
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
788,458 | Crystal for the curious Ruby on Rails Developer | Have you been hearing about the language Crystal lately and you're curious what it's all about? Well,... | 0 | 2021-08-11T14:46:16 | https://dev.to/seesethcode/crystal-for-the-curious-ruby-on-rails-developer-1dc | crystal, webdev, alwayslearning, 12monthsofmakes | Have you been hearing about the language [Crystal](https://www.crystal-lang.org) lately and you're curious what it's all about? Well, I'm right there with you! Specifically I'm curious how Crystal can be used to create web applications that are highly performant but use less resources.
##A little about me
My name is Seth and I'm a self-taught full-stack Ruby on Rails developer. My strong suites are mostly back-end and infrastructure.
##The goal of this article
Since I'm self-taught, and because of the way I learn, I rely heavily on video tutorials to help me build my understanding of how Ruby, Javascript, HTML/CSS and infrastructure work together to create functional web applications.
Crystal caught my attention because of it's similarity to Ruby, but with benefits of a compiled language that I think Ruby is naturally trying to move towards. The challenge I find myself having is... **a lack of videos helping introduce the different frameworks and the language**.
So, I decided I'll take multiple Crystal web frameworks for a test drive and we'll build the same app in each one to explore how each one is different. I plan to personally highlight the differences I notice between the Crystal framework and Rails because most of my app development experience is with Rails.
##Crystal Web Frameworks I'll Be Exploring
Here's the list of frameworks I will be making videos for. I'll be creating the same simple blog app on each framework so that anyone following along can compare how each one. I'll update each list item with a link to the article specifically about the framework with links to the videos and the source code for anyone to clone/fork and play around with. So if you don't see a link yet, please check back in the future 😄
- [Amber](https://amberframework.org/)
- [Lucky](https://www.luckyframework.org/)
- [Spider Gazelle](https://spider-gazelle.net/)
- [Kemal](https://github.com/kemalcr/kemal)
- [Athena](https://athenaframework.org/)
The order here is roughly based on the full featured-ness of the framework. I say that because from my current experience Lucky is more fully featured as an out of the box system, but I'm already working with Amber currently and I'm more familiar with it so I plan to start there. Kemal and Athena are much lighter weight and are better compared to a Sinatra type framework.
##Blog Project Outline
I'm rarely this structured, but a simple blog site is a good way to explore a frameworks ORM, controller and view layer, routing, simple user authentication and all of the basic CRUD actions.
Since the purpose of this project is to explore the frameworks themselves I'll be using bootstrap for the front-end and making all of the projects look essentially the same with standard bootstrap styling. If I use any Javascript, it'll be through Webpack and using Stimulus or just plain Javascript (clearly I haven't decided yet).
###Pages
- Home: This will act as the index page for the posts, displaying up to 10 posts and paginating any additional posts.
- Sign Up
- Sign In
- Post: the individual post page displaying the post contents. Post pages will accept comments from non-signed in users.
- User Account: screen showing all of the posts belonging to the signed in user, with all of the CRUD actions for all the posts belonging to that user.
All pages will have a sticky top nav with links to sign in/out and create/manage posts.
##And there you have it!
I'll update this post as I finish the videos and posts with each framework. If this has helped you, or caused you to have more questions that I didn't answer, please let me know. I'd love to get your feedback! | seesethcode |
788,576 | Um errinho em Elixir | Elixir não é uma linguagem perfeita, claro. O "erro" que vou comentar aqui está na função... | 0 | 2021-08-11T15:10:21 | https://dev.to/elixir_utfpr/um-errinho-em-elixir-1dof | elixir, erlang | Elixir não é uma linguagem perfeita, claro.
O "erro" que vou comentar aqui está na função [Enum.at/3](https://hexdocs.pm/elixir/1.12/Enum.html#at/3).
Deixa explicar melhor. Se eu tenho uma lista com 5 elementos:
```elixir
[:a, :b, :c, :d, :e]
```
e eu perguntar a você qual é o terceiro elemento, obviamente você vai me responder que é o `:c`.
Mas se eu usar [Enum.at/3](https://hexdocs.pm/elixir/1.12/Enum.html#at/3) da seguinte forma:
```elixir
Enum.at([:a, :b, :c, :d, :e],3)
```
o resultado vai ser:
```elixir
iex> Enum.at([:a, :b, :c, :d, :e],3)
:d
```
Interessante é que é um "erro" (coloco entre aspas por não ser um erro de verdade mas sim uma escolha que eu acredito ser errada) que [não veio do Erlang](https://erlang.org/doc/man/lists.html#nth-2):
```erlang
> lists:nth(3, [a, b, c, d, e]).
c
```
O Maxsuel Maccari explicou [neste tweet](https://twitter.com/maxmaccari/status/1425476422425092106?s=20) a razão provável deste erro estar em Elixir. Ruby faz isso. Veja [aqui](https://ruby-doc.org/core-2.7.0/Array.html) e abaixo:
```ruby
arr = [1, 2, 3, 4, 5, 6]
arr[2] #=> 3
arr[100] #=> nil
arr[-3] #=> 4
```
Ruby adiciona requintes de crueldade permitindo índices negativos.
| elixir_utfpr |
788,645 | #14) Explain Closures in JS❓ | ✅A Closure is the combination of function enclosed with refrences to it's surrounding state. OR ✅A... | 13,804 | 2021-08-11T16:24:51 | https://dev.to/myk/14-explain-closures-in-js-h8g | javascript, webdev, beginners, career | ✅A Closure is the combination of function enclosed with refrences to it's surrounding state.
`OR`
✅A Closure gives you the access to an outer function's scope from an inner function.
✅Closure are created every time a function is created.
✅It is an ability of a function to remember the variables and function declared in it's outer scope.

Let's talk about the above code👇
💠The function `car` gets executed and return a function when we assign it to a variable.
`var closureFun = car();`
💠The returned function is then executed when we invoke closureFun:
`closureFun();`
💠Because of closure the output is `Audi is expensive💰🤑`
When the function _car()_ runs, it sees that the returning function is using the variable _name_ inside it:
`console.log(name + " is expensive💰🤑");`
💠Therefore car(), instead of destroying the value of name after execution, saves the value in the memory for further reference.
💠This is the reason why the returning function is able to use the variable declared in the outer scope even after the function is already executed.
✔This ability of a function to store a variable for further reference even after it is executed, is called Closure.
__________________________________________________________________ | myk |
788,658 | How to Install Elementor Pro in WordPress 2021 | How to Install Elementor Pro in WordPress 2021 | How to Buy Elementor Pro To Buy and Install... | 0 | 2021-08-11T16:48:56 | https://dev.to/hmawebdesign/how-to-install-elementor-pro-in-wordpress-2021-48o9 | wordpress, programming, php, webdev | How to Install Elementor Pro in WordPress 2021 | How to Buy Elementor Pro
To Buy and Install Elementor Pro version in WordPress follow these steps:
1. Go to the elementor.com website link
2. Go to pricing and choose 'essential plan' for the Elementor Pro WordPress Plugin.
3. Create a new account to download the Elementor Pro version.
4. After filling in the billing details, download the elementor Pro Plugin
**How to Install the Elementor Pro - Vodeo Tutorial!**
{% youtube ERQn0Vh84ik %}
5. After complete the downloading, open WordPress, go to plugins, and click add new.
6. Upload the downloaded zip file of Elementor Pro Plugin and install.
7. After installation activates the Plugin.
8. Must install elementor now, to use the pro version of Elementor Plugin.
9. Now, connect and activate the plugin with provided license key.
10. Congratulations! Elementor Pro is activated and ready to use.
| hmawebdesign |
788,666 | Frontend Environment Variables – What, Why and How | Photo by Pascal Debrunner on Unsplash What If you ever touched backend code you probably... | 0 | 2021-09-05T14:58:24 | https://dev.to/henriqueinonhe/frontend-environment-variables-what-why-and-how-1c1 | frontend, javascript, webpack, environment | *Photo by [Pascal Debrunner](https://unsplash.com/@debrupas?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)*
## What
If you ever touched backend code you probably already know that environment variables really come in handy when dealing with multiple environments, like local, dev, qa, prod by decoupling configuration from code.
In case you didn't, you may think of environment variables as **inputs** that you application take as parameters, after all, a program is pretty much like a function, with inputs, outputs and sometimes side effects.
So, just as with functions, where parametrizing values that were previously hardcoded in the function's body yields a more flexible implementation, we may extract **hardcoded values** from our frontend code as **environment variables**, so that we are able to change our application behavior without touching the code itself.
## Why
When working with a real project you'll probably deal with multiple environments (local, dev, qa, prod) and each of these environments will most likely have its own dedicated API service, and thus each one will be accessed using a different URL.
So instead of hardcoding the API URL, we read this value from an environment variable so that we can deploy the same code for all these different environments.
Another interesting use case for environment variables is to implement **feature flags** which are used to enable or disable certain features depending on the context (e.g. A/B testing or the application might serve multiple countries/regions and some features might not be available in some of them).
Currently at the place I work we also rely on environment variables to set the "check for updates" polling interval and to tweak some testing scenarios.
In summary, environment variables are a widely supported way of decoupling **configuration** from **code**. (See [12factorapp](https://12factor.net/config) for an in depth explanation)
## How
If we were talking about environment variables at the backend we could just `npm install dotenv` and `dotenv.config()` and then call it a day.
However, as the frontend runs on the client's machine it can't access environment variables (and even if it could, it would make no sense), so we need a different approach.
### Enter the compiler
As reading environment variables at **run time** is not an option for the frontend, we must fallback to **compile time** substitution.
Nowadays you'll most likely be using a compiler for the frontend, either because you're using JSX, or relying on Babel polyfills, or maybe you recognize the value of static type checking and need to transpile from Typescript.
Even if you don't really care about any of those things, you'll probably be minifying your JS code to reduce the bundle size and get that perfect Page Speed (*is this still relevant?*) score.
What we're going to do then is use the compiler to substitute environment variables in the code by their actual values at **build/compile time**.
In this example I'll be using **Webpack** as it is the standard bundler.
So, supposing you already have your build configuration in place with Webpack, setting up environment variables is a 3-step process:
```js
//webpack.config.js
//1. Read environment variables from our .env file
import dotenv from "dotenv";
dotenv.config();
//2. List environment variables you'll use
// The keys listed here are the ones that will
// be replaced by their actual value in the code.
// Also, their presence will be validated, so that
// if they're undefined webpack will complain and
// refuse to proceed with compilation
const environmentVariables = [
"API_BASE_URL",
"CHECK_FOR_UPDATES_TIME_INTERVAL"
];
//...
//3. Use Webpack's EnvironmentPlugin
plugins: [
//...
new webpack.EnvironmentPlugin(environmentVariables)
//...
],
//...
```
And then you can use environment variables the same way you'd do with backend code:
```js
const response = await fetch(`${process.env.API_BASE_URL}/login`);
```
Once again it is very important to keep in mind that what actually happens is essentially **textual substitution** of environment variables in build time, and a fortunate consequence of this is that for some cases like with feature flags, the minification process is even able to completely wipe out unreachable code branches, eliminating code related to unused features.
By the way, if you ever programmed with C or C++, this substitution process works pretty much the same way the C/C++ preprocessor would when you're using `#define`. | henriqueinonhe |
798,308 | Best Programming Stuff. | I have seen some of the programming stuff article on internet as usual sharing it with you... | 0 | 2021-08-20T15:21:28 | https://dev.to/stuffsuggested/best-programming-stuff-5a88 | I have seen some of the programming stuff article on internet as usual sharing it with you guys...Some of the websites are having affiliate links.
## 1. Best Monitors For Programming ##
When programming or coding for long periods, it's essential to have a comfortable monitor to keep eye strain to a minimum.
1. [Best Monitor For Programming](https://suggestedstuff.com/best-monitors-for-programming-in-india-2021/)
2. [Best Monitor For Programming](https://www.rtings.com/monitor/reviews/best/by-usage/programming-and-coding)
3. [Best Monitor for Programming & Coding (2021 Update)](https://www.guru99.com/best-monitor-programming.html)
## 2. Best Keyboard For Programing ##
As developers we don’t need many tools to work, many would say that we just need a laptop or computer, and even though that’s true, there’s a difference between having the minimum required to work to have the tools that you need to work comfortably, productive and healthy.
1. [List of Best keyboard for programming India 2021](https://cmsinstallation.blogspot.com/2021/04/best-keyboards-for-programming-in-2021.html)
2. [8 Best Keyboards for Programming in India 2021](https://www.thecrazyprogrammer.com/2020/09/best-keyboards-for-programming-in-india.html)
3. [Best Keyboard for Programming & Coding in 2021](https://www.guru99.com/best-keyboards.html)
## 3. Best Mouse For Programing ##
Programmer, Gammers, and coders spend their whole day with computers. So they have comfortable things for use. A standard mouse is irritating to use for a long time. A mouse that puts your hand in an unprejudiced position is maybe the best way to reduce these problems you just have to find a vertical or trackball mouse. Here, I've listed the Best mouse for programming.
1. [7 Best Mouse For Developer / Gaming / Coding](https://cmsinstallation.blogspot.com/2021/05/7-best-mouse-for-developer-gaming-coding.html)
2. [Best MOUSE for Programming & Coding (2021 Updated List)](https://www.guru99.com/best-mouse-programming.html)
3. [The best mouse of 2021: 10 top computer mice compared](https://www.techradar.com/in/news/computing-components/peripherals/what-mouse-10-best-mice-compared-1027809)
| stuffsuggested | |
788,668 | New JavaScript Features improving the Web Design World | The new decade has been a year of discovery and introduction of novice features for web developers... | 0 | 2021-08-11T17:10:07 | https://dev.to/dailydevnews/new-javascript-features-improving-the-web-design-world-2b5g | The new decade has been a year of discovery and introduction of novice features for web developers and programmers. JavaScript has been on the forefront of these innovations and system developments. In the current world, JavaScript has been defined as a well-thought-out programming language based on its user-friendly code and versatility. JavaScript platforms and tools are well recognized and globally appreciated for creating top-notch and cutting edge online casino games available in sites such as [onlinecasinosincanada.ca](http://onlinecasinosincanada.ca/).
Programmers and online casino games developers agree that JavaScript platforms creates fully-fledged games that offer the most fascinating user experience and the start of the art of security. The best part of JavaScript is the capacity to develop new features in constant frequentness with the aim of aiding their clients have the best experience and create more powerful, reliable, and efficient sites and applications. Let’s take you through some of the new JavaScript features that will enable the development of super cool online casino games.
###Dynamic import
This new JS feature saves us the challenge of importing files as modules. The most intriguing factor about this feature is how it enables the use to ship-on-demand request codes or conduct a code splitting function without the unnecessary module bundlers or even the overhead of web pack. It helps in making an import without adulterating the global namespace.
Dynamic import is a syntax that has solved the ever-evolving problems of failing to dynamically produce the parameters of import. Users have widely expressed their contention in regards to the dynamic import capacities that include the factor that it can be called from any place in the code and that it returns a promise that resolves into a module object. The previous features that are made in static means that developers will use more compile-time checking while the dynamism aspect provides for analyzable information at a lesser build time. Dynamic import enhances the use of one bundle for a single app and this enables sites built through JavaScript to be faster and efficient for demanding tasks such as the online casino games.
###BigInt
BigInt value or popularly known as BigInt is a new addition to the JavaScript programming that adds integer value or string value to the integers. It simply means that the feature gives developers the power to have greater integer representation as they code with JavaScript for improved data processing during data handling procedure.
The feature operates by adding an appended n at the end of the numeral to give the JavaScript engine the notion of treating it differently allowing the engine to support numbers of larger sizes. Strong sites such as online casino websites require a code that allows larger and more integers to reduce downtime and create more value for the user.
###Nullish coalescing
For a longer period developers have had the challenge of assigning values to be either false or null due to predictability hardships. But not anymore, the nullish coalescing feature provides through and efficient specification of assigning values. The feature handles default values through short-circuiting operators by assigning them as “truthy” or “falsy”. For instance, if a code is assigned to the left-hand side, it is considered as false while in the right-hand side it is considered as truth without leading to bugs.
Developers enjoy an added advantage of in that nullish coalescing evaluates its operands at most once which means it reduces the time used for evaluation increasing the value and reducing time used. For online casino web developers, this is a simple and invaluable addition to their repositories that will enable efficiency, predictability, and clean coding.
###Prototype based programming
Prototype-based programming refers to the object-oriented programming design where the behavior re-use involves cloning and extending objects and re-using them to serve as prototypes. This distinctive procedure gives objects the capacity to just inherit from other objects directly as opposed to creating something from nothing.
This feature gives [programmers using JavaScript language](http://www.forbes.com/sites/forbestechcouncil/2017/03/14/what-language-should-budding-programmers-learn-first/) the opportunity to create more objects by just cloning the initial ones. Cloning for this case is viewed as a style of developing new objects by simply copying the behaviors of an existing object where the clone or the prototype carries the qualities of the original object. This is a simpler, faster, and more efficient process that gives developers an upper hand in their activities.
###Import.meta
Import.meta is a uniquely designed feature that allows the object to provide precise metadata elements to the defined JavaScript module. This feature is known for bringing out or exposing the information about the module and in this case the information may include the module’s URL and resolve. For the URL obtained can be from the script; that is for external scripts, or it can be document base URL for the inline scripts.
An important thing to note is that the obtained URL will provide other details such as the query parameters or hash. [Programmers also need to understand](https://dev.to/hrishikesh1990/using-python-to-print-variable-in-strings-1d11) that the import meta object was created using the ECMAScript implementation.
###Optional chaining
This remains among the most fascinating features that have been recently introduced into the JS programming language. Previously, identification of a deep-rooted value has been a humongous challenge since you have to check if the intermediate node exist. Another challenge has been that the object maybe assigned as undefined or null but you want to get the result when the object is defined.
As a result, the optional chaining feature gives the user the ability to read the value of a property that is deeply located in a cycle of inter-joined objects without necessary having to [check](https://www.deviantart.com/us-news/posts) the validity of each reference within the chain. Developers note that optional chaining is a syntax with the capacity to access deeply nested object properties without being concerned of their existence.
Basically, it provides shorter expressions due to its short-circuiting capacities which eliminates the error reference. The other advantage of this feature is that it aids in the exploration of object context in cases when there is no guarantee of the properties.
| dailydevnews | |
788,718 | AluraChallenges #2 ( Semana 2) | No post anterior, nós fizemos todas as implementações que tínhamos da semana 1, deixando nossa API de... | 14,064 | 2021-09-01T21:50:33 | https://dev.to/delucagabriel/alurachallenges-2-semana-2-4d33 | nestjs, typescript, jest, typeorm | No post anterior, nós fizemos todas as implementações que tínhamos da semana 1, deixando nossa API de vídeos pronta para consumo.
Só que ainda temos desafios pela frente e nessa semana faremos a inserção de categorias, para classificarmos os nossos vídeos.
A história dessa semana é a seguinte:
> Depois de alguns testes com usuários, foi definido que a próxima feature a ser desenvolvida nesse projeto é a divisão dos vídeos por categoria, para melhorar a experiência de organização da lista de vídeos pelo usuário.
Então, faremos nesse post as seguintes [implementações](https://trello.com/b/iX8Xeg4k/alura-challenge-backend-semana-2) :
* **Adicionar `categorias` e seus campos na base de dados**;
* **Rotas CRUD para `/categorias`**;
* **Incluir campo `categoriaId` no modelo `video`**;
* **Escrever os testes unitários**.
Vamos começar fazendo os dois primeiros pontos, e novamente usaremos o generate do Nest, para criamos o recurso Categorias.
```bash
nest generate resource categorias
```
Após a criação, faremos a definição da nossa classe CreateCategoriaDto:
```typescript
// src/categorias/dto/create-categoria.dto.ts
import { Video } from '../../videos/entities/video.entity';
export class CreateCategoriaDto {
id: number;
titulo: string;
cor: string;
videos: Video[];
}
```
e alteraremos o nosso CreateVideoDto, adicionando a categoria:
```typescript
// src/videos/dto/create-video.dto.ts
import { Categoria } from '../../categorias/entities/categoria.entity';
export class CreateVideoDto {
...
categoria: Categoria;
}
```
Agora vamos na nossa "entity" e precisaremos fazer um pouco diferente.
Como será necessário ligar as tabelas de videos e categorias, utilizaremos o decorator @OneToMany(), que significa que teremos 1 categoria para vários vídeos:
```typescript
// src/categorias/entities/categoria.entity.ts
import { IsNotEmpty, IsString } from 'class-validator';
import { Video } from '../../videos/entities/video.entity';
import { Column, Entity, OneToMany, PrimaryGeneratedColumn } from 'typeorm';
@Entity()
export class Categoria {
@PrimaryGeneratedColumn()
id: number;
@IsNotEmpty()
@IsString()
@Column()
titulo: string;
@IsNotEmpty()
@IsString()
@Column()
cor: string;
@OneToMany(() => Video, (video) => video.categoria)
videos: Video[];
}
```
Será necessário alterar nossa "entity" Video também, informando que teremos varios vídeos para cada categoria. Utilizaremos o decorator @ManyToOne() após todos os atributos que já temos:
```typescript
// src/videos/entities/video.entity.ts
import { PrimaryGeneratedColumn, Column, Entity, ManyToOne } from 'typeorm';
import { IsNotEmpty, IsString, IsUrl } from 'class-validator';
import { Categoria } from '../../categorias/entities/categoria.entity';
@Entity()
export class Video {
...
@ManyToOne(() => Categoria, (categoria) => categoria.id, { nullable: false })
categoria: Categoria;
}
```
Entidades ajustadas, vamos para o nosso "categoria.service" para implementar as funcionalidades dela.
A diferença nela está no findAll, que passamos o parâmetro indicando a relação (relations: ['videos']) e já pedindo para trazer os dados dessa relação (loadEagerRelations: true):
```typescript
// src/categorias/categorias.service.ts
import { Injectable } from '@nestjs/common';
import { InjectRepository } from '@nestjs/typeorm';
import { Repository } from 'typeorm';
import { CreateCategoriaDto } from './dto/create-categoria.dto';
import { UpdateCategoriaDto } from './dto/update-categoria.dto';
import { Categoria } from './entities/categoria.entity';
@Injectable()
export class CategoriasService {
@InjectRepository(Categoria)
private categoriaRepository: Repository<Categoria>;
create(createCategoriaDto: CreateCategoriaDto) {
return this.categoriaRepository.save(createCategoriaDto);
}
findAll() {
return this.categoriaRepository.find({
relations: ['videos'],
loadEagerRelations: true,
});
}
findOne(id: number) {
return this.categoriaRepository.findOne(id);
}
update(id: number, updateCategoriaDto: UpdateCategoriaDto) {
return this.categoriaRepository.update(id, updateCategoriaDto);
}
async remove(id: number) {
const categoria = await this.findOne(id);
return this.categoriaRepository.remove(categoria);
}
}
```
Novamente, temos que ajustar nosso "video.service" também, que no caso, só terá alteração no método "findAll()":
```typescript
// src/videos/videos.service.ts
...
findAll() {
return this.videoRepository.find({
relations: ['categoria'],
loadEagerRelations: true,
});
}
...
```
Agora, para que a tabela de categorias seja criada no banco e identificada pelo Nest, precisamos ir no categorias.module e importar o TypeOrmModule passando a Categoria como parâmetro:
```typescript
// src/categorias/categorias.module.ts
import { Module } from '@nestjs/common';
import { CategoriasService } from './categorias.service';
import { CategoriasController } from './categorias.controller';
import { Categoria } from './entities/categoria.entity';
import { TypeOrmModule } from '@nestjs/typeorm';
@Module({
imports: [TypeOrmModule.forFeature([Categoria])],
controllers: [CategoriasController],
providers: [CategoriasService],
})
export class CategoriasModule {}
```
Maravilha, implementamos a categoria para os nossos videos, porém, temos um card que pede para que ao acessar a rota "/categorias/:id/videos" retorne os vídeos de uma determinada categoria:
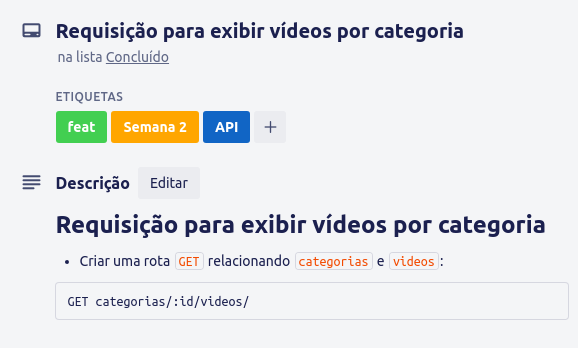
Para que isso seja possível, vamos precisar de uma nova rota no nosso controller de categorias.
A nova rota vai ficar assim:
```typescript
// src/categorias/categorias.controller.ts
...
@Get(':id/videos')
findVideosByCategoryId(@Param('id') id: string) {
return this.categoriasService.findVideoByCategory(+id);
}
...
```
Mas espera aí, nós não temos esse método "categoriasService.findVideoByCategory()".
Precisamos criar esse método lá no nosso serviço "categorias.service":
```typescript
// src/categorias/categorias.service.ts
...
async findVideoByCategory(id: number): Promise<Video[]> {
const categoria = await this.findOne(id);
return categoria.videos;
}
...
```
Mas se tentarmos acessar a rota, veremos uma tela branca, sem retorno de nenhum dado. --'
Para que seja retornado, precisamos alterar também o nosso método findOne, passando um objeto de configuração, informando que queremos que ele faça o carregamento dos dados relacionados à essa tabela.
O método ficará assim:
```typescript
// src/categorias/categorias.service.ts
...
findOne(id: number) {
return this.categoriaRepository.findOne(id, {
relations: ['videos'],
loadEagerRelations: true,
});
}
...
```
Agora sim, ao acessar nossa rota ".../categorias/1/videos", teremos nossos vídeos referentes à essa categoria.
O próximo card, tem a seguinte descrição:
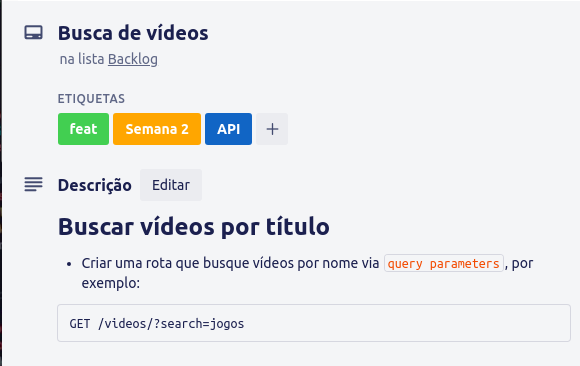
Para atender a esse requisito, precisaremos alterar nosso controller e nosso service de videos:
```typescript
// src/videos/videos.controller.ts
...
@Get()
findAll(@Query() query) {
return this.videosService.findAll(query.search);
}
...
```
```typescript
// src/videos/videos.service.ts
...
findAll(search = '') {
return this.videoRepository.find({
where: { titulo: ILike(`%${search}%`) },
relations: ['categoria'],
});
}
...
```
Próximo card:

Como já criamos uma categoria anteriormente, vamos enviar uma requisição de update para a categoria de ID 1, alterando o título para LIVRE
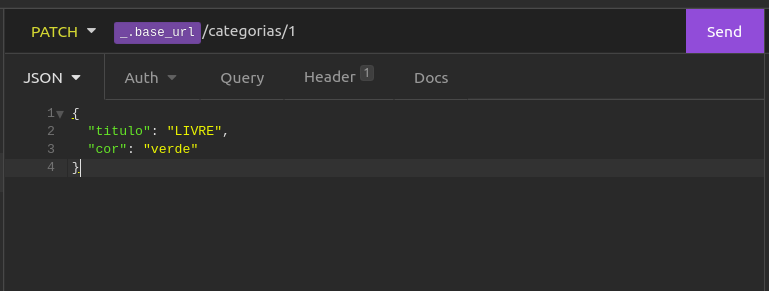
E após isso, vamos no videos.service e alteraremos a lógica do método create:
```typescript
// src/videos/videos.service.ts
...
create(createVideoDto: CreateVideoDto) {
if (!createVideoDto.categoria)
return this.videoRepository.save({
...createVideoDto,
categoria: { id: 1 },
});
return this.videoRepository.save(createVideoDto);
}
...
```
Pronto, requisito atendido!
>(Faça uma requisição criando um vídeo sem informar a categoria e veja se está tudo funcionando como o esperado, o retorno deve ser o vídeo criado e com a "categoria":{"id": 1})
O próximo requisito é para que se crie os testes automatizados e aí que o negócio começa a ficar legal.
## Implementando testes automatizados
Para facilitar nossos mocks, vamos inserir um construtor para as nossas entidades, deixando elas assim:
```typescript
// src/categorias/entities/categoria.entity.ts
...
constructor(private categoria?: Partial<Categoria>) {}
```
```typescript
// src/categorias/entities/categoria.entity.ts
...
constructor(private video?: Partial<Categoria>) {}
```
Vamos criar também uma pasta common dentro de src e nela criar uma pasta test, que ficarão os arquivos necessário e comum à todos os testes. Por agora, teremos dois stubs:
videos.stub.ts (crie esse arquivo)
```typescript
// src/common/test/videos.stub.ts
import { Categoria } from '../../categorias/entities/categoria.entity';
import { Video } from '../../videos/entities/video.entity';
import { categoriasStub } from './categorias.stub';
export const videosStub: Video[] = [
new Video({
id: 1,
titulo: 'título qualquer',
descricao: 'descrição qualquer',
url: 'http://url_qualquer.com',
categoria: new Categoria({ id: 1, titulo: 'LIVRE', cor: 'verde' }),
}),
new Video({
id: 2,
titulo: 'outro título qualquer',
descricao: 'outra descrição qualquer',
url: 'http://outra_url_qualquer.com',
categoria: categoriasStub[1],
}),
new Video({
id: 3,
titulo: 'titulo qualquer',
descricao: 'descrição qualquer',
url: 'http://url_qualquer.com',
categoria: categoriasStub[1],
}),
];
```
e categorias.stub.ts (crie também)
```typescript
// src/common/test/categorias.stub.ts
import { Categoria } from '../../categorias/entities/categoria.entity';
export const categoriasStub: Categoria[] = [
new Categoria({ id: 1, titulo: 'LIVRE', cor: 'verde' }),
new Categoria({ id: 2, titulo: 'Programação', cor: 'azul' }),
];
```
### Testando os controllers
Vamos rodas os testes e ver no que vai dar.
```bash
npm run test
```
Que delícia, nenhum teste passou!
Isso acontece pois alteramos e implementamos tudo sem criar nenhum teste o que não é muito legal, mas enfim, vamos começar a ajustar as coisa...
#### Testando nosso categorias.controller
O Nestjs já deixa uma estrutura pré-montada, então, vamos até o nosso arquivo categorias.controller.spec.ts para trabalhar nele.
Nosso controller tem como dependência o service e para que ele seja disponibilizado no teste precisamos prover ele.
Faremos dessa forma:
```typescript
// src/categorias/categorias.controller.spec.ts
import { Test, TestingModule } from '@nestjs/testing';
import { categoriasStub } from '../common/test/categorias.stub';
import { CategoriasController } from './categorias.controller';
import { CategoriasService } from './categorias.service';
import { videosStub } from '../common/test/videos.stub';
describe('CategoriasController', () => {
let controller: CategoriasController;
let service: CategoriasService;
beforeEach(async () => {
const module: TestingModule = await Test.createTestingModule({
controllers: [CategoriasController],
providers: [
CategoriasService,
{
provide: CategoriasService,
useValue: {
create: jest.fn().mockResolvedValue(categoriasStub[0]),
findAll: jest.fn().mockResolvedValue(categoriasStub),
findOne: jest.fn().mockResolvedValue(categoriasStub[0]),
findVideoByCategory: jest.fn().mockResolvedValue(videosStub),
update: jest.fn().mockResolvedValue(categoriasStub[0]),
remove: jest.fn().mockResolvedValue(categoriasStub[0]),
},
},
],
}).compile();
controller = module.get<CategoriasController>(CategoriasController);
service = module.get<CategoriasService>(CategoriasService);
});
it('should be defined', () => {
expect(controller).toBeDefined();
expect(service).toBeDefined();
});
});
```
repare que nós criamos um mock para cada função que temos no serviço e definimos o retorno delas com nosso stub da categoria.
com isso, podemos rodar novamente o comando de testes do npm, só que agora, deixaremos ele em modo watch para que ele fique observando as alterações, enquanto implementamos os testes, mas faremos somente para o arquivo que estamos trabalhando no momento:
```bash
npm run test:watch -t /home/gabriel/Documentos/alura-challenges-2/src/categorias/categorias.controller.spec.ts
# substitua essa parte '/home/gabriel/Documentos' pelo caminho do seu computador, é claro.
```
Feito isso, o teste vai rodar e faremos a implementação do restante.
No final, esse arquivo ficará assim:
```typescript
// src/categorias/categorias.controller.spec.ts
import { Test, TestingModule } from '@nestjs/testing';
import { categoriasStub } from '../common/test/categorias.stub';
import { CategoriasController } from './categorias.controller';
import { CategoriasService } from './categorias.service';
import { videosStub } from '../common/test/videos.stub';
describe('CategoriasController', () => {
let controller: CategoriasController;
let service: CategoriasService;
beforeEach(async () => {
const module: TestingModule = await Test.createTestingModule({
controllers: [CategoriasController],
providers: [
CategoriasService,
{
provide: CategoriasService,
useValue: {
create: jest.fn().mockResolvedValue(categoriasStub[0]),
findAll: jest.fn().mockResolvedValue(categoriasStub),
findOne: jest.fn().mockResolvedValue(categoriasStub[0]),
findVideoByCategory: jest.fn().mockResolvedValue(videosStub),
update: jest.fn().mockResolvedValue(categoriasStub[0]),
remove: jest.fn().mockResolvedValue(categoriasStub[0]),
},
},
],
}).compile();
controller = module.get<CategoriasController>(CategoriasController);
service = module.get<CategoriasService>(CategoriasService);
});
it('should be defined', () => {
expect(controller).toBeDefined();
expect(service).toBeDefined();
});
describe('create', () => {
it('should create a category', async () => {
const result = await service.create(categoriasStub[0]);
expect(result).toEqual(categoriasStub[0]);
expect(service.create).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'create').mockRejectedValueOnce(new Error());
expect(service.create(categoriasStub[0])).rejects.toThrowError();
expect(service.create).toHaveBeenCalledTimes(1);
});
});
describe('findAll', () => {
it('should return a category list', async () => {
const result = await service.findAll();
expect(result).toEqual(categoriasStub);
expect(service.findAll).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'findAll').mockRejectedValueOnce(new Error());
expect(service.findAll()).rejects.toThrowError();
expect(service.findAll).toHaveBeenCalledTimes(1);
});
});
describe('findOne', () => {
it('should return a category', async () => {
const result = await service.findOne(categoriasStub[0].id);
expect(result).toEqual(categoriasStub[0]);
expect(service.findOne).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'findOne').mockRejectedValueOnce(new Error());
expect(service.findOne(1)).rejects.toThrowError();
expect(service.findOne).toHaveBeenCalledTimes(1);
});
});
describe('findVideosByCategoryId', () => {
it('should return videos from a category', async () => {
const result = await service.findVideoByCategory(categoriasStub[0].id);
expect(result).toEqual(videosStub);
expect(service.findVideoByCategory).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest
.spyOn(service, 'findVideoByCategory')
.mockRejectedValueOnce(new Error());
expect(service.findVideoByCategory(1)).rejects.toThrowError();
expect(service.findVideoByCategory).toHaveBeenCalledTimes(1);
});
});
describe('update', () => {
it('should return a updated category', async () => {
const result = await service.update(
categoriasStub[0].id,
categoriasStub[0],
);
expect(result).toEqual(categoriasStub[0]);
expect(service.update).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'update').mockRejectedValueOnce(new Error());
expect(service.update(1, categoriasStub[0])).rejects.toThrowError();
expect(service.update).toHaveBeenCalledTimes(1);
});
});
describe('remove', () => {
it('should return a removed category', async () => {
const result = await service.remove(categoriasStub[0].id);
expect(result).toEqual(categoriasStub[0]);
expect(service.remove).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'remove').mockRejectedValueOnce(new Error());
expect(service.remove(1)).rejects.toThrowError();
expect(service.remove).toHaveBeenCalledTimes(1);
});
});
});
```
Passou todos os testes? vamos para o próximo!
#### Testando nosso videos.controller
```bash
npm run test:watch -t /home/gabriel/Documentos/alura-challenges-2/src/videos/videos.controller.spec.ts
# substitua essa parte '/home/gabriel/Documentos' pelo caminho do seu computador, é claro.
```
A ideia é a mesma para cá, então, esse arquivo fica assim:
```typescript
// src/videos/videos.controller.spec.ts
import { Test, TestingModule } from '@nestjs/testing';
import { VideosController } from './videos.controller';
import { VideosService } from './videos.service';
import { videosStub } from '../common/test/videos.stub';
describe('VideosController', () => {
let controller: VideosController;
let service: VideosService;
beforeEach(async () => {
const module: TestingModule = await Test.createTestingModule({
controllers: [VideosController],
providers: [
VideosService,
{
provide: VideosService,
useValue: {
create: jest.fn().mockResolvedValue(videosStub[0]),
findAll: jest.fn().mockResolvedValue(videosStub),
findOne: jest.fn().mockResolvedValue(videosStub[0]),
update: jest.fn().mockResolvedValue(videosStub[0]),
remove: jest.fn().mockResolvedValue(videosStub[0]),
},
},
],
}).compile();
controller = module.get<VideosController>(VideosController);
service = module.get<VideosService>(VideosService);
});
it('should be defined', () => {
expect(controller).toBeDefined();
expect(service).toBeDefined();
});
describe('create', () => {
it('should create a video', async () => {
const result = await service.create(videosStub[0]);
expect(result).toEqual(videosStub[0]);
expect(service.create).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'create').mockRejectedValueOnce(new Error());
expect(service.create(videosStub[0])).rejects.toThrowError();
expect(service.create).toHaveBeenCalledTimes(1);
});
});
describe('findAll', () => {
it('should return a video list', async () => {
const result = await service.findAll();
expect(result).toEqual(videosStub);
expect(service.findAll).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'findAll').mockRejectedValueOnce(new Error());
expect(service.findAll()).rejects.toThrowError();
expect(service.findAll).toHaveBeenCalledTimes(1);
});
});
describe('findOne', () => {
it('should return a video', async () => {
const result = await service.findOne(videosStub[0].id);
expect(result).toEqual(videosStub[0]);
expect(service.findOne).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'findOne').mockRejectedValueOnce(new Error());
expect(service.findOne(1)).rejects.toThrowError();
expect(service.findOne).toHaveBeenCalledTimes(1);
});
});
describe('update', () => {
it('should return a updated video', async () => {
const result = await service.update(videosStub[0].id, videosStub[0]);
expect(result).toEqual(videosStub[0]);
expect(service.update).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'update').mockRejectedValueOnce(new Error());
expect(service.update(1, videosStub[0])).rejects.toThrowError();
expect(service.update).toHaveBeenCalledTimes(1);
});
});
describe('remove', () => {
it('should return a removed video', async () => {
const result = await service.remove(videosStub[0].id);
expect(result).toEqual(videosStub[0]);
expect(service.remove).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(service, 'remove').mockRejectedValueOnce(new Error());
expect(service.remove(1)).rejects.toThrowError();
expect(service.remove).toHaveBeenCalledTimes(1);
});
});
});
```
Testes dos controllers ok, vamos para os services.
### Testando os services
Sem muitas mudanças para cá também, faremos o mesmo que nos controllers, exceto pelo fato de que a dependência deixa de ser o serviço (óbvio, pois estamos no serviço rs) e passa a ser o nosso repository.
Trecho para prestar atenção:
```typescript
// src/categorias/categorias.service.spec.ts
...
beforeEach(async () => {
const module: TestingModule = await Test.createTestingModule({
providers: [
CategoriasService,
{
provide: getRepositoryToken(Categoria),
useValue: {
save: jest.fn().mockResolvedValue(categoriasStub[0]),
find: jest.fn().mockResolvedValue(categoriasStub),
findOne: jest.fn().mockResolvedValue(categoriasStub[0]),
update: jest.fn().mockResolvedValue(categoriasStub[0]),
remove: jest.fn().mockResolvedValue(categoriasStub[0]),
},
},
],
}).compile();
service = module.get<CategoriasService>(CategoriasService);
repository = module.get(getRepositoryToken(Categoria));
});
...
```
Dada a devida atenção para o que muda dos controllers, vamos para as implementações dos services.
#### Testando nosso categorias.service
```bash
npm run test:watch -t /home/gabriel/Documentos/alura-challenges-2/src/categorias/categorias.service.spec.ts
# substitua essa parte '/home/gabriel/Documentos' pelo caminho do seu computador, é claro.
```
O código para testar nosso service de categorias ficará assim:
```typescript
// src/categorias/categorias.service.spec.ts
import { Test, TestingModule } from '@nestjs/testing';
import { CategoriasService } from './categorias.service';
import { getRepositoryToken } from '@nestjs/typeorm';
import { Categoria } from './entities/categoria.entity';
import { categoriasStub } from '../common/test/categorias.stub';
import { Repository } from 'typeorm';
describe('CategoriasService', () => {
let service: CategoriasService;
let repository: Repository<Categoria>;
beforeEach(async () => {
const module: TestingModule = await Test.createTestingModule({
providers: [
CategoriasService,
{
provide: getRepositoryToken(Categoria),
useValue: {
save: jest.fn().mockResolvedValue(categoriasStub[0]),
find: jest.fn().mockResolvedValue(categoriasStub),
findOne: jest.fn().mockResolvedValue(categoriasStub[0]),
update: jest.fn().mockResolvedValue(categoriasStub[0]),
remove: jest.fn().mockResolvedValue(categoriasStub[0]),
},
},
],
}).compile();
service = module.get<CategoriasService>(CategoriasService);
repository = module.get(getRepositoryToken(Categoria));
});
it('should be defined', () => {
expect(service).toBeDefined();
expect(repository).toBeDefined();
});
describe('save', () => {
it('should create a category', async () => {
const newCategory: Omit<Categoria, 'id'> = categoriasStub[0];
const result = await service.create(newCategory);
expect(result).toEqual(categoriasStub[0]);
expect(repository.save).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'save').mockRejectedValueOnce(new Error());
expect(service.create(categoriasStub[0])).rejects.toThrowError();
expect(repository.save).toHaveBeenCalledTimes(1);
});
});
describe('findAll', () => {
it('should return a categories list', async () => {
const result = await service.findAll();
expect(result).toEqual(categoriasStub);
expect(repository.find).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'find').mockRejectedValueOnce(new Error());
expect(service.findAll()).rejects.toThrowError();
expect(repository.find).toHaveBeenCalledTimes(1);
});
});
describe('findOne', () => {
it('should return a category', async () => {
const result = await service.findOne(categoriasStub[0].id);
expect(result).toEqual(categoriasStub[0]);
expect(repository.findOne).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'findOne').mockRejectedValueOnce(new Error());
expect(service.findOne(1)).rejects.toThrowError();
expect(repository.findOne).toHaveBeenCalledTimes(1);
});
});
describe('update', () => {
it('should return a updated category', async () => {
const result = await service.update(
categoriasStub[0].id,
categoriasStub[0],
);
expect(result).toEqual(categoriasStub[0]);
expect(repository.update).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'update').mockRejectedValueOnce(new Error());
expect(service.update(1, categoriasStub[0])).rejects.toThrowError();
expect(repository.update).toHaveBeenCalledTimes(1);
});
});
describe('remove', () => {
it('should return a removed category', async () => {
const result = await service.remove(categoriasStub[0].id);
expect(result).toEqual(categoriasStub[0]);
expect(repository.remove).toHaveBeenCalledTimes(1);
expect(repository.findOne).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'remove').mockRejectedValueOnce(new Error());
expect(service.remove(1)).rejects.toThrowError();
expect(repository.findOne).toHaveBeenCalledTimes(1);
});
});
});
```
#### Testando nosso videos.service
E para o nossos testes do service de videos:
```bash
npm run test:watch -t /home/gabriel/Documentos/alura-challenges-2/src/videos/videos.service.spec.ts
# substitua essa parte '/home/gabriel/Documentos' pelo caminho do seu computador, é claro.
```
```typescript
// src/videos/videos.service.spec.ts
import { Test, TestingModule } from '@nestjs/testing';
import { getRepositoryToken } from '@nestjs/typeorm';
import { Repository } from 'typeorm';
import { videosStub } from '../common/test/videos.stub';
import { Video } from './entities/video.entity';
import { VideosService } from './videos.service';
describe('VideosService', () => {
let service: VideosService;
let repository: Repository<Video>;
beforeEach(async () => {
const module: TestingModule = await Test.createTestingModule({
providers: [
VideosService,
{
provide: getRepositoryToken(Video),
useValue: {
save: jest.fn().mockResolvedValue(videosStub[0]),
find: jest.fn().mockResolvedValue(videosStub),
findOne: jest.fn().mockResolvedValue(videosStub[0]),
update: jest.fn().mockResolvedValue(videosStub[0]),
remove: jest.fn().mockResolvedValue(videosStub[0]),
},
},
],
}).compile();
service = module.get<VideosService>(VideosService);
repository = module.get(getRepositoryToken(Video));
});
it('should be defined', () => {
expect(service).toBeDefined();
expect(repository).toBeDefined();
});
describe('save', () => {
const newVideo: Omit<Video, 'id'> = videosStub[0];
it('should create a video', async () => {
const result = await service.create(newVideo);
expect(result).toEqual(videosStub[0]);
expect(repository.save).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'save').mockRejectedValueOnce(new Error());
expect(service.create(videosStub[0])).rejects.toThrowError();
expect(repository.save).toHaveBeenCalledTimes(1);
});
});
describe('findAll', () => {
it('should return a videos list if search is not informed', async () => {
const result = await service.findAll();
expect(result).toEqual(videosStub);
expect(repository.find).toHaveBeenCalledTimes(1);
});
it('should return a videos list if search is informed', async () => {
//Arrange
const expectedResult = videosStub.filter((video) =>
video.titulo?.includes('teste'),
);
jest.spyOn(repository, 'find').mockResolvedValue(expectedResult);
//Act
const result = await service.findAll('teste');
//Assert
expect(result).toEqual([]);
expect(repository.find).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'find').mockRejectedValueOnce(new Error());
expect(service.findAll()).rejects.toThrowError();
expect(repository.find).toHaveBeenCalledTimes(1);
});
});
describe('findOne', () => {
it('should return a video', async () => {
const result = await service.findOne(videosStub[0].id);
expect(result).toEqual(videosStub[0]);
expect(repository.findOne).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'findOne').mockRejectedValueOnce(new Error());
expect(service.findOne(1)).rejects.toThrowError();
expect(repository.findOne).toHaveBeenCalledTimes(1);
});
});
describe('update', () => {
it('should return a updated video', async () => {
const result = await service.update(videosStub[0].id, videosStub[0]);
expect(result).toEqual(videosStub[0]);
expect(repository.update).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'update').mockRejectedValueOnce(new Error());
expect(service.update(1, videosStub[0])).rejects.toThrowError();
expect(repository.update).toHaveBeenCalledTimes(1);
});
});
describe('remove', () => {
it('should return a removed video', async () => {
const result = await service.remove(videosStub[0].id);
expect(result).toEqual(videosStub[0]);
expect(repository.remove).toHaveBeenCalledTimes(1);
expect(repository.findOne).toHaveBeenCalledTimes(1);
});
it('should throw an exception', () => {
jest.spyOn(repository, 'remove').mockRejectedValueOnce(new Error());
expect(service.remove(1)).rejects.toThrowError();
expect(repository.findOne).toHaveBeenCalledTimes(1);
});
});
});
```
E com isso, fechamos as implementações da segunda semana.
Aaaah, estou fazendo meus commits conforme vou implementando as coisas... (Padronizadinho, conforme configuramos no início)
Está lá no meu [Github](https://github.com/delucagabriel).
Abraços e até a próxima semana! | delucagabriel |
788,731 | Pandas Core Components - The Data Frame Object
| • The DataFrame Object • 1. Constructing a DataFrame From a Series Object • 2. Constructing a... | 0 | 2021-08-11T19:11:05 | https://dev.to/222010301035/pandas-core-components-the-data-frame-object-4dl1 | dataframe, pandas, series, columns | • The DataFrame Object
• 1. Constructing a DataFrame From a Series Object
• 2. Constructing a DataFrame From a Dictionary
• 3. Constructing a Dataframe by Importing Data From a File
The DataFrame Object #
In the previous lesson, we learned about Series. The next fundamental
structure in Pandas that we will learn about is the DataFrame. While a Series
is essentially a column, a DataFrame is a multi-dimensional table made
up of a collection of Series. Dataframes allow us to store and manipulate
tabular data where rows consist of observations and columns represent
variables.
There are several ways to create a DataFrame using pd.DataFrame() . For
example, we can create a DataFrame by passing multiple Series into the
DataFrame object, we can convert a dictionary to a DataFrame or we can
import data from a csv file. Let’s look at each of these in detail.
1. Constructing a DataFrame From a Series Object #
We can create a DataFrame from a single Series by passing the Series object as
input to the DataFrame creation method, along with an optional input
parameter, column, which allows us to name the columns:
import pandas as pd
data_s1 = pd.Series([12, 24, 33, 15],
index=['apples', 'bananas', 'strawberries', 'oranges'])
# 'quantity' is the name for our column
dataframe1 = pd.DataFrame(data_s1, columns=['quantity'])
print(dataframe1)
2. Constructing a DataFrame From a Dictionary #
We can construct a DataFrame form any list of dictionaries. Say we have a
dictionary with countries, their capitals and some other variable (population,
size of that country, number of schools, etc.):
dict = {"country": ["Norway", "Sweden", "Spain", "France"],
"capital": ["Oslo", "Stockholm", "Madrid", "Paris"],
"SomeColumn": ["100", "200", "300", "400"]}
data = pd.DataFrame(dict)
print(data)
We can also construct a DataFrame from a dictionary of Series objects. Say we
have two different Series; one for the price of fruits and one for their quantity.
We want to put all the fruits related data together into a single table. We can
do this like so:
import pandas as pd
quantity = pd.Series([12, 24, 33, 15],
index=['apples', 'bananas', 'strawberries', 'oranges'])
price = pd.Series([4, 4.5, 8, 7.5],
index=['apples', 'bananas', 'strawberries', 'oranges'])
df = pd.DataFrame({'quantity': quantity,
'price': price})
print(df)
3. Constructing a Dataframe by Importing Data From a File #
It’s quite simple to load data from various file formats, e.g., CSV, Excel, json
into a DataFrame. We will be importing actual data for analyzing the IMDB-
movies dataset in the next lesson. Here is what loading data from different file
formats looks like in code:
import pandas as pd
# Given we have a file called data1.csv in our working directory:
df = pd.read_csv('data1.csv')
#given json data
df = pd.read_json('data2.json')
We have only just scratched the surface and learned how to construct
DataFrames. In the next lessons we will go deeper and learn-by-doing the
many methods that we can call on these powerful objects. | 222010301035 |
788,755 | Testing Authenticated Routes in AdonisJS | If you haven't created an AdonisJS 5.0 app yet, you can check out my previous post or follow the... | 0 | 2021-08-12T00:22:59 | https://warrenwong.org/posts/testing-authenticated-routes-in-adonisjs | adonisjs, node, testing, typescript | ---
title: Testing Authenticated Routes in AdonisJS
published: true
date: 2021-08-11 00:00:00 UTC
tags: [AdonisJS, NodeJS, Testing, TypeScript]
canonical_url: https://warrenwong.org/posts/testing-authenticated-routes-in-adonisjs
---
> If you haven't created an AdonisJS 5.0 app yet, you can check out my [previous post](https://warrenwong.org/posts/posts/setting-up-vscode-for-adonisjs) or follow the docs [here](https://preview.adonisjs.com/guides/quick-start).
> We'll be testing authenticated routes, so if you haven't added authentication to your AdonisJS project, take a look at **[Add Authentication to Your AdonisJS Project](https://warrenwong.org/posts/posts/add-authentication-to-adonisjs)**. For some background on the libraries used, check out [this post](https://docs.adonisjs.com/cookbooks/testing-adonisjs-apps#sidenav-open) [Aman Virk](https://twitter.com/AmanVirk1) wrote.
## Set Up the Test Runner
So it's time to add tests to your brand new AdonisJS project, but what to do? AdonisJS doesn't come with a test-runner out-of-the-box at the moment. Well, for the most part, it's fairly simple if you just follow these simple steps.
First, install the dependencies:
```bash
# npm
npm i -D japa execa get-port supertest @types/supertest jsdom @types/jsdom
# yarn
yarn add -D japa execa get-port supertest @types/supertest jsdom @types/jsdom
```
Now, just copy `japaFile.ts` from the [article here](https://docs.adonisjs.com/cookbooks/testing-adonisjs-apps#interacting-with-the-database). We'll need to interact with the database so just copy it verbatim and place it at the base directory of the project:
```ts
import { HttpServer } from "@adonisjs/core/build/src/Ignitor/HttpServer";
import execa from "execa";
import getPort from "get-port";
import { configure } from "japa";
import { join } from "path";
import "reflect-metadata";
import sourceMapSupport from "source-map-support";
process.env.NODE_ENV = "testing";
process.env.ADONIS_ACE_CWD = join(__dirname);
sourceMapSupport.install({ handleUncaughtExceptions: false });
export let app: HttpServer;
async function runMigrations() {
await execa.node("ace", ["migration:run"], {
stdio: "inherit",
});
}
async function rollbackMigrations() {
await execa.node("ace", ["migration:rollback"], {
stdio: "inherit",
});
}
async function startHttpServer() {
const { Ignitor } = await import("@adonisjs/core/build/src/Ignitor");
process.env.PORT = String(await getPort());
app = new Ignitor(__dirname).httpServer();
await app.start();
}
async function stopHttpServer() {
await app.close();
}
configure({
files: ["test/**/*.spec.ts"],
before: [runMigrations, startHttpServer],
after: [stopHttpServer, rollbackMigrations],
});
```
To run the test, we'll create a test script in our `package.json` file:
```json
{
"scripts": {
"test": "node -r @adonisjs/assembler/build/register japaFile.ts"
}
}
```
When working locally, I like to have a different database for `dev` and `testing`. AdonisJS can read the `.env.testing` file when `NODE_ENV=testing`, which was set in the `japaFile.ts` file. The easiest thing to do is to copy the `.env` file and rename it to `.env.testing`. Then go and add `_test` to the end of the current database name you have for your dev environment.
```bash
...
PG_DB_NAME=todos_test
```
Since we configured our test runner to look in the `test` directory for any file with the `.spec.ts` extension, we can just place any file matching that pattern in the test directory, and we will run it with the `npm test` command.
## Set Up the Authentication Secured Routes (To-dos)
As with any tutorial, we want to have a simple, but practical, example. Let's just use a Tt-do list app as an example. Let's go over what we want to do with our To-dos.
I want a user to be signed-in in order to create and/or update a todo. What good are todos if no one can see them? So let's allow anyone to look at the list of todos, as well as look at each individual todo. I don't think I want anyone to delete a todo, maybe just to change the status (Open, Completed, or Closed).
Let's leverage the generators to create the model, controller, and migration.
### Let's `make:migration`
```bash
node ace make:migration todos
```
Let's add a `name`, a `description`, and a foreign key of `user_id` to our new table:
```ts
import BaseSchema from "@ioc:Adonis/Lucid/Schema";
export default class Todos extends BaseSchema {
protected tableName = "todos";
public async up() {
this.schema.createTable(this.tableName, table => {
table.increments("id");
table.string("name").notNullable();
table.text("description");
table.integer("user_id").notNullable();
/**
* Uses timestamptz for PostgreSQL and DATETIME2 for MSSQL
*/
table.timestamp("created_at", { useTz: true });
table.timestamp("updated_at", { useTz: true });
table.foreign("user_id").references("users_id");
});
}
public async down() {
this.schema.dropTable(this.tableName);
}
}
```
Run the migration:
```bash
node ace migration:run
```
### Let's `make:model`
```bash
node ace make:model Todo
```
We'll want to add the same 3 fields we added to our migration, but we'll also want to add a `belongsTo` relationship to our model linking the `User` through the `creator` property:
```ts
import { BaseModel, BelongsTo, belongsTo, column } from "@ioc:Adonis/Lucid/Orm";
import { DateTime } from "luxon";
import User from "App/Models/User";
export default class Todo extends BaseModel {
@column({ isPrimary: true })
public id: number;
@column()
public userId: number;
@column()
public name: string;
@column()
public description: string;
@belongsTo(() => User)
public creator: BelongsTo<typeof User>;
@column.dateTime({ autoCreate: true })
public createdAt: DateTime;
@column.dateTime({ autoCreate: true, autoUpdate: true })
public updatedAt: DateTime;
}
```
Add the corresponding `hasMany` relationship to the `User` model now:
```ts
...
import Todo from "App/Models/Todo";
export default class User extends BaseModel {
...
@hasMany(() => Todo)
public todos: HasMany<typeof Todo>;
...
}
```
### Let's `make:controller`
```bash
node ace make:controller Todo
```
Now let's add our new `/todos` path to the `routes.ts` file:
```ts
...
Route.resource("todos", "TodosController").except(["destroy"]).middleware({
create: "auth",
edit: "auth",
store: "auth",
update: "auth",
});
```
Here, we want a RESTful resource, except `destroy`. I also want the request to run through the "auth" middleware for the `create`, `edit`, `store`, and `update` resources. Basically, anyone can view `index` and `show`, but anything else will require authentication.
We can see a list of our new routes with the `node ace list:routes` command. It's handy that it show which routes require authentication. It also lists the route names (handy for redirecting the linking).
```
┌────────────┬────────────────────────────────────┬────────────────────────────┬────────────┬────────────────────────┐
│ Method │ Route │ Handler │ Middleware │ Name │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ HEAD, GET │ / │ Closure │ │ home │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ HEAD, GET │ /login │ SessionsController.create │ │ login │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ POST │ /login │ SessionsController.store │ │ │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ POST │ /logout │ SessionsController.destroy │ │ │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ HEAD, GET │ /register │ UsersController.create │ │ │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ POST │ /register │ UsersController.store │ │ │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ HEAD, GET │ /users/:id │ UsersController.show │ │ users.show │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ HEAD, GET │ /todos │ TodosController.index │ │ todos.index │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ HEAD, GET │ /todos/create │ TodosController.create │ auth │ todos.create │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ POST │ /todos │ TodosController.store │ auth │ todos.store │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ HEAD, GET │ /todos/:id │ TodosController.show │ │ todos.show │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ HEAD, GET │ /todos/:id/edit │ TodosController.edit │ auth │ todos.edit │
├────────────┼────────────────────────────────────┼────────────────────────────┼────────────┼────────────────────────┤
│ PUT, PATCH │ /todos/:id │ TodosController.update │ auth │ todos.update │
└────────────┴────────────────────────────────────┴────────────────────────────┴────────────┴────────────────────────┘
```
## Back to Our Tests
Let's create a new test file called `test/functional/todos.spec.ts`. While I normally just start writing tests as I they come to my head, that's probably not idea. For just a high level overview, I know I'd like to test the To-do features. So far, it's just creating, saving, editing, and updating. Also, I'd want to make sure I test that anyone can access the `index` and `show` routes, but only an authenticated user can see the others.
### Testing "To-dos"
- Todo list shows up at the `index` route.
- Individual todo shows up a the `show` route.
- Create a todo and check the `show` route to see if it exists.
- Edit a todo and check the `show` route to see if the data is updated.
- Navigate to the `create` route without logging in to test if we get redirected to the sign-in page.
- Navigate to the `edit` route without loggin in to test if we get redirected to the sign-in page.
This should cover it for now. As always, feel free to add more if you feel like it.
## Write the tests
### Testing the `index` Route
Anyone should be able to view the list of todos. A good question to ask is what should someone see if there are no todos to see (the null state). Well, there should at least be a link to the `create` route to create a new todo. If there are todos, we should show them.
First, let's start off testing for a page to load when we go to the `index` route, `/todos`. I have an inkling that I will massively refactor this later, but let's just start out simple. No point in premature optimization, expecially if it turns out we need less tests than we think.
```ts
import supertest from "supertest";
import test from "japa";
const baseUrl = `http://${process.env.HOST}:${process.env.PORT}`;
test.group("Todos", () => {
test("'index' should show a link to create a new todo", async assert => {
await supertest(baseUrl).get("/todos").expect(200);
});
});
```
Here we use the [supertest](https://github.com/visionmedia/supertest) library to see if we get a status of 200 back when we navigate to `/todos`. After running the test with `npm test`, it looks like we forgot to even open up our controller file.
```
Missing method "index" on "TodosController"
...
✖ 'index' should show a link to create a new todo
Error: expected 200 "OK", got 500 "Internal Server Error"
```
Let's go a create that `index` method and the Edge template that goes along with it:
```ts
import { HttpContextContract } from "@ioc:Adonis/Core/HttpContext";
export default class TodosController {
public async index({ view }: HttpContextContract) {
return await view.render("todos/index");
}
}
```
```bash
node ace make:view todos/index
```
```handlebars
@layout('layouts/default')
@section('body')
<a href="{{ route('todos.create') }}">Create Todo</a>
@endsection
```
Looks like we're passing the tests after adding this little bit of code. Red-green-refactor FTW!
Let's add some more to our test. I want to test for that link.
```ts
test("'index' should show a link to create a new todo", async assert => {
const { text } = await supertest(baseUrl).get("/todos").expect(200);
const { document } = new JSDOM(text).window;
const createTodosLink = document.querySelector("#create-todo");
assert.exists(createTodosLink);
});
```
Here I want to query the document for an element with the `create-todos` `id`. Once I put the `id` on my "Create Todo" link, I should be green again.
```handlebars
<a href="{{ route('todos.create') }}" id="create-todo">Create Todo</a>
```
Now comes time to actually persist some `Todo`s in the database and test to see if we can see them on `/todos`. Let's just simply create 2 new todos and test for their existence on the page.
```ts
test("'index' should show all todos created", async assert => {
const items = ["Have lunch", "Grocery shopping"];
items.forEach(async name => await Todo.create({ name }));
const { text } = await supertest(baseUrl).get("/todos");
assert.include(text, items[0]);
assert.include(text, items[1]);
});
```
This looks simple enough. Let's create 2 `Todo`s, "Have lunch" and "Grocery shopping". Once these are saved, I should be able to navigate to `/todos` and see both. Since we're doing red-green-refactor, let's run our tests first to get our "red" before we try to turn it "green" by implementing our solution.
```
"uncaughtException" detected. Process will shutdown
error: insert into "todos" ("created_at", "name", "updated_at") values ($1, $2, $3) returning "id" - null value in column "user_id" of relation "todos" violates not-null constraint
```
Oops, looks like we forgot to add a `user_id` to our `Todo`. Let's create a user first, then add these `Todo`s as "related" to the `User`.
```ts
test("'index' should show all todos created", async assert => {
const items = ["Have lunch", "Grocery shopping"];
const user = await User.create({ email: "alice@email.com", password: "password" });
await user.related("todos").createMany([{ name: items[0] }, { name: items[1] }]);
const { text } = await supertest(baseUrl).get("/todos");
assert.include(text, items[0]);
assert.include(text, items[1]);
});
```
Okay, now we're still not passing, but we don't have that knarly "uncaughtException" anymore. Now let's render out our list of todos. To do that, we'll need to query for the list of all todos in the controller, and then pass it to our view.
```ts
import Todo from "App/Models/Todo";
export default class TodosController {
public async index({ view }: HttpContextContract) {
const todos = await Todo.all();
return await view.render("todos/index", { todos });
}
}
```
```handlebars
@section('body')
<ul>
@each(todo in todos)
<li>{{ todo.name }}</li>
@endeach
</ul>
<a href="{{ route('todos.create') }}" id="create-todo">Create Todo</a>
@endsection
```
Awesome. Back to "green".
Now let's work on the `show` route. We should be able to navigate there once the todo has been created.
```ts
test.group("Todos", () => {
...
test("'show' should show the todo details", async assert => {
const user = await User.create({ email: "alice@email.com", password: "password" });
const todo = await user
.related("todos")
.create({ name: "Buy shoes", description: "Air Jordan 1" });
const { text } = await supertest(baseUrl).get(`/todos/${todo.id}`);
assert.include(text, todo.name);
assert.include(text, todo.description);
});
});
```
We're flying now. Our tests seem to have a lot of similar setup code. Possible refactor candidate. I'll note that for later.
```ts
export default class TodosController {
...
public async show({ params, view }: HttpContextContract) {
const id = params["id"];
const todo = await Todo.findOrFail(id);
return await view.render("todos/show", { todo });
}
}
```
As with the `index` route, we'll need to create the view for our `show` route:
```bash
node ace make:view todos/show
```
```handlebars
@layout('layouts/default')
@section('body')
<h1>{{ todo.name }}</h1>
<p>{{ todo.description }}</p>
@endsection
```
Great, let's run the tests to see where we're at.
```
✖ 'show' should show the todo details
error: insert into "users" ("created_at", "email", "password", "updated_at") values ($1, $2, $3, $4) returning "id" - duplicate key value violates unique constraint "users_email_unique"
```
Okay, you might have already thought, why's this guy creating another `User` with the same email? Well, what if I created this user in a test that's at the bottom of the file separated by hundreds of lines? What if the user was created for a test in another file? It would be really hard if we had to depend on some database state created who knows where.
Let's make sure we start each test, as if the database were brand new. Let's add some setup and teardown code:
```ts
test.group("Todos", group => {
group.beforeEach(async () => {
await Database.beginGlobalTransaction();
});
group.afterEach(async () => {
await Database.rollbackGlobalTransaction();
});
...
});
```
Alright! Back to green. So far, we've knocked off 2 tests from our "Testing todos" list we wrote before we started all the testing work.
Now it's time to tackle the `create` and `update` tests. Let's start it off like we started the others, with a test. Let's turn our "green" tests back to "red".
```ts
test("'create' should 'store' a new `Todo` in the database", async assert => {
const { text } = await supertest(baseUrl).get("/todos/create").expect(200);
const { document } = new JSDOM(text).window;
const createTodoForm = document.querySelector("#create-todo-form");
assert.exists(createTodoForm);
});
```
```
✖ 'create' should 'store' a new `Todo` in the database
Error: expected 200 "OK", got 302 "Found"
```
Ahh, there we go. Our first issue with authentication. We need to be signed in to view this route, but how can we do that? After some Googling, looks like the `supertest` library has our solution. `supertest` allows you to access [`superagent`](https://github.com/visionmedia/superagent), which will retain the session cookies between requests, so we'll just need to "register" a new user prior to visiting the `store` route.
```ts
test("'create' should 'store' a new `Todo` in the database", async assert => {
const agent = supertest.agent(baseUrl);
await User.create({ email: "alice@email.com", password: "password" });
await agent
.post("/login")
.field("email", "alice@email.com")
.field("password", "password");
const { text } = await agent.get("/todos/create").expect(200);
const { document } = new JSDOM(text).window;
const createTodoForm = document.querySelector("#create-todo-form");
assert.exists(createTodoForm);
});
```
```ts
export default class TodosController {
...
public async create({ view }: HttpContextContract) {
return await view.render("todos/create");
}
}
```
```bash
node ace make:view todos/create
```
```handlebars
@layout('layouts/default')
@section('body')
<form action="{{ route('todos.store') }}" method="post" id="create-todo-form">
<div>
<label for="name"></label>
<input type="text" name="name" id="name">
</div>
<div>
<label for="description"></label>
<textarea name="description" id="description" cols="30" rows="10"></textarea>
</div>
</form>
@endsection
```
We really are flying now. By adding the form with the `id` of `create-todo-form`, we're passing our tests again. We've checked that the form is there, but does it work? That's the real question. And from the experience of signing the user in with `supertest.agent`, we know that we just need to post to the `store` route with fields of `name` and `description`.
```ts
test("'create' should 'store' a new `Todo` in the database", async assert => {
...
await agent
.post("/todos")
.field("name", "Clean room")
.field("description", "It's filthy!");
const todo = await Todo.findBy("name", "Clean room");
assert.exists(todo);
});
```
Okay, back to "red" with a missing `store` method on `TodosController`. By now, you don't even need to read the error message and you'll know what to do. But still, it's nice to run the tests at every step so you only work on the smallest bits to get your tests to turn back "green".
```ts
import Todo, { todoSchema } from "App/Models/Todo";
...
export default class TodosController {
...
public async store({
auth,
request,
response,
session,
}: HttpContextContract) {
const { user } = auth;
if (user) {
const payload = await request.validate({ schema: todoSchema });
const todo = await user.related("todos").create(payload);
response.redirect().toRoute("todos.show", { id: todo.id });
} else {
session.flash({ warning: "Something went wrong." });
response.redirect().toRoute("login");
}
}
}
```
```ts
import { schema } from "@ioc:Adonis/Core/Validator";
...
export const todoSchema = schema.create({
name: schema.string({ trim: true }),
description: schema.string(),
});
```
We're doing a little more with this one. First off, the signed in user is already exists in the context of the application and is accessible through the `auth` property. I created a schema called `todoSchema` which is used to validate the data passed from the form. This does 2 things that I don't have to worry about explicitly, if there are any errors, those errors will be available from `flashMessages` upon the next view render (which will be the `create` form). The resulting `payload` can be used directly to create the new `Todo`.
If, for some reason, I don't find the signed in user from `auth`, I can flash a warning message and redirect the user back to the login screen.
Now let's test our `edit` route. Since I had to sign for this test as well, I extracted that functionality to a helper function called `loginUser`. `agent` retains the session cookies and the `User` is returned to use to associate the newly created `Todo`. I update the `name` and `description` of the `Todo` then navigate to the `show` route and make sure the updated values exist on the page.
```ts
test.group("Todos", group => {
...
test("'edit' should 'update' an existing `Todo` in the database", async assert => {
const user = await loginUser(agent);
const todo = await user.related("todos").create({
name: "See dentist",
description: "Root canal",
});
await agent.get(`/todos/${todo.id}/edit`).expect(200);
await agent
.put(`/todos/${todo.id}`)
.field("name", "See movie")
.field("name", "Horror flick!");
const { text } = await agent.get(`/todos/${todo.id}`).expect(200);
assert.include(text, "See movie");
assert.include(text, "Horror flick!");
});
});
async function loginUser(agent: supertest.SuperAgentTest) {
const user = await User.create({
email: "alice@email.com",
password: "password",
});
await agent
.post("/login")
.field("email", "alice@email.com")
.field("password", "password");
return user;
}
```
As with the `create` test, the `edit` should show a form, but prepopulated with the current values. For now, let's just copy the `todos/create` view template for `todos/edit`. We'll need to update the values of the input and textarea elements with the current values.
```ts
export default class TodosController {
...
public async edit({ params, view }: HttpContextContract) {
const id = params["id"];
const todo = Todo.findOrFail(id);
return await view.render("todos/edit", { todo });
}
}
```
```bash
node ace make:view todos/edit
```
```handlebars
@layout('layouts/default')
@section('body')
<form action="{{ route('todos.update', {id: todo.id}, {qs: {_method: 'put'}}) }}" method="post" id="edit-todo-form">
<div>
<label for="name"></label>
<input type="text" name="name" id="name" value="{{ flashMessages.get('name') || todo.name }}">
</div>
<div>
<label for="description"></label>
<textarea name="description" id="description" cols="30" rows="10">
{{ flashMessages.get('description') || todo.description }}
</textarea>
</div>
<div>
<input type="submit" value="Create">
</div>
</form>
@endsection
```
Here we need to do some [method spoofing](https://docs.adonisjs.com/cookbooks/validating-server-rendered-forms#form-method-spoofing), thus you see the strange action. This is just a way for AdonisJS spoof `PUT`, since HTTP only has `GET` and `POST`. You'll have to go to the `app.ts` file and set `allowMethodSpoofing` to `true`.
```ts
export const http: ServerConfig = {
...
allowMethodSpoofing: true,
...
}
```
```ts
public async update({ params, request, response }: HttpContextContract) {
const id = params["id"];
const payload = await request.validate({ schema: todoSchema });
const todo = await Todo.updateOrCreate({ id }, payload);
response.redirect().toRoute("todos.show", { id: todo.id });
}
```
The last 2 tests we need to write are to check that going to `create` or `edit` redirects us to the sign-in page. There isn't any implementation since these are already done, but the negative case test is nice to have in case something breaks in the future.
```ts
test("unauthenticated user to 'create' should redirect to signin", async assert => {
const response = await agent.get("/todos/create").expect(302);
assert.equal(response.headers.location, "/login");
});
test("unauthenticated user to 'edit' should redirect to signin", async assert => {
const user = await User.create({
email: "bob@email.com",
password: "password",
});
const todo = await user.related("todos").create({ name: "Go hiking" });
const response = await agent.get(`/todos/${todo.id}/edit`).expect(302);
assert.equal(response.headers.location, "/login");
});
```
These should both pass immediately. And now we're "green". We hit all the test cases we initially wanted to write, but our job is far from over. There's a fair bit of refactoring that needs to be done, not in the production code, but in the tests. If you see your tests as "documentation of intent", then there is definitely more editing to make things more clear.
While we're not done, this is a good place to stop. We've completed a feature. We have completed the tests we initially set out to write. We cycled between "red" and "green" several times. Now it's your turn. Are there any more tests you think you'd need to write. How about some refactoring? | wrrnwng |
788,842 | How to use Sunburst Chart in Excel 365? ~ Easy Tricks!! | Have you ever tried to Use Sunburst Chart on your Excel sheet? Do you have any good methods for... | 0 | 2021-08-18T12:54:50 | https://geekexcel.com/how-to-use-sunburst-chart-in-excel-365-easy-tricks/ | usesunburstchart | ---
title: How to use Sunburst Chart in Excel 365? ~ Easy Tricks!!
published: true
date: 2021-08-11 16:43:45 UTC
tags: UseSunburstChart
canonical_url: https://geekexcel.com/how-to-use-sunburst-chart-in-excel-365-easy-tricks/
---
Have you ever tried to **Use Sunburst Chart** on your Excel sheet? Do you have any good methods for solving this task in Excel? Here I will introduce you to some quick tricks to deal with this problem. Let’s get them below!! Get an official version of MS Excel from the following link: **[https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)**
## Create Sunburst Chart
- You need to **enter the data** in the Excel spreadsheet.
- For instance, we have created a list of **student mark list for each subject**.
<figcaption>List of student mark list for each subject</figcaption>
- Then, you have to **select the data** in Excel worksheet.
- Now, you need to go to the **Insert tab**.
- After that, you have to click on the **Insert Hierarchical charts** under the **Chart** section.
<figcaption>Click on the Insert Hierarchical charts</figcaption>
- Finally, you need to select **Sunburst Charts.**
<figcaption>Sunburst chart</figcaption>
## Wind-Up
Hope you like this article on **how to Use Sunburst Chart In Excel 365**. Let me know if you have any **doubts** regarding this article or any other Excel/VBA topic.
Thank you so much for visiting **[Geek Excel](https://geekexcel.com/)!! **If you want to learn more helpful formulas, check out [**Excel Formulas**](https://geekexcel.com/excel-formula/) **!! ** | excelgeek |
788,927 | We confuse visibility with competency | Perhaps there is a bit of a remote hiring boom at the moment, but I have noticed a massive uptick in... | 0 | 2021-08-25T03:50:49 | https://rachsmith.com/we-confuse-visibility-with-competency/ | work, development, productivity | ---
title: We confuse visibility with competency
published: true
date: 2021-08-11 20:43:04 UTC
tags: work,development,productivity
canonical_url: https://rachsmith.com/we-confuse-visibility-with-competency/
---
Perhaps there is a bit of a remote hiring boom at the moment, but I have noticed a massive uptick in the amount of solicitations from people wanting to "have a conversation" about hiring me in 2021. Almost always, people find their way to my inbox because they remember me from Twitter. I have a modest 16K+ following after all. I used to have more.
The reason I have that many followers is that I spent several years tweeting regularly. Sure, I've also written some coding articles, and created open source code via CodePens, and spoken at a few conferences. But most of my follower growth results from tweeting and interacting with other tweets.
Most people make this mistake, with engineers and developers on Twitter, where they assume the number of followers they have must correlate with how good of an engineer they are. When the only thing a sizeable Twitter following actually shows is how good they are at writing tweets. I would even argue that the more time you spend on Twitter, the less effective you probably are as an engineer.
This has certainly been the case in my personal experience. In 2016, I read Cal Newport's [Deep Work](https://www.calnewport.com/books/deep-work/) and had to face the fact that spending time on Twitter was seriously effecting my ability to produce good work. At that time I would often work for 20-30 minutes, check Twitter, work, check Twitter, repeat. You don't get much serious thinking done when you can focus on something for 25 minutes max before you're off riding the dopamine rollercoaster again.
I increased the time between social media checks while working, and then in 2020 I gave Twitter up all together. The quality of my work went up while the time I needed to spend on work went down, meaning I could get in, get it done, and spend more time on other things that are important to me.
Paradoxically, the less I use Twitter, the better I am at my day job, but also the less likely I am to get approached with opportunities to change my day job. So the thing that makes me a more desirable candidate is the thing that makes me less likely to be a candidate in the first place.
Please note, I'm not saying that it isn't possible to be a great engineer and also have a large following on Twitter. Such people definitely exist, and I'm sure they successfully straddle both because they have better boundaries around their Twitter usage than I ever did. But you can't convince me that someone who is checking Twitter all day long is producing quality work. I'm not buying it.
And yet, if someone new to Engineering asked me how to fast-track their career via job-hopping up the ladder, especially in the world of startups, I would suggest they get to tweeting. I would love to say that the most effective thing you could do is work on your skills, and the community will reward your hard work with new opportunities. But that would be dishonest, as unfortunately, it’s not how the world works.
<!--kg-card-end: markdown--> | rachsmith |
789,023 | Quick Notes Based On "Functions" Section of Frontend Masters' "Complete Intro to Web Development, v2" | What I did (in code) - 1 of 3: function addTwo() { return 5 + 2 } ... | 0 | 2021-08-12T03:49:32 | https://dev.to/benboorstein/quick-notes-based-on-functions-section-of-frontend-masters-complete-intro-to-web-development-v2-a5 | javascript, fundamentals, functions, frontendmasters | What I did (in code) - 1 of 3:
`function addTwo() {`
`return 5 + 2`
`}`
`console.log(addTwo())`
Logs: `7`
What I did (in English) - 1 of 3:
- The first block of code above (everything above `console.log...`) is the function definition (which can also be called a "function declaration" or "function statement").
- The function's name is `addTwo`, and because it's a function, it needs `()` after it.
- Inside the curly braces is what the `addTwo` function "returns". According to MDN, "The return statement ends function execution and specifies a value to be returned to the function caller." In the case of this `addTwo` function, what's returned is simple: `5 + 2`.
- Log to the console `addTwo()`. What is this? The `addTwo()` within the `()` of `console.log()` is the "function call". Notice that `addTwo()` here does not have the JavaScript keyword `function` in front of it (as it does in the function definition) nor any variable name or `=` or anything else in front of it. This is how you know it's the function call and not part of the function definition.
What I did (in code) - 2 of 3:
`function addTwo(num) {`
`return num + 2`
`}`
`console.log(addTwo(5))`
Logs: `7`
What I did (in English) - 2 of 3:
- This example is the same as the first example, with one small difference: Instead of using the number `5` directly in the body of the function definition, `num` (for "number") is being used instead. How do we know what `num` represents? Because `num` is "passed in" to `function addTwo(num)` and we can see that `5` is what's "passed in" to the function call. `num` is known as the "parameter", and `5` is known as the "argument". So the `addTwo` function takes a parameter of `num` which represents (i.e., is a stand-in for) the function call's argument, which is `5`. Why set this function up this way instead of the first way since it seems to just make things more complicated? Because having parameters makes a function more reusable. In other words, we can call this function as many times as we want, each time with a different argument. For instance, we could pass in an argument of `5`, as we did, or an argument of `6` or `7` or `103` or `3246945`, and so on.
What I did (in code) - 3 of 3:
`const birthCity = 'Ann Arbor'`
`const birthState = 'Michigan'`
`const birthCountry = 'USA'`
`function logBirthPlace(city, state, country) {`
`` console.log(`You were born in ${city}, ${state}, ${country}.`) ``
`}`
`console.log(logBirthPlace(birthCity, birthState, birthCountry))`
Logs: `You were born in Ann Arbor, Michigan, USA.`
What I did (in English) - 3 of 3:
- This example shows that a function can take multiple parameters and that, as a result, a function call can take multiple arguments.
What I practiced:
- Same as above.
What I learned:
- From the above code, I didn't learn anything new.
- From other parts of this section of instruction, I learned that generally it's a good idea (it's a good habit to form) to make function names verbs, because functions do something. I believe this was already my practice most of the time, but I hadn't thought of it in these simple terms before.
What I still might not understand:
- How to better describe (i.e., describe more explicitly, more clearly) a function definition, how `return` works, and how a function call works. | benboorstein |
789,239 | Generate Types from Contentful | I'm developing an app with nextjs and Contentful. https://fetools.vercel.app/ I think I implemented... | 0 | 2021-08-12T06:41:59 | https://dev.to/0xkoji/generate-types-from-contentful-49p8 | typescript, contentful | I'm developing an app with [nextjs](https://nextjs.org/) and [Contentful](https://www.contentful.com/).
https://fetools.vercel.app/
I think I implemented the basic functionality. So it is time to set up Typescript dev environment for this app.
In this post, I will introduce you how to generate types from Contentful data model.
Actually, the steps are quite straightforward if you read the repo `carefully` and follow the steps `carefully`.
{% github intercom/contentful-typescript-codegen %}
The steps are below.
Step1. Install packages
Step2. Add a script to package.json
Step3. Put tokens on `.env` file
Step4. Add `getContentfulEnvironment.js`
Step5. Run the command (from Step2)
### Step1. Install packages
This step is very easy.
If you didn't install packages for TypeScript, you would need the following.
```zsh
# yarn
$ yarn add -D typescript @types/react @types/react-dom @types/node
# npm
$ npm i -D typescript @types/react @types/react-dom @types/node
```
```zsh
# yarn
$ yarn add -D contentful-typescript-codegen contentful-management dotenv
# npm
$ npm i -D contentful-typescript-codegen contentful-management dotenv
```
### Step2. Add a script to package.json
This step is also easy.
If you use next.js, the last script may be `lint`. So, you just need add the below after the `,`
```json
"scripts": {
"contentful-typescript-codegen": "contentful-typescript-codegen --output @types/generated/contentful.d.ts"
}
```
Here is mine. Basically, we won't need to execute this after generating types, so the long name is totally fine, but I like a simple command, so I set `codegen` as a command.
This is totally up to you.
```json
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "eslint src --ext .js",
"format": "prettier --write --ignore-path .gitignore './**/*.{js,jsx,ts,tsx,json,css}'",
"codegen": "contentful-typescript-codegen --output @types/generated/contentful.d.ts"
},
```
### Step3. Put tokens on `.env` file
This step isn't difficult but I took some time to generate types because I didn't read the instruction/readme carefully.
In this step, we need to generate a new token.
Login Contentful > Settings > API Keys
If you use Contentful, you have `Space ID`, `Content Delivery API - access token`, `Content Preview API - access token`, and `Environments & Environment Aliases`
What we need to set to generate Types is `Content management tokens`. I used Content Delivery API instead of that and got 403 error. I was like whyyyyyyyyyyy 🤬 🤬 🤬 lol.
I believe the most important thing in this post is to generate `Content management tokens` lol.
```zsh
AccessTokenInvalid: {
"status": 403,
"statusText": "Forbidden",
"message": "The access token you sent could not be found or is invalid.",
"details": {},
"request": {
```
After generating the token, you will need to add it to `.env` file.
```
CONTENTFUL_SPACE_ID=aaaaaa
CONTENTFUL_ACCESS_TOKEN=bbbbb
CONTENTFUL_ENVIRONMENT=master
NEXT_PUBLIC_GOOGLE_ANALYTICS=ccccc
CONTENTFUL_PREVIEW_TOKEN=ddddddd
CONTENTFUL_MANAGEMENT_API_ACCESS_TOKEN=eeeeee <- new!!!
```
### Step4. Add `getContentfulEnvironment.js`
getContentfulEnvironment.js needs three items from `.env`.
- CONTENTFUL_MANAGEMENT_API_ACCESS_TOKEN
- CONTENTFUL_SPACE_ID
- CONTENTFUL_ENVIRONMENT
```js
require('dotenv').config();
const contentfulManagement = require('contentful-management');
// console.log('accessToken', process.env.CONTENTFUL_ACCESS_TOKEN);
module.exports = function () {
const contentfulClient = contentfulManagement.createClient({
accessToken: process.env.CONTENTFUL_MANAGEMENT_API_ACCESS_TOKEN,
});
return contentfulClient
.getSpace(process.env.CONTENTFUL_SPACE_ID)
.then((space) => space.getEnvironment(process.env.CONTENTFUL_ENVIRONMENT));
};
```
Step5. Run the command (from Step2)
We are almost there.
Finally we need to run the command.
```zsh
# yarn
$ yarn codegen
# npm
$ npm run codegen
```
The command works properly, you will see `@types/generated/contentful.d.ts` under the root folder.
The following is mine.
```ts
// THIS FILE IS AUTOMATICALLY GENERATED. DO NOT MODIFY IT.
import { Asset, Entry } from 'contentful';
import { Document } from '@contentful/rich-text-types';
export interface IFeToolsFields {
/** Title */
title: string;
/** Thumbnail */
thumbnail?: Asset | undefined;
/** Link */
link: string;
/** Tag */
tag?: string[] | undefined;
/** Description */
description?: string | undefined;
/** Category */
category: 'font' | 'html/css' | 'image' | 'js/ts' | 'other';
}
```
As I emphasized the very top, the process is very straightforward and easy if you read the instruction carefully. Hope you won't waste time like me 😜 | 0xkoji |
789,254 | Main and Master repo in Github - How to solve | I had a problem before where there are two branches in my github rep: main master Although both... | 14,981 | 2021-08-12T07:26:48 | https://dev.to/jeden/main-and-master-repo-in-github-how-to-solve-31n2 | devjournal, github, devops, 100daysofcode | I had a problem before where there are two branches in my github rep:
*main*
*master*
Although both should have the same function (as main replaced master), a 'master' branch was instantly created when I try to push my local repo to remote repo.
After some digging, I found a simple solution. Here's what I did:
```bash
Eden Jose@EdenJose MINGW64 ~/Desktop/Git/1-KodeKloud (master)
$ git branch -m master main
Eden Jose@EdenJose MINGW64 ~/Desktop/Git/1-KodeKloud (main)
$ git branch
* main
Eden Jose@EdenJose MINGW64 ~/Desktop/Git/1-KodeKloud (main)
$ git push -f --set-upstream origin main
Total 0 (delta 0), reused 0 (delta 0), pack-reused 0
To https://github.com/joseeden/KodeKloud_Tasks.git
+ 6a54f03...4fe82a2 main -> main (forced update)
Branch 'main' set up to track remote branch 'main' from 'origin'.
Eden Jose@EdenJose MINGW64 ~/Desktop/Git/1-KodeKloud (main)
$ git branch -a
* main
remotes/origin/main
remotes/origin/master
git push origin --delete master
```
You can check out more about this in the links below:
- [*My Github repo has 'main' and 'master' branches - what is their purpose?*](https://stackoverflow.com/questions/65020647/my-github-repo-has-main-and-master-branches-what-is-their-purpose)
- [*5 steps to change GitHub default branch from master to main*](https://stevenmortimer.com/5-steps-to-change-github-default-branch-from-master-to-main/) | jeden |
789,403 | Google's Machine Learning Crash Course - 43 Rules of Machine Learning (summary) | At the end of this article, you will understand the basic knowledge of machine learning and get the... | 0 | 2021-08-12T10:58:51 | https://dev.to/steminstructor/google-s-machine-learning-crash-course-43-rules-of-machine-learning-summary-2f0p | machinelearning, python, programming | At the end of this article, you will understand the basic knowledge of machine learning and get the benefit of Google's best practices in machine learning:
This approach will work well for a long time. Diverge from this approach only when there are no more simple tricks to get you any farther.
Rule #1: Don’t be afraid to launch a product without machine learning
Rule #2: First, design and implement metrics.
Rule #3: Choose machine learning over a complex heuristic.
Rule #4: Keep the first model simple and get the infrastructure right.
Rule #5: Test the infrastructure independently from the machine learning.
Rule #6: Be careful about dropped data when copying pipelines.
Rule #7: Turn heuristics into features, or handle them externally.
Rule #8: Know the freshness requirements of your system.
Rule #9: Detect problems before exporting models.
Rule #10: Watch for silent failures.
Rule #11: Give feature columns owners and documentation.
Rule #12: Don’t overthink which objective you choose to directly optimize.
Rule #13: Choose a simple, observable and attributable metric for your first objective.
Rule #14: Starting with an interpretable model makes debugging easier.
Rule #15: Separate Spam Filtering and Quality Ranking in a Policy Layer.
Rule #16: Plan to launch and iterate.
Rule #17: Start with directly observed and reported features as opposed to learned features.
Rule #18: Explore with features of content that generalize across contexts.
Rule #19: Use very specific features when you can.
Rule #20: Combine and modify existing features to create new features in human¬-understandable ways.
Rule #21: The number of feature weights you can learn in a linear model is roughly proportional to the amount of data you have.
Rule #22: Clean up features you are no longer using.
Rule #23: You are not a typical end user.
Rule #24: Measure the delta between models.
Rule #25: When choosing models, utilitarian performance trumps predictive power.
Rule #26: Look for patterns in the measured errors, and create new features.
Rule #27: Try to quantify observed undesirable behavior.
Rule #28: Be aware that identical short-term behavior does not imply identical long-term behavior.
Rule #29: The best way to make sure that you train like you serve is to save the set of features used at serving time, and then pipe those features to a log to use them at training time.
Rule #30: Importance-weight sampled data, don’t arbitrarily drop it!
Rule #31: Beware that if you join data from a table at training and serving time, the data in the table may change.
Rule #32: Re-use code between your training pipeline and your serving pipeline whenever possible.
Rule #33: If you produce a model based on the data until January 5th, test the model on the data from January 6th and after.
Rule #34: In binary classification for filtering (such as spam detection or determining interesting emails), make small short-term sacrifices in performance for very clean data.
Rule #35: Beware of the inherent skew in ranking problems.
Rule #36: Avoid feedback loops with positional features.
Rule #37: Measure Training/Serving Skew.
Rule #38: Don’t waste time on new features if unaligned objectives have become the issue.
Rule #39: Launch decisions are a proxy for long-term product goals.
Rule #40: Keep ensembles simple.
Rule #41: When performance plateaus, look for qualitatively new sources of information to add rather than refining existing signals.
Rule #42: Don’t expect diversity, personalization, or relevance to be as correlated with popularity as you think they are.
Rule #43: Your friends tend to be the same across different products. Your interests tend not to be.
| steminstructor |
789,500 | Day 1 - Your first week in NodeJS | I believe you know something about Node.js before starting on this course, just to refresh your... | 14,078 | 2021-08-12T12:35:48 | https://www.learnwithgurpreet.com/posts/day-1-your-first-week-in-nodejs/ | javascript, node, tutorial, webdev | I believe you know something about Node.js before starting on this course, just to refresh your memory. Node.js is a JavaScript runtime, built on Chrome's V8 JavaScript engine. Node.js uses an event-driven, non-blocking model that makes it lightweight and efficient.
Node.js package ecosystem, npm, is the largest ecosystem of open source libraries in the world.
**Let's jump on Day 1 agenda now.**
## 1. Installation
You can simply go to [official Node.js website](https://nodejs.org/en/download/) and download the latest stable version (LTS) based on your OS.

After the installation, you can simply open your terminal/command prompt, to check if it's running or not.
```cmd
$ node --version
// v14.16.1 (in my case)
```
In addition to the above, you can also go to any editor and create a file `app.js` (or any name).
```js
// app.js
console.log("node is working");
```
Now run this file using Node.js
```
$ node app.js
// node is working
```
You have installed Node.js on your machine 🏆
## 2. Global Objects
After installing Node.js, let's quickly touch upon **Global objects** which we can use without any objection and third-party imports. These objects/functions are nothing but built-in into Node.js objects. If you are already working on JavaScript you defiantly know about some of these objects like (console, setInterval, setTimeout, etc.).
The main difference between JavaScript (window) vs. Node.js global objects is, you can't get access to the screen-related function example: scroll, style, etc.
You can try following code examples in Node.js
```js
// app.js
setTimeout(() => {
console.log("5 seconds have passed");
}, 5000);
// Run this code again
$ node app.js
```
Another useful global object is `process`, we will use this a lot in further lessons. `process` holds the latest state of your Node.js running process. It gives you access to read which environment your server is running or you can set custom environment variables while starting your server.
The common use case is to store credentials inside `process` to later use them in your program.
```
// Setting process variable
$ export DB_NAME=demo_db
$ export DB_PASSWORD=yes_you_are_right
// Run your app
$ node app.js
// app.js
const {DB_NAME, DB_PASSWORD} = process.env
console.log(DB_NAME); // demo_db
console.log(DB_PASSWORD); // yes_you_are_right
```
## 3. Modules + `require()`
So far (above), we wrote everything in a single file, which is good for practice programs and all. If you want to work on a real project where you might have other teams/people surrounding you and working on the same project, then recommended approach is to work with modules.
**Modules** are nothing but an approach to split your code into different-2 re-usable pieces.
It can be a file or a function within the same file, you must have heard of the philosophy of pure-functional programming where every function is responsible to do a single job.
### Let's take an example, you want to count the `length` of an array.
```js
// Create a new file next to your app.js
// count.js
const count = (arr) => {
return arr.length
}
```
Now you have `count.js` in place, it's time to make it re-usable for the application.
> Before calling it a module, we need to make some changes to the `count.js` file.
```js
// count.js
const count = (arr) => {
return arr.length
}
module.exports = count; // It will export this component as a module
```
Since we have the `count` module ready to include, let's call it in `app.js`.
```js
// app.js
const count = require('./count'); // including `count` function as a module
cosole.log(count([1, 98, 22, 41])) // return: 4
```
You can send multiple modules from your single file.
```js
// utils.js
const add = (a, b) => {
return a + b;
}
const sub = (a, b) => {
return a - b;
}
const getDatabaseName = () => process.env.DB_NAME;
module.exports = {
add,
sub,
getDatabaseName,
};
// You also change your public function names
module.exports = {
plus: add,
minus: sub,
DBName: getDatabaseName,
};
```
```js
// app.js
const utils = require("./utils");
console.log(utils.add(1, 2)); // result: 3
console.log(utils.sub(2, 1)); // result: 1
console.log(utils.getDatabaseName()); // result: demo_db
```
## 4. Event emitting
Like the above-defined module, we have some built-in core Node.js modules available to use. One of the examples is the `events` module.
Similar to JavaScript `click`/`onChange` events Node.js has the capability to define your own events which can be used when needed.
```js
// custom-events.js
const events = require('events');
const utils = require("./utils");
const eventEmitter = new events.EventEmitter();
eventEmitter.on("showSum", (a, b) => {
console.log(`Sum is: ${utils.add(a, b)}`);
});
module.exports = eventEmitter;
```
Our event emitter module is now ready, let's use it in our application.
```js
// app.js
const customEvents = require("./custom-events");
customEvents.emit("showSum", {a: 1, b: 2}); // Sum is: 3
```
## 5. Read/Write/Steam files
After learning event handling in Node.js let's do a quick check on file handling with Node.js core module `fs`.
Let's read the file first in order to try the `fs` module. But first, we need a file to read. Let's create a file first.
### Read operation ()
```cmd
// Inside the same directory
$ touch read.txt
$ vim ./read.text // Add some content and save the file.
```
```js
// app.js
const fs = require("fs");
const readMeFile = fs.readFileSync("./read.txt", "utf-8");
console.log(readMeFile); // File contents
```
### Write operation
```js
// app.js
const fs = require("fs");
const readMeFile = fs.readFileSync("./read.txt", "utf-8");
fs.writeFileSync("./read-new.txt", readMeFile);
```
The above statement will simply read the contents from the `read.txt` file write another file `read-new.txt` file with its content.
There are two ways to read/write files, synchronous/asynchronous, above we are using sync. method to read the file. It prevents the program execute unless it reads the entire file.
On the other hand `fs.readFile` can read files asynchronously, sometime we use this method too.
> Let's quick touch upon async. file read operation:
```js
const fs = require("fs");
fs.readFile("./read.txt", "utf-8", (err, data) => {
if(err) {
console.error(err);
}
console.log(data);
});
console.log("Am I first?");
// Result:
// file content
// Am I first?
```
In the example above you can see, text outside the `readFile` operation logged first. Async. operation is beneficial when your further operations are independent of the file read/write operations.
Hope you like the starting of the series, stay tuned for further posts in this series.
Happy reading!
## Useful Links
[Install Node.js](https://nodejs.org/en/download/)
[Global Objects](https://nodejs.org/dist/latest-v14.x/docs/api/globals.html)
[Events](https://nodejs.org/dist/latest-v14.x/docs/api/events.html)
[File system](https://nodejs.org/dist/latest-v14.x/docs/api/fs.html)
| gsin11 |
790,237 | 🏀 Animación de cards al estilo Jordan 🏀 | Este diseñ fue creado usando unicamente css y html, lenguajes de programaciones sobre los cuales... | 0 | 2021-08-13T04:16:22 | https://dev.to/joseamayadev/animacion-de-cards-al-estilo-jordan-2mod | css, html, github, figma | 
<br>
Este diseñ fue creado usando unicamente css y html, lenguajes de programaciones sobre los cuales se fundamente la web.
<br>
Abajo te explico como utilizar este diseño en tu web o relacionados otros de tus elementos para crear una mejor experiencia de usuario.
<br><br>
### Veamos como se ve el diseño final
<br>

## ¿Conocimiento importantes para el desarrollo?
* CSS / Position Relative
```
.card {
position: relative;
width: 100%;
height: 100%;
z-index: 10000;
transition: 0.6s;
}
```
* CSS / Position Absolute
```
img {
position: absolute;
max-width: 280px;
left: 20px;
top: 80px;
transform: rotate(-35deg);
transition: 0.5s;
}
```
* CSS / Hover Selector
```
.contenedor:hover .card img {
left: 20px;
top: 40px;
transition: 0.5s;
}
```
* CSS / ::Before and After Pseudo ELements
```
.contenedor:hover::before {
width: 250px;
height: 250px;
right: -35px;
top: -30px;
}
```
> Sí no conoces CSS te costará mil veces .
<br>
<br>
## El código en Javascript que permite cambiar las zapatillas
<br>
Es bien sabido que javascript es el lenguaje por mucho mas usado en la web, pero para generar dinamismo esto puede servirte como un compoente y de esa forma te permite generar ids, enlaces dinamicos entre otras cosas para que tus compoentes sean totalmente reactivos o simplemente integrar la card a un motor de plantilla o lo que quieras hacer con ella.
<br>
* Código en js
```
btnMorado.addEventListener("click", () => {
document.getElementById("imagen").src = "img/awesome-shoes-violet.png";
});
```
Qué simplemente detecta el elemento y te permite cambiar dinamicamente la imagen previamente almacenada en el repo, o generar una función para extraer estos datos desde el backend y generar ids personalizados de forma dinamica y no manual que es mi caso particular.
<br><br>
Este es mi correo profesional ***jose@joseamaya.tech***, si me escribes te aseguro que tendrás una respuesta.
Atentamente,
### Link al repo: [Github Repo](https://github.com/syntaxter/ui-animation-cards-jordan)
### Link a la demo: [Demo](https://syntaxter.github.io/ui-animation-cards-jordan)
<br>

**José A. Amaya**
| joseamayadev |
790,264 | AdonisJs - Installation and Database Setup | Now that you have all the requirements we need to be installed, let's set up the project. If you're... | 14,084 | 2021-08-16T08:58:44 | https://tngeene.com/blog/series/everything-you-need-to-know-about-adonisjs | javascript, adonis, typescript, node | Now that you have all the requirements we need to be installed, let's set up the project.
> If you're having any problems setting up or installing the dependencies, feel free to leave a comment or shoot me a DM.
What we'll be covering in this post.
1. [Creating a new project](#create-a-new-project)
2. [Adonis Project Structures](#adonis-project-structures)
3. [IDE Setup](#vs-code-setup)
4. [Starting the Development Server](#starting-the-development-server)
5. [Database Setup](#database-setup)
## Create a new project
To initialize a new project, all we need is a simple command on the terminal.
Simply navigate to the directory you'd like the project to be located and type the following;
`npm init adonis-ts-app fitit` or `yarn create adonis-ts-app fitit`
Let's break down this command for context.
1. `npm init` - this is simply initializing the project. Since we're using npm as the package manager, we use `npm`.
2. `adonis-ts-app` - we're initializing the project as a typescript project. If you wish not to use typescript and stick to vanilla JavaScript, you can use the `adonis new fitit`. This would involve installing the adonis cli. For more details on this, head over to [this link.](https://legacy.adonisjs.com/docs/3.2/adonis-blog-part1#_creating_new_application) However, I recommend using the typescript version.
3. `fitit` - this is the name of the application.
In general, the general structure of creating a new Adonis application is
```
npm init adonis-ts-app <project_name>
```
After you've typed the project initialization command, npm first installs the necessary adonis packages, which then prompts you to choose a preferred project structure.

## Adonis Project structures
You can choose between one of the following project structures.
- `web project` structure is ideal for creating classic server-rendered applications. We configure the support for sessions and also install the AdonisJS template engine(edge). Also, the support for serving static files like images is provided.
- `api project` structure is ideal for creating an API server. This also configures the support for CORS.
- `slim project` structure creates the smallest possible AdonisJS application and does not install any additional packages, except the framework core. This sort of allows for flexibility. It's up to the developer to build the application ground-up.
It's worth noting that apart from some minor differences, the overall project structure is almost similar.
For this project, we'll be using the `api project` structure. The reason for this is that I'm mostly going to be using Adonis as an API server, which I'll then hook to a vue.js frontend.
> If you're using vs code, the command prompt will ask for additional configurations. These are prettier and eslint-related. I advise using both formatters.
After the project has been created, you'll get a message like this on the terminal.

## Vs Code Setup
> This section is intended for anyone using vs code as their IDE. If you use any other IDE, you can skip over to the next section.
Some extensions will make your adonis development easier in vs code. These are;
1. [Prettier](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode) and [eslint](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint) - As I'd mentioned earlier you need to have prettier and eslint installed. This will be set up during the installation process.
2. [JavaScript and TypeScript Nightly](https://marketplace.visualstudio.com/items?itemName=ms-vscode.vscode-typescript-next)
3. [Adonis JS Snippets](https://marketplace.visualstudio.com/items?itemName=hridoy.adonisjs-snippets) - provides insightful snippets.
4. [Adonis Js Go to controller](https://marketplace.visualstudio.com/items?itemName=stef-k.adonis-js-goto-controller) will come in handy when we start working with routes.
## Starting the Development server
Navigate to the project directory and open it on your IDE now that the project has been created.
Run the following command to spin up your local development server
`node ace serve --watch`

Open up your browser, and visit `localhost:3333`. If you did everything right, then you should see a screen with `hello world` text. Congratulations on setting up your first Adonis project! 🎉🎊
From here, things start to get interesting, we'll set up the database but before we head there, you might be wondering what `node ace serve --watch` is.
`ace` is a command-line framework that is embedded within your app. It allows you to create project-specific commands and run them using `node ace`. We'll be using ace commands throughout the tutorial, each with it's own purpose. For a more detailed explanation on ace commands, head over to this [article](https://dev.to/amanvirk1/introducing-adonisjs-part-3-65k) by @amanvirk1
For the above command, let's break down what it does.
- The `serve` command starts the HTTP server and performs an in-memory compilation of TypeScript to JavaScript.
- The `-watch` flag is meant to watch the file system for changes and restart the server automatically(hot reload).
## Database Setup
Before we wind up, let's connect our application to a database.
> I'll assume that you have some knowledge of setting up Postgres or SQL databases and already have one on your computer. If this is not the case, you can use sqlite, which will be a file created on your machine once we start defining the database configuration.
AdonisJS has first class support for SQL databases. The data layer of the framework is powered by Lucid(AdonisJs ORM) and the package must be installed separately.
Simply run `npm i @adonisjs/lucid`
Upon successful installation, we'll configure our database driver and create a database. For this tutorial, I'll be using postgres. So my configs will be postgres-related. However, if you're using SQL, then use relevant configuration.
If you choose sqlite, no configuration will be required.
Once done, run
```
node ace configure @adonisjs/lucid
```
or
```
node ace invoke @adonisjs/lucid
```

The ace configure and invoke commands executes the instructions Javascript file exposed by the package.
Since I decided to go with postgres, I'll copy the code for validating the environment variables to the env.ts file.

> Environment variables are injected from outside. The env.ts file validates that they type match and that the app is always running with the correct set of configuration values.
Your env.ts file should now look like this.
```
import Env from '@ioc:Adonis/Core/Env'
export default Env.rules({
HOST: Env.schema.string({ format: 'host' }),
PORT: Env.schema.number(),
APP_KEY: Env.schema.string(),
APP_NAME: Env.schema.string(),
PG_HOST: Env.schema.string({ format: 'host' }),
PG_PORT: Env.schema.number(),
PG_USER: Env.schema.string(),
PG_PASSWORD: Env.schema.string.optional(),
PG_DB_NAME: Env.schema.string(),
NODE_ENV: Env.schema.enum(['development', 'production', 'testing'] as const),
})
```
- The `config/database.ts` file holds all the configuration related to the database. For more details on this, check out the [documentation.](https://docs.adonisjs.com/guides/database/introduction)
Next, we'll configure our database on postgres.
You can name your database whatever name you wish.
Finally, go to your `.env` file and modify these values
```
DB_CONNECTION=pg
PG_HOST=localhost
PG_PORT=5432
PG_USER=postgres
PG_PASSWORD=<your_postgres_password>
PG_DB_NAME=<your_db_name>
```
## Testing Database connection.
Adonis comes with a neat health checker that checks if the database connection is working.
Navigate to `start/routes.ts` and paste the following code.
```
import HealthCheck from '@ioc:Adonis/Core/HealthCheck'
import Route from '@ioc:Adonis/Core/Route'
// check db connection
Route.get('health', async ({ response }) => {
const report = await HealthCheck.getReport()
return report.healthy ? response.ok(report) : response.badRequest(report)
})
```
With your server still running, open a browser tab and type `localhost:3333/health`
If everything worked fine and your database is connected, it should display the following screen.

## Closing Thoughts
Thank you for following along, if you like the content and would like to know more about Adonis Development, bookmark this series, head over to my [personal website](https://tngeene.com/) or follow me on [Twitter](https://twitter.com/Ngeene_kihiu). You can also leave a comment in case you need any clarification or would like to point out an addition.
For the next piece, I'll be covering database models and relationships.
You can also follow the series on my [personal website.](https://tngeene.com/blog/series/everything-you-need-to-know-about-adonisjs)
Stay tuned! | tngeene |
790,276 | Primer intento Dibujando con CSS - Mario's Mushroom PowerUp | Es mi primera vez intentando dibujar con CSS, la verdad me sorprendí con el resultado. Siempre que... | 0 | 2021-08-13T06:48:26 | https://dev.to/betocabadev/primer-intento-dibujando-con-css-mario-s-mushroom-powerup-323e | codepen, css | Es mi primera vez intentando dibujar con CSS, la verdad me sorprendí con el resultado. Siempre que veía a los desarrolladores que publicaban sus dibujos hechos con HTML y CSS me decía a mi mismo "Woow, espero algún día poder hacer dibujos así de buenos con CSS" y pues hoy me animé.
Todo comenzó al estar revisando mis suscripciones en YouTube, encontré un video donde @midudev estaba desarrollado un componente o app llamado <a href="https://codi.link" target="_blank">codi.link</a> que más que nada es para picar código de manera rápida (y si que es rápido) en fin, mientras la utilizaba se me ocurrió hacer este dibujo del honguito de Mario por curioso y cuando vi el resultado quede impactado (<a href="https://codi.link/PGgyPkNTUyBEcmF3PC9oMj4NCjxwPk1hcmlvIEJyb3RoZXIncyBNdXNocm9vbSBQb3dlciBVcDwvcD4NCjxkaXYgY2xhc3M9Im11c2hyb29tIj4NCiAgICA8ZGl2IGNsYXNzPSJtdXNocm9vbS10b3AiPg0KICAgICAgICA8ZGl2IGNsYXNzPSJtdXNocm9vbS10b3AtbWFyayI+PC9kaXY+DQogICAgPC9kaXY+DQogICAgPGRpdiBjbGFzcz0ibXVzaHJvb20tYm90dG9tIj48L2Rpdj4NCjwvZGl2Pg==%7CKnsNCiAgICBtYXJnaW46MDsNCiAgICBib3gtc2l6aW5nOiBib3JkZXItYm94Ow0KfQ0KDQpib2R5ew0KICAgIGRpc3BsYXk6IGZsZXg7DQogICAgZmxleC1mbG93OiBjb2x1bW47DQogICAganVzdGlmeS1jb250ZW50OiBjZW50ZXI7DQogICAgYWxpZ24taXRlbXM6IGNlbnRlcjsNCiAgICB3aWR0aDogMTAwdnc7DQogICAgaGVpZ2h0OiAxMDB2aDsNCiAgICBmb250LWZhbWlseTogSGVsdmV0aWNhLCBzYW5zLXNlcmlmOw0KICAgIGNvbG9yOiAjMWExYTFhOw0KfQ0KDQpwew0KICAgIG1hcmdpbi1ib3R0b206IDIuNXJlbTsNCn0NCg0KLm11c2hyb29tew0KICAgIGRpc3BsYXk6IGJsb2NrOw0KICAgIHBvc2l0aW9uOiByZWxhdGl2ZTsNCiAgICBmaWx0ZXI6IGRyb3Atc2hhZG93KDAgNHB4IDEycHggcmdiYSgwLDAsMCwuMikpOw0KICAgIHdpZHRoOiAxNTBweDsNCiAgICBoZWlnaHQ6IDE1MHB4Ow0KICB0cmFuc2Zvcm06IHNjYWxlKC44MCk7DQogIHRyYW5zZm9ybS1vcmlnaW46IGJvdHRvbTsNCiAgdHJhbnNpdGlvbjogdHJhbnNmb3JtIC4ycyBlYXNlLW91dDsNCiAgY3Vyc29yOiBwb2ludGVyOw0KfQ0KDQoubXVzaHJvb206aG92ZXJ7DQogIHRyYW5zZm9ybTogc2NhbGUoLjgzKTsNCn0NCg0KLm11c2hyb29tLnBvd2VyVXB7DQogIHRyYW5zZm9ybTogc2NhbGUoMSk7DQp9DQoNCi5tdXNocm9vbS5wb3dlclVwOmhvdmVyew0KICB0cmFuc2Zvcm06IHNjYWxlKC45Nyk7DQp9DQoNCi5tdXNocm9vbS10b3B7DQogICAgZGlzcGxheTogYmxvY2s7DQogICAgcG9zaXRpb246IHJlbGF0aXZlOw0KICAgIHdpZHRoOiAxMDAlOw0KICAgIGhlaWdodDogOTAlOw0KICAgIGJhY2tncm91bmQtY29sb3I6ICNmNjE5MTk7DQogICAgLyogYmFja2dyb3VuZC1pbWFnZTogbGluZWFyLWdyYWRpZW50KHRvIGJvdHRvbSwgcmVkLCBkYXJrcmVkKTsgKi8NCiAgICBib3gtc2hhZG93OiBpbnNldCAtMTVweCAtMzBweCA2MHB4IHJnYmEoNTQsIDEwLCAxMCwgMC42KTsNCg0KICAgIGJvcmRlci10b3AtcmlnaHQtcmFkaXVzOiA5NSUgMTIwJTsNCiAgICBib3JkZXItdG9wLWxlZnQtcmFkaXVzOiA5NSUgMTIwJTsNCiAgICBib3JkZXItYm90dG9tLXJpZ2h0LXJhZGl1czogNjAlIDgwJTsNCiAgICBib3JkZXItYm90dG9tLWxlZnQtcmFkaXVzOiA2MCUgODAlOw0KDQogICAgb3ZlcmZsb3c6IGhpZGRlbjsNCn0NCg0KLm11c2hyb29tLXRvcC1tYXJrLCAubXVzaHJvb20tdG9wLW1hcms6OmJlZm9yZSwgLm11c2hyb29tLXRvcC1tYXJrOjphZnRlcnsNCiAgICB3aWR0aDogNTUlOw0KICAgIGhlaWdodDogNTclOw0KICAgIGJhY2tncm91bmQtY29sb3I6ICNmM2YyZTQ7DQogICAgYm94LXNoYWRvdzogaW5zZXQgLTVweCAtMTVweCAyMHB4IHJnYmEoMCwwLDAsLjE1KTsNCiAgICB6LWluZGV4OiAxMDsNCiAgICBwb3NpdGlvbjogYWJzb2x1dGU7DQogICAgYm9yZGVyLXJhZGl1czogMTMwcHg7DQogICAgbGVmdDogNTAlOw0KICAgIHRvcDogNTAlOw0KICAgIHRyYW5zZm9ybTogdHJhbnNsYXRlKC01MCUsIC04MCUpOw0KfQ0KDQoubXVzaHJvb20tdG9wLW1hcms6OmJlZm9yZXsNCiAgICBjb250ZW50OiIiOw0KICAgIHdpZHRoOiA2MCU7DQogICAgaGVpZ2h0OiAxMDUlOw0KICAgIHRvcDogMjAlOw0KICAgIGxlZnQ6IC04NSU7DQogICAgdHJhbnNmb3JtOiBub25lOw0KfQ0KDQoubXVzaHJvb20tdG9wLW1hcms6OmFmdGVyew0KICAgIGNvbnRlbnQ6IiI7DQogICAgd2lkdGg6IDYwJTsNCiAgICBoZWlnaHQ6IDEwNSU7DQogICAgdG9wOiAyMCU7DQogICAgbGVmdDogYXV0bzsNCiAgICByaWdodDogLTg1JTsNCiAgICB0cmFuc2Zvcm06IG5vbmU7DQp9DQoNCi5tdXNocm9vbS1ib3R0b217DQogICAgcG9zaXRpb246IHJlbGF0aXZlOw0KICAgIGRpc3BsYXk6IGZsZXg7DQogICAganVzdGlmeS1jb250ZW50OiBzcGFjZS1iZXR3ZWVuOw0KICAgIGFsaWduLWl0ZW1zOiBjZW50ZXI7DQogICAgcGFkZGluZy1ib3R0b206OCU7DQogICAgcGFkZGluZy1sZWZ0OiAyMCU7DQogICAgcGFkZGluZy1yaWdodDogMjAlOw0KICAgIGJhY2tncm91bmQtY29sb3I6ICNmMGRlOTU7DQogICAgd2lkdGg6IDY1JTsNCiAgICBoZWlnaHQ6IDM3LjUlOw0KICAgIG1hcmdpbjotMjQlIGF1dG8gMDsNCg0KICAgIGJveC1zaGFkb3c6DQogICAgICAgIGluc2V0IC0yMHB4IC0xNnB4IDZweCByZ2JhKDU4LCA0MywgMTksIDAuMSksDQogICAgICAgIGluc2V0IC0xMHB4IC0xNXB4IDE1cHggcmdiYSg1OCwgNDMsIDE5LC4zNSksDQogICAgICAgIGluc2V0IDAgNXB4IDVweCByZ2JhKDU4LCA0MywgMTksLjIpOw0KDQogICAgYm9yZGVyLXRvcC1yaWdodC1yYWRpdXM6IDYwJSAzNSU7DQogICAgYm9yZGVyLXRvcC1sZWZ0LXJhZGl1czogNjAlIDM1JTsNCiAgICBib3JkZXItYm90dG9tLXJpZ2h0LXJhZGl1czogNDAlIDgwJTsNCiAgICBib3JkZXItYm90dG9tLWxlZnQtcmFkaXVzOiA0MCUgODAlOw0KfQ0KDQoubXVzaHJvb20tYm90dG9tOjpiZWZvcmUsIC5tdXNocm9vbS1ib3R0b206OmFmdGVyew0KICAgIGNvbnRlbnQ6IiI7DQogICAgZGlzcGxheTogYmxvY2s7DQogICAgaGVpZ2h0OiA1MCU7DQogICAgd2lkdGg6IDIxJTsNCiAgICBiYWNrZ3JvdW5kLWNvbG9yOiB3aGl0ZTsNCiAgICBib3gtc2hhZG93Og0KICAgICAgICBpbnNldCAwIC0xOHB4IDVweCByZ2JhKDAsMCwwLCAuOCksDQogICAgICAgIGluc2V0IDAgLTlweCA2cHggcmdiYSgwLDAsMCwuNiksDQogICAgICAgIGluc2V0IDAgMnB4IDRweCByZ2JhKDAsMCwwLC4zNSk7DQogICAgDQogICAgYm9yZGVyLXRvcC1yaWdodC1yYWRpdXM6IDYwJSA0MCU7DQogICAgYm9yZGVyLXRvcC1sZWZ0LXJhZGl1czogNjAlIDQwJTsNCiAgICBib3JkZXItYm90dG9tLXJpZ2h0LXJhZGl1czogNjAlIDQwJTsNCiAgICBib3JkZXItYm90dG9tLWxlZnQtcmFkaXVzOiA2MCUgNDAlOw0KfQ==%7CY29uc3QgbXVzaHJvb20gPSBkb2N1bWVudC5xdWVyeVNlbGVjdG9yKCcubXVzaHJvb20nKQ0KDQptdXNocm9vbS5hZGRFdmVudExpc3RlbmVyKCdjbGljaycsIGUgPT57DQogIG11c2hyb29tLmNsYXNzTGlzdC50b2dnbGUoJ3Bvd2VyVXAnKQ0KfSk=)" target="_blank">resultado en codi.link</a>) pero cómo no pude guardarlo salvo por la posibilidad de compartir el enlace pues me pase a hacerlo en <a href="https://codepen.io/betocabadev" target="_blank">codepen</a> para guardarlo y comenzar a subir en un futuro.
Las reglas serán sencillas, escoger un dibujo e intentar realizarlo con HTML y CSS sin ver tutoriales, de ser necesario documentación para llegar al mejor resultado posible.
Espero les guste, aquí el código:
{% codepen https://codepen.io/betocabadev/pen/poPYdaM %} | betocabadev |
790,326 | The ExpressJS Way To Write APIs | The ExpressJS Way To Write APIs This article will cover the basics of express from the... | 0 | 2021-08-13T07:24:50 | https://dev.to/bgoonz/the-expressjs-way-to-write-apis-3g0 | # The ExpressJS Way To Write APIs
This article will cover the basics of express from the perspective of a beginner without concerning its self with the underlying mechanisms...
---
---
### The ExpressJS Way To Write APIs
---
#### This article will cover the basics of express from the perspective of a beginner without concerning its self with the underlying mechanisms and theory that underlies the application of the framework.
<figure><img src="https://cdn-images-1.medium.com/max/800/0*yUozFGA0FQpjcXFf.gif" class="graf-image" /></figure>### For starters, what is express JS¿
When introduced, node.js gave developers the chance to use JavaScript to write software that, up to that point, could only be written using lower level languages like C, C++, Java, Python...
This tutorial will cover how to write **web services** that can communicate with clients (the front end application) using **J**ava**S**cript **O**bject **N**otation (JSON).
- <span id="5334">JavaScript is asynchronous, which allows us to take full advantage of the processor it's running on. Taking full advantage of the processor is crucial because the node process will be running on a single CPU.</span>
- <span id="0b8b">Using JavaScript gives us access to the npm repository. This repository is the largest ecosystem of useful libraries (most of them free to use) in **npm modules**.</span>
<figure><img src="https://cdn-images-1.medium.com/max/800/0*PTKhCN2p9S8EDZ4r.gif" class="graf-image" /></figure>
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Explain what Node.js is and its core features
<span class="graf-dropCap">T</span>raditionally, developers only used the JavaScript language in web browsers. But, in 2009, **Node.js** was unveiled, and with it, the developer tool kit expanded greatly. Node.js gave developers the chance to use JavaScript to write software that, up to that point, could only be written using C, C++, Java, Python, Ruby, C#, and the like.
---
#### We will use Node to write server code. Specifically, **web services** that can communicate with clients using the **J**ava**S**cript **O**bject **N**otation (JSON) format for data interchange.
Some of the advantages of using Node.js for writing server-side code are:
- <span id="51f9">Uses the same programming language (JavaScript) and paradigm for both client and server. Using the same language, we minimize context switching and make it easy to share code between the client and the server.</span>
- <span id="ad6f">JavaScript is single-threaded, which removes the complexity involved in handling multiple threads.</span>
- <span id="c797">JavaScript is asynchronous, which allows us to take full advantage of the processor it's running on. Taking full advantage of the processor is crucial because the node process will be running on a single CPU.</span>
- <span id="7654">Using JavaScript gives us access to the npm repository. This repository is the largest ecosystem of useful libraries (most of them free to use) in **npm modules**.</span>
Some of the disadvantages of using Node.js for writing server-side code are:
- <span id="0f56">By strictly using JavaScript on the server, we lose the ability to use the right tool (a particular language) for the job.</span>
- <span id="cd1e">Because JavaScript is single-threaded, we can't take advantage of servers with multiple cores/processors.</span>
- <span id="12c7">Because JavaScript is asynchronous, it is harder to learn for developers that have only worked with languages that default to synchronous operations that block the execution thread.</span>
- <span id="07dc">In the npm repository, there are often too many packages that do the same thing. This excess of packages makes it harder to choose one and, in some cases, may introduce vulnerabilities into our code.</span>
To write a simple web server with `Node.js`:
1. <span id="b4ff">Use Node's `HTTP` module to abstract away complex network-related operations.</span>
2. <span id="9e58">Write the single **_request handler_** function to handle all requests to the server.</span>
The request handler is a function that takes the `request` coming from the client and produces the `response`. The function takes two arguments: 1) an object representing the `request` and 2) an object representing the `response`.
This process works, but the resulting code is verbose, even for the simplest of servers. Also, note that when using only Node.js to build a server, we use a single request handler function for all requests.
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Try It Out:
Using only Node.js, let's write a simple web server that returns a message. Create a folder for the server and add an `index.js` file inside.
Next, add the following code to the `index.js` file:
```js
const http = require("http"); // built in node.js module to handle http traffic
const hostname = "127.0.0.1"; // the local computer where the server is running
const port = 3000; // a port we'll use to watch for traffic
const server = http.createServer((req, res) => {
// creates our server
res.statusCode = 200; // http status code returned to the client
res.setHeader("Content-Type", "text/plain"); // inform the client that we'll be returning text
res.end("Hello World from Node\\n"); // end the request and send a response with the specified message
});
server.listen(port, hostname, () => {
// start watching for connections on the port specified
console.log(`Server running at <http://$>{hostname}:${port}/`);
});
```
---
#### Now navigate to the folder in a terminal/console window and type: `node index.js` to execute your file. A message that reads "_Server running at_ <a href="http://127.0.0.1:3000" class="markup--anchor markup--p-anchor"><em>http://127.0.0.1:3000</em></a>" should be displayed, and the server is now waiting for connections.
Open a browser and visit: `http://localhost:3000`. `localhost` and the IP address `127.0.0.1` point to the same thing: your local computer. The browser should show the message: "_Hello World from Node_". There you have it, your first web server, built from scratch using nothing but `Node.js`.
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Explain what Express is and its core features:
Node's built-in `HTTP` module provides a powerful way to build web applications and services. However, it requires a lot of code for everyday tasks like sending an HTML page to the browser.
Introducing Express, a light and unopinionated framework that **sits on top of Node.js**, making it easier to create web applications and services. Sending an HTML file or image is now a one-line task with the `sendFile` helper method in `Express`.
Ultimately, Express is **just a Node.js module** like any other module.
What can we do with Express? So many things! For example:
- <span id="0317">Build web applications.</span>
- <span id="6ae8">Serve _Single Page Applications_ (SPAs).</span>
- <span id="308c">Build RESTful web services that work with JSON.</span>
- <span id="7a9e">Serve static content, like HTML files, images, audio files, PDFs, and more.</span>
- <span id="823e">Power real-time applications using technologies like **Web Sockets** or **WebRTC**.</span>
Some of the benefits of using Express are that it is:
- <span id="fdf7">Simple</span>
- <span id="7f62">Unopinionated</span>
- <span id="63a7">Extensible</span>
- <span id="09a9">Light-weight</span>
- <span id="d44f">Compatible with <a href="https://www.npmjs.com/package/connect" class="markup--anchor markup--li-anchor">connect middleware (Links to an external site.)</a>. This compatibility means we can tap into an extensive collection of modules written for `connect`.</span>
- <span id="6dbf">All packaged into a clean, intuitive, and easy-to-use API.</span>
- <span id="cc47">Abstracts away common tasks (writing web applications can be verbose, hence the need for a library like this).</span>
Some of the drawbacks of Express are:
- <span id="e9d2">It's not a one-stop solution. Because of its simplicity, it does very little out of the box. Especially when compared to frameworks like **Ruby on Rails** and **Django**.</span>
- <span id="9bb7">We are forced to make more decisions due to the flexibility and control it provides.</span>
---
### Main Features of Express
<a href="https://expressjs.com/en/guide/writing-middleware.html" class="markup--anchor markup--mixtapeEmbed-anchor" title="https://expressjs.com/en/guide/writing-middleware.html"><strong>Writing middleware for use in Express apps</strong><br />
<em>Middleware functions are functions that have access to the request object ( req), the response object ( res), and the...</em>expressjs.com</a><a href="https://expressjs.com/en/guide/writing-middleware.html" class="js-mixtapeImage mixtapeImage u-ignoreBlock"></a>
<figure><img src="https://cdn-images-1.medium.com/max/800/0*rdSEy1R5exC2Rpul.png" class="graf-image" /></figure>### Middleware
Middleware functions can get the request and response objects, operate on them, and (when specified) trigger some action. Examples are logging or security.
Express's middleware stack is an array of functions.
Middleware _can_ change the request or response, but it doesn't have to.
---
### Routing
Routing is a way to select which request handler function is executed. It does so based on the URL visited and the HTTP method used. Routing provides a way to break an application into smaller parts.
---
### Routers for Application Modularity
---
#### We can break up applications into **routers**. We could have a router to serve our SPA and another router for our API. Each router can have its own middleware and routing. This combination provides improved functionality.
---
### Convenience Helpers
Express has many helpers that provide out of the box functionality to make writing web applications and API servers easier.
A lot of those helpers are extension methods added to the request and response objects.
Examples <a href="https://expressjs.com/en/4x/api.html" class="markup--anchor markup--p-anchor">from the Api Reference (Links to an external site.)</a> include: `response.redirect()`, `response.status()`, `response.send()`, and `request.ip`.
---
### Views
Views provide a way to dynamically render HTML on the server and even generate it using other languages.
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Try It:
Let's write our first server using Express:
- <span id="1a5f">Create a new file called `server.js` to host our server code.</span>
- <span id="2d2f">Type `npm init -y` to generate a `package.json`.</span>
- <span id="8b3a">Install the `express` npm module using: `npm install express`.</span>
Inside `server.js` add the following code:
```js
const express = require('express'); // import the express package
const server = express(); // creates the server
// handle requests to the root of the api, the / route
server.get('/', (req, res) => {
res.send('Hello from Express');
});
// watch for connections on port 5000
server.listen(5000, () =>
console.log('Server running on <http://localhost:5000>')
);
```
Run the server by typing: `node server.js` and visit `http://localhost:5000` in the browser.
To stop the server, type `Ctrl + c` at the terminal window.
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Create an API that can respond to GET requests
The steps necessary to build a simple Web API that returns the string "Hello World" on every incoming `GET` request. The program should return the string every time a request comes into the root route ("/"). For now, you don't need to code along, just read through the steps.
To make things easier, we'll use an existing repository as the base for our API. Later in the week, as we learn more about Node.js and Express, we'll create an API from scratch.
To build our first API, we will:
1. <span id="ff64">clone the <a href="https://github.com/LambdaSchool/node-express-mini" class="markup--anchor markup--li-anchor">node-express-mini repository (Links to an external site.)</a> to a folder on our computer.</span>
2. <span id="288f">Navigate into the folder using `cd`.</span>
3. <span id="2043">Use `npm install` to download all dependencies.</span>
4. <span id="be2a">Add a file called `index.js` at the folder's root, next to the `package.json` file.</span>
5. <span id="d92a">Open the `index.js` file using our favorite code editor.</span>
6. <span id="d337">Add the following code:</span>
```js
// require the express npm module, needs to be added to the project using "npm install express"
const express = require('express');
// creates an express application using the express module
const server = express();
// configures our server to execute a function for every GET request to "/"
// the second argument passed to the .get() method is the "Route Handler Function"
// the route handler function will run on every GET request to "/"
server.get('/', (req, res) => {
// express will pass the request and response objects to this function
// the .send() on the response object can be used to send a response to the client
res.send('Hello World');
});
// once the server is fully configured we can have it "listen" for connections on a particular "port"
// the callback function passed as the second argument will run once when the server starts
server.listen(8000, () => console.log('API running on port 8000'));
```
**make sure to save your changes to** `index.js`**.**
---
#### We are using the `express` npm module in our code, so we need to add it as a dependency to our project. To do this:
- <span id="e9eb">Open a terminal/console/command prompt window and navigate to the root of our project.</span>
- <span id="b744">Add express to our `package.json` file by typing `npm install express`.</span>
---
#### Now we're ready to test our API!
In the terminal, still at the root of our project:
- <span id="04b6">Type: `npm run server` to run our API. The message _"Api running on port 8000"_ should appear on the terminal.</span>
- <span id="440e">Open a web browser and navigate to "<a href="http://localhost:8000" class="markup--anchor markup--li-anchor">http://localhost:8000</a>".</span>
There we have it, our first API!
A lot is going on in those few lines of code (only six lines if we remove the comments and white space). We will cover every piece of it in detail over the following modules, but here is a quick rundown of the most important concepts.
First, we used `require()` to **import** the `express module` and make it available to our application. `require()` is similar to the `import` keyword we have used before. The line `const express = require('express');` is equivalent to `import express from 'express';` if we were using ES2015 syntax.
The following line creates our Express application. The return of calling `express()` is an instance of an Express application that we can use to configure our **server** and, eventually, start listening for and responding to requests. Notice we use the word server, not API. An Express application is generic, which means we can use it to serve static content (HTML, CSS, audio, video, PDFs, and more). We can also use an Express application to serve dynamically generated web pages, build real-time communications servers, and more. We will use it statically to accept requests from clients and respond with data in JSON format.
An Express application publishes a set of methods we can use to configure functions. We are using the `.get()` method to set up a **route handler** function that will run on every `GET` request. As a part of this handler function, we specify the URL which will trigger the request. In this case, the URL is the site's root (represented by a `/`). There are also methods to handle the `POST`, `PUT`, and `DELETE` HTTP verbs.
The first two arguments passed by `express` to a route handler function are 1) an object representing the `request` and 2) an object representing the `response`. Express expands those objects with a set of useful properties and methods. Our example uses the `.send()` method of the response object to specify the data we will send to the client as the response body. You can call the first two arguments anything you want, but it is prevalent to see them dubbed `req` and `res`.
That's all the configuring we need to do for this first example We'll see other ways of configuring our server as we go forward.
After configuring the server, it's time to turn it on. We use the `.listen()` method to monitor a port on the computer for any incoming connections and respond to those we have configured. Our server will only respond to `GET` requests made to the `/` route on port `8000`.
That's it for our first Web API, and now it's time for you to follow along as we add a new **endpoint** to our server that returns JSON data!
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Try It Out:
Let's try returning JSON instead of just a simple string.
Please follow the steps outlined on the overview, but, to save time, copy and paste the content of `index.js` instead of typing it. Then run your API through a browser to make sure it works.
---
#### Now follow along as we code a new _endpoint_ that returns an array of movie characters in JSON format.
The first step is to define a new _route handler_ to respond to `GET` requests at the `/hobbits` endpoint.
```js
server.get('/hobbits', (req, res) => {
// route handler code here
});
```
Next, we define the return data that our endpoint will send back to the client. We do this inside the newly defined route handler function.
```js
const hobbits = [
{
id: 1,
name: 'Samwise Gamgee',
},
{
id: 2,
name: 'Frodo Baggins',
},
];
```
---
#### Now we can return the `hobbits` array. We could use `.send(hobbits)` as we did for the string on the `/` endpoint, but this time we'll learn about two other useful methods we find in the response object.
```js
res.status(200).json(hobbits);
```
---
#### We should provide as much useful information as possible to the clients using our API. One such piece of data is the `HTTP status code` that reflects the client's operation outcome. In this case, the client is trying to get a list of a particular `resource`, a `hobbits` list. Sending back a `200 OK` status code communicates to the client that the operation was successful.
---
#### We will see other status codes as we continue to build new endpoints during this week. You can see a list by following <a href="https://developer.mozilla.org/en-US/docs/Web/HTTP/Status" class="markup--anchor markup--p-anchor">this link to the documentation about HTTP Response Codes on the Mozilla Developer Network site (Links to an external site.)</a>.
---
#### We can use the `.status()` method of the response object to send any valid `HTTP status code`.
---
#### We are also chaining the `.json()` method of the response object. We do this to communicate to both the client making the request and the next developer working with this code that we intend to send the data in `JSON format`.
> The complete code for `index.js` should now look like so:
```js
const express = require('express');
const server = express();
server.get('/', (req, res) => {
res.send('Hello World');
});
server.get('/hobbits', (req, res) => {
const hobbits = [
{
id: 1,
name: 'Samwise Gamgee',
},
{
id: 2,
name: 'Frodo Baggins',
},
];
res.status(200).json(hobbits);
});
server.listen(8000, () => console.log('API running on port 8000'));
```
---
#### Now we can visit `http://localhost:8000/hobbits` in our browser, and we should get back our JSON array.
---
###### If you are using the Google Chrome browser, <a href="https://chrome.google.com/webstore/detail/jsonview/chklaanhfefbnpoihckbnefhakgolnmc" class="markup--anchor markup--p-anchor">this extension (Links to an external site.)</a> can format the JSON data in a more readable fashion.
Congratulations! You just built an API that can return data in JSON format.
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Let's look at a basic example of routing in action.
**First, to make our Express application respond to `GET` requests on different URLs, add the following endpoints:**
```js
// this request handler executes when making a GET request to /about
server.get('/about', (req, res) => {
res.status(200).send('<h1>About Us</h1>');
});
// this request handler executes when making a GET request to /contact
server.get('/contact', (req, res) => {
res.status(200).send('<h1>Contact Form</h1>');
});
```
**Two things to note:**
> 1.) We are using the same HTTP Method on both endpoints, but express looks at the URL and executes the corresponding request handler.
> 2.) We can return a string with valid HTML!
**Open a browser and navigate to the `/about` and `/contact` routes. The appropriate route handler will execute.**
#### Now we write endpoints that execute different request handlers on the same URL by changing the HTTP method.
##### Let's start by adding the following code after the `GET` endpoint to `/hobbits`:
```js
// this request handler executes when making a POST request to /hobbits
server.post('/hobbits', (req, res) => {
res.status(201).json({ url: '/hobbits', operation: 'POST' });
});
```
Note that we return HTTP status code 201 (created) for successful `POST` operations.
Next, we need to add an endpoint for `PUT` requests to the same URL.
```js
// this request handler executes when making a PUT request to /hobbits
server.put('/hobbits', (req, res) => {
res.status(200).json({ url: '/hobbits', operation: 'PUT' });
});
```
**For successful `PUT` operations, we use HTTP Status Code 200 (OK).**
##### Finally, let's write an endpoint to handle `DELETE` requests.
```js
// this request handler executes when making a DELETE request to /hobbits
server.delete('/hobbits', (req, res) => {
res.status(204);
});
```
---
#### We are returning HTTP Status Code 204 (No Content). Suppose you are returning any data to the client, perhaps the removed resource, on successful deletes. In that case, you'd change that to be 200 instead.
You may have noticed that we are not reading any data from the request, as that is something we'll learn later in the module. We are about to learn how to use a tool called `Postman` to test our `POST`, `PUT`, and `DELETE` endpoints.
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Reading and Using Route Parameters
Let's revisit our `DELETE` endpoint.
```js
server.delete('/hobbits', (req, res) => {
res.status(204);
});
```
**How does the client let the API know which hobbit should be deleted or updated? One way, the one we'll use, is through `route parameters`. Let's add support for route parameters to our `DELETE` endpoint.**
---
#### We define route parameters by adding it to the URL with a colon (`:`) in front of it. Express adds it to the `.params` property part of the request object. Let's see it in action:
```js
server.delete('/hobbits/:id', (req, res) => {
const id = req.params.id;
// or we could destructure it like so: const { id } = req.params;
res.status(200).json({
url: `/hobbits/${id}`,
operation: `DELETE for hobbit with id ${id}`,
});
});
```
_This route handler will execute every `DELETE` for a URL that begins with `/hobbits/` followed by any value. So, `DELETE` requests to `/hobbits/123` and `/hobbits/frodo` will both trigger this request handler. The value passed after `/hobbits/` will end up as the `id` property on `req.params`_
_The value for a route parameter will always be `string`, even if the value passed is numeric. When hitting `/hobbits/123` in our example, the type of `req.params.id` will be `string`._
_Express routing has support for multiple route parameters. For example, defining a route URL that reads `/hobbits/:id/friends/:friendId`, will add properties for `id` and `friendId` to `req.params`._
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Using the Query String
_The query string is another strategy using the URL to pass information from clients to the server. The query string is structured as a set of key/value pairs. Each pair takes the form of `key=value`, and pairs are separated by an `&`. To mark the beginning of the query string, we add `?` and the end of the URL, followed by the set of key/value pairs._
**An example of a query string would be: `https://www.google.com/search?q=lambda&tbo=1`. The query string portion is `?q=lambda&tbo=1` and the key/value pairs are `q=lambda` and `tbo=1`**.
###### Let's add sorting capabilities to our API. We'll provide a way for clients to hit our `/hobbits` and pass the field they want to use to sort the responses, and our API will sort the data by that field in ascending order.
---
### Here's the new code for the `GET /hobbits` endpoint:
```js
server.get('/hobbits', (req, res) => {
// query string parameters get added to req.query
const sortField = req.query.sortby || 'id';
const hobbits = [
{
id: 1,
name: 'Samwise Gamgee',
},
{
id: 2,
name: 'Frodo Baggins',
},
];
// apply the sorting
const response = hobbits.sort(
(a, b) => (a[sortField] < b[sortField] ? -1 : 1)
);
res.status(200).json(response);
});
```
Visit `localhost:8000/hobbits?sortby=name`, and the list should be sorted by `name`. Visit `localhost:8000/hobbits?sortby=id`, and the list should now be sorted by `id`. If no `sortby` parameter is provided, it should default to sorting by `id`.
To read values from the query string, we use the `req.query` object added by Express. There will be a key and a value in the `req.query` object for each key/value pair found in the query string.
The parameter's value will be of type `array` if more than one value is passed for the same key and `string` when only one value is passed. For example, in the query string `?id=123`, `req.query.id` will be a string, but for `?id=123&id=234`, it will be an array.
Another gotcha is that the names of query string parameters are case sensitive, `sortby` and `sortBy` are two different parameters.
The rest of the code sorts the array before sending it back to the client.
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Reading Data from the Request Body
---
#### We begin by taking another look at the `POST /hobbits` endpoint. We need to read the hobbit's information to add it to the `hobbits` array. Let's do that next:
```js
// add this code right after const server = express();
server.use(express.json());
let hobbits = [
{
id: 1,
name: 'Bilbo Baggins',
age: 111,
},
{
id: 2,
name: 'Frodo Baggins',
age: 33,
},
];
let nextId = 3;
// and modify the post endpoint like so:
server.post('/hobbits', (req, res) => {
const hobbit = req.body;
hobbit.id = nextId++;
hobbits.push(hobbit);
res.status(201).json(hobbits);
});
```
To make this work with the hobbits array, we first move it out of the get endpoint into the outer scope. Now we have access to it from all route handlers.
#### Then we define a variable for manual id generation. When using a database, this is not necessary as the database management system generates ids automatically.
To read data from the request body, we need to do two things:
- <span id="02f1">Add the line: `server.use(express.json());` after the express application has been created.</span>
- <span id="5111">Read the data from the body property that Express adds to the request object. Express takes all the client's information from the body and makes it available as a nice JavaScript object.</span>
**Note that we are skipping data validation to keep this demo simple, but in a production application, you would validate before attempting to save to the database.**
Let's test it using Postman:
- <span id="2351">Change the method to POST.</span>
- <span id="ca2a">Select the `Body` tab underneath the address bar.</span>
- <span id="ce2e">Click on the `raw` radio button.</span>
- <span id="fbac">From the dropdown menu to the right of the `binary` radio button, select \`JSON (application/json).</span>
- <span id="447b">Add the following JSON object as the body:</span>
```json
{
"name": "Samwise Gamgee",
"age": 30
}
```
Click on `Send`, and the API should return the list of hobbits, including Sam!
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Try It:
Please code along as we implement the `PUT` endpoint and a way for the client to specify the sort direction.
---
### Implement Update Functionality
Let's continue practicing reading route parameters and information from the request body. Let's take a look at our existing PUT endpoint:
```js
server.put('/hobbits', (req, res) => {
res.status(200).json({ url: '/hobbits', operation: 'PUT' });
});
```
---
#### We start by adding support for a route parameter the clients can use to specify the id of the hobbit they intend to update:
```js
server.put('/hobbits/:id', (req, res) => {
res.status(200).json({ url: '/hobbits', operation: 'PUT' });
});
```
Next, we read the hobbit information from the request body using `req.body` and use it to update the existing hobbit.
```js
server.put('/hobbits/:id', (req, res) => {
const hobbit = hobbits.find(h => h.id == req.params.id);
if (!hobbit) {
res.status(404).json({ message: 'Hobbit does not exist' });
} else {
// modify the existing hobbit
Object.assign(hobbit, req.body);
res.status(200).json(hobbit);
}
});
```
Concentrate on the code related to reading the `id` from the `req.params` object and reading the hobbit information from `req.body`. The rest of the code will change as this is a simple example using an in-memory array. Most production APIs will use a database.
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### TBC.......................................
---
### If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
<a href="https://gist.github.com/bgoonz" class="markup--anchor markup--mixtapeEmbed-anchor" title="https://gist.github.com/bgoonz"><strong>bgoonz's gists</strong><br />
<em>Instantly share code, notes, and snippets. Web Developer, Electrical Engineer JavaScript | CSS | Bootstrap | Python |...</em>gist.github.com</a><a href="https://gist.github.com/bgoonz" class="js-mixtapeImage mixtapeImage u-ignoreBlock"></a>
<a href="https://github.com/bgoonz" class="markup--anchor markup--mixtapeEmbed-anchor" title="https://github.com/bgoonz"><strong>bgoonz --- Overview</strong><br />
<em>Web Developer, Electrical Engineer JavaScript | CSS | Bootstrap | Python | React | Node.js | Express | Sequelize...</em>github.com</a><a href="https://github.com/bgoonz" class="js-mixtapeImage mixtapeImage u-ignoreBlock"></a>
---
### Discover More:
<a href="https://bgoonz-blog.netlify.app/" class="markup--anchor markup--mixtapeEmbed-anchor" title="https://bgoonz-blog.netlify.app/"><strong>Web-Dev-Hub</strong><br />
<em>Memoization, Tabulation, and Sorting Algorithms by Example Why is looking at runtime not a reliable method of...</em>bgoonz-blog.netlify.app</a><a href="https://bgoonz-blog.netlify.app/" class="js-mixtapeImage mixtapeImage u-ignoreBlock"></a>
<figure><img src="https://cdn-images-1.medium.com/max/1200/1*nGyJHK1Q_sSB6fjbBbF3xA.png" class="graf-image" /></figure>
---
### Update(Bonus Best Practices):
---
### Things to do in your code
---
### Here are some things you can do in your code to improve your application's performance:
- <span id="b2b0"><a href="#use-gzip-compression" class="markup--anchor markup--li-anchor" title="#use-gzip-compression">Use gzip compression</a></span>
- <span id="23bb"><a href="#dont-use-synchronous-functions" class="markup--anchor markup--li-anchor" title="#dont-use-synchronous-functions">Don't use synchronous functions</a></span>
- <span id="904e"><a href="#do-logging-correctly" class="markup--anchor markup--li-anchor" title="#do-logging-correctly">Do logging correctly</a></span>
- <span id="f619"><a href="#handle-exceptions-properly" class="markup--anchor markup--li-anchor" title="#handle-exceptions-properly">Handle exceptions properly</a></span>
---
### Use gzip compression
Gzip compressing can greatly decrease the size of the response body and hence increase the speed of a web app. Use the <a href="https://www.npmjs.com/package/compression" class="markup--anchor markup--p-anchor" title="https://www.npmjs.com/package/compression">compression</a> middleware for gzip compression in your Express app. For example:
```js
let compression = require('compression')
let express = require('express')
let app = express()
app.use(compression())
```
For a high-traffic website in production, the best way to put compression in place is to implement it at a reverse proxy level (see <a href="#use-a-reverse-proxy" class="markup--anchor markup--p-anchor" title="#use-a-reverse-proxy">Use a reverse proxy</a>). In that case, you do not need to use compression middleware. For details on enabling gzip compression in Nginx, see <a href="http://nginx.org/en/docs/http/ngx_http_gzip_module.html" class="markup--anchor markup--p-anchor" title="http://nginx.org/en/docs/http/ngx_http_gzip_module.html">Module ngx_http_gzip_module</a> in the Nginx documentation.
---
### Don't use synchronous functions
Synchronous functions and methods tie up the executing process until they return. A single call to a synchronous function might return in a few microseconds or milliseconds, however in high-traffic websites, these calls add up and reduce the performance of the app. Avoid their use in production.
Although Node and many modules provide synchronous and asynchronous versions of their functions, always use the asynchronous version in production. The only time when a synchronous function can be justified is upon initial startup.
---
###### If you are using Node.js 4.0+ or io.js 2.1.0+, you can use the `--trace-sync-io` command-line flag to print a warning and a stack trace whenever your application uses a synchronous API. Of course, you wouldn't want to use this in production, but rather to ensure that your code is ready for production. See the <a href="https://nodejs.org/api/cli.html#cli_trace_sync_io" class="markup--anchor markup--p-anchor" title="https://nodejs.org/api/cli.html#cli_trace_sync_io">node command-line options documentation</a> for more information.
---
### Do logging correctly
In general, there are two reasons for logging from your app: For debugging and for logging app activity (essentially, everything else). Using `console.log()` or `console.error()` to print log messages to the terminal is common practice in development. But <a href="https://nodejs.org/api/console.html#console_console_1" class="markup--anchor markup--p-anchor" title="https://nodejs.org/api/console.html#console_console_1">these functions are synchronous</a> when the destination is a terminal or a file, so they are not suitable for production, unless you pipe the output to another program.
---
#### For debugging
---
###### If you're logging for purposes of debugging, then instead of using `console.log()`, use a special debugging module like <a href="https://www.npmjs.com/package/debug" class="markup--anchor markup--p-anchor" title="https://www.npmjs.com/package/debug">debug</a>. This module enables you to use the DEBUG environment variable to control what debug messages are sent to `console.error()`, if any. To keep your app purely asynchronous, you'd still want to pipe `console.error()` to another program. But then, you're not really going to debug in production, are you?
---
#### For app activity
---
###### If you're logging app activity (for example, tracking traffic or API calls), instead of using `console.log()`, use a logging library like <a href="https://www.npmjs.com/package/winston" class="markup--anchor markup--p-anchor" title="https://www.npmjs.com/package/winston">Winston</a> or <a href="https://www.npmjs.com/package/bunyan" class="markup--anchor markup--p-anchor" title="https://www.npmjs.com/package/bunyan">Bunyan</a>. For a detailed comparison of these two libraries, see the StrongLoop blog post <a href="https://strongloop.com/strongblog/compare-node-js-logging-winston-bunyan/" class="markup--anchor markup--p-anchor" title="https://strongloop.com/strongblog/compare-node-js-logging-winston-bunyan/">Comparing Winston and Bunyan Node.js Logging</a>.
---
### Handle exceptions properly
Node apps crash when they encounter an uncaught exception. Not handling exceptions and taking appropriate actions will make your Express app crash and go offline. If you follow the advice in <a href="#ensure-your-app-automatically-restarts" class="markup--anchor markup--p-anchor" title="#ensure-your-app-automatically-restarts">Ensure your app automatically restarts</a> below, then your app will recover from a crash. Fortunately, Express apps typically have a short startup time. Nevertheless, you want to avoid crashing in the first place, and to do that, you need to handle exceptions properly.
To ensure you handle all exceptions, use the following techniques:
- <span id="4365"><a href="#use-try-catch" class="markup--anchor markup--li-anchor" title="#use-try-catch">Use try-catch</a></span>
- <span id="25cc"><a href="#use-promises" class="markup--anchor markup--li-anchor" title="#use-promises">Use promises</a></span>
Before diving into these topics, you should have a basic understanding of Node/Express error handling: using error-first callbacks, and propagating errors in middleware. Node uses an "error-first callback" convention for returning errors from asynchronous functions, where the first parameter to the callback function is the error object, followed by result data in succeeding parameters. To indicate no error, pass null as the first parameter. The callback function must correspondingly follow the error-first callback convention to meaningfully handle the error. And in Express, the best practice is to use the next() function to propagate errors through the middleware chain.
For more on the fundamentals of error handling, see:
- <span id="e3b5"><a href="https://www.joyent.com/developers/node/design/errors" class="markup--anchor markup--li-anchor" title="https://www.joyent.com/developers/node/design/errors">Error Handling in Node.js</a></span>
- <span id="af28"><a href="https://strongloop.com/strongblog/robust-node-applications-error-handling/" class="markup--anchor markup--li-anchor" title="https://strongloop.com/strongblog/robust-node-applications-error-handling/">Building Robust Node Applications: Error Handling</a> (StrongLoop blog)</span>
---
#### What not to do
One thing you should _not_ do is to listen for the `uncaughtException` event, emitted when an exception bubbles all the way back to the event loop. Adding an event listener for `uncaughtException` will change the default behavior of the process that is encountering an exception; the process will continue to run despite the exception. This might sound like a good way of preventing your app from crashing, but continuing to run the app after an uncaught exception is a dangerous practice and is not recommended, because the state of the process becomes unreliable and unpredictable.
Additionally, using `uncaughtException` is officially recognized as <a href="https://nodejs.org/api/process.html#process_event_uncaughtexception" class="markup--anchor markup--p-anchor" title="https://nodejs.org/api/process.html#process_event_uncaughtexception">crude</a>. So listening for `uncaughtException` is just a bad idea. This is why we recommend things like multiple processes and supervisors: crashing and restarting is often the most reliable way to recover from an error.
---
#### We also don't recommend using <a href="https://nodejs.org/api/domain.html" class="markup--anchor markup--p-anchor" title="https://nodejs.org/api/domain.html">domains</a>. It generally doesn't solve the problem and is a deprecated module.
---
#### Use try-catch
Try-catch is a JavaScript language construct that you can use to catch exceptions in synchronous code. Use try-catch, for example, to handle JSON parsing errors as shown below.
Use a tool such as <a href="http://jshint.com/" class="markup--anchor markup--p-anchor" title="http://jshint.com/">JSHint</a> or <a href="http://www.jslint.com/" class="markup--anchor markup--p-anchor" title="http://www.jslint.com/">JSLint</a> to help you find implicit exceptions like <a href="http://www.jshint.com/docs/options/#undef" class="markup--anchor markup--p-anchor" title="http://www.jshint.com/docs/options/#undef">reference errors on undefined variables</a>.
---
### Here is an example of using try-catch to handle a potential process-crashing exception. This middleware function accepts a query field parameter named "params" that is a JSON object.
```js
app.get('/search', function (req, res) {
// Simulating async operation
setImmediate(function () {
let jsonStr = req.query.params
try {
let jsonObj = JSON.parse(jsonStr)
res.send('Success')
} catch (e) {
res.status(400).send('Invalid JSON string')
}
})
})
```
> However, try-catch works only for synchronous code. Because the Node platform is primarily asynchronous (particularly in a production environment), try-catch won't catch a lot of exceptions.
---
#### Use promises
Promises will handle any exceptions (both explicit and implicit) in asynchronous code blocks that use `then()`. Just add `.catch(next)` to the end of promise chains. For example:
```
```
```js
app.get('/', function (req, res, next) {
// do some sync stuff
queryDb()
.then(function (data) {
// handle data
return makeCsv(data)
})
.then(function (csv) {
// handle csv
})
.catch(next)
})
app.use(function (err, req, res, next) {
// handle error
})
```
---
#### Now all errors asynchronous and synchronous get propagated to the error middleware.
> However, there are two caveats:
1. <span id="f314">All your asynchronous code must return promises (except emitters). If a particular library does not return promises, convert the base object by using a helper function like <a href="http://bluebirdjs.com/docs/api/promise.promisifyall.html" class="markup--anchor markup--li-anchor" title="http://bluebirdjs.com/docs/api/promise.promisifyall.html">Bluebird.promisifyAll()</a>.</span>
2. <span id="319a">Event emitters (like streams) can still cause uncaught exceptions. So make sure you are handling the error event properly; for example:</span>
3. <span id="b3a0">const wrap = fn => (...args) => fn(...args).catch(args\[2])</span>
4. <span id="37a8">app.get(‘/', wrap(async (req, res, next) => { const company = await getCompanyById(<a href="http://req.query.id" class="markup--anchor markup--li-anchor" title="http://req.query.id">req.query.id</a>) const stream = getLogoStreamById(<a href="http://company.id" class="markup--anchor markup--li-anchor" title="http://company.id">company.id</a>) stream.on(‘error', next).pipe(res) }))</span>
The `wrap()` function is a wrapper that catches rejected promises and calls `next()` with the error as the first argument. For details, see <a href="https://strongloop.com/strongblog/async-error-handling-expressjs-es7-promises-generators/#cleaner-code-with-generators" class="markup--anchor markup--p-anchor" title="https://strongloop.com/strongblog/async-error-handling-expressjs-es7-promises-generators/#cleaner-code-with-generators">Asynchronous Error Handling in Express with Promises, Generators and ES7</a>.
For more information about error-handling by using promises, see <a href="https://strongloop.com/strongblog/promises-in-node-js-with-q-an-alternative-to-callbacks/" class="markup--anchor markup--p-anchor" title="https://strongloop.com/strongblog/promises-in-node-js-with-q-an-alternative-to-callbacks/">Promises in Node.js with Q --- An Alternative to Callbacks</a>.
---
### Things to do in your environment / setup
---
### Here are some things you can do in your system environment to improve your app's performance:
- <span id="4d6b"><a href="#set-node_env-to-production" class="markup--anchor markup--li-anchor" title="#set-node_env-to-production">Set NODE_ENV to "production"</a></span>
- <span id="05f1"><a href="#ensure-your-app-automatically-restarts" class="markup--anchor markup--li-anchor" title="#ensure-your-app-automatically-restarts">Ensure your app automatically restarts</a></span>
- <span id="c8e0"><a href="#run-your-app-in-a-cluster" class="markup--anchor markup--li-anchor" title="#run-your-app-in-a-cluster">Run your app in a cluster</a></span>
- <span id="f4af"><a href="#cache-request-results" class="markup--anchor markup--li-anchor" title="#cache-request-results">Cache request results</a></span>
- <span id="4d4a"><a href="#use-a-load-balancer" class="markup--anchor markup--li-anchor" title="#use-a-load-balancer">Use a load balancer</a></span>
- <span id="121c"><a href="#use-a-reverse-proxy" class="markup--anchor markup--li-anchor" title="#use-a-reverse-proxy">Use a reverse proxy</a></span>
---
### Set NODE_ENV to "production"
The NODE_ENV environment variable specifies the environment in which an application is running (usually, development or production). One of the simplest things you can do to improve performance is to set NODE_ENV to "production."
Setting NODE_ENV to "production" makes Express:
- <span id="3499">Cache view templates.</span>
- <span id="83b7">Cache CSS files generated from CSS extensions.</span>
- <span id="456c">Generate less verbose error messages.</span>
<a href="http://apmblog.dynatrace.com/2015/07/22/the-drastic-effects-of-omitting-node_env-in-your-express-js-applications/" class="markup--anchor markup--p-anchor" title="http://apmblog.dynatrace.com/2015/07/22/the-drastic-effects-of-omitting-node_env-in-your-express-js-applications/">Tests indicate</a> that just doing this can improve app performance by a factor of three!
---
###### If you need to write environment-specific code, you can check the value of NODE_ENV with `process.env.NODE_ENV`. Be aware that checking the value of any environment variable incurs a performance penalty, and so should be done sparingly.
In development, you typically set environment variables in your interactive shell, for example by using `export` or your `.bash_profile` file. But in general you shouldn't do that on a production server; instead, use your OS's init system (systemd or Upstart). The next section provides more details about using your init system in general, but setting NODE_ENV is so important for performance (and easy to do), that it's highlighted here.
With Upstart, use the `env` keyword in your job file. For example:
```sh
# /etc/init/env.conf
env NODE_ENV=production
```
For more information, see the <a href="http://upstart.ubuntu.com/cookbook/#environment-variables" class="markup--anchor markup--p-anchor" title="http://upstart.ubuntu.com/cookbook/#environment-variables">Upstart Intro, Cookbook and Best Practices</a>.
With systemd, use the `Environment` directive in your unit file. For example:
```sh
# /etc/systemd/system/myservice.service
Environment=NODE_ENV=production
```
For more information, see <a href="https://coreos.com/os/docs/latest/using-environment-variables-in-systemd-units.html" class="markup--anchor markup--p-anchor" title="https://coreos.com/os/docs/latest/using-environment-variables-in-systemd-units.html">Using Environment Variables In systemd Units</a>.
---
### Ensure your app automatically restarts
In production, you don't want your application to be offline, ever. This means you need to make sure it restarts both if the app crashes and if the server itself crashes. Although you hope that neither of those events occurs, realistically you must account for both eventualities by:
- <span id="9675">Using a process manager to restart the app (and Node) when it crashes.</span>
- <span id="d5af">Using the init system provided by your OS to restart the process manager when the OS crashes. It's also possible to use the init system without a process manager.</span>
Node applications crash if they encounter an uncaught exception. The foremost thing you need to do is to ensure your app is well-tested and handles all exceptions (see <a href="#handle-exceptions-properly" class="markup--anchor markup--p-anchor" title="#handle-exceptions-properly">handle exceptions properly</a> for details). But as a fail-safe, put a mechanism in place to ensure that if and when your app crashes, it will automatically restart.
---
#### Use a process manager
In development, you started your app simply from the command line with `node server.js` or something similar. But doing this in production is a recipe for disaster. If the app crashes, it will be offline until you restart it. To ensure your app restarts if it crashes, use a process manager. A process manager is a "container" for applications that facilitates deployment, provides high availability, and enables you to manage the application at runtime.
In addition to restarting your app when it crashes, a process manager can enable you to:
- <span id="bf0c">Gain insights into runtime performance and resource consumption.</span>
- <span id="47ed">Modify settings dynamically to improve performance.</span>
- <span id="f0ed">Control clustering (StrongLoop PM and pm2).</span>
The most popular process managers for Node are as follows:
- <span id="1163"><a href="http://strong-pm.io/" class="markup--anchor markup--li-anchor" title="http://strong-pm.io/">StrongLoop Process Manager</a></span>
- <span id="bb4a"><a href="https://github.com/Unitech/pm2" class="markup--anchor markup--li-anchor" title="https://github.com/Unitech/pm2">PM2</a></span>
- <span id="1264"><a href="https://www.npmjs.com/package/forever" class="markup--anchor markup--li-anchor" title="https://www.npmjs.com/package/forever">Forever</a></span>
For a feature-by-feature comparison of the three process managers, see <a href="http://strong-pm.io/compare/" class="markup--anchor markup--p-anchor" title="http://strong-pm.io/compare/">http://strong-pm.io/compare/</a>. For a more detailed introduction to all three, see <a href="/%7B%7B%20page.lang%20%7D%7D/advanced/pm.html" class="markup--anchor markup--p-anchor" title="/%7B%7B%20page.lang%20%7D%7D/advanced/pm.html">Process managers for Express apps</a>.
Using any of these process managers will suffice to keep your application up, even if it does crash from time to time.
> However, StrongLoop PM has lots of features that specifically target production deployment. You can use it and the related StrongLoop tools to:
- <span id="0a60">Build and package your app locally, then deploy it securely to your production system.</span>
- <span id="db02">Automatically restart your app if it crashes for any reason.</span>
- <span id="e1d5">Manage your clusters remotely.</span>
- <span id="6f8a">View CPU profiles and heap snapshots to optimize performance and diagnose memory leaks.</span>
- <span id="51e9">View performance metrics for your application.</span>
- <span id="7393">Easily scale to multiple hosts with integrated control for Nginx load balancer.</span>
As explained below, when you install StrongLoop PM as an operating system service using your init system, it will automatically restart when the system restarts. Thus, it will keep your application processes and clusters alive forever.
---
### Cache request results
Another strategy to improve the performance in production is to cache the result of requests, so that your app does not repeat the operation to serve the same request repeatedly.
Use a caching server like <a href="https://www.varnish-cache.org/" class="markup--anchor markup--p-anchor" title="https://www.varnish-cache.org/">Varnish</a> or <a href="https://www.nginx.com/resources/wiki/start/topics/examples/reverseproxycachingexample/" class="markup--anchor markup--p-anchor" title="https://www.nginx.com/resources/wiki/start/topics/examples/reverseproxycachingexample/">Nginx</a> (see also <a href="https://serversforhackers.com/nginx-caching/" class="markup--anchor markup--p-anchor" title="https://serversforhackers.com/nginx-caching/">Nginx Caching</a>) to greatly improve the speed and performance of your app.
---
### Use a load balancer
No matter how optimized an app is, a single instance can handle only a limited amount of load and traffic. One way to scale an app is to run multiple instances of it and distribute the traffic via a load balancer. Setting up a load balancer can improve your app's performance and speed, and enable it to scale more than is possible with a single instance.
A load balancer is usually a reverse proxy that orchestrates traffic to and from multiple application instances and servers. You can easily set up a load balancer for your app by using <a href="http://nginx.org/en/docs/http/load_balancing.html" class="markup--anchor markup--p-anchor" title="http://nginx.org/en/docs/http/load_balancing.html">Nginx</a> or <a href="https://www.digitalocean.com/community/tutorials/an-introduction-to-haproxy-and-load-balancing-concepts" class="markup--anchor markup--p-anchor" title="https://www.digitalocean.com/community/tutorials/an-introduction-to-haproxy-and-load-balancing-concepts">HAProxy</a>.
With load balancing, you might have to ensure that requests that are associated with a particular session ID connect to the process that originated them. This is known as _session affinity_, or _sticky sessions_, and may be addressed by the suggestion above to use a data store such as Redis for session data (depending on your application). For a discussion, see <a href="http://socket.io/docs/using-multiple-nodes/" class="markup--anchor markup--p-anchor" title="http://socket.io/docs/using-multiple-nodes/">Using multiple nodes</a>.
---
### Use a reverse proxy
A reverse proxy sits in front of a web app and performs supporting operations on the requests, apart from directing requests to the app. It can handle error pages, compression, caching, serving files, and load balancing among other things.
Handing over tasks that do not require knowledge of application state to a reverse proxy frees up Express to perform specialized application tasks. For this reason, it is recommended to run Express behind a reverse proxy like <a href="https://www.nginx.com/" class="markup--anchor markup--p-anchor" title="https://www.nginx.com/">Nginx</a> or <a href="http://www.haproxy.org/" class="markup--anchor markup--p-anchor" title="http://www.haproxy.org/">HAProxy</a> in production.
| bgoonz | |
790,470 | wp2vite | wp2vite,A front-end project automatic conversion tool, You can make your webpack project support... | 0 | 2021-08-13T09:39:12 | https://dev.to/dravenww/wp2vite-49c8 | wp2vite,A front-end project automatic conversion tool, You can make your webpack project support vite.
wp2vite will not delete your webpack configuration, but will inject vite configuration into your project to support vite.
updated!!!!! | dravenww | |
790,492 | Embracing Failure: A journey from Tester to Tech Lead | Many interesting career stories don't follow a linear path; very few do, in fact. This is the account of how I ended up where I am today, following a winding path. | 0 | 2021-08-17T19:54:26 | https://dev.to/hughzurname/embracing-failure-a-journey-from-tester-to-tech-lead-3bo2 | career, dev, test, techlead | ---
title: Embracing Failure: A journey from Tester to Tech Lead
published: true
description: Many interesting career stories don't follow a linear path; very few do, in fact. This is the account of how I ended up where I am today, following a winding path.
tags: career, dev, test, techlead
cover_image: https://storage.googleapis.com/degouveia-me.appspot.com/bilbo-baggings-going-on-an-adventure.jpg
---
It started with one of the biggest failures of the last few decades, the sub-prime mortgage market, and several other factors that caused the failure of the global financial system. This isn't ideal when you're contracting for companies that earn most of their money installing network infrastructure for banks 🙋🏻♂️.
It was 2008, and I lived in London, 24 years old and recently married (too young), having been in the U.K. since 2005. I effectively worked as a labourer, just with extra steps, meaning I installed network cabling on various building sites. The job was pretty great for someone without a university education; it paid well. I got to work in some exciting places (the McLaren F1 development facility was definitely a highlight), and it was technically demanding. The point is, I enjoyed the job and was good at it. Unfortunately, the economy had other plans. Right, okay, cool, but...
### Isn't this supposed to be about the tech industry?
So we managed to stay in London until the end of 2008 through the recession. I had not worked for about 4 months at this point, and remaining in London on a single salary for two people just wasn't feasible. We somewhat randomly decided to move to Newark-on-Trent, having never set foot in the place; it's a great little town, though. This put me in the Midlands with no work and minimal savings; it was very hard not to feel like I had failed at doing London in my 20's at this point. I needed to find a job fast, so I wasn't expecting anything significant and kept my expectations very low. I guess this is where the story actually begins ✨.
I interviewed for a job in Lincoln at a software company as a support engineer. Honestly, I wasn't expecting to get the job. After being stonewalled by pretty much everyone, I was happy to just get the opportunity to interview. I got the job, possibly because I have spent most of my life tinkering with computers and was already providing tech support to my family for free. I started on £12k, which was a £13k pay cut 😅.
I had just begun doing something that I loved. I highly doubt that would have happened without leaving London; all it took was a global financial crisis, easy. It was clear that I had developed a skill for this kind of work. I moved from 1st to 2nd line support pretty quickly due to the technical nature of the cases I was dealing with. Shortly after that, I moved to the Quality Assurance team. And...
### What does testing have to do with failure?
So besides the obvious "this thing failed x tests for y reasons", there's a subtler and more insidious issue that most new testers experience. When you're new to a job, new-ish to a culture (I'm South African) and new to a project, understanding how to navigate the conversation of "there is a problem with x" is hard. Approaching the devs feels a lot like the response is going to be "[Oh? You're Approaching Me?](https://www.youtube.com/watch?v=4Zev7cJkuJc)" regardless of what the person is actually like, it feels like you're guaranteed to fail. It is, however, your literal job to communicate these issues, so embracing that feeling is necessary for everyone to succeed.
Suppose I didn't welcome that initial discomfort as motivation to learn how to present helpful, actionable information as transparently as possible? I wouldn't have lasted very long as a tester. I believe it is this skill that separates good testers from great ones. I decided that the best way for me to do this would be to tell people precisely what part of the application code failed and for what reason. It meant getting much more in-depth and hands-on with code than many testers ever do.
It's around 2013, I have been testing desktop applications initially written in Delphi, and we are most of the way through migrating everything to C# and .Net. These applications are integrated with large supplier catalogues using SOAP web services backed by mainframe systems. I learnt a lot here, but I didn't realise at the time that the most valuable lesson was not to allow complacency to prevent me from moving on from something comfortable. I would need to learn this a second time before it sunk in.
Next, I take a job in Nottingham with a company that is SaaS-based with some mobile offerings. The tech is a lot more exciting, and the pay is much better. The commute to the new place kind of sucks, though. Lincoln had low salaries for tech jobs, which is probably why [Rockstar had its testing dungeon there](https://www.gamesindustry.biz/articles/2018-10-26-rockstars-broken-work-ethics). Over the next year, I mostly get to grips with new ways of working (using "proper" agile methods) and a complex system with challenging release cycles.
This is also around the time my [marriage fails](https://www.nytimes.com/2016/05/29/opinion/sunday/why-you-will-marry-the-wrong-person.html); which was another source of valuable lessons and an opportunity to develop and grow as a person. One of the driving factors for moving to the city centre where I worked was having a commute that didn't suck. As a result, I had more time to evaluate where I was in my career. This evaluation kicked off a doom spiral (🤘🏻) that made me enrol on a part-time course with the Open University in Computer Science & Statistics. I also started spending a lot more of my spare time writing software; I wasn't getting a chance to do this as a tester. I felt like I had failed to make opportunities for myself and was course-correcting pretty violently. I also began to look for new jobs, again much later than I should have.
In 2016 I started a new testing role for a Big Data company; I was absolutely stoked that I got the job. It came with a hefty pay rise, and I thought it was out of my league; they didn't; this was a recurring theme with how I valued myself. It was the largest company I had worked for by a _significant_ margin. I had exposure to some incredible tech and phenomenal talent; the access to training was top-notch, and the pay was excellent. At this point, I was focusing on massive scale performance tests; I was writing more code than performing manual testing. Those years of testing had developed my ability to keep the big-picture structure of large-scale distributed systems in my mind while focusing on low-level detail. It is unconditionally one of my most valuable skills in designing systems.
I absolutely despised working there and only just forced myself to eke out a year despite all of what I have just mentioned. The problem is, large companies have a lot of space for people coast in. When you're going through a phase of immense self-development, it really kills your buzz to be met with that resistance to improvement. I felt like I had failed to crack working in a big corporation, but I learned what kind of culture I need to thrive. So...
### What does software development have to do with failure?
After the foray into the corporate world, I started a limited company planning on contracting. I began working for a small insure-tech company instead, which was awesome. I wanted to build cool things with exciting tech and was not disappointed; it was a great cultural fit. I created a test automation framework, contributed to open-source projects and contributed components to the platform that we were building. I learnt so much here, but more than anything, it just reinforced my love of solving problems with creative software solutions. I think it was here where I really stopped fitting into a "Tester" or "Developer" box.
REPL driven development is my preferred way to work, which is conveniently explained in [this article](https://dev.to/jr0cket/repl-driven-development-ano) where John Stevenson mentions getting fast feedback as a core benefit. This, in my opinion, is closely related to a systems design concept called [fail-fast](https://en.wikipedia.org/wiki/Fail-fast). To be horribly reductive in the pursuit of a point, detecting failure early on helps you avoid [sunk cost bias](https://en.wikipedia.org/wiki/Sunk_cost). Acknowledging something isn't working, identifying elements that did work and moving on early is almost always, in my experience, the best approach. I view software development as a process of continuous failure that ultimately culminates in success. This approach is core to how I work. Back then, it meant building tools to enable people to get feedback on whether something was working as quickly and unobtrusively as possible. Today, it means evaluating options and making decisions as pragmatically as possible and communicating this in a way that lets people buy into the strategy.
So at this startup, the whole team was super motivated and passionate; the product and the timing were both excellent, which meant we had many interested investors and clients. However, the eagerness to please and the number of "suitors" we had for growth meant simply __too many__ opportunities. We got pulled in multiple directions, ultimately leading to the company failing to capitalise on any of them, which is a shame. I had already moved on whilst the final steps towards this were being taken, which brings us to...
### What does seemingly abandoning your career have to do with failure?
It was scary to decide to walk away from a company that I loved working for, where I was doing something that I loved. The prospect of going from a decent salary to a student loan was _terrifying_. I think that I must have gone back and forth about whether to do this about a thousand times before ultimately taking steps to do it. Having just finished the first year (two years part-time) of my Open University course, I weighed up my choices. I did not enjoy distance learning. I love learning, but something about doing it remotely just doesn't work for me. So I tentatively decided to send some applications out to universities offering full-time courses with in-person lectures.
I felt like getting a degree was somehow necessary to legitimise my transition from testing to software development. Even though I had already proven this by doing my job and doing it well, I often fail (or refuse?) to see evidence of my own ability. Of the 5 universities I applied to, 4 got back to me, 3 offered me a place, and 1 said no almost immediately. Amusingly, the one that rejected me was also the only one I contacted ahead of time for advice on whether it was a futile attempt; thanks, Nottingham 😘. Without that rejection, I wouldn't get the chance to spend my time focusing on deepening my knowledge and understanding of computer science or discovering a love for psychology, neuroscience and philosophy. I also wouldn't be living in Sheffield, easily one of my favourite places in the U.K. so far.
My enthusiasm didn't stop me from failing and needing to resit a maths module in my first year to progress. It turns out not doing "serious" maths for 14 years and then suddenly diving in is hard. There is nothing like failing at something you've staked your career on to light a fire under your arse. Going to university for the first time when you're in your 30's is tough. However, I feel like you're a lot more motivated to engage with the subject matter; perhaps you're in less of a rush to get out there and start working and earning money.
Speaking of earning money and my worries about not being able to eat on a student budget 😬. I built relationships with a few clients doing freelance work whilst working at the startup and used this to supplement my income. The work ranged from various web dev tasks to building a service that would run performance tests on point-of-sale systems at multiple sites worldwide and continually send results to a central hub. All fun challenges with unique quirks and constraints, with many failed attempts at building things, but ultimately successful. Having let go of the security of a fixed income really allowed me to reframe my thinking around how I earned money. This led to me finally making that move into contracting...
### What does working for yourself have to do with failure?
Having a [Personal Service Company](https://www.simplybusiness.co.uk/knowledge/articles/2021/02/what-is-a-personal-service-company/) requires some curious mental acrobatics. You are not an individual; you are a business, but at the same time, you are the owner and sole service deliverer for that business. As a creative (yes, we are), you put a lot of yourself into your work; it can be hard to separate them. Engaging with feedback on what you create and building on it separates good developers from great ones. When that feedback is delivered to a business and not an individual, well, let's just say the delivery of it is a [little less restrained](https://youtu.be/tmNGYnFVjcI?t=15). This is, of course, a good thing once you get over the discomfort. Even better, it hones that ability to determine what is a good fit for you and how to walk away when something isn't.
Leading up to the summer break at university, a former client contacted me about some new work. I had helped them build a performance testing framework the previous year. They wanted me back to help define and build an automation strategy for a new stream of work. Unfortunately, the people initially involved in bringing me back moved on after a year to other projects. What we had discussed and agreed on changed quite drastically. New stakeholders with wildly different expectations got involved, and the relationship soured not long after that. In retrospect, that engagement should have ended after that initial year when everyone was happy. The following contract aligned perfectly in the end; it was a _much_ better fit, and I continued to work with this client for some time on a few projects.
Managing a business throws several interesting new things in your way. It gives you a taste of the challenges of running something much larger and more successful and perhaps a much healthier appreciation of the work involved in doing that. Most importantly, though, it gives you an appreciation of what failure means and how it can shape your future positively.
I have shelved contracting and have taken a permanent role as a Principal Engineer and Tech Lead for a former client of my business. I did this because I believe that what they are doing is incredibly exciting. I get to work on a diverse set of projects solving unique and complex problems. I could have easily carried on contracting, but I absolutely love the people I work with. Every day, I am reminded how worthwhile the change was. Being somewhere because you want to be, not because you have to, is excellent. Cool story, bro, but...
### What does failure have to do with me?
Increasingly we are becoming more comfortable with failure as an industry and a society, treating it as a learning opportunity, and this is a remarkable thing. That being said, I believe it is still important to share your experiences to possibly help others. What it means for you is one of two things. Either it will serve as a valuable source of inspiration if you are someone along a similar path and unsure about some risk or perception of things going wrong. Or you are in a similar position but feel that you have your own story to share, which could help someone, and the text above may inspire.
Writing this article has helped me gain a new appreciation for some aspects of my journey that I had forgotten about. It's also the first thing I have ever written for a public forum, so any feedback you can frame as a JoJo reference is gladly welcomed.
Failure never feels good while it is happening. I hope that this retelling of my career's meandering path will provide some compelling examples of all the ways seeming failure often results in new opportunities. Whether in understanding your role, direction, or self, embracing failure and allowing it to shape you will pay off. Just perhaps not as quickly or in the way you expect. It will inevitably lead to you being more resilient, capable and accepting of the interesting little curveballs life throws at you.
And remember:
 | hughzurname |
790,615 | Controlling Streaming Services with Alexa - Part 1 | One of the biggest problems that I’ve found with the sheer amount of streaming services is which one... | 0 | 2021-08-23T08:39:56 | https://mikegrant.org.uk/2021/08/13/controlling-streaming-services-with-alexa-1.html | homeautomation, smarthome, voiceassistant | ---
title: Controlling Streaming Services with Alexa - Part 1
published: true
date: 2021-08-12 23:00:00 UTC
tags: HomeAutomation,SmartHome,VoiceAssistant
canonical_url: https://mikegrant.org.uk/2021/08/13/controlling-streaming-services-with-alexa-1.html
---
One of the biggest problems that I’ve found with the sheer amount of streaming services is which one has what? Sometimes I’ll miss great content on Amazon Prime because I get frustrated browsing their app on my TV, or I want to watch a certain film, can’t find it on Netflix, and just assume that it’s not available to be streamed from anywhere. Why can’t I just ask my voice assistant (Alexa) to play a TV show or film and it plays on my TV irrespective of which streaming service it is on?
I currently use Alexa to control a lot of things in my house through Home Assistant and a custom skill for some of the more complicated tasks, so I set about creating a custom Alexa skill that will allow me to play content from the streaming services that I’ve subscribed to, on my TV. (Think “Okay Google, play Stranger Things on TV”)
## What do I need?
Before starting working on this project, I sat down and thought about what I needed to make this work, and the list was surprisingly small.
- Control of my TVs (via ADB)
- Intent information for each streaming service
- Data about what content is available on each service
- Alexa Skill
## Controlling the TV
Before we can play anything on the TV, we need to find a way to open the content that we want on the TV. As I have Android based devices, this is relatively easy for me. I can use ADB and [intents](https://developer.android.com/guide/components/intents-filters). As part of my home automation system, I already have an ADB server running in a container, which is connected to my TVs. This saves me having to open and close connections to each of my TVs everytime I want to control them.
To open content on the TV, I’ve used the intent URL scheme so that everything is uniform and easier to work with. After trawling the internet I compiled this list of intents for the three main streaming services that I use.
```
Netflix - intent://www.netflix.com/watch/CONTENTID#Intent;launchFlags=0x00800000;scheme=https;package=com.netflix.ninja;S.source=30;end Amazon Prime - intent://com.amazon.tv.launcher/detail?provider=aiv&providerId=ASIN#Intent;package=com.amazon.tv.launcher;scheme=amzn;end Disney+ - intent://disneyplus.com/VIDEOID#Intent;launchFlags=0x00800000;scheme=https;package=com.disney.disneyplus;end
```
We can validate these intents are working by using an adb shell that is connected to one of the TVs.
```
am start intent://www.netflix.com/watch/CONTENTID#Intent;launchFlags=0x00800000;scheme=https;package=com.netflix.ninja;S.source=30;end
```
This will start Netflix on the device and the content will beging playing within a couple of seconds.
## Playing content on the TV
Now that we can control our TV using ADB, we can build upon this by creating a simple script that takes a Netflix video link and sends the command to my TV via the ADB server.
```
var adb = require('@devicefarmer/adbkit') var client = adb.createClient({ host: '127.0.0.1', port: '5037' }) contentIntent = 'intent://www.netflix.com/watch/80126025#Intent;launchFlags=0x00800000;scheme=https;package=com.netflix.ninja;S.source=30;end' client.shell('192.168.1.1', `am start "${contentIntent}"`).then(function (response) { console.log(response) }).catch(function (err) { console.log(err); })
```
Running this script will open Star Trek: Discovery on the TV and we’ve validated that the idea will work.
## Seeing it in action
<iframe width="560" height="315" src="https://www.youtube.com/embed/dgJOmTapo2A" frameborder="0" allowfullscreen=""> </iframe>
Check back soon for more details on this project. | mikegrant |
790,701 | Making a Media Library with Redwood | Having a customizable media library can help you keep track of relevant content and manage settings around it. In this post, we'll create a media library that can be extended to cover a lot of different needs. | 0 | 2021-08-13T13:09:01 | https://dev.to/flippedcoding/making-a-media-library-with-redwood-2do7 | javascript, react, graphql | ---
title: Making a Media Library with Redwood
published: true
description: Having a customizable media library can help you keep track of relevant content and manage settings around it. In this post, we'll create a media library that can be extended to cover a lot of different needs.
tags: #javascript, #react, #graphql
cover_image: https://cdn.sanity.io/images/5ad74sb4/production/2f445a1119750cd17ecc6945f332c4385a51ce35-1000x420.png?w=2000&h=2000&fit=max
---
You might have a blog or a site that specializes in giving users video and image content. You can make yourself a media library to manage all of your content and keep it relevant to your users. That way you can see the exact data you need and you can arrange your images and videos in ways that don't affect users.
In this tutorial, we'll make a small media library to handle videos and images for us. You'll be able to upload the videos and images to Cloudinary and then show them in your own library. We'll be storing references to that content in our own Postgres database that we could use to reference images in other places.
## Setting up a Cloudinary account
The first thing we'll do is set up a Cloudinary account. You can [sign up for a free account here](https://cloudinary.com/signup).
Then you'll have a single place to upload all of your users' media content. That way you don't have to worry about storing all of your content and you can just fetch and upload your videos.
## Setting up the Redwood app
Now you can go to a terminal and we'll make our new Redwood app with the following command.
`yarn create redwood-app media-library`
When this finishes, you'll have a full-stack app that just needs a little updating. In the `api` folder you'll find all of the code to handle your database and GraphQL back-end. In the `web` folder you'll find the code for the React front-end. We'll start with the database schema because Redwood uses this to handle a lot of work for us.
### Making the models
Open `schema.prisma` in the `api > db` directory. Make sure to update your `provider` to `postgresql` instead of `sqlite` since we'll using a Postgres database. Take a moment to update the `.env` file in the root of the project. You'll need to uncomment the `DATABASE_URL` value and update it to your Postgres connection string. It might look like this.
`DATABASE_URL=postgres://postgres:admin@localhost:5432/media_library`
If you don't have Postgres installed locally, [you can download it here](https://www.postgresql.org/download/) and get your connection string from pgAdmin once the installation is finished.
You can close `.env` now and go back to `schema.prisma` because we need to add our models. You can delete the example model in the file and add the following ones.
```javascript
model Video {
id Int @id @default(autoincrement())
name String
duration Float
url String
}
model Image {
id Int @id @default(autoincrement())
name String
url String
}
```
We have the database schema ready so we can run a quick migration to set up the database.
`yarn rw prisma migrate dev`
This will create the tables with the columns and constraints we defined in the models. Just to have some data to look at, we'll seed our database.
### Seeding the database
Inside of `api > db`, open `seed.js` and delete all of the commented out code in the `main` function. We'll be adding our own seed calls with the following code.
```javascript
await db.video.create({
data: { name: 'Beth_vid', duration: 765.34, url: 'example.com' },
})
await db.image.create({
data: { name: 'Beth_img', url: 'example.com/beth.jpg' },
})
```
Now you can run this command to seed your database.
```bash
yarn rw prisma db seed
```
With your fresh data applied, we can move on to the best part of Redwood.
## Using Redwood to generate the front-end and back-end
Now we'll use my favorite Redwood command to generate the CRUD to work with videos for the front-end and back-end of this project.
`yarn rw g scaffold video`
This one command generates a React front-end to handle everything we need to add video records to the database. If you look in `api > db > src > graphql`, you'll see a new sdl file that contains all of the types for our queries and mutations for handling videos. In `api > db > src > services`, you'll see a new `videos` directory. This folder has all of the resolvers to handle the database updates. It also has a test that you can add on to.
On the front-end of the app, take a look at `web > src > pages`, you'll see a lot of new directories for videos. These contain pages that show different aspects of the CRUD functionality.
Take a look in `web > src > components` and you'll see even more directories for videos. These directories contain the files that handle the data on the front-end and the form we could use to handle adding videos to the database.
We're going to run the `scaffold` command one more time to generate all of the files for images.
```bash
yarn rw g scaffold image
```
This is everything we need to start working with the Cloudinary upload widget.
## Adding the Cloudinary upload widget
We're not actually going to use the form to add videos to the database. We're going to do that automatically after we upload the videos to Cloudinary. To start with, we'll add the Cloudinary widget to the `NewVideo` component. We can use a package to add this widget so we'll install that in the `web` directory first.
```bash
yarn add react-cloudinary-upload-widget
```
Let's go to `web > src > components > NewVideo` and edit the file there. This is where the edit form for the video gets pulled in. We'll add the import for the upload widget components we need along with the other imports.
```javascript
import { WidgetLoader, Widget } from 'react-cloudinary-upload-widget'
```
Then we'll add the uploader widget components. In the code right above the `VideoForm`, add this code.
```javascript
<WidgetLoader />
<Widget
sources={['local', 'camera']}
cloudName={process.env.CLOUD_NAME}
uploadPreset={process.env.UPLOAD_PRESET}
buttonText={'Open'}
style={{
color: 'white',
border: 'none',
width: '120px',
backgroundColor: 'green',
borderRadius: '4px',
height: '25px',
}}
folder={'test0'}
onSuccess={successCallBack}
/>
```
While you can check out what each of these props does for the widget in the [README in the repo](https://github.com/bubbaspaarx/react-cloudinary-upload-widget#readme), there are a few we need to highlight. The `CLOUD_NAME` and `UPLOAD_PRESET` need to be defined in your `.env`.
### Making an upload preset in the Cloudinary console
You'll need the values for these two fields and you'll get those from your Cloudinary console. The cloud name is on the dashboard as soon as you log in.

You'll need to go to the [settings page for uploads](https://cloudinary.com/console/settings/upload) and create a new unsigned upload preset. Your upload setting page will look something like this.
If you scroll down the page a bit, you'll see the "Upload presets" section. Click on "Add upload preset" to create a new unsigned preset. You be taken to a page that looks like this and the only thing you need to do is change "Signed" to "Unsigned" and save that change.
The value you see for "Upload preset name" is what you will need to set for your `UPLOAD_PRESET` in the `.env`. With these two values, you're `.env` should look similar to this.
```bash
CLOUD_NAME=test0
UPLOAD_PRESET=rftg435ebtre4
```
### Making the success callback
Now that we have those values in place, we need to define the callback for a successful video upload. This is where we'll get the URL to store in the database and where we'll make that GraphQL call now. You can delete the form now!
The success callback will look like this. It'll go right above the `return` statement.
```javascript
const successCallBack = (results) => {
const videoInfo = results.info
const input = {
name: videoInfo.original_filename,
duration: videoInfo.duration,
url: videoInfo.url,
}
createVideo({ variables: { input } })
}
```
When you run the app with `yarn rw dev` and go to `http://localhost:8910/videos/new` in your browser, you should see a new button above the form that says "Open". This opens the Cloudinary upload widget.


Upload a few videos and you'll see you get redirected to the main videos page that has a table with references to all your videos.
All that's left now is to show the videos on this page in a library format!
## Showing the media
Now you'll need to go to `web > src > components > Videos` and open `Video.js`. This is the file that has the table we see with our video info listed. We're going to keep the table and add the videos above it.
Since this component already has all of the video data fetched, we're going to add another `.map` over the videos and create new elements. Add this code right above the table element.
```javascript
<div
style={{
display: 'flex',
flexWrap: 'wrap',
justifyContent: 'space-evenly',
marginBottom: '24px',
}}
>
{videos.map((video) => (
<video width="320" height="240" controls>
<source src={video.url} type="video/mp4" />
Your browser does not support the video tag.
</video>
))}
</div>
```
If you reload your page, you should see something similar to this, but with your videos.
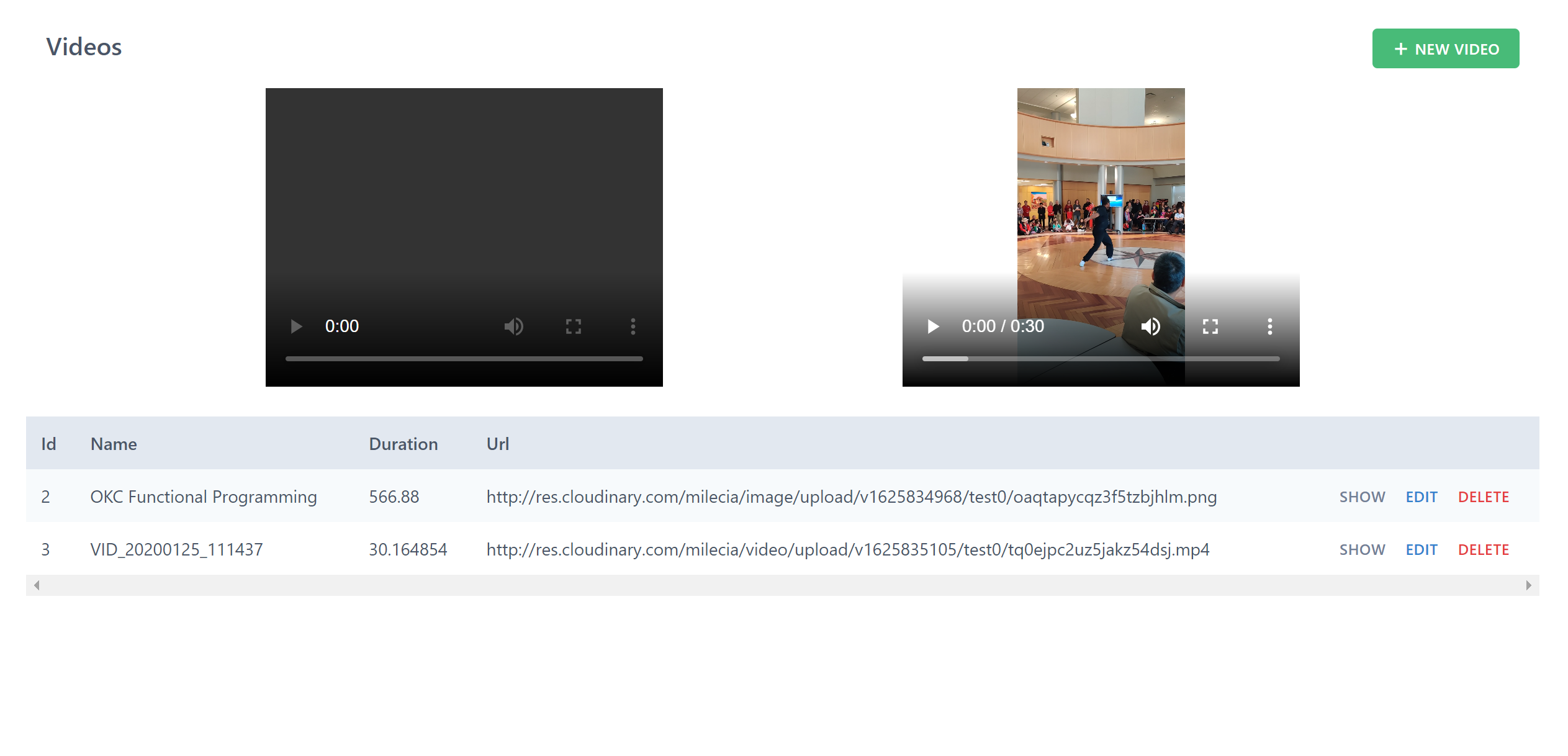
We're done! Now you have a fully functional media library. You can customize how content is displayed and how users interact with it if you add a little more imagination to what we started. You could add this functionality to the `Image` components we didn't cover. (It's why I put them in this guide.)
## Finished code
You can check out the full code in this GitHub repo in the `media-library` directory. Or you can check out the front-end in this [Code Sandbox](https://codesandbox.io/s/beautiful-shape-n5gjs).
_Note: You won't be able to see everything in the Code Sandbox because it doesn't support monorepos like Redwood._
## Conclusion
Storing media references to your own database can give you the flexibility to monitor changes over time. They can also act as a buffer against people trying to access your Cloudinary account. Some performance aspects might also make media references in your database useful.
Regardless of what your reasons are, now you know how to handle this use case quickly with the help of Redwood.
| flippedcoding |
797,160 | # Como funciona os navegadores web? | Existem muitas coisas do nosso dia a dia que não pensamos sobre o funcionamento, quando iniciamos... | 0 | 2021-08-19T13:49:35 | https://dev.to/deborafelix/como-funciona-os-navegadores-web-35k7 | braziliandevs, beginners | Existem muitas coisas do nosso dia a dia que não pensamos sobre o funcionamento, quando iniciamos nossa carreira de tecnologia, às vezes, não temos tempo ou curiosidade, ou caminhos neuronais para entender algumas coisas por debaixo dos panos. Aprender o funcionamento dos navegadores foi assim para mim. O intuito desse post é trazer de maneira simples esse funcionamento e se tiver curiosidade, aconselho fortemente ler os links que eu indico ao final do post.
Quando pedimos algo ao servidor com o enter na URL, passamos por todos os processos apresentados nos últimos posts, e ao chegar essa resposta, começa o processo de renderização, cada tipo de código passa por analisadores diferentes, verificando sintaxe e as instruções daquele trecho do código, é criada uma árvore (algumas, na verdade) com esses atributos que são chamados _nós_ e eles têm o papel de identificar o lugar, cor e características de cada componente. Caso os analisadores encontrem alguma inconsistência eles consideram o documento como inválido e dependendo da gravidade, não renderizam o componente ou até o site na tela.
O HTML por não ser uma gramática livre de contexto, não pode ser analisado facilmente, então durante a construção da árvore DOM ela é modificada algumas vezes durante o processo e existem algumas tolerâncias de sintaxe inválida.
Para mudanças dinâmicas, os navegadores tentam executar o mínimo de ações, usando a árvore, porém algumas modificações podem precisar de um recalculo de tudo, novo layout e nova pintura de toda a árvore, um exemplo disso seria a mudança de tamanho da fonte.
Além disso, cada navegador tem um motor de renderização diferente com especificidades e alguns consideram estilos pré-estilizados do usuário, fazendo com que desenvolvedores front-end não tenham um minuto de paz. risos.
Os navegadores evoluiriam muito, assim como as ferramentas para a criação de conteúdo dos mesmo, além dos sites cada vez mais dinâmicos, algumas das aplicações desktop que você utiliza no seu dia a dia, também utilizam motores dos navegadores, como Spotify, Discord e muitas outras.
Se você ficou interessado sobre navegadores:
1. [Como os navegadores funcionam: bastidores dos navegadores modernos](https://www.html5rocks.com/pt/tutorials/internals/howbrowserswork/)
2. [Como os motores de navegadores modernos funcionam?](https://medium.com/valestart/como-os-motores-de-navegadores-modernos-funcionam-38c4d266f284)
3. [Como os navegadores processam os códigos de uma página web?](https://canaltech.com.br/navegadores/como-os-navegadores-processam-os-codigos-de-uma-pagina-web/)
Se você gostou do post, comenta algo que você sempre quis saber como funciona embaixo dos panos! | deborafelix |
797,178 | A Tale of Two Build Systems: Launchpad and Copr | Whoa, a blog post! Haven’t written one of those in a while. I’ll make another one to go over what’s... | 0 | 2021-08-19T15:41:54 | https://dev.to/dvdmuckle/a-tale-of-two-build-systems-launchpad-and-copr-59p1 | copr, fedora, launchpad, ubuntu | ---
title: A Tale of Two Build Systems: Launchpad and Copr
published: true
date: 2021-08-19 13:00:00 UTC
tags: copr,fedora,launchpad,ubuntu
canonical_url:
---
Whoa, a blog post! Haven’t written one of those in a while. I’ll make another one to go over what’s happened since my last post, but right now, let’s focus on something very specific: package managers, and the build systems that support them. It’s Ubuntu vs Fedora, RPM vs DEB, apt vs dnf (or yum), Launchpad vs Copr.
## Fedora and Copr
Let’s start off at the beginning. I use Fedora on my desktop and personal laptop. It’s great! I like how cutting edge yet stable everything is. But before that I used Ubuntu. And that’s probably the case with a lot of other people. Ubuntu is very popular and easy to get started with, and because of that there’s a lot of guides for how to use it and how to install things. Its popularity has basically grown because of its popularity, in short. There’s so many flavors and distros based on Ubuntu too. Ubuntu and Fedora both have something in common as well: the groups behind them both have a platform that lets you build and host packages for them. Ubuntu has Launchpad, and the PPA, or Personal Package Archive, and Fedora has Copr.
Let’s start chronologically for me. I first used Copr… Four years ago? It’s been a bit, and I’m decently familiar with it. There are a handful of tools you can use to build an RPM package. RPM is the packaging format that Fedora and related distros use. To start, you have to write a spec file. This file can be pretty simple, or very large, but what it’s responsible for is describing what your package is, how to build it, and where all the files to install are located. Here’s an example of one I made a while back.
```
%define name minsh
%define build_timestamp %{lua: print(os.date("%Y%m%d"))}
%define version 1.9.1
Name: %{name}
Version: %{version}
Release: %{build_timestamp}%{?dist}
Summary: A very simple shell
Source0: https://github.com/dvdmuckle/minsh/archive/master.tar.gz#/%{name}-%{version}-%{release}.tar.gz
License: GPLv3
Packager: David Muckle <dvdmuckle@dvdmuckle.xyz>
BuildRequires: gcc make
%description
A very simple shell that supports running commands and output redirection.
%global debug_package %{nil}
%prep
%autosetup -n %{name}-master
%build
make
%install
mkdir %{buildroot}%{_bindir} -p
install -s minsh.o %{buildroot}%{_bindir}/minsh
%clean
rm -rf %{buildroot}
%files
%{_bindir}/minsh
%doc
%changelog
```
This is a spec for a small shell in C I wrote in college. I got the actual class project itself done in an afternoon, and had some time to package it up before the thing was due. Thus, this is pretty simple. The spec describes where you can get the code to build this under `Source0`, what prep work needs to be done to build it, what building it looks like, what installing it looks like, and where the other files are. For this, there’s only one file, the binary. This also describes the tools requires to build the package. Note this doesn’t include any runtime dependencies. There technically are some, but they’re all libraries included in `libc` which is a library package that’s just about always installed on any system.
In order to use this spec file to build your RPM, there are a few ways. Back then, I used `spectool` and `rpmbuild`, and `builddep`. `spectool` lets you lint the spec file and get the sources, `rpmbuild` does the actual building, and `builddep` lets you make sure all your build dependencies are installed. One of the cool things you can build is something called an SRPM, which is basically this spec file and your sources wrapped into a fancy archive file. It’s an RPM waiting to happen, just add water! Or a build system! Or, you can take another route and use `mock`, which is very nice as it will build your package in a chroot and manage all your build dependencies for you. Instead of having to remember two tools and the flags needed to do what you want, you can use one tool. And you can build for multiple OSes! So long as they use RPM, that is. This tool is more or less the same as what Copr does, so it’s a great way to make sure your build will work on Copr.
Copr is the first build system I used. You can feed it either a spec or an SRPM, either uploaded directly or cloned from a git repo. It’ll get your source (or use the one in the SRPM you uploaded), get all the dependencies in order, execute your instructions, and upload the resulting package to a repo anyone can add to their system. The most important detail is building an RPM is pretty flexible. Sure, there are some standards, but if you break the rules things usually won’t fail outright. For example, let’s say you want to build a binary written in Golang. It’s 2021, you probably have a `go.mod` file, right? One that specifies all your dependencies? And a `go.sum` file that specifies the versions of those dependencies, right? So why manage those dependencies in the spec file as well? With Copr you can run a build with internet access, which allows for you to pop a `go mod vendor` into your build instructions, so your dependencies are satisfied. This is technically against the packaging “code” for Fedora packages, but, well…

It’s important to note that both Fedora and Debian/Ubuntu have standards for packaging. These standards are more for if your package is going to be published in one of their repositories, but it’s still useful to keep the standards in mind.
One final thing before we move on from Copr is that with Copr, you can specify the versions of Fedora (and friends) as well as the architectures you want your package to be built for with just a check of a checkbox. And you only need one spec written! Generally speaking Fedora packages don’t change names or anything between versions, so this shouldn’t break any of your build and runtime dependencies.
… Okay one last _last_ thing and then we move on to Debian packaging. Spec files also allow you to put dynamic stuff into the file. Notice how the `build_timestamp` uses some Lua to get the current time? What a pain it would be to specify that manually every time! There’s also probably a macro for that too! There’s a number of packages that Fedora supplies that include macros, which can be useful for building things such as Golang-based packages. (Wow all this talk of Golang, you’d think I had [some kind of Golang project I’ve been working on packaging…](https://github.com/dvdmuckle/spc)). These macros can do a whole slew of things including specifying how your package is built and where any binaries are installed. The downside to that is unless you know what precisely the macro does, it can be hard to debug when something goes wrong, and to an outside observer it can be hard to figure out what’s going on.
## Ubuntu/Debian and Launchpad
Okay! Now on to Debian packaging. This is going to be a lot of me saying “I don’t know what this is exactly,” because I literally figured this out a day ago. I am going to figure out a lot of that though, and probably publish an addendum post to this, so a lot of my opinions will probably also change, but for now this is a lot of “This is what I had to do to get this working.”
As previously stated, there’s a handful of tools to build a DEB package. Which is a lot compared to the maybe four or so tools for RPM. You can even use `dpkg`, the package manager for DEB, to build packages! This is largely a bad idea because it literally creates an archive you can install, with nothing else involved, and assumes a lot like that your binary will run on other systems with potentially different library versions. Cool you can do it, though. As an aside, while `dpkg` is the actual package manager used by Debian based systems, and thus Ubuntu, usually it’s used via `apt` or `apt-get`. Debian based systems also have their own version of `mock` system, called `pbuilder`… and also `cowbuilder`??? One uses the other under the hood, I think, but I couldn’t get either of them working, but either way, they both build in a chroot and are in theory a good way to build for multiple distro versions.
For the package I built, I ended up using a combination of `debuild` and `dpkg-buildpackage`. Technically speaking they can both generate the same files you need for Launchpad, so I ended up with `debuild` since it requires fewer command line arguments. `debuild` also uses `dpkg-buildpackage` and the like under the hood along with some other linting stuff. To generate all the files to actually build this package, I used `dh-make-golang`. This is related to `dh-make`, which basically allows you to provide some things like your package’s name, what kind it is, and some other arguments to generate all of those files you need to build your package. And there’s, uh, more than just one, compared to RPM. At least they all go into the same `debian` directory…
Let’s start alphabetically. You’ve got your `changelog` file that has some very specific formatting to do a couple things. It lists your current and past versions for your package, as well as, well, your changelog, and what distro you’re building for. I think the distro part can be templated out so when the time comes to send generate the files to send to Launchpad, you can have one changelog for multiple distros. For now I’m just building for Ubuntu 20.04 since it’s the latest LTS release. The formatting here is so specific there’s a command just for updating the changelog, `dch`, that will do things like put the date in there correctly, bump the version number, and put in your email.
Your `control` file will list all of the metadata about your package. What it’s called, the maintainer, any build dependencies. One weird oddity I ran into is the package that enables shell completion in Ubuntu, `bash-completion`, also provides the files required to implement shell completion when building a package. Which is a little weird, initially I thought the package to allow for this would be some kind of package specific to building packages, much like the macros packages in Fedora.
The last major file (There are many others but they’re things like `copyright` which includes licensing stuff, and a couple other things I don’t even remember generating.) is the `rules` file. If you’re familiar with `make`, this will probably look familiar. It’s a Makefile! And it’s executable, but it gets executed by some other helper programs, so maybe don’t try executing it yourself if you’re new to this. This file is basically where you define how to go from source to binary for your package, and will probably also utilize an existing Makefile you already have. My `rules` file… does not do that, it uses a `dh` command with some other Golang-specific flags to build my binary, so I don’t know entirely what it does. What I do know is I had to add the `--with=bash-completion` flag and then add a `spc.bash-completion` file with all the shell completion stuff. Remember how I said macros can complicate things and make it hard to figure out what’s happening? Well the shoe’s on the other foot now. I clearly have a lot of learning to do in terms of how Debian packaging works, but what I do want to share are a couple gripes I’ve run into thus far.
## Miscellaneous Headaches
At first I ran into some issues with building the files necessary for Launchpad because it didn’t want to allow uncommited files in my repository when creating the source archive. Well, tough cookies, I need to include my vendored Golang libraries, because according to my research Launchpad doesn’t allow for building with internet access, so it can’t go off and get the necessary files for me to build. Copr can do builds with internet access, so while it would be cool for Launchpad to do that, I get why they may want to disallow it. At the time I was using [this](https://people.debian.org/~stapelberg/2015/07/27/dh-make-golang.html) guide to `dh-make-golang` in order get it working, which uses a couple other different tools later on in order to do the actual package build. I don’t need to do a full package build, however, I just need to generate the Debian equivalent of a SRPM, so I checked out a couple other tools. Eventually I settled on `debuild`, which lets me build just my source and other files, most of which are variants on the above files, sign things with my GPG key, and also ignore that I don’t have my build dependencies installed, since those include library packages I don’t need.
This was another pain point. Launchpad has a _heavy_ reliance on GPG keys. You have to upload the public key to Ubuntu’s keyserver, then import it to Launchpad. The whole process can take anywhere from thirty minutes to an hour. It’s _slow_. Granted we’re talking about Ubuntu infrastructure, infrastructure supporting one of if not the most popular Linux distro on the planet, so I get why it might be slow. Still, it’s hard to not be annoyed. On top of that, once you get the build going, it can take a few minutes after it’s completed for the DEB package to be available in the PPA. With Copr, it’s available nearly immediately, and there’s no need to use GPG keys for authentication. For both systems, keys will be generated for the package repository itself, so the GPG key you use with Launchpad, as far as I can tell, is only use to authenticate you and your files when you use `dput` to upload to Launchpad. This operation is apparently straight-up FTP. Also, if you screw up the GPG stuff from earlier, you can end up in a position where your Launchpad build fails silently and you can’t reuse that version for a build, and will be forced to increment the build number and rebuild.
## Conclusion
That all being said… I did it! I solved for Launchpad! Now I can focus on automating all of this with GitHub actions, something I’m not completely looking forward to. Overall, these two build systems allow you to do some neat stuff and make it very user friendly to install a package that isn’t in the main repositories. The way it gets to there, however, is very different. Debian package builds have a lot of rules and certain ways you have to do things, in addition to having many tools that do the same thing in ever so slightly different ways. Debian packaging also has documentation of mixed quality. The basics are well documented, but trying to do something a little more exotic like using `dh-make-golang` isn’t as documented as I would have liked. Fedora packaging has a handful of useful tools, with mostly up to date documentation to boot. The vibe I get from these build systems is they tend to reflect the OS you can build for. Fedora is cutting edge while being solid and pretty user friendly, whereas Ubuntu is incredibly well supported but, at least for LTS releases, you may not be getting the latest thing. Again, this is all my opinion as someone new to Launchpad and only decently knowledgeable with RPM packages. I’ll do more research into how to do a lot of these things, but this has been my journey thus far.
The post [A Tale of Two Build Systems: Launchpad and Copr](https://dvdmuckle.xyz/index.php/2021/08/19/a-tale-of-two-build-systems-launchpad-and-copr/) appeared first on [dvdmuckle](https://dvdmuckle.xyz). | dvdmuckle |
797,224 | How To Enable Real-Time Merge Conflict Detection in IntelliJ | Ah, the dreaded resolve conflicts popup. You've finished crafting the perfect code, just a quick... | 0 | 2021-08-23T11:52:16 | https://dev.to/gitlive/how-to-enable-real-time-merge-conflict-detection-in-intellij-3033 | webdev, programming, productivity, git | Ah, the dreaded resolve conflicts popup. You've finished crafting the perfect code, just a quick merge in of master (ahem, main) before you submit your PR, and then... 💥

If only there was an early warning system for merge conflicts so you could be better prepared or even avoid the conflicts in the first place I hear you say? Well if you are an IntelliJ user today is your lucky day!
Firstly, you'll need to install and set up [GitLive](https://plugins.jetbrains.com/plugin/11955-gitlive). Then if you right click the gutter on IntelliJ, you will see the option to “Show Other's Changes”.

It will be disabled if the file open in the editor is not from git or there are no other changes to it from contributors working on other branches (aka you are safe from conflicts). If it's enabled there will be one or more change indicators in the gutter of the editor.

These will show you where your teammates have made changes compared to your version of the file and even update in real-time as you and your teammates are editing.

If you've made a conflicting change you will see the bright red conflict indicator. These conflicts can be uncommitted local changes you have not pushed yet or existing changes on your branch that conflict with your teammates’ changes.
Click your teammate’s icon in the gutter to see the diff between your version and theirs, the branch the offending changes are from, and the issue connected to that branch if there is one.

From this popup you can also cherry-pick your teammate’s change directly from their local version of the file. For simple conflicts this can be a quick way to resolve them as identical changes on different branches will merge cleanly.
Unfortunately, it's not always possible to resolve a conflict straight away but with the early warning, you'll be better prepared, avoiding any nasty surprises at merge time!
Check out [this blog post](https://blog.git.live/gitlive-11.0-Real-time-merge-conflict-detection) or the [GitLive docs](https://docs.git.live/docs/mergeconflicts/) if you want to learn more.
| itsmichael1 |
797,226 | Intro to Blockchain with ArcGIS JSAPI | You've probably heard of blockchain and web 3.0 in passing. A huge benefit of working with a... | 0 | 2021-08-19T14:47:29 | https://odoe.net/blog/intro-blockchain | blockchain, javascript, mapping | You've probably heard of [blockchain](https://en.wikipedia.org/wiki/Blockchain) and [web 3.0](https://ethdocs.org/en/latest/introduction/web3.html) in passing. A huge benefit of working with a blockchain like Ethereum, is the ability to create [Smart Contracts](https://en.wikipedia.org/wiki/Smart_contract). A smart contract is basically code on the blockchain defining how you interact with it. Once a contract is deployed, you can only interact with it based on how it was written. I won't go into details about use cases, but suffice to say, this brings a lot of utility to building decentralized applications.
So how could a developer use something like this with an ArcGIS API for JavaScript application? I'm sure there are a number of scenarios you could think up, but one of the most basic ways might be to document an edit transaction. The contract could store the editor, the location, timestamp, and the globalId of the edited feature. Honestly, I don't know how useful that really is, but it's basic and something to easily grasp.
## Tools
In order to build a decentralized app (Dapp), there are a number of libraries and tools available to developers. For myself, I like using the [Truffle Suite](https://www.trufflesuite.com/). I use [Ganache](https://www.trufflesuite.com/ganache) to load a local blockchain on my machine to deploy contracts to and perform transactions. It also provides a ton of fake Ethereum to make me feel like a baller. To compile and deploy this contracts, I can use the [truffle](https://www.trufflesuite.com/truffle) library in my apps. I also need a local wallet to perform transactions with the blockchain. For that, I use [MetaMask](https://metamask.io/). There are some other web wallets, but I'm used to this one. To interact with the wallet and perform transactions, I can use a library called [web3js](https://web3js.readthedocs.io/en/v1.3.4/).
With the core tools out of the way, I can move on to trying to write a contact.
## Smart'ish Contract
I like to prototype writing contracts using [remixe.ethereum](https://remix.ethereum.org/). It will let me compile and deploy my contract to a test blockchain so I can test out ideas and make sure the contract works as expected before I start writing my application. In this case, I'm going to write a basic contract that can be used to hold an asset, in my case, a location or pair of coordinates. I'll be using [Solidity](https://soliditylang.org/) to write the smart contract. You don't have to use Solidity, smart contracts can be written in a number of languages from JavaScript and C#, to Haskell. Solidity is just kind of a standard way to write smart contracts, and I think it's fairly easy to work with. Granted, I am a complete Solidity noob, so what do I know.
Let's look at a very basic smart contract to hold a latitude and longitude.
```java
// SPDX-License-Identifier: MIT
pragma solidity >=0.4.22 <0.9.0;
contract GeoAsset {
string globalId;
address user;
string public lat;
string public lon;
STATUSES public status;
enum STATUSES {
CREATED,
COMPLETE
}
event Action (
string name,
address account,
uint timestamp
);
constructor(string memory _lat, string memory _lon) public {
user = msg.sender;
status = STATUSES.CREATED;
lat = _lat;
lon = _lon;
emit Action("CREATED", user, block.timestamp);
}
function update(string memory _globalId) public {
require(msg.sender == user);
require(status == STATUSES.CREATED);
globalId = _globalId;
status = STATUSES.COMPLETE;
emit Action("COMPLETE", user, block.timestamp);
}
}
```
Ok, let's cover the basics here. First thing you might notice here is that my lat/long are stored as strings?? What am I thinking? Solidity doesn't have a [type](https://docs.soliditylang.org/en/develop/types.html) for numeric decimals. It has other ways handle currency of tokens, but for simplicity sake, I'll just store them as strings. When the contract is created, I can pass it the lat/long and store them. I'll also update the status of the contract and store the `msg.sender`, which would be the person creating the contract. `msg` is a global you work with in Solidity. Then I can emit a custom event that I can listen for in an application if I want. I also have an `update` method that can be used to update the `globalId` and updates the `status`. Notice the `require` methods used here. This is how Solidity adds some validity checks, in this case, in order for this function to execute, the user of the contract must be the same one calling the function, and the status must also be `CREATED`. The will prevent someone hijacking the contract or a user making erroneous updates.
Once I've tested this out on remix, I can copy the code to my application and [compile it with truffle](https://www.trufflesuite.com/docs/truffle/getting-started/compiling-contracts). Now, how would I create, deploy, and interact with this contact in an application?
## web3 for you and me
I'm going to be using a simple [create-react-app](https://create-react-app.dev/) app to get started here. I won't get into detail on the ArcGIS JSAPI bits of this application, I have plenty of content out there on that, so let's focus on the smart contract part.
```js
import GeoAsset from './contracts/GeoAsset.json'
import Web3 from 'web3';
```
When truffle compiles my `.sol` file, it will create a JSON file holding all the important bits of how to create the contract in my application. I have a method set up to ask for permission to connect to my MetaMask wallet to interact with my smart contract.
```js
const loadWeb3 = async () => {
if (typeof window.ethereum === "undefined") {
alert("Please install metamask");
return;
}
// asks for wallet permission
window.ethereum.enable();
const web3 = new Web3(window.ethereum);
const accounts = await web3.eth.getAccounts();
const account = accounts[0];
const contract = new web3.eth.Contract(GeoAsset.abi);
if (account) {
setWeb3State({
account,
contract,
web3,
});
}
};
```
This snippet of code will prompt the MetaMask wallet to connect to my application, get access to a current MetaMask account, and create an instance of my smart contract. The contract is not deployed at this point, I've basically created an instance I can use to deploy the contract later. I'm not sure this is ideally how I want to do it, but again, I'm still learning, so if anyone sees flaws here, please let me know.
I should also point out that my MetaMask wallet is using an account that was created with Ganache, so it's filled with fake Ethereum I can use to pay for transactions to my local blockchain.
So here is the workflow I am looking at for my smart contract.
* Click on the map to get a lat/long
* Deploy the contract with the collected lat/long
* Save the edits to the FeatureLayer
* Update the contract with the globalId from the success of my edit
What does that look like?
```js
const { contract, account, web3 } = web3State;
view.when(async () => {
view.on("click", async ({ mapPoint }) => {
const lat = mapPoint.latitude;
const lon = mapPoint.longitude;
let contractAddress;
await contract
.deploy({
data: GeoAsset.bytecode,
arguments: [lat.toString(), lon.toString()],
})
.send({
from: account,
})
.once("receipt", async (receipt) => {
// save address for later
contractAddress = receipt.contractAddress;
});
// create contract
const geoAsset = new web3.eth.Contract(GeoAsset.abi, contractAddress);
const { addFeatureResults } = await layer.applyEdits({
addFeatures: [
{
attributes: {
IncidentType: 3,
IncidentDescription: contractAddress,
},
geometry: {
type: "point",
latitude: lat,
longitude: lon,
},
},
],
});
const { globalId } = addFeatureResults[0];
await geoAsset.methods.update(globalId).send({
from: account,
});
const latitude = await geoAsset.methods.lat().call();
const longitude = await geoAsset.methods.lon().call();
console.log("lat/lon", latitude, longitude);
});
});
```
Ok, I know this is a lot to take in at once. I'm using the `contract.deploy()` method to deploy my contract to the blockchain with the data from my compiled contract, and passing the lat/long to it. Notice I then have to use the `send()` method and let the contact know it's coming from my current account. This will cost a transaction fee since I am interacting with the blockchain network. This is commonly referred to as a gas fee. On the live Ethereum network, depending on how congested the network is at the time, this could be costly. Any time I use the `send()` method, this is a transaction with costs associated. I can then wait for the `receipt` of this transaction and save the contract address.
After I perform my edit, I can retrieve the contract from the saved `contractAddress` and now I can use the `update()` method to update the globalId of the contract. Again, this is a transaction, so I need to pay a gas fee. When the contract has been updated, I can retrieve public properties, but instead of using the `send()` method, I can use the `call()` method. This is not a transaction, I'm just reading data from the contract, so there is no gas fee associated with this method.
That was a lot. If I were smart, I would probably write this contract in such a way to limit the number of transactions to cut down on the gas fees, but I really just wanted to demonstrate a workflow of using a smart contract in this kind of scenario.
## Summary
The code for this project can be [found on github](https://github.com/odoe/arcgis-simple-dapp).
Lately, I have become really interested in the technology of smart contracts and working with the blockchain. Most blockchain projects have to do with decentralized finance or something similar. But there are quite a few projects focused on asset management, internet of things, and more that I find have some interesting uses. [Foam](https://foam.space/) is a project that uses the blockchain for points of interest and networks. I don't know the current status of the project, but the frontend is written in PureScript and I think the backend is in Haskell, so I really dig that.
I should also point out that I've spent quite a few hours going over videos from [DappUniversity](https://www.dappuniversity.com/) on Youtube. It was a great start for me to get my feet wet in working with web3 and smart contracts.
I have some other ideas for stuff I want to try with smart contracts and using the ArcGIS API for JavaScript, so expect some more content like this in the future.
If you want to learn more about this Dapp in detail, check out my vide below.
{% youtube 0oQNvZvG43M %}
| odoenet |
797,286 | SDC: DBs and Servers | Here's where I am on SDC: I've got my API routes in shape. I've got an Express server and... | 0 | 2021-08-19T14:53:22 | https://dev.to/zbretz/sdc-dbs-and-servers-5a1a | ###Here's where I am on SDC:
- I've got my API routes in shape.
- I've got an Express server and a Postgres server active and listening on different ports on localhost.
- My Postgres server is seeded with the data in imprecisely defined tables.
- My Express server can retrieve data from the DB with queries that approximate the shape of the API we're replacing.
This morning I spun up two EC2 instances - one for the API (Express) and the other for the DB. The former is about as bare bones as it gets - I created the barest test db/table/record but I can confirm that a Postman request to my remote API creates a connection to the *also* remote DB that serves it the query result that it returns to Postman.
###Here's what's next:
I'm setting aside tuning my tables and queries for now. I think those will take some nitty-gritty work, but those are within my current comprehension.
Some bigger questions are looming.
Here's where it gets fun and where I'm charting totally new territory.
I know I'll need to:
- get my data onto my EC2 Postgres instance.
- scale horizontally by using more instances.
- is that db instances or service (API) instances?
- load balance to use those instances efficiently
- stress test by sending automated requests
Those are just some of the high level things and I really don't know how any of it will go.
| zbretz | |
797,366 | Web Scraping with F# | NOTE: The content of this post is based on this code, check it for the full... | 11,670 | 2021-08-19T15:09:07 | https://blog.tunaxor.me/blog/2021-08-18-web-scrapping-with-fsharp-1fic.html | fsharp, webscrapping, dotnet, playwright | [Playwright]: https://playwright.dev/dotnet/
[.NET SDK]: https://dotnet.microsoft.com/download
[Ionide]: https://ionide.io/
[Rider]: https://www.jetbrains.com/rider/
[Visual Studio]: https://visualstudio.microsoft.com/vs/community/
[Task]: https://docs.microsoft.com/en-us/dotnet/api/system.threading.tasks.task?view=net-5.0
[Async]: https://docs.microsoft.com/en-us/dotnet/fsharp/tutorials/asynchronous-and-concurrent-programming/async
> ***NOTE***: The content of this post is based on this code, check it for the full example.
>
> https://github.com/AngelMunoz/Escalin
## Simple things in FSharp
Hey there, this is the next entry in ***Simple Things in F#***
If you've ever wanted to pull data periodically from a website, or you are a QA automation person looking to do E2E (end to end) testing, then [Playwright] might be an option for you. Similar to Cypress or PhantomJS, Playwright is a library that allows you to automate ineractions with websites, you can even take screenshots and PDFs!
Playwright offers access to the following browsers
- Chromium
- Edge
- Chrome
- Firefox
- Webkit
Normally these tools are made with javascript in mind (playwright is no exception) but, Playwright offers .NET libraries as well so if you like to use F#, VB or even C#, you can do some web scrapping, E2E with playwright.
## Pre-requisites
We will focus on F# here so you are required to have the [.NET SDK] installed on your machine, also you will need the playwright global cli tool (there's an npm version as well if you prefer to install that
```powershell
dotnet tool install --global Microsoft.Playwright.CLI
```
Once installed we can create a new console project in the following way:
```powershell
# feel free to use VB o C# if you prefer it
dotnet new console -lang F# -o Escalin
```
In this case I made a poject called `Escalin`, once created the project we'll install these dependencies.
```powershell
cd Escalin
dotnet add package Microsoft.Playwright
dotnet build
# this is required in order to install the browsers playwright uses
# if you've installed them before (via npm or even the same tool)
# you can omit this step
playwright install
```
> ***SCRIPTING***: You can actually use playwright with F# scripts as well but you will need to install the playwright browsers first on that machine either by creating a dummy project and run the dotnet tool or using playwright npm tool to download them
Once we have our dependencies ready, we can start digging in with the code in VSCode using [Ionide], [Rider] or [Visual Studio].
## Exercise
For today's exercise we will do a web scrapping of my own blog, and get a list of the post summaries in the index page and save them as a json file
To do that, we will need to do the following:
- Navigate to `https://blog.tunaxor.me`
- Select all of the post entries in the index page
- Extract all the text from each entry
- Generate a "Post" from each text block
- Write a JSON file called `posts.json`
Let's start with the namespaces and a few types we will need to get our work done.
```fsharp
open Microsoft.Playwright
// Playwright is very heavy on task methods we'll need this
open System.Threading.Tasks
// This one is to write to disk
open System.IO
// Json serialization
open System.Text.Json
// Playwright offers different browsers so let's
// declare a Discrimiated union with our choices
type Browser =
| Chromium
| Chrome
| Edge
| Firefox
| Webkit
// let's also define a "pretty" representation of those
member instance.AsString =
match instance with
| Chromium -> "Chromium"
| Chrome -> "Chrome"
| Edge -> "Edge"
| Firefox -> "Firefox"
| Webkit -> "Webkit"
type Post =
{ title: string
author: string
summary: string
tags: string array
date: string }
```
Also, our main's goal is to have something like this:
```fsharp
[<EntryPoint>]
let main _ =
Playwright.CreateAsync()
|> getBrowser Firefox
|> getPage "https://blog.tunaxor.me"
|> getPostSummaries
|> writePostsToFile
|> Async.AwaitTask
|> Async.RunSynchronously
0
```
That means we will need to create the following functions
- `getBrowser` - that takes both a browser and a [Task] with a playwright instance
- `getPage` - that takes both a string (url) and a [Task] with a browser instance
- `getPostSummaries` - that takes a [Task] with a page instance
- `WritePostsToFile` - that takes a [Task] with a post array
in the case of `Async.AwaitTask` and `Async.RunSynchronously` it's not necessary since they are FSharp.Core implementations, we'll also use the pipe operator `|>` to apply the last's function result as a parameter for the next function.
> The `pipe` operator is very useful in F# [it could also make it to javascript at some point](https://github.com/tc39/proposal-pipeline-operator)
>
> if we want to visualize that in another way, we can think of it as this:
>
> `64 |> addNumbers 10` is equivalent to `addNumbers 10 64`
>
Let's get started with `getBrowser`
> ***NOTE***: I changed the parameters here vs the source code be more readable
```fsharp
let getBrowser (kind: Browser) (getPlaywright: Task<IPlaywright>) =
task {
// it's like we wrote
// let playwright = await getPlaywright
let! playwright = getPlaywright
printfn $"Browsing with {kind.AsString}"
/// return! is like `return await`
return!
match kind with
| Chromium -> pl.Chromium.LaunchAsync()
| Chrome ->
let opts = BrowserTypeLaunchOptions()
opts.Channel <- "chrome"
pl.Chromium.LaunchAsync(opts)
| Edge ->
let opts = BrowserTypeLaunchOptions()
opts.Channel <- "msedge"
pl.Chromium.LaunchAsync(opts)
| Firefox -> pl.Firefox.LaunchAsync()
| Webkit -> pl.Webkit.LaunchAsync()
}
```
In this case, we're not doing much rather than just creating a browser instance and returning it, think about it as a simple helper function that you can also modify to pass in browser options and other things if you need them further down the line.
We are also taking the task as the parameter, so we can use the `pipe` operator easily the downside here I guess is that we have to do `let! playwright = getPlaywright` but I don't think too much about it, the benefit is that we can make our main function more legible and gives us a clear indication of how we want to proceed.
The next is `getPage`
```fsharp
let getPage (url: string) (getBrowser: Task<IBrowser>) =
task {
let! browser = getBrowser
printfn $"Navigating to \"{url}\""
// we'll get a new page first
let! page = browser.NewPageAsync()
// let's navigate right into the url
let! res = page.GotoAsync url
// we will ensure that we navigated successfully
if not res.Ok then
// we could use a result here to better handle errors, but
// for simplicity we'll just fail of we couldn't navigate correctly
return failwith "We couldn't navigate to that page"
return page
}
```
This function is also short, we just open a new page and go yo a particular URL and ensure we did it correctly, once we're done that we just return the page
The next function is `getPostSummaries` that will find all of the post summaries in the page we just visited on the last function.
```fsharp
let getPostSummaries (getPage: Task<IPage>) =
task {
let! page = getPage
// The first scrapping part, we'll get all of the elements that have
// the "card-content" class
let! cards = page.QuerySelectorAllAsync(".card-content")
printfn $"Getting Cards from the landing page: {cards.Count}"
return!
cards
// we'll convert the readonly list to an array
|> Seq.toArray
// we'll use the `Parallel` module to precisely process each post
// in parallel and apply the `convertElementToPost` function
|> Array.Parallel.map convertElementToPost
// at this point we have a Task<Post>[]
// so we'll pass it to the next function to ensure all of the tasks
// are resolved
|> Task.WhenAll // return a Task<Post[]>
}
```
Before we get to the next one, we need to check what is `convertElementToPost` doing, how did we go from an element read only list to a post array? let's make a list of things we need to do in order to get a post so the code doesn't look too alien
1. Inside of the element, search for the title
2. Inside of the element, search for the author
3. Inside of the element, search for the content
4. Extract the text from the title and the author
5. The content will be split in an array where the text has `...`
6. For the summary we'll get the first element of the array or return an empty string
7. The second element will be divided where we have the `\n` character
1. To the first element of that array, we'll divide it as well where we have a `#` to get our tags.
2. Trim the strings from extra spaces and filter out empty strings
3. The second element will get trimmed from spaces as well and that will be our date
All of this, based on knowing that the content might come like this
```
Simple things in F If you come from PHP, Javascript this might help you understand a... #dotnet #fsharp #mvc #saturn \nJul 16, 2021
```
```fsharp
let convertElementToPost (element: IElementHandle) =
task {
// steps 1, 2 y 3
let! headerContent = element.QuerySelectorAsync(".title")
let! author = element.QuerySelectorAsync(".subtitle a")
let! content = element.QuerySelectorAsync(".content")
// step 4
let! title = headerContent.InnerTextAsync()
let! authorText = author.InnerTextAsync()
let! rawContent = content.InnerTextAsync()
// step 5
let summaryParts = rawContent.Split("...")
let summary =
// step 6
summaryParts
|> Array.tryHead
|> Option.defaultValue ""
// try to split the tags and the date
let extraParts =
// step 7
(summaryParts
|> Array.tryLast
// we'll default to a single character string to ensure we will have
// at least an array with two elements ["", ""]
|> Option.defaultValue "\n")
.Split '\n'
// split the tags given that each has a '#' and trim it, remove it if it's whitespace
let tags =
// step 7.1
(extraParts
|> Array.tryHead
|> Option.defaultValue "")
.Split('#')
// step 7.2
|> Array.map (fun s -> s.Trim())
|> Array.filter (System.String.IsNullOrWhiteSpace >> not)
let date =
// step 7.3
extraParts
|> Array.tryLast
|> Option.defaultValue ""
printfn $"Parsed: {title} - {authorText}"
// return el post
return
{ title = title
author = authorText
tags = tags
summary = $"{summary}..."
date = date }
}
```
Phew! that was intense right? string handling is a mess specially if I'm around, that's what my mind could produce but hey _as long as it works_! the other web scrapping thing we did here was at the beggining, once we knew we were inside a _card_, we could safely query elements and know they were going to be only children of that _card_ after we processed the text we're ready to go.
Let's get to the last step in our main `writePostsToFile`, this will just take the post array task we returned on the last function chain and then just write that to the disk.
```fsharp
let writePostsToFile (getPosts: Task<Post array>) =
task {
let! posts = getPosts
let opts =
let opts = JsonSerializerOptions()
opts.WriteIndented <- true
opts
let json =
// serialize the array with the base class library System.Text.Json
JsonSerializer.SerializeToUtf8Bytes(posts, opts)
printfn "Saving to \"./posts.json\""
// write those bytes to dosk
return! File.WriteAllBytesAsync("./posts.json", json)
}
```
Once we're done with all of that we just apply the result to `Async.AwaitTask` given that F#'s Async/Task aren't the same,
> check [Async] and [Task] docs to have a better overview
F# doesn't really have an async `main` so that's why we run that last task synchronously and return 0 at the end
The result should look like this
> NOTE: that gif contains old code but produces the same output
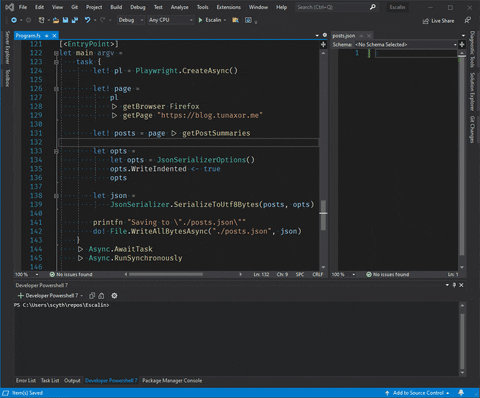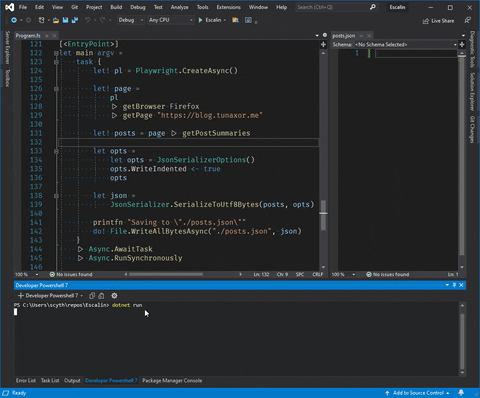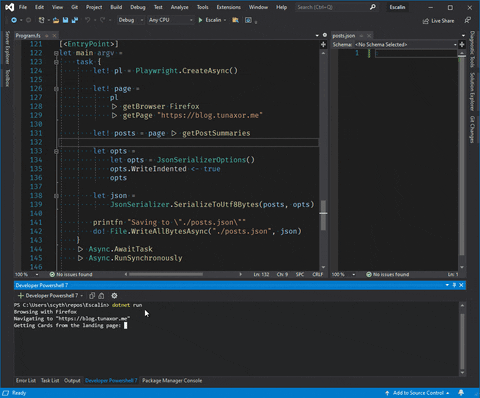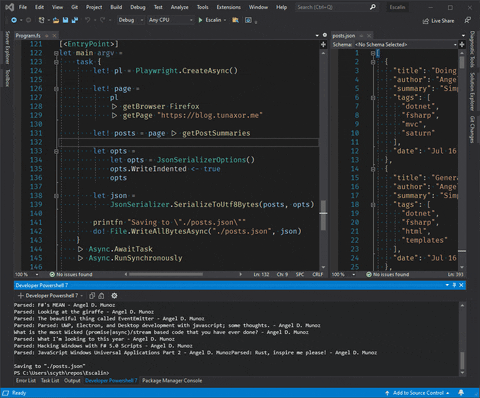
### Notes and Conclusions
The process I went through to get to this code was basically to go to my blog, inspect it with my browser and start analyzing the website's structure, once I kind of knew what was the ideal path to do it and what where the classes/elements I needed to look for I started with the web scrapping part.
Keep in mind that playwright has many many options, you can perform clicks, text inputs get screenshots, pdfs, do mouse events and a lot of things that can help you archieve your goals either by doing Testing or doing some web scrapping as I just showed you.
F# is a pretty concise language, and just think about if for a minute, async and parallel programing could be some of the most complex to mentalize yet we just did both and even mixed them in a way that really felt natural or at least I hope it felt that way for you as well isn't that amazing?
have fun and I will see you again in the next entry!
### **Update**:
From F# 6.0 and .NET6 Ply is not needed anymore, `task {}` has been incorporated into F# Core | tunaxor |
798,327 | Krayin - Opensource Laravel CRM Package | Krayin is free & Opensource Laravel CRM package for enhanced productivity and empower customer relationships. | 0 | 2021-08-20T15:36:54 | https://dev.to/pathaksaurav/krayin-opensource-laravel-crm-package-373e | laravel, php, crm, opensource | ---
title: Krayin - Opensource Laravel CRM Package
published: true
description: Krayin is free & Opensource Laravel CRM package for enhanced productivity and empower customer relationships.
tags: laravel, PHP, CRM, opensource
//cover_image: https://direct_url_to_image.jpg
---
[Krayin](https://krayincrm.com/) is a Free & Opensource Laravel CRM solution for SMEs and Enterprises for complete customer lifecycle management. It automates your organization’s Sales and Marketing Operations, as a result, exponential growth in sales.
## Easy Installation
Create the krayin project with just a few installation command
```sh
composer create-project krayin/laravel-crm
```
```sh
php artisan krayin-crm:install
```
Major features of Krayin are as follows:
### Lead Management
Lead Management simply refers to system activities, lead capturing, lead tracking, and convert leads into opportunities.
Assign leads to the sales team and manage your employee activities with the customers to do the right follow-up. Mark lead as won or lost so that you can view live records on the dashboard.
### ACL System
ACL is the best way to define who gets to access what. Assign users to a specific role so that users have access to certain records.
Control on who can edit the records, who can create the records and who can delete the records. As an administrator, you can configure users and roles.
### Activities Management
Activities are actions and responsibilities the software exists to help your company’s team to avoid missing opportunities.
Laravel CRM activities include meetings, calls, and notes. So the sales team will not miss any follow-up.
Github: https://github.com/krayin/laravel-crm
Demo: https://demo.krayincrm.com/admin/login | pathaksaurav |
797,371 | Exploring Kanban: Origin and Key Functionality of JavaScript Kanban Boards | The story of using the Kanban approach begins in the late 1940s. Toyota started exploring ways to... | 0 | 2021-08-24T12:26:50 | https://dev.to/plazarev/exploring-kanban-origin-and-key-functionality-of-javascript-kanban-boards-4ogo | javascript, agile, projectmanagement, webdev | The story of using the Kanban approach begins in the late 1940s. Toyota started exploring ways to improve their parts inventory control and supply customers with cars as quickly and low-costly as possible. They studied supermarkets' workflow and applied shelf-stocking techniques to factory floors.
Starting from the 1950s, workers used cards, or “kanbans”, to report on capacity levels between teams in real-time. Cards were attached to a box of spare parts used on the production line. A worker emptied the box and then sent a kanban to the warehouse with information about how many parts were needed, where, and when.

The warehouse, in turn, sent a full box with a new card describing spares made. The kanban received was passed to the parts factories. Therefore, workers produced and delivered the necessary parts in the needed amount and in due time. As a result, the company reduced wait time between processes and avoided overstocking.
Fast-forward to the 2000s, where David Anderson was the first person to use Kanban methodology in software development. He developed the Kanban approach’s idea and introduced the Kanban board, as we know it today.
The tool was used by the Microsoft software development team to improve the bug fixing process. A developer could pick a task to work on from a buffer and then forward it to the next stage of the development process by adding it to another list.
To date, Kanban boards are applied by multiple industries for managing their projects. If used properly, the tool allows teams to work more efficiently by tracking what is in progress at a glance and identifying project bottlenecks.
However, how to choose a proper Kanban solution for your team? Let’s discuss the key feature set using the upcoming [JavaScript Kanban board](https://dhtmlx.com/docs/products/dhtmlxKanban/) by DHTMLX as an example.
##5 Essential Features of Kanban Board
###Task Management
Cards are a key element of a Kanban board as they are a visual representation of tasks. Thus, DHTMLX Kanban allows creating an unlimited amount of cards and editing them from the UI. Users can work with plain text via input and textarea controls, upload files, assign a task using a combobox, and set due dates via date and timepicker. It’s also possible to customize card appearance by adding an image or setting a color via a colorpicker.
###Adding Columns & Swimlanes
A simple but extremely important feature is the ability to add columns and swimlanes. A Kanban board usually includes 3 and more columns which represent different stages of your workflow. Your team members can pass cards between columns until successful task fulfillment.
Swimlanes are the horizontal lines you can use to divide the Kanban board into two or more parts. They come in handy when you need to manage several projects on one board or split a complex project into smaller parts where teams from different departments are working on their set of tasks, etc.
###Drag-n-Drop
Moving tasks between columns is required to visualize the workflow process and keep the team up to date. With DHTMLX Kanban, users can drag-n-drop cards between columns as well as reorder them within a column, e.g. for prioritizing tasks.
###Touch Support
Support for touch screen events should simplify the use of Kanban boards during the team's daily routine. Therefore, users may create new tasks with a tap, edit or delete them by triggering a context menu, as well as move a card to the proper column or row with a touch drag-n-drop gesture.
###Synchronization with Third-Party Project Management Tools
You may improve your Kanban experience and create a comprehensive project management solution by combining several products. Thus, for example, you may consider using DHTMLX [Gantt chart](https://dhtmlx.com/docs/products/dhtmlxGantt/) or [Scheduler event calendar](https://dhtmlx.com/docs/products/dhtmlxScheduler/).
The first library allows dividing a complex project into manageable tasks and subtasks, estimating the project timeline, allocating resources needed, and visualizing dependencies between tasks. The second one is a Google-like calendar component, which includes an intuitive drag-n-drop interface and 10 views to book your appointments.
Summing up, the Kanban approach is helpful for visualizing your workflow, identifying its weaknesses, and speeding up product delivery time. It is successfully used by different industries from manufacturing to software development as a Kanban board. You can choose the most suitable tool or build your own solution that would offer such essential features, as cards and columns management, intuitive drag-n-drop, touch support, and third-party integrations.
DHTMLX Kanban is under development now. You can [leave a request](https://dhtmlx.com/docs/products/dhtmlxKanban/) on the website and receive the first version as soon as it gets released. | plazarev |
797,388 | Data Science Workflow | DATASCIENCE WORKFLOW-CRISPDM(Cross-industry standard process for data mining. We use... | 0 | 2021-08-19T15:36:48 | https://dev.to/wanjohichristopher/data-science-workflow-25ee | database, datascience | #### DATASCIENCE WORKFLOW-CRISPDM(Cross-industry standard process for data mining.
We use CRISP-DM methodology as show below:
-we will go through the whole workflow process in details:
Let’s Get Started…………………………………………………………………………………………
AI IS THE NEW ELECTRICITY ~ANDREW NG
#### 1.Business Understanding
This section requires domain expertise in which you as a data scientist you are supposed to understand
the problem at hand well and in depth.
At this point a data scientist need not to work alone,he or she needs to interact with different teams in
the company in order to make decisions in the right order.
The objectives to achieve to accomplish in a project are indicated here.
The type of problem is determined here ii.e in machine learning.
#### 2.Data Understanding
This section a data scientist need to understand the data well,checking at its variable
descriptions,quantifying what they mean regarding the data provided and problem definition.
The following functions(questions)are done in order to understand data more namely:
We will take examples using python programming languages.
.Importing required libraries to work on data---eg.import pandas as pd
.Reading the data using pandas usually might be in different formats eg.csv,xlsx,txt,.tab.—eg pd.read_csv/excel()
.Checking number of columns and rows,missing
values,duplicates,nunique values,information
about data,datatypes,preview of data. | wanjohichristopher |
797,407 | Center an image with css on responsive without distorting | Hi, If my designer wants to see the middle of the image on the middle of any device screen, I take... | 0 | 2021-08-19T16:25:27 | https://dev.to/dgloriaweb/center-an-image-with-css-on-responsive-without-distorting-4mj4 | Hi,
If my designer wants to see the middle of the image on the middle of any device screen, I take the height of the image, and calculate the left margin from it. I use an image that's near to rectangle, to be able to handle the wildest aspect ratio, in this case my app is portrait only. In this example my image is h=1000px w=776px. (Heads up, if your image might not be wide enough for some devices, also be prepared for landscape view. Better to use square image and decide if you use height or width as baseline.)
I position the image to the corner like this:
```
position: fixed;
top: 0;
left: 0;
```
Then I set the height to 100vh
```
height: 100vh;
```
Now I can calculate my offset for the image from the left, by adjusting the left-margin
```
margin-left: calc((-77.6vh / 2) + 50vw);
```
briefly my image is 77.6vh wide (that's calculated from 100vh *77.6, because this is the aspect ratio), so I get half of that value, and move the whole thing 50vw to the right. That is where my image will start. I don't need to mess about with pixels, it's calculated for me. | dgloriaweb | |
797,431 | GraphQL Response Caching with Envelop | Caching GraphQL endpoints can be tricky. Let's take a look at the theory behind making it possible and learn how to do it with Envelop. | 0 | 2021-08-19T17:15:37 | https://www.envelop.dev/docs/guides/adding-a-graphql-response-cache | graphql | > This article was published on 2021-08-19 by [Laurin Quast](https://twitter.com/n1rual) @ [The Guild Blog](https://the-guild.dev/)
## A brief Introduction to Caching
Huge GraphQL query operations can slow down your server as deeply nested selection sets can cause a lot of subsequent database reads or calls to other remote services. Tools like `DataLoader` can reduce the amount of concurrent and subsequent requests via batching and caching during the execution of a single GraphQL operation. Features like `@defer` and `@stream` can help with streaming slow-to-retrieve result partials to the clients progressively. However, for subsequent requests we hit the same bottle-neck over and over again.
What if we don't need to go through the execution phase at all for subsequent requests that execute the same query operation with the same variables?
A common practice for reducing slow requests is to leverage caching. There are many types of caching available. E.g. We could cache the whole HTTP responses based on the POST body of the request or an in memory cache within our GraphQL field resolver business logic in order to hit slow services less frequently.
Having a cache comes with the drawback of requiring some kind of cache invalidation mechanism. Expiring the cache via a TTL (time to live) is a widespread practice, but can result in hitting the cache too often or too scarcely. Another popular strategy is to incorporate cache invalidation logic into the business logic. Writing such logic can potentially become too verbose and hard to maintain. Other systems might use database write log observers for invalidating entities based on updated database rows.
In a strict REST API environment, caching entities is significantly easier, as each endpoint represents one resource, and thus a `GET` method can be cached and a `PATCH` method can be used for automatically invalidating the cache for the corresponding `GET` request, which is described via the HTTP path (`/api/user/12`).
With GraphQL such things become much harder and complicated. First of all, we usually only have a single HTTP endpoint `/graphql` that only accepts `POST` requests. A query operation execution result could contain many different types of entities, thus, we need different strategies for caching GraphQL APIs.
SaaS services like FastQL and GraphCDN started popping providing proxies for your existing GraphQL API, that magically add response based caching. But how does this even work?
## How does GraphQL Response Caching work?
### Caching Query Operations
In order to cache a GraphQL execution result (response) we need to build an identifier based on the input that can be used to identify whether a response can be served from the cache or must be executed and then stored within the cache.
**Example: GraphQL Query Operation**
```graphql
query UserProfileQuery($id: ID!) {
user(id: $id) {
__typename
id
login
repositories
friends(first: 2) {
__typename
id
login
}
}
}
```
**Example: GraphQL Variables**
```json
{
"id": "1"
}
```
Usually those inputs are the Query operation document and the variables for such an operation document.
Thus a response cache can store the execution result under a cache key that is built from those inputs:
```
OperationCacheKey (e.g. SHA1) = hash(GraphQLOperationString, Stringify(GraphQLVariables))
```
Under some circumstances it is also required to cache based on the request initiator. E.g. a user requesting his profile should not receive the cached profile of another user. In such a scenario, building the operation cache key should also include a partial that uniquely identifies the requestor. This could be a user ID extracted from an authorization token.
```
OperationCacheKey (e.g. SHA1) = hash(GraphQLOperationString, Stringify(GraphQLVariables), RequestorId)
```
This allows us to identify recurring operations with the same variables and serve it from the cache for subsequent requests. If we can serve a response from the cache we don't need to parse the GraphQL operation document and furthermore can skip the expensive execution phase. That will result in significant speed improvements.
But in order to make our cache smart we still need a suitable cache invalidation mechanism.
### Invalidating cached GraphQL Query Operations
Let's take a look at a possible execution result for the GraphQL operation.
**Example: GraphQL Execution Result**
```json
{
"data": {
"user": {
"__typename": "User",
"id": "1",
"login": "dotan",
"repositories": ["codegen"],
"friends": [
{
"__typename": "User",
"id": "2",
"login": "urigo"
},
{
"__typename": "User",
"id": "3",
"login": "n1ru4l"
}
]
}
}
}
```
Many frontend frameworks cache GraphQL operation results in a normalized cache. The identifier for storing the single entities of a GraphQL operation result within the cache is usually the `id` field of object types for schemas that use global unique IDs or a compound of the `__typename` and `id` field for schemas that use non global ID fields.
**Example: Normalized GraphQL Client Cache**
```json
{
"User:1": {
"__typename": "User",
"id": "1",
"login": "dotan",
"repositories": ["codegen"],
"friends": ["$$ref:User:2", "$$ref:User:3"]
},
"User:2": {
"__typename": "User",
"id": "2",
"login": "urigo"
},
"User:3": {
"__typename": "User",
"id": "3",
"login": "n1ru4l"
}
}
```
Interestingly, the same strategy for constructing cache keys on the client can also be used on the backend for tracking which GraphQL operations contain which entities. That allows invalidating GraphQL query operation results based on
entity IDs.
For the execution result entity IDS that could be used for invalidating the operation are the following: `User:1`, `User:2` and `User:3`.
And also keep a register that maps entities to operation cache keys.
```
Entity List of Operation cache keys that reference a entity
User:1 OperationCacheKey1, OperationCacheKey2, ...
User:2 OperationCacheKey2, OperationCacheKey3, ...
User:3 OperationCacheKey3, OperationCacheKey1, ...
```
This allows us to keep track of which GraphQL operations must be invalidated once a certain entity becomes stale.
The remaining question is, how can we track an entity becoming stale?
As mentioned before, listening to a database write log is a possible option - but the implementation is very specific and differs based on the chosen database type. Time to live is also a possible, but a very inaccurate solution.
Another solution is to add invalidation logic within our GraphQL mutation resolver. By the GraphQL Specification mutations are meant to modify our GraphQL graph.
A common pattern when sending mutations from clients is to select and return affected/mutated entities with the selection set.
For our example from above the following could be a possible mutation for adding a new repository to the repositories field on the user entity.
**Example: GraphQL Mutation**
```graphql
mutation RepositoryAddMutation($userId: ID, $repositoryName: String!) {
repositoryAdd(userId: $userId, repositoryName: $repositoryName) {
user {
id
repositories
}
}
}
```
**Example: GraphQL Mutation Execution Result**
```json
{
"data": {
"repositoryAdd": {
"user": {
"id": "1",
"repositories": ["codegen", "envelop"]
}
}
}
}
```
Similar to how we build entity identifiers from the execution result of query operations for identifying what entities are referenced in which operations, we can extract the entity identifiers from the mutation operation result for invalidating affected operations.
In this specific case all operations that select `User:1` should be invalidated.
Such an implementation makes the assumption that all mutations by default select affected entities and, furthermore, all mutations of underlying entities are done through the GraphQL gateway via mutations. In a scenario where we have actors that are not GraphQL services or services that operate directly on the database, we can use this approach in a hybrid model with other methods such as listening to database write logs.
## Envelop Response Cache
The envelop response cache plugin now provides primitives and a reference in memory store implementation for adopting such a cache with all the features mentioned above with any GraphQL server.
The goal of the response cache plugin is to educate how such mechanisms are implemented and furthermore give developers the building blocks for constructing their own global cache with their cloud provider of choice.
Adding a response cache to an existing envelop GraphQL server setup is as easy as adding the plugin:
```ts
import { envelop } from '@envelop/core'
import { useResponseCache } from '@envelop/response-cache'
const getEnveloped = envelop({
plugins: [
// ... other plugins ...
useResponseCache()
]
})
```
If you need to imperatively invalidate you can do that by providing the cache to the plugin:
```ts
import { envelop } from '@envelop/core'
import { useResponseCache, createInMemoryCache } from '@envelop/response-cache'
import { emitter } from './event-emitter'
const cache = createInMemoryCache()
emitter.on('invalidate', (entity) => {
cache.invalidate([
{
typename: entity.type,
id: entity.id
}
])
})
const getEnveloped = envelop({
plugins: [
// ... other plugins ...
useResponseCache({ cache })
]
})
```
The caching behavior can be fully customized. A TTL can be provided global or more granular per type or schema coordinate.
```ts
import { envelop } from '@envelop/core'
import { useResponseCache } from '@envelop/response-cache'
const getEnveloped = envelop({
plugins: [
// ... other plugins ...
useResponseCache({
// cache operations for 1 hour by default
ttl: 60 * 1000 * 60,
ttlPerType: {
// cache operation containing Stock object type for 500ms
Stock: 500
},
ttlPerSchemaCoordinate: {
// cache operation containing Query.rocketCoordinates selection for 100ms
'Query.rocketCoordinates': 100
},
// never cache responses that include a RefreshToken object type.
ignoredTypes: ['RefreshToken']
})
]
})
```
Need to cache based on the user? No problem.
```ts
import { envelop } from '@envelop/core'
import { useResponseCache } from '@envelop/response-cache'
const getEnveloped = envelop({
plugins: [
// ... other plugins ...
useResponseCache({
// context is the GraphQL context that would be used for execution
session: (context) => (context.user ? String(context.user.id) : null),
// never serve cache for admin users
enabled: (context) =>
context.user ? isAdmin(context.user) === false : true
})
]
})
```
Don't want to automatically invalidate based on mutations? Also configurable!
```ts
import { envelop } from '@envelop/core'
import { useResponseCache } from '@envelop/response-cache'
const getEnveloped = envelop({
plugins: [
// ... other plugins ...
useResponseCache({
// some might prefer invalidating only based on a database write log
invalidateViaMutation: false
})
]
})
```
Want a global cache on Redis? Build a cache that implements the `Cache` interface and share it with the community!
```ts
export type Cache = {
/** set a cache response */
set(
/** id/hash of the operation */
id: string,
/** the result that should be cached */
data: ExecutionResult,
/** array of entity records that were collected during execution */
entities: Iterable<CacheEntityRecord>,
/** how long the operation should be cached */
ttl: number
): PromiseOrValue<void>
/** get a cached response */
get(id: string): PromiseOrValue<Maybe<ExecutionResult>>
/** invalidate operations via typename or id */
invalidate(entities: Iterable<CacheEntityRecord>): PromiseOrValue<void>
}
```
More information about all possible configuration options can be found on [the response cache docs on the Plugin Hub](https://envelop.dev/plugins/use-response-cache).
\{% youtube 1EBphPltkA4 %}
## What is next?
We are excited to explore new directions and make enterprise solutions accessible for all kinds of developers.
What if the response cache could be used as a proxy on edge cloud functions distributed around the world, which would allow using envelop as a http proxy to your existing GraphQL server?
This is something we would love to explore more (or even see contirbutions and projects from other open-source developers).
We also want to make other practices such as rate limits based on operation cost calculation as used by huge corporations like Shopify available as envelop plugins.
Do you have any ideas, want to contribute or report issues? Start a GitHub discussion/issue or contact us via the chat!
| theguild_ |
797,462 | How to Become an Intermediate Level React Developer from Zero Knowledge | Introduction This is a complete crash course series tutorial about React to be compatible... | 0 | 2021-08-19T18:35:23 | https://dev.to/maniruzzamanakash/how-to-become-an-intermediate-level-react-developer-from-zero-knowledge-43n2 | react, reactlearning, reacttutorial, portfolio | ##Introduction
This is a complete crash course series tutorial about React to be compatible with Latest React Hooks and all...
In this tutorial, I’ve shown **many more important concepts** of React JS and **completed 3 projects** using React JS. Let’s dive into it and Learn to React Together.
##Demo Final Portfolio Website
Before Going to In-depth video series, first, you can check our Live React Developed portfolio site on that video tutorial — https://maniruzzamanakash.github.io/React-Crash-Course
##Full Crash Course Video
{% youtube B9xGzJBJFyY %}
##Full Tutorial
https://devsenv.com/tutorials/learn-react-complete-crash-course-with-three-complete-project-devsenv
##Topics Discussed in this React JS Crash Course
####Pre-Requisite to Start
1. Setup Visual Studio Code Editor with Better Code Snippet — https://devsenv.com/tutorials/3-enable-additional-plugins-for-better-react-development-react-basic-to-pro-series
1. Basic JavaScript Knowledge — https://www.w3schools.com/js
Basic ES6 Knowledge -
1. Let, Const, Var difference and More — https://devsenv.com/tutorials/4-let-vs-const-vs-var-clear-the-es6-concepts-and-makes-simpler-path-to-learn-react
1. ES6 Arrow Function — https://devsenv.com/tutorials/5-es6-basic-arrow-function-in-javascript-react-basic-to-pro
1. How Virtual DOM Works — https://devsenv.com/tutorials/7-how-react-work-%7C-real-dom-vs-virtual-dom-%7C-coding-structure-%7C-naming-convention
1. What is React & What it’s Done
a) React Is a UI Library. Made by Facebook & Now used by millions of Dev.
b) Responsible to make a dynamic page and make the frontend awesome.
####How to Setup React
Setup Node JS — https://nodejs.org/en/
Create-React-App (CRA) Setup
https://reactjs.org/docs/create-a-new-react-app.html
```bash
npx create-react-app my-app
```
####What is Component in React
React is fully based on component.
Component is a Minimal Part of UI.
It’s Just a Library, Not any Javascript Framework. It only handles the view Part
####What is Used in React
JavaScript
JSX Element
####How Many Components in React
a) Class-Base Component
b) Functional Component
####Class-Base Component
Demo Class base component
####Functional Component
Demo Functional Component
####Class based component State Manage and Important Life Cycle Hook
```js
this.state = {
data: 'Hello'
}
componentDidMount();
```
####Hooks in React
```js
useState()
useEffect()
useMemo()
useContext()
useReducer()
useCallback()
```
####Component to Component Communication in React
Parent Component to Child Component props
Child Component to Parent Component onHandleClick
####Styling & External Styling in React JS
CSS
Modular CSS
Bootstrap CSS
####Conditional Renderings in React
View Data in conditional rendering
####Loop through data in React
Loop through Task List Data
####Input Handling in React
Complete Task Form and
Task List show
####Simple Counter App in React
Simple Increment and Decrement Counter Project
####Simple Contact Form in React
Same as the Concept of Task Title Entry Form
####React Router Setup
React Router Quick Start — https://reactrouter.com/web/guides/quick-start
####Complete a portfolio website using React using Fake Data
1. Demo Website Portfolio Link — https://akash.devsenv.com
1. Demo Fake Data List -
1. Use React Bootstrap
1. Master Layout of a Portfolio Website Using React
Home Page
1. Portfolio Page
1. About Page
## Download Project From Github
https://github.com/ManiruzzamanAkash/React-Crash-Course.git
You can get their code classes based on topics. | maniruzzamanakash |
797,645 | Resolving Concurrent Exceptions in Hibernate Logger | Recently while working on a Hibernate ORM project, I ran into an interesting issue when an entity... | 14,192 | 2021-08-19T20:55:21 | https://michaelborn.me/entry/resolving-concurrent-exceptions-in-hibernate-logger | cfml, coldfusion, hibernate, orm | Recently while working on a Hibernate ORM project, I ran into an interesting issue when an entity with relationships is saved inside a transaction.
transaction{
var myEntity = entityLoadByPK( "Person", theEntityID );
myEntity.setAddress( otherEntity );
myEntity.save();
// throws "ConcurrentModificationException" on transaction end.
}
_Note this is not a complete test case - simply an example of when the issue occurs._
When the transaction completes, Lucee tries to flush the entity modifications, but this fails with the following error:
lucee.runtime.exp.NativeException: java.util.ConcurrentModificationException
at java.base/java.util.HashMap$HashIterator.nextNode(HashMap.java:1493)
at java.base/java.util.HashMap$EntryIterator.next(HashMap.java:1526)
at java.base/java.util.HashMap$EntryIterator.next(HashMap.java:1524)
at org.hibernate.internal.util.EntityPrinter.toString(EntityPrinter.java:112)
at org.hibernate.event.internal.AbstractFlushingEventListener.logFlushResults(AbstractFlushingEventListener.java:128)
at org.hibernate.event.internal.AbstractFlushingEventListener.flushEverythingToExecutions(AbstractFlushingEventListener.java:104)
at org.hibernate.event.internal.DefaultFlushEventListener.onFlush(DefaultFlushEventListener.java:39)
at org.hibernate.event.service.internal.EventListenerGroupImpl.fireEventOnEachListener(EventListenerGroupImpl.java:93)
at org.hibernate.internal.SessionImpl.doFlush(SessionImpl.java:1362)
at org.hibernate.internal.SessionImpl.flush(SessionImpl.java:1349)
at org.lucee.extension.orm.hibernate.HibernateORMTransaction.end(HibernateORMTransaction.java:57)
at lucee.runtime.orm.ORMConnection.setAutoCommit(ORMConnection.java:213)
at lucee.runtime.orm.ORMDatasourceConnection.setAutoCommit(ORMDatasourceConnection.java:336)
at lucee.runtime.db.DatasourceManagerImpl.end(DatasourceManagerImpl.java:350)
at lucee.runtime.db.DatasourceManagerImpl.end(DatasourceManagerImpl.java:330)
at lucee.runtime.tag.Transaction.doFinally(Transaction.java:160)
It turns out this issue is related to the Hibernate debug logger. In Lucee, Hibernate's log4j logger is set to a `DEBUG` level by default. That's fine, but it seems the logger actually _mutates_ the logged entities during logging. Thus we get a concurrent modification exception.
To resolve this, all we have to do is de-escalate the logging level from `DEBUG` to `WARN`.
/**
* Resolves Hibernate ConcurrentModificationException when flushing an entity save with one-to-many relationships.
*
* @see https://access.redhat.com/solutions/29774
*/
var Logger = createObject( "java", "org.apache.log4j.Logger" );
var level = createObject( "java", "org.apache.log4j.Level" );
var log = Logger.getLogger( "org.hibernate" );
log.setLevel( level.WARN );
This should be done in the `Application.cfc` before ORM initializes - say, just below the `this.ormSettings{}` configuration block.
All thanks to [@jclausen](https://twitter.com/jclausen) for this awesome find and easy fix! | mikeborn |
797,659 | Day 434: Fall In Line | liner notes: Professional : Had a couple of meetings today and then worked on finishing up some... | 0 | 2021-08-19T21:42:14 | https://dev.to/dwane/day-434-fall-in-line-2p6c | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Had a couple of meetings today and then worked on finishing up some tasks. Pretty much it.
- Personal : Went through some tracks for the radio show this week last night. I also decided to finish watching the final episodes of the "Invincible" season 1. It was only a couple of episodes. It was a really good series and looking forward to the next season. I think that's it.
Can't believe it's Thursday already! I've been working on backing up a bunch of my files to the cloud so I can clear space on my laptop to give it to my mother since I have the new one that came in. I've also been waiting on a new device that should replace two of the devices I use to record and broadcast the radio show. Trying to pair down the equipment so I don't have too much when I start travelling again. Looks like delivery on a couple of adapters I ordered have been pushed back, so I may not be able to use it for this week's show. We'll see. I've also finally decided to take the plunge and get into crypto mining, but not Bitcoin or anything like that. In order to get the mining equipment, I had to set up a crypto account. I transferred money to the account but it can take up to 7 days before I can use it to buy the equipment. Just been looking into ways to invest in stuff that will do some good and actually give a return on investment. I've been researching it before, but some things have come up that make it an even better move to get started now. It'll also factor into how I look for land to purchase as well. Yeah, a lot of stuff. Just need to try and get things to fall in line as much as possible. Probably do more research tonight and work on the radio show.
Have a great night!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube HqSFc-bhdTk %} | dwane |
797,716 | Generar aplicaciónes NodeJs | Cuando recién iniciaba en este mundo del desarrollo en NodeJs mi pregunta era ¿como iniciar un... | 0 | 2021-08-20T00:43:09 | https://dev.to/dannieldev/generar-aplicaciones-nodejs-44jo | node, javascript, backend, spanish | Cuando recién iniciaba en este mundo del desarrollo en NodeJs mi pregunta era ¿como iniciar un proyecto de forma correcta implementado las cosas bien? pero lo único que encontraba era de forma manual. Pero el que busca y busca encuentra y de esta forma me encentre con una aplicación del mismo expressJs y que mejor que utilizar uno de los mejores frameworks de NodeJs y de forma sencilla. Y entonces manos a la obra: Lo primero tenemos que hacer es instalar nuestra aplicación con el siguiente comando en la terminal:
```bash
$ npm install express-generator -g
```
Lo instalamos con la opción -g para que este quede en nuestro computador y no en el proyecto. Teniendo esto instalado ya podemos generar nuestra aplicación:
```bash
$ express --view=pug miAplicacion
```
Cuando termina nos dirigimos a la nueva carpeta que creo express-generator e instalamos las dependencias:
```bash
$ cd miAplicacion
$ npm install
```
Para iniciar en Linux ejecutamos el siguiente comando:
```bash
$ DEBUG=myapp:* npm start
```
Nuestro árbol queda de la siguiente forma:
.
├── app.js
├── bin
│ └── www
├── package.json
├── public
│ ├── images
│ ├── javascripts
│ └── stylesheets
│ └── style.css
├── routes
│ ├── index.js
│ └── users.js
└── views
├── error.pug
├── index.pug
└── layout.pug
Y con esto terminamos ya tenemos lo necesario para nuestro proyecto, entonces a desarrollar. | dannieldev |
797,792 | Animate Your Web Content Using Animate On Scroll Library | About 3 months ago, while developing my website, I thought about making my website even cooler.... | 0 | 2021-08-22T05:36:21 | https://medium.com/geekculture/how-to-make-an-animation-using-animate-on-scroll-8f57ef73924c | webdev, programming, css | 
About 3 months ago, while developing my website, I thought about making my website even cooler. This is what I want to do : I want items on my website to appear only when I scroll to them. In other words, before scrolling, the item will not exist. Hard enough to imagine? Roughly the result like this:

This animation can be created with the Animate On Scroll (AOS) library by michalsnik at [michalsnik.github.io](michalsnik.github.io/aos).
## Get Started
There are 2 ways to add this library to your website. The first way is to install it, and the second way is through the CDN service. I myself use a CDN service. Here is some code you should add.
### CSS
add this code inside the `head` tag in your HTML code.
```html
<link href="https://unpkg.com/aos@2.3.1/dist/aos.css" rel="stylesheet">
```
### Javascript
add this code at the very bottom of your `body` tag.
```html
<script src="https://unpkg.com/aos@2.3.1/dist/aos.js"></script>
```
### Initialize AOS
Finally, add the following code to your javascript file.
```javascript
AOS.init();
```
If you have done all of the things above, then you are ready to use this library.
## Animation
In order to have an animation, add the data-aos attribute to the html tag you want. With this `data-aos`, your tags now have animations. There are different values in the `data-aos` attribute, different values mean different animations. Here are some of them :
- `data-aos="fade-up"` , for moving-up
- `data-aos="fade-down"` ,for moving-down
- `data-aos="fade-right"`, for move to the right
- `data-aos="fade-left"`, for move to the left
- `data-aos="fade-flip-left"`, for flip to the left
- `data-aos="fade-flip-right"`, for flip to the right
- `data-aos="zoom-in"`, for zoom in
- `data-aos="zoom-out"`, for zoom-out
Actually, there are many more data-aos values available. For more complete data-aos, you can visit the official Animate On Scroll website at michelsnik.github.io.
## Live Demo
I will show you how to use animate on scroll library.
### 1. Set Up Standard HTML Tag
this file contains the basic html tags to create a box with the words box 1 , box 2 and so on.
```html
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<div class='container'>
<div class='box'>box 1</div>
<div class='box'>box 2</div>
<div class='box'>box 3</div>
<div class='box'>box 4</div>
</div>
</body>
</html>
```
### 2. Prepare CSS files for basic styles
This file contains the basic styles for box such as background color, padding, margins, and so on.
```css
.box{
text-align:center;
font-size:2em;
padding:90px;
border-radius:8px;
border:5px #33ff33;
margin: 30px;
background:#66ff66;
width:auto;
height:30px;
}
.container{
background:#3385ff;
padding:auto;
padding-top:20px;
padding-bottom:20px;
}
```
### 3. Add CDN code to import AOS library
#### CSS
Add this code inside the head tag
```html
<link href="https://unpkg.com/aos@2.3.1/dist/aos.css" rel="stylesheet">
```
#### Javascript
add this code at the very bottom of your body tag.
```html
<script src="https://unpkg.com/aos@2.3.1/dist/aos.js"></script>
```
### 4. Initialize AOS
add the following code to the javascript file.
```javascript
AOS.init();
```
after all of the things above is done, the result will be like this:
{% codepen https://codepen.io/fikrinotes/pen/RwVGrXG %}
Keep in mind that you can change the style of the above CSS as you wish. In the example above I only use 4 types of data-aos. You can see more complete documentation on [this website](michalsnik.github.io/aos).
To see the implementation of this AOS data on the website, you can visit my website which also uses the AOS library [here](https://fikrinotes.netlify.app/boring_math).
| fikrinotes |
797,828 | Vim: Buffers | Introduction I have talked about Vim Tabs, Window splits in the previous articles, and... | 0 | 2021-08-20T04:45:45 | https://www.meetgor.com/vim-buffers/ | vim, terminal, linux | ## Introduction
I have talked about Vim [Tabs](https://dev.to/mr_destructive/vim-tabs-4bga), [Window splits](https://dev.to/mr_destructive/vim-window-splits-p3p) in the previous articles, and now I am quite keen on explaining the finest unit of file that you can open using Vim and that is a buffer. Tabs are a collection of windows, Windows are the viewport on buffers (collection to view the buffers), and Buffers are the memory that holds text in the file. So let us explore buffer in detail. This article won't cover each and every tiny detail about buffers but surely enough to make you understand what a buffer is and how to manage those.
## What is a Vim buffer
Vim buffers are the chunks of memory that hold the text in a file. Vim buffers are used from opening a file to using, installing, upgrading the Plugins, using file managers, and everything you can edit and work within Vim.
So, why bother using Vim buffer, you'll ask. Well, you will need it to make some complex tasks possible in Vim, such as configuring it as your IDE or having much more control over what and how you open and close files in Vim. You might not need it in the broader sense but having a grasp of what you are using and understanding the process under the hood is vital whatsoever.
## Creating a buffer
No need to create a buffer, if you are editing a file, that's already a buffer :) If you open Vim, a fresh open, then you already have that current buffer as an empty buffer. You can create an empty buffer by entering the command `:enew`. This will actually make a new empty buffer, if you have edited the contents of the previous buffer you need to specify to write/save the buffer in a file.
You can see the details of the buffers opened currently by using the command `:ls` or `:buffers`. This will open a list of buffers currently loaded in the Vim instance. You will see the output somewhat like this:
We can see the name of the current buffer which in this case it is `"No name"` this will be replaced with a file name if we had a file open. This won't only print the current buffer but all the loaded buffers in the present Window of Vim. We will explore the details of this command in the next section.
## Navigating through the buffers list
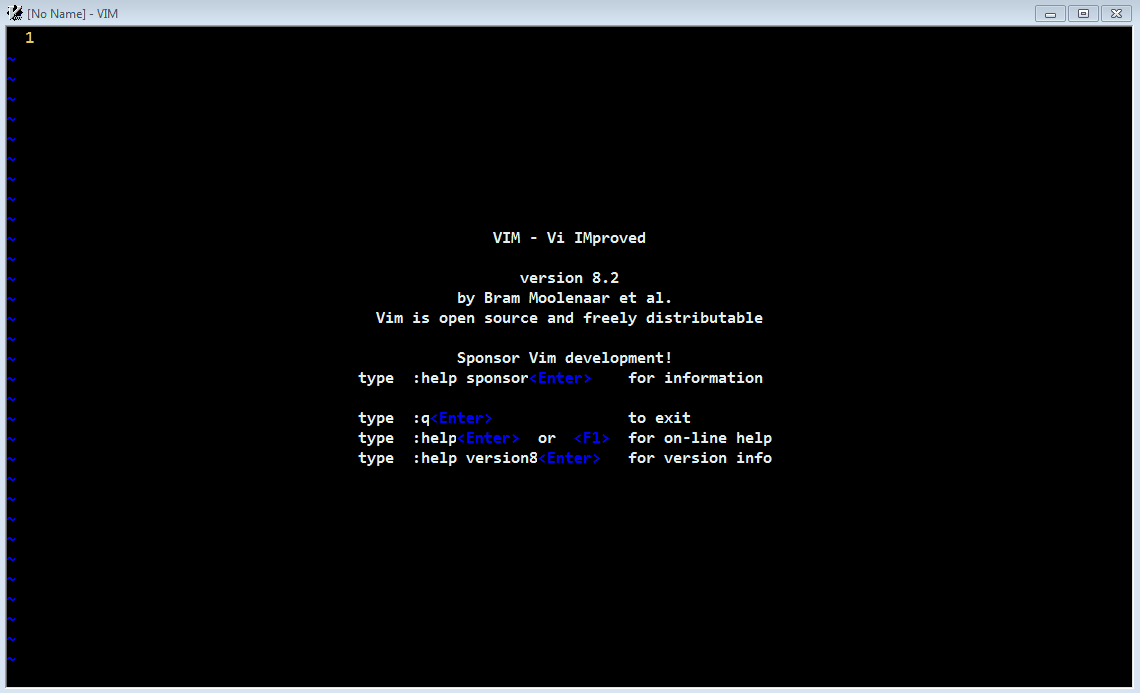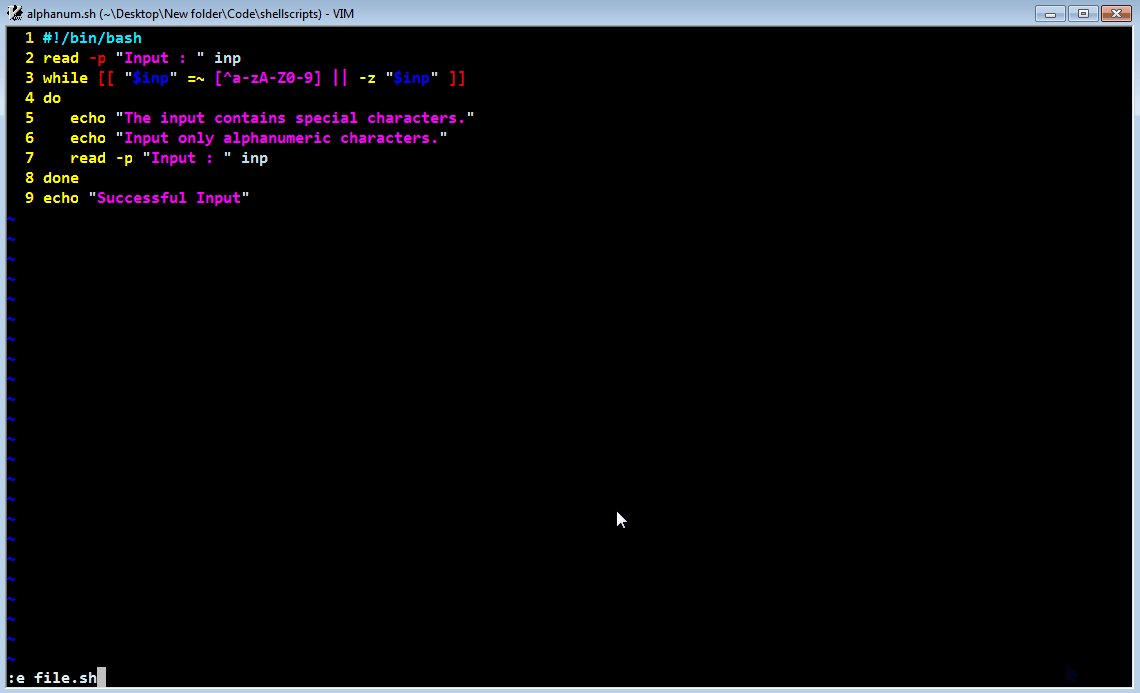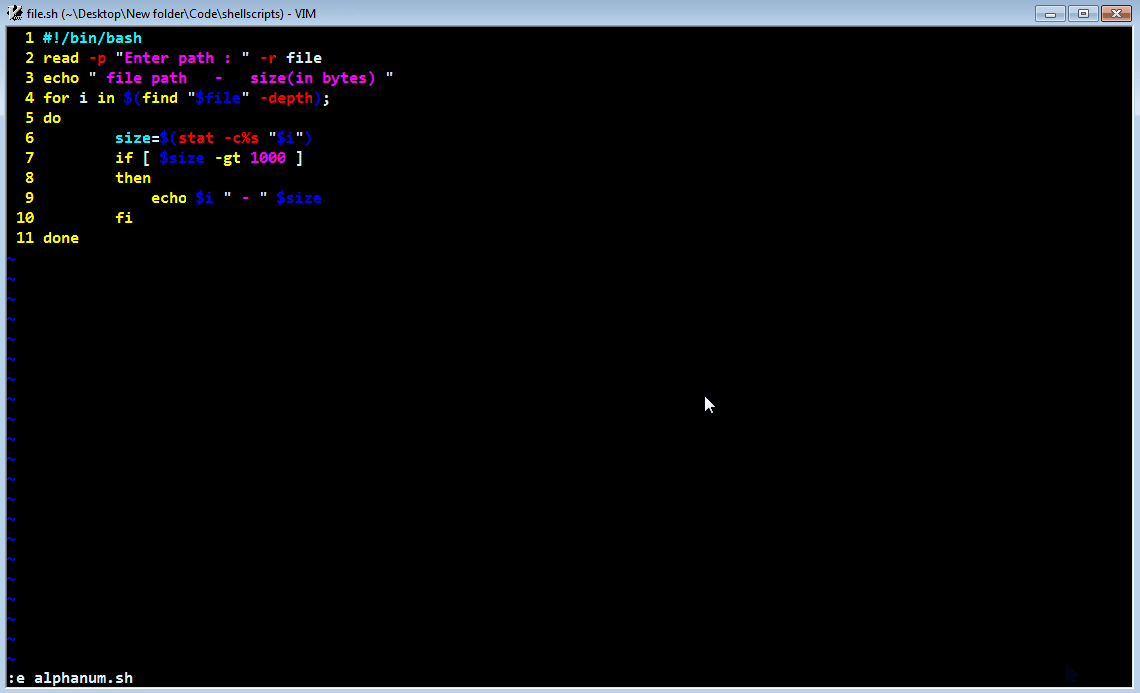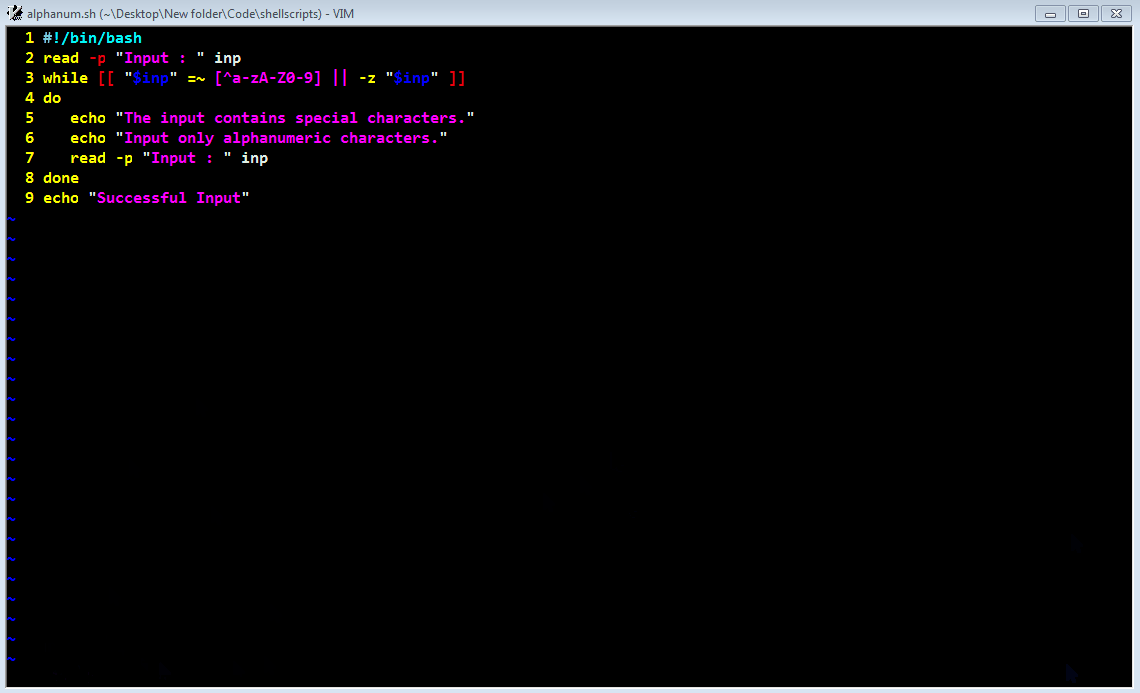
In the first column in the only row, you can see `1` indicating the number of the buffer, secondly, there are indicators `%a` and `#` and others as well. These are used for referencing the buffers using certain attributes those have like :
- `%` stands for the buffer in the current window.
- `a` stands for the currently active buffer.
- `#` stands for the alternate buffer (previously edited).
- `h` stands for the hidden buffer ( used for navigating to other files without saving changes ).
We also have additional attributes or indicators for the buffers like:
- `+` indicating the buffer is modified.
- `-` indicating the buffer cannot be modified.
- `=` indicating the buffer is read only.
To use the attribute `h`, you have to set the option in the current window only, you can use `:set hiddden` to hide the files i.e to edit another file without saving changes to the current buffer(with the file loaded). If you want a permanent option of hidden files you can add `set hidden` in your `vimrc` file.
If you have enabled a hidden file in the window and you modify the file, you can see the `+` symbol in the `:ls` command output before the file, indicating that the file has been modified. If you try to quit the window, it will prompt you to save those unsaved modifications.
This is the power of Vim buffers, you can get really fast in terms of editing multiple files and saving all of them at once. This feature can allow you to work more effectively and flawlessly with Window Splits and Tabs as they can contain multiple buffers within them.
Now we will see how to move between those buffers. We can pretty effectively use the numbers in the buffer list to directly jump to that buffer. We can use `:b n` where n is any number of the buffer in the list of buffers to move through the buffers. Optionally we can use `:buffer n` but that is quite a long command.
We can move to the previous buffer as `:bp` to move to the previous buffer in the list. Similarly, we can use `:bn` to move to the next buffer in the list, and `:bfirst` and `:blast` to move to the first and the last buffer respectively.
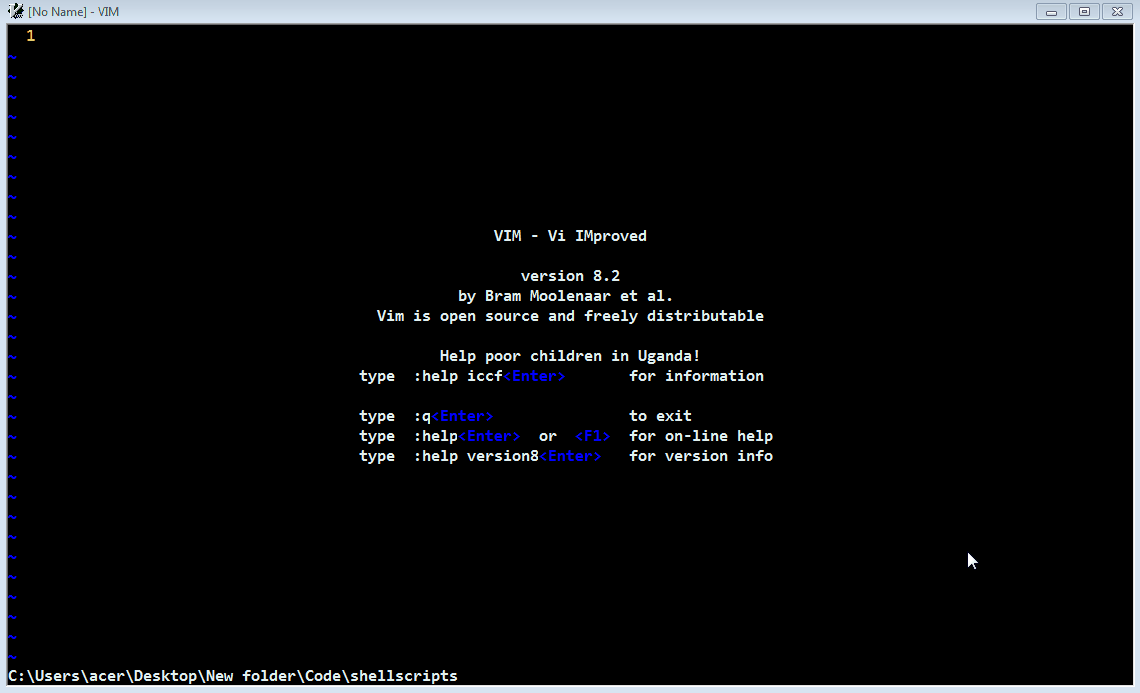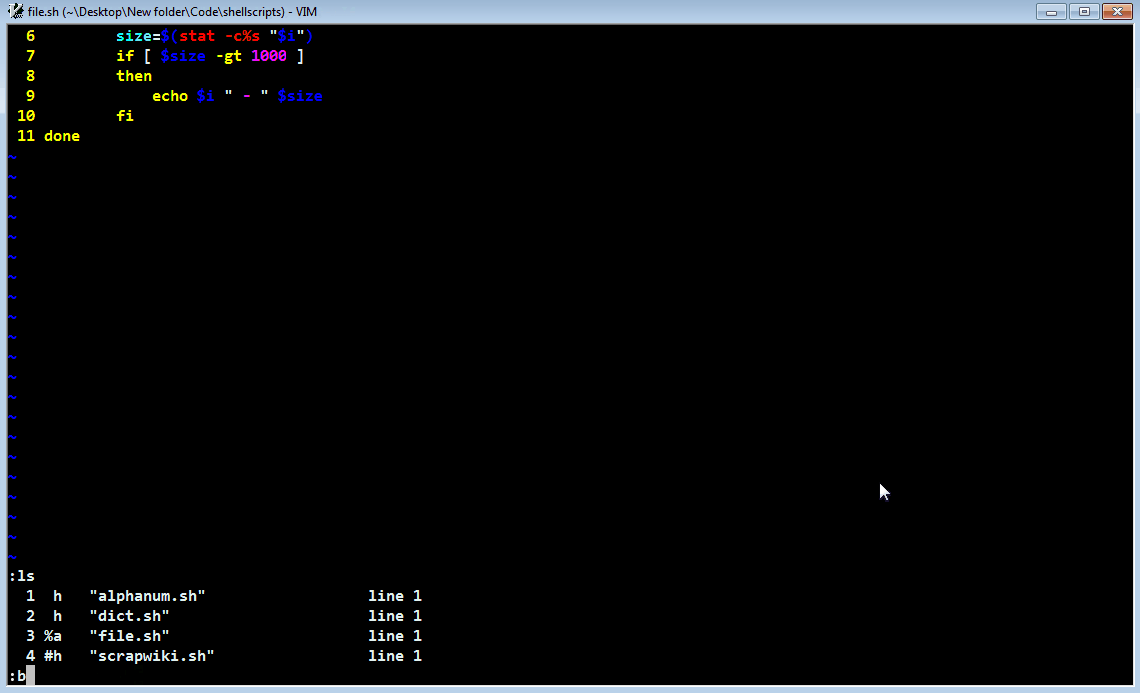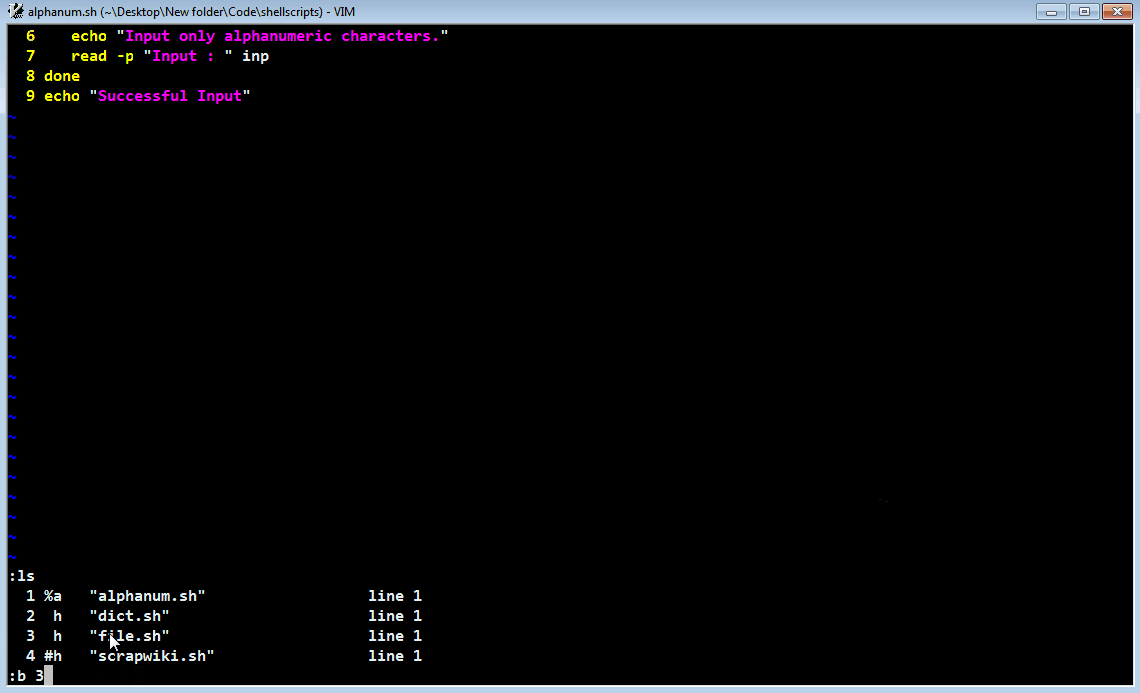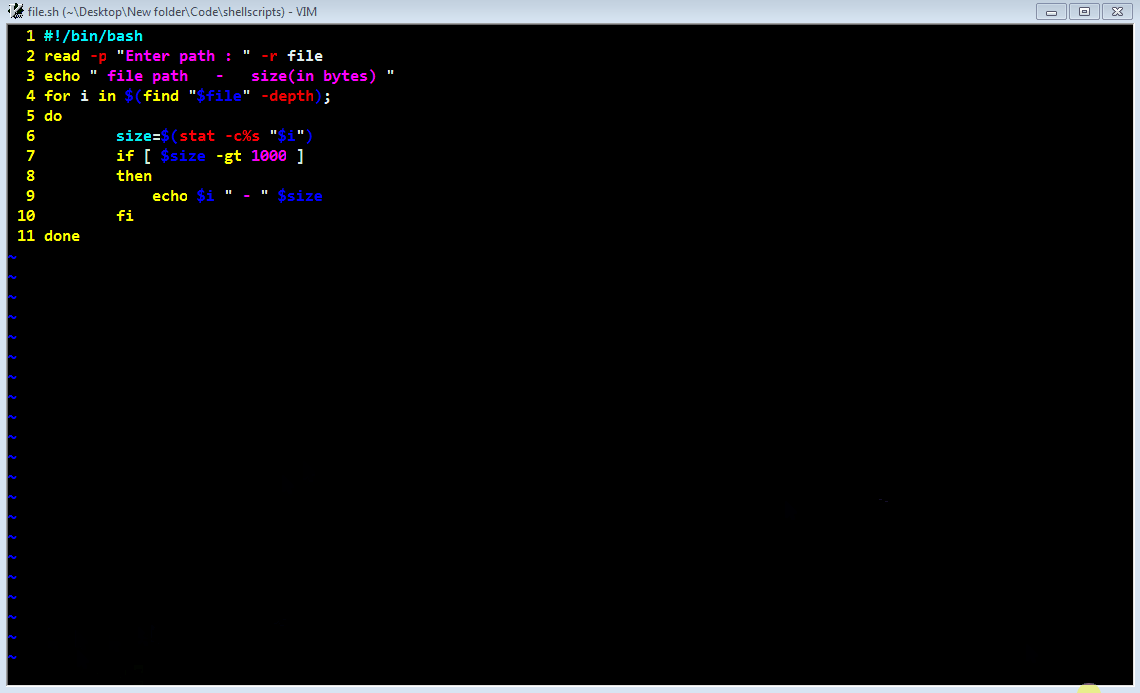
## Moving through the buffers
We can move through our opened buffers using `Ctrl + o` to move backward a buffer and `Ctrl + i` to move forward a buffer. This can be helpful if you do not want to remember the numbers associated with the buffers.
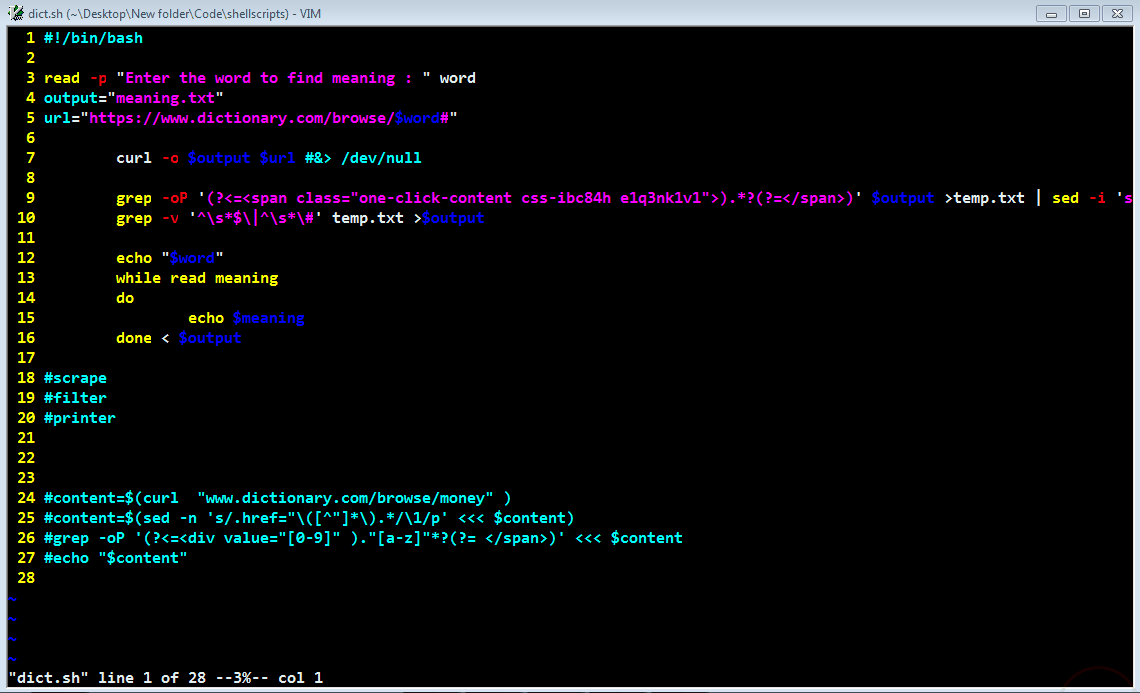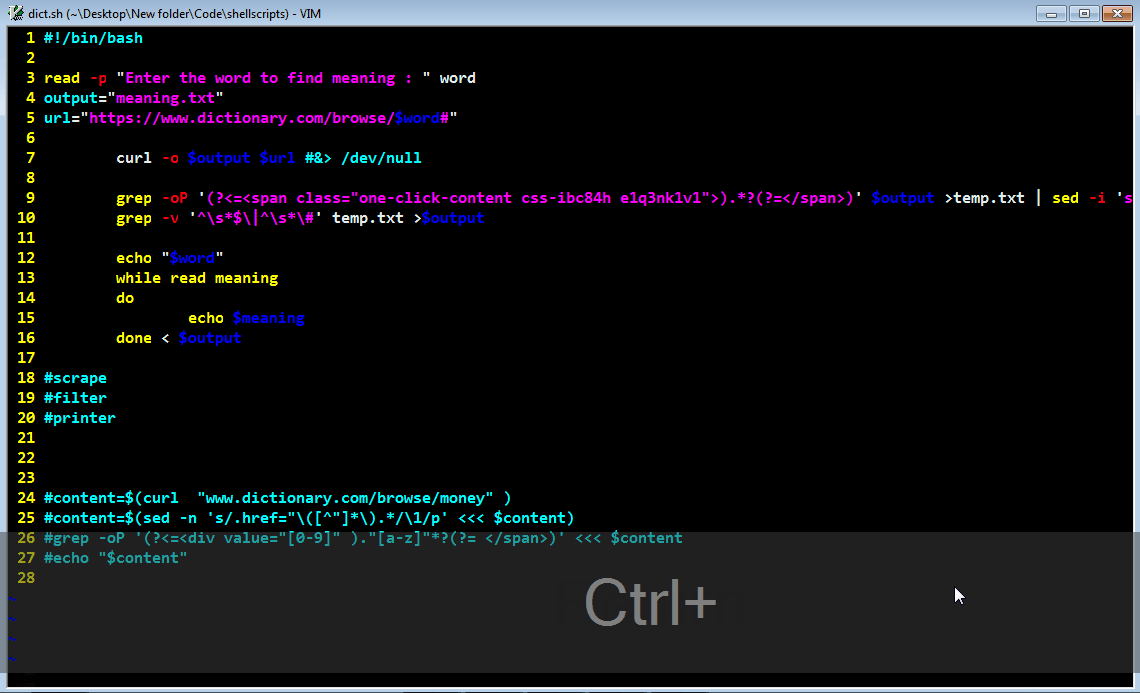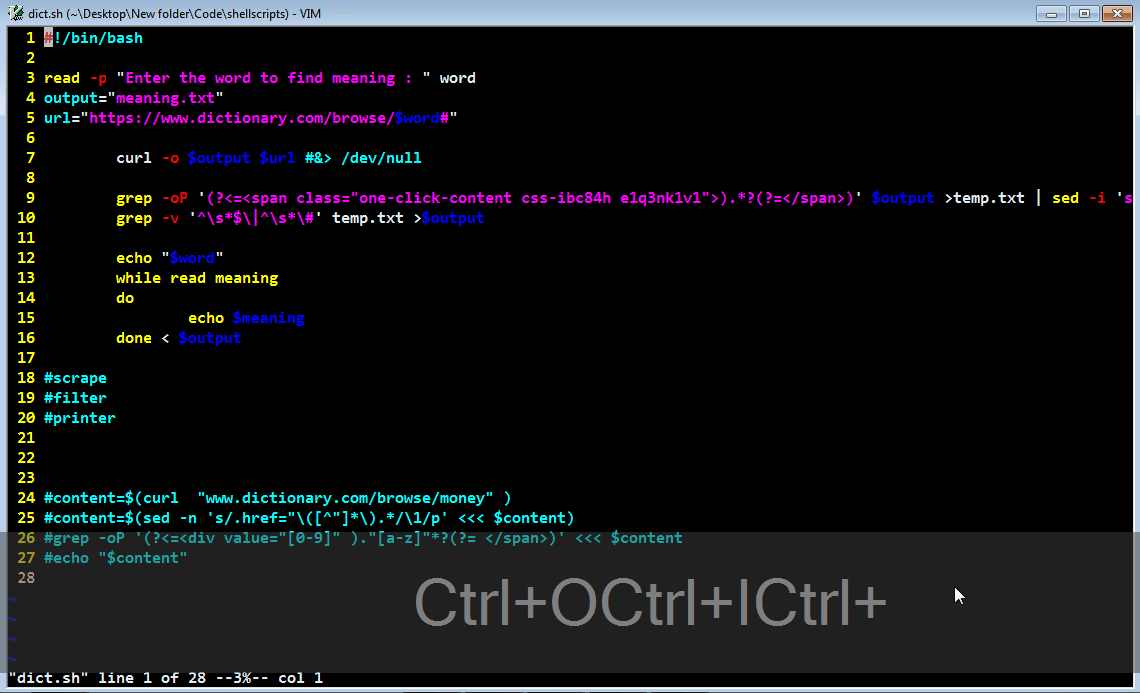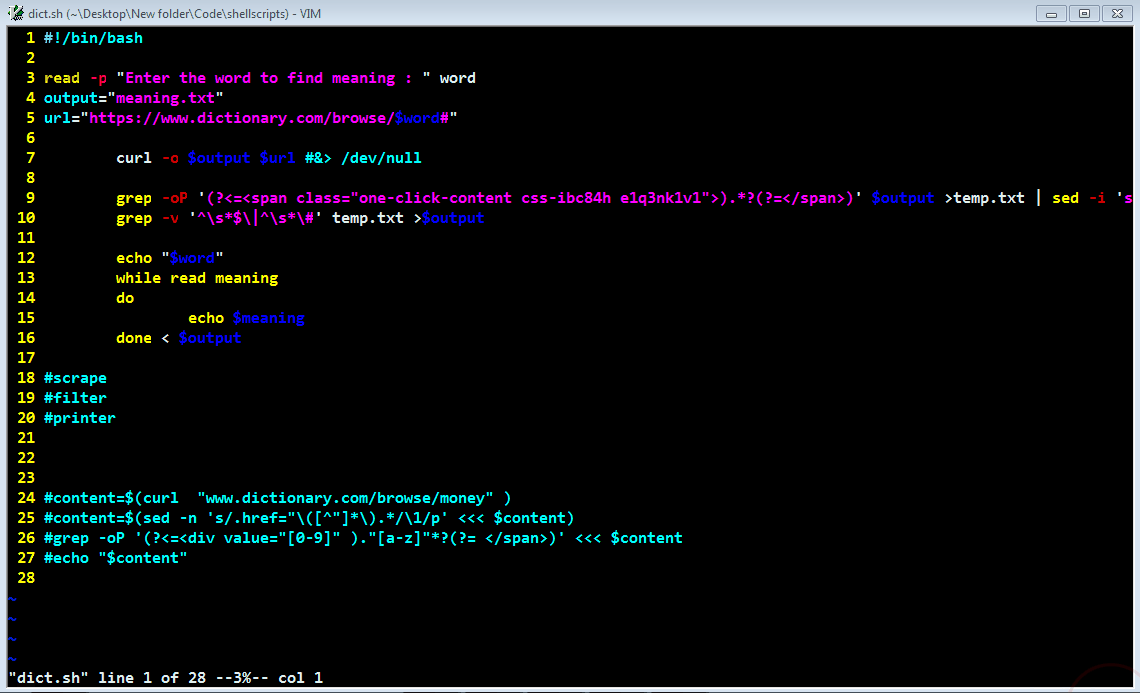
We can scan through the current buffers opened and jump through them one by one and it becomes quite effective in switching between few files. This could probably be suited for Web development where you can hop between HTML/CSS/JS files or in Android development for java/XML files, and so on you get the idea for using it as per your needs.
## Deleting buffers
Now we will see how to delete the loaded buffers, we can simply use `:bd n` where n is the number of the buffer in the list to delete the buffer, optionally we can use `:bd filename` to delete the buffer loaded with that file.
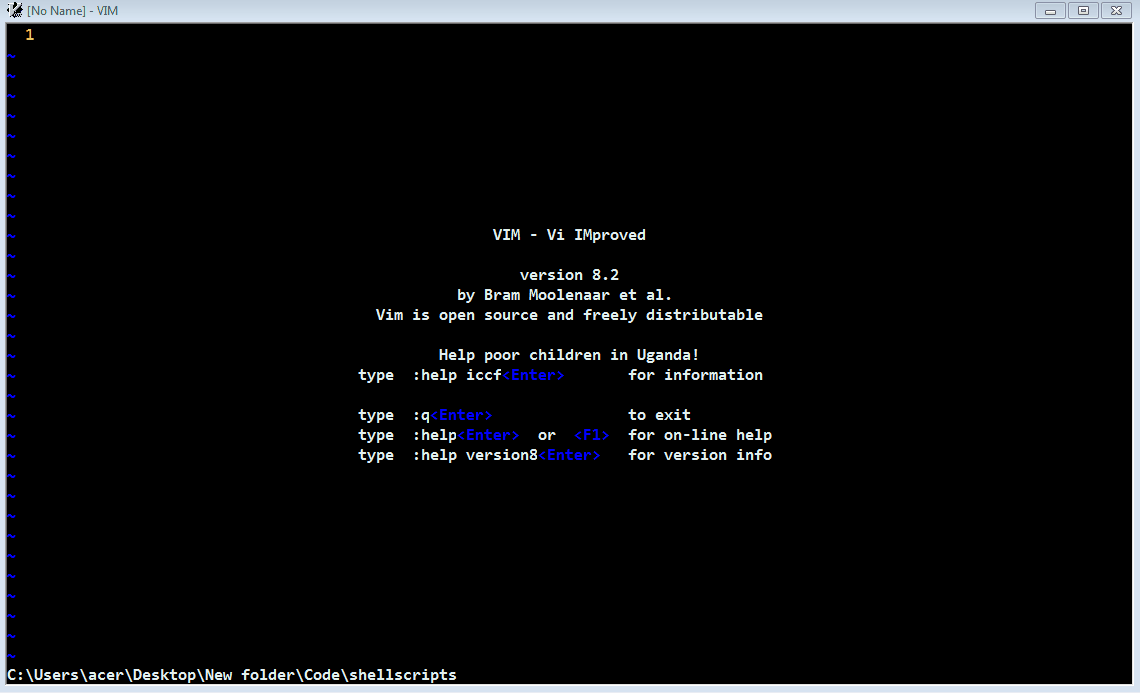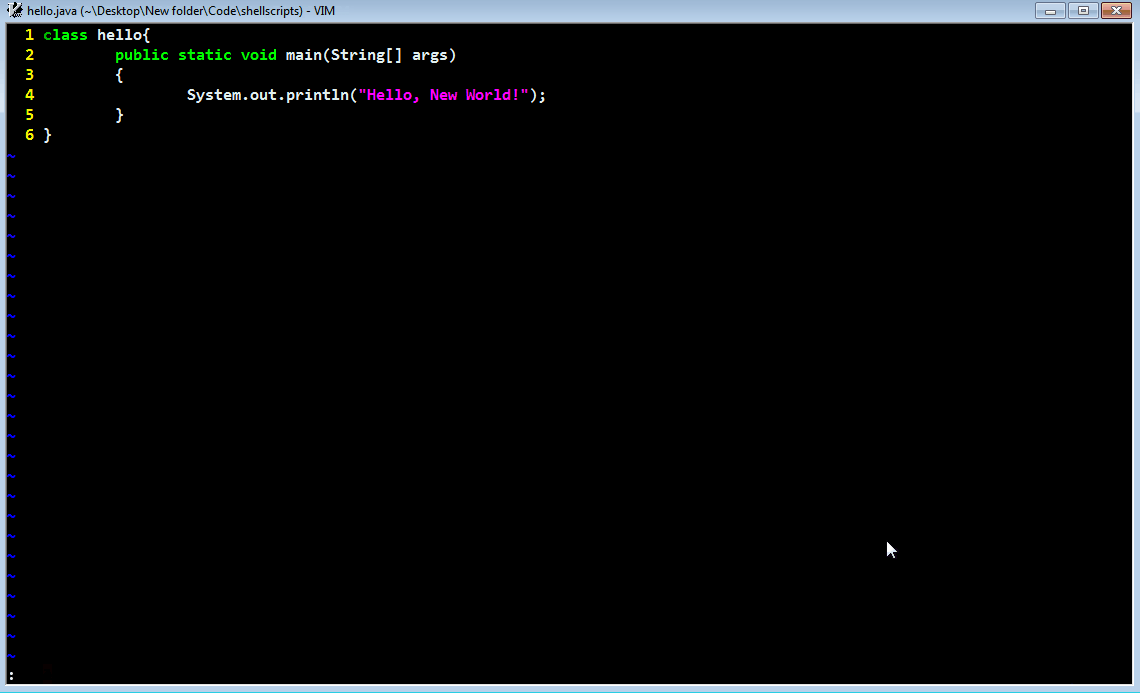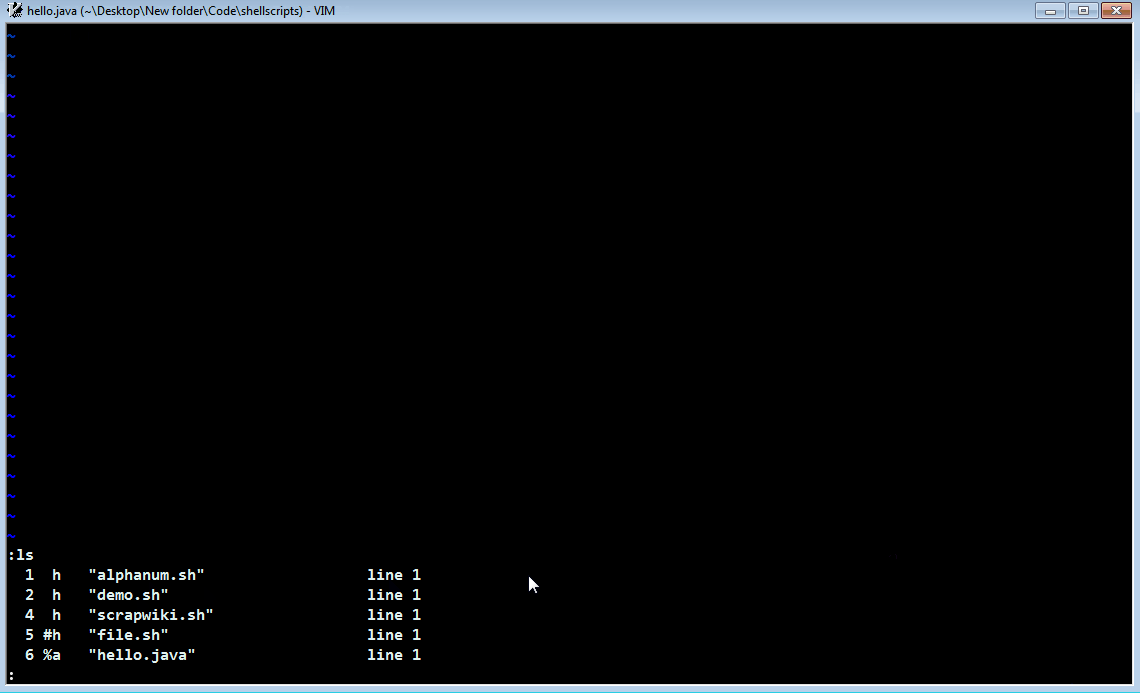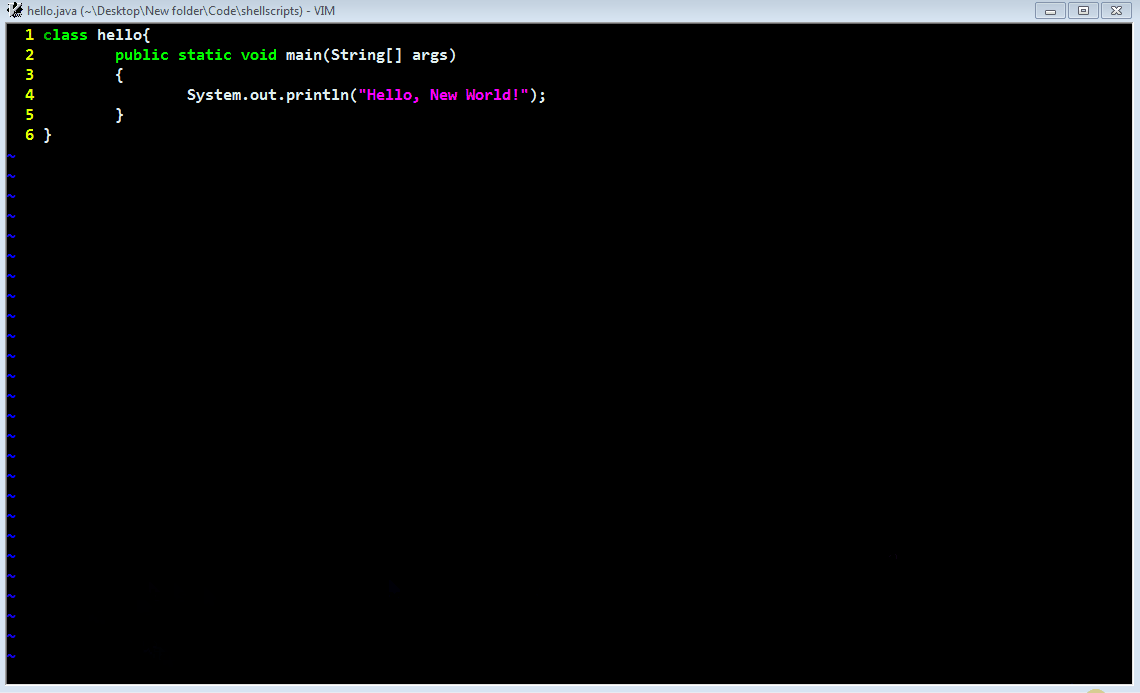
We can also delete a number of buffers at a time using a range of buffers like `:n,mbd` where `n` is the first buffer and `m` is the last buffer. We will delete every buffer between `n` and `m` including `n` and `m` using the above command.
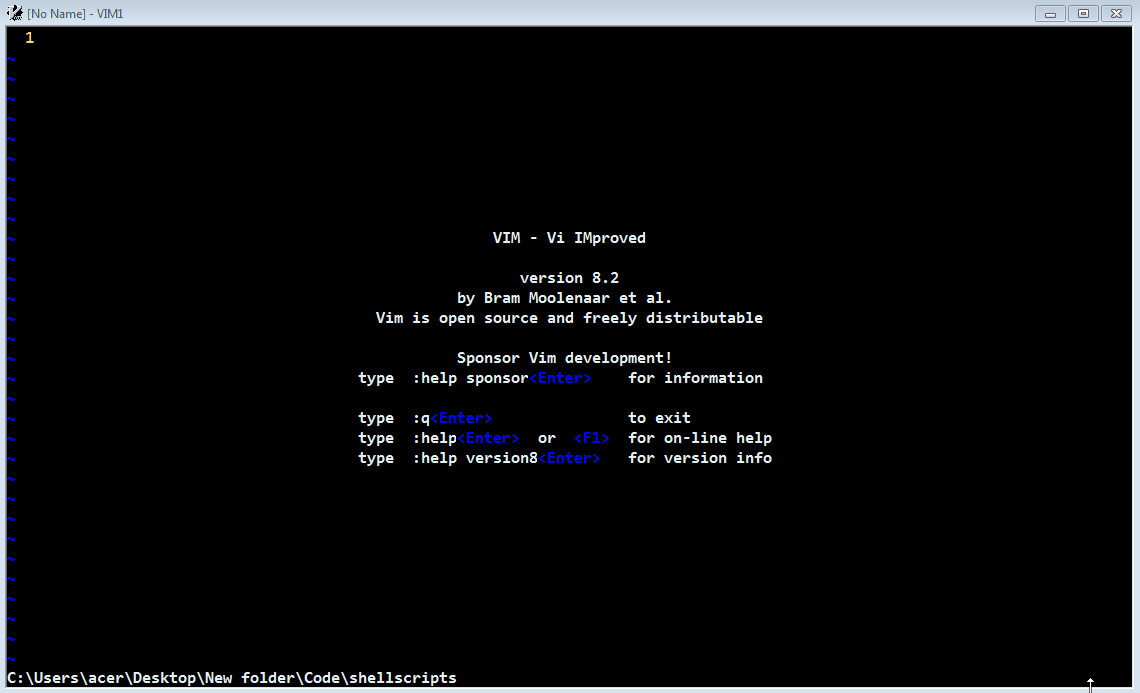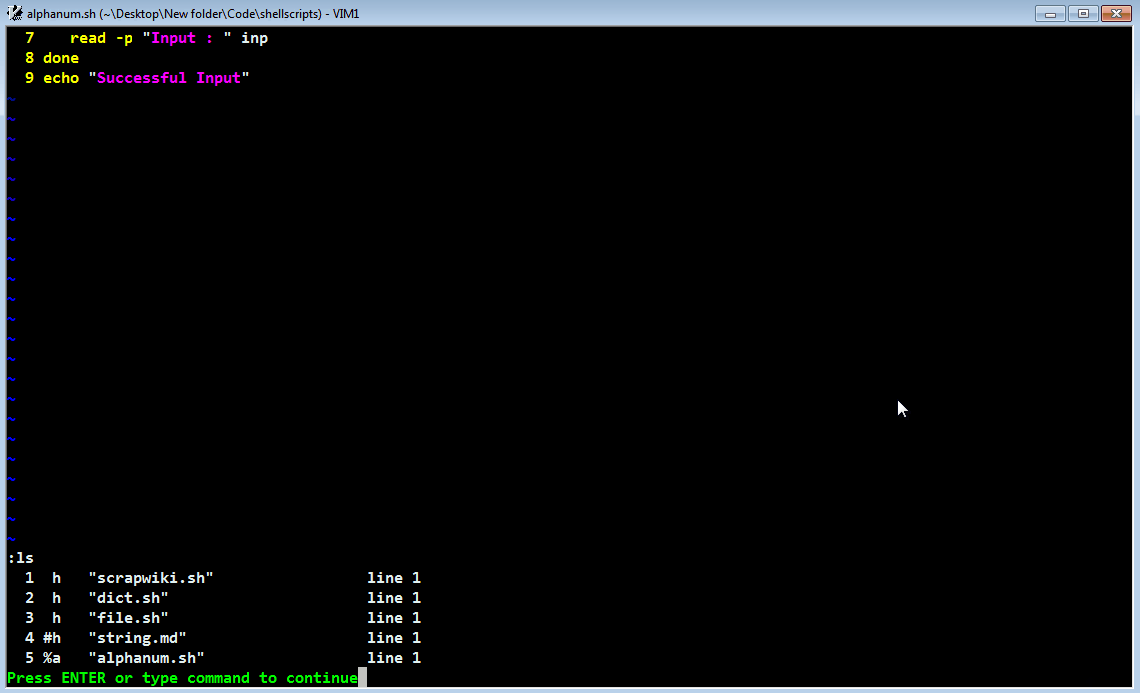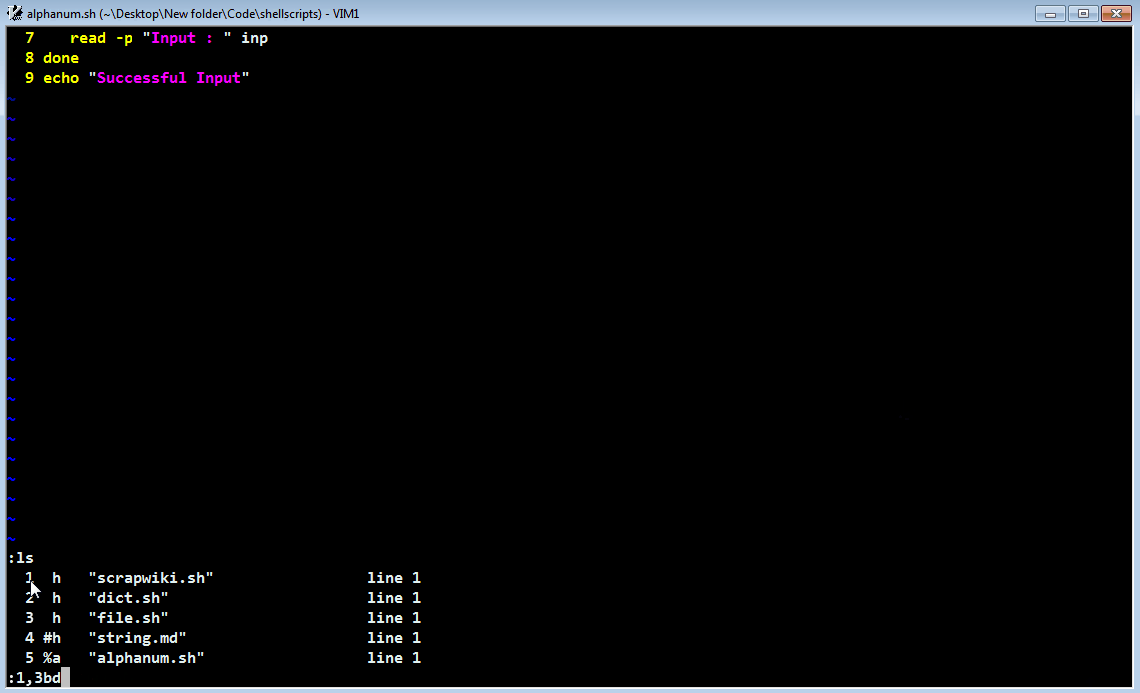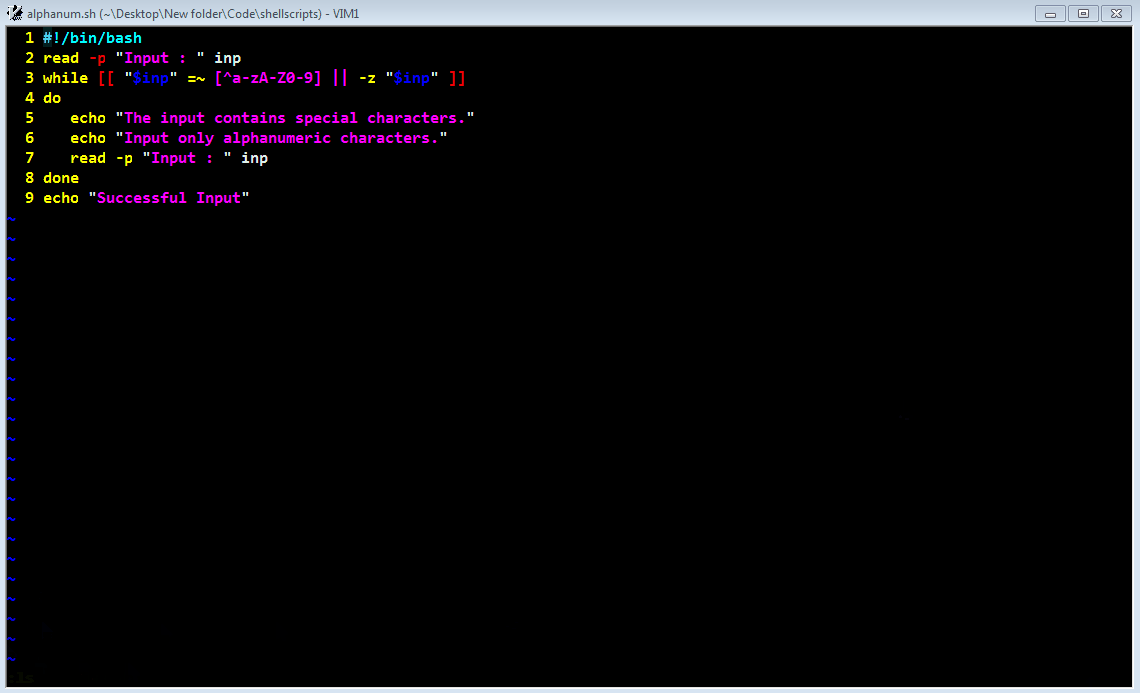
Just a quick fact, if you do not delete buffers, they will stay in memory even if you use `:q` they won't get erased from the buffer list, you are just exiting the buffer view and not removing the buffer from the current memory. This can get really messy if you are opening too many files and keeping them in memory.
## Creating splits in buffer
We can even create splits in buffers, basically a window split but we will see this with the view of buffers this time. To create a horizontal split, we can type in `:new filename` to open the file in the split. We can even create a vertical split with `:vnew filename` to open a vertical split with the provided file.
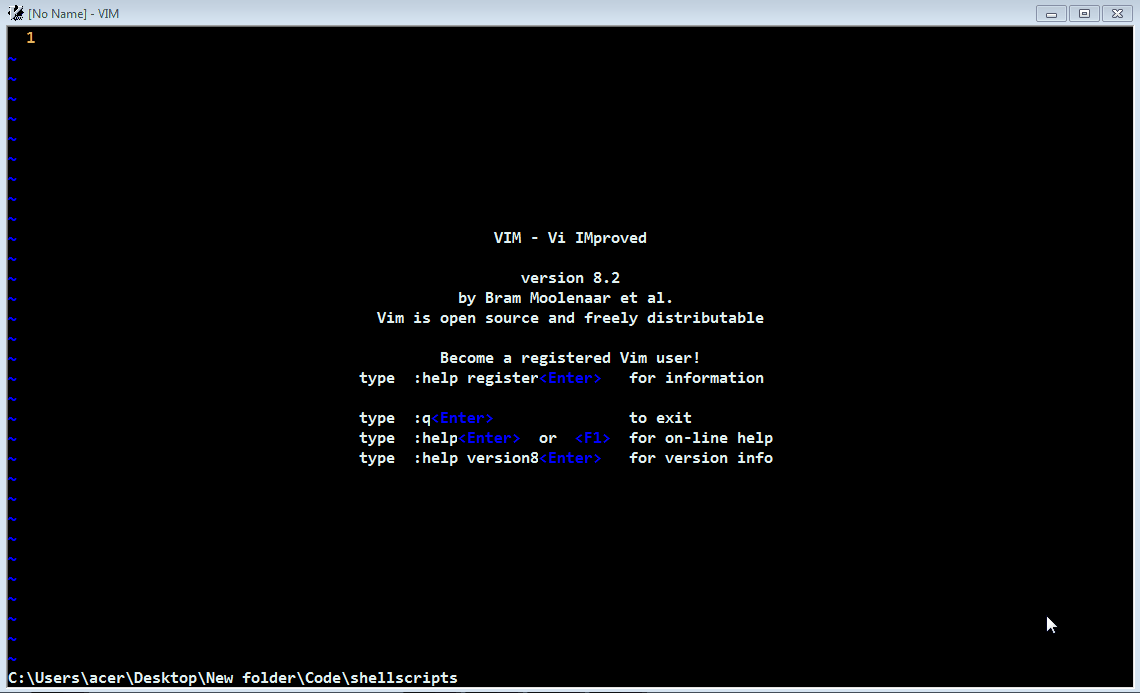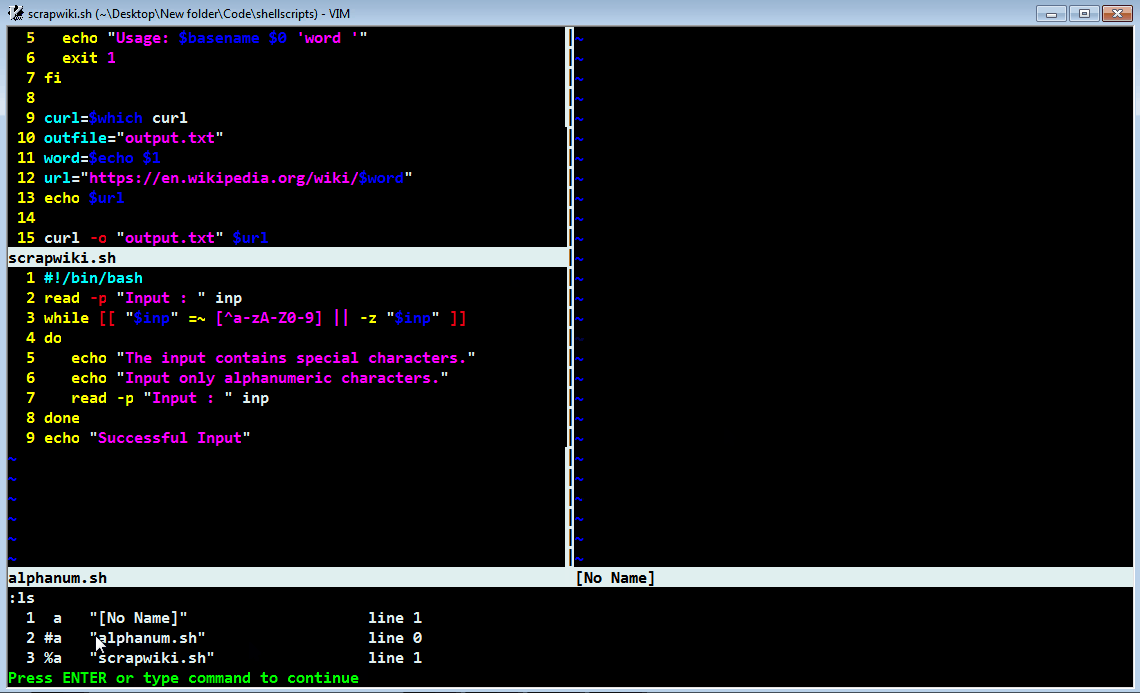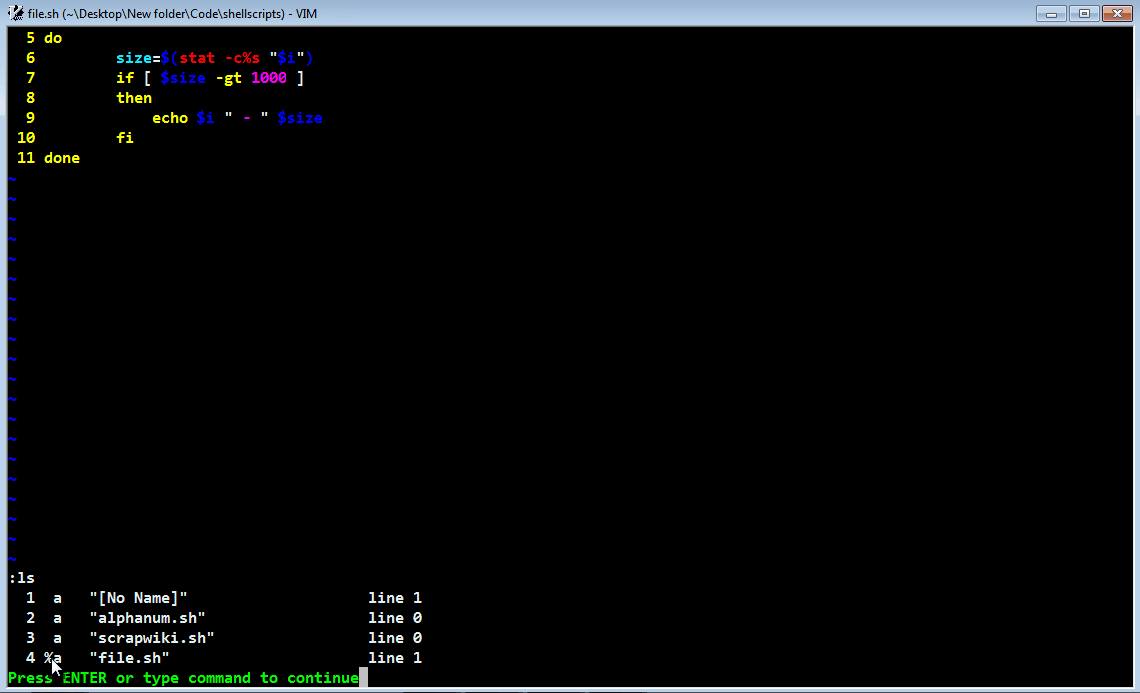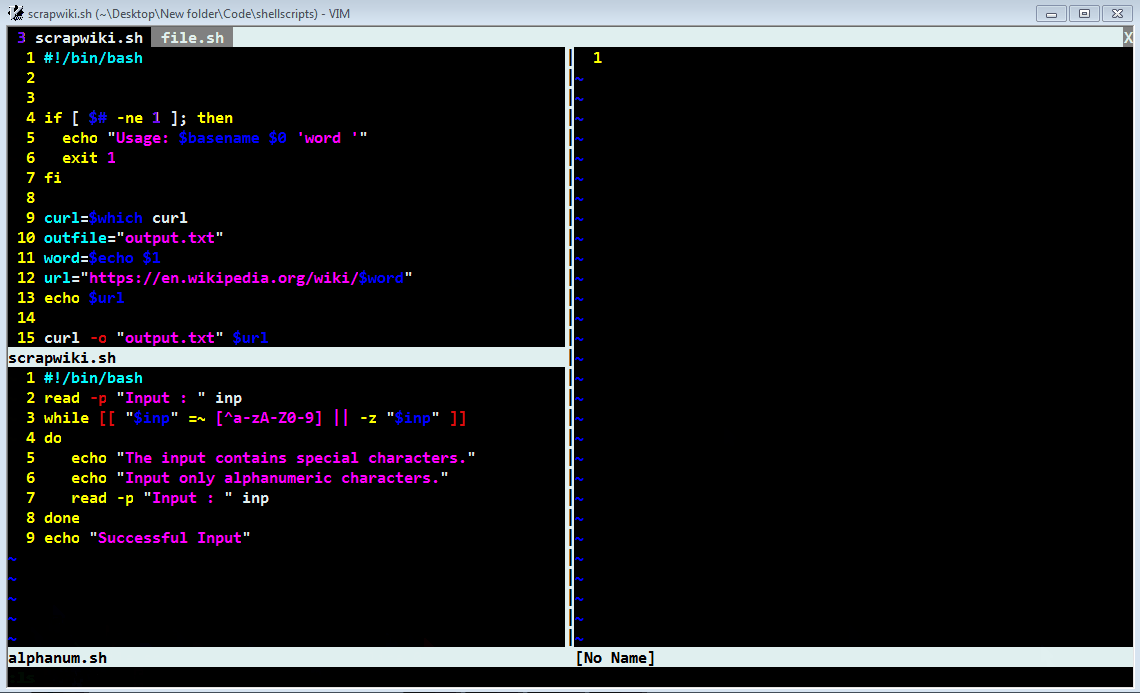
We can see some wired things in the ls menu if we open a new tab in the current instance of Vim. The list command shows all the buffers in the current Tab as well as in the previous tab.
We can also open buffers in splits by using numbers or file names. We can use `:sb n` to open the contents of the buffer n(any number of buffer), and with `:sb filename` to open the file in a split this will only be a horizontal split.
We can use `:sba` to open all the buffers in the split windows. This can be quite handy to find any file which you cannot remember was edited or wanted at the moment, this opens every buffer loaded in the current instance. We can also use `:sbp` and `:sbn` to open the previous and next buffer respectively in a split.
Additionally, we also have `:vertical ba` and `:ba` (`:ball`)to open all the buffers in vertical and horizontal splits respectively.
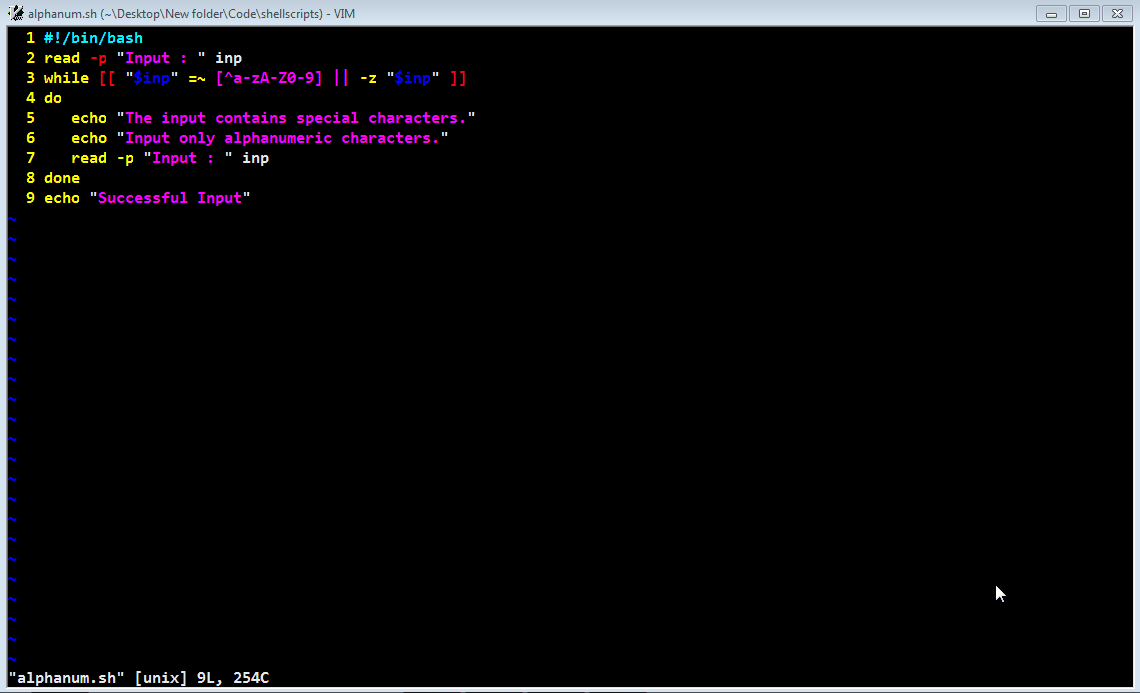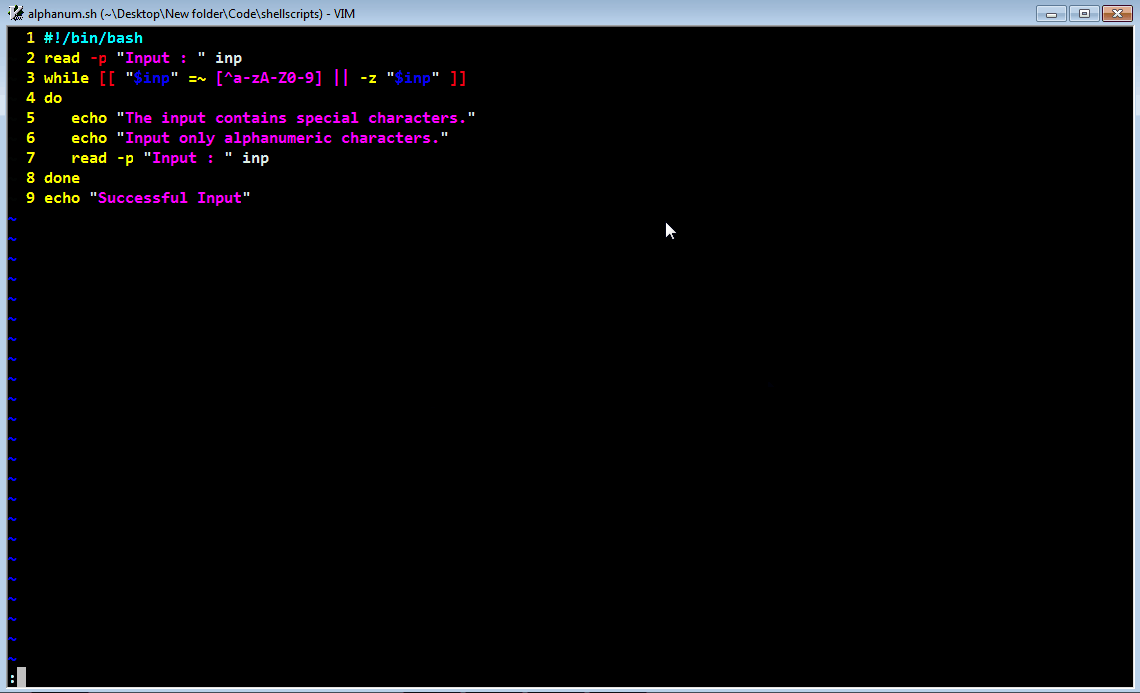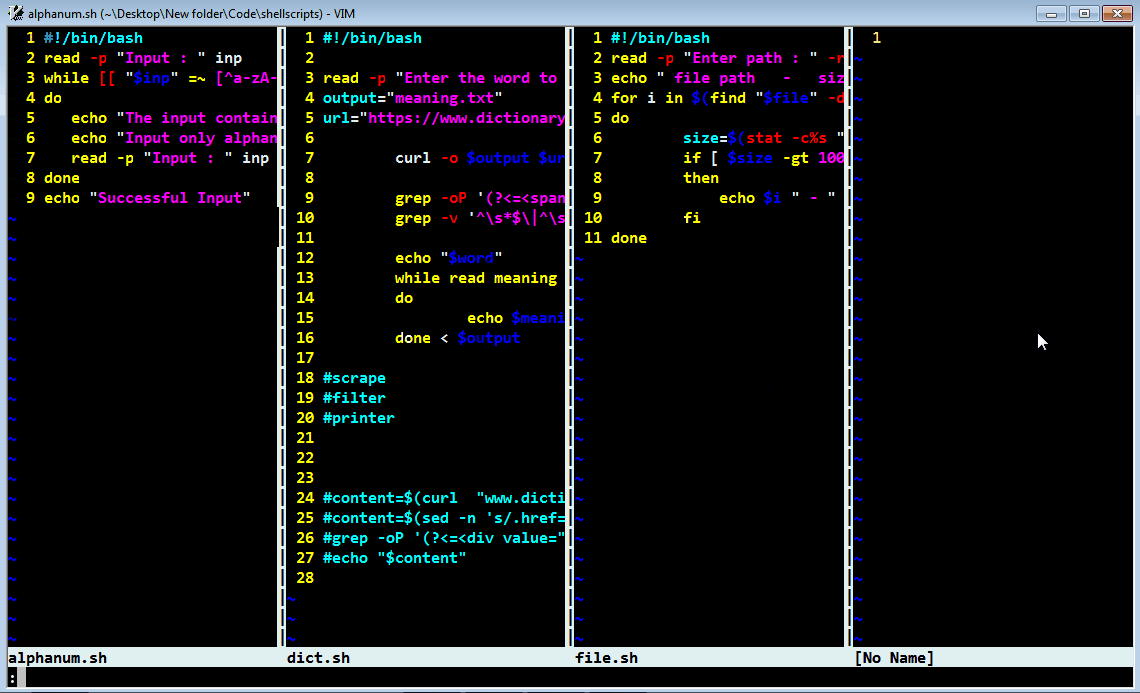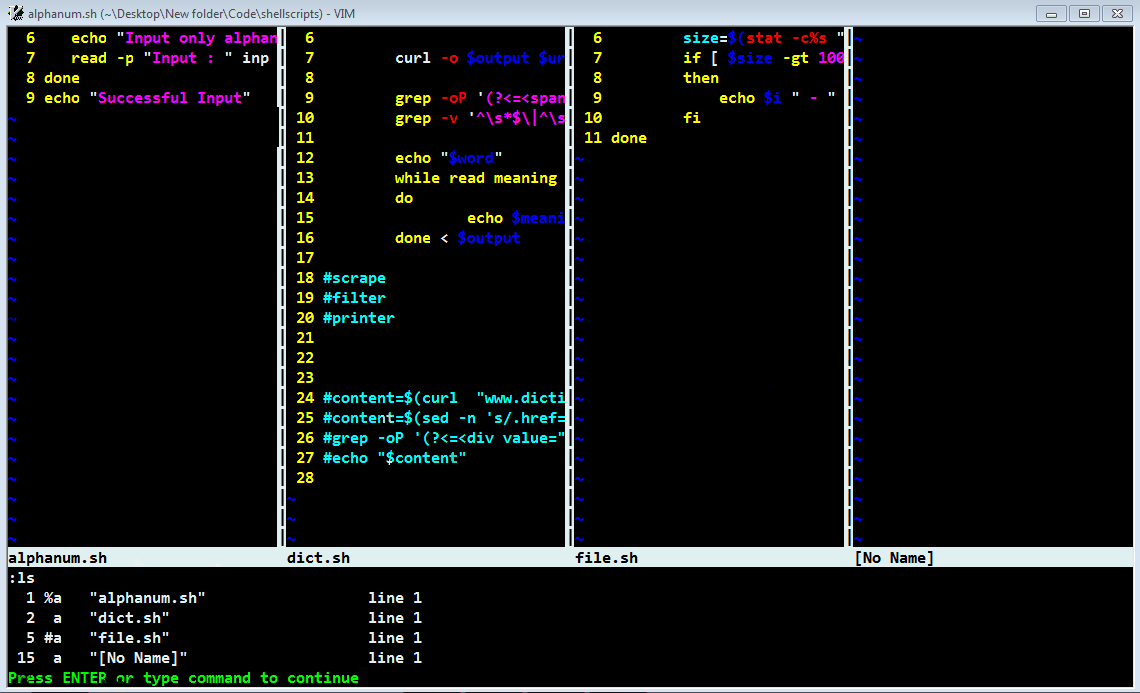
**Also**, We have `:tab ba` or `:tab ball` to open all the buffers as tabs in the current instance.
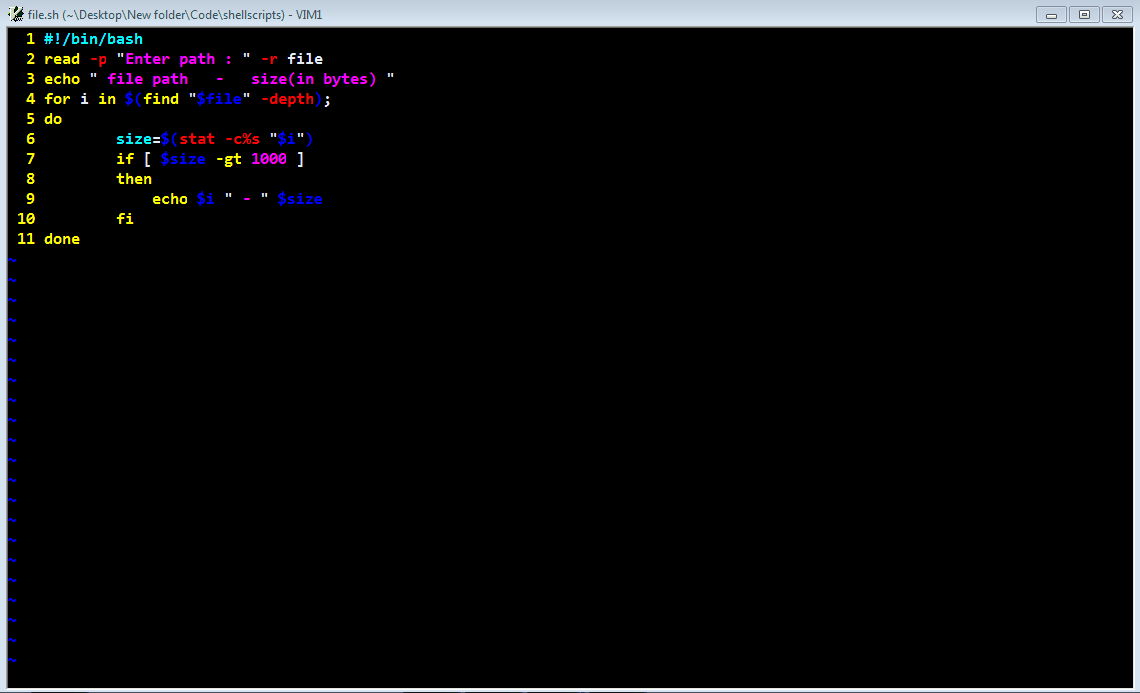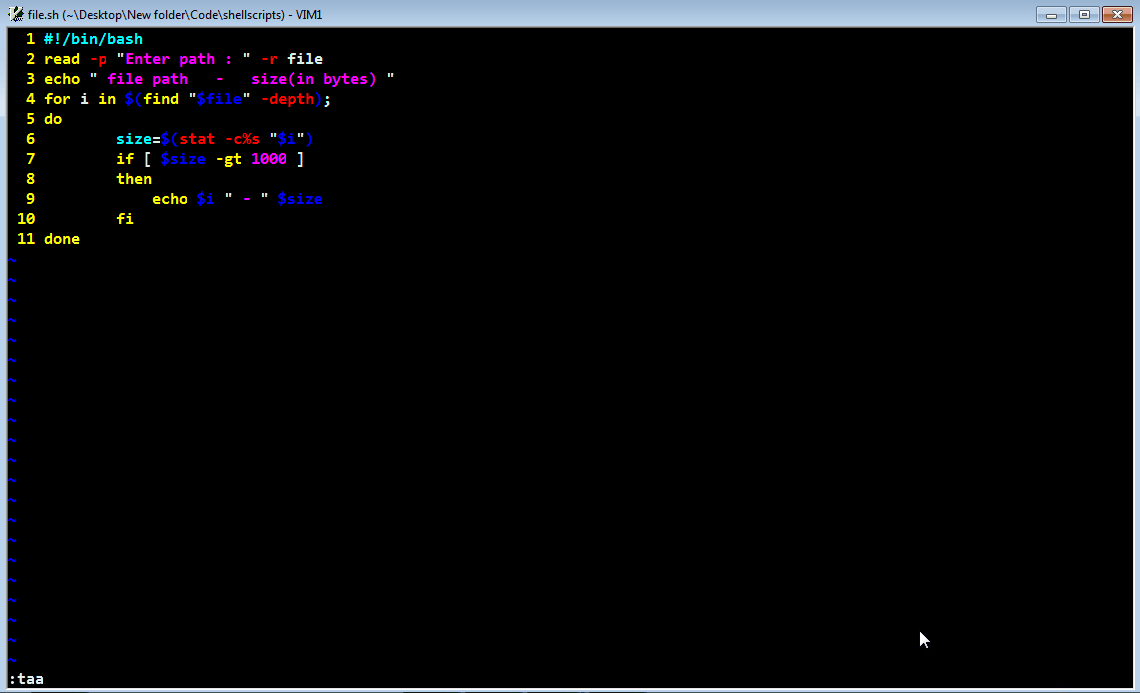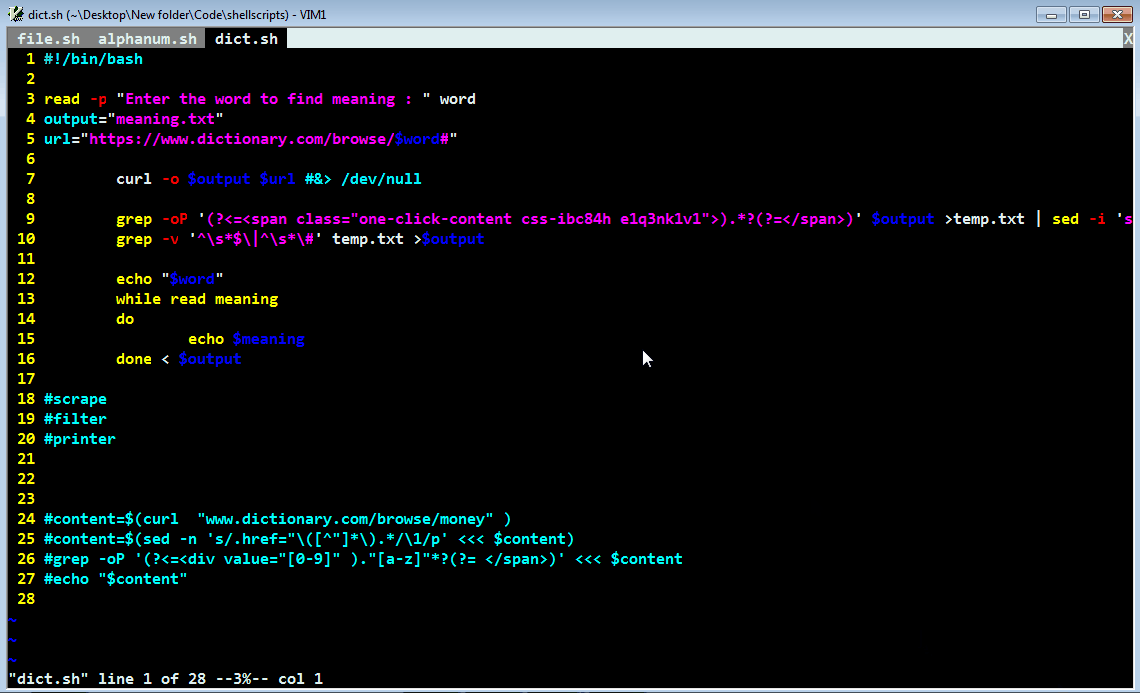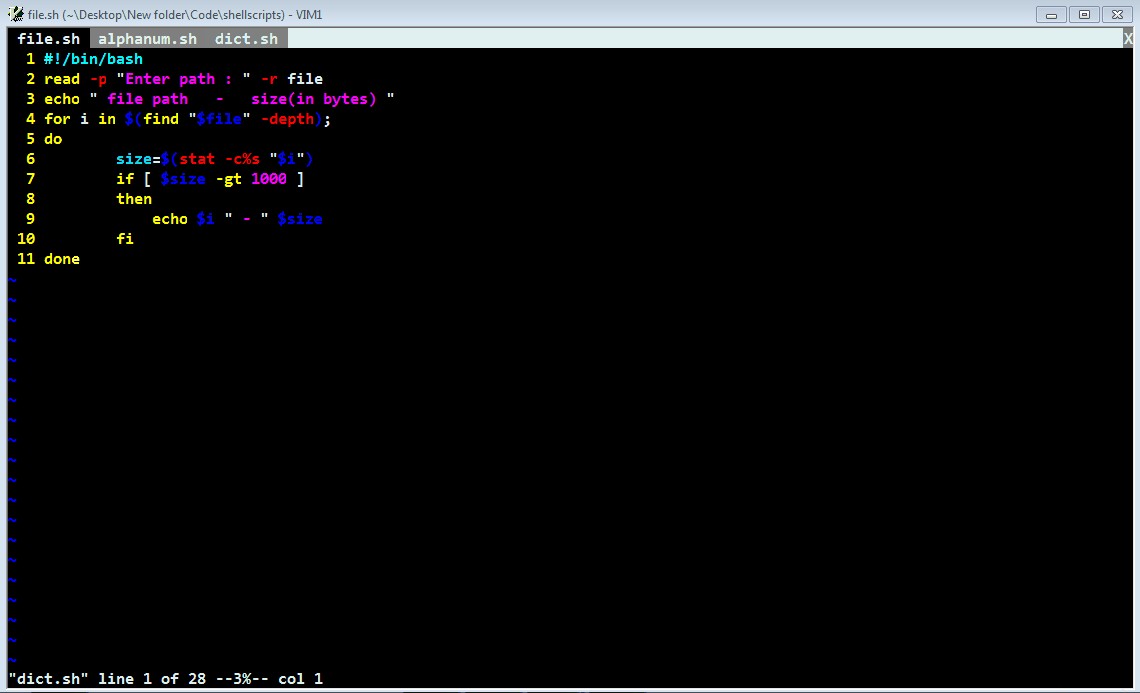
You can add more layers of effectiveness or customization using keymaps to split certain buffers and make use of the above set of commands more powerful and make them work according to your needs.
## Conclusion
So, from the above sections, we were able to see what happens under the hood when you open, close, or edit a file in Vim. Though it was not an in-depth view of each and every detail of the buffers in Vim. But enough to make you understand what and how buffers work and how to use them to become more effective. Hopefully, you have understood how to perform movements with buffers and create and delete them with tremendous control over what files you could edit. Thank you for reading till here.
### Buffers < Window Splits < Tabs
So from these three articles, we were able to understand the terminology of Buffers, Window Splits, and Tabs. These all are the units of the Vim file system/ Way of grouping Files. We can use buffers to load the file from the memory, we can split various buffers into windows which are all contained in a tab. Some might prefer using buffers, splits, or tabs but hey! what are you even talking about? They are all part of tabs so use everything as per need don't force yourself to use only one thing.
**Use buffers for opening few files, if you need to open many files regularly use window splits, If that's not enough use tabs to separate from different folders or directories**. Don't stop Viming, Happy Coding :)
### References
- [Vim Fandom: Buffers](https://vim.fandom.com/wiki/Buffers)
- [Vim Buffers FAQ](https://vim.fandom.com/wiki/Vim_buffer_FAQ)
- [Linux Hint - Understanding and using VIM Buffers ](https://linuxhint.com/how_vim_buffers_work/) | mr_destructive |
797,838 | Rendering Gatsby Images from Contentful Rich Text | I built this blog using Gatsby and Contentful, a combination that I love. Contentful is one of my... | 0 | 2021-08-24T23:36:46 | https://davidboland.site/blog/rendering-gatsby-images-from-contentful-rich-text | gatsby, contentful | ---
title: Rendering Gatsby Images from Contentful Rich Text
published: true
date: 2021-08-19 05:00:00 UTC
tags: #Gatsby #Contentful
canonical_url: https://davidboland.site/blog/rendering-gatsby-images-from-contentful-rich-text
cover_image: https://images.ctfassets.net/advboymm7uww/2ChNm8mRL4GquPAzX9wMk7/a6e5d7e6285cee729d1882547f9cce19/25392390163_d6a5321bfb_o.jpg
---
I built this blog using Gatsby and Contentful, a combination that I love. Contentful is one of my favorite CMS to work with. And Gatsby makes building blogs so easy.
When I first built the site, I had the challenge of migrating over content. For some of the pages that have images embedded in the text, I had a problem.
Gatsby is great at rendering images. To do this, you need to leverage the Gatsby Image Plugin. For most of the images on the site, that is no problem. For images in Rich Text, or any references, Contentful returns custom objects.
At the time I didn't think of a reasonable way to translate that to something I can pass into the Gatsby Image plugin. For Markdown, I was at least able add srcset HTML markup. Although this was super inefficient.
For Rich Text, I was forced to just process the asset and as a standard `img` tag. While I had access to the fuild data for the image, I would end up using the file url data as an `img` for the `[BLOCKS.EMBEDDED_ASSET]` render option.
While it worked to a degree, how I was rendering the image was inefficient.
## Solution
After my most recent Gatsby upgrade, I decided to revisit the issue.
I started out by including gatsbyImageData in my GraphQL fragment for Rich Text. If you don't know what I mean by "fragment", check out the blog post I did on [organizing your GraphQL calls](https://davidboland.site/blog/organize-your-graphql-calls-with-fragments "organizing your GraphQL calls").
```markup
fragment RichTextBlock on ContentfulRichText {
id
content {
raw
references {
gatsbyImageData(layout: CONSTRAINED, quality: 80, formats: [WEBP, AUTO], placeholder: BLURRED)
contentful_id
title
}
}
sys {
contentType {
sys {
id
}
}
}
}
```
This gets us all the images that are inside the rich text. The only problem is that they are all together in a single collection. There is no context as to where in the rich text they appear. So we need a way to determine where in the rich text to render them.
What I ended up doing, was creating a dictionary. It's key was the Contentful Id, the value an object containing the gatsbyImageData and title. The title I leverage for alt text.
```js
const richTextImages = {};
class RichText extends React.Component {
render() {
this.props.content.content.references.map(reference => (
richTextImages[reference.contentful_id] = {"image": reference.gatsbyImageData, "alt": reference.title}
))
return (
<div>
{ documentToReactComponents(JSON.parse(this.props.content.content.raw), options) }
</div>
)
}
}
```
I stored this in a variable in my component called `richTextImages`. I used that same variable in the options I configured for Contentful's `documentToReactComponents`. In the option for `[BLOCKS.EMBEDDED_ASSET]`, I had access to the Contentful Id of the asset rendering. From there, its a matter of pulling the data from the dictionary, and leveraging Gatsby Image.
```js
const Bold = ({ children }) => <b>{children}</b>;
const Text = ({ children }) => <p className="align-center">{children}</p>;
const richTextImages = {};
const options = {
renderMark: {
[MARKS.BOLD]: text => <Bold>{text}</Bold>,
},
renderNode: {
[BLOCKS.PARAGRAPH]: (node, children) => <Text>{children}</Text>,
[BLOCKS.EMBEDDED_ASSET]: (node, children) => {
// render the EMBEDDED_ASSET as you need
const imageData = richTextImages[node.data.target.sys.id];
const image = getImage(imageData.image)
return (
<div className="align-center">
<GatsbyImage image={image} alt={imageData.alt}/>
</div>
);
},
},
};
```
And that's it! I can now add images from Contentful in Rich Text with the Gatsby Image plugin.
While there might be other solutions out there, this one worked for me. Since my blog posts still use Markdown, they do not leverage this fix. But you can check it out on one of my [other pages](https://davidboland.site/optimizely).
There are a few items that I want to explore further. Expanding the Asset model in Contentful and storing Gatsby Image properties is one.
Please let me know if you came up other options. I would love to see how others got this working.
Thanks to #WOCinTech for the teaser photo used in this post! | debpu06 |
797,968 | Modify HTML pages on the fly using NGINX | It may occur to you that you want to change the content of a web page on the fly. For example, when... | 0 | 2021-08-20T07:21:16 | https://samanbaboli.medium.com/modify-html-pages-on-the-fly-using-nginx-2e7a2d069086 | nginx, webserver, html | It may occur to you that you want to change the content of a web page on the fly. For example, when you proxy a web page, maybe you want to edit some HTML tags, add some scripts, and etc.
Let’s find out how we can do it using NGINX.
##Example 1: Replace a string with another
Consider the following NGINX configuration:
```
server {
server_name example.com www.example.com
location / {
proxy_pass http://localhost:3000;
}
}
```
In this page that was served from `127.0.0.1:3000` we have some links and IMG tags that their hostname is `127.0.0.1:3002` , and we want to replace them with example.com .
The `ngx_http_sub_module` is a filter that modifies a response by replacing one specified string by another. This module is not built by default, it should be enabled with the `--with-http_sub_module` configuration parameter.
The sub_filter sets a string to replace and a replacement string.
```
server {
server_name example.com www.example.com
location / {
proxy_pass http://localhost:3000;
sub_filter '<a href="http://127.0.0.1:3002/' '<a href="https://example.com/';
sub_filter '<img src="http://127.0.0.1:3002/' '<img src="https://example.com/';
sub_filter_once on;
}
}
```
In the above example we replaced `<a href=”http://127.0.0.1:3002/` with `<a href=”https://example.com/`
Note that because we only want to replace `<a>` and `<img>` tags, we use tags in our replacement. If we want to replace all strings from `127.0.0.1:3002` into `example.com`, we will use the following configuration:
```
server {
server_name example.com www.example.com
location / {
proxy_pass http://localhost:3000;
sub_filter 'http://127.0.0.1:3002/' 'https://example.com/';
sub_filter_once on;
}
}
```
After you are done with your configuration, just reload the NGINX and enjoy :)
`$ service nginx reload`
##Example 2: Add a script to a web page
In this example we will add a script before the `</head>`tag without any changes in our source code.
```
server {
server_name example.com www.example.com
location / {
proxy_pass http://localhost:3000;
sub_filter '</head>' '<script>alert("Hi👋")</script></head>';
sub_filter_once on;
}
}
```
In order to add the script before the `</head>`, we first choose this string to replace, and then replace it with another string (we put our script before </head> tag in our new string).
And after you are done with your configuration, don’t forget to reload NGINX.
`$ service nginx reload`
##Example 3: Remove a string from a web page
In order to remove a string from a web page, we must replace that string with an empty string (space) like below.
```
server {
server_name example.com www.example.com
location / {
proxy_pass http://localhost:3000;
sub_filter '<p>Remove me</p>' ' ';
sub_filter_once on;
}
}
```
As you see, It was As Easy As ABC :) so you can go further and do exciting things using NGINX.
If you want to read more about this module, you can read it’s [documentation on NGINX website](http://nginx.org/en/docs/http/ngx_http_sub_module.html).
Feel free to leave your comments below if you have any question or idea about this topic. | samanbaboli |
798,184 | SailPoint Vs Oracle Identity Management: Which one should you choose? | Decide which product suits you the most between SailPoint and Oracle IM.Learn about their... | 0 | 2021-08-20T11:03:26 | https://sennovate.com/sailpoint-vs-oracle-im-comparison/ | iam, sailpoint, oracle, sennovate |
Decide which product suits you the most between SailPoint and Oracle IM.Learn about their products,their pricing,features, components and more,all in this comparison of
### SailPoint Vs Oracle Identity Management
Before going forward with the comparison between Sailpoint and OIM, Let’s have a quick overview of IGA.
**Identity Governance & Administration (IGA)**, also simply known as identity Governance, is both a policy framework and set of security solutions that enables organizations to mitigate access-related risks and manage identity chaos within their business more effectively.
IGA(Identity Governance) is considered part of identity and Access Management (IAM).Identity Governance offers organizations increased visibility into the identities and access privileges of users, so they can better manage **who has access to what systems, and when.**
IGA is at the center of IT operations, enabling and securing digital identities for all users, applications, and data. IGA automates the creation, management, and certification of user accounts, roles, and access rights for individual users in an organization. This means companies can streamline user provisioning, password management, policy management, access governance, and access reviews within their business.
In Simple Words, “IGA means leveraging the most intelligent and efficient path to mitigating identity risk in your business”.
### Overview of SailPoint
SailPoint is an open-source identity governance platform that gives organizations of all sizes the power to create an identity-enabled enterprise by combining data, devices, and applications. It is a reliable solution built to deliver operational efficiency, security, and compliance to business with multi-faceted IT environments.
SailPoint solves the most complex IAM challenges with cloud-based and on-premises solutions designed to facilitate services such as compliance, password management, analytics, and more. So, they manage:
- Who has access to what?
- Who should get the access to what?
- How is the access being used?
### Features OF SailPoint:
- Compliance Control
- Automated Provisioning
- Identity Governance for files
- Account Management
- Access Request Management
- Password Management
- Role Management
### Benefits of Using Sailpoint:
- Cost-effective and Quick Migration to SailPoint compared to OIM upgrade
- Upgrades are Streamlined
- On-prem deployments incurring low hardware costs
- Less-cost for Sustainability
- Minimal TCO (Total Cost of Ownership)
- More than 100 Out-Of-the-Box connectors
- Broad Cloud-deployment options(Relevant image showing process the flow/features)
Clearly, SailPoint does provide a lot of features when it comes to Component Maintenance and Upgrade.
### Overview of Oracle Identity Management
Oracle Identity Management is a complete suite of cloud-based identity management solutions. This next-generation platform comprises identity governance, access management, and directory solution that modernizes and scales identity management.
OIM enables organizations to effectively manage the end-to-end lifecycle of user identities across all enterprise resources, both within and beyond the firewall and into the cloud.
### Features of OIM:
- Access Control
- Alert/Notifications
- Application Security
- Compliance Management
- Password Management
- Reporting / Analytics
- Self- Service Access Request
- Single Sign On
- Two-Factor Authentication
OIM needs individual connectors and requires installation,while in case of SailPoint all the connectors come as default, without any configuration necessary. Additional upgrade is also required for all the individual connectors in case of OIM.
#### Have questions about SailPoint and Oracle Identity Management?
*Call us at +1 (925) 918-6618 the consultation is free.*
### About Sennovate
Sennovate delivers custom identity and access management solutions to businesses around the world. With global partners and a library of 1000+ integrations, we implement world-class cybersecurity solutions that save your company time and money. We offer a seamless experience with integration across all cloud applications, and a single price for product, implementation, and support. Have questions? The consultation is always free. Email hello@sennovate.com or call us at: +1 (925) 918-6618.
| sennovate |
798,248 | How I stay productive | You read the title. Let's get straight into it. (This is not advice.) I don't try to be... | 0 | 2021-08-20T13:11:14 | https://dev.to/dhaiwat10/how-i-stay-productive-54d6 | career, programming, devjournal | You read the title. Let's get straight into it.
(This is not advice.)
## I don't try to be productive all the time
Trying to be productive all the time is not practical. No one can be productive all the time. We aren't machines. We are subject to ups and downs in our energy levels and motivation. We all need to 'go slow' every once in a while. I don't feel bad about it. It is perfectly normal.
I like to think of life as a marathon, rather than a sprint. The slow and the steady wins the race. I like to slow down, recharge and go for it again — rather than constantly trying hard and inevitably burning out.
## Breaks
Timely breaks are a game-changer. When I feel like I've hit a dead-end, I take a short break and come back to the problem later. I usually come back with a completely different set of ideas & make the problem easier. The break could be a short walk (the best!), reading a book, listening to a podcast, a game of Warzone — anything!
Changing things up is the key. I need something that takes my mind away from the problem and gives it some time to relax. I am often surprised by the wonders our brains can do when we approach problems differently.
## Lifestyle over 'rapid growth'
When I first started out as a developer in the industry, I used to say _yes_ to every opportunity in my reach. Over the years, I have learnt to say _no_.
Sure, saying yes to every other project that comes my away would make me a lot of money — but at what cost? I used to spend my entire day working on low-quality projects. Even though I was making more money, the pleasure was short-lived. My inner self used to feel disappointed with myself. I wasn't treating myself like I knew I should. At one point, I flicked the switch.
I started only taking on projects that allowed me to grow & had a great work environment — even if that meant that I would be making a less money, at least temporarily.
In the long term, this has allowed me to make much more money. 😉 This is why I hold the opinion that too much speed is bad. When it feels like too much is happening at the same time, I slow down. I take a deep breath, re-assess and say no to some things.
I choose, and will continue to choose, lifestyle over 'rapid career growth'.
## Intrinsic motivation
I have desired traveling the world ever since I was a kid. There is lots to do on our beautiful planet — mysterious places to visit, awesome people to meet and tasty food to enjoy!
But I come from a humble background. I have never stepped foot outside of India. I need a lot of money for that. I knew could earn a lot of money by being a good software developer. Coincidentally, I happened to fall in love with computers as a 5-year-old kid. A match made in heaven.
The dream of going to all those places I've always wanted to see is what keeps me going. I'm not quite there yet, but I will be. One day.
## I utilize procrastination
Utilizing procrastination? Doesn't make a lot of sense. Let me explain.
Whenever I find myself procrastinating, I don't fight it. I use it as information. I think — 'If I _really_ wanted to do it, I would have jumped into action already. I wouldn't wait. Nothing would stop me.' As [Daniel Vassallo](https://twitter.com/dvassallo/status/1384727283387142151?s=20) would say, procrastination helps me avoid things that don't give me energy. It can't tell me what I should do, but it can tell what I _shouldn't_ do. Whenever I can afford to, I try to use this information to guide myself.
Embracing procrastination rather than fighting it has changed my life for the better.
## I try to help
I am _really_ grateful for the tech community — be it on Twitter, Hashnode, DEV or anywhere else. I am forever in debt of some folks from the community who held my hand when I was a newbie. I owe so much.
This is why I try to give back whenever I can. Most of my contributions come in the form of open source contributions & articles. How does this help me in being productive? It gives me inner peace, reduces stress. I feel proud of the person I see when I look in the mirror. This might not make any difference for some people but it impacts my life drastically. It just works.
> **'Happiness is only real when shared'**
> — Christopher McCandless
## Parting remarks
Like I mentioned earlier, please do not consider this as advice. No 'advice' is ever universal. What works for me might not work for you. These are my experiences and I tried to share them from a very personal point of view.
If you found my insights interesting, consider [following me on Twitter.](https://twitter.com/dhaiwat10)
Cover photo by [Murray Campbell.](https://unsplash.com/photos/B_TdfGFuGwA) | dhaiwat10 |
798,255 | #100DaysOfCode Day 4 | Day 4 - #100DaysOfCode Hello everybody! I hope everyone is having a great day. Just sharing what... | 0 | 2021-08-20T13:23:17 | https://dev.to/aaronwager/100daysofcode-day-4-2gf2 | html, css, 100daysofcode, codenewbie | Day 4 - #100DaysOfCode
Hello everybody!
I hope everyone is having a great day.
Just sharing what I've learnt today
-The DOM (what it is, how it's used, etc)
-Progress on Udacity NanoDegree Front End Developer
-Using GitHub Pages to host my project online for free | aaronwager |
798,415 | How to use the TBILLPRICE function in Excel Office 365? | TBILLPRICE function returns the price per $100 face value for a Treasury bill, and it takes the... | 0 | 2021-08-25T02:36:12 | https://geekexcel.com/how-to-use-the-tbillprice-function-in-excel-office-365/ | tousethetbillpricefu, excel, excelfunctions | ---
title: How to use the TBILLPRICE function in Excel Office 365?
published: true
date: 2021-08-20 13:49:57 UTC
tags: ToUseTheTBILLPRICEFu,Excel,ExcelFunctions
canonical_url: https://geekexcel.com/how-to-use-the-tbillprice-function-in-excel-office-365/
---
**TBILLPRICE function** returns the **price per $100 face value** for a Treasury bill, and it takes the **settlement date and maturity date as argument dates** along with the **discount rate**. In this article, we are going to see how to **use the TBILLPRICE Function In Excel Office 365**. Let’s get into this article!! Get an official version of MS Excel from the following link: **[https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)**
## TBILLPRICE function syntax
```
=TBILLPRICE (settlement, maturity, discount)
```
**Syntax Explanation:**
- **settlement** : settlement date of bill.
- **maturity** : maturity date of bill.
- **discount** : discount rate on bill.
## Example
- Firstly, you have to **create a data** with **settlement date, maturity date** and **discount rate** for the treasury bill.
<figcaption>Sample data</figcaption>
- Then, you need to calculate the **TBILLPRICE function** by using the below given **formula**.
```
=TBILLPRICE(A2,A3,A4)
```
<figcaption>TBILLPRICE function</figcaption>
- Now, you have to calculate the **PRICE function** by using the same formula.
<figcaption>PRICE function</figcaption>
**Check this too:** [How to use the BINOM.DIST function in Excel Office 365?](https://geekexcel.com/how-to-use-the-binom-dist-function-in-excel-office-365/)
**NOTES:**
- Excel stores **dates as serial numbers** and is used in calculation by the **function**.
- It is used to recommend to use **dates as cell reference** instead of giving **direct argument to the function**.
- You need to check the **date values** if the function returns **#VALUE! Error**.
- Then, the **security settlement date** is the date after the issue date when the security is traded to the buyer.
- Now, the arguments like **settlement date & maturity date** are truncated to **integers**.
- After that, the function returns the **#VALUE! Error** if the **settlement date & maturity date** is not a **valid date format**.
- Finally, the function returns the **#NUM! Error** if:
- If maturity date settlement value.
- If discount rate argument is < 0
## Wrap-Up
Hope you understood how to **use the TBILLPRICE Function In Excel Office 365**. Please feel free to state your query or feedback for the above article. Thank you for Reading!! To learn more, check out **[Geek Excel](https://geekexcel.com/)!! **and [**Excel Formulas**](https://geekexcel.com/excel-formula/) **!!**
**Read Also:**
- **[Excel Formulas to Get the Percentage Discount ~ Useful Tricks!!](https://geekexcel.com/excel-formulas-to-get-the-percentage-discount/)**
- **[Excel Formulas to Find Original Price from Percentage Discount!!](https://geekexcel.com/excel-formulas-to-find-original-price-from-percentage-discount/)**
- **[Formulas to Lookup a Latest Price ~ A Complete Tutorial!!](https://geekexcel.com/lookup-a-latest-price-excel-formula/)**
- **[Excel Formulas to Calculate the Interest Rate for Loan ~ Easy Tricks!!](https://geekexcel.com/excel-formulas-to-calculate-the-interest-rate-for-loan/)** | excelgeek |
798,520 | WebApp Sandboxing & Challenges of Executing User's Code | I've recently wanted to create a web app(in javascript) that has an online code editor and executes a... | 0 | 2021-08-20T22:21:16 | https://dev.to/chrislemus/webapp-sandboxing-challenges-of-executing-user-s-code-499k | I've recently wanted to create a web app(in javascript) that has an online code editor and executes a user's code. I expected the code editor implementation to be a simple task. And that I could use the `eval()` JS function to evaluate the user's code. But I soon found out that there is a significant security flaw to this approach. So in this blog, I will go over some security challenges you need to think about when executing a user's code.
## Preventing your app from crashing
Sandboxing is an excellent way to prevent your app from crashing and provide better security. Sandboxing refers to creating two separate environments, one for executing untested code and another for your production environment(your app). Failing to isolate the two environments will likely crash your app when the user's code throws an error. Or when the user manipulates the DOM in a way that is not intended.
Want to see how DOM manipulation could render your app useless? Visit any site on your browse and run the code below in the browser's developer tools console.
```javascript
document.querySelector('body').innerHTML = ''
```
If you executed the code above, your browser's window would be blank, similar to the image above.
## Avoid sharing malicious code
When it comes to security, you need to be careful if you plan on letting users share code similar to the CodePen site. The main concern with code sharing is that other users may accidentally run malicious code and expose sensitive data.
Want to see how easy it is to expose sensitive information on the browser? For our next example, I will visit Facebook's homepage and run the code below in the console. The code will add an event listener to all the inputs and extracts the value.
```javascript
const inputs = document.querySelectorAll('input')
const logInputValue = (e) => console.log(e.target.value)
inputs.forEach(input => input.addEventListener('change', logInputValue))
```
Even though the code logs the login credentials to the console, a malicious user can instead send the login credentials to themselves, thus making the account vulnerable. Not only are we able to access input values, but there are also vulnerabilities you should be aware of, such as allowing access to local storage.
## A simple solution to sandboxing
There are a couple of ways of creating a sandboxed environment. A common way that most online editors create a sandboxed environment is by running multiple servers. One server will run the app, and another will receive, bundle, and send back the code preview.
Luckily, you could also achieve similar results using the `iframe` HTML element. If you would like to follow along, open your favorite code editor and create a new `index.html` file. Then add the code below into your HTML file.
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<iframe sandbox="allow-scripts" srcdoc="
<html>
<body>
<textarea></textarea>
<button id='submit-btn'>Submit</button>
</body>
</html>">
</iframe>
</body>
</html>
```
Now let's go over the two attributes we've provided to our iframe element. The `sandbox` attribute adds multiple restrictions to the `iframe` element. By default, all restrictions will apply to the `iframe` if you provide an empty string to the `sandbox` attribute. And any value token provided to `sandbox` will lift the particular restriction. In this case, we just want to run javascript code, so we'll provide `allow-scripts` as a value to the `sandbox` attribute.
The `srcdoc` attribute is straightforward. Instead of providing an external link to the `iframe` content. We use `srcdoc` to provide the content directly to our iframe HTML element.
### How can we confirm that both environments have restricted access?
Want to make sure that your `iframe` element has restricted access? Follow the steps below. Please note that I will be using google chrome as my browser for this demo.
1. Open the `index.html` file in your browser running a live server. If you are using VSCode, you can right-click on the HTML file and select `Open with Live Server`
2. Open the developer tools; Option + ⌘ + J (on macOS), or Shift + CTRL + J (on Windows/Linux).
3.Navigate to the `Console` tab.
4. If you run the `localStorage` command in the console, you will get information about your local storage.
5. Now select your `iframe` element in the `Javascript Context` dropdown and run the `localStorage` command once more. And this time, you will receive an error because we have successfully restricted access to the `iframe` element.
Sandboxing and executing the user's code using iframe is a fast and straightforward solution, though it might not be the best for all applications. Therefore, I advise that you do further research to provide a secured sandboxed environment for your users. I hope this article has helped you understand how sandboxing works and some things you should be aware of when building out your project.
| chrislemus | |
798,530 | One-Tap Deployments with Nginx and Docker: Configuring for Load Balancing ⚖ | Welcome back, in the previous article, we briefly introduced reverse proxies, and how we could use... | 14,198 | 2021-08-20T19:46:29 | https://dev.to/paulafahmy/one-tap-deployments-with-nginx-and-docker-configuring-for-load-balancing-56b | nginx, docker, devops, cloud | Welcome back, in the [previous article](https://dev.to/paulafahmy/one-tap-deployments-with-nginx-and-docker-introduction-to-reverse-proxies-156c), we briefly introduced reverse proxies, and how we could use some of them, namely **Nginx**, to load balance our app, for an **easier scale-out and serving**. We also concluded the final architecture we'll be after as our final result:
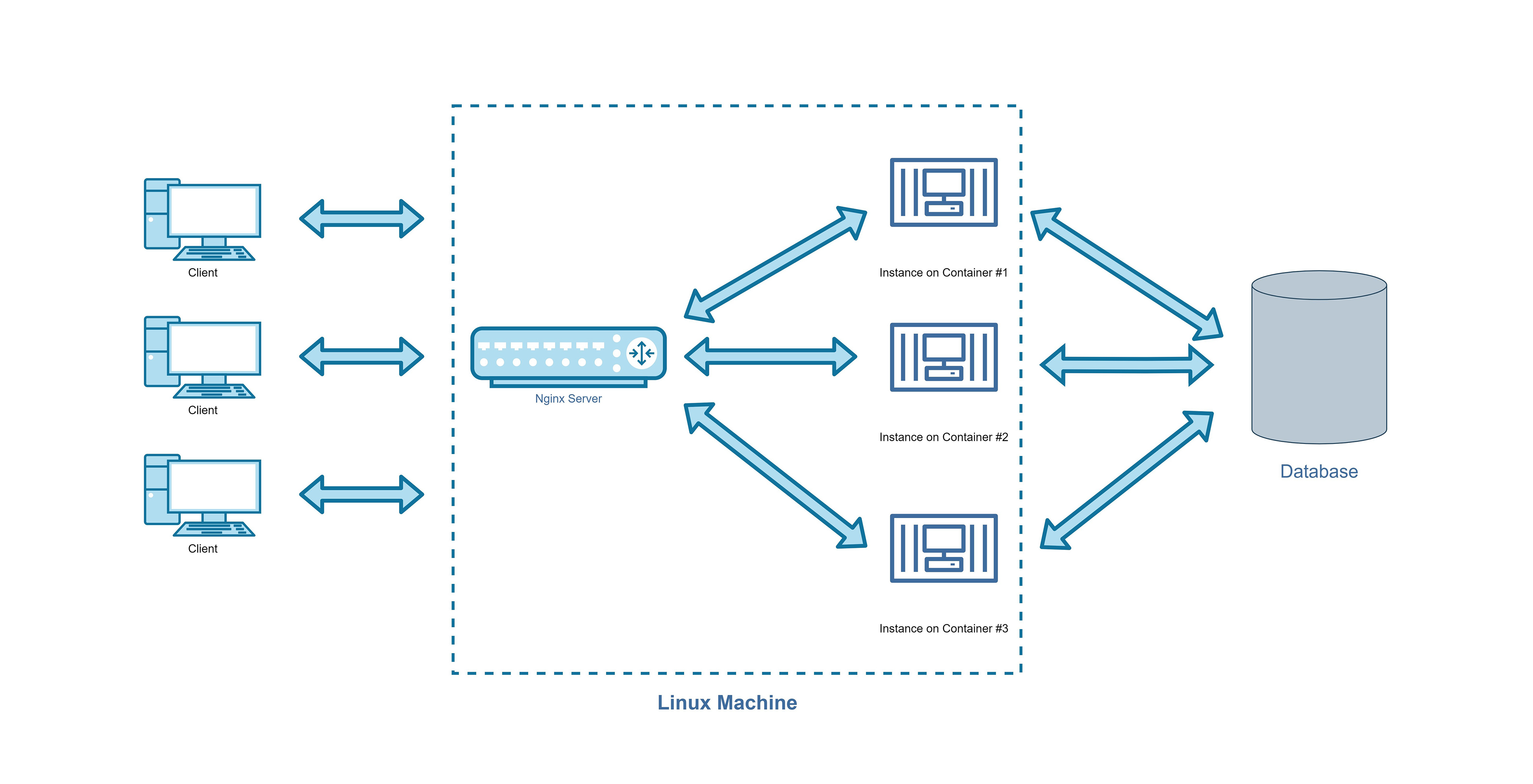
Today, we'll jump right into the basics of **Nginx**, so first up, make sure you have it installed on your machine.
Once you have it installed, we can navigate to the configuration folder where all the magic really happens. Start off by navigating to this path `/etc/nginx/` (if you're on Linux), you should be able to see an `nginx.conf` file, launch it using your favorite text editor, and let's have a look in there.
The file is not empty, and it has some default configurations already set, lets delete everything and start from scratch.
We will learn today **3 basic setups**:
1. Serving local files
2. Serving a hosted URL
3. Accessing multiple instances through **Load Balancing**
## Serving Local Files
The basic skeleton of a `nginx.conf` file should (in most scenarios) contain these two directives.
```nginx
http {
}
events {
}
```
We'll leave `events` empty for now and focus on the other directive, `http` which is where we'll be configuring **Nginx as an HTTP server**.
> Before we continue, note that we'll be stopping and starting Nginx multiple times whenever we apply changes to the `conf` file, so if Nginx is not already running, run it using `nginx` command.
> If it is already running and we need to restart it, we'll have to stop it using `nginx -s stop` command, and then start it once again using `nginx`.
> If you're on Linux make sure that you are running these commands in an elevated grant using `sudo`.
Let's add an HTTP server, which listens on port **`8080`**:
```nginx
http {
server {
listen 8080;
}
}
events { }
```
Save the file, restart Nginx and navigate to `localhost:8080`, you should be able to see the following welcome screen:
Nginx has pulled this static HTML file from a default path because we've not yet set any. We'll be setting one now, I created a simple HTML file called `index.html` in a folder called `Nginx_Article` on the Desktop:
```htmlembedded
<html>
<body>
CUSTOM NGINX PAGE, YAY!
</body>
</html>
```
Its full path should be **`/home/{myusername}/Desktop/Nginx_Article/`**, remember I'm using Linux, so this path might be a little bit different in your case, also don't forget to replace `{myusername}` with your account's username (without the curly braces of course).
Now let's configure Nginx to point to this web page when we hit port number `8080`:
```nginx
http {
server {
listen 8080;
root /home/{myusername}/Desktop/Nginx_Article/;
}
}
events { }
```
Restart Nginx and reload `localhost:8080`, and you should be able to see our `index.html` nicely served.
Now, let's go **a level higher**, what if we've got multiple directories that need to be served, not just a single root?
Easy,
```nginx
http {
server {
listen 8080;
location /images {
root /home/{myusername}/Desktop/Nginx_Article_Another_Directory/;
}
location /videos {
root /path/to/another/root/;
}
}
}
events { }
```
Here we used the `root` directive inside a `location` directive, this setup will ask Nginx to serve this directory: `/home/{myusername}/Desktop/Nginx_Article_Another_Directory/images` in case `localhost:8080/images` was requested.
Don't forget to create the directory on your machine, and maybe add some images to test requesting them.
**Important Note:** The directory `/images` should have an `index.html` file to be served by default **OR** you'll have to ask for a specific file, for example: `localhost:8080/images/cat.jpg`, and if no files are saved in `/images`, the previous request will return **forbidden status**.
Another way of path mapping is using the **`alias`** directive as below:
```nginx
http {
server {
listen 8080;
location /documents {
alias /home/{myusername}/Desktop/Nginx_Article_Another_Directory/top_secret;
}
}
}
events { }
```
The **alias** directive will ask Nginx to serve this directory: `home/{myusername}/Desktop/Nginx_Article_Another_Directory/top_secret` in case `localhost:8080/documents` was requested.
#### 🧾 Let's Summarize
1. In case of `alias` directory, we have to provide the full path to which Nginx was supposed to navigate, on the other hand, the `root` directory just had the root path of the directory, and the location value is to be appended to that path.
2. There is no actual directory named `/documents` inside `Nginx_Article_Another_Directory`, we are just creating an **"alias"** for the directory `/top_secret`.
## Serving a hosted URL
Let's say we're building a reverse proxy to **www.example.com**, we want users to view the site from our own domain, this could be done easily through the following configuration:
```nginx
http {
server {
listen 8080;
location / {
proxy_pass http://www.example.com/;
}
}
}
events { }
```
Try navigating to `localhost:8080` after restarting Nginx, you should be able to see the exact same page as that of example.com.
This could be used the same way when serving a locally hosted application (in our case, **the backend application**) that's accessible through port **`5000`**,
```nginx
http {
server {
listen 8080;
location / {
proxy_pass http://127.0.0.1:5000/;
}
}
}
events { }
```
## Accessing multiple instances through load balancing
For this use case, we are going to deploy a simple Hello World app, with minimal setup, all you'll need is a working Docker setup on your machine.
Head down to your favorite terminal app, and spin up 3 instances of the same app, each on its **own container**, we'll be using the **"helloworld" Docker Image**, which is exposed internally on port `80`, when requested, it will print the Id of the container for the response:
```console
foo@bar:~$ docker run -p 1111:80 -d strm/helloworld-http
478405720f2106d718edb1602812528ae53011cb196dc3731447c64d0bd8f2ff
foo@bar:~$ docker run -p 1112:80 -d strm/helloworld-http
a374ce45bf07b9747573e7feb1ae9742e72d2a31d74c2da3caa43abd5586a108
foo@bar:~$ docker run -p 1113:80 -d strm/helloworld-http
422efc18f418772cb96ea6088f2f801854ad4da21436da2c485f3ef80cca20ec
```
**Notice** that docker prints the ID of each container after each run command, also notice that we deployed 3 instances of the app, each accessible from outside its housing container through ports **`:1111`**, **`:1112`**, **`:1113`**. So for example, to navigate to the first instance of the app, you'll need to head to `localhost:1111`, and so on.
Now let's play with the `conf` file to set it up to balance an incoming load over our 3 instances.
```nginx
http {
upstream allinstances{
server 127.0.0.1:1111;
server 127.0.0.1:1112;
server 127.0.0.1:1113;
}
server {
listen 8080;
location / {
proxy_pass http://allinstances/;
}
}
}
events { }
```
Looks like we've added a new directive to our deck, `upstream`, where our `proxy_pass` now points at.
> `upstream` defines a cluster that you can proxy requests to. It's commonly used for defining a web server cluster for load balancing.
Basically, this tells Nginx to **[Round-Robin](https://en.wikipedia.org/wiki/Round-robin_scheduling)** each incoming request so that each server serves an equal number of requests. Each time you hit the refresh button, you are going to be greeted with a different server.
You could get creative with the location directive, maybe you'd want to split users down to two `proxy_passes`, so `/odd` would navigate to `1111` or `1113`, and `/even` would navigate to port `1112`.
What if your application is saving user data in memory? You'd then need to make a user's session "sticky" by hashing IP addresses of the users so that a given user is guaranteed to hit the same server as long as his IP address did not change:
```nginx
upstream allinstances{
ip_hash; # << Will hash the user's IP address and resolve to a single server
server 127.0.0.1:1111;
server 127.0.0.1:1112;
server 127.0.0.1:1113;
}
```
After adding the `ip_hash` command, no matter how much you refresh the page, you'll always be served by the same server.
I think you now have the basics that can get you up and going. In our [next article](https://dev.to/paulafahmy/one-tap-deployments-with-nginx-and-docker-serving-your-web-cluster-w-compose-29f6) we will be packaging the whole setup into containers (including Nginx) and deploying it through a single `docker-compose` command.
I'd like to end this one with a small but powerful quote by Oscar Wilde, **“Experience is the name everyone gives to their mistakes.”**
Keep up the good work 🚀. | paulafahmy |
798,823 | Testing Without Excuses | Every app has that last inch (or mile) of code that's not covered by tests. Usually it's an... | 0 | 2021-08-21T04:14:07 | https://dev.to/tonymet/testing-without-excuses-59p0 | tutorial, bash, testing, devops | Every app has that last inch (or mile) of code that's not covered by tests. Usually it's an interactive cycle of compile-run-inspect on the command line like
## You Test
```
curl -X POST https://reqbin.com/echo/post/json
```
##👀 You Expect:
```
{"success":"true"}
```
Despite having 3-4 testing frameworks for unit tests, e2e, regression etc-- there's always a gap where you find yourself re-playing commands in the terminal to test.
A common case is 🔥firefighting where ad-hoc tests are needed to validate an emergency config change or deployment.
Not only is this a waste of time, it's error prone and reduces the number of assertions per run.
With `Test::More`, you can easily run dozens of assertions in < 1 second. Moreover, you can run them in a loop with `watch perl test.t` (read to the end to find out)
## Close the Testing Gap with Perl
To close this Gap, you want a basic testing framework to easily test assertions on the command line: asserting expected output or return status (e.g. success == 0, failure >= 1)
Perl Test::More is an elegant solution:
- it has a trivial and easy-to-remember interface: `ok()`, `is()`, `isnt()`
- it easily tests shell scripts like `head myfile.txt` to test output, or `system grep needle < haystack` to test return code
- is universally available on every distro. No apt-get, npm-install, downloading, linking, compiling needed.
## Let's Get Started
```
use Test::More tests => 1; # or
# basic test of stdout
is(`echo -n "hello dev.to"`, "hello dev.to", "test echo")
```
The most basic `is()` test using actual backticks. First arg is the command, second arg is expected output, third is a test description.
### Testing Return Status Code Success
```
# test success status code = 0
is((system "echo hello dude | grep -q dude"), 0, "test output contains dude");
```
Similar to above, but use (system "COMMAND") to test the return status code instead of the output
### Test For Failure / Status code = 1
In this case, grep for "dude", assert that it fails (status=1)
```
# test failure status code = 1 (shift left by 8)
is((system "echo hello bob | grep -q dude"), 1<<8, "test output does not contain dude");
```
To test non-zero, bit-shift by 8 (read the docs for `system` to understand why)
### Test File Contents
```
# test reading a file
is(`head -n 1 /etc/passwd`, "root:x:0:0:root:/root:/bin/bash\n", 'top of passwd')
```
This pattern is useful, using head , tail or grep to test for file content. Works well for testing log output upon running a command.
### Testing APIs
```
# test curl output with special chars and newline
is(`curl -X POST https://reqbin.com/echo/post/json`,
<<WANT
{"success":"true"}
WANT
, "test post req");
```
Use "heredoc" (multi-line doc) to test special characters & newlines without needing lots of escapes.
### Run the Suite in the Background
```
use Test::More tests => 6; # or
# basic test of stdout
is(`echo -n "hello dev.to"`, "hello dev.to", "test echo");
# test success status code = 0
is((system "echo hello dude | grep -q dude"), 0, "test output contains dude");
# test failure status code = 1 (shift left by 8)
is((system "echo hello bob | grep -q dude"), 1<<8, "test output does not contain dude");
is((system "false"), 1<<8, "false not ok");
# test reading a file
is(`head -n 1 /etc/passwd`, "root:x:0:0:root:/root:/bin/bash\n", 'top of passwd');
# test curl output with special chars and newline
is(`curl -X POST https://reqbin.com/echo/post/json`,
<<WANT
{"success":"true"}
WANT
, "test post req");
```
Now you have a suite of 6 tests, open a second terminal and run it with `watch perl test.t`
```
Every 2.0s: perl test.t pi4plus: Sat Aug 21 05:09:50 2021
1..6
ok 1 - test echo
ok 2 - test output contains dude
ok 3 - test output does not contain dude
ok 4 - false not ok
ok 5 - top of passwd
ok 6 - test post req
```
With Perl shell tests running in a loop, you can focus on code changes and your terminal will ring if a test case breaks.
## Wrap Up
I hope this helps you close that last gap of code that's not tested. Even in the middle of a fire, you can copy-paste your tests into a `test.t` file within the terminal.
Read the Perl Docs for More Info on [Test::More](https://perldoc.perl.org/Test::More) & [system](https://perldoc.perl.org/functions/system)
| tonymet |
798,982 | Improved and Removed Features in Java | Important Changes and Information The deployment stack required for running applets and web... | 0 | 2021-08-21T09:17:17 | https://dev.to/coderlegi0n/improved-and-removed-features-in-java-50kl | Important Changes and Information
The deployment stack required for running applets and web applications has been removed from JDK which was deprecated in JDK 9.
Entire section of supported browsers has been removed from list of supported configurations due to unavailability of deployment stack.
Auto-update has been removed from JRE installations in Windows and MacOS.
JavaFX and Java Mission Control is now available as a separate download.
Java language translation for French, German, Italian, Korean, Portuguese (Brazilian), Spanish, and Swedish is no longer provided.
In this version, JRE or Server JRE is no longer offered. Only JDK is offered.
Updated packaging format for Windows has changed from tar.gz to .zip
Updated package format for macOS has changed from .app to .dmg.
Removed Features and Options
Removal of com.sun.awt.AWTUtilities Class
Removal of Lucida Fonts from Oracle JDK
Removal of appletviewer Launcher
Oracle JDK’s javax.imageio JPEG Plugin No Longer Supports Images with alpha
Removal of sun.misc.Unsafe.defineClass
Removal of Thread.destroy() and Thread.stop(Throwable) Methods
Removal of sun.nio.ch.disableSystemWideOverlappingFileLockCheck Property
Removal of sun.locale.formatasdefault Property
Removal of JVM-MANAGEMENT-MIB.mib
Removal of SNMP Agent
Removal of Java Deployment Technologies
Removal of JMC from the Oracle JDK
Removal of JavaFX from the Oracle JDK
JEP 320 Remove the Java EE and CORBA Modules. | coderlegi0n | |
800,286 | Common Array Methods in Javascript | Wether you are building the new facebook or studying for that next technical interview, you are going... | 0 | 2021-08-23T03:08:25 | https://dev.to/turpp/common-array-methods-in-javascript-9p8 | javascript, beginners | Wether you are building the new facebook or studying for that next technical interview, you are going to be working with arrays. In Javascript and Array is an object that stores multiple values to a single variable. This data structure can be manipulated in many different ways with array methods. There are tons of array methods built into Javascript. In this article I’ll go over some very common methods and let you know what they look like and what they do!
###unshift()
`unshift()` will add elements to the beginning of the array. This method modifies the original array and will return the length of the array after adding the element.
```javascript
let numbers = [2,3,4,5,6]
numbers.unshift(1) //returns 6
numbers == [1,2,3,4,5,6]
```
###pop()
`pop()` will remove the last element of an array. This methods return value is the last element that it just removed. IMPORTANT: This will change the original array.
```javascript
let dogs = ["Ada", "Taz"]
dogs.pop() //returns "Taz"
dogs == ["Ada"] //true
```
###forEach()
`forEach()` will iterate through the entire array and pass the element into a function where you can then do some logic. This methods return is dependent on what is inside of the function that the elements are being passed to.
```javascript
let dogs = ["Ada", "Taz"]
dogs.forEach(dog => {
console.log(`Who is a good dog? ${dog} is!`);
}
```
###join()
`join()` will take all the elements of an array and make them a string. This string will have all the elements separated by a comma. This method will return a string and will not modify the original array.
```javascript
let smallNumbers = [1,2,3,4,5,6,20]
smallNumbers.join() // returns “1,2,3,4,5,6,20”
```
###map()
`map()` is very similar to the forEach(). They both iterate through an array but `map()` will create and return a new array. This new array will be made based on the logic you pass inside of the function. This does not modify the original array.
```javascript
let numbers = [2,4,6,8]
numbers.map(num => num * 2)
//returns [4,8,12,16]
```
###filter()
`filter()` creates a new array with elements of the original array that pass a test. This method returns a new array and does not alter the original array.
```javascript
let smallNumbers = [1,2,3,4,5,6,20]
smallNumbers.filter(num => num < 10); //returns [1,2,3,4,5,6]
```
###concat()
`concat()` is used to join two or more arrays. This method will return a copy of the joined arrays. This way you don’t have to worry about changing the original arrays.
```javascript
let dogs = ["Ada", "Taz"]
let owners = ["Tripp", "Melissa"]
let dogsAndOwners = dogs.concat(owners)
```
###every()
`every()` will check to see if all the elements pass a certain test. If all elements pass the test it will return true. If even on element fails the test then it will return false. This does not modify the original array. It just returns a boolean value based on your test.
```javascript
let smallNumbers = [1,2,3,4,5,6,20]
smallNumbers.every(num => num < 10); //returns false since 20 is larger than 10
```
###find()
`find()` will look for the first element in the array that passes a condition. Its important to remember that if there are more than one match in the test array that it will only return the first match. If this method finds a match it will return true and stop. If it finds no match it will return undefined.
```javascript
let smallNumbers = [1,20,3,4,5,6,20]
smallNumbers.filter(num => num > 10); //returns 20. To be specific it returns the second element since it is the first to pass the conditional.
```
###includes()
`includes()` will look in the array for a specific element that you tell it to. If it finds the element it will return true if it does not find the element it will return false. It is important to remember that this is case sensitive.
```javascript
let dogs = ["Ada", "Taz"]
dogs.includes("snoopy") //returns false
dogs.includes("ada") //returns false since "ada" is lower case and its capitalized in the array
dogs.includes("Taz") //returns true
```
###reduce()
`reduce()` can be a tricky method to get down but it is so useful in the right situations. This method will iterate through the entire array and return a single value that is the accumulated result of all the elements being passed through the reducer function. This will perform logic on one element and remember the results and then use that results on the next element in the array. You can also set the default value that the reducer will start. It defaults to 0 but if you prefer to start you calculations at 100 you can. This does not change the original array.
```javascript
let numbers = [1,2,3]
let reducer = (accumulator, currentValue) => accumulator + currentValue
numbers.reduce(reducer) //returns 6
numbers.reduce(reducer, 100) //returns 106
```
###reverse()
`reverse()` will reverse the order of the array. This will modify the original array.
```javascript
let dogs = ["Ada", "Taz"]
dogs.reverse() //returns ["Taz", "Ada"]
```
###shift()
`shift()` will remove the first element of an array and will return the element it removed. This method does change the original array.
```javascript
let dogs = ["Ada", "Taz"]
dogs.shift() //returns ["Ada"]
dogs == ["Taz"]
```
###slice()
`slice()` will return a selection of elements in the array as a new array. You can be very creative with this method to get the section of the method you want. This method requires a start argument and and end argument. The end argument you pass is where you want it to stop, but it does not include that number. The start and stop locations are based off the array index. Its easy to forget this. This does not change the original array.
```javascript
let number = [1,2,3,4,5,6]
number.slice(1,4) // returns [2,3,4]
```
###sort()
`sort()` will modify the original array and sort it. This is great to use if you want to sort and array of strings. It will default to sorting it alphabetically. You can also sort numbers and it will default to sorting in ascending order.
```javascript
let dogs = ["Taz", "Ada"]
let numbers = [1,3,2,4,6,5]
dogs.sort() //returns ["Ada", "Taz"]
numbers.sort() //returns [1,2,3,4,5,6]
```
###splice()
`splice()` adds and removes elements from the array. This method requires an index to start at. It also takes an argument for how many you would like to remove and the new element(s) you want to add. Basically you tell it what element to start if/how many elements you want to remove and then the elements in the order that you want to add in that place. This changes the original array. It will return the removed elements.
```javascript
let numbers = [1,3,4,5,6]
//splice(start, deleteCount, item1ToAdd, item2toAdd, etc);
numbers.splice(1,0,2) //returns [ ] because it did not remove anything
numbers == [1,2,3,4,5,6]
```
I hope you found this list of methods helpful. Bookmark this page and use it as a quick reference as you learn these methods and become an expert JavaScript programmer! | turpp |
798,994 | Can you succeed as a remote junior developer? | Working remote has traditionally been seen as a nice goal to attain at some point during a developer... | 0 | 2021-08-21T10:01:52 | https://careerswitchtocoding.com/blog/can-you-succeed-as-a-remote-junior-developer | career, webdev, beginners, codenewbie | Working remote has traditionally been seen as a nice goal to attain at some point during a developer career. Once you are confident and trusted by your company then hopefully they allow you to work from home, or better yet you join a fully remote team and live that true digital lifestyle.
To do that as a junior? For your first role? Impossible .... until COVID poured lighter fluid on the digital transformation that businesses have been laggardly working through over the past 25 years. Now everyone is remote, including junior developers, a role that actually really benefits from in person work.
So, how do you succeed in this new world being a remote junior developer? If you think back to my post [Expectations on Junior Developers are Not What You Think](https://careerswitchtocoding.com/blog/expectations-on-junior-developers-are-not-what-you-think) you will understand that you're not expected to be a genius cranking out amazing code from the get go. In fact the expectation is often that your coding ability will be pretty low. It will be expected you can code simple solutions to simple isolated problems but after that your main priorities are to:
- That you will listen and learn
- That you will help where you can
- You are keen no matter the technology
Let's form a strategy to make sure you crush these goals and also make the most of your time as a junior.
## Communication
Your team would rather hear from you on a regular basis than wonder what you're doing and have to come asking. We are taught from a young age though to not interrupt, you need to forget this. In remote work you will always feel like you are interrupting someone, because you likely are! You don't know what they are doing when you message or call them and you'll need to get comfortable with this otherwise you'll sit and stew on a problem for hours longer than you should.
So people know what you're up to you give very short status updates in the team group channel or if you have found something interesting in the last half a day then pop it as well. If you get your first ticket done then mention it in that same channel, also ask for code review at the same time. Basically tell people what you're up to.
This might seem overly communicative but it makes up for the chit chat in the kitchen or overheard conversations when in the office. When you share an office with people it's impossible to not get an idea of what everyone is doing and how they are getting on, that is all stripped away in remote work so replicating that with little messages here and there brings the context back in.
## Inquisitive
You're going to be left to your own devices much more than in person working, so go exploring. You should have access to the company wiki (if not, ask for it) from day one. Spending time at the end of each day looking through it and asking a couple of questions will broaden your knowledge very quickly and get you used to reading documentation.
Go spelunking through the database. Run some select queries or browse throughs some documents by yourself. Data drives all applications and knowing what your company's data looks like, where it lives and how's its structured will enable you to form great questions when the time comes.
If you see something interesting then ask about it in the group chat. Even if you feel stupid asking the question it doesn't matter, it's all about learning and gathering information. Get into the mindset that you would rather look stupid than actually be stupid.
In fact say this to your team, tell them you may ask a lot of questions but it's because you want to learn and be as helpful as possible as soon as possible. So long as you are [asking good questions](https://careerswitchtocoding.com/blog/10-must-follow-rules-for-asking-coding-questions) they wont' mind.
## Openness
Be open about your skill level, what you find challenging, what you find straight forward and what you have worked with before. Pretending you know something when you don't is a quick way to loose the trust of your team and start to feel isolated. In daily stand up talk about what you have accomplished but also what is holding you back, where you struggled and ask for suggestions on where to look to improve.
It is much easier in person for people to pick up the body language and vocal queues that you might not fully understand something and so you can be saved the embarrassment of outright saying you're confused. So you need to be proactive and clear in what you get and don't get.
## Journalling
I'm not a big one for keeping a daily journal about my feelings, however I am a big proponent of keeping a daily work journal about what I did, what problems I had, how I solved them and any interesting things I learned. It doesn't need to be anything fancy, mine is just a new notion page for each day in "YYYY-MM-DD DayName" format and a list of bullet points, screenshots, links and code snippets that I can refer back to.
This is to solidify your learning and give you something to go back to in the future when you remember something you once looked at but aren't quite sure. I also keep a note of the Jira tickets I work on each day to help when searching.
## Barriers
Working remotely adds a barrier that none of us can get round, even sitting on an open Skype call when working all day (which I personally hate) can't make up for being in the same office as the rest of your team. Once you are settled in your career this is just another one of those minor work inconveniences that you navigate and handle, but as a junior this barrier can exacerbate all the fear and anxieties you have.
So be pro-active about reducing the impact of that barrier. Be a bit more interactive on Slack than you might otherwise like, be clear and open about what you are doing, ask questions that come off the back of your own research on the code base and find out what other developers are working on. | allthecode |
799,008 | Create Your Own Token! | Developcoins | Introduction Imagine a world where you can send money directly to someone without a bank &... | 0 | 2021-08-21T10:52:08 | https://dev.to/hasaragk/create-your-own-token-developcoins-cdp | blockchain, token, cryptocurrency | Introduction
Imagine a world where you can send money directly to someone without a bank & transaction fees it is possible only via Blockchain Technology. Position your business for growth with the future of digital transactions via Blockchain. Each token belongs to a blockchain address.It’s secure platform.
This trust is built on blockchain’s enhanced security, greater transparency, and instant traceability. Beyond matters of trust, blockchain delivers even more business benefits, including the cost savings from increased speed, efficiency, and automation.
What is Blockchain token?
A token addresses a bunch of rules encoded in a smart contract. Every token has a place with a blockchain address. It's a computerized resource that is put away safely on the blockchain. Tokens can be used for investment purposes, to store value, or to make purchases.
Tokens are frequently referred to be digital currencies like Bitcoin or Ether tokens.
How it works ,
A token is a cryptographically secure line of information or data. Tokens are created on an existing blockchain.
Tokens work on a blockchain to work with exchanges for creating decentralize applications and execute brilliant agreements. tokens are appropriated in standard ICO Process.
Make your token on top blockchain stages and raise assets as individuals put resources into your token. Or then again, make a non-fungible symbolic commercial center where crypto devotees can purchase and sell their NFTs.
Types of Tokens
●Security/Equity Tokens
●Reward Tokens
●Utility Tokens
●Asset Tokens
●Currency Tokens
Token Development Solutions
If you are looking for token development solutions then you are in the right place, Developcoins is a top-notch token development company that offers complete token development solutions based on clinet requirements. Our pool of blockchain developers who create a token on top of the blockchain platforms like Ethereum, Tron, Binance Smart chain etc
●Ethereum Token Development
●Tron Token Development
●BEP20 Token Development
●Mintable Token Development
●Non-Fungible Token (NFT) Development
●Decentralized Non- Fungible Token (DNFT) Development
●DNFT Development Services Company
●Semi Fungible Token (SFT) Development
●SFT Development Services Company
●Token Generator Platform Development
We used different types of Platform, such us
●IDO Platform Development
●ICO Platform Development
●Banking and financial services
●IEO Platform Development
●STO Platform Development
Industries Leveraging Token Development Services,
Healthcare
Media and entertainment
Retail and consumer goods
Ecommerce
Gaming
Telecommunications
Travel and transportation
Digital Records
Automotive
Supply chain
Why choose Developcoins for Token Development?
Developcoins is one of the best Token Development company and provides different types solutions . Our team delivere the project on time. Our experts of blockchain designers assists with fostering your own token on the highest point of the blockchain stage like Ethereum, Tron, EOS, Binance Smart Chain, Matic, Ripple and that's just the beginning.
We provides,
●Technical support
●Skillful blockchain developers
●Multiple token standards
●Increased security
●Quality assessment
●ICO launch
Create Your Own Token Now! -- https://www.developcoins.com/custom-altcoin-creation#create-your-own-token
Visit : https://www.developcoins.com/token-development
Book A Free Consultation via #Call/Whatsapp: +91 9843555651 Telegram - https://t.me/Developcoin
| hasaragk |
799,160 | Building a responsive, horizontal photo grid | When I set to build a webpage for my photography, laying out the photos in a grid was the biggest... | 0 | 2021-08-21T16:20:00 | https://dev.to/lucianbc/building-a-responsive-horizontal-photo-grid-14kn | javascript, gatsby, react | When I set to build a webpage for my photography, laying out the photos in a grid was the biggest challenge. It turns out displaying photos of different aspect ratios in a grid is not that simple and there are a few trade-offs that have to be made. In this post, I describe the way I implemented such a layout. To see the result, check out my [photography page](https://photos.lucianbc.com/).
## Problem description
We want to display multiple photos in something similar to feed, with multiple photos per row. We also want this grid to be responsive, meaning that on wider devices it shows multiple photos, while on mobile phones it shows one or a maximum of two photos per row. The photos should have some space between them, let's say 10 pixels.
As for the layout, we want the photos to be displayed in something that could be called a staggered horizontal grid, meaning a variable number of photos per row. I like how this layout creates a brick-wall pattern, accomodating both landscape and portrait photos and keeping straight rows and a left-to-right focus. However, making this layout responsive, fast and with no javascript at runtime required a few tricks.
_Horizontal Staggered Grid_
## Implementation details
This layout was popularised by apps such as [flickr](https://www.flickr.com/search/?text=landscape) and [500px](https://500px.com/search?q=landscape&type=photos&sort=relevance). Flicker open-sourced their algorithm for creating the photo grid on their website and wrote a blog post about it [here](https://code.flickr.net/2016/04/05/our-justified-layout-goes-open-source/). I based my solution on their algorithm, but I won't go into details of how it works. Their observation was that you can't build a photo grid with a consistent row height, while also accomodating a collection of photos with arbitrary aspect ratios and in an arbitrary order. However, you don't need consistent row heights for the layout to look good, and laying out photos one by one, deciding whether to add the current photo to the last row or create a new one leads to a good enough solution.
Simply using this algorithm and also having the layout being responsive requires running it on every window resize. It also has the typical problem with client-side rendering - displaying the photos only after the initial page renders and having to support an initial, empty state. I wanted my page to be fast and server-side rendered.
### Pre-rendering layouts
To get past the initial load issue, I figured out I can run the Flickr algorithm at build time. Moreover, to make the layout responsive, I can create multiple configurations for the Flickr algorithm, one for each media query that I want to support. These configurations specify a layout width and the desired height and yield an array of boxes with absolute values (in pixels) for the width and height of each photo in my collection. To make the photos resizable, I can divide the width of each box to the container width how much per cent of the full width each photo should take. Then I render each photo in a `flexbox` container and with the `flex: 0 0 ${box.widthPercent}` CSS property. I used [gatsby](https://www.gatsbyjs.com/) to build my page, which allowed me to use react and [styled-components](https://styled-components.com/) to interpolate the javascript-computed `box.widthPercent` into CSS media-queries and have all of this logic run at built time. The simplified code that implements what is described above:
```js
// import the Flickr algorithm
import layout from "justified-layout";
const breakPoints = [
// media query is null for the default style
{ mediaQuery: null, containerWidth: 400 },
{ mediaQuery: 568, containerWidth: 600 },
// add more if needed
];
const PhotoGrid = ({ photos }) => {
const ratios = photos.map((photo) => photo.aspectRatio);
const layouts = breakPoints.map((breakPoint) => ({
breakPoint,
layout: layout(ratios, {
boxSpacing: 0,
containerPadding: 0,
containerWidth: breakPoint.containerWidth,
}),
}));
const getRatiosAndBreakpointsForPhoto = (photoIndex) => {
// returns an array containing the media query and the width percentage the photo should take on that media query
// example: [{ mediaQuery: null, ratio: 0.3 }, { mediaQuery: null, ratio: 0.8 }]
return layouts.map((layout) => ({
mediaQuery: layout.breakPoint.mediaQuery,
ratio:
(layout.boxes[photoIndex].width / layout.breakPoint.containerWidth) *
100,
}));
};
return (
<div style={{ display: "flex", flexWrap: "wrap" }}>
{photos.map((photo, index) => {
<PhotoBox responsiveRatios={getRatiosAndBreakpointsForPhoto(index)}>
<ImageComponent photo={photo} />
</PhotoBox>;
})}
</div>
);
};
const flexCssValue = (photoBreakPoint) =>
photoBreakPoint.mediaQuery === null
? `flex: 0 0 ${photoBreakPoint.ratio}%;`
: `@media (min-width: ${photoBreakPoint.breakpoint}px) {
flex: 0 0 ${photoBreakPoint.ratio}%;
}`;
const PhotoBox = styled`
${(props) => {
return props.responsiveRatios.map((r) => flexCssValue(r)).join("\n");
}}
`;
```
Note that the media queries are written mobile-first, meaning the default, non `@media` annotated flex value is the one that should be rendered on a mobile device. To give the default configuration in our `breakPoints` array, we simply set it to null. As an interesting observation, `styled-components` allows injecting javascript values into the resulting stylesheet at build time. This is supported by the `gatsby-plugin-styled-components` plugin. Make sure to check the [official guide](https://www.gatsbyjs.com/docs/how-to/styling/styled-components/) to get styled-components in gatsby. The `ImageComponent` is not implemented - it could be as basic as an `<img style={{width: '100%}} />` tag.
In this way, we pushed computing the actual image size to the browser's CSS engine rather than us reacting to viewport changes. The media queries enable us to switch the layout based on the viewport size.
### Gap between photos
Adding a gap between photos will require a new tradeoff with the above approach. The Flickr justified layout algorithm can be configured with the `boxSpacing` and `containerPadding` properties and they work great when running the algorithm with the actual `containerWidth`. However, the above approach picks a handful of reference container widths and renders the in-between widths as percentages based on these references. If we keep the spacing fixed and increase the actual container width to be bigger than the active reference width, the photos on any giver row will grow by a different factor because the spacing stays fixed. Moreover, given that the photos have different aspect ratios, the heights will go out of sync and small misalignments will appear. I won't include the math because it's quite boring.
To fix this issue, a slight crop is introduced. We compute the layout as though there is no padding and let the `PhotoBox`es fill the rows with no spacing. Then, in CSS, we make them `box-sizing: border-box` and add some padding. For a spacing of `10px`, we add to each box a padding of `5px`. Then, to not stretch the image in weird ways and to also keep the gaps consistent, we set the `object-fit: cover` CSS property on the image. You can read more about it [here](https://developer.mozilla.org/en-US/docs/Web/CSS/object-fit), but long story short, it sizes up the image to fill the container and clips whatever is out of the bounds of the container. This approach paired with granular enough media queries ensures that whenever a layout will require too much of a crop from the photos, photos will be added or removed from each row to keep them looking good.
## Conclusion
This was my approach to displaying a pre-rendered, vertical staggered photo grid. I am content with its trade-offs and technical complexity. There is probably a way to achieve this with pure CSS and no cropping and I've read a guide to such an implementation [here](https://github.com/xieranmaya/blog/issues/6). I will probably dive deeper into this at some later point, but in the meantime, I'm focusing on further developing my photos webpage. I will document here any other interesting challenge I might find.
| lucianbc |
799,164 | 8 examples to show Customer Obsession as a Software Engineer | Customer Obsession is manifested in many of the career ladders of the top technology companies. But... | 0 | 2021-08-21T15:41:46 | https://getworkrecognized.com/blog/customer-obsession-examples-software-engineer | career, growth, promotion, programming | Customer Obsession is manifested in many of the career ladders of the top technology companies. But why is that and how can you, as a Software Engineer, show this principle right now at your current job?
## What is Customer Obsession?
Customer obsession is a principle that describes your effort to make your customer happy. It can be applied to almost all positions in a world where you are working on problems that not only you have. This goes from end-customer-facing roles to internal roles where your customer is another employee.
To make your customer happy there are different methods you can apply to make it work. The most important one is to know what your customer wants and for that, you have to be able to put yourself into the customer’s perspective and try out the work you have been doing from that perspective. See where you can improve things and be proactive with your actions to make the customer love your work.
## Who is using Customer Obsession as a Leadership Principle?
The biggest technology companies are actively using this principle:
- [Amazon](https://getworkrecognized.com/tools/career-ladders-explorer/amazon-2020)
- [Klarna](https://getworkrecognized.com/tools/career-ladders-explorer/klarna-2020)
- [GitHub](https://getworkrecognized.com/tools/career-ladders-explorer/github-2020)
- [And Many more](https://getworkrecognized.com/tools/career-ladders-explorer)
[](https://getworkrecognized.com/login?utm_source=blog&utm_medium=devto&utm_campaign=customer-obsession-examples-software-engineer)
A lot of companies have made this principle a core principle of them, and that has a reason. Within the last 10 to 20 years our software was getting closer and closer to the end customer. Everyone has experience with top-notch experiences provided by big apps like Instagram, Facebook, TikTok, or Uber to name a few. They just work, as expected, and without any problems. Why? Because the customer loves them.
So let us jump into the examples.
## Examples you can do to show customer obsession
Practicing customer obsession is difficult on day to day basis as a software engineer. This is because they do not have everyday contact with the customers of the product they create. But there are many indirect touchpoints, you can have. Let us discover them!
### Supporting the customer when needed
Ever got asked a question by your support or salesperson in the company about a customer problem? This is a big opportunity to show customer obsession. Try to understand the salesperson or the support person first. Listen. And ask a lot of questions. And also if possible get to the direct words of the customer. Once you have gathered enough information you can answer questions quite easily, but get the whole picture first.

In bigger companies, you are mostly shielded away from direct customer feedback, and your product owner will probably talk to you regarding the "customer’s" problems. Make sure that the data backs this up, and that this is something the customer wanted.
## Seek to understand the customer
In the example presented before you could see already that you should be able to understand the customer by listening to third parties like someone in the company. But now let us go one step further. Someone in the company will have calls with customers from time to time. Ask them to join from time to time. Maybe once per month for an hour will work out. But this will be a worthwhile hour, you will learn a lot. And in these sessions, take notes of what the customer wants, how they think, and how you could affect them with your work.
## Think ahead, exceed customer’s expectation
Features and bugs are normally driven by the customer. A customer wants something to be done in your company’s product or found a mistake blocking their workflow in one way or another. The special skill to have now is to think more ahead, especially for features. The customer requests a feature, but the problem might be that the customer wants to achieve a lot more than they requested. To solve this, you need to think like the customer and think what are the next steps for this feature. Is there a relation or can it be made easier? For example, if you do frontend development it would be a simple idea to count the clicks till a customer will achieve what they wanted. Is there a way to reduce the clicks for the customer by prefilling fields in a clever way like they have used it last time, or based on other suggestions? Or when it is a backend problem, [you can put extra focus on error messages and guide the customer to a solution](https://uxplanet.org/how-to-write-good-error-messages-858e4551cd4) or what they should have done instead. Most errors are simply describing only the state, good errors will give hints what the customer should do instead.
## Put yourself into the customer’s shoes
As we have learned in the last examples you will have to get a feeling of how the customer is seeing your product. This is difficult:
> _If there is any secret of success, it lies in the ability to get the other person's point of view and see things from that person's angle as well as from your own._ - Henry Ford
But no problem, you can learn it. Listen to the customers and use your product. Write down the smallest things that are problematic for you. Wrong colors, wrong behavior, and whatnot. You will get a feeling of what the customer "could" feel. Not all humans, and also not all customers, are equal. Some see one thing as a problem but others look at different problems. Try to understand each perspective. It will be golden for your whole career.
## Find Problems within your product
As we mentioned before, finding problems and barriers in your product is worthwhile. From now on simply spend 1 hour with your product every week where you write down annoyances when you are using it. Gather these thoughts and present them to your product owner or create tickets for these problems.
## Find data to understand customer satisfaction and loyalty
A problem most companies have with customer obsession is that it is not measured. Most companies just have abstract KPIs like revenue or user numbers. But what impacts the customer obsession is probably two metrics:
- Customer Churn
- Customer Satisfaction
Both can be measured. Customer churn is easy to measure but customer satisfaction is difficult. For this, you could work together with your product owner to [send out surveys to the users](https://www.hotjar.com/blog/customer-satisfaction-survey/) of your product every month. If response rates are low, invite them to an "interview". People love being interviewed instead of being just a data point. But work on getting these metrics and make sure the company is using them for product development.
## Create documentation for your customer
Earlier we mentioned that customers ask questions and have demands. A problem is mostly that customers are not dumb but cannot find the answer they are looking for. This can be a user experience problem but also simply because there is no content. So what can you do? It’s easy, write documentation and guides on how your product can be used. For example, if you get asked a question twice by internal teams, write that question down in a FAQ and share it with your team and company peers.
If it is external even write some documentation for them. Most of the time something is better than nothing. A big point should be made that documentation is hard to write. A good guide can be found here though: [The documentation system](https://documentation.divio.com/). Read through this guide and make it a goal to write down questions in a FAQ and provide documentation.
## Look at competitors how they make the customer happy
> _Good artists copy, great artists steal._ - Pablo Picasso
With that quote, it becomes clear that it is fine to look at other customers and how they show customer obsession. For example, just simply look at competitor’s documentation and write down why it is better to use them instead of your company’s product. The same can be applied to everything else, like how APIs are designed, how many clicks you need to get to the result the customer wanted, or when your customer is an internal person, how you present them with a solution that should be of high quality. So spy on your area of work on how competitors are doing, what they might do better, and what you can improve for your customers. Copy the good parts.
## Understand what customer problems might appear in the future
Outlook is a big part of the higher you want to climb the career ladder. Employees that can establish a vision on behalf of the customer are golden. Based on KPIs and data from existing customers it should be clear already what is needed in the future. Formalizing this data and bringing the company or even team on the right track is important. Especially when it is about revenue and how the product could generate more profits for the company. Have a look at customer support requests and other data and see if you are observing trends in the whole industry that could be a business opportunity, whether it will be a completely new product or just a new feature. But with enough data, you can present it to your product owner to get validation and lead a project that will be successful. But more importantly, you will tackle the problems of customers that they mostly do not even recognize yet.
[](https://getworkrecognized.com/login?utm_source=blog&utm_medium=devto&utm_campaign=customer-obsession-examples-software-engineer)
## Conclusion
We hope we could give you some ideas on what you can do as a software engineer to do when you want or need to show more customer obsession. After all, there are many more examples of how you can show customer obsession. If you want to have a free lifetime license, feel free to reach out to us with an example of how you showed customer obsession at your job.
| igeligel |
799,322 | Diving into tech with HNG Internship | Joining tech has always been one of my goals, and hng internship has presented that opportunity to... | 0 | 2021-08-21T19:00:40 | https://dev.to/jennyferbernard/diving-into-tech-with-hng-internship-52fd | Joining tech has always been one of my goals, and [hng internship](https://internship.zuri.team) has presented that opportunity to me, I will be joining [the internship](https://zuri.team) so that I can diversify my knowledge and network with other developers and build interesting applications. My goal for this internship is to gain as much knowledge as I can about new technologies, tech stacks, programming languages and possibly be a finalist at the internship. I was unfortunate not to be a part of [zuri training](https://zuri.team) which will have given me a little experience on what the [intership](https://zuri.team) will bring, but I'm optimistic that I will do great in this [internship](https://zuri.team).
So far I was able to gain some ground with tutorials I found over the internet, so if you will like to know more about frontend development, here are tutorials that helped me.
[Ui/Ux Design](https://www.youtube.com/watch?v=4W4LvJnNegA)
[Version control "git"](https://www.youtube.com/watch?v=SWYqp7iY_Tc)
[Html](https://www.youtube.com/watch?v=UB1O30fR-EE)
[Javascript](https://www.youtube.com/watch?v=hdI2bqOjy3c) | jennyferbernard | |
799,330 | Mytemplate.xyz | A no-code personal website builder for developers | A No-Code developer website builder side project created with ReScript. Why the... | 0 | 2021-08-21T19:43:42 | https://dev.to/bodhish/mytemplate-xyz-a-no-code-personal-website-builder-for-developers-52p7 | opensource, tailwindcss, react, nocode | A No-Code developer website builder side project created with ReScript.
# Why the builder?

Its super hard to find time updating a personal website. I wanted a simple flow with which I could take out that pain. The editor tries to make the personal website management simple with features like display blogs from Dev.to and projects from Github
## Hosting with Github
Once you are done with editing click the download button. Commit the 'index.html' file that you downloaded to your github repository. Open Github setting and enable 'Github Pages'. Set source as your 'main' branch and folder as root. Commit the '_redirects' file to your repo. Your site will be live in few minutes. [_redirects file](https://github.com/bodhish/bodhish.github.io/blob/master/_redirects), [Watch Video](https://vimeo.com/520421685)
## Hosting with Netlify
Once you are done with editing click the download button. Commit the `index.html` file that you downloaded to your github repository. Open Netlify and click 'New site from Git' button. Choose your repository from Github and click 'deploy site'. Add `netlify.toml` file to your repo if you have added a blog. [netlify.toml](https://github.com/bodhish/bodhish.github.io/blob/master/netlify.toml)
## How to use import?
You can easly import the index file exported from mytemplate. Click the import button on the top right corner of this page. Enter your Github repositor in the required format and press the check icon on the import tab. This will import the file from Github, once the import is complete you can click the 'Open in Editor' button to complete import. [Watch Video](https://vimeo.com/520424952)
## Tech Stack?
The editor is created with ReasonReact(Rescript) and TailwindCSS.
## Where to report Bugs?
Create a issue with details of the bug in [mytemplate repo](https://github.com/bodhish/mytemplate.xyz/)
Examples
- [bodhish.in](bodhish.in)

- [gigin.dev](gigin.dev)
| bodhish |
799,592 | Lessons I wish I knew when I started dealing with clients as a Dev Solutions Architect | Back in 2019, I was employed as an Infrastructure Engineer in an e-commerce company. Our work was... | 0 | 2021-10-17T11:26:45 | https://dev.to/awscommunity-asean/lessons-i-wish-i-knew-when-i-started-dealing-with-clients-as-a-dev-solutions-architect-4fi6 | career, startup, softskills, devops | Back in 2019, I was employed as an Infrastructure Engineer in an e-commerce company. Our work was focused mainly on making features our business team believed would drive the most revenue. In a way, our clients were the business team. Working with them for a long time, our interactions became more predictable. As a technical person, this was ideal for me because I could focus on the code.
In 2020, I moved to eCloudValley, a tech consultancy that specializes in AWS. I am now the Team Lead for the Cloud Native Development Team. Aside from developing cloud-native applications, I also meet with clients and create proposals.
Coming from my previous job, this was all very new to me. At one point, I was meeting with three different companies in a week. In the first few months of the new role, this part of the job was mostly a hit or miss for me. Sometimes, the meeting goes well; sometimes, it goes south.

But as I gained more experience, I learned a few things that can help boost my chances of landing that deal:
## (1) It's about your customer and their problem. Listen first.
As a dev, I often get excited when I hear a problem. I almost couldn't contain myself—my head races to the solution. When I first started as an SA, I often interrupted the customer to:
- ask a follow-up question even before they finish talking
- gave a solution early that would have changed had I heard the full context

When meeting a client for the first time, introduce yourself and your company briefly. Then, start asking the customer about their pain points. During this time, listen, take notes, and ask follow-up questions. This time is about the customer. You can suggest high-level solutions, but only as a way to scope out the problem. The more detailed bits should be saved for a later meeting.
## (2) First impressions are essential. Prove your credibility without being a hard sell.
When a customer gets the service of a consultancy partner (like the one I'm working for), they would usually dish out lots of hard-earned cash. And of course, they'd want to spend it on someone who they can rely on. The first 10-15 minutes of your interactions set the entire tone of your relationship (at least until the deal gets signed).
Build your credibility. Before the meeting, study what business and industry the customer is in. Take a look at the LinkedIn of the people you are meeting. Do you have common industries or companies that you both worked in before? Or maybe know someone in those companies they worked in.
Customers also don't like to be the guinea pig for things. They want someone who's tried and tested, and ideally some who has solved problems for a company similar to theirs. Casually telling them about parallel experience you had would reassure them that you know what you are doing, since this is not your first time doing this. It also shows they can rely on you.
## (3) People love to work with people they like. Find ways to "click" with the customer.
This took me a while to get. For some clients, we would be laughing like old friends in the initial meeting. It would be very formal for some, and we both couldn't wait for our allocated hour to end so we could get on with our days. While I haven't fully cracked the formula yet, here are some things I have tried (or seen others tried):
- Mention people whom you that they might have worked.
- Occasionally, share anecdotes from your own experience similar to the pain point the customer is sharing right now.
- Meetings start in a professional tone. But like any other social interaction, it would have its ups and downs - times of excitement and boredom. It is helpful to "mirror" the customer's ups. When they are excited about something, probe deeper into it and find reasons to be **genuinely** excited with him.
- Try to make your presentations engaging by occasionally mentioning your counterparts by name and asking them how it affects their group (i.e Ms. Allen, in leading the customer services team, what other pain points might you have which has not been addressed yet with the solution?).
## (4) It's always more complex than they make it seem. Always pad your estimates.
When customers come to you, they only have a high-level idea of what they want. It is usually through the successive meetings during the pre-sales stage where you discover their needs in-depth. Don't cut corners when creating the scope of work. Ask the relevant questions. Think of all the miscellaneous expenses and out-of-scope items. At the proposal stage, it never hurt anybody to be as specific as possible.

When you cut corners in creating the proposal, the implementation team suffers (which, unfortunately for me, is also my team). They have to bring to life everything you promised in the proposal in that short time. This means getting delayed or your team spending countless nights and weekends catching up. (Hint: It's usually the latter).
At the start, it would be hard to estimate the effort. Lean on the side of safe, and pad yourself. The key is to have at least 20% padding on the man-days you will give.
## (5) Client obsession does not mean they can push you around.
They say, "Whoever Has the Gold Makes the Rules." That's true to a certain extent. The paying party gets to demand to the party being paid - they want to get their money's worth after all. But this shouldn't be an excuse to bully around the supplier. Learn to stand up for yourself and your team.
## (6) Get used to rejection
Half the customers that I have pursued for months don't sign with us. And that's just the fact of life. Sometimes they decide not to push through with the project. Or sometimes they do, just with someone else who can do it cheaper. Rejection is a fact of life in this business.
At the start, these rejections would be rough. But dusting yourself off and getting up from each rejection will be critical to your survival (and you thriving in the company). And as they say, on to the next!
## (7) Let your reputation bring your team forward
As you and your team deliver great work, word spreads around. Your clients, happy with your work, start availing you again or recommend you to their friends in other company subsidiaries. These "hot referrals" are gold. They make initial meetings easier since your credibility has been established even before you enter the room.
This tip is a long-game tactic. Keep doing great work, and you will have your job easier for you over time.

**This post is dedicated to a close friend of mine who is about to start a client-facing job. I hope this helps! And as always, a big thank you to Allen for being my editor**
Photo by <a href="https://unsplash.com/@dylandgillis?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Dylan Gillis</a> on <a href="https://unsplash.com/s/photos/clients-presentation?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
| raphael_jambalos |
799,607 | Introducing PromiViz - visualize and learn JavaScript promise APIs | If you found this article helpful, you will most likely find my tweets useful too. So here is the... | 13,426 | 2021-08-22T06:40:38 | https://blog.greenroots.info/introducing-promiviz-visualize-and-learn-javascript-promise-apis | javascript, codenewbie, beginners, node | *If you found this article helpful, you will most likely find my tweets useful too. So here is the [Twitter Link](https://twitter.com/tapasadhikary) to follow me for information about web development and content creation. This article was originally published on my [Blog](https://blog.greenroots.info/).*
<hr />
Why does JavaScript `promise` sounds a bit more complex than many other topics? Besides the factors that we have [already discussed](https://blog.greenroots.info/series/javascript-promises), we also need to know how it executes, what's the background story? After spending a considerable amount of time practicing and thinking about the promises using pen and paper, I got an idea to make a simple yet powerful tool for developers.
# Meet PromiViz
[Promiviz](https://promiviz.vercel.app/) is an open-source tool to try out the promise methods in intuitive ways. You can configure promises with delays, rejections and run them to see what's exactly happening behind the scene. It captures the log of each of the operations so that your understanding gets firmed as you use it. It is a tool for developers by a developer!
Please check out this short video to know more about the tool.
{% youtube webs_tRKIIg %}
Here are the important links:
- The app: [https://promiviz.vercel.app/](https://promiviz.vercel.app/)
- GitHub Repo: [https://github.com/atapas/promiviz](https://github.com/atapas/promiviz)
In this article, we will learn the Promise API methods using the `PromiViz` tool.
# JavaScript Promise APIs
The `Promise` object in JavaScript has six practical methods that serve several use cases.
1. Promise.all
1. Promise.any
1. Promise.race
1. Promise.allSettled
1. Promise.resolve
1. Promise.reject
These methods take one or more promises as input and return a new promise to find the result or error. The first four methods are significant when it comes to handling multiple promises.
To demonstrate examples for each of these methods, we will use three promises. Each of these promises resolves with a color name, red, green, and blue respectively,
```js
// It resolves with the value red after 1 second
const red = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('red');
}, 1000);
});
// It resolves with the value green after 3 seconds
const green = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('green');
}, 3000);
});
// It resolves with the value blue after 5 seconds
const blue = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('blue');
}, 5000);
});
```
# Promise.all
The method `Promise.all` executes multiple promises in parallel and returns a new promise. It waits for the execution of all the premises to complete. So, the execution time of the `Promise.all` method will be the same as the max time taken by an input promise.
Let's use our example promises(red, green, and blue) to explain the `Promise.all` method.
```js
const testAll = async () => {
const colors = await Promise.all([red, green, blue]);
console.log(colors);
colors.forEach(color => {
console.log(color);
});
}
testAll();
```
Here we use the [async/await](https://blog.greenroots.info/javascript-async-and-await-in-plain-english-please) keywords. As the `Promise.all` method returns a new promise, we use the `await` keyword in front of it. By rule, we must use an `async` keyword for a function that uses `await` in it.
The variable `colors` is an array with all the resolved values,

A few points to consider here,
- The total time needs to execute the `Promise.all` method is 5 seconds. The `blue` promise takes the max time(5 secs) to complete.
- The resulting array has the resolved value in the same order of the promises passed to the `Promise.all` method.
- If any of the input promises reject(or error out), the `Promise.all` rejects immediately. It means the rest of the input promises do not execute.
Let's try these with [Promiviz](https://promiviz.vercel.app/#). First, execute the `Promise.all` API and observe the output in the `log` window.

Have a look at the execution time there. It took 5 seconds. That is the time the `blue` promise took to finish. Now let's reject a promise, say, the `green` one!

Again, look at the time in the log window. The `Promise.all` is rejected within 3 seconds(the time `green` takes to execute). It didn't even wait for the `blue` promise to execute.
> Frequent mistake: All the input promises run parallel with the `Promise.all` method. Hence the total time to execute all the promises successfully is **NOT** the sum of their time. It is the max time taken by an input promise. In our example, it is 5 seconds(time taken by `blue`), not 9 seconds(1 + 3 + 5).
Let's move onto the following promise API method.
# Promise.any
Similar to `Promise.all`, the `any` method also takes a collection of input promises. However, it returns a new promise when `any` of the input promises is `fulfilled`.
```js
const testAny = async () => {
const color = await Promise.any([red, green, blue]);
console.log(color);
}
testAny();
```
In this case, the first promise, `red` takes the least time to execute and resolves. Hence the output will be red.
A few points to consider,
- If any of the input promises are rejects or errors out, the `Promise.any` method continues to execute other promises.
- If all of the input promises reject, the `Promise.any` method rejects with `AggregateError`.
Let's try these using `PromiViz`. Select the `Promise.any` API method and observe the log window.
The API method took 1 second to execute the `red` promise and resolves with it. What happens when you reject the red promise. Let's do it.
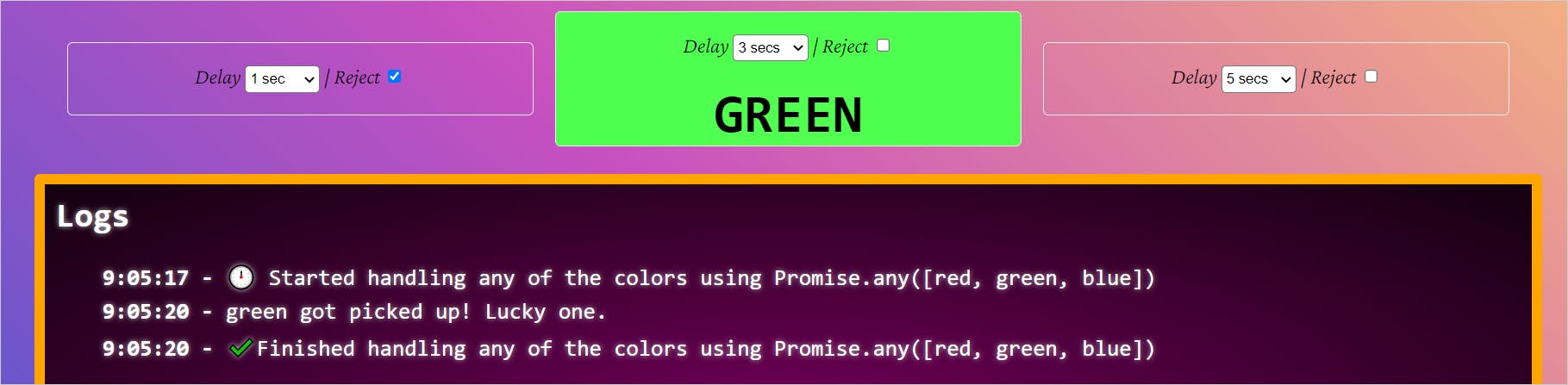
Now, the `green` promise resolves as it is the next one to pick. If we now reject red and green, the API will resolve the last input promise, `blue`. Let us now reject all the promises and see what happens.

It is `AggregateError`. Notice the time taken to execute, and it is 5 seconds, the max time taken by an input promise(blue).
# Promise.race
As the name suggests, it is the race between all the input promises, and the fastest promise wins! The `Promise.race` API method accepts a collection of input promises and returns a new promise when the fastest promise resolves.
```js
const testRace = async () => {
const color = await Promise.race([red, green, blue]);
console.log(color);
}
testRace();
```
In our example, the `red` promise is the clear winner. It resolves within 1 second.
A point to consider,
- If the fastest promise rejects(or error out), the `Promise.race` API method returns a rejected promise. It is a fundamental difference between the `race` method with the `any` method. The `any` method keeps trying, whereas the `race` is all about making the fastest win else all lost.
Let's understand it using `PromiViz`. Would you please run the `Promise.race` API method? We see `red` wins the race in 1 second.
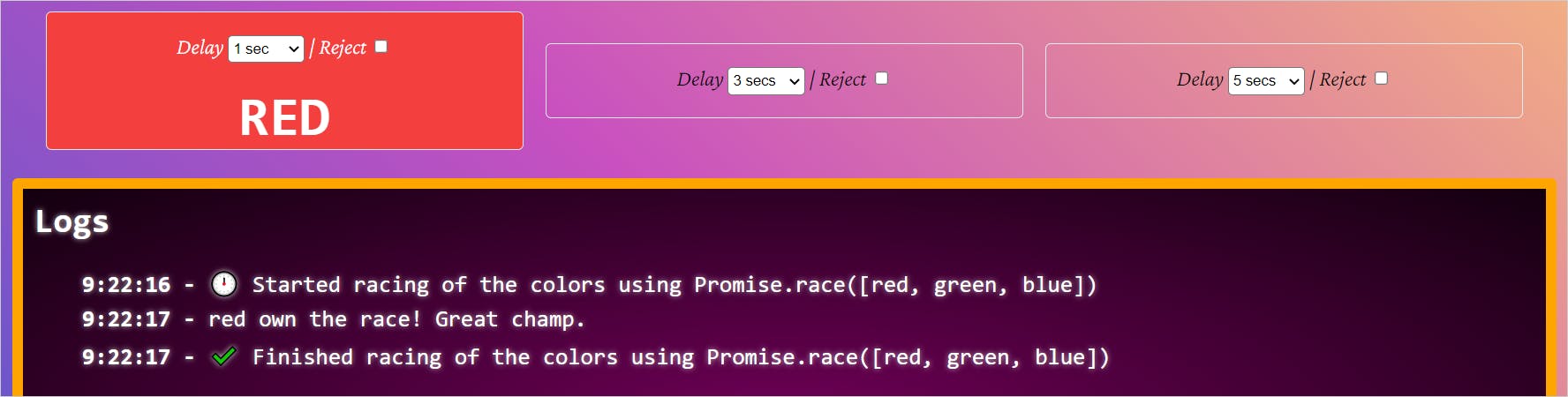
Now adjust the delays. Make it 3 seconds for `red`, 2 seconds for `green`. You should see the `green` winning the race now as it is the fastest.
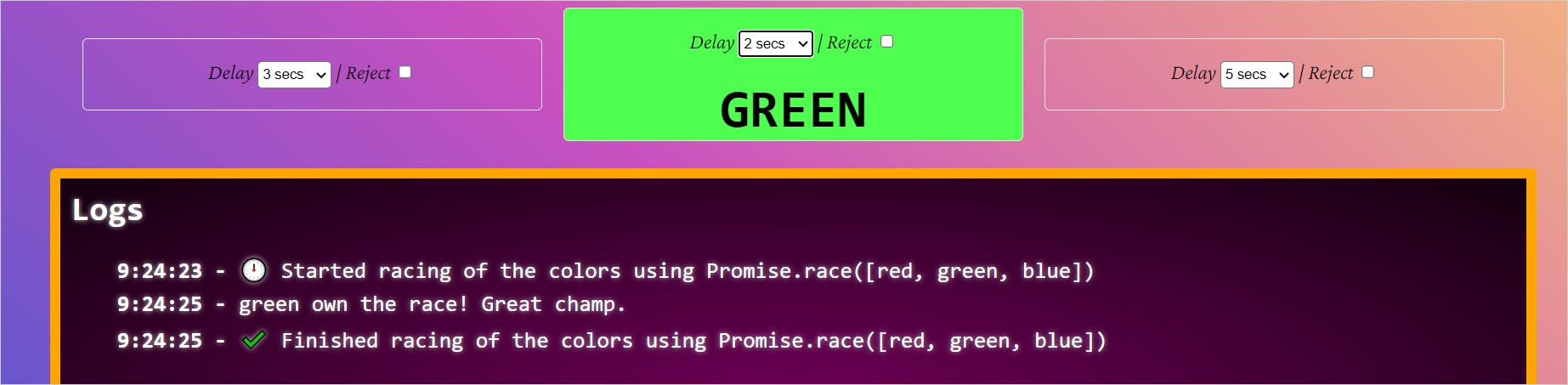
Now reject green. What do you think will happen? You have rejected the fastest promise. So, by rule, the `Promise.race` will not continue the execution of others. We will get a rejected promise that we need to handle.

Alright, let's move onto the following important API method.
# Promise.allSettled
The `Promise.allSettled` method is the newest inclusion to the promise API method list. Just like the methods we have seen so far, it takes an array of input promises.
Unlike the `Promise.all` method, it doesn't reject all if any input promises reject or error out. It continues to execute and returns an array of settled promises, including their state, value, and the reason for an error.
Let's assume the red and green promises resolves successfully and the blue promise rejects due to an error. Let's run `Promise.allSettled` using these promises,
```js
const testAllSettled = async () => {
const colors = await Promise.allSettled([red, green, blue]);
console.log(colors);
colors.forEach(color => {
console.log(color);
});
}
```
See the output,

It returns all the settled promises with status, value for a resolved promise, and reason for the rejection for a rejected promise. Here is the execution result of the `Promise.allSettled` API method using `PromiViz`. Please note, we reject the blue promise here.
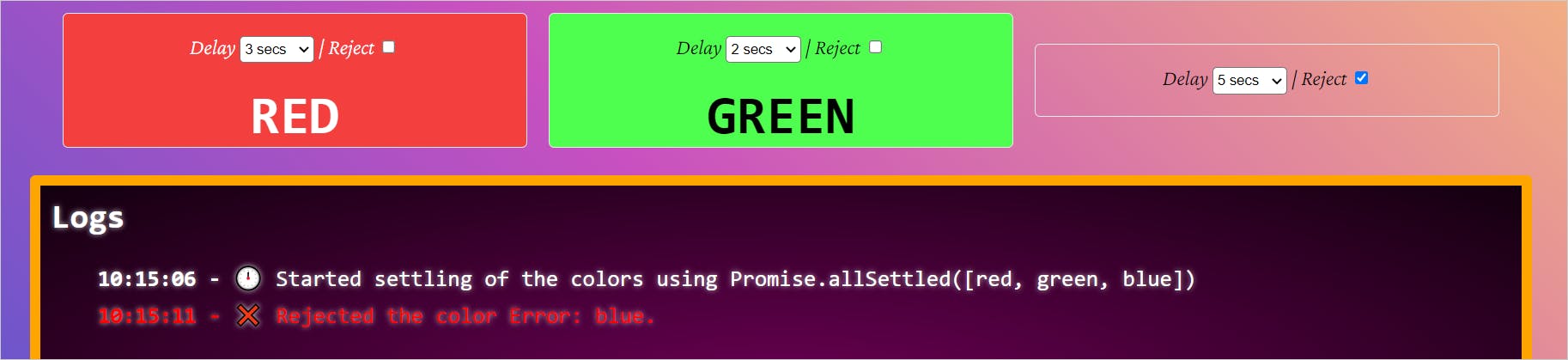
It took the entire 5 seconds to complete execution. It never rejected the other two promises.
# Promise.resolve and Promise.reject
The last two methods are `Promise.resolve` and `Promise.reject`. The first creates a resolved promise with a value, and the latter creates a rejected promise with an error.
```js
// It resolves with the value green after 3 seconds
const green = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('green');
}, 3000);
});
const resolveOne = async () => {
const result = await Promise.resolve(green);
console.log(result);
}
resolveOne();
```
In most cases, you would probably prefer using `async/await` instead of these two methods. However, consider these methods when you create promises manually like this,
```js
new Promise(function (resolve, reject) {
resolve(value);
}).then(/* handle it */);
```
The better and short syntax is,
```js
Promise.resolve(value).then(/* handle it */);
```
Similarly, for reject,
```js
Promise.reject(value).catch(/* handle it */);
```
Congratulations!!! You have learned about all the Promise API methods.
# Examples and Analogies
Here are some examples and analogies you may find helpful.
| Promise API Methods | Example |
|-------------------------------|----------------------------------------|
| **Promise.all** | I am downloading multiple files from different sources. |
| **Promise.allSettled** | I am downloading multiple files from different sources, and I am okay with whatever was downloaded successfully. |
| **Promise.any** | I am downloading my profile image of different resolutions from several sources. I am OK with any that I get **first**. |
| **Promise.race** | I am downloading my profile images of different resolutions from several sources. I want to get the **fastest** one to proceed. |
# So, What's Next?
We have [come a long way](https://blog.greenroots.info/series/javascript-promises) in understanding the core concepts of asynchronous programming in JavaScript. To recap, we learned about,
- [The JavaScript Promises, how to resolve and reject them](https://blog.greenroots.info/javascript-promises-explain-like-i-am-five)
- [How to tackle promises with the Promise Chain, how to handle errors](https://blog.greenroots.info/javascript-promise-chain-the-art-of-handling-promises)
- [Async/Await keywords and their togetherness with plain-old promises](https://blog.greenroots.info/javascript-async-and-await-in-plain-english-please)
- Promise API methods in this article.
Thank you for letting me know, you are enjoying the series so far. Next, we will learn about the `common mistakes` we make with promises and get better at `answering the interview questions`. Until then, you can look into the source code used in the article from this repository and try it out using [PomiViz](https://promiviz.vercel.app).
{% github atapas/promise-interview-ready no-readme %}
<hr />
I hope you enjoyed this article or found it helpful. Let's connect. Please find me on [Twitter(@tapasadhikary)](https://twitter.com/tapasadhikary), sharing thoughts, tips, and code practices. Would you please give a follow?
| atapas |
799,630 | What You Should Know About CSS Link Pseudo-classes? | CSS Link Pseudo Classes provide a way for you to improve the user experience of your website by... | 0 | 2021-08-22T08:28:13 | https://dev.to/gathoni/what-you-should-know-about-css-link-pseudo-classes-4ea8 | css3, css, beginners | CSS Link Pseudo Classes provide a way for you to improve the user experience of your website by styling different states of the HTML links differently.
Until recently, I was only aware of the `:hover` and `:active` pseudo-classes... no I am not joking.
Well, there are others and they are amazing to use.
In this post, I will be talking about these CSS link pseudo-classes and looking at how we can use in our code.
- :link
- :visited
- :hover
- :active
- :focus
## But first... What are pseudo-classes?
According to [MDN](https://developer.mozilla.org/en-US/docs/Web/CSS/Pseudo-classes) ,
> A CSS pseudo-class is a keyword added to a selector that specifies a special state of the selected element(s)
So when you append a state to a selector and specify how an element should behave in that state, you are using a pseudo-class.
For instance,
```css
a:hover {
color: red;
}
```
`:hover` is the pseudo-class appended to the `a` selector. So when a user hovers over the `a` tag, its font color will change to red.
### Syntax
```css
selector:pseudo-class {
property: value;
}
```
*There should be no space between the selector and the pseudo-class. It won't work.*
*You can chain together as many pseudo-classes as you want*
## What CSS link Pseudo-classes do
`:link`: Selects links that have not been visited.
`:visited`: Selects links that have not been visited.
`:hover`: Selects links that have the mouse pointer over them
`:active`: A state where the user clicks on a link
`:focus`: When a user focuses on a link after clicking it.
> The styles that can be applied to the `:visited` pseudo-class is limited due to the browser's support for privacy. Sometimes disclosing links a user has visited can be insecure.
## Chaining Pseudo-classes
Like most CSS classes, you can also chain link pseudo-classes. You can do this when you want a link in more than one state to behave a certain way.
For instance, you want to change the opacity to .9 of a visited link when a mouse pointer hovers on it.
```css
a:visited:hover {
opacity: 0.9;
}
// but an unvisited link to 0.7
a:link:hover {
opacity: 0.7
}
```
## Order of CSS Link Pseudo-classes
If you know a bit of CSS, you probably know about specificity.
CSS specificity is how browsers determine what styles will be applied to an element i.e it determines the most relevant styles.
When two selectors match in specificity, the styles appearing last in the CSS stylesheet are applied.
Consider the following:
```css
a:hover{
color:red;
}
a:visited{
color:blue;
}
```
Maybe you would expect the visited link to change color to red on hover, but that won't happen.
Because visited comes after hover, it will override the hover pseudo-class.
The correct way of writing the above code would be:
```css
a:visited{
color:blue;
}
a:hover{
color:red;
}
```
The order goes from `:link`, `:visited`, `:hover`, `:focus` to`:active`
> Always use both `:focus` and `:hover` to make it more accessible since not all users hover on the links.
That's it! I hope you learned something new!
Stay awesome ;)
### Important Links
- [CSS Specificity](https://developer.mozilla.org/en-US/docs/Web/CSS/Specificity)
- [Pseudo Classes in CSS ](https://developer.mozilla.org/en-US/docs/Web/CSS/Pseudo-classes)
| gathoni |
802,064 | Distributed Version Control | In the previous article, where we looked at the history of version control systems, we talked about... | 13,904 | 2021-08-24T15:24:08 | https://ahmedgouda.hashnode.dev/distributed-version-control | git, github, tutorial, computerscience | In the previous article, where we looked at the history of version control systems, we talked about SCCS, RCS, CVS and SVN, four of the most popular version control systems of the past but all four of these use a central code repository model. That's where one central place is used to store the master copy of your code. And when you're working with the code, you check out a copy from that master repository. You work with it to make your changes, and then you submit those changes back to the central repository. Other users can also work with that repository, submitting their changes, and it's up to us as users to keep up to date with whatever's happening in that central code repository to make sure that we pull down and update any changes that other people have made.</br>
### Git Workflow
Git doesn't work that way. Git is distributed version control. Different users each maintain their own repositories instead of working from a central repository, and the changes are stored as sets or patches, and we're focused on tracking changes, not the versions of the documents. Now that's a subtle difference. You may think well, CVS and SVN, those track changes too. They track the changes that it takes to get from version to version of each different file, or the different states of a directory. Git doesn't work that way. Git really focuses on these change sets, and encapsulating a change set as a discrete unit, and then those change sets can be exchanged between repositories. We're not trying to keep up to date with the latest version of something. Instead the question is do we have a change set applied or not? So you might say that you merge in change sets or you apply patches between the different repositories. So there's no single master repository. There's just many working copies, each with their own combination of change sets.
### Example
Imagine that we have changes to a single document as sets A, B, C, D, E, and F. We're just going to give them arbitrary letter names so that we can help see it. We could have a first repository that has all six of those change sets in it. We can have repository two that only has four of those changes in it. It's not that it's behind repository one, or that it needs to be brought up to date. It just simply doesn't have the same change sets. We can have repository three that has sets A, B, C, and E, and repository four that has A, B, E, and F.
- Repo 1: A, B, C, D, E, F
- Repo 2: A, B, C, D
- Repo 3: A, B, C, E
- Repo 4: A, B, E, F
None of these repositories is right, and none of them is wrong. No one of them is the master repository, and the others are somehow out of date or out of sync with it. They're all just different repositories that happen to have different change sets in them. We could just as easily add change set G to repository three, and then we could share it with repository four without ever having to go to any kind of central server at all, whereas with CVS and SVN, for example, you would need to submit those changes to a central server, and then people would need to pull down those changes to update their versions of the file.
Now by convention, we often do designate a repository as being the master repository, but that's not built into Git. It's not part of the Git architecture. It's just a convention, that we say okay, this is going to be the master repository and everyone is going to submit their changes to this repository, and we're all going to stay in sync from that one, but we don't have to. We can actually have three or four different master repositories that have different versions in them, and we could all be contributing to those equally and just swapping changes between them.
### Advantages
Now because it's distributed, that has a couple of advantages.
- There's no need to communicate with a central server, and that makes things faster and it means that it's not necessary to have network access to submit our changes. We can work on an airplane, for example.
- There's no single point of failure. With CVS and SVN, if something goes wrong with that central repository, that can be a real show stopper for everyone else who's working off of that central repository. With Git we don't have that problem. Everyone can keep working. They've each got their own repository that they're working from, not just a copy that they're trying to keep in sync with some central repository.
- It also encourages participation in forking projects, and this is really important for the open source community because developers can work independently. They can make changes, they can make bug fixes, feature improvements, and then they can submit those back to the project for either inclusion or rejection, and if you're working on an open source project and you don't like the way that it's going, you can fork that project, create your own version and take it in a completely different direction. That becomes a really powerful and flexible feature that's well suited to collaboration between teams, especially loose groups of distributed developers like you have in the open source world.
Distributed version control is an important part of the Git architecture, and it's important to learn about it, especially if you have previous experience with other version control systems like CVS or SVM. For now, just make sure that you understand that there is no central repository that we all work from. All repositories are considered equal by Git. | ahmedgouda |
799,766 | Javascript Clean Code Tips & Good Practices | Code should be written in such a way that is self-explanatory, easy to understand, and easy to modify... | 0 | 2021-08-22T10:17:53 | https://apoorvtyagi.tech/javascript-clean-code-tips-and-good-practices | javascript, codenewbie, beginners, webdev | Code should be written in such a way that is self-explanatory, easy to understand, and easy to modify or extend for the new features. Because code is read more than it is written that's why so much emphasis is given to clean code.
The more readable our source code is:
* The easier it is to maintain
* The less time required to understand an implementation for a new developer
* The easier it is to discover what code can be reused
In this blog post, I will share some general clean coding principles that I've adopted over time as well as some JavaScript-specific clean code practices.
## 0. Naming
Don't turn naming into a riddle game. **Name your variables and functions in a way that they reveal the intention behind why they were created in the first place**.
This way they become searchable and easier to understand if let's say a new developer joins the team.
> Only go for Shortening and abbreviating names when you want the next developer working on your code to guess what you were thinking about 😉
**Bad 👎**
```javascript
let x = 10;
let y = new Date().getFullYear();
if (x > 30) {
//...
}
if (y - x >1990) {
//...
}
```
**Good 👍**
```javascript
let userAge = 30;
let currentYear = new Date().getFullYear();
if (userAge > 30) {
//...
}
if (currentYear - userAge >1990) {
//...
}
```

Also, don’t add extra unnecessary letters to the variable or functions names.
**Bad 👎**
```javascript
let nameValue;
function theProduct();
```
**Good 👍**
```javascript
let name;
function product();
```
## 1. Conditionals
**Avoid negative conditionals**. Negatives are just a bit harder to understand than positives.
**Bad 👎**
```javascript
if (!userExist(user)) {
//...
}
```
**Good 👍**
```javascript
if (userExist(user)) {
//...
}
```
## 2. Functions should do one thing
**The function should not have more than an average of 30 lines (excluding spaces and comments)**. The smaller the function the better it is to understand and refactor. Try making sure your function is either modifying or querying something but not both.
## 3. Use default arguments
Use default arguments instead of short-circuiting or conditionals.
**Default arguments are often cleaner than short-circuiting**. Remember that if you use them, your function will only provide default values for undefined arguments. Other *falsy* values such as '', "", false, null, 0, and NaN, will not be replaced by a default value.
**Bad 👎**
```javascript
function getUserData(name) {
const userName = userName || "Patrick Collision";
// ...
}
```
**Good 👍**
```javascript
function getUserData(name = "Patrick Collision") {
// ...
}
```
## 4. Single Level of Abstraction(SLA)
While writing any function, **if you have more than one level of abstraction, your function is usually doing more than one thing**. Dividing a bigger function into multiple functions leads to reusability and easier testing.
> Functions should do one thing. They should do it well. They should do it only. — Robert C. Martin

**Bad 👎**
```javascript
function checkSomething(statement) {
const REGEXES = [
// ...
];
const statements = statement.split(" ");
const tokens = [];
REGEXES.forEach(REGEX => {
statements.forEach(statement => {
// ...
});
});
const names= [];
tokens.forEach(token => {
// lex...
});
names.forEach(node => {
// parse...
});
}
```
**Good 👍**
```javascript
function checkSomething(statement) {
const tokens = tokenize(statement);
const syntaxTree = parse(tokens);
syntaxTree.forEach(node => {
// parse...
});
}
function tokenize(code) {
const REGEXES = [
// ...
];
const statements = code.split(" ");
const tokens = [];
REGEXES.forEach(REGEX => {
statements.forEach(statement => {
tokens.push(/* ... */);
});
});
return tokens;
}
function parse(tokens) {
const syntaxTree = [];
tokens.forEach(token => {
syntaxTree.push(/* ... */);
});
return syntaxTree;
}
```
## 5. Don't ignore caught errors
Doing nothing with a caught error doesn't give you the ability to fix or react to that particular error.
Logging the error to the console (console.log) isn't much better as oftentimes it can get lost among other things printed to the console.
If you wrap any bit of code in a try/catch it means you think an error may occur there and therefore you should have a plan for when it occurs.
**Bad 👎**
```javascript
try {
functionThatMightThrow();
} catch (error) {
console.log(error);
}
```
**Good 👍**
```javascript
try {
functionThatMightThrow();
} catch (error) {
notifyUserOfError(error);
reportErrorToService(error);
}
```
## 6. Minimize Comments
**Only comment the part of the code that has business logic complexity**.
Comments are not a requirement. Good code mostly documents itself.
**Bad 👎**
```javascript
function hashing(data) {
// The hash
let hash = 0;
// Length of string
const length = data.length;
// Loop through every character in data
for (let i = 0; i < length; i++) {
// Get character code.
const char = data.charCodeAt(i);
// Make the hash
hash = (hash << 5) - hash + char;
// Convert to 32-bit integer
hash &= hash;
}
}
```
**Good 👍**
```javascript
function hashing(data) {
let hash = 0;
const length = data.length;
for (let i = 0; i < length; i++) {
const char = data.charCodeAt(i);
hash = (hash << 5) - hash + char;
// Convert to 32-bit integer
hash &= hash;
}
}
```
> “Redundant comments are just places to collect lies and misinformation.” ― Robert C. Martin
## 7. Remove commented code
**Don't leave commented out code in your codebase**, Version control exists for a reason. Leave old code in your history. If you ever need them back, pick them up from your git history.
**Bad 👎**
```javascript
doSomething();
// doOtherStuff();
// doSomeMoreStuff();
// doSoMuchStuff();
```
**Good 👍**
```javascript
doSomething();
```
## 8. Import only what you need
Destructuring was introduced with ES6. It makes it possible to unpack values from arrays, or properties from objects, into distinct variables. You can use this for any kind of object or module.
For instance, if you only require to `add()` and `subtract()` function from another module:
**Bad 👎**
```javascript
const calculate = require('./calculations')
calculate.add(4,2);
calculate.subtract(4,2);
```
**Good 👍**
```javascript
const { add, subtract } = require('./calculations')
add(4,2);
subtract(4,2);
```
It makes sense to only import the functions you need to use in your file instead of the whole module, and then access the specific functions from it.

## 9. Keep Function arguments 3 or less (ideally)
Limiting the number of function parameters is really important because it makes testing your function easier. Having more than three parameters leads you to test tons of different cases with each separate argument.
1-3 arguments are the ideal case, anything above that should be avoided if possible.
> Usually, if you have more than three arguments then your function is trying to do too much. Which ultimately leads to the violation of the SRP(Single Responsibility Principle).
## 10. Use array spreads to copy arrays.
Bad 👎
```javascript
const len = items.length;
const itemsCopy = [];
let i;
for (i = 0; i < len; i += 1) {
itemsCopy[i] = items[i];
}
```
Good 👍
```javascript
const itemsCopy = [...items];
```
## 11. Write linear code
Nested code is hard to understand. **Always write the linear code as much as possible**. It makes our code simple, clean, easy to read, and maintain, thus making developer life easier.
For Example, **Using promises over callbacks can increase readability multiple times**.
## 12. Use ESLint and Prettier
Always **use ESLint and Prettier to enforce common coding styles across teams and developers**.
Also try and use JavaScript's latest features to write code, like destructuring, spread operator, async-await, template literals, optional chaining, and more.
## 13. Use proper parentheses
When working with operators, enclose them in parentheses. The only exception is the standard arithmetic operators: +, -, and \*\* since their precedence is broadly understood. It is highly recommended to enclose /, \*, and % in parentheses because their precedence can be ambiguous when they are used together.
This improves readability and clarifies the developer’s intention.
Bad 👎
```javascript
const foo = a && b < 0 || c > 0 || d + 1 === 0;
if (a || b && c) {
return d;
}
```
Good 👍
```javascript
const foo = (a && b < 0) || c > 0 || (d + 1 === 0);
if (a || (b && c)) {
return d;
}
```
Make sure your code doesn't lead to situations like this:
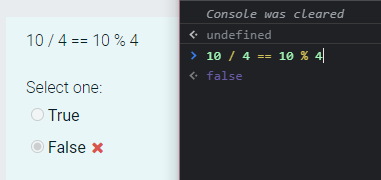
## 14. Return early from functions
To avoid deep nesting of if-statements, always return a function's value as early as possible.
Bad 👎
```javascript
function isPercentage(val) {
if (val >= 0) {
if (val < 100) {
return true;
} else {
return false;
}
} else {
return false;
}
}
```
Good 👍
```javascript
function isPercentage(val) {
if (val < 0) {
return false;
}
if (val > 100) {
return false;
}
return true;
}
```
This particular example can even improve further:
```javascript
function isPercentage(val) {
var isInRange = (val >= 0 && val <= 100);
return isInRange;
}
```
Similarly, the same thing can be applied to Loops as well.
Looping over large cycles can surely consume a lot of time. That is why you should always try to break out of a loop as early as possible.
## Conclusion
There’s a saying in the development community that you should always write your code like the next developer that comes after you is a serial killer.
Following this rule, I have shared 15 tips here that can (probably) save you from your fellow developers when they will look into your code.
If you find any updates or corrections to improve these 15 tips or want to add one of your own that you think can be helpful, please feel free to share them in the comments.
For further reading I would highly suggest you go through these 3 resources:
* [Airbnb JS style guide](https://github.com/airbnb/javascript)
* [Google JS style guide](https://google.github.io/styleguide/jsguide.html)
* [Javascript Clean Code](https://github.com/ryanmcdermott/clean-code-javascript)
---
### Starting out in web development?? 💻
Checkout ▶ [HTML To React: The Ultimate Guide](https://gumroad.com/a/316675187)
This ebook is a comprehensive guide that teaches you **everything you need to know to be a web developer through a ton of easy-to-understand examples and proven roadmaps**
It contains 👇
✅ Straight to the point explanations
✅ Simple code examples
✅ 50+ Interesting project ideas
✅ 3 Checklists of secret resources
✅ A Bonus Interview prep
You can even check out [a free sample from this book](https://drive.google.com/drive/u/0/folders/1GJECqmBUbOwgg5eQvGlMwHcDShqxKISJ)
and here's the [link](https://gumroad.com/a/316675187) with 60% off on the original price on the complete book set ⬇
[](https://gumroad.com/a/316675187)
| apoorvtyagi |
799,789 | RO Services In Patna | Need RO Service Center in Bihar? Ro Walla provides best RO water purifier repair services in Bihar.... | 0 | 2021-08-22T11:37:25 | https://dev.to/maximusnew/ro-services-in-patna-48ak | Need RO Service Center in Bihar? Ro Walla provides best RO water purifier repair services in Bihar. We have dedicated team of RO repair, installation, service for residential & commercial RO systems. Just Call us:- 7079992137.
https://rowalla.com/ | maximusnew | |
799,797 | Uploading iOS apps with special characters to App Store Connect | Solving the error 'Invalid Signature. A sealed resource is missing or invalid.' | 0 | 2021-08-22T12:10:53 | https://dev.to/osamaqarem/uploading-ios-apps-with-special-characters-to-app-store-connect-60k | xcode, reactnative, ios, swift | ---
title: Uploading iOS apps with special characters to App Store Connect
published: true
description: Solving the error 'Invalid Signature. A sealed resource is missing or invalid.'
tags: xcode,reactnative,ios,swift
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/3j1o5y17kjjmx7p6r5oy.png
---
Suppose you have an Xcode project where the product name includes special characters like an umlaut 'ü':
If you try to archive it and upload it to App Store Connect you might be faced with the following mysterious error:
![ERROR ITMS-90035: "Invalid Signature. A sealed resource is missing or invalid. The file at path [Dümmy.app/Dümmy] is not properly signed. Make sure you have signed your application with a distribution certificate, not an ad hoc certificate or a development certificate. Verify that the code signing settings in Xcode are correct at the target level (which override any values at the project level).](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/7o2gcgf19wqr94q6h1ke.jpg)
> ERROR ITMS-90035: "Invalid Signature. A sealed resource is missing or invalid. The file at path [Dümmy.app/Dümmy] is not properly signed. Make sure you have signed your application with a distribution certificate, not an ad hoc certificate or a development certificate. Verify that the code signing settings in Xcode are correct at the target level (which override any values at the project level).
This happens because the default Xcode configuration uses the same variable to set both the names of the `.app` package and the `.ipa` archive - both of which may not have special characters. And in this case it is set to "Dümmy".
The `Info.plist` file will have the following keys:
- `PRODUCT_NAME`: the name of the `.app` bundle and executable file.
- `CFBundleName`: the [app name](https://developer.apple.com/documentation/bundleresources/information_property_list/cfbundlename) when `CFBundleDisplayName` isn't set.
The tricky part is `CFBundleName` which is set to the value of `$(PRODUCT_NAME)` by default. What Apple docs do not mention is that starting with Xcode 12 and beyond it also represents the `.ipa` file name.
The solution is to set both `PRODUCT_NAME` and `CFBundleName` to values with no special characters and to explicitly set the display name under _Project Navigator → General → Display Name_. This will generate a new key `CFBundleDisplayName` whose value will be preferred over `CFBundleName` for the app name.
Now you can keep the app name with special characters, but remove them from the file names for the app package and archive.
------------------
This article was cross-posted from my personal blog. Do [subscribe](https://osamaqarem.com/?join=true) to me there!
| osamaqarem |
799,810 | Exploring the Go fmt package | fmt is pronounced “fumpt” is one of Go’s core packages. It's mainly used for printing information to... | 0 | 2021-08-22T12:48:18 | https://dev.to/robogeek95/exploring-the-go-fmt-package-1p44 | go, beginners | ---
title: Exploring the Go fmt package
published: true
description:
tags: go, beginner
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/k6hngofcawq6xt5x9mls.jpg
---
fmt is pronounced “fumpt” is one of Go’s core packages. It's mainly used for printing information to the terminal. fmt package has a broader purpose like helping us format data, for this reason, it's sometimes referred to as the format package.
## Functions in Go fmt package:
The package three set of functions based on their usage
- Functions used to format and print data in various ways and use cases:
- Println()
- Print()
- Printf()
- Functionsthat only formats the data and prints nothing
- Sprint()
- Sprintln()
- Sprintf()
- And a Functions to read user input from the terminal
- Scan()
## Functions used to format and print data in various ways and use cases
The Go fmt package gives two closely-related functions for formatting a string to be displayed on the terminal.
### .Print()
When the arguments are strings, it concatenates them without any spacing and prints the result to the console.
``` go
fmt.Print("My", "name", "is", "Lukman")
// MynameisLukman
```
When none of the arguements is a string, the Print function adds spaces between them.
``` go
fmt.Print(10, 20)
// 10 20
```
### .Println()
on the other hand always adds a space between its arguements and appends a new line or a line break at the end
``` go
fmt.Println("My", "name", "is", "Lukman")
fmt.Println("new", "line")
// My name is Lukman
// new line
```
## .Printf()
The Go.Printf() function in fmt provides custom formatting of a string using one or more verbs. A verb is a placeholder for a named value (constant or variable) to be formatted according to these conventions:
- %v represents the named value in its default format
- %d expects the named value to be an integer type
- %f expects the named value to be a float type
- %T represents the type for the named value
but unlike .Println(), .Printf() does not append a newline to the formatted string.
```go
name := "Lukman"
fmt.Printf("My name is %v", name)
// My name is Lukman
age := 90
fmt.Printf("I am %d years old", age)
// I am 90 years old
```
## Functions that only formats the data and prints nothing
Unlike the .Print() and .Println() functions, the fmt package provides other functions that don’t print strings, but format them instead: The fmt.Sprint() and fmt.Sprintln().
### fmt.Sprint()
```go
user := "Kenny"
Feedback := "Nice book!"
userFeedback := fmt.Sprint(user, "feedback on your book is", feedback)
fmt.Print(userFeedback)
// Prints: Kenny feedback on your book is Nice book!
```
Take a closer look at userFeedback and how calling fmt.Sprint() doesn’t print out anything. Rather, it returned a value that we store in userFeedback. When a value is returned, it means that a function did some computation and is giving back the computed value. Afterward, we can use the returned value for later usage. we’ve formatted one string by concatenating four separate strings. To see the value of userFeedback, we have to use a print statement.
### fmt.Sprintln()
fmt.Sprintln() works like fmt.Sprint() but it automatically includes spaces between the arguments for us (just like fmt.Println() and fmt.Print()):
```go
quote = fmt.Sprintln("see here,", "no spaces!")
fmt.Print(quote) // Prints see here, no spaces!
Even though we didn’t add a trailing space in "see here," or a leading space in "no spaces!", quote is concatenated with a space in between: "see here,", "no spaces!".
```
## The Sprintf function
when we have to interpolate a string, without printing it, then we can use fmt.Sprintf().
Just like fmt.Printf(), fmt.Sprintf() can also use verbs:
``` go
user := "userA"
winner := fmt.Sprintf("The winner is… %v!", user)
fmt.Print(answer) // Prints: The winner is is… userA!
```
fmt.Sprintf() works very similarly to fmt.Printf(), the major difference is that fmt.Sprintf() returns its value instead of printing it out!
## Function for reading user input
The Go fmt .Scan() function scans user input from the terminal and extracts text delimited by spaces into successive arguments. A newline is considered a space. This function expects an address of each argument to be passed.
```go
package main
import "fmt"
func main() {
var name string
var age int
fmt.Println("What's your name?")
fmt.Scan(&name)
fmt.Println("and what's your age?")
fmt.Scan(&age)
fmt.Printf("%v is %d years old!", name, age)
}
//$ What's your name?
//$ Lukman
//$ now what's your age?
//$ 90
//$ Lukman is 90 years old!
```
we have looked into seven functions exposed from the go fmt package, now you can fully utilize the fmt package in your Go applications.
now it's time to harness the full power of go

what next: check out the [official documentation]
(https://golang.org/pkg/fmt/) to learn more about these functions.
| robogeek95 |
799,834 | Testando Detalhes de Implementação | Testar detalhes de implementação é uma fórmula para o desastre. Por quê? E o que isso significa? Na... | 0 | 2021-08-23T14:34:28 | https://dev.to/exploitmik/testando-detalhes-de-implementacao-40nc | testing, react, javascript, webdev | Testar detalhes de implementação é uma fórmula para o desastre. Por quê? E o que isso significa?
Na época em que eu estava usando enzyme (como todo mundo na época), tive cuidado com certas APIs. Eu [evitei completamente shallow rendering](https://kentcdodds.com/blog/why-i-never-use-shallow-rendering/) para nunca usar APIs como instance(), state() ou find('ComponentName'). E em revisões de código de pull requests de outras pessoas, expliquei repetidamente por que é importante evitar essas APIs. O motivo é que cada uma delas permite testar detalhes de implementação de seus componentes. Muitas vezes as pessoas me perguntam o que quero dizer com "detalhes de implementação". Quero dizer: é difícil testar do jeito que está! Por que temos que fazer todas essas regras para torná-lo mais difícil?
<hr />
## Por que testar os detalhes de implementação é uma má prática?
Há dois motivos distintos pelos quais é importante evitar detalhes de implementação. Testes que testam os detalhes de implementação:
1. Podem falhar ao refatorar o código da aplicação. **Falsos negativos;**
2. Podem não falhar quando você quebrar o código da aplicação. **Falso-positivo.**
> Para ser claro, o teste é: "o software funciona". Se o teste for bem-sucedido, isso significa que o resultado do teste foi "positivo" (o software está funcionando). Caso contrário, isso significa que o teste retorna "negativo" (não encontrou o software funcionando). O termo "Falso" refere-se a quando o teste retornou com um resultado incorreto, significando que o software está realmente corrompido, mas o teste foi aprovado (falso positivo) ou o software está realmente funcionando, mas o teste falhou (falso negativo).
Vamos dar uma olhada em cada um deles, usando um simples componente Accordion como exemplo:
```react
// accordion.js
import * as React from 'react'
import AccordionContents from './accordion-contents'
class Accordion extends React.Component {
state = {openIndex: 0}
setOpenIndex = openIndex => this.setState({openIndex})
render() {
const {openIndex} = this.state
return (
<div>
{this.props.items.map((item, index) => (
<>
<button onClick={() => this.setOpenIndex(index)}>
{item.title}
</button>
{index === openIndex ? (
<AccordionContents>{item.contents}</AccordionContents>
) : null}
</>
))}
</div>
)
}
}
export default Accordion
```
Se você está se perguntando por que estou usando um componente antigo de classe e não um componente funcional moderno (com hooks) para esses exemplos, continue lendo, é uma revelação interessante (que alguns de vocês experimentaram com enzyme que você já deve estar esperando).
E aqui está um teste que testa os detalhes de implementação:
```js
// __tests__/accordion.enzyme.js
import * as React from 'react'
// if you're wondering why not shallow,
// then please read https://kcd.im/shallow
import Enzyme, {mount} from 'enzyme'
import EnzymeAdapter from 'enzyme-adapter-react-16'
import Accordion from '../accordion'
// Setup enzyme's react adapter
Enzyme.configure({adapter: new EnzymeAdapter()})
test('setOpenIndex sets the open index state properly', () => {
const wrapper = mount(<Accordion items={[]} />)
expect(wrapper.state('openIndex')).toBe(0)
wrapper.instance().setOpenIndex(1)
expect(wrapper.state('openIndex')).toBe(1)
})
test('Accordion renders AccordionContents with the item contents', () => {
const hats = {title: 'Favorite Hats', contents: 'Fedoras are classy'}
const footware = {
title: 'Favorite Footware',
contents: 'Flipflops are the best',
}
const wrapper = mount(<Accordion items={[hats, footware]} />)
expect(wrapper.find('AccordionContents').props().children).toBe(hats.contents)
})
```
Levante a mão se você viu (ou escreveu) testes como este em sua base de código (🙌). Ok, agora vamos dar uma olhada em como as coisas quebram com esses testes...
<hr />
## Falsos-Negativos ao refatorar
Um número surpreendente de pessoas acha testes desagradáveis, especialmente o teste de interface do usuário. Por que? Existem várias razões para isso, mas uma grande razão que ouço repetidamente é que as pessoas passam muito tempo cuidando dos testes. "Cada vez que faço uma alteração no código, os testes quebram!" Este é um verdadeiro obstáculo à produtividade! Vamos ver como nossos testes são vítimas desse problema frustrante.
Digamos que eu esteja refatorando este accordion para prepará-lo para permitir que vários itens de accordion sejam abertos ao mesmo tempo. Uma refatoração não muda o comportamento existente, apenas muda a implementação. Portanto, vamos mudar a implementação de uma forma que não mude o comportamento.
Digamos que estamos trabalhando para adicionar a capacidade de vários elementos de accordion serem abertos de uma vez, então estamos mudando nosso estado interno de `openIndex` para `openIndexes`:
```diff
class Accordion extends React.Component {
- state = {openIndex: 0}
- setOpenIndex = openIndex => this.setState({openIndex})
+ state = {openIndexes: [0]}
+ setOpenIndex = openIndex => this.setState({openIndexes: [openIndex]})
render() {
- const {openIndex} = this.state
+ const {openIndexes} = this.state
return (
<div>
{this.props.items.map((item, index) => (
<>
<button onClick={() => this.setOpenIndex(index)}>
{item.title}
</button>
- {index === openIndex ? (
+ {openIndexes.includes(index) ? (
<AccordionContents>{item.contents}</AccordionContents>
) : null}
</>
))}
</div>
)
}
}
```
Incrível, fazemos uma verificação rápida no aplicativo e tudo ainda está funcionando corretamente, então quando chegarmos a este componente mais tarde para permitir a abertura de vários accordions, será muito fácil! Em seguida, executamos os testes e 💥kaboom💥 eles quebram. Qual deles quebrou? `setOpenIndex sets the open index state properly.`
Qual é a mensagem de erro?
```
expect(received).toBe(expected)
Expected value to be (using ===):
0
Received:
undefined
```
Essa falha no teste está nos alertando sobre um problema real? Não! O componente ainda funciona bem.
Isso é o que chamamos de falso-negativo. Isso significa que tivemos uma falha no teste, mas foi por causa de um teste quebrado, não do código da aplicação. Sinceramente, não consigo pensar em uma situação de falha de teste mais irritante. Bem, vamos prosseguir e corrigir nosso teste:
```diff
test('setOpenIndex sets the open index state properly', () => {
const wrapper = mount(<Accordion items={[]} />)
- expect(wrapper.state('openIndex')).toEqual(0)
+ expect(wrapper.state('openIndexes')).toEqual([0])
wrapper.instance().setOpenIndex(1)
- expect(wrapper.state('openIndex')).toEqual(1)
+ expect(wrapper.state('openIndexes')).toEqual([1])
})
```
A lição: **testar detalhes de implementação pode fornecer um falso negativo quando você refatorar seu código. Isso leva a testes frágeis e frustrantes que parecem falhar sempre que você olha o código.**
<hr />
## Falso-positivo
Ok, agora digamos que seu colega de trabalho está trabalhando no Accordion e vê este código:
```react
<button onClick={() => this.setOpenIndex(index)}>{item.title}</button>
```
Imediatamente, seus sentimentos de otimização prematura surgem e eles dizem: "Ei! As arrow functions inline no render são [ruins para o desempenho](https://medium.com/@ryanflorence/react-inline-functions-and-performance-bdff784f5578), então vou corrigir isso! Acho que isso deve funcionar, vou mudá-lo bem rápido e executar os testes."
```react
<button onClick={this.setOpenIndex}>{item.title}</button>
```
Legal. Execute os testes e... ✅✅ incrível! Eles aceitam o código sem verificá-lo no navegador porque os testes dão confiança, certo? Esse commit vai em um PR completamente não relacionado que muda milhares de linhas de código e é compreensivelmente perdido. O accordion quebra na produção e Nancy não consegue os ingressos para ver Wicked in Salt Lake. Nancy está chorando e sua equipe se sente horrível.
Então, o que deu errado? Não tínhamos um teste para verificar se o estado muda quando `setOpenIndex` é chamado e se o conteúdo do accordion é exibido de forma adequada!? Sim, você fez! Mas o problema é que não houve nenhum teste para verificar se o botão estava conectado a `setOpenIndex` corretamente.
**Isso é chamado de falso-positivo.** Significa que não tivemos uma falha no teste, mas deveríamos! Então, como nos precavemos para garantir que isso não aconteça novamente? Precisamos adicionar outro teste para verificar se ao clicar no botão o estado é atualizado corretamente. E então preciso adicionar um limite de 100% de cobertura de código para que não cometamos esse erro novamente. Ah, e eu deveria escrever uma dúzia ou mais de plugins ESLint para garantir que as pessoas não usem essas APIs que incentivam testar os detalhes de implementação!
...Mas não vou incomodar ... Ugh, estou tão cansado de todos esses falsos-positivos e negativos que quase prefiro não escrever testes. APAGUE TODOS OS TESTES!
Não seria bom se tivéssemos uma ferramenta que entregasse um [Pit](https://twitter.com/kentcdodds/status/859994199738900480) of [Success](https://blog.codinghorror.com/falling-into-the-pit-of-success) mais amplo? Sim, seria! E adivinhe, nós temos essa ferramenta!
<hr />
## Testes sem detalhes de implementação
Portanto, poderíamos reescrever todos esses testes com enzyme, nos limitando a APIs que não contenham detalhes de implementação, mas, em vez disso, vou apenas usar a [React Testing Library](https://github.com/testing-library/react-testing-library), o que tornará muito difícil incluir detalhes de implementação em meus testes. Vamos verificar isso agora!
```js
// __tests__/accordion.rtl.js
import '@testing-library/jest-dom/extend-expect'
import * as React from 'react'
import {render, screen} from '@testing-library/react'
import userEvent from '@testing-library/user-event'
import Accordion from '../accordion'
test('can open accordion items to see the contents', () => {
const hats = {title: 'Favorite Hats', contents: 'Fedoras are classy'}
const footware = {
title: 'Favorite Footware',
contents: 'Flipflops are the best',
}
render(<Accordion items={[hats, footware]} />)
expect(screen.getByText(hats.contents)).toBeInTheDocument()
expect(screen.queryByText(footware.contents)).not.toBeInTheDocument()
userEvent.click(screen.getByText(footware.title))
expect(screen.getByText(footware.contents)).toBeInTheDocument()
expect(screen.queryByText(hats.contents)).not.toBeInTheDocument()
})
```
Maravilha! Um único teste que verifica muito bem todo o comportamento. E este teste passa se o meu estado é chamado `openIndex`, `openIndexes` ou `tacosAreTasty` 🌮. Legal! Livre-se daquele falso-negativo! E se eu conectar meu manipulador de cliques incorretamente, este teste falhará. Legal, livre-se daquele falso-positivo também! E não precisei memorizar nenhuma lista de regras. Eu apenas uso a ferramenta a partir de sua semântica e recebo um teste que realmente pode me dar confiança de que meu accordion está funcionando como o usuário também deseja.
<hr />
## Então... Quais são os detalhes de implementação?
Esta é a definição mais simples que posso fazer:
> Os detalhes de implementação são coisas que os usuários do seu código normalmente não usarão, verão ou mesmo saberão.
Portanto, a primeira pergunta que precisamos responder é: "Quem é o usuário deste código." Bem, o usuário final que estará interagindo com nosso componente no navegador é definitivamente um usuário. Eles estarão observando e interagindo com os botões e conteúdos renderizados. Mas também temos o desenvolvedor que renderizará o accordion com propriedades (no nosso caso, uma determinada lista de itens). Portanto, os componentes React normalmente têm dois usuários: usuários finais e desenvolvedores. **Usuários finais e desenvolvedores são os dois "usuários" que nosso código precisa considerar.**
Ótimo, então quais partes do nosso código cada um desses usuários usa, vê e conhece? O usuário final verá/interagirá com o que renderizamos no método `render`. O desenvolvedor verá/interagirá com as propriedades que ele passa para o componente. Portanto, nosso teste normalmente deve apenas ver/interagir com as propriedades que foram passadas e a saída renderizada.
Isso é precisamente o que o [React Testing Library](https://github.com/testing-library/react-testing-library) faz. Damos a ele nosso próprio elemento React do componente Accordion com nossas propriedades falsas, então interagimos com a saída renderizada, consultando a saída para o conteúdo que será exibido para o usuário (ou garantindo que não será exibido) e clicando nos botões que são renderizados.
Agora considere o teste com enzyme. Com enzyme, acessamos o `state` de `openIndex`. Isso não é algo com que nenhum de nossos usuários se preocupe diretamente. Eles não sabem como é chamado, não sabem se o índice aberto é armazenado como um único valor primitivo ou armazenado como um array e, francamente, eles não se importam. Eles também não sabem ou não se importam com o método `setOpenIndex` especificamente. E ainda, nosso teste conhece esses dois detalhes de implementação.
Isso é o que torna nosso teste em enzyme sujeito a falsos-negativos. Porque, **ao fazer nosso teste usar o componente de maneira diferente dos usuários finais e desenvolvedores, criamos um terceiro usuário que nosso código de aplicativo precisa considerar: os testes!** E, francamente, os testes são um usuário com o qual ninguém se importa. Não quero que o código da minha aplicação considere os testes. Que completa perda de tempo. Não quero testes escritos para seu próprio bem. Os testes automatizados devem verificar se o código da aplicação funciona para os usuários de produção.
> [Quanto mais seus testes se assemelham à forma como o software é usado, mais confiança eles podem lhe dar](https://twitter.com/kentcdodds/status/977018512689455106). - Kent C. Dodds
> Leia mais sobre isso em [Evitar o usuário Teste](https://kentcdodds.com/blog/avoid-the-test-user).
<hr />
## Então, e os hooks
Bem, ao que parece, o [enzyme ainda tem muitos problemas com hooks](https://github.com/enzymejs/enzyme/issues/2263). Acontece que quando você está testando os detalhes de implementação, uma mudança na implementação tem um grande impacto em seus testes. Isso é uma grande chatice porque se você estiver migrando componentes de classe para componentes de função com hooks, então seus testes não podem ajudá-lo a saber que você não quebrou nada no processo.
React Testing Library, por outro lado, funciona de qualquer maneira. Verifique o link codesandbox no final para vê-lo em ação. Gosto de chamar testes que você escreve com o React Testing Library:
> Livres de detalhes de implementação e fáceis de refatorar.
<hr />
## Conclusão
Então, como você evita testar os detalhes de implementação? Usar as ferramentas certas é um bom começo. Aqui está um processo de como saber o que testar. Seguir este processo ajuda você a ter a mentalidade certa ao testar e, naturalmente, evitará os detalhes de implementação:
1. Qual parte de sua base de código não testada seria realmente ruim se quebrasse? (O processo de checkout);
2. Tente restringir a uma unidade ou algumas unidades de código (ao clicar no botão "checkout", uma solicitação com os itens do carrinho é enviada para /checkout);
3. Olhe para esse código e considere quem são os "usuários" (o desenvolvedor processando o formulário de checkout, o usuário final clicando no botão);
4. Escreva uma lista de instruções para que o usuário teste manualmente esse código para se certificar de que não está corrompido. (renderize o formulário com alguns dados falsos no carrinho, clique no botão checkout, certifique-se de que a API mock/checkout foi chamada com os dados corretos, responda com uma resposta falsa bem-sucedida, certifique-se de que a mensagem de sucesso seja exibida);
5. Transforme essa lista de instruções em um teste automatizado.
Espero que seja útil para você! Se você realmente deseja levar seus testes para o próximo nível, eu definitivamente recomendo que você obtenha uma licença Pro para [TestingJavaScript.com](https://testingjavascript.com/) 🏆
Boa sorte!
PS: Se você gostaria de brincar com tudo isso, [aqui está um codesandbox](https://codesandbox.io/s/rlnw1r5nxo).
<hr />
Tradução livre do artigo “[Testing Implementation Details](https://kentcdodds.com/blog/testing-implementation-details)” originalmente escrito por Kent C. Dodds, publicado em 17 de Agosto de 2020. | exploitmik |
799,836 | This week in Flutter #17 | I am not a big fan of Medium for tech articles. It is a closed platform, with a horrible user... | 12,898 | 2021-08-22T13:32:27 | https://ishouldgotosleep.com/this-week-in-flutter-17/ | flutter, dart, news, dartlang | I am not a big fan of Medium for tech articles. It is a [closed platform](<https://opensubscriptionplatforms.com>), with a [horrible](<https://medium.com/@nikitonsky/medium-is-a-poor-choice-for-blogging-bb0048d19133>) user experience - try to copy and paste some terminal command in a medium article and let me know.
So I was pleased when I learned that Hashnode [got ](<https://townhall.hashnode.com/dollar67m-in-series-a-funding-to-build-the-next-gen-developer-blogging-community>)(more) [funding](<https://townhall.hashnode.com/dollar67m-in-series-a-funding-to-build-the-next-gen-developer-blogging-community>). Hashnode is a blogging platform for developers, like [Dev.to](<https://dev.to>). If you are starting a tech blog, and you do not want to host your own website then look at those two before going to Medium.
<small>- Michele Volpato</small>
## 🧑💻 Development
### [An approach to error handling on Flutter](<https://aquilarafael.hashnode.dev/an-approach-to-error-handling-on-flutter>)
[Rafael Áquila](<https://hashnode.com/@aquila>) shows a couple of ways to handle errors in a Dart program. He starts with the usual "print on catch" code, and then he provides the `ResultWrapper<T>` class that you can use to hold the error or the expected result. Finally, he also shows a functional approach using [Dartz](<https://pub.dev/packages/dartz>), a functional programming package for Dart.
---
### [How to Parse JSON in Dart/Flutter with Code Generation using Freezed](<https://codewithandrea.com/articles/parse-json-dart-codegen-freezed/>)
As a continuation of the [article](<https://ishouldgotosleep.com/this-week-in-flutter-16/#how-to-parse-json-in-dartflutter-the-essential-guide>) from last week, [Andrea Bizzotto](<https://twitter.com/biz84>) pushes JSON parsing to the limit with code generation. I am all for automating repetitive tasks, but I do not use code generation intensively. I find the needed annotations annoying, and not easy to understand for a new member of the team. I still use it sometimes, and when I use it I commit the generated files to the repository. Andrea argues that the code reviews become harder to perform, but you can easily [exclude generated files from the merge diff](<https://git-scm.com/docs/gitattributes#_defining_macro_attributes>).
---
### [The Ultimate Flutter Layout Guide](<https://blog.adityasharma.co/the-ultimate-flutter-layout-guide>)
Ok, I am not sure this is the "ultimate" guide, but it is a good idea to keep it next to you when you really cannot understand why that container is not properly aligned/sized/visible. Thanks, [Aditya Sharma](<https://hashnode.com/@BetaPundit>).
---
### [Keys In Flutter - UniqueKey, ValueKey, ObjectKey, PageStorageKey, GlobalKey](<https://dhruvnakum.xyz/keys-in-flutter-uniquekey-valuekey-objectkey-pagestoragekey-globalkey>)
In this comprehensive article, [Dhruv Nakum](<https://twitter.com/dhruv_nakum>) talks about `Key`s in Flutter. We have seen keys in a [previous issue](<https://ishouldgotosleep.com/this-week-in-flutter-11/>), but Dhruv goes straight to the point in this article.
---
### [Creating a custom progress indicator](<https://dev.to/danko56666/creating-a-custom-progress-indicator-346e>)
Get your hands dirty with some `CustomPaint` and create a new progress indicator with this article by [Daniel Ko](<https://twitter.com/danko566>). Warning: there is math in there.
---
### [Flutter Timer vs Ticker: A Case Study](<https://codewithandrea.com/articles/flutter-timer-vs-ticker/>)
[Andrea Bizzotto](<https://twitter.com/biz84>) publishes a lesson from his [Flutter Animation Masterclass](<https://codewithandrea.com/courses/flutter-animations-masterclass/>), where he explains why you should use `Ticker` instead of `Timer` when building a stopwatch. I bought the course, and I must say that it is well done. If you are learning Flutter, and want to know more about animations, you should consider it. Just to be clear: I am not affiliated with Andrea and I paid full price for the course.
---
### [A guide to theming your app in Flutter](<https://blog.logrocket.com/theming-your-app-flutter-guide/>)
A quick and easy article about getting started with `<a href="https://pub.dev/packages/adaptive_theme">adaptive_theme</a>` and [Riverpod](<https://pub.dev/packages/flutter_riverpod>) to handle themes in your app, by Chinedu Imoh.
---
### [Master The Art of Dependency Injection 🐱👤](<https://dhruvnakum.xyz/master-the-art-of-dependency-injection>)
Dependency injection is important to keep your code loosely coupled and highly testable. Are there special considerations about dependency injection when working on a Flutter app? We could have a very deep widget tree, forcing us to inject the dependency from the root to the leaf. Read more about dependency injection in Flutter from [Dhruv Nakum](<https://twitter.com/dhruv_nakum>).
---
## 🛠 Tools
### [freeRASP](<https://github.com/talsec/Free-RASP-Community>)
A tool like **Crashlytics but for threats.** You deploy it with your app, and it notifies you about attempts to clone it or reverse engineer it. I am not sure about what you can do after being notified. I consider the apps I distribute as at risk of being studied and cloned. You should not have secrets in the app, because it runs on a device you have no control of. Secrets should be managed only on platforms you fully control, like a backend server.
---
[...]
[Read the rest on ishouldgotosleep.com](https://ishouldgotosleep.com/this-week-in-flutter-17/)
| mvolpato |
799,991 | PayPal Payment Integration using Braintree in Ionic 5 apps | In this tutorial, we will go through PayPal payment using Braintree in Ionic 5. Previously Paypal... | 0 | 2021-08-23T18:12:46 | https://enappd.com/blog/paypal-integration-in-ionic-apps-and-pwa/142 | ionic, paypal, braintree, payment | <main role="main"><article class=" u-minHeight100vhOffset65 u-overflowHidden postArticle postArticle--full is-supplementalPostContentLoaded is-withAccentColors" lang="en" ><div class="postArticle-content js-postField js-notesSource editable" id="editor_7" g_editable="true" role="textbox" contenteditable="false" data-default-value="Title
Tell your story…"><section name="296f" class="section section--body section--first"><div class="section-divider"><hr class="section-divider"></div><div class="section-content"><div class="section-inner sectionLayout--insetColumn"><p name="a2aa" class="graf graf--p graf-after--figure">In this tutorial, we will go through PayPal payment using Braintree in Ionic 5. Previously Paypal supported the <a href="https://ionicframework.com/docs/native/paypal" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Cordova PayPal Plugin</a>, which is no more maintained by PayPal, hence it has issues while making payment using PayPal Login. PayPal now recommends using Braintree for mobile payments, while web payment still works fine with the generic PayPal JS script. You can read more about the web integration in our blog — <a href="https://enappd.com/blog/paypal-integration-in-ionic-apps-and-pwa/142/" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">PayPal integration in Ionic PWA</a>.</p><blockquote name="40ae" class="graf graf--blockquote graf-after--p">For ease of development, it is recommended to have same payment method i.e. Braintree for both mobile and web, instead of PayPal for web and Braintree for mobile.</blockquote><p name="3d8b" class="graf graf--p graf-after--blockquote">This type of integration requires a Backend (server) to generate several tokens and final transaction is also done by the server. For this tutorial, we will be using a Node JS server and will be calling APIs from Ionic app using HTTP client.</p><p name="8703" class="graf graf--p graf-after--p">We will follow below steps to implement PayPal integration using Braintree.</p><h3 name="36b4" class="graf graf--h3 graf-after--p">Steps to Implement PayPal Integration Using Braintree :-</h3><ol class="postList"><li name="5fcc" class="graf graf--li graf-after--h3">Create Braintree sandbox account and get the required keys</li><li name="67e4" class="graf graf--li graf-after--li">Setup Ionic 5 project</li><li name="28c9" class="graf graf--li graf-after--li">Setup Node JS project</li><li name="c3bf" class="graf graf--li graf-after--li">Creating Node JS API’s for Braintree</li><li name="bde3" class="graf graf--li graf-after--li">Braintree/PayPal integration in Ionic app using Node JS API’s</li><li name="dbeb" class="graf graf--li graf-after--li">Testing</li></ol><p name="eec2" class="graf graf--p graf-after--li">Before we proceed, a little bit about Ionic and Braintree</p><h3 name="58e7" class="graf graf--h3 graf-after--p">What is Braintree ?</h3><p name="9cab" class="graf graf--p graf-after--h3">Braintree offers a variety of products that make it easy for users to accept payments in their apps or website. Think of Braintree as the credit card terminal you swipe your card through at the grocery store. Braintree supports following major types of payment methods</p><ul class="postList"><li name="c3b1" class="graf graf--li graf-after--p">ACH Direct Debit</li><li name="b53b" class="graf graf--li graf-after--li">Apple Pay</li><li name="5268" class="graf graf--li graf-after--li">Google Pay</li><li name="d80f" class="graf graf--li graf-after--li">PayPal</li><li name="c129" class="graf graf--li graf-after--li">Samsung Pay</li><li name="7134" class="graf graf--li graf-after--li">Credit / Debit cards</li><li name="3c75" class="graf graf--li graf-after--li">Union Pay</li><li name="b9cb" class="graf graf--li graf-after--li">Venmo</li></ul><h3 name="6591" class="graf graf--h3 graf-after--li">What is Ionic ?</h3><p name="d89f" class="graf graf--p graf-after--h3">Ionic framework is a mobile app framework, which supports other front-end frameworks like Angular, React, Vue and Vanilla JS, and builds apps for both Android and iOS from same code.</p><p name="43e6" class="graf graf--p graf-after--p">If you create Native apps in Android, you code in Java. If you create Native apps in iOS, you code in Obj-C or Swift. Both of these are powerful but complex languages. <strong class="markup--strong markup--p-strong">With Ionic you can write a single piece of code for your app that can run on both iOS and Android </strong>and web (as PWA), that too with the simplicity of HTML, CSS, and JS.</p><p name="2b1a" class="graf graf--p graf-after--p">It is important to note the contribution of Cordova/Capacitor in this. Ionic is only a UI wrapper made up of HTML, CSS and JS. So, by default, Ionic cannot run as an app in an iOS or Android device. Cordova/Capacitor is the build environment that containerizes (sort of) this Ionic web app and converts it into a device installable app, along with providing this app access to native APIs like Camera, web access etc.</p><h3 name="82e2" class="graf graf--h3 graf-after--p">Ionic and Payment Gateways</h3><p name="b85f" class="graf graf--p graf-after--h3">Ionic can create a wide variety of apps, and hence a wide variety of payment gateways can be implemented in Ionic apps. The popular ones are PayPal, Stripe, Braintree, in-app purchase etc. For more details on payment gateways, you can read our blogs on <a href="https://medium.com/enappd/payment-solutions-in-ionic-8c4bb28ce5cc" class="markup--anchor markup--p-anchor" target="_blank">Payment Gateway Solutions in Ionic</a>, <a href="https://enappd.com/blog/ionic-5-stripe-payment-integration-firebase-cloud-functions-vs-node-express-based-server/159" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Stripe integration in Ionic</a>, <a href="https://enappd.com/blog/how-to-integrate-apple-pay-in-ionic-4-apps/21" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Apple pay in Ionic</a> etc.</p><p name="b8c2" class="graf graf--p graf-after--p">Also, there are different types of Ionic Apps you can build for same functionality. Most popular ones are :</p><ol class="postList"><li name="bee1" class="graf graf--li graf-after--p"><strong class="markup--strong markup--li-strong">Front-end: Angular | Build environment : Cordova</strong></li><li name="4677" class="graf graf--li graf-after--li">Front-end: Angular | Build environment : Capacitor <strong class="markup--strong markup--li-strong">✅</strong></li><li name="7c35" class="graf graf--li graf-after--li">Front-end: React | Build environment : Capacitor</li><li name="c4d1" class="graf graf--li graf-after--li">Front-end: Vue | Build environment : Capacitor</li></ol><p name="9fc6" class="graf graf--p graf-after--li">PayPal can be integrated in websites as well as mobile apps. In this blog we’ll learn <strong class="markup--strong markup--p-strong">how to integrate PayPal payment gateway in Angular/Capacitor Ionic 5 apps using Braintree.</strong></p><p name="8c2f" class="graf graf--p graf-after--p">OK, enough of talking, let’s start building our PayPal Braintree Payment System.</p><h3 name="045e" class="graf graf--h3 graf-after--figure"><strong class="markup--strong markup--h3-strong">Step 1 :- Create Braintree sandbox account and get the required keys</strong></h3><p name="59a9" class="graf graf--p graf-after--h3">This steps is required to proceed further, we will be needing several keys to integrate PayPal in Ionic 5 app as well as in Node JS script. To get these keys go to <a href="https://sandbox.braintreegateway.com/login" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Braintree Sandbox Account</a>. Once you login, you can go to settings and select API.</p><figure tabindex="0" contenteditable="false" name="a86c" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 700px; max-height: 175px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 24.9%;"></div><img class="graf-image" data-image-id="1*4Z_gnQyxm4qzSa1fszFVfA.png" data-width="1363" data-height="340" src="https://cdn-images-1.medium.com/max/800/1*4Z_gnQyxm4qzSa1fszFVfA.png"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Braintree Sandbox settings to get API keys</figcaption><br></figure><p name="e115" class="graf graf--p graf-after--figure">In API section, scroll down and you will get the Required API key. We need three keys to initialize Braintree in Node JS scripts</p><ol class="postList"><li name="dd59" class="graf graf--li graf-after--p">Merchant Id</li><li name="6e93" class="graf graf--li graf-after--li">Public Key and</li><li name="2772" class="graf graf--li graf-after--li">Private Key</li></ol><figure tabindex="0" contenteditable="false" name="3944" class="graf graf--figure graf-after--li"><div class="aspectRatioPlaceholder is-locked" style="max-width: 700px; max-height: 135px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 19.3%;"></div><img class="graf-image" data-image-id="1*QSv8L8ofyjBN6l-voJ3WMQ.png" data-width="1282" data-height="248" src="https://cdn-images-1.medium.com/max/800/1*QSv8L8ofyjBN6l-voJ3WMQ.png"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Public Key and Private Key in Braintree settings</figcaption><br></figure><figure tabindex="0" contenteditable="false" name="7903" class="graf graf--figure graf-after--figure"><div class="aspectRatioPlaceholder is-locked" style="max-width: 700px; max-height: 230px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 32.800000000000004%;"></div><img class="graf-image" data-image-id="1*c3hzrZdf94LcBV4CRPSYsA.png" data-width="1353" data-height="444" src="https://cdn-images-1.medium.com/max/800/1*c3hzrZdf94LcBV4CRPSYsA.png"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Braintree Merchat ID</figcaption><br></figure><p name="15de" class="graf graf--p graf-after--figure">Save these IDs, we will use them in initializing the Braintree on server-side.</p><h3 name="5c31" class="graf graf--h3 graf-after--p">Step 2 — <strong class="markup--strong markup--h3-strong">Setup Ionic 5 project</strong></h3><p name="42a4" class="graf graf--p graf-after--h3">In this part, we will create and configure Ionic 5 Project and also setup new Node JS Script.</p><h4 name="98b5" class="graf graf--h4 graf-after--p">Creating and configuring the Ionic 5 application.</h4><p name="7c58" class="graf graf--p graf-after--h4">To create new Ionic 5 project, run the below command :-</p><pre name="cd20" class="graf graf--pre graf-after--p">$ ionic start PayPal --blank --type=angular</pre><p name="7543" class="graf graf--p graf-after--pre">This will create blank app in the working directory and if you want to know more about creating the Ionic 5 project, go to <a href="https://enappd.com/blog/how-to-create-an-ionic-app-for-beginners/144/" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Ionic 5 Beginners Blog</a>. Now once we have created the Ionic app, we can configure the app for Braintree, to do that flow the below steps.</p><p name="1076" class="graf graf--p graf-after--p"><strong class="markup--strong markup--p-strong">a) Add CDN to </strong><code class="markup--code markup--p-code"><strong class="markup--strong markup--p-strong">index.html</strong></code><strong class="markup--strong markup--p-strong"> file</strong><br>How will Ionic app know we want to use Braintree ? Currently there is no Cordova or Capacitor plugin for Braintree. Hence we will add the CDN to parent file i.e. index.html, below is the CDN for Braintree JavaScript SDK.</p><pre name="e725" class="graf graf--pre graf-after--p"><script src="https://js.braintreegateway.com/js/braintree-2.32.1.min.js"></script></pre><p name="b16c" class="graf graf--p graf-after--pre">By adding this SDK CDN, Braintree will be available throughout the application. We can simply use it in any of the pages in our Ionic app.</p><p name="ef1e" class="graf graf--p graf-after--p"><strong class="markup--strong markup--p-strong">b) Using Braintree variable in Ionic 5 application<br></strong>Once we import the SDK CDN, we can use the Braintree variable in any page by using below defined syntax</p><pre name="2c13" class="graf graf--pre graf-after--p">declare const braintree;</pre><p name="51b9" class="graf graf--p graf-after--pre">Now later in Payment-gateway page, we will use this variable to setup the Client side application for successful payment.</p><h3 name="d72e" class="graf graf--h3 graf-after--p">Step 3 — Setup Node JS project</h3><p name="ec68" class="graf graf--p graf-after--h3">Create a separate folder for node server. To create Node JS script, we will run<strong class="markup--strong markup--p-strong"> </strong><code class="markup--code markup--p-code"><strong class="markup--strong markup--p-strong">npm init</strong></code> in the working directory .</p><pre name="8885" class="graf graf--pre graf-after--p">$ npm init</pre><p name="6345" class="graf graf--p graf-after--pre">Above command will ask few basic questions and creates the <code class="markup--code markup--p-code">package.json</code> file in working directory. Now you can create the <code class="markup--code markup--p-code">index.js</code> file (All logic will be contained in index file because we’re making a simple server).</p><p name="39a2" class="graf graf--p graf-after--p">We have to install some of the libraries that will help in implementing node script. To install the libraries run the below command :-</p><pre name="a596" class="graf graf--pre graf-after--p">$ npm install <em class="markup--em markup--pre-em">cors express braintree body-parser</em></pre><p name="1c12" class="graf graf--p graf-after--pre">To know more about <a href="https://www.npmjs.com/package/cors" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank"><em class="markup--em markup--p-em">cors</em></a>, <a href="https://www.npmjs.com/package/express" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank"><em class="markup--em markup--p-em">express</em></a>, <a href="https://www.npmjs.com/package/body-parser" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank"><em class="markup--em markup--p-em">body-parser</em></a> and <a href="https://www.npmjs.com/package/braintree" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank"><em class="markup--em markup--p-em">braintree</em></a><em class="markup--em markup--p-em"> </em>you can follow the links. You can also check official <a href="https://ionicframework.com/docs/troubleshooting/cors" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Ionic documentation on CORS</a> which we believe is very good for understanding.</p><figure tabindex="0" contenteditable="false" name="33b1" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 291px; max-height: 143px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 49.1%;"></div><img class="graf-image" data-image-id="1*1-_17l8nH7ybzjl8BD7RxA.jpeg" data-width="291" data-height="143" alt="Project Structure" src="https://cdn-images-1.medium.com/max/800/1*1-_17l8nH7ybzjl8BD7RxA.jpeg"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Project Structure</figcaption><br></figure><p name="bb14" class="graf graf--p graf-after--figure">Now we have all the basic requirements to start our node script.</p><p name="9f84" class="graf graf--p graf-after--p"><strong class="markup--strong markup--p-strong">Note</strong> — Check your project’s <code class="markup--code markup--p-code">package.json</code> file, it should contain the value stated below in scripts section. If it doesn’t, just add manually :-</p><figure tabindex="0" contenteditable="false" name="c5e4" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 624px; max-height: 100px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 16%;"></div><img class="graf-image" data-image-id="1*aueX2NUPIkFc-V1LCwNi7w.png" data-width="624" data-height="100" alt="package.json file" src="https://cdn-images-1.medium.com/max/800/1*aueX2NUPIkFc-V1LCwNi7w.png"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">package.json file for node server</figcaption><br></figure><h3 name="73fa" class="graf graf--h3 graf-after--figure">Step 4 — <strong class="markup--strong markup--h3-strong">Creating Node JS APIs for Braintree</strong></h3><p name="3932" class="graf graf--p graf-after--h3">Creating Braintree APIs will allow us to get the <strong class="markup--strong markup--p-strong">Client ID</strong> requested from client side. We will use Braintree package to implement those APIs. First of all, import the Braintree using below command in <code class="markup--code markup--p-code">index.js</code> file</p><pre name="ad23" class="graf graf--pre graf-after--p"><em class="markup--em markup--pre-em">const</em> braintree = require("braintree");</pre><p name="e039" class="graf graf--p graf-after--pre">Now using Braintree object to initialize the Braintree Gateway. This initialization requires those keys (which we have saved in step 2) and environment value (i.e. for now we are using <strong class="markup--strong markup--p-strong"><em class="markup--em markup--p-em">Sandbox</em></strong>, later you can use production value). Use the below command to initialize the Gateway.</p><pre name="6121" class="graf graf--pre graf-after--p"><em class="markup--em markup--pre-em">const</em> gateway = new braintree.BraintreeGateway({<br> environment: braintree.Environment.Sandbox,<br> merchantId: "USE_YOUR_MERCHENT_ID",<br> publicKey: "USE_YOUR_PUBLIC_KEY",<br> privateKey: "USE_YOUR_PRIVATE_KEY"<br>});</pre><p name="7094" class="graf graf--p graf-after--pre">This Gateway object will be used to get the <strong class="markup--strong markup--p-strong">Client ID</strong> and used in doing transaction.</p><h4 name="2869" class="graf graf--h4 graf-after--p">Payment Flow with Braintree</h4><p name="6e27" class="graf graf--p graf-after--h4">The following flowchart will get you up to speed with the payment flow. With this in mind, you’ll be able to better follow the code steps given further</p><figure tabindex="0" contenteditable="false" name="052b" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 700px; max-height: 573px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 81.89999999999999%;"></div><img class="graf-image" data-image-id="1*kAd0KmHKlhYfMVmYrAxHPg.png" data-width="1221" data-height="1000" src="https://cdn-images-1.medium.com/max/800/1*kAd0KmHKlhYfMVmYrAxHPg.png"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Braintree Payment flow with Ionic app and node server</figcaption><br></figure><p name="8071" class="graf graf--p graf-after--figure">First our Ionic application will call the Node JS API that will return the CLIENT ID generated using API mentioned below :-</p><pre name="1bdb" class="graf graf--pre graf-after--p">app.get("/brainTreeClientToken", (<em class="markup--em markup--pre-em">req</em>, <em class="markup--em markup--pre-em">res</em>) <em class="markup--em markup--pre-em">=></em> {<br> gateway.clientToken.generate({}).then((<em class="markup--em markup--pre-em">response</em>) <em class="markup--em markup--pre-em">=></em> {<br> <em class="markup--em markup--pre-em">console</em>.log('Token', response);<br> res.send(response);<br> });<br>});</pre><p name="3900" class="graf graf--p graf--startsWithSingleQuote graf-after--pre"><strong class="markup--strong markup--p-strong">‘/brainTreeClientToken’</strong> API will be called from Ionic app using <strong class="markup--strong markup--p-strong">HTTP Client</strong> (later we will see in step 4). Once client side (Ionic app-side) gets the token it will setup the Braintree using setup call (will see in step 4). After setup, client will initiate payment using Pay with PayPal button. Clicking PayPal button will open In App Browser and sandbox will create a random user and provide info containing nonce (token string used in making transaction successful).</p><p name="aefd" class="graf graf--p graf-after--p">For making transaction, we will create Node JS API that will checkout payment using amount and nonce. Below is the transaction API :-</p><pre name="1144" class="graf graf--pre graf-after--p">app.post("/checkoutWithPayment", jsonParser, (<em class="markup--em markup--pre-em">req</em>, <em class="markup--em markup--pre-em">res</em>) <em class="markup--em markup--pre-em">=></em> {<br> <em class="markup--em markup--pre-em">const</em> nonceFromTheClient = req.body.nonceFromTheClient;<br> <em class="markup--em markup--pre-em">const</em> payment = req.body.paymentAmount;<br> gateway.transaction.sale({<br> amount: payment,<br> paymentMethodNonce: nonceFromTheClient,<br> options: {<br> submitForSettlement: true<br> }<br> }).then((<em class="markup--em markup--pre-em">result</em>) <em class="markup--em markup--pre-em">=></em> {<br> res.send(result);<br> });<br>});</pre><p name="e958" class="graf graf--p graf-after--pre">In above API <strong class="markup--strong markup--p-strong">nonceFromTheClient </strong>and <strong class="markup--strong markup--p-strong">paymentAmount </strong>will be passed through Ionic 5 app and using gateway object will make a transaction. This will return a transaction status containing complete info about customer, payment and also contains status of payment. This will complete the flow of payment using PayPal. Below is the complete script code :-</p><figure tabindex="0" contenteditable="false" name="7206" class="graf graf--figure graf--iframe graf-after--p is-defaultValue"><div class="aspectRatioPlaceholder is-locked"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 154.714%;"></div><div class="iframeContainer">{% gist https://gist.github.com/vaibhavgehani/03be0e85a99d510b88f765a798dbba93.js %}</div></div></figure><p name="7da2" class="graf graf--p graf-after--figure"><strong class="markup--strong markup--p-strong">Note</strong></p><ul class="postList"><li name="7342" class="graf graf--li graf-after--p">In the above script, you can replace <code class="markup--code markup--li-code">route</code> in the <code class="markup--code markup--li-code">app.listen</code> with the port <code class="markup--code markup--li-code">3000</code> . So it becomes <code class="markup--code markup--li-code">app.listen(3000,()=>...</code></li><li name="5e8a" class="graf graf--li graf-after--li">You can also create <code class="markup--code markup--li-code">.catch</code> for the <code class="markup--code markup--li-code">.generate</code> and <code class="markup--code markup--li-code">.sale</code> methods in the server. This way, if you get any error from Braintree server, you will be able to see that in node server terminal</li></ul><p name="4392" class="graf graf--p graf-after--li">Run the server using <code class="markup--code markup--p-code">npm start</code> or if you want to deploy code to some cloud server you can do that as well. If you’re running the server in local system, the APIs will have a <code class="markup--code markup--p-code">localhost</code> URL. You can test web payments directly in local system. For phone payments you might have to deploy the node server on a cloud.</p><h3 name="1229" class="graf graf--h3 graf-after--p">Step 5 — <strong class="markup--strong markup--h3-strong">Braintree integration in Ionic App using Node JS APIs</strong></h3><p name="5abb" class="graf graf--p graf-after--h3">In this part we will go through client side (Ionic app) integration, using which we can make the PayPal transaction. We have seen how to initialize Braintree in Ionic app (stated in step 2).</p><pre name="0459" class="graf graf--pre graf-after--p">declare const braintree</pre><p name="cd1f" class="graf graf--p graf-after--pre">Following method can be used to retrieve client ID from server. This method will be called during Braintree setup.</p><pre name="c60b" class="graf graf--pre graf-after--p">async getClientTokenForPaypal() {<br> return await<br>this.http.get('http://localhost:3000/brainTreeClientToken').toPromise();<br>}</pre><p name="6718" class="graf graf--p graf-after--pre">Now we can setup Braintree using below code. <strong class="markup--strong markup--p-strong">Notice that the </strong><code class="markup--code markup--p-code"><strong class="markup--strong markup--p-strong">.setup</strong></code><strong class="markup--strong markup--p-strong"> is the function which defines for the first time that we are going to use PayPal as the payment gateway, using Braintree as the provider.</strong></p><blockquote name="c64c" class="graf graf--blockquote graf-after--p">Keep in mind this setup will require the CLIENT_ID that will be generated by server API (mentioned in Step 3). So first we will call the server API and then pass the CLIENT_ID to setup method. You can call this function when page loads ( i.e. in ngOnInit() or ionViewWillEnter() methods).</blockquote><pre name="0dff" class="graf graf--pre graf-after--blockquote">initalizeBrainTree() {<br> <em class="markup--em markup--pre-em">const</em> that = this;<br> this.getClientTokenForPaypal().then((<em class="markup--em markup--pre-em">res</em>: <em class="markup--em markup--pre-em">any</em>) <em class="markup--em markup--pre-em">=></em> {<br> <em class="markup--em markup--pre-em">let</em> checkout;<br> braintree.setup(res.clientToken, 'custom', {<br> paypal: {<br> container: 'paypal-container',<br> },<br> onReady: <em class="markup--em markup--pre-em">function</em> (<em class="markup--em markup--pre-em">integration</em>) {<br> checkout = integration;<br> },<br> onCancelled: (<em class="markup--em markup--pre-em">obj</em>) <em class="markup--em markup--pre-em">=></em> {<br> <em class="markup--em markup--pre-em">console</em>.log('Cancelled', obj);<br> checkout.teardown(() <em class="markup--em markup--pre-em">=></em> { checkout = null });<br> },<br> onPaymentMethodReceived: (<em class="markup--em markup--pre-em">obj</em>) <em class="markup--em markup--pre-em">=></em> {<br> checkout.teardown(() <em class="markup--em markup--pre-em">=></em> {<br> checkout = null;<br> that.handleBraintreePayment(obj.nonce);<br> });<br> }<br> });<br> });<br>}</pre><p name="0247" class="graf graf--p graf-after--pre">In above method, first we call the <code class="markup--code markup--p-code">getClientTokenForPaypal()</code> method that will call the Node JS server <code class="markup--code markup--p-code">brainTreeClientToken</code> API and returns the token. Once we get client token, we can setup Braintree using it. This setup method will initialize the PayPal-container that will be used to render the PayPal button in HTML file.</p><p name="c560" class="graf graf--p graf-after--p">Once the client token is obtained, Paypal button will be automatically rendered in HTML file in this place. Make sure you have this in your HTML file</p><pre name="3f94" class="graf graf--pre graf-after--p"><ion-button class="paypalBtn" id="paypal-container"></ion-button></pre><p name="a038" class="graf graf--p graf-after--pre">This will render the Paypal button in Page view and will look like below screen :-</p><figure tabindex="0" contenteditable="false" name="d116" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 430px; max-height: 54px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 12.6%;"></div><img class="graf-image" data-image-id="1*MvORSvPtD4H1XJWxH7aS-A.jpeg" data-width="430" data-height="54" src="https://cdn-images-1.medium.com/max/800/1*MvORSvPtD4H1XJWxH7aS-A.jpeg"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Paypal button rendered in Ionic HTML view after client ID is obtained</figcaption><br></figure><p name="480a" class="graf graf--p graf-after--figure">Now we have completed the setup and we can make payment using this button. When we click the button it will open the In-app Browser and sandbox will handle the payment and users info. This will return the nonce value in the callback defined in setup call.</p><p name="2e73" class="graf graf--p graf-after--p">One more thing we have to keep in mind that sometimes, PayPal payment screen does not go off when we make a payment (due to some screen refresh angular issues). To remove it manually, we have to use <strong class="markup--strong markup--p-strong">teardown()</strong> method defined in checkout variable (initialized on <strong class="markup--strong markup--p-strong">onReady()</strong> callback).</p><pre name="4d74" class="graf graf--pre graf-after--p">onReady: <em class="markup--em markup--pre-em">function</em> (<em class="markup--em markup--pre-em">integration</em>) {<br> checkout = integration;<br>},</pre><p name="4cd2" class="graf graf--p graf-after--pre">Below is the callback that will handle the nonce token and pass on to other method that will handle the transaction.</p><pre name="4eda" class="graf graf--pre graf-after--p">onPaymentMethodReceived: (<em class="markup--em markup--pre-em">obj</em>) <em class="markup--em markup--pre-em">=></em> {<br> checkout.teardown(() <em class="markup--em markup--pre-em">=></em> {<br> checkout = null;<br> that.handleBraintreePayment(obj.nonce);<br> });<br>}</pre><p name="a491" class="graf graf--p graf-after--pre">We will pass the nonce value to <strong class="markup--strong markup--p-strong">handleBraintreePayment()</strong> method that will further call the transaction API defined in Node JS server. Here you can console the final response after payment.</p><pre name="fd87" class="graf graf--pre graf-after--p">async handleBraintreePayment(<em class="markup--em markup--pre-em">nonce</em>) {<br> this.api.makePaymentRequest(this.payableAmount, nonce).then((<em class="markup--em markup--pre-em">transaction</em>) <em class="markup--em markup--pre-em">=></em> {<br> <em class="markup--em markup--pre-em">console</em>.log('Transaction', transaction);<br> })<br>}</pre><p name="c21b" class="graf graf--p graf-after--pre">Above <strong class="markup--strong markup--p-strong">makePaymentRequest()</strong> method will call the transaction API defined in Node JS server, that will make the original payment using Braintree. Below is the function call :-</p><pre name="caef" class="graf graf--pre graf-after--p">async makePaymentRequest(<em class="markup--em markup--pre-em">amount</em>, <em class="markup--em markup--pre-em">nonce</em>) {<br> <em class="markup--em markup--pre-em">const</em> paymentDetails = {<br> paymentAmount: amount,<br> nonceFromTheClient: nonce<br> }<br> return await this.http.post('http://localhost:3000/checkoutWithPayment', paymentDetails).toPromise();<br>}</pre><p name="d097" class="graf graf--p graf-after--pre">Above function will contain the paymentAmount and nonce value and will passed them to the server API. That will return the transaction object and we can decide the client end logic according to the response that we get from server. This will complete the PayPal Braintree integration from both client side and server side.</p><h3 name="1faf" class="graf graf--h3 graf-after--p">Step 6 — Testing</h3><p name="c3f4" class="graf graf--p graf-after--h3">As mentioned earlier, it is easy to test this setup in a web domain, because the server can run on localhost, and the Ionic app can call the server while running with <code class="markup--code markup--p-code">ionic serve</code> . Here how the payment flow looks</p><figure tabindex="0" contenteditable="false" name="db10" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 485px; max-height: 650px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 134%;"></div><img class="graf-image" data-image-id="1*-YE2LgNaTROcl-RbMYBNhg.gif" data-width="485" data-height="650" src="https://cdn-images-1.medium.com/max/800/1*-YE2LgNaTROcl-RbMYBNhg.gif"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">PayPal payment in Ionic app using Braintree</figcaption><br></figure><p name="451f" class="graf graf--p graf-after--figure">To test it in your device, you will need to deploy the server on a cloud so you can call the APIs from the app. If there is a way you can call localhost APIs from your app (I don’t know any), that should work as well !</p><h3 name="c806" class="graf graf--h3 graf-after--p">Troubleshooting</h3><h4 name="57b4" class="graf graf--h4 graf-after--h3"><strong class="markup--strong markup--h4-strong">>> braintree is not defined</strong></h4><p name="2b1d" class="graf graf--p graf-after--h4">Check if you included the Braintree script in <code class="markup--code markup--p-code">index.html</code></p><h4 name="2d5e" class="graf graf--h4 graf-after--p">>> Authentication error in API</h4><p name="2777" class="graf graf--p graf-after--h4">Check if you have entered correct API keys and Merchant Id in node server. Also check if you are using Production keys in Sandbox, or vice versa</p><h3 name="6071" class="graf graf--h3 graf-after--p">Conclusion :-</h3><p name="cb42" class="graf graf--p graf-after--h3">Congratulations !! 🎉 You just learnt how to integrate the awesome Braintree payment system to make payments using PayPal.</p><p name="bba7" class="graf graf--p graf-after--p">You can make payments using both PayPal account and Debit / Credit Cards. This way of integration can work both in Web view and mobile apps. If you want to know more about any feature integration, you can check out our amazing tutorials at <a href="https://enappd.com/blog/" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Enappd Blogs</a>.</p><p name="956c" class="graf graf--p graf-after--p graf--trailing">Happy coding !</p></div></div></section><section name="d6b0" class="section section--body"><div class="section-divider"><hr class="section-divider"></div><div class="section-content"><div class="section-inner sectionLayout--insetColumn"><h3 name="0647" class="graf graf--h3 graf--leading">Next Steps</h3><p name="ee74" class="graf graf--p graf-after--h3 graf--trailing">If you liked this blog, you will also find the following blogs interesting and helpful. Feel free to ask any questions in the comment section</p></div></div></section><section name="06ac" class="section section--body"><div class="section-divider"><hr class="section-divider"></div><div class="section-content"><div class="section-inner sectionLayout--insetColumn"><h3 name="bdf7" class="graf graf--h3 graf--leading">Ionic Capacitor</h3><ul class="postList"><li name="5f8e" class="graf graf--li graf-after--h3"><strong class="markup--strong markup--li-strong">Basic</strong> — <a href="https://enappd.com/blog/use-geolocation-geocoding-and-reverse-geocoding-in-ionic-capacitor/131" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Geolocation</a> | <a href="https://enappd.com/blog/qr-code-and-barcode-scanning-with-ionic-capacitor/127" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Barcode & QR code</a> | <a href="https://enappd.com/blog/facebook-login-in-capacitor-apps-with-ionic-angular/128" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Facebook Login</a> (Angular) | <a href="https://enappd.com/blog/facebook-login-in-ionic-react-capacitor-apps/118" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Facebook Login (React)</a> | <a href="https://enappd.com/blog/icon-splash-in-ionic-react-capacitor-apps/114" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Icon and Splash</a> | <a href="https://enappd.com/blog/camera-and-gallery-in-ionic-react-app-using-capacitor/110" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Camera & Photo Gallery</a> | <a href="https://enappd.com/blog/debugging-ionic-apps-using-chrome-and-safari-developers-tools/167" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Debugging with browser</a>|<a href="https://enappd.com/blog/make-awesome-theme-switcher-in-ionic-5/170" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Theming in Ionic apps</a></li><li name="0f51" class="graf graf--li graf-after--li"><strong class="markup--strong markup--li-strong">Advanced</strong> — <a href="https://enappd.com/blog/implement-admob-in-ionic-react-capacitor-apps/135" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">AdMob</a> | <a href="https://enappd.com/blog/local-notifications-in-ionic-5-capacitor/132" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Local Notifications</a> | <a href="https://enappd.com/blog/google-login-in-ionic-react-capacitor-apps/122" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Google Login</a> | <a href="https://enappd.com/blog/twitter-login-in-ionic-react-capacitor-app/121" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Twitter Login</a> | <a href="https://enappd.com/blog/html5-games-in-ionic-capacitor-using-phaser/115" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Games using Phaser</a> | <a href="https://enappd.com/blog/play-music-in-ionic-capacitor-apps/112" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Play music</a> | <a href="https://enappd.com/blog/firebase-push-notification-in-ionic-react-capacitor/111" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Push Notifications</a></li></ul><h3 name="da78" class="graf graf--h3 graf-after--li">Ionic Cordova</h3><ul class="postList"><li name="23b7" class="graf graf--li graf-after--h3"><a href="https://enappd.com/blog/ionic-app-with-nodejs-express-mysql-sequelize-taxi-app/160" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Taxi Booking App example with Ionic, Node, Express and MySQL</a></li><li name="e3ed" class="graf graf--li graf-after--li">Ionic Payment Gateways — <a href="https://enappd.com/blog/integrate-stripe-payment-gateway-in-ionic-5-apps-and-pwa-using-firebase/158" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Stripe with Firebase</a> | <a href="https://enappd.com/blog/ionic-5-stripe-payment-integration-firebase-cloud-functions-vs-node-express-based-server/159" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Stripe with NodeJS</a> | <a href="https://enappd.com/blog/paypal-integration-in-ionic-apps-and-pwa/142" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">PayPal</a> |<a href="https://enappd.com/blog/paypal-payment-integration-using-braintree-in-ionic-5-apps/177/" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">PayPal with Braintree</a>| <a href="https://enappd.com/blog/how-to-integrate-apple-pay-in-ionic-4-apps/21" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Apple Pay</a> | <a href="https://enappd.com/blog/how-to-integrate-razorpay-in-ionic-4-apps-and-pwa/20" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">RazorPay</a></li><li name="4ecb" class="graf graf--li graf-after--li">Ionic Charts with — <a href="https://enappd.com/blog/ionic-4-charts-using-google-charts/66" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Google Charts </a>| <a href="https://enappd.com/blog/adding-charts-in-ionic-4-apps-and-pwa-part-3/60" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">HighCharts</a> | <a href="https://enappd.com/blog/adding-charts-in-ionic-4-apps-and-pwa-part-2/54" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">d3.js</a> | <a href="https://enappd.com/blog/charts-in-ionic-4-apps-and-pwa-part-1/52" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Chart.js</a></li><li name="7dc9" class="graf graf--li graf-after--li">Ionic Authentications — <a href="https://enappd.com/blog/firebase-email-authentication-in-ionic-apps/153" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Via Email</a> | <a href="https://enappd.com/blog/implement-anonymous-login-in-ionic-apps-with-firebase/154" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Anonymous</a> | <a href="https://enappd.com/blog/facebook-login-in-ionic-apps-using-firebase/150" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Facebook</a> | <a href="https://enappd.com/blog/implement-google-login-in-ionic-apps-using-firebase/147" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Google</a> | <a href="https://enappd.com/blog/twitter-login-in-ionic-4-apps-using-firebase/24" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Twitter</a> | <a href="https://enappd.com/blog/firebase-phone-authentication-in-ionic-5-apps/169" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Via Phone</a></li><li name="1310" class="graf graf--li graf-after--li">Ionic Features — <a href="https://enappd.com/blog/ionic-5-complete-guide-on-geolocation/141" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Geolocation</a>| <a href="https://enappd.com/blog/ionic-complete-guide-barcode-qrcode-scan/140" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">QR Code reader</a> | <a href="https://enappd.com/blog/best-fitness-plugins-for-ionic-4-how-to-use-pedometer/15" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Pedometer</a>| <a href="https://enappd.com/blog/implement-signature-pad-in-ionic-apps/145" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Signature</a> <a href="https://enappd.com/blog/implement-signature-pad-in-ionic-apps/145" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Pad</a> | <a href="https://enappd.com/blog/using-background-geolocation-in-ionic-angular-apps/165" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Background Geolocation</a> | <a href="https://enappd.com/blog/detect-wifi-and-data-network-in-ionic-5-apps/173" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Network Detection</a></li><li name="5a5f" class="graf graf--li graf-after--li">Media in Ionic — <a href="https://enappd.com/blog/spotify-like-music-in-ionic-4-apps/48" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Audio</a> | <a href="https://enappd.com/blog/adding-video-player-in-ionic-4-app/64" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Video</a> | <a href="https://enappd.com/blog/camera-and-image-picker-in-ionic-apps/148" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Image Picker</a> | <a href="https://enappd.com/blog/how-to-add-image-cropper-in-ionic-apps/149" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Image Cropper</a> | <a href="https://enappd.com/blog/implement-sounds-and-vibration-in-ionic-apps/172" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Sounds and Vibrations</a></li><li name="71f9" class="graf graf--li graf-after--li">Ionic Essentials — <a href="https://enappd.com/blog/debugging-ionic-apps-using-chrome-and-safari-developers-tools/167" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Debugging with browser</a>| <a href="https://enappd.com/blog/ionic-4-save-and-retrieve-data-locally-on-device/59" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Native Storage</a> | <a href="https://enappd.com/blog/how-to-translate-in-ionic-internationalization-and-localization/143" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Translations</a> | <a href="https://enappd.com/blog/how-to-use-rtl-right-to-left-in-ionic-apps-pwa/152" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">RTL</a> | <a href="https://enappd.com/blog/using-sentry-error-monitoring-with-ionic-angular-applications/164" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Sentry Error Monitoring</a> | <a href="https://enappd.com/blog/social-sharing-component-in-ionic-5-mobile-web-apps/168" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Social sharing</a> | <a href="https://enappd.com/blog/how-to-generate-and-download-pdf-in-ionic-apps/174" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">PDF generation</a></li><li name="58ce" class="graf graf--li graf-after--li">Ionic messaging — <a href="https://enappd.com/blog/how-to-implement-firebase-push-notifications-in-ionic-apps/157" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Firebase Push</a> | <a href="https://enappd.com/blog/how-to-automatically-read-sms-in-ionic-5-apps/175" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Reading SMS</a> | <a href="https://enappd.com/blog/local-notifications-in-ionic-5-capacitor/132" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Local Notifications</a></li><li name="0b6b" class="graf graf--li graf-after--li">Ionic with Firebase — <a href="https://enappd.com/blog/how-to-integrate-firebase-in-ionic-4-apps/23" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Basics</a> | <a href="https://enappd.com/blog/firebase-with-ionic-4-hosting-auth-and-db-connection/58" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Hosting and DB</a> | <a href="https://enappd.com/blog/firebase-cloud-functions-in-ionic-5-complete-guide/166" class="markup--anchor markup--li-anchor" rel="noopener" target="_blank">Cloud functions</a> | <a href="https://enappd.com/blog/github-actions-deploying-ionic-angular-app-to-firebase-hosting/146" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Deploy App to Firebase</a> | <a href="https://enappd.com/blog/how-to-use-firebase-emulators-with-ionic-angular-applications/163" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Firebase simulator</a></li><li name="eaef" class="graf graf--li graf-after--li graf--trailing">Unit Testing in Ionic — <a href="https://enappd.com/blog/beginners-guide-to-ionic-angular-unit-testing-part-1/151" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Part 1</a> | <a href="https://enappd.com/blog/beginners-guide-to-ionic-angular-unit-testing-part-2-mocks-and-spies/155" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Mocks & Spies</a>| <a href="https://enappd.com/blog/beginners-guide-to-ionic-angular-unit-testing-async-testing/156" class="markup--anchor markup--li-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Async Testing</a></li></ul></div></div></section><section name="5071" class="section section--body section--last"><div class="section-divider"><hr class="section-divider"></div><div class="section-content"><div class="section-inner sectionLayout--insetColumn"><h3 name="ad14" class="graf graf--h3 graf--leading">Ionic React Full App with Capacitor</h3><p name="4fa5" class="graf graf--p graf-after--h3">If you need a base to start your next Ionic 5 React Capacitor app, you can make your next awesome app using <a href="https://store.enappd.com/product/ionic-react-full-app-capacitor/" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Ionic 5 React Full App in Capacitor</a></p><figure tabindex="0" contenteditable="false" name="0d2d" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 700px; max-height: 441px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 63%;"></div><img class="graf-image" data-image-id="1*G3yOFVX4oABx9MhUy-3kng.png" data-width="760" data-height="479" alt="Ionic 5 React Full App in Capacitor from Enappd" src="https://cdn-images-1.medium.com/max/800/1*G3yOFVX4oABx9MhUy-3kng.png"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Ionic 5 React Full App in Capacitor from Enappd</figcaption><br></figure><h3 name="30ba" class="graf graf--h3 graf-after--figure">Ionic Capacitor Full App (Angular)</h3><p name="9a60" class="graf graf--p graf-after--h3">If you need a base to start your next Angular <strong class="markup--strong markup--p-strong">Capacitor app</strong>, you can make your next awesome app using <a href="https://store.enappd.com/product/capacitor-full-app-with-ionic-angular/" class="markup--anchor markup--p-anchor" rel="noopener nofollow noopener noopener noopener" target="_blank">Capacitor Full App</a></p><figure tabindex="0" contenteditable="false" name="c219" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 700px; max-height: 761px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 108.7%;"></div><img class="graf-image" data-image-id="0*UwSHcofTMStMnzAX.png" data-width="736" data-height="800" alt="Capacitor Full App with huge number of layouts and features" src="https://cdn-images-1.medium.com/max/800/0*UwSHcofTMStMnzAX.png"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Capacitor Full App with huge number of layouts and features</figcaption><br></figure><h3 name="2f1c" class="graf graf--h3 graf-after--figure">Ionic Full App (Angular and Cordova)</h3><p name="1008" class="graf graf--p graf-after--h3">If you need a base to start your next Ionic 5 app, you can make your next awesome app using <a href="https://store.enappd.com/product/ionic-full-app" class="markup--anchor markup--p-anchor" rel="noopener" target="_blank">Ionic 5 Full App</a></p><figure tabindex="0" contenteditable="false" name="16d6" class="graf graf--figure graf-after--p"><div class="aspectRatioPlaceholder is-locked" style="max-width: 700px; max-height: 442px;"><div class="aspectRatioPlaceholder-fill" style="padding-bottom: 63.1%;"></div><img class="graf-image" data-image-id="0*1ArpKyhiDHZnevwB.jpeg" data-width="700" data-height="442" alt="Ionic Full App with huge number of layouts and features" src="https://cdn-images-1.medium.com/max/800/0*1ArpKyhiDHZnevwB.jpeg"><div class="crosshair u-ignoreBlock"></div></div><figcaption class="imageCaption" contenteditable="true" data-default-value="Type caption for image (optional)">Ionic Full App in Cordova, with huge number of layouts and features</figcaption><br></figure><p name="2fc6" class="graf graf--p graf--empty graf-after--figure graf--trailing is-selected" ><br></p></div></div></section></div></article></main> | abhijeetrathor2 |
800,093 | How to use the MDURATION function in Excel office 365? | MDURATION function returns the modified duration in years for security for an assumed $100 par value... | 0 | 2021-08-25T09:28:50 | https://geekexcel.com/how-to-use-the-mduration-function-in-excel-office-365/ | tousethemdurationfun, excel, excelfunctions | ---
title: How to use the MDURATION function in Excel office 365?
published: true
date: 2021-08-22 15:04:21 UTC
tags: ToUseTheMDURATIONFun,Excel,ExcelFunctions
canonical_url: https://geekexcel.com/how-to-use-the-mduration-function-in-excel-office-365/
---
**MDURATION function** returns the **modified duration in years for security** for an assumed **$100 par value** with some required terms. These required terms are given as **arguments for the function**. In this article, we are going to see how to **use the MDURATION Function In Excel Office 365.** Let’s get into this article!! Get an official version of MS Excel from the following link: **[https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)**
## MDURATION function syntax
```
=MDURATION( settlement, maturity , rate , yld , redemption , frequency, [basis])
```
**Syntax Explanation:**
- **Settlement :** Settlement **date of the security**.
- **Maturity :** Maturity **date of the security**. The maturity date is the date when the security expires.
- **rate : ** The security’s **annual coupon rate**.
- **yld :** The security’s **annual yield rate**.
- **frequency** – **payments per year** (1 = annual, 2 = semi, 4= quarterly).
- **basis ** – [optional] **Day count basis**. **Default is 0**.
## Example
- Firstly, you need to create **sample data with value and arguments**.
<figcaption>Sample data</figcaption>
- Then, you have to calculate the **MDURATION function in year**.
- Now, you need to use the following **formula** given below.
```
=MDURATION( B2 , B3 , B4 , B5 , 2 , 0 )
```
<figcaption>MDURATION Function</figcaption>
- After that, you have to use the same arguments to calculate the **duration function**.
- Now, you need to use the following **formula** given below.
```
=DURATION( B2 , B3 , B4 , B5 , 2 , 0 )
```
<figcaption>DURATION formula</figcaption>
**Check this too:** [List of Excel ‘Information Functions’ in Office 365!!](https://geekexcel.com/list-of-excel-information-functions-in-office-365/)
**NOTES:**
- Excel stores **dates as serial numbers** and is used in calculation by the **function**.
- It is used to recommend to use **dates as cell reference** instead of giving **direct argument to the function**.
- You need to check the **date values** if the function returns **#VALUE! Error**.
- Then, the **security settlement date** is the date after the issue date when the security is traded to the buyer.
- Now, the arguments like **settlement date & maturity date** , **frequency & basis** are truncated to **integers**.
- After that, the function returns the **#VALUE! Error** if the **settlement date & maturity date** is not a **valid date format**.
- Finally, the function returns the **#NUM! Error** if:
- If maturity date settlement value.
- If the **basis argument** is **either < 0 or > 4**
- **Payment Frequency** argument is **not one of the three** (1, 2 or 4).
- If **coupon rate or yield rate argument** is **< 0**
- The function generates **#VALUE! Error** if arguments to the function is **non – numeric**.
## Closure:
This article gives you clarity on **how to use the MDURATION Function In Excel Office 365.** Is this article helpful? Don’t forget to share your valuable **queries/suggestions** in the below comment box & also drop your **worthwhile feedback**.
Thanks for visiting **[Geek Excel!!](https://geekexcel.com/)** Keep Learning with us!!
**Keep Reading:**
- **[Insert Sheet in Microsoft Excel 2007?](https://geekexcel.com/insert-sheet-in-microsoft-excel-2007/)**
- **[Excel Formulas to Calculate the Time Duration With Number of Days!!](https://geekexcel.com/excel-formulas-to-calculate-the-time-duration-with-number-of-days/)**
- **[Formulas to Calculate the Annual Compound Interest Schedule!!](https://geekexcel.com/excel-formulas-calculate-annual-compound-interest-schedule/)**
- **[Excel Formulas to Calculate the Effective Annual Interest Rate!!](https://geekexcel.com/excel-formulas-to-calculate-the-effective-annual-interest-rate/)** | excelgeek |
800,139 | Token Authentication in Django Rest Framework | Authentication is the mechanism of associating an incoming request with some credentials that would... | 0 | 2021-08-22T19:44:20 | https://devnotfound.wordpress.com/2020/10/23/token-authentication-in-django-rest-framework/ | Authentication is the mechanism of associating an incoming request with some credentials that would be later used to determine whether the credentials is valid or not and might be frequently used to determine if the user has the permission for the request.
One of the most widely used authentication mechanism is Token Authentication. In this article we would explore Token Authentication and how to setup token authentication in Django Rest Framework. Token Authentication is appropriate for client-server setups for example native desktop clients or mobile clients or it might be used for web clients.
Token Authentication is an authentication process in which the verification of a user is done using a token. This token is a long string of random numbers and English letters. It is generated when a user registers to a system. Every time the user signs in, the server provides him this token along with other information. This token is provided in every request that requires an associated user. (if an API endpoints does not need to verify user, then it’s not required to provide it, for example: sign in, sign up requests doesn’t need it). Server receives this token before doing the usual stuff that it needs to do for the request and verifies the user.
How to use it in Django Rest Framework
Configuring settings :
To use Token Authentication we need some configuration in our django project’s settings file.
First we need to add TokenAuthentication in authentication classes.
```python
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': [
...
'rest_framework.authentication.TokenAuthentication',
]
}
```
Next, we need to include rest_framework.authtoken in our INSTALLED_APPS settings.
```python
INSTALLED_APPS = [
...
'rest_framework.authtoken'
]
```
Now, rest_framework.authtoken provides database migrations. So, we need to run manage.py migrate command.
Generating a token :
Next up, we need to create a token when a user registers in our system. Creating a token is very simple .
```python
from rest_framework.authtoken.models import Token
token = Token.objects.create(user=...)
print(token.key)
```
This way the token is created for the user. But the way we are creating the tokjen right now won’t serve our use case. We need to create the token only when the user registers or when a new user object is created. To do that, we can use django signals. The post_save signal is just perfect for that. We can detect if the user instance is created or updated using the created parameter. If the user is created then we would create the token for that user.
```python
from django.conf import settings
from django.db.models.signals import post_save
from django.dispatch import receiver
from rest_framework.authtoken.models import Token
@receiver(post_save, sender=settings.AUTH_USER_MODEL)
def create_auth_token(sender, instance=None, created=False, **kwargs):
if created:
Token.objects.create(user=instance)
```
Now, this is not the only way to do that. For example we can generate this token when it needs to be accessed for the first time using django ORM’s get_or_create(). We can do the same thing if we already have some existing users.
Using the token in requests :
We have generated the token for a user, but how would we use it our requests. The answer is simple. We would pass it in Authorization HTTP header. The token key should be prefixed by “Token” string and a white-space separating them.
```curl
Authorization: Token 9944b09199c62bcf9418ad846dd0e4bbdfc6ee4b
```
API Endpoint to retrieve token using credentials :
Now, we may need an api endpoint that would return the user his token when username and password is provided. Django Rest Framework already does that for us. We can use it’s built in view to create that api endpoint.
```python
from rest_framework.authtoken import views
urlpatterns = [
path('api-token-auth/', views.obtain_auth_token)
]
```
Now, this endpoint would return a JSON response containing then token. But, if we ever need a custom response we can either subclass DRF’s ObtainAuthToken or create a custom API view that would do the work for us.
Procedure of subclassing the ObtainAuthToken view and returning a custom response is like this:
```python
from rest_framework.authtoken.views import ObtainAuthToken
from rest_framework.authtoken.models import Token
from rest_framework.response import Response
class CustomAuthToken(ObtainAuthToken):
def post(self, request, *args, **kwargs):
serializer = self.serializer_class(data=request.data,
context={'request': request})
serializer.is_valid(raise_exception=True)
user = serializer.validated_data['user']
token, created = Token.objects.get_or_create(user=user)
return Response({
'token': token.key,
'username': user.username,
'email': user.email
})
```
Now in our urls.py file we can add a route for this view and use it same as the builtin view, but this time the response would be customized.
That is it for Token Authentication in DRF. This article was based on Django Rest Framework’s documentation. Read the documentation for more in-depth understanding and also you can dig deep into other Authentication schema as well. | aaman007 | |
800,140 | Building Dinerd using js, HTML, and CSS | Dinerd You can see Dinerd in action or watch me walk through the app. Turn to Dinerd to... | 0 | 2021-08-22T20:10:33 | https://dev.to/joedietrichdev/building-dinerd-using-js-html-and-css-232l | javascript, node, beginners | ## Dinerd
*You can see [***Dinerd*** in action](https://joedietrich-dev.github.io/dinerd/) or watch me [walk through the app](https://www.youtube.com/watch?v=Ov_H7td_QYk).*
Turn to *Dinerd* to help you answer the age-old question:
> "Where do you want to eat tonight?"
## Purpose
I developed *Dinerd* to help me break out of one of the routines I found myself falling into during the past year - always going to or ordering from the same restaurants over and over again.
Comfort food is great! But every so often it's good to branch out and try new things - and this is where *Dinerd* comes in. *Dinerd* leverages the [Yelp Fusion API](https://www.yelp.com/developers/documentation/v3/get_started) to serve the prospective diner random restaurants near them, and lets them skip ones they've already been to!
## Basic Features
When a diner first lands on *Dinerd*, they will see a form that asks them for a location, the distance from that location they'd like results from, and a price-level preference. After they have submitted their selections, *Dinerd* presents the diner with a randomized list of up to 20 restaurants, pulling details from Yelp Fusion.
If a diner has already visited a particular restaurant, they can mark it as visited and it will no longer show up in their search results. They can see the restaurants they have already visited in a pop-out sidebar menu and remove them from the visited list.
## Development Strategy and Process
Before I built *Dinerd*, I researched restaurant-locator APIs. Yelp was the best I found by far, with a generous daily API limit and high-quality data. After doing research on the data I could expect to fetch from the Yelp Fusion API, I signed up for an API key, and then started creating simple wireframes using Figma - one for the landing form, one for the visited restaurant sidebar, and one for the restaurant card.
Then I started to code.
I started by trying to play with the API. I quickly realized that building a purely front-end application with the Yelp Fusion API [wouldn't work](https://github.com/Yelp/yelp-fusion/issues/386) (and would also expose my API key to the world, which made me uncomfortable).
### Back-end Code
[View the full back-end source](https://github.com/joedietrich-dev/dinerd-backend).
#### Setup
I had previously researched creating a server using Node.js, so my mind immediately went in that direction to solve my problems. I would build a very small Node.js server to:
* Pass my front-end queries on to the Yelp Fusion API
* Return the results of the query back to the front-end application
* Allow me keep my API key secret
* Provide the opportunity for future expansion (logins, database integrations, result processing and caching)
While it would have been possible to meet my requirements using vanilla Node.js, I deceided to use [Express](https://expressjs.com) to create the server and [Axios](https://axios-http.com) to retrieve the API data from Yelp Fusion in an asyncronous, promise-friendly way.
To start, I initialized a Node.js project using `npm init`, and followed the prompts in my console. Then I created a few files I knew I would need, aside from the `package.json` file created by `npm init`:
* `index.js` - The gateway for the application, and where I put all the code for the server.
* `.env` - The file where I stored my environment variables (in this case, primarily the API key). It has two lines:
```
YELP_KEY=<yelp secret key>
PORT=3000
```
* `.gitignore` - The file that tells git to ignore other files and folders. This is important to ensure the `.env` file doesn't get synced to a cloud repository like GitHub, potentially exposing the secrets it contains. Configured correctly, it will also prevent the node_modules folder from being synced as well. For these purposes, it should contain at least these two lines:
```
node_modules/
.env
```
Once those files were properly configured, I ran the command `npm i express axios dotenv`, which installed the Express, Axios, and dotenv dependencies in my Node.js project.
#### index.js
At the top of the `index.js` file, I put the `require` statements, which make the dependences I previously installed available in the code. I also defined the port the application listens on and initialized the Express server:
```js
require('dotenv').config();
const axios = require('axios');
const express = require('express');
const port = process.env.PORT || 80;
const app = express();
```
The next few lines set up the route we'll use to query the Yelp Fusion API:
```js
app.get('/restaurants', (req, res) => {
if (req.query.location && req.query.price && req.query.distance) {
axios({
method: 'get',
url: `https://api.yelp.com/v3/businesses/search?term=food&limit=50&location=${req.query.location}&radius=${req.query.distance}&price=${req.query.price}`,
headers: {
Authorization: `Bearer ${process.env.YELP_KEY}`
}
}).then(yelpResponse => res.send(yelpResponse.data))
.catch(err => res.status(400).send(err.message));
} else {
res.status(404).send('No match for requested URL found.');
}
})
```
`app` is the server object. `.get` is a method that takes a route and a callback. When someone tries to access the route provided using the `GET` http method, Express will call the callback method provided as the second parameter to `.get`, passing in information about the request as the first parameter, and information about the response to the request as the second parameter.
For *Dinerd*, I expect my client-side application to make a request that contains three parameters - the three fields on the initial form:
* location
* price options
* distance from location chosen
If the `req` (request) contains the query parameters `location`, `price`, and `distance`, then I use Axios to send the request through to the Yelp Fusion API. For my purposes, I passed in an object containing the http method to use with Axios (`get`), the url to send the request to (the Yelp Fusion API `search` endpoint, with my query parameters interpolated), and the required `Authorization` header. The header contains a reference to the API key stored in my `.env` file.
If Yelp Fusion responds to my request with valid data, I pass it back to the requester in the `res` object, using the response's `send` method. If there were no results for the search parameters passed in, I respond to the client with a `400` error indicating a bad request, and the error message from Yelp.
If the `req` is not well-formed - that is, if it does not contain a location, price, and distance - then I respond to the client with a `404` error, since the url is not valid and doesn't match the required pattern.
All of the above sets up the Express server, but it's no good if it doesn't start listening for requests:
```js
app.listen(port, () => console.log('Listening on port ' + port));
```
This code tells the server to listen on the port provided. And with that, the *Dinerd* back end is ready - or almost.
#### CORS
If you run the command `node index.js` now, the server will start up and start listening for connections.
**But**: Try to issue a fetch request from the browser:
```js
fetch('http://localhost:3000/restaurants?price=1,2,3,4&location=10001&distanc=2000').then(res=>res.json())
```
And you'll see an error like the following:
```http
Access to fetch at 'http://localhost:3000/restaurants?price=1,2,3,4&location=10001&distance=2000' from origin 'http://localhost:5500' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.
```
This is a [CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS), or Cross-Origin Resource Sharing, error. For security reasons, most browsers will prevent HTTP requests made from within a script or a browser's console from being successfully completed if the requested resource is on a different origin, or domain. For example, a site at `https://example-a.com/` can make a successful request to `https://example-a.com/api`, but not necessarily to `https://example-b.com/api`.
One way around this is to specify which origins a specific resource accepts requests from. In *Dinerd*, I did this using an [Express middleware](https://expressjs.com/en/guide/using-middleware.html#using-middleware) function to set the headers on every response from my server. I placed the below in `index.js` above the `app.get` line.
```js
app.use((req, res, next) => {
res.header('Access-Control-Allow-Origin', '*');
next();
})
```
Express middleware has access to the request and response objects. With the above code, I intercept the responses the server sends out and add a line to the header. As written, this will signal to the requester that any origin (`*`) is allowed to access the resources on my server.
With the above in place, the backend is ready to go!
### Front-end Code
(View the full front-end source)[https://github.com/joedietrich-dev/dinerd].
*Dinerd*'s front end is written in vanilla javascript, HTML, and CSS. The form you see when you land on the home view is fully in the static HTML, with event listeners added when the javascript loads.
I use `fetch` to make calls to the back-end server created above, and render the restaurant cards using a `renderRestaurant` function that I created to translate the JSON data into visible and interactive components. The map on each card is created using the [Leaflet](https://leafletjs.com) library and [Open Streetmap](https://www.openstreetmap.org/) data, combined with each restaurant's location data returned from the API.
For this version of the app, I use the browser's local storage to persist a diner's previously visited restaurants. This means their choices will only be visible when they're using the same browser on the same device, and will be removed if they clear their local caches, but it does remove the need for a back-end database.
All animations including the sidebar slidein, error state appearance and disappearance, and card transitions are executed using CSS transistions.
## Future Plans
In future iterations of this app, I would like to add:
* Login and restaurant selection persistence using a back-end database instead of local storage.
* More filtering options when selecting a restaurant, including the ability to select only restaurants that are open when the search is performed.
* Autofilling the location from the device's gps
* Improved styles on very wide screens
* Swipe to navigate cards
## Tools / Libraries / APIs Used
### Front-end
- [Figma](https://figma.com) - Design and wireframing tool.
- [Leaflet](https://leafletjs.com) - Library for mapping location data. Uses [Open Streetmap](https://www.openstreetmap.org/) data.
- [Stamen Toner](http://maps.stamen.com/toner) - Map tile theme.
- [localStorage](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage) - The Web Storage API method for storing and retrieving data within a user's browser.
- [Pattern Monster](https://pattern.monster/) - SVG Pattern generator, as seen in the site's background.
- [Favicon Generator](https://realfavicongenerator.net/) - Multi-platform favicon generator.
- [Icon Finder](https://iconfinder.com/) - Source of MIT licensed SVG icons.
- [Normalize CSS](https://necolas.github.io/normalize.css/) - Provide a better cross-browser baseline for CSS styles.
### Back-end
- [Yelp Fusion API](https://www.yelp.com/developers/documentation/v3/get_started) - Source of data on restaurants by location.
- [Node.js](https://nodejs.org) - JavaScript runtime that powers the back-end of Dinerd.
- [Express](https://expressjs.com) - Web application framework used to create API route to pass queries to Yelp and return results to client application.
- [Axios](https://axios-http.com) - HTTP client for Node.js (like fetch, but for Node).
- [dotenv](https://www.npmjs.com/package/dotenv) - NPM package that loads environment variables from a .env file into a location accessible by a Node.js application.
 | joedietrichdev |
800,144 | Development with Golang Resources | Basics If you are new to golang then the first thing you should do is to know about the... | 0 | 2021-08-22T19:52:02 | https://devnotfound.wordpress.com/2021/04/02/development-with-golang-resources/ | ## Basics
If you are new to golang then the first thing you should do is to know about the language itself. And the place that I found very helpful was [gobyexample](https://gobyexample.com/)
The site has covered almost everything to get you started with golang.
## Web Development with Golang
The next thing you need to know is how to build web applications with goland and how to maintain structure of your project. Todd Mcleod’s course from udemy was one of the course that I followed to learn about this. It was a great course where I was able to learn core stuffs about web development with Golang. Here’s the link for the course:
[Web Development w/ Google’s Go (golang) Programming Language](https://www.udemy.com/course/go-programming-language/)
## Production-grade Golang Web Apps
When you have learned about how to build web servers with golang, how to use templates and how to follow MVC pattern, the next thing you need to know is how to build production-grade web apps with Golang. And Jon Calhoun comes in your support. His course was one of the greatest course I have completed. In the course he goes through the book he wrote on web development with Golang. If you are not a fan of reading then this is the course for you. Spot on explanation, maintaining standard project structure and many more are taught in this course. Here’s the link to the course:
[UseGolang](https://www.usegolang.com/)
You can also follow his website and other courses related to Golang
on [this blog](https://www.calhoun.io/)
## Rest API with Golang
Now to get a taste of how to buld rest api using golang you can follow the crash course of Brad Traversy on youtube.
## What’s Next
Now for to continue learning more about Golang I have decided to follow the bellow links:
Documentation: [docs](https://golang.org/doc/)
Jon Calhoun: [blog](https://www.calhoun.io/)
GopherAcademy: [YT Channel](https://www.youtube.com/channel/UCx9QVEApa5BKLw9r8cnOFEA)
Todd Mcleod: [YT Channel](https://www.youtube.com/channel/UCElzlyMtkoXaO3kFa5HL0Xw)
Coding Train: [YT Channel](https://www.youtube.com/channel/UCtxCXg-UvSnTKPOzLH4wJaQ)
National Conferences (GothamGo): [YT Channel](https://www.youtube.com/channel/UCgRpkkcigKZk52JyAOYNs6w)
Others: [https://dave.cheney.net/resources-for-new-go-programmers](https://dave.cheney.net/resources-for-new-go-programmers) | aaman007 | |
800,413 | Resume Blog | I'm Jonathan my skills include Javascript, C#, HTML, CSS, and Jquery. I've been trying to build an... | 0 | 2021-08-23T05:15:50 | https://dev.to/jonathan_marquez_9f01646d/resume-blog-336o | resume, blog, school | I'm Jonathan my skills include Javascript, C#, HTML, CSS, and Jquery. I've been trying to build an app that would help people's business boom by taking appointments for them and keep track of the booking. Let me tell you why you should hire me. My goal is to help people's business grow and what better way by evolving in a modern way. | jonathan_marquez_9f01646d |
800,473 | My first freelance job | I thought a lot about writing this ... I don't know how beneficial it will be for my professional... | 0 | 2021-08-23T07:59:42 | https://dev.to/guadalupe182/my-first-freelance-job-hkn | webdev, javascript, html, css | I thought a lot about writing this ...
I don't know how beneficial it will be for my professional development, but I don't want to be left with the desire to share this first experience.
It all started helping a girl to develop a website for a company (as a school project), after that she contacted me to propose me a business.
The design that I had implemented in her project they had liked and she needed my help to make another similar and improved one and this time paid because the first time I supported this person I didn't charge anything.
I decided to implement a landing page with a minimalist style, intuitive, and full contact with the customer through messenger (my first proposal was an e-commerce) but they found it too expensive...
so I elaborated the design and presented it with an estimated delivery time of 1 month to 1 month and a half always sticking to spring methodology.
The first mistake was not to generate a contract with the specifications that the client should test and respect during the delivery time because the person I was supporting assured me that they were totally trustworthy and that she had already worked with them before.
Anyway ... once the design was presented and approved I got down to work but the client constantly delayed me with changes he wanted at the last minute and it should be noted that I shortened the delivery time to about 3 weeks or 2.
So I decided to see it as a challenge and not as an abuse by this company....
In the first instance I asked for 50% of the total payment in advance but they refused, they said that since it was the first time they would work with me the payment would be made until the final delivery of the project (at least that's what this person told me) since being their clients they did not allow me to have any contact with them.
So well ... I delivered in time and form and surprise ... the payment did not arrive as agreed .... I told them that there was no problem and that I would wait no problem ... the day arrived .... and the payment ... still did not arrive .... then they told me that next week I would have my money now that they had had economic problems and that now it was a fact but what do you think?
Exactly. the payment never arrived ....
in the last contact I had with them....
they told me that they already had a SECOND PROJECT haha but they didn't mention anything about the money they owed me ...
so I decided to unsubscribe the page ...
and well ... I am left ... with the code .... and my time invested ... and yes .... without money ....
I guess this has happened to more than one of you, I would like to read your opinions about it.
at the moment I am trying to join Workana ... but ... my profile is still pending review ....
if you have any suggestions for freelancer sites I would appreciate it.
and again leave your comments
thank you very much and best regards !
| guadalupe182 |
800,685 | Best VS Code extensions you should use as a Developer. | Top 12 VS Code extensions which makes your life much easier as a developer. 1.... | 0 | 2021-08-23T09:56:36 | https://dev.to/aman2221/best-vs-code-extensions-you-should-use-as-a-developer-5815 | webdev, react, vscode, javascript | ##Top 12 VS Code extensions which makes your life much easier as a developer.
###1. Auto Rename Tag
Automatically rename paired HTML/XML tag, same as Visual Studio IDE does.

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=formulahendry.auto-rename-tag)
###2. Babel ES6/ES7
This is a standalone version of the syntax given with vscode-flowtype. Improves majorly on the grammar distributed by default with vscode. This language extension brings no changes to the intellisense.

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=dzannotti.vscode-babel-coloring)
###3. Bracket Pair Colorizer
This extension allows matching brackets to be identified with colours. The user can define which characters to match, and which colours to use.

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=CoenraadS.bracket-pair-colorizer)
###4. Code Spell Checker
A basic spell checker that works well with camelCase code.
The goal of this spell checker is to help catch common spelling errors while keeping the number of false positives low.

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=streetsidesoftware.code-spell-checker)
###5. ES7 React/Redux/GraphQL/React-Native snippets
JavaScript and React/Redux snippets in ES7+ with Babel plugin features for VS Code
Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=dsznajder.es7-react-js-snippets)
###6. Live Server
Launch a local development server with live reload feature for static & dynamic pages.

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer)
###7. Material Icon Theme
Get the Material Design icons into your VS Code.

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=PKief.material-icon-theme)
###8. Polacode-2020
Polaroid for your code 📸.
Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=jeff-hykin.polacode-2019)
###9. Prettier - Code formatter
Prettier is an opinionated code formatter. It enforces a consistent style by parsing your code and re-printing it with its own rules that take the maximum line length into account, wrapping code when necessary.

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode)
###10. Tabnine
Tabnine is the AI code completion tool trusted by millions of developers to code faster with fewer errors. Whether you are a new dev or a seasoned pro, working solo or part of a team.
![tab]](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/goylocq5j8nufw8cfmsi.jpg)
Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=TabNine.tabnine-vscode)
###11. Thunder

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=Steve-DevOps.thunder-lwc)
###12. Visual Studio IntelliCode
The Visual Studio IntelliCode extension provides AI-assisted development features for Python, TypeScript/JavaScript and Java developers in Visual Studio Code, with insights based on understanding your code context combined with machine learning.

Link : [Click Me](https://marketplace.visualstudio.com/items?itemName=VisualStudioExptTeam.vscodeintellicode)
Thank You❤️️❤️️ | aman2221 |
800,760 | 60+ TYPO3 Tutorials To Follow in 2021 | TYPO3 tutorials allow you to extend the power of TYPO3. Fortunately most with grateful TYPO3... | 0 | 2021-08-23T10:38:27 | https://dev.to/t3terminal/60-typo3-tutorials-to-follow-in-2021-3oge | TYPO3 tutorials allow you to extend the power of TYPO3. Fortunately most with grateful TYPO3 community, most of the TYPO3 Tutorials are free. With step-by-step TYPO3 tutorials, it is easy to understand and follows the TYPO3 best practices. These TYPO3 tutorials contain real-life examples, tips, and hacks that allow you to learn TYPO3 faster!
The great thing about blogging and TYPO3 is the community that you can become a member of. Contributing to the niche you are blogging about will be very helpful to TYPO3 people seeking help for their specific needs.
There are many benefits of using TYPO3, and I’ll cover a significant list of TYPO3 Blogs where you can find the best TYPO3 Tutorials, tips, and guides. This blog contains the ultimate TYPO3 tutorial collection useful for everyone ranging from TYPO3 developer to TYPO3 site admin to TYPO3 beginners.
TYPO3 Tutorial Collection
TYPO3 Tutorials for TYPO3 Integrators
TYPO3 Tutorials for TYPO3 Developers
TYPO3 Tutorials for TYPO3 Editors
TYPO3 Tutorials for TYPO3 Administrators
TYPO3 Deployment Tutorial
TYPO3 Search Tutorial
TYPO3 Security Tutorials
TYPO3 Performance Tutorial
TYPO3 SEO Tutorials
TYPO3 Development Server Tutorial
TYPO3 Headless Tutorial
TYPO3 Certification Tutorial
TYPO3 Miscellaneous Tutorial
Conclusion!
Bookmark this blog for your go-to tutorials!
To read the whole blog, https://t3terminal.com/blog/typo3-tutorial/ | t3terminal | |
800,799 | Welcome to Creative Tim New Visual Identity | Hello Web Design lovers, Huge news! Today is a big day for Creative Tim, as we are saying goodbye to... | 0 | 2021-08-23T12:26:14 | https://www.creative-tim.com/blog/announcement/welcome-to-creative-tim-new-logo/ | Hello Web Design lovers,
Huge news! Today is a big day for Creative Tim, as we are saying goodbye to the logo that defined our brand identity and work for 8 years. This way, we are happy to welcome the new Creative Tim visual identity that better defines our new vision and evolution.
###**Why new Visual Identity**
We loved our old logo, and probably you did the same. However, this breakup does not have to be sad. Here we are to explain why we decided to move forward.
Creative Tim is growing and evolving since we launched our first product, [Get Shit Done](https://www.creative-tim.com/product/get-shit-done-kit), which was embraced by more than 60,000 developers and designers worldwide. Now we have over 1.6 million people that use our products each year.
[](https://www.creative-tim.com/product/get-shit-done-kit)
<center>[Get Shit Done Kit](https://www.creative-tim.com/product/get-shit-done-kit)</center>
<br>
After 8 years and a closer look at who Creative Tim is and who our brand became, we felt it is time for a change.
In the last years, we've been through many changes, starting from the way we develop our products, the design we implement, the services we offer to a major change in our business strategy that our team is currently hard-working on.
Therefore, the last months we've worked in collaboration with [Studio VRLN](https://www.vrln.studio/) on refreshing our logo to express who we are today and to symbolize our future.
Let's see how it came together.
###**The Old Logo**
Our previous logo was created when the company launched. It was distinctive, innocent, "nice" and was to describe the positivity of a young team of web design enthusiasts. Our first logo did a really great job for our beginnings, but we've grown mature, experienced, and the time has come to move on.
As amusing the old Tim seems, as naive and static in communication it actually is. Even if the team behind Creative Tim smiles and appears laid-back, this is solely because of its expertise and creativity self-awareness. The Creative Tim products have a crisp and clean design, they are easy to use and easy to customize and precisely these attributes should be conveyed in the brand communication.

Moreover, the limits of the old logo set out the limits of brand communication. The Creative Tim logo used to be just a logo, without any visual style or font of its own. The apparently easygoing look & feel of the logo failed to meet the needs of our brand which was evolving rapidly and was in need of a real set of communication tools for the products.
Though everyone loved it, the old logo wasn’t able anymore to adapt to the new rhythm of life.
###**The New Logo**
The talented designer Paul Virlan from [Studio VRLN](https://www.vrln.studio/) was the designer on this project. Let's see Paul's creation stages of our new brand identity.
**Research Stage**
The first thing that drew the designer's attention to the old logo was Tim’s face expression, that particular smile he wanted to keep at all costs. Well, that smile was about to embody all the brand information we have collected during a discussion with Alex, the Creative Tim founder. That smile would have had a dominant presence and a reassuring effect, unless covered in unnecessary details.
Keeping that smile in mind, Paul went back to the research stage and he looked up if math and computer science could ever seem fun. He ultimately understood that real intelligence without a sense of humor doesn’t exist and so he bumped into Homological Identities among Yangian-invariants and Brainfuck.
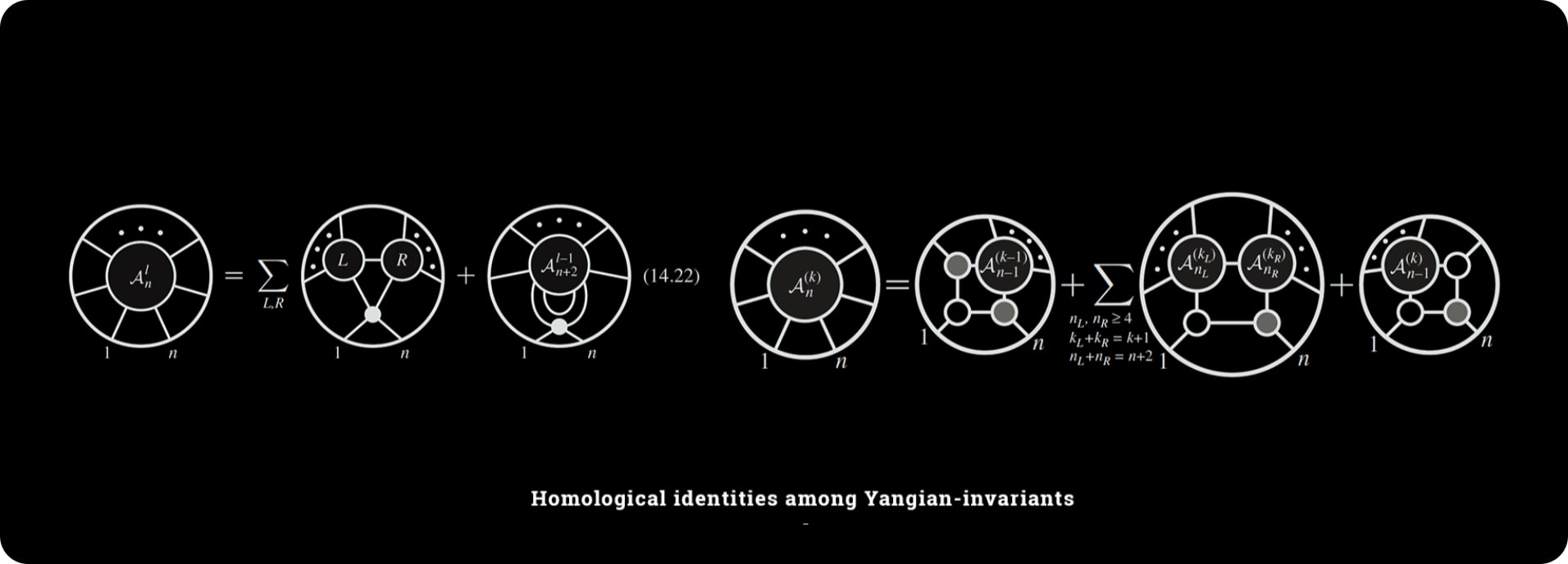

Then, back to the drawing board.
**Step 1: Try**
The designer started by simplifying forms and expressions. He tried different concepts, different solutions to make a modular and engaging system.

**Step 2: Investigation**
Passing through dozens of ideas, Paul understood what works and what doesn’t and kept only a couple of them on which to build the graphic elements.
Many of them were just amusing, other ideas would have had a chance to be smart as well, but they eventually failed the originality test. For example:
**Step 3: Make**
###**Concept Development**
Then, finally, he had the solution! A robot! A “T” robot made with UI elements. A modular system that conveys the main values of those behind Creative Tim: being engaged and being creative. This system now satisfies everybody's needs and also helps the brand to communicate in social media through a special language and a wide variety of emotions.

<center>Robot made with UI elements</center>
<br>
###**Font**
Now that we have a powerful story-driven logomark with a lot of visual potential, it’s time to invest some time in the logotype as well. After a wide research, he has discovered Roboto Slab Typeface and he wasn’t able to move forward anymore. (Because of its name and the T Robot; we could make that Roboto joke).
Unfortunately, Roboto Slab was similar to a monospaced font used in a programming console (we really liked that), but the alliance between the logomark and his logotype was really bad and the “creative and fun” part could have easily became “boring and sad”.

<center>New Logo using Roboto Slab typography</center>
<br>
The designer continued to search for something super clean and not too formal that could be easily integrated into my concept. Montserrat (created by Julieta Ulanovsky) satisfied the needs and it was love at first sight with the capital letters, the clean letter design, and the wide array of characters.

<center>New Logo Typography Examples</center>
<br>
After some minimal interventions, it looked perfect. Moreover, we decided to keep this typeface as a brand font as well, because of its versatility in weights and sizes and its modern look that could be easily associated with the new Tim.

<center>New Logo using Montserrat typography</center>
<br>
###**The result**
In conclusion, we decided to keep the old logo' soul and upgrade it to a new rhythm of life. It became a robot with a human smile that can now find solutions to any problems and communicate with all of us. The new Tim is still amusing but no longer naive. Tim has now an emotional intelligence that conveys more inner life than any other human being.

<center>Old Logo vs. New Logo</center>

<center>Variants of Creative Tim New Logo</center>
<center>New Logo Emotions</center>
<br>
And let's see some brand communication:

<center>Creative Tim Business Cards</center>

<center>Creative Tim Smart Devices</center>

<center>Creative Tim T-shirts</center>
<br>
###**Final Thoughts**


Enough with the details for now. We just wanted to share with you this important change around our company. Also, we are very happy with the new Tim and we hope you will embrace it as well.
The task in the upcoming period will be to align other visuals around Creative Tim to the new logo. We've already started with our [website](https://www.creative-tim.com/), [blog](https://www.creative-tim.com/blog/), social media accounts ([Facebook](https://www.facebook.com/CreativeTim), [Twitter](https://twitter.com/CreativeTim), [Instagram](https://instagram.com/creativetimofficial/), [TikTok](https://www.tiktok.com/@creative.tim?lang=en)), where you can see it in action.
Share your thoughts about the rebranding on our [social media](https://twitter.com/CreativeTim/status/1428627756787585027), and Thank You for being with us ❤️
Cheers,
Creative Tim team
| creativetim_official | |
800,858 | Ternary if in Dart | What we call Ternary If is a short use of the if control structure. You can see its usage in the... | 0 | 2021-08-23T14:13:24 | https://dev.to/baransel/ternary-operators-in-dart-49g8 | dart, dartlang, flutter, tutorial | What we call Ternary If is a short use of the if control structure. You can see its usage in the example below.
Syntax:
```
condition ? exprIfTrue : exprIfFalse
```
Normal if else usage:
```dart
int height = 185;
String heightCategory = '';
main() {
if (height > 175) {
heightCategory = 'Tall';
} else {
heightCategory = 'Short';
}
print(heightCategory);
}
```
Using Ternary If operators:
```dart
main() {
int height = 185;
String heightCategory = height > 175 ? "Tall" : "Short";
print(heightCategory);
}
```
Operators and function structures are no different from other C-based programming languages. We will not go into details.
Follow my blog for more [baransel.dev](https://baransel.dev/). | baransel |
801,095 | Building Serverless URL Shortener Service on AWS | Walk-through of a serverless implementation of an URL Shortener Service without AWS Lambda... | 0 | 2021-08-23T16:21:58 | https://dev.to/aws-builders/building-serverless-url-shortener-service-on-aws-1895 | aws, serverless, urlshortener, dynamodb | <h4> Walk-through of a serverless implementation of an URL Shortener Service without AWS Lambda Functions</h4>
---
## The AWS Serverless Ecosystem
> Serverless is a way to describe the services, practices, and strategies that enable you to build more agile applications so you can innovate and respond to change faster. With serverless computing, infrastructure management tasks like capacity provisioning and patching are handled by AWS, so you can focus on only writing code that serves your customers.
***Serverless Computing = FaaS [Functions as a Service] + BaaS [Backend as a Service]***
### Serverless Services of AWS:
* **Compute**: AWS Lambda, AWS Fargate
* **Storage**: Amazon DynamoDB, Amazon S3, etc.
* **Application Integration**: Amazon API Gateway, etc.
---
## Introduction
In this walkthrough, we are going to develop an URL Shortener Service using various services of the AWS Serverless Ecosystem. We are going to focus mainly on the backend of the application.
To implement our project in a simplified way, we will use only the 2 most important services: the **API Gateway** and **DynamoDB**.
*Architecture Diagram*
### AWS Lambda
AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers, creating workload-aware cluster scaling logic, maintaining event integrations, or managing runtimes. With Lambda, you can run code for virtually any type of application or backend service ΓÇö all with zero administration.
In this application, we are not going to use AWS Lambda, since our application runs on simpler logic ΓÇö i.e. to store short-URLs into the Database and re-direct to the long-URLs once we call the short-URL.
### Amazon API Gateway
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the ΓÇ£front doorΓÇ¥ for applications to access data, business logic, or functionality from your backend services.
In our application, we are going to utilize the functionality of the API Gateway through which we can perform ETL operations during the transit of data between the API Gateway and DynamoDB.
### Amazon DynamoDB
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. ItΓÇÖs a fully managed, multi-region, multi-active, durable database with built-in security, backup and restores, and in-memory caching for internet-scale applications.
DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second.
---
## Getting Started
To follow this project, you only need to have an AWS account. The entire application would be developed within the AWS Web Console.
Let's understand the workflow of the application. We are currently focussing on 2 main features prevalent to all URL-Shorteners.
### 1. Storing the Short-URL, Long-URL and owner inside DynamoDB
In the backend, once a user sends a POST request to the Route, with all the required parameters, the API Gateway receives the data, transforms it and pushes it into the DynamoDB.
### 2. Redirecting to the Long-URL once the short-URL is hit
Once a user mentions the short-URL in the HTTP header, the API gateway receives the data, processes it and searches it inside DynamoDB. Once the corresponding Long URL is found, the API Gateway redirects to the Long URL.
---
## Setting Up DynamoDB Database
First of all, we need to configure our Database. For that, we need to create a Table.
The table would be consisting of 3 Columns: longURL , **shortId** , owner . We would be using the shortId attribute as the **Primary key** of the table.
In the configuration, please use the exact names mentioned.
* **Table Name:** URL-Shortener
* **Primary Key:** shortId
* **Table settings:** Use Default Settings
Once you create the Table, you would land on the following page mentioning all the Table Details:
---
## Setting up the API Gateway
This is the most important service in our architecture. Through this service, we are going to perform multiple operations.
1. Create API Endpoints for **GET** and **POST** requests.
1. Transform request parameters received from the API into DynamoDB understandable format.
1. Convert the response received from the DynamoDB into a format understandable by browsers for re-direction.
We need to create an API of the type Rest API from the API Gateway console.
After selecting the **REST-API Gateway type**, we need to select the following configurations.
* **Protocol**: REST
* **Create a new API:** New API
* **API name:** URLShortener
***This would create a new API.***
*API Gateway Console*
Now, we need to create an New Resource under the / route. The name of the resource is set as: url-shortener .
Under this resource, we need to create multiple methods for **GET **and **POST **requests.
---
## Setting Up POST Request
Under the /url-shortener resource, we need to create a method named ΓÇ£POSTΓÇ¥. In this method, we are going to modify our POST request.
Once the POST Method is selected, we have to use the following information during its setup:
* **Integration type:** AWS Service
* **AWS Region:** ap-south-1 [region where the DynamoDB Instance would be running]
* **AWS Service:** DynamoDB
* **HTTP method:** POST
* **Action:** UpdateItem
* **Execution role:** [ IAM Role in which DynamoDB write permissions are given ]
Once the setup is completed, we land on the following page:
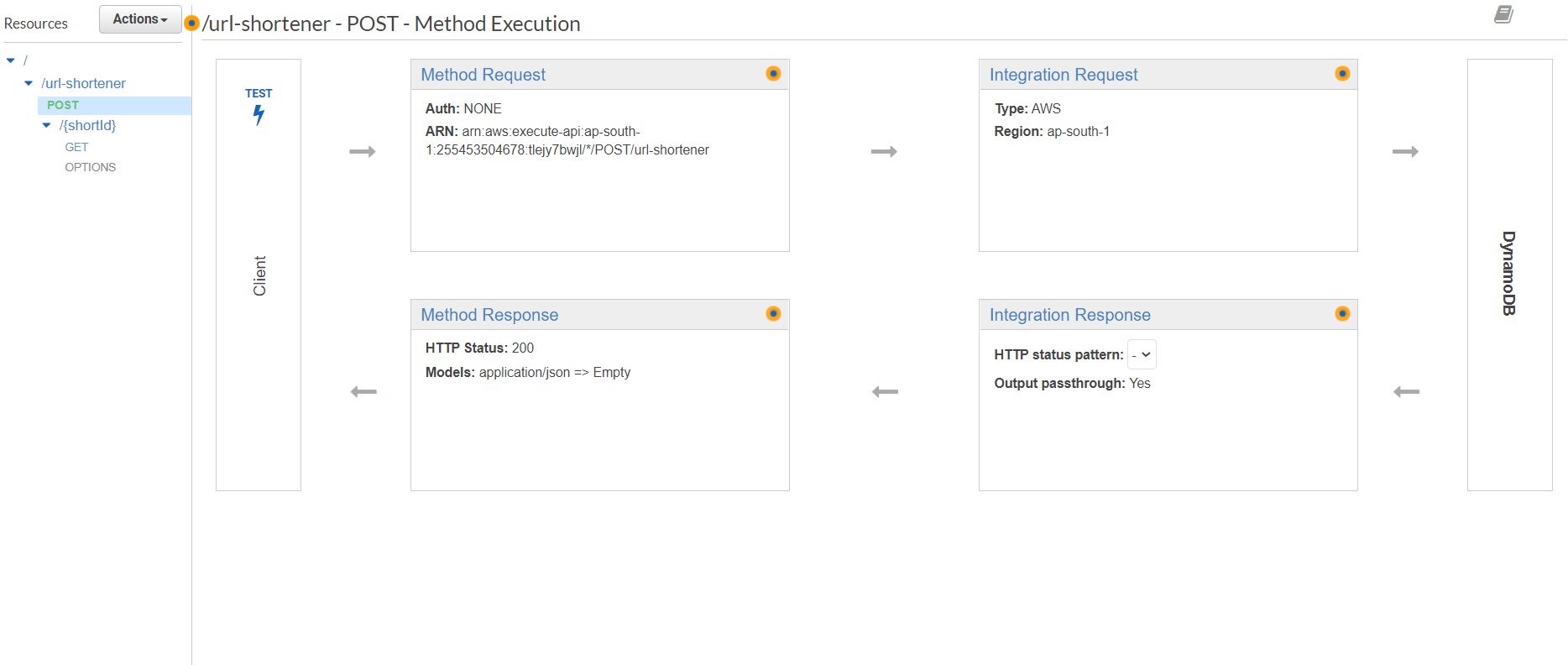
Now, we need to transform the request parameters received from the client into something that would be understood by DynamoDB.
For this, we are going to utilize the Integration Request feature of the API Gateway. Through this feature, we are going to add a **Mapping Template** based on which the transformation would take place.
On clicking the **Integration Request** from the above page, we would be landing on the following page:

Under the **Mapping Templates section**, we need to add the following code:
{% gist https://gist.github.com/Lucifergene/180738ec994ce28d4b4d8fa7c71bbab7 %}
Now, we have set up the process through which data would be saved into the DynamoDB. But now, we have to also format the Response that DynamoDB would be sending, to a format understandable by the Client.
For this, we need to set up another **Mapping Template** in the Integration Response section.
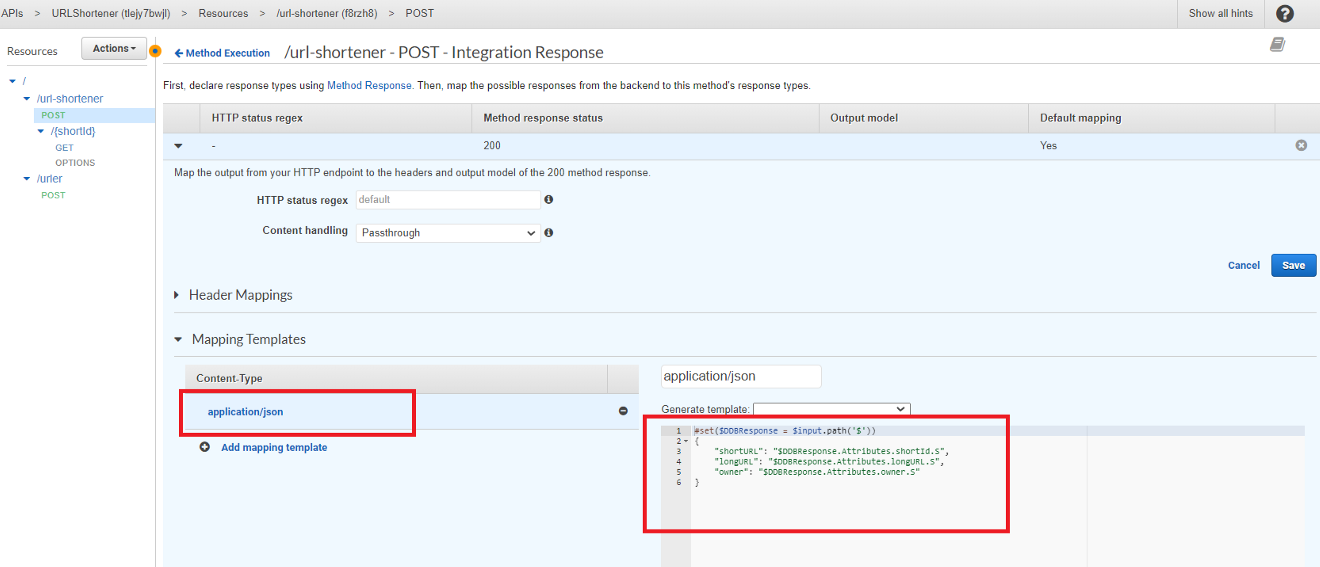
Under the **Mapping Templates section**, we need to add the following code:
{% gist https://gist.github.com/Lucifergene/39bf8dc169f4ca6d1f1d5eaa591f5e9e %}
Once this is set up, the response of the DynamoDB would be converted in a form understandable by the client.
Thus, we have set up our POST request, which would save the request parameters in the DynamoDB and would send the response back to the client. To test, we need to click on the **TEST **option from the above console.
In the Request Body, we need to type the following:
{
"longURL": "[https://www.google.co.in](https://www.google.co.in)",
"owner": "Avik",
"shortURL": "Google"
}
On submitting the above JSON, we must receive a 200 Status code and a similar response body as the following. Thus we have successfully saved the contents to the DynamoDB.
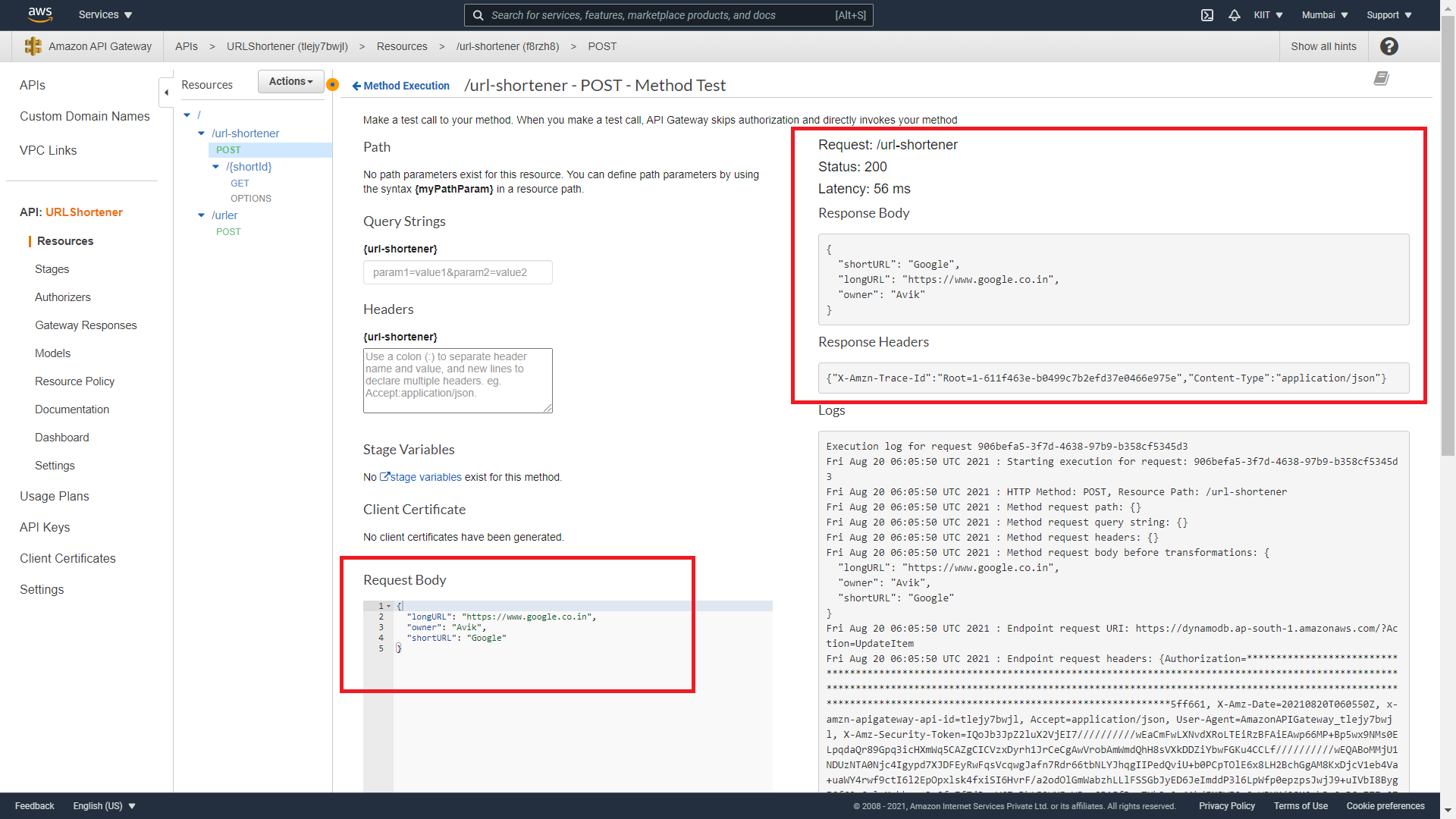
---
## Setting Up GET Request
The GET request is somewhat different from the POST request. Here, the user would be appending the short URL to the API endpoint. This shortURL would be sent to the DynamoDB by the API Gateway to perform the search operation. Once the associated long URL is found, the API Gateway automatically re-directs to the long URL.
Under the /url-shortener resource, **we create another resource named as {shortURL}**, which would be having a dynamic resource path, as it is the place where the short URLs would be appended.
Inside the newly created sub-resource, we create the GET request with the following settings:
* **Integration type:** AWS Service
* **AWS Region:** ap-south-1 [region where the DynamoDB Instance would be running]
* **AWS Service:** DynamoDB
* **HTTP method:** POST
* **Action:** GetItem
* **Execution role:** [ IAM Role in which DynamoDB write permissions are given ]
Once the setup is completed, we land on the following page:
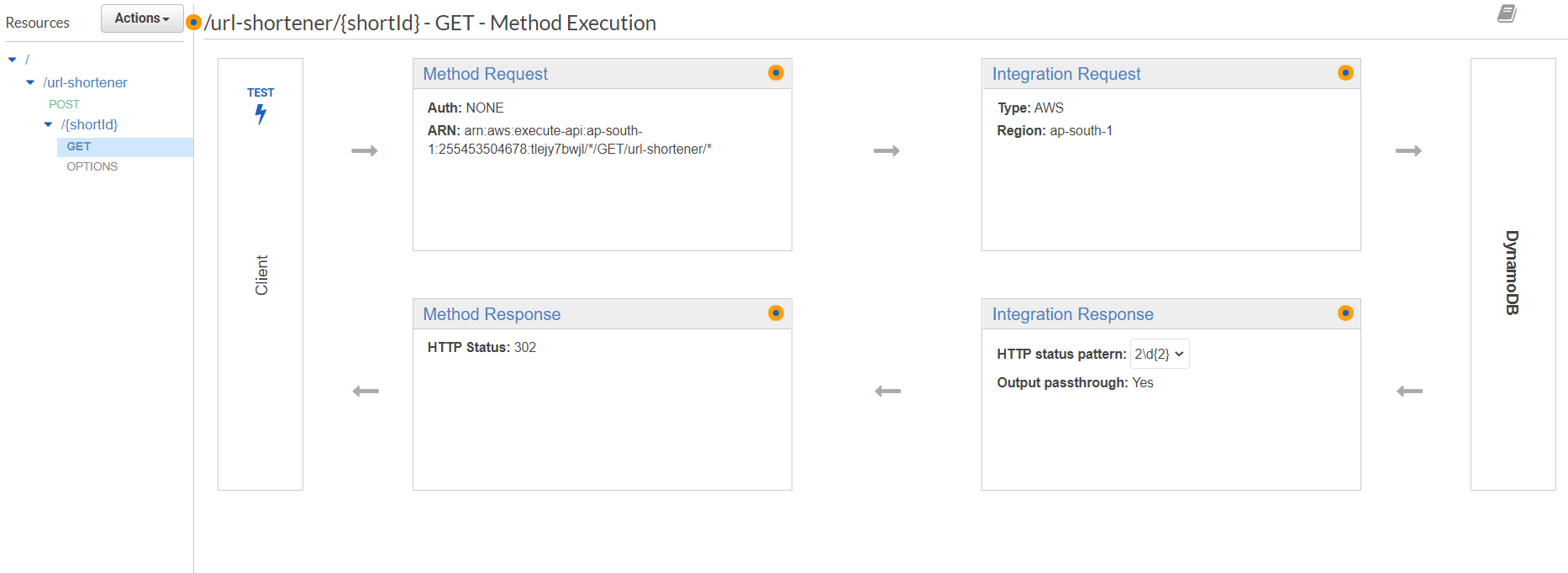
Now, we have to perform 3 transformations while the data would be transferred back and forth between the API Gateway and DynamoDB.
### A. Integration Request
First, we need to transform the request parameters received from the client into something that would be understood by DynamoDB. For this, we are going to utilize the **Integration Request **feature of the API Gateway. Through this feature, we are going to add a **Mapping Template** based on which the transformation would take place.
On clicking the **Integration Request** from the above page, we would be landing on the following page:
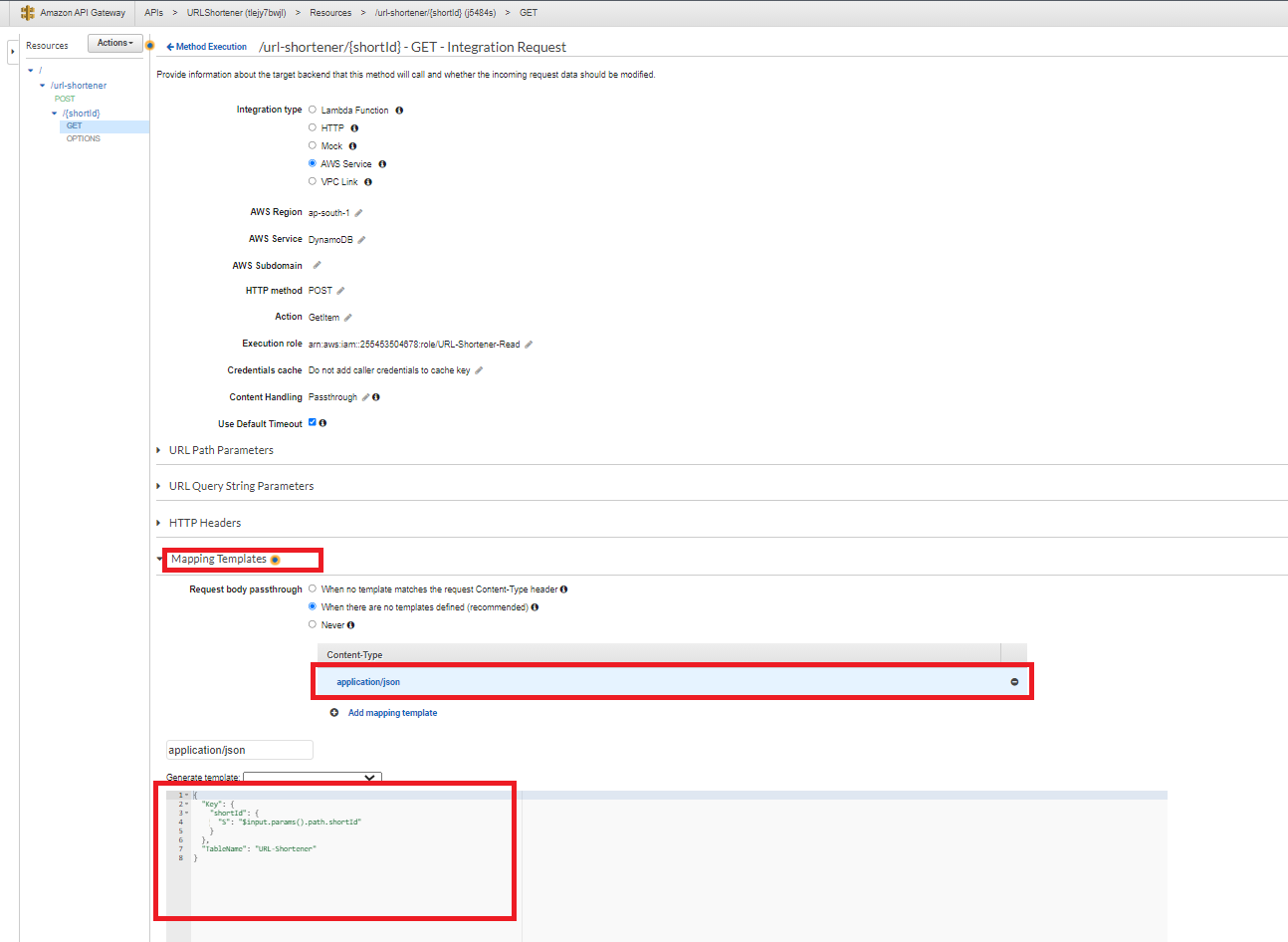
Under the **Mapping Templates section**, we need to add the following code:
{% gist https://gist.github.com/Lucifergene/ca5e96a9744d4eeecd478ba6d097600b %}
### B. Method Response
We know that for URL redirections, **302 HTTP Status code** is used. Therefore in the response header, we need to set the appropriate status code since by default **200**is** **set.
In the **Method Response** section, we need to **delete the 200 status code association** and **add the 302 HTTP Status Code**. To instruct the API gateway to redirect to the URL set in the Location key in the Response header, we need to add it to the corresponding 302 Response Header.
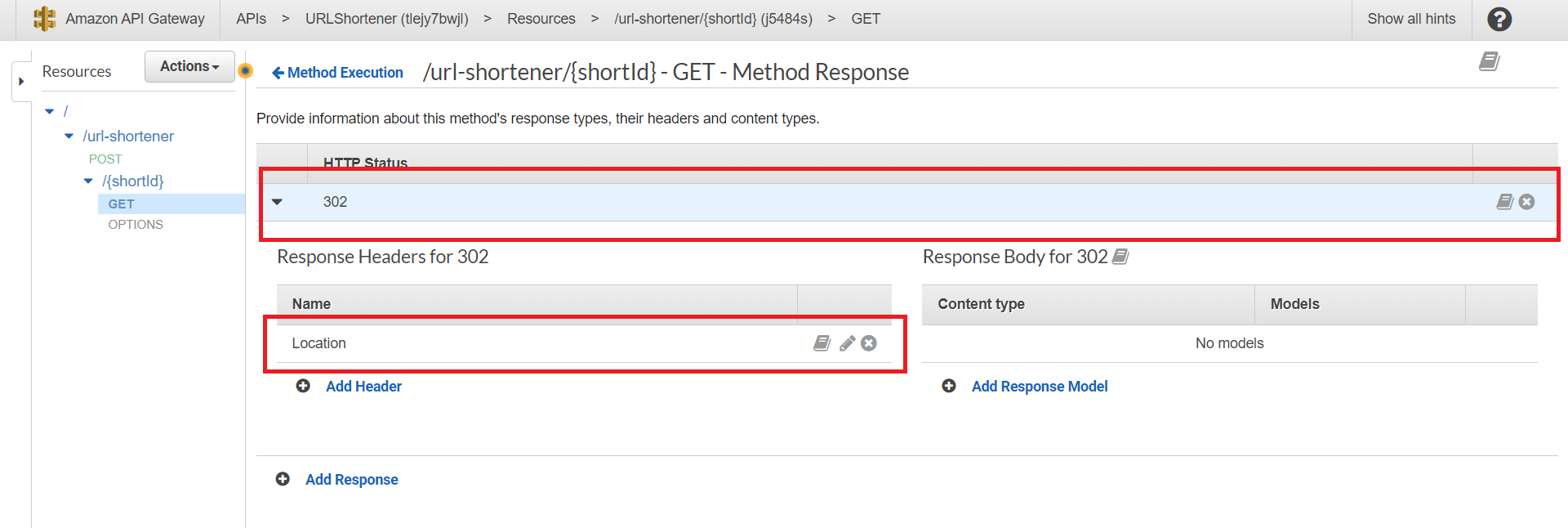
### C. Integration Response
After setting up the **Method Response**, now, we have to also format the Response that DynamoDB would be sending, to a format understandable by the Client.
For this, we need to set up another **Mapping Template** in the Integration Response section.
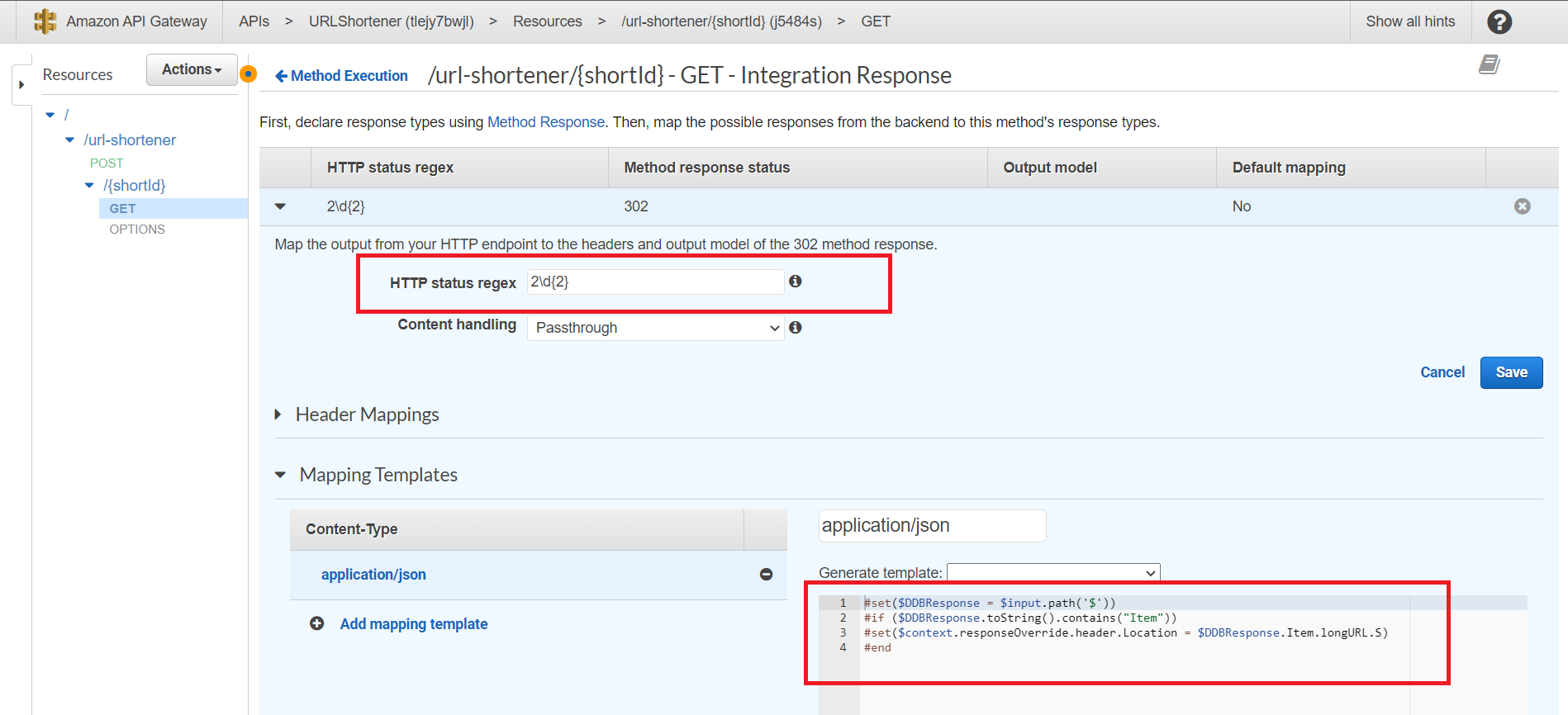
Under the **Mapping Templates section**, we need to add the following code:
{% gist https://gist.github.com/Lucifergene/b2be264e74bf4cb5c38bf57bd5f710af %}
Thus, we have set up our GET request, which would redirect the short URL to the actual LongURL after fetching it from DynamoDB.
To test, we need to click on the **TEST** option from the above console. In the {shortId} field, we need to enter the shortId of the URL and click on the **TEST** button.
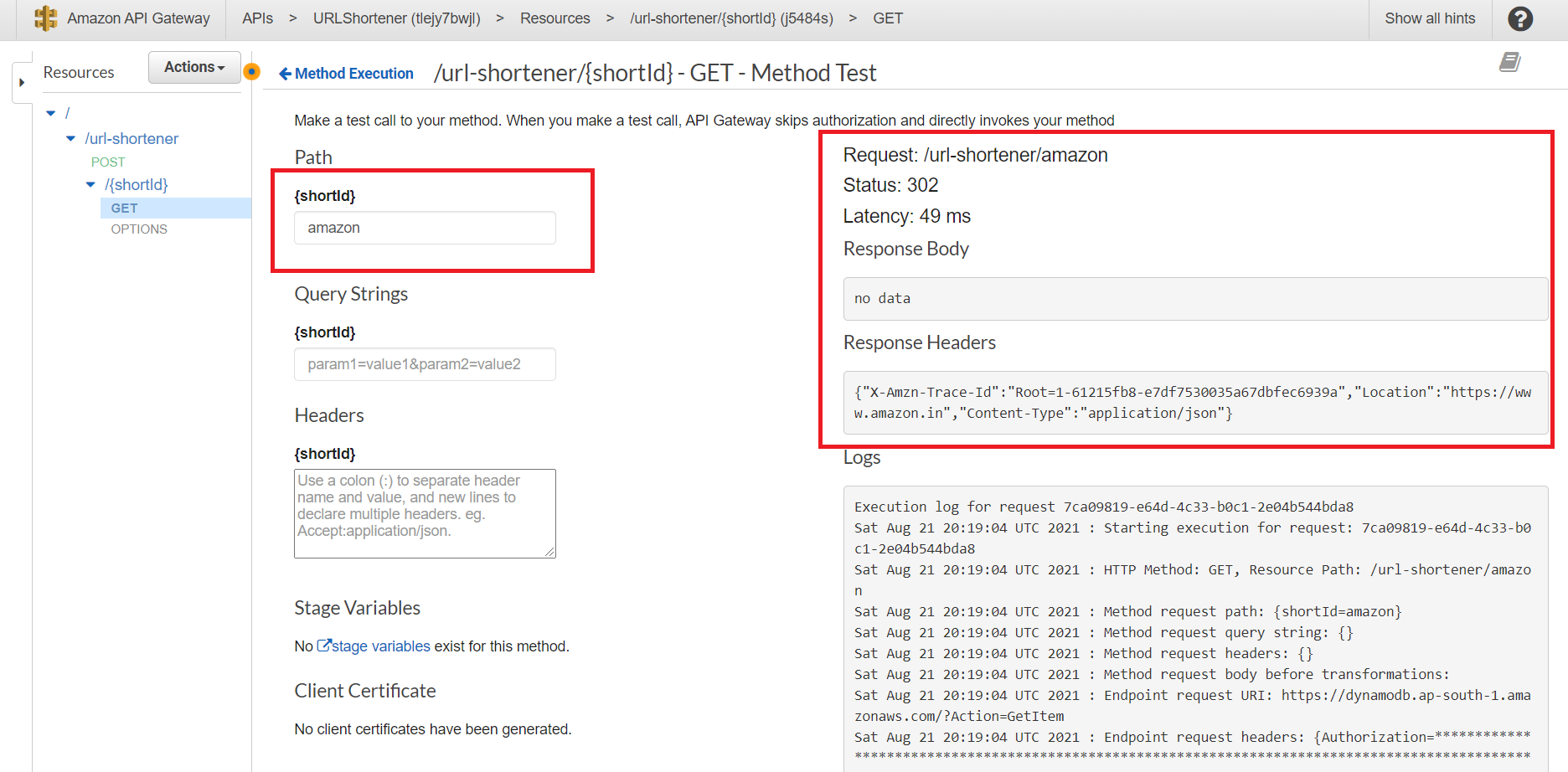
Thus we have received a **302** response code and upon studying the response header, we see a location key that contains the actual Long URL.
---
**And we reached the end of the solution!!!**
You can visit the repository from below:
{% github Lucifergene/Serverless-URL-Shortener %}
---
You can reach out on my [Twitter](https://twitter.com/avik6028), [Instagram](https://instagram.com/avik6028), or [LinkedIn](https://linkedin.com/in/avik-kundu-0b837715b) if you need more help. I would be more than happy.
If you have come up to this, do drop an :heart: if you liked this article.
**Good Luck** :sunglasses: and **happy coding** :computer:
| avik6028 |
801,169 | Blitz.js: The Fullstack React Framework - Part 3 | 👋 Welcome Back, Hey Developers, welcome back to part 3 of the series "Learn by Building -... | 14,193 | 2021-08-23T18:40:01 | https://cb-ashik.hashnode.dev/blitzjs-the-fullstack-react-framework-part-3 | blitzjs, blitz, fullstack, nextjs | # 👋 Welcome Back,
Hey Developers, welcome back to part 3 of the series ["Learn by Building - Blitz.js"](https://dev.to/chapagainashik/series/14193). Today we'll create the UI for projects and tasks models. And also add the functionalities in the UI to CRUD from the database.
# Index
- [Recap of the previous part](#recap-of-the-previous-part)
- [Today's objectives 🎯](#todays-objectives)
- [Layout](#layout)
- [Header](#header)
- [Index page](#index-page)
- [Project](#project)
- [Create Page](#create-page)
- [Index Page](#index-page)
- [Single Page](#single-page)
- [Edit](#edit)
- [Tasks](#tasks)
- [Create and Update](#create-and-update)
- [Index](#index)
- [Conclusion](#conclusion)
# Recap of the previous part
In the previous part of this series, we updated the database schema and updated and understand the logic for the CRUD operation of projects and tasks. And also build the UI for the authentication pages.
By looking at the above line, it looks like that the previous article doesn't include much information, but it crosses more than 2900 words. 🤯
# Today's objectives 🎯
In today's articles, we'll create the UI for the CRUD operations of projects and tasks model and connect the UI with the logic. And we'll also learn to add the search functionalities for both projects and tasks.
Today, we'll start by editing the `Layout Component`. We used `AuthLayout` for the authentication pages, and now we'll use `Layout Component` for other pages.
# Layout
Open `app/core/layouts/layout.tsx` and add the `<Header/>` tag after `<Head/>` tag like below and also wrap `{children}` with `div` of class `container mx-auto px-4`:
```jsx
// app/core/layouts/layout.tsx
import { Header } from "../components/Header"
...
</Head>
<Header />
<div className="container mx-auto px-4">{children}</div>
...
```
In the `<Layout />` component, we have used the `<Header />` component, so let's build it.
## Header
Create a new file at `app/core/components/Header.tsx` and add the following code.
```jsx
// app/core/components/Header.tsx
import logout from "app/auth/mutations/logout"
import { Link, Routes, useMutation } from "blitz"
import { Suspense } from "react"
import { useCurrentUser } from "../hooks/useCurrentUser"
import { Button } from "./Button"
const NavLink = ({ href, children }) => {
return (
<Link href={href}>
<a className="bg-purple-600 text-white py-2 px-3 rounded hover:bg-purple-800 block">
{children}
</a>
</Link>
)
}
const Nav = () => {
const currentUser = useCurrentUser()
const [logoutMutation] = useMutation(logout)
return (
<nav>
{!currentUser ? (
<ul className="flex gap-8">
<li>
<NavLink href={Routes.LoginPage()}>Login</NavLink>
</li>
<li>
<NavLink href={Routes.SignupPage()}>Register</NavLink>
</li>
</ul>
) : (
<ul className="">
<li>
<Button
onClick={async () => {
await logoutMutation()
}}
>
Logout
</Button>
</li>
</ul>
)}
</nav>
)
}
export const Header = () => {
return (
<header className="flex sticky top-0 z-30 bg-white justify-end h-20 items-center px-6 border-b">
<Suspense fallback="Loading...">
<Nav />
</Suspense>
</header>
)
}
```
With this, you'll get the header like as shown below:
When a user is not logged in,

When a user is authenticated,

In the header component, there are some lines that you might not understand. So, let's know what they really do.
- `<Suspense>...</Suspense>`: <Suspense> component that lets you “wait” for some code to load and declaratively specify a loading state (like a spinner) while we’re waiting. ( [React Docs](https://reactjs.org/docs/concurrent-mode-suspense.html))
- `useCurrentUser()`: It is a react hook that returns a authenticated session of a user. ([Blitz.js Dccs](https://blitzjs.com/docs/authorization#displaying-different-content-based-on-user-role))
- `useMutation(logout)`: Logout task is a mutation and to run the mutation we use the powerful hook `useMutation` provided by Blitz.js.( [Blitz.js Docs](https://blitzjs.com/docs/use-mutation) )
If you look over the `onClick` event listener in the `Logout` button. There we are using async/await, because `mutations` return promises.
Now, let's display the `User Email` on the index page and add a link to go to the projects index page.
# Index page
If you guys, remembered we have removed the content from the `index.tsx` page. Now, we'll display the email of the authenticated user and make that page accessible only by the logged-in user.
To work with the index page, first, go to the [signup](http://localhost:3000/signup) page and create an account. And then you will get redirected to the `index` page.
Now, replace everything in `app/pages/index.tsx`with the given content.
```jsx
// app/pages/index.tsx
import { Suspense } from "react"
import { Image, Link, BlitzPage, useMutation, Routes } from "blitz"
import Layout from "app/core/layouts/Layout"
import { useCurrentUser } from "app/core/hooks/useCurrentUser"
import logout from "app/auth/mutations/logout"
import logo from "public/logo.png"
import { CustomLink } from "app/core/components/CustomLink"
/*
* This file is just for a pleasant getting started page for your new app.
* You can delete everything in here and start from scratch if you like.
*/
const UserInfo = () => {
const user = useCurrentUser()
return (
<div className="flex justify-center my-4">{user && <div>Logged in as {user.email}.</div>}</div>
)
}
const Home: BlitzPage = () => {
return (
<>
<Suspense fallback="Loading User Info...">
<UserInfo />
</Suspense>
<div className="flex justify-center">
<CustomLink href="/projects">Manage Projects</CustomLink>
</div>
</>
)
}
Home.suppressFirstRenderFlicker = true
Home.getLayout = (page) => <Layout title="Home">{page}</Layout>
Home.authenticate = true
export default Home
```
If you see the third last line in the code, `Home.authenticate = true`, this means, this page requires a user to be authenticated to access this page.
Now, the index page should look like this:
Click on the `Manage projects` to see how the `projects` index page looks like.
Now, let's customize the project creation page. We are not editing the index page, first because we need to show the data on the `index` page.
# Project
## Create Page
If you go to [`/projects/new`](http://localhost:3000/projects/new), currently it should look like this.
Now, let's customize this page.
In our schema, we have a `description` field for the `projects` model. So, let's add the text area for the description field.
We also need a text area for the task model too. So, we'll create a new component for the text area. For this I have created a new file `/app/core/components/LabeledTextAreaField.tsx` and copied the content of `LabeledTextField` and customized it for `textarea`.
```jsx
// app/core/components/LabeledTextAreaField
import { forwardRef, PropsWithoutRef } from "react"
import { Field, useField } from "react-final-form"
export interface LabeledTextFieldProps extends PropsWithoutRef<JSX.IntrinsicElements["input"]> {
/** Field name. */
name: string
/** Field label. */
label: string
/** Field type. Doesn't include radio buttons and checkboxes */
type?: "text" | "password" | "email" | "number"
outerProps?: PropsWithoutRef<JSX.IntrinsicElements["div"]>
}
export const LabeledTextAreaField = forwardRef<HTMLInputElement, LabeledTextFieldProps>(
({ name, label, outerProps, ...props }, ref) => {
const {
input,
meta: { touched, error, submitError, submitting },
} = useField(name, {
parse: props.type === "number" ? Number : undefined,
})
const normalizedError = Array.isArray(error) ? error.join(", ") : error || submitError
return (
<div {...outerProps}>
<label className="flex flex-col items-start">
{label}
<Field
component={"textarea"}
className="px-1 py-2 border rounded focus:ring focus:outline-none ring-purple-200 block w-full my-2"
{...props}
{...input}
disabled={submitting}
></Field>
</label>
{touched && normalizedError && (
<div role="alert" className="text-sm" style={{ color: "red" }}>
{normalizedError}
</div>
)}
</div>
)
}
)
export default LabeledTextAreaField
```
After doing this, now you can use it in the `/app/projects/components/ProjectForm.tsx`.
```jsx
// app/projects/components/ProjectForm.tsx
import { Form, FormProps } from "app/core/components/Form"
import { LabeledTextField } from "app/core/components/LabeledTextField"
import { LabeledTextAreaField } from "app/core/components/LabeledTextAreaField"
import { z } from "zod"
export { FORM_ERROR } from "app/core/components/Form"
export function ProjectForm<S extends z.ZodType<any, any>>(props: FormProps<S>) {
return (
<Form<S> {...props}>
<LabeledTextField name="name" label="Name" placeholder="Name" />
<LabeledTextAreaField name="description" label="Description" placeholder="Description" />
</Form>
)
}
```
Now `/projects/new` page should look like.
Now, you can use that form to create a project.
But, there is still many thing to customize in this page.
```js
// app/pages/projects/new
import { Link, useRouter, useMutation, BlitzPage, Routes } from "blitz"
import Layout from "app/core/layouts/Layout"
import createProject from "app/projects/mutations/createProject"
import { ProjectForm, FORM_ERROR } from "app/projects/components/ProjectForm"
import { CustomLink } from "app/core/components/CustomLink"
const NewProjectPage: BlitzPage = () => {
const router = useRouter()
const [createProjectMutation] = useMutation(createProject)
return (
<div className="mt-4">
<h1 className="text-xl mb-4">Create New Project</h1>
<ProjectForm
....
/>
<p className="mt-4">
<CustomLink href={Routes.ProjectsPage()}>
<a>Projects</a>
</CustomLink>
</p>
</div>
)
}
NewProjectPage.authenticate = true
NewProjectPage.getLayout = (page) => <Layout title={"Create New Project"}>{page}</Layout>
export default NewProjectPage
```
Here, I have added some class in `h1` and `divs` and replace `Link` tag with our `CustomLink` component.
After this, the page will look like this.
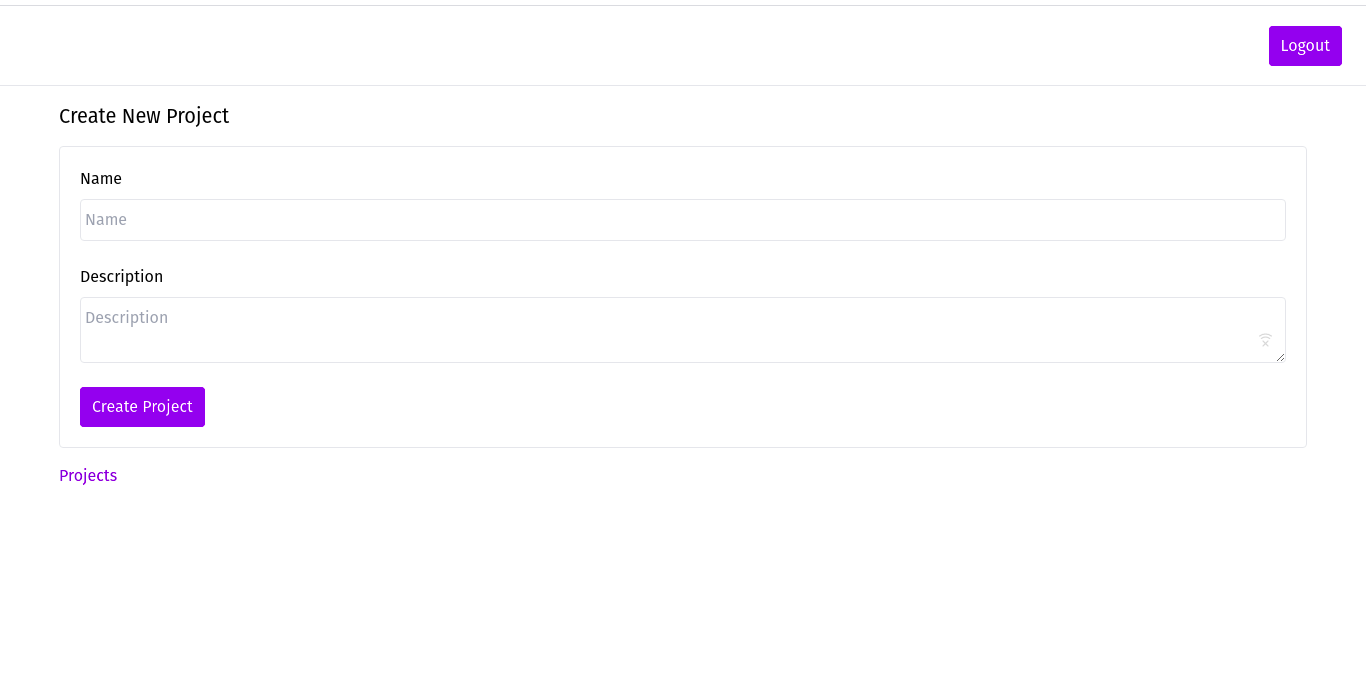
Now, let's style the index page ' [/projects](http://localhost:3000/projects) '.
## Index Page
Before styling the index page, add some of the projects to play with.
After adding them. You'll get redirected to `single` project page. Go to `/projects`.
This is what your page will look like.

Now, paste the following content in `app/pages/projects/index.tsx`.
```jsx
// app/pages/projects/index.tsx
import { Suspense } from "react"
import { Head, Link, usePaginatedQuery, useRouter, BlitzPage, Routes } from "blitz"
import Layout from "app/core/layouts/Layout"
import getProjects from "app/projects/queries/getProjects"
import { CustomLink } from "app/core/components/CustomLink"
import { Button } from "app/core/components/Button"
const ITEMS_PER_PAGE = 100
export const ProjectsList = () => {
const router = useRouter()
const page = Number(router.query.page) || 0
const [{ projects, hasMore }] = usePaginatedQuery(getProjects, {
orderBy: { id: "asc" },
skip: ITEMS_PER_PAGE * page,
take: ITEMS_PER_PAGE,
})
const goToPreviousPage = () => router.push({ query: { page: page - 1 } })
const goToNextPage = () => router.push({ query: { page: page + 1 } })
return (
<div className="mt-4">
<h2>Your projects</h2>
<ul className="mb-4 mt-3 flex flex-col gap-4">
{projects.map((project) => (
<li key={project.id}>
<CustomLink href={Routes.ShowProjectPage({ projectId: project.id })}>
<a>{project.name}</a>
</CustomLink>
</li>
))}
</ul>
<div className="flex gap-2">
<Button disabled={page === 0} onClick={goToPreviousPage}>
Previous
</Button>
<Button disabled={!hasMore} onClick={goToNextPage}>
Next
</Button>
</div>
</div>
)
}
const ProjectsPage: BlitzPage = () => {
return (
<>
<Head>
<title>Projects</title>
</Head>
<div>
<p>
<CustomLink href={Routes.NewProjectPage()}>Create Project</CustomLink>
</p>
<Suspense fallback={<div>Loading...</div>}>
<ProjectsList />
</Suspense>
</div>
</>
)
}
ProjectsPage.authenticate = true
ProjectsPage.getLayout = (page) => <Layout>{page}</Layout>
export default ProjectsPage
```
And let's make the `Button` component looks unclickable when it is disabled.
For that, you can add `disabled:bg-purple-400 disabled:cursor-not-allowed` class in `Button` component.
```jsx
// app/core/components/Button.tsx
export const Button = ({ children, ...props }) => {
return (
<button
className="... disabled:bg-purple-400 disabled:cursor-not-allowed"
>
{children}
</button>
)
}
```
Now, projects index page should look like:

## Single Page
Before editing, project single page looks like.
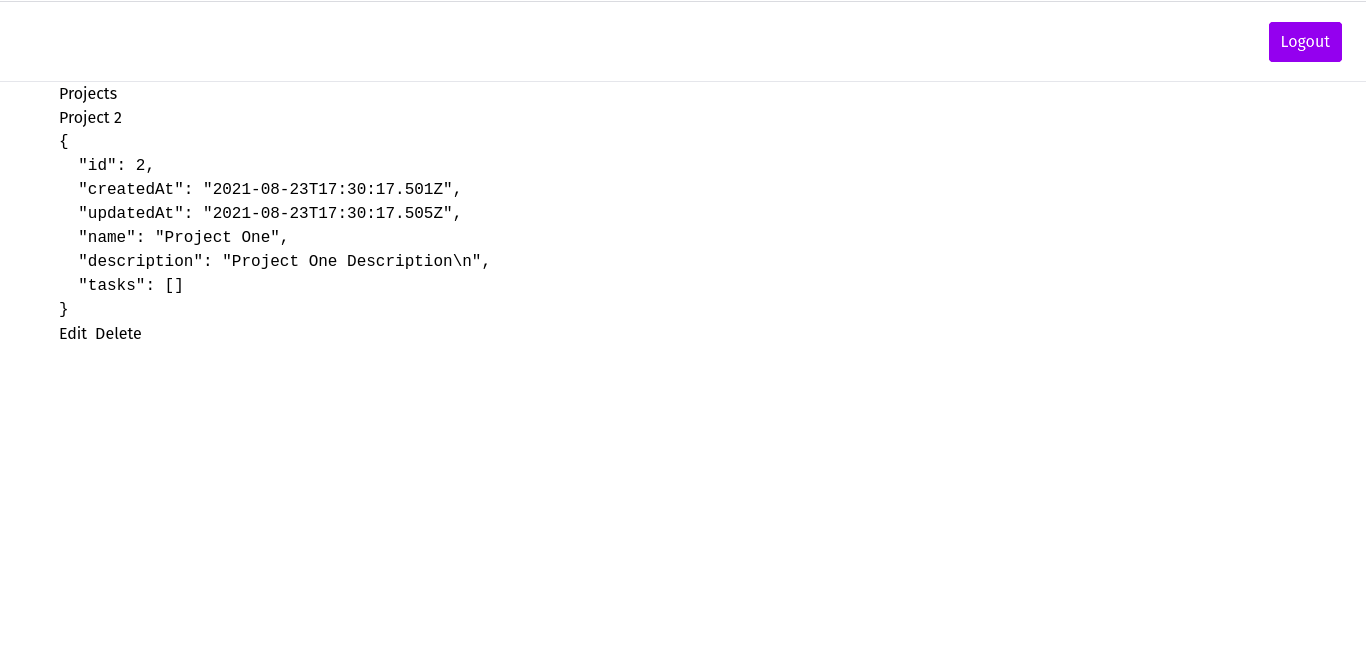
Now, replace the code of `app/pages/projects/[projectId].tsx` with following.
```jsx
// app/pages/projects/[projectId].tsx
import { Suspense } from "react"
import { Head, Link, useRouter, useQuery, useParam, BlitzPage, useMutation, Routes } from "blitz"
import Layout from "app/core/layouts/Layout"
import getProject from "app/projects/queries/getProject"
import deleteProject from "app/projects/mutations/deleteProject"
import { CustomLink } from "app/core/components/CustomLink"
import { Button } from "app/core/components/Button"
export const Project = () => {
const router = useRouter()
const projectId = useParam("projectId", "number")
const [deleteProjectMutation] = useMutation(deleteProject)
const [project] = useQuery(getProject, { id: projectId })
return (
<>
<Head>
<title>Project {project.id}</title>
</Head>
<div>
<h1>Project {project.id}</h1>
<pre>{JSON.stringify(project, null, 2)}</pre>
<CustomLink href={Routes.EditProjectPage({ projectId: project.id })}>Edit</CustomLink>
<Button
type="button"
onClick={async () => {
if (window.confirm("This will be deleted")) {
await deleteProjectMutation({ id: project.id })
router.push(Routes.ProjectsPage())
}
}}
style={{ marginLeft: "0.5rem", marginRight: "0.5rem" }}
>
Delete
</Button>
<CustomLink href={Routes.TasksPage({ projectId: project.id })}>Tasks</CustomLink>
</div>
</>
)
}
const ShowProjectPage: BlitzPage = () => {
return (
<div className="mt-2">
<p className="mb-2">
<CustomLink href={Routes.ProjectsPage()}>Projects</CustomLink>
</p>
<Suspense fallback={<div>Loading...</div>}>
<Project />
</Suspense>
</div>
)
}
ShowProjectPage.authenticate = true
ShowProjectPage.getLayout = (page) => <Layout>{page}</Layout>
export default ShowProjectPage
```
Now the page should look like.
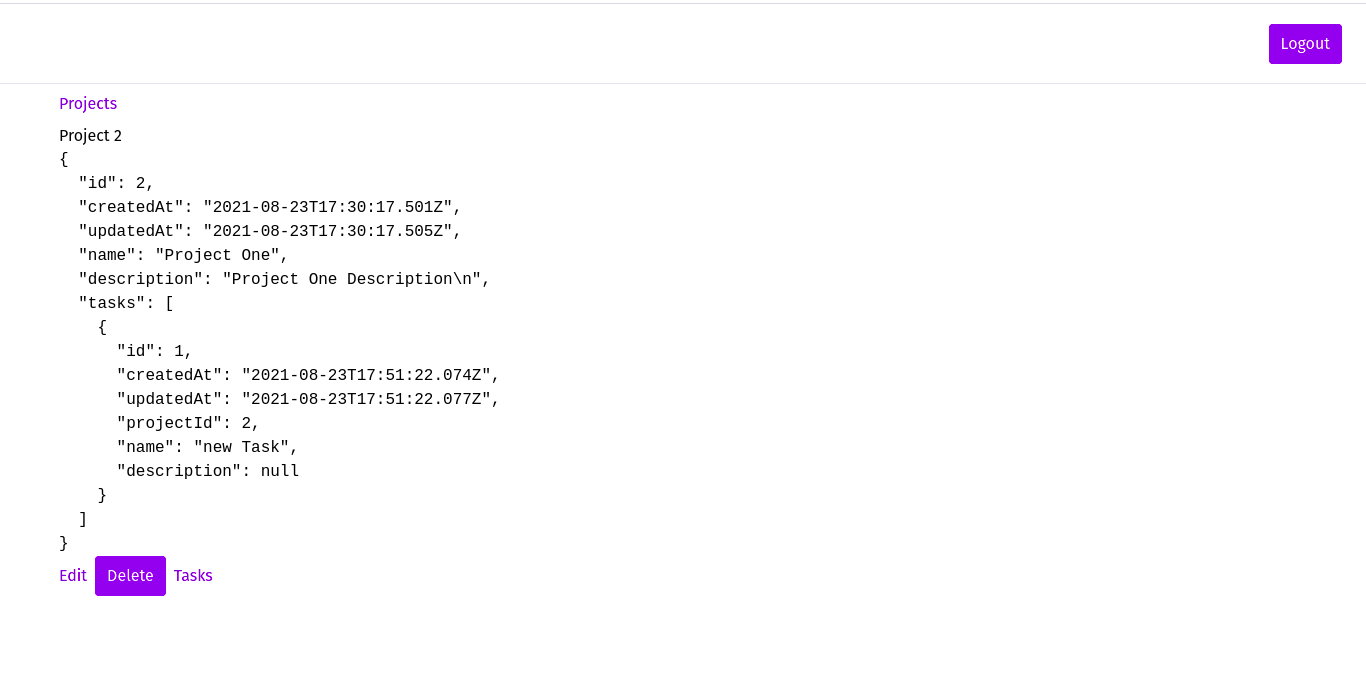
## Edit
We'll do a decent style on the edit page. We'll just replace `<Link>` tag with `<CustomLink>` component and add `text-lg` class to `h1`.
```jsx
// From
<Link href={Routes.ProjectsPage()}>
<a>Projects</a>
</Link>
// To
<CustomLink href={Routes.ProjectsPage()}>
Projects
</CustomLink>
```
```
// From
<h1>Edit Project {project.id}</h1>
// To
<h1 className="text-lg">Edit Project {project.id}</h1>
```
Now, it's time to edit the Tasks pages.
# Tasks
## Create and Update
We have added description field in the schema, so let's add textarea for description in the form.
Both create and update use the same form, we don't have to customize them seperately.
```jsx
// app/tasks/components/TaskForm.tsx
import { Form, FormProps } from "app/core/components/Form"
import LabeledTextAreaField from "app/core/components/LabeledTextAreaField"
import { LabeledTextField } from "app/core/components/LabeledTextField"
import { z } from "zod"
export { FORM_ERROR } from "app/core/components/Form"
export function TaskForm<S extends z.ZodType<any, any>>(props: FormProps<S>) {
return (
<Form<S> {...props}>
<LabeledTextField name="name" label="Name" placeholder="Name" />
<LabeledTextAreaField name="description" label="Description" placeholder="Description" />
</Form>
)
}
```
I have already written on how to customize the pages for projects so, you can follow the same to customize tasks pages. So, now I'll not style any pages.
## Index
In the index page, you need to add `projectId` in query param.
```jsx
...
<ul>
{tasks.map((task) => (
<li key={task.id}>
<Link href={Routes.ShowTaskPage({ projectId, taskId: task.id })}>
<a>{task.name}</a>
</Link>
</li>
))}
</ul>
...
```
# Conclusion
Now, all the functionalities works fine. So this much for today guys, In next article. We'll see how to deploy this app. In that I will show you the complete guide to deploy in multiple platform.
| chapagainashik |
801,267 | How to Use Excel SORTBY Function in Excel Office 365? | The SORTBY Function of Excel can return a sorted array by another independent array , and you can add... | 0 | 2021-08-26T08:56:02 | https://geekexcel.com/how-to-use-excel-sortby-function-in-excel-office-365/ | touseexcelsortbyfunc, excel, excelfunctions | ---
title: How to Use Excel SORTBY Function in Excel Office 365?
published: true
date: 2021-08-23 15:59:16 UTC
tags: ToUseExcelSORTBYFunc,Excel,ExcelFunctions
canonical_url: https://geekexcel.com/how-to-use-excel-sortby-function-in-excel-office-365/
---
The **SORTBY Function** of Excel can return a **sorted array** by **another independent array** , and you can **add levels of sorting**. In this tutorial, we are going to see how to **use the Excel SORTBY Function In Excel Office 365**. Let’s get into this article!! Get an official version of ** MS Excel** from the following link: [https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)
## SORTBY Function Syntax
```
=SORTBY(array,sorting_array1,[order],…)
```
**Syntax Explanation:**
- **Array** : This is the array that you want to sort.
- **Sorting\_array1** : This is the array by which you want to sort the array. The dimension of this array should be compatible with the array.
- **[order]**: Optional. Set it to -1 if you want the order to be descending. By default, it is ascending(1).
## Example
- You need to **create a sample data** of participants with their **IDs and scores**.
<figcaption>Sample data</figcaption>
- Then, you have to get the **names sorted** by their **IDs** using the **SORTBY function**.
- Now, you need to use the generic **formula** to get the **ascending sorted names by ID column**.
```
=SORTBY(A2:A10,B2:B10)
```
<figcaption>ascending sorted names</figcaption>
- After that, if you want to get whole table, than just give reference of whole table.
```
=SORTBY(A2:A10,B2:B10)
```
- Then, if you want the **range** to be **sorted descending by ID column** , then the **formula** will be:
```
=SORTBY(A2:A10,B2:B10,-1)
```
**Example: Sort Array by More Than One Column**
- Here, in the above examples, you have **sorted the array** by just **one column**.
- Then, you want to **first sort** the above table **ascending by ID** and then **sort the array descending by the score**.
- Now, you need to use the formula given below.
```
=SORTBY(A2:A10,B2:B10,1,C2:C10,-1)
```
**Check this too:** [How to Use Excel SORT Function in Office 365? – [with Example]](https://geekexcel.com/excel-sort-function/)
## Wrap-Up
Hope you understood how to **use the Excel SORTBY Function In Excel Office 365**. Please feel free to state your query or feedback for the above article. Thank you so much for Reading!! To learn more, check out **[Geek Excel](https://geekexcel.com/)!! **and [**Excel Formulas**](https://geekexcel.com/excel-formula/) **!!**
**Read Ahead:**
- **[Excel Formulas to Get the Left Lookup with INDEX and MATCH!!](https://geekexcel.com/excel-formulas-get-left-lookup-with-index-and-match/)**
- **[Excel Formulas: INDEX and MATCH Descending Order ~ Easy Guide!!](https://geekexcel.com/excel-formulas-index-and-match-descending-order/)**
- **[How to Use Excel SORT Function in Office 365? – [with Example]](https://geekexcel.com/excel-sort-function/)**
- **[Excel Formulas to Convert the String into Array ~ Quick Tricks!!](https://geekexcel.com/excel-formulas-to-convert-the-string-into-array/)**
- **[How to Create an Array of Numbers in Excel Office 365?](https://geekexcel.com/how-to-create-an-array-of-numbers-in-excel-office-365/)** | excelgeek |
801,268 | Create a Netflix clone from Scratch: JavaScript PHP + MySQL Day 29 | Netflix provides streaming movies and TV shows to over 75 million subscribers across the globe.... | 0 | 2021-08-24T04:12:36 | https://dev.to/cglikpo/create-a-netflix-clone-from-scratch-javascript-php-mysql-day-29-2l9p | php, javascript, webdev, tutorial | Netflix provides streaming movies and TV shows to over 75 million subscribers across
the globe. Customers can watch as many shows/ movies as they want as long as they are
connected to the internet for a monthly subscription fee of about ten dollars. Netflix produces
original content and also pays for the rights to stream feature films and shows.
In this video,we will be Configure admin dashboard
{% youtube ttWgUd_rxlU %}
If you like my work, please consider
[](https://www.buymeacoffee.com/cglikpo)
so that I can bring more projects, more articles for you
If you want to learn more about Web Development, feel free to [follow me on Youtube!](https://www.youtube.com/c/ChristopherGlikpo) | cglikpo |
801,300 | Terraform Associate Certification: Count & Count index | Let's assume, you need to create two EC2 instances in AWS. One of the common approaches is to define... | 14,268 | 2021-08-23T20:30:28 | https://dev.to/danihuerta/terraform-associate-certification-count-count-index-2aan | terraform, devops, cloud, aws | Let's assume, you need to create two EC2 instances in AWS. One of the common approaches is to define two separate resource blocks for *aws_instance* such as follows:
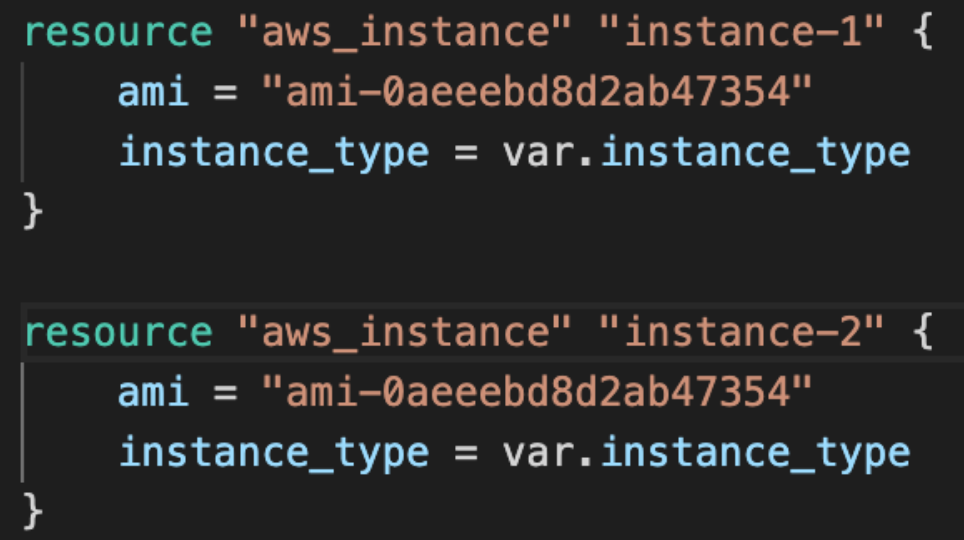
Two EC2 instances is not a real problem, but what if we need to create more than that, maybe 10 instances?! 😖 It doesn't seem to be really cool right?
Well, in Terraform there is something named *Count Parameter* and it can simplify configurations and let you scale resources by simply incrementing a number.
## Count parameter
With it, we can simply specify the count value and the resource can be scaled accordingly, for example, let's create 3 EC2 instances with this parameter:
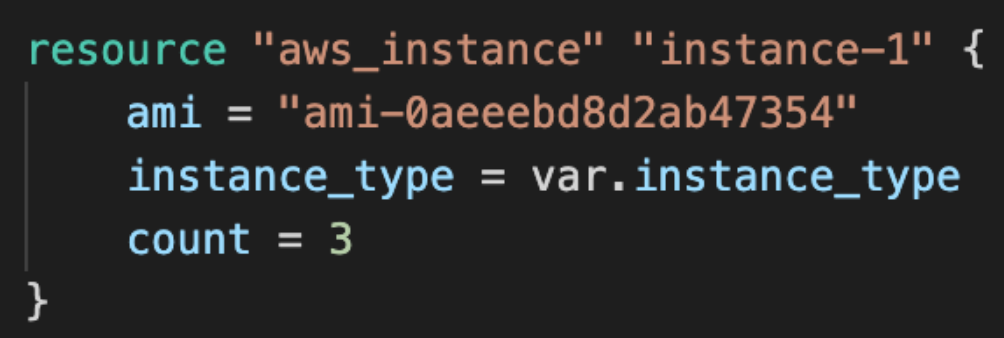
The instances will be ordered as a list, we will be able to access to them using the position of it, for example *instance-1[0]*.
## Count index
In resource blocks where count is set, an additional count object is available in expressions, so you can modify the configuration of each instance.
This object has one attribute:
- *Count index*: the distinct index number (starting with 0) corresponding to this instance.
For example:
With the below code, terraform will create 5 IAM users. But the problem is that all will have the same name:
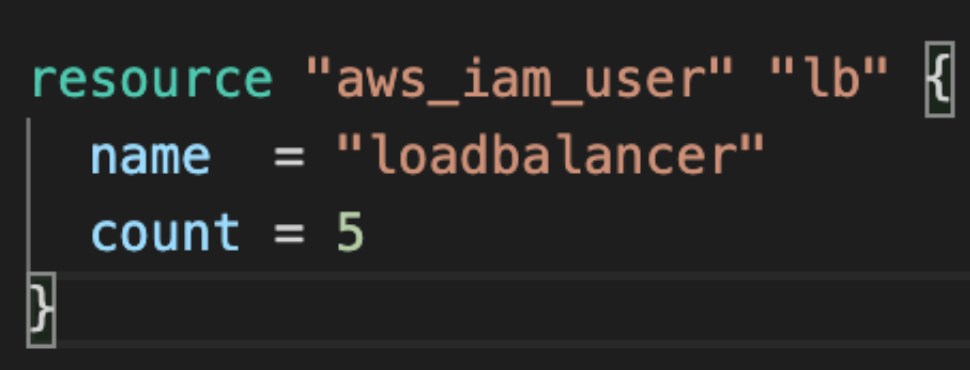
*Count.index* allows to fetch the index of **each iteration** in the loop:
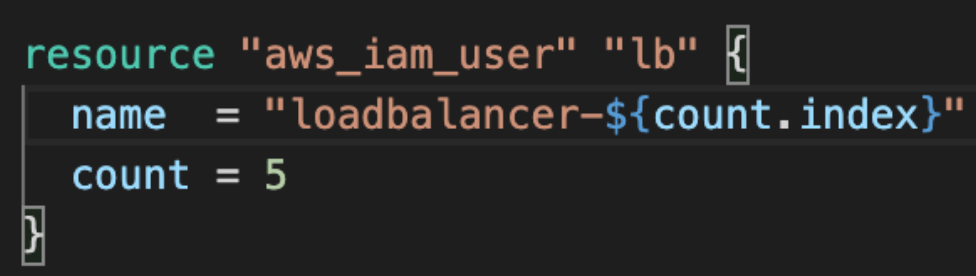
## Closure
Now that you know how to scale resources using this parameter, you can combine it with other TF things such as variables.
We can take advantage of the *count.index* to use it in a different way:
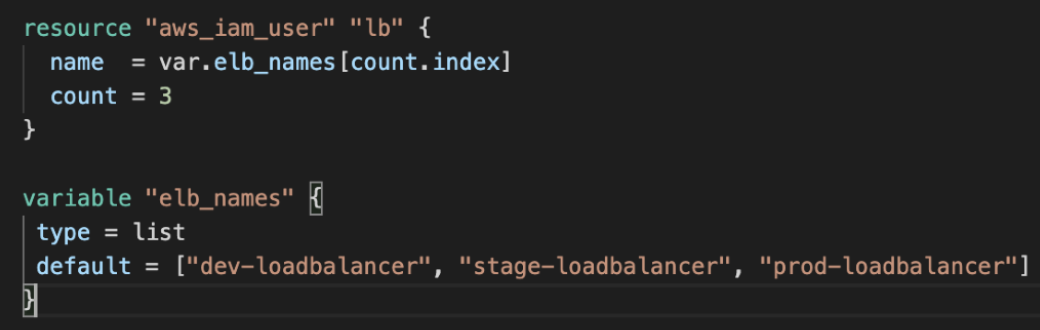
In this example we are setting the name of each IAM user according to the position of the variable named *elb_names*.
Any comments are welcome, remember we are here to help each other 😃💙.
| danihuerta |
801,461 | Do you (still) code for fun? | So I used to code in my spare time. Working on several side projects, going to hackathons, meetups,... | 0 | 2021-08-24T02:18:41 | https://dev.to/emmanuelobo/do-you-code-for-fun-1ph1 | discuss, career, productivity | So I used to code in my spare time. Working on several side projects, going to hackathons, meetups, etc. I really enjoyed it but part of why I was doing it was to improve my skills, strengthen my portfolio and potentially make a profit if it turned into a success.
But now I have a great job that challenges me and allows me to be creative in my approach to building tools.
Lately I've been getting an ich to get back into free-time coding. But I feel like it would be a waste of time now. And I'm at the point in my life where I really need to utilize my time wisely. So if I'm dedicating a chunk of time to something it has to be beneficial.
What do you guys think? Anyone in a similar situation? Or different, doesn't matter just want to get some thoughts. | emmanuelobo |
801,474 | TIL: Como converter célcius para fahrenheit em Elixir | Hoje eu aprendi a converter célcius para fahrenheit em Elixir. Fórmula: (0 °C × 9/5) + 32 = 32... | 0 | 2021-08-24T15:32:23 | https://dev.to/humrenan/til-como-converter-celcius-para-fahrenheit-em-elixir-1n18 | todayilearned | Hoje eu aprendi a converter célcius para fahrenheit em Elixir. Fórmula: (0 °C × 9/5) + 32 = 32 °F
Primeiro defini um módulo Celcius_to_fahrenheit e dentro uma função c_to_f/1 onde recebe o valor em graus celcius e converte para fahrenheit.

| humrenan |
801,489 | The New Creator Economy - DAOs, Community Ownership, and Cryptoeconomics | Web3 is Reshaping the Digital World | 0 | 2021-08-26T12:11:43 | https://dev.to/dabit3/the-new-creator-economy-daos-community-ownership-and-cryptoeconomics-lnl | webdev, web3, blockchain, ethereum | ---
title: The New Creator Economy - DAOs, Community Ownership, and Cryptoeconomics
published: true
description: Web3 is Reshaping the Digital World
tags: webdev, web3, blockchain, ethereum
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ax65k2orrz1dsie68jh4.jpg
---
{% twitter 1428368687644364805 %}
Since I first had what I can only describe as a spiritual awakening about 10 years ago to the fact that technology would (figuratively) rule the world, I've been obsessed with wanting to understand how software works and how to build it.
Since that moment, my life has changed significantly for the better. I can only attribute it to the simple fact that I have relied not only on my own instincts, but of those of people much smarter and more experienced than me.
My hypothesis is this - try to find and follow the lead of those who have exhibited a long track record of success, find interests in their wake, and do my best to excel at them (while continuing to explore my own curiosities).
This approach has led me to try and master JavaScript, and then React, and finally to build a successful consultancy ultimately landing me on a team at AWS in a life changing experience that lasted a little over 3 years. All of this with [no high school diploma or college degree](https://twitter.com/dabit3/status/1259471051429478400).
During this time (like many developers) I've relentlessly dived into books, podcasts, blog posts, YouTube videos, and source code of every kind, but there has always been a topic that has captured my curiosity the most - futurism.
Futurists like [Gerd Leonhard](https://twitter.com/gleonhard) and [Michio Kaku](https://twitter.com/michiokaku) speak of a future, sometimes beautiful and sometimes bleak, but always with the passion and phrasing that make your thoughts wander and move past the current moment in time and into a mind boggling world that does not yet exist.
I recently had another "aha" moment, similar to my technological awakening, that has completely changed the direction of my career and my life. In the spirit of these futurists, I want to talk about why [Web3](https://www.freecodecamp.org/news/what-is-web3/) excites me just as much as their ideas, but is instead happening as we speak.
## Web3
> This post is meant to dive more into what I think are the benefits and repercussions of Web3. If you want to know my interpretation of what Web3 is, see my thoughts [here](https://www.freecodecamp.org/news/what-is-web3/).
Web3 represents a handful of ideas which together bring about entirely new mental models, organizational structures, and community incentives forcing us to rethink many things that we have become accustomed to.
All of the recent innovation happening is being made possible because of decentralized protocols.
The internet itself has thrived because of native internet protocols that we use everyday, like http, ftp, tcp, and ssh. One of the reasons these protocols have been so successful was that they were widely adopted and not subject to change. If I build a site using http, people can use it without any centralized intermediary - we can trust that it is going to work.
There were two major pieces of native functionality that have been left out up until recently - payments and state.
Blockchains have enabled both of these things, opening the door for programmable money and state without the need of a centralized server, bank, or any intermediary at all.
### Ownership
One of the driving forces and the one that resonates with most people (and me) is that Web3 enables ownership.
#### Gaming
At some point the internet and gaming became almost indistinguishable. Not only because most games continue to receive updates over time, but the most popular ones are often the most interactive.
Fortnite took a lot of people by surprise because it created an innovative new combination of gameplay, peer-to-peer connection, and a unique business model - and everyone gets the game for free. The experience is very interactive, you can join old friends and make new ones, there are constant improvements and enhancements that just happen automatically - the game is consistently evolving.
The monetization strategy was also innovative. Fortnite allows players to buy in-game currency as well as skins that they can wear in the game. If you have a child you know that the $65 you may have spent on the game itself is probably peanuts compared to the amount of money kids spend over the lifetime of their gameplay.
The problem though is this: when the player decides to stop playing the game or outgrows it, where has all that money gone? More importantly, who is allowed as a creator to benefit from all of the purchasing power? The answer is, well, Fortnite (the platform).
What if, instead, players retained ownership of their items and were able to keep or sell them. Their items would maintain, increase, or decrease in value like any physical asset. These types of experiences and communities are now being made possible via NFTs. NFTs (and other digital tokens) enable scarcity in a world where there was in the past no scarcity.
[Axie Infinity](https://axieinfinity.com/) is an example of how this looks in practice. It is a blockchain-based game that is the most successful of it's kind, and has recently had explosive growth, catapulting it to over [$1 billion in sales](https://hypebeast.com/2021/8/axie-infinity-ethereum-first-nft-game-1-bilion-sales-info) with over $780 million in the 30 days ending August 10 2021.
The best part about Axie is that, instead of 100% of the revenue going to the platform, they only keep 5%. This means that 95% of the revenue gets distributed directly back to the gamers.
[Parallel](https://parallel.life/faq/) is an online card game that has done over $100 million in sales and is still extremely early. [Dark Forest](https://zkga.me/) enables players to [get paid to play the game](https://twitter.com/BlaineBublitz/status/1399397415732400129).
When players realize they can retain much of the value of their time and investments while still enjoying the benefit of the game, it not only changes the way they view gaming and where they spend their money, it aligns new incentives around the game itself. If the game succeeds, they can share in that success, therefore they become even more invested.
The combination of ownership, community, and creators who have built audiences creates a whirlwind of new and exciting opportunities that we are just starting to begin see explored throughout the Web3 world.
[Ryan Watt](https://twitter.com/Fwiz), the head of YouTube gaming agrees.
{% twitter 1429108126234546182 %}
Mar Pincus, founder of Zynga, says "Play 2 earn and play 2 win is next evolution of freemium. Player owned and directed economies could change games and other industries forever. Cant wait!"
{% twitter 1444698585447104512 %}
EA has called blockchain games "the future of our industry."
{% twitter 1456039561403027462 %}
And web3 gaming is experiencing never-before seen levels of investment across the board.
{% twitter 1456616150775832586 %}
### Social media and art
Social media platforms were revolutionary in that they allowed anyone from almost any background the ability to grow and foster large audiences using tools that were made free to anyone with a device and an internet connection. There are no gatekeepers to becoming famous on social media as there have been in the past in film and TV, the intermediary was abstracted away — peer to peer connections and direct content sharing was made possible.
The flaw in these implementations is that they offer a terrible monetization system, not just for the platform but for the creator as well. Advertising and the exploitation of user data is the go to play. Also almost all of the money generated by the platform, goes to the platform - the platform monetizes the content being created by its users in exchange of use of the platform itself. This is how social media works today.
In Web3, both creators and the community are able to gain and retain ownership within a platform, creating a synergy that, once experienced, makes the legacy interactions of the past seem archaic and undesirable. When I say ownership, I don't only mean ownership of content, but actual equity as well.
We are seeing the beginnings of this in the art world of Web3. Artists who were, in the past, often barely making it are now able to leverage their platforms, often in collaboration with other community members or causes, creating one of ones or collections of many. [Foundation](https://foundation.app/), [Super Rare](https://superrare.com/), and [Zora](https://zora.co/) enable digital artists to finally begin earning the type of incomes that their brothers and sisters in other parts of the tech sector have been enjoying for the past couple of decades, all enabled by blockchain technology and digital scarcity.
Art and code are also beginning to overlap.
[MoonshotBots](https://opensea.io/collection/moonshotbots-v3), launched by [Austin Griffith](https://twitter.com/austingriffith) and [Kevin Owocki](https://twitter.com/owocki) raised [over $2 million](https://decrypt.co/79606/moonshot-bots-nfts-gitcoin-ethereum-grants-1-8-million) to give to developers working on Open Source through [Gitcoin](https://gitcoin.co/) grants.
Projects like [Generative Masks](https://generativemasks.on.fleek.co/#/) allow talented creators like [Takawo Shunsuke](https://twitter.com/takawo) to leverage the skills he's acquired throughout his career to generate over $3 million in sales for his collection in just a few minutes, spreading awareness for himself and his cause, and creating another new community (of owners) simultaneously. The best part is that he's giving all of the money to the communities he's benefited from. On top of that, smart contracts allow him to programmatically enable a commission for any future sale that happens going forward, and in just a couple of weeks that amounts to another over $600,000.00.
{% twitter 1427807893458497544 %}
Generative art itself is an emerging category that combines code and creativity and is something that could alone warrant an entire post, but it suits the coming era particularly well as it enables artists to scale their creativity, community, and distribution.
There will continue to be a larger and larger percentage of digital artists because they can use powerful tools and programs to create art that can then be used in an infinite number of ways. They can then put it for sale on an international, 24 hour, liquid market.
Open Sea, the top online art marketplace today, has seen an absolute explosion in growth the past few months.
{% twitter 1429965382849343490 %}
Even recently surpassing Etsy in sales.
{% twitter 1427453596858294272 %}
Whether this type of volume continues, I have no idea. My guess is that there will be some volatility and fairly large swings both up and down. But there is definitely _something_ there.
Another NFT platform, [Super Rare](https://superrare.com/), did [a retroactive token drop](https://decrypt.co/78773/ethereum-nft-marketplace-superrare-token-airdrop) to reward and provide equity to early supporters of their platform. 15% of the total supply of their token was given to artists and collectors who had already used the platform, amounting to anywhere between a few thousand to [over a hundred thousand dollars](https://twitter.com/DCLBlogger/status/1427860274808197124) per user.
Most of these NFT projects are launched on Ethereum. Ethereum is soon merging [a new consensus mechanism](https://ethereum.org/en/eth2/) that will make NFTs orders of magnitude more environmentally friendly as a means of sales and transfer of art than how we physically do today, which in the past all required ground transportation.
#### Future of social media
As it stands today, users of social media platforms can begin leveraging Web3 tools, communities, and platforms to begin monetizing their audience. I believe there will be a breakthrough app that will disrupt social media as we know it built in the in the next 1 - 3 years that blends all of these ideas together in a way that we haven't experienced yet.
Many people have echoed a similar sentiment. [Aave](https://twitter.com/AaveAave), a very successful DeFi protocol built on Ethereum, has already begun work on [a decentralized version of Twitter](https://decrypt.co/76278/defi-project-aave-to-release-ethereum-based-twitter-alternative-this-year):
{% twitter 1416385933549654016 %}
Jack Dorsey of Twitter is also working on a Decentralized version of Twitter, though I believe that this type of application will ultimately come from the community or a DAO.
{% twitter 1427314482154414080 %}
Then there's Reddit, who's founder Alexis Ohanian is extremely bullish on web3:
{% twitter 1454943945633398787 %}
Reddit is moving into the space claiming to have a goal to "Decentralize social media"
{% twitter 1455950490366263301 %}
And of course there's the company previously known as Facebook who is unabashedly diving head first into the Metaverse, renaming their company to Meta, issuing their own token, [and supporting NFTs](https://www.coindesk.com/business/2021/10/28/facebooks-metaverse-will-support-nfts/).
### DAOs, grants, community ownership, and social tokens
> DAO stands for Decentralized Autonomous Organization. You can read about what a DAO is [here](https://www.notboring.co/p/the-dao-of-daos), [here](https://linda.mirror.xyz/Vh8K4leCGEO06_qSGx-vS5lvgUqhqkCz9ut81WwCP2o), and [here](https://decrypt.co/resources/decentralized-autonomous-organization-dao), but I want to focus on how DAOs will play a part in the new creator economy.
Shared ownership is a characteristic you'll see carried across all areas of Web3, including how we think about companies and incentive structures around how business is done.
In web2 companies, cash usually comes from large investors and there is no value returned to them for years. Ownership is largely concentrated in the first handful of employees along with their investors. Also, the average person has no chance of investing early in these companies. This funnels more money and more opportunity to the upper class, most connected, and most privileged among us and widening income disparities around the world.
These investments are also not liquid. It also usually takes years to reach a point where investors or employees with equity can begin to see any return on their investment and time spent, those revenues often through the old ways of advertising and exploitation of user data.
Web3 and blockchains bring about entirely new business models, made possible by [tokenization](https://www.gemini.com/cryptopedia/what-is-tokenization-definition-crypto-token#section-security-tokens-utility-tokens-and-cryptocurrencies) and [cryptoeconomic protocols](https://thegraph.com/blog/modeling-cryptoeconomic-protocols-as-complex-systems-part-1).
In web3, communities and companies are built from the bottom up. Ownership can be created and issued to people in the form of tokens. Almost anyone can invest and participate in these communities and protocols much earlier on. Ownership is distributed much more evenly and fairly than in traditional companies. Developers and others can help build these communities, apps, and protocols in exchange for ownership. Unlike stock in startups which is not liquid, these tokens are indeed usually liquid.
DAOs enable communities to be owned by their participants. For example, developers often spend time helping answer questions in some company's Discord or on Stack Overflow. They might spend hours per month, taking time out of there day to do so. At the end of the day, the platform or company is benefitting and monetizing the value from that person, and they are not paid anything in return. In a DAO, community members hold ownership in the form of a token (usually either an NFT or an ERC20). The success of the community will determine the value of their stake, creating incentives for participants to make it successful, increasing the value they retain if the community continues to remain succesful.
There are quite literally countless ways that these tokens are being utilized to create new ways of collaboration and building, ranging from DAOs to web infrastructure to [micro-economies](https://coopahtroopa.mirror.xyz/gWY6Kfebs9wHdfoZZswfiLTBVzfKiyFaIwNf2q8JpgI):
- [Developer DAO](https://twitter.com/developer_dao) which was created in September of 2021 already has over 3,000 members, a rapidly growing Twitter following, production projects, and investments to the tune of hundreds of thousands of dollars.
- [PartyDAO](https://twitter.com/prtyDAO) which [created over $200,000 in revenue in its first day](https://twitter.com/nnnnicholas/status/1423428739589943300), was "built in 3 months by a small group of internet friends working part-time", and is backed by a smart contract
- [Compound](https://compound.finance/), a decentralized finance protocol that allows you to lend and borrow cryptocurrency without trusting a third party with your funds with a market cap of over $2 billion as of this writing
- [Audius](https://audius.co/) is a music streaming platform that enables them to create, grow, and directly monetize their fanbase directly without the need to sign a record deal or give all of the earnings to the platform like with apps like Spotify or Apple music. Investors include [Nas, Pusha T, Katy Perry, and Jason Derulo](https://www.rollingstone.com/pro/news/audius-blockchain-nft-crypto-streaming-platform-1226559/).
- [Gitcoin](https://gitcoin.co/) is a platform that enables developers to get paid for working on open source projects
- [Graph Protocol](https://thegraph.com/) is a decentralized web infrastructure protocol that allows developers to build APIs to enable the performant querying of blockchain data, all enabled by it's native utility token
- [Seed Club](https://twitter.com/seedclubhq) is a social token incubator that’s focused on helping creators launch and grow social tokens
- [Friends with Benefits](https://twitter.com/fwbtweets) is a social DAO and community that I'm part of that is 100% owned and governed by the participants recently valued at a market cap of around $250 million.
- [PleasrDAO](https://twitter.com/pleasrdao) allows investors to come together to purchase high-value non-fungible tokens like [this piece](https://foundation.app/@Snowden/stay-free-edward-snowden-2021-24437) from Edward Snowden
Most DAOs have [desirable grants programs](https://thegraph.com/blog/wave-one-funding), enabling developers and other participants to work with various teams and projects at their will, on things they find interesting or that fit their skill set. There are more and more people beginning to work full time for grants and with DAOs vs traditional full time employment.
{% twitter 1418307358946701319 %}
### Conclusion
If this sounds like something you're interested in being involved, I'd suggest to jump right in. Try P2E (play to earn), get involved with a DAO, or even mint your own NFT.
Also check out [How to Get Into Ethereum | Crypto | Web3 as a Developer](https://dev.to/dabit3/how-to-get-into-ethereum-crypto-web3-as-a-developer-9l6) which is what I put together after getting my own start in the space.
If you want to learn more about these ideas, I encourage you to follow some of the people I mention in this post:
{% twitter 1430865775011803137 %}
{% twitter 1430865775766740994 %}
Also, here are some of my favorite articles that touch on some of the stuff I've outlined here:
- [The Rise of Micro-Economies](https://coopahtroopa.mirror.xyz/gWY6Kfebs9wHdfoZZswfiLTBVzfKiyFaIwNf2q8JpgI)
- [The Creator Economy: Today Vs. 2025](https://www.rushil2cents.com/the-creator-economy-today-vs-2025/)
- [The Value Chain of the Open Metaverse](https://www.notboring.co/p/the-value-chain-of-the-open-metaverse)
- [The DAO of DAOs](https://www.notboring.co/p/the-dao-of-daos)
- [Non-Fungible Talent](https://hyperionmagazine.com/featured/non-fungible-talent/)
Thanks to [Aditi](https://twitter.com/adeets_22) for helping me with ideas and edits as I was getting this across the finish line 🙏
{% twitter 1430585405662011397 %} | dabit3 |
801,639 | Various methods in Python to check the type of an object | In this short tutorial, we look at how to use Python to check the type of objects. We take a look at... | 0 | 2021-08-25T10:54:51 | https://flexiple.com/python-check-type/ | python, programming, tutorial, beginners | In this short tutorial, we look at how to use Python to check the type of objects. We take a look at all the various methods that can be used.
This tutorial is a part of our initiative at [Flexiple](https://flexiple.com/), to write short curated tutorials around often used or interesting concepts.
### Table of Contents:
- [Python check type](#python-check-type)
- [Using the type() function](#using-the-raw-type-endraw-function)
- [Using isinstance()](#using-raw-isinstance-endraw-)
- [Closing thoughts](#closing-thoughts)
## TL;DR - How to check the type of an object in Python?
The `type()` function takes in an argument and returns the type of the object. Apart from this method the `isinstance()` function can check if an argument is an instance of a particular class or type.
## Python check type:
Unlike most programming languages Python does not require you to specify the data type of a particular object. Python assigns them during compilation. Experienced developers may not have a problem identifying data type, however, beginners might find this a little tricky.
Python facilitates this with the help of two in-built functions. We have explained both these methods in detail below.
## Using the `type()` function:
The `type()` is used to check the type of an object. This function exists for this exact purpose and is the most commonly used method.
The `type()` method takes in an argument (object) and returns the class type assigned to the particular object.
### The Syntax of `type()` is as follows:
```python
type(object)
```
### Code to check type using type()
```python
language = "Python"
year = 1991
version = 3.9
print(type(language))
print(type(year))
print(type(version))
```
The output is as follows:
```python
<class 'str'>
<class 'int'>
<class 'float'>
```
This is how we use `type()` to check the type of an object.
## Using `isinstance()`:
`Isinstance()` can also be used to check type. However, unlike the `type()` function here we pass the classinfo along with the object the function returns a boolean value.
This will be true if the object belongs to a particular class and vice versa. However, do keep in mind that it only returns a boolean value in case it’s true and would not return the correct type in case it is false.
### Syntax of `isinstance()`:
```python
isinstance(object, type)
```
### Code using isinstance():
```python
language = "Python"
year = 1991
version = 3.9
print(isinstance(language, str))
print(isinstance(year, int))
print(isinstance(version, int))
```
The output is as follows:
```python
True
True
False
```
As the classinfo for version was passed as int, the isinstance method returns a false. This is how you use the `isinstance()` method.
## Closing thoughts
The `type()` method is the most recommended method to check the type of an object. The `isinstance()` method stands out as it can be used to check if an object is part of a class as well.
Hence, I would always recommend using the `type()` method to check the type of an object.
Do let me know your thoughts in the comments section below. :)
| hrishikesh1990 |
801,657 | One-to-Many relationships and the process of data modelling in DynamoDB | Today we'll talk about a topic I've been interested in for a few months now: data modelling in NoSQL... | 0 | 2021-08-24T06:44:02 | https://aws-blog.de/2021/03/modelling-a-product-catalog-in-dynamodb.html | aws, database, cloud, dynamodb | Today we'll talk about a topic I've been interested in for a few months now: data modelling in NoSQL databases, especially DynamoDB. This article assumes basic knowledge of DynamoDB, which you can get from reading [DynamoDB in 15 minutes](https://aws-blog.de/2021/03/dynamodb-in-15-minutes.html). I was inspired to write this by a question that I answered on [stackoverflow](https://stackoverflow.com/q/65579206/6485881) a while ago. This finally gave me an excuse to write about the topic.
I'm going to introduce you to a user story first, then we're going to discuss the process of data modelling in NoSQL environments. Afterwards we'll move on to building the data model for the user story. Sprinkled throughout this, I'll show you some code examples for your data access layer.
## User Story

Fromatoz is a fictional online retailer that offers a platform, where **products** from different **brands** across various **product categories** are being sold. Customers can browse products by brand and have the option to filter the products from the brand by categories. Another way customers can use the product catalog is that they look at a specific category and see the products all brands offer in that category. Since the products have varying kinds of properties, Fromatoz wants to use a NoSQL database because of its flexible schema.
The customer also wants to track the stockpile for each product. This means that the available stock should be decreased upon purchases made by customers and increased upon arrival of new shipments. The inventory team needs to be able to quickly retrieve the current stock level for a given product.
Let's talk about the process we can use to turn Fromatoz' requirements into reality.
## Data modelling in NoSQL environments
The process of data modelling in a non-relational world is somewhat different from traditional data modelling for relational databases. Fortunately there are some steps you can follow to create your data model.
Since I didn't come up with these steps myself, I'm going to quote from the DynamoDB book by AWS Data Hero [Alex DeBrie](https://alexdebrie.com).
The steps are:
> - Understand your application
> - Create an entity-relationship diagram ("ERD")
> - Write out all of your access patterns
> - Model your primary key structure
> - Satisfy additional access patterns with secondary indexes and streams
>
> — <cite>Alex DeBrie, The DynamoDB Book - chapter 7.2</cite>
The first step should seem fairly obvious, we need to have an understanding of the domain we're working in. In our case I've outlined the required information above and since you've most likely used a webshop in the past, you should be good to go.
Creating an entity-relationship-diagram may not seem obvious at first, since we're talking about a non-relational database. Actually the term non-relational database is misleading, in my opinion, because data in it still has relationships. The way these relationships are handled and modelled is just different from relational databases. In order to have a common basis to discuss requirements, query patterns and all of these fancy constructs, an ERD is a good start.
Once we've gotten an understanding of which entities exist and how they're related, we have to find out and define how these are queried. This step is critical - our access patterns will determine how we store and index our data.
The next two steps are what makes or breaks our data model: we create the primary key structure to satisfy our primary access patterns and use local and global secondary indexes as well as DynamoDB streams to enable additional access patterns.
Now that we've talked about the process and introduced the use case along with the challenges it presents, let's move on to step two: the entity relationship diagram.
## Entity Relationship Diagram
Here's a simple ERD for our use case (I'm aware it's not up to UML standards, but it's good enough):
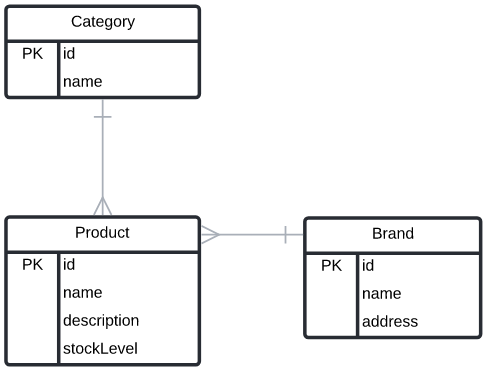
The diagram is fairly simple and consists only of three entities, product, brand and category. Categories can have multiple products and brands can have multiple products. Each product belongs to one brand and one category. This means we're going to have to model two one-to-many relationships (I'll talk about many to many relationships in a future post).
That takes care of the entity relationship diagram, let's talk about access patterns.
## Access Patterns
In order to understand how we'll access the data in the product catalog, we need to take a closer look at the use case description again. From there we can come up with these access patterns:
1. Get all brands
2. Get all categories
3. Get product by id (for the stock level query)
4. Decrease stock level for product
5. Increase stock level for product
6. Get products by brand
7. Get products by brand and category
8. Get products by category
9. _(Get products by category and brand)_
Access pattern 9 is optional, because the result of a query would be identical to that of access pattern 7. From the perspective of a user interface the difference between 7 and 9 matters, but the data layer would return the same results. We will still model access pattern 9, because, depending on the distribution of the data, it may be advantageous to choose one over the other.
Now it's time to build a model for these access patterns.
## Building the model
First we take a closer look at the access patterns and structure them for ourselves. We identify the entities affected by each access pattern and the information that will be sent via the parameters to perform the read or write operations.
| # | Entity | Description | Parameters |
| --- | --- | --- | --- |
| 1 | Brand | Get all | |
| 2 | Category | Get all | |
| 3 | Product | Get by id | `<pid>` (Product ID) |
| 4 | Product | Decrease stock | `<pid>` + `<stockDecrement>`|
| 5 | Product | Increase stock | `<pid>` + `<stockIncrement>` |
| 6 | Product | List by brand | `<bid>` (Brand ID) |
| 7 | Product | List by brand and category | `<bid>` + `<cid>` (Category ID) |
| 8 | Product | List by category | `<cid>` |
| 9 | Product | List by category and brand | `<cid>` + `<bid>`|
From this table we can see, that the majority of access patterns affect the product entity, which shouldn't come as a surprise, as this is a product catalog. Before we talk about the more complex entity, let's begin modelling with the brand and category entities, which account for the access patterns 1 and 2.
Both of them require a list of **all** entities of that type.
If we recall the APIs available to us, we know that there are three ways to get **multiple** items out of DynamoDB:
1. `BatchGetItem`, which batches multiple `GetItem` calls together and requires us to know the partition and sort key for all items we want to select.
2. `Query`, which allows us to work on collections of items (those that share the same partition key) and optionally do some filtering on the sort key in the partition.
3. `Scan` is essentially a table scan and by far the slowest and most expensive operation.
Since we don't know all primary keys for all brands or categories, we can rule out `BatchGetItem`. We want to avoid `Scan` at all costs. So let's see how we can do this using `Query`. With `Query` we can easily get a whole item collection by querying for a partition key and not filtering on the sort key. This is what we're going to use to enable the access patterns 1 and 2. I have started modelling the table below:
| **PK** (Partition Key) | **SK** (Sort Key) | **type** | name | brandId | categoryId |
|---|---|---|---|---|---|
| BRANDS | B#1 | BRAND | Microsoft | 1 | |
| BRANDS | B#2 | BRAND | Google | 2 | |
| BRANDS | B#3 | BRAND | Tesla | 3 | |
| CATEGORIES | C#1 | CATEGORY | Cars | | 1 |
| CATEGORIES | C#2 | CATEGORY | Boats | | 2 |
| CATEGORIES | C#3 | CATEGORY | Phones | | 3 |
Our table has a composite primary key, that's made up of `PK` as the partition key and `SK` as the sort key. I have decided to prefix the sort key values with `B#` for brand ids and `C#` for category ids. You'll see me doing this throughout the post. This helps with namespacing items in **the** table, since we're putting all entities in a single table. Another thing you can observe is that the brand ids and category ids are both attributes as well as values for key-attributes. This duplication is introduced on purpose to help distinguish between key-attributes and what I like to call payload-attributes. It makes serialization and deserialization easier. The `type` attribute also helps with deserialization.
To get a list of brands, we can now do a simple query like this one in python, which would return the first three rows of the table - the code for the `CATEGORIES` collection would look very similar:
```python
import typing
import boto3
import boto3.dynamodb.conditions as conditions
def get_all_brands() -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("data")
response = table.query(
KeyConditionExpression=conditions.Key("PK").eq("BRANDS")
)
return response["Items"]
```
> **Note:** If there are lots of reads/writes to these partitions you can consider read/write sharding-techniques, but that's beyond the scope of this article. They help avoid hot partitions at the cost of data access layer complexity.
Moving on to the **product** entity. We have seven access patterns to eventually deal with, but we'll tackle them in batches. First we'll model fetching of a product by its product id as well as incrementing and decrementing of stock values. Since a product id is unique, this is an ideal use case for a `GetItem` operation, because we only want to fetch one item and know the key information for it. We'll use the same table we already used for the other entities, this is called single-table-design. Because of space constraints the layout of the table is flipped here and only focuses on the product entity.
| Attribute | value |
| --- | --- |
| PK | P#1 |
| SK | METADATA |
| type | PRODUCT |
| name | Model 3 |
| productId | 1 |
| stockLevel | 70 |
| categoryId | 1 |
| brandId | 3 |
By setting it up this way we can easily request a product by it's ID and also increment and decrement the stock level. Below you can see an example implementation in python for `get_product_by_id` and `increment_product_stock_level` - the decrement would look very similar.
```python
import boto3
def get_product_by_id(product_id: str) -> dict:
table = boto3.resource("dynamodb").Table("data")
response = table.get_item(
Key={
"PK": f"P#{product_id}",
"SK": "METADATA"
}
)
return response["Item"]
def increment_product_stock_level(product_id: str, stock_level_increment: int) -> None:
table = boto3.resource("dynamodb").Table("data")
table.update_item(
Key={
"PK": f"P#{product_id}",
"SK": f"METADATA",
},
UpdateExpression="SET #stock_level = #stock_level + :increment",
ExpressionAttributeNames={
"#stock_level": "stockLevel"
},
ExpressionAttributeValues={
":increment": stock_level_increment
}
)
```
Let's take a look at the table we've created so far. The diagram below doesn't contain exactly the same values as the tables above - it's designed to show our key patterns. I suggest that you go through the five query patterns we've implemented so far in your head and try to visualize how they're retrieved from the table.
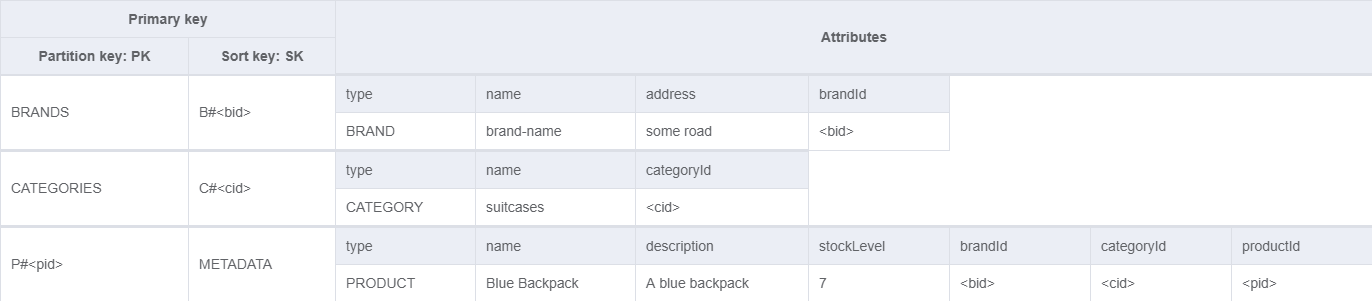
---
Now it's time to talk about the remaining four access patterns.
| # | Entity | Description | Parameters |
| --- | --- | --- | --- |
| 6 | Product | List by brand | `<bid>` (Brand ID) |
| 7 | Product | List by brand and category | `<bid>` + `<cid>` (Category ID) |
| 8 | Product | List by category | `<cid>` |
| 9 | Product | List by category and brand | `<cid>` + `<bid>`|
After taking a closer look at them, we can see that these four access patterns can be divided into two groups that are very similar. Patterns 6 and 7 both start with the brand id as a first filter and 7 adds the category as an additional filter to the result from 6. Patterns 8 and 9 are similar - 8 filters based on a category and 9 is an additional filter on the result from 8. That means if we solve either of the combinations, we have a pattern that we can re-use for the other.
I usually start at the top of the list and work my way downwards, but it doesn't really matter. So let's consider 6 and 7 first. Access pattern 6 essentially requires us to model the one-to-many relationship between a brand and its products. We've already seen a pattern that allows us to do this. Use the partition key for the parent and the sort key for the children, which allows us to query for them. We can use this here as well, but there is a problem. The primary index for our table and the product index is already being used to satisfy the access patterns 3 to 5.
Since our primary index is already in use, we should take a look at the secondary indexes. A local secondary index would require us to use the same partition key, but we could choose a different sort key. This doesn't help us here, because the product's partition key is its ID and we would need that to be the brand it belongs to. That leaves us with a global secondary index (GSI), which allows us to choose both a different partition and sort key.
Let's add a GSI, which we're going to call `GSI1` with `GSI1PK` as its partition- and `GSI1SK` as its sort key. Generic names again, because we could use them to fulfill multiple access patterns.
The simplified table looks like this.
| PK | SK | type | GSI1PK | GSI1SK |
|---|---|---|---|---|
| `P#<pid>` | `METADATA` | `PRODUCT` | `B#<bid>` | `P#<pid>` |
This design allows us to deliver on access pattern 6. If we take a look at access pattern 7, we have already observed that it's essentially another filter on the result of 6. There are multiple ways to implement this, but there is a particular one that I prefer. When using `Query` to fetch items from a table, we can do some filtering on the sort key - among others there is a `begins_with` operator - which we can use to utilize `GSI1` for query pattern 7 as well. To achieve that, we slightly modify our key-schema from above to look like this:
| PK | SK | type | GSI1PK | GSI1SK |
|---|---|---|---|---|
| `P#<pid>` | `METADATA` | `PRODUCT` | `B#<bid>` | `C#<cid>#P#<pid>` |
We prepend the category ID to `GSI1SK`, which allows us to use `begins_with` on it, while at the same time retaining the ability to do the query for 6. The product ID still needs to be kept as part of the sort key, because we need each product to show up and that only happens, if the products are distinct in the GSI. An implementation in Python for these two might look something like this:
```python
import typing
import boto3
import boto3.dynamodb.conditions as conditions
def get_products_by_brand(brand_id: str) -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("data")
response = table.query(
IndexName="GSI1",
KeyConditionExpression=conditions.Key("GSI1PK").eq(f"B#{brand_id}")
)
return response["Items"]
def get_products_by_brand_and_category(brand_id: str, category_id: str) -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("data")
response = table.query(
IndexName="GSI1",
KeyConditionExpression=conditions.Key("GSI1PK").eq(f"B#{brand_id}") \
& conditions.Key("GSI1SK").begins_with(f"C#{category_id}#")
)
return response["Items"]
```
This takes care of access patterns 6 and 7. I have added a further optimization, which isn't visible in the code, because it relates to `GSI1`. When you define a GSI in DynamoDB you can select which attributes should be projected into that index. There are three possible configuration parameters:
- `KEYS_ONLY` - only the keys for the GSI are projected into the GSI (least expensive)
- `INCLUDE` - you get to specify which attributes are projected into the GSI
- `ALL` - projects all attributes into the GSI (most expensive)
Since we only really care about the `type`, `name`, `description`, `stockLevel` and `productId` when we query for products, I chose `INCLUDE` as the projection type and only projected these onto the index. This results in GSI1 looking like this:

---
To implement the remaining two access patterns, we essentially do the same. We can't reuse `GSI1` here, because, in this case, our partition key will have to be the category id. That's why we set up `GSI2` with the partition and sort keys `GSI2PK` and `GSI2SK` with the same projection as `GSI1`. The data in `GSI2` looks very similar to `GSI1` as a result of that (except for the primary key).

Earlier I mentioned that access patterns 7 and 9 are essentially identical in the items they return, but that it's advantageous to use one over the other depending on the data distribution. For this we have to consider how data is layed out in DynamoDB internally. Item collections are assigned to a storage partition depending on their partition key, i.e. all items with the same partition key live on the same storage partition. To improve scalability we try to spread out the load across these partitions evenly. One way to do that is by querying the item collections with many distinct values. If we have many brands but few categories, that means we'll have many brand partitions and using `GSI1` for that spreads out the load more evenly. Should we have many more categories than brands, `GSI2` will be better suited for this. The data model allows us this flexibility at the cost of a few more bytes in storage space.
---
**Now we've created a table structure that supports all of your nine access patterns!** Let's check out the final table. First we start with our key structure. The table below shows the attributes each entity needs for the access patterns to work. By now you should be able to see how we can use each of them to fulfill the access patterns.
|Entity| PK | SK | GSI1PK | GSI1SK | GSI2PK | GSI2SK |
|---|---|---|---|---|---|---|
|**Brand**| `BRANDS` | `B#<bid>` |
|**Category**| `CATEGORIES` | `C#<cid>` |
|**Product**| `P#<pid>` | `METADATA` | `B#<bid>` | `C#<cid>#P#<pid>` |`C#<cid>` | `B#<bid>#P#<pid>` |
If we now look at the whole table, we can see that it's starting to get fairly complex. That's part of the reason, why browsing a DynamoDB table based on single-table-design from the console isn't that convenient. I prefer to build a CLI tool, that uses my data access layer, to browse through the table; but that's application specific and a topic for another day.
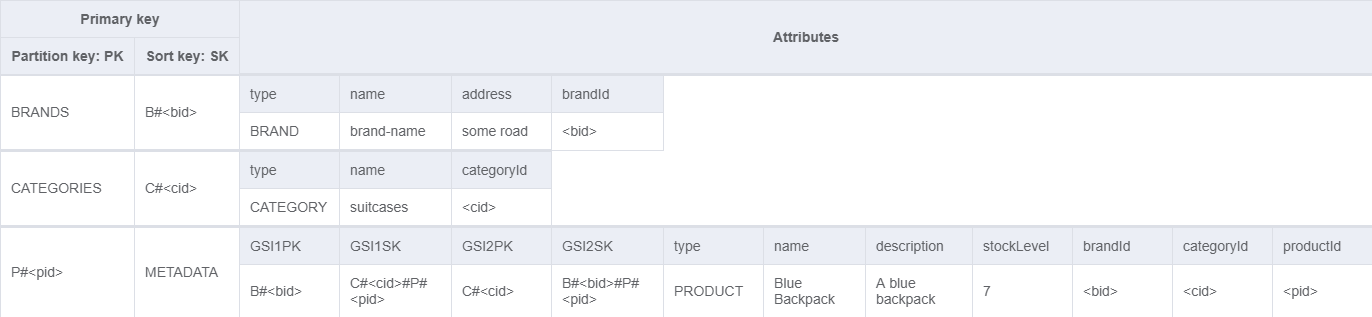
## Wrap up
Let's wrap this up for today. In this post we have gone through the process of modelling a product catalog in DynamoDB. We started with the use case description, then built an entity relationship diagram, identified our access patterns and then designed our primary key structure as well as secondary indexes to implement the access patterns. We also looked at some code examples of how a data access layer could fetch the data and perform update operations.
This article has been focused on one-to-many relationships and the different ways they can be modelled as well as the process of turning a use case description into a data model. If you have feedback, questions or want to get in touch to discuss projects, feel free to reach out to me through the social media channels in my bio or leave a comment.
— Maurice
(This article has been first published in March 2021 on [our company blog](https://aws-blog.de/2021/03/modelling-a-product-catalog-in-dynamodb.html)) | mauricebrg |
801,678 | Monitor your Python application with OpenTelemetry and SigNoz 📊🐍 | OpenTelemetry is a vendor-agnostic instrumentation library under CNCF. It can be used to instrument... | 0 | 2021-09-02T13:17:47 | https://signoz.io/opentelemetry/python/ | python, monitoring, webdev, devops | OpenTelemetry is a vendor-agnostic instrumentation library under CNCF. It can be used to instrument your Python applications to generate telemetry data. Let's learn how it works and see how to visualize that data with SigNoz.
[](https://bit.ly/2WkkmL4)
**The cost of a millisecond.**<br></br>
TABB Group, a financial services industry research firm, <a href="https://research.tabbgroup.com/report/v06-007-value-millisecond-finding-optimal-speed-trading-infrastructure" rel="noopener noreferrer nofollow" target="_blank">estimates</a> that if a broker's electronic trading platform is 5 milliseconds behind the competition, it could cost $4 million in revenue per millisecond.
The cost of latency is too high in the financial services industry, and the same is true for almost any software-based business today. Half a second is enough to kill user satisfaction to a point where they abandon an app's service.
Capturing and analyzing data about your production environment is critical. You need to proactively solve stability and performance issues in your web application to avoid system failures and ensure a smooth user experience.
In a microservices architecture, the challenge is to solve availability and performance issues quickly. You need observability for your applications. And, observability is powered with telemetry data.
## What is OpenTelemetry?
OpenTelemetry emerged as a single project after the merging of OpenCensus(from Google) and OpenTracing(from Uber) into a single project. The project aims to make telemetry data(logs, metrics, and traces) a built-in feature of cloud-native software applications.
OpenTelemetry has laguage-specific implementation for generating telemetry data which includes OpenTelemetry Python libraries.
You can check out the current releases of <a href = "https://github.com/open-telemetry/opentelemetry-python/releases" rel="noopener noreferrer nofollow" target="_blank">opentelemetry-python</a>.
OpenTelemetry only generates telemetry data and lets you decide where to send your data for analysis and visualization. In this article, we will be using [SigNoz](https://signoz.io/) - an open-source full-stack application performance monitoring tool as our analysis backend.
**Steps to get started with OpenTelemetry for a Python application:**
- Installing SigNoz
- Installing sample Python app
- Instrumentation with OpenTelemetry and sending data to SigNoz
## Installing SigNoz
You can get started with SigNoz using just three commands at your terminal if you have Docker installed. You can read about other deployment options from [SigNoz documentation](https://signoz.io/docs/deployment/docker).
```
git clone https://github.com/SigNoz/signoz.git
cd signoz/deploy/
./install.sh
```
You will have an option to choose between ClickHouse or Kafka + Druid as a storage option. Trying out SigNoz with ClickHouse database takes less than 1.5GB of memory, and for this tutorial, we will use that option.
When you are done installing SigNoz, you can access the UI at: `http://localhost:3000`
The application list shown in the dashboard is from a sample app called HOT R.O.D that comes bundled with the SigNoz installation package.
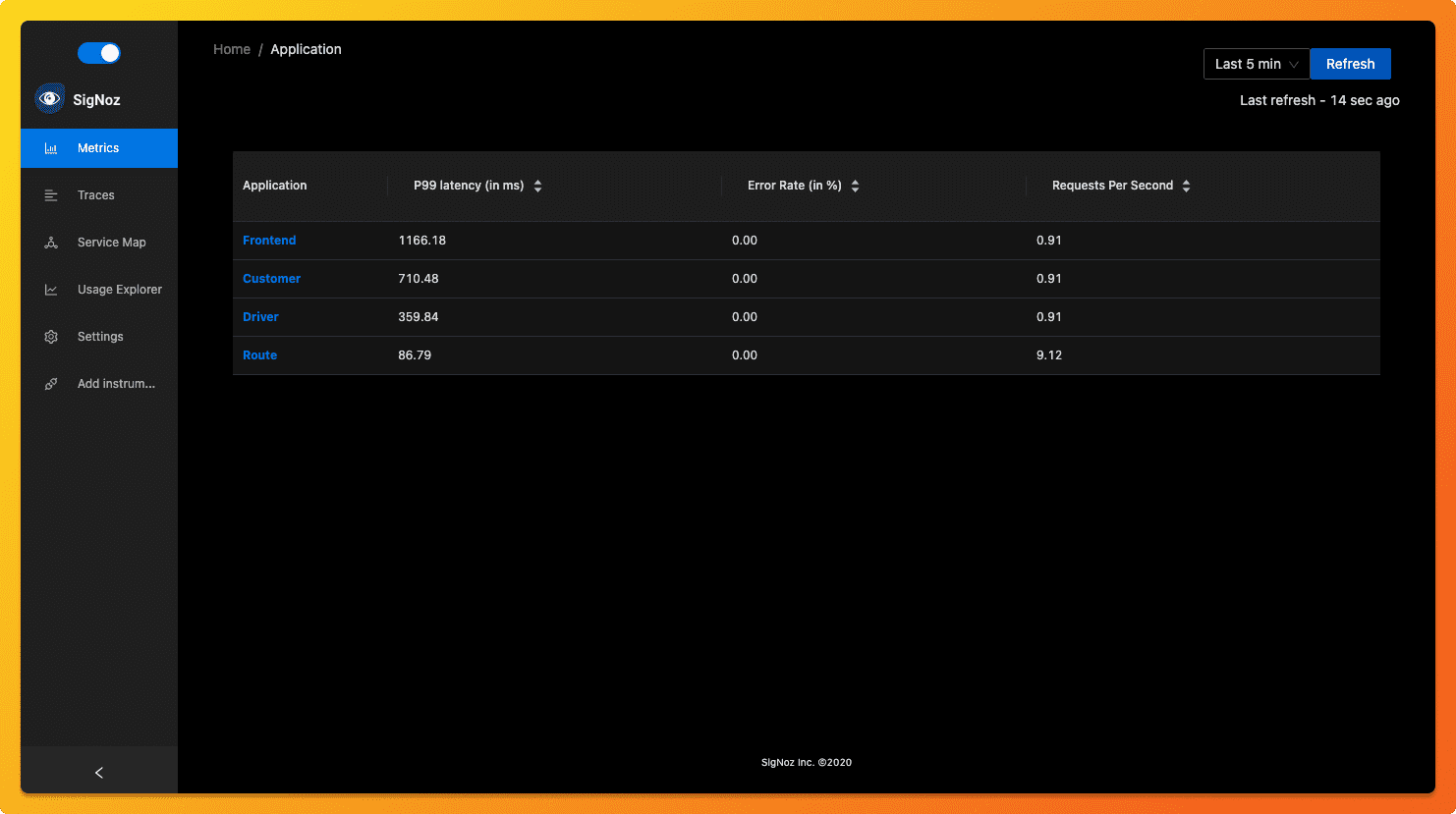<figcaption>SigNoz dashboard</figcaption>
## Installing sample Python app
**Prerequisites**
1. Python 3.4 or newer
If you do not have Python installed on your system, you can download it from the <a href="https://www.python.org/downloads/" rel="noopener noreferrer nofollow" target="_blank">link</a>. Check the version of Python using `python3 --version` on your terminal to see if Python is properly installed or not.
2. MongoDB
If you already have MongoDB services running on your system, you can skip this step.
For macOS:
Download link: https://docs.mongodb.com/manual/tutorial/install-mongodb-on-os-x/
For Linux: https://docs.mongodb.com/manual/administration/install-on-linux/
For Windows: https://docs.mongodb.com/manual/tutorial/install-mongodb-on-windows/
On MacOS the installation is done using Homebrew's brew package manager. Once the installation is done, don't forget to start MongoDB services using `brew services start mongodb/brew/mongodb-community@4.4` on your macOS terminal.
<figcaption>start mongodb services</figcaption>
### Steps to get the Python app up and running
1. Clone sample Flask app repository and go to the root folder
```
git clone https://github.com/SigNoz/sample-flask-app.git
cd sample-flask-app
```
2. Check if the app is running
```
python3 app.py
```
<figcaption>Running Python app from terminal</figcaption>
You can now access the UI of the app on your local host: http://localhost:5000/
<figcaption>Python App UI accessed on port 5000</figcaption>
## Instrumentation with OpenTelemetry and sending data to SigNoz
1. Opentelemetry Python instrumentation installation<br></br>
Your app folder contains a file called requirements.txt. This file contains all the necessary commands to set up OpenTelemetry Python instrumentation. All the mandatory packages required to start the instrumentation are installed with the help of this file. Make sure your path is updated to the root directory of your sample app and run the following command:
```
pip3 install -r requirements.txt
```
If it hangs while installing `grpcio` during **pip3 install opentelemetry-exporter-otlp** then follow below steps as suggested in <a href="https://stackoverflow.com/questions/56357794/unable-to-install-grpcio-using-pip-install-grpcio/62500932#62500932" rel="noopener noreferrer nofollow" target="_blank">this stackoverflow link</a>.
- pip3 install --upgrade pip
- python3 -m pip install --upgrade setuptools
- pip3 install --no-cache-dir --force-reinstall -Iv grpcio
2. Install application specific packages
This step is required to install packages specific to the application. Make sure to run this command in the root directory of your installed application. This command figures out which instrumentation packages the user might want to install and installs it for them:
```
opentelemetry-bootstrap --action=install
```
3. Configure a span exporter and run your application
You're almost done. In the last step, you just need to configure a few environment variables for your OTLP exporters. Environment variables that need to be configured:
- SERVICE_NAME **-** application service name (you can name it as you like)
- ENDPOINT_ADDRESS **-** OTLP gRPC collector endpoint address (IP of SigNoz)
After taking care of these environment variables, you only need to run your instrumented application.
Accomplish all these by using the following command at your terminal.
```
OTEL_RESOURCE_ATTRIBUTES=service.name=pythonApp OTEL_METRICS_EXPORTER=none OTEL_EXPORTER_OTLP_ENDPOINT="http://<IP of SigNoz>:4317" opentelemetry-instrument python3 app.py
```
`Ip of SigNoz` can be replaced with localhost in this case. Hence, the final command becomes:
```
OTEL_RESOURCE_ATTRIBUTES=service.name=pythonApp OTEL_METRICS_EXPORTER=none OTEL_EXPORTER_OTLP_ENDPOINT="http://localhost:4317" opentelemetry-instrument python3 app.py
```
And, congratulations! You have instrumented your sample Python app. You can now access the SigNoz dashboard at http://localhost:3000 to monitor your app for performance metrics.
<figcaption>Python app appearing in the list of applications</figcaption>
## Metrics and Traces of the Python application
SigNoz makes it easy to visualize metrics and traces captured through OpenTelemetry instrumentation.
SigNoz comes with out of box RED metrics charts and visualization. RED metrics stands for:
- Rate of requests
- Error rate of requests
- Duration taken by requests
<figcaption>Measure things like application latency, requests per sec, error percentage and see your top endpoints</figcaption>
You can then choose a particular timestamp where latency is high to drill down to traces around that timestamp.
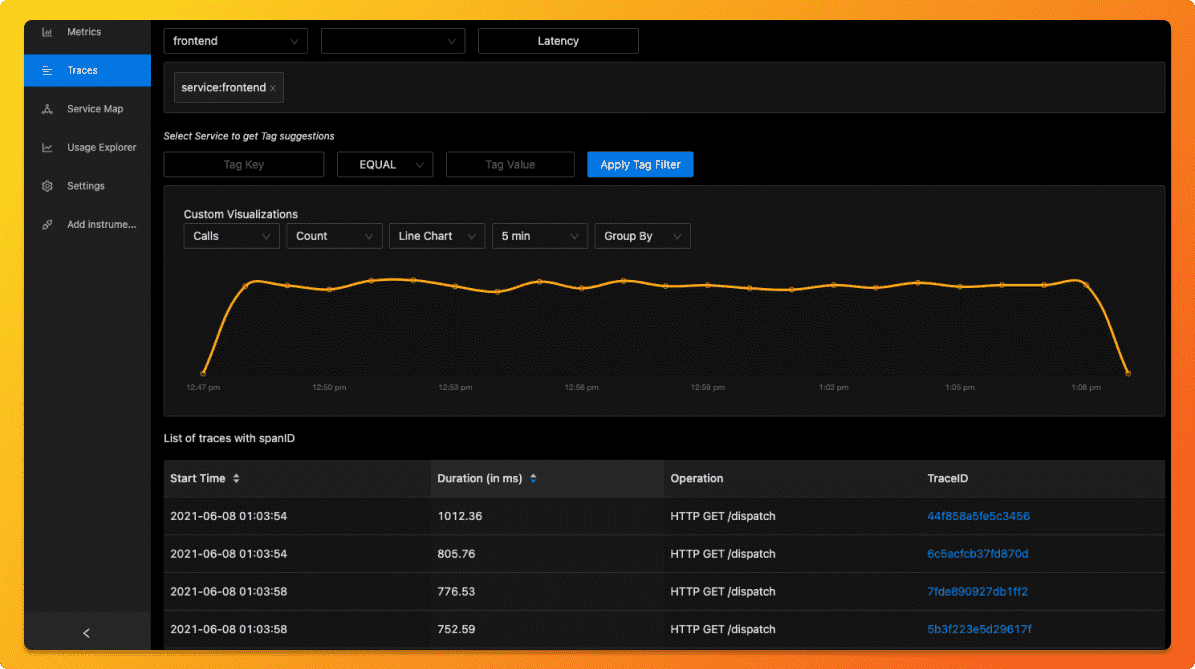<figcaption>View of traces at a particular timestamp</figcaption>
You can use flamegraphs to exactly identify the issue causing the latency.
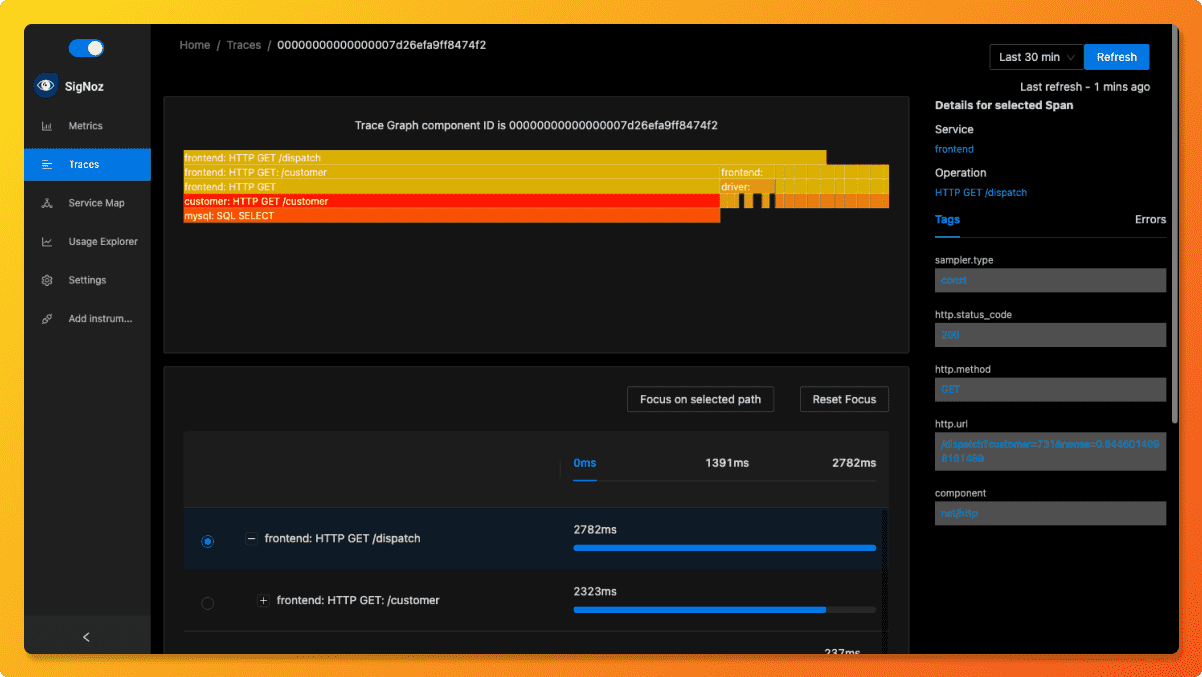<figcaption>Flamegraphs showing exact duration taken by each spans - a concept of distributed tracing</figcaption>
## Conclusion
OpenTelemetry makes it very convenient to instrument your Python application. You can then use an open-source APM tool like SigNoz to analyze the performance of your app. As SigNoz offers a full-stack observability tool, you don't have to use multiple tools for your monitoring needs.
You can try out SigNoz by visiting its GitHub repo 👇<br></br>
[](https://bit.ly/2WkkmL4)
If you face any issues while trying out SigNoz, feel free to write to us at: support@signoz.io
If you want to read more about SigNoz 👇<br></br>
[Golang Application Performance Monitoring with SigNoz](https://signoz.io/blog/monitoring-your-go-application-with-signoz/)
[Nodejs Application Performance Monitoring with SigNoz](https://signoz.io/blog/nodejs-opensource-application-monitoring/)
| ankit01oss |
801,681 | Başlangıç İçin Ubuntu Kılavuzu | Ubuntu Nedir? Linux çekirdeğini kullanan Window ve MacOS gibi işletim sistemidir. Daha... | 0 | 2021-08-24T07:44:51 | https://dev.to/mehmet_erim/baslangic-i-cin-ubuntu-kilavuzu-1e6k | ubuntu, linux, beginners, learning | ## Ubuntu Nedir?
Linux çekirdeğini kullanan Window ve MacOS gibi işletim sistemidir.
Daha fazla bilgi
için (https://ubuntu.com/download/desktop) adresine gidin .
## Neden Ubuntu'yu Kurmalıyım?
Linux rakiplerine göre kurulumu ve kullanımı çok kolaydır. Buda Ubuntu'yu diğer rakiplerinden üstün göstermektedir.
Her tür iş için mevcut tüm alternatif program bulması kolaydır.
## Ubuntu Nasıl Yüklenir ?
Önyüklenebilir bir aygıt oluşturun. Nasıl?
(https://rufus.ie) ve yazılımı indirin ve ubuntu işletim sistemini aygıtınıza aktarıp kuruluma hazırsınız demektir. Ubuntu kurulumunu internet üzerinden birçok kaynak üzerinden bulabilirsiniz.
### 1. Terminal
Tüm sihrin gerçekleştiği yer burasıdır. Terminale erişmek için ctrl+atl+t Windows düğmesine ve arama yerinde terminali bulabilirsiniz.
### 2. Sürüm Güncelleme ve Yükseltme
Terminal üzerinden `sudo apt-get update && sudo apt-get upgrade` komutunu çalıştırarak bu işlemi gerçekleştirebilirsiniz.
### 3. Program Kurmak
Devamı için; [kodsozluk.com](https://kodsozluk.com/mehmeterim/baslangic-icin-ubuntu-kilavuzu)
| mehmet_erim |
801,715 | What Is Web Hosting And 22 Good Hosting For Your Website | What is Web Hosting? Web Hosting is a service that allows you to post your website on the... | 0 | 2021-08-24T09:13:38 | https://www.niemvuilaptrinh.com/article/nhung-nha-cung-cap-web-hosting-mien-phi-tot-nhat | #What is Web Hosting?
Web Hosting is a service that allows you to post your website on the Internet. When users want to see your website, they just need to type the address of the site (domain name) on the browser. At this time, the server will receive the information, process and return the results to the user.

#Popular Types of Web Hosting
Normally, web projects will often vary in size, number of visitors, level of server processing requirements, etc., so people will divide web hosting into 6 main types to suit the needs of customers:
##Shared Web Hosting:
Your website is hosted on the same server as other websites. The strength of this type is the low cost, which is often suitable for personal blogs, small and medium businesses.
##Virtual private servers (VPS):
Also share a server but it will give you an additional virtual private server with full access to configure the website. In my opinion, this type of security is better than Shared Web Hosting. If your website has grown large enough and has a lot of traffic, I recommend using VPS to host your website.
##Dedicated Hosting:
It gives you dedicated server without sharing the server with other websites. You have full control such as integrating the appropriate applications you like, making changes to the operating systems, reconfiguring the server... However, the cost to use is a bit high and requires knowledge. Good way to set up the server service.
##Cloud Hosting:
This is a virtual server running in a cloud computing environment and the solution can be said to be hot at the moment. What I really like about this service is that if the server has a problem, it will be automatically transferred to another server immediately, it helps users to access your website at any time. At the same time cost the site to use.

#Things To Keep In Mind When Choosing Hosting
##Speed
According to Google, website loading speed is also considered an SEO factor because it will directly impact the user experience. According to the report, if a website's load time is longer than 2s, it will make it easier for customers to leave. Therefore, you should carefully consider the speed of the server service you are providing.
To estimate the speed of the service, you should go through the review websites about the type of hosting you are looking to use. Here there are many people who have used and will have the most honest reviews about the hosting you are planning to use. However, you should also pay attention to find really trustworthy review sites because many times people judge only based on the commission received from affiliate marketing for that product.

##Support;
In my opinion, it is preferable to choose web hosting that has good customer support services such as 24/7 support, can be contacted through many means such as phone, email, message to the support team, support Highly qualified and enthusiastic staff... In addition, you can also evaluate by the way the support staff answers questions from customers on the support page or articles providing knowledge to use the service. The service is written from the staff of the service....

##The Utilities Of Hosting Service:
Usually when you choose to consider hosting, you will usually focus on the accompanying utilities that the service provides such as:
Bandwidth: the amount of data the website sends to the user. Usually, hosting services will provide unlimited packages, but there are also services that will charge if the bandwidth exceeds the allowed threshold.
Storage: Is the storage space for the website (Used to store images, HTML, CSS, Javascript...) limited or not.
Free Domain Registration: Free domaind registration for the website.
Number of websites that can be used on hosting.
Is CDN included for the website?
...
As you can see, each hosting service will provide different utilities. Therefore, you should clearly determine what type of website you want to build, what type of website you want to build, whether the amount of storage, traffic is large or not?... So that we can choose web hosting that provides appropriate utilities.

##Server Storage Location:
The time it takes to transfer data from the server to the user will depend a lot on the service's server location. That's when choosing hosting, you should pay attention to where the server of that service is located. For example, when we are in Vietnam, it is best to choose a server in Vietnam, and if not, you should choose hosting that provides servers in Asia such as Singapore, Tokyo...

##Ability of expand:
For my case, I was also a beginner to create a website, so it will not be possible to calculate in detail the amount of bandwidth, storage, speed ... that the website needs to use. So when choosing a hosting service, I will also focus on whether the upgradeability of the hosting is easy?
There is also a case I need to pay attention to you is the ability to reduce to lower packages. Because in reality our website will not use all the utilities that the package provides. At this point you should think down to more attractive packages to reduce the cost to pay for the server.

##Security:
This is considered an extremely important factor for the website when we choose web hosting. Some criteria to evaluate the security of a hosting are:
Is there an SSL certificate for the website?
Is the security level of the firewall good?
Are web management versions regularly updated?
Is it okay to back up the website's data?
Is it possible to detect malware (malware) embedded in the website?
....

##Hosting Prices:
This is considered the final criterion that I evaluate a hosting. Usually, the average price to sign up for a website host will usually range from $5 to $10.
However, today on the market there are many hosting service providers with unbelievable prices. So with these prices, should you choose for the website or not?
Actually, in my opinion, it depends, not all hosting providers with cheap prices are not good. However, I have some notes when you decide to choose these hosting:
Pay attention to promotions: The hosting will offer us a promotional price for the first one to two years of use. However then they will charge up the standard fee (which is usually quite high). Therefore, you should read the information carefully before buying!
The costs incurred: Many hosting providers will let the package price be really cheap, but when we pay, there will be a lot of services and costs involved.
Limit some utilities: Actually when using free hosting, there will often be ads embedded in the website or limit the bandwidth, storage, and latency of the website. Therefore, you should carefully read the utility that the service provides!

#Free Static Website Hosting Services
Static Website is a website with fixed content and is often used with three main languages: HTML, CSS, and Javascript. In addition, you can also use front-end javascript to create this type of website such as React, Vue, Nuxt... Usually these websites will not have a database but will use data via API, archive files... It is often used for landing pages, product introduction, information pages...
Now we will go into finding out the free static website hosting services!
##Netlify:
Salient features of Netlify free plan are:
Automatically build from Git.
Deployed on the global Edge network.
Bandwidth: 100GB/Month.
Number of websites: Unlimited.
Can restore to any version

[Netlify](https://www.netlify.com/)
##GitHub Pages:
Key features of the GitHub Pages free plan are:
Websites can be up to 1GB in size.
Bandwidth: 100Gb per month.
You can manually set up the domain name for the website via CNAME.
There is support for HTPPS for the website.

[GitHub Pages](https://pages.github.com/)
##Render:
Highlights of the free Render package are:
100GB/month for bandwidth.
Lightning-fast CDN.
Can custom domain with full SSL functionality.
Automatically deploy on Git.

[Render](https://render.com/)
##Vercel:
Highlights of the Vercel free plan are:
Improve website performance with Edge Network.
Unlimited websites and APIs.
Can custom domain with full SSL functionality.
Serverless Functions are provided.

[Vercel](https://vercel.com/)
##Surge:
Salient features of the Surge free plan are:
Provides 404.html page functionality.
Unlimited websites and APIs.
Can custom domain.
Easy to deploy via CLI.
Unlimited websites.

[Surge](https://surge.sh/)
##Glitch:
Highlights of the Glitch free plan are:
Provides 4000 requests/hour.
The server handles 512MN of RAM.
512MB storage capacity..
Cons: will sleep after 5 minutes if the site takes no action.

[Glitch](https://glitch.com/)
##Hostman:
The parameters of the Hostman free plan are:
Allows creating 10 websites.
100GB/month of bandwidth.
Automatically build from Git.
Free SSL-certificate.
Deploy website with CDN service.

[Hostman](https://hostman.com/)
##Fleek:
The specifications of the Fleek free plan are:
Support editing domain.
Provides https service.
3GB storage.
Unlimited websites.
Automatically deploy on Git.

[Fleek](https://fleek.co/)
#Free Web Hosting Services
##000webhost:
The parameters of the 000webhost free plan are:
1 Website.
300MB Storage.
Usable Bandwidth 3GB.
Defect:
No Email Account.
There is no 24/7 support service.

[000webhost](https://www.000webhost.com/)
##FreeHostingNoAds:
The parameters of the FreeHostingNoAds free plan are:
1 Domain Name.
3 Sub Domains.
1GB Storage.
There is Automated Website Building Software.
Bandwidth 5GB/month.
24/7/365 support is available.
Provide 1 Email Account.
Defect:
No Free SSL Support.
No weekly data backup service.

[FreeHostingNoAds](https://freehostingnoads.net/)
##AwardSpace:
The specifications of the AwardSpace free plan are:
5GB Bandwidth.
1000MB Storage.
24/7 Support.
1 Domain and 3 Subdomains.
1 Email Account.
Defect:
CNAME Records Not Supported.
Not Support Data Backup.
Does Not Offer Editing of 404 Pages.

[AwardSpace](https://www.awardspace.com/)
##Infinity Free:
The specifications of the Infinity Free package are:
Unlimited Storage.
Unlimited Bandwidth.
Free Subdomains.
Free SSL For Domain.
Free DSN Service.
Defect:
Slow Load Time

[Infinity Free](https://infinityfree.net/)
##FreeHostingEU
The parameters of the FreeHostingEU free plan are:
4GB Bandwidth/month.
5 Domains For Websites.
Provide Website Builder Tool.
Free Domain With Extension .eu5.net.
Free Hosting For Wordpress And Joomla.
Defect:
No Data Backup
No Anti-Virus Programs.

[FreeHostingEU](https://www.freehostingeu.com/)
##Free Web Hosting Area
The parameters of the Free Web Hosting Area free plan are:
Unlimited Bandwidth.
1.5GB Storage.
Weekly Data Backup.
24/7/365 Support.
Defect:
If There Is No 1 Visit/Month, Account Will Be Deleted Automatically.

[Free Web Hosting Area](https://freewebhostingarea.com/)
#Good Web Hosting Services For Websites
##A2 Hosting
The parameters of the A2 Hosting package are:
Price: $2.99
1 Website.
100GB Storage.
24/7/365 Support Service.
Unlimited Bandwidth.
Servers Available in Asia.
Defect:
No Automatic Data Backup.
Renewal Price May Be Higher than Initial Rate.

[A2 Hosting](https://www.a2hosting.com/)
##HostGator
The parameters of the HostGator package are:
Price: $2.75 -> $6.95
1 Website.
Free Domain 1 Year.
Unlimited Bandwidth And Storage.
Free SSL/HTTPS.
24/7 Support.
Defect:
Fees Required For Additional Services.
Load Time Quite Slow.

[HostGator](https://partners.hostgator.com/9mP4e)
##Bluehost
The specifications of the Bluehost package are:
Price: 3.95$ -> 5.95$
1 Website.
Free Domain 1 Year.
50GB Storage.
Free SSL/HTTPS.
Free CDN For Website.
24/7 Support.
Defect:
The Renewal Price Is A Little High.
No Data Backup.

[Bluehost](https://www.bluehost.com/track/haycuoilennao3/)
##DREAMHOST
The parameters of the DREAMHOST package are:
Price: $3.95 -> $4.95
There is a Website Builder.
Have Database Data Backup.
Unlimited Bandwidth And Storage.
Free SSL/HTTPS.
Many Utility Functions For Wordpress.
24/7 Support.
Defect:
Paying Extra Money To Buy Email Hosting.

[DREAMHOST](https://www.dreamhost.com/)
##NameCheap
The parameters of the NameCheap package are:
Price: $1.58 -> $4.88
There is a Website Builder.
Free 3 Domains For Hosting.
Free SSL/HTTPS.
20GB Unlimited Storage And Bandwidth.
24/7 Support.
Defect:
No Data Backup.
Storage Limits

[NameCheap](namecheap.pxf.io/QOJdez)
##Stable Host
The parameters of the Stable Host package are:
Price: 1.75$ -> 5.95$
There is a Website Builder.
Maximum 1 Website.
Unlimited Storage And Bandwidth.
24/7 Support.
Defect:
Spam Filtering is not supported.

[Stable Host](https://www.stablehost.com/)
##Hawk Host
The parameters of the Hawk Host package are:
Price: $2.99
Free Weebly Site Builder.
Unlimited Domain Names.
Free SSL/HTTPS.
Unlimited Bandwidth .
24/7 Support.
10GB Storage
Defect:
Limited Storage Capacity.

[Hawk Host](https://www.hawkhost.com/)
Through this, I hope the article will provide you with useful web hosting for web development and design and if you have any questions, just send me an email and I will respond as soon as possible. I hope you continue to support the site so that I can write more good articles. Have a nice day!
If you want more information please go to [Niemvuilaptrinh](https://www.niemvuilaptrinh.com/) | haycuoilennao19 | |
801,748 | How to assign Static IP on application load balancer using AWS Global Accelerator | “Challenges faced to find the solution of how to assign a static ip on Application Load... | 0 | 2021-08-24T10:17:38 | https://dev.to/aws-builders/how-to-assign-static-ip-on-application-load-balancer-using-aws-global-accelerator-4chf | aws, security, awsglobalaccelerator, applicationloadbalancer | “Challenges faced to find the solution of how to assign a static ip on Application Load Balancer(ALB)”. First and foremost, I thought about how it will be possible to assign the Static IP on my ALB. Then I tried to search for a solution and went through many documents because I have never heard that it is possible. Then i got some documents in which i found that it is possible using network load balancer in front of application load balancer. As we all know in Network Load Balancer(NLB) it is possible to assign a static ip as we can select a single AZ in it but application load balancer is always in multi AZ so it will not be possible. So I have checked the approx cost of using NLB and also how to secure it from public access as NLB do not have a security group. Also i got a document in which i can take NLB with ALB using cloudformation but in both cases the costing is high as per my budget. Also I need to assign the ip on my existing ALB infra, so i have checked the AWS Global accelerator service and the cost for using it. Then I felt using AWS global accelerator with ALB is more easy and cost friendly for me instead of having NLB or Cloudformation.
AWS Global Accelerator is a service in which you create accelerators to improve availability and performance of your applications for local and global users. Global Accelerator directs traffic to optimal endpoints over the AWS global network. This improves the availability and performance of your internet applications that are used by a global audience. Global Accelerator is a global service that supports endpoints in multiple AWS Regions, which are listed in the [AWS Region Table](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/).
By default, Global Accelerator provides you with two static IP addresses that you associate with your accelerator.(Or you can configure these entry points to be IPV4 addresses from your own IP address ranges). The static IP addresses are anycast from the AWS edge network and distribute incoming application traffic across multiple endpoint resources in multiple AWS Regions, which increases the availability of your applications.
Endpoints can be Network Load Balancers, Application Load Balancers, Amazon EC2 instances or Elastic IP addresses that are located in one AWS Region or multiple Regions. Global Accelerator uses the AWS global network to route traffic to the optimal regional endpoint based on health, client location, and policies that you configure. The service reacts instantly to changes in health or configuration to ensure that internet traffic from clients is always directed to healthy endpoints. To learn more, read the [AWS Global Accelerator](https://docs.aws.amazon.com/global-accelerator/latest/dg/what-is-global-accelerator.html).
In this post, you will get to know how to assign static ip on application load balancer using AWS Global Accelerator. Here I have taken a centos ec2 server and created an internet-facing application load balancer in which I need to assign a static ip for improving performance of application and ease of access by users.
#Prerequisites
You’ll need an Amazon EC2 Server for this post. [Getting started with amazon EC2](https://aws.amazon.com/ec2/getting-started/) provides instructions on how to launch an EC2 Server.
You’ll also need an Application Load Balancer. [Getting started with ALB](https://docs.aws.amazon.com/elasticloadbalancing/latest/application/create-application-load-balancer.html) provides instructions on how to create an ALB. For this blog, I assume that I have an ec2 server and an internet-facing application load balancer which servers the application.
#Architecture Overview
Diagram 1
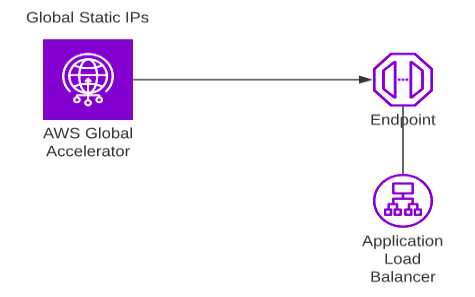
Diagram 2
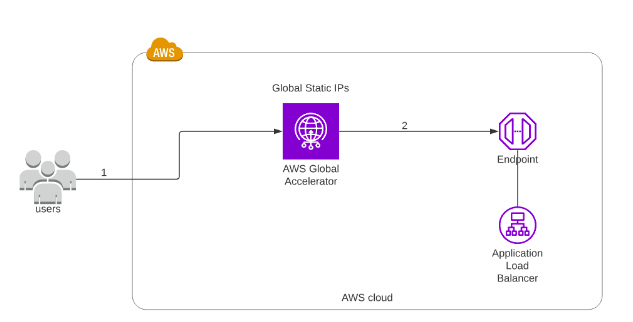
Diagram 3
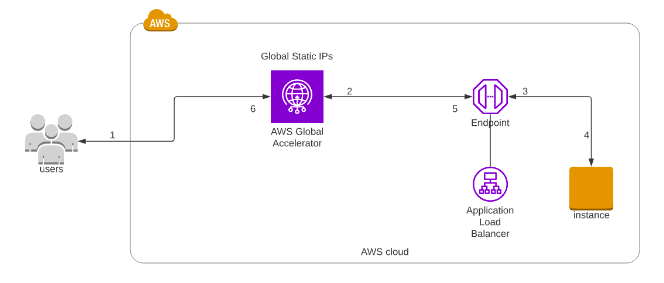
The architectural diagrams show the overall deployment architecture with data flow, Ec2 instance, Application Load Balancer and AWS Global Accelerator.
#Solution overview
The blog post consists of the following phases:
1. Enter the name of AWS Global Accelerator.
2. Add listeners in AWS Global Accelerator.
3. Add endpoint groups in AWS Global Accelerator.
4. Add endpoints in AWS Global Accelerator and create the global accelerator.
5. Edit of created AWS Global Accelerator(If need to do the changes).
6. Testing of static ip assigned on application load balancer.
I have a ec2 server and an internet-facing application load balancer as below →
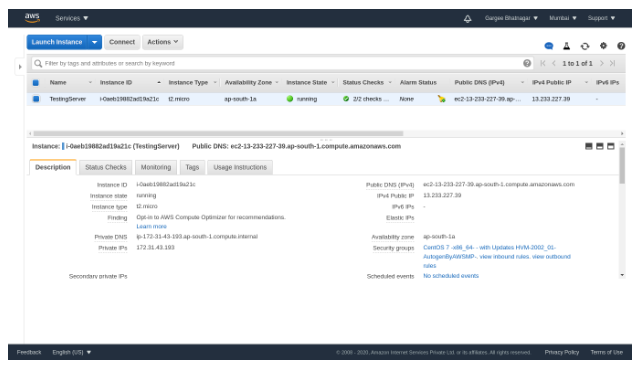
##Phase 1: Enter the name of AWS Global Accelerator
1. Open the AWS Global Accelerator service in the aws console and click on the create accelerator button.
2. You can see the Basic configuration page where you need to enter the name of global accelerator service. I have entered the accelerator name as Testingserver-static ip.
3. In the IP address type tab by default its chosen option as IPv4.
4. In the IP address pool selection option, click on the arrow in front of it and you can see by default the static ip address1 and static ip address 2 tab having Amazon’s pool of ip address option set.
5. In the Tags option, click on the arrow in front of it and then you can add tags by clicking on the add tag button.
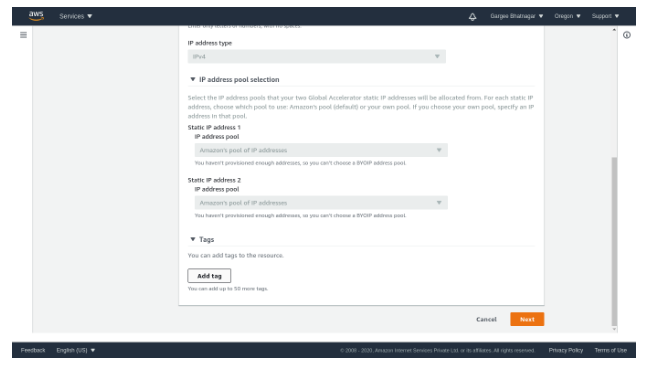
6. In the key tab, you can enter any custom tag key I have entered as “NAME”.
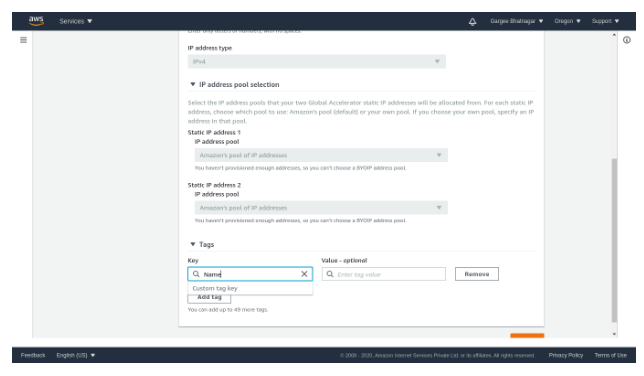
7. In the value tab, you can enter any value as you want I have entered as “testingserver”. Also you can add as many tags as you want with different keys and values. And can able to remove the assigned tag using the remove button.
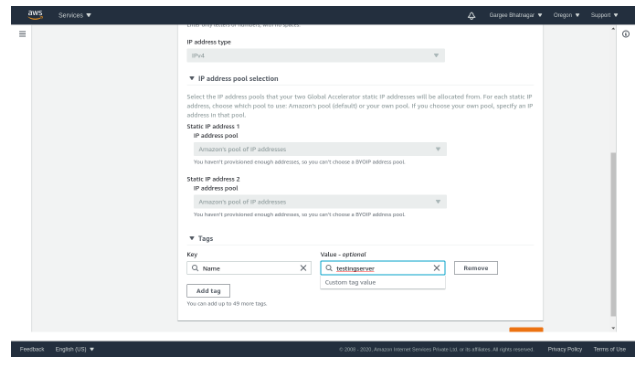
8. Click on the next button.
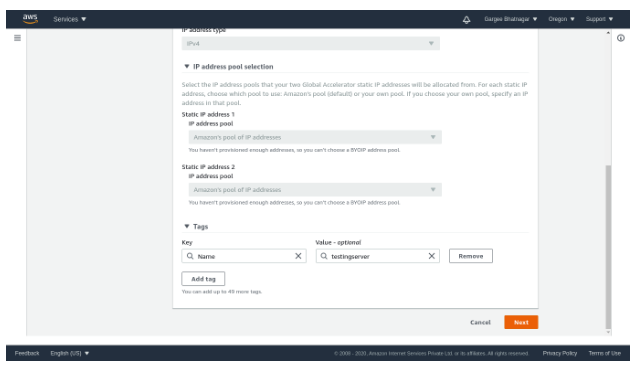
##Phase 2: Add listeners in AWS Global Accelerator
1. In the listeners page you need to enter the port in the ports tab I have entered as 80.
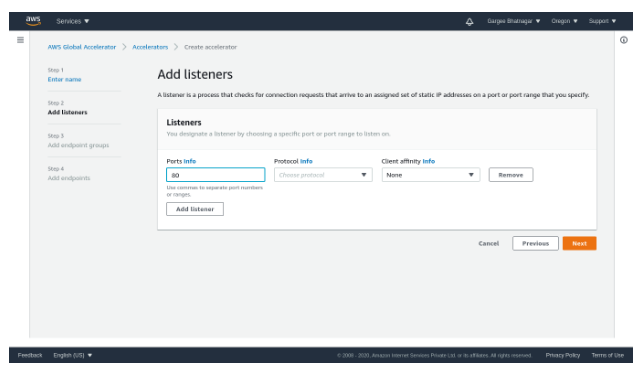
2. In the protocol tab, you can choose the type as TCP or UDP I have chosen as TCP option.
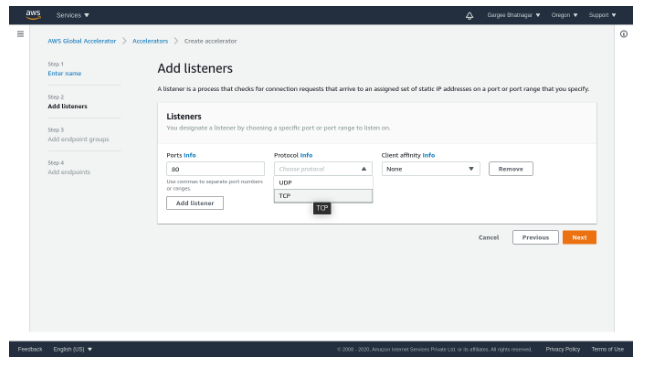
3. In the client affinity tab, you can choose option as None or source IP I have chosen option as None.
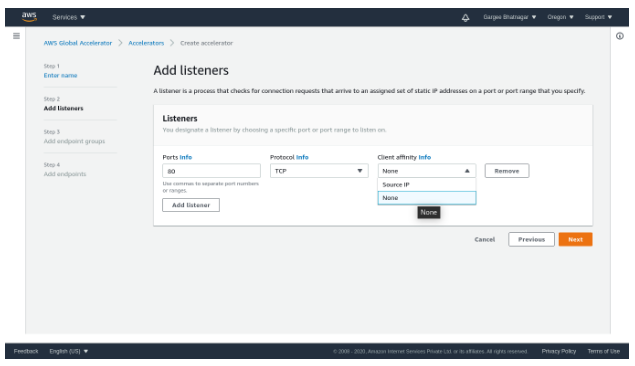
4. You can add as many listeners as you want with different ports, protocol and client affinity by clicking on the add listener button.
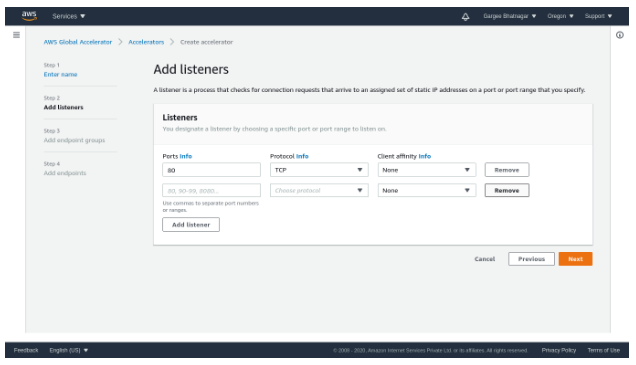
5. You are able to remove the listeners if you want to by clicking on the remove button. And then click on the next button.
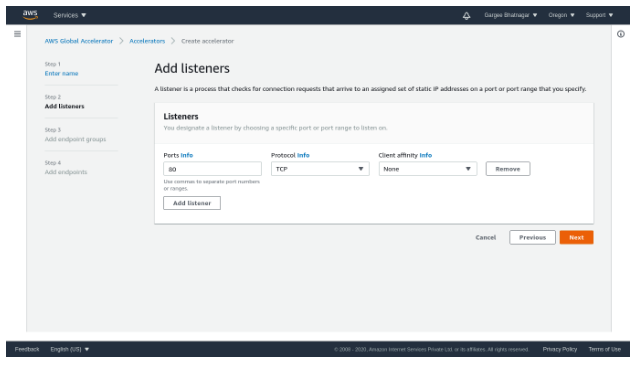
##Phase 3: Add endpoint groups in AWS Global Accelerator
1. In regions tab, you can choose the endpoint group region in which the endpoint exists.
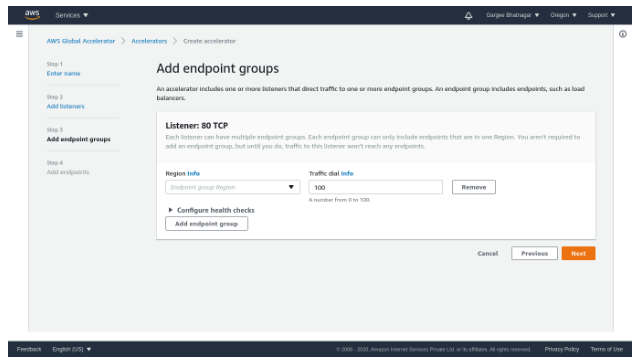
2. I have chosen the region as ap-south-1 for my endpoint.
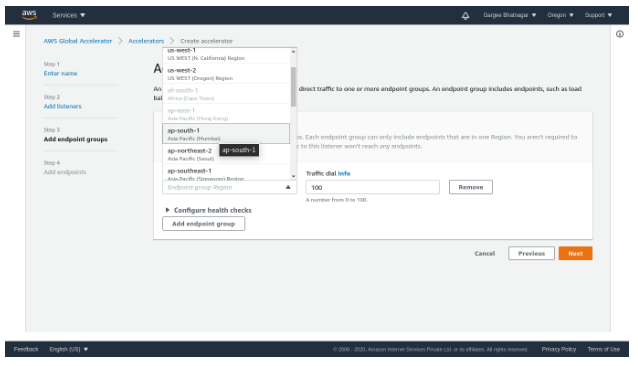
3. In the traffic dial option, you are able to enter the value as per range from 0 to 100. I have set it as 100. And you are able to remove it as well using the remove button.
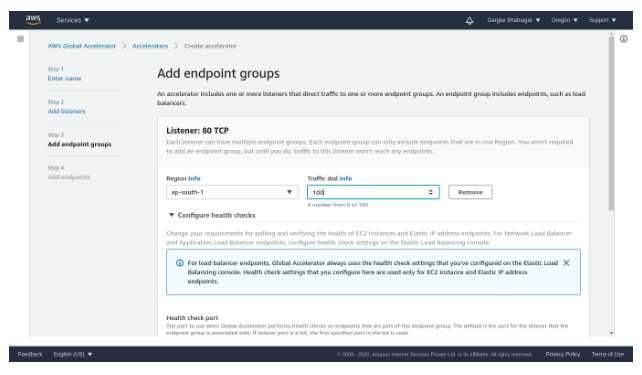
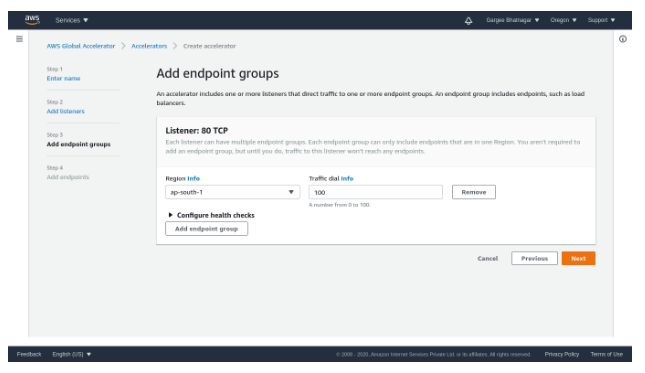
4. You can add endpoint groups as many you want with different regions.
5. In the configure health checks option you can click on the arrow in front of it and can set the health check option as per requirement. In the health check port tab, I have set the port as 80. Range available as 1 to 65535.
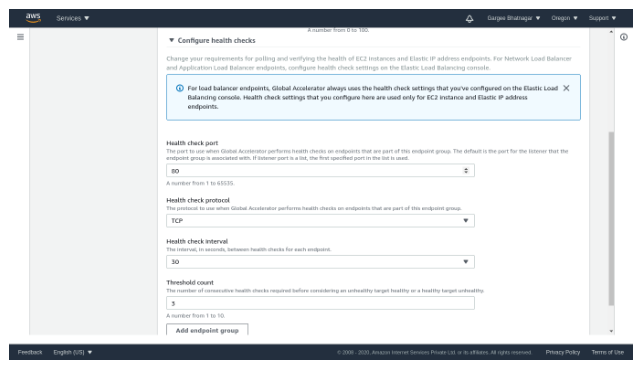
6. In the health check protocol tab, I have set the option as HTTP. Option available as TCP, HTTP and HTTPS.
7. In the health check interval option, I have chosen value as 30. Options available as 10 or 30.
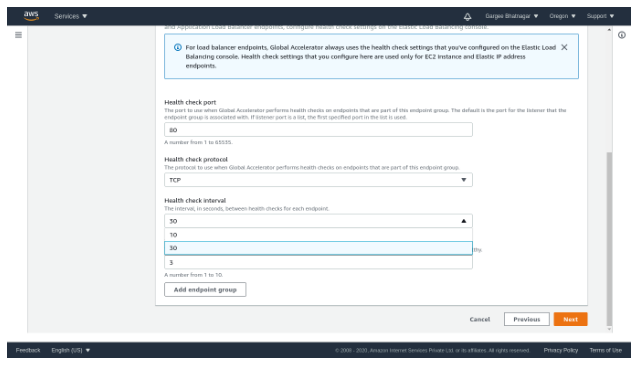
8. In the threshold count option, I have set value as 3. Range available from 1 to 10.
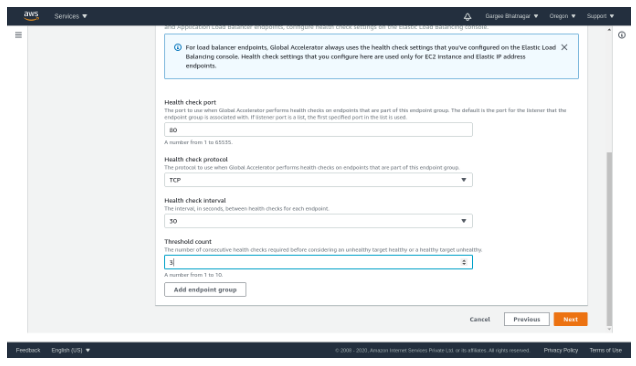
9. Click on the next button.
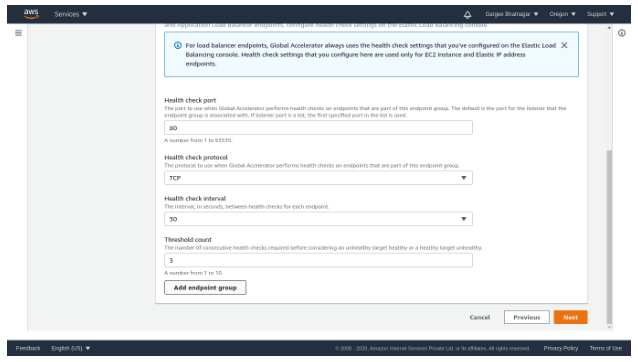
##Phase 4: Add endpoints in AWS Global Accelerator and create the global accelerator.
1. In the endpoint group, you can add the endpoint by clicking on the add endpoint button and also can add as many endpoints as you want. Also able to remove it using the remove button.
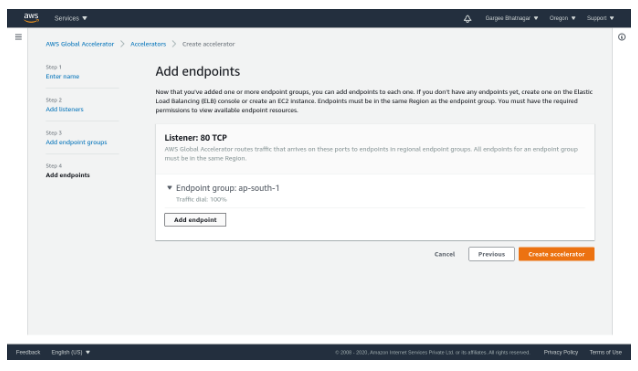
2. In the endpoint type tab, I have chosen the endpoint as application load balancer. Options available as application load balancer, network load balancer, ec2 instance and elastic ip address.
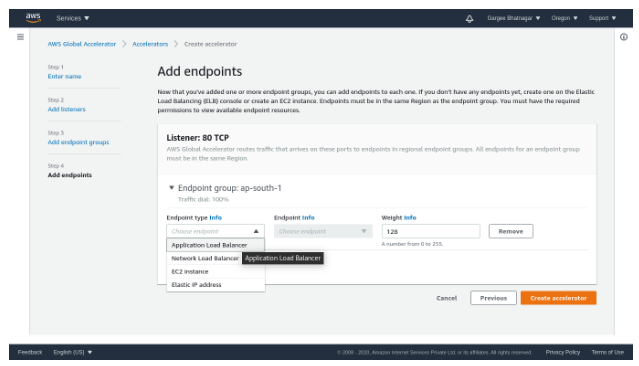
3. In the endpoint tab, you can choose the endpoint on which you need to assign the static ip. I have chosen the application load balancer endpoint.
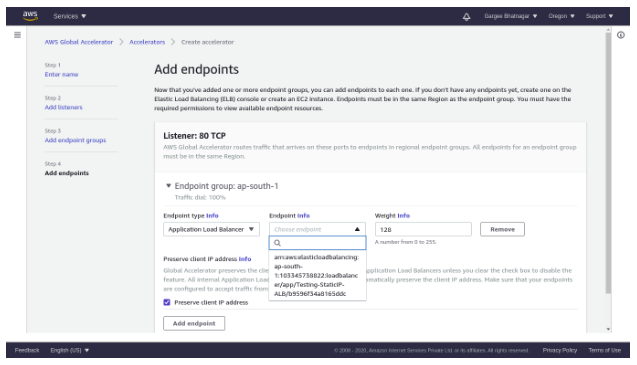
4. In the weight option, I have set the value as 128. Range available as 0 to 255. Also tick on preserve client ip address and click on the create accelerator button.
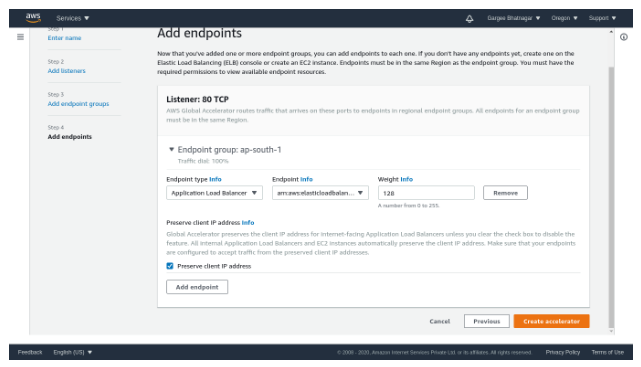
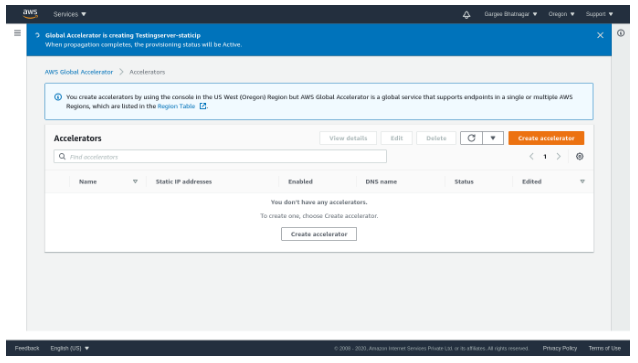
5. Global accelerator successfully created as below with “Testingserver-staticip”.
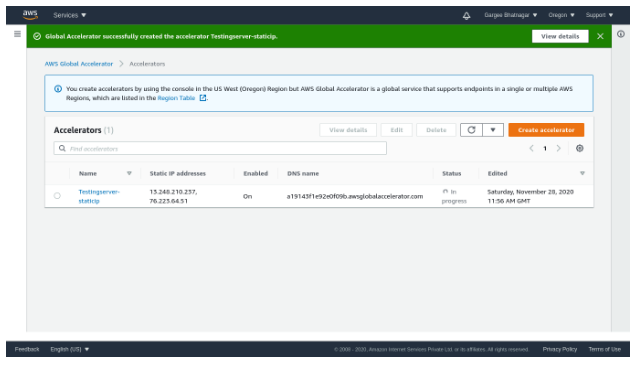
##Phase 5: Edit of created AWS Global Accelerator(If need to do the changes).
1. Goto accelerator and choose edit option. And you are able to enable or disable the accelerator created using the on or off option while editing the accelerator.
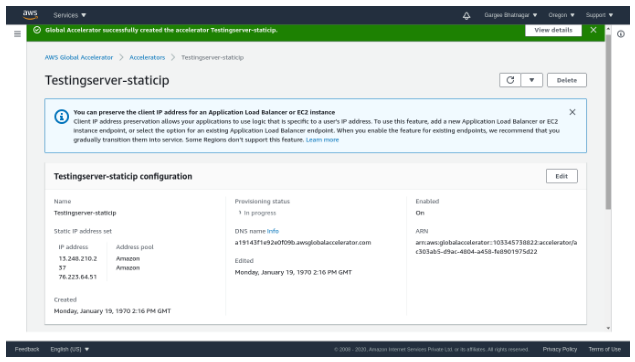
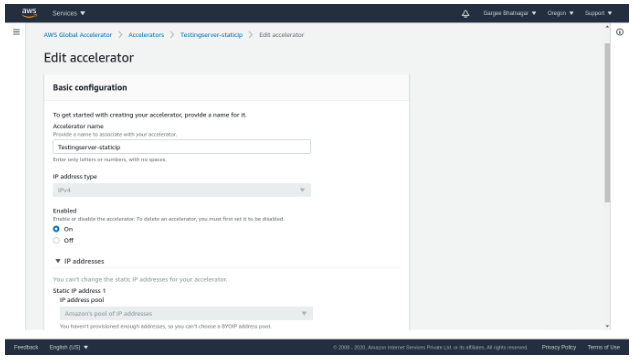
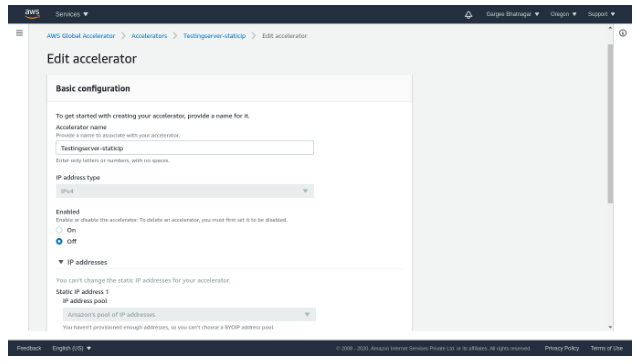
2. Select the listener and choose the edit option. Also you are able to check the listener status as “All healthy” if everything is fine with the listener.
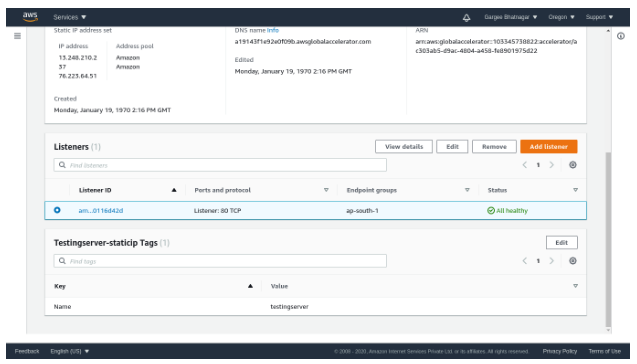
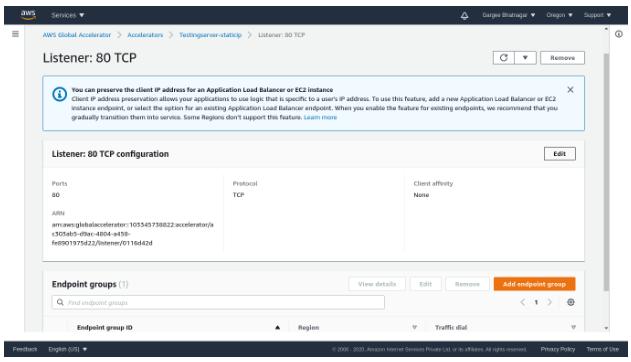
3. You can edit the endpoint group as below for changing health check settings.
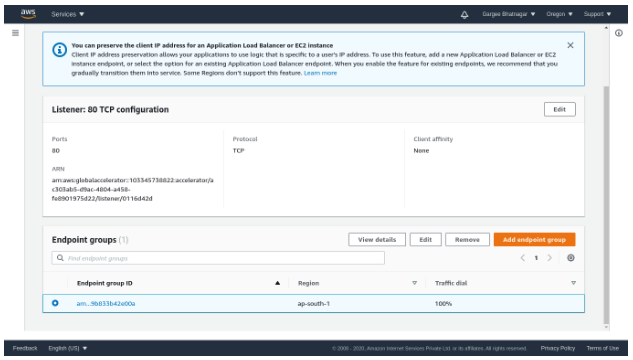
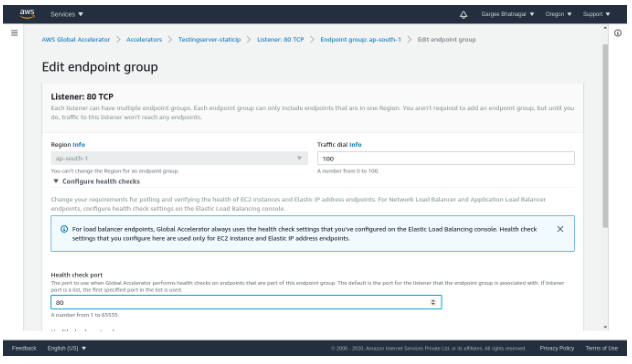
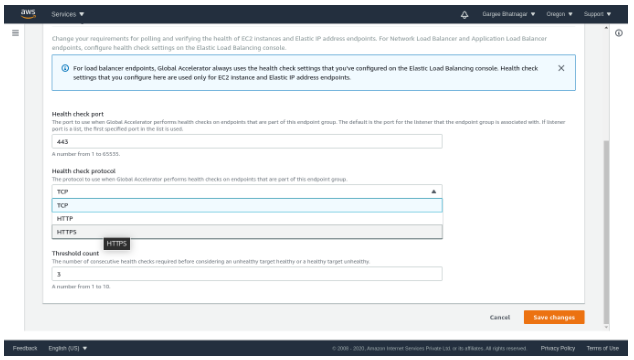
4. You can see the status of the accelerator as “In Progress” while creating. Status will be as “Deployed” once the accelerator is ready.
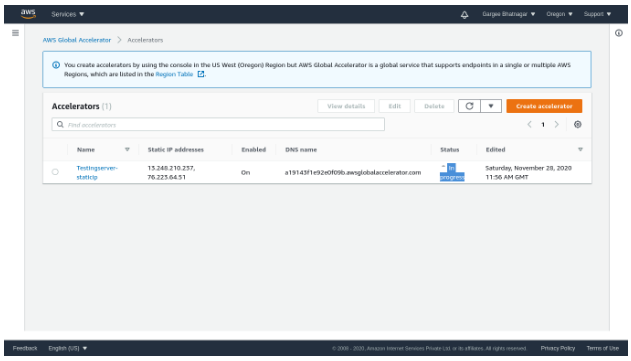
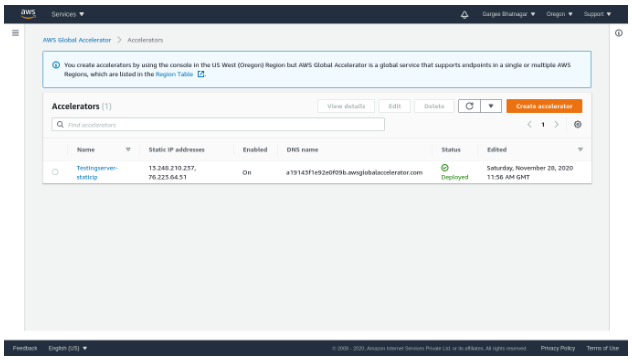
##Phase 6: Testing of static ip assigned on application load balancer.
1. Page display from ec2 server ip.
2. Page display from application load balancer endpoint.
3. Page display from two static ip assigned on application load balancer.
4. If we will disable the accelerator, then the application page will not be displayed from static ip.
#Clean-up
Delete the environment as: EC2, Application Load Balancer, AWS Global Accelerator.
#Pricing
I review the pricing and estimated cost of this example.
For every accelerator that is provisioned (both enabled and disabled), you are charged a fixed hourly fee and an incremental charge over your standard Data Transfer rates, also called a Data Transfer-Premium fee (DT-Premium). DT-Premium is calculated every hour on the dominant direction of your traffic, i.e. inbound traffic to your application or outbound traffic from your application to your users on the internet.
Fixed fee: For every full or partial hour when an accelerator runs in your account, you are charged $0.025 until it is deleted.
Data Transfer-Premium fee (DT-Premium): This is a rate per gigabyte of data transferred over the AWS network.
You can learn more by visiting the [AWS Global Accelerator pricing](https://aws.amazon.com/global-accelerator/pricing/) service details page.
In my case, costing of using AWS global accelerator service:
Monthly fixed fee --
Assuming your accelerator runs 24 hours a day for 30 days in a month, you are charged a $18 monthly fixed rate for that accelerator.
Monthly DT-Premium fee --
If the monthly amount of data transferred over the AWS network via your accelerator is 10,000 GB, 60% of your traffic is outbound traffic from your application to your users on the internet, and the remaining 40% is inbound traffic from your users on the internet to your application in the AWS Regions. Every hour, you are charged only for the outbound traffic to your users, as that's the dominant direction of your traffic. So, you are charged for 6,000 GB a month and not all 10,000 GB.
6000 GB - monthly charge - $0.032/GB - $192 per month
If monthly data transferred outbound traffic -->
1000 GB - monthly charge - $0.032/GB - $32 per month
Your monthly DT-Premium charge is $32 and, including the $18 monthly fixed fee, your total AWS Global Accelerator monthly bill is $50.
#Summary
In this post, I had shown you how to assign static ip on application load balancer using AWS Global Accelerator.
For more details on global accelerator service, Checkout Get started with AWS Global Accelerator, open the [AWS Global Accelerator console](https://us-west-2.console.aws.amazon.com/ec2/v2/home?region=us-west-2#GlobalAcceleratorHome:). To learn more, read the [AWS Global Accelerator documentation](https://docs.aws.amazon.com/global-accelerator/index.html).
Thanks for reading!
Connect with me: [Linkedin](https://www.linkedin.com/in/gargee-bhatnagar-6b7223114) | bhatnagargargee |
801,769 | How to Install & Configure TYPO3 with PostgreSQL | Are you looking for a quick handbook guide for TYPO3 PostgreSQL? You landed at the right place; In... | 0 | 2021-08-24T10:28:27 | https://dev.to/t3terminal/how-to-install-configure-typo3-with-postgresql-4211 | Are you looking for a quick handbook guide for TYPO3 PostgreSQL? You landed at the right place; In this article, you will find the installation and configuration of the PostgreSQL server and set up TYPO3 CMS using the PostgreSQL database.
Most of our TYPO3 customers prefer to use the MySQL/MariaDB database. But, sometimes, we get requests to install & configure the TYPO3 PostgreSQL Database. Fortunately, TYPO3 supports multiple database servers like MySQL, PostgreSQL, Oracle, etc. I think TYPO3 is one of the only Opensource CMS which supports such a wide range of database servers - that’s the power of TYPO3 :)
Guide to TYPO3 PostgreSQL Database
Quick Intro to PostgreSQL
MySQL vs PostgreSQL
What is Doctrine DBAL (Database Abstraction Layer)?
How Technically TYPO3 Database Connection?
TYPO3 Doctrine DBAL and Doctrine ORM
Which Are Supported Databases in TYPO3 CMS?
Which PostgreSQL versions does TYPO3 support?
Install PostgreSQL Server for TYPO3
Let's Check PostgreSQL Installation
Login Access to PostgreSQL Database Server
How to Add a New Role in PostgreSQL?
Create TYPO3 PostgreSQL Database
Connecting to PostgreSQL with the New User
pgAdmin - PostgreSQL Database Tool
Installation of TYPO3 PostgreSQL Database
Configuration of TYPO3 PostgreSQL Database
Multiple Database Use
TYPO3 PostgreSQL @ DDEV Docker
Wrapping-up!
Read the whole blog at, https://t3terminal.com/blog/typo3-postgresql/ | t3terminal | |
801,865 | BEM vs CSS Grid | Everything you might like about Grids always has been a part of BEM | 0 | 2021-08-28T05:14:18 | https://dev.to/thekashey/bem-vs-css-grid-22e8 | bem, css, maintenance, webdev | ---
title: BEM vs CSS Grid
published: true
description: Everything you might like about Grids always has been a part of BEM
tags: bem, css, maintenance, webdev
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/nehq74qg1p9r3uhddejg.jpeg
---
`BEM` is not a “naming convention”. It’s a separation between `Blocks` and `Elements`. And `Modifiers`... but let’s just forget about them for a while.
Today we better focus on something different.
So, I've written this article because people do not understand the core principles behind `BEM`, not to be able to see them behind other features.
This is why let’s forget about `BEM` for a while as well.
To get things started we all can generally agree that…
# CSS Grids are awesome 🥳
The main difference between `display block` and `display flex` is that the first one sees all children nodes as a separate elements, while they act like a Team🤜 within `flex` – they can _grow_ and _shrink_.
They are connected.
`Grid` fosters this connection, lets you handle bigger blocks, giving more power and more control.
But there is one big difference, really __BIG__ difference, - the majority of power and control is given to the “grid parent”, not “grid element”
Let's imagine a conversation between Grid and Cell:
🤖: Dear Grid-Item, I've prepared a place for you, where shall you stay according to my very plan 😈
📦: Can I have my own opinion?
🤖: Dear Grid-Item, well yes, some of you can move self to other places, but not particularly you 😅. Please stay within my template because I do have a plan for you 👮🏻♂️.
And like the `Grid`, which can use `grid template` or `grid areas` to control all direct children, BEM also has a plan...
# BEM has a Plan
Technically speaking `BEM` works in the same way as `Grid` - they share the same ideology. `BEM` is just not bound to the "2d grid" and one level of children nodes.
It can be easier to think about `BEM` from a `Component Model` point of view:
- there is a `Parent` component and a few `Elements`
- _according to the plan_ `Elements` has to be placed in some well known location.
- children `Elements` should not think or even know about their placement.
```tsx
const ParentTemplate = () => (
<html>
<body>
<header>
<slot>
<Component1 /> <--- Another block
</slot>
</header>
<main>
<slot>
<Component2 /> <--- Another block
</slot>
</main>
</body>
</html>
```
# A few rules
Let me be honest - there are two major sites about BEM methodology, where you can read some information - http://getbem.com/ and https://en.bem.info/. I hope you likely to see the key information hidden between the lines, but according to my experience no one has seen it yet.
> BEM is not about that-strange__naming--convention
BEM is about the Separation between `B` and `E`
Here is what you might miss:
- __Elements do not lay themselves out__. Parent `Block` does
- __Block style themselves and layout only their children__.
- __Blocks cannot be (visually) styled 🎨 outside__, except via own known `Modifiers`
- __Every `Element` can be a `Block`__
> Note: "Children" is not an "immediate DOM node". Still easy to think in React terms - children is everything defined among component
```tsx
const List = () => (
<ul> // children
<li> // also children
<SomeItem> // still children, but also a Block
</li>
</ul>
```
# Rule them all
How `Block` can rule children? Usually (for the last 15 years? BEM was created back in 2006) by passing extra `classname`, which is expected to obey the principles above and cannot _style_ `children`, except using `modifiers` defined in the `children`.
> `modifiers` are _equal_ to (React) `props`
`Block` only can:
- _lay_ `Elements` inside. In the same way `Grid` can _lay_ `Grid-Items` inside.
- configure own children by picking/using different modifiers/props, but only among the explicitly supported by children Components. Well, you can do the same with `Grids`, not something particular bound to BEM.
Look like there are at least something in common between BEM and Grid. Grids are just more about "how" to do something - they are providing a particular way to command a Browser Engine. While BEM 🤷♂️ it's just a way to keep things clear
Both Grid and BEM define layout for their children gently asking those children not to interfere.
> While this moment might sounds like NOT something really important - it is the core essence of both technologies
Step away from technical implementation. Try to understand the intent behind the actual approach and principles according to which both technologies ended like this.
# What to do
- (dimension) do not let components define own dimensions - different Parents can have different Plans
- and your parent will configure "you" one way or another - or by placing "you" in `grid` (browser layout) or by giving you extra classname with `flex` styles (explicit layout). That is not "your" problem.
- (gaps) do not let components define margins - that gonna break any order anyone will try to establish
- margins are still file, just define it "inside" block, the area under your control, not "outside", creating unexpected behaviour for consumers.
- (isolation) do not style other components, tell them what they shall do
# So what?
So please stop writing random code, which always ends in some messy, completely unmaintainable state, causing a lot of performance issues, especially if you overuse CSS-in-JS for no reason.
Think structurally. Think in relationships. Think about you styles in the same way you think about your code, files, function and packages - and I believe there are some rules you follow and some pain you've experienced due to bad habits.
---
Well, apart of Grids there is another concept which should explain you the main point behind separation of responsibilities and concerns - [Open Closed Principle](https://en.wikipedia.org/wiki/Open%E2%80%93closed_principle), a part of [SOLID pattern](https://en.wikipedia.org/wiki/SOLID)
> software entities should be open for extension, but closed for modification
Which, in this case, controls what Elements can be _asked_ to do by Blocks(blocks are "extension"), and how Blocks could not affect Elements(which are "closed for modification")
## See also:
- https://non-traditional.dev/encapsulated-css-the-key-to-composable-layouts-94f11c177cc1
- https://www.joshwcomeau.com/css/styled-components/#isolated-css
- https://mxstbr.com/thoughts/margin/
### Wait!
Should you read anything about BEM methodology in particular?
No, because:
- you don't need naming pattern with CSSModules, and especially CSS-in-JS
- the main thing is a separation, and frankly speaking it does not have to be exactly the same separation
Keep the last point in mind. Remember how Grids work. Only then go and research information about BEM you can found in other places.
And keep in your mind one more thing - as I've mentioned above the vast majority of developers, including the ones who uses BEM, "did not get the point", something more than that_strange__naming--pattern.
I know this for sure. I was among them. | thekashey |
801,924 | How to Add Breadcrumbs to Your Laravel Website | Introduction Breadcrumbs are a great way of improving the UI (user interface) and UX (user... | 0 | 2021-08-24T11:05:01 | https://ashallendesign.co.uk/blog/how-to-add-breadcrumbs-to-your-laravel-website | laravel, php, ux, webdev | ## Introduction
Breadcrumbs are a great way of improving the UI (user interface) and UX (user experience) of your applications and websites. They can help to reduce the chances of users getting lost and can make it easier for users to navigate around your site.
In this article, we're going to cover what breadcrumbs are, the benefits of them and how you can add them to your own Laravel website or application.
If you're interested in finding out different ways that you can improve your website, make sure to check out one of my recent articles called [17 Ways to Get Your Website Ready to Win](https://ashallendesign.co.uk/blog/17-ways-to-get-your-website-ready-to-win).
## What Are the Benefits of Using Breadcrumbs?
Breadcrumbs come from the story of [Hansel and Grettel](https://en.wikipedia.org/wiki/Hansel_and_Gretel), which is a fairytale about a brother and sister who leave a trail of breadcrumbs when they're in the forest so that they can find their way back. In the web development world, breadcrumbs work in the same way; they leave a trail for us so that we know where we are in the system and how to get back.
You've almost definitely come across breadcrumbs before. For example, let's imagine that we're on a clothing site and that we're looking at the men's t-shirts. You might see something similar to this near the top of the page:
**<u>Home</u> > <u>Men's Clothing</u> > T-shirts**
This is a breadcrumb and it's showing us that we're on the men's t-shirts page. Typically, each "crumb" is a link that takes you back to another page.
Breadcrumbs are beneficial because:
1. They can decrease bounces rates and reduce the chances of users getting lost. If your users start to get confused about where they are in a website or application, they can become frustrated. This can sometimes cause them to leave. So, breadcrumbs address this issue by providing your user with a bit more visibility where they are.
1. They can provide a way for your visitors or users to "move up a level". For example, let's imagine that a visitor has searched for "men's t-shirts" in Google and has landed on your website's t-shirt page. But, now they want to look at the other men's clothing you offer. Instead of them having to go to your site's main navigation, they could potentially click up a level to "Men's Clothing". By presenting the breadcrumb in a simple way, you've allowed the user to navigate straight to their navigation without needing to hunt around.
1. If your breadcrumbs are set up correctly, they can be incredibly useful for SEO purposes. They help search engine crawlers to get a better idea of your site's page structure. This structure can then sometimes be shown in your search engine results.
If you're interested in reading about more benefits of using breadcrumbs, check out these two articles written by the [Nielsen Norman Group](https://www.nngroup.com/articles/breadcrumb-navigation-useful/) and [Infidigit](https://www.infidigit.com/blog/breadcrumbs/).
## How to Add Them to Your Laravel Website
To add the breadcrumbs to your Laravel project, we're going to be using the [diglactic/laravel-breadcrumbs](https://github.com/diglactic/laravel-breadcrumbs) package. I've used this in quite a few projects now, ranging from small websites to fairly large applications, and I've always found it really easy to set up and easy to use.
### Installation and Configuration
Let's start by installing the package using Composer with the following command:
```
composer require diglactic/laravel-breadcrumbs
```
Now that we've installed the package, we can publish the config file using the following command:
```
php artisan vendor:publish --tag=breadcrumbs-config
```
You should now have a newly created `config/breadcrumbs.php` file that you can use to edit the package's config. In this particular article, we're only going to be bothered about the `view` option in the config file. But, feel free to explore the file though and change it to suit your needs.
By default, when we output the breadcrumbs to our page, the package will style them using [Bootstrap 5](https://getbootstrap.com/). So, if you're styling your UI using Bootstrap 5, you shouldn't need to make any changes straight away.
However, if you're using [Tailwind](https://tailwindcss.com) for your CSS, you can update the `view` in the `breadcrumbs.php` config file so that the package uses Tailwind to render rather than Bootstrap. In this case, you could update your config file like so:
```php
return [
// ...
'view' => 'breadcrumbs::tailwind',
// ...
];
```
### Using Custom Styles for Your Breadcrumbs
In my personal opinion, I quite like the default styling of the Tailwind version of the breadcrumbs. However, if you find that you want a more bespoke looking design, you can easily add this yourself.
First, you can create a new `resources/views/partials/breadcrumbs.blade.php` file. The documentation provides a handy little template that you can get started with by dropping straight into this file:
```
@unless ($breadcrumbs->isEmpty())
<ol class="breadcrumb">
@foreach ($breadcrumbs as $breadcrumb)
@if (!is_null($breadcrumb->url) && !$loop->last)
<li class="breadcrumb-item"><a href="{{ $breadcrumb->url }}">{{ $breadcrumb->title }}</a></li>
@else
<li class="breadcrumb-item active">{{ $breadcrumb->title }}</li>
@endif
@endforeach
</ol>
@endunless
```
You can now add your own styling and structure to this template and make it fit more with your application or website's design. In past projects, I've used this approach so that I could add breadcrumbs using styling from Tailwind UI.
All that's left to do to use our custom style is to update the config file. We just need to change the `view` field to point to our new Blade file that we've just created. Here's an example of how it might look:
```php
return [
// ...
'view' => 'partials/breadcrumbs',
// ...
];
```
### Defining the Breadcrumbs
Now that we've got the config for the package set up, we can start defining our breadcrumbs ready for displaying.
Before we start defining any breadcrumbs, let's take this basic, example `routes/web.php` file:
```php
<?php
use App\Http\Controllers\UserController;
use Illuminate\Support\Facades\Route;
Route::get('/users', [UserController::class, 'index'])->name('users.index');
Route::get('/users/{user}', [UserController::class, 'show'])->name('users.show');
Route::get('/users/{user}/edit', [UserController::class, 'edit'])->name('users.edit');
```
The package works by us defining a breadcrumb for each route that we have. So, in this particular example, because we have 3 routes, we'll need to define 3 breadcrumbs.
To do this, we'll first need to define a new, empty `routes/breadcrumbs.php` file. Once we've created it, we can add define our first breadcrumb:
```php
use App\Models\User;
use Diglactic\Breadcrumbs\Breadcrumbs;
use Diglactic\Breadcrumbs\Generator as BreadcrumbTrail;
Breadcrumbs::for('users.index', function (BreadcrumbTrail $trail): void {
$trail->push('Users', route('users.index'));
});
```
Let's quickly look at what the code above is doing. We're basically defining a breadcrumb for the page that you can access via the `users.index` route. We're then telling the package to push `Users` on to a stack for displaying and to display with a link to the `users.index` page.
We'll define our other routes and take another look at what our breadcrumbs file might look like:
```php
use App\Models\User;
use Diglactic\Breadcrumbs\Breadcrumbs;
use Diglactic\Breadcrumbs\Generator as BreadcrumbTrail;
Breadcrumbs::for('users.index', function (BreadcrumbTrail $trail): void {
$trail->push('Users', route('users.index'));
});
Breadcrumbs::for('users.show', function (BreadcrumbTrail $trail, User $project): void {
$trail->parent('users.index');
$trail->push($user->name, route('users.show', $user));
});
Breadcrumbs::for('users.edit', function (BreadcrumbTrail $trail, User $project): void {
$trail->parent('users.show');
$trail->push('Edit', route('users.edit', $user));
});
```
In the lines above, we've defined two more breadcrumbs for the two other routes.
For the first route, we've added a breadcrumb which will push the user's name on to the stack as a link to the user's 'show' route. If we were to navigate to this route in our browser, the breadcrumb would have the following structure as an example:
**<u>Users</u> > Ash Allen**
For the second route, we've added a breadcrumb which will push 'Edit' on to the stack as a link to the user's show route. If we were to navigate to this route in our browser, the breadcrumb would have the following structure as an example:
**<u>Users</u> > <u>Ash Allen</u> > Edit**
### Displaying the Breadcrumbs
We're nearly there! Now that we've defined our breadcrumbs, we can now output them to our page for our visitors to start using. To do this, we just need to find a place in our Blade view file where we want to render them and then add:
```php
{{ Breadcrumbs::render() }}
```
That's it! That's all you need to do!
You should now be able to see your breadcrumbs displaying on your page and should be able to click through the different links to navigate through the different pages.
The package is quite thorough, so I would definitely recommend checking out their documentation and looking at the other cool things that you can do.
## Conclusion
Hopefully, this article should have explained the benefits of using breadcrumbs and how they can help your users. It should have also given you some insight into how you can add them to your own Laravel applications pretty easily.
If this post helped you out, I'd love to hear about it. Likewise, if you have any feedback to improve this post, I'd also love to hear that too.
If you're interested in getting updated each time I publish a new post, feel free to [sign up for my newsletter](https://ashallendesign.co.uk/blog).
Keep on building awesome stuff! 🚀 | ashallendesign |
801,946 | How Real-Time Video Streaming Can Benefit Your Business | The Internet and creative mobile apps are the new marketplaces and the main outlet of any business in... | 0 | 2021-08-24T12:00:06 | https://dev.to/arya00123/how-real-time-video-streaming-can-benefit-your-business-pnf | realtimevideostreaming, realtimestreaming, videostreaming, benefitsofvideostreaming | The Internet and creative mobile apps are the new marketplaces and the main outlet of any business in this trending era. Likes, Comments and Shares in social media are playing a major role to convert the efforts into money. Every user's attention in social media are more precious. Each Company, Producers, and Business persons are taking parts for every spectator.
##What is Real-time?
Real-time content is the next partition of the forwarding voyage of content marketing. **[Live video streaming](https://webnexs.com/vod-platform.php)** systems have been a great insertion to social media and mobile apps currently. Facebook, Twitter, YouTube, and others have joined this trend. If you want to do the same, this post may help with the answer. A simple guideline is also available to create an extraordinary application or a useful extension of information to an existing app.
##How Real-time video streaming protocol helps to expand the business?
The live streaming platform allows enterprises and speculators to attach with followers and colleagues in Real-time, presenting amazing content instead of an unpleasant advertisement. Live video streams can link with marketing brands to a new level. They are an affordable price for small businesses and individuals.
##Real-time Video Streaming can be used in different fields:
**Entertainment:** There are more popular gaming live **[video streaming apps](https://webnexs.com/vod-platform.php)**. Video game lovers can view the other players while playing their favourite games. Online live video streaming permit matches to join virtually before meeting IRL.
**Retail:** In this sector, marketing is based on the visible tempt of goods. A live-streamed launch of a new product is the best start. The distributor can increase sales by allowing customers to make purchases over live video streams.
**Real Estate:** Live streaming can be used to show goods to approaching buyers. Customers can get information about the area location, neighbours, provisions, taxes, etc., only with the companies app with high security.
**Webinars:** Live video streams not only transform business presentations. They also shorten the gap between the supplier and the receiver. Most of the companies need a platform to provide online debate or Q&A, to share stuff, and get a quick reply from the customers.
**Healthcare:** Live video streaming technology can promote patient support, guidance and training for beginners, conferences with partners, presentations, etc.
Live video streams became the trend in video marketing. Marketings are densely investing in social media platforms, messengers, and IoT solutions. Creators **[pick to create their channels](webnexs.com/vod-platform.php)** and let others take part for the customer’s attention. | arya00123 |
802,060 | How to Use GitHub Codespaces With Your docfx Project | A little over a year ago, we re-launched the NUnit docs site using the docfx project. Since then,... | 0 | 2021-09-20T14:07:02 | https://seankilleen.com/2021/08/how-to-use-github-codespaces-with-your-docfx-project/ | docfx, github, codespaces, documentation | ---
title: How to Use GitHub Codespaces With Your docfx Project
published: true
date: 2021-08-24 14:00:00 UTC
tags: docfx,github,codespaces,docs
canonical_url: https://seankilleen.com/2021/08/how-to-use-github-codespaces-with-your-docfx-project/
---
A little over a year ago, we [re-launched the NUnit docs site](https://dev.to/seankilleen/announcement-i-am-now-the-lead-for-the-nunit-docs-project-3fl2) using the [docfx project](https://dotnet.github.io/docfx/). Since then, we’ve built out the workflow a bit – adding spell-checking, markdown linting, etc. to allow us to consistently create better content.
But I wanted to take it to the next level. I wanted anyone to be able to spin up the docs in GitHub Codespaces and have a fully working environment that did what needed to be done.
So, dear reader, that’s what we did. Below is how we made it happen.
## First Up: A Container
GitHub Codespaces allows us to work within a containerized environment so that we can script everything we need and boot right into it. This means that we can add a `Dockerfile` to our repository in the right place and Codespaces will pick up on it.
Previously, we set up our build process to use [our own `docfx-action` GitHub Action](https://github.com/nunit/docfx-action) – lovingly forked from Niklas Mollenhauer ([@nikeee on GitHub](https://github.com/nikeee/docfx-action)). Part of this GitHub action is a `Dockerfile` that defines a container. We published our own take on it at Dockerhub at [https://hub.docker.com/r/nunitdocs/docfx-action](https://hub.docker.com/r/nunitdocs/docfx-action).
This highlights what I believe are two great things:
- Because of the awesomeness of OSS, we were able to build upon someone else’s work, and the community is better for it.
- Because of the awesomeness of containers, we can re-use this entire environment for our GitHub Codespace as well.
How is the container built? Working backward, the chain is:
- `nunitdocs/docfx-action`
- …is built upon the `mono` container
- …which is built upon Debian `buster-slim` Linux
## Setting Up our Codespaces Directory
Now that the container exists, how do we build upon it? In our repository, we create a `.devcontainer` folder. Inside that folder is a `Dockerfile`, with the contents:
```docker
FROM nunitdocs/docfx-action:latest
EXPOSE 8080
```
This defines our `Dockerfile`, which builds on our general `docfx` container and also exposes port 8080, which will come in handy shortly.
## The `devcontainer.json` file
In our `.devcontainer` folder, we define a `devcontainer.json` file that looks like:
```json
{
"name": "nunit-docs",
"build": {
"dockerfile": "Dockerfile"
},
"forwardPorts": [8080]
}
```
This:
- Defines the name of our Codespace
- Tells Codespaces to use our Dockerfile to build
- Tells Codespaces to forward port `8080`.
## But What About Extensions?
We use a spell-checker and markdown linting vs code extension, and we don’t want our Codespaces experience to be any different. Luckily, Codespaces allows us to define that right in our JSON file, which we modify to look like:
```json
{
"name": "nunit-docs",
"build": {
"dockerfile": "Dockerfile"
},
"forwardPorts": [8080],
"extensions": [
"streetsidesoftware.code-spell-checker",
"oderwat.indent-rainbow",
"mdickin.markdown-shortcuts",
"davidanson.vscode-markdownlint",
"redhat.vscode-yaml"
]
}
```
## How Do We Work Within it?
When we open GitHub Codespaces instance, we see a VS Code window in our browser.
- To build our docs site, we can `cd docs` and then `docfx build`. This will create a `_site` folder
- We can then run `docfx serve _site -n "*"`. This runs `docfx serve`, which serves a web app on mono. The `-n "*"` allows all bindings. When it runs, Codespaces sees it running on port 80, and “automagically” creates a URL that you can view in your browser to see things running.
## What’s Next?
- I’d love for it to be a little easier for folks to build and run the site. I’ll figure out the recommended approach to allow folks to open a terminal and run `build` or `serve` without having to know the directory. Not sure if it’ll be a `.bashrc` file, or something with VS Code settings and aliases, or the command palette – excited to find out!
- Our build process uses `cSpell` and `markdown-lint`, both of which are installed as `npm` global packages. I plan to update our Codespaces container image to install node and those packages, and then to add some shortcuts to easily enable their use.
- I love the idea of using the [VS Code Tour extension](https://github.com/microsoft/codetour) to show people around the place, so I’ll probably try to do something with that too.
## Check it out!
You can see what the current setup looks like [over at the NUnit docs repository](https://github.com/nunit/docs/tree/master/.devcontainer). | seankilleen |
196,612 | The Five-Minute Rule | How to know whether a technology stack is good within 5 minutes | 0 | 2019-10-28T04:11:35 | https://dev.to/jcs224/the-five-minute-rule-11l0 | webdev, dx, beginners, productivity | ---
title: The Five-Minute Rule
published: true
description: How to know whether a technology stack is good within 5 minutes
tags: webdev,dx,beginners,productivity
---
In the world of web development (or any kind of dev for that matter), there are *so* many stacks and tools to choose from to accomplish our tasks. But, the paradox of choice can paralyze us. Usually, the choice comes down to:
- What we have experience with already
- If a certain tool/language/stack/whatever is best suited to the task
However, if we're beginners, trying to tackle a brand-new problem, or are simply curious about trying other things out, we can really get bogged down by all the options.
I've reflected on this recently, as I come up with new ideas for apps sometimes, and I wonder how I should go about building them. I usually like to take this opportunity to experiment with other tools without investing too heavily. If I find a bunch of different options that I think might fit my requirements and development style, I try to give them all a chance.
After doing this for a while, I've come up with an interesting formula that has actually sort of worked for me (when I practice it). I call it the "Five-Minute Rule".
How does it work?
Well, I try to install the stack on my computer. While the timer hasn't technically started yet, I do judge on how easy it is to set up. It has to have great documentation and/or a super-easy, streamlined install process that doesn't require me to reconfigure my machine very much.
Once I have it set up, I try to run a typical "hello world" scenario. At this point, my judging criteria is:
- How quickly I could create a working example, however small
- See if I can do something slightly more sophisticated and get the expected result
- Determine if it fits my "philosophy" of how to further build upon this starting point
It's a little nebulous, but my favorite tools over the years have been determined by this method. It really allows me to try a bunch of stacks without investing too much into any one of them.
Here are some examples of great tools I've discovered through this method, and they span disciplines:
### Back-end
- [Laravel](https://laravel.com/)
- [AdonisJS](https://adonisjs.com/)
- [Rust](https://www.rust-lang.org/)
### CSS
- [Bootstrap](https://getbootstrap.com/)
- [Tailwind](https://tailwindcss.com/)
### JS (front-end)
- [Vue](https://vuejs.org/)
- [Mithril](https://mithril.js.org/)
### Build tools
- [Parcel](https://parceljs.org/)
### Game dev
- [Godot](https://godotengine.org/)
One thing all of these tools have in common is that they have great documentation, very easy setup, or both. Also, these are all fully open-source tools, making this exercise much easier. Other factors include:
- Community/popularity
- Aesthetics
- Does it "feel good"?
- Attention to detail
- What has been built with it already
So, my advice is to simply try a few technologies that you're trying to decide between, and not commit immediately. If you find one that feels right and you are impressed with it, do some further due diligence to make sure it can meet your future needs. Then, commit to success and start working on your project. | jcs224 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.