the overall user experience. Google serves as an excellent platform for customers to leave reviews since the majority of users engage with it organically. When you purchase Buy Google 5 Star Reviews, you have the potential to influence a large number of people either positively or negatively. Positive reviews can attract customers to purchase your products, while negative reviews can deter potential customers.\n\nIf you choose to Buy Google 5 Star Reviews, people will be more inclined to consider your products. However, it is important to recognize that reviews can have both positive and negative impacts on your business. Therefore, take the time to determine which type of reviews you wish to acquire. Our experience indicates that purchasing Buy Google 5 Star Reviews can engage and connect you with a wide audience. By purchasing positive reviews, you can enhance your business profile and attract online traffic. Additionally, it is advisable to seek reviews from reputable platforms, including social media, to maintain a positive flow. We are an experienced and reliable service provider, highly knowledgeable about the impacts of reviews. Hence, we recommend purchasing verified Google reviews and ensuring their stability and non-gropability.\n\nLet us now briefly examine the direct and indirect benefits of reviews:\nReviews have the power to enhance your business profile, influencing users at an affordable cost.\nTo attract customers, consider purchasing only positive reviews, while negative reviews can be acquired to undermine your competitors. Collect negative reports on your opponents and present them as evidence.\nIf you receive negative reviews, view them as an opportunity to understand user reactions, make improvements to your products and services, and keep up with current trends.\nBy earning the trust and loyalty of customers, you can control the market value of your products. Therefore, it is essential to buy online reviews, including Buy Google 5 Star Reviews.\nReviews serve as the captivating fragrance that entices previous customers to return repeatedly.\nPositive customer opinions expressed through reviews can help you expand your business globally and achieve profitability and credibility.\nWhen you purchase positive Buy Google 5 Star Reviews, they effectively communicate the history of your company or the quality of your individual products.\nReviews act as a collective voice representing potential customers, boosting your business to amazing heights.\nNow, let’s delve into a comprehensive understanding of reviews and how they function:\nGoogle, with its significant organic user base, stands out as the premier platform for customers to leave reviews. When you purchase Buy Google 5 Star Reviews , you have the power to positively influence a vast number of individuals. Reviews are essentially written submissions by users that provide detailed insights into a company, its products, services, and other relevant aspects based on their personal experiences. In today’s business landscape, it is crucial for every business owner to consider buying verified Buy Google 5 Star Reviews, both positive and negative, in order to reap various benefits.\n\nWhy are Google reviews considered the best tool to attract customers?\nGoogle, being the leading search engine and the largest source of potential and organic customers, is highly valued by business owners. Many business owners choose to purchase Google reviews to enhance their business profiles and also sell them to third parties. Without reviews, it is challenging to reach a large customer base globally or locally. Therefore, it is crucial to consider buying positive Buy Google 5 Star Reviews from reliable sources. When you invest in Buy Google 5 Star Reviews for your business, you can expect a significant influx of potential customers, as these reviews act as a pheromone, attracting audiences towards your products and services. Every business owner aims to maximize sales and attract a substantial customer base, and purchasing Buy Google 5 Star Reviews is a strategic move.\n\nAccording to online business analysts and economists, trust and affection are the essential factors that determine whether people will work with you or do business with you. However, there are additional crucial factors to consider, such as establishing effective communication systems, providing 24/7 customer support, and maintaining product quality to engage online audiences. If any of these rules are broken, it can lead to a negative impact on your business. Therefore, obtaining positive reviews is vital for the success of an online business\n\nWhat are the benefits of purchasing reviews online?\nIn today’s fast-paced world, the impact of new technologies and IT sectors is remarkable. Compared to the past, conducting business has become significantly easier, but it is also highly competitive. To reach a global customer base, businesses must increase their presence on social media platforms as they provide the easiest way to generate organic traffic. Numerous surveys have shown that the majority of online buyers carefully read customer opinions and reviews before making purchase decisions. In fact, the percentage of customers who rely on these reviews is close to 97%. Considering these statistics, it becomes evident why we recommend buying reviews online. In an increasingly rule-based world, it is essential to take effective steps to ensure a smooth online business journey.\n\nBuy Google 5 Star Reviews\nMany people purchase reviews online from various sources and witness unique progress. Reviews serve as powerful tools to instill customer trust, influence their decision-making, and bring positive vibes to your business. Making a single mistake in this regard can lead to a significant collapse of your business. Therefore, it is crucial to focus on improving product quality, quantity, communication networks, facilities, and providing the utmost support to your customers.\n\nReviews reflect customer demands, opinions, and ratings based on their experiences with your products or services. If you purchase Buy Google 5-star reviews, it will undoubtedly attract more people to consider your offerings. Google is the ideal platform for customers to leave reviews due to its extensive organic user involvement. Therefore, investing in Buy Google 5 Star Reviews can significantly influence a large number of people in a positive way.\n\nHow to generate google reviews on my business profile?\nFocus on delivering high-quality customer service in every interaction with your customers. By creating positive experiences for them, you increase the likelihood of receiving reviews. These reviews will not only help to build loyalty among your customers but also encourage them to spread the word about your exceptional service. It is crucial to strive to meet customer needs and exceed their expectations in order to elicit positive feedback. If you are interested in purchasing affordable Google reviews, we offer that service.\n\n\n\n\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | bikacaj604 |
1,909,215 | ByteDance’s RsPack: The Future of Web Bundling || Shahin Islam Arpon || a4arpon | ByteDance and JavaScript Web development is always changing, and ByteDance, the company... | 0 | 2024-07-02T17:21:18 | https://dev.to/a4arpon/bytedances-rspack-the-future-of-web-bundling-shahin-islam-arpon-a4arpon-op4 | webdev, javascript, tiktok, rust | ## ByteDance and JavaScript
Web development is always changing, and ByteDance, the company behind TikTok and CapCut, is leading the way with a new tool called RsPack. This tool promises to make developers' lives easier by solving common problems with bundling JavaScript. Here's what you need to know about RsPack.
## ... | a4arpon |
1,909,153 | Como um Malware opera, quais são os seus tipos e como se proteger. | No mundo digital de hoje, a segurança cibernética se torna cada vez mais importante. Entre as... | 0 | 2024-07-02T17:19:47 | https://dev.to/jaque_py/como-um-malware-opera-quais-sao-os-seus-tipos-e-como-se-proteger-26e8 | cybersecurity, malware, security, beginners | No mundo digital de hoje, a segurança cibernética se torna cada vez mais importante. Entre as principais ameaças, os **malwares** se destacam por sua capacidade de causar danos significativos a dispositivos, redes e dados. Entender o funcionamento, os tipos e as medidas de proteção contra malwares é essencial para gara... | jaque_py |
1,909,151 | “ A Complete Guide to Obtaining a Work Permit Visa for New Zealand: Step-by-Step” | Are you thinking about starting a new job and living and working in New Zealand? Renowned for its... | 0 | 2024-07-02T17:16:46 | https://dev.to/aman_kapoor_ea3f94d4f74a0/-a-complete-guide-to-obtaining-a-work-permit-visa-for-new-zealand-step-by-step-93g | skilled, worker, visa, techsavvyimmigration | Are you thinking about starting a new job and living and working in New Zealand?
Renowned for its stunning scenery and dynamic culture, New Zealand presents fantastic prospects for proficient laborers over the globe.
The[ **[New Zealand Skilled Worker Visa]](https://www.techsavvyimmigration.com/how-to-apply-for-a-new... | aman_kapoor_ea3f94d4f74a0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.