
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,909,657 | Navigating the Maze: Exploring Cybersecurity Certifications (OSCP, CEH, CISSP) | The cybersecurity landscape demands a skilled workforce equipped with the right knowledge and... | 0 | 2024-07-03T04:16:50 | https://dev.to/epakconsultant/navigating-the-maze-exploring-cybersecurity-certifications-oscp-ceh-cissp-3gmn | The cybersecurity landscape demands a skilled workforce equipped with the right knowledge and certifications. This article delves into three prominent certifications – OSCP (Offensive Security Certified Professional), CEH (Certified Ethical Hacker), and CISSP (Certified Information Systems Security Professional) – help... | epakconsultant | |
1,909,654 | Unveiling the Arsenal: Exploring Essential Cybersecurity Tools | In the ever-evolving landscape of cybersecurity, having the right tools at your disposal is... | 0 | 2024-07-03T04:10:45 | https://dev.to/epakconsultant/unveiling-the-arsenal-exploring-essential-cybersecurity-tools-3e0d | cybersecurity | In the ever-evolving landscape of cybersecurity, having the right tools at your disposal is paramount. This article delves into four powerful tools – Metasploit, Burp Suite, Nmap, and Wireshark – exploring their functionalities and highlighting their applications in ethical hacking and vulnerability assessments. Rememb... | epakconsultant |
1,909,595 | Graphql Fundamental | GraphQL provides a complete and understandable description of the API, including both "API endpoints"... | 27,944 | 2024-07-03T04:07:28 | https://dev.to/jacktt/graphql-fundamental-236k | graphql | GraphQL provides a complete and understandable description of the API, including both "API endpoints" and response data schema.
It empowers clients to request exactly what they need, ensuring that the server returns only the requested fields instead of a fixed response schema in RESTful API.
To do that, GraphQL decla... | jacktt |
1,909,652 | Simplifying Tag Management: Unveiling the Benefits of Google Tag Manager | Juggling multiple marketing and analytics tags on your website can be a tedious task. Enter Google... | 0 | 2024-07-03T04:05:52 | https://dev.to/epakconsultant/simplifying-tag-management-unveiling-the-benefits-of-google-tag-manager-13d1 | gtm | Juggling multiple marketing and analytics tags on your website can be a tedious task. Enter Google Tag Manager (GTM), a free tool that simplifies tag management, streamlines workflows, and empowers you to optimize your website's performance. This article delves into the core functionalities of GTM and explores the nume... | epakconsultant |
1,909,650 | Installing Canvas LMS: A Step-by-Step Guide for Different Systems | Canvas LMS, a popular learning management system, empowers educators and institutions to create... | 0 | 2024-07-03T04:01:31 | https://dev.to/epakconsultant/installing-canvas-lms-a-step-by-step-guide-for-different-systems-2l67 | Canvas LMS, a popular learning management system, empowers educators and institutions to create engaging online learning experiences. But before diving into its functionalities, installing Canvas LMS on your system is the first crucial step. This guide explores the installation process for different operating systems, ... | epakconsultant | |
1,909,649 | Optimization + Tuning Spark | Other Issues and How to Address Them We have also touched on another very common issue with Spark... | 0 | 2024-07-03T04:00:20 | https://dev.to/congnguyen/optimization-tuning-spark-1dme | **Other Issues and How to Address Them**
We have also touched on another very common issue with Spark jobs that can be harder to address: everything working fine but just taking a very long time. So what do you do when your Spark job is (too) slow?
**Insufficient resources**
Often while there are some possible ways o... | congnguyen | |
1,909,254 | JWT for Developers: Behind the Scenes. | 90% of developers just use the jsonwebtoken library without really understanding what’s happening... | 0 | 2024-07-03T03:58:03 | https://dev.to/andres_fernandez_05a8738d/jwt-for-developers-behind-the-scenes-445p | node, javascript, api, security |
90% of developers just use the jsonwebtoken library without really understanding what’s happening behind the scenes. Be part of the percentage that does. Grab a coffee and enjoy the learning journey ☕🤯.
**Technical definition JWT:**
The Internet Engineering Task Force (IETF) is a globally recognized organization ... | andres_fernandez_05a8738d |
1,909,647 | Learning Conditional Statements in Python | Introduction Conditional statements are an essential part of programming that allows you... | 0 | 2024-07-03T03:53:49 | https://dev.to/davitacols/learning-conditional-statements-in-python-3224 | webdev, python, softwaredevelopment | ## Introduction
Conditional statements are an essential part of programming that allows you to execute certain pieces of code based on specific conditions. In Python, these are typically implemented using `if`, `elif`, and `else` statements. This guide will help you understand how to use these statements effectively.
... | davitacols |
1,909,646 | ROC-AUC Curve in Machine Learning | In machine learning, evaluating the performance of your models is crucial. One powerful tool for this... | 0 | 2024-07-03T03:51:52 | https://dev.to/harsimranjit_singh_0133dc/roc-auc-curve-in-machine-learning-55ig | In machine learning, evaluating the performance of your models is crucial. One powerful tool for this purpose is the ROC-AUC curve. This article will explore what the ROC-AUC curve is, and how it works.
## Understanding the ROC Curve
The ROC curve visually represents the model's performance across all possible classif... | harsimranjit_singh_0133dc | |
1,909,645 | when i was fix the tag i was have loss google toporanking | how to created the SEO Code the SEO Optimize i was just input Head but the content less 1000 word ... | 0 | 2024-07-03T03:49:42 | https://dev.to/athip_duanthana_36ce9ed64/when-i-was-fix-the-tag-i-was-have-loss-google-toporanking-2888 | how to created the SEO Code
the SEO Optimize i was just input Head but the content less 1000 word the Google seacrh only index little word
How i will to fix that
visit mysite
with Keyword [รับทำ SEO](https://www.allconnective.com/) [บริษัททำSEO ](https://www.allconnective.com/).... | athip_duanthana_36ce9ed64 | |
1,909,644 | Exploring Leonardo AI: Features, Benefits, and Applications | Artificial intelligence (AI) is rapidly transforming our world, and Leonardo AI is at the forefront... | 0 | 2024-07-03T03:48:34 | https://dev.to/jettliya/exploring-leonardo-ai-features-benefits-and-applications-3ncg | Artificial intelligence (AI) is rapidly transforming our world, and Leonardo AI is at the forefront of this revolution. But what exactly is Leonardo AI, and how does it work? Let's dive in and explore the fascinating world of Leonardo AI.
**Understanding Leonardo AI**
**Origins and Development**
Leonardo AI is a state... | jettliya | |
1,909,643 | Dr. Swati's Dental Clinic: Your Best Choice for Dental Care in Jaipur | Finding the perfect dental clinic can be a daunting task, but if you're looking for the best... | 0 | 2024-07-03T03:44:44 | https://dev.to/drswati12/dr-swatis-dental-clinic-your-best-choice-for-dental-care-in-jaipur-1pbg |

Finding the perfect[ dental clinic](https://drswaticlinic.com/
) can be a daunting task, but if you're looking for the best dentist in Jaipur,[ Dr. Swati's Dental Clinic](https://www.google.com/maps/place/Dr.+Swati... | drswati12 | |
1,909,642 | Migrating data in production (with zero downtime) | When running Reform, we often faced the issue of having to migrate data in our database. We were an... | 0 | 2024-07-03T03:38:24 | https://dev.to/bjorndcode/migrating-data-in-production-with-zero-downtime-29lm | laravel, database, webdev | When running [Reform](https://www.reform.app/), we often faced the issue of having to migrate data in our database. We were an early-stage startup, so we built features as needed. Down the road we ran into scenarios where we realised we hadn’t chosen the correct data model.
The nature of the product (a form builder) m... | bjorndcode |
1,909,640 | Implementing Type-Safe Next.js Server Actions with Zsa: A Comprehensive Guide | In the realm of web development, ensuring type safety and validation is crucial for building robust... | 0 | 2024-07-03T03:27:38 | https://dev.to/vyan/implementing-type-safe-nextjs-server-actions-with-zsa-a-comprehensive-guide-25bn | webdev, nextjs, react, javascript | In the realm of web development, ensuring type safety and validation is crucial for building robust and reliable applications. Next.js, a popular React framework, offers powerful server-side capabilities, but achieving end-to-end type safety can be challenging. Enter the Zsa package, a powerful tool that combines Zod a... | vyan |
1,909,639 | HTTPS: How HTTPS Works - Handshake | What is HTTPS? HTTPS (HyperText Transfer Protocol Secure) is an extension of HTTP and uses... | 0 | 2024-07-03T03:24:26 | https://dev.to/zeeshanali0704/https-how-https-works-handshake-1mjo | systemdesignwithzeeshanali, systemdesign | # What is HTTPS?
HTTPS (HyperText Transfer Protocol Secure) is an extension of HTTP and uses TLS (Transport Layer Security) to encrypt data between the client and server. The HTTPS handshake is a critical part of this process, ensuring that the communication is secure.
### Working of HTTPS Handshake
HTTPS (HyperText... | zeeshanali0704 |
1,909,638 | Working With Time Deltas in Python | This lab guides you through the process of working with time deltas in Python using the pandas library. A time delta represents a duration or difference in time. We will explore different ways to construct, manipulate, and operate on time deltas. | 27,675 | 2024-07-03T03:23:13 | https://labex.io/tutorials/python-working-with-time-deltas-65456 | pandas, coding, programming, tutorial |
## Introduction
This lab guides you through the process of working with time deltas in Python using the pandas library. A time delta represents a duration or difference in time. We will explore different ways to construct, manipulate, and operate on time deltas.
### VM Tips
After the VM startup is done, click the t... | labby |
1,909,464 | Azure Blob Storage. | Azure Blob Storage is a service for storing large amount of unstructured object data in the... | 0 | 2024-07-03T03:16:39 | https://dev.to/tojumercy1/azure-blob-storage-1gm8 | azure, stepfunctions, github, softwaredevelopment | ## Azure Blob Storage is a service for storing large amount of unstructured object data in the cloud that doesn't adhere to a particular data model or definition, such as text or binary data. Blob stands for Binary Large Object. Blob storage is also referred to as object storage or container storage.
Task 1: Create a ... | tojumercy1 |
1,909,594 | Is Your Website Penalized by Google? Recovery and Prevention Guide | Google, as the world's biggest search engine, is key to driving traffic to your website through... | 0 | 2024-07-03T03:09:11 | https://dev.to/juddiy/is-your-website-penalized-by-google-recovery-and-prevention-guide-21db | website, seo, learning, google | Google, as the world's biggest search engine, is key to driving traffic to your website through search result rankings. But sometimes, websites can get penalized for breaking Google's rules, which can really hurt their ranking and visibility. Here are some signs that might indicate your website has been penalized by Go... | juddiy |
1,909,593 | Is Your Website Penalized by Google? Recovery and Prevention Guide | Google, as the world's biggest search engine, is key to driving traffic to your website through... | 0 | 2024-07-03T03:09:00 | https://dev.to/juddiy/is-your-website-penalized-by-google-recovery-and-prevention-guide-38l2 | website, seo, learning, google | Google, as the world's biggest search engine, is key to driving traffic to your website through search result rankings. But sometimes, websites can get penalized for breaking Google's rules, which can really hurt their ranking and visibility. Here are some signs that might indicate your website has been penalized by Go... | juddiy |
1,909,592 | PCI-E SSD | PCIe SSDs (Peripheral Component Interconnect Express Solid State Drives) represent the pinnacle of... | 0 | 2024-07-03T03:08:44 | https://dev.to/pciessd/pci-e-ssd-2fd | PCIe SSDs (Peripheral Component Interconnect Express Solid State Drives) represent the pinnacle of high-speed data storage technology, offering unparalleled performance for both consumer and enterprise applications. Leveraging the PCIe interface, these SSDs deliver exceptional data transfer speeds and significantly low... | pciessd | |
1,909,591 | Spinning Hyperbolic Vortex | Check out this Pen I made! | 0 | 2024-07-03T03:00:57 | https://dev.to/dan52242644dan/spinning-hyperbolic-vortex-4jf8 | codepen, webdev, beginners, ai | Check out this Pen I made!
{% codepen https://codepen.io/Dancodepen-io/pen/jOoZovB %} | dan52242644dan |
1,909,589 | Sistemas Operacionais: FIFO | Os sistemas operacionais são a espinha dorsal de qualquer computador, gerenciando hardware e software... | 0 | 2024-07-03T02:54:01 | https://dev.to/iamthiago/sistemas-operacionais-fifo-4ebo | Os sistemas operacionais são a espinha dorsal de qualquer computador, gerenciando hardware e software para garantir que tudo funcione de maneira eficiente e eficaz. Um dos conceitos fundamentais no gerenciamento de processos e recursos é o FIFO, que significa "First In, First Out" (Primeiro a Entrar, Primeiro a Sair). ... | iamthiago | |
1,909,588 | What Chat GPT thought of me over the entire time I used it at work. | Nowadays, the questions that a person asks also become a criterion for his assessment. After all, by... | 0 | 2024-07-03T02:52:51 | https://dev.to/mibii/what-chat-gpt-thought-of-me-over-the-entire-time-i-used-it-at-work-pdk | resume, chatgpt | Nowadays, the questions that a person asks also become a criterion for his assessment. After all, by the understanding a person demonstrates in his question on a topic that interests him, you can also say a lot about a person. I found it interesting what Chat GPT thought of me over the entire time I used it at work. ... | mibii |
1,909,129 | Testing SAW (Scrape Any Website | SAW, which stands for Scrape Any Website, is a Windows application designed to facilitate web... | 0 | 2024-07-02T16:38:10 | https://dev.to/dorcasbd/testing-saw-scrape-any-website-4p57 | testing, saw, qualityassurance, webdev |
SAW, which stands for Scrape Any Website, is a Windows application designed to facilitate web scraping tasks. It allows users to scrape and extract data from various websites efficiently, providing a user-friendly interface for organizing and gathering information from the web.
**Key Features of SAW**
- User-Friendl... | dorcasbd |
1,909,587 | Formik vs. React Hook Form | Forms are crucial components of web applications. Information is mostly gotten from users using... | 0 | 2024-07-03T02:52:21 | https://dev.to/abelotegbola/formik-vs-react-hook-form-3dcj | Forms are crucial components of web applications. Information is mostly gotten from users using forms. Usually, Building interactive and engaging online apps requires developers to create forms that are both efficient and easy to use. React provides libraries that facilitate the handling of forms.
Two well-known Rea... | abelotegbola | |
1,909,584 | Set GitHub Actions timeout-minutes | In this article I introduce a GitHub Actions' setting timeout-minutes and tools related to... | 0 | 2024-07-03T02:46:43 | https://dev.to/suzukishunsuke/set-github-actions-timeout-minutes-1jkk | In this article I introduce a GitHub Actions' setting `timeout-minutes` and tools related to `timeout-minutes`.
- What's timeout-minutes?
- Why should you set timeout-minutes?
- Linters to enforce timeout-minutes
- A command line tool to set timeout-minutes to all GitHub Actions jobs
- Set timeout-minutes to your all ... | suzukishunsuke | |
1,909,583 | Issue with NPM Package Installing Globally | I was not able to install npm packages globally in mac os(using npm install -g), but able to install... | 0 | 2024-07-03T02:36:34 | https://dev.to/kiranuknow/issue-with-npm-package-installing-globally-cgi | node, npm, nodemodules |
I was not able to install npm packages globally in mac os(using npm install -g), but able to install locally in the project. Installing locally in every project will increase the total node_modules folder size and for every project we need to install the same packages that will be tedious and unnecessary.
Here are th... | kiranuknow |
1,909,581 | Exploring the Power of Python and Object-Oriented Programming | Python, a versatile and widely-used programming language, is known for its simplicity and... | 0 | 2024-07-03T02:33:53 | https://dev.to/minorpianokeys/exploring-the-power-of-python-and-object-oriented-programming-4ai3 |
Python, a versatile and widely-used programming language, is known for its simplicity and readability. One of its most powerful features is its support for Object-Oriented Programming (OOP). OOP is a programming paradigm that uses objects and classes to structure software programs. It allows developers to create modul... | minorpianokeys | |
1,909,580 | User Management Automation in Linux Using Bash Script | Scenario As a SysOps engineer, you have been tasked to write a bash script that creates... | 0 | 2024-07-03T02:27:10 | https://dev.to/sarahligbe/user-management-automation-in-linux-using-bash-script-197l | bash, automation, linux, devops | ## Scenario
As a SysOps engineer, you have been tasked to write a bash script that creates Users, Groups, and home directories with appropriate permissions for new employees in your company.
This article will walk you through writing the bash script to automate the process of creating users and groups in a Linux syste... | sarahligbe |
1,909,578 | Figma launches new AI features | Stability AI lands a lifeline from Sean Parker, Greycroft Stability AI secured new funding... | 0 | 2024-07-03T02:26:34 | https://aisnapshot.beehiiv.com/p/figma-launches-new-ai-features | ai, news, programming, python | ## Stability AI lands a lifeline from Sean Parker, Greycroft
Stability AI secured new funding from notable investors like Sean Parker and Greycroft, amid financial difficulties and leadership changes. The startup behind the image-generating model Stable Diffusion has struggled with cash flow and mounting operational co... | ai-snapshot |
1,909,577 | Hello | Hi, I'm Mike Selva, I am a Self-Learning Full Stack Developer, I am 17 years old now. I have been... | 0 | 2024-07-03T02:26:08 | https://dev.to/mikeselva123/hello-35kn | Hi, I'm Mike Selva, I am a Self-Learning Full Stack Developer, I am 17 years old now. I have been coding for over two weeks,
I have joined Github and am Creating, editing and updating my projects,
You can find my own GitHub at [My Github Account](https://github.com/mikeselva123)
Well,
See you next time,
Bye | mikeselva123 | |
1,909,575 | CERTIFIED RECOVERY SPECIALIST // CONSULT DIGITAL WEB RECOVERY | As a German citizen residing in Western Australia, I found myself embroiled in a harrowing ordeal... | 0 | 2024-07-03T02:22:01 | https://dev.to/margaret_dalley_cabfa4fa2/certified-recovery-specialist-consult-digital-web-recovery-4h4f | As a German citizen residing in Western Australia, I found myself embroiled in a harrowing ordeal stemming from a devastating loss in my crypto investments. In 2021, at the age of 28, I encountered a distressing setback when the value of my investments plummeted due to what was purported to be the result of COVID-19 de... | margaret_dalley_cabfa4fa2 | |
1,909,574 | Seamless Automation: Integrating Vacuum Cylinders into Production Lines | Pros of using Vacuum Cylinders in Automation Automation is becoming more and popular for simplifying... | 0 | 2024-07-03T02:20:49 | https://dev.to/katie_abrahamkqjagsa_759/seamless-automation-integrating-vacuum-cylinders-into-production-lines-4plg | vacuumcylinder | Pros of using Vacuum Cylinders in Automation
Automation is becoming more and popular for simplifying work processes to improve productivity in this modern era. What companies want to do is keep operations in the wheelhouse, improve efficiency and put more of an emphasis on work safety. The inclusion of vacuum cylinder... | katie_abrahamkqjagsa_759 |
1,909,552 | Leetcode Day 2: Palindrome Number Explained | The problem is as follows: Given an integer x, return true if x is a palindrome, and false... | 0 | 2024-07-03T02:19:12 | https://dev.to/simona-cancian/leetcode-day-2-palindrome-number-377i | leetcode, python, beginners, codenewbie | The problem is as follows:
Given an integer `x`, return `true` if `x` is a **palindrome**, and `false` _otherwise_.
Example 1:
```
Input: x = 121
Output: true
Explanation: 121 reads as 121 from left to right and from right to left.
```
Example 2:
```
Input: x = -121
Output: false
Explanation: From left to right, it r... | simona-cancian |
1,909,551 | Day 1: Error: "Module not found: Error: Can't resolve '@angular/core'" | Scenario: This error often occurs when you try to run your Angular application after... | 0 | 2024-07-03T02:16:14 | https://dev.to/dipakahirav/day-1-error-module-not-found-error-cant-resolve-angularcore-2il0 | angular, webdev, javascript, errors |
#### Scenario:
This error often occurs when you try to run your Angular application after installing or upgrading Angular packages and it can't find the `@angular/core` module.
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?sub_confirmation=1
) to support my channel and get more we... | dipakahirav |
1,909,549 | NoInfer in Typescript 5.4 | I introduce NoInfer which is new feature in TypeScript 5.4. What is NoInfer? NoInfer is a feature in... | 0 | 2024-07-03T02:12:35 | https://dev.to/makoto0825/noinfer-in-typescript-54-4k72 | I introduce NoInfer which is new feature in TypeScript 5.4.
**What is NoInfer?**
NoInfer is a feature in TypeScript that suppresses type inference. For example, we have following the code.
```typescript
const func1 = <T extends string>(array: T[], searchElement: T) => {
return array.indexOf(searchElement);
};
con... | makoto0825 | |
1,909,547 | LED transparent screen: visual revolution and technological breakthrough in the new era | With the continuous advancement of technology and the growing market demand, LED transparent screens... | 0 | 2024-07-03T02:09:00 | https://dev.to/sostrondylan/led-transparent-screen-visual-revolution-and-technological-breakthrough-in-the-new-era-5gh6 | led, transparent, screen | With the continuous advancement of technology and the growing market demand, [LED transparent screens](https://sostron.com/products/crystal-transparent-led-screen/) stand out in the advertising and display fields with their unique advantages. This article will explore in depth the core competitive advantages of LED tra... | sostrondylan |
1,909,303 | Git and GitHub Explained Like You're Five | Imagine that you have an application or a project folder. And you want to collaborate with other... | 0 | 2024-07-03T02:06:00 | https://dev.to/thekarlesi/git-and-github-explain-like-youre-five-2c2p | webdev, beginners, programming, tutorial | Imagine that you have an application or a project folder. And you want to collaborate with other people on that project.
Or imagine that you have your application, and you uploaded some new code into your application. You added a new feature for example.
And now your application breaks.
Let's say your application is... | thekarlesi |
1,909,546 | Pressure Infusion Bags: Enhancing Medical Care with Reliable Suppliers | Do you know just what a Pressure Infusion Bag is? It's a bag that is unique will help experts which... | 0 | 2024-07-03T02:04:38 | https://dev.to/katie_abrahamkqjagsa_759/pressure-infusion-bags-enhancing-medical-care-with-reliable-suppliers-2m88 | infusionbag |
Do you know just what a Pressure Infusion Bag is? It's a bag that is unique will help experts which can be medical medicine and fluids to patients faster and more safely. Pressure infusion bag are created by special companies called manufacturers who make sure they are good quality and safe to use
Benefits:
... | katie_abrahamkqjagsa_759 |
1,909,536 | Linux User Creation With Bash Script | Introduction Managing users and groups in a Unix-like operating system can be a tedious... | 0 | 2024-07-03T02:00:16 | https://dev.to/daniaernest/linux-user-creation-with-bash-script-46ec | devops, linux, bash | ## Introduction
Managing users and groups in a Unix-like operating system can be a tedious task, especially when dealing with multiple users. To simplify this process, we can use a Bash script to automate the creation of users and groups, set up home directories, generate random passwords, and log all actions. This blo... | daniaernest |
1,909,542 | Top ShowdownJS Extensions and Their Usage | Top 20 ShowdownJS Extensions and Their Usage ShowdownJS is a powerful Markdown to HTML... | 0 | 2024-07-03T01:41:23 | https://dev.to/sh20raj/top-showdownjs-extensions-and-their-usage-18an | showdownjs, extensions, javascript, webdev | ## Top 20 ShowdownJS Extensions and Their Usage
ShowdownJS is a powerful Markdown to HTML converter. To extend its capabilities, developers have created numerous extensions. Here's a comprehensive guide to 20 of the top ShowdownJS extensions, categorized by their functionality.
### Syntax Highlighting
1. **Showdown ... | sh20raj |
1,909,540 | Greetings! | Greetings all. I'm really excited to be here. I'm a new developer, working hard to build up my... | 0 | 2024-07-03T01:37:56 | https://dev.to/bearmsu/greetings-512l | programming, python, learning | Greetings all. I'm really excited to be here. I'm a new developer, working hard to build up my skills. I focus mostly on Python and SQL, but am also learning full-stack web development (HTML, CSS, and JS). I'm really excited to join this community. I'm always looking to learn and never pass up the opportunity get bette... | bearmsu |
1,909,539 | Razor Delivery Service | Razor Delivery Service: The Prescription Delivery Solution! Simplify your pharmacy’s prescription... | 0 | 2024-07-03T01:37:34 | https://dev.to/razordelivery/razor-delivery-service-4l77 | razordeliveryservice, razordelivery, razordeliverynewyorkcity | Razor Delivery Service:
The Prescription Delivery Solution!
Simplify your pharmacy’s prescription delivery process to improve operational efficiency, minimize patient burden & improve drug adherence.
Features:
Delivery Service
We are on time. Always on time. we know the time importance. Faster than you can imagine.... | razordelivery |
1,909,538 | HNG STAGE ZERO: ANALYZING RETAIL SALES DATA AT FIRST GLANCE | Introduction The Kaggle dataset “Sample Sales Data” by Kyanyoga provides a sample dataset... | 0 | 2024-07-03T01:31:53 | https://dev.to/devbassey/hng-stage-zero-analyzing-retail-sales-data-at-first-glance-2gp3 | data, datascience, database, dataengineering | ## Introduction
The Kaggle dataset “[Sample Sales Data](https://www.kaggle.com/datasets/kyanyoga/sample-sales-data?resource=download)” by Kyanyoga provides a sample dataset for sales data analysis. It includes sales data with attributes such as order details, product information, customer details, and geographical data... | devbassey |
1,908,413 | How to use an auto-tiling technique in your next game project | As a game developer, if the thought of hand crafting a level does not appeal to you, then you may... | 0 | 2024-07-03T01:15:10 | https://excaliburjs.com/blog/Autotiling%20Technique | gamedev, typescript, tutorial, algorithms | As a game developer, if the thought of hand crafting a level does not appeal to you, then you may consider looking into procedural generation for your next project. Even using procedural generation, however, you still need to be able to turn your generated map arrays into a tilemap with clean, contiguous walls, and spr... | jyoung4242 |
1,909,520 | 20 Ways to Improve Node.js Performance at Scale 🚀 | Node.js is a powerful platform for building scalable and high-performance applications. However, as... | 0 | 2024-07-03T01:13:48 | https://dev.to/dipakahirav/20-ways-to-improve-nodejs-performance-at-scale-25nf | node, javascript, learning | Node.js is a powerful platform for building scalable and high-performance applications. However, as your application grows, maintaining optimal performance can become challenging. Here are twenty effective strategies to enhance Node.js performance at scale, complete with examples and tips. 💡
please subscribe to my [Y... | dipakahirav |
1,909,519 | 6 Best Database Tools for SQL Server-2024 | In this article, we discuss the 6 best tools: 3 data modeling tools for SQL Server, and 3 for... | 0 | 2024-07-03T01:13:25 | https://dev.to/concerate/8-best-database-tools-for-sql-server-37mh | In this article, we discuss the 6 best tools: 3 data modeling tools for SQL Server, and 3 for creating, testing, and managing SQL Server databases.
**The Best Data Modelers for SQL Server**
Data modeling is analyzing, arranging, and presenting the data, its relationships, and other information. Standard notations are ... | concerate | |
1,900,797 | How to deal with race conditions using Java and PostgreSQL | Using locking to control database concurrency Imagine you are working on an e-commerce... | 0 | 2024-07-03T01:00:59 | https://dev.to/ramoncunha/how-to-deal-with-race-conditions-using-java-and-postgresql-4jk6 | postgres, java, lock, database | ## Using locking to control database concurrency
Imagine you are working on an e-commerce system and thousands of people try to buy the last remaining product at the same time. However, many of them could proceed to the checkout and finish the order. When you check your stock, you have a product with a negative quanti... | ramoncunha |
1,909,513 | Shanghai EMTH Import and Export Co., LTD: Transforming Challenges into Opportunities | Shanghai EMTH Import and Export Co., LTD: Rising In The Face Of Challenges Shanghai EMTH Import and... | 0 | 2024-07-03T00:53:57 | https://dev.to/elsina_edmondqksj_ff4837/shanghai-emth-import-and-export-co-ltd-transforming-challenges-into-opportunities-20i9 | coldroom | Shanghai EMTH Import and Export Co., LTD: Rising In The Face Of Challenges
Shanghai EMTH Import and Export Co., LTD is a popular enterprise, engaged in the production and distribution of an excellent array of aluminum goods such as windows doors curtain walls. The company was able to surpass the odds by using exciting... | elsina_edmondqksj_ff4837 |
1,909,512 | Did You Know You Can Use GitHub to Host Your Site for Free? | In this guide, I'll walk you through how to use GitHub Pages to host your personal website or simple... | 0 | 2024-07-03T00:52:29 | https://asafhuseyn.com/blog/2024/07/03/Did-You-Know-You-Can-Use-GitHub-to-Host-Your-Site-for-Free.html | github, githubpages, githubgist, jekyll |
In this guide, I'll walk you through how to use GitHub Pages to host your personal website or simple blog for free. Based on my experiences, I'll explain the process with examples.
## Contents
1. [What is GitHub Pages?](#what-is-github-pages)
2. [Step 1: Creating a Repository](#step-1-creating-a-repository)
3. [Step... | asafhuseyn |
1,909,466 | Automating Creation of Users and groups using Bash Script (Step-by-Step Guide) | As a DevOps engineer, it is quite a common task to create, update, and delete users and groups.... | 0 | 2024-07-03T00:44:10 | https://dev.to/sudobro/automating-creation-of-users-and-groups-using-bash-script-step-by-step-guide-3dm0 | devops, linux, learning, bash | As a DevOps engineer, it is quite a common task to create, update, and delete users and groups. Automating this process can save a lot of time and help reduce human errors, especially when onboarding numerous users. In this article, I'll walk you through using bash to automate the creation of users and their respective... | sudobro |
1,909,509 | My First Task In HNG Internship | I signup for an internship program named HNG. It is expected that the intern should have an... | 0 | 2024-07-03T00:40:39 | https://dev.to/ik_again/my-first-task-in-hng-internship-12f6 | I signup for an internship program named HNG. It is expected that the intern should have an intermediate to advance experience for any track they wish to participate in. For more information regarding the internship, your can follow this link https://hng.tech/internship and applying for a job at HNG you can also checko... | ik_again | |
1,909,508 | Scraping Twitter comments with selenium(Python): step-by-step guide | In today's world full of data, everyone uses social media to express themselves and contribute to the... | 0 | 2024-07-03T00:40:34 | https://dev.to/david_hdz/scraping-twitter-comments-with-seleniumpython-step-by-step-guide-d51 | selenium, webscraping, automation | In today's world full of data, everyone uses social media to express themselves and contribute to the public voice. This is such valuable information that is just publically available to anyone, you can gather a lot of insights, feedback, and very good advice from this public opinion.
That is why, I bring you this step... | david_hdz |
1,909,507 | Issue 51 of AWS Cloud Security Weekly | (This is just the highlight of Issue 51 of AWS Cloud Security weekly @... | 0 | 2024-07-03T00:34:30 | https://aws-cloudsec.com/p/issue-51 | (This is just the highlight of Issue 51 of AWS Cloud Security weekly @ https://aws-cloudsec.com/p/issue-51 << Subscribe to receive the full version in your inbox weekly for free!!).
**What happened in AWS CloudSecurity & CyberSecurity last week June 20-July 02, 2024?**
- Amazon GuardDuty EC2 Runtime Monitoring eBPF s... | aws-cloudsec | |
1,909,506 | Vault Secret as an External Secret | This guide to help people who are new to Vault create a Kubernetes Secret through Vault There are... | 0 | 2024-07-03T00:34:11 | https://dev.to/tinhtq97/vault-secret-as-an-external-secret-357 | This guide to help people who are new to Vault create a Kubernetes Secret through Vault
There are two ways to use Vault Secret:
- Adding the annotations
- Use External Secret Operator
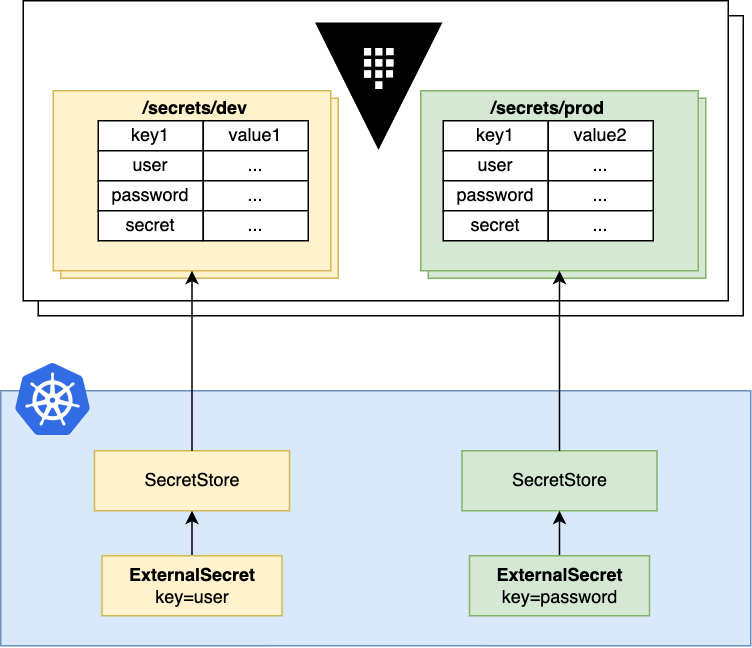*<small>Source: external-secret... | tinhtq97 | |
1,909,505 | Building Interactive Voice Response Systems with Twilio | Introduction Interactive Voice Response (IVR) systems are an essential part of modern... | 0 | 2024-07-03T00:33:08 | https://dev.to/kartikmehta8/building-interactive-voice-response-systems-with-twilio-b7j | javascript, beginners, programming, tutorial | ## Introduction
Interactive Voice Response (IVR) systems are an essential part of modern businesses, allowing customers to interact with a company's automated phone system through voice or touch-tone inputs. With the rise of remote work and digital communication, building IVR systems has become increasingly important ... | kartikmehta8 |
1,909,504 | Data Fetching in Next.js 14: A Comprehensive Guide | Data fetching is a crucial aspect of building robust and dynamic applications. With the release of... | 0 | 2024-07-03T00:27:48 | https://dev.to/usmanghani1518/data-fetching-in-nextjs-14-a-comprehensive-guide-1dc | react, nextjs, javascript, webdev | Data fetching is a crucial aspect of building robust and dynamic applications. With the release of Next.js 14, developers have even more powerful tools at their disposal to fetch data efficiently and seamlessly. In this post, we will explore the various data fetching methods in Next.js 14, complete with examples and be... | usmanghani1518 |
1,909,500 | Another Approach to Screen Routing in SwiftUI | First of all, why custom routing? there are several answers and reasons for implementing custom... | 0 | 2024-07-03T00:18:02 | https://dev.to/mrasyadc/another-approach-to-screen-routing-in-swiftui-42ao | swift, ios | First of all, why custom routing? there are several answers and reasons for implementing custom routing in Swift. from the technical side, implementing custom routing will significantly reduce boilerplate code that tends to be nasty to implement another view from other files. the approach is similar to when we use rout... | mrasyadc |
1,909,499 | Automating User and Group Management with a Bash Script. | Managing users on a Linux system can be a time-consuming task, especially in environments where users... | 0 | 2024-07-03T00:17:01 | https://dev.to/candy-devops/automating-user-and-group-management-with-a-bash-script-2jli | Managing users on a Linux system can be a time-consuming task, especially in environments where users frequently join or leave. Automating this process can save administrators a lot of time and reduce human error. In this article, we'll walk through a Bash script designed to automate the creation of Linux users and the... | candy-devops | |
1,812,681 | Welcome Thread - v283 | Leave a comment below to introduce yourself! You can talk about what brought you here, what... | 0 | 2024-07-03T00:00:00 | https://dev.to/devteam/welcome-thread-v283-g1a | welcome | ---
published_at : 2024-07-03 00:00 +0000
---

---
1. Leave a comment below to introduce yourself! You can talk about what brought you here, what you're learning, or just a fun fact about yourself.
2... | sloan |
1,909,497 | User creation script using bash shell. | In this article, I will demonstrate how a sysop administrator employs bash shell scripting to create... | 0 | 2024-07-02T23:57:05 | https://dev.to/linuxinator/user-creation-script-using-bash-shell-kem | In this article, I will demonstrate how a sysop administrator employs bash shell scripting to create multiple users and assign them unique passwords to different groups.
Well, who's a sysOps admin?
A SysOps (System Operations) Administrator, also known as a Systems Administrator or SysAdmin is a professional respons... | linuxinator | |
1,909,496 | Best AI Tools - for June 2024 🎊 | Best AI tools for June - Substack :) MAIN LIST:... | 0 | 2024-07-02T23:51:21 | https://dev.to/pinkmashpotato/best-ai-tools-for-june-2024-2pl7 | webdev, javascript, beginners, programming | [Best AI tools for June - Substack](https://bestaitoolsforyou.substack.com/p/best-ai-tools-for-june-2024)
:)
MAIN LIST: https://github.com/pink-mash-potato/awesome-ai-tools
#adhd #productivity #ai #neurospicy #aitools #genai | pinkmashpotato |
1,909,495 | The HNG11 Internship program can significantly help me achieve my goals in several ways: | Professional Objectives: Design Leadership: HNG's team-based projects and collaborations can help... | 0 | 2024-07-02T23:50:44 | https://dev.to/leke_jeremiah_1997/the-hng11-internship-program-can-significantly-help-me-achieve-my-goals-in-several-ways-1e4l | Professional Objectives:
1. _Design Leadership_: HNG's team-based projects and collaborations can help me develop leadership skills and experience.
2. _Expertise Expansion_: HNG's diverse projects and mentorship can expose me to emerging design technologies and best practices.
3. _Cross-Functional Collaboration_: HNG'... | leke_jeremiah_1997 | |
1,909,489 | Explorando el Ecosistema de JavaScript: Un Mapa Completo de Frameworks y Librerías | JavaScript ha evolucionado enormemente desde sus inicios, convirtiéndose en uno de los lenguajes de... | 0 | 2024-07-02T23:21:41 | https://dev.to/deveg4/explorando-el-ecosistema-de-javascript-un-mapa-completo-de-frameworks-y-librerias-41ek | javascript |
JavaScript ha evolucionado enormemente desde sus inicios, convirtiéndose en uno de los lenguajes de programación más versátiles y utilizados en el desarrollo web y móvil. Con una comunidad vibrante y en constante cr... | deveg4 |
1,909,494 | Custom CRM Software Development for Real Estate Agencies | In the competitive Australian real estate market, staying ahead requires more than just a keen eye... | 0 | 2024-07-02T23:47:06 | https://dev.to/brokeralvin/custom-crm-software-development-for-real-estate-agencies-2bnd | realestate, customsoftwaredevelopment, customsoftwaredevelopers, softwaredevelopment | In the competitive Australian real estate market, staying ahead requires more than just a keen eye for property values. It demands efficient management of leads, listings, and client communications. While off-the-shelf CRM solutions exist, they often fall short in addressing the unique challenges faced by real estate a... | brokeralvin |
1,909,493 | Hello there, lets talk! | Hi there, I'm Carlos. I'm an Angolan 21 year old computer science student who lives in Lisbon,... | 0 | 2024-07-02T23:46:15 | https://dev.to/carlituscg/hello-there-lets-talk-3kci | webdev, networking, beginners | Hi there, I'm Carlos.
I'm an Angolan 21 year old computer science student who lives in Lisbon, Portugal. Lately I've been trying to build some connections and network, so I figured out it'd just be better to create an account over here.
Right now I've been exploring Web Development and UX/UI and my goal is to share my... | carlituscg |
1,909,491 | Construindo um Blog Simples com Server.js: Uma Introdução Prática ao Desenvolvimento Web com Node.js | Neste tutorial, exploraremos como o server.js, um framework ágil e robusto para Node.js, pode ser... | 0 | 2024-07-02T23:28:57 | https://dev.to/gustavogarciapereira/construindo-um-blog-simples-com-serverjs-uma-introducao-pratica-ao-desenvolvimento-web-com-nodejs-5f8b | javascript, beginners, node, serverjs | Neste tutorial, exploraremos como o server.js, um framework ágil e robusto para Node.js, pode ser utilizado para criar um blog simples mas funcional. Demonstraremos passo a passo como configurar o servidor, gerenciar rotas, e processar dados, tudo isso utilizando a elegância e a simplicidade que o server.js oferece. Es... | gustavogarciapereira |
1,909,490 | Level up your Git security: Verified commits with Kleopatra! | I just finished securing my GitHub workflow by setting up verified commits using Kleopatra and... | 0 | 2024-07-02T23:25:59 | https://dev.to/deni_sugiarto_1a01ad7c3fb/level-up-your-git-security-verified-commits-with-kleopatra-5147 | git, security, github, programming | I just finished securing my GitHub workflow by setting up verified commits using Kleopatra and followed this awesome guide: [YouTube Verified Commits on GitHub from Windows PC](https://www.youtube.com/watch?v=xj9OiJL56pM)
**Why verified commits?**
Having a green checkmark next to your commits on GitHub isn't just for ... | deni_sugiarto_1a01ad7c3fb |
1,909,480 | Automating User Creation and Management with Bash: A Step-by-Step Guide | Automating user creation and management can save time, reduce errors, and enhance security for SysOps... | 0 | 2024-07-02T23:18:51 | https://dev.to/centinno88/automating-user-creation-and-management-with-bash-a-step-by-step-guide-3afm | Automating user creation and management can save time, reduce errors, and enhance security for SysOps engineers. In this article, we will go over a Bash script that automates the creation of users and groups, sets up home directories, and manages passwords securely. The script reads from a text file where each line con... | centinno88 | |
1,909,479 | List of top AI tools and products directories | I recently check lots of ai directories to find top ai tool for you. :) Top Tools - AI Tools... | 0 | 2024-07-02T23:13:40 | https://dev.to/pinkmashpotato/list-of-top-ai-tools-and-products-directories-3e61 | ai, directories, javascript, programming | I recently check lots of ai directories to find top ai tool for you.
:)
- [Top Tools](https://www.toptools.ai/) - AI Tools Directory
- [Tool Pilot](https://www.toolpilot.ai) - Navigate the World of AI Tools
- [TopAI.tools](https://topai.tools/) - Discover the best AI tools Everyday
- [Top AI Tools Hub](https://www.... | pinkmashpotato |
1,909,477 | Very First Post | Well, here goes... So I will openly admit I am unsure of what to even put in this very first blog of... | 0 | 2024-07-02T23:09:59 | https://dev.to/joebush4466/very-first-post-14af | blog, javascript, learning, beginners | Well, here goes...
So I will openly admit I am unsure of what to even put in this very first blog of mine. I joined the FlatIron School Software Engineering online program and am trying to make radical changes in my life. I am looking forward to the program and getting into the IT workforce. I am not sure yet which av... | joebush4466 |
1,909,476 | Automating User and Group Management on Linux with a Shell Script | In the world of system administration, managing users and groups efficiently is crucial. This article... | 0 | 2024-07-02T23:08:53 | https://dev.to/hayzeddev/automating-user-and-group-management-on-linux-with-a-shell-script-5b60 | bash, shell, linux | In the world of system administration, managing users and groups efficiently is crucial. This article presents a shell script that automates user and group management on Linux systems, making the process seamless and efficient. The script takes in a file which consists of users to be added to a machine and their corres... | hayzeddev |
1,909,475 | My HNG Journey. Stage One: Automating Linux User and Group Management using a Bash Script | Introduction With a new HNG stage, comes a new and slightly difficult task. This is going... | 0 | 2024-07-02T23:07:00 | https://dev.to/ravencodess/my-hng-journey-stage-one-creating-a-multi-purpose-bash-script-559j | bash, backend, github, linux | ## Introduction
With a new [HNG ](https://hng.tech/internship)stage, comes a new and slightly difficult task.
This is going to be a long read, so I'll keep the introduction short and just get into it
The source code can be found on my [GitHub repo](https://github.com/Ravencodess/shell-script-stage-1.git)
### Requirem... | ravencodess |
1,909,474 | A Beginner's Guide to Open Source Contributions on GitHub | Contents Introduction Preparation Ways to Contribute Raise an issue or make a... | 0 | 2024-07-02T23:06:42 | https://dev.to/jjpark987/a-beginners-guide-to-open-source-contributions-on-github-4c3p | tutorial, beginners, github, opensource | ## Contents
- [Introduction](#introduction)
- [Preparation](#preparation)
- [Ways to Contribute](#ways-to-contribute)
- [Raise an issue or make a suggestion](#raise-an-issue-or-make-a-suggestion)
- [Reproduce a reported bug](#reproduce-a-reported-bug)
- [Test a pull request](#test-a-pull-request)
- [Solve a report... | jjpark987 |
1,908,482 | Design Facebook - a social network | Problem definition Facebook is a social media platform for users to connect with people and engage... | 0 | 2024-07-02T23:03:26 | https://dev.to/muhammad_salem/design-facebook-a-social-network-4li8 |
**Problem definition**
Facebook is a social media platform for users to connect with people and engage with different types of media and content. Users can connect with other users by sending friend requests or using the direct messaging feature. Each user has a profile where they can create posts to share with thei... | muhammad_salem | |
1,908,262 | How To Automate The Creation Of Users And Groups In Linux Using Bash Script. | INTRODUCTION Imagine you work in very big firm, and your company recruited about 100 new staffs and... | 0 | 2024-07-02T23:00:16 | https://dev.to/onyeka_embedded/how-to-automate-the-creation-of-users-and-groups-in-linux-using-bash-script-33am | linux, aws, devops, cloudcomputing | ---
**INTRODUCTION**
Imagine you work in very big firm, and your company recruited about 100 new staffs and you are saddle with the responsibility of creating user accounts for them as well as adding them to different groups in a Linux system.
Performing this tasks manually can be very tiring and also error prone. In... | onyeka_embedded |
1,909,472 | BITCOIN RECOVERY EXPERT | OPTIMUM HACKERS RECOVERY IS THE BEST CRYPTO EXPERT TO RECOVER ALL YOUR LOST BTC AND HACKED BANK... | 0 | 2024-07-02T22:59:06 | https://dev.to/seren_williams/bitcoin-recovery-expert-4833 | bitcoin, recovery, retriever, lostfunds | OPTIMUM HACKERS RECOVERY IS THE BEST CRYPTO EXPERT TO RECOVER ALL YOUR LOST BTC AND HACKED BANK ACCOUNTS. RECOVER YOUR LOST ASSETS WITH OPTIMUM HACKERS RECOVERY
Hello everyone, I’d like to use this medium to express my gratitude to OPTIMUM HACKERS RECOVERY for assisting me in recovering my stolen crypto worth $821,550... | seren_williams |
1,909,471 | React Js vs Vue Js: A comparative journey in frontend development | This article compares two popular frontend technologies, Vue.js and ReactJS, highlighting their key... | 0 | 2024-07-02T22:57:02 | https://dev.to/vicztech/react-js-vs-vue-js-a-comparative-journey-in-frontend-development-45ei | This article compares two popular frontend technologies, Vue.js and ReactJS, highlighting their key differences, strengths, and weaknesses.
ReactJS: Solving the "Phantom Problem"
ReactJS was developed by Facebook to address the "Phantom Problem" — UI synchronization issues that arose as Facebook's user base grew. Rea... | vicztech | |
1,908,935 | Technical Article | Introduction SysOps engineers must automate user and group management in today's fast-paced... | 0 | 2024-07-02T12:29:11 | https://dev.to/rufus_chibuike_1652bc4801/technical-article-46hb |
Introduction
SysOps engineers must automate user and group management in today's fast-paced technology landscape. This article examines create_users.sh, a comprehensive Bash script that automates user creation, group assignment, and password management on Linux systems.
Script Overview
The create_users.sh script re... | rufus_chibuike_1652bc4801 | |
1,909,470 | HACKED FUNDS FINALLY RECOVERED BY A BTC RECOVERY EXPERT// HIRE OPTIMUM HACKERS RECOVERY TO RECOVER YOUR LOST ASSETS | OPTIMUM HACKERS RECOVERY IS THE BEST CRYPTO EXPERT TO RECOVER ALL YOUR LOST BTC AND HACKED BANK... | 0 | 2024-07-02T22:56:01 | https://dev.to/seren_williams/hacked-funds-finally-recovered-by-a-btc-recovery-expert-hire-optimum-hackers-recovery-to-recover-your-lost-assets-39i3 | bitcoinrecovery, btcrecovery, recoveryexpert, bitcoinretriever | OPTIMUM HACKERS RECOVERY IS THE BEST CRYPTO EXPERT TO RECOVER ALL YOUR LOST BTC AND HACKED BANK ACCOUNTS. RECOVER YOUR LOST ASSETS WITH OPTIMUM HACKERS RECOVERY
Hello everyone, I’d like to use this medium to express my gratitude to OPTIMUM HACKERS RECOVERY for assisting me in recovering my stolen crypto worth $821,550... | seren_williams |
1,909,469 | User and groups creation automation in linux | Hey there! Ever wondered how tech teams smoothly integrate new members into their systems? Scripting... | 0 | 2024-07-02T22:53:48 | https://dev.to/celestina/user-and-groups-creation-automation-in-linux-41pb | **Hey there! Ever wondered how tech teams smoothly integrate new members into their systems? Scripting has become the unsung hero! Imagine effortlessly setting up user accounts, creating personalized groups, and ensuring security—all with a few lines of code. In this article, we'll explore how automation through script... | celestina | |
1,907,106 | Object-Oriented Analysis and Design (OOAD) for the Parking Lot System | Problem definition A parking lot is a designated area for parking vehicles and is a feature found in... | 0 | 2024-07-02T22:52:09 | https://dev.to/muhammad_salem/object-oriented-analysis-and-design-ooad-for-the-parking-lot-system-i2o |
**Problem definition**
A parking lot is a designated area for parking vehicles and is a feature found in almost all popular venues such as shopping malls, sports stadiums, offices, etc. In a parking lot, there are a fixed number of parking spots available for different types of vehicles. Each of these spots is cha... | muhammad_salem | |
1,909,039 | ClippyAI - Developing a Local AI Agent | Introduction As a developer, I’ve always been passionate about creating tools that solve... | 0 | 2024-07-02T22:50:48 | https://dev.to/mrdoe/clippyai-59h7 | ai, dotnet, avalonia | ## Introduction
As a developer, I’ve always been passionate about creating tools that solve real-world problems. But there was one issue that consistently irked me: the never-ending stream of repetitive emails. Whether it was customer inquiries, tech support requests, or project updates, my inbox overflowed with simil... | mrdoe |
1,909,468 | Bootstrap - Sistema de cuadricula | Sistema de cuadricula. En Bootstrap, el sistema de cuadrícula es útil para crear... | 0 | 2024-07-02T22:50:04 | https://dev.to/fernandomoyano/bootstrap-sistema-de-cuadricula-31cl | # Sistema de cuadricula.
---
En Bootstrap, el sistema de cuadrícula es útil para crear diseños rápidos de páginas web que respondan a los diferentes dispositivos según el tamaño de las pantallas.
El sistema de cuadrícula de arranque utilizará una serie de contenedores , filas y columnas para definir el diseño y aline... | fernandomoyano | |
1,887,210 | Boost Team Efficiency with Smaller PRs | Ever felt overwhelmed by massive Pull Requests (PRs) that drag on for days, or even weeks? John Kline... | 0 | 2024-07-02T22:37:28 | https://dev.to/merico/boost-team-efficiency-with-smaller-prs-4314 | engineering, productivity, devops, cicd | Ever felt overwhelmed by massive Pull Requests (PRs) that drag on for days, or even weeks? John Kline from Riot Games has the answers you’ve been looking for. In a recent [DevLogue episode](https://www.youtube.com/watch?v=CVMbUcBRk4c), John dished out game-changing insights on how reducing PR size can supercharge your ... | joshuapoddoku |
1,909,418 | Day 983 : Weary | liner notes: Professional : Had a couple of meetings. I responded to a couple of community... | 0 | 2024-07-02T22:18:40 | https://dev.to/dwane/day-983-weary-370a | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Had a couple of meetings. I responded to a couple of community questions. I created a sample application to test a new feature and got it working. Asked the team some questions about what I found while building the application. Day went by pretty quickly.
- Personal : Last night, I went... | dwane |
1,909,417 | RETRIEVING LOST OR STOLEN BITCOIN // DIGITAL TECH GUARD RECOVERY | When a trusted family friend turned against me, I felt completely devastated. This individual... | 0 | 2024-07-02T22:17:37 | https://dev.to/helen_turner_7bff9f3bab77/retrieving-lost-or-stolen-bitcoin-digital-tech-guard-recovery-5g2a | recovery | When a trusted family friend turned against me, I felt completely devastated. This individual accessed my laptop and stole my cryptocurrency wallet, containing $120,000 worth of Bitcoin, which represented years of savings and investments. The sense of loss and violation was overwhelming. Upon a close friend's suggestio... | helen_turner_7bff9f3bab77 |
1,909,416 | Using a Bash script to Automate the Creation of Users and Groups | is a typical responsibility for a DevOps engineer to add, modify, and remove users and groups. Time... | 0 | 2024-07-02T22:15:53 | https://dev.to/christian_ochenehipeter_/using-a-bash-script-to-automate-the-creation-of-users-and-groups-2i8e | is a typical responsibility for a DevOps engineer to add, modify, and remove users and groups. Time can be saved and mistakes can be decreased by automating this procedure, particularly when onboarding numerous new developers. This tutorial will guide you through the building of a Bash script that can be used to automa... | christian_ochenehipeter_ | |
1,909,413 | Migrating from Nuxt 2 to Nuxt 3: A Comprehensive Guide | Migrating from Nuxt 2 to Nuxt 3 can be a tough challenge depending on the scope of your project and... | 0 | 2024-07-02T22:08:16 | https://dev.to/fido1hn/migrating-from-nuxt-2-to-nuxt-3-a-comprehensive-guide-56na | vue, nuxt, webdev, javascript | Migrating from Nuxt 2 to Nuxt 3 can be a tough challenge depending on the scope of your project and the depth of your knowledge regarding these frameworks.
As of 30th, June 2024, Nuxt 2 has officially reached it’s EOL(End of life) and will no longer receive support from the Nuxt team, as efforts have shifted to maint... | fido1hn |
1,909,411 | Overcoming Backend Challenges: My Journey and Aspirations with HNG Internship | Introduction Hello, I'm Kingsley, and I'm embarking on an exciting journey with the HNG Internship.... | 0 | 2024-07-02T22:03:50 | https://dev.to/that_khayy/overcoming-backend-challenges-my-journey-and-aspirations-with-hng-internship-42jc | backenddevelopment, hng, node, softwaredevelopment |
**Introduction**
Hello, I'm Kingsley, and I'm embarking on an exciting journey with the HNG Internship. As a budding backend developer, I recently encountered a particularly challenging problem that tested my skills and perseverance. In this blog post, I will walk you through the problem I faced, how I tackled it, a... | that_khayy |
1,909,409 | Understanding NDAs and Why You Must Sign NDA Online with OpenSign | In today's fast-paced and interconnected business world, safeguarding confidential information is... | 0 | 2024-07-02T22:01:18 | https://dev.to/docusignlog-in/understanding-ndas-and-why-you-must-sign-nda-online-with-opensign-4p71 | programming, opensource, signndaonline, digitalsignatures | In today's fast-paced and interconnected business world, safeguarding confidential information is more critical than ever. Whether you're a startup founder, a seasoned entrepreneur, or a professional navigating corporate landscapes, Non-Disclosure Agreements (NDAs) play a pivotal role in protecting sensitive informatio... | alexopensource |
1,909,410 | Enhancing Content Testing with Comprehensive Bug Reporting | In a modern software organization, a robust testing strategy is essential for ensuring the quality of... | 0 | 2024-07-02T21:59:35 | https://dev.to/maria_koko_474/enhancing-content-testing-with-comprehensive-bug-reporting-5gii |
In a modern software organization, a robust testing strategy is essential for ensuring the quality of your digital products. One key aspect of this testing strategy is the use of content testing techniques - a set of methods and tools that allow you to evaluate the effectiveness, usability, and performance of your web... | maria_koko_474 | |
1,884,337 | Generating PDF documents in Laravel | Laravel and DomPDF: Step by step guide to generating PDF Documents with Images and... | 0 | 2024-07-02T21:56:47 | https://dev.to/alphaolomi/generating-pdf-documents-in-laravel-n07 | webdev, laravel, php, tutorial | # Laravel and DomPDF: Step by step guide to generating PDF Documents with Images and CSS
Creating PDF documents is a common requirement in web applications, especially for generating invoices, receipts, certificates, tickets, and various reports. In this comprehensive tutorial, we'll delve into using Laravel and DomPD... | alphaolomi |
1,909,408 | [Game of Purpose] Day 45 - HUD | Today I added HUD. The first version includes engine status. It properly reacts to its change. | 27,434 | 2024-07-02T21:49:19 | https://dev.to/humberd/game-of-purpose-day-45-hud-51h7 | gamedev | Today I added HUD. The first version includes engine status. It properly reacts to its change.
{% embed https://youtu.be/B05i21UdWA4 %} | humberd |
1,909,407 | Automating User Management with Advanced Bashscript | As part of the requirements of my DevOps internship with HNG, I am required to create a bash script... | 0 | 2024-07-02T21:49:10 | https://dev.to/laraadeboye/automating-user-management-with-advanced-bashscript-4m8p | bash, advancedbashscripting, createusersinlinux, automation | As part of the requirements of my DevOps internship with [HNG](https://hng.tech/internship), I am required to create a bash script to automate user management.
Managing users in a Linux environment can be a repetitive and error-prone task if done manually, especially when dealing with a large number of users. To simpli... | laraadeboye |
1,909,406 | Automating User Creation and Management with Bash: A Step-by-Step Guide | Automating user creation and management can save time, reduce errors, and enhance security for SysOps... | 0 | 2024-07-02T21:45:58 | https://dev.to/victorthegreat7/automating-user-creation-and-management-with-bash-a-step-by-step-guide-2oma | Automating user creation and management can save time, reduce errors, and enhance security for SysOps engineers. In this article, we will go over a Bash script that automates the creation of users and groups, sets up home directories, and manages passwords securely. The script reads from a text file where each line con... | victorthegreat7 | |
1,909,404 | A new react dev slack group | Hi all! We just launched our slack group focused on react but mainly frontend development. We want... | 0 | 2024-07-02T21:40:32 | https://dev.to/jhobbie_board_3a35020a47f/a-new-react-dev-slack-group-44e6 | community, react, nextjs, reactnative | Hi all!
We just launched our slack group focused on react but mainly frontend development. We want to build a community of frontends devs (and all devs) that is welcoming and supportive for one another. So whether you’re just interested in frontend development or you’ve been doing it for years join us!
https://join.s... | jhobbie_board_3a35020a47f |
1,909,403 | Understanding Chain-of-Thought Prompting: A Revolution in Artificial Intelligence | What is Chain-of-Thought Prompting? Chain-of-Thought Prompting is a method that guides... | 0 | 2024-07-02T21:32:47 | https://dev.to/sgaglione/understanding-chain-of-thought-prompting-a-revolution-in-artificial-intelligence-36i1 | llm, python, ia, ai | ## What is Chain-of-Thought Prompting?
Chain-of-Thought Prompting is a method that guides language models through a series of logical steps to arrive at an answer or solution. Unlike traditional approaches where models generate responses directly, CoT encourages models to “think out loud,” detailing their reasoning pr... | sgaglione |
1,909,338 | Automating User On-Boarding With Bash Scripting. | Introduction In Modern day IT administration, automation must become part of your... | 0 | 2024-07-02T21:32:29 | https://dev.to/eben/automating-user-on-boarding-with-bash-scripting-3p00 | ## Introduction
In Modern day IT administration, automation must become part of your day-to-day activity. This is because automation is crucial in maintaining uniformity, and security policies of the organization as well as avoiding time wastage in doing the same things over again.
One of those repetitive tasks autom... | eben | |
1,909,372 | Install Module in Powershell without Install-Module | The term ‘Install-Module’ is not recognized as the name of a cmdlet. Have you ever found... | 0 | 2024-07-02T21:26:27 | https://medium.com/@kinneko-de/77dc0380efff | powershell, help, windows, installmodul | ## The term ‘Install-Module’ is not recognized as the name of a cmdlet.
Have you ever found yourself in trouble because your Powershell is not working anymore after a colleague told you to just delete every module of Windows Powershell? No problem… you can just use Install-Module to reinstall everything. Oops… Install... | kinneko-de |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.