
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,909,150 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-07-02T17:15:25 | https://dev.to/bikacaj604/buy-verified-paxful-account-1m23 | tutorial, react, python, ai | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\n \n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | bikacaj604 |
1,909,147 | Unveiling the Fibonacci Sequence in C Programming | 𝐖𝐡𝐚𝐭 𝐢𝐬 𝐭𝐡𝐞 𝐅𝐢𝐛𝐨𝐧𝐚𝐜𝐜𝐢 𝐒𝐞𝐫𝐢𝐞𝐬? The Fibonacci series is a sequence of numbers where each number is the... | 0 | 2024-07-02T17:05:29 | https://dev.to/moksh57/unveiling-the-fibonacci-sequence-in-c-programming-218p | 𝐖𝐡𝐚𝐭 𝐢𝐬 𝐭𝐡𝐞 𝐅𝐢𝐛𝐨𝐧𝐚𝐜𝐜𝐢 𝐒𝐞𝐫𝐢𝐞𝐬?
The Fibonacci series is a sequence of numbers where each number is the sum of the two preceding ones. It starts from 0 and 1, and the series looks something like this:
0,1,1,2,3,5,8,13,21,34,…
𝐖𝐡𝐲 𝐢𝐬 𝐢𝐭 𝐈𝐦𝐩𝐨𝐫𝐭𝐚𝐧𝐭?
The Fibonacci series transcends its... | moksh57 | |
1,909,148 | My GDSC Lead Interview 2024 | Okay so let me go step by step... Decoding the GDSC Lead Interview: The email arrived,... | 0 | 2024-07-02T17:04:27 | https://dev.to/kaustubhpaul18/my-gdsc-lead-interview-2024-56n7 | google, interview, googlecloud | Okay so let me go step by step...
## Decoding the GDSC Lead Interview:
The email arrived, crisp and official: **"GDSC Lead Interview Invitation."** My heart pounded with a mix of excitement and nervousness. Leading a Google Developers Student Clubs (GDSC) chapter was a dream I'd nurtured for a while, and the intervi... | kaustubhpaul18 |
1,909,146 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-07-02T17:02:30 | https://dev.to/bikacaj604/buy-verified-cash-app-account-4kjf | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\t\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n\n\n" | bikacaj604 |
1,908,006 | Backend and solving problems | I was building a grocery app. The grocery app required a feature that allowed store managers to add... | 0 | 2024-07-01T17:21:30 | https://dev.to/uti/backend-and-solving-problems-2mff | I was building a grocery app. The grocery app required a feature that allowed store managers to add new products dynamically. This task required a deep understanding of database operations and efficient coding practices.
The requirements for the feature included input validation, database interaction, error handling, ... | uti | |
1,909,145 | Functional Patterns: Interfaces and Functors | This is part 3 of a series of articles entitled Functional Patterns. Make sure to check out the... | 0 | 2024-07-02T17:00:57 | https://dev.to/if-els/functional-patterns-interfaces-and-functors-359e | programming, haskell, learning, go | > This is part 3 of a series of articles entitled *Functional Patterns*.
>
> Make sure to check out the rest of the articles!
>
> 1. [The Monoid](https://dev.to/if-els/functional-patterns-the-monoid-22ef)
> 2. [Compositions and Implicitness](https://dev.to/if-els/functional-patterns-composition-and-implicitness-4n08)
... | if-els |
1,909,144 | Essentialism in KPIs: Focusing on Key Metrics for Software Development Success | Introduction In the fast-paced world of software development, tracking progress and... | 0 | 2024-07-02T17:00:44 | https://dev.to/davitacols/essentialism-in-kpis-focusing-on-key-metrics-for-software-development-success-mdo | softwaredevelopment, software, kpi, webdev | ## Introduction
In the fast-paced world of software development, tracking progress and ensuring project success can be challenging. Key Performance Indicators (KPIs) are crucial metrics that help project managers and teams monitor performance, identify issues, and drive improvements. This guide explores essential KPIs... | davitacols |
1,909,141 | Embracing the Evolution of Web Development: Trends and Best Practices for 2024 | As we stride into 2024, the landscape of web development continues to evolve at an astonishing pace.... | 0 | 2024-07-02T16:58:33 | https://dev.to/abdul_rahman_19d731503a82/embracing-the-evolution-of-web-development-trends-and-best-practices-for-2024-56ca | As we stride into 2024, the landscape of web development continues to evolve at an astonishing pace. With new technologies, frameworks, and best practices emerging, developers need to stay ahead of the curve to build robust, scalable, and efficient web applications. In this article, we'll explore the latest trends shap... | abdul_rahman_19d731503a82 | |
1,909,140 | Hello Everyone! | I have just started here. So, nothing is known yet. But I hope to get familiar soon.😊 | 0 | 2024-07-02T16:56:27 | https://dev.to/emon12700/hello-everyone-2akh | I have just started here. So, nothing is known yet. But I hope to get familiar soon.😊 | emon12700 | |
1,909,138 | Temu New User Coupon [AAV67880]: Up To 75% OFF For First-Time Users | Offers: AAV67880 Up to 75% discount for new users Up to 90% discount on select items and clearance... | 0 | 2024-07-02T16:50:51 | https://dev.to/sonuprasad/temu-new-user-coupon-aav67880-up-to-75-off-for-first-time-users-216d | temu, temu100off, temudiscount, temucouponcod | - Offers: AAV67880
- Up to 75% discount for new users
- Up to 90% discount on select items and clearance sales
- 40% discount for existing users
Validity: July 2024
Our Temu first-time user coupon codes are designed just for new customers, offering the biggest discounts and the best deals currently available on Temu. T... | sonuprasad |
1,909,137 | 🚀 🚀 Working with hierarchical data in .Net Core using the hierarchyid data type.(.Net Core 8) 🚀 🚀 | 🚀 HierarchyId Data Type The hierarchyid data type was introduced with SQL Server 2008. It’s... | 23,809 | 2024-07-02T16:48:55 | https://dev.to/ahmedshahjr/working-with-hierarchical-data-in-net-core-using-the-hierarchyid-data-typenet-core-8-1315 | webdev, dotnet, beginners, programming |
🚀 HierarchyId Data Type
The hierarchyid data type was introduced with SQL Server 2008. It’s specifically designed to represent and manipulate hierarchical data.
Hierarchical data structures contain parent-child relationships, and hierarchyid provides an efficient way to store and query such data.
In the contex... | ahmedshahjr |
1,909,124 | My Journey into Mobile Development with HNG Internship. | Hi there! I'm excited to share my journey as I start the HNG Internship and dive into mobile... | 0 | 2024-07-02T16:47:38 | https://dev.to/ogodo_moses_dacb80df1025b/my-journey-into-mobile-development-with-hng-internship-5o5 | programming, tutorial, flutter, intern | Hi there! I'm excited to share my journey as I start the HNG Internship and dive into mobile development. Mobile apps are a big part of our lives, and making them is both fun and challenging. Let's talk about the platforms we use to build these apps and the common software architecture patterns.
**MOBILE APPS DEVELOPM... | ogodo_moses_dacb80df1025b |
1,909,103 | Using experiments to ship faster | Eliminate the all the hard stuff early. | 0 | 2024-07-02T16:47:00 | https://dev.to/joshnuss/using-experiments-to-ship-faster-5329 | productivity, webdev, programming | ---
title: Using experiments to ship faster
published: true
description: Eliminate the all the hard stuff early.
tags: productivity, webdev, programming
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/el4tjgo2h58m6bb8wy1m.png
published_at: 2024-07-02 16:47 +0000
---
Has this ever happened to you?... | joshnuss |
1,902,676 | AWS Lambda Rust EMF metrics helper | Photo by Isaac Smith on Unsplash Introduction In the AWS Lambda ecosystem, there is an... | 0 | 2024-07-02T16:44:06 | https://dev.to/aws-builders/aws-lambda-rust-emf-metrics-helper-4glp | aws, rust, serverless | Photo by <a href="https://unsplash.com/@isaacmsmith?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Isaac Smith</a> on <a href="https://unsplash.com/photos/pen-om-paper-AT77Q0Njnt0?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Unsplash</a>
# Introduction
In the AWS Lambda e... | szymonszym |
1,909,136 | Migration from NoSql to Sql , MongoDB to PostgreSql with PRISMA. | In my career as a backend developer, I've recently come across a big challenge, that of moving from a... | 0 | 2024-07-02T16:43:46 | https://dev.to/christian_birego_e9b83eaa/migration-from-nosql-to-sql-mongodb-to-postgresql-with-prisma-dem | javascript, prisma, mongodb, postgres | In my career as a backend developer, I've recently come across a big challenge, that of moving from a Nosql database to an sql database. This task turned out to be complicated, but it gave me the ability to learn more. Today I'm going to share my experience with you!
an application using mongodb to store data, but for... | christian_birego_e9b83eaa |
1,909,135 | openai/whisper-large-v3-torrent | https://aitorrent.zerroug.de/openai-whisper-large-v3/ | 0 | 2024-07-02T16:43:01 | https://dev.to/octobreak/openaiwhisper-large-v3-torrent-28id | ai, machinelearning, openai, beginners | https://aitorrent.zerroug.de/openai-whisper-large-v3/ | octobreak |
1,909,134 | Advances in Deep Learning for Time Series Forecasting 2024 | https://medium.com/deep-data-science/advances-in-deep-learning-for-time-series-forecasting-classifica... | 0 | 2024-07-02T16:40:51 | https://dev.to/isaacmg/advances-in-deep-learning-for-time-series-forecasting-2024-876 | deeplearning, pytorch, timeseriesforecasting, opensource | https://medium.com/deep-data-science/advances-in-deep-learning-for-time-series-forecasting-classification-winter-2024-a3fd31b875b0 | isaacmg |
1,909,133 | Issue facing with Global Setup | I am facing one issue related to global setup and teardown approach : --> i have to run mutliple... | 0 | 2024-07-02T16:40:51 | https://dev.to/chandansh27/issue-facing-with-global-setup-4pnk | I am facing one issue related to global setup and teardown approach :
--> i have to run mutliple spec files , which are in different folders under test and wanted to login once and logout once all the spec files are executed.
-> So i have created global-setup.ts file and global-teardown.ts file for storing the state ... | chandansh27 | |
1,909,132 | Evolving Landscape Of Software Development With AI Agents | The world of software development is undergoing a revolution driven by Artificial Intelligence (AI)... | 0 | 2024-07-02T16:40:17 | https://www.techdogs.com/td-articles/trending-stories/evolving-landscape-of-software-development-with-ai-agents | softwaredevelopment, ai, technology, programming | The world of software development is undergoing a revolution driven by [Artificial Intelligence (AI)](https://www.techdogs.com/category/ai) agents. These intelligent assistants are transforming how we create software, automating tasks, improving efficiency, and opening doors to exciting new possibilities.
AI agents go... | td_inc |
1,908,821 | Unveiling the Truth: Debunking Myths and Misconceptions about 2FA | In the ever-evolving landscape of cybersecurity, two-factor authentication (2FA) stands as a beacon... | 0 | 2024-07-02T16:38:42 | https://dev.to/verifyvault/unveiling-the-truth-debunking-myths-and-misconceptions-about-2fa-2a1f | opensource, security, cybersecurity, github | In the ever-evolving landscape of cybersecurity, two-factor authentication (2FA) stands as a beacon of hope against data breaches and identity theft. Yet, despite its crucial role in safeguarding our online accounts, there are numerous myths and misconceptions that surround this powerful security measure. Let's dive in... | verifyvault |
1,909,091 | 10 Fun JavaScript Ideas to Try Today | JavaScript is a powerful programming language that allows developers to build dynamic and interactive... | 0 | 2024-07-02T16:37:48 | https://dev.to/mukeshb/10-fun-javascript-ideas-to-try-today-1gha | javascript, webdev, html, bitcoin | JavaScript is a powerful programming language that allows developers to build dynamic and interactive web applications. Whether you're just starting out or have years of experience, working on real projects is a great way to improve your JavaScript skills.
This guide presents a collection of practical JavaScript examp... | mukeshb |
1,908,039 | Million.js adoption guide: Overview, examples, and alternatives | Written by Isaac Okoro✏️ The frontend ecosystem has seen lots of recent improvements for making... | 0 | 2024-07-02T16:37:42 | https://blog.logrocket.com/million-js-adoption-guide | millionjs, webdev | **Written by [Isaac Okoro](https://blog.logrocket.com/author/isaacjunior/)✏️**
The frontend ecosystem has seen lots of recent improvements for making development easier and increasing productivity. Some of these improvements have come through the introduction of faster tools and frameworks like Svelte, Bun, Preact, Bl... | leemeganj |
1,909,128 | Svelte and React | Beyond Buttons: A Frontend Showdown - Svelte vs. React Hey there, code enthusiasts! Today, we're... | 0 | 2024-07-02T16:35:32 | https://dev.to/expectationshack/svelte-and-react-4j5c |
**Beyond Buttons: A Frontend Showdown - Svelte vs. React**
Hey there, code enthusiasts! Today, we're diving into the dynamic world of frontend development and comparing two hot technologies: Svelte and React. Both are rockstars in building user interfaces, but they take different approaches. Let's see which one shine... | expectationshack | |
1,909,127 | EVM Reverse Engineering Challenge 0x02 | The third challenge it's here. I'll keep it simple like the other ones, but in order to help you out... | 27,871 | 2024-07-02T16:34:19 | https://gealber.com/evm-reverse-challenge-0x02 | evm, ethereum, challenge, reverseengineer | The third challenge it's here. I'll keep it simple like the other ones, but in order to help you out a bit I will always give you super useful hint like in this case. Also I'll suggest you to make the challenges in order because you will possible need to use previous challenges exploits. Here is the address of the cont... | gealber |
1,909,125 | How do I close my DEV account | I no longer want an account with this system. I want to remove my information. How do I close this... | 0 | 2024-07-02T16:31:25 | https://dev.to/michael_riat_4fd70bc4717e/how-do-i-close-my-dev-account-3lk | dev | I no longer want an account with this system. I want to remove my information. How do I close this account? | michael_riat_4fd70bc4717e |
1,908,384 | Mastering Serverless Debugging | Introduction to Serverless Computing Challenges of Serverless Debugging Disconnected... | 20,817 | 2024-07-02T16:26:02 | https://debugagent.com/mastering-serverless-debugging | lambda, tutorial, serverless, developers | - [Introduction to Serverless Computing](#introduction-to-serverless-computing)
- [Challenges of Serverless Debugging](#challenges-of-serverless-debugging)
* [Disconnected Environments](#disconnected-environments)
* [Lack of Standardization](#lack-of-standardization)
* [Limited Debugging Tools](#limited-debugg... | codenameone |
1,909,102 | Apprendre .NET Aspire en français | En mai dernier, durant Microsoft Build, .NET Aspire a été officiellement annoncé. Cette nouvelle pile... | 0 | 2024-07-02T16:24:47 | https://dev.to/azure/apprendre-net-aspire-en-francais-94a | dotnet, french, webdev, cloudnative |
En mai dernier, durant Microsoft Build, .NET Aspire a été officiellement annoncé. Cette nouvelle pile prête pour le cloud et conçue pour .NET, visant à permettre aux développeurs de créer rapidement et facilement des applications natives cloud.
... | 0 | 2024-07-02T16:17:40 | https://dev.to/jensen1806/understanding-kubernetes-namespaces-isolation-connectivity-and-practical-use-cases-45h4 | kubernetes, docker, containers, namespaces | ### Introduction
Welcome back to the blog series on Certified Kubernetes Administrator (CKA) preparation. In today's post, we'll delve into the concept of namespaces in Kubernetes. We'll explore why namespaces are essential, how they provide isolation within a cluster, and perform hands-on tasks to demonstrate connecti... | jensen1806 |
1,909,092 | Discover Perfect Quality Replica Products at Affordable Prices with RRMALL | 오늘날의 시장에서 합리적인 가격에 고품질 제품을 찾는 것은 어려울 수 있습니다. RRMALL은 이러한 간극을 메우며 최고의 품질과 최저가를 보장하는 레플리카 제품을 도매가로... | 0 | 2024-07-02T15:59:46 | https://dev.to/replicaproducts/discover-perfect-quality-replica-products-at-affordable-prices-with-rrmall-284i |
오늘날의 시장에서 합리적인 가격에 고품질 제품을 찾는 것은 어려울 수 있습니다. RRMALL은 이러한 간극을 메우며 최고의 품질과 최저가를 보장하는 레플리카 제품을 도매가로 제공합니다. 직접 공장 거래를 통해 RRMALL은 고객들에게 최상의 품질과 최저가를 보장합니다. 이제 RRMALL이 레플리카 제품을 위한 최고의 목적지인 이유를 자세히 알아보겠습니다.
**도매가로 제공되는 탁월한 품질**
RRMALL은 원본 제품을 모든 면에서 모방한 레플리카 제품을 고객에게 제공합니다. 재료부터 제작 기술까지 모든 제품은 높은 기준을 충족하도록 설계되어 내구성과 미적 매력을... | replicaproducts | |
1,909,099 | DevOps Beginnings: Mastering Python and Golang! | 🌟 Exciting News! 🌟 I'm thrilled to share that I've started my journey into the world of DevOps! As a... | 0 | 2024-07-02T16:15:23 | https://dev.to/upendra_verma_74415c5652e/devops-beginnings-mastering-python-and-golang-l0d | python, devops, go, productivity | 🌟 Exciting News! 🌟
I'm thrilled to share that I've started my journey into the world of DevOps! As a first step, I'm diving deep into learning the basics of Python and Golang. 🚀
I'm looking forward to connecting with fellow developers and DevOps professionals to exchange knowledge and experiences. Let's grow and i... | upendra_verma_74415c5652e |
1,909,097 | Automating User and Group Management on Linux with Bash | Managing user accounts and groups is a fundamental aspect of system administration. In dynamic... | 0 | 2024-07-02T16:12:22 | https://dev.to/christian_ochenehipeter_/automating-user-and-group-management-on-linux-with-bash-10cb | Managing user accounts and groups is a fundamental aspect of system administration. In dynamic environments, such as those in software development companies, the ability to automate this process can save time and reduce errors. This article explains a Bash script designed to automate the creation of user accounts and g... | christian_ochenehipeter_ | |
1,909,095 | The Difference Between indexOf and findIndex in JavaScript | indexOf is a method available for both arrays and strings in JavaScript, used to search for the first... | 0 | 2024-07-02T16:06:28 | https://dev.to/sbabaeizadeh/the-difference-between-indexof-and-findindex-in-javascript-42ij | webdev, javascript, programming |
indexOf is a method available for both arrays and strings in JavaScript, used to search for the first occurrence of a value using strict equality ("===").
findIndex is a higher-order function specifically designed for arrays, used to search for the first element that satisfies a condition specified by a callback fun... | sbabaeizadeh |
1,898,451 | Context API vs. Redux: When and Why to Use Them in React | Before starting to explore the differences and use cases of both Context API and Redux, it is... | 0 | 2024-07-02T16:03:07 | https://dev.to/zahidkhanxen/context-api-vs-redux-when-and-why-to-use-them-in-react-2c8d | Before starting to explore the differences and use cases of both Context API and Redux, it is essential to understand why these two solutions were developed.
In simple React, we can pass down data from parent components to child components. The parent component is where your main component is rendering. For example:
... | zahidkhanxen | |
1,909,093 | User Creation Aumation in Linux with a Bash Script | Introduction In the world of a SysOps engineer, one of the common tasks you will encouter... | 0 | 2024-07-02T16:00:42 | https://dev.to/clintt/user-creation-aumation-in-linux-with-a-bash-script-630 | ## **Introduction**
In the world of a SysOps engineer, one of the common tasks you will encouter is the creation and management of users and groups. Automation helps simplify this process, making it efficient and time saving. In this blog post, we'll go through a bash script createusers.sh that automates the creation o... | clintt | |
1,909,090 | An application form asked me what I feel about their value "doing what it takes". I shared a story about an old dog. | "One of our values is 'Do-What-It-Takes.' Please provide an example of a time you’ve applied this and... | 0 | 2024-07-02T15:55:30 | https://dev.to/tacodes/some-application-form-asked-me-what-i-feel-about-their-value-doing-what-it-takes-i-shared-a-story-about-an-old-dog-den | application, jobhunt, story | "One of our values is 'Do-What-It-Takes.' Please provide an example of a time you’ve applied this and what the impact was."
I'm kind of tired of the rinse-and-repeat job description-focused answers. 'I always met deadlines cause I *did what it took*', 'the customers were 99.98% happy with the results', etc... They've ... | tacodes |
1,909,089 | 350. Intersection of Two Arrays II | 350. Intersection of Two Arrays II Easy Given two integer arrays nums1 and nums2, return an array... | 27,523 | 2024-07-02T15:48:03 | https://dev.to/mdarifulhaque/350-intersection-of-two-arrays-ii-3fgm | php, leetcode, algorithms, programming | 350\. Intersection of Two Arrays II
Easy
Given two integer arrays `nums1` and `nums2`, return _an array of their intersection_. Each element in the result must appear as many times as it shows in both arrays, and you may return the result in **any order**.
**Example 1:**
- **Input:** nums1 = [1,2,2,1], nums2 = [2,2... | mdarifulhaque |
1,909,088 | Ringing in Savings: A Guide to Home Phone Deals in the Age of Mobiles | In a world dominated by smartphones, you might be wondering if a home phone still holds value.... | 0 | 2024-07-02T15:47:24 | https://dev.to/andy_wilson_783aeb2815937/ringing-in-savings-a-guide-to-home-phone-deals-in-the-age-of-mobiles-23nn | In a world dominated by smartphones, you might be wondering if a home phone still holds value. Surprisingly, for many households, a landline phone remains a reliable and cost-effective communication tool. Whether it's for business calls, keeping in touch with elderly relatives, or simply a backup option in case of emer... | andy_wilson_783aeb2815937 | |
1,909,087 | Unlock the Power of C# in Polyglot Notebooks | This article shows how to use C# skills in polyglot notebooks for better data management and... | 0 | 2024-07-02T15:46:11 | https://dev.to/andreaslennartz/unlock-the-power-of-c-in-polyglot-notebooks-3kj2 | jupyter, csharp, etl, polyglot | This article shows how to use C# skills in polyglot notebooks for better data management and analysis.
### C# and Polyglot Notebooks
C# is a powerful programming language widely used for building a variety of applications, from web apps to complex data processing systems. Polyglot notebooks, like Jupyter notebooks, a... | andreaslennartz |
1,909,083 | Event Delegation | Funny Example Alright, let's use a funny example with a classroom and students. Imagine a... | 0 | 2024-07-02T15:37:42 | https://dev.to/__khojiakbar__/event-delegation-1f8 | event, delegation, javascript | ## Funny Example
Alright, let's use a funny example with a classroom and students. Imagine a classroom full of students, and each student is holding a card. When you tap a student's card, they say something funny. Instead of going to each student and asking them to say something funny when tapped, you tell the teacher... | __khojiakbar__ |
1,909,082 | Start of Coding | I made a website with react, I just started today, I need to post this, so I can get better. The... | 0 | 2024-07-02T15:36:19 | https://dev.to/ad31aid/start-of-coding-d20 | I made a website with react, I just started today, I need to post this, so I can get better. The website is quite shit, but it will get better!
https://seven1personalsite.onrender.com | ad31aid | |
1,909,081 | The Tee: A History of Comfort, Rebellion, and Self-Expression | It started life as a practical undergarment in the late 19th century, then evolved into a symbol of... | 0 | 2024-07-02T15:35:06 | https://dev.to/pegance_teevibe_7cd8c4acb/the-tee-a-history-of-comfort-rebellion-and-self-expression-4eh | tshirt, mens, womenstshirt, online | It started life as a practical undergarment in the late 19th century, then evolved into a symbol of casualness and self-expression.
Early versions were basic tees made from wool or cotton, worn for warmth and sweat absorption. The U.S. Navy adopted a similar design in the 1890s, solidifying its association with practic... | pegance_teevibe_7cd8c4acb |
1,909,080 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-07-02T15:32:59 | https://dev.to/nebise5872/buy-verified-cash-app-account-2410 | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | nebise5872 |
1,908,282 | Working with Databases in Django Using PostgreSQL | Introduction Django simplifies database interaction with its Object-Relational Mapping... | 0 | 2024-07-02T15:29:07 | https://dev.to/kihuni/working-with-databases-in-django-using-postgresql-9co | webdev, beginners, python, devops | # Introduction
Django simplifies database interaction with its Object-Relational Mapping (ORM) system, enabling Python code to be used for working with databases instead of writing SQL. This guide provides essential information on using PostgreSQL in Django, from database setup to performing CRUD operations.
## Setti... | kihuni |
1,909,067 | July 3: Virtual AI, Machine Learning and Computer Vision Meetup | Don’t forget to join us this Wed on July 3 for the monthly AI, Machine Learning and Computer Vision... | 0 | 2024-07-02T15:21:36 | https://dev.to/voxel51/july-3-virtual-ai-machine-learning-and-computer-vision-meetup-3i51 | computervision, ai, machinelearning, datascience | Don’t forget to join us this Wed on July 3 for the monthly AI, Machine Learning and Computer Vision Meetup!
**Register for the Zoom**: [https://voxel51.com/computer-vision-events/ai-machine-learning-computer-vision-meetup-july-3-2024/](https://voxel51.com/computer-vision-events/ai-machine-learning-computer-vision-meet... | jguerrero-voxel51 |
1,909,066 | API Test Automation: A Comprehensive Guide | Introduction Application Programming Interfaces (APIs) are the backbone of modern software... | 0 | 2024-07-02T15:18:35 | https://dev.to/keploy/api-test-automation-a-comprehensive-guide-59c5 | api, javascript, ai, productivity |

Introduction
Application Programming Interfaces (APIs) are the backbone of modern software architectures. They enable different software systems to communicate with each other, facilitating the seamless integration ... | keploy |
1,909,063 | How to Create a Node API With Knex and PostgreSQL | Creating a strong and well-structured backend is very important to aiding database management systems... | 0 | 2024-07-02T15:15:37 | https://dev.to/mmili_01/how-to-create-a-node-api-with-knex-and-postgresql-4329 | Creating a strong and well-structured backend is very important to aiding database management systems in programming. As a developer, you may need help writing raw SQL queries and manually handling database migrations and transactions. Knex.js helps you easily create complex queries to select, insert, update and delete... | mmili_01 | |
1,909,061 | Discover the Fascinating World of Computation and Logic with Inf1 from the University of Edinburgh 🧠 | Explore the fundamentals of computation and logic with this comprehensive course from the University of Edinburgh. Access weekly schedules, previous materials, and a birds-eye overview of the subject matter. | 27,844 | 2024-07-02T15:14:39 | https://getvm.io/tutorials/inf1-computation-and-logic-2015-university-of-edinburgh | getvm, programming, freetutorial, universitycourses |
Are you curious about the fundamental principles of computation and logic? Look no further than the Inf1 - Computation and Logic course offered by the prestigious University of Edinburgh! 🏫
## Course Overview
This comprehensive course will take you on a captivating journey through the core concepts of computation ... | getvm |
1,909,060 | Bug Report for SAW | Date: 01/07/2024 Summary: The application has multiple issues affecting its usability, particularly... | 0 | 2024-07-02T15:11:35 | https://dev.to/abdielbytes/bug-report-for-saw-3hf9 |
Date: 01/07/2024
**Summary:**
The application has multiple issues affecting its usability, particularly with the URL management functionalities. Various buttons and features do not perform as expected, and some operations cause the application to crash or behave unpredictably.
**Detailed Description of Issues:**
U... | abdielbytes | |
1,908,071 | Work Breakdown Structure (WBS) | As a part of my course on Software Project Management, I learned about this new thing: Work Breakdown... | 0 | 2024-07-02T15:09:56 | https://dev.to/abedin022/work-breakdown-structure-wbs-1n1g | programming, projectmanagement, softwareengineering, workbreakdownstructure | As a part of my course on Software Project Management, I learned about this new thing: Work Breakdown Structure (WBS). After doing an ample amount of research on this topic, I decided to write an article about it explaining WBS in the simplest terms.
### What is WBS?
Every complex thing has to be broken down into sma... | abedin022 |
1,909,059 | Boost Your Testing Game | JavaScript Testing Frameworks Jest Summary: A comprehensive testing framework... | 0 | 2024-07-02T15:08:26 | https://dev.to/gadekar_sachin/boost-your-testing-game-344c |
### JavaScript Testing Frameworks
1. **Jest**
- **Summary**: A comprehensive testing framework developed by Facebook. It's widely used for testing JavaScript applications, particularly those built with React.
- **Features**: Built-in test runners, coverage reports, snapshot testing, and mock functions.
2. **M... | gadekar_sachin | |
1,906,108 | All the Lists in .NET MAUI | This blog is part of the .NET MAUI UI July 2024 series with a new post every day of the month. See... | 0 | 2024-07-02T15:04:00 | https://dev.to/davidortinau/all-the-lists-in-net-maui-33bd | dotnet, dotnetmaui, mobile, mauiuijuly | > This blog is part of the [.NET MAUI UI July 2024](https://goforgoldman.com/posts/mauiuijuly-24/) series with a new post every day of the month. See the [full schedule](https://goforgoldman.com/posts/mauiuijuly-24/#net-maui-ui-july-schedule) for more.
In any app project, you will inevitably have a list of things to ... | davidortinau |
1,909,057 | NPX vs NGX vs NPM | npx: an npm package runner Enter fullscreen mode Exit fullscreen mode ... | 0 | 2024-07-02T15:03:49 | https://dev.to/kiranuknow/npx-vs-ngx-3f7m | ```
npx: an npm package runner
```
```
ngx packages are used by Angular
ngx : used by Angular to run Angular projects.
```
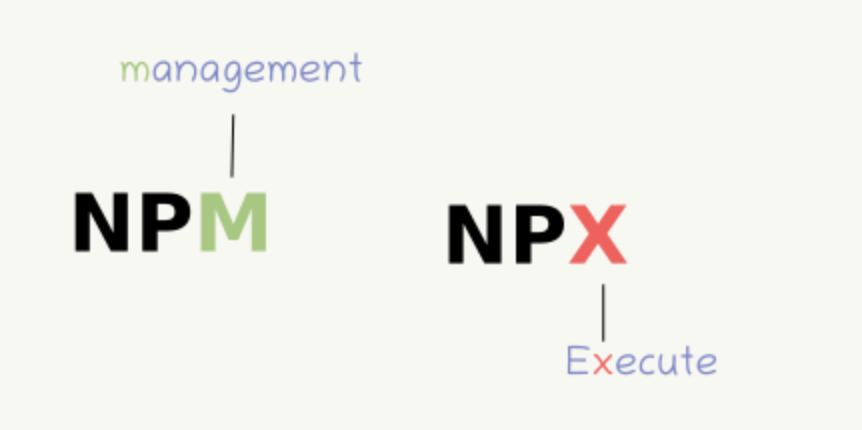
NPM => Is a JS package manager.
NPX => Is a tool for executing Node packages and execu... | kiranuknow | |
1,909,056 | FIRST GLANCE ANALYSIS | Hi guys, I have always wanted to write technical reports and share my knowledge in data analytics,... | 0 | 2024-07-02T15:03:10 | https://dev.to/benaj/first-glance-analysis-40k5 | data, analytics, datacleaning, firstglance | Hi guys,
I have always wanted to write technical reports and share my knowledge in data analytics, this is my first time and if I can, you can too!
Today, I am going to be uncovering initial insights from a dataset at first glance. The data we are using contains 3 years of vehicle sales from 2003 - 2005.
WOOAHHH! L... | benaj |
1,780,887 | Como Configurar e Integrar o MiniO com Java | O MiniO é uma solução de armazenamento compatível com S3, ideal para empresas que precisam armazenar... | 0 | 2024-07-02T15:01:10 | https://dev.to/adrianoaguiar/minio-com-spring-boot-32bl | O MiniO é uma solução de armazenamento compatível com S3, ideal para empresas que precisam armazenar dados internamente. Além de oferecer capacidade de armazenamento de arquivos, essa solução permite a criação de data lakes, sendo especialmente útil para profissionais que lidam com grandes volumes de dados.
Neste arti... | adrianoaguiar | |
1,909,050 | i will develop new and advanced software | A post by Bealu Girma | 0 | 2024-07-02T14:45:23 | https://dev.to/bealu_girma_b6761abb446ff/i-will-develop-new-and-advanced-software-8bb | **_[](url)_** | bealu_girma_b6761abb446ff | |
1,908,726 | 🚀 Karpor Has Been Open-Sourced! We Build a Kubernetes Visualization Tool in the AI era | 🔔 What is Karpor? Today we are excited to announce that Karpor is now open-source! 🎉🎉🎉... | 27,936 | 2024-07-02T15:00:00 | https://dev.to/elliotxx/karpor-has-been-open-sourced-we-build-a-kubernetes-visualization-tool-in-the-ai-era-18am | kubernetes, opensource, cloudnative, ai | ## 🔔 What is Karpor?
Today we are excited to announce that Karpor is now open-source! 🎉🎉🎉
Karpor is a **Modern Kubernetes Visualization Tool**. Its core features focus on **🔍 Search, 📊 Insight and ✨ AI**. The goal is to connect platforms and multi-clusters more easily and quickly, and use AI to empower Kuberne... | elliotxx |
1,908,795 | Bootstrap Tutorials: Grid system | Grid system Bootstrap grid is a powerful system for building mobile-first websites. It... | 27,869 | 2024-07-02T15:00:00 | https://dev.to/keepcoding/bootstrap-tutorials-grid-system-4ka7 | bootstrap, learning, grid, design | ## Grid system
Bootstrap grid is a powerful system for building mobile-first websites. It uses a series of containers, rows, and columns to layout and align content. It’s built with flexbox and is fully responsive.
Some people even think that grid is the most important reason to use Bootstrap, so in this lesson, we w... | keepcoding |
1,909,054 | The right way to email your users | Overcome common issues when email users from your web application, using open-source notification system Tattler. A tutorial from zero to integrated. | 0 | 2024-07-02T14:53:50 | https://dev.to/mmic/the-right-way-to-email-your-users-2pnn | notifications, email, sms, python | ---
title: The right way to email your users
published: true
description: Overcome common issues when email users from your web application, using open-source notification system Tattler. A tutorial from zero to integrated.
tags: notifications, email, sms, python
# cover_image: https://tattler.dev/images/logo/logo-dark... | mmic |
1,909,055 | JavaScript | Top 20 React.JS interview questions. javascript react interview node As a React developer, it is... | 0 | 2024-07-02T14:53:24 | https://dev.to/mahadizulfiker/javascript-om8 | javascript, webdev, beginners, programming |
Top 20 React.JS interview questions.
#
javascript
#
react
#
interview
#
node
As a React developer, it is important to have a solid understanding of the framework's key concepts and principles. With this in mind, I have put together a list of 20 important questions that every React developer should know, whether they ... | mahadizulfiker |
1,909,051 | Top 5 best UI libraries to Use in your Next Project | Introduction Are you looking to speed up your web development process? A UI library might... | 0 | 2024-07-02T14:46:33 | https://strapi.io/blog/top-5-best-ui-libraries-to-use-in-your-next-project | webdev, javascript, beginners, react | ## Introduction
Are you looking to speed up your web development process? A UI library might be just what you need! This article explores the top 5 modern UI libraries that can help you build stunning web applications quickly and efficiently.
A UI library is a collection of pre-designed and pre-built user interface e... | syakirurahman |
1,909,045 | AWS Well-Architected Framework Review: Empowering Healthcare Industry | Technology is quintessential in the evolving field of healthcare and life sciences to elevate patient... | 0 | 2024-07-02T14:45:09 | https://dev.to/techpartner/aws-well-architected-framework-review-empowering-healthcare-industry-3hg | healthcare, aws, wellarchitected | Technology is quintessential in the evolving field of healthcare and life sciences to elevate patient care, automate operations and in medical research. It can be daunting to handle and enhance these technological systems. This is where the AWS Well Architected Framework with a Healthcare lens becomes extremely benefic... | arunasri |
1,909,047 | Technical Article: User Management Script with Enhanced Security | This article explores a Bash script designed to automate user creation and management on Linux... | 0 | 2024-07-02T14:40:58 | https://dev.to/divinechizoba/technical-article-1lkc | This article explores a Bash script designed to automate user creation and management on Linux systems. It prioritizes security by utilizing secure file permissions and secure password storage.
**Learning More about HNG Internship**
This script can be a valuable tool for system administrators managing user accounts w... | divinechizoba | |
1,909,044 | Introduction to Cassandra Database: Features, Commands, and Data Structures | Introduction Apache Cassandra is an open-source NoSQL database renowned for its... | 0 | 2024-07-02T14:38:06 | https://blog.spithacode.com/posts/87840dea-3ac0-478c-8353-c3ff91ce0f42 | nosql, webdev, javascript, beginners | ## Introduction
Apache Cassandra is an open-source NoSQL database renowned for its scalability and high availability without compromising performance. This article provides a detailed introduction to Cassandra, covering its main features, commands, data structures, and the underlying principles that make it an ideal ... | stormsidali2001 |
1,885,526 | A Guide to Higher-Order Functions in JavaScript | Photo by Growtika on Unsplash If you work with JavaScript, then you might have encountered... | 0 | 2024-07-02T14:35:35 | https://blog.stackademic.com/a-guide-to-higher-order-functions-in-javascript-65d061b0465c | javascript, beginners, programming |
Photo by [Growtika](https://unsplash.com/@growtika?utm_source=medium&utm_medium=referral) on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)
If you work with JavaScript, then you might have encountered higher-order functions. This is not to mean that they are only limited to JavaScript alone. O... | muchai_joseph |
1,909,043 | Average City Temperature Calculation Interview Question EPAM | Problem Statement: Average Temperature Calculation You are tasked with implementing a Java... | 0 | 2024-07-02T14:30:38 | https://dev.to/codegreen/average-city-temperature-calculation-interview-question-epam-ldd | java, collections, epam, coding | ##Problem Statement: Average Temperature Calculation
You are tasked with implementing a Java method that calculates and prints the average temperature for each city from given arrays of cities and temperatures.
Constraints:
You are provided with two arrays:
`String[] cities`: An array where each element represents t... | manishthakurani |
1,909,042 | How does Kalajadu removal function differently from other methods of spiritual clearing | Introduction: The issue of Kalajadu removal resonates deeply with many cultures and belief systems... | 0 | 2024-07-02T14:29:39 | https://dev.to/astrologer_sharma_53a12bd/how-does-kalajadu-removal-function-differently-from-other-methods-of-spiritual-clearing-3ck0 | Introduction:
The issue of [Kalajadu removal](https://www.bestpsychichealers.com/) resonates deeply with many cultures and belief systems throughout the world. In order to understand how it differents from other methods of spiritual clearing, it is necessary to examine its principles, practices, and cultural contexts.... | astrologer_sharma_53a12bd | |
1,909,030 | Automating User and Group Creation Using Bash script | Automating the creation of users and groups can help with administrative tasks and ensure adequate... | 0 | 2024-07-02T14:29:39 | https://dev.to/adebimpe_peter_285cdfed0c/automating-user-and-group-creation-using-bash-script-a00 | bash, linux | Automating the creation of users and groups can help with administrative tasks and ensure adequate consistency across systems. This demonstrates how to create a Bash script that reads user and group information from a file and processes it accordingly.
**Below is a Bash script that reads from a file called users.txt, ... | adebimpe_peter_285cdfed0c |
1,909,041 | Gone in 120 seconds | This article was originally published on the Resourcely blog, and is guest-written by Haoxi... | 0 | 2024-07-02T14:25:44 | https://dev.to/resourcely/gone-in-60-seconds-3gcl | security, cybersecurity, hacks | This article was [originally published](https://www.resourcely.io/post/cloud-exfil-speed) on the Resourcely blog, and is guest-written by Haoxi Tan.
There's been a significant increase in the number of SaaS and cloud based data breaches, from [API abuse](https://www.bleepingcomputer.com/news/security/trello-api-abused... | csreuter |
1,908,740 | Automating User and Group Management in Linux with a Bash Script | Let's make your manual and tedious repetitive task of creating users and groups for new employees... | 0 | 2024-07-02T14:23:56 | https://dev.to/afolabi_harfoh/automating-user-and-group-management-in-linux-with-a-bash-script-2d8f | linux, devops, automation | Let's make your manual and tedious repetitive task of creating users and groups for new employees interesting with bash scripting to boost your productivity as a SysOps Engineer.
Before we get into the task, this take was made possible by the HNG Internship, HNG is a prestigious program designed to empower young devel... | afolabi_harfoh |
1,909,040 | Access to Large Language Models via API from the Control panel! | We've launched a new service: now you can access large language models (LLM) via API directly from... | 0 | 2024-07-02T14:21:38 | https://dev.to/serverspace/access-to-large-language-models-via-api-from-the-control-panel-2de5 | cloud, cloudcomputing, gpt, llm | We've launched a new service: now you can access large language models ([LLM](https://serverspace.us/services/serverspace-gpt-api/)) via API directly from your control panel. Multiple use cases:
— **Automate customer support:** get accurate answers to user queries.
— **Create content:** generate articles and promotion... | serverspace |
1,909,034 | Unhandled Error during execution of scheduler flush. | Windows 11 Microsoft Edge v126.0.2592.81 Vue3 3.4.27 I have two vuetify select components... | 0 | 2024-07-02T14:18:36 | https://dev.to/keyboardkowboy/unhandled-error-during-execution-of-scheduler-flush-9a | vue | Windows 11
Microsoft Edge v126.0.2592.81
Vue3 3.4.27
I have two vuetify select components interacting with each other with a method, like so:
```
<v-select v-model="selectCountry"
:items="dataCountries"
@update:modelValue="selectedCountry"
item-title="title"
item-value="value"
label="Countries"
... | keyboardkowboy |
1,908,031 | daisyUI adoption guide: Overview, examples, and alternatives | Written by David Omotayo✏️ daisyUI is an open source component library built on top of Tailwind CSS.... | 0 | 2024-07-02T14:18:29 | https://blog.logrocket.com/daisyui-adoption-guide | daisyui, webdev | **Written by [David Omotayo](https://blog.logrocket.com/author/davidomotayo/)✏️**
daisyUI is an open source component library built on top of Tailwind CSS. It’s designed to enhance the development experience for web designers and developers.
In this adoption guide, we’ll explore the origins of daisyUI, its purpose, ... | leemeganj |
1,909,033 | Top Free OCR Receipt Parser APIs, and Open Source models | What is Receipt Parser API? Receipt Parser is a technology that extracts and digitizes... | 0 | 2024-07-02T14:14:03 | https://www.edenai.co/post/top-free-ocr-receipt-parser-apis-and-open-source-models | ai, api, opensource | ## What is [Receipt Parser API](https://www.edenai.co/feature/ocr-receipt-parsing-apis?referral=top-free-receipt-parser-apis-and-open-source-models)?
[Receipt Parser](https://www.edenai.co/feature/ocr-receipt-parsing-apis?referral=top-free-receipt-parser-apis-and-open-source-models) is a technology that extracts and di... | edenai |
1,909,032 | Anthony Pompliano on AI and Bitcoin: Catalysts for Wealth Creation | Artificial intelligence and blockchain have become key players in the transformation of various... | 0 | 2024-07-02T14:13:59 | https://36crypto.com/anthony-pompliano-on-ai-and-bitcoin-catalysts-for-wealth-creation/ | cryptocurrency, blockchain, ai, news |
Artificial intelligence and blockchain have become key players in the transformation of various spheres of life. In particular, the intersection of these two technologies has long been discussed by leading opinion leaders in the crypto industry. Recently, Anthony Pompliano, a well-known investor and founder of Pomp In... | hryniv_vlad |
1,909,031 | Unearthing Efficiency: My Experience Bug Hunting with SAW | Scrape Any Website (SAW) promises to be a powerful tool for web data extraction. But as with any... | 0 | 2024-07-02T14:13:56 | https://dev.to/marg4cf3553b4099/unearthing-efficiency-my-experience-bug-hunting-with-saw-4h37 | Scrape Any Website (SAW) promises to be a powerful tool for web data extraction. But as with any software, a keen eye can uncover areas for improvement. This blog post details my exploration of SAW, highlighting the bugs I encountered and suggesting potential solutions.
## Exploratory Testing: Delving into SAW's Funct... | marg4cf3553b4099 | |
1,909,029 | ## Supercharge Your Coding with Codebot: An AI-Powered Assistant 🚀 | Hello Dev.to community! 👋 I'm excited to introduce Codebot, an AI-driven code assistant designed to... | 0 | 2024-07-02T14:13:26 | https://dev.to/aviralgarg05/-supercharge-your-coding-with-codebot-an-ai-powered-assistant-2l0a | javascript, github, ai, llm | Hello Dev.to community! 👋
I'm excited to introduce **[Codebot](https://github.com/aviralgarg05/Codebot)**, an AI-driven code assistant designed to enhance your coding experience. Let's dive into what makes Codebot so awesome and how it can help you write better code faster.
### What is Codebot? 🤖
Codebot is a powe... | aviralgarg05 |
1,909,028 | Automating User Account Management in Linux with a Bash Script | User Management is an integral part of a Sys Ops Engineer, as this is useful in day-to-day activity.... | 0 | 2024-07-02T14:12:40 | https://dev.to/hollyphat/automating-user-account-management-in-linux-with-a-bash-script-248n | automation, hng11, bash | User Management is an integral part of a Sys Ops Engineer, as this is useful in day-to-day activity. This is usually required when onboarding new members of staff. In this piece, we will go through the process of creating and assigning new users.
This is part of HNG Internship requirements. You can learn more about HN... | hollyphat |
1,909,025 | A Comprehensive Guide to NumPy with Python 🐍🎲 | NumPy, short for Numerical Python, is a fundamental package for scientific computing in Python. It... | 0 | 2024-07-02T14:09:05 | https://dev.to/kammarianand/a-comprehensive-guide-to-numpy-with-python-2mc9 | python, numpy, datascience, beginners |
NumPy, short for Numerical Python, is a fundamental package for scientific computing in Python. It provides support for arrays, matrices, and many mathematical functions. If you're working with data in Python, understanding NumPy is essential. In this post, we'll explore the basics of NumPy and dive into various exam... | kammarianand |
1,909,024 | React VS Vue | HNG internship | Introduction React and Vue are two of the most popular JavaScript frameworks. Both have unique... | 0 | 2024-07-02T14:08:30 | https://dev.to/clarenceg01/react-vs-vue-hng-internship-209e | webdev, react, javascript, programming | **Introduction**
React and Vue are two of the most popular JavaScript frameworks. Both have unique strengths and weaknesses and choosing either of the two to use in a project can be difficult. This article aims to help developers make an informed choice.
**React**
React is a JavaScript library developed and maintained... | clarenceg01 |
1,909,023 | How to Drive Traffic to Your Website | How to Drive Traffic to Your Website: A Comprehensive Guide Driving traffic to your... | 0 | 2024-07-02T14:07:39 | https://dev.to/sh20raj/how-to-drive-traffic-to-your-website-3m68 | webdev, javascript, beginners, programming | ### How to Drive Traffic to Your Website: A Comprehensive Guide
Driving traffic to your website is crucial for increasing brand awareness, generating leads, and achieving your business goals. With so many platforms and strategies available, it's essential to utilize a combination of methods to attract visitors effecti... | sh20raj |
1,909,020 | Automating Linux User Creation with Bash Script | Managing users and groups on a Linux system can be a complex and time-consuming task, especially in... | 0 | 2024-07-02T14:03:07 | https://dev.to/codereaper0/automating-linux-user-creation-with-bash-script-3p3 | Managing users and groups on a Linux system can be a complex and time-consuming task, especially in environments with frequent changes. Automation can significantly simplify this process, ensuring consistency and saving valuable time. In this article, we will walk through the implementation of a Bash script that automa... | codereaper0 | |
1,905,141 | writing my first mentoring plan | I've recently got into a career mentoring program with my local JuniorDev community which runs for 2... | 0 | 2024-07-02T14:02:58 | https://dev.to/ohchloeho/writing-my-first-mentoring-plan-1bpo | career, mentorship, networking | I've recently got into a career mentoring program with my local JuniorDev community which runs for 2 months with check-ins every 2 weeks. Being a mentee, I thought it would be helpful for both my mentors and I to list what I want to learn from them and what I want to achieve at the end of the program.
## 1. Embodying ... | ohchloeho |
1,881,459 | Are you a Beginner, Intermediate or Expert Programmer? | That is a good question is it not? That is something I have been struggling to figure out. I have... | 0 | 2024-07-02T14:00:00 | https://dev.to/anitaolsen/are-you-a-beginner-intermediate-or-expert-programmer-2p8m | discuss | That is a good question is it not? That is something I have been struggling to figure out.
I have been wondering for a while if I am still a beginner or at least moving towards being intermediate? I am pretty sure I am not an expert as many things are still very difficult for me (if not too difficult?!) and I feel at... | anitaolsen |
1,909,019 | Comparing ReactJS and Vue.js: A Comprehensive Guide | In the ever-changing world of web development, choosing the correct front-end technology can be... | 0 | 2024-07-02T13:58:09 | https://dev.to/nicholchuks/comparing-reactjs-and-vuejs-a-comprehensive-guide-5a4a | In the ever-changing world of web development, choosing the correct front-end technology can be critical to a project's success. ReactJS and Vue.js have become two of the most well-liked and potent JavaScript frameworks out of all accessible options. The purpose of this post is to assist developers in making informed d... | nicholchuks | |
1,908,752 | Automating User Creation and Management with a Bash Script | As a SysOps engineer, automating user creation and management is essential for maintaining system... | 0 | 2024-07-02T13:56:51 | https://dev.to/powei_erewejoh_1b18d805c2/automating-user-creation-and-management-with-a-bash-script-2ib2 | As a SysOps engineer, automating user creation and management is essential for maintaining system efficiency and security, especially when onboarding new developers. This article presents a robust Bash script to read a text file with usernames and group names, create the necessary users and groups, set up home director... | powei_erewejoh_1b18d805c2 | |
1,909,018 | What are the security best practices you follow when developing a Drupal website? | Ensuring the security of a Drupal website is paramount given the frequent cyber threats and... | 0 | 2024-07-02T13:55:32 | https://dev.to/chariesdevil/what-are-the-security-best-practices-you-follow-when-developing-a-drupal-website-1i52 | drupal, website, development, hire | Ensuring the security of a Drupal website is paramount given the frequent cyber threats and vulnerabilities that can affect web applications. Following best practices in Drupal development helps protect the site, its data, and its users.
**Here are the key security best practices for developing a secure Drupal websit... | chariesdevil |
1,909,017 | Is Operating a Adult Webcam Business Legal? | In recent years, the adult webcam industry has seen substantial growth, offering lucrative... | 0 | 2024-07-02T13:53:32 | https://dev.to/scarlettevans09/is-operating-a-adult-webcam-business-legal-13i | In recent years, the adult webcam industry has seen substantial growth, offering lucrative opportunities for entrepreneurs interested in online entertainment. However, the legality and complexities surrounding operating a webcam business can vary widely depending on jurisdiction and compliance with legal regulations.
... | scarlettevans09 | |
1,909,016 | -Event delegation, Event propagtion, Bubling, Capturing | Stop Propagation - | 0 | 2024-07-02T13:53:14 | https://dev.to/husniddin6939/-event-delegation-event-propagtion-bubling-capturing-mf3 | 1. Stop Propagation -
| husniddin6939 | |
1,909,009 | Things to Expect from a System | Every System out there which serves a purpose, have all this. Leaders are those, who actively... | 0 | 2024-07-02T13:52:06 | https://dev.to/paihari/things-to-expect-from-a-system-590c | nfr, systemofrecords, systemofengagement |
Every System out there which serves a purpose, have all this.
Leaders are those, who actively identify, adapt and even change before the due time.
**Performance:** The speed at which a system operates and processes data, including response time, throughput, and latency.
**Reliability:**The ability of a system to ... | paihari |
1,909,014 | How Much Does AI Cost? Exploring Pricing Factors and Implementation Types | AI has revolutionized the world, promising giant breakthroughs everywhere. Many businesses dream of... | 0 | 2024-07-02T13:51:06 | https://dev.to/devler_io/how-much-does-ai-cost-exploring-pricing-factors-and-implementation-types-e8f | webdev, ai | AI has revolutionized the world, promising giant breakthroughs everywhere. Many businesses dream of repeating the success of #ChatGPT, 🧐 but there is one simple question to answer:
What’s the price, and is the game worth a candle? 🤔
You may be surprised that simple #AI models cost as little as $5,000. It’s not suc... | devler_io |
1,907,492 | Data Organisation: Ensuring data quality in backend systems | When it comes to backend development, one of the biggest challenges we face is managing the issues... | 0 | 2024-07-02T13:46:57 | https://dev.to/blessingtutka/data-organisation-ensuring-data-quality-in-backend-systems-380b | backend, data, database, performance | When it comes to backend development, one of the biggest challenges we face is managing the issues that arise from disorganized data. In the world of backend development, data is king. It's the fuel that powers our applications, providing the information that drives the user experience. This data before it becomes the ... | blessingtutka |
1,909,011 | Effortless Image Uploads in React Using ImageKit | It's good Imagekit is an amazing and easy-to-use tool that streamlines the process... | 0 | 2024-07-02T13:46:28 | https://dev.to/leg_end/effortless-image-uploads-in-react-using-imagekit-hoh | javascript, webdev, softwaredevelopment, programming | ## It's good
[Imagekit](https://imagekit.io/) is an amazing and easy-to-use tool that streamlines the process of:
1. Managing both videos and images
2. Work with various storage locations
3. Manipulate digital assets
## In React project
[Integrating ImageKit](https://imagekit.io/docs/integration/react#setup-imagekit-... | leg_end |
1,909,010 | Waakif Technologies Private Limited | Waakif Technologies Private Limited: Unleash the Power of AI to Transform Your Customer... | 0 | 2024-07-02T13:45:13 | https://dev.to/waakif/waakif-technologies-private-limited-1145 | ai, digitalworkplace | **[Waakif Technologies Private Limited](https://www.waakif.com/)**: Unleash the Power of AI to Transform Your Customer Experience
Transform customer churn into explosive growth. Waakif, your AI-powered business partner, empowers you to skyrocket retention and triple customer engagement. Through intelligent automation... | waakif |
1,909,006 | Bar Programming #03 — Clean Code Chapter 1 | In the today post, I will write a resume of what I learn and understood about the first chapter of... | 0 | 2024-07-02T13:41:22 | https://dev.to/samoht/bar-programming-03-clean-code-chapter-1-39d6 | beginners, learning | In the today post, I will write a resume of what I learn and understood about the first chapter of “Clean Code”, probably I will write more texts like this about the other chapters. So, if you have interest in Clean Code or want to understand a little about, you are more than welcome to continue reading this possible s... | samoht |
1,909,005 | Cleaning Fairies VA Expert Cleaning Services in North Virginia. | A clean home is a happy home! Cleaning Fairies provides top-rated cleaning services across Virginia,... | 0 | 2024-07-02T13:40:54 | https://dev.to/cleaningfairiesva/cleaning-fairies-va-expert-cleaning-services-in-north-virginia-42gb | cleaning, cleaningfairiesva, cleaningservices, northvirginia | A clean home is a happy home! Cleaning Fairies provides top-rated cleaning services across Virginia, including home cleaning services, residential cleaning, move-out cleaning, and commercial cleaning. We take the stress out of keeping your space spotless so you can focus on what matters most. Get a free quote today.
| cleaningfairiesva |
1,909,002 | Content Projection Fallback in ng-content in Angular | Introduction In this blog post, I want to describe a new Angular 18 feature called content... | 27,826 | 2024-07-02T13:38:46 | https://www.blueskyconnie.com/content-projection-fallback-with-ng-content-in-angular-18/ | angular, tutorial | ##Introduction
In this blog post, I want to describe a new Angular 18 feature called content projection fallback in ng-content. When content exists between the ng-content opening and closing tags, it becomes the fallback value. When projection does not occur, the fallback value is displayed.
###Bootstrap Application
... | railsstudent |
1,897,279 | Merging Startup.cs and Program.cs in .NET 8: A Simplified Approach | As .NET evolves, so does the way we structure our applications. One notable change introduced in... | 0 | 2024-07-02T13:38:05 | https://www.webscope.io/blog/merging-startup.cs-and-program.cs-in-.net-8-a-simp | As .NET evolves, so does the way we structure our applications. One notable change introduced in recent versions of .NET is the ability to merge `Startup.cs` and `Program.cs` into a single file. This approach streamlines the setup process, making it more cohesive and manageable. This article will discuss the rationale ... | manhhungtran | |
1,909,004 | Implementing Pinia for Efficient State Management in Nuxt.js Online Stores | Check this post in my web notes! In this article, we will talk about the Pinia store for Nuxt.js... | 27,540 | 2024-07-02T13:35:12 | https://webcraft-notes.com/blog/implementing-pinia-for-efficient-state-management-in | nuxt, vue, javascript, tutorial |

> Check [this post](https://webcraft-notes.com/blog/implementing-pinia-for-efficient-state-management-in) in [my web notes](https://webcraft-notes.com/blog/)... | webcraft-notes |
1,909,003 | Journey to Backend Development | Having been a frontend developer for years, transitioning to backend development was a bit of a... | 0 | 2024-07-02T13:35:03 | https://dev.to/nifilat/journey-to-backend-development-4pla | Having been a frontend developer for years, transitioning to backend development was a bit of a struggle, but a fun one.
I started my journey in tech by learning Python, and it always stuck with me. That's why there was no surprise when I decided to choose Django as the backend framework I wanted to learn.
Starting o... | nifilat |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.