
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
802,255 | Participate in a study: Gender in Online Software Communities | Participate in Gender Research | 0 | 2021-08-24T16:16:06 | https://dev.to/mccurcio/participate-in-a-study-gender-in-online-software-communities-5441 | discuss, learning, career | ---
title: Participate in a study: Gender in Online Software Communities
published: true
description: Participate in Gender Research
tags: #discuss #learning #career
//cover_image: https://home.cc.umanitoba.ca/~maftounm/static/UofM-Logo.png
---
Greetings all, I had an interesting time participating in this study.
Check it out: https://home.cc.umanitoba.ca/~maftounm/
Mahya Maftouni is conducting a user study to explore the role of a design element that emphasizes prosocial behavior in addition to content accuracy in Q&A communities and see if such interventions affect people of different genders.
Who can participate: You are invited to participate if
- You are 18 years old or over,
- You are a Stack Overflow member and visit Stack Overflow at least monthly,
- You have a computer with a browser installed (preferably chrome).
What will you do:
If you decide to participate, you will be asked to interact with a mock Q&A site for 15 minutes. You are not expected to post any questions, answers, or comments. After exploring the prototype, you will be given a short survey that gathers your feedback. In the end, there will be an interview.
Time commitment and compensation:
This study will take approximately one hour. As a thank you for your participation, you will receive $20 CAD (converted to requested currency) at the start of the study. Depending on your preference, it can be provided as an Amazon gift card or cash (via Paypal or e-Transfer).
I had an interesting time participating in this study. | mccurcio |
802,293 | TinyML: Deploying TensorFlow models to Android | What is TinyML? Tiny machine learning (TinyML) is a field that focuses on running machine... | 0 | 2021-08-24T17:21:30 | https://dev.to/badasstechie/tinyml-deploying-tensorflow-models-to-android-2i73 | machinelearning, deeplearning, tinyml, tensorflow | ## What is TinyML?
Tiny machine learning (TinyML) is a field that focuses on running machine learning (mostly deep learning) algorithms directly on edge devices such as microcontrollers and mobile devices. The algorithms have to be highly optimized to be able to run on such systems since most of them are low powered.
## Wait, what do you mean by 'edge devices'?
An edge device is the device which makes use of the **final** output of machine learning algorithms, for instance, a camera that displays the result of image recognition, or a smartphone that plays speech synthesized from text. Most practitioners run machine learning models on more powerful devices, then send the output to edge devices, but this is starting to change with the advent of TinyML.
## Why TinyML?
The need to run machine learning directly on edge devices and the convenience that comes with this has made TinyML become one of the fastest growing fields in deep learning.
## How does one go about deploying ML to edge devices?
1. Train a machine learning model on a more powerful environment such as a cloud virtual machine or a faster computer.
2. Optimize the model, say, by reducing the number of parameters, or by using low precision data types such as 16 bit floats. This will make the model smaller and the inference faster and more power efficient at the cost of accuracy, which is a compromise you'll have to take.
3. Run the model 'on the edge'!
## TensorFlow Lite Quick Start
TensorFlow Lite is TensorFlow's take on TinyML.
### Converting a saved model from TensorFlow to TensorFlow Lite
```python
import tensorflow as tf
model=tf.keras.models.load_model("/path_to_model.h5")
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
open("/tflite_model.tflite", "wb").write(tflite_model)
```
As you can see, it only takes a few lines of code 😊.
### Running a TensorFlow Lite model in TensorFlow Lite's Python Interpreter
```python
import tensorflow as tf
interpreter = tf.lite.Interpreter(model_path="/tflite_model.tflite") #initialize interpreter with model
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
inputs = [] #list of input tensors
for index,item in enumerate(inputs):
interpreter.set_tensor(input_details[index]['index'], item)
interpreter.invoke() #run model
outputs = [] #output tensors
num_outputs = len(output_details) #number of output tensors
for index in range(num_outputs):
outputs.append(interpreter.get_tensor(output_details[index]['index']))
```
### Running a TensorFlow Lite model in an Android application
#### 1. Create a new Android Studio Project
#### 2. Import the model into Android Studio
Copy the .tflite model to app/src/main/assets/ - create the assets folder if it does not exist.
#### 3. Import TensorFlow Lite into your project
Add the following dependency to your app-level build.gradle
`implementation 'org.tensorflow:tensorflow-lite:+'`
#### 4. Load Model
Load the .tflite model you placed in your assets folder as a MappedByteBuffer.
```java
private MappedByteBuffer loadModelFile(Context c, String MODEL_FILE) throws IOException {
AssetFileDescriptor fileDescriptor = c.getAssets().openFd(MODEL_FILE);
FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel();
long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}
model = loadModelFile(this, 'name_of_model.tflite')
```
#### 5. Initialize Interpreter
```java
try {
interpreter = new Interpreter(model);
}
catch (IOException e) {
e.printStackTrace();
}
```
#### 6. Run Model
```Java
Object[] inputs = {input1, input2, ...} //the objects in inputs{} are jagged arrays - what in TensorFlow would be considered tensors
Map<Integer, Object> outputs = new HashMap<>(); //same for outputs
outputs.put(0, output1); //add outputs to the map
interpreter.runForMultipleInputsOutputs(inputs, outputs); //get inference from interpreter
```
And there you go.
## Sample project
[Here is source code](https://github.com/badass-techie/IAmNotReal) for a [GAN](https://en.wikipedia.org/wiki/Generative_adversarial_network) deployed to an Android app with TensorFlow Lite. [Here is the android app](https://play.google.com/store/apps/details?id=com.apptasticmobile.iamnotreal) for you to play with.
| badasstechie |
802,297 | Making programs interact using qtalk | qtalk-go is a versatile IPC/RPC library for Go | 0 | 2021-08-24T18:53:49 | https://dev.to/progrium/making-programs-interact-using-qtalk-4gdc | programming, showdev, go | ---
title: Making programs interact using qtalk
published: true
description: qtalk-go is a versatile IPC/RPC library for Go
tags: programming, showdev, go
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/t3bazpkc56ju321zlsvk.gif
---
Today I'm releasing a beta of [qtalk-go](https://github.com/progrium/qtalk-go), a versatile IPC/RPC library for Go. I've been using and iterating on it for 5 years to get it as simple and clear as possible.
```golang
// client.go
package main
import (
"context"
"log"
"github.com/progrium/qtalk-go/codec"
"github.com/progrium/qtalk-go/fn"
"github.com/progrium/qtalk-go/talk"
)
func main() {
ctx := context.Background()
// use talk.Dial to get a client
client, err := talk.Dial("tcp", "localhost:9999", codec.JSONCodec{})
if err != nil {
log.Fatal(err)
}
defer client.Close()
// call Upper and print the string return value
var ret string
_, err = client.Call(ctx, "Upper", fn.Args{"hello world"}, &ret)
if err != nil {
log.Fatal(err)
}
log.Println(ret)
// call Error and expect err to be the returned error
_, err = client.Call(ctx, "Error", fn.Args{"user error"}, nil)
log.Println(err)
// Output:
// HELLO WORLD
// remote: user error [/Error]
}
```
qtalk is based on over a decade of building and cataloging approaches, patterns, anti-patterns, and best practices in network programming. My interest goes all the way back to high school when I first started playing with Winsock attempting to make massively multiplayer games. Then as a young web developer, pushing the limits of HTTP, discovering how to stream real-time to the browser years before Websocket was dreamed up. Then further abusing HTTP to model other protocols like DNS and IMAP. I pioneered distributed callbacks with webhooks, which got me working at early Twilio where I started going deep on scalable, highly-available messaging architectures. This led me into distributed systems: discovery, coordination, scheduling, etc. I've seen a lot.
I originally wanted to release qtalk with a paper describing all the significant choices to consider when building a stack like this: message framing, data formats, transports, security mechanisms, protocol flows, queuing, multiplexing, batching, layering, schemas, IDLs, symmetrical vs asymmetrical, stateful vs stateless, TCP vs UDP, etc. It would be a sort of guide for building your own stack. I'd still like to write that at some point, but this post will have to suffice for now.
**qtalk makes no significant claims other than being the most bang for buck in simplicity and versatility.** I've made a full walkthrough of various ways it can be used on the [wiki](https://github.com/progrium/qtalk-go/wiki/Examples), but I'll share a taste here.
Here is the server to the client code from above for you to try. Together they show qtalk being used in the simplest case, traditional RPC:
```golang
// server.go
package main
import (
"fmt"
"log"
"net"
"strings"
"github.com/progrium/qtalk-go/codec"
"github.com/progrium/qtalk-go/fn"
"github.com/progrium/qtalk-go/rpc"
)
type service struct{}
func (svc *service) Upper(s string) string {
return strings.ToUpper(s)
}
// methods can opt-in to receive the call as last argument.
// also, errors can be returned to be received as remote errors.
func (svc *service) Error(s string, c *rpc.Call) error {
return fmt.Errorf("%s [%s]", s, c.Selector)
}
func main() {
// create a tcp listener
l, err := net.Listen("tcp", "localhost:9999")
if err != nil {
log.Fatal(err)
}
// setup a server using fn.HandlerFrom to
// handle methods from the service type
srv := &rpc.Server{
Codec: codec.JSONCodec{},
Handler: fn.HandlerFrom(new(service)),
}
// serve until the listener closes
srv.Serve(l)
}
```
## Features
Some basic features of qtalk-go are:
* heavily `net/http` inspired API
* pluggable format codecs
* optional reflection handlers for funcs and methods
* works over any `io.ReadWriteCloser`, including STDIO
* easily portable to other languages
The more unique features of qtalk-go I want to talk about are:
* connection multiplexing
* bidirectional calling
## Multiplexing Layer
The connection multiplexing layer is based on [qmux](https://github.com/progrium/qmux), a subset of SSH that I've [written about previously](https://dev.to/progrium/the-history-and-future-of-socket-level-multiplexing-1d5n). It was designed to optionally be swapped out with QUIC as needed. Either way, everything in qtalk happens over flow-controlled channels, which can be used like embedded TCP streams. Whatever you do with qtalk, you can also tunnel other connections and protocols on the same connection.
RPC is just a layer on top, where each call gets its own channel. This makes request/reply correlation simple, streaming call input/output easy, and lets you hijack the call channel to do something else without interrupting other calls. You can start with an RPC call and then let it become a full-duplex bytestream pipe. Imagine a call that provisions a database and then becomes a client connection to it.
## Bidirectional Calling
Bidirectional calling allows both the client and server to make and respond to calls. Decoupling the caller and responder roles from the connection topology lets you implement patterns like the worker pattern, where a worker connects to a coordinator and responds to its calls.
This also allows for various forms of callbacks in either direction. Not only do callbacks let you build more extensible services, but generally open up more ways for processes to talk to each other. Especially when combined with the other aspects of qtalk.
Imagine a TCP proxy with an API letting services register a callback whenever a connection comes through, and the callback includes a tee of the client bytestream letting this external service monitor and maybe close the connection when it sees something it doesn't like.
## State Synchronization
State synchronization isn't a feature but a common pattern you can easily implement in a number of ways with qtalk. While many people think about pubsub with messaging, which you can also implement with qtalk, I've learned you usually actually want state synchronization instead. Below is a simple example.
Our server will have a list of usernames connected, which is our state. When a client connects, it calls Join to add its username to the list. This also registers the client to receive a callback passing the list of usernames whenever it changes. The client can then call Leave, or if it disconnects abruptly it will be unregistered with the next update.
```golang
// server.go
package main
import (
"context"
"log"
"net"
"sync"
"github.com/progrium/qtalk-go/codec"
"github.com/progrium/qtalk-go/fn"
"github.com/progrium/qtalk-go/rpc"
)
// State contains a map of usernames to callers,
// which are used as a callback client to that user
type State struct {
users sync.Map
}
// Users gets a list of usernames from the keys of the sync.Map
func (s *State) Users() (users []string) {
s.users.Range(func(k, v interface{}) bool {
users = append(users, k.(string))
return true
})
return
}
// Join adds a username and caller using the injected rpc.Call
// value, then broadcasts the change
func (s *State) Join(username string, c *rpc.Call) {
s.users.Store(username, c.Caller)
s.broadcast()
}
// Leave removes the user from the sync.Map and broadcasts
func (s *State) Leave(username string) {
s.users.Delete(username)
s.broadcast()
}
// broadcast uses the rpc.Caller values to perform a callback
// with the "state" selector, passing the current list of
// usernames. any callers that return an error are added to
// gone and then removed with Leave
func (s *State) broadcast() {
users := s.Users()
var gone []string
s.users.Range(func(k, v interface{}) bool {
_, err := v.(rpc.Caller).Call(context.Background(), "state", users, nil)
if err != nil {
log.Println(k.(string), err)
gone = append(gone, k.(string))
}
})
for _, u := range gone {
s.Leave(u)
}
}
func main() {
// create a tcp listener
l, err := net.Listen("tcp", "localhost:9999")
if err != nil {
log.Fatal(err)
}
// setup a server using fn.HandlerFrom to
// handle methods from the state value
srv := &rpc.Server{
Codec: codec.JSONCodec{},
Handler: fn.HandlerFrom(new(State)),
}
// serve until the listener closes
srv.Serve(l)
}
```
The Call pointer that handlers can receive has a reference to a Caller, which is a client to make calls back to the caller, allowing callbacks.
Our client is straightforward. After setting up a connection and a handler to receive and display an updated username listing, we call Join with a username, wait for SIGINT, and call Leave before exiting.
```golang
// client.go
package main
import (
"context"
"flag"
"fmt"
"log"
"os"
"os/signal"
"github.com/progrium/qtalk-go/codec"
"github.com/progrium/qtalk-go/fn"
"github.com/progrium/qtalk-go/rpc"
"github.com/progrium/qtalk-go/talk"
)
func fatal(err error) {
if err != nil {
log.Fatal(err)
}
}
func main() {
flag.Parse()
// establish connection to server
client, err := talk.Dial("tcp", "localhost:9999", codec.JSONCodec{})
fatal(err)
// state callback handler that redraws the user list
client.Handle("state", rpc.HandlerFunc(func(r rpc.Responder, c *rpc.Call) {
var users interface{}
if err := c.Receive(&users); err != nil {
log.Println(err)
return
}
// the nonsense are terminal escape codes
// to return to the last line and clear it
fmt.Println("\u001B[1A\u001B[K", users)
}))
// respond to incoming calls
go client.Respond()
// call Join passing a username from arguments
_, err = client.Call(context.Background(), "Join", fn.Args{flag.Arg(0)}, nil)
fatal(err)
// wait until we get SIGINT
ch := make(chan os.Signal)
signal.Notify(ch, os.Interrupt)
<-ch
// call Leave before finishing
_, err = client.Call(context.Background(), "Leave", fn.Args{flag.Arg(0)}, nil)
fatal(err)
}
```
See the [Examples wiki page](https://github.com/progrium/qtalk-go/wiki/Examples) for more code examples, including tunnels and proxies, selector routing, and streaming responses.
## Roadmap
I'm trying to get to a 1.0 for [qtalk-go](https://github.com/progrium/qtalk-go), so I'd like more people to use and review its code. I also haven't actually gotten around to [putting in QUIC](https://github.com/progrium/qtalk-go/issues/2) as a usable base layer, which I think should be in a 1.0 release. It's in the name, qtalk was started with QUIC in mind. Not only will QUIC improve performance, resolve head of line blocking, and eventually be native to browsers, but being UDP-based means that hole punching can be used to establish peer-to-peer qtalk connections. I'd like to one day be able to use qtalk directly between machines behind NAT.
Meanwhile, I'm wrapping up a JavaScript implementation (in TypeScript) to officially release soon. I have the start of a Python implementation I could use help with, and I'd love to have a C# implementation.
That's it for now. A big thanks to my [sponsors](https://github.com/sponsors/progrium) for making this happen and thanks to you for reading!
---
*For more great posts like this sent directly to your inbox and to find out what all I'm up to, get on the list at [progrium.com](http://progrium.com) ✌️* | progrium |
802,371 | Operadores Lógicos: Exemplos (Parte 2) | Vou criar quatro variáveis com valores definidos: const A = 5; const B = 3; const C = 7; const D =... | 0 | 2021-09-04T14:52:02 | https://ananopaisdojavascript.hashnode.dev/operadores-logicos-exemplos-parte-2 | javascript, algorithms | Vou criar quatro variáveis com valores definidos:
```javascript
const A = 5;
const B = 3;
const C = 7;
const D = 2;
```
Vamos ver na prática como funcionam os operadores lógicos.
```javascript
A > B && C > D; // true
```
`A` é maior do que `B` e `C` é maior do que `D`. As duas afirmações são verdadeiras, portanto o resultado geral é `true`.
```javascript
A < B && C > D; // false
```
`A` não é menor do que `B` e `C` é maior do que `D`. A primeira afirmação é falsa, portanto o resultado geral será `false`.
```javascript
A < B || C > D; // true
```
Usei as mesmas expressões do exemplo anterior, agora com `||`. A primeira afirmação é falsa, porém a segunda é verdadeira, portanto o resultado geral será `true`.
```javascript
const isThisNumberEven = false;
console.log(!isThisNumberEven); // true
```
A variável `isThisNumberEven` foi declarada com um valor `false`. Porém, com o uso do `!`, o valor tornou-se `true`.
E aí? Gostaram? Até a próxima anotação! 😊 | ananopaisdojavascript |
802,493 | Day 437 : So Ambitious | liner notes: Professional : Had a group meeting in the morning. After that, just worked on cleaning... | 0 | 2021-08-24T23:40:29 | https://dev.to/dwane/day-437-so-ambitious-2hdn | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Had a group meeting in the morning. After that, just worked on cleaning up some code for one demo and figured out a workaround for another demo. Yeah, pretty good day. It went by super quick.
- Personal : Last night, I started back watching Boruto. I actually remembered the story line. Also took a look at where I left off with my side project when I first started it in the beginning of the year. I got a lot more done than I remember. I was so ambitious. haha I'm going to pull it back a little to make sure I can launch by the deadline I set for myself. I also tested out the new equipment for the radio show. Everything worked as expected. I think I'll be using it for this week's radio show.
Normally I try to get the blog posted before eating dinner, but I was pretty hungry. haha. I'm going to see if I can get an idea I had for the side project working in a Codepen before implementing it into my code. I've been researching yet another camera to do some live streams. It's similar to the one I backed on IndieGogo, but I can't get it to transmit video to my media server like other cameras I have. It may have to do with the encoding of the video, but I'm not sure. This other camera looks like it has more controls of the video that is transmitted. I don't need the camera until I start travelling again, so what I may do is put the money into some sort of account to gain more interest than my regular savings account. We'll see, more research to be done.
Have a great night!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube Z0Hb0BS8FOg %} | dwane |
802,657 | COMPUTATIONAL THINKING | Future of education is impossible without the use of communication technologies. It emphasized that... | 0 | 2021-08-25T03:48:20 | https://dev.to/viktorilie/computational-thinking-37bi | algorithms, programming, computerscience, logic | Future of education is impossible without the use of communication technologies. It emphasized that it is necessary to start computer programming from the lowest levels of education.
It has been observed that programming in a child development is a logical way of thinking that contributes to creative problem solving. In a way it prepares the child for the future by developing a number of skills such as:
• Persistence;
• Successful teamwork;
• Practice thinking;
• Precision
This helps to successfully overcome the problems of everyday life activities.
It helps to master easily and successfully the contents in other branches of education (other subjects).
**Computational thinking** is a thinking process that formulates the problem and creates its solution in a way that is understandable to the machine (computer) and that can be performed mechanically.
In other words, it allows us to understand a complex problem:
• the nature of the problem
• to develop possible solutions that can be presented in a way that the computer, human, or both can understand.
Computer thinking is used in algorithmic problem solving. A person who has the ability to think computerically is able to logically organize and analyze data, and is able to break the problem into smaller pieces, to solve it using some programming techniques such as iterations, logic operations and the like.
In addition, knowing how to identify, analyze and apply possible solutions in order to achieve the most efficient problem solving.
There are four main techniques of computer thinking:
• **Decomposition**
• **Pattern recognition**
• **Abstraction**
• **Algorithms**
**Decomposition** is the breakdown of a complex problem into smaller problems.
A complex problem is a problem that at first glance we do not understand or do not know how to solve. Therefore, we break it down into smaller problems that are easy to understand and solve.
We solve all minor problems. We integrate their solutions, and through their integration we solve the complex problem.
**Pattern recognition** is a process that takes place after the decomposition process.
During this process, each smaller problem obtained by breaking down the big problem is analyzed and the similarities and connections between the smaller problems are sought.
Once they are found, questions are asked about how to make the best use of that knowledge.
It is a way of solving new problems based on solutions to previous problems and previous experiences.
Solutions to some specific problems can be adapted and used to solve a whole class of similar problems.
Namely, the solutions to similar problems are grouped in a general solution. So whenever we encounter problems of a similar kind, for their solution, we use this general solution.
In educational practice this method can be used very effectively.
Students are given a set of tasks to solve.They look for similarities between the set tasks, ie common elements between those tasks. After that they find a solution for one task that is adaptable for everyone else.
**Abstraction** is a process that facilitates thinking about a problem.
Abstraction means focusing only on important information and ignoring unimportant details.
It makes the problem understandable by removing unnecessary details.
The basic motto of abstraction is to remove details that can be neglected to make the problem easier, but at the same time nothing of what is important for solving it must be lost.
**Algorithms** are a precise description of the rules and procedures needed to achieve the desired result.
The algorithm is a procedure (procedure) that describes to the last detail the activities and their order, necessary to process the input data to reach the output data, respectively to reach the solution.
All operations performed in the algorithm must be simple enough to be performed, accurately and at the final time, using pencil and paper.
The algorithm must complete a finite number of steps. The procedure that has all the properties as the algorithm, but does not have to end in a final number of steps is a computer procedure.
The procedures for making algorithms are not simple and often require a great deal of creativity. There are no hard and fast rules for defining an algorithm.
Algorithms can be represented in different ways:
• Descriptive, with sentences;
• Graphically, with block diagram of the flow;
• In a language close to human (pseudocode)
• In a strictly formalized programming language.
However, the program on the computer is always in binary form only.
Each of these four techniques mentioned above is equally important.
To successfully solve the problem, it is recommended to use all techniques, ie to be used in combination.
If a technique is not used, there is a possibility that the problem will not be solved successfully.The order of using the techniques depends on the type of problem.Order is very important when solving various tasks. If it is not set correctly, then we can get the wrong result.
Also, when solving a logical task, if we use different sequences, different results can be obtained.
| viktorilie |
802,681 | How to setup the dlink wifi extender? | Overcome poor network signals in your home with the dlink extender. You don’t have to always stick to... | 0 | 2021-08-25T05:30:51 | https://dev.to/customertechn12/how-to-setup-the-dlink-wifi-extender-57fj | dlinkwifiextender, dlinklogin | Overcome poor network signals in your home with the dlink extender. You don’t have to always stick to a particular location in order to benefit from a fast internet speed. With the <a href="https://www.d-linkap.net/">D-Link WiFi Extender Setup</a> in your house, you can increase productivity and multi-task without any kind of disruption.
<a href="https://www.d-linkap.net/dlinkrouter-local/">Dlinkrouter.local</a>
<a href="https://www.d-linkap.net/">Dlinkap.local</a>
| customertechn12 |
802,848 | Search Meter für WordPress | Es gibt WordPress-Plugins, die scheinen erst einmal unwichtig zu sein.... WordPress ist eine... | 0 | 2021-08-25T09:32:41 | https://bloggerpilot.com/search-meter/ | wordpress, seo, wordpressplugins | ---
title: Search Meter für WordPress
published: true
date: 2021-08-25 08:44:32 UTC
tags: WordPress,seo,WordPressPlugins
canonical_url: https://bloggerpilot.com/search-meter/
---

Es gibt [WordPress-Plugins](https://bloggerpilot.com/search-meter/), die scheinen erst einmal unwichtig zu sein....
1. WordPress ist eine großartige Möglichkeit, einen Blog zu erstellen
2. Einfach zu installieren und zu benutzen
3. Du wirst ein Plugin installieren müssen, das dir hilft, etwas zu tun (was im Titel hinzugefügt werden sollte)
3. Dieses Plugin wird dir helfen, etwas zu tun (was im Titel hinzugefügt werden sollte)
4. Dieses Plugin wird dein Leben einfacher machen
5. Und es kann mit nur wenigen Klicks installiert werden | j0e |
802,859 | Creating The Sign Up Page Part I | Hello, glad to see you here again. In today's part of the series, we are going to create the sign up... | 14,274 | 2021-08-25T10:03:13 | https://dev.to/earthcomfy/creating-a-django-registration-login-app-part-ii-3k6 | python, django, webdev, codenewbie | Hello, glad to see you here again. In today's part of the series, we are going to create the sign up page.
------------------------------------------------------------------
Okay to create users we need a model right, we need to define what kind of attributes users should have. Django comes with a built in User model whose primary attributes are:
* username
* password
* email
* first_name
* last_name
If we want our users to have more attributes than this built in model gives us, there are a couple of ways to do that and we will see one way in the future when we create a user profile. But for now we are using the Django User model as it is so we should be fine.
Next, we need a form that will be displayed to the users, validate the data and save it to the database. Luckily we don't have to reinvent the wheel because Django has a built in easy to use UserCreationForm.
> UserCreationForm is a form that creates a user, with no privileges, from the given username and password. - [docs](https://docs.djangoproject.com/en/1.8/_modules/django/contrib/auth/forms/)
- Looks good, but what if we want to include extra fields in our form and get other information about the user upon sign up?
For that, we can just simply extend the built in model form and add more fields. I'm going to add email, firstname, and lastname of the user.
**Don't forget that the fields am adding are already in the User model**
Create forms.py module inside the users app and first let's import the necessary dependencies.
forms.py
```python
from django import forms
from django.contrib.auth.models import User
from django.contrib.auth.forms import UserCreationForm
```
- Forms in Django is a class whose fields map to HTML form elements.
- forms class has different fields for handling different types of data. For example, CharField, DateField... Check out the [docs](https://docs.djangoproject.com/en/3.2/ref/forms/fields/#built-in-field-classes) here to look at more of these fields.
- These form fields are represented to the user as an HTML widget (Widgets render HTML form elements) therefore unless we explicitly specify the widget for our form field, Django will use default widgets which may not look that good.
- By overriding the default widget for the form field, we can bootstrapify our form fields.
forms.py
```python
from django import forms
from django.contrib.auth.models import User
from django.contrib.auth.forms import UserCreationForm
class RegisterForm(UserCreationForm):
# fields we want to include and customize in our form
first_name = forms.CharField(max_length=100,
required=True,
widget=forms.TextInput(attrs={'placeholder': 'First Name',
'class': 'form-control',
}))
last_name = forms.CharField(max_length=100,
required=True,
widget=forms.TextInput(attrs={'placeholder': 'Last Name',
'class': 'form-control',
}))
username = forms.CharField(max_length=100,
required=True,
widget=forms.TextInput(attrs={'placeholder': 'Username',
'class': 'form-control',
}))
email = forms.EmailField(required=True,
widget=forms.TextInput(attrs={'placeholder': 'Email',
'class': 'form-control',
}))
password1 = forms.CharField(max_length=50,
required=True,
widget=forms.PasswordInput(attrs={'placeholder': 'Password',
'class': 'form-control',
'data-toggle': 'password',
'id': 'password',
}))
password2 = forms.CharField(max_length=50,
required=True,
widget=forms.PasswordInput(attrs={'placeholder': 'Confirm Password',
'class': 'form-control',
'data-toggle': 'password',
'id': 'password',
}))
class Meta:
model = User
fields = ['first_name', 'last_name', 'username', 'email', 'password1', 'password2']
```
- I added an id for the password fields because we are gonna use a plugin that shows password hide/show icon - you know that weird looking eye icon. But more on that later when we create the template.
- Under Meta class we can create the link between our model's fields and the different fields we want to have in our form(order matters).
Alright! Let's head over to *views.py* and use the form we just created.
Here I'm using class-based view to handle the register form. Check the [docs](https://docs.djangoproject.com/en/3.2/topics/class-based-views/intro/) for more info about what am using.
views.py
```python
from django.shortcuts import render, redirect
from django.contrib import messages
from django.views import View
from .forms import RegisterForm
class RegisterView(View):
form_class = RegisterForm
initial = {'key': 'value'}
template_name = 'users/register.html'
def get(self, request, *args, **kwargs):
form = self.form_class(initial=self.initial)
return render(request, self.template_name, {'form': form})
def post(self, request, *args, **kwargs):
form = self.form_class(request.POST)
if form.is_valid():
form.save()
username = form.cleaned_data.get('username')
messages.success(request, f'Account created for {username}')
return redirect(to='/')
return render(request, self.template_name, {'form': form})
```
- First by overriding the `form_class` attribute, we are able to tell django which form to use, `template_name` -> the template we want django to look for
- If the request is get, it creates a new instance of an empty form.
- If the request is post,
-- It creates a new instance of the form with the post data. Then checks if the form is valid or not by calling the [`form.is_valid()`](https://docs.djangoproject.com/en/3.2/ref/forms/api/) method.
-- Then if the form is valid, process the cleaned form data and save the user to our database.
- To let the user know that his/her account is successfully created, we can generate a flash message and display his/her username to the page they are getting redirected to(home page).
Next let's map our urlpatterns to our register view.
users/urls.py
```python
from django.urls import path
from .views import home, RegisterView # Import the view here
urlpatterns = [
path('', home, name='users-home'),
path('register/', RegisterView.as_view(), name='users-register'), # This is what we added
]
```
This is getting kinda long so, we will create the template in the next part.
Thanks for your time, you can find the finished app in [github](https://github.com/earthcomfy/Django-registration-and-login-system).
Feel free to ask, and any suggestions are welcome. See ya!
| earthcomfy |
802,886 | Mastering Web Scraping in Python: Scaling to Distributed Crawling | Wondering how to build a website crawler and parser at scale? Implement a project to crawl, scrape,... | 0 | 2021-08-25T13:35:12 | https://www.zenrows.com/blog/mastering-web-scraping-in-python-scaling-to-distributed-crawling | python, beginners, tutorial, webdev | Wondering how to build a website crawler and parser at scale? Implement a project to crawl, scrape, extract content, and store it at scale in a distributed and fault-tolerant manner. We will take all the knowledge from previous posts and combine it.
First, we learned about [pro techniques to scrape content](https://dev.to/anderrv/mastering-web-scraping-in-python-from-zero-to-hero-4fj4), although we'll only use CSS selectors today. Then [tricks to avoid blocks](https://dev.to/anderrv/stealth-web-scraping-in-python-avoid-blocking-like-a-ninja-16ok), from which we will add proxies, headers, and headless browsers. And lastly, we [built a parallel crawler](https://dev.to/anderrv/mastering-web-scraping-in-python-crawling-from-scratch-1dgd), and this blog post begins with that code.
If you do not understand some part or snippet, it might be in an earlier post. Brace yourselves; lengthy snippets are coming.
### Prerequisites
For the code to work, you will need [Redis](https://redis.io/) and [python3](https://www.python.org/downloads/) installed. Some systems have it pre-installed. After that, install all the necessary libraries by running pip install.
```bash
pip install install requests beautifulsoup4 playwright "celery[redis]"
npx playwright install
```
## Intro to Celery and Redis
[Celery](https://docs.celeryproject.org/en/stable/getting-started/introduction.html) "is an open source asynchronous task queue." We created a simple parallel version in the last blog post. Celery takes it a step further by providing an actual distributed queue implementation. We will use it to distribute our load among workers and servers.
[Redis](https://redis.io/) "is an open source, in-memory data structure store, used as a database, cache, and message broker." Instead of using arrays and sets to store all the content (in memory), we will use Redis as a database. Moreover, Celery can use Redis as a broker, so we won't need other software to run it.
## Simple Celery Task
Our first step will be to create a task in Celery that prints the value received by parameter. Save the snippet in a file called `tasks.py` and run it. If you run it as a regular python file, only one string will be printed. The console will print two different lines if you run it with `celery -A tasks worker`.
The difference is in the `demo` function call. Direct call implies "execute that task," while `delay` means "enqueue it for a worker to process." Check the docs for more info on [calling tasks](https://docs.celeryproject.org/en/stable/userguide/calling.html#basics).
{% gist https://gist.github.com/AnderRV/f741355b768c7f4faee9ed5c4cd15f55 %}
The `celery` command will not end; we need to kill it by exiting the console (i.e., `ctrl + C`). We'll need it several times because Celery does not reload after code changes.
## Crawling from Task
The next step is to connect a Celery task with the crawling process. This time we will be using a slightly altered version of the [helper functions](https://www.zenrows.com/blog/mastering-web-scraping-in-python-crawling-from-scratch#final-code) seen in the last post. `extract_links` will get all the links on the page except the `nofollow` ones. We will add filtering options later.
{% gist https://gist.github.com/AnderRV/4e06185b0e53da256622a4f85479db14 %}
We could loop over the retrieved links and enqueue them, but that would end up crawling the same pages repeatedly. We saw the basics to execute tasks, and now we will start splitting into files and keeping track of the pages on Redis.
## Redis for Tracking URLs
We already said that relying on memory variables is not an option anymore. We will need to persist all that data: visited pages, the ones being currently crawled, keep a "to visit" list, and store some content later on. For all that, instead of enqueuing directly to Celery, we will use Redis to avoid re-crawling and duplicates. And enqueue URLs only once.
We won't go into further details on Redis, but we will use [lists](https://redis.io/commands#list), [sets](https://redis.io/commands#set), and [hashes](https://redis.io/commands#hash).
Take the last snippet and remove the last two lines, the ones calling the task. Create a new file `main.py` with the following content. We will create a list named `crawling:to_visit` and push the starting URL. Then we will go into a loop that will query that list for items and block for a minute until an item is ready. When an item is retrieved, we call the `crawl` function, enqueuing its execution.
{% gist https://gist.github.com/AnderRV/22c4e888e547a1bcd029038a4122f730 %}
It does almost the same as before but allows us to add items to the list, and they will be automatically processed. We could do that easily by looping over `links` and pushing them all, but it is not a good idea without deduplication and a maximum number of pages. We will keep track of all the `queued` and `visited` using sets and exit once their sum exceeds the maximum allowed.
{% gist https://gist.github.com/AnderRV/05702a70a0368a51d826acce8faf08d5 %}
{% gist https://gist.github.com/AnderRV/ca76b6733c381c0949fdc2be45900881 %}
After executing, everything will be in Redis, so running again won't work as expected. We need to clean manually. We can do that by using `redis-cli` or a GUI like [redis-commander](https://github.com/joeferner/redis-commander#readme). There are commands for deleting keys (i.e., `DEL crawling:to_visit`) or [flushing the database](https://redis.io/commands/flushdb) (careful with this one).
## Separate Responsabilities
We will start to separate concepts before the project grows. We already have two files: `tasks.py` and `main.py`. We will create another two to host crawler-related functions (`crawler.py`) and database access (`repo.py`). Please look at the snippet below for the repo file, it is not complete, but you get the idea. There is a [GitHub repository](https://github.com/ZenRows/scaling-to-distributed-crawling) with the final content in case you want to check it.
{% gist https://gist.github.com/AnderRV/797bfb64cbdd5e4e2d996dc184c121c4 %}
And the `crawler` file will have the functions for crawling, extracting links, and so on.
## Allow Parser Customization
As mentioned above, we need some way to extract and store content and add only a particular subset of links to the queue. We need a new concept for that: default parser (`parsers/defaults.py`).
{% gist https://gist.github.com/AnderRV/4c0dfe8a584334a49eef09cd30287028 %}
And in the repo.py file:
{% gist https://gist.github.com/AnderRV/e00bdaa8652518dca9c4c3e91a63a474 %}
There is nothing new here, but it will allow us to abstract the link and content extraction. Instead of hardcoding it in the crawler, it will be a set of functions passed as parameters. Now we can substitute the calls to these functions by an import (for the moment).
For it to be completely abstracted, we need a generator or factory. We'll create a new file to host it - `parserlist.py`. To simplify a bit, we allow one custom parser per domain. The demo includes two domains for testing: [scrapeme.live](https://scrapeme.live/shop/page/1/) and [quotes.toscrape.com](http://quotes.toscrape.com/page/1/).
There is nothing done for each domain yet so that we will use the default parser for them.
{% gist https://gist.github.com/AnderRV/004d891f58cb88e52d6f4048209bb24e %}
We can now modify the task with the new per-domain-parsers.
{% gist https://gist.github.com/AnderRV/004d891f58cb88e52d6f4048209bb24e %}
## Custom Parser
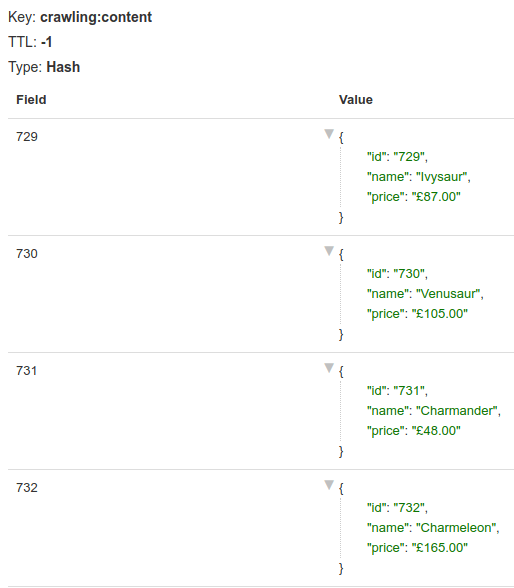
We will use `scrapeme` first as an example. Check the [repo](https://github.com/ZenRows/scaling-to-distributed-crawling/blob/main/parsers/scrapemelive.py) for the final version and the other custom parser.
Knowledge of the page and its HTML is required for this part. Take a look at it if you want to get the feeling. To summarize, we will get the product id, name, and price for each item in the product list. Then store that in a set using the id as the key. As for the links allowed, only the ones for pagination will go through the filtering.
{% gist https://gist.github.com/AnderRV/a1a33d102e43893f278b379dd17e104c %}
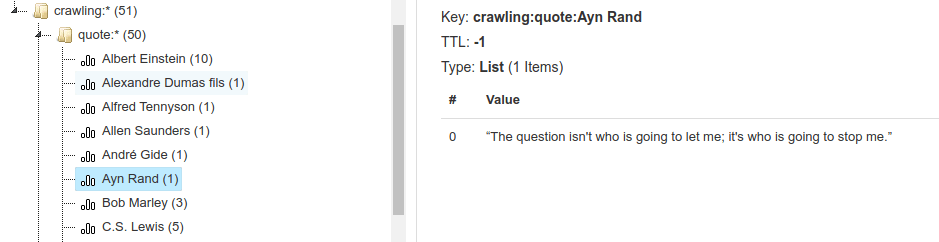
In the `quotes` site, we need to handle it differently since there is no ID per quote. We will extract the author and quote for each entry in the list. Then, in the `store_content` function, we'll create a list for each author and add that quote. Redis handles the creation of the lists when necessary.
{% gist https://gist.github.com/AnderRV/08feeafc01861b10a414b0e4675a17cf %}
With the last couple of changes, we have introduced custom parsers that will be easy to extend. When adding a new site, we must create one file per new domain and one line in `parserlist.py` referencing it. We could go a step further and "auto-discover" them, but no need to complicate it even more.
## Get HTML: Headless Browsers
Until now, every page visited was done using `requests.get`, which can be inadequate in some cases. Say we want to use a different library or headless browser, but just for some cases or domains. Loading a browser is memory-consuming and slow, so we should avoid it when it is not mandatory. The solution? Even more customization. New concept: collector.
We will create a file named `collectors/basic.py` and paste the already known `get_html` function. Then change the defaults to use it by importing it. Next, create a new file, `collectors/headless_firefox.py`, for the new and shiny method of getting the target HTML. As in the previous post, we will be using [playwright](https://playwright.dev/python/docs/intro/). And we will also parametrize headers and proxies in case we want to use them. _Spoiler: we will_.
{% gist https://gist.github.com/AnderRV/deb0b6231eed6cc8133159bf841ef4f0 %}
If we want to use a headless Firefox for some domain, merely modify the `get_html` for that parser (i.e., `parsers/scrapemelive.py`).
{% gist https://gist.github.com/AnderRV/56fa3a6d8e58cb3cb8d73015997a69d7 %}
As you can see in the [final repo](https://github.com/ZenRows/scaling-to-distributed-crawling/blob/main/collectors/fake.py), we also have a `fake.py` collector used in `scrapemelive.py`. Since we used that website for intense testing, we downloaded all the product pages the first time and stored them in a `data` folder. We can customize with a headless browser, but we can do the same with a file reader, hence the "fake" name.
{% gist https://gist.github.com/AnderRV/75bb1291af682e1d2678656b5dd1800d %}
## Avoid Detection with Headers and Proxies
You guessed it: we want to add custom headers and use proxies. We will start with the headers creating a file `headers.py`. We won't paste the entire content here, there are three different sets of headers for a Linux machine, and it gets pretty long. Check the [repo](https://github.com/ZenRows/scaling-to-distributed-crawling/blob/main/headers.py) for the details.
{% gist https://gist.github.com/AnderRV/ababe91d84e3d5486c2294853b6db33a %}
We can import a concrete set of headers or call the `random_headers` to get one of the available options. We will see a usage example in a moment.
The same applies to the proxies: create a new file, `proxies.py`. It will contain a list of them grouped by the provider. In our example, we will include only [free proxies](https://free-proxy-list.net/). Add your paid ones in the `proxies` dictionary and change the default type to the one you prefer. If we were to complicate things, we could add a retry with a different provider in case of failure.
_Note that these [free proxies](https://free-proxy-list.net/) might not work for you. They are short-time lived._
{% gist https://gist.github.com/AnderRV/663a0667e384c79bcedcda8e1d8eff27 %}
And the usage in a parser:
{% gist https://gist.github.com/AnderRV/3a4e6b582cbf3027025ee937c42ce637 %}
## Bringing it All Together
It's been a long and eventful trip. It is time to put an end to it by completing the puzzle. We hope you understood the whole process and all the challenges that scraping and crawling at scale have.
We cannot show here the final code, so take a look at the [repository](https://github.com/ZenRows/scaling-to-distributed-crawling) and do not hesitate to comment or contact us with any doubt.
The two entry points are `tasks.py` for Celery and `main.py` to start queueing URLs. From there, we begin storing URLs in Redis to keep track and start crawling the first URL. A custom or the default parser will get the HTML, extract and filter links, and generate and store the appropriate content. We add those links to a list and start the process again. Thanks to Celery, once there is more than one link in the queue, the parallel/distributed process starts.
## Points Still Missing
We already covered a lot of ground, but there is always a step more. Here are a few functionalities that we did not include. Also, note that most of the code does not contain error handling or retries for brevity's sake.
### Distributed
We didn't include it, but Celery offers it out-of-the-box. For local testing, we can start two different workers `celery -A tasks worker --concurrency=20 -n worker1` and `... -n worker2`. The way to go is to do the same in other machines as long as they can connect to the broker (Redis in our case). We could even add or remove workers and servers on the fly, no need to restart the rest. Celery handles the workers and distributes the load.
It is important to note that the worker's name is essential, especially when starting several in the same machine. If we execute the above command twice without changing the worker's name, Celery won't recognize them correctly. Thus launch the second one as `-n worker2`.
### Rate Limit
Celery does not allow a rate limit per task and parameter (in our case, domain). Meaning that we can throttle workers or queues, but not to a fine-grained detail as we would like to. There are several [issues](https://github.com/celery/celery/issues/5732) open and [workarounds](https://stackoverflow.com/questions/29854102/celery-rate-limit-on-tasks-with-the-same-parameters). From reading several of those, the take-away is that we cannot do it without keeping track of the requests ourselves.
We could easily rate-limit to 30 requests per minute for each task with the provided param `@app.task(rate_limit="30/m")`. But remember that it would affect the task, not the crawled domain.
### Robots.txt
Along with the `allow_url_filter` part, we should also add a robots.txt checker. For that, the [robotparser library](https://docs.python.org/3/library/urllib.robotparser.html) can take a URL and tell us if it is allowed to crawl it. We can add it to the default or as a standalone function, and then each scraper decides whether to use it. We thought it was complex enough and did not implement this functionality.
If you were to do it, consider the last time the file was accessed with `mtime()` and reread it from time to time. And also, cache it to avoid requesting it for every single URL.
## Conclusion
Building a custom crawler/parser at scale is not an easy nor straightforward task. We provided some guidance and tips, hopefully helping you all with your day-to-day tasks.
Before developing something as big as this project at scale, think about some important take-aways:
1. Separate responsabilities.
2. Use abstractions when necessary, but do not over-engineer.
3. Don't be afraid of using specialized software instead of building everything.
4. Think about scaling even if you don't need it now; just keep it in mind.
Thanks for joining us until the end. It's been a fun series to write, and we hope it's also been attractive from your side. If you liked it, you might be interested in [the Javascript Web Scraping guide](https://www.zenrows.com/blog/web-scraping-with-javascript-and-nodejs?utm_source=devto&utm_medium=blog&utm_campaign=distributed_crawling).
Do not forget to take a look at the rest of the posts in this series.
+ [Crawling from Scratch](https://www.zenrows.com/blog/mastering-web-scraping-in-python-crawling-from-scratch?utm_source=devto&utm_medium=blog&utm_campaign=distributed_crawling) (3/4)
+ [Avoid Blocking Like a Ninja](https://www.zenrows.com/blog/stealth-web-scraping-in-python-avoid-blocking-like-a-ninja?utm_source=devto&utm_medium=blog&utm_campaign=distributed_crawling) (2/4)
+ [Mastering Extraction](https://www.zenrows.com/blog/mastering-web-scraping-in-python-from-zero-to-hero?utm_source=devto&utm_medium=blog&utm_campaign=distributed_crawling) (1/4)
Did you find the content helpful? Please, spread the word and share it. 👈
---
Originally published at [https://www.zenrows.com](https://www.zenrows.com/blog/mastering-web-scraping-in-python-scaling-to-distributed-crawling?utm_source=devto&utm_medium=blog&utm_campaign=distributed_crawling) | anderrv |
803,089 | How does wrinkle treatment with injections work? | https://osloplastikkirurgi.no/behandlinger/behandlinger-hos-kvinner/rynkebehandling/ | 0 | 2021-08-25T12:46:15 | https://dev.to/osloplastikkir1/how-does-wrinkle-treatment-with-injections-work-38e9 | plastikkirurg | https://osloplastikkirurgi.no/behandlinger/behandlinger-hos-kvinner/rynkebehandling/ | osloplastikkir1 |
803,458 | Day 183 | Day 183/200 of #100DaysOfCode Solved three problems on Codewars. Practice webpack using... | 11,311 | 2021-08-25T17:57:07 | https://dev.to/rb_wahid/day-183-5di9 | 100daysofcode, programming | Day 183/200 of #100DaysOfCode
- Solved three problems on Codewars.
- Practice webpack using babel-loader, css-loader, html-loader | rb_wahid |
803,533 | Producing packages for Windows Package Manager | In my previous articles about winget I talked about installing packages but I did not talk about... | 0 | 2021-08-25T22:03:02 | https://techwatching.dev/posts/wingetcreate | winget, windows, tooling, githubactions | ---
title: Producing packages for Windows Package Manager
published: true
date: 2021-08-25 00:00:00 UTC
tags: winget, windows, tooling, githubactions
canonical_url: https://techwatching.dev/posts/wingetcreate
---
In my [previous articles about winget](https://www.techwatching.dev/tags/winget) I talked about installing packages but I did not talk about producing packages for Windows Package Manager. So let's set things right.
## About winget packages
Windows Package Manager allows you to search and install applications that are referenced by the sources you have configured to be used by the winget tool. Sources are repositories that list applications that can be installed by winget and the data needed for them to be installed (in the form of a manifest file containing information such as the installer location of a package for instance). The default source is the [Windows Package Manager Community Repository](https://github.com/microsoft/winget-pkgs) which is a public GitHub repository where everyone can submit its application package manifest to make an applications available for installation to Windows Package Manager users.
Once you know that, if you are the developer of an application you want to distribute on Windows through a the Windows Package Manager you have to create a manifest for your application and publish it through a Pull Request on the Windows Package Manager Community Repository. And each time you release a new version of you application, you have to update your app manifest with the information of your new package version (new version number, new installer location...) and create a PR to the Windows Package Manager Community Repository with this updated version of your manifest. For more details you can have a look at the official [documentation](https://docs.microsoft.com/en-us/windows/package-manager/package/)
As a package creator you probably do not want to create and update this app manifest manually. Luckily for you there is a tool to do that for you.
## WingetCreate to the rescue
### Introducing WingetCreate
[Windows Package Manager Manifest Creator](https://github.com/microsoft/winget-create) aka WingetCreate is a tool "designed to help generate or update manifest files for the Community repo" (quoting the readme of WingetCreate repository). At the time of writing it is still in preview but you can already use it to help you with your manifest files. You can download the installer from [this link](https://aka.ms/wingetcreate/latest) but of course it is available from winget: `winget install wingetcreate`.
The main commands are [New](https://github.com/microsoft/winget-create/blob/main/doc/new.md), [Update](https://github.com/microsoft/winget-create/blob/main/doc/update.md) and [Submit](https://github.com/microsoft/winget-create/blob/main/doc/submit.md).
### The `New` command
It allows you to create a new manifest from scratch. If you don't really know where to start to deal with manifest files it is a nice way of getting started. Yet having a look at existing manifests in the [winget community repository](https://github.com/microsoft/winget-pkgs) can be sometimes more efficient.
### The `Update` command
It allows you to update an existing manifest, that is to say to create an updated version of your manifest when you have released a new version of your application (so new version number and new installer url). You can use this command to `submit` your updated package to the Windows Package Manager Community Repository. In my opinion it is the most useful command from WingetCreate as it can be easily be integrated in a build pipeline to publish your installer.
### The `Submit` command
It allows you to submit an existing manifest (you created earlier on disk with the create or update command) to the Windows Package Manager Community Repository automatically. Basically what it does it that is uses the Github personal access token you give it to create a Pull Request with your manifest in this repository.
### What else ?
If you look at the [settings command](https://github.com/microsoft/winget-create/blob/main/doc/settings.md) you will see that you can specify the name of the GitHub repository to target for your package submission. This is really interesting if you want to host a private source for winget available to your organization only where you will publish applications for related to your business needs and that you don't want to make available publicly.
WingetCreate is a really helpful tool to create, update and validate a manifest for you winget package. Still you probably don't want to manually run WingetCreate each time you release a new package version. So let's see how to automate that with GitHub Actions.
## Automating your app manifest upgrade with GitHub Actions
### Why using GitHub Actions to demonstrate the automation of app manifests upgrades ?
In my daily work, Azure Pipelines are the pipelines I used to do CI/CD and they are great. Currently they offer more functionalities than GitHub Actions and as the code I develop is hosted in Azure Repos it makes more sense to use the Azure DevOps built-in CI/CD tool than something else (although Azure DevOps does not enforce at all you to choose their tools). However there is already in WingetCreate's readme a section with a link to an example about using WingetCreate with Azure Pipelines, but there is no example with GitHub Actions.
Moreover I think many applications that are available or will want to be available as a winget package are open source applications whose code are hosted in a GitHub repository and that are already using GitHub Actions for their CI/CD. So I though it could be useful to have an example of using WingetCreate with GitHub Actions, especially as GitHub has this concept of "releases".
### An interesting use case for with Nushell
[Nushell](https://www.nushell.sh/) is a cross platform shell written in Rust. Nushell's developers took the best of existing shells (like the structured data approach from PowerShell) and created a shell that feels modern, easy-to-use and very useful in my opinion.
There was a [GitHub issue](https://github.com/nushell/nushell/issues/1859) to support the new official Windows package manager so I though it was the opportunity to contribute to Nushell. Contributing to this project was something that I had not been able to do yet because I did not know Rust, writing CI/CD pipelines however is something I can do.
Nushell already uses GitHub Actions for its continuous integration and to create releases. If you are not familiar with GitHub releases you can read the [official documentation](https://docs.github.com/en/github/administering-a-repository/releasing-projects-on-github/about-releases) but basically a release is a version of your software (corresponding to a git tag in your repository) that you make available with release notes and binaries files.
Therefore, the idea was to update Nushell manifest with the latest version of Nushell using `WingetCreate` each time a new release of Nushell is published.
### Triggering a new workflow from a release event
Automating the app manifest upgrade of Nushell just meant creating a `job` in a GitHub Actions workflow that would call `WingetCreate` with the new version number and the new installer url.
I first wanted to modify the existing Nushell GitHub Actions workflow that was creating the releases by adding a new `job` at the end of the workflow just after the release was created. Well this is was a bad idea, I pushed this change and during the next release of Nushell the workflow failed because I did not pay attention the workflow was creating releases in draft, so the installer url of the new version did not exist when my job called `WingetCreate`.
Because of that I decided to create a separate workflow that would be triggered each time a Nushell release is published. In Nushell this is done manually (passing from draft to release) but even if it were done automatically by the release workflow I think it is a better idea to have a specific workflow triggered by the publication of a release.
```
name: Submit Nushell package to Windows Package Manager Community Repository
on:
release:
types: [published]
jobs:
winget:
name: Publish winget package
```
I really like how it is possible with GitHub Actions to trigger on many different GitHub events. It is something that seems more limited in Azure Pipelines.
### Calling `WingetCreate` from a GitHub Actions workflow.
Windows Package Manager Manifest Creator needs to be run in windows so we need to specify that in the job that will submit a new version of Nushell package to Windows Package Manager Community Repository:
```
jobs:
winget:
name: Publish winget package
runs-on: windows-latest
```
This job will only contain one step that is the execution of the commands to call `WingetCreate`. These commands will be in PowerShell as this is the default runner (`pwsh`) in a windows job.
```
winget:
name: Publish winget package
runs-on: windows-latest
steps:
- name: Submit package to Windows Package Manager Community Repository
run: |
```
First we need to download latest version of `WingetCreate` by using the following command :
```
iwr https://aka.ms/wingetcreate/latest -OutFile wingetcreate.exe
```
Second we want to retrieve the version number and the installer url of the new package. These 2 pieces of information will be needed as parameter to the WingetCreate update command. We can find these in the github context which contains the release event that triggered the workflow. We are using these 2 lines of PowerShell to get assets associated to the release and filter on the msi file which is the Windows installer of Nushell.
```
$github = Get-Content '${{ github.event_path }}' | ConvertFrom-Json
$installerUrl = $github.release.assets | Where-Object -Property name -match 'windows.msi' | Select -ExpandProperty browser_download_url -First 1
```
> 💡 I just though that instead of doing this in PowerShell we could have done this in Nushell, which would have been fun 'using Nushell to provide a new version of Nushell' but as it is not installed by default on windows agents it would mean a loss of time each time the workflow runs.
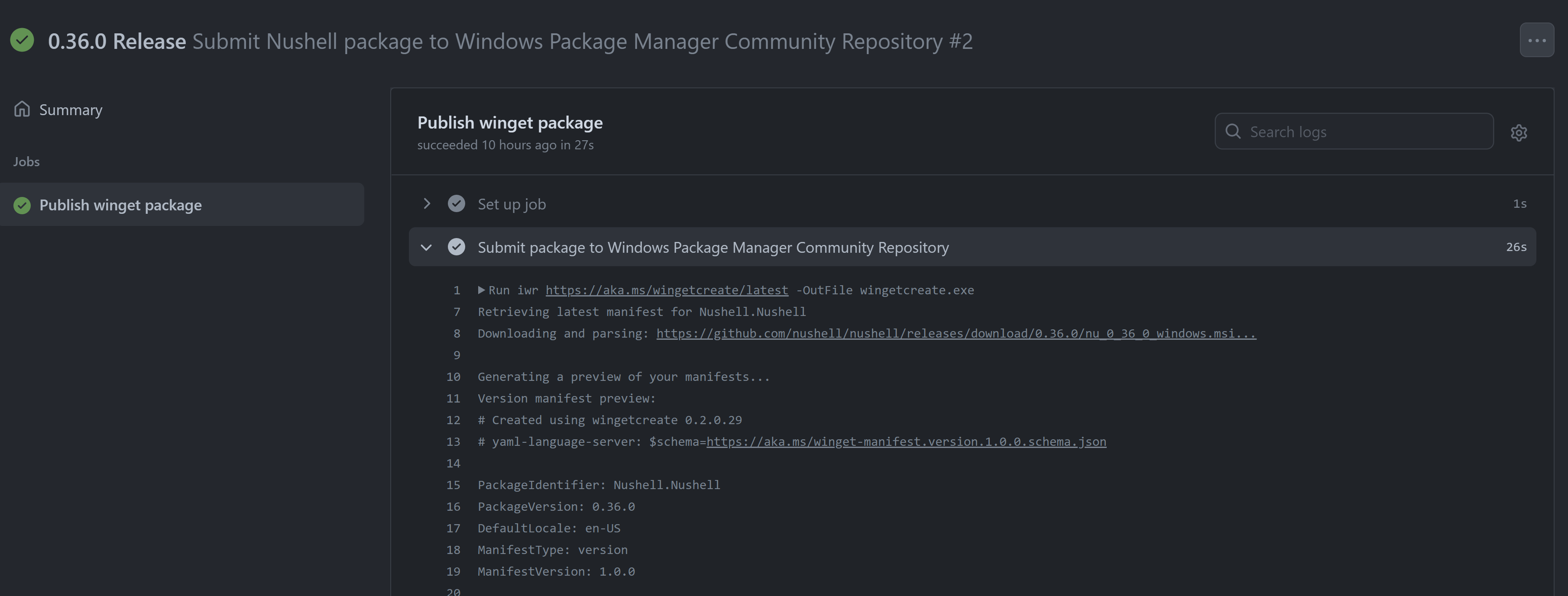
Third we can call the `WingetCreate` update command by specifying the version, the url of the installer, and a Personal Access Token that will be use by `WingetCreate`to make the Pull Request in the Windows Package Manager Community Repository. This PAT needs to be created by a maintainer of the repository with the permission and added to the secrets of the project.
Here you can see a run of the workflow in GitHub:
## Overview of the created workflow
You can find the complete workflow below and [here](https://github.com/nushell/nushell/blob/main/.github/workflows/winget-submission.yml) in the Nushell repository.
```
name: Submit Nushell package to Windows Package Manager Community Repository
on:
release:
types: [published]
jobs:
winget:
name: Publish winget package
runs-on: windows-latest
steps:
- name: Submit package to Windows Package Manager Community Repository
run: |
iwr https://aka.ms/wingetcreate/latest -OutFile wingetcreate.exe
$github = Get-Content '${{ github.event_path }}' | ConvertFrom-Json
$installerUrl = $github.release.assets | Where-Object -Property name -match 'windows.msi' | Select -ExpandProperty browser_download_url -First 1
.\wingetcreate.exe update Nushell.Nushell -s -v $github.release.tag_name -u $installerUrl -t ${{ secrets.NUSHELL_PAT }}
```
Here is what a Pull Request generated by the GitHub Actions workflow looks like:
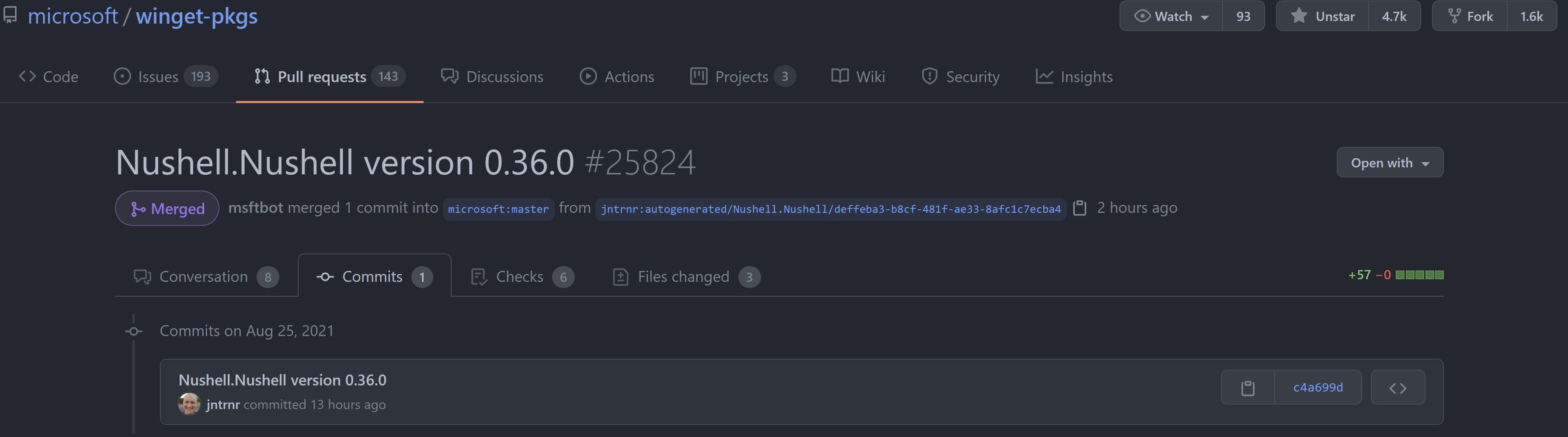
## To summarize
We have introduced the notion of source for winget packages, and in particular the Windows Package Manager Community Repository where we can open PR to submit a new application or new versions of an existing application. We have seen how Windows Package Manager Manifest Creator could help us doing that and how it could be automated from a GitHub Actions workflow like it was done for the Nushell project.
Do not hesitate to copy some of the GitHub Actions workflow I showed you. I hope this will inspire you to do the same to distribute your applications through winget.
A big thank you to [Edward Thomson](https://twitter.com/ethomson) who explained to me how to retrieve GitHub Actions contexts in PowerShell. Thanks also to [Darren Schroeder](https://twitter.com/fdncred) and [Jonathan Turner](https://twitter.com/jntrnr) who supported me to set up a workflow that publish new releases of Nushell in winget. | techwatching |
803,622 | JS Coding Question #2: Reverse a string [Common Question - 3 Solutions] | Front end job interview question, Reverse a string | 14,457 | 2021-08-25T22:02:24 | https://dev.to/frontendengineer/technical-interview-1-reverse-a-string-33pb | challenge, javascript, tutorial, career | ---
title: JS Coding Question #2: Reverse a string [Common Question - 3 Solutions]
published: true
description: Front end job interview question, Reverse a string
tags: challenge, javascript, tutorial, career
cover_image: https://images.unsplash.com/photo-1565688527174-775059ac429c?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1650&q=80
series: Job Interview Preparation Materials
---
#### Interview Question #2:
Write a function that reverses a string❓🤔
> If you need practice, try to solve this on your own. I have included 3 potential solutions below.
> Note: There are many other potential solutions to this problem.
Feel free to bookmark 🔖 even if you don't need this for now. You may need to refresh/review down the road when it is time for you to look for a new role.
Code: https://codepen.io/angelo_jin/pen/LYBPrKo
#### Solution #1: Array methods
- very simple solution that will utilize array methods to reverse the string.
```js
function reverseString(str) {
return str.split("").reverse().join("");
}
```
#### Solution #2: Array forEach
- will cycle through each characters and push it on the temp variable created one by one in reversed order.
```js
function reverseString(str) {
let reversedString = ''
str.split('').forEach(char => {
reversedString = char + reversedString
})
return reversedString
}
```
#### Solution #3: Array reduce
- slightly better than second solution above. Will use reduce and add the result to the empty string in reverse.
```js
function reverseString(str) {
return str.split('')
.reduce((prev, curr) => curr + prev, '')
}
```
Happy coding and good luck if you are interviewing!
If you want to support me - [Buy Me A Coffee](https://www.buymeacoffee.com/letscode77)
In case you like a video instead of bunch of code 👍😊
{% youtube Ol-vKinc6s0 %}
| frontendengineer |
810,307 | Google Cloud Run Combines Serverless with Containers | When it comes to managed Kubernetes services, Google Kubernetes Engine (GKE) is a great choice if you... | 0 | 2021-09-01T13:34:26 | https://dev.to/spawar1991/google-cloud-run-combines-serverless-with-containers-5433 | containers, serverless, googlecloud, kubernetes | When it comes to managed Kubernetes services, Google Kubernetes Engine (GKE) is a great choice if you are looking for a container orchestration platform that offers advanced scalability and configuration flexibility. GKE gives you complete control over every aspect of container orchestration, from networking to storage, to how you set up observability—in addition to supporting stateful application use cases.
However, if your application does not need that level of cluster configuration and monitoring, then a fully managed Cloud Run might be the right solution for you.
> Cloud Run is a fully-managed compute environment for deploying and scaling serverless containerized microservices.
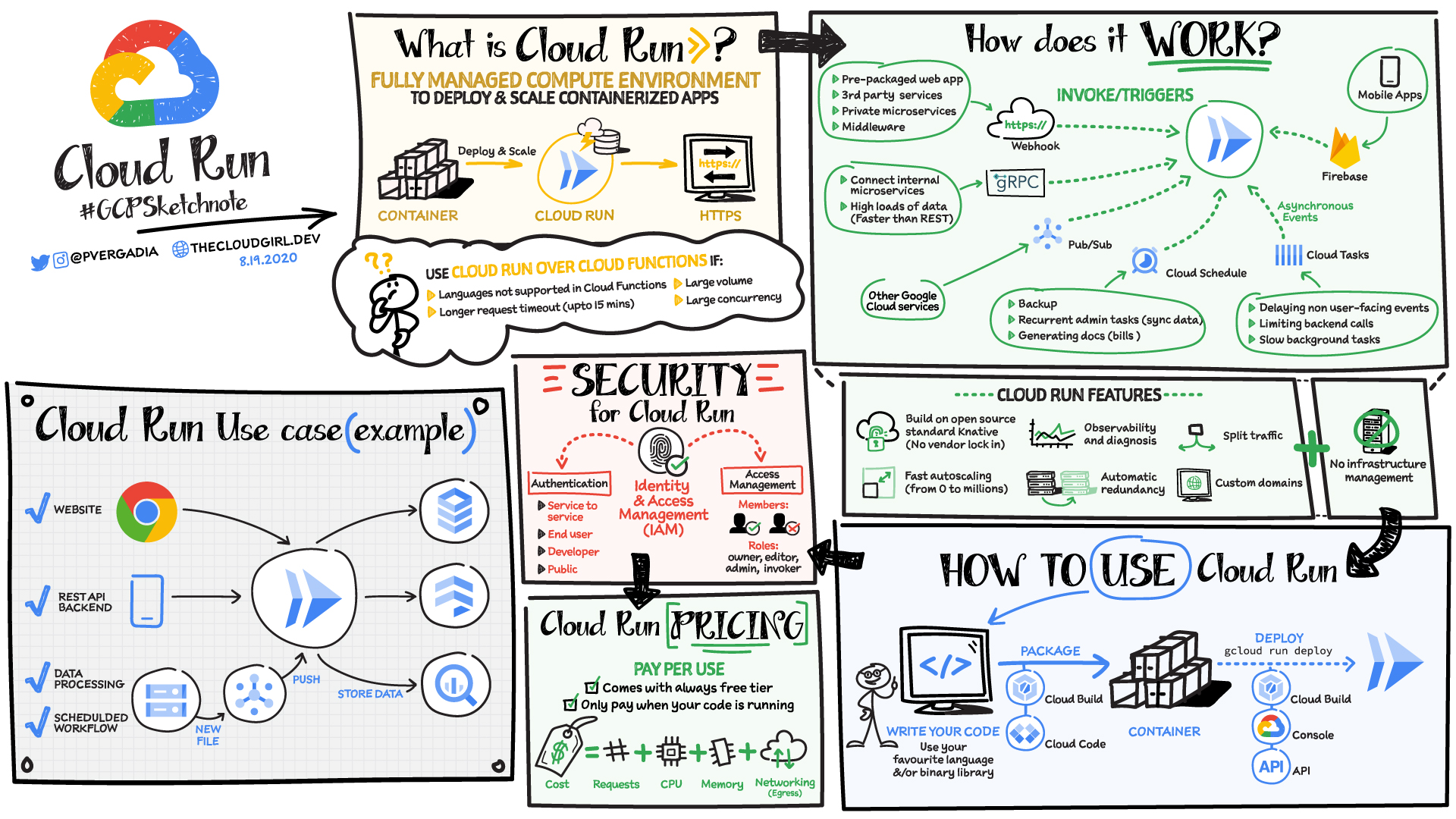
Fully managed Cloud Run is an ideal serverless platform for stateless containerized microservices that don’t require Kubernetes features like namespaces, co-location of containers in pods (sidecars), or node allocation and management.
### **You must be thinking, Why Cloud Run?**
Cloud Run is a fully managed compute environment for deploying and scaling serverless HTTP containers without worrying about provisioning machines, configuring clusters, or autoscaling.
The managed serverless compute platform Cloud Run provides a number of features and benefits:
* **Easy deployment of microservices.** A containerized microservice can be deployed with a single command without requiring any additional service-specific configuration. Si
* **Simple and unified developer experience.** Each microservice is implemented as a Docker image, Cloud Run’s unit of deployment.
* **Scalable serverless execution.** A microservice deployed into managed Cloud Run scales automatically based on the number of incoming requests, without having to configure or manage a full-fledged Kubernetes cluster. Managed Cloud Run scales to zero if there are no requests, i.e., uses no resources.
* **Support for code written in any language.** Cloud Run is based on containers, so you can write code in any language, using any binary and framework.
* **No vendor lock-in** - Because Cloud Run takes standard OCI containers and implements the standard Knative Serving API, you can easily port over your applications to on-premises or any other cloud environment.
* **Split traffic** - Cloud Run enables you to split traffic between multiple revisions, so you can perform gradual rollouts such as canary deployments or blue/green deployments.
* **Automatic redundancy** - Cloud Run offers automatic redundancy so you don’t have to worry about creating multiple instances for high availability
Cloud Run is available in two configurations:
* Fully managed Google Cloud Service.
* Cloud Run For Anthos (s (this option deploys Cloud Run into an Anthos GKE cluster).
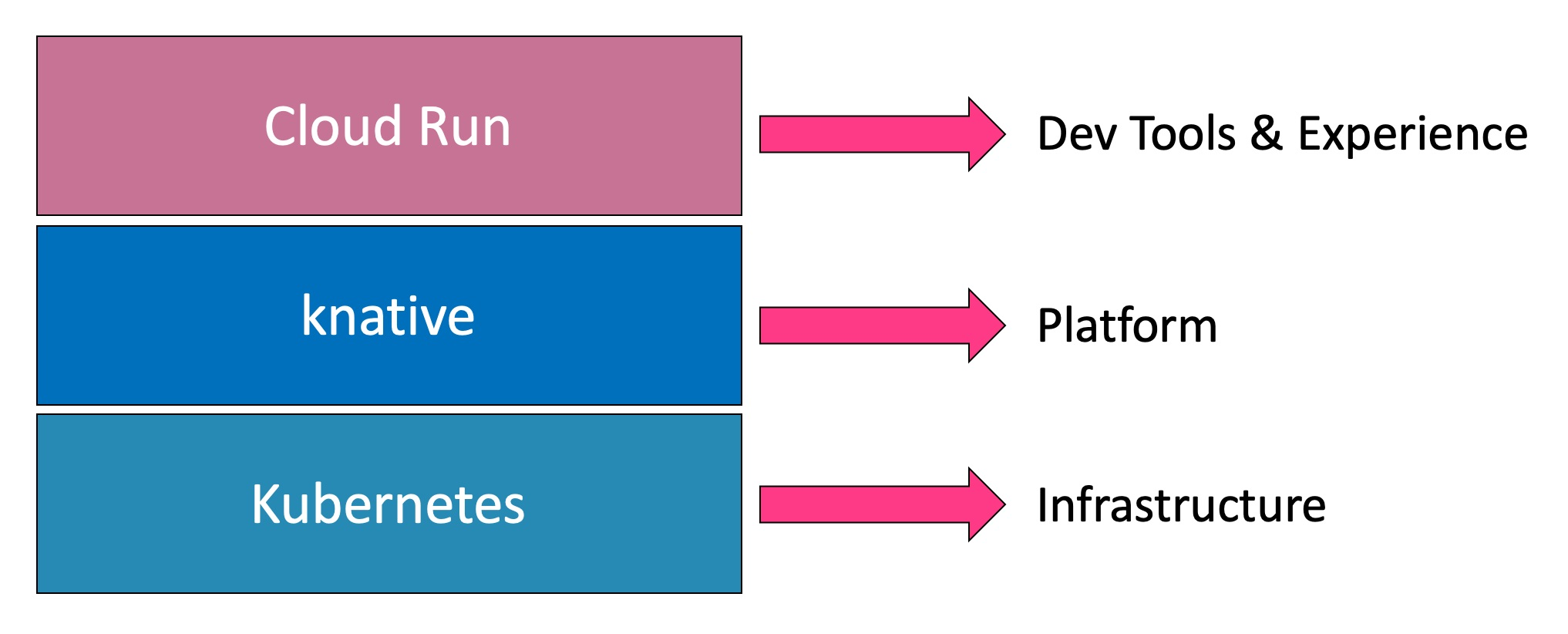
Cloud Run is a layer that Google built on top of Knative to simplify deploying serverless applications on the Google Cloud Platform.
> Google is one of the first public cloud providers to deliver a commercial service based on the open-source Knative project. Like the way it offered a managed Kubernetes service before any other provider, Google moved fast in exposing Knative through Cloud Run to developers.
Knative has a set of building blocks for building a serverless platform on Kubernetes. But dealing with it directly doesn’t make developers efficient or productive. While it acts as the meta-platform running on the core Kubernetes infrastructure, the developer tooling and workflow are left to the platform providers.
### **How does Cloud Run work?**
Cloud Run service can be invoked in the following ways:
**HTTPS:** You can send HTTPS requests to trigger a Cloud Run-hosted service. Note that all Cloud Run services have a stable HTTPS URL. Some use cases include:
1. Custom RESTful web API
2. Private microservice
3. HTTP middleware or reverse proxy for your web applications
4. Prepackaged web application
**gRPC:** You can use gRPC to connect Cloud Run services with other services—for example, to provide simple, high-performance communication between internal microservices. gRPC is a good option when you:
1. Want to communicate between internal microservices
2. Support high data loads (gRPC uses protocol buffers, which are up to seven times faster than REST calls)
3. Need only a simple service definition you don't want to write a full client library
4. Use streaming gRPCs in your gRPC server to build more responsive applications and APIs
**WebSockets:** WebSockets applications are supported on Cloud Run with no additional configuration required. Potential use cases include any application that requires a streaming service, such as a chat application.
**Trigger from Pub/Sub:** You can use Pub/Sub to push messages to the endpoint of your Cloud Run service, where the messages are subsequently delivered to containers as HTTP requests. Possible use cases include:
1. Transforming data after receiving an event upon a file upload to a Cloud Storage bucket
2. Processing your Google Cloud operations suite logs with Cloud Run by exporting them to Pub/Sub
3. Publishing and processing your own custom events from your Cloud Run services
**Running services on a schedule:** You can use Cloud Scheduler to securely trigger a Cloud Run service on a schedule. This is similar to using cron jobs.
Possible use cases include:
1. Performing backups on a regular basis
2. Performing recurrent administration tasks, such as regenerating a sitemap or deleting old data, content, configurations, synchronizations, or revisions
3. Generating bills or other documents
**Executing asynchronous tasks:** You can use Cloud Tasks to securely enqueue a task to be asynchronously processed by a Cloud Run service.
Typical use cases include:
1. Handling requests through unexpected production incidents
2. Smoothing traffic spikes by delaying work that is not user-facing
3. Reducing user response time by delegating slow background operations, such as database updates or batch processing, to be handled by another service,
4. Limiting the call rate to backend services like databases and third-party APIs
**Events from Eventrac:** You can trigger Cloud Run with events from more than 60 Google Cloud sources. For example:
1. Use a Cloud Storage event (via Cloud Audit Logs) to trigger a data processing pipeline
2. Use a BigQuery event (via Cloud Audit Logs) to initiate downstream processing in Cloud Run each time a job is completed
### **How is Cloud Run different from Cloud Functions?**
Cloud Run and Cloud Functions are both fully managed services that run on Google Cloud’s serverless infrastructure, auto-scale, and handle HTTP requests or events. They do, however, have some important differences:
* Cloud Functions lets you deploy snippets of code (functions) written in a limited set of programming languages, while Cloud Run lets you deploy container images using the programming language of your choice.
* Cloud Run also supports the use of any tool or system library from your application; Cloud Functions does not let you use custom executables.
* Cloud Run offers a longer request timeout duration of up to 60 minutes, while with Cloud Functions the requests timeout can be set as high as 9 mins.
* Cloud Functions only sends one request at a time to each function instance, while by default Cloud Run is configured to send multiple concurrent requests on each container instance. This is helpful to improve latency and reduce costs if you're expecting large volumes.
----------------------------------------------------------------
If you enjoyed this article, you might also like:
* [Whitepaper: Serverless At Scale ](https://services.google.com/fh/files/misc/whitepaper_serverless_at_scale_2020.pdf )
* [3 cool Cloud Run features that developers love—and that you will too | Google Cloud Blog ](https://cloud.google.com/blog/products/serverless/3-cool-cloud-run-features-that-developers-love-and-that-you-will-too)
* [Cloud Run: Container to production in seconds | Google Cloud] (https://cloud.google.com/run)
* [Serverless at Google (Cloud Next '19) ] (https://www.youtube.com/watch?v=DRyn--7cZWs) | spawar1991 |
803,842 | Liman Üzerinden Politika ile NTP Server Tanımlama | Network Time Protocol (NTP), bilgisayar sistemleri arasında saat senkronizasyonu sağlamak için olan... | 0 | 2021-09-01T08:44:31 | https://dev.to/aciklab/liman-uzerinden-politika-ile-ntp-server-tanimlama-4c9d | Network Time Protocol (NTP), bilgisayar sistemleri arasında saat senkronizasyonu sağlamak için olan bir ağ protokolüdür. 1985'ten bu yana kullanımda olan NTP, mevcut kullanımdaki en eski İnternet protokollerinden biridir.
## Politika Detaylarından NTP Sunucusu Ayarlama
Politikanın üstüne tıkladıktan sonra "Zaman (NTP) Sunucusu" nu seçin.
NTP genellikle domain controllerlarda bulunduğu için
"Adres" kısmına domain controller ip adresini girin.
## Örnek Kullanım
| mehmettahademircan | |
803,925 | An ultimate guide to Logging in JavaScript | In this post we'll also learn more about Logging in JavaScript. This post is for everyone who wants... | 0 | 2021-08-26T07:54:52 | https://devbookmark.com/an-ultimate-guide-to-logging-in-javascript | javascript, webdev, programming, guide | In this post we'll also learn more about Logging in JavaScript. This post is for everyone who wants final guide to Logging in JavaScript.
---
The console is part of the window object that gives you access to the browser's console. It lets you output strings, arrays and objects that help debug your code.
We can get access to the console on one of two ways:
```js
window.console.log("Hello World!");
console.log("I'm sammy");
// Hello World
// I'm sammy
```
The most common element of the console object is `console.log()`. For most scenarios, you'll use it to get the job done.
There are four different ways of outputting a message to the console:
- log
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616817742750/8SxL44ciq.png?auto=compress">
- info
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616817783335/YTt8A_xkn.png?auto=compress">
- warn
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616817843829/hqFKPVqpu.png?auto=compress">
- error
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616817870907/OW1ekLUb3.png?auto=compress">
Where `console.error` and `console.warn` out puts to **stderr**, the other output to **stdout**.
---
With the console object and its logging methods, long are the days of calling `alert()` to debug and get a variable's value.
Besides the general logging methods that we have discussed in the previous part, there are few more methods that we can play around with.
Now we will cover:
- Stack tracing
- Asserting
### Stack tracing
The `console.trace()` method displays a trace that show how to code ended up at certain point.
Take a look at the below example, to understand how `console.trace()` works.
```js
function hey(name) {
console.trace('name:', name);
return `Hello ${name}!`;
}
hey('sammy');
// OUTPUT
// "Hello sammy!"
```
### Asserting
The `console.assert` method is an easy way to run assertion tests. If the assertion of the 1st argument fails, the subsequent argument gets printed to the console.
Let's look at this example,
```js
// this will pass, nothing will be logged
console.assert(1 == '1', '1 not == to "1"');
```
The below assertion fails,
```js
// this will pass, nothing will be logged
console.assert(1 === '1', '1 not == to "1"');
```
Output:
```js
Assertion failed: 1 not == to "1"
```
---
## Formatting Logs
There is a way to print out objects in a nice formatted way using `console.dir()`.
For example:
```js
const sammy = {
topic: 'Logging',
platform: 'Javascript',
date: {
year: '2020',
month: 'March',
day: 'Saturday'
}
};
console.dir(sammy);
```
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616819016518/fbHExT-rb.png?auto=compress">
You can print out a DOM element's markup in a formatted way using `console.dirxml()`.
for example:
```html
<body>
<h1>Hey</h1>
<script>
console.dirxml(document.body)
</script>
</body>
```
The same will be the output 😅
#### Countings
The `console.count()` method is used to count the number of times it has been invokedd with the same provided label.
For example, here we have two counter, one for even values and another on for odd values.
```js
[1, 2, 3, 4, 5].forEach(nb => {
if (nb % 2 === 0) {
console.count('even');
} else {
console.count('odd');
}
});
```
#### Clearing the logs:
You can clear out all the console logs using the `console.clear()` method.
---
### Record Timings
You can record how long an operation took to complete using console. You can start a timer with `console.time` and then end it with `console.endTime`.
For Example:
```js
console.time('timer');
setTimeout(() => console.log, 1000);
console.timeEnd('timer');
// timer: 0.123945114ms
```
Note: Passing the label in console.time is optional. If you use a label with `console.time` you must pass-in that same label when calling `console.timeEnd`.
### Grouping logs
You can group the console messages together with console. Use `console.group` and `console.groupEnd` to group console messages together.
For Example:
```js
console.group('Even Numbers');
console.log(2);
console.log(4);
console.log(6);
console.groupEnd('Even Numbers');
```
<img>
### Nested grouping logs
Groups ca also be nested to another one. Take a look at the below example,
```js
console.group('Even');
console.log('2');
console.group('Odd');
console.log('1');
console.log('2');
console.groupEnd();
console.log('6');
console.groupEnd();
```
<img>
### Styling your logs:
Console logging can be styled using the delimiter `%c`. The first argument is the message to displayed. Everything that comes after the first `%c` will be styled by the string provided by the secong argument, then everything after the next `%c` is styled by the following string argumnet, and so on.
```js
console.log(
'Hello %csammy%c!',
'color: blue; font-weight: bold; font-size: 1rem;',
'color: hotpink; font-weight: bold; font-size: 1rem;'
);
```
<img>
### Tabular visualization of logs
The `console.table()` allows to display data in the console in a nice tabular format.
```js
const jsonData = [
{
color: "red",
value: "#f00"
},
{
color: "green",
value: "#0f0"
},
{
color: "blue",
value: "#00f"
}
];
console.table(jsonData);
```
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616821591744/oY2AIh8p0.png?auto=compress">
Any type of JSON can be represented in a tabular view. You can display an Array in a tabular view
```js
const y = [
["One", "Two"],
["Three", "Four"]
];
```
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616821909570/9om9JSKgk.png?auto=compress">
And, you can also display an object in a tabular view. You may wonder how? Take a look at this example.
```js
const x = { a: 1, v: { a: 1 } };
```
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616821970521/Pxa8ZBp2B.png?auto=compress">
console.table() displays nay object data in a tabular view. But, if a JSON has multiple nested objects inside, it just prints the root level objects in the tabular view.
Let's see that in this example:
```js
const x = [
{ p: 123, i: 1 },
{
p: 124,
i: 2,
x: {
a: 1,
b: { s: 23 }
}
}
];
```
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616822319169/2JnZByG6J.png?auto=compress">
### Sorting in logs
`console.table()` comes with an inbuilt sorting. Yoou can sort the table by a particular column by clicking on that column's label.
```js
const y = [
["One", "Two"],
["Three", "Four"]
];
console.table(y);
```
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1616822372891/8PQRsIs3n.png?auto=compress">
---
⚡Thanks For Reading | Happy Coding🚀
| devbookmark |
803,926 | VMworld 2021 is right around the corner! Here are my top 10 sessions! | VMworld 2021 is online this year I'll really miss some of the sessions and exploration... | 0 | 2021-09-02T19:45:49 | https://dev.to/ngschmidt/vmworld-2021-is-right-around-the-corner-here-are-my-top-10-sessions-2cj5 | avi, networkautomation, networksecurity, nsxt | ---
title: VMworld 2021 is right around the corner! Here are my top 10 sessions!
published: true
date: 2021-08-26 07:20:00 UTC
tags: Avi,NetworkAutomation,NetworkSecurity,NSXT
canonical_url:
---
## [VMworld 2021 is online](https://bit.ly/3DbHgp3%20) this year
I'll really miss some of the sessions and exploration we've had in past years in person, but I think VMware made the right call this year. We can expect to see a fundamental shift with online conventions - and this will need some unique strategy compared to previous years.
## The Basics
I attended my first VMworld in 2016, and to describe it as information overload would be an understatement. It's only been a few years, but here's what I have to say to new VMworld attendees:
- **Give yourself time between sessions:** it's too easy to switch between video streams at home - but it's a trap. Your brain needs time to process new information, and normally stretching your legs and walking around would help with that. After a particularly heavy session, get away from your keyboard and give yourself time to think. It's like college, if you take too many classes you will perform less effectively than if you capped out your class time.
- **Talk to people:** The [Orbital Jigsaw Discord](https://top.gg/servers/694661808350298132) server can serve as a water cooler of sorts here - remember that you always can learn more with others than on your own.
- **Be kind to your mind:** I'm mentioning it twice, and I don't care. trying to absorb everything will be stressful, the single most important thing you can do is take care of yourself. Don't skip meals, don't skip time with the kids, don't skip out on rest.
VMware has provided a **lot** more content in the breakout sessions this year, and it's because we can't do stuff like the fun run. Here are my sessions of interest:
## Fundamentally Important Sessions
At its core - I'd like to break out sessions that would be of **critical importance,** aforementioned biases notwithstanding:
- **Enhance Data Center Network Design with NSX and VMware Cloud Foundation [NET1789]**
- Nimish Desai is an extremely colorful presenter. In my first VMworld, I was actually wandering around the halls and heard yelling from one of the auditoriums, and decided to wander in and take a look. It turns out he was asking some questions about OSPF and I answered one right and ended up with some trucker cap he'd glued a marketing-noncompliant NSX logo onto and didn't leave the auditorium for about 3 hours. **This was on NSX-V Fundamentals** - for a director he is an extremely capable teacher and presenter.
- I consider this (other names before it, it's basically NSX fundamentals) session every year a foundation for just about everything VMware and SDN.
- **NSX-T Design, Performance and Sizing for Stateful Services [NET1212]**
- This one has to be good. My other favorite presenter on NSX has always been Samuel Kommu, he specializes in flaying whatever SDN platform crosses his desk within an inch of its life, and then squeezing a little bit more than that out of it. He was the first engineer to get NSX-V past 40 Gigabits/s. Nicolas Michel is a capable engineer in the newer NSX-T team, they appear to be based out of EMEA, and is a total Linux and Open Source guy too. NSX-T is based almost completely on open source software and his team is working to recreate the old NSX functionality with F/OSS.
- In this case, we're visiting how to build out the stateful back-end (Tier-1) services, essentially the bits that make a network "smart". NSX-T has some highly unique next-gen scaling capabilities for these service types. Packet inspection devices are **the bottleneck** in nearly all modern enterprise networks, this will present a fresh perspective on solving this problem!
- **Extreme Performance Series: vSphere Advanced Performance Boot Camp [MCL2033]**
- This class every year is basically required for anyone interested in their VCAP (DCV) as it handles the most important subject for virtualization - getting the absolute most value out of your equipment. It is a Tech+ pass session but probably justifies it by itself. If you're having trouble putting together the in-book subjects while studying for VCAP/VCP, this is where you want to go.
## Interesting Sessions
- **Apply SRE’s Golden Signals for Monitoring Toward Network Operations [NET1088]**
- The title more or less says it all, this would be step 4 after a round-trip of fundamentals. The first thing I try to do when encountering a new technology is to make it reliable, and this is a logical progression.
- **(Tech+)Future-Proof Your Network with IPv6, Platform Security and Compliance [EDG1024]**
- If you haven't guessed, **IPv6 is coming and you can't avoid it**. With that out of the way, VMware's Networking and Security Business Unit (NSBU) has covered significant ground getting the rest of the company IPv6-ready. This is a Tech+ session primarily focused on SD-WAN, so if you're interested in how an enterprise can become IPv6-ready, this is where to start.
- **(Tech+)NSX-T Reference Designs for vSphere with Tanzu [NET1426]**
- NSX-T's hidden superpower is actually container networking. It's designed from the ground up with two Container Plugins -[Antrea](https://www.vmware.com/products/antrea-container-networking.html) and NCP - that support container networking without complex Flannel/IPTables configurations **simply to get stuff to work**.
- **Getting Started with NSX Infrastructure as Code [NET2272]**
- I'll be blunt here, I've made several series of blog posts on this already, but **NSX-T is a complicated animal** , and it's important to build it right. In my opinion, the best way to do this is to prototype your deployment repeatedly until it's as close to perfect as you can get it.
- There are two major paths to automate NSX-T here:
- The platform: Ansible/Terraform helps us here to maintain configured state. In a previous life I crushed concrete cylinders to see if they're strong enough, this is like that but digital (and safer!)
- The services: vRealize Automation / vCloud Director provides services on top of the base networking we provide, it is important to understand how people consume networks we build.
- **NSX-T and Infrastructure as Code [CODE2741]**
- **Yes, this will take more than one session to absorb.** VMware understands that - Nicolas Michel is front-ending this one too, he's working on a YouTube channel called [vPackets](https://www.youtube.com/channel/UCpr1GyU4XFt1FAVrW_gppLw) to capture some of this automation knowledge.
## Telecom Sessions
I'm breaking this out because **"there are dozens of us!"**
Apparently, VMware thinks there are more of us than that - and is diving head-first into the breach. VMware has developed a robust hosting and automation suite of services to help accelerate telecommunication delivery.
I'm hoping this will possibly transform smaller ISPs into more of an Edge model, where the telecom provides the pipe and "stuff" on top of it as an additional revenue source. It'd be pretty exciting - even if you don't have a 4-post rack and some cooling, you could loan some cycles from a colocation space as needed. Despite most complaints, telecommunications companies have a few strengths here, namely:
- **Drive**. Telecom engineers do what they do to connect people to information - regardless of how one will often complain about how their internet sucks, these guys are out there working nonstop to help make things just that little bit better.
- **Connectivity.** While this ought to be a given, do you as a customer want to deal with the stress of relocating your server farm while down-sizing offices due to COVID?
- **Connectivity (people)** believe it or not, running cable in every major city will build up quite the Rolodex. If anyone can find a viable physical space to fit your equipment/services, it'd be the telecom company.
Before I go too far, there is a **ton** of sensationalism on "**The Edge!(tm)**" All this really means is what I've explained here - your telecommunications provider would be empowered to deploy distributed compute stacks regionally to fit your (low latency? more like cost-effective!) workload needs. This is especially important in Alaska, where reaching out to the data center the "next town over" [is a microwave relay system reaching hundreds of miles](https://www.gci.com/business/resources/connecting-alaska).
There's also quite a bit of misinformation on 5G, which fits into my top priority session in this category:
- **A Tour of the Heart of the 5G Network with Nokia and VMware [EDG1935]**
- You probably haven't heard of **this** Nokia Networks. It doesn't matter, attend this session if you're interested in 5G - the architecture changes from 4G to 5G are myriad, the organization maintaining the standards (3GPP) made dramatic improvements in terms of technical design, and this will give you a bird's eye view.
- Nokia Networks is a name to track in the future, VMware's NSX-T platform and Nokia's [new SR-Linux platform](https://www.nokia.com/networks/dc-fabric/simplify/) are going to take the data center by storm. Nokia's recent interest in Open Source has culminated in a **telecommunication grade workload based on Linux** - and they seem to have thought of everything, model-based configuration, automated testing in a container pipeline, the **sky is the limit!**
- **Demystifying Performance: Meeting Stringent Latency Requirements for RAN [EDG2872]**
- I still groan every time someone states that it's "impossible to virtualize x because of latency!" We wouldn't have a **connected Alaska** today if we felt that wasn't a good enough reason to try. These guys succeeded.
I look forward to seeing you all there! I'll try my best to be reachable via Twitter [@engyak907](https://twitter.com/engyak907?lang=en) and in the Orbital Jigsaw server when I can. | ngschmidt |
804,195 | 7 REASONS WHY SHOULD YOU MIGRATE TO MAGENTO 2! | In a world where the market can rule by the online business units, a good website building platform... | 0 | 2021-08-26T12:58:41 | https://dev.to/tecksky/7-reasons-why-should-you-migrate-to-magento-2-mmn | magento2migration, magento, magentodevelopmentcompany | In a world where the market can rule by the online business units, a good website building platform has become important. Each program has to extend some features various from others.
Are you perplexed whether to stay on Magento 1 or to migrate to Magento 2? Many of us are in the same confusion after the launch of Magento 2 was announced in 2015. In a world where the market is ruled by the online business units, a good website building platform has become important.
Magento 2 Migration Services is not an upgrade version of Magento 1 but it is a complete transformation of the earlier version using, each platform has to offer some features improving the quality of service. It grows very difficult which features to choose and which one to sacrifice. The significant news is, it is an open-source platform that provides adequate flexibility and enables its users to employ both creative and third-party plug-ins to streamline their online business.
With beyond 6+ years of experience as Magento Development Company and have successfully fulfilled innumerable E-commerce stores for companies, we know the development cycle within out.
Streamlined Checkout Process
Enhanced ADMIN DASHBOARD
Easier Product Uploads
INSTALLATION OF MODULES EASIER
Integrated Payment Gateways
Easy to Installations and Upgrades
If you choose to migrate from Magento 1 to Magento 2 on your own, you can refer here or choose the easy and various secure way out by opting for the expert Magento 2 Migration Service offered by certified developers at Tecksky Technologies! | tecksky |
804,275 | Are you putting your business logic at correct place? | This blog is a continuation of the last one where we built an expense manager application with... | 13,997 | 2021-08-26T13:44:17 | https://blog.akhilgautam.me/are-you-putting-your-business-logic-correctly | rails, ruby, webdev, beginners | >This blog is a continuation of the last one where we built an `expense manager` application with business logic scattered in the controller.
## Design pattern
Design pattern is a set of rules that encourage us to arrange our code in a way that makes it more readable and well structured. It not only helps new developers onboard smoothly but also helps to find bugs. 🐛
In Rails' world, there are a lot of design patterns followed like **Service Objects**, **Form Objects**, **Decorator**, **Interactor**, and a lot more.
## Interactor
In this blog, we are going to look at **Interactor** using [interactor gem](https://github.com/collectiveidea/interactor). It is quite easy to integrate into an existing project.
- every `interactor` should follow SRP(single responsibility principle).
- `interactor` is provided with a *context* which contains everything that the `interactor` needs to run as an independent unit.
- every `interactor` has to implement a `call` method which will be exposed to the external world.
- if the business logic is composed of several independent steps, it can have multiple `interactors` and one `organizer` that will call all the `interactors` serially in the order they are written.
- `context.something = value` can be used to set something in the context.
- `context.fail!` makes the interactor cease execution.
- `context.failure?` & and `context.success?` can be used to verify the failure and success status.
- in case of `organizers` if one of the `organized interactors` fails, the execution is stopped and the later `interactors` are not executed at all.
### Let's refactor our expense manager
We can create interactors for the following:
- create user
- authenticate user
- process a transaction
- create a transaction record
- update user's balance
Create a directory named `interactors` under `app` to keep the `interactors`.
#### app/interactors/create_user.rb
```ruby
class CreateUser
include Interactor
def call
user = User.new(context.create_params)
user.auth_token = SecureRandom.hex
if user.save
context.message = 'User created successfully!'
else
context.fail!(error: user.errors.full_messages.join(' and '))
end
end
end
```
#### app/interactors/authenticate_user.rb
```ruby
class AuthenticateUser
include Interactor
def call
user = User.find_by(email: context.email)
if user.authenticate(context.password)
context.user = user
context.token = user.auth_token
else
context.fail!(message: "Email & Password did not match.")
end
end
end
```
---
#### app/interactors/process_transaction.rb
```ruby
class ProcessTransaction
include Interactor::Organizer
organize CreateTransaction, UpdateUserBalance
end
```
#### app/interactors/create_transaction.rb
```ruby
class CreateTransaction
include Interactor
def call
current_user = context.user
user_transaction = current_user.user_transactions.build(context.params)
if user_transaction.save
context.transaction = user_transaction
else
context.fail!(error: user_transaction.errors.full_messages.join(' and '))
end
end
end
```
#### app/interactors/update_user_balance.rb
```ruby
class UpdateUserBalance
include Interactor
def call
transaction = context.transaction
current_user = context.user
existing_balance = current_user.balance
if context.transaction.debit?
current_user.update(balance: existing_balance - transaction.amount)
else
current_user.update(balance: existing_balance + transaction.amount)
end
end
end
```
#### app/interactors/fetch_transactions.rb
```ruby
class FetchTransactions
include Interactor
def call
user = context.user
params = context.params
transactions = user.user_transactions
if params[:filters]
start_date = params[:filters][:start_date] && DateTime.strptime(params[:filters][:start_date], '%d-%m-%Y')
end_date = params[:filters][:end_date] && DateTime.strptime(params[:filters][:end_date], '%d-%m-%Y')
context.transactions = transactions.where(created_at: start_date..end_date)
else
context.transactions = transactions
end
end
end
```
---
Let's now refactor our controllers to use the above `interactors`.
#### app/controllers/users_controller.rb
```ruby
class UsersController < ApplicationController
skip_before_action :verify_user?
# POST /users
def create
result = CreateUser.call(create_params: user_params)
if result.success?
render json: { message: result.message }, status: :created
else
render json: { message: result.error }, status: :unprocessable_entity
end
end
def balance
render json: { balance: current_user.balance }, status: :ok
end
def login
result = AuthenticateUser.call(login_params)
if result.success?
render json: { auth_token: result.token }, status: :ok
else
render json: { message: result.message }, status: :unprocessable_entity
end
end
private
def user_params
params.require(:user).permit(:name, :email, :password, :balance)
end
def login_params
params.require(:user).permit(:email, :password)
end
end
```
#### app/controllers/user_transactions_controller.rb
```ruby
class UserTransactionsController < ApplicationController
before_action :set_user_transaction, only: [:show]
def index
result = FetchTransactions.call(params: params, user: current_user)
render json: result.transactions, status: :ok
end
def show
render json: @user_transaction
end
def create
result = ProcessTransaction.call(params: user_transaction_params, user: current_user)
if result.success?
render json: result.transaction, status: :created
else
render json: { message: result.error }, status: :unprocessable_entity
end
end
private
def set_user_transaction
@user_transaction = current_user.user_transactions.where(id: params[:id]).first
end
def user_transaction_params
params.require(:user_transaction).permit(:amount, :details, :transaction_type)
end
end
```
✅✅ That is it. Our `controllers` look much cleaner. Even if someone looks at the project for the first time, they will know where to find the business logic. Let's go through some of the pros & cons of the `interactor` gem.
#### Pros 👍
- easy to integrate
- straightforward DSL(domain-specific language)
- organizers help follow the SRP(single responsibility principle)
#### Cons 👎
- argument/contract validation not available
- the gem looks dead, no active maintainers
---
That is it for this blog. It is hard to cover more than one `design pattern` in one blog. In the next one, we will see how we can use [active_interaction](https://github.com/AaronLasseigne/active_interaction) and achieve a much better result by extracting the validations out of the models.
Thanks for reading. Do share your suggestions in the comments down below.
| akhilgautam |
804,347 | Zozo House Pet Shop | Zozo House's là Petshop chuyên cung cấp thức ăn, vật dụng, phụ kiện & đồ chơi cho thú cưng uy tín... | 0 | 2021-08-26T16:25:31 | https://dev.to/zozohousevn/zozo-house-pet-shop-294b | Zozo House's là Petshop chuyên cung cấp thức ăn, vật dụng, phụ kiện & đồ chơi cho thú cưng uy tín hàng đầu. Với dịch vụ cắt tỉa lông móng, tắm rửa và grooming chất lượng cao Zozo House's sẽ là lựa chọn tuyệt vời cho chó mèo cưng của bạn
Website: https://zozohouse.vn/
SĐT: 0906682299
#zozohouse #zozohouse_petshop
| zozohousevn | |
810,197 | My mentoring journey as a mentee (so far) | Illustration by Casey Schumacher. Mentoring connects experienced and entry level developers in order... | 0 | 2021-09-01T12:29:53 | https://dev.to/studio_m_song/my-mentoring-journey-as-a-mentee-so-far-4ddj | career, beginners, mentorship, motivation | *Illustration by [Casey Schumacher](https://dribbble.com/shots/5838433-GP-Office-Hours-Illustration/attachments/5838433-GP-Office-Hours-Illustration?mode=media).*
Mentoring connects experienced and entry level developers in order to provide some kind of personalized training and exchange for early career programmers. It frequently happens in the sphere of a company as an educational initiative for employees, but it can also happen outside of a company. At SinnerSchrader, we initiated, as we like to call it, a mentoring support group. Colleagues from various backgrounds take care of kicking off new pairings and offer their help along the way.
Mentoring can take many forms and is super diverse which is why we asked mentors & mentees to talk about their experiences.
This article was written by Alice Grandjean.
## Table of Contents:
* [Introduction](#chapter-1)
* [Part 1: The start of the journey](#chapter-2)
* [Part 2: A well-designed frame for the meetings](#chapter-3)
* [Part 3: Content of a session](#chapter-4)
* [Part 4: Community & support group](#chapter-5)
* [Conclusion](#chapter-6)
### Introduction <a name="chapter-1"></a>
A mentor as Google defines it, is “an experienced and trusted adviser”. A mentee is someone like me! In this case, a junior developer with her head full of questions. It was a unique chance for me to have a mentor, but the mentoring process was not so linear to set up. This article is a small insight from my experience of being a mentee.
### Part 1: The start of the journey <a name="chapter-2"></a>
When I joined my company, I was not familiar with many aspects of the developer’s usual journey. I had some technical knowledge learned in an online bootcamp and I had some work experience collected in a previous company, but I used to always learn things the hard way: self-teaching. Mentoring was quite a foreign concept for me.
It took some weeks until the first mentoring session took place. My mentor and I were working on the same project. At the beginning, we kept our meetings casual and met every now and then. We mainly talked about the tasks from our common project. We would often pair program, go through programming solutions or discuss core concepts of JavaScript.
This situation went well overall. As a junior developer I was quite inexperienced and I enjoyed discussing my tasks with someone. Sometimes if we were in a rush, we would define a “period of exchange” where we would meet before the daily every day for 15 minutes. I much appreciated the flexibility of the team and the patience of my colleagues.
Six months ago, I got a new project and I had to pair with a new mentor. We were not working on the same project anymore. We decided to establish a different structure for our meeting: we would meet for one hour every week. I also decided to plan a little bit more in advance the topics of our meetings and I set up an agenda for it. That also helped me to keep track of our discussions.
## Part 2: A well-designed frame for the meetings <a name="chapter-3"></a>
I think the frame of your mentoring meeting is very important. As mentees, we should keep in mind that we are equally responsible for getting the most out of the meetings. I understood that eventually and I would come up with topics or precise questions to put on the agenda. My mentor would give me a new perspective on these topics and as I was keeping notes of them, I could easily go back to them later.
It worked very well. I can share with you the agenda we usually followed:
1) Opening questions: How are we doing? How are our projects going on?
2) One thing we learned this week
3) Blockers we experimented
4) Pair programming session
5) Exchange on tech news, tech speakers, Youtube channels
We would not go over all the points in one session but spontaneously decide what would make more sense to do.
This weekly one-hour space turned out to be very helpful for me. It was like an available window focused on me for specific questions. It forced me to gather topics and have a deeper look into them. It was also very beneficial to exchange views on a programming issue or the implementation of a feature. It happened many times that I had a different approach than my mentor. After discussion, I would see the task in a new light, and I would see possible solutions that I didn’t see in the beginning.
### Part 3: Content of a session <a name="chapter-4"></a>
In my opinion, pair programming brings the most valuable experience on the mentee’s side. It was also probably the hardest thing for me to ask for as it took me a lot of mental load. When you pair programming you cannot hide behind your computer, you have to find new ideas fast and you have to admit you don’t know when you don’t know. That is not so easy to do at the beginning, but I got used to it. I would really recommend using the extensions from VS code: Live Share and Live Share Audio. It’s great because it allows people to work on the same file simultaneously: each person can write code and “follow” each other in real time.
The best examples of pair programming we used to do were katas from Codewars. The word “kata” comes from Japan. It refers to a detailed choreographed pattern of martial arts movements to memorize and perfect alone. In the programming world, a code kata is an exercise which helps programmers master their skills through practice and repetition. Codewars is great because it clusters the katas into categories and levels of difficulties. After resolving a kata, your solution is saved and you gain access to the solutions found by the community. This offers the possibility of comparing the solutions between each other.
Recommendations of a fun kata: https://www.codewars.com/kata/57b4da8eb69bfc1b0a000b44 :)
Below you can find more topics from our meetings:
- Tasks from the project (ticket, bug, blocker…)
- Personal project (application, website…)
- Katas
- List of skills
- Javascript challenge e.g.: https://javascript30.com/
- Preparation of a small tech presentation
- Conceptual questions: JS / Typescript / React / API /
Node / architecture…
- Reaction over Dan Abramov’s newsletter regarding Javascript mental model: https://justjavascript.com/
- Discussion over some YouTube channels (this list sadly only has male youtuber, please feel free to share with me non-male tech youtubers):
Syed Maaz Ali Shah https://www.youtube.com/channel/UC5tOulpb9kv_87ZCW1S0XMA
Ben Awad https://www.youtube.com/user/99baddawg
Will Sentance Codesmith https://www.youtube.com/channel/UCAU_6P-M2VHKePIpu5736ag
Brad Traversy https://www.youtube.com/user/TechGuyWeb
Colt Steel https://www.youtube.com/channel/UCrqAGUPPMOdo0jfQ6grikZw
### Part 4: Community & support group <a name="chapter-5"></a>
I strongly believe that belonging to a community or a group can be very beneficial for a junior developer. In this time of remote work, it is easy to feel isolated and disconnected from each other. It can help to find a support group.
My company is quite big and the management set up a monthly meeting with every new junior developers. We would talk about our experiences and try to help each other out on difficult tasks or difficult situations. I really enjoyed these meetings. It was a time of self retrospection and a safe space to exchange. I realized most of us shared the same everyday challenges. Most of us also experienced what is called “impostor syndrome”. It is a psychological symptom where people tend to excessively doubt their skills or accomplishments. For me talking about all these sensitive topics was relieving. It also helped me to find new ideas for my mentoring sessions.
On the side of the mentors, the same kind of meeting happened as well in order to discuss ways to improve the mentoring process. I found this mirroring initiative great!
### Conclusion <a name="chapter-6"></a>
When I look back, I can see mentoring accelerated my progress curve faster than I would have thought at the beginning. I feel lucky to have found two amazing mentors. Besides positive outcomes like knowledge sharing or skills development I could feel our team spirit growing.
In conclusion, if I were to meet the “me” who started the beginning of her career 18 months ago I would say these things:
- Be active (ask for mentoring and define yourselves the frame of your mentoring time)
- Be patient and persistent (don’t try to learn everything but learn small steps at a time)
- Be shameless regarding communication (if you think: “should I ask someone” stop thinking and ask someone)
- Work on your technical communication skills
- Keep track of your successes, failures, achievements
- Measure your progress (in 6 months how would you see the same issue)
- Keep yourselves up to date: reddit, hacker news…
- Get inspired of people (your mentor, your colleagues)
- Open yourselves to others when doubting
- Look for a mentee community
- Say thank you to the people who helped you grow
========================================================================
Ressources:
Live Share: https://visualstudio.microsoft.com/services/live-share/
Kata website: https://www.codewars.com
30 days Javascript: https://javascript30.com/
Javascript newsletter: https://justjavascript.com/
Youtube channel from Syed Maaz Ali Shah: https://www.youtube.com/channel/UC5tOulpb9kv_87ZCW1S0XMA
Youtube channel from Ben Awad: https://www.youtube.com/user/99baddawg
Youtube channel from Will Sentance Codesmith: https://www.youtube.com/channel/UCAU_6P-M2VHKePIpu5736ag
Youtube channel from Brad Traversy: https://www.youtube.com/user/TechGuyWeb | s2engineers_all |
810,215 | Politika ile Kullanıcıya veya Gruba Komut Çalıştırma Yetkisi Verme | Liman üzerinden Domain eklentisi-> politikanız-> politika detaylarından "Yetkili Kullanıcı"... | 0 | 2021-09-08T19:48:11 | https://dev.to/aciklab/politika-ile-kullaniciya-veya-gruba-komut-calistirma-yetkisi-verme-4f9e | Liman üzerinden Domain eklentisi-> politikanız->
politika detaylarından "Yetkili Kullanıcı" altında
"Komut İçin İzin Ver" kısmını doldurun.
Kullanıcı adı: Yetki vermek istediğimiz kullanıcı
Grup adı: Yetki vermek istediğimiz grup
Komut: Yetki verdiğimiz kullanıcının veya grubun çalıştırabileceği komut.
Bu komutu parolasız çalıştırmaya izin ver: Komutu çalıştırmadan önce parola isteyip istemeyeceğini seçin.
## Örnek Kullanım
taha adlı kullanıcıya "apt" komutunu çalıştırma yetkisi verme.

| mehmettahademircan | |
810,220 | 5 Reasons Why You Should Replace the Default Navigation Bar with Syncfusion’s Blazor Sidebar | Almost every application needs a navigation system to better organize multilevel menus and easily... | 0 | 2021-09-01T13:19:42 | https://www.syncfusion.com/blogs/post/replace-default-navigation-with-syncfusion-blazor-sidebar.aspx | blazor, csharp, dotnet, webdev | ---
title: 5 Reasons Why You Should Replace the Default Navigation Bar with Syncfusion’s Blazor Sidebar
published: true
date: 2021-09-01 10:30:14 UTC
tags: blazor, csharp, dotnet, webdev
canonical_url: https://www.syncfusion.com/blogs/post/replace-default-navigation-with-syncfusion-blazor-sidebar.aspx
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/gnrfk74f5zmbgzdxuoa1.png
---
Almost every application needs a navigation system to better organize multilevel menus and easily move through the application. Though Blazor has default navigation, it often falls short of expectations and can make your app look outdated. If you ever had this problem and thought about replacing the default navigation, then this post is for you.
The Syncfusion [Blazor Sidebar](https://www.syncfusion.com/blazor-components/blazor-sidebar "Link to Blazor Sidebar") is an expandable and collapsible component. It typically acts as a side container to place primary or secondary content alongside the main content. It provides flexible options to be shown and hidden based on user interactions.
<figcaption>Blazor Sidebar Component</figcaption>
In this blog post, we will see the following 5 major features of our Blazor Sidebar that make it better than the default navigation:
- [Different types of transitions](#different-types-of-transitions)
- [HTML side content position](#html-side-content-position)
- [HTML slide panel content docking](#add-and-dock-the-html-slide-panel-content)
- [Sidebar menu toggling](#sidebar-menu-toggling)
- [Mobile-friendly side navigation menu](#mobile-friendly-side-navigation-menu)
## Different types of transitions
Different types of slide-out transitions in the Blazor Sidebar give users the flexibility to view or hide content over or above the main content by pushing, sliding, or overlaying it.
**Note:** Refer to the [Customizing the different types of sidebar documentation](https://blazor.syncfusion.com/documentation/sidebar/style#customizing-the-different-types-of-sidebar "Link to customizing the different types of sidebar documentation").
## HTML side content position
The sidebars can be placed on the left, right, or both sides of the application. This helps us see both the primary and secondary content simultaneously.
<figcaption>Customizing the Sidebar Based on the Position</figcaption>
**Note:** For more details, refer to the [Customizing the sidebar based on position](https://blazor.syncfusion.com/documentation/sidebar/style#customizing-the-sidebar-based-on-the-positions "Link to customizing the sidebar based on the positions documentation") documentation.
## Add and dock the HTML slide panel content
You can place any type of HTML content or component in the Sidebar for quick access and easy navigation, like quick references, menus, lists, and tree views. Also, you can use the **Target** property to set the context element to initialize the Sidebar inside any HTML element apart from the body element.
**Note:** For more details, refer to the [Sidebar for specific content in Blazor Sidebar Component](https://blazor.syncfusion.com/documentation/sidebar/custom-context "Link to sidebar for specific content in Sidebar component documentation") documentation.
When you dock the side content, it will give the main content more space. The navigation text will become a shortened view of icons like in the following .gif image.
<figcaption>Docking in Blazor Sidebar</figcaption>
**Note:** For more details, refer to the [Docking in Blazor Sidebar Component](https://blazor.syncfusion.com/documentation/sidebar/docking-sidebar "Link to dock in Blazor Sidebar component documentation") documentation.
## Sidebar menu toggling
You can also bind any custom action to any element (hamburger menu or buttons) to toggle the Sidebar.
<figcaption>Balzor Sidebar Menu Toggling</figcaption>
## Mobile-friendly side navigation menu
The Blazor Sidebar component behaves differently on mobile and desktop screens. Its responsive mode gives an adaptive, redesigned UI appearance for mobile devices.
You can also customize the expand and collapse states of the Sidebar according to the resolution using the **MediaQuery** property.
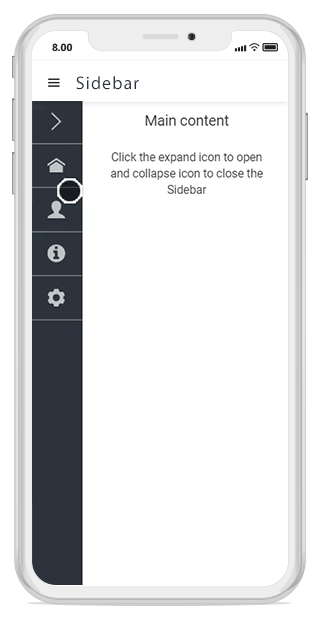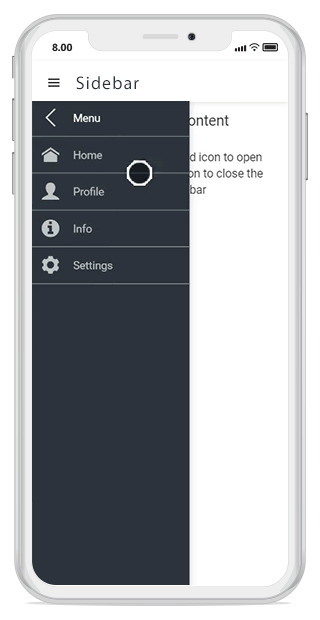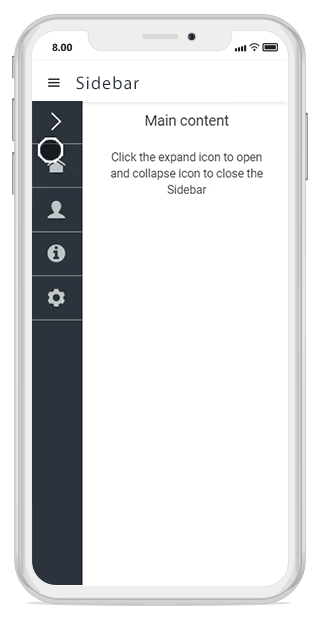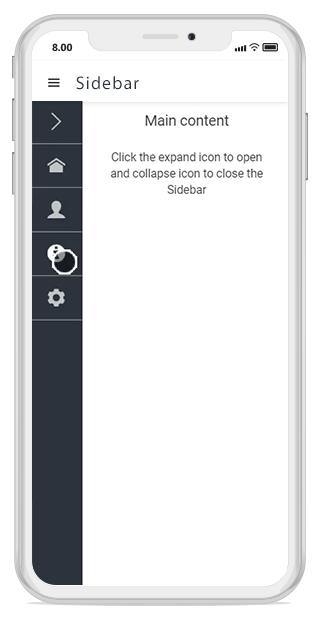<figcaption>Mobile-Friendly Side Navigation Menu in Blazor Sidebar</figcaption>
**Note:** For more details, refer to the [Responsive Sidebar in Blazor Sidebar Component](https://blazor.syncfusion.com/documentation/sidebar/auto-close "Link to Blazor responsive Sidebar Component documentation") documentation.
So far, we have seen the features of our Blazor Sidebar component that make it better than the default navigation.
Now, let’s see how to replace the default navigation with the Blazor Sidebar in two simple steps!
## Replacing default navigation with the Syncfusion Blazor Sidebar
To initialize the Syncfusion Blazor Sidebar in place of the default navigation sidebar in an application, please follow these steps:
**Step #1:** First, install the Syncfusion.Blazor.Navigations NuGet package in the Blazor application by referring to this [documentation](https://blazor.syncfusion.com/documentation/sidebar/getting-started#using-syncfusion-blazor-individual-nuget-packages-new-standard "Link to use Syncfusion Blazor individual NuGet packages [New standard] documentation").
**Step #2:** Then, remove the following code for the **sidebar** element from the **MainLayout.razor** page.
```html
@using Syncfusion.Blazor.Navigations
<div class="dock">
<ul>
<li class="sidebar-item" id="toggle" @onclick="@Toggle">
<span class="e-icons expand"></span>
<span class="e-text" title="menu">Menu</span>
</li>
<li class="sidebar-item">
<span class="e-icons home"></span>
<span class="e-text" title="home">Home</span>
</li>
<li class="sidebar-item">
<span class="e-icons profile"></span>
<span class="e-text" title="profile">Profile</span>
</li>
<li class="sidebar-item">
<span class="e-icons info"></span>
<span class="e-text" title="info">Info</span>
</li>
<li class="sidebar-item">
<span class="e-icons settings"></span>
<span class="e-text" title="settings">Settings</span>
</li>
</ul>
</div>
@code {
[Parameter]
public SfSidebar SidebarInstance { get; set; }
public void Toggle()
{
SidebarInstance.Toggle();
}
}
```
**Step #3:** Then, include the following code for the **SfSidebar** within the **MainLayout.razor** file.
```html
@inherits LayoutComponentBase
@using Syncfusion.Blazor.Navigations
<SfSidebar Width="220px" DockSize="72px" EnableDock="true" @ref="Sidebar" HtmlAttributes="@HtmlAttribute">
<ChildContent>
<NavMenu SidebarInstance="Sidebar">
</NavMenu>
</ChildContent>
</SfSidebar>
<div id="main-content container-fluid col-md-12">
<div class="title">Main content</div>
<div class="sub-title">
<p>Click the expand icon to open and collapse icon to close the sidebar</p>
</div>
</div>
@code{
SfSidebar Sidebar;
Dictionary<string, object> HtmlAttribute = new Dictionary<string, object>()
{
{"class", "dockSidebar" }
};
}
<style>
.title {
text-align: center;
font-size: 20px;
padding: 15px;
}
.sub-title {
text-align: center;
font-size: 16px;
padding: 10px;
}
#wrapper .sub-title .column {
display: inline-block;
padding: 10px;
}
/* custom code start */
.center {
text-align: center;
display: none;
font-size: 13px;
font-weight: 400;
margin-top: 20px;
}
.sb-content-tab .center {
display: block;
}
/* custom code end */
/* end of content area styles */
/* Sidebar styles */
.dockSidebar.e-sidebar.e-right.e-close {
visibility: visible;
transform: translateX(0%);
}
.dockSidebar .e-icons::before {
font-size: 25px;
}
/* dockbar icon Style */
.dockSidebar .home::before {
content: '\e102';
}
.dockSidebar .profile::before {
content: '\e10c';
}
.dockSidebar .info::before {
content: '\e11b';
}
.dockSidebar .settings::before {
content: '\e10b';
}
.e-sidebar .expand::before,
.e-sidebar.e-right.e-open .expand::before {
content: '\e10f';
}
.e-sidebar.e-open .expand::before,
.e-sidebar.e-right .expand::before {
content: '\e10e';
}
/* end of dockbar icon Style */
.dockSidebar.e-close .sidebar-item {
padding: 5px 20px;
}
.dockSidebar.e-dock.e-close span.e-text {
display: none;
}
.dockSidebar.e-dock.e-open span.e-text {
display: inline-block;
}
.dockSidebar li {
list-style-type: none;
cursor: pointer;
}
.dockSidebar ul {
padding: 0px;
}
.dockSidebar.e-sidebar ul li:hover span {
color: white
}
.dockSidebar span.e-icons {
color: #c0c2c5;
line-height: 2
}
.e-open .e-icons {
margin-right: 16px;
}
.e-open .e-text {
overflow: hidden;
text-overflow: ellipsis;
line-height: 23px;
font-size: 15px;
}
.sidebar-item {
text-align: center;
border-bottom: 1px solid rgba(229, 229, 229, 0.54);
}
.e-sidebar.e-open .sidebar-item {
text-align: left;
padding-left: 15px;
color: #c0c2c5;
}
.dockSidebar.e-sidebar {
background: #2d323e;
overflow: hidden;
}
app {
display: inherit;
}
@@font-face {
font-family: 'e-icons';
src: url(data:application/x-font-ttf;charset=utf-8;base64,AAEAAAAKAIAAAwAgT1MvMjciQ6oAAAEoAAAAVmNtYXBH1Ec8AAABsAAAAHJnbHlmKcXfOQAAAkAAAAg4aGVhZBLt+DYAAADQAAAANmhoZWEHogNsAAAArAAAACRobXR4LvgAAAAAAYAAAAAwbG9jYQukCgIAAAIkAAAAGm1heHABGQEOAAABCAAAACBuYW1lR4040wAACngAAAJtcG9zdEFgIbwAAAzoAAAArAABAAADUv9qAFoEAAAA//UD8wABAAAAAAAAAAAAAAAAAAAADAABAAAAAQAAlbrm7l8PPPUACwPoAAAAANfuWa8AAAAA1+5ZrwAAAAAD8wPzAAAACAACAAAAAAAAAAEAAAAMAQIAAwAAAAAAAgAAAAoACgAAAP8AAAAAAAAAAQPqAZAABQAAAnoCvAAAAIwCegK8AAAB4AAxAQIAAAIABQMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUGZFZABA4QLhkANS/2oAWgPzAJYAAAABAAAAAAAABAAAAAPoAAAD6AAAA+gAAAPoAAAD6AAAA+gAAAPoAAAD6AAAA+gAAAPoAAAD6AAAAAAAAgAAAAMAAAAUAAMAAQAAABQABABeAAAADgAIAAIABuEC4QnhD+ES4RvhkP//AADhAuEJ4QvhEuEa4ZD//wAAAAAAAAAAAAAAAAABAA4ADgAOABYAFgAYAAAAAQACAAYABAADAAgABwAKAAkABQALAAAAAAAAAB4AQABaAQYB5gJkAnoCjgKwA8oEHAAAAAIAAAAAA+oDlQAEAAoAAAEFESERCQEVCQE1AgcBZv0mAXQB5P4c/g4Cw/D+lwFpAcP+s24BTf6qbgAAAAEAAAAAA+oD6gALAAATCQEXCQEHCQEnCQF4AYgBiGP+eAGIY/54/nhjAYj+eAPr/ngBiGP+eP54YwGI/nhjAYgBiAAAAwAAAAAD6gOkAAMABwALAAA3IRUhESEVIREhFSEVA9b8KgPW/CoD1vwq6I0B64wB640AAAEAAAAAA+oD4QCaAAABMx8aHQEPDjEPAh8bIT8bNS8SPxsCAA0aGhgMDAsLCwoKCgkJCQgHBwYGBgUEBAMCAgECAwUFBggICQoLCwwMDg0GAgEBAgIDBAMIBiIdHh0cHBoZFhUSEAcFBgQDAwEB/CoBAQMDBAUGBw8SFRYYGhsbHB0cHwsJBQQEAwIBAQMEDg0NDAsLCQkJBwYGBAMCAQEBAgIDBAQFBQYGBwgICAkJCgoKCwsLDAwMGRoD4gMEBwQFBQYGBwgICAkKCgsLDAwNDQ4ODxAQEBEWFxYWFhYVFRQUExIRERAOFxMLCggIBgYFBgQMDAwNDg4QDxERERIJCQkKCQkJFRQJCQoJCQgJEhERERAPDw4NDQsMBwgFBgYICQkKDAwODw8RERMTExUUFhUWFxYWFxEQEBAPDg4NDQwMCwsKCgkICAgHBgYFBQQEBQQAAAAAAwAAAAAD8wPzAEEAZQDFAAABMx8FFREzHwYdAg8GIS8GPQI/BjM1KwEvBT0CPwUzNzMfBR0CDwUrAi8FPQI/BTMnDw8fFz8XLxcPBgI+BQQDAwMCAT8EBAMDAwIBAQIDAwMEBP7cBAQDAwMCAQECAwMDBAQ/PwQEAwMDAgEBAgMDAwQE0AUEAwMDAgEBAgMDAwQFfAUEAwMDAgEBAgMDAwQFvRsbGRcWFRMREA4LCQgFAwEBAwUHCgsOEBETFRYXGRocHR4eHyAgISIiISAgHx4eHRsbGRcWFRMREA4LCQgFAwEBAwUHCgsOEBETFRYXGRsbHR4eHyAgISIiISAgHx4eAqYBAgIDBAQE/rMBAQEDAwQEBGgEBAQDAgIBAQEBAgIDBAQEaAQEBAMDAQEB0AECAwMDBAVoBAQDAwMCAeUBAgIEAwQEaAUEAwMDAgEBAgMDAwQFaAQEAwQCAgElERMVFhcZGhwdHh4fICAhIiIhICAfHh4dGxsZFxYVExEQDgsJCAUDAQEDBQcKCw4QERMVFhcZGxsdHh4fICAhIiIhICAfHh4dHBoZFxYVExEQDgsKBwUDAQEDBQcKCw4AAAIAAAAAA9MD6QALAE8AAAEOAQcuASc+ATceAQEHBgcnJgYPAQYWHwEGFBcHDgEfAR4BPwEWHwEeATsBMjY/ATY3FxY2PwE2Ji8BNjQnNz4BLwEuAQ8BJi8BLgErASIGApsBY0tKYwICY0pLY/7WEy4nfAkRBWQEAwdqAwNqBwMEZAURCXwnLhMBDgnICg4BEy4mfQkRBGQFAwhpAwNpCAMFZAQSCH0mLhMBDgrICQ4B9UpjAgJjSkpjAgJjAZWEFB4yBAYIrggSBlIYMhhSBhIIrggFAzIfE4QJDAwJhBQeMgQGCK4IEgZSGDIYUgYSCK4IBQMyHxOECQwMAAEAAAAAAwED6gAFAAAJAicJAQEbAef+FhoBzf4zA+v+Ff4VHwHMAc0AAAAAAQAAAAADAQPqAAUAAAEXCQEHAQLlHf4zAc0a/hYD6x7+M/40HwHrAAEAAAAAA/MD8wALAAATCQEXCQE3CQEnCQENAY7+cmQBjwGPZP5yAY5k/nH+cQOP/nH+cWQBjv5yZAGPAY9k/nEBjwAAAwAAAAAD8wPzAEAAgQEBAAAlDw4rAS8dPQE/DgUVDw4BPw47AR8dBRUfHTsBPx09AS8dKwEPHQL1DQ0ODg4PDw8QEBAQERERERUUFBQTExITEREREBAPDw0ODAwLCwkJCAcGBgQEAgIBAgIEAwUFBgYHBwkICQoCygECAgQDBQUGBgcHCQgJCv3QDQ0ODg4PDw8QEBAQERERERUUFBQTExITEREREBAPDw0ODAwLCwkJCAcGBgQEAgL8fgIDBQUHCAkKCwwNDg8PERESExQUFRYWFhgXGBkZGRoaGRkZGBcYFhYWFRQUExIREQ8PDg0MCwoJCAcFBQMCAgMFBQcICQoLDA0ODw8RERITFBQVFhYWGBcYGRkZGhoZGRkYFxgWFhYVFBQTEhERDw8ODQwLCgkIBwUFAwLFCgkICQcHBgYFBQMEAgIBAgIEBAYGBwgJCQsLDAwODQ8PEBARERETEhMTFBQUFREREREQEBAQDw8PDg4ODQ31ERERERAQEBAPDw8ODg4NDQIwCgkICQcHBgYFBQMEAgIBAgIEBAYGBwgJCQsLDAwODQ8PEBARERETEhMTFBQUFRoZGRkYFxgWFhYVFBQTEhERDw8ODQwLCgkIBwUFAwICAwUFBwgJCgsMDQ4PDxEREhMUFBUWFhYYFxgZGRkaGhkZGRgXGBYWFhUUFBMSEREPDw4NDAsKCQgHBQUDAgIDBQUHCAkKCwwNDg8PERESExQUFRYWFhgXGBkZGQAAAQAAAAAD6gPqAEMAABMhHw8RDw8hLw8RPw6aAswNDgwMDAsKCggIBwUFAwIBAQIDBQUHCAgKCgsMDAwODf00DQ4MDAwLCgoICAcFBQMCAQECAwUFBwgICgoLDAwMDgPrAQIDBQUHCAgKCgsLDA0NDv00Dg0NDAsLCgoICAcFBQMCAQECAwUFBwgICgoLCwwNDQ4CzA4NDQwLCwoKCAgHBQUDAgAAABIA3gABAAAAAAAAAAEAAAABAAAAAAABAA0AAQABAAAAAAACAAcADgABAAAAAAADAA0AFQABAAAAAAAEAA0AIgABAAAAAAAFAAsALwABAAAAAAAGAA0AOgABAAAAAAAKACwARwABAAAAAAALABIAcwADAAEECQAAAAIAhQADAAEECQABABoAhwADAAEECQACAA4AoQADAAEECQADABoArwADAAEECQAEABoAyQADAAEECQAFABYA4wADAAEECQAGABoA+QADAAEECQAKAFgBEwADAAEECQALACQBayBlLWljb25zLW1ldHJvUmVndWxhcmUtaWNvbnMtbWV0cm9lLWljb25zLW1ldHJvVmVyc2lvbiAxLjBlLWljb25zLW1ldHJvRm9udCBnZW5lcmF0ZWQgdXNpbmcgU3luY2Z1c2lvbiBNZXRybyBTdHVkaW93d3cuc3luY2Z1c2lvbi5jb20AIABlAC0AaQBjAG8AbgBzAC0AbQBlAHQAcgBvAFIAZQBnAHUAbABhAHIAZQAtAGkAYwBvAG4AcwAtAG0AZQB0AHIAbwBlAC0AaQBjAG8AbgBzAC0AbQBlAHQAcgBvAFYAZQByAHMAaQBvAG4AIAAxAC4AMABlAC0AaQBjAG8AbgBzAC0AbQBlAHQAcgBvAEYAbwBuAHQAIABnAGUAbgBlAHIAYQB0AGUAZAAgAHUAcwBpAG4AZwAgAFMAeQBuAGMAZgB1AHMAaQBvAG4AIABNAGUAdAByAG8AIABTAHQAdQBkAGkAbwB3AHcAdwAuAHMAeQBuAGMAZgB1AHMAaQBvAG4ALgBjAG8AbQAAAAACAAAAAAAAAAoAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAwBAgEDAQQBBQEGAQcBCAEJAQoBCwEMAQ0AB2hvbWUtMDELQ2xvc2UtaWNvbnMHbWVudS0wMQR1c2VyB0JUX2luZm8PU2V0dGluZ19BbmRyb2lkDWNoZXZyb24tcmlnaHQMY2hldnJvbi1sZWZ0CE1UX0NsZWFyDE1UX0p1bmttYWlscwRzdG9wAAA=) format('truetype');
font-weight: normal;
font-style: normal;
}
</style>
```
Refer to the following .gif image.
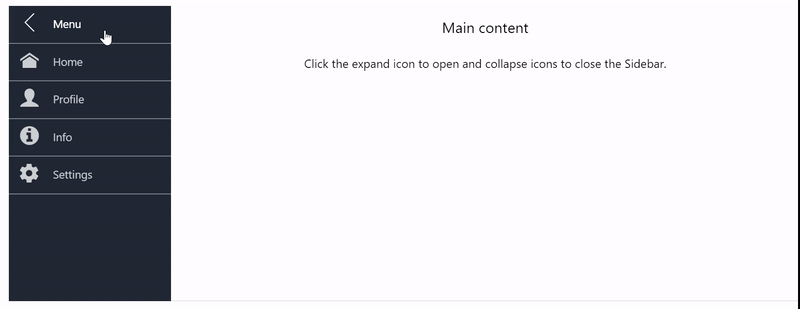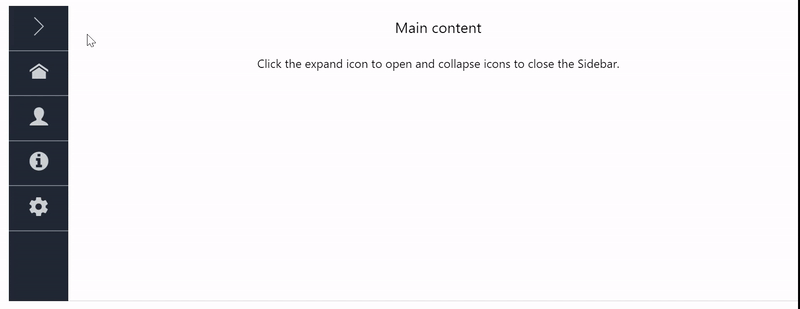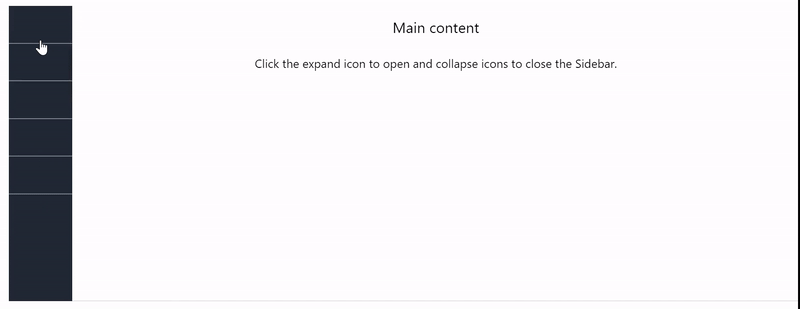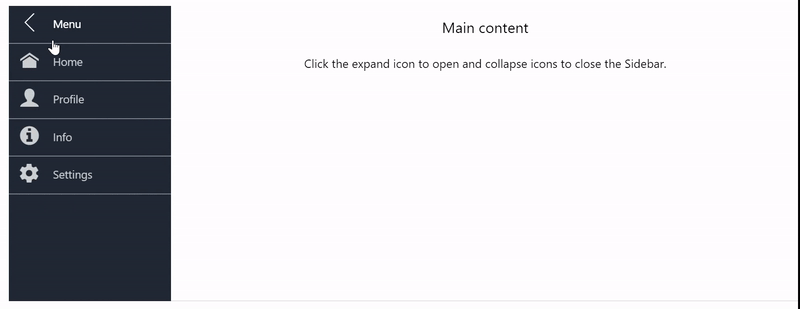<figcaption>Replacing the Default Navigation with Syncfusion’s Blazor Sidebar component</figcaption>
## GitHub reference
Also, you can download the complete demo to [Replace the Default Navigation with the Syncfusion Blazor Sidebar](https://github.com/SyncfusionExamples/blazor-sidebar-replace-default-navigation "Link to replace default navigation bar with Syncfusion Blazor Sidebar demo on GitHub").
## Conclusion
In this blog, we have seen the reasons and steps to replace your default navigation with the Syncfusion [Blazor Sidebar](https://www.syncfusion.com/blazor-components/blazor-sidebar "Link to Blazor Sidebar") component. Try out them and leave your feedback in the comments section of this blog post!
Our Sidebar component is also available in our ASP.NET ([Core](https://www.syncfusion.com/aspnet-core-ui-controls/sidebar "Link to ASP.NET Core Sidebar"), [MVC](https://www.syncfusion.com/aspnet-mvc-ui-controls/sidebar "Link to ASP.NET MVC Sidebar")), [JavaScript](https://www.syncfusion.com/javascript-ui-controls/js-sidebar "Link to JavaScript Sidebar"), [Angular](https://www.syncfusion.com/angular-ui-components/angular-sidebar "Link to Angular Sidebar"), [React](https://www.syncfusion.com/react-ui-components/react-sidebar "Link to React Sidebar"), and [Vue](https://www.syncfusion.com/vue-ui-components/vue-sidebar "Link to Vue Sidebar") platforms.
For existing customers, the new version is available for download from the [License and Downloads](https://www.syncfusion.com/account/downloads "Link to license and download page of Essential Studio") page. If you are not yet a Syncfusion customer, you can try our 30-day [free trial](https://www.syncfusion.com/downloads "Link to the free evaluation of the Syncfusion Essential Studio") to check out our available features. Also, try our samples from this [GitHub](https://github.com/syncfusion "Link to Syncfusion UI controls demos on GitHub") location.
Also, you can contact us through our [support forum](https://www.syncfusion.com/forums "Link to the Syncfusion support forum"), [Direct-Trac](https://www.syncfusion.com/support/directtrac/incidents "Link to the Syncfusion support system Direct Trac"), or [feedback portal](https://www.syncfusion.com/feedback/blazor-components "Link to Syncfusion Feedback Portal"). We are always happy to assist you!
If you liked this blog post, we think you’ll also like the following articles:
- [Introducing Individual NuGet Packages for Syncfusion Blazor UI Components](https://dev.to/sureshmohan/introducing-individual-nuget-packages-for-syncfusion-blazor-ui-components-42nc-temp-slug-1418695 "Link to Introducing Individual NuGet Packages for Syncfusion Blazor UI Components blog") [Blog]
- [How to Preview Images in Syncfusion Blazor File Upload Component](https://dev.to/syncfusion/how-to-preview-images-in-syncfusion-blazor-file-upload-component-3ohn "Link to How to Preview Images in Syncfusion Blazor File Upload Component blog") [Blog]
- [How to Create a Dynamic Form Builder in Blazor](https://dev.to/syncfusion/how-to-create-a-dynamic-form-builder-in-blazor-j80 "Link to How to Create a Dynamic Form Builder in Blazor blog") [Blog]
- [_Blazor WebAssembly Succinctly_](https://www.syncfusion.com/ebooks/blazor_webassembly_succinctly "Link to the eBook Blazor WebAssembly Succinctly") [Ebook]
- [_Blazor Succinctly_](https://www.syncfusion.com/ebooks/blazor-succinctly "Link to the eBook Blazor Succinctly") [Ebook] | sureshmohan |
245,211 | You Got This 2020 | I've just got back from what must be one of the best tech conferences going, and what makes it so spe... | 4,384 | 2020-01-20T18:51:31 | https://dev.to/buck06191/you-got-this-2020-50ek | career, inclusion, beginners | I've just got back from what must be one of the best tech conferences going, and what makes it so special is that it isn't even really about tech. YouGotThis is an annual, single-stream, "tech" conference which focusses on the oft-forgotten "core skills" that are key to working in tech in a way that is both healthy and productive. It's aimed at early career developers, be those junior devs or people that are still looking for that first role, but I actually think that much more senior developers and managers could really benefit from attending. In fact, I think that a lot of what was covered in the talks is relevant far outside of tech specific roles and everyone could benefit from attending!
# TOC
* [The Event](#the-event)
* [Topics](#topics)
* [Your needs ≠ your workplace's needs
](#your-needs)
* [Build a personal brand](#personal-brand)
* [Make a brag doc](#brag-doc)
* [Work with your manager](#manager)
* [Be part of the community](#community)
* [You're more than your job](#more-than-your-job)
# The Event <a name="the-event"></a>

_Photo: [Venues of Excellence](https://www.venuesofexcellence.co.uk/wp-content/uploads/2019/06/Platform-5-672x372.jpg)_
This year the conference took place in Birmingham at Millennium Point. It was really great to see a conference like this take place outside of London, shining a light on the tech world outside of Silicon Roundabout. Underland, who organised the event, did a fantastic job at making the event truly accessible. The toilets inside the event area were all gender neutral, with typical toilet facilities available elsewhere in the venue, and attendees all wore name badges with a pronouns field. All of the food was vegan and the event was a *dry event.* They also offered a couple of schemes to widen the event up to under represented groups. Ticket scholarships were offered for these groups which included, but wasn't limited to:
> LGBTQIA+ people, people of colour, women, non-binary people, and those with disabilities.
This was funded in part by other attendees buying an extra ticket alongside their own which could then be used in this scholarship scheme. Underland also offered full scholarships which covered travel and accommodation alongside the ticket cost.
These little touches do a great job of making the event far more accessible to people who might otherwise feel excluded. All of the information about their inclusion work for the event can be found at [https://2020.yougotthis.io/inclusion](https://2020.yougotthis.io/inclusion)
# Topics<a name="topics"></a>

_Photo: [Underland Events](https://twitter.com/underlandevents/status/1218593260505063424/photo/1)_
There were 9 separate talks on at the event:
1. It's not your job to love your job - Keziyah Lewis [@KeziyahL](https://twitter.com/KeziyahL)
2. Learning to invest in your future - Matthew Gilliard [@MaximumGilliard](https://twitter.com/maximumgilliard)
3. How to find your perfect mentor - Amina Adewusi [@a_adewusi](https://twitter.com/a_adewusi)
4. So good they can't ignore you! - Gargi Sharma
5. Level up: Developing developers - Melinda Seckington [@mseckington](https://twitter.com/mseckington)
6. Making your first days count - Nathaniel Okenwa [@chatterboxCoder](https://twitter.com/chatterboxCoder)
7. Company culture, performance reviews and you - Ruth Lee [@yoursruthlessly](https://twitter.com/yoursruthlessly)
8. Unions got this: Organising the tech trade - Dan Parkes
9. Real talk about when to walk away - Amy Dickens [@RedRoxProjects](https://twitter.com/RedRoxProjects)
I'm not going to write up all of these talks word for word, because that feels a lot like plagiarism and I honestly couldn't do them justice. What I would like to do though is summarise the key themes that I found across all the talks.
## Your needs ≠ your workplace's needs<a name="your-needs"></a>
Now, this one isn't always true, especially if you're a freelance developer that works for themselves. But for a lot of developers, we're working for companies that want to sell themselves to their employees, investors and customers are being revolutionary, game changing forces for good. The reality though is that we live in a capitalist world and the company doesn't care about you. Your manager might care about you. Your colleagues might care. Even the CEO might care. But the company is an entity whose sole purpose is to maximise its own value above all else. Keziyah Lewis, Ruth Lee and Amy Dickens all covered this in great detail.
This isn't to say that your company is your enemy. What it does mean though is that you need to make sure to look after yourself, because the company won't do it for you. For example, a performance review is not a ground truth, objective analysis of your skills. What it is, is a way for your colleagues, managers and other associates to provide feedback that then assesses how you fit the company's culture. A well established company or team will have different values and a different culture to something like a start up. Remembering this is the best way to make sure you're both in the right role and company for you, and to properly assess how your strengths suit the needs of that role/company.
## Build a personal brand<a name="personal-brand"></a>
So it should be noted that I'm both British and introverted, so things like "building a personal brand" trigger some sort of deep rooted suspicion inside me, and before attending YouGotThis I'd probably have listened to it. But so many people mentioned it and extolled its virtues that I think I need to give it a second chance.
For me, building a personal brand seems to be about establishing and defining who you are. Your values, your goals, your needs. It's only after you've started to sketch these things out that you can really start to put in the time required to make sure you're both being your best and getting the best out of your job. Once you've started to work on this you can find the right company to work for, find your working style, figure out the best way to learn, make sure you're being recognised for the work you do, and then so much more. It helps you in **planning for the future, assessing the present and reflecting on the past.**
## Make a Brag Doc<a name="brag-doc"></a>
I had never heard of a brag doc before attending this conference, but following Gargi Sharma's talk where she mentioned it, almost every speaker afterwards brought it up. There's a really great blog post about building a brag doc by Julia Evans that Gargi mentioned. I'll leave that here ([https://jvns.ca/blog/brag-documents/](https://jvns.ca/blog/brag-documents/)) instead of writing it all out again and you should definitely give it a read.
By building a brag doc, you're highlighting your skills and your work. There are all sorts of tasks that you do every day, big and small, that might go unrecognised unless you point them out and *brag about them*. Also, you won't remember everything you did in the last week/month/quarter unless you make a note of them. Maybe put together some important documentation or made a small improvement to the codebase that fixed a security hole. Write it down, share it with your manager and your colleagues that give you feedback. They're just as human as you and they're bound to forget most of the work you've done recently. All you're doing by sharing your doc is reminding them of the things you so that they can be reminded of how awesome you are!
## Work *with* your manager<a name="manager"></a>
Your manager is there to help support you in your journey as a developer. A great example of this is from Melinda Seckington's talk about how your engineering manager can help you to develop by using ideas from game design. Right the way from starting a new game (joining the company) through to leveling up (developing your skills), your manager is in a great position to help you out through fast and constructive feedback and providing plenty of opportunities for you to develop your skills.
Nathaniel Okenwa's talk about settling into a new role and then accelerating your growth highlighted **building a productive working relationship** with your manager as a key component of the first of three phases in starting a new role. (The three phases he focused on were *Observe*, *Understand* and *Create*).
So with all that in mind take some time to build a **good relationship** with your manager. They're not just there to tell you what to do.
## Be part of the community<a name="community"></a>
Maybe this comes in part from being at a conference, but there was definitely a running background theme across the talks about being involved in the tech community. Whether it was Amina Adewusi's talk about the benefits of finding and being a mentor, Matthew Gilliard's advice to use social learning as a way to improve, or Gargi's tips for networking as an introvert by writing a blog or leveraging one on one conversations to build connection, being part of the tech community is a great way to "level up" as a developer.
This blog is actually my first step towards doing this. I'm hoping that by writing this blog, I can build up my network and contribute towards the tech community. With that in mind, I'll be posting in the next few weeks about other steps I want to take towards giving back to the community and being part of it.
## **You are more than your job!** <a name="more-than-your-job"></a>
One of the most important things to come out of this conference was about respecting yourself and your needs. You need to make sure that whatever you do in your job, you're doing it for you as well as your company, and that you're maintaining a healthy work/life balance. The value that you gain from this benefits you **and** them.
And the best way to do this is to implement some of the ideas above. Figure out who you are, build a brag doc to highlight your strengths and the work you do, work with your manager to develop yourself and be part of the community.
___
I'm going to follow up this blog post with some of the specific things I'm going to be doing in 2020 to try and follow through on what I've learnt.
I'm also going to (eventually) get this up on my own blog. So when that happens I'll keep you posted about it :)
Thanks,
Josh | buck06191 |
810,318 | Chakra UI Flex component using react, typescript, styled-components and styled-system | Introduction Let us continue building our chakra components clone using styled-components... | 14,414 | 2021-09-01T13:50:00 | https://dev.to/yaldram/chakra-ui-flex-component-using-react-typescript-styled-components-and-styled-system-3ch9 | react, typescript | ### Introduction
Let us continue building our chakra components clone using `styled-components` & `styled-system`. In this tutorial we will be cloning the Chakra UI `Flex` component.
- I would like you to first check the chakra docs for [flex](https://chakra-ui.com/docs/layout/flex).
- We will **compose** (extend) our `Box` component to create the `Flex` component and further extend the `Flex` component to create a `Spacer` component.
- All the code for this tutorial can be found under the **atom-layout-flex** branch [here](https://github.com/yaldram/chakra-ui-clone).
### Prerequisite
Please check the previous post where we have completed the Box Component. Also please check the Chakra Flex Component code [here](https://github.com/chakra-ui/chakra-ui/blob/main/packages/layout/src/flex.tsx). In this tutorial we will -
- Create a Flex component.
- Create a Spacer component.
- Create story for the Flex component.
### Setup
- First let us create a branch, from the main branch run -
```bash
git checkout -b atom-layout-flex
```
- Under the `components/atoms/layout` folder create a new folder called `flex`. Under flex folder create 2 files `index.tsx` and `flex.stories.tsx`.
- So our folder structure stands like - **src/components/atoms/layout/flex**.
### Flex Component
- First lets import the necessary stuff -
```tsx
import * as React from "react";
import styled from "styled-components";
import { system, FlexboxProps } from "styled-system";
import { Box, BoxProps } from "../box";
```
- Compose the Box component to create the `BaseFlex` styled component. By composing our `Box`, we extend it meaning our `BaseFlex` also takes in all props that we pass to `Box`, inherits the variants and the system extensions we had for our `Box` (marginStart & marginEnd).
```tsx
const BaseFlex = styled(Box)`
display: flex;
${system({
direction: {
property: "flexDirection",
},
align: {
property: "alignItems",
},
justify: {
property: "justifyContent",
},
wrap: {
property: "flexWrap",
},
})}
`;
```
- We also are extending the system using the system function so that we can have shorthands for our props like `align instead of alignItems`, just like chakra ui [flex props](https://chakra-ui.com/docs/layout/flex#props).
- If the above code makes no sense, I request you to please check the previous post. Also check my [introductory post](https://dev.to/yaldram/working-with-styled-system-using-typescript-4mkj).
- Let us create the type for our props, now given that we are composing our Box component for making our Flex component it will inherit all props by default, but we don't want the user to pass display prop to our Flex component so we will omit that prop from the type. Let me show you what I mean the below code is pretty self-explanatory -
```tsx
type FlexOmitted = "display";
type FlexOptions = {
direction?: FlexboxProps["flexDirection"];
align?: FlexboxProps["alignItems"];
justify?: FlexboxProps["justifyContent"];
wrap?: FlexboxProps["flexWrap"];
};
type BaseFlexProps = FlexOptions & BoxProps;
```
- We create the FlexOptions prop to cover the system props, and finally create the `BaseFlexProps` which is a union type of FlexOptions and BoxProps. Pass the `BaseFlexProps` type to `BaseFlex`.
```tsx
const BaseFlex = styled(Box)<BaseFlexProps>`...`;
```
- Now we will create our Flex component. The complete code is as follows -
```tsx
import * as React from "react";
import styled from "styled-components";
import { system, FlexboxProps } from "styled-system";
import { Box, BoxProps } from "../box";
type FlexOmitted = "display";
type FlexOptions = {
direction?: FlexboxProps["flexDirection"];
align?: FlexboxProps["alignItems"];
justify?: FlexboxProps["justifyContent"];
wrap?: FlexboxProps["flexWrap"];
};
type BaseFlexProps = FlexOptions & BoxProps;
const BaseFlex = styled(Box)<BaseFlexProps>`
display: flex;
${system({
direction: {
property: "flexDirection",
},
align: {
property: "alignItems",
},
justify: {
property: "justifyContent",
},
wrap: {
property: "flexWrap",
},
})}
`;
export interface FlexProps extends Omit<BaseFlexProps, FlexOmitted> {}
export const Flex = React.forwardRef<HTMLDivElement, FlexProps>(
(props, ref) => {
const { direction = "row", children, ...delegated } = props;
return (
<BaseFlex ref={ref} direction={direction} {...delegated}>
{children}
</BaseFlex>
);
}
);
```
- I really like this pattern of separating the styled component from the React component so that it becomes easy to intercept any props before passing on, adding default values to props, consistent types and also passing the ref.
- Keep in mind we neither export the `BaseFlexProps` or `BaseFlex` we export `FlexProps` and `Flex`.
### Spacer Component
- Please check the docs and first understand how spacer works [here](https://chakra-ui.com/docs/layout/flex#using-the-spacer).
- In its essence it is a flexible flex component that expands along the major axis of its containing flex layout. It renders a `div` by default, and takes up any available space.
- If we use `Spacer` and `Flex` component together, the children will span the entire width of the container and also have equal spacing between them.
- Paste the following code for Spacer component below the Flex component code -
```tsx
type SpaceOmitted = "flex" | "justifySelf" | "alignSelf";
export interface SpacerProps extends Omit<BoxProps, SpaceOmitted> {}
export const Spacer = React.forwardRef<HTMLDivElement, SpacerProps>(
(props, ref) => {
const { children, ...delegated } = props;
return (
<Box
ref={ref}
flex="1"
justifySelf="stretch"
alignSelf="stretch"
{...delegated}
>
{children}
</Box>
);
}
);
```
### Story
- With the above our `Flex` and `Spacer` components are completed, let us create a story.
- Under the `src/components/atoms/layout/flex/flex.stories.tsx` file we add the below story code.
- We will create 2 stories one for the Playground for `Flex` and one for `Spacer`.
```tsx
import * as React from "react";
import { Box } from "../box";
import { Flex, FlexProps, Spacer } from ".";
export default {
title: "Atoms/Layout/Flex",
};
export const Playground = {
argTypes: {
direction: {
name: "direction",
type: { name: "string", required: false },
defaultValue: "row",
description: "Shorthand for flexDirection style prop",
table: {
type: { summary: "string" },
defaultValue: { summary: "row" },
},
control: {
type: "select",
options: [
"initial",
"inherit",
"unset",
"revert",
"row",
"row-reverse",
"column",
"column-reverse",
],
},
},
justify: {
name: "justify",
type: { name: "string", required: false },
defaultValue: "flex-start",
description: "Shorthand for justifyContent style prop",
table: {
type: { summary: "string" },
defaultValue: { summary: "flex-start" },
},
control: {
type: "select",
options: [
"justify-content",
"flex-start",
"flex-end",
"center",
"space-between",
"space-around",
"space-evenly",
"initial",
"inherit",
],
},
},
align: {
name: "align",
type: { name: "string", required: false },
defaultValue: "stretch",
description: "Shorthand for alignItems style prop",
table: {
type: { summary: "string" },
defaultValue: { summary: "stretch" },
},
control: {
type: "select",
options: [
"stretch",
"center",
"flex-start",
"flex-end",
"baseline",
"initial",
"inherit",
],
},
},
},
render: (args: FlexProps) => (
<Flex justify="space-between" color="white" {...args}>
<Box size="100px" bg="green500">
Box 1
</Box>
<Box size="100px" bg="blue500">
Box 2
</Box>
<Box basis="300px" size="100px" bg="tomato">
Box 3
</Box>
</Flex>
),
};
export const FlexSpacer = {
argTypes: {
direction: {
name: "direction",
type: { name: "string", required: false },
defaultValue: "row",
description: "Shorthand for flexDirection style prop",
table: {
type: { summary: "string" },
defaultValue: { summary: "row" },
},
control: {
type: "select",
options: [
"initial",
"inherit",
"unset",
"revert",
"row",
"row-reverse",
"column",
"column-reverse",
],
},
},
},
render: (args: FlexProps) => (
<Flex h="80vh" color="white" {...args}>
<Box size="100px" p="md" bg="red400">
Box 1
</Box>
<Spacer />
<Box size="100px" p="md" bg="green400">
Box 2
</Box>
</Flex>
),
};
```
- Now run `npm run storybook` check the stories. Under the Playground stories check the controls section play with the props, add more controls if you like.
### Build the Library
- Under the `/layout/index.ts` file and paste the following -
```tsx
export * from "./box";
export * from "./flex";
```
- Now `npm run build`.
- Under the folder `example/src/App.tsx` we can test our `Flex` component. Copy paste the following code and run `npm run start` from the `example` directory.
```tsx
import * as React from "react";
import { Box, Flex, Spacer } from "chakra-ui-clone";
export function App() {
return (
<Flex color="white">
<Box size="100px" p="md" bg="red400">
Box 1
</Box>
<Spacer />
<Box size="100px" p="md" bg="green400">
Box 2
</Box>
</Flex>
);
}
```
### Summary
There you go guys in this tutorial we created `Flex` and `Spacer` components just like chakra ui and stories for them. You can find the code for this tutorial under the **atom-layout-flex** branch [here](https://github.com/yaldram/chakra-ui-clone). In the next tutorial we will create stack component. Until next time PEACE.
| yaldram |
810,483 | How do I use react in some part on my laravel website. | Can I use react in some view of my... | 0 | 2021-09-01T14:46:11 | https://dev.to/boichase/how-do-i-use-react-in-some-part-on-my-laravel-website-503 | {% stackoverflow 69015983 %} | boichase | |
810,556 | Software Dev Weekly Update #6: "With our combined powers!" | I don't know it anyone remembers that old show Captain Planet and the Planeteers, but much like our... | 0 | 2021-09-01T15:52:59 | https://dev.to/realnerdethan/software-dev-weekly-update-6-with-our-combined-powers-4hph | javascript, beginners, webdev, mongodb | I don't know it anyone remembers that old show Captain Planet and the Planeteers, but much like our planet saving heroes and with their powers combined we used MongoDB, Mongoose & Express to build a fully functioning CRUD (Create, Read, Update, Delete) web app!
> *Meet the most fully functional and inspired roadside farm stand application we've seen yet.* -Trendy News Today

Ok... it's not so pretty to look at and it is probably missing some functionality *but* it successfully combines those technologies into a great example of something more complex than static HTML and the fake JSON database files that we've been working with so far.
To make this project happen, we learned about a few key topics:
- [MongoDB Common Commands](https://github.com/RealNerdEthan/web-dev-bootcamp-2021/blob/master/Section%2036%20-%20Our%20First%20Database%20MongoDB/commands.txt)
- [Connecting Mongoose to MongoDB](https://mongoosejs.com/docs/index.html)
- Mongoose [Schema](https://mongoosejs.com/docs/api/schema.html) & [Model](https://mongoosejs.com/docs/api/model.html)
Those combined with the HTML templating we spoke about in [update #4](https://dev.to/realnerdethan/software-dev-weekly-update-4-new-tools-new-community-1kbl), gives us the bones to build something more complex.
##What the heck is Mongoose?
Nick Karnik over at FreeCodeCamp has a great writeup about Mongoose and he says:
> *Mongoose is an Object Data Modeling (ODM) library for MongoDB and Node.js. It manages relationships between data, provides schema validation, and is used to translate between objects in code and the representation of those objects in MongoDB.*
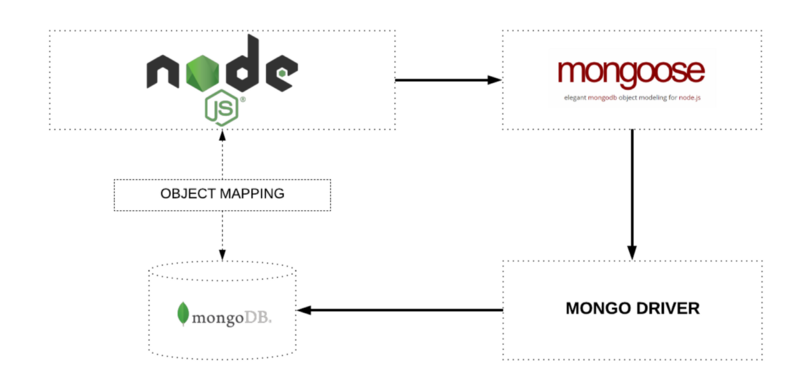
I **highly** recommend you [check out his writeup](https://www.freecodecamp.org/news/introduction-to-mongoose-for-mongodb-d2a7aa593c57/) if you want to know more about Mongoose and how it connects with MongoDB and NodeJS.
##Week In Review##

This week was about combining past knowledge with the last missing piece of the pie, MongoDB. We finally made something that can persist data across sessions and from here on out we'll be refining our knowledge of the basics to build better web applications.
Our next major focus is to expand on existing knowledge and start building the capstone project, something called YelpCamp. I will share more on that over the next few weeks.
I'm no where near out of the woods yet, but I'm on a good path.
> *"Education is the key, and perseverance opens the door."* - [Zach Al-Kharusy](https://www.linkedin.com/in/zach-al-kharusy-7850a612a/)
---
I hope you enjoyed the read!
Feel free to follow me on [GitHub](https://github.com/RealNerdEthan), [LinkedIn](https://www.linkedin.com/in/ethan-goddard-a4376952/) and [DEV](https://dev.to/realnerdethan) for more! | realnerdethan |
810,561 | Memory allocations in Go | To understand how memory allocations in Go works, we need to understand the types of memories in... | 0 | 2021-09-01T19:44:37 | https://dev.to/karankumarshreds/memory-allocations-in-go-1bpa | discuss, go, programming | To understand how memory allocations in Go works, we need to understand the types of memories in programming context, which are **Stack** and **Heap**.
If you are familiar with typical memory representation of C, you must already be aware of these two terms.
## Stack vs Heap
**Stack**: The stack is a memory set aside as a scratch space for the execution of thread. When a function in called, a `block` is reserved on top of the stack for local variables and some bookkeeping data. This block of memory is referred to as a **stack frame**. Initial stack memory allocation is done by the OS when the `program is compiled`. When a function returns, the block becomes **unused** and can be used the next time any function is called (in the world of JS this is similar to function's execution context).
The stack is always reserved in LIFO (last in first out), the most recent block added will be freed(marked as unused) first. The `size` of the memory allocated to the function and it's variable on the stack is known to the compiler and as soon as the function call is over, the memory is de-allocated.
**Heap**: In heap there is no particular order to the way the items are placed. Heap allocation requires manual housekeeping of what memory is to be reserved and what is to be cleaned. The heap memory is allocated at the `run time`. Sometimes the memory allocator will perform maintenance tasks such as `defragmenting` allocated memory (fragmenting: when small free blocks are scattered, but when request for large memory allocation comes, there is no free memory left in heap even though small free blocks combined may be large. this is bad!) OR `garbage collecting` (identifying at *runtime* when memory is no longer in scope and deallocating it).
**What makes one faster?**
The stack is faster because all free memory is always contiguous. No list needs to be maintained of all the segments of free memory, just a single pointer to the current top of the stack.
In case of goroutines (**kind of** simultaneously executing go functions) we have multiple stack memories for each go routines as shown in the below figure:
---
# Variable allocations
But how do we know which memory will the variable be assigned in the go program out of Stack and Heap?
**NOTE**: Th term `free` (in the diagrams) refer to the memory that is acquired by a stack frame (`valid memory`). And `unused` means the `invalid` memory in the stack.
1 Let us consider the following code. The function `main` has its local variables n and n2. `main` function is assigned a stack frame in the stack. Same goes for the function `square`.
2 Now as soon as the function `square` returns the value, the variable `n2` will become `16` and the memory function `square` is **NOT** cleaned up, it will still be there and marked as **invalid** (unused).
3 Now when the `Println` function is called, the same `unused` memory on stack left behind by the square function is consumed by the `Println` function. (take a look at the memory address for `a`)
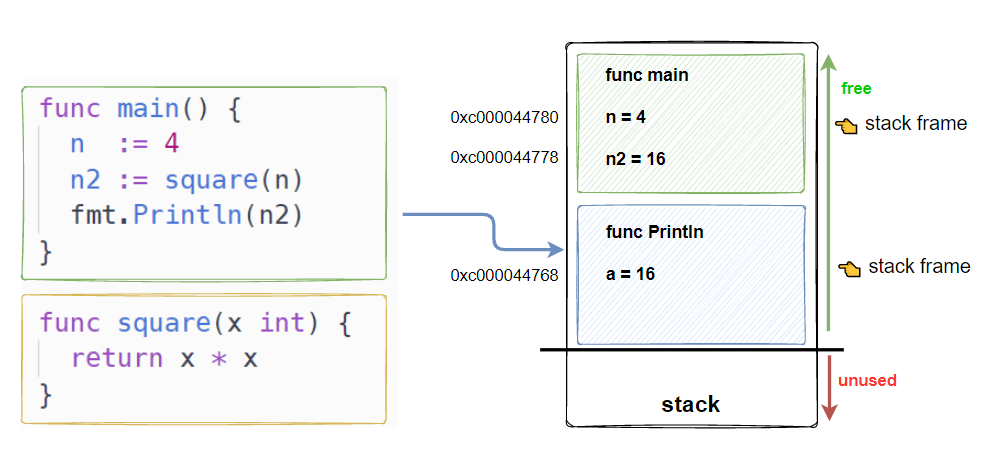
---
**With Pointers**
1 Let us do the same thing with pointers. Here we have a main function which passes the reference to the variable to a function that increments the value.
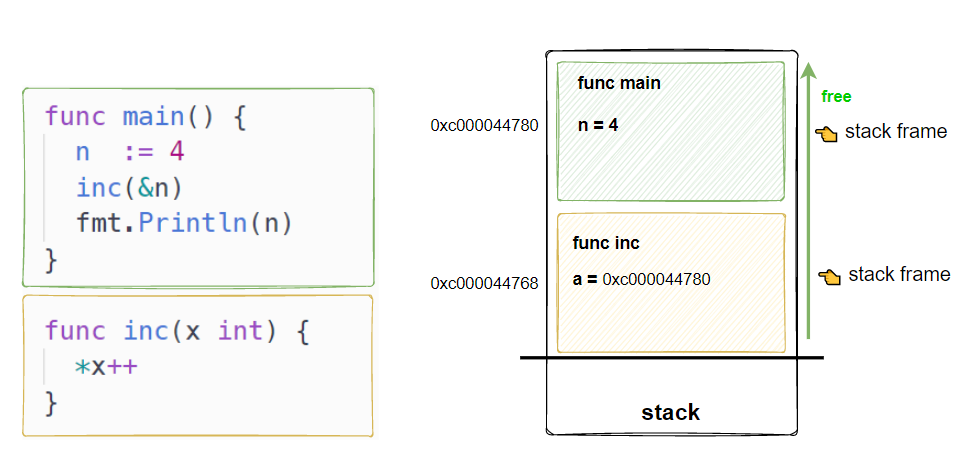
2 Now as function **inc** `dereferences` the pointer and increments the value that it points to, and does its work, the stack frame of `inc` is again unused/invalid (freed for other functions allocation).
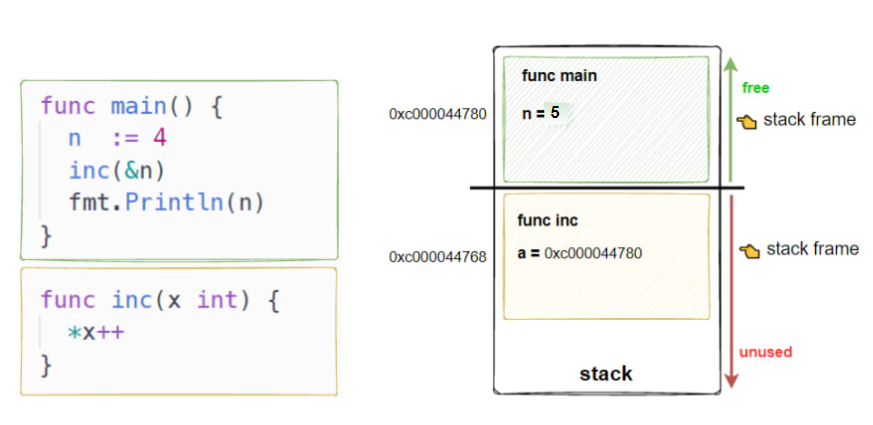
3 as the function `Println` runs, it acquires the memory that was freed up by the `inc` function as shown in the below figure
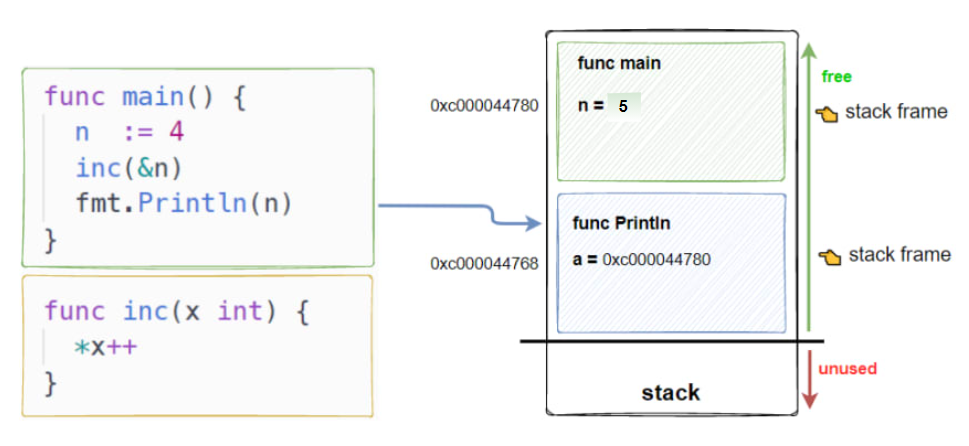
**This is where Go Compiler kicks in 🚩**
*Sharing down of the variables (passing references) typically stays on the stack*. Notice the word `typically`. This is because, the GO Compiler takes the decision whether a referenced variable needs to stay on the stack or on the heap.
**But when would the referenced variable be put on Heap?**
Let us understand that.
Let us consider an example where we are **returning pointers**.
1 So we have a function `main` that has a variable `n` who's value is assigned by a function `answer` which returns a `pointer` to it's local variable. This is how the stack frame allocation is done initially for both the functions
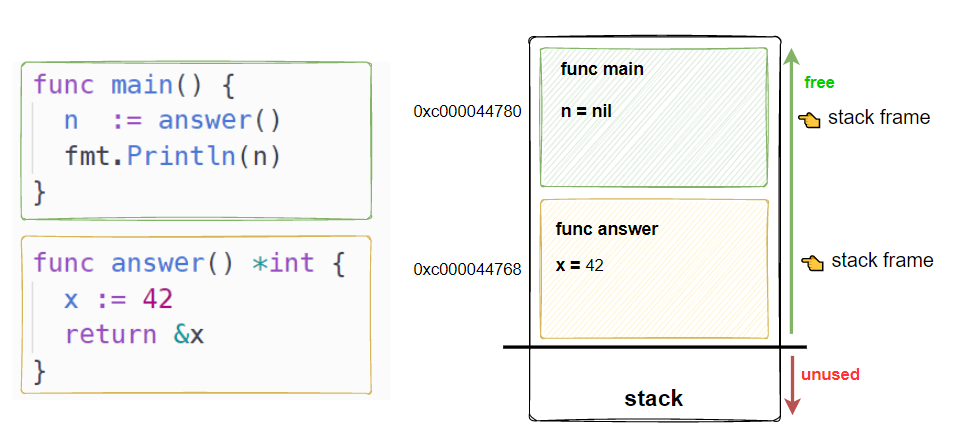
2 Now when the function `answer` executes and returns the pointer, the address for `x` is assigned to the variable `n` in the main function and the `answer` function's stack frame gets freed up (unused)
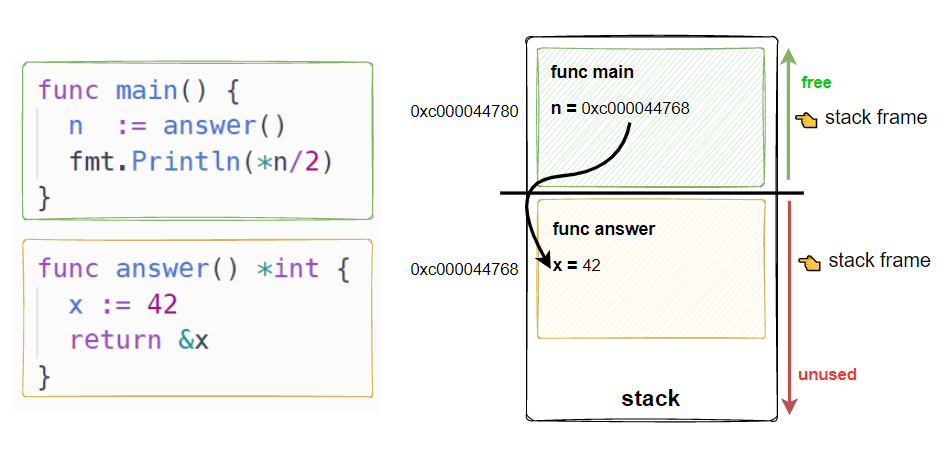
**Here's the catch 🚩**
We have a problem here, we have a pointer pointing down to the unused (invalid memory) in the stack. **But how is that a problem?**
Let us see what happens when the `Println` function is called.
3 `Println` function takes the space freed up by the `answer` function (notice the memory address) and takes reference to the returned value and divides it by 2 (making it 21).
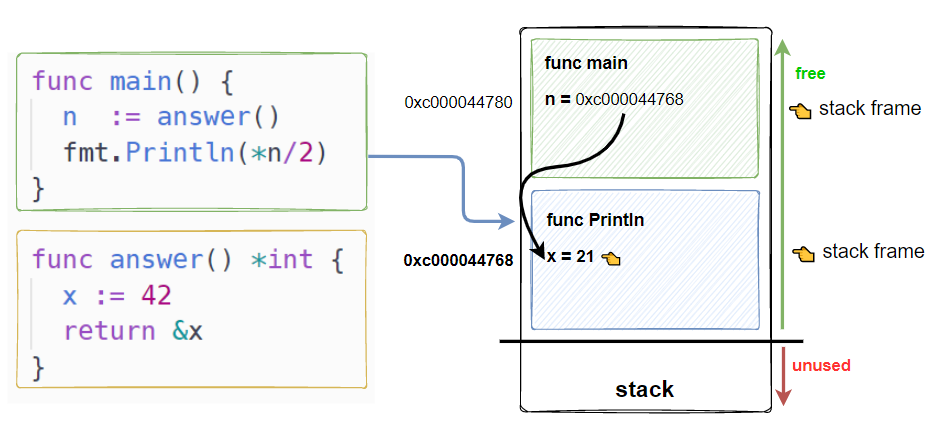
This is the problem here, the value which `n` was pointing to (which was originally 42) has been overwritten by the Println call which made it 21. And since `Println` took over the `memory address` of `answer` function (after answer function freed up the space), now that memory has the value **21** (instead of **42**)
---
## What is the solution?
Thanks to Go compiler, we do not have to worry about this. Go compiler is smart enough to handle this.
This is what really happens:
*Compiler knows it was NOT safe to leave the pointer variable on the stack.* So what it does is, it declares `x` (from the answer function) somewhere on the **Heap**
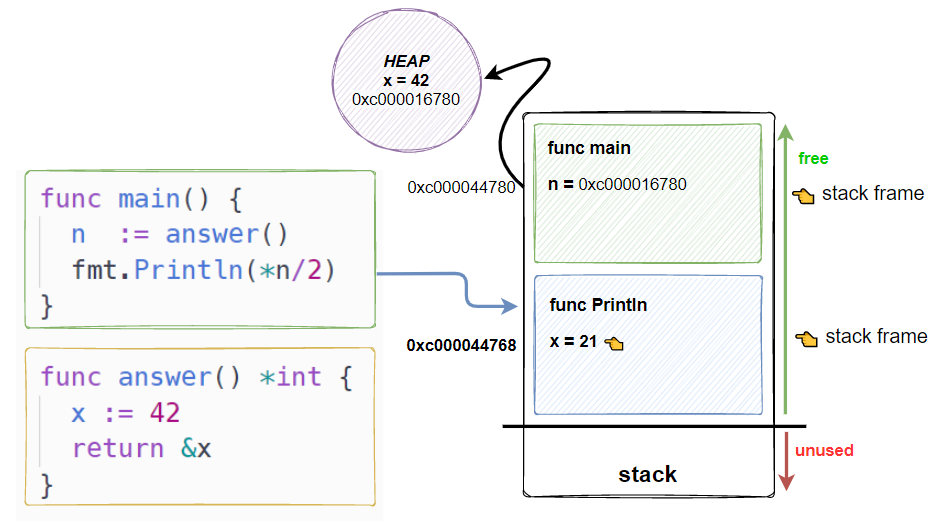
This means when the `Println` function is called, which changes the value to `half`, it will not clobber the value of `x`. This is called **Escaping To The Heap** which is done during the `compile time`.
Therefore, *sharing up (returning pointers) typically escapes to the Heap*.
| karankumarshreds |
810,587 | Tracking guest users | How does an app like tiktok track a device that is not signed up on the app, but might signup later;... | 0 | 2021-09-01T16:17:08 | https://dev.to/whynotmarryj/tracking-guest-users-h02 | help | How does an app like tiktok track a device that is not signed up on the app, but might signup later; therefore, initially missing an accountId stored in a data warehouse? My dim_users table can only insert rows given the null accountId attached to that device machineId. I still can track the activity of this device but won’t know exactly who they’re initially. | whynotmarryj |
810,625 | How to Visualize Data Categories in Python With Pandas | If you have a dataset which is divided into categories of data like: kickstarter projects, flower... | 0 | 2021-09-04T12:49:20 | https://dev.to/code_jedi/how-to-visualize-data-categories-in-python-with-pandas-2pgn | python, datascience, machinelearning, programming | **If you have a dataset which is divided into categories of data like: kickstarter projects, flower species or most popular car brands, then it's a good idea to visualize those data categories to see the amount of values within each category.**
Here's a dataset of over 300,000 kickstarter projects as well as their categories, goal, No. of backers and much more: https://www.kaggle.com/kemical/kickstarter-projects.
When looking at the dataset, you would notice that every one of those 300,000+ projects are put into different categories such as: Games, Music, Art and Technology.
***************
**To make a Python script that will display each category as a fraction of a donut plot based on the number of projects belonging to it, first add the necessary libraries and load in the dataset:**
```python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('ks-projects.csv')
df = pd.DataFrame(data)
```
Next, to get the number of projects within each category, add this line of code to your script:
```
category_values = df.pivot_table(columns=['main_category'], aggfunc='size')
```
Now to display "category_values" in a doughnut graph, add this to the end of your script:
```python
plt.pie(category_values)
my_circle=plt.Circle( (0,0), 0.7, color='white')
p=plt.gcf()
p.gca().add_artist(my_circle)
plt.show()
```
Now if you run your script, your doughnut plot should look something like this:
As you can see, it displays the amount of projects within each category as a fraction of the doughnut plot, but it doesn't label the categories.
**************
**To label the categories, add these lines of code before your doughnut plot:**
```python
category_names = data['main_category']
categories = category_names.unique()
categories.sort()
```
This will count the number of unique category names within the dataset and sort them in alphabetical order.
The reason for sorting them in alphabetical order is because the category values we defined earlier are ordered alphabetically( first value is Art: 28153 and last value is Theater: 10913).
*********
**Now to display the doughnut plot with its corresponding labels, replace**
```python
plt.pie(category_values)
```
with
```python
plt.pie(category_values, labels=categories)
```
Full code:
```python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('ks-projects.csv')
df = pd.DataFrame(data)
category_values = df.pivot_table(columns=['main_category'], aggfunc='size')
category_names = data['main_category']
categories = category_names.unique()
categories.sort()
plt.pie(category_values, labels=categories)
my_circle=plt.Circle( (0,0), 0.7, color='white')
p=plt.gcf()
p.gca().add_artist(my_circle)
plt.show()
```
####Now if your run your script, you should see a doughnut plot that displays the fraction of projects each category contains, as well as the categories' labels:
 | code_jedi |
810,640 | How to use MySql with Django - For Beginners | The article explains how to configure Django to switch from the default SQLite to MySql | 0 | 2021-09-01T18:09:31 | https://docs.appseed.us/content/how-to/use-mysql-with-django | webdev, django, mysql | ---
title: How to use MySql with Django - For Beginners
published: true
description: The article explains how to configure Django to switch from the default SQLite to MySql
tags: webdev, django, mysql
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/pfmus1ynfyuyy1f22gjk.jpg
canonical_url: https://docs.appseed.us/content/how-to/use-mysql-with-django
---
Hello Coders,
This article explains **[How to use MySql with Django](https://docs.appseed.us/content/how-to/use-mysql-with-django)** and switch from the default SQLite database to a production-ready DBMS (**MySql**). This topic might sound like a trivial subject but during my support sessions, I got this question over and over, especially from beginners.
> 👉 [Django Admin Dashboards](https://appseed.us/admin-dashboards/django/) - a curated list
For newcomers, **[Django](https://www.djangoproject.com/)** is a leading Python web framework built by experts using a `bateries-included` concept. Being such a mature framework, Django provides an easy way to switch from the default SQLite database to other database engines like MySql, PostgreSQL, or Oracle. MySql is a powerful open-source relational database where the information is correlated and saved in one or more tables.
---
## Django Database System
Django provides a generic way to access multiple database backends using a generic interface. In theory, Django empowers us to switch between DB Engines without updating the SQL code. The default SQLite database usually covers all requirements for small or demo projects but for production use, a more powerful database engine like MySql or PostgreSQL is recommended.
The database settings are saved in the file referred by `manage.py` file. In my Django projects, this file is saved inside the `core` directory:
```bash
< PROJECT ROOT >
|
|-- manage.py # Specify the settings file
|
|-- core/ # Implements app logic
| |-- settings.py # Django app bootstrapper
| |-- wsgi.py # Start the app in production
| |-- urls.py # Define URLs served by all apps/nodes
```
Let's visualize the contents of the `settings.py` file that configures the database interface.
```python
# File: core/settings.py
...
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME' : 'db.sqlite3',
}
}
...
```
The above snippet is provided by when Django scaffolds the project. We can see that the **SQLite** driver is specified by the `ENGINE` variable.
---
Update Django for MySql
To use MySql as the backend engine for a Django project, we need to follow a simple setup:
- Install the MySql Server (we can also use a remote one)
- Install the Mysql Python driver - used by Django to connect and communicate
- Create the Mysql database and the user
- Update settings Django
- Execute the Django migration and create the project tables
---
## Install MySql Server
The installation process is different on different systems but this phase should not be a blocking point because Unix systems provide by default a MySql server and for Windows, we can use a visual installer. For more information please access the download page and select the installer that matches your operating system:
- [MySql](https://www.mysql.com/) - official website
- [MySql Downloads](https://dev.mysql.com/downloads/) page
---
## Install the Python Driver
To successfully access the Mysql Engine, Django needs a driver (aka a connector) to translate the Python queries to pure SQL instructions.
```bash
$ pip install mysqlclient
```
The above instruction will install the Python MySql driver globally in the system. Another way is to use a `virtual environment` that sandboxes the installation.
```bash
$ # Create and activate the virtual environment
$ virtualenv env
$ source env/bin/activate
$
$ # install the mysql driver
$ pip install mysqlclient
```
---
## Create the MySql Database
During the initial setup, Django creates the project tables but cannot create the database. To have a usable project we need the database credentials used later by the Django project. The database can be created visually using a database tool (like [MySQL Workbench](https://www.mysql.com/products/workbench/)) or using the terminal:
```sql
CREATE DATABASE mytestdb;
```
> Create a new MySql user
```sql
CREATE USER 'test'@'localhost' IDENTIFIED BY 'Secret_1234';
```
> Grant all privileges to the newly created user
```sql
GRANT ALL PRIVILEGES ON `mytestdb` . * TO 'test'@'localhost';
FLUSH PRIVILEGES;
```
---
## Update Django Settings
Once the MySql database is created we can move on and update the project settings to use a MySql server.
```python
# File: core/settings.py
...
DATABASES = {
'default': {
'ENGINE' : 'django.db.backends.mysql', # <-- UPDATED line
'NAME' : 'mytestdb', # <-- UPDATED line
'USER' : 'test', # <-- UPDATED line
'PASSWORD': 'Secret_1234', # <-- UPDATED line
'HOST' : 'localhost', # <-- UPDATED line
'PORT' : '3306',
}
}
...
```
---
## Start the project
The next step in our simple tutorial is to run the Django migration that will create all necessary tables.
```bash
$ # Create tables
$ python manage.py makemigrations
$ python manage.py migrate
```
> Start the Django project
```bash
$ # Start the application (development mode)
$ python manage.py runserver
```
At this point, Django should be successfully connected to the Mysql Server and we can check the database and list the newly created tables during the database migration.

---
> Thanks for reading! For more resources feel free to access:
- [Django Dashboards](https://appseed.us/admin-dashboards/django) - a curated index with simple starters
- [Free Dashboards](https://appseed.us/admin-dashboards/open-source) - open-source projects crafted in different technologies (Flask, Django, React) | sm0ke |
810,653 | Malli schema as an ergonomical documentation? | So this is probably some niche stuff, but from time to time I have to configure kafka clients... | 0 | 2021-09-01T18:30:09 | https://dev.to/kschltz/malli-schema-as-an-ergonomical-documentation-1j5n | clojure, kafka, docs | So this is probably some niche stuff, but from time to time I have to configure kafka clients (consumer, producer, admin) and more often then not I completely forgot what the configuration entries are, or what value should they map to, so I thought to myself, what if I translate kafka configuration classes to malli schemas?
Then I could validate the whole thing and have it tell exactly how stupid I am and what's wrong with the configuration I provided, so this is a first draft
```clojure
(ns foo
(:require [malli.core :as malli]
[malli.error :as malli.error]
[malli.generator :as mg])
(:import (org.apache.kafka.clients.producer ProducerConfig)
(org.apache.kafka.common.config ConfigDef ConfigDef$ConfigKey)
(org.apache.kafka.common.config.types Password)))
(defn assert-model [model x]
(when-some [errors (malli.error/humanize (malli/explain model x))]
(throw (ex-info "Invalid data" {:errors errors}))))
;; For some of those more odd cases we'd want custom generators
(def types->custom-generators
{"CLASS" {:gen/elements [Object]}
"PASSWORD" {:gen/elements [(Password. "supersecret")]}})
;; We can have predicates for each type defined in config classes
(def types->pred
{"LIST" [:sequential some?]
"STRING" string?
"LONG" integer?
"INT" int?
"CLASS" [:and some? [:fn (fn [x] (class? x))]]
"PASSWORD" [:and some? [:fn (fn [x] (instance? Password x))]]
"DOUBLE" double?
"SHORT" int?
"BOOLEAN" boolean?})
(defn config-def->opts-model [^ConfigDef config-def]
(->> (.configKeys config-def)
(map (fn [[configuration-name ^ConfigDef$ConfigKey cfgk]]
(let [type-name (str (.type cfgk))]
[configuration-name
(merge {:optional true} (get types->custom-generators type-name))
(get types->pred type-name)])))
(into [:map {:closed true} ])))
(def producer-opts-model
(config-def->opts-model (ProducerConfig/configDef)))
```
We can now validate entries
```clojure
;; throws clojure.lang.ExceptionInfo: Invalid data {:errors {:name ["disallowed key"]}}
(assert-model producer-opts-model {:name "Kaue"})
```
Or even generate examples of whats accepted, with the caveat that the values generated will be only as good as the generators you provided
```clojure
;; Give me an example of whats a valid producer config map
(mg/generate producer-opts-model {:size 1})
=>
{"send.buffer.bytes" 0,
"metrics.sample.window.ms" 0,
"sasl.kerberos.ticket.renew.window.factor" 3.0,
"client.dns.lookup" "5",
"ssl.endpoint.identification.algorithm" "o",
"transactional.id" "",
"ssl.provider" "",
"bootstrap.servers" [],
"security.providers" "R",
"ssl.protocol" "N",
"ssl.keystore.password" #object[org.apache.kafka.common.config.types.Password 0xc9dcd6 "[hidden]"],
"sasl.login.class" java.lang.Object,
"sasl.login.refresh.window.jitter" -0.5,
"connections.max.idle.ms" 0,
"metrics.num.samples" -1,
"ssl.truststore.certificates" #object[org.apache.kafka.common.config.types.Password 0xc9dcd6 "[hidden]"],
"ssl.cipher.suites" [],
"enable.idempotence" true,
"metadata.max.age.ms" 0,
"max.block.ms" -1,
"ssl.keystore.type" "o",
"retries" 0,
"socket.connection.setup.timeout.ms" -1,
"delivery.timeout.ms" -1,
"buffer.memory" 0,
"max.in.flight.requests.per.connection" 0,
"ssl.secure.random.implementation" "j",
"ssl.truststore.type" "",
"transaction.timeout.ms" 0,
"sasl.kerberos.min.time.before.relogin" 0,
"sasl.kerberos.ticket.renew.jitter" 2.0,
"compression.type" "F"}
``` | kschltz |
810,845 | responsive bulma.io navbar | So you want a responsive nav bar? Well you've come to the right place! A nav bar is one of... | 0 | 2021-09-02T00:10:24 | https://dev.to/isaaccodes2021/responsive-bulma-io-navbar-23ol | javascript, html, react | ## So you want a responsive nav bar? Well you've come to the right place!
A nav bar is one of the most commonly used features of any website, so it's a good idea to know how to build one or at least have a go to resource. In this tutorial I will show you how to build a responsive navbar using the bulma.io library.
## step 1
Import the link to the bulma stylesheet into the head of your document.
```html
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bulma@0.9.3/css/bulma.min.css">
```
## step 2
Build the inital structure of your navbar.
```html
<!-- step 1.1 -->
<nav class="navbar" id="my-nav" role="navigation">
<!-- step 1.2 -->
<div class="navbar-menu">
<!-- step 1.3 -->
<div class="navbar-start">
<!-- step 1.4 -->
<a class="navbar-item">navbaritem</a>
<a class="navbar-item">navbaritem</a>
<a class="navbar-item">navbaritem</a>
<!-- step 1.5 -->
<div class="navbar-item has-dropdown is-hoverable">
<!-- step 1.6 -->
<p class="navbar-link">more</p>
<!-- step 1.7 -->
<div class="navbar-dropdown">
<a class="navbar-item">navbaritem</a>
<a class="navbar-item">navbaritem</a>
</div>
</div>
</div>
</div>
</nav>
```
A brief explanation of what is happening above:
<ol>
<li>The nav element with the class of navbar(provided by bulma) creates the navbar container where we will store the rest of our elements</li>
<li>The div wit the bulma class of navbar-menu will give us some of the responsiveness so when this window shrinks to a certian size, the navbar disappears</li>
<li>The div with the bulma class of navbar-start will allign our navbar-items by creating a flex box for us</li>
<li>you can put a number of different elements here, most relevent to me though is putting <a href="https://dev.to/isaaccodes2021/react-router-multi-page-apps-3o41">React Router</a> Link tags. The navbar-item bulma class adds a onMouseOver effect which imporves the ux</li>
<li>The following steps are optional but if you want to add a dropdown menu into your navbar, this is a way that you could do it. <br/>There are two new bulma classes applied to this div, the first being the has-dropdown which on its own does nothing but when paired with the step 7 it will give us a working drop down. The second is the is-hoverable class which makes the div we created highlight when the mouse is above it</li>
<li>The p tag with the class navbar-link creates a chevron and adds text to differentiate that this is a dropdown manu and not a navbar item</li>
<li>The div with the navbar-dropdown bulma class will hide the navbar items that are contained within it</li>
</ol>
<br/>
### Now that we have a desktop friendly navbar now lets make it mobile friendly!
## step 3
now we are going to add another chunk of html to our `nav` element.
If you are building the app in HTML your code should look like this:
```html
<a role="button" id="burger" class="navbar-burger">
<span aria-hidden="true"></span>
<span aria-hidden="true"></span>
<span aria-hidden="true"></span>
</a>
```
The class above 'navbar-burger' creates the navbar and the three spans are required to display the three lines in the hamburger
<img src="https://tse3.mm.bing.net/th?id=OIP.m06keoROIW-5fbz88OAZLgAAAA&pid=Api" height="100px">
Now if we got into our browser and shrink the window we should see the navbar items disappear and see the burger reappear on the right, cool! WAIT when we click the button nothing happens!!
## step 4
If you are building a in react app skip to step 4.5
This step will consist of the javascript logic required to toggle the view of the hamburger menu above and link it to the HTML file we are in.
A brief explanation of the following code: First we are searching for the elements in our HTML with the tags of my-nav and burger and saving them to variables, after that we need the menu to appear when the user clicks so we add an event listener that listens for a click event and then executes a callback function that comes after the comma. Inside said callback function we need to add a class to both the my-nav and the burger elements, more specifically toggle between the two so we grab a list of the classes in the document and add the toggle method with the class we need to toggle between which is in this case is-active. The toggle method in JS searches for the presence of a given argument and if the argument is present it removes it and if it is not, it adds it.
```Javascript
const myNav = document.querySelector("#my-nav")
const burger = document.querySelector("#burger")
burger.addEventListener('click', ()=> {
myNav.classList.toggle("is-active")
burger.classList.toggle("is-active")
})
```
## step 4.5 - react burger
if you are following along in react add this to the a element: ```onClick={toggleDropdown} ```
now we are going to declare that function and put some logic in it, insert the following code into your NavBar component
```JavaScript
function toggleDropdown() {
const myNav = document.querySelector("#my-nav")
const burger = document.querySelector("#burger")
myNav.classList.toggle("is-active")
burger.classList.toggle("is-active")
}
```
The the snippets of code above perform the same logic as explained in step 4 and with that you should have a functioning responsive nav bar!
| isaaccodes2021 |
810,934 | Operador CortoCircuito | En el camino del aprendizaje de cualquier lenguaje de programación te encuentras con ciertas cosas... | 0 | 2021-09-02T03:08:16 | https://dev.to/kevingo710/operador-cortocircuito-3dgk | javascript | En el camino del aprendizaje de cualquier lenguaje de programación te encuentras con ciertas cosas que para unos son obvias y para otros no tanto en este post voy a compartir ciertos tips interesantes que puede servir también en otros lenguajes.
Adicional te quiero recordar que los trucos son interesantes y divertidos pero de nada sirve si no se aplican.
Empezemos
**Evaluación de corto-circuito**
Este concepto se describe así mismo pero de que forma?, partiendo que en JavaScript y en los lenguajes de programación los operadores lógicos (&& || !) se evaluan de izquierda a derecha en el caso del OR ( || ) si el primer valor es verdadero se provoca un corto-circuito y ni si quiera evalua la segunda expresion.
Observemos ejemplos
```javascript
let a
let b = null;
let c = undefined;
let d = 4;
let e = 'five';
let f = a || b || c || d || e;
console.log(f);
```
Cual seria el resultado el valor de f?
Claro 4 porque es el primer valor que no es falso podría ser **e = 'five'** pero este valor no se alcanza a evaluar por el cortocircuito provocado
Otro ejemplo ya aplicado en algo muy común es en nodejs cuando se usa para conectarse a una base datos
Forma Larga
```javascript
let dbHost;
if(process.env.DB_HOST){
dbHost = process.env.DB_HOST;
} else {
dbHost = 'localhost'
}
```
Este fragmento de código es para usar colocar el valor del host a usarse, y se resume de la siguiente forma: si existe usa una variable de entorno 'DB_HOST' caso contrario usa 'localhost' se entiende fácilmente pero ahora veamos la versión abreviada
Forma Corta
```javascript
let dbHost = process.env.DB_HOST || 'localhost' ;
``` | kevingo710 |
811,480 | Apiumhub achieves highest growth in 7 years | Barcelona, Spain – September 2, 2021 Apiumhub, the leading provider of quality working... | 0 | 2021-12-01T09:42:21 | https://apiumhub.com/tech-blog-barcelona/announcement-apiumhub-achieves-highest-growth/ | apiumhub | ---
title: Apiumhub achieves highest growth in 7 years
published: true
date: 2021-09-02 09:28:06 UTC
tags: Apiumhub
canonical_url: https://apiumhub.com/tech-blog-barcelona/announcement-apiumhub-achieves-highest-growth/
---
##### Barcelona, Spain – September 2, 2021
Apiumhub, the leading provider of quality working software architecture solutions, recently opened multiple software development positions in Barcelona & Madrid, to accommodate rapid growth and leverage the area’s diverse high-technology talent pool.
In addition to the main development team, the new open positions workforce aims to support the company’s growth strategy. Apiumhub’s recent growth contributed almost 67% to turnover, last quarter Apiumhub doubled the developer workforce and the plan for the last semester of 2021 is to double it again. This is a growth that Apiumhub has never experienced before and is currently sustainable with a 95% retention rate. This demonstrates the company’s commitment to quality throughout the value chain, i.e. from software design to ready-made digital products.
“It feels great being able to create jobs in these pandemic times. But it feels even better getting an instant connection with a candidate and knowing that this relationship is there to last” said Evgeny Predein, CEO. “We have the opportunity to further expand software architecture teams in different countries, creating a powerful team of software development experts and entering new markets.”
### Apiumhub focus on quality
Apiumhub creates exceptional software and products, empowering motivated software developers to deliver world-class software architecture, scalability, and automation to medium-sized and big companies. Apiumhub powers multiple organizations, delivering software architecture, web development, mobile app development, DevOps, product ownership & data-driven services and processing 4 million euro in payroll this year. For more information, visit [apiumhub.com](https://apiumhub.com)
#### Media Contact
Ekaterina Novoseltseva, CMO
[ekaterina.novoseltseva@apiumhub.com ](mailto:katerina.novoseltseva@apiumhub.com) | apium_hub |
810,956 | Operators and Object Destructuring in JS before learning React | what is React and JSX? REACT is an open-source JavaScript library to create user... | 14,424 | 2021-09-02T09:53:56 | https://dev.to/rajshreevats/operators-and-object-destructuring-in-js-before-learning-react-4gh1 | react, javascript, beginners, webdev | ##what is React and JSX?
__REACT__ is an open-source JavaScript __library__ to create user interfaces. It's popular among web developers for creating web applications. But React can be used to create __cross platform__ applications through React Native.
__JSX__ stands for _JavaScript Syntax Extension_. React uses a special syntax known as __JavaScript XML (JSX)__. The HTML/XML is converted into JavaScript __before__ the code is __compiled__. By using JSX, you can rely on JavaScript syntax for __logic__.
##Why learning JavaScript before React?
Beforehand knowledge of __JavaScript__ concepts helps you learn React smoothly without roadblocks. After learning React, I come to the conclusion that React is all about JavaScript. It boils down to JavaScript ES6 features and syntax, ternary operators, shorthand versions in the language. Also the JavaScript __built-in functions (map, reduce, filter)__ or _general concepts_ such as __composability, reusability or higher-order functions__.
If you know some JavaScript fundamentals well, it will make React learning smooth, and you can focus more on utilizing the functionalities of React itself.
------
##Variables & Operators
###Variables
`var`,`const` and `let` are the keywords used to declare variables. Let’s see how each of these differ from one another and when to use what?
__Scope__ of `var` is Function in which the variable is declared. __Scope__ of `let` and `const` is Block in which the variable is declared. ( Block scopes are code inside loops, iteration)
`var` isn't used widely because `let` and `const` is more specific, The variables assigned using `const` are __read-only__ which means that once they are initialized using `const`, they cannot be reassigned. `let` is used when you want to re-assign the variable in future such as in a for loop for incrementing the iterator, `const` is normally used for keeping JavaScript variables unchanged.
###Operators
JavaScript operators are categorized into two categories i.e., __Unary__(takes only one operand) and __Binary__(takes two operands) operators.
1. __Binary Operators__ : following are the different types of binary operators:
* Arithmetic Operators (+, -, *, /+,−,∗,/)
* Assignment Operators (=, +=, -=, *=)
* Logical Operators ($&&, ||, ! $)
* Comparison Operators (<, >, ==, !=<,>,==,!=)
* Comma Operator (,): The Comma operator evaluates each
operand from left to right and returns the value of right
most operand.
* Bitwise Operators (&, |, ^) and Conditional Operators (?
:?:)
2. __Unary Operators__ : It takes only __one__ operand and perform a __specific__ operation. Following are some of the unary operators:
* `Increment Operators` : ++, --
* `typeof`: Returns the type of the given operand
* `delete` : Deletes an object, object’s attribute or an instance in an array
* `void`: Specifies that an expression does not return anything
```There is one special operator which takes three operands and perform as a conditional statement.```
__Ternary/Conditional Operator__
A ternary operator takes three operands and returns a value based on some condition. It’s an alternative for if statement. This could be used for multiple purposes and is used in REACT too!
syntax :
```javascript
condition ? expression_1 : expression_2;
```
If the condition is true, expression_1 is returned, otherwise it will return expression_2.
------
##Object Destructuring
For web developers, It’s often the case to access plenty of properties from _state or props_ in the component. _Object destructuring_ makes it easy to create variables from an object's properties Rather than assigning them to a variable one by one.
JavaScript __Object Destructuring__ is the syntax that makes it possible to __extract__ values from arrays, or properties from objects, and assigning them to a __variable__.
example of destructuring :
```javascript
// no destructuring
const post = this.state.post;
const article = this.state.article;
// destructuring
const { post, article } = this.state;
```
The destructuring also works for __JavaScript arrays__. Another great feature is the __rest destructuring__. It is often used for __splitting__ out a part of an object, but keeping the remaining __properties__ in another object.
Example:
```javascript
// rest destructuring
const { users, ...rest } = this.state;
```
Find more on _object destructuring_ [here](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment#description).
####Thanks for Reading
I hope it was worth your while. I will be creating series of [JavaScript Fundamentals Required to learn React](https://dev.to/rajshreevats/series/14424).
You can follow me if you want :) .
[github](https://github.com/RajshreeVats)
[LinkedIn](https://www.linkedin.com/in/rajshree-vatsa-6493371b8/)
[Twitter](https://twitter.com/RajshreeVatsa/)
| rajshreevats |
811,080 | PowerPoint Automation in .NET and Java Applications | PowerPoint automation has emerged as a powerful solution in various business use cases to generate or... | 0 | 2021-09-02T06:22:24 | https://dev.to/usmanaziz/powerpoint-automation-in-net-and-java-applications-1bbe | powerpoint | PowerPoint automation has emerged as a powerful solution in various business use cases to generate or manipulate presentations. In this post, I am just listing a few useful articles that cover PowerPoint automation and provide basic as well as advanced knowledge of how to create or manipulate PowerPoint presentations using Java, C#, or VB.NET.
* [Create MS PowerPoint Presentations in C#](https://blog.aspose.com/2020/12/04/create-powerpoint-presentations-in-csharp/ "Permalink to Create MS PowerPoint Presentations in C#")
* [Create PowerPoint Presentations using Java](https://blog.aspose.com/2021/01/18/create-powerpoint-presentations-using-java/ "Permalink to Create PowerPoint Presentations using Java")
* [Create Charts in PowerPoint Presentations using Java](https://blog.aspose.com/2021/07/29/create-charts-in-powerpoint-using-java/ "Permalink to Create Charts in PowerPoint Presentations using Java")
* [Create Charts in PowerPoint Presentations using C#](https://blog.aspose.com/2021/02/01/create-charts-in-powerpoint-using-csharp/ "Permalink to Create Charts in PowerPoint Presentations using C#")
* [Convert PowerPoint PPTX to JPG Images using Java](https://blog.aspose.com/2020/10/21/convert-pptx-to-jpg-images-using-java/ "Permalink to Convert PowerPoint PPTX to JPG Images using Java")
* [Convert PowerPoint PPTX/PPT to PNG Images in C#](https://blog.aspose.com/2021/09/01/convert-powerpoint-to-png-in-csharp/ "Permalink to Convert PowerPoint PPTX/PPT to PNG Images in C#")
* [Set Slide Background in PowerPoint Presentations using C#](https://blog.aspose.com/2021/08/31/set-background-in-powerpoint-using-csharp/ "Permalink to Set Slide Background in PowerPoint Presentations using C#")
* [Generate Thumbnails for PowerPoint PPTX or PPT using C#](https://blog.aspose.com/2021/08/30/generate-pptx-thumbnails-using-csharp/ "Permalink to Generate Thumbnails for PowerPoint PPTX or PPT using C#")
* [Apply Animation to Text in PowerPoint using C#](https://blog.aspose.com/2021/08/20/apply-animation-to-text-in-powerpoint-using-csharp/ "Permalink to Apply Animation to Text in PowerPoint using C#")
* [Convert PowerPoint Presentations to SVG in C#](https://blog.aspose.com/2021/08/17/convert-powerpoint-slides-to-svg-in-csharp/ "Permalink to Convert PowerPoint Presentations to SVG in C#")
* [Find and Replace Text in PowerPoint PPTX/PPT using C#](https://blog.aspose.com/2021/08/12/find-and-replace-text-in-powerpoint-using-csharp/ "Permalink to Find and Replace Text in PowerPoint PPTX/PPT using C#")
* [Convert PowerPoint PPTX/PPT to TIFF using C#](https://blog.aspose.com/2021/08/11/convert-powerpoint-to-tiff-using-csharp/ "Permalink to Convert PowerPoint PPTX/PPT to TIFF using C#")
* [Print PowerPoint Presentations using C#](https://blog.aspose.com/2021/08/10/print-powerpoint-presentations-using-csharp/ "Permalink to Print PowerPoint Presentations using C#")
* [Add, Extract, and Remove VBA Macros in PowerPoint using Java](https://blog.aspose.com/2021/08/03/work-with-vba-macros-in-powerpoint-using-java/ "Permalink to Add, Extract, and Remove VBA Macros in PowerPoint using Java")
* [Convert PowerPoint Presentation to Word Document using C#](https://blog.aspose.com/2021/08/02/convert-powerpoint-to-word-using-csharp/ "Permalink to Convert PowerPoint Presentation to Word Document using C#")
* [Convert PowerPoint PPTX/PPT to PNG Images in Java](https://blog.aspose.com/2021/08/01/convert-powerpoint-to-png-in-java/ "Permalink to Convert PowerPoint PPTX/PPT to PNG Images in Java")
* [Extract Text from PowerPoint Files using Java](https://blog.aspose.com/2021/07/28/extract-text-from-powerpoint-files-using-java/ "Permalink to Extract Text from PowerPoint Files using Java")
* [Convert PowerPoint Presentations to SVG in Java](https://blog.aspose.com/2021/07/22/convert-powerpoint-to-svg-in-java/ "Permalink to Convert PowerPoint Presentations to SVG in Java")
* [Find and Replace Text in PowerPoint PPTX/PPT using Java](https://blog.aspose.com/2021/07/13/find-and-replace-text-in-powerpoint-using-java/ "Permalink to Find and Replace Text in PowerPoint PPTX/PPT using Java")
* [Convert PowerPoint PPTX/PPT to TIFF using Java](https://blog.aspose.com/2021/07/13/convert-powerpoint-to-tiff-using-java/ "Permalink to Convert PowerPoint PPTX/PPT to TIFF using Java")
* [Add Watermark to PowerPoint Slides using Java](https://blog.aspose.com/2021/06/13/add-watermark-to-powerpoint-using-java/ "Permalink to Add Watermark to PowerPoint Slides using Java")
* [Add, Connect, Remove, or Clone PowerPoint Shapes in Java](https://blog.aspose.com/2021/04/09/add-connect-remove-or-clone-powerpoint-shapes-in-java/ "Permalink to Add, Connect, Remove, or Clone PowerPoint Shapes in Java")
* [Add, Extract, and Remove VBA Macros in PowerPoint using C#](https://blog.aspose.com/2021/03/31/add-extract-remove-vba-macros-in-powerpoint-chsarp/ "Permalink to Add, Extract, and Remove VBA Macros in PowerPoint using C#")
* [Manipulate Document Properties in PowerPoint Presentations in C#](https://blog.aspose.com/2021/09/10/manipulate-properties-in-powerpoint-files-using-csharp/)
Cheers!
| usmanaziz |
811,142 | How to Internationalize a React App | This article was originally published on my personal blog Internationalization, or i18n, is... | 0 | 2021-09-02T07:59:17 | https://blog.shahednasser.com/how-to-internationalize-a-react-app/ | react, javascript, css, tutorial | ---
title: How to Internationalize a React App
published: true
date: 2021-09-02 07:12:51 UTC
tags: React,Javascript,CSS,tutorial
canonical_url: https://blog.shahednasser.com/how-to-internationalize-a-react-app/
cover_image: https://blog.shahednasser.com/static/575f09aa1b1fb35308181d2a3f70cf12/ferenc-almasi-c8h0n7fSTqs-unsplash-2.jpg
---
_This article was originally published on [my personal blog](https://blog.shahednasser.com/how-to-internationalize-a-react-app/)_
Internationalization, or i18n, is supporting different languages in your website or app. It allows you to gain users from different parts of the world, which leads to growing your website's traffic.
In this tutorial, we'll learn how to internationalize a React website including translating content and changing the layout's direction based on the language chosen.
You can find the full code for this tutorial in [this GitHub repository](https://github.com/shahednasser/react-i18n-tutorial).
## Setup Website
First, we'll set up the React website with [Create React App (CRA)](https://create-react-app.dev).
Run the following command:
```
npx create-react-app react-i18n-tutorial
```
Once that is done, change the directory to the project:
```
cd react-i18n-tutorial
```
You can then start the server:
```
npm start
```
## Install Dependencies
The easiest way to internationalize a React app is to use the library [i18next](https://www.i18next.com). i18next is an internationalization framework written in Javascript that can be used with many languages and frameworks, but most importantly with [React](https://react.i18next.com).
Run the following command to install i18next:
```
npm install react-i18next i18next --save
```
In addition, we need to install [i18next-http-backend](https://github.com/i18next/i18next-http-backend) which allows us to fetch translations from a directory, and [i18next-browser-languagedetector](https://github.com/i18next/i18next-browser-languageDetector) which allows us to detect the user's language:
```
npm i i18next-http-backend i18next-browser-languagedetector
```
Last, we'll install [React Bootstrap](https://react-bootstrap.github.io) for simple styling:
```
npm install react-bootstrap@next bootstrap@5.1.0
```
## Create the Main Page
We'll create the main page of the website before working on the internationalization.
### Navigation Bar
We first need the Navigation component. Create `src/components/Navigation.js` with the following content:
```
import { Container, Nav, Navbar, NavDropdown } from "react-bootstrap";
function Navigation () {
return (
<Navbar bg="light" expand="lg">
<Container>
<Navbar.Brand href="#">React i18n</Navbar.Brand>
<Navbar.Toggle aria-controls="basic-navbar-nav" />
<Navbar.Collapse id="basic-navbar-nav">
<Nav className="me-auto">
<NavDropdown title="Language" id="basic-nav-dropdown">
<NavDropdown.Item href="#">English</NavDropdown.Item>
<NavDropdown.Item href="#">العربية</NavDropdown.Item>
</NavDropdown>
</Nav>
</Navbar.Collapse>
</Container>
</Navbar>
);
}
export default Navigation;
```
### Heading
Then, we'll create `src/components/Greeting.js` with the following content:
```
function Greeting () {
return (
<h1>Hello</h1>
);
}
export default Greeting;
```
### Text
Next, we'll create `src/components/Text.js` with the following content:
```
function Text () {
return (
<p>Thank you for visiting our website.</p>
)
}
export default Text;
```
Finally, we need to show these components on the website. Change the content of `src/App.js`:
```
import React from 'react';
import { Container } from 'react-bootstrap';
import 'bootstrap/dist/css/bootstrap.min.css';
import Greeting from './components/Greeting';
import Loading from './components/Loading';
import Navigation from './components/Navigation';
import Text from './components/Text';
function App() {
return (
<>
<Navigation />
<Container>
<Greeting />
<Text />
</Container>
</>
);
}
export default App;
```
Run the server now, if it isn't running already. You'll see a simple website with a navigation bar and some text.

### Configuring i18next
The first step of internationalizing React with i18next is to configure and initialize it.
Create `src/i18n.js` with the following content:
```
import i18n from "i18next";
import { initReactI18next } from "react-i18next";
import Backend from 'i18next-http-backend';
import I18nextBrowserLanguageDetector from "i18next-browser-languagedetector";
i18n
.use(Backend)
.use(I18nextBrowserLanguageDetector)
.use(initReactI18next) // passes i18n down to react-i18next
.init({
fallbackLng: 'en',
debug: true,
interpolation: {
escapeValue: false // react already safes from xss
}
});
export default i18n;
```
We're first importing `i18n` from `i18next`. Then, we're adding `i18next-http-backend` and `i18next-browser-languagedetector` as plugins to `i18n`. We're also adding `initReactI18next` as a plugin to ensure that `i18next` works with React.
Next, we're initializing `i18n` by passing it an object of options. There are [many options](https://www.i18next.com/overview/configuration-options) you can pass to the initializer, but we're passing 3 only.
`fallbackLng` acts as the default language in i18n if no language is detected. Language is detected either from the user's preferred language, or a language they previously chose when using the website.
`debug` enables debug messages in the console. This should not be used in production.
As for `escapeValue` in `interpolation`, we're setting it to false since React already escapes all strings and is safe from [Cross-Site Scripting (XSS)](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwi3o9eav9vyAhXHX8AKHe31CgAQFnoECAMQAQ&url=https%3A%2F%2Fowasp.org%2Fwww-community%2Fattacks%2Fxss%2F&usg=AOvVaw38Aj4XcszVjxrjA0YToyVk).
## Adding the Translation Files
By default, `i18next-http-backend` looks for translation files in `public/locales/{language}/translation.json`, where `{language}` would be the code of the language chosen. For example, en for English.
In this tutorial, we'll have 2 languages on our website, English and Arabic. So, we'll create the directory `locales` and inside we'll create 2 directories `en` and `ar`.
Then, create the file `translation.json` inside `en`:
```
{
"greeting": "Hello",
"text": "Thank you for visiting our website.",
"language": "Language"
}
```
This will create 3 translation keys. When these keys are used, the string value that the key corresponds to will be outputted based on the chosen language. So, each language file should have the same keys but with the values translated to that language.
Next, we'll create the file `translation.json` inside `ar`:
```
{
"greeting": "مرحبا",
"text": "شكرا لزيارة موقعنا",
"language": " اللغة"
}
```
## Using the i18n Instance
The next step is importing the file with the settings we just created in `App.js`:
```
import i18n from './i18n';
```
Next, to make sure that the components are rendered once i18next and the translation files have been loaded, we need to surround our components with [Suspense from React](https://reactjs.org/docs/concurrent-mode-suspense.html#what-is-suspense-exactly):
```
<Suspense fallback={<Loading />}>
<Navigation />
<Container>
<Greeting />
<Text />
</Container>
</Suspense>
```
As you can see, we're passing a new component `Loading` as a fallback while i18next loads with the translation files. So, we need to create `src/components/Loading.js` with the following content:
```
import { Spinner } from "react-bootstrap";
function Loading () {
return (
<Spinner animation="border" role="status">
<span className="visually-hidden">Loading...</span>
</Spinner>
)
}
export default Loading;
```
Now, we're able to translate strings in the `App` components and its sub-components.
## Translating Strings with useTranslation
There are different ways you can translate strings in i18next, and one of them is using `useTranslation` hook. With this hook, you'll get the translation function which you can use to translate strings.
We'll start by translating the `Greeting` component. Add the following at the beginning of the component:
```
function Greeting () {
const { t } = useTranslation();
...
}
```
Then, inside the returned JSX, instead of just placing the text "Hello", we'll replace it with the translation function `t` that we received from `useTranslation`:
```
return (
<h1>{t('greeting')}</h1>
);
```
Note how we're passing the translation function a key that we added in the `translation.json` files for each of the languages. i18next will fetch the value based on the current language.
We'll do the same thing for the `Text` component:
```
import { useTranslation } from "react-i18next";
function Text () {
const { t } = useTranslation();
return (
<p>{t('text')}</p>
)
}
export default Text;
```
Finally, we'll translate the text "Language" inside the `Navigation` component:
```
<NavDropdown title={t('language')} id="basic-nav-dropdown">
```
If you open the website now, you'll see that nothing has changed. The text is still in English.
Although technically nothing has changed, considering we are using the translation function passing it the keys instead of the actual strings and it's outputting the correct strings, that means that i18next is loading the translations and is displaying the correct language.
If we try to change the language using the dropdown in the navigation bar, nothing will happen. We need to change the language based on the language clicked.
## Changing the Language of the Website
The user should be able to change the language of a website. To manage and change the current language of the website, we need to create a context that's accessible by all the parts of the app.
Creating a context eliminates the need to pass a state through different components and levels.
Create the file `src/LocaleContext.js` with the following content:
```
import React from "react";
const defaultValue = {
locale: 'en',
setLocale: () => {}
}
export default React.createContext(defaultValue);
```
Then, create the state `locale` inside `src/App.js`:
```
function App() {
const [locale, setLocale] = useState(i18n.language);
```
As you can see, we're passing `i18n.language` as an initial value. The `language` property represents the current language chosen.
However, as it takes time for i18n to load with the translations, the initial value will be `undefined`. So, we need to listen to the `languageChanged` event that `i18n` triggers when the language is first loaded and when it changes:
```
i18n.on('languageChanged', (lng) => setLocale(i18n.language));
```
Finally, we need to surround the returned JSX with the provider of the context:
```
<LocaleContext.Provider value={{locale, setLocale}}>
<Suspense fallback={<Loading />}>
<Navigation />
<Container>
<Greeting />
<Text />
</Container>
</Suspense>
</LocaleContext.Provider>
```
Now, we can access the locale and its setter from any of the subcomponents.
To change the language, we need to have a listener function for the click events on the dropdown links.
In `src/components/Navigation.js` get the locale state from the context at the beginning of the function:
```
const { locale } = useContext(LocaleContext);
```
Then, add a listener component that will change the language in `i18n`:
```
function changeLocale (l) {
if (locale !== l) {
i18n.changeLanguage(l);
}
}
```
Finally, we'll bind the listener to the click event for both of the dropdown links:
```
<NavDropdown.Item href="#" onClick={() => changeLocale('en')}>English</NavDropdown.Item>
<NavDropdown.Item href="#" onClick={() => changeLocale('ar')}>العربية</NavDropdown.Item>
```
If you go on the website and try to change the language, you'll see that the language changes successfully based on what you choose. Also, if you try changing the language then refreshing the page, you'll see that the chosen language will persist.

## Changing the Location of the Translation Files
As mentioned earlier, the default location of the translation files is in `public/locales/{language}/translation.json`. However, this can be changed.
To change the default location, change this line in `src/i18n.js`:
```
.use(Backend)
```
To the following:
```
.use(new Backend(null, {
loadPath: '/translations/{{lng}}/{{ns}}.json'
}))
```
Where the `loadPath` is relative to `public`. So, if you use the above path it means the translation files should be in a directory called `translations`.
`{{lng}}` refers to the language, for example, `en`. `{{ns}}` refers to the namespace, which by default is `translation`.
You can also provide a function as a value of `loadPath` which takes the language as the first parameter and the namespace as the second parameter.
## Changing Document Direction
The next essential part of internationalization and localization is supporting different directions based on the languages you support.
If you have Right-to-Left (RTL) languages, you should be able to change the direction of the document when the RTL language is chosen.
If you use our website as an example, you'll see that although the text is translated when the Arabic language is chosen, the direction is still Left-to-Right (LTR).
This is not related to i18next as this is done through CSS. In this tutorial, we'll see how we can use [RTL](https://getbootstrap.com/docs/5.1/getting-started/rtl/) in Bootstrap 5 to support RTL languages.
The first thing we need to do is adding the `dir` and `lang` attributes to the `<html>` tag of the document. To do that, we need to install [React Helmet](https://www.npmjs.com/package/react-helmet):
```
npm i react-helmet
```
Then, inside `Suspense` in the returned JSX of the `App` component add the following:
```
<Helmet htmlAttributes={{
lang: locale,
dir: locale === 'en' ? 'ltr' : 'rtl'
}} />
```
This will change the `lang` and `dir` attributes of `<html>` based on the value of the locale.
The next thing we need to do is surround the Bootstrap components with `ThemeProvider` which is a component from `react-bootstrap`:
```
<ThemeProvider dir={locale === 'en' ? 'ltr' : 'rtl'}>
<Navigation />
<Container>
<Greeting />
<Text />
</Container>
</ThemeProvider>
```
As you can see we're passing it the `dir` prop with the direction based on the locale. This is necessary as `react-bootstrap` will load the necessary stylesheet based on whether the current direction is `rtl` or `ltr`.
Finally, we need to change the class name of `Nav` in the `Navigation` component:
```
<Nav className={locale === 'en' ? 'ms-auto' : 'me-auto'}>
```
This is only necessary since there seems to be a problem in the support for `ms-auto` when switching to RTL.
If you try opening the website now and changing the language to Arabic, you'll see that the direction of the document is changed as well.

## Conclusion
i18next facilitates internationalizing your React app, as well as other frameworks and languages. By internationalizing your app or website, you are inviting more users from around the world to use it.
The main parts of internationalization are translating the content, supporting the direction of the chosen language in your website's stylesheets, and remembering the user's choice. Using i18next you're able to easily translate the content as well as remembering the user's choice. | shahednasser |
811,159 | Sober Look at Microservices | What you need to know before choosing microservices | 0 | 2021-09-02T08:46:44 | https://dev.to/siy/sober-look-at-microservices-574h | beginners, architecture, microservices | ---
title: Sober Look at Microservices
published: true
description: What you need to know before choosing microservices
tags: #beginners #architecture #microservices
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ck15leqob1b4cl3e327a.png
---
_This article is not attempt to make reader choose or not choose microservices. Intead I’m trying to fill some gaps in the microservices-related information so reader may make informed decision._
It's hard or even impossible to ignore microservices hype. Every day one can see more and more new articles describing how good and advanced microservices, that everyone who does not do microservices should start doing them immediately, which patterns to use and which avoid, and so on and so forth.
This flood of shameless microservices propaganda leaves very little room for objective analysis of advantages and disadvantages of "microservices architecture".
Perhaps, it's worth to start from explanation, why in last sentence "microservices architecture" provided in quotes. The answer is pretty simple — because there is no such thing as "microservices architecture". There also no such thing as "monolithic architecture" either. For many microservices-based applications, it is possible to repackage them into a single deployable artifact just by changing build/packaging options/configuration. The resulting "monolith" application will have identical architecture, but will not be microservice-based anymore. Hence, __microservices/monolith are just a packaging options from the point of view of architecture__.
Of course, use of microservices affects architectural decisions, but this does not mean that microservices are architecture. For example, software stack also affects architecture decisions, but nobody tries to call it "architecture".
>Curious observation: this is not always possible to do a transition from single to multiple deployable artifacts, or "break the monolith". Not necessarily because "monolith" is poorly designed or implemented (this also happens, but it's another story). The actual reason is that internal architecture might be not service-based. For example, Hexagonal Architecture is hard or impossible to refactor into service-based architecture. Another possible cause — for business reasons, it might be impossible to split domains into services. After all, applications are created to solve business problems, not vice versa.
Actually, if you take a look at all those tons of articles dedicated to transition to microservices, you might notice that the only choice of architecture you have is a specific variant of Service-Oriented Architecture with several microservice-specific patterns applied. In other words, __microservices limit the number of possible architectural choices__.
It also worth to mention some microservices-related patterns:
- Domain-scoped services
- Single DB per service
- Communication between services via unreliable channels and barely suitable protocols like HTTP (there are other options, but they're very rarely even mentioned, even less discussed)
- Traditional ACID transactions are replaced with Saga pattern
__Most of these patterns attempt to solve problems which are brought in by microservices and do not exist in traditional systems. And most of them have their own issues.__
In return, microservices proponents promise numerous advantages like separate deployment, easy scaling, failure isolation and fault tolerance, independent development of services, improved testability, etc.
I'm going to analyze these advantages one by one, but it is worth to look at the high level picture of the microservices-based system first.
## Microservices and System Complexity
Complexity of each software system depends on two main parts: number of components and number of links between components.
Usual approach is to reduce complexity as much as possible, because it has far fetching consequences of the system and organization which uses it.
This is not the case for microservices: every microservices-based system looks like a traditional application turned inside out — all internal dependencies between services are exposed to the external world. In addition to pre-existing internal complexity, this transition added few more sources of complexity (in no particular order):
- Increased response time (achieving SLA is more complex).
- Each invocation of other service may fail.
- Data scattered across services, complicating access and often causing duplication and/or much more complex retrieval/processing
- Any transaction which crosses service boundary now gets much more complex.
- Infrastructure used to deploy individual services now is an integral part of the system.
- Each service need to be configured.
Usually, when complexity is increased, this is justified by advantages provided by increased complexity. For example, modern car is far more complex than Ford Model T. In return we got better performance, comfort and safety. Microservices bring a lot of additional complexity, but what we get in return?
## Separate Deployment
Separate deployment is an inherent property of the microservices — they just can't be made ready together at once. __Until all services are ready, the whole system is non-functional__. Re-deployment of one service also makes the whole system non-functional unless service is put behind load balancer and there are more than one instance of service running.
Usually it is advertised that separate deployment enables possibility to update services independently. This indeed an advantage if traditionally packaged application takes too long to start. But if is not, there is no sensible advantage in the separate deployment.
Separate deployment has its own downsides as well:
- Application of changes which cross service boundaries is much more complicated.
- API changes require special attention and management.
## Easy Scaling
In theory, a microservices-based system can be scaled by adding more instances of the necessary service. In practice, it does mean that each service, which we're going to scale, need to be put behind the load balancer. This, obviously, means more infrastructure configuration and maintenance.
But the complications didn't end here. As mentioned above, one of the microservices patterns is "Single DB per service". If more than one instance of the service need to be launched, there are three possible choices:
- Use independent DB’s per instance
- Use sharding
- Use same DB
The first choice is usually not an option since instances need to be identical from the point of view of external user/service. If they use independent DB's, then there is no simple way to ensure data consistency.
The second option is more interesting. Sharding is a well-known and widely used technique to scale databases. The problem here is that all shards need to be accessible to make sure all data is available. This means that there is no simple way to replace a single shard or reconfigure shards dynamically. In other words, while this option is possible, it does not allow dynamic scaling as advertised.
Finally, the last choice just shifts the bottleneck from service to DB. Unfortunately, this makes sense only in a narrow number of cases. Usually, a properly designed and implemented service is I/O bound (in particular, DB I/O), so scaling by adding new instances will not improve performance. So, this approach makes sense only if it does some heavy computations or written with popular resource hogs like Spring.
Let's take a look at the microservice scaling in general. It appears that microservices-based systems assume only one way of scaling — by launching more instances, with all relevant operations expenses. There are numerous other options, which are not available for microservices, for example, scaling by shifting load to other containers, which are not so heavily loaded. None of them available for microservices. As a consequence, scaling options not only limited, but even available resources are used inefficiently.
## Failure Isolation and Fault Tolerance
In theory, microservices enable failure isolation — when one service fails, the remaining continue to work.
In reality, a partially working system not always what is actually needed/desired because it is prone to data loss or corruption. Traditional desing is to make application stop when it meets unrecoverable failure. While this might make the system less available, at the same time it makes the system much more resistant to data loss and corruption. It's also worth to keep in mind that the number of possible failure scenarios is quite limited (out of memory, no disk space, etc.) and barely changes as the system evolves.
So, to prevent data loss/corruption, the microservices-based system should be designed with possible failure scenarios in mind. All of them. Microservices is a distributed system, so, beside well known traditional failures, there are communication failures which need to be taken into account. Adding a new microservice increases the number of possible failure scenarios. Worse is that, __the whole failure handling happens at the business logic level, i.e. developer ought to keep in mind possible failures while writing business logic. This clearly violates the separation of concerns principle, and this issue is inherent to microservices.__
Another possible approach is to deploy services into service mesh and launch few instances of the service. This will solve, or, at least, mitigate, many of the mentioned above issues. Unfortunately, this approach is quite expensive in regard to efforts and operational expenses. Worse is that this approach provides no guarantees of failt tolerance. After all, if some specific load/request caused the failure of one instance, most likely it will cause the failure of other instances as well.
Another important question: should we consider a system able to survive failure of one part (service) fault tolerant? According to common definition, to be considered fault tolerant, the system must be able to continue operation after failure, perhaps with reduced throughput and/or increased response time. According to this definition, __microservices-based systems have no inherent fault tolerance — failure of one service makes the system incapable to handle requests.__
## Independent Services Development
It should be noted, that this property is not technical. It's purely organizational and therefore can be applied to any type of system. Nevertheless, microservices should be credited for much wider acceptance of Domain Driven Design. Also, microservices leave no room for "shortcuts", which usually possible in traditional design. Overall, this makes design of the whole system much more clean.
But, again, this property is not unique to microservices. It is still possible to use similar approaches to design and implementation of other types of systems.
## Reliance on the Infrastructure
As mentioned above, infrastructure is an integral part of any microservices-based system. This fact has several implications:
- Infrastructure complexity. Each service is unique and has its own dependencies and configuration.
- There is no way to launch the system without infrastructure.
- The system is usually tied to a single cloud provider. Change of provider is possible, but quite expensive.
- Operational expenses are significantly higher.
- __Attempt to adopt microservices without skilled operations team almost inevitably doomed from the very beginning.__
At some point infrastructure complexity grows so much that it is necessary to introduce even more infrastructure managament tools, like service meshes.
> Few curious observations:
- Average microservices-dedicated article tries to avoid the fact that in order to transition to microservices, organization must have well established and skilled operations team.
- Microservices require fault-tolerant and reliable infrastructure in order to operate (like Kubernetes or cloud provider), while they are not fault tolerant itself. It feels wrong, that we build unreliable systems on top of reliable ones.
## Testability
In theory, since each service is relatively small, testing is simpler and easier. Unfrotunately, this claim compares testing of subsystem with whole system test.
## Freedom in Software Stack Choice
In theory, each team responsible for particular service, may freely choose software stack for implementation.
In practice most large organizations trying to limit number of choices as much as possible, because supporting diverse stacks is inefficient and expensive in the long run.
## Let's Sum Up
Almost every aspect of microservices increases complexity of system design, implementation and operation. The only real benefit — ability to develop services more or less independently, but this benefit is not specific to microservices.
Numerous "success stories" of switching to microservices attribute success to microservices. Unfortunately, they miss the key point — transition to microservices forced them to change and/or cleanup design of original system. In other words, there are two changes — packaging (monolith/microservices) and design. None of these "success stories" did comparison of new design with different packaging. Why success is attributed to packaging but not the design — I don’t know.
## Who Benefits from Microservices Hype?
One who did read this far, perhaps noticed, that two things are mentioned most often — complexity and infrastructure. And infrastructure complexity. Microservices are not just increasing but multiplying demand for infrastructure. Obviously, companies which provide this infrastructure benefit most. In other words, your organization may or may not benefit from transiton to microservices, but cloud providers will definitely make profit on this transition.
_Originally published at [Medium](https://sergiy-yevtushenko.medium.com/sober-look-at-microservices-858b3a4f7e0b)_ | siy |
811,414 | Recursion In React | Recursion is a powerful beast. Nothing satisfies me more than solving a problem with a recursive... | 0 | 2021-09-10T07:27:57 | https://dev.to/seanhurwitz/recursion-in-react-4j1l | react, javascript | Recursion is a powerful beast. Nothing satisfies me more than solving a problem with a recursive function that works seamlessly.
In this article I will present a simple use case to put your recursion skills to work when building out a nested Sidenav React Component.
## Setting Up
I am using React version `17.0.2`
First off, let's get a boilerplate React App going. Make sure you have Nodejs installed on your machine, then type:
`npx create-react-app sidenav-recursion`
in your terminal, in your chosen directory.
Once done, open in your editor of choice:
`cd sidenav-recursion`
`code .`
Let's install [Styled Components](https://styled-components.com), which I'll use to inject css and make it look lovely. I also very much like the [Carbon Components React](https://www.carbondesignsystem.com/guidelines/icons/library/) icons library.
`yard add styled-components @carbon/icons-react`
and finally, `yarn start` to open in your browser.

Ok, let's make this app our own!
First, I like to wipe out everything in App.css and replace with:
```css
* {
box-sizing: border-box;
margin: 0;
padding: 0;
}
```
Then I add a file in `src` called `styles.js` and start with this code:
```javascript
import styled, { css } from "styled-components";
const Body = styled.div`
width: 100vw;
height: 100vh;
display: grid;
grid-template-columns: 15% 85%;
grid-template-rows: auto 1fr;
grid-template-areas:
"header header"
"sidenav content";
`;
const Header = styled.div`
background: darkcyan;
color: white;
grid-area: header;
height: 60px;
display: flex;
align-items: center;
padding: 0.5rem;
`;
const SideNav = styled.div`
grid-area: sidenav;
background: #eeeeee;
width: 100%;
height: 100%;
padding: 1rem;
`;
const Content = styled.div`
grid-area: content;
width: 100%;
height: 100%;
padding: 1rem;
`;
export { Body, Content, Header, SideNav };
```
and then set up App.js like this:
```javascript
import "./App.css";
import { Body, Header, Content, SideNav } from "./styles";
function App() {
return (
<Body>
<Header>
<h3>My Cool App</h3>
</Header>
<SideNav>This is where the sidenav goes</SideNav>
<Content>Put content here</Content>
</Body>
);
}
export default App;
```
And you should have something like this:
Well done for getting this far! Now for the fun stuff.
First, we need a list of sidenav options, so lets write some in a new file, `sidenavOptions.js`:
```javascript
const sidenavOptions = {
posts: {
title: "Posts",
sub: {
authors: {
title: "Authors",
sub: {
message: {
title: "Message",
},
view: {
title: "View",
},
},
},
create: {
title: "Create",
},
view: {
title: "View",
},
},
},
users: {
title: "Users",
},
};
export default sidenavOptions;
```
Each object will have a title and optional nested paths. You can nest as much as you like, but try not go more than 4 or 5, for the users' sakes!
I then built my Menu Option style and added it to `styles.js`
```javascript
const MenuOption = styled.div`
width: 100%;
height: 2rem;
background: #ddd;
display: flex;
align-items: center;
justify-content: space-between;
padding: ${({ level }) => `0 ${0.5 * (level + 1)}rem`};
cursor: pointer;
:hover {
background: #bbb;
}
${({ isTop }) =>
isTop &&
css`
background: #ccc;
:not(:first-child) {
margin-top: 0.2rem;
}
`}
`;
```
and imported it accordingly. Those string literal functions I have there allow me to pass props through the React Component and use directly in my Styled Component. You will see how this works later on.
## The Recursive Function
I then imported sidenavOptions to App.js and began to write the recursive function within the App.js component:
```javascript
import { Fragment } from "react";
import "./App.css";
import sidenavOptions from "./sidenavOptions";
import { Body, Content, Header, SideNav, Top } from "./styles";
function App() {
const [openOptions, setOpenOptions] = useState([]);
const generateSideNav = (options, level = 0) => {
return Object.values(options).map((option, index) => {
const openId = `${level}.${index}`;
const { sub } = option;
const isOpen = openOptions.includes(openId);
const caret = sub && (isOpen ? <CaretDown20 /> : <CaretRight20 />);
return (
<Fragment>
<MenuOption
isTop={level === 0}
level={level}
onClick={() =>
setOpenOptions((prev) =>
isOpen ? prev.filter((i) => i !== openId) : [...prev, openId]
)
}
>
{option.title}
{caret}
</MenuOption>
{isOpen && sub && generateSideNav(sub, level + 1)}
</Fragment>
);
});
};
return (
<Body>
<Header>
<h3>My Cool App</h3>
</Header>
<SideNav>{generateSideNav(sidenavOptions)}</SideNav>
<Content>Put content here</Content>
</Body>
);
}
export default App;
```
Let's slowly digest what's going on here.
first, I create a state that allows me to control which options I have clicked and are "open". This is if I have drilled down into a menu option on a deeper level. I would like the higher levels to stay open as I drill down further.
Next, I am mapping through each value in the initial object and assigning a unique (by design) openId to the option.
I destructure the `sub` property of the option, if it exists, make a variable to track whether the given option is open or not, and finally a variable to display a caret if the option can be drilled down or not.
The component I return is wrapped in a Fragment because I want to return the menu option itself and any open submenus, if applicable, as sibling elements.
The `isTop` prop gives the component slightly different styling if it's the highest level on the sidenav.
The `level` prop gives a padding to the element which increases slightly as the level rises.
When the option is clicked, the menu option opens or closes, depending on its current state and if it has any submenus.
Finally, the recursive step! First I check that the given option has been clicked open, and it has submenus, and then I merely call the function again, now with the `sub` as the main option and the level 1 higher. Javascript does the rest!
You should have this, hopefully, by this point.
## Let's add routing!
I guess the sidenav component is relatively useless unless each option actually points to something, so let's set that up. We will also use a recursive function to check that this specific option and its parent tree is the active link.
First, let's add the [React Router](https://reactrouter.com) package we need:
`yarn add react-router-dom`
To access all the routing functionality, we need to update our `index.js` file to wrap everything in a `BrowserRouter` component:
```javascript
import React from "react";
import ReactDOM from "react-dom";
import { BrowserRouter as Router } from "react-router-dom";
import App from "./App";
import "./index.css";
import reportWebVitals from "./reportWebVitals";
ReactDOM.render(
<React.StrictMode>
<Router>
<App />
</Router>
</React.StrictMode>,
document.getElementById("root")
);
// If you want to start measuring performance in your app, pass a function
// to log results (for example: reportWebVitals(console.log))
// or send to an analytics endpoint. Learn more: https://bit.ly/CRA-vitals
reportWebVitals();
```
Now we need to update our sideNavOptions to include links. I also like to house all routes in my project in a single config, so I never hard-code a route. This is what my updated sidenavOptions.js looks like:
```javascript
const routes = {
createPost: "/posts/create",
viewPosts: "/posts/view",
messageAuthor: "/posts/authors/message",
viewAuthor: "/posts/authors/view",
users: "/users",
};
const sidenavOptions = {
posts: {
title: "Posts",
sub: {
authors: {
title: "Authors",
sub: {
message: {
title: "Message",
link: routes.messageAuthor,
},
view: {
title: "View",
link: routes.viewAuthor,
},
},
},
create: {
title: "Create",
link: routes.createPost,
},
view: {
title: "View",
link: routes.viewPosts,
},
},
},
users: {
title: "Users",
link: routes.users,
},
};
export { sidenavOptions, routes };
```
Notice I don't have a default export anymore. I will have to modify the import statement in App.js to fix the issue.
```javascript
import {sidenavOptions, routes} from "./sidenavOptions";
```
In my `styles.js`, I added a definite color to my MenuOption component:
`color: #333;`
and updated my recursive function to wrap the MenuOption in a Link component, as well as adding basic Routing to the body. My full App.js:
```javascript
import { CaretDown20, CaretRight20 } from "@carbon/icons-react";
import { Fragment, useState } from "react";
import { Link, Route, Switch } from "react-router-dom";
import "./App.css";
import { routes, sidenavOptions } from "./sidenavOptions";
import { Body, Content, Header, MenuOption, SideNav } from "./styles";
function App() {
const [openOptions, setOpenOptions] = useState([]);
const generateSideNav = (options, level = 0) => {
return Object.values(options).map((option, index) => {
const openId = `${level}.${index}`;
const { sub, link } = option;
const isOpen = openOptions.includes(openId);
const caret = sub && (isOpen ? <CaretDown20 /> : <CaretRight20 />);
const LinkComponent = link ? Link : Fragment;
return (
<Fragment>
<LinkComponent to={link} style={{ textDecoration: "none" }}>
<MenuOption
isTop={level === 0}
level={level}
onClick={() =>
setOpenOptions((prev) =>
isOpen ? prev.filter((i) => i !== openId) : [...prev, openId]
)
}
>
{option.title}
{caret}
</MenuOption>
</LinkComponent>
{isOpen && sub && generateSideNav(sub, level + 1)}
</Fragment>
);
});
};
return (
<Body>
<Header>
<h3>My Cool App</h3>
</Header>
<SideNav>{generateSideNav(sidenavOptions)}</SideNav>
<Content>
<Switch>
<Route
path={routes.messageAuthor}
render={() => <div>Message Author!</div>}
/>
<Route
path={routes.viewAuthor}
render={() => <div>View Author!</div>}
/>
<Route
path={routes.viewPosts}
render={() => <div>View Posts!</div>}
/>
<Route
path={routes.createPost}
render={() => <div>Create Post!</div>}
/>
<Route path={routes.users} render={() => <div>View Users!</div>} />
<Route render={() => <div>Home Page!</div>} />
</Switch>
</Content>
</Body>
);
}
export default App;
```
So now, the routing should be all set up and working.
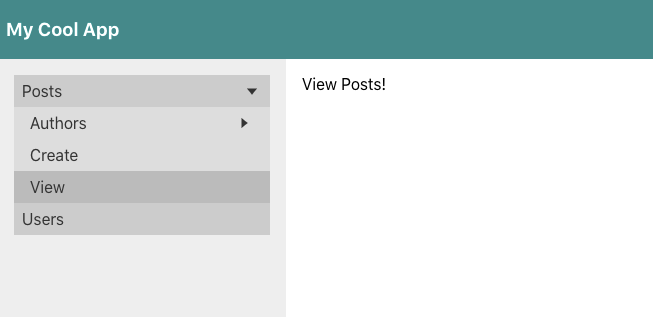
The last piece of the puzzle is to determine if the link is active and add some styling. The trick here is not only to determine the Menu Option of the link itself, but to ensure the styling of the entire tree is affected so that if a user refreshes the page and all the menus are collapsed, the user will still know which tree holds the active, nested link.
Firstly, I will update my MenuOption component in `styles.js` to allow for an isActive prop:
```javascript
const MenuOption = styled.div`
color: #333;
width: 100%;
height: 2rem;
background: #ddd;
display: flex;
align-items: center;
justify-content: space-between;
padding: ${({ level }) => `0 ${0.5 * (level + 1)}rem`};
cursor: pointer;
:hover {
background: #bbb;
}
${({ isTop }) =>
isTop &&
css`
background: #ccc;
:not(:first-child) {
margin-top: 0.2rem;
}
`}
${({ isActive }) =>
isActive &&
css`
border-left: 5px solid #333;
`}
`;
```
And my final App.js:
```javascript
import { CaretDown20, CaretRight20 } from "@carbon/icons-react";
import { Fragment, useCallback, useState } from "react";
import { Link, Route, Switch, useLocation } from "react-router-dom";
import "./App.css";
import { routes, sidenavOptions } from "./sidenavOptions";
import { Body, Content, Header, MenuOption, SideNav } from "./styles";
function App() {
const [openOptions, setOpenOptions] = useState([]);
const { pathname } = useLocation();
const determineActive = useCallback(
(option) => {
const { sub, link } = option;
if (sub) {
return Object.values(sub).some((o) => determineActive(o));
}
return link === pathname;
},
[pathname]
);
const generateSideNav = (options, level = 0) => {
return Object.values(options).map((option, index) => {
const openId = `${level}.${index}`;
const { sub, link } = option;
const isOpen = openOptions.includes(openId);
const caret = sub && (isOpen ? <CaretDown20 /> : <CaretRight20 />);
const LinkComponent = link ? Link : Fragment;
return (
<Fragment>
<LinkComponent to={link} style={{ textDecoration: "none" }}>
<MenuOption
isActive={determineActive(option)}
isTop={level === 0}
level={level}
onClick={() =>
setOpenOptions((prev) =>
isOpen ? prev.filter((i) => i !== openId) : [...prev, openId]
)
}
>
{option.title}
{caret}
</MenuOption>
</LinkComponent>
{isOpen && sub && generateSideNav(sub, level + 1)}
</Fragment>
);
});
};
return (
<Body>
<Header>
<h3>My Cool App</h3>
</Header>
<SideNav>{generateSideNav(sidenavOptions)}</SideNav>
<Content>
<Switch>
<Route
path={routes.messageAuthor}
render={() => <div>Message Author!</div>}
/>
<Route
path={routes.viewAuthor}
render={() => <div>View Author!</div>}
/>
<Route
path={routes.viewPosts}
render={() => <div>View Posts!</div>}
/>
<Route
path={routes.createPost}
render={() => <div>Create Post!</div>}
/>
<Route path={routes.users} render={() => <div>View Users!</div>} />
<Route render={() => <div>Home Page!</div>} />
</Switch>
</Content>
</Body>
);
}
export default App;
```
I am getting the current `pathname` from the `useLocation` hook in React Router. I then declare a `useCallback` function that only updates when the pathname changes. This recursive function `determineActive` takes in an option and, if it has a link, checks to see if the link is indeed active, and if not it recursively checks any submenus to see if any children's link is active.
Hopefully now the Sidenav component is working properly!
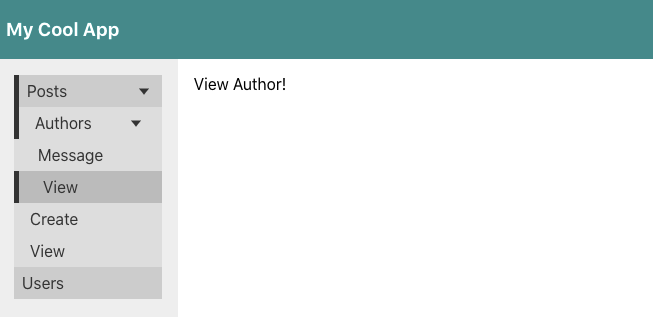
And as you can see, the entire tree is active, even if everything is collapsed:
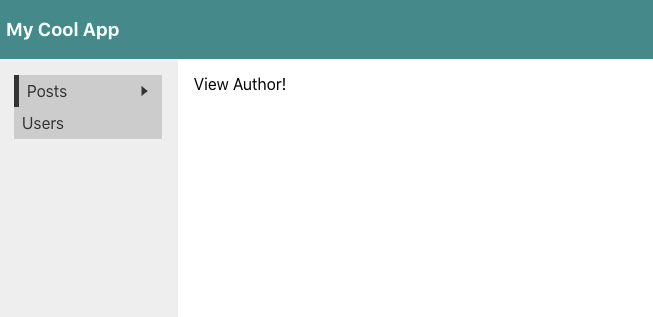
There you have it! I hope this article was insightful and helps you find good use cases for recursion in React Components!
Signing off,
~ Sean Hurwitz | seanhurwitz |
811,496 | 💻 TinyGo: Good Things Come in Small Packages | 📚 TinyGo is Golang’s baby brother. Read more about it on a beginner's guide into the world... | 0 | 2021-09-02T14:31:48 | https://dev.to/robertinoc_dev/tinygo-good-things-come-in-small-packages-3i1c | go, tinygo, programming | #### 📚 TinyGo is Golang’s baby brother. Read more about it on a beginner's guide into the world of IoT with TinyGo.
### <br>
**TL;DR:** The concept of coding for IoT devices, CLIs and WebAssembly is not a new concept. However, what if I told you that it is possible to use Golang for all three. [TinyGo](https://tinygo.org/) is a specialized project specifically designed and used for development in small places. This article explains the benefits of TinyGo, what it is, and how you can use it. It also provides you with a Golang IoT code example for you to see TinyGo in action.
## What Is TinyGo?
TinyGo is Golang's baby brother. It is a compiler that allows a user to write the Golang code they are familiar with and run it in places people wouldn't have thought were possible. What this means is that the barriers to entry into some tech spaces are being gradually lowered. I say this because I am writing through experience.
## How Is TinyGo Different from Golang?
Out of the box, Golang is a feature-rich, highly-performant, compiled language, which means that Golang is compiled to machine-readable code (those funky `1` 's and `0` 's everyone talks about).
In turn, being compiled to machine code allows it to run directly on the hardware — all that CPU/RAM power! Another really cool feature of Golang is that when building a binary of the written program, it includes extensive cross-compatibility for a wide from of different system architectures.
Once a binary has been built, it can be run on any compatible distribution/architecture, providing it has been specified during the build process. To find the list of supported architectures (after installing Go on your machine), run this command into your terminal: `go tool dist list`.
The output will look something like this:
```bash
aix/ppc64
android/386
android/amd64
android/arm
android/arm64
darwin/amd64
darwin/arm64
dragonfly/amd64
freebsd/386
...
```
So, how is TinyGo different? Well, it's the same Golang you know and love, but TinyGo is a smaller compiler based on [LLVM](https://llvm.org/) technologies. It has essentially cherry-picked a number of important and available libraries and trimmed a lot of the fat from the core language.
By doing that, TinyGo becomes an even more powerful and efficient language that you can run in unexpected places. As an example of fat that's been trimmed, the library `html/template` cannot be imported by TinyGo as it relies upon other dependencies, which in turn are not able to be imported.
> To read up on the packages supported by TinyGo, visit the [documentation pages](https://tinygo.org/docs/reference/lang-support/stdlib/).
[Read more...](https://auth0.com/blog/tinygo-good-things-come-in-small-packages/?utm_source=content_synd&utm_medium=sc&utm_campaign=golang) | robertinoc_dev |
811,562 | Deletion From a Simple Linked List Using Python | Deleting a node from a linked list is straightforward but there are a few cases we need to... | 16,769 | 2021-09-02T16:37:23 | https://dev.to/hurayraiit/deletion-from-a-simple-linked-list-using-python-1045 | beginners, programming, python, algorithms | ### Deleting a node from a linked list is straightforward but there are a few cases we need to account for:
- 1. The list is empty
- 2. The node to remove is the only node in the linked list
- 3. We are removing the head node
- 4. We are removing the tail node
- 5. The node to remove is somewhere in between the head and tail node
- 6. The item to remove does not exist in the linked list.
---
## Step 1: If the list is empty then print a message and return.
```python
def delete(self, key):
# If the list is empty
if self.head is None:
print('Deletion Error: The list is empty.')
return
```
---
## Step 2: If the head holds the key, delete the head by assigning head to the next node of head.
```python
# If the key is in head
if self.head.data == key:
self.head = self.head.next
return
```
---
## Step 3: Find the first occurrence of the key in the linked list.
```python
# Find position of first occurrence of the key
current = self.head
while current:
if current.data == key:
break
previous = current
current = current.next
```
## If the key was found then point the previous node to the next node of the key. Otherwise print an error message.
```python
# If the key was not found
if current is None:
print('Deletion Error: Key not found.')
else:
previous.next = current.next
```
---
## Step 4: Check sample test cases for the code.
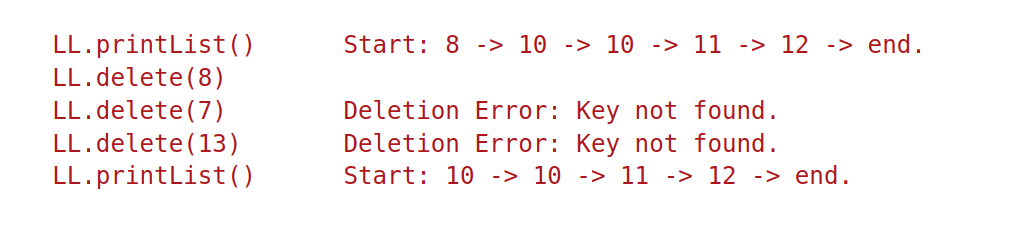
---
## The complete code is given below:
```python
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def printList(self):
temp = self.head
if not temp:
print('List is empty.')
return
else:
print('Start:', end=' ')
while temp:
print(temp.data, end=' -> ')
temp = temp.next
print('end.')
def insert(self, data):
new_node = Node(data)
# If the linked list is empty
if self.head is None:
self.head = new_node
# If the data is smaller than the head
elif self.head.data >= new_node.data:
new_node.next = self.head
self.head = new_node
else:
# Locate the node before the insertion point
current = self.head
while current.next and new_node.data > current.next.data:
current = current.next
# Insertion
new_node.next = current.next
current.next = new_node
def delete(self, key):
# If the list is empty
if self.head is None:
print('Deletion Error: The list is empty.')
return
# If the key is in head
if self.head.data == key:
self.head = self.head.next
return
# Find position of first occurrence of the key
current = self.head
while current:
if current.data == key:
break
previous = current
current = current.next
# If the key was not found
if current is None:
print('Deletion Error: Key not found.')
else:
previous.next = current.next
if __name__=='__main__':
# Create an object
LL = LinkedList()
print('')
# Insert some nodes
LL.insert(10)
LL.insert(12)
LL.insert(8)
LL.insert(11)
LL.insert(10)
LL.printList()
LL.delete(7)
LL.delete(8)
LL.delete(13)
LL.printList()
```
---
## Thank you for reading the article. Please leave you feedback. :smile:
---
References:
1. https://www.geeksforgeeks.org/linked-list-set-3-deleting-node/
2. CLRS: Introduction to Algorithms [book]
| hurayraiit |
811,816 | AzureFunBytes Episode 55 - Programming for Accessibility with @rorypreddy | AzureFunBytes is a weekly opportunity to learn more about the fundamentals and foundations that make... | 0 | 2021-09-02T19:16:19 | https://dev.to/azure/azurefunbytes-episode-55-programming-for-accessibility-with-rorypreddy-3mp | a11y, software, cloud, azure | AzureFunBytes is a weekly opportunity to learn more about the fundamentals and foundations that make up Azure. It's a chance for me to understand more about what people across the Azure organization do and how they do it. Every week we get together at 11 AM Pacific on [Microsoft LearnTV](https://cda.ms/226) and learn more about Azure.

This week on AzureFunBytes we're talking about how to create applications for everyone. Accessibility is the design of products, services, and devices that focus on making environments the most welcome and usable to any user. Different people have different methods they may interface with the applications you create. By focusing in on accessibility earlier in your software development process, you make for a more available product to everyone. What software developers create should include considerations for vision, hearing, neurodiversity, mobility, and even mental health. Through the use of assistive technology, AI, and cognitive services we can strive to consider all of our differences in order to improve accessibility.
To help me further understand the benefits of accessibility in our software development, I've tapped Senior Cloud Advocate [Rory Preddy](https://twitter.com/rorypreddy) for some help.
Our agenda:
- Accessibility concepts
- Achieving accessible milestones
- Measure and automate
- Tooling
{% youtube sFCkRSKeiLM %}
[00:00:00 - Intro](https://www.youtube.com/watch?v=sFCkRSKeiLM)
[00:02:32 - Microsoft Accessibility video](https://youtu.be/sFCkRSKeiLM?t=152)
[00:05:29 - Let's meet Rory](https://youtu.be/sFCkRSKeiLM?t=329)
[00:15:35 - Accessibility is about improving everyone's quality of life](https://youtu.be/sFCkRSKeiLM?t=935)
[00:20:28 - What is Accessibility?](https://youtu.be/sFCkRSKeiLM?t=1228)
[00:22:48 - The Hydra](https://youtu.be/sFCkRSKeiLM?t=1368)
[00:25:42 -Disability does not equal personal health condition](https://youtu.be/sFCkRSKeiLM?t=1542)
[00:28:44 - How legislation impacts Accessibility](https://youtu.be/sFCkRSKeiLM?t=1724)
[00:31:41 - Persona Spectrum](https://youtu.be/sFCkRSKeiLM?t=1901)
[00:35:42 - Tools for improving Accessibility](https://youtu.be/sFCkRSKeiLM?t=2142)
[00:36:39 - Demo time](https://youtu.be/sFCkRSKeiLM?t=2197)
[00:41:36 - Shifting left with DevOps](https://youtu.be/sFCkRSKeiLM?t=2496)
[00:45:50 - Immersive Reader Demo](https://youtu.be/sFCkRSKeiLM?t=2750)
[00:51:57 - Enabling better image recognition](https://youtu.be/sFCkRSKeiLM?t=3117)
[00:54:42 - Conclusion](https://youtu.be/sFCkRSKeiLM?t=3282)
Here's a description of what we cover in Rory's own words:
*"My life is a hilarious roller coaster of miss-intended programming bugs because at 4 foot tall and 65 kilograms I completely fall off your radar.*
*What did my scale call me! Why does facial recognition see me as a child? These are all valid questions I often ask myself as I navigate my weird and different world. Have you heard the phrase “You have to be this tall for Micro-services”? well, what about: “You have to be this tall to operate a mobile phone?”. I am finding it harder and harder to reach any button except for “#” and “9”.*
*Building accessibility into the planning stages of programming can eliminate barriers for participation and create an inclusive environment for people with disabilities. Programming for diversity serves as an unquestionable indicator that your software embraces the diversity of your users and cares about their safety and comfort.*
*Join me on a fascinating and thought-provoking look at how you can program for accessibility."*
So check out this important session that Rory was kind enough to take part in and let's make our software experiences glorious for everyone!
------
Learn about Azure fundamentals with me!
Live stream is normally found on Twitch, YouTube, and [LearnTV](https://cda.ms/226) at 11 AM PT / 2 PM ET Thursday. You can also find the recordings here as well:
[AzureFunBytes on Twitch](https://twitch.tv/azurefunbytes)
[AzureFunBytes on YouTube](https://aka.ms/jaygordononyoutube)
[Azure DevOps YouTube Channel](https://www.youtube.com/channel/UC-ikyViYMM69joIAv7dlMsA)
[Follow AzureFunBytes on Twitter](https://twitter.com/azurefunbytes)
[Get $200 in free Azure Credit](https://cda.ms/219)
[Microsoft Learn: Introduction to Azure fundamentals](https://cda.ms/243)
[Microsoft Learn: Accessibility Fundamentals](https://aka.ms/accessibility-fundamentals)
[Microsoft Learn: Digital accessibility](https://cda.ms/2wL)
[Microsoft Learn: Configure Microsoft Teams meetings and calls for inclusion](https://cda.ms/2wQ)
[Experience the web as personas with access needs](https://alphagov.github.io/accessibility-personas/)
[Web Content Accessibility Guidelines (WCAG) Overview](https://www.w3.org/WAI/standards-guidelines/wcag/)
[Computer Vision](https://cda.ms/2wK)
[Speech Translation](https://cda.ms/2wG)
[Accessibility Insights Tools](https://accessibilityinsights.io)
[Accessibility Technology & Tools - Microsoft](https://cda.ms/2wN)
[Chief Accessibility Officer Jenny Lay-Flurrie: Stories from inside Microsoft’s journey to design a more accessible world](https://cda.ms/2wP)
[No Caps](https://nocaps.org) | jaydestro |
811,869 | A Multi-line CSS only Typewriter effect | After the scalable one-line typewriter and the crazy "scrabble"-writer let's do another one: The... | 14,439 | 2021-09-02T22:36:57 | https://dev.to/afif/a-multi-line-css-only-typewriter-effect-3op3 | css, html, webdev, beginners | After the [scalable one-line typewriter](https://dev.to/afif/a-scalable-css-only-typewriter-effect-2opn) and the [crazy "scrabble"-writer](https://dev.to/afif/the-css-scrabble-writer-the-next-gen-typewriter-fbi) let's do another one: **The multi-line typewriter.**
A CSS-only solution of course:
{% codepen https://codepen.io/t_afif/pen/ExXyXpB %}
The effect relies on using a Monospace font and knowing the number of characters. Yes, I am starting with the drawbacks but that was the price for a generic and easy-to-use code.
The HTML is very basic:
```html
This is a <span class="type" style="--n:53">CSS only solution for a multi-line typewriter effect.</span>
```
A span with our text and the number of characters as a variable.
For the CSS:
```css
.type {
font-family: monospace;
color:#0000;
background:
linear-gradient(-90deg,#00DFFC 5px,#0000 0) 10px 0,
linear-gradient(#00DFFC 0 0) 0 0;
background-size:calc(var(--n)*1ch) 200%;
-webkit-background-clip:padding-box,text;
background-clip:padding-box,text;
background-repeat:no-repeat;
animation:
b .7s infinite steps(1),
t calc(var(--n)*.3s) steps(var(--n)) forwards;
}
@keyframes t{
from {background-size:0 200%}
}
@keyframes b{
50% {background-position:0 -100%,0 0}
}
```
A few lines of CSS code with no hard-coded values. We only need to update the variable `--n`.
---
### How does it work?
The trick relies on background properties so as a reference I always recommend this article:
{% post https://dev.to/this-is-learning/all-you-need-to-know-about-background-position-3aac %}
We have two background layers. The first layer will color the text and the second one will create the blinking caret.
The idea of the first layer is to apply a discrete animation of `background-size` to create a filling effect from the first character to the last one using a gradient coloration.
Here is a step-by-step illustration to understand the trick:
{% codepen https://codepen.io/t_afif/pen/ZEyOJNW %}
The second layer is our caret. Here we will perform two animations. The first one is a `background-size` animation similar to the text coloration since the caret needs to follow the text. The second one is a `background-position` animation to create the blinking effect.
Another step-by-step to understand:
{% codepen https://codepen.io/t_afif/pen/gORMGMy %}
The width of the caret is controlled by the `5px` inside the gradient and we add a small offset (`10px`) to avoid having an overlap with the text animation.
That's it! Simply imagine both layers animating at the same time and we have our CSS-only typewriter effect.
✔️ No Javascript
✔️ A basic HTML code
✔️ No complex CSS code. Less than 10 declarations and no hard-coded values
✔️ Accessible. The text is written within the HTML code (no pseudo-element, no duplicated text)
❌ Require a monospace font
⚠️ You can use any text without changing the code but you have to update one variable
 | afif |
811,980 | Calling an Azure AD secured API with Postman | Secure APIs are all the rage, but how can we easily test them. If you're using Postman, then this... | 0 | 2021-09-02T23:59:31 | https://dev.to/425show/calling-an-azure-ad-secured-api-with-postman-22co | Secure APIs are all the rage, but how can we easily test them. If you're using Postman, then this blog post will show you how to configure and use Postman to call an Azure AD-secured API.
The secure API expects an access token to be passed. Therefore, Postman needs to acquire and use an Access Token when calling the API. If there is no token attached to the request, then you'll most likely receive an HTTP 401 error (unauthenticated) - which is right. If you pass an Access Token with your request but don't have the right scope, if your API has been coded correctly, you should receive an HTTP 403 error (unauthorized) - which is also right. Let's see how we can test our APIs with Postman!
## Configure the App Registration for Postman
In order for Postman to be able to acquire an Access Token, it needs to have a corresponding Azure AD App Registration. In this section, we'll configure the App Registration in Azure AD. If you don't have an Azure AD already (I doubt it since you're reading this), you can get a FREE, full-blown P1 Azure AD Tenant through the [Microsoft 365 Developer Program](https://aka.ms/425Show/devevn).
Sign in to your [Azure AD portal](aad.portal.azure.com), navigate to **App Registrations** and click on the **+ New Registration** button. Give the app a meaningful name and press **Register**.
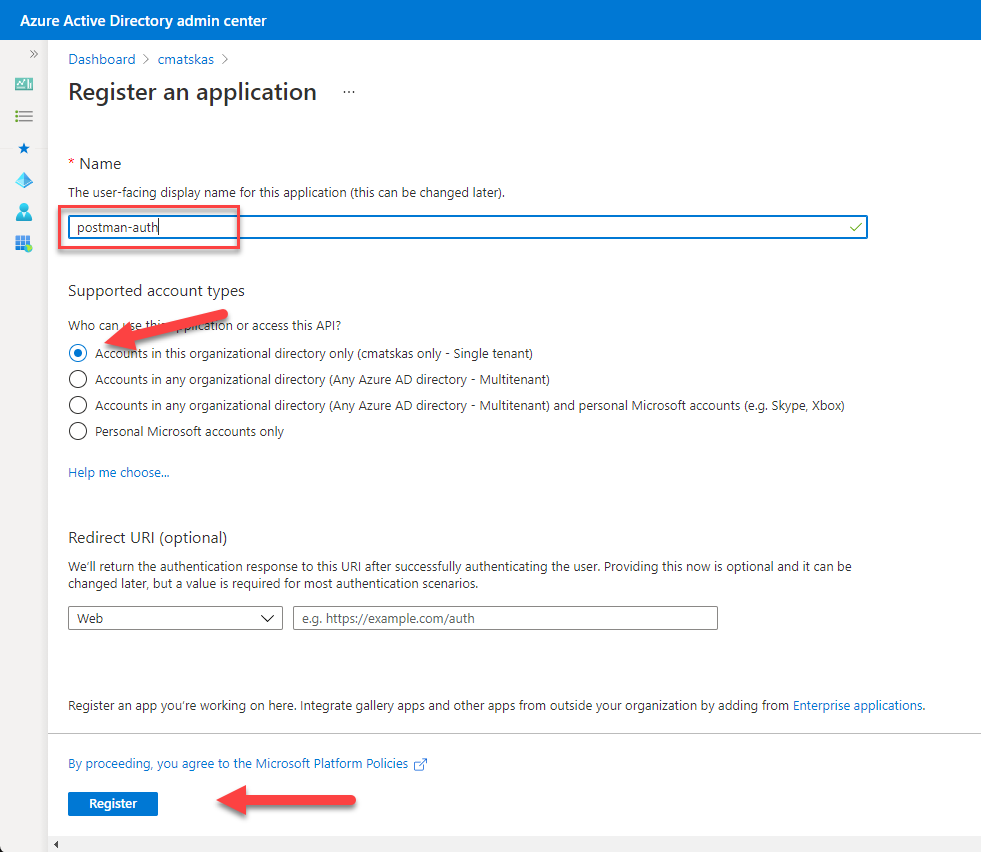
Then, open the **Authentication** tab and **Add a platform**. Select **Web** for the platform. In the **Redirect URI** add the following `https://oauth.pstmn.io/v1/callback` and then press **Configure**.
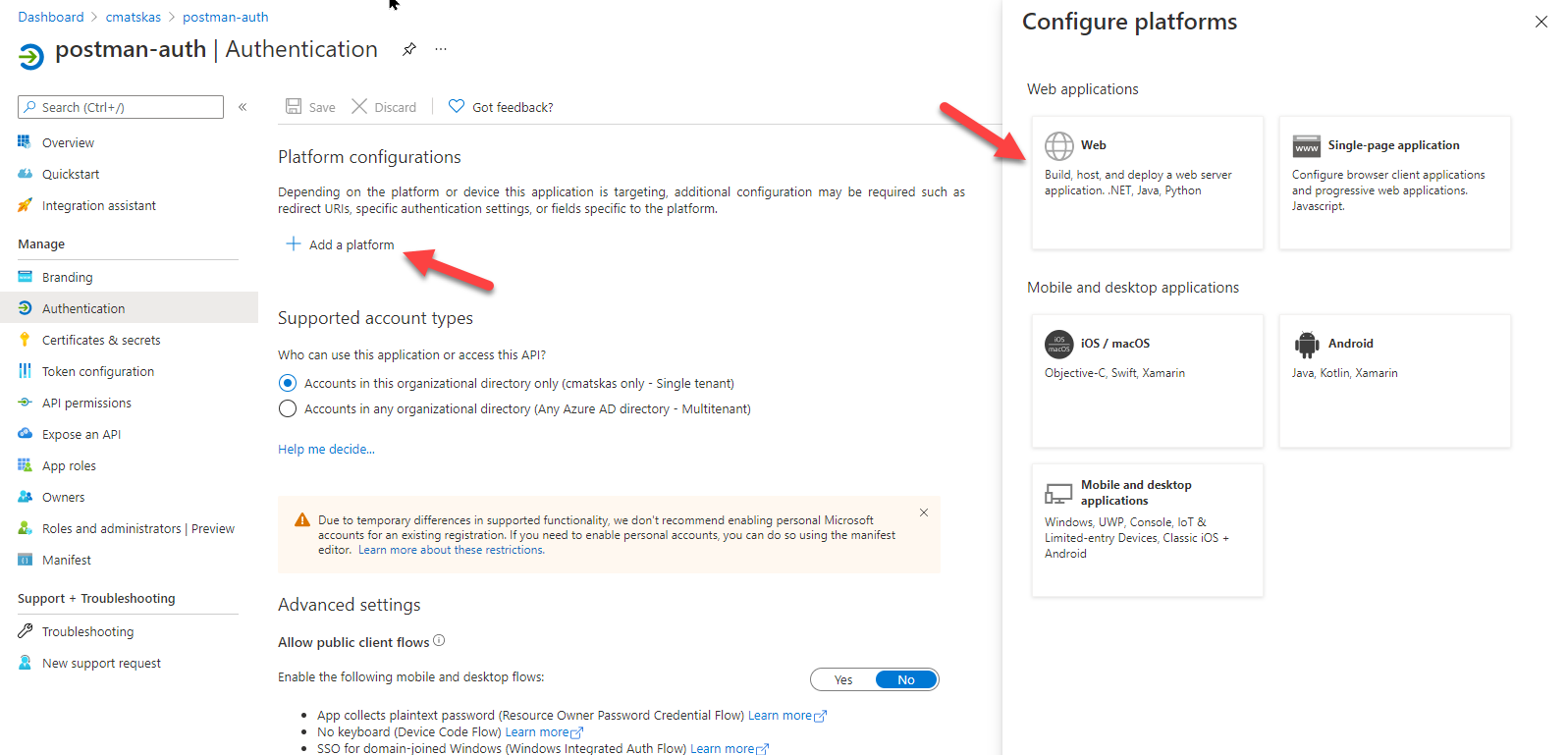
We also need a client secret. Navigate to the **Certificates and Secrets** tab and create a new secret. Make sure to copy the secret value as it will be unavailable once you navigate off this tab (but you can always delete it and recreate it).
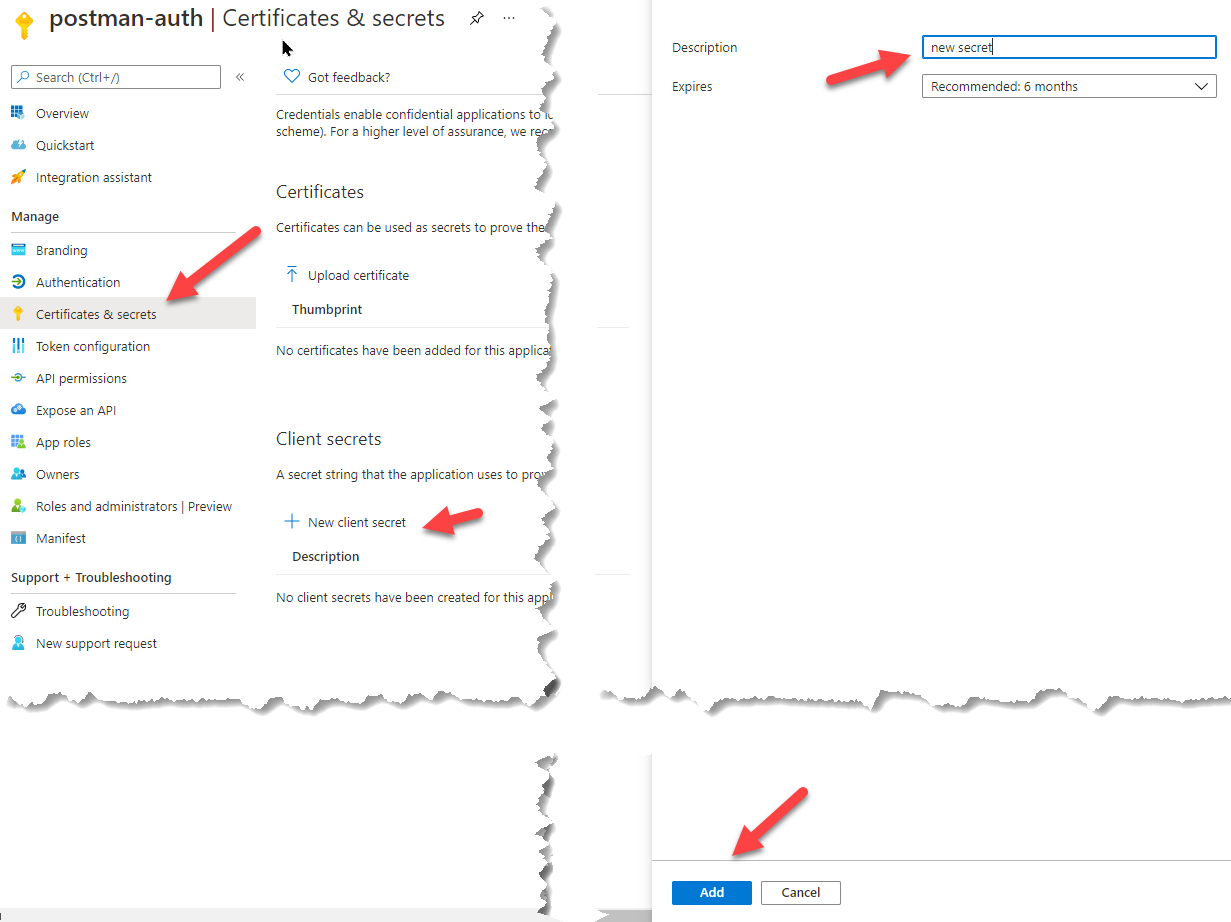
Information needed for Postman
- Client Id: Can be found in the Overview Tab
- Client Secret: Was created and copied in the previous step
- Auth URL: In the Overview Tab, click on **Endpoints**
- Access Token URL: In the Overview Tab, click on **Endpoints**
- Scope: e.g `api://279cfdb1-18d5-4fd6-b563-291dcd4b561a/weather.read`
You can find the right scope in your API App Registration in Azure AD -> open the **Expose an API** tab -> Copy the **Scope**
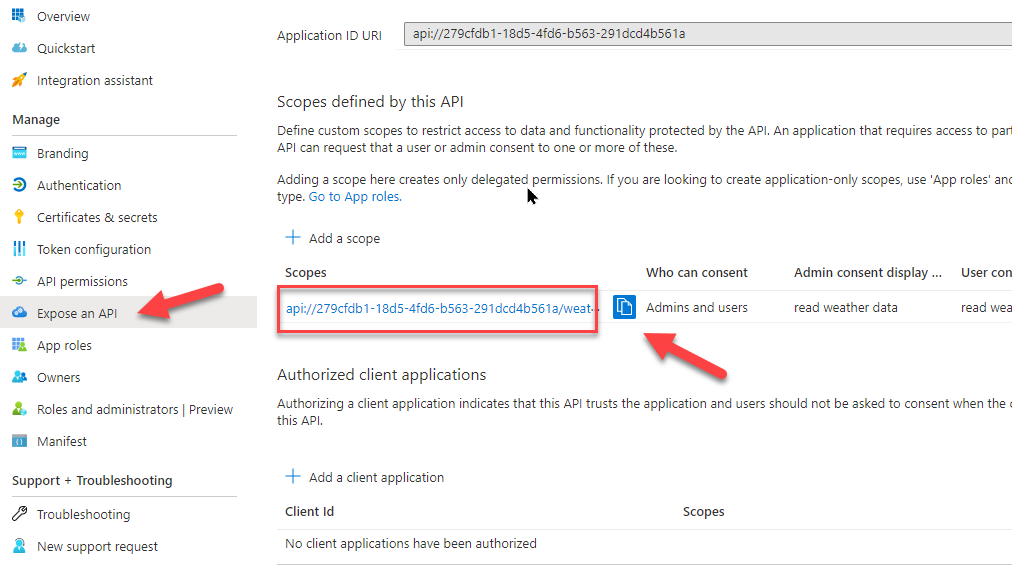
Copy the v2 URLs for the Authorization and Token endpoints as per the image below:
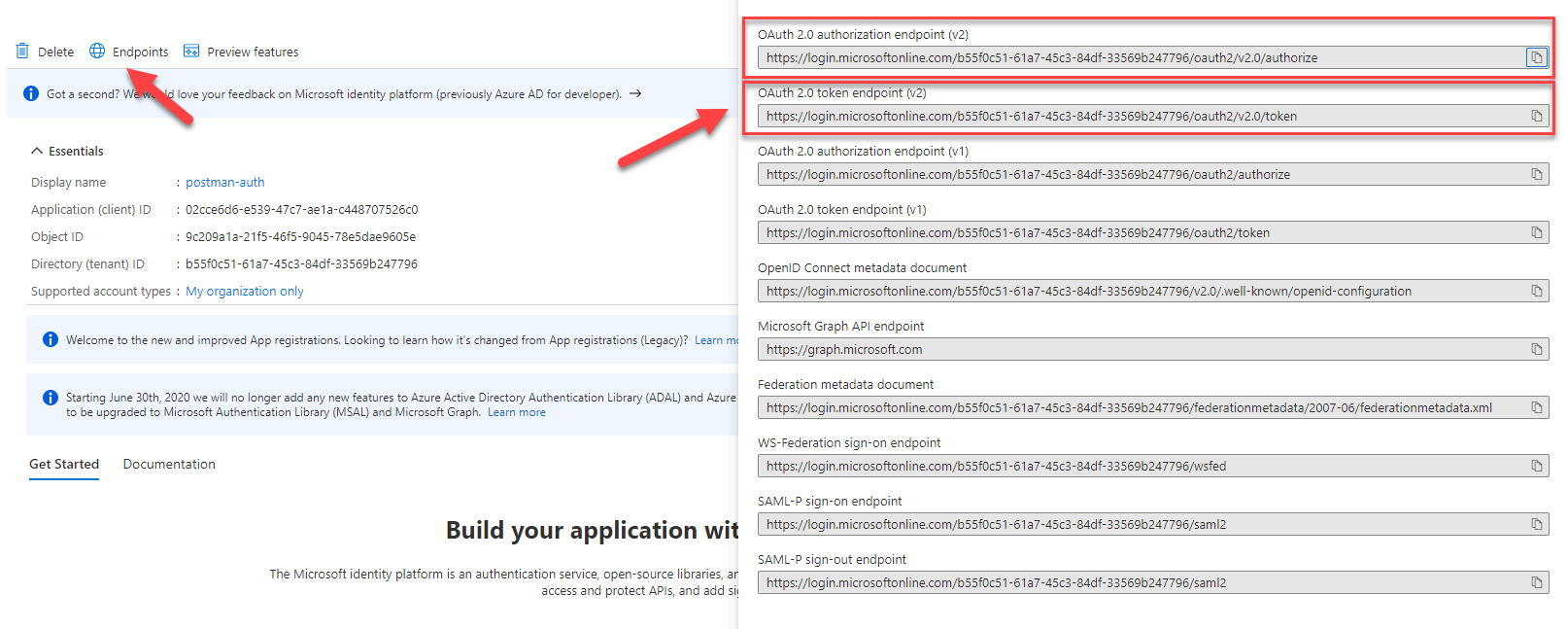
## Configure Postman
We now have everything we need to configure our Auth settings in Postman. In your Postman, create a new Request and navigate to the **Authorization** tab. Next populate the fields as shown in the image below, using all the settings we gathered in the previous section.
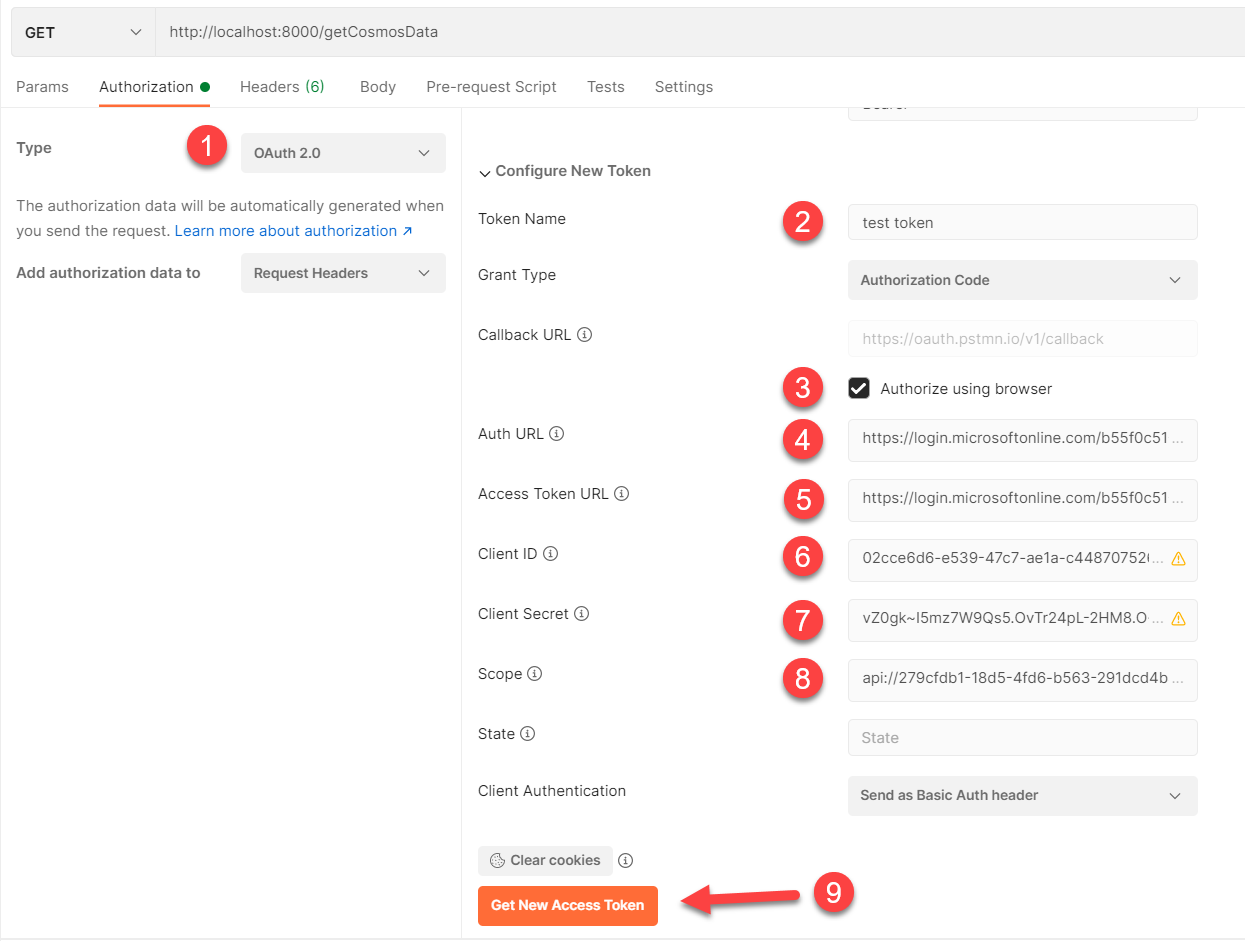
> Note: you'll need to check the **Authorize using browser** checkbox and ensure that your browser is not blocking any popups.
We are now ready to test our configuration. Press the **Get New Access Token** in Postman. If everything's configured correctly, you should see something similar as per the video below:
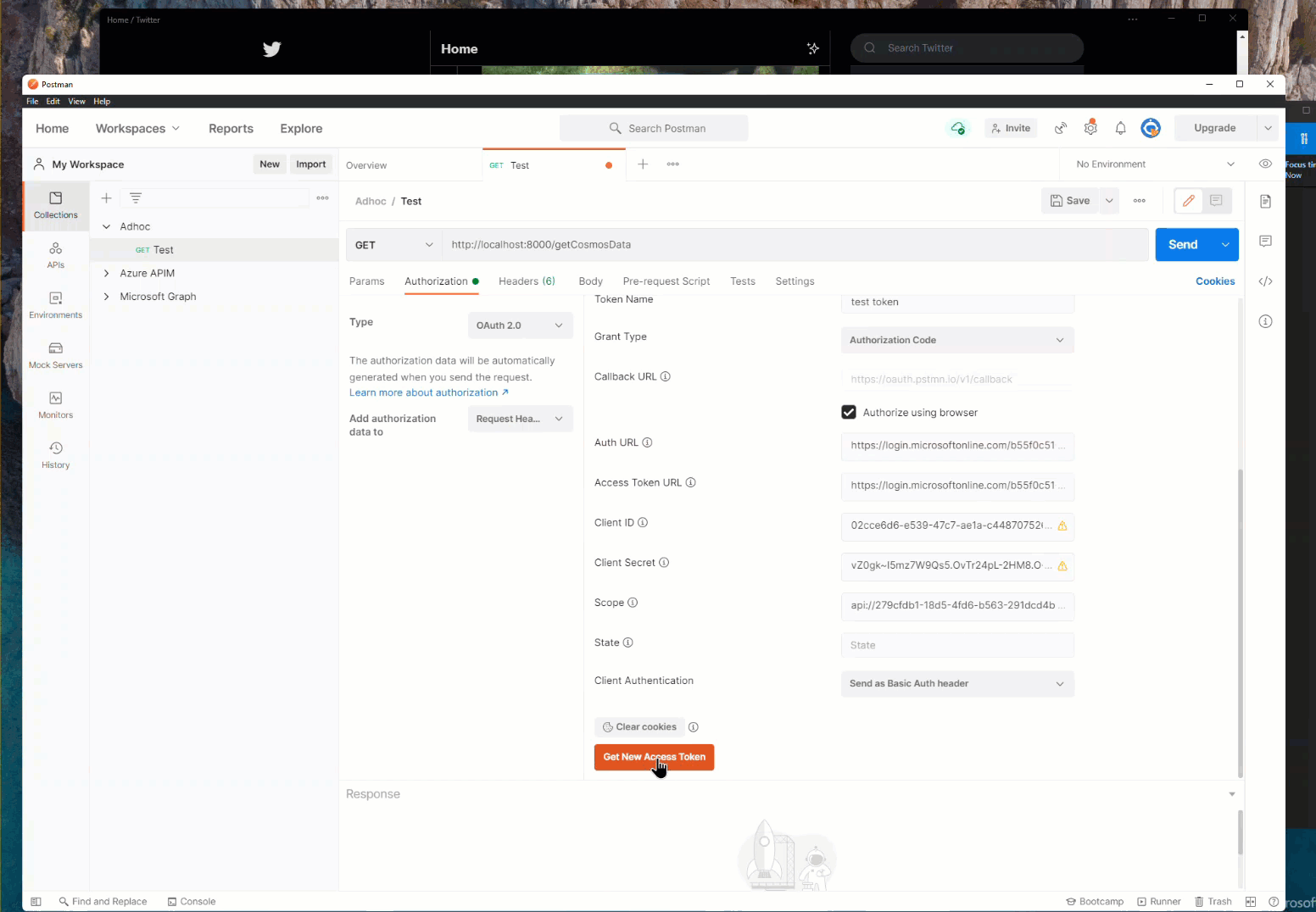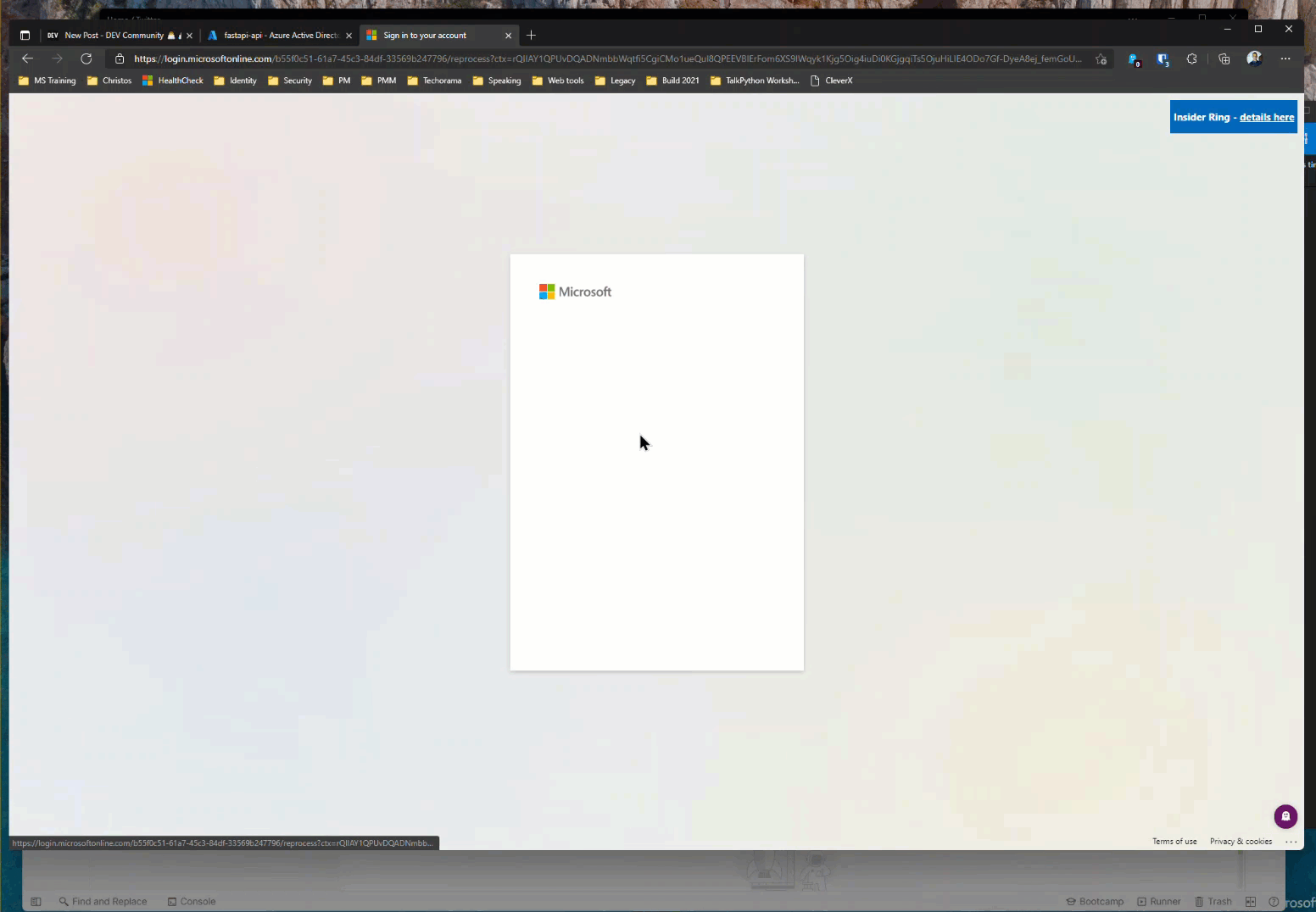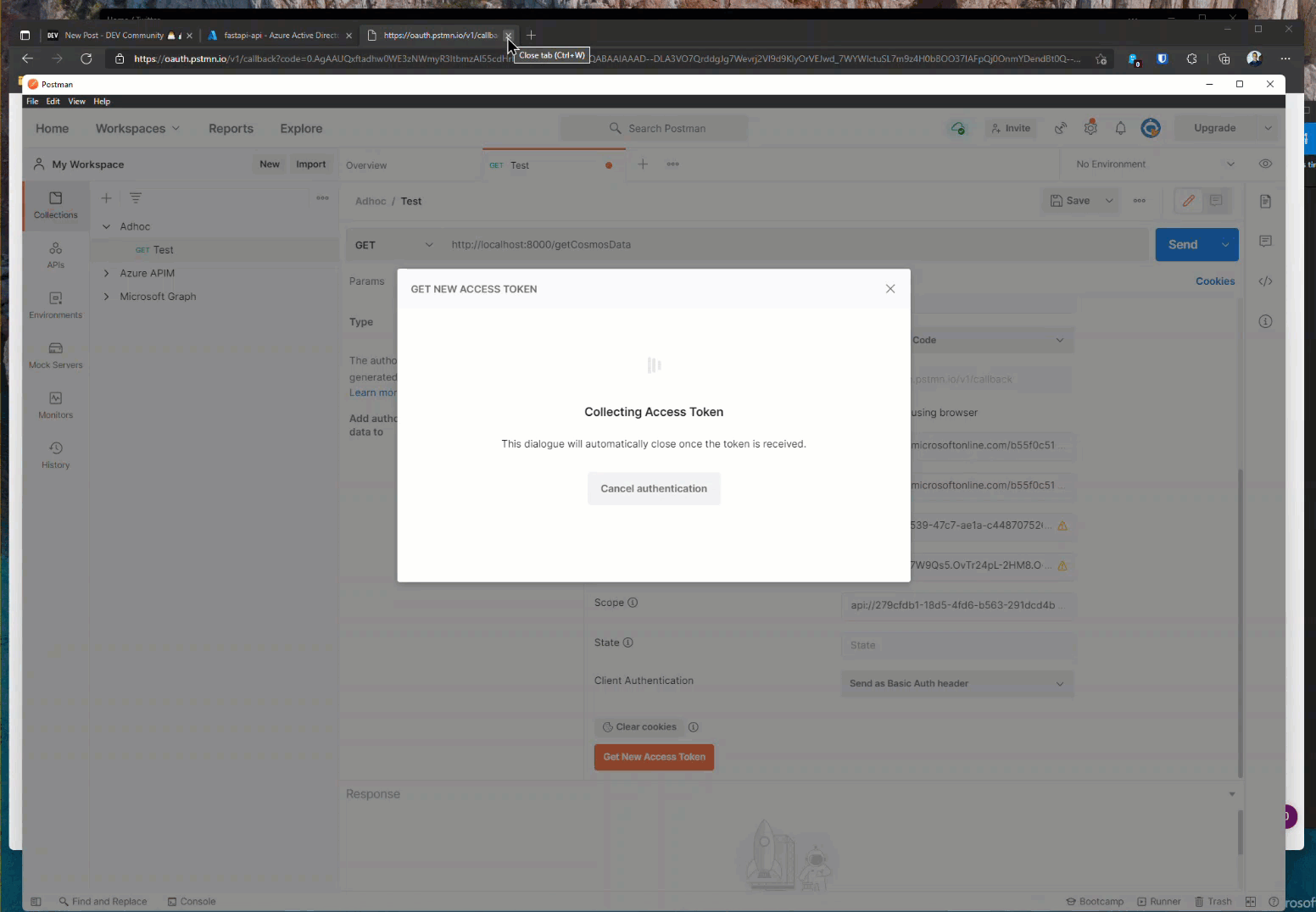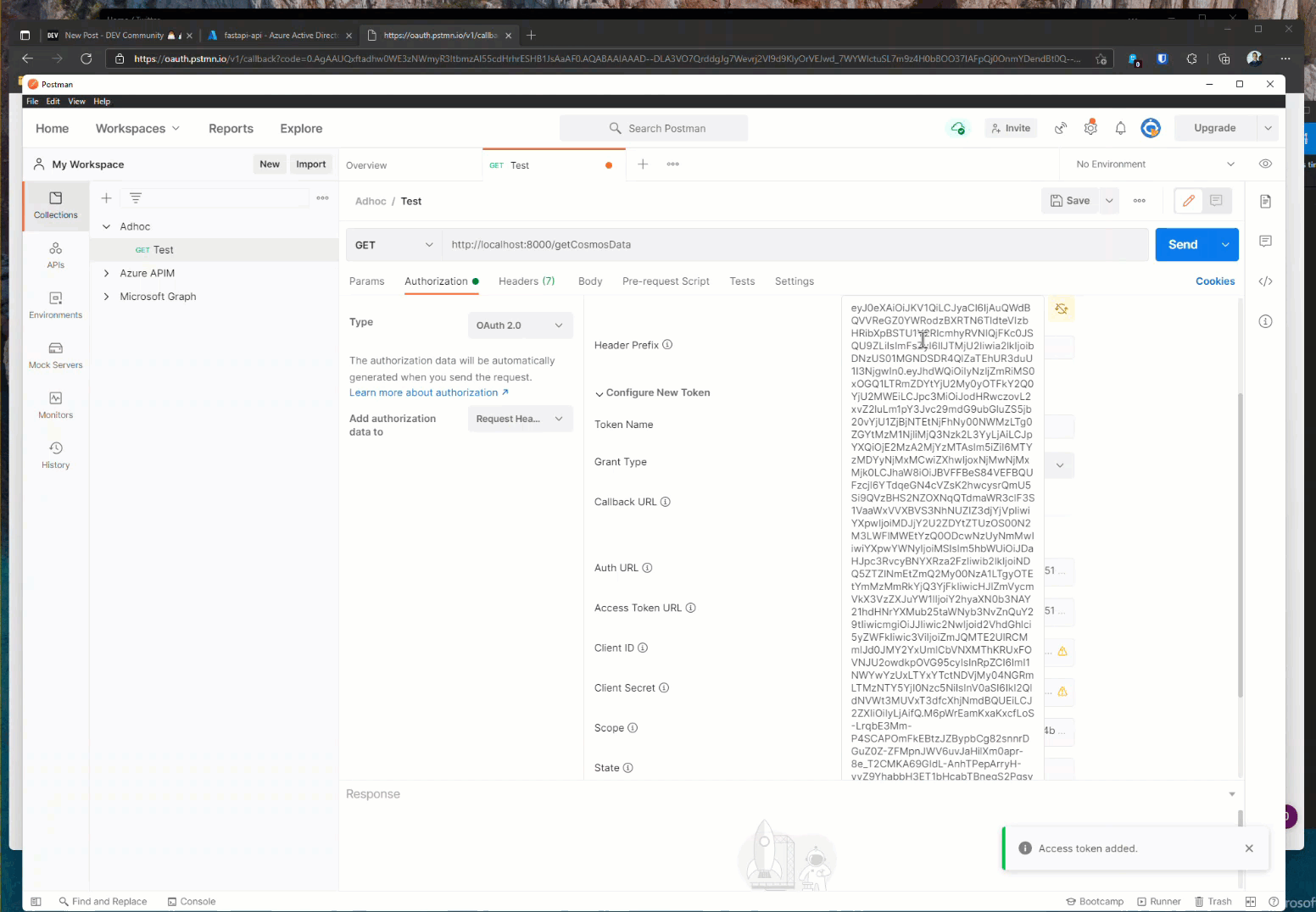
You can now use Postman to call various API endpoints. Note that if you need different scopes for different parts of the API, you'll need to add them to the scopes which will need to be space delimited.
Have fun securing and testing your APIs and make sure to join our [Discord](https://aka.ms/425Show/Discord/join) if you have any Identity or Azure related questions.
| christosmatskas | |
813,844 | hello | A post by RASHED ALMANSOORI | 0 | 2021-09-05T03:09:45 | https://dev.to/abudhabi/hello-18f1 | abudhabi | ||
812,007 | September 2nd, 2021: What did you learn this week? | It's that time of the week again. So wonderful devs, what did you learn this week? It could be... | 10,645 | 2021-09-03T01:39:45 | https://dev.to/nickytonline/september-2nd-2021-what-did-you-learn-this-week-5en8 | weeklylearn, discuss, weeklyretro | It's that time of the week again. So wonderful devs, what did you learn this week? It could be programming tips, career advice etc.
<center>

</center>
Feel free to comment with what you learnt and/or reference your TIL post to give it some more exposure.
{%tag todayilearned %} | nickytonline |
812,153 | Animation React - Bem-te-vi | Today I'm bringing another animation made with GSAP / React, you can see in my github all the... | 14,442 | 2021-09-03T03:09:54 | https://dev.to/guscarpim/react-animation-bem-te-vi-ojl | react, javascript, webdev, design | Today I'm bringing another animation made with GSAP / React, you can see in my github all the code.
This animation is for those who like the bird "Bem-te-vi", if you have ideas for improvements, the code is open, I'll be happy to receive your PR.
When accessing the site, I recommend opening the sound.
Hope you like it:

See the complete code here on GitHub <a href="https://github.com/GuScarpim/bird-animation" target="_blank"><b>Click here</b></a>
Check out the Project in action <a href="https://bem-te-vi.netlify.app/"><b>Deploy</b></a>
Thanks for reading. | guscarpim |
812,173 | Understanding Slices And The Internals In Go | Exploring slices in Go, what they are and how to use them effectively. | 0 | 2021-09-04T15:15:01 | https://dev.to/herocod3r/understanding-slices-and-the-internals-in-go-4hb1 | go, slices, arrays | ---
title: Understanding Slices And The Internals In Go
published: true
description: Exploring slices in Go, what they are and how to use them effectively.
tags: golang,slices,arrays
//cover_image: https://direct_url_to_image.jpg
---
For many languages designed over the years, we have seen alot of them take lessons from the existing to improve the experience and generally make it better. The Go design team, has also done alot of research in this area.
One area that is not appreciated as much are **slices** in Go. Slices provide a very simple abstraction over **Arrays** in Go. Slices allow you to have a _dynamic window_ overview on an array.
So, we know an array is basically "contiguous" blocks of memory. For many languages when you allocate an array you have to define the size, this is to allow a memory safe reserved space for that array.
In Go, an array can be defined like this
```Go
var array [5]int
```
This would allocate 5 blocks of either 64bits or 32bits in memory (depending on the cpu architecture). so for example
> 64*5 = 320bits = 40bytes
This is nice, assuming i know ahead of time the size of what i want to store. What if in the cause of my program i needed to add more int values ?
Well since, we already allocated fixed size of blocks, then we might need to allocate another with sufficient size and copy the old.
Well, this is where Go shines 😁. Slices provide a "dynamic window" over an array, internally there is an array, but all the magic of copying, sizing etc is abstracted away by slices.
So in that example, we could write like this with slices
```Go
slice := make([]int,5)
slice[4] = 23
slice = append(slice,5)
```
So yea, in this example, `make` internally allocates an array with a size of 5, and then when we needed to add another item to make it 6, `append` allocated a larger array and simply copied over the items in the first array, and we didnt have to do anything.
But, from the code above, when we added a new element that was clearly out of bounds, and append did all that magic what is the new length ?
if we print out the length of that slice it would simply be `6`, does that mean append only created a 6 blocks array ?
So one thing to note here, is to dig into the internals or the components that make up a slice, A slice is a dynamic view over an array and internally it can be represented as this
``` Go
type Slice struct {
Array unsafe.Pointer
cap int
len int
}
```
`Array` is a pointer to the internal array, `cap` keeps the real length of the array, `len` is the size of the `view` which is the length we get after append. When we called `append` the `cap` size changed obviously because it allocated a larger array.
Going a little more low level, can we prove these claims ? yes we can get access back to the internal array.
``` Go
slice := []int{1,2,3,4}
sliceStruct := (*Slice)(unsafe.Pointer(&slice))
arrayPtr := (*[4]int)(sliceStruct.Array)
array := *arrayPtr
```
If we run the code above, we see that we can see the internals of the slice when casting the pointer to a pointer of our Slice struct.
Im sure people with maybe java experience, would think, well isnt this just `ArrayList` or .Net engineers `List`. Yes infact it is, but done correctly with native language syntax support. For example, you can `slice` a `slice` to get a different view
```Go
slice := []int{1,2,3,4,5}
sliceB := slice[1:2]
```
In the example above, the sliceB slices the slice from the second index, with a length of 2. You would think, ok this might allocate another array ? since we are getting a slice from the second position of another.
Well no, the Array pointer in Slice, points to the memory block of the first element in the array, so when we replaced the slice, sliceB just pointed to the second block, and `len` and `cap` followed suite no expensive memory copying anywhere, so slices are very very efficient.
if we do
```Go
sliceB[0] = 7
fmt.Println(slice[1])
```
We notice, that the value is changed across, because like we said, slices is just a `view` over the memory nothing more. C# engineers might see something similar with `Span<T>`, same thing.
In summary, a `slice` is a simple efficient solution to a general problem in many other languages, which provides an efficient dynamic view over memory. | herocod3r |
812,179 | A simple tip to keep GitHub commit history less cluttered | No matter what Git branching strategy you are using, you’ll still open a pull request (PR) for peer... | 0 | 2021-09-04T16:34:55 | https://dev.to/akdevcraft/a-simple-tip-to-keep-github-commit-history-less-cluttered-1edn | github, git, sourcecontrol, tutorial | No matter what Git branching strategy you are using, you’ll still open a pull request (PR) for peer review. No one is perfect and anyone hardly remembers their code after few weeks😬
Once PR is reviewed and approved, you would merge it to the destination branch. But, at this point when we're merging the PR, we can decide whether to use "**Merge pull request**" or "**Squash and merge**". Any of these options will ultimately merge the code into the destination branch, however, we can control how commit history is propagated to the destination branch.
The recommendation is to choose the "**Squash and merge**" option, as it just creates one single commit in the destination branch, hiding all the commits coming from the source branch i.e. as the name says, it squashes all commits into one commit.
And yet we have the option to see commits that came from the source by traversing through the newly created commit. In other words, by clicking on the PR number that was merged e.g. #1 in the above screenshot. This helps to keep the destination/main branch's commit history neat and tidy.
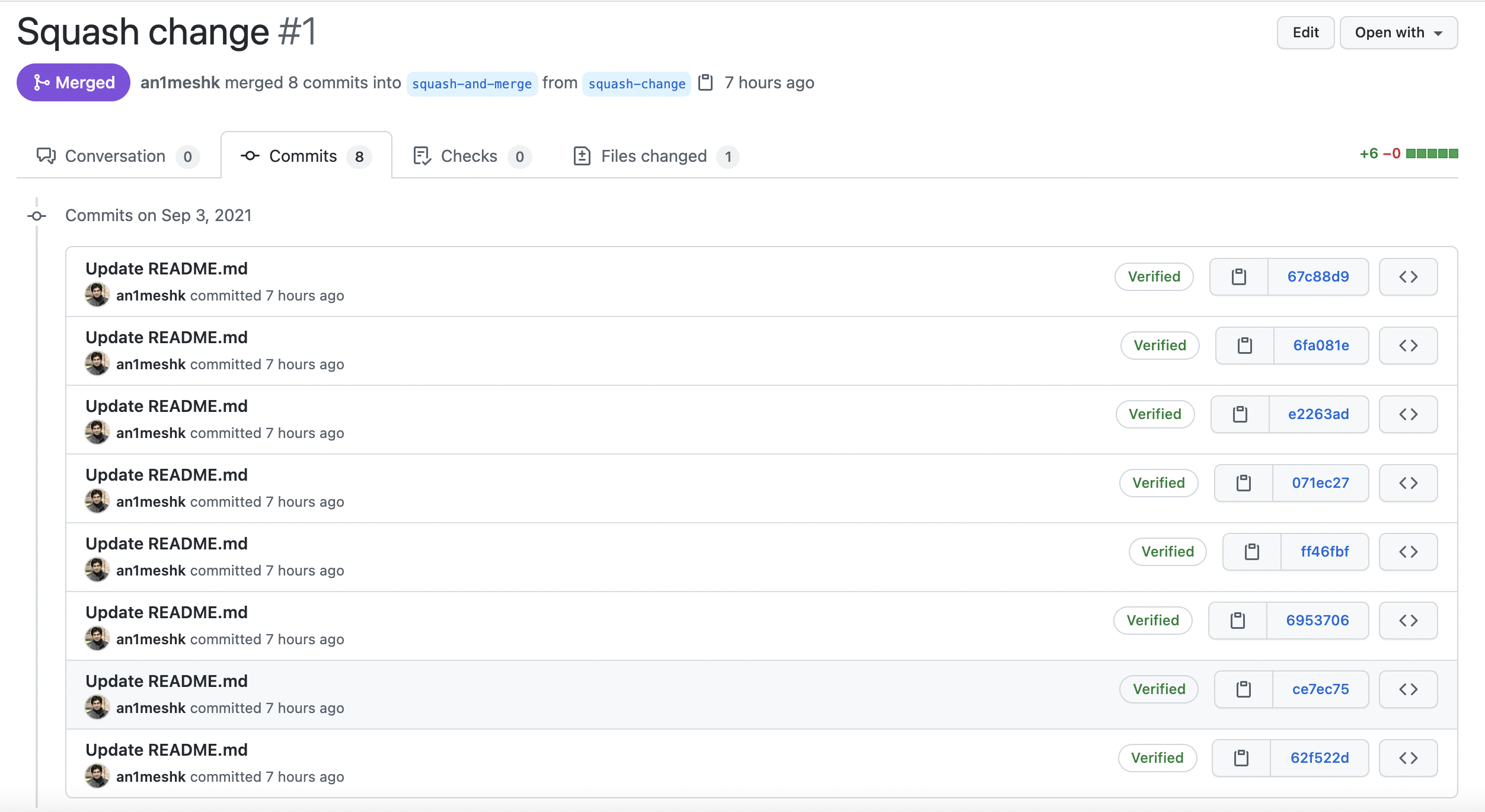
Whereas, if we choose the "**Merge pull request**" option, all commits along with a new commit for the PR will be created in the destination branch. And that looks like finding commit in a haystack.
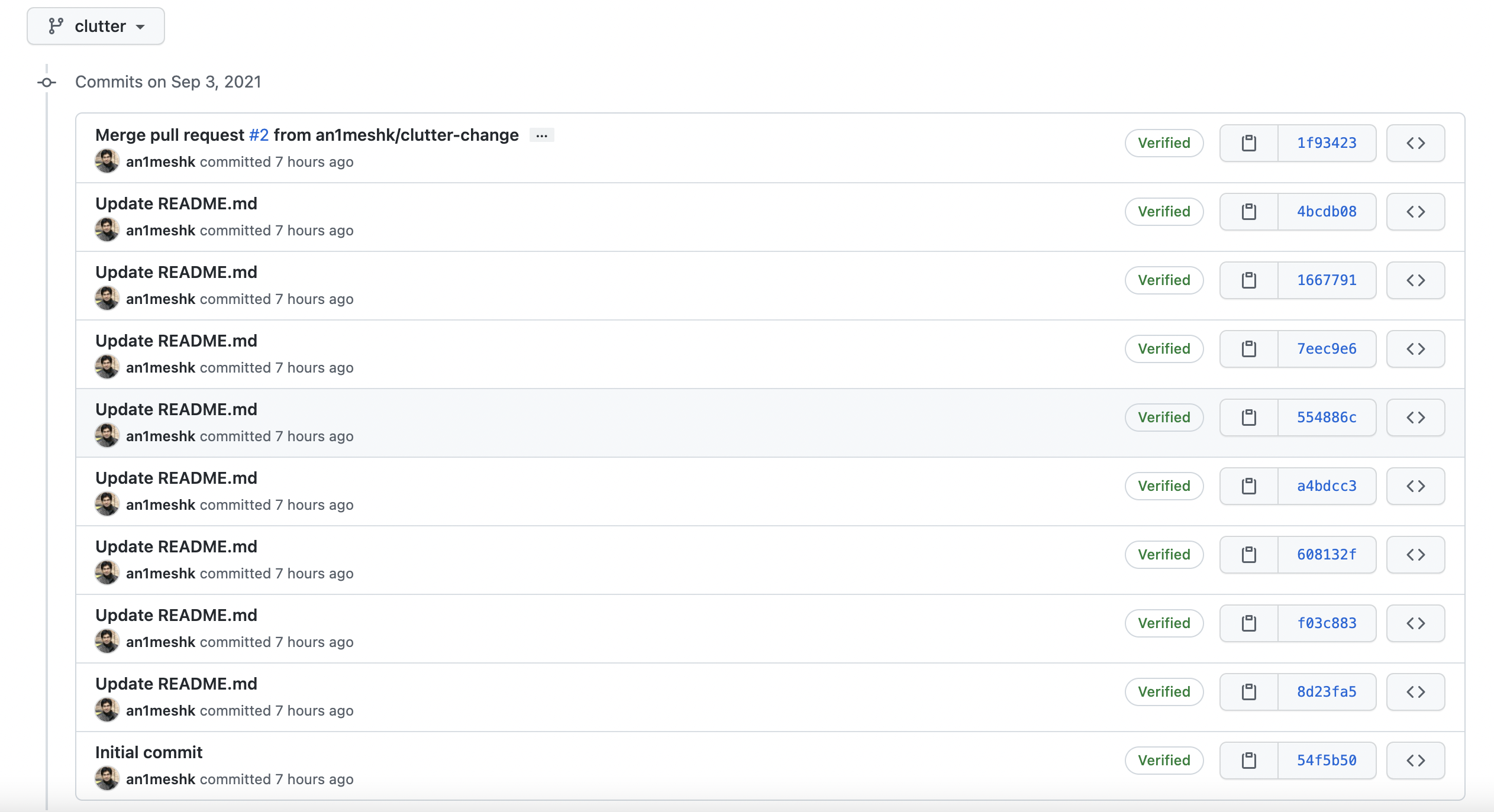
But in the end, it's up to you how you want to maintain your branch's commit history😃. Whatever you choose, **May the force be with you**!
_If you have reached here, then I did a satisfactory effort to keep you reading. Please be kind to leave any comments or ask for any corrections. **Happy Coding!**_ | akdevcraft |
812,194 | Introduction to Omit typescript utility types | The Omit utility construct a type by picking all properties from type and then removing keys. This... | 0 | 2021-09-03T06:28:13 | https://dev.to/es404020/introduction-to-omit-typescript-utility-types-go7 | typescript, nextjs, node, angular | The Omit utility construct a type by picking all properties from type and then removing keys. This allows you to remove property from any object .
```
interface Todo {
title: string;
description: string;
completed: boolean;
createdAt: number;
}
```
1. Single Omit
```
type TodoPreview = Omit<Todo, "description">;
const todo: TodoPreview = {
title: "Clean room",
completed: false,
createdAt: 1615544252770,
};
todo;
```
2.Multiple Omit
```
type TodoInfo = Omit<Todo, "completed" | "createdAt">;
const todoInfo: TodoInfo = {
title: "Pick up kids",
description: "Kindergarten closes at 5pm",
};
todoInfo;
``` | es404020 |
812,421 | New EyeDropper Web API | So, there is new cool Web API which currently is in draft state, but has all chances to be released... | 0 | 2021-09-03T14:21:30 | https://dev.to/defite/new-eyedropper-api-26bf | todayilearned, webapi, eyedropper | So, there is new cool Web API which currently is in draft state, but has all chances to be released in all modern browsers. EyeDropper lets you pick colors not only in your browser, but in other windows, which is cool for online editors like Figma, for example.
You can look at specs [here](https://wicg.github.io/eyedropper-api/) and [here](https://github.com/WICG/eyedropper-api).
To try new API we need to download Chrome Canary (the exact support is starting from Chrome 95 version).
First, let's make classic check for Eyedropper support:
```js
if (window.EyeDropper == undefined) {
console.error('EyeDropper API is not supported on this platform');
}
```
This will ensure, that we have support of this feature and can go on.
Now, time for magic 🪄
```js
await new EyeDropper().open()
```

To be more specific, I've prepared a little demo of how this might work.
{% codesandbox eyedropper-api-test-etjt4 %}
| defite |
812,509 | Cloud Technology News of the Month: August 2021 | The summer might be slowly coming to an end, but here’s something to invigorate you: another portion... | 0 | 2021-09-03T12:51:47 | https://cast.ai/blog/cloud-technology-news-of-the-month-august-2021/ | cloudnative, kubernetes, aws, googlecloud | <!-- wp:paragraph -->
<p>The summer might be slowly coming to an end, but here’s something to invigorate you: another portion of fresh cloud technology news. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>This series brings you up to speed with the latest releases, acquisitions, research, and hidden gems in the world of cloud computing – the stuff actually worth reading. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Here’s what happened in the cloud world this August.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>_____</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Story of the month: Multi cloud is here, there’s no denying it anymore</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>HashiCorp recently published its inaugural State of Cloud Strategy Survey, which showed that <strong>multi cloud is the new normal</strong>.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The company surveyed 3,205 tech practitioners and decision-makers from companies of different sizes and industries and hailing from various locations around the world. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Here are the most interesting findings:</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Multi cloud is real</h3>
<!-- /wp:heading -->
<!-- wp:image -->
<figure class="wp-block-image"><img src="https://lh6.googleusercontent.com/VY8_Wo8C7UUPuGQslSMc3_d7CeOmmT3A3kwoh22_HcWqDfWscGZek-Ss1-8dpMAGzDm4fZOHDRoy0nrSb0WMf7xcpKHeemgGgVvGSBnVGtA6KldJYcTP-wZSgmdj-In6pfLguBs1=s0" alt="Multi-Cloud Adoption Pie Chart"/></figure>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>Source: HashiCorp</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>76% of respondents are already working in multi cloud environments</strong>, using more than one public or private cloud. Multi cloud is no longer an inspirational idea - it’s an everyday reality. And since 86% of tech practitioners expect to be using multi cloud within the next two years, the adoption of multi cloud will only grow.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Who goes multi cloud?</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To no surprise, multi cloud adoption is greatest among larger organizations - <strong>90% of companies with more than 5k employees are already using multi cloud</strong>. Still, 60% of small businesses (counting <100 employees) already have multi cloud environments, and 81% of them expect to embrace this approach within the next two years.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>What drives multi cloud adoption?</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Why are all of these companies adopting the multi cloud approach? The top reason lies in <strong>digital transformation programs</strong>. This is interesting because we all thought it was all about cost optimization and avoiding vendor lock-in.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Here are the top driving forces behind multi cloud:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li><strong>34%</strong> - digital transformation initiatives, </li><li><strong>30%</strong> - avoiding single cloud vendor lock-in, </li><li><strong>28%</strong> - cost reduction, </li><li><strong>25%</strong> - ability to scale. </li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Digital transformation was especially strong among enterprises as 50% of them pointed to this factor. But it also caught the attention of the financial services industry, where 41% of respondents consider it a top driver.</p>
<!-- /wp:paragraph -->
<!-- wp:image -->
<figure class="wp-block-image"><img src="https://lh5.googleusercontent.com/sQdg2m70Q91lS8RVGXmTGz28xz7skC03FeSO8tMaietHzT1WUuOsPvwaU6iDBc06QvbCX6MM-H3oK0q7eHnQaIky0KfH0mxbIITan2vYyZbOT9qZBzMkcMsEVtFIQTU_-yTrpRi6=s0" alt="What are the business and technology factors driving your multi-cloud adoption?"/></figure>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>Source: HashiCorp</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>What are the key inhibitors to multi cloud’s rise to fame?</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Two things make moving to multi cloud hard: <strong>skill shortage and security</strong>. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>More than half (57%) of respondents consider skill shortage as the top challenge that hinders building multi cloud capabilities. Next, we see inconsistent workflows across cloud environments (33%) and team siloization (29%).</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Another problem is security, the top-three inhibitors on many cloud journeys. Almost half (47%) of respondents said that security is the issue - be it governance, regulatory compliance and risk management, or data and privacy protection.</p>
<!-- /wp:paragraph -->
<!-- wp:image -->
<figure class="wp-block-image"><img src="https://lh5.googleusercontent.com/ahtyfFDWV0lZWiFZsgnhm0Iy05ACNVTBSq0E5iwqsk6t21j4daYgCn_RrrmGE6_dJdfgnMYND9dCr2zg_P1RtrBuI-m38NGRck3c5wEWM0iEuuxVP1ZaoFauYs-Hw4__pCs9No9F=s0" alt="Top security concerns bar chart"/></figure>
<!-- /wp:image -->
<!-- wp:heading {"level":3} -->
<h3>And a final gem: 46% of tech leaders don’t think it’s COVID-19 that’s driving them to the cloud</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Many ascribe the spread of cloud technologies to the pandemic’s impact on the global economy, but this seems to be an incomplete picture. Almost <strong>half of the survey respondents (46%) said that COVID-19 didn’t affect their move to the cloud</strong>, and another 19% said it had a low impact (speeding the shift by some 6-12 months).</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>This shows that in most organizations, cloud efforts were well underway before the pandemic started and are bound to continue in the post-pandemic future. </strong></p>
<!-- /wp:paragraph -->
<!-- wp:image -->
<figure class="wp-block-image"><img src="https://lh5.googleusercontent.com/Yy9vDBPj2TGVOukL-xN7IfTU26SrWsyl2zoZkZGHJLDmHHCG63drxg1mCBDC_rfEnE3eDiwE45_mflla-nJRcG4LobZ4c2aLP44leVa3-mBezymShzwYquiWPSEpst_62Gr9e6_s=s0" alt="Covid's cloud impact chart"/></figure>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>Interestingly, in response to the pandemic, many companies embraced modern, cloud native technologies like:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li>Infrastructure as Code (49%), </li><li>container orchestration (41%), </li><li>network infrastructure automation (33%), </li><li>and said self-service infrastructure (32%).</li></ul>
<!-- /wp:list -->
<!-- wp:quote {"className":"is-style-large"} -->
<blockquote class="wp-block-quote is-style-large"><p>At CAST AI, we believe that multi cloud is the future, leading to the democratization of cloud services and reduced vendor lock-in. That’s why our platform comes with a host of multi cloud features - find out more about them here:<strong> </strong><a href="https://cast.ai/blog/how-to-spin-a-multi-cloud-application-with-cast-ai/"><strong>How to spin a multi cloud application with CAST AI</strong></a><strong>.</strong></p></blockquote>
<!-- /wp:quote -->
<!-- wp:paragraph -->
<p>Source: <a href="https://www.hashicorp.com/blog/hashicorp-state-of-cloud-strategy-survey-welcome-to-the-multi-cloud-era">HashiCorp</a> </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><figure class="wp-block-image size-full"><img src="https://cast.ai/wp-content/uploads/2021/08/dollar-banner.png" alt="" class="wp-image-3380" onclick="Calendly.initPopupWidget({url: 'https://calendly.com/matas-c?utm_source=website&background_color=f1f1f1&text_color=082939&primary_color=2acd7f'});return false;"></figure></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>_____</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>The Business of Cloud</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Rumor has it <strong>Databricks</strong> - the cloud data company that raised $1 billion earlier this year - agreed to a new deal that includes <strong>its valuation at a smashing $38 billion</strong>. Morgan Stanley is to lead the investment round said to bring at least $1.5 billion to the company. These figures prove that the cloud market is hotter than ever and we’re bound to see more investments into cloud companies in the near future.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Source: <a href="https://www.bloomberg.com/news/articles/2021-08-18/databricks-funding-will-bring-valuation-to-38-billion">Bloomberg</a></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>GE Appliances</strong> <strong>signed a multi-year partnership with Google Cloud </strong>to develop next-gen smart home technologies. The company will benefit from the cloud giant’s expertise in data, AI, machine learning, and smooth integration with other Google technologies like Android, Google Assistant, and Vision AI. Let’s keep a close eye on the IoT scene and see what comes out of this collaboration.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Source: <a href="https://cloud.google.com/press-releases/2021/0819/gea">Google Cloud</a> </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>61% of public cloud comes from AWS, Microsoft Azure, and Google Cloud</strong>, according to the analytics company Canalys. <strong>AWS now accounts for 31% of global cloud infrastructure </strong>spending, bringing in home revenue of some $59 billion per year (that’s more than HP or Lenovo!). At a 22% market share, <strong>Microsoft Azure</strong> is the second-largest cloud provider (and growing by more than half from 2020Q2!).</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Source: <a href="https://canalys.com/newsroom/global-cloud-services-q2-2021">Canalys</a> </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>_____</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Food for thought</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>The cloud gets political, this time in the tug-of-war between the US and China.</strong> The cloud is said to become China’s next objective - and things are certainly looking good. During the pandemic, Chinese cloud providers noted incredible growth. Huawei more than doubled its global IaaS market share. Modern societies increasingly depend on the cloud and all the digital services it connects - from email to AI applications. It’s high time US policymakers started seeing the cloud as a strategic investment.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Source: <a href="https://www.politico.com/newsletters/politico-china-watcher/2021/08/26/us-at-risk-of-losing-cloud-computing-edge-to-china-494105">Politico</a> </p>
<!-- /wp:paragraph -->
{% twitter 1382746372756082693 %}
<!-- wp:paragraph -->
<p>The UK government now officially<strong> advises that companies move to the cloud to curb carbon emissions</strong>. Cloud migration was listed by the Department for Business, Energy and Industrial Strategy (BEIS) as one of the steps businesses should take to fight climate change. This comes as part of the government’s border push to inspire companies to support its net-zero emissions campaign that assumes cutting carbon footprints by half by 2030.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>If you’re interested in this topic, be sure to check out the session co-hosted by our Product Marketing Manager Annie Talvasto at the upcoming <strong>KubeCon + CloudNativeCon North America</strong>: <em>How Event Driven Autoscaling in Kubernetes Can Combat Climate Change - Annie Talvasto, CAST AI & Adi Polak, Microsoft </em>(more info <a href="https://sched.co/lV4B">here</a>).</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Source: <a href="https://www.computerweekly.com/news/252505293/UK-government-tells-firms-to-use-cloud-to-curb-their-carbon-emissions-and-fight-climate-change">Computer Weekly</a> </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>_____</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>New in CAST AI</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>And here are some new product features hot off the press: </p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li>We released the first version of the <strong>cluster metrics endpoint</strong> that provides visibility into the CAST AI-captured metrics (explore the setup guide on <a href="https://github.com/castai/examples/tree/main/metrics">Github</a>). We will be expanding the list of exposed metrics, so stay tuned.</li><li>Our team implemented the <strong>Node Root Volume Policy policy </strong>that allows the configuration of root volume size based on the CPU count. That way, nodes with a high CPU count can have a larger root disk allocated to them.</li><li>We enhanced the <strong>Spot instance policy</strong> for EKS and Kops, so you can provision the least interrupted instances, the most cost-effective ones, or just go with the default balanced approach. </li><li><strong>CAST AI agent v.0.20.0 </strong>was released – it now supports auto-discovery of GKE clusters, so there’s no need to enter any cluster details manually.</li><li><strong>Cluster headroom</strong> and <strong>Node constraints policies</strong> are now separated and can be used simultaneously.</li><li>We made it easier for users to set <strong>correct node CPU and Memory constraints </strong>that adhere to the supported ratios.</li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>P.S. Be the first one to optimize a GKE cluster with CAST AI. </strong>Connect your cluster, get a self-served savings report now and <a href="https://console.cast.ai/external-clusters/new">start saving</a>. Not a GKE user? Share this link with someone who is.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>_____</p>
<!-- /wp:paragraph --> | castai |
812,665 | I want to complete connect with "ekkarat.w@gmail.com" | Connect to ekkarat.w@gmail.com | 0 | 2021-09-03T16:13:57 | https://dev.to/ekkarat/i-want-to-complete-connect-with-ekkarat-w-gmail-com-5c77 | Connect to ekkarat.w@gmail.com | ekkarat | |
812,881 | Old MacDonald | # exercise1.py # This program prints the lyrics for five different animals to the # "Old... | 0 | 2021-09-03T18:14:52 | https://dev.to/sagordondev/old-macdonald-53pi | python, computerscience, functional | ```python
# exercise1.py
# This program prints the lyrics for five different animals to the
# "Old MacDonald" song to demonstate functions.
# by: Scott Gordon
# Create functions for verses that repeat
def verse1():
return "Old MacDonald had a farm, Ee-igh, Ee-igh, Oh!"
def verse2(animal):
return f"And on that farm he had a {animal}, Ee-igh, Ee-igh, Oh!"
def verse3(sound):
return f"With a {sound}, {sound} here and a {sound}, {sound} there."
def verse4(sound):
return f"Here a {sound}, there a {sound}, everywhere a {sound}, {sound}."
# Create a function to run all the functions through
def song_verse_creator(animal, sound):
print(verse1())
print(verse2(animal))
print(verse3(sound))
print(verse4(sound))
print(verse1())
# Run 5 different functions
song_verse_creator("cow", "moo")
print()
song_verse_creator("chicken", "cluck")
print()
song_verse_creator("dog", "woof")
print()
song_verse_creator("duck", "quack")
print()
song_verse_creator("horse", "neigh")
```
Photo by <a href="https://unsplash.com/@calanthe?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Zosia Korcz</a> on <a href="https://unsplash.com/s/photos/farm-animal?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
| sagordondev |
812,888 | Why I haven't committed to React (yet) | JSX is the one contribution to my overall development experience over the last few years, I have used... | 0 | 2021-09-03T18:34:32 | https://dev.to/adam_cyclones/why-i-haven-t-to-learned-react-yet-ei | javascript, react | JSX is the one contribution to my overall development experience over the last few years, I have used JSX / TSX in Vue.js and really preferred it over SFCs for a good long while.
Then I picked up lit-html and saw another more natural way to write templates, but then google kind of merged the project with lit-element. It's okay... But lit-element added a ton of boilerplate on top of the simple templating language I was attracted to, mostly declaratively defined OOP which I will tolerate but not enjoy.
Finally I finished my trip to obscurity with another JSX powered beast, Stencil - a way of writing web components that is so good, for two years, I couldn't bring myself to learn React, and not stand out. Stencil like Svelte is a compiler and scores incredibly well in performance out of the box, 100 performances, yes please! It also manages to do SSR with web components, yeah, no idea how 🧙♂️, today I'm not going to learn about that.
React is kind of the jQuery of today (in it's popularity and future tech debt hangover), so everyone must know it, which sucks for me because I could pick up React projects which I often do, but am I a React expert? Kinda, sorts, no.. so no CV entry 😅
But React functional components, they look nice, and all the libraries I personally will never finish in order to get to my end goal, well they already exist In React... So today with great caution, I am going to try and get React on my CV, like everyone else, I'm so mainstream.
useEffect go! | adam_cyclones |
814,679 | AWS CloudFormation - Hands On | Last article we studied what is AWS CloudFormation in this article we will create a basic AWS cloud... | 14,478 | 2021-09-06T03:02:49 | https://dev.to/this-is-learning/aws-cloudformation-hands-on-4dae | aws, cloud, devops, tutorial | Last article we studied what is AWS CloudFormation in this article we will create a basic AWS cloud formation template. To setup a template in AWS CloudFormation follow the steps below:-
* Search for AWS CloudFormation in the search bar and go to AWS cloud formation
* You will get to the dashboard click on create stack
* In the prepare template select `Template is ready`. Here we can select other options to like use `Sample template` which uses an already created template or you can also choose to `Create template in designer` which helps you create templates visually.
* After that select `upload a template file` You can also select a templete file form your S3 bucket. Upload the following `aws-example.yaml` file
```yaml
Resources:
HelloBucket:
Type: AWS::S3::Bucket
```
You can also click on `View in Designer` to visually see how your stacks looks like
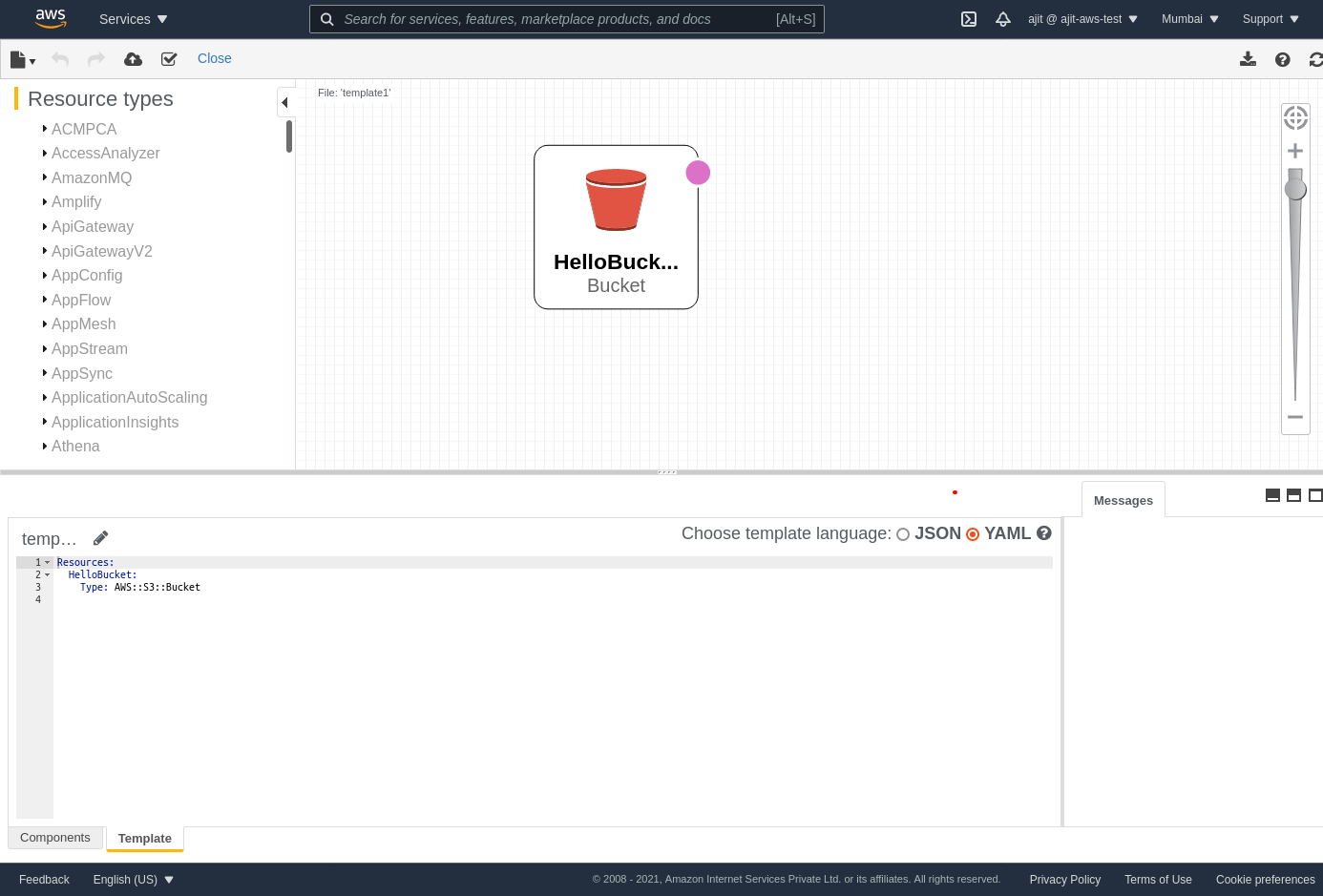
* Click next enter a stack name like `CloudFormationdemo` and click next
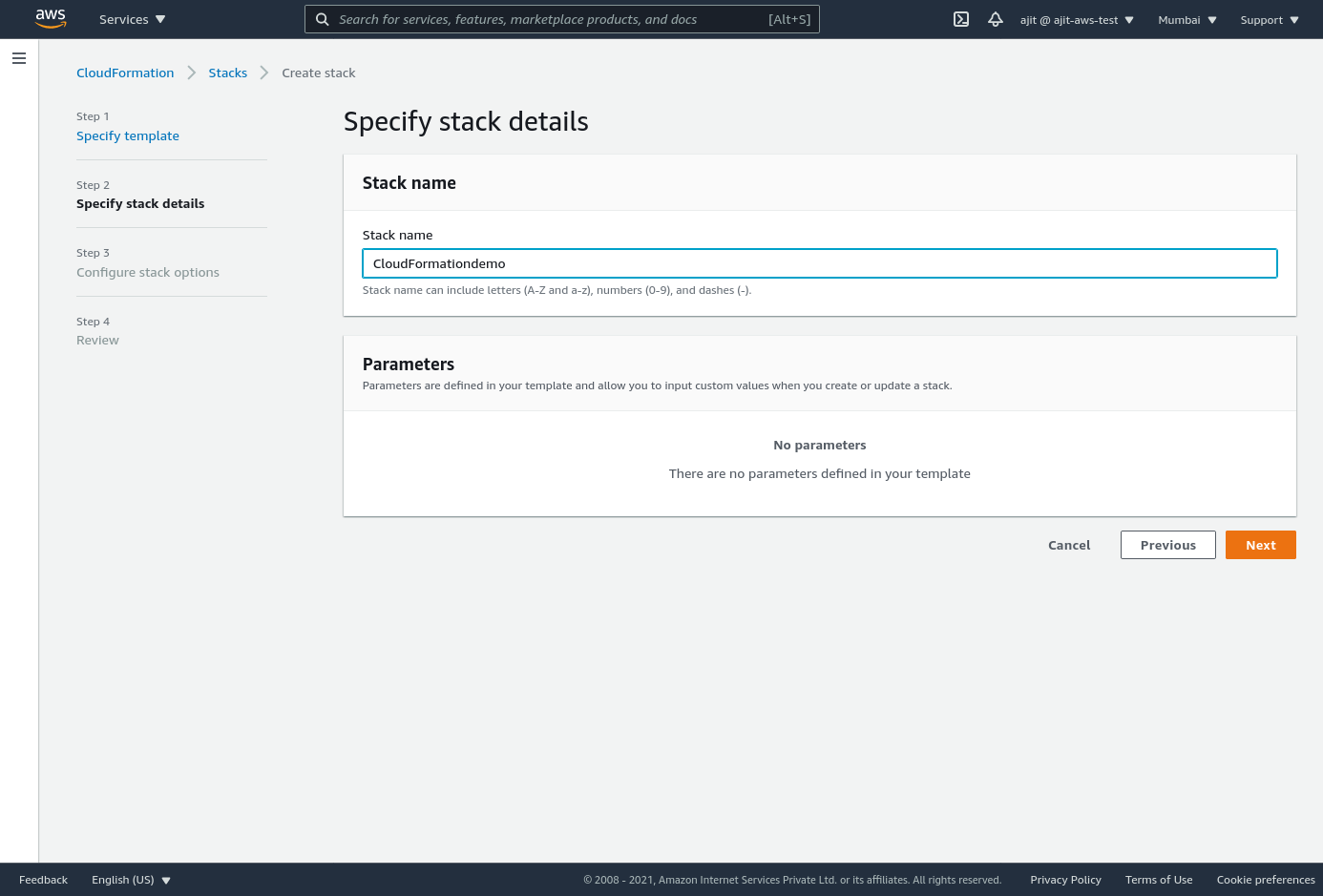
* Next you can add tags to identify your cloud formation resources and r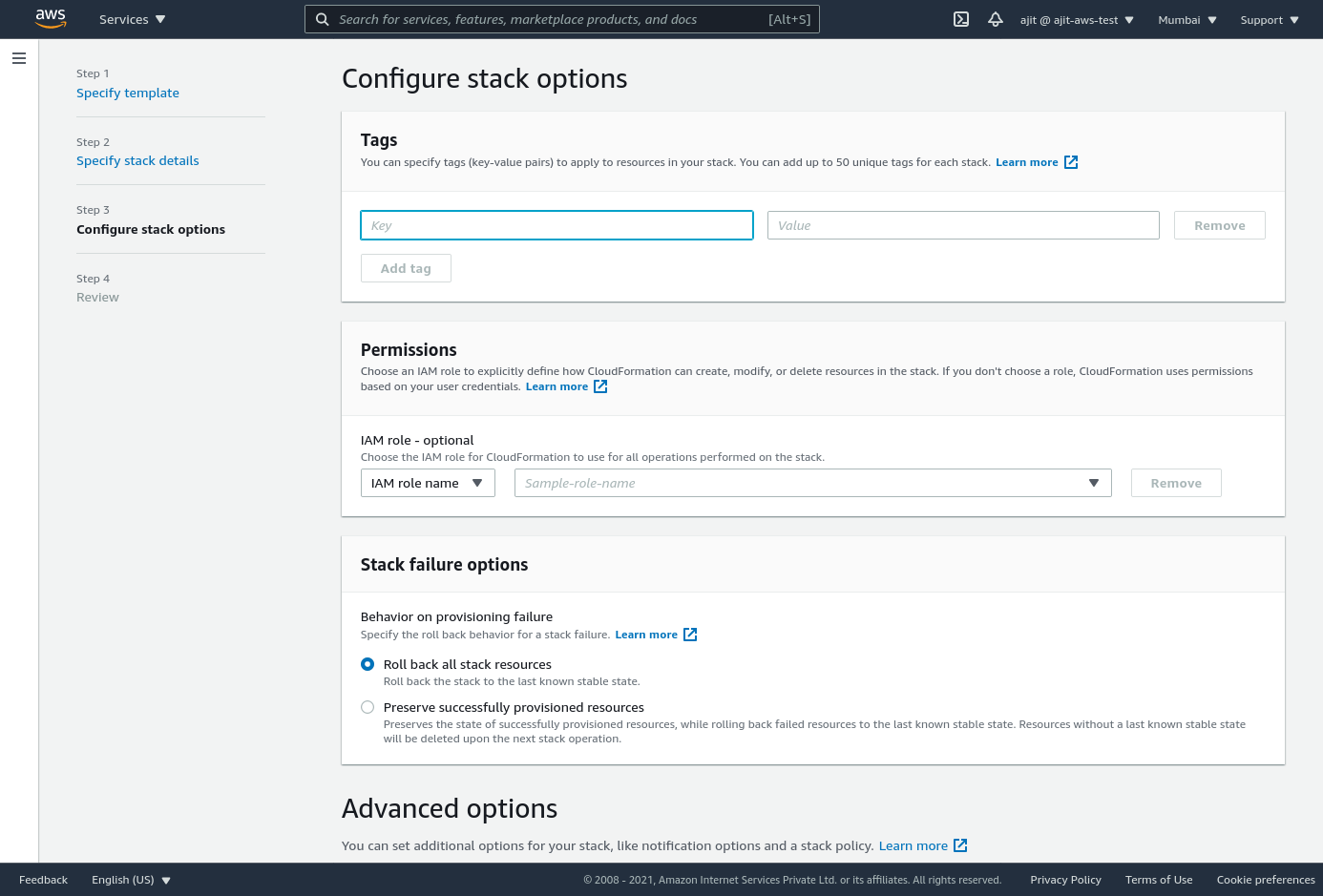
oles to give access to various services we don't need roles and set the tag as name `CloudFormation` you can use any other tag.
. Then click on next. You can review all your values are correct and click on create stack
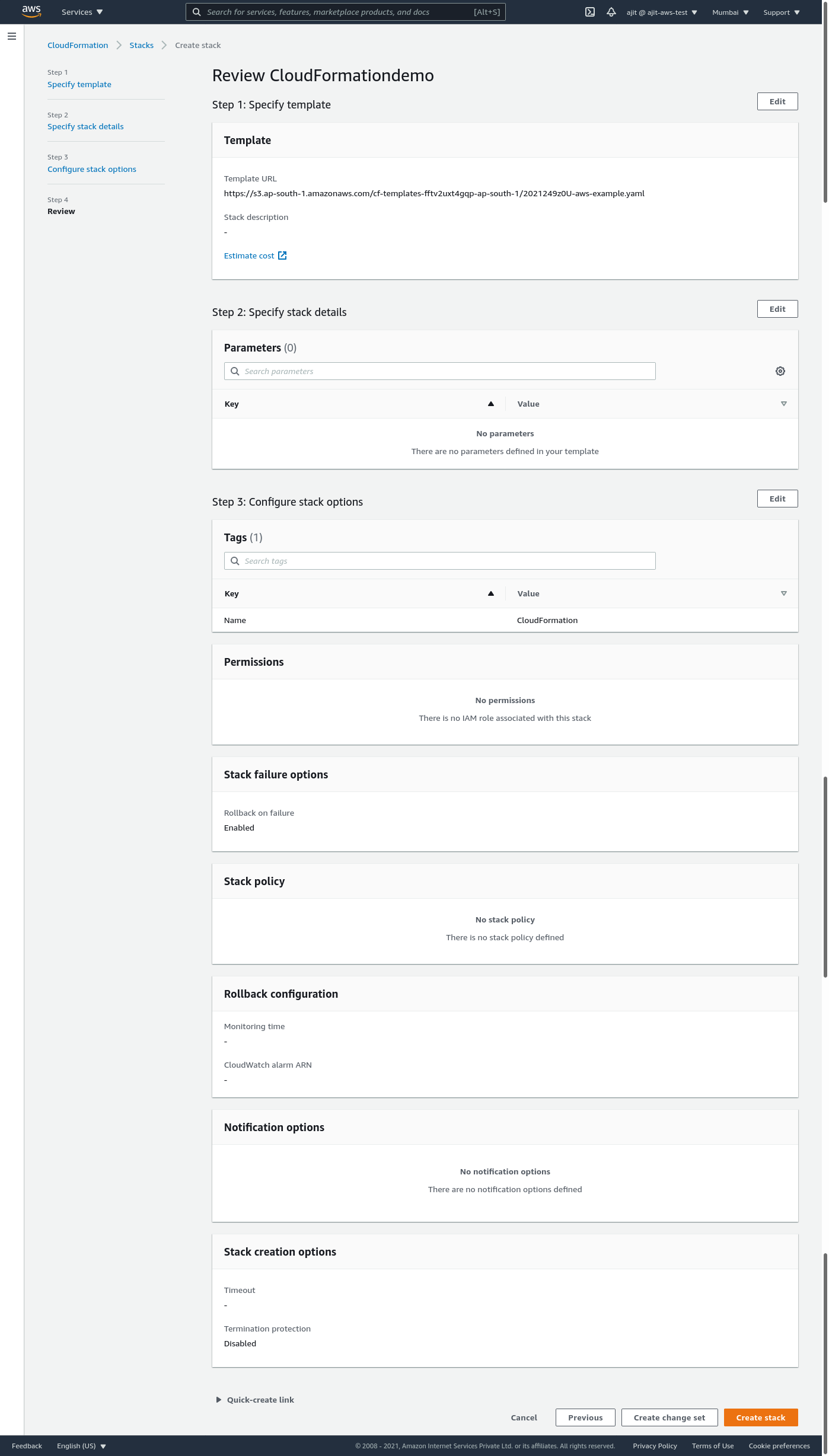
* It will show you all the events that happened while creating a cloud formation template
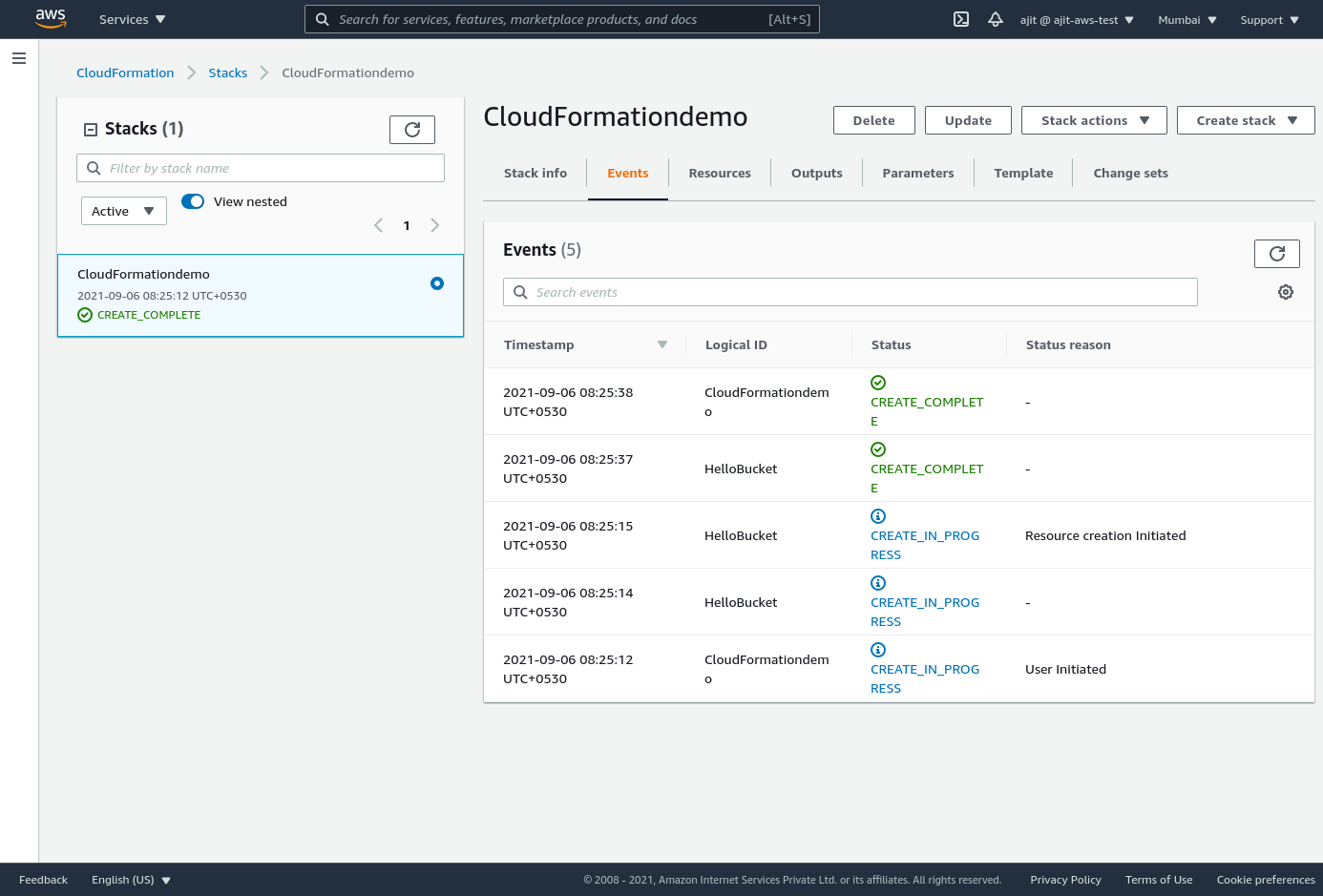
* Go to your S3 console and you can see that there is a bucket Cloudformationdemo
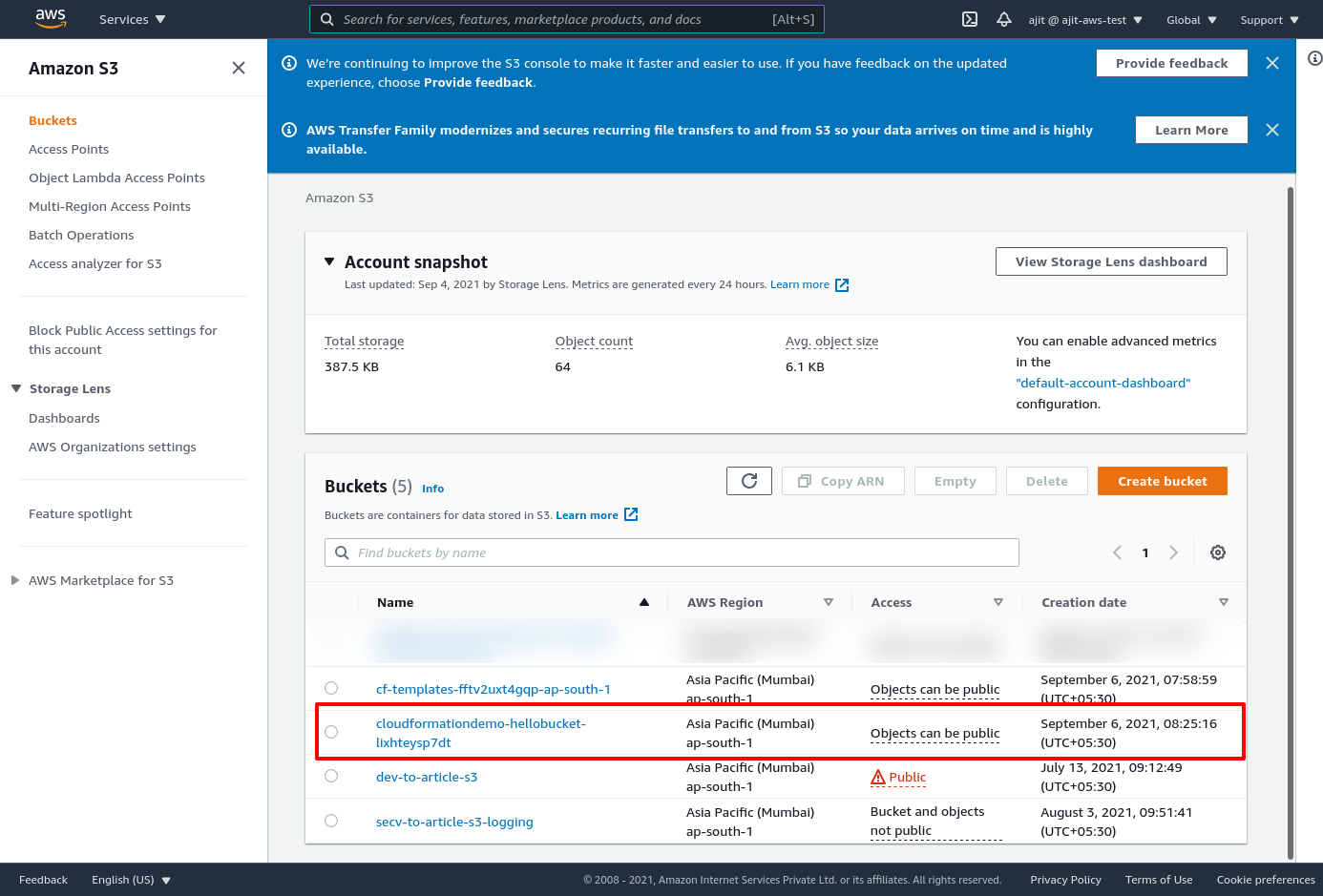
* This is way to create a Cloud Formation Stack don't forget to delete your CloudFormation stack if you are doing this as a demo
Next we will study about Amazon Beanstalk.
| ajitsinghkaler |
812,927 | Ou Isso ou Aquilo: Exemplos com Operador Ternário (Parte 5) | Vou pegar alguns exemplos do livro Algoritmos: Lógica para Desenvolvimento de Programação de... | 0 | 2021-09-09T14:56:27 | https://ananopaisdojavascript.hashnode.dev/ou-isso-ou-aquilo-exemplos-com-operador-ternario-parte-5 | javascript, algorithms | Vou pegar alguns exemplos do livro **Algoritmos: Lógica para Desenvolvimento de Programação de Computadores** de José Augusto N. G. Manzano e Jayr Figueiredo de Oliveira (Editora Érica).
## Exemplo 1
### Desenvolver um programa que efetue a leitura de um valor numérico inteiro e apresente-o caso esse valor seja divisível por 4 e 5. Não sendo divisível por 4 e 5 o programa deverá apresentar a seguinte mensagem "Não é divisível por 4 e 5".
O usuário vai digitar um número inteiro. Um programa vai determinar se esse valor é divisível por 4 e 5 e o mostrará na tela. Vou criar uma variável para esse número:
```javascript
const valor = Number(prompt("Digite um número inteiro qualquer"));
```
Agora vem a parte legal! Vou criar um operador ternário para fazer a verificação:
```javascript
const numeroDivisivelPor4E5 = (valor % 4 === 0 && valor % 5 === 0) ? console.log(`O número ${valor} é divisível por 4 e 5`) : console.log(`O número ${valor} não é divisível por 4 nem por 5`);
```
Legal, não é mesmo?
## Exemplo 2
### Ler um valor numérico inteiro que esteja na faixa de valores de 1 até 9. O programa deve apresentar a mensagem "O valor está na faixa permitida" caso o valor informado esteja entre 1 e 9. Se o valor estiver fora da faixa, o programa deve apresentar a mensagem "O valor está fora da faixa permitida"
Vou criar uma variável para que o usuário digite um número entre 1 e 9:
```javascript
const valor = Number(prompt("Digite um número inteiro qualquer entre 1 e 9"));
```
Vou criar um operador ternário para verificar se o número digitado está dentro da faixa desejada:
```javascript
const faixa = (valor >= 1 && valor <= 9) ? console.log("O valor está na faixa permitida") : console.log("O valor está fora da faixa permitida");
```
## Exemplo 3
### Ler os valores de quatro notas escolares de um aluno. Calcular a média aritmética e apresentar a mensagem "Aprovado" se a média obtida for maior ou igual a 5; caso contrário, apresentar a mensagem "Reprovado". Informar junto de cada mensagem o valor da média obtida.
Vou criar quatro variáveis para receber as notas que o usuário vai inserir.
```javascript
const nota1 = Number(prompt("Digite a primeira nota"));
const nota2 = Number(prompt("Digite a segunda nota"));
const nota3 = Number(prompt("Digite a terceira nota"));
const nota4 = Number(prompt("Digite a quarta nota"));
```
Vou criar uma variável para calcular a média. Se a média for igual ou maior do que 5, exibir a mensagem "Aprovado". Caso contrário, exibir a mensagem "Reprovado".
```javascript
const somaNotas = nota1 + nota2 + nota3 + nota4;
const media = somaNotas / 4;
const aprovadoOuReprovado = (media >= 5)
? console.log(`Aprovado. Média ${media.toFixed(2)}`)
: console.log(`Reprovado. Média ${media.toFixed(2)}`);
```
### BIBLIOGRAFIA
MANZANO, José Augusto N. G., OLIVEIRA, Jayr Figueiredo de. **Algoritmos: Lógica para Desenvolvimento de Programação**. São Paulo, Editora Érica Ltda., 2005.
E aí? Gostaram? Até a próxima anotação! ☺ | ananopaisdojavascript |
813,168 | Keep trying, Never Give up | No matter how hard it gets, Keep trying, No matter how low you get, Keep trying! Life is about... | 0 | 2021-09-04T05:28:33 | https://dev.to/jokeer/keep-trying-never-give-up-1i60 | keep, trying, never | No matter how hard it gets, Keep trying, No matter how low you get, Keep trying!
Life is about testing you to see what type of person you want to be, So Keep trying, Never Give up | jokeer |
813,190 | 20 Essential Spring Boot Interview Questions | Hello, fellow developers, I have compiled a list of essential Spring Boot interview questions that I... | 0 | 2021-09-14T12:08:17 | https://flexiple.com/spring-boot/interview-questions/ | programming, tutorial, beginners | Hello, fellow developers, I have compiled a list of essential Spring Boot interview questions that I felt every developer should know.
Do drop your thoughts in the comments section below. Also, feel free to comment in case you find any content to be incorrect.
## 1. What are Spring Boot starters, and what are the different starters available?
Spring Boot starters were built to address the various dependency management issues that arise while working on a complex project.
They are a set of convenient dependency descriptors that you could easily include in your application. They automatically manage dependencies, allowing you to focus on other important parts of your projects.
There are numerous starters available that can help you get your project running. All starters in the Spring Boot framework follow a similar naming scheme: spring-boot-starter-*, where * refers to a particular application.
The following are a few commonly used Spring Boot starters, however, you can find the entire list of starters here.
- The Web Starter (spring-boot-starter-web)
- The Test Starter (spring-boot-starter-test)
- The Data JPA Starter (spring-boot-starter-data-jpa)
- The Mail Starter (spring-boot-starter-mail)
## 2. What do you mean by Auto-Configuration in Spring Boot?
Auto-configuration in Spring Boot automatically attempts to configure your Spring application based on your jar dependencies.
The most commonly used example is the HSQLDB classpath. Let’s say HSQLDB is on your classpath but you are yet to configure any database connection beans, then Spring Boot attempts to auto-configure an in-memory database.
## 3. What is CLI in Spring Boot? Also, mention some of its features?
The Spring Boot CLI is a command-line tool that allows you to quickly start developing a Spring application. This CLI allows you to run Groovy scripts. These scripts have a Java-like syntax with minimal overlap.
Some of the main features that Spring Boot CLI provides are:
- Auto configurations
- Dependency management
- Application servers
- Endpoint management
## 4. What are the various methods used to create a Spring Boot application?
Spring Boot comes inbuilt with multiple quick and handy methods that allow you to create an application. Listed below are a few methods.
- Spring Initializer
- Boot CLI
- Using Maven
- IDE project wizard
## 5. What is Spring Boot Initializr? and what are the advantages of using it?
Spring Boot Initializr is a web-based tool that makes bootstrapping Spring Boot or Spring applications easier. Spring Boot Initializr provides a simple interface and is integrated with major Java IDEs.
The major advantages of Spring Boot Initializr are:
- Reduced time in creating a Spring or Spring Boot application
- Extensible API support to quickly generate and start projects
- A configured structure that helps define all the aspects related to the projects
## 6. What are the steps required to override default properties in Spring Boot?
Spring Boot applications have their configuration externalized through the application.properties file. Although these properties work as default values, they can be overridden.
The steps to do this are as follows:
- Start by creating an application.properties file in the classpath to override specific properties. For Spring Boot, the file to be overridden in the classpath is application.yml.
- For Maven projects, the file will be under /src/main/resource
- Change the Server HTTP port, the default port would be 8080. Add the following code to the application.properties file to change the port to 9090
```
server.port=9090
```
## 7. What are the various embedded containers that Spring Boot supports?
Spring Boot supports the following embedded containers
- Tomcat
- Undertow
- Jetty
## 8. Why are Actuators used in Spring Boot?
Spring Boot Actuators allow developers to include production-ready features into their applications. Actuators are mainly used to display operational information about the application.
Some examples of this type of information are the health metrics, info, dump, etc and this data can be used to monitor our application, gather metrics, understand traffic, etc.
The following code can be used to enable a Spring Boot Actuator.
```html
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
```
## 9. How are custom endpoints created in Spring Boot?
In order to create a custom endpoint in Spring, the user must expose the instance of the custom endpoint class as a bean.
In the code below, we have implemented the Endpoint <T> interface.
```java
@Component
public class CustomEndpoint implements Endpoint {
//method implementation
}
```
## 10. How is security implemented for Spring boot applications?
While using Spring Boot, security can be easily implemented by using the Spring Boot security starter (spring-boot-starter-security).
This code is used to add the security starter to your application.
```html
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
```
## 11. How are databases configured using Spring Boot?
Spring Boot provides comprehensive support while working with databases. SQL databases can be easily configured.
In order to configure your database and your application, you could either use the spring-boot-starter-jbdc or spring-boot-starter-data-jpa starter. Furthermore, to configure the data source, the application.properties file can be used.
The following code can be used to configure a MySQL database and is the answer to the aforementioned Spring Boot interview question:
```java
spring.datasource.url=jdbc:mysql://localhost/flexiple
spring.datasource.username=root
spring.datasource.password=
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
```
## 12. Why is spring-boot-maven-plugin used?
This Maven plugin provides Spring Boot support to Apache Maven. This allows users to create and package an executable jar or war archives. It also allows you to start your application before running integration tests.
To add the plugin to your project, add this XML code in the plugin section in your pom.xml as shown below.
The following code can be used to configure a MySQL database and is the answer to the aforementioned Spring Boot interview question:
```html
<project>
<modelVersion>4.0.0</modelVersion>
<artifactId>getting-started</artifactId>
<!-- ... -->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
```
## 13. What is YAML? Why is it used?
Spring boot YAML can also be used to define properties and is an alternative to the application.properties file. Whenever the SnakeYAML library is in your classpath, the SpringApplication class automatically supports YAML as an alternative to properties.
## 14. How do you set an active profile in Spring Boot?
Active profiles can be set using the following methods:
Passing the active profile as an argument during launch
Setting the active profile using the application.property file
Code to set a profile as active in Spring Boot:
```java
java -jar -Dspring.profiles.active=production application-1.0.0-RELEASE.jar
spring.profiles.active=production
```
## 15. How are web server configurations disabled in a Spring Boot application?
Applications in Spring boot automatically start in the webserver mode if the web module is present in the classpath. Subsequently setting the webApplciationType to none in the application.properties file will disable it.
Web server disabling code for the aforementioned Spring Boot interview question:
```java
spring.main.web-application-type=none
```
## 16. How is ApplicationContext created by Spring Boot?
Once the SpringApplication.run() is executed, Spring Boot creates the ApplicationContext. Spring Boot then returns the ConfigurableApplicationContext which extends the ApplicationContext.
ConfigurableApplicationContext code for the aforementioned Spring Boot interview question:
```java
public ConfigurableAppContext run(String...args) {
//preparing the AppContext
ConfigurableAppContext context = null;
//To create and return the app context
context = createAppContext();
}
protected ConfigurableAppContext createAppContext() {
Class << ? > contextClass = this.appContextClass;
if (contextClass == null) {
try {
switch (this.webAppType) {
case SERVLET:
contextClass = Class.forName(DEFAULT_SERVLET_WEB_CONTEXT_CLASS);
break;
case REACTIVE:
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default:
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
} catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Could not create a default AppContext, " +
"specify an AppContextClass",
ex);
}
}
return (ConfigurableAppContext) BeanUtils.instantiateClass(contextClass);
}
```
## 17. How are HTTP Response Compressions enabled in Spring Boot?
Insert this code in the application.properties file
```
server.compression.enabled=true
```
Then use the server.compression.min-response-size to set compression length.
## 18. Write a code snippet to implement bubble sort?
Spring Boot binds environment properties to beans using relaxed binding. What this essentially means is that Spring Boot does not force an exact match between the environment property and the bean names. These names could be written in different cases or separated by a dash but Spring Boot would still bind the following values.
The below code snippet is the answer to the above-mentioned Spring Boot interview question.
```java
@ConfigurationProperties(prefix="flexiple.demoapplication-project.person")
public class CustomerProperties {
private String Name;
public String getName() {
return this.Name;
}
public void setName(String Name) {
this.Name = Name;
}
}
```
## 19. What are the uses of the application.properties file in Spring Boot?
The application.properties file is a single file that contains all the properties of your application allowing it to run in different environments. In essence, this file is the control system for your Spring Boot application.
## 20. What are dependency injections in Spring Boot?
Injecting dependent beans into target bean objects is called dependency injection.
The three types of Dependency Injections are:
- Setter Injection
- Constructor Injection
- Field Injection | hrishikesh1990 |
813,223 | Closures in javascript... | Function bind together with its lexical environment/scope(its local+parent scope) function x(){ ... | 0 | 2021-09-04T08:25:11 | https://dev.to/jasmeetbali/closures-in-javascript-41c9 | javascript, core | - **Function bind together with its lexical environment/scope(its local+parent scope)**
function x(){
var a = 7;
function y(){
console.log(a)
}
y();
}
x();
# output
7
# debugger for line
# console.log(a)
Closure(x)
a:7
- **returning a function inside function**
function x(){
var a = 7;
function y(){
console.log(a)
}
return y;
}
let res = x();
console.log(res);
# output
F:y(){
console.log(a);
}
- **though after returning from x() x is completely vannished from call stack, still y() will remember the variables and functions associated to it in closure**
# the inner function remembers the binding variables and the functions due to closure and even after the function that calls inner function gets vanished from call stack the inner fnction will remember the refferences to the outer function.
function x(){
var a = 7;
function y(){
console.log(a)
}
return y;
}
let res = x();
res();
OR
function x(){
var a = 7;
return function y(){
console.log(a);
}
}
let res = x();
res();
# output
7
- **so whenever the inner function is returned within the other function then it is actually returning the closure of inner function+its lexical scope and it remembers the refferences to its parent**
- **Some output prediction questions on closures**
function x(){
var a = 7;
function y(){
console.log(a);
}
a = 100;
return y;
}
let res = x();
res();
# output
100
- **remember the inner function on returning also returns the refference(original address) of the parent scope/lexical scope variables, and changing the value will direclty change that parent scoped variable also as shown above code**
- **A multilevel closure**
function z(){
var b = 900;
function x(){
var a = 7;
function y(){
console.log(a,b);
}
y();
}
x();
}
z();
# debugger at console.log(a,b)
Closure (x)
a:7
Closure (z)
b:900
## Uses of Closures
- Module Design Pattern
- Currying
- Functions like once
- memoize
- maintaining state in async world
- setTimeouts
- Iterators
---
## setTimeout + Closures Interview Questions
function x(){
var i = 1;
setTimeout(function(){
console.log(i);
},3000)
}
x();
# output
# prints 1 after 3 second from
# the time the x is called
1
function x(){
var i = 1;
setTimeout(function(){
console.log(i);
},3000);
console.log("olaaa");
}
x();
# output
olaaa
#after 3 seconds
1
- **Remember tide,time and javascript dont wait for anyone**
- **Tricky question problem is to print number from 1 to 5 like 1 should print after 1 second 2 should print in 2 second and so on**
function x(){
for(var i=1;i<=5;i++){
setTimeout(function(){
console.log(i);
},i * 1000);
}
console.log("olaaa");
}
x();
# output
olaaa
6
6
6
6
6
- **the above code gives such output due to closure since the setTimeout callback is reffering to the memory space of i by the time the console.log(i) is executed the loop has already incremented to 6 and thus each time the console.log(i) now executes it prints 6.**
- **to solve this problem we can use let instead of var, as let has block scope and each time loop runs i is a new variable altogether i.e new copy of i is made i.e different memory location is used for each changed value of i when using let**
function x(){
for(let i=1; i <= 5; i++){
setTimeout(function(){
console.log(i);
},i * 1000);
}
console.log("olaaa");
}
x();
# output
olaaa
1
2
3
4
5
- **IMPORTANT Solution without using let via help of closures i.e making a function and putting the setTimeout inside of it so that each time the innerfunction is called it creates new memeory location for i**
function x(){
for(var i=1; i <= 5; i++){
# making a explicit closure for setTimeout
function close(i){
setTimeout(function(){
console.log(i);
},i * 1000);
}
# we are calling the close() function with new copy of i different memory location
close(i);
}
console.log("olaaa");
}
x();
# output
olaaa
1
2
3
4
5
You My Friend Have A Great Day!! | jasmeetbali |
813,343 | My Personal IT Learning Journey | I am so much excited about "Learning in public" concept. Yesterday, someone asked me about this and... | 0 | 2021-09-04T09:14:23 | https://dev.to/attaullahshafiq10/my-personal-it-learning-journey-3mdh |
I am so much excited about "Learning in public" concept. Yesterday, someone asked me about this and said something which we all have heard many times that "Work in Silence and Let your Success make the Noise". I had no logical answer to that except my own experience which I shared with him, which I would share with you as well.
My personal IT learning journey was sort of triggered by watching a David Bombal video randomly on YouTube, in Jan 2019. Actually I was struggling with project (part of my Bachelor Degree in Telecom) based on Networking. It needed knowledge of RADIUS server, Linux and some coding stuff. And I had not much idea of any of these things. So I kept figuring out the things and somehow completed the project. But while doing all this, I was 100% clear that I have to learn Coding, Networking, ML, Linux and Cloud technologies. Then exams, internship and COVID, all messed up. Then I planned that now I will learn all that.
So as always, I made a super-exciting plan to cover everything in this year i.e. 2020-2021. And yes, by this time, I had procured all my devices etc and also joined lot of online platforms to learn nNetworking, Cloud and SecOps etc and earned some certifications. I do not want to defame them by mentioning here, but I wasted my hard earned.
But anyways, I did not lose heart and planned to start again. 😎
So again with full enthusiasm 😍😎 and to learn everything I bought annual subscriptions of CBT Nuggets, A Cloud Guru and Codecademy. I tried to convince many of my classmates and friends to start learning with me, but unfortunately they all had their own things to do. So I kept struggling alone. You must have figured out my mistake by now, like I was getting overwhelmed. Studying Engineering deree, then all these courses, no idea what to start, in what order etc. Then one night, I came across a session of Gul Iqbal's on CCNA. Something clicked or I don't know what I thought that this guy may help me. May be it was his high pitch voice or speaking in my native language (Urdu), I thought I should join them. So I joined.
Now things started changing gradually. I was studying full time, and attending classes from 8 AM to 3 PM. It was CCNA, MCSA and LINUX all three simultaneously, 5 days a week. Then I got to know that Jan 02 is the last date to pass for MCSA certification and it was also required at my goals (as most of the machines were Windows Server Network, so I gave my 100% towards that but did not passed all 3 exams. But cleared four Major Azure Cloud certifications.
Then I again got stuck in an important project at work for 2 months, so after that I again started for SecOps in March 2021. Thankfully, Gul Iqbal allowed me to discuss the live classes and parallelly I started utilising my CBT Nuggets subscription as well. This time, things were making little more sense to me and I covered both the programs in June 2021.
Then I started reading books as I heard from many experienced guys that books are must to pass the exams, which is true also. But my enthusiasm was dying and I was feeling sort of bored 🙄. As still, I was alone in my journey.😔 There was nobody with whom I could share what I was learning, what are the challenges I am facing, not even my small accomplishments etc etc.
Then 1 day, I came across "6 months to cloud journey" plan by Gwyneth Peña-Siguenza and Rishab Kumar and also this concept of "Learning in Public". I sincerely thank them both for sharing this as I do not know why and how, but this is working for me wonderfully. May be it appealed to me as it was starting of July and almost 180 days were left, like I thought I can still make it all by the end of this year. But more importantly I think its the details of the plan. Like what exactly you should do, what resources you should follow, what you can expect at every stage and what are the projects you should/could make. Really wonderful, you can check it out: https://lnkd.in/gXrt8e_b
So now as you may have seen in my regular posts that I am going through CCNA Official Cert guide by Wendell Odom, almost one chapter a week. I am also enrolled in CCNP batch, and attend those classes as well, twice per week. EIGRP, OSPF and BGP all going full-on. I am not there yet as you know, but I love when someone is talking about them.🥰 Pls do not get me wrong, but this is how I am😎. And also I am fully confident that very soon I would be well versed in these technologies as well. 👍
Some of you may think, I am still messing it up. But NO, its all good now. Everything is getting on track, day by day. Yes, it is true.
And the reason for all that is - YOU.
Yes, you all. Especially those who have given me valuable comments specially on linkedIn on my regular posts 😀. I am so much grateful to you guys that I can't explain in words.
When I was planning to start this "learning in public" thing, my frnds warned me that - "DO NOT DO THIS, YOU WILL MAKE FUN OF YOURSELF, and that too PUBLICALLY."
But I do not why, but I was having sort of clairvoyance that it will work. And it worked. Yes, It has already done its job.
I am feeling so much confident that I can't say. My time is getting managed properly day by day. I started with studying 15 min per day and now I am studying almost 6 hours per day. And its increasing day by day.
One more big thing I have done in last few weeks is that I have strongly motivated my very close mentor friend (Faisal Ahmed). So I mean to say, lots of lots of stuff going on, I can't tell you in words.
But I can say for sure that all this is happening because I am connected to you guys, I do not know you but I can feel you. I can feel that some of you relate with me and my situation. It's totally different experience for me. But it's awesome. So many many thanks to Gul Iqbal and Iftikhar. you can even see the genuineness in the faces of both of them. So I think, I should be grateful to them.
And I thought I am the only one doing this courageous act, but now everyday I am finding guys and girls who are practicing this, and they all are doing wonders. And it looks so cool too.
So I have written all this as a gesture of gratitude for all of you, knowing or unknowingly I do not know, but you have changed my life. Just by giving valuable comments and tapping on those like or love buttons. Hope you have read about that "Butterfly effect".
So big thanks for that. And also, if you are also stuck in your learning journey somewhere, try it. I can guarantee, you won't regret.
Life is a brief happening and its very beautiful.
So live it fully and enjoy every moment, even your learning.
Hafiz Muhammad Attaullah
attaullah@ieee.org
https://www.linkedin.com/in/attaullahshafiq10/ | attaullahshafiq10 | |
813,529 | Amazon EKS Distro (EKS-D) | Since June 2018, AWS has provided Amazon Elastic Kubernetes Service (EKS) to its customers. It is an... | 0 | 2021-09-04T14:24:00 | https://dev.to/dorraelboukari/amazon-eks-distro-eks-d-3cim | aws, kubernetes, devops, cloudnative | Since June 2018, AWS has provided Amazon Elastic Kubernetes Service (EKS) to its customers. It is an upstream and certified conformant version of Kubernetes. This service helped to manage containerized workloads and services in the AWS Cloud and in on-premises. Amazon EKS have always guaranteed scalability, reliability, performance and high availability.
This service was satisfying for many users as they have enjoyed applying it effeciently to their projects.
On the 1st of December 2020, AWS announced their new service Amazon EKS Distro (EKS-D) to the audience interested in Kubernetes, the portable, extensible and open-source platform of orchestration. As everyone was curious about this concept, a myriad of questions immerged: What is EKS-D? Why Amazon created this product? What is the advantage of EKS-D?
To answer those questions, we have to explain first the meaning of "Kubernetes distribution" to avoid any confusion.
#What is a Kubernetes Distribution?
The Cloud Native Computing Foundation (CNCF) defined this term a long time ago, as the pieces that an end-user needs to install and run Kubernetes on the public cloud or on the on-premises. Here is a spreadsheet that details Kubernetes Distributions and Platforms: [link](https://docs.google.com/spreadsheets/d/1LxSqBzjOxfGx3cmtZ4EbB_BGCxT_wlxW_xgHVVa23es/edit#gid=0)
#What is EKS-D?
EKS-D is a Kubernetes distribution that relies basically on Amazon EKS and holds the same benefits that his 'ancestor' has. At this point, I found it useful to use the word 'Ancestor' because it is crystal clear that EKS-D is just an evolution and exploitation of the Amazon EKS service. But it is more sophisticated since it creates reliable and secure clusters to host Kubernetes.
#Why EKS Distro?
Amazon EKS is convenient for many users, but not all users can take advantage of it. To explain that, you have to consider the Amazon EKS responsibility model in the figure below.
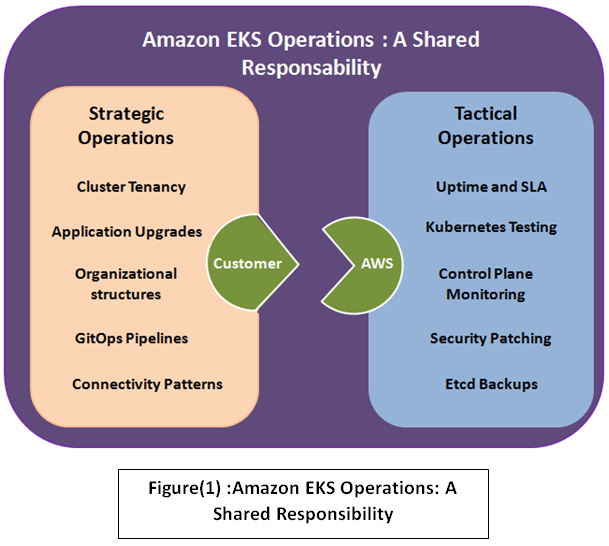
AWS wants to simplify Kubernetes managing for the customers who may not find the right approach to leverage their applications. Customers must spend a minimal duration on operating Kubernetes. Instead, they need to focus on their business. This is the reason why Amazon EKS takes responsibility for *Tactical Operations*. This sounds great, but in fact, it deprives a considerable number of customers of using Amazon EKS.
Some users need for example to apply their custom tools on the control plane as their applications require a customization of the control plane flags. Another category of customers may have specific security patches to apply according to their compliance. Others have a wide variety of computing requirements (Hardware, CPU, environment, etc.)
Those considerable requirements urged the appearance of EKS Distro. It aims to help users get consistent Kubernetes builds and have a more reliable and secure distribution for an extended number of versions. Customers can now run Kubernetes on your own self-provisioned hardware infrastructure, on bare-metal or on cloud environment.
For more details about the subject , visit: https://aws.amazon.com/eks/eks-distro/
| dorraelboukari |
813,712 | Large GeoTiff (raster) files on GeoServer using COG | Publish large geotiff (raster) files on GeoServer and be able to access them in no time with... | 0 | 2021-09-04T19:17:30 | https://dev.to/ibrahimawadhamid/large-geotiff-raster-files-on-geoserver-using-cog-546h | geoserver, cloudoptimizedgeotiff, cog, raster | ### Publish large geotiff (raster) files on GeoServer and be able to access them in no time with COG (Cloud Optimized Geotiff)
The challenge here is that you might have a really large geotiff file (or a normal one). Publishing that file on geoserver would require any client to download the whole file before rendering it (not a good thing if you have a 500MB geotiff!).
The solution is fairly simple with **COG** (Cloud Optimized Geotiff). You can check all about COG on the [official website](https://www.cogeo.org/), or you can simply read their explanation of COG as:
> A Cloud Optimized GeoTIFF (COG) is a regular GeoTIFF file, aimed at being hosted on a HTTP file server, with an internal organization that enables more efficient workflows on the cloud. It does this by leveraging the ability of clients issuing HTTP GET range requests to ask for just the parts of a file they need.
Let's do it through these steps together:
- Download and use COG validation script.
Thanks to [rouault](https://github.com/rouault/) for creating this awesome [script](https://github.com/rouault/cog_validator/blob/master/validate_cloud_optimized_geotiff.py). Save it to your local machine, we will use it in a second.
- Get your large (or normal) geotiff file in the same directory as the validation [script](https://github.com/rouault/cog_validator/blob/master/validate_cloud_optimized_geotiff.py).
For the sake of this demo, I will use this [geotiff](http://leoworks.terrasigna.com/files/Envisat_ASAR_2003-08-04.tif), download it, rename it to `envisat.tif` and save it next to the validation [script](https://github.com/rouault/cog_validator/blob/master/validate_cloud_optimized_geotiff.py).
- Validate the file that it is a geotiff, but not yet a COG.
run the following command:
```
python validate_cloud_optimized_geotiff.py envisat.tif
```
you should see an output telling you that it is `NOT a valid cloud optimized geotiff` like this screenshot.
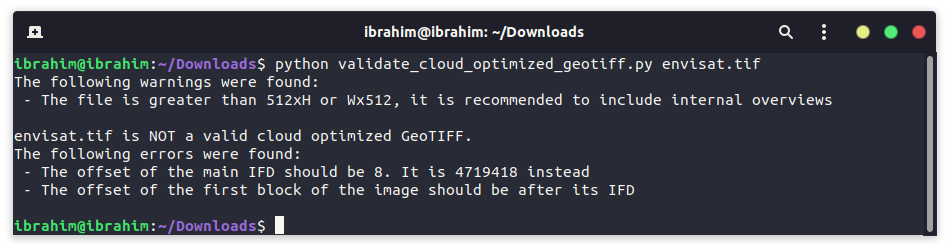
- Convert the geotiff file into a cloud optimized geotiff file (COG).
In order to do that, we will use GDAL, make sure you have it installed on your machine. for GDAL 3.2 and later, it's a simple one line command, for older versions than 3.2, it's two separate commands. We will cover both cases.
* GDAL >= 3.2
run this command on the geotiff file
```
gdal_translate envisat.tif envisat_cog.tif -of COG -co COMPRESS=LZW
```
The larger the file, the more time it will take to convert it, at the end you should see an output like this.

Now let's try and validate the file again, run the validation command again, but this time on the **output** file:
```
python validate_cloud_optimized_geotiff.py envisat_cog.tif
```
you should see and output message telling you that `envisat_cog.tif is a valid cloud optimized GeoTIFF` like this one.

* GDAL < 3.2
We have to make this manually by creating the internal overviews, then create the tiles in the files.
Run the following command to create the internal overviews:
```
gdaladdo -r average envisat.tif 2 4 8 16
```
It can take some time depending on the file size, but when it completes, we are ready for the next step which is creating the tiles. Run the following command on the file:
```
gdal_translate envisat.tif envisat_cog.tif -co COMPRESS=LZW -co TILED=YES -co INTERLEAVE=BAND
```
This command also can take some time depending on the file size, but when it completes, you should have a valid COG file. We can easily validate that, by running the validation script on the **output** file:
```
python validate_cloud_optimized_geotiff.py envisat_cog.tif
```
It should tell you that `envisat_cog.tif is a valid cloud optimized GeoTIFF`
## Halfway done!
You can now have a break and bring in a cup of coffee ☕ (or tea) since we made some good progress here. We have our COG file ready to be served by GeoServer.
Let's continue.
GeoServer doesn't support COG files out of the box, luckily there is a community module that adds support to that.
- Go ahead and open GeoServer's [nightly build](https://build.geoserver.org/geoserver/) directory.
- Choose your version of GeoServer `2.16.x` `2.17.x` `2.18.x` `2.19.x`
- Open `community-latest`
- Search for the word `cog`, you should have only **1** search hit, which is a module named `geoserver-2.x-SNAPSHOT-cog-plugin.zip` where `x` is GeoServer minor version.
- Download the module's zip file and extract the content to GeoServer's `WEB-INF/lib` directory then **restart** GeoServer.
### Congratulations! GeoServer now supports COG
- Open up GeoServer's homepage (usually at localhost:8080/geoserver) and login with your credentials (usually admin:geoserver)
- From the left side menu, under `Data`, select `Workspaces`, then click on `Add new workspace`
- Create a new workspace called `cog`
- Navigate to GeoServer's data directory, create a folder called `cogs` then copy and paste or cog file `envisat_cog.tif` into that directory.
- Back to GeoServer's console, from the left side menu, under `Data`, select `Stores`. Every geotiff (COG) file you publish is a complete store. click on `Add new store`.


- From the long menu of GeoServer's data sources, under `Raster Data Sources`, click on `GeoTIFF`.
- A wizard will appear, for `Workspace` select our newly created workspace called `cog`.
- For the `Data source name`, I will type `envisat`.
- For the `Description`, I will type `envisat_store`.
- Next to the `URL` field, click on the `Browse` button and select the `envisat_cog.tif` file.
- Mark the checkbox `Cloud Optimized GeoTIFF (COG)`
Leave all the other settings as is, you should have something like this.
- Click `Save`
- You'll find yourself in the wizard that creates a new layer (that is a good thing!), and your new layer is ready to be published.

- Click on `Publish`
- The wizard for `Edit Layer` is opened automatically, I will change the layer name to `envisat` and the title to `Envisat`, then I will click `Save`.
- The layer is created and added to the layers list.

- Preview the layer from the `Layer Preview` menu item under `Data` from the left menu.

- Click on `OpenLayers`
It Does not matter how large your layer is, it will load up in seconds (or less), and when you zoom in/out it will load up almost instantly thanks to **COG**.
 | ibrahimawadhamid |
813,719 | A 100 Day #thePersonalMSDS Journey | The Machine Learning landscape is in a state of continuous change. New research, technologies and... | 0 | 2021-09-04T19:33:38 | https://dev.to/eshbanthelearner/a-100-day-thepersonalmsds-journey-1gc5 | productivity, motivation, datascience | The Machine Learning landscape is in a state of continuous change. New research, technologies and tools are put out every day. This sometimes makes it hard to keep up with the latest trends. Besides that, the vastness of the domain can induce the imposter syndrome in practitioners. This is perfectly put in the following tweet

I too had felt this over the years. Either I feel that I know too little or feel like I’m out of touch. To combat this, I’ve been following some challenges to get in touch with my skills and learn new ones along the way. One of the challenges I recently completed is #thePersonalMSDS.
\#thePersonalMSDS was an initiative by one of my seniors, [Muhammad Hamza Javaid](https://www.linkedin.com/in/mhjhamza/) to get industry professionals and students to follow a self-curated Data Science Masters roadmap to develop new skills and hone existing ones. The partaker can decide the number of days (usually 100) and the number of hours they want to dedicate towards learning per day. I first came across it in January 2020 and decided to pledge for 100 days of following a customized roadmap. I completed the challenge from January 13th 2020 to April 22nd 2020. During those 100 days, I studied various topics with the help of online courses and articles. Some of the things I studied back then included
- Statistics and Probability
- Big Data with Apache Spark
- AI for Business
- Investment Fundamentals & Data Analytics
- Data Engineering on GCP
- Basic Bash Scripting and Shell Programming
- Data Science Project Management
As it might be seen, I customized my learning path based on my needs and interests. This challenge not only helped me learn new skills but also to get on top of my existing skills. More recently I pledged the last 100 days, from May 26th 2021 to September 2nd 2021 to the #thePersonalMSDS challenge. I learned some new topics that I hadn’t learned before and also worked on some of the skills that I already have. I got a discount coupon for Databricks Data Science Pathway and I spent 36 days completing it. I earned 41 certificates in these 36 days, some of which you can check [here](https://www.linkedin.com/in/eshban-suleman-624a49113/). Some other topics/technologies that I studied apart from this were
- Deploying Machine Learning Models
- Spatial Analysis and Geospatial Data Science
- Data Privacy
- ElasticSearch (ELK Stack)
- HuggingFace Transformers
- Customer Segmentation
- Time Series Analysis and Forecasting
You can track my detailed learnings [here](https://github.com/EshbanTheLearner/thepersonalMSDS-v2/blob/main/todayilearned.md). A question that I get a lot is how I find the motivation to start and continue. This is a great question and it is a very common problem. I too have gone off the track a few times so, through the process of trial and error, I worked out some methods that work for me. I hope you find them useful too.
# Plan Ahead of Time
A good plan will help you stay on top of your skills and it’ll show how self-aware you are regarding your strengths and weaknesses. I like to make 2 separate lists, one dedicated to topics and skills that I want to learn and one for the skills that I’ve already learnt but either feel out of touch with or just want to study in-depth. Then I pick topics from both lists that I feel are both important and fun. Remember, you can always add or redact topics later.
# Find a Community
Get your friends and/or colleagues to sign up for the challenge with you. If nobody wants to join, find people on the internet with the same interests. Become a part of online study groups. Most importantly share your daily progress on the internet with proper hashtags. It’ll get you the exposure you need to find people that are interested in what you’re doing and keep you motivated to meet the daily goal.
# Stay Positive
Maintaining a routine like this along with work or studies can be cumbersome and frustrating at times. Sometimes it may feel like you are going nowhere but that is the moment where you need to look at how far you’ve come, how many new things you’ve learned, how many people you connect with along the way. This will help you stay positive and motivated.
# Take Breaks
Self-learning is all about flexibility. You don’t need to burden yourself with covering a lot of topics in a short period of time. If you’re feeling tired, just take a break. Take as many breaks as necessary to relieve your stress and come back more focused. You are your own in charge.
# Have Fun
The most important factor in staying motivated is to have fun while learning. The more you make your learning fun, the more you’ll look forward to it. Everyone has their own methods of having fun, e.g. you can do mini-projects using the skills you’re learning, make video tutorials, write blogs about it etc. I like to take handwritten notes and do mini-projects. You pick your poison.
So, if you are planning to learn something new or even brush up on your skills, start today, start now because tomorrow never comes. I wish you all the very best for your future.
<div style="width:100%;height:0;padding-bottom:75%;position:relative;"><iframe src="https://giphy.com/embed/J7jsbfcJ2O5eo" width="100%" height="100%" style="position:absolute" frameBorder="0" class="giphy-embed" allowFullScreen></iframe></div><p><a href="https://giphy.com/gifs/shia-labeouf-just-do-it-J7jsbfcJ2O5eo">via GIPHY</a></p> | eshbanthelearner |
813,729 | Native Bracket Pair Colourization in VS Code | I’m a big fan of the Bracket Pair Colorizer extension, but it looks like this is native in VS Code... | 0 | 2021-09-04T20:08:55 | https://community.vscodetips.com/nickytonline/native-bracket-pair-colourization-in-vs-code-310a | vscode | I’m a big fan of the [Bracket Pair Colorizer](https://marketplace.visualstudio.com/items?itemName=CoenraadS.bracket-pair-colorizer) extension, but it looks like this is [native in VS Code now](https://code.visualstudio.com/updates/v1_60#_high-performance-bracket-pair-colorization) and much faster!
{%twitter 1434229375860240385 %}
## Configure native bracket pair colourization
1. Make sure to remove the Bracket Pair Colorizer extension.
2. Update VS Code
3. Open your user settings via <kbd>CMD</kbd> (<kbd>CTRL</kbd> for non-Mac users) + <kbd>Shift</kbd> + <kbd>P</kbd> and type settings. The settings JSON file will open. Add the following:
```json
"editor.bracketPairColorization.enabled": true
```
All colors are themeable and up to six colors can be configured.
James Q. Quick has a video about getting this all set up
{%youtube KZC2_OMaEpc %}
More tips at [https://vscodetips.com](vscodetips.com)!
Happy VS Coding! | nickytonline |
813,755 | Para além das linhas de códigos | Eu sempre quis trabalhar com pessoas, ajudar pessoas a resolverem seus problemas e que a tecnologia... | 0 | 2021-09-06T14:17:05 | https://dev.to/biosbug/para-alem-das-linhas-de-codigos-1ed8 | Eu sempre quis trabalhar com pessoas, ajudar pessoas a resolverem seus problemas e que a tecnologia seria uma ferramenta para isso.
Eu sabia que não queria estudar para um cargo específico, que não mirava um setor específico, mas que sim eu precisava me desenvolver para ajudar pessoas e que ser multidiciplinar seria importante.
Hoje estou desenvolvedor de software, mas já fui técnico de manutenção de hardware, suporte de infraestrutura, vendedor, supervisor financeiro e outros mais...
As linguagens evoluem, novos frameworks são criados, profissões deixam de existir, negócios se transformam.
Quando comecei minha empresa de suporte e consultoria, existia o analista de sistema que era o profissional que traduzia a vontade do cliente em comunicação que os programadores entendiam.
O desenvolvedor de software hoje precisa ter habilidades tanto de negócios quanto de códigos, portanto, Devs de hoje não são os programadores de ontem.
Quanto mais você conhecer sobre os mais diversos tipos de negócios: mineração, logística, marketing, supply chain, aviação civil, processos jurídicos, impostos, comércio, mais rápido será sua evolução como profissional.
Leva algum tempo para se aprender código e leva o dobro de tempo para conhecer sobre o negócio, assim o melhor investimento do Dev que quer ter uma carreira, é investir tempo para entender o negócio em que sua empresa está inserida, pois essa habilidade é de fora da nossa bolha e exige habilidades que nem sempre são lógicas.
Empresas que eu admiro, são empresas que apoiam muito equipes multidisciplinares, pois ninguém faz nada sozinho.
Empresas que realmente estão inovando, estão virando empresas de tecnologia, e com isso entendam, são empresas que cuidam de pessoas usando a tecnologia como ferramenta.
Concordo que ter foco é bastante importante, mas olha só, o mundo não vai parar porquê você precisa ter foco, então Dev Junior, foco na tecnologia e atenção em resolver problemas e aprender sobre negócios, o quanto antes você ficar a vontade com isso melhor será para a sua carreira.
Software é sobre humanidades, sobre como podemos ajudar pessoas, portanto, usar tecnologia é uma forma de conseguirmos isso.
Já rolou por aqui:
[Pensar em Testes](https://dev.to/biosbug/testes-sao-formas-de-organizar-pensamentos-e-nao-apenas-usar-ferramentas-n3e)
[Básico SQL](https://dev.to/biosbug/o-basico-sobre-sql-5g9g)
[Aprenda GIT](https://dev.to/biosbug/aprenda-git-com-imagens-3f66)
| biosbug | |
813,836 | How Pros Automate Repetitive Code using VS Code | While Programming, you are bound to encounter Repetitive Code, writing which is a complete waste of... | 12,730 | 2021-09-05T04:02:44 | https://dev.to/ruppysuppy/how-pros-automate-repetitive-code-using-vs-code-53b | vscode, productivity, programming, json | While **Programming**, you are bound to encounter _Repetitive Code_, writing which is a complete **waste of time**. I am not talking about **Non-DRY Code**, but _Essentials Code_ that is necessary to be written. An example of this would be connecting **State**/**Dispatch** to **Props** using **React-Redux**.
Anyone who has worked on a decent-sized **React-Redux** project knows how many times you have to write the same code to connect the **Redux Store Data** to the **Component Props**.
Today we are going to fix that and provide you with a way to _streamline **ANY** Repetitive Code_ you have and **Maximize your Productivity**.
# What are **Snippets** in **VS Code**?
**VS Code** is an Amazing Code Editor that provides a _plethora of tools_ to take your **productivity** to the **next level**. **Snippets** are just one such tool.
**Snippets** can be thought of as **Templates** that enable you _write code once_ and reuse it, _as per requirement_. It allows **Variables** as well as **Dynamic User Inputs**.
If you have been using **VS Code** for some time, you are bound to come across **Snippets**.
Some **Snippets** come pre-built with **VS Code**. You can install some extensions to add event more **Snippets**, but most importantly, you can create your own **Snippets** to cater to your very own needs.
# Creating our first **Snippets**
Creating a **Snippets** is fairly simple:
1. Go to **File > Preferences > User Snippets** (possibly **Code > Preferences > User Snippets** on macOS).
Or you might use `F1` to bring up the **Command Palette** and search for **User Snippets**
2. Select the type of **Snippet** you want to create (**language-specific**, **project-specific** or **global**)
3. Add the following in the created `.code-snippets` file
```json
{
"Signature": {
"scope": "html",
"prefix": "hello",
"body": [
"Hello!!!"
],
"description": "Hello"
}
}
```
4. Done! Now when you type **"hello"** in an **HTML** file, you would be to use the **Snippet**
This wasn't a practical example, but we did manage to get our feet wet at making **Snippets**.
On inspecting the **Snippet** definition, we find the `scope` that declares which files the **Snippet** should be used in. The `prefix` mentions the **prefix text** that will trigger the **Snippet** to show up. The `body` defines the **body** of the **Snippet**(each line of the **Snippet** would be a new **string** in array). And finally, `description` is a short description of the **Snippet**'s function.
Let us make a couple of **practical ones** to _deepen our understanding_ and solve the issue mentioned in the _Intro of the article_ (connecting **State**/**Dispatch** to **Props** using **React-Redux**).
# Snippet 1: Leaving a Signature
Let's try making a snippet that leaves a _signature_ like this in any file and isn't restricted to only **Python**
```py
"""
Name: Tapajyoti Bose
Modified on: 05 September 2021 08:38:35
"""
```
We would also like the **Snippet** to update the **date** and **time** dynamically, of course.
Luckily, **VS Code** provides a bunch of **variables** for this purpose.
We would be using `BLOCK_COMMENT_START` and `BLOCK_COMMENT_END` to automatically generate the block comments for any language and `CURRENT_DATE`, `CURRENT_MONTH_NAME`, `CURRENT_YEAR`, `CURRENT_HOUR`, `CURRENT_MINUTE`, & `CURRENT_SECOND` to generate the **date** and **time** dynamically.
**NOTE**: To get the complete list of **variables**, [click here](https://code.visualstudio.com/docs/editor/userdefinedsnippets#_variables)
So the **Snippet** would initially look like this:
```json
"Signature": {
"scope": "python,javascript,typescript,html,css",
"prefix": "signature",
"body": [
"$BLOCK_COMMENT_START",
"Name: Tapajyoti Bose",
"Modified on: $CURRENT_DATE $CURRENT_MONTH_NAME $CURRENT_YEAR $CURRENT_HOUR:$CURRENT_MINUTE:$CURRENT_SECOND",
"$BLOCK_COMMENT_END"
],
"description": "Leave a signature"
}
```
Now within **Python**, **Javascript**, **Typescript**, **HTML**, **CSS** files, you would be able to leave a signature.
You might be wondering if _extending the functionality_ to _all languages_ would require you to add the _names of all languages_. Luckily there is an easy solution: just remove the `scope` from the **Snippet** definition and **Viola!** the functionality is extended to all languages!
# Snippet 2: Connecting Redux to React Props
This is even easier than the **Signature Snippet**. Just copy the following code in the snippet definition, and you are done:
```json
"Connect Component to Redux": {
"scope": "javascriptreact,typescriptreact",
"prefix": "connect",
"body": [
"const mapStateToProps = (state) => ({",
"\t$1",
"})",
"",
"const mapDispatchToProps = (dispatch) => ({",
"\t$0",
"})",
"",
"export default connect(mapStateToProps, mapDispatchToProps)($TM_FILENAME_BASE)"
],
"description": "Connect React Component to Redux"
}
```
Let us examine what is being done.
We are scoping the **Snippet** to **React** based projects for obvious reasons.
In the body, you might be seeing `$0` and `$1` for the first time. These are placeholders for **tab-able** positions where the user should enter _their own logic_ (the parts of the **store** they want to connect to the **props** in this case).
We are using the **File Name** as the **Component Name**, as in _most_ cases, the convention is using the **Component Name** to be the same as the **File Name**.
# Wrapping Up
In this article, we went over how you can **Automate Repetitive Code** using **VS Code Snippets**. Now you can create **Custom Snippets** that solve your own problems and boost your productivity to new heights.
**Happy Developing!**

Finding **personal finance** too intimidating? Checkout my **Instagram** to become a [**Dollar Ninja**](https://www.instagram.com/the.dollar.ninja/)
# Thanks for reading
Want to work together? Contact me on [Upwork](https://www.upwork.com/o/profiles/users/~01c12e516ee1d35044/)
Want to see what I am working on? Check out my [GitHub](https://github.com/ruppysuppy)
I am a freelancer who will start off as a Digital Nomad in mid-2022. Want to catch the journey? Follow me on [Instagram](https://www.instagram.com/tapajyotib/)
Follow my blogs for weekly new tidbits on [Dev](https://dev.to/ruppysuppy)
**FAQ**
These are a few commonly asked questions I get. So, I hope this **FAQ** section solves your issues.
1. **I am a beginner, how should I learn Front-End Web Dev?**
Look into the following articles:
1. [Front End Development Roadmap](https://dev.to/ruppysuppy/front-end-developer-roadmap-zero-to-hero-4pkf)
2. [Front End Project Ideas](https://dev.to/ruppysuppy/5-projects-to-master-front-end-development-57p)
2. **Would you mentor me?**
Sorry, I am already under a lot of workload and would not have the time to mentor anyone.
3. **Would you like to collaborate on our site?**
As mentioned in the _previous question_, I am in a time crunch, so I would have to pass on such opportunities.
**Connect to me on**
- [LinkedIn](https://www.linkedin.com/in/tapajyoti-bose-429a601a0)
- [Portfolio](https://tapajyoti-bose.vercel.app)
- [Upwork](https://www.upwork.com/o/profiles/users/~01c12e516ee1d35044/)
- [GitHub](https://github.com/ruppysuppy)
- [Instagram](https://www.instagram.com/tapajyotib/) | ruppysuppy |
813,972 | Chakra UI: Theme - Update Tab style | I'm working on a project with Chakra UI where I need to create a navigation but it's more like tabs... | 0 | 2021-09-05T07:54:34 | https://dev.to/ekimkael/chakra-ui-theme-update-tab-style-1cdl | react, styledcomponent, emotion | I'm working on a project with **Chakra UI** where I need to create a navigation but it's more like tabs so I chose to use Chakra UI Tabs. I'm personally not a fan of the approach of writing CSS rules in components so I always prefer to modify the theme to fit my needs.
In this case, I really needed my Tabs to look like a classic `navbar` so I took the `unstyled` **variant**.
```
<Tabs variant="unstyled">
<TabList>
<Tab>Tab 1</Tab>
<Tab>Tab 2</Tab>
</TabList>
<TabPanels>
<TabPanel>
<p>one!</p>
</TabPanel>
<TabPanel>
<p>two!</p>
</TabPanel>
</TabPanels>
</Tabs>
```
And here is how to change the style of a `Tab` in the `theme` file 👇🏾
The first thing to note is that all child styles end up in Tabs.
So if you want to change `Tablist` or `TabPanel`, it will also be done in the Tabs attribute at the theme file.
```
export const theme = extendTheme({
Tabs: {
variants: {
unstyled: {
paddingY: '4',
marging: '0',
tab: {
_selected: {
color: 'white',
boxShadow: 'none',
},
},
},
},
},
},
});
```
🎉
| ekimkael |
813,988 | How to configure TypeScript environment? | What is TypeScript? TypeScript is a superset of JavaScript. It provides all the features... | 0 | 2021-09-05T09:24:29 | https://dev.to/vivekalhat/how-to-configure-typescript-environment-42a | typescript, javascript, npm, webdev | ## What is TypeScript?
TypeScript is a superset of JavaScript. It provides all the features of JavaScript along with its own set of features. TypeScript provides optional static typing, classes, and interfaces. One of the main benefits of using TypeScript is you can spot and eliminate common errors as you code. You can learn more about TypeScript on their official [docs](https://www.typescriptlang.org/docs/).
In this article, I am going to explain how you can configure your windows machine for TypeScript development. The steps should be fairly similar for Linux & Mac as well.
## Prerequisites
To run TypeScript, you should have two things installed on your system.
- Node
- A Package Manager - NPM or Yarn
In this tutorial, I am going to use NPM. Feel free to use Yarn if you want to.
### Installing Node & NPM
You can install Node on your system using two different methods :
- NVM
- Node executable - You can [download](https://nodejs.org/en/) the executable file from the Node website and run it to install Node on your system.
I am going to install Node using NVM. NVM stands for *Node Version Manager*. It is a utility program using which you can install any version of Node as required. You can install Node using NVM by following the given steps:
- Open this [link](https://github.com/coreybutler/nvm-windows/releases) in your browser and download **nvm-setup.zip** for the most recent release.
- Extract the folder and run the **nvm-setup.exe** file.
- Follow the installation steps to install NVM.
- Once the installation is complete, open command prompt or Powershell and run the `nvm ls` command. You will see **No installations recognized** in your prompt if you don't have Node installed on your machine otherwise you will see the installed Node versions.
- Run `nvm list available` to see the list of available Node versions.

- I recommend installing the recent LTS version. I am going to install version **14.7.6**. You can install any version you want. Just replace the 14.7.6 with your selected version. To install the Node, run `nvm install 14.17.6`.
- After the command is executed successfully, run `nvm use 14.17.6` to start using the Node in your system.
- You have now successfully installed Node and NPM on your system.
## Installing TypeScript
To install TypeScript globally, run the following command -
`npm install --global typescript`
This command will install TypeScript globally upon successful completion.
You can now start using TypeScript in your projects.
## How to run a TypeScript program?
- Create a directory anywhere in your system.
- I will write a sample TS program. TypeScript programs have extension **.ts**.
```
Sample.ts
const addNumbers = (num1: number, num2: number) : number => {
return num1 + num2;
}
addNumbers(5,7);
```
- To run this code, we will use the TypeScript compiler.
- In command prompt/Powershell run `tsc Sample.ts`.
- You will see `Sample.js` after successful compilation.
- You have successfully created and executed your first TypeScript program.
### Note
You can customize the TypeScript compiler or **tsc** using various options. These options can be passed as flags or you can create a config file called **tsconfig.json**. You can write compiler configuration inside this file. TypeScript compiler will then automatically follow the specified options inside the config file.
- You can use `tsc -w or tsc --watch` followed by program name (optional). This command will continuously watch for any changes in the TypeScript file. It will compile the file whenever any change is encountered.
- Running `npx tsc —init` will generate tsconfig.json file for you.
You can read more about tsconfig [here](https://www.typescriptlang.org/docs/handbook/tsconfig-json.html).
Thank you for reading the article. Happy coding! | vivekalhat |
814,187 | How To Validate 10 Digit Mobile Number Using Regular Expression | In this article we will see how to validate 10 digit mobile number using regular expression in PHP or... | 0 | 2021-09-06T03:27:57 | https://techsolutionstuff.com/post/how-to-validate-10-digit-mobile-number-using-regular-expression | laravel, php, javascript, validation | In this article we will see how to validate 10 digit mobile number using regular expression in PHP or Laravel. here i will give you example of regex for 10 digit mobile number in jQuery.
Regular Expression through user can enter numbers in different format as per their requirements. When we are working with form validation at that time you need to restrict user to enter invalid value and users allow only numeric value or valid number.
So let's see regular expression for 10 digit mobile number
Example :
```
<html>
<head>
<title>How To Validate 10 Digit Mobile Number Using Regular Expression - techsolutionstuff.com
</title>
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css">
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
</head>
<body>
<form>
<h1>How To Validate 10 Digit Mobile Number Using Regular Expression - techsolutionstuff.com</h1>
<div class="col-md-6">
<label>Mobile Number: </label>
<input class="form-control" type="text" name="mo_no" placeholder="Mobile Number" minlength="10" maxlength="10" required>
<br>
<label>Mobile Number: </label>
<input type="text" class="form-control" name="mo_no" placeholder="Mobile Number" pattern="[1-9]{1}[0-9]{9}" required ><br>
<button type="submit" class="btn btn-success">Submit</button>
</div>
</form>
</body>
</html>
```
---

---
You might also like :
- **_[Read More : Laravel 6 CRUD Tutorial with Example
](https://techsolutionstuff.com/post/laravel-6-crud-tutorial-with-example)_**
- **_[Read More : Laravel Datatable Example Tutorial](https://www.techsolutionstuff.com/post/laravel-datatable-example-tutorial)_**
- **_[Read More : Create Dummy Data Using Tinker In Laravel](https://www.techsolutionstuff.com/post/create-dummy-data-using-tinker-in-laravel)_** | techsolutionstuff |
814,323 | Angular directives | Angular directives | decorator | Attributes | Structural |... | 0 | 2021-09-05T15:34:14 | https://dev.to/gaetanrdn/angular-directives-p36 | {% medium https://link.medium.com/NHsiY9V6ijb %} | gaetanrdn | |
814,385 | How to Display the Progress of Promises in JavaScript | Contents Overview Implementation Conclusion Overview Displaying the... | 0 | 2021-09-06T07:33:10 | https://dev.to/jrdev_/how-to-display-the-progress-of-promises-in-javascript-lh0 | javascript, tutorial, webdev, codenewbie | ### Contents
1. [Overview](#overview)
2. [Implementation](#implementation)
3. [Conclusion](#conclusion)
-----
### Overview
Displaying the progress of multiple tasks as they are completed can be helpful to the user as it indicates how long they may need to wait for the remaining tasks to finish.
We can accomplish this by incrementing a counter after each promise has resolved.
*The video version of this tutorial can be found here...*
{% youtube I2UPGd0qsfY %}
Our desired output will look something like this, as the tasks are in progress.
```
Loading 7 out of 100 tasks
```
-----
### Implementation
**Let's start with the markup!**
All you need is a script tag to point to a JavaScript file (which will be implemented below), and one div element, whose text will be manipulated to update the progress counter of tasks completed.
```html
<!DOCTYPE html>
<html>
<body>
<div id="progress"></div>
<script src="app.js"></script>
</body>
</html>
```
---
**Next up, the JavaScript!**
We will begin by creating a function which resolves a promise after a random time has passed.
We do this as it closely resembles how it will work in a real-world application, e.g. HTTP requests resolving at different times.
```javascript
async function task() {
return new Promise(res => {
setTimeout(res, Math.random() * 5000);
})
}
```
---
Secondly, we will create an array of 100 promises and update the progress text to inform the user when **all** of the tasks have finished.
```javascript
const loadingBar = document.getElementById('loadingBar');
(async() => {
const promises = new Array(100)
.fill(0)
.map(task);
loadingBar.textContent = `Loading...`;
await Promise.all(promises);
loadingBar.textContent = `Loading Finished`;
})();
```
Now imagine if this takes 30 seconds to complete. All the user will see on screen is the text 'Loading...' whilst it is in progress.
That is not a very useful message!
---
Let's improve this now by updating the progress text after each task has resolved.
*The code snippet below is the full implementation.*
```javascript
const loadingBar = document.getElementById('loadingBar');
async function task() {
return new Promise(res => {
setTimeout(res, Math.random() * 5000);
})
}
function loadingBarStatus(current, max) {
loadingBar.textContent = `Loading ${current} of ${max}`;
}
(async() => {
let current = 1;
const promises = new Array(100)
.fill(0)
.map(() => task().then(() => loadingBarStatus(current++, 100)));
await Promise.all(promises);
loadingBar.textContent = `Loading Finished`;
})();
```
Now, you can see that as each promise is resolved, the counter is incremented and displayed to the user.
---
### Conclusion
In short, all you need to do is update the progress as each promise is resolved.
I hope you found this short tutorial helpful.
Let me know your thoughts in the comments below. 😊 | jrdev_ |
814,387 | How to implement Stripe revenue verification? | I am building AcquireBase - a marketplace for buying and selling side-projects, micro-SaaS, etc. As... | 0 | 2021-09-05T17:59:09 | https://dev.to/attacomsian/how-to-implement-stripe-revenue-verification-21nd | help | I am building [AcquireBase](https://acquirebase.com) - a marketplace for buying and selling side-projects, micro-SaaS, etc.
As part of our upcoming feature, we want to allow our seller to verify their reported MRR via Stripe - something IH already does for products.
It has been over 1 month since I am trying to figure out how to do this. I tried Google search but nothing came up useful. Stripe's documentation did help either.
Now, I'm getting frustrated.
Is there anyone who has successfully implemented Stripe revenue verification or knows how to do this?
I'd highly appreciate it if you share the info with me.
Thanks! | attacomsian |
814,410 | Ruby Conditional Statements | In this post we look at if, else, elsif statement .This are the conditional operation which perform... | 0 | 2021-09-05T19:03:07 | https://dev.to/es404020/ruby-conditional-statements-3g6b | ruby, rails, programming, webdev | In this post we look at if, else, elsif statement .This are the conditional operation which perform an action based on the Boolean response it pretty straight forward to use
```
state=true
if state
puts "you pick true"
elsif !state
puts "you pick false"
else
puts "nothing was picked"
end
```
That all thanks for reading | es404020 |
814,465 | How to use Excel VBA Variable Scope in Excel Office 365? | In this article, you will learn how to use Excel VBA Variable Scope in Excel Office 365. Let’s see... | 0 | 2021-09-06T01:20:42 | https://geekexcel.com/how-to-use-excel-vba-variable-scope-in-excel-office-365/ | touseexcelvbavariabl, vbamacros | ---
title: How to use Excel VBA Variable Scope in Excel Office 365?
published: true
date: 2021-09-05 17:47:20 UTC
tags: ToUseExcelVBAVariabl,VBAMacros
canonical_url: https://geekexcel.com/how-to-use-excel-vba-variable-scope-in-excel-office-365/
---
In this article, you will learn **how to use Excel VBA Variable Scope in Excel Office 365**. Let’s see them below!! Get the official version of **MS Excel** from the following link: [https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)
## VBA Variable Scope
In all the **programming languages** , we have **variable access specifiers** that define from where a **defined variable can be accessed**. Excel VBA is no Exception. VBA too has scope specifiers. These scope specifiers can be used to set the visibility/scope of a variable in Excel VBA.
## Types of scope specifiers
- Procedure Level
- Private – Module Level
- Public – Project Level
## VBA Procedure Level Variable Scope
- Firstly, in the Excel Worksheet, you have to go to the **Developer Tab.**
- Then, you need to ** ** select the **Visual Basic** option under the **Code** section.
<figcaption>Select Visual Basics</figcaption>
- Now, you have to **copy and paste the code** given below.
```
Option Explicit
Sub scopeTest()
Dim x, y As Integer ' Procedure level variable in VBA
x = 2
y = 3
Debug.Print x + y
End Sub
Sub sum()
x = 5
y = 7
Debug.Print x + y
End Sub
```
- After that, you need to **save the code** by selecting it and then **close the window**.
<figcaption>Save the Code</figcaption>
- Again, you have to go to the **Excel Spreadsheet** , and click on the **Developer Tab**.
- You need to choose the **Macros option** in the Code section.
<figcaption>Macro option</figcaption>
- Now, you have to make sure that your **macro name is selected** and click the **Run** button.
<figcaption>Run the Code</figcaption>
- Finally, you will receive the **output** in the Microsoft Excel.
<figcaption>Output</figcaption>
## VBA Private Variable- Module Level Scope
- Firstly, in the Excel Worksheet, you have to go to the **Developer Tab.**
- Then, you need to ** ** select the **Visual Basic** option under the **Code** section.
<figcaption>Select Visual Basic</figcaption>
- Now, you have to **copy and paste the code** given below.
```
Option Explicit
'Module level variable in VBA. Both variables x and y are private to this module. and
'can be accessed from any sub or function within this module.
Dim x As Integer
Private y As Integer
Sub scopeTest() 'This can be accessed from any module in the project
x = 2
y = 3
Debug.Print x + y
End Sub
Private Sub sum() ' This can't be accessed from other modules
x = 5
y = 7
Debug.Print x + y
End Sub
```
- After that, you need to **save the code** by selecting it and then **close the window**.
<figcaption>Save the Code</figcaption>
- Again, you have to go to the **Excel Spreadsheet** , and click on the **Developer Tab**.
- You need to choose the **Macros option** in the Code section.
<figcaption>Choose Macro option</figcaption>
- Now, you have to make sure that your **macro name is selected** and click the **Run** button.
<figcaption>Run the Code</figcaption>
- Finally, you will receive the **output** in the Microsoft Excel.
## Public Variables- Project Level Scope
- Firstly, in the Excel Worksheet, you have to go to the **Developer Tab.**
- Then, you need to ** ** select the **Visual Basic** option under the **Code** section.
<figcaption>Select Visual Basic</figcaption>
- Now, you have to **copy and paste the code** given below.
```
Option Explicit
'Project level variable in VBA.
Public x As Integer
Public y As Integer
Public Sub scopeTest() 'This can be accessed from any module in the project
x = 2
y = 3
End Sub
Private Sub sum() ' This can't be accessed from other modules
x = 5
y = 7
Debug.Print x + y
End Sub
```
- After that, you need to **save the code** by selecting it and then **close the window**.
<figcaption>Save the Code</figcaption>
- Again, you have to go to the **Excel Spreadsheet** , and click on the **Developer Tab**.
- You need to choose the **Macros option** in the Code section.
<figcaption>Choose Macro option</figcaption>
- Now, you have to make sure that your **macro name is selected** and click the **Run** button.
<figcaption>Run the Code</figcaption>
- Finally, you will receive the **output** in the Microsoft Excel.
## Wind-Up
We hope that this short tutorial gives you guidelines to **use Excel VBA Variable Scope in Excel Office 365. ** Please leave a comment in case of any **queries,** and don’t forget to mention your valuable **suggestions** as well. Thank you so much for Visiting Our Site!! Continue learning on **[Geek Excel](https://geekexcel.com/)!! **Read more on [**Excel Formulas**](https://geekexcel.com/excel-formula/) **!!**
**Read Next:**
- **[Excel Formulas to Remove the Text By Variable Position ~ Quickly!!](https://geekexcel.com/excel-formulas-to-remove-the-text-by-variable-position/)**
- **[Excel Formulas to Get the Maximum Value with Variable Columns!!](https://geekexcel.com/excel-formulas-maximum-value-with-variable-columns/)**
- **[Formulas to Count Variable Range with COUNTIFS Function!!](https://geekexcel.com/excel-formulas-to-count-variable-range-with-countifs-function/)**
- **[Excel Office 365 VBA Variables & Data Types - A Complete Guide!!](https://geekexcel.com/excel-office-365-vba-variables-data-types-a-complete-guide/)**
- **[How to use the CONFIDENCE.NORM function in Excel office 365?](https://geekexcel.com/how-to-use-the-confidence-norm-function-in-excel-office-365/)** | excelgeek |
814,523 | Emoções | Oi eu sou João tenho 27 anos, acho que a gente já conhece. Vim aqui contar um pouco sobre uma crise... | 0 | 2021-09-05T23:11:41 | https://dev.to/arthuzuga/emocoes-la2 | Oi eu sou João tenho 27 anos, acho que a gente já conhece.
Vim aqui contar um pouco sobre uma crise emocional que eu tive recentemente e como que ela me fez sair em uma aventura de autoconhecimento.
Mas pra isso vou pedir ajuda ao pessoal do divertidamente pra explicar essas emoções comigo.
---
Pra começo de conversa, o trio da nojinho, tristeza e alegria foi o primeiro a entrar no palco.
Como todo mundo aqui que viveu 2020 sabe, estamos passando por uma pandemia e com isso a nojinho ativou o meu instinto do autopreservação físico e mental, me fazendo ficar dentro de casa para evitar o contato com o vírus.
A tristeza veio para apresentar as formas da saudade que a gente ia começar a ter por lembrar do tempo que passávamos fora de casa com amigos, amores e familiares.
E a alegria veio se apresentar pra mim na forma de otimismo. Ela queria segurar as rédeas dos sentimentos ruins e nos falar: calma que vai passar, vai ser coisa de 6 meses e o mais tardar 1 ano. Vamos ser fortes pra não preocupar ninguém.
E assim, lideradas pelo otimismos, esse trio veio por um bom tempo coordenando o console do meu humor.
---
Atividades como trabalhar de home office, o privilégio de receber tudo em casa sem precisar me por em risco na rua, ter a infraestrutura de ocupação mental seja com os livros, os vídeo games e streamings. Pra que me preocupar?
Aprendei a me reinventar. A saudade do abraço, se resolvia com as ligações de video chamada. Os momentos de solidão, com Netflix e combo de vídeo games com podcasts.
Assim novos hobbies e planejamentos acabaram nascendo. Comecei aulas de japonês e de piano a distância, estruturei uma viagem pro Japão em 2023, pesquisei possibilidades de levantar uma casa perto da praia. Pra mim tudo estava se tornando bem grandioso.
---
Tudo parecia tão bem até o dia que comecei a ver o especial na Netflix chamado Inside. Aí que a ficha começou a cair, quando me enxerguei nos fases do Bo Burnham e reparei que as coisas não estavam tão bem assim.
Olhar pro meu apartamento me deixava enjoado, os dias pareciam todos iguais, olhar no espelho e olhar para o meu cabelo crescendo sem cuidado representava o que não estava tão bem assim por dentro.
Assim, Medo começou a se aproximar do painel de controle, e alegria passou o joystick pra ele que assumiu a forma de ansiedade e nervosismo.
---
Comecei a querer resolver todos os meus problemas de uma vez. Pelo fato deu estar com tempo livre, resolvi pensar antecipadamente em todas as possibilidades.
Etapas da vida que tinha em mente, primeiro mudar pra salvador, viagem ao Japão, comprar um terreno, ir pro Canadá cursar cinema, levantar a casa dos sonhos, fazer dinheiro com investimentos.
Assim basicamente a ansiedade planejou toda uma vida até 2026. Achava que naquele momento nada poderia dar de errado.
---
Mas alegria não poderia deixar de ser a principal jogadora. Ela tinha que voltar com tudo, o otimismo e felicidade não poderia deixar de existir, temos que fazer alguma coisa. O plano foi, vamos depositar nossas expectativas nos outros, vamos fazer planos com outras pessoas (mas elas não podem saber até nos encontrarmos pessoalmente tá?).
Assim a alegria se contagiou com a ansiedade e tomou o console de volta, começou a usar amigos com planos para as viagens, a garota que eu gosto com presente e planos de uma vida pós pandemia, família pra ser meu depósito financeiro de longo prazo.
Mas tem um detalhe que eu não imaginava seria que quando o otimismo vira extremo, ele nos dá um sinal do quão estamos sendo ingênuo. E se não deixamos as emoções transparecer, entramos em um modo de atuação superficial; onde apenas um momento de falha, tudo colapsa pro cansaço e frustração.
---
Apesar da alegria estar dominando, a tristeza também teve a sua vez. Ela explorou a esperança que a notícia da vacina havia chegado e me causou uma saudade que virou banzo ao invés de nostalgia. Me deu uma vontade de querer reviver tudo que havia passado aumentava a agonia que sentia todos os dias.
Com todo o cenário de cansaço e instabilidade montado, foi assim que o nosso último personagem entra em cena, a raiva. E foi em um momento de má interpretação de texto, julguei mensagens das pessoas que mais gosto que me causou uma desilusão dos planos que formei.
Alegria ficou em choque, Medo foi segurar o joystick, mas Raiva foi mais rápido. E naquele sábado, eu explodi em silêncio em casa.
---
Todos os planos de até 2026 estavam desmoronando, tudo que eu tinha de segurança eram dependências emocionais em terceiros. Espero não ter ofendido ninguém naquele dia, se te ofendi, me perdoe.
No dia seguinte não havia chances de ficar no apartamento, raiva e medo me colocaram para fora de casa depois de muito tempo.
Apesar de nojinho está presente pra cuidar de mim e não ter contato com pessoas, medo me fez ter um ataque de ansiedade no meu restaurante favorito. Mas pelo lado bom, também me fez pedir ajuda pra alguns amigos.
---
Assim, na segunda-feira pedi ajuda para a minha psicóloga. Conversamos e comecei a dar nome no que hoje uso para ilustrar as emoções que vivi. Assim aprendendo a começar a identificar os seus sinais.
Com isso, decidir experimentar uma nova vida. Resolvi entender as emoções com ajuda do livro, o lado bom do lado ruim. Resolvi também fazer uma faxina digital, com base em estudos sobre minimalismo digital. Que me fez afastar de todos os lugares que me provocavam antecipação de informações por ansiedade.
Comecei a fazer atividade física, a pisar no freio da vida e entender mais sobre o que é essencial pra um hakuna matata.
---
Lidar com as emoções não tem formula certa, é algo aos poucos, com auto-conhecimento e auxilio de um psicologo e, se precisar, de medicamentos. Cada dia é uma vitória e um momento que se vale curtir o presente.
---
E essa foi a minha jornada com as emoções. E se houver outros temas sobre como tô identificando elas e como minha nova rotina me for interessante, talvez faça um novo vídeo.
Fiquem bem. | arthuzuga | |
814,542 | Doing the Impossible — Building a Persistent Audio Player in Ruby on Rails | Today we’re going to learn how to build a Ruby on Rails app that accomplishes what some folks think... | 0 | 2021-09-05T22:02:32 | https://www.colby.so/posts/doing-the-impossible-persistent-audio-player-in-rails | webdev, ruby, rails | Today we’re going to learn how to build a Ruby on Rails app that accomplishes what some folks think is [impossible](https://mobile.twitter.com/Rich_Harris/status/1433057805477552132) in a multi-page application — persisting an audio player while navigating around an application.
We’ll use Ruby on Rails and [Turbo](https://turbo.hotwired.dev/) to accomplish this, but we could use Turbo’s predecessor, [Turbolinks](https://github.com/turbolinks/turbolinks) to achieve the same result, and Rails is only incidental to the finished project. We could just as easily use Turbo with any other "multi-page" framework and deliver the same experience.
When we’re finished, our application will allow users to create and manage Ideas along with a persistent audio player tuned to a white noise internet radio station, to help them focus while they generate ideas.
Users will be able to start and stop the audio using a standard `<audio>` input. When audio is playing, it will continue playing as the user navigates around the application.
The application will look like this:
After we've built our application, we'll spend a time talking about myths in web development, and how to avoid falling into the expert-led myth-trap.
This article assumes basic familiarity with Ruby on Rails, but no prior experience with Turbo is required, and you should be able to follow along even if you’ve never seen Rails code before.
Let’s get started.
## Application Setup
To begin, we'll create a standard Ruby on Rails app, install Turbo, and scaffold an Ideas resource that we'll use to demonstrate the "multi-page" part of the application.
```shell
rails new rails_focused_ideas
cd rails_focused_ideas
bundle add turbo-rails
rails turbo:install
rails g scaffold Idea title:string description:text
rails db:migrate
```
To finish installing Turbo, open `app/packs/application.js` and update it like this:
```javascript
import Rails from "@rails/ujs"
import "@hotwired/turbo-rails"
import * as ActiveStorage from "@rails/activestorage"
import "channels"
Rails.start()
ActiveStorage.start()
```
Here we've removed any references to turbolinks and added the `import "@hotwired/turbo-rails"` line to use Turbo throughout our application.
When you've finished setting up the application, start your rails server (`rails s` from your terminal) and navigate to [http://localhost:3000/ideas](http://localhost:3000/ideas).
## Add audio player to layout
Next up, we'll add an audio element to our application layout (`app/views/layouts/application.html.erb`), just after the opening `<body>` tag:
```erb
<audio
controls
src="http://uk1.internet-radio.com:8267/listen.pls&t=.m3u">
Your browser does not support the
<code>audio</code> element.
</audio>
```
The `src` attribute in this code is a random white noise internet station and it could go down tomorrow or ten years from now. You're free to use whatever you like for the source, including a local file accessible to your Rails server or any other [internet radio station](https://www.internet-radio.com/) you like.
Now if we refresh the page, we'll see our audio element is there and we can start and stop it, but every time we navigate to a new page, the audio stops playing.
How do we make it persist?
## Persisting the audio player across page turns
To make the audio persist across page turns, update the `<audio>` element like this:
```erb
<audio
data-turbo-permanent
id="white-noise-player"
controls
src="http://uk1.internet-radio.com:8267/listen.pls&t=.m3u">
Your browser does not support the
<code>audio</code> element.
</audio>
```
We've done the impossible and made our audio element persistent across page turns by making two changes.
First, we added `data-turbo-permanent` to the element to tell Turbo that this element should [persisted across page loads](https://turbo.hotwired.dev/handbook/building#persisting-elements-across-page-loads). Next, we added an `id` to the audio element, which Turbo uses to match the element when it renders pages.
With these small changes in place, we can refresh the page, start up the audio player, and then navigate around our application, clicking links and navigating through the browser history to our hearts content without ever stopping the audio player.
Magical.
## Why write this article?
The problem we solved today — building a persistent audio player with Turbo(links) — has been [solved](https://changelog.com/posts/why-we-chose-turbolinks) for a long time.
Why take the time to write up something that’s so simple?
Because, as we saw in the tweet linked in the introduction, dangerous misconceptions exist in web development. These misconceptions are often spread by folks who want you to believe that their way is the One True Path.
Downstream of this bad information are developers researching problems who absorb the bad information and trust it because it comes from someone who has such a big platform that they must know what they’re talking about.
Some of those developers will then make decisions based on the bad information and justify their decisions in conversations with other developers by repeating the bad information until it is eventually picked up and presented as truth by a new flock of experts.
The bad information continues flowing, poisoning the conversation for years to come, turning into myths based on half-truths, misunderstandings, and overconfidence.

This is how myths like “Rails doesn’t scale” propagate and persist, when even a cursory amount of research disproves the idea.
## Defending against myths
You can avoid falling for these myths by remembering that everyone writing about web development on the internet only knows a tiny fraction of all that there is to know about web development.
No one is an expert on every language and every method for building web applications. Instead, all of us, at best, know a lot about a few things, and a little about a lot more things.
We make decisions and recommendations based on that very limited knowledge, which means we can never confidently speak in absolutes. We can only share what we think is best, based on our own knowledge, for better or worse.
There is no One True Path in web development. Many different valid solutions exist, each with their own set of benefits and tradeoffs.
Fortunately, we don't need One True Path. Many paths can lead to the same destination.

With this in mind, try to follow these rules to be a good consumer when you’re exposed to web development content:
* Discard any absolute opinion about one technology or framework being “the best” way to solve any particular problem
* Don't listen to people who frequently speak in absolutes about languages or frameworks without contextualizing their opinion
* When comparing languages or frameworks, anyone who says “[x] can’t be used for [y] you have to use [z] instead” is probably just trying to sell you on [z]
* If someone refuses to acknowledge the weaknesses of their chosen approach, assume they’re not being honest
* When someone is an expert on a tool, you can probably trust what they’re saying about that specific tool
* If you don’t like a particular tool or framework there are probably a dozen other tools to solve the same problem that you can use instead
## Wait… aren’t you presenting yourself as an expert? Why should I listen to you?
Fair. Since I am 1) on the internet and 2) talking about web development, I should share what my particular motivations and interests are so you can have that information as you consider this article.
I don’t have a big platform (~150 followers on [dev.to](https://dev.to/davidcolbyatx) and the same on [Twitter](https://twitter.com/davidcolbyatx), and ~2,000 people per month reading [my blog](https://colby.so)). I write weekly about Ruby on Rails and the broader Rails ecosystem to a very small audience.
My writing is mostly aimed at helping newer Rails developers learn how to solve common UX problems that they’ll encounter as they work, and to share some of the modern tools available in the broader Rails ecosystem that enable performant, modern user experiences without needing to turn to a SPA.
My opinions on Rails are built from ~a decade of working on large production Rails applications and I consider myself to be Pretty Good at building Rails-powered web applications.
I encourage folks to consider Rails as an alternative to SPAs and JavaScript-everything not because I think JavaScript frameworks are bad, but because I think that Ruby and Rails are wonderful tools, and I’d like more developers to experience them.
That's me — now you can decide whether to throw my thoughts on everything in the trash or not.
## Wrapping up
Today we built a persistent audio player inside of a simple, multi-page application — from one perspective, an impossible task, from another, very simple.
We used this impossible/simple problem to talk a little about the myths of web development, and how experts with large platforms can spread those myths (often unintentionally!) to their audience. These myths then propagate through the community at large, and cause unnecessary, impossible to resolve arguments for years to come.
While we can’t stop experts with large platforms from sharing bad information, as developers, we can be informed about how we consume content. We can be more thoughtful about how we approach learning and growing when we know that absolutes rarely exist and objectively correct answers about which language or framework to use are few and far between in the world of web development.
As always, thanks for reading!
| davidcolbyatx |
814,809 | Top 10 Visual Studio Code Extensions That Every Developer Should Use It | Visual Studio Code is by far one of the most popular code editors for web, mobile, and hardware... | 0 | 2021-09-06T06:02:04 | https://dev.to/suhailkakar/top-10-visual-studio-code-extensions-that-every-developer-should-use-it-1nf0 | productivity, programming, vscode |
Visual Studio Code is by far one of the most popular code editors for web, mobile, and hardware developers. More than 2,600,000 people use VS Code every month, up by over 160% in the last year.
In this guide, we’ll explore the top 20 VS Code extensions that every developer should know in 2021.
### Bracket Pair Colorizer
If you are working on big projects where functions and components become very complicated, bracket pair colorizer is the one who can help you
This extension allows matching brackets to be identified with colors. The user can define which characters to match, and which colors to use. It is one of the must-have extensions for all developers.
Link : https://marketplace.visualstudio.com/items?itemName=CoenraadS.bracket-pair-colorizer
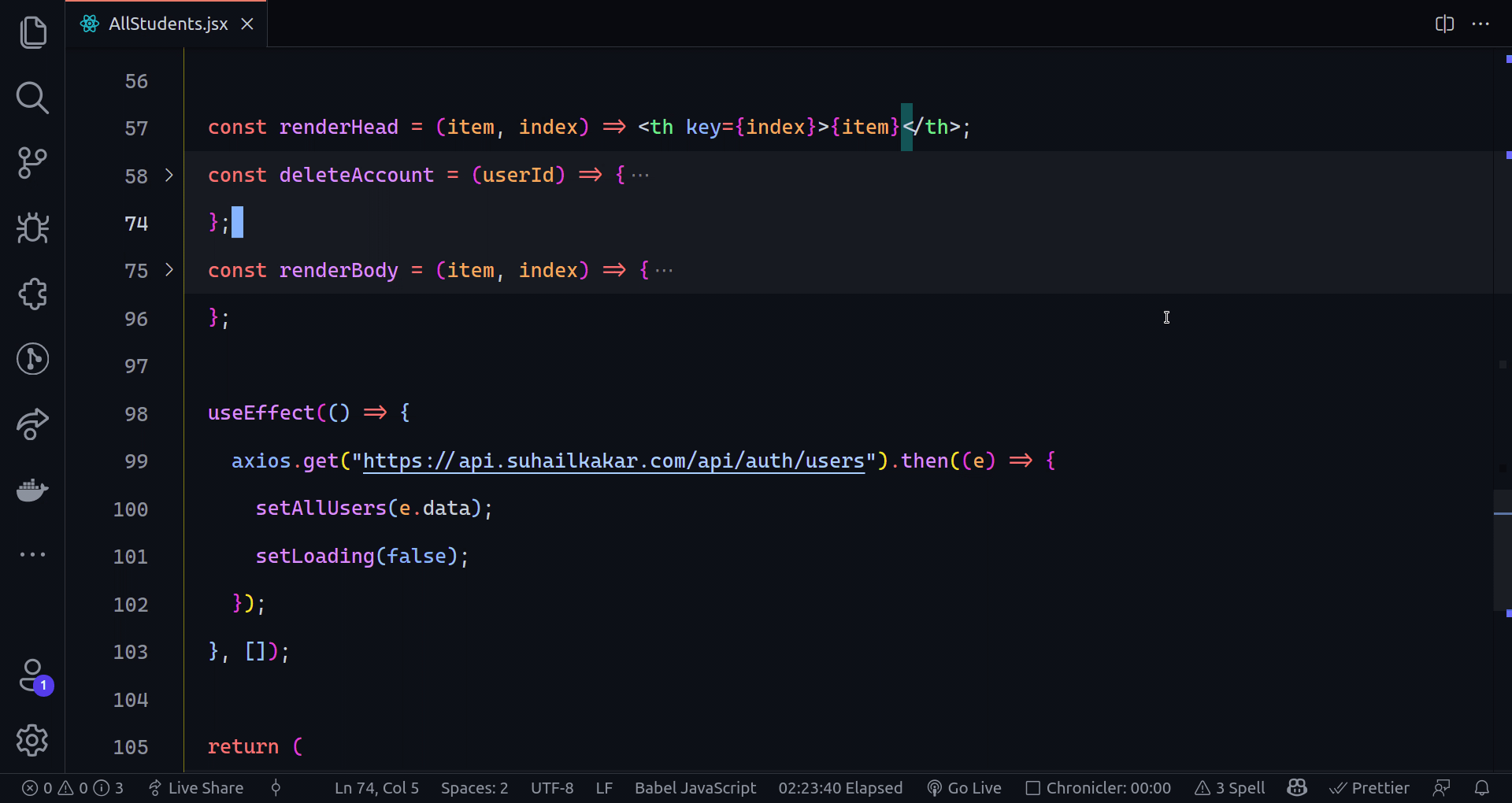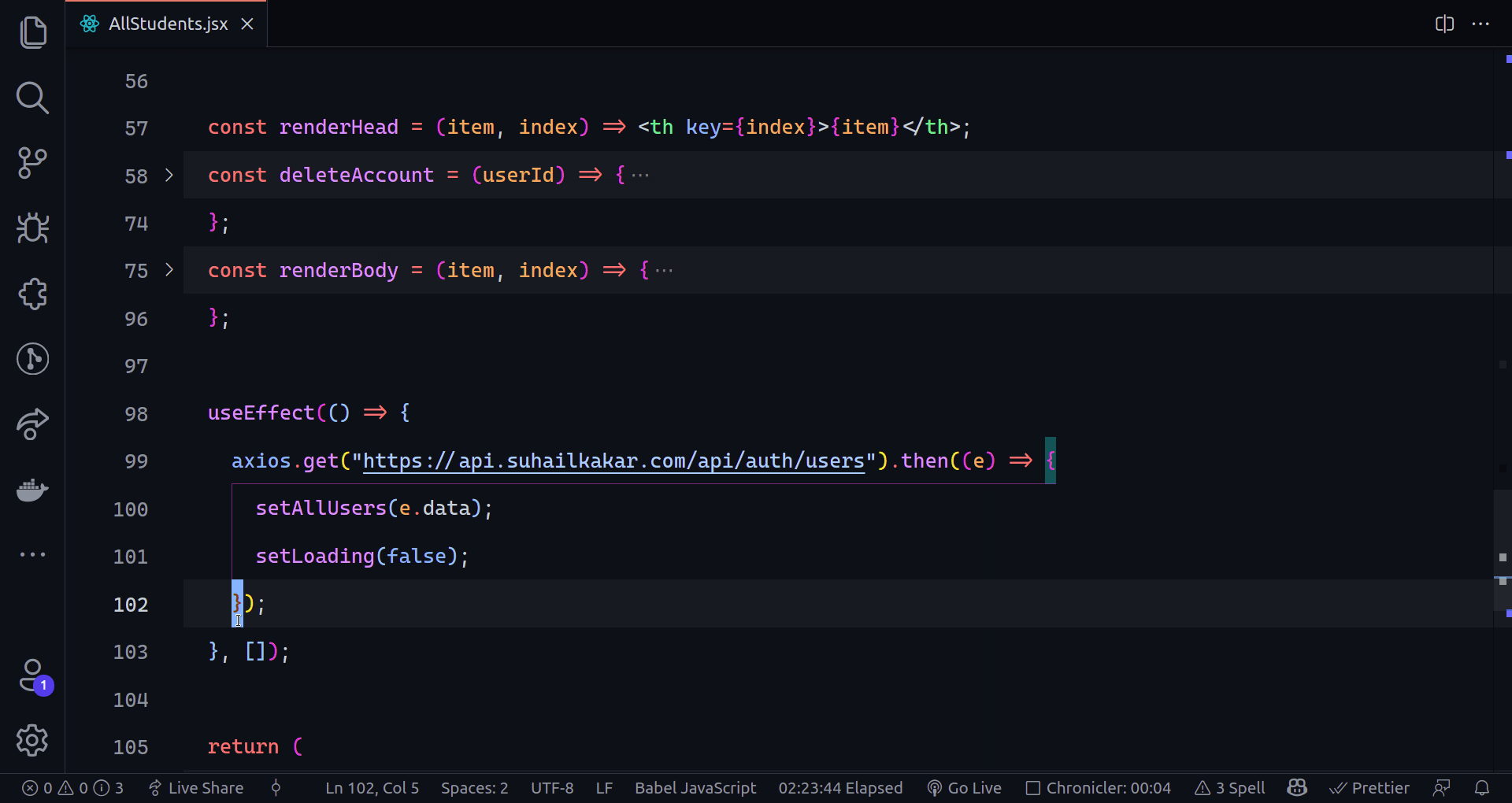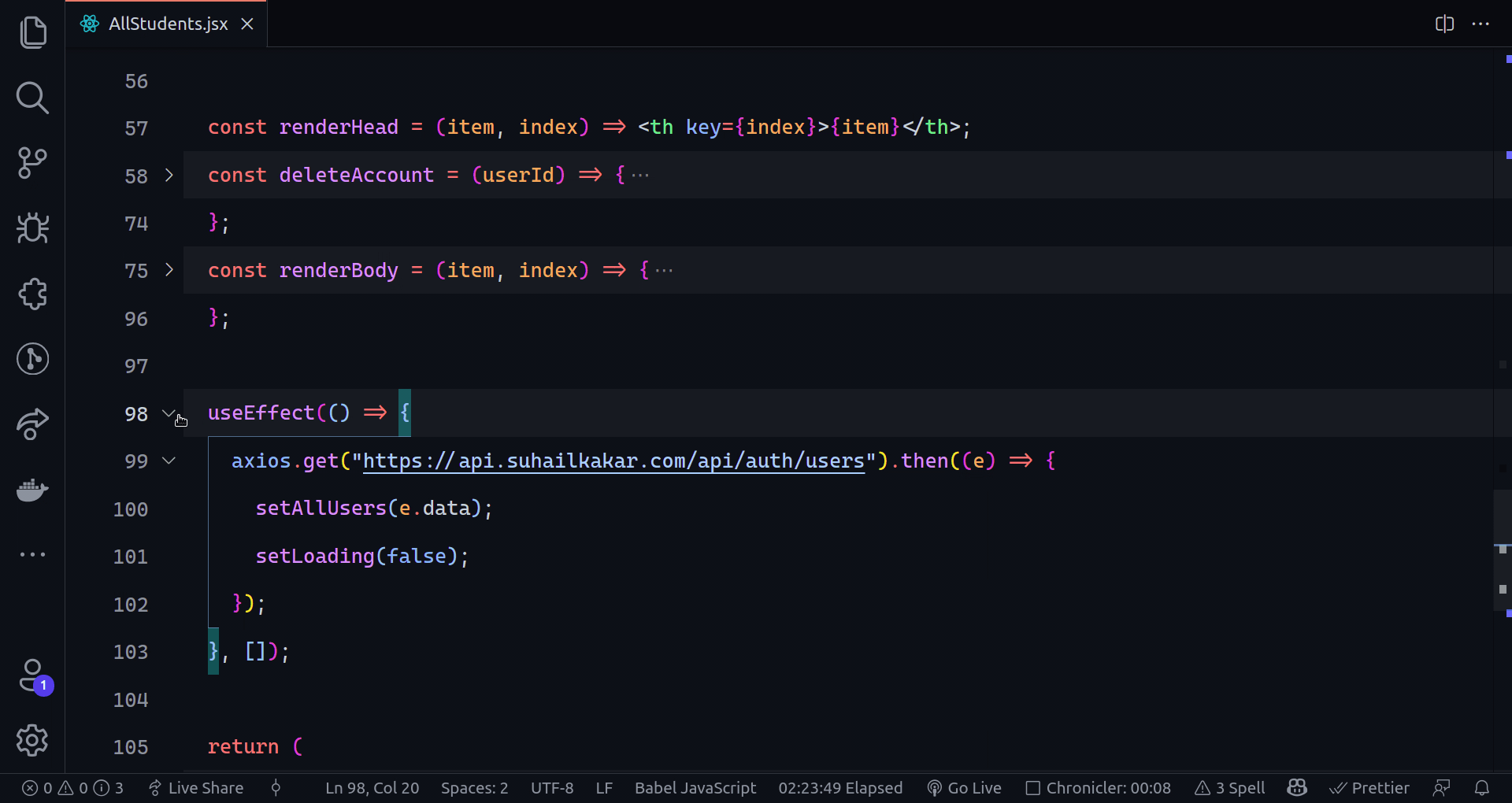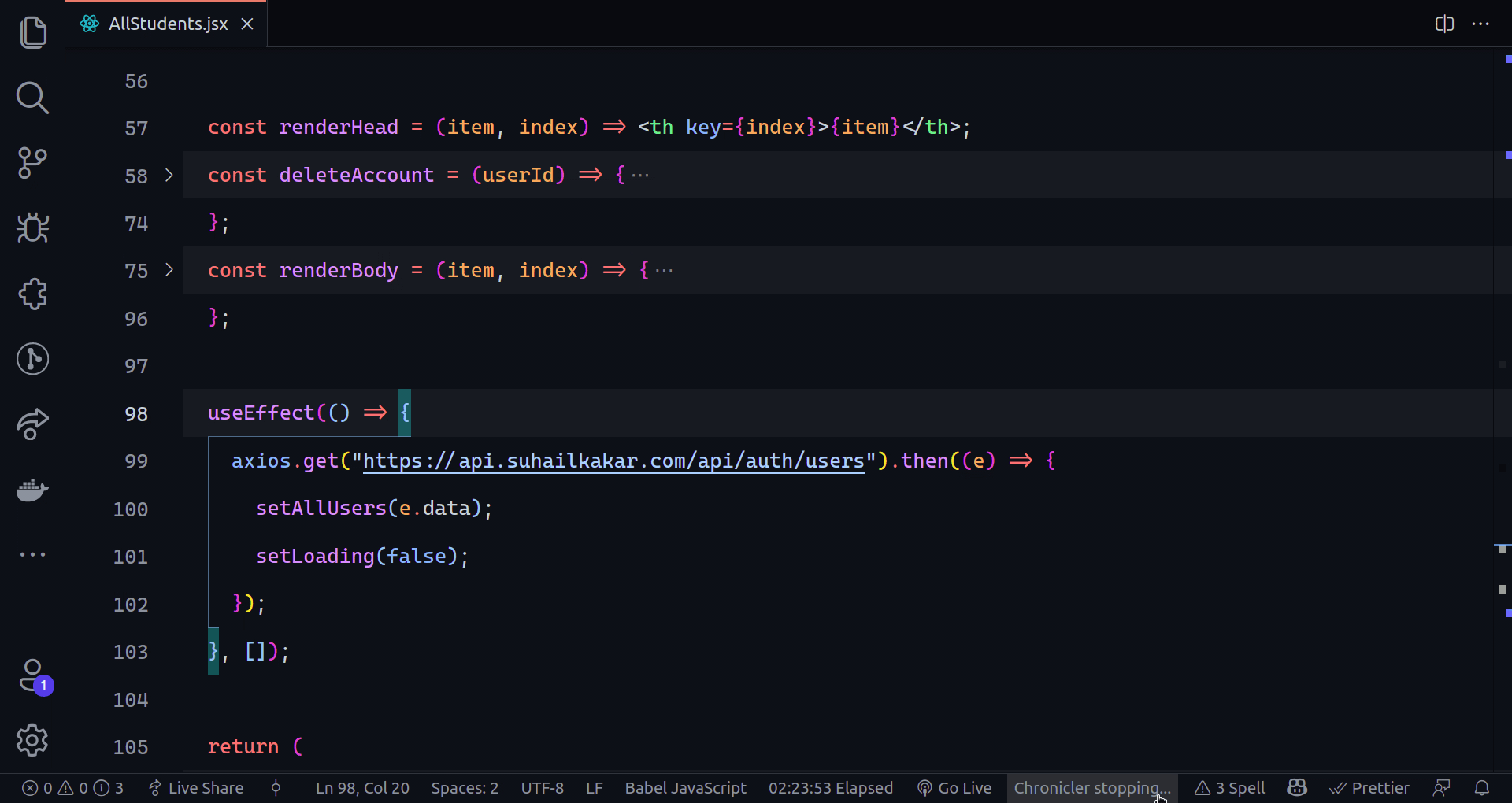
### Auto Rename Tag
For web developers, Auto Rename Tag is a fantastic VS Code extension. Auto Rename Tag, as the name implies, renames the second tag as the first is updated, and vice versa.
Link : https://marketplace.visualstudio.com/items?itemName=formulahendry.auto-rename-tag
### Better Comments
Having descriptive comments can save a lot of time for you and your team. The Better Comments extension will help you create more human-friendly comments in your code. With this extension, you will be able to categorize your annotations into :
- Alerts
- Queries
- TODOs Highlights
- Commented out code can also be styled to make it clear the code shouldn't be there
- Any other comment styles you'd like can be specified in the settings
Link: https://marketplace.visualstudio.com/items?itemName=aaron-bond.better-comments
### Stack Overflow View
After installing this extension you don't need to go Stack Overflow website again, you can get all your answers in VS Code. It is a Visual Studio Code extension for access to Stack Overflow inside of the editor. It supports English, Spanish, Russian, Portuguese, Japanese.
Link: https://marketplace.visualstudio.com/items?itemName=4tron.stack-overflow-view
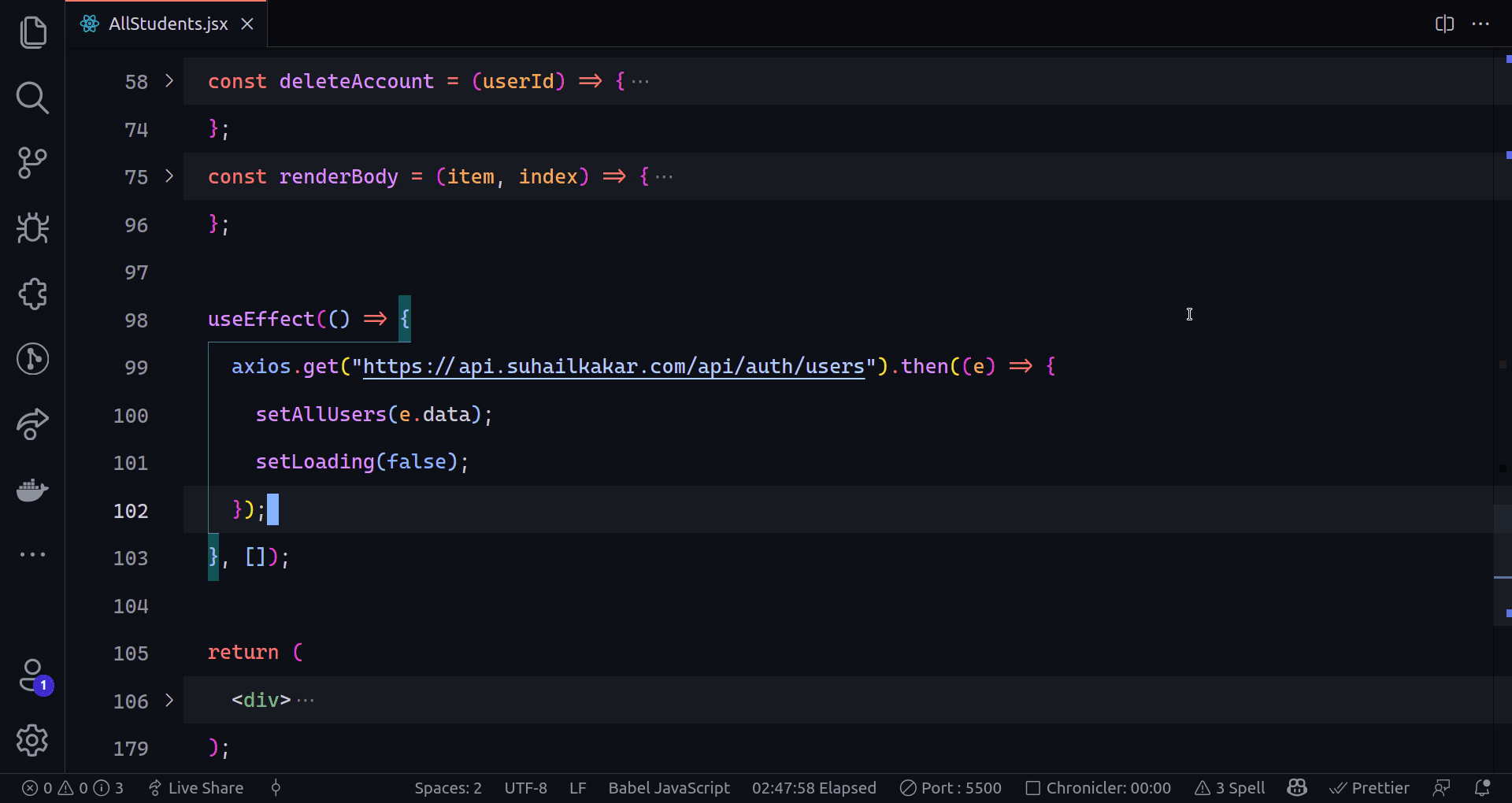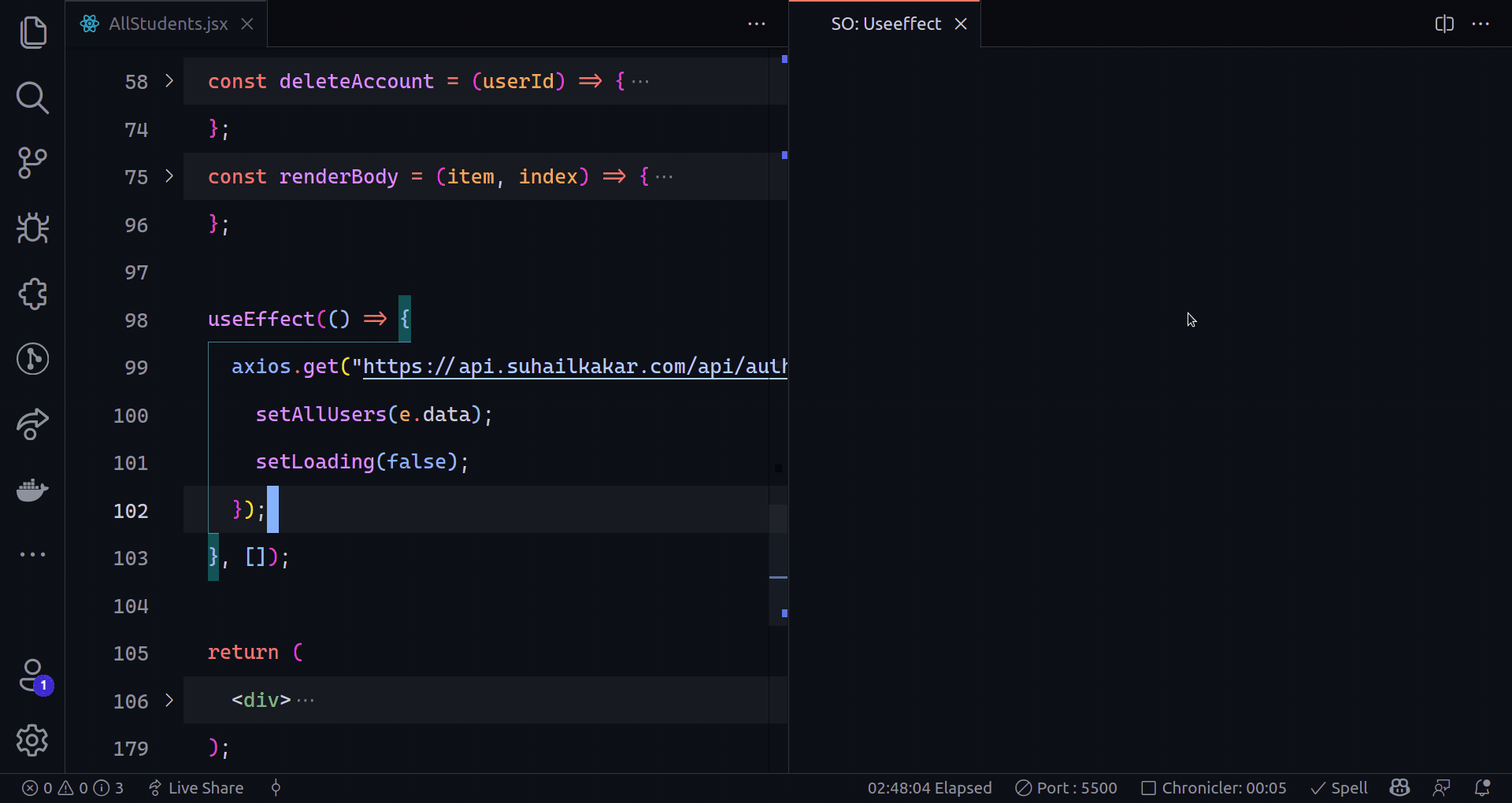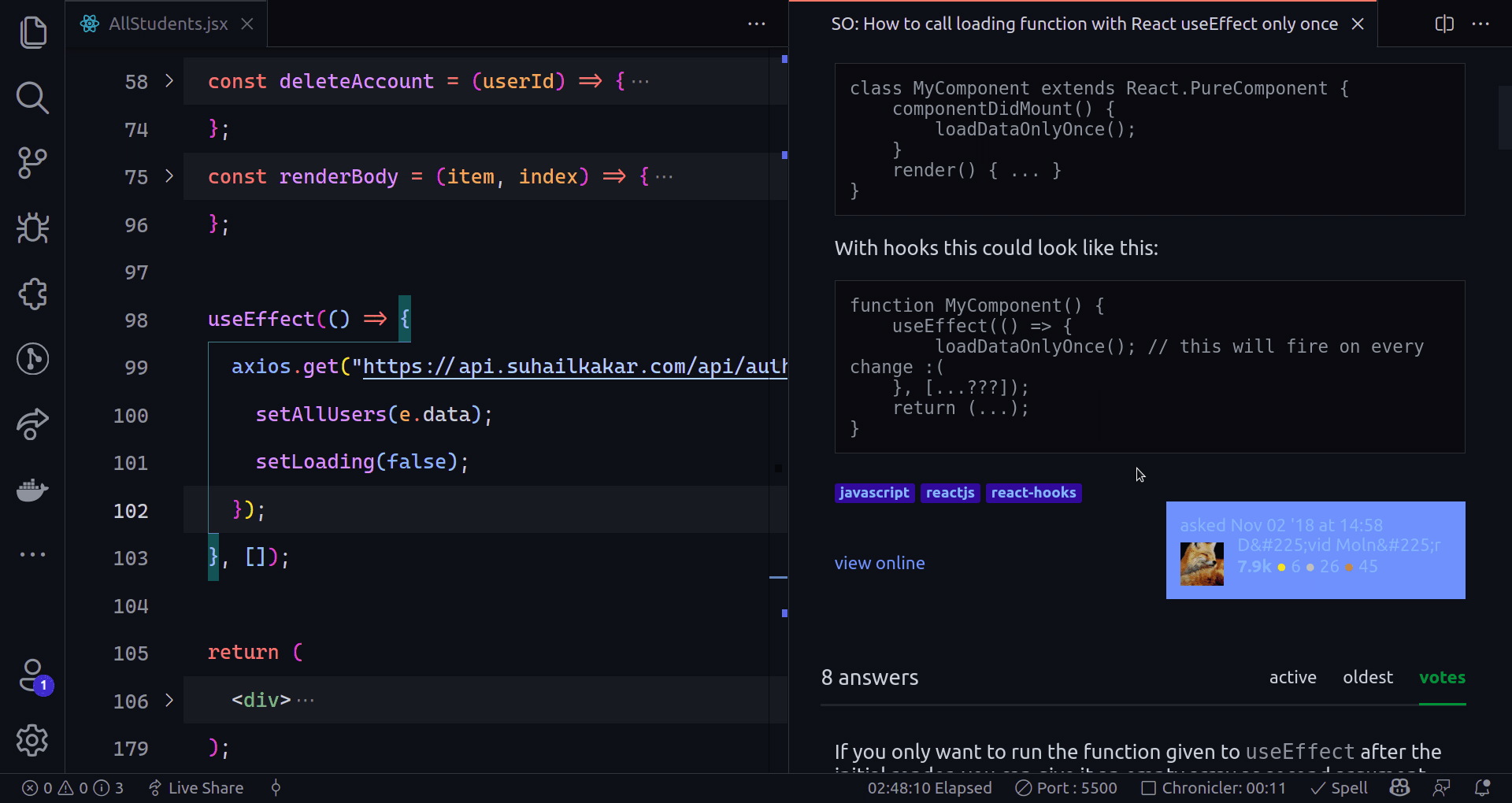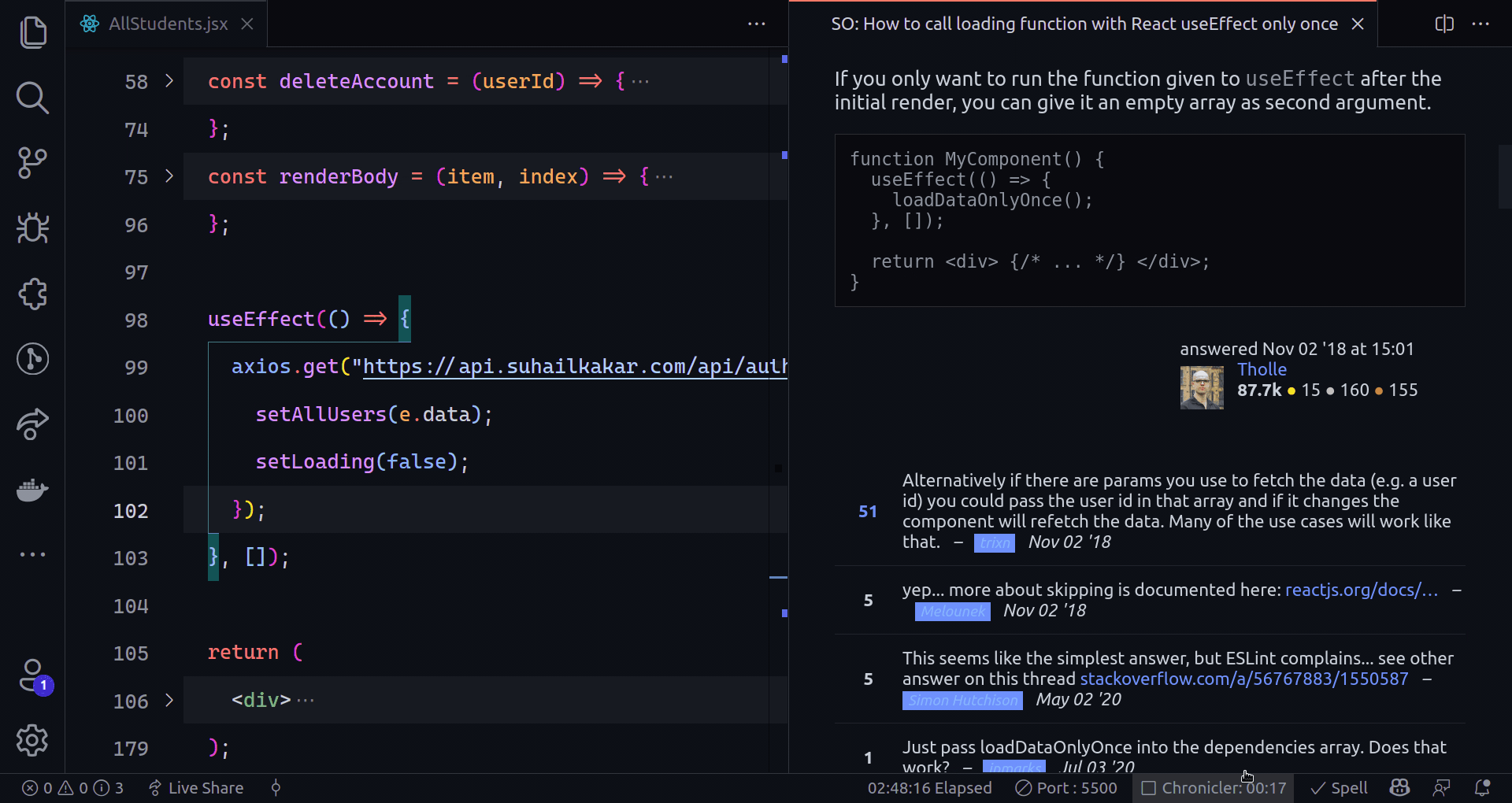
### Prettier
Prettier is an opinionated code formatter. It enforces a consistent style by parsing your code and re-printing it with its own rules that take the maximum line length into account, wrapping code when necessary. It supports JavaScript, TypeScript, Flow, JSX, JSON, CSS, SCSS, LessHTML, Vue, Angular GraphQL, Markdown, YAML and etc.
Link: https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode
### Code Spell Checker
A simple source code spell checker for multiple programming languages. A basic spell checker that works well with camelCase code. The goal of this spell checker is to help catch common spelling errors while keeping the number of false positives low.
Link: https://marketplace.visualstudio.com/items?itemName=streetsidesoftware.code-spell-checker
### Thunder Client
Thunder Client is a lightweight Rest API Client Extension for Visual Studio Code, hand-crafted by Ranga Vadhineni with a simple and clean design.
Link: https://marketplace.visualstudio.com/items?itemName=rangav.vscode-thunder-client
### Settings Sync
Instead of specifying your settings each time, you can save them in the editor and restore them on a new system with this plugin. This is important for customizing the development environment in the editors.
Link: https://marketplace.visualstudio.com/items?itemName=Shan.code-settings-sync
### Import Cost
Import Cost is a VS Code addon that estimates the size of an import package in your code. It's critical not to jeopardize the user experience by importing large packages when working on a project.
Link: https://marketplace.visualstudio.com/items?itemName=wix.vscode-import-cost
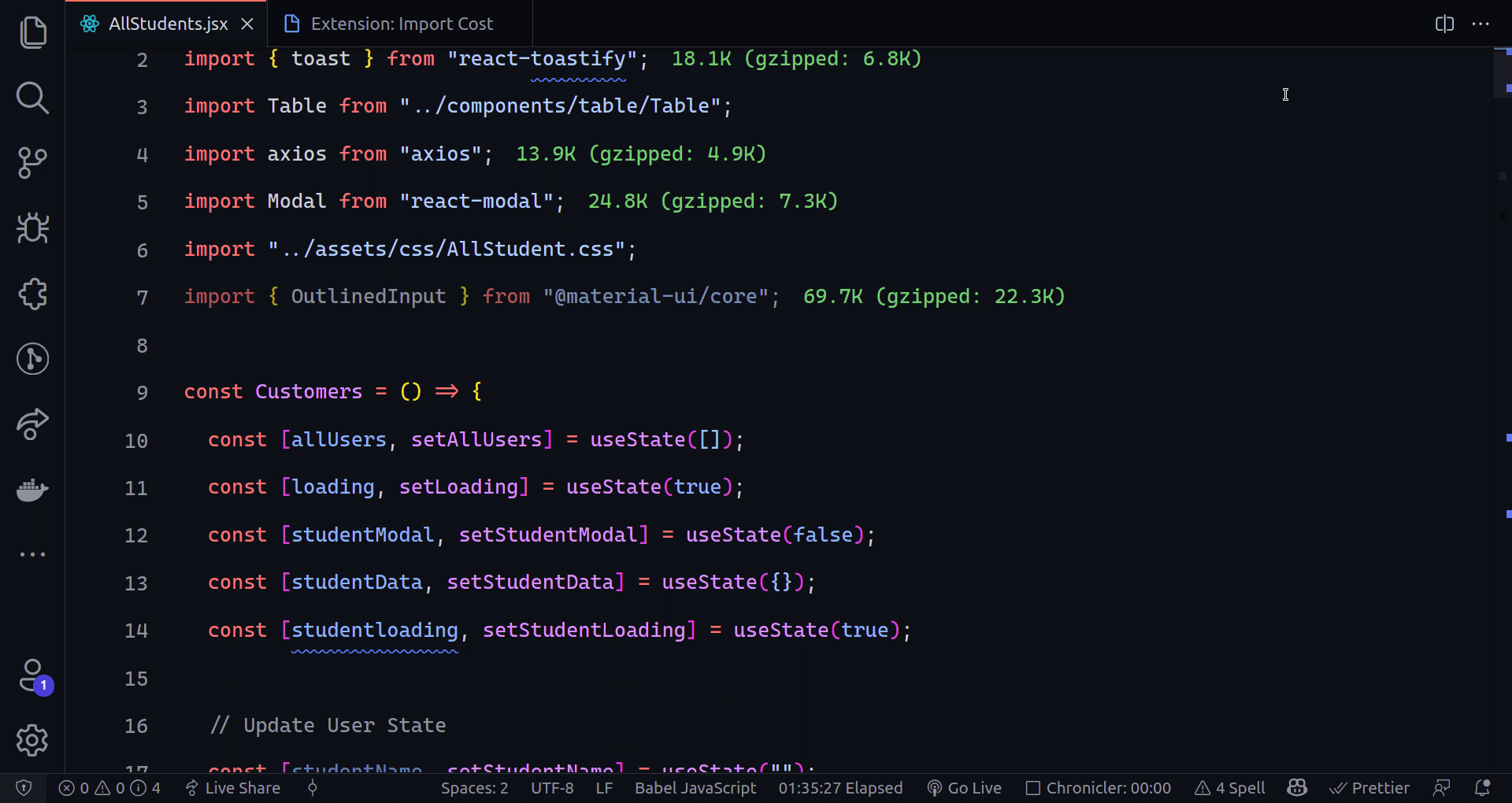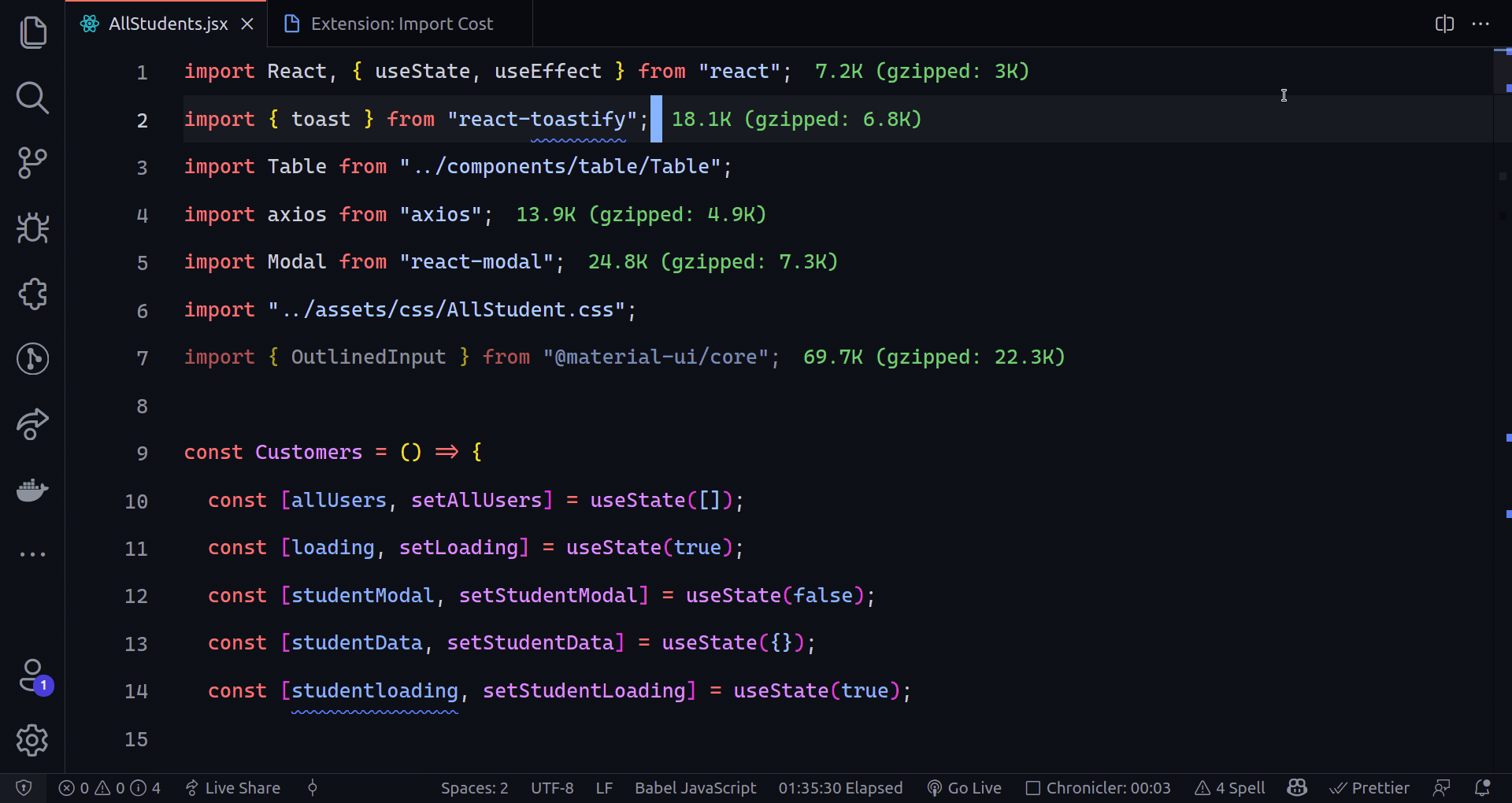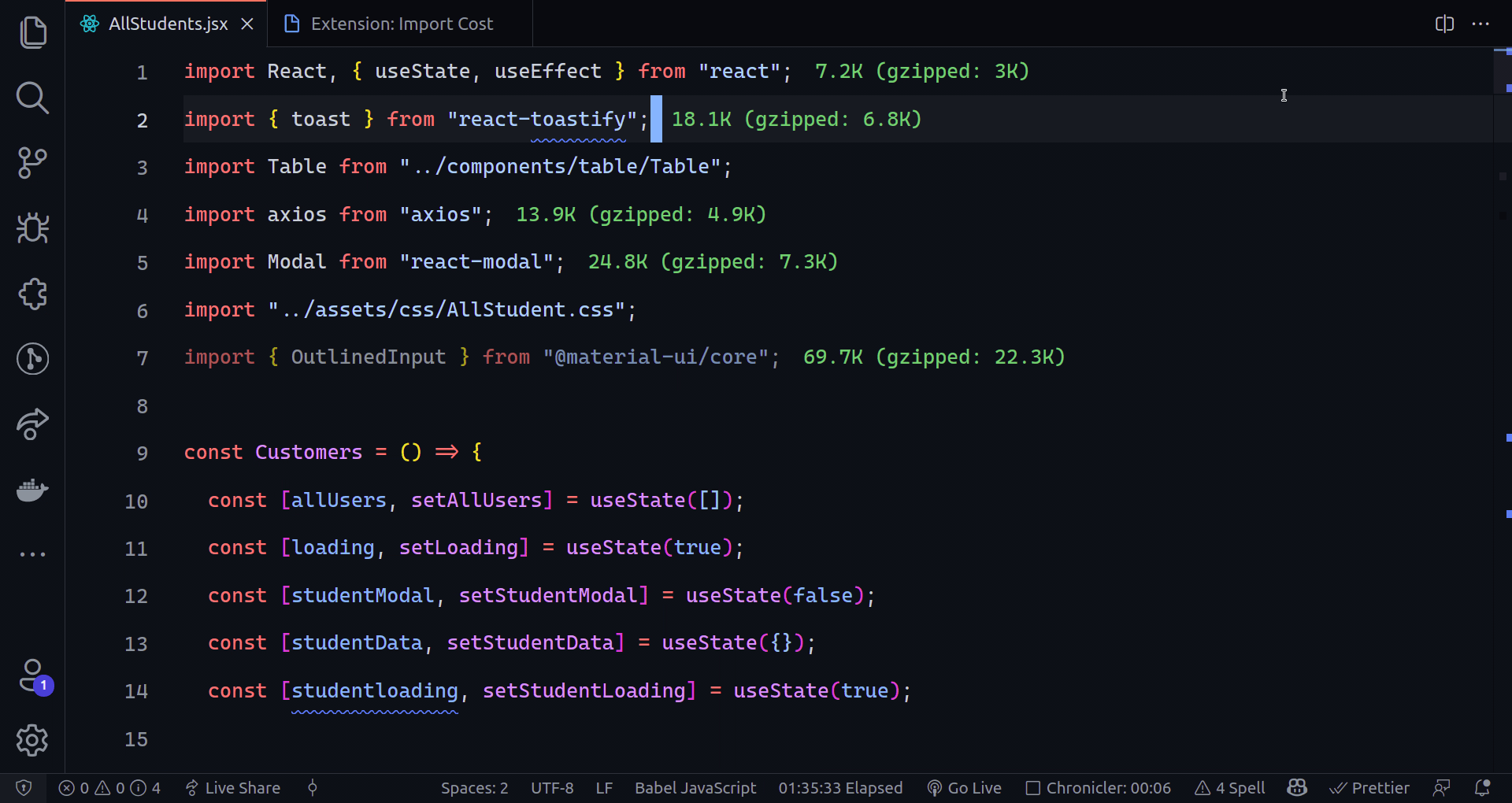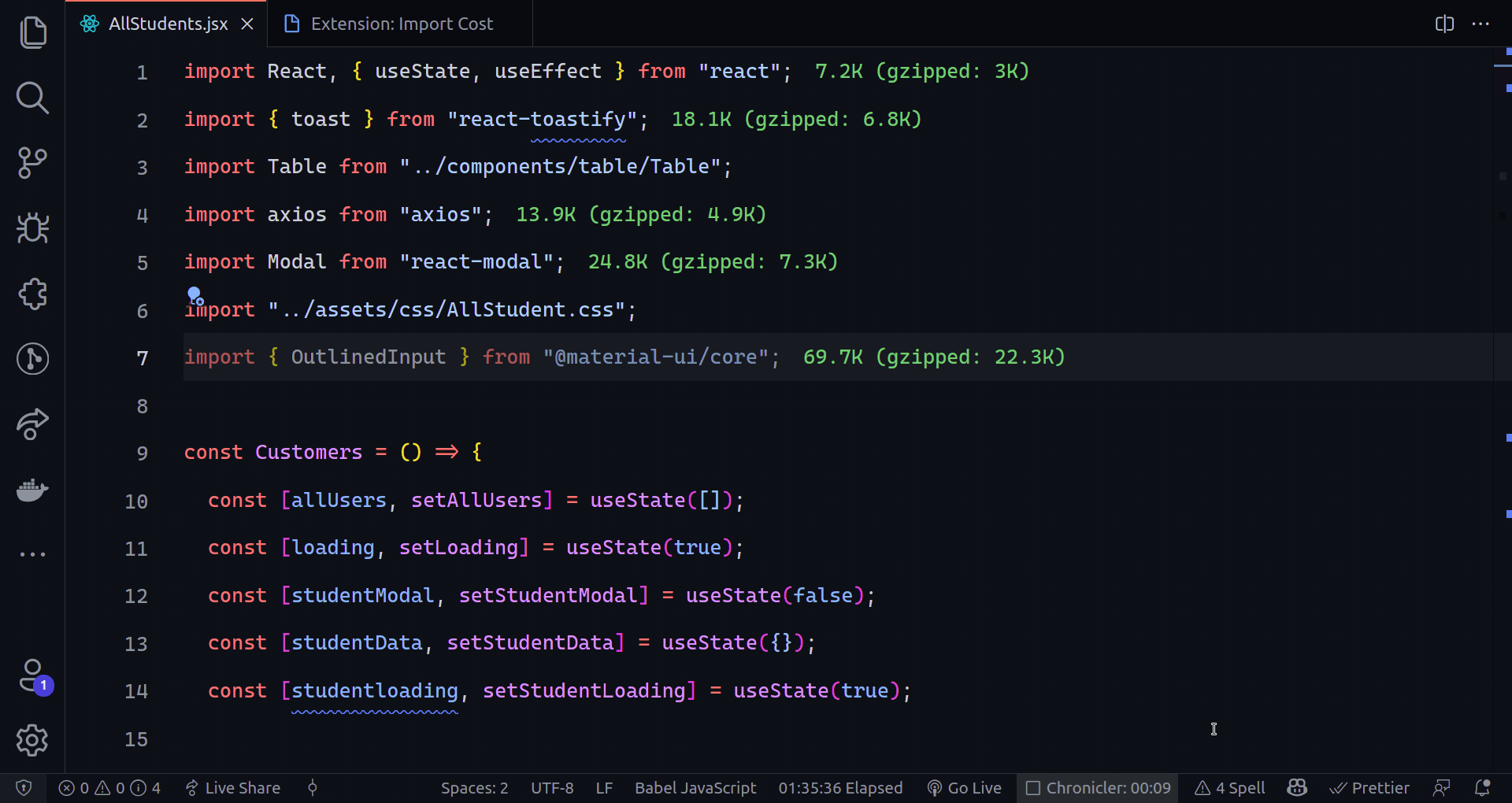
### Live Share
Visual Studio Live Share enables you to collaboratively edit and debug with others in real-time, regardless of what programming languages you're using or app types you're building. It allows you to instantly (and securely) share your current project, and then as needed, share debugging sessions, terminal instances, localhost web apps, voice calls, and more.
Link: https://marketplace.visualstudio.com/items?itemName=MS-vsliveshare.vsliveshare
## Conclusion
I hope you’re eager to use these 10 amazing VS Code Extensions to develop your application. If you need any help please let me know in the comment section.
Would you like to buy me a coffee, You can do it [here](https://www.buymeacoffee.com/suhailkakar).
Let's connect on [Twitter](https://twitter.com/suhailkakar) and [LinkedIn](https://www.linkedin.com/in/suhailkakar/).
👋 Thanks for reading, See you next time
| suhailkakar |
814,810 | Scraping the Web with Ease: Building a Python Web Scraper with Flask | Websites currently contain a wealth of valuable information, which is consumed daily by users all... | 0 | 2021-09-07T15:27:21 | https://dev.to/ondiek/building-a-python-web-scraper-in-flask-b87 | python, webdev, programming, datascience | Websites currently contain a wealth of valuable information, which is consumed daily by users all around the world. These statistics are a useful asset for any subject of study or special interest. When gathering this information, you will almost definitely find yourself manually copying and pasting.
That, of course, does not sit well with you.You need a simple and more automated method for this, which is where web scraping comes in.
**So, what exactly is web scraping?** As the name implies, it is simply the automated extraction of a web page's unstructured HTML information in a specified format, structuring it, and storing it in a database or saving it as a CSV file for future consumption.
Python libraries are at the top of the list of web scraping technologies accessible today. [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/) is the most popular Python web scraping library.
In this tutorial, we'll look at web scraping using Beautiful Soup and [Requests](https://docs.python-requests.org/en/master/user/quickstart/). We'll build a web scrapper app with [Flask](https://flask.palletsprojects.com/en/2.0.x/), Python's most lightweight web framework.
### How it works
- Load the application
- Provide a target URL and a tag to be fetched example *img,p, title*
- Receive a response - the requested element(s) content.
- For images, there will be a download functionality that will save the images to your downloads directory
**NB** Live preview available [here](https://scrap-the-web.herokuapp.com/)
### 1. Project setup.
For this project, I'll concentrate on backend functionality, as well as jinja templating and looping. I won't go into detail about CSS or the rest of the HTML code.Find the full project codes [here](https://github.com/Dev-Elie/Simple-Web-Crawler).
To get this project running on your local machine follow the steps [here](https://github.com/Dev-Elie/Simple-Web-Crawler#readme).
> Don't worry if you don't understand what's going on behind the scenes now that your project is up and running. Fill your coffee mug, because things are about to get interesting.
### 2. Project details.
Our primary discussion files will be as follows:
- app.py
- templates/index.html
#### app.py
As stated in the introduction, we will utilize Flask, Beautiful Soup, and request libraries. First and foremost, we'll import some functionality from Flask and Beautiful Soup into the app.py file.
We need to validate and parse the URLs we get, so we import the URL handling module for Python- [urllib](https://docs.python.org/3/library/urllib.html), as well as some other built-in libraries.
```python
from flask import (
Flask,
render_template,
request,
redirect,
flash,
url_for,
current_app
)
import urllib.request
from urllib.parse import urlparse,urljoin
from bs4 import BeautifulSoup
import requests,validators,json ,uuid,pathlib,os
```
A flask instance must be created as shown below.
```python
app = Flask(__name__)
```
Next, for our first route, we'll construct a function that returns an HTML template, as seen below.
```python
@app.route("/",methods=("GET", "POST"), strict_slashes=False)
def index():
# Actual parsing codes goes here
return render_template("index.html")
```
To begin our scrap, we must ensure that the user has sent a Post request.
```python
if request.method == "POST":
```
Inside our function we handle the actual parsing using Beautiful Soup
```python
try:
global requested_url,specific_element,tag
requested_url = request.form.get('urltext')
tag = request.form.get('specificElement')
source = requests.get(requested_url).text
soup = BeautifulSoup(source, "html.parser")
specific_element = soup.find_all(tag)
counter = len(specific_element)
image_paths = image_handler(
tag,
specific_element,
requested_url
)
return render_template("index.html",
url = requested_url,
counter=counter,
image_paths=image_paths,
results = specific_element
)
except Exception as e:
flash(e, "danger")
```
To explain the following scripts, since we'll be writing a function to accept image paths and generate a complete URL from them, the form field inputs must be available globally, so we define them as global variables.
```python
global requested_url,specific_element,tag
```
The next step is to set values to the two global variables from our form field, as seen below.
```python
requested_url = request.form.get('urltext')
tag = request.form.get('specificElement')
```
The following lines of code; the first line sends an HTTP request to the user-specified URL - `requested_url`. The server answers the request by delivering the raw HTML content of the webpage, which we then transform to text- `.text()` and assign to the variable `source`.
```python
source = requests.get(requested_url).text
```
We need to parse the page after we've extracted the HTML content in text format, and we'll utilize `html.parser` as our parsing library. We're merely generating a nested/tree structure of the HTML data by doing this.
```python
soup = BeautifulSoup(source, "html.parser")
```
Because we don't need the entire document, we navigate through the tree to discover the element we require. The tag that the user will enter in the form field.
```python
specific_element = soup.find_all(tag)
```
We also require a count of the results discovered. As a result, we create a variable -`counter` to record the count, as demonstrated.
```python
counter = len(specific_element)
```
As we can see, the variable `image_paths` is linked to a function called -`image_handler()`, which accepts the user-supplied URL, tag, and the specific element we extracted from the parsed page. We'll skip this function and come back to it later to see what it does.
```python
image_paths = image_handler(
tag,
specific_element,
requested_url
)
```
We pass the results of our parsing along with the return statement to make them available on the HTML template.
```python
return render_template("index.html",
url = requested_url,
counter=counter,
image_paths=image_paths,
results = specific_element
)
```
When referencing images on websites, developers frequently use either absolute URLs or relative URLs. Absolute URLs are simple to handle, but relative routes require some processing.
Paths such as `/uploads/image.png`, for example, will be difficult to determine where they originate. So we'll create a function similar to the one we called earlier to validate our image paths.
```python
def image_handler(tag,specific_element,requested_url):
image_paths = []
if tag == 'img':
images = [img['src'] for img in specific_element]
for i in specific_element:
image_path = i.attrs['src']
valid_imgpath = validators.url(image_path)
if valid_imgpath == True:
full_path = image_path
else:
full_path = urljoin(requested_url, image_path)
image_paths.append(full_path)
return image_paths
```
The function checks if the provided `tag` is an image tag, then extracts the images' src attribute value and verifies it to see if it's an absolute path. If this is not the case, it joins the relative path to the target's base URL.
> ```python
https://example.com + /uploads/image.png
```
These picture paths are then saved in a list and returned when the function is revoked.
**templates/index.html**
What comes next? We must provide the scrap results to the user. We'll use jinja templating and looping in this case.
```html
<div class="col-md-8">
<p><span class="badge bg-success">{{ counter }}</span> Scrap Results for <a
href="{{ url }}"> {{ url }}</a> </p>
<div class="bg-white shadow p-4 rounded results">
{% if results %}
{% for result in results %}
<p> {{ result | join(' ') }} </p>
{% endfor %}
{% endif %}
{% for path in image_paths %}
<a href=" {{ path }} "> <img src=" {{ path }} " class="img"> </a>
{% endfor %}
</div>
{% if image_paths %}
<a href="{{url_for('downloader')}}" class="btn btn-primary m-2" id="download">Download
Images<i class="bi bi-cloud-arrow-down-fill m-2"></i></a>
{% endif %}
</div>
```
In the above html code fragment, we print the number of results found as well as the URL that was scraped. Take a look at the sample below.

<figcaption>Results count and the URL</figcaption>
We first verify if the results list is available below the count and the URL, and if it is, we iterate printing each. This is for the texts that were retrieved.
However, when you print the output, you will see `| join(' ')` It operates similarly to `|striptags` in that it removes all HTML tags from the variable result.
Consequently, instead of

We'll have;

We use anchor tags to enclose the pictures and pass the paths as values to the `href` and `src` properties.
```html
{% for path in image_paths %}
<a href=" {{ path }} ">
<img src=" {{ path }} " class="img">
</a>
{% endfor %}
```
In addition, we'd like to display the download option only if images are retrieved. So we use jinja if statements to accomplish this. See the code below.
```html
{% if image_paths %}
<a href="{{url_for('downloader')}}" class="btn btn-primary m-2" id="download">
Download Images
<i class="bi bi-cloud-arrow-down-fill m-2"></i>
</a>
{% endif %}
```
Last but not least,we need to download images too.
```python
@app.route("/download",methods=("GET", "POST"), strict_slashes=False)
def downloader():
try:
for img in image_handler(tag,specific_element,requested_url):
image_url = img
filename = str(uuid.uuid4())
file_ext = pathlib.Path(image_url).suffix
picture_filename = filename + file_ext
downloads_path = str(pathlib.Path.home() / "Downloads")
picture_path = os.path.join(downloads_path, picture_filename
)
flash("Images saved in your Downloads directory", "success")
except Exception as e:
flash(e, "danger")
return redirect(url_for('index'))
```
The `uuid` library is used by the download function above to produce unique names for the downloaded files.
```python
filename = str(uuid.uuid4())
```
then `pathlib.Path()` to strip the image extension from the image path.
```python
file_ext = pathlib.Path(image_url).suffix
```
The two are combined to generate an image name that includes an extension. The image is then embedded with the downloads directory path. This will allow us to designate where we want the images saved.
```python
picture_path = os.path.join(downloads_path, picture_filename)
```
The line of code following handles the actual image download.
```python
urllib.request.urlretrieve(image_url, picture_path)
```
As parameters, `urllib.request.urlretrieve()` accepts the image(s) to be downloaded and the directory where it should be saved with its new name. As a result, the photos are saved in the downloads directory within the static directory.
Finally we instruct flask to run the application as a module.
```python
if __name__ == "__main__":
app.run(debug=True)
```
Thank you for taking the time to read this, and please leave some feedback if you found it useful.
Like, share, and leave a comment in the section below. Follow me on Twitter for further updates and tips on Flask and React development.
<p align="center"> <a href="https://twitter.com/dev_elie" target="blank"><img src="https://img.shields.io/twitter/follow/dev_elie?logo=twitter&style=for-the-badge" alt="dev_elie" /></a> </p>

| ondiek |
814,829 | Building Desktop Passport Scanner with Qt and USB Camera | If you search for passport scanner software or MRZ reader software, you will find many of them are... | 0 | 2021-09-06T07:02:45 | https://www.dynamsoft.com/codepool/passport-scanner-qt-desktop-camera.html | qt, camera, passport, ocr | If you search for passport scanner software or MRZ reader software, you will find many of them are only available for mobile devices. For police officers, scanning passports by mobile devices is convenient when they are patrolling. However, for customs and immigration officers, they usually use desktop system and professional passport scanner or reader, which cost a lot, to check passengers' passport information. Dynamsoft's OCR SDK is available for both mobile and desktop scenarios. In this article, I will demonstrate an economic way that uses a cheap USB web camera (less than $20), [Qt](https://www.qt.io/), and [Dynamsoft MRZ SDK](https://www.dynamsoft.com/use-cases/mrz-scanner/) to build a desktop passport scanner application for Windows and Linux.
## Prerequisites
- [](https://www.dynamsoft.com/label-recognition/downloads)
- [](https://www.dynamsoft.com/customer/license/trialLicense?product=dlr)
- Qt 5.12.11
- [Windows](https://www.qt.io/download)
- Linux
```bash
sudo apt-get install qt5-default
```
## The Skeleton of Qt C++ Project for Desktop Passport Scanner
Before getting started, let's get the codebase of the barcode scanning application that I implemented recently.
```bash
git clone https://github.com/yushulx/Qt-desktop-barcode-reader.git
```
The codebase has implemented the file loading and camera video streaming functions. What I need to do is to replace barcode recognition SDK with MRZ recognition SDK. In addition, the project needs to import extra character models (trained by Caffe) for OCR and a template file for providing MRZ recognition parameters.
**Character model files**
```bash
NumberUppercase.caffemodel
NumberUppercase.prototxt
NumberUppercase.txt
NumberUppercase_Assist_1lIJ.caffemodel
NumberUppercase_Assist_1lIJ.prototxt
NumberUppercase_Assist_1lIJ.txt
NumberUppercase_Assist_8B.caffemodel
NumberUppercase_Assist_8B.prototxt
NumberUppercase_Assist_8B.txt
NumberUppercase_Assist_8BHR.caffemodel
NumberUppercase_Assist_8BHR.prototxt
NumberUppercase_Assist_8BHR.txt
NumberUppercase_Assist_number.caffemodel
NumberUppercase_Assist_number.prototxt
NumberUppercase_Assist_number.txt
NumberUppercase_Assist_O0DQ.caffemodel
NumberUppercase_Assist_O0DQ.prototxt
NumberUppercase_Assist_O0DQ.txt
NumberUppercase_Assist_upcase.caffemodel
NumberUppercase_Assist_upcase.prototxt
NumberUppercase_Assist_upcase.txt
```
**Template file**
```json
{
"CharacterModelArray" : [
{
"DirectoryPath": "CharacterModel",
"FilterFilePath": "",
"Name": "NumberUppercase"
}
],
"LabelRecognizerParameterArray" : [
{
"BinarizationModes" : [
{
"BlockSizeX" : 0,
"BlockSizeY" : 0,
"EnableFillBinaryVacancy" : 1,
"LibraryFileName" : "",
"LibraryParameters" : "",
"Mode" : "BM_LOCAL_BLOCK",
"ThreshValueCoefficient" : 15
}
],
"CharacterModelName" : "NumberUppercase",
"LetterHeightRange" : [ 5, 1000, 1 ],
"LineStringLengthRange" : [44, 44],
"MaxLineCharacterSpacing" : 130,
"LineStringRegExPattern" : "(P[OM<][A-Z]{3}([A-Z<]{0,35}[A-Z]{1,3}[(<<)][A-Z]{1,3}[A-Z<]{0,35}<{0,35}){(39)}){(44)}|([A-Z0-9<]{9}[0-9][A-Z]{3}[0-9]{2}[(01-12)][(01-31)][0-9][MF][0-9]{2}[(01-12)][(01-31)][0-9][A-Z0-9<]{14}[0-9<][0-9]){(44)}",
"MaxThreadCount" : 4,
"Name" : "locr",
"TextureDetectionModes" :[
{
"Mode" : "TDM_GENERAL_WIDTH_CONCENTRATION",
"Sensitivity" : 8
}
],
"ReferenceRegionNameArray" : [ "DRRegion" ]
}
],
"LineSpecificationArray" : [
{
"Name":"L0",
"LineNumber":"",
"BinarizationModes" : [
{
"BlockSizeX" : 30,
"BlockSizeY" : 30,
"Mode" : "BM_LOCAL_BLOCK"
}
]
}
],
"ReferenceRegionArray" : [
{
"Localization" : {
"FirstPoint" : [ 0, 0 ],
"SecondPoint" : [ 100, 0 ],
"ThirdPoint" : [ 100, 100 ],
"FourthPoint" : [ 0, 100 ],
"MeasuredByPercentage" : 1,
"SourceType" : "LST_MANUAL_SPECIFICATION"
},
"Name" : "DRRegion",
"TextAreaNameArray" : [ "DTArea" ]
}
],
"TextAreaArray" : [
{
"LineSpecificationNameArray" : ["L0"],
"Name" : "DTArea",
"FirstPoint" : [ 0, 0 ],
"SecondPoint" : [ 100, 0 ],
"ThirdPoint" : [ 100, 100 ],
"FourthPoint" : [ 0, 100 ]
}
]
}
```
## Desktop Passport Scanner for Windows and Linux
Since we have already got the codebase, it won't take too much time to get the application work.
### Library Linking
We extract the library files from the downloaded archive and put them into the corresponding folders:
- Windows
Copy `DynamsoftLabelRecognizerx64.lib` to `platform/windows/lib`.
Copy `DynamicPdfx64.dll`, `DynamsoftLabelRecognizerx64.dll`, `DynamsoftLicenseClientx64.dll` and `vcomp140.dll` to `platform/windows/bin`.
- Linux
Copy `libDynamicPdf.so`, `libDynamsoftLabelRecognizer.so`, and `libDynamsoftLicenseClient.so` to `platform/linux`.
After that, we update the `CMakeLists.txt` file to link libraries and copy model and template files:
```cmake
if (CMAKE_HOST_WIN32)
target_link_libraries(${PROJECT_NAME} PRIVATE Qt5::Widgets Qt5::MultimediaWidgets "DynamsoftLabelRecognizerx64")
elseif(CMAKE_HOST_UNIX)
target_link_libraries(${PROJECT_NAME} PRIVATE Qt5::Widgets Qt5::MultimediaWidgets "DynamsoftLabelRecognizer")
endif()
# Copy DLLs
if(CMAKE_HOST_WIN32)
add_custom_command(TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_directory
"${PROJECT_SOURCE_DIR}/platform/windows/bin/"
$<TARGET_FILE_DIR:${PROJECT_NAME}>)
endif()
# Copy template
add_custom_command(TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_directory
"${PROJECT_SOURCE_DIR}/template/"
$<TARGET_FILE_DIR:${PROJECT_NAME}>)
# Copy model files
add_custom_command(TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_directory
"${PROJECT_SOURCE_DIR}/CharacterModel"
$<TARGET_FILE_DIR:${PROJECT_NAME}>/CharacterModel)
```
### Steps to Modify the Code for MRZ Recognition
Next, we import `DynamsoftLabelRecognizer.h` and `DynamsoftCore.h` to `mainwindow.h`:
```cpp
#include "DynamsoftLabelRecognizer.h"
#include "DynamsoftCore.h"
```
In `mainwindow.cpp`, we search for the line of invoking `DBR_DecodeFile()` method and then replace the line with:
```cpp
int errorCode = DBR_DecodeFile(reader, fileName.toStdString().c_str(), "");
```
Add the following code block to get passport information:
```cpp
DLR_Result **results = handler->results;
for (int ri = 0; ri < handler->resultsCount; ++ri)
{
DLR_Result* result = handler->results[ri];
int lCount = result->lineResultsCount;
for (int li = 0; li < lCount; ++li)
{
DM_Point *points = result->lineResults[li]->location.points;
int x1 = points[0].x, y1 = points[0].y;
int x2 = points[1].x, y2 = points[1].y;
int x3 = points[2].x, y3 = points[2].y;
int x4 = points[3].x, y4 = points[3].y;
}
if (lCount < 2)
{
continue;
}
string line1 = result->lineResults[0]->text;
string line2 = result->lineResults[1]->text;
if (line1.length() != 44 || line2.length() != 44)
{
continue;
}
if (line1[0] != 'P')
continue;
else {
// Type
string tmp = "Type: ";
tmp.insert(tmp.length(), 1, line1[0]);
out += QString::fromStdString(tmp) + "\n";
// Issuing country
tmp = "Issuing country: "; line1.substr(2, 5);
tmp += line1.substr(2, 3);
out += QString::fromStdString(tmp) + "\n";
// Surname
int index = 5;
tmp = "Surname: ";
for (; index < 44; index++)
{
if (line1[index] != '<')
{
tmp.insert(tmp.length(), 1, line1[index]);
}
else
{
break;
}
}
out += QString::fromStdString(tmp) + "\n";
// Given names
tmp = "Given Names: ";
index += 2;
for (; index < 44; index++)
{
if (line1[index] != '<')
{
tmp.insert(tmp.length(), 1, line1[index]);
}
else
{
tmp.insert(tmp.length(), 1, ' ');
}
}
out += QString::fromStdString(tmp) + "\n";
// Passport number
tmp = "Passport number: ";
index = 0;
for (; index < 9; index++)
{
if (line2[index] != '<')
{
tmp.insert(tmp.length(), 1, line2[index]);
}
else
{
break;
}
}
out += QString::fromStdString(tmp) + "\n";
// Nationality
tmp = "Nationality: ";
tmp += line2.substr(10, 3);
out += QString::fromStdString(tmp) + "\n";
// Date of birth
tmp = line2.substr(13, 6);
tmp.insert(2, "/");
tmp.insert(5, "/");
tmp = "Date of birth (YYMMDD): " + tmp;
out += QString::fromStdString(tmp) + "\n";
// Sex
tmp = "Sex: ";
tmp.insert(tmp.length(), 1, line2[20]);
out += QString::fromStdString(tmp) + "\n";
// Expiration date of passport
tmp = line2.substr(21, 6);
tmp.insert(2, "/");
tmp.insert(5, "/");
tmp = "Expiration date of passport (YYMMDD): " + tmp;
out += QString::fromStdString(tmp) + "\n";
// Personal number
if (line2[28] != '<')
{
tmp = "Personal number: ";
for (index = 28; index < 42; index++)
{
if (line2[index] != '<')
{
tmp.insert(tmp.length(), 1, line2[index]);
}
else
{
break;
}
}
out += QString::fromStdString(tmp) + "\n";
}
}
}
DLR_FreeResults(&handler);
```
So far, the static image recognition is completed. In the following, we will implement real-time passport scanning by camera video stream.
To store MRZ recognition information and share it between threads, we create a new class `MRZInfo`:
```cpp
#ifndef MRZINFO_H
#define MRZINFO_H
#include <QString>
class MRZInfo
{
public:
MRZInfo() = default;
~MRZInfo(){};
bool isNull();
public:
QString text;
int x1, y1, x2, y2, x3, y3, x4, y4, xx1, yy1, xx2, yy2, xx3, yy3, xx4, yy4;
};
#endif // MRZINFO_H
```
Open `work.h` to add a new slot function `detectMRZ()`, which works in a worker thread for recognizing MRZ:
```cpp
void Work::detectMRZ()
{
while (m_bIsRunning)
{
QImage image;
m_mutex.lock();
// wait for QList
if (queue.isEmpty())
{
m_listIsEmpty.wait(&m_mutex);
}
if (!queue.isEmpty())
{
image = queue.takeFirst();
}
m_mutex.unlock();
if (!image.isNull())
{
// Detect MRZ
}
}
}
```
To recognize MRZ and extract passport information, we firstly convert `QImage` to `ImageData` and then call `DLR_RecognizeByBuffer()` method:
```cpp
// Convert QImage to ImageData
ImageData data;
data.bytes = (unsigned char *)image.bits();
data.width = image.width();
data.height = image.height();
data.stride = image.bytesPerLine();
data.format = IPF_ARGB_8888;
data.bytesLength = image.byteCount();
QDateTime start = QDateTime::currentDateTime();
int errorCode = DLR_RecognizeByBuffer(recognizer, &data, "locr");
QDateTime end = QDateTime::currentDateTime();
DLR_ResultArray *handler = NULL;
DLR_GetAllResults(recognizer, &handler);
std::vector<MRZInfo> all;
QString out = "Elapsed time: " + QString::number(start.msecsTo(end)) + "ms\n\n";
DLR_Result **results = handler->results;
for (int ri = 0; ri < handler->resultsCount; ++ri)
{
DLR_Result* result = handler->results[ri];
int lCount = result->lineResultsCount;
if (lCount < 2)
{
continue;
}
DLR_LineResult *l1 = result->lineResults[0];
DLR_LineResult *l2 = result->lineResults[1];
string line1 = l1->text;
string line2 = l2->text;
if (line1.length() != 44 || line2.length() != 44)
{
continue;
}
if (line1[0] != 'P')
continue;
MRZInfo info;
DM_Point *points = l1->location.points;
int x1 = points[0].x, y1 = points[0].y;
int x2 = points[1].x, y2 = points[1].y;
int x3 = points[2].x, y3 = points[2].y;
int x4 = points[3].x, y4 = points[3].y;
DM_Point *points2 = l2->location.points;
int xx1 = points2[0].x, yy1 = points2[0].y;
int xx2 = points2[1].x, yy2 = points2[1].y;
int xx3 = points2[2].x, yy3 = points2[2].y;
int xx4 = points2[3].x, yy4 = points2[3].y;
// Type
string tmp = "Type: ";
tmp.insert(tmp.length(), 1, line1[0]);
out += QString::fromStdString(tmp) + "\n";
// Issuing country
tmp = "Issuing country: "; line1.substr(2, 5);
tmp += line1.substr(2, 3);
out += QString::fromStdString(tmp) + "\n";
// Surname
int index = 5;
tmp = "Surname: ";
for (; index < 44; index++)
{
if (line1[index] != '<')
{
tmp.insert(tmp.length(), 1, line1[index]);
}
else
{
break;
}
}
out += QString::fromStdString(tmp) + "\n";
// Given names
tmp = "Given Names: ";
index += 2;
for (; index < 44; index++)
{
if (line1[index] != '<')
{
tmp.insert(tmp.length(), 1, line1[index]);
}
else
{
tmp.insert(tmp.length(), 1, ' ');
}
}
out += QString::fromStdString(tmp) + "\n";
// Passport number
tmp = "Passport number: ";
index = 0;
for (; index < 9; index++)
{
if (line2[index] != '<')
{
tmp.insert(tmp.length(), 1, line2[index]);
}
else
{
break;
}
}
out += QString::fromStdString(tmp) + "\n";
// Nationality
tmp = "Nationality: ";
tmp += line2.substr(10, 3);
out += QString::fromStdString(tmp) + "\n";
// Date of birth
tmp = line2.substr(13, 6);
tmp.insert(2, "/");
tmp.insert(5, "/");
tmp = "Date of birth (YYMMDD): " + tmp;
out += QString::fromStdString(tmp) + "\n";
// Sex
tmp = "Sex: ";
tmp.insert(tmp.length(), 1, line2[20]);
out += QString::fromStdString(tmp) + "\n";
// Expiration date of passport
tmp = line2.substr(21, 6);
tmp.insert(2, "/");
tmp.insert(5, "/");
tmp = "Expiration date of passport (YYMMDD): " + tmp;
out += QString::fromStdString(tmp) + "\n";
// Personal number
if (line2[28] != '<')
{
tmp = "Personal number: ";
for (index = 28; index < 42; index++)
{
if (line2[index] != '<')
{
tmp.insert(tmp.length(), 1, line2[index]);
}
else
{
break;
}
}
out += QString::fromStdString(tmp) + "\n";
}
info.text = out;
info.x1 = x1;
info.y1 = y1;
info.x2 = x2;
info.y2 = y2;
info.x3 = x3;
info.y3 = y3;
info.x4 = x4;
info.y4 = y4;
info.xx1 = xx1;
info.yy1 = yy1;
info.xx2 = xx2;
info.yy2 = yy2;
info.xx3 = xx3;
info.yy3 = yy3;
info.xx4 = xx4;
info.yy4 = yy4;
all.push_back(info);
}
DLR_FreeResults(&handler);
surface->appendResult(all);
```
### How to Build the Qt CMake Project
The CMake build commands are a bit different between Windows and Linux:
```bash
# Windows
mkdir build
cd build
cmake -G "MinGW Makefiles" ..
cmake --build .
MRZRecognizer.exe
# Linux
mkdir build
cd build
cmake ..
cmake --build .
./MRZRecognizer
```
### Running Passport Scanner
When running the program, you need to enter a valid license key:
Then you can scan passport information from static images or webcam.
## Source Code
[https://github.com/yushulx/passport-scanner](https://github.com/yushulx/passport-scanner)
| yushulx |
814,861 | Why copying tutorial projects does not help you to learn React | One year ago I needed React for a Project at work. I have wanted to learn it before, but I never had... | 0 | 2021-10-13T06:13:31 | https://dev.to/tim012432/why-copying-tutorial-projects-does-not-help-you-to-learn-react-jhn | react, codenewbie, tutorial, beginners | One year ago I needed React for a Project at work. I have wanted to learn it before, but I never had the time to do it. Now the time has come and I decided to dive deeper into web development with the React framework.
First of all I decided to watch some tutorials on YouTube because that's what you usually do when learning new programming things.
> 
> Fig.1 - YouTube search results for React Tutorials
My first decision was a very informative tutorial by [DevEd](https://www.youtube.com/watch?v=pCA4qpQDZD8) where he shows how to develop a simple to-do app.
After that, I watched more and more tutorials and copied their projects.
**In my opinion that was not the best start I could have had. By just copying and following a tutorial, you do not learn the basics. It would be better to learn concepts and understand how the framework itself works than just copy lines of code.**
<br>
## Comparison
### Todo App
My first ever React project.
Obviously not only mine.
> 
> Fig.2 - TodoList by [Chirag](https://chiragsaini.github.io/Todo-List/)
<br>
> 
> Fig.3 - TodoList by [Auxfuse](https://auxfuse.github.io/todoR/)
<br>
> 
> Fig.4 - [My version of the TodoList](https://todos.tim0-12432.me/)
As you see, the difference between the compared screenshots of to-do apps is not wide.
Even if I conquered my weaker self and extended the feature set, it seems like they are a one to one copy of each other. No wonder.
### Corona Tracker
In Covid-19 pandemic, I wanted to create a page where I can find all important key numbers for Germany.
For that I followed a tutorial by Javascript Mastery and extended it.
> 
> Fig.5 - Corona Tracker by [JavascriptMastery](https://covid19statswebsite.netlify.app/)
<br>
> 
> Fig.6 - [My version of the Corona Tracker](https://covid.tim0-12432.me/)
The difference is a bit wider than in the above example. Most likely because of the added dark mode (#hateAgainstLightMode xD). But with a closer look you can see the components are very similar.
## Better approach
1. Search for a good project at the skill level that suits you
2. Implement the idea in the way you image it
3. Search for solutions or best practices on the internet whenever you don't know how to achieve a certain behavior, or you want a better way of implementation
4. As a sideline you can watch videos explaining little concepts such as states, context and so on
## Conclusion
For a first entry point to learning a new framework or language, it could help to copy a tutorial and enhance it a bit afterwards.
But after copying one or two projects, copying does not lead you to getting better, learning the technique really or understanding basic principles.
**Try to write code yourself.**
<br>
---
*Please feel free to write your opinion in the comment section!*
{% user tim012432 %}
- GitHub: [tim0-12432](https://github.com/tim0-12432) | tim012432 |
814,917 | Troubleshooting for Huawei's App Performance Management SDK | I encountered a few issues in the process of integrating the APM SDK. In this post, I will share... | 0 | 2021-09-06T10:18:45 | https://dev.to/devwithzachary/troubleshooting-for-huawei-s-app-performance-management-sdk-4dbo | huawei, android, sdk, apm | I encountered a few issues in the process of integrating the APM SDK. In this post, I will share these cases for you, so that you will have a sense of how to resolve them.
#Issue 1: Error "miss client id" Is Reported After the APM SDK Is Integrated
The detailed error message is as follows:
>I/com.huawei.agc.apms: failed to fetch remote config: client token request miss client id, please check whether the 'agconnect-services.json' is configured correctly
##Troubleshooting
By searching through the forum, I found that the issue is caused by the absence of the AppGallery Connect plugin. For details, please refer to [this forum post](https://forums.developer.huawei.com/forumPortal/en/topic/0203417432150160006).
To solve the problem, just add the following code to the app-level build.gradle file:
> apply plugin: 'com.huawei.agconnect'
#Issue 2: Cannot Find the Reported APM Logs on the Device
When the APM SDK is integrated, there was no app performance data on the App performance management page. I wanted to locate the problem based on the Logcat logs on the device.
However, I wasn't sure how to find the APM logs.
##Troubleshooting
I checked the APM documentation and found out how to access the logs:
Open the AndroidManifest.xml file of the app, and add the meta-data element to application.
```xml
<application>
<meta-data
android:name="apms_debug_log_enabled"
android:value=" true" />
</application>
```
After the APM debug log function is enabled, you can use the Logcat log filter function com.huawei.agc.apms or apms to view the logs.
Please note that only the value of resultCode is 200 indicates that the data is reported successfully.
>I/HiAnalyticsSDK: SendMission=> events PostRequest sendevent TYPE : oper, TAG : APMS, resultCode: 200 ,reqID:b639daae0490c378cf242544916a9c36
#Issue 3: No Successfully Uploaded AMPS Logs in the Logcat.
The meta-data element has been added and set to true. The contains and sending logs can be viewed in the Logcat, with the exception of the successfully uploaded AMPS logs.
##Troubleshooting
The check result shows that the agconnect-services.json file was downloaded before the APM service was enabled. This indicates that it needs to be updated.
Before the service was enabled, the JSON file contained only 29 lines. After the service was enabled, more parameters were added to the file that it has contained 52 lines.
Update the JSON file, and you'll be able to view the successfully uploaded AMP logs.
#Issue 4: No APM Data Displayed in AppGallery Connect While Logs Are Available
When locating this problem, I found a log in which the result code is 200. However, still no APM data is available in AppGallery Connect.
The corresponding logs are as follows:
>I/HiAnalyticsSDK: hmsSdk=> events PostRequest sendevent TYPE : maint, TAG : _hms_config_tag, resultCode: 200 ,reqID:842927417075465ab9ad990e2ce92646
##Troubleshooting
The value of TAG in the preceding log is not APMS. Therefore, it cannot be the log that indicates that the APM data is successfully loaded.
I analyzed the logs and found some authentication failure logs.
>E/HiAnalyticsSDK: HttpTransportCommander=> NE-004|IO Exception.timeout
>D/HiAnalyticsSDK: HttpTransportCommander=> request times: 1
>I/HiAnalyticsSDK: getPubKey=> result code : -102
After contacting Huawei technical support, I learned that the data reporting channel of the HiAnalyticsSDK used by APM has an authentication problem.
I went to My projects > HUAWEI Analytics in AppGallery Connect and enabled HUAWEI Analytics. After a while, the authentication was successful.
#Issue 5: No Related Network Request Performance Data Is Displayed.
All of the performance data is normal with the exception of the network request data, which is not displayed in AppGallery Connect.
##Troubleshooting
According to the [official documentation](https://developer.huawei.com/consumer/en/doc/development/AppGallery-connect-Guides/agc-apm-android-getstarted-0000001052887262), obtaining network request data depends on the APM plugin. The data can only be obtained after the APM plugin has been correctly integrated.
To integrate the plugin, do as follows:
1. In the project-level build.gradle file, add the following code in dependencies:
classpath 'com.huawei.agconnect:agconnect-apms-plugin:1.4.1.305'
2. In the app-level build.gradle file, add the following code:
apply plugin: 'com.huawei.agconnect.apms'
| devwithzachary |
815,097 | All about Functions and Scopes in JavaScript | Hello everyone, we would be covering all about JS functions, callbacks, scopes, closures in-depth... | 0 | 2021-09-06T11:01:18 | https://dev.to/sjsouvik/all-about-functions-and-scopes-in-javascript-1ac5 | javascript, webdev, programming, beginners | Hello everyone, we would be covering all about JS functions, callbacks, scopes, closures in-depth here which would help you to
- understand different types of functions declaration
- make better use of functions
- understand how different scopes and scope chain work in JS
- learn about closures and how to use it
So, keep reading till the end and I hope you'll learn something from it.
### Functions
Functions allow us to package up lines of code so that we can use (and reuse) a block of code in our programs. Sometimes, they take some values as `parameters` to do the operation and return some value as a result of the operation.
```javascript
function add(a, b){ //a, b are the parameters of this function
//code to do the operation
return a + b; //return statement
}
add(2, 3); //invoking the function; 2, 3 are arguments here
```
### First-Class Citizen
Functions are considered as First-Class Citizen in JavaScript, which means we can do anything we want with functions.
We can
- store function in a variable
- pass a function as an argument to another function
- return a function from another function
### Function Expressions
When a function is stored inside a variable it's called a **function expression**. This can be named or anonymous. If a function doesn't have any name and is stored in a variable, then it would be known as **anonymous function expression**. Otherwise, it would be known as **named function expression**.
```javascript
//Anonymous function expression
const add = function (a, b){
return a + b;
}
//Named function expression
const subtractResult = function subtract(a, b){
return a - b;
}
console.log(add(3, 2)); // 5
console.log(subtractResult(3, 2)); // 1
```
### Callbacks
Storing a function in a variable makes it really easy to pass a function to another function as an argument. A function that takes other functions as arguments or returns a function is known as **higher-order function**. A function that is passed as an argument into another function is known as **callback** function.
```javascript
function showLength(name, callback){
callback(name);
}
//function expression `nameLength`
const nameLength = function (name){
console.log(`Given Name ${name} is ${name.length} chars long`) // Given Name Souvik is 6 chars long
}
showLength("Souvik", nameLength); //passing `nameLength` as a callback function
```
Generally, we use callback function in array methods - `forEach()`, `map()`, `filter()`, `reduce()`.
### Scope
**Scope** in JS tells us what variables and functions are accessible and not accessible in a given part of the code.
There're 3 kinds of scopes in JavaScript.
- Global scope
- Function scope
- Block scope
Variables declared outside of all functions are known as global variables and in **global scope**. Global variables are accessible anywhere in the program.
Variables that are declared inside a function are called local variables and in **function scope**. Local variables are accessible anywhere inside the function.
The code inside a function has access to
- the function's arguments
- local variables declared inside the function
- variables declared in its parent function's scope
- global variables
```javascript
const name = "Souvik";
function introduceMyself(greet){
const audience = "students";
function introduce(){
console.log(`${greet} ${audience}, I am ${name}`); // Hello students, I am Souvik
}
introduce();
}
introduceMyself("Hello");
```
**Block scope** tells us that any variable declared inside a block ({}) can be accessed only inside that block.
Now, what is **block** 🤔? a block {} is used to group JavaScript statements together into 1 group so that can be used anywhere in the program where only 1 statement is expected to be written.
> Block scope is related to variables declared with `let` and `const` only. Variables declared with `var` do not have block scope.
```javascript
{
let a = 3;
var b = 2;
}
console.log(a); //Uncaught ReferenceError: a is not defined
console.log(b); // 2 `as variables declared with `var` is functionally and globally scoped NOT block scoped`
```
### Scope chain
Whenever our code tries to access a variable during the function call, it starts the searching from local variables. And if the variable is not found, it'll continue searching in its outer scope or parent functions' scope until it reaches the global scope and completes searching for the variable there. Searching for any variable happens along the **scope chain** or in different scopes until we get the variable.
If the variable is not found in the global scope as well, a reference error is thrown.
```javascript
const name = "Souvik";
function introduceMyself(greet){
const audience = "students";
function introduce(){
console.log(`${greet} ${audience}, my name is ${name}`); // Hello students, my name is Souvik
}
introduce();
}
introduceMyself("Hello");
```
In the given example above, when the code attempts to access variable `name` inside the `introduce()` function, it didn't get the variable there and tried to search in its parent function's (`introduceMyself()`) scope. And as it was not there, it finally went up to global scope to access the variable and got the value of the variable `name`.
### Variable shadowing
If we declare a variable with the same name as another variable in the scope chain, the variable with local scope will shadow the variable at the outer scope. This is known as **variable shadowing**.
Example 1:
```javascript
let name = "Abhijit";
var sector = "Government";
{
let name = "Souvik";
var sector = "Private"; //as `var` is NOT block scoped(globally scoped here), it'll update the value
console.log(name); //Souvik
console.log(sector); //Private
}
console.log(name); //Abhijit
console.log(sector); //Private
```
Example 2:
```javascript
let name = "Abhijit";
var sector = "Government";
function showDetails(){
let name = "Souvik";
var sector = "Private"; //`var` is functionally scoped here, so it'll create new reference with the given value for organization
console.log(name); //Souvik
console.log(sector); //Private
}
showDetails();
console.log(name); //Abhijit
console.log(sector); //Government
```
In case of example 1, the `name` variable is shadowing the variable with the same name at the outer scope inside the block as we have used `let` to declare the variable. But, the `sector` variable is also updating the value at the same time as we have used `var` to declare it. And as we know `var` is functionally and globally scoped, the declaration with the same name(`sector`) inside the block will update the value at the same reference.
Whereas in case of example 2, the `sector` variable inside the function is function scoped and will create a new reference which will just shadow the variable with the same name declared outside.
### Closure
Closure is an ability of a function to remember the variables and functions that are declared in its outer scope.
MDN defines closure as:
> the combination of a function bundled together with references to its surrounding state or the **lexical environment**
Now, if you're thinking 🤔 what's **lexical environment**? function's local environment along with its parent function's environment forms lexical environment.
```javascript
function closureDemo(){
const a = 3;
return function (){
console.log(a);
}
}
const innerFunction = closureDemo(); //returns the definition of inner function
innerFunction(); // 3
```
In the above example, when the `closureDemo()` function is called, it'll return the inner function along with its lexical scope. Then when we attempt to execute the returned function, it'll try to log the value of `a` and get the value from its lexical scope's reference. This is called **closure**. Even after the outer function's execution, the returned function still holds the reference of the lexical scope.
#### Advantages:
- Currying
- Memoization
- Module design pattern
Discussing these in detail would take another blog 😀. So, will do it later sometime to discuss problems and solutions using a closure.
#### Disadvantages:
- Overconsumption of memory might lead up to the memory leak as the innermost function holds the reference of the lexical scope and the variables declared in its lexical scope won't be garbage collected even after the outer function has been executed.
### Immediately-Invoked Function Expression(IIFE)
An immediately-invoked function expression or IIFE(pronounced as iify) is a function that's called immediately once it's defined.
```javascript
(function task(){
console.log("Currently writing a blog on JS functions");
})();
```
We're basically wrapping a function in parenthesis and then adding a pair of parenthesis at the end to invoke it.
### Passing arguments into IIFE
We can also pass arguments into IIFE. The second pair of parenthesis not only can be used to invoke the function immediately but also can be used to pass any arguments into the IIFE.
```javascript
(function showName(name){
console.log(`Given name is ${name}`); // Given name is Souvik
})("Souvik");
```
### IIFE and private scope
If we can use IIFE along with closure, we can create a private scope and can protect some variables from being accessed externally. The same idea is used in module design pattern to keep variables private.
```javascript
//module pattern
let greet = (function (){
const name = "Souvik Jana"; //private variable
return {
introduce: function(){
console.log(`Hi, I am ${name}`);
}
}
})();
console.log(greet.name); //undefined
greet.introduce(); // Hi, I am Souvik Jana
```
IIFE helps to prevent access to the `name` variable here. And the returned object's `introduce()` method retains the scope of its parent function(due to closure), we got a public interface to interact with `name`.
That's all 😀. Thanks for reading it till now🙏.
If you want to read more on these, refer to [Functions MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Functions), [Closures MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Closures), [IIFE MDN](https://developer.mozilla.org/en-US/docs/Glossary/IIFE).
Share this blog with your network if you found it useful and feel free to comment if you've any doubts about the topic.
You can connect 👋 with me on [GitHub](https://github.com/sjsouvik), [Twitter](https://twitter.com/sjsouvik), [Linkedin](https://www.linkedin.com/in/souvik-jana)
| sjsouvik |
815,139 | TezID - the Identity Oracle for Tezos | Imagine a world where you can choose whether to reveal your identity or not. The more of a stake you... | 0 | 2021-09-06T12:13:49 | https://dev.to/jonarnes/tezid-the-identity-oracle-for-tezos-36lj | blockchain | Imagine a world where you can choose whether to reveal your identity or not. The more of a stake you have in such a world, the more likely others will want to know who you are. This is why providing evidence verifying someone's identity will be just as crucial as owning property or having access to services. This blog post will discuss how [$IDZ tokens](https://blog.tezid.net/idz-9f233a127e4c) will fuel the future of self-sovereign identity and introduce its tokenomics.
## What is TezID?
[TezID](https://tezid.net) is an identity oracle that provides users with a standard way to prove their identity in the Tezos ecosystem.
TezID runs on top of the proof-of-stake blockchain used by the Tezos protocol, but it is not dependent on that specific blockchain consensus algorithm to operate. It can provide this function for any proof-of-stake blockchain system. TezID offers the following identity solutions:
* Authentication of identity using cryptographic signatures
* Proof of ownership of an identity string
* Creation, revocation and renewal of identities
* Decentralized lookup services for identities under its control
* Verifying that an identity, previously created by TezID, has not been revoked (and thus is still valid)
* Validating that an identity was not produced more than once at the same time
The first four of these functions are explained in detail on TezID's website. The intersection of cryptography and game theory allows TezID to achieve these functions in a trustless, decentralized manner.
## $IDZ Tokenomics
$IDZ is a FA2 token with a maximum supply of 10,000,000 tokens. It will have many valuable utilities and be available for purchase in an upcoming public sale on Rocket Launchpad! There will also be an airdrop, so make sure you *sign up early if you want some free tokens*!
In order to provide a strong incentive to the $IDZ holders and contribute to the growth of the TezID community, the TezID team has clearly outlined the $IDZ utilities.
### Revenue Sharing
The TezID team is introducing a revenue-sharing model that allows token holders, stakers and official farming participants to earn income from the proof registration fees. They start at 50% of all income distributed this way but hope to increase over time through an automated process controlled by DAO. This will encourage people to hold onto their tokens and help spread the use cases for its platform so it can grow even more rapidly!
Only token holders that have unlocked their tokens will be able to earn income from this venture. This means founders, advisors, and private sale participants cannot share in the profits until they unlock their own tokens!
### Decentralized Proofs
In the blockchain space, most people are looking beyond nation-states and want to create new social norms on-chain. This means they might be hesitant to provide national identification papers or even have access to those documents. Therefore a [decentralized identity](https://blog.tezid.net/tezid-roadmap-9bf200237dd4) becomes useful as it provides a set of tools and incentives for individuals to prove that they're real human beings anonymously--without providing government documentation.
TezID aims to distribute [decentralized identity](https://blog.tezid.net/tezid-roadmap-9bf200237dd4) proofs that require payment from the requester (registering the proof), which will, in turn, be used as payment for verifiers who verify their identities. All of this is conducted using $IDZ.
### Custom Prooftypes
You might want to share many things securely with a dapp, including your contract terms or role at an organization. You can prove that they're yours by demonstrating "control" over some custom resources, which TezID will facilitate via proof of ownership.
The team strongly believes [custom prooftypes](https://blog.tezid.net/tezid-roadmap-9bf200237dd4) will be necessary for many future applications. They have plans to explore this opportunity and offer their development resources to implement these proofs.
All custom prooftypes payments will be done using $IDZ!
### Proof Payment
TezID will accept proof payment in $IDZ. However, to ensure that the process remains simple for our users to register proofs, they will continue supporting the use of XTZ and QuipuSwap as the conversion currency behind the scenes.
## Public Sale
The $IDZ public sale will take place on *September 12, 2021, at 14:00 UTC.* There is a minimum of 50 XTZ and no maximum purchase amount.
The first-come, first-serve system applies based on the Rocket Tier System, which assigns priority status to those who buy more tokens for TGEs in the past (or are part of Quipu). Tokens will be liquid immediately after-sale concludes!
40% of the amount raised from the TGE will be assigned to an AMM contract set up with QuipuSwap using Crunchy Deep Freezer technology that handles all transactions automatically by the team here at Rockets HQ.
## Final Thoughts
Remember, the $IDZ public token sale has a minimum requirement price of 50 XTZ, but there's also no upper limit cap!
Anyone who has registered a proof on tezid.net before 12.09.2021 14:00 UTC will be eligible for the airdrop!
| jonarnes |
815,166 | How to identify and avoid burnout as a software developer | Developer burnout is a very common occurrence. So it becomes important to notice when it is about to happen. This give you mechanisms and techniques to identify burnout and how to deal with it. | 0 | 2021-09-06T13:23:54 | https://dev.to/codewithluke/how-to-identify-and-avoid-burnout-as-a-software-developer-1e4i | discuss, javascript, webdev, beginners | ---
title: How to identify and avoid burnout as a software developer
published: true
description: Developer burnout is a very common occurrence. So it becomes important to notice when it is about to happen. This give you mechanisms and techniques to identify burnout and how to deal with it.
tags: discuss, javascript, webdev, beginners
---
Recently me and some friends have been working on a side project. Since we had been hanging out together a lot more you start to get some insight into how they manage their time, as well as see how they burnout.
This started to get me thinking that in the current tech space there is this constant need for validation and push towards always learning. However it is not talked about how on top of your regular job these extra learnings, side projects and general life start to add up and contribute to burnout.
I recently made a video that outlines the issues and how to deal with burnout.
{% youtube IZVZkVG283A %}
However I will also discuss it here.
## The Problem
I will focus on one main point within this article and that has to do with how developers (the ones in the frontend space in particular) are swamped with a so much information, tools, frameworks etc.
This is not a bad thing. However I am sure there are people that have reached a point where they have been reading articles or been in software long enough to see the infamous
- **x framework vs y framework**,
- **Top 10 tools this week**,
- **What you need to know to be a good developer**.
Once again these are not necessarily bad. I am more focusing on the mindset. The feeling newer developers start to experience when either coming into the industry or just starting. I know I felt it when I first started and that was when half the current tools didn't exist yet. This feeling of a massive amount of learning.
If I had to list every single tool or framework I have worked with or learnt, either in my free time or work the list would be quite a nice chunky read. The frontend ecosystem is always growing and evolving. However there is always pressure on people to try and learn it all as quick as they can. There is a reason there is a meme behind "Have 3 years of experience in X framework" when it has only been around for a year. This pressure to learn the latest and newest things as fast as possible, causes a ripple effect across the industry.
What does this result in? New and existing developers feeling pressure to dedicate what little time they have and this can lead to burnout and lifestyle imbalances.
## The Controversy
This take might seem somewhat double edged. On one hand its important to grow your skills. However on the other it is also important to not just wither away learning something that may not even be relevant in a few years time. Or rather, just to live a little.
Some might say that learning is what they enjoy. That is fine and maybe then this article is not something that would really appeal to you. The idea behind this is to identify unhealthy habits that some people have when it comes to learning in their free time, on top of a job, side project and just a general busy schedule.
## So what's the solution?
The solution is not to stop learning. The solution is to schedule your time accordingly.
As an example I dedicate 30min in the morning and evening (this is more a time to wind down and relax) to reading. During my day job, at lunch I use the gym to stay in shape and ensure I stay healthy.
After work it becomes a choice, dedicate an hour or two to studies/articles/videos or on my side project. The rest of my time is dedicated to what I enjoy, playing games with my friends or watching some TV.
By scheduling this time it ensures that I am getting the right amount of sleep and balance. This balance allows not only for me to grow as a developer but also to grow as a person and enjoy the things I want.
I just want to re-iterate. If what you find as fun is learning and doing little code projects this is 100% fine. The point behind the solution is not to stop coding and doing those things. It is about managing your time in order to ensure that you get sleep/exercise/eat well and stay hydrated. What you do for fun is up to you. However that fun should not make you feel pressured or induce anxiety and stress to do it. That fun time should be the stuff that allows you to unwind and reset mentally in order to avoid a prolonged or new burnout.
I hope this was helpful to some as I have found this is what works best for me. Feel free to leave any questions and if you did check out that video that is much appreciated as well!
| codewithluke |
815,174 | When Should I Start Applying for Software Developer Jobs | Immediately after learning some slightly deeper concepts. What do you we by deep concepts? Here is... | 14,352 | 2021-09-06T13:33:20 | https://techmaniac649449135.wordpress.com/2021/09/06/when-should-i-start-applying-for-software-developer-jobs/ | Immediately after learning some slightly deeper concepts. What do you we by deep concepts? Here is the thing. Taking a four-year course or attending an 8-month bootcamp is enough to prepare you for any software development job.
1. The time you committed
Mark Zuckerberg will tell you that a good programmer must spend 1000 hours writing codes. Yes, it's true, for you to call yourself an experienced programmer in a certain language or field, then you must have spent much time learning various concepts. Let us be honest, programming is difficult, it requires more time of commitment.
For a 6-12 month bootcamp, you need like 8 hours per day, please let it be consecutive. For a 4 year course, if you could give 5 hours per day programming and doing research, you are good to solve complex programs. But don't confuse the quality and quantity, lol.
2. Basic understanding
A full grasp of the basic concept is the core value of solving ambiguous problems. Please just follow this. If you want to solve complex problems, you must understand their roots. Therefore, if you are into web development, HTML5, CSS3, and JavaScript must be fully revised. Not just once, but frequently. Warning! You don’t need to know the whole of JavaScript, everyone experiences difficulty in this language, even senior engineers.
3. Framework
Have you learned any frameworks by this time? If you are a front-end engineer then react, vuejs or angular must be in your toolbox. I don’t mean all of them, but choose one. If you are a backend engineer in the web development field, then nodejs, PHP/Laravel, or Django must be fully grasped. Chose one, for my case I learned Django in three months.
4. Projects on a resume.
What projects have you handled? It can be a fully optimized site. Make sure you have deployed it live on Netfly or Heroku. Have in mind that Heroku hosts dynamic projects, while netfly hosts static websites. If you are working with java or python, then let your project be on your GitHub account.
5. Able to read other people's code
Throughout your learning journey, kindly collaborate. Or take other people's code and try to read through it, look at how they write clean codes. Look at their comments, the naming of JavaScript variables, and functions. Be keen. You will realize how people write simple codes that might take you longer to write. But don’t panic, your time will come.
6. Is your Github green?
Please! Please! Have a Github account. Then, look at open-source projects and contribute. Have some 50% knowledge of how Github works. Because when you get a job, I am sure you are going to work with a team. This is where you will be getting your feedback on where each of you has reached.
They will let you know if you are on the right or wrong track. Master the basics before applying for any job. Also, more interaction with GitHub, posting a few projects daily or weekly will make it green. The algorithm will show how consistent and determined you are. No company will give you a job without looking at your Github account.
7. I can do it
The last thing is to believe in what you have learned. Don’t doubt your mind, not even your ability to handle some complex problems. Kindly, don’t rush applying to the big four companies if you are fresh from a local Bootcamp. Unless you join their own Bootcamps. But if you have been on a four-year computer science degree, it's your chance to give it a try.
The big question is simple, do you understand the algorithm? That’s the full technical interview with large tech companies.
Have hope and trust in God. It’s a matter of time and you will be a senior engineer.
| techmaniacc | |
815,366 | How to get GitHub Notifications in Discord Server? | Are you interested in receiving all of your GitHub notifications on your Discord server? Here's how... | 0 | 2021-09-06T17:32:02 | https://cb-ashik.hashnode.dev/how-to-get-github-notifications-in-discord-server | github, discord, notifications, server | Are you interested in receiving all of your GitHub notifications on your Discord server?
Here's how to do that.
We will go over how to get GitHub notifications in Discord Server in this article. Now, let's begin.
To begin, I'm assuming you have a Discord and GitHub account.
## Index
- [Creating Discord Server](#creating-discord-server)
- [Creating GitHub Repo](#creating-github-repo)
- [Receiving Notifications](#receiving-notifications)
- [Testing](#testing)
- [Conclusion](#conclusion)
Let's start by creating a Discord Server.
## Creating Discord Server
1. In the bottom left corner, click on the `+` icon.
2. Once you've done that, click on `Create My Own.`
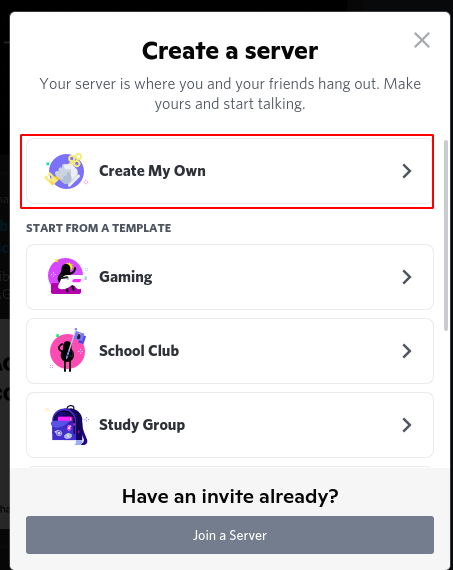
3. Choose `For me and my friends`
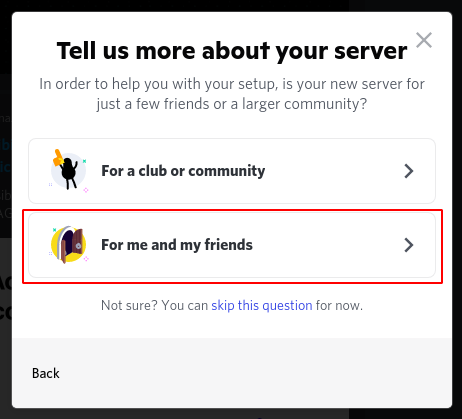
4. Now, give your server a name. After that, select `Create`.
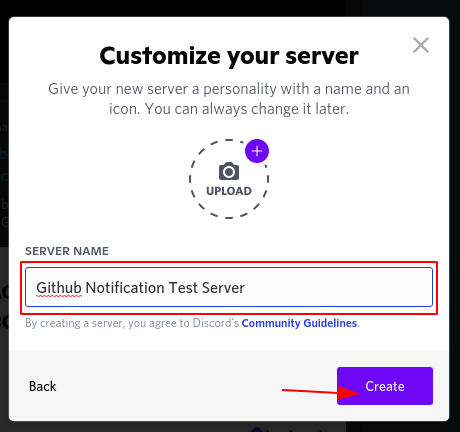
Now, the discord server is ready, if you want to get Github Notification notices delivered to a separate text channel, you may create a new one.
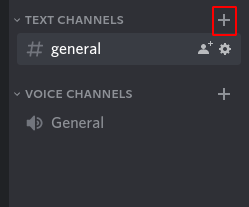
Now, let's create a GitHub repo.
## Creating GitHub Repo
1. Click [here](https://github.com/new) to create a new GitHub repo.
2. Give your repo a name and click `Create Repository`.
Now, our GitHub repo is also ready, now, it's time to setup our Discord server to receive GitHub notifications.
## Receiving Notifications
1. Click on the ⚙️ icon just right of the text channel where you want to receive notifications.
2. Next, click on `Integrations` and then click on `Create Webhook`.
3. Now, a new webhook is created, if you want to change it's name, you can do so. But I'll leave it as it is.
4. Then click on `Copy Webhook URL`.
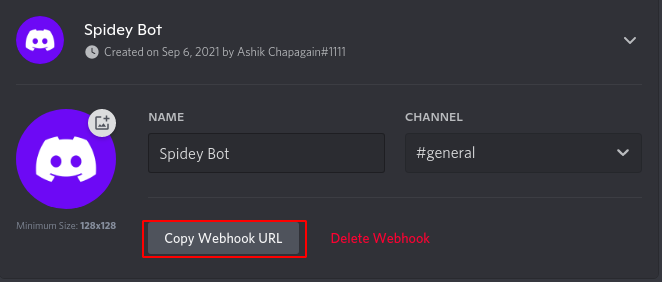
Once the `Webhook URL` is copied,
- Go to your GitHub repo and click on settings.
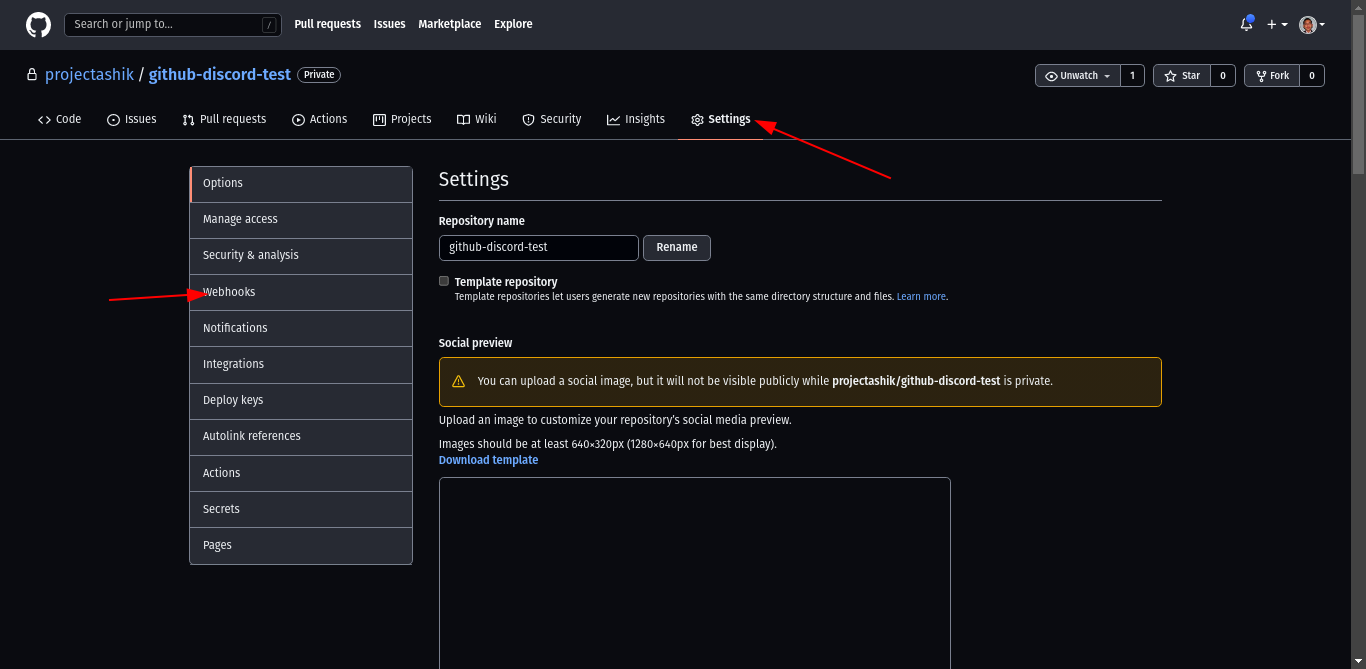
- Then click on `Webhooks`.
- Next, click on `Add webhook`.
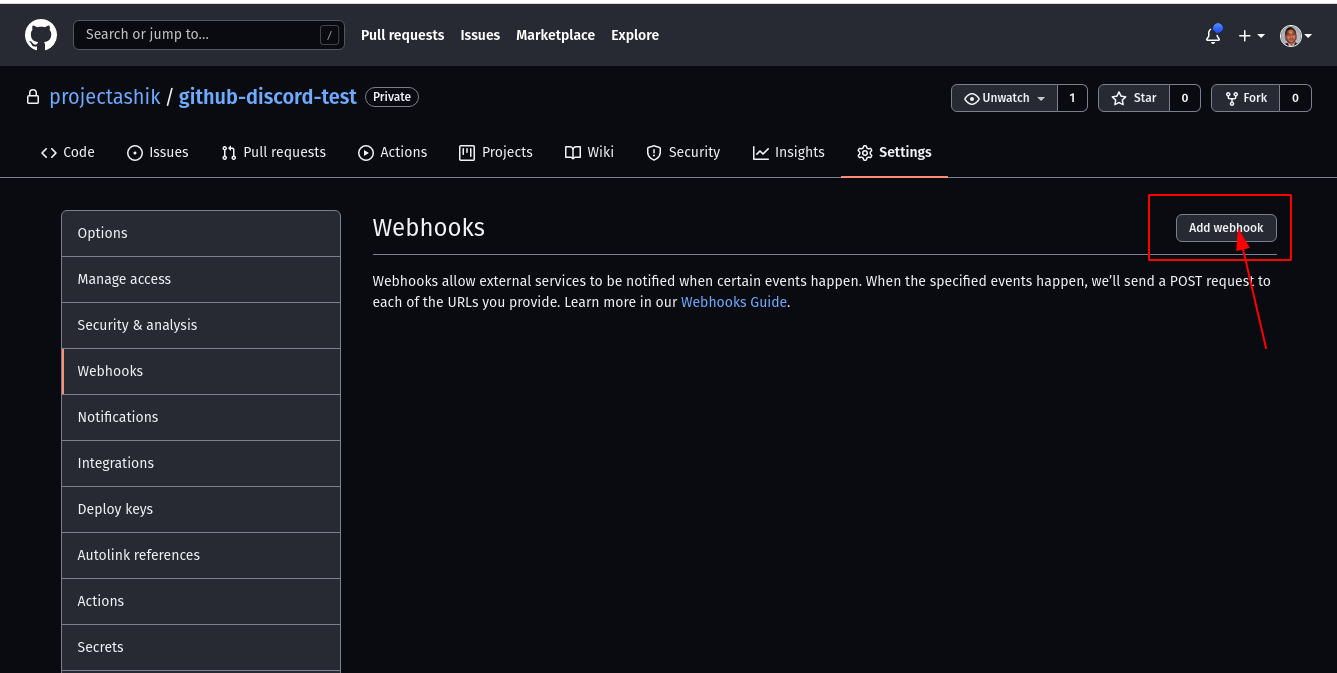
Then you might need to confirm your password.
- Now add the `web hook` URL with `/github` on the end in `Payload URL`.
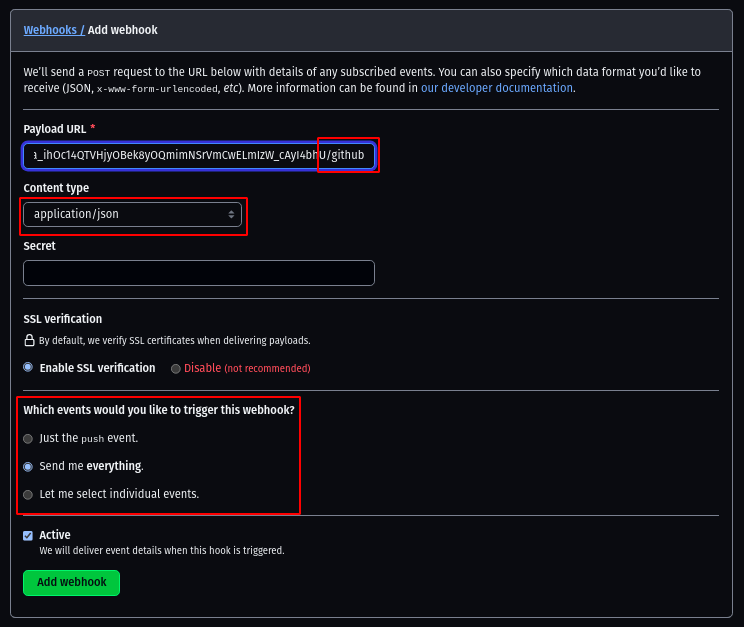
- Now, set the content type to `application/json`.
- In the `Which events would you like to trigger this webhook?` section, select `Send me everything.` to receive every GitHub notification.
- Now click on `Add Webhook`, and now, you can receive all GitHub notifications in your discord server .🥳🥳🥳
> If everything was set up perfectly, then you should see the `green tick` on the webhook.
## Testing
For testing, let's clone the clone and push a commit.
1. Clone the repo
```bash
git clone https://github.com/YOUR_USERNAME/YOUR_REPO.git
```
2. Create a new random file, I will create `README.md` with following content.
```md
# Testing
```
3. Run the following commands
```bash
git add .
git commit -m "Added readme.md"
git branch -M main
git push -u origin main
```
4. Now, go to your discord server and you should see something like this.
## Conclusion
This was a short article on how to receive GitHub notification to your Discord Server. Hope you like this article. If you got any problem or have any feedback or suggestion for me, comment it.
**Connect with me:**
- [Twitter](https://twitter.com/@chapagainashik)
- [Polywork](https://polywork.com/projectashik) | chapagainashik |
815,377 | I Created an OpenSource Portfolio Template for Developers 🚀 | Launching 🚀 Dopefolio 🔥 - An OpenSource Multipage Portfolio Website Template for Developers... | 0 | 2021-09-06T18:02:29 | https://dev.to/rammcodes/i-created-an-opensource-portfolio-template-for-developers-1ij9 | career, javascript, css, opensource | **Launching** 🚀
## **Dopefolio** 🔥 - **An OpenSource Multipage Portfolio Website Template for Developers** 🚀
---
<div align="center">
<img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/9coge98bpo59p1crr6pc.gif" alt="Dopefolio Demo" width="100%" style="margin: 0;"/>
<br>
</div>
## **Github Repo Link**: https://github.com/rammcodes/Dopefolio ⭐
---
Creating a **Portfolio Website** from scratch is time-consuming and that's why I have created an **OpenSource Portfolio Website Template for Developers** so developers don't have to build their website from scratch. 💯
Instead, **Developers** can focus on building better **Projects** for their **Portfolio** without worrying about the **Portfolio** Website itself. 🤘
---
### **Features**:
- **Easy to Setup** ✅
- **Free to Use ( OpenSource )** ✅
- **No Additional Frameworks** ✅
- **No Additional Libraries** ✅
- **Multi Page** ✅
- **Fully Responsive** ✅
- **Super Fast and Optimized for SEO** ✅
<img src="https://i.ibb.co/1dD8Mky/Screenshot-from-2021-08-28-14-38-30.png" alt="Dopefolio Audits" width="100%" style="margin: 0;" />
---
The project is made with **HTML, CSS**, some **JavaScript**, and **SASS** to write CSS. Don't worry if you don't know any, I have provided the instructions on how to use **Dopefolio** and set up your own Portfolio using it in the **README.md** file inside the Github Repository.
* Check out the **[Github Repository](https://github.com/rammcodes/Dopefolio)** 👨💻
* Drop a Github Star ⭐ 😉
* Fork the Repository 🍴
* Start using it for your own Portfolio 🙌
---
The **Demo Link** of the template is also provided in the **[Github Repository](https://github.com/rammcodes/Dopefolio)** along with the **Colors Playground** Link ✅
Hope this Portfolio Template will help you in your journey as a Developer 😇
---
## Important 😸
I regularly post useful content related to **Web Development and Programming** on **Linkedin**. You should consider **Connecting with me or Following** me on **Linkedin**.
**Linkedin Profile**: https://linkedin.com/in/rammcodes
You can also connect with me on **Twitter**
**Twitter Profile**: https://twitter.com/rammcodes
---
## Support 😇
If you find this project to be useful then you can **support** me using the **Buy Me a Coffee** link below so I can continue chasing my dream of building useful **Projects** that will help the developer community and the general audience and will allow me to change my life as well 😇
### **[Buy Me A Coffee](https://www.buymeacoffee.com/rammcodes)** ❤️
---
Feel free to **Like** and **Share** this post 😇
Share your feedback by **Commenting** below 💬
Drop me a **Follow** for more **Awesome** content related to **Web Development** and **Programming** 🙌
#### **Thank you for your support** ❤️
| rammcodes |
815,415 | Refactoring does not solve all problems… right away | Is it an improvement? I guess wheel never know with these uphill battles I read and summarise... | 0 | 2021-09-06T19:10:43 | https://chuniversiteit.nl/papers/why-refactoring-for-understandability-does-not-give-immediate-benefits | programming | ---
canonical_url: https://chuniversiteit.nl/papers/why-refactoring-for-understandability-does-not-give-immediate-benefits
---
> _Is it an improvement? I guess wheel never know with these uphill battles_
**I read and summarise software engineering papers for fun, and today we’re having a look at [Old habits die hard: Why refactoring for understandability does not give immediate benefits](https://doi.org/10.1109/SANER.2015.7081865) (2015) by Ammerlaan, Veninga, and Zaidman.**
Whenever shortcuts are taken during the development of a software system, it accumulates technical debt.
This debt makes it harder to understand and make changes to the system, so the development speed for a system with a lot of technical debt will eventually come to a grinding halt.
## Why it matters
Refactoring is a process where the structure of code is improved without changing the functionality of the system. Many in the software development community argue that well-structured code is easier to understand, and thus easier to modify and less prone to bugs.
Unfortunately there is little empirical evidence that refactoring actually has beneficial effects on developer productivity. This study tries to shed some light on the matter.
## How the study was conducted
A comparative experiment was conducted at Exact, a software company that produces business software with development teams that are distributed over multiple continents.
The study consists of 5 different experiments and included 30 participants (all developers) from 11 different teams and two different countries (Malaysia and The Netherlands).
In each experiment, a developer was asked to perform a small coding task on components from a codebase with 2.7 millions of lines of code: they either had to fix a small bug or make a small change in functionality. Participants in the experimental group were given a refactored version of the code, while those in the control group were given the original code.
The experiment includes three types of refactorings:
- **small** _Rename_ [_field_](https://refactoring.com/catalog/renameField.html) or [_variable_](https://refactoring.com/catalog/renameVariable.html), and [_Extract function_](https://refactoring.com/catalog/extractFunction.html) refactorings;
- **medium** [_Extract class_](https://refactoring.com/catalog/extractClass.html) and [_Adapter pattern_](https://en.wikipedia.org/wiki/Adapter_pattern) refactorings, accompanied by one or more unit tests;
- **large** refactorings to _divide responsibilities_, also accompanied by unit tests.
## What discoveries were made
Results were mixed.
### Results
In the first (small) experiment some helper methods were extracted from the code. Surprisingly, developers who saw the refactored version needed _more_ time to make the requested change, not less.
The second (small) experiment had a similar setup, but was (apparently) easier to complete. This means that the productivity measurements for this experiment are less noisy. In this case, about 75% of the participants in the experimental group finished before 25% of the developers with the original code.
The third (small) experiment again used similar refactorings and also resulted in lower finishing times for those who saw the original code without refactorings. It’s possible that flow of method arguments and return values between multiple smaller methods was harder to understand than a linear flow in a large method.
In the fourth (medium) experiment participants were asked to fix a bug. It appears that those in the experimental group had slightly lower finishing times than those in the control group. Another notable finding is that developers who were quite experienced in unit testing performed better than other participants.
In the fifth (large) experiment, developers who saw the original code once again did _much better_ than developers who had to work with the refactored code, presumably because it takes more time to understand the relations between classes that emerge from a large refactoring. However, the quality of solutions also differed: whereas most developers in the control group fixed the bug using a “quick fix”, those in the experimental group managed to fix the root cause.
### Discussion
The experimental results show that most of the time the original, unrefactored code was “better” for productivity. However, when the original and refactored code were shown to participants side-by-side, most preferred the refactored code.
The authors argue that this discrepancy can be explained by the habits of developers, who are used to reading long, procedural methods and thus simply need more time to get used to dealing with multiple classes and methods.
However, even if refactorings lead to a (possibly temporary) decrease in understandability, the possible increases in maintainability and testability could still make the refactoring worthwhile. | chuniversiteit |
815,544 | Help!! | Can anyone help me with basic project tutorials in Python? | 0 | 2021-09-06T21:21:11 | https://dev.to/felix_fleku/beginner-4po7 | python, beginners, programming, websites | Can anyone help me with basic project tutorials in Python? | felix_fleku |
815,548 | Automatically Unsubscribe from Emails in Rails (and Control Email Preferences) | In this tutorial, I'll show you how to add a link to any Rails Mailer that will allow a user to... | 0 | 2021-09-07T10:07:12 | https://stevepolito.design/blog/auto-unsubscribe-from-email-in-rails/ | tutorial, rails | In this tutorial, I'll show you how to add a link to any Rails Mailer that will allow a user to automatically unsubscribe from that email. As an added bonus, we'll build a page allowing a user to update their email preferences across all mailers.
Inspired by [GoRails](https://gorails.com/episodes/rails-email-unsubscribe-links).
## Step 1: Build Mailers
1. Generate mailers.
```
rails g mailer marketing promotion
rails g mailer notification notify
```
2. Update previews by passing a user into the mailer. This assumes your database has at least one user record.
```ruby
# test/mailers/previews/marketing_mailer_preview.rb
class MarketingMailerPreview < ActionMailer::Preview
def promotion
MarketingMailer.with(
user: User.first,
...
).promotion
end
end
```
```ruby
# test/mailers/previews/notification_mailer_preview.rb
class NotificationMailerPreview < ActionMailer::Preview
def notify
NotificationMailer.with(
user: User.first
...
).notify
end
end
```
## Step 2: Build a Model to Save Email Preferences
1. Generate the model and migration.
```
rails g model mailer_subscription user:references subscribed:boolean mailer:string
```
2. Add a null constraint to the mailer column, and a unique index on the user_id and mailer columns. This will prevent duplicate records.
```ruby
class CreateMailerSubscriptions < ActiveRecord::Migration[6.1]
def change
create_table :mailer_subscriptions do |t|
t.references :user, null: false, foreign_key: true
t.boolean :subscribed
t.string :mailer, null: false
t.timestamps
end
add_index(:mailer_subscriptions, [:user_id, :mailer], unique: true)
end
end
```
> **What's Going On Here?**
>
> - We add `null: false` to the `mailer` column to prevent empty values from being saved, since this column is required.
> - We add a [unique index](https://api.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_index) on the `user_id` and `mailer` columns to prevent a user from having multiple preferences for a mailer.
3. Run the migrations.
```
rails db:migrate
```
4. Build the MailerSubscription model.
```ruby
# app/models/mailer_subscription.rb
class MailerSubscription < ApplicationRecord
belongs_to :user
MAILERS = OpenStruct.new(
items: [
{
class: "MarketingMailer",
name: "Marketing Emails",
description: "Updates on promotions and sales."
},
{
class: "NotificationMailer",
name: "Notification Emails",
description: "Notifications from the website."
}
]
).freeze
validates :subscribed, inclusion: [true, false], allow_nil: true
validates :mailer, presence: true
validates :mailer, inclusion: MAILERS.items.map{ |item| item[:class] }
validates :user, uniqueness: { scope: :mailer }
# @mailer_subscription.details
# => [{:class => "MarketingMailer", :name => "Marketing Emails", :description => "Updates on promotions and sales."}]
def details
MailerSubscription::MAILERS.items.select {|item| item[:class] == mailer }
end
# @mailer_subscription.name
# => "Marketing Emails"
def name
details[0][:name]
end
# @mailer_subscription.name
# => "Updates on promotions and sales."
def description
details[0][:description]
end
# @mailer_subscription.name
# => "Subscribe to"
def action
subscribed? ? "Unsubscribe from" : "Subscribe to"
end
# @mailer_subscription.name
# => "Subscribe to Marketing Emails"
def call_to_action
"#{action} #{name}"
end
end
```
> **What's Going On Here**
>
> - We add a constant to store a list of mailers a user will be able to subscribe/unsubscribe from. The class value must match the name of a Mailer class.
> - We use the values stored in the constant to constrain what values can be set on the `mailer` column. This prevents us from accidentally creating a record with an invalid mailer.
> - We add a [uniqueness validator](https://guides.rubyonrails.org/active_record_validations.html#uniqueness) between the `user` and `mailer`. This is made possible by the unique index we created in the migration. This will ensure a user cannot have multiple preferences for the same mailer.
> - We use the values stored in the constant to create a variety of helper methods that can be used in views.
5. Add method to check if a user is subscribed to a specific mailer.
```ruby
# app/models/user.rb
class User < ApplicationRecord
has_many :mailer_subscriptions, dependent: :destroy
# @user.subscribed_to_mailer? "MarketingMailer"
# => true
def subscribed_to_mailer?(mailer)
MailerSubscription.find_by(
user: self,
mailer: mailer,
subscribed: true
).present?
end
end
```
> **What's Going On Here?**
>
> - We add a method that checks if a user is subscribed to a particular mailer. If the method finds a matching record, then the user is subscribed. Otherwise, they are not. Note that this is an opt-in strategy. We're deliberately looking for records where `subscribed` is set to `true`. This means that if there is no record in the database, they'll be considered unsubscribed.
> - To make this an opt-out strategy, you could simply replace `subscribed: true` with `subscribed: false`.
## Step 3: Allow a User to Automatically Unsubscribe from a Mailer
1. Generate a controller to handle automatic unsubscribes.
```
rails g controller mailer_subscription_unsubcribes
```
```ruby
# config/routes.rb
Rails.application.routes.draw do
...
resources :mailer_subscription_unsubcribes, only: [:show, :update]
end
```
2. Build the endpoints.
```ruby
# app/controllers/mailer_subscription_unsubcribes_controller.rb
class MailerSubscriptionUnsubcribesController < ApplicationController
before_action :set_user, only: [:show, :update]
before_action :set_mailer_subscription, only: [:show, :update]
def show
if @mailer_subscription.update(subscribed: false)
@message = "You've successfully unsubscribed from this email."
else
@message = "There was an error"
end
end
def update
if @mailer_subscription.toggle!(:subscribed)
redirect_to root_path, notice: "Subscription updated."
else
redirect_to root_path, notice: "There was an error."
end
end
private
def set_user
@user = GlobalID::Locator.locate_signed params[:id]
@message = "There was an error" if @user.nil?
end
def set_mailer_subscription
@mailer_subscription = MailerSubscription.find_or_initialize_by(
user: @user,
mailer: params[:mailer]
)
end
end
```
3. Build the view.
```html+erb
<%# app/views/mailer_subscription_unsubcribes/show.html.erb %>
<h1>Unsubscribe</h1>
<p><%= @message %></p>
<%= button_to @mailer_subscription.call_to_action, mailer_subscription_unsubcribe_path, method: :patch, params: { mailer: params[:mailer] } if @mailer_subscription.present? %>
```
You can test this be getting the [Global ID](https://github.com/rails/globalid) of a user and going to the endpoint.
```ruby
User.first.to_sgid.to_s
# => "abc123..."
```
http://localhost:3000/mailer_subscription_unsubcribes/abc123...?mailer=MarketingMailer

> **What's Going On Here?**
>
> - We create an endpoint that will automatically unsubscribe a user from a particular mailer. This is a little unconventional since we're creating a record on a GET request (instead of a POST request). We're forced to do this because a user will be clicking a link from an email to unsubscribe. If emails supported forms, we could create a POST request.
> - We add a button on that page that will allow the user to resubscribe to the mailer. Note that we don't redirect back to the `show` action because that would end up unsubscribing the user from the mailer again.
> - We find the user through their GlobalID in the URL which makes the URLs difficult to discover. Otherwise the URL would just accept the user's ID which is much easier to guess. This will prevent a bad actor from from unsubscribing a user from a mailer.
## Step 4: Build a Page for User to Update Their Email Preferences
1. Generate a controller for the MailerSubscription model.
```
rails g controller mailer_subscriptions
```
```ruby
# config/routes.rb
Rails.application.routes.draw do
...
resources :mailer_subscription_unsubcribes, only: [:show, :update]
resources :mailer_subscriptions, only: [:index, :create, :update]
end
```
2. Build the endpoints.
```ruby
# app/controllers/mailer_subscriptions_controller.rb
class MailerSubscriptionsController < ApplicationController
before_action :authenticate_user!
before_action :set_mailer_subscription, only: :update
before_action :handle_unauthorized, only: :update
def index
@mailer_subscriptions = MailerSubscription::MAILERS.items.map do |item|
MailerSubscription.find_or_initialize_by(mailer: item[:class], user: current_user)
end
end
def create
@mailer_subscription = current_user.mailer_subscriptions.build(mailer_subscription_params)
@mailer_subscription.subscribed = true
if @mailer_subscription.save
redirect_to mailer_subscriptions_path, notice: "Preferences updated."
else
redirect_to mailer_subscriptions_path, alter: "#{@mailer_subscription.errors.full_messages.to_sentence}"
end
end
def update
if @mailer_subscription.toggle!(:subscribed)
redirect_to mailer_subscriptions_path, notice: "Preferences updated."
else
redirect_to mailer_subscriptions_path, alter: "#{@mailer_subscription.errors.full_messages.to_sentence}"
end
end
private
def mailer_subscription_params
params.require(:mailer_subscription).permit(:mailer)
end
def set_mailer_subscription
@mailer_subscription = MailerSubscription.find(params[:id])
end
def handle_unauthorized
redirect_to root_path, status: :unauthorized, notice: "Unauthorized." and return if current_user != @mailer_subscription.user
end
end
```
> **What's Going On Here?**
>
> - We create a page allowing a user to subscribe/unsubscribe from all possible mailers that are defined in `MailerSubscription::MAILERS`. We can't call `@user.mailer_subscriptions` because they may not have any records.
> - We create a `handle_unauthorized` method to prevent a user from subscribing/unsubscribing another user from mailers. We need to do this because we're passing in the ID of the `MailerSubscription` through the params hash which can be altered via the browser.
3. Build the views.
```html+erb
<%# app/views/mailer_subscriptions/index.html.erb %>
<ul style="list-style:none;">
<%= render @mailer_subscriptions %>
</ul>
```
```html+erb
<%# app/views/mailer_subscriptions/_mailer_subscription.html.erb %>
<% if mailer_subscription.new_record? %>
<li style="margin-bottom: 16px;">
<p><%= mailer_subscription.description %></p>
<%= button_to mailer_subscriptions_path, params: { mailer_subscription: mailer_subscription.attributes } do %>
<%= mailer_subscription.call_to_action %>
<% end %>
<hr/>
</li>
<% else %>
<li style="margin-bottom: 16px;">
<p><%= mailer_subscription.description %></p>
<%= button_to mailer_subscription_path(mailer_subscription), method: :put do %>
<%= mailer_subscription.call_to_action %>
<% end %>
<hr/>
</li>
<% end %>
```
> **What's Going On Here?**
>
> - We loop through each `MailerSubscription` instance. If it's a [new_record?](https://api.rubyonrails.org/classes/ActiveRecord/Persistence.html#method-i-new_record-3F) we create a `MailerSubscription`. Otherwise, it's an existing record and we [toggle!](https://api.rubyonrails.org/classes/ActiveRecord/Persistence.html#method-i-toggle-21) the `subscribed` value.
> - In either case we use a [button_to](https://api.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-button_to) to hit the correct endpoint. Note that when we're creating a new `MailerSubscription` we pass `mailer_subscription.attributes` as params, but we're only permitting the `mailer` value in our controller.
http://localhost:3000/mailer_subscriptions

## Step 5: Add Unsubscribe Link to Mailer and Prevent Delivery if User Has Unsubscribed
1. Add shared logic to `ApplicationMailer`.
```ruby
# app/mailers/application_mailer.rb
class ApplicationMailer < ActionMailer::Base
before_action :set_user
before_action :set_unsubscribe_url, if: :should_unsubscribe?
before_action :set_mailer_subscriptions_url, if: :should_unsubscribe?
after_action :prevent_delivery_if_recipient_opted_out, if: :should_unsubscribe?
default from: 'from@example.com'
layout 'mailer'
private
def prevent_delivery_if_recipient_opted_out
mail.perform_deliveries = @user.subscribed_to_mailer? self.class.to_s
end
def set_user
@user = params[:user]
end
def set_unsubscribe_url
@unsubscribe_url = mailer_subscription_unsubcribe_url(@user.to_sgid.to_s, mailer: self.class)
end
def set_mailer_subscriptions_url
@mailer_subscriptions_url = mailer_subscriptions_url
end
def should_unsubscribe?
@user.present? && @user.respond_to?(:subscribed_to_mailer?)
end
end
```
> **What's Going On Here?**
>
> - We add several [action mailer callbacks](https://guides.rubyonrails.org/action_mailer_basics.html#action-mailer-callbacks) to the `ApplicationMailer` in order for this logic to be shared across all mailers.
> - We call `prevent_delivery_if_recipient_opted_out` which will conditionally prevent the mailer from being sent if the user is not subscribed to that mailer. This is accomplished by setting `mail.perform_deliveries` to `true` or `false` based on the return value of `@user.subscribed_to_mailer? self.class.to_s`. Note that calling `self.class.to_s` will return the name of the mailer (i.e. MarketingMailer).
> - We call `@user.to_sgid.to_s` to ensure the the URL is unique and does not contain the user's id. Otherwise a bad actor could unsubscribe any user from a mailer.
> - We conditionally call these callbacks with `should_unsubscribe?` to ensures we've passed a user to the mailer.
1. Conditionally render unsubscribe links in mailer layouts.
```html+erb
<%# app/views/layouts/mailer.html.erb %>
<!DOCTYPE html>
<html>
...
<body>
<%= yield %>
<%= render "shared/mailers/unsubscribe_links" if @unsubscribe_url.present? %>
</body>
</html>
```
```html+erb
<%# app/views/layouts/mailer.txt.erb %>
<%= yield %>
<%= render "shared/mailers/unsubscribe_links" if @unsubscribe_url.present? %>
```
---
Did you like this post? [Follow me on Twitter](https://twitter.com/stevepolitodsgn) to get even more tips. | stevepolitodesign |
815,557 | How To Break Into Data Engineering And Why It's So Hard | Photo by Mick Haupt on Unsplash Being a data engineer can be both challenging and rewarding. But... | 0 | 2021-09-06T22:06:29 | https://dev.to/seattledataguy/how-to-break-into-data-engineering-and-why-it-s-so-hard-4koi | database, datascience, career, beginners | Photo by [Mick Haupt](https://unsplash.com/@rocinante_11?utm_source=medium&utm_medium=referral) on [Unsplash](https://unsplash.com/?utm_source=medium&utm_medium=referral)
Being a data engineer can be both challenging and rewarding. But it's not always easy to break into this part of the tech field.
Data engineering in itself is such a broad term filled with tools, buzzwords and ambiguous roles.
This can make it very difficult for developers and prospective graduate to get these roles as well as understand how they can create a career path towards said role.
Let's talk about the different challenges you will face trying to become a data engineer. While finishing this article off with some solutions and paths you can take in order to break into the data engineering field.
## Challenges With Learning Data Engineering
One of the biggest challenges with this career trajectory is related to a lack of general opportunity and gaps in the process of making your way from one level of experience and mastery to another. There may not be an easy path for you to follow as you work your way up to the higher levels of this type of expertise.
It starts with a relative lack of relevant college and university programs that really prepare you for the ins and outs of data engineering, such as dealing with wild or unstructured data or higher-level database concepts.
Much of the available higher education in this realm has more to do with other aspects of data science or with software development as a specific practice. That's all well and good, but what about specialization in data engineering? [Data engineering](https://seattledataguy.substack.com/p/are-companies-hiring-fewer-data-scientists) as a concept is a more elusive part of a given college program.
In fact, experts who understand the pathways to becoming a data engineer often see what they would call a "gap" between the education that's available and the skills and experience that are required on the job. That's something you'll have to deal with as you put together your career strategy for this type of role.
## A Lack Of Junior Data Engineer Positions
Another related problem is that there are a finite number of junior data engineering positions available at today's companies, as well as challenges with building the skill sets and experience that take you from a junior to a senior position as you go.
For example, getting the requisite experience with [ETL](https://www.theseattledataguy.com/what-are-etls-and-why-we-use-them/) processes and [data warehousing](https://seattledataguy.substack.com/p/what-is-cloud-data-warehousing) can be difficult.
Without access to large complex data sets as well as complex infrastructure, it can be difficult to really replicate the challenges you will face as a data engineer.
So without a wide range of junior positions, many employees who may want to become a data engineer, might not have an easy route. Now I do think I am seeing some companies trying to fix this problem but its a slow process.
## Developing A Good Enough Data Engineering Project
So what about doing projects on your own and building a portfolio that any professional would be proud of?
There are some challenges with that too. If you're not in the field, in a practical position, it's likely that you're not seeing a lot of the specific challenges you would encounter with unruly data or workarounds to particular enterprise problems. Trying to re-create these in a vacuum is also tough, to put it mildly.
It's not to say that it's impossible. In fact I did put together a list of [data engineering projects](https://www.theseattledataguy.com/5-data-engineering-projects-to-add-to-your-resume/) I thought looked really great. However, it can be challenging because data engineering also doesn't lend itself as much to applications compared to software engineering.
## One More Challenge: Diversity in Skill Sets
In talking about why it's so hard to break into data engineering, we should also talk about the breadth of skills that are needed.
A good data engineer will have a basis in programming, not just with Python or Scala but in a diverse environment of technologies. Employers and headhunters talk about the "full-stack data scientist or engineer" as a holy grail in the industry, but they don't often talk about how that personal achievement gets unlocked.
Or if it ever truly gets unlocked.
In addition to programming, supposedly the successful data engineer should also have a good understanding of around DevOps. He or she should understand the setup of cloud services and APIs, know how to work with SQL as well as interact with NoSQL database, and how open source and vendor tools can work together. He or she should have some hands-on experience with data pipelines and data warehousing.
All of that is a tall order!
So how do you get it done?
## Ways to Become a Data Engineer
Now we can talk about some of the solutions that may put you closer to your goals as a professional data engineer.
## Becoming a Data Engineer: Analysts and Software Engineers
One of the best ways to work toward a career in data engineering is to start in a related position that's a bit more common or maybe more geared toward the entry-level end of the spectrum.
To put it another way, the analyst is a fairly standard role in IT. Like the associate in retail, being an analyst in IT can mean various things. You may have a role as a data analyst, business analyst or financial analyst. There really are a ton of roles with the term analyst that can require some similar skills. For example, you will likely need some SQL and you will also need to understand data warehouses. These are the beginning skills of a data engineer.
In this way you will likely be working close to a data engineering position and maybe even have the chance to occasionally build a data pipeline or two. Setting up a clear path for you to go from [analyst to data engineer](https://www.youtube.com/watch?v=lGzh-QendJc).
The basic idea is that, as you do these things, you build skills that are directly parallel to what you would do as a data engineer. As you do that, you also are hopefully networking toward having more prominence in your particular company. You're getting some of that proximity to the types of problem-solving we talked about above that will come in handy in the trenches.
There is a similar thing to be said for people wanting to go from software engineer to data engineer.
## Working With Startups
Another route to a successful data engineering career is to get yourself into a team situation where you are one of a few people taking on a new and exciting project from scratch.
Startups are a great place to start a tech career.
The idea of the startup is that small, scrappy teams are competing with those established blue-chip companies and their armies of developers and engineers to come up with their own data solutions.
The reason I sometimes suggest working with startups is that you have a lot more general skill-building opportunities. You have more skin in the game, and you're closer to the heart of the machine. You tend to wear a lot of hats, but as you go, you develop more skills accordingly.
It's not always as lucrative as working for a FAANG, but it will likely be a great learning opportunity.
## The Internship Route
There is a very different way to approach data engineering that you might think about.
If you don't want the uphill challenge of trying to design work from a startup perspective, you can try for an internship at one of those more established companies, where others before you have likely fine-tuned DevOps and cloud approaches and other elements of data engineering.
The pros and cons are evident. On one hand, you won't be blazing a trail. On the other hand, you have a defined structure to work with as you try to climb the ladder.
In addition, if you perform well, then you are likely to get a return offer and you won't have to stress about getting a job once you graduate.
## Next Steps
The truth is for many people reading this article, you may not even know what role you want. I often have people asking me how they would know which role they would enjoy. The truth is, this is so variable depending not only on the person but also the company and team that you end up working on.
In some cases you may really enjoy working as a data engineer at a start-up and dislike at a different company. Some companies use lots of code to develop their pipelines, others use drag and drop code.
All in all, your next steps is to start your journey. [Try building a data engineering project or get an internship at a company.](https://www.youtube.com/watch?v=KfFm-ZQEe74)
Good luck!
## Read/Watch These Next
- [Modernizing Your Data Architecture With The "Modern Data Stack"](https://seattledataguy.substack.com/p/modernizing-your-data-architecture)
- [How I Went From Analyst To Data Engineer](https://www.youtube.com/watch?v=lGzh-QendJc)\
*How to become a data engineer --- and know if it's right for you*
- [How To Start A Consulting Business As A Consultant](https://www.youtube.com/watch?v=ZK-5yS7jJC8&t=1s)\
*Getting Your First Client*
## ✉️ [Subscribe to my Mailing List For Community Updates And Freebies](https://seattledataguy.substack.com/p/scaling-a-data-analytics-team-for)
## Connect with Me on Social Network
✅ YouTube:[https://www.youtube.com/channel/SeattleDataGuy](https://www.youtube.com/channel/UCmLGJ3VYBcfRaWbP6JLJcpA)\
✅ Website: <https://www.theseattledataguy.com/>\
✅ LinkedIn: <https://www.linkedin.com/company/18129251>\
✅ Personal Linkedin: <https://www.linkedin.com/in/benjaminrogojan/>\
✅ FaceBook: [https://www.facebook.com/SeattleDataGu](https://www.facebook.com/SeattleDataGuy)y | seattledataguy |
815,608 | Improving Time To First Byte and Web Vitals | In this post we will cover quite a few different concepts that influence the page speed, how they relate to Core Web Vitals and how to improve them! | 0 | 2021-09-07T00:47:11 | https://dev.to/peaonunes/improving-time-to-first-byte-and-web-vitals-44hc | cache, performance, ttfb, web | ---
title: Improving Time To First Byte and Web Vitals
published: true
description: In this post we will cover quite a few different concepts that influence the page speed, how they relate to Core Web Vitals and how to improve them!
tags: cache, performance, ttfb, web
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/rl1e4r6pmxklggnhkh84.png
---
In this post we will cover quite a few different concepts I recently explored that influence the page speed, how they relate to Core Web Vitals and how to improve them!
Let's start by agreeing on some terminologies and concepts that will be often referred on this post!
**Time To First Byte (TTFB)**
> TTFB measures the duration from the user or client making an HTTP request to the first byte of the page being received by the client's browser.
[https://en.wikipedia.org/wiki/Time_to_first_byte](https://en.wikipedia.org/wiki/Time_to_first_byte)
This measure is used to indicate the responsiveness of the resource, our websites, our servers and so forth. This is often displayed in milliseconds (ms) in the tools, and the [rule of thumb](https://dictionary.cambridge.org/dictionary/english/rule-of-thumb) recommended by [several players in the industry](https://developers.google.com/speed/docs/insights/Server#overview) is `200ms`!
This concept alone is important enough to look for improvements that will impact our customer's experience. However, it becomes better when we correlate it with another customer-focused metric, the Largest Contentful Paint.
**Web Vitals**
The [Core Web Vitals (CWV)](https://web.dev/vitals/) initiated is meant to help us quantify the experience of our sites and find improvements that will result in a better customer experience. Besides providing metrics to look after and improve, these factors are now considered a [ranking signal for the Google Search algorithm](https://developers.google.com/search/blog/2020/11/timing-for-page-experience).
From the CWV metrics, we will be focusing on Largest Contentful Paint (LCP). If you are interested in knowing more about these metrics, check the [Web Vitals](https://web.dev/vitals/) page.
> LCP metric reports the render time of the largest image or text block visible within the viewport relative to when the page started loading.
[https://web.dev/lcp/](https://web.dev/lcp/)
The time it takes to render our website's largest image or text block depends on how fast we deliver our pages and how fast they download any additional assets that make it.
So knowing that TTFB measures the responsiveness of our websites, then the LCP is probably the most important metric we can influence from those of CWV. And that is why we are going to focus on improving TTFB in this post.
 _The element associated with LCP on [spotify.com](http://spotify.com)._
Now we know what these concepts are and how to interpret them, let's see how to measure them!
**Measuring where the time is spent**
Before jumping on ways to improve metrics, we need to understand the current state of our applications and where the bottlenecks are.
Knowing how to measure changes is the most important step to get confidence out of our initiatives.
It is possible to track TTFB on;
- Devtools, [on previewing time breakdown](https://developer.chrome.com/docs/devtools/network/reference/#timing-preview) that highlights the value for every resource requested by the browser, including the website itself. That is present in every modern browser.
- [cURL](https://curl.se/), on your terminal, can tell you the TTFB of any request. [There are plenty of gists on how to do it](https://www.notion.so/1f5fbdbdd89551ba7925abe2645f92b5).
- Using other tools/sites like Bytecheck or KeyCDN.
- Application Performance Monitoring (APMs) can also help us track this from within our clients (CSR) and servers (SSR).
There are also a few ways you can track LCP;
- [Lighthouse](https://developers.google.com/web/tools/lighthouse/) is available on Chrome or as a standalone app on [wed.dev](http://wed.dev) and generates a report about Performance that tells you the LCP of the page inspected.
- Other websites like [WebPageTest](https://webpagetest.org) will review your website and provide useful and detailed reports on areas of improvement.
- Some tools, like [Calibre](https://calibreapp.com/), help us automate and track progress over time.
- Application Performance Monitoring (APMs) can also help us track this from our clients and servers #2!
The problem can be anywhere in between our routing infrastructure to the application code! Thankfully these tools help us understand better where the issues lay.

My advice here is to start small and start early. Pick the tool we are currently more familiar with, or the one we find easier to start and then move on until we reached its limits!
Let's talk improvements now!
**Improving TTFB for websites**
[CDNs](https://en.wikipedia.org/wiki/Content_delivery_network) are an excellent way to speed up the responsiveness of your pages, assets, etc. That is especially true when serving assets that do not change so often or rarely change. We should aim to have CDN caches on top of our fonts, images, data payloads, and entire pages (when possible).
This directly impacts several customer experience factors, more evident on LCP, as the customer will be downloading our pages much faster than if they had to reach the server.
 _Photo by NASA on Unsplash_
Next is the data source closer to the server and the server closer to the customer!
Caching strategies are ineffective when the requests are unique or too distributed to a point CDNs will not get many hits. This scenario increases the importance of;
1. Having our server as close to the customer as possible, distributing our sites globally when possible.
2. Having our data stores as close as possible to the servers. If our pages fetch data from databases or APIs to render ([CSR or SSR](https://developers.google.com/web/updates/2019/02/rendering-on-the-web)), then let's ensure these resources are in the same region as our servers.
Both of these strategies avoid round-trips between regions and avoid adding a lot of latency to the requests.
**Improving TTFB of the assets in your websites**
Occasionally we can also observe a good time spent on the "pre-transfer" phase. The DNS resolution/Handshake/SSL is part of the initial setup of a request lifecycle, and they can take a considered portion of the time of the request.
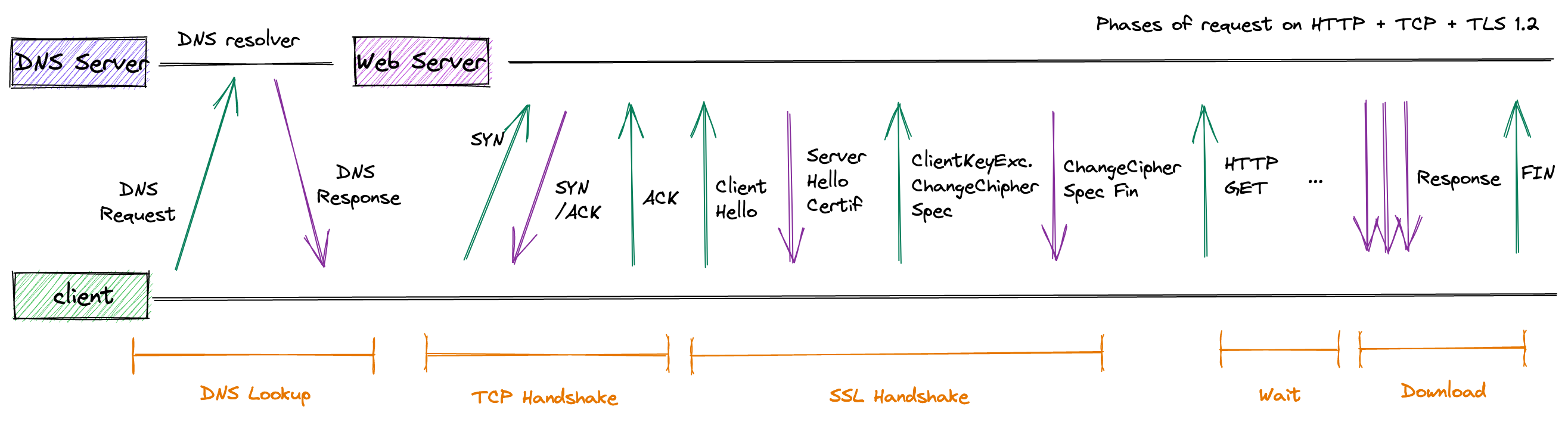
Web request time breakdown considering HTTP + TCP + TLS as per [Timing web requests](https://blog.cloudflare.com/a-question-of-timing/).
Anecdotally I often observe around 200ms spent on this phase on various sites and their respective resources.
The following `rel` values for the `link` tags are good ways to speed up your TTFB on our websites.
- [DNS prefetching](https://developer.mozilla.org/en-US/docs/Web/Performance/dns-prefetch); adding this rel to a link tag pointing to the domain you will download the resource will make the browser attempt resolving the domain before that resource is requested on the page. Effectively saving time when you actually need the resource. Example; `<link rel="dns-prefetch" href="[https://fonts.googleapis.com/](https://fonts.googleapis.com/)">`.
- [Preconnect](https://developer.mozilla.org/en-US/docs/Web/HTML/Link_types/preconnect); adding this rel to a link tag results in the DNS resolution, and also the TCP handshake, connection establishment (on HTTPS). Example; `<link rel="preconnect" href="[https://fonts.googleapis.com/](https://fonts.googleapis.com/)" crossorigin>`.
- [Preload](https://developer.mozilla.org/en-US/docs/Web/HTML/Link_types/preload); adding this rel to a link tag results in the browser fetching the asset while looking at that tag in the `head` of our documents. This will make the resources available sooner and avoid blocking or delaying the rendering! Example`<link rel="preload" href="style.css" as="style">`.
⚠️ Utilising DNS-prefetch or preconnect against the same website domain is ineffective because that would already be resolved and cached by the browser. So target other domains!
⚠️ Because these are all tags included in the head of our documents, if we are already preloading assets under a DNS, we are less likely to have the compounding effect of using preload+prefetch+preconnect.
⚠️ Do not preload too many assets; otherwise, we can make things worse than before! Any preloaded asset will compete for bandwidth with other resources of ours pages.
💡 Consider using both preconnect and prefetching together so while one will save time on the resolution, the other will save time on the handshake.
💡 Consider using preload for assets above the fold only to optimise LCP, for example, hero images or fonts. Additionally, consider using prefetch and preconnect for resources that live in other domains and will be requested later in the page lifecycle.
**Improving TTFB on server**
Reviewing the connections between the servers and other data sources (databases, APIs, ...) is important because the pre-transfer phase can take a long time there too!
This can positively impact all requests on the servers and not only initial page loads.
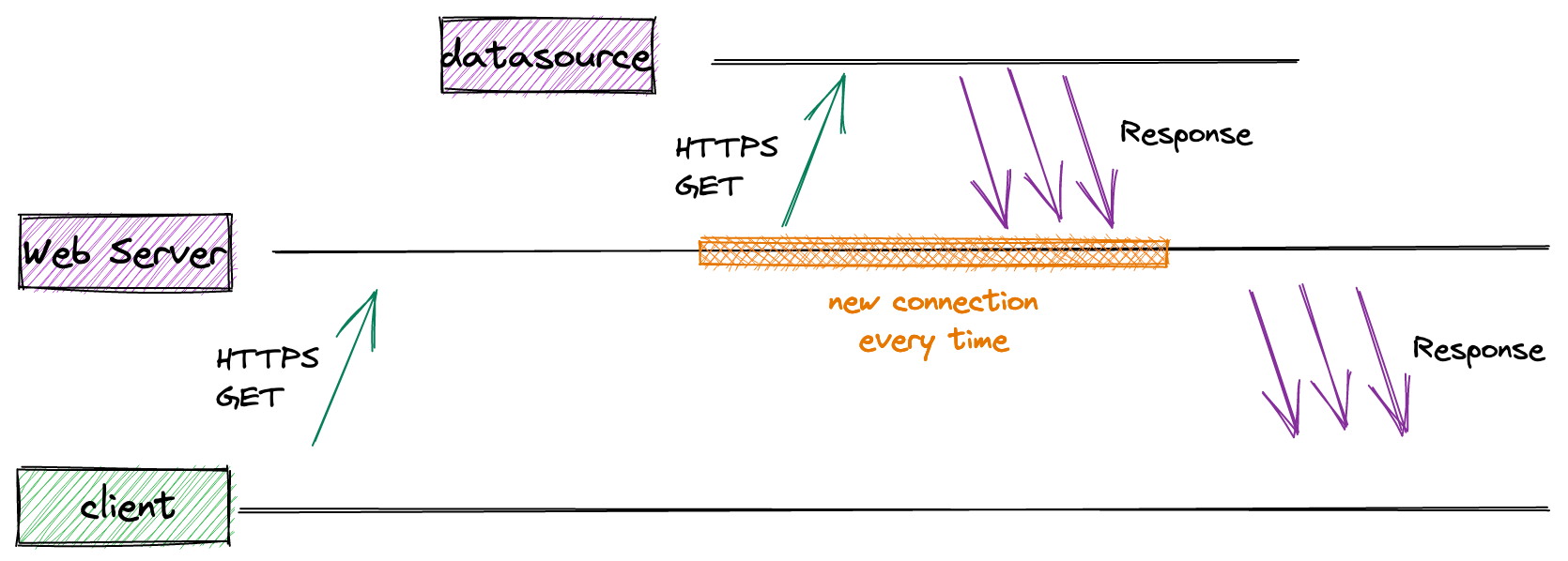
Request breakdown when fetching extra resources from a data source on the server
The most impactful advice regarding TTFB is to utilise [keep-alive](https://en.wikipedia.org/wiki/HTTP_persistent_connection) when possible.
- Keep-alive is a property of an HTTP connection that maintains a connection alive after being established and used for the first time. Subsequent requests to the same destination will reuse that connection as opposed to creating new ones every time.
- This is commonly supported by HTTP clients in the vast majority of frameworks and languages. For instance, in Node.js, we could do it by doing `const agent = new https.Agent({ keepAlive: true });`.
I hope we can see now how we can save time spent on pre-transfer protocols on **every request ****when utilising this.
⚠️ Worth pointing out that maintaining keep-alive connections on the server can impact load balancing and memory consumption, so [there are valid reasons to keep it disabled](https://www.quora.com/Are-there-any-disadvantages-of-enabling-Keep-Alive-on-WebServer). It requires testing!
When using [HTTP/2](https://en.wikipedia.org/wiki/HTTP/2), this will probably be handled for us when utilizing their clients, and it is even more powerful.
**The impact**
TL: DR; The higher your TTFB, the higher the LCP will be! However, I could not find a linear correlation between TTFB and LCP in my endeavours on page performance. For instance, in some experiments, I noticed:
- A small delay in the request time, `50ms` to `200ms`, did not clearly affect the LCP.
- A longer delay, `1s` to `2s`, correlated to an increase of the LCP time, but not by the same values, maybe from `0.5` to `1` second?
My personal conclusion is that chasing up improvements of `< 200ms` is less likely to improve LCP scores individually, but if that is an improvement on the TTFB of your website, then it is awesome!
The point is not to get fixated on the metrics! Depending on your website and infrastructure, different initiatives can yield many different results!
Ensuring we review our websites and APIs from [first principles](https://en.wikipedia.org/wiki/First_principle) is important to identify potential improvements and deliver better customer experiences!
I hope this was useful, and I see you next time 👋
**Related readings**
- [Time To First Byte](https://en.wikipedia.org/wiki/Time_to_first_byte), [Improve server response time](https://developers.google.com/speed/docs/insights/Server#overview)
- [Core Web Vitals](https://web.dev/vitals/)
- [Timing for bringing page experience to Google Search](https://developers.google.com/search/blog/2020/11/timing-for-page-experience)
- [Largest Contentful Paint (LCP)](https://web.dev/lcp/)
- [Previewing time breakdown](https://developer.chrome.com/docs/devtools/network/reference/#timing-preview), [cURL](https://curl.se/)
- [Timing web requests](https://blog.cloudflare.com/a-question-of-timing/)
- [Content Delivery Network](https://en.wikipedia.org/wiki/Content_delivery_network), [Page Rendering](https://developers.google.com/web/updates/2019/02/rendering-on-the-web)
- [Using NS-Prefetch](https://developer.mozilla.org/en-US/docs/Web/Performance/dns-prefetch), [Using preconnect](https://developer.mozilla.org/en-US/docs/Web/HTML/Link_types/preconnect), [Link preload](https://developer.mozilla.org/en-US/docs/Web/HTML/Link_types/preload)
- [HTTP Keep-alive](https://en.wikipedia.org/wiki/HTTP_persistent_connection), [Disadvantages of keep-alive](https://www.quora.com/Are-there-any-disadvantages-of-enabling-Keep-Alive-on-WebServer) | peaonunes |
815,949 | Simplifying Event Filtering and Value Aggregation with RudderStack | Dealing with event data is dirty work at times. Developers may transmit events with errors because of... | 0 | 2021-09-07T13:44:48 | https://rudderstack.com/blog/simplifying-event-filtering-and-value-aggregation-with-rudderstack | eventfiltering, rudderstack, javascript, valueaggregation | Dealing with event data is dirty work at times. Developers may transmit events with errors because of a change a developer made. Also, sometimes errors could be introduced if the data engineering team decides to change something on the data warehouse schema. Due to these changes to the schema, data type conflict may occur. How can someone deal with all the different event data issues that might arise in a production environment? This blog discusses how [RudderStack](http://www.rudderstack.com) handles event filtering and value aggregation without introducing manual errors.
RudderStack’s solution is a sophisticated mechanism. Here, you can implement custom logic using JavaScript to define transformations. You can apply these transformations to the incoming events.
Having an expressive environment like RudderStack offers endless possibilities of how a data engineering team can interact with the data. In this blog post, we will explore just two of the most common use cases we’ve encountered among the RudderStack community. Event filtering and value aggregation are universal, simple to implement, yet very powerful.
User Transformation for Event Filtering and Value Aggregation
-------------------------------------------------------------
You can define user transformations in the Configuration Plane of your RudderStack setup. Few sample user transformations are available on our [GitHub](https://github.com/rudderlabs/sample-user-transformers). This blog provides an insight into one such sample transformation that you can use for:
* **Event Filtering:** This stops events from passing to a destination. You might need to filter events where an organization employs multiple tools/platforms for addressing different business requirements. Also, you may want to route only specific events to specific tool/platform destinations.
* **Value aggregation:** This allows aggregation of values on specific attributes of particular event types. You might need to aggregate values where an organization is not looking to employ a tool/platform to perform transaction-level record keeping and/or analysis. Instead, they want consolidated records/analytics. So, this kind of transformation helps in reducing the network traffic, and request/message volume. This is because the system can replace multiple events of a particular type by a single event of the same type with the aggregated value(s). This transformation also helps in cost reduction, where the destination platform charges by volume of events/messages.
You can view the sample transformation on our [GitHub](https://github.com/rudderlabs/sample-user-transformers/blob/master/SelectiveEventRemoval.js) page.
Implementation
--------------
You need to contain all logic within the `transform` function, which takes an array of events as input and returns an array of transformed events. The `transform` function is the entry-point function for all user transformations.
```javascript
function transform(events) {
const filterEventNames = [
// Add list of event names that you want to filter out
"game_load_time",
"lobby_fps"
];
//remove events whose name match those in above list
const filteredEvents = events.filter(event => {
const eventName = event.event;
return !(eventName && filterEventNames.includes(eventName));
});
```
The code snippet above shows how you can use the `filter` function of JavaScript arrays to filter out events based on the event name.
A variation of this code is also possible. Here, the values in the array of event names are the ones you _want_ to retain, and you remove the not (`!`) condition from the `return` statement in the penultimate line.
Below code shows event removal based on a simple check like event name match but more complex logic involving checking the presence of value for a related attribute.
```javascript
//remove events of a certain type if related property value does not satisfy the pre-defined condition
//in this example, if 'total_payment' for a 'spin' event is null or 0, then it would be removed.
//Only non-null, non-zero 'spin' events would be considered
const nonSpinAndSpinPayerEvents = filteredEvents.filter( event => {
const eventName = event.event;
// spin events
if(eventName.toLowerCase().indexOf('spin') >= 0) {
if(event.userProperties && event.userProperties.total_payments
&& event.userProperties.total_payments > 0) {
return true;
} else {
return false;
}
} else {
return true;
}
});
```
As you can see from the above examples, you can use the filtered array available as output from one step as the input to the next. As a result, you can daisy-chain the transformation conditions.
Finally, the following code shows how you can prepare aggregates for specific attributes across events of a particular type present in a batch. After this, the code returns a single event of the concerned type. Also, the code returns the aggregated values for the corresponding attributes.
```javascript
//remove events of a certain type if related property value does not satisfy the pre-defined condition
//in this example, if 'total_payment' for a 'spin' event is null or 0, then it would be removed.
//Only non-null, non-zero 'spin' events would be considered
const nonSpinAndSpinPayerEvents = filteredEvents.filter( event => {
const eventName = event.event;
// spin events
if(eventName.toLowerCase().indexOf('spin') >= 0) {
if(event.userProperties && event.userProperties.total_payments
&& event.userProperties.total_payments > 0) {
return true;
} else {
return false;
}
} else {
return true;
}
});
```
Conclusion
----------
In the above snippet:
* First, the code collects the `spin_result` events into an array.
* Then, the code aggregates the values for three attributes – `bet_amount`, `win_amount`, and `no_of_spin` by iterating over the elements of the above array.
* After this, the system assigns the aggregated values to the respective attributes of the first `spin_result` event in the array.
* Now, the code separates the events that are not of the target type (`spin_result` in this case) into another array. If there were no such events, an empty array is created.
* Finally, the system adds the `single spin_result` event to the array created in the previous step, and the result is returned.
## Sign up for Free and Start Sending Data
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app. [Get started](https://app.rudderlabs.com/signup?type=freetrial). | teamrudderstack |
815,962 | Getting Started With CSS Flexbox [Tutorial] | CSS has become the backbone of front-end web development and is now more sophisticated and an... | 0 | 2021-09-07T07:42:14 | https://www.lambdatest.com/blog/css-flexbox-tutorial/ | css, webdev | CSS has become the backbone of front-end web development and is now more sophisticated and an efficient problem solver than ever. What a web developer used to perform with extensive JavaScript code is slowly being brought to CSS with specific properties. Be it CSS aspect ratio, CSS scroll-snap, or [CSS subgrids](https://www.lambdatest.com/blog/what-is-css-subgrid/?utm_source=dev&utm_medium=Blog&utm_campaign=Harish-7092021&utm_term=Harish); the CSS library has been expanding ever since. Still, achieving responsiveness has been a significant challenge in aligning multiple elements on a web page. With CSS Flexbox coming into the picture, we can now introduce various items without worrying about how they will be arranged or overflow. Instead, it gives results to complex website design and perfectly spaced elements!

This CSS Flexbox tutorial will help you develop responsive and [browser compatible websites](https://www.lambdatest.com/blog/how-to-make-a-cross-browser-compatible-website/?utm_source=dev&utm_medium=Blog&utm_campaign=Harish-7092021&utm_term=Harish) and web apps to ensure their cross browser compatibility. We will deep dive into the construction of the CSS Flexbox and the range of properties it offers to create convenient yet beautiful CSS Flexbox [responsive web designs](https://www.lambdatest.com/blog/responsive-web-design-all-you-need-to-know/?utm_source=dev&utm_medium=Blog&utm_campaign=Harish-7092021&utm_term=Harish).
Let’s begin with our CSS Flexbox tutorial!
## What is CSS Flexbox?
CSS Flexbox is a CSS property to align and organize the elements inside a container efficiently. A CSS Flexbox starts by creating a flexible space on the web page called a container (the outer layer) that can expand as we insert various elements into it, called items. The expansion also includes the spacing that each item would take to fill the space in the container. The Flexbox grows in the direction of a single axis which can be either horizontal or vertical, which we will demonstrate later in this CSS Flexbox tutorial.
A simple Flexbox will look as follows:
### Flexbox Container And Items
A Flexbox comprises two elements: **a container and an item(s)**.
The container is the outside layer, while the items are the elements encapsulated in it. So, the above Flexbox image can be dissected into container and items as follows:
**The Container:**

**The Items:**

The container works in the direction of the main axis, which the developer can alter through the flex-direction property (discussed later). The default direction is horizontal left to right, though.
The main axis is shown in the following figure:

Perpendicular to the main axis lies the cross-axis of the Flexbox. Once the items in the main axis are filled, the arrangements move in the cross-axis direction. To alter any default setting on the CSS Flexbox, we can use in-built Flexbox properties. These properties are either applied to the container or the child elements (the items). From the next section of the CSS Flexbox tutorial, let’s see them one by one.
## CSS Flexbox Container Properties
The basics of CSS Flexbox are limited to what is mentioned in the previous sections. A container and multiple elements inside it, and that is it. We work our way inside the container, adjusting the items within that space quickly. But what makes Flexbox “efficient” is the properties of its container and elements.
Let’s have a look at these container properties.
### Creating a Flexbox Container
To work with the CSS Flexbox, we need to create one Flexbox on our web page. Flexbox is not something like a block element “div” as a foundation. Instead, we convert one such element into the Flexbox.
Remember that the property we use is for Flexbox container only. Below is the following syntax to define a Flexbox container.
```
.Flexboxcontainer {
display: flex;
}
```
Once we have attached the “display: flex” property to a container, everything inside the container will work according to the flex properties.
In the below code output, the display is not set to flex. It is due to the “div” inside in which these items are, is a block-level element expanding vertically with newer elements.
Below is the same code with the display: flex property.
```
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<title>Flexbox demo</title>
<style>
.container {
display: flex;
background-color: rgb(191, 110, 48);
width: 500px;
}
.item {
background-color: rgb(240, 175, 125);
height: 100px;
padding: 10px;
margin: 10px;
width: 100px;
}
</style>
</head>
<body>
<br>
<center>
<div class = "container">
<div class = "item">Item</div>
<div class = "item">Item</div>
<div class = "item">Item</div>
<div class = "item">Item</div>
<div class = "item">Item</div>
</div>
</center>
</body>
</html>
```
The output of the display: flex property is shown below.
Notice how the elements move in the direction of the main axis, from left to right, rather than stacking up on one another.
### The Direction Of The Flexbox: flex-direction property
By default, as seen in the previous code, the items inside the Flexbox container are arranged horizontally from left to right. It is our default main axis. However, this is not a strict regulation and can be controlled through the flex-direction property.
```
.container {
display: flex;
flex-direction: row-reverse;
}
```
Below the Flexbox code to show the number of items.
```
<div class = "container">
<div class = "item">Item 1</div>
<div class = "item">Item 2</div>
<div class = "item">Item 3</div>
<div class = "item">Item 4</div>
<div class = "item">Item 5</div>
</div>
```
Our CSS Flexbox now looks as follows.
Notice the direction of item numbers has changed now even though the main axis is still on the same plane.
The flex-direction property takes the following values:
- **row:** This is the default arrangement. If the writing mode is ltr then the row will arrange the items in the left to the right direction or else right to left.
- **row-reverse:** This is the reverse of what the value row would have produced in both the writing modes.
- **column:** Column value will make the main axis vertical, and the items will be arranged from top to bottom with this value.
- **column-reverse:** This is the reverse of what the value column would have produced.
For more information on writing modes in HTML, please refer to our blog [Complete Guide To CSS Writing Modes](https://www.lambdatest.com/blog/css-writing-mode-cross-browser-compatibility/?utm_source=dev&utm_medium=Blog&utm_campaign=Harish-7092021&utm_term=Harish).
The following image shows the **column-reverse** arrangement.
#### **Browser Compatibility for flex-direction**
The flex-direction property comes with great support from the browsers. All the browsers, including the internet explorer, support the flex-direction property.
### Wrapping Flexbox Items: flex-wrap property
Like the word-wrap property, the flex-wrap property seeks to wrap the items inside the container to the next line in case of insufficient space. By default, the items do not wrap and are arranged in a single line along the main axis—the flex-wrap works from top to bottom.
Below is the syntax for the flex-wrap property.
```
.container {
display: flex;
flex-wrap: <value>
}
```
The output of the flex-wrap property is shown below.
The flex-wrap property takes on the following values:
- **nowrap:** The items will be arranged in a single line. It is the default value of flex-wrap and can lead to the overflow of the flex container.
- **wrap:** Wrap the items to the next line when required.
- **wrap-reverse:** Wrap the items to the next line when needed but in the reverse order.
The flex-wrap: wrap-reverse property will look as shown below.
**Tip:** The flex-flow property can also be used as a shorthand for the flex-direction and flex-wrap property, defining both the values in a single line.
The below code contains the flex-direction and flex-wrap properties.
```
.container {
display: flex;
flex-direction: row-reverse
flex-wrap: wrap-reverse;
}
```
Therefore the shorthand notation for the above code is as follows.
```
.container {
display: flex;
flex-wrap: row-reverse wrap-reverse;
}
```
Output for the above shorthand code.
#### **Browser Compatibility For flex-wrap**
Similar to the flex-direction property, flex-wrap too enjoys excellent support from the browsers.
The internet explorer supports the property, but there have been many complaints regarding inconsistent outputs on different screen sizes. Therefore, it is not recommended to use flex-wrap on internet explorer.
### Align Flexbox Elements On Main Axis: justify-content property
The justify-content property aligns the elements along the main axis and distributes the leftover space equally within these items.
Below is the syntax for the justify-content property
```
.container {
display: flex;
justify-content: <value>;
}
```
The justify-content property in CSS Flexbox takes the following values:
- **flex-start:** The Flexbox items are arranged towards the start of the axis.
- **flex-end:** The Flexbox items are arranged towards the end of the axis.
- **start:** The items are arranged toward the start of the writing mode direction.
- **end:** The items are arranged towards the end of the writing mode direction.
- **center:** The items are packed along the center of the container (or main axis).
- **space-between:** The items are spaced equally on the line, with the first item at the start of the line and the last item at the end of the line.
- **space-around:** The items have an equal amount of space around them. With this value, the first item does not touch the container as in space-between. The same rule applies to the last item.
- **space-evenly:** The items are packed with equal space all around them. The difference in space-around and space-evenly is that in space-around, the edge space is x in the start item while the right space is 2x. It is because the next item will also have a space of x around it.
In the following two images, notice the first item’s space towards the edge in space-around and space-evenly values.
**Space-Around:**
**Space-Evenly:**
You may find some more values while learning about justify-content, but they are rarely used while designing the Flexbox. Also, most of them are not considered as they are not still included in the browsers and should be avoided.
#### **Browser Support For Justify-Content Property**
The browser support for the justify-content property is good, but it also depends on the value you use. The values “start” and “end” have inferior support and therefore are not recommended. It is always advisable, therefore, to check the browser support for the value you are using. As far as the property is concerned, only internet explorer and Opera mini are still reluctant to include it in their browsers.
## CSS Flexbox Items Properties
All the above properties are applied to the CSS Flexbox container and do not directly affect the items (they do indirectly). In this section of the CSS Flexbox tutorial, we will see a few properties applied to the Flexbox items and directly affect them.
### Changing The Order Of Flexbox Items: The order property
The appearance of the Flexbox items is fixed according to how they are written inside the HTML source code. So an element (say A) written before another element (say B) will appear ahead of B in the Flexbox container. This order, however, can be altered with the “order” property of the Flexbox items.
The order property takes an integer value and arranges the elements from lower to higher-order (lower number means high priority). You can also consider this arrangement in ascending order.
The following code demonstrates the order property of Flexbox items.
```
itemclass {
order: <value>
}
```
The complete code would look as follows, with each item with its own style.
```
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<title>Flexbox demo</title>
<style>
.container {
display: flex;
background-color: rgb(191, 110, 48);
width: 500px;
}
.item {
background-color: rgb(240, 175, 125);
height: 100px;
padding: 10px;
margin: 10px;
width: 100px;
}
.item1 {
order: 3;
}
.item2 {
order: 5;
}
.item3 {
order: 2;
}
.item4 {
order: 1;
}
.item5 {
order: 4;
}
</style>
</head>
<body>
<br>
<center>
<div class = "container">
<div class = "item item1">Item 1</div>
<div class = "item item2">Item 2</div>
<div class = "item item3">Item 3</div>
<div class = "item item4">Item 4</div>
<div class = "item item5">Item 5</div>
</div>
</center>
</body>
</html>
```
Notice the order value of each item in the style tag. The output of the above code would be as follows.
_ **The items with the same order value are represented according to their appearance in the source code.** _
So if an item (say A) and another item (say B) have the same order but B is written before A in the source code will bring B ahead in the output.
The order attribute in CSS Flexbox also accepts negative numbers.
#### **Browser Compatibility For Order property**
Every browser from very early versions supports the order property of Flexbox items!
### Change The Width Of Flexbox Items: The flex-grow property
By default, all the Flexbox items expand in the same ratio and take the same amount of space in the container (equal width). But it can be changed through the flex-grow property. However, remember that the flex-grow property will change the dimension aligned with the container’s main axis. If the flex-direction is set to “row,” the item’s width will change, and if the flex-direction is set to “column,” the item’s height will change.
The flex-grow property takes a positive integer or fractional value. Negative values are not allowed in the flex-grow. All the negative values are considered as 0. If an item has a flex-grow set to 2, it will take twice as much remaining space as other elements (considering other elements have flex-grow as 1).
The remaining space is the difference in the amount of space in the container and the space taken by all the items.
```
.item1 {
flex-grow: 1;
}
.item2 {
flex-grow: 2;
}
.item3 {
flex-grow: 1;
}
```
**Output:**

As seen in the output, it is clear that even though the flex-grow of the middle item is set at 2, it does not mean it will be extended to twice the size of other items. Therefore, the word “remaining phrase” was used in the introduction of this property. To check their width, we can also inspect these items and confirm the proportion they have extended.
Item1 and Item3 have a width of 190.
Here the Item2 has a width of 260, which is not twice of 190.
#### **Browser Compatibility For flex-grow property**
Every browser supports the flex-grow property of CSS Flexbox.
### Shrink The Flexbox Item: The flex-shrink property
The flex-shrink property in the CSS Flexbox is just the opposite of the flex-grow property. The flex-shrink property shrinks the item with respect to the other element’s width. This happens when there is not enough space to accommodate all the items inside the container.
```
.item1 {
flex-shrink: 2;
}
.item2 {
flex-shrink: 1;
}
.item3 {
flex-shrink: 1;
}
```
**Output** :
You can also inspect these items as we did in flex-grow to see their width and the proportion they have shrunk. Also, it is essential to remember that flex-shrink works only when the container size is not big enough to accommodate the items inside it. For example, if we increase the container size to a comfortable width, Item1 will have equal width to Item2 and Item3.
You will see the same results if the size is smaller for the items to accommodate, but you have used the flex-wrap property to “wrap.” Again, it is due to the flex items having permission to move to the next line if space is not enough.
```
.container {
display: flex;
background-color: rgb(191, 110, 48);
width: 300px;
flex-wrap: wrap;
}
.item {
background-color: rgb(240, 175, 125);
height: 100px;
padding: 10px;
margin: 10px;
width: 100px;
}
.item1 {
flex-shrink: 2;
}
.item2 {
flex-shrink: 1;
}
.item3 {
flex-shrink: 1;
}
```
**Output:**
The default value of flex-shrink is one and indicates that all the items in the Flexbox will shrink to an equal proportion. Hence, they will be equal in size.
#### **Browser Compatibility For Flex-Shrink**
Like the flex-grow property of CSS Flexbox, flex-shrink enjoys excellent support from all the browsers from their legacy versions.
Both of these properties are used mainly to deal with the cross-browser compatibility issues to tackle the different screen sizes in the market. You can learn more about cross browser testing in the linked post.
```
.item1 {
flex-basis: 200px;
}
```
**Output:**
You can try to experiment with the flex-basis with other properties to see the effect.
The flex-basis property takes a percentage and fixed value as defined above. Other values include auto, and content is not supported in older browsers.
#### **Browser Compatibility For flex-basis**
The browser support for flex-basis depends on the value you are using in the property. For example, the “content” property has poor support while all the browsers support the “auto.”
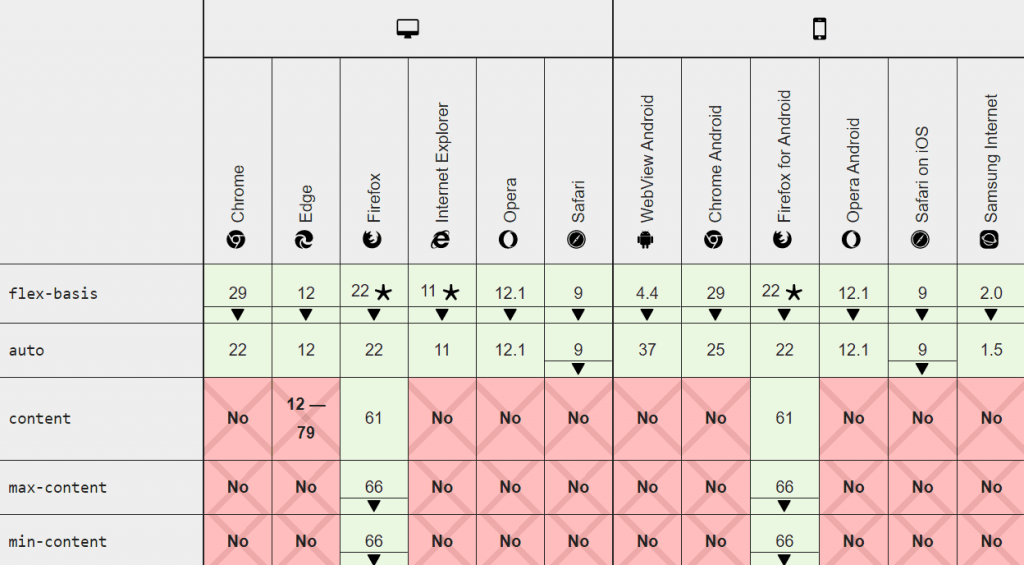
It is recommended to either use fixed value (px or percentage) or go with the auto for a better cross-browser compatible design. Both of these are supported by all the browsers.
### Shorthand For flex-shrink, flex-basis, And flex-grow: the flex property
Since CSS Flexbox provides several properties, sometimes it results in long codes as we define each property in one line. In such cases, shorthands offer a concise way of defining multiple properties in a single line. One such shorthand is the “flex” property.
The flex property defines three different sets of values. The first one is for “flex-grow,” the second one for flex-shrink, and the last one for flex-basis. So, the syntax would follow the following structure:
```
.item {
flex: 0 2 200px;
}
```
#### **Browser Compatibility For flex property**
Since the flex property uses the three most popular and most acceptable properties as a combination, there could be no doubt about its popularity. Moreover, the flex property is supported in all browsers.
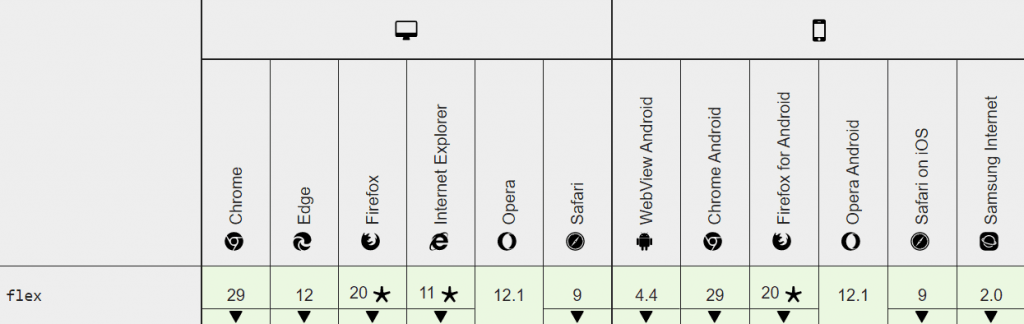
## Is CSS Flexbox Responsive?
CSS Flexbox has taken down the usage of plugins, JS code, and calculative prediction in CSS since its introduction. In addition, CSS Flexbox is highly responsive to create Flexbox responsive designs that can mould on any device screen.
But, as we discussed in this CSS Flexbox tutorial, Flexbox comes with many important properties, and apart from few properties, all are used popularly in constructing a Flexbox. Due to many influences working on the container and its items, assuming everything would be responsive naturally can be a mistake. That is why it is necessary to check CSS Flexbox’s responsive design before pushing code to prhttps://youtu.be/Vn1RX9GMXtwoduction. It can be done in a variety of ways, with the best one being a responsive tool.
One such tool is the [LT Browser](https://www.lambdatest.com/lt-browser?utm_source=dev&utm_medium=Blog&utm_campaign=Harish-7092021&utm_term=Harish). LT Browser is developed to fulfill our responsive needs to assure that our website renders seamlessly across different screen sizes. LT Browser is a dedicated native browser application that comes with pre-installed features which make responsive testing highly efficient. Some of these features are pre-installed popular mobile, tablet, desktop, and laptop screens, performance reports of websites for desktop and mobile, network throttling to [test websites on different networks](https://www.lambdatest.com/blog/test-mobile-websites-on-different-network-conditions/?utm_source=dev&utm_medium=Blog&utm_campaign=Harish-7092021&utm_term=Harish), live mobile-view debugging, bug sharing, and session recording. As a web developer, the LT Browser is a must-try tool for web development.
[](https://downloads.lambdatest.com/lt-browser/LTBrowser.exe)
[](https://downloads.lambdatest.com/lt-browser/LTBrowser.AppImage)
[](https://downloads.lambdatest.com/lt-browser/LTBrowser.dmg)
@[](https://youtu.be/Vn1RX9GMXtw)
The demonstration of CSS Flexbox on two different device viewports in LT Browser is shown below.
## CSS Grids Vs. CSS Flexbox
[CSS grids](https://www.lambdatest.com/blog/what-is-css-subgrid/?utm_source=dev&utm_medium=Blog&utm_campaign=Harish-7092021&utm_term=Harish) and Flexbox are popular among the developers as it looks like both create a box structure and fills elements inside them. In reality, they are similar in many aspects but different in many too!
The basic principle in CSS grids and CSS Flexbox is that CSS grids work in two dimensions, i.e., row-wise and column-wise, simultaneously. It does not happen in CSS Flexbox. As discussed in the flex-direction, the CSS Flexbox moves in a single dimension along its main axis. If you require it to move in both axes, CSS grids are probably a better choice.
The next parameter is whether you need to place items without worrying about their size or you do? CSS Flexbox creates a container space and fills items into it after that. These items will take the required space in the container (as a part of moving in a single direction). On the other hand, CSS grids create tracks in the container with fixed-sized items. The items are then filled inside the boxes with limited size.
The following image shows a Flexbox with five items.
Changing the container to grid gives the following output.

While both the modules serve their purpose, it is up to the web developer how he wants to publish the items on a web page.
Even if all of these conditions are satisfied by your project on CSS grids and CSS Flexbox, the decision will come down to the properties each of them offer. The property that gives you more convenience is a better property for that project. As a point to remember, if you are changing too many properties and making too many adjustments, you probably are using the wrong module.
## Conclusion
CSS Flexbox comes with different vital properties, but in my experience, there will be hardly any instance when you will not use any of them. This is because they are essential in web design and give the Flexbox the strength and power for which it was developed.
While using CSS Flexbox, it becomes imperative to perform cross browser compatibility testing due to its unpredictable output in different browsers. Unfortunately, even if we observe the issue, it is not that simple to get rid of them without changing the meaning of the Flexbox.

In this CSS Flexbox tutorial, we discussed the Flexbox properties with examples to demonstrate how they change the CSS Flexbox accordingly. CSS Flexbox does magical things that are pleasing to a developer. We appreciate such codes and hence would love to see them in the comment section. It will help the developers practice Flexbox in a better way. | harishrajora12 |
816,044 | Connecting the dots.. from Azure to AWS - Part 1 | Way back in my graduation days, our professor in the physics class was asking to look at the parity... | 0 | 2021-09-14T03:04:16 | https://dev.to/surjyob/connecting-the-dots-from-azure-to-aws-part-1-2l52 | azure, aws, mapping, artifacts | Way back in my graduation days, our professor in the physics class was asking to look at the parity between forces of nature.
Gravitational force is directly proportional to mass and indirectly proportional to the square of the distance between the two objects. Electrostatic forces follow similar principle (replace mass by charge). So there is a principal of parity.
Coming to the cloud platform , I jumped into Azure which was natural coming from Microsoft technologies background. Now when I am required to learn AWS cloud platform, I was trying to bring the principal of parity i.e. connecting the dots of the artifacts between the 2 platforms.
## 1. Availability Zones and Availability Regions ##
Azure Region -- > AWS Region
Azure Availability Region --> AWS Availability Zones
## 2. Portal ##
https://portal.azure.com
--> https://aws.amazon.com/console/
AZURE CLI --> AWS CLI (can be launched from the portal itself)
## 3. Account ##
In Azure, there is a structure, where in Azure subscriptions with its assigned owner is created and all resources are created as part of the subscription. In AWS any resources created under the AWS account are tied to that account.

## 4. Identity ##
Azure Active Directory (Azure AD) --> Identity & Access Management (IAM) services in AWS
Although Azure Active directory can not be considered an exact equivalent to the Windows Active Directory , but it offers quite a bit of flexibility to implement multi-cloud identity solutions.
## 5.RBAC - IAM Policies ##
A policy is an object in AWS that, when associated with an identity or resource, defines their permissions. AWS evaluates these policies when an IAM principal (user or role) makes a request. Permissions in the policies determine whether the request is allowed or denied. AWS supports six types of policies: identity-based policies, resource-based policies, permissions boundaries, Organizations SCPs, ACLs, and session policies.
In Azure we have RBAC policies. The policies at the role level when applied to users or groups will give the entities access or restrict access to the resources based on the policies.
## 6.Virtual Machines ##
Azure Virtual Machines --> Amazon EC2
AWS instance types and Azure virtual machine sizes are categorized similarly, but the RAM, CPU, and storage capabilities differ between the two.
## 7.VM Disk Storage ##
Durable data storage for Azure VMs is provided by data disks residing in blob storage.
EC2 instances store disk volumes on Elastic Block Store (EBS). Azure temporary storage also provides VMs with the same low-latency temporary read-write storage as ###EC2 Instance Storage### (also called ephemeral storage). Azure Files provides the VMs with the same functionality as Amazon EFS.
Higher performance disk I/O is supported using Azure premium storage. This is similar to the Provisioned IOPS storage options provided by AWS.
## 8. Azure Traffic Manager - AWS Route53 ##
In AWS, Route 53 provides both DNS name management and DNS-level traffic routing and failover services.
In Azure this is handled through two services: Azure DNS provides domain and DNS management.
Traffic Manager provides DNS level traffic routing, load balancing, and failover capabilities.
| surjyob |
816,086 | What is IoT Technology? Importance in Modern World | The Internet of Things, or IoT, applies to several actual gadgets linked to the web and gathering and... | 0 | 2021-09-07T11:36:14 | https://dev.to/elizabethjones/what-is-iot-technology-importance-in-modern-world-7n2 |
The Internet of Things, or IoT, applies to several actual gadgets linked to the web and gathering and swapping data all over the globe. It is currently feasible to turn everything, from a pill to a jet, into a part of the Internet of Things, because of the advent of extremely inexpensive PC chips and the widespread accessibility of broadband networks. Linking all of these diverse products and attaching detectors to them gives gadgets that could normally be daft a degree of technological cognition, allowing them to convey real-time data without engaging a person. The IoT is bringing the technological and real worlds together to ensure that the things surrounding us are intelligent and increasingly reactive.
##What is IoT Technology?
The Internet of Things is a network of interconnected operating systems, analog and virtual machinery, items, creatures, and individuals possessing primary keys and the transferring of data without needing human-to-human or human-to-computer communication.
It could be an individual who got a transplant of a holter monitor, a domestic animal featuring an injectable ID chip, a vehicle with integrated detectors for warning the driver whenever the air pressure in tires is low or any other genuine or artificial items that are capable of being appointed an Internet Protocol (IP) address and capable of relocating some information over a network.
Businesses across a wide range of sectors are rapidly turning to the Internet of Things to boost operational efficiency, effectively comprehend clients in order to provide excellent service to clients, enhance verdict, and boost the worth of their businesses.
##Internet of Things challenges
The Internet of Things difficulties will develop in tandem with the quantity of genuine applications (devices) that require intelligent connectivity among themselves. The following are illustrations of such problems.
###Smart interconnection
Detectors and gadgets linked and communicating via the IoT architecture might seek to modify their statistics or characteristics to keep up with developments in their surroundings. The Internet of Things is an intelligent architecture that is capable of processing data and making the necessary judgments to enhance itself and modify the patterns or characteristics of linked gadgets to adapt developments in the surroundings. It is an intelligent technology that allows all linked objects to upgrade automatically in response to developments in their surroundings and to adapt and operate in any bizarre situation with exceptional precision. So, intelligent linked models can be created if smart architecture is effectively built to accurately treat the data obtained from gadgets and set up the necessary choices.
###Maintaining the highest levels of privacy and defense for all linked gadgets

The primary goal of implementing the IoT is to create an intelligent network that connects gadgets worldwide. By 2020, 50 billion gadgets are estimated to be linked via IoT gadgets. To eliminate frauds and provide exceptional degrees of data security, linking such a large quantity of gadgets necessitated stringent defense measures. So, attaining a great degree of protection is a crucial problem in gaining the necessary confidence from enterprises and individuals to exchange data via the IoT.
###Handling huge quantity of data
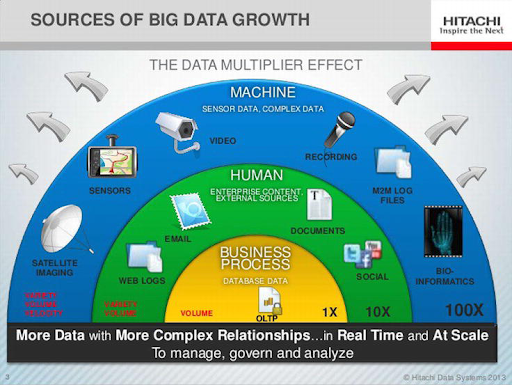
The most significant problem of utilizing the IoT is the massive increase in data sent amid linked gadgets. The main three data sources in the world include:
the database utilized in the organizational processes,
individual everyday activities like email, Facebook, and weblogs, and
the interconnection of actual gadgets like cameras and microphones.
It is worth noting that over the last two years, 90 percent of the planet's data has been produced. This causes dealing with the exponential expansion of produced data extremely difficult for IoT architecture developers.
##Internet of Things Applications
The Internet of Things is widely acknowledged as among the most crucial regions of upcoming innovations, with widespread use in intelligent cities, military, education, hospitals, homeland security gadgets, carrier and independent connected cars, agricultural productivity, intelligent shopping devices, and other advanced innovations. One of the most common apps that attempts utilizing the IoT architecture to link multiple detectors is house automation. The detectors can detect and gather information from the environment, which is then utilized to manage various house gadgets like light and defense.
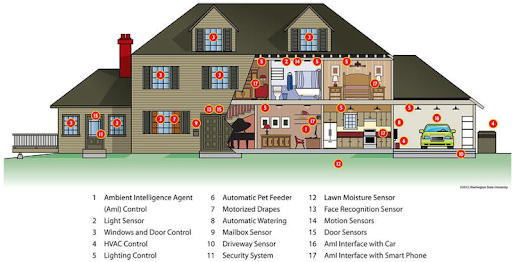
Intelligent bridges and intelligent tunnels are only two examples of utilizations that make use of Internet of Things architecture. Temperature and vibration detectors, as well as closed circuit television (CCTV) systems, can be installed on a bridge to identify unusual activity and deliver SMS alerts. Controlling the traffic density on a bridge can also be done through video processing analysis. If a problem is found, the smart tunnel can use numerous detectors to observe humidity, displacement, and temperature and alert proper repair. All of these utilizations use detectors to detect and gather data, which is then utilized to make an informed choice that keeps the installations secure.
##Importance in Modern World
IoT is viewed as a crucial frontier that features the potential to enhance practically every aspect of our lives. Most gadgets that haven't been linked to the web before can now be interconnected and react in a similar manner as intelligent technologies do. Here are a couple of the advantages of this automation:
The IoT encourages resource efficiency.
In many facets of life, it reduces human effort.
Enabling IoT will lower manufacturing costs while increasing returns.
It improves the speed and accuracy of analytical decisions.
It promotes product marketing in real time.
Improve the customer experience
It ensures high-quality data as well as safe operation.
Given the intricate ecology of IoT, it is necessary to highlight the strategic edge of IoT and the stakeholders, allowing consumers to maintain total authority over the secure distribution of their data and rely as much as possible on their content.
##Conclusion
Our surroundings would become increasingly packed with intelligent gadgets as the volume of linked gadgets keeps climbing – if we are ready to attain the defense and privacy agreement. The forthcoming time of smart things would be welcomed by some. Others will yearn for the simpler periods when a table was just that: a table.
| elizabethjones | |
816,514 | Disable Zoom on pinch in mobile using HTML tag | As a user when you open a site in mobile, we tend to pinch and zoom the page to see things more... | 14,232 | 2021-09-07T16:43:12 | https://blog.kritikapattalam.com/disable-zoom-on-pinch-in-mobile-using-html-tag | html, webdev, beginners, programming | As a user when you open a site in mobile, we tend to pinch and zoom the page to see things more clearly. Have you ever wondered if that feature can be disabled?.
Yes, it can be disabled. What's more interesting is that it can be done by just a single line of code in HTML.
### How to disable zoom on pinch
- On the head section of the HTML, include the following piece of line which is a meta tag that tells the browser the details of what should happen on a device's viewport
```html
<!doctype html>
<html lang="en">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1.0 ,
maximum-scale=1.0 , user-scalable=no"/>
...
</head>
<body>...</body>
</html>
```
> name="viewport"
this means that this meta tag is used for device viewport
> width=device-width
assigns the width of the device as the viewport width
> initial-scale and maximum-scale is set to 1 -
which means it occupies the full 100% of the viewport on page load
> user-scalable=no,
setting the value to no or 0 is what tells the browser to prevent the page from scaling(zoom) in/out
### Things to keep in mind while using this
- This can affect accessibility, people with poor vision will have concerns when visiting the page, since it will prevent them for zooming/out and viewing content closely when required. So use wisely.
- iOS or safari still lets the users zoom for the above mentioned accessibility reason, so this fix might not work in those platform.
Lets connect on [Twitter](https://twitter.com/KritikaPattalam) | [LinkedIn](https://www.linkedin.com/in/kritika-p-296739155/) for more web development related chats.
| kritikapattalam |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.